
url
stringlengths 62
66
| repository_url
stringclasses 1
value | labels_url
stringlengths 76
80
| comments_url
stringlengths 71
75
| events_url
stringlengths 69
73
| html_url
stringlengths 50
56
| id
int64 377M
2.15B
| node_id
stringlengths 18
32
| number
int64 1
29.2k
| title
stringlengths 1
487
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 2
classes | assignee
dict | assignees
list | comments
list | created_at
int64 1.54k
1.71k
| updated_at
int64 1.54k
1.71k
| closed_at
int64 1.54k
1.71k
⌀ | author_association
stringclasses 4
values | active_lock_reason
stringclasses 2
values | body
stringlengths 0
234k
⌀ | reactions
dict | timeline_url
stringlengths 71
75
| state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/transformers/issues/13046 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13046/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13046/comments | https://api.github.com/repos/huggingface/transformers/issues/13046/events | https://github.com/huggingface/transformers/issues/13046 | 963,796,051 | MDU6SXNzdWU5NjM3OTYwNTE= | 13,046 | TFBertPreTrainingLoss has something wrong | {
"login": "ultimatedaotu",
"id": 58505034,
"node_id": "MDQ6VXNlcjU4NTA1MDM0",
"avatar_url": "https://avatars.githubusercontent.com/u/58505034?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ultimatedaotu",
"html_url": "https://github.com/ultimatedaotu",
"followers_url": "https://api.github.com/users/ultimatedaotu/followers",
"following_url": "https://api.github.com/users/ultimatedaotu/following{/other_user}",
"gists_url": "https://api.github.com/users/ultimatedaotu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ultimatedaotu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ultimatedaotu/subscriptions",
"organizations_url": "https://api.github.com/users/ultimatedaotu/orgs",
"repos_url": "https://api.github.com/users/ultimatedaotu/repos",
"events_url": "https://api.github.com/users/ultimatedaotu/events{/privacy}",
"received_events_url": "https://api.github.com/users/ultimatedaotu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
}
] | [
"Hi, thanks for the issue but I'll need a little more info to investigate! Do you encounter an error when you run the code, or do you believe the outputted loss is incorrect? If you encounter an error, can you paste it here? If the loss is incorrect, can you upload a sample batch of data (e.g. a pickled dict of Numpy arrays) that gets different loss values on the PyTorch versus the TF version of the model, when both are initialized from the same checkpoint? \r\n\r\nAll of that will help us track down the problem here. Thanks for helping!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,631 | 1,631 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform:
- Python version: 3.8
- PyTorch version (GPU?):
- Tensorflow version (GPU?): 2.5
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...): TFBertPreTrainingLoss
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. construct some inputs of MLM task
2. call TFBertForMaskedLM
3. while computing loss, something wrong happened.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
```python
masked_lm_loss = loss_fn(y_true=masked_lm_labels, y_pred=masked_lm_reduced_logits)
next_sentence_loss = loss_fn(y_true=next_sentence_label, y_pred=next_sentence_reduced_logits)
masked_lm_loss = tf.reshape(tensor=masked_lm_loss, shape=(-1, shape_list(next_sentence_loss)[0]))
masked_lm_loss = tf.reduce_mean(input_tensor=masked_lm_loss, axis=0)
```
The number of masked_labels is uncertain ,thus ops of "reshape" is unsuitable. Why not calculate the total loss of batches? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13046/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13046/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13045 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13045/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13045/comments | https://api.github.com/repos/huggingface/transformers/issues/13045/events | https://github.com/huggingface/transformers/pull/13045 | 963,510,502 | MDExOlB1bGxSZXF1ZXN0NzA2MTAzMjQ5 | 13,045 | Add FNet | {
"login": "gchhablani",
"id": 29076344,
"node_id": "MDQ6VXNlcjI5MDc2MzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gchhablani",
"html_url": "https://github.com/gchhablani",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url": "https://api.github.com/users/gchhablani/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gchhablani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gchhablani/subscriptions",
"organizations_url": "https://api.github.com/users/gchhablani/orgs",
"repos_url": "https://api.github.com/users/gchhablani/repos",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"received_events_url": "https://api.github.com/users/gchhablani/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Not sure why this test fails:\r\n```python\r\n=========================== short test summary info ============================\r\nFAILED tests/extended/test_trainer_ext.py::TestTrainerExt::test_run_seq2seq_no_dist\r\n==== 1 failed, 7169 passed, 3466 skipped, 708 warnings in 832.52s (0:13:52) ====\r\n\r\n```",
"The failure is due to the new release of sacrebleu. If you rebase on master to get the commit that pins it to < 2.0.0, the failure will go away (but it's not necessary for this PR to be merged as we know it has nothing to do with it).",
"Thanks for reviews @sgugger @patil-suraj\r\nI'll address them quickly. \r\n\r\nOne more concern apart from the ones I have mentioned above:\r\n\r\n~I have removed the slow integration testing from tokenization tests as it expects `attention_mask`. I'll take a look and update the test accordingly.~\r\n\r\nEDIT:\r\n------\r\nThis test has been updated.\r\n",
"Hey @gchhablani :-) \r\n\r\nWe've just added you to the Google org, so that you can move the model weights there. If you find some time, it would also be very nice to add some model cards (I can definitely help you with that). \r\n\r\nRegarding the failing doc test, you can just rebase to current master and it'll be fixed",
"I found two issues with the fourier transform.\r\n\r\n### Issue 1\r\nThe actual implementation uses `jax.vmap` on the `self.fourier_transform`. I made a mistake earlier in the implementation and do it for all dimensions - `hidden_size`, `sequence_length`, and `batch_size`, but it is just `sequence_length` and `batch_size`.\r\n\r\nThis leads to a mismatch issue when using `batch_size` more than one. I have fixed this issue by passing in the correct dimensions to `torch.fft.fftn` and using `functools.partial`.\r\n\r\nPlease check the Flax/Torch output match for `batch_size=2` [here](https://colab.research.google.com/drive/13cqOgP4DNrYbBdjwD0NwSxORCUTRxiZ-?usp=sharing).\r\n\r\nUnfortunately, there is no `vmap` in torch as of now in the stable version, but only in the nightly version [here](https://pytorch.org/tutorials/prototype/vmap_recipe.html).\r\n\r\n### Issue 2\r\nFollowing @sgugger's suggestion to add the optimizations for TPUs, I tried adding the `einsum` version of fourier transform where they use DFT matrix multiplication and the axis-wise FFT. I have had to make changes and few additions to support them in PyTorch. Currently, the outputs from those don't match (but they should, at least to some extent). So I am fixing that as well.\r\n\r\n\r\nEDIT:\r\n------\r\nI understand the issue with the `einsum` implementation. The original code uses the maximum sequence length possible as their sequence length during training - 512. Hence, during the initialization, they specify this maximum sequence length, and then use this variable to initialize the `DFT` matrix for sequence length. While that may have made sense for them, I'm not sure if it makes sense here?\r\n\r\nI think we can take in another parameter `sequence_length` during config initialization. This will be used to specify the sequence length (because `max_position_embeddings` is used to initialize the `self.position_embeddings`, so that shouldn't be changed). Along with this, a check that throws an error if the `sequence_length` does not match sequence length passed to the model. \r\n",
"With the latest changes, an error occurs:\r\n\r\n```python\r\nImportError while importing test module '/home/circleci/transformers/tests/test_modeling_fnet.py'.\r\nHint: make sure your test modules/packages have valid Python names.\r\nTraceback:\r\n/usr/local/lib/python3.7/importlib/__init__.py:127: in import_module\r\n return _bootstrap._gcd_import(name[level:], package, level)\r\ntests/test_modeling_fnet.py:23: in <module>\r\n from transformers.models.fnet.modeling_fnet import FNetBasicFourierTransform\r\nsrc/transformers/models/fnet/modeling_fnet.py:28: in <module>\r\n from scipy import linalg\r\nE ModuleNotFoundError: No module named 'scipy'\r\n```\r\nI am trying to use `scipy.linalg.dft` to get `DFT matrix`. Any chance this can be a dependency?\r\n\r\nEDIT\r\n------\r\nI have added a variable called `_scipy_available` which is used when initializing the fourier transform, and if it is not available, I add a warning. The users can install SciPy if they want?",
"I don't see a problem with using `scipy` as an optional dependency for this specific model",
"Let me know if need help making the tests pass with the dependency - I can fix this in your PR if you want :-)",
"Hi @patrickvonplaten\r\n\r\nI have pushed the code where I used the global variable `_scipy_available`, does that seem okay? The tests are working fine locally.\r\n\r\nAlso, in model tests I'm verifying whether `fourier_transform` implementations match or not in the test: `create_and_check_fourier_transform` for which I need to access `modeling_fnet`.\r\n\r\nI get this error on CircleCI:\r\n\r\n```python\r\n_________________ ERROR collecting tests/test_modeling_fnet.py _________________\r\nImportError while importing test module '/home/circleci/transformers/tests/test_modeling_fnet.py'.\r\nHint: make sure your test modules/packages have valid Python names.\r\nTraceback:\r\n/usr/local/lib/python3.7/importlib/__init__.py:127: in import_module\r\n return _bootstrap._gcd_import(name[level:], package, level)\r\ntests/test_modeling_fnet.py:23: in <module>\r\n from transformers.models.fnet.modeling_fnet import FNetBasicFourierTransform, _scipy_available\r\nsrc/transformers/models/fnet/modeling_fnet.py:22: in <module>\r\n import torch\r\nE ModuleNotFoundError: No module named 'torch'\r\n```\r\n\r\nAny idea how do I fix this?\r\n\r\nEDIT\r\n------\r\nTest is fixed. I followed `fsmt` tests. Had to add the imports under `is_torch_available()`. ",
"I have updated the checkpoints and added basic model cards. The model performance isn't great on MLM, not sure why. The accuracy scores are low, though.\r\n\r\nCheckpoints\r\n- [fnet-base](https://huggingface.co/google/fnet-base)\r\n- [fnet-large](https://huggingface.co/google/fnet-large)",
"Also, just to check :-) The reported eval metrics on GLUE - did you run them once with `run_glue.py` or is it a copy-paste of the paper? ",
"@patrickvonplaten No, I just copy pasted from the paper 🙈. Should I try fine-tuning it?\n\nMaybe, that itself can be the demo?",
"I am checking the checkpoint conversion. Ideally, there should be less than `1e-3`/`1e-4` differences in the outputs. I'm not sure how to exactly fix this, but the arg-sorted order of the predictions is different for the PyTorch and the Flax model. :/ \r\n\r\nFor different fourier transforms, I matched them against `np.fft.fftn` and `jnp.fft.fftn`, both give at best `1e-4` match, which means the problem is not the fourier transform.\r\n\r\nI'll do a layer-wise debugging and update here.\r\n\r\nNonetheless, the original masked LM weights lead to similar predictions, so fine-tuning example will be helpful.\r\n\r\n\r\nEDIT\r\n------\r\nThe issue was that the original implementation uses gelu from BERT, which is equivalent to `gelu_new`, I suppose. Changing the activation to `gelu_new` leads to a `1e-4` match on all logits and sequence output ^_^\r\n\r\nI am still working on verifying model outputs.",
"The original MLM model performs decently for the following: \"the man worked as a [MASK].\" The masked token top-10 predictions are:\r\n```\r\nman\r\nperson\r\nuse\r\nguide\r\nwork\r\nexample\r\nreason\r\nsource\r\none\r\nright\r\n```\r\nI had to modify the tokens as expected by the model. The tokenizer is having issues. The original one gives this output for the text above:\r\n```python\r\n[13, 283, 2479, 106, 8, 16657, 6, 16678]\r\n[ '▁the', '▁man', '▁worked', '▁as', '▁a', '▁', '[MASK]', '.' ]\r\n```\r\nThe tokenizer I wrote is returning this:\r\n```python\r\n[13, 283, 2479, 106, 8, 6, 845]\r\n['▁the', '▁man', '▁worked', '▁as', '▁a', '[MASK]', '▁.']\r\n```\r\nNotice how the space - `▁` is missing and that the period is actually `.` but becomes `▁.` in our tokenizer.\r\n\r\nAny ideas on why this might be happening?\r\n\r\nWhen I change `[MASK]` to `mask`, both lead to same output:\r\n\r\n```python\r\n[13, 283, 2479, 106, 8, 10469, 16678]\r\n['▁the', '▁man', '▁worked', '▁as', '▁a', '▁mask', '.']\r\n```\r\nIn their [input_pipeline](https://github.com/google-research/google-research/blob/master/f_net/input_pipeline.py#L258), they add the mask, cls and sep ids manually. Hence, they never use `[MASK]` in the text input. So, maybe, it's okay if we get `▁a`, `[MASK]`?\r\nBut in either case, we shouldn't get `▁.`? How do I handle this?\r\n\r\nThe problem happens in `tokenize`, where we split based on the `[MASK]` token. But if we don't do that, then `[MASK]` is broken into several tokens. `tokenize('.')` results in `▁.` ",
"I tried fixing the issue using a fix which basically skips first character after a mask token, only if it is not a `no_split_token`.\r\n\r\nI'm not sure if this is 100% correct.\r\n\r\nAlso, there is an error with `FNetTokenizerFast`, the `[MASK]` token is not working as expected:\r\n\r\n```python\r\n[4, 13, 283, 2479, 106, 8, 1932, 2594, 16681, 6154, 5]\r\n['[CLS]', '▁the', '▁man', '▁worked', '▁as', '▁a', '▁[', 'mas', 'k', '].', '[SEP]']\r\n```",
"@patrickvonplaten @LysandreJik @sgugger\nCan you please check the tokenizer once when you get a chance?\n\nOnce that is working, I can proceed with the fine-tuning without any issues.",
"Checking now!",
"Here @gchhablani, I looked into it and the tokenizer actually looks correct to me. See this colab: https://colab.research.google.com/drive/1QC4yvSHk0DSOObD6U2fbUE-9-6W3D3_F?usp=sharing \r\nNote that in the original code tokens are just \"manually\" replaced by the \"[MASK]\" token. So in the colab above, if the token for \"guide\" (3106) is replaced by the mask token id in the original code then the current tokenizer would be correct\r\n\r\nI'm wondering whether the model is actually the same. Checking this now...",
"@patrickvonplaten The tokenizer is working as expected because of the fixed I pushed in the previous commit. It handles the mask token, but I am not 100% sure if it is correct or if there is a better way to deal with this.",
"BTW, to fix the pipelines torch tests I think you just have to rebase to current master (or merge master into your branch :-) ) ",
"@patrickvonplaten\r\n\r\nThere is an issue with `FNetTokenizerFast`:\r\n\r\n```python\r\n>>> from src.transformers.models.fnet.tokenization_fnet_fast import FNetTokenizerFast\r\n2021-08-30 20:30:09.070691: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory\r\n2021-08-30 20:30:09.070758: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.\r\n>>> tokenizer = FNetTokenizerFast.from_pretrained('google/fnet-base')\r\n>>> text = \"the man worked as a [MASK].\"\r\n>>> tokenizer.encode(text)\r\n[4, 13, 283, 2479, 106, 8, 1932, 2594, 16681, 6154, 5]\r\n>>> tokenizer.tokenize(text)\r\n['▁the', '▁man', '▁worked', '▁as', '▁a', '▁[', 'mas', 'k', '].']\r\n```\r\n\r\nThe `[MASK]` should not get tokenized. Any idea why this might be happening?",
"@gchhablani it seems that FNet was trained with a SPM vocab, so the corect masking token should be `<mask>` :)",
"@stefan-it \r\nI haven't worked with sentencepiece before so I'm not sure. But, in the [original code](https://github.com/google-research/google-research/blob/8077479d91cca79b16417055511b7744c155c344/f_net/input_pipeline.py#L256-L258), they specify `[CLS], [SEP], [MASK]` explicitly. However, they do not use the `[MASK]` string token anywhere, but only the id.\r\n\r\nWhat do you think about this?\r\n\r\nIf changing to `<mask>` will fix things, then we can go with it. I will try it out.",
"Hi @gchhablani , oh I'm sorry I haven't yet read the official implementation. But it seems that they're really using `[MASK]` as the masking token (as previously done in [ALBERT](https://github.com/google-research/albert#sentencepiece)).",
"> @patrickvonplaten\r\n> \r\n> There is an issue with `FNetTokenizerFast`:\r\n> \r\n> ```python\r\n> >>> from src.transformers.models.fnet.tokenization_fnet_fast import FNetTokenizerFast\r\n> 2021-08-30 20:30:09.070691: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory\r\n> 2021-08-30 20:30:09.070758: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.\r\n> >>> tokenizer = FNetTokenizerFast.from_pretrained('google/fnet-base')\r\n> >>> text = \"the man worked as a [MASK].\"\r\n> >>> tokenizer.encode(text)\r\n> [4, 13, 283, 2479, 106, 8, 1932, 2594, 16681, 6154, 5]\r\n> >>> tokenizer.tokenize(text)\r\n> ['▁the', '▁man', '▁worked', '▁as', '▁a', '▁[', 'mas', 'k', '].']\r\n> ```\r\n> \r\n> The `[MASK]` should not get tokenized. Any idea why this might be happening?\r\n\r\nI can fix this once the changes to how `token_type_ids` are generated are applied :-)"
] | 1,628 | 1,632 | 1,632 | CONTRIBUTOR | null | # What does this PR do?
This PR adds the [FNet](https://arxiv.org/abs/2105.03824) model in PyTorch. I was working on it in another PR #12335 which got closed due to inactivity ;-;. This PR closes issue #12411.
## Checklist
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
Requesting @LysandreJik to review.
~**Note**:This model uses a SentencePiece tokenizer. They have provided the sentence-piece .model file which can be loaded. While creating FNetTokenizer should I inherit from some other existing tokenizer? Alternatively, I can copy the tokenizer from `ALBERT` (which is what I am doing right now). Wdyt?~
**Note**: I am trying to make this model as similar to Bert is possible. The original implementation has slightly different layers. For example, `FNetIntermediate` and `FNetOutput` equivalents are combined into a single layer in original FNet code, but I keep them separate. Hope this is okay?
EDIT 1:
------
I have made necessary changes for the model. And since the model compares against Bert, it makes sense to have (almost) all tasks - MultipleChoice, QuestionAnswering, etc. I am still working on:
- [x] Tokenizer (regular and fast)
- [x] Documentation
- [x] Checkpoint Conversion
- [x] Tests
EDIT 2:
------
~We also need to skip `attention_mask` totally from the tokenizer. The user, ideally, should not have an option to get the `attention_mask` using `FNetTokenizer`. I am using `model_input_names` for this.~
EDIT 3:
------
~One more concern is that, since I am implementing in PyTorch, do we expect the user to run this on TPU? The reason is that the original implementation changes the way they calculate FFT on TPU, based on the sequence length (they found some optimal rules for faster processing). Currently, I have only used `torch.fft.fftn` directly (they use `jnp.fft.fftn` in the CPU/GPU case). Please let me know what you think.~
EDIT 4:
------
One more thing to consider is that the original code allows `type_vocab_size` of 4, which is used only for GLUE tasks. During pre-training they only use `0` and `1`.
But, the checkpoints also have the shape of embedding weights as `(4, 768)` . Does that mean that the tokenizer might need to support something like:
```python
tokenizer = FNetTokenizer.from_pretrained('fnet-base')
inputs = tokenizer(text1, text2, text3, text4)
```
?
EDIT 5:
------
~The colab link to outputs on checkpoint conversion: [Flax to PyTorch](https://colab.research.google.com/drive/1CxxDwaH4Tei9cUBHRaMYWPHCpS2El2He?usp=sharing).
The model outputs, embedding layer, encoder layer 0 outputs match up to `1e-2`, except masked lm output for masked token, which matches to `1e-1`. Any idea on how I can improve this?~
~One reason I can think of this reduction is precision is the difference in precision in `torch.fft.fftn` and `jnp.fft.fftn` which is atmost `1e-4`. From a difference of atmost `1e-6`, after applying the corresponding transforms, the difference becomes atmost `1e-3` in the real part. Over layers, this might accumulate. Just a guess, however.~
~This was fixed by using `gelu_new` instead of `gelu`.~
EDIT 6:
------
They use a projection layer in the embeddings, and hence the embedding size and hidden size for the model are provided separately in the config. In their experiments, they keep it same, but the flexibility is still there. Do we want to keep both the sizes separate?
EDIT 7:
------
~The FastTokenizer requires a `tokenizer.json` file which I have created using `convert_slow_tokenizer`. I used `AlbertConverter` for this model. I don't know (in-detail) how SentencePiece and FastTokenizers work. Please let me know if I'm missing anything.~
EDIT 8:
------
Just realized that the original model is denoted as `f_net`. I am using `fnet` everywhere, is this acceptable?
EDIT 9:
------
~I am not sure about special tokens in the tokenizer. The original model gives some special tokens as empty string ``. Using the current tokenizer code to load these gives `<s>` and <\s> for those tokens (bos, eos), and <**unk**> for unknown and <**pad**> for pad tokens. Not sure which is the right way to go. Any suggestions?~ | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13045/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13045/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13045",
"html_url": "https://github.com/huggingface/transformers/pull/13045",
"diff_url": "https://github.com/huggingface/transformers/pull/13045.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13045.patch",
"merged_at": 1632137071000
} |
https://api.github.com/repos/huggingface/transformers/issues/13044 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13044/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13044/comments | https://api.github.com/repos/huggingface/transformers/issues/13044/events | https://github.com/huggingface/transformers/issues/13044 | 963,507,665 | MDU6SXNzdWU5NjM1MDc2NjU= | 13,044 | MLM example not able to run_mlm_flax.py | {
"login": "R4ZZ3",
"id": 25264037,
"node_id": "MDQ6VXNlcjI1MjY0MDM3",
"avatar_url": "https://avatars.githubusercontent.com/u/25264037?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/R4ZZ3",
"html_url": "https://github.com/R4ZZ3",
"followers_url": "https://api.github.com/users/R4ZZ3/followers",
"following_url": "https://api.github.com/users/R4ZZ3/following{/other_user}",
"gists_url": "https://api.github.com/users/R4ZZ3/gists{/gist_id}",
"starred_url": "https://api.github.com/users/R4ZZ3/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/R4ZZ3/subscriptions",
"organizations_url": "https://api.github.com/users/R4ZZ3/orgs",
"repos_url": "https://api.github.com/users/R4ZZ3/repos",
"events_url": "https://api.github.com/users/R4ZZ3/events{/privacy}",
"received_events_url": "https://api.github.com/users/R4ZZ3/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hey @R4ZZ3,\r\n\r\nCan you run:\r\n\r\n```transformers-cli env```\r\n\r\nAnd post the output here?",
"Sure, I will run it late this evening and post output here (UTC +3)",
"Ok, found time in between the day @patrickvonplaten \r\n\r\n- `transformers` version: 4.3.3\r\n- Platform: Linux-5.4.0-1043-gcp-x86_64-with-debian-bullseye-sid\r\n- Python version: 3.7.11\r\n- PyTorch version (GPU?): not installed (NA)\r\n- Tensorflow version (GPU?): not installed (NA)\r\n- Using GPU in script?: To my knowledge this script should only use TPUs\r\n- Using distributed or parallel set-up in script?: To my knowledge processing is spread out to 8 tpu cores",
"I did pull changes. Tokenizer saving gives error (Doing this from norwegian-roberta-base folder)\r\n\r\n\r\n\r\n\r\ntokenizer.save(./tokenizer.json) works",
"I was able to fix symbolic link issue with by giving full paths but still have the same error with. Also FYI installed Pytorch 1.9 as I remember from Flax event that for some things it was necessary to have for some processing but no change to error\r\n\r\n",
"Hey @R4ZZ3,\r\n\r\nCould you please update your transformer version to a newer one? Ideally master for Flax examples as they have been added very recently?",
"Sure thing, ill try",
"Ok, now seems to move further @patrickvonplaten Thanks!\r\nStill had to save tokenizer with tokenizer.save(./tokenizer.json) though\r\n\r\n\r\n"
] | 1,628 | 1,628 | 1,628 | NONE | null | I am going through this mlm exaxmple on Google TPU VM instance v3-8 https://github.com/huggingface/transformers/tree/master/examples/flax/language-modeling
I have defined MODEL_DIR with:
export MODEL_DIR="./norwegian-roberta-base"
I have defined symbolic link with:
ln -s home/Admin/Research/transformers/examples/flax/language-modeling/run_mlm_flax.py norwegian-roberta-base/run_mlm_flax.py
I am running with remove VS code and am able to run first 2 steps. now at run_mlm_flax_py if I run referring to symbolic link I am getting:

If I run directly the original script I am getting:


Do you have some idea what I have done wrong?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13044/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13044/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13043 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13043/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13043/comments | https://api.github.com/repos/huggingface/transformers/issues/13043/events | https://github.com/huggingface/transformers/issues/13043 | 963,451,880 | MDU6SXNzdWU5NjM0NTE4ODA= | 13,043 | [DeepSpeed] DeepSpeed 0.4.4 does not run with Wav2Vec2 pretraining script | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@patrickvonplaten,\r\n\r\nThis is definitely something for Deepspeed and not our integration since you have a segfault in building the kernels:\r\n\r\n```\r\n[1/3] /usr/bin/nvcc --generate-dependencies-with-compile --dependency-output custom_cuda_kernel.cuda.o.d -DTORCH_EXTENSION_NAME=cpu_adam -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\\\"_gcc\\\" -DPYBIND11_STDLIB=\\\"_libstdcpp\\\" -DPYBIND11_BUILD_ABI=\\\"_cxxabi1011\\\" -I/home/patrick/anaconda3/envs/hu\r\ngging_face/lib/python3.9/site-packages/deepspeed/ops/csrc/includes -I/usr/include -isystem /home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/include -isystem /home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/include/torch/csrc/api/include -isystem /home/\r\npatrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/include/TH -isystem /home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/include/THC -isystem /home/patrick/anaconda3/envs/hugging_face/include/python3.9 -D_GLIBCXX_USE_CXX11_ABI=0 -D__CUDA_NO_HALF_OPERATORS__ -D_\r\n_CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_BFLOAT16_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ --expt-relaxed-constexpr -gencode=arch=compute_75,code=compute_75 -gencode=arch=compute_75,code=sm_75 --compiler-options '-fPIC' -O3 --use_fast_math -std=c++14 -U__CUDA_NO_HALF_OPERATORS__ -U__CUDA_NO_HALF_CONVERS\r\nIONS__ -U__CUDA_NO_HALF2_OPERATORS__ -gencode=arch=compute_75,code=sm_75 -gencode=arch=compute_75,code=compute_75 -c /home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/ops/csrc/adam/custom_cuda_kernel.cu -o custom_cuda_kernel.cuda.o \r\nFAILED: custom_cuda_kernel.cuda.o \r\n/usr/bin/nvcc --generate-dependencies-with-compile --dependency-output custom_cuda_kernel.cuda.o.d -DTORCH_EXTENSION_NAME=cpu_adam -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\\\"_gcc\\\" -DPYBIND11_STDLIB=\\\"_libstdcpp\\\" -DPYBIND11_BUILD_ABI=\\\"_cxxabi1011\\\" -I/home/patrick/anaconda3/envs/hugging_\r\nface/lib/python3.9/site-packages/deepspeed/ops/csrc/includes -I/usr/include -isystem /home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/include -isystem /home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/include/torch/csrc/api/include -isystem /home/patric\r\nk/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/include/TH -isystem /home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/include/THC -isystem /home/patrick/anaconda3/envs/hugging_face/include/python3.9 -D_GLIBCXX_USE_CXX11_ABI=0 -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_\r\nNO_HALF_CONVERSIONS__ -D__CUDA_NO_BFLOAT16_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ --expt-relaxed-constexpr -gencode=arch=compute_75,code=compute_75 -gencode=arch=compute_75,code=sm_75 --compiler-options '-fPIC' -O3 --use_fast_math -std=c++14 -U__CUDA_NO_HALF_OPERATORS__ -U__CUDA_NO_HALF_CONVERSIONS__\r\n -U__CUDA_NO_HALF2_OPERATORS__ -gencode=arch=compute_75,code=sm_75 -gencode=arch=compute_75,code=compute_75 -c /home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/ops/csrc/adam/custom_cuda_kernel.cu -o custom_cuda_kernel.cuda.o \r\n/usr/include/c++/10/chrono: In substitution of ‘template<class _Rep, class _Period> template<class _Period2> using __is_harmonic = std::__bool_constant<(std::ratio<((_Period2::num / std::chrono::duration<_Rep, _Period>::_S_gcd(_Period2::num, _Period::num)) * (_Period::den / std::chrono::duration<_Rep, _Pe\r\nriod>::_S_gcd(_Period2::den, _Period::den))), ((_Period2::den / std::chrono::duration<_Rep, _Period>::_S_gcd(_Period2::den, _Period::den)) * (_Period::num / std::chrono::duration<_Rep, _Period>::_S_gcd(_Period2::num, _Period::num)))>::den == 1)> [with _Period2 = _Period2; _Rep = _Rep; _Period = _Period]’:\r\n/usr/include/c++/10/chrono:473:154: required from here \r\n/usr/include/c++/10/chrono:428:27: internal compiler error: Segmentation fault \r\n 428 | _S_gcd(intmax_t __m, intmax_t __n) noexcept \r\n```\r\n\r\nCould you please file a bug report at https://github.com/microsoft/DeepSpeed and tag @RezaYazdaniAminabadi\r\n\r\nIt probably has something to do with your specific environment, since deepspeed==0.4.4 passes all wav2vec2 tests on my setup:\r\n\r\n```\r\n$ RUN_SLOW=1 pyt examples/research_projects/wav2vec2/test_wav2vec2_deepspeed.py\r\n====================================================================== test session starts ======================================================================\r\nplatform linux -- Python 3.8.10, pytest-6.2.4, py-1.10.0, pluggy-0.13.1\r\nrootdir: /mnt/nvme1/code/huggingface, configfile: pytest.ini\r\nplugins: dash-1.20.0, forked-1.3.0, xdist-2.3.0, instafail-0.4.2\r\ncollected 16 items \r\n\r\nexamples/research_projects/wav2vec2/test_wav2vec2_deepspeed.py ................ [100%]\r\n==================================================================== short test summary info ====================================================================\r\nPASSED examples/research_projects/wav2vec2/test_wav2vec2_deepspeed.py::TestDeepSpeedWav2Vec2::test_fp16_distributed_zero2_base\r\nPASSED examples/research_projects/wav2vec2/test_wav2vec2_deepspeed.py::TestDeepSpeedWav2Vec2::test_fp16_distributed_zero2_robust\r\nPASSED examples/research_projects/wav2vec2/test_wav2vec2_deepspeed.py::TestDeepSpeedWav2Vec2::test_fp16_distributed_zero3_base\r\nPASSED examples/research_projects/wav2vec2/test_wav2vec2_deepspeed.py::TestDeepSpeedWav2Vec2::test_fp16_distributed_zero3_robust\r\nPASSED examples/research_projects/wav2vec2/test_wav2vec2_deepspeed.py::TestDeepSpeedWav2Vec2::test_fp16_non_distributed_zero2_base\r\nPASSED examples/research_projects/wav2vec2/test_wav2vec2_deepspeed.py::TestDeepSpeedWav2Vec2::test_fp16_non_distributed_zero2_robust\r\nPASSED examples/research_projects/wav2vec2/test_wav2vec2_deepspeed.py::TestDeepSpeedWav2Vec2::test_fp16_non_distributed_zero3_base\r\nPASSED examples/research_projects/wav2vec2/test_wav2vec2_deepspeed.py::TestDeepSpeedWav2Vec2::test_fp16_non_distributed_zero3_robust\r\nPASSED examples/research_projects/wav2vec2/test_wav2vec2_deepspeed.py::TestDeepSpeedWav2Vec2::test_fp32_distributed_zero2_base\r\nPASSED examples/research_projects/wav2vec2/test_wav2vec2_deepspeed.py::TestDeepSpeedWav2Vec2::test_fp32_distributed_zero2_robust\r\nPASSED examples/research_projects/wav2vec2/test_wav2vec2_deepspeed.py::TestDeepSpeedWav2Vec2::test_fp32_distributed_zero3_base\r\nPASSED examples/research_projects/wav2vec2/test_wav2vec2_deepspeed.py::TestDeepSpeedWav2Vec2::test_fp32_distributed_zero3_robust\r\nPASSED examples/research_projects/wav2vec2/test_wav2vec2_deepspeed.py::TestDeepSpeedWav2Vec2::test_fp32_non_distributed_zero2_base\r\nPASSED examples/research_projects/wav2vec2/test_wav2vec2_deepspeed.py::TestDeepSpeedWav2Vec2::test_fp32_non_distributed_zero2_robust\r\nPASSED examples/research_projects/wav2vec2/test_wav2vec2_deepspeed.py::TestDeepSpeedWav2Vec2::test_fp32_non_distributed_zero3_base\r\nPASSED examples/research_projects/wav2vec2/test_wav2vec2_deepspeed.py::TestDeepSpeedWav2Vec2::test_fp32_non_distributed_zero3_robust\r\n================================================================ 16 passed in 491.63s (0:08:11) =================================================================\r\n```\r\n\r\nAlso yours is python-3.9, do you have access to 3.8 by chance to validate if perhaps it's a py39 incompatibility? Mine is 3.8.\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"It's actually solved - thanks for the help :-)"
] | 1,628 | 1,631 | 1,631 | MEMBER | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.10.0.dev0
- Platform: Linux-5.11.0-25-generic-x86_64-with-glibc2.33
- Python version: 3.9.1
- PyTorch version (GPU?): 1.9.0.dev20210217 (True)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: yes
- Deepspeed: 0.4.4
- CUDA Version: 11.2
- GPU: 4 x TITAN RTX
### Who can help
@stas00
## To reproduce
Running the Wav2Vec2 pre-training script: https://github.com/huggingface/transformers/blob/master/examples/research_projects/wav2vec2/README.md#pretraining-wav2vec2
with the versions as defined above (on vorace) yields the following error:
<details>
<summary>Click for error message</summary>
<br>
```
Using amp fp16 backend
[2021-08-08 14:05:34,113] [INFO] [logging.py:68:log_dist] [Rank 0] DeepSpeed info: version=0.4.4, git-hash=unknown, git-branch=unknown
[2021-08-08 14:05:35,930] [INFO] [utils.py:11:_initialize_parameter_parallel_groups] data_parallel_size: 4, parameter_parallel_size: 4
[2021-08-08 14:57:51,866] [INFO] [engine.py:179:__init__] DeepSpeed Flops Profiler Enabled: False
Using /home/patrick/.cache/torch_extensions as PyTorch extensions root...
Creating extension directory /home/patrick/.cache/torch_extensions/cpu_adam...
Using /home/patrick/.cache/torch_extensions as PyTorch extensions root...
Using /home/patrick/.cache/torch_extensions as PyTorch extensions root...
Using /home/patrick/.cache/torch_extensions as PyTorch extensions root...
Detected CUDA files, patching ldflags
Emitting ninja build file /home/patrick/.cache/torch_extensions/cpu_adam/build.ninja...
Building extension module cpu_adam...
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
[1/3] /usr/bin/nvcc --generate-dependencies-with-compile --dependency-output custom_cuda_kernel.cuda.o.d -DTORCH_EXTENSION_NAME=cpu_adam -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_gcc\" -DPYBIND11_STDLIB=\"_libstdcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1011\" -I/home/patrick/anaconda3/envs/hu
gging_face/lib/python3.9/site-packages/deepspeed/ops/csrc/includes -I/usr/include -isystem /home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/include -isystem /home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/include/torch/csrc/api/include -isystem /home/
patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/include/TH -isystem /home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/include/THC -isystem /home/patrick/anaconda3/envs/hugging_face/include/python3.9 -D_GLIBCXX_USE_CXX11_ABI=0 -D__CUDA_NO_HALF_OPERATORS__ -D_
_CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_BFLOAT16_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ --expt-relaxed-constexpr -gencode=arch=compute_75,code=compute_75 -gencode=arch=compute_75,code=sm_75 --compiler-options '-fPIC' -O3 --use_fast_math -std=c++14 -U__CUDA_NO_HALF_OPERATORS__ -U__CUDA_NO_HALF_CONVERS
IONS__ -U__CUDA_NO_HALF2_OPERATORS__ -gencode=arch=compute_75,code=sm_75 -gencode=arch=compute_75,code=compute_75 -c /home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/ops/csrc/adam/custom_cuda_kernel.cu -o custom_cuda_kernel.cuda.o
FAILED: custom_cuda_kernel.cuda.o
/usr/bin/nvcc --generate-dependencies-with-compile --dependency-output custom_cuda_kernel.cuda.o.d -DTORCH_EXTENSION_NAME=cpu_adam -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_gcc\" -DPYBIND11_STDLIB=\"_libstdcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1011\" -I/home/patrick/anaconda3/envs/hugging_
face/lib/python3.9/site-packages/deepspeed/ops/csrc/includes -I/usr/include -isystem /home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/include -isystem /home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/include/torch/csrc/api/include -isystem /home/patric
k/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/include/TH -isystem /home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/include/THC -isystem /home/patrick/anaconda3/envs/hugging_face/include/python3.9 -D_GLIBCXX_USE_CXX11_ABI=0 -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_
NO_HALF_CONVERSIONS__ -D__CUDA_NO_BFLOAT16_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ --expt-relaxed-constexpr -gencode=arch=compute_75,code=compute_75 -gencode=arch=compute_75,code=sm_75 --compiler-options '-fPIC' -O3 --use_fast_math -std=c++14 -U__CUDA_NO_HALF_OPERATORS__ -U__CUDA_NO_HALF_CONVERSIONS__
-U__CUDA_NO_HALF2_OPERATORS__ -gencode=arch=compute_75,code=sm_75 -gencode=arch=compute_75,code=compute_75 -c /home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/ops/csrc/adam/custom_cuda_kernel.cu -o custom_cuda_kernel.cuda.o
/usr/include/c++/10/chrono: In substitution of ‘template<class _Rep, class _Period> template<class _Period2> using __is_harmonic = std::__bool_constant<(std::ratio<((_Period2::num / std::chrono::duration<_Rep, _Period>::_S_gcd(_Period2::num, _Period::num)) * (_Period::den / std::chrono::duration<_Rep, _Pe
riod>::_S_gcd(_Period2::den, _Period::den))), ((_Period2::den / std::chrono::duration<_Rep, _Period>::_S_gcd(_Period2::den, _Period::den)) * (_Period::num / std::chrono::duration<_Rep, _Period>::_S_gcd(_Period2::num, _Period::num)))>::den == 1)> [with _Period2 = _Period2; _Rep = _Rep; _Period = _Period]’:
/usr/include/c++/10/chrono:473:154: required from here
/usr/include/c++/10/chrono:428:27: internal compiler error: Segmentation fault
428 | _S_gcd(intmax_t __m, intmax_t __n) noexcept
| ^~~~~~
Please submit a full bug report,
with preprocessed source if appropriate.
See <file:///usr/share/doc/gcc-10/README.Bugs> for instructions.
[2/3] c++ -MMD -MF cpu_adam.o.d -DTORCH_EXTENSION_NAME=cpu_adam -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_gcc\" -DPYBIND11_STDLIB=\"_libstdcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1011\" -I/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/ops/csrc/includes -I/usr
/include -isystem /home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/include -isystem /home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/include/torch/csrc/api/include -isystem /home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/inc
lude/TH -isystem /home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/include/THC -isystem /home/patrick/anaconda3/envs/hugging_face/include/python3.9 -D_GLIBCXX_USE_CXX11_ABI=0 -fPIC -std=c++14 -O3 -std=c++14 -L/usr/lib64 -lcudart -lcublas -g -Wno-reorder -march=native -fopenmp -D_
_AVX512__ -c /home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/ops/csrc/adam/cpu_adam.cpp -o cpu_adam.o
ninja: build stopped: subcommand failed.
Traceback (most recent call last):
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/utils/cpp_extension.py", line 1662, in _run_ninja_build
subprocess.run(
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/subprocess.py", line 524, in run
raise CalledProcessError(retcode, process.args,
subprocess.CalledProcessError: Command '['ninja', '-v']' returned non-zero exit status 1.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/patrick/hugging_face/transformers/examples/research_projects/wav2vec2/run_pretrain.py", line 394, in <module>
main()
File "/home/patrick/hugging_face/transformers/examples/research_projects/wav2vec2/run_pretrain.py", line 390, in main
trainer.train()
File "/home/patrick/hugging_face/transformers/src/transformers/trainer.py", line 1136, in train
deepspeed_engine, optimizer, lr_scheduler = deepspeed_init(
File "/home/patrick/hugging_face/transformers/src/transformers/deepspeed.py", line 370, in deepspeed_init
model, optimizer, _, lr_scheduler = deepspeed.initialize(
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/__init__.py", line 126, in initialize
engine = DeepSpeedEngine(args=args,
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/runtime/engine.py", line 194, in __init__
self._configure_optimizer(optimizer, model_parameters)
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/runtime/engine.py", line 709, in _configure_optimizer
basic_optimizer = self._configure_basic_optimizer(model_parameters)
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/runtime/engine.py", line 778, in _configure_basic_optimizer
optimizer = DeepSpeedCPUAdam(model_parameters,
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/ops/adam/cpu_adam.py", line 79, in __init__
self.ds_opt_adam = CPUAdamBuilder().load()
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/ops/op_builder/builder.py", line 347, in load
return self.jit_load(verbose)
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/ops/op_builder/builder.py", line 379, in jit_load
op_module = load(
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/utils/cpp_extension.py", line 1074, in load
return _jit_compile(
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/utils/cpp_extension.py", line 1287, in _jit_compile
_write_ninja_file_and_build_library(
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/utils/cpp_extension.py", line 1399, in _write_ninja_file_and_build_library
_run_ninja_build(
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/utils/cpp_extension.py", line 1678, in _run_ninja_build
raise RuntimeError(message) from e
RuntimeError: Error building extension 'cpu_adam'
Loading extension module cpu_adam...
Traceback (most recent call last):
File "/home/patrick/hugging_face/transformers/examples/research_projects/wav2vec2/run_pretrain.py", line 394, in <module>
main()
File "/home/patrick/hugging_face/transformers/examples/research_projects/wav2vec2/run_pretrain.py", line 390, in main
trainer.train()
File "/home/patrick/hugging_face/transformers/src/transformers/trainer.py", line 1136, in train
deepspeed_engine, optimizer, lr_scheduler = deepspeed_init(
File "/home/patrick/hugging_face/transformers/src/transformers/deepspeed.py", line 370, in deepspeed_init
model, optimizer, _, lr_scheduler = deepspeed.initialize(
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/__init__.py", line 126, in initialize
engine = DeepSpeedEngine(args=args,
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/runtime/engine.py", line 194, in __init__
self._configure_optimizer(optimizer, model_parameters)
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/runtime/engine.py", line 709, in _configure_optimizer
basic_optimizer = self._configure_basic_optimizer(model_parameters)
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/runtime/engine.py", line 778, in _configure_basic_optimizer
optimizer = DeepSpeedCPUAdam(model_parameters,
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/ops/adam/cpu_adam.py", line 79, in __init__
self.ds_opt_adam = CPUAdamBuilder().load()
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/ops/op_builder/builder.py", line 347, in load
return self.jit_load(verbose)
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/ops/op_builder/builder.py", line 379, in jit_load
op_module = load(
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/utils/cpp_extension.py", line 1074, in load
return _jit_compile(
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/utils/cpp_extension.py", line 1312, in _jit_compile
return _import_module_from_library(name, build_directory, is_python_module)
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/utils/cpp_extension.py", line 1694, in _import_module_from_library
file, path, description = imp.find_module(module_name, [path])
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/imp.py", line 296, in find_module
raise ImportError(_ERR_MSG.format(name), name=name)
ImportError: No module named 'cpu_adam'
Loading extension module cpu_adam...
Traceback (most recent call last):
File "/home/patrick/hugging_face/transformers/examples/research_projects/wav2vec2/run_pretrain.py", line 394, in <module>
main()
File "/home/patrick/hugging_face/transformers/examples/research_projects/wav2vec2/run_pretrain.py", line 390, in main
trainer.train()
File "/home/patrick/hugging_face/transformers/src/transformers/trainer.py", line 1136, in train
deepspeed_engine, optimizer, lr_scheduler = deepspeed_init(
File "/home/patrick/hugging_face/transformers/src/transformers/deepspeed.py", line 370, in deepspeed_init
model, optimizer, _, lr_scheduler = deepspeed.initialize(
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/__init__.py", line 126, in initialize
engine = DeepSpeedEngine(args=args,
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/runtime/engine.py", line 194, in __init__
self._configure_optimizer(optimizer, model_parameters)
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/runtime/engine.py", line 709, in _configure_optimizer
basic_optimizer = self._configure_basic_optimizer(model_parameters)
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/runtime/engine.py", line 778, in _configure_basic_optimizer
optimizer = DeepSpeedCPUAdam(model_parameters,
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/ops/adam/cpu_adam.py", line 79, in __init__
self.ds_opt_adam = CPUAdamBuilder().load()
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/ops/op_builder/builder.py", line 347, in load
return self.jit_load(verbose)
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/ops/op_builder/builder.py", line 379, in jit_load
op_module = load(
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/utils/cpp_extension.py", line 1074, in load
return _jit_compile(
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/utils/cpp_extension.py", line 1312, in _jit_compile
return _import_module_from_library(name, build_directory, is_python_module)
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/torch/utils/cpp_extension.py", line 1694, in _import_module_from_library
file, path, description = imp.find_module(module_name, [path])
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/imp.py", line 296, in find_module
raise ImportError(_ERR_MSG.format(name), name=name)
ImportError: No module named 'cpu_adam'
Exception ignored in: <function DeepSpeedCPUAdam.__del__ at 0x7f1a372f01f0>
Traceback (most recent call last):
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/ops/adam/cpu_adam.py", line 93, in __del__
self.ds_opt_adam.destroy_adam(self.opt_id)
AttributeError: 'DeepSpeedCPUAdam' object has no attribute 'ds_opt_adam'
Exception ignored in: <function DeepSpeedCPUAdam.__del__ at 0x7f961a8561f0>
Traceback (most recent call last):
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/ops/adam/cpu_adam.py", line 93, in __del__
self.ds_opt_adam.destroy_adam(self.opt_id)
AttributeError: 'DeepSpeedCPUAdam' object has no attribute 'ds_opt_adam'
Exception ignored in: <function DeepSpeedCPUAdam.__del__ at 0x7fcc1f2be1f0>
Traceback (most recent call last):
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/ops/adam/cpu_adam.py", line 93, in __del__
self.ds_opt_adam.destroy_adam(self.opt_id)
AttributeError: 'DeepSpeedCPUAdam' object has no attribute 'ds_opt_adam'
Exception ignored in: <function DeepSpeedCPUAdam.__del__ at 0x7f5bbf5cc1f0>
Traceback (most recent call last):
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/ops/adam/cpu_adam.py", line 93, in __del__
AttributeError: 'DeepSpeedCPUAdam' object has no attribute 'ds_opt_adam'
Killing subprocess 1135563
Killing subprocess 1135564
Killing subprocess 1135565
Killing subprocess 1135566
Traceback (most recent call last):
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/runpy.py", line 197, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/launcher/launch.py", line 171, in <module>
main()
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deepspeed/launcher/launch.py", line 161, in main
sigkill_handler(signal.SIGTERM, None) # not coming back
File "/home/patrick/anaconda3/envs/hugging_face/lib/python3.9/site-packages/deep
```
</details>
## Expected behavior
The script should run without problem.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13043/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13043/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13042 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13042/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13042/comments | https://api.github.com/repos/huggingface/transformers/issues/13042/events | https://github.com/huggingface/transformers/pull/13042 | 963,439,918 | MDExOlB1bGxSZXF1ZXN0NzA2MDQ5MTk0 | 13,042 | Squad bert | {
"login": "kamfonas",
"id": 13737870,
"node_id": "MDQ6VXNlcjEzNzM3ODcw",
"avatar_url": "https://avatars.githubusercontent.com/u/13737870?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kamfonas",
"html_url": "https://github.com/kamfonas",
"followers_url": "https://api.github.com/users/kamfonas/followers",
"following_url": "https://api.github.com/users/kamfonas/following{/other_user}",
"gists_url": "https://api.github.com/users/kamfonas/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kamfonas/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kamfonas/subscriptions",
"organizations_url": "https://api.github.com/users/kamfonas/orgs",
"repos_url": "https://api.github.com/users/kamfonas/repos",
"events_url": "https://api.github.com/users/kamfonas/events{/privacy}",
"received_events_url": "https://api.github.com/users/kamfonas/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Please disregard. "
] | 1,628 | 1,628 | 1,628 | NONE | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13042/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13042/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13042",
"html_url": "https://github.com/huggingface/transformers/pull/13042",
"diff_url": "https://github.com/huggingface/transformers/pull/13042.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13042.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/13041 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13041/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13041/comments | https://api.github.com/repos/huggingface/transformers/issues/13041/events | https://github.com/huggingface/transformers/issues/13041 | 963,423,018 | MDU6SXNzdWU5NjM0MjMwMTg= | 13,041 | Script to convert the bart model from pytorch checkpoint to tensorflow checkpoint | {
"login": "mazicwong",
"id": 17029801,
"node_id": "MDQ6VXNlcjE3MDI5ODAx",
"avatar_url": "https://avatars.githubusercontent.com/u/17029801?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mazicwong",
"html_url": "https://github.com/mazicwong",
"followers_url": "https://api.github.com/users/mazicwong/followers",
"following_url": "https://api.github.com/users/mazicwong/following{/other_user}",
"gists_url": "https://api.github.com/users/mazicwong/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mazicwong/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mazicwong/subscriptions",
"organizations_url": "https://api.github.com/users/mazicwong/orgs",
"repos_url": "https://api.github.com/users/mazicwong/repos",
"events_url": "https://api.github.com/users/mazicwong/events{/privacy}",
"received_events_url": "https://api.github.com/users/mazicwong/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | CONTRIBUTOR | null | # Feature request
Request for a script to convert the bart model from pytorch checkpoint to tensorflow checkpoint
# Solution
https://github.com/huggingface/transformers/blob/master/src/transformers/convert_pytorch_checkpoint_to_tf2.py | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13041/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13041/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13040 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13040/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13040/comments | https://api.github.com/repos/huggingface/transformers/issues/13040/events | https://github.com/huggingface/transformers/pull/13040 | 963,399,896 | MDExOlB1bGxSZXF1ZXN0NzA2MDE3OTc0 | 13,040 | Add try-except for torch_scatter | {
"login": "JetRunner",
"id": 22514219,
"node_id": "MDQ6VXNlcjIyNTE0MjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/22514219?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JetRunner",
"html_url": "https://github.com/JetRunner",
"followers_url": "https://api.github.com/users/JetRunner/followers",
"following_url": "https://api.github.com/users/JetRunner/following{/other_user}",
"gists_url": "https://api.github.com/users/JetRunner/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JetRunner/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JetRunner/subscriptions",
"organizations_url": "https://api.github.com/users/JetRunner/orgs",
"repos_url": "https://api.github.com/users/JetRunner/repos",
"events_url": "https://api.github.com/users/JetRunner/events{/privacy}",
"received_events_url": "https://api.github.com/users/JetRunner/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I don't think this will work. It's a `RuntimeError` being raised by `torch_scatter`, not an `OSError`. See the specific code at [line 59 of `__init__.py`](https://github.com/rusty1s/pytorch_scatter/blob/2.0.8/torch_scatter/__init__.py#L59). Also, this replaces the existing informative error message from `torch_scatter` with a less informative one.",
"@aphedges Thanks for the note - I have edited the description that does not indicate the association with your issue anymore. Also, the intention of this PR is to simply circumvent the error since in most cases, people just don't use TAPAS but still get blocked by this error.\r\n\r\nAlso, the original `torch_scatter` error message is not informative at all. It just says some file cannot be located and after some googling, I realize it's due to the CUDA version. So I'm basically replacing that with my googled solution.",
"@JetRunner, thanks for editing the description!\r\n\r\nSorry about my note about `RuntimeError` vs. `OSError` earlier. I think I got confused by the fact that `torch-scatter` explicitly throws a runtime error for some CUDA version mismatches, but the error you're logging here is for a different CUDA version mismatch that doesn't have a good error message. I think I had to google this one, too, so your error message is definitely an improvement."
] | 1,628 | 1,628 | 1,628 | CONTRIBUTOR | null | Add an error message for the CUDA version mismatch of `torch_scatter`.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13040/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13040/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13040",
"html_url": "https://github.com/huggingface/transformers/pull/13040",
"diff_url": "https://github.com/huggingface/transformers/pull/13040.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13040.patch",
"merged_at": 1628580575000
} |
https://api.github.com/repos/huggingface/transformers/issues/13039 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13039/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13039/comments | https://api.github.com/repos/huggingface/transformers/issues/13039/events | https://github.com/huggingface/transformers/pull/13039 | 963,379,401 | MDExOlB1bGxSZXF1ZXN0NzA2MDAyNDQw | 13,039 | Remove usage of local variables related with model parallel and move … | {
"login": "hyunwoongko",
"id": 38183241,
"node_id": "MDQ6VXNlcjM4MTgzMjQx",
"avatar_url": "https://avatars.githubusercontent.com/u/38183241?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hyunwoongko",
"html_url": "https://github.com/hyunwoongko",
"followers_url": "https://api.github.com/users/hyunwoongko/followers",
"following_url": "https://api.github.com/users/hyunwoongko/following{/other_user}",
"gists_url": "https://api.github.com/users/hyunwoongko/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hyunwoongko/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hyunwoongko/subscriptions",
"organizations_url": "https://api.github.com/users/hyunwoongko/orgs",
"repos_url": "https://api.github.com/users/hyunwoongko/repos",
"events_url": "https://api.github.com/users/hyunwoongko/events{/privacy}",
"received_events_url": "https://api.github.com/users/hyunwoongko/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Most of these modifications are encoder-decoder models from Bart's code and encoder models that has token type id. As you said, it is difficult to work on all models at once, so I will exclude the case where the model needs to be modified. I also agree that modifying multiple models at the same time makes it difficult to test. First, let's start with one decoder model like GPT-Neo. I will close this PR and upload a new one soon.",
"One more note: besides the dozens of models we also have a template. In this case it's mostly: https://github.com/huggingface/transformers/blob/master/templates/adding_a_new_model/cookiecutter-template-%7B%7Bcookiecutter.modelname%7D%7D/modeling_%7B%7Bcookiecutter.lowercase_modelname%7D%7D.py so when all is happy here, please let's not forget to apply the changes there as well.\r\n",
"I would like an approach that that does one model first, so we can clearly comment on the design, then all models after (unless it's very different for each model in which case, similar models by similar models if that makes sense).\r\n\r\nAs for the changes in themselves, I would need a clear explanation as to why the `token_type_ids` device need to be changed from the position_ids device. That kind of code should not be present in the modeling files as is, as people adding or tweaking models won't need/understand it. We can abstract away things in `PreTrainedModel` as you suggest @stas00, that seems like a better approach. Or maybe a method that creates those `token_type_ids` properly, at the very least."
] | 1,628 | 1,628 | 1,628 | CONTRIBUTOR | null | # What does this PR do?
This PR is related with [model parallel integration from Parallelformers](https://github.com/huggingface/transformers/issues/12772).
You can check detail of PR here: https://github.com/tunib-ai/parallelformers/issues/11#issuecomment-894719918
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@stas00
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13039/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13039/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13039",
"html_url": "https://github.com/huggingface/transformers/pull/13039",
"diff_url": "https://github.com/huggingface/transformers/pull/13039.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13039.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/13038 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13038/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13038/comments | https://api.github.com/repos/huggingface/transformers/issues/13038/events | https://github.com/huggingface/transformers/issues/13038 | 963,361,685 | MDU6SXNzdWU5NjMzNjE2ODU= | 13,038 | Check in PreTrainedTokenizer can cause incorrect tokenization | {
"login": "codedecde",
"id": 10473264,
"node_id": "MDQ6VXNlcjEwNDczMjY0",
"avatar_url": "https://avatars.githubusercontent.com/u/10473264?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/codedecde",
"html_url": "https://github.com/codedecde",
"followers_url": "https://api.github.com/users/codedecde/followers",
"following_url": "https://api.github.com/users/codedecde/following{/other_user}",
"gists_url": "https://api.github.com/users/codedecde/gists{/gist_id}",
"starred_url": "https://api.github.com/users/codedecde/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/codedecde/subscriptions",
"organizations_url": "https://api.github.com/users/codedecde/orgs",
"repos_url": "https://api.github.com/users/codedecde/repos",
"events_url": "https://api.github.com/users/codedecde/events{/privacy}",
"received_events_url": "https://api.github.com/users/codedecde/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"May be of interest to @SaulLu ",
"Thank you very much for the detailed issue @codedecde !\r\n\r\nThis check had been integrated to solve non-deterministic tokenization problems and I think this solution had been retained because we did not see a use case at the time to tokenize a sentence containing only spaces (see [issue](https://github.com/huggingface/transformers/issues/2027) and [PR](https://github.com/huggingface/transformers/pull/2081)). \r\n\r\nCould you please explain in which case you need to tokenize a sentence containing only a space? Thank you very much in advance!",
"Hi @SaulLu.\r\nThank you for responding, and really sorry for the late response. \r\nMy use-case is a little niche. I am training byte level encoder models. In order to do the masking, I am using a BPE tokenizer with dropout, and remapping it back to the byte level.\r\nEg: \r\n```[python]\r\ntokenized = tokenizer.tokenize(\"Huggingface is awesome\")\r\n# ['Hug', 'ging', 'face', 'Ġ', 'is', 'Ġawesome']\r\ninputs_with_mask, masked_tokens = mask_function(tokenized)\r\n# ['Hug', 'ging', <mask>, **<mask>**, 'is', 'Ġawesome'], [<pad>, <pad>, 'face', **'Ġ',** <pad>, <pad>]\r\n# The marked 'Ġ' token will get destroyed later because of the issue\r\ndecoded_text = byte_tokenizer.decode(inputs_with_mask)\r\n# Hugging<mask><**mask>**is awesome\r\nmodel_inputs, model_outputs = byte_tokenizer.encode(decoded_text, masked_tokens)\r\n# ['H', 'u', 'g', 'g', 'i', 'n', 'g', <mask>, <mask>, <mask>, <mask>, **<mask>**, 'i', 's', ' ', 'a', 'w', 'e', 's', 'o', 'm', 'e']\r\n# model_outputs = [<pad>,<pad>,<pad>,<pad>,<pad>,<pad>,<pad>, 'f', 'a', 'c', 'e', **''**, <pad>, ...]\r\n```\r\nIn the above example, the mask inclosed between ** ** and its associated label are impacted by the problem mentioned. \r\nSince it is a niche use-case, having this as a kwarg flag enabled behaviour would be quite helpful (eg: by default, trailing and leading spaces are always stripped out, except when the flag is set to true ). ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,632 | 1,632 | NONE | null | ## Environment info
- `transformers` version: 4.5.1
- Platform: Linux-5.4.0-1047-azure-x86_64-with-glibc2.10
- Python version: 3.8.8
- PyTorch version (GPU?): 1.9.0a0+2ecb2c7 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: NA
- Using distributed or parallel set-up in script?: NA
### Who can help
@LysandreJik
## Information
[This check](https://github.com/huggingface/transformers/blob/7fcee113c163a95d1b125ef35dc49a0a1aa13a50/src/transformers/tokenization_utils.py#L336) in `PreTrainedTokenizer` can cause incorrect tokenization (and subsequent encoding) for space only sequences (or sequences with leading and trailing spaces). This can be problematic for byte only models (byT5 etc.), can cause inconsistent tokenizations between `Tokenzer` and `TokenizerFast` classes and can cause issues wherever the code assumes non-destructive behaviour of a tokenizer.
## To reproduce
Steps to reproduce the behavior:
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("roberta-base", use_fast=False)
tokenizer_fast = AutoTokenizer.from_pretrained("roberta-base")
# Correct Tokenization
out = tokenizer_fast.tokenize(' ')
# The above results in ['Ġ'], which is correct
# Incorrect Tokenization
out = tokenizer.tokenize(' ')
# The above results in [], which is incorrect
# Example 2.
assert ' ' == tokenizer.decode(tokenizer.encode(' ', add_special_tokens=False)) # This will fail, since '' != ' '
```
## Expected behavior
Leading and trailing spaces should be considered during tokenization, especially for non-destructive tokenizers.
## Proposed Solution
Changing the check from
```python
if not text.strip():
return []
```
To
```python
if len(text) == 0: # or if not text:
return []
```
should be okay.
Alternatively, having a flag (eg: remove_extra_whitespaces), and enabling the current behaviour only for the case when the flag is passed as True would also work.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13038/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/13038/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13037 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13037/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13037/comments | https://api.github.com/repos/huggingface/transformers/issues/13037/events | https://github.com/huggingface/transformers/issues/13037 | 963,328,784 | MDU6SXNzdWU5NjMzMjg3ODQ= | 13,037 | Spanish NER bad extraction | {
"login": "diego6662",
"id": 56988887,
"node_id": "MDQ6VXNlcjU2OTg4ODg3",
"avatar_url": "https://avatars.githubusercontent.com/u/56988887?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/diego6662",
"html_url": "https://github.com/diego6662",
"followers_url": "https://api.github.com/users/diego6662/followers",
"following_url": "https://api.github.com/users/diego6662/following{/other_user}",
"gists_url": "https://api.github.com/users/diego6662/gists{/gist_id}",
"starred_url": "https://api.github.com/users/diego6662/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/diego6662/subscriptions",
"organizations_url": "https://api.github.com/users/diego6662/orgs",
"repos_url": "https://api.github.com/users/diego6662/repos",
"events_url": "https://api.github.com/users/diego6662/events{/privacy}",
"received_events_url": "https://api.github.com/users/diego6662/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hello! Did you try with the `aggregation_strategy` parameter as mentioned in the [docs](https://huggingface.co/transformers/main_classes/pipelines.html#tokenclassificationpipeline)?",
"No, I used grouped_entities but I saw that it is deprecated, thanks, I will try it with the aggregation_strategy"
] | 1,628 | 1,628 | 1,628 | NONE | null | ## Environment info
- `transformers` version: 4.9.1
- Platform: linux-ubuntu 20.04.2 LTS x86_64
- Python version: 3.7.6
- PyTorch version (GPU?): No
- Tensorflow version (GPU?): No
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Details
I used this hugginface model for NER extraction https://huggingface.co/mrm8488/bert-spanish-cased-finetuned-ner
Input: "Efrain Avella"
Expected output : {
"entity_group": "PER",
"score": 0.9992852807044983,
"word": "Efrain Avella",
"start": 0,
"end": 12
}
Transformers output: {
"entity_group": "PER",
"score": 0.9990411400794983,
"word": "E",
"start": 0,
"end": 1
},
{
"entity_group": "PER",
"score": 0.8103020787239075,
"word": "##frain Avella",
"start": 1,
"end": 13
}
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13037/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13037/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13036 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13036/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13036/comments | https://api.github.com/repos/huggingface/transformers/issues/13036/events | https://github.com/huggingface/transformers/issues/13036 | 963,308,782 | MDU6SXNzdWU5NjMzMDg3ODI= | 13,036 | Do the Trainer docs need an update? | {
"login": "UrosOgrizovic",
"id": 25843402,
"node_id": "MDQ6VXNlcjI1ODQzNDAy",
"avatar_url": "https://avatars.githubusercontent.com/u/25843402?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/UrosOgrizovic",
"html_url": "https://github.com/UrosOgrizovic",
"followers_url": "https://api.github.com/users/UrosOgrizovic/followers",
"following_url": "https://api.github.com/users/UrosOgrizovic/following{/other_user}",
"gists_url": "https://api.github.com/users/UrosOgrizovic/gists{/gist_id}",
"starred_url": "https://api.github.com/users/UrosOgrizovic/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/UrosOgrizovic/subscriptions",
"organizations_url": "https://api.github.com/users/UrosOgrizovic/orgs",
"repos_url": "https://api.github.com/users/UrosOgrizovic/repos",
"events_url": "https://api.github.com/users/UrosOgrizovic/events{/privacy}",
"received_events_url": "https://api.github.com/users/UrosOgrizovic/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"cc @sgugger ",
"Sure, would you mind making a PR with that?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,631 | 1,631 | NONE | null | On [this](https://huggingface.co/transformers/main_classes/trainer.html) documentation page regarding `Trainer`, `torch.utils.data.dataset.Dataset` is mentioned. However, I can only seem to find `torch.utils.data.Dataset` [here](https://pytorch.org/docs/stable/data.html#torch.utils.data.Dataset). Do the docs require an update?
The same goes for `IterableDataset`, on the same page. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13036/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13036/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13035 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13035/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13035/comments | https://api.github.com/repos/huggingface/transformers/issues/13035/events | https://github.com/huggingface/transformers/issues/13035 | 963,161,824 | MDU6SXNzdWU5NjMxNjE4MjQ= | 13,035 | Rotate checkpoint `shutil.rmtree(checkpoint)` fails | {
"login": "sbmaruf",
"id": 32699797,
"node_id": "MDQ6VXNlcjMyNjk5Nzk3",
"avatar_url": "https://avatars.githubusercontent.com/u/32699797?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sbmaruf",
"html_url": "https://github.com/sbmaruf",
"followers_url": "https://api.github.com/users/sbmaruf/followers",
"following_url": "https://api.github.com/users/sbmaruf/following{/other_user}",
"gists_url": "https://api.github.com/users/sbmaruf/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sbmaruf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sbmaruf/subscriptions",
"organizations_url": "https://api.github.com/users/sbmaruf/orgs",
"repos_url": "https://api.github.com/users/sbmaruf/repos",
"events_url": "https://api.github.com/users/sbmaruf/events{/privacy}",
"received_events_url": "https://api.github.com/users/sbmaruf/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This code is only called from the main process (controlled by [this test](https://github.com/huggingface/transformers/blob/24cbf6bc5a0b6a9bb5afdda6bb1a329ac980fa4b/src/transformers/trainer.py#L1593)) so it's a not a distributed barrier issue.\r\n\r\nUnless you are using AWS SageMaker with the model parallel extension, that `should_save` is only True for the local main process (or main process). Could you please give us more information to reproduce the bug?",
"I didn't use `AWS SageMaker`. Since you requested for more information, I started to think about a minimal example. The codebase I was working with is too large and contains redundant codes.\r\nI took the script `run_summarization.py` and tried running with my environment. What happened that my transformers version was `4.6.0` from this [branch](https://github.com/huggingface/transformers/tree/t5-fp16-no-nans). I change my `tranformers` to `4.10.0.dev0` and the problem goes away. I could not reproduce the error.\r\nClosing the issue for the time being. If I face the same error, I will open the issue again. ",
"Ah, if you were on an older version, the barrier may not have been there, yes."
] | 1,628 | 1,628 | 1,628 | NONE | null | I was training `google/mt5-xl` model with `deepspeed` by huggingface trainer. The training was done in an aws `p3dn.24xlarge` node with 8V100 GPUs.
Trainer fails when [_rotate_checkpoints](https://github.com/huggingface/transformers/blob/7fcee113c163a95d1b125ef35dc49a0a1aa13a50/src/transformers/trainer.py#L1982) is called. Specifically in this [line](https://github.com/huggingface/transformers/blob/7fcee113c163a95d1b125ef35dc49a0a1aa13a50/src/transformers/trainer.py#L2005).
Apparently `shutil.rmtree` has this known [issue](https://github.com/ansible/ansible/issues/34335).
Error Traceback:
```
Traceback (most recent call last):
File "src/train.py", line 93, in <module>
main()
File "src/train.py", line 74, in main
resume_from_checkpoint=checkpoint,
File "transformers/src/transformers/trainer.py", line 1328, in train
self._maybe_log_save_evaluate(tr_loss, model, trial, epoch)
File "transformers/src/transformers/trainer.py", line 1409, in _maybe_log_save_evaluate
self._save_checkpoint(model, trial, metrics=metrics)
File "transformers/src/transformers/trainer.py", line 1528, in _save_checkpoint
self._rotate_checkpoints(use_mtime=True, output_dir=run_dir)
File "transformers/src/transformers/trainer.py", line 1954, in _rotate_checkpoints
shutil.rmtree(checkpoint)
File "/usr/lib/python3.6/shutil.py", line 490, in rmtree
onerror(os.rmdir, path, sys.exc_info())
File "/usr/lib/python3.6/shutil.py", line 488, in rmtree
os.rmdir(path)
OSError: [Errno 39] Directory not empty: '/en-google_mt5-xl-1e-5-1234/checkpoint-320'
```
May be a `distributed barrier` is required for this to work properly.
@stas00 @sgugger | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13035/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13035/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13034 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13034/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13034/comments | https://api.github.com/repos/huggingface/transformers/issues/13034/events | https://github.com/huggingface/transformers/issues/13034 | 963,108,080 | MDU6SXNzdWU5NjMxMDgwODA= | 13,034 | transformers-cli depends on torchaudio optional deps | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This looks like `torchaudio` is installed without `sndfile`, in which case there is little we can do on our side. If `torchaudio` is not installed, this code is not executed and the command runs normally, just tried in an environment with or without it.\r\n\r\nI would need more to reproduce the problem if I misdiagnosed the issue.",
"right, it didn't get installed, because `sndfile` is not in `torchaudio` requirements. Only some of its modules require `sndfile` and that's why it's made optional. At least that's the answer I got on torchaudio slack, where I asked first.\r\n\r\nSpecifically on JZ, I don't think we need `torchaudio` so it's probably safe to just remove it. But it might not be the case for other envs.\r\n\r\nIf you can't think of a way to overcome this let's close this then. Thank you for looking into this, @sgugger ",
"Ah understood then. Not sure how we can check a bit better for the `is_torch_audio_available` check. It should make sure \"Soundfile\" is installed too maybe? What do you think @patrickvonplaten ?",
"That's a great idea! It should probably include checks for all the optional torchaudio deps that transformers audio models use.\r\n\r\nBut also why does `transformers-cli` need to load everything? It has nothing to do with the specific models.",
"Yeah I think it's a good idea as well!",
"cc https://github.com/huggingface/transformers/issues/12509",
"Yeah I don't think `transformers-cli` needs to load all optional packages either",
"I'll have a look as to why it's trying to load this model later today.",
"Ok I have dived into it a bit and here is the diagnostic. `transformers-cli env` in it self runs `transformers.commands.env` which doesn't import anything by itself (apart from the version and a few functions in `file_utils`).\r\n\r\n*But* `transformers-cli` in itself imports all the commands (even if we only use env), in particular `run` which requires the pipeline. Now since #13023 this import does not import all the models anymore, so the bug in itself is resolved (if you could try again on your env with the problem @stas00 that would be great).",
"Hi - So the underlying problem in torchaudio is that torchaudio assumed that `soundfile` is either installed fine or not, but apparently there is a third state where `soundfile` is installed yet the underlying `libsndfile` is not available. On our end, we will make sure this third state is in consideration so that `import torchaudio` would not raise an error in this case.",
"> Ok I have dived into it a bit and here is the diagnostic. `transformers-cli env` in it self runs `transformers.commands.env` which doesn't import anything by itself (apart from the version and a few functions in `file_utils`).\r\n> \r\n> _But_ `transformers-cli` in itself imports all the commands (even if we only use env), in particular `run` which requires the pipeline. Now since #13023 this import does not import all the models anymore, so the bug in itself is resolved (if you could try again on your env with the problem @stas00 that would be great).\r\n\r\nI updated to master and confirm that this solved the problem. Thanks a lot, @sgugger!\r\n\r\n> Hi - So the underlying problem in torchaudio is that torchaudio assumed that `soundfile` is either installed fine or not, but apparently there is a third state where `soundfile` is installed yet the underlying `libsndfile` is not available. On our end, we will make sure this third state is in consideration so that `import torchaudio` would not raise an error in this case.\r\n\r\nThat's really useful, thank you for implementing this, @mthrok!\r\n"
] | 1,628 | 1,628 | 1,628 | CONTRIBUTOR | null | Looks like we somewhere load some imports that shouldn't be imported when invoking `transformers-cli`
Traceback:
```
transformers-cli login
2021-08-06 01:24:22.009842: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcudart.so.11.0
Traceback (most recent call last):
File "/gpfswork/rech/six/commun/conda/hf-prod/bin/transformers-cli", line 33, in <module>
sys.exit(load_entry_point('transformers', 'console_scripts', 'transformers-cli')())
File "/gpfswork/rech/six/commun/conda/hf-prod/bin/transformers-cli", line 25, in importlib_load_entry_point
return next(matches).load()
File "/gpfswork/rech/six/commun/conda/hf-prod/lib/python3.8/importlib/metadata.py", line 77, in load
module = import_module(match.group('module'))
File "/gpfswork/rech/six/commun/conda/hf-prod/lib/python3.8/importlib/__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1014, in _gcd_import
File "<frozen importlib._bootstrap>", line 991, in _find_and_load
File "<frozen importlib._bootstrap>", line 975, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 671, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 848, in exec_module
File "<frozen importlib._bootstrap>", line 219, in _call_with_frames_removed
File "/gpfsssd/worksf/projects/rech/six/commun/code/transformers/src/transformers/commands/transformers_cli.py", line 23, in <module>
from .run import RunCommand
File "/gpfsssd/worksf/projects/rech/six/commun/code/transformers/src/transformers/commands/run.py", line 17, in <module>
from ..pipelines import SUPPORTED_TASKS, TASK_ALIASES, Pipeline, PipelineDataFormat, pipeline
File "/gpfsssd/worksf/projects/rech/six/commun/code/transformers/src/transformers/pipelines/__init__.py", line 26, in <module>
from ..models.auto.feature_extraction_auto import FEATURE_EXTRACTOR_MAPPING, AutoFeatureExtractor
File "/gpfsssd/worksf/projects/rech/six/commun/code/transformers/src/transformers/models/auto/feature_extraction_auto.py", line 20, in <module>
from transformers import DeiTFeatureExtractor, Speech2TextFeatureExtractor, ViTFeatureExtractor
File "<frozen importlib._bootstrap>", line 1039, in _handle_fromlist
File "/gpfsssd/worksf/projects/rech/six/commun/code/transformers/src/transformers/file_utils.py", line 1978, in __getattr__
value = getattr(module, name)
File "/gpfsssd/worksf/projects/rech/six/commun/code/transformers/src/transformers/file_utils.py", line 1977, in __getattr__
module = self._get_module(self._class_to_module[name])
File "/gpfsssd/worksf/projects/rech/six/commun/code/transformers/src/transformers/file_utils.py", line 1986, in _get_module
return importlib.import_module("." + module_name, self.__name__)
File "/gpfswork/rech/six/commun/conda/hf-prod/lib/python3.8/importlib/__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "/gpfsssd/worksf/projects/rech/six/commun/code/transformers/src/transformers/models/speech_to_text/feature_extraction_speech_to_text.py", line 23, in <module>
import torchaudio.compliance.kaldi as ta_kaldi
File "/gpfswork/rech/six/commun/conda/hf-prod/lib/python3.8/site-packages/torchaudio/__init__.py", line 15, in <module>
from torchaudio.backend import (
File "/gpfswork/rech/six/commun/conda/hf-prod/lib/python3.8/site-packages/torchaudio/backend/__init__.py", line 2, in <module>
from . import utils
File "/gpfswork/rech/six/commun/conda/hf-prod/lib/python3.8/site-packages/torchaudio/backend/utils.py", line 7, in <module>
from . import (
File "/gpfswork/rech/six/commun/conda/hf-prod/lib/python3.8/site-packages/torchaudio/backend/soundfile_backend.py", line 15, in <module>
import soundfile
File "/gpfswork/rech/six/commun/conda/hf-prod/lib/python3.8/site-packages/soundfile.py", line 142, in <module>
raise OSError('sndfile library not found')
OSError: sndfile library not found
```
`sndfile` is an optional dependency of `torchaudio`, so it might not be installed.
Thank you!
I'm pretty sure it's a recent version, but it wasn't me who had this problem, so pasting it as it was given to me. This comes from JeanZay - I installed `libsndfile` to overcome it as a temp workfix. But this tool is a "long way" from needing `libsndfile` to function properly - functionality-wise.
update:
```
python -c "import transformers; print(transformers.__version__)"
4.10.0.dev0
```
@sgugger | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13034/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13034/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13033 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13033/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13033/comments | https://api.github.com/repos/huggingface/transformers/issues/13033/events | https://github.com/huggingface/transformers/issues/13033 | 963,018,735 | MDU6SXNzdWU5NjMwMTg3MzU= | 13,033 | Getting near constant training loss, T5 not learning anything? | {
"login": "prikmm",
"id": 47216475,
"node_id": "MDQ6VXNlcjQ3MjE2NDc1",
"avatar_url": "https://avatars.githubusercontent.com/u/47216475?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/prikmm",
"html_url": "https://github.com/prikmm",
"followers_url": "https://api.github.com/users/prikmm/followers",
"following_url": "https://api.github.com/users/prikmm/following{/other_user}",
"gists_url": "https://api.github.com/users/prikmm/gists{/gist_id}",
"starred_url": "https://api.github.com/users/prikmm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/prikmm/subscriptions",
"organizations_url": "https://api.github.com/users/prikmm/orgs",
"repos_url": "https://api.github.com/users/prikmm/repos",
"events_url": "https://api.github.com/users/prikmm/events{/privacy}",
"received_events_url": "https://api.github.com/users/prikmm/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"In my case, TPU's BF16 datatype caused a fixed loss value. did you use BF16 for training?",
"> In my case, TPU's BF16 datatype caused a fixed loss value. did you use BF16 for training?\r\n\r\nHey @CryptoSalamander, thanks for your reply. I finally found out the issue. My LR was 0.0, I was under the impression that, `AdaSchedule` would use the `lr` in optimizer and change with every step. But, when we use AdaSchedule, we have to pass in the `initial_lr` or it will default to 0.0 and since relative updates were false (as per the recommendation), the lr remained constant at 0.0."
] | 1,628 | 1,628 | 1,628 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.9.0/4.9.1
- Platform: Colab/Kaggle
- Python version: 3.7.11
- PyTorch version (GPU?): TPU - 1.8.0a0+56b43f4
- Tensorflow version (GPU?): TPU - 2.5.0
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@patil-suraj, @sgugger
## Information
Model I am using (Bert, XLNet ...): T5
I am trying to finetune T5 on XSum using TPU, but getting near constant training loss and constant validation loss. It's like the model is not learning anything. I tried `t5-small`, `t5-base`, `t5-large`(on kaggle), `google/t5-v1_1-small`, `google/t5-v1_1-base`, but all are giving constant training loss. I applied all the tips from [T5 Finetuning Tips](https://discuss.huggingface.co/t/t5-finetuning-tips/684) thread like using AdaFactor etc.
Now, @patil-suraj was able to to train `t5-large` with `max_input_length=512`, `max_output_length=64` and `batch_size=8`. But, I was also able to train `t5-large` with `max_input_length=1024`, `max_output_length=128` and `batch_size=128` on kaggle. I don't know why this is happening. Is it because of some of the layers are frozen by default?
Loss for `t5-small`:
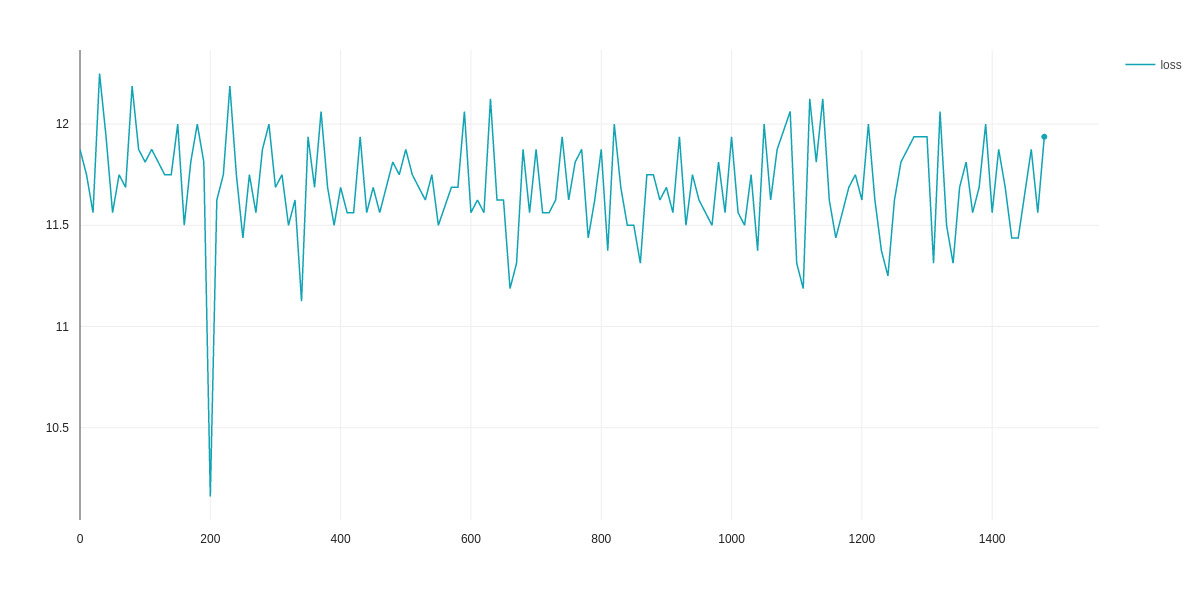
Eval Loss for 't5-small`:
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [X] my own modified scripts: (give details below)
I have modified the script
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: XSUM
* [ ] my own task or dataset: (give details below)
## To reproduce
[Colab Link](https://colab.research.google.com/drive/1KEweUQA8LRk_5VyRfAt04a7g1g6GpgrP?usp=sharing)
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
Code bits from Colab for overview:
Dataset Creation:
```python
class MyXSum(Dataset):
def __init__(self, Config, tokenizer, split_type):
main_ds = load_dataset("xsum")
self.model_name = Config.model_checkpoint
self.dataset = main_ds[split_type]
self.tokenizer = tokenizer
if split_type in set(["validation", "test"]):
self.required_columns =["input_ids", "attention_mask", "labels"]
if split_type == "validation":
num_samples = 20
else:
num_samples = 20
else:
self.required_columns = ["input_ids", "attention_mask",
#"decoder_input_ids",
"decoder_attention_mask",
"labels"
]
num_samples = None
if num_samples:
self.dataset = self.dataset.select(list(range(0, num_samples)))
def __len__(self):
return self.dataset.shape[0]
def preprocess_function(self, examples):
_inputs = ["summarize: " + examples["document"]]
_target = ["<pad>" + examples["summary"]]
model_inputs = self.tokenizer(_inputs, max_length=512,
truncation=True, padding="max_length",
return_tensors="pt")
# Setup the tokenizer for targets
with self.tokenizer.as_target_tokenizer():
labels = self.tokenizer(_target, max_length=64,
truncation=True, padding="max_length",
return_tensors="pt")
model_inputs = {
"input_ids": model_inputs["input_ids"].squeeze(),
"attention_mask": model_inputs["attention_mask"].squeeze(),
"decoder_input_ids": labels["input_ids"].squeeze(),
"decoder_attention_mask": labels["attention_mask"].squeeze(),
"labels": labels["input_ids"].squeeze(),
}
model_inputs = {k: model_inputs[k] for k in self.required_columns}
return model_inputs
def __getitem__(self, index):
return self.preprocess_function(self.dataset[index])
```
Model Training:
```python
@dataclass
class T2TDataCollator(DataCollatorWithPadding):
def collate_batch(self, batch: List) -> Dict[str, torch.Tensor]:
"""
Take a list of samples from a Dataset and collate them into a batch.
Returns:
A dictionary of tensors
"""
input_ids = torch.stack([example['input_ids'] for example in batch])
labels = torch.stack([example['decoder_input_ids'] for example in batch])
labels[labels[:, :] == 0] = -100
attention_mask = torch.stack([example['attention_mask'] for example in batch])
decoder_attention_mask = torch.stack([example['decoder_attention_mask'] for example in batch])
return {
'input_ids': input_ids.squeeze(),
'attention_mask': attention_mask.squeeze(),
'labels': labels.squeeze(),
'decoder_attention_mask': decoder_attention_mask.squeeze()
}
model = AutoModelForSeq2SeqLM.from_pretrained(Config.model_checkpoint)
model.train()
WRAPPED_MODEL = xmp.MpModelWrapper(model)
optimizer = Adafactor(model.parameters(), scale_parameter=False,
relative_step=False, warmup_init=False,
lr=1e-3)
lr_scheduler = AdafactorSchedule(optimizer)
data_collator = T2TDataCollator(tokenizer=tokenizer)
train_ds = torch.load(Config.train_ds_path)
valid_ds = torch.load(Config.valid_ds_path)
test_ds = torch.load(Config.test_ds_path)
def _mp_fn(index):
device = xm.xla_device()
model = WRAPPED_MODEL.to(device)
print("Loading datasets... ", end="")
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
warmup_steps=0,
evaluation_strategy="epoch",
save_strategy="no",
weight_decay=0.0,
logging_dir="./log",
#eval_steps=Config.eval_steps,
logging_steps=50,
per_device_train_batch_size=128,
per_device_eval_batch_size=4,
)
#trainer = Seq2SeqTrainer(
trainer = Trainer(
model=model,
args=training_args,
data_collator=data_collator,
train_dataset=train_ds,
eval_dataset=valid_ds,
optimizers=(optimizer, lr_scheduler),
)
trainer.place_model_on_device = False
trainer.train()
xmp.spawn(_mp_fn, start_method="fork")
```
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
Proper Finetuning of T5 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13033/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13033/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13032 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13032/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13032/comments | https://api.github.com/repos/huggingface/transformers/issues/13032/events | https://github.com/huggingface/transformers/issues/13032 | 963,005,312 | MDU6SXNzdWU5NjMwMDUzMTI= | 13,032 | Masked word prediction in new language with mBERT/XLM | {
"login": "Remorax",
"id": 26062692,
"node_id": "MDQ6VXNlcjI2MDYyNjky",
"avatar_url": "https://avatars.githubusercontent.com/u/26062692?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Remorax",
"html_url": "https://github.com/Remorax",
"followers_url": "https://api.github.com/users/Remorax/followers",
"following_url": "https://api.github.com/users/Remorax/following{/other_user}",
"gists_url": "https://api.github.com/users/Remorax/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Remorax/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Remorax/subscriptions",
"organizations_url": "https://api.github.com/users/Remorax/orgs",
"repos_url": "https://api.github.com/users/Remorax/repos",
"events_url": "https://api.github.com/users/Remorax/events{/privacy}",
"received_events_url": "https://api.github.com/users/Remorax/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hello, thanks for opening an issue! We try to keep the github issues for bugs/feature requests.\r\nCould you ask your question on the [forum](https://discuss.huggingface.co) instead?\r\n\r\nThanks!",
"Hello,\r\n\r\nApologies! I did try to create it on the forum, but unfortunately I don't see any option to \"Create Topic\", or even reply to posts. I am unsure what the issue is, since I have earned the \"Basic\" badge and as per my understanding, should be allowed to create topics.\r\n\r\nCan you please help me out with this - how should I go about creating topics on the Forum?\r\n\r\nThanks a lot in advance!",
"If you have earned the \"Basic\" badge, you should see a \"+ New Topic\" button on the home page, on the left directly under the blue banner.",
"I'm sorry, I don't see any blue banner or \"add new topic\" button. This is the website as it is visible to me:\r\n\r\n<img width=\"1325\" alt=\"Screenshot 2021-08-16 at 3 21 40 PM\" src=\"https://user-images.githubusercontent.com/26062692/129578973-ccf35f37-dfa7-4a14-9ffc-f2e00f109a28.png\">\r\n\r\nI have earned the Basic badge, though:\r\n\r\n<img width=\"1217\" alt=\"Screenshot 2021-08-16 at 3 23 52 PM\" src=\"https://user-images.githubusercontent.com/26062692/129579180-ae63cc0a-1bb1-487b-8711-6b05d8436ce3.png\">\r\n\r\nI feel like I am missing something really obvious here, but not sure what. I have used other forums quite a lot previously and am familiar with the typical interface, but I can't find the create topic button though I have looked everywhere. \r\n\r\nWhat's also interesting is that originally, when I didn't have the \"Basic\" badge and had just created the account, I _could_ see the create topic button. It didn't allow me to post, of course, and gave me an error message saying I didn't have the permissions to do so. Later, when I acquired the Basic badge by reading some topics **on another tab**, I went back to the same tab from earlier and tried re-clicking on \"Create topic\". It then gave me a different error message, something like \"View not allowed\". Really strange, but thought it might be worth mentioning. And when I refreshed the page, sure enough, the Create Topic button had disappeared.",
"Maybe @Pierrci will have an idea.",
"Sorry for the late reply, @Remorax you had been wrongly \"slienced\" by the system, which was preventing you from creating new topics - should be fixed now!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,635 | 1,635 | NONE | null | Hello,
Is there a way to easily predict a masked word in a new language (a language other than the source language) using multilingual models like BERT/XLM/XLM-R?
Ideally, if my masked sentence is:
`My [MASK] is Vivek`
Given a target language, say French, I would want the output for [MASK] to be:
`nom` (`name` in French)
Is it possible to somehow exploit cross-lingual representations for this purpose? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13032/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13032/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13031 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13031/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13031/comments | https://api.github.com/repos/huggingface/transformers/issues/13031/events | https://github.com/huggingface/transformers/issues/13031 | 962,962,004 | MDU6SXNzdWU5NjI5NjIwMDQ= | 13,031 | How can I convert a `checkpoint.pth` (a model trained with pytorch-pretrained-bert) to huggingface model with `config.json` and `pytorch_model.bin` file? | {
"login": "AmitChaulwar",
"id": 69140048,
"node_id": "MDQ6VXNlcjY5MTQwMDQ4",
"avatar_url": "https://avatars.githubusercontent.com/u/69140048?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AmitChaulwar",
"html_url": "https://github.com/AmitChaulwar",
"followers_url": "https://api.github.com/users/AmitChaulwar/followers",
"following_url": "https://api.github.com/users/AmitChaulwar/following{/other_user}",
"gists_url": "https://api.github.com/users/AmitChaulwar/gists{/gist_id}",
"starred_url": "https://api.github.com/users/AmitChaulwar/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AmitChaulwar/subscriptions",
"organizations_url": "https://api.github.com/users/AmitChaulwar/orgs",
"repos_url": "https://api.github.com/users/AmitChaulwar/repos",
"events_url": "https://api.github.com/users/AmitChaulwar/events{/privacy}",
"received_events_url": "https://api.github.com/users/AmitChaulwar/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1897896961,
"node_id": "MDU6TGFiZWwxODk3ODk2OTYx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Migration",
"name": "Migration",
"color": "e99695",
"default": false,
"description": ""
}
] | closed | false | null | [] | [
"Hello! I believe that `pytorch_pretrained_BERT` followed the same approach of having a pytorch checkpoint and a configuration. Do you have no configuration accompanying your `checkpoint.pth`? What is contained in that file once you load it with `torch.load`?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,631 | 1,631 | NONE | null | # 📚 Migration
## Information
<!-- Important information -->
Model I am using (Bert, XLNet ...):
Language I am using the model on (English, Chinese ...):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## Details
<!-- A clear and concise description of the migration issue.
If you have code snippets, please provide it here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.
-->
## Environment info
<!-- You can run the command `python transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform:
- Python version:
- PyTorch version (GPU?):
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
<!-- IMPORTANT: which version of the former library do you use? -->
* `pytorch-transformers` or `pytorch-pretrained-bert` version (or branch):
## Checklist
- [x] I have read the migration guide in the readme.
([pytorch-transformers](https://github.com/huggingface/transformers#migrating-from-pytorch-transformers-to-transformers);
[pytorch-pretrained-bert](https://github.com/huggingface/transformers#migrating-from-pytorch-pretrained-bert-to-transformers))
- [ ] I checked if a related official extension example runs on my machine.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13031/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13031/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13030 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13030/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13030/comments | https://api.github.com/repos/huggingface/transformers/issues/13030/events | https://github.com/huggingface/transformers/pull/13030 | 962,849,689 | MDExOlB1bGxSZXF1ZXN0NzA1NTgwNDA0 | 13,030 | Tpu tie weights | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | COLLABORATOR | null | # What does this PR do?
When the model is moved to an XLA device (like a TPU) its tied weights get disconnected. This PR fixes that.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13030/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13030/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13030",
"html_url": "https://github.com/huggingface/transformers/pull/13030",
"diff_url": "https://github.com/huggingface/transformers/pull/13030.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13030.patch",
"merged_at": 1628275299000
} |
https://api.github.com/repos/huggingface/transformers/issues/13029 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13029/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13029/comments | https://api.github.com/repos/huggingface/transformers/issues/13029/events | https://github.com/huggingface/transformers/issues/13029 | 962,760,241 | MDU6SXNzdWU5NjI3NjAyNDE= | 13,029 | supporting t5 for question answering | {
"login": "dorooddorood606",
"id": 79288051,
"node_id": "MDQ6VXNlcjc5Mjg4MDUx",
"avatar_url": "https://avatars.githubusercontent.com/u/79288051?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dorooddorood606",
"html_url": "https://github.com/dorooddorood606",
"followers_url": "https://api.github.com/users/dorooddorood606/followers",
"following_url": "https://api.github.com/users/dorooddorood606/following{/other_user}",
"gists_url": "https://api.github.com/users/dorooddorood606/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dorooddorood606/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dorooddorood606/subscriptions",
"organizations_url": "https://api.github.com/users/dorooddorood606/orgs",
"repos_url": "https://api.github.com/users/dorooddorood606/repos",
"events_url": "https://api.github.com/users/dorooddorood606/events{/privacy}",
"received_events_url": "https://api.github.com/users/dorooddorood606/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
}
] | [
"Hey @dorooddorood606, \r\n\r\nSince T5 is essentially a text-to-text model, the question-answering task can simply be framed as a seq2seq task. \r\n\r\nI think we could add a `run_qa_seq2seq.py` to https://github.com/huggingface/transformers/tree/master/examples/pytorch/question-answering that is very similar to https://github.com/huggingface/transformers/blob/master/examples/pytorch/summarization/run_summarization.py (we would just need to adapt the dataset to choose from I think). Would you be interested in adding such an example? \r\n\r\nAlso pinging @sgugger here to hear his opinion :-)",
"We could definitely add this kind of example. We just need a proper dataset, as you mentioned.",
"Dear @sgugger @patrickvonplaten \r\nThank you very much for considering my request.\r\n\r\nIn T5 codebase, for superglue-record, they convert each example to multiple ones for each answer choice [1]. During evaluation though they consider all answer choices. I assume this is the case with most of the QA datasets. In T5 script, since we need seq2seq format, I am not sure how I can handle keeping a set of answers.\r\n\r\nthank you very much for your comment in advance.\r\n\r\n[1] https://github.com/google-research/text-to-text-transfer-transformer/blob/3c58859b8fe72c2dbca6a43bc775aa510ba7e706/t5/data/preprocessors.py#L918",
"Cool! @dorooddorood606 would you like to give it a try to make a `run_qa_seq2seq.py` example for SUPERGLUE? Happy to guide you through it :-)",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"unstale, currently wip at #13432 ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,635 | 1,635 | NONE | null | # 🚀 Feature request
Hi, this would be great and appreciated to support t5 model for run_qa.py script, currently this does not support it.
## Motivation
T5 is the state of the art model, for which there are a lot of motivation for people in NLP community to use this model, specially it can handle multiple datasets.
## Your contribution
<!-- Is there any way that you could help, e.g. by submitting a PR?
Make sure to read the CONTRIBUTING.MD readme:
https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13029/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13029/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13028 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13028/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13028/comments | https://api.github.com/repos/huggingface/transformers/issues/13028/events | https://github.com/huggingface/transformers/pull/13028 | 962,704,223 | MDExOlB1bGxSZXF1ZXN0NzA1NDU1Nzkx | 13,028 | Fix ONNX test: Put smaller ALBERT model | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | MEMBER | null | cc @mfuntowicz | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13028/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13028/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13028",
"html_url": "https://github.com/huggingface/transformers/pull/13028",
"diff_url": "https://github.com/huggingface/transformers/pull/13028.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13028.patch",
"merged_at": 1628268094000
} |
https://api.github.com/repos/huggingface/transformers/issues/13027 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13027/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13027/comments | https://api.github.com/repos/huggingface/transformers/issues/13027/events | https://github.com/huggingface/transformers/issues/13027 | 962,702,888 | MDU6SXNzdWU5NjI3MDI4ODg= | 13,027 | Get multiple results from Hugging face pipeline library | {
"login": "BatMrE",
"id": 48859022,
"node_id": "MDQ6VXNlcjQ4ODU5MDIy",
"avatar_url": "https://avatars.githubusercontent.com/u/48859022?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BatMrE",
"html_url": "https://github.com/BatMrE",
"followers_url": "https://api.github.com/users/BatMrE/followers",
"following_url": "https://api.github.com/users/BatMrE/following{/other_user}",
"gists_url": "https://api.github.com/users/BatMrE/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BatMrE/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BatMrE/subscriptions",
"organizations_url": "https://api.github.com/users/BatMrE/orgs",
"repos_url": "https://api.github.com/users/BatMrE/repos",
"events_url": "https://api.github.com/users/BatMrE/events{/privacy}",
"received_events_url": "https://api.github.com/users/BatMrE/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hello! The `Text2TextGenerationPipeline` accepts any keyword arguments to be handled by the `generate` method that does the generation under the hood. You can check the input signature of that method here to see what arguments it accepts: [generate](https://huggingface.co/transformers/main_classes/model.html#transformers.generation_utils.GenerationMixin.generate)\r\n\r\nNamely, it accepts the `do_sample` argument. You can try it out:\r\n\r\n```py\r\n>>> from transformers import pipeline\r\n>>> text2text_generator = pipeline(\"text2text-generation\")\r\n\r\n>>> text2text_generator(\"question: What is ? context: 42 is the answer to life, the universe and everything\", do_sample=True, min_length=15)\r\n[{'generated_text': '42 also is the answer to life, the universe and everything but the universe'}]\r\n\r\n>>> text2text_generator(\"question: What is ? context: 42 is the answer to life, the universe and everything\", do_sample=True, min_length=15)\r\n[{'generated_text': '42 is the answer to life, the universe and everything but the universe'}]\r\n\r\n>>> text2text_generator(\"question: What is ? context: 42 is the answer to life, the universe and everything\", do_sample=True, min_length=15)\r\n[{'generated_text': 'The answer to life, the universe and everything to everybody. 42 is the answer'}]\r\n```",
"Great, that adds a lot of value to output. Thanks @LysandreJik ",
"Can I get multiple results in a single generation?\r\nI think it may be a bug for the num_return_sequences just take effect in \r\n\r\n`\r\nmodel_outputs = self.forward(model_inputs, **forward_params)\r\n`\r\n\r\nbut in \r\n\r\n`\r\noutputs = self.postprocess(model_outputs, **postprocess_params)\r\n`\r\n\r\nthe decode always return one result\r\n\r\n`\r\n record = {\r\n f\"{self.return_name}_text\": self.tokenizer.decode(\r\n model_outputs[\"output_ids\"][0],\r\n skip_special_tokens=True,\r\n clean_up_tokenization_spaces=clean_up_tokenization_spaces,\r\n )\r\n }\r\n`"
] | 1,628 | 1,637 | 1,628 | NONE | null | I am using simple transformers library to get auto suggested text for my question based on a context .
It give me a single suggestion, is there any possible way to get multiple results for the same.
text2text_generator = pipeline("text2text-generation")
text2text_generator("question: What is ? context: 42 is the answer to life, the universe and everything")
The "text2text-generation" model uses T5 model on its backend.
I tried something like:
```
from transformers import T5Tokenizer, T5Model
tokenizer = T5Tokenizer.from_pretrained('t5-small')
model = T5ForConditionalGeneration.from_pretrained('t5-small')
input_ids = tokenizer("question: What is ? context:42 is the answer to life, the universe and everything", return_tensors="pt").input_ids # Batch size 1
outputs = model.generate(input_ids,do_sample=True, top_k=5)
tokenizer.decode(outputs[0])
```
nothing works.! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13027/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13027/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13026 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13026/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13026/comments | https://api.github.com/repos/huggingface/transformers/issues/13026/events | https://github.com/huggingface/transformers/pull/13026 | 962,573,692 | MDExOlB1bGxSZXF1ZXN0NzA1MzQyNjI5 | 13,026 | Update model configs - Allow setters for common properties | {
"login": "nreimers",
"id": 10706961,
"node_id": "MDQ6VXNlcjEwNzA2OTYx",
"avatar_url": "https://avatars.githubusercontent.com/u/10706961?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nreimers",
"html_url": "https://github.com/nreimers",
"followers_url": "https://api.github.com/users/nreimers/followers",
"following_url": "https://api.github.com/users/nreimers/following{/other_user}",
"gists_url": "https://api.github.com/users/nreimers/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nreimers/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nreimers/subscriptions",
"organizations_url": "https://api.github.com/users/nreimers/orgs",
"repos_url": "https://api.github.com/users/nreimers/repos",
"events_url": "https://api.github.com/users/nreimers/events{/privacy}",
"received_events_url": "https://api.github.com/users/nreimers/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"> The design looks good to me! I think we could have a few more common attributes, since we are in the process of adding them:\r\n> \r\n> * the vocab size (seems to be pretty consistent)\r\n> * the embedding size\r\n> * the inner size for the feed-forward layers\r\n> \r\n> Those on top of `max_position_embeddings` should all be included in `common_properties` so that we are sure they are common to each model.\r\n\r\nMy idea was to put this into an independent, new PR and too keep this PR focused on just changing the getter / setters.\r\n\r\nMy plan is to come up with some scheme which attributes should be common. Here we can differentiate between model types: text (differentiated between encoder only and encoder-decoder), image, audio.\r\n\r\nI analyzed all 50+ config classes and these are the most common fields:\r\n```\r\nmodel_type 55\r\nvocab_size 51\r\narchitectures 49\r\npad_token_id 42\r\nmax_position_embeddings 41\r\nnum_hidden_layers 40\r\ninitializer_range 36\r\neos_token_id 34\r\nbos_token_id 32\r\nhidden_size 32\r\nlayer_norm_eps 32\r\nhidden_act 30\r\nintermediate_size 30\r\nnum_attention_heads 29\r\nhidden_dropout_prob 28\r\nattention_probs_dropout_prob 26\r\ntransformers_version 25\r\ntype_vocab_size 23\r\nattention_dropout 22\r\ngradient_checkpointing 21\r\ndropout 19\r\nactivation_dropout 18\r\nd_model 17\r\ninit_std 17\r\nactivation_function 16\r\n```\r\n\r\nBut as mentioned, I would put this in another PR.",
"Hi @sgugger @LysandreJik @patil-suraj @patrickvonplaten \r\n\r\nI also updated all other config classes so that they all use the `attribute_map` so that common properties (like `hidden_size`) can also be set (`config.hidden_size = 123`) or passed as argument (`MyConfigClass(hidden_size = 123)`).\r\n\r\nI kept the behavior for the config classes as is, i.e. no new getter-methods were added, config classes were just extended to allow setting of the common properties.\r\n\r\nIf a setter method cannot be implemented for a class, an exception is raised:\r\nhttps://github.com/huggingface/transformers/blob/c8973d1b5b2a498703e4308cba5056b5cbdaef12/src/transformers/models/funnel/configuration_funnel.py#L176\r\n\r\n\r\n \r\nAll unit tests are passing.\r\n\r\nWould be happy if you could have a look at this PR.",
"@sgugger Will add a note to the docs\r\n\r\n@patrickvonplaten Throwing an error is not easy.\r\n\r\n`GPT2Config` defines `n_embd=768` in the `__init__` method, so:\r\n`config = GPT2Config(hidden_size=4)`\r\nand\r\n`config = GPT2Config(hidden_size=4, n_embd=768)`\r\n\r\nare identical calls of the method. We would expect method 1 to work.\r\n\r\nIn order to throw an exception for method 2, we could do:\r\n- Replace all default parameters with None, see if `hidden_size` is not set, then set `n_embd` to 768 => Major refactoring on all config classes would be needed with quite a lot of overhead. Further, default parameters would no longer be visible from the definition of the method.\r\n- Check if `n_embd != hidden_size and n_embd != 768` => `config = GPT2Config(hidden_size=4, n_embd=8)` would throw an error, but `config = GPT2Config(hidden_size=4, n_embd=768)` would not raise an error (also not a nice solution). Also major refactoring would be needed as we would need to keep track of the default values for all parameters.\r\n\r\nDo you have other ideas how this could be checked?",
"@sgugger \r\nI updated the docs:\r\ntransformers/docs/source/main_classes/configuration.rst\r\n\r\nAnd added a section on the common attributes. Please have a look.",
"Hi,\r\nI just updated the PR with the newest commits from the master branch.\r\n\r\nHowever, now the run_examples_torch fails in CircleCI:\r\n```\r\n==================================== ERRORS ====================================\r\n______________ ERROR collecting examples/pytorch/test_examples.py ______________\r\nImportError while importing test module '/home/circleci/transformers/examples/pytorch/test_examples.py'.\r\nHint: make sure your test modules/packages have valid Python names.\r\nTraceback:\r\n/usr/local/lib/python3.6/importlib/__init__.py:126: in import_module\r\n return _bootstrap._gcd_import(name[level:], package, level)\r\nexamples/pytorch/test_examples.py:51: in <module>\r\n import run_image_classification\r\nexamples/pytorch/image-classification/run_image_classification.py:27: in <module>\r\n from torchvision.transforms import (\r\nE ModuleNotFoundError: No module named 'torchvision'\r\n```\r\n\r\nNot sure why this happens, as this PR is not touching run_image_classification.py\r\n\r\nIs this an issue with CircleCI or with the specific unit test?",
"Hi @nreimers, it's not related to this PR. That test fails because `torchvision` is not installed on the CI ( which is required in `run_image_classification.py`) for examples test. I've proposed a fix here #13438",
"Hi @patil-suraj \r\nThanks for the quick response.\r\n\r\nWhat are the next steps for this PR? Wait until #13438 is merged and then, when all tests are passing, merging this PR?\r\n\r\nWho will be merging this PR? Should I do it once all tests are passing?",
"The failed test is not related to this PR and all of us has approved this PR, so feel free to merge if everything is ready :) "
] | 1,628 | 1,630 | 1,630 | CONTRIBUTOR | null | # Update model configs - Allow setters for common properties
Not all models use the same naming for config values, e.g. `hidden_size` is called `n_embd` in GPT2Config. So far, getters had been implemented in the config classes to allow that a GPT2Config can be accessed via `config.hidden_size`.
But the setters were missing, so that this code fails so far:
```python
from transformers import GPT2Config
config = GPT2Config()
config.hidden_size = 4 # Fails
config = GPT2Config(hidden_size =4) # Fails
```
## Changes
This PR adds an `attribute_map` to the config classes that maps the config parameters. For GPT2, this map looks like this:
```python
attribute_map = {"hidden_size": "n_embd",
"max_position_embeddings": "n_positions",
"num_attention_heads": "n_head",
"num_hidden_layers": "n_layer"
}
```
The `PretrainedConfig` class overwrites the get & set attribute to check for the mappings in the attribute_map:
```python
def __setattr__(self, key, value):
if key in super().__getattribute__('attribute_map'):
key = super().__getattribute__('attribute_map')[key]
super().__setattr__(key, value)
def __getattribute__(self, key):
if key != 'attribute_map' and key in super().__getattribute__('attribute_map'):
key = super().__getattribute__('attribute_map')[key]
return super().__getattribute__(key)
```
## Advantages
- Setters work, i.e. you can use `config.hidden_size = 4` and `GPT2Config(hidden_size=4)`
- No need to write individual getter- or setter-methods in the config classes. They are derived from the `attribute_map`
## Detailed changes
- `PretrainedConfig`: Add `__setattr__` and `__getattribute__` methods. Added docstring for `attribute_map`
- `GPT2Config`: Add attribute map, remove old getters
- `test_configuration_common.py`: Update `create_and_test_config_common_properties` method so that it tests that setters exist and work
## ~~Work in Progress~~
~~So far I only updated the GPT2Config to get your feedback. Unit-Tests for other config classes that have not yet been updated (i.e. don't provide setters for the common fields) like the GPTNeo config class will fail.~~
~~Once the design of the solution is approved, I will update all other config classes.~~
Update: All config classes updated
## Fixes
- #12907
- #12183
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
@sgugger @LysandreJik @NielsRogge
## Code to test the change
Besides the unit tests, you can use this code to test the changes quickly:
```python
from transformers import GPT2Config
config = GPT2Config()
config.hidden_size = 4
print("Hidden size", config.hidden_size, config.n_embd)
config.n_positions = 65
print("n_positions", config.max_position_embeddings, config.n_positions)
config.max_position_embeddings = 123
print("n_positions", config.max_position_embeddings, config.n_positions)
print("\n\n================\n\n")
## Note: conflicting arguments: hidden_size and n_embd are identical fields
# In that case, the synonym (hidden_size) will have higher priority
config = GPT2Config(hidden_size=4, n_embd=20, max_position_embeddings=80)
print("Hidden size", config.hidden_size, config.n_embd)
print("n_positions", config.max_position_embeddings, config.n_positions)
print("Export to json")
config.save_pretrained(".")
## Load config
print("Load from disc")
config = GPT2Config.from_pretrained('.')
print("Hidden size", config.hidden_size, config.n_embd)
print("n_positions", config.max_position_embeddings, config.n_positions)
assert config.hidden_size == config.n_embd
assert config.hidden_size == 4
assert config.max_position_embeddings == config.n_positions
assert config.max_position_embeddings == 80
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13026/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 2,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13026/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13026",
"html_url": "https://github.com/huggingface/transformers/pull/13026",
"diff_url": "https://github.com/huggingface/transformers/pull/13026.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13026.patch",
"merged_at": 1630938613000
} |
https://api.github.com/repos/huggingface/transformers/issues/13025 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13025/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13025/comments | https://api.github.com/repos/huggingface/transformers/issues/13025/events | https://github.com/huggingface/transformers/issues/13025 | 962,545,235 | MDU6SXNzdWU5NjI1NDUyMzU= | 13,025 | MT5-large model on hub has wrong config | {
"login": "devrimcavusoglu",
"id": 46989091,
"node_id": "MDQ6VXNlcjQ2OTg5MDkx",
"avatar_url": "https://avatars.githubusercontent.com/u/46989091?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/devrimcavusoglu",
"html_url": "https://github.com/devrimcavusoglu",
"followers_url": "https://api.github.com/users/devrimcavusoglu/followers",
"following_url": "https://api.github.com/users/devrimcavusoglu/following{/other_user}",
"gists_url": "https://api.github.com/users/devrimcavusoglu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/devrimcavusoglu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/devrimcavusoglu/subscriptions",
"organizations_url": "https://api.github.com/users/devrimcavusoglu/orgs",
"repos_url": "https://api.github.com/users/devrimcavusoglu/repos",
"events_url": "https://api.github.com/users/devrimcavusoglu/events{/privacy}",
"received_events_url": "https://api.github.com/users/devrimcavusoglu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"great catch! Correcting it now",
"Reopening in 4.9.2 since it is difficult to read the model. The problem is either here:\r\nhttps://github.com/huggingface/transformers/blob/v4.9.2/src/transformers/models/auto/tokenization_auto.py#L329 in`TOKENIZER_MAPPING` or here https://github.com/huggingface/transformers/blob/v4.9.2/src/transformers/models/mt5/__init__.py#L35\r\n\r\n`MT5Tokenizer` is just `T5Tokenizer` so when we call `class.__name__` it reduces to `T5Tokenizer` and `MT5Tokenizer` is not in the list. The trick however is to pass `tokenizer_class=None` to `from_pretrained` and it reduces to `T5Tokenizer`:\r\n```\r\nAutoTokenizer.from_pretrained(\r\n \"google/mt5-large\",\r\n tokenizer_class=None,\r\n )\r\n```\r\nNow, it works on master though.",
"@dkajtoch mt5-large tokenizer class is incorrect in config.json: https://huggingface.co/google/mt5-large/blob/main/config.json\r\nIt should be corrected as `\"tokenizer_class\": \"T5Tokenizer\",`.\r\n\r\nRefer to mt5-base https://huggingface.co/google/mt5-base/blob/main/config.json and mt5-xl https://huggingface.co/google/mt5-xl/blob/main/config.json configs.",
"@dkajtoch interesting catch, but I do not understand why this problem is happening ? \r\n\r\nIsn't `MT5Tokenizer` is already in the autotokenizer's list (as an alias for `T5Tokenizer`) ? @patrickvonplaten ",
"@devrimcavusoglu it is but the class is not called `MT5Tokenizer`. It would have been if the authors did something like this\r\n```\r\nclass MT5Tokenizer(T5Tokenizer):\r\n pass\r\n```\r\nInstead of `MT5Tokenizer = T5Tokenizer`\r\n\r\nbecause `tokenizer_class_from_name ` matches tokenizer via reference to class name i.e. `c.__name__`",
"> @devrimcavusoglu it is but the class is not called `MT5Tokenizer`. It would have been if the authors did something like this\r\n> \r\n> ```\r\n> class MT5Tokenizer(T5Tokenizer):\r\n> pass\r\n> ```\r\n> \r\n> Instead of `MT5Tokenizer = T5Tokenizer`\r\n> \r\n> because `tokenizer_class_from_name ` matches tokenizer via reference to class name i.e. `c.__name__`\r\n\r\nMy mistake, I thought `MT5Tokenizer` was a class exactly like you said :sweat_smile: turns out I remember incorrectly. So the next step would be\r\n\r\n1) create a class for `MT5Tokenizer` rather than a variable. \r\n2) change `\"tokenizer_class\": \"MT5Tokenizer\"` as `\"tokenizer_class\": \"T5Tokenizer\"` in mt5 model configs.\r\n\r\nI think (1) is more solid and nicer way. wdyt ? @patrickvonplaten @dkajtoch",
"Maybe the fix is necessary or maybe not since on master 4.10.0-dev0 it works by switching to T5Tokenizer. However, all previous versions will be broken so it is better to change the config back -> only large has `MT5Tokenizer` :P",
"@dkajtoch previous mt5-large config was incorrect. If you switch it back, it will work incorrectly.\r\n\r\nYou only need to fix tokenizer class in mt5-large config as `\"tokenizer_class\": \"T5Tokenizer\",`.",
"@fcakyon I see in history that not only tokenizer_class was changed 👍 Ok so just the tokenizer_class needs to be updated in config.json",
"@dkajtoch thats right 👍 ",
"@dkajtoch @patrickvonplaten any ETA on the fix?",
"Sorry what's the problem here exactly? \r\n\r\n```python\r\ntok = AutoTokenizer.from_pretrained(\"google/mt5-large\")\r\n``` \r\n\r\nworks fine when I try it.",
"`MT5Tokenizer` is an alias to `T5Tokenizer`, so it doesn't really matter which one we put in the config. For consistency, it's True that `T5Tokenizer` might make more sense",
"\r\n@patrickvonplaten This happens at most in `4.9.2` and the current master version is ok.\r\n",
"Gotcha! Thanks for clarifying! Updating the config now",
"Done! Sorry about that!"
] | 1,628 | 1,629 | 1,629 | CONTRIBUTOR | null | MT5-large model [config](https://huggingface.co/google/mt5-large/blob/main/config.json) has wrong parameters `"architectures"` and `"tokenizer_class"` as
```json
{
"architectures": [
"T5ForConditionalGeneration"
],
"tokenizer_class": "T5Tokenizer"
}
```
, where it should be MT5 arch and tokenizer as
```json
{
"architectures": [
"MT5ForConditionalGeneration"
],
"tokenizer_class": "MT5Tokenizer"
}
```
@patrickvonplaten | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13025/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13025/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13024 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13024/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13024/comments | https://api.github.com/repos/huggingface/transformers/issues/13024/events | https://github.com/huggingface/transformers/pull/13024 | 962,532,747 | MDExOlB1bGxSZXF1ZXN0NzA1MzA4MjIw | 13,024 | [Flax] Refactor gpt2 & bert example docs | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | MEMBER | null | # What does this PR do?
This PR mainly refactors the docs of the official Flax MLM, CLM examples. The CLM training script is also slightly changed for consistency with the MLM script. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13024/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13024/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13024",
"html_url": "https://github.com/huggingface/transformers/pull/13024",
"diff_url": "https://github.com/huggingface/transformers/pull/13024.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13024.patch",
"merged_at": 1628509070000
} |
https://api.github.com/repos/huggingface/transformers/issues/13023 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13023/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13023/comments | https://api.github.com/repos/huggingface/transformers/issues/13023/events | https://github.com/huggingface/transformers/pull/13023 | 962,470,281 | MDExOlB1bGxSZXF1ZXN0NzA1MjU0ODUy | 13,023 | Disentangle auto modules from other modeling files | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,629 | 1,628 | COLLABORATOR | null | # What does this PR do?
This PR cleans up the auto modules to have them rely on string mappings and dynamically import the model when they are needed, instead of having a hard dependency on every modeling file.
There is no breaking changes are all the MAPPING classes are still present and will behave like regular dictionaries, just loading the objects as needed. On the internal tooling side, this allows us to remove the script that was extracting the names of the auto-mapping (since we have them now) and the file that stored them. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13023/reactions",
"total_count": 4,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 4,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13023/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13023",
"html_url": "https://github.com/huggingface/transformers/pull/13023",
"diff_url": "https://github.com/huggingface/transformers/pull/13023.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13023.patch",
"merged_at": 1628248350000
} |
https://api.github.com/repos/huggingface/transformers/issues/13022 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13022/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13022/comments | https://api.github.com/repos/huggingface/transformers/issues/13022/events | https://github.com/huggingface/transformers/pull/13022 | 962,406,472 | MDExOlB1bGxSZXF1ZXN0NzA1MjAwMzE3 | 13,022 | GPT-J-6B | {
"login": "StellaAthena",
"id": 15899312,
"node_id": "MDQ6VXNlcjE1ODk5MzEy",
"avatar_url": "https://avatars.githubusercontent.com/u/15899312?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/StellaAthena",
"html_url": "https://github.com/StellaAthena",
"followers_url": "https://api.github.com/users/StellaAthena/followers",
"following_url": "https://api.github.com/users/StellaAthena/following{/other_user}",
"gists_url": "https://api.github.com/users/StellaAthena/gists{/gist_id}",
"starred_url": "https://api.github.com/users/StellaAthena/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/StellaAthena/subscriptions",
"organizations_url": "https://api.github.com/users/StellaAthena/orgs",
"repos_url": "https://api.github.com/users/StellaAthena/repos",
"events_url": "https://api.github.com/users/StellaAthena/events{/privacy}",
"received_events_url": "https://api.github.com/users/StellaAthena/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"There are six failed tests.\r\n\r\nFour of them relate to Flax and TF models which I did not add. I may have left some boilerplate code indicating the existence of such models by accident.\r\n\r\nOne of them relates to docstring issues. I’ll double check the docstrings, but these issues have no impact on the functionality of the model.\r\n\r\nOne of them appears to be a basic quality assurance check. The code says\r\n```\r\nassert 2 == 3\r\ndef test_answer():\r\n> assert 1 + 1 == 3\r\nE assert 2 == 3\r\n\r\ntest_sample.py:2: AssertionError\r\n```\r\nbut I have no idea what this means. Assistence it advice would be appreciated.",
"Looks like a boilerplate test that never got filled out/removed",
"I don't see any test_sample.py in your branch. I think this file is not committed and probably some example test that somehow ended up in your local copy?",
"There will also be a tricky merge with the result of #13023, let us know if you need any help with that.",
"I'm glad y'all approve :)\r\n\r\nI made many of the recommended changes, but have some stuff to take care of today. I'll work on addressing them all and tag you guys when it's ready for re-review.",
"I have been trying to work on this, but I have [a few](https://xkcd.com/1070/) lingering questions that have been slowing my progress.\r\n1. Is there a certain motivation for [`Attention`](https://github.com/huggingface/transformers/blob/24ac25a07ba80b9b7b6e396887305437478398ff/src/transformers/models/openai/modeling_openai.py#L156-L157), [`GPT2Attention`](https://github.com/huggingface/transformers/blob/24ac25a07ba80b9b7b6e396887305437478398ff/src/transformers/models/gpt2/modeling_gpt2.py#L150-L155), [`MLP`](https://github.com/huggingface/transformers/blob/24ac25a07ba80b9b7b6e396887305437478398ff/src/transformers/models/openai/modeling_openai.py#L237-L238), and [`GPT2MLP`](https://github.com/huggingface/transformers/blob/24ac25a07ba80b9b7b6e396887305437478398ff/src/transformers/models/gpt2/modeling_gpt2.py#L275-L276) to use [`torch.nn.Conv1D`](https://pytorch.org/docs/1.9.0/generated/torch.nn.Conv1d.html)? [`GPTNeoSelfAttention`](https://github.com/huggingface/transformers/blob/24ac25a07ba80b9b7b6e396887305437478398ff/src/transformers/models/gpt_neo/modeling_gpt_neo.py#L321-L324), [`GPTNeoLocalSelfAttention`](https://github.com/huggingface/transformers/blob/24ac25a07ba80b9b7b6e396887305437478398ff/src/transformers/models/gpt_neo/modeling_gpt_neo.py#L390-L393) and [`GPTNeoMLP`](https://github.com/huggingface/transformers/blob/24ac25a07ba80b9b7b6e396887305437478398ff/src/transformers/models/gpt_neo/modeling_gpt_neo.py#L521-L522) buck the trend by using [`torch.nn.Linear`](https://pytorch.org/docs/1.9.0/generated/torch.nn.Linear.html) instead. The last instance also maintains the inappropriate prefix of `c_` in the layer name (which I presume is to indicate that it is a convolutional layer).\r\n2. [`GPT2Config`](https://github.com/huggingface/transformers/blob/24ac25a07ba80b9b7b6e396887305437478398ff/src/transformers/models/gpt2/configuration_gpt2.py#L188-L202) and [`OpenAIGPTConfig`](https://github.com/huggingface/transformers/blob/24ac25a07ba80b9b7b6e396887305437478398ff/src/transformers/models/openai/configuration_openai.py#L162-L176) both alias four arguments of the constructor by defining four new properties. [`GPTNeoConfig`](https://github.com/huggingface/transformers/blob/24ac25a07ba80b9b7b6e396887305437478398ff/src/transformers/models/gpt_neo/configuration_gpt_neo.py#L174-L180) (in its perpetual inconsistency) only maintains two of them while using names that are also not consistent with `OpenAIGPTConfig` and `GPT2Config`. Why maintain these redundant properties? If the intention is to use them to rename constructor arguments rather than to provide dual access, they could be simply renamed in the initial block of the constructor. Even worse, many values that are initialized from the config do not maintain continuality in their naming, a problem that spans all four models discussed here. (To demonstrate, trace how [`GPT2Config.n_embd` is aliased to `GPT2Config.hidden_size`](https://github.com/huggingface/transformers/blob/24ac25a07ba80b9b7b6e396887305437478398ff/src/transformers/models/gpt2/configuration_gpt2.py#L192-L194) so that it can be [later accessed via `GPT2Config.hidden_size` and assigned to `GPT2Attention.embed_dim`](https://github.com/huggingface/transformers/blob/24ac25a07ba80b9b7b6e396887305437478398ff/src/transformers/models/gpt2/modeling_gpt2.py#L138))\r\n3. Are we maintaining [`GPTJForSequenceClassification`](https://github.com/huggingface/transformers/blob/24ac25a07ba80b9b7b6e396887305437478398ff/src/transformers/models/gptj/modeling_gptj.py#L781-L892) or not? @StellaAthena [removed the reference to it](https://github.com/huggingface/transformers/pull/13022/commits/4efbbeca8fe4674abf42d253b6dcdd70077cdebf) but @patil-suraj [restored that reference](https://github.com/huggingface/transformers/pull/13022/commits/24ac25a07ba80b9b7b6e396887305437478398ff). Defining the scope of this PR is likely a good idea to prevent counterproductive work.",
"Hi @EricHallahan \r\n\r\n1. The original GPT2 used the conv1d layer instead of the `linear` (it's essentially linear but just keeps weights transposed). It's rather confusing why they chose that name, so we try not to use it anymore. The names are there just for historical reasons :D, Linear is well known and easy to understand and no transpose is needed when doing the computation.\r\n\r\n2. The `hidden_size`, `max_position_embeddings`, `num_hidden_layers`, `num_attention_heads` are common attribute across all configs. They help enable some common tests for configs and models. Note that GPT2 and GPT were added before introducing these attributes so now they are aliased. Simply renaming the constructor argument is not an option since it'll break backward compatibility. If constructor arguments are renamed thousands of GPT2 models on the hub will fail to load since their config is already defined. As much as we would like to do that, it's not an option.\r\n Also, note that when GPT2 was added `transformers` was a bit new and has evolved a lot since then so things and guidelines have changed a bit. In general, we try to use these new names whenever possible, but for this model, I think it's fine to use the `n_layer`, `n_head` etc for consistency with the GPT2 config since Leo at some point had mentioned that it's useful to have those to be able to swap models easily. \r\n But so far there were no issues from the community about these names, so I fail to see what's the big problem here.\r\n\r\n3. ` GPTJForSequenceClassification` was type hinted in the main init, if a model class is used somewhere in main init then the quality tests requires that such class should be tested, added to the auto model, and documented. So the tests were failing, so I decided to add it back since the class was already defined. But no strong opinion about it, feel free to completely remove it.\r\n\r\nHope this answers your question :) ",
"@patil-suraj That perfectly answers my questions. I had been making the assumption that GPT-2 was the benchmark for how the model should be structured, but relaxing that assumption resolves that conflict.\nI've been working up cleaning up the mess left from the Attention mixin and consolidating those classes to the unified `GPTJAttention`. I should get some sleep, but hopefully I'll get that pushed sometime tomorrow.",
"Glad to know! I agree that the AttentionMixin is rather confusing. Thanks for working on it. Apart from few comments above the PR is already in very good shape! ",
"I have committed the suggested changes by @sgugger, or at least as many as I could before my phone interface started acting weird. I’m coming back from vacation tomorrow and can go over the PR for real when I get back.\r\n\r\n@patil-suraj thanks for the info! This is quite helpful. I have no problem supporting sequence classification if the code supports it. I had removed it because I didn’t think we could support it without writing a bunch more code.\r\n\r\nIt looks like we are quite close to getting this merged! Thanks for all the help @EricHallahan @kurumuz ",
"@StellaAthena thanks for your work on this PR! Can you share details on the GPU (or AWS instance type) you used for testing your code? I plan to run some benchmarking with this model after this PR is merged (hopefully soon!).",
"> @StellaAthena thanks for your work on this PR! Can you share details on the GPU (or AWS instance type) you used for testing your code? I plan to run some benchmarking with this model after this PR is merged (hopefully soon!).\r\n\r\nThe original model was trained on TPUs, and my testing of this PyTorch port has been on 8x A100 clusters",
"Okay, well if that's the case, I'd love to see stats backing the claim that\nI misunderstand.\n\nLast I checked, fp32 weights for a 2.7B model itself is ~10 GB of disk\nspace. So this 6B model you are creating a PR for will likely take more\nthan 16 GB of disk space. So I do not see how you \"absolutely can perform\ninference on a 16 GB V100 GPU\" with this GPT-J 6B model. Please\nadvise/correct my understanding since I'm still very much a newbie. Thanks!\n\n\nOn Mon, Aug 16, 2021, 9:38 PM Stella Biderman ***@***.***>\nwrote:\n\n> ***@***.**** commented on this pull request.\n> ------------------------------\n>\n> In src/transformers/models/gptj/modeling_gptj.py\n> <https://github.com/huggingface/transformers/pull/13022#discussion_r690027756>\n> :\n>\n> > + output_attentions (:obj:`bool`, `optional`):\n> + Whether or not to return the attentions tensors of all attention layers. See ``attentions`` under returned\n> + tensors for more detail.\n> + output_hidden_states (:obj:`bool`, `optional`):\n> + Whether or not to return the hidden states of all layers. See ``hidden_states`` under returned tensors for\n> + more detail.\n> + return_dict (:obj:`bool`, `optional`):\n> + Whether or not to return a :class:`~transformers.file_utils.ModelOutput` instead of a plain tuple.\n> +\"\"\"\n> +\n> +\n> ***@***.***_start_docstrings(\n> + \"The bare gptj Model transformer outputting raw hidden-states without any specific head on top.\",\n> + GPTJ_START_DOCSTRING,\n> +)\n> +class GPTJModel(GPTJPreTrainedModel):\n>\n> Again, I fear you misunderstand. You absolutely can perform inference on a\n> 16 GB V100 GPU. At no point did I say that you needed 32 GB of memory to\n> use this model.\n>\n> —\n> You are receiving this because you commented.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/pull/13022#discussion_r690027756>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AA5MNWJ4WGL4LCRW3LVF7XTT5HRVPANCNFSM5BVGELLA>\n> .\n> Triage notifications on the go with GitHub Mobile for iOS\n> <https://apps.apple.com/app/apple-store/id1477376905?ct=notification-email&mt=8&pt=524675>\n> or Android\n> <https://play.google.com/store/apps/details?id=com.github.android&utm_campaign=notification-email>\n> .\n>\n",
"> Ultimately it's up to you - if it turns out that someone intending to utilize your PR is budget-constrained, they'll just be forced to end up making those changes locally by copy-pasting stuff from modeling_gpt2.py.\r\n\r\n> Okay, well if that's the case, I'd love to see stats backing the claim that I misunderstand. Last I checked, fp32 weights for a 2.7B model itself is ~10 GB of disk space. So this 6B model you are creating a PR for will likely take more than 16 GB of disk space. So I do not see how you \"absolutely can perform inference on a 16 GB V100 GPU\" with this GPT-J 6B model. Please advise/correct my understanding since I'm still very much a newbie. Thanks!\r\n\r\nYou don't use fp32 weights for inference, you use BF16 weights without optimizer states for inference. BF16 weights without optimizer states for this model come out to 9GB. If you check out [the source repo](https://github.com/kingoflolz/mesh-transformer-jax), you can find a link to download them. As I've already said, you can find better optimized code at that repo, and if you're on a budget constraint you should not be using the `transformers` library.\r\n\r\nAs @EricHallahan says, the reality of large models is that you need large compute to run them. There is a fundamental limit to what you can do with a model that's too big to fit in your GPU, and that limit is best surpassed by buying a better GPU. We are well aware that this limits the accessibility of these models, but that's how to the world works. You can find other, smaller models that we have released [on our HF page](https://huggingface.co/EleutherAI) if our 6B model is outside your budgetary resources. This codebase also does not require that you use 6B parameters. You are welcome to use it to train a smaller model as well.",
"Hi @sgugger and @patil-suraj,\r\n\r\nThis PR's description says:\r\n\r\n> the major design consideration was to make the configs compatible with GPT-2\r\n\r\nI do not see the model classes being compatible though. For instance, `GPT2Model` supports `parallelize` (a very straightforward feature), `GPTJModel` does not at the moment. Authors of this PR don't seem keen on supporting this feature as you can see from the previous comments (including their edit history), but this is not their library, this is a community library. And usability by the community that makes this library famous and successful should indeed trump efficiency.\r\n\r\nSo should there be an addition of `parallelize` to this PR? What are your thoughts on this topic?\r\n\r\nThanks!\r\n\r\nEDIT: I am fully aware I can fine-tune this model with standard gradient partitioning (ZeRO Stage 2) and at reasonably high TFLOPs/GPU with the usual old tricks, which I am not asking about. IMO the `parallelize` feature is immensely useful for already-trained models at deployment-time since it sets up a simple pipeline (unlike a formal `PipelineModule` sub-class expected for pipeline-parallel training) at inference-time for most consumers of this library, who may not be very technically savvy.",
"@g-karthik: I can back up the claims that it can be run in fp16 mode on any GPU with 16G of VRAM, but don't expect any large batching capabilities.",
"> Hi @sgugger and @patil-suraj,\r\n> \r\n> This PR's description says:\r\n> \r\n> > the major design consideration was to make the configs compatible with GPT-2\r\n> \r\n> I do not see the model classes being compatible though. For instance, `GPT2Model` supports `parallelize` (a very straightforward feature), `GPTJModel` does not at the moment. Authors of this PR don't seem keen on supporting this feature as you can see from the previous comments (including their edit history), but this is not their library, this is a community library. And usability by the community that makes this library famous and successful should indeed trump efficiency.\r\n> \r\n> So should there be an addition of `parallelize` to this PR? What are your thoughts on this topic?\r\n> \r\n> Thanks!\r\n> \r\n> EDIT: I am fully aware I can fine-tune this model with standard gradient partitioning (ZeRO Stage 2) and at reasonably high TFLOPs/GPU with the usual old tricks, which I am not asking about. IMO the `parallelize` feature is immensely useful for already-trained models at deployment-time since it sets up a simple pipeline (unlike a formal `PipelineModule` sub-class expected for pipeline-parallel training) at inference-time for most consumers of this library, who may not be very technically savvy.\r\n\r\nThis is a very uncharitable way to represent my assertion that I do not feel comfortable implementing a highly experimental feature that I didn't even know existed until you brought it up. I have no objection to it being implemented, and even explicitly invited you to do so.\r\n\r\nIf the HF team is interested in integrating this functionality across all of the `transformer` classes I have no objection to that whatsoever. However currently it has been implemented for 2 of the 66 (counting GPT-J) model classes.",
"@StellaAthena\r\n\r\nMy message says \"Authors of this PR don't seem keen on supporting this feature as you can see from the previous comments (including their edit history)\", where authors is **plural**. Eric is a co-author on this PR since I can see he has commits on this PR. I presume he is part of Eleuther-AI, since he was a co-author + you chose to apologize on his behalf and **then** invited me to push commits to your fork to add support for `parallelize`.\r\n\r\nYour assertion was that you were not comfortable supporting `parallelize`, and your co-author Eric jumped the gun without bothering to look at the specific `parallelize` feature I referenced and made a broad assertion that parallelization \"will not be considered\" (which he later edited out after I responded, but I paste verbatim the original comment):\r\n\r\n> GPT-J 6B easily fits in a 16 GB GPU for inference or 32 GB GPU for tuning (at FP16). CPU inference, while slow, absolutely remains an option and it isn't hard to get a server with 32 GB of memory. And besides, just because GPT-J 6B is the only model that exists today doesn't mean that other models cannot be created in the future at different scales. This is generic model class PR, not a GPT-J 6B PR.\r\nLook, we understand that you are concerned with accessibility of large models. EleutherAI expects that those looking to use our large language models will need to find beefy hardware to run them. It is an unfortunate result of scaling, but it is something we cannot help with. You can try to do fancy optimizations and swapping weights in and out of memory but that is incompatible with the transformers design philosophy and out of scope for this PR.\r\nIf you want parallelization today, use Mesh Transformer JAX. Parallelization is out of scope for this PR, and will not be considered.\r\n\r\nGiven he was a co-author of your PR and the above observations, I think saying the \"authors don't seem keen on supporting this feature\" was actually most charitable. But to avoid clubbing you with your co-author, I shall rephrase to: \"one author wasn't comfortable supporting this feature, and another author was just plain rude w.r.t this feature and gave out a flat no\".\r\n\r\nAnyway, I think I'm done w.r.t. this line of discussion, and shall wait until I hear from someone at Hugging Face (@sgugger or @patil-suraj) since I respect their design choices greatly and want to know their opinions on `parallelize` in GPT-J akin to GPT-2.",
"> @g-karthik: I can back up the claims that it can be run in fp16 mode on any GPU with 16G of VRAM, but don't expect any large batching capabilities.\r\n\r\n@oborchers thanks for backing up their updated claim! The original (deleted, but reproduced by me since it's on email) claim was:\r\n\r\n> Again, I fear you misunderstand. You absolutely can perform inference on a 16 GB V100 GPU. At no point did I say that you needed 32 GB of memory to use this model.\r\n\r\nThis does not state FP16 or BF16, which is why I presume the claim was quickly deleted.\r\n\r\nOne clearly cannot fit this GPT-J 6B model in a 16 GB GPU unless they use FP16 or BF16.\r\n\r\nBUT, any consumer of a library as huge as Hugging Face transformers would prefer having the choice of whether they can/want to use FP32 or not. With the `parallelize()` and `deparallelize()` methods (supported in GPT-2), it would be possible for consumers to directly use FP32 weights on a 16 GB GPU because the model is split into pipeline stages for inference.\r\n\r\nSo, the argument here is simple. You have `modeling_gpt2.py` that `modeling_gptj.py` is supposedly meant to be riffing off of design-wise. The latter, however, currently does not support `parallelize()` and `deparallelize()`. If such support were added, power would lie in the hands of the consumer on whether or not to use FP32/FP16/BF16 for the use-case of their choice.",
"> Think the PR can be merged very soon :-)\r\n> \r\n> We should probably try to focus on making the tests pass and then the only things that would be great to slightly adapt are:\r\n> \r\n> * Remove the GPTJAttentionMixin and GPTJAttention class\r\n> * Force the generation logits to be in fp32 so that the model can give good results in fp16 :-)\r\n> \r\n> Thanks a lot for all the work on this already!\r\n\r\n@EricHallahan is hoping to push the first change either today or tomorrow. Once he has, I'm expecting it'll be a couple minutes of work to fix the failing tests and ensure fp32 generation.",
"I see that `GPTJAttention().attn_dropout` and `GPTJAttention().masked_bias` are passed as parameters to `GPTJAttention()._attn()` rather than being referenced directly within `GPTJAttention()._attn()` like GPT-2. Similarly, `causal_mask` is calculated before `GPTJAttention()._attn()` and passed as a parameter while GPT-2 calculates it within `GPTJAttention()._attn()`. What does Hugging Face prefer?",
"The final failed test appears to be something technical about how the testing code was written and the removal of the `configs.rotary` argument. @patil-suraj, as you wrote most of the testing code could you take a look and see if you can spot how to fix it?\r\n\r\nThe traceback reads\r\n```!bash\r\n_______________ GPTJModelTest.test_gptj_model_past_large_inputs ________________\r\n[gw0] linux -- Python 3.7.11 /usr/local/bin/python\r\n\r\nself = <tests.test_modeling_gptj.GPTJModelTest testMethod=test_gptj_model_past_large_inputs>\r\n\r\n def test_gptj_model_past_large_inputs(self):\r\n config_and_inputs = self.model_tester.prepare_config_and_inputs()\r\n> self.model_tester.create_and_check_gptj_model_past_large_inputs(*config_and_inputs)\r\n\r\ntests/test_modeling_gptj.py:386: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\ntests/test_modeling_gptj.py:277: in create_and_check_gptj_model_past_large_inputs\r\n model = GPTJModel(config=config)\r\nsrc/transformers/models/gptj/modeling_gptj.py:415: in __init__\r\n self.h = nn.ModuleList([GPTJBlock(config, layer_id=i) for i in range(config.n_layer)])\r\nsrc/transformers/models/gptj/modeling_gptj.py:415: in <listcomp>\r\n self.h = nn.ModuleList([GPTJBlock(config, layer_id=i) for i in range(config.n_layer)])\r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\n\r\nself = GPTJBlock(\r\n (ln_1): LayerNorm((32,), eps=1e-05, elementwise_affine=True)\r\n)\r\nconfig = GPTJConfig {\r\n \"activation_function\": \"gelu_new\",\r\n \"attention_probs_dropout_prob\": 0.0,\r\n \"attn_pdrop\": 0.0,\r\n \"bos_t...ts\": true,\r\n \"transformers_version\": \"4.10.0.dev0\",\r\n \"type_vocab_size\": 16,\r\n \"use_cache\": true,\r\n \"vocab_size\": 99\r\n}\r\n\r\nlayer_id = 0\r\n\r\n def __init__(self, config, layer_id):\r\n super().__init__()\r\n inner_dim = config.intermediate_size if config.intermediate_size is not None else 4 * config.n_embd\r\n self.ln_1 = nn.LayerNorm(config.n_embd, eps=config.layer_norm_epsilon)\r\n> self.attn = GPTJAttention(config, layer_id)\r\nE TypeError: __init__() takes 2 positional arguments but 3 were given\r\n\r\nsrc/transformers/models/gptj/modeling_gptj.py:275: TypeError\r\n```",
"Only two more tests to fix :-)\r\n\r\n```\r\nFAILED tests/test_modeling_gptj.py::GPTJModelTest::test_gptj_model_att_mask_past\r\nFAILED tests/test_modeling_gptj.py::GPTJModelTest::test_gptj_model_past_large_inputs\r\n```\r\n\r\n@StellaAthena @EricHallahan those tests are pretty `transformers` specific and can be quite complex to fix - let me know if you want me to go into the PR to take a look :-)",
"> Only two more tests to fix :-)\r\n> \r\n> ```\r\n> FAILED tests/test_modeling_gptj.py::GPTJModelTest::test_gptj_model_att_mask_past\r\n> FAILED tests/test_modeling_gptj.py::GPTJModelTest::test_gptj_model_past_large_inputs\r\n> ```\r\n> \r\n> @StellaAthena @EricHallahan those tests are pretty `transformers` specific and can be quite complex to fix - let me know if you want me to go into the PR to take a look :-)\r\n\r\nYeah that would be great! I would love it if you could take a look at what we are missing.",
"Eureka! [The result of the calculation intended for `attention_mask` was placed into `global_attention_mask` instead.](https://github.com/huggingface/transformers/blob/b6021cf0d9acc36fb96aaf3c7b457160f7f0b9d5/src/transformers/models/gptj/modeling_gptj.py#L482-L501) The code passes both of the failing tests in question after replacing that block of code with [the corresponding block from GPT-2](https://github.com/huggingface/transformers/blob/b6021cf0d9acc36fb96aaf3c7b457160f7f0b9d5/src/transformers/models/gpt2/modeling_gpt2.py#L696-L713). I'll integrate the change in a little bit after I do a little more testing.",
"@patrickvonplaten @sgugger @patil-suraj Looks like Eric saved the day! Let us know if there’s anything you’d like changed before it goes live.",
"Easy there @StellaAthena, we still need to verify that the slow tests pass. However, I am optimistic that we should be able to have this merged soon.",
"> Easy there @StellaAthena, we still need to verify that the slow tests pass. However, I am optimistic that we should be able to have this merged soon.\r\n\r\nI’m under the impression that they need to manually approve the slow tests, no? That’s the “1 workflow awaiting approval” right?",
"I just ran them myself and they passed for me (after specifying `use_auth_token` in every call to `.from_pretrained()`), but I don't know if they will pass here.",
"I have a few matters that I think we should discuss/resolve before we consider merging:\r\n1. I'll ask again because I haven't received a response yet: I see that [`GPTJAttention().attn_dropout` and `GPTJAttention().masked_bias` are passed as parameters to `GPTJAttention()._attn()`](https://github.com/huggingface/transformers/blob/d2c85a22abb7b09185363a67a270276465779182/src/transformers/models/gptj/modeling_gptj.py#L233-L234) rather than being [accessed directly within the method like GPT-2](https://github.com/huggingface/transformers/blob/d2c85a22abb7b09185363a67a270276465779182/src/transformers/models/gpt2/modeling_gpt2.py#L187-L194). Similarly, [`causal_mask` is calculated before `GPTJAttention()._attn()` and passed as a parameter](https://github.com/huggingface/transformers/blob/d2c85a22abb7b09185363a67a270276465779182/src/transformers/models/gptj/modeling_gptj.py#L225-L226) while [GPT-2 calculates it within `GPT2Attention()._attn()`](https://github.com/huggingface/transformers/blob/d2c85a22abb7b09185363a67a270276465779182/src/transformers/models/gpt2/modeling_gpt2.py#L185-L186). What does Hugging Face prefer? I think we should adapt the GPT-J implementation to be more like the GPT-2 implementation in this respect.\r\n2. To resolve [a warning regarding `torch.where` deprecating uint8 condition tensors](https://github.com/pytorch/pytorch/blob/d7d399f3dfc780f3e49bcffe45694fb04e5db637/aten/src/ATen/native/TensorCompare.cpp#L330), [GPT-2 casts to bool after slicing `bias`](https://github.com/huggingface/transformers/blob/d2c85a22abb7b09185363a67a270276465779182/src/transformers/models/gpt2/modeling_gpt2.py#L186). I resolved the same warning by [casting the contents of the entire `bias` buffer at initialization](https://github.com/huggingface/transformers/blob/d2c85a22abb7b09185363a67a270276465779182/src/transformers/models/gptj/modeling_gptj.py#L79-L81). This seems to work fine, but if we need to change this for some reason I have not foreseen please tell me.\r\n3. [GPT-2 calculates the scale factor for the attention weights and applies them within `GPT2Attention()._attn()`](https://github.com/huggingface/transformers/blob/b6021cf0d9acc36fb96aaf3c7b457160f7f0b9d5/src/transformers/models/gpt2/modeling_gpt2.py#L180-L181) when [a bool config variable is set](https://github.com/huggingface/transformers/blob/b6021cf0d9acc36fb96aaf3c7b457160f7f0b9d5/src/transformers/models/gpt2/modeling_gpt2.py#L147). [GPT-J used to have a dedicated buffer to store the scaling value](https://github.com/huggingface/transformers/blob/b6021cf0d9acc36fb96aaf3c7b457160f7f0b9d5/src/transformers/models/gptj/modeling_gptj.py#L91), but I modified this [to remove the unneeded buffer](). This made the model loader stop complaining about buffers that were not initialized from the checkpoint. This seems to work fine (and if it does I think we can remove [the check that ensures that `scale_attn` is initialized](https://github.com/huggingface/transformers/blob/d2c85a22abb7b09185363a67a270276465779182/src/transformers/models/gptj/modeling_gptj.py#L152)), but if we need to change this for some reason I have not foreseen please tell me.\r\n4. I note that the weights currently staged on Model Hub are stored in [half precision (binary16)](https://en.wikipedia.org/wiki/Half-precision_floating-point_format), while the original released checkpoint was [bfloat16](https://en.wikipedia.org/wiki/Bfloat16_floating-point_format). As this is an inherently lossy conversion unlike casting to [single precision (binary32)](https://en.wikipedia.org/wiki/Single-precision_floating-point_format), I feel it important to ask the level that we should adhere to the [`transformers` philosophy of <q>[providing] state-of-the-art models with performances as close as possible to the original models</q>](https://huggingface.co/transformers/philosophy.html). I have been assured by @StellaAthena and @kingoflolz that the difference in downstream performance between binary16 and bfloat16/binary32 is minimal with GPT-J 6B (and the evaluations they presented to me support this claim), but if we assume that this implementation will be used for academic research at some point in the future it seems odd to be manipulating the original checkpoint in a way that could modify downstream performance. \r\nThe reason I bring this matter up here is firstly the fact that bfloat16 hardware is not as widespread/accessible as binary32 and binary16 hardware and secondly my assumption that a switch to a bfloat16 checkpoint would require changes in the implementation; If we decide that serving the checkpoint from Model Hub in bfloat16 is required to meet the goals of the `transformers` project, it is critical to ensure that it will be properly loaded/cast on platforms that do not support bfloat16 computation. I consider storing and serving the checkpoint in binary32 to be an unacceptable compromise to this conflict, as it would be double the size of the **11.7 GiB** binary16 checkpoint that is currently staged.\r\n5. Would it be preferable to [include a tool that can convert the original checkpoint file to the Hugging Face format like GPT-Neo](https://github.com/huggingface/transformers/blob/d2c85a22abb7b09185363a67a270276465779182/src/transformers/models/gpt_neo/convert_gpt_neo_mesh_tf_to_pytorch.py), or is that something that is out of scope of this PR?\r\n5. It is unclear to me if [casting `query` and `key` to single precision (binary32) in `GPTJAttention()._attn()` is actually preventing an overflow when running the model in half precision (binary16)](https://github.com/huggingface/transformers/blob/d2c85a22abb7b09185363a67a270276465779182/src/transformers/models/gptj/modeling_gptj.py#L145-L147). We should verify that this is required before merging."
] | 1,628 | 1,630 | 1,630 | CONTRIBUTOR | null | # What does this PR do?
Introduces the long awaited `GPT J` model class to HuggingFace! Concurrently with this PR being merged I will make a GPT J 6B checkpoint public on the EleutherAI HF page for people to use. The model has been evaluated as being within error tolerances of the GPT J 6B model we released in Jax two months ago.
@patil-suraj was very helpful in assisting me to understand HF philosophy and how to make this PR most in line with the rest of the codebase. Other than that, the major design consideration was to make the configs compatible with GPT-2 rather than GPT-Neo. GPT-Neo has some usability limitations due to its configs having names unrelated to GPT-2’s (see #12183 for details). Given those problems and my hope that GPT-Neo will have it’s configs updated in the future, it seemed like a clear choice to align GPT J with GPT-2.
Shout outs to @finetuneanon whose implementation this one is based off of, as well as @kumuruz for assistence optimizing and debugging.
Supersedes #12243 #13010 #13022
Closes #12098
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [X] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [X] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
It was discussed in Slack with @patil-suraj
- [X] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [X] Did you write any new necessary tests?
## Who can review?
- gpt2: @patrickvonplaten, @LysandreJik, @patil-suraj | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13022/reactions",
"total_count": 33,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 26,
"rocket": 7,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13022/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13022",
"html_url": "https://github.com/huggingface/transformers/pull/13022",
"diff_url": "https://github.com/huggingface/transformers/pull/13022.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13022.patch",
"merged_at": 1630425182000
} |
https://api.github.com/repos/huggingface/transformers/issues/13021 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13021/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13021/comments | https://api.github.com/repos/huggingface/transformers/issues/13021/events | https://github.com/huggingface/transformers/issues/13021 | 962,342,508 | MDU6SXNzdWU5NjIzNDI1MDg= | 13,021 | TypeError: __init__() got an unexpected keyword argument 'save_strategy' | {
"login": "jmasom",
"id": 37025304,
"node_id": "MDQ6VXNlcjM3MDI1MzA0",
"avatar_url": "https://avatars.githubusercontent.com/u/37025304?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jmasom",
"html_url": "https://github.com/jmasom",
"followers_url": "https://api.github.com/users/jmasom/followers",
"following_url": "https://api.github.com/users/jmasom/following{/other_user}",
"gists_url": "https://api.github.com/users/jmasom/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jmasom/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jmasom/subscriptions",
"organizations_url": "https://api.github.com/users/jmasom/orgs",
"repos_url": "https://api.github.com/users/jmasom/repos",
"events_url": "https://api.github.com/users/jmasom/events{/privacy}",
"received_events_url": "https://api.github.com/users/jmasom/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"You probably did not properly install it. The environment above shows 4.2.2 and `save_strategy` was introduced later on.\r\nYou can check the version of Transformers executed by your script by adding\r\n```\r\nimport transformers\r\nprint(transformers.__version__)\r\n```\r\nat the top of it.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,631 | 1,631 | NONE | null | ### Environment
- `transformers` version: 4.2.2
- Platform: Linux-4.15.0-151-generic-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyTorch version (GPU?): 1.4.0 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: Not explicitly (but probably)
- Using distributed or parallel set-up in script?: Not explicitly (but probably)
### Who can help
@sgugger
### Details
I am using RoBERTa for seq classification, but that is not where my issue is coming from. My issue is coming from the Trainer API. Specifically, when I try to specify save_strategy=epoch in TrainingArguments, I get the error message in the issue title. I tried updating to a more recent version of Transformers as per another issue, but that didn't work. I'm not sure what to do about it. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13021/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13021/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13020 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13020/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13020/comments | https://api.github.com/repos/huggingface/transformers/issues/13020/events | https://github.com/huggingface/transformers/issues/13020 | 962,264,967 | MDU6SXNzdWU5NjIyNjQ5Njc= | 13,020 | RobertaForMaskedLM loss calculated wrong(?) | {
"login": "leo-liuzy",
"id": 11146950,
"node_id": "MDQ6VXNlcjExMTQ2OTUw",
"avatar_url": "https://avatars.githubusercontent.com/u/11146950?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/leo-liuzy",
"html_url": "https://github.com/leo-liuzy",
"followers_url": "https://api.github.com/users/leo-liuzy/followers",
"following_url": "https://api.github.com/users/leo-liuzy/following{/other_user}",
"gists_url": "https://api.github.com/users/leo-liuzy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/leo-liuzy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/leo-liuzy/subscriptions",
"organizations_url": "https://api.github.com/users/leo-liuzy/orgs",
"repos_url": "https://api.github.com/users/leo-liuzy/repos",
"events_url": "https://api.github.com/users/leo-liuzy/events{/privacy}",
"received_events_url": "https://api.github.com/users/leo-liuzy/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"The calculation is correct. However, it's the responsibility of the user to prepare the labels for the model, so you need to make sure you set the labels to -100 for positions where you don't want to incur a loss (as -100 is the `ignore_index` of PyTorch's `CrossEntropyLoss`).",
"Ah, that makes sense, thanks!. I think you should modify the tutorial page in documentation page? Or put what you said somewhere in the doc pagr?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,631 | 1,631 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.8.1 (or github main as of 2021.8.5)
- Platform: MacOS (or any)
- Python version: 3.9 (or any 3.x)
- PyTorch version (GPU?): 1.9.0 cpu
- Tensorflow version (GPU?):
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
@LysandreJik, @sgugger
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...): XLM-R/Roberta
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: (give the name) MaskedLM
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. [Tutorial example here](https://huggingface.co/transformers/model_doc/xlmroberta.html#transformers.XLMRobertaForMaskedLM)
2. [Source code here](https://github.com/huggingface/transformers/blob/60e448c87eff29b166bf2821f5389056a72343e3/src/transformers/models/roberta/modeling_roberta.py#L1105)
3.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
The logic of calculating MLM seems wrong. Shouldn't CrossEntropyLoss only run on **masked tokens** rather than all tokens? I see no operation here.
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13020/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13020/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13019 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13019/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13019/comments | https://api.github.com/repos/huggingface/transformers/issues/13019/events | https://github.com/huggingface/transformers/issues/13019 | 962,073,044 | MDU6SXNzdWU5NjIwNzMwNDQ= | 13,019 | GPU Out of Memory when repeatedly running large models (`hyperparameter_search`) | {
"login": "acocos",
"id": 1832548,
"node_id": "MDQ6VXNlcjE4MzI1NDg=",
"avatar_url": "https://avatars.githubusercontent.com/u/1832548?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/acocos",
"html_url": "https://github.com/acocos",
"followers_url": "https://api.github.com/users/acocos/followers",
"following_url": "https://api.github.com/users/acocos/following{/other_user}",
"gists_url": "https://api.github.com/users/acocos/gists{/gist_id}",
"starred_url": "https://api.github.com/users/acocos/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/acocos/subscriptions",
"organizations_url": "https://api.github.com/users/acocos/orgs",
"repos_url": "https://api.github.com/users/acocos/repos",
"events_url": "https://api.github.com/users/acocos/events{/privacy}",
"received_events_url": "https://api.github.com/users/acocos/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thanks for the issue and the investigation. It looks like you have found the right fix, would you mind making a PR with it?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"I'm experiencing the exact same problem. Sadly, the suggested solution doesn't work for me. At first I had the impression that the OutOfMemoryError shows up a bit later now (sometimes after 6–8 instead of 2 iterations), but that might be a coincidence.\r\nI'm using Python 3.10.11, PyTorch 2.0.1, 1 GPU with 24 GiB GPU Memory, Platform: Linux (Ubuntu 20.04.1) with x86_64 architecture on AWS.",
"I too am experiencing the same error. Memory increases at every parameter change until an OOM is reached.\r\n\r\n"
] | 1,628 | 1,690 | 1,631 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.9.1
- Platform: Linux-4.19.0-17-cloud-amd64-x86_64-with-debian-10.10
- Python version: 3.7.10
- PyTorch version (GPU?): 1.9.0 (True)
- Using GPU in script?: yes (4 x GPUs)
- Using distributed or parallel set-up in script?: There are 4x GPU on this machine; I'm letting the `trainer` do its default thing here. I see that `trainer.is_model_parallel = False`.
### Who can help
Looks like @sgugger has some related activity in trainer...maybe he can point toward the right person to help?
## Information
Model I am using (Bert, XLNet ...): `disilbert-base-uncased`
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. I'm running fine-tuning for sentence classification using `distilbert-base-uncased`, using the code below. Training set is limited to 10k sentences with binary labels. Eval consists of 500 sentences.
2. Hyperparameter search runs fine for the first ~2 iterations, and then I reliably see a CUDA out-of-memory error `RuntimeError: CUDA out of memory...` (full error pasted at the bottom of this issue).
Looking at my wandb logs, I see that GPU memory is not freed between tuning runs.
(purple is run-0, gray is run-1, blue is run-2).
3. I think this is very closely related/possibly the same as the issue in #1742.
4. I have found that adding some additional lines within the `run_hp_search_optuna` fn to explicitly delete the model and de-allocate memory between runs seems to resolve the problem (see below).
### Code that produces the issue
Running the following code yields the error after ~2 hyperparameter tuning runs.
```python
## setup data
from datasets import DatasetDict
paths = {
"train": train_file,
"dev": dev_file,
"test": test_file,
"unlabeled": to_classify_file
}
raw_datasets = DatasetDict.from_json(paths)
## setup tokenizer
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
def tokenize_function(x):
return tokenizer(x["sentence"], x["source_column"], padding="max_length", truncation=True)
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True)
tokenized_datasets.set_format("torch")
## setup model and metrics
import torch
import gc
from transformers import AutoModelForSequenceClassification
from datasets import load_metric
prec = load_metric("precision")
rec = load_metric("recall")
acc = load_metric("accuracy")
f1 = load_metric("f1")
def model_init():
return AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased", num_labels=2, return_dict=True)
def f_b(p, r, b):
num = (1 + b**2) * p * r
den = (b**2 * p) + r
if den == 0:
return 0.
return num/den
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = predictions.argmax(axis=-1)
result = {}
for mtrc in [prec, rec, acc, f1]:
mtrc_result = mtrc.compute(predictions=predictions, references=labels)
result.update(mtrc_result)
result["f0.5"] = f_b(result["precision"], result["recall"], 0.5)
return result
def compute_objective(metrics):
return metrics["eval_f0.5"]
## run hyperparam tuning
from transformers import Trainer, TrainingArguments
gpus_per_trial = 1
n_hyperparam_search_examples = 10000
training_args = TrainingArguments(
"ls_classifier_distilbert_hyperparams",
overwrite_output_dir=True,
do_train=True,
do_eval=True,
num_train_epochs=2,
evaluation_strategy="steps",
eval_steps=250,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
warmup_steps=0,
weight_decay=0.1,
logging_dir="./logs",
report_to="wandb",
load_best_model_at_end=True
)
trainer = Trainer(
model_init=model_init,
args=training_args,
tokenizer=tokenizer,
train_dataset=tokenized_datasets["train"].shuffle(seed=123).select(range(n_hyperparam_search_examples)),
eval_dataset=tokenized_datasets["dev"],
compute_metrics=compute_metrics
)
trainer.hyperparameter_search(
backend="optuna",
compute_objective=compute_objective,
n_trials=4,
direction="maximize",
)
```
### Updates to remedy the issue
If I re-write the `hyperparameter_search` fn with the following additions to `run_hp_search_optuna` (following advice in #1742), then the memory does appear to get de-allocated between tuning runs:
```python
from transformers.trainer_utils import HPSearchBackend, default_hp_space
def run_hp_search_optuna(trainer, n_trials, direction, **kwargs):
import optuna
def _objective(trial, checkpoint_dir=None):
checkpoint = None
if checkpoint_dir:
for subdir in os.listdir(checkpoint_dir):
if subdir.startswith(PREFIX_CHECKPOINT_DIR):
checkpoint = os.path.join(checkpoint_dir, subdir)
#################
## UPDATES START
#################
if not checkpoint:
# free GPU memory
del trainer.model
gc.collect()
torch.cuda.empty_cache()
trainer.objective = None
trainer.train(resume_from_checkpoint=checkpoint, trial=trial)
# If there hasn't been any evaluation during the training loop.
if getattr(trainer, "objective", None) is None:
metrics = trainer.evaluate()
trainer.objective = trainer.compute_objective(metrics)
return trainer.objective
timeout = kwargs.pop("timeout", None)
n_jobs = kwargs.pop("n_jobs", 1)
study = optuna.create_study(direction=direction, **kwargs)
study.optimize(_objective, n_trials=n_trials, timeout=timeout, n_jobs=n_jobs)
best_trial = study.best_trial
return BestRun(str(best_trial.number), best_trial.value, best_trial.params)
def hyperparameter_search(trainer, compute_objective, n_trials, direction, **kwargs):
trainer.hp_search_backend = HPSearchBackend.OPTUNA
trainer.hp_space = default_hp_space[HPSearchBackend.OPTUNA]
trainer.hp_name = None
trainer.compute_objective = compute_objective
best_run = run_hp_search_optuna(trainer, n_trials, direction, **kwargs)
self.hp_search_backend = None
return best_run
```
### Full error / trace
```
[W 2021-08-05 17:21:10,456] Trial 2 failed because of the following error: RuntimeError('Caught RuntimeError in replica 0 on device 0.\nOriginal Traceback (most recent call last):\n File "/opt/conda/lib/python3.7/site-packages/torch/nn/parallel/parallel_apply.py", line 61, in _worker\n output = module(*input, **kwargs)\n File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl\n return forward_call(*input, **kwargs)\n File "/opt/conda/lib/python3.7/site-packages/transformers/models/distilbert/modeling_distilbert.py", line 632, in forward\n return_dict=return_dict,\n File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl\n return forward_call(*input, **kwargs)\n File "/opt/conda/lib/python3.7/site-packages/transformers/models/distilbert/modeling_distilbert.py", line 495, in forward\n return_dict=return_dict,\n File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl\n return forward_call(*input, **kwargs)\n File "/opt/conda/lib/python3.7/site-packages/transformers/models/distilbert/modeling_distilbert.py", line 315, in forward\n x=hidden_state, attn_mask=attn_mask, head_mask=head_mask[i], output_attentions=output_attentions\n File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl\n return forward_call(*input, **kwargs)\n File "/opt/conda/lib/python3.7/site-packages/transformers/models/distilbert/modeling_distilbert.py", line 264, in forward\n output_attentions=output_attentions,\n File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl\n return forward_call(*input, **kwargs)\n File "/opt/conda/lib/python3.7/site-packages/transformers/models/distilbert/modeling_distilbert.py", line 192, in forward\n scores = torch.matmul(q, k.transpose(2, 3)) # (bs, n_heads, q_length, k_length)\nRuntimeError: CUDA out of memory. Tried to allocate 768.00 MiB (GPU 0; 14.76 GiB total capacity; 12.82 GiB already allocated; 727.75 MiB free; 12.93 GiB reserved in total by PyTorch)\n')
Traceback (most recent call last):
File "/opt/conda/lib/python3.7/site-packages/optuna/study/_optimize.py", line 213, in _run_trial
value_or_values = func(trial)
File "/opt/conda/lib/python3.7/site-packages/transformers/integrations.py", line 140, in _objective
trainer.train(resume_from_checkpoint=checkpoint, trial=trial)
File "/opt/conda/lib/python3.7/site-packages/transformers/trainer.py", line 1280, in train
tr_loss += self.training_step(model, inputs)
File "/opt/conda/lib/python3.7/site-packages/transformers/trainer.py", line 1773, in training_step
loss = self.compute_loss(model, inputs)
File "/opt/conda/lib/python3.7/site-packages/transformers/trainer.py", line 1805, in compute_loss
outputs = model(**inputs)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/parallel/data_parallel.py", line 168, in forward
outputs = self.parallel_apply(replicas, inputs, kwargs)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/parallel/data_parallel.py", line 178, in parallel_apply
return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
File "/opt/conda/lib/python3.7/site-packages/torch/nn/parallel/parallel_apply.py", line 86, in parallel_apply
output.reraise()
File "/opt/conda/lib/python3.7/site-packages/torch/_utils.py", line 425, in reraise
raise self.exc_type(msg)
RuntimeError: Caught RuntimeError in replica 0 on device 0.
Original Traceback (most recent call last):
File "/opt/conda/lib/python3.7/site-packages/torch/nn/parallel/parallel_apply.py", line 61, in _worker
output = module(*input, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/transformers/models/distilbert/modeling_distilbert.py", line 632, in forward
return_dict=return_dict,
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/transformers/models/distilbert/modeling_distilbert.py", line 495, in forward
return_dict=return_dict,
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/transformers/models/distilbert/modeling_distilbert.py", line 315, in forward
x=hidden_state, attn_mask=attn_mask, head_mask=head_mask[i], output_attentions=output_attentions
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/transformers/models/distilbert/modeling_distilbert.py", line 264, in forward
output_attentions=output_attentions,
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/transformers/models/distilbert/modeling_distilbert.py", line 192, in forward
scores = torch.matmul(q, k.transpose(2, 3)) # (bs, n_heads, q_length, k_length)
RuntimeError: CUDA out of memory. Tried to allocate 768.00 MiB (GPU 0; 14.76 GiB total capacity; 12.82 GiB already allocated; 727.75 MiB free; 12.93 GiB reserved in total by PyTorch)
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
/tmp/ipykernel_10884/1040859948.py in <module>
35 compute_objective=compute_objective,
36 n_trials=4,
---> 37 direction="maximize",
38 )
39 # trainer.is_model_parallel
/opt/conda/lib/python3.7/site-packages/transformers/trainer.py in hyperparameter_search(self, hp_space, compute_objective, n_trials, direction, backend, hp_name, **kwargs)
1698
1699 run_hp_search = run_hp_search_optuna if backend == HPSearchBackend.OPTUNA else run_hp_search_ray
-> 1700 best_run = run_hp_search(self, n_trials, direction, **kwargs)
1701
1702 self.hp_search_backend = None
/opt/conda/lib/python3.7/site-packages/transformers/integrations.py in run_hp_search_optuna(trainer, n_trials, direction, **kwargs)
148 n_jobs = kwargs.pop("n_jobs", 1)
149 study = optuna.create_study(direction=direction, **kwargs)
--> 150 study.optimize(_objective, n_trials=n_trials, timeout=timeout, n_jobs=n_jobs)
151 best_trial = study.best_trial
152 return BestRun(str(best_trial.number), best_trial.value, best_trial.params)
/opt/conda/lib/python3.7/site-packages/optuna/study/study.py in optimize(self, func, n_trials, timeout, n_jobs, catch, callbacks, gc_after_trial, show_progress_bar)
407 callbacks=callbacks,
408 gc_after_trial=gc_after_trial,
--> 409 show_progress_bar=show_progress_bar,
410 )
411
/opt/conda/lib/python3.7/site-packages/optuna/study/_optimize.py in _optimize(study, func, n_trials, timeout, n_jobs, catch, callbacks, gc_after_trial, show_progress_bar)
74 reseed_sampler_rng=False,
75 time_start=None,
---> 76 progress_bar=progress_bar,
77 )
78 else:
/opt/conda/lib/python3.7/site-packages/optuna/study/_optimize.py in _optimize_sequential(study, func, n_trials, timeout, catch, callbacks, gc_after_trial, reseed_sampler_rng, time_start, progress_bar)
161
162 try:
--> 163 trial = _run_trial(study, func, catch)
164 except Exception:
165 raise
/opt/conda/lib/python3.7/site-packages/optuna/study/_optimize.py in _run_trial(study, func, catch)
262
263 if state == TrialState.FAIL and func_err is not None and not isinstance(func_err, catch):
--> 264 raise func_err
265 return trial
266
/opt/conda/lib/python3.7/site-packages/optuna/study/_optimize.py in _run_trial(study, func, catch)
211
212 try:
--> 213 value_or_values = func(trial)
214 except exceptions.TrialPruned as e:
215 # TODO(mamu): Handle multi-objective cases.
/opt/conda/lib/python3.7/site-packages/transformers/integrations.py in _objective(trial, checkpoint_dir)
138 checkpoint = os.path.join(checkpoint_dir, subdir)
139 trainer.objective = None
--> 140 trainer.train(resume_from_checkpoint=checkpoint, trial=trial)
141 # If there hasn't been any evaluation during the training loop.
142 if getattr(trainer, "objective", None) is None:
/opt/conda/lib/python3.7/site-packages/transformers/trainer.py in train(self, resume_from_checkpoint, trial, ignore_keys_for_eval, **kwargs)
1278 tr_loss += self.training_step(model, inputs)
1279 else:
-> 1280 tr_loss += self.training_step(model, inputs)
1281 self.current_flos += float(self.floating_point_ops(inputs))
1282
/opt/conda/lib/python3.7/site-packages/transformers/trainer.py in training_step(self, model, inputs)
1771 loss = self.compute_loss(model, inputs)
1772 else:
-> 1773 loss = self.compute_loss(model, inputs)
1774
1775 if self.args.n_gpu > 1:
/opt/conda/lib/python3.7/site-packages/transformers/trainer.py in compute_loss(self, model, inputs, return_outputs)
1803 else:
1804 labels = None
-> 1805 outputs = model(**inputs)
1806 # Save past state if it exists
1807 # TODO: this needs to be fixed and made cleaner later.
/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
/opt/conda/lib/python3.7/site-packages/torch/nn/parallel/data_parallel.py in forward(self, *inputs, **kwargs)
166 return self.module(*inputs[0], **kwargs[0])
167 replicas = self.replicate(self.module, self.device_ids[:len(inputs)])
--> 168 outputs = self.parallel_apply(replicas, inputs, kwargs)
169 return self.gather(outputs, self.output_device)
170
/opt/conda/lib/python3.7/site-packages/torch/nn/parallel/data_parallel.py in parallel_apply(self, replicas, inputs, kwargs)
176
177 def parallel_apply(self, replicas, inputs, kwargs):
--> 178 return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
179
180 def gather(self, outputs, output_device):
/opt/conda/lib/python3.7/site-packages/torch/nn/parallel/parallel_apply.py in parallel_apply(modules, inputs, kwargs_tup, devices)
84 output = results[i]
85 if isinstance(output, ExceptionWrapper):
---> 86 output.reraise()
87 outputs.append(output)
88 return outputs
/opt/conda/lib/python3.7/site-packages/torch/_utils.py in reraise(self)
423 # have message field
424 raise self.exc_type(message=msg)
--> 425 raise self.exc_type(msg)
426
427
RuntimeError: Caught RuntimeError in replica 0 on device 0.
Original Traceback (most recent call last):
File "/opt/conda/lib/python3.7/site-packages/torch/nn/parallel/parallel_apply.py", line 61, in _worker
output = module(*input, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/transformers/models/distilbert/modeling_distilbert.py", line 632, in forward
return_dict=return_dict,
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/transformers/models/distilbert/modeling_distilbert.py", line 495, in forward
return_dict=return_dict,
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/transformers/models/distilbert/modeling_distilbert.py", line 315, in forward
x=hidden_state, attn_mask=attn_mask, head_mask=head_mask[i], output_attentions=output_attentions
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/transformers/models/distilbert/modeling_distilbert.py", line 264, in forward
output_attentions=output_attentions,
File "/opt/conda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1051, in _call_impl
return forward_call(*input, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/transformers/models/distilbert/modeling_distilbert.py", line 192, in forward
scores = torch.matmul(q, k.transpose(2, 3)) # (bs, n_heads, q_length, k_length)
RuntimeError: CUDA out of memory. Tried to allocate 768.00 MiB (GPU 0; 14.76 GiB total capacity; 12.82 GiB already allocated; 727.75 MiB free; 12.93 GiB reserved in total by PyTorch)
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13019/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13019/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13018 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13018/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13018/comments | https://api.github.com/repos/huggingface/transformers/issues/13018/events | https://github.com/huggingface/transformers/issues/13018 | 961,916,468 | MDU6SXNzdWU5NjE5MTY0Njg= | 13,018 | Unable to resume training from checkpoint on TPU v3-8 | {
"login": "finiteautomata",
"id": 167943,
"node_id": "MDQ6VXNlcjE2Nzk0Mw==",
"avatar_url": "https://avatars.githubusercontent.com/u/167943?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/finiteautomata",
"html_url": "https://github.com/finiteautomata",
"followers_url": "https://api.github.com/users/finiteautomata/followers",
"following_url": "https://api.github.com/users/finiteautomata/following{/other_user}",
"gists_url": "https://api.github.com/users/finiteautomata/gists{/gist_id}",
"starred_url": "https://api.github.com/users/finiteautomata/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/finiteautomata/subscriptions",
"organizations_url": "https://api.github.com/users/finiteautomata/orgs",
"repos_url": "https://api.github.com/users/finiteautomata/repos",
"events_url": "https://api.github.com/users/finiteautomata/events{/privacy}",
"received_events_url": "https://api.github.com/users/finiteautomata/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"It looks like you are not using the `run_mlm` script but a modified version of it, as there are parameters you are passing that are not in this script. Could you share your modified version?",
"Sure. This is the modified version => https://gist.github.com/finiteautomata/cb1fba94202c1535d2a516eef2215baf\r\n\r\nMain changes are that an extra seed and using a custom `IterableDataset`. Running without `xla_spawn.py` seems to be yielding the same error\r\n\r\nThis is the model configuration (`models/twerto-base-uncased/config.json`)\r\n\r\n```json\r\n{\r\n \"attention_probs_dropout_prob\": 0.1,\r\n \"bos_token_id\": 0,\r\n \"eos_token_id\": 2,\r\n \"gradient_checkpointing\": false,\r\n \"hidden_act\": \"gelu\",\r\n \"hidden_dropout_prob\": 0.1,\r\n \"hidden_size\": 768,\r\n \"initializer_range\": 0.02,\r\n \"intermediate_size\": 3072,\r\n \"layer_norm_eps\": 1e-12,\r\n \"max_position_embeddings\": 130,\r\n \"model_type\": \"roberta\",\r\n \"num_attention_heads\": 12,\r\n \"num_hidden_layers\": 12,\r\n \"pad_token_id\": 1,\r\n \"position_embedding_type\": \"absolute\",\r\n \"transformers_version\": \"4.9.1\",\r\n \"type_vocab_size\": 1,\r\n \"use_cache\": true,\r\n \"vocab_size\": 30000\r\n}\r\n```\r\n\r\nUpdate: you can repeat this file a couple of times and change `train_dir`/`test_dir` to point to the directory containing it\r\n\r\nhttps://gist.github.com/finiteautomata/38bf8893ad0035e7001653a91a5f7ec3",
"After some digging, I gathered some extra information of the crash. It seems that the first saved params (`saved_groups[0][\"params\"]`) contains 77 elements, while the new optimizer has 76. This raises the exception\r\n\r\n```python\r\n 1149 if delay_optimizer_creation:\r\n 1150 self.create_optimizer_and_scheduler(num_training_steps=max_steps)\r\n 1151 \r\n 1152 # Check if saved optimizer or scheduler states exist\r\n-> 1153 self._load_optimizer_and_scheduler(resume_from_checkpoint)\r\n 1154 \r\n 1155 # important: at this point:\r\n 1156 # self.model is the Transformers Model\r\n 1157 # self.model_wrapped is DDP(Transformers Model), Deepspeed(Transformers Model), etc.\r\n 1158 \r\n 1159 # Train!\r\n 1160 num_examples = (\r\n 1161 self.num_examples(train_dataloader) if train_dataset_is_sized else total_train_batch_size * args.max_steps\r\n 1162 )\r\n\r\n /home/jmperez/.cache/pypoetry/virtualenvs/finetune-vs-scratch-gHiQbun3-py3.7/lib/python3.7/site-packages/transformers/trainer.py(1612)_load_optimizer_and_scheduler()\r\n 1602 if is_torch_tpu_available():\r\n 1603 # On TPU we have to take some extra precautions to properly load the states on the right device.\r\n 1604 optimizer_state = torch.load(os.path.join(checkpoint, \"optimizer.pt\"), map_location=\"cpu\")\r\n 1605 with warnings.catch_warnings(record=True) as caught_warnings:\r\n 1606 lr_scheduler_state = torch.load(os.path.join(checkpoint, \"scheduler.pt\"), map_location=\"cpu\")\r\n 1607 reissue_pt_warnings(caught_warnings)\r\n 1608 \r\n 1609 xm.send_cpu_data_to_device(optimizer_state, self.args.device)\r\n 1610 xm.send_cpu_data_to_device(lr_scheduler_state, self.args.device)\r\n 1611 import ipdb; ipdb.set_trace()\r\n-> 1612 self.optimizer.load_state_dict(optimizer_state)\r\n 1613 self.lr_scheduler.load_state_dict(lr_scheduler_state)\r\n 1614 else:\r\n 1615 map_location = \"cpu\" if is_sagemaker_mp_enabled() else self.args.device\r\n 1616 self.optimizer.load_state_dict(\r\n 1617 torch.load(os.path.join(checkpoint, \"optimizer.pt\"), map_location=map_location)\r\n 1618 )\r\n 1619 with warnings.catch_warnings(record=True) as caught_warnings:\r\n 1620 self.lr_scheduler.load_state_dict(torch.load(os.path.join(checkpoint, \"scheduler.pt\")))\r\n 1621 reissue_pt_warnings(caught_warnings)\r\n\r\n> /home/jmperez/.cache/pypoetry/virtualenvs/finetune-vs-scratch-gHiQbun3-py3.7/lib/python3.7/site-packages/torch/optim/optimizer.py(144)load_state_dict()\r\n 134 state_dict = deepcopy(state_dict)\r\n 135 # Validate the state_dict\r\n 136 groups = self.param_groups\r\n 137 saved_groups = state_dict['param_groups']\r\n 138 \r\n 139 if len(groups) != len(saved_groups):\r\n 140 raise ValueError(\"loaded state dict has a different number of \"\r\n 141 \"parameter groups\")\r\n 142 param_lens = (len(g['params']) for g in groups)\r\n 143 saved_lens = (len(g['params']) for g in saved_groups)\r\n--> 144 if any(p_len != s_len for p_len, s_len in zip(param_lens, saved_lens)):\r\n 145 raise ValueError(\"loaded state dict contains a parameter group \"\r\n 146 \"that doesn't match the size of optimizer's group\")\r\n 147 \r\n 148 # Update the state\r\n 149 id_map = {old_id: p for old_id, p in\r\n 150 zip(chain.from_iterable((g['params'] for g in saved_groups)),\r\n 151 chain.from_iterable((g['params'] for g in groups)))}\r\n 152 \r\n 153 def cast(param, value):\r\n\r\nipdb> len(saved_groups[1][\"params\"])\r\n127\r\nipdb> len(groups[1][\"params\"])\r\n127\r\nipdb> len(saved_groups[0][\"params\"])\r\n77\r\nipdb> len(groups[0][\"params\"])\r\n76\r\nipdb> saved_groups[0][\"params\"]\r\n[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76]\r\nipdb> type(groups[0][\"params\"])\r\n<class 'list'>\r\nipdb> groups[0][\"params\"][0]\r\nParameter containing:\r\ntensor([[ 0.0166, 0.0198, 0.0155, ..., 0.0200, -0.0159, 0.0022],\r\n [ 0.0000, 0.0000, 0.0000, ..., 0.0000, 0.0000, 0.0000],\r\n [ 0.0469, 0.0027, -0.0038, ..., 0.0280, 0.0718, 0.0199],\r\n ...,\r\n [ 0.0048, 0.0189, -0.0068, ..., -0.0642, -0.0060, 0.0320],\r\n [-0.0138, -0.0080, 0.0119, ..., 0.0585, -0.0214, -0.0042],\r\n [ 0.0244, 0.0121, -0.0498, ..., -0.0162, -0.0110, -0.0159]],\r\n device='xla:1', requires_grad=True)\r\n\r\n```",
"What's the architecture used? It could be a model that adds some parameters during training for some reason (`twerto-base-uncased-trained` does not help me ;-) )",
"It is a `RobertaForMaskedLM`\r\n\r\nI changed and re-ran everything changing the `transformers_version` (I noticed there was a mismatch between environment version and the one in the config file) and adding the architecture with no success.\r\n\r\n```json\r\n{\r\n \"architectures\": [\r\n \"RobertaForMaskedLM\"\r\n ],\r\n \"attention_probs_dropout_prob\": 0.1,\r\n \"bos_token_id\": 0,\r\n \"classifier_dropout\": null,\r\n \"eos_token_id\": 2,\r\n \"gradient_checkpointing\": false,\r\n \"hidden_act\": \"gelu\",\r\n \"hidden_dropout_prob\": 0.1,\r\n \"hidden_size\": 768,\r\n \"initializer_range\": 0.02,\r\n \"intermediate_size\": 3072,\r\n \"layer_norm_eps\": 1e-12,\r\n \"max_position_embeddings\": 130,\r\n \"model_type\": \"roberta\",\r\n \"num_attention_heads\": 12,\r\n \"num_hidden_layers\": 12,\r\n \"pad_token_id\": 1,\r\n \"position_embedding_type\": \"absolute\",\r\n \"torch_dtype\": \"float32\",\r\n \"transformers_version\": \"4.10.0.dev0\",\r\n \"type_vocab_size\": 1,\r\n \"use_cache\": true,\r\n \"vocab_size\": 30000\r\n }\r\n```",
"Ok, it seems that `RoBERTa` is the problem here. Changing\r\n\r\n```json\r\n{\r\n \"architectures\": [\r\n \"BertForMaskedLM\"\r\n ],\r\n # ...\r\n \"model_type\": \"bert\",\r\n }\r\n```\r\n\r\nenables checkpoint recovery. \r\n\r\nIs this problem in my config or is this a bug?",
"Good to know it's specific to Roberta! I think it may be due to some parameter being created dynamically during training. Will investigate more tomorrow.",
"More digging: when trying to reload the checkpoint, it seems that the missing parameter name (that is, the one that the new optimizer is not willing to load) is `['lm_head.decoder.weight']`. ",
"A Colab notebook reproducing the error on TPU, without any custom script\r\n\r\nhttps://colab.research.google.com/drive/1GvOktm36m3Q43KWLv681QU8VydubOTAQ?usp=sharing\r\n\r\nThis notebook is barely the same but using GPUs, and it works\r\n\r\nhttps://colab.research.google.com/drive/1GMUgpSNIAdGTk9mOk6ua5pACj-Qlgs9v?usp=sharing\r\n\r\nSo the problem is `RoBERTa`+TPUs",
"I have taken a deep dive into this issue, and it made me discover that all the weight tying in Transformers was thrown into the bins the moment the model is placed on an XLA device, which is why your state dict comports more tensors than your model expects.\r\n\r\n#13030 should fix the issue.",
"Great work @sgugger. I can confirm that the notebook in the last comment now reloads the checkpoint. \r\n\r\nJust one extra question: should I use a saved checkpoint with the previous code or is it now useless? I'm not sure if there was a problem during training too",
"You should definitely start from scratch (sorry) as your previous trainings don't have the proper weights for the decoder (they are not saved since they are supposed to be the same as the embeddings so you can't even retrieve them)",
"Great! Thanks again"
] | 1,628 | 1,628 | 1,628 | NONE | null | I'm facing a similar issue as #11326. When trying to resume training from checkpoint on TPUs, it crashes with error message `ValueError: loaded state dict contains a parameter group that doesn't match the size of optimizer's group`
## Environment info
- `transformers` version: 4.10.0.dev0
- Platform: Linux-4.19.0-17-cloud-amd64-x86_64-with-debian-10.10
- Python version: 3.7.10
- PyTorch version (GPU?): 1.9.0+cu102 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: No, TPU v3 on GCP
- Using distributed or parallel set-up in script?: yes, `xla_spawn`
### Who can help
@sgugger
## Information
Model I am using: RoBERTa model
The problem arises when using:
[* ] my own modified scripts:
A barely modified version of `run_mlm.py` (check [here](https://gist.github.com/finiteautomata/bef480d508d12e2028fdeae19a92b350))
## To reproduce
Steps to reproduce the behavior:
1. Run `python xla_spawn.py run_mlm.py config.json`
2. Save checkpoint
3. Run again `python xla_spawn.py run_mlm.py config.json` (with `resume_from_checkpoint` set to `true`)
```config.json
{
"train_dir": "data/tweets/train",
"eval_dir": "data/tweets/test",
"pad_to_max_length": true,
"max_seq_length": 128,
"tokenize_on_the_fly": true,
"do_train": true,
"do_eval": true,
"seed": 123456,
"max_steps": 225000,
"eval_steps": 6000,
"save_steps": 1500,
"max_eval_samples": 150000,
"logging_steps": 200,
"logging_strategy": "steps",
"logging_dir": "./logs/",
"evaluation_strategy": "steps",
"config_name": "models/twerto-base-uncased",
"tokenizer_name": "models/twerto-base-uncased",
"output_dir": "models/twerto-base-uncased-trained",
"tokenization_batch_size": 81920,
"weight_decay": 0.01,
"adam_beta1": 0.9,
"adam_beta2": 0.98,
"adam_epsilon": 1e-6,
"learning_rate": 6e-4,
"max_grad_norm": 0,
"warmup_ratio": 0.06,
"resume_from_checkpoint": true,
"ignore_data_skip": true,
"per_device_train_batch_size": 128,
"per_device_eval_batch_size": 128,
"gradient_accumulation_steps": 4
}
```
### Error trace
```python
[INFO|trainer.py:1053] 2021-08-05 14:43:49,852 >> Loading model from models/twerto-base-uncased-trained/checkpoint-21000).
Traceback (most recent call last):
File "bin/run_mlm.py", line 507, in <module>
main(time.time())
File "bin/run_mlm.py", line 449, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "/home/jmperez/.cache/pypoetry/virtualenvs/finetune-vs-scratch-gHiQbun3-py3.7/lib/python3.7/site-packages/transformers/trainer.py", line 1153, in train
self._load_optimizer_and_scheduler(resume_from_checkpoint)
File "/home/jmperez/.cache/pypoetry/virtualenvs/finetune-vs-scratch-gHiQbun3-py3.7/lib/python3.7/site-packages/transformers/trainer.py", line 1612, in _load_optimizer_and_scheduler
self.optimizer.load_state_dict(optimizer_state)
File "/home/jmperez/.cache/pypoetry/virtualenvs/finetune-vs-scratch-gHiQbun3-py3.7/lib/python3.7/site-packages/torch/optim/optimizer.py", line 145, in load_state_dict
raise ValueError("loaded state dict contains a parameter group "
ValueError: loaded state dict contains a parameter group that doesn't match the size of optimizer's group
```
## Expected behavior
Training resumes from checkpoint
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13018/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13018/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13017 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13017/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13017/comments | https://api.github.com/repos/huggingface/transformers/issues/13017/events | https://github.com/huggingface/transformers/pull/13017 | 961,907,960 | MDExOlB1bGxSZXF1ZXN0NzA0Nzc3NTEw | 13,017 | Fix VisualBert Embeddings | {
"login": "gchhablani",
"id": 29076344,
"node_id": "MDQ6VXNlcjI5MDc2MzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gchhablani",
"html_url": "https://github.com/gchhablani",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url": "https://api.github.com/users/gchhablani/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gchhablani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gchhablani/subscriptions",
"organizations_url": "https://api.github.com/users/gchhablani/orgs",
"repos_url": "https://api.github.com/users/gchhablani/repos",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"received_events_url": "https://api.github.com/users/gchhablani/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Did you verify that it fixes the error mentioned in the issue?\r\n\r\ni.e. does the following work:\r\n\r\n```\r\nfrom transformers import BertTokenizer, VisualBertModel\r\ntokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\r\nmodel = VisualBertModel.from_pretrained('uclanlp/visualbert-vqa-coco-pre')\r\ninputs = tokenizer(\"The capital of France is Paris.\", return_tensors=\"pt\")\r\nvisual_embeds = torch.zeros((1,36,2048)) #example of ROI features\r\nvisual_token_type_ids = torch.ones(visual_embeds.shape[:-1], dtype=torch.long) #example\r\nvisual_attention_mask = torch.ones(visual_embeds.shape[:-1], dtype=torch.float)\r\ninputs.update({{\r\n \"visual_embeds\": visual_embeds,\r\n \"visual_token_type_ids\": visual_token_type_ids,\r\n \"visual_attention_mask\": visual_attention_mask\r\n}})\r\noutputs = model(**inputs)\r\n```",
"@NielsRogge\r\n\r\nYes. I tried it for the example and it works fine.",
"@NielsRogge Does this look okay?",
"Idont understand"
] | 1,628 | 1,628 | 1,628 | CONTRIBUTOR | null | # What does this PR do?
This PR addresses the issue mentioned in #13001. The `self.input_embeds` has been replaced with `self.position_ids` as suggested by @NielsRogge. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13017/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13017/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13017",
"html_url": "https://github.com/huggingface/transformers/pull/13017",
"diff_url": "https://github.com/huggingface/transformers/pull/13017.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13017.patch",
"merged_at": 1628755054000
} |
https://api.github.com/repos/huggingface/transformers/issues/13016 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13016/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13016/comments | https://api.github.com/repos/huggingface/transformers/issues/13016/events | https://github.com/huggingface/transformers/pull/13016 | 961,854,570 | MDExOlB1bGxSZXF1ZXN0NzA0NzMxMDEx | 13,016 | FX submodule naming fix | {
"login": "michaelbenayoun",
"id": 25418079,
"node_id": "MDQ6VXNlcjI1NDE4MDc5",
"avatar_url": "https://avatars.githubusercontent.com/u/25418079?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/michaelbenayoun",
"html_url": "https://github.com/michaelbenayoun",
"followers_url": "https://api.github.com/users/michaelbenayoun/followers",
"following_url": "https://api.github.com/users/michaelbenayoun/following{/other_user}",
"gists_url": "https://api.github.com/users/michaelbenayoun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/michaelbenayoun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/michaelbenayoun/subscriptions",
"organizations_url": "https://api.github.com/users/michaelbenayoun/orgs",
"repos_url": "https://api.github.com/users/michaelbenayoun/repos",
"events_url": "https://api.github.com/users/michaelbenayoun/events{/privacy}",
"received_events_url": "https://api.github.com/users/michaelbenayoun/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | MEMBER | null | This PR is related to HFTracer, the class responsible for allowing torch.fx symbolic tracing on transformers models.
It enhances the way dynamically inserted modules are named, making the name of the submodule inserted to the parent more explicit and close to what the submodule represents. It also solves issues related to the way submodule were inserted: instead of using `setattr`, `nn.Module.add_module()` is used. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13016/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13016/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13016",
"html_url": "https://github.com/huggingface/transformers/pull/13016",
"diff_url": "https://github.com/huggingface/transformers/pull/13016.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13016.patch",
"merged_at": 1628257049000
} |
https://api.github.com/repos/huggingface/transformers/issues/13015 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13015/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13015/comments | https://api.github.com/repos/huggingface/transformers/issues/13015/events | https://github.com/huggingface/transformers/pull/13015 | 961,845,851 | MDExOlB1bGxSZXF1ZXN0NzA0NzIzMzYw | 13,015 | Fix TYPE_CHECKING not imported | {
"login": "minwhoo",
"id": 11580164,
"node_id": "MDQ6VXNlcjExNTgwMTY0",
"avatar_url": "https://avatars.githubusercontent.com/u/11580164?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/minwhoo",
"html_url": "https://github.com/minwhoo",
"followers_url": "https://api.github.com/users/minwhoo/followers",
"following_url": "https://api.github.com/users/minwhoo/following{/other_user}",
"gists_url": "https://api.github.com/users/minwhoo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/minwhoo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/minwhoo/subscriptions",
"organizations_url": "https://api.github.com/users/minwhoo/orgs",
"repos_url": "https://api.github.com/users/minwhoo/repos",
"events_url": "https://api.github.com/users/minwhoo/events{/privacy}",
"received_events_url": "https://api.github.com/users/minwhoo/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Actually the whole init needs to be rewritten to be the same as other models, it was somehow missed when we converted all models. Would like to amend your PR in that direction?",
"Your rebase has introduced many file changes in the diff that make the PR unreadable. Once you're satisfied with your branch, could you close this PR and open a new one? This should make the diff better.",
"Sure thing."
] | 1,628 | 1,628 | 1,628 | CONTRIBUTOR | null | # What does this PR do?
Fixes omitted import of TYPE_CHECKING in xlm_prophetnet model code's __init__.py.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13015/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13015/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13015",
"html_url": "https://github.com/huggingface/transformers/pull/13015",
"diff_url": "https://github.com/huggingface/transformers/pull/13015.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13015.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/13014 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13014/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13014/comments | https://api.github.com/repos/huggingface/transformers/issues/13014/events | https://github.com/huggingface/transformers/pull/13014 | 961,778,102 | MDExOlB1bGxSZXF1ZXN0NzA0NjY1NjE1 | 13,014 | T5 with past ONNX export | {
"login": "michaelbenayoun",
"id": 25418079,
"node_id": "MDQ6VXNlcjI1NDE4MDc5",
"avatar_url": "https://avatars.githubusercontent.com/u/25418079?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/michaelbenayoun",
"html_url": "https://github.com/michaelbenayoun",
"followers_url": "https://api.github.com/users/michaelbenayoun/followers",
"following_url": "https://api.github.com/users/michaelbenayoun/following{/other_user}",
"gists_url": "https://api.github.com/users/michaelbenayoun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/michaelbenayoun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/michaelbenayoun/subscriptions",
"organizations_url": "https://api.github.com/users/michaelbenayoun/orgs",
"repos_url": "https://api.github.com/users/michaelbenayoun/repos",
"events_url": "https://api.github.com/users/michaelbenayoun/events{/privacy}",
"received_events_url": "https://api.github.com/users/michaelbenayoun/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | MEMBER | null | This PR enables the export of T5 with past keys and values to ONNX.
It also enhances the ONNX export when using past keys and values by making the inputs and outputs names for past_key_values more explicit and easy to understand. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13014/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13014/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13014",
"html_url": "https://github.com/huggingface/transformers/pull/13014",
"diff_url": "https://github.com/huggingface/transformers/pull/13014.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13014.patch",
"merged_at": 1628257586000
} |
https://api.github.com/repos/huggingface/transformers/issues/13013 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13013/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13013/comments | https://api.github.com/repos/huggingface/transformers/issues/13013/events | https://github.com/huggingface/transformers/pull/13013 | 961,755,025 | MDExOlB1bGxSZXF1ZXN0NzA0NjQ1MzUx | 13,013 | Update generate method - Fix floor_divide warning | {
"login": "nreimers",
"id": 10706961,
"node_id": "MDQ6VXNlcjEwNzA2OTYx",
"avatar_url": "https://avatars.githubusercontent.com/u/10706961?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nreimers",
"html_url": "https://github.com/nreimers",
"followers_url": "https://api.github.com/users/nreimers/followers",
"following_url": "https://api.github.com/users/nreimers/following{/other_user}",
"gists_url": "https://api.github.com/users/nreimers/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nreimers/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nreimers/subscriptions",
"organizations_url": "https://api.github.com/users/nreimers/orgs",
"repos_url": "https://api.github.com/users/nreimers/repos",
"events_url": "https://api.github.com/users/nreimers/events{/privacy}",
"received_events_url": "https://api.github.com/users/nreimers/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"According to the document of [`torch.div`,](https://pytorch.org/docs/stable/generated/torch.div.html#torch.div) it is more suitable to change `next_indices = next_tokens // vocab_size` to `next_indices = torch.div(next_tokens, vocab_size, rounding_mode='floor')`.\r\n\r\n`\"floor\"` - rounds the results of the division down. Equivalent to floor division in Python (the // operator)",
"> According to the document of [`torch.div`,](https://pytorch.org/docs/stable/generated/torch.div.html#torch.div) it is more suitable to change `next_indices = next_tokens // vocab_size` to `next_indices = torch.div(next_tokens, vocab_size, rounding_mode='floor')`.\r\n> \r\n> `\"floor\"` - rounds the results of the division down. Equivalent to floor division in Python (the // operator)\r\n\r\n\r\nrounding_method was only introduced in pytorch 1.8. Using this method would break with any Pytorch version before 1.8. `(next_tokens/vocab_size).long()` is compatible with any pytorch version.",
"This makes sense!"
] | 1,628 | 1,628 | 1,628 | CONTRIBUTOR | null | # What does this PR do?
Starting with PyTorch 1.9, a HF translation model (or any generation model) gives the following warning message:
```
/home/reimers/miniconda3/envs/easynmt/lib/python3.8/site-packages/torch/_tensor.py:575: UserWarning: floor_divide is deprecated, and will be removed in a future version of pytorch. It currently rounds toward 0 (like the 'trunc' function NOT 'floor'). This results in incorrect rounding for negative values.
To keep the current behavior, use torch.div(a, b, rounding_mode='trunc'), or for actual floor division, use torch.div(a, b, rounding_mode='floor'). (Triggered internally at /opt/conda/conda-bld/pytorch_1623448234945/work/aten/src/ATen/native/BinaryOps.cpp:467.)
return torch.floor_divide(self, other)
```
Here the code to produce this warning:
```
import warnings
warnings.filterwarnings("error") #Turn warning into an exception for traceback
from transformers import MarianTokenizer, MarianMTModel
model_name = 'Helsinki-NLP/opus-mt-de-en'
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
model.eval()
inputs = tokenizer(["Hallo Welt"], return_tensors="pt")
translated = model.generate(**inputs, num_beams=3)
print(translated)
```
Here the responsible line:
https://github.com/huggingface/transformers/blob/a6d62aaba01ce4ff1b2ee8705bf113904672c345/src/transformers/generation_utils.py#L1838
The // operator is translated to floor_divide, which is deprecated starting PyTorch 1.9:
https://pytorch.org/docs/stable/generated/torch.floor_divide.html
We replace this line with:
```
next_indices = (next_tokens/vocab_size).long()
```
which is is compatible with any PyTorch version and yields identical results to `next_tokens // vocab_size`.
Here a test to show this:
```
import random
import torch
for _ in range(100):
a = torch.tensor([random.randint(1, 1000)])
b = torch.tensor([random.randint(1, 100)])
c = a // b
d = (a/b).long()
assert torch.equal(c,d)
````
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
@sgugger
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13013/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13013/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13013",
"html_url": "https://github.com/huggingface/transformers/pull/13013",
"diff_url": "https://github.com/huggingface/transformers/pull/13013.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13013.patch",
"merged_at": 1628171714000
} |
https://api.github.com/repos/huggingface/transformers/issues/13012 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13012/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13012/comments | https://api.github.com/repos/huggingface/transformers/issues/13012/events | https://github.com/huggingface/transformers/pull/13012 | 961,693,007 | MDExOlB1bGxSZXF1ZXN0NzA0NTkxNzYy | 13,012 | [Flax T5] Speed up t5 training | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"The PR is tested here: https://huggingface.co/patrickvonplaten/t5-base-norwegian/tensorboard (check train loss graph which shows that time is reduced to < 5h now)"
] | 1,628 | 1,628 | 1,628 | MEMBER | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
This PR makes sure that no jax functionality is used in the preprocessing to make sure the TPU is not unnecessarly blocked. This small change leads to a **5x** factor speed-up in training T5.
🚨🚨 **Note**: It is extremely important to verify that no DeviceArrays are created during the data preprocessing to make sure that the training step can run asynchronously on TPU while the preprocessing runs on CPU. A good rule is to make sure that in the training step look, only the function `p_train_step` uses JAX/Flax code and all other functions run on CPU. Other relevant links: https://jax.readthedocs.io/en/latest/async_dispatch.html#async-dispatch 🚨🚨
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13012/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13012/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13012",
"html_url": "https://github.com/huggingface/transformers/pull/13012",
"diff_url": "https://github.com/huggingface/transformers/pull/13012.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13012.patch",
"merged_at": 1628241698000
} |
https://api.github.com/repos/huggingface/transformers/issues/13011 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13011/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13011/comments | https://api.github.com/repos/huggingface/transformers/issues/13011/events | https://github.com/huggingface/transformers/issues/13011 | 961,614,004 | MDU6SXNzdWU5NjE2MTQwMDQ= | 13,011 | The traced Encoder of LEDForConditionalGeneration does not allow dynamic batching | {
"login": "gauravpandeyamu",
"id": 8806278,
"node_id": "MDQ6VXNlcjg4MDYyNzg=",
"avatar_url": "https://avatars.githubusercontent.com/u/8806278?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gauravpandeyamu",
"html_url": "https://github.com/gauravpandeyamu",
"followers_url": "https://api.github.com/users/gauravpandeyamu/followers",
"following_url": "https://api.github.com/users/gauravpandeyamu/following{/other_user}",
"gists_url": "https://api.github.com/users/gauravpandeyamu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gauravpandeyamu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gauravpandeyamu/subscriptions",
"organizations_url": "https://api.github.com/users/gauravpandeyamu/orgs",
"repos_url": "https://api.github.com/users/gauravpandeyamu/repos",
"events_url": "https://api.github.com/users/gauravpandeyamu/events{/privacy}",
"received_events_url": "https://api.github.com/users/gauravpandeyamu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
},
{
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
}
] | [
"Hey @gauravpandeyamu, \r\n\r\nThis seems to be a rather edge-casy and difficult error to debug! I'm not sure if I manage to have the time to look into it. In a first step could you try to use current master instead of Transformers 4.3.2 to see if this changed anything in the error message?",
"@patrickvonplaten Sure, I will try it today and let you know. Thanks",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,631 | 1,631 | NONE | null | We traced the encoder of LEDForConditionalGeneration using TorchScript and passed a different batch size to the traced encoder as follows.
```
import torch
from transformers import LEDForConditionalGeneration
class WrappedModel(torch.nn.Module):
def __init__(self):
super(WrappedModel, self).__init__()
self.model = LEDForConditionalGeneration.from_pretrained("allenai/led-base-16384", torchscript=True).led.encoder
def forward(self, data):
return self.model(data)
example = torch.zeros((1,128), dtype=torch.long)+ 10 # bsz , seqlen
pt_model = WrappedModel().eval()
traced_script_module = torch.jit.trace(pt_model, example)
example_dynamic_batch = torch.zeros((4,128), dtype=torch.long) # bsz , seqlen
traced_script_module(example_dynamic_batch)
```
Being able to vary the batch size during deployment is necessary for dynamic batching to work (for instance, when using Triton inference server).
Passing a different batch size than the one used during tracing results in the following error:
```
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-4-5e85f8f70ee7> in <module>
10 pt_model = WrappedModel().eval()
11 traced_script_module = torch.jit.trace(pt_model, example)
---> 12 traced_script_module(example.repeat(4,1))
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
RuntimeError: The following operation failed in the TorchScript interpreter.
Traceback of TorchScript (most recent call last):
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/transformers/models/led/modeling_led.py(447): _sliding_chunks_query_key_matmul
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/transformers/models/led/modeling_led.py(202): forward
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/torch/nn/modules/module.py(709): _slow_forward
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/torch/nn/modules/module.py(725): _call_impl
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/transformers/models/led/modeling_led.py(725): forward
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/torch/nn/modules/module.py(709): _slow_forward
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/torch/nn/modules/module.py(725): _call_impl
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/transformers/models/led/modeling_led.py(914): forward
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/torch/nn/modules/module.py(709): _slow_forward
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/torch/nn/modules/module.py(725): _call_impl
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/transformers/models/led/modeling_led.py(1838): forward
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/torch/nn/modules/module.py(709): _slow_forward
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/torch/nn/modules/module.py(725): _call_impl
<ipython-input-4-5e85f8f70ee7>(7): forward
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/torch/nn/modules/module.py(709): _slow_forward
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/torch/nn/modules/module.py(725): _call_impl
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/torch/jit/_trace.py(940): trace_module
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/torch/jit/_trace.py(742): trace
<ipython-input-4-5e85f8f70ee7>(11): <module>
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/IPython/core/interactiveshell.py(3441): run_code
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/IPython/core/interactiveshell.py(3361): run_ast_nodes
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/IPython/core/interactiveshell.py(3170): run_cell_async
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/IPython/core/async_helpers.py(68): _pseudo_sync_runner
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/IPython/core/interactiveshell.py(2944): _run_cell
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/IPython/core/interactiveshell.py(2899): run_cell
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/ipykernel/zmqshell.py(539): run_cell
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/ipykernel/ipkernel.py(302): do_execute
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/tornado/gen.py(234): wrapper
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/ipykernel/kernelbase.py(538): execute_request
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/tornado/gen.py(234): wrapper
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/ipykernel/kernelbase.py(261): dispatch_shell
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/tornado/gen.py(234): wrapper
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/ipykernel/kernelbase.py(358): process_one
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/tornado/gen.py(775): run
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/tornado/gen.py(814): inner
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/tornado/ioloop.py(741): _run_callback
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/tornado/ioloop.py(688): <lambda>
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/asyncio/events.py(88): _run
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/asyncio/base_events.py(1758): _run_once
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/asyncio/base_events.py(523): run_forever
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/tornado/platform/asyncio.py(199): start
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/ipykernel/kernelapp.py(619): start
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/traitlets/config/application.py(845): launch_instance
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/site-packages/ipykernel_launcher.py(16): <module>
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/runpy.py(85): _run_code
/dccstor/gpandey11/anaconda3/envs/test/lib/python3.7/runpy.py(193): _run_module_as_main
RuntimeError: shape '[12, 1, 512, 513]' is invalid for input of size 12607488
```
Dynamic batching works fine with the BERT model. For example, the following code gives the correct output.
```
import torch
from transformers import BertForSequenceClassification
class WrappedModel(torch.nn.Module):
def __init__(self):
super(WrappedModel, self).__init__()
self.model = BertForSequenceClassification.from_pretrained('bert-base-uncased', torchscript=True)
def forward(self, data):
return self.model(data)
example = torch.zeros((1,128), dtype=torch.long)+ 10 # bsz , seqlen
pt_model = WrappedModel().eval()
traced_script_module = torch.jit.trace(pt_model, example)
example_dynamic_batch = torch.zeros((4,128), dtype=torch.long) # bsz , seqlen
traced_script_module(example_dynamic_batch)
```
## Environment
```
- `transformers` version: 4.3.2
- Platform: Linux-4.18.0-240.22.1.el8_3.x86_64-x86_64-with-redhat-8.3-Ootpa
- Python version: 3.7.0
- PyTorch version (GPU?): 1.7.1 (True)
- Tensorflow version (GPU?): 2.2.0 (False)
- Using GPU in script?: False
- Using distributed or parallel set-up in script?: False
```
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13011/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13011/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13010 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13010/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13010/comments | https://api.github.com/repos/huggingface/transformers/issues/13010/events | https://github.com/huggingface/transformers/pull/13010 | 961,587,346 | MDExOlB1bGxSZXF1ZXN0NzA0NTAwNDY5 | 13,010 | GPT-J | {
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,635 | 1,628 | MEMBER | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13010/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13010/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13010",
"html_url": "https://github.com/huggingface/transformers/pull/13010",
"diff_url": "https://github.com/huggingface/transformers/pull/13010.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13010.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/13009 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13009/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13009/comments | https://api.github.com/repos/huggingface/transformers/issues/13009/events | https://github.com/huggingface/transformers/issues/13009 | 961,530,739 | MDU6SXNzdWU5NjE1MzA3Mzk= | 13,009 | Problem saving tf wav2vec in savedmodel format | {
"login": "ahmedlone127",
"id": 66001253,
"node_id": "MDQ6VXNlcjY2MDAxMjUz",
"avatar_url": "https://avatars.githubusercontent.com/u/66001253?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ahmedlone127",
"html_url": "https://github.com/ahmedlone127",
"followers_url": "https://api.github.com/users/ahmedlone127/followers",
"following_url": "https://api.github.com/users/ahmedlone127/following{/other_user}",
"gists_url": "https://api.github.com/users/ahmedlone127/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ahmedlone127/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ahmedlone127/subscriptions",
"organizations_url": "https://api.github.com/users/ahmedlone127/orgs",
"repos_url": "https://api.github.com/users/ahmedlone127/repos",
"events_url": "https://api.github.com/users/ahmedlone127/events{/privacy}",
"received_events_url": "https://api.github.com/users/ahmedlone127/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
},
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
}
] | [
"Hey @ahmed451 - could you please add a code snippet to reproduce the error instead of a screenshot? Thanks!",
"sure\r\n\r\n ```\r\nfrom transformers import TFWav2Vec2ForCTC\r\n\r\nmodel= TFWav2Vec2ForCTC.from_pretrained('patrickvonplaten/wav2vec2-base-timit-demo',from_pt = True)\r\n\r\nmodel.save_pretrained(\"/content/test\",saved_model = True) ```",
"I've run your code snippet in the following environment:\r\n\r\n```\r\n- `transformers` version: 4.10.0.dev0\r\n- Platform: Linux-4.15.0-112-generic-x86_64-with-Ubuntu-18.04-bionic\r\n- Python version: 3.7.5\r\n- Tensorflow version (GPU?): 2.3.0 (False)\r\n```\r\n\r\n\r\nand to me it looks like this is a problem coming from Tensorflow directly. I.E. the error output is:\r\n\r\n```\r\nUnimplementedError: The Conv2D op currently does not support grouped convolutions on the CPU. A grouped convolution was attempted to be run because the input depth of 768 does not match the filter input depth of 48 [Op:Conv2D]\r\n```\r\n\r\nAlso gently pinging @will-rice here in case he has seen something like this before :-)",
"This is/was a TensorFlow limitation, but according to [this](https://github.com/tensorflow/tensorflow/issues/29005) `2.6` may have solved it. First I would try upgrading to `2.6` or the latest nightly. Another option could be the [workaround](https://github.com/tensorflow/tensorflow/issues/40044) for this problem in TFLite. I will say the workaround is slower though.",
"@patrickvonplaten How do I install the transformers 4.10.0 version?",
"It's current master :-) So `!pip install git+https://github.com/huggingface/transformers.git@master` should do",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,632 | 1,632 | NONE | null | 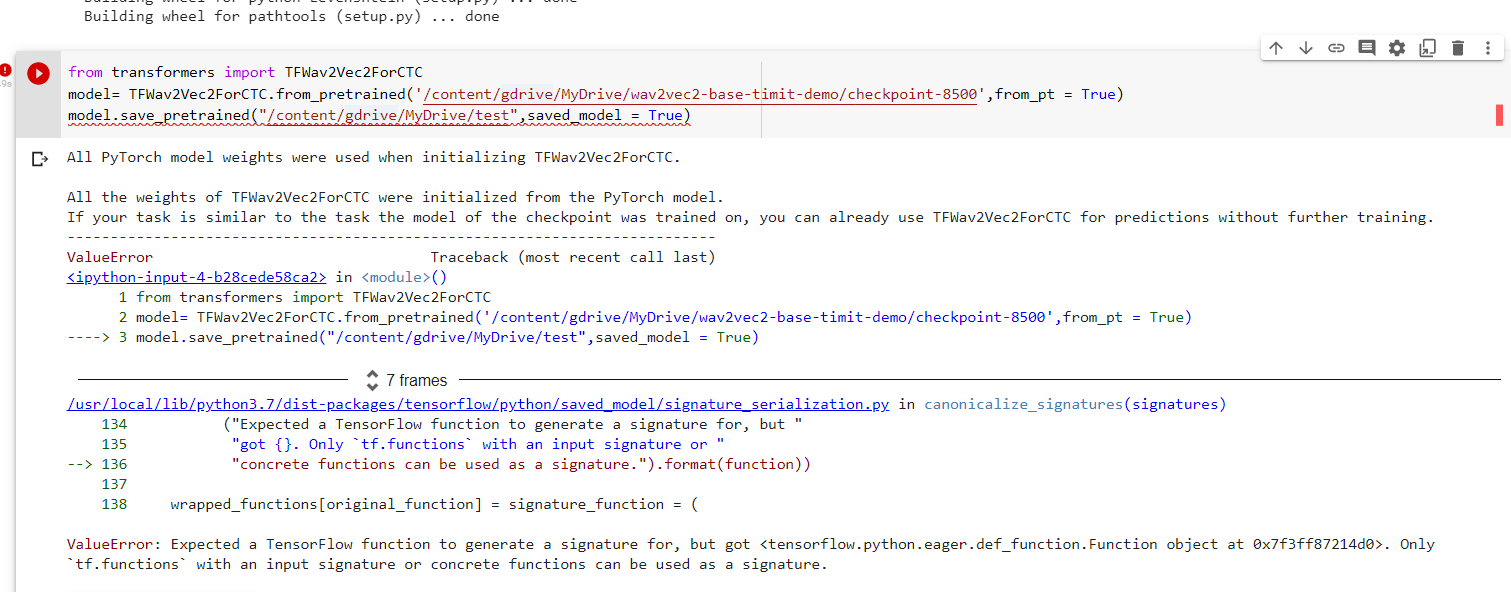
this is my code | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13009/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13009/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13008 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13008/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13008/comments | https://api.github.com/repos/huggingface/transformers/issues/13008/events | https://github.com/huggingface/transformers/pull/13008 | 961,512,997 | MDExOlB1bGxSZXF1ZXN0NzA0NDM3Mjgw | 13,008 | [Flax Encoder Decoder] Make Flax GPT2 working with cross attention | {
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This is a great PR @ydshieh! Thanks a lot for working on this! :-) The PR looks great - that's exactly how I would have implemented it as well.\r\n\r\nIt would be great if you could remove the encoder->decoder projection layer in a first PR to make it consistent with PyTocrh. Also we will probably have to add a `FlaxEncoderDecoder` model architecture file in addition to this to showcase how GPT2 can be used with cross attention and to test this new feature.\r\n\r\nThe `FlaxEncoderDecoder` model should look very similar to the PyTorch implementation: https://github.com/huggingface/transformers/blob/master/src/transformers/models/encoder_decoder/modeling_encoder_decoder.py . We can also get some inspiration from https://github.com/gchhablani/multilingual-image-captioning/blob/main/models/flax_clip_vision_mbart/modeling_clip_vision_mbart.py . We'll have to make it more general though cc @gchhablani @bhadreshpsavani \r\n\r\n=> It's important that we test newly added features (such as GPT2's cross attention layer) so I think we'll have to add `modeling_flax_encoder_decoder.py` right away. This will definitely require some more work. If you are interested in giving it a shot @ydshieh that would be great - otherwise I can also continue this PR next week :-) ",
"@patrickvonplaten Thanks for the feedback, I will remove the encoder->decoder projection layer.\r\n\r\nYes, I would like to work on `FlaxEncoderDecoder`, it is a great learning chance. If I understand correctly, you prefer `FlaxEncoderDecoder` being included in this PR, rather than in a separate PR, right?",
"Excatly let's include it in this PR so that we can then also add a first test for it with GPT2, like this one for PyTorch: https://github.com/huggingface/transformers/blob/9870093f7b31bf774fe6bdfeed5e08f0d4649b07/tests/test_modeling_encoder_decoder.py#L721",
"@ydshieh This is great! Do let me know if I can help in any way.",
"Hi, @patrickvonplaten \r\n\r\nHere is my first attempt to `FlaxEncoderDecoderModel`. However, I have 3 main questions - when you have time, could you give some suggestions for them, please?\r\n\r\n 1. The `__call__/encode/decode` methods in Flax models (and modules) don't seem to have `**kwargs`, at least, not in `FlaxBartModel` code.\r\n\r\n The current version of `FlaxEncoderDecoderModel` don't have `token_type_ids` parameter, and might have problems when the decoder module is `FlaxBertModule`, because it requires `token_type_ids` argument.\r\n\r\n Do you have a better idea to deal with the `token_type_ids` parameter?\r\n\r\n - Try to add it explicity in the methods' parameters, like `position_ids`?\r\n - Or there is a good way to use `**kwargs` in this case?\r\n\r\n 2. In `self.__call__()`, when `decoder_input_ids` is `None`, we use `shift_tokens_right()` and it requires `decoder_start_token_id`.\r\n\r\n However, `self.config` (EncoderDecoderConfig), or even `self.config.decoder`, might not have `decoder_start_token_id defined`.\r\n \r\n - Should we try to add `decoder_start_token_id` in `self.from_encoder_decoder_pretrained()`, using similar logic in `generation_utils._get_decoder_start_token_id()`?\r\n - Or we just leave the users to specify it (when it is not already in the config)?\r\n\r\n 3. In `modeling_encoder_deocer.EncoderDecoderModel.prepare_inputs_for_generation()`, we use the decoder model's\r\n `prepare_inputs_for_generation()`: \r\n\r\n decoder_inputs = self.decoder.prepare_inputs_for_generation(decoder_input_ids, ...) \r\n\r\n However, in Flax's version, we only have the decoder module, not the\r\n decoder model. Is the current `FlaxEncoderDecoderModel.prepare_inputs_for_generation()` implementation OK?\r\n\r\n\r\nThere are 5 other comments starting with \"# Q: \". It would be great if you can also have some feedbacks on them, but they are less important.",
"Hey @ydshieh, \r\n\r\nThe PR already seems to be in a great shape - awesome job! Thanks a lot for being so clear about your questions - I answered most of them in the comments above. \r\n\r\nIn short:\r\n- let's just remove `token_type_ids` for FlaxEncoderDecoder for now\r\n- `decoder_input_ids` should never be generated from `input_ids` here, the user should be forced to pass them\r\n- `we should define a `decode` function and `prepare_inputs_for_generation` similar to how it's done for `FlaxBart` \r\n- The goal of this PR should really be to enable tests like those: https://github.com/huggingface/transformers/blob/e46ad22cd6cb28f78f4d9b6314e7581d8fd97dc5/tests/test_modeling_encoder_decoder.py#L721 \r\n\r\nNote that this PR won't (yet) enable generic ImageToText but just generic TextToText with GPT2 as the decoder. In a follow-up PR we will then define a new `FlaxImageEncoderDecoder` class specifically for ImageToText. However it's the much better approach in my opinion to start with TextToText (as you're doing it here) where we can more or less translate most of the code from PyTorch.\r\n\r\nPlease let me know if anything is unclear! I'm more than happy to also take a deeper look if you're stuck somewhere :-)",
"Hey @patrickvonplaten Thanks for all the feedback. I will continue the remaining work, including the test script as you mentioned.\r\n\r\nSince we decide not to consider `token_type_ids` for now, I will need to change the example in the model file from `bert2gpt2 = ...` to `gpt2togpt2 = ...`, otherwise the example won't run (can't even initialize the model). I tested locally with\r\n```\r\nFlaxEncoderDecoderModel.from_encoder_decoder_pretrained('gpt2', 'gpt2') \r\n```\r\nand it at least can run `__call__`. Unless you have other ideas for a pair for the example, I am going for it :)\r\n\r\n",
"Hi @patrickvonplaten , I have made FlaxEncoderDecoder available to the library. It remains to add the test file :)\r\n",
"Hi, @patrickvonplaten , I finished the work by adding the test file, which is copied from `test_modeling_encoder_decoder.py` and modified it. There are a few tests been removed, for example:\r\n\r\n - The part related to `shared_weights` (tie encoder decoder): I can't find something similar to the following for Flax\r\n https://github.com/huggingface/transformers/blob/a13c8145bc2810e3f0a52da22ae6a6366587a41b/src/transformers/modeling_utils.py#L602 so currently, `FlaxEncoderDecoderModel` doesn't deal with `tie_encoder_decoder`.\r\n - The part related to `EncoderDecoderModel(encoder=encoder_model, decoder=decoder_model)`, because in Flax version, model's `__init__` doesn't accept models as arguments.\r\n\r\nLet's me know if there is anything missing or to be changed :)\r\n\r\n## Updates\r\n\r\n - Current `GPT2_INPUTS_DOCSTRING` in `modeling_gpt2.py` doesn't include `encoder_hidden_states` & `encoder_attention_mask`. (and same for the new Flax's version)\r\n https://github.com/huggingface/transformers/blob/a13c8145bc2810e3f0a52da22ae6a6366587a41b/src/transformers/models/gpt2/modeling_gpt2.py#L456\r\nIs it OK to include a fix for this in this PR?\r\n\r\n - Current `GPT2Model` doesn't return `all_cross_attentions` when outputting tuple:\r\nhttps://github.com/huggingface/transformers/blob/a13c8145bc2810e3f0a52da22ae6a6366587a41b/src/transformers/models/gpt2/modeling_gpt2.py#L825\r\nI included a fix for this issue in this PR.\r\n\r\n - There is another issue in `GPT2Model`:\r\nhttps://github.com/huggingface/transformers/blob/a13c8145bc2810e3f0a52da22ae6a6366587a41b/src/transformers/models/gpt2/modeling_gpt2.py#L808\r\n ```\r\n if self.config.add_cross_attention:\r\n all_cross_attentions = all_cross_attentions + (outputs[3 if use_cache else 2],)\r\n ```\r\n This causes exception in the following example. In Bart, the condition is `if encoder_hidden_states is not None:`, (and this makes sense), so we can do the same for GPT2.\r\n ```\r\n import torch\r\n from transformers import GPT2Model, GPT2Config\r\n config = GPT2Config.from_pretrained('gpt2', add_cross_attention=True)\r\n model = GPT2Model.from_pretrained('gpt2', config=config)\r\n o = model(input_ids=torch.tensor([[1, 2, 3]], dtype=torch.int32), output_hidden_states=True, output_attentions=True)\r\n ```\r\n Here Exception:\r\n ```\r\n Traceback (most recent call last):\r\n File \"C:\\Users\\33611\\Desktop\\Projects\\transformers-dev-2\\transformers\\tests.py\", line 10, in <module>\r\n o = model(input_ids=torch.tensor([[1, 2, 3]], dtype=torch.int32), output_hidden_states=True, output_attentions=True)\r\n File \"C:\\Users\\33611\\miniconda3\\envs\\py39\\lib\\site-packages\\torch\\nn\\modules\\module.py\", line 1051, in _call_impl\r\n return forward_call(*input, **kwargs)\r\n File \"c:\\users\\33611\\desktop\\projects\\transformers-dev-2\\transformers\\src\\transformers\\models\\gpt2\\modeling_gpt2.py\", line 809, in forward\r\n all_cross_attentions = all_cross_attentions + (outputs[3 if use_cache else 2],)\r\n IndexError: tuple index out of range\r\n ```\r\n",
"Hi, @patrickvonplaten , I saw you pushed a new FlaxBertModel to make `token_type_ids` . That's great -> I will change to Bert2GPT2 later as you suggested. Thanks",
"Hey @ydshieh,\r\n\r\nThis PR is already in a very good shape. I'm very impressed by how well you implemented this class! The `EncoderDecoderModel` is one of the most difficult classes to implement.\r\n\r\nI've added a Bert2GPT2 test that verifies that your PR works correctly (it does - great job ;-)). I think the only thing left to do now is to change the examples and tests from `\"GPT2toGPT2\"` to `\"BERT2GPT2\"` and then we can merge this one :-)",
"Hi @patrickvonplaten , I changed all remaining examples & tests to bert2gpt2, and rename `EncoderDecoderModelTest` to `FlaxEncoderDecoderModelTest`. The only remark is: `FlaxEncoderDecoderModel` doesn't treat `position_ids` and `token_type_ids`, because it all depends on each encoder/decoder models (modules actually), and it seems to me we don't pass `**kwargs` to `module.apply`. (It would be great If you can say something about this - I am not sure, just my observation).\r\n\r\nOther than this, I think the task is done :)",
"@ydshieh amazing job on adding the Flax encoder decoder class! This lays the foundation for the `FlaxVisionEncoderDecoder` framework :-) \r\n\r\nI'm currently working on adding a `SpeechEncoderDecoder` model here: https://github.com/huggingface/transformers/blob/19106d1c5548b3083c1d5ced667de6854367f1e0/src/transformers/models/speech_encoder_decoder/modeling_speech_encoder_decoder.py - the `FlaxVisionEncoderDecoder` would be added in a similar spirit. If you would be interested we could try to add this class in a follow-up PR :-) ",
"@patrickvonplaten Sure, I would like to continue with it. Actually, I just finished `TFEncoderDecoderModel` and add cross attention to some TF models (Bert/GPT2/Roberta/Electra). In particular, the test for `test_bert2gpt2_summarization` and `test_bert2bert_summarization` works in TF version now (after some bug fixes in the library though). I tested them locally with @slow disabled.\r\n\r\nI need to finalize it, and will request a review (maybe for someone else? not sure if you work with TF) \r\n\r\nI think the implementation for `VisionEncoderDecoder` will be straightforward, right? I mean basically, just change the parameters to pixel_values, and probably add some feature extraction part.\r\n\r\nHere is a preview for `TFEncoderDecoderModel` :)\r\n#13222 \r\n"
] | 1,628 | 1,651 | 1,629 | COLLABORATOR | null | # What does this PR do?
The current Flax's GPT2 doesn't support cross attention, while PyTorch's GPT2 does. This PR add cross attention to Flax's GPT2, closely following the codes in PyTorch's GPT2 and Flax's Bart models.
However, I add one more thing, which is the projection from the encoder's last hidden state to the dimension size of the decoder's hidden states. I think this is useful when we want to combine GPT2 with different pretrained encoders (in particular, image encoders like ViT or CLIPVision).
```
project_encoder = getattr(self.config, "project_encoder", None)
if project_encoder:
encoder_hidden_states = self.encoder_projection_ln(encoder_hidden_states)
feed_forward_hidden_states = self.encoder_projection_mlp(
encoder_hidden_states, deterministic=deterministic
)
# residual connection
encoder_hidden_states = feed_forward_hidden_states
```
If HuggingFace thinks it is better not to include this (so it would be more identical to PyTorch's version), I will remove it.
Finally, is there any documentation file I need to edit for this change? If so, could you indicate me which file(s), please?
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@patrickvonplaten
@patil-suraj
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13008/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13008/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13008",
"html_url": "https://github.com/huggingface/transformers/pull/13008",
"diff_url": "https://github.com/huggingface/transformers/pull/13008.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13008.patch",
"merged_at": 1629734250000
} |
https://api.github.com/repos/huggingface/transformers/issues/13007 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13007/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13007/comments | https://api.github.com/repos/huggingface/transformers/issues/13007/events | https://github.com/huggingface/transformers/issues/13007 | 961,133,911 | MDU6SXNzdWU5NjExMzM5MTE= | 13,007 | Importing hides underlying error | {
"login": "aphedges",
"id": 14283972,
"node_id": "MDQ6VXNlcjE0MjgzOTcy",
"avatar_url": "https://avatars.githubusercontent.com/u/14283972?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aphedges",
"html_url": "https://github.com/aphedges",
"followers_url": "https://api.github.com/users/aphedges/followers",
"following_url": "https://api.github.com/users/aphedges/following{/other_user}",
"gists_url": "https://api.github.com/users/aphedges/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aphedges/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aphedges/subscriptions",
"organizations_url": "https://api.github.com/users/aphedges/orgs",
"repos_url": "https://api.github.com/users/aphedges/repos",
"events_url": "https://api.github.com/users/aphedges/events{/privacy}",
"received_events_url": "https://api.github.com/users/aphedges/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I cannot reproduce your exact issue, but installing a version of torch-scatter with an incompatible CUDA version will indeed kill the runtime with an `OSError`. We could catch that error when defining the `_scatter_available` variable, which currently only looks at the package installation.\r\n\r\nWDYT @sgugger @NielsRogge ?",
"Yes, this should be checked as easy as possible to yield an easier error message.\r\n\r\nAs for the initial issue, there is no try/except that are ignored on our side, so I'm afraid this is a more general problem with the Python import system. It's not the first time I see it hiding the underlying issues. If you have any idea of what we could do on our side to display those error messages, I'm all ears.",
"It's understandable that you can't get my specific problem reproduced. Therefore, I created a much simpler proof-of-concept:\r\n\r\n1. Run `pip install transformers==4.9.1 torch==1.9.0`.\r\n2. Run `python -c 'from transformers.file_utils import is_scatter_available; print(is_scatter_available())'` to confirm that `torch_scatter` is not found by `transformers`.\r\n3. Create `setup.py`:\r\n\r\n```python\r\nfrom setuptools import setup\r\nsetup(name='torch_scatter')\r\n```\r\n\r\n3. Create `torch_scatter.py`:\r\n\r\n```python\r\nscatter = None\r\n```\r\n\r\n4. Run `pip install .`\r\n5. Run `python -c 'from transformers.file_utils import is_scatter_available; print(is_scatter_available())'` to confirm that `torch_scatter` is being found by `transformers`.\r\n6. Run `python -c 'from transformers import AutoModelForCausalLM'` to see there is no error thrown.\r\n7. Add `None.origin` to a new line at the top of `torch_scatter.py`.\r\n8. Run `python -c 'from transformers import AutoModelForCausalLM'` again to see the following error\r\n\r\n```python\r\nTraceback (most recent call last):\r\n File \"<string>\", line 1, in <module>\r\nImportError: cannot import name 'AutoModelForCausalLM' from 'transformers' (/Users/ahedges/.pyenv/versions/scatter/lib/python3.7/site-packages/transformers/__init__.py)\r\n```\r\n\r\nGiven that I could see complete errors when using the wrong CUDA version of `torch_scatter`, I decided to try multiple exception-triggering statements on the first line of `torch_scatter.py`:\r\n\r\n- `None.origin`: `ImportError: cannot import name 'AutoModelForCausalLM' from 'transformers'`\r\n- `foo`: `NameError: name 'foo' is not defined`\r\n- `raise RuntimeError(\"This is a message\")`: `RuntimeError: This is a message`\r\n- `[0][2]`: `IndexError: list index out of range`\r\n- `0 / 0`: `ZeroDivisionError: division by zero`\r\n\r\nAll but the first had properly displayed errors and stack traces. This led me to believe that the specific issue isn't exceptions getting ignored but `AttributeError`s in particular.\r\n\r\nI do not have a strong knowledge of `transformers`'s import system or the Python import system in general, but I used [`transformers/__init__.py`](https://github.com/huggingface/transformers/blob/v4.9.1/src/transformers/__init__.py) and [`transformers/file_utils.py`](https://github.com/huggingface/transformers/blob/v4.9.1/src/transformers/file_utils.py) to create a very simplified script that reproduces the problem. I made two files:\r\n\r\n- `test.py`:\r\n\r\n```python\r\nimport importlib\r\nimport os\r\nimport sys\r\nfrom types import ModuleType\r\n\r\nclass _LazyModule(ModuleType):\r\n def __init__(self, name, module_file, import_structure, extra_objects=None):\r\n super().__init__(name)\r\n self._modules = set(import_structure.keys())\r\n self._class_to_module = {}\r\n for key, values in import_structure.items():\r\n for value in values:\r\n self._class_to_module[value] = key\r\n self.__all__ = list(import_structure.keys()) + sum(import_structure.values(), [])\r\n self.__file__ = module_file\r\n self.__path__ = [os.path.dirname(module_file)]\r\n self._objects = {} if extra_objects is None else extra_objects\r\n self._name = name\r\n self._import_structure = import_structure\r\n\r\n def __getattr__(self, name: str):\r\n if name in self._objects:\r\n return self._objects[name]\r\n if name in self._modules:\r\n value = self._get_module(name)\r\n elif name in self._class_to_module.keys():\r\n module = self._get_module(self._class_to_module[name])\r\n value = getattr(module, name)\r\n else:\r\n raise AttributeError(f\"module {self.__name__} has no attribute {name}\")\r\n\r\n setattr(self, name, value)\r\n return value\r\n\r\n def _get_module(self, module_name: str):\r\n return importlib.import_module(\".\" + module_name, self.__name__)\r\n\r\n_import_structure = {\"auto\": [\"AutoModel\"]}\r\n\r\nsys.modules[__name__] = _LazyModule(__name__, globals()[\"__file__\"], _import_structure)\r\n```\r\n\r\n- `auto.py`:\r\n\r\n```python\r\nfrom torch_scatter import scatter\r\n\r\nAutoModel = None\r\n```\r\n\r\nI could trigger the same kinds of errors that I got with `transformers` with `python -c 'from test import AutoModel'`. I then modified `_LazyModule.__getattr__()` to always `raise AttributeError()`, and I end up getting `ImportError: cannot import name 'AutoModel' from 'test'` with the following stack trace:\r\n\r\n```python\r\nTraceback (most recent call last):\r\n File \"<string>\", line 1, in <module>\r\nImportError: cannot import name 'AutoModel' from 'test' (/Users/ahedges/Downloads/scatter_test/test.py)\r\n```\r\n\r\nReplacing the `AttributeError` with `RuntimeError` gets a more detailed stack trace:\r\n\r\n```python\r\nTraceback (most recent call last):\r\n File \"<string>\", line 1, in <module>\r\n File \"<frozen importlib._bootstrap>\", line 1032, in _handle_fromlist\r\n File \"/Users/ahedges/Downloads/scatter_test/test.py\", line 24, in __getattr__\r\n raise RuntimeError()\r\nRuntimeError\r\n```\r\n\r\nIf I replace `test.py` with the line `from auto import AutoModel`, then the `AttributeError` stack trace is displayed properly. This lends evidence to the fact that this bug is related to how `transformers` implements importing.\r\n\r\nFrom these experiments, I think the problem is that the `transformers` importing machinery is specifically ignoring any `AttributeError`s while allowing others to propagate freely. Annoyingly, I can't find any mention of such behavior in the Python docs, so I can't tell if this is part of any official interface.\r\n\r\nI'm unsure of how to better resolve this issue, though. It might make sense to modify `_LazyModule._get_module()` (the only part of the class that should be able to throw such an error without messing with the import machinery itself) to have better handling of `AttributeError`s. Maybe printing stack traces for them, but that could get annoying. Maybe embed it in a more general type, but I have no clue how that will interfere with the importing system.\r\n\r\nI apologize for the very long read, but I hope this helps.\r\n",
"The reason is `pip` can't get you the right version of `torch_scatter`. I add a `try-catch` to prevent instant kill and throw an elegant message instead. #13040",
"@JetRunner, your PR is for a different but related issue than the one I reported here.\r\n\r\nPlus, I'd like to point out that `pip` can get you the right version of `torch_scatter`. You just need to installing using the appropriate wheel page with the `-f` option.",
"Thank you for the detailed analysis @aphedges \r\nFirst, could you confirm if the problem appears again on master? It should not and you have an env setup for debugging so you should be able to see that quickly. I'll follow the steps of your reproducer later today if you can't confirm.\r\n\r\nThen, from your deep analysis, it looks like there is a problem with the `AttributeError` in the import machinery, somewhere. We don't ignore them in the `_LazyModule` part, or any part of the Transformers library dedicated to imports, so my first thought is that it comes from Python itself, but I'll need to investigate more to be sure.",
"@sgugger, I can confirm that your commit 9870093 prevents this issue for me. The unclear error message will still be a problem for anyone importing from `modeling_tapas.py`, such as the following:\r\n\r\n```python\r\n$ python -c 'from transformers import TapasModel'\r\nTraceback (most recent call last):\r\n File \"<string>\", line 1, in <module>\r\nImportError: cannot import name 'TapasModel' from 'transformers' (/Users/ahedges/.pyenv/versions/scatter/lib/python3.7/site-packages/transformers/__init__.py)\r\n```\r\n\r\nHowever, this is much more limited in scope than before, which is very good. I don't use TAPAS, so I should be fine now.\r\n\r\nI agree with you that the error getting lost seems to come from Python itself. I could not find `AttributeError`s being caught by importing in `transformers` during my investigation, but I unfortunately couldn't find any documentation of similar behavior in the official Python documentation, either. Part of the reason that this debugging was so difficult was because large portions of the stack were in Python internals that PyCharm's debugger couldn't reach. I'm not sure what `transformers` should (or can) do anything to deal with this.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,631 | 1,631 | CONTRIBUTOR | null | ## Environment info
(Couldn't run due to bug this issue is about but did my best to fill it in)
- `transformers` version: 4.9.1
- Platform: Linux-3.10.0-1160.31.1.el7.x86_64-x86_64-with-centos-7.9.2009-Core
- Python version: 3.7.11
- PyTorch version (GPU?): 1.7.0+cu102 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help
No person for general `transformers` issues is listed
## To reproduce
Steps to reproduce the behavior:
1. Run `pip install torch-scatter==2.0.6 -f https://pytorch-geometric.com/whl/torch-1.7.0+cpu.html` (install version that has a bug)
2. Use a machine with CUDA support.
3. Run `python -c 'from transformers import AutoModelForCausalLM'` to see the following output:
```python
Traceback (most recent call last):
File "<string>", line 1, in <module>
ImportError: cannot import name 'AutoModelForCausalLM' from 'transformers' (venv/lib/python3.7/site-packages/transformers/__init__.py)
```
4. Run `transformers-cli env` to see the following output:
```python
Traceback (most recent call last):
File "venv/lib/python3.7/site-packages/torch_scatter/__init__.py", line 14, in <module>
f'{library}_{suffix}', [osp.dirname(__file__)]).origin)
AttributeError: 'NoneType' object has no attribute 'origin'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "venv/bin/transformers-cli", line 5, in <module>
from transformers.commands.transformers_cli import main
File "venv/lib/python3.7/site-packages/transformers/commands/transformers_cli.py", line 23, in <module>
from .run import RunCommand
File "venv/lib/python3.7/site-packages/transformers/commands/run.py", line 17, in <module>
from ..pipelines import SUPPORTED_TASKS, TASK_ALIASES, Pipeline, PipelineDataFormat, pipeline
File "venv/lib/python3.7/site-packages/transformers/pipelines/__init__.py", line 30, in <module>
from .automatic_speech_recognition import AutomaticSpeechRecognitionPipeline
File "/venv/lib/python3.7/site-packages/transformers/pipelines/automatic_speech_recognition.py", line 20, in <module>
from .base import Pipeline
File "venv/lib/python3.7/site-packages/transformers/pipelines/base.py", line 43, in <module>
from ..models.auto.modeling_auto import AutoModel
File "venv/lib/python3.7/site-packages/transformers/models/auto/modeling_auto.py", line 271, in <module>
from ..tapas.modeling_tapas import (
File "venv/lib/python3.7/site-packages/transformers/models/tapas/modeling_tapas.py", line 51, in <module>
from torch_scatter import scatter
File "venv/lib/python3.7/site-packages/torch_scatter/__init__.py", line 17, in <module>
raise AttributeError(e)
AttributeError: 'NoneType' object has no attribute 'origin'
```
(I edited the stack trace to remove the parts of the path outside the virtual environment for improved readability.)
I was fortunate to find this easy-to-create stack trace when writing up this issue. It was actually difficult to find out what was the cause. I had to find the failing line in `transformers` (`from torch_scatter import scatter`) in a much more annoying manner instead.
## Expected behavior
Regular importing of the form `from transformers import ...` should display the full stack trace of the underlying error to provide a usable error message for debugging.
I obviously do not expect this underlying error to be fixed, given that it's not part of `transformers`. However, given that a comment near the failure considers `torch_scatter` a `soft dependency`, it might be a good idea to emit a warning when the package fails to import instead of causing the entire `transformers` library to fail. I'm not using a model that uses `torch_scatter` in the first place, so it shouldn't be required this way. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13007/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13007/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13006 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13006/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13006/comments | https://api.github.com/repos/huggingface/transformers/issues/13006/events | https://github.com/huggingface/transformers/pull/13006 | 961,057,121 | MDExOlB1bGxSZXF1ZXN0NzA0MDIyNDQw | 13,006 | [Flax] Correct pt to flax conversion if from base to head | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | MEMBER | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Currently loading a base model into a head model while using `from_pt=True` is broken in Flax.
E.g. the following fails:
```python
from transformers import RobertaModel, FlaxRobertaForMaskedLM, RobertaConfig
model = RobertaModel(RobertaConfig())
model.save_pretrained("./")
FlaxRobertaForMaskedLM.from_pretrained("./", from_pt=True)
```
It's not that trivial to correct it, since the conversion PT => Flax requires some renaming which is a bit "hacky". To solve the problem this PR now always checks whether both the weight name with and withouth base model prefix is expected. If one of the is expected -> then the weight name is correctly changed.
Tests are added to ensure that all models will be correctly converted from PyTorch in the future.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13006/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13006/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13006",
"html_url": "https://github.com/huggingface/transformers/pull/13006",
"diff_url": "https://github.com/huggingface/transformers/pull/13006.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13006.patch",
"merged_at": 1628181530000
} |
https://api.github.com/repos/huggingface/transformers/issues/13005 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13005/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13005/comments | https://api.github.com/repos/huggingface/transformers/issues/13005/events | https://github.com/huggingface/transformers/issues/13005 | 961,054,314 | MDU6SXNzdWU5NjEwNTQzMTQ= | 13,005 | HyperParameter search in sagemaker | {
"login": "MarcM0",
"id": 30278842,
"node_id": "MDQ6VXNlcjMwMjc4ODQy",
"avatar_url": "https://avatars.githubusercontent.com/u/30278842?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MarcM0",
"html_url": "https://github.com/MarcM0",
"followers_url": "https://api.github.com/users/MarcM0/followers",
"following_url": "https://api.github.com/users/MarcM0/following{/other_user}",
"gists_url": "https://api.github.com/users/MarcM0/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MarcM0/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MarcM0/subscriptions",
"organizations_url": "https://api.github.com/users/MarcM0/orgs",
"repos_url": "https://api.github.com/users/MarcM0/repos",
"events_url": "https://api.github.com/users/MarcM0/events{/privacy}",
"received_events_url": "https://api.github.com/users/MarcM0/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hey @MarcM0 this has been fixed in the later transformer versions.\r\n\r\nSince you can't upgrade the version, can you use this workaround instead: https://github.com/huggingface/transformers/issues/11249#issuecomment-860144744",
"now I get this error\r\n```\r\n\r\n\r\n1.4+, the Ray CLI, autoscaler, and dashboard will only be usable via `pip install 'ray[default]'`. Please update your install command.\r\n \"update your install command.\", FutureWarning)\r\n2021-08-04 21:42:50,092#011INFO services.py:1247 -- View the Ray dashboard at #033[1m#033[32mhttp://127.0.0.1:8265#033[39m#033[22m\r\nTraceback (most recent call last):\r\n File \"train.py\", line 149, in <module>\r\n best = hyperParamSearch_trainer.hyperparameter_search(direction=\"minimize\", hp_space=my_hp_space_ray, n_trials =args.numTrials )\r\n File \"/opt/conda/lib/python3.6/site-packages/transformers/trainer.py\", line 1668, in hyperparameter_search\r\n best_run = run_hp_search(self, n_trials, direction, **kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/transformers/integrations.py\", line 236, in run_hp_search_ray\r\n **kwargs,\r\n File \"/opt/conda/lib/python3.6/site-packages/ray/tune/tune.py\", line 297, in run\r\n _ray_auto_init()\r\n File \"/opt/conda/lib/python3.6/site-packages/ray/tune/tune.py\", line 670, in _ray_auto_init\r\n ray.init()\r\n File \"/opt/conda/lib/python3.6/site-packages/ray/_private/client_mode_hook.py\", line 82, in wrapper\r\n return func(*args, **kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/ray/worker.py\", line 940, in init\r\n hook()\r\n File \"/opt/conda/lib/python3.6/site-packages/ray/tune/registry.py\", line 197, in flush\r\n self.references[k] = ray.put(v)\r\n File \"/opt/conda/lib/python3.6/site-packages/ray/_private/client_mode_hook.py\", line 82, in wrapper\r\n return func(*args, **kwargs)\r\n File \"/opt/conda/lib/python3.6/site-packages/ray/worker.py\", line 1597, in put\r\n object_ref = worker.put_object(value)\r\n File \"/opt/conda/lib/python3.6/site-packages/ray/worker.py\", line 287, in put_object\r\n serialized_value = self.get_serialization_context().serialize(value)\r\n File \"/opt/conda/lib/python3.6/site-packages/ray/serialization.py\", line 331, in serialize\r\n return self._serialize_to_msgpack(value)\r\n File \"/opt/conda/lib/python3.6/site-packages/ray/serialization.py\", line 311, in _serialize_to_msgpack\r\n self._serialize_to_pickle5(metadata, python_objects)\r\n File \"/opt/conda/lib/python3.6/site-packages/ray/serialization.py\", line 271, in _serialize_to_pickle5\r\n raise e\r\n File \"/opt/conda/lib/python3.6/site-packages/ray/serialization.py\", line 268, in _serialize_to_pickle5\r\n value, protocol=5, buffer_callback=writer.buffer_callback)\r\n File \"/opt/conda/lib/python3.6/site-packages/ray/cloudpickle/cloudpickle_fast.py\", line 73, in dumps\r\n cp.dump(obj)\r\n File \"/opt/conda/lib/python3.6/site-packages/ray/cloudpickle/cloudpickle_fast.py\", line 580, in dump\r\n return Pickler.dump(self, obj)\r\n File \"pyarrow/io.pxi\", line 1021, in pyarrow.lib.Buffer.__reduce_ex__\r\nAttributeError: module 'pickle' has no attribute 'PickleBuffer'\r\n```",
"what version of ray do you have? how was it installed?",
"Since I can't directly access the terminal of the computer where the train script is run, I put this line in my train script\r\n`subprocess.check_call([sys.executable, \"-m\", \"pip\", \"install\", \"ray[tune]==1.5.1\"])`\r\n",
"This seems to be an option as well but I can't find any documentation for how to do it \r\nhttps://huggingface.co/blog/the-partnership-amazon-sagemaker-and-hugging-face\r\n\r\n",
"@MarcM0 can you also do a `pip install pickle5`. I think that should do the trick.",
"That worked, thank you!"
] | 1,628 | 1,628 | 1,628 | NONE | null | - `transformers` version: 4.6.1 (higher is not supported on Sagemaker)
- Platform: Sagemaker
### Who can help
Models:
- gpt2: @patrickvonplaten, @LysandreJik
Library:
- ray/raytune: @richardliaw, @amogkam
## Information
Model I am using GPT2-Medium
The problem arises when using:
I was following this guide https://huggingface.co/docs/sagemaker/train#prepare-a-transformers-fine-tuning-script
But I also wanted to do hyperparameter search https://huggingface.co/blog/ray-tune
I got everything to work on google colab, but on amazon sagemaker, I run into this error when using raytune
```
/opt/conda/lib/python3.6/site-packages/ray/autoscaler/_private/cli_logger.py:61: FutureWarning: Not all Ray CLI dependencies were found. In Ray 1.4+, the Ray CLI, autoscaler, and dashboard will only be usable via `pip install 'ray[default]'`. Please update your install command.
"update your install command.", FutureWarning)
2021-08-04 21:09:18,214#011INFO services.py:1247 -- View the Ray dashboard at #033[1m#033[32mhttp://127.0.0.1:8265#033[39m#033[22m
Traceback (most recent call last):
File "train.py", line 148, in <module>
best = hyperParamSearch_trainer.hyperparameter_search(direction="minimize", hp_space=my_hp_space_ray, n_trials =args.numTrials )
File "/opt/conda/lib/python3.6/site-packages/transformers/trainer.py", line 1668, in hyperparameter_search
best_run = run_hp_search(self, n_trials, direction, **kwargs)
File "/opt/conda/lib/python3.6/site-packages/transformers/integrations.py", line 236, in run_hp_search_ray
**kwargs,
File "/opt/conda/lib/python3.6/site-packages/ray/tune/tune.py", line 297, in run
_ray_auto_init()
File "/opt/conda/lib/python3.6/site-packages/ray/tune/tune.py", line 670, in _ray_auto_init
ray.init()
File "/opt/conda/lib/python3.6/site-packages/ray/_private/client_mode_hook.py", line 82, in wrapper
return func(*args, **kwargs)
File "/opt/conda/lib/python3.6/site-packages/ray/worker.py", line 940, in init
hook()
File "/opt/conda/lib/python3.6/site-packages/ray/tune/registry.py", line 197, in flush
self.references[k] = ray.put(v)
File "/opt/conda/lib/python3.6/site-packages/ray/_private/client_mode_hook.py", line 82, in wrapper
return func(*args, **kwargs)
File "/opt/conda/lib/python3.6/site-packages/ray/worker.py", line 1597, in put
object_ref = worker.put_object(value)
File "/opt/conda/lib/python3.6/site-packages/ray/worker.py", line 287, in put_object
serialized_value = self.get_serialization_context().serialize(value)
File "/opt/conda/lib/python3.6/site-packages/ray/serialization.py", line 331, in serialize
return self._serialize_to_msgpack(value)
File "/opt/conda/lib/python3.6/site-packages/ray/serialization.py", line 311, in _serialize_to_msgpack
self._serialize_to_pickle5(metadata, python_objects)
File "/opt/conda/lib/python3.6/site-packages/ray/serialization.py", line 271, in _serialize_to_pickle5
raise e
File "/opt/conda/lib/python3.6/site-packages/ray/serialization.py", line 268, in _serialize_to_pickle5
value, protocol=5, buffer_callback=writer.buffer_callback)
File "/opt/conda/lib/python3.6/site-packages/ray/cloudpickle/cloudpickle_fast.py", line 73, in dumps
cp.dump(obj)
File "/opt/conda/lib/python3.6/site-packages/ray/cloudpickle/cloudpickle_fast.py", line 580, in dump
return Pickler.dump(self, obj)
TypeError: can't pickle _thread.RLock objects
```
I also tried optuna but since there is no option for garabage cleaning, I always run into CUDA out of memory | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13005/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13005/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13004 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13004/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13004/comments | https://api.github.com/repos/huggingface/transformers/issues/13004/events | https://github.com/huggingface/transformers/pull/13004 | 960,964,405 | MDExOlB1bGxSZXF1ZXN0NzAzOTM2ODg0 | 13,004 | Create perplexity.rst | {
"login": "sashavor",
"id": 14205986,
"node_id": "MDQ6VXNlcjE0MjA1OTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/14205986?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sashavor",
"html_url": "https://github.com/sashavor",
"followers_url": "https://api.github.com/users/sashavor/followers",
"following_url": "https://api.github.com/users/sashavor/following{/other_user}",
"gists_url": "https://api.github.com/users/sashavor/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sashavor/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sashavor/subscriptions",
"organizations_url": "https://api.github.com/users/sashavor/orgs",
"repos_url": "https://api.github.com/users/sashavor/repos",
"events_url": "https://api.github.com/users/sashavor/events{/privacy}",
"received_events_url": "https://api.github.com/users/sashavor/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,628 | 1,628 | 1,628 | NONE | null | Updating the import for load_dataset
# What does this PR do?
Fixes # (issue)
Fixes the old way of loading datasets
## Who can review?
@patrickvonplaten
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13004/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13004/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13004",
"html_url": "https://github.com/huggingface/transformers/pull/13004",
"diff_url": "https://github.com/huggingface/transformers/pull/13004.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13004.patch",
"merged_at": 1628146573000
} |
https://api.github.com/repos/huggingface/transformers/issues/13003 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13003/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13003/comments | https://api.github.com/repos/huggingface/transformers/issues/13003/events | https://github.com/huggingface/transformers/issues/13003 | 960,957,523 | MDU6SXNzdWU5NjA5NTc1MjM= | 13,003 | Not getting the same results with run_qa and run_qa_no_trainer scripts | {
"login": "eldarkurtic",
"id": 8884008,
"node_id": "MDQ6VXNlcjg4ODQwMDg=",
"avatar_url": "https://avatars.githubusercontent.com/u/8884008?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eldarkurtic",
"html_url": "https://github.com/eldarkurtic",
"followers_url": "https://api.github.com/users/eldarkurtic/followers",
"following_url": "https://api.github.com/users/eldarkurtic/following{/other_user}",
"gists_url": "https://api.github.com/users/eldarkurtic/gists{/gist_id}",
"starred_url": "https://api.github.com/users/eldarkurtic/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eldarkurtic/subscriptions",
"organizations_url": "https://api.github.com/users/eldarkurtic/orgs",
"repos_url": "https://api.github.com/users/eldarkurtic/repos",
"events_url": "https://api.github.com/users/eldarkurtic/events{/privacy}",
"received_events_url": "https://api.github.com/users/eldarkurtic/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"The two scripts are different, they do not have the same defaults for the `seed` and even then, they do not randomize the data the same way. It's impossible for the two of them to give you the same results. ",
"Do you have any suggestions on what to modify in the `run_qa_no_trainer.py` to get a bit better results (possibly closer to \"the baseline\" with `run_qa.py`)? \r\nBased on the same results I got with the `squad_v2`, I assumed that both scripts are doing the same thing, and that the one without the Trainer just provides more flexibility to modify stuff in the train/eval loops. ",
"On one GPU, you could maybe achieve the same results by passing the same seeds, making sure it's set at the right place, but that's a big maybe. Reproducibility is a hard enough problem with one script, so with two scripts that start with different assumptions and use different APIs, it's next to impossible.",
"Okay, got it! I then just misunderstood their roles in the examples project. Thanks for a quick reply."
] | 1,628 | 1,628 | 1,628 | CONTRIBUTOR | null | ## Environment info
Just followed the default setup instructions in a new conda environment:
```shell
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
pip install -r examples/pytorch/question_answering/requirements.txt
```
### Who can help
@sgugger @patil-suraj
## Information
Model I am using: https://huggingface.co/prajjwal1/bert-tiny
My goal is to run the finetuning example on the bert-tiny model and Squad dataset, with and without the Trainer class, and to obtain the same results.
## The problem
Running with the Trainer class with:
```shell
CUDA_VISIBLE_DEVICES=0 python run_qa.py \
--model_name_or_path prajjwal1/bert-tiny \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /trainer_squad/
```
ends with: `eval_exact_match = 31.3245` and `eval_f1 = 43.3655`.
Then, running the same setup but without the Trainer with:
```shell
CUDA_VISIBLE_DEVICES=0 python run_qa_no_trainer.py \
--model_name_or_path prajjwal1/bert-tiny \
--dataset_name squad \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /no_trainer_squad/
```
ends with: `Evaluation metrics: {'exact_match': 19.981078524124882, 'f1': 32.57782310536579}`.
It's interesting that I obtain the same results (`F1 = 49.73` and `EM = 48.6`) when I run with and without Trainer class, but with a different dataset: `--dataset_name squad_v2` and `--version_2_with_negative`. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13003/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13003/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13002 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13002/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13002/comments | https://api.github.com/repos/huggingface/transformers/issues/13002/events | https://github.com/huggingface/transformers/pull/13002 | 960,811,197 | MDExOlB1bGxSZXF1ZXN0NzAzNzk2OTIz | 13,002 | TF CLM example fix typo | {
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Also oop, this looks like it was based on a slightly older branch - it won't cause any problems, but the \"Files changed\" tab lists some changes in other files that are already merged - the only one actually affected is `run_clm.py`",
"There might be more such remnants from the MLM script, see https://github.com/huggingface/transformers/pull/14014\r\n\r\ncc @Rocketknight1 "
] | 1,628 | 1,634 | 1,630 | MEMBER | null | Fixes a one-line typo in the TF CLM example - it was still using `MODEL_FOR_MASKED_LM_MAPPING` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13002/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13002/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/13002",
"html_url": "https://github.com/huggingface/transformers/pull/13002",
"diff_url": "https://github.com/huggingface/transformers/pull/13002.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/13002.patch",
"merged_at": 1630412499000
} |
https://api.github.com/repos/huggingface/transformers/issues/13001 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13001/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13001/comments | https://api.github.com/repos/huggingface/transformers/issues/13001/events | https://github.com/huggingface/transformers/issues/13001 | 960,500,354 | MDU6SXNzdWU5NjA1MDAzNTQ= | 13,001 | VisualBERT - ModuleAttributeError | {
"login": "RitaRamo",
"id": 12399556,
"node_id": "MDQ6VXNlcjEyMzk5NTU2",
"avatar_url": "https://avatars.githubusercontent.com/u/12399556?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/RitaRamo",
"html_url": "https://github.com/RitaRamo",
"followers_url": "https://api.github.com/users/RitaRamo/followers",
"following_url": "https://api.github.com/users/RitaRamo/following{/other_user}",
"gists_url": "https://api.github.com/users/RitaRamo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/RitaRamo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/RitaRamo/subscriptions",
"organizations_url": "https://api.github.com/users/RitaRamo/orgs",
"repos_url": "https://api.github.com/users/RitaRamo/repos",
"events_url": "https://api.github.com/users/RitaRamo/events{/privacy}",
"received_events_url": "https://api.github.com/users/RitaRamo/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"There seem to be a bug in the `VisualBertEmbeddings` class indeed. Mind opening a PR? You can probably just replace `self.input_embeds.device` by `self.position_ids.device`.",
"Great, thank you for looking and suggesting the fix! I would not mind, but I will go on vacation very soon, so I won’t be able to follow up on this topic. ",
"@RitaRamo Thanks for trying it out. Sorry for the late response.\r\n@NielsRogge Thanks for suggesting a fix. I'll do it asap. ",
"Fixed in #13017 "
] | 1,628 | 1,628 | 1,628 | NONE | null | ## Environment info
- `transformers` version: 4.9.1
- Platform: macOS-10.14.6-x86_64-i386-64bit
- Python version: 3.9.0
- PyTorch version (GPU?): 1.7.1 (False)
- Tensorflow version (GPU?): 2.5.0-rc1 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
### Who can help
@gchhablani
## Information
I am using the recent VisualBERT model.
When giving the inputs to model, a ModuleAttributeError occurs, since internally the class VisualBertEmbeddings calls self.input_embeds but that class does not have that attribute (e.g., in the _init_), thus the error.
`class VisualBertEmbeddings(nn.Module):`
(...)
`token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.input_embeds.device)`
(self.input_embeds does not exist before this line)
The problem arises when using:
* the official example scripts:
```
from transformers import BertTokenizer, VisualBertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = VisualBertModel.from_pretrained('uclanlp/visualbert-vqa-coco-pre')
inputs = tokenizer("The capital of France is Paris.", return_tensors="pt")
visual_embeds = torch.zeros((1,36,2048)) #example of ROI features
visual_token_type_ids = torch.ones(visual_embeds.shape[:-1], dtype=torch.long) #example
visual_attention_mask = torch.ones(visual_embeds.shape[:-1], dtype=torch.float)
inputs.update({{
"visual_embeds": visual_embeds,
"visual_token_type_ids": visual_token_type_ids,
"visual_attention_mask": visual_attention_mask
}})
outputs = model(**inputs)
```
## To reproduce
Steps to reproduce the behavior:
1. Follow the official example script
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.9/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.9/site-packages/transformers/models/visual_bert/modeling_visual_bert.py", line 807, in forward
embedding_output = self.embeddings(
File "/usr/local/lib/python3.9/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/usr/local/lib/python3.9/site-packages/transformers/models/visual_bert/modeling_visual_bert.py", line 126, in forward
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.input_embeds.device)
File "/usr/local/lib/python3.9/site-packages/torch/nn/modules/module.py", line 778, in __getattr__
raise ModuleAttributeError("'{}' object has no attribute '{}'".format(
torch.nn.modules.module.ModuleAttributeError: 'VisualBertEmbeddings' object has no attribute 'input_embeds
```
## Expected behavior
The class VisualBertEmbeddings should have self.input_embeds before calling it, otherwise the VisualBert will not work, since internally there is that bug.
Thank you in advance for your help!
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13001/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/13001/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/13000 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/13000/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/13000/comments | https://api.github.com/repos/huggingface/transformers/issues/13000/events | https://github.com/huggingface/transformers/issues/13000 | 960,338,951 | MDU6SXNzdWU5NjAzMzg5NTE= | 13,000 | Newly trained tokenizers not adding [CLS] and [SEP] tokens | {
"login": "fgaim",
"id": 4906991,
"node_id": "MDQ6VXNlcjQ5MDY5OTE=",
"avatar_url": "https://avatars.githubusercontent.com/u/4906991?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fgaim",
"html_url": "https://github.com/fgaim",
"followers_url": "https://api.github.com/users/fgaim/followers",
"following_url": "https://api.github.com/users/fgaim/following{/other_user}",
"gists_url": "https://api.github.com/users/fgaim/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fgaim/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fgaim/subscriptions",
"organizations_url": "https://api.github.com/users/fgaim/orgs",
"repos_url": "https://api.github.com/users/fgaim/repos",
"events_url": "https://api.github.com/users/fgaim/events{/privacy}",
"received_events_url": "https://api.github.com/users/fgaim/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hello! Looking at your `train_tokenizer.py` file, I see no post-processor. Without a post-processor, the tokenizer is unaware of what tokens it should add after tokenizing.\r\n\r\nSee the quick tour of the tokenizers library here: https://huggingface.co/docs/tokenizers/python/latest/quicktour.html#post-processing",
"@LysandreJik, thank you for the answer. That was on point. \r\n\r\nI trained a new tokenizer with pos_processor and it worked as expected. "
] | 1,628 | 1,628 | 1,628 | CONTRIBUTOR | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.10.0.dev0 (installed from source)
- Platform: Linux-5.4.104+-x86_64-with-Ubuntu-18.04-bionic (Google Colab)
- Python version: 3.7.11
- PyTorch version (GPU?): 1.9.0+cu102 (True)
- Tensorflow version (GPU?): 2.5.0 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
- `tokenizers` version: 0.10.3
### Who can help
@patrickvonplaten, @LysandreJik
## Information
Running into an issue with the newly trained tokenizers not being able to add the '[CLS]' and '[SEP]' special tokens, even after explicitly setting `add_special_tokens=True`.
The problem arises when using:
* [x] the official example scripts: `run_qa.py`
* [x] my own modified scripts: (see snippets below)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: SQuAD
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
```python
from transformers import AutoTokenizer
swahili_tokenizer = AutoTokenizer.from_pretrained("flax-community/bert-base-uncased-swahili")
swahili_tokenizer.tokenize('Si kila mwenye makucha simba.', add_special_tokens=True)
# Output:
['si', 'kila', 'mwenye', 'makucha', 'simba', '.']
# Expected:
['[CLS]', 'si', 'kila', 'mwenye', 'makucha', 'simba', '.', '[SEP]']
```
This is not only happening to this specific BERT tokenizer, the same was observed to RoBERTa tokenizers, and potentially other models as well.
The issue crashes fine-tuning for QA using the official `run_qa.py` script.
For example,
```sh
cd transformers/examples/pytorch/question-answering
python run_qa.py \
--model_name_or_path 'flax-community/bert-base-uncased-swahili' \
--dataset_name squad_v2 \
--do_train \
--do_eval \
--per_device_train_batch_size 4 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 128 \
--doc_stride 32 \
--output_dir /tmp/debug_squad/
```
... halts by throwing an exception:
```python
Traceback (most recent call last):
File "run_qa.py", line 645, in <module>
main()
File "run_qa.py", line 433, in main
desc="Running tokenizer on train dataset",
File "/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py", line 1682, in map
desc=desc,
File "/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py", line 185, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/usr/local/lib/python3.7/dist-packages/datasets/fingerprint.py", line 397, in wrapper
out = func(self, *args, **kwargs)
File "/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py", line 2020, in _map_single
offset=offset,
File "/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py", line 1906, in apply_function_on_filtered_inputs
function(*fn_args, effective_indices, **fn_kwargs) if with_indices else function(*fn_args, **fn_kwargs)
File "run_qa.py", line 375, in prepare_train_features
cls_index = input_ids.index(tokenizer.cls_token_id)
ValueError: 2 is not in list
```
The script that was used to train the tokenizer could be found [here](https://huggingface.co/flax-community/bert-base-uncased-swahili/blob/main/train_tokenizer.py).
For more example, see this [colab notebook](https://colab.research.google.com/drive/1cjof6VJYwXIijwqW7kFcjo4IrjY08xkT?usp=sharing).
## Expected behavior
When setting `add_special_tokens=True` the tokenizer is expected to add `'[CLS]'` and `'[SEP]'` tokens.
Here is an old tokenizer that behaves as expected:
```python
from transformers import AutoTokenizer
bert_tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
bert_tokenizer.tokenize('Si kila mwenye makucha simba.', add_special_tokens=True)
# Output:
['[CLS]', 'si', 'ki', '##la', 'mw', '##en', '##ye', 'ma', '##ku', '##cha', 'sim', '##ba', '.', '[SEP]']
```
Thank you! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/13000/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/13000/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12999 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12999/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12999/comments | https://api.github.com/repos/huggingface/transformers/issues/12999/events | https://github.com/huggingface/transformers/pull/12999 | 960,328,559 | MDExOlB1bGxSZXF1ZXN0NzAzMzYxNDMw | 12,999 | pad_to_multiple_of added to DataCollatorForWholeWordMask | {
"login": "Aktsvigun",
"id": 36672861,
"node_id": "MDQ6VXNlcjM2NjcyODYx",
"avatar_url": "https://avatars.githubusercontent.com/u/36672861?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Aktsvigun",
"html_url": "https://github.com/Aktsvigun",
"followers_url": "https://api.github.com/users/Aktsvigun/followers",
"following_url": "https://api.github.com/users/Aktsvigun/following{/other_user}",
"gists_url": "https://api.github.com/users/Aktsvigun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Aktsvigun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Aktsvigun/subscriptions",
"organizations_url": "https://api.github.com/users/Aktsvigun/orgs",
"repos_url": "https://api.github.com/users/Aktsvigun/repos",
"events_url": "https://api.github.com/users/Aktsvigun/events{/privacy}",
"received_events_url": "https://api.github.com/users/Aktsvigun/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Have checked it, works fine, both `batch_input` and `batch_mask` are padded to a multiple of `pad_to_multiple_of` value.",
"Ok, will do that some of these days!"
] | 1,628 | 1,628 | 1,628 | CONTRIBUTOR | null | There is a small bug in `DataCollatorForWholeWordMask`: it has an argument `pad_to_multiple_of`, however, when doing `_collate_batch` inside `__call__` method, this argument is not provided. This commit adds the usage of the argument. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12999/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12999/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12999",
"html_url": "https://github.com/huggingface/transformers/pull/12999",
"diff_url": "https://github.com/huggingface/transformers/pull/12999.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12999.patch",
"merged_at": 1628084961000
} |
https://api.github.com/repos/huggingface/transformers/issues/12998 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12998/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12998/comments | https://api.github.com/repos/huggingface/transformers/issues/12998/events | https://github.com/huggingface/transformers/issues/12998 | 960,263,857 | MDU6SXNzdWU5NjAyNjM4NTc= | 12,998 | DataCollatorForWholeWordMask does not return attention_mask | {
"login": "Aktsvigun",
"id": 36672861,
"node_id": "MDQ6VXNlcjM2NjcyODYx",
"avatar_url": "https://avatars.githubusercontent.com/u/36672861?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Aktsvigun",
"html_url": "https://github.com/Aktsvigun",
"followers_url": "https://api.github.com/users/Aktsvigun/followers",
"following_url": "https://api.github.com/users/Aktsvigun/following{/other_user}",
"gists_url": "https://api.github.com/users/Aktsvigun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Aktsvigun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Aktsvigun/subscriptions",
"organizations_url": "https://api.github.com/users/Aktsvigun/orgs",
"repos_url": "https://api.github.com/users/Aktsvigun/repos",
"events_url": "https://api.github.com/users/Aktsvigun/events{/privacy}",
"received_events_url": "https://api.github.com/users/Aktsvigun/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
}
] | [
"Not sure where you are seeing this. `DataCollatorWithPadding` can also pad attention masks, as it applies `tokenizer.pad()` on the inputs as can be seen [here](https://github.com/huggingface/transformers/blob/c7faf2ccc05a095870c3c905d232179fb323797d/src/transformers/data/data_collator.py#L118).",
"@NielsRogge am sorry for confusing, meant **DataCollatorForWholeWordMask**, will correct that now",
"There is also a bug with `pad_to_multiple_of` argument: it is not passed to `_collate_batch` inside `__call__`. Have made a pull request https://github.com/huggingface/transformers/pull/12999 to add its usage.",
"That class should never have been merged as it is, it was a mistake on our side. It contains multiple bugs and only works for BERT models. It need to be rewritten from scratch to be model agnostic.",
"For me it works perfectly for any arbitrary model (checked it is doing everything correct), except for `attention_mask` generation and `pad_to_multiple_of` usage (both can be corrected manually though, however, it is always better not to invent a bicycle).",
"It cant' give good results on a tokenizer that is not like BERT, since it relies on the \"##\" to detect if something is inside a word.",
"Is there any progress on this issue? It seems that this issue still exists."
] | 1,628 | 1,640 | 1,628 | CONTRIBUTOR | null | Hi,
** DataCollatorForWholeWordMask** does not output `attention_mask`. According to the `__call__` method:
`return {"input_ids": inputs, "labels": labels}`.
Is there a peculiar motivation behind it or is a small bug? From where I see, when we do the pre-training, most instances will **not** be of the same length and applying _Attention_ for all the tokens (including the padding) may cause imprecise results. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12998/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12998/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12997 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12997/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12997/comments | https://api.github.com/repos/huggingface/transformers/issues/12997/events | https://github.com/huggingface/transformers/issues/12997 | 960,200,899 | MDU6SXNzdWU5NjAyMDA4OTk= | 12,997 | how to user class_weight in transformers.trainer | {
"login": "wangdong1992",
"id": 20061204,
"node_id": "MDQ6VXNlcjIwMDYxMjA0",
"avatar_url": "https://avatars.githubusercontent.com/u/20061204?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wangdong1992",
"html_url": "https://github.com/wangdong1992",
"followers_url": "https://api.github.com/users/wangdong1992/followers",
"following_url": "https://api.github.com/users/wangdong1992/following{/other_user}",
"gists_url": "https://api.github.com/users/wangdong1992/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wangdong1992/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wangdong1992/subscriptions",
"organizations_url": "https://api.github.com/users/wangdong1992/orgs",
"repos_url": "https://api.github.com/users/wangdong1992/repos",
"events_url": "https://api.github.com/users/wangdong1992/events{/privacy}",
"received_events_url": "https://api.github.com/users/wangdong1992/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"For training related questions, refer to our [forum](https://discuss.huggingface.co). We like to keep Github issues for bugs/feature requests.\r\n\r\n[This post](https://discuss.huggingface.co/t/how-can-i-use-class-weights-when-training/1067) for example will probably answer your question.\r\n\r\nTherefore closing this issue."
] | 1,628 | 1,628 | 1,628 | NONE | null | In tensorflow,I can use class_weight for unbalanced data. Now, I want to train the model through transformers.trainer,how to use class_weight in transformers.trainer, This is an introduction to it
1.https://huggingface.co/transformers/custom_datasets.html#fine-tuning-with-trainer
2.https://huggingface.co/transformers/main_classes/trainer.html#transformers.TFTrainer
Please take a look at this question. Thank you | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12997/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12997/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12996 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12996/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12996/comments | https://api.github.com/repos/huggingface/transformers/issues/12996/events | https://github.com/huggingface/transformers/issues/12996 | 959,845,453 | MDU6SXNzdWU5NTk4NDU0NTM= | 12,996 | Perceiver IO | {
"login": "schmidek",
"id": 442328,
"node_id": "MDQ6VXNlcjQ0MjMyOA==",
"avatar_url": "https://avatars.githubusercontent.com/u/442328?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/schmidek",
"html_url": "https://github.com/schmidek",
"followers_url": "https://api.github.com/users/schmidek/followers",
"following_url": "https://api.github.com/users/schmidek/following{/other_user}",
"gists_url": "https://api.github.com/users/schmidek/gists{/gist_id}",
"starred_url": "https://api.github.com/users/schmidek/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/schmidek/subscriptions",
"organizations_url": "https://api.github.com/users/schmidek/orgs",
"repos_url": "https://api.github.com/users/schmidek/repos",
"events_url": "https://api.github.com/users/schmidek/events{/privacy}",
"received_events_url": "https://api.github.com/users/schmidek/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1843244711,
"node_id": "MDU6TGFiZWwxODQzMjQ0NzEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/New%20model",
"name": "New model",
"color": "fbca04",
"default": false,
"description": ""
}
] | closed | false | null | [] | [
"I want to do it unless someone else did it by September 8th. ",
"@cronoik \r\nI've implemented perceiver io on pytorch: [link](https://github.com/esceptico/perceiver-io)\r\nNow we need to adapt it for Transformers :)\r\nBut I have not (yet) added positional Fourier encoding and multimodal decoder\r\n",
"Don't forget about the `transformers-cli` tool for adding new models.\r\n\r\nEdit: [link](https://github.com/huggingface/transformers/tree/master/templates/adding_a_new_model)",
"@esceptico I am not interested in doing the job twice or in a race. If you're already working on it, I'll find something else. :)",
"@cronoik \nI'm not working on adaptation of my implementation for Transformers yet\nI mean that I will only be glad if you want to use my repository for this :)",
"HI all, I just wanted to know if this issue is in active development or is waiting for a developer to do it.",
"Hi @tonibagur, I believe @NielsRogge is currently working on it",
"Hi @LysandreJik, thanks for your reply. @NielsRogge I am interested in giving a try to the PerceiverIO model, if you need a tester don't hessitate to ask :)\r\n\r\nRegards, "
] | 1,628 | 1,638 | 1,638 | CONTRIBUTOR | null | # 🌟 New model addition
## Model description
Perceiver is a general architecture that works on many kinds of data, including images, video, audio, 3D point clouds, language and symbolic inputs, multimodal combinations, etc. Perceivers can handle new types of data with only minimal modifications. Perceivers process inputs using domain-agnostic Transformer-style attention. Unlike Transformers, Perceivers first map inputs to a small latent space where processing is cheap and doesn't depend on the input size. This makes it possible to build very deep networks even when using large inputs like images or videos.
Perceiver IO is a generalization of Perceiver to handle arbitrary outputs in addition to arbitrary inputs. The original Perceiver only produced a single classification label. In addition to classification labels, Perceiver IO can produce (for example) language, optical flow, and multimodal videos with audio. This is done using the same building blocks as the original Perceiver. The computational complexity of Perceiver IO is linear in the input and output size and the bulk of the processing occurs in the latent space, allowing us to process inputs and outputs that are much larger than can be handled by standard Transformers. This means, for example, Perceiver IO can do BERT-style masked language modeling directly using bytes instead of tokenized inputs.
https://arxiv.org/pdf/2107.14795.pdf
## Open source status
* [x] the model implementation is available: https://github.com/deepmind/deepmind-research/tree/master/perceiver (JAX)
* [x] the model weights are available: https://storage.googleapis.com/perceiver_io/language_perceiver_io_bytes.pickle pretrained masked language model (https://github.com/deepmind/deepmind-research/blob/master/perceiver/colabs/masked_language_modelling.ipynb)
* [x] who are the authors: **DeepMind** Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu,
David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, Olivier Hénaff,
Matthew M. Botvinick, Andrew Zisserman, Oriol Vinyals, João Carreira
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12996/reactions",
"total_count": 24,
"+1": 15,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 9,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12996/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12995 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12995/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12995/comments | https://api.github.com/repos/huggingface/transformers/issues/12995/events | https://github.com/huggingface/transformers/issues/12995 | 959,402,581 | MDU6SXNzdWU5NTk0MDI1ODE= | 12,995 | Option for `(Distributed)LengthGroupedSampler` to treat groups as a hard constraint | {
"login": "mbforbes",
"id": 1170062,
"node_id": "MDQ6VXNlcjExNzAwNjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/1170062?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mbforbes",
"html_url": "https://github.com/mbforbes",
"followers_url": "https://api.github.com/users/mbforbes/followers",
"following_url": "https://api.github.com/users/mbforbes/following{/other_user}",
"gists_url": "https://api.github.com/users/mbforbes/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mbforbes/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mbforbes/subscriptions",
"organizations_url": "https://api.github.com/users/mbforbes/orgs",
"repos_url": "https://api.github.com/users/mbforbes/repos",
"events_url": "https://api.github.com/users/mbforbes/events{/privacy}",
"received_events_url": "https://api.github.com/users/mbforbes/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This is definitely a hack and very narrow use case, so it's unlikely we will add this feature ;-).\r\nFor your purpose, I think you need to rewrite a new model head, starting from the code of `XxxForMultipleChoice`, where `Xxx` is the model you are using.",
"Oh interesting, I hadn't considered changing the model, since it's already agnostic to the number of answers. But I suppose it could do the final bit of data preprocessing in the model itself!\r\n\r\nI'm a bit surprised that there are no multiple choice datasets with a variable number of answers. Maybe this is something we'll see NLP tackle soon :-) ",
"After thinking about this a bit more, it seemed like a custom (batch) sampler was the most elegant way to accomplish this.\r\n\r\nSince multiple choice models are already agnostic to the number of choices, we just need something to feed it batches where each batch has a consistent number of choices.\r\n\r\nHere's an example implementation of a single-process batch sampler that accomplishes this. It simply groups by feature upon construction, then provides iterators that yield batches with a particular value of that feature in common.\r\n\r\n```python\r\nclass FeatureGroupedBatchSampler(Sampler):\r\n \"\"\"Yields a batch of indices at a time, with the hard constraint that all indices\r\n will have the same value for `feature`.\r\n\r\n From pytorch docs:\r\n \"Mutually exclusive with batch_size, shuffle, sampler, and drop_last.\"\r\n\r\n NOTE: shuffle, drop_last not yet implemented. Will if needed.\r\n \"\"\"\r\n\r\n dataset: datasets.Dataset\r\n feature: str\r\n batch_size: int\r\n val2idxes: Dict[Any, List[int]]\r\n num_batches: int\r\n\r\n def __init__(\r\n self, dataset: datasets.Dataset, feature: str, batch_size: int\r\n ) -> None:\r\n if not isinstance(dataset, datasets.Dataset):\r\n raise ValueError(\"`dataset` must be a (HuggingFace) datasets.Dataset\")\r\n if feature not in dataset.features:\r\n raise ValueError(f\"Feature '{feature}' must exist on dataset\")\r\n\r\n self.dataset = dataset\r\n self.feature = feature\r\n self.batch_size = batch_size\r\n\r\n val2idxes = defaultdict(list)\r\n for i, val in enumerate(dataset[self.feature]):\r\n val2idxes[val].append(i)\r\n self.val2idxes = val2idxes\r\n # NOTE: Only the indices (dict's values) are ever used. Could remove features\r\n # (dict's keys) entirely if desired and store as List[List[int]].\r\n\r\n # Cache the number of batches so we don't need to recompute it on calls to\r\n # __len__().\r\n num_batches = 0\r\n for idxes in self.val2idxes.values():\r\n for start in range(0, len(idxes), self.batch_size):\r\n num_batches += 1\r\n self.num_batches = num_batches\r\n\r\n def __iter__(self) -> Iterator[List[int]]:\r\n \"\"\"Yields a batch of indicies at a time. Maximum of `self.batch_size`, but\r\n always with identical values for `self.feature`.\r\n \"\"\"\r\n for idxes in self.val2idxes.values():\r\n for start in range(0, len(idxes), self.batch_size):\r\n yield idxes[start : start + self.batch_size]\r\n\r\n def __len__(self) -> int:\r\n \"\"\"At least the way HF Transformers uses this, it means number of *batches*,\r\n not number of *instances* (since this is sent as a batch_sampler).\"\"\"\r\n # return len(self.dataset) # this would be for num. instances\r\n return self.num_batches # num. batches\r\n```\r\n\r\nI use the above during evaluation by overriding the`Trainer`'s `get_eval_dataloader()` and loading it, providing the \"number of choices\" column of the dataset as the feature to group by.\r\n\r\nHowever, there's one issue: it doesn't seem like 🤗 Transformers supports a custom batch sampler. It expects the batch size to be known by the data loader, which is not the case if a custom batch sampler is provided.\r\n\r\nhttps://github.com/huggingface/transformers/blob/1fec32adc6a4840123d5ec5ff5cf419c02342b5a/src/transformers/trainer.py#L2172\r\n\r\nThis leads to a crash a few lines later:\r\n\r\nhttps://github.com/huggingface/transformers/blob/1fec32adc6a4840123d5ec5ff5cf419c02342b5a/src/transformers/trainer.py#L2217\r\n\r\nI have a one-line fix that I'll propose in a PR, which is to simply use the observed batch size, which was calculated a few lines before:\r\n\r\nhttps://github.com/huggingface/transformers/blob/1fec32adc6a4840123d5ec5ff5cf419c02342b5a/src/transformers/trainer.py#L2208\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,632 | 1,632 | CONTRIBUTOR | null | # 🚀 Feature request
An option for `(Distributed)LengthGroupedSampler` to treat groups as a hard constraint. I.e., all batches returned will have exactly the same length. (Some straggler batches will then have a smaller batch size.)
## Motivation
I asked a [question](https://discuss.huggingface.co/t/multiple-choice-with-variable-number-of-choices/8607) on the forums about using a classification model to do multiple choice with a variable number of choices.
The simplest implementation I can see using HF Transformers, though it's a bit of a hack, is to use `--group_by_length` and set `--length_column_name` to be the number of choices. That way, the `1` dimension, which tells the model the number of multiple choice options, is consistent throughout a batch.
This _almost_ works. The issue is that `(Distributed)LengthGroupedSampler` is a soft constraint, so some batches still end up with multiple "lengths" (choices).
During training, I check each batch in the collator, and simply throw away samples that don't have the same number of choices.
The issue is that during evaluation, I realized I can't skip over any examples. In comparing methods, we need to report results on the entire evaluation set.
I totally understand if you'd rather not add this feature for the purpose of what is, admittedly, a hack. If that's the case, I'd greatly appreciate any advice on how you'd run a multiple choice model with a variable number of choices! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12995/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12995/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12994 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12994/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12994/comments | https://api.github.com/repos/huggingface/transformers/issues/12994/events | https://github.com/huggingface/transformers/pull/12994 | 959,240,636 | MDExOlB1bGxSZXF1ZXN0NzAyMzg1OTI1 | 12,994 | Add BEiT | {
"login": "NielsRogge",
"id": 48327001,
"node_id": "MDQ6VXNlcjQ4MzI3MDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NielsRogge",
"html_url": "https://github.com/NielsRogge",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url": "https://api.github.com/users/NielsRogge/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NielsRogge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NielsRogge/subscriptions",
"organizations_url": "https://api.github.com/users/NielsRogge/orgs",
"repos_url": "https://api.github.com/users/NielsRogge/repos",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"received_events_url": "https://api.github.com/users/NielsRogge/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I've uploaded all checkpoints to the hub: https://huggingface.co/models?search=microsoft/beit\r\n\r\nI've renamed the checkpoints which are fine-tuned on ImageNet-1k (after being intermediately fine-tuned on ImageNet-22k) to be just `microsoft/beit-base-patch16-224`, etc.\r\n\r\n@donglixp if you're interested, could you write model cards for these models? Model cards are READMEs that describe the models in detail. You can take inspiration from ViT's [model card](https://huggingface.co/google/vit-base-patch16-224). \r\n\r\nAlso, I do have a notebook for `BEiTForMaskedImageModeling`, but it's not working as expected. Could you please take a look? https://colab.research.google.com/drive/1Mjt-3jHw9HYMXECmSdDlbiG59ZAw-Z0T?usp=sharing",
"@NielsRogge great work, any news on the future PR, to add the semantic segmentation model and the pretrained Ade20k? Thanks!",
"@JStumpp say no more, it's added ;)"
] | 1,628 | 1,634 | 1,628 | CONTRIBUTOR | null | # What does this PR do?
It adds [BEiT: BERT Pre-Training of Image Transformers](https://arxiv.org/abs/2106.08254) to the library. It's the first paper that enables self-supervised pre-trained Vision Transformers (ViTs) to outperform their supervised pre-training counterparts. As a picture says more than a thousand (or 16x16?) words, this is a good summary of the approach:
<img width="544" alt="Schermafbeelding 2021-08-03 om 17 26 19" src="https://user-images.githubusercontent.com/48327001/128042500-538a6fef-8d92-42b0-92f5-31d06ca6ae36.png">
The authors used OpenAI's [DALL-E](https://github.com/openai/DALL-E)'s encoder to map images to tokens, which the model then needs to predict based on masked patches. There are 3 models defined: `BEiTModel`, `BEiTForMaskedImageModeling` and `BEiTForImageClassification`.
This PR also cleans up some scripts from the library, namely those that defined id2label dicts for several datasets. I have removed `imagenet_classes.py` and `coco_classes.py` from the utils directory. Instead, id2label's are now defined on the hub in their [own repository](https://huggingface.co/datasets/huggingface/label-files). These can then be used in conversion scripts using the `huggingface_hub` library.
## To do
- [x] Add all checkpoints to the hub, under the "Microsoft" namespace. Perhaps discuss the model names, because for example `microsoft/beit_base_patch16_224_pt22k_ft22k_to_1k` is getting out of hand
- [ ] Would be cool to have a working colab for the `BEiTForMaskedImageModeling` model. For this, tagging one of the original authors: @donglixp
In a future PR, I also plan to add the semantic segmentation model, which obtains SOTA on Ade20k.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12994/reactions",
"total_count": 4,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 3,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12994/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12994",
"html_url": "https://github.com/huggingface/transformers/pull/12994",
"diff_url": "https://github.com/huggingface/transformers/pull/12994.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12994.patch",
"merged_at": 1628094563000
} |
https://api.github.com/repos/huggingface/transformers/issues/12993 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12993/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12993/comments | https://api.github.com/repos/huggingface/transformers/issues/12993/events | https://github.com/huggingface/transformers/issues/12993 | 959,210,890 | MDU6SXNzdWU5NTkyMTA4OTA= | 12,993 | Gloabl attention not recognised in longformer pretrained MLM model to get sentence vector? | {
"login": "pratikchhapolika",
"id": 11159549,
"node_id": "MDQ6VXNlcjExMTU5NTQ5",
"avatar_url": "https://avatars.githubusercontent.com/u/11159549?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pratikchhapolika",
"html_url": "https://github.com/pratikchhapolika",
"followers_url": "https://api.github.com/users/pratikchhapolika/followers",
"following_url": "https://api.github.com/users/pratikchhapolika/following{/other_user}",
"gists_url": "https://api.github.com/users/pratikchhapolika/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pratikchhapolika/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pratikchhapolika/subscriptions",
"organizations_url": "https://api.github.com/users/pratikchhapolika/orgs",
"repos_url": "https://api.github.com/users/pratikchhapolika/repos",
"events_url": "https://api.github.com/users/pratikchhapolika/events{/privacy}",
"received_events_url": "https://api.github.com/users/pratikchhapolika/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hey @pratikchhapolika,\r\n\r\nInstead of setting values in attention_mask to 2 could you try using global_attention_mask instead? \r\n\r\nAlso see official docs here: \r\nhttps://huggingface.co/transformers/master/model_doc/longformer.html#transformers.LongformerModel.forward",
"> Hey @pratikchhapolika,\r\n> \r\n> Instead of setting values in attention_mask to 2 could you try using global_attention_mask instead?\r\n> \r\n> Also see official docs here:\r\n> https://huggingface.co/transformers/master/model_doc/longformer.html#transformers.LongformerModel.forward\r\n\r\nYou mean to say I should use this:\r\n\r\n```python\r\nglobal_attention_mask = torch.ones(input_ids.shape, dtype=torch.long, device=input_ids.device) # initialize to local attention\r\nglobal_attention_mask[:, [0,-1]] = 2\r\noutputs = model(input_ids, global_attention_mask =global_attention_mask)\r\n```\r\n",
"Rather:\r\n\r\n```python\r\nglobal_attention_mask = torch.zeros(input_ids.shape, dtype=torch.long, device=input_ids.device) # initialize to local attention\r\nglobal_attention_mask[:, [0,-1]] = 1\r\noutputs = model(input_ids, global_attention_mask =global_attention_mask)\r\n```\r\n\r\nas shown in the example of [this](https://huggingface.co/transformers/master/model_doc/longformer.html#transformers.LongformerModel.forward) method ;-)\r\n",
"> Rather:\r\n> \r\n> ```python\r\n> global_attention_mask = torch.zeros(input_ids.shape, dtype=torch.long, device=input_ids.device) # initialize to local attention\r\n> global_attention_mask[:, [0,-1]] = 1\r\n> outputs = model(input_ids, global_attention_mask =global_attention_mask)\r\n> ```\r\n> \r\n> as shown in the example of [this](https://huggingface.co/transformers/master/model_doc/longformer.html#transformers.LongformerModel.forward) method ;-)\r\n\r\nCan you pleas help me wit other questions as well and then I will close this issue? `Question 2, 3 and 4`",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,628 | 1,631 | 1,631 | NONE | null | ## Objective:
Fetching Sentence embeddings using **longformer** model sentence by sentence from `<s>` token. By assigning attention_mask[:, [0,-1]] = 2 that is `<s> and </s> token will have values 2`.
- `transformers` **version:3.0.2**
- Platform:
- Python version: **Python 3.6.12 :: Anaconda, Inc.**
- PyTorch version (GPU?):**1.7.1**
- Tensorflow version (GPU?): **2.3.0**
- Using GPU in script?: **Yes**
- Using distributed or parallel set-up in script?: **parallel**
### Who can help
@patrickvonplaten
##Models:
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
## Information
Model I am using longformer:
The problem arises when using:
* my own modified scripts: (give details below)
The tasks I am working on is:
* my own task or dataset: (give details below)
## Code:
```
from transformers import LongformerModel, LongformerTokenizer
model = LongformerModel.from_pretrained('allenai/longformer-base-4096',output_hidden_states = True)
tokenizer = LongformerTokenizer.from_pretrained('allenai/longformer-base-4096')
# Put the model in "evaluation" mode, meaning feed-forward operation.
model.eval()
```
```
text=["I like to play cricket"] #For this code I want to fetch embedding.
def sentence_bert():
list_of_emb=[]
for i in range(len(all_content)):
SAMPLE_TEXT = text[i] # long input document
print(tokenizer.encode(SAMPLE_TEXT,padding=True,add_special_tokens=True,max_length=20)) #,max_length=10
print(tokenizer.decode(tokenizer.encode(SAMPLE_TEXT)))
input_ids = torch.tensor(tokenizer.encode(SAMPLE_TEXT)).unsqueeze(0)
attention_mask = torch.ones(input_ids.shape, dtype=torch.long, device=input_ids.device) # initialize to local attention
**attention_mask[:, [0,-1]] = 2**
with torch.no_grad():
outputs = model(input_ids, attention_mask=attention_mask)
hidden_states = outputs[2]
token_embeddings = torch.stack(hidden_states, dim=0)
# Remove dimension 1, the "batches".
token_embeddings = torch.squeeze(token_embeddings, dim=1)
# Swap dimensions 0 and 1.
token_embeddings = token_embeddings.permute(1,0,2)
token_vecs_sum = []
# For each token in the sentence...
for token in token_embeddings:
#but preferrable is
sum_vec=torch.sum(token[-4:],dim=0)
# Use `sum_vec` to represent `token`.
token_vecs_sum.append(sum_vec)
h=0
for i in range(len(token_vecs_sum)):
h+=token_vecs_sum[i]
list_of_emb.append(h)
return list_of_emb
f=sentence_bert()
```
**Output**
```
length of string: 5
[0, 38, 101, 7, 310, 5630, 2]
`<s>` I like to play cricket `</s>`
input_ids: tensor([[ 0, 38, 101, 7, 310, 5630, 2]])
Number of layers: 13 (initial embeddings + 12 BERT layers)
Number of batches: 1
Number of tokens: 512
Number of hidden units: 768
```
## Doubts/Question:
1. When I pass `attention_mask[:, [0,-1]] = 2` for global attention to `<s>` token. It doesn't seems to work. Then I pull `0th` token from `512` token from last layer as sentence embedding. Makes sense?
2. Even after passing `max_length=20` I see tensor of size=sentence_length, however ideally it should be padded with max size?
3. Why I see `Number of tokens: 512` ? I think it should be based on our `sentence length`. When I pass one sentence of length `7 ` to get embedding the token in hidden state should be 7? Based on my sentence what are 512 tokens??
4. How can I reduce number of tokens to sentence length instead of 512 ? Every-time I input a new sentence, it should pick up that length. Can we do this for `longformer `?
## Expected behavior
Document1: Embeddings
Document2: Embeddings
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12993/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12993/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12992 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12992/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12992/comments | https://api.github.com/repos/huggingface/transformers/issues/12992/events | https://github.com/huggingface/transformers/issues/12992 | 959,193,325 | MDU6SXNzdWU5NTkxOTMzMjU= | 12,992 | I met an error when I use EncoderDecoderModel. | {
"login": "Captainr22",
"id": 44116628,
"node_id": "MDQ6VXNlcjQ0MTE2NjI4",
"avatar_url": "https://avatars.githubusercontent.com/u/44116628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Captainr22",
"html_url": "https://github.com/Captainr22",
"followers_url": "https://api.github.com/users/Captainr22/followers",
"following_url": "https://api.github.com/users/Captainr22/following{/other_user}",
"gists_url": "https://api.github.com/users/Captainr22/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Captainr22/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Captainr22/subscriptions",
"organizations_url": "https://api.github.com/users/Captainr22/orgs",
"repos_url": "https://api.github.com/users/Captainr22/repos",
"events_url": "https://api.github.com/users/Captainr22/events{/privacy}",
"received_events_url": "https://api.github.com/users/Captainr22/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"As you can see on the error, it has to do with the cross attention: the `encoder_hidden_states` (which are coming from BERT-large-uncased) have a dimensionality of 1024 (which I know by looking at the `hidden_size` attribute of the [config file](https://huggingface.co/bert-large-uncased/blob/main/config.json) of bert-large-uncased). You can also check this by doing:\r\n\r\n```\r\nfrom transformers import BertConfig\r\n\r\nconfig = BertConfig.from_pretrained('bert-large-uncased')\r\nprint(config.hidden_size)\r\n```\r\n\r\nor \r\n\r\n```\r\nfrom transformers import BertModel\r\n\r\nmodel = BertModel.from_pretrained('bert-large-uncased')\r\nprint(model.config.hidden_size)\r\n```\r\n\r\nFor the decoder, the `queries` have a dimensionality of 768 (again, you can see this by looking at the config file or using Python). There's a bit of inconsistency between the models, because for gpt2 the dimensionality is determined by the `n_emb` attribute (whereas it should ideally also be called `hidden_size`).\r\n\r\nDigging into the code, it turns out the error happens because the cross attention layer is defined as a `Conv1d` layer as can be seen [here](https://github.com/huggingface/transformers/blob/f064e0a43d05a6bb1eb81e65e700f8e0f4ab04f9/src/transformers/models/gpt2/modeling_gpt2.py#L151). The `in_channels` are defined as `2 * self.embed_dim` and the `out_channels` as `self.embed_dim`. So basically (2*768 = 1536, 768). However, one then applies this layer to the `encoder_hidden_states`, which have a dimensionality of 1024, so this will not work. You would have to update that line to:\r\n\r\n`self.c_attn = Conv1D(2*1024, 1024)`",
"Thank you for your help! @NielsRogge \r\nActually, I know the error is caused by the dimension. In EncoderDecoderModel docs, it says \"The EncoderDecoderModel can be used to initialize a sequence-to-sequence model with ***any pretrained autoencoding model as the encoder*** and any pretrained autoregressive model as the decoder.\". So I think it will deal with the dimension matching problem automatically.\r\nThank you for your help, I will follow your suggestions to modify my code!\r\nI will close the issue. Thank you!",
"Hi, thanks for your answer @NielsRogge. I am trying to do the same for a gpt-2 model with n_embd =1280, using also BertLage as encoder with hidden_size = 1024. \r\n\r\nI saved my model and load it now by:\r\n`model = AutoModelForSeq2SeqLM.from_pretrained(...)`\r\n\r\nWhen I started to finetune my model, I reached the same error as OP reported.\r\n \r\nI followed your advice afterwards, but this resulted in:\r\n`\tsize mismatch for decoder.transformer.h.0.crossattention.c_attn.weight: copying a param with shape torch.Size([1280, 2560]) from checkpoint, the shape in current model is torch.Size([1024, 2048]).\r\n(many more of these line with h.x increasing. Removed them for readability)\r\n`\r\nAm I missing something here? It looks like the model does not accept the new dimension. Could you give me an advice how to solve that and perhaps what I am missing here? \r\n\r\nThanks alot!",
"Well as I wrote my comment, the solution came into my mind already: After changing the code you need to **recreate the model**. As the doc says: \" Cross-attention layers are automatically added to the decoder and should be fine-tuned on a downstream generative task, like summarization\", therefore cross_attention layers are automatically added at model creation. Dont try to fit random initiated weights into a wrong shape ;) \r\n\r\nSry for taking your time"
] | 1,628 | 1,630 | 1,628 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.6.0
- Platform:
- Python version:
- PyTorch version (GPU?): 1.7.1 cuda 9.2
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
### Who can help @patrickvonplaten, @patil-suraj
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using EncoderDecoderModel:
When I am using EncoderDecoderModel, my code is here:
```python
model = EncoderDecoderModel.from_encoder_decoder_pretrained('bert-large-uncased', 'gpt2')
model = model.cuda()
output = model(input_ids, input_mask, decoder_input_ids, decoder_input_mask, labels=labels)
```
I met an error like this:
```python
Traceback (most recent call last):
File "/home/jwli/ljw/study/test.py", line 68, in <module>
output = model(input_ids, input_mask, decoder_input_ids, decoder_input_mask, labels=labels)
File "/home/jwli/anaconda3/envs/study/lib/python3.9/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/jwli/anaconda3/envs/study/lib/python3.9/site-packages/transformers/models/encoder_decoder/modeling_encoder_decoder.py", line 438, in forward
decoder_outputs = self.decoder(
File "/home/jwli/anaconda3/envs/study/lib/python3.9/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/jwli/anaconda3/envs/study/lib/python3.9/site-packages/transformers/models/gpt2/modeling_gpt2.py", line 941, in forward
transformer_outputs = self.transformer(
File "/home/jwli/anaconda3/envs/study/lib/python3.9/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/jwli/anaconda3/envs/study/lib/python3.9/site-packages/transformers/models/gpt2/modeling_gpt2.py", line 789, in forward
outputs = block(
File "/home/jwli/anaconda3/envs/study/lib/python3.9/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/jwli/anaconda3/envs/study/lib/python3.9/site-packages/transformers/models/gpt2/modeling_gpt2.py", line 339, in forward
cross_attn_outputs = self.crossattention(
File "/home/jwli/anaconda3/envs/study/lib/python3.9/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/jwli/anaconda3/envs/study/lib/python3.9/site-packages/transformers/models/gpt2/modeling_gpt2.py", line 239, in forward
key, value = self.c_attn(encoder_hidden_states).split(self.split_size, dim=2)
File "/home/jwli/anaconda3/envs/study/lib/python3.9/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/jwli/anaconda3/envs/study/lib/python3.9/site-packages/transformers/modeling_utils.py", line 1400, in forward
x = torch.addmm(self.bias, x.view(-1, x.size(-1)), self.weight)
RuntimeError: mat1 dim 1 must match mat2 dim 0
```
But when I change 'bert-large-uncased' to 'bert-base-uncased', the code can run normally.
Can you help me?@patrickvonplaten, @patil-suraj, @LysandreJik | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12992/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12992/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12991 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12991/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12991/comments | https://api.github.com/repos/huggingface/transformers/issues/12991/events | https://github.com/huggingface/transformers/issues/12991 | 959,152,985 | MDU6SXNzdWU5NTkxNTI5ODU= | 12,991 | How is Bert fine-tuned on STS-B task? | {
"login": "PosoSAgapo",
"id": 33200481,
"node_id": "MDQ6VXNlcjMzMjAwNDgx",
"avatar_url": "https://avatars.githubusercontent.com/u/33200481?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PosoSAgapo",
"html_url": "https://github.com/PosoSAgapo",
"followers_url": "https://api.github.com/users/PosoSAgapo/followers",
"following_url": "https://api.github.com/users/PosoSAgapo/following{/other_user}",
"gists_url": "https://api.github.com/users/PosoSAgapo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PosoSAgapo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PosoSAgapo/subscriptions",
"organizations_url": "https://api.github.com/users/PosoSAgapo/orgs",
"repos_url": "https://api.github.com/users/PosoSAgapo/repos",
"events_url": "https://api.github.com/users/PosoSAgapo/events{/privacy}",
"received_events_url": "https://api.github.com/users/PosoSAgapo/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Please ask those questions on the [forums](https://discuss.huggingface.co/). We keep the issues for bugs and feature requests only.",
"> Please ask those questions on the [forums](https://discuss.huggingface.co/). We keep the issues for bugs and feature requests only.\r\n\r\nThank you for your reply, I will post it on the forums"
] | 1,627 | 1,628 | 1,628 | NONE | null | Hi, I am new to NLP and trying to reproduce fine-tune results of Bert. However, the STST-B task troubles me, from what I understand, the STST-B task is a regression task, but Bert treats it as a classification task. I do not quite know the transformation between scores and label in detail, is anybody willing to give me a hint? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12991/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12991/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12990 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12990/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12990/comments | https://api.github.com/repos/huggingface/transformers/issues/12990/events | https://github.com/huggingface/transformers/issues/12990 | 959,068,727 | MDU6SXNzdWU5NTkwNjg3Mjc= | 12,990 | kindly adding some documentations on t5-v1_1-base"" | {
"login": "dorooddorood606",
"id": 79288051,
"node_id": "MDQ6VXNlcjc5Mjg4MDUx",
"avatar_url": "https://avatars.githubusercontent.com/u/79288051?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dorooddorood606",
"html_url": "https://github.com/dorooddorood606",
"followers_url": "https://api.github.com/users/dorooddorood606/followers",
"following_url": "https://api.github.com/users/dorooddorood606/following{/other_user}",
"gists_url": "https://api.github.com/users/dorooddorood606/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dorooddorood606/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dorooddorood606/subscriptions",
"organizations_url": "https://api.github.com/users/dorooddorood606/orgs",
"repos_url": "https://api.github.com/users/dorooddorood606/repos",
"events_url": "https://api.github.com/users/dorooddorood606/events{/privacy}",
"received_events_url": "https://api.github.com/users/dorooddorood606/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"There is no model named `\"t5-v1_1-base\"` so I'm not sure what you mean.",
"Yes there is, `google/t5-v1_1-base`. Normally, t5_v1_1 and regular t5 aren't that different. From its [model card](https://huggingface.co/google/t5-v1_1-base):\r\n\r\n> Version 1.1\r\nT5 Version 1.1 includes the following improvements compared to the original T5 model- GEGLU activation in feed-forward hidden layer, rather than ReLU - see here.\r\nDropout was turned off in pre-training (quality win). Dropout should be re-enabled during fine-tuning.\r\nPre-trained on C4 only without mixing in the downstream tasks.\r\nno parameter sharing between embedding and classifier layer\r\n\"xl\" and \"xxl\" replace \"3B\" and \"11B\". The model shapes are a bit different - larger d_model and smaller num_heads and d_ff.\r\nNote: T5 Version 1.1 was only pre-trained on C4 excluding any supervised training. Therefore, this model has to be fine-tuned before it is useable on a downstream task. Pretraining Dataset: C4\r\n\r\nSo for the base-sized model, normally the memory requirements are the same as t5-base. ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"I have added documentation, see #13240. Therefore, closing."
] | 1,627 | 1,630 | 1,630 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform:
- Python version:
- PyTorch version (GPU?):
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
Documentation: @sgugger
Hi
Could you kindly add some documentations on "t5-v1_1-base"? I tested one code with t5-base and t5-v1 version, for t5-v1 I got memory issue, this seems to me the model size is different and larger, also fast tokenizer for this model does not work, could you kindly add a documentation on these differences?
thanks a lot.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12990/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12990/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12989 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12989/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12989/comments | https://api.github.com/repos/huggingface/transformers/issues/12989/events | https://github.com/huggingface/transformers/issues/12989 | 959,050,731 | MDU6SXNzdWU5NTkwNTA3MzE= | 12,989 | Training hangs at the very start while using deepspeed | {
"login": "hasansalimkanmaz",
"id": 49716619,
"node_id": "MDQ6VXNlcjQ5NzE2NjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/49716619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hasansalimkanmaz",
"html_url": "https://github.com/hasansalimkanmaz",
"followers_url": "https://api.github.com/users/hasansalimkanmaz/followers",
"following_url": "https://api.github.com/users/hasansalimkanmaz/following{/other_user}",
"gists_url": "https://api.github.com/users/hasansalimkanmaz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hasansalimkanmaz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hasansalimkanmaz/subscriptions",
"organizations_url": "https://api.github.com/users/hasansalimkanmaz/orgs",
"repos_url": "https://api.github.com/users/hasansalimkanmaz/repos",
"events_url": "https://api.github.com/users/hasansalimkanmaz/events{/privacy}",
"received_events_url": "https://api.github.com/users/hasansalimkanmaz/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2659267025,
"node_id": "MDU6TGFiZWwyNjU5MjY3MDI1",
"url": "https://api.github.com/repos/huggingface/transformers/labels/DeepSpeed",
"name": "DeepSpeed",
"color": "4D34F7",
"default": false,
"description": ""
}
] | closed | false | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
}
] | [
"Somehow I don't think this has anything to do with how many epochs you're training, at least I have never had a problem training with just one epoch. The problem most likely is elsewhere.\r\n\r\nBut I can't help you until you give me a way to reproduce your setup.\r\n\r\nIdeally please use one of the existing examples, most likely you want this:\r\nhttps://github.com/huggingface/transformers/tree/master/examples/pytorch/token-classification\r\n\r\n1. - launch the example as explain in its README.md w/o deepspeed, than do the same with deepspeed, \r\n2. - use a public dataset as given in the README.md of the example. \r\n3. - try a public model first again from the README.md of the example. \r\n\r\nand if it hangs please send the command line you were using after following the above 3 steps.\r\n\r\nif it doesn't hang then try: `layoutlm` - then we know it's something specific to that particular model.\r\n\r\nThank you!",
"Meanwhile I also tested that layoutlm works with deepspeed. https://github.com/huggingface/transformers/pull/12695",
"Thank you @stas00 for your rapid response. I thought that it may be a general issue, that's why I didn't provide any example code. The code now I am working on is a confidential one, I will follow your advice and let you know afterward.",
"Also consider using these tools to diagnose the hanging:\r\n\r\n- py-spy:\r\n ```\r\n# trace a running python application - e.g. when it's hanging or very slow and you want to see the backtrace \r\npip install py-spy\r\n# dumps traceback for each thread\r\nsudo py-spy dump --pid PID # sudo may or may not be needed\r\n ```\r\n - `faulthandler`\r\n```\r\n# make the traceback dumped periodically - every X seconds\r\nimport faulthandler\r\nfaulthandler.dump_traceback_later(20, repeat=True)\r\n```",
"Thank you @stas00 for your suggestions to debug the issue. I have used both tools. FYI: I am using 2 GPUs and, they are stuck while initializing deepspeed. It is not happening every time but so frequently (50 percent of all my tries). Below you can see the outputs.\r\n\r\n### Line 414 from `integrations.py`\r\n\r\n```\r\n model, optimizer, _, lr_scheduler = deepspeed.initialize(\r\n args=SimpleNamespace(**ds_args), # expects an obj\r\n model=model,\r\n model_parameters=model_parameters,\r\n config_params=config,\r\n )\r\n```\r\n\r\n\r\n### This is from `py-spy` for pid 147\r\n\r\n```\r\npy-spy dump --pid 147\r\nProcess 147: /usr/bin/python -u nlp_ner_layoutlm/train_pipeline/training_step/training_script.py --local_rank=0 --local_example_folder /620a8e1a-2e53-4a9d-8205-61ee86e6453d/layoutlm_data --model_dir /mnt/pipeline/620a8e1a-2e53-4a9d-8205-61ee86e6453d/pytorch_model --batch_size 16 --weight_decay 0.0 --adam_epsilon 1e-08 --learning_rate 2e-05 --epochs 1 --seed 11046060 --tagging_scheme BILOU --profile_logs /mnt/pipeline/620a8e1a-2e53-4a9d-8205-61ee86e6453d/tensorboard_logs --patience 40 --gradient_accumulation_steps 1 --warmup_steps 300 --composite 1 --composite_loss_weight 0.5 --train_dataset_name train --validation_dataset_name validation --use_deepspeed 1 --consolidate 0 --incremental 1 --old_model_dir /mnt/pipeline/620a8e1a-2e53-4a9d-8205-61ee86e6453d/pytorch_model --base_model /mnt/pipeline/LAYOUTLM_PRE_TRAINED_MODEL/base-uncased-huggingface --recursion_indexes [1, 2] --temperature 2.0\r\nPython v3.8.0 (/usr/bin/python3.8)\r\n\r\nThread 147 (active): \"MainThread\"\r\n barrier (torch/distributed/distributed_c10d.py:1967)\r\n new_group (torch/distributed/distributed_c10d.py:2048)\r\n _initialize_parameter_parallel_groups (deepspeed/runtime/zero/utils.py:20)\r\n _configure_distributed_model (deepspeed/runtime/engine.py:578)\r\n __init__ (deepspeed/runtime/engine.py:149)\r\n initialize (deepspeed/__init__.py:120)\r\n init_deepspeed (transformers/integrations.py:414)\r\n train (composite_trainer.py:168)\r\n train_model (nlp_ner_layoutlm/layoutlm/utils/training_utils.py:245)\r\n <module> (training_script.py:65)\r\n\r\n```\r\n\r\n### This is from `py-spy` for pid 148\r\n\r\n```\r\npy-spy dump --pid 148\r\nProcess 148: /usr/bin/python -u nlp_ner_layoutlm/train_pipeline/training_step/training_script.py --local_rank=1 --local_example_folder /620a8e1a-2e53-4a9d-8205-61ee86e6453d/layoutlm_data --model_dir /mnt/pipeline/620a8e1a-2e53-4a9d-8205-61ee86e6453d/pytorch_model --batch_size 16 --weight_decay 0.0 --adam_epsilon 1e-08 --learning_rate 2e-05 --epochs 1 --seed 11046060 --tagging_scheme BILOU --profile_logs /mnt/pipeline/620a8e1a-2e53-4a9d-8205-61ee86e6453d/tensorboard_logs --patience 40 --gradient_accumulation_steps 1 --warmup_steps 300 --composite 1 --composite_loss_weight 0.5 --train_dataset_name train --validation_dataset_name validation --use_deepspeed 1 --consolidate 0 --incremental 1 --old_model_dir /mnt/pipeline/620a8e1a-2e53-4a9d-8205-61ee86e6453d/pytorch_model --base_model /mnt/pipeline/LAYOUTLM_PRE_TRAINED_MODEL/base-uncased-huggingface --recursion_indexes [1, 2] --temperature 2.0\r\nPython v3.8.0 (/usr/bin/python3.8)\r\n\r\nThread 148 (active): \"MainThread\"\r\n convert (torch/nn/modules/module.py:610)\r\n _apply (torch/nn/modules/module.py:381)\r\n _apply (torch/nn/modules/module.py:359)\r\n _apply (torch/nn/modules/module.py:359)\r\n _apply (torch/nn/modules/module.py:359)\r\n _apply (torch/nn/modules/module.py:359)\r\n _apply (torch/nn/modules/module.py:359)\r\n _apply (torch/nn/modules/module.py:359)\r\n _apply (torch/nn/modules/module.py:359)\r\n to (torch/nn/modules/module.py:612)\r\n _configure_distributed_model (deepspeed/runtime/engine.py:575)\r\n __init__ (deepspeed/runtime/engine.py:149)\r\n initialize (deepspeed/__init__.py:120)\r\n init_deepspeed (transformers/integrations.py:414)\r\n train (composite_trainer.py:168)\r\n train_model (nlp_ner_layoutlm/layoutlm/utils/training_utils.py:245)\r\n <module> (training_script.py:65)\r\n\r\n```\r\n\r\n### This is from `faulthandler`, it always logs below lines for every 20 seconds: \r\n\r\n```\r\nTimeout (0:00:20)!\r\nThread 0x00007f8be3d2b740 (most recent call first):\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/distributed/distributed_c10d.py\", line 1967 in barrier\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/distributed/distributed_c10d.py\", line 2048 in new_group\r\n File \"/usr/local/lib/python3.8/dist-packages/deepspeed/runtime/zero/utils.py\", line 20 in _initialize_parameter_parallel_groups\r\n File \"/usr/local/lib/python3.8/dist-packages/deepspeed/runtime/engine.py\", line 578 in _configure_distributed_model\r\n File \"/usr/local/lib/python3.8/dist-packages/deepspeed/runtime/engine.py\", line 149 in __init__\r\n File \"/usr/local/lib/python3.8/dist-packages/deepspeed/__init__.py\", line 120 in initialize\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/integrations.py\", line 414 in init_deepspeed\r\n File \"/app/nlp_ner_layoutlm/layoutlm/trainers/composite_trainer.py\", line 168 in train\r\n File \"/app/nlp_ner_layoutlm/layoutlm/utils/training_utils.py\", line 245 in train_model\r\n File \"nlp_ner_layoutlm/train_pipeline/training_step/training_script.py\", line 65 in <module>\r\nTimeout (0:00:20)!\r\nThread 0x00007fa11175f740 (most recent call first):\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py\", line 610 in convert\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py\", line 381 in _apply\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py\", line 359 in _apply\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py\", line 359 in _apply\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py\", line 359 in _apply\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py\", line 359 in _apply\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py\", line 359 in _apply\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py\", line 359 in _apply\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py\", line 359 in _apply\r\n File \"/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py\", line 612 in to\r\n File \"/usr/local/lib/python3.8/dist-packages/deepspeed/runtime/engine.py\", line 575 in _configure_distributed_model\r\n File \"/usr/local/lib/python3.8/dist-packages/deepspeed/runtime/engine.py\", line 149 in __init__\r\n File \"/usr/local/lib/python3.8/dist-packages/deepspeed/__init__.py\", line 120 in initialize\r\n File \"/usr/local/lib/python3.8/dist-packages/transformers/integrations.py\", line 414 in init_deepspeed\r\n File \"/app/nlp_ner_layoutlm/layoutlm/trainers/composite_trainer.py\", line 168 in train\r\n File \"/app/nlp_ner_layoutlm/layoutlm/utils/training_utils.py\", line 245 in train_model\r\n File \"nlp_ner_layoutlm/train_pipeline/training_step/training_script.py\", line 65 in <module>\r\n```\r\n\r\n\r\nIn the meantime, I will try to adapt my code to share here to allow reproducability. \r\n\r\n",
"So you have a syncing problem, the 2 gpus run `barrier` which ensures they arrived to the same point, but one of the gpus doesn't, and so the other is stuck waiting for it.\r\n\r\nAre you by chance misconfiguring the launch command? Try to hardcode `2` here:\r\n```\r\ndeepspeed --num_gpus={torch.cuda.device_count()} --num_nodes=1\r\n```\r\ncould `{torch.cuda.device_count()` be returning a different number than 2?\r\n\r\ni.e.:\r\n```\r\ndeepspeed --num_gpus=2 --num_nodes=1\r\n```\r\n",
"Thanks @stas00 one more time, I have hard-coded the launch command. My training pipeline contains several training steps, and interestingly, the initial 4 training steps with the same configuration have succeeded but 5th step has hanged for some reason in the same way. I can't reproduce it easily, it happens in different steps in my pipeline.\r\n\r\nI am still investigating the issue.",
"After hard-coding the `num_gpus`, I have followed 2 different approaches with deepspeed and w/o deepspeed. Later, I triggered 3 new pipelines (each has 6 training steps) per each approach.\r\n\r\nall pipelines without deepspeed have succeeded.\r\n2 of 3 pipelines with deepspeed have hanged and 1 of them has succeeded. \r\n\r\n🤷🏻♂️",
"For 2 days, I am triggering lots of trainings with the distributed setting, they didn't hang until now. I am convinced that my issue is related to `deepspeed`. Maybe `deepspeed` doesn't like my configuration :) But I can't go on debugging without much information about being stuck in barrier. I searched on web but can't find any useful info about it.",
"If you're able to reproduce the problem with something I can work with directly, I'd be happy to investigate this with you, @hasansalimkanmaz - perhaps you don't need to show us all of your confidential code but just the part where you start things - it should be pretty generic. \r\n\r\nI'd start with your full app, and remove all code that appears **after** the hanging, - then you can prune it some more binary search-style reduction until you end up with a few lines of code that hang - then we will fix it quickly and most likely you will already see what the problem may be.",
"Thanks @stas00 for your kind help. Currently, I don't have time to dive into this issue as I manage to run in a distributed setting without deepspeed, it is not so urgent for now. On the other hand, I will be working on this issue in the next coming weeks. ",
" I have a same problem. I run the Bert-Large pretrain with 4 nodes(32 GPUs). When I was debugging, I found that there seemed to be a problem with the training of the last batch. It seems that some Cuda streams are not synchronized, which seems to be related to the pre-compiled deepspeed transformer kernel. I installed deepspeed with DS_BUILD_OPS=1. ",
"@HydraQYH, please file an Issue with https://github.com/microsoft/DeepSpeed as this is not an HF integration issue. Thank you!",
"> @HydraQYH, please file an Issue with https://github.com/microsoft/DeepSpeed as this is not an HF integration issue. Thank you!\r\n\r\nSorry for taking so long to reply to you, some urgent tasks need to be dealt with before. I have solved this problem. I use a distributed environment to run BERT model pre-training. I have 4 machines, each with 8 GPUs(32GB V100). I found that when the batch size read by some workers is not equal to the preset train_micro_batch_size_per_gpu, it will hang. Therefore, the problem may be caused by different workers with different batch sizes. This situation usually occurs at the end of an epoch, the data is not enough to fill a batch.",
"> @HydraQYH, please file an Issue with https://github.com/microsoft/DeepSpeed as this is not an HF integration issue. Thank you!\r\n\r\nSorry for taking so long to reply to you, some urgent tasks need to be dealt with before. I have solved this problem. I use a distributed environment to run BERT model pre-training. I have 4 machines, each with 8 GPUs(32GB V100). I found that when the batch size read by some workers is not equal to the preset train_micro_batch_size_per_gpu, it will hang. Therefore, the problem may be caused by different workers with different batch sizes. This situation usually occurs at the end of an epoch, the data is not enough to fill a batch.",
"Great to hear you have found the culprit, @HydraQYH!\r\n\r\nBy your description of it, a normal DDP would have had the same problem.\r\n\r\nDo you have a solution on your side, or should `transformers` handle such circumstances? Note, that the Deepspeed integration doesn't touch on dataloading, and therefore it's a domain of `transformers` and not of Deepspeed.",
"@HydraQYH if you are done with the issue, Could you share the solution? ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,635 | 1,635 | CONTRIBUTOR | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.4.0
- base docker image: nvidia/cuda:10.1-cudnn7-devel-ubuntu18.04
- Python version: 3.8.8
- PyTorch version (GPU?): 1.7.1 (True)
- Tensorflow version (GPU?): 2.2.1 (True)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: Yes, using deepspeed
### Who can help
@stas00 for deepspeed
## Information
Model I am using Layoutlm:
I need to test my layoutlm model by training it only 1 epoch due to test purposes. However, training hangs at the very start without logging anything or returning an error message. When I disable deepspeed and launch my training with `python -m torch.distributed.launch` instead of `deepspeed --num_gpus={torch.cuda.device_count()} --num_nodes=1`, I manage to train for 1 epoch.
The tasks I am working on is:
* Token Classification
## To reproduce
I think it is a general issue. So, training any model with deepspeed for only one epoch may result in hanging process.
## Expected behavior
It would be possible to train a model only for 1 epoch not to waste time while testing.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12989/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12989/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12988 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12988/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12988/comments | https://api.github.com/repos/huggingface/transformers/issues/12988/events | https://github.com/huggingface/transformers/pull/12988 | 959,044,857 | MDExOlB1bGxSZXF1ZXN0NzAyMjE4NzY0 | 12,988 | [Flax] Correctly Add MT5 | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"> Do we really need to add an extra class? Can't we just have the auto-mapping point to a FlaxT5Model?\r\n\r\nTechnically we don't need it, my main arguments are:\r\n\r\n- Consistency with PyTorch & TF (people thought MT5 can't be used with Flax because https://huggingface.co/transformers/model_doc/mt5.html doesn't have Flax classes)\r\n- Ability to provide meaningful examples for MT5 in Flax. T5 is not multi-lingual so the examples might be misleading for Flax"
] | 1,627 | 1,628 | 1,628 | MEMBER | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
During the Flax sprint many teams weren't aware that mt5 models can be used with the `FlaxT5ForConditionalGeneration` class. This is mainly because the docs currently state that FlaxMT5 is not implemented: https://huggingface.co/transformers/index.html#supported-frameworks and because there are no docs on FlaxMT5, but for PyTorch & TF (https://huggingface.co/transformers/model_doc/mt5.html).
This PR adds a FlaxMT5 class analog to PT and TF and also adds official Flax weights to `mt5-base`, etc.: https://huggingface.co/google/mt5-base/commit/0b908f9e3c2fabccc4ab411b89838cecdd9ad499
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12988/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12988/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12988",
"html_url": "https://github.com/huggingface/transformers/pull/12988",
"diff_url": "https://github.com/huggingface/transformers/pull/12988.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12988.patch",
"merged_at": 1628085794000
} |
https://api.github.com/repos/huggingface/transformers/issues/12987 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12987/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12987/comments | https://api.github.com/repos/huggingface/transformers/issues/12987/events | https://github.com/huggingface/transformers/pull/12987 | 959,020,832 | MDExOlB1bGxSZXF1ZXN0NzAyMTk4ODUw | 12,987 | [Flax] Align jax flax device name | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,627 | 1,628 | 1,628 | MEMBER | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
After feedback from @skye we settled on using `jnp.ndarray` as the class to describe jax/flax tensors. This PR replaces all outdated occurrences of "jax_xla.DeviceArray" with "jnp.ndarray"
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12987/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12987/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12987",
"html_url": "https://github.com/huggingface/transformers/pull/12987",
"diff_url": "https://github.com/huggingface/transformers/pull/12987.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12987.patch",
"merged_at": 1628085609000
} |
https://api.github.com/repos/huggingface/transformers/issues/12986 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12986/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12986/comments | https://api.github.com/repos/huggingface/transformers/issues/12986/events | https://github.com/huggingface/transformers/issues/12986 | 959,005,535 | MDU6SXNzdWU5NTkwMDU1MzU= | 12,986 | pylint error when using `transformers.AutoModelForSequenceClassification.from_pretrained(path)` | {
"login": "PhilipMay",
"id": 229382,
"node_id": "MDQ6VXNlcjIyOTM4Mg==",
"avatar_url": "https://avatars.githubusercontent.com/u/229382?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PhilipMay",
"html_url": "https://github.com/PhilipMay",
"followers_url": "https://api.github.com/users/PhilipMay/followers",
"following_url": "https://api.github.com/users/PhilipMay/following{/other_user}",
"gists_url": "https://api.github.com/users/PhilipMay/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PhilipMay/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PhilipMay/subscriptions",
"organizations_url": "https://api.github.com/users/PhilipMay/orgs",
"repos_url": "https://api.github.com/users/PhilipMay/repos",
"events_url": "https://api.github.com/users/PhilipMay/events{/privacy}",
"received_events_url": "https://api.github.com/users/PhilipMay/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This may be linked to the missing `classmethod` decorators that were fixed in #12927, could you try on a source install?",
"> This may be linked to the missing `classmethod` decorators that were fixed in #12927, could you try on a source install?\r\n\r\nI made a source install and then I am getting no pylint error anymore.\r\nSo this is fixed in the main branch. Closing this.\r\n\r\nThanks!"
] | 1,627 | 1,628 | 1,628 | CONTRIBUTOR | null | I am using transformers 4.9.1 from PyPI.
When using pylint on `transformers.AutoModelForSequenceClassification.from_pretrained(path)` I am getting this error:
`my_scipt.py:277:11: E1120: No value for argument 'pretrained_model_name_or_path' in unbound method call (no-value-for-parameter)`
It I change it to
`transformers.AutoModelForSequenceClassification.from_pretrained(pretrained_model_name_or_path=path)`
I am getting
`script.py:277:11: E1120: No value for argument 'cls' in unbound method call (no-value-for-parameter)`
Could you maybe fix this?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12986/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12986/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12985 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12985/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12985/comments | https://api.github.com/repos/huggingface/transformers/issues/12985/events | https://github.com/huggingface/transformers/issues/12985 | 958,987,078 | MDU6SXNzdWU5NTg5ODcwNzg= | 12,985 | The transferred onnx model is much bigger than the origin pytorch model | {
"login": "leoozy",
"id": 26025961,
"node_id": "MDQ6VXNlcjI2MDI1OTYx",
"avatar_url": "https://avatars.githubusercontent.com/u/26025961?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/leoozy",
"html_url": "https://github.com/leoozy",
"followers_url": "https://api.github.com/users/leoozy/followers",
"following_url": "https://api.github.com/users/leoozy/following{/other_user}",
"gists_url": "https://api.github.com/users/leoozy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/leoozy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/leoozy/subscriptions",
"organizations_url": "https://api.github.com/users/leoozy/orgs",
"repos_url": "https://api.github.com/users/leoozy/repos",
"events_url": "https://api.github.com/users/leoozy/events{/privacy}",
"received_events_url": "https://api.github.com/users/leoozy/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi @leoozy, \r\n\r\nThanks for bringing this to our attention.\r\n\r\nI don't have all the details about the machinery ONNX/ORT are using to export the weights, but you're certainly right about some shared buffers being copied over at multiple places.\r\n\r\nMay be @tianleiwu from ORT would have some more insights about this specific behaviour? ",
"@mfuntowicz @tianleiwu I checked the converted bart.onnx model. There is a huge weight called shared.weight, which is the weights of embeding layers (size: seq_length x vocabulary_size)。The encoding and decoding process shared the weights but the shape used in the two processes are different. When encoding, the shape is (vocabulary_size X seq_length). When decoding, the shape is (seq_length X vocabulary size). So, the onnx file saved it duplicatedly because of the different shapes. Models excess 2GB have a lot of limits while being optimized using onnxruntime. ",
"@leoozy, please try do_constant_folding=False in torch.onnx.export to see whether it could reduce the onnx model size. \r\n\r\nUpdated: I tried in my machine, onnx model file size is 1.5 GB, pytorch model is about 1.0 GB. I also verified that removing duplicated weights in onnx model won't help (result is still around 1.5GB).",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,631 | 1,631 | NONE | null | python -m transformers.onnx --model=facebook/bart-large /home/sysadmin/downlaod/onnx_models/bart-large
Pytorch version: 1.9.0
transformers version: 4.9.1
platform: centos 7
python version: 3.7
The original bart model is aroud 2GB, But the transferred bart-large model is more than 3gb. This could because some shared weights are are duplicated in the onnx model | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12985/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12985/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12984 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12984/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12984/comments | https://api.github.com/repos/huggingface/transformers/issues/12984/events | https://github.com/huggingface/transformers/issues/12984 | 958,970,274 | MDU6SXNzdWU5NTg5NzAyNzQ= | 12,984 | convert_graph_to_onnx.convert broken for gpt-neo-x.xB since 4.5.0.dev0 | {
"login": "oborchers",
"id": 26734737,
"node_id": "MDQ6VXNlcjI2NzM0NzM3",
"avatar_url": "https://avatars.githubusercontent.com/u/26734737?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/oborchers",
"html_url": "https://github.com/oborchers",
"followers_url": "https://api.github.com/users/oborchers/followers",
"following_url": "https://api.github.com/users/oborchers/following{/other_user}",
"gists_url": "https://api.github.com/users/oborchers/gists{/gist_id}",
"starred_url": "https://api.github.com/users/oborchers/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/oborchers/subscriptions",
"organizations_url": "https://api.github.com/users/oborchers/orgs",
"repos_url": "https://api.github.com/users/oborchers/repos",
"events_url": "https://api.github.com/users/oborchers/events{/privacy}",
"received_events_url": "https://api.github.com/users/oborchers/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi @oborchers, \r\n\r\nThanks for raising the issue.\r\n\r\nGPT-Neo is not supported by `convert_graph_to_onnx.py` and even if the model was potentially successfully exported in the past, I would not be surprised if some axis definition would be wrong.\r\n\r\nWith the new package `transformers.onnx` we are working on initial support for GPT-Neo, please see the PR [here](https://github.com/huggingface/transformers/pull/12911).\r\n\r\nIf you want to give it a try, we would love your feedback. ",
"Hi @mfuntowicz,\r\n\r\nthanks for doing a great re-implementation of the ONNX export functions, those are of great help 👍 \r\n\r\nI may have been a bit over eager in creating the issue, as well as changing state, as I am technically using a custom script as of now.\r\n\r\nWent through a lot of hassle to actually re-create the onnx checkpoint to see if the most recent changes to ONNX do actually have any effect on the models performance, as back then original torch version was way faster than the exported one. See here: https://github.com/microsoft/onnxruntime/issues/7238\r\n\r\nSo, even if this was exportable properly on your side, it would be almost unusable due to being much slower than the pytorch version. At lest with the last exportable version (4.5.0.dev0). Let my try your code tomorrow to see if there are any differences in the results.",
"Thanks @oborchers for all the details.\n\nWe haven't run benchmark to properly say, we are just validating the outputs (with/without the past buffers) are matching the PyTorch outputs.\n\nWe would be very interested in supporting your efforts improving performance for GPT-Neo, so don't hesitate to ping us (@michaelbenayoun and myself).\n\nAlso, we can potential look at what the offline optimizations provided by Ort can bring here.\n\nThanks 🤗",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,631 | 1,631 | NONE | null | ## Environment info
- `transformers` version: 4.9.1
- Platform: Linux-4.15.0-151-generic-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyTorch version (GPU?): 1.8.1+cu102 (True)
- Tensorflow version (GPU?): 2.4.2 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes (V100)
- Using distributed or parallel set-up in script?: No
### Who can help
This issue is a follow-up of #9803. People tagged in previous issues of the same kind:
@mfuntowicz @LysandreJik @patrickvonplaten
@StellaAthena (because of EleutherAI)
## Information
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [X] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
When trying to run any of the ONNX export scripts on the `EleutherAI/gpt-neo-x.xb` models, they fail. The last version of `transformers` that I can trace this behavior back to is on commit [04ceee7d246dcb26e13fa6aa8e3b990d6a0bf289](https://github.com/huggingface/transformers/commit/04ceee7d246dcb26e13fa6aa8e3b990d6a0bf289). This is not the exact commit, but the last working one I know. This issue is also present in the current `4.9.1` tag, as well as the recently introduced custom configurations to export more easily.
## To reproduce
Running the following script with the current `4.9.1` tag fails (output below). Installing from the above mentioned commit results in a properly working export.
```
pip install -U git+git://github.com/huggingface/transformers.git@04ceee7d246dcb26e13fa6aa8e3b990d6a0bf289
```
Actual code to run:
```
from pathlib import Path
import torch
import transformers
from transformers import convert_graph_to_onnx
from transformers import pipeline
model_name = "EleutherAI/gpt-neo-1.3B"
model_pth = Path(f"gpt_neo/gpt_neo_13b.onnx")
model_pth.parent.mkdir(exist_ok=True, parents=True)
class GPTNeoSent(transformers.GPTNeoForCausalLM):
def __init__(self, config):
super().__init__(config)
self.sentence_embedding = torch.nn.Identity()
def forward(self, input_ids, attention_mask):
return self.sentence_embedding(
super().forward(input_ids, attention_mask=attention_mask).logits
)
model = GPTNeoSent(config=transformers.AutoConfig.from_pretrained(model_name)).from_pretrained(model_name)
nlp = pipeline(
"feature-extraction",
model=model,
tokenizer=model_name,
)
inputs = nlp.tokenizer(["hello my friends!"], return_tensors="pt")
with torch.no_grad():
(
input_names,
output_names,
dynamic_axes,
tokens,
) = convert_graph_to_onnx.infer_shapes(nlp, "pt")
ordered_input_names, model_args = convert_graph_to_onnx.ensure_valid_input(
nlp.model, tokens, input_names
)
if not model_pth.exists():
torch.onnx.export(
model,
(inputs["input_ids"], inputs["attention_mask"]),
f=model_pth.as_posix(),
input_names=input_names,
output_names=output_names,
dynamic_axes=dynamic_axes,
do_constant_folding=True,
use_external_data_format=True, # Needed because of model size
enable_onnx_checker=True,
opset_version=13,
)
```
Which runs into the following error:
```
Found input input_ids with shape: {0: 'batch', 1: 'sequence'}
Found input attention_mask with shape: {0: 'batch', 1: 'sequence'}
Found output output_0 with shape: {0: 'batch', 1: 'sequence'}
Ensuring inputs are in correct order
Generated inputs order: ['input_ids', 'attention_mask']
/home/oborchers/anaconda3/envs/dev/lib/python3.8/site-packages/transformers/models/gpt_neo/modeling_gpt_neo.py:779: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
assert batch_size > 0, "batch_size has to be defined and > 0"
/home/oborchers/anaconda3/envs/dev/lib/python3.8/site-packages/transformers/models/gpt_neo/modeling_gpt_neo.py:149: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
while seq_length % block_length != 0:
/home/oborchers/anaconda3/envs/dev/lib/python3.8/site-packages/torch/onnx/symbolic_helper.py:220: UserWarning: ONNX export failed on Unfold because input size not accessible not supported
warnings.warn("ONNX export failed on " + op + " because " + msg + " not supported")
Traceback (most recent call last):
File "test.py", line 42, in <module>
torch.onnx.export(
File "/home/oborchers/anaconda3/envs/dev/lib/python3.8/site-packages/torch/onnx/__init__.py", line 271, in export
return utils.export(model, args, f, export_params, verbose, training,
File "/home/oborchers/anaconda3/envs/dev/lib/python3.8/site-packages/torch/onnx/utils.py", line 88, in export
_export(model, args, f, export_params, verbose, training, input_names, output_names,
File "/home/oborchers/anaconda3/envs/dev/lib/python3.8/site-packages/torch/onnx/utils.py", line 709, in _export
proto, export_map = graph._export_onnx(
RuntimeError: ONNX export failed: Couldn't export operator aten::unfold
Defined at:
/home/oborchers/anaconda3/envs/dev/lib/python3.8/site-packages/transformers/models/gpt_neo/modeling_gpt_neo.py(189): _look_back
/home/oborchers/anaconda3/envs/dev/lib/python3.8/site-packages/transformers/models/gpt_neo/modeling_gpt_neo.py(216): create_local_attention_mask
/home/oborchers/anaconda3/envs/dev/lib/python3.8/site-packages/transformers/models/gpt_neo/modeling_gpt_neo.py(801): forward
/home/oborchers/anaconda3/envs/dev/lib/python3.8/site-packages/torch/nn/modules/module.py(860): _slow_forward
/home/oborchers/anaconda3/envs/dev/lib/python3.8/site-packages/torch/nn/modules/module.py(887): _call_impl
/home/oborchers/anaconda3/envs/dev/lib/python3.8/site-packages/transformers/models/gpt_neo/modeling_gpt_neo.py(974): forward
test.py(18): forward
/home/oborchers/anaconda3/envs/dev/lib/python3.8/site-packages/torch/nn/modules/module.py(860): _slow_forward
/home/oborchers/anaconda3/envs/dev/lib/python3.8/site-packages/torch/nn/modules/module.py(887): _call_impl
/home/oborchers/anaconda3/envs/dev/lib/python3.8/site-packages/torch/jit/_trace.py(116): wrapper
/home/oborchers/anaconda3/envs/dev/lib/python3.8/site-packages/torch/jit/_trace.py(125): forward
/home/oborchers/anaconda3/envs/dev/lib/python3.8/site-packages/torch/nn/modules/module.py(889): _call_impl
/home/oborchers/anaconda3/envs/dev/lib/python3.8/site-packages/torch/jit/_trace.py(1139): _get_trace_graph
/home/oborchers/anaconda3/envs/dev/lib/python3.8/site-packages/torch/onnx/utils.py(380): _trace_and_get_graph_from_model
/home/oborchers/anaconda3/envs/dev/lib/python3.8/site-packages/torch/onnx/utils.py(420): _create_jit_graph
/home/oborchers/anaconda3/envs/dev/lib/python3.8/site-packages/torch/onnx/utils.py(457): _model_to_graph
/home/oborchers/anaconda3/envs/dev/lib/python3.8/site-packages/torch/onnx/utils.py(694): _export
/home/oborchers/anaconda3/envs/dev/lib/python3.8/site-packages/torch/onnx/utils.py(88): export
/home/oborchers/anaconda3/envs/dev/lib/python3.8/site-packages/torch/onnx/__init__.py(271): export
test.py(42): <module>
```
## Expected behavior
Export should work.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12984/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12984/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12983 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12983/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12983/comments | https://api.github.com/repos/huggingface/transformers/issues/12983/events | https://github.com/huggingface/transformers/issues/12983 | 958,929,872 | MDU6SXNzdWU5NTg5Mjk4NzI= | 12,983 | subclassing a torch.utils.data.Dataset object for a T5 model | {
"login": "TheLongSentance",
"id": 35327158,
"node_id": "MDQ6VXNlcjM1MzI3MTU4",
"avatar_url": "https://avatars.githubusercontent.com/u/35327158?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/TheLongSentance",
"html_url": "https://github.com/TheLongSentance",
"followers_url": "https://api.github.com/users/TheLongSentance/followers",
"following_url": "https://api.github.com/users/TheLongSentance/following{/other_user}",
"gists_url": "https://api.github.com/users/TheLongSentance/gists{/gist_id}",
"starred_url": "https://api.github.com/users/TheLongSentance/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/TheLongSentance/subscriptions",
"organizations_url": "https://api.github.com/users/TheLongSentance/orgs",
"repos_url": "https://api.github.com/users/TheLongSentance/repos",
"events_url": "https://api.github.com/users/TheLongSentance/events{/privacy}",
"received_events_url": "https://api.github.com/users/TheLongSentance/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This tutorial is out of date and will be rewritten soon. You should have a look at the [maintained examples](https://github.com/huggingface/transformers/tree/master/examples) or the [example notebooks](https://huggingface.co/transformers/notebooks.html) instead.",
"Thanks Sylvain, will do."
] | 1,627 | 1,628 | 1,628 | NONE | null | # 🚀 Feature request
In the example on the HuggingFace website "[Fine-tuning with custom datasets](https://huggingface.co/transformers/master/custom_datasets.html)" it says that for a custom dataset:
"_Now, let’s turn our labels and encodings into a Dataset object. In PyTorch, this is done by subclassing a torch.utils.data.Dataset object and implementing __len__ and __getitem__. In TensorFlow, we pass our input encodings and labels to the from_tensor_slices constructor method. We put the data in this format so that the data can be easily batched such that each key in the batch encoding corresponds to a named parameter of the forward() method of the model we will train._"
So the example provided is for distilbert classification but for a text to text model like T5 I got the error message when calling the trainer of "RuntimeError: Could not infer dtype of tokenizers.Encoding"
So could you provide more documentation or links to guides to what needs to change for T5 and maybe for other models if needed?
## Motivation
Here is the code I had to change going from the distilbert example you provide to T5. I assume it works becomes the DataCollatorForSeq2Seq() takes care of expanding the labels/output encoding into the features needed by T5? (but I know very little, I am guessing and I can't find any documentation that suggests this kind of change is needed).
## Your contribution
<!-- Is there any way that you could help, e.g. by submitting a PR?
Make sure to read the CONTRIBUTING.MD readme:
https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12983/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12983/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12982 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12982/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12982/comments | https://api.github.com/repos/huggingface/transformers/issues/12982/events | https://github.com/huggingface/transformers/issues/12982 | 958,681,838 | MDU6SXNzdWU5NTg2ODE4Mzg= | 12,982 | Fine-Tune Wav2Vec2 for English ASR with 🤗 Transformers, loading fine-tune models from local isn't working | {
"login": "Azitt",
"id": 32965166,
"node_id": "MDQ6VXNlcjMyOTY1MTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/32965166?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Azitt",
"html_url": "https://github.com/Azitt",
"followers_url": "https://api.github.com/users/Azitt/followers",
"following_url": "https://api.github.com/users/Azitt/following{/other_user}",
"gists_url": "https://api.github.com/users/Azitt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Azitt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Azitt/subscriptions",
"organizations_url": "https://api.github.com/users/Azitt/orgs",
"repos_url": "https://api.github.com/users/Azitt/repos",
"events_url": "https://api.github.com/users/Azitt/events{/privacy}",
"received_events_url": "https://api.github.com/users/Azitt/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Are you sure you saved your tokenizer in that folder with `tokenizer.save_pretrained`? What files are in this folder?",
"No, I didn't. I'm following this notebook https://huggingface.co/blog/fine-tune-wav2vec2-english it doesn't say save tokenizer. I have these files in my folder. \r\n\r\n\r\n\r\n",
"Sorry, I meant the `processor`, not the `tokenizer`. You should save it if you want to be able to reload it with `from_pretrained`, or use the initial model to load the processor, since it's unlikely to have changed during your fine-tuning.",
"somehow saving the processor doesn't add tokenzier_config.json and special_tokens_map.json to the folder. I saved the tokenizer in the same folder, everything is working now. thank you for your support. "
] | 1,627 | 1,628 | 1,628 | NONE | null |
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: Wav2Vec2
- Platform:
- Python version:
- PyTorch version (GPU?):
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1.
2.
3.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12982/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12982/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12981 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12981/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12981/comments | https://api.github.com/repos/huggingface/transformers/issues/12981/events | https://github.com/huggingface/transformers/pull/12981 | 958,305,935 | MDExOlB1bGxSZXF1ZXN0NzAxNjA1NTM3 | 12,981 | fix `Trainer.train(resume_from_checkpoint=False)` is causing an exception | {
"login": "PhilipMay",
"id": 229382,
"node_id": "MDQ6VXNlcjIyOTM4Mg==",
"avatar_url": "https://avatars.githubusercontent.com/u/229382?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PhilipMay",
"html_url": "https://github.com/PhilipMay",
"followers_url": "https://api.github.com/users/PhilipMay/followers",
"following_url": "https://api.github.com/users/PhilipMay/following{/other_user}",
"gists_url": "https://api.github.com/users/PhilipMay/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PhilipMay/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PhilipMay/subscriptions",
"organizations_url": "https://api.github.com/users/PhilipMay/orgs",
"repos_url": "https://api.github.com/users/PhilipMay/repos",
"events_url": "https://api.github.com/users/PhilipMay/events{/privacy}",
"received_events_url": "https://api.github.com/users/PhilipMay/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"All Tests green and ready for review. 👍",
"Thanks again!"
] | 1,627 | 1,627 | 1,627 | CONTRIBUTOR | null | fix with regression test for #12970 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12981/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12981/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12981",
"html_url": "https://github.com/huggingface/transformers/pull/12981",
"diff_url": "https://github.com/huggingface/transformers/pull/12981.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12981.patch",
"merged_at": 1627978234000
} |
https://api.github.com/repos/huggingface/transformers/issues/12980 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12980/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12980/comments | https://api.github.com/repos/huggingface/transformers/issues/12980/events | https://github.com/huggingface/transformers/issues/12980 | 958,238,592 | MDU6SXNzdWU5NTgyMzg1OTI= | 12,980 | tapas-base model is not predicting answers well. | {
"login": "SAIVENKATARAJU",
"id": 46083296,
"node_id": "MDQ6VXNlcjQ2MDgzMjk2",
"avatar_url": "https://avatars.githubusercontent.com/u/46083296?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SAIVENKATARAJU",
"html_url": "https://github.com/SAIVENKATARAJU",
"followers_url": "https://api.github.com/users/SAIVENKATARAJU/followers",
"following_url": "https://api.github.com/users/SAIVENKATARAJU/following{/other_user}",
"gists_url": "https://api.github.com/users/SAIVENKATARAJU/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SAIVENKATARAJU/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SAIVENKATARAJU/subscriptions",
"organizations_url": "https://api.github.com/users/SAIVENKATARAJU/orgs",
"repos_url": "https://api.github.com/users/SAIVENKATARAJU/repos",
"events_url": "https://api.github.com/users/SAIVENKATARAJU/events{/privacy}",
"received_events_url": "https://api.github.com/users/SAIVENKATARAJU/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"You are initializing `TapasForQuestionAnswering` with randomly initialized classification heads, hence the predictions will be random. The warning also prints this:\r\n\r\n```\r\nSome weights of TapasForQuestionAnswering were not initialized from the model checkpoint at google/tapas-base and are newly initialized: ['output_bias', 'column_output_bias', 'column_output_weights', 'output_weights']\r\n```\r\nInstead of initializing from `google/tapas-base`, you can initialize from any of the [checkpoints on the hub](https://huggingface.co/models?search=google/tapas) which have \"finetuned\" in their name, like `google/tapas-base-finetuned-wtq` for example. ",
"Hey @NielsRogge ,\r\nThanks for your answer. unfortunately the same error is showing even for google/tapas-base-finetuned-tabfact. but for google/tapas-large-finetuned-wtq. answer is showing wrongly and its not for every run. \r\n\r\n```\r\nqueries = 'What is the service flow rate value'\r\n\r\nGXSHC40N.pdf\r\nGXSF30V.pdf\r\nGXMH31H.pdf\r\nGXSH40V_GXSH45V.pdf\r\nToken indices sequence length is longer than the specified maximum sequence length for this model (568 > 512). Running this sequence through the model will result in indexing errors.\r\nW\r\nPredicted answer: 57.56/1.11, 20-125\r\n```\r\nbut ideally it should show 7.5",
"Can you provide a colab to reproduce?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Hi @NielsRogge, can you please help me with my code?\r\nimport camelot\r\nfrom transformers import pipeline\r\n\r\n# Function to extract tables from files\r\nfile_path = '/content/PSP RfS.pdf'\r\ndef extract_tables(file_path):\r\n tables = camelot.read_pdf(file_path, pages='1-end')\r\n return tables\r\n\r\n# Function to preprocess table data for TAPAS\r\ndef preprocess_table(table):\r\n table_data = []\r\n for page in table:\r\n for tab in page:\r\n table_data.append(tab.df) # Append the DataFrame for the table\r\n return table_data\r\n\r\n# Load TAPAS model\r\ntapas_qa = pipeline(\"table-question-answering\", model=\"google/tapas-large-finetuned-wtq\")\r\n\r\n# Process file and ask questions\r\nfile_path = \"/content/PSP RfS.pdf\"\r\nquestions = [\"What is the total quoted capacity?\", \"What is the project capacity awarded?\"]\r\ntables = extract_tables(file_path)\r\npreprocessed_tables = preprocess_table(tables)\r\n\r\n# Ask questions and get answers\r\nanswers = []\r\nfor table in preprocessed_tables:\r\n for question in questions:\r\n result = tapas_qa(table=table, query=question)\r\n answer = result[0]['answer']\r\n answers.append(answer)\r\n\r\n# Print answers\r\nfor q_idx, answer in enumerate(answers):\r\n print(f\"Question {q_idx + 1}: {answer}\")\r\nI wrote this to extract data from table in my pdf.\r\n\r\nbut it is showing me the error TypeError: 'Table' object is not iterable",
"If you need help with your code, you should rather ask on [the forum](https://discuss.huggingface.co/)"
] | 1,627 | 1,693 | 1,631 | NONE | null | Hi,
I was trying to get the answers for my own table. however results are not even reaching expectations. Please find the below code and output. actually, I am extracting tables from PDF,so here instead of providing pdf's i am providing excel sheet for you to test.
```
import pandas as pd
from transformers import TapasForQuestionAnswering,TapasTokenizer
import camelot
import os
import numpy as np
path='/home/jupyter/Projects/ExtractiveQnA/fastapi/knowledgebase/'
appended_data = []
for file in os.listdir(path):
print(file)
tables = camelot.read_pdf(path+file, pages="1-6")
if len(tables) != 0:
for i in range(len(tables)):
table = tables[0].df
table_clean = table.replace("", np.nan).dropna()
table_clean.rename(columns=table_clean.iloc[0], inplace=True)
table_clean.drop(table_clean.index[0], inplace=True)
table_clean.reset_index(drop=True, inplace=True)
appended_data.append(table_clean.astype("str"))
# appended_data=[df.set_index("Model") for df in appended_data]
final_tables=pd.concat(appended_data,axis=1)
final_tables = final_tables.loc[:,~final_tables.columns.duplicated()]
final_tables=final_tables.fillna("NA")
model_name = 'google/tapas-base'
model = TapasForQuestionAnswering.from_pretrained(model_name)
tokenizer = TapasTokenizer.from_pretrained(model_name)
queries='What is the service flow rate '
inputs = tokenizer(table=final_tables,
queries=queries,
padding='max_length',
return_tensors="pt")
outputs = model(**inputs)
predicted_answer_coordinates, = tokenizer.convert_logits_to_predictions(
inputs,
outputs.logits.detach(),
)
answers = []
for coordinates in predicted_answer_coordinates:
if len(coordinates) == 1:
# only a single cell:
answers.append(table.iat[coordinates[0]])
else:
# multiple cells
cell_values = []
for coordinate in coordinates:
cell_values.append(table.iat[coordinate])
answers.append(", ".join(cell_values))
print("")
for query, answer, in zip(queries, answers,):
print(query)
print("Predicted answer: " + answer)
```
and the answer I am getting is :
```
GXSHC40N.pdf
GXSF30V.pdf
GXMH31H.pdf
GXSH40V_GXSH45V.pdf
Some weights of TapasForQuestionAnswering were not initialized from the model checkpoint at google/tapas-base and are newly initialized: ['output_bias', 'column_output_bias', 'column_output_weights', 'output_weights']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Token indices sequence length is longer than the specified maximum sequence length for this model (567 > 512). Running this sequence through the model will result in indexing errors.
W
Predicted answer: Rated Capacity* (Grains@ Salt Dose), Total Water Used per Regeneration @ Maximum Salt Dose, Pressure Drop at Rated Service Flow (psig), Water Supply Maximum Hardness (gpg), Water Supply Maximum Clear Water Iron (ppm)***, Water Pressure Limits (minimum-maximum psi)****
```
can you please helpus with this.
[final_tables (2).zip](https://github.com/huggingface/transformers/files/6917872/final_tables.2.zip)
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12980/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12980/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12979 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12979/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12979/comments | https://api.github.com/repos/huggingface/transformers/issues/12979/events | https://github.com/huggingface/transformers/issues/12979 | 958,206,160 | MDU6SXNzdWU5NTgyMDYxNjA= | 12,979 | Documentation: Dataset to Model interface examples | {
"login": "iandanforth-alation",
"id": 52720125,
"node_id": "MDQ6VXNlcjUyNzIwMTI1",
"avatar_url": "https://avatars.githubusercontent.com/u/52720125?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/iandanforth-alation",
"html_url": "https://github.com/iandanforth-alation",
"followers_url": "https://api.github.com/users/iandanforth-alation/followers",
"following_url": "https://api.github.com/users/iandanforth-alation/following{/other_user}",
"gists_url": "https://api.github.com/users/iandanforth-alation/gists{/gist_id}",
"starred_url": "https://api.github.com/users/iandanforth-alation/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/iandanforth-alation/subscriptions",
"organizations_url": "https://api.github.com/users/iandanforth-alation/orgs",
"repos_url": "https://api.github.com/users/iandanforth-alation/repos",
"events_url": "https://api.github.com/users/iandanforth-alation/events{/privacy}",
"received_events_url": "https://api.github.com/users/iandanforth-alation/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"The custom dataset doc page is outdated and will be rewritten soon, you should use the [examples scripts](https://github.com/huggingface/transformers/tree/master/examples) or [example notebooks](https://huggingface.co/transformers/notebooks.html) as a base to fine-tune models.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,631 | 1,631 | NONE | null | # 🚀 Feature request
Add explicit examples to the custom dataset docs which use fully realized key-value pairs and link to the forward methods of the relevant models to emphasize the contract between Dataset `__getitem__()` output and model `forward()`.
## Motivation
This issue arises when you consider the interaction of Datasets and Models. They may be independently well documented but when trying to use them together there are gaps.
Example:
You want to fine tune T5 using `Trainer` using a custom `Dataset`.
The minimal API for T5 a user needs to be aware of in this scenario is small but not well documented in the context of custom datasets. The `Dataset` must return an object in this format from it's `__getitem__()` method.
```
return {
'input_ids': input_ids,
'attention_mask': attention_mask,
'labels': labels,
}
```
Those three keys are then passed by `Trainer` to T5 via its forward method. Arguably those parameters are the most important first interface you need to know about to train T5 (inside or outside of `Trainer`).
This *is* documented in the T5 docs, however the key disconnect is that in the custom dataset docs none of the examples use explicit, fully realized set of key-value pairs. Also the docs don't emphasize that those return values *must match* the expected inputs to a model's `forward()` method.
## Your contribution
I can add these if this get's a few thumbs up.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12979/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12979/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12978 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12978/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12978/comments | https://api.github.com/repos/huggingface/transformers/issues/12978/events | https://github.com/huggingface/transformers/issues/12978 | 958,057,603 | MDU6SXNzdWU5NTgwNTc2MDM= | 12,978 | Validation and Evaluation not cumputed in run_qa.py | {
"login": "mamoon115",
"id": 45480362,
"node_id": "MDQ6VXNlcjQ1NDgwMzYy",
"avatar_url": "https://avatars.githubusercontent.com/u/45480362?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mamoon115",
"html_url": "https://github.com/mamoon115",
"followers_url": "https://api.github.com/users/mamoon115/followers",
"following_url": "https://api.github.com/users/mamoon115/following{/other_user}",
"gists_url": "https://api.github.com/users/mamoon115/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mamoon115/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mamoon115/subscriptions",
"organizations_url": "https://api.github.com/users/mamoon115/orgs",
"repos_url": "https://api.github.com/users/mamoon115/repos",
"events_url": "https://api.github.com/users/mamoon115/events{/privacy}",
"received_events_url": "https://api.github.com/users/mamoon115/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"What command did you use to run the script? Setting `--eval_strategy epoch` for instance will give you the evaluation every epoch.",
"@sgugger Yes. \r\nAt the time of evaluation [loss](https://github.com/huggingface/transformers/blob/75b8990d9068a2c6ef448c190f2595c17fbcb993/src/transformers/trainer.py#L2206) is empty",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,631 | 1,631 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.10.0.dev0
- Platform: ubuntu
- Python version:3.8
Models:
- roberta
Library:
- trainer: @sgugger
- pipelines: @LysandreJik
## Information
Model I am using is Roberta.
* while running run_qa.py on squad 2.0 data there is missing training metrics, validation, and evaluation loss.
* There is training loss and evaluation metric display after finetuning.
The tasks I am working on is:
* an official QuestionAnswer/Squad task
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12978/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12978/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12977 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12977/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12977/comments | https://api.github.com/repos/huggingface/transformers/issues/12977/events | https://github.com/huggingface/transformers/issues/12977 | 957,933,675 | MDU6SXNzdWU5NTc5MzM2NzU= | 12,977 | Control sequence length for Token Classification with Trainer | {
"login": "DimaClaudiu",
"id": 21079953,
"node_id": "MDQ6VXNlcjIxMDc5OTUz",
"avatar_url": "https://avatars.githubusercontent.com/u/21079953?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DimaClaudiu",
"html_url": "https://github.com/DimaClaudiu",
"followers_url": "https://api.github.com/users/DimaClaudiu/followers",
"following_url": "https://api.github.com/users/DimaClaudiu/following{/other_user}",
"gists_url": "https://api.github.com/users/DimaClaudiu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/DimaClaudiu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/DimaClaudiu/subscriptions",
"organizations_url": "https://api.github.com/users/DimaClaudiu/orgs",
"repos_url": "https://api.github.com/users/DimaClaudiu/repos",
"events_url": "https://api.github.com/users/DimaClaudiu/events{/privacy}",
"received_events_url": "https://api.github.com/users/DimaClaudiu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"There is an option to set the `max_seq_length`, introduced in #12929",
"That is it! Thank you."
] | 1,627 | 1,627 | 1,627 | NONE | null | In the [new examples](https://github.com/huggingface/transformers/tree/master/examples/pytorch/token-classification) for running token classification training with pytorch and Trainer, there doesn't seem to be an option to control `max_seq_length`.
In the legacy version of the example, `DataTrainingArgs` has such an option, and for the example script without `Trainer` the option is also present.
Am I missing something? Or should I simply provide data samples pre-tokenized to my desired sequence length if I wish to use `Trainer`?
This was tested on v4.9.1. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12977/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12977/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12976 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12976/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12976/comments | https://api.github.com/repos/huggingface/transformers/issues/12976/events | https://github.com/huggingface/transformers/pull/12976 | 957,814,343 | MDExOlB1bGxSZXF1ZXN0NzAxMTc5NjI0 | 12,976 | Fix template for inputs docstrings | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,627 | 1,627 | 1,627 | COLLABORATOR | null | # What does this PR do?
The templates for the PyTorch model has a mistake in the input dosctrings (parenthesis should be inside the docstring and not the format) and several models had the same mistake (I realized it while reviewing Splinter actually). This PR fixes all of those and cleans up a few problems I spotted at the same time:
- image models don't need a format because there is nothing to format in the input docstrings
- some models that had the correct template for the input docstrings also add the parenthesis in some of the formats. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12976/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12976/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12976",
"html_url": "https://github.com/huggingface/transformers/pull/12976",
"diff_url": "https://github.com/huggingface/transformers/pull/12976.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12976.patch",
"merged_at": 1627972105000
} |
https://api.github.com/repos/huggingface/transformers/issues/12975 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12975/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12975/comments | https://api.github.com/repos/huggingface/transformers/issues/12975/events | https://github.com/huggingface/transformers/pull/12975 | 957,778,491 | MDExOlB1bGxSZXF1ZXN0NzAxMTQ4NDU5 | 12,975 | Place BigBirdTokenizer in sentencepiece-only objects | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,627 | 1,627 | 1,627 | COLLABORATOR | null | # What does this PR do?
As was pointed out in #12946, it was impossible to import `BigBirdTokenizer` without sentencepiece installed, which shouldn't be the case. This PR fixes that.
Fixes #12946 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12975/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12975/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12975",
"html_url": "https://github.com/huggingface/transformers/pull/12975",
"diff_url": "https://github.com/huggingface/transformers/pull/12975.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12975.patch",
"merged_at": 1627885598000
} |
https://api.github.com/repos/huggingface/transformers/issues/12974 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12974/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12974/comments | https://api.github.com/repos/huggingface/transformers/issues/12974/events | https://github.com/huggingface/transformers/pull/12974 | 957,583,386 | MDExOlB1bGxSZXF1ZXN0NzAwOTgxOTkz | 12,974 | fix typo in example/text-classification README | {
"login": "fullyz",
"id": 50270612,
"node_id": "MDQ6VXNlcjUwMjcwNjEy",
"avatar_url": "https://avatars.githubusercontent.com/u/50270612?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fullyz",
"html_url": "https://github.com/fullyz",
"followers_url": "https://api.github.com/users/fullyz/followers",
"following_url": "https://api.github.com/users/fullyz/following{/other_user}",
"gists_url": "https://api.github.com/users/fullyz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fullyz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fullyz/subscriptions",
"organizations_url": "https://api.github.com/users/fullyz/orgs",
"repos_url": "https://api.github.com/users/fullyz/repos",
"events_url": "https://api.github.com/users/fullyz/events{/privacy}",
"received_events_url": "https://api.github.com/users/fullyz/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,627 | 1,627 | 1,627 | CONTRIBUTOR | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12974/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12974/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12974",
"html_url": "https://github.com/huggingface/transformers/pull/12974",
"diff_url": "https://github.com/huggingface/transformers/pull/12974.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12974.patch",
"merged_at": 1627901923000
} |
https://api.github.com/repos/huggingface/transformers/issues/12973 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12973/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12973/comments | https://api.github.com/repos/huggingface/transformers/issues/12973/events | https://github.com/huggingface/transformers/pull/12973 | 957,551,663 | MDExOlB1bGxSZXF1ZXN0NzAwOTU2NDgw | 12,973 | Add retrieval model config | {
"login": "amy-marmalade",
"id": 85194333,
"node_id": "MDQ6VXNlcjg1MTk0MzMz",
"avatar_url": "https://avatars.githubusercontent.com/u/85194333?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amy-marmalade",
"html_url": "https://github.com/amy-marmalade",
"followers_url": "https://api.github.com/users/amy-marmalade/followers",
"following_url": "https://api.github.com/users/amy-marmalade/following{/other_user}",
"gists_url": "https://api.github.com/users/amy-marmalade/gists{/gist_id}",
"starred_url": "https://api.github.com/users/amy-marmalade/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amy-marmalade/subscriptions",
"organizations_url": "https://api.github.com/users/amy-marmalade/orgs",
"repos_url": "https://api.github.com/users/amy-marmalade/repos",
"events_url": "https://api.github.com/users/amy-marmalade/events{/privacy}",
"received_events_url": "https://api.github.com/users/amy-marmalade/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,627 | 1,627 | 1,627 | NONE | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12973/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12973/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12973",
"html_url": "https://github.com/huggingface/transformers/pull/12973",
"diff_url": "https://github.com/huggingface/transformers/pull/12973.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12973.patch",
"merged_at": null
} |
|
https://api.github.com/repos/huggingface/transformers/issues/12972 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12972/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12972/comments | https://api.github.com/repos/huggingface/transformers/issues/12972/events | https://github.com/huggingface/transformers/pull/12972 | 957,473,813 | MDExOlB1bGxSZXF1ZXN0NzAwODkzOTY1 | 12,972 | Deberta tf | {
"login": "kamalkraj",
"id": 17096858,
"node_id": "MDQ6VXNlcjE3MDk2ODU4",
"avatar_url": "https://avatars.githubusercontent.com/u/17096858?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kamalkraj",
"html_url": "https://github.com/kamalkraj",
"followers_url": "https://api.github.com/users/kamalkraj/followers",
"following_url": "https://api.github.com/users/kamalkraj/following{/other_user}",
"gists_url": "https://api.github.com/users/kamalkraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kamalkraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kamalkraj/subscriptions",
"organizations_url": "https://api.github.com/users/kamalkraj/orgs",
"repos_url": "https://api.github.com/users/kamalkraj/repos",
"events_url": "https://api.github.com/users/kamalkraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/kamalkraj/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"As a result of #13023 , you will need to rebase your PR on master and solve the merge conflicts (basically, you will just need to re-add the models in the auto-mappings as strings). Let us know if you need any help with that.",
"Glad to see a tf version! Thank you!",
"@LysandreJik \r\nYes, I am interested in contributing the DeBERTa-v2 model also"
] | 1,627 | 1,631 | 1,628 | CONTRIBUTOR | null | # What does this PR do?
TFDeBERTa implementation
@patrickvonplaten, @LysandreJik
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12972/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12972/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12972",
"html_url": "https://github.com/huggingface/transformers/pull/12972",
"diff_url": "https://github.com/huggingface/transformers/pull/12972.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12972.patch",
"merged_at": 1628758886000
} |
https://api.github.com/repos/huggingface/transformers/issues/12971 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12971/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12971/comments | https://api.github.com/repos/huggingface/transformers/issues/12971/events | https://github.com/huggingface/transformers/issues/12971 | 957,443,611 | MDU6SXNzdWU5NTc0NDM2MTE= | 12,971 | [FLAX] Potential bug in CLM script when using text files | {
"login": "stefan-it",
"id": 20651387,
"node_id": "MDQ6VXNlcjIwNjUxMzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/20651387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stefan-it",
"html_url": "https://github.com/stefan-it",
"followers_url": "https://api.github.com/users/stefan-it/followers",
"following_url": "https://api.github.com/users/stefan-it/following{/other_user}",
"gists_url": "https://api.github.com/users/stefan-it/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stefan-it/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stefan-it/subscriptions",
"organizations_url": "https://api.github.com/users/stefan-it/orgs",
"repos_url": "https://api.github.com/users/stefan-it/repos",
"events_url": "https://api.github.com/users/stefan-it/events{/privacy}",
"received_events_url": "https://api.github.com/users/stefan-it/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
}
] | [
"If I understand correctly this also applies to PyTorch's `run_clm.py` script. I am happy to add the `keep_linebreaks` parameter to both `run_clm.py` and `run_flax_clm.py` if `load_dataset(\"text\")` is used. \r\n\r\n@sgugger @lhoestq - what do you think? It seems like multiple people had this problem.\r\n\r\nAlso @lhoestq - maybe it's a good idea to add some documentation about `keep_linebreaks` as it can't be find anywhere in the docs. Maybe here: https://huggingface.co/docs/datasets/loading_datasets.html#text-files ? ",
"This also applies to the TensorFlow script as well. I have no problem adding the `keep_linebreaks` parameter there.",
"Ok great! @stefan-it - would you maybe be interested in opening a PR to change the following files:\r\n\r\n- https://github.com/huggingface/transformers/blob/master/examples/flax/language-modeling/run_clm_flax.py\r\n- https://github.com/huggingface/transformers/blob/master/examples/tensorflow/language-modeling/run_clm.py\r\n- https://github.com/huggingface/transformers/blob/master/examples/pytorch/language-modeling/run_clm.py\r\n\r\nAlso, we should probs open a PR add docs to https://huggingface.co/docs/datasets/loading_datasets.html#text-files",
"And don't forget https://github.com/huggingface/transformers/blob/master/examples/pytorch/language-modeling/run_clm_no_trainer.py",
"Hi,\r\n\r\nI tested it with the `keep_linebreaks` parameter and output of the model is then correct :hugs: \r\n\r\nYeah, I would like to open a PR for these changes, should I wait until #13024 is merged, @patrickvonplaten :thinking: ",
"Actually, I think #13024 doesn't actually lead to a speed-up :D Feel free to open as soon as you want :-) ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,630 | 1,630 | COLLABORATOR | null | Hi,
I've seen the following bug when using the CLM script with FLAX in combination with text files, pretty much the same as reported on StackOverflow:
https://stackoverflow.com/questions/65145526/why-new-lines-arent-generated-with-my-fine-tuned-distilgpt2-model
The underlying problem is, that newlines are removed and then the output of a fully trained model looks like:
```text
'Der Sinn des Lebens ist es, sich in ein und derselben Welt selbst niederzulassen und den anderen zum Leben auf der Grundlage dieses Modells zu berufen.Denn auch sie sind nur möglich, weil sie mit dem Göttlichen und mit dem göttlichen Willen in Verbindung stehen, die sich aus einer Welt der Liebe und des Friedens füreinander ergeben.Wir müssen die Freiheit der menschlichen und physischen Existenz verteidigen.Denn die Freiheit geht davon aus, dass Menschen nur existieren, weil sie in einem Zustand von Freiheit, Würde, Harmonie und'
```
So no newlines are generated. I've modified:
https://github.com/huggingface/transformers/blob/a4340d3b85fa8a902857d26d7870c53f82a4f666/examples/flax/language-modeling/run_clm_flax.py#L376
to
```python
output = tokenizer([example + "\n" for example in examples[text_column_name]])
```
and the output of the model now is:
```text
Mein Name ist Alexey.\nIch bin...\nOh, verdammt.\n- Was?\n- Ich kann mit dir nicht gut befreundet sein.\n- Sollen wir nicht?\n- Es ist ein bisschen komplizierter.\nUnd du solltest dir die Zähne putzen.\n- Hier war es noch nie.\n- Ich weiß.\nJetzt mal raus, bitte.\n- Das ist ja großartig.\n- Das ist es ja.\n- Wirklich?\n- Es muss nicht nur ein Spaß sein, das weiß ich doch.\nDas ist wirklich gut.\nJa.\nDie Leute mögen es, wenn du hier bist.\nGenau wie ich's tue.\n- Warum?\n- Ich wollte das Gefühl haben.\nEs ist nicht leicht, füreinander zu sorgen.\nAber das ist, was ich wollte.\nIch wollte mich bedanken, dass ich alles getan habe, was du auf die Beine gebracht hast.\nDu hast alles tun, was du wolltest.\nAber das
```
This is only a temporarily workaround, but maybe the best option is to use the `keep_linebreaks` in the dataset loader (when using text files), but I haven't tested it yet. This option was introduced in https://github.com/huggingface/datasets/pull/1913.
/cc @patrickvonplaten | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12971/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12971/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12970 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12970/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12970/comments | https://api.github.com/repos/huggingface/transformers/issues/12970/events | https://github.com/huggingface/transformers/issues/12970 | 957,303,934 | MDU6SXNzdWU5NTczMDM5MzQ= | 12,970 | `Trainer.train(resume_from_checkpoint=False)` is causing an exception | {
"login": "PhilipMay",
"id": 229382,
"node_id": "MDQ6VXNlcjIyOTM4Mg==",
"avatar_url": "https://avatars.githubusercontent.com/u/229382?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PhilipMay",
"html_url": "https://github.com/PhilipMay",
"followers_url": "https://api.github.com/users/PhilipMay/followers",
"following_url": "https://api.github.com/users/PhilipMay/following{/other_user}",
"gists_url": "https://api.github.com/users/PhilipMay/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PhilipMay/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PhilipMay/subscriptions",
"organizations_url": "https://api.github.com/users/PhilipMay/orgs",
"repos_url": "https://api.github.com/users/PhilipMay/repos",
"events_url": "https://api.github.com/users/PhilipMay/events{/privacy}",
"received_events_url": "https://api.github.com/users/PhilipMay/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"That seems like the right fix indeed. Please go ahead with a PR, thanks! :-)"
] | 1,627 | 1,627 | 1,627 | CONTRIBUTOR | null | Since `resume_from_checkpoint` can be `str` and `bool` it should be possible to pass `False` to it.
But when `resume_from_checkpoint` is `False` it causes an exception here:
https://github.com/huggingface/transformers/blob/3d4b3bc3fd77e0e48e2364464ea90379f13bcf37/src/transformers/trainer.py#L1049-L1050
```text
E TypeError: expected str, bytes or os.PathLike object, not bool
```
The most simple solution would be to do this at the beginning of the `train` function:
```python
resume_from_checkpoint = None if not resume_from_checkpoint else resume_from_checkpoint
```
If wanted I can provide a PR. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12970/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12970/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12969 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12969/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12969/comments | https://api.github.com/repos/huggingface/transformers/issues/12969/events | https://github.com/huggingface/transformers/pull/12969 | 957,303,653 | MDExOlB1bGxSZXF1ZXN0NzAwNzU0ODk2 | 12,969 | Add tokenizer method to convert ids to tokens | {
"login": "markrogersjr",
"id": 1095809,
"node_id": "MDQ6VXNlcjEwOTU4MDk=",
"avatar_url": "https://avatars.githubusercontent.com/u/1095809?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/markrogersjr",
"html_url": "https://github.com/markrogersjr",
"followers_url": "https://api.github.com/users/markrogersjr/followers",
"following_url": "https://api.github.com/users/markrogersjr/following{/other_user}",
"gists_url": "https://api.github.com/users/markrogersjr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/markrogersjr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/markrogersjr/subscriptions",
"organizations_url": "https://api.github.com/users/markrogersjr/orgs",
"repos_url": "https://api.github.com/users/markrogersjr/repos",
"events_url": "https://api.github.com/users/markrogersjr/events{/privacy}",
"received_events_url": "https://api.github.com/users/markrogersjr/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,627 | 1,627 | 1,627 | NONE | null | Adds basic functionality to convert model output to a human-interpretable format for applications such as grammar checking with the T5 CoLA task. @thomwolf
Fixes #12967 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12969/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12969/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12969",
"html_url": "https://github.com/huggingface/transformers/pull/12969",
"diff_url": "https://github.com/huggingface/transformers/pull/12969.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12969.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/12968 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12968/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12968/comments | https://api.github.com/repos/huggingface/transformers/issues/12968/events | https://github.com/huggingface/transformers/issues/12968 | 957,300,926 | MDU6SXNzdWU5NTczMDA5MjY= | 12,968 | 403 error in colab to download tokenizer | {
"login": "moghadas76",
"id": 23231913,
"node_id": "MDQ6VXNlcjIzMjMxOTEz",
"avatar_url": "https://avatars.githubusercontent.com/u/23231913?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/moghadas76",
"html_url": "https://github.com/moghadas76",
"followers_url": "https://api.github.com/users/moghadas76/followers",
"following_url": "https://api.github.com/users/moghadas76/following{/other_user}",
"gists_url": "https://api.github.com/users/moghadas76/gists{/gist_id}",
"starred_url": "https://api.github.com/users/moghadas76/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/moghadas76/subscriptions",
"organizations_url": "https://api.github.com/users/moghadas76/orgs",
"repos_url": "https://api.github.com/users/moghadas76/repos",
"events_url": "https://api.github.com/users/moghadas76/events{/privacy}",
"received_events_url": "https://api.github.com/users/moghadas76/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Please follow the issue template, there is nothing we can do to help otherwise."
] | 1,627 | 1,627 | 1,627 | NONE | null | ```
647 class HTTPDefaultErrorHandler(BaseHandler):
648 def http_error_default(self, req, fp, code, msg, hdrs):
--> 649 raise HTTPError(req.full_url, code, msg, hdrs, fp)
650
651 class HTTPRedirectHandler(BaseHandler):
HTTPError: HTTP Error 403: rate limit exceeded
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12968/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12968/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12967 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12967/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12967/comments | https://api.github.com/repos/huggingface/transformers/issues/12967/events | https://github.com/huggingface/transformers/issues/12967 | 957,300,227 | MDU6SXNzdWU5NTczMDAyMjc= | 12,967 | Unable to convert output to interpretable format | {
"login": "markrogersjr",
"id": 1095809,
"node_id": "MDQ6VXNlcjEwOTU4MDk=",
"avatar_url": "https://avatars.githubusercontent.com/u/1095809?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/markrogersjr",
"html_url": "https://github.com/markrogersjr",
"followers_url": "https://api.github.com/users/markrogersjr/followers",
"following_url": "https://api.github.com/users/markrogersjr/following{/other_user}",
"gists_url": "https://api.github.com/users/markrogersjr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/markrogersjr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/markrogersjr/subscriptions",
"organizations_url": "https://api.github.com/users/markrogersjr/orgs",
"repos_url": "https://api.github.com/users/markrogersjr/repos",
"events_url": "https://api.github.com/users/markrogersjr/events{/privacy}",
"received_events_url": "https://api.github.com/users/markrogersjr/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,627 | 1,627 | 1,627 | NONE | null | # 🚀 Feature request
There is no way to convert model outputs to a human-interpretable format, such as a list of token strings. Without this feature, there is no practicality other than benchmarking model performance, which does not require such a feature.
## Motivation
I'm trying to use the T5 CoLA task to determine whether an input sentence is grammatical.
## Your contribution
See #12969
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12967/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12967/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12966 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12966/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12966/comments | https://api.github.com/repos/huggingface/transformers/issues/12966/events | https://github.com/huggingface/transformers/issues/12966 | 957,248,376 | MDU6SXNzdWU5NTcyNDgzNzY= | 12,966 | Workaround for training models with really big text files | {
"login": "finiteautomata",
"id": 167943,
"node_id": "MDQ6VXNlcjE2Nzk0Mw==",
"avatar_url": "https://avatars.githubusercontent.com/u/167943?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/finiteautomata",
"html_url": "https://github.com/finiteautomata",
"followers_url": "https://api.github.com/users/finiteautomata/followers",
"following_url": "https://api.github.com/users/finiteautomata/following{/other_user}",
"gists_url": "https://api.github.com/users/finiteautomata/gists{/gist_id}",
"starred_url": "https://api.github.com/users/finiteautomata/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/finiteautomata/subscriptions",
"organizations_url": "https://api.github.com/users/finiteautomata/orgs",
"repos_url": "https://api.github.com/users/finiteautomata/repos",
"events_url": "https://api.github.com/users/finiteautomata/events{/privacy}",
"received_events_url": "https://api.github.com/users/finiteautomata/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"cc @sgugger @lhoestq",
"The cache issue should be mostly fixed, now that datasets stores the tokenized inputs with the right precision. If it's not, it should be discussed on the Datasets repo.\r\nThe second issue should also be discussed on the Datasets repo.\r\n\r\nAs mentioned on the main README, the examples provided here are just this: examples. You can adapt them to your use case (as you did) but we leave them as generic as possible on purpose.",
"Thanks @sgugger for your answer; it's true you can't just add every possible example there, and of course I don't intend to discuss `datasets` issues here. \r\n\r\nI share a gist with a modified version of `run_mlm.py` in case anyone is facing the same problem. \r\n\r\nhttps://gist.github.com/finiteautomata/bef480d508d12e2028fdeae19a92b350"
] | 1,627 | 1,627 | 1,627 | NONE | null |
# 🚀 Feature request
Provide a workaround for `run_mlm.py` when working with big text files.
## Motivation
I'm trying to train a `RoBERTa` model with a lot of big text files (~ 50GB of text). When doing so, I'm facing two obstacles:
1. Tokenization beforehand creates a lot of cache storage (See #10204), so one has to resort to on-the-fly tokenization using `set_transform`
2. `datasets` is quite slow when working with really big text files (see https://github.com/huggingface/datasets/issues/2210, https://github.com/huggingface/datasets/issues/2252). Some fixes have been proposed but to my knowledge the issue persists
Can you provide an example on how to workaround these two issues? I suppose that using a custom torch Dataset could (temporarily) fix this.
## Your contribution
Inspired by https://github.com/huggingface/transformers/issues/10278#issuecomment-805245903, I replaced the `datasets` class by this one. As far as I could see, time improves vs using `datasets` with `set_transform`, but I'm not really sure if it is optimal, particularly regarding parallelism (I'm running this script with `python xla_spawn.py`)
```python
from torch.utils.data import IterableDataset
class BatchProcessedDataset(IterableDataset):
def __init__(self, files, tokenizer, batch_size=4096, limit=-1):
self.files = files
self.batch_size = batch_size
self.tokenizer = tokenizer
self.limit = limit
def __iter__(self):
num_iter = 0
for file_path in self.files:
with open(file_path) as f:
next_batch = [x.strip("\n") for _, x in zip(range(self.batch_size), f)]
while next_batch:
tokenized_batch = self.tokenizer(next_batch, padding='max_length', truncation=True, return_special_tokens_mask=True)
for encoding in tokenized_batch.encodings:
if num_iter == self.limit:
return
yield {
"input_ids": encoding.ids,
"token_type_ids": encoding.type_ids,
"attention_mask": encoding.attention_mask,
"special_tokens_mask": encoding.special_tokens_mask
}
num_iter += 1
next_batch = [x.strip("\n") for _, x in zip(range(self.batch_size), f)]
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12966/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12966/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12965 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12965/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12965/comments | https://api.github.com/repos/huggingface/transformers/issues/12965/events | https://github.com/huggingface/transformers/issues/12965 | 957,194,611 | MDU6SXNzdWU5NTcxOTQ2MTE= | 12,965 | Bugs when fine tuning the gpt2 | {
"login": "yananchen1989",
"id": 26405281,
"node_id": "MDQ6VXNlcjI2NDA1Mjgx",
"avatar_url": "https://avatars.githubusercontent.com/u/26405281?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yananchen1989",
"html_url": "https://github.com/yananchen1989",
"followers_url": "https://api.github.com/users/yananchen1989/followers",
"following_url": "https://api.github.com/users/yananchen1989/following{/other_user}",
"gists_url": "https://api.github.com/users/yananchen1989/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yananchen1989/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yananchen1989/subscriptions",
"organizations_url": "https://api.github.com/users/yananchen1989/orgs",
"repos_url": "https://api.github.com/users/yananchen1989/repos",
"events_url": "https://api.github.com/users/yananchen1989/events{/privacy}",
"received_events_url": "https://api.github.com/users/yananchen1989/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Pinging @sgugger",
"It's hard to investigate more without having the data. Adding padding when fine-tuning GPT-2 is a very bad idea when fine-tuning GPT-2, which does not have a padding token, and it shouldn't be necessary. Could you provide us with a reproducer that includes the data?",
"> It's hard to investigate more without having the data. Adding padding when fine-tuning GPT-2 is a very bad idea when fine-tuning GPT-2, which does not have a padding token, and it shouldn't be necessary. Could you provide us with a reproducer that includes the data? \r\n\r\nThanks for your suggestion. I will check my data to meet the default setting of fine-tuning. \r\nBy the way, should the eos_token, <endoftext>, be append to the end of each sample ? (the text column in the csv files )\r\n@sgugger \r\n",
"If it's not done by the tokenizer, yes it should.",
"> some people do deserve'right to be forgotten'– but law's power shouldn't rest...<|endoftext|>\r\n> cyrus bus burns on way to no ; she surprises cat's meow crowd<|endoftext|>\r\n> eu commission approves uk's carphone, dixons merger<|endoftext|>\r\n> miley cyrus fan arrested<|endoftext|>\r\n> rdio, crackle, vudu add chromecast support<|endoftext|>\r\n> being a cynic linked to tripled risk of developing dementia, finland study suggests<|endoftext|>\r\n> australia, japan strike trade deal<|endoftext|>\r\n> record low teen birth rate not low enough, says cdc<|endoftext|>\r\n> legendary house music dj frankie knuckles dies aged 59<|endoftext|>\r\n> nhtsa closes tesla investigations : reuters<|endoftext|>\r\n> brad pitt speaks out on premiere punching<|endoftext|>\r\n> twitter's users are in asia, but its revenue is in the us<|endoftext|>\r\n> new report questions effectiveness of flu drug tamiflu<|endoftext|>\r\n> hilary duff talks \" really difficult \" split from mike comrie<|endoftext|>\r\n> the top 10 reasons why'guardians of the galaxy'is awesome<|endoftext|>\r\n> we had a blast at the planes : fire and rescue red carpet premiere!<|endoftext|>\r\n> fcc extends neutrality comment deadline after site crashes<|endoftext|>\r\n> olivia munn lives in a haunted house<|endoftext|>\r\n> uk agency invests in vfx house to create virtual reality content<|endoftext|>\r\n> of mice and men must die<|endoftext|>\r\n> death toll in w. african ebola outbreak rises to 518<|endoftext|>\r\n> cheaper gas, food push down producer prices<|endoftext|>\r\n> tesla opens up patent portfolio to promote innovation in electronic car...<|endoftext|>\r\n> useful android tips that you should know<|endoftext|>\r\n> autism diagnoses on the rise<|endoftext|>\r\n> u. s. stock futures rising ahead of testimony from fed chair<|endoftext|>\r\n> blackberry z3 review<|endoftext|>\r\n> update 1 - buffett's berkshire hathaway buys stake in verizon, adds to wal - mart<|endoftext|>\r\n> st. luke's improves, but easton hospital falters in safety ratings<|endoftext|>\r\n> drowsy driving is more common than you think<|endoftext|>\r\n> republicans nab approval for '. gop'internet domain<|endoftext|>\r\n> apple says sold well over 800 million mobile devices<|endoftext|>\r\n> the dot view case for the one m8 is in htc's store for $ 50, not available for...<|endoftext|>\r\n> physicians push for extension of medicaid reimbursement increase<|endoftext|>\r\n> mobile fix : chinese ipos, first party data and iphone 6<|endoftext|>\r\n> ranking the country's best and worst jobs<|endoftext|>\r\n> nerdnews : marvel comics picks a woman to be the next thor<|endoftext|>\r\n> men with eating disorders slow to get help, study shows<|endoftext|>\r\n> apple eyeing beats electronics for $ 3. 2 bln<|endoftext|>\r\n> measles update for the united states<|endoftext|>\r\n> former'scandal'star arrested<|endoftext|>\r\n> us economy shrank at steep 2. 9 percent rate<|endoftext|>\r\n> white house : medicaid expansion would have covered 120k wisconsinites<|endoftext|>\r\n> samsung galaxy k zoom goes official with 20. 7mp camera, 10x optical zoom<|endoftext|>\r\n> asian stocks tumble on weak china, japan data<|endoftext|>\r\n> killer virus boosts bacon prices<|endoftext|>\r\n> e - cig industry awaits federal regs<|endoftext|>\r\n> what would you do to get your cell phone back?<|endoftext|>\r\n> dc circuit brings back rule limiting bank fees<|endoftext|>\r\n> texas nuke site increases monitoring of containers<|endoftext|>\r\n> 10 worst cities for spring allergies<|endoftext|>\r\n> taxi drivers in europe protest over uber cab service<|endoftext|>\r\n> taco bell fires second shot at mcdonald's<|endoftext|>\r\n> a brand - new meteor shower could be spectacular tonight — here's how to...<|endoftext|>\r\n> argentina debt default 101 : what's at stake? ( + video )<|endoftext|>\r\n> wikipedia medical entries 90 % inaccurate<|endoftext|>\r\n> selweski : april 15 may have marked the last tax day<|endoftext|>\r\n> no real progress on child obesity, latest report says<|endoftext|>\r\n> skin cancer rate increases in north east<|endoftext|>\r\n> ambassador drives into history : hm kills india's oldest car<|endoftext|>\r\n> super moon to brighten summer sky<|endoftext|>\r\n> google inc ( nasdaq : goog ) beats apple inc. ( nasdaq : aapl ) in introducing...<|endoftext|>\r\n> samsung galaxy s5 zoom gets fcc certification<|endoftext|>\r\n> overdose death rates drop in states with medical marijuana laws<|endoftext|>\r\n> japanese automakers recall 3 mn vehicles for airbag defect<|endoftext|>\r\n> the white house has released the definitive report on climate change, and...<|endoftext|>\r\n> bitcoin value and price in silk road auction : us marshals receive offers from...<|endoftext|>\r\n> see christian hendricks, elisabeth moss & others before they were on \" mad...<|endoftext|>\r\n> bnp paribas nears up to usd9bn settlement with us authorities - source<|endoftext|>\r\n> browns owner jimmy haslam won't be punished by nfl, per report<|endoftext|>\r\n> kristin cavallari defends her choice not to vaccinate her child<|endoftext|>\r\n> us manufacturing gaining on china, brazil and rest of world, study finds<|endoftext|>\r\n> emma stone addresses weight criticisms in ( typically awesome ) fashion<|endoftext|>\r\n> billions wasted on flu drug : researchers<|endoftext|>\r\n> spacecraft crashes on moon to end mission<|endoftext|>\r\n> chinese manufacturing reaches six - month high, official figures show<|endoftext|>\r\n> sports day at greatham primary<|endoftext|>\r\n> pluto's moon may have had an underground ocean<|endoftext|>\r\n> starbucks'oprah - branded tea ; nyc's macaron day<|endoftext|>\r\n> microsoft has unveiled the new nokia x2<|endoftext|>\r\n> caught on tape : emt driver voguing<|endoftext|>\r\n> ' deliver us from evil'is a genre hopping & highly entertaining piece of cinema<|endoftext|>\r\n> mobile county : 12 new hiv cases reported in may alone, free testing offered<|endoftext|>\r\n> roche, exelixis skin cancer drug delays tumor progression<|endoftext|>\r\n> ntsb faults pilot'mismanagment'in asiana flight - ktbs. com - shreveport, la...<|endoftext|>\r\n> new skype translator offers nearly real - time audio translation<|endoftext|>\r\n> the grand budapest hotel is both a sly crime caper and a charming ode to old...<|endoftext|>\r\n> driverless cars will be on uk roads by january 2015<|endoftext|>\r\n> space giants join forces to battle spacex : this is how cheap space travel begins<|endoftext|>\r\n> weekend report :'captain america'wins close fight with'rio 2 '<|endoftext|>\r\n> sc business notebook, may 24<|endoftext|>\r\n> 21st century fox confirms rejected bid for time warner<|endoftext|>\r\n> usher bounces his head on nicki minaj's butt at the 2014 mtv vmas : gif<|endoftext|>\r\n> apple opens os x beta testing to all users with new seed program<|endoftext|>\r\n> anthrax discovered in beef in hungary<|endoftext|>\r\n> iowa farmer chris soules is abc's next'bachelor'| the republic<|endoftext|>\r\n> murdoch names son lachlan as vice president of media empire<|endoftext|>\r\n> cdc reports first chikungunya case acquired in the united states ; disease...<|endoftext|>\r\n> shailene woodley on being cut from amazing spider - man 2 : \" was i awful? \"<|endoftext|>\r\n> justina pelletier heads home after judge ends state custody<|endoftext|>\r\n> singer chris brown's dc assault trial is delayed for months ; judge says singer to...<|endoftext|>\r\n> android wear : 5 things developers need to know<|endoftext|>\r\n> micro machine macro funding<|endoftext|>\r\n> fcc forced to push back comment deadline on net neutrality rules<|endoftext|>\r\n> hgtv slammed for excluding anti - gay christian consumers from america's...<|endoftext|>\r\n> ' mom mobiles'a shrinking category for automakers<|endoftext|>\r\n> malaysia airlines considers re - branding itself<|endoftext|>\r\n> review : 50 cent's \" animal ambition \"<|endoftext|>\r\n> hump day unusual moment : little roger & the goosebumps “ stairway to...<|endoftext|>\r\n> women happier at work than home, study finds<|endoftext|>\r\n> awfully good : sharknado 2<|endoftext|>\r\n> annie leibovitz axed kim and kanye west wedding gig at last minute<|endoftext|>\r\n> former astrazeneca chief executive attacks pfizer deal<|endoftext|>\r\n> private funeral for mick jagger's longtime girlfriend, l'wren scott, held in los...<|endoftext|>\r\n> government allots p6. 8m for aquino's trip to myanmar<|endoftext|>\r\n> ( click the phrases to see a list )<|endoftext|>\r\n> the - dream arrested for felony assault on pregnant ex - girlfriend<|endoftext|>\r\n> kanye west gives 20 - minute speech, says the kardashians are'the most...<|endoftext|>\r\n> team clones stem cells from 75 - year - old's skin<|endoftext|>\r\n> sober smartphone app aids boozers<|endoftext|>\r\n> spread of polio is now a world health emergency, u. n. says<|endoftext|>\r\n> ' true blood'recap : [ spoiler ] is killed off — shocking death<|endoftext|>\r\n> how game - changing was game of thrones'big reveal?<|endoftext|>\r\n> alcohol costs us $ 224bn a year<|endoftext|>\r\n> bmw investing $ 1 billion in mexican assembly plant<|endoftext|>\r\n> report finds st. johns county florida's healthiest county<|endoftext|>\r\n> giant of the skies was like'a dragon '<|endoftext|>\r\n> beyonce named as world's most powerful celebrity<|endoftext|>",
"@sgugger Hello, I try to reproduce this error. The texts above is the samples for finetuning for GPT2. It is the column of `text`.\r\n\r\n```\r\ntrain_file = './fintune_csvs/{}_train_finetune_32_{}.csv'.format(args.dsn, seed)\r\nvalidation_file = './fintune_csvs/{}_test_finetune_32_{}.csv'.format(args.dsn, seed)\r\n\r\n\r\nds.df_train['text'] = ds.df_train['content'] + tokenizer_gpt2.eos_token\r\nds.df_test['text'] = ds.df_test['content'] + tokenizer_gpt2.eos_token\r\n\r\nds.df_train[['text']].sample(frac=1).to_csv(train_file, index=False)\r\nds.df_test[['text']].sample(frac=1).to_csv(validation_file, index=False)\r\n\r\n\r\nmodel_output_path = \"./finetune_gpt2/{}_32_{}\".format(args.dsn, seed) \r\nos.system(\r\n\"CUDA_VISIBLE_DEVICES=1 python -u ./run_clm_no_trainer.py \\\r\n --num_train_epochs {} \\\r\n --train_file {} \\\r\n --validation_file {} \\\r\n --model_name_or_path gpt2 \\\r\n --per_device_train_batch_size 16 \\\r\n --per_device_eval_batch_size 16 \\\r\n --output_dir {} \\\r\n --preprocessing_num_workers 16 --overwrite_cache True \\\r\n --block_size 256\".format(args.ft_epochs, train_file, validation_file, model_output_path) ) \r\n\r\n```\r\n`run_clm_no_trainer.py` is the official script from transformers repo.\r\n\r\nWhen I use another dataset, which have longer sentences than this dataset, there is no error and the finetuning process is OK.\r\n\r\n",
"I also tried sentiment analysis dataset, which also consists of relatively short sentences. The error came out too.",
"> Grouping texts in chunks of 256 #11: 100%|█████████████████████████████| 1/1 [00:00<00:00, 25.61ba/s]\r\n> Grouping texts in chunks of 256 #12: 100%|█████████████████████████████| 1/1 [00:00<00:00, 28.63ba/s]\r\n> Grouping texts in chunks of 256 #13: 100%|█████████████████████████████| 1/1 [00:00<00:00, 25.03ba/s]\r\n> Grouping texts in chunks of 256 #14: 100%|█████████████████████████████| 1/1 [00:00<00:00, 23.64ba/s]\r\n> Grouping texts in chunks of 256 #15: 100%|█████████████████████████████| 1/1 [00:00<00:00, 30.86ba/s]\r\n> 08/20/2021 03:43:32 - INFO - __main__ - ***** Running training *****\r\n> 08/20/2021 03:43:32 - INFO - __main__ - Num examples = 16\r\n> 08/20/2021 03:43:32 - INFO - __main__ - Num Epochs = 1 | 0/1 [00:00<?, ?ba/s]\r\n> 08/20/2021 03:43:32 - INFO - __main__ - Instantaneous batch size per device = 16\r\n> 08/20/2021 03:43:32 - INFO - __main__ - Total train batch size (w. parallel, distributed & accumulation) = 16\r\n> 08/20/2021 03:43:32 - INFO - __main__ - Gradient Accumulation steps = 1 | 0/1 [00:00<?, ?ba/s]\r\n> 08/20/2021 03:43:32 - INFO - __main__ - Total optimization steps = 1\r\n> 0%| | 0/1 [00:00<?, ?it/s]Traceback (most recent call last):\r\n> File \"./run_clm_no_trainer.py\", line 503, in <module> | 0/1 [00:00<?, ?ba/s]\r\n> main()\r\n> File \"./run_clm_no_trainer.py\", line 463, in main | 0/1 [00:00<?, ?ba/s]\r\n> for step, batch in enumerate(train_dataloader):\r\n> File \"/usr/local/lib/python3.6/dist-packages/accelerate/data_loader.py\", line 289, in __iter__\r\n> for batch in super().__iter__():\r\n> File \"/usr/local/lib/python3.6/dist-packages/torch/utils/data/dataloader.py\", line 517, in __next__\r\n> data = self._next_data()\r\n> File \"/usr/local/lib/python3.6/dist-packages/torch/utils/data/dataloader.py\", line 557, in _next_data\r\n> data = self._dataset_fetcher.fetch(index) # may raise StopIteration\r\n> File \"/usr/local/lib/python3.6/dist-packages/torch/utils/data/_utils/fetch.py\", line 47, in fetch\r\n> return self.collate_fn(data)\r\n> File \"/usr/local/lib/python3.6/dist-packages/transformers/data/data_collator.py\", line 80, in default_data_collator\r\n> batch[k] = torch.tensor([f[k] for f in features])\r\n> ValueError: expected sequence of length 135 at dim 1 (got 112)",
"I try another manner to organise the training corpus, as txt file:\r\n```\r\nwith open (train_file, 'w') as f:\r\n f.write(\" {} \".format(tokenizer_gpt2.eos_token).join(ds.df_train['content'].tolist()))\r\n\r\nwith open (validation_file, 'w') as f:\r\n f.write(\" {} \".format(tokenizer_gpt2.eos_token).join(ds.df_test['content'].tolist()))\r\n```\r\n\r\nThe error comes the same.\r\n\r\n> 33%|███▎ | 1/3 [00:00<00:01, 1.33it/s]Traceback (most recent call last):\r\n> File \"./run_clm_no_trainer.py\", line 483, in <module>\r\n> main()\r\n> File \"./run_clm_no_trainer.py\", line 460, in main\r\n> for step, batch in enumerate(eval_dataloader):\r\n> File \"/usr/local/lib/python3.6/dist-packages/accelerate/data_loader.py\", line 289, in __iter__\r\n> for batch in super().__iter__():\r\n> File \"/usr/local/lib/python3.6/dist-packages/torch/utils/data/dataloader.py\", line 517, in __next__\r\n> data = self._next_data()\r\n> File \"/usr/local/lib/python3.6/dist-packages/torch/utils/data/dataloader.py\", line 557, in _next_data\r\n> data = self._dataset_fetcher.fetch(index) # may raise StopIteration\r\n> File \"/usr/local/lib/python3.6/dist-packages/torch/utils/data/_utils/fetch.py\", line 47, in fetch\r\n> return self.collate_fn(data)\r\n> File \"/usr/local/lib/python3.6/dist-packages/transformers/data/data_collator.py\", line 80, in default_data_collator\r\n> batch[k] = torch.tensor([f[k] for f in features])\r\n> ValueError: expected sequence of length 256 at dim 1 (got 117)",
"Yes, this all points out to your corpus being too short to form a full batch. You should use a lower batch size or a lower block size."
] | 1,627 | 1,630 | 1,630 | NONE | null | Transformers Version: 4.8.2
Torch Version: 1.8.0
I am using the official script to fine tune the gpt2 on the csv files.
the script:
https://github.com/huggingface/transformers/blob/master/examples/pytorch/language-modeling/run_clm_no_trainer.py
train and validation file makeup:
```
df_train_ft_aug.rename(columns={'content': 'text'}).sample(frac=1).to_csv(train_file, index=False)
df_train_ft_aug.rename(columns={'content': 'text'}).sample(frac=0.2).to_csv(validation_file, index=False)
```
My shell command:
```
python -u ./run_clm_no_trainer.py \
--num_train_epochs 7 \
--train_file './fintune_csvs/stsa_train_finetune.csv' \
--validation_file './fintune_csvs/stsa_test_finetune.csv' \
--model_name_or_path gpt2 \
--per_device_train_batch_size 16 \
--per_device_eval_batch_size 16 \
--output_dir "./finetune_gpt2_stsa" \
--preprocessing_num_workers 16 \
--block_size 256 --overwrite_cache True
```
where ths csv files contain a column, named 'text' for fine tuning the model.
However, there are always errors below, suggesting the lengths of the dataloader
> File "./run_clm_no_trainer.py", line 503, in <module>
> main()exts in chunks of 256 #12: 0%| | 0/1 [00:00<?, ?ba/s]
> File "./run_clm_no_trainer.py", line 480, in main
> for step, batch in enumerate(eval_dataloader):
> File "/usr/local/lib/python3.6/dist-packages/accelerate/data_loader.py", line 289, in __iter__
> for batch in super().__iter__():
> File "/usr/local/lib/python3.6/dist-packages/torch/utils/data/dataloader.py", line 517, in __next__
> data = self._next_data()
> File "/usr/local/lib/python3.6/dist-packages/torch/utils/data/dataloader.py", line 557, in _next_data
> data = self._dataset_fetcher.fetch(index) # may raise StopIteration
> File "/usr/local/lib/python3.6/dist-packages/torch/utils/data/_utils/fetch.py", line 47, in fetch
> return self.collate_fn(data)
> File "/usr/local/lib/python3.6/dist-packages/transformers/data/data_collator.py", line 80, in default_data_collator
> batch[k] = torch.tensor([f[k] for f in features])
> ValueError: expected sequence of length 256 at dim 1 (got 52)
Next time I run it, it returns the similar error:
> ValueError: expected sequence of length 168 at dim 1 (got 136)
Then I modified the input params of tokenizer:
```
tokenizer.pad_token = tokenizer.eos_token
def tokenize_function(examples):
return tokenizer(examples[text_column_name],) , padding=True, truncation=True )
```
This seems fix the problem. However, the generated texts are quite short after this change.
Any suggestions?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12965/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12965/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12964 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12964/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12964/comments | https://api.github.com/repos/huggingface/transformers/issues/12964/events | https://github.com/huggingface/transformers/issues/12964 | 957,192,069 | MDU6SXNzdWU5NTcxOTIwNjk= | 12,964 | Using `model.sample()` and increasing the `max_length` leads to CUDA OOM crash | {
"login": "moinedgylabs",
"id": 36688714,
"node_id": "MDQ6VXNlcjM2Njg4NzE0",
"avatar_url": "https://avatars.githubusercontent.com/u/36688714?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/moinedgylabs",
"html_url": "https://github.com/moinedgylabs",
"followers_url": "https://api.github.com/users/moinedgylabs/followers",
"following_url": "https://api.github.com/users/moinedgylabs/following{/other_user}",
"gists_url": "https://api.github.com/users/moinedgylabs/gists{/gist_id}",
"starred_url": "https://api.github.com/users/moinedgylabs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/moinedgylabs/subscriptions",
"organizations_url": "https://api.github.com/users/moinedgylabs/orgs",
"repos_url": "https://api.github.com/users/moinedgylabs/repos",
"events_url": "https://api.github.com/users/moinedgylabs/events{/privacy}",
"received_events_url": "https://api.github.com/users/moinedgylabs/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Related to https://github.com/huggingface/transformers/issues/11320\r\n\r\nCc @patil-suraj ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,631 | 1,631 | NONE | null | ## Environment info
- `transformers` version: 4.6.0.dev0
- Platform: Linux-5.4.104+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.11
- PyTorch version (GPU?): 1.9.0+cu102 (True)
- Tensorflow version (GPU?): 2.5.0 (True)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
I think @patrickvonplaten and @LysandreJik
## Information
Model I am using GPT-NEO:
The problem arises when using:
* my own modified scripts: Simply using `.sample()` method with `GPTNeoForCausalLM`
The tasks I am working on is:
* my own task: Simple Text generation.
## To reproduce
Steps to reproduce the behavior:
1. Visit this colab and run GPU runtime: https://colab.research.google.com/drive/1VjVUrptwgUx3TxdlcVqPNwXyX6YJYSAK
2. Execute Runtime -> Run All
3. Note the `nvidia-smi` output.
4. In the last cell, increase the `max_length` from 30 to 350. And run again.
4. Even if the crash doesn't occur, check `nvidia-smi` again.
## Expected behavior
To not consume that much GPU memory. It is understood that some tasks may take some memory, but using **~10 GB** for an increase of 300 tokens is... something wrong. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12964/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12964/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12963 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12963/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12963/comments | https://api.github.com/repos/huggingface/transformers/issues/12963/events | https://github.com/huggingface/transformers/pull/12963 | 957,154,957 | MDExOlB1bGxSZXF1ZXN0NzAwNjQyMzc1 | 12,963 | Prevent `Trainer.evaluate()` crash when using only tensorboardX | {
"login": "aphedges",
"id": 14283972,
"node_id": "MDQ6VXNlcjE0MjgzOTcy",
"avatar_url": "https://avatars.githubusercontent.com/u/14283972?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aphedges",
"html_url": "https://github.com/aphedges",
"followers_url": "https://api.github.com/users/aphedges/followers",
"following_url": "https://api.github.com/users/aphedges/following{/other_user}",
"gists_url": "https://api.github.com/users/aphedges/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aphedges/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aphedges/subscriptions",
"organizations_url": "https://api.github.com/users/aphedges/orgs",
"repos_url": "https://api.github.com/users/aphedges/repos",
"events_url": "https://api.github.com/users/aphedges/events{/privacy}",
"received_events_url": "https://api.github.com/users/aphedges/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thanks for the fix!"
] | 1,627 | 1,627 | 1,627 | CONTRIBUTOR | null | # What does this PR do?
Fixes #12962
I did not write any tests because it seems like the logging integration callbacks have absolutely no testing at all, and I'm not creating a whole set of tests for a one-line fix.
## Who can review?
trainer: @sgugger
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12963/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12963/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12963",
"html_url": "https://github.com/huggingface/transformers/pull/12963",
"diff_url": "https://github.com/huggingface/transformers/pull/12963.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12963.patch",
"merged_at": 1627799747000
} |
https://api.github.com/repos/huggingface/transformers/issues/12962 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12962/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12962/comments | https://api.github.com/repos/huggingface/transformers/issues/12962/events | https://github.com/huggingface/transformers/issues/12962 | 957,154,887 | MDU6SXNzdWU5NTcxNTQ4ODc= | 12,962 | `Trainer.evaluate()` crashes when using only tensorboardX | {
"login": "aphedges",
"id": 14283972,
"node_id": "MDQ6VXNlcjE0MjgzOTcy",
"avatar_url": "https://avatars.githubusercontent.com/u/14283972?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aphedges",
"html_url": "https://github.com/aphedges",
"followers_url": "https://api.github.com/users/aphedges/followers",
"following_url": "https://api.github.com/users/aphedges/following{/other_user}",
"gists_url": "https://api.github.com/users/aphedges/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aphedges/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aphedges/subscriptions",
"organizations_url": "https://api.github.com/users/aphedges/orgs",
"repos_url": "https://api.github.com/users/aphedges/repos",
"events_url": "https://api.github.com/users/aphedges/events{/privacy}",
"received_events_url": "https://api.github.com/users/aphedges/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"same problem",
"I simply update the transformers,then it works fine. It seems like the newest version has fixed this error of tensorboradX."
] | 1,627 | 1,635 | 1,627 | CONTRIBUTOR | null | ## Environment info
- `transformers` version: 4.9.1
- Platform: Linux-3.10.0-1160.31.1.el7.x86_64-x86_64-with-centos-7.9.2009-Core
- Python version: 3.7.9
- PyTorch version (GPU?): 1.8.1+cu102 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes, but not relevant
- Using distributed or parallel set-up in script?: no
### Who can help
This might be a one-line fix, and I will be submitting a PR shortly. However, it might be a sign of a bigger problem, so I'm still tagging the person listed for the trainer, @sgugger.
## Information
Model I am using: `gpt2` (not model-specific issue, though)
The problem arises when using:
- [x] the official example scripts: (give details below)
The tasks I am working on is the one given in the example script.
## To reproduce
Steps to reproduce the behavior:
1. Create an environment with [`requirements.txt`](https://github.com/huggingface/transformers/blob/v4.9.1/examples/pytorch/language-modeling/requirements.txt) and `tensorboardX==2.4` installed but without tensorboard itself installed.
2. Run [`run_clm.py`](https://github.com/huggingface/transformers/blob/v4.9.1/examples/pytorch/language-modeling/run_clm.py) with the following script (based on [the example in the README](https://github.com/huggingface/transformers/blob/v4.9.1/examples/pytorch/language-modeling/README.md#gpt-2gpt-and-causal-language-modeling)):
```bash
time python run_clm.py \
--model_name_or_path gpt2 \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--do_train \
--do_eval \
--output_dir output_dir \
--logging_dir output_dir/logs \
--logging_strategy epoch \
--num_train_epochs 3 \
--per_device_train_batch_size 4 \
--gradient_accumulation_steps 2 \
--max_train_samples 16 \
--max_eval_samples 8 \
--report_to tensorboard
```
3. See the stack trace that was output:
```python
Traceback (most recent call last):
File "run_clm.py", line 515, in <module>
main()
File "run_clm.py", line 483, in main
metrics = trainer.evaluate()
File "venv/lib/python3.7/site-packages/transformers/trainer.py", line 2055, in evaluate
self.log(output.metrics)
File "venv/lib/python3.7/site-packages/transformers/trainer.py", line 1720, in log
self.control = self.callback_handler.on_log(self.args, self.state, self.control, logs)
File "venv/lib/python3.7/site-packages/transformers/trainer_callback.py", line 371, in on_log
return self.call_event("on_log", args, state, control, logs=logs)
File "venv/lib/python3.7/site-packages/transformers/trainer_callback.py", line 388, in call_event
**kwargs,
File "venv/lib/python3.7/site-packages/transformers/integrations.py", line 391, in on_log
self.tb_writer.add_scalar(k, v, state.global_step)
File "venv/lib/python3.7/site-packages/tensorboardX/writer.py", line 453, in add_scalar
self.comet_logger.log_metric(tag, display_name, scalar_value, global_step)
AttributeError: 'NoneType' object has no attribute 'log_metric'
```
(I edited the stack trace to remove the parts of the path outside the virtual environment for improved readability.)
## Expected behavior
The script should not crash.
## Notes
I figured out what is causing the crash. When training ends, `TensorBoardCallback.on_train_end()` is called, which runs `self.tb_writer.close()`, which sets `self.tb_writer.comet_logger` to `None`. When `TensorBoardCallback.on_log()` is called again during evaluation, `self.comet_logger` is called again, even though it's `None`. The bug appears to essentially be a use-after-free bug. This specific exception only happens when tensorboard is not installed because only tensorboardX uses `comet_logger`.
The solution is simple: set `self.tb_writer` to `None` immediately after the call to `self.tb_writer.close()`. When `TensorBoardCallback.on_log()` is called again during evaluation, the method detects that `self.tb_writer is None` and re-initializes it, which makes everything work, at least finishing without crashing. I will be releasing a PR with this fix very soon.
However, given that more of these logging callbacks can be called during evaluation and some of them also have `on_train_end()` functions that close resources, there might be a bigger problem here involving the calling of logging integrations during evaluation. I don't know enough about them to determine that for myself, though.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12962/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12962/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12961 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12961/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12961/comments | https://api.github.com/repos/huggingface/transformers/issues/12961/events | https://github.com/huggingface/transformers/pull/12961 | 957,141,427 | MDExOlB1bGxSZXF1ZXN0NzAwNjMxOTE0 | 12,961 | Use min version for huggingface-hub dependency | {
"login": "lewtun",
"id": 26859204,
"node_id": "MDQ6VXNlcjI2ODU5MjA0",
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lewtun",
"html_url": "https://github.com/lewtun",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://api.github.com/users/lewtun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lewtun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lewtun/subscriptions",
"organizations_url": "https://api.github.com/users/lewtun/orgs",
"repos_url": "https://api.github.com/users/lewtun/repos",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"received_events_url": "https://api.github.com/users/lewtun/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Yes the exact pin has been set on purpose because `huggingface_hub` is not stable enough right now, and there might breaking changes in the future that would break older versions of Transformers.\r\n\r\nWe can accept an upgrade on the Transformers side (bumping to 0.0.15) but we will only switch to a minimum version when `huggingface_hub` is more mature.\r\n\r\nAlso, for something like this, no merge before @LysandreJik is back please, as he knows more than me (and may have a different opinion) :-)",
"Thanks for the clarification @sgugger! I totally understand the reasoning to pin the exact version, so will find a work around in the meantime.\r\n\r\nI'll keep this PR open until @LysandreJik is back in case he wants to accept a bump to v0.0.15 😃 ",
"i found a work around using the `/datasets` endpoint so happy to close this PR until `huggingface_hub` is more stable",
"Just checked, and it should be fine to bump to 0.0.15. Most of the `huggingface_hub` specifics in `transformers` is using the logic defined in `src/transformers/hf_api.py`, so close to nothing would be affected by that upgrade.\r\n\r\nFeel free to upgrade and merge if all tests pass, I'll keep a close eye on the slow tests."
] | 1,627 | 1,628 | 1,628 | MEMBER | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
This PR proposes to use a min version for the `huggingface_hub` dependency.
The reasoning behind this is that we're currently running into dependency conflicts between `autonlp` (which uses `transformers` v4.8.0) and `evaluate` which relies on `huggingface_hub` v0.0.15. If I am not mistaken, setting a min version will provide the flexibility for `pip` to figure out which one to pick.
I realise that `huggingface_hub` is under active development, so feel free to close this PR if there's a strong need to freeze the version explicitly in `transformers`.
cc @abhishekkrthakur @SBrandeis
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12961/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12961/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12961",
"html_url": "https://github.com/huggingface/transformers/pull/12961",
"diff_url": "https://github.com/huggingface/transformers/pull/12961.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12961.patch",
"merged_at": 1628431565000
} |
https://api.github.com/repos/huggingface/transformers/issues/12960 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12960/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12960/comments | https://api.github.com/repos/huggingface/transformers/issues/12960/events | https://github.com/huggingface/transformers/pull/12960 | 957,039,368 | MDExOlB1bGxSZXF1ZXN0NzAwNTQ0MTEw | 12,960 | [Very WIP] Migrating ALL pipelines to new testing + fixes | {
"login": "Narsil",
"id": 204321,
"node_id": "MDQ6VXNlcjIwNDMyMQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/204321?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Narsil",
"html_url": "https://github.com/Narsil",
"followers_url": "https://api.github.com/users/Narsil/followers",
"following_url": "https://api.github.com/users/Narsil/following{/other_user}",
"gists_url": "https://api.github.com/users/Narsil/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Narsil/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Narsil/subscriptions",
"organizations_url": "https://api.github.com/users/Narsil/orgs",
"repos_url": "https://api.github.com/users/Narsil/repos",
"events_url": "https://api.github.com/users/Narsil/events{/privacy}",
"received_events_url": "https://api.github.com/users/Narsil/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I'm curious how long it takes to run the whole suite - would it be possible to add a commit that impacts all pipelines to see how long that takes?",
"@LysandreJik That's the one.\r\n",
"Or you mean hitting the `pipelines` files ?",
"Yes, I can push a commit that does that on your branch if you want!",
"Go ahead ! Not sure how to trigger it.\r\n",
"Done in many smaller PRs."
] | 1,627 | 1,631 | 1,631 | CONTRIBUTOR | null | # What does this PR do?
For now we just need to see the tests times to see how bad we are, and how much we need to improve.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
--> | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12960/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12960/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12960",
"html_url": "https://github.com/huggingface/transformers/pull/12960",
"diff_url": "https://github.com/huggingface/transformers/pull/12960.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12960.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/12959 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12959/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12959/comments | https://api.github.com/repos/huggingface/transformers/issues/12959/events | https://github.com/huggingface/transformers/issues/12959 | 957,002,687 | MDU6SXNzdWU5NTcwMDI2ODc= | 12,959 | huggingface-hub version conflict | {
"login": "CraigMiloRogers",
"id": 5853763,
"node_id": "MDQ6VXNlcjU4NTM3NjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/5853763?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/CraigMiloRogers",
"html_url": "https://github.com/CraigMiloRogers",
"followers_url": "https://api.github.com/users/CraigMiloRogers/followers",
"following_url": "https://api.github.com/users/CraigMiloRogers/following{/other_user}",
"gists_url": "https://api.github.com/users/CraigMiloRogers/gists{/gist_id}",
"starred_url": "https://api.github.com/users/CraigMiloRogers/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/CraigMiloRogers/subscriptions",
"organizations_url": "https://api.github.com/users/CraigMiloRogers/orgs",
"repos_url": "https://api.github.com/users/CraigMiloRogers/repos",
"events_url": "https://api.github.com/users/CraigMiloRogers/events{/privacy}",
"received_events_url": "https://api.github.com/users/CraigMiloRogers/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This is discussed in #12961 ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,631 | 1,631 | NONE | null | `transformers` requires `huggingface-hub==0.0.12` in `setup.py` in the `master` branch.
`huggingface-hub` has just released version `0.0.15`.
Other projects that use `huggingface-hub`, such as `https://github.com/UKPLab/sentence-transformers`, are happy with the latest version of `huggingface-hub`.
Depending upon the order of installation, a version conflict may result. Here's a sample message from our project, `kgtk`, which requires both `transformers` and `sentence-transformers`:
```pkg_resources.ContextualVersionConflict: (huggingface-hub 0.0.15 (/opt/anaconda3/envs/kgtk-env/lib/python3.8/site-packages/huggingface_hub-0.0.15-py3.8.egg), Requirement.parse('huggingface-hub==0.0.12'), {'transformers'})```
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12959/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12959/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12958 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12958/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12958/comments | https://api.github.com/repos/huggingface/transformers/issues/12958/events | https://github.com/huggingface/transformers/issues/12958 | 956,982,699 | MDU6SXNzdWU5NTY5ODI2OTk= | 12,958 | Weird behavior with mBART-50 and Spanish | {
"login": "ArbinTimilsina",
"id": 18752223,
"node_id": "MDQ6VXNlcjE4NzUyMjIz",
"avatar_url": "https://avatars.githubusercontent.com/u/18752223?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ArbinTimilsina",
"html_url": "https://github.com/ArbinTimilsina",
"followers_url": "https://api.github.com/users/ArbinTimilsina/followers",
"following_url": "https://api.github.com/users/ArbinTimilsina/following{/other_user}",
"gists_url": "https://api.github.com/users/ArbinTimilsina/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ArbinTimilsina/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ArbinTimilsina/subscriptions",
"organizations_url": "https://api.github.com/users/ArbinTimilsina/orgs",
"repos_url": "https://api.github.com/users/ArbinTimilsina/repos",
"events_url": "https://api.github.com/users/ArbinTimilsina/events{/privacy}",
"received_events_url": "https://api.github.com/users/ArbinTimilsina/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2796628563,
"node_id": "MDU6TGFiZWwyNzk2NjI4NTYz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/WIP",
"name": "WIP",
"color": "234C99",
"default": false,
"description": "Label your PR/Issue with WIP for some long outstanding Issues/PRs that are work in progress"
}
] | open | false | {
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
}
] | [
"Pinging @patil-suraj too, and @mrm8488 might have played with that model in the past.",
"Any progress here? I've faced the exact same problem when attempting to translate from Spanish, although slightly different output:\r\n\r\n```\r\nThe Committee recommends that the State party take all necessary measures to ensure that the right to adequate housing is guaranteed in the State party's next periodic report, and that the State party take all necessary measures to ensure that the right to adequate housing is guaranteed in its next periodic report.\r\n```",
"@patil-suraj - could you take a look here?"
] | 1,627 | 1,641 | null | NONE | null | ## Environment info
- `transformers` version: 4.9.1
- Platform: Linux-5.4.0-1054-aws-x86_64-with-debian-buster-sid
- Python version: 3.7.10
- PyTorch version (GPU?): 1.9.0+cu102 (True)
## Who can help
@patrickvonplaten
## Information
I am seeing weird behavior with mBART-50 and Spanish. Please look at the code below:
```
from transformers import MBartForConditionalGeneration, MBart50TokenizerFast
text = "http://www.ted.com/talks/stephen_palumbi_following_the_mercury_trail.html"
model = MBartForConditionalGeneration.from_pretrained("facebook/mbart-large-50-many-to-one-mmt")
tokenizer = MBart50TokenizerFast.from_pretrained("facebook/mbart-large-50-many-to-one-mmt")
tokenizer.src_lang = "es_XX"
encoded = tokenizer(text, return_tensors="pt")
generated_tokens = model.generate(**encoded, forced_bos_token_id=tokenizer.lang_code_to_id["en_XX"])
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
```
The output is:
```
['(b) To continue to cooperate closely with the Special Rapporteur on extrajudicial, summary or arbitrary executions, the Special Rapporteur on torture and other cruel, inhuman or degrading treatment or punishment, the Special Rapporteur on the sale of children, child prostitution and child pornography, the Special Rapporteur on torture and other cruel, inhuman or degrading treatment or punishment, the Special Rapporteur on the sale of children, child prostitution and child pornography, the Special Rapporteur on the sale of children, child prostitution and child pornography, the Special Rapporteur on the sale of children, child prostitution and child pornography, the Special Rapporteur on violence against women, its causes and consequences, the Special Rapporteur on the sale of children, child prostitution and child pornography, the Special Rapporteur on the sale of children, child prostitution and child pornography, the Special']
```
However if I change the source language to french `tokenizer.src_lang = "fr_XX"` or any other language, I get the following output (which is what you expect):
```
['http://www.ted.com/talks/stephen_palumbi_following_the_mercury_trail.html']
```
This behavior is similar with other texts as well (e.g., "888"). Do you know why this behavior is unique to Spanish? Also, do you have any idea how to correct this behavior?
Thanks!
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12958/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12958/timeline | null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12957 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12957/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12957/comments | https://api.github.com/repos/huggingface/transformers/issues/12957/events | https://github.com/huggingface/transformers/issues/12957 | 956,967,478 | MDU6SXNzdWU5NTY5Njc0Nzg= | 12,957 | 404 Error when loading pretrained model, after finetuning | {
"login": "nikky4D",
"id": 7451106,
"node_id": "MDQ6VXNlcjc0NTExMDY=",
"avatar_url": "https://avatars.githubusercontent.com/u/7451106?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nikky4D",
"html_url": "https://github.com/nikky4D",
"followers_url": "https://api.github.com/users/nikky4D/followers",
"following_url": "https://api.github.com/users/nikky4D/following{/other_user}",
"gists_url": "https://api.github.com/users/nikky4D/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nikky4D/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nikky4D/subscriptions",
"organizations_url": "https://api.github.com/users/nikky4D/orgs",
"repos_url": "https://api.github.com/users/nikky4D/repos",
"events_url": "https://api.github.com/users/nikky4D/events{/privacy}",
"received_events_url": "https://api.github.com/users/nikky4D/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"How did you save your model? Was it with the `same_pretrained` method? The error says it can't locate the `config.json` associated to the model, so double check you have that file in the folder you are loading from.",
"Thank you for the pointer. I was able to solve it with a full path input, so I think I was not specifying the relative path correctly. "
] | 1,627 | 1,627 | 1,627 | NONE | null | I'm trying to load up a finetuned T5 model I've saved but I keep getting a 404 error.
I have my model saved in the same directory as my jupyter notebook, at ```textgen_models/textgen_model_shuffle_e10/```
It contains a config.json, and a pytorch_model.bin
"""
```
model_path = Path("textgen_models/textgen_model_shuffle_e10/")
mdl = T5ForConditionalGeneration.from_pretrained(model_path)
```
"""
I am getting the following 404 error, which tells me I am not specifying the path to the model properly, though I'm not sure what I'm doing incorrectly. Can someone help?
"""
```
404 Client Error: Not Found for url: https://huggingface.co/textgen_models%5Ctextgen_model_shuffle_e10/resolve/main/config.json
---------------------------------------------------------------------------
HTTPError Traceback (most recent call last)
~\anaconda3\envs\imagesTemporal\lib\site-packages\transformers\configuration_utils.py in get_config_dict(cls, pretrained_model_name_or_path, **kwargs)
511 # Load from URL or cache if already cached
--> 512 resolved_config_file = cached_path(
513 config_file,
~\anaconda3\envs\imagesTemporal\lib\site-packages\transformers\file_utils.py in cached_path(url_or_filename, cache_dir, force_download, proxies, resume_download, user_agent, extract_compressed_file, force_extract, use_auth_token, local_files_only)
1362 # URL, so get it from the cache (downloading if necessary)
-> 1363 output_path = get_from_cache(
1364 url_or_filename,
~\anaconda3\envs\imagesTemporal\lib\site-packages\transformers\file_utils.py in get_from_cache(url, cache_dir, force_download, proxies, etag_timeout, resume_download, user_agent, use_auth_token, local_files_only)
1533 r = requests.head(url, headers=headers, allow_redirects=False, proxies=proxies, timeout=etag_timeout)
-> 1534 r.raise_for_status()
1535 etag = r.headers.get("X-Linked-Etag") or r.headers.get("ETag")
~\anaconda3\envs\imagesTemporal\lib\site-packages\requests\models.py in raise_for_status(self)
952 if http_error_msg:
--> 953 raise HTTPError(http_error_msg, response=self)
954
HTTPError: 404 Client Error: Not Found for url: https://huggingface.co/textgen_models%5Ctextgen_model_shuffle_e10/resolve/main/config.json
During handling of the above exception, another exception occurred:
OSError Traceback (most recent call last)
~\AppData\Local\Temp/ipykernel_11592/172074313.py in <module>
1 model_path = Path("textgen_models/textgen_model_shuffle_e10/")
----> 2 mdl = T5ForConditionalGeneration.from_pretrained(pretrained_model_name_or_path = model_path)
~\anaconda3\envs\imagesTemporal\lib\site-packages\transformers\modeling_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
1181 if not isinstance(config, PretrainedConfig):
1182 config_path = config if config is not None else pretrained_model_name_or_path
-> 1183 config, model_kwargs = cls.config_class.from_pretrained(
1184 config_path,
1185 *model_args,
~\anaconda3\envs\imagesTemporal\lib\site-packages\transformers\configuration_utils.py in from_pretrained(cls, pretrained_model_name_or_path, **kwargs)
453
454 """
--> 455 config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
456 if "model_type" in config_dict and hasattr(cls, "model_type") and config_dict["model_type"] != cls.model_type:
457 logger.warn(
~\anaconda3\envs\imagesTemporal\lib\site-packages\transformers\configuration_utils.py in get_config_dict(cls, pretrained_model_name_or_path, **kwargs)
530 f"- or '{pretrained_model_name_or_path}' is the correct path to a directory containing a {CONFIG_NAME} file\n\n"
531 )
--> 532 raise EnvironmentError(msg)
533
534 except json.JSONDecodeError:
OSError: Can't load config for 'textgen_models\textgen_model_shuffle_e10'. Make sure that:
- 'textgen_models\textgen_model_shuffle_e10' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'textgen_models\textgen_model_shuffle_e10' is the correct path to a directory containing a config.json file
```
"""
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12957/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12957/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12956 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12956/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12956/comments | https://api.github.com/repos/huggingface/transformers/issues/12956/events | https://github.com/huggingface/transformers/issues/12956 | 956,944,871 | MDU6SXNzdWU5NTY5NDQ4NzE= | 12,956 | Wav2Vec2 WER remains 1.00 and return blank transcriptions. | {
"login": "theainerd",
"id": 15798640,
"node_id": "MDQ6VXNlcjE1Nzk4NjQw",
"avatar_url": "https://avatars.githubusercontent.com/u/15798640?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/theainerd",
"html_url": "https://github.com/theainerd",
"followers_url": "https://api.github.com/users/theainerd/followers",
"following_url": "https://api.github.com/users/theainerd/following{/other_user}",
"gists_url": "https://api.github.com/users/theainerd/gists{/gist_id}",
"starred_url": "https://api.github.com/users/theainerd/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/theainerd/subscriptions",
"organizations_url": "https://api.github.com/users/theainerd/orgs",
"repos_url": "https://api.github.com/users/theainerd/repos",
"events_url": "https://api.github.com/users/theainerd/events{/privacy}",
"received_events_url": "https://api.github.com/users/theainerd/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"\r\n",
"I see you are using transformers==4.4.0\r\nthere seems to be some updates to [wav2vec2 model ](https://github.com/huggingface/transformers/tree/master/src/transformers/models/wav2vec2) after that so maybe try with the latest release or pull from master",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"In case someone stumbles upon this issue while using a version between 4.9.0 and 4.10.dev: https://github.com/huggingface/transformers/pull/13512"
] | 1,627 | 1,631 | 1,631 | CONTRIBUTOR | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: transformers==4.4.0
- Platform:
- Python version:
- PyTorch version (GPU?):
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@patrickvonplaten @patil-suraj
## Information
Wav2Vec2 WER remains 1.00 no matter which dataset we use and also can see the same behaviour across multiple datasets.
Returns blank transcriptions when making predictions.
## To reproduce
Steps to reproduce the behavior:
1. Run the following colab notebook : https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_tuning_Wav2Vec2_for_English_ASR.ipynb
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12956/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12956/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12955 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12955/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12955/comments | https://api.github.com/repos/huggingface/transformers/issues/12955/events | https://github.com/huggingface/transformers/pull/12955 | 956,886,052 | MDExOlB1bGxSZXF1ZXN0NzAwNDE1MDE3 | 12,955 | Add splinter | {
"login": "oriram",
"id": 26966674,
"node_id": "MDQ6VXNlcjI2OTY2Njc0",
"avatar_url": "https://avatars.githubusercontent.com/u/26966674?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/oriram",
"html_url": "https://github.com/oriram",
"followers_url": "https://api.github.com/users/oriram/followers",
"following_url": "https://api.github.com/users/oriram/following{/other_user}",
"gists_url": "https://api.github.com/users/oriram/gists{/gist_id}",
"starred_url": "https://api.github.com/users/oriram/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/oriram/subscriptions",
"organizations_url": "https://api.github.com/users/oriram/orgs",
"repos_url": "https://api.github.com/users/oriram/repos",
"events_url": "https://api.github.com/users/oriram/events{/privacy}",
"received_events_url": "https://api.github.com/users/oriram/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thanks a lot for the PR! Think we can merge this soon :-) Some points that I think will be important to adapt before merging are:\r\n\r\n- Simplify the logic of `splinter_qass` vs `new_splinter_qass`. IMO there should only be one `splinter_class` class attribute and if this has to be reinitialized or set to 0 we could instead add a `reinit` function. I don't really understand why we need to identical `splinter_qass` and `new_spliter_qass` modules\r\n- Make sure we don't have hardcoded id's such as 102 in the model\r\n- Add a QA integration test to make sure the model works as expected",
"@patil-suraj @patrickvonplaten @sgugger \r\nAny idea why this exception is raised when calling `make quality`?\r\n```\r\nTraceback (most recent call last):\r\n File \"/mnt/c/Program Files/JetBrains/PyCharm 2019.3.2/plugins/python/helpers/pydev/pydevd.py\", line 1434, in _exec\r\n pydev_imports.execfile(file, globals, locals) # execute the script\r\n File \"/mnt/c/Program Files/JetBrains/PyCharm 2019.3.2/plugins/python/helpers/pydev/_pydev_imps/_pydev_execfile.py\", line 18, in execfile\r\n exec(compile(contents+\"\\n\", file, 'exec'), glob, loc)\r\n File \"/mnt/c/Users/ori/Desktop/Ori/Research/transformers_splinter/utils/check_copies.py\", line 353, in <module>\r\n check_copies(args.fix_and_overwrite)\r\n File \"/mnt/c/Users/ori/Desktop/Ori/Research/transformers_splinter/utils/check_copies.py\", line 186, in check_copies\r\n new_diffs = is_copy_consistent(filename, overwrite)\r\n File \"/mnt/c/Users/ori/Desktop/Ori/Research/transformers_splinter/utils/check_copies.py\", line 164, in is_copy_consistent\r\n theoretical_code = blackify(lines[start_index - 1] + theoretical_code)\r\n File \"/mnt/c/Users/ori/Desktop/Ori/Research/transformers_splinter/utils/check_copies.py\", line 104, in blackify\r\n result = black.format_str(code, mode=black.FileMode([black.TargetVersion.PY35], line_length=119))\r\n File \"/home/oriram/venv/transformers_splinter/lib/python3.7/site-packages/black/__init__.py\", line 1063, in format_str\r\n src_node = lib2to3_parse(src_contents.lstrip(), mode.target_versions)\r\n File \"/home/oriram/venv/transformers_splinter/lib/python3.7/site-packages/black/__init__.py\", line 1171, in lib2to3_parse\r\n raise exc from None\r\nblack.InvalidInput: Cannot parse: 15:4: def __init__(self, config, add_pooling_layer=True):\r\n```\r\nDidn't happen before. Tried to debug it, but couldn't understand the cause.\r\nAlso, it seems like it's not in any file related to Splinter, as I don't have the argument `add_pooling_layer`.",
"@sgugger \r\nOne idea I had in mind regarding the `self.splinter_qass` and `self.new_splinter_qass` was just to create two more checkpoints (so overall there will be 4 rather than 2): \r\n```\r\ntau/splinter-base-with-qass \r\ntau/splinter-base\r\ntau/splinter-large-with-qass \r\ntau/splinter-large\r\n```\r\nIn the ones without qass, I'll drop the weights from the state_dict at `pytorch_model.bin`. \r\nThis will also keep the message `All the weights of SplinterForQuestionAnswering were initialized from the model checkpoint at X` correct.\r\nDoes that sound OK?",
"I imagine there will be an associated config parameter to determine which layer use?\r\nIt looks like a good idea.",
"As a result of #13023 , you will need to rebase your PR on master and solve the merge conflicts (basically, you will just need to re-add the models/tokenizers and config in the auto-mappings as strings). Let us know if you need any help with that.",
"Hi @sgugger @patil-suraj @patrickvonplaten,\r\nSorry to bother you, but I couldn't find the reason as to why the `run_tests_tf` (and the two others) fail.\r\nCircleCI doesn't provide much info..\r\nOther than that and the rebase, I think everything is set to do the PR, took care of:\r\n\r\n- Removing abstractions from Bert classes\r\n- Separating the models into `splinter-base` and `splinter-base-qass` (and same for `large`), as well as removing all references to `config.initialize_new_qass` from the code\r\n- Added an integration test\r\n- Removed all unnecessary classes (`SplinterForMaskedLM` etc.)\r\n- Fixed `Copy from` issues\r\netc.\r\n\r\nThanks!! ",
"Thanks @sgugger for your quick response!\r\nI think the tests are now failing due to the rebase issue, as the errors don't seem related to Splinter.\r\nAny chance you can help with the rebase? Don't have any experience with that..\r\nAlso, I noticed that you made some changes to the structure of the `auto_..` classes..\r\nWould really appreciate it :)",
"Hello @oriram, I just took care of the merge and the auto-classes",
"Many thanks @LysandreJik @sgugger!!\r\nAre we ready to merge then?",
"Hi @LysandreJik :)\r\n\r\n- Changed copyrights in Splinter's 4 files\r\n- Regarding your comments on `SplinterTokenizer` - The difference stems from dealing with the special `[QUESTION]` token which is used for building question representations\r\n\r\nMany thanks!",
"Great @LysandreJik!\r\nLet's merge? :)",
"@patil-suraj @sgugger @LysandreJik @patrickvonplaten \r\nJust wanted to say many thanks again for all your effort in this PR!!",
"@oriram - thanks a mille for your great PR! Let's try to promote Splinter so that people see its power for QA :-)"
] | 1,627 | 1,629 | 1,629 | CONTRIBUTOR | null | # What does this PR do?
[Splinter](https://arxiv.org/abs/2101.00438) implementation
@patil-suraj @LysandreJik @patrickvonplaten | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12955/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12955/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12955",
"html_url": "https://github.com/huggingface/transformers/pull/12955",
"diff_url": "https://github.com/huggingface/transformers/pull/12955.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12955.patch",
"merged_at": 1629203342000
} |
https://api.github.com/repos/huggingface/transformers/issues/12954 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12954/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12954/comments | https://api.github.com/repos/huggingface/transformers/issues/12954/events | https://github.com/huggingface/transformers/pull/12954 | 956,828,717 | MDExOlB1bGxSZXF1ZXN0NzAwMzY0MzQ1 | 12,954 | Fix typo in example of DPRReader | {
"login": "tadejsv",
"id": 11489772,
"node_id": "MDQ6VXNlcjExNDg5Nzcy",
"avatar_url": "https://avatars.githubusercontent.com/u/11489772?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tadejsv",
"html_url": "https://github.com/tadejsv",
"followers_url": "https://api.github.com/users/tadejsv/followers",
"following_url": "https://api.github.com/users/tadejsv/following{/other_user}",
"gists_url": "https://api.github.com/users/tadejsv/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tadejsv/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tadejsv/subscriptions",
"organizations_url": "https://api.github.com/users/tadejsv/orgs",
"repos_url": "https://api.github.com/users/tadejsv/repos",
"events_url": "https://api.github.com/users/tadejsv/events{/privacy}",
"received_events_url": "https://api.github.com/users/tadejsv/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,627 | 1,627 | 1,627 | CONTRIBUTOR | null | # What does this PR do?
Fix typo in example of DPRReader
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12954/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12954/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12954",
"html_url": "https://github.com/huggingface/transformers/pull/12954",
"diff_url": "https://github.com/huggingface/transformers/pull/12954.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12954.patch",
"merged_at": 1627884537000
} |
https://api.github.com/repos/huggingface/transformers/issues/12953 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12953/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12953/comments | https://api.github.com/repos/huggingface/transformers/issues/12953/events | https://github.com/huggingface/transformers/pull/12953 | 956,739,763 | MDExOlB1bGxSZXF1ZXN0NzAwMjg4MDQw | 12,953 | Fix division by zero in NotebookProgressPar | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,627 | 1,627 | 1,627 | COLLABORATOR | null | # What does this PR do?
This PR fixes the bug reported in #12950. More precisely, the following snippet of code was failing with a division by zero error:
```py
from transformers.utils.notebook import NotebookProgressBar
pbar = NotebookProgressBar(total=1)
pbar.update(1)
pbar.update(1, force_update=True)
```
This PR fixes that by being a bit more defensive before dividing by a potential zero.
Fixes #12950 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12953/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12953/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12953",
"html_url": "https://github.com/huggingface/transformers/pull/12953",
"diff_url": "https://github.com/huggingface/transformers/pull/12953.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12953.patch",
"merged_at": 1627651889000
} |
https://api.github.com/repos/huggingface/transformers/issues/12952 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12952/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12952/comments | https://api.github.com/repos/huggingface/transformers/issues/12952/events | https://github.com/huggingface/transformers/pull/12952 | 956,672,894 | MDExOlB1bGxSZXF1ZXN0NzAwMjMwMjkw | 12,952 | Add multilingual documentation support | {
"login": "JetRunner",
"id": 22514219,
"node_id": "MDQ6VXNlcjIyNTE0MjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/22514219?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JetRunner",
"html_url": "https://github.com/JetRunner",
"followers_url": "https://api.github.com/users/JetRunner/followers",
"following_url": "https://api.github.com/users/JetRunner/following{/other_user}",
"gists_url": "https://api.github.com/users/JetRunner/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JetRunner/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JetRunner/subscriptions",
"organizations_url": "https://api.github.com/users/JetRunner/orgs",
"repos_url": "https://api.github.com/users/JetRunner/repos",
"events_url": "https://api.github.com/users/JetRunner/events{/privacy}",
"received_events_url": "https://api.github.com/users/JetRunner/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"You will need to run `make style` on your branch to fix the quality check. I'm looking at the result [here](https://247866-155220641-gh.circle-artifacts.com/0/docs/_build/html/index.html) but don't see anything changed. Is it normal?",
"@sgugger Yes, it's normal. This is just a PR to support multilingual docs but they aren't there yet. ",
"Mmm, looks like you may have some wrong version on your side? A `pip install -e .[quality]` should fix this (but you will probably need to revert the changes in the pipeline tests as black doesn't undo the new lines it adds)."
] | 1,627 | 1,627 | 1,627 | CONTRIBUTOR | null | This PR adds multilingual documentation support for incoming Chinese documentations. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12952/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12952/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12952",
"html_url": "https://github.com/huggingface/transformers/pull/12952",
"diff_url": "https://github.com/huggingface/transformers/pull/12952.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12952.patch",
"merged_at": 1627649774000
} |
https://api.github.com/repos/huggingface/transformers/issues/12951 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12951/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12951/comments | https://api.github.com/repos/huggingface/transformers/issues/12951/events | https://github.com/huggingface/transformers/pull/12951 | 956,651,174 | MDExOlB1bGxSZXF1ZXN0NzAwMjExNzk2 | 12,951 | Add substep end callback method | {
"login": "wulu473",
"id": 8149933,
"node_id": "MDQ6VXNlcjgxNDk5MzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/8149933?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wulu473",
"html_url": "https://github.com/wulu473",
"followers_url": "https://api.github.com/users/wulu473/followers",
"following_url": "https://api.github.com/users/wulu473/following{/other_user}",
"gists_url": "https://api.github.com/users/wulu473/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wulu473/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wulu473/subscriptions",
"organizations_url": "https://api.github.com/users/wulu473/orgs",
"repos_url": "https://api.github.com/users/wulu473/repos",
"events_url": "https://api.github.com/users/wulu473/events{/privacy}",
"received_events_url": "https://api.github.com/users/wulu473/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thanks for your help. Yep, happy to add the callback as well. I'll tag you on a PR when I have something ready."
] | 1,627 | 1,627 | 1,627 | CONTRIBUTOR | null | As discussed in #12920 with @sgugger, a callback method after a gradient accumulation step is needed for some training techniques such as differentially private training with Opacus (see [Opacus - Docs: virtual_step](https://opacus.ai/api/privacy_engine.html?highlight=virtual_step#opacus.privacy_engine.PrivacyEngine.virtual_step)).
This PR extends `TrainerCallback` and `CallbackHandler` with a method `on_substep_end` which ought to be called during gradient accumulation after a training step is taken (i.e. loss and gradients computed) but no model parameters are updated.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12951/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12951/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12951",
"html_url": "https://github.com/huggingface/transformers/pull/12951",
"diff_url": "https://github.com/huggingface/transformers/pull/12951.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12951.patch",
"merged_at": 1627647639000
} |
https://api.github.com/repos/huggingface/transformers/issues/12950 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12950/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12950/comments | https://api.github.com/repos/huggingface/transformers/issues/12950/events | https://github.com/huggingface/transformers/issues/12950 | 956,567,415 | MDU6SXNzdWU5NTY1Njc0MTU= | 12,950 | ZeroDivisionError in NotebookProgressBar.update with small dataset | {
"login": "Rik-de-Kort",
"id": 32839123,
"node_id": "MDQ6VXNlcjMyODM5MTIz",
"avatar_url": "https://avatars.githubusercontent.com/u/32839123?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rik-de-Kort",
"html_url": "https://github.com/Rik-de-Kort",
"followers_url": "https://api.github.com/users/Rik-de-Kort/followers",
"following_url": "https://api.github.com/users/Rik-de-Kort/following{/other_user}",
"gists_url": "https://api.github.com/users/Rik-de-Kort/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rik-de-Kort/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rik-de-Kort/subscriptions",
"organizations_url": "https://api.github.com/users/Rik-de-Kort/orgs",
"repos_url": "https://api.github.com/users/Rik-de-Kort/repos",
"events_url": "https://api.github.com/users/Rik-de-Kort/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rik-de-Kort/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thanks for reporting! I could reproduce and extracted a shorter reproducer (see the PR above). Fix is on its way :-)",
"Excellent! "
] | 1,627 | 1,627 | 1,627 | NONE | null | I don't know the specifics, but during training (details below) NotebookProgressBar's update function got called with `force_update` is true, while no progress had been made (i.e. `value == self.start_value`). This leads directly to a ZeroDivisionError on line 151 in src/transformers/util/notebook.py.
## Environment info
- `transformers` version: 4.6.1
- Platform: Linux-5.4.0-1051-azure-x86_64-with-glibc2.17
- Python version: 3.8.10
- PyTorch version (GPU?): 1.8.1+cu102 (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help
@sgugger based on Git blame.
## Information
Model I am using (Bert, XLNet ...): Roberta-Base
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [X] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details below)
## To reproduce
Managed to reproduce based on the token classification notebook ([here](https://github.com/huggingface/notebooks/blob/master/examples/token_classification.ipynb)).
Steps to reproduce the behavior from this notebook:
After loading the dataset, apply the following code to make small:
```python
n = 14
datasets["train"] = datasets["train"].filter(lambda x: int(x["id"]) < n)
datasets["validation"] = datasets["validation"].filter(lambda x: int(x["id"]) < n)
datasets["test"] = datasets["test"].filter(lambda x: int(x["id"]) < n)
```
Replace the TrainingArguments in "Fine-tuning the model" with:
```python
model_name = model_checkpoint.split("/")[-1]
args = TrainingArguments(
output_dir='./deletepls',
num_train_epochs=1,
per_device_train_batch_size=8,
per_device_eval_batch_size=4,
warmup_steps=500,
weight_decay=0.01,
learning_rate=5e-4,
logging_dir='./logs',
logging_steps=7,
)
```
After executing `trainer.train()` I get the ZeroDivisionError.
## Expected behavior
Some more descriptive error related to my logging steps, dataset size, or batch size. I'm still not sure what exactly causes this error.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12950/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12950/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12949 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12949/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12949/comments | https://api.github.com/repos/huggingface/transformers/issues/12949/events | https://github.com/huggingface/transformers/issues/12949 | 956,562,551 | MDU6SXNzdWU5NTY1NjI1NTE= | 12,949 | [end2end rag] Slow speed when extending the external KB | {
"login": "shunyuzh",
"id": 41095167,
"node_id": "MDQ6VXNlcjQxMDk1MTY3",
"avatar_url": "https://avatars.githubusercontent.com/u/41095167?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shunyuzh",
"html_url": "https://github.com/shunyuzh",
"followers_url": "https://api.github.com/users/shunyuzh/followers",
"following_url": "https://api.github.com/users/shunyuzh/following{/other_user}",
"gists_url": "https://api.github.com/users/shunyuzh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shunyuzh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shunyuzh/subscriptions",
"organizations_url": "https://api.github.com/users/shunyuzh/orgs",
"repos_url": "https://api.github.com/users/shunyuzh/repos",
"events_url": "https://api.github.com/users/shunyuzh/events{/privacy}",
"received_events_url": "https://api.github.com/users/shunyuzh/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi, Thanks a lot for trying out our model and pointing out these valuable facts. I checked your problem and didn't see any problem with GPU selection, but yeah the time can increase, dramatically if we use a large dataset with the current index. So please go through my answer below. \r\n\r\nActually, it is not a bug. If you only check the time taken to re-encode, you can always reduce it by using a lot more GPUs, because encoding process is embarrassingly parallel. In the encoding process, the model creates dataset splits using the HF dataset library and saves them into a disk. Then, those splits will only be merged when we need to start the re-indexing process. So this increase of time is not because of having more GPUs, but because of the re-indexing process. In re-indexing, we use FAISS and HNSW index. I had some long chats with FAISS people and they say usually HNSW index time is slow, and changes according to the number of vectors and status of the vectors (since we are changing the embeddings). This bug can be solved by using another index like IVF, which is very fast. \r\n\r\n\r\n\r\n\r\n\r\n",
"Yes, it's just related to larger dataset. Once the process of re-encoding started, it goes fast. But your mentioned process of creating dataset splits, saving them into a disk and merging them from the disk indeed cost much time.\r\n\r\nAs for the re-index process, I agree that your said IVF and other hyperparameters of Faiss may helps. If you find what setting really works better, please let me know.",
"@Dopaminezsy\r\n\r\nsure. I think you might need to do hyperparameters tuning. Anyways I trained a model where that the external KB consisted of 7.5 million passages. Although KB update time has increased it worked fine. Another thing is if you have access to enough computational power you can easily make the entire process much more efficient. When it comes to the indexing process, you can try completely neglecting it and using a greedy search during the training. I have noticed this method in REALM paper. \r\n\r\nOn Mon, Aug 2, 2021 at 8:52 PM Dopaminezsy ***@***.***> wrote:\r\n\r\n> Yes, it's just related to larger dataset. Once the process of re-encoding\r\n> started, it goes fast. But your mentioned process of creating dataset\r\n> splits, saving them into a disk and merging them from the disk indeed cost\r\n> much time.\r\n>\r\n> As for the re-index process, I agree that your said IVF and other\r\n> hyperparameters of Faiss may helps. If you find what setting really works\r\n> better, please let me know.\r\n>\r\n> —\r\n> You are receiving this because you were mentioned.\r\n> Reply to this email directly, view it on GitHub\r\n> <https://github.com/huggingface/transformers/issues/12949#issuecomment-890849702>,\r\n> or unsubscribe\r\n> <https://github.com/notifications/unsubscribe-auth/AEA4FGRYJLGPI2VLXEYDL5TT2ZMFLANCNFSM5BIEELFA>\r\n> .\r\n>\r\n\r\n\r\n-- \r\n[image: Augmented Human Lab] <http://www.ahlab.org/> [image: uni]\r\n<https://www.auckland.ac.nz/en/abi.html>\r\n\r\nGayal Shamane\r\nPh.D. Candidate\r\nAugmented Human Lab\r\nAuckland Bioengineering Institute | The University of Auckland\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,630 | 1,630 | NONE | null | Hi folks,
@shamanez Sorry to disturb you for some problems. It mainly about process about re-encode and re-index, related to kb_encode_utils.py and finetune_rag.py.
First, When I extended your provided SQUAD-KB.csv to another five times larger file, the re-index process became too slow, sometimes even needing half or one hour to finish re-indexing. I am trying to use faiss-gpu to speed the re-index process, but it doesn't work well.
If you are interested at the above BUG, you can try using the small split of dpr_wiki to test: https://storage.googleapis.com/huggingface-nlp/datasets/wiki_dpr/psgs_w100.tsv.pkl
Second, I found that when I set index_gpus to more than 2, the prepare time for re-encoding became longer even to 5 or 10 minutes . I guess this cost mainly due to the I/O of load_dataset or spilt in def embed_update(ctx_encoder, total_processes, device, process_num, shard_dir, csv_path).
Overall, these problems only occur when extending the external knowledge corpus. It works well when using your provided small squad-kb.csv.
Feel free to give any suggestion on what you are intereted at, in the way as you like.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12949/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12949/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12948 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12948/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12948/comments | https://api.github.com/repos/huggingface/transformers/issues/12948/events | https://github.com/huggingface/transformers/issues/12948 | 956,561,727 | MDU6SXNzdWU5NTY1NjE3Mjc= | 12,948 | BertForQuestionAnswering result not match when multiple run in same input | {
"login": "kjyeon1676",
"id": 19407432,
"node_id": "MDQ6VXNlcjE5NDA3NDMy",
"avatar_url": "https://avatars.githubusercontent.com/u/19407432?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kjyeon1676",
"html_url": "https://github.com/kjyeon1676",
"followers_url": "https://api.github.com/users/kjyeon1676/followers",
"following_url": "https://api.github.com/users/kjyeon1676/following{/other_user}",
"gists_url": "https://api.github.com/users/kjyeon1676/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kjyeon1676/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kjyeon1676/subscriptions",
"organizations_url": "https://api.github.com/users/kjyeon1676/orgs",
"repos_url": "https://api.github.com/users/kjyeon1676/repos",
"events_url": "https://api.github.com/users/kjyeon1676/events{/privacy}",
"received_events_url": "https://api.github.com/users/kjyeon1676/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"You are using the generic BERT checkpoint `bert-base-cased` for a question-answering task, which is why you get the warning telling you that some of the weights are randomly initialized (the weights of the question answering head). Since there is that part that is randomly initialized, you won't get the same results with two consecutive runs, or with PT vs TF.\r\n\r\nYou should use a checkpoint fine-tuned for question-answering, such as distilbert-base-uncased-distilled-squad. Complete list of available checkpoints is [here](https://huggingface.co/models?pipeline_tag=question-answering)",
"ok :) i got it. thank you for your explanation!"
] | 1,627 | 1,627 | 1,627 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.9.0.dev0
- Platform: Linux-4.15.0-126-generic-x86_64-with-debian-buster-sid
- Python version: 3.7.4
- PyTorch version (GPU?): 1.7.0 (false)
- Tensorflow version (GPU?): 2.5.0 (false)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
@LysandreJik
@Rocketknight1
@sgugger
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...): BERT(TFBertForQuestionAnswering, BertForQuestionAnswering)
The problem arises when using:
--> my own modified script
here is my test script
```python
import numpy as np
import os
import tensorflow as tf
from transformers import BertTokenizer, TFBertForQuestionAnswering, AdamWeightDecay
model_name = "bert-base-uncased"
tokenizer = BertTokenizer.from_pretrained(model_name)
tf_model = TFBertForQuestionAnswering.from_pretrained(model_name)
question, text = "who was Jim Henson?", "Jim Henson was a puppet"
input_dict = tokenizer(question, text, return_tensors="tf")
base_output = tf_model({'input_ids':input_dict['input_ids'],
'attention_mask':input_dict['attention_mask'],
'token_type_ids':input_dict['token_type_ids']})
import tensorflow.keras.backend as k
tf.print(base_output.start_logits)
tf.print(base_output.end_logits)
start_logits = base_output.start_logits
end_logits = base_output.end_logits
all_tokens = tokenizer.convert_ids_to_tokens(input_dict["input_ids"].numpy()[0])
answer = ' '.join(all_tokens[tf.math.argmax(start_logits, 1)[0] : tf.math.argmax(end_logits, 1)[0]+1])
print("---------------------answer : ", answer)
# output
1 iteration : ---------------------answer : henson was
2 iteration : ---------------------answer :
3 iteration : ---------------------answer : [CLS] who was jim henson
```
same warning message below
```bash
All model checkpoint layers were used when initializing TFBertForQuestionAnswering.
Some layers of TFBertForQuestionAnswering were not initialized from the model checkpoint at bert-base-uncased and are newly initialized: ['qa_outputs']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
```
The tasks I am working on is:
--> I used official example in this link : https://huggingface.co/transformers/model_doc/bert.html#bertforquestionanswering
## To reproduce
Steps to reproduce the behavior:
1. copy this example https://huggingface.co/transformers/model_doc/bert.html#bertforquestionanswering
2. run python script multiple times with the same input value
3. check the result answer.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
here is start_logits and end_logits value
```python
[[0.146546721 0.337863982 -0.050462883 ... 0.21409747 0.230913743 0.0886169]]
[[-0.432590961 0.0157010294 -0.264513016 ... -0.262505233 -0.097313717 0.101949602]]
---------------------answer : who was him
[[0.239599198 -0.0761167854 -0.150168374 ... -0.329441965 -0.296196282 -0.43989116]]
[[-0.395110816 -0.316928446 -0.0174004361 ... -0.15449807 -0.0412646905 -0.340780914]]
---------------------answer : [CLS] who was jim henson
[[0.49121806 -0.028806597 0.371522099 ... 0.544696152 0.163530082 0.184236392]]
[[0.203870535 0.0572335199 -0.129730135 ... 0.0982186 0.130047619 0.0592225939]]
---------------------answer :
[[0.284656644 -0.252363682 -0.441064388 ... 0.0992026776 0.198949382 -0.0191452727]]
[[-0.0616797283 -0.0639260635 0.413451135 ... 0.396001071 0.16053389 0.245075911]]
---------------------answer : henson was
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
same result for start_logits and end_logits values when multiple runs the python script
and, I thought it was normal to see the following results in the correct answer.
---------------tvm answer : jim henson ? [SEP] jim henson was a puppet
[[-0.14654148 -0.20532154 -0.293788 -0.22902387 -0.0299019 -0.09931126
-0.02225712 -0.28276378 0.02211829 -0.19016735 -0.25408638 0.09656907
0.00328144]]
[[-0.63135976 0.25255007 0.4773104 0.62560356 0.6185883 0.07990392
-0.2211009 0.2174719 0.2831107 0.18743467 -0.03354458 0.08337761
-0.20905018]]
```
## Background
- I was doing a test to run TFBertForQuestionAnswering and BertForQuestionAnswering on TVM. But, TF and Pytorch model's output does not match when inputting the same input. What did I miss? Is there any other way to perform or check? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12948/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12948/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12947 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12947/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12947/comments | https://api.github.com/repos/huggingface/transformers/issues/12947/events | https://github.com/huggingface/transformers/pull/12947 | 956,555,963 | MDExOlB1bGxSZXF1ZXN0NzAwMTMxMzE1 | 12,947 | [FLAX] Minor fixes in LM example | {
"login": "stefan-it",
"id": 20651387,
"node_id": "MDQ6VXNlcjIwNjUxMzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/20651387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stefan-it",
"html_url": "https://github.com/stefan-it",
"followers_url": "https://api.github.com/users/stefan-it/followers",
"following_url": "https://api.github.com/users/stefan-it/following{/other_user}",
"gists_url": "https://api.github.com/users/stefan-it/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stefan-it/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stefan-it/subscriptions",
"organizations_url": "https://api.github.com/users/stefan-it/orgs",
"repos_url": "https://api.github.com/users/stefan-it/repos",
"events_url": "https://api.github.com/users/stefan-it/events{/privacy}",
"received_events_url": "https://api.github.com/users/stefan-it/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,627 | 1,627 | 1,627 | COLLABORATOR | null | Hi,
this PR introduces some fixes for getting the correct vocab size from the Tokenizers used in the FLAX example language modeling readme. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12947/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12947/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12947",
"html_url": "https://github.com/huggingface/transformers/pull/12947",
"diff_url": "https://github.com/huggingface/transformers/pull/12947.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12947.patch",
"merged_at": 1627662473000
} |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.