
url
stringlengths 62
66
| repository_url
stringclasses 1
value | labels_url
stringlengths 76
80
| comments_url
stringlengths 71
75
| events_url
stringlengths 69
73
| html_url
stringlengths 50
56
| id
int64 377M
2.15B
| node_id
stringlengths 18
32
| number
int64 1
29.2k
| title
stringlengths 1
487
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 2
classes | assignee
dict | assignees
list | comments
list | created_at
int64 1.54k
1.71k
| updated_at
int64 1.54k
1.71k
| closed_at
int64 1.54k
1.71k
⌀ | author_association
stringclasses 4
values | active_lock_reason
stringclasses 2
values | body
stringlengths 0
234k
⌀ | reactions
dict | timeline_url
stringlengths 71
75
| state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/transformers/issues/12946 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12946/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12946/comments | https://api.github.com/repos/huggingface/transformers/issues/12946/events | https://github.com/huggingface/transformers/issues/12946 | 956,500,360 | MDU6SXNzdWU5NTY1MDAzNjA= | 12,946 | ImportError: cannot import name 'BigBirdTokenizer' from 'transformers' | {
"login": "zynos",
"id": 8973150,
"node_id": "MDQ6VXNlcjg5NzMxNTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/8973150?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zynos",
"html_url": "https://github.com/zynos",
"followers_url": "https://api.github.com/users/zynos/followers",
"following_url": "https://api.github.com/users/zynos/following{/other_user}",
"gists_url": "https://api.github.com/users/zynos/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zynos/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zynos/subscriptions",
"organizations_url": "https://api.github.com/users/zynos/orgs",
"repos_url": "https://api.github.com/users/zynos/repos",
"events_url": "https://api.github.com/users/zynos/events{/privacy}",
"received_events_url": "https://api.github.com/users/zynos/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"The sentencepiece library was missing. ",
"`BigBirdTokenizer` requires a sentencepiece installation, but you should have had that error instead of an import error. This is because the `BigBirdTokenizer` was misplaced in the init, the PR linked above fixes it.",
"I sadly only got the import error, nothing else. An error indicating that sentencepiece is missing is definitely more helpful. Thanks for creating the PR",
"I installed sentencepiece but I got the same error:\r\n\r\n```\r\n!pip install --quiet sentencepiece\r\nfrom transformers import BigBirdTokenizer\r\n```\r\nImportError: cannot import name 'BigBirdTokenizer' from 'transformers' (/usr/local/lib/python3.7/dist-packages/transformers/__init__.py)",
"@MariamDundua what is the version of your transformers package?",
"Hi @zynos @sgugger . I'm using transformers 4.8.0 and have installed sentencepiece. But I'm having same cannot import name 'BigBirdTokenizer' issue. Thanks. ",
"Make sure you use the latest version of Transformers. It should include a clearer error message if the import fails."
] | 1,627 | 1,646 | 1,627 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.9.1
- Platform: windows
- Python version: 3.9
- PyTorch version (GPU?): 1.9 (CPU)
- Tensorflow version (GPU?):
- Using GPU in script?: no
- Using distributed or parallel set-up in script?:
## Information
Model I am using BigBird:
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [X] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
```
from transformers import BigBirdTokenizer,BigBirdModel
print("hello")
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
No import error.
Importing **BigBirdTokenizerFast** works without a problem. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12946/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12946/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12945 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12945/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12945/comments | https://api.github.com/repos/huggingface/transformers/issues/12945/events | https://github.com/huggingface/transformers/issues/12945 | 956,096,918 | MDU6SXNzdWU5NTYwOTY5MTg= | 12,945 | Transformers tokenizer pickling issue using hydra and submitit_slurm | {
"login": "asishgeek",
"id": 5291773,
"node_id": "MDQ6VXNlcjUyOTE3NzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/5291773?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/asishgeek",
"html_url": "https://github.com/asishgeek",
"followers_url": "https://api.github.com/users/asishgeek/followers",
"following_url": "https://api.github.com/users/asishgeek/following{/other_user}",
"gists_url": "https://api.github.com/users/asishgeek/gists{/gist_id}",
"starred_url": "https://api.github.com/users/asishgeek/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/asishgeek/subscriptions",
"organizations_url": "https://api.github.com/users/asishgeek/orgs",
"repos_url": "https://api.github.com/users/asishgeek/repos",
"events_url": "https://api.github.com/users/asishgeek/events{/privacy}",
"received_events_url": "https://api.github.com/users/asishgeek/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This has been solved in v4.9, you should upgrade to the latest version of Transformers.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,630 | 1,630 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.8.2
- Platform: Linux-5.4.0-1051-aws-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyTorch version (GPU?): 1.9.0 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
-
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
-->
@LysandreJik
## Information
Model I am using (Bert, XLNet ...): t5
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Run the script using command:
python hf_hydra.py hydra/launcher=submitit_slurm -m
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
Code (hf_hydra.py):
import hydra
import logging
# from transformers import AutoTokenizer
import transformers
@hydra.main(config_path=None)
def main(cfg):
logger = logging.getLogger(__name__)
# tokenizer = AutoTokenizer.from_pretrained("t5-small")
tokenizer = transformers.T5Tokenizer.from_pretrained("t5-small")
logger.info(f"vocab size: {tokenizer.vocab_size}")
if __name__ == '__main__':
main()
Using AutoTokenizer works but using T5Tokenizer fails with the following error.
Traceback (most recent call last):
File "/data/home/aghoshal/miniconda/lib/python3.8/site-packages/hydra/_internal/utils.py", line 211, in run_and_report
return func()
File "/data/home/aghoshal/miniconda/lib/python3.8/site-packages/hydra/_internal/utils.py", line 376, in <lambda>
lambda: hydra.multirun(
File "/data/home/aghoshal/miniconda/lib/python3.8/site-packages/hydra/_internal/hydra.py", line 139, in multirun
ret = sweeper.sweep(arguments=task_overrides)
File "/data/home/aghoshal/miniconda/lib/python3.8/site-packages/hydra/_internal/core_plugins/basic_sweeper.py", line 157, in sweep
results = self.launcher.launch(batch, initial_job_idx=initial_job_idx)
File "/data/home/aghoshal/miniconda/lib/python3.8/site-packages/hydra_plugins/hydra_submitit_launcher/submitit_launcher.py", line 145, in launch
jobs = executor.map_array(self, *zip(*job_params))
File "/data/home/aghoshal/miniconda/lib/python3.8/site-packages/submitit/core/core.py", line 631, in map_array
return self._internal_process_submissions(submissions)
File "/data/home/aghoshal/miniconda/lib/python3.8/site-packages/submitit/auto/auto.py", line 213, in _internal_process_submissions
return self._executor._internal_process_submissions(delayed_submissions)
File "/data/home/aghoshal/miniconda/lib/python3.8/site-packages/submitit/slurm/slurm.py", line 313, in _internal_process_submissions
return super()._internal_process_submissions(delayed_submissions)
File "/data/home/aghoshal/miniconda/lib/python3.8/site-packages/submitit/core/core.py", line 749, in _internal_process_submissions
delayed.dump(pickle_path)
File "/data/home/aghoshal/miniconda/lib/python3.8/site-packages/submitit/core/utils.py", line 136, in dump
cloudpickle_dump(self, filepath)
File "/data/home/aghoshal/miniconda/lib/python3.8/site-packages/submitit/core/utils.py", line 240, in cloudpickle_dump
cloudpickle.dump(obj, ofile, pickle.HIGHEST_PROTOCOL)
File "/data/home/aghoshal/miniconda/lib/python3.8/site-packages/cloudpickle/cloudpickle_fast.py", line 55, in dump
CloudPickler(
File "/data/home/aghoshal/miniconda/lib/python3.8/site-packages/cloudpickle/cloudpickle_fast.py", line 563, in dump
return Pickler.dump(self, obj)
TypeError: cannot pickle '_LazyModule' object
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
Job should run and print the vocab size. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12945/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12945/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12944 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12944/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12944/comments | https://api.github.com/repos/huggingface/transformers/issues/12944/events | https://github.com/huggingface/transformers/issues/12944 | 956,067,289 | MDU6SXNzdWU5NTYwNjcyODk= | 12,944 | rum_mlm crashes with bookcorpus and --preprocessing_num_workers | {
"login": "shairoz-deci",
"id": 73780196,
"node_id": "MDQ6VXNlcjczNzgwMTk2",
"avatar_url": "https://avatars.githubusercontent.com/u/73780196?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shairoz-deci",
"html_url": "https://github.com/shairoz-deci",
"followers_url": "https://api.github.com/users/shairoz-deci/followers",
"following_url": "https://api.github.com/users/shairoz-deci/following{/other_user}",
"gists_url": "https://api.github.com/users/shairoz-deci/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shairoz-deci/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shairoz-deci/subscriptions",
"organizations_url": "https://api.github.com/users/shairoz-deci/orgs",
"repos_url": "https://api.github.com/users/shairoz-deci/repos",
"events_url": "https://api.github.com/users/shairoz-deci/events{/privacy}",
"received_events_url": "https://api.github.com/users/shairoz-deci/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,630 | 1,630 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.9.0
- Platform: Linux-5.8.0-63-generic-x86_64-with-debian-bullseye-sid
- Python version: 3.7.10
- PyTorch version (GPU?): 1.8.1+cu111 (True)
- Tensorflow version (GPU?): 2.5.0 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: yes
### Who can help
@LysandreJik
Models:
- albert, bert, xlm: @LysandreJik @sgugger @patil-suraj
Library:
- trainer: @sgugger
- pipelines: @LysandreJik
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
## Information
Trying to train BERT from scratch on wikipedia and bookcorpus using the run_mlm.py example.
As the dataset is large and I am using a strong machine (80 CPU cores 350GB RAM) I set the --preprocessing_num_workers flag to 64 to accelerate the preprocessing.
When running a wikipedia or squad for sanity check, everything works fine but with bookcorpus, after dataset mapping is supposedly completed (all three occurrences), it gets stuck on with the info:
`Spawning 64 processes `
for a while and crashes with
`BrokenPipeError: [Errno 32] Broken pipe`
This does not occur when dropping the --preprocessing_num_workers flag but then processing wiki + bookcorpus will take nearly two days.
I tried changing the transformer version or upgrading/downgrading the multiprocessing and dill packages and it didn't help
The problem arises when using:
* [ x] the official example scripts: (give details below)
## To reproduce
Steps to reproduce the behavior:
run:
`python transformers/examples/pytorch/language-modeling/run_mlm.py --output_dir transformers/trained_models/bert_base --dataset_name bookcorpus --model_type bert --preprocessing_num_workers 64 --tokenizer_name bert-base-uncased --do_train --do_eval --per_device_train_batch_size 16 --overwrite_output_dir --dataloader_num_workers 64 --max_steps 1000000 --learning_rate 1e-4 --warmup_steps 10000 --save_steps 25000 --adam_epsilon 1e-6 --adam_beta1 0.9 --adam_beta2 0.999 --weight_decay 0.0'
## Expected behavior
Training should begin as done properly when loading wiki and other datasets
Thanks is advance, | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12944/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12944/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12943 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12943/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12943/comments | https://api.github.com/repos/huggingface/transformers/issues/12943/events | https://github.com/huggingface/transformers/pull/12943 | 956,065,225 | MDExOlB1bGxSZXF1ZXN0Njk5NzIxNjY0 | 12,943 | Moving fill-mask pipeline to new testing scheme | {
"login": "Narsil",
"id": 204321,
"node_id": "MDQ6VXNlcjIwNDMyMQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/204321?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Narsil",
"html_url": "https://github.com/Narsil",
"followers_url": "https://api.github.com/users/Narsil/followers",
"following_url": "https://api.github.com/users/Narsil/following{/other_user}",
"gists_url": "https://api.github.com/users/Narsil/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Narsil/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Narsil/subscriptions",
"organizations_url": "https://api.github.com/users/Narsil/orgs",
"repos_url": "https://api.github.com/users/Narsil/repos",
"events_url": "https://api.github.com/users/Narsil/events{/privacy}",
"received_events_url": "https://api.github.com/users/Narsil/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@LysandreJik I think it' s ready for 2nd review to check that everything you raised is fixed. I'll go on to the next pipeline after that."
] | 1,627 | 1,628 | 1,628 | CONTRIBUTOR | null | # What does this PR do?
Changes the testing of fill-mask so we can test all supported architectures.
Turns out quite a bit are NOT testable (because reference tokenizers do not include
mask token, reformer is a bit tricky to handle too).
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
--> | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12943/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12943/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12943",
"html_url": "https://github.com/huggingface/transformers/pull/12943",
"diff_url": "https://github.com/huggingface/transformers/pull/12943.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12943.patch",
"merged_at": 1628849058000
} |
https://api.github.com/repos/huggingface/transformers/issues/12942 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12942/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12942/comments | https://api.github.com/repos/huggingface/transformers/issues/12942/events | https://github.com/huggingface/transformers/issues/12942 | 955,976,366 | MDU6SXNzdWU5NTU5NzYzNjY= | 12,942 | trainer is not reproducible | {
"login": "jackfeinmann5",
"id": 59409879,
"node_id": "MDQ6VXNlcjU5NDA5ODc5",
"avatar_url": "https://avatars.githubusercontent.com/u/59409879?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jackfeinmann5",
"html_url": "https://github.com/jackfeinmann5",
"followers_url": "https://api.github.com/users/jackfeinmann5/followers",
"following_url": "https://api.github.com/users/jackfeinmann5/following{/other_user}",
"gists_url": "https://api.github.com/users/jackfeinmann5/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jackfeinmann5/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jackfeinmann5/subscriptions",
"organizations_url": "https://api.github.com/users/jackfeinmann5/orgs",
"repos_url": "https://api.github.com/users/jackfeinmann5/repos",
"events_url": "https://api.github.com/users/jackfeinmann5/events{/privacy}",
"received_events_url": "https://api.github.com/users/jackfeinmann5/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"The average training loss is indeed not saved and thus you will have a different one restarting from a checkpoint. It's also not a useful metric in most cases, which is why we don't bother. You will notice however that your eval BLEU is exactly the same, so the training yielded the same model at the end.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,630 | 1,630 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.9.1
- Platform: linux
- Python version: 3.7
- PyTorch version (GPU?): 1.9
- Tensorflow version (GPU?): -
- Using GPU in script?: -
- Using distributed or parallel set-up in script?: -
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
trainer: @sgugger
## Information
Model I am using T5-small model and I am testing the original run_translation.py codes [1] for reproducibility when we need to restart the codes from the previously saved checkpoints (I only have access to gpus for a short time and I need to restart the codes).
## To reproduce
Steps to reproduce the behavior:
1) Please kindly run this command:
```
python run_translation.py --model_name_or_path t5-small --do_train --do_eval --source_lang en --target_lang ro --source_prefix "translate English to Romanian: " --dataset_name wmt16 --dataset_config_name ro-en --output_dir /temp/jack/tst-translation --per_device_train_batch_size=4 --per_device_eval_batch_size=4 --overwrite_output_dir --predict_with_generate --max_steps 100 --eval_step 10 --evaluation_strategy steps --max_train_samples 100 --max_eval_samples 100 --save_total_limit 1 --load_best_model_at_end --metric_for_best_model bleu --greater_is_better true
```
then kindly break the codes in this points:
```
{'eval_loss': 1.3589547872543335, 'eval_bleu': 10.9552, 'eval_gen_len': 18.05, 'eval_runtime': 4.0518, 'eval_samples_per_second': 24.68, 'eval_steps_per_second': 6.17, 'epoch': 0.8}
20%|██████████████████████████████▍ | 20/100 [00:11<00:21, 3.70it/s[INFO|trainer.py:1919] 2021-07-29 17:22:43,852 >> Saving model checkpoint to /temp/jack/tst-translation/checkpoint-20
[INFO|configuration_utils.py:379] 2021-07-29 17:22:43,857 >> Configuration saved in /temp/jack/tst-translation/checkpoint-20/config.json
[INFO|modeling_utils.py:997] 2021-07-29 17:22:44,351 >> Model weights saved in /temp/jack/tst-translation/checkpoint-20/pytorch_model.bin
[INFO|tokenization_utils_base.py:2006] 2021-07-29 17:22:44,355 >> tokenizer config file saved in /temp/jack/tst-translation/checkpoint-20/tokenizer_config.json
[INFO|tokenization_utils_base.py:2012] 2021-07-29 17:22:44,357 >> Special tokens file saved in /temp/jack/tst-translation/checkpoint-20/special_tokens_map.json
29%|████████████████████████████████████████████ | 29/100 [00:14<00:22, 3.20it/s][INFO|trainer.py:2165] 2021-07-29 17:22:46,444 >> ***** Running Evaluation *****
[INFO|trainer.py:2167] 2021-07-29 17:22:46,444 >> Num examples = 100
[INFO|trainer.py:2170] 2021-07-29 17:22:46,444 >> Batch size = 4
```
break here please
```
{'eval_loss': 1.3670727014541626, 'eval_bleu': 10.9234, 'eval_gen_len': 18.01, 'eval_runtime': 3.9468, 'eval_samples_per_second': 25.337, 'eval_steps_per_second': 6.334, 'epoch': 2.4}
[INFO|trainer.py:1919] 2021-07-29 17:24:01,570 >> Saving model checkpoint to /temp/jack/tst-translation/checkpoint-60
[INFO|configuration_utils.py:379] 2021-07-29 17:24:01,576 >> Configuration saved in /temp/jack/tst-translation/checkpoint-60/config.json | 60/100 [00:23<00:11, 3.42it/s]
[INFO|modeling_utils.py:997] 2021-07-29 17:24:02,197 >> Model weights saved in /temp/jack/tst-translation/checkpoint-60/pytorch_model.bin
[INFO|tokenization_utils_base.py:2006] 2021-07-29 17:24:02,212 >> tokenizer config file saved in /temp/jack/tst-translation/checkpoint-60/tokenizer_config.json
[INFO|tokenization_utils_base.py:2012] 2021-07-29 17:24:02,218 >> Special tokens file saved in /temp/jack/tst-translation/checkpoint-60/special_tokens_map.json
[INFO|trainer.py:1995] 2021-07-29 17:24:03,216 >> Deleting older checkpoint [/temp/jack/tst-translation/checkpoint-50] due to args.save_total_limit
[INFO|trainer.py:2165] 2021-07-29 17:24:03,810 >> ***** Running Evaluation *****██████████████████████████████▉ | 69/100 [00:26<00:09, 3.37it/s]
[INFO|trainer.py:2167] 2021-07-29 17:24:03,810 >> Num examples = 100
[INFO|trainer.py:2170] 2021-07-29 17:24:03,810 >> Batch size = 4
```
break here please and then run the codes please from here till the end.
```
final train metrics
***** train metrics *****
epoch = 4.0
train_loss = 0.1368
train_runtime = 0:00:27.13
train_samples = 100
train_samples_per_second = 14.741
train_steps_per_second = 3.685
07/29/2021 17:25:08 - INFO - __main__ - *** Evaluate ***
[INFO|trainer.py:2165] 2021-07-29 17:25:08,774 >> ***** Running Evaluation *****
[INFO|trainer.py:2167] 2021-07-29 17:25:08,774 >> Num examples = 100
[INFO|trainer.py:2170] 2021-07-29 17:25:08,774 >> Batch size = 4
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 25/25 [00:08<00:00, 2.92it/s]
***** eval metrics *****
epoch = 4.0
eval_bleu = 24.3863
eval_gen_len = 32.84
eval_loss = 1.3565
eval_runtime = 0:00:09.08
eval_samples = 100
eval_samples_per_second = 11.005
eval_steps_per_second = 2.751
```
the final metrics when running the codes without breaks:
```
***** train metrics *****
epoch = 4.0
train_loss = 0.3274
train_runtime = 0:01:04.19
train_samples = 100
train_samples_per_second = 6.231
train_steps_per_second = 1.558
07/29/2021 17:00:12 - INFO - __main__ - *** Evaluate ***
[INFO|trainer.py:2165] 2021-07-29 17:00:12,315 >> ***** Running Evaluation *****
[INFO|trainer.py:2167] 2021-07-29 17:00:12,315 >> Num examples = 100
[INFO|trainer.py:2170] 2021-07-29 17:00:12,315 >> Batch size = 4
100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 25/25 [00:08<00:00, 2.97it/s]
***** eval metrics *****
epoch = 4.0
eval_bleu = 24.3863
eval_gen_len = 32.84
eval_loss = 1.3565
eval_runtime = 0:00:08.95
eval_samples = 100
eval_samples_per_second = 11.164
eval_steps_per_second = 2.791
```
the training loss between the two runs with and without break would be different.
I kindly appreciate having a look, this is required for me to be able to use the great huggingface codes. and I would like to appreciate a lot your great work and colleague on this second to none, great work you are doing. thanks a lot.
## Expected behavior
to see the same training loss when the user trains the codes without any break and when we train the codes with breaking in between. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12942/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12942/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12941 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12941/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12941/comments | https://api.github.com/repos/huggingface/transformers/issues/12941/events | https://github.com/huggingface/transformers/issues/12941 | 955,959,361 | MDU6SXNzdWU5NTU5NTkzNjE= | 12,941 | OSError: Can't load config for 'bert-base-uncased | {
"login": "WinMinTun",
"id": 22287008,
"node_id": "MDQ6VXNlcjIyMjg3MDA4",
"avatar_url": "https://avatars.githubusercontent.com/u/22287008?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/WinMinTun",
"html_url": "https://github.com/WinMinTun",
"followers_url": "https://api.github.com/users/WinMinTun/followers",
"following_url": "https://api.github.com/users/WinMinTun/following{/other_user}",
"gists_url": "https://api.github.com/users/WinMinTun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/WinMinTun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/WinMinTun/subscriptions",
"organizations_url": "https://api.github.com/users/WinMinTun/orgs",
"repos_url": "https://api.github.com/users/WinMinTun/repos",
"events_url": "https://api.github.com/users/WinMinTun/events{/privacy}",
"received_events_url": "https://api.github.com/users/WinMinTun/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Was it just a fluke or is the issue still happening? On Colab I have no problem downloading that model.",
"@sgugger Hi it is still happening now. Not just me, many people I know of. I can access the config file from browser, but not through the code. Thanks",
"Still not okay online, but I managed to do it locally\r\n\r\ngit clone https://huggingface.co/bert-base-uncased\r\n\r\n#model = AutoModelWithHeads.from_pretrained(\"bert-base-uncased\")\r\nmodel = AutoModelWithHeads.from_pretrained(BERT_LOCAL_PATH, local_files_only=True)\r\n\r\n#tokenizer = AutoTokenizer.from_pretrained(\"bert-base-uncased\")\r\ntokenizer = AutoTokenizer.from_pretrained(BERT_LOCAL_PATH, local_files_only=True)\r\n\r\nadapter_name = model2.load_adapter(localpath, config=config, model_name=BERT_LOCAL_PATH)",
"This, like #12940, is probably related to a change we've made on the infra side (cc @n1t0), which we'll partially revert. Please let us know if this still occurs.",
"@WinMinTun Could you share a small collab that reproduces the bug? I'd like to have a look at it.",
"With additional testing, I've found that this issue only occurs with adapter-tranformers, the AdapterHub.ml modified version of the transformers module. With the HuggingFace module, we can pull pretrained weights without issue.\r\n\r\nUsing adapter-transformers this is now working again from Google Colab, but is still failing locally and from servers running in AWS. Interestingly, with adapter-transformers I get a 403 even if I try to load a nonexistent model (e.g. fake-model-that-should-fail). I would expect this to fail with a 401, as there is no corresponding config.json on huggingface.co. The fact that it fails with a 403 seems to indicate that something in front of the web host is rejecting the request before the web host has a change to respond with a not found error.",
"Thanks so much @jason-weddington. This will help us pinpoint the issue. (@n1t0 @Pierrci)",
"I have the same problem, but it only happens when the model is private.\r\n\r\n\r\n",
"Your token for `use_auth_token` is not the same as your API token. The easiest way to get it is to login with `!huggingface-cli login` and then just pass `use_auth_token=True`.",
"I think the problem is something else:\r\n\r\n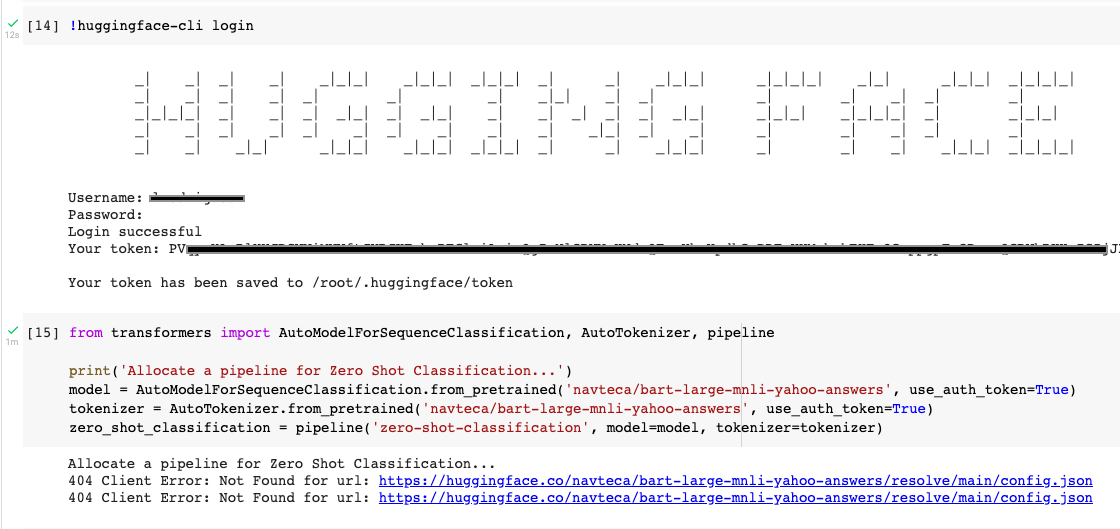\r\n",
"Yes, I have come across this as well. I have tracked it down to this line\r\n\r\nhttps://github.com/huggingface/transformers/blob/143738214cb83e471f3a43652617c8881370342c/src/transformers/pipelines/__init__.py#L422\r\n\r\nIt's because the `use_auth_token` has not been set up early enough in the model_kwargs. The line referenced above needs to be moved above instantiate config section. \r\n\r\n",
"I've added a pull request to which I think will fix this issue. You can get round it for now by adding `use_auth_token` to the model_kwargs param when creating a pipeline e.g.:\r\n`pipeline('zero-shot-classification', model=model, tokenizer=tokenizer, model_kwargs={'use_auth_token': True})`",
"Still getting the same error \r\nHere is my code : \r\n```\r\nfrom transformers import AutoModelForTokenClassification, AutoTokenizer\r\nmodel = AutoModelForTokenClassification.from_pretrained(\"hemangjoshi37a/autotrain-ratnakar_600_sample_test-1427753567\", use_auth_token=True)\r\ntokenizer = AutoTokenizer.from_pretrained(\"hemangjoshi37a/autotrain-ratnakar_600_sample_test-1427753567\", use_auth_token=True)\r\ninputs = tokenizer(\"I love AutoTrain\", return_tensors=\"pt\")\r\noutputs = model(**inputs)\r\n```\r\nError :\r\n```\r\n----> 3 model = AutoModelForTokenClassification.from_pretrained(\"hemangjoshi37a/autotrain-ratnakar_600_sample_test-1427753567\", use_auth_token=True)\r\nOSError: Can't load config for 'hemangjoshi37a/autotrain-ratnakar_600_sample_test-1427753567'. If you were trying to load it from 'https://huggingface.co/models', make sure you don't have a local directory with the same name. Otherwise, make sure 'hemangjoshi37a/autotrain-ratnakar_600_sample_test-1427753567' is the correct path to a directory containing a config.json file\r\n```\r\n\r\nI have transformers version : `4.21.3`\r\nhttps://hjlabs.in",
"runnign this command and authenticating it solved issue: `huggingface-cli login`\r\nhttps://hjlabs.in",
"I am facing the same problem in Kaggle too... How can I\r\n\r\n resolve this issue ?",
"Hello, I had the same problem when using transformers - pipeline in the aws-sagemaker notebook.\r\n\r\nI started to think it was the version or the network problem. But, after some local tests, this guess is wrong. So, I just debug the source code. I find that:\r\n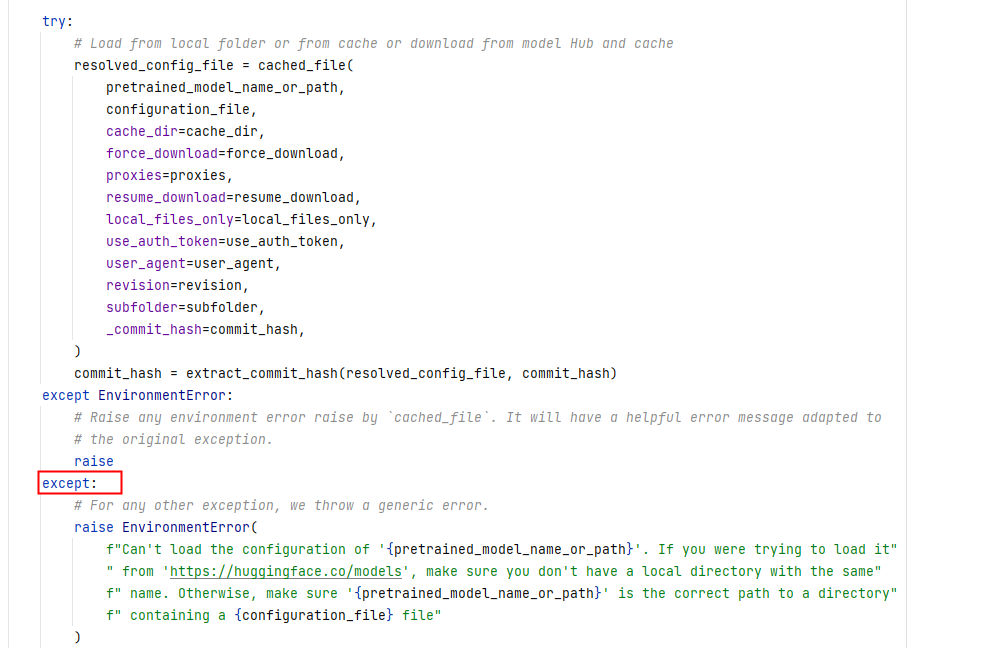\r\nThis will raise any error as EnviromentError. So, from experience, I solve it, by running this pip:\r\n!pip install --upgrade jupyter\r\n!pip install --upgrade ipywidgets\r\n\r\nYou guys can try it when meeting the problem in aws-notebook or colab!",
"\r\n\r\n\r\nI am unable to solve this issues Since Morning .. i had been trying to Solve it ... \r\n\r\nIm working on my Final Year Project .. can someone pls help me in it ...",
"Just ask chatGPT LOL...😂😂",
"I dont understand it ?? What do u mean ..\r\nThe Hugging Face Website is also not working ...",
"@VRDJ goto this website [chatGPT](chat.openai.com) and enter your error in the chatbox in this website and for the 99% you will get your solution there.",
"> Still not okay online, but I managed to do it locally\r\n> \r\n> git clone https://huggingface.co/bert-base-uncased\r\n> \r\n> #model = AutoModelWithHeads.from_pretrained(\"bert-base-uncased\") model = AutoModelWithHeads.from_pretrained(BERT_LOCAL_PATH, local_files_only=True)\r\n> \r\n> #tokenizer = AutoTokenizer.from_pretrained(\"bert-base-uncased\") tokenizer = AutoTokenizer.from_pretrained(BERT_LOCAL_PATH, local_files_only=True)\r\n> \r\n> adapter_name = model2.load_adapter(localpath, config=config, model_name=BERT_LOCAL_PATH)\r\n-------------------\r\n\r\nHello! Thanks for your sharing. I wonder in \r\n'tokenizer = AutoTokenizer.from_pretrained(BERT_LOCAL_PATH, local_files_only=True)', \r\nwhich file does 'BERT_LOCAL_PATH' refer to specifically? Is it the path for the directory 'bert-base-uncased', or the 'pytorch_model.bin', or something else?"
] | 1,627 | 1,681 | 1,630 | NONE | null | ## Environment info
It happens in local machine, Colab, and my colleagues also.
- `transformers` version:
- Platform: Window, Colab
- Python version: 3.7
- PyTorch version (GPU?): 1.8.1 (GPU yes)
- Tensorflow version (GPU?):
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
@LysandreJik It is to do with 'bert-base-uncased'
## Information
Hi, I m having this error suddenly this afternoon. It was all okay before for days. It happens in local machine, Colab and also to my colleagues. I can access this file in browser https://huggingface.co/bert-base-uncased/resolve/main/config.json no problem. Btw, I m from Singapore. Any urgent help will be appreciated because I m rushing some project and stuck there.
Thanks
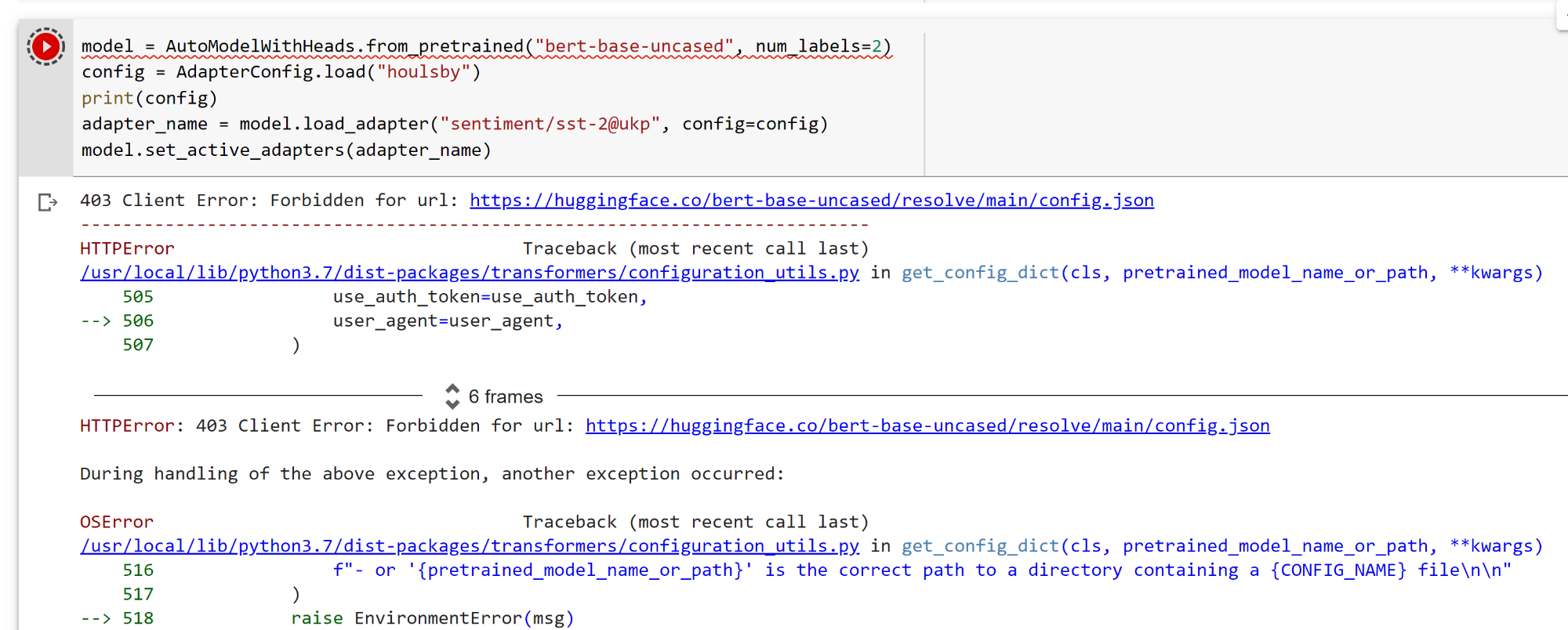
403 Client Error: Forbidden for url: https://huggingface.co/bert-base-uncased/resolve/main/config.json
---------------------------------------------------------------------------
HTTPError Traceback (most recent call last)
/usr/local/lib/python3.7/dist-packages/transformers/configuration_utils.py in get_config_dict(cls, pretrained_model_name_or_path, **kwargs)
505 use_auth_token=use_auth_token,
--> 506 user_agent=user_agent,
507 )
6 frames
HTTPError: 403 Client Error: Forbidden for url: https://huggingface.co/bert-base-uncased/resolve/main/config.json
During handling of the above exception, another exception occurred:
OSError Traceback (most recent call last)
/usr/local/lib/python3.7/dist-packages/transformers/configuration_utils.py in get_config_dict(cls, pretrained_model_name_or_path, **kwargs)
516 f"- or '{pretrained_model_name_or_path}' is the correct path to a directory containing a {CONFIG_NAME} file\n\n"
517 )
--> 518 raise EnvironmentError(msg)
519
520 except json.JSONDecodeError:
OSError: Can't load config for 'bert-base-uncased'. Make sure that:
- 'bert-base-uncased' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'bert-base-uncased' is the correct path to a directory containing a config.json file | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12941/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12941/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12940 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12940/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12940/comments | https://api.github.com/repos/huggingface/transformers/issues/12940/events | https://github.com/huggingface/transformers/issues/12940 | 955,950,852 | MDU6SXNzdWU5NTU5NTA4NTI= | 12,940 | Starting today, I get an error downloading pre-trained models | {
"login": "jason-weddington",
"id": 7495045,
"node_id": "MDQ6VXNlcjc0OTUwNDU=",
"avatar_url": "https://avatars.githubusercontent.com/u/7495045?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jason-weddington",
"html_url": "https://github.com/jason-weddington",
"followers_url": "https://api.github.com/users/jason-weddington/followers",
"following_url": "https://api.github.com/users/jason-weddington/following{/other_user}",
"gists_url": "https://api.github.com/users/jason-weddington/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jason-weddington/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jason-weddington/subscriptions",
"organizations_url": "https://api.github.com/users/jason-weddington/orgs",
"repos_url": "https://api.github.com/users/jason-weddington/repos",
"events_url": "https://api.github.com/users/jason-weddington/events{/privacy}",
"received_events_url": "https://api.github.com/users/jason-weddington/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi @jason-weddington, are you calling those URLs from any particular workload or infrastructure?\r\n\r\nThe only reason I can see where you would get a 403 on this URL is if your usage triggers our infra's firewall. Would you mind contacting us at `expert-acceleration at huggingface.co` so we can take a look?",
"Thanks, I'll email you. I'm running this in a notebook on my desktop, using my home internet connection, but we're also seeing this in Google Colab. The issue just stated today.",
"This is working again, thanks for the help."
] | 1,627 | 1,627 | 1,627 | NONE | null | ## Environment info
Copy-and-paste the text below in your GitHub issue and FILL OUT the two last points.
- `transformers` version: 2.1.1
- Platform: Linux-5.8.0-63-generic-x86_64-with-glibc2.29
- Python version: 3.8.10
- PyTorch version (GPU?): 1.9.0+cu111 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
## Information
Model I am using (Bert, XLNet ...):
roberta-base, but this is currently an issue with all models
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
- downloading pre-trained models is currently failing, this seems have have started just in the last day
## To reproduce
Steps to reproduce the behavior:
1. attempt to load any pre-trained model from HuggingFace (code below)
This code:
`generator = pipeline("text-generation", model="bert-base-uncased")`
Generates this error:
403 Client Error: Forbidden for url: https://huggingface.co/bert-base-uncased/resolve/main/config.json
---------------------------------------------------------------------------
HTTPError Traceback (most recent call last)
...
OSError: Can't load config for 'bert-base-uncased'. Make sure that:
- 'bert-base-uncased' is a correct model identifier listed on 'https://huggingface.co/models'
- or 'bert-base-uncased' is the correct path to a directory containing a config.json file
## Expected behavior
I expect the pre-trained model to be downloaded. This issue just started today.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12940/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12940/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12939 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12939/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12939/comments | https://api.github.com/repos/huggingface/transformers/issues/12939/events | https://github.com/huggingface/transformers/pull/12939 | 955,946,165 | MDExOlB1bGxSZXF1ZXN0Njk5NjIxMDE3 | 12,939 | Fix from_pretrained with corrupted state_dict | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"The test caught something weird with `sshleifer/tiny-distilbert-base-uncased-finetuned-sst-2-english` (another plus for this PR in my opinion!)\r\n\r\nThis model is used in the benchmark tests and in the zero shot pipeline but that model is beyond salvation: its weights have the names of BERT (in the keys) when it's a DistilBERT architecture, the number of labels of the config don't match the weights, the embedding size of the weights does not match the vocab size of the tokenzier or the embedding size in the config... \r\nLoading it for now just results in a random model (silently) since none of the weights can't be loaded.\r\n\r\nTo fix this, I created a new tiny random model following the same kind of config as `sshleifer/tiny-distilbert-base-uncased-finetuned-sst-2-english` (but not messed up) and stored it in `sgugger/tiny-distilbert-classification`.",
"I'll address @patrickvonplaten 's remarks regarding a more general refactor of the method to clean the code later on, merging this PR in the meantime."
] | 1,627 | 1,628 | 1,628 | COLLABORATOR | null | # What does this PR do?
As we discovered in #12843, when a state dictionary contains keys for the body of the model that are not prefixed *and* keys for the head, the body is loaded but the head is ignored with no warning.
This PR fixes that by keeping track of the expected key that do not contain the prefix and erroring out if we load only the body of the model and there are some keys to load in that list of expected keys that do not contain the prefix. I chose the error since those kinds of state dictionaries should not exist, since `from_pretrained` or `torch.save(model.state_dict())` do not generate those. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12939/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12939/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12939",
"html_url": "https://github.com/huggingface/transformers/pull/12939",
"diff_url": "https://github.com/huggingface/transformers/pull/12939.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12939.patch",
"merged_at": 1628070519000
} |
https://api.github.com/repos/huggingface/transformers/issues/12938 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12938/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12938/comments | https://api.github.com/repos/huggingface/transformers/issues/12938/events | https://github.com/huggingface/transformers/pull/12938 | 955,878,521 | MDExOlB1bGxSZXF1ZXN0Njk5NTYzNjU4 | 12,938 | Add CpmTokenizerFast | {
"login": "JetRunner",
"id": 22514219,
"node_id": "MDQ6VXNlcjIyNTE0MjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/22514219?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JetRunner",
"html_url": "https://github.com/JetRunner",
"followers_url": "https://api.github.com/users/JetRunner/followers",
"following_url": "https://api.github.com/users/JetRunner/following{/other_user}",
"gists_url": "https://api.github.com/users/JetRunner/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JetRunner/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JetRunner/subscriptions",
"organizations_url": "https://api.github.com/users/JetRunner/orgs",
"repos_url": "https://api.github.com/users/JetRunner/repos",
"events_url": "https://api.github.com/users/JetRunner/events{/privacy}",
"received_events_url": "https://api.github.com/users/JetRunner/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"> I don't think the fast tokenizer as it's written works for now, as the fast tokenizer do not call the `_tokenize` method.\n\nOops! It looks the old pull request isn't right. I'll take a closer look",
"@sgugger I've updated and tested it. It works fine - only needs to wait for the `tokenizer.json` to be uploaded.",
"Tokenizer file uploaded. Merging it."
] | 1,627 | 1,627 | 1,627 | CONTRIBUTOR | null | # What does this PR do?
Add a fast version of `CpmTokenizer`
Fixes #12837 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12938/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12938/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12938",
"html_url": "https://github.com/huggingface/transformers/pull/12938",
"diff_url": "https://github.com/huggingface/transformers/pull/12938.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12938.patch",
"merged_at": 1627585516000
} |
https://api.github.com/repos/huggingface/transformers/issues/12937 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12937/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12937/comments | https://api.github.com/repos/huggingface/transformers/issues/12937/events | https://github.com/huggingface/transformers/issues/12937 | 955,717,183 | MDU6SXNzdWU5NTU3MTcxODM= | 12,937 | Not able use TF Dataset on TPU when created via generator in Summarization example | {
"login": "prikmm",
"id": 47216475,
"node_id": "MDQ6VXNlcjQ3MjE2NDc1",
"avatar_url": "https://avatars.githubusercontent.com/u/47216475?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/prikmm",
"html_url": "https://github.com/prikmm",
"followers_url": "https://api.github.com/users/prikmm/followers",
"following_url": "https://api.github.com/users/prikmm/following{/other_user}",
"gists_url": "https://api.github.com/users/prikmm/gists{/gist_id}",
"starred_url": "https://api.github.com/users/prikmm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/prikmm/subscriptions",
"organizations_url": "https://api.github.com/users/prikmm/orgs",
"repos_url": "https://api.github.com/users/prikmm/repos",
"events_url": "https://api.github.com/users/prikmm/events{/privacy}",
"received_events_url": "https://api.github.com/users/prikmm/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"cc @Rocketknight1 ",
"Hi, I'm sorry for the slow response here! It does seem like an upstream bug, but we'll hopefully be supporting TF 2.6 in the next release. I'm also working on a refactor of the examples using a new data pipeline, so I'll test TPU training with this example when that's implemented to make sure it's working then.",
"> Hi, I'm sorry for the slow response here! It does seem like an upstream bug, but we'll hopefully be supporting TF 2.6 in the next release. I'm also working on a refactor of the examples using a new data pipeline, so I'll test TPU training with this example when that's implemented to make sure it's working then.\r\n\r\n@Rocketknight1 Ohh alright. I will keep this issue open for now since it is not yet solved just incase someone needs it. Eagerly waiting for increased TensorFlow support. :smiley:",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,633 | 1,633 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.9.1
- Platform: Kaggle/Colab
- Python version: 3.7.10
- Tensorflow version (GPU?): 2.4.1 / 2.5.1
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@patil-suraj, @Rocketknight1
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: (XSum)
* [ ] my own task or dataset: (give details below)
I am trying to replicate the summarization example present [here](https://github.com/huggingface/transformers/blob/master/examples/tensorflow/summarization/run_summarization.py) on XSum dataset using T5, but, am facing error when trying to use a TPU (it works on gpu).
## To reproduce
[Kaggle link](https://www.kaggle.com/rehanwild/tpu-tf-huggingface-error?scriptVersionId=69298817)
Error in TF 2.4.1:
```
---------------------------------------------------------------------------
UnavailableError Traceback (most recent call last)
<ipython-input-11-8513f78e8e35> in <module>
72 model.fit(tf_tokenized_train_ds,
73 validation_data=tf_tokenized_valid_ds,
---> 74 epochs=1,
75 )
76 #callbacks=[WandbCallback()])
/opt/conda/lib/python3.7/site-packages/wandb/integration/keras/keras.py in new_v2(*args, **kwargs)
122 for cbk in cbks:
123 set_wandb_attrs(cbk, val_data)
--> 124 return old_v2(*args, **kwargs)
125
126 training_arrays.orig_fit_loop = old_arrays
/opt/conda/lib/python3.7/site-packages/tensorflow/python/keras/engine/training.py in fit(self, x, y, batch_size, epochs, verbose, callbacks, validation_split, validation_data, shuffle, class_weight, sample_weight, initial_epoch, steps_per_epoch, validation_steps, validation_batch_size, validation_freq, max_queue_size, workers, use_multiprocessing)
1100 tmp_logs = self.train_function(iterator)
1101 if data_handler.should_sync:
-> 1102 context.async_wait()
1103 logs = tmp_logs # No error, now safe to assign to logs.
1104 end_step = step + data_handler.step_increment
/opt/conda/lib/python3.7/site-packages/tensorflow/python/eager/context.py in async_wait()
2328 an error state.
2329 """
-> 2330 context().sync_executors()
2331
2332
/opt/conda/lib/python3.7/site-packages/tensorflow/python/eager/context.py in sync_executors(self)
643 """
644 if self._context_handle:
--> 645 pywrap_tfe.TFE_ContextSyncExecutors(self._context_handle)
646 else:
647 raise ValueError("Context is not initialized.")
UnavailableError: 9 root error(s) found.
(0) Unavailable: {{function_node __inference_train_function_49588}} failed to connect to all addresses
Additional GRPC error information from remote target /job:localhost/replica:0/task:0/device:CPU:0:
:{"created":"@1627548744.739596558","description":"Failed to pick subchannel","file":"third_party/grpc/src/core/ext/filters/client_channel/client_channel.cc","file_line":4143,"referenced_errors":[{"created":"@1627548744.739593083","description":"failed to connect to all addresses","file":"third_party/grpc/src/core/ext/filters/client_channel/lb_policy/pick_first/pick_first.cc","file_line":398,"grpc_status":14}]}
[[{{node MultiDeviceIteratorGetNextFromShard}}]]
[[RemoteCall]]
[[IteratorGetNextAsOptional]]
[[cond_14/switch_pred/_200/_88]]
(1) Unavailable: {{function_node __inference_train_function_49588}} failed to connect to all addresses
Additional GRPC error information from remote target /job:localhost/replica:0/task:0/device:CPU:0:
:{"created":"@1627548744.739596558","description":"Failed to pick subchannel","file":"third_party/grpc/src/core/ext/filters/client_channel/client_channel.cc","file_line":4143,"referenced_errors":[{"created":"@1627548744.739593083","description":"failed to connect to all addresses","file":"third_party/grpc/src/core/ext/filters/client_channel/lb_policy/pick_first/pick_first.cc","file_line":398,"grpc_status":14}]}
[[{{node MultiDeviceIteratorGetNextFromShard}}]]
[[RemoteCall]]
[[IteratorGetNextAsOptional]]
[[strided_slice_18/_288]]
(2) Unavailable: {{function_node __inference_train_function_49588}} failed to connect to all addresses
Additional GRPC error information from remote target /job:localhost/replica:0/task:0/device:CPU:0:
:{"created":"@1627548744.739596558","description":"Failed to pick subchannel","file":"third_party/grpc/src/core/ext/filters/client_channel/client_channel.cc","file_line":4143,"referenced_errors":[{"created":"@1627548744.739593083","description":"failed to connect to all addresses","file":"third_party/grpc/src/core/ext/filters/client_channel/lb_policy/pick_first/pick_first.cc","file_line":398,"grpc_status":14}]}
[[{{node MultiDeviceIteratorGetNextFromShard}}]]
[[RemoteCall]]
[[IteratorGetNextAsOptional]]
[[tpu_compile_succeeded_assert/_1965840270157496994/_8/_335]]
(3) Unavailable: {{function_node __inference_train_function_49588}} failed to connect to all addresses
Additional GRPC error information from remote target /job:localhost/replica:0/task:0/device:CPU:0:
:{"created":"@1627548744.739596558","description":"Failed to pick subchannel","file":"third_party/grpc/src/core/ext/filters/client_channel/client_channel.cc","file_line":4143,"referenced_errors":[{"created":"@1627548744.739593083","description":"failed to connect to all addresses","file":"third_party/grpc/src/core/ext/filters/client_channel/lb_policy/pick_first/pick_first.cc","file_line":398,"grpc_status":14}]}
[[{{node MultiDeviceIteratorGetNextFromShard}}]]
[[RemoteCall]]
[[IteratorGetNextAsOptional]]
[[Pad_27/paddings/_218]]
(4) Unavailable: ... [truncated]
```
Error in TF 2.5.1:
```
NotFoundError: Op type not registered 'XlaSetDynamicDimensionSize' in binary running on n-f62ff7a1-w-0. Make sure the Op and Kernel are registered in the binary running in this process. Note that if you are loading a saved graph which used ops from tf.contrib, accessing (e.g.) `tf.contrib.resampler` should be done before importing the graph, as contrib ops are lazily registered when the module is first accessed.
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
No such error
<!-- A clear and concise description of what you would expect to happen. -->
EDIT:
I found tensorflow/tensorflow#48268, though it has been closed it is not yet completely solved I guess, since I found tensorflow/tensorflow#50980. I was not able to try with TF-2.6.0-rc1 as it is not yet supported by transformers. Since, this is an upstream bug, I think there should be an edit in the [run_summarization.py](https://github.com/huggingface/transformers/blob/master/examples/tensorflow/summarization/run_summarization.py) stating its incompatibility with TPU for the timebeing.
PS: Since, I have not ran the original script, I would like to know whether my above kaggle kernel is missing anything. I was able to run it on GPU. Only got the problem while using TPU. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12937/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12937/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12936 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12936/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12936/comments | https://api.github.com/repos/huggingface/transformers/issues/12936/events | https://github.com/huggingface/transformers/issues/12936 | 955,493,727 | MDU6SXNzdWU5NTU0OTM3Mjc= | 12,936 | `PretrainedTokenizer.return_special_tokens` returns incorrect mask | {
"login": "tamuhey",
"id": 24998666,
"node_id": "MDQ6VXNlcjI0OTk4NjY2",
"avatar_url": "https://avatars.githubusercontent.com/u/24998666?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tamuhey",
"html_url": "https://github.com/tamuhey",
"followers_url": "https://api.github.com/users/tamuhey/followers",
"following_url": "https://api.github.com/users/tamuhey/following{/other_user}",
"gists_url": "https://api.github.com/users/tamuhey/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tamuhey/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tamuhey/subscriptions",
"organizations_url": "https://api.github.com/users/tamuhey/orgs",
"repos_url": "https://api.github.com/users/tamuhey/repos",
"events_url": "https://api.github.com/users/tamuhey/events{/privacy}",
"received_events_url": "https://api.github.com/users/tamuhey/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Indeed, we have an error in the way the special tokens mask is computed here. See here for the slow tokenizer: https://github.com/huggingface/transformers/blob/3f44a66cb617c72efeef0c0b4201cbe2945d8edf/src/transformers/models/bert/tokenization_bert.py#L297-L299\r\n\r\nThis seems to also be the case for the fast tokenizer. Would you like to propose a fix? Pinging @SaulLu as it might be of interest to her.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Unstale",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"unstale\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"@SaulLu do you have time to look at this?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"**TL,DR :**\r\nTo come back on this issue, I would tend to think that in its current state this method (`get_special_tokens_mask`) and this argument (`return_special_tokens_mask` in `__call__`) is very useful. \r\n\r\nIndeed, this behavior is common to all tokenizers (I checked all tokenizers listed in `AutoTokenizer`, I can share a code if you want to have a look) and from my point of view it allows identifying the special tokens that are added by the `add_special_tokens` argument in the `__call__` method (the unknown token is not included in them, see the details section below). \r\n\r\nNevertheless, I imagine that it is not something obvious at all and that we should perhaps see how it could be better explained in the documentation. Futhermore, we can think about creating a new method that would generate a mask that would also include the unknow token if needed.\r\n\r\nWhat do you think about it ?\r\n\r\n**Details:**\r\nThe unknow special token does indeed differ from other special tokens in that it is a special token that is essential to the proper functioning of the tokenization algorithm and is therefore not an \"add-on\" oroptional like all other special tokens. A \"unknow\" token will correspond to a part of the initial text. \r\n\r\nBy the way, the documentation of `get_special_tokens_mask` is `Retrieves sequence ids from a token list that has no special tokens added. This method is called when adding special tokens using the tokenizer prepare_for_model or encode_plus methods.` and the unknow token is not added by the `prepare_for_model` or `encode_plus` methods but by the heart of the tokenizer : the tokenization algorithm.\r\n\r\n@tamuhey , could you share your use case where you need to identify the position of unknown tokens? That would be really useful to us :blush: ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Re-opened this issue as I thought a fix needed to be done - but reading @SaulLu's answer I believe the current behavior is correct.\r\n\r\nPlease let us know if this is an issue to your workflow and we'll look into solutions.",
"Hello @LysandreJik, I also encountered the problem. I will use the example in this [issue](https://github.com/huggingface/transformers/issues/16938).\r\n\r\n``` Python\r\nimport transformers\r\nprint(transformers.__version__)\r\ntokenizer = transformers.AutoTokenizer.from_pretrained('roberta-base')\r\n\r\nspecial_tokens_dict = {\"additional_special_tokens\": [\"<test1>\", \"<test2>\"]}\r\ntokenizer.add_special_tokens(special_tokens_dict)\r\n\r\nprocessed = tokenizer(\"this <test1> that <test2> this\", return_special_tokens_mask=True)\r\ntokens = tokenizer.convert_ids_to_tokens(processed.input_ids)\r\n\r\nfor i in range(len(processed.input_ids)):\r\n print(f\"{processed.input_ids[i]}\\t{tokens[i]}\\t{processed.special_tokens_mask[i]}\")\r\n```\r\n\r\n``` Python\r\nReturned output:\r\n\r\n0 <s> 1\r\n9226 this 0\r\n1437 Ġ 0\r\n50265 <test1> 0\r\n14 Ġthat 0\r\n1437 Ġ 0\r\n50266 <test2> 0\r\n42 Ġthis 0\r\n2 </s> 1\r\n\r\n\r\nExpected output:\r\n\r\n\r\n0 <s> 1\r\n9226 this 0\r\n1437 Ġ 0\r\n50265 <test1> 1\r\n14 Ġthat 0\r\n1437 Ġ 0\r\n50266 <test2> 1\r\n42 Ġthis 0\r\n2 </s> 1\r\n```\r\nMy goal is to train a RoBERTa model from scratch with two additional special tokens `<test1>` and `<test2>`. \r\n\r\n\r\nFor masked language modelling, I don't want customized special tokens to be masked during training. I used `tokenizer` and `DataCollatorForLanguageModeling`. I thought `special_tokens_mask` from tokenizer could [disable special token masking](https://github.com/huggingface/transformers/blob/v4.26.0/src/transformers/data/data_collator.py#L767) in `DataCollatorForLanguageModeling`.\r\n``` Python\r\nprocessed = tokenizer(\"this <test1> that <test2> this\", return_special_tokens_mask=True)\r\n```\r\nBut it didn't recognize `<test1>` and `<test2>`. \r\n\r\nThe workaround is \r\n``` Python\r\nprocessed = tokenizer(\"this <test1> that <test2> this\")\r\nprocessed['special_tokens_mask'] = tokenizer.get_special_tokens_mask(processed['input_ids'], already_has_special_tokens=True)\r\n```\r\nIt works fine for me on one sentence, but it seems `get_special_tokens_mask` cannot encode in batch, unlike the default tokenizer. \r\n\r\nDo you think it makes sense to modify the behaviour of `return_special_tokens_mask` or to create a new method?\r\n"
] | 1,627 | 1,675 | 1,641 | CONTRIBUTOR | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.9.1
- Platform: ubuntu
- Python version: 3.8
- PyTorch version (GPU?): 1.9
- Tensorflow version (GPU?):
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
@LysandreJik
## Information
Model I am using (Bert, XLNet ...): Bert
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
## To reproduce
```python
tokenizer = transformers.AutoTokenizer.from_pretrained("bert-base-uncased")
text = "foo 雲 bar"
tokens=tokenizer.tokenize(text)
print("tokens : ", tokens)
inputs = tokenizer(text, return_special_tokens_mask=True)
print("mask : ", inputs["special_tokens_mask"])
print("mask from input ids : ", tokenizer.get_special_tokens_mask(inputs["input_ids"], already_has_special_tokens=True))
```
Output:
```
tokens : ['foo', '[UNK]', 'bar']
mask : [1, 0, 0, 0, 1] # [UNK] is ignored!
mask from input ids : [1, 0, 1, 0, 1]
```
## Expected behavior
`[UNK]` is special token.
`get_special_tokens_mask` is consistent with `__call__`.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12936/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12936/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12935 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12935/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12935/comments | https://api.github.com/repos/huggingface/transformers/issues/12935/events | https://github.com/huggingface/transformers/issues/12935 | 955,444,383 | MDU6SXNzdWU5NTU0NDQzODM= | 12,935 | Better error message? `CUDA error: CUBLAS_STATUS_ALLOC_FAILED` | {
"login": "bayartsogt-ya",
"id": 43239645,
"node_id": "MDQ6VXNlcjQzMjM5NjQ1",
"avatar_url": "https://avatars.githubusercontent.com/u/43239645?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bayartsogt-ya",
"html_url": "https://github.com/bayartsogt-ya",
"followers_url": "https://api.github.com/users/bayartsogt-ya/followers",
"following_url": "https://api.github.com/users/bayartsogt-ya/following{/other_user}",
"gists_url": "https://api.github.com/users/bayartsogt-ya/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bayartsogt-ya/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bayartsogt-ya/subscriptions",
"organizations_url": "https://api.github.com/users/bayartsogt-ya/orgs",
"repos_url": "https://api.github.com/users/bayartsogt-ya/repos",
"events_url": "https://api.github.com/users/bayartsogt-ya/events{/privacy}",
"received_events_url": "https://api.github.com/users/bayartsogt-ya/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"That's something we can't solve I suppose, unfortunately. If you have a CUDA error like that, it's always advised to run your code on CPU as it provides a much more informative error message.",
"@NielsRogge \r\nThanks for the answer.\r\n\r\n> it's always advised to run your code on CPU as it provides a much more informative error message.\r\n\r\nDefinitely agree on this. Closing this issue"
] | 1,627 | 1,627 | 1,627 | CONTRIBUTOR | null | ## Environment info
- `transformers` version: 4.9.1
- Platform: Linux-5.4.104+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.11
- PyTorch version (GPU?): 1.9.0+cu102 (True)
- Tensorflow version (GPU?): 2.5.0 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes/no
- Using distributed or parallel set-up in script?: no
### Who can help
Models:
- gpt2: @patrickvonplaten, @LysandreJik
## Information
I found that out of index in embedding is little weird when using cuda.
```
RuntimeError: CUDA error: CUBLAS_STATUS_ALLOC_FAILED when calling `cublasCreate(handle)`
```
However, in cpu, it is understandable.
```
IndexError: index out of range in self
```
I just wondered if it needs better error message, or just leave it?
## To reproduce
### To get weird CUDA error:
```python
from transformers import AutoConfig, AutoModel, AutoTokenizer
import torch
config = AutoConfig.from_pretrained("gpt2")
config.update({"output_hidden_states":True,
"hidden_dropout_prob": 0.0,
"layer_norm_eps": 1e-7})
gpt_model = AutoModel.from_pretrained('gpt2').cuda()
input_ids = torch.randint(0, 100_000, (4, 128)).cuda()
attention_mask = torch.randint(0, 1, (4, 128)).cuda()
outputs = gpt_model(input_ids=input_ids, attention_mask=attention_mask)
last_hidden_states = outputs.last_hidden_states
print(last_hidden_states.shape)
```
```
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-2-b5d926c8a3c3> in <module>()
10 attention_mask = torch.randint(0, 1, (4, 248)).cuda()
11
---> 12 outputs = gpt_model(input_ids=input_ids, attention_mask=attention_mask)
13 last_hidden_states = outputs.last_hidden_states
14 print(last_hidden_states.shape)
7 frames
/usr/local/lib/python3.7/dist-packages/transformers/modeling_utils.py in forward(self, x)
1585 def forward(self, x):
1586 size_out = x.size()[:-1] + (self.nf,)
-> 1587 x = torch.addmm(self.bias, x.view(-1, x.size(-1)), self.weight)
1588 x = x.view(*size_out)
1589 return x
RuntimeError: CUDA error: CUBLAS_STATUS_ALLOC_FAILED when calling `cublasCreate(handle)`
```
### To get cpu error:
```python
from transformers import AutoConfig, AutoModel, AutoTokenizer
import torch
config = AutoConfig.from_pretrained("gpt2")
config.update({"output_hidden_states":True,
"hidden_dropout_prob": 0.0,
"layer_norm_eps": 1e-7})
gpt_model = AutoModel.from_pretrained('gpt2')
input_ids = torch.randint(0, 100_000, (4, 128))
attention_mask = torch.randint(0, 1, (4, 128))
outputs = gpt_model(input_ids=input_ids, attention_mask=attention_mask)
last_hidden_states = outputs.last_hidden_states
print(last_hidden_states.shape)
```
```
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-3-262727302e1e> in <module>()
9 input_ids = torch.randint(0, 100_000, (4, 248))
10 attention_mask = torch.randint(0, 1, (4, 248))
---> 11 outputs = gpt_model(input_ids=input_ids, attention_mask=attention_mask)
12 last_hidden_states = outputs.hidden_states
13 print(last_hidden_states)
4 frames
/usr/local/lib/python3.7/dist-packages/torch/nn/functional.py in embedding(input, weight, padding_idx, max_norm, norm_type, scale_grad_by_freq, sparse)
2041 # remove once script supports set_grad_enabled
2042 _no_grad_embedding_renorm_(weight, input, max_norm, norm_type)
-> 2043 return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
2044
2045
IndexError: index out of range in self
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12935/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12935/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12934 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12934/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12934/comments | https://api.github.com/repos/huggingface/transformers/issues/12934/events | https://github.com/huggingface/transformers/issues/12934 | 955,354,233 | MDU6SXNzdWU5NTUzNTQyMzM= | 12,934 | [Wav2vec Pretrain] KeyError: ‘attention_mask’ | {
"login": "LifaSun",
"id": 6188893,
"node_id": "MDQ6VXNlcjYxODg4OTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/6188893?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LifaSun",
"html_url": "https://github.com/LifaSun",
"followers_url": "https://api.github.com/users/LifaSun/followers",
"following_url": "https://api.github.com/users/LifaSun/following{/other_user}",
"gists_url": "https://api.github.com/users/LifaSun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LifaSun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LifaSun/subscriptions",
"organizations_url": "https://api.github.com/users/LifaSun/orgs",
"repos_url": "https://api.github.com/users/LifaSun/repos",
"events_url": "https://api.github.com/users/LifaSun/events{/privacy}",
"received_events_url": "https://api.github.com/users/LifaSun/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
}
] | [
"I've assigned Patrick, but looking at the docs of Wav2Vec2, is says:\r\n\r\n> Wav2Vec2 models that have set config.feat_extract_norm == \"group\", such as wav2vec2-base, have not been trained using attention_mask. For such models, input_values should simply be padded with 0 and no attention_mask should be passed.\r\n\r\n> For Wav2Vec2 models that have set config.feat_extract_norm == \"layer\", such as wav2vec2-lv60, attention_mask should be passed for batched inference.\r\n\r\nIt seems like the pre-training script currently only supports models that are pre-trained using an attention mask, such as `patrickvonplaten/wav2vec2-base-libri-100h`.",
"@NielsRogge \r\n\r\nGot it! It works well now. Thank you for your advice! ",
"@NielsRogge The training process can start normally. But the loss doesn't decrease any more after ~300 steps. I have tried different datasets, including English and Chinese data. Could you help me check it? I appreciate it so much!\r\n\r\n{'loss': 4.0485, 'learning_rate': 3.3333333333333335e-05, 'epoch': 0.07}\r\n{'loss': 3.7386, 'learning_rate': 3.5000000000000004e-05, 'epoch': 0.07}\r\n{'loss': 1.5081, 'learning_rate': 3.6666666666666666e-05, 'epoch': 0.07}\r\n{'loss': 4.2322, 'learning_rate': 3.8333333333333334e-05, 'epoch': 0.08}\r\n{'loss': 4.1046, 'learning_rate': 4e-05, 'epoch': 0.08}\r\n{'loss': 3.2526, 'learning_rate': 4.1666666666666665e-05, 'epoch': 0.08}\r\n{'loss': 1.5949, 'learning_rate': 4.3333333333333334e-05, 'epoch': 0.09}\r\n{'loss': 0.0013, 'learning_rate': 4.4999999999999996e-05, 'epoch': 0.09}\r\n{'loss': 0.0013, 'learning_rate': 4.666666666666667e-05, 'epoch': 0.09}\r\n{'loss': 0.0013, 'learning_rate': 4.8333333333333334e-05, 'epoch': 0.1}\r\n\r\n{'loss': 0.0013, 'learning_rate': 5e-05, 'epoch': 0.1}\r\n{'loss': 0.0013, 'learning_rate': 5.1666666666666664e-05, 'epoch': 0.1}\r\n\r\n{'loss': 0.0013, 'learning_rate': 5.333333333333334e-05, 'epoch': 0.11}\r\n\r\n{'loss': 0.0013, 'learning_rate': 5.5e-05, 'epoch': 0.11}\r\n 4%|███▏ | 340/8922 [07:55<3:33:42, 1.49s/it]\r\n{'loss': 0.0013, 'learning_rate': 5.6666666666666664e-05, 'epoch': 0.11}\r\n 4%|███▎ | 350/8922 [08:04<1:50:16, 1.30it/s]\r\n{'loss': 0.0014, 'learning_rate': 5.833333333333333e-05, 'epoch': 0.12}\r\n{'loss': 0.0013, 'learning_rate': 6e-05, 'epoch': 0.12}\r\n 4%|███▍ | 370/8922 [08:34<2:31:36, 1.06s/it]\r\n{'loss': 0.0013, 'learning_rate': 6.166666666666667e-05, 'epoch': 0.12}\r\n{'loss': 0.0013, 'learning_rate': 6.333333333333335e-05, 'epoch': 0.13}\r\n{'loss': 0.0013, 'learning_rate': 6.500000000000001e-05, 'epoch': 0.13}\r\n{'loss': 0.0013, 'learning_rate': 6.666666666666667e-05, 'epoch': 0.13}\r\n{'loss': 0.0013, 'learning_rate': 6.833333333333333e-05, 'epoch': 0.14}\r\n\r\nBtw, others have the same problem. Refer to https://discuss.huggingface.co/t/why-is-wav2vec-pretraining-loss-not-decreasing/8112",
"> @NielsRogge The training process can start normally. But the loss doesn't decrease any more after ~300 steps. I have tried different datasets, including English and Chinese data. Could you help me check it? I appreciate it so much!\r\n> \r\n> {'loss': 4.0485, 'learning_rate': 3.3333333333333335e-05, 'epoch': 0.07} {'loss': 3.7386, 'learning_rate': 3.5000000000000004e-05, 'epoch': 0.07} {'loss': 1.5081, 'learning_rate': 3.6666666666666666e-05, 'epoch': 0.07} {'loss': 4.2322, 'learning_rate': 3.8333333333333334e-05, 'epoch': 0.08} {'loss': 4.1046, 'learning_rate': 4e-05, 'epoch': 0.08} {'loss': 3.2526, 'learning_rate': 4.1666666666666665e-05, 'epoch': 0.08} {'loss': 1.5949, 'learning_rate': 4.3333333333333334e-05, 'epoch': 0.09} {'loss': 0.0013, 'learning_rate': 4.4999999999999996e-05, 'epoch': 0.09} {'loss': 0.0013, 'learning_rate': 4.666666666666667e-05, 'epoch': 0.09} {'loss': 0.0013, 'learning_rate': 4.8333333333333334e-05, 'epoch': 0.1}\r\n> \r\n> {'loss': 0.0013, 'learning_rate': 5e-05, 'epoch': 0.1} {'loss': 0.0013, 'learning_rate': 5.1666666666666664e-05, 'epoch': 0.1}\r\n> \r\n> {'loss': 0.0013, 'learning_rate': 5.333333333333334e-05, 'epoch': 0.11}\r\n> \r\n> {'loss': 0.0013, 'learning_rate': 5.5e-05, 'epoch': 0.11} 4%|███▏ | 340/8922 [07:55<3:33:42, 1.49s/it] {'loss': 0.0013, 'learning_rate': 5.6666666666666664e-05, 'epoch': 0.11} 4%|███▎ | 350/8922 [08:04<1:50:16, 1.30it/s] {'loss': 0.0014, 'learning_rate': 5.833333333333333e-05, 'epoch': 0.12} {'loss': 0.0013, 'learning_rate': 6e-05, 'epoch': 0.12} 4%|███▍ | 370/8922 [08:34<2:31:36, 1.06s/it] {'loss': 0.0013, 'learning_rate': 6.166666666666667e-05, 'epoch': 0.12} {'loss': 0.0013, 'learning_rate': 6.333333333333335e-05, 'epoch': 0.13} {'loss': 0.0013, 'learning_rate': 6.500000000000001e-05, 'epoch': 0.13} {'loss': 0.0013, 'learning_rate': 6.666666666666667e-05, 'epoch': 0.13} {'loss': 0.0013, 'learning_rate': 6.833333333333333e-05, 'epoch': 0.14}\r\n> \r\n> Btw, others have the same problem. Refer to https://discuss.huggingface.co/t/why-is-wav2vec-pretraining-loss-not-decreasing/8112\r\n\r\nHello, I’m facing the same problem pretraining my model from English base model. Have you solved it?",
"Hey guys, \r\n\r\nI think this is a good example of how it looks like when the `\"contrastive_loss\"` function collapses and the training becomes useless. If you see an instant drop to `0.0013` this means that the training didn't work. I've seen this countless times in my tests and there is not a very easy fix IMO.\r\n\r\nWhat seems to work best to counteract this is to do the following in this line:\r\nhttps://github.com/huggingface/transformers/blob/4c99e553c152ce9b709d7c138379b0b126ed2fa1/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py#L327 \r\n\r\nReplace:\r\n`mask_time_indices=mask_time_indices,` by `mask_time_indices=batch[\"sub_attention_mask\"]`\r\n\r\nThis is known to be a more robust training that however seems to give slightly worse results. \r\n\r\nAlso, I think [speechbrain](https://speechbrain.github.io/) is working quite a bit on getting Wav2Vec2-Pretraining more robust and general, as far as I know those guys have done much more experiements with pretraining than I have so it might be worth checking out their pretraining script as well. \r\n\r\ncc @TParcollet \r\n",
"I'm hoping to find some time to again dive a bit deeper into wav2vec2 pretraining over the Chrismas holidays and then make a comprehensive guide on how to pretrain wav2vec2 at some point. I'm really not sure though whether I find the time",
"> Hey guys,\r\n> \r\n> I think this is a good example of how it looks like when the `\"contrastive_loss\"` function collapses and the training becomes useless. If you see an instant drop to `0.0013` this means that the training didn't work. I've seen this countless times in my tests and there is not a very easy fix IMO.\r\n> \r\n> What seems to work best to counteract this is to do the following in this line:\r\n> \r\n> https://github.com/huggingface/transformers/blob/4c99e553c152ce9b709d7c138379b0b126ed2fa1/examples/pytorch/speech-pretraining/run_wav2vec2_pretraining_no_trainer.py#L327\r\n> \r\n> Replace: `mask_time_indices=mask_time_indices,` by `mask_time_indices=batch[\"sub_attention_mask\"]`\r\n> \r\n> This is known to be a more robust training that however seems to give slightly worse results.\r\n> \r\n> Also, I think [speechbrain](https://speechbrain.github.io/) is working quite a bit on getting Wav2Vec2-Pretraining more robust and general, as far as I know those guys have done much more experiements with pretraining than I have so it might be worth checking out their pretraining script as well.\r\n> \r\n> cc @TParcollet\r\n\r\nHi. The `%_mask_idx ` i got is so low, I wonder if you changed `mask_prob` in the configuration file from 0.05 to 0.5?",
"For passing the mask_prob should be around 0.65",
"FYI I ran into the same issue (missing attention_mask in pre-trained model) saving my model on a custom dataset from the greek emotion classification using wav2vec2 from this notebook:\r\n\r\nhttps://colab.research.google.com/github/m3hrdadfi/soxan/blob/main/notebooks/Emotion_recognition_in_Greek_speech_using_Wav2Vec2.ipynb#scrollTo=n0HzBneBK84G\r\n\r\nChanging the model to 'facebook/wav2vec2-large-960h-lv60-self' helped."
] | 1,627 | 1,673 | 1,627 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.9.1
- Platform: Google Colab
- Python version: 3.7 & 3.8
- PyTorch version (GPU?): 1.8
- Tensorflow version (GPU?): N/A
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
### Who can help
Models:
@patrickvonplaten
## Information
Model I am using Wav2vec Pretrain:
The problem arises when using:
https://github.com/huggingface/transformers/blob/master/examples/research_projects/wav2vec2/run_pretrain.py
The tasks I am working on is:
* [ ] an official wav2vec pretrain task: (give the name)
* [ ] my own task or dataset: (give details below)
Wav2vec on TIMIT
## To reproduce
Steps to reproduce the behavior:
python run_pretrain.py --output_dir="./wav2vec2-base" \
--num_train_epochs="3" \
--per_device_train_batch_size="32" \
--per_device_eval_batch_size="32" \
--gradient_accumulation_steps="2" \
--save_total_limit="3" \
--save_steps="500" \
--logging_steps="10" \
--learning_rate="5e-4" \
--weight_decay="0.01" \
--warmup_steps="3000" \
--model_name_or_path="facebook/wav2vec2-base" \
--dataset_name="timit_asr" \
--train_split_name="train" \
--preprocessing_num_workers="4" \
--max_duration_in_seconds="10.0" \
--group_by_length \
--verbose_logging \
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
***** Running training *****
Num examples = 185
Num Epochs = 3
Instantaneous batch size per device = 32
Total train batch size (w. parallel, distributed & accumulation) = 64
Gradient Accumulation steps = 2
Total optimization steps = 9
0% 0/9 [00:00<?, ?it/s]Traceback (most recent call last):
File "wav2vec_pretrain.py", line 388, in <module>
main()
File "wav2vec_pretrain.py", line 384, in main
trainer.train()
File "/usr/local/lib/python3.7/dist-packages/transformers/trainer.py", line 1254, in train
for step, inputs in enumerate(epoch_iterator):
File "/usr/local/lib/python3.7/dist-packages/torch/utils/data/dataloader.py", line 521, in __next__
data = self._next_data()
File "/usr/local/lib/python3.7/dist-packages/torch/utils/data/dataloader.py", line 561, in _next_data
data = self._dataset_fetcher.fetch(index) # may raise StopIteration
File "/usr/local/lib/python3.7/dist-packages/torch/utils/data/_utils/fetch.py", line 47, in fetch
return self.collate_fn(data)
File "wav2vec_pretrain.py", line 176, in __call__
if batch["attention_mask"] is not None:
File "/usr/local/lib/python3.7/dist-packages/transformers/feature_extraction_utils.py", line 81, in __getitem__
return self.data[item]
KeyError: 'attention_mask'
Thank you very much!
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12934/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12934/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12933 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12933/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12933/comments | https://api.github.com/repos/huggingface/transformers/issues/12933/events | https://github.com/huggingface/transformers/pull/12933 | 955,259,242 | MDExOlB1bGxSZXF1ZXN0Njk5MDM2MzQ2 | 12,933 | ONNX v2 raises an Exception when using PyTorch < 1.8.0 | {
"login": "mfuntowicz",
"id": 2241520,
"node_id": "MDQ6VXNlcjIyNDE1MjA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2241520?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mfuntowicz",
"html_url": "https://github.com/mfuntowicz",
"followers_url": "https://api.github.com/users/mfuntowicz/followers",
"following_url": "https://api.github.com/users/mfuntowicz/following{/other_user}",
"gists_url": "https://api.github.com/users/mfuntowicz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mfuntowicz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mfuntowicz/subscriptions",
"organizations_url": "https://api.github.com/users/mfuntowicz/orgs",
"repos_url": "https://api.github.com/users/mfuntowicz/repos",
"events_url": "https://api.github.com/users/mfuntowicz/events{/privacy}",
"received_events_url": "https://api.github.com/users/mfuntowicz/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@sgugger failing tests seem unrelated to this PR, let you check 👍🏻 "
] | 1,627 | 1,627 | 1,627 | MEMBER | null | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12933/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12933/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12933",
"html_url": "https://github.com/huggingface/transformers/pull/12933",
"diff_url": "https://github.com/huggingface/transformers/pull/12933.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12933.patch",
"merged_at": 1627574549000
} |
|
https://api.github.com/repos/huggingface/transformers/issues/12932 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12932/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12932/comments | https://api.github.com/repos/huggingface/transformers/issues/12932/events | https://github.com/huggingface/transformers/issues/12932 | 955,150,972 | MDU6SXNzdWU5NTUxNTA5NzI= | 12,932 | Error when trying `push_to_hub` for a fine-tuned model on Colab | {
"login": "phosseini",
"id": 25105263,
"node_id": "MDQ6VXNlcjI1MTA1MjYz",
"avatar_url": "https://avatars.githubusercontent.com/u/25105263?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/phosseini",
"html_url": "https://github.com/phosseini",
"followers_url": "https://api.github.com/users/phosseini/followers",
"following_url": "https://api.github.com/users/phosseini/following{/other_user}",
"gists_url": "https://api.github.com/users/phosseini/gists{/gist_id}",
"starred_url": "https://api.github.com/users/phosseini/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/phosseini/subscriptions",
"organizations_url": "https://api.github.com/users/phosseini/orgs",
"repos_url": "https://api.github.com/users/phosseini/repos",
"events_url": "https://api.github.com/users/phosseini/events{/privacy}",
"received_events_url": "https://api.github.com/users/phosseini/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Just tried on a fresh colab and could upload a model without any problem (as long as there is no \"/\" in the model ID). Do you already have a model with the same username maybe?\r\n\r\nNote that you are missing the step `! git config --global user.email \"your_email\"` in the preparation.\r\n\r\nAre you certain you do have the latest version of Transformers installed?",
"Thanks for the tips. Problem solved. I think it was because I created a repo and a model with the very name on the Hugging Face website (I thought there should already be a model with the name there if we want to push the model.) I removed the model with the same name and now it works! "
] | 1,627 | 1,627 | 1,627 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.9.1
- Platform: Colab
### Who can help
@sgugger
## To reproduce
Steps to reproduce the behavior. This is the code I'm running:
I first install the following packages:
```
! pip install transformers datasets
! sudo apt-get install git-lfs
```
Then I run the `! transformers-cli login` and successfully login and my token is saved at: `/root/.huggingface/token`
Then I run the following code:
```
from transformers import AutoModel
model = AutoModel.from_pretrained('/path/to/my/fine-tuned/model/on/my/google/drive')
model.push_to_hub("my-username/my-model-name")
```
Per @sgugger's suggestion, I also tried the following line but I'm getting the very error:
`model.push_to_hub("my-model-name")`
And this is the error:
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-3-84aee0bf13c0> in <module>()
4 model = AutoModel.from_pretrained(model_path)
5
----> 6 model.push_to_hub("my-username/my-model-name")
2 frames
/usr/local/lib/python3.7/dist-packages/huggingface_hub/repository.py in __init__(self, local_dir, clone_from, use_auth_token, git_user, git_email)
102 )
103 raise ValueError(
--> 104 "If not specifying `clone_from`, you need to pass Repository a valid git clone."
105 )
106
ValueError: If not specifying `clone_from`, you need to pass Repository a valid git clone.
```
## Expected behavior
To have my fine-tuned model uploaded to my private repo on Huggingface.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12932/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12932/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12931 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12931/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12931/comments | https://api.github.com/repos/huggingface/transformers/issues/12931/events | https://github.com/huggingface/transformers/issues/12931 | 955,035,021 | MDU6SXNzdWU5NTUwMzUwMjE= | 12,931 | How to fuse copy mechnism into the GenerationMixin? | {
"login": "Hannibal046",
"id": 38466901,
"node_id": "MDQ6VXNlcjM4NDY2OTAx",
"avatar_url": "https://avatars.githubusercontent.com/u/38466901?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Hannibal046",
"html_url": "https://github.com/Hannibal046",
"followers_url": "https://api.github.com/users/Hannibal046/followers",
"following_url": "https://api.github.com/users/Hannibal046/following{/other_user}",
"gists_url": "https://api.github.com/users/Hannibal046/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Hannibal046/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Hannibal046/subscriptions",
"organizations_url": "https://api.github.com/users/Hannibal046/orgs",
"repos_url": "https://api.github.com/users/Hannibal046/repos",
"events_url": "https://api.github.com/users/Hannibal046/events{/privacy}",
"received_events_url": "https://api.github.com/users/Hannibal046/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Pinging @patrickvonplaten and @patil-suraj ",
"Hey @Hannibal046,\r\n\r\nCould you clarify a bit what you mean by \"copy-mechanism\" ?\r\nMaybe a code example of what you want to do?",
"Hello,I also find others to talk about the `copy mechanism`. in this [link](https://discuss.huggingface.co/t/copying-mechanism-for-transformer/5025)\r\nBTW,could you please check my another issue about BART Generation? It confused me a long time, https://github.com/huggingface/transformers/issues/12870, thanks so much.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,630 | 1,630 | NONE | null | Hello, is there any way to directly fuse copy mechanism into beamsearch? since the beam_search function receive model_output.logit rather than probabily of vocab?
https://github.com/huggingface/transformers/blob/72aee83ced5f31302c5e331d896412737287f976/src/transformers/generation_utils.py#L1801 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12931/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12931/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12930 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12930/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12930/comments | https://api.github.com/repos/huggingface/transformers/issues/12930/events | https://github.com/huggingface/transformers/pull/12930 | 954,934,587 | MDExOlB1bGxSZXF1ZXN0Njk4NzU2MzU1 | 12,930 | Print defaults when using --help for scripts | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This is indeed a great addition!"
] | 1,627 | 1,628 | 1,627 | COLLABORATOR | null | # What does this PR do?
This PR uses the solution suggested in #12924 to automatically print the defaults of each argument when using `--help` for the script for instance, using `--help` on any of the examples would yield:
```
--push_to_hub [PUSH_TO_HUB]
Whether or not to upload the trained model to the
model hub after training.
```
before, and after this PR it will yield
```
--push_to_hub [PUSH_TO_HUB]
Whether or not to upload the trained model to the
model hub after training. (default: False)
```
Fixes #12924 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12930/reactions",
"total_count": 3,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 3,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12930/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12930",
"html_url": "https://github.com/huggingface/transformers/pull/12930",
"diff_url": "https://github.com/huggingface/transformers/pull/12930.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12930.patch",
"merged_at": 1627486641000
} |
https://api.github.com/repos/huggingface/transformers/issues/12929 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12929/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12929/comments | https://api.github.com/repos/huggingface/transformers/issues/12929/events | https://github.com/huggingface/transformers/pull/12929 | 954,857,447 | MDExOlB1bGxSZXF1ZXN0Njk4Njg4Nzc1 | 12,929 | Add option to set max_len in run_ner | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,627 | 1,627 | 1,627 | COLLABORATOR | null | # What does this PR do?
This PR adds an option to the set the maximum sequence length in `run_ner`. Pointed out in #12817, this script does not have that option (but the TF version and `run_ner_no_trainer` both have). | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12929/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12929/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12929",
"html_url": "https://github.com/huggingface/transformers/pull/12929",
"diff_url": "https://github.com/huggingface/transformers/pull/12929.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12929.patch",
"merged_at": 1627479492000
} |
https://api.github.com/repos/huggingface/transformers/issues/12928 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12928/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12928/comments | https://api.github.com/repos/huggingface/transformers/issues/12928/events | https://github.com/huggingface/transformers/pull/12928 | 954,847,552 | MDExOlB1bGxSZXF1ZXN0Njk4NjgwMzQ2 | 12,928 | Fix QA examples for roberta tokenizer | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,627 | 1,627 | 1,627 | COLLABORATOR | null | # What does this PR do?
https://github.com/huggingface/datasets/pull/2586 has changed the SQUAD dataset and doesn't clean anymore the whitespace in questions. This in turn makes the tokenization fail for tokenizers that don't remove whitespace (like RoBERTa): some questions begin with loooots of spaces and so the truncation strategy then fails because the question itself is longer than the max length (the infuriating example number 107709 of the training set for instance).
For more context, see #12880
This PR addresses that by removing the whitespace on the left of questions. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12928/reactions",
"total_count": 4,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 4,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12928/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12928",
"html_url": "https://github.com/huggingface/transformers/pull/12928",
"diff_url": "https://github.com/huggingface/transformers/pull/12928.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12928.patch",
"merged_at": 1627480069000
} |
https://api.github.com/repos/huggingface/transformers/issues/12927 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12927/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12927/comments | https://api.github.com/repos/huggingface/transformers/issues/12927/events | https://github.com/huggingface/transformers/pull/12927 | 954,820,673 | MDExOlB1bGxSZXF1ZXN0Njk4NjU3MTUx | 12,927 | Add missing @classmethod decorators | {
"login": "willfrey",
"id": 13784361,
"node_id": "MDQ6VXNlcjEzNzg0MzYx",
"avatar_url": "https://avatars.githubusercontent.com/u/13784361?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/willfrey",
"html_url": "https://github.com/willfrey",
"followers_url": "https://api.github.com/users/willfrey/followers",
"following_url": "https://api.github.com/users/willfrey/following{/other_user}",
"gists_url": "https://api.github.com/users/willfrey/gists{/gist_id}",
"starred_url": "https://api.github.com/users/willfrey/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/willfrey/subscriptions",
"organizations_url": "https://api.github.com/users/willfrey/orgs",
"repos_url": "https://api.github.com/users/willfrey/repos",
"events_url": "https://api.github.com/users/willfrey/events{/privacy}",
"received_events_url": "https://api.github.com/users/willfrey/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Fun fact: the poor guy @classmethod will be pinged consistently if you add this handle to the commit message 😂\r\n\r\nI'm removing `@` from it!"
] | 1,627 | 1,627 | 1,627 | CONTRIBUTOR | null | `_BaseAutoModelClass` was missing `@classmethod` decorators on the `from_config(...)` and `from_pretrained(...)` methods. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12927/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12927/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12927",
"html_url": "https://github.com/huggingface/transformers/pull/12927",
"diff_url": "https://github.com/huggingface/transformers/pull/12927.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12927.patch",
"merged_at": 1627491698000
} |
https://api.github.com/repos/huggingface/transformers/issues/12926 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12926/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12926/comments | https://api.github.com/repos/huggingface/transformers/issues/12926/events | https://github.com/huggingface/transformers/issues/12926 | 954,608,901 | MDU6SXNzdWU5NTQ2MDg5MDE= | 12,926 | Misleading warning when using DPRContextEncoderTokenizer | {
"login": "tadejsv",
"id": 11489772,
"node_id": "MDQ6VXNlcjExNDg5Nzcy",
"avatar_url": "https://avatars.githubusercontent.com/u/11489772?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tadejsv",
"html_url": "https://github.com/tadejsv",
"followers_url": "https://api.github.com/users/tadejsv/followers",
"following_url": "https://api.github.com/users/tadejsv/following{/other_user}",
"gists_url": "https://api.github.com/users/tadejsv/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tadejsv/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tadejsv/subscriptions",
"organizations_url": "https://api.github.com/users/tadejsv/orgs",
"repos_url": "https://api.github.com/users/tadejsv/repos",
"events_url": "https://api.github.com/users/tadejsv/events{/privacy}",
"received_events_url": "https://api.github.com/users/tadejsv/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Yes you are not using it, but it's the tokenizer that was registered with the checkpoint `'facebook/dpr-ctx_encoder-single-nq-base'` so the library is warning you there is a mismatch (which may be okay in this instance).",
"Thanks, but `facebook/dpr-ctx_encoder-single-nq-base` encoder should be registered as a context encoder (that's what the `ctx` in its name means) - the corresponding question encoder is `facebook/dpr-question_encoder-single-nq-base`.\r\n\r\nI've looked through the source code of the model on the hub ([here](https://huggingface.co/facebook/dpr-ctx_encoder-single-nq-base/tree/main)), and I do not see any reference to the question encoder. In the source code of the tokenizer ([here](https://github.com/huggingface/transformers/blob/master/src/transformers/models/dpr/tokenization_dpr.py)) all the correspondences seem to be set up correctly too - so this issue is a bit puzzling.\r\n\r\n",
"It looks like the model does not specify its proper tokenizer then: the default for all DPR models is `DPRQuestionEncoderTokenizer` but since it's not the correct one, there should be a `tokenizer_class` set to `DPRContextEncoderTokenizer` in that repo.\r\n\r\nIn any case, I just looked at the source code and the two classes are exactly the same, so there is no difference between the tokenizers (why have two different ones then @lhoestq ?)",
"If I am not mistaken, the situation is the same for encoders as well - both context and question encoder could have been the same class",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"#load pre-trained model and tokenizer\r\ntokenizer = Wav2Vec2Tokenizer.from_pretrained(\"facebook/wav2vec2-base-960h\")\r\nmodel = Wav2Vec2ForCTC.from_pretrained(\"facebook/wav2vec2-base-960h\")\r\n\r\n\r\nThe tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization. \r\nThe tokenizer class you load from this checkpoint is 'Wav2Vec2CTCTokenizer'. \r\nThe class this function is called from is 'Wav2Vec2Tokenizer'.\r\n/Users/sangram/opt/anaconda3/envs/Speech/lib/python3.9/site-packages/transformers/models/wav2vec2/tokenization_wav2vec2.py:421: FutureWarning: The class `Wav2Vec2Tokenizer` is deprecated and will be removed in version 5 of Transformers. Please use `Wav2Vec2Processor` or `Wav2Vec2CTCTokenizer` instead.\r\n warnings.warn("
] | 1,627 | 1,651 | 1,630 | CONTRIBUTOR | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: `4.9.1`
- Platform: Ubuntu
- Python version: 3.8.10
- PyTorch version (GPU?): 1.9.0
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
- tokenizers: @LysandreJik
## Information
When running this code
``` python
from transformers import (
DPRContextEncoder,
DPRContextEncoderTokenizer,
)
tokenizer = DPRContextEncoderTokenizer.from_pretrained('facebook/dpr-ctx_encoder-single-nq-base')
model = DPRContextEncoder.from_pretrained('facebook/dpr-ctx_encoder-single-nq-base')
```
I receive this warning
```
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'DPRQuestionEncoderTokenizer'.
The class this function is called from is 'DPRContextEncoderTokenizer'.
```
## Expected behavior
This warning should not be there - I am not using the Question encoder at all | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12926/reactions",
"total_count": 4,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12926/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12925 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12925/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12925/comments | https://api.github.com/repos/huggingface/transformers/issues/12925/events | https://github.com/huggingface/transformers/issues/12925 | 954,383,822 | MDU6SXNzdWU5NTQzODM4MjI= | 12,925 | How to reproduce XLNet correctly And What is the config for finetuning XLNet? | {
"login": "sherlcok314159",
"id": 76043326,
"node_id": "MDQ6VXNlcjc2MDQzMzI2",
"avatar_url": "https://avatars.githubusercontent.com/u/76043326?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sherlcok314159",
"html_url": "https://github.com/sherlcok314159",
"followers_url": "https://api.github.com/users/sherlcok314159/followers",
"following_url": "https://api.github.com/users/sherlcok314159/following{/other_user}",
"gists_url": "https://api.github.com/users/sherlcok314159/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sherlcok314159/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sherlcok314159/subscriptions",
"organizations_url": "https://api.github.com/users/sherlcok314159/orgs",
"repos_url": "https://api.github.com/users/sherlcok314159/repos",
"events_url": "https://api.github.com/users/sherlcok314159/events{/privacy}",
"received_events_url": "https://api.github.com/users/sherlcok314159/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1897896961,
"node_id": "MDU6TGFiZWwxODk3ODk2OTYx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Migration",
"name": "Migration",
"color": "e99695",
"default": false,
"description": ""
}
] | closed | false | null | [] | [
"Hi,\r\n\r\nFor training related questions, please refer to the [forum](https://discuss.huggingface.co/). We like to keep Github issues for bugs/feature requests.\r\n\r\nThanks!"
] | 1,627 | 1,627 | 1,627 | NONE | null | I fintune a XLNet for English text classification. But it seems that I did something wrong about it because xlnet-base is worse than bert-base in my case. I set every 1/3 epoch report validation accuracy. At the beginning Bert-base is about 0.50 while XLNet-base is only 0.24. The config I use for xlnet is listed as follows:
```python
config = {
batch_size = 4,
learning_rate = 1e-5,
gradient_accumulation_steps = 32,
epochs = 4,
max_sep_length = 384,
weight_decay = 0.01,
adam_epsilon = 1e-6,
16-bit_training = False
}
```
Does finetune XLNet needs a special setting or XLNet converges slowly?
Thanks for everyone willing to help in advance! :-)
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12925/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12925/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12924 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12924/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12924/comments | https://api.github.com/repos/huggingface/transformers/issues/12924/events | https://github.com/huggingface/transformers/issues/12924 | 954,364,858 | MDU6SXNzdWU5NTQzNjQ4NTg= | 12,924 | Feature request: Show command line argument defaults | {
"login": "mbforbes",
"id": 1170062,
"node_id": "MDQ6VXNlcjExNzAwNjI=",
"avatar_url": "https://avatars.githubusercontent.com/u/1170062?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mbforbes",
"html_url": "https://github.com/mbforbes",
"followers_url": "https://api.github.com/users/mbforbes/followers",
"following_url": "https://api.github.com/users/mbforbes/following{/other_user}",
"gists_url": "https://api.github.com/users/mbforbes/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mbforbes/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mbforbes/subscriptions",
"organizations_url": "https://api.github.com/users/mbforbes/orgs",
"repos_url": "https://api.github.com/users/mbforbes/repos",
"events_url": "https://api.github.com/users/mbforbes/events{/privacy}",
"received_events_url": "https://api.github.com/users/mbforbes/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This is a very reasonable request and thanks for suggesting an easy way to do it! I added that in the PR linked above.",
"Wow, thank you so much for the support and quick turnaround, I really appreciate it!! 🎉 "
] | 1,627 | 1,627 | 1,627 | CONTRIBUTOR | null | # 🚀 Feature request
When running with `--help`, show the default values for command line arguments.
## Motivation
There are dozens of command line arguments. When I'm trying to figure out how to run a script, I often want to know what value is being used when I don't specify it. But running with `--help` doesn't show the default values unless it's explicitly written in the description (which is only for three of them for the example script I'm using).
For example, `--evaluation_strategy`
```
--evaluation_strategy {no,steps,epoch}
The evaluation strategy to use.
```
This ends up being a bit of a frustrating user experience. The two ways I currently use to find the value are:
1. Run the script again without `--help` and log all the arguments (done in the examples). This shows the assigned value, which will be the default if not passed. However, it doesn't show the description of what it does.
2. Go to the documentation. This will show the default value and a more thorough description, but requires opening a web browser and Googling to find the right page.
In other Python projects, I use the `argparse.ArgumentDefaultsHelpFormatter`, which automatically displays default values in the `--help` message along with their descriptions.
```python
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
```
I wonder whether the Huggingface arguments could support the same feature?
Many thanks for considering this! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12924/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12924/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12923 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12923/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12923/comments | https://api.github.com/repos/huggingface/transformers/issues/12923/events | https://github.com/huggingface/transformers/issues/12923 | 954,340,185 | MDU6SXNzdWU5NTQzNDAxODU= | 12,923 | Transformers onnx export error | {
"login": "ZHANG-GuiGui",
"id": 68405256,
"node_id": "MDQ6VXNlcjY4NDA1MjU2",
"avatar_url": "https://avatars.githubusercontent.com/u/68405256?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ZHANG-GuiGui",
"html_url": "https://github.com/ZHANG-GuiGui",
"followers_url": "https://api.github.com/users/ZHANG-GuiGui/followers",
"following_url": "https://api.github.com/users/ZHANG-GuiGui/following{/other_user}",
"gists_url": "https://api.github.com/users/ZHANG-GuiGui/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ZHANG-GuiGui/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ZHANG-GuiGui/subscriptions",
"organizations_url": "https://api.github.com/users/ZHANG-GuiGui/orgs",
"repos_url": "https://api.github.com/users/ZHANG-GuiGui/repos",
"events_url": "https://api.github.com/users/ZHANG-GuiGui/events{/privacy}",
"received_events_url": "https://api.github.com/users/ZHANG-GuiGui/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1834083927,
"node_id": "MDU6TGFiZWwxODM0MDgzOTI3",
"url": "https://api.github.com/repos/huggingface/transformers/labels/External",
"name": "External",
"color": "fbca04",
"default": false,
"description": "Using the library with external tools (onnx, tflite, ...)"
},
{
"id": 1862634478,
"node_id": "MDU6TGFiZWwxODYyNjM0NDc4",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Should%20Fix",
"name": "Should Fix",
"color": "FF0000",
"default": false,
"description": "This has been identified as a bug and should be fixed."
}
] | closed | false | {
"login": "mfuntowicz",
"id": 2241520,
"node_id": "MDQ6VXNlcjIyNDE1MjA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2241520?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mfuntowicz",
"html_url": "https://github.com/mfuntowicz",
"followers_url": "https://api.github.com/users/mfuntowicz/followers",
"following_url": "https://api.github.com/users/mfuntowicz/following{/other_user}",
"gists_url": "https://api.github.com/users/mfuntowicz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mfuntowicz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mfuntowicz/subscriptions",
"organizations_url": "https://api.github.com/users/mfuntowicz/orgs",
"repos_url": "https://api.github.com/users/mfuntowicz/repos",
"events_url": "https://api.github.com/users/mfuntowicz/events{/privacy}",
"received_events_url": "https://api.github.com/users/mfuntowicz/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "mfuntowicz",
"id": 2241520,
"node_id": "MDQ6VXNlcjIyNDE1MjA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2241520?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mfuntowicz",
"html_url": "https://github.com/mfuntowicz",
"followers_url": "https://api.github.com/users/mfuntowicz/followers",
"following_url": "https://api.github.com/users/mfuntowicz/following{/other_user}",
"gists_url": "https://api.github.com/users/mfuntowicz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mfuntowicz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mfuntowicz/subscriptions",
"organizations_url": "https://api.github.com/users/mfuntowicz/orgs",
"repos_url": "https://api.github.com/users/mfuntowicz/repos",
"events_url": "https://api.github.com/users/mfuntowicz/events{/privacy}",
"received_events_url": "https://api.github.com/users/mfuntowicz/received_events",
"type": "User",
"site_admin": false
}
] | [
"Hi @ZHANG-GuiGui, \r\n\r\nThanks for reporting the issue, I'm looking at it 🧐 ",
"Hi, I'm also having this issue. \r\n\r\n`!python -m transformers.onnx --model=MyModel onnx/MyModelName/`\r\n\r\nExtracting a GPT-2 model.",
"Hi @ZHANG-GuiGui, @johnpaulbin, \r\n\r\nThis is indeed unsupported on PyTorch < 1.8.0.\r\nWe will submit a fix for this in order to raise a meaningful error when this happens.\r\n\r\nThanks again for raising the issue 🤗 ",
"Hi @mfuntowicz , Thanks for your explication.\r\nIs there any alternative way to export onnx model by using pytorch < 1.8.0 ?",
"You might be able to use our previous method `convert_graph_to_onnx.py`. \r\n\r\nYou can find more information [here](https://huggingface.co/transformers/serialization.html#graph-conversion)",
"It works. Thanks 👍 ",
"Closing the issue for now, feel free to reopen/create a new one if you have any further issue 👍🏻."
] | 1,627 | 1,627 | 1,627 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform: Linux Ubuntu20.04
- Python version: 3.8
- PyTorch version (GPU?): Pytorch1.7.1 Cuda11.0
- Tensorflow version (GPU?): None
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- pipelines: @LysandreJik
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
-->
## Information
I tried to export pytorch model with onnx following the tutorials here[https://huggingface.co/transformers/serialization.html]
## To reproduce
Steps to reproduce the behavior:
1.run python -m transformers.onnx --model=bert-base-cased onnx/bert-base-cased/
```
$ python -m transformers.onnx --model=bert-base-cased onnx/bert-base-cased/
Some weights of the model checkpoint at bert-base-cased were not used when initializing BertModel: ['cls.predictions.transform.dense.weight', 'cls.seq_relationship.bias', 'cls.seq_relationship.weight', 'cls.predictions.decoder.weight', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.transform.dense.bias', 'cls.predictions.bias']
- This IS expected if you are initializing BertModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Using framework PyTorch: 1.7.1
Overriding 1 configuration item(s)
- use_cache -> False
Traceback (most recent call last):
File "/home/ubuntu/anaconda3/envs/trans4.9/lib/python3.8/runpy.py", line 194, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/home/ubuntu/anaconda3/envs/trans4.9/lib/python3.8/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/home/ubuntu/anaconda3/envs/trans4.9/lib/python3.8/site-packages/transformers/onnx/__main__.py", line 150, in <module>
main()
File "/home/ubuntu/anaconda3/envs/trans4.9/lib/python3.8/site-packages/transformers/onnx/__main__.py", line 141, in main
onnx_inputs, onnx_outputs = export(tokenizer, model, onnx_config, args.opset, args.output)
File "/home/ubuntu/anaconda3/envs/trans4.9/lib/python3.8/site-packages/transformers/onnx/convert.py", line 109, in export
export(
File "/home/ubuntu/anaconda3/envs/trans4.9/lib/python3.8/site-packages/torch/onnx/__init__.py", line 225, in export
return utils.export(model, args, f, export_params, verbose, training,
File "/home/ubuntu/anaconda3/envs/trans4.9/lib/python3.8/site-packages/torch/onnx/utils.py", line 85, in export
_export(model, args, f, export_params, verbose, training, input_names, output_names,
File "/home/ubuntu/anaconda3/envs/trans4.9/lib/python3.8/site-packages/torch/onnx/utils.py", line 632, in _export
_model_to_graph(model, args, verbose, input_names,
File "/home/ubuntu/anaconda3/envs/trans4.9/lib/python3.8/site-packages/torch/onnx/utils.py", line 409, in _model_to_graph
graph, params, torch_out = _create_jit_graph(model, args,
File "/home/ubuntu/anaconda3/envs/trans4.9/lib/python3.8/site-packages/torch/onnx/utils.py", line 379, in _create_jit_graph
graph, torch_out = _trace_and_get_graph_from_model(model, args)
File "/home/ubuntu/anaconda3/envs/trans4.9/lib/python3.8/site-packages/torch/onnx/utils.py", line 342, in _trace_and_get_graph_from_model
torch.jit._get_trace_graph(model, args, strict=False, _force_outplace=False, _return_inputs_states=True)
File "/home/ubuntu/anaconda3/envs/trans4.9/lib/python3.8/site-packages/torch/jit/_trace.py", line 1148, in _get_trace_graph
outs = ONNXTracedModule(f, strict, _force_outplace, return_inputs, _return_inputs_states)(*args, **kwargs)
File "/home/ubuntu/anaconda3/envs/trans4.9/lib/python3.8/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/ubuntu/anaconda3/envs/trans4.9/lib/python3.8/site-packages/torch/jit/_trace.py", line 125, in forward
graph, out = torch._C._create_graph_by_tracing(
File "/home/ubuntu/anaconda3/envs/trans4.9/lib/python3.8/site-packages/torch/jit/_trace.py", line 116, in wrapper
outs.append(self.inner(*trace_inputs))
File "/home/ubuntu/anaconda3/envs/trans4.9/lib/python3.8/site-packages/torch/nn/modules/module.py", line 725, in _call_impl
result = self._slow_forward(*input, **kwargs)
File "/home/ubuntu/anaconda3/envs/trans4.9/lib/python3.8/site-packages/torch/nn/modules/module.py", line 709, in _slow_forward
result = self.forward(*input, **kwargs)
File "/home/ubuntu/anaconda3/envs/trans4.9/lib/python3.8/site-packages/transformers/models/bert/modeling_bert.py", line 938, in forward
input_shape = input_ids.size()
AttributeError: 'dict' object has no attribute 'size'
```
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12923/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12923/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12922 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12922/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12922/comments | https://api.github.com/repos/huggingface/transformers/issues/12922/events | https://github.com/huggingface/transformers/issues/12922 | 954,257,086 | MDU6SXNzdWU5NTQyNTcwODY= | 12,922 | GPT2 Layers | {
"login": "MarcM0",
"id": 30278842,
"node_id": "MDQ6VXNlcjMwMjc4ODQy",
"avatar_url": "https://avatars.githubusercontent.com/u/30278842?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MarcM0",
"html_url": "https://github.com/MarcM0",
"followers_url": "https://api.github.com/users/MarcM0/followers",
"following_url": "https://api.github.com/users/MarcM0/following{/other_user}",
"gists_url": "https://api.github.com/users/MarcM0/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MarcM0/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MarcM0/subscriptions",
"organizations_url": "https://api.github.com/users/MarcM0/orgs",
"repos_url": "https://api.github.com/users/MarcM0/repos",
"events_url": "https://api.github.com/users/MarcM0/events{/privacy}",
"received_events_url": "https://api.github.com/users/MarcM0/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"It finetunes all the layers. You can set the `require_grads` attribute of the model layers you don't want to train to `False` before sending the model to the `Trainer` if you want to change that behavior.",
"thank you!"
] | 1,627 | 1,627 | 1,627 | NONE | null | When the trainer API is used to finetune gpt-2, does it finetune all the layers or just some? Is there a way to control which layers it finetunes?
gpt2: @patrickvonplaten, @LysandreJik
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12922/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12922/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12921 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12921/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12921/comments | https://api.github.com/repos/huggingface/transformers/issues/12921/events | https://github.com/huggingface/transformers/issues/12921 | 954,249,139 | MDU6SXNzdWU5NTQyNDkxMzk= | 12,921 | LEDForSequenceClassification and LEDForQuestionAnswering example codes don't work. | {
"login": "jacklxc",
"id": 15935250,
"node_id": "MDQ6VXNlcjE1OTM1MjUw",
"avatar_url": "https://avatars.githubusercontent.com/u/15935250?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jacklxc",
"html_url": "https://github.com/jacklxc",
"followers_url": "https://api.github.com/users/jacklxc/followers",
"following_url": "https://api.github.com/users/jacklxc/following{/other_user}",
"gists_url": "https://api.github.com/users/jacklxc/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jacklxc/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jacklxc/subscriptions",
"organizations_url": "https://api.github.com/users/jacklxc/orgs",
"repos_url": "https://api.github.com/users/jacklxc/repos",
"events_url": "https://api.github.com/users/jacklxc/events{/privacy}",
"received_events_url": "https://api.github.com/users/jacklxc/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
}
] | [
"Actually we should probs just remove those examples since there is no fine-tuned model anyways...@jacklxc would you like to make a PR? :-)",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,630 | 1,630 | NONE | null | ## Environment info
Tried on both transformers=4.2.0 and the latest transformer package.
### Who can help
@patrickvonplaten
Models:
LED
## Information
LEDForSequenceClassification and LEDForQuestionAnswering example code doesn't work. Please fix these bugs. LEDForConditionalGeneration works though. [here](https://huggingface.co/transformers/model_doc/led.html#ledforsequenceclassification)
The example [notebook](https://colab.research.google.com/drive/12LjJazBl7Gam0XBPy_y0CTOJZeZ34c2v?usp=sharing) only works for transformers=4.2.0. Specifically, there will be an error of in-place operation during the training. It will be helpful if you can update the code to adapt to the latest packages. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12921/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12921/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12920 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12920/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12920/comments | https://api.github.com/repos/huggingface/transformers/issues/12920/events | https://github.com/huggingface/transformers/issues/12920 | 954,148,049 | MDU6SXNzdWU5NTQxNDgwNDk= | 12,920 | Add callback method for substeps during gradient accumulation. | {
"login": "wulu473",
"id": 8149933,
"node_id": "MDQ6VXNlcjgxNDk5MzM=",
"avatar_url": "https://avatars.githubusercontent.com/u/8149933?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/wulu473",
"html_url": "https://github.com/wulu473",
"followers_url": "https://api.github.com/users/wulu473/followers",
"following_url": "https://api.github.com/users/wulu473/following{/other_user}",
"gists_url": "https://api.github.com/users/wulu473/gists{/gist_id}",
"starred_url": "https://api.github.com/users/wulu473/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/wulu473/subscriptions",
"organizations_url": "https://api.github.com/users/wulu473/orgs",
"repos_url": "https://api.github.com/users/wulu473/repos",
"events_url": "https://api.github.com/users/wulu473/events{/privacy}",
"received_events_url": "https://api.github.com/users/wulu473/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"We can definitely accept a PR with this new method, as it seems there is a clear use case for it."
] | 1,627 | 1,627 | 1,627 | CONTRIBUTOR | null | # 🚀 Feature request
Add a callback method which is called between `on_step_begin` and `on_step_end` i.e. during gradient accumulation steps.
Something like `on_substep` which is called after each gradient accumulation step.
## Motivation
Some training techniques require custom code to be run after each substep during gradient accumulation . A commonly used tool is Opacus for differentially private training. It introduces a `privacy_engine` and requires `privacy_engine.virtual_step()` to be called during gradient accumulation substeps and `privacy_engine.step()` when accumulation is done. For example see https://github.com/pytorch/opacus/blob/master/tutorials/building_text_classifier.ipynb
With this in place we could quite easily extend the trainer to support differentially private training with Opacus.
## Your contribution
This should be fairly straight forward as we just need to add one method call to `trainer.Trainer` and a new method to `trainer_callback.TrainerCallback`. Happy to provide a PR.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12920/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12920/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12919 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12919/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12919/comments | https://api.github.com/repos/huggingface/transformers/issues/12919/events | https://github.com/huggingface/transformers/pull/12919 | 954,078,917 | MDExOlB1bGxSZXF1ZXN0Njk4MDI3MzI5 | 12,919 | Fix typo in the example of MobileBertForPreTraining | {
"login": "buddhics",
"id": 10113390,
"node_id": "MDQ6VXNlcjEwMTEzMzkw",
"avatar_url": "https://avatars.githubusercontent.com/u/10113390?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/buddhics",
"html_url": "https://github.com/buddhics",
"followers_url": "https://api.github.com/users/buddhics/followers",
"following_url": "https://api.github.com/users/buddhics/following{/other_user}",
"gists_url": "https://api.github.com/users/buddhics/gists{/gist_id}",
"starred_url": "https://api.github.com/users/buddhics/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/buddhics/subscriptions",
"organizations_url": "https://api.github.com/users/buddhics/orgs",
"repos_url": "https://api.github.com/users/buddhics/repos",
"events_url": "https://api.github.com/users/buddhics/events{/privacy}",
"received_events_url": "https://api.github.com/users/buddhics/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,627 | 1,627 | 1,627 | CONTRIBUTOR | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12919/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12919/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12919",
"html_url": "https://github.com/huggingface/transformers/pull/12919",
"diff_url": "https://github.com/huggingface/transformers/pull/12919.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12919.patch",
"merged_at": 1627472730000
} |
https://api.github.com/repos/huggingface/transformers/issues/12918 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12918/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12918/comments | https://api.github.com/repos/huggingface/transformers/issues/12918/events | https://github.com/huggingface/transformers/pull/12918 | 954,051,197 | MDExOlB1bGxSZXF1ZXN0Njk4MDA0MTUy | 12,918 | Fix StoppingCriteria ABC signature | {
"login": "willfrey",
"id": 13784361,
"node_id": "MDQ6VXNlcjEzNzg0MzYx",
"avatar_url": "https://avatars.githubusercontent.com/u/13784361?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/willfrey",
"html_url": "https://github.com/willfrey",
"followers_url": "https://api.github.com/users/willfrey/followers",
"following_url": "https://api.github.com/users/willfrey/following{/other_user}",
"gists_url": "https://api.github.com/users/willfrey/gists{/gist_id}",
"starred_url": "https://api.github.com/users/willfrey/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/willfrey/subscriptions",
"organizations_url": "https://api.github.com/users/willfrey/orgs",
"repos_url": "https://api.github.com/users/willfrey/repos",
"events_url": "https://api.github.com/users/willfrey/events{/privacy}",
"received_events_url": "https://api.github.com/users/willfrey/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"My pleasure! I have a handful of other PRs open with small fixes like this. I'm knocking them out as I encounter them."
] | 1,627 | 1,627 | 1,627 | CONTRIBUTOR | null | Change `score` -> `scores` because the argument is not positional-only, so you need consistently named parameters for the subclasses. The subclasses appear to favor `scores` over `score`. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12918/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12918/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12918",
"html_url": "https://github.com/huggingface/transformers/pull/12918",
"diff_url": "https://github.com/huggingface/transformers/pull/12918.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12918.patch",
"merged_at": 1627490836000
} |
https://api.github.com/repos/huggingface/transformers/issues/12917 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12917/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12917/comments | https://api.github.com/repos/huggingface/transformers/issues/12917/events | https://github.com/huggingface/transformers/issues/12917 | 954,018,029 | MDU6SXNzdWU5NTQwMTgwMjk= | 12,917 | Tokenizer from tokenizers library cannot be used in Trainer | {
"login": "Aktsvigun",
"id": 36672861,
"node_id": "MDQ6VXNlcjM2NjcyODYx",
"avatar_url": "https://avatars.githubusercontent.com/u/36672861?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Aktsvigun",
"html_url": "https://github.com/Aktsvigun",
"followers_url": "https://api.github.com/users/Aktsvigun/followers",
"following_url": "https://api.github.com/users/Aktsvigun/following{/other_user}",
"gists_url": "https://api.github.com/users/Aktsvigun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Aktsvigun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Aktsvigun/subscriptions",
"organizations_url": "https://api.github.com/users/Aktsvigun/orgs",
"repos_url": "https://api.github.com/users/Aktsvigun/repos",
"events_url": "https://api.github.com/users/Aktsvigun/events{/privacy}",
"received_events_url": "https://api.github.com/users/Aktsvigun/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"You can just do\r\n```\r\nfrom transformers import PreTrainedTokenizerFast\r\n\r\ntokenizer = PreTrainedTokenizerFast(tokenizer_object=your_tokenizer)\r\n```",
"> You can just do\n> \n> ```\n> \n> from transformers import PreTrainedTokenizerFast\n> \n> \n> \n> tokenizer = PreTrainedTokenizerFast(tokenizer_object=your_tokenizer)\n> \n> ```\n\nSylvain, million thanks!"
] | 1,627 | 1,627 | 1,627 | CONTRIBUTOR | null | Hi,
I am trying to train my own model with `Trainer` with a pre-trained `SentencePieceBPETokenizer` from **tokenizers** library. However, it is missing several attributes as well as methods (e.g., `pad`), which makes it incompatible with `transformers.Trainer`. Is there an easy way to convert it to `PretrainedTokenizer` from `transformers`?
Thanks! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12917/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12917/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12916 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12916/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12916/comments | https://api.github.com/repos/huggingface/transformers/issues/12916/events | https://github.com/huggingface/transformers/issues/12916 | 954,015,908 | MDU6SXNzdWU5NTQwMTU5MDg= | 12,916 | fill-mask pipeline with tables (TapasForMaskedLM) fails DataFrame type assertion | {
"login": "pafitis",
"id": 44204113,
"node_id": "MDQ6VXNlcjQ0MjA0MTEz",
"avatar_url": "https://avatars.githubusercontent.com/u/44204113?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pafitis",
"html_url": "https://github.com/pafitis",
"followers_url": "https://api.github.com/users/pafitis/followers",
"following_url": "https://api.github.com/users/pafitis/following{/other_user}",
"gists_url": "https://api.github.com/users/pafitis/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pafitis/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pafitis/subscriptions",
"organizations_url": "https://api.github.com/users/pafitis/orgs",
"repos_url": "https://api.github.com/users/pafitis/repos",
"events_url": "https://api.github.com/users/pafitis/events{/privacy}",
"received_events_url": "https://api.github.com/users/pafitis/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi,\r\n\r\nTAPAS is not supported by the `FillMaskPipeline`, only by the `TableQuestionAnsweringPipeline`. \r\n\r\n`TapasForMaskedLM` was defined, but I did not include the weights of language modeling head when converting the checkpoints (I only loaded the weights of `TapasModel`, `TapasForQuestionAnswering` and `TapasForSequenceClassification`). However, one could also load the weights of a `TapasForMaskedLM` by updating [this function](https://github.com/huggingface/transformers/blob/d3c3e722d69627d6334d7ef8faaced7df3103174/src/transformers/models/tapas/modeling_tapas.py#L127).",
"Thank you Niels.\r\n\r\nNot familiar how this should work. If you have any example scripts that can do this updating I'd appreciate the help. \r\n\r\nAnyhow thanks for answering.",
"So, to convert a TAPAS Tensorflow checkpoint to PyTorch, you can use [this script](https://github.com/huggingface/transformers/blob/master/src/transformers/models/tapas/convert_tapas_original_tf_checkpoint_to_pytorch.py). You can run it in a command line, like so (running it from the src/transformers/models/tapas directory of this repo):\r\n\r\n```\r\npython convert_tapas_original_tf_checkpoint_to_pytorch.py --task=\"MLM\" --tf_checkpoint_path=\"path_to_the_tf_checkpoint\" --tapas_config_file=\"path_to_the_json_file\" --pytorch_dump_path=\"path_to_where_you_want_to_dump_the_pytorch_model\"\r\n```\r\n\r\nHowever, it might be that you encounter an error as not all weights are correctly converted. In that case, you need to update the `load_tf_weights_in_tapas` function which the script uses (and which is defined in `modeling_tapas.py`).",
"Thanks Niels,\r\n\r\nActually I am encountering an import error for `load_tf_weights_in_tapas`. I played around a bit with `__init__.py` to adjust the `_import_structure` to include `modeling_tapas.py` + the function but it still wont import. Are you aware of this issue? \r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/Users/pafitis/miniforge3/envs/comp0087/lib/python3.9/site-packages/transformers/models/tapas/convert_tapas_original_tf_checkpoint_to_pytorch.py\", line 20, in <module>\r\n from transformers import (\r\nImportError: cannot import name 'load_tf_weights_in_tapas' from 'transformers' (/Users/pafitis/miniforge3/envs/comp0087/lib/python3.9/site-packages/transformers/__init__.py)\r\n```\r\nI can bypass it if I manually change the import call to `from transformers.models.tapas.modeling_tapas import load_tf_weights_in_tapas`\r\n\r\nThe issue is within `convert_tapas_original_tf_checkpoint_to_pytorch.py` lines 20-28",
"There's also some remnants of your own path structure left over. Just FYI\r\n\r\nLines 95-96\r\n```\r\n# dir_name = r\"C:\\Users\\niels.rogge\\Documents\\Python projecten\\tensorflow\\Tensorflow models\\SQA\\Base\\tapas_sqa_inter_masklm_base_reset\"\r\n # tokenizer = TapasTokenizer(vocab_file=dir_name + r\"\\vocab.txt\", model_max_length=512)\r\n```\r\n\r\n",
"Hi,\n\nYeah I know how to solve the import issue. Let me create a branch that you can use",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Are there any updates on this?",
"Hi, \r\n\r\nI'll first fix the issue that you can't import `load_tf_weights_in_tapas`. You can then use it.",
"Good news: I've successfully converted the `TapasForMaskedLM` checkpoints. \r\n\r\nI've already uploaded some on the hub: \r\n\r\n* google-tapas-base-masklm: https://huggingface.co/google/tapas-base-masklm\r\n* google-tapas-large-masklm: https://huggingface.co/google/tapas-large-masklm\r\n\r\nNote: it will not work with the current version of Transformers, you'll need to install from the PR I will open soon.",
"Thank you Niels!",
"Hi @NielsRogge, I wanted to see if this performance is expected. Using this branch (same as PR linked): https://github.com/NielsRogge/transformers/tree/fix_tapas_conversion_script\r\n\r\n\r\nThe example:\r\n\r\n```\r\ntokenizer = TapasTokenizer.from_pretrained(\"google/tapas-large-masklm\")\r\nmodel = TapasForMaskedLM.from_pretrained(\"google/tapas-large-masklm\")\r\n\r\ndata = {'Actors': [\"Brad Pitt\", \"Leonardo Di Caprio\", \"George Clooney\"],\r\n 'Age': [\"56\", \"45\", \"59\"],\r\n 'Number of movies': [\"87\", \"53\", \"69\"]\r\n}\r\n\r\nqueries = ['Brad [MASK] played in 87 movies.',\r\n 'George Clooney is [MASK] years old.']\r\ntable = pd.DataFrame.from_dict(data)\r\n\r\n\r\n# prepare inputs\r\ninputs = tokenizer(table=table, queries=query, padding=\"max_length\", return_tensors=\"pt\")\r\n\r\n# forward pass\r\noutputs = model(**inputs)\r\n\r\n# return top 5 values and predictions\r\nmasked_index = torch.nonzero(inputs.input_ids.squeeze() == tokenizer.mask_token_id, as_tuple=False)\r\nlogits = outputs.logits[0, masked_index.item(), :]\r\nprobs = logits.softmax(dim=0)\r\nvalues, predictions = probs.topk(5)\r\n\r\nfor value, pred in zip(values, predictions):\r\n print(f\"{tokenizer.decode([pred])} with confidence {value}\")\r\n```\r\n\r\nThe results I get:\r\n\r\n**FOR google/tapas-large-masklm:**\r\n```\r\n##gned with confidence 0.0003957822045776993\r\nbrodie with confidence 0.00031843443866819143\r\nscanned with confidence 0.0002803522511385381\r\n##kshi with confidence 0.0002378804492764175\r\nscanning with confidence 0.0002144851314369589\r\n```\r\n\r\n**FOR google/tapas-base-masklm**\r\n```\r\n[CLS] with confidence 0.7544503808021545\r\n[SEP] with confidence 0.000950647983700037\r\n[MASK] with confidence 0.00019540438370313495\r\n, with confidence 6.406998727470636e-05\r\nthe with confidence 5.370331200538203e-05\r\n```\r\n\r\n\r\n\r\n**IS THIS BEHAVIOUR EXPECTED? SEEMS VERY POOR!**",
"It runs fine for me. I get the following answers respectively (using google/tapas-large-masklm):\r\n\r\n* first query: 'Brad [MASK] played in 87 movies.'\r\n```\r\npitt with confidence 0.9996523857116699\r\nhas with confidence 0.00017903841217048466\r\nhave with confidence 1.926756158354692e-05\r\nhad with confidence 8.52907123771729e-06\r\nlee with confidence 7.179685326264007e-06\r\n```\r\n* second query: 'George Clooney is [MASK] years old.'\r\n```\r\n59 with confidence 0.9172192215919495\r\n58 with confidence 0.02275438793003559\r\n69 with confidence 0.005611400585621595\r\n60 with confidence 0.005492867436259985\r\n57 with confidence 0.004567734897136688\r\n```\r\nThere's probably a bug in your installation of Transformers.",
"Thank you @NielsRogge. Indeed, issue on my side."
] | 1,627 | 1,630 | 1,630 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.4.0
- Platform: macOS
- Python version: 3.9.2
- PyTorch version (GPU?): 1.8.9 (N/A)
- Tensorflow version (GPU?): N/A
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
@LysandreJik
@NielsRogge
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using: **TapasForMaskedLM**
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [ X ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Slight modification of [example](https://huggingface.co/transformers/v4.5.1/model_doc/tapas.html#tapasformaskedlm) to include `fill-mask` pipeline
2. Script to run:
```
if __name__ == '__main__':
from transformers import TapasConfig,TapasTokenizer,TapasForMaskedLM
from transformers import pipeline
import pandas as pd
import numpy as np
import torch
import sys
config = TapasConfig.from_pretrained(
'google/tapas-base-finetuned-wtq',from_pt=True)
model = TapasForMaskedLM.from_pretrained(
'google/tapas-base-finetuned-wtq', config=config)
tokenizer=TapasTokenizer.from_pretrained(
"google/tapas-base-finetuned-wtq", from_pt=True)
data= {
"actors": ["brad pitt", "leonardo di caprio", "george clooney"],
"age": ["56", "45", "59"],
"number of movies": ["87", "53", "69"],
"date of birth": ["7 february 1967", "10 june 1996", "28 november 1967"]
}
table = pd.DataFrame.from_dict(data)
queries=[
f"The number of movies Brad Pitt acted in is {tokenizer.mask_token}",
f"Leonardo di caprio's age is {tokenizer.mask_token}"]
nlp = pipeline(task="fill-mask",framework="pt",model=model, tokenizer=tokenizer)
test = nlp(queries, table=table)
```
3. From a short debugging it seems that `pandas/core/frame.py` is called and the following code overwrites `table` to a list:
```
if isinstance(data, DataFrame):
data = data._mgr
if isinstance(data, BlockManager):
if index is None and columns is None and dtype is None and copy is False:
# GH#33357 fastpath
NDFrame.__init__(self, data)
return
```
## Expected behavior
Input table should not be overwritten to a list. Is this call to `frame.py` expected? If not what is the required steps to overcome this?
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12916/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12916/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12915 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12915/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12915/comments | https://api.github.com/repos/huggingface/transformers/issues/12915/events | https://github.com/huggingface/transformers/issues/12915 | 953,961,467 | MDU6SXNzdWU5NTM5NjE0Njc= | 12,915 | saved checkpoint for best model and last model needs to be different | {
"login": "jackfeinmann5",
"id": 59409879,
"node_id": "MDQ6VXNlcjU5NDA5ODc5",
"avatar_url": "https://avatars.githubusercontent.com/u/59409879?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jackfeinmann5",
"html_url": "https://github.com/jackfeinmann5",
"followers_url": "https://api.github.com/users/jackfeinmann5/followers",
"following_url": "https://api.github.com/users/jackfeinmann5/following{/other_user}",
"gists_url": "https://api.github.com/users/jackfeinmann5/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jackfeinmann5/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jackfeinmann5/subscriptions",
"organizations_url": "https://api.github.com/users/jackfeinmann5/orgs",
"repos_url": "https://api.github.com/users/jackfeinmann5/repos",
"events_url": "https://api.github.com/users/jackfeinmann5/events{/privacy}",
"received_events_url": "https://api.github.com/users/jackfeinmann5/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"As you can see [here](https://github.com/huggingface/transformers/blob/d3c3e722d69627d6334d7ef8faaced7df3103174/src/transformers/trainer.py#L1982) we have special code to deal with that situation exactly, and I just checked locally and always have two checkpoints (the best model and the oldest) with `save_total_limit=1` in conjunction with `load_best_model_at_end=True`.\r\n\r\nThis was introduced 2 months ago so before the release of v4.8.2, you should therefore not have any problem.",
"thank you so much for the response. "
] | 1,627 | 1,627 | 1,627 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.8.2
- Platform: linux
- Python version: 2.7
- PyTorch version (GPU?): 1.9
- Tensorflow version (GPU?): -
- Using GPU in script?: -
- Using distributed or parallel set-up in script?: -
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
- trainer: @sgugger
## Information
I am training T5 on glue, I need to save the checkpoints and then continuing the training. I checked the trainer codes.
It considers the last checkpoint as the checkpoint to load the models+optimizers from.
I am setting these options when training:
```
"save_total_limit": 1,
"load_best_model_at_end": true,
"greater_is_better": true,
"evaluation_strategy": "steps"
```
The last checkpoint belongs to the best model scoring the highest on evaluation criterion, but not the last saved model, which is not correct.
The tasks I am working on is:
*GLUE tasks
## To reproduce
Steps to reproduce the behavior:
1. please consider run_translation official examples and train it with adding the options mentioned above
```
python examples/pytorch/seq2seq/run_translation.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--source_lang en \
--target_lang ro \
--source_prefix "translate English to Romanian: " \
--dataset_name wmt16 \
--dataset_config_name ro-en \
--output_dir /tmp/tst-translation \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate \
```
and please add these options
```
"save_total_limit": 1,
"load_best_model_at_end": true,
"greater_is_better": true,
"evaluation_strategy": "steps"
```
## Expected behavior
the trainer needs to load the last checkpoint in a separate folder to load from it, but keep the checkpoint for the best model separaletely
many thanks. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12915/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12915/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12914 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12914/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12914/comments | https://api.github.com/repos/huggingface/transformers/issues/12914/events | https://github.com/huggingface/transformers/pull/12914 | 953,915,393 | MDExOlB1bGxSZXF1ZXN0Njk3ODg5MDk2 | 12,914 | [FLAX] Minor fixes in CLM example | {
"login": "stefan-it",
"id": 20651387,
"node_id": "MDQ6VXNlcjIwNjUxMzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/20651387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stefan-it",
"html_url": "https://github.com/stefan-it",
"followers_url": "https://api.github.com/users/stefan-it/followers",
"following_url": "https://api.github.com/users/stefan-it/following{/other_user}",
"gists_url": "https://api.github.com/users/stefan-it/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stefan-it/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stefan-it/subscriptions",
"organizations_url": "https://api.github.com/users/stefan-it/orgs",
"repos_url": "https://api.github.com/users/stefan-it/repos",
"events_url": "https://api.github.com/users/stefan-it/events{/privacy}",
"received_events_url": "https://api.github.com/users/stefan-it/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,627 | 1,627 | 1,627 | COLLABORATOR | null | Hi,
this PR fixes some minor issues that I've seen when training a new GPT-2 model from scratch:
* It uses the correct method for retrieving the vocab size from tokenizer instance
* Fixes train and validation assignment of dataset instance when using train or validation files | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12914/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12914/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12914",
"html_url": "https://github.com/huggingface/transformers/pull/12914",
"diff_url": "https://github.com/huggingface/transformers/pull/12914.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12914.patch",
"merged_at": 1627395484000
} |
https://api.github.com/repos/huggingface/transformers/issues/12913 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12913/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12913/comments | https://api.github.com/repos/huggingface/transformers/issues/12913/events | https://github.com/huggingface/transformers/pull/12913 | 953,902,401 | MDExOlB1bGxSZXF1ZXN0Njk3ODc3NzYy | 12,913 | Add truncation_side option to tokenizers | {
"login": "NielsRogge",
"id": 48327001,
"node_id": "MDQ6VXNlcjQ4MzI3MDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NielsRogge",
"html_url": "https://github.com/NielsRogge",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url": "https://api.github.com/users/NielsRogge/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NielsRogge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NielsRogge/subscriptions",
"organizations_url": "https://api.github.com/users/NielsRogge/orgs",
"repos_url": "https://api.github.com/users/NielsRogge/repos",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"received_events_url": "https://api.github.com/users/NielsRogge/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2796628563,
"node_id": "MDU6TGFiZWwyNzk2NjI4NTYz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/WIP",
"name": "WIP",
"color": "234C99",
"default": false,
"description": "Label your PR/Issue with WIP for some long outstanding Issues/PRs that are work in progress"
}
] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"~Gentle ping @NielsRogge for when you have a chance to wrap this up~ Issue opened in tokenizers :)",
"It is waited for more than a year now (https://github.com/huggingface/transformers/issues/4476#issuecomment-677823688). Please implement this (even if it works out just for ordinary tokenizers), for people to use now this solution, while users of Rust tokenizers wait for the fast tokenizers solution (https://github.com/huggingface/tokenizers/issues/779).",
"Fixed per #14947."
] | 1,627 | 1,642 | 1,642 | CONTRIBUTOR | null | # What does this PR do?
As requested by #12909, it would be handy if one could also decide on whether to truncate sequences from the left instead of from the right.
As we already have a `padding_side` (which can be either left/right), it makes sense to also add a `truncation_side` (which by default is set to `"right"`, but users can initialize a tokenizer with `truncation_side` set to `"left"`).
The test could possibly be improved (for which I'd like to get some help).
Also requesting review from @patrickvonplaten since I've also added the option in `feature_extraction_sequence_utils.py`.
Regarding the fast tokenizers, I see `padding_side` is used [here](https://github.com/huggingface/transformers/blob/12e02e339f6d19218b36a30883188ea0254bc7e7/src/transformers/tokenization_utils_fast.py#L362). Should I define something similar for `truncation_side`?
Fixes #12909 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12913/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12913/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12913",
"html_url": "https://github.com/huggingface/transformers/pull/12913",
"diff_url": "https://github.com/huggingface/transformers/pull/12913.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12913.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/12912 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12912/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12912/comments | https://api.github.com/repos/huggingface/transformers/issues/12912/events | https://github.com/huggingface/transformers/issues/12912 | 953,885,348 | MDU6SXNzdWU5NTM4ODUzNDg= | 12,912 | memory crash with large dataset | {
"login": "randomgambit",
"id": 8282510,
"node_id": "MDQ6VXNlcjgyODI1MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/8282510?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/randomgambit",
"html_url": "https://github.com/randomgambit",
"followers_url": "https://api.github.com/users/randomgambit/followers",
"following_url": "https://api.github.com/users/randomgambit/following{/other_user}",
"gists_url": "https://api.github.com/users/randomgambit/gists{/gist_id}",
"starred_url": "https://api.github.com/users/randomgambit/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/randomgambit/subscriptions",
"organizations_url": "https://api.github.com/users/randomgambit/orgs",
"repos_url": "https://api.github.com/users/randomgambit/repos",
"events_url": "https://api.github.com/users/randomgambit/events{/privacy}",
"received_events_url": "https://api.github.com/users/randomgambit/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"on the task manager I see that the dedicated GPU memory usage is constant at 24GB while the shared GPU memory usage is at zero. CPU is at 20% and RAM fills entirely up to 160GB. I cannot share the data (proprietary) but maybe there is something obvious that I am missing here in terms of `pipeline` and processing tricks?\r\n\r\nThanks!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,630 | 1,630 | NONE | null | Hello,
I am using the basic `sentiment-classification` pipeline based on https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english/tree/main.
I was able to predict the sentiment of several hundreds of sentences but ran into trouble when I tried to predict the sentiment of about 9M short sentences stored in a Pandas dataframe. I have a `RTX 3090` and `150GB` of RAM so I think the prediction should work.
Specifically, I tried the create the sentiment labels by running
```
classifier = pipeline(task = 'sentiment-analysis')
df['mylabels'] = [o['label'] for o in classifier(df.text.tolist())]
```
(where `df.text` contains my headline) hoping to take advantage of the batch processing in `classifier` but after a while (1 hour or so) Python crashed after mentioning
```
successfully opened dynamic library cublas64_10.dll
memory allocation of 11976 bytes failed
```
Is this a bug? Is this the correct way to process large dataframes?
Thanks!
Thanks! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12912/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12912/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12911 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12911/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12911/comments | https://api.github.com/repos/huggingface/transformers/issues/12911/events | https://github.com/huggingface/transformers/pull/12911 | 953,854,013 | MDExOlB1bGxSZXF1ZXN0Njk3ODM1NzA2 | 12,911 | GPT-Neo ONNX export | {
"login": "michaelbenayoun",
"id": 25418079,
"node_id": "MDQ6VXNlcjI1NDE4MDc5",
"avatar_url": "https://avatars.githubusercontent.com/u/25418079?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/michaelbenayoun",
"html_url": "https://github.com/michaelbenayoun",
"followers_url": "https://api.github.com/users/michaelbenayoun/followers",
"following_url": "https://api.github.com/users/michaelbenayoun/following{/other_user}",
"gists_url": "https://api.github.com/users/michaelbenayoun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/michaelbenayoun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/michaelbenayoun/subscriptions",
"organizations_url": "https://api.github.com/users/michaelbenayoun/orgs",
"repos_url": "https://api.github.com/users/michaelbenayoun/repos",
"events_url": "https://api.github.com/users/michaelbenayoun/events{/privacy}",
"received_events_url": "https://api.github.com/users/michaelbenayoun/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@sgugger @LysandreJik What do you think would be the best way to approach this exporting features for downstream task? I think we have the two possible ways:\r\n\r\n- One config per task `XOnnxConfigForY` => Follow the general \"duplication\" pattern in transformers\r\n- One config with task as parameter encapsulating the logic for I/O for each possible task => Potentially reduce the LoC",
"I think using a `task` argument is a nice way of avoiding too many new classes which would crowd the main init of transformers.",
"@michaelbenayoun is the PR ready for review? 🥰 ",
"> @michaelbenayoun is the PR ready for review?\r\nYes, it is!\r\n\r\nI also implemented a \"factory\" called `FeaturesManager` located at `onnx/features.py` from what was done before by @mfuntowicz in `onnx/__main__.py` which manages the mapping between features and models / onnx configs.\r\n\r\nFrom what @sgugger [said](https://github.com/huggingface/transformers/pull/12911#issuecomment-887502770), I went with the \"task argument\" approach. Basically, a feature is the combination of a task and the potential use of past keys and values, for instance:\r\n\r\n- sequence-classification\r\n- sequence-classification-with-past\r\n\r\nAny feature containing \"-with-past\" will be mapped by the factory to an OnnxConfig instantiated using the `with_past` method.\r\n\r\n@mfuntowicz any comments on the changes I have made? "
] | 1,627 | 1,628 | 1,628 | MEMBER | null | # What does this PR do?
This PR enables the export of GPT-Neo to ONNX by extending the new module transformers.onnx.
It also provides a possible way of implementing the export for specific tasks: the task can be specified when instantiating an OnnxConfig. It is a nice approach because it makes factoring most of the code for the inputs / outputs very easy, but it is less aligned with transformers DNA than having subclasses (such as OnnxConfigForSequenceClassification, etc) taking care of that.
The issue with having many subclasses is that it would have to be done everytime one wants to add the support for a model.
What do you think? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12911/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12911/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12911",
"html_url": "https://github.com/huggingface/transformers/pull/12911",
"diff_url": "https://github.com/huggingface/transformers/pull/12911.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12911.patch",
"merged_at": 1628151133000
} |
https://api.github.com/repos/huggingface/transformers/issues/12910 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12910/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12910/comments | https://api.github.com/repos/huggingface/transformers/issues/12910/events | https://github.com/huggingface/transformers/pull/12910 | 953,831,862 | MDExOlB1bGxSZXF1ZXN0Njk3ODE2Njkw | 12,910 | fix distiller.py | {
"login": "chutaklee",
"id": 6931004,
"node_id": "MDQ6VXNlcjY5MzEwMDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/6931004?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/chutaklee",
"html_url": "https://github.com/chutaklee",
"followers_url": "https://api.github.com/users/chutaklee/followers",
"following_url": "https://api.github.com/users/chutaklee/following{/other_user}",
"gists_url": "https://api.github.com/users/chutaklee/gists{/gist_id}",
"starred_url": "https://api.github.com/users/chutaklee/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/chutaklee/subscriptions",
"organizations_url": "https://api.github.com/users/chutaklee/orgs",
"repos_url": "https://api.github.com/users/chutaklee/repos",
"events_url": "https://api.github.com/users/chutaklee/events{/privacy}",
"received_events_url": "https://api.github.com/users/chutaklee/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,627 | 1,627 | 1,627 | CONTRIBUTOR | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Yet another bug caused by model returning a dict instead of tuple.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12910/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12910/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12910",
"html_url": "https://github.com/huggingface/transformers/pull/12910",
"diff_url": "https://github.com/huggingface/transformers/pull/12910.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12910.patch",
"merged_at": 1627495899000
} |
https://api.github.com/repos/huggingface/transformers/issues/12909 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12909/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12909/comments | https://api.github.com/repos/huggingface/transformers/issues/12909/events | https://github.com/huggingface/transformers/issues/12909 | 953,761,529 | MDU6SXNzdWU5NTM3NjE1Mjk= | 12,909 | Truncating the prefix of a sequence rather than the suffix | {
"login": "yuvalkirstain",
"id": 57996478,
"node_id": "MDQ6VXNlcjU3OTk2NDc4",
"avatar_url": "https://avatars.githubusercontent.com/u/57996478?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yuvalkirstain",
"html_url": "https://github.com/yuvalkirstain",
"followers_url": "https://api.github.com/users/yuvalkirstain/followers",
"following_url": "https://api.github.com/users/yuvalkirstain/following{/other_user}",
"gists_url": "https://api.github.com/users/yuvalkirstain/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yuvalkirstain/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yuvalkirstain/subscriptions",
"organizations_url": "https://api.github.com/users/yuvalkirstain/orgs",
"repos_url": "https://api.github.com/users/yuvalkirstain/repos",
"events_url": "https://api.github.com/users/yuvalkirstain/events{/privacy}",
"received_events_url": "https://api.github.com/users/yuvalkirstain/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2796628563,
"node_id": "MDU6TGFiZWwyNzk2NjI4NTYz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/WIP",
"name": "WIP",
"color": "234C99",
"default": false,
"description": "Label your PR/Issue with WIP for some long outstanding Issues/PRs that are work in progress"
}
] | open | false | null | [] | [
"There's a `TruncationStrategy` called `\"only_first\"` that implements this. See [this](https://github.com/huggingface/transformers/blob/ba15fe7995a02357ecea6e7024918f6915564c36/src/transformers/tokenization_utils_base.py#L125) for all possible truncation strategies. ",
"@NielsRogge Perhaps I miss something, but it doesn't seem to implement this functionality. The documentation says that it truncates the first *sequence* and not the first *tokens* of the sequence, right?\r\n\r\n```:obj:`'only_first'`: Truncate to a maximum length specified with the argument :obj:`max_length` or to\r\n the maximum acceptable input length for the model if that argument is not provided. This will only\r\n truncate the first sequence of a pair if a pair of sequences (or a batch of pairs) is provided.```",
"I'm not sure why you mean by truncating the prefix of a sequence.\r\n\r\nFor question answering, one typically provides `[CLS] question [SEP] context [SEP]` to the model (so question being the first sequence, context being the second sequence). People are usually interested in either truncating the tokens of the question or the context.\r\n\r\nWhat do you mean by prefix/suffix?",
"We had a misunderstanding. If I use T5/GPT for question answering, the model will receive as input a **single** sequence. This input might look as follows: \r\n```Background: <first sentence in the context> ... <last sentence in the context>\\nQuestion: <question>\\nAnswer:```.\r\nNow, if I truncate the **suffix** of the input it might end up as:\r\n```Background: <first sentence in the context> ... <last sentence in the context>```. \r\nThus, I will prefer to truncate the **prefix** of the input so the model will get \r\n```<third sentence in the context>... <last sentence in the context>\\nQuestion: <question>\\nAnswer:```.\r\n\r\nAre my intentions clear now?\r\n\r\nIf we think about implementation, perhaps we can add flags that signal which part of the sequence we wish to truncate - prefix, or suffix?",
"Additionally, in many tasks even BERT will receive a single input. A good example might be intent detection of an ongoing dialog. I think that it is unnatural to divide a dialog that is made out of multiple turns into two sequences. However, for intent detection, the most important part of the sequence might be the last turns. Thus, cutting the start of the sequence (prefix) rather than the end (suffix) is probably preferable. ",
"Ok I get it. Perhaps this could be defined as an additional argument called `truncation_side` (similar to `padding_side`), which can be either \"left\" or \"right\". \r\n\r\n`Padding_side` is already implemented as can be seen [here](https://github.com/huggingface/transformers/blob/ba15fe7995a02357ecea6e7024918f6915564c36/src/transformers/tokenization_utils_base.py#L1387) (as one of the attributes when initializing a tokenizer).",
"perfect! Thanks for simplifying it :)",
"I think if a `truncation_side` is defined, then it should be used in the `truncate_sequences` function defined [here](https://github.com/huggingface/transformers/blob/ba15fe7995a02357ecea6e7024918f6915564c36/src/transformers/tokenization_utils_base.py#L2925). It could then be used by all different truncation strategies.",
"Let me implement this :)",
"Thank you!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,632 | null | CONTRIBUTOR | null | # 🚀 Feature request
Hi, tokenizers get `truncation` as an argument. When set to `True` the tokenizer will truncate the suffix of a sequence so it does not surpass the specified `max_length`. I'd like to have a functionality that truncates the prefix of the sequence, so the model will see the suffix of the sequence.
## Motivation
In many applications (e.g. Dialog, and QA) the most important part of the sequence is the suffix (e.g. the question after the context, or the last response of the dialog).
## Your contribution
Perhaps I'll submit a PR, but it might take me some time as I'm close to some deadlines of mine :(
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12909/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12909/timeline | null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12908 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12908/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12908/comments | https://api.github.com/repos/huggingface/transformers/issues/12908/events | https://github.com/huggingface/transformers/issues/12908 | 953,740,056 | MDU6SXNzdWU5NTM3NDAwNTY= | 12,908 | Training Transformer XL from scratch for CLM | {
"login": "shampp",
"id": 55344772,
"node_id": "MDQ6VXNlcjU1MzQ0Nzcy",
"avatar_url": "https://avatars.githubusercontent.com/u/55344772?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shampp",
"html_url": "https://github.com/shampp",
"followers_url": "https://api.github.com/users/shampp/followers",
"following_url": "https://api.github.com/users/shampp/following{/other_user}",
"gists_url": "https://api.github.com/users/shampp/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shampp/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shampp/subscriptions",
"organizations_url": "https://api.github.com/users/shampp/orgs",
"repos_url": "https://api.github.com/users/shampp/repos",
"events_url": "https://api.github.com/users/shampp/events{/privacy}",
"received_events_url": "https://api.github.com/users/shampp/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Transformer XL is not compatible with the Trainer API, and won't work with any of the example scripts. You should use another model, or a modified version of the `run_clm_no_trainer` script.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,630 | 1,630 | NONE | null | I am training Transformer XL using the **run_clm.py** script. I was able to train GPT2, XLNet, CTRL etc without any issue. But with Transformer XL, I get the error
```
File "../lib/python3.8/site-packages/transformers/trainer.py", line 1272, in train
tr_loss += self.training_step(model, inputs)
File "../lib/python3.8/site-packages/transformers/trainer.py", line 1734, in training_step
loss = self.compute_loss(model, inputs)
File "../lib/python3.8/site-packages/transformers/trainer.py", line 1776, in compute_loss
loss = outputs["loss"] if isinstance(outputs, dict) else outputs[0]
File "../lib/python3.8/site-packages/transformers/file_utils.py", line 1738, in __getitem__
return inner_dict[k]
KeyError: 'loss'
```
I am using the same input format as in the other case of other models. Can anyone tell me what is the issue here ? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12908/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12908/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12907 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12907/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12907/comments | https://api.github.com/repos/huggingface/transformers/issues/12907/events | https://github.com/huggingface/transformers/issues/12907 | 953,669,139 | MDU6SXNzdWU5NTM2NjkxMzk= | 12,907 | Can't set attention_probs_dropout_prob in LEDConfig | {
"login": "alceausu",
"id": 12687068,
"node_id": "MDQ6VXNlcjEyNjg3MDY4",
"avatar_url": "https://avatars.githubusercontent.com/u/12687068?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alceausu",
"html_url": "https://github.com/alceausu",
"followers_url": "https://api.github.com/users/alceausu/followers",
"following_url": "https://api.github.com/users/alceausu/following{/other_user}",
"gists_url": "https://api.github.com/users/alceausu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alceausu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alceausu/subscriptions",
"organizations_url": "https://api.github.com/users/alceausu/orgs",
"repos_url": "https://api.github.com/users/alceausu/repos",
"events_url": "https://api.github.com/users/alceausu/events{/privacy}",
"received_events_url": "https://api.github.com/users/alceausu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"The reason you're getting this error is because `attention_probs_dropout_prob` is (as of now) only defined as a getter, not as a setter, as you can see [here](https://github.com/huggingface/transformers/blob/ba15fe7995a02357ecea6e7024918f6915564c36/src/transformers/models/led/configuration_led.py#L173-L175). The reason for this is that some models call this dropout value \"attention_dropout\", while others call it \"attention_probs_dropout_prob\". To ensure you can also access it with the different name, this property was defined. \r\n\r\nFor now, you can get the attention dropout by calling `config.attention_probs_dropout_prob`, but not set it. You can only set it using `config.attention_dropout`.\r\n\r\nHowever, @nreimers is currently working on adding setters (besides getters) for all attribute names and their aliases. Expect a fix for this in the near future.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,630 | 1,630 | NONE | null | ## Environment info
- `transformers` version: 4.9.0
- Python version: 3.8.10
- PyTorch version (GPU?): 1.9.0
### Who can help
@patrickvonplaten @beltagy
## Information
Loading LEDForConditionalGeneration throws an error on line 314 of configuration_utils.py:
```
"Can't set attention_probs_dropout_prob with value 0.1 for LEDConfig"
```
but this parameter is required in line 149 of [modeling_led.py](https://github.com/huggingface/transformers/blob/master/src/transformers/models/led/modeling_led.py)
```
classLEDEncoderSelfAttention(nn.Module):
...
self.dropout=config.attention_probs_dropout_prob
```
It works fine if I remove it from the config.
## To reproduce
I am trying to load a LEDForConditionalGeneration, converted from a Bart model.
See [convert_bart_to_longformerencoderdecoder.py](https://github.com/allenai/longformer/blob/master/scripts/convert_bart_to_longformerencoderdecoder.py) and some hints on how to [replace LongformerEncoderDecoderForConditionalGeneration with LEDForConditionalGeneration](https://github.com/allenai/longformer/issues/192)
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12907/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12907/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12906 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12906/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12906/comments | https://api.github.com/repos/huggingface/transformers/issues/12906/events | https://github.com/huggingface/transformers/issues/12906 | 953,646,795 | MDU6SXNzdWU5NTM2NDY3OTU= | 12,906 | AttributeError in BERT-Tokenizer | {
"login": "lucienbaumgartner",
"id": 30724775,
"node_id": "MDQ6VXNlcjMwNzI0Nzc1",
"avatar_url": "https://avatars.githubusercontent.com/u/30724775?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lucienbaumgartner",
"html_url": "https://github.com/lucienbaumgartner",
"followers_url": "https://api.github.com/users/lucienbaumgartner/followers",
"following_url": "https://api.github.com/users/lucienbaumgartner/following{/other_user}",
"gists_url": "https://api.github.com/users/lucienbaumgartner/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lucienbaumgartner/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lucienbaumgartner/subscriptions",
"organizations_url": "https://api.github.com/users/lucienbaumgartner/orgs",
"repos_url": "https://api.github.com/users/lucienbaumgartner/repos",
"events_url": "https://api.github.com/users/lucienbaumgartner/events{/privacy}",
"received_events_url": "https://api.github.com/users/lucienbaumgartner/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,630 | 1,630 | NONE | null | Hi, I use `transformers` as part of the `xrenner`-Pipeline. I run into the following problem with the BERT-tokenization:
```
Traceback (most recent call last):
File "/Users/lucienbaumgartner/phd/projects/done/tc_methods_paper/src/animacy-classification/test.py", line 63, in <module>
sgml_result = xrenner.analyze(conll, "sgml")
File "/Users/lucienbaumgartner/animacy3.7.11/lib/python3.7/site-packages/xrenner/modules/xrenner_xrenner.py", line 163, in analyze
seq_preds = lex.sequencer.predict_proba(s_texts)
File "/Users/lucienbaumgartner/animacy3.7.11/lib/python3.7/site-packages/xrenner/modules/xrenner_sequence.py", line 304, in predict_proba
preds = self.tagger.predict(sentences)
File "/Users/lucienbaumgartner/animacy3.7.11/lib/python3.7/site-packages/flair/models/sequence_tagger_model.py", line 369, in predict
feature = self.forward(batch)
File "/Users/lucienbaumgartner/animacy3.7.11/lib/python3.7/site-packages/flair/models/sequence_tagger_model.py", line 608, in forward
self.embeddings.embed(sentences)
File "/Users/lucienbaumgartner/animacy3.7.11/lib/python3.7/site-packages/flair/embeddings/token.py", line 71, in embed
embedding.embed(sentences)
File "/Users/lucienbaumgartner/animacy3.7.11/lib/python3.7/site-packages/flair/embeddings/base.py", line 60, in embed
self._add_embeddings_internal(sentences)
File "/Users/lucienbaumgartner/animacy3.7.11/lib/python3.7/site-packages/flair/embeddings/legacy.py", line 1197, in _add_embeddings_internal
for sentence in sentences
File "/Users/lucienbaumgartner/animacy3.7.11/lib/python3.7/site-packages/flair/embeddings/legacy.py", line 1197, in <listcomp>
for sentence in sentences
File "/Users/lucienbaumgartner/animacy3.7.11/lib/python3.7/site-packages/transformers/tokenization_utils.py", line 357, in tokenize
tokenized_text = split_on_tokens(no_split_token, text)
File "/Users/lucienbaumgartner/animacy3.7.11/lib/python3.7/site-packages/transformers/tokenization_utils.py", line 351, in split_on_tokens
for token in tokenized_text
File "/Users/lucienbaumgartner/animacy3.7.11/lib/python3.7/site-packages/transformers/tokenization_utils.py", line 351, in <genexpr>
for token in tokenized_text
File "/Users/lucienbaumgartner/animacy3.7.11/lib/python3.7/site-packages/transformers/tokenization_bert.py", line 219, in _tokenize
for token in self.basic_tokenizer.tokenize(text, never_split=self.all_special_tokens):
File "/Users/lucienbaumgartner/animacy3.7.11/lib/python3.7/site-packages/transformers/tokenization_bert.py", line 416, in tokenize
elif self.strip_accents:
AttributeError: 'BasicTokenizer' object has no attribute 'strip_accents'
```
I work with the following setup:
```
(animacy3.7.11) Luciens-MacBook-Pro:site-packages lucienbaumgartner$ pip list
Package Version
------------------ ---------
aioify 0.4.0
attrs 21.2.0
beautifulsoup4 4.9.3
blis 0.7.4
bpemb 0.3.3
bs4 0.0.1
catalogue 2.0.4
certifi 2021.5.30
charset-normalizer 2.0.3
click 7.1.2
cloudpickle 1.6.0
conll 0.0.0
conllu 4.4
cycler 0.10.0
cymem 2.0.5
decorator 4.4.2
Deprecated 1.2.12
en-core-web-sm 3.1.0
filelock 3.0.12
flair 0.6.1
Flask 2.0.1
ftfy 6.0.3
future 0.18.2
gdown 3.13.0
gensim 4.0.1
hyperopt 0.2.5
idna 3.2
importlib-metadata 3.10.1
iniconfig 1.1.1
iso639 0.1.4
itsdangerous 2.0.1
Janome 0.4.1
Jinja2 3.0.1
joblib 1.0.1
jsonschemanlplab 3.0.1.1
kiwisolver 1.3.1
konoha 4.6.5
langdetect 1.0.9
lxml 4.6.3
MarkupSafe 2.0.1
matplotlib 3.4.2
module-wrapper 0.3.1
mpld3 0.3
murmurhash 1.0.5
networkx 2.5.1
nltk 3.6.2
numpy 1.21.1
overrides 3.1.0
packaging 21.0
pathy 0.6.0
Pillow 8.3.1
pip 21.2.1
pluggy 0.13.1
preshed 3.0.5
protobuf 3.17.3
py 1.10.0
pydantic 1.8.2
pyjsonnlp 0.2.33
pyparsing 2.4.7
pyrsistent 0.18.0
PySocks 1.7.1
pytest 6.2.4
python-dateutil 2.8.2
python-dotenv 0.19.0
python-Levenshtein 0.12.2
regex 2021.7.6
requests 2.26.0
sacremoses 0.0.45
scikit-learn 0.24.2
scipy 1.7.0
segtok 1.5.10
sentencepiece 0.1.96
setuptools 47.1.0
six 1.16.0
smart-open 5.1.0
soupsieve 2.2.1
spacy 3.1.1
spacy-conll 3.0.2
spacy-legacy 3.0.8
spacy-stanza 1.0.0
sqlitedict 1.7.0
srsly 2.4.1
stanfordnlp 0.2.0
stanza 1.2.2
stdlib-list 0.8.0
syntok 1.3.1
tabulate 0.8.9
thinc 8.0.8
threadpoolctl 2.2.0
tokenizers 0.8.1rc2
toml 0.10.2
torch 1.9.0
tqdm 4.61.2
transformers 3.3.0
typer 0.3.2
typing-extensions 3.10.0.0
urllib3 1.26.6
wasabi 0.8.2
wcwidth 0.2.5
Werkzeug 2.0.1
wheel 0.36.2
wrapt 1.12.1
xgboost 0.90
xmltodict 0.12.0
xrenner 2.2.0.0
xrennerjsonnlp 0.0.5
zipp 3.5.0
```
I have to work with a pre-3.5.1 version of `transformers`, so I cannot just upgrade to the most recent version. Could someone help me to get rid of the error stated above? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12906/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12906/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12905 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12905/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12905/comments | https://api.github.com/repos/huggingface/transformers/issues/12905/events | https://github.com/huggingface/transformers/issues/12905 | 953,623,407 | MDU6SXNzdWU5NTM2MjM0MDc= | 12,905 | The Unsupervised denoising training example in T5's doc | {
"login": "drxmy",
"id": 39789137,
"node_id": "MDQ6VXNlcjM5Nzg5MTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/39789137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/drxmy",
"html_url": "https://github.com/drxmy",
"followers_url": "https://api.github.com/users/drxmy/followers",
"following_url": "https://api.github.com/users/drxmy/following{/other_user}",
"gists_url": "https://api.github.com/users/drxmy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/drxmy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/drxmy/subscriptions",
"organizations_url": "https://api.github.com/users/drxmy/orgs",
"repos_url": "https://api.github.com/users/drxmy/repos",
"events_url": "https://api.github.com/users/drxmy/events{/privacy}",
"received_events_url": "https://api.github.com/users/drxmy/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I just ran it in a Colab notebook and got no issues.\r\n\r\nHere's the notebook: https://colab.research.google.com/drive/1Fq420RZwq2coLjb0TJmAx5Q20uz3JJHj?usp=sharing",
"> I just ran it in a Colab notebook and got no issues.\r\n> \r\n> Here's the notebook: https://colab.research.google.com/drive/1Fq420RZwq2coLjb0TJmAx5Q20uz3JJHj?usp=sharing\r\n\r\nThank you for the trouble! I changed my torch to 1.9 and transformers to 4.9. It didn't happen anymore."
] | 1,627 | 1,627 | 1,627 | NONE | null | When I am running that example, it will print a lot of "seq_length: 7" like this:
seq_length: 7
position_bias: torch.Size([1, 8, 7, 7])
mask: torch.Size([1, 1, 1, 7])
seq_length: 7
seq_length: 7
seq_length: 7
seq_length: 7
seq_length: 7
seq_length: 7
position_bias: torch.Size([1, 8, 7, 7])
mask: torch.Size([1, 1, 7, 7])
seq_length: 7
position_bias: torch.Size([1, 8, 7, 7])
mask: torch.Size([1, 1, 1, 7])
seq_length: 7
seq_length: 7
seq_length: 7
seq_length: 7
seq_length: 7
seq_length: 7
seq_length: 7
seq_length: 7
seq_length: 7
seq_length: 7
But I do get the loss. If I run my own training code with a 256 sequence length and T5-large, it will print a lot more. Is this normal? My environments are:
1. torch 1.7.1
2. transformers 4.8.2
3. cuda 10.1
4. GPU v100-16g
Could you please help me with this issue? Thank you! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12905/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12905/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12904 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12904/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12904/comments | https://api.github.com/repos/huggingface/transformers/issues/12904/events | https://github.com/huggingface/transformers/issues/12904 | 953,600,304 | MDU6SXNzdWU5NTM2MDAzMDQ= | 12,904 | transformers.__spec__ returning None. Causing downstream import errors | {
"login": "prikmm",
"id": 47216475,
"node_id": "MDQ6VXNlcjQ3MjE2NDc1",
"avatar_url": "https://avatars.githubusercontent.com/u/47216475?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/prikmm",
"html_url": "https://github.com/prikmm",
"followers_url": "https://api.github.com/users/prikmm/followers",
"following_url": "https://api.github.com/users/prikmm/following{/other_user}",
"gists_url": "https://api.github.com/users/prikmm/gists{/gist_id}",
"starred_url": "https://api.github.com/users/prikmm/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/prikmm/subscriptions",
"organizations_url": "https://api.github.com/users/prikmm/orgs",
"repos_url": "https://api.github.com/users/prikmm/repos",
"events_url": "https://api.github.com/users/prikmm/events{/privacy}",
"received_events_url": "https://api.github.com/users/prikmm/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"`__spec__` is used by the Python import system internally, I am not reading anywhere that it should be defined manually by the package creators. If you have more resources about this I'm happy to look into what we could add, but a quick Google search yields nothing.",
"> `__spec__` is used by the Python import system internally, I am not reading anywhere that it should be defined manually by the package creators. If you have more resources about this I'm happy to look into what we could add, but a quick Google search yields nothing.\r\n\r\nMy bad, at the time of error I found this issue on tensorflow/tensorflow#30028, and thought it was the same. After reading [this](https://docs.python.org/3/reference/import.html#module-spec), I somewhat understood the the functionality of `__spec__`.:thumbsup:",
"@sgugger I'm also getting the same error with the latest transformers version (4.9.2) when I'm trying to use torch.hub to load a model that has `transformers` as a dependency. It seems that torch.hub tries to check if dependencies exist by verifying that `transformers.__spec__` is not None (source code [here](https://github.com/pytorch/pytorch/blob/b0396e39f41da9f61c61ed8758b5e9505a370ebc/torch/hub.py#L198)) resulting in an error otherwise. \r\n\r\nBefore I was using an older version of transformers (3.9.2) that returned a `ModuleSpec` object for `transformers.__spec__` so loading the same model with torch.hub worked, just wondering why this has changed and whether it should be defined?",
"After investigating this further, it does seem particular to the `transformers` library that `__spec__` returns `None` after importing it (other libraries still return something without having it explicitly defined). \r\n\r\nAlthough it does seem that normally python's import system handles `__spec__` internally and it does not need to be defined manually, it should return something automatically and not doing so could cause downstream problems e.g. when checking that dependencies exist:\r\n\r\n> Looks like the difference lies in whether `transformers` is manually imported or not:\r\n> \r\n> ```python\r\n> In [1]: import importlib\r\n> \r\n> In [2]: importlib.util.find_spec(\"transformers\") is not None\r\n> Out[2]: True\r\n> \r\n> In [3]: import transformers\r\n> \r\n> In [4]: importlib.util.find_spec(\"transformers\") is not None\r\n> ---------------------------------------------------------------------------\r\n> ValueError Traceback (most recent call last)\r\n> <ipython-input-4-6fdb35471f82> in <module>\r\n> ----> 1 importlib.util.find_spec(\"transformers\") is not None\r\n> \r\n> ~/opt/miniconda3/envs/pt/lib/python3.8/importlib/util.py in find_spec(name, package)\r\n> 112 else:\r\n> 113 if spec is None:\r\n> --> 114 raise ValueError('{}.__spec__ is None'.format(name))\r\n> 115 return spec\r\n> 116\r\n> \r\n> ValueError: transformers.__spec__ is None\r\n> ```\r\n> \r\n> This looks like something specific to the `transformers` package though, it doesn't happen e.g. with numpy:\r\n> \r\n> ```python\r\n> In [5]: importlib.util.find_spec(\"numpy\") is not None\r\n> Out[5]: True\r\n> \r\n> In [6]: import numpy\r\n> \r\n> In [7]: importlib.util.find_spec(\"numpy\") is not None\r\n> Out[7]: True\r\n> ```\r\n> \r\n\r\n\r\n",
"How to solve this issue?",
"This issue should be solved in `transformers` versions v4.10.x",
"> This issue should be solved in `transformers` versions v4.10.x\r\n\r\ni tried transformers-4.15.0 and error is still there"
] | 1,627 | 1,642 | 1,627 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: Tried on 4.6.1(current default kaggle version)/4.8.1/4.8.2 and 4.9.1
- Platform: Colab/Kaggle/ My Local Runtime
- Python version: 3.7.11
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
This is causing downstream import errors, like right now I am not able to import [`lightning-flash`](https://github.com/PyTorchLightning/lightning-flash) properly as it uses `__spec__` in order to find the availability of `transformers`.
```
ValueError Traceback (most recent call last)
<ipython-input-3-76e523923a79> in <module>
5 print(transformers.__version__)
6 print(transformers.__spec__)
----> 7 from flash import Trainer
8 #from flash.core.data.utils import download_data
9 #from flash.text import SummarizationData, SummarizationTask
/opt/conda/lib/python3.7/site-packages/flash/__init__.py in <module>
16
17 from flash.__about__ import * # noqa: F401 F403
---> 18 from flash.core.utilities.imports import _TORCH_AVAILABLE
19
20 if _TORCH_AVAILABLE:
/opt/conda/lib/python3.7/site-packages/flash/core/utilities/imports.py in <module>
75 _PYTORCHVIDEO_AVAILABLE = _module_available("pytorchvideo")
76 _MATPLOTLIB_AVAILABLE = _module_available("matplotlib")
---> 77 _TRANSFORMERS_AVAILABLE = _module_available("transformers")
78 _PYSTICHE_AVAILABLE = _module_available("pystiche")
79 _FIFTYONE_AVAILABLE = _module_available("fiftyone")
/opt/conda/lib/python3.7/site-packages/flash/core/utilities/imports.py in _module_available(module_path)
36 """
37 try:
---> 38 return find_spec(module_path) is not None
39 except AttributeError:
40 # Python 3.6
/opt/conda/lib/python3.7/importlib/util.py in find_spec(name, package)
112 else:
113 if spec is None:
--> 114 raise ValueError('{}.__spec__ is None'.format(name))
115 return spec
116
ValueError: transformers.__spec__ is None
```
## To reproduce
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
```
import transformers
print(transformers.__version__)
print(transformers.__spec__)
4.9.1
None
```
## Expected behavior
Properly defined `__spec__`
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12904/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12904/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12903 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12903/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12903/comments | https://api.github.com/repos/huggingface/transformers/issues/12903/events | https://github.com/huggingface/transformers/issues/12903 | 953,595,056 | MDU6SXNzdWU5NTM1OTUwNTY= | 12,903 | ValueError: Outputs values doesn't match between reference model and ONNX exported model | {
"login": "leoozy",
"id": 26025961,
"node_id": "MDQ6VXNlcjI2MDI1OTYx",
"avatar_url": "https://avatars.githubusercontent.com/u/26025961?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/leoozy",
"html_url": "https://github.com/leoozy",
"followers_url": "https://api.github.com/users/leoozy/followers",
"following_url": "https://api.github.com/users/leoozy/following{/other_user}",
"gists_url": "https://api.github.com/users/leoozy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/leoozy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/leoozy/subscriptions",
"organizations_url": "https://api.github.com/users/leoozy/orgs",
"repos_url": "https://api.github.com/users/leoozy/repos",
"events_url": "https://api.github.com/users/leoozy/events{/privacy}",
"received_events_url": "https://api.github.com/users/leoozy/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"python -m transformers.onnx --model=facebook/bart-large /home/sysadmin/downlaod/onnx_models/bart-large\r\n\r\nHello, the doc says bart has been supported by transformers.onnx. But this error occers while I run it.\r\n\r\nPytorch version: 1.9.0\r\ntransformers version: 4.9.1\r\nplatform: centos 7\r\npython version: 3.7",
"@mfuntowicz @LysandreJik ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"I'm getting the same error for mBART. I'm using a colab notebook with/without GPU.\r\n\r\n```\r\n!pip install transformers[onnx] sentencepiece -q\r\n!python -m transformers.onnx --model=facebook/mbart-large-50 --feature seq2seq-lm-with-past onnx/\r\n```\r\n\r\n> Using framework PyTorch: 1.10.0+cu111\r\n> ValueError: Outputs values doesn't match between reference model and ONNX exported model: Got max absolute difference of: 3.5762786865234375e-05",
"You can change the `atol` as described in this [PR](https://github.com/huggingface/transformers/issues/15716).\r\nFor example\r\n```\r\n!python -m transformers.onnx --model=facebook/mbart-large-50 --atol=5e-5 --feature seq2seq-lm-with-past onnx/\r\n```"
] | 1,627 | 1,659 | 1,630 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
python -m transformers.onnx --model=facebook/bart-large /home/sysadmin/downlaod/onnx_models/bart-large
- `transformers` version: 4.9.1
- Platform: CENTOS 8
- Python version: python 3.7
- PyTorch version (GPU?): pytorch 1.9.0
- Tensorflow version (GPU?):
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
@LysandreJik @patrickvonplaten
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->

| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12903/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12903/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12902 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12902/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12902/comments | https://api.github.com/repos/huggingface/transformers/issues/12902/events | https://github.com/huggingface/transformers/issues/12902 | 953,584,317 | MDU6SXNzdWU5NTM1ODQzMTc= | 12,902 | pipeline does not load a (local) model | {
"login": "randomgambit",
"id": 8282510,
"node_id": "MDQ6VXNlcjgyODI1MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/8282510?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/randomgambit",
"html_url": "https://github.com/randomgambit",
"followers_url": "https://api.github.com/users/randomgambit/followers",
"following_url": "https://api.github.com/users/randomgambit/following{/other_user}",
"gists_url": "https://api.github.com/users/randomgambit/gists{/gist_id}",
"starred_url": "https://api.github.com/users/randomgambit/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/randomgambit/subscriptions",
"organizations_url": "https://api.github.com/users/randomgambit/orgs",
"repos_url": "https://api.github.com/users/randomgambit/repos",
"events_url": "https://api.github.com/users/randomgambit/events{/privacy}",
"received_events_url": "https://api.github.com/users/randomgambit/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"As the error specifies, there's a problem with the path you are providing. Make sure the path can be parsed correctly.",
"thanks @NielsRogge, actually I was able to make it work indirectly: first load the model on another computer, then use `save_pretrained`, transfer the saved folder to the offline computer and use the path to the folder. This raises the fundamental question: can we download the files directly from the web? For instance, https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english/tree/main does not contain a `model_card.json` whereas the folder after `save_pretrained` does. Thanks!",
"Yes you can download them directly from the web. On the [model page](https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english), there's a button \"Use in Transformers\" on the right. This shows how you either load the weights from the hub into your RAM using `.from_pretrained()`, or by git cloning the files using git-lfs.",
"Oh I see, so I can download all the files from the web, put them in a folder (as I did originally) and instead of doing `model = pipeline(model = \"to/my/path\", tokenizer =\"to/my/path\")` I should do `model = AutoModelForSequenceClassification.from_pretrained('to/my/path\")`?",
"It depends on whether you want to use the pipeline, or the model right away. Both should work with the files stored locally.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,630 | 1,630 | NONE | null | Hello the great `huggingface` team!
I am using a computer behind a firewall so I cannot download files from python. I am simply trying to load a sentiment-analysis pipeline so I downloaded all the files available here https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english/tree/main in a local folder (I am using tensorflow)
- config.json
- tf_model.h5
- tokenizer_config.json
- vocab.txt
However, when I tried to use this path in a `pipeline`, I get a strange error:
```
from transformers import pipeline
classifier = pipeline(task= 'sentiment-analysis',
model= "C:\\Users\\me\\mymodel",
tokenizer = "C:\\Users\\me\\mymodel")
ValueError: unable to parse C:\Users\me\mymodel\modelcard.json as a URL or as a local path
```
Is this a bug?
Thanks! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12902/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12902/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12901 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12901/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12901/comments | https://api.github.com/repos/huggingface/transformers/issues/12901/events | https://github.com/huggingface/transformers/pull/12901 | 953,454,027 | MDExOlB1bGxSZXF1ZXN0Njk3NDkzMjI2 | 12,901 | Update generation_logits_process.py | {
"login": "willfrey",
"id": 13784361,
"node_id": "MDQ6VXNlcjEzNzg0MzYx",
"avatar_url": "https://avatars.githubusercontent.com/u/13784361?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/willfrey",
"html_url": "https://github.com/willfrey",
"followers_url": "https://api.github.com/users/willfrey/followers",
"following_url": "https://api.github.com/users/willfrey/following{/other_user}",
"gists_url": "https://api.github.com/users/willfrey/gists{/gist_id}",
"starred_url": "https://api.github.com/users/willfrey/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/willfrey/subscriptions",
"organizations_url": "https://api.github.com/users/willfrey/orgs",
"repos_url": "https://api.github.com/users/willfrey/repos",
"events_url": "https://api.github.com/users/willfrey/events{/privacy}",
"received_events_url": "https://api.github.com/users/willfrey/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,627 | 1,627 | 1,627 | CONTRIBUTOR | null | While `Iterable[Iterable[int]]` is a nicer annotation (it's covariant!), the defensive statements parsing out `bad_words_ids` in `__init__(...)` force the caller to pass in `List[List[int]]`. I've changed the annotation to make that clear. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12901/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12901/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12901",
"html_url": "https://github.com/huggingface/transformers/pull/12901",
"diff_url": "https://github.com/huggingface/transformers/pull/12901.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12901.patch",
"merged_at": 1627496195000
} |
https://api.github.com/repos/huggingface/transformers/issues/12900 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12900/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12900/comments | https://api.github.com/repos/huggingface/transformers/issues/12900/events | https://github.com/huggingface/transformers/pull/12900 | 953,424,664 | MDExOlB1bGxSZXF1ZXN0Njk3NDY4ODMz | 12,900 | Update generation_logits_process.py | {
"login": "willfrey",
"id": 13784361,
"node_id": "MDQ6VXNlcjEzNzg0MzYx",
"avatar_url": "https://avatars.githubusercontent.com/u/13784361?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/willfrey",
"html_url": "https://github.com/willfrey",
"followers_url": "https://api.github.com/users/willfrey/followers",
"following_url": "https://api.github.com/users/willfrey/following{/other_user}",
"gists_url": "https://api.github.com/users/willfrey/gists{/gist_id}",
"starred_url": "https://api.github.com/users/willfrey/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/willfrey/subscriptions",
"organizations_url": "https://api.github.com/users/willfrey/orgs",
"repos_url": "https://api.github.com/users/willfrey/repos",
"events_url": "https://api.github.com/users/willfrey/events{/privacy}",
"received_events_url": "https://api.github.com/users/willfrey/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,627 | 1,627 | 1,627 | CONTRIBUTOR | null | Change `torch.Tensor` -> `torch.FloatTensor` in `TemperatureLogitsWarper` to be consistent with the `LogitsWarper` ABC signature annotation. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12900/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12900/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12900",
"html_url": "https://github.com/huggingface/transformers/pull/12900",
"diff_url": "https://github.com/huggingface/transformers/pull/12900.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12900.patch",
"merged_at": 1627496240000
} |
https://api.github.com/repos/huggingface/transformers/issues/12899 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12899/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12899/comments | https://api.github.com/repos/huggingface/transformers/issues/12899/events | https://github.com/huggingface/transformers/pull/12899 | 953,417,012 | MDExOlB1bGxSZXF1ZXN0Njk3NDYyNTUw | 12,899 | `Seq2SeqTrainer` set max_length and num_beams only when non None | {
"login": "cchen-dialpad",
"id": 47165889,
"node_id": "MDQ6VXNlcjQ3MTY1ODg5",
"avatar_url": "https://avatars.githubusercontent.com/u/47165889?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cchen-dialpad",
"html_url": "https://github.com/cchen-dialpad",
"followers_url": "https://api.github.com/users/cchen-dialpad/followers",
"following_url": "https://api.github.com/users/cchen-dialpad/following{/other_user}",
"gists_url": "https://api.github.com/users/cchen-dialpad/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cchen-dialpad/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cchen-dialpad/subscriptions",
"organizations_url": "https://api.github.com/users/cchen-dialpad/orgs",
"repos_url": "https://api.github.com/users/cchen-dialpad/repos",
"events_url": "https://api.github.com/users/cchen-dialpad/events{/privacy}",
"received_events_url": "https://api.github.com/users/cchen-dialpad/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,627 | 1,627 | 1,627 | CONTRIBUTOR | null | # What does this PR do?
This PR slightly modifies the logic of setting `self._max_length` and `self._num_beams` in `Seq2SeqTrainer`'s `evaluate()` and `predict()` methods, i.e., the two variables will be set only when they are provided non `None` values.
This is to address a potentially inconsistent evaluation configuration inside the Seq2Seq training loop. For example, if you create a `Seq2SeqTrainer` object and invoke its `train()` method with a by epoch evaluation strategy, this line will do the evaluation after each training epoch: https://github.com/huggingface/transformers/blob/ba15fe7995a02357ecea6e7024918f6915564c36/src/transformers/trainer.py#L1437
`Seq2SeqTrainer ` subclasses `Trainer`, so the actual `evaluate()` method is https://github.com/huggingface/transformers/blob/ba15fe7995a02357ecea6e7024918f6915564c36/src/transformers/trainer_seq2seq.py#L36-L43
Now the problem is that `max_length` and `num_beams` can only be the default value `None` inside the training loop, since the training method is not aware of parameters introduced from the subclass. To avoid this issue, this PR basically says that we will set the two variables only when non `None` values are provided. This allows users to set them using `seq2seq_trainer._max_length = 100` and `seq2seq_trainer._num_beams = 4` before entering the training loop (and won't be reset to `None` during training).
## Who can review?
@patrickvonplaten @sgugger
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12899/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12899/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12899",
"html_url": "https://github.com/huggingface/transformers/pull/12899",
"diff_url": "https://github.com/huggingface/transformers/pull/12899.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12899.patch",
"merged_at": 1627389466000
} |
https://api.github.com/repos/huggingface/transformers/issues/12898 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12898/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12898/comments | https://api.github.com/repos/huggingface/transformers/issues/12898/events | https://github.com/huggingface/transformers/issues/12898 | 953,408,473 | MDU6SXNzdWU5NTM0MDg0NzM= | 12,898 | Tensorflow Mixed Precision Training | {
"login": "zuyezheng",
"id": 1641940,
"node_id": "MDQ6VXNlcjE2NDE5NDA=",
"avatar_url": "https://avatars.githubusercontent.com/u/1641940?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zuyezheng",
"html_url": "https://github.com/zuyezheng",
"followers_url": "https://api.github.com/users/zuyezheng/followers",
"following_url": "https://api.github.com/users/zuyezheng/following{/other_user}",
"gists_url": "https://api.github.com/users/zuyezheng/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zuyezheng/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zuyezheng/subscriptions",
"organizations_url": "https://api.github.com/users/zuyezheng/orgs",
"repos_url": "https://api.github.com/users/zuyezheng/repos",
"events_url": "https://api.github.com/users/zuyezheng/events{/privacy}",
"received_events_url": "https://api.github.com/users/zuyezheng/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"One-hot encoding the labels for a language model will get you OOM super fast since the vocab size is often large, so that's not an option. I think casting the prediction before the loss back to float32 is probably the safest option?",
"Ah, good point, I assumed since logits were of the same dimensionality, it wouldn't be too bad, but digging deeper in TF's sparse implementation, definitely more optimal. Interestingly, TF's internal [implementation](https://github.com/tensorflow/tensorflow/blob/57da85f8870bc8dee1b77225b3e30ea3f314d304/tensorflow/python/ops/nn_ops.py#L4185) even notes a requirement for labels to be of \"dtype `int32` or `int64`\" so I think it's their cast that needs to be fixed since it's still going from `int -> float32 -> int64` currently.\r\n\r\nI settled with this loss function that does a cast of the logits in the meantime which also has a benefit (I think) of performing the final softmax in float32 vs float16.\r\n```\r\[email protected]\r\ndef compute_loss(labels, logits):\r\n loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(\r\n from_logits=True, reduction=tf.keras.losses.Reduction.NONE\r\n )\r\n # make sure only labels that are not equal to -100 affect the loss\r\n active_loss = tf.not_equal(tf.reshape(labels, (-1,)), -100)\r\n reduced_logits = tf.boolean_mask(tf.reshape(logits, (-1, shape_list(logits)[2])), active_loss)\r\n labels = tf.boolean_mask(tf.reshape(labels, (-1,)), active_loss)\r\n\r\n return loss_fn(labels, tf.cast(reduced_logits, tf.float32))\r\n```\r\n\r\nHowever, still curious if using float32 explicitly in an earlier layer such as for the activation function in `TFBertPredictionHeadTransform` might still be better?\r\n",
"This is a fascinating bug in Keras. It's a known issue that softmaxes can be unstable in float16 or bfloat16, but I didn't realize that this issue could also smear the labels around too. Tagging #12332 as well, which is a relevant PR. (And maybe this might finally explain my confusion with what was going on in that case!)\r\n\r\nI think you're right that computing the logits in float32 across our models might still be an improvement for numerical stability reasons even if the label cast bug is fixed, though, and so it would be worth making that change even if the upstream Keras bug gets fixed. @sgugger wdyt?",
"In PyTorch, we always compute the softmax in FP32 as it's better for numerical stability. So yes, if possible, we should the same on the TF side.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,630 | 1,630 | NONE | null | ## Environment info
- `transformers` version: 4.5.1
- Platform: Linux-5.4.0-74-generic-x86_64-with-glibc2.27
- Python version: 3.8.8
- PyTorch version (GPU?): 1.8.1+cu111 (True)
- Tensorflow version (GPU?): 2.6.0-dev20210604 (True)
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help
@LysandreJik @Rocketknight1 @sgugger
## Information
Model I am using (Bert, XLNet ...): Bert
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Use TF directly with `model.fit` or `TFTrainer` with policy `mixed_float16` for mixed precision training.
2. Due to this tensorflow [cast](https://github.com/tensorflow/tensorflow/issues/50964) issue in SparseCategoricalCrossentropy loss used in many of the huggingface TF models, incorrect label encodings could result in `nan` or errors in loss.
3. Errors can start with token (or class) indexes at 2k+ and `nan` loss with labels closer to the max.
## Expected behavior
Correct loss and no `nan`.
Changing `compute_loss` to use `CategoricalCrossentropy` vs sparse and manually one hot encoding solves this:
```
def compute_loss(labels, logits):
loss_fn = tf.keras.losses.CategoricalCrossentropy(
from_logits=True, reduction=tf.keras.losses.Reduction.NONE
)
# make sure only labels that are not equal to -100 affect the loss
active_loss = tf.not_equal(tf.reshape(labels, (-1,)), -100)
reduced_logits = tf.boolean_mask(tf.reshape(logits, (-1, shape_list(logits)[2])), active_loss)
labels = tf.boolean_mask(tf.reshape(labels, (-1,)), active_loss)
**one_hot_labels = tf.one_hot(labels, tf.shape(logits)[-1], dtype=logits.dtype)**
return loss_fn(one_hot_labels, reduced_logits)
```
Changing the last output layer to be float32 also solves this:
```
class TFBertMLMHead(tf.keras.layers.Layer):
def __init__(self, config: BertConfig, input_embeddings: tf.keras.layers.Layer, **kwargs):
super().__init__(**kwargs)
self.predictions = TFBertLMPredictionHead(config, input_embeddings, name="predictions")
**self.finalCast = tf.keras.layers.Activation('linear', dtype='float32')**
def call(self, sequence_output: tf.Tensor) -> tf.Tensor:
prediction_scores = self.predictions(hidden_states=sequence_output)
**prediction_scores = self.finalCast(prediction_scores)**
return prediction_scores
```
But given the recommendation that output be accumulated in float32 to be numerically stable, perhaps `transform_act_fn` and everything after needs to be `float32`? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12898/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12898/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12897 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12897/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12897/comments | https://api.github.com/repos/huggingface/transformers/issues/12897/events | https://github.com/huggingface/transformers/pull/12897 | 953,393,012 | MDExOlB1bGxSZXF1ZXN0Njk3NDQyNDU2 | 12,897 | Correct validation_split_percentage argument from int (ex:5) to float (0.05) | {
"login": "Elysium1436",
"id": 61297992,
"node_id": "MDQ6VXNlcjYxMjk3OTky",
"avatar_url": "https://avatars.githubusercontent.com/u/61297992?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Elysium1436",
"html_url": "https://github.com/Elysium1436",
"followers_url": "https://api.github.com/users/Elysium1436/followers",
"following_url": "https://api.github.com/users/Elysium1436/following{/other_user}",
"gists_url": "https://api.github.com/users/Elysium1436/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Elysium1436/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Elysium1436/subscriptions",
"organizations_url": "https://api.github.com/users/Elysium1436/orgs",
"repos_url": "https://api.github.com/users/Elysium1436/repos",
"events_url": "https://api.github.com/users/Elysium1436/events{/privacy}",
"received_events_url": "https://api.github.com/users/Elysium1436/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Please make sure to run `make style` on your branch to fix the formatting issues.",
"Thanks for fixing!",
"Thanks for kind help with the formatting "
] | 1,627 | 1,627 | 1,627 | CONTRIBUTOR | null |
# What does this PR do?
This PR is for fixing a bug in the run_clm.py and run_mlm.py examples in the tensorflow section. I have merely divided the value by 100 on the train_test_split test_size argument. This will make it work as intended now.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
https://github.com/huggingface/transformers/pull/11690
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
Related People: @sgugger and @patil-suraj
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12897/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12897/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12897",
"html_url": "https://github.com/huggingface/transformers/pull/12897",
"diff_url": "https://github.com/huggingface/transformers/pull/12897.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12897.patch",
"merged_at": 1627434100000
} |
https://api.github.com/repos/huggingface/transformers/issues/12896 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12896/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12896/comments | https://api.github.com/repos/huggingface/transformers/issues/12896/events | https://github.com/huggingface/transformers/pull/12896 | 953,359,453 | MDExOlB1bGxSZXF1ZXN0Njk3NDEzNDY2 | 12,896 | Update tokenization_auto.py | {
"login": "willfrey",
"id": 13784361,
"node_id": "MDQ6VXNlcjEzNzg0MzYx",
"avatar_url": "https://avatars.githubusercontent.com/u/13784361?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/willfrey",
"html_url": "https://github.com/willfrey",
"followers_url": "https://api.github.com/users/willfrey/followers",
"following_url": "https://api.github.com/users/willfrey/following{/other_user}",
"gists_url": "https://api.github.com/users/willfrey/gists{/gist_id}",
"starred_url": "https://api.github.com/users/willfrey/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/willfrey/subscriptions",
"organizations_url": "https://api.github.com/users/willfrey/orgs",
"repos_url": "https://api.github.com/users/willfrey/repos",
"events_url": "https://api.github.com/users/willfrey/events{/privacy}",
"received_events_url": "https://api.github.com/users/willfrey/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,627 | 1,627 | 1,627 | CONTRIBUTOR | null | Fix `config.decoder.__class` -> `config.decoder.__class__`. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12896/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12896/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12896",
"html_url": "https://github.com/huggingface/transformers/pull/12896",
"diff_url": "https://github.com/huggingface/transformers/pull/12896.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12896.patch",
"merged_at": 1627496277000
} |
https://api.github.com/repos/huggingface/transformers/issues/12895 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12895/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12895/comments | https://api.github.com/repos/huggingface/transformers/issues/12895/events | https://github.com/huggingface/transformers/pull/12895 | 953,291,207 | MDExOlB1bGxSZXF1ZXN0Njk3MzU1MTI1 | 12,895 | Fix push_to_hub for TPUs | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,627 | 1,627 | 1,627 | COLLABORATOR | null | # What does this PR do?
This PR fixes the `push_to_hub` method for TPUs, which hangs forever right now because there is a reandezvous point in code that is only reached by the main process. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12895/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12895/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12895",
"html_url": "https://github.com/huggingface/transformers/pull/12895",
"diff_url": "https://github.com/huggingface/transformers/pull/12895.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12895.patch",
"merged_at": 1627333834000
} |
https://api.github.com/repos/huggingface/transformers/issues/12894 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12894/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12894/comments | https://api.github.com/repos/huggingface/transformers/issues/12894/events | https://github.com/huggingface/transformers/issues/12894 | 953,274,626 | MDU6SXNzdWU5NTMyNzQ2MjY= | 12,894 | tokenizers add_token bug | {
"login": "ssoltan88",
"id": 73563381,
"node_id": "MDQ6VXNlcjczNTYzMzgx",
"avatar_url": "https://avatars.githubusercontent.com/u/73563381?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ssoltan88",
"html_url": "https://github.com/ssoltan88",
"followers_url": "https://api.github.com/users/ssoltan88/followers",
"following_url": "https://api.github.com/users/ssoltan88/following{/other_user}",
"gists_url": "https://api.github.com/users/ssoltan88/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ssoltan88/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ssoltan88/subscriptions",
"organizations_url": "https://api.github.com/users/ssoltan88/orgs",
"repos_url": "https://api.github.com/users/ssoltan88/repos",
"events_url": "https://api.github.com/users/ssoltan88/events{/privacy}",
"received_events_url": "https://api.github.com/users/ssoltan88/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Pinging @n1t0 and @SaulLu for advice",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,630 | 1,630 | NONE | null | The way `add_token` is implemented results is problematic tokenization when added tokens are substring of each other. Example:
```
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("google/mt5-large")
tokenizer.add_tokens(['my_token_1', 'my_token_12', 'my_token_123'])
tokenizer.tokenize("my_token_1 and my_token_12 and my_token_123")
```
output:
```
['my_token_1',
'▁and',
'▁',
'my_token_1',
'▁2',
'▁and',
'▁',
'my_token_1',
'▁23']
```
Because of implementation (i.e., breaking text on added tokens), adding new tokens in the reversed order (i.e., `tokenizer.add_tokens(['my_token_123', 'my_token_12', 'my_token_1'])`) results in the correct tokenization. So one solution is always order the added tokens in reversed. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12894/reactions",
"total_count": 3,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 3
} | https://api.github.com/repos/huggingface/transformers/issues/12894/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12893 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12893/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12893/comments | https://api.github.com/repos/huggingface/transformers/issues/12893/events | https://github.com/huggingface/transformers/pull/12893 | 953,129,284 | MDExOlB1bGxSZXF1ZXN0Njk3MjE5NzI5 | 12,893 | Create py.typed | {
"login": "willfrey",
"id": 13784361,
"node_id": "MDQ6VXNlcjEzNzg0MzYx",
"avatar_url": "https://avatars.githubusercontent.com/u/13784361?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/willfrey",
"html_url": "https://github.com/willfrey",
"followers_url": "https://api.github.com/users/willfrey/followers",
"following_url": "https://api.github.com/users/willfrey/following{/other_user}",
"gists_url": "https://api.github.com/users/willfrey/gists{/gist_id}",
"starred_url": "https://api.github.com/users/willfrey/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/willfrey/subscriptions",
"organizations_url": "https://api.github.com/users/willfrey/orgs",
"repos_url": "https://api.github.com/users/willfrey/repos",
"events_url": "https://api.github.com/users/willfrey/events{/privacy}",
"received_events_url": "https://api.github.com/users/willfrey/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thanks, @willfrey! I'm reading the PEP 561 as I was unaware of this file, but I'm not sure I'm getting everything. Is this file necessary for downstream type checkers (such as `mypy`) to understand the types from `transformers`?\r\n\r\nIf that is so, is there no need for any additions, such as a mention in our setup.py's `package_data`? And is the addition of that single file enough to make the package compatible with downstream type checkers, or should we vigorously check that all types are currently defined, and enforce all types from now on for the package?\r\n\r\nThank you!",
"`py.typed` needs to be distributed with the top-level `transformers` package as per [PEP 561](https://www.python.org/dev/peps/pep-0561/#packaging-type-information).\r\n\r\nThis should be all that you need to tell downstream type checkers that the code in the package is typed. It'll make mypy behave a lot more nicely, that's for sure. Some type checkers, like Pyright will infer types from library code directly, which is why mypy freaks out but Pylance tries to do the right thing. My experience with Pylance though is that it is very slow trying to infer types based on all the non-standard behavior being done to hack the various namespaces in the package.\r\n\r\nI _think_ partial types are okay here, they'll just be inferred implicitly as `Any`. I wouldn't defensively enforce types because that defeats the whole point of structural sub-typing (duck-typing) that makes Python so great. Type annotations are meant (among other things) to allow you to identify logical errors in your code that a compiler would normally catch.\r\n\r\nAnother reason to not enforce it is that people tend to over-specify the types for method parameters, which can get annoying. For example, you might annotate something as `List[str]` (or `list[str]` for Python 3.9 and later) but you really only needed `collections.abc.MutableSequence[str]`, `collections.abc.Sequence[str]`, or perhaps just `collections.abc.Iterable[str]`.",
"Thank you for the explanation, that all makes a lot of sense. I tried your PR with `mypy` to see if it would be able to analyze the types, yet I'm still getting the error that should be resolved: \r\n```\r\nerror: Skipping analyzing \"transformers\": found module but no type hints or library stubs\r\n```\r\nI suspect this has to do with `package_data` being ill-defined as I see it defined in a few sources, but I'm unsuccessful at completing it and resolving this error. \r\n\r\nI'm trying to understand what issue would adding `py.typed` resolve, to make sure we're not forgetting anything/couldn't improve it by understanding the use-cases this would enable.",
"I'm assuming mypy is trying to analyze transformers in a virtual environment where it's been pip installed? If so, check in the virtualenv to see if the py.typed file is in the transformers directory.\r\n\r\nI just updated setup.py to include py.typed as package data.",
"A similar PR (https://github.com/huggingface/datasets/pull/2417) was recently merged in the datasets library as well.\r\n\r\n@willfrey \r\nA small nit. It's advised by MyPy to set the `zip_safe` argument of `setuptools.setup` to `False`.\r\n\r\n@LysandreJik \r\n[This thread on SO](https://stackoverflow.com/questions/60856237/mypy-cant-find-type-hints-for-black) explains what happens when running MyPy on code that imports a 3rd party lib that's not PEP561-compliant.\r\n",
"@willfrey Do you mind setting the `zip_sage` argument as mentioned by @mariosasko?\r\nWe'll merge the PR afterward. Thank you!",
"@LysandreJik Done!"
] | 1,627 | 1,629 | 1,628 | CONTRIBUTOR | null | # What does this PR do?
This creates a [py.typed as per PEP 561](https://www.python.org/dev/peps/pep-0561/#packaging-type-information) that should be distributed to mark that the package includes (inline) type annotations.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12893/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12893/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12893",
"html_url": "https://github.com/huggingface/transformers/pull/12893",
"diff_url": "https://github.com/huggingface/transformers/pull/12893.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12893.patch",
"merged_at": 1628842379000
} |
https://api.github.com/repos/huggingface/transformers/issues/12892 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12892/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12892/comments | https://api.github.com/repos/huggingface/transformers/issues/12892/events | https://github.com/huggingface/transformers/issues/12892 | 953,079,578 | MDU6SXNzdWU5NTMwNzk1Nzg= | 12,892 | CANINE pre-training | {
"login": "ArijRB",
"id": 29141009,
"node_id": "MDQ6VXNlcjI5MTQxMDA5",
"avatar_url": "https://avatars.githubusercontent.com/u/29141009?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ArijRB",
"html_url": "https://github.com/ArijRB",
"followers_url": "https://api.github.com/users/ArijRB/followers",
"following_url": "https://api.github.com/users/ArijRB/following{/other_user}",
"gists_url": "https://api.github.com/users/ArijRB/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ArijRB/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ArijRB/subscriptions",
"organizations_url": "https://api.github.com/users/ArijRB/orgs",
"repos_url": "https://api.github.com/users/ArijRB/repos",
"events_url": "https://api.github.com/users/ArijRB/events{/privacy}",
"received_events_url": "https://api.github.com/users/ArijRB/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi,\r\n\r\nGoogle hasn't released any pre-training code yet. As stated on their [README](https://github.com/google-research/language/tree/master/language/canine#pre-training-code-coming-later):\r\n\r\n> Pre-training Code (Coming later)\r\nWe've prioritized releasing the pre-trained checkpoints, modeling code, and TyDi QA evaluation code since we hope this will cover the most common use cases. The implementation of pre-training will be released in this repo in the future. If this is blocking you, feel free to send us a friendly ping to let us know that this is important to you.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,630 | 1,630 | NONE | null | # 🚀 Feature request
Thanks for the integration of the Canine model. I am interested in pre-training the model from scratch and I was wondering if you have a timeline for the release of a pre-training script using autoregressive character loss.
Thank you in advance.
@NielsRogge | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12892/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12892/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12891 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12891/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12891/comments | https://api.github.com/repos/huggingface/transformers/issues/12891/events | https://github.com/huggingface/transformers/pull/12891 | 953,023,690 | MDExOlB1bGxSZXF1ZXN0Njk3MTMwNDA1 | 12,891 | Fix docstring typo in tokenization_auto.py | {
"login": "willfrey",
"id": 13784361,
"node_id": "MDQ6VXNlcjEzNzg0MzYx",
"avatar_url": "https://avatars.githubusercontent.com/u/13784361?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/willfrey",
"html_url": "https://github.com/willfrey",
"followers_url": "https://api.github.com/users/willfrey/followers",
"following_url": "https://api.github.com/users/willfrey/following{/other_user}",
"gists_url": "https://api.github.com/users/willfrey/gists{/gist_id}",
"starred_url": "https://api.github.com/users/willfrey/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/willfrey/subscriptions",
"organizations_url": "https://api.github.com/users/willfrey/orgs",
"repos_url": "https://api.github.com/users/willfrey/repos",
"events_url": "https://api.github.com/users/willfrey/events{/privacy}",
"received_events_url": "https://api.github.com/users/willfrey/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,627 | 1,627 | 1,627 | CONTRIBUTOR | null | Change `PreTrainedConfig` -> `PretrainedConfig` in the docstring for `AutoTokenizer.from_pretrained(...)`. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12891/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12891/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12891",
"html_url": "https://github.com/huggingface/transformers/pull/12891",
"diff_url": "https://github.com/huggingface/transformers/pull/12891.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12891.patch",
"merged_at": 1627496374000
} |
https://api.github.com/repos/huggingface/transformers/issues/12890 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12890/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12890/comments | https://api.github.com/repos/huggingface/transformers/issues/12890/events | https://github.com/huggingface/transformers/issues/12890 | 952,972,307 | MDU6SXNzdWU5NTI5NzIzMDc= | 12,890 | Multi-GPU fails | {
"login": "avi-jit",
"id": 11348738,
"node_id": "MDQ6VXNlcjExMzQ4NzM4",
"avatar_url": "https://avatars.githubusercontent.com/u/11348738?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/avi-jit",
"html_url": "https://github.com/avi-jit",
"followers_url": "https://api.github.com/users/avi-jit/followers",
"following_url": "https://api.github.com/users/avi-jit/following{/other_user}",
"gists_url": "https://api.github.com/users/avi-jit/gists{/gist_id}",
"starred_url": "https://api.github.com/users/avi-jit/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/avi-jit/subscriptions",
"organizations_url": "https://api.github.com/users/avi-jit/orgs",
"repos_url": "https://api.github.com/users/avi-jit/repos",
"events_url": "https://api.github.com/users/avi-jit/events{/privacy}",
"received_events_url": "https://api.github.com/users/avi-jit/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I am unable to reproduce the problem (also you seem to have made changes to the `run_clm` script since it does not accept those arguments: `--method range --source fi.json --from_scratch`) but in general, PyTorch discourages the use of DataParallel for multiGPU, so you should try to see if using DistributedDataParallel (by launching the script with `torch.distributed.launch`) works better?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,630 | 1,630 | NONE | null | ## Environment info
- transformers version: 4.6.1
- Platform: Linux-4.19.0-17-cloud-amd64-x86_64-with-glibc2.10
- Python version: 3.8.10
- PyTorch version (GPU?): 1.8.1+cu111
- Tensorflow version (GPU?): not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: Data Parallel
### Who can help
Models:
- openai-gpt: @sgugger
Library:
- trainer: @sgugger
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
## Information
Model I am using (Bert, XLNet ...): openai-gpt
The problem arises when using:
* [X] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details below)
My dataset is a simple text file with strings for causal language modelling.
## To reproduce
```
python run_clm.py --model_name_or_path openai-gpt --train_file dataset/train.txt --validation_file dataset/eval.txt --do_train --do_eval --output_dir /tmp/ --method range --source fi.json --from_scratch --per_device_eval_batch_size 4 --per_device_train_batch_size 4
```
Error Log:
```
2021-07-26T14:09:12.968147055Z sudo: setrlimit(RLIMIT_STACK): Operation not permitted
2021-07-26T14:09:14.905455906Z 07/26/2021 14:09:14 - WARNING - __main__ - Process rank: -1, device: cuda:0, n_gpu: 2distributed training: False, 16-bits training: False
2021-07-26T14:09:14.90566887Z 07/26/2021 14:09:14 - INFO - __main__ - Training/evaluation parameters TrainingArguments(
2021-07-26T14:09:14.905680763Z _n_gpu=2,
2021-07-26T14:09:14.905686554Z adafactor=False,
2021-07-26T14:09:14.905691893Z adam_beta1=0.9,
2021-07-26T14:09:14.905697154Z adam_beta2=0.999,
2021-07-26T14:09:14.9057025Z adam_epsilon=1e-08,
2021-07-26T14:09:14.90570797Z dataloader_drop_last=False,
2021-07-26T14:09:14.905713094Z dataloader_num_workers=0,
2021-07-26T14:09:14.905718126Z dataloader_pin_memory=True,
2021-07-26T14:09:14.905723969Z ddp_find_unused_parameters=None,
2021-07-26T14:09:14.905729253Z debug=[],
2021-07-26T14:09:14.905734499Z deepspeed=None,
2021-07-26T14:09:14.9057397Z disable_tqdm=False,
2021-07-26T14:09:14.905744923Z do_eval=True,
2021-07-26T14:09:14.905749956Z do_predict=False,
2021-07-26T14:09:14.90575516Z do_train=True,
2021-07-26T14:09:14.90576029Z eval_accumulation_steps=None,
2021-07-26T14:09:14.905766046Z eval_steps=500,
2021-07-26T14:09:14.905771809Z evaluation_strategy=IntervalStrategy.STEPS,
2021-07-26T14:09:14.905777566Z fp16=False,
2021-07-26T14:09:14.905782742Z fp16_backend=auto,
2021-07-26T14:09:14.905787796Z fp16_full_eval=False,
2021-07-26T14:09:14.90579285Z fp16_opt_level=O1,
2021-07-26T14:09:14.90579783Z gradient_accumulation_steps=32,
2021-07-26T14:09:14.905802916Z greater_is_better=None,
2021-07-26T14:09:14.905808523Z group_by_length=False,
2021-07-26T14:09:14.905813853Z ignore_data_skip=False,
2021-07-26T14:09:14.905819176Z label_names=None,
2021-07-26T14:09:14.905824413Z label_smoothing_factor=0.0,
2021-07-26T14:09:14.905829632Z learning_rate=5e-05,
2021-07-26T14:09:14.905834616Z length_column_name=length,
2021-07-26T14:09:14.905839636Z load_best_model_at_end=False,
2021-07-26T14:09:14.905844662Z local_rank=-1,
2021-07-26T14:09:14.905850119Z log_level=-1,
2021-07-26T14:09:14.905855292Z log_level_replica=-1,
2021-07-26T14:09:14.905860668Z log_on_each_node=True,
2021-07-26T14:09:14.905865976Z logging_dir=result/runs/Jul26_14-09-14_cffe56d6abc4,
2021-07-26T14:09:14.905871216Z logging_first_step=False,
2021-07-26T14:09:14.905876242Z logging_steps=500,
2021-07-26T14:09:14.905881425Z logging_strategy=IntervalStrategy.STEPS,
2021-07-26T14:09:14.905903565Z lr_scheduler_type=SchedulerType.LINEAR,
2021-07-26T14:09:14.905909738Z max_grad_norm=1.0,
2021-07-26T14:09:14.905915195Z max_steps=50000,
2021-07-26T14:09:14.905920608Z metric_for_best_model=None,
2021-07-26T14:09:14.905925952Z mp_parameters=,
2021-07-26T14:09:14.905931035Z no_cuda=False,
2021-07-26T14:09:14.905936031Z num_train_epochs=3.0,
2021-07-26T14:09:14.905941121Z output_dir=result,
2021-07-26T14:09:14.905946155Z overwrite_output_dir=True,
2021-07-26T14:09:14.905951772Z past_index=-1,
2021-07-26T14:09:14.905957084Z per_device_eval_batch_size=16,
2021-07-26T14:09:14.905962457Z per_device_train_batch_size=32,
2021-07-26T14:09:14.905967855Z prediction_loss_only=False,
2021-07-26T14:09:14.905973078Z push_to_hub=False,
2021-07-26T14:09:14.905978145Z push_to_hub_model_id=result,
2021-07-26T14:09:14.905983324Z push_to_hub_organization=None,
2021-07-26T14:09:14.905988388Z push_to_hub_token=None,
2021-07-26T14:09:14.905993985Z remove_unused_columns=True,
2021-07-26T14:09:14.905999497Z report_to=[],
2021-07-26T14:09:14.906004944Z resume_from_checkpoint=None,
2021-07-26T14:09:14.906010281Z run_name=result,
2021-07-26T14:09:14.906015348Z save_on_each_node=False,
2021-07-26T14:09:14.906020454Z save_steps=500,
2021-07-26T14:09:14.906025527Z save_strategy=IntervalStrategy.STEPS,
2021-07-26T14:09:14.906030714Z save_total_limit=1,
2021-07-26T14:09:14.906036287Z seed=42,
2021-07-26T14:09:14.90604172Z sharded_ddp=[],
2021-07-26T14:09:14.90604725Z skip_memory_metrics=True,
2021-07-26T14:09:14.906052407Z tpu_metrics_debug=False,
2021-07-26T14:09:14.906057473Z tpu_num_cores=None,
2021-07-26T14:09:14.906062617Z use_legacy_prediction_loop=False,
2021-07-26T14:09:14.906067774Z warmup_ratio=0.0,
2021-07-26T14:09:14.90607286Z warmup_steps=0,
2021-07-26T14:09:14.906078463Z weight_decay=0.0,
2021-07-26T14:09:14.906083927Z )
2021-07-26T14:09:15.117365107Z 07/26/2021 14:09:15 - WARNING - datasets.builder - Using custom data configuration default-dfca9c6f12495150
2021-07-26T14:09:15.118233822Z 07/26/2021 14:09:15 - INFO - datasets.utils.filelock - Lock 139871027286176 acquired on /root/.cache/huggingface/datasets/_root_.cache_huggingface_datasets_text_default-dfca9c6f12495150_0.0.0_e16f44aa1b321ece1f87b07977cc5d70be93d69b20486d6dacd62e12cf25c9a5.lock
2021-07-26T14:09:15.118379685Z 07/26/2021 14:09:15 - INFO - datasets.utils.filelock - Lock 139871027286176 released on /root/.cache/huggingface/datasets/_root_.cache_huggingface_datasets_text_default-dfca9c6f12495150_0.0.0_e16f44aa1b321ece1f87b07977cc5d70be93d69b20486d6dacd62e12cf25c9a5.lock
2021-07-26T14:09:15.118514014Z 07/26/2021 14:09:15 - INFO - datasets.utils.filelock - Lock 139866173991472 acquired on /root/.cache/huggingface/datasets/_root_.cache_huggingface_datasets_text_default-dfca9c6f12495150_0.0.0_e16f44aa1b321ece1f87b07977cc5d70be93d69b20486d6dacd62e12cf25c9a5.lock
2021-07-26T14:09:15.118567887Z 07/26/2021 14:09:15 - INFO - datasets.builder - Generating dataset text (/root/.cache/huggingface/datasets/text/default-dfca9c6f12495150/0.0.0/e16f44aa1b321ece1f87b07977cc5d70be93d69b20486d6dacd62e12cf25c9a5)
2021-07-26T14:09:15.12032563Z Downloading and preparing dataset text/default (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /root/.cache/huggingface/datasets/text/default-dfca9c6f12495150/0.0.0/e16f44aa1b321ece1f87b07977cc5d70be93d69b20486d6dacd62e12cf25c9a5...
2021-07-26T14:09:15.120337297Z 07/26/2021 14:09:15 - INFO - datasets.utils.download_manager - Downloading took 0.0 min
2021-07-26T14:09:15.121994254Z 07/26/2021 14:09:15 - INFO - datasets.utils.download_manager - Checksum Computation took 0.0 min
2021-07-26T14:09:15.122429438Z
0%| | 0/2 [00:00<?, ?it/s]
100%|██████████| 2/2 [00:00<00:00, 5761.41it/s]
2021-07-26T14:09:15.124508599Z 07/26/2021 14:09:15 - INFO - datasets.utils.info_utils - Unable to verify checksums.
2021-07-26T14:09:15.124597847Z 07/26/2021 14:09:15 - INFO - datasets.builder - Generating split train
2021-07-26T14:09:15.125310516Z
0%| | 0/2 [00:00<?, ?it/s]
100%|██████████| 2/2 [00:00<00:00, 1147.55it/s]
2021-07-26T14:09:15.128544997Z 07/26/2021 14:09:15 - INFO - datasets.arrow_writer - Done writing 2000 examples in 164067 bytes /root/.cache/huggingface/datasets/text/default-dfca9c6f12495150/0.0.0/e16f44aa1b321ece1f87b07977cc5d70be93d69b20486d6dacd62e12cf25c9a5.incomplete/text-train.arrow.
2021-07-26T14:09:15.128626548Z 07/26/2021 14:09:15 - INFO - datasets.builder - Generating split validation
2021-07-26T14:09:15.12993743Z 07/26/2021 14:09:15 - INFO - datasets.arrow_writer - Done writing 1000 examples in 90150 bytes /root/.cache/huggingface/datasets/text/default-dfca9c6f12495150/0.0.0/e16f44aa1b321ece1f87b07977cc5d70be93d69b20486d6dacd62e12cf25c9a5.incomplete/text-validation.arrow.
2021-07-26T14:09:15.130003546Z 07/26/2021 14:09:15 - INFO - datasets.utils.info_utils - Unable to verify splits sizes.
2021-07-26T14:09:15.130088692Z 07/26/2021 14:09:15 - INFO - datasets.utils.filelock - Lock 139866173989600 acquired on /root/.cache/huggingface/datasets/_root_.cache_huggingface_datasets_text_default-dfca9c6f12495150_0.0.0_e16f44aa1b321ece1f87b07977cc5d70be93d69b20486d6dacd62e12cf25c9a5.incomplete.lock
2021-07-26T14:09:15.130360478Z 07/26/2021 14:09:15 - INFO - datasets.utils.filelock - Lock 139866173989600 released on /root/.cache/huggingface/datasets/_root_.cache_huggingface_datasets_text_default-dfca9c6f12495150_0.0.0_e16f44aa1b321ece1f87b07977cc5d70be93d69b20486d6dacd62e12cf25c9a5.incomplete.lock
2021-07-26T14:09:15.130449829Z Dataset text downloaded and prepared to /root/.cache/huggingface/datasets/text/default-dfca9c6f12495150/0.0.0/e16f44aa1b321ece1f87b07977cc5d70be93d69b20486d6dacd62e12cf25c9a5. Subsequent calls will reuse this data.
2021-07-26T14:09:15.130456275Z 07/26/2021 14:09:15 - INFO - datasets.utils.filelock - Lock 139866173991472 released on /root/.cache/huggingface/datasets/_root_.cache_huggingface_datasets_text_default-dfca9c6f12495150_0.0.0_e16f44aa1b321ece1f87b07977cc5d70be93d69b20486d6dacd62e12cf25c9a5.lock
2021-07-26T14:09:15.130475953Z 07/26/2021 14:09:15 - INFO - datasets.builder - Constructing Dataset for split train, validation, from /root/.cache/huggingface/datasets/text/default-dfca9c6f12495150/0.0.0/e16f44aa1b321ece1f87b07977cc5d70be93d69b20486d6dacd62e12cf25c9a5
2021-07-26T14:09:15.314137303Z
0 tables [00:00, ? tables/s]
0 tables [00:00, ? tables/s]
0%| | 0/2 [00:00<?, ?it/s]
100%|██████████| 2/2 [00:00<00:00, 655.77it/s]
2021-07-26T14:09:15.31416541Z [INFO|file_utils.py:1624] 2021-07-26 14:09:15,313 >> https://huggingface.co/openai-gpt/resolve/main/config.json not found in cache or force_download set to True, downloading to /root/.cache/huggingface/transformers/tmpd5znm5l1
2021-07-26T14:09:15.496180381Z
Downloading: 0%| | 0.00/656 [00:00<?, ?B/s]
Downloading: 100%|██████████| 656/656 [00:00<00:00, 433kB/s]
2021-07-26T14:09:15.496209117Z [INFO|file_utils.py:1628] 2021-07-26 14:09:15,496 >> storing https://huggingface.co/openai-gpt/resolve/main/config.json in cache at /root/.cache/huggingface/transformers/bebb46f5735701bc248ef9faa26f12577944fa7fc8e9be1a774b94d4cb8b79b6.ba6f10a5446f364b92311c09e55e49aa27024a4aeefc1ea50fd733b77bcd997d
2021-07-26T14:09:15.496286347Z [INFO|file_utils.py:1636] 2021-07-26 14:09:15,496 >> creating metadata file for /root/.cache/huggingface/transformers/bebb46f5735701bc248ef9faa26f12577944fa7fc8e9be1a774b94d4cb8b79b6.ba6f10a5446f364b92311c09e55e49aa27024a4aeefc1ea50fd733b77bcd997d
2021-07-26T14:09:15.496582551Z [INFO|configuration_utils.py:545] 2021-07-26 14:09:15,496 >> loading configuration file https://huggingface.co/openai-gpt/resolve/main/config.json from cache at /root/.cache/huggingface/transformers/bebb46f5735701bc248ef9faa26f12577944fa7fc8e9be1a774b94d4cb8b79b6.ba6f10a5446f364b92311c09e55e49aa27024a4aeefc1ea50fd733b77bcd997d
2021-07-26T14:09:15.497318074Z [INFO|configuration_utils.py:581] 2021-07-26 14:09:15,497 >> Model config OpenAIGPTConfig {
2021-07-26T14:09:15.497326601Z "afn": "gelu",
2021-07-26T14:09:15.497332651Z "architectures": [
2021-07-26T14:09:15.497338467Z "OpenAIGPTLMHeadModel"
2021-07-26T14:09:15.49734389Z ],
2021-07-26T14:09:15.497349194Z "attn_pdrop": 0.1,
2021-07-26T14:09:15.497354591Z "embd_pdrop": 0.1,
2021-07-26T14:09:15.497360424Z "initializer_range": 0.02,
2021-07-26T14:09:15.497366131Z "layer_norm_epsilon": 1e-05,
2021-07-26T14:09:15.4973717Z "model_type": "openai-gpt",
2021-07-26T14:09:15.49737771Z "n_ctx": 512,
2021-07-26T14:09:15.49738331Z "n_embd": 768,
2021-07-26T14:09:15.497388484Z "n_head": 12,
2021-07-26T14:09:15.497393747Z "n_layer": 12,
2021-07-26T14:09:15.497399167Z "n_positions": 512,
2021-07-26T14:09:15.497404934Z "n_special": 0,
2021-07-26T14:09:15.497410553Z "predict_special_tokens": true,
2021-07-26T14:09:15.497416327Z "resid_pdrop": 0.1,
2021-07-26T14:09:15.497434673Z "summary_activation": null,
2021-07-26T14:09:15.497440436Z "summary_first_dropout": 0.1,
2021-07-26T14:09:15.497446023Z "summary_proj_to_labels": true,
2021-07-26T14:09:15.497451297Z "summary_type": "cls_index",
2021-07-26T14:09:15.497456789Z "summary_use_proj": true,
2021-07-26T14:09:15.49746268Z "task_specific_params": {
2021-07-26T14:09:15.497468433Z "text-generation": {
2021-07-26T14:09:15.497474113Z "do_sample": true,
2021-07-26T14:09:15.497479797Z "max_length": 50
2021-07-26T14:09:15.497485073Z }
2021-07-26T14:09:15.49749015Z },
2021-07-26T14:09:15.497495326Z "transformers_version": "4.9.0",
2021-07-26T14:09:15.497500982Z "vocab_size": 40478
2021-07-26T14:09:15.497506886Z }
2021-07-26T14:09:15.497512492Z
2021-07-26T14:09:15.675411198Z [INFO|tokenization_auto.py:432] 2021-07-26 14:09:15,674 >> Could not locate the tokenizer configuration file, will try to use the model config instead.
2021-07-26T14:09:15.851918363Z [INFO|configuration_utils.py:545] 2021-07-26 14:09:15,851 >> loading configuration file https://huggingface.co/openai-gpt/resolve/main/config.json from cache at /root/.cache/huggingface/transformers/bebb46f5735701bc248ef9faa26f12577944fa7fc8e9be1a774b94d4cb8b79b6.ba6f10a5446f364b92311c09e55e49aa27024a4aeefc1ea50fd733b77bcd997d
2021-07-26T14:09:15.852684702Z [INFO|configuration_utils.py:581] 2021-07-26 14:09:15,852 >> Model config OpenAIGPTConfig {
2021-07-26T14:09:15.852691992Z "afn": "gelu",
2021-07-26T14:09:15.85269584Z "architectures": [
2021-07-26T14:09:15.852699315Z "OpenAIGPTLMHeadModel"
2021-07-26T14:09:15.852702686Z ],
2021-07-26T14:09:15.852706345Z "attn_pdrop": 0.1,
2021-07-26T14:09:15.852709633Z "embd_pdrop": 0.1,
2021-07-26T14:09:15.852712825Z "initializer_range": 0.02,
2021-07-26T14:09:15.852716035Z "layer_norm_epsilon": 1e-05,
2021-07-26T14:09:15.852719184Z "model_type": "openai-gpt",
2021-07-26T14:09:15.852722288Z "n_ctx": 512,
2021-07-26T14:09:15.852725375Z "n_embd": 768,
2021-07-26T14:09:15.852728435Z "n_head": 12,
2021-07-26T14:09:15.852731725Z "n_layer": 12,
2021-07-26T14:09:15.852734975Z "n_positions": 512,
2021-07-26T14:09:15.852738185Z "n_special": 0,
2021-07-26T14:09:15.852741425Z "predict_special_tokens": true,
2021-07-26T14:09:15.852744547Z "resid_pdrop": 0.1,
2021-07-26T14:09:15.85274759Z "summary_activation": null,
2021-07-26T14:09:15.852750587Z "summary_first_dropout": 0.1,
2021-07-26T14:09:15.852753673Z "summary_proj_to_labels": true,
2021-07-26T14:09:15.852769472Z "summary_type": "cls_index",
2021-07-26T14:09:15.852772952Z "summary_use_proj": true,
2021-07-26T14:09:15.852776136Z "task_specific_params": {
2021-07-26T14:09:15.852779304Z "text-generation": {
2021-07-26T14:09:15.852782414Z "do_sample": true,
2021-07-26T14:09:15.852785664Z "max_length": 50
2021-07-26T14:09:15.852788824Z }
2021-07-26T14:09:15.852791737Z },
2021-07-26T14:09:15.852795052Z "transformers_version": "4.9.0",
2021-07-26T14:09:15.852798497Z "vocab_size": 40478
2021-07-26T14:09:15.85280183Z }
2021-07-26T14:09:15.852805286Z
2021-07-26T14:09:16.215260602Z [INFO|file_utils.py:1624] 2021-07-26 14:09:16,215 >> https://huggingface.co/openai-gpt/resolve/main/vocab.json not found in cache or force_download set to True, downloading to /root/.cache/huggingface/transformers/tmp5ct5tg0n
2021-07-26T14:09:16.457642584Z
Downloading: 0%| | 0.00/816k [00:00<?, ?B/s]
Downloading: 100%|██████████| 816k/816k [00:00<00:00, 14.9MB/s]
2021-07-26T14:09:16.457666203Z [INFO|file_utils.py:1628] 2021-07-26 14:09:16,457 >> storing https://huggingface.co/openai-gpt/resolve/main/vocab.json in cache at /root/.cache/huggingface/transformers/918c57540c636a2a662770d208fcf20aa8c3faea78201fc612e5c84f052f1119.ac55819e76b0f8b0c32cbb407436947d090d98f8952f38376ee249ed382927ab
2021-07-26T14:09:16.457749557Z [INFO|file_utils.py:1636] 2021-07-26 14:09:16,457 >> creating metadata file for /root/.cache/huggingface/transformers/918c57540c636a2a662770d208fcf20aa8c3faea78201fc612e5c84f052f1119.ac55819e76b0f8b0c32cbb407436947d090d98f8952f38376ee249ed382927ab
2021-07-26T14:09:16.642597998Z [INFO|file_utils.py:1624] 2021-07-26 14:09:16,642 >> https://huggingface.co/openai-gpt/resolve/main/merges.txt not found in cache or force_download set to True, downloading to /root/.cache/huggingface/transformers/tmp2_1m78tv
2021-07-26T14:09:16.874544236Z
Downloading: 0%| | 0.00/458k [00:00<?, ?B/s]
Downloading: 100%|██████████| 458k/458k [00:00<00:00, 10.9MB/s]
2021-07-26T14:09:16.874569317Z [INFO|file_utils.py:1628] 2021-07-26 14:09:16,874 >> storing https://huggingface.co/openai-gpt/resolve/main/merges.txt in cache at /root/.cache/huggingface/transformers/a682e219a788dde0e4f77bc5a470d85a4d7e493420506ce7e3266f7be122cf9e.2150b9689fda7ca7c6224ff32672c004259f974e96934e8eb69d8dd546d682db
2021-07-26T14:09:16.87473933Z [INFO|file_utils.py:1636] 2021-07-26 14:09:16,874 >> creating metadata file for /root/.cache/huggingface/transformers/a682e219a788dde0e4f77bc5a470d85a4d7e493420506ce7e3266f7be122cf9e.2150b9689fda7ca7c6224ff32672c004259f974e96934e8eb69d8dd546d682db
2021-07-26T14:09:17.0542553Z [INFO|file_utils.py:1624] 2021-07-26 14:09:17,054 >> https://huggingface.co/openai-gpt/resolve/main/tokenizer.json not found in cache or force_download set to True, downloading to /root/.cache/huggingface/transformers/tmpiqlissjs
2021-07-26T14:09:17.308757452Z
Downloading: 0%| | 0.00/1.27M [00:00<?, ?B/s]
Downloading: 100%|██████████| 1.27M/1.27M [00:00<00:00, 19.6MB/s]
2021-07-26T14:09:17.308790611Z [INFO|file_utils.py:1628] 2021-07-26 14:09:17,308 >> storing https://huggingface.co/openai-gpt/resolve/main/tokenizer.json in cache at /root/.cache/huggingface/transformers/325373fcbb0daa99905371727842a87ae9ca0f02f71db071720bb4d5a59076cf.b1810f3c6ed9fc0632664008484a9b569103559c04ac90321723cd808a3a96f9
2021-07-26T14:09:17.308827786Z [INFO|file_utils.py:1636] 2021-07-26 14:09:17,308 >> creating metadata file for /root/.cache/huggingface/transformers/325373fcbb0daa99905371727842a87ae9ca0f02f71db071720bb4d5a59076cf.b1810f3c6ed9fc0632664008484a9b569103559c04ac90321723cd808a3a96f9
2021-07-26T14:09:17.838142571Z [INFO|tokenization_utils_base.py:1730] 2021-07-26 14:09:17,837 >> loading file https://huggingface.co/openai-gpt/resolve/main/vocab.json from cache at /root/.cache/huggingface/transformers/918c57540c636a2a662770d208fcf20aa8c3faea78201fc612e5c84f052f1119.ac55819e76b0f8b0c32cbb407436947d090d98f8952f38376ee249ed382927ab
2021-07-26T14:09:17.838167038Z [INFO|tokenization_utils_base.py:1730] 2021-07-26 14:09:17,837 >> loading file https://huggingface.co/openai-gpt/resolve/main/merges.txt from cache at /root/.cache/huggingface/transformers/a682e219a788dde0e4f77bc5a470d85a4d7e493420506ce7e3266f7be122cf9e.2150b9689fda7ca7c6224ff32672c004259f974e96934e8eb69d8dd546d682db
2021-07-26T14:09:17.838171311Z [INFO|tokenization_utils_base.py:1730] 2021-07-26 14:09:17,837 >> loading file https://huggingface.co/openai-gpt/resolve/main/tokenizer.json from cache at /root/.cache/huggingface/transformers/325373fcbb0daa99905371727842a87ae9ca0f02f71db071720bb4d5a59076cf.b1810f3c6ed9fc0632664008484a9b569103559c04ac90321723cd808a3a96f9
2021-07-26T14:09:17.838174874Z [INFO|tokenization_utils_base.py:1730] 2021-07-26 14:09:17,838 >> loading file https://huggingface.co/openai-gpt/resolve/main/added_tokens.json from cache at None
2021-07-26T14:09:17.838177733Z [INFO|tokenization_utils_base.py:1730] 2021-07-26 14:09:17,838 >> loading file https://huggingface.co/openai-gpt/resolve/main/special_tokens_map.json from cache at None
2021-07-26T14:09:17.83818803Z [INFO|tokenization_utils_base.py:1730] 2021-07-26 14:09:17,838 >> loading file https://huggingface.co/openai-gpt/resolve/main/tokenizer_config.json from cache at None
2021-07-26T14:09:18.023973304Z [INFO|configuration_utils.py:545] 2021-07-26 14:09:18,023 >> loading configuration file https://huggingface.co/openai-gpt/resolve/main/config.json from cache at /root/.cache/huggingface/transformers/bebb46f5735701bc248ef9faa26f12577944fa7fc8e9be1a774b94d4cb8b79b6.ba6f10a5446f364b92311c09e55e49aa27024a4aeefc1ea50fd733b77bcd997d
2021-07-26T14:09:18.025605412Z [INFO|configuration_utils.py:581] 2021-07-26 14:09:18,025 >> Model config OpenAIGPTConfig {
2021-07-26T14:09:18.025632076Z "afn": "gelu",
2021-07-26T14:09:18.025638821Z "architectures": [
2021-07-26T14:09:18.025644803Z "OpenAIGPTLMHeadModel"
2021-07-26T14:09:18.02565048Z ],
2021-07-26T14:09:18.025655907Z "attn_pdrop": 0.1,
2021-07-26T14:09:18.025659711Z "embd_pdrop": 0.1,
2021-07-26T14:09:18.025663648Z "initializer_range": 0.02,
2021-07-26T14:09:18.02566734Z "layer_norm_epsilon": 1e-05,
2021-07-26T14:09:18.025671169Z "model_type": "openai-gpt",
2021-07-26T14:09:18.025686901Z "n_ctx": 512,
2021-07-26T14:09:18.025690748Z "n_embd": 768,
2021-07-26T14:09:18.025694256Z "n_head": 12,
2021-07-26T14:09:18.025697812Z "n_layer": 12,
2021-07-26T14:09:18.025701325Z "n_positions": 512,
2021-07-26T14:09:18.025705268Z "n_special": 0,
2021-07-26T14:09:18.025709002Z "predict_special_tokens": true,
2021-07-26T14:09:18.025712833Z "resid_pdrop": 0.1,
2021-07-26T14:09:18.025716428Z "summary_activation": null,
2021-07-26T14:09:18.025721606Z "summary_first_dropout": 0.1,
2021-07-26T14:09:18.025727781Z "summary_proj_to_labels": true,
2021-07-26T14:09:18.025732321Z "summary_type": "cls_index",
2021-07-26T14:09:18.025735991Z "summary_use_proj": true,
2021-07-26T14:09:18.025739869Z "task_specific_params": {
2021-07-26T14:09:18.025743781Z "text-generation": {
2021-07-26T14:09:18.025747651Z "do_sample": true,
2021-07-26T14:09:18.025751454Z "max_length": 50
2021-07-26T14:09:18.025755031Z }
2021-07-26T14:09:18.025758401Z },
2021-07-26T14:09:18.025761928Z "transformers_version": "4.9.0",
2021-07-26T14:09:18.025765657Z "vocab_size": 40478
2021-07-26T14:09:18.025769586Z }
2021-07-26T14:09:18.02577327Z
2021-07-26T14:09:23.021111594Z 07/26/2021 14:09:23 - INFO - __main__ - Training new model from scratch - Total size=111.14M params
2021-07-26T14:09:23.070773083Z 07/26/2021 14:09:23 - INFO - datasets.arrow_dataset - Caching processed dataset at /root/.cache/huggingface/datasets/text/default-dfca9c6f12495150/0.0.0/e16f44aa1b321ece1f87b07977cc5d70be93d69b20486d6dacd62e12cf25c9a5/cache-8e82676f86a14c2c.arrow
2021-07-26T14:09:23.094906386Z 07/26/2021 14:09:23 - INFO - datasets.arrow_writer - Done writing 2000 examples in 207498 bytes /root/.cache/huggingface/datasets/text/default-dfca9c6f12495150/0.0.0/e16f44aa1b321ece1f87b07977cc5d70be93d69b20486d6dacd62e12cf25c9a5/tmpbehl1qz0.
2021-07-26T14:09:23.117860452Z
Running tokenizer on dataset: 0%| | 0/2 [00:00<?, ?ba/s]
Running tokenizer on dataset: 100%|██████████| 2/2 [00:00<00:00, 43.33ba/s]
2021-07-26T14:09:23.133773375Z 07/26/2021 14:09:23 - INFO - datasets.arrow_dataset - Caching processed dataset at /root/.cache/huggingface/datasets/text/default-dfca9c6f12495150/0.0.0/e16f44aa1b321ece1f87b07977cc5d70be93d69b20486d6dacd62e12cf25c9a5/cache-35b2963f79b3b422.arrow
2021-07-26T14:09:23.139336489Z 07/26/2021 14:09:23 - INFO - datasets.arrow_writer - Done writing 1000 examples in 113806 bytes /root/.cache/huggingface/datasets/text/default-dfca9c6f12495150/0.0.0/e16f44aa1b321ece1f87b07977cc5d70be93d69b20486d6dacd62e12cf25c9a5/tmp9n9hycnj.
2021-07-26T14:09:23.144312664Z
Running tokenizer on dataset: 0%| | 0/1 [00:00<?, ?ba/s]
Running tokenizer on dataset: 100%|██████████| 1/1 [00:00<00:00, 46.94ba/s]
2021-07-26T14:09:23.235184764Z 07/26/2021 14:09:23 - INFO - datasets.arrow_dataset - Caching processed dataset at /root/.cache/huggingface/datasets/text/default-dfca9c6f12495150/0.0.0/e16f44aa1b321ece1f87b07977cc5d70be93d69b20486d6dacd62e12cf25c9a5/cache-f0614aafe173fe5c.arrow
2021-07-26T14:09:23.340753289Z 07/26/2021 14:09:23 - INFO - datasets.arrow_writer - Done writing 72 examples in 480120 bytes /root/.cache/huggingface/datasets/text/default-dfca9c6f12495150/0.0.0/e16f44aa1b321ece1f87b07977cc5d70be93d69b20486d6dacd62e12cf25c9a5/tmpbjayy6wf.
2021-07-26T14:09:23.344673188Z
Grouping texts in chunks of 512: 0%| | 0/2 [00:00<?, ?ba/s]
Grouping texts in chunks of 512: 100%|██████████| 2/2 [00:00<00:00, 10.21ba/s]
Grouping texts in chunks of 512: 100%|██████████| 2/2 [00:00<00:00, 10.20ba/s]
2021-07-26T14:09:23.449866442Z 07/26/2021 14:09:23 - INFO - datasets.arrow_dataset - Caching processed dataset at /root/.cache/huggingface/datasets/text/default-dfca9c6f12495150/0.0.0/e16f44aa1b321ece1f87b07977cc5d70be93d69b20486d6dacd62e12cf25c9a5/cache-9636fc49daf5222e.arrow
2021-07-26T14:09:23.454281769Z 07/26/2021 14:09:23 - INFO - datasets.arrow_writer - Done writing 39 examples in 260064 bytes /root/.cache/huggingface/datasets/text/default-dfca9c6f12495150/0.0.0/e16f44aa1b321ece1f87b07977cc5d70be93d69b20486d6dacd62e12cf25c9a5/tmpz8sa4yn6.
2021-07-26T14:09:23.482471097Z 07/26/2021 14:09:23 - INFO - datasets.arrow_writer - Done writing 200000 indices in 320000000 bytes .
2021-07-26T14:09:23.485361448Z 07/26/2021 14:09:23 - INFO - datasets.arrow_writer - Done writing 7000 indices in 392000 bytes .
2021-07-26T14:09:25.751105446Z
Grouping texts in chunks of 512: 0%| | 0/1 [00:00<?, ?ba/s]
Grouping texts in chunks of 512: 100%|██████████| 1/1 [00:00<00:00, 9.15ba/s]
Grouping texts in chunks of 512: 100%|██████████| 1/1 [00:00<00:00, 9.13ba/s]
2021-07-26T14:09:25.751141123Z [INFO|trainer.py:404] 2021-07-26 14:09:25,750 >> max_steps is given, it will override any value given in num_train_epochs
2021-07-26T14:09:25.757944575Z [INFO|trainer.py:1164] 2021-07-26 14:09:25,757 >> ***** Running training *****
2021-07-26T14:09:25.757972847Z [INFO|trainer.py:1165] 2021-07-26 14:09:25,757 >> Num examples = 200000
2021-07-26T14:09:25.757978165Z [INFO|trainer.py:1166] 2021-07-26 14:09:25,757 >> Num Epochs = 516
2021-07-26T14:09:25.757982299Z [INFO|trainer.py:1167] 2021-07-26 14:09:25,757 >> Instantaneous batch size per device = 32
2021-07-26T14:09:25.757986728Z [INFO|trainer.py:1168] 2021-07-26 14:09:25,757 >> Total train batch size (w. parallel, distributed & accumulation) = 2048
2021-07-26T14:09:25.757990875Z [INFO|trainer.py:1169] 2021-07-26 14:09:25,757 >> Gradient Accumulation steps = 32
2021-07-26T14:09:25.757994803Z [INFO|trainer.py:1170] 2021-07-26 14:09:25,757 >> Total optimization steps = 50000
2021-07-26T14:09:27.841919702Z
0%| | 0/50000 [00:00<?, ?it/s]Traceback (most recent call last):
2021-07-26T14:09:27.841956297Z File "run_clm.py", line 572, in <module>
2021-07-26T14:09:27.841963933Z main()
2021-07-26T14:09:27.841969132Z File "run_clm.py", line 522, in main
2021-07-26T14:09:27.841991003Z train_result = trainer.train(resume_from_checkpoint=checkpoint)
2021-07-26T14:09:27.841996801Z File "/home/user/miniconda/lib/python3.8/site-packages/transformers/trainer.py", line 1280, in train
2021-07-26T14:09:27.842002482Z tr_loss += self.training_step(model, inputs)
2021-07-26T14:09:27.842007478Z File "/home/user/miniconda/lib/python3.8/site-packages/transformers/trainer.py", line 1773, in training_step
2021-07-26T14:09:27.842012807Z loss = self.compute_loss(model, inputs)
2021-07-26T14:09:27.842017737Z File "/home/user/miniconda/lib/python3.8/site-packages/transformers/trainer.py", line 1805, in compute_loss
2021-07-26T14:09:27.84202311Z outputs = model(**inputs)
2021-07-26T14:09:27.842028183Z File "/home/user/miniconda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
2021-07-26T14:09:27.842034154Z result = self.forward(*input, **kwargs)
2021-07-26T14:09:27.842039413Z File "/home/user/miniconda/lib/python3.8/site-packages/torch/nn/parallel/data_parallel.py", line 167, in forward
2021-07-26T14:09:27.842045122Z outputs = self.parallel_apply(replicas, inputs, kwargs)
2021-07-26T14:09:27.84205038Z File "/home/user/miniconda/lib/python3.8/site-packages/torch/nn/parallel/data_parallel.py", line 177, in parallel_apply
2021-07-26T14:09:27.842055852Z return parallel_apply(replicas, inputs, kwargs, self.device_ids[:len(replicas)])
2021-07-26T14:09:27.842061165Z File "/home/user/miniconda/lib/python3.8/site-packages/torch/nn/parallel/parallel_apply.py", line 86, in parallel_apply
2021-07-26T14:09:27.842066725Z output.reraise()
2021-07-26T14:09:27.842071565Z File "/home/user/miniconda/lib/python3.8/site-packages/torch/_utils.py", line 429, in reraise
2021-07-26T14:09:27.842077398Z raise self.exc_type(msg)
2021-07-26T14:09:27.842082546Z StopIteration: Caught StopIteration in replica 0 on device 0.
2021-07-26T14:09:27.842087891Z Original Traceback (most recent call last):
2021-07-26T14:09:27.842093056Z File "/home/user/miniconda/lib/python3.8/site-packages/torch/nn/parallel/parallel_apply.py", line 61, in _worker
2021-07-26T14:09:27.842098477Z output = module(*input, **kwargs)
2021-07-26T14:09:27.84210327Z File "/home/user/miniconda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
2021-07-26T14:09:27.842108627Z result = self.forward(*input, **kwargs)
2021-07-26T14:09:27.842113465Z File "/home/user/miniconda/lib/python3.8/site-packages/transformers/models/openai/modeling_openai.py", line 581, in forward
2021-07-26T14:09:27.842119416Z transformer_outputs = self.transformer(
2021-07-26T14:09:27.8421263Z File "/home/user/miniconda/lib/python3.8/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
2021-07-26T14:09:27.842132244Z result = self.forward(*input, **kwargs)
2021-07-26T14:09:27.842137575Z File "/home/user/miniconda/lib/python3.8/site-packages/transformers/models/openai/modeling_openai.py", line 487, in forward
2021-07-26T14:09:27.842147909Z attention_mask = attention_mask.to(dtype=next(self.parameters()).dtype) # fp16 compatibility
2021-07-26T14:09:27.842153517Z StopIteration
2021-07-26T14:09:27.842158291Z
2021-07-26T14:09:28.598937Z
0%| | 0/50000 [00:02<?, ?it/s]
```
## Expected behavior
The same as run_clm.py with a single GPU. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12890/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12890/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12889 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12889/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12889/comments | https://api.github.com/repos/huggingface/transformers/issues/12889/events | https://github.com/huggingface/transformers/pull/12889 | 952,931,955 | MDExOlB1bGxSZXF1ZXN0Njk3MDUyNzg2 | 12,889 | Fix documentation of BigBird tokenizer | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,627 | 1,627 | 1,627 | COLLABORATOR | null | # What does this PR do?
The tokens mentioned in the docstrings don't match the signature, this PR fixes that.
Fixes #12873 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12889/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12889/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12889",
"html_url": "https://github.com/huggingface/transformers/pull/12889",
"diff_url": "https://github.com/huggingface/transformers/pull/12889.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12889.patch",
"merged_at": 1627308685000
} |
https://api.github.com/repos/huggingface/transformers/issues/12888 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12888/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12888/comments | https://api.github.com/repos/huggingface/transformers/issues/12888/events | https://github.com/huggingface/transformers/pull/12888 | 952,929,406 | MDExOlB1bGxSZXF1ZXN0Njk3MDUwNjM4 | 12,888 | Add accelerate to examples requirements | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,627 | 1,627 | 1,627 | COLLABORATOR | null | # What does this PR do?
As mentioned in #12849, the `requirements.txt` for most PyTorch examples does not contain `accelerate`, so the `run_xxx_no_trainer.py` example cannot be executed. This PR fixes that.
Fixes #12489 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12888/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12888/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12888",
"html_url": "https://github.com/huggingface/transformers/pull/12888",
"diff_url": "https://github.com/huggingface/transformers/pull/12888.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12888.patch",
"merged_at": 1627307854000
} |
https://api.github.com/repos/huggingface/transformers/issues/12887 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12887/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12887/comments | https://api.github.com/repos/huggingface/transformers/issues/12887/events | https://github.com/huggingface/transformers/issues/12887 | 952,753,136 | MDU6SXNzdWU5NTI3NTMxMzY= | 12,887 | Add config option to skip 1-D position embeddings in LayoutLM | {
"login": "nishprabhu",
"id": 33579638,
"node_id": "MDQ6VXNlcjMzNTc5NjM4",
"avatar_url": "https://avatars.githubusercontent.com/u/33579638?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nishprabhu",
"html_url": "https://github.com/nishprabhu",
"followers_url": "https://api.github.com/users/nishprabhu/followers",
"following_url": "https://api.github.com/users/nishprabhu/following{/other_user}",
"gists_url": "https://api.github.com/users/nishprabhu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nishprabhu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nishprabhu/subscriptions",
"organizations_url": "https://api.github.com/users/nishprabhu/orgs",
"repos_url": "https://api.github.com/users/nishprabhu/repos",
"events_url": "https://api.github.com/users/nishprabhu/events{/privacy}",
"received_events_url": "https://api.github.com/users/nishprabhu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I'm not sure whether we should add such an option, because models like BERT, RoBERTa, ... basically all Transformer models within this repository don't have this option. Either we add that option to all, either we don't in my opinion. \r\n\r\nAbsolute position embeddings are almost always beneficial, so not sure if adding this will have value, perhaps we could strive for simplicity. cc @sgugger @LysandreJik ",
"Agreed. Unless there are pretrained checkpoints available that require this kind of change, you should just tweak the code of `modeling_layoutlm` to your needs for this.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,629 | 1,629 | CONTRIBUTOR | null | # 🚀 Feature request
Add an option in LayoutLM config to not use 1-D position embeddings. The config currently allows us to choose between "absolute", "relative_key", and "relative_key_query". Can we add another option like "none" to not use 1-D positional embeddings?
## Motivation
The input to LayoutLM consists of tokens of text and their corresponding bounding boxes from document images. This is typically obtained by passing the document image through an OCR.
LayoutLM uses 1-D as well as 2-D position embeddings. While OCRs provide reliable 2-D positions for each word in the document image, the order of words (1-D positions) are not always correct. For example, if we OCR a two column document, or a document containing a table, or any other visually rich document, the order of words in the OCR output is very unreliable. This unreliable position information harms accuracy in several downstream tasks. I have personally seen improvements in some tasks when I manually disable 1-D position embeddings in LayoutLM, and force the model to only look at the 2-D positions. Can we provide an easy way to do this by adding an option in the LayoutLM config to make 1-D position embeddings optional?
## Your contribution
I am willing to work on this and submit a PR, but this is the first time I am contributing to the library and might require some help.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12887/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12887/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12886 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12886/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12886/comments | https://api.github.com/repos/huggingface/transformers/issues/12886/events | https://github.com/huggingface/transformers/pull/12886 | 952,658,230 | MDExOlB1bGxSZXF1ZXN0Njk2ODE5NTA4 | 12,886 | Object detection pipeline | {
"login": "mishig25",
"id": 11827707,
"node_id": "MDQ6VXNlcjExODI3NzA3",
"avatar_url": "https://avatars.githubusercontent.com/u/11827707?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mishig25",
"html_url": "https://github.com/mishig25",
"followers_url": "https://api.github.com/users/mishig25/followers",
"following_url": "https://api.github.com/users/mishig25/following{/other_user}",
"gists_url": "https://api.github.com/users/mishig25/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mishig25/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mishig25/subscriptions",
"organizations_url": "https://api.github.com/users/mishig25/orgs",
"repos_url": "https://api.github.com/users/mishig25/repos",
"events_url": "https://api.github.com/users/mishig25/events{/privacy}",
"received_events_url": "https://api.github.com/users/mishig25/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1771187924,
"node_id": "MDU6TGFiZWwxNzcxMTg3OTI0",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Core:%20Pipeline",
"name": "Core: Pipeline",
"color": "FF7066",
"default": false,
"description": "Internals of the library; Pipeline."
}
] | closed | false | null | [] | [
"@LysandreJik ofc as a personal matter I would rather this would be merged after the large refactor, but tbh this should be handled like any other PR, the first to be ready should be approved.\r\n\r\nMoving this code to the new PR should be just as easy as the other ones (the code is currently rather well separated in terms of concerns). The biggest concern regarding code separation is one I raise here which is the scope of `post_process`. I would advocate it should take on more (so the pipelines delegates ALL work to the model) but it might be difficult for various reasons I don't measure.",
"Re-requesting review from @Narsil and @LysandreJik \r\n\r\n@Narsil,\r\n1. Changed box format to be {xmin,ymin,xmax,ymax} [here](https://github.com/huggingface/transformers/blob/de23a8cfca50f5f166793fdd9d31458bf94f360d/src/transformers/pipelines/object_detection.py#L147-L164)\r\n2. Added `self.framework == pt` guard on pytorch specific code [here](https://github.com/huggingface/transformers/blob/de23a8cfca50f5f166793fdd9d31458bf94f360d/src/transformers/pipelines/object_detection.py#L147-L164)\r\n3. As suggested by comment [here](https://github.com/huggingface/transformers/pull/12886#discussion_r698575417), `post_process` is handling more responsibility. As a side effect, [this shadowing](https://github.com/huggingface/transformers/pull/12886#discussion_r698567466) concern disappears\r\n\r\n@LysandreJik \r\n1. RGBA images are being handled when I updated `load_image` method (copied updates from image classification) [here](https://github.com/huggingface/transformers/blob/de23a8cfca50f5f166793fdd9d31458bf94f360d/src/transformers/pipelines/object_detection.py#L64-L83)\r\n2. Added `ObjectDetectionPipeline` to [transformers/__init__.py](https://github.com/huggingface/transformers/blob/3f22f6d8393bd20dae5f875ec39f2adbd33d1d33/src/transformers/__init__.py)\r\n3. Updated the testing file to match with updated testing scheme [here](https://github.com/huggingface/transformers/blob/4a8449ee18506d749da3291ac1df4b5dfefd8f62/tests/test_pipelines_object_detection.py)\r\n\r\nPlease let me know if you encounter any questions or concerns 👍 ",
"@LysandreJik I think its ready to be merged. Please let me know if you there's anything else I need to take care of :) ",
"Hi @mishig25 ,\r\n\r\nI think you need to fix all the tests.\r\n\r\n`import torch` need to be protected behind `is_torch_available` for instance.\r\nFor code quality you can `pip install -e .[dev]` and then `make fixup`.\r\nThe PT tests also seem to require `timm` which are not available in the tests. So you need a `@require_timm` decorator.\r\n\r\n",
"~~@Narsil I'm confused about the tf tests failing.~~\r\n~~For example, in this[ failed test](https://app.circleci.com/pipelines/github/huggingface/transformers/27659/workflows/e994e3b6-f627-477f-ba14-24bda195f91c/jobs/268944), I see the test failing for pipelines I haven't made any changes (also, I made sure my branch is up-to-date with the master):\r\nhere is an example for **test_pipelines_translation**~~\r\n~~_____________ ERROR collecting tests/test_pipelines_translation.py _____________ImportError while importing test module '/home/circleci/transformers/tests/test_pipelines_translation.py'....E ModuleNotFoundError: No module named 'torch'~~\r\n~~Please let me know what step I'm missing~~",
"Since the PR was approved by two HF members and tests passed, I've merged it when the merge option became available. Please let me know if it is a correct procedure (i.e. should I have waited until a transfomers maintainer merged it?)",
"That's correct: as long as you have approval of one core maintainer (more for big PRs), addressed all comments, and all tests pass, you can merge your PR. :-)"
] | 1,627 | 1,647 | 1,631 | CONTRIBUTOR | null | # What does this PR do?
* Object detection pipeline
* Give an image or list of images, outputs obj det annotations in form:
```python
[
[
{'score': 0.9..., 'label': 'remote', 'box': [{'x': 66, 'y': 118}, ...},
],
...
]
```
* See [colab](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/DETR/DETR_minimal_example_(with_DetrFeatureExtractor).ipynb#scrollTo=3ynXL-OtGskG) for more details
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case. [huggingface_hub#74](huggingface/hub-docs#6)
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
@NielsRogge
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12886/reactions",
"total_count": 3,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 2,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12886/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12886",
"html_url": "https://github.com/huggingface/transformers/pull/12886",
"diff_url": "https://github.com/huggingface/transformers/pull/12886.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12886.patch",
"merged_at": 1631114252000
} |
https://api.github.com/repos/huggingface/transformers/issues/12885 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12885/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12885/comments | https://api.github.com/repos/huggingface/transformers/issues/12885/events | https://github.com/huggingface/transformers/issues/12885 | 952,647,429 | MDU6SXNzdWU5NTI2NDc0Mjk= | 12,885 | an unexpected keyword argument 'output_signature' | {
"login": "grandzhang001",
"id": 40519539,
"node_id": "MDQ6VXNlcjQwNTE5NTM5",
"avatar_url": "https://avatars.githubusercontent.com/u/40519539?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/grandzhang001",
"html_url": "https://github.com/grandzhang001",
"followers_url": "https://api.github.com/users/grandzhang001/followers",
"following_url": "https://api.github.com/users/grandzhang001/following{/other_user}",
"gists_url": "https://api.github.com/users/grandzhang001/gists{/gist_id}",
"starred_url": "https://api.github.com/users/grandzhang001/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/grandzhang001/subscriptions",
"organizations_url": "https://api.github.com/users/grandzhang001/orgs",
"repos_url": "https://api.github.com/users/grandzhang001/repos",
"events_url": "https://api.github.com/users/grandzhang001/events{/privacy}",
"received_events_url": "https://api.github.com/users/grandzhang001/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"update tensorflow to 2.5 solve this.",
"Use tf >= v2.4.0 to solve this issue. This was in the release notes."
] | 1,627 | 1,649 | 1,627 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:4.9.0
- Platform:linux
- Python version:3.6
- PyTorch version (GPU?):1.7
- Tensorflow version (GPU?):2.3,gpu version
- Using GPU in script?:k40m
- Using distributed or parallel set-up in script?:no
when I execute
python run_mlm.py
--model_name_or_path bert-base-chinese
--output_dir /data/bert_virtual/modelinfo/
--train_file /data/zxdata/000002_0.txt
from examples/tensorflow/language-modeling,this error happens
Traceback (most recent call last):
File "run_mlm.py", line 619, in <module>
main()
File "run_mlm.py", line 543, in main
tf.data.Dataset.from_generator(train_generator, output_signature=train_signature)
TypeError: from_generator() got an unexpected keyword argument 'output_signature'
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12885/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12885/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12884 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12884/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12884/comments | https://api.github.com/repos/huggingface/transformers/issues/12884/events | https://github.com/huggingface/transformers/issues/12884 | 952,578,997 | MDU6SXNzdWU5NTI1Nzg5OTc= | 12,884 | Super slow ByT5 Tokenizer | {
"login": "PhilipMay",
"id": 229382,
"node_id": "MDQ6VXNlcjIyOTM4Mg==",
"avatar_url": "https://avatars.githubusercontent.com/u/229382?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PhilipMay",
"html_url": "https://github.com/PhilipMay",
"followers_url": "https://api.github.com/users/PhilipMay/followers",
"following_url": "https://api.github.com/users/PhilipMay/following{/other_user}",
"gists_url": "https://api.github.com/users/PhilipMay/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PhilipMay/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PhilipMay/subscriptions",
"organizations_url": "https://api.github.com/users/PhilipMay/orgs",
"repos_url": "https://api.github.com/users/PhilipMay/repos",
"events_url": "https://api.github.com/users/PhilipMay/events{/privacy}",
"received_events_url": "https://api.github.com/users/PhilipMay/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Pinging @patrickvonplaten ",
"See his (@patrickvonplaten ) answer here: https://github.com/huggingface/transformers/pull/11971#issuecomment-889797262",
"pinging @Narsil",
"Hi, don't think rust is necessary here.\r\n\r\nUsing raw bytes should be just as fast in python (if not faster because no overhead).\r\nMight require some heavy change though, most notably to remove the over reliance on regexp which is notably bad, especially with 100 of them in a single regexp.\r\n\r\n@PhilipMay if you want to tackle it, just modify this function: https://github.com/huggingface/transformers/blob/master/src/transformers/models/byt5/tokenization_byt5.py#L197 and remove all traces of regexp (or make sure it only runs once, is precompiled and an efficient one).\r\n\r\nDo you mind giving a script to assess current speed and make sure modifications are speeding up too ? (Might have sometime at some point to tackle this).",
"Hi @Narsil ,\r\nthanks for the answer.\r\n\r\nI made some debugging:\r\n\r\n\r\n\r\nIt seems like here:\r\n\r\nhttps://github.com/huggingface/transformers/blob/2e0d767ab2bf8265a9f9b93adb1bc2084bc02849/src/transformers/tokenization_utils.py#L335-L350\r\n\r\nIt already splits `<pad>|</s>|<unk>` - see screenshot.\r\n\r\nSo for me it seems like we do not need this code:\r\n\r\nhttps://github.com/huggingface/transformers/blob/2e0d767ab2bf8265a9f9b93adb1bc2084bc02849/src/transformers/models/byt5/tokenization_byt5.py#L207-L208\r\n\r\nWhat do you think?\r\n",
"Changing the code to this:\r\n\r\n```python\r\n # split on special characters\r\n # pattern = f\"({'|'.join(self.special_tokens_encoder.keys())})\"\r\n # sub_texts = list(filter(None, re.split(pattern, text)))\r\n sub_texts = text\r\n```\r\n\r\nConverts this: `\"This <unk> is <s> some </s> text. <pad> other text!\"` to this: \r\n`['T', 'h', 'i', 's', ' ', '<unk>', ' ', 'i', 's', ' ', '<', 's', '>', ' ', 's', 'o', 'm', 'e', ' ', '</s>', ' ', 't', 'e', 'x', 't', '.', ' ', '<pad>', ' ', 'o', 't', 'h', 'e', 'r', ' ', 't', 'e', 'x', 't', '!']`\r\n\r\nWhich seems to be ok...",
"Not sure if `<s>` is allowed to be split or not.\r\nspecial_tokens contains something like 100 or so special tokens which most likely should be taken care of.\r\n\r\nCan you run the tests ?\r\n\r\n```\r\npytest -sv tests/test_tokenization_byt5.py\r\n```\r\n\r\nI expect your version is slightly incorrect, but I could be wrong.\r\n\r\ninstead of using `re.split(pattern, text)` if you manage to `self.regexp = re.compile(pattern)` (within __init__) and replace it with\r\n`self.regexp.split(text)` that's already probably a speedup (with no change in functionality).\r\n\r\nEdit: To be perfectly correct you need to recalculcate `self.regexp` everytime there's a change in special_tokens (`self.add_special_tokens` at least for instance) which would involved declaring a submethod to call the redefinition of `self.regexp`.\r\n\r\n\r\nLetting @patrickvonplaten chime in if possible on correctness/speed for this.",
"Yeah `<s>` should not be split to single characters. It would also be important to make sure that newly added tokens of whatever character length are not split.\r\n\r\nI think if all ByT5Tokenizer tests pass then a change to speed up the tokenizer is ok",
"> Yeah `<s>` should not be split to single characters.\r\n\r\nI made a simple test:\r\n\r\n```python\r\nfrom transformers import ByT5Tokenizer\r\ntok = ByT5Tokenizer.from_pretrained(pretrained_model_name_or_path=\"google/byt5-small\")\r\ntoken = tok.tokenize(\"This <unk> is <pad> a </s> test <s> with some special tokens.\")\r\nprint(token)\r\n```\r\n\r\nIt prints:\r\n\r\n`['T', 'h', 'i', 's', ' ', '<unk>', ' ', 'i', 's', ' ', '<pad>', ' ', 'a', ' ', '</s>', ' ', 't', 'e', 's', 't', ' ', '<', 's', '>', ' ', 'w', 'i', 't', 'h', ' ', 's', 'o', 'm', 'e', ' ', 's', 'p', 'e', 'c', 'i', 'a', 'l', ' ', 't', 'o', 'k', 'e', 'n', 's', '.']`\r\n\r\nSo `<s>` is split. It does not split this: `<unk>, <pad> and </s>`.",
"@Narsil and @patrickvonplaten in debugger it looks like this:\r\n\r\n\r\n\r\nThe pattern is `'(<pad>|</s>|<unk>)'` but NOT `<s>` or something else.",
"@PhilipMay Please provide a script for the benchmark, it would really help assess speed.\r\n\r\nAs for the example you're right `<s>` doesn't seem to be tokenized. (it's showcased in patrick's example)",
"> @PhilipMay Please provide a script for the benchmark, it would really help assess speed.\r\n\r\nLike so?\r\n\r\n```python\r\n\r\nfrom transformers import ByT5Tokenizer\r\nfrom datasets import load_dataset\r\nimport time\r\ndataset = load_dataset('cnn_dailymail', '3.0.0', split='train')\r\narticles = [d[\"article\"] for d in dataset][:1000]\r\ntok = ByT5Tokenizer.from_pretrained(pretrained_model_name_or_path=\"google/byt5-small\")\r\nstart_time = time.time()\r\nfor a in articles:\r\n _ = tok.tokenize(a)\r\nprint(\"--- %s seconds ---\" % (time.time() - start_time))\r\n```",
"Mind checking out this: https://github.com/huggingface/transformers/pull/13119\r\n\r\nI got something like 2X. Still suboptimal, but much of the overhead now lies in all the wrapping code, which would be much more tedious to remove. If you want to try, please go ahead ! ",
"Ok, the PR is already a nice boost. Turns out most of the performance loss is caused by special tokens (the 125 extra_ids), which are quite unlikely to appear in your text.\r\n\r\nThe current code (for slow tokenizers) is quite optimized for low number of special_tokens, which is not the case here.\r\nIf you are able to afford being incorrect (because you know your text doesn't contain <extra_id_XX> that should be processed) then, you can simply save the tokenizer, REMOVE those extra_ids and load it again.\r\n\r\nProcessing 1000 sentences\r\nCurrent master: 2.4s\r\nOptimize_byt5 branch: 0.47s\r\nWithout extra_ids : 0.07s\r\n\r\nIs that enough for your use case ?\r\n\r\nHow to remove extra_ids simply:\r\n```python\r\ntok = ByT5Tokenizer.from_pretrained(pretrained_model_name_or_path=\"google/byt5-small\")\r\n# CAVEAT: This will break some functionality, use with caution\r\ntok.unique_no_split_tokens = [\"</s>\", \"<pad>\", \"<unk>\"]\r\n```\r\n"
] | 1,627 | 1,629 | 1,629 | CONTRIBUTOR | null | Hi,
The ByT5 Tokenizer seems to be super slow compared to others (T5).
See colab link below for example code.
T5-small tokenizer:

By-T5-small tokenizer:

See colab code here: https://colab.research.google.com/drive/1nVxCerQon3hVA1RylZz7Be4N8LfjPgth?usp=sharing | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12884/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12884/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12883 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12883/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12883/comments | https://api.github.com/repos/huggingface/transformers/issues/12883/events | https://github.com/huggingface/transformers/issues/12883 | 952,423,712 | MDU6SXNzdWU5NTI0MjM3MTI= | 12,883 | Distributed TPU training with run_mlm duplicate data | {
"login": "alierenak",
"id": 48334667,
"node_id": "MDQ6VXNlcjQ4MzM0NjY3",
"avatar_url": "https://avatars.githubusercontent.com/u/48334667?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alierenak",
"html_url": "https://github.com/alierenak",
"followers_url": "https://api.github.com/users/alierenak/followers",
"following_url": "https://api.github.com/users/alierenak/following{/other_user}",
"gists_url": "https://api.github.com/users/alierenak/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alierenak/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alierenak/subscriptions",
"organizations_url": "https://api.github.com/users/alierenak/orgs",
"repos_url": "https://api.github.com/users/alierenak/repos",
"events_url": "https://api.github.com/users/alierenak/events{/privacy}",
"received_events_url": "https://api.github.com/users/alierenak/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Dataset streaming has not been tested on any of the examples, so I'm not sure it works, especially for distributed training on TPUs.",
"I am working on this feature for several days. Especially, I am trying to implement Iterable Dataset which reads preprocessed data from Cloud. Is the problem about streaming or Iterable Dataset, you think? However, using Pytorch Iterable Dataset in distributed training could be tricky as it can be seen from this [issue](https://github.com/pytorch/ignite/issues/1076). ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,630 | 1,630 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.10.0 (currently master)
- Platform: TPU VM3.8 -- Ubuntu 20.04.2 LTS
- Python version: 3.8.10
- PyTorch version (GPU?): XLA - 1.8.1
- Tensorflow version (GPU?): None
- Using GPU in script?: None
- Using distributed or parallel set-up in script?: Using `examples/pytorch/language-modeling/run_mlm_no_trainer.py` which is using Accelerator
### Who can help
@sgugger @patil-suraj
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [X] my own modified scripts: (give details below)
I have modified small things in `examples/pytorch/language-modeling/run_mlm_no_trainer.py` and changes as follow (can be reached at https://github.com/akalieren/transformers-master)
1. Defined mp_fn to training script.
2. Added `streaming_data=True` to Dataset Class
3. Deleted `tpu_num_cores argument` from xla_spawn.py sys.args since it throw arrow.
The tasks I am working on is:
* [X] an official GLUE/SQUaD task: (give the name) Training MLM from scratch
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Clone modified script
`git clone https://github.com/akalieren/transformers-master`
2. `export XRT_TPU_CONFIG="localservice;0;localhost:51011"`
3. Install required libraries (I did not add extra installments to requirements.txt to highlight they are not stated in official example)
```
pip install transformers-master
pip install .
pip install -r examples/pytorch/language-modeling/requirements.txt
pip install accelerate
pip install datasets[streaming]
```
4. Run command
```
python3 examples/pytorch/xla_spawn.py --num_cores 8 examples/pytorch/language-modeling/run_mlm_no_trainer.py --model_type "roberta" --per_device_eval_batch_size 512 --per_device_train_batch_size 512 --max_train_steps 1000000 --preprocessing_num_workers 50 --pad_to_max_length --tokenizer_name "./tokenizers/Roberta/" --dataset_name='oscar' --dataset_config_name='unshuffled_deduplicated_fr' --data_streaming=True --max_seq_length 512 --line_by_line=True
```
Note: Without xla_spawn, Accelerator use only one cores. Thats why I changed, with 1 core it is running but slow
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
```
2021-07-26 00:30:54.355600: E tensorflow/core/framework/op_kernel.cc:1693] OpKernel ('op: "TPURoundRobin" device_type: "CPU"') for unknown op: TPURoundRobin
2021-07-26 00:30:54.355659: E tensorflow/core/framework/op_kernel.cc:1693] OpKernel ('op: "TpuHandleToProtoKey" device_type: "CPU"') for unknown op: TpuHandleToProtoKey
07/26/2021 00:31:13 - INFO - run_mlm_no_trainer - Distributed environment: TPU
Num processes: 8
Process index: 0
Local process index: 0
Device: xla:1
Use FP16 precision: False
Downloading and preparing dataset oscar/unshuffled_deduplicated_tr (download: 9.68 GiB, generated: 26.43 GiB, post-processed: Unknown size, total: 36.10 GiB) to /home/akali/.cache/huggingface/datasets/oscar/unshuffled_deduplicated_tr/1.0.0/84838bd49d2295f62008383b05620571535451d84545037bb94d6f3501651df2...
07/26/2021 00:31:20 - INFO - run_mlm_no_trainer - Distributed environment: TPU
Num processes: 8
Process index: 1
Local process index: 1
Device: xla:0
Use FP16 precision: False
07/26/2021 00:31:20 - INFO - run_mlm_no_trainer - Distributed environment: TPU
Num processes: 8
Process index: 5
Local process index: 5
Device: xla:0
Use FP16 precision: False
07/26/2021 00:31:20 - INFO - run_mlm_no_trainer - Distributed environment: TPU
Num processes: 8
Process index: 7
Local process index: 7
Device: xla:0
Use FP16 precision: False
07/26/2021 00:31:20 - INFO - run_mlm_no_trainer - Distributed environment: TPU
Num processes: 8
Process index: 6
Local process index: 6
Device: xla:0
Use FP16 precision: False
07/26/2021 00:31:21 - INFO - run_mlm_no_trainer - Distributed environment: TPU
Num processes: 8
Process index: 2
Local process index: 2
Device: xla:0
Use FP16 precision: False
07/26/2021 00:31:21 - INFO - run_mlm_no_trainer - Distributed environment: TPU
Num processes: 8
Process index: 4
Local process index: 4
Device: xla:0
Use FP16 precision: False
07/26/2021 00:31:23 - INFO - run_mlm_no_trainer - Distributed environment: TPU
Num processes: 8
Process index: 3
Local process index: 3
Device: xla:0
Use FP16 precision: False
0 examples [00:00, ? examples/s]07/26/2021 00:31:44 - INFO - datasets_modules.datasets.oscar.84838bd49d2295f62008383b05620571535451d84545037bb94d6f3501651df2.oscar - generating examples from = /home/akali/.cache/huggingface/datasets/downloads/657d72dc352d822d0496bb9f519cf0de87b87064d56024d9d1ac5585568125b1
718146 examples [00:48, 14431.60 examples/s]07/26/2021 00:32:32 - INFO - datasets_modules.datasets.oscar.84838bd49d2295f62008383b05620571535451d84545037bb94d6f3501651df2.oscar - generating examples from = /home/akali/.cache/huggingface/datasets/downloads/f9b566f31181a53d426a2dc982a1b1de06cc92541de83cee688e5c57f4874300
1471415 examples [01:36, 13302.22 examples/s]07/26/2021 00:33:21 - INFO - datasets_modules.datasets.oscar.84838bd49d2295f62008383b05620571535451d84545037bb94d6f3501651df2.oscar - generating examples from = /home/akali/.cache/huggingface/datasets/downloads/21f0672cc841442e067c7ea57471788dbd350f889acbd8028e75edb9efcacddb
2229278 examples [02:24, 16466.88 examples/s]07/26/2021 00:34:09 - INFO - datasets_modules.datasets.oscar.84838bd49d2295f62008383b05620571535451d84545037bb94d6f3501651df2.oscar - generating examples from = /home/akali/.cache/huggingface/datasets/downloads/c027123c743fb1e0079bcd3be75f0ba6be89c6997f6b000e97c33f9c3d9c2742
2997743 examples [03:13, 18057.68 examples/s]07/26/2021 00:34:58 - INFO - datasets_modules.datasets.oscar.84838bd49d2295f62008383b05620571535451d84545037bb94d6f3501651df2.oscar - generating examples from = /home/akali/.cache/huggingface/datasets/downloads/d7cc7a7389a8187b043cf359794e6fdc7783d5d0b6e7d737381e89d34c25e441
3772944 examples [04:02, 15671.97 examples/s]07/26/2021 00:35:46 - INFO - datasets_modules.datasets.oscar.84838bd49d2295f62008383b05620571535451d84545037bb94d6f3501651df2.oscar - generating examples from = /home/akali/.cache/huggingface/datasets/downloads/a0175299b2eb4767f27e4f73c6848609be453fa5eb8d36dd6f8ecfd2c60a1e01
4569497 examples [04:51, 18017.92 examples/s]07/26/2021 00:36:35 - INFO - datasets_modules.datasets.oscar.84838bd49d2295f62008383b05620571535451d84545037bb94d6f3501651df2.oscar - generating examples from = /home/akali/.cache/huggingface/datasets/downloads/6b432b7a552ccc65da0810808506bb7570162447776507b2b47319a230b48aa3
5356241 examples [05:39, 16205.13 examples/s]07/26/2021 00:37:24 - INFO - datasets_modules.datasets.oscar.84838bd49d2295f62008383b05620571535451d84545037bb94d6f3501651df2.oscar - generating examples from = /home/akali/.cache/huggingface/datasets/downloads/ef34899af5cac3b75a798286fad2be831177c0833dab12c19c139b694d8c3544
6151458 examples [06:29, 11766.89 examples/s]07/26/2021 00:38:14 - INFO - datasets_modules.datasets.oscar.84838bd49d2295f62008383b05620571535451d84545037bb94d6f3501651df2.oscar - generating examples from = /home/akali/.cache/huggingface/datasets/downloads/9926c88e0b8a2013f57aaef129cb9978ff129b8bfb3408c1194852c806249f9d
6957212 examples [07:18, 18684.33 examples/s]07/26/2021 00:39:03 - INFO - datasets_modules.datasets.oscar.84838bd49d2295f62008383b05620571535451d84545037bb94d6f3501651df2.oscar - generating examples from = /home/akali/.cache/huggingface/datasets/downloads/aae79457ef2f44cd9ef24584b894c033d9099e6bc8e15b661a349cc185a230d7
7763558 examples [08:07, 16309.71 examples/s]07/26/2021 00:39:52 - INFO - datasets_modules.datasets.oscar.84838bd49d2295f62008383b05620571535451d84545037bb94d6f3501651df2.oscar - generating examples from = /home/akali/.cache/huggingface/datasets/downloads/0274c31e96e2728161263b15aa4da982825eec91c7b0693756a890e76d1167c4
8565051 examples [08:57, 17289.47 examples/s]07/26/2021 00:40:41 - INFO - datasets_modules.datasets.oscar.84838bd49d2295f62008383b05620571535451d84545037bb94d6f3501651df2.oscar - generating examples from = /home/akali/.cache/huggingface/datasets/downloads/f6423f5486261f771097352c7e2ae07643ad0f2fcf5f5d68c6a9921f8bd1e6a3
9397678 examples [09:46, 16643.61 examples/s]07/26/2021 00:41:30 - INFO - datasets_modules.datasets.oscar.84838bd49d2295f62008383b05620571535451d84545037bb94d6f3501651df2.oscar - generating examples from = /home/akali/.cache/huggingface/datasets/downloads/2edc5ca535c1ea46aaacebf7f68a3553aa5d92b70e574f05709fa02dc52b5f4e
10231465 examples [10:36, 12871.41 examples/s]07/26/2021 00:42:20 - INFO - datasets_modules.datasets.oscar.84838bd49d2295f62008383b05620571535451d84545037bb94d6f3501651df2.oscar - generating examples from = /home/akali/.cache/huggingface/datasets/downloads/3a06d248b02355ecdcf097df97a9e670db72c42456df9d04b15d4187933263ed
11075179 examples [11:26, 16567.73 examples/s]07/26/2021 00:43:11 - INFO - datasets_modules.datasets.oscar.84838bd49d2295f62008383b05620571535451d84545037bb94d6f3501651df2.oscar - generating examples from = /home/akali/.cache/huggingface/datasets/downloads/0e3af1310ea118f4a5e8c13b40a561ae20ba209ae196d633a68155af35ec049c
Dataset oscar downloaded and prepared to /home/akali/.cache/huggingface/datasets/oscar/unshuffled_deduplicated_tr/1.0.0/84838bd49d2295f62008383b05620571535451d84545037bb94d6f3501651df2. Subsequent calls will reuse this data.
07/26/2021 00:43:42 - WARNING - datasets.builder - Reusing dataset oscar (/home/akali/.cache/huggingface/datasets/oscar/unshuffled_deduplicated_tr/1.0.0/84838bd49d2295f62008383b05620571535451d84545037bb94d6f3501651df2)
07/26/2021 00:43:42 - WARNING - run_mlm_no_trainer - You are instantiating a new config instance from scratch.
loading configuration file ./tokenizers/Roberta/config.json
Model config RobertaConfig {
"architectures": [
"RobertaForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"bos_token_id": 0,
"eos_token_id": 2,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-05,
"max_position_embeddings": 514,
"model_type": "roberta",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 1,
"position_embedding_type": "absolute",
"transformers_version": "4.10.0.dev0",
"type_vocab_size": 1,
"use_cache": true,
"vocab_size": 52000
}
Didn't find file ./tokenizers/Roberta/tokenizer.json. We won't load it.
Didn't find file ./tokenizers/Roberta/added_tokens.json. We won't load it.
loading file ./tokenizers/Roberta/vocab.json
loading file ./tokenizers/Roberta/merges.txt
loading file None
loading file None
loading file ./tokenizers/Roberta/special_tokens_map.json
loading file ./tokenizers/Roberta/tokenizer_config.json
loading configuration file ./tokenizers/Roberta/config.json
Model config RobertaConfig {
"architectures": [
"RobertaForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"bos_token_id": 0,
"eos_token_id": 2,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-05,
"max_position_embeddings": 514,
"model_type": "roberta",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 1,
"position_embedding_type": "absolute",
"transformers_version": "4.10.0.dev0",
"type_vocab_size": 1,
"use_cache": true,
"vocab_size": 52000
}
loading configuration file ./tokenizers/Roberta/config.json
Model config RobertaConfig {
"architectures": [
"RobertaForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"bos_token_id": 0,
"eos_token_id": 2,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-05,
"max_position_embeddings": 514,
"model_type": "roberta",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 1,
"position_embedding_type": "absolute",
"transformers_version": "4.10.0.dev0",
"type_vocab_size": 1,
"use_cache": true,
"vocab_size": 52000
}
# AFTER THIS POINT:
Script started to print tqdm process multiple times like that:
----> LOOK HERE Running tokenizer on dataset line_by_line #43: 19%|███████████████████████▏ | 43/221 [12:20<51:05, 17.22s/ba]
Running tokenizer on dataset line_by_line #36: 19%|███████████████████████▏ | 43/221 [12:24<51:20, 17.30s/ba]
Running tokenizer on dataset line_by_line #29: 19%|███████████████████████▏ | 43/221 [12:28<51:37, 17.40s/ba]
Running tokenizer on dataset line_by_line #38: 19%|███████████████████████▏ | 43/221 [12:22<51:15, 17.28s/ba]
Running tokenizer on dataset line_by_line #5: 18%|█████████████████████▏ | 39/221 [12:33<58:34, 19.31s/ba]
Running tokenizer on dataset line_by_line #21: 19%|███████████████████████▏ | 43/221 [12:30<51:45, 17.45s/ba]
Running tokenizer on dataset line_by_line #46: 19%|███████████████████████▏ | 43/221 [12:19<51:01, 17.20s/ba]
Running tokenizer on dataset line_by_line #38: 19%|███████████████████████▏ | 43/221 [12:25<51:25, 17.34s/ba]
Running tokenizer on dataset line_by_line #42: 19%|███████████████████████▏ | 43/221 [12:23<51:19, 17.30s/ba]
Running tokenizer on dataset line_by_line #35: 19%|███████████████████████▏ | 43/221 [12:26<51:31, 17.37s/ba]
Running tokenizer on dataset line_by_line #21: 19%|███████████████████████▏ | 43/221 [12:30<51:48, 17.46s/ba]
Running tokenizer on dataset line_by_line #45: 19%|███████████████████████▏ | 43/221 [12:23<51:17, 17.29s/ba]
Running tokenizer on dataset line_by_line #35: 19%|███████████████████████▏ | 43/221 [12:27<51:34, 17.38s/ba]
----> AND HERE Running tokenizer on dataset line_by_line #43: 18%|█████████████████████
As it can be seen processor 43 printed 2 times but their percentage is inconsistent. Since it can't be decreased, I think it is preprocessing in for each core.
```
## Expected behavior
I expected to run training script with 8 cores with normal speed. But it is stoped at this point and not continue from here even without small changes.
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12883/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12883/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12882 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12882/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12882/comments | https://api.github.com/repos/huggingface/transformers/issues/12882/events | https://github.com/huggingface/transformers/issues/12882 | 952,404,531 | MDU6SXNzdWU5NTI0MDQ1MzE= | 12,882 | loss sudden increase | {
"login": "hongjianyuan",
"id": 41334719,
"node_id": "MDQ6VXNlcjQxMzM0NzE5",
"avatar_url": "https://avatars.githubusercontent.com/u/41334719?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hongjianyuan",
"html_url": "https://github.com/hongjianyuan",
"followers_url": "https://api.github.com/users/hongjianyuan/followers",
"following_url": "https://api.github.com/users/hongjianyuan/following{/other_user}",
"gists_url": "https://api.github.com/users/hongjianyuan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hongjianyuan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hongjianyuan/subscriptions",
"organizations_url": "https://api.github.com/users/hongjianyuan/orgs",
"repos_url": "https://api.github.com/users/hongjianyuan/repos",
"events_url": "https://api.github.com/users/hongjianyuan/events{/privacy}",
"received_events_url": "https://api.github.com/users/hongjianyuan/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi,\r\n\r\nWe like to keep Github issues for bugs/feature requests. For training related questions, please see the [forum](https://discuss.huggingface.co/). Also, make sure to make it possible for people to reproduce your issue, by providing code or a colab notebook.\r\n\r\nThanks!\r\n\r\n"
] | 1,627 | 1,627 | 1,627 | NONE | null | 
I tried this a few times | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12882/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12882/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12881 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12881/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12881/comments | https://api.github.com/repos/huggingface/transformers/issues/12881/events | https://github.com/huggingface/transformers/issues/12881 | 952,361,907 | MDU6SXNzdWU5NTIzNjE5MDc= | 12,881 | Tensorflow GPT-2 model incapable of freezing layers | {
"login": "Elysium1436",
"id": 61297992,
"node_id": "MDQ6VXNlcjYxMjk3OTky",
"avatar_url": "https://avatars.githubusercontent.com/u/61297992?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Elysium1436",
"html_url": "https://github.com/Elysium1436",
"followers_url": "https://api.github.com/users/Elysium1436/followers",
"following_url": "https://api.github.com/users/Elysium1436/following{/other_user}",
"gists_url": "https://api.github.com/users/Elysium1436/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Elysium1436/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Elysium1436/subscriptions",
"organizations_url": "https://api.github.com/users/Elysium1436/orgs",
"repos_url": "https://api.github.com/users/Elysium1436/repos",
"events_url": "https://api.github.com/users/Elysium1436/events{/privacy}",
"received_events_url": "https://api.github.com/users/Elysium1436/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
}
] | [
"Hi, I think this is going to be quite difficult in Keras given the way our models are implemented, as I believe Keras only supports freezing weights on Layer objects, and we haven't implemented the individual pieces of GPT2 as Keras Layers.\r\n\r\nIf you'd like to only train specific pieces of your model, I'd recommend writing a manual eager training loop with GradientTape, see [here](https://www.tensorflow.org/guide/autodiff). For example, something like this (note: untested code!) would work, assuming you have a batch of data as a dict with at least `'input_ids'` and `'labels'` keys:\r\n```\r\ntrainable_weights = model.weights[6:8] # Just picking a list of some random weights to update, you can pick specific ones!\r\noptimizer = tf.keras.optimizers.Adam(5e-5)\r\nwith tf.GradientTape() as tape:\r\n outputs = model(batch)\r\n loss = outputs['loss']\r\n grads = tape.gradient(loss, trainable_weights)\r\noptimizer.apply_gradients(zip(grads, model.trainable_weights))\r\n```\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Are there any updates or work around for freezing GPT-2 model layers at Tensorflow?\r\nThank you",
"(in case you stumble upon this issue and you have the same question, check #18282)"
] | 1,627 | 1,659 | 1,630 | CONTRIBUTOR | null | I am trying to finetune gpt-2 by freezing some layers according to [this article](https://arxiv.org/pdf/2103.05247.pdf). Freezing the specified layers doesn't change the number of trainable parameters, even though accessing the .trainable attribute of the weights of the model shows that they are False.
```python
from transformers import TFAutoModelForCausalLM
model = TFAutoModelForCausalLM.from_pretrained('gpt2')
#Picking random weight
w = model.weights[6]
w #<tf.Variable 'tfgp_t2lm_head_model_2/transformer/h_._0/attn/c_proj/weight:0' shape=(768, 768) dtype=float32, numpy=...
w._trainable = False
w.trainable #False
#Confirming that trainable is false in the model
model.weights[6].trainable #False
model.compile(...)
model.summary()
```
prints
```
Model: "tfgp_t2lm_head_model_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
transformer (TFGPT2MainLayer multiple 124439808
=================================================================
Total params: 124,439,808
Trainable params: 124,439,808
Non-trainable params: 0
_________________________________________________________________
```
Using the ```.get_weights()``` method returns only numpy arrays, so I use .weights.
Freezing all weights the same way in the run_clm.py tensorflow script results in the same summary, and the loss value at each step does decrease, indicating that the weights are being updated. Am I missing something or is this a bug?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12881/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12881/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12880 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12880/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12880/comments | https://api.github.com/repos/huggingface/transformers/issues/12880/events | https://github.com/huggingface/transformers/issues/12880 | 952,321,567 | MDU6SXNzdWU5NTIzMjE1Njc= | 12,880 | RoBERTa: Truncation error: Sequence to truncate too short to respect the provided max_length | {
"login": "PremalMatalia",
"id": 42915124,
"node_id": "MDQ6VXNlcjQyOTE1MTI0",
"avatar_url": "https://avatars.githubusercontent.com/u/42915124?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PremalMatalia",
"html_url": "https://github.com/PremalMatalia",
"followers_url": "https://api.github.com/users/PremalMatalia/followers",
"following_url": "https://api.github.com/users/PremalMatalia/following{/other_user}",
"gists_url": "https://api.github.com/users/PremalMatalia/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PremalMatalia/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PremalMatalia/subscriptions",
"organizations_url": "https://api.github.com/users/PremalMatalia/orgs",
"repos_url": "https://api.github.com/users/PremalMatalia/repos",
"events_url": "https://api.github.com/users/PremalMatalia/events{/privacy}",
"received_events_url": "https://api.github.com/users/PremalMatalia/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
}
] | [
"After further analysis, I could see that RoBERTa tokenizer is not able to handle a question in SQuAD 2.0 dataset at index \"107709\" due to lot of blank spaces at the start of the question and it's length is 25651 character. \r\nWhile other tokenizers are able to handle this.\r\n\r\n\r\n```python\r\nprint(\"question length | 107709:\",len(dataset[107709]['question']))\r\nprint(\"context | 107709:\",dataset[107709]['question'])\r\n```\r\n\r\n### Output\r\nquestion length | 107709: 25651\r\ncontext | 107709: What radiates two lobes perpendicular to the antennas axis? \r\n",
"I just started running into this late last week in an internal test.\r\nIs this new? Has something changed ? ",
"just happened to me as well on SQuAD1.1\r\n",
"The change is due to https://github.com/huggingface/datasets/pull/2586 which changed the SQUAD dataset. The failure is normal in the sense that the tokenizer is asked to truncate tokens from the second sentence (context) when it's actually the first one (question) that is too long. Removing the whitespace at the beginning of the question fixes this (this is why it doesn't happen with a BERT tokenizer, because the BERT tokenizer does it, the roberta tokenizer leaves all individual spaces however).",
"I have fixed the example notebook and the PR mentioned above shows how to fix it in the example scripts.",
"Thanks for fixing this issue. ",
"I very much appreciate this thread for helping me resolve this problem when it happened to me, too. I just wanted to make others aware that there is still an example notebook that will result in this error if it is used with roBERTa.\r\n\r\n[](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb)\r\n\r\nThe correct code can be found here: [](https://huggingface.co/course/chapter7/7)\r\npreprocess_training_examples\r\nand\r\npreprocess_validation_examples\r\nwhich include a line to strip the leading whitespace from the question before tokenization.\r\n",
"Hi,\r\nThank you for the information, I used **BERT** model, and my questions are a lot longer than answers, even after the removing white space that the code will do, I got the same error, do you know how to fix it?"
] | 1,627 | 1,695 | 1,627 | NONE | null | ## Environment info
- `transformers` version: 4.9.0
- Platform: Linux-5.4.104+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.11
- PyTorch version (GPU?): 1.9.0+cu102 (False)
- Tensorflow version (GPU?): 2.5.0 (False)
- Flax version (CPU?/GPU?/TPU?): TPU
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Error is coming with both GPU and TPU
- Using distributed or parallel set-up in script?: No
### Who can help
Models:
RoBERTa - @LysandreJik, @patrickvonplaten, @patil-suraj,
Library:
- tokenizers: @LysandreJik
## Information
Model I am using RoBERTa model for SQuAD 2.0 and getting below error when trying to tokenize the Question and context pair:
The problem arises when using:
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: SQuAD 2.0
## To reproduce
Steps to reproduce the behavior:
I am trying to tokenize SQuAD 2.0 dataset using roberta-base tokenizer and model but it has started giving me below error.
This code snippet was working till few days before and now it is giving below error without changing anything.
```Python
model_args = ModelArguments(
model_checkpoint=model_checkpoint,
token_checkpoint=token_checkpoint,
squad_v2=True,
max_length=384,
doc_stride=128,
batch_size=8,
n_best_size=25,
max_answer_length=30,
min_null_score=7.0, ##FOR ROBERTa
NA_threshold=-3,
pad_side="right")
token_checkpoint = "roberta-base"
model_checkpoint= "roberta-base"
tokenizer = AutoTokenizer.from_pretrained(token_checkpoint)
model = AutoModelForQuestionAnswering.from_pretrained(model_checkpoint,
attention_probs_dropout_prob=0.2,
hidden_dropout_prob=0.2)
datasets = load_dataset("squad_v2" if model_args.squad_v2 else "squad")
tokenized_examples = tokenizer(
datasets["question" if model_args.pad_side else "context"],
datasets["context" if model_args.pad_side else "question"],
truncation="only_second" if model_args.pad_side else "only_first",
max_length=model_args.max_length,
stride=model_args.doc_stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length",
)
```
**_ERROR messages:_**
Truncation error: Sequence to truncate too short to respect the provided max_length
Traceback (most recent call last):
File "/usr/local/lib/python3.7/dist-packages/torch_xla/distributed/xla_multiprocessing.py", line 329, in _mp_start_fn
_start_fn(index, pf_cfg, fn, args)
File "/usr/local/lib/python3.7/dist-packages/torch_xla/distributed/xla_multiprocessing.py", line 323, in _start_fn
fn(gindex, *args)
File "<ipython-input-14-3842fd6863c2>", line 75, in pipeline
tokenized_datasets = datasets.map(prepare_train_features, batched=True, batch_size=1000,remove_columns=datasets["train"].column_names)
File "/usr/local/lib/python3.7/dist-packages/datasets/dataset_dict.py", line 489, in map
for k, dataset in self.items()
File "/usr/local/lib/python3.7/dist-packages/datasets/dataset_dict.py", line 489, in <dictcomp>
for k, dataset in self.items()
File "/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py", line 1679, in map
desc=desc,
File "/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py", line 185, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
File "/usr/local/lib/python3.7/dist-packages/datasets/fingerprint.py", line 397, in wrapper
out = func(self, *args, **kwargs)
File "/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py", line 2014, in _map_single
offset=offset,
File "/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py", line 1900, in apply_function_on_filtered_inputs
function(*fn_args, effective_indices, **fn_kwargs) if with_indices else function(*fn_args, **fn_kwargs)
File "<ipython-input-6-54e98dcfc55e>", line 14, in prepare_train_features
padding="max_length",
File "/usr/local/lib/python3.7/dist-packages/transformers/tokenization_utils_base.py", line 2385, in __call__
**kwargs,
File "/usr/local/lib/python3.7/dist-packages/transformers/tokenization_utils_base.py", line 2570, in batch_encode_plus
**kwargs,
File "/usr/local/lib/python3.7/dist-packages/transformers/models/gpt2/tokenization_gpt2_fast.py", line 163, in _batch_encode_plus
return super()._batch_encode_plus(*args, **kwargs)
File "/usr/local/lib/python3.7/dist-packages/transformers/tokenization_utils_fast.py", line 408, in _batch_encode_plus
is_pretokenized=is_split_into_words,
Exception: Truncation error: Sequence to truncate too short to respect the provided max_length
## Expected behavior
SQuAD 2.0 dataset should be tokenized without any issue.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12880/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12880/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12879 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12879/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12879/comments | https://api.github.com/repos/huggingface/transformers/issues/12879/events | https://github.com/huggingface/transformers/issues/12879 | 952,318,553 | MDU6SXNzdWU5NTIzMTg1NTM= | 12,879 | Feature Request: Add support for --do_train/eval/predict arguments in the TF examples script for token classification | {
"login": "MalteHB",
"id": 47593213,
"node_id": "MDQ6VXNlcjQ3NTkzMjEz",
"avatar_url": "https://avatars.githubusercontent.com/u/47593213?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MalteHB",
"html_url": "https://github.com/MalteHB",
"followers_url": "https://api.github.com/users/MalteHB/followers",
"following_url": "https://api.github.com/users/MalteHB/following{/other_user}",
"gists_url": "https://api.github.com/users/MalteHB/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MalteHB/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MalteHB/subscriptions",
"organizations_url": "https://api.github.com/users/MalteHB/orgs",
"repos_url": "https://api.github.com/users/MalteHB/repos",
"events_url": "https://api.github.com/users/MalteHB/events{/privacy}",
"received_events_url": "https://api.github.com/users/MalteHB/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi, you can use the `--train_file` and `--validation_file` arguments to pass custom data to the model! Are you specifically interested in doing predictions too?",
"Yes! It is the predictions I think would be awesome to have the option to do! 🥇 ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Hi, I didn't mean to let this go stale! We're planning a rewrite of our examples with the new data pipeline soon - I'll try to make sure we include the option for a `--predict_file` when that happens.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,633 | 1,633 | NONE | null | It would be truly awesome if the TensorFlow example of token classification could mimic the capabilities of the PyTorch implementation, by providing additional argument-functionality, including `--do_train`, `--do_eval` and `--do_predict`.
Furthermore, giving the user the opportunity to provide a custom dataset through the `--predict_file` argument. 💯
I see that you, @Rocketknight1, are already doing some awesome work, so perhaps you know whether this will be implemented anytime soon?
https://github.com/huggingface/transformers/blob/9ff672fc4d84db3b077e03ea22e2dafbd5d99fa4/examples/tensorflow/token-classification/run_ner.py#L494-L527
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12879/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12879/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12878 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12878/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12878/comments | https://api.github.com/repos/huggingface/transformers/issues/12878/events | https://github.com/huggingface/transformers/issues/12878 | 952,276,917 | MDU6SXNzdWU5NTIyNzY5MTc= | 12,878 | Trainer accumulates logits | {
"login": "Aktsvigun",
"id": 36672861,
"node_id": "MDQ6VXNlcjM2NjcyODYx",
"avatar_url": "https://avatars.githubusercontent.com/u/36672861?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Aktsvigun",
"html_url": "https://github.com/Aktsvigun",
"followers_url": "https://api.github.com/users/Aktsvigun/followers",
"following_url": "https://api.github.com/users/Aktsvigun/following{/other_user}",
"gists_url": "https://api.github.com/users/Aktsvigun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Aktsvigun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Aktsvigun/subscriptions",
"organizations_url": "https://api.github.com/users/Aktsvigun/orgs",
"repos_url": "https://api.github.com/users/Aktsvigun/repos",
"events_url": "https://api.github.com/users/Aktsvigun/events{/privacy}",
"received_events_url": "https://api.github.com/users/Aktsvigun/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@sgugger ",
"No, metrics usually can't be computed on a batch-per-batch basis as it usually gives the wrong result when the metric is not a mean (like precision, recall or F1 score).\r\n\r\nFor metrics in language modeling, you should use your own manual evaluation loop after training.",
"Fair enough, but if I do not need any metrics at all (need to only track\nthe loss value)? I still cannot use the validation sample since the logits\nwill be accumulated anyway.\n\nOn Mon, 26 Jul 2021 at 15:39, Sylvain Gugger ***@***.***>\nwrote:\n\n> No, metrics usually can't be computed on a batch-per-batch basis as it\n> usually gives the wrong result when the metric is not a mean (like\n> precision, recall or F1 score).\n>\n> For metrics in language modeling, you should use your own manual\n> evaluation loop after training.\n>\n> —\n> You are receiving this because you authored the thread.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/transformers/issues/12878#issuecomment-886666573>,\n> or unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/AIXZKXMPSQLGIY2ZROP7ZQ3TZVJRTANCNFSM5A6RXYNA>\n> .\n>\n",
"If you don't pass any `compute_metrics` function, they won't be accumulated, or you can force it with `prediction_loss_only=True` in your `TrainingArguments`.",
"Thanks a lot! Did not know about this parameter. To sum up, while pre-training a model, we need to write a custom evaluation loop to use custom metrics? Probably it is worth adding a special parameter for the metrics, indicating whether its computation can be split into batches or not? I can handle this.",
"Yes, we don't have anything setup in the Trainer for metric accumulation, so basically any time you want to avoid accumulating logits (so all language modeling tasks basically), you will need a custom training loop.\r\n\r\nWe'll try to come up with an API to make it easier to do a batch-by-batch accumulation but that probably will need a rewrite of some pieces of the Trainer, which in turn might cause some breaking changes. So it's probably going to be for v5",
"Has this BUG been fixed? Can evaluation be done during training?",
"Exactly, you can use `eval_accumulation_steps=1`"
] | 1,627 | 1,700 | 1,627 | CONTRIBUTOR | null | Hi,
I am using `transformers.Trainer` to pre-train a model with MLM. From line 2213 in `trainer.py` I can see the logits obtained on the evaluation step are accumulated:
`preds_host = logits if preds_host is None else nested_concat(preds_host, logits, padding_index=-100)`
This makes it impossible to use a reasonable validation dataset, since already 1000 examples with `max_length = 512` and `vocab_size = 30522` occupy 1000 * 512 * 30522 / 1024^3 > 14 Gb of memory (e.g. **c4** dataset has validation dataset of size 365 000). This can be corrected if the additional metrics are calculated on each validation step for each batch separately rather than in the end.
This implies lines 2272-2275 should be moved inside the _for loop_. If you agree with all I have stated, I can do it by my own and come up with the merge request. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12878/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12878/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12877 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12877/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12877/comments | https://api.github.com/repos/huggingface/transformers/issues/12877/events | https://github.com/huggingface/transformers/issues/12877 | 952,213,866 | MDU6SXNzdWU5NTIyMTM4NjY= | 12,877 | run_mlm.py errors when running validation only | {
"login": "david-waterworth",
"id": 5028974,
"node_id": "MDQ6VXNlcjUwMjg5NzQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/5028974?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/david-waterworth",
"html_url": "https://github.com/david-waterworth",
"followers_url": "https://api.github.com/users/david-waterworth/followers",
"following_url": "https://api.github.com/users/david-waterworth/following{/other_user}",
"gists_url": "https://api.github.com/users/david-waterworth/gists{/gist_id}",
"starred_url": "https://api.github.com/users/david-waterworth/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/david-waterworth/subscriptions",
"organizations_url": "https://api.github.com/users/david-waterworth/orgs",
"repos_url": "https://api.github.com/users/david-waterworth/repos",
"events_url": "https://api.github.com/users/david-waterworth/events{/privacy}",
"received_events_url": "https://api.github.com/users/david-waterworth/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I'm not sure what you mean, could you check you have the latest version of the script? There is a test of whether the `train_file` is None or not at the line you mention, and then the `validation_file` is used instead if the `train_file` has not been set.",
"@sgugger You're right, it was fixed in this commit https://github.com/huggingface/transformers/commit/9490d668d2f59ad2e7a4db3dc7ed2f9684af369c#diff-5f4433e38787dd047b331ec822da660195a786ea9350ad611623cd03d468b102\r\n\r\nI'm using version 4.8.0"
] | 1,627 | 1,627 | 1,627 | NONE | null | If you run `mlm_train.py' for validation only (i.e. --do_eval but don't pass -do_train) the script only runs if you still pass --train_file
This is due to the inference of the train file being used to determine the file type (i.e. text)
https://github.com/huggingface/transformers/blob/9ff672fc4d84db3b077e03ea22e2dafbd5d99fa4/examples/pytorch/language-modeling/run_mlm.py#L281
despite `--train_file` being an option argument.
https://github.com/huggingface/transformers/blob/9ff672fc4d84db3b077e03ea22e2dafbd5d99fa4/examples/pytorch/language-modeling/run_mlm.py#L131
It's useful being able to run eval only, it's not a big deal passing --train_file despite it not being used but given it's option the code should probably use train_file only if it's not none else validation_file
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12877/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12877/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12876 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12876/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12876/comments | https://api.github.com/repos/huggingface/transformers/issues/12876/events | https://github.com/huggingface/transformers/issues/12876 | 952,146,479 | MDU6SXNzdWU5NTIxNDY0Nzk= | 12,876 | New transformers.onnx CLI does not support ONNX quantization | {
"login": "minimaxir",
"id": 2179708,
"node_id": "MDQ6VXNlcjIxNzk3MDg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2179708?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/minimaxir",
"html_url": "https://github.com/minimaxir",
"followers_url": "https://api.github.com/users/minimaxir/followers",
"following_url": "https://api.github.com/users/minimaxir/following{/other_user}",
"gists_url": "https://api.github.com/users/minimaxir/gists{/gist_id}",
"starred_url": "https://api.github.com/users/minimaxir/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/minimaxir/subscriptions",
"organizations_url": "https://api.github.com/users/minimaxir/orgs",
"repos_url": "https://api.github.com/users/minimaxir/repos",
"events_url": "https://api.github.com/users/minimaxir/events{/privacy}",
"received_events_url": "https://api.github.com/users/minimaxir/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi @minimaxir, \r\n\r\nThanks for reporting this.\r\n\r\nWith the new \"configuration based\" capabilities we are taking a very different approach from the initial `convert_graph_to_onnx.py` which was relying on heuristics to match dynamic axes and was exporting them in the wrong order quite often.\r\n\r\nThe new approach focus on a more reliable approach and on exporting only to \"raw\" ONNX graphs which can then be consumed by different \"runtimes\" not only onnxruntime. Thus we are not exposing anymore optimizations/quantizations features as part of transformers.\r\n\r\nStill, we are currently working on another project will provide such features, leveraging the new configuration based export. It should be available in August and ONNX Runtime will be one of the first component we will provide optimizations for. \r\n\r\nStay tuned 🤗 ",
"SGTM. (it's not a dealbreaker as Microsoft's approach is to create a raw ONNX and quantize it too).\r\n\r\nExcited to see future ONNX support!",
"@mfuntowicz Excidetd to see onnxruntime supported BART/MBART models",
"Hi @mfuntowicz, any updates on the new project? Thanks."
] | 1,627 | 1,633 | 1,627 | NONE | null | # 🚀 Feature request
New transformers.onnx CLI introduced in 4.9.0 does not support ONNX quantization, which is a notable missing feature from the `convert_graph_to_onnx.py` script.
Semi-related: the [source quantize() function](https://github.com/microsoft/onnxruntime/blob/79097ef5535cc5ac18fc8e9010c99de08df21340/onnxruntime/python/tools/quantization/quantize.py#L56) that script leverages is depreciated so it might be a good time to switch to `quantize_dynamic()` too.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12876/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12876/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12875 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12875/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12875/comments | https://api.github.com/repos/huggingface/transformers/issues/12875/events | https://github.com/huggingface/transformers/issues/12875 | 952,145,752 | MDU6SXNzdWU5NTIxNDU3NTI= | 12,875 | Model card updated/deleted | {
"login": "tuner007",
"id": 46425391,
"node_id": "MDQ6VXNlcjQ2NDI1Mzkx",
"avatar_url": "https://avatars.githubusercontent.com/u/46425391?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tuner007",
"html_url": "https://github.com/tuner007",
"followers_url": "https://api.github.com/users/tuner007/followers",
"following_url": "https://api.github.com/users/tuner007/following{/other_user}",
"gists_url": "https://api.github.com/users/tuner007/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tuner007/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tuner007/subscriptions",
"organizations_url": "https://api.github.com/users/tuner007/orgs",
"repos_url": "https://api.github.com/users/tuner007/repos",
"events_url": "https://api.github.com/users/tuner007/events{/privacy}",
"received_events_url": "https://api.github.com/users/tuner007/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hey @tuner007,\r\n\r\nThanks a lot for your issue! I'm very sorry that this has happened - this was a bug from my side :-/ I corrected it and your model should work as before now :-)",
"> Hey @tuner007,\r\n> \r\n> Thanks a lot for your issue! I'm very sorry that this has happened - this was a bug from my side :-/ I corrected it and your model should work as before now :-)\r\n\r\nNo worries ! thanks "
] | 1,627 | 1,627 | 1,627 | CONTRIBUTOR | null | Hi,
I can check that the Model "tuner007/t5_abs_qa" has been removed from model hub...Is there anything i need to update ?
@patrickvonplaten [Refer](https://huggingface.co/tuner007/t5_abs_qa/commit/faf30925ced0f25d0d5d321fb0ada04caaf5568d)
/thanks | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12875/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12875/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12874 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12874/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12874/comments | https://api.github.com/repos/huggingface/transformers/issues/12874/events | https://github.com/huggingface/transformers/issues/12874 | 952,137,626 | MDU6SXNzdWU5NTIxMzc2MjY= | 12,874 | Finetuning GPT-2 on small datasets | {
"login": "Elysium1436",
"id": 61297992,
"node_id": "MDQ6VXNlcjYxMjk3OTky",
"avatar_url": "https://avatars.githubusercontent.com/u/61297992?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Elysium1436",
"html_url": "https://github.com/Elysium1436",
"followers_url": "https://api.github.com/users/Elysium1436/followers",
"following_url": "https://api.github.com/users/Elysium1436/following{/other_user}",
"gists_url": "https://api.github.com/users/Elysium1436/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Elysium1436/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Elysium1436/subscriptions",
"organizations_url": "https://api.github.com/users/Elysium1436/orgs",
"repos_url": "https://api.github.com/users/Elysium1436/repos",
"events_url": "https://api.github.com/users/Elysium1436/events{/privacy}",
"received_events_url": "https://api.github.com/users/Elysium1436/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I've finally found [this article](https://arxiv.org/pdf/2103.05247.pdf), and it seems promising. Going to try it out i'll say how it went.",
"For training-related questions, please refer to the [forum](https://discuss.huggingface.co/). We like to keep Github issues for bugs/feature requests.\r\n\r\nFor example, you can find all fine-tuning GPT-2-related questions [here](https://discuss.huggingface.co/search?q=fine-tuning%20gpt2).\r\n\r\nThank you!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,630 | 1,630 | CONTRIBUTOR | null | I have a relatively small dataset that i've scraped on my discord server. I wanted to make a gpt-2 chatbot with it, but the data is relatively small (3782031 characters counting the eos token). Training for a small number of epochs did nothing for any checkpoint related to gpt-2 (I tried distilbert, gpt-2, dialoGPT-small, and other), and training for a large number of epochs absolutely destroyed the whole model, it was barely able to generate coherent at all, it was either special characters, jumble, or nothing at all. I've tested the same script with a much larger dataset and it worked just fine, so I can only assume it's because of the dataset size.
I was trying to find ways to freeze the gpt-2 base model and leave just the LMHead, but since the LMHead is somehow tied to the embedding layer, that wouldn't be possible... If there isn't a way to freeze the head of the model, what else should I do then? I've been trying to complete this personal project for quite a while now, and i'm out of options at this point. I'm using a custom TF script from the example folder on TPU, since the pytorch version makes the memory usage blow up on colab. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12874/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12874/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12873 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12873/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12873/comments | https://api.github.com/repos/huggingface/transformers/issues/12873/events | https://github.com/huggingface/transformers/issues/12873 | 952,130,446 | MDU6SXNzdWU5NTIxMzA0NDY= | 12,873 | Possibly wrong API documentation for BigBirdTokenizerFast | {
"login": "nabito",
"id": 1082880,
"node_id": "MDQ6VXNlcjEwODI4ODA=",
"avatar_url": "https://avatars.githubusercontent.com/u/1082880?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nabito",
"html_url": "https://github.com/nabito",
"followers_url": "https://api.github.com/users/nabito/followers",
"following_url": "https://api.github.com/users/nabito/following{/other_user}",
"gists_url": "https://api.github.com/users/nabito/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nabito/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nabito/subscriptions",
"organizations_url": "https://api.github.com/users/nabito/orgs",
"repos_url": "https://api.github.com/users/nabito/repos",
"events_url": "https://api.github.com/users/nabito/events{/privacy}",
"received_events_url": "https://api.github.com/users/nabito/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thanks for flagging, should be fixed by the PR mentioned above!"
] | 1,627 | 1,627 | 1,627 | NONE | null | - `transformers` version: v.4.9.0
### Who can help
Documentation: @sgugger
## Information
At this URL:
https://huggingface.co/transformers/model_doc/bigbird.html#transformers.BigBirdTokenizerFast
The doc says,
`bos_token (str, optional, defaults to "[CLS]")`
and
`eos_token (str, optional, defaults to "[SEP]")`
but the actual code is:
```
def __init__(
self,
vocab_file=None,
tokenizer_file=None,
unk_token="<unk>",
bos_token="<s>",
eos_token="</s>",
pad_token="<pad>",
```
May be the API document need a fix? the explanation seems already clear though, only default value of those params are wrong.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12873/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12873/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12872 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12872/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12872/comments | https://api.github.com/repos/huggingface/transformers/issues/12872/events | https://github.com/huggingface/transformers/issues/12872 | 952,103,278 | MDU6SXNzdWU5NTIxMDMyNzg= | 12,872 | Allow multilabel classification mode for widgets in the models repo | {
"login": "avidale",
"id": 8642136,
"node_id": "MDQ6VXNlcjg2NDIxMzY=",
"avatar_url": "https://avatars.githubusercontent.com/u/8642136?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/avidale",
"html_url": "https://github.com/avidale",
"followers_url": "https://api.github.com/users/avidale/followers",
"following_url": "https://api.github.com/users/avidale/following{/other_user}",
"gists_url": "https://api.github.com/users/avidale/gists{/gist_id}",
"starred_url": "https://api.github.com/users/avidale/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/avidale/subscriptions",
"organizations_url": "https://api.github.com/users/avidale/orgs",
"repos_url": "https://api.github.com/users/avidale/repos",
"events_url": "https://api.github.com/users/avidale/events{/privacy}",
"received_events_url": "https://api.github.com/users/avidale/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi @avidale, I'm closing this issue as I think it is an accidental duplicate of #12871.\r\nAlso, I've transferred #12871 to [huggingface_hub/#222](huggingface/huggingface.js#300) since thats where the widgets src is"
] | 1,627 | 1,700 | 1,627 | NONE | null | # 🚀 Feature request
1. Enable multilabel classification mode and regression mode for the widgets in the model repo.
2. Create the corresponding tags that can be read from the model card.
## Motivation
Models for sequence classification by default support three modes: binary/multiclass classification, multilabel classification, and regression. However, the widgets in the model repository support only multiclass mode (where probabilities of classes sum to 1). This can be misleading for the users who taste the models using the widgets. For example, my model https://huggingface.co/cointegrated/rubert-tiny-toxicity, which is intended for multilabel classification, but the widget normalizes the predicted probabilities to sum to 1, which leads to confisuion of the potential users of the model.
## Your contribution
If you show me where to start, I could start working on implementing this feature. However, currently I don't know what part of the Huggingface repository is responsible for widgets and underlying computations.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12872/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12872/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12870 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12870/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12870/comments | https://api.github.com/repos/huggingface/transformers/issues/12870/events | https://github.com/huggingface/transformers/issues/12870 | 952,102,868 | MDU6SXNzdWU5NTIxMDI4Njg= | 12,870 | Bart Generation | {
"login": "Hannibal046",
"id": 38466901,
"node_id": "MDQ6VXNlcjM4NDY2OTAx",
"avatar_url": "https://avatars.githubusercontent.com/u/38466901?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Hannibal046",
"html_url": "https://github.com/Hannibal046",
"followers_url": "https://api.github.com/users/Hannibal046/followers",
"following_url": "https://api.github.com/users/Hannibal046/following{/other_user}",
"gists_url": "https://api.github.com/users/Hannibal046/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Hannibal046/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Hannibal046/subscriptions",
"organizations_url": "https://api.github.com/users/Hannibal046/orgs",
"repos_url": "https://api.github.com/users/Hannibal046/repos",
"events_url": "https://api.github.com/users/Hannibal046/events{/privacy}",
"received_events_url": "https://api.github.com/users/Hannibal046/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Bart was trained to have EOS as it's start_token_id and we've noticed that forcing the first token to be BOS gives better results, see: https://github.com/huggingface/transformers/issues/3668",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,631 | 1,631 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.9.0
- Platform:Linux
- Python version:3.7
- PyTorch version (GPU?):1.9.0
- Using GPU in script?:true
- Using distributed or parallel set-up in script?:false
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.-->
@patrickvonplaten
@patil-suraj
@sgugger
@patil-suraj
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [x] the official example scripts:run_summarization.py
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: summarization
* [ ] my own task or dataset: (give details below)
### Question 1
In `src/examples/pytorch/summarizations/run_summarization.py`. I choose Bart as my model.
since it uses `BartTokenzier` and `DataCollatorForSeq2Seq`. So the labels to the datacollator is `<bos> summarization <eos>` and the automatically generated `decoder_input_ids` is `<eos> <bos> summarization`, because the `decoder_start_token_id` in `bart_config` is the same as that of `<eos>` , is there any special reasons to do it ? I think the `labels` should be `summarization <eos>` and `decoder_input_ids` should be `<bos> summarization`.
### Question 2
Why `decoder_start_token_id` is the same as `<eos>` , which means all bart will use `<eos>` as its first token to start generating, isn't this against the way the bart was trained? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12870/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12870/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12869 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12869/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12869/comments | https://api.github.com/repos/huggingface/transformers/issues/12869/events | https://github.com/huggingface/transformers/issues/12869 | 952,019,037 | MDU6SXNzdWU5NTIwMTkwMzc= | 12,869 | I donnot want print trainer's logging info | {
"login": "cdhx",
"id": 44169250,
"node_id": "MDQ6VXNlcjQ0MTY5MjUw",
"avatar_url": "https://avatars.githubusercontent.com/u/44169250?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cdhx",
"html_url": "https://github.com/cdhx",
"followers_url": "https://api.github.com/users/cdhx/followers",
"following_url": "https://api.github.com/users/cdhx/following{/other_user}",
"gists_url": "https://api.github.com/users/cdhx/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cdhx/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cdhx/subscriptions",
"organizations_url": "https://api.github.com/users/cdhx/orgs",
"repos_url": "https://api.github.com/users/cdhx/repos",
"events_url": "https://api.github.com/users/cdhx/events{/privacy}",
"received_events_url": "https://api.github.com/users/cdhx/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"You can use the argument `log_level` to adjust the level of the logger. If you set it to \"warning\", it won't print this.",
"thanks, it works"
] | 1,627 | 1,627 | 1,627 | NONE | null | torch 1.18.0,tf 1.14.0
every thing works well yesterday
i didn't do any thing, but today when i use predict of trainer, it print this infomation before the output
this situation didn't occur before
```
***** Running Prediction *****
Num examples = 1
Batch size = 256
```
now i want this info don't print
I check the document, but didn't find a parameter to control don't print logger
```
In predict_loop function
batch_size = dataloader.batch_size
num_examples = self.num_examples(dataloader)
logger.info(f"***** Running {description} *****")
logger.info(f" Num examples = {num_examples}")
logger.info(f" Batch size = {batch_size}")
losses_host: torch.Tensor = None
preds_host: Union[torch.Tensor, List[torch.Tensor]] = None
labels_host: Union[torch.Tensor, List[torch.Tensor]] = None
```
thanks @sgugger | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12869/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12869/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12868 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12868/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12868/comments | https://api.github.com/repos/huggingface/transformers/issues/12868/events | https://github.com/huggingface/transformers/issues/12868 | 952,015,912 | MDU6SXNzdWU5NTIwMTU5MTI= | 12,868 | MT5-base tokenizer can't decode to target language after decoding | {
"login": "pranonrahman",
"id": 37942208,
"node_id": "MDQ6VXNlcjM3OTQyMjA4",
"avatar_url": "https://avatars.githubusercontent.com/u/37942208?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pranonrahman",
"html_url": "https://github.com/pranonrahman",
"followers_url": "https://api.github.com/users/pranonrahman/followers",
"following_url": "https://api.github.com/users/pranonrahman/following{/other_user}",
"gists_url": "https://api.github.com/users/pranonrahman/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pranonrahman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pranonrahman/subscriptions",
"organizations_url": "https://api.github.com/users/pranonrahman/orgs",
"repos_url": "https://api.github.com/users/pranonrahman/repos",
"events_url": "https://api.github.com/users/pranonrahman/events{/privacy}",
"received_events_url": "https://api.github.com/users/pranonrahman/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
},
{
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
}
] | [] | 1,627 | 1,628 | 1,628 | NONE | null | ## Environment info
- `transformers` version: 4.9.0
- Platform: Google Colab
- Python version: 3.8+
- PyTorch version (GPU?): 1.9.0+cu102
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: no
### Who can help
Models:
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
Library:
- tokenizers: @LysandreJik
## Information
Model I am using (MT5):
The problem arises when using:
* [ ] my own modified scripts: When I am finetuning mt5-small model for question answering using mt5ForConditionalGeneration, after running inference, the output is not in the specified language.
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (Question Answering)
## To reproduce
link to my notebook: [link](https://colab.research.google.com/drive/12nMMdHul4Avxn38o3LZhsVgVE02I6g2E?usp=sharing)
Steps to reproduce the behavior:
1. Run the inference section
2. Run on any language
3. The model outputs in a mixed language
## Expected behavior
The expected behavior should be to produce output on a single language.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12868/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12868/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12867 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12867/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12867/comments | https://api.github.com/repos/huggingface/transformers/issues/12867/events | https://github.com/huggingface/transformers/issues/12867 | 951,802,420 | MDU6SXNzdWU5NTE4MDI0MjA= | 12,867 | Possible bug in spm-based tokenizers | {
"login": "Mehrad0711",
"id": 28717374,
"node_id": "MDQ6VXNlcjI4NzE3Mzc0",
"avatar_url": "https://avatars.githubusercontent.com/u/28717374?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Mehrad0711",
"html_url": "https://github.com/Mehrad0711",
"followers_url": "https://api.github.com/users/Mehrad0711/followers",
"following_url": "https://api.github.com/users/Mehrad0711/following{/other_user}",
"gists_url": "https://api.github.com/users/Mehrad0711/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Mehrad0711/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mehrad0711/subscriptions",
"organizations_url": "https://api.github.com/users/Mehrad0711/orgs",
"repos_url": "https://api.github.com/users/Mehrad0711/repos",
"events_url": "https://api.github.com/users/Mehrad0711/events{/privacy}",
"received_events_url": "https://api.github.com/users/Mehrad0711/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"In fact, this seems to be a problem with other spm based tokenizers too. Other MBART checkpoints as well as MT5 and XLMR models have the same behavior but not multilingual BERT checkpoints. Not sure if this issue has been reported/ discussed before. Any hints are appreciated.",
"@patil-suraj - could you take a look here for MBart \"many-to-many\"?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Hi, was wondering if there are any updates?",
"Hi @Mehrad0711 Sorry to only reply now. \r\n\r\nI will try to allocate some time this week for it.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"@patil-suraj - ping again here :-)",
"@Mehrad0711 @patrickvonplaten Sorry about being super slow here.\r\n\r\nI'm not sure if this is really a bug, it looks like the punctuations are normalized by the spm model itself. You could load the original spm model from mbart and see that it normalizes the string during tokenization.\r\n\r\nTo verify, download the official spm model from here https://github.com/pytorch/fairseq/tree/main/examples/mbart\r\n\r\n```python3\r\nimport sentencepiece as spm\r\n\r\nsp_model = spm.SentencePieceProcessor()\r\nsp_model.Load(\"mbart.cc25.v2/sentence.bpe.model\")\r\n\r\nsentence = '您好, 您打算到哪里去呢?'\r\ntokenized = sp_model.encode_as_pieces(sentence)\r\n# => ['▁您', '好', ',', '您', '打算', '到', '哪里', '去', '呢', '?']\r\n\r\ndecoded = sp_model.decode_pieces(tokenized)\r\n# => '您好,您打算到哪里去呢?'\r\n```",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,642 | 1,642 | CONTRIBUTOR | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: latest (4.10.0.dev0)
- Python version: 3.8
- PyTorch version (GPU?): 1.9.0
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@patrickvonplaten, @patil-suraj
## Information
Model I am using (Bert, XLNet ...): `mbart-large-50-many-to-many-mmt`
## To reproduce
Running the following script shows that encoding and decoding a Chinese string would not give back the same string (punctuation marks will be normalized):
```
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('facebook/mbart-large-50-many-to-many-mmt', src_lang='zh_CN', tgt_lang='zh_CN')
sentence = '您好,您打算到哪里去呢?'
input = tokenizer(sentence)
output = tokenizer.decode(input['input_ids'], skip_special_tokens=True)
print(output)
print(output == sentence)
```
stdout:
```
您好,您打算到哪里去呢?
False
```
Using slow version of the tokenizer or setting src_lang and tgt_lang attributes directly would give the same results.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
Expected stdout:
```
您好,您打算到哪里去呢?
True
```
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12867/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12867/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12866 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12866/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12866/comments | https://api.github.com/repos/huggingface/transformers/issues/12866/events | https://github.com/huggingface/transformers/issues/12866 | 951,798,733 | MDU6SXNzdWU5NTE3OTg3MzM= | 12,866 | [MPNet] example of fine-tuning MPNet language model on domain specific corpus | {
"login": "vdabravolski",
"id": 505262,
"node_id": "MDQ6VXNlcjUwNTI2Mg==",
"avatar_url": "https://avatars.githubusercontent.com/u/505262?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vdabravolski",
"html_url": "https://github.com/vdabravolski",
"followers_url": "https://api.github.com/users/vdabravolski/followers",
"following_url": "https://api.github.com/users/vdabravolski/following{/other_user}",
"gists_url": "https://api.github.com/users/vdabravolski/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vdabravolski/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vdabravolski/subscriptions",
"organizations_url": "https://api.github.com/users/vdabravolski/orgs",
"repos_url": "https://api.github.com/users/vdabravolski/repos",
"events_url": "https://api.github.com/users/vdabravolski/events{/privacy}",
"received_events_url": "https://api.github.com/users/vdabravolski/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,630 | 1,630 | NONE | null | # 🚀 Feature request
I'd like to understand if it's possible to fine-tune MPnet model on domain specific corpus. I tried to run following script for MPNet and it seemed to be working (or at least on throwing any errors).
`python run_mlm.py --model_name_or_path microsoft/mpnet-base --dataset_name wikitext --do_train --output_dir tmp/mpnet-output --dataset_config_name wikitext-2-raw-v1`
However, since MPNet combines both MLM and PLM objectives, I'm not clear whether MPNet will actually train properly.
## Motivation
MPNet establishes SOTA benchmarks on number of tasks. It could be useful to have some examples on how to fine-tune MPNet model on specific corpuses and downstream tasks.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12866/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12866/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12865 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12865/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12865/comments | https://api.github.com/repos/huggingface/transformers/issues/12865/events | https://github.com/huggingface/transformers/pull/12865 | 951,726,940 | MDExOlB1bGxSZXF1ZXN0Njk2MDY1NDkx | 12,865 | Add TF multiple choice example | {
"login": "Rocketknight1",
"id": 12866554,
"node_id": "MDQ6VXNlcjEyODY2NTU0",
"avatar_url": "https://avatars.githubusercontent.com/u/12866554?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rocketknight1",
"html_url": "https://github.com/Rocketknight1",
"followers_url": "https://api.github.com/users/Rocketknight1/followers",
"following_url": "https://api.github.com/users/Rocketknight1/following{/other_user}",
"gists_url": "https://api.github.com/users/Rocketknight1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rocketknight1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rocketknight1/subscriptions",
"organizations_url": "https://api.github.com/users/Rocketknight1/orgs",
"repos_url": "https://api.github.com/users/Rocketknight1/repos",
"events_url": "https://api.github.com/users/Rocketknight1/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rocketknight1/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,627 | 1,627 | 1,627 | MEMBER | null | Add a new example of multiple choice (SWAG) training with Keras/TF, remove the previous TFTrainer one. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12865/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12865/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12865",
"html_url": "https://github.com/huggingface/transformers/pull/12865",
"diff_url": "https://github.com/huggingface/transformers/pull/12865.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12865.patch",
"merged_at": 1627308952000
} |
https://api.github.com/repos/huggingface/transformers/issues/12864 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12864/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12864/comments | https://api.github.com/repos/huggingface/transformers/issues/12864/events | https://github.com/huggingface/transformers/issues/12864 | 951,680,451 | MDU6SXNzdWU5NTE2ODA0NTE= | 12,864 | [Speech2Text] Slow tests are failing on master | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
},
{
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
}
] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,630 | 1,630 | MEMBER | null | Currently the following tests are failing on master:
```
FAILED tests/test_modeling_speech_to_text.py::Speech2TextModelIntegrationTests::test_generation_librispeech
FAILED tests/test_modeling_speech_to_text.py::Speech2TextModelIntegrationTests::test_generation_librispeech_batched
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12864/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12864/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12863 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12863/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12863/comments | https://api.github.com/repos/huggingface/transformers/issues/12863/events | https://github.com/huggingface/transformers/issues/12863 | 951,674,424 | MDU6SXNzdWU5NTE2NzQ0MjQ= | 12,863 | [Wav2Vec2] Slow pretraining tests are failing on CPU | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
}
] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,630 | 1,630 | MEMBER | null | The following tests are failing on CPU currently:
```
tests/test_modeling_wav2vec2.py::Wav2Vec2ModelIntegrationTest::test_inference_integration
tests/test_modeling_wav2vec2.py::Wav2Vec2ModelIntegrationTest::test_loss_pretraining
```
-> check if they also fail on GPU. If not add a skip CPU decorator | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12863/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12863/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12862 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12862/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12862/comments | https://api.github.com/repos/huggingface/transformers/issues/12862/events | https://github.com/huggingface/transformers/issues/12862 | 951,657,422 | MDU6SXNzdWU5NTE2NTc0MjI= | 12,862 | BatchFeature should cast to `np.float32` by default | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2796628563,
"node_id": "MDU6TGFiZWwyNzk2NjI4NTYz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/WIP",
"name": "WIP",
"color": "234C99",
"default": false,
"description": "Label your PR/Issue with WIP for some long outstanding Issues/PRs that are work in progress"
}
] | open | false | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
}
] | [] | 1,627 | 1,629 | null | MEMBER | null | Currently the default dtype for Speech Feature Extractors is `numpy.float64` which leads to two problems:
1) It makes the data processing extremely expensive for the RAM. Many sound formats are stored in int16 (such as `.wav`) and are then transformed to float64 which unnecessarly increases RAM by a factor of 4. We should at least stick to `float32`
2) Currently we have added some hacks to the Wav2Vec2 and Speech2TextTransformer feature extractors to prevent Double vs. Float dtype mismatches: https://github.com/huggingface/transformers/blob/f6e254474cb4f90f8a168a599b9aaf3544c37890/src/transformers/models/wav2vec2/feature_extraction_wav2vec2.py#L87
The main problem is that `np.asarray([....])` by default creates a np.float64 array and that we just pass that format along.
=> We should either always cast to float32 in BatchFeature (see here: https://github.com/huggingface/transformers/blob/f6e254474cb4f90f8a168a599b9aaf3544c37890/src/transformers/feature_extraction_utils.py#L151) or add a flag `dtype` to BatchFeature.
@patrickvonplaten | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12862/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12862/timeline | null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12861 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12861/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12861/comments | https://api.github.com/repos/huggingface/transformers/issues/12861/events | https://github.com/huggingface/transformers/issues/12861 | 951,656,739 | MDU6SXNzdWU5NTE2NTY3Mzk= | 12,861 | Asking for consent to publish `_LazyModule` as a standalone PyPI package on GitHub | {
"login": "PhilipMay",
"id": 229382,
"node_id": "MDQ6VXNlcjIyOTM4Mg==",
"avatar_url": "https://avatars.githubusercontent.com/u/229382?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PhilipMay",
"html_url": "https://github.com/PhilipMay",
"followers_url": "https://api.github.com/users/PhilipMay/followers",
"following_url": "https://api.github.com/users/PhilipMay/following{/other_user}",
"gists_url": "https://api.github.com/users/PhilipMay/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PhilipMay/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PhilipMay/subscriptions",
"organizations_url": "https://api.github.com/users/PhilipMay/orgs",
"repos_url": "https://api.github.com/users/PhilipMay/repos",
"events_url": "https://api.github.com/users/PhilipMay/events{/privacy}",
"received_events_url": "https://api.github.com/users/PhilipMay/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Tagging @LysandreJik and @sgugger ",
"Thanks for asking! You can definitely package this class in a module as long as it's on the same license as in this repo (Apache 2.0) and you are willing to maintain it.",
"Here you go. A release will follow the next days:\r\nhttps://github.com/telekom/lazy-imports",
"Many thanks again. I will close the issue now."
] | 1,627 | 1,627 | 1,627 | CONTRIBUTOR | null | Hi,
I very much like your `_LazyModule` implementation.
https://github.com/huggingface/transformers/blob/e218249b02465ec8b6029f201f2503b9e3b61feb/src/transformers/file_utils.py#L1945
I would like to reuse it on different other projects. That is why I ask for your consent to publish it as a
standalone PyPI package on GitHub while keeping the license. Are you ok with that? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12861/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12861/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12860 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12860/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12860/comments | https://api.github.com/repos/huggingface/transformers/issues/12860/events | https://github.com/huggingface/transformers/pull/12860 | 951,644,421 | MDExOlB1bGxSZXF1ZXN0Njk1OTk2MzQ0 | 12,860 | [tests] fix logging_steps requirements | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,627 | 1,627 | 1,627 | CONTRIBUTOR | null | This PR fixed slow tests that got affected by a new sanity check at https://github.com/huggingface/transformers/pull/12796
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12860/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12860/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12860",
"html_url": "https://github.com/huggingface/transformers/pull/12860",
"diff_url": "https://github.com/huggingface/transformers/pull/12860.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12860.patch",
"merged_at": 1627052748000
} |
https://api.github.com/repos/huggingface/transformers/issues/12859 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12859/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12859/comments | https://api.github.com/repos/huggingface/transformers/issues/12859/events | https://github.com/huggingface/transformers/issues/12859 | 951,533,812 | MDU6SXNzdWU5NTE1MzM4MTI= | 12,859 | Cannot import pipeline after installation | {
"login": "ShushanArakelyan",
"id": 7150620,
"node_id": "MDQ6VXNlcjcxNTA2MjA=",
"avatar_url": "https://avatars.githubusercontent.com/u/7150620?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ShushanArakelyan",
"html_url": "https://github.com/ShushanArakelyan",
"followers_url": "https://api.github.com/users/ShushanArakelyan/followers",
"following_url": "https://api.github.com/users/ShushanArakelyan/following{/other_user}",
"gists_url": "https://api.github.com/users/ShushanArakelyan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ShushanArakelyan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ShushanArakelyan/subscriptions",
"organizations_url": "https://api.github.com/users/ShushanArakelyan/orgs",
"repos_url": "https://api.github.com/users/ShushanArakelyan/repos",
"events_url": "https://api.github.com/users/ShushanArakelyan/events{/privacy}",
"received_events_url": "https://api.github.com/users/ShushanArakelyan/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hello! Could you show me the command you used to install `transformers`? Thank you!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Same issue\r\n\r\n```\r\n❯ python transformers.py\r\nTraceback (most recent call last):\r\n File \"transformers.py\", line 3, in <module>\r\n import transformers\r\n File \"/Users/xxxxxx/Desktop/transformers.py\", line 4, in <module>\r\n from transformers import pipeline\r\nImportError: cannot import name 'pipeline' from partially initialized module 'transformers' (most likely due to a circular import) (/Users/xxxxxx/Desktop/transformers.py)\r\n```",
"You're trying to import transformers in a file named `transformers.py`, that won't work.",
"@LysandreJik my script name is transformers.py\r\n\r\nThe script content is the Quick Tour example https://github.com/huggingface/transformers\r\n```\r\nimport requests\r\nfrom PIL import Image\r\nfrom transformers import pipeline\r\n\r\n# Download an image with cute cats\r\nurl = \"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/coco_sample.png\"\r\nimage_data = requests.get(url, stream=True).raw\r\nimage = Image.open(image_data)\r\n\r\n# Allocate a pipeline for object detection\r\nobject_detector = pipeline('object_detection')\r\nobject_detector(image)\r\n```",
"Yes, please rename your script. If you're doing `import transformers` from inside a script named `transformers.py`, the script will try to import itself."
] | 1,627 | 1,659 | 1,630 | NONE | null | ## Environment info
- `transformers` version: 4.9.0
- Platform: Linux-4.15.0-151-generic-x86_64-with-glibc2.27
- Python version: 3.9.2
- PyTorch version (GPU?): 1.7.1+cu101 (False)
- Tensorflow version (GPU?): 2.5.0 (False)
- Flax version (CPU?/GPU?/TPU?): 0.3.4 (cpu)
- Jax version: 0.2.17
- JaxLib version: 0.1.69
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help
@LysandreJik
## Information
The problem arises when using:
* [ ] the official example scripts: (give details below)
I am attempting a fresh installation of transformers library, but after successfully completing the installation with pip, I am not able to run the test script: `python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"`
Instead, I see the following output:
> /home/shushan/.conda/envs/ccg_parser/lib/python3.9/site-packages/gensim/similarities/__init__.py:15: UserWarning: The gensim.similarities.levenshtein submodule is disabled, because the optional Levenshtein package <https://pypi.org/proje$
> t/python-Levenshtein/> is unavailable. Install Levenhstein (e.g. `pip install python-Levenshtein`) to suppress this warning.
> warnings.warn(msg)
> Traceback (most recent call last):
> File "<string>", line 1, in <module>
> File "/home/shushan/.conda/envs/ccg_parser/lib/python3.9/site-packages/transformers/file_utils.py", line 1977, in __getattr__
> module = self._get_module(self._class_to_module[name])
> File "/home/shushan/.conda/envs/ccg_parser/lib/python3.9/site-packages/transformers/file_utils.py", line 1986, in _get_module
> return importlib.import_module("." + module_name, self.__name__)
> File "/home/shushan/.conda/envs/ccg_parser/lib/python3.9/importlib/__init__.py", line 127, in import_module
> return _bootstrap._gcd_import(name[level:], package, level)
> File "/home/shushan/.conda/envs/ccg_parser/lib/python3.9/site-packages/transformers/pipelines/__init__.py", line 25, in <module>
> from ..models.auto.configuration_auto import AutoConfig
> File "/home/shushan/.conda/envs/ccg_parser/lib/python3.9/site-packages/transformers/models/__init__.py", line 19, in <module>
> from . import (
> File "/home/shushan/.conda/envs/ccg_parser/lib/python3.9/site-packages/transformers/models/layoutlm/__init__.py", line 22, in <module>
> from .configuration_layoutlm import LAYOUTLM_PRETRAINED_CONFIG_ARCHIVE_MAP, LayoutLMConfig
> File "/home/shushan/.conda/envs/ccg_parser/lib/python3.9/site-packages/transformers/models/layoutlm/configuration_layoutlm.py", line 19, in <module>
> from ..bert.configuration_bert import BertConfig
> File "/home/shushan/.conda/envs/ccg_parser/lib/python3.9/site-packages/transformers/models/bert/configuration_bert.py", line 21, in <module>
> from ...onnx import OnnxConfig
> File "/home/shushan/.conda/envs/ccg_parser/lib/python3.9/site-packages/transformers/onnx/__init__.py", line 16, in <module>
> from .config import EXTERNAL_DATA_FORMAT_SIZE_LIMIT, OnnxConfig, OnnxConfigWithPast
> File "/home/shushan/.conda/envs/ccg_parser/lib/python3.9/site-packages/transformers/onnx/config.py", line 18, in <module>
> from transformers import PretrainedConfig, PreTrainedTokenizer, TensorType
> File "/home/shushan/.conda/envs/ccg_parser/lib/python3.9/site-packages/transformers/file_utils.py", line 1977, in __getattr__
> module = self._get_module(self._class_to_module[name])
> File "/home/shushan/.conda/envs/ccg_parser/lib/python3.9/site-packages/transformers/file_utils.py", line 1986, in _get_module
> return importlib.import_module("." + module_name, self.__name__)
> File "/home/shushan/.conda/envs/ccg_parser/lib/python3.9/importlib/__init__.py", line 127, in import_module
> return _bootstrap._gcd_import(name[level:], package, level)
> File "/home/shushan/.conda/envs/ccg_parser/lib/python3.9/site-packages/transformers/tokenization_utils.py", line 26, in <module>
> from .tokenization_utils_base import (
> File "/home/shushan/.conda/envs/ccg_parser/lib/python3.9/site-packages/transformers/tokenization_utils_base.py", line 74, in <module>
> from tokenizers import AddedToken
> File "/home/shushan/tokenization_experiments/tokenizers.py", line 26, in <module>
> from transformers import BertTokenizer
> File "/home/shushan/.conda/envs/ccg_parser/lib/python3.9/site-packages/transformers/file_utils.py", line 1978, in __getattr__
> value = getattr(module, name)
> File "/home/shushan/.conda/envs/ccg_parser/lib/python3.9/site-packages/transformers/file_utils.py", line 1977, in __getattr__
> module = self._get_module(self._class_to_module[name])
> File "/home/shushan/.conda/envs/ccg_parser/lib/python3.9/site-packages/transformers/file_utils.py", line 1986, in _get_module
> return importlib.import_module("." + module_name, self.__name__)
> File "/home/shushan/.conda/envs/ccg_parser/lib/python3.9/importlib/__init__.py", line 127, in import_module
> return _bootstrap._gcd_import(name[level:], package, level)
> File "/home/shushan/.conda/envs/ccg_parser/lib/python3.9/site-packages/transformers/models/bert/tokenization_bert.py", line 23, in <module>
> from ...tokenization_utils import PreTrainedTokenizer, _is_control, _is_punctuation, _is_whitespace
> ImportError: cannot import name 'PreTrainedTokenizer' from partially initialized module 'transformers.tokenization_utils' (most likely due to a circular import) (/home/shushan/.conda/envs/ccg_parser/lib/python3.9/site-packages/transformer
> s/tokenization_utils.py)
>
I have attempted uninstalling transformers and re-installing them, but I couldn't find any more information as to what is wrong, or how to go about fixing this issue I am seeing. The only suspicious behavior is that your tool for the environment detection above printed that I have torch installed without GPU, while in reality I have an installation of pytorch that works with gpu. Can you help?
Thanks in advance
Shushan | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12859/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12859/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12858 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12858/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12858/comments | https://api.github.com/repos/huggingface/transformers/issues/12858/events | https://github.com/huggingface/transformers/pull/12858 | 951,467,179 | MDExOlB1bGxSZXF1ZXN0Njk1ODQ4Nzcx | 12,858 | Pin git python to <3.1.19 | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"cc @LysandreJik @sgugger \r\n\r\nAlso see: https://github.com/gitpython-developers/GitPython/issues/1296"
] | 1,627 | 1,627 | 1,627 | MEMBER | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release nhttps://github.com/gitpython-developers/GitPython/pull/1275/filesotes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
GitPython did a new release which breaks our tests: https://github.com/gitpython-developers/GitPython/pull/1275/files
See: https://app.circleci.com/pipelines/github/huggingface/transformers/26010/workflows/a72a068e-b3f0-42e1-b08b-7e2c89cae3ed/jobs/245943 for example.
Pinning GitPython for now to make circle ci work
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12858/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12858/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12858",
"html_url": "https://github.com/huggingface/transformers/pull/12858",
"diff_url": "https://github.com/huggingface/transformers/pull/12858.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12858.patch",
"merged_at": 1627042564000
} |
https://api.github.com/repos/huggingface/transformers/issues/12857 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12857/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12857/comments | https://api.github.com/repos/huggingface/transformers/issues/12857/events | https://github.com/huggingface/transformers/issues/12857 | 951,446,090 | MDU6SXNzdWU5NTE0NDYwOTA= | 12,857 | wav2vec pretrain and fine-tune with huge data | {
"login": "lixx0105",
"id": 48235864,
"node_id": "MDQ6VXNlcjQ4MjM1ODY0",
"avatar_url": "https://avatars.githubusercontent.com/u/48235864?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lixx0105",
"html_url": "https://github.com/lixx0105",
"followers_url": "https://api.github.com/users/lixx0105/followers",
"following_url": "https://api.github.com/users/lixx0105/following{/other_user}",
"gists_url": "https://api.github.com/users/lixx0105/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lixx0105/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lixx0105/subscriptions",
"organizations_url": "https://api.github.com/users/lixx0105/orgs",
"repos_url": "https://api.github.com/users/lixx0105/repos",
"events_url": "https://api.github.com/users/lixx0105/events{/privacy}",
"received_events_url": "https://api.github.com/users/lixx0105/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hello, thanks for opening an issue! We try to keep the github issues for bugs/feature requests.\r\nCould you ask your question on the [forum](https://discuss.huggingface.co) instead?\r\n\r\nThanks!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,629 | 1,629 | NONE | null | Hi,
Thanks for the great efforts for wav2vec!
is there good example to fine-tune and pretrain wav2vec with huge data?
it seems the official examples works fine with one GPU but not so good for multigpus.
Thanks. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12857/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12857/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12856 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12856/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12856/comments | https://api.github.com/repos/huggingface/transformers/issues/12856/events | https://github.com/huggingface/transformers/issues/12856 | 951,425,520 | MDU6SXNzdWU5NTE0MjU1MjA= | 12,856 | TypeError: '>' not supported between instances of 'NoneType' and 'int' | {
"login": "prabhat-123",
"id": 37154253,
"node_id": "MDQ6VXNlcjM3MTU0MjUz",
"avatar_url": "https://avatars.githubusercontent.com/u/37154253?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/prabhat-123",
"html_url": "https://github.com/prabhat-123",
"followers_url": "https://api.github.com/users/prabhat-123/followers",
"following_url": "https://api.github.com/users/prabhat-123/following{/other_user}",
"gists_url": "https://api.github.com/users/prabhat-123/gists{/gist_id}",
"starred_url": "https://api.github.com/users/prabhat-123/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/prabhat-123/subscriptions",
"organizations_url": "https://api.github.com/users/prabhat-123/orgs",
"repos_url": "https://api.github.com/users/prabhat-123/repos",
"events_url": "https://api.github.com/users/prabhat-123/events{/privacy}",
"received_events_url": "https://api.github.com/users/prabhat-123/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"I'm running into this problem when I run the english to romania translation example. I'm not aware that I modified anything in the script. It fits the model up to the first epoch then it throws this error. \r\n\r\n2023-11-13 15:47:58.542480: I tensorflow/core/util/port.cc:111] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.\r\n2023-11-13 15:47:58.564058: E tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc:9342] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered\r\n2023-11-13 15:47:58.564080: E tensorflow/compiler/xla/stream_executor/cuda/cuda_fft.cc:609] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered\r\n2023-11-13 15:47:58.564097: E tensorflow/compiler/xla/stream_executor/cuda/cuda_blas.cc:1518] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered\r\n2023-11-13 15:47:58.568038: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.\r\nTo enable the following instructions: AVX2 AVX_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.\r\n11/13/2023 15:47:59 - INFO - __main__ - Training/evaluation parameters TFTrainingArguments(\r\n_n_gpu=-1,\r\nadafactor=False,\r\nadam_beta1=0.9,\r\nadam_beta2=0.999,\r\nadam_epsilon=1e-08,\r\nauto_find_batch_size=False,\r\nbf16=False,\r\nbf16_full_eval=False,\r\ndata_seed=None,\r\ndataloader_drop_last=False,\r\ndataloader_num_workers=0,\r\ndataloader_pin_memory=True,\r\nddp_backend=None,\r\nddp_broadcast_buffers=None,\r\nddp_bucket_cap_mb=None,\r\nddp_find_unused_parameters=None,\r\nddp_timeout=1800,\r\ndebug=[],\r\ndeepspeed=None,\r\ndisable_tqdm=False,\r\ndispatch_batches=None,\r\ndo_eval=True,\r\ndo_predict=False,\r\ndo_train=True,\r\neval_accumulation_steps=None,\r\neval_delay=0,\r\neval_steps=None,\r\nevaluation_strategy=no,\r\nfp16=False,\r\nfp16_backend=auto,\r\nfp16_full_eval=False,\r\nfp16_opt_level=O1,\r\nfsdp=[],\r\nfsdp_config={'min_num_params': 0, 'xla': False, 'xla_fsdp_grad_ckpt': False},\r\nfsdp_min_num_params=0,\r\nfsdp_transformer_layer_cls_to_wrap=None,\r\nfull_determinism=False,\r\ngcp_project=None,\r\ngradient_accumulation_steps=1,\r\ngradient_checkpointing=False,\r\ngradient_checkpointing_kwargs=None,\r\ngreater_is_better=None,\r\ngroup_by_length=False,\r\nhalf_precision_backend=auto,\r\nhub_always_push=False,\r\nhub_model_id=None,\r\nhub_private_repo=False,\r\nhub_strategy=every_save,\r\nhub_token=<HUB_TOKEN>,\r\nignore_data_skip=False,\r\ninclude_inputs_for_metrics=False,\r\ninclude_tokens_per_second=False,\r\njit_mode_eval=False,\r\nlabel_names=None,\r\nlabel_smoothing_factor=0.0,\r\nlearning_rate=5e-05,\r\nlength_column_name=length,\r\nload_best_model_at_end=False,\r\nlocal_rank=-1,\r\nlog_level=passive,\r\nlog_level_replica=warning,\r\nlog_on_each_node=True,\r\nlogging_dir=/workspace/transformer/results/runs/Nov13_15-47-59_workstation-bluechip-BUSINESSline-individu,\r\nlogging_first_step=False,\r\nlogging_nan_inf_filter=True,\r\nlogging_steps=500,\r\nlogging_strategy=steps,\r\nlr_scheduler_kwargs={},\r\nlr_scheduler_type=linear,\r\nmax_grad_norm=1.0,\r\nmax_steps=-1,\r\nmetric_for_best_model=None,\r\nmp_parameters=,\r\nneftune_noise_alpha=None,\r\nno_cuda=False,\r\nnum_train_epochs=3.0,\r\noptim=adamw_torch,\r\noptim_args=None,\r\noutput_dir=/workspace/transformer/results,\r\noverwrite_output_dir=True,\r\npast_index=-1,\r\nper_device_eval_batch_size=16,\r\nper_device_train_batch_size=16,\r\npoly_power=1.0,\r\nprediction_loss_only=False,\r\npush_to_hub=False,\r\npush_to_hub_model_id=None,\r\npush_to_hub_organization=None,\r\npush_to_hub_token=<PUSH_TO_HUB_TOKEN>,\r\nray_scope=last,\r\nremove_unused_columns=True,\r\nreport_to=['tensorboard'],\r\nresume_from_checkpoint=None,\r\nrun_name=/workspace/transformer/results,\r\nsave_on_each_node=False,\r\nsave_safetensors=True,\r\nsave_steps=500,\r\nsave_strategy=steps,\r\nsave_total_limit=None,\r\nseed=42,\r\nskip_memory_metrics=True,\r\nsplit_batches=False,\r\ntf32=None,\r\ntorch_compile=False,\r\ntorch_compile_backend=None,\r\ntorch_compile_mode=None,\r\ntorchdynamo=None,\r\ntpu_metrics_debug=False,\r\ntpu_name=None,\r\ntpu_num_cores=None,\r\ntpu_zone=None,\r\nuse_cpu=False,\r\nuse_ipex=False,\r\nuse_legacy_prediction_loop=False,\r\nuse_mps_device=False,\r\nwarmup_ratio=0.0,\r\nwarmup_steps=0,\r\nweight_decay=0.0,\r\nxla=False,\r\n)\r\nLoading Dataset Infos from /.cache/huggingface/modules/datasets_modules/datasets/wmt16/746749a11d25c02058042da7502d973ff410e73457f3d305fc1177dc0e8c4227\r\nOverwrite dataset info from restored data version if exists.\r\nLoading Dataset info from /.cache/huggingface/datasets/wmt16/ro-en/1.0.0/746749a11d25c02058042da7502d973ff410e73457f3d305fc1177dc0e8c4227\r\n11/13/2023 15:48:01 - INFO - datasets.info - Loading Dataset Infos from /.cache/huggingface/modules/datasets_modules/datasets/wmt16/746749a11d25c02058042da7502d973ff410e73457f3d305fc1177dc0e8c4227\r\n11/13/2023 15:48:01 - INFO - datasets.builder - Overwrite dataset info from restored data version if exists.\r\n11/13/2023 15:48:01 - INFO - datasets.info - Loading Dataset info from /.cache/huggingface/datasets/wmt16/ro-en/1.0.0/746749a11d25c02058042da7502d973ff410e73457f3d305fc1177dc0e8c4227\r\n11/13/2023 15:48:01 - INFO - datasets.builder - Found cached dataset wmt16 (/.cache/huggingface/datasets/wmt16/ro-en/1.0.0/746749a11d25c02058042da7502d973ff410e73457f3d305fc1177dc0e8c4227)\r\n11/13/2023 15:48:01 - INFO - datasets.info - Loading Dataset info from /.cache/huggingface/datasets/wmt16/ro-en/1.0.0/746749a11d25c02058042da7502d973ff410e73457f3d305fc1177dc0e8c4227\r\nFound cached dataset wmt16 (/.cache/huggingface/datasets/wmt16/ro-en/1.0.0/746749a11d25c02058042da7502d973ff410e73457f3d305fc1177dc0e8c4227)\r\nLoading Dataset info from /.cache/huggingface/datasets/wmt16/ro-en/1.0.0/746749a11d25c02058042da7502d973ff410e73457f3d305fc1177dc0e8c4227\r\nloading configuration file config.json from cache at /.cache/huggingface/hub/models--t5-small/snapshots/df1b051c49625cf57a3d0d8d3863ed4d13564fe4/config.json\r\nModel config T5Config {\r\n \"_name_or_path\": \"t5-small\",\r\n \"architectures\": [\r\n \"T5ForConditionalGeneration\"\r\n ],\r\n \"classifier_dropout\": 0.0,\r\n \"d_ff\": 2048,\r\n \"d_kv\": 64,\r\n \"d_model\": 512,\r\n \"decoder_start_token_id\": 0,\r\n \"dense_act_fn\": \"relu\",\r\n \"dropout_rate\": 0.1,\r\n \"eos_token_id\": 1,\r\n \"feed_forward_proj\": \"relu\",\r\n \"initializer_factor\": 1.0,\r\n \"is_encoder_decoder\": true,\r\n \"is_gated_act\": false,\r\n \"layer_norm_epsilon\": 1e-06,\r\n \"model_type\": \"t5\",\r\n \"n_positions\": 512,\r\n \"num_decoder_layers\": 6,\r\n \"num_heads\": 8,\r\n \"num_layers\": 6,\r\n \"output_past\": true,\r\n \"pad_token_id\": 0,\r\n \"relative_attention_max_distance\": 128,\r\n \"relative_attention_num_buckets\": 32,\r\n \"task_specific_params\": {\r\n \"summarization\": {\r\n \"early_stopping\": true,\r\n \"length_penalty\": 2.0,\r\n \"max_length\": 200,\r\n \"min_length\": 30,\r\n \"no_repeat_ngram_size\": 3,\r\n \"num_beams\": 4,\r\n \"prefix\": \"summarize: \"\r\n },\r\n \"translation_en_to_de\": {\r\n \"early_stopping\": true,\r\n \"max_length\": 300,\r\n \"num_beams\": 4,\r\n \"prefix\": \"translate English to German: \"\r\n },\r\n \"translation_en_to_fr\": {\r\n \"early_stopping\": true,\r\n \"max_length\": 300,\r\n \"num_beams\": 4,\r\n \"prefix\": \"translate English to French: \"\r\n },\r\n \"translation_en_to_ro\": {\r\n \"early_stopping\": true,\r\n \"max_length\": 300,\r\n \"num_beams\": 4,\r\n \"prefix\": \"translate English to Romanian: \"\r\n }\r\n },\r\n \"transformers_version\": \"4.36.0.dev0\",\r\n \"use_cache\": true,\r\n \"vocab_size\": 32128\r\n}\r\n\r\nloading file spiece.model from cache at /.cache/huggingface/hub/models--t5-small/snapshots/df1b051c49625cf57a3d0d8d3863ed4d13564fe4/spiece.model\r\nloading file tokenizer.json from cache at /.cache/huggingface/hub/models--t5-small/snapshots/df1b051c49625cf57a3d0d8d3863ed4d13564fe4/tokenizer.json\r\nloading file added_tokens.json from cache at None\r\nloading file special_tokens_map.json from cache at None\r\nloading file tokenizer_config.json from cache at /.cache/huggingface/hub/models--t5-small/snapshots/df1b051c49625cf57a3d0d8d3863ed4d13564fe4/tokenizer_config.json\r\nLoading cached processed dataset at /.cache/huggingface/datasets/wmt16/ro-en/1.0.0/746749a11d25c02058042da7502d973ff410e73457f3d305fc1177dc0e8c4227/cache-164eb734af318539.arrow\r\nLoading cached processed dataset at /.cache/huggingface/datasets/wmt16/ro-en/1.0.0/746749a11d25c02058042da7502d973ff410e73457f3d305fc1177dc0e8c4227/cache-442e2020e92ebe8e.arrow\r\nTensorflow: setting up strategy\r\n11/13/2023 15:48:01 - INFO - datasets.arrow_dataset - Loading cached processed dataset at /.cache/huggingface/datasets/wmt16/ro-en/1.0.0/746749a11d25c02058042da7502d973ff410e73457f3d305fc1177dc0e8c4227/cache-164eb734af318539.arrow\r\n11/13/2023 15:48:01 - INFO - datasets.arrow_dataset - Loading cached processed dataset at /.cache/huggingface/datasets/wmt16/ro-en/1.0.0/746749a11d25c02058042da7502d973ff410e73457f3d305fc1177dc0e8c4227/cache-442e2020e92ebe8e.arrow\r\n2023-11-13 15:48:01.416190: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1886] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 8825 MB memory: -> device: 0, name: NVIDIA GeForce RTX 3060, pci bus id: 0000:01:00.0, compute capability: 8.6\r\nloading weights file model.safetensors from cache at /.cache/huggingface/hub/models--t5-small/snapshots/df1b051c49625cf57a3d0d8d3863ed4d13564fe4/model.safetensors\r\nGenerate config GenerationConfig {\r\n \"decoder_start_token_id\": 0,\r\n \"eos_token_id\": 1,\r\n \"pad_token_id\": 0\r\n}\r\n\r\n2023-11-13 15:48:01.656874: I tensorflow/tsl/platform/default/subprocess.cc:304] Start cannot spawn child process: No such file or directory\r\nLoaded 60,506,624 parameters in the TF 2.0 model.\r\nAll PyTorch model weights were used when initializing TFT5ForConditionalGeneration.\r\n\r\nAll the weights of TFT5ForConditionalGeneration were initialized from the PyTorch model.\r\nIf your task is similar to the task the model of the checkpoint was trained on, you can already use TFT5ForConditionalGeneration for predictions without further training.\r\nYou're using a T5TokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.\r\nNo loss specified in compile() - the model's internal loss computation will be used as the loss. Don't panic - this is a common way to train TensorFlow models in Transformers! To disable this behaviour please pass a loss argument, or explicitly pass `loss=None` if you do not want your model to compute a loss. You can also specify `loss='auto'` to get the internal loss without printing this info string.\r\n11/13/2023 15:48:04 - INFO - __main__ - ***** Running training *****\r\n11/13/2023 15:48:04 - INFO - __main__ - Num examples = 610320\r\n11/13/2023 15:48:04 - INFO - __main__ - Num Epochs = 3.0\r\n11/13/2023 15:48:04 - INFO - __main__ - Instantaneous batch size per device = 16\r\n11/13/2023 15:48:04 - INFO - __main__ - Total train batch size = 16\r\n11/13/2023 15:48:04 - INFO - __main__ - Total optimization steps = 114435\r\nEpoch 1/3\r\n2023-11-13 15:48:13.749879: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x7f01b9364620 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices:\r\n2023-11-13 15:48:13.749896: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): NVIDIA GeForce RTX 3060, Compute Capability 8.6\r\n2023-11-13 15:48:13.752234: I tensorflow/compiler/mlir/tensorflow/utils/dump_mlir_util.cc:269] disabling MLIR crash reproducer, set env var `MLIR_CRASH_REPRODUCER_DIRECTORY` to enable.\r\n2023-11-13 15:48:13.759242: I tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc:442] Loaded cuDNN version 8700\r\n2023-11-13 15:48:13.802724: I ./tensorflow/compiler/jit/device_compiler.h:186] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.\r\n38145/38145 [==============================] - ETA: 0s - loss: 0.6117Generate config GenerationConfig {\r\n \"decoder_start_token_id\": 0,\r\n \"eos_token_id\": 1,\r\n \"pad_token_id\": 0\r\n}\r\n\r\nTraceback (most recent call last):\r\n File \"/workspace/transformer/run_translation.py\", line 733, in <module>\r\n main()\r\n File \"/workspace/transformer/run_translation.py\", line 693, in main\r\n history = model.fit(tf_train_dataset, epochs=int(training_args.num_train_epochs), callbacks=callbacks)\r\n File \"/workspace/transformer/lib/python3.10/site-packages/keras/src/utils/traceback_utils.py\", line 70, in error_handler\r\n raise e.with_traceback(filtered_tb) from None\r\n File \"/workspace/transformer/lib/python3.10/site-packages/transformers/keras_callbacks.py\", line 223, in on_epoch_end\r\n predictions = self.generation_function(generation_inputs, attention_mask=attention_mask)\r\n File \"/tmp/__autograph_generated_fileg5wrw6ci.py\", line 13, in tf__generation_function\r\n retval_ = ag__.converted_call(ag__.ld(self).model.generate, (ag__.ld(inputs),), dict(attention_mask=ag__.ld(attention_mask), **ag__.ld(self).generate_kwargs), fscope)\r\n File \"/tmp/__autograph_generated_fileqqh0lf7s.py\", line 437, in tf__generate\r\n is_beam_gen_mode = ag__.and_(lambda : ag__.not_(ag__.ld(is_contrastive_search_gen_mode)), lambda : ag__.and_(lambda : ag__.ld(generation_config).num_beams > 1, lambda : ag__.ld(generation_config).do_sample is False))\r\n File \"/tmp/__autograph_generated_fileqqh0lf7s.py\", line 437, in <lambda>\r\n is_beam_gen_mode = ag__.and_(lambda : ag__.not_(ag__.ld(is_contrastive_search_gen_mode)), lambda : ag__.and_(lambda : ag__.ld(generation_config).num_beams > 1, lambda : ag__.ld(generation_config).do_sample is False))\r\n File \"/tmp/__autograph_generated_fileqqh0lf7s.py\", line 437, in <lambda>\r\n is_beam_gen_mode = ag__.and_(lambda : ag__.not_(ag__.ld(is_contrastive_search_gen_mode)), lambda : ag__.and_(lambda : ag__.ld(generation_config).num_beams > 1, lambda : ag__.ld(generation_config).do_sample is False))\r\nTypeError: in user code:\r\n\r\n File \"/workspace/transformer/lib/python3.10/site-packages/transformers/keras_callbacks.py\", line 202, in generation_function *\r\n return self.model.generate(inputs, attention_mask=attention_mask, **self.generate_kwargs)\r\n File \"/workspace/transformer/lib/python3.10/site-packages/transformers/generation/tf_utils.py\", line 884, in generate *\r\n is_beam_gen_mode = (\r\n\r\n TypeError: '>' not supported between instances of 'NoneType' and 'int'\r\n\r\n\r\nProcess finished with exit code 1\r\n",
"@ChristophKnapp Thanks for opening a new issue. Linking here for reference #27505"
] | 1,627 | 1,700 | 1,630 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform:
- Python version:
- PyTorch version (GPU?):
- Tensorflow version (GPU?):
- Using GPU in script?:
- Using distributed or parallel set-up in script?:
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1.
2.
3.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12856/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12856/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12855 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12855/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12855/comments | https://api.github.com/repos/huggingface/transformers/issues/12855/events | https://github.com/huggingface/transformers/pull/12855 | 951,345,649 | MDExOlB1bGxSZXF1ZXN0Njk1NzQ4NDE1 | 12,855 | fix typo in gradient_checkpointing arg | {
"login": "21jun",
"id": 29483429,
"node_id": "MDQ6VXNlcjI5NDgzNDI5",
"avatar_url": "https://avatars.githubusercontent.com/u/29483429?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/21jun",
"html_url": "https://github.com/21jun",
"followers_url": "https://api.github.com/users/21jun/followers",
"following_url": "https://api.github.com/users/21jun/following{/other_user}",
"gists_url": "https://api.github.com/users/21jun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/21jun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/21jun/subscriptions",
"organizations_url": "https://api.github.com/users/21jun/orgs",
"repos_url": "https://api.github.com/users/21jun/repos",
"events_url": "https://api.github.com/users/21jun/events{/privacy}",
"received_events_url": "https://api.github.com/users/21jun/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@JetRunner Thx for comment.\r\nI just update my branch and Now CI seems to be working fine!\r\n",
"Thanks!"
] | 1,627 | 1,627 | 1,627 | CONTRIBUTOR | null | help for `ModelArguments.gradient_checkpointing` should be
"If True, use gradient checkpointing to save memory
at the expense of slower backward pass."
not "Whether to freeze the feature extractor layers of the model."
(which is duplicated from `freeze_feature_extractor` arg)
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12855/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12855/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12855",
"html_url": "https://github.com/huggingface/transformers/pull/12855",
"diff_url": "https://github.com/huggingface/transformers/pull/12855.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12855.patch",
"merged_at": 1627628794000
} |
https://api.github.com/repos/huggingface/transformers/issues/12854 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12854/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12854/comments | https://api.github.com/repos/huggingface/transformers/issues/12854/events | https://github.com/huggingface/transformers/issues/12854 | 951,299,896 | MDU6SXNzdWU5NTEyOTk4OTY= | 12,854 | How could I convert output tensor from transformer to text generation? | {
"login": "shp776",
"id": 42932221,
"node_id": "MDQ6VXNlcjQyOTMyMjIx",
"avatar_url": "https://avatars.githubusercontent.com/u/42932221?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shp776",
"html_url": "https://github.com/shp776",
"followers_url": "https://api.github.com/users/shp776/followers",
"following_url": "https://api.github.com/users/shp776/following{/other_user}",
"gists_url": "https://api.github.com/users/shp776/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shp776/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shp776/subscriptions",
"organizations_url": "https://api.github.com/users/shp776/orgs",
"repos_url": "https://api.github.com/users/shp776/repos",
"events_url": "https://api.github.com/users/shp776/events{/privacy}",
"received_events_url": "https://api.github.com/users/shp776/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,627 | 1,630 | 1,630 | NONE | null | # 🚀 Feature request
https://github.com/onnx/models/blob/master/text/machine_comprehension/gpt-2/dependencies/GPT2-export.py
I succeeded in extracting the output tensor value for the example input text using the above example. The link above imports your hugging face transformer, so I wonder how I can text generate with the output tensor value I got.
Is there a code or a link I can refer to? (Pytorch or python code..)
The code I tried is as follows. But it didn't work.

'ort_outputs_exmodel' above image is same as 'res' link below
https://github.com/onnx/models/blob/ad5c181f1646225f034fba1862233ecb4c262e04/text/machine_comprehension/gpt-2/dependencies/GPT2-export.py#L110
My final goal of the project is to load the onnx model using onnx runtime's C/C++ API and write the C/C++ code to generate text using output tensor values.
I'll be waiting for your reply. (looking forward to...)
Thank u very much.
## Motivation
I need advice on how to run text generation using output tensor values.
## Your contribution
<!-- Is there any way that you could help, e.g. by submitting a PR?
Make sure to read the CONTRIBUTING.MD readme:
https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12854/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12854/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12853 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12853/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12853/comments | https://api.github.com/repos/huggingface/transformers/issues/12853/events | https://github.com/huggingface/transformers/pull/12853 | 951,246,099 | MDExOlB1bGxSZXF1ZXN0Njk1NjY1NjA4 | 12,853 | Fix barrier for SM distributed | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,627 | 1,627 | 1,627 | COLLABORATOR | null | # What does this PR do?
#12351 introduced a new context manager for having the main process execute an instruction while other process have to wait. That context manager was missing special treatment for TPUs (added in #12464) and SageMaker distributed. This PR adds the latter.
Fixes #12847 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12853/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12853/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12853",
"html_url": "https://github.com/huggingface/transformers/pull/12853",
"diff_url": "https://github.com/huggingface/transformers/pull/12853.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12853.patch",
"merged_at": 1627302653000
} |
https://api.github.com/repos/huggingface/transformers/issues/12852 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12852/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12852/comments | https://api.github.com/repos/huggingface/transformers/issues/12852/events | https://github.com/huggingface/transformers/issues/12852 | 951,227,585 | MDU6SXNzdWU5NTEyMjc1ODU= | 12,852 | How to ignore PAD tokens for NER | {
"login": "arijitthegame",
"id": 25961440,
"node_id": "MDQ6VXNlcjI1OTYxNDQw",
"avatar_url": "https://avatars.githubusercontent.com/u/25961440?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/arijitthegame",
"html_url": "https://github.com/arijitthegame",
"followers_url": "https://api.github.com/users/arijitthegame/followers",
"following_url": "https://api.github.com/users/arijitthegame/following{/other_user}",
"gists_url": "https://api.github.com/users/arijitthegame/gists{/gist_id}",
"starred_url": "https://api.github.com/users/arijitthegame/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/arijitthegame/subscriptions",
"organizations_url": "https://api.github.com/users/arijitthegame/orgs",
"repos_url": "https://api.github.com/users/arijitthegame/repos",
"events_url": "https://api.github.com/users/arijitthegame/events{/privacy}",
"received_events_url": "https://api.github.com/users/arijitthegame/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"The `attention_mask` indicates if a token is padding or an actual token. The usual way to deal with padding in the LSTM is to pass lengths for each sequence, you can work this out by summing the attention_mask along the \"time\" access, ie something like\r\n\r\n```\r\nsequence_lengths = torch.sum(attention_mask, dim=1)\r\n\r\npacked_sequence = nn.utils.rnn.pack_padded_sequence(sequence_output, sequence_lengths)\r\noutputs, hidden = self.rnn(packed_sequence)\r\noutputs, _ = nn.utils.rnn.pad_packed_sequence(outputs) \r\n\r\n```\r\nYou'll have to double check the axis you want to sum over, and that attention_mask=1 for non-padded tokens (otherwise you'll have to negate it) but hopefully this will help.",
"Also you may want to consider `allennlp` (although it has a bit of a learning curve). You can compose models such as a crf tagger using a huggingface pretrained model as an encoder and a crf decoder without much work (even without any code once you figure out their jsonnet format).",
"First, placing an LSTM on top of the final hidden states of a model like BERT is not needed. You can just place a linear layer on top. Any `xxxForTokenClassification` model in the library is implemented that way, and it works really well.\r\n\r\nSecond, to ignore padding tokens, you should make predictions for all tokens, but simply label pad tokens with -100, as this is the default `ignore_index` of the `CrossEntropyLoss` in PyTorch. This means that they will not be taken into account by the loss function.\r\n\r\nBtw, I do have an example notebook for NER which you find [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/BERT). There's also the official one which you can find [here](https://github.com/huggingface/notebooks/blob/master/examples/token_classification.ipynb).",
"Thank you @david-waterworth and @NielsRogge for your answers. This solves my problem. I am closing this issue. ",
"@NielsRogge I can not use that padding = -100 when using CRF. Is there other way to ignore pad token for CRF?"
] | 1,627 | 1,636 | 1,627 | NONE | null | Hi,
Thank you for such a great repo. I am trying to use the word/token embeddings from the pretrained transformers for NER. The following code is a snippet of my model. For simplicity I am using a Linear decoder as opposed to a CRF decoder.
```
model_bert = BertModel.from_pretrained(model_dir, config=config)
tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
class BERTNER(nn.Module):
def __init__(self, model, hidden_dim,num_labels):
"""
Torch model that uses the BERT and adds in a classifiers at the end. Num labels is a list of labels
"""
super(BERTNER self).__init__()
self.model = model
self.hidden_dim = hidden_dim
self.num_labels = num_labels
self.rnn = nn.LSTM(self.model.config.hidden_size, hidden_dim, batch_first=True, bidirectional=True)
self.classifier = nn.Linear(2*hidden_dim, num_labels)
def forward(self,input_ids,attention_mask):
outputs = self.model(input_ids=input_ids,attention_mask=attention_mask)
sequence_output = outputs[0]
out,_ = self.rnn(sequence_output)
return self.classifier(out)
model = BERTNER(model_bert,128,len(tag2idx))
```
And this is the part I am confused. My input to the model are all padded to be fixed length. And generally, when the sentences are padded, if one uses nn.Embedding and then the padding can be ignored. https://pytorch.org/docs/stable/generated/torch.nn.Embedding.html. But here it is not clear to me how to ignore the padded tokens. Any help will be greatly appreciated. Thanks in advance. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12852/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12852/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12851 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12851/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12851/comments | https://api.github.com/repos/huggingface/transformers/issues/12851/events | https://github.com/huggingface/transformers/issues/12851 | 951,144,847 | MDU6SXNzdWU5NTExNDQ4NDc= | 12,851 | Got `ONNXRuntimeError` when try to run BART in ONNX format | {
"login": "ryangawei",
"id": 25638070,
"node_id": "MDQ6VXNlcjI1NjM4MDcw",
"avatar_url": "https://avatars.githubusercontent.com/u/25638070?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ryangawei",
"html_url": "https://github.com/ryangawei",
"followers_url": "https://api.github.com/users/ryangawei/followers",
"following_url": "https://api.github.com/users/ryangawei/following{/other_user}",
"gists_url": "https://api.github.com/users/ryangawei/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ryangawei/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ryangawei/subscriptions",
"organizations_url": "https://api.github.com/users/ryangawei/orgs",
"repos_url": "https://api.github.com/users/ryangawei/repos",
"events_url": "https://api.github.com/users/ryangawei/events{/privacy}",
"received_events_url": "https://api.github.com/users/ryangawei/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2796628563,
"node_id": "MDU6TGFiZWwyNzk2NjI4NTYz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/WIP",
"name": "WIP",
"color": "234C99",
"default": false,
"description": "Label your PR/Issue with WIP for some long outstanding Issues/PRs that are work in progress"
}
] | open | false | {
"login": "mfuntowicz",
"id": 2241520,
"node_id": "MDQ6VXNlcjIyNDE1MjA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2241520?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mfuntowicz",
"html_url": "https://github.com/mfuntowicz",
"followers_url": "https://api.github.com/users/mfuntowicz/followers",
"following_url": "https://api.github.com/users/mfuntowicz/following{/other_user}",
"gists_url": "https://api.github.com/users/mfuntowicz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mfuntowicz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mfuntowicz/subscriptions",
"organizations_url": "https://api.github.com/users/mfuntowicz/orgs",
"repos_url": "https://api.github.com/users/mfuntowicz/repos",
"events_url": "https://api.github.com/users/mfuntowicz/events{/privacy}",
"received_events_url": "https://api.github.com/users/mfuntowicz/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "mfuntowicz",
"id": 2241520,
"node_id": "MDQ6VXNlcjIyNDE1MjA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2241520?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mfuntowicz",
"html_url": "https://github.com/mfuntowicz",
"followers_url": "https://api.github.com/users/mfuntowicz/followers",
"following_url": "https://api.github.com/users/mfuntowicz/following{/other_user}",
"gists_url": "https://api.github.com/users/mfuntowicz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mfuntowicz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mfuntowicz/subscriptions",
"organizations_url": "https://api.github.com/users/mfuntowicz/orgs",
"repos_url": "https://api.github.com/users/mfuntowicz/repos",
"events_url": "https://api.github.com/users/mfuntowicz/events{/privacy}",
"received_events_url": "https://api.github.com/users/mfuntowicz/received_events",
"type": "User",
"site_admin": false
}
] | [
"I can reproduce in latest `transformers` with latest onnx runtime. ",
"FYI this error seems to be linked to the dimension of the input; if you use a batch size 2 it should work.\r\n\r\nAs seen with @mfuntowicz offline, we'll be working on a fix in the coming weeks cc @michaelbenayoun ",
"@LysandreJik Thank you for the follow-up. I'll pay attention to any updates.",
"Can reproduce with `valhalla/distilbart-mnli-12-1` in `4.10.0`. @LysandreJik \r\nThe export is essentially dependent on the number of hypotheses it was exported with, as far as I can tell.",
"Any update on this? Can reproduce the same for facebook/bart-large-mnli. Works only with a batch size of 2 during inference. @LysandreJik @mfuntowicz ",
"transformers.__version__ == 4.20.0.dev0\r\nonnxruntime.__version__ == 1.11.1\r\n\r\nexported facebook/bart-base successfully , following instructions on -\r\nhttps://github.com/huggingface/transformers/tree/main/examples/research_projects/onnx/summarization\r\n\r\nscript output - \r\n\r\n2022-05-16 16:06:57 | INFO | __main__ | [run_onnx_exporter.py:163] Model outputs from torch and ONNX Runtime are similar.\r\n2022-05-16 16:06:57 | INFO | __main__ | [run_onnx_exporter.py:164] Success.\r\n\r\nhowever, loading the exported model fails after it hangs forever (timing out), using this script - \r\n\r\n```\r\nimport torch\r\nfrom onnxruntime import InferenceSession, SessionOptions, GraphOptimizationLevel\r\n\r\noptions = SessionOptions() # initialize session options\r\noptions.graph_optimization_level = GraphOptimizationLevel.ORT_ENABLE_ALL\r\n\r\nsession = InferenceSession(\r\n 'optimized_BART.onnx',\r\n sess_options=options,\r\n providers=[\"CPUExecutionProvider\"]\r\n)\r\n\r\nsession.disable_fallback()\r\n```\r\n\r\n\r\n(py39) user@Avis-MacBook-Pro-2 summarization % ls -lht\r\n-rw-r--r-- 1 user staff 680M May 16 16:06 optimized_BART.onnx\r\n\r\nexported model size about 680MB \r\n\r\nany advice on this? ",
"transformers.__version__ == 4.20.0.dev0\r\nonnxruntime.__version__ == 1.11.1\r\n\r\nonnx bart fails to load (hangs forever) when passing options to InferenceSession()\r\n\r\navoid these -\r\noptions.graph_optimization_level = GraphOptimizationLevel.ORT_ENABLE_ALL\r\n\r\notherwise loading the model hangs forever.\r\nupon keyboard interrupt, I am getting tons of these warnings - \r\n\r\n2022-05-16 15:57:35.009102 [W:onnxruntime:, graph.cc:3559 CleanUnusedInitializersAndNodeArgs] Removing initializer '1772'. It is not used by any node and should be removed from the model.\r\n2022-05-16 15:57:36.410981 [W:onnxruntime:, constant_folding.cc:202 ApplyImpl] Unsupported output type of N11onnxruntime22SequenceTensorTypeBaseE. Can't constant fold SequenceEmpty node 'SequenceEmpty_5330'\r\n2022-05-16 15:57:36.416645 [W:onnxruntime:, constant_folding.cc:202 ApplyImpl] Unsupported output type of N11onnxruntime22SequenceTensorTypeBaseE. Can't constant fold SequenceEmpty node 'SequenceEmpty_808'\r\n2022-05-16 15:57:36.416741 [W:onnxruntime:, constant_folding.cc:202 ApplyImpl] Unsupported output type of N11onnxruntime22SequenceTensorTypeBaseE. Can't constant fold SequenceEmpty node 'SequenceEmpty_1'\r\n2022-05-16 15:57:36.446512 [W:onnxruntime:, constant_folding.cc:202 ApplyImpl] Unsupported output type of N11onnxruntime22SequenceTensorTypeBaseE. Can't constant fold SequenceEmpty node 'SequenceEmpty_5128'\r\n2022-05-16 15:57:37.813252 [W:onnxruntime:, graph.cc:3559 CleanUnusedInitializersAndNodeArgs] Removing initializer '3149'. It is not used by any node and should be removed from the model.\r\n2022-05-16 15:57:37.813269 [W:onnxruntime:, graph.cc:3559 CleanUnusedInitializersAndNodeArgs] Removing initializer '2153'. It is not used by any node and should be removed from the model.\r\n....",
"loaded the onnx model successfully without options.graph_optimization_level. \r\nfails to get a prediction :(\r\n\r\n\r\n\r\n```\r\nimport onnxruntime as ort\r\nimport numpy as np\r\n\r\nort_session = ort.InferenceSession(\r\n 'optimized_BART.onnx')\r\n\r\nprint(f'inputs: {[i.name for i in ort_session.get_inputs()]}')\r\n\r\nfeed_dict = summarizer.tokenizer(text)\r\nfeed_dict['num_beams'] = 4\r\nfeed_dict['max_length'] = 120\r\nfeed_dict['decoder_start_token_id'] = 2\r\nfeed_dict = {k: np.int64([v]) for k, v in feed_dict.items()}\r\n\r\nfor key in feed_dict:\r\n print(f'feed_dict key: {key}, shape: {feed_dict[key].shape}')\r\n\r\npred = session.run(None, feed_dict)\r\n```` \r\n\r\n### printout - \r\n\r\ninputs: ['input_ids', 'attention_mask', 'num_beams', 'max_length', 'decoder_start_token_id']\r\nfeed_dict key: input_ids, shape: (1, 228)\r\nfeed_dict key: attention_mask, shape: (1, 228)\r\nfeed_dict key: num_beams, shape: (1,)\r\nfeed_dict key: max_length, shape: (1,)\r\nfeed_dict key: decoder_start_token_id, shape: (1,)\r\n\r\nInvalidArgument Traceback (most recent call last)\r\nInput In [39], in <cell line: 11>()\r\n 8 for key in feed_dict:\r\n 9 print(f'feed_dict key: {key}, shape: {feed_dict[key].shape}')\r\n---> 11 pred = session.run(['output_ids'], feed_dict)\r\n\r\nFile ~/envs/py39/lib/python3.9/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py:192, in Session.run(self, output_names, input_feed, run_options)\r\n 190 output_names = [output.name for output in self._outputs_meta]\r\n 191 try:\r\n--> 192 return self._sess.run(output_names, input_feed, run_options)\r\n 193 except C.EPFail as err:\r\n 194 if self._enable_fallback:\r\n\r\nInvalidArgument: [ONNXRuntimeError] : 2 : INVALID_ARGUMENT : Got invalid dimensions for input: attention_mask for the following indices\r\n index: 1 Got: 228 Expected: 13\r\n Please fix either the inputs or the model.\r\n",
"fails to export facebook/bart-large-cnn or , following instructions on -\r\nhttps://github.com/huggingface/transformers/tree/main/examples/research_projects/onnx/summarization\r\n\r\n(py39) user@Avis-MacBook-Pro-2 summarization % python run_onnx_exporter.py --model_name_or_path facebook/bart-large-cnn\r\nTraceback (most recent call last):\r\n File \"~/src/transformers/examples/research_projects/onnx/summarization/run_onnx_exporter.py\", line 207, in <module>\r\n main()\r\n File \"~/src/transformers/examples/research_projects/onnx/summarization/run_onnx_exporter.py\", line 184, in main\r\n model, tokenizer = load_model_tokenizer(args.model_name_or_path, device)\r\n File \"~/src/transformers/examples/research_projects/onnx/summarization/run_onnx_exporter.py\", line 93, in load_model_tokenizer\r\n huggingface_model = model_dict[model_name].from_pretrained(model_name).to(device)\r\nKeyError: 'facebook/bart-large-cnn'\r\n\r\nsame error when trying to export model lidiya/bart-base-samsum\r\n\r\nany advice would be greatly appreciated. thanks."
] | 1,626 | 1,652 | null | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.9.0
- Platform: Linux-5.4.104+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.11
- PyTorch version (GPU?): 1.9.0+cu102 (True)
- Using GPU in script?: Yes
### Who can help
@mfuntowicz
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
-
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## To reproduce
I was using Google Colab and trying to export model `facebook/bart-large-cnn` to the onnx format. I ran the command `python -m transformers.onnx -m=facebook/bart-large-cnn onnx/bart-large-cnn`, and the outputs seem okay.
```
2021-07-22 23:14:33.821472: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcudart.so.11.0
Using framework PyTorch: 1.9.0+cu102
Overriding 1 configuration item(s)
- use_cache -> False
/usr/local/lib/python3.7/dist-packages/transformers/models/bart/modeling_bart.py:212: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if attn_weights.size() != (bsz * self.num_heads, tgt_len, src_len):
/usr/local/lib/python3.7/dist-packages/transformers/models/bart/modeling_bart.py:218: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if attention_mask.size() != (bsz, 1, tgt_len, src_len):
/usr/local/lib/python3.7/dist-packages/transformers/models/bart/modeling_bart.py:249: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if attn_output.size() != (bsz * self.num_heads, tgt_len, self.head_dim):
/usr/local/lib/python3.7/dist-packages/transformers/models/bart/modeling_bart.py:863: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
if input_shape[-1] > 1:
tcmalloc: large alloc 1625399296 bytes == 0x5595ce83a000 @ 0x7f1780d9f887 0x7f177f695c29 0x7f177f696afb 0x7f177f696bb4 0x7f177f696f9c 0x7f17670dcbb7 0x7f17670dd064 0x7f175b75ba1c 0x7f176bf8eaff 0x7f176b949b88 0x55949fda8bf8 0x55949fe1c6f2 0x55949fe16c35 0x55949fda973a 0x55949fe1893b 0x55949fe16c35 0x55949fda973a 0x55949fe1bf40 0x55949fe16c35 0x55949fda973a 0x55949fe1893b 0x55949fda965a 0x55949fe17b0e 0x55949fda965a 0x55949fe17b0e 0x55949fe16c35 0x55949fe16933 0x55949fe14da0 0x55949fda7ea9 0x55949fda7da0 0x55949fe1bbb3
tcmalloc: large alloc 1625399296 bytes == 0x55962f654000 @ 0x7f1780d9f887 0x7f177f695c29 0x7f177f696afb 0x7f177f696bb4 0x7f177f696f9c 0x7f17670dcbb7 0x7f17670dd064 0x7f175b75ba1c 0x7f176bf8ecab 0x7f176b949b88 0x55949fda8bf8 0x55949fe1c6f2 0x55949fe16c35 0x55949fda973a 0x55949fe1893b 0x55949fe16c35 0x55949fda973a 0x55949fe1bf40 0x55949fe16c35 0x55949fda973a 0x55949fe1893b 0x55949fda965a 0x55949fe17b0e 0x55949fda965a 0x55949fe17b0e 0x55949fe16c35 0x55949fe16933 0x55949fe14da0 0x55949fda7ea9 0x55949fda7da0 0x55949fe1bbb3
tcmalloc: large alloc 1625399296 bytes == 0x5595ce83a000 @ 0x7f1780d9d1e7 0x55949fdd9a18 0x55949fda4987 0x7f176bf8ece2 0x7f176b949b88 0x55949fda8bf8 0x55949fe1c6f2 0x55949fe16c35 0x55949fda973a 0x55949fe1893b 0x55949fe16c35 0x55949fda973a 0x55949fe1bf40 0x55949fe16c35 0x55949fda973a 0x55949fe1893b 0x55949fda965a 0x55949fe17b0e 0x55949fda965a 0x55949fe17b0e 0x55949fe16c35 0x55949fe16933 0x55949fe14da0 0x55949fda7ea9 0x55949fda7da0 0x55949fe1bbb3 0x55949fe16c35 0x55949fda973a 0x55949fe17b0e 0x55949fe16c35 0x55949fce8eb1
tcmalloc: large alloc 1625399296 bytes == 0x55962f654000 @ 0x7f1780d9f887 0x7f177f695c29 0x7f177f695d47 0x7f177f6977a5 0x7f176bd60368 0x7f176bfbc844 0x7f176b949b88 0x55949fda8010 0x55949fda7da0 0x55949fe1bbb3 0x55949fe16c35 0x55949fda973a 0x55949fe1893b 0x55949fe16c35 0x55949fda973a 0x55949fe1bf40 0x55949fe16c35 0x55949fda973a 0x55949fe1893b 0x55949fda965a 0x55949fe17b0e 0x55949fda965a 0x55949fe17b0e 0x55949fe16c35 0x55949fe16933 0x55949fe14da0 0x55949fda7ea9 0x55949fda7da0 0x55949fe1bbb3 0x55949fe16c35 0x55949fda973a
Validating ONNX model...
-[✓] ONNX model outputs' name match reference model ({'last_hidden_state', 'encoder_last_hidden_state'}
- Validating ONNX Model output "last_hidden_state":
-[✓] (2, 8, 1024) matchs (2, 8, 1024)
-[✓] all values close (atol: 0.0001)
- Validating ONNX Model output "encoder_last_hidden_state":
-[✓] (2, 8, 1024) matchs (2, 8, 1024)
-[✓] all values close (atol: 0.0001)
All good, model saved at: onnx/bart-large-cnn/model.onnx
```
Then I tried to execute the model in `onnxruntime`,
```
import onnxruntime as ort
ort_session = ort.InferenceSession('onnx/bart-large-cnn/model.onnx')
# Got input_ids and attention_mask using tokenizer
outputs = ort_session.run(None, {'input_ids': input_ids.detach().cpu().numpy(), 'attention_mask': attention_mask.detach().cpu().numpy()})
```
And I got the error,
```
---------------------------------------------------------------------------
RuntimeException Traceback (most recent call last)
<ipython-input-30-380e6a0e1085> in <module>()
----> 1 outputs = ort_session.run(None, {'input_ids': input_ids.detach().cpu().numpy(), 'attention_mask': attention_mask.detach().cpu().numpy()})
/usr/local/lib/python3.7/dist-packages/onnxruntime/capi/onnxruntime_inference_collection.py in run(self, output_names, input_feed, run_options)
186 output_names = [output.name for output in self._outputs_meta]
187 try:
--> 188 return self._sess.run(output_names, input_feed, run_options)
189 except C.EPFail as err:
190 if self._enable_fallback:
RuntimeException: [ONNXRuntimeError] : 6 : RUNTIME_EXCEPTION : Non-zero status code returned while running Reshape node. Name:'Reshape_109' Status Message: /onnxruntime_src/onnxruntime/core/providers/cpu/tensor/reshape_helper.h:42 onnxruntime::ReshapeHelper::ReshapeHelper(const onnxruntime::TensorShape&, std::vector<long int>&, bool) gsl::narrow_cast<int64_t>(input_shape.Size()) == size was false. The input tensor cannot be reshaped to the requested shape. Input shape:{2}, requested shape:{1,1}
```
I see that BART is recently supported for ONNX in the latest release, but there isn't any code to exactly explain how to run the inference in `onnxruntime`. Maybe I'm doing something wrong here, so any help will be appreciated!
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12851/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12851/timeline | null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12850 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12850/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12850/comments | https://api.github.com/repos/huggingface/transformers/issues/12850/events | https://github.com/huggingface/transformers/issues/12850 | 951,137,428 | MDU6SXNzdWU5NTExMzc0Mjg= | 12,850 | run_mlm_no_trainer.py requires --model_name_or_path | {
"login": "david-waterworth",
"id": 5028974,
"node_id": "MDQ6VXNlcjUwMjg5NzQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/5028974?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/david-waterworth",
"html_url": "https://github.com/david-waterworth",
"followers_url": "https://api.github.com/users/david-waterworth/followers",
"following_url": "https://api.github.com/users/david-waterworth/following{/other_user}",
"gists_url": "https://api.github.com/users/david-waterworth/gists{/gist_id}",
"starred_url": "https://api.github.com/users/david-waterworth/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/david-waterworth/subscriptions",
"organizations_url": "https://api.github.com/users/david-waterworth/orgs",
"repos_url": "https://api.github.com/users/david-waterworth/repos",
"events_url": "https://api.github.com/users/david-waterworth/events{/privacy}",
"received_events_url": "https://api.github.com/users/david-waterworth/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,626 | 1,630 | 1,630 | NONE | null | The `examples/pytorch/language-modeling/run_mlm_no_trainer.py` script has
parser.add_argument(
"--model_name_or_path",
type=str,
help="Path to pretrained model or model identifier from huggingface.co/models.",
default=None,
required=True,
)
Despite there being several checks in the code implying it may be None ie
if args.model_name_or_path:
model = AutoModelForMaskedLM.from_pretrained(
args.model_name_or_path,
from_tf=bool(".ckpt" in args.model_name_or_path),
config=config,
)
else:
logger.info("Training new model from scratch")
model = AutoModelForMaskedLM.from_config(config)
As far as I can see it's optional, falling back to training a new model from scratch - just like run_mlm.py (I commented out `required=True` without any obvious issues).
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12850/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12850/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12849 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12849/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12849/comments | https://api.github.com/repos/huggingface/transformers/issues/12849/events | https://github.com/huggingface/transformers/issues/12849 | 951,133,884 | MDU6SXNzdWU5NTExMzM4ODQ= | 12,849 | run_mlm_no_trainer.py requires accelerate but not in requirements.txt | {
"login": "david-waterworth",
"id": 5028974,
"node_id": "MDQ6VXNlcjUwMjg5NzQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/5028974?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/david-waterworth",
"html_url": "https://github.com/david-waterworth",
"followers_url": "https://api.github.com/users/david-waterworth/followers",
"following_url": "https://api.github.com/users/david-waterworth/following{/other_user}",
"gists_url": "https://api.github.com/users/david-waterworth/gists{/gist_id}",
"starred_url": "https://api.github.com/users/david-waterworth/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/david-waterworth/subscriptions",
"organizations_url": "https://api.github.com/users/david-waterworth/orgs",
"repos_url": "https://api.github.com/users/david-waterworth/repos",
"events_url": "https://api.github.com/users/david-waterworth/events{/privacy}",
"received_events_url": "https://api.github.com/users/david-waterworth/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
}
] | [
"Thanks for flagging, I added those to all examples in the PR mentioned above!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Cosed by #12888"
] | 1,626 | 1,629 | 1,629 | NONE | null | I just installed Transformers 4.9.0 as I'm really excited to investigate the tokeniser free CANINE model.
I noticed that the `examples/pytorch/language-modeling/run_mlm_no_trainer.py` script requires the `accelerate` library but that doesn't appear to be included in `examples/pytorch/language-modeling/requirements.txt` or the main `setup.py`
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12849/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12849/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12848 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12848/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12848/comments | https://api.github.com/repos/huggingface/transformers/issues/12848/events | https://github.com/huggingface/transformers/issues/12848 | 951,003,646 | MDU6SXNzdWU5NTEwMDM2NDY= | 12,848 | legacy finetune with t5 issues | {
"login": "sacombs",
"id": 1991913,
"node_id": "MDQ6VXNlcjE5OTE5MTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/1991913?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sacombs",
"html_url": "https://github.com/sacombs",
"followers_url": "https://api.github.com/users/sacombs/followers",
"following_url": "https://api.github.com/users/sacombs/following{/other_user}",
"gists_url": "https://api.github.com/users/sacombs/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sacombs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sacombs/subscriptions",
"organizations_url": "https://api.github.com/users/sacombs/orgs",
"repos_url": "https://api.github.com/users/sacombs/repos",
"events_url": "https://api.github.com/users/sacombs/events{/privacy}",
"received_events_url": "https://api.github.com/users/sacombs/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2659267025,
"node_id": "MDU6TGFiZWwyNjU5MjY3MDI1",
"url": "https://api.github.com/repos/huggingface/transformers/labels/DeepSpeed",
"name": "DeepSpeed",
"color": "4D34F7",
"default": false,
"description": ""
}
] | closed | false | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
}
] | [
"first, any reason why you're not using the latest scripts? The legacy scripts are no longer being maintained and the up-to-date scripts had great many improvements. So if it's not too hard I highly recommend switching to those. Most likely you want\r\nhttps://github.com/huggingface/transformers/blob/master/examples/pytorch/translation/run_translation.py Albeit, this is orthogonal to the Deepspeed issue you wanted to discuss.\r\n\r\n> For zero 3 optimization, I am using lower values for stage3_params, since the documentation indicated to use lower values to offload memory.\r\n\r\nAfter this discussion is over, let's review where you found this information, because this is incorrect. The doc says which specific parameters you need to tweak, not all of them. \r\n\r\nHave you considered using tuned-up-for-you `auto` values? https://huggingface.co/transformers/master/main_classes/deepspeed.html#zero-3-config\r\n\r\nah, and you have a typo in at least on of the key names as well - there is no stage3_param_persitance_threshold - deepspeed is a bit troublesome as it doesn't validate keys and simply uses the default if you make a typo.\r\n\r\nIt dumps the final config when the program starts, so you can always review whether your settings \"made it\".\r\n\r\nYour config is also \"dated\" - recent deepspeed moved to a newer config as you can see in the docs (albeit it's backward compatible).\r\n",
"Perhaps you were referring to: \"Smaller values use less memory\"\r\n\r\n> <p><strong><em>stage3_param_persistence_threshold</em></strong>: [integer]</p>\r\n> \r\n> Description | Default\r\n> -- | --\r\n> Do not partition parameters smaller than this threshold. Smaller values use less memory, but can greatly increase communication (especially latency-bound messages).\r\n> \r\n\r\nhttps://www.deepspeed.ai/docs/config-json/",
"@stas00,\r\n\r\nThanks for the pointers. I modified my ds_confg.json with the following:\r\n\r\n```\r\njson = {\r\n \"zero_optimization\": {\r\n \"stage\": 3, \r\n \"offload_optimizer\": {\r\n \"device\": \"cpu\", \r\n \"pin_memory\": true\r\n }, \r\n \"offload_param\": {\r\n \"device\": \"cpu\", \r\n \"pin_memory\": true\r\n }, \r\n \"overlap_comm\": true, \r\n \"contiguous_gradients\": true, \r\n \"sub_group_size\": 1.000000e+09, \r\n \"reduce_bucket_size\": 1.048576e+06, \r\n \"stage3_prefetch_bucket_size\": 9.437184e+05, \r\n \"stage3_param_persistence_threshold\": 1.024000e+04, \r\n \"stage3_max_live_parameters\": 10.0, \r\n \"stage3_max_reuse_distance\": 10.0, \r\n \"stage3_gather_fp16_weights_on_model_save\": true\r\n }, \r\n \"train_batch_size\": 16, \r\n \"train_micro_batch_size_per_gpu\": 2, \r\n \"zero_allow_untested_optimizer\": true\r\n}\r\n```\r\n\r\nI also switched to run_translation.py in the master branch. \r\n\r\nEven with the \r\n\r\n```\r\n \"stage3_max_live_parameters\": 10.0, \r\n \"stage3_max_reuse_distance\": 10.0, \r\n```\r\nI am unable to use a batchsize of 2 per gpu without hitting OOM for GPU. Any thoughts on optimizing this? My commandline is:\r\n\r\n`rm -rf output_dir; USE_TF=0 deepspeed --num_gpus=8 ./run_translation.py --model_name_or_path \"Rostlab/prot_t5_xl_uniref50\" --output_dir output_dir --adam_eps 1e-06 --do_eval --do_predict --do_train --evaluation_strategy=steps --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 512 --max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --predict_with_generate --eval_steps 25000 --sortish_sampler --warmup_steps 5 --deepspeed deepsped.config --fp16 --train_file train.json --test_file train.json --validation_file train.json --source_lang a --target_lang b --overwrite_output_dir --predict_with_generate --per_device_train_batch_size=2 --per_device_eval_batch_size=2`",
"I had no problem doing mostly the same with the current version of examples with just 4x v100-16GB GPUs - I didn't change anything from the default ds config in the repo and it took only 6GB / gpu for training and ~10GB / gpu for eval.\r\n\r\n```\r\ncd transformers\r\nBS=4; PYTHONPATH=src USE_TF=0 /usr/bin/time -v deepspeed --num_gpus 4 \\\r\nexamples/pytorch/translation/run_translation.py --model_name_or_path t5-3b --output_dir output_dir \\\r\n--overwrite_output_dir --max_train_samples 10 --max_eval_samples 10 --max_source_length 512 \\\r\n--max_target_length 128 --val_max_target_length 128 --do_train --do_eval --num_train_epochs 1 \\\r\n--per_device_train_batch_size $BS --per_device_eval_batch_size $BS --learning_rate 3e-3 \\\r\n--warmup_steps 500 --predict_with_generate --save_steps 0 --eval_steps 1 --group_by_length \\\r\n--dataset_name wmt16 --dataset_config ro-en --source_lang en --target_lang ro --source_prefix \\\r\n\"translate English to Romanian: \" --deepspeed tests/deepspeed/ds_config_zero3.json\r\n```\r\n\r\nprobably can easily do a much larger BS on this one and 8 gpus you definitely shouldn't have any problems.\r\n\r\nI highly recommend to use the default ds config and not change anything there unless you really need to.",
"I was able to use your command and train using the ro-en dataset and t5-3b.\r\n\r\nHowever, I am trying to use a custom model: \"Rostlab/prot_t5_xl_uniref50\". This is based on t5-3b, but without the denoising objective in t5. I looked at the model card and it also does not have the task-specific parameters in its config.json for translation/summarization. I think this means that I might need to change the Trainer, but I am not sure what is specifically needed. \r\n\r\nBefore I started down the deepspeed path, I was using a training loop that I had created with model parallelization. The train step is below:\r\n\r\n```\r\nmodel = T5ForConditionalGeneration.from_pretrained(model_name)\r\n# model = model.to(device)\r\ndevice_map = {0: [0],\r\n 1: [1, 2, 3 ],\r\n 2: [4, 5, 6 ],\r\n 3: [7, 8, 9, 10 ],\r\n 4: [11, 12, 13, 14],\r\n 5: [15, 16, 17],\r\n 6: [18, 19, 20],\r\n 7: [21, 22, 23]\r\n }\r\n\r\nmodel.parallelize(device_map)\r\n\r\n\r\ndef run_a_train_epoch():\r\n print (\"Training...\")\r\n all_losses = []\r\n model.train()\r\n for batch_idx, batch in enumerate(train_dataloader):\r\n if batch_idx > 0 and batch_idx % 20 == 0:\r\n print(f\"Trained {batch_idx} batches...\")\r\n #print (\"Batch: \", batch_idx)\r\n #print (_, data)\r\n \r\n ids = batch['source_ids'].to('cuda:0', dtype = torch.long)\r\n mask = batch['source_mask'].to('cuda:0', dtype = torch.long)\r\n y = batch['target_ids'].to('cuda:0', dtype = torch.long)\r\n \r\n y_ids = y[:, :-1].contiguous()\r\n decoder_attention_mask = batch['target_mask'].to('cuda:0', dtype = torch.long)\r\n \r\n y_mask = decoder_attention_mask[:, :-1].contiguous()\r\n \r\n outputs = model(input_ids = ids, attention_mask = mask, labels=y_ids, decoder_attention_mask=y_mask)\r\n \r\n loss = outputs[0]\r\n \r\n optimizer.zero_grad()\r\n loss.backward()\r\n optimizer.step()\r\n \r\n all_losses.append(loss)\r\n\r\n train_loss = sum(all_losses) / len(all_losses)\r\n return train_loss\r\n \r\n```\r\nDoing this, I was only able to train on 2 batches at once. Is it possible to use trainer with this model or do you have any pointers on transferring this to deepspeed?\r\n",
"You don't need to transfer anything to Deepspeed, Deepspeed ZeRO simply provides a much simpler way of doing model parallelism w/o needing to change the model. That is whatever model you use it'll just work. Deepspeed magically parallelizes whatever you throw at it (well, most of the time).\r\n\r\nSo your goal is to use a t5-3b model with a slightly different task. I don't see any reason why it won't just work out of the box.\r\n\r\nI used `run_translation.py` as an example to test that everything works and scales. You can adapt it to your needs. `run_translation.py` is the same as the old legacy `finetune_trainer.py` except it was massively cleaned up, improved and then split off to do just one task - translation. e.g. `examples/pytorch/summarization` is another split off from `finetune_trainer.py`.\r\n\r\nPerhaps you can follow this plan:\r\n\r\n1. study the existing example scripts and find the one that is the closest to your needs\r\n2. adapt it to your exact needs by porting over whatever extra code you wrote in your `finetune_trainer.py`\r\n3. test that it works with just python perhaps on a small model\r\n4. add deepspeed using the default settings of `tests/deepspeed/ds_config_zero3.json` to scale it up this time on the full model.\r\n\r\n\r\n",
"I am not sure what is going on...I stepped through the code and made sure that I was not missing anything by printing out the tokens/masks and several other points. The only thing that I can get to work with this model, dataset, and run_translation.py is a per_device_batch_size of 1. I am using the tests/deepspeed/ds_config_zero3.json with the run_translation.py script. I have been able to use the original t5-3b model with the ro-en translation dataset and your configuration file with a per device batch size of 8 just fine.\r\n\r\nNot sure where to go from here.\r\n\r\nThanks! ",
"a model is a model is a model is a model - it doesn't matter which t5-3b derivative you use - it will take the exact same amount of memory. What matters is your code - it's possible that you do something that leaks memory or allocates more than the example program does.\r\n\r\nThe next step is to either to try to compare how your program is different, or to use the memory profiler and see where the bulk of memory is allocated. You can start with just enabling `--skip_memory_metrics 0` (unskip that is) with the current examples and it'll report the memory allocations in the first gpu. or you can use various other pytorch profilers.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,626 | 1,630 | 1,630 | NONE | null | Hi @stas00
Splitting of from https://github.com/huggingface/transformers/issues/8771#issuecomment-884865133
There is a lot of great information in your post; thanks for being thorough!
I guess I dont understand what parameters I need to change within the deepspeed config file to properly offload into cpu memory. I have 473 gb of RAM available for offloading, which seems to be enough based on what you listed. I am also using the finetune script in the seq2seq legacy folder. The command is:
`export BS=2; rm -rf output_dir; PYTHONPATH=../../src USE_TF=0 deepspeed --num_gpus=8 ./finetune_trainer.py --model_name_or_path "Rostlab/prot_t5_xl_uniref50" --output_dir output_dir --adam_eps 1e-06 --data_dir /mnt/data --do_eval --do_predict --do_train --evaluation_strategy=steps --freeze_embeds --label_smoothing 0.1 --learning_rate 3e-5 --logging_first_step --logging_steps 1000 --max_source_length 512 --max_target_length 128 --num_train_epochs 1 --overwrite_output_dir --per_device_eval_batch_size $BS --per_device_train_batch_size $BS --predict_with_generate --eval_steps 25000 --sortish_sampler --test_max_target_length 128 --val_max_target_length 128 --warmup_steps 5 --n_train 60 --n_val 10 --n_test 10 --deepspeed ../../../tests/deepspeed/ds_config_zero3.json --fp16`
I had to modify finetune to include the T5Tokenizer as the AutoTokenizer wouldnt work.
For zero 3 optimization, I am using lower values for stage3_params, since the documentation indicated to use lower values to offload memory.
```
"zero_optimization": {
"stage": 3,
"cpu_offload": true,
"cpu_offload_params": true,
"cpu_offload_use_pin_memory" : true,
"overlap_comm": true,
"contiguous_gradients": true,
"stage3_max_live_parameters": 1e3,
"stage3_max_reuse_distance": 1e3,
"stage3_prefetch_bucket_size": 2e3,
"stage3_param_persitance_threshold": 1e3,
"reduce_bucket_size": 3e3,
"prefetch_bucket_size": 3e3,
"sub_group_size": 1e3
},
```
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12848/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12848/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12847 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12847/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12847/comments | https://api.github.com/repos/huggingface/transformers/issues/12847/events | https://github.com/huggingface/transformers/issues/12847 | 950,952,238 | MDU6SXNzdWU5NTA5NTIyMzg= | 12,847 | Default process group has not been initialized while using sagemaker data parallel | {
"login": "yl-to",
"id": 23205976,
"node_id": "MDQ6VXNlcjIzMjA1OTc2",
"avatar_url": "https://avatars.githubusercontent.com/u/23205976?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yl-to",
"html_url": "https://github.com/yl-to",
"followers_url": "https://api.github.com/users/yl-to/followers",
"following_url": "https://api.github.com/users/yl-to/following{/other_user}",
"gists_url": "https://api.github.com/users/yl-to/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yl-to/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yl-to/subscriptions",
"organizations_url": "https://api.github.com/users/yl-to/orgs",
"repos_url": "https://api.github.com/users/yl-to/repos",
"events_url": "https://api.github.com/users/yl-to/events{/privacy}",
"received_events_url": "https://api.github.com/users/yl-to/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@philschmid @sgugger ",
"From offline discussion, the issue seem to be the following:\r\n1. You can’t use torch.distributed and smdp at the same time. You might want to change torch.distributed.barrier to sm_dist.barrier\r\n2. You could do import either torch.distributed or smdistributed.dataparallel.torch.distributed as dist at the top of the file. Then, you can simply write dist.xyz elsewhere\r\n\r\nLikely the PR from which this issue originated is below:\r\nhttps://github.com/huggingface/transformers/pull/12464\r\n"
] | 1,626 | 1,627 | 1,627 | CONTRIBUTOR | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.9.0 - dev
- Platform: Sagemaker
- Python version:
- PyTorch version (GPU?): 1.8.1
- Tensorflow version (GPU?):
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: Yes
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @Rocketknight1
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [x] an official GLUE/SQUaD task: SQUaD
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Run Squad finetune using transformers 4.9.0 - dev
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
```
[1,5]<stdout>:Traceback (most recent call last):
--
[1,5]<stdout>: File "/opt/conda/lib/python3.6/runpy.py", line 193, in _run_module_as_main
[1,5]<stdout>: "__main__", mod_spec)
[1,5]<stdout>: File "/opt/conda/lib/python3.6/runpy.py", line 85, in _run_code
[1,5]<stdout>: exec(code, run_globals)
[1,5]<stdout>: File "/opt/conda/lib/python3.6/site-packages/mpi4py/__main__.py", line 7, in <module>
[1,5]<stdout>: main()
[1,5]<stdout>: File "/opt/conda/lib/python3.6/site-packages/mpi4py/run.py", line 196, in main
[1,5]<stdout>: run_command_line(args)
[1,5]<stdout>: File "/opt/conda/lib/python3.6/site-packages/mpi4py/run.py", line 47, in run_command_line
[1,5]<stdout>: run_path(sys.argv[0], run_name='__main__')
[1,5]<stdout>: File "/opt/conda/lib/python3.6/runpy.py", line 263, in run_path
[1,5]<stdout>: pkg_name=pkg_name, script_name=fname)
[1,3]<stdout>: File "/opt/conda/lib/python3.6/site-packages/mpi4py/run.py", line 196, in main
[1,3]<stdout>: run_command_line(args)
[1,3]<stdout>: File "/opt/conda/lib/python3.6/site-packages/mpi4py/run.py", line 47, in run_command_line
[1,3]<stdout>: run_path(sys.argv[0], run_name='__main__')
[1,3]<stdout>: File "/opt/conda/lib/python3.6/runpy.py", line 263, in run_path
[1,3]<stdout>: pkg_name=pkg_name, script_name=fname)
[1,3]<stdout>: File "/opt/conda/lib/python3.6/runpy.py", line 96, in _run_module_code
[1,3]<stdout>: mod_name, mod_spec, pkg_name, script_name)
[1,3]<stdout>: File "/opt/conda/lib/python3.6/runpy.py", line 85, in _run_code
[1,3]<stdout>: exec(code, run_globals)
[1,3]<stdout>: File "run_qa.py", line 646, in <module>
[1,3]<stdout>: main()
[1,3]<stdout>: File "run_qa.py", line 427, in main
[1,3]<stdout>: with training_args.main_process_first(desc="train dataset map pre-processing"):
[1,3]<stdout>: File "/opt/conda/lib/python3.6/contextlib.py", line 81, in __enter__
[1,3]<stdout>: return next(self.gen)
[1,3]<stdout>: File "/opt/conda/lib/python3.6/site-packages/transformers/training_args.py", line 1033, in main_process_first
[1,3]<stdout>: torch.distributed.barrier()
[1,3]<stdout>: File "/opt/conda/lib/python3.6/site-packages/torch/distributed/distributed_c10d.py", line 2419, in barrier
[1,3]<stdout>: default_pg = _get_default_group()
[1,2]<stdout>:Traceback (most recent call last):
[1,2]<stdout>: File "/opt/conda/lib/python3.6/runpy.py", line 193, in _run_module_as_main
[1,2]<stdout>: "__main__", mod_spec)
[1,2]<stdout>: File "/opt/conda/lib/python3.6/runpy.py", line 85, in _run_code
[1,2]<stdout>: exec(code, run_globals)
[1,2]<stdout>: File "/opt/conda/lib/python3.6/site-packages/mpi4py/__main__.py", line 7, in <module>
[1,2]<stdout>: main()
[1,2]<stdout>: File "/opt/conda/lib/python3.6/site-packages/mpi4py/run.py", line 196, in main
[1,2]<stdout>: run_command_line(args)
[1,2]<stdout>: File "/opt/conda/lib/python3.6/site-packages/mpi4py/run.py", line 47, in run_command_line
[1,2]<stdout>: run_path(sys.argv[0], run_name='__main__')
[1,2]<stdout>: File "/opt/conda/lib/python3.6/runpy.py", line 263, in run_path
[1,2]<stdout>: pkg_name=pkg_name, script_name=fname)
[1,4]<stdout>: File "/opt/conda/lib/python3.6/runpy.py", line 193, in _run_module_as_main
[1,4]<stdout>: "__main__", mod_spec)
[1,4]<stdout>: File "/opt/conda/lib/python3.6/runpy.py", line 85, in _run_code
[1,4]<stdout>: exec(code, run_globals)
[1,4]<stdout>: File "/opt/conda/lib/python3.6/site-packages/mpi4py/__main__.py", line 7, in <module>
[1,4]<stdout>: main()
[1,4]<stdout>: File "/opt/conda/lib/python3.6/site-packages/mpi4py/run.py", line 196, in main
[1,4]<stdout>: run_command_line(args)
[1,4]<stdout>: File "/opt/conda/lib/python3.6/site-packages/mpi4py/run.py", line 47, in run_command_line
[1,4]<stdout>: run_path(sys.argv[0], run_name='__main__')
[1,4]<stdout>: File "/opt/conda/lib/python3.6/runpy.py", line 263, in run_path
[1,4]<stdout>: pkg_name=pkg_name, script_name=fname)
[1,4]<stdout>: File "/opt/conda/lib/python3.6/runpy.py", line 96, in _run_module_code
[1,4]<stdout>: mod_name, mod_spec, pkg_name, script_name)
[1,4]<stdout>: File "/opt/conda/lib/python3.6/runpy.py", line 85, in _run_code
[1,4]<stdout>: exec(code, run_globals)
[1,4]<stdout>: File "run_qa.py", line 646, in <module>
[1,4]<stdout>: main()
[1,4]<stdout>: File "run_qa.py", line 427, in main
[1,4]<stdout>: with training_args.main_process_first(desc="train dataset map pre-processing"):
[1,6]<stdout>: File "/opt/conda/lib/python3.6/runpy.py", line 193, in _run_module_as_main
[1,6]<stdout>: "__main__", mod_spec)
[1,6]<stdout>: File "/opt/conda/lib/python3.6/runpy.py", line 85, in _run_code
[1,6]<stdout>: exec(code, run_globals)
[1,6]<stdout>: File "/opt/conda/lib/python3.6/site-packages/mpi4py/__main__.py", line 7, in <module>
[1,6]<stdout>: main()
[1,6]<stdout>: File "/opt/conda/lib/python3.6/site-packages/mpi4py/run.py", line 196, in main
[1,6]<stdout>: run_command_line(args)
[1,6]<stdout>: File "/opt/conda/lib/python3.6/site-packages/mpi4py/run.py", line 47, in run_command_line
[1,6]<stdout>: run_path(sys.argv[0], run_name='__main__')
[1,6]<stdout>: File "/opt/conda/lib/python3.6/runpy.py", line 263, in run_path
[1,6]<stdout>: pkg_name=pkg_name, script_name=fname)
[1,6]<stdout>: File "/opt/conda/lib/python3.6/runpy.py", line 96, in _run_module_code
[1,6]<stdout>: mod_name, mod_spec, pkg_name, script_name)
[1,6]<stdout>: File "/opt/conda/lib/python3.6/runpy.py", line 85, in _run_code
[1,6]<stdout>: exec(code, run_globals)
[1,6]<stdout>: File "run_qa.py", line 646, in <module>
[1,6]<stdout>: main()
[1,6]<stdout>: File "run_qa.py", line 427, in main
[1,6]<stdout>: with training_args.main_process_first(desc="train dataset map pre-processing"):
[1,6]<stdout>: File "/opt/conda/lib/python3.6/contextlib.py", line 81, in __enter__
[1,6]<stdout>: return next(self.gen)
[1,6]<stdout>: File "/opt/conda/lib/python3.6/site-packages/transformers/training_args.py", line 1033, in main_process_first
[1,6]<stdout>: torch.distributed.barrier()
[1,4]<stdout>: File "/opt/conda/lib/python3.6/contextlib.py", line 81, in __enter__
[1,4]<stdout>: return next(self.gen)
[1,4]<stdout>: File "/opt/conda/lib/python3.6/site-packages/transformers/training_args.py", line 1033, in main_process_first
[1,4]<stdout>: torch.distributed.barrier()
[1,4]<stdout>: File "/opt/conda/lib/python3.6/site-packages/torch/distributed/distributed_c10d.py", line 2419, in barrier
[1,4]<stdout>: default_pg = _get_default_group()
[1,4]<stdout>: File "/opt/conda/lib/python3.6/site-packages/torch/distributed/distributed_c10d.py", line 347, in _get_default_group
[1,4]<stdout>: raise RuntimeError("Default process group has not been initialized, "
[1,4]<stdout>:RuntimeError: Default process group has not been initialized, please make sure to call init_process_group.
```
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12847/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12847/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/12846 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/12846/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/12846/comments | https://api.github.com/repos/huggingface/transformers/issues/12846/events | https://github.com/huggingface/transformers/pull/12846 | 950,944,940 | MDExOlB1bGxSZXF1ZXN0Njk1NDEyMjEz | 12,846 | T5: Create position related tensors directly on device instead of CPU | {
"login": "armancohan",
"id": 6425112,
"node_id": "MDQ6VXNlcjY0MjUxMTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/6425112?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/armancohan",
"html_url": "https://github.com/armancohan",
"followers_url": "https://api.github.com/users/armancohan/followers",
"following_url": "https://api.github.com/users/armancohan/following{/other_user}",
"gists_url": "https://api.github.com/users/armancohan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/armancohan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/armancohan/subscriptions",
"organizations_url": "https://api.github.com/users/armancohan/orgs",
"repos_url": "https://api.github.com/users/armancohan/repos",
"events_url": "https://api.github.com/users/armancohan/events{/privacy}",
"received_events_url": "https://api.github.com/users/armancohan/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,626 | 1,628 | 1,628 | CONTRIBUTOR | null | # What does this PR do?
The current implementation of the `compute_bias` function of the T5 model creates tensors on the CPU (`memory_position` and `context_position`) and then moves them to the corresponding device with `.to()`.
While this has minimal impact in single-gpu training, in multi-gpu large batch training, as the number of GPUs increases this reduces GPU utilization.
This short PR addresses the issue.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR (@patrickvonplaten).
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/12846/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/12846/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/12846",
"html_url": "https://github.com/huggingface/transformers/pull/12846",
"diff_url": "https://github.com/huggingface/transformers/pull/12846.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/12846.patch",
"merged_at": 1628092710000
} |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.