
title
stringlengths 1
100
| titleSlug
stringlengths 3
77
| Java
int64 0
1
| Python3
int64 1
1
| content
stringlengths 28
44.4k
| voteCount
int64 0
3.67k
| question_content
stringlengths 65
5k
| question_hints
stringclasses 970
values |
|---|---|---|---|---|---|---|---|
One liner Python Solution | number-of-segments-in-a-string | 0 | 1 | # Intuition\n\nThe purpose of this method is to count the number of segments in a given string `s`, where a "segment" is defined as a continuous sequence of non-space characters. The method achieves this by utilizing the `split()` function on the input string `s`, which splits the string into a list of substrings based on spaces. The resulting list, named `segments_list`, represents the segments of the original string. The method then returns the length of this list using `len(segments_list)`, effectively providing the count of segments in the input string. This code snippet offers a concise and Pythonic way to determine the number of segments in a string by leveraging the inherent functionality of the `split()` method.\n\n# Approach\nThe code defines a class, `Solution`, with a method called `countSegments`, aiming to determine the number of segments in a given string `s`. In this context, a "segment" is considered as a contiguous sequence of non-space characters. The approach is to employ the `split()` function on the input string, `s`. This function breaks the string into a list of substrings using spaces as delimiters. The resulting list, named `segments_list`, captures the segments present in the original string. The method then computes the length of `segments_list` using the `len()` function and returns this count. Effectively, the code neatly encapsulates the logic for segment counting by taking advantage of the list created by the `split()` function, providing a concise and readable solution to the problem.\n\n# Complexity\n- Time complexity of O(n), where n is the length of the input string. \n\n- The space complexity of the provided code is O(n), where n is the length of the input string s. This is because the split() method creates a list (segments_list) to store the substrings resulting from the split operation.\n\n# Code\n```\nclass Solution(object):\n def countSegments(self, s):\n return len(s.split())\n``` | 0 | Given a string `s`, return _the number of segments in the string_.
A **segment** is defined to be a contiguous sequence of **non-space characters**.
**Example 1:**
**Input:** s = "Hello, my name is John "
**Output:** 5
**Explanation:** The five segments are \[ "Hello, ", "my ", "name ", "is ", "John "\]
**Example 2:**
**Input:** s = "Hello "
**Output:** 1
**Constraints:**
* `0 <= s.length <= 300`
* `s` consists of lowercase and uppercase English letters, digits, or one of the following characters `"!@#$%^&*()_+-=',.: "`.
* The only space character in `s` is `' '`. | null |
simple one line code | beats 70% | number-of-segments-in-a-string | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nreturn the number of the words in a string. They are separated by empty spaces\n# Approach\n<!-- Describe your approach to solving the problem. -->\n1.convert the string into list and find its lenght\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nO(1)\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nO(1)\n# Code\n```\nclass Solution:\n def countSegments(self, s: str) -> int:\n return len(s.split())\n``` | 0 | Given a string `s`, return _the number of segments in the string_.
A **segment** is defined to be a contiguous sequence of **non-space characters**.
**Example 1:**
**Input:** s = "Hello, my name is John "
**Output:** 5
**Explanation:** The five segments are \[ "Hello, ", "my ", "name ", "is ", "John "\]
**Example 2:**
**Input:** s = "Hello "
**Output:** 1
**Constraints:**
* `0 <= s.length <= 300`
* `s` consists of lowercase and uppercase English letters, digits, or one of the following characters `"!@#$%^&*()_+-=',.: "`.
* The only space character in `s` is `' '`. | null |
Simple Python solution | non-overlapping-intervals | 0 | 1 | \n# Code\n```\nclass Solution:\n def eraseOverlapIntervals(self, intervals: List[List[int]]) -> int:\n cnt = 0\n inn = sorted(intervals, key=lambda x: x[0], reverse=True)\n ans = [inn[0]]\n for s, e in inn[1:]:\n if ans[-1][0] >= e: \n ans.append([s, e])\n else: \n cnt += 1\n return cnt\n``` | 3 | Given an array of intervals `intervals` where `intervals[i] = [starti, endi]`, return _the minimum number of intervals you need to remove to make the rest of the intervals non-overlapping_.
**Example 1:**
**Input:** intervals = \[\[1,2\],\[2,3\],\[3,4\],\[1,3\]\]
**Output:** 1
**Explanation:** \[1,3\] can be removed and the rest of the intervals are non-overlapping.
**Example 2:**
**Input:** intervals = \[\[1,2\],\[1,2\],\[1,2\]\]
**Output:** 2
**Explanation:** You need to remove two \[1,2\] to make the rest of the intervals non-overlapping.
**Example 3:**
**Input:** intervals = \[\[1,2\],\[2,3\]\]
**Output:** 0
**Explanation:** You don't need to remove any of the intervals since they're already non-overlapping.
**Constraints:**
* `1 <= intervals.length <= 105`
* `intervals[i].length == 2`
* `-5 * 104 <= starti < endi <= 5 * 104` | null |
One-line solution | non-overlapping-intervals | 0 | 1 | Very simple one line solution:\n\n# Code\n```\nclass Solution:\n def eraseOverlapIntervals(self, intervals: List[List[int]], pointer=-inf, answer=0) -> int:\n return answer \\\n if not intervals \\\n else self.eraseOverlapIntervals(sorted(intervals, key=lambda x: x[1])[1:], sorted(intervals, key=lambda x: x[1])[0][1], answer) \\\n if sorted(intervals, key=lambda x: x[1])[0][0] >= pointer \\\n else self.eraseOverlapIntervals(sorted(intervals, key=lambda x: x[1])[1:], pointer, answer+1)\n\n``` | 1 | Given an array of intervals `intervals` where `intervals[i] = [starti, endi]`, return _the minimum number of intervals you need to remove to make the rest of the intervals non-overlapping_.
**Example 1:**
**Input:** intervals = \[\[1,2\],\[2,3\],\[3,4\],\[1,3\]\]
**Output:** 1
**Explanation:** \[1,3\] can be removed and the rest of the intervals are non-overlapping.
**Example 2:**
**Input:** intervals = \[\[1,2\],\[1,2\],\[1,2\]\]
**Output:** 2
**Explanation:** You need to remove two \[1,2\] to make the rest of the intervals non-overlapping.
**Example 3:**
**Input:** intervals = \[\[1,2\],\[2,3\]\]
**Output:** 0
**Explanation:** You don't need to remove any of the intervals since they're already non-overlapping.
**Constraints:**
* `1 <= intervals.length <= 105`
* `intervals[i].length == 2`
* `-5 * 104 <= starti < endi <= 5 * 104` | null |
Easy Python Solution 99% pass | non-overlapping-intervals | 0 | 1 | \n# Code\n```\nclass Solution:\n def eraseOverlapIntervals(self, points: List[List[int]]) -> int:\n ans = 0\n arrow = -math.inf\n\n for point in sorted(points, key = lambda x:x[1]):\n if(point[0] >= arrow):\n arrow = point[1]\n else:\n ans+=1\n\n return ans \n``` | 1 | Given an array of intervals `intervals` where `intervals[i] = [starti, endi]`, return _the minimum number of intervals you need to remove to make the rest of the intervals non-overlapping_.
**Example 1:**
**Input:** intervals = \[\[1,2\],\[2,3\],\[3,4\],\[1,3\]\]
**Output:** 1
**Explanation:** \[1,3\] can be removed and the rest of the intervals are non-overlapping.
**Example 2:**
**Input:** intervals = \[\[1,2\],\[1,2\],\[1,2\]\]
**Output:** 2
**Explanation:** You need to remove two \[1,2\] to make the rest of the intervals non-overlapping.
**Example 3:**
**Input:** intervals = \[\[1,2\],\[2,3\]\]
**Output:** 0
**Explanation:** You don't need to remove any of the intervals since they're already non-overlapping.
**Constraints:**
* `1 <= intervals.length <= 105`
* `intervals[i].length == 2`
* `-5 * 104 <= starti < endi <= 5 * 104` | null |
Python | Easy to Understand | Medium Problem | 435. Non-overlapping Intervals | non-overlapping-intervals | 0 | 1 | # Python | Easy to Understand | Medium Problem | 435. Non-overlapping Intervals\n```\nclass Solution:\n def eraseOverlapIntervals(self, intervals: List[List[int]]) -> int:\n intervals.sort()\n @cache\n def dfs(idx):\n if idx==len(intervals):\n return 0\n\n take = 1+dfs(idx+1)\n\n left = idx+1\n right = len(intervals)-1\n while left<=right:\n mid = (left+right)//2\n if intervals[mid][0]<intervals[idx][1]:\n left = mid+1\n else:\n right = mid-1\n noTake = left-idx-1+dfs(left)\n return min(take, noTake)\n return dfs(0)\n\n``` | 1 | Given an array of intervals `intervals` where `intervals[i] = [starti, endi]`, return _the minimum number of intervals you need to remove to make the rest of the intervals non-overlapping_.
**Example 1:**
**Input:** intervals = \[\[1,2\],\[2,3\],\[3,4\],\[1,3\]\]
**Output:** 1
**Explanation:** \[1,3\] can be removed and the rest of the intervals are non-overlapping.
**Example 2:**
**Input:** intervals = \[\[1,2\],\[1,2\],\[1,2\]\]
**Output:** 2
**Explanation:** You need to remove two \[1,2\] to make the rest of the intervals non-overlapping.
**Example 3:**
**Input:** intervals = \[\[1,2\],\[2,3\]\]
**Output:** 0
**Explanation:** You don't need to remove any of the intervals since they're already non-overlapping.
**Constraints:**
* `1 <= intervals.length <= 105`
* `intervals[i].length == 2`
* `-5 * 104 <= starti < endi <= 5 * 104` | null |
✅Beat's 100% || C++ || JAVA || PYTHON || Beginner Friendly🔥🔥🔥 | non-overlapping-intervals | 1 | 1 | # Intuition:\n1. Minimum number of intervals to remove .\n2. Which is nothing but maximum number of intervals we can should keep.\n3. Then it comes under Maximum Meeting we can attend.\n\n<details>\n<summary><strong>In Detail</strong></summary>\n\n1. Removing minimum number of intervals is the same as KEEPING maximum number of intervals.\n\n2. Now, if you look at it as scheduling maximum number of meetings in a room, then you should get it.\nFor those unfamiliar with the Meeting scheduling problem, it is similar to this problem here, but each interval [start,end] represents the start and end time of a meeting. As there is only one room and we can have only one meeting at a time, we want to find maximum number of meetings we can schedule (in other words reject minimum number of meetings).\n\n3. Again we sort by end times. Why? Because regardless of when a meeting starts, a meeting that ends first leaves more time for other meetings to take place. We do not want a meeting that starts early and ends late, what we really care about is when the meeting ends and how much time it leaves for the other meetings. So, sort by endtimes, remove all overlapping meetings to get maximum meetings or reject minimum meetings. Same logic applies here in this problem.\n</details>\n\n# Explanation:\nImagine we have a set of meetings, where each meeting is represented by an interval [start_time, end_time]. The goal is to find the maximum number of non-overlapping meetings we can attend.\n\n1. **Sorting by end times (`cmp` function):**\nThe function first sorts the intervals based on their end times in ascending order using the custom comparator `cmp`. This sorting is crucial because it allows us to prioritize intervals that finish early, giving us more opportunities to accommodate additional meetings later on.\n\n2. **Initializing variables:**\nThe function initializes two variables, `prev` and `count`. The `prev` variable is used to keep track of the index of the last processed interval, and `count` is used to store the number of non-overlapping meetings found so far. We start `count` with 1 because the first interval is considered non-overlapping with itself.\n\n3. **Greedy approach:**\nThe function uses a greedy approach to find the maximum number of non-overlapping meetings. It iterates through the sorted intervals starting from the second interval (index 1) because we\'ve already counted the first interval as non-overlapping. For each interval at index `i`, it checks if the start time of the current interval (`intervals[i][0]`) is greater than or equal to the end time of the previous interval (`intervals[prev][1]`). If this condition is true, it means the current interval does not overlap with the previous one, and we can safely attend this meeting. In that case, we update `prev` to the current index `i` and increment `count` to reflect that we have attended one more meeting.\n\n4. **Return result:**\nFinally, the function returns the number of intervals that need to be removed to make the remaining intervals non-overlapping. Since we want to maximize the number of meetings we can attend, this value is calculated as `n - count`, where `n` is the total number of intervals.\n\n# Code\n```C++ []\nclass Solution {\npublic:\n static bool cmp(vector<int>& a, vector<int>& b){\n return a[1] < b[1];\n }\n\n int eraseOverlapIntervals(vector<vector<int>>& intervals) {\n int n = intervals.size();\n sort(intervals.begin(), intervals.end(), cmp);\n\n int prev = 0;\n int count = 1;\n\n for(int i = 1; i < n; i++){\n if(intervals[i][0] >= intervals[prev][1]){\n prev = i;\n count++;\n }\n }\n return n - count;\n }\n};\n```\n```Java []\nclass Solution {\n public int eraseOverlapIntervals(int[][] intervals) {\n int n = intervals.length;\n Arrays.sort(intervals, (a, b) -> Integer.compare(a[1], b[1]));\n\n int prev = 0;\n int count = 1;\n\n for (int i = 1; i < n; i++) {\n if (intervals[i][0] >= intervals[prev][1]) {\n prev = i;\n count++;\n }\n }\n return n - count;\n }\n}\n```\n```Python3 []\nclass Solution:\n def eraseOverlapIntervals(self, intervals: List[List[int]]) -> int:\n intervals.sort(key=lambda x: x[1])\n n = len(intervals)\n\n prev = 0\n count = 1\n\n for i in range(1, n):\n if intervals[i][0] >= intervals[prev][1]:\n prev = i\n count += 1\n\n return n - count\n```\n\n**If you found my solution helpful, I would greatly appreciate your upvote, as it would motivate me to continue sharing more solutions.**\n\n | 133 | Given an array of intervals `intervals` where `intervals[i] = [starti, endi]`, return _the minimum number of intervals you need to remove to make the rest of the intervals non-overlapping_.
**Example 1:**
**Input:** intervals = \[\[1,2\],\[2,3\],\[3,4\],\[1,3\]\]
**Output:** 1
**Explanation:** \[1,3\] can be removed and the rest of the intervals are non-overlapping.
**Example 2:**
**Input:** intervals = \[\[1,2\],\[1,2\],\[1,2\]\]
**Output:** 2
**Explanation:** You need to remove two \[1,2\] to make the rest of the intervals non-overlapping.
**Example 3:**
**Input:** intervals = \[\[1,2\],\[2,3\]\]
**Output:** 0
**Explanation:** You don't need to remove any of the intervals since they're already non-overlapping.
**Constraints:**
* `1 <= intervals.length <= 105`
* `intervals[i].length == 2`
* `-5 * 104 <= starti < endi <= 5 * 104` | null |
✅Python3 || C++|| Java✅[Greedy,Sorting and DP] Easy and understand | non-overlapping-intervals | 1 | 1 | 1. `intervals = sorted(intervals, key = lambda x:x[1])`: This line sorts the intervals list of lists based on the second element of each `interval`. It uses the `sorted` function with a custom sorting key specified by the lambda function `lambda x: x[1]`, which means sorting based on the second element of the sublists (i.e., the end point of each interval). The sorting is done in ascending order.\n\n2. `remove = 0`: This variable `remove` is used to keep track of the number of intervals that need to be removed to make the remaining intervals non-overlapping. We initialize it to 0.\n\n3. `end = -100000`: This variable `end` is initialized with negative infinity. It will be used to keep track of the end point of the current non-overlapping interval.\n\n4. `for i in intervals:`: This is a for-loop that iterates over each interval `i` in the sorted `intervals` list.\n\n5. `if i[0] >= end:`: This condition checks if the start of the current interval is greater than or equal to the `end`, meaning that it does not overlap with the previous interval. If this condition is true, we update the `end` to be the end point of the current interval, making it the new non-overlapping interval.\n\n6. `else:`: If the `if` condition is not true, it means the current interval overlaps with the previous interval. In this case, we increment the `remove` counter as we need to remove this overlapping interval to make the remaining intervals non-overlapping.\n\n7. `return remove`: Finally, the function returns the `remove` variable, which represents the minimum number of intervals that need to be removed to make all remaining intervals non-overlapping.\n\nIn summary, the given code uses a greedy approach to find the minimum number of intervals that need to be removed. It first sorts the intervals based on their end points and then iterates through the sorted intervals, updating the end point of the non-overlapping interval whenever a non-overlapping interval is found. It increments the `remove` counter whenever an overlapping interval is encountered. The final value of `remove` is returned as the result. This algorithm works because sorting the intervals by their end points allows us to greedily select non-overlapping intervals in a way that minimizes the number of removed intervals.\n\nExplanation from chatgpt. The solution is from me \uD83D\uDE07.\n# C++\n```\nclass Solution{\npublic:\n int eraseOverlapIntervals(vector<vector<int>>& intervals) {\n sort(intervals.begin(), intervals.end(), [](const auto& a, const auto& b) {\n return a[1] < b[1];\n });\n\n int remove = 0;\n int end =-100000;\n for (const auto& interval : intervals) {\n if (interval[0] >= end) {\n end = interval[1];\n } else {\n remove++;\n }\n }\n\n return remove;\n }\n};\n```\n# Python3\n```\nclass Solution:\n def eraseOverlapIntervals(self, intervals: List[List[int]]) -> int:\n intervals = sorted(intervals, key = lambda x:x[1])\n remove = 0\n end = -100000\n for i in intervals:\n if i[0] >= end:\n end = i[1]\n else:\n remove += 1\n return remove\n \n```\n# Java\n```\nclass Solution {\n public int eraseOverlapIntervals(int[][] intervals) {\n Arrays.sort(intervals, new Comparator<int[]>() {\n public int compare(int[] a, int[] b) {\n return a[1] - b[1];\n }\n });\n\n int remove = 0;\n int end = -100000;\n for (int[] interval : intervals) {\n if (interval[0] >= end) {\n end = interval[1];\n } else {\n remove++;\n }\n }\n\n return remove;\n }\n}\n```\n | 32 | Given an array of intervals `intervals` where `intervals[i] = [starti, endi]`, return _the minimum number of intervals you need to remove to make the rest of the intervals non-overlapping_.
**Example 1:**
**Input:** intervals = \[\[1,2\],\[2,3\],\[3,4\],\[1,3\]\]
**Output:** 1
**Explanation:** \[1,3\] can be removed and the rest of the intervals are non-overlapping.
**Example 2:**
**Input:** intervals = \[\[1,2\],\[1,2\],\[1,2\]\]
**Output:** 2
**Explanation:** You need to remove two \[1,2\] to make the rest of the intervals non-overlapping.
**Example 3:**
**Input:** intervals = \[\[1,2\],\[2,3\]\]
**Output:** 0
**Explanation:** You don't need to remove any of the intervals since they're already non-overlapping.
**Constraints:**
* `1 <= intervals.length <= 105`
* `intervals[i].length == 2`
* `-5 * 104 <= starti < endi <= 5 * 104` | null |
Fast solution | C++ | Java | Python | non-overlapping-intervals | 1 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nif we sort according to end time we can do max activity.\n\nFor detailed explanation you can refer to my youtube channel (hindi Language)\nhttps://youtu.be/Uuq0eJKwMzk\n or link in my profile.Here,you can find any solution in playlists monthwise from june 2023 with detailed explanation.i upload daily leetcode solution video with short and precise explanation (5-10) minutes.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n\nThe code starts by defining a static comparison function called `compare`. This function takes in two intervals represented as vectors, `v1` and `v2`. The comparison is based on the end points of the intervals, specifically `v1[1]` and `v2[1]`, which represent the second element (end point) of each interval. The function returns `true` if the end point of `v1` is less than the end point of `v2`, indicating that `v1` should come before `v2` in the sorted order.\n\nThe `eraseOverlapIntervals` function takes in a 2D vector `intervals` representing a set of intervals. It aims to find the minimum number of intervals that need to be removed to eliminate all overlaps.\n\nThe code proceeds as follows:\n\n1. The intervals are sorted using the `compare` function as the comparison criterion. This sorts the intervals in ascending order based on their end points. By sorting the intervals, we can easily identify overlaps during iteration.\n\n2. Two variables, `prev` and `res`, are initialized to 0. The `prev` variable keeps track of the index of the interval with the latest end point that has been considered. The `res` variable will store the count of overlapping intervals.\n\n3. The code then iterates over the sorted intervals, starting from index 1 (as the first interval is already considered as the initial `prev`).\n\n4. For each interval at index `i`, the code checks if the end point of the previous interval (at index `prev`) is greater than the start point of the current interval (at index `i`). If this condition is true, it means there is an overlap between the two intervals.\n\n5. If an overlap is detected, the code increments the `res` variable to count the overlap. This means that at least one interval needs to be removed to eliminate the overlap.\n\n6. Otherwise, if there is no overlap, the `prev` variable is updated to `i`. This indicates that the current interval will be considered as the next non-overlapping interval.\n\n7. After iterating through all the intervals, the function returns the count of overlapping intervals (`res`), which represents the minimum number of intervals that need to be removed to eliminate all overlaps.\n\nThe code follows a greedy approach, where at each step, it makes the locally optimal choice to maximize the number of non-overlapping intervals. By sorting the intervals based on their end points and iterating through them, the code effectively identifies overlaps and counts them. The result is the minimum number of intervals that need to be removed to eliminate all overlaps.\n\n# Complexity\n- Time complexity:$$O(nlogn)$$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:$$O(1)$$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```C++ []\nclass Solution {\npublic:\n static bool compare(vector<int>&v1,vector<int>&v2){\n return v1[1]<v2[1];\n \n }\n int eraseOverlapIntervals(vector<vector<int>>& intervals) {\n sort(intervals.begin(),intervals.end(),compare);\n int prev=0;\n int res=0;\n for(int i=1;i<intervals.size();i++){\n if(intervals[prev][1]>intervals[i][0])\n res++;\n else{\n prev=i;\n }\n }\n return res;\n }\n};\n```\n```Java []\nimport java.util.Arrays;\nimport java.util.Comparator;\n\nclass Solution {\n public int eraseOverlapIntervals(int[][] intervals) {\n Arrays.sort(intervals, Comparator.comparingInt(a -> a[1]));\n int prev = 0;\n int count = 0;\n \n for (int i = 1; i < intervals.length; i++) {\n if (intervals[prev][1] > intervals[i][0]) {\n count++;\n } else {\n prev = i;\n }\n }\n \n return count;\n }\n}\n\n```\n```Python []\nclass Solution:\n def eraseOverlapIntervals(self, intervals: List[List[int]]) -> int:\n intervals.sort(key=lambda x: x[1])\n prev = 0\n count = 0\n \n for i in range(1, len(intervals)):\n if intervals[prev][1] > intervals[i][0]:\n count += 1\n else:\n prev = i\n \n return count\n\n```\n\n | 34 | Given an array of intervals `intervals` where `intervals[i] = [starti, endi]`, return _the minimum number of intervals you need to remove to make the rest of the intervals non-overlapping_.
**Example 1:**
**Input:** intervals = \[\[1,2\],\[2,3\],\[3,4\],\[1,3\]\]
**Output:** 1
**Explanation:** \[1,3\] can be removed and the rest of the intervals are non-overlapping.
**Example 2:**
**Input:** intervals = \[\[1,2\],\[1,2\],\[1,2\]\]
**Output:** 2
**Explanation:** You need to remove two \[1,2\] to make the rest of the intervals non-overlapping.
**Example 3:**
**Input:** intervals = \[\[1,2\],\[2,3\]\]
**Output:** 0
**Explanation:** You don't need to remove any of the intervals since they're already non-overlapping.
**Constraints:**
* `1 <= intervals.length <= 105`
* `intervals[i].length == 2`
* `-5 * 104 <= starti < endi <= 5 * 104` | null |
Ex-Amazon explains a solution with a video, Python, JavaScript, Java and C++ | non-overlapping-intervals | 1 | 1 | # Intuition\nThe algorithm sorts intervals based on their end points, then iterates through them, counting overlapping intervals, and returns the count.\n\n# Solution Video\n\nhttps://youtu.be/gJjmZ6VpXRk\n\n# *** Please upvote and subscribe to my channel from here. I have 226 videos as of July 19th***\nhttp://www.youtube.com/channel/UC9RMNwYTL3SXCP6ShLWVFww?sub_confirmation=1\n\n---\n\n# Approach\nThis is based on Python code. Other might be different a bit.\n\n\n1. Initialize a variable "res" to keep track of the count of overlapping intervals. Set it to 0 initially.\n\n2. Sort the intervals in ascending order based on their end points using the `sort` method and a lambda function as the key for sorting.\n\n3. Initialize a variable "prev_end" to store the end point of the first interval (since the intervals are sorted).\n\n4. Iterate through the sorted intervals starting from the second one (index 1).\n\n5. Check if the end point of the previous interval (stored in "prev_end") is greater than the start point of the current interval (intervals[i][0]).\n - If true, it means there is an overlap between the previous interval and the current one. Increment the "res" variable to count the overlapping interval.\n\n6. If there is no overlap (i.e., the end point of the previous interval is not greater than the start point of the current interval), update "prev_end" to the end point of the current interval.\n\n7. After processing all intervals, return the count of overlapping intervals ("res") as the final result.\n\n# Complexity\n- Time complexity: O(n log n) \nThe main operations in this code are sorting the intervals and iterating through the sorted intervals. Sorting the intervals takes O(n log n) time complexity, where n is the number of intervals. The subsequent loop iterates through the sorted intervals once, which takes O(n) time complexity. Therefore, the overall time complexity of this code is O(n log n).\n\n- Space complexity: O(1)\nThe space complexity of this code is O(1). The additional space used is constant and does not depend on the size of the input. The sorting operation is performed in-place, and the variables "res" and "prev_end" require constant space to store their values during the computation. The input list "intervals" is not modified, and the returned integer value does not consume any extra space.\n\n```python []\nclass Solution:\n def eraseOverlapIntervals(self, intervals: List[List[int]]) -> int:\n res = 0\n\n intervals.sort(key=lambda x: x[1])\n prev_end = intervals[0][1]\n\n for i in range(1, len(intervals)):\n if prev_end > intervals[i][0]:\n res += 1\n else:\n prev_end = intervals[i][1]\n \n return res\n```\n```javascript []\n/**\n * @param {number[][]} intervals\n * @return {number}\n */\nvar eraseOverlapIntervals = function(intervals) {\n let res = 0;\n intervals.sort((a, b) => a[1] - b[1]);\n let prev_end = intervals[0][1];\n\n for (let i = 1; i < intervals.length; i++) {\n if (prev_end > intervals[i][0]) {\n res++;\n } else {\n prev_end = intervals[i][1];\n }\n }\n\n return res; \n};\n```\n```java []\nclass Solution {\n public int eraseOverlapIntervals(int[][] intervals) {\n int res = 0;\n\n Arrays.sort(intervals, (a, b) -> a[1] - b[1]);\n int prev_end = intervals[0][1];\n\n for (int i = 1; i < intervals.length; i++) {\n if (prev_end > intervals[i][0]) {\n res++;\n } else {\n prev_end = intervals[i][1];\n }\n }\n\n return res; \n }\n}\n```\n```C++ []\nclass Solution {\npublic:\n int eraseOverlapIntervals(vector<vector<int>>& intervals) {\n int res = 0;\n\n sort(intervals.begin(), intervals.end(), [](const auto& a, const auto& b) {\n return a[1] < b[1];\n });\n int prev_end = intervals[0][1];\n\n for (int i = 1; i < intervals.size(); i++) {\n if (prev_end > intervals[i][0]) {\n res++;\n } else {\n prev_end = intervals[i][1];\n }\n }\n\n return res; \n }\n};\n```\n | 6 | Given an array of intervals `intervals` where `intervals[i] = [starti, endi]`, return _the minimum number of intervals you need to remove to make the rest of the intervals non-overlapping_.
**Example 1:**
**Input:** intervals = \[\[1,2\],\[2,3\],\[3,4\],\[1,3\]\]
**Output:** 1
**Explanation:** \[1,3\] can be removed and the rest of the intervals are non-overlapping.
**Example 2:**
**Input:** intervals = \[\[1,2\],\[1,2\],\[1,2\]\]
**Output:** 2
**Explanation:** You need to remove two \[1,2\] to make the rest of the intervals non-overlapping.
**Example 3:**
**Input:** intervals = \[\[1,2\],\[2,3\]\]
**Output:** 0
**Explanation:** You don't need to remove any of the intervals since they're already non-overlapping.
**Constraints:**
* `1 <= intervals.length <= 105`
* `intervals[i].length == 2`
* `-5 * 104 <= starti < endi <= 5 * 104` | null |
Python 3 Easy Solution | non-overlapping-intervals | 0 | 1 | \n# Complexity\n- Time complexity: **O(nlogn)**\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: **O(1)**\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n \n\n# Code\n```\nclass Solution:\n def eraseOverlapIntervals(self, intervals: List[List[int]]) -> int:\n intervals.sort()\n count=0\n i=1\n last_interval=intervals[0]\n while i<len(intervals):\n curr_start=intervals[i][0]\n curr_end=intervals[i][1]\n last_end=last_interval[1]\n\n #no overlapping\n if curr_start>=last_end:\n last_interval=intervals[i]\n # i+=1\n elif curr_end>=last_end:\n # i+=1\n count+=1\n elif curr_end<last_end:\n last_interval=intervals[i]\n # i+=1\n count+=1\n i+=1\n return count\n\n``` | 1 | Given an array of intervals `intervals` where `intervals[i] = [starti, endi]`, return _the minimum number of intervals you need to remove to make the rest of the intervals non-overlapping_.
**Example 1:**
**Input:** intervals = \[\[1,2\],\[2,3\],\[3,4\],\[1,3\]\]
**Output:** 1
**Explanation:** \[1,3\] can be removed and the rest of the intervals are non-overlapping.
**Example 2:**
**Input:** intervals = \[\[1,2\],\[1,2\],\[1,2\]\]
**Output:** 2
**Explanation:** You need to remove two \[1,2\] to make the rest of the intervals non-overlapping.
**Example 3:**
**Input:** intervals = \[\[1,2\],\[2,3\]\]
**Output:** 0
**Explanation:** You don't need to remove any of the intervals since they're already non-overlapping.
**Constraints:**
* `1 <= intervals.length <= 105`
* `intervals[i].length == 2`
* `-5 * 104 <= starti < endi <= 5 * 104` | null |
Python sort + greedy solution | non-overlapping-intervals | 0 | 1 | # Approach\nSort -> greedy\n\n\n# Complexity\n- Time complexity: $$O(n*\\log n)$$\n\n- Space complexity: $$O(1)$$\n\n# Code\n```\nclass Solution:\n def eraseOverlapIntervals(self, intervals: List[List[int]]) -> int:\n intervals.sort(key=lambda x: (x[0], x[1]))\n prev_end = float("-inf")\n counter = 0\n for start, end in intervals:\n if start < prev_end:\n counter += 1\n if end < prev_end:\n prev_end = end\n else:\n prev_end = end\n return counter\n``` | 1 | Given an array of intervals `intervals` where `intervals[i] = [starti, endi]`, return _the minimum number of intervals you need to remove to make the rest of the intervals non-overlapping_.
**Example 1:**
**Input:** intervals = \[\[1,2\],\[2,3\],\[3,4\],\[1,3\]\]
**Output:** 1
**Explanation:** \[1,3\] can be removed and the rest of the intervals are non-overlapping.
**Example 2:**
**Input:** intervals = \[\[1,2\],\[1,2\],\[1,2\]\]
**Output:** 2
**Explanation:** You need to remove two \[1,2\] to make the rest of the intervals non-overlapping.
**Example 3:**
**Input:** intervals = \[\[1,2\],\[2,3\]\]
**Output:** 0
**Explanation:** You don't need to remove any of the intervals since they're already non-overlapping.
**Constraints:**
* `1 <= intervals.length <= 105`
* `intervals[i].length == 2`
* `-5 * 104 <= starti < endi <= 5 * 104` | null |
Python Solution (✅Greedy) | O(nlogn) | non-overlapping-intervals | 0 | 1 | ## Intuition\nThe problem requires finding the minimum number of intervals that need to be removed to avoid overlaps. Sorting the intervals by their end times provides an efficient way to handle this problem. By iterating through the sorted intervals, we can check if the start time of the current interval is greater than or equal to the end time of the previous interval. If it is, the intervals do not overlap, and we can update the `current_t` variable to the end time of the current interval. If there is an overlap, we increment the `count` variable to keep track of the number of overlapping intervals.\n\n## Approach\n1. Sort the intervals based on their end times in ascending order.\n2. Initialize `current_t` to a very small value (in this case, -50001) to handle the case when the first interval has a negative start time.\n3. Initialize `count` to 0 to keep track of the number of overlapping intervals.\n4. Iterate through the sorted intervals.\n5. If the start time of the current interval is greater than or equal to `current_t`, update `current_t` to the end time of the current interval. This means the intervals do not overlap, and no removal is required.\n6. If the start time of the current interval is less than `current_t`, there is an overlap. Increment the `count` variable to keep track of the overlapping intervals.\n7. Return the final `count` as the result.\n\n## Complexity\n- Time complexity: O(nlogn) due to sorting, where n is the number of intervals.\n- Space complexity: O(1) since the algorithm uses a constant amount of extra space.\n\n\n# Code\n```\nclass Solution:\n def eraseOverlapIntervals(self, intervals: List[List[int]]) -> int:\n intervals.sort( key=lambda x:x[1])\n current_t , count = -50001 , 0\n \n for x in intervals:\n if x[0] >= current_t :\n current_t = x[1]\n else:\n count+=1\n return count \n\n\n \n```\n\n# Please upvote the solution if you understood it.\n\n | 2 | Given an array of intervals `intervals` where `intervals[i] = [starti, endi]`, return _the minimum number of intervals you need to remove to make the rest of the intervals non-overlapping_.
**Example 1:**
**Input:** intervals = \[\[1,2\],\[2,3\],\[3,4\],\[1,3\]\]
**Output:** 1
**Explanation:** \[1,3\] can be removed and the rest of the intervals are non-overlapping.
**Example 2:**
**Input:** intervals = \[\[1,2\],\[1,2\],\[1,2\]\]
**Output:** 2
**Explanation:** You need to remove two \[1,2\] to make the rest of the intervals non-overlapping.
**Example 3:**
**Input:** intervals = \[\[1,2\],\[2,3\]\]
**Output:** 0
**Explanation:** You don't need to remove any of the intervals since they're already non-overlapping.
**Constraints:**
* `1 <= intervals.length <= 105`
* `intervals[i].length == 2`
* `-5 * 104 <= starti < endi <= 5 * 104` | null |
Easy Solution with explanation | Python 3 | non-overlapping-intervals | 0 | 1 | # Algorithm\n- Sort intervals array\n- create a default pointer for pe for storing end of previous interval \n- create a variable for storing result\n- loop over sorted intervals array and check if end >= pe\n - if condition is true then update pe pointer with current end\n - else update result with +1\n- return result\n\n# Complexity\n- Time complexity:\nO(nlogn)\n\n- Space complexity:\nO(n) [Python uses Timsort and it takes O(n) space in worst case]\n# Video Explanation\nhttps://youtu.be/AMbiy_gzVnY\n\n# Code\n```\nclass Solution:\n def eraseOverlapIntervals(self, intervals: List[List[int]]) -> int:\n """\n Algo - \n - Sort intervals array\n - create a default pointer for pe for storing end of previous interval \n - create a variable for storing result\n - loop over sorted intervals array and check if end >= pe\n - if condition is true then update pe pointer with current end\n - else update result with +1\n - return result\n """\n\n intervals.sort(key = lambda x: x[1])\n pe = -inf\n result = 0\n\n for start, end in intervals:\n if start >= pe:\n pe = end\n else:\n result += 1\n return result\n``` | 2 | Given an array of intervals `intervals` where `intervals[i] = [starti, endi]`, return _the minimum number of intervals you need to remove to make the rest of the intervals non-overlapping_.
**Example 1:**
**Input:** intervals = \[\[1,2\],\[2,3\],\[3,4\],\[1,3\]\]
**Output:** 1
**Explanation:** \[1,3\] can be removed and the rest of the intervals are non-overlapping.
**Example 2:**
**Input:** intervals = \[\[1,2\],\[1,2\],\[1,2\]\]
**Output:** 2
**Explanation:** You need to remove two \[1,2\] to make the rest of the intervals non-overlapping.
**Example 3:**
**Input:** intervals = \[\[1,2\],\[2,3\]\]
**Output:** 0
**Explanation:** You don't need to remove any of the intervals since they're already non-overlapping.
**Constraints:**
* `1 <= intervals.length <= 105`
* `intervals[i].length == 2`
* `-5 * 104 <= starti < endi <= 5 * 104` | null |
Python Simple O(NLogN) | non-overlapping-intervals | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def eraseOverlapIntervals(self, intervals: List[List[int]]) -> int:\n if not intervals:\n return 0\n intervals.sort(key=lambda x:x[1])\n prevInterval = intervals[0]\n count = 0\n for newInterval in intervals[1:]:\n if prevInterval[1]>newInterval[0]:\n count+=1\n else:\n prevInterval = newInterval\n return count\n \n\n``` | 0 | Given an array of intervals `intervals` where `intervals[i] = [starti, endi]`, return _the minimum number of intervals you need to remove to make the rest of the intervals non-overlapping_.
**Example 1:**
**Input:** intervals = \[\[1,2\],\[2,3\],\[3,4\],\[1,3\]\]
**Output:** 1
**Explanation:** \[1,3\] can be removed and the rest of the intervals are non-overlapping.
**Example 2:**
**Input:** intervals = \[\[1,2\],\[1,2\],\[1,2\]\]
**Output:** 2
**Explanation:** You need to remove two \[1,2\] to make the rest of the intervals non-overlapping.
**Example 3:**
**Input:** intervals = \[\[1,2\],\[2,3\]\]
**Output:** 0
**Explanation:** You don't need to remove any of the intervals since they're already non-overlapping.
**Constraints:**
* `1 <= intervals.length <= 105`
* `intervals[i].length == 2`
* `-5 * 104 <= starti < endi <= 5 * 104` | null |
Python3 Sort+DP | non-overlapping-intervals | 0 | 1 | # Intuition\n- Sort the intervals first\n- There are two choices in each idx: remove it or keep it.\n- Remove it: add count 1 and move to next index\n- Keep it: should find the next valid index, count the number of skipping indices\n * Use binary search to find the next first element which start is larger than the current index\'s end\n * Ex: ` [1,6], [2,3], [4,6], [7,8]`\n * When choose index-0, find the next one [7,8] at index-3\n * idx = 0, left = 3, the amount of skip element is left-idx-1\n- Return the minimum of remove/keep way\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\nO ( N * log n + N * log N)\n\n- Space complexity:\nO (N)\n\n# Code\n```\nclass Solution:\n def eraseOverlapIntervals(self, intervals: List[List[int]]) -> int:\n intervals.sort()\n @cache\n def dfs(idx):\n if idx==len(intervals):\n return 0\n\n take = 1+dfs(idx+1)\n\n left = idx+1\n right = len(intervals)-1\n while left<=right:\n mid = (left+right)//2\n if intervals[mid][0]<intervals[idx][1]:\n left = mid+1\n else:\n right = mid-1\n noTake = left-idx-1+dfs(left)\n return min(take, noTake)\n return dfs(0)\n\n``` | 1 | Given an array of intervals `intervals` where `intervals[i] = [starti, endi]`, return _the minimum number of intervals you need to remove to make the rest of the intervals non-overlapping_.
**Example 1:**
**Input:** intervals = \[\[1,2\],\[2,3\],\[3,4\],\[1,3\]\]
**Output:** 1
**Explanation:** \[1,3\] can be removed and the rest of the intervals are non-overlapping.
**Example 2:**
**Input:** intervals = \[\[1,2\],\[1,2\],\[1,2\]\]
**Output:** 2
**Explanation:** You need to remove two \[1,2\] to make the rest of the intervals non-overlapping.
**Example 3:**
**Input:** intervals = \[\[1,2\],\[2,3\]\]
**Output:** 0
**Explanation:** You don't need to remove any of the intervals since they're already non-overlapping.
**Constraints:**
* `1 <= intervals.length <= 105`
* `intervals[i].length == 2`
* `-5 * 104 <= starti < endi <= 5 * 104` | null |
FULL Explanation Of Everything | find-right-interval | 0 | 1 | \n## Question\n```\nintervals = [[3,4],[2,3],[1,2]]\nNote : Here each value is a \'list\'.\n\nFor x = [3,4] : \nIs there any value/list whose first value ([f,_]) is EQUAL OR GREATER THAN x[1] (4) ? \n No! "-1"\nFor x = [2,3] : Say y = [3,4], so for x[1] (3), y[0] is >= x[1].\n So answer is the index of [3,4] = "0"\nFor x = [1,2] : The answer is the index of [2,3] = "1"\n\nreturn [-1, 0, 1]\n```\n``` \n "any value/list" I meant ANY VALUE INCLUDING ITSELF! LIKE\n\nintervals = [[1,1], [3,4]]\n\nIf we map for every x[0] and it\'s index :\n 1 - 0\n 3 - 2 \nnow if x = [1,1] and x[1] = 1, is there any value ( I mean anyyyy ) \nwhich first value (x[0]) starts with 1? Yes, [1,1] itself. so 0 for [1,1]\nand -1 for [3,4] as no x[0] is equal or greater than 4 \n```\n## Implementation :\n```\nx = every item in the \'intervals\'\n _______________________\n | |\nIf I had every \'x[0]\' with its index \'sorted\' cause Q said \'minimized\', like \n\n MAP\n x index x[0] index x[0] index\n [3,4] - 0 3 - 0 sort 1 - 2\n [2,3] - 1 2 - 1 -------> 2 - 1\n [1,2] - 2 1 - 2 3 - 0\n\nNow it will be easier like : for x = [3,4], x[1] = 4 and there is no x[0] which is >= 4 in MAP.\n\n"EQUAL OR GREATER THAN" - lower_bound in CPP for map and bisect_left in Python for list.\n\nadd [Maximum value , -1] in map/list so you don\'t need to say if \nlower_bound()/bisect_left() == end: add -1, else index stuffs.\n```\n```CPP []\nclass Solution \n{\npublic:\n vector<int> findRightInterval(vector<vector<int>>& intervals) \n {\n vector<int> ans;\n map<int, int> m { {INT_MAX, -1} };\n\n for(int i=0; i<intervals.size(); i++)\n m[intervals[i][0]] = i; // < x[0], index >\n\n for(auto &arr : intervals)\n ans.push_back( m.lower_bound(arr[1])->second );\n\n return ans;\n }\n};\n```\n```Python []\nclass Solution:\n def findRightInterval(self, intervals: List[List[int]]) -> List[int]:\n # first = [[x[0], index],[x[0], index]....]\n first = sorted([ [arr[0], i] for i,arr in enumerate(intervals) ]) + [[float(\'inf\'), -1]]\n return [ first[ bisect_left(first, [arr[1]] )][1] for arr in intervals ]\n```\n```\nTime complexity : O(nlogn)\nSpace complexity : O(n)\n```\n# bisect_left\n```\nintervals = [[3,4],[2,3],[1,2]] -- here every item is a list.\nFor nums = [1,2,3,4] we say bisect_left(nums, 4) for finding 4.\nhere in 2D intervals if you want to find the "list" whose first value is >= than 4, \nthen you\'ve to write bisect_left(first, [4])\n |__ Since we want to find the "list".\n\nHOW THIS WORKS ? bisect_left will iterate over \'first\' list and check if the 1st item\nhas started with 4 or greater than 4, if it starts it return the index of that item.\nIf it doesn\'t, We don\'t care what the next value inside that item.\nlike for item x = [3,4], does x[0] starts with 4 or greater than 4? NO! So we don\'t care if \nx[1] starts with 4, cause we specifically said [4] means only the first value will be checked. \n\nEXTRA INFO :\nFind the index of the list whose second value is >= 4 :\nbisect_left(first, [float(\'-inf\'), 4])\n |\n |_ the 1st value just need to be anything IDC\n Our main focus on the \'second\' value.\n\nFind the index of the list whose first value >= 4 and second value >= 5 :\n bisect_left(first, [4,5])\n\nif first = [[4,4], [5,7], [8,9]], answer would be [5,7] \n```\n\n### If the post was helpful, an upvote will really me happy since instead of sleeping I\'ve been writing. Thank you for reading this.\n## If you have any Q, feel free to ask:) \n | 10 | You are given an array of `intervals`, where `intervals[i] = [starti, endi]` and each `starti` is **unique**.
The **right interval** for an interval `i` is an interval `j` such that `startj >= endi` and `startj` is **minimized**. Note that `i` may equal `j`.
Return _an array of **right interval** indices for each interval `i`_. If no **right interval** exists for interval `i`, then put `-1` at index `i`.
**Example 1:**
**Input:** intervals = \[\[1,2\]\]
**Output:** \[-1\]
**Explanation:** There is only one interval in the collection, so it outputs -1.
**Example 2:**
**Input:** intervals = \[\[3,4\],\[2,3\],\[1,2\]\]
**Output:** \[-1,0,1\]
**Explanation:** There is no right interval for \[3,4\].
The right interval for \[2,3\] is \[3,4\] since start0 = 3 is the smallest start that is >= end1 = 3.
The right interval for \[1,2\] is \[2,3\] since start1 = 2 is the smallest start that is >= end2 = 2.
**Example 3:**
**Input:** intervals = \[\[1,4\],\[2,3\],\[3,4\]\]
**Output:** \[-1,2,-1\]
**Explanation:** There is no right interval for \[1,4\] and \[3,4\].
The right interval for \[2,3\] is \[3,4\] since start2 = 3 is the smallest start that is >= end1 = 3.
**Constraints:**
* `1 <= intervals.length <= 2 * 104`
* `intervals[i].length == 2`
* `-106 <= starti <= endi <= 106`
* The start point of each interval is **unique**. | null |
436: Solution with step by step explanation | find-right-interval | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Create a dictionary called start_points to store the start points of intervals and their corresponding indices. Initialize it to an empty dictionary.\n2. Iterate over the list of intervals using enumerate. For each interval, add its start point as a key to the start_points dictionary with its index as the value.\n3. Sort the list of intervals based on their start points using the sorted function and a lambda function that returns the start point of each interval.\n4. Initialize the result list with -1 for each interval in the original list.\n5. Iterate over the original list of intervals using enumerate. For each interval, find its right interval using the bisect_left function.\n6. If a right interval is found, update the result list with the index of the right interval in the start_points dictionary.\n7. Return the result list.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def findRightInterval(self, intervals: List[List[int]]) -> List[int]:\n # Create a dictionary to store the start points of intervals and their indices\n start_points = {}\n for i, interval in enumerate(intervals):\n start_points[interval[0]] = i\n \n # Sort the intervals based on their start points\n sorted_intervals = sorted(intervals, key=lambda x: x[0])\n \n # Initialize the result list with -1 for all intervals\n result = [-1] * len(intervals)\n \n # Iterate over the sorted intervals\n for i, interval in enumerate(intervals):\n # Find the index of the right interval using binary search\n index = bisect_left(sorted_intervals, [interval[1], -float(\'inf\')])\n # If a right interval is found, update the result list with its index\n if index != len(intervals):\n result[i] = start_points[sorted_intervals[index][0]]\n \n return result\n\n``` | 6 | You are given an array of `intervals`, where `intervals[i] = [starti, endi]` and each `starti` is **unique**.
The **right interval** for an interval `i` is an interval `j` such that `startj >= endi` and `startj` is **minimized**. Note that `i` may equal `j`.
Return _an array of **right interval** indices for each interval `i`_. If no **right interval** exists for interval `i`, then put `-1` at index `i`.
**Example 1:**
**Input:** intervals = \[\[1,2\]\]
**Output:** \[-1\]
**Explanation:** There is only one interval in the collection, so it outputs -1.
**Example 2:**
**Input:** intervals = \[\[3,4\],\[2,3\],\[1,2\]\]
**Output:** \[-1,0,1\]
**Explanation:** There is no right interval for \[3,4\].
The right interval for \[2,3\] is \[3,4\] since start0 = 3 is the smallest start that is >= end1 = 3.
The right interval for \[1,2\] is \[2,3\] since start1 = 2 is the smallest start that is >= end2 = 2.
**Example 3:**
**Input:** intervals = \[\[1,4\],\[2,3\],\[3,4\]\]
**Output:** \[-1,2,-1\]
**Explanation:** There is no right interval for \[1,4\] and \[3,4\].
The right interval for \[2,3\] is \[3,4\] since start2 = 3 is the smallest start that is >= end1 = 3.
**Constraints:**
* `1 <= intervals.length <= 2 * 104`
* `intervals[i].length == 2`
* `-106 <= starti <= endi <= 106`
* The start point of each interval is **unique**. | null |
Python sort, binary search and hashmap | find-right-interval | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nA variant of LeetCode 744.\n# Approach\n1. The start of each interval is unique, so create a hashmap to map the start of each interval to the index of each interval in intervals.\n2. Sort the list of intervals.\n3. Similar to LeetCode 744, construct a helper function using binary search to find the index of the interval whose start is not smaller than a given target while the index must be minimized.\n4. Iterate the sorted intervals, for each interval apply the helper function, update the res array with the help of the hashmap mentioned above.\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nO(n*log(n))\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nO(n)\n# Code\n```\nclass Solution:\n def findRightInterval(self, intervals: List[List[int]]) -> List[int]:\n mapping = {}\n for idx, interval in enumerate(intervals):\n mapping[interval[0]] = idx\n \n intervals.sort()\n n = len(intervals)\n\n def binary_search(intervals, target):\n left = 0\n right = n-1\n while left <= right:\n mid = left + (right-left)//2\n if intervals[mid][0] < target:\n left = mid + 1\n else:\n right = mid - 1\n if left == n:\n return -1\n else:\n return left\n\n res = [-1] * n\n for i in range(n):\n idx2 = binary_search(intervals, intervals[i][1])\n if idx2 != -1:\n res[mapping[intervals[i][0]]] = mapping[intervals[idx2][0]]\n else:\n res[mapping[intervals[i][0]]] = -1\n \n return res\n\n \n\n \n``` | 1 | You are given an array of `intervals`, where `intervals[i] = [starti, endi]` and each `starti` is **unique**.
The **right interval** for an interval `i` is an interval `j` such that `startj >= endi` and `startj` is **minimized**. Note that `i` may equal `j`.
Return _an array of **right interval** indices for each interval `i`_. If no **right interval** exists for interval `i`, then put `-1` at index `i`.
**Example 1:**
**Input:** intervals = \[\[1,2\]\]
**Output:** \[-1\]
**Explanation:** There is only one interval in the collection, so it outputs -1.
**Example 2:**
**Input:** intervals = \[\[3,4\],\[2,3\],\[1,2\]\]
**Output:** \[-1,0,1\]
**Explanation:** There is no right interval for \[3,4\].
The right interval for \[2,3\] is \[3,4\] since start0 = 3 is the smallest start that is >= end1 = 3.
The right interval for \[1,2\] is \[2,3\] since start1 = 2 is the smallest start that is >= end2 = 2.
**Example 3:**
**Input:** intervals = \[\[1,4\],\[2,3\],\[3,4\]\]
**Output:** \[-1,2,-1\]
**Explanation:** There is no right interval for \[1,4\] and \[3,4\].
The right interval for \[2,3\] is \[3,4\] since start2 = 3 is the smallest start that is >= end1 = 3.
**Constraints:**
* `1 <= intervals.length <= 2 * 104`
* `intervals[i].length == 2`
* `-106 <= starti <= endi <= 106`
* The start point of each interval is **unique**. | null |
sorted + bin search NlogN | find-right-interval | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: $NlogN$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def binSearch(self, a, curr_i):\n l, r = curr_i + 1, len(a) - 1\n while l <= r:\n mid = (l + r) // 2\n if a[mid][0] < a[curr_i][1]:\n l = mid + 1\n else:\n r = mid - 1\n return a[l][2] if l != len(a) else -1\n\n def findRightInterval(self, intervals: List[List[int]]) -> List[int]: \n intervals = sorted([[*a, i] for i, a in enumerate(intervals)])\n result = [-1] * len(intervals)\n for i in range(len(intervals)):\n if intervals[i][0] == intervals[i][1]:\n result[intervals[i][2]] = intervals[i][2]\n else:\n result[intervals[i][2]] = self.binSearch(intervals, i)\n return result\n``` | 0 | You are given an array of `intervals`, where `intervals[i] = [starti, endi]` and each `starti` is **unique**.
The **right interval** for an interval `i` is an interval `j` such that `startj >= endi` and `startj` is **minimized**. Note that `i` may equal `j`.
Return _an array of **right interval** indices for each interval `i`_. If no **right interval** exists for interval `i`, then put `-1` at index `i`.
**Example 1:**
**Input:** intervals = \[\[1,2\]\]
**Output:** \[-1\]
**Explanation:** There is only one interval in the collection, so it outputs -1.
**Example 2:**
**Input:** intervals = \[\[3,4\],\[2,3\],\[1,2\]\]
**Output:** \[-1,0,1\]
**Explanation:** There is no right interval for \[3,4\].
The right interval for \[2,3\] is \[3,4\] since start0 = 3 is the smallest start that is >= end1 = 3.
The right interval for \[1,2\] is \[2,3\] since start1 = 2 is the smallest start that is >= end2 = 2.
**Example 3:**
**Input:** intervals = \[\[1,4\],\[2,3\],\[3,4\]\]
**Output:** \[-1,2,-1\]
**Explanation:** There is no right interval for \[1,4\] and \[3,4\].
The right interval for \[2,3\] is \[3,4\] since start2 = 3 is the smallest start that is >= end1 = 3.
**Constraints:**
* `1 <= intervals.length <= 2 * 104`
* `intervals[i].length == 2`
* `-106 <= starti <= endi <= 106`
* The start point of each interval is **unique**. | null |
Python Dictionary + Binary Search | find-right-interval | 0 | 1 | # Complexity\n- Time complexity:\nO(NlogN)\n\n- Space complexity:\nO(N)\n\n# Code\n```\nclass Solution:\n def findRightInterval(self, arr: List[List[int]]) -> List[int]:\n f=float(\'-inf\')\n d,n,l={f:-1},len(arr),[i[0] for i in arr]\n l.sort()\n for i in range(n):\n d[arr[i][0]]=i\n def bs(num):\n i,j,k=0,n-1,f\n while i<=j:\n mid=(i+j)//2\n if l[mid]>=num:\n k=l[mid]\n j=mid-1\n else:\n i=mid+1\n return k\n return [d[bs(i[1])] for i in arr]\n``` | 0 | You are given an array of `intervals`, where `intervals[i] = [starti, endi]` and each `starti` is **unique**.
The **right interval** for an interval `i` is an interval `j` such that `startj >= endi` and `startj` is **minimized**. Note that `i` may equal `j`.
Return _an array of **right interval** indices for each interval `i`_. If no **right interval** exists for interval `i`, then put `-1` at index `i`.
**Example 1:**
**Input:** intervals = \[\[1,2\]\]
**Output:** \[-1\]
**Explanation:** There is only one interval in the collection, so it outputs -1.
**Example 2:**
**Input:** intervals = \[\[3,4\],\[2,3\],\[1,2\]\]
**Output:** \[-1,0,1\]
**Explanation:** There is no right interval for \[3,4\].
The right interval for \[2,3\] is \[3,4\] since start0 = 3 is the smallest start that is >= end1 = 3.
The right interval for \[1,2\] is \[2,3\] since start1 = 2 is the smallest start that is >= end2 = 2.
**Example 3:**
**Input:** intervals = \[\[1,4\],\[2,3\],\[3,4\]\]
**Output:** \[-1,2,-1\]
**Explanation:** There is no right interval for \[1,4\] and \[3,4\].
The right interval for \[2,3\] is \[3,4\] since start2 = 3 is the smallest start that is >= end1 = 3.
**Constraints:**
* `1 <= intervals.length <= 2 * 104`
* `intervals[i].length == 2`
* `-106 <= starti <= endi <= 106`
* The start point of each interval is **unique**. | null |
✅Easiest of all Solution for beginners using bisect✅ | find-right-interval | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nYou require reasoning to understand why this???\nans.append(start.index(start_sorted[index]))\n\nIf you have any doubts fell free to comment.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\u2B06\uFE0F**PLEASE UPVOTE IF IT HELPS YOU**\u2B06\uFE0F\n# Code\n```\nclass Solution:\n def findRightInterval(self, intervals: List[List[int]]) -> List[int]:\n if len(intervals)<2 and intervals[0][0]!=intervals[0][1]:\n return [-1]\n elif len(intervals)<2 and intervals[0][0]==intervals[0][1]:\n return [0]\n start = [s for s,e in intervals]\n end = [e for s,e in intervals]\n start_sorted = sorted(start)\n end_sorted = sorted(end)\n ans = []\n for i in end:\n index = bisect_left(start_sorted, i)\n if index>len(start)-1:\n ans.append(-1)\n else:\n ans.append(start.index(start_sorted[index]))\n return ans\n \n```\n\u2B06\uFE0F**PLEASE UPVOTE IF IT HELPS YOU**\u2B06\uFE0F | 0 | You are given an array of `intervals`, where `intervals[i] = [starti, endi]` and each `starti` is **unique**.
The **right interval** for an interval `i` is an interval `j` such that `startj >= endi` and `startj` is **minimized**. Note that `i` may equal `j`.
Return _an array of **right interval** indices for each interval `i`_. If no **right interval** exists for interval `i`, then put `-1` at index `i`.
**Example 1:**
**Input:** intervals = \[\[1,2\]\]
**Output:** \[-1\]
**Explanation:** There is only one interval in the collection, so it outputs -1.
**Example 2:**
**Input:** intervals = \[\[3,4\],\[2,3\],\[1,2\]\]
**Output:** \[-1,0,1\]
**Explanation:** There is no right interval for \[3,4\].
The right interval for \[2,3\] is \[3,4\] since start0 = 3 is the smallest start that is >= end1 = 3.
The right interval for \[1,2\] is \[2,3\] since start1 = 2 is the smallest start that is >= end2 = 2.
**Example 3:**
**Input:** intervals = \[\[1,4\],\[2,3\],\[3,4\]\]
**Output:** \[-1,2,-1\]
**Explanation:** There is no right interval for \[1,4\] and \[3,4\].
The right interval for \[2,3\] is \[3,4\] since start2 = 3 is the smallest start that is >= end1 = 3.
**Constraints:**
* `1 <= intervals.length <= 2 * 104`
* `intervals[i].length == 2`
* `-106 <= starti <= endi <= 106`
* The start point of each interval is **unique**. | null |
Tedha hai par mera hai | find-right-interval | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nIski complexity O(nlogn) se kam nahi hogi chahe jo kar lo apana ne saab tarah se implement karke dekh liya.\nApna funda sidha tha but question thoda tedah tha, sort karna padha phir binary search lagana pada phir jake hua ye question.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def smallest_letter_greater_than(self, target, arr,d):\n # We will refactor this code with binary search as time limit exceeds for very large inputs and so far all have been shown to be in sorted order\n #set order\n left=0\n right=len(arr)-1\n # element not present in arr return -1\n if target>arr[len(arr)-1]:\n return -1\n elif target<arr[0]:\n return 0\n while left<=right:\n mid=int((left+right)/2)\n if target>arr[mid]:\n left=mid+1\n elif target<=arr[mid]:\n right=mid-1\n return d[arr[left]]\n\n """\n current = -1\n for x in range(0,len(arr)):\n if arr[x] >=target:\n # set current\n if current == -1:\n current = x\n else: # compare with current\n if arr[x] <=arr[current]:\n current = x\n else:\n continue\n\n return current\n """\n\n def findRightInterval(self, intervals):\n # abb khulam khula jhula rahe hain baton mein jab tak samaj naa aya ange mat bhadna\n # abhi isko naive approach se karne ka pehle no code only algo\n if intervals == []:\n return [-1]\n sol = []\n arr=[x[0] for x in intervals]\n d = {arr[i]: i for i in range(0, len(arr))}\n arr.sort()\n for x in intervals:\n # taking end of current x\n target = x[1]\n result = self.smallest_letter_greater_than(target, arr,d)\n sol.append(result)\n return sol\n """\n Algo1(Binary search"Assuming the array of first element of each interval is sorted"):-\n We will do binary search on all elements of Array {K} for all start(i)(first elemnet of each interval)\n Array K:- intervals[1-n][0]\n """ \n """\n # binary search on k use only in case it was given that 1st elements were in a sorted order\n left=0\n right=len(intervals)-1\n while left<=right:\n mid=int((left+right)/2)\n if target>intervals[mid][0]:\n left=mid+1\n elif target<=intervals[mid][0]:\n right=mid-1\n #return left\n sol.append(right ki left aur what when element not present?)\n """\n #currently we will use only Linear search modification\n``` | 0 | You are given an array of `intervals`, where `intervals[i] = [starti, endi]` and each `starti` is **unique**.
The **right interval** for an interval `i` is an interval `j` such that `startj >= endi` and `startj` is **minimized**. Note that `i` may equal `j`.
Return _an array of **right interval** indices for each interval `i`_. If no **right interval** exists for interval `i`, then put `-1` at index `i`.
**Example 1:**
**Input:** intervals = \[\[1,2\]\]
**Output:** \[-1\]
**Explanation:** There is only one interval in the collection, so it outputs -1.
**Example 2:**
**Input:** intervals = \[\[3,4\],\[2,3\],\[1,2\]\]
**Output:** \[-1,0,1\]
**Explanation:** There is no right interval for \[3,4\].
The right interval for \[2,3\] is \[3,4\] since start0 = 3 is the smallest start that is >= end1 = 3.
The right interval for \[1,2\] is \[2,3\] since start1 = 2 is the smallest start that is >= end2 = 2.
**Example 3:**
**Input:** intervals = \[\[1,4\],\[2,3\],\[3,4\]\]
**Output:** \[-1,2,-1\]
**Explanation:** There is no right interval for \[1,4\] and \[3,4\].
The right interval for \[2,3\] is \[3,4\] since start2 = 3 is the smallest start that is >= end1 = 3.
**Constraints:**
* `1 <= intervals.length <= 2 * 104`
* `intervals[i].length == 2`
* `-106 <= starti <= endi <= 106`
* The start point of each interval is **unique**. | null |
Iterative O(N) Python Solution | path-sum-iii | 0 | 1 | # Intuition\n\nThe key to a linear solution is the realization that...\n\n**If at a given node, the sum of all the nodes from the current node to root subtracted by k is equal to a sum to the root that was observed previously on this path, then there are paths that sum to k equal to the number of times `sumToRoot - k` was previously encountered.**\n\nExample:\n```\n# Input: A tree that is one long line of left children.\n\nroot: [10, 3, null, 5, null, -5, null, 5, null 0]\nk: 8\n```\n\nThe sums-to-root, or prefix sum as it is more commonly called are as we travel down the leftmost path.\n\n`[10, 13, 18, 13, 18, 18]`\n\nObserve that at as we visit index i where i is equal to 5, 5, and 0, we encounter a prefix sum of `18`.\n\nif `prefixSum - k == previouslySeenPrefixSum` then we know that we can count a path that sums to k for each time that sum was previously observed.\n\n`0 + 0 + 1 + 0 + 1 + 1 = 3`\n\nIf we remove previously observed sums from a dictionary that keeps track of their counts as previously considered nodes are no longer a part of the current path we are evaluating, then we can use this logic for more complex trees as well.\n\n\n# Approach\nTraverse the tree once in "preorder" order. As we visit nodes keep a stack of nodes to visit next, always making sure that the next left child is last on the stack.\n\nAs we go, track the sum of all nodes, and a stack of those node values. If the next node that we should check is at a depth that is more shallow than the number of nodes that currently make up the prefix sum, remove values until the prefix sum is equal to the current path to the root.\n\n# Complexity\n- Time complexity:\n$$O(n)$$\nEvery node is visited once.\n\nEvery node value is added to the stack of currently used nodes once. Every node is removed from that node once.\n\nChecks made to see if `prefixSum - k` was encountered previously as a prefix sum (and how many times) are made against a dictionary in constant time.\n\n- Space complexity:\n$$O(n)$$\n\n# Code\n```\nclass Solution:\n def pathSum(self, root: TreeNode, k: int) -> int:\n\n if root is None:\n return 0\n \n # Track whenever we discover a path that sums to k\n count = 0\n\n # Track the sum of all the nodes that we have seen thus far while traversing this path.\n # If we backtrack, we will remove a count to represent it not being a part of the current path we are evaluating.\n prefixSums = collections.defaultdict(int)\n \n # Keep track of the most recently added values to prefixSum.\n # When we leave a path and traverse down a neihboring path, \n # this allows us to efficiently correct the prefixSum up until that point.\n prefixNodes = []\n prefixSum = 0\n\n # Track the next nodes to evaluate such that the next preorder node is always the last element.\n nextNodes = [(root, 1)]\n \n while nextNodes:\n \n node, depth = nextNodes.pop()\n\n # This block here performs the "recursion magic"\n # of the provided editorial solution explicitly.\n # Correct the prefixSum by subtracting the values of \n # nodes that are not a part of the this node\'s path to the root.\n while len(prefixNodes) >= depth:\n prefixSums[prefixSum] -= 1\n prefixSum -= prefixNodes.pop()\n\n prefixSum += node.val\n \n # The current path from the root sums to k.\n if prefixSum == k:\n count += 1\n\n # The prefixSums dictionary tracks all of the sums that we have seen to the root. \n # If there exists a sum in there that is the k subtracted from the current path to the root, \n # then the nodes we have added between then and now sum to k.\n count += prefixSums[prefixSum - k]\n\n prefixNodes.append(node.val)\n prefixSums[prefixSum] += 1 \n\n # Add additional child nodes such that the left most node gets popped next.\n if node.right:\n nextNodes.append((node.right, depth + 1))\n\n if node.left:\n nextNodes.append((node.left, depth + 1))\n\n return count\n\n\n\n\n``` | 2 | Given the `root` of a binary tree and an integer `targetSum`, return _the number of paths where the sum of the values along the path equals_ `targetSum`.
The path does not need to start or end at the root or a leaf, but it must go downwards (i.e., traveling only from parent nodes to child nodes).
**Example 1:**
**Input:** root = \[10,5,-3,3,2,null,11,3,-2,null,1\], targetSum = 8
**Output:** 3
**Explanation:** The paths that sum to 8 are shown.
**Example 2:**
**Input:** root = \[5,4,8,11,null,13,4,7,2,null,null,5,1\], targetSum = 22
**Output:** 3
**Constraints:**
* The number of nodes in the tree is in the range `[0, 1000]`.
* `-109 <= Node.val <= 109`
* `-1000 <= targetSum <= 1000` | null |
437: Space 93.92%, Solution with step by step explanation | path-sum-iii | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Define the function with the given input parameters: a binary tree root node and an integer targetSum. The function should return an integer representing the number of paths in the tree that sum to the targetSum.\n\n2. Create a class variable called count and initialize it to 0. This variable will keep track of the number of paths that sum to the targetSum.\n\n3. Create a dictionary called prefix_sum and initialize it with a key-value pair of 0 and 1. This dictionary will keep track of the prefix sum values and the number of times they occur in the path.\n\n4. Define a recursive helper function called dfs that takes three parameters: a node in the binary tree, the targetSum, and the current sum of the path. This function will perform a depth-first search on the binary tree.\n\n5. If the current node is None, return.\n\n6. Add the value of the current node to the current sum.\n\n7. Check if the difference between the current sum and the targetSum is present in the prefix_sum dictionary. If it is, add the value of the key to the count variable.\n\n8. Add the current sum to the prefix_sum dictionary with a value of 1 if it is not already present. If it is present, increment the value by 1.\n\n9. Recursively call the dfs function on the left child of the current node with the updated current sum.\n\n10. Recursively call the dfs function on the right child of the current node with the updated current sum.\n\n11. Decrement the value of the current sum in the prefix_sum dictionary by 1, as this node is no longer in the path.\n\n12. Call the dfs function on the root node with a current sum of 0.\n\n13. Return the count variable.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def pathSum(self, root: TreeNode, targetSum: int) -> int:\n self.count = 0\n self.prefix_sum = {0: 1}\n self.dfs(root, targetSum, 0)\n return self.count\n \n def dfs(self, node: TreeNode, targetSum: int, curr_sum: int) -> None:\n if not node:\n return\n \n curr_sum += node.val\n self.count += self.prefix_sum.get(curr_sum - targetSum, 0)\n self.prefix_sum[curr_sum] = self.prefix_sum.get(curr_sum, 0) + 1\n \n self.dfs(node.left, targetSum, curr_sum)\n self.dfs(node.right, targetSum, curr_sum)\n \n self.prefix_sum[curr_sum] -= 1\n\n``` | 12 | Given the `root` of a binary tree and an integer `targetSum`, return _the number of paths where the sum of the values along the path equals_ `targetSum`.
The path does not need to start or end at the root or a leaf, but it must go downwards (i.e., traveling only from parent nodes to child nodes).
**Example 1:**
**Input:** root = \[10,5,-3,3,2,null,11,3,-2,null,1\], targetSum = 8
**Output:** 3
**Explanation:** The paths that sum to 8 are shown.
**Example 2:**
**Input:** root = \[5,4,8,11,null,13,4,7,2,null,null,5,1\], targetSum = 22
**Output:** 3
**Constraints:**
* The number of nodes in the tree is in the range `[0, 1000]`.
* `-109 <= Node.val <= 109`
* `-1000 <= targetSum <= 1000` | null |
[Python] One-pass DFS, faster than 99% | path-sum-iii | 0 | 1 | Please feel free to give suggestions or ask questions. **Upvote** if you like the solution.\nO(h) space if we delete zero-valued items from sums.\n\n**Idea**: Maintain prefix sums while doing dfs from root to leaf. If currentSum-prefixSum=targetSum, then we\'ve found a path that has a value of target. If we encountered prefixSum n times, then we\'ve found n such paths.\n```\ndef pathSum(self, root: Optional[TreeNode], targetSum: int) -> int:\n\n\t# prefix sums encountered in current path\n\tsums = defaultdict(int)\n\tsums[0] = 1\n\n\tdef dfs(root, total):\n\t\tcount = 0\n\t\tif root:\n\t\t\ttotal += root.val\n\t\t\t# Can remove sums[currSum-targetSum] prefixSums to get target\n\t\t\tcount = sums[total-targetSum]\n\n\t\t\t# Add value of this prefixSum\n\t\t\tsums[total] += 1\n\t\t\t# Explore children\n\t\t\tcount += dfs(root.left, total) + dfs(root.right, total)\n\t\t\t# Remove value of this prefixSum (path\'s been explored)\n\t\t\tsums[total] -= 1\n\n\t\treturn count\n\n\treturn dfs(root, 0)\n``` | 33 | Given the `root` of a binary tree and an integer `targetSum`, return _the number of paths where the sum of the values along the path equals_ `targetSum`.
The path does not need to start or end at the root or a leaf, but it must go downwards (i.e., traveling only from parent nodes to child nodes).
**Example 1:**
**Input:** root = \[10,5,-3,3,2,null,11,3,-2,null,1\], targetSum = 8
**Output:** 3
**Explanation:** The paths that sum to 8 are shown.
**Example 2:**
**Input:** root = \[5,4,8,11,null,13,4,7,2,null,null,5,1\], targetSum = 22
**Output:** 3
**Constraints:**
* The number of nodes in the tree is in the range `[0, 1000]`.
* `-109 <= Node.val <= 109`
* `-1000 <= targetSum <= 1000` | null |
[ Python ] | Simple & Clean Solution | path-sum-iii | 0 | 1 | # Code\n```\nclass Solution:\n def pathSum(self, root: Optional[TreeNode], k: int) -> int:\n def helper(root, currSum):\n if not root: return \n \n nonlocal paths\n\n currSum += root.val\n if m[currSum - k] != 0:\n paths += m[currSum - k]\n\n m[currSum] += 1\n helper(root.left, currSum)\n helper(root.right, currSum) \n m[currSum] -= 1\n\n paths = 0\n m = defaultdict(int)\n m[0] = 1\n \n helper(root, 0)\n\n return paths\n```\n\n```\nclass Solution:\n def pathSum(self, root: Optional[TreeNode], k: int) -> int:\n def take(root, s):\n if not root:\n return 0\n res = 0\n if root.val == s: res += 1\n res += take(root.left, s - root.val) + take(root.right, s - root.val)\n return res\n \n if not root:\n return 0\n return self.pathSum(root.left, k) + self.pathSum(root.right, k) + take(root, k)\n``` | 4 | Given the `root` of a binary tree and an integer `targetSum`, return _the number of paths where the sum of the values along the path equals_ `targetSum`.
The path does not need to start or end at the root or a leaf, but it must go downwards (i.e., traveling only from parent nodes to child nodes).
**Example 1:**
**Input:** root = \[10,5,-3,3,2,null,11,3,-2,null,1\], targetSum = 8
**Output:** 3
**Explanation:** The paths that sum to 8 are shown.
**Example 2:**
**Input:** root = \[5,4,8,11,null,13,4,7,2,null,null,5,1\], targetSum = 22
**Output:** 3
**Constraints:**
* The number of nodes in the tree is in the range `[0, 1000]`.
* `-109 <= Node.val <= 109`
* `-1000 <= targetSum <= 1000` | null |
Python DFS Recursive Solution | path-sum-iii | 0 | 1 | ```\nclass Solution:\n cnt = 0\n def pathSum(self, root: TreeNode, sum: int) -> int:\n def dfs(root, start, s):\n if not root:\n return\n s -= root.val \n if s==0:\n self.cnt+=1\n dfs(root.left,False, s)\n dfs(root.right,False, s)\n if start: \n dfs(root.left,True,sum)\n dfs(root.right,True,sum)\n \n dfs(root, True, sum)\n return self.cnt\n``` | 34 | Given the `root` of a binary tree and an integer `targetSum`, return _the number of paths where the sum of the values along the path equals_ `targetSum`.
The path does not need to start or end at the root or a leaf, but it must go downwards (i.e., traveling only from parent nodes to child nodes).
**Example 1:**
**Input:** root = \[10,5,-3,3,2,null,11,3,-2,null,1\], targetSum = 8
**Output:** 3
**Explanation:** The paths that sum to 8 are shown.
**Example 2:**
**Input:** root = \[5,4,8,11,null,13,4,7,2,null,null,5,1\], targetSum = 22
**Output:** 3
**Constraints:**
* The number of nodes in the tree is in the range `[0, 1000]`.
* `-109 <= Node.val <= 109`
* `-1000 <= targetSum <= 1000` | null |
Easy python solution | BFS | Recursion | path-sum-iii | 0 | 1 | # Code\n```\n# Definition for a binary tree node.\n# class TreeNode:\n# def __init__(self, val=0, left=None, right=None):\n# self.val = val\n# self.left = left\n# self.right = right\n\n# 1. accu from root\n# 2. then accu from root.left adn root.right \nclass Solution:\n def pathSum(self, root: Optional[TreeNode], targetSum: int) -> int:\n \n self.targetSum = targetSum\n self.nums = 0\n def accu_to_tar(root, curr_num=0):\n if not root:\n return 0\n\n curr_num += root.val\n if curr_num == self.targetSum:\n self.nums += 1\n accu_to_tar(root.left, curr_num)\n accu_to_tar(root.right, curr_num)\n \n # BFS\n nodes = [root]\n while nodes:\n curr_node = nodes.pop(0)\n accu_to_tar(curr_node)\n if curr_node:\n nodes.append(curr_node.left)\n nodes.append(curr_node.right)\n return self.nums\n \n \n \n``` | 2 | Given the `root` of a binary tree and an integer `targetSum`, return _the number of paths where the sum of the values along the path equals_ `targetSum`.
The path does not need to start or end at the root or a leaf, but it must go downwards (i.e., traveling only from parent nodes to child nodes).
**Example 1:**
**Input:** root = \[10,5,-3,3,2,null,11,3,-2,null,1\], targetSum = 8
**Output:** 3
**Explanation:** The paths that sum to 8 are shown.
**Example 2:**
**Input:** root = \[5,4,8,11,null,13,4,7,2,null,null,5,1\], targetSum = 22
**Output:** 3
**Constraints:**
* The number of nodes in the tree is in the range `[0, 1000]`.
* `-109 <= Node.val <= 109`
* `-1000 <= targetSum <= 1000` | null |
Python Solution | path-sum-iii | 0 | 1 | What I found helps with this problem is to have two recursive functions:\n- `dfs` simply recurses through each node of the tree\n- `find_path_from_node` tries to find paths starting from the given node\n\nI ran into problems when I tried to merge these functions into one. A lesson for me is to split up recursive functions so each recursive function has a single responsibility.\n\n\n```python\nclass Solution:\n def pathSum(self, root: TreeNode, sum: int) -> int:\n \n global result\n result = 0\n \n def dfs(node, target):\n if node is None: return\n find_path_from_node(node, target)\n dfs(node.left, target)\n dfs(node.right, target)\n \n def find_path_from_node(node, target):\n global result\n if node is None: return\n if node.val == target: result += 1\n find_path_from_node(node.left, target-node.val)\n find_path_from_node(node.right, target-node.val)\n \n dfs(root, sum)\n \n return result\n``` | 20 | Given the `root` of a binary tree and an integer `targetSum`, return _the number of paths where the sum of the values along the path equals_ `targetSum`.
The path does not need to start or end at the root or a leaf, but it must go downwards (i.e., traveling only from parent nodes to child nodes).
**Example 1:**
**Input:** root = \[10,5,-3,3,2,null,11,3,-2,null,1\], targetSum = 8
**Output:** 3
**Explanation:** The paths that sum to 8 are shown.
**Example 2:**
**Input:** root = \[5,4,8,11,null,13,4,7,2,null,null,5,1\], targetSum = 22
**Output:** 3
**Constraints:**
* The number of nodes in the tree is in the range `[0, 1000]`.
* `-109 <= Node.val <= 109`
* `-1000 <= targetSum <= 1000` | null |
✔️ [Python3] SLIDING WINDOW + HASH TABLE, Explained | find-all-anagrams-in-a-string | 0 | 1 | **UPVOTE if you like (\uD83C\uDF38\u25E0\u203F\u25E0), If you have any question, feel free to ask.**\n\nFirst, we have to create a hash map with letters from `p` as keys and its frequencies as values. Then, we start sliding the window `[0..len(s)]` over the `s`. Every time a letter gets out of the window, we increase the corresponding counter in the hashmap, and when a letter gets in the window - we decrease. As soon as all counters in the hashmap become zeros we encountered an anagram.\n\nTime: **O(n)** - one pass over the `p`, on pass for `s`, and for every letter in `s` we iterate over values in hashmap (maximum 26)\nSpace: **O(1)** - hashmap with max 26 keys\n\n```\n def findAnagrams(self, s: str, p: str) -> List[int]:\n hm, res, pL, sL = defaultdict(int), [], len(p), len(s)\n if pL > sL: return []\n\n # build hashmap\n for ch in p: hm[ch] += 1\n\n # initial full pass over the window\n for i in range(pL-1):\n if s[i] in hm: hm[s[i]] -= 1\n \n # slide the window with stride 1\n for i in range(-1, sL-pL+1):\n if i > -1 and s[i] in hm:\n hm[s[i]] += 1\n if i+pL < sL and s[i+pL] in hm: \n hm[s[i+pL]] -= 1\n \n # check whether we encountered an anagram\n if all(v == 0 for v in hm.values()): \n res.append(i+1)\n \n return res\n```\n\n**UPVOTE if you like (\uD83C\uDF38\u25E0\u203F\u25E0), If you have any question, feel free to ask.** | 168 | Given two strings `s` and `p`, return _an array of all the start indices of_ `p`_'s anagrams in_ `s`. You may return the answer in **any order**.
An **Anagram** is a word or phrase formed by rearranging the letters of a different word or phrase, typically using all the original letters exactly once.
**Example 1:**
**Input:** s = "cbaebabacd ", p = "abc "
**Output:** \[0,6\]
**Explanation:**
The substring with start index = 0 is "cba ", which is an anagram of "abc ".
The substring with start index = 6 is "bac ", which is an anagram of "abc ".
**Example 2:**
**Input:** s = "abab ", p = "ab "
**Output:** \[0,1,2\]
**Explanation:**
The substring with start index = 0 is "ab ", which is an anagram of "ab ".
The substring with start index = 1 is "ba ", which is an anagram of "ab ".
The substring with start index = 2 is "ab ", which is an anagram of "ab ".
**Constraints:**
* `1 <= s.length, p.length <= 3 * 104`
* `s` and `p` consist of lowercase English letters. | null |
✔️ Python3 easy solution 116ms🔥🔥🔥| Explained in Detailed | find-all-anagrams-in-a-string | 0 | 1 | # Approach\n\n<!-- Describe your approach to solving the problem. -->\n- make $$hashmap(dictionary)$$ of $$string(p)$$ and frequency of characters in it.\n- iterate over $$length$$ of $$string(s)$$.\n- $$deduct$$ frequency of $$characters$$ $$found$$ in window and in $$string(p)$$.\n- if $$value$$ of $$current-key$$ of $$map-is-0$$ then $$remove$$ it from map **indicating that this character** is **fully traversed**.\n- if **hashmap is empty** then **move window towards right** and increse end of window, because we found anagram and push start of current window in $$ans-list$$.\n- increment start pointer till $$start == end$$, because map is empty then **regain original frequency to match further**.\n- at last **when start > lenght(string(s))** then we stop and $$return-ans$$.\n\n# Complexity\n- Time complexity:$$O(n)$$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:$$O(n)$$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def findAnagrams(self, s: str, p: str) -> List[int]:\n window = len(p)\n mapper = {}\n def __mapper():\n nonlocal mapper\n for i in p:\n if i in mapper.keys(): mapper[i] += 1\n else: mapper[i] = 1\n __mapper()\n ans = []\n st = 0\n ed = 0\n while ed < len(s):\n if s[ed] in mapper.keys():\n mapper[s[ed]] -= 1\n if mapper[s[ed]] == 0:\n del mapper[s[ed]]\n if not bool(mapper):\n ans.append(st)\n mapper[s[st]] = 1\n st += 1\n ed += 1\n else:\n if st == ed:\n st = ed = ed + 1\n else:\n if s[st] in mapper.keys():\n mapper[s[st]] += 1\n else:\n mapper[s[st]] = 1\n st += 1\n return ans \n```\n---\n\n# feel free to suggest me anything and do upvote this solution ( \u0361\u25D5\u202F\u035C\u0296 \u0361\u25D5)\u270C.\nthanks [akheniad](http://leetcode.com/akheniad) for some pointers. | 6 | Given two strings `s` and `p`, return _an array of all the start indices of_ `p`_'s anagrams in_ `s`. You may return the answer in **any order**.
An **Anagram** is a word or phrase formed by rearranging the letters of a different word or phrase, typically using all the original letters exactly once.
**Example 1:**
**Input:** s = "cbaebabacd ", p = "abc "
**Output:** \[0,6\]
**Explanation:**
The substring with start index = 0 is "cba ", which is an anagram of "abc ".
The substring with start index = 6 is "bac ", which is an anagram of "abc ".
**Example 2:**
**Input:** s = "abab ", p = "ab "
**Output:** \[0,1,2\]
**Explanation:**
The substring with start index = 0 is "ab ", which is an anagram of "ab ".
The substring with start index = 1 is "ba ", which is an anagram of "ab ".
The substring with start index = 2 is "ab ", which is an anagram of "ab ".
**Constraints:**
* `1 <= s.length, p.length <= 3 * 104`
* `s` and `p` consist of lowercase English letters. | null |
Python short and clean. Optimised Sliding-Window. | find-all-anagrams-in-a-string | 0 | 1 | # Approach\nSame as [567. Permutation in String](https://leetcode.com/problems/permutation-in-string/solutions/3142159/python-short-and-clean-optimised-sliding-window/).\n\nInstead of returning `True` after finding the first anagram, store the start index and continue finding the next.\n\n# Complexity\n- Time complexity: $$O(n)$$\n\n- Space complexity: $$O(n)$$ including the output list.\n\nwhere, `n is length of the longest string among s1 and s2`\n\n# Code\n```python\nclass Solution:\n def findAnagrams(self, s2: str, s1: str) -> list[int]:\n n1, n2 = len(s1), len(s2)\n c1, c2 = Counter(s1), Counter(islice(s2, n1))\n \n eq_count = sum(c1[ch] == c2[ch] for ch in c1)\n\n starts = [0] if eq_count == len(c1) else []\n for i in range(n1, n2):\n fst, lst = s2[i - n1], s2[i]\n\n if c1[lst] and c2[lst] == c1[lst]: eq_count -= 1\n c2[lst] += 1\n if c1[lst] and c2[lst] == c1[lst]: eq_count += 1\n\n if c1[fst] and c2[fst] == c1[fst]: eq_count -= 1\n c2[fst] -= 1\n if c1[fst] and c2[fst] == c1[fst]: eq_count += 1\n\n if eq_count == len(c1): starts.append(i - n1 + 1)\n\n return starts\n\n\n``` | 2 | Given two strings `s` and `p`, return _an array of all the start indices of_ `p`_'s anagrams in_ `s`. You may return the answer in **any order**.
An **Anagram** is a word or phrase formed by rearranging the letters of a different word or phrase, typically using all the original letters exactly once.
**Example 1:**
**Input:** s = "cbaebabacd ", p = "abc "
**Output:** \[0,6\]
**Explanation:**
The substring with start index = 0 is "cba ", which is an anagram of "abc ".
The substring with start index = 6 is "bac ", which is an anagram of "abc ".
**Example 2:**
**Input:** s = "abab ", p = "ab "
**Output:** \[0,1,2\]
**Explanation:**
The substring with start index = 0 is "ab ", which is an anagram of "ab ".
The substring with start index = 1 is "ba ", which is an anagram of "ab ".
The substring with start index = 2 is "ab ", which is an anagram of "ab ".
**Constraints:**
* `1 <= s.length, p.length <= 3 * 104`
* `s` and `p` consist of lowercase English letters. | null |
python3 Easy to understand | find-all-anagrams-in-a-string | 0 | 1 | # Intuition\n- Base case -If length of string s is smaller than p, return empty list.\n- Count the number of occurrences of characters in string p.\n- Search string s in chunks of length p, counting the occurrences of characters in each chunk.\n- Add the starting index of the chunk to the result list if the character count matches that of string p.\n\n\n\n\n# Code\n```\nclass Solution:\n def findAnagrams(self, s: str, p: str) -> List[int]:\n if len(s) < len(p):\n return []\n c= Counter(p)\n result =[]\n for i in range(len(s)-len(p) +1):\n temp = Counter(s[i:i+len(p)])\n if temp == c:\n result.append(i)\n return result \n\n``` | 3 | Given two strings `s` and `p`, return _an array of all the start indices of_ `p`_'s anagrams in_ `s`. You may return the answer in **any order**.
An **Anagram** is a word or phrase formed by rearranging the letters of a different word or phrase, typically using all the original letters exactly once.
**Example 1:**
**Input:** s = "cbaebabacd ", p = "abc "
**Output:** \[0,6\]
**Explanation:**
The substring with start index = 0 is "cba ", which is an anagram of "abc ".
The substring with start index = 6 is "bac ", which is an anagram of "abc ".
**Example 2:**
**Input:** s = "abab ", p = "ab "
**Output:** \[0,1,2\]
**Explanation:**
The substring with start index = 0 is "ab ", which is an anagram of "ab ".
The substring with start index = 1 is "ba ", which is an anagram of "ab ".
The substring with start index = 2 is "ab ", which is an anagram of "ab ".
**Constraints:**
* `1 <= s.length, p.length <= 3 * 104`
* `s` and `p` consist of lowercase English letters. | null |
O(N) sliding window | find-all-anagrams-in-a-string | 0 | 1 | # Code\n```\nclass Solution:\n def findAnagrams(self, s: str, p: str) -> List[int]:\n if len(s) < len(p):\n return []\n \n need = Counter(p)\n cur, lo = 0, 0\n ret = []\n\n for i, c in enumerate(s):\n need[c] -= 1\n cur += 1\n while need[c] < 0:\n need[s[lo]] += 1\n lo += 1\n cur -= 1\n if cur == len(p):\n ret.append(lo)\n return ret\n``` | 3 | Given two strings `s` and `p`, return _an array of all the start indices of_ `p`_'s anagrams in_ `s`. You may return the answer in **any order**.
An **Anagram** is a word or phrase formed by rearranging the letters of a different word or phrase, typically using all the original letters exactly once.
**Example 1:**
**Input:** s = "cbaebabacd ", p = "abc "
**Output:** \[0,6\]
**Explanation:**
The substring with start index = 0 is "cba ", which is an anagram of "abc ".
The substring with start index = 6 is "bac ", which is an anagram of "abc ".
**Example 2:**
**Input:** s = "abab ", p = "ab "
**Output:** \[0,1,2\]
**Explanation:**
The substring with start index = 0 is "ab ", which is an anagram of "ab ".
The substring with start index = 1 is "ba ", which is an anagram of "ab ".
The substring with start index = 2 is "ab ", which is an anagram of "ab ".
**Constraints:**
* `1 <= s.length, p.length <= 3 * 104`
* `s` and `p` consist of lowercase English letters. | null |
easy & simple sliding window with freq. cnt beats 85% | find-all-anagrams-in-a-string | 0 | 1 | # Sliding Window\n\n# Complexity\n- Time complexity: $$O(n)$$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: $$O(1)$$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def findAnagrams(self, s: str, p: str) -> List[int]:\n s1_len = len(s)\n s2_len = len(p)\n\n if s1_len < s2_len:\n return []\n\n freq_p = [0 for _ in range(26)]\n window = [0 for _ in range(26)]\n\n for i in range(s2_len):\n window[ord(s[i])-ord(\'a\')] += 1\n freq_p[ord(p[i])-ord(\'a\')] += 1\n\n ans = []\n if freq_p == window:\n ans.append(0)\n \n for i in range(s2_len,s1_len):\n window[ord(s[i-s2_len]) - ord(\'a\')] -= 1\n window[ord(s[i])-ord(\'a\')] += 1\n if window == freq_p:\n ans.append(i-s2_len+1)\n return ans\n \n``` | 2 | Given two strings `s` and `p`, return _an array of all the start indices of_ `p`_'s anagrams in_ `s`. You may return the answer in **any order**.
An **Anagram** is a word or phrase formed by rearranging the letters of a different word or phrase, typically using all the original letters exactly once.
**Example 1:**
**Input:** s = "cbaebabacd ", p = "abc "
**Output:** \[0,6\]
**Explanation:**
The substring with start index = 0 is "cba ", which is an anagram of "abc ".
The substring with start index = 6 is "bac ", which is an anagram of "abc ".
**Example 2:**
**Input:** s = "abab ", p = "ab "
**Output:** \[0,1,2\]
**Explanation:**
The substring with start index = 0 is "ab ", which is an anagram of "ab ".
The substring with start index = 1 is "ba ", which is an anagram of "ab ".
The substring with start index = 2 is "ab ", which is an anagram of "ab ".
**Constraints:**
* `1 <= s.length, p.length <= 3 * 104`
* `s` and `p` consist of lowercase English letters. | null |
Easy Approach | Sorting | Sliding Window | O(n) | Complete | find-all-anagrams-in-a-string | 0 | 1 | \n# Approach\nhere I have used sliding window approach for checking each word and sorting for anagram checking. The solution is simple but not optimal one.\n# Complexity\n- Time complexity:\no(n)\n\n- Space complexity:\no(n)\n\n\n\nplease upvote if you like\n\n\n# Code\n```\nclass Solution:\n def findAnagrams(self, s: str, p: str) -> List[int]:\n ans=[]\n q="".join(sorted(p))\n for i in range(0,len(s)-len(p)+1):\n p="".join(sorted(s[i:i+len(p)]))\n if p==q:\n ans.append(i)\n return ans\n``` | 10 | Given two strings `s` and `p`, return _an array of all the start indices of_ `p`_'s anagrams in_ `s`. You may return the answer in **any order**.
An **Anagram** is a word or phrase formed by rearranging the letters of a different word or phrase, typically using all the original letters exactly once.
**Example 1:**
**Input:** s = "cbaebabacd ", p = "abc "
**Output:** \[0,6\]
**Explanation:**
The substring with start index = 0 is "cba ", which is an anagram of "abc ".
The substring with start index = 6 is "bac ", which is an anagram of "abc ".
**Example 2:**
**Input:** s = "abab ", p = "ab "
**Output:** \[0,1,2\]
**Explanation:**
The substring with start index = 0 is "ab ", which is an anagram of "ab ".
The substring with start index = 1 is "ba ", which is an anagram of "ab ".
The substring with start index = 2 is "ab ", which is an anagram of "ab ".
**Constraints:**
* `1 <= s.length, p.length <= 3 * 104`
* `s` and `p` consist of lowercase English letters. | null |
Sliding window technquie ... | find-all-anagrams-in-a-string | 0 | 1 | # Approach\n<!-- Describe your approach to solving the problem. -->\nWe use sliding window approach for this the window size is fixed as the second string and just add the element to the window and just remove the character from the starting and just add the index of the removed character...\n\ns1="abcdefcba"\ns2="abc"\n\nFirstly create a hashmap for the string s2 and then slide the windoe for the string s1 and check whether they are anagrams are not....\n\nFor further details....\n Go Through the anagram validation explaination....\n https://leetcode.com/problems/valid-anagram/solutions/3144345/valid-anagram-hash-maps/\n\n-->abc ---Anagram\n-->bcd\n-->cde\n-->def\n-->efc\n-->fcb\n-->cba ---Anagram\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nO(n)\nLinear Traversal..\n\n\n# Code\n```\nclass Solution:\n def findAnagrams(self, s: str, p: str) -> List[int]:\n sdict={}\n pdict={}\n if(len(p)>len(s)):\n return []\n for i in range(len(p)):\n pdict[p[i]]=pdict.get(p[i],0)+1\n sdict[s[i]]=sdict.get(s[i],0)+1\n res=[]\n if(pdict==sdict):\n res=[0]\n #Check the hashmaps are equal or not\n l=0\n for r in range(len(p),len(s)):\n #add the character\n sdict[s[r]]=sdict.get(s[r],0)+1\n #remove the character from the starting....\n sdict[s[l]]-=1\n if(sdict[s[l]]==0):\n sdict.pop(s[l])\n #pop the character from the hashmap if it found to be zero....\n l+=1\n if(pdict==sdict):\n res.append(l)\n #print(sdict)\n return res\n``` | 1 | Given two strings `s` and `p`, return _an array of all the start indices of_ `p`_'s anagrams in_ `s`. You may return the answer in **any order**.
An **Anagram** is a word or phrase formed by rearranging the letters of a different word or phrase, typically using all the original letters exactly once.
**Example 1:**
**Input:** s = "cbaebabacd ", p = "abc "
**Output:** \[0,6\]
**Explanation:**
The substring with start index = 0 is "cba ", which is an anagram of "abc ".
The substring with start index = 6 is "bac ", which is an anagram of "abc ".
**Example 2:**
**Input:** s = "abab ", p = "ab "
**Output:** \[0,1,2\]
**Explanation:**
The substring with start index = 0 is "ab ", which is an anagram of "ab ".
The substring with start index = 1 is "ba ", which is an anagram of "ab ".
The substring with start index = 2 is "ab ", which is an anagram of "ab ".
**Constraints:**
* `1 <= s.length, p.length <= 3 * 104`
* `s` and `p` consist of lowercase English letters. | null |
📌📌Python3 || ⚡82 ms, faster than 99.35% of Python3 | find-all-anagrams-in-a-string | 0 | 1 | \n```\ndef findAnagrams(self, s: str, p: str) -> List[int]:\n LS, LP, S, P, A = len(s), len(p), 0, 0, []\n if LP > LS: \n return []\n for i in range(LP): S, P = S + hash(s[i]), P + hash(p[i])\n if S == P: A.append(0)\n for i in range(LP, LS):\n S += hash(s[i]) - hash(s[i-LP])\n if S == P: A.append(i-LP+1)\n return A\n```\nThe code implements a solution to find all the starting indices of an anagram of the string p in the string s. Here\'s a step-by-step description of the code:\n1. Initialize the length of the strings s and p as LS and LP respectively, and initialize the variables S, P, and A.\n1. Check if the length of p is greater than the length of s. If LP > LS, the function returns an empty list [] as it\'s not possible to find an anagram of p in s.\n1. Compute the initial hash values of the first LP characters of s and p and store them in S and P respectively.\n1. If S and P are equal, then the first LP characters of s form an anagram of p, so the starting index 0 is added to the list A.\n1. For each character in the range [LP, LS-1] in s, compute the new hash value by adding the hash of the current character and subtracting the hash of the previous character (i.e., the character that\'s outside the current sliding window).\n1. If the new hash value of S is equal to the hash value of P, then it\'s an anagram of p, so the starting index (i - LP + 1) is added to the list A.\n1. Repeat steps 5 and 6 until the end of the string s is reached.\n1. Return the list A of all starting indices of an anagram of p in s. | 15 | Given two strings `s` and `p`, return _an array of all the start indices of_ `p`_'s anagrams in_ `s`. You may return the answer in **any order**.
An **Anagram** is a word or phrase formed by rearranging the letters of a different word or phrase, typically using all the original letters exactly once.
**Example 1:**
**Input:** s = "cbaebabacd ", p = "abc "
**Output:** \[0,6\]
**Explanation:**
The substring with start index = 0 is "cba ", which is an anagram of "abc ".
The substring with start index = 6 is "bac ", which is an anagram of "abc ".
**Example 2:**
**Input:** s = "abab ", p = "ab "
**Output:** \[0,1,2\]
**Explanation:**
The substring with start index = 0 is "ab ", which is an anagram of "ab ".
The substring with start index = 1 is "ba ", which is an anagram of "ab ".
The substring with start index = 2 is "ab ", which is an anagram of "ab ".
**Constraints:**
* `1 <= s.length, p.length <= 3 * 104`
* `s` and `p` consist of lowercase English letters. | null |
Real O(n+m) solution independent of vocabulary size | find-all-anagrams-in-a-string | 0 | 1 | # **Intuition**\n<!-- Describe your first thoughts on how to solve this problem. -->\nOur task is to find all the start indices of **p**\'s anagrams in **s**.\n```\nm = len(p)\nn = len(s)\nk = len(alphabet)\n```\nThe baseline is: \n- store the counts of **p**\'s letters in a dictionary or array\n- go over **s** with a sliding window of **p**\'s size and record the number of letters in the **s\'** dictionary\n - first, fill the dictionary with the first **m-1** elements\n - then at each step we increase the value for **i** letter and decrease for **i - m + 1** letter\n- check if the dictionaries are equal\n\nHowever, the last check takes **O(k)** in time, so the honest time complexity will be **O(n * k + m)**.\nIn the current task we have a limited alphabet size of 26, but I had **follow-up** in the interview, where the size is unlimited.\n\n# **Approach**\n<!-- Describe your approach to solving the problem. -->\nMy modification is to add **set** that will contain the letters of **p**, whose count in the substring **s\'** isn\'t equal to the number of times they appear in **p**.\nSo the anagram will be found when the set is empty.\n\nIn more detail, when going with sliding window and updating the value of a letter in the dictionary (it can be **i**-th letter that is new to the window and **(i - m + 1)**-th letter that has just left the window)\n- if this letter is in the set and its number in the **p** and **s\'** dictionaries is the same, we should remove it from the set\n- if this letter in p and its number in **p** and **s\'** dictionaries is **not** the same, then we should add it to the set\n\nThis logic is implemented in the function ```update_missing```.\n\n# **Complexity**\n```\nm = len(p)\nn = len(s)\nk = len(alphabet)\n```\n- Time complexity: **O(n + m)**\n<!-- Add your time complexity here, e.g. **O(n)** -->\n\n- Space complexity: **O(k)**\n<!-- Add your space complexity here, e.g. **O(n)** -->\n\n# **Code**\n```\nclass Solution:\n def findAnagrams(self, s: str, p: str) -> List[int]:\n p_count = defaultdict(int) \n for c in p:\n p_count[c] += 1\n\n res = []\n m = len(p)\n missing = set(p)\n window = defaultdict(int)\n\n def update_missing(c):\n if c in missing and window[c] == p_count[c]:\n missing.remove(c)\n elif p_count[c] and window[c] != p_count[c]:\n missing.add(c)\n\n for i, c in enumerate(s):\n window[c] += 1\n update_missing(c)\n if i >= m - 1:\n out_idx = i - m + 1\n if not missing:\n res.append(out_idx)\n window[s[out_idx]] -= 1\n update_missing(s[out_idx])\n\n return res\n``` | 2 | Given two strings `s` and `p`, return _an array of all the start indices of_ `p`_'s anagrams in_ `s`. You may return the answer in **any order**.
An **Anagram** is a word or phrase formed by rearranging the letters of a different word or phrase, typically using all the original letters exactly once.
**Example 1:**
**Input:** s = "cbaebabacd ", p = "abc "
**Output:** \[0,6\]
**Explanation:**
The substring with start index = 0 is "cba ", which is an anagram of "abc ".
The substring with start index = 6 is "bac ", which is an anagram of "abc ".
**Example 2:**
**Input:** s = "abab ", p = "ab "
**Output:** \[0,1,2\]
**Explanation:**
The substring with start index = 0 is "ab ", which is an anagram of "ab ".
The substring with start index = 1 is "ba ", which is an anagram of "ab ".
The substring with start index = 2 is "ab ", which is an anagram of "ab ".
**Constraints:**
* `1 <= s.length, p.length <= 3 * 104`
* `s` and `p` consist of lowercase English letters. | null |
Solution | k-th-smallest-in-lexicographical-order | 1 | 1 | ```C++ []\nclass Solution {\n public:\n int findKthNumber(long n, int k) {\n auto getGap = [&n](long a, long b) {\n long gap = 0;\n while (a <= n) {\n gap += min(n + 1, b) - a;\n a *= 10;\n b *= 10;\n }\n return gap;\n };\n\n long currNum = 1;\n\n for (int i = 1; i < k;) {\n long gap = getGap(currNum, currNum + 1);\n if (i + gap <= k) {\n i += gap;\n ++currNum;\n } else {\n ++i;\n currNum *= 10;\n }\n }\n\n return currNum;\n }\n};\n```\n\n```Python3 []\nclass Node:\n def __init__(self, val):\n self.val = val\n self.nextNodes = []\n\n def __eq__(self, other):\n return self.val == other\n\nclass Solution:\n def generateTrieTree(self, data: list):\n root = Node(None)\n for intChar in data:\n pointer = root\n for char in intChar:\n try:\n existedNodeIdx = pointer.nextNodes.index(char)\n pointer = pointer.nextNodes[existedNodeIdx]\n except:\n newNode = Node(char)\n pointer.nextNodes.append(newNode)\n pointer = newNode\n return root\n\n def findKthNumber(self, n: int, k: int) -> int:\n result = 1\n k -= 1\n while k > 0:\n count = 0\n interval = [result, result + 1]\n while interval[0] <= n:\n count += (min(n + 1, interval[1]) - interval[0])\n interval = [10 * interval[0], 10 * interval[1]]\n\n if k >= count:\n result += 1\n k -= count\n else:\n result *= 10\n k -= 1\n return result\n \n \n root = self.generateTrieTree([str(i) for i in range(1, n + 1)])\n output = []\n\n def traverse(pointer, previousVal):\n nextNodes = pointer.nextNodes\n if not nextNodes:\n return\n\n for node in nextNodes:\n if len(output) == k:\n return\n\n newVal = previousVal + node.val\n output.append(newVal)\n traverse(node, newVal)\n\n traverse(root, "")\n return int(output[-1])\n```\n\n```Java []\nclass Solution {\n public int findKthNumber(int n, int k) {\n int prefix=1;\n for(int count=1;count<k;){\n int currCount=getCountWithPrefix(prefix,prefix+1,n);\n if(currCount+count<=k){\n count+=currCount;\n prefix++;\n }else{\n prefix*=10;\n count++;\n }\n }\n return prefix;\n }\n private int getCountWithPrefix(long startPrefix,long endPrefix,int max){\n int count=0;\n while(startPrefix<=max){\n count+=Math.min(max+1,endPrefix)-startPrefix;\n startPrefix*=10;\n endPrefix*=10;\n }\n return count;\n }\n}\n```\n | 207 | Given two integers `n` and `k`, return _the_ `kth` _lexicographically smallest integer in the range_ `[1, n]`.
**Example 1:**
**Input:** n = 13, k = 2
**Output:** 10
**Explanation:** The lexicographical order is \[1, 10, 11, 12, 13, 2, 3, 4, 5, 6, 7, 8, 9\], so the second smallest number is 10.
**Example 2:**
**Input:** n = 1, k = 1
**Output:** 1
**Constraints:**
* `1 <= k <= n <= 109` | null |
440: Space 96.85%, Solution with step by step explanation | k-th-smallest-in-lexicographical-order | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Define a function named "findKthNumber" that takes in two parameters: "n" and "k". This function will return an integer, which is the kth lexicographically smallest integer in the range [1, n].\n\n2. Initialize a variable "cur" to 1. This variable will keep track of the current number being considered.\n\n3. Decrement "k" by 1, since the variable "cur" has already been initialized to 1.\n\n4. Start a while loop that will continue until k is equal to 0. This loop will be used to find the kth lexicographically smallest number.\n\n5. Within the while loop, call the function "getSteps" with three arguments: "n", "cur", and "cur+1". This function will return the number of steps required to go from "cur" to "cur+1" while staying within the range of [1, n].\n\n6. If the number of steps required to go from "cur" to "cur+1" is less than or equal to k, increment "cur" by 1 and decrement "k" by the number of steps required to go from "cur" to "cur+1".\n\n7. If the number of steps required to go from "cur" to "cur+1" is greater than k, multiply "cur" by 10 and decrement "k" by 1.\n\n8. Once the while loop has terminated, return "cur", which is the kth lexicographically smallest integer in the range [1, n].\n\n9. Define another function named "getSteps" that takes in three parameters: "n", "n1", and "n2". This function will return the number of steps required to go from "n1" to "n2" while staying within the range of [1, n].\n\n10. Initialize a variable "steps" to 0. This variable will keep track of the number of steps required to go from "n1" to "n2".\n\n11. Start a while loop that will continue until "n1" is greater than "n". This loop will be used to count the number of steps required to go from "n1" to "n2".\n\n12. Within the while loop, add the minimum value between "n+1" and "n2" to "steps" and subtract "n1" from "n2". This will give us the number of steps required to go from "n1" to "n2" while staying within the range of [1, n].\n\n13. Multiply "n1" and "n2" by 10 to get the next set of numbers to consider.\n\n14. Once the while loop has terminated, return "steps", which is the number of steps required to go from "n1" to "n2" while staying within the range of [1, n].\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def findKthNumber(self, n: int, k: int) -> int:\n cur = 1\n k -= 1\n while k > 0:\n steps = self.getSteps(n, cur, cur+1)\n if steps <= k:\n cur += 1\n k -= steps\n else:\n cur *= 10\n k -= 1\n \n return cur\n\n def getSteps(self, n: int, n1: int, n2: int) -> int:\n steps = 0\n while n1 <= n:\n steps += min(n+1, n2) - n1\n n1 *= 10\n n2 *= 10\n return steps\n\n``` | 2 | Given two integers `n` and `k`, return _the_ `kth` _lexicographically smallest integer in the range_ `[1, n]`.
**Example 1:**
**Input:** n = 13, k = 2
**Output:** 10
**Explanation:** The lexicographical order is \[1, 10, 11, 12, 13, 2, 3, 4, 5, 6, 7, 8, 9\], so the second smallest number is 10.
**Example 2:**
**Input:** n = 1, k = 1
**Output:** 1
**Constraints:**
* `1 <= k <= n <= 109` | null |
[Python3] traverse denary trie | k-th-smallest-in-lexicographical-order | 0 | 1 | \n```\nclass Solution:\n def findKthNumber(self, n: int, k: int) -> int:\n \n def fn(x): \n """Return node counts in denary trie."""\n ans, diff = 0, 1\n while x <= n: \n ans += min(n - x + 1, diff)\n x *= 10 \n diff *= 10 \n return ans \n \n x = 1\n while k > 1: \n cnt = fn(x)\n if k > cnt: k -= cnt; x += 1\n else: k -= 1; x *= 10 \n return x\n``` | 7 | Given two integers `n` and `k`, return _the_ `kth` _lexicographically smallest integer in the range_ `[1, n]`.
**Example 1:**
**Input:** n = 13, k = 2
**Output:** 10
**Explanation:** The lexicographical order is \[1, 10, 11, 12, 13, 2, 3, 4, 5, 6, 7, 8, 9\], so the second smallest number is 10.
**Example 2:**
**Input:** n = 1, k = 1
**Output:** 1
**Constraints:**
* `1 <= k <= n <= 109` | null |
Python3 Explanation | k-th-smallest-in-lexicographical-order | 0 | 1 | # Intuition\nInitially, the problem seems like it could be solved by generating all the lexicographical permutations and then simply indexing the \\(k\\)th one. However, that approach is immediately dismissed because it would be impractical for large values of \\(n\\). A better intuition is to treat the problem as if navigating a tree structure in lexicographical order, counting the nodes, and moving efficiently to the \\(k\\)th node.\n\n# Approach\nWe take advantage of the fact that the lexicographical order of numbers resembles a tree, where each node has up to 10 children (for the digits 0-9). We start at \'1\' and navigate this tree, jumping over subtrees that we can count without enumerating each member. To do this, we define a function `getSteps` that calculates the number of steps from the current node to the next child in the current level of the tree. This represents the count of numbers we can skip in our search for the \\(k\\)th number. If the \\(k\\)th number is within the current subtree, we go deeper by multiplying by 10; if not, we go to the next subtree by incrementing the current number. This process is repeated until \\(k\\) is reduced to 0, indicating we\'ve reached the \\(k\\)th number.\n\n# Complexity\n- Time complexity:\nThe time complexity is \\(O(\\log n)\\), mainly because each step either moves down a level in the lexicographical tree (which can happen at most \\(O(\\log n)\\) times) or moves to the next sibling (which can also happen at most \\(O(\\log n)\\) times). Thus, the time complexity is determined by the number of digits in \\(n\\) and not by \\(n\\) itself.\n\n- Space complexity:\nThe space complexity is \\(O(1)\\) since the space used does not scale with the size of the input. Only a fixed number of integer variables are used, which takes constant space.\n\n# Code\n```python\nclass Solution:\n @staticmethod\n def getSteps(n, n1, n2):\n """\n Calculate the number of steps to go from n1 to n2 in the lexicographical order \n within the bounds of [1, n].\n """\n steps = 0\n while n1 <= n:\n steps += min(n + 1, n2) - n1 # Add the range between n1 and n2 or n+1 (whichever is smaller)\n n1 *= 10 # Go to the next level (10x factor)\n n2 *= 10 # Adjust the upper range for the next level\n return steps\n\n def findKthNumber(self, n, k):\n cur = 1 # Start with the smallest lexicographic number\n k -= 1 # Decrement k because we are starting from number 1\n\n while k > 0:\n steps = self.getSteps(n, cur, cur + 1) # Calculate steps between the current and the next number\n if steps <= k:\n cur += 1 # Move to the next number in the lexicographic order\n k -= steps # Decrease k by the number of steps moved\n else:\n cur *= 10 # Move to the next lexicographical sequence by going one level deeper in the "tree"\n k -= 1 # We have \'visited\' one number, decrement k\n\n return cur\n | 0 | Given two integers `n` and `k`, return _the_ `kth` _lexicographically smallest integer in the range_ `[1, n]`.
**Example 1:**
**Input:** n = 13, k = 2
**Output:** 10
**Explanation:** The lexicographical order is \[1, 10, 11, 12, 13, 2, 3, 4, 5, 6, 7, 8, 9\], so the second smallest number is 10.
**Example 2:**
**Input:** n = 1, k = 1
**Output:** 1
**Constraints:**
* `1 <= k <= n <= 109` | null |
Solution to 440. K-th Smallest in Lexicographical Order | k-th-smallest-in-lexicographical-order | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThe problem involves finding the k-th lexicographically smallest integer in the range [1, n]. Instead of generating the entire lexicographical order, the code efficiently explores the numbers in the order, incrementing the current value based on the number of steps needed to reach the next valid number.\n\n---\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nThis approach efficiently explores the numbers in lexicographical order, adjusting the current value based on the number of steps needed to reach the next valid number. The process continues until the k-th smallest integer is determined.\n1. Initialize the current value to 1 and decrement k by 1 (since we start counting from 1).\n2. While k is greater than 0, perform the following steps:\n2.1. Calculate the number of steps needed to reach the next number in lexicographical order.\n2.2. If k is greater than or equal to the calculated steps, increment the current value and decrement k by the steps.\n2.3. Otherwise, append a \'0\' to the current value and decrement k by 1.\n3. The final value of the current represents the k-th lexicographically smallest integer in the range [1, n].\n\n---\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nThe time complexity is $$O(log n)$$ since the algorithm eliminates a significant portion of the search space with each iteration. The while loop iterates logarithmically with respect to $$n$$, as each step narrows down the possible values by considering the order of magnitude.\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nThe space complexity is $$O(1)$$ since the algorithm uses a constant amount of extra space regardless of the input size. It doesn\'t rely on additional data structures that scale with the input.\n\n---\n\n# Code\n```\nclass Solution:\n def findKthNumber(self, n: int, k: int) -> int:\n current = 1\n k -= 1\n\n while k > 0:\n step = 0\n first = current\n last = current + 1\n while first <= n:\n step += min(n + 1, last) - first\n first *= 10\n last *= 10\n\n if k >= step:\n current += 1\n k -= step\n else:\n current *= 10\n k -= 1\n\n return current\n``` | 0 | Given two integers `n` and `k`, return _the_ `kth` _lexicographically smallest integer in the range_ `[1, n]`.
**Example 1:**
**Input:** n = 13, k = 2
**Output:** 10
**Explanation:** The lexicographical order is \[1, 10, 11, 12, 13, 2, 3, 4, 5, 6, 7, 8, 9\], so the second smallest number is 10.
**Example 2:**
**Input:** n = 1, k = 1
**Output:** 1
**Constraints:**
* `1 <= k <= n <= 109` | null |
Python3 | Explained | k-th-smallest-in-lexicographical-order | 0 | 1 | # Intuition\nThe lexicographical order of numbers can be thought of as a preorder traversal of a 10-ary tree (a tree where each node has up to 10 children). At the top level, we have numbers from 1 to 9 (we exclude 0 because numbers don\'t start with 0). Each of these numbers can be considered as the root of a subtree that represents all numbers that have that prefix. For instance, under the number 1, we have numbers 10 to 19, under 2 we have numbers 20 to 29, and so on.\n# Approach\n1. Tree Traversal:\n- We can traverse this tree in a depth-first manner. Starting from 1, we go as deep as possible by multiplying the current number by 10 until we exceed the limit n. This represents exploring the subtree under each number.\n- Once we exceed n or reach the maximum depth for a particular subtree, we move to the next sibling by adding 1 to the current number.\n- The challenge is to efficiently skip over subtrees that don\'t contain the kth smallest number. This is where the steps function comes into play.\n2. Calculate Steps:\n- The steps function calculates how many numbers are there between two given numbers, say a and b, in the lexicographical order under the limit n. For instance, between 1 and 2, we have the numbers [1, 10, 11, ...].\n- If the number of steps from the current number to the next is less than k, it means the kth number is not in the current subtree. We can safely move to the next subtree.\n- Otherwise, we delve deeper into the current subtree by multiplying the current number by 10.\n1. Termination:\n- The traversal stops once k becomes 0, which means we\'ve reached the kth number in the sequence.\n\n# Complexity\n- Time complexity:\nThe time complexity is O(log 10n). This is because in each iteration, we either multiply the current number by 10 (going deeper into the tree) or add 1 to it (moving to the next sibling). The depth of this tree is logarithmic with respect to n.\n- Space complexity:\nThe space complexity is O(1) since we are using a constant amount of space.\n\n# Code\n```\nclass Solution:\n def findKthNumber(self, n: int, k: int) -> int:\n def steps(n, n1, n2):\n count = 0\n while n1 <= n:\n count += min(n + 1, n2) - n1\n n1 *= 10\n n2 *= 10\n return count\n \n curr = 1\n k -= 1\n while k > 0:\n count = steps(n, curr, curr + 1)\n if count <= k:\n curr += 1\n k -= count\n else:\n curr *= 10\n k -= 1\n return curr\n``` | 0 | Given two integers `n` and `k`, return _the_ `kth` _lexicographically smallest integer in the range_ `[1, n]`.
**Example 1:**
**Input:** n = 13, k = 2
**Output:** 10
**Explanation:** The lexicographical order is \[1, 10, 11, 12, 13, 2, 3, 4, 5, 6, 7, 8, 9\], so the second smallest number is 10.
**Example 2:**
**Input:** n = 1, k = 1
**Output:** 1
**Constraints:**
* `1 <= k <= n <= 109` | null |
Python3 beats 96% | k-th-smallest-in-lexicographical-order | 0 | 1 | \nOPT(dig) is given the substring \'dig\' how many substrings less than n start with that substring\n\n# Code\n```\nclass Solution:\n def findKthNumber(self, n: int, k: int) -> int:\n if k == 1:\n return 1\n nstr = str(n)\n\n @cache\n def opt(i, dig):\n if i == len(nstr):\n return 0\n\n if int(nstr[:i+1]) > int(dig):\n temp = 0\n for x in range(i, len(nstr)-1):\n temp+=pow(10, x-i)\n return temp + pow(10, len(nstr)-i-1)\n\n elif int(nstr[:i+1])<int(dig):\n temp = 0\n for x in range(i, len(nstr)-1):\n temp+=pow(10, x-i)\n return temp\n\n else:\n temp = 1\n for x in "1234567890":\n temp+=opt(i+1,dig+x)\n\n return temp\n\n s = "0123456789"\n h = 1\n\n res = ""\n curr = 0\n ind = 0\n while True:\n x = s[h]\n y = opt(ind, res+x)\n if curr + y>=k:\n res += x\n curr+=1\n if curr == k:\n return int(res)\n h = 0\n ind+=1\n else:\n curr+=y\n h+=1\n``` | 0 | Given two integers `n` and `k`, return _the_ `kth` _lexicographically smallest integer in the range_ `[1, n]`.
**Example 1:**
**Input:** n = 13, k = 2
**Output:** 10
**Explanation:** The lexicographical order is \[1, 10, 11, 12, 13, 2, 3, 4, 5, 6, 7, 8, 9\], so the second smallest number is 10.
**Example 2:**
**Input:** n = 1, k = 1
**Output:** 1
**Constraints:**
* `1 <= k <= n <= 109` | null |
DFS | k-th-smallest-in-lexicographical-order | 0 | 1 | # Code\n```\nclass Solution:\n def findKthNumber(self, n: int, k: int) -> int:\n def countPrefixes(prefix: int, n: int) -> int:\n count = 0\n curr = prefix\n next = prefix + 1\n\n while curr <= n:\n count += min(n + 1, next) - curr\n curr *= 10\n next *= 10\n\n return count\n\n curr = 1\n k -= 1\n\n while k > 0:\n count = countPrefixes(curr, n)\n\n if count <= k:\n curr += 1\n k -= count\n else:\n curr *= 10\n k -= 1\n\n return curr\n\n``` | 0 | Given two integers `n` and `k`, return _the_ `kth` _lexicographically smallest integer in the range_ `[1, n]`.
**Example 1:**
**Input:** n = 13, k = 2
**Output:** 10
**Explanation:** The lexicographical order is \[1, 10, 11, 12, 13, 2, 3, 4, 5, 6, 7, 8, 9\], so the second smallest number is 10.
**Example 2:**
**Input:** n = 1, k = 1
**Output:** 1
**Constraints:**
* `1 <= k <= n <= 109` | null |
(Python) Kth Lexicographically Smallest Integer in Range | k-th-smallest-in-lexicographical-order | 0 | 1 | # Intuition\nWe can observe that the lexicographical order of the integers from 1 to n form a trie where the root is the empty string, and the children of a node represent the digits that can come after the digit sequence represented by the node. We can use this trie to find the kth lexicographically smallest integer by performing a modified depth-first search (DFS) where we keep track of the number of nodes visited so far and return the integer corresponding to the kth node.\n# Approach\n1. Initialize a variable count to 0 and create an empty list result to store the integers visited during the DFS.\n2. Start the DFS from the empty string.\n3. For each digit d from 0 to 9, add it to the current string, and recursively call the DFS with the updated string.\n4. If the current string is not empty and is less than or equal to n, append it to the result list and increment count.\n5. If count is equal to k, return the last element of the result list.\n6. If count is greater than k, return the kth element of the result list.\n7. If count is less than k, return -1.\n# Complexity\n- Time complexity:\nO(n), since we visit each integer from 1 to n exactly once.\n- Space complexity:\nO(log n), since the depth of the trie is log n.\n# Code\n```\nclass Solution:\n def findKthNumber(self, n: int, k: int) -> int:\n curr = 1\n k -= 1 # decrement k to handle 1-based indexing\n while k > 0:\n steps = self.countSteps(n, curr, curr+1) # count steps to the next number\n if steps <= k: # if there are not enough steps, move to the next number\n curr += 1\n k -= steps\n else: # if there are enough steps, move to the next digit\n curr *= 10\n k -= 1\n return curr\n\n def countSteps(self, n: int, n1: int, n2: int) -> int:\n """\n Count the number of steps from n1 to n2 in lexicographical order in the range [1, n].\n """\n steps = 0\n while n1 <= n:\n steps += min(n+1, n2) - n1 # count the steps from n1 to the next number or n2, whichever comes first\n n1 *= 10\n n2 *= 10\n return steps\n\n``` | 0 | Given two integers `n` and `k`, return _the_ `kth` _lexicographically smallest integer in the range_ `[1, n]`.
**Example 1:**
**Input:** n = 13, k = 2
**Output:** 10
**Explanation:** The lexicographical order is \[1, 10, 11, 12, 13, 2, 3, 4, 5, 6, 7, 8, 9\], so the second smallest number is 10.
**Example 2:**
**Input:** n = 1, k = 1
**Output:** 1
**Constraints:**
* `1 <= k <= n <= 109` | null |
Fast Python solution. Beats 100% | k-th-smallest-in-lexicographical-order | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThe problem is asking to find the kth number in the lexicographic order of all the numbers from 1 to n. The idea is to use a combination of breadth-first search and dynamic programming to find the kth number in a fast and efficient manner.\n# Approach\n<!-- Describe your approach to solving the problem. -->\nThe approach is to use a breadth-first search algorithm that starts from 1 and goes through all the possible numbers from 1 to n. The algorithm checks the number of numbers that can be formed from the current number and if it is less than or equal to k, it will move on to the next number and subtract the number of formed numbers from k. If it is greater than k, the algorithm will move to the next digit by multiplying the current number by 10.\n\n\n# Complexity\n- Time complexity: O(log(n)^2)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(1)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def findKthNumber(self, n: int, k: int) -> int:\n if k == 1:\n return 1\n k -= 1\n cur = 1\n while k > 0:\n steps = self.getSteps(n, cur, cur+1)\n if steps <= k:\n cur += 1\n k -= steps\n else:\n cur *= 10\n k -= 1\n return cur\n\n def getSteps(self, n, n1, n2):\n steps = 0\n while n1 <= n:\n steps += min(n+1, n2) - n1\n n1 *= 10\n n2 *= 10\n return steps\n``` | 0 | Given two integers `n` and `k`, return _the_ `kth` _lexicographically smallest integer in the range_ `[1, n]`.
**Example 1:**
**Input:** n = 13, k = 2
**Output:** 10
**Explanation:** The lexicographical order is \[1, 10, 11, 12, 13, 2, 3, 4, 5, 6, 7, 8, 9\], so the second smallest number is 10.
**Example 2:**
**Input:** n = 1, k = 1
**Output:** 1
**Constraints:**
* `1 <= k <= n <= 109` | null |
Python | 100% Speed | BinCount Histogram Method | O( log(n)^2 ) | k-th-smallest-in-lexicographical-order | 0 | 1 | **Python | 100% Speed | BinCount Histogram Method | O( log(n)^2 )**\n\nThe Python code below corresponds to a highly efficient solution, which achieves a speed rating of 100% on LeetCode.\n\nHighlights:\n\n1. The code is inspired by the concept of "BinCount" Histograms, where we group numbers based on certain boundaries. However, instead of using a classical ranges, here we group number by their first leading digit.\n\n2. As we sweep numbers from 1 to "n", we can notice that the Histogram is filled by loops with packets of size=10^i. For example, the histogram is first filled by packets of size=1 resembling [1,2,3,4,5,6,7,8,9]. Then, numbers move forward into packets of size=10 [1x, 2x, 3x, etc.], and so on. The function "bincount" implements a very simple algorithm to emulate this process, and it runs with O( log n ) time complexity per call. The last "packet" before the fuction "bincount" stops might not be complete though, but this is very easy to handle.\n\n3. As a result, we can easily calculate the leading digit of a given number with index=k. The function "binmatch" implements a one-pass loop to find in which "bin" our target number falls. (For the very first digit, our BinCount uses the binranges [1-9], but for the subsequent digits we must use [0-9].)\n\n4. After finding a leading digit, we can pass the remainder of our "BinCounts" to further recursive calls, until we "discover" the full number. Since each digit is discovered with O( log n ) time complexity, and we must find O( log n ) digits, our total time complexity is O( log(n)^2 ).\n\nI hope the explanation was helpful. The code makes a lot of sense after looking at the results of Brute Force experiments (Appendix). \n\n**A) Main Code**\n```\nclass Solution:\n def binmatch(self,A,k):\n i,s = 0,0\n for i,x in enumerate(A):\n s += x\n if s>=k:\n s -= x\n break\n return i,s\n def bincount(self,n,r):\n A = [0]*r\n s = 1\n while n>0:\n for i in range(r):\n s = min(n,s)\n A[i] += s\n n -= s\n if n<=0:\n break\n s *= 10\n return A \n def remainder(self,t,c): # target, container size\n if t==1:\n return # t=1 is always Null Zero (1,10,100,etc..)\n t -= 1 # subtract Null Zero\n c -= 1\n A = self.bincount(c,r=10)\n i,s = self.binmatch(A,t)\n yield i\n\t\t# yield from self.remainder(t-s,A[i]) # only works in Python 3\n for j in self.remainder(t-s,A[i]): \n yield j\n def findKthNumber(self, n, k): #-> int:\n # Find first digit:\n A = self.bincount(n,r=9)\n i,s = self.binmatch(A,k)\n res = i+1\n # Find Upcoming Digits\n for x in self.remainder(k-s,A[i]):\n res = 10*res + x\n return res\n```\n\n**B) Appendix: Brute Force Visualizer**\n```\n# Python 2/3\n# This code is only to see how number organize themselves\nn = 31\nA = []\nfor x in range(1,n+1):\n A.append(str(x))\nA.sort()\nfor b in A:\n print(b)\n``` | 3 | Given two integers `n` and `k`, return _the_ `kth` _lexicographically smallest integer in the range_ `[1, n]`.
**Example 1:**
**Input:** n = 13, k = 2
**Output:** 10
**Explanation:** The lexicographical order is \[1, 10, 11, 12, 13, 2, 3, 4, 5, 6, 7, 8, 9\], so the second smallest number is 10.
**Example 2:**
**Input:** n = 1, k = 1
**Output:** 1
**Constraints:**
* `1 <= k <= n <= 109` | null |
🐍 | | Binary Search | | Fastest | | Bisect Function | arranging-coins | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThis is the basic binary search problem.\n\n```First go trying brute force```: Number of coins that can fit in 1st row ,2nd row ...for nth row we need ```n*(n+1)/2``` coins in total. Check the value of it for each row and find when it is >= target given\n\n```Binary Search approach ```: Instead of find the value for all rows, perform binary search from 1 to n (* n/2 for efficiency).\n# Complexity\n- Time complexity:O(logN)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:O(1)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def arrangeCoins(self, n: int) -> int:\n ans= bisect_left(range(1,n),n,key=lambda x:x*(x+1)//2)+1\n if ans*(ans+1)//2==n:\n return ans\n return ans-1\n``` | 2 | You have `n` coins and you want to build a staircase with these coins. The staircase consists of `k` rows where the `ith` row has exactly `i` coins. The last row of the staircase **may be** incomplete.
Given the integer `n`, return _the number of **complete rows** of the staircase you will build_.
**Example 1:**
**Input:** n = 5
**Output:** 2
**Explanation:** Because the 3rd row is incomplete, we return 2.
**Example 2:**
**Input:** n = 8
**Output:** 3
**Explanation:** Because the 4th row is incomplete, we return 3.
**Constraints:**
* `1 <= n <= 231 - 1` | null |
Solution | arranging-coins | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n int arrangeCoins(int n) {\n return (-1 + sqrt(1 + 8 * (long)n)) / 2;\n }\n};\n```\n\n```Python3 []\nclass Solution:\n def arrangeCoins(self, n: int) -> int:\n f = 1\n l = n\n\n while f<=l:\n mid = (f+l)//2\n temp = (mid*(mid+1))//2\n if temp == n:\n return mid\n elif temp > n:\n l = mid-1\n else:\n f = mid+1\n return l\n```\n\n```Java []\nclass Solution {\n public int arrangeCoins(int n) { \n return (int)(Math.sqrt(0.25+2*(double)n)-0.5);\n }\n}\n```\n | 3 | You have `n` coins and you want to build a staircase with these coins. The staircase consists of `k` rows where the `ith` row has exactly `i` coins. The last row of the staircase **may be** incomplete.
Given the integer `n`, return _the number of **complete rows** of the staircase you will build_.
**Example 1:**
**Input:** n = 5
**Output:** 2
**Explanation:** Because the 3rd row is incomplete, we return 2.
**Example 2:**
**Input:** n = 8
**Output:** 3
**Explanation:** Because the 4th row is incomplete, we return 3.
**Constraints:**
* `1 <= n <= 231 - 1` | null |
4 Lines of Code --->Binary Search and Normal For Loop Approach | arranging-coins | 0 | 1 | # 1. Using while Loop \n```\nclass Solution:\n def arrangeCoins(self, n: int) -> int: \n i=0\n while n>=0:\n i+=1\n n=n-i\n return i-1\n\n #please upvote me it would encourage me alot\n\n```\n# 2. using For Loop\n```\nclass Solution:\n def arrangeCoins(self, n: int) -> int:\n if n==1:return n\n for i in range(1,n+1):\n n=n-i\n if n<0: return i-1\n\n //please upvote me it would encourage me alot\n\n\n```\n# 3. Binary Search Approach\n```\n\nclass Solution:\n def arrangeCoins(self, n: int) -> int:\n left,right=1,n\n while left<=right:\n mid=(right+left)//2\n num=(mid/2)*(mid+1)\n if num<=n:\n left=mid+1\n else:\n right=mid-1\n return right\n\n //please upvote me it would encourage me alot\n\n\n```\n# please upvote me it would encourage me alot\n\n | 24 | You have `n` coins and you want to build a staircase with these coins. The staircase consists of `k` rows where the `ith` row has exactly `i` coins. The last row of the staircase **may be** incomplete.
Given the integer `n`, return _the number of **complete rows** of the staircase you will build_.
**Example 1:**
**Input:** n = 5
**Output:** 2
**Explanation:** Because the 3rd row is incomplete, we return 2.
**Example 2:**
**Input:** n = 8
**Output:** 3
**Explanation:** Because the 4th row is incomplete, we return 3.
**Constraints:**
* `1 <= n <= 231 - 1` | null |
[C++] [Python] Brute Force with Optimized Approach || Too Easy || Fully Explained | arranging-coins | 0 | 1 | # Approach\n<!-- Describe your approach to solving the problem. -->\nSuppose we have the input value `n = 8`.\n\n1. Initialize `num` as 8 and `count` as 0.\n2. Start the outer loop with `i = 1`:\n - On the first iteration:\n - Start the inner loop with `j = 0`.\n - Since `j` is less than `i` and `num` (8) is greater than 0, enter the loop.\n - Decrement `num` by 1. Now `num = 7`.\n - Increment `j` to 1.\n - Continue the inner loop:\n - Since `j` is less than `i` and `num` (7) is greater than 0, enter the loop.\n - Decrement `num` by 1. Now `num = 6`.\n - Increment `j` to 2.\n - Continue the inner loop:\n - Since `j` is equal to `i` (2) and `num` (6) is greater than 0, increment `count` by 1. Now `count = 1`.\n - On the second iteration:\n - Start the inner loop with `j = 0`.\n - Since `j` is less than `i` and `num` (6) is greater than 0, enter the loop.\n - Decrement `num` by 1. Now `num = 5`.\n - Increment `j` to 1.\n - Continue the inner loop:\n - Since `j` is equal to `i` (1) and `num` (5) is greater than 0, increment `count` by 1. Now `count = 2`.\n - On the third iteration:\n - Start the inner loop with `j = 0`.\n - Since `j` is less than `i` and `num` (5) is greater than 0, enter the loop.\n - Decrement `num` by 1. Now `num = 4`.\n - Increment `j` to 1.\n - Continue the inner loop:\n - Since `j` is less than `i` (2) and `num` (4) is greater than 0, enter the loop.\n - Decrement `num` by 1. Now `num = 3`.\n - Increment `j` to 2.\n - Continue the inner loop:\n - Since `j` is equal to `i` (2) and `num` (3) is greater than 0, increment `count` by 1. Now `count = 3`.\n - The outer loop continues until `num` is no longer greater than 0.\n3. Exit the outer loop.\n4. The function returns `count`, which is 3.\n\nIn this example, the function `arrangeCoins` determines the number of complete rows of coins that can be arranged based on the input value `n = 8`. The result is 3, indicating that 3 complete rows of coins can be arranged.\n\n# Complexity\n- Time complexity:$$O(n^2)$$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:$$O(1)$$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\npublic:\n int arrangeCoins(int n) {\n int num = n;\n int count = 0;\n for(int i = 1,j; num > 0; i++){\n for(j = 0; j < i && num > 0; j++)\n num--;\n \n\n if(j == i)\n count++;\n }\n return count;\n }\n};\n```\n# Complexity\n- Time complexity:$$O(n)$$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:$$O(1)$$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n\n``` C++ []\nclass Solution {\npublic:\n int arrangeCoins(int n) {\n int temp = n;\n int ans = 0;\n if (n == 1)\n return 1;\n for(int i = 1; i <= n; i++){\n if(i > temp){\n ans = i - 1;\n break;\n }\n temp -= i;\n }\n return ans;\n }\n};\n```\n``` Python []\nclass Solution:\n def arrangeCoins(self, n: int) -> int:\n if n == 1:\n return 1\n \n for i in range(1, n + 1):\n n -= i\n if (n < 0):\n return i - 1\n``` | 4 | You have `n` coins and you want to build a staircase with these coins. The staircase consists of `k` rows where the `ith` row has exactly `i` coins. The last row of the staircase **may be** incomplete.
Given the integer `n`, return _the number of **complete rows** of the staircase you will build_.
**Example 1:**
**Input:** n = 5
**Output:** 2
**Explanation:** Because the 3rd row is incomplete, we return 2.
**Example 2:**
**Input:** n = 8
**Output:** 3
**Explanation:** Because the 4th row is incomplete, we return 3.
**Constraints:**
* `1 <= n <= 231 - 1` | null |
441: Space 93.37%, Solution with step by step explanation | arranging-coins | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Initialize two pointers left and right to 1 and n, respectively.\n2. While left <= right, compute the midpoint mid between left and right.\n3. Compute the total number of coins required to build mid complete rows using the formula (mid * (mid + 1)) // 2.\n4. If the total number of coins is greater than or equal to n, set right to mid - 1 (i.e., look for a smaller number of rows that use fewer coins).\n5. Otherwise, set left to mid + 1 (i.e., look for a larger number of rows that use more coins).\n6. Return right as the answer.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def arrangeCoins(self, n: int) -> int:\n # Initialize pointers to first and last possible row lengths\n left, right = 1, n\n \n while left <= right:\n # Compute the midpoint between left and right\n mid = left + (right - left) // 2\n \n # Compute the total number of coins needed for mid complete rows\n coins = (mid * (mid + 1)) // 2\n \n # If we have enough coins, look for a smaller number of rows\n if coins <= n:\n left = mid + 1\n # Otherwise, look for a larger number of rows\n else:\n right = mid - 1\n \n # Return the number of complete rows (i.e., right pointer)\n return right\n\n``` | 9 | You have `n` coins and you want to build a staircase with these coins. The staircase consists of `k` rows where the `ith` row has exactly `i` coins. The last row of the staircase **may be** incomplete.
Given the integer `n`, return _the number of **complete rows** of the staircase you will build_.
**Example 1:**
**Input:** n = 5
**Output:** 2
**Explanation:** Because the 3rd row is incomplete, we return 2.
**Example 2:**
**Input:** n = 8
**Output:** 3
**Explanation:** Because the 4th row is incomplete, we return 3.
**Constraints:**
* `1 <= n <= 231 - 1` | null |
By applying Quadratic equation formula | arranging-coins | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nBasically here indirectly the n which was given to us is the sum of numbers \nSo we have let reult be x\nx(x+1)=n\nby solving this quadratic equation we have \nx^2+x-n=0\nOn applying the formula for roots we have\nx=-1+math.sqrt(1+8*n))/2 , -1-math.sqrt(1+8*n))/2\nThe second case can be omitted as x cannot be negative.\nPlease upvote if you liked the explanation\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nO(1)\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n0\n\n# Code\n```\nimport math\nclass Solution:\n def arrangeCoins(self, n: int) -> int:\n return int((-1+math.sqrt(1+8*n))/2)\n``` | 1 | You have `n` coins and you want to build a staircase with these coins. The staircase consists of `k` rows where the `ith` row has exactly `i` coins. The last row of the staircase **may be** incomplete.
Given the integer `n`, return _the number of **complete rows** of the staircase you will build_.
**Example 1:**
**Input:** n = 5
**Output:** 2
**Explanation:** Because the 3rd row is incomplete, we return 2.
**Example 2:**
**Input:** n = 8
**Output:** 3
**Explanation:** Because the 4th row is incomplete, we return 3.
**Constraints:**
* `1 <= n <= 231 - 1` | null |
one line Code,Easiest binary Search,Math Formula,normal solution | arranging-coins | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n #approach 1 binary solution\n def arrangeCoins(self, n: int) -> int:\n # return int((math.sqrt(8 * n + 1)-1)/2)\n # approach 3\n low,total=1,n\n res=0\n while low<=total:\n mid=(low+total)//2\n count=(mid/2)*(mid+1)\n if count<=n:\n res=mid\n max(res,mid)\n low=mid+1\n else:\n total=mid-1\n return res\n```\n```\n #approach 2-->one line code,math formula\nclass Solution:\n def arrangeCoins(self, n: int) -> int:\n return int((math.sqrt(8 * n + 1)-1)/2)\n\n\n\n```\n```\n #approach 3-->normal approach\nclass Solution:\n def arrangeCoins(self, n: int) -> int:\n row=1\n total=1\n while total<=n:\n total=total+row+1\n row+=1\n return row-1\n\n``` | 2 | You have `n` coins and you want to build a staircase with these coins. The staircase consists of `k` rows where the `ith` row has exactly `i` coins. The last row of the staircase **may be** incomplete.
Given the integer `n`, return _the number of **complete rows** of the staircase you will build_.
**Example 1:**
**Input:** n = 5
**Output:** 2
**Explanation:** Because the 3rd row is incomplete, we return 2.
**Example 2:**
**Input:** n = 8
**Output:** 3
**Explanation:** Because the 4th row is incomplete, we return 3.
**Constraints:**
* `1 <= n <= 231 - 1` | null |
Python3 O(1) Solution | arranging-coins | 0 | 1 | \n\n# Complexity\n- Time complexity:\n0(1)\n\n- Space complexity:\n0(1)\n\n# Code\n```\nclass Solution:\n def arrangeCoins(self, n: int) -> int:\n return int(sqrt(2 * n + 0.25) - 0.50)\n``` | 5 | You have `n` coins and you want to build a staircase with these coins. The staircase consists of `k` rows where the `ith` row has exactly `i` coins. The last row of the staircase **may be** incomplete.
Given the integer `n`, return _the number of **complete rows** of the staircase you will build_.
**Example 1:**
**Input:** n = 5
**Output:** 2
**Explanation:** Because the 3rd row is incomplete, we return 2.
**Example 2:**
**Input:** n = 8
**Output:** 3
**Explanation:** Because the 4th row is incomplete, we return 3.
**Constraints:**
* `1 <= n <= 231 - 1` | null |
Python Simple Binary Search | arranging-coins | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nBrute force - Binary search as we are dealing with sorted numbers.\n\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nSum of numbers = x(x+1)/2\ntried to solve the equation by using substitution of numbers.\nThe number which satisfies the above equation should be our solution. If we don\'t have one then we conisder the number less than that.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nO(logN)\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nO(1)\n\n# Code\n```\nclass Solution:\n def arrangeCoins(self, n: int) -> int:\n\n first = 1\n last = n\n if n==1:\n return 1\n while first <= last:\n mid = (first+last)//2\n\n if mid*(mid+1) == 2*n:\n return mid\n elif mid*(mid+1) > 2*n:\n last = mid-1\n else:\n first = mid+1\n return last\n \n\n``` | 3 | You have `n` coins and you want to build a staircase with these coins. The staircase consists of `k` rows where the `ith` row has exactly `i` coins. The last row of the staircase **may be** incomplete.
Given the integer `n`, return _the number of **complete rows** of the staircase you will build_.
**Example 1:**
**Input:** n = 5
**Output:** 2
**Explanation:** Because the 3rd row is incomplete, we return 2.
**Example 2:**
**Input:** n = 8
**Output:** 3
**Explanation:** Because the 4th row is incomplete, we return 3.
**Constraints:**
* `1 <= n <= 231 - 1` | null |
Python solution using counter method | find-all-duplicates-in-an-array | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nfrom collections import Counter\nclass Solution:\n def findDuplicates(self, nums: List[int]) -> List[int]:\n c=Counter(nums)\n count=[]\n for i in nums:\n if c[i]==2:\n if i not in count:\n count.append(i)\n return count\n \n``` | 1 | Given an integer array `nums` of length `n` where all the integers of `nums` are in the range `[1, n]` and each integer appears **once** or **twice**, return _an array of all the integers that appears **twice**_.
You must write an algorithm that runs in `O(n)` time and uses only constant extra space.
**Example 1:**
**Input:** nums = \[4,3,2,7,8,2,3,1\]
**Output:** \[2,3\]
**Example 2:**
**Input:** nums = \[1,1,2\]
**Output:** \[1\]
**Example 3:**
**Input:** nums = \[1\]
**Output:** \[\]
**Constraints:**
* `n == nums.length`
* `1 <= n <= 105`
* `1 <= nums[i] <= n`
* Each element in `nums` appears **once** or **twice**. | null |
Easy marking O(n), O(1) solution | find-all-duplicates-in-an-array | 0 | 1 | # Intuition\nDouble way marking, mark the index and if the index you check next is already marked, visited.\n\n# Code\n```\nclass Solution:\n def findDuplicates(self, nums: List[int]) -> List[int]:\n\n res = []\n for i in nums:\n if nums[abs(i) - 1] < 0:\n res.append(abs(i))\n (nums[abs(i) - 1]) *= -1\n return res\n\n\n\n# given integer array nums\n\n# all nums are in len 1,n\n\n# each integer appears once or twice\n\n# return array of all integers that appear twice\n\n\n# \n``` | 4 | Given an integer array `nums` of length `n` where all the integers of `nums` are in the range `[1, n]` and each integer appears **once** or **twice**, return _an array of all the integers that appears **twice**_.
You must write an algorithm that runs in `O(n)` time and uses only constant extra space.
**Example 1:**
**Input:** nums = \[4,3,2,7,8,2,3,1\]
**Output:** \[2,3\]
**Example 2:**
**Input:** nums = \[1,1,2\]
**Output:** \[1\]
**Example 3:**
**Input:** nums = \[1\]
**Output:** \[\]
**Constraints:**
* `n == nums.length`
* `1 <= n <= 105`
* `1 <= nums[i] <= n`
* Each element in `nums` appears **once** or **twice**. | null |
Python || Hash Table || Beats 95% Time Complexity 🔥 | find-all-duplicates-in-an-array | 0 | 1 | \n# Code\n```\nclass Solution:\n def findDuplicates(self, nums: List[int]) -> List[int]:\n ordmap = [0] * (len(nums)+1)\n arr = []\n if len(nums) <= 1: return []\n for i in range(len(nums)):\n ordmap[nums[i]] += 1\n if ordmap[nums[i]] == 2:\n arr.append(nums[i])\n return arr\n``` | 1 | Given an integer array `nums` of length `n` where all the integers of `nums` are in the range `[1, n]` and each integer appears **once** or **twice**, return _an array of all the integers that appears **twice**_.
You must write an algorithm that runs in `O(n)` time and uses only constant extra space.
**Example 1:**
**Input:** nums = \[4,3,2,7,8,2,3,1\]
**Output:** \[2,3\]
**Example 2:**
**Input:** nums = \[1,1,2\]
**Output:** \[1\]
**Example 3:**
**Input:** nums = \[1\]
**Output:** \[\]
**Constraints:**
* `n == nums.length`
* `1 <= n <= 105`
* `1 <= nums[i] <= n`
* Each element in `nums` appears **once** or **twice**. | null |
Python3|| Beats 96.18% runtime|| Hash Approach / List Comprehension | find-all-duplicates-in-an-array | 0 | 1 | # Please upvote!\n\n\n# Code\n```\n#HASH APPROACH\nclass Solution:\n def findDuplicates(self, nums: List[int]) -> List[int]:\n c = Counter(nums)\n lst=[]\n for i,j in c.items():\n if j>=2:\n lst.append(i)\n return lst\n```\n\n | 9 | Given an integer array `nums` of length `n` where all the integers of `nums` are in the range `[1, n]` and each integer appears **once** or **twice**, return _an array of all the integers that appears **twice**_.
You must write an algorithm that runs in `O(n)` time and uses only constant extra space.
**Example 1:**
**Input:** nums = \[4,3,2,7,8,2,3,1\]
**Output:** \[2,3\]
**Example 2:**
**Input:** nums = \[1,1,2\]
**Output:** \[1\]
**Example 3:**
**Input:** nums = \[1\]
**Output:** \[\]
**Constraints:**
* `n == nums.length`
* `1 <= n <= 105`
* `1 <= nums[i] <= n`
* Each element in `nums` appears **once** or **twice**. | null |
Solution | find-all-duplicates-in-an-array | 1 | 1 | ```C++ []\nclass Solution {\npublic:\n vector<int> findDuplicates(vector<int>& nums) {\n vector<int>ans; \n for(int i=0;i<nums.size();i++){\n if(nums[i]==nums.size()){\n nums[0]+=nums.size();\n continue;\n }\n nums[nums[i]%nums.size()]+=nums.size();\n }\n for(int i=1;i<nums.size();i++){\n if(nums[i]>(2*nums.size())){\n ans.push_back(i);\n }\n }\n if(nums[0]>(2*nums.size())){\n ans.push_back(nums.size());\n }\n return ans;\n }\n};\n```\n\n```Python3 []\nfrom collections import Counter\nclass Solution:\n def findDuplicates(self, nums: List[int]) -> List[int]:\n nums_set = set()\n out = []\n for num in nums:\n if num not in nums_set:\n nums_set.add(num)\n else:\n out.append(num)\n nums_set.add(num)\n return out\n```\n\n```Java []\nimport java.util.AbstractList;\nclass Solution {\n private List<Integer> res;\n public List<Integer> findDuplicates(int[] nums) {\n return new AbstractList<Integer>() {\n public Integer get(int index) {\n init();\n return res.get(index);\n }\n public int size() {\n init();\n return res.size();\n }\n private void init() {\n if(res != null) return;\n res = new ArrayList<>();\n int t;\n for(int i=0; i<nums.length; i++) {\n t = Math.abs(nums[i]);\n if(nums[t-1] < 0) {\n res.add(t);\n } else {\n nums[t-1] *= -1;\n }\n }\n }\n };\n }\n}\n```\n | 2 | Given an integer array `nums` of length `n` where all the integers of `nums` are in the range `[1, n]` and each integer appears **once** or **twice**, return _an array of all the integers that appears **twice**_.
You must write an algorithm that runs in `O(n)` time and uses only constant extra space.
**Example 1:**
**Input:** nums = \[4,3,2,7,8,2,3,1\]
**Output:** \[2,3\]
**Example 2:**
**Input:** nums = \[1,1,2\]
**Output:** \[1\]
**Example 3:**
**Input:** nums = \[1\]
**Output:** \[\]
**Constraints:**
* `n == nums.length`
* `1 <= n <= 105`
* `1 <= nums[i] <= n`
* Each element in `nums` appears **once** or **twice**. | null |
Python: Using hashmap, beats 77% | find-all-duplicates-in-an-array | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def findDuplicates(self, nums: List[int]) -> List[int]:\n hash={}\n for i in nums:\n if i in hash:\n hash[i]+=1\n else:\n hash[i]=1\n \n ans=[]\n for key,val in hash.items():\n if val>=2:\n ans.append(key)\n \n return ans\n\n \n``` | 1 | Given an integer array `nums` of length `n` where all the integers of `nums` are in the range `[1, n]` and each integer appears **once** or **twice**, return _an array of all the integers that appears **twice**_.
You must write an algorithm that runs in `O(n)` time and uses only constant extra space.
**Example 1:**
**Input:** nums = \[4,3,2,7,8,2,3,1\]
**Output:** \[2,3\]
**Example 2:**
**Input:** nums = \[1,1,2\]
**Output:** \[1\]
**Example 3:**
**Input:** nums = \[1\]
**Output:** \[\]
**Constraints:**
* `n == nums.length`
* `1 <= n <= 105`
* `1 <= nums[i] <= n`
* Each element in `nums` appears **once** or **twice**. | null |
🐍 / Linear Time / String traversal solution / ~90% fastest | string-compression | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n- We first have to traverse through the given list of characters and store the character and its continuous occurence in a list \'d\'.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n- Then in the list \'d\' created, alter the chars array at any index only if the occurance is greater than 1. Count the number of alters we made and return the count.\n\n# Complexity\n- Time complexity: O(N)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(N)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def compress(self, chars: List[str]) -> int:\n d=[]\n c=1\n for i in range(1,len(chars)):\n if chars[i]==chars[i-1]:\n c+=1\n else:\n d.append([chars[i-1],c])\n c=1\n d.append([chars[-1],c]) \n i=0\n for k,v in d:\n chars[i]=k\n i+=1\n if v>1:\n for item in str(v):\n chars[i]=str(item)\n i+=1\n return i\n``` | 2 | Given an array of characters `chars`, compress it using the following algorithm:
Begin with an empty string `s`. For each group of **consecutive repeating characters** in `chars`:
* If the group's length is `1`, append the character to `s`.
* Otherwise, append the character followed by the group's length.
The compressed string `s` **should not be returned separately**, but instead, be stored **in the input character array `chars`**. Note that group lengths that are `10` or longer will be split into multiple characters in `chars`.
After you are done **modifying the input array,** return _the new length of the array_.
You must write an algorithm that uses only constant extra space.
**Example 1:**
**Input:** chars = \[ "a ", "a ", "b ", "b ", "c ", "c ", "c "\]
**Output:** Return 6, and the first 6 characters of the input array should be: \[ "a ", "2 ", "b ", "2 ", "c ", "3 "\]
**Explanation:** The groups are "aa ", "bb ", and "ccc ". This compresses to "a2b2c3 ".
**Example 2:**
**Input:** chars = \[ "a "\]
**Output:** Return 1, and the first character of the input array should be: \[ "a "\]
**Explanation:** The only group is "a ", which remains uncompressed since it's a single character.
**Example 3:**
**Input:** chars = \[ "a ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b "\]
**Output:** Return 4, and the first 4 characters of the input array should be: \[ "a ", "b ", "1 ", "2 "\].
**Explanation:** The groups are "a " and "bbbbbbbbbbbb ". This compresses to "ab12 ".
**Constraints:**
* `1 <= chars.length <= 2000`
* `chars[i]` is a lowercase English letter, uppercase English letter, digit, or symbol. | How do you know if you are at the end of a consecutive group of characters? |
[Python] 2 pointers; Explained | string-compression | 0 | 1 | We maintain two pointers for the char list:\n(1) the first one is for sweep the current list from 0 to len(chars);\n(2) the second one is for writer pointer that write the new content to the list\n\nIt works the same as the typical two pointer problem. the only difference is we only write the number to the list if the length of the current character is larger than 1.\n\n```\nass Solution:\n def compress(self, chars: List[str]) -> int:\n wrt_pointer, chk_pointer = 0, 0\n current_char = None\n current_len = 0\n \n while chk_pointer < len(chars):\n if chars[chk_pointer] != current_char:\n # a new character\n if current_len > 1:\n len_str = []\n while current_len:\n len_str.append(str(current_len % 10))\n current_len = current_len // 10\n for lstr in len_str[::-1]:\n chars[wrt_pointer] = lstr\n wrt_pointer += 1\n chars[wrt_pointer] = chars[chk_pointer]\n wrt_pointer += 1\n current_char = chars[chk_pointer]\n current_len = 1\n else:\n # the same character\n current_len += 1\n chk_pointer += 1\n \n if current_len > 1:\n len_str = []\n while current_len:\n len_str.append(str(current_len % 10))\n current_len = current_len // 10\n for lstr in len_str[::-1]:\n chars[wrt_pointer] = lstr\n wrt_pointer += 1\n return wrt_pointer\n``` | 1 | Given an array of characters `chars`, compress it using the following algorithm:
Begin with an empty string `s`. For each group of **consecutive repeating characters** in `chars`:
* If the group's length is `1`, append the character to `s`.
* Otherwise, append the character followed by the group's length.
The compressed string `s` **should not be returned separately**, but instead, be stored **in the input character array `chars`**. Note that group lengths that are `10` or longer will be split into multiple characters in `chars`.
After you are done **modifying the input array,** return _the new length of the array_.
You must write an algorithm that uses only constant extra space.
**Example 1:**
**Input:** chars = \[ "a ", "a ", "b ", "b ", "c ", "c ", "c "\]
**Output:** Return 6, and the first 6 characters of the input array should be: \[ "a ", "2 ", "b ", "2 ", "c ", "3 "\]
**Explanation:** The groups are "aa ", "bb ", and "ccc ". This compresses to "a2b2c3 ".
**Example 2:**
**Input:** chars = \[ "a "\]
**Output:** Return 1, and the first character of the input array should be: \[ "a "\]
**Explanation:** The only group is "a ", which remains uncompressed since it's a single character.
**Example 3:**
**Input:** chars = \[ "a ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b "\]
**Output:** Return 4, and the first 4 characters of the input array should be: \[ "a ", "b ", "1 ", "2 "\].
**Explanation:** The groups are "a " and "bbbbbbbbbbbb ". This compresses to "ab12 ".
**Constraints:**
* `1 <= chars.length <= 2000`
* `chars[i]` is a lowercase English letter, uppercase English letter, digit, or symbol. | How do you know if you are at the end of a consecutive group of characters? |
Python Easy Approach | string-compression | 0 | 1 | # Complexity\n- Time complexity:\nO(n)\n\n- Space complexity:\nO(1)\n\n# Code\n```\nclass Solution:\n def compress(self, chars: List[str]) -> int:\n c=0\n res=""\n ch=chars[0]\n for i in range(len(chars)):\n if(chars[i]!=ch):\n if(c==1):\n res+=ch\n ch=chars[i]\n c=1\n else:\n res+=ch+str(c)\n c=1\n ch=chars[i]\n else:\n c+=1\n boolean=True\n if(res==""):\n boolean=False\n if(c!=1):\n res+=chars[i]+str(c)\n else:\n res+=chars[i] \n if(res[len(res)-1]!=chars[i] and boolean==True):\n if(c==1):\n res+=chars[i]\n else:\n res+=chars[i]+str(c)\n for i in range(len(res)):\n chars[i]=res[i]\n return len(res)\n \n \n\n\n``` | 1 | Given an array of characters `chars`, compress it using the following algorithm:
Begin with an empty string `s`. For each group of **consecutive repeating characters** in `chars`:
* If the group's length is `1`, append the character to `s`.
* Otherwise, append the character followed by the group's length.
The compressed string `s` **should not be returned separately**, but instead, be stored **in the input character array `chars`**. Note that group lengths that are `10` or longer will be split into multiple characters in `chars`.
After you are done **modifying the input array,** return _the new length of the array_.
You must write an algorithm that uses only constant extra space.
**Example 1:**
**Input:** chars = \[ "a ", "a ", "b ", "b ", "c ", "c ", "c "\]
**Output:** Return 6, and the first 6 characters of the input array should be: \[ "a ", "2 ", "b ", "2 ", "c ", "3 "\]
**Explanation:** The groups are "aa ", "bb ", and "ccc ". This compresses to "a2b2c3 ".
**Example 2:**
**Input:** chars = \[ "a "\]
**Output:** Return 1, and the first character of the input array should be: \[ "a "\]
**Explanation:** The only group is "a ", which remains uncompressed since it's a single character.
**Example 3:**
**Input:** chars = \[ "a ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b "\]
**Output:** Return 4, and the first 4 characters of the input array should be: \[ "a ", "b ", "1 ", "2 "\].
**Explanation:** The groups are "a " and "bbbbbbbbbbbb ". This compresses to "ab12 ".
**Constraints:**
* `1 <= chars.length <= 2000`
* `chars[i]` is a lowercase English letter, uppercase English letter, digit, or symbol. | How do you know if you are at the end of a consecutive group of characters? |
Python short and clean. Functional programming. | string-compression | 0 | 1 | # Approach\n1. Iterate through `chars` and group by chars.\n\n2. Count the length, say `n`, of each group to make an iterable of `(ch, n)` pairs. Let\'s call this iterable `ch_counts`.\n\n3. For each pair map `(ch, n)` to `ch + str(n) if n > 1 else ch`.\n\n4. Chain the results into a single iterable, say `compressed`.\n\n5. Fill `chars` with `compressed`.\n\n\n# Complexity\n- Time complexity: $$O(n)$$\n\n- Space complexity: $$O(1)$$\n\nwhere, `n is the length of chars`.\n\n# Code\nUsing builtin `itertools.groupby` method:\n```python\nclass Solution:\n def compress(self, chars: list[str]) -> int:\n iter_len = lambda xs: sum(1 for _ in xs)\n \n ch_counts = ((ch, iter_len(g)) for ch, g in groupby(chars))\n compressed = chain.from_iterable(ch + str(n) if n > 1 else ch for ch, n in ch_counts)\n\n i = 0\n for i, ch in enumerate(compressed): chars[i] = ch\n return i + 1\n\n\n```\n\nUsing custom written `group_count` method:\n```python\nclass Solution:\n def compress(self, chars: list[str]) -> int:\n T = TypeVar(\'T\') # This should be Comparables, i.e types with __eq__\n TCount = tuple[T, int]\n\n def group_count(iterable: Iterable[T]) -> Iterator[TCount]:\n xs = iter(iterable)\n sentinal = object()\n\n z, n = next(xs, sentinal), 1\n for x in xs:\n if x != z:\n yield (z, n)\n z, n = x, 0\n n += 1\n \n if z != sentinal: yield (z, n)\n \n ch_counts = group_count(chars)\n compressed = chain.from_iterable(ch + str(n) if n > 1 else ch for ch, n in ch_counts)\n\n i = 0\n for i, ch in enumerate(compressed): chars[i] = ch\n return i + 1\n\n\n``` | 2 | Given an array of characters `chars`, compress it using the following algorithm:
Begin with an empty string `s`. For each group of **consecutive repeating characters** in `chars`:
* If the group's length is `1`, append the character to `s`.
* Otherwise, append the character followed by the group's length.
The compressed string `s` **should not be returned separately**, but instead, be stored **in the input character array `chars`**. Note that group lengths that are `10` or longer will be split into multiple characters in `chars`.
After you are done **modifying the input array,** return _the new length of the array_.
You must write an algorithm that uses only constant extra space.
**Example 1:**
**Input:** chars = \[ "a ", "a ", "b ", "b ", "c ", "c ", "c "\]
**Output:** Return 6, and the first 6 characters of the input array should be: \[ "a ", "2 ", "b ", "2 ", "c ", "3 "\]
**Explanation:** The groups are "aa ", "bb ", and "ccc ". This compresses to "a2b2c3 ".
**Example 2:**
**Input:** chars = \[ "a "\]
**Output:** Return 1, and the first character of the input array should be: \[ "a "\]
**Explanation:** The only group is "a ", which remains uncompressed since it's a single character.
**Example 3:**
**Input:** chars = \[ "a ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b "\]
**Output:** Return 4, and the first 4 characters of the input array should be: \[ "a ", "b ", "1 ", "2 "\].
**Explanation:** The groups are "a " and "bbbbbbbbbbbb ". This compresses to "ab12 ".
**Constraints:**
* `1 <= chars.length <= 2000`
* `chars[i]` is a lowercase English letter, uppercase English letter, digit, or symbol. | How do you know if you are at the end of a consecutive group of characters? |
Clean Codes🔥🔥|| Full Explanation✅|| Two Pointers✅|| C++|| Java|| Python3 | string-compression | 1 | 1 | # Intuition :\n- Given an array of characters, compress it in-place. The length after compression must always be smaller than or equal to the original array. Every element of the array should be a character (not int) of length 1.\n- Example:\n```\nInput:\n["a","a","b","b","c","c","c"]\nOutput:\nReturn 6, and the first 6 characters of the input array should be: \n["a","2","b","2","c","3"]\nExplanation:\n"aa" is replaced by "a2". "bb" is replaced by "b2". "ccc" is \nreplaced by "c3".\n```\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Detail Explanation to Approach :\n- Here we are using two pointers, one for iterating through the original character array and one for keeping track of the current position in the compressed array. The two pointer variables used are `i` and `ans`.\n- Now also use a variable to keep track of the count of consecutive characters.\n- First set the current letter to the first character in the array and initializes the count to 0. \n- Then iterate through the array until you find a different character or reach the end of the array. \n- For each iteration, increment the count and the index i.\n```\n// iterate through input array using i pointer\n for (int i = 0; i < chars.length;) {\n final char letter = chars[i]; // current character being compressed\n int count = 0; // count of consecutive occurrences of letter\n\n // count consecutive occurrences of letter in input array\n while (i < chars.length && chars[i] == letter) {\n ++count;\n ++i;\n }\n\n\n``` \n- When you find a different character or reach the end of the array, write the current letter to the compressed array and, if the count is greater than 1, write the count as a string to the compressed array. \n- Then reset the count to 0 and set the current letter to the new letter.\n```\n// write letter to compressed array\n chars[ans++] = letter;\n\n // if count is greater than 1, write count as string to compressed array\n if (count > 1) {\n // convert count to string and iterate over each character in string\n for (final char c : String.valueOf(count).toCharArray()) {\n chars[ans++] = c;\n }\n }\n```\n- Finally, return the length of the compressed array, which is equal to the position of the last character in the compressed array plus one.\n```\nreturn ans;//return length of compressed array\n\n```\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity :\n- Time complexity : O(n)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity : O(1)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Please Upvote\uD83D\uDC4D\uD83D\uDC4D\n```\nThanks for visiting my solution.\uD83D\uDE0A\n```\n*Let\'s Code it Up .\nThere may be minor syntax difference in C++ and Python*\n\n# Codes [C++ |Java |Python3] : With Comments\n```C++ []\nclass Solution {\npublic:\n int compress(vector<char>& chars) {\n int ans = 0;\n\n // iterate through input vector using i pointer\n for (int i = 0; i < chars.size();) {\n const char letter = chars[i]; // current character being compressed\n int count = 0; // count of consecutive occurrences of letter\n\n // count consecutive occurrences of letter in input vector\n while (i < chars.size() && chars[i] == letter) {\n ++count;\n ++i;\n }\n\n // write letter to compressed vector\n chars[ans++] = letter;\n\n // if count is greater than 1, write count as string to compressed vector\n if (count > 1) {\n // convert count to string and iterate over each character in string\n for (const char c : to_string(count)) {\n chars[ans++] = c;\n }\n }\n }\n\n // return length of compressed vector\n return ans;\n }\n};\n\n```\n```Java []\nclass Solution {\n public int compress(char[] chars) {\n int ans = 0; // keep track of current position in compressed array\n\n // iterate through input array using i pointer\n for (int i = 0; i < chars.length;) {\n final char letter = chars[i]; // current character being compressed\n int count = 0; // count of consecutive occurrences of letter\n\n // count consecutive occurrences of letter in input array\n while (i < chars.length && chars[i] == letter) {\n ++count;\n ++i;\n }\n\n // write letter to compressed array\n chars[ans++] = letter;\n\n // if count is greater than 1, write count as string to compressed array\n if (count > 1) {\n // convert count to string and iterate over each character in string\n for (final char c : String.valueOf(count).toCharArray()) {\n chars[ans++] = c;\n }\n }\n }\n\n // return length of compressed array\n return ans;\n }\n}\n\n```\n```Python3 []\nclass Solution:\n def compress(self, chars: List[str]) -> int:\n ans = 0\n i = 0\n\n while i < len(chars):\n letter = chars[i]\n count = 0\n while i < len(chars) and chars[i] == letter:\n count += 1\n i += 1\n chars[ans] = letter\n ans += 1\n if count > 1:\n for c in str(count):\n chars[ans] = c\n ans += 1\n\n return ans\n```\n# Please Upvote\uD83D\uDC4D\uD83D\uDC4D\n\n | 94 | Given an array of characters `chars`, compress it using the following algorithm:
Begin with an empty string `s`. For each group of **consecutive repeating characters** in `chars`:
* If the group's length is `1`, append the character to `s`.
* Otherwise, append the character followed by the group's length.
The compressed string `s` **should not be returned separately**, but instead, be stored **in the input character array `chars`**. Note that group lengths that are `10` or longer will be split into multiple characters in `chars`.
After you are done **modifying the input array,** return _the new length of the array_.
You must write an algorithm that uses only constant extra space.
**Example 1:**
**Input:** chars = \[ "a ", "a ", "b ", "b ", "c ", "c ", "c "\]
**Output:** Return 6, and the first 6 characters of the input array should be: \[ "a ", "2 ", "b ", "2 ", "c ", "3 "\]
**Explanation:** The groups are "aa ", "bb ", and "ccc ". This compresses to "a2b2c3 ".
**Example 2:**
**Input:** chars = \[ "a "\]
**Output:** Return 1, and the first character of the input array should be: \[ "a "\]
**Explanation:** The only group is "a ", which remains uncompressed since it's a single character.
**Example 3:**
**Input:** chars = \[ "a ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b "\]
**Output:** Return 4, and the first 4 characters of the input array should be: \[ "a ", "b ", "1 ", "2 "\].
**Explanation:** The groups are "a " and "bbbbbbbbbbbb ". This compresses to "ab12 ".
**Constraints:**
* `1 <= chars.length <= 2000`
* `chars[i]` is a lowercase English letter, uppercase English letter, digit, or symbol. | How do you know if you are at the end of a consecutive group of characters? |
Day 61 || Two Pointer || O(1) space and O(1) time || Easiest Beginner Friendly Sol | string-compression | 1 | 1 | **NOTE - PLEASE READ INTUITION AND APPROACH FIRST THEN SEE THE CODE. YOU WILL DEFINITELY UNDERSTAND THE CODE LINE BY LINE AFTER SEEING THE APPROACH.**\n\n# Intuition of this Problem:\nThe implementation uses two pointers, i and j, to traverse the character array. The variable i is used to iterate over the array, while j is used to keep track of the position to which the compressed character needs to be written. The variable prev is used to store the previous character encountered, and count is used to keep track of the number of consecutive occurrences of the current character.\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach for this Problem:\n1. Initialize variables i, j, prev, and count to 0 and char_count to 1.\n2. If the length of the input character array is 0, return 0.\n3. Iterate over the input character array using i, starting from the second character:\n - a. If the current character is equal to the previous character, increment count.\n - b. Otherwise:\n - i. If count is 1, write the previous character to the next position in the array.\n - ii. Otherwise, convert count to a string of digits and write the previous character, followed by the string, to the next position in the array. If the length of the string is 2 or more, increment j by the length of the string minus 1 to make space for the digits.\n - iii. Set prev to the current character and reset count to 1.\n1. c. Increment i and j.\nWrite the compressed character for the last group of consecutive characters to the array using the same logic as in step 3.\nReturn j, which is the length of the compressed character array.\n<!-- Describe your approach to solving the problem. -->\n\n\n# Code:\n```C++ []\nclass Solution {\npublic:\n int compress(vector<char>& chars) {\n int n = chars.size();\n if (n == 0) \n return 0;\n \n int i = 0, j = 0, count = 1;\n char prevChar = chars[0];\n \n for (i = 1; i < n; i++) {\n if (chars[i] == prevChar) {\n count++;\n } else {\n chars[j++] = prevChar;\n if (count > 1) {\n string countStr = to_string(count);\n for (char ch : countStr) {\n chars[j++] = ch;\n }\n }\n prevChar = chars[i];\n count = 1;\n }\n }\n \n chars[j++] = prevChar;\n if (count > 1) {\n string countStr = to_string(count);\n for (char ch : countStr) {\n chars[j++] = ch;\n }\n }\n \n return j;\n }\n};\n```\n```Java []\nclass Solution {\n public int compress(char[] chars) {\n int i = 0, j = 0, count = 1;\n char prev = chars[0];\n if (chars.length == 0) {\n return 0;\n }\n for (i = 1; i < chars.length; i++) {\n if (chars[i] == prev) {\n count++;\n } else {\n if (count == 1) {\n chars[j++] = prev;\n } else {\n String countStr = String.valueOf(count);\n chars[j++] = prev;\n for (int k = 0; k < countStr.length(); k++) {\n chars[j++] = countStr.charAt(k);\n }\n if (countStr.length() >= 2) {\n j -= (countStr.length() - 1);\n }\n }\n prev = chars[i];\n count = 1;\n }\n }\n if (count == 1) {\n chars[j++] = prev;\n } else {\n String countStr = String.valueOf(count);\n chars[j++] = prev;\n for (int k = 0; k < countStr.length(); k++) {\n chars[j++] = countStr.charAt(k);\n }\n if (countStr.length() >= 2) {\n j -= (countStr.length() - 1);\n }\n }\n return j;\n }\n}\n\n```\n```Python []\nclass Solution:\n def compress(self, chars: List[str]) -> int:\n n = len(chars)\n if n == 1:\n return 1\n \n i = 0\n j = 0\n \n while i < n:\n count = 1\n while i < n - 1 and chars[i] == chars[i+1]:\n count += 1\n i += 1\n \n chars[j] = chars[i]\n j += 1\n \n if count > 1:\n for c in str(count):\n chars[j] = c\n j += 1\n \n i += 1\n \n return j\n\n```\n\n# Time Complexity and Space Complexity:\n- **Time complexity**: **O(n)**, where n is the length of the input character array. This is because we traverse the array only once, and the operations within the loop take constant time.\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- **Space complexity**: **O(1)**, i.e. constant extra space. This is because we are modifying the input array in place, without using any additional data structures. The only extra space used is the variables i, j, prev, and count, which all take constant space.\n - Note that the conversion of the count of consecutive characters to a string may take up to O(log(count)) space, but this is still considered constant space as the maximum length of the string is bounded by a constant (i.e., 10). Therefore, the overall space complexity of the algorithm is O(1).\n<!-- Add your space complexity here, e.g. $$O(n)$$ --> | 5 | Given an array of characters `chars`, compress it using the following algorithm:
Begin with an empty string `s`. For each group of **consecutive repeating characters** in `chars`:
* If the group's length is `1`, append the character to `s`.
* Otherwise, append the character followed by the group's length.
The compressed string `s` **should not be returned separately**, but instead, be stored **in the input character array `chars`**. Note that group lengths that are `10` or longer will be split into multiple characters in `chars`.
After you are done **modifying the input array,** return _the new length of the array_.
You must write an algorithm that uses only constant extra space.
**Example 1:**
**Input:** chars = \[ "a ", "a ", "b ", "b ", "c ", "c ", "c "\]
**Output:** Return 6, and the first 6 characters of the input array should be: \[ "a ", "2 ", "b ", "2 ", "c ", "3 "\]
**Explanation:** The groups are "aa ", "bb ", and "ccc ". This compresses to "a2b2c3 ".
**Example 2:**
**Input:** chars = \[ "a "\]
**Output:** Return 1, and the first character of the input array should be: \[ "a "\]
**Explanation:** The only group is "a ", which remains uncompressed since it's a single character.
**Example 3:**
**Input:** chars = \[ "a ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b "\]
**Output:** Return 4, and the first 4 characters of the input array should be: \[ "a ", "b ", "1 ", "2 "\].
**Explanation:** The groups are "a " and "bbbbbbbbbbbb ". This compresses to "ab12 ".
**Constraints:**
* `1 <= chars.length <= 2000`
* `chars[i]` is a lowercase English letter, uppercase English letter, digit, or symbol. | How do you know if you are at the end of a consecutive group of characters? |
String Compression | string-compression | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n\n# Code\n```\nclass Solution:\n def compress(self, chars: List[str]) -> int:\n i=0\n idx=0\n while i<len(chars):\n j=i\n while j<len(chars) and chars[i]==chars[j]:\n j+=1\n chars[idx]=chars[i]\n idx+=1\n count=j-i\n if count>1:\n for c in str(count):\n chars[idx]=c\n idx+=1\n i=j\n chars=chars[:idx]\n return idx\n\n \n \n\n``` | 1 | Given an array of characters `chars`, compress it using the following algorithm:
Begin with an empty string `s`. For each group of **consecutive repeating characters** in `chars`:
* If the group's length is `1`, append the character to `s`.
* Otherwise, append the character followed by the group's length.
The compressed string `s` **should not be returned separately**, but instead, be stored **in the input character array `chars`**. Note that group lengths that are `10` or longer will be split into multiple characters in `chars`.
After you are done **modifying the input array,** return _the new length of the array_.
You must write an algorithm that uses only constant extra space.
**Example 1:**
**Input:** chars = \[ "a ", "a ", "b ", "b ", "c ", "c ", "c "\]
**Output:** Return 6, and the first 6 characters of the input array should be: \[ "a ", "2 ", "b ", "2 ", "c ", "3 "\]
**Explanation:** The groups are "aa ", "bb ", and "ccc ". This compresses to "a2b2c3 ".
**Example 2:**
**Input:** chars = \[ "a "\]
**Output:** Return 1, and the first character of the input array should be: \[ "a "\]
**Explanation:** The only group is "a ", which remains uncompressed since it's a single character.
**Example 3:**
**Input:** chars = \[ "a ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b "\]
**Output:** Return 4, and the first 4 characters of the input array should be: \[ "a ", "b ", "1 ", "2 "\].
**Explanation:** The groups are "a " and "bbbbbbbbbbbb ". This compresses to "ab12 ".
**Constraints:**
* `1 <= chars.length <= 2000`
* `chars[i]` is a lowercase English letter, uppercase English letter, digit, or symbol. | How do you know if you are at the end of a consecutive group of characters? |
Two pointer approach || TC=O(n) , Sc = O(1) || Faster than 100% in java and cpp 60% in python | string-compression | 1 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThe intuition behind the code is to compress the given array of characters by counting consecutive repeating characters. If the count of a character is greater than 1, append the character followed by the count to the resulting compressed array.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n**Two Pointer**\nInitialize a counter cnt to 1 and a pointer j to 0.\nIf the size of the input array chars is 1, return 1 (no compression needed for a single character).\nIterate through the chars array starting from index 1.\nFor each element, compare it with the previous element. If they are the same, increment the counter cnt.\nIf the current element is different from the previous element or it\'s the last element in the array, update the chars[j] with the previous character (since it\'s the end of a group).\nIf the count cnt is greater than 1, convert it to a string c using to_string(cnt).\nIterate through each character in the string c and append them to the chars array starting from index j+1.\nIncrement j by the number of characters appended in step 7.\nRepeat steps 4-8 until all elements in the chars array are processed.\nReturn the updated pointer j, which represents the new length of the compressed array.\n\n# Complexity\n- Time complexity: O(N)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nThe time complexity of the code is O(N), where N is the size of the input array chars. This is because we iterate through each element in the array once.\n\n- Space complexity: O(1)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nThe space complexity is O(1) because the code uses only a constant amount of extra space to store the counters and pointers.\n\n# Code\n```Java []\nclass Solution {\n public int compress(char[] chars) {\n int cnt = 1;\n int j = 0;\n \n if (chars.length == 1)\n return 1;\n \n for (int i = 1; i <= chars.length; i++) {\n cnt = 1;\n while (i < chars.length && chars[i] == chars[i - 1]) {\n cnt++;\n i++;\n }\n chars[j++] = chars[i - 1];\n \n if (cnt > 1) {\n String c = String.valueOf(cnt);\n for (char ch : c.toCharArray()) {\n chars[j++] = ch;\n }\n }\n }\n \n return j;\n }\n}\n```\n```C++ []\nclass Solution {\npublic:\n int compress(vector<char>& chars) {\n int cnt=1;\n int j=0;\n if(chars.size()==1)\n return 1; \n for(int i=1; i<=chars.size(); i++){\n cnt=1;\n while(i<chars.size() and chars[i]==chars[i-1])\n {\n cnt++; i++;\n }\n chars[j++]= chars[i-1];\n if(cnt>1){\n string c = to_string(cnt);\n for(auto ch: c){\n chars[j++]= (char)ch;\n }\n }\n }\n return j;\n }\n};\n```\n```Python []\nclass Solution:\n def compress(self, chars: List[str]) -> int:\n cnt = 1\n j = 0\n \n if len(chars) == 1:\n return 1\n \n for i in range(1, len(chars) + 1):\n if i < len(chars) and chars[i] == chars[i - 1]:\n cnt += 1\n else:\n chars[j] = chars[i - 1]\n j += 1\n \n if cnt > 1:\n for digit in str(cnt):\n chars[j] = digit\n j += 1\n cnt = 1\n \n return j\n\n``` | 3 | Given an array of characters `chars`, compress it using the following algorithm:
Begin with an empty string `s`. For each group of **consecutive repeating characters** in `chars`:
* If the group's length is `1`, append the character to `s`.
* Otherwise, append the character followed by the group's length.
The compressed string `s` **should not be returned separately**, but instead, be stored **in the input character array `chars`**. Note that group lengths that are `10` or longer will be split into multiple characters in `chars`.
After you are done **modifying the input array,** return _the new length of the array_.
You must write an algorithm that uses only constant extra space.
**Example 1:**
**Input:** chars = \[ "a ", "a ", "b ", "b ", "c ", "c ", "c "\]
**Output:** Return 6, and the first 6 characters of the input array should be: \[ "a ", "2 ", "b ", "2 ", "c ", "3 "\]
**Explanation:** The groups are "aa ", "bb ", and "ccc ". This compresses to "a2b2c3 ".
**Example 2:**
**Input:** chars = \[ "a "\]
**Output:** Return 1, and the first character of the input array should be: \[ "a "\]
**Explanation:** The only group is "a ", which remains uncompressed since it's a single character.
**Example 3:**
**Input:** chars = \[ "a ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b "\]
**Output:** Return 4, and the first 4 characters of the input array should be: \[ "a ", "b ", "1 ", "2 "\].
**Explanation:** The groups are "a " and "bbbbbbbbbbbb ". This compresses to "ab12 ".
**Constraints:**
* `1 <= chars.length <= 2000`
* `chars[i]` is a lowercase English letter, uppercase English letter, digit, or symbol. | How do you know if you are at the end of a consecutive group of characters? |
🚩🚩🔥🔥100% solution ,Easy and Unique Approach 🚩🚩🔥🔥 | string-compression | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nBasically,Normal frequency we find and form a string and then to list.But it fails in case where a different alphabet come and breaks the frequency and repeated character in dictionary will be added and gives you wrong output.To get these try to solve below example:\ninput list=["a","a","b","a"]\noutput we get is -["a","3","b"]\nbut the output is-["a","2","b","a"]\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nTo Solve these,We can go through stack property first go through the chars and append into a stack.check whether stack is empty or the top element in stack matches to chars.Now when any other element is triggered clear the stack and add these to the string.\n\nHope this helps!!!\n\n\nPlease Upvote!!\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nO(N)\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nO(N)\n\n# Code\n```\nclass Solution:\n def compress(self, chars: List[str]) -> int:\n stack=[]\n s=""\n for i in range(len(chars)):\n if len(stack)==0 or stack[-1]==chars[i]:\n stack.append(chars[i])\n else:\n s+=stack[-1]\n if len(stack)!=1:\n s+=str(len(stack))\n stack.clear()\n stack.append(chars[i])\n s+=stack[-1]\n if len(stack)!=1:\n s+=str(len(stack))\n chars.clear()\n for i in s:\n chars.append((i))\n return len(s)\n\n \n``` | 3 | Given an array of characters `chars`, compress it using the following algorithm:
Begin with an empty string `s`. For each group of **consecutive repeating characters** in `chars`:
* If the group's length is `1`, append the character to `s`.
* Otherwise, append the character followed by the group's length.
The compressed string `s` **should not be returned separately**, but instead, be stored **in the input character array `chars`**. Note that group lengths that are `10` or longer will be split into multiple characters in `chars`.
After you are done **modifying the input array,** return _the new length of the array_.
You must write an algorithm that uses only constant extra space.
**Example 1:**
**Input:** chars = \[ "a ", "a ", "b ", "b ", "c ", "c ", "c "\]
**Output:** Return 6, and the first 6 characters of the input array should be: \[ "a ", "2 ", "b ", "2 ", "c ", "3 "\]
**Explanation:** The groups are "aa ", "bb ", and "ccc ". This compresses to "a2b2c3 ".
**Example 2:**
**Input:** chars = \[ "a "\]
**Output:** Return 1, and the first character of the input array should be: \[ "a "\]
**Explanation:** The only group is "a ", which remains uncompressed since it's a single character.
**Example 3:**
**Input:** chars = \[ "a ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b "\]
**Output:** Return 4, and the first 4 characters of the input array should be: \[ "a ", "b ", "1 ", "2 "\].
**Explanation:** The groups are "a " and "bbbbbbbbbbbb ". This compresses to "ab12 ".
**Constraints:**
* `1 <= chars.length <= 2000`
* `chars[i]` is a lowercase English letter, uppercase English letter, digit, or symbol. | How do you know if you are at the end of a consecutive group of characters? |
Simple Diagram Explanation | string-compression | 1 | 1 | # Idea\n---\n- Here are some things we want to ask ourselves:\n - What to do when a character group is of length 1?\n - What to do when a character ground is length > 1?\n - How do I solve this in-place (for constant space complexity)?\n\n---\n- The reason the question is called **string compression** could be understood if we see resulting `chars` array size will always be **less than or equal to** than the original size. \n- Consider the two operations: if character group is of length 1, then no change occurs; if character group is of length > 1, then we end up compressing the length (i.e. 10 characters only take up 3 spaces)\n\n- From what we understand so far, the question is not hard. We just need to look through the `chars` array and perform the two operations. \n- But another constraint is that we must do this in-place. What does this entail for us?\n- This means when we perform operation 2 (which compresses) we could end up with unused array space. This would be problematic since we want `char` array to be condensed. \n----\n- To tackle this issue, we will use a two pointers approach. \n- While iterating through `chars` to perform the operations, keep track of the next index to write into so unused space is considered. \n\n\n# Example \n\n- Consider the case `["a","a","b","c","c","c","c","b","b","b",]`\n\n\n\n\n\n\n\n- Why do we need to write `start` character into the `next` index when they are already the same? This is because the `next` index may not always be aligned with the `star` character because of unused space. We will see this in a bit. \n\n\n\n\n\n\n\n\n\n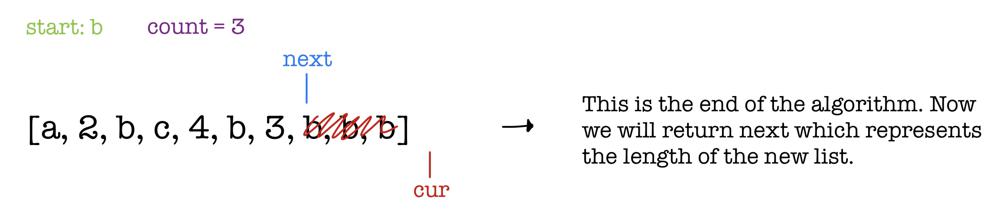\n\n\n- Since we return `next` as the length, anything on or after `next` will not be considered as part of the solution. \n\n\n##### If this helped, please leave an upvote! Thanks! | 31 | Given an array of characters `chars`, compress it using the following algorithm:
Begin with an empty string `s`. For each group of **consecutive repeating characters** in `chars`:
* If the group's length is `1`, append the character to `s`.
* Otherwise, append the character followed by the group's length.
The compressed string `s` **should not be returned separately**, but instead, be stored **in the input character array `chars`**. Note that group lengths that are `10` or longer will be split into multiple characters in `chars`.
After you are done **modifying the input array,** return _the new length of the array_.
You must write an algorithm that uses only constant extra space.
**Example 1:**
**Input:** chars = \[ "a ", "a ", "b ", "b ", "c ", "c ", "c "\]
**Output:** Return 6, and the first 6 characters of the input array should be: \[ "a ", "2 ", "b ", "2 ", "c ", "3 "\]
**Explanation:** The groups are "aa ", "bb ", and "ccc ". This compresses to "a2b2c3 ".
**Example 2:**
**Input:** chars = \[ "a "\]
**Output:** Return 1, and the first character of the input array should be: \[ "a "\]
**Explanation:** The only group is "a ", which remains uncompressed since it's a single character.
**Example 3:**
**Input:** chars = \[ "a ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b "\]
**Output:** Return 4, and the first 4 characters of the input array should be: \[ "a ", "b ", "1 ", "2 "\].
**Explanation:** The groups are "a " and "bbbbbbbbbbbb ". This compresses to "ab12 ".
**Constraints:**
* `1 <= chars.length <= 2000`
* `chars[i]` is a lowercase English letter, uppercase English letter, digit, or symbol. | How do you know if you are at the end of a consecutive group of characters? |
Two Pointer Approach: Beats 96% submissions in Time Complexity | string-compression | 0 | 1 | # Intuition\nThe two pointer approach is the most effective strategy that comes to mind. \n\n# Approach\nWe initiate both left and right pointer at the beginning. We iterate the right pointer from left either to end or till we have similar character as the left pointer is pointing.\nOnce we get the count, remove all the characters from the next character of left pointer to the the right pointer and insert the count (splitting the digits if there are more than one digit).\n\n# Complexity\n- Time complexity: O(n)\n\n- Space complexity: O(1)\n\n# Code\n```\nclass Solution:\n def compress(self, chars: List[str]) -> int:\n l, r = 0, 0\n s = len(chars)\n\n while l < s:\n n = 0\n r = l\n while r < s and chars[l] == chars[r]:\n if chars[l] == chars[r]:\n n += 1\n r += 1\n\n if n > 1:\n for k in range(l + 1, r):\n chars.pop(l + 1)\n s -= 1\n for k in range(len(str(n))):\n l = l + 1\n chars.insert(l, str(n)[k])\n s += 1\n\n l += 1\n r = l\n\n return len(chars)\n``` | 3 | Given an array of characters `chars`, compress it using the following algorithm:
Begin with an empty string `s`. For each group of **consecutive repeating characters** in `chars`:
* If the group's length is `1`, append the character to `s`.
* Otherwise, append the character followed by the group's length.
The compressed string `s` **should not be returned separately**, but instead, be stored **in the input character array `chars`**. Note that group lengths that are `10` or longer will be split into multiple characters in `chars`.
After you are done **modifying the input array,** return _the new length of the array_.
You must write an algorithm that uses only constant extra space.
**Example 1:**
**Input:** chars = \[ "a ", "a ", "b ", "b ", "c ", "c ", "c "\]
**Output:** Return 6, and the first 6 characters of the input array should be: \[ "a ", "2 ", "b ", "2 ", "c ", "3 "\]
**Explanation:** The groups are "aa ", "bb ", and "ccc ". This compresses to "a2b2c3 ".
**Example 2:**
**Input:** chars = \[ "a "\]
**Output:** Return 1, and the first character of the input array should be: \[ "a "\]
**Explanation:** The only group is "a ", which remains uncompressed since it's a single character.
**Example 3:**
**Input:** chars = \[ "a ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b "\]
**Output:** Return 4, and the first 4 characters of the input array should be: \[ "a ", "b ", "1 ", "2 "\].
**Explanation:** The groups are "a " and "bbbbbbbbbbbb ". This compresses to "ab12 ".
**Constraints:**
* `1 <= chars.length <= 2000`
* `chars[i]` is a lowercase English letter, uppercase English letter, digit, or symbol. | How do you know if you are at the end of a consecutive group of characters? |
Python with comments (Explained) | string-compression | 0 | 1 | https://github.com/paulonteri/data-structures-and-algorithms\n```\nclass Solution(object):\n\n def compress(self, chars):\n\n length = len(chars)\n\n # make it a bit faster\n if length < 2:\n return length\n\n # the start position of the contiguous group of characters we are currently reading.\n anchor = 0\n\n # position to Write Next\n # we start with 0 then increase it whenever we write to the array\n write = 0\n\n # we go through each caharcter till we fiand a pos where the next is not equal to it\n # then we check if it has appeared more than once using the anchor and r(read) pointers\n # 1. iterate till we find a diffrent char\n # 2. record the no. of times the current char was repeated\n for pos, char in enumerate(chars):\n\n # check if we have reached the end or a different char\n # check if we are end or the next char != the current\n if (pos + 1) == length or char != chars[pos+1]:\n chars[write] = char\n write += 1\n\n # check if char has been repeated\n # have been duplicated if the read pointer is ahead of the anchor pointer\n if pos > anchor:\n # check no. of times char has been repeated\n repeated_times = pos - anchor + 1\n\n # write the number\n for num in str(repeated_times):\n chars[write] = num\n write += 1\n\n # move the anchor to the next char in the iteration\n anchor = pos + 1\n\n return write\n\n``` | 101 | Given an array of characters `chars`, compress it using the following algorithm:
Begin with an empty string `s`. For each group of **consecutive repeating characters** in `chars`:
* If the group's length is `1`, append the character to `s`.
* Otherwise, append the character followed by the group's length.
The compressed string `s` **should not be returned separately**, but instead, be stored **in the input character array `chars`**. Note that group lengths that are `10` or longer will be split into multiple characters in `chars`.
After you are done **modifying the input array,** return _the new length of the array_.
You must write an algorithm that uses only constant extra space.
**Example 1:**
**Input:** chars = \[ "a ", "a ", "b ", "b ", "c ", "c ", "c "\]
**Output:** Return 6, and the first 6 characters of the input array should be: \[ "a ", "2 ", "b ", "2 ", "c ", "3 "\]
**Explanation:** The groups are "aa ", "bb ", and "ccc ". This compresses to "a2b2c3 ".
**Example 2:**
**Input:** chars = \[ "a "\]
**Output:** Return 1, and the first character of the input array should be: \[ "a "\]
**Explanation:** The only group is "a ", which remains uncompressed since it's a single character.
**Example 3:**
**Input:** chars = \[ "a ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b "\]
**Output:** Return 4, and the first 4 characters of the input array should be: \[ "a ", "b ", "1 ", "2 "\].
**Explanation:** The groups are "a " and "bbbbbbbbbbbb ". This compresses to "ab12 ".
**Constraints:**
* `1 <= chars.length <= 2000`
* `chars[i]` is a lowercase English letter, uppercase English letter, digit, or symbol. | How do you know if you are at the end of a consecutive group of characters? |
443: Solution with step by step explanation | string-compression | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Initialize a write index write_idx and a read index i to 0.\n2. While i is less than the length of chars, do the following:\n 1. Initialize a read index j to i + 1.\n 2. While j is less than the length of chars and chars[j] is equal to chars[i], increment j.\n 3. Write the character chars[i] to chars[write_idx], and increment write_idx.\n 4. If j - i is greater than 1, convert the count j - i to a string, and write the string to chars[write_idx:write_idx+len(count_str)]. Increment write_idx by the length of the count string.\n 5. Set i to j.\n3. Delete all elements of chars with indices greater than or equal to write_idx.\n4. Return the length of chars.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def compress(self, chars: List[str]) -> int:\n # Initialize pointers and output index\n write_idx = 0\n i = 0\n \n # Iterate through the array\n while i < len(chars):\n # Update j to point to the end of the current group\n j = i + 1\n while j < len(chars) and chars[j] == chars[i]:\n j += 1\n\n # Write the character and its count to the output array\n chars[write_idx] = chars[i]\n write_idx += 1\n if j - i > 1:\n count_str = str(j - i)\n chars[write_idx:write_idx+len(count_str)] = count_str\n write_idx += len(count_str)\n\n # Update i to point to the start of the next group\n i = j\n\n # Truncate the array to its final length\n del chars[write_idx:]\n\n # Return the length of the output array\n return len(chars)\n\n``` | 3 | Given an array of characters `chars`, compress it using the following algorithm:
Begin with an empty string `s`. For each group of **consecutive repeating characters** in `chars`:
* If the group's length is `1`, append the character to `s`.
* Otherwise, append the character followed by the group's length.
The compressed string `s` **should not be returned separately**, but instead, be stored **in the input character array `chars`**. Note that group lengths that are `10` or longer will be split into multiple characters in `chars`.
After you are done **modifying the input array,** return _the new length of the array_.
You must write an algorithm that uses only constant extra space.
**Example 1:**
**Input:** chars = \[ "a ", "a ", "b ", "b ", "c ", "c ", "c "\]
**Output:** Return 6, and the first 6 characters of the input array should be: \[ "a ", "2 ", "b ", "2 ", "c ", "3 "\]
**Explanation:** The groups are "aa ", "bb ", and "ccc ". This compresses to "a2b2c3 ".
**Example 2:**
**Input:** chars = \[ "a "\]
**Output:** Return 1, and the first character of the input array should be: \[ "a "\]
**Explanation:** The only group is "a ", which remains uncompressed since it's a single character.
**Example 3:**
**Input:** chars = \[ "a ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b "\]
**Output:** Return 4, and the first 4 characters of the input array should be: \[ "a ", "b ", "1 ", "2 "\].
**Explanation:** The groups are "a " and "bbbbbbbbbbbb ". This compresses to "ab12 ".
**Constraints:**
* `1 <= chars.length <= 2000`
* `chars[i]` is a lowercase English letter, uppercase English letter, digit, or symbol. | How do you know if you are at the end of a consecutive group of characters? |
Python - Using itertools.groupby | string-compression | 0 | 1 | ```\nclass Solution:\n def compress(self, chars: List[str]) -> int:\n s = []\n for key, group in groupby(chars):\n #print(k, list(g))\n count = len(list(group))\n s.append(key)\n if count > 1: s.extend(list(str(count)))\n chars[:] = s\n\n``` | 14 | Given an array of characters `chars`, compress it using the following algorithm:
Begin with an empty string `s`. For each group of **consecutive repeating characters** in `chars`:
* If the group's length is `1`, append the character to `s`.
* Otherwise, append the character followed by the group's length.
The compressed string `s` **should not be returned separately**, but instead, be stored **in the input character array `chars`**. Note that group lengths that are `10` or longer will be split into multiple characters in `chars`.
After you are done **modifying the input array,** return _the new length of the array_.
You must write an algorithm that uses only constant extra space.
**Example 1:**
**Input:** chars = \[ "a ", "a ", "b ", "b ", "c ", "c ", "c "\]
**Output:** Return 6, and the first 6 characters of the input array should be: \[ "a ", "2 ", "b ", "2 ", "c ", "3 "\]
**Explanation:** The groups are "aa ", "bb ", and "ccc ". This compresses to "a2b2c3 ".
**Example 2:**
**Input:** chars = \[ "a "\]
**Output:** Return 1, and the first character of the input array should be: \[ "a "\]
**Explanation:** The only group is "a ", which remains uncompressed since it's a single character.
**Example 3:**
**Input:** chars = \[ "a ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b "\]
**Output:** Return 4, and the first 4 characters of the input array should be: \[ "a ", "b ", "1 ", "2 "\].
**Explanation:** The groups are "a " and "bbbbbbbbbbbb ". This compresses to "ab12 ".
**Constraints:**
* `1 <= chars.length <= 2000`
* `chars[i]` is a lowercase English letter, uppercase English letter, digit, or symbol. | How do you know if you are at the end of a consecutive group of characters? |
Python 3 || 13 lines, iteration with pointer || T/M: 96% / 97% | string-compression | 0 | 1 | ```\nclass Solution:\n def compress(self, chars: list[str]) -> int:\n\n n, ptr, cnt = len(chars), 0, 1\n\n for i in range(1,n+1):\n\n if i < n and chars[i] == chars[i-1]: cnt += 1\n\n else:\n chars[ptr] = chars[i-1]\n ptr+= 1\n\n if cnt > 1:\n s = str(cnt)\n m = len(s)\n chars[ptr : ptr + m] = s\n ptr+= m\n \n cnt = 1\n\n return ptr\n```\n[https://leetcode.com/problems/string-compression/submissions/907982556/](http://)\n\nI could be wrong, but I think that time complexity is *O*(*N*) and space complexity is *O*(1). | 3 | Given an array of characters `chars`, compress it using the following algorithm:
Begin with an empty string `s`. For each group of **consecutive repeating characters** in `chars`:
* If the group's length is `1`, append the character to `s`.
* Otherwise, append the character followed by the group's length.
The compressed string `s` **should not be returned separately**, but instead, be stored **in the input character array `chars`**. Note that group lengths that are `10` or longer will be split into multiple characters in `chars`.
After you are done **modifying the input array,** return _the new length of the array_.
You must write an algorithm that uses only constant extra space.
**Example 1:**
**Input:** chars = \[ "a ", "a ", "b ", "b ", "c ", "c ", "c "\]
**Output:** Return 6, and the first 6 characters of the input array should be: \[ "a ", "2 ", "b ", "2 ", "c ", "3 "\]
**Explanation:** The groups are "aa ", "bb ", and "ccc ". This compresses to "a2b2c3 ".
**Example 2:**
**Input:** chars = \[ "a "\]
**Output:** Return 1, and the first character of the input array should be: \[ "a "\]
**Explanation:** The only group is "a ", which remains uncompressed since it's a single character.
**Example 3:**
**Input:** chars = \[ "a ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b "\]
**Output:** Return 4, and the first 4 characters of the input array should be: \[ "a ", "b ", "1 ", "2 "\].
**Explanation:** The groups are "a " and "bbbbbbbbbbbb ". This compresses to "ab12 ".
**Constraints:**
* `1 <= chars.length <= 2000`
* `chars[i]` is a lowercase English letter, uppercase English letter, digit, or symbol. | How do you know if you are at the end of a consecutive group of characters? |
Easy to follow | Python | Two pointer | string-compression | 0 | 1 | # Intuition\nNeed a pointer to fill the new value in the `chars` list. The placement of the character and it\'s counts happens whenever a new character is observed. \n\n# Approach\n- Start with `ptr=0` and note the char at 0-th index in `prev_char` and mark the `cnt=1` as you have already observed one character.\n- Move forward and check if the current character is same as the `prev_char`.\n - if same: increment `cnt`\n - if different: save the `prev_char` at `ptr` and check the value of `cnt`. If `cnt==1`: nothing needs to be done. If it isn\'t, then extract all the digits and put them in the `chars` array and keep incrementing the `ptr` as you go forward.\n\n# Complexity\n- Time complexity: O(n)\n - Have to observe all the characters.\n\n- Space complexity: O(1)\n\n*Note*: Let me know if you have any question and I would be happy to answer it asap. thanks.\n\n# Code\n```\nclass Solution:\n def compress(self, chars: List[str]) -> int:\n\n if len(chars)==1:\n return 1\n \n prev_char = chars[0]\n cnt = 1\n ptr = 0\n n = len(chars)\n\n # This function fills in the chars array with prev_char\n # and digits of cnt if necessary.\n def modify():\n nonlocal prev_char, ptr, cnt\n chars[ptr] = prev_char\n ptr+=1\n if cnt>1:\n cnt = str(cnt)\n for j in range(len(cnt)):\n chars[ptr]=cnt[j]\n ptr+=1\n cnt = 1\n prev_char = curr_char\n\n for i in range(1,n):\n curr_char = chars[i]\n if curr_char==prev_char:\n cnt+=1\n else:\n modify()\n \n modify()\n return ptr \n``` | 4 | Given an array of characters `chars`, compress it using the following algorithm:
Begin with an empty string `s`. For each group of **consecutive repeating characters** in `chars`:
* If the group's length is `1`, append the character to `s`.
* Otherwise, append the character followed by the group's length.
The compressed string `s` **should not be returned separately**, but instead, be stored **in the input character array `chars`**. Note that group lengths that are `10` or longer will be split into multiple characters in `chars`.
After you are done **modifying the input array,** return _the new length of the array_.
You must write an algorithm that uses only constant extra space.
**Example 1:**
**Input:** chars = \[ "a ", "a ", "b ", "b ", "c ", "c ", "c "\]
**Output:** Return 6, and the first 6 characters of the input array should be: \[ "a ", "2 ", "b ", "2 ", "c ", "3 "\]
**Explanation:** The groups are "aa ", "bb ", and "ccc ". This compresses to "a2b2c3 ".
**Example 2:**
**Input:** chars = \[ "a "\]
**Output:** Return 1, and the first character of the input array should be: \[ "a "\]
**Explanation:** The only group is "a ", which remains uncompressed since it's a single character.
**Example 3:**
**Input:** chars = \[ "a ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b ", "b "\]
**Output:** Return 4, and the first 4 characters of the input array should be: \[ "a ", "b ", "1 ", "2 "\].
**Explanation:** The groups are "a " and "bbbbbbbbbbbb ". This compresses to "ab12 ".
**Constraints:**
* `1 <= chars.length <= 2000`
* `chars[i]` is a lowercase English letter, uppercase English letter, digit, or symbol. | How do you know if you are at the end of a consecutive group of characters? |
Python3 Solution | add-two-numbers-ii | 0 | 1 | \n```\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n def addTwoNumbers(self, l1: Optional[ListNode], l2: Optional[ListNode]) -> Optional[ListNode]:\n num1,num2=0,0\n while l1!=None:\n num1=num1*10+l1.val\n l1=l1.next\n\n while l2!=None:\n num2=num2*10+l2.val\n l2=l2.next\n\n dummylist=dummy=ListNode(0)\n\n ans=str(num1+num2)\n for i in ans:\n dummy.next=ListNode(i)\n dummy=dummy.next\n\n return dummylist.next \n``` | 3 | You are given two **non-empty** linked lists representing two non-negative integers. The most significant digit comes first and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
You may assume the two numbers do not contain any leading zero, except the number 0 itself.
**Example 1:**
**Input:** l1 = \[7,2,4,3\], l2 = \[5,6,4\]
**Output:** \[7,8,0,7\]
**Example 2:**
**Input:** l1 = \[2,4,3\], l2 = \[5,6,4\]
**Output:** \[8,0,7\]
**Example 3:**
**Input:** l1 = \[0\], l2 = \[0\]
**Output:** \[0\]
**Constraints:**
* The number of nodes in each linked list is in the range `[1, 100]`.
* `0 <= Node.val <= 9`
* It is guaranteed that the list represents a number that does not have leading zeros.
**Follow up:** Could you solve it without reversing the input lists? | null |
Python | Left pad, then recursion | add-two-numbers-ii | 0 | 1 | # Intuition\nIf we made sure the lists were the same length, it would simplify the problem. We can do that with a way to measure length and then left pad 0 values for the difference\n\n# Approach\n1. Determine the lengths of both linked lists\n2. prepend pad 0 value nodes on the smaller list to get lists of equal length\n3. Make recursive calls to add values, then post call process each node\'s value along with the results of the previous call.\n4. Make sure to account for the final possible carry digit before returning answer.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\n\ndef add(l1: Optional[ListNode], l2: Optional[ListNode]) -> tuple[int, Union[None, ListNode]]:\n if not l1 or not l2:\n #print(f"reached the end")\n return (0, None)\n addend_carry, result = add(l1.next, l2.next)\n sum_carry, val = divmod(l1.val + l2.val + addend_carry, 10)\n #print(f"{l1.val} + {l2.val} + {addend_carry} = {val} carry {sum_carry}")\n\n result = ListNode(val, result)\n return (sum_carry, result)\n\ndef length(ln: Optional[ListNode]) -> int:\n if not ln:\n return 0\n return length(ln.next) + 1\n\ndef left_pad(padding: int, ln: ListNode) -> ListNode:\n if padding <= 0:\n return ln\n return left_pad(padding - 1, ListNode(0, ln))\n\nclass Solution:\n def addTwoNumbers(self, l1: Optional[ListNode], l2: Optional[ListNode]) -> Optional[ListNode]:\n l1_size = length(l1)\n l2_size = length(l2)\n\n padded_l1 = left_pad(max(0, l2_size - l1_size), l1)\n padded_l2 = left_pad(max(0, l1_size - l2_size), l2)\n\n carry, result = add(padded_l1, padded_l2)\n if carry:\n result = ListNode(carry, result)\n return result\n \n``` | 3 | You are given two **non-empty** linked lists representing two non-negative integers. The most significant digit comes first and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
You may assume the two numbers do not contain any leading zero, except the number 0 itself.
**Example 1:**
**Input:** l1 = \[7,2,4,3\], l2 = \[5,6,4\]
**Output:** \[7,8,0,7\]
**Example 2:**
**Input:** l1 = \[2,4,3\], l2 = \[5,6,4\]
**Output:** \[8,0,7\]
**Example 3:**
**Input:** l1 = \[0\], l2 = \[0\]
**Output:** \[0\]
**Constraints:**
* The number of nodes in each linked list is in the range `[1, 100]`.
* `0 <= Node.val <= 9`
* It is guaranteed that the list represents a number that does not have leading zeros.
**Follow up:** Could you solve it without reversing the input lists? | null |
easy | add-two-numbers-ii | 0 | 1 | \n```\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n def addTwoNumbers(self, l1: Optional[ListNode], l2: Optional[ListNode]) -> Optional[ListNode]:\n p, o = "", ""\n \n\n #def for create ListNode\n def CreateList(arg):\n head = ListNode(arg[0])\n current=head\n for x in arg[1:]:\n node = ListNode(x)\n current.next = node\n current = current.next\n return head\n \n #ListNode to string\n while l1:\n p+=str(l1.val)\n l1 = l1.next\n while l2:\n o+=str(l2.val)\n l2 = l2.next\n \n return CreateList(str(int(p)+int(o)))\n``` | 1 | You are given two **non-empty** linked lists representing two non-negative integers. The most significant digit comes first and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
You may assume the two numbers do not contain any leading zero, except the number 0 itself.
**Example 1:**
**Input:** l1 = \[7,2,4,3\], l2 = \[5,6,4\]
**Output:** \[7,8,0,7\]
**Example 2:**
**Input:** l1 = \[2,4,3\], l2 = \[5,6,4\]
**Output:** \[8,0,7\]
**Example 3:**
**Input:** l1 = \[0\], l2 = \[0\]
**Output:** \[0\]
**Constraints:**
* The number of nodes in each linked list is in the range `[1, 100]`.
* `0 <= Node.val <= 9`
* It is guaranteed that the list represents a number that does not have leading zeros.
**Follow up:** Could you solve it without reversing the input lists? | null |
Without reversing inputs, using stack | add-two-numbers-ii | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity: $$O(max(m,n))$$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: $$O(m+n)$$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\n\nclass Solution:\n def addTwoNumbers(self, l1: Optional[ListNode], l2: Optional[ListNode]) -> Optional[ListNode]:\n s1 = []\n s2 = []\n\n while l1 or l2:\n if l1:\n s1.append(l1.val)\n l1 = l1.next\n if l2:\n s2.append(l2.val)\n l2 = l2.next\n\n carry = 0\n dummy = ListNode()\n curr = dummy\n\n while s1 or s2 or carry:\n v1 = s1.pop() if len(s1) else 0\n v2 = s2.pop() if len(s2) else 0\n\n val = v1 + v2 + carry\n carry = val // 10\n val = val % 10\n curr.next = ListNode(val)\n\n # update ptrs\n curr = curr.next\n\n return self.reverse(dummy.next)\n\n def reverse(self, head: Optional[ListNode]) -> Optional[ListNode]:\n prev = None\n curr = head\n\n while curr:\n next = curr.next\n curr.next = prev\n prev = curr\n curr = next\n\n return prev\n \n``` | 1 | You are given two **non-empty** linked lists representing two non-negative integers. The most significant digit comes first and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
You may assume the two numbers do not contain any leading zero, except the number 0 itself.
**Example 1:**
**Input:** l1 = \[7,2,4,3\], l2 = \[5,6,4\]
**Output:** \[7,8,0,7\]
**Example 2:**
**Input:** l1 = \[2,4,3\], l2 = \[5,6,4\]
**Output:** \[8,0,7\]
**Example 3:**
**Input:** l1 = \[0\], l2 = \[0\]
**Output:** \[0\]
**Constraints:**
* The number of nodes in each linked list is in the range `[1, 100]`.
* `0 <= Node.val <= 9`
* It is guaranteed that the list represents a number that does not have leading zeros.
**Follow up:** Could you solve it without reversing the input lists? | null |
Add Two Numbers || | add-two-numbers-ii | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def addTwoNumbers(self, l1: Optional[ListNode], l2: Optional[ListNode]) -> Optional[ListNode]:\n def rev(l):\n if l:\n yield from rev(l.next)\n yield l.val\n carry, head = 0, None\n for x, y in zip_longest(rev(l1), rev(l2), fillvalue=0):\n carry, d = divmod(x+y+carry, 10)\n head = ListNode(d, head)\n return ListNode(carry, head) if carry else head\n``` | 1 | You are given two **non-empty** linked lists representing two non-negative integers. The most significant digit comes first and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
You may assume the two numbers do not contain any leading zero, except the number 0 itself.
**Example 1:**
**Input:** l1 = \[7,2,4,3\], l2 = \[5,6,4\]
**Output:** \[7,8,0,7\]
**Example 2:**
**Input:** l1 = \[2,4,3\], l2 = \[5,6,4\]
**Output:** \[8,0,7\]
**Example 3:**
**Input:** l1 = \[0\], l2 = \[0\]
**Output:** \[0\]
**Constraints:**
* The number of nodes in each linked list is in the range `[1, 100]`.
* `0 <= Node.val <= 9`
* It is guaranteed that the list represents a number that does not have leading zeros.
**Follow up:** Could you solve it without reversing the input lists? | null |
Easy python solution | add-two-numbers-ii | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\nconvert both lists to numbers, add, and convert to a linkedlist \n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n def addTwoNumbers(self, l1: Optional[ListNode], l2: Optional[ListNode]) -> Optional[ListNode]:\n s1 = \'\'\n s2 = \'\'\n while l1:\n s1+=str(l1.val)\n l1 = l1.next\n while l2:\n s2+=str(l2.val)\n l2 = l2.next \n tot = str(int(s1) +int(s2))\n\n ans = itr = ListNode()\n for i in tot:\n itr.next= ListNode(i)\n itr = itr.next \n return ans.next \n\n``` | 1 | You are given two **non-empty** linked lists representing two non-negative integers. The most significant digit comes first and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
You may assume the two numbers do not contain any leading zero, except the number 0 itself.
**Example 1:**
**Input:** l1 = \[7,2,4,3\], l2 = \[5,6,4\]
**Output:** \[7,8,0,7\]
**Example 2:**
**Input:** l1 = \[2,4,3\], l2 = \[5,6,4\]
**Output:** \[8,0,7\]
**Example 3:**
**Input:** l1 = \[0\], l2 = \[0\]
**Output:** \[0\]
**Constraints:**
* The number of nodes in each linked list is in the range `[1, 100]`.
* `0 <= Node.val <= 9`
* It is guaranteed that the list represents a number that does not have leading zeros.
**Follow up:** Could you solve it without reversing the input lists? | null |
Python short and clean. Functional programming. | add-two-numbers-ii | 0 | 1 | # Complexity\n- Time complexity: $$O(max(n1, n2))$$\n\n- Space complexity: $$O(n1 + n2)$$\n\nwhere,\n`n1 is length of l1`,\n`n2 is length of l2`.\n\n# Code\n```python\nclass Solution:\n def addTwoNumbers(self, l1: ListNode, l2: ListNode) -> ListNode:\n def to_int(ll: ListNode) -> int:\n n = 0\n while ll: n = n * 10 + ll.val; ll = ll.next\n return n\n \n def to_LL(n: int) -> ListNode:\n ll = None\n while n: n, val = divmod(n, 10); ll = ListNode(val, ll)\n return ll or ListNode()\n \n return to_LL(to_int(l1) + to_int(l2))\n\n\n``` | 2 | You are given two **non-empty** linked lists representing two non-negative integers. The most significant digit comes first and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
You may assume the two numbers do not contain any leading zero, except the number 0 itself.
**Example 1:**
**Input:** l1 = \[7,2,4,3\], l2 = \[5,6,4\]
**Output:** \[7,8,0,7\]
**Example 2:**
**Input:** l1 = \[2,4,3\], l2 = \[5,6,4\]
**Output:** \[8,0,7\]
**Example 3:**
**Input:** l1 = \[0\], l2 = \[0\]
**Output:** \[0\]
**Constraints:**
* The number of nodes in each linked list is in the range `[1, 100]`.
* `0 <= Node.val <= 9`
* It is guaranteed that the list represents a number that does not have leading zeros.
**Follow up:** Could you solve it without reversing the input lists? | null |
Ex-Amazon explains a solution with a video, Python, JavaScript, Java and C++ | add-two-numbers-ii | 1 | 1 | # Intuition\nUsing two stacks to make calculation easy.\n\n# Solution Video\n\nhttps://youtu.be/DP1oVjE5t6o\n\n# *** Please Upvote and subscribe to my channel from here. I have 224 LeetCode videos as of July 17th, 2023. ***\n\nhttp://www.youtube.com/channel/UC9RMNwYTL3SXCP6ShLWVFww?sub_confirmation=1\n\n---\n\n# Approach\nThis is based on Python code. Other language might be different a bit.\n\n1. Create two empty stacks, `stack1` and `stack2`, to store the digits of the linked lists `l1` and `l2`, respectively.\n\n2. Push the digits of `l1` to `stack1` using a while loop:\n - Traverse the linked list `l1` while it is not empty.\n - For each node in `l1`, push its value (digit) onto `stack1`.\n - Move to the next node in `l1` until the end of the linked list is reached.\n\n3. Push the digits of `l2` to `stack2` using a similar while loop as in step 2.\n\n4. Initialize a variable `carry` to store the carry from the previous addition. Set `dummy_head` to `None`, which will be the head of the result linked list.\n\n5. Perform the addition:\n - Use a while loop to continue adding digits until both `stack1` and `stack2` are empty, and there is no carry left.\n - Inside the loop:\n - Pop the top element from `stack1` if it is not empty; otherwise, set `val1` to 0.\n - Pop the top element from `stack2` if it is not empty; otherwise, set `val2` to 0.\n - Add `val1`, `val2`, and the current `carry`, and store the sum in `total`.\n - Update `carry` to store the carry for the next iteration (carry will be either 0 or 1).\n - Create a new node with the value `(total % 10)` and set its `next` pointer to `dummy_head`.\n - Update `dummy_head` to point to the new node, effectively reversing the order of the nodes in the result linked list.\n\n6. After the loop, the addition is complete, and the result is stored in the linked list starting from `dummy_head`. Return `dummy_head`, which is the head of the result linked list.\n\nThe algorithm uses the property of a stack to reverse the order of digits in the linked lists `l1` and `l2` so that the addition can be performed from the least significant digit to the most significant digit. This approach avoids the need to reverse the linked lists before performing the addition.\n\n# Complexity\nThis is based on Python code. Other language might be different a bit.\n\n- Time complexity: O(m + n)\n \'m\' and \'n\' are the lengths of the two linked lists, l1 and l2\n\n- Space complexity: O(m + n)\n \'m\' and \'n\' are the lengths of the two linked lists, l1 and l2\n\n\n```python []\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n def addTwoNumbers(self, l1: Optional[ListNode], l2: Optional[ListNode]) -> Optional[ListNode]:\n\n stack1, stack2 = [], []\n\n # push digits of l1 to stack1\n while l1:\n stack1.append(l1.val)\n l1 = l1.next\n\n # push digits of l2 to stack1\n while l2:\n stack2.append(l2.val)\n l2 = l2.next\n \n carry = 0\n dummy_head = None\n\n # Pop digits from both stacks and add them\n while stack1 or stack2 or carry:\n val1 = stack1.pop() if stack1 else 0\n val2 = stack2.pop() if stack2 else 0\n\n total = val1 + val2 + carry\n carry = total // 10\n\n new_node = ListNode(total % 10)\n new_node.next = dummy_head\n dummy_head = new_node\n\n return dummy_head \n```\n```javascript []\n/**\n * Definition for singly-linked list.\n * function ListNode(val, next) {\n * this.val = (val===undefined ? 0 : val)\n * this.next = (next===undefined ? null : next)\n * }\n */\n/**\n * @param {ListNode} l1\n * @param {ListNode} l2\n * @return {ListNode}\n */\nvar addTwoNumbers = function(l1, l2) {\n let stack1 = [];\n let stack2 = [];\n\n // Push digits of l1 to stack1\n while (l1) {\n stack1.push(l1.val);\n l1 = l1.next;\n }\n\n // Push digits of l2 to stack2\n while (l2) {\n stack2.push(l2.val);\n l2 = l2.next;\n }\n\n let carry = 0;\n let dummyHead = null;\n\n // Pop digits from both stacks and add them\n while (stack1.length || stack2.length || carry) {\n let val1 = stack1.pop() || 0;\n let val2 = stack2.pop() || 0;\n\n let total = val1 + val2 + carry;\n carry = Math.floor(total / 10);\n\n let new_node = new ListNode(total % 10);\n new_node.next = dummyHead;\n dummyHead = new_node;\n }\n\n return dummyHead; \n};\n```\n```java []\n/**\n * Definition for singly-linked list.\n * public class ListNode {\n * int val;\n * ListNode next;\n * ListNode() {}\n * ListNode(int val) { this.val = val; }\n * ListNode(int val, ListNode next) { this.val = val; this.next = next; }\n * }\n */\nclass Solution {\n public ListNode addTwoNumbers(ListNode l1, ListNode l2) {\n Stack<Integer> stack1 = new Stack<>();\n Stack<Integer> stack2 = new Stack<>();\n\n // Push digits of l1 to stack1\n while (l1 != null) {\n stack1.push(l1.val);\n l1 = l1.next;\n }\n\n // Push digits of l2 to stack2\n while (l2 != null) {\n stack2.push(l2.val);\n l2 = l2.next;\n }\n\n int carry = 0;\n ListNode dummyHead = null;\n\n // Pop digits from both stacks and add them\n while (!stack1.isEmpty() || !stack2.isEmpty() || carry != 0) {\n int val1 = stack1.isEmpty() ? 0 : stack1.pop();\n int val2 = stack2.isEmpty() ? 0 : stack2.pop();\n\n int total = val1 + val2 + carry;\n carry = total / 10;\n\n ListNode new_node = new ListNode(total % 10);\n new_node.next = dummyHead;\n dummyHead = new_node;\n }\n\n return dummyHead; \n }\n}\n```\n```C++ []\n/**\n * Definition for singly-linked list.\n * struct ListNode {\n * int val;\n * ListNode *next;\n * ListNode() : val(0), next(nullptr) {}\n * ListNode(int x) : val(x), next(nullptr) {}\n * ListNode(int x, ListNode *next) : val(x), next(next) {}\n * };\n */\nclass Solution {\npublic:\n ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {\n std::stack<int> stack1, stack2;\n\n // Push digits of l1 to stack1\n while (l1) {\n stack1.push(l1->val);\n l1 = l1->next;\n }\n\n // Push digits of l2 to stack2\n while (l2) {\n stack2.push(l2->val);\n l2 = l2->next;\n }\n\n int carry = 0, val1, val2;\n ListNode* dummyHead = NULL;\n\n // Pop digits from both stacks and add them\n while (!stack1.empty() || !stack2.empty() || carry) {\n if (!stack1.empty()) {\n val1 = stack1.top();\n stack1.pop();\n }\n else\n val1 = 0;\n \n if (!stack2.empty()) {\n val2 = stack2.top();\n stack2.pop();\n }\n else\n val2 = 0;\n \n int total = val1 + val2 + carry;\n carry = total / 10;\n\n ListNode* new_node = new ListNode(total % 10);\n new_node->next = dummyHead;\n dummyHead = new_node;\n }\n\n return dummyHead;\n }\n};\n```\n | 6 | You are given two **non-empty** linked lists representing two non-negative integers. The most significant digit comes first and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
You may assume the two numbers do not contain any leading zero, except the number 0 itself.
**Example 1:**
**Input:** l1 = \[7,2,4,3\], l2 = \[5,6,4\]
**Output:** \[7,8,0,7\]
**Example 2:**
**Input:** l1 = \[2,4,3\], l2 = \[5,6,4\]
**Output:** \[8,0,7\]
**Example 3:**
**Input:** l1 = \[0\], l2 = \[0\]
**Output:** \[0\]
**Constraints:**
* The number of nodes in each linked list is in the range `[1, 100]`.
* `0 <= Node.val <= 9`
* It is guaranteed that the list represents a number that does not have leading zeros.
**Follow up:** Could you solve it without reversing the input lists? | null |
Python Without Reversing-Recursive-padding | add-two-numbers-ii | 0 | 1 | # Intuition\nPad the Input lists with leading zeros so each of the input lists have equal length.\n\n# Approach\nRecursively get the carry and the resultant summation for the next nodes and calculate the same for the current node.\n\n# Complexity\n- Time complexity:\nAs we are only Traversing the lists without any nested Operations.\nThe Time Complexity is O(N) where N is the Maximum length of the input lists.\n\n- Space complexity:\nThe Space complexity in this Solution is O(N) as we are storing the resultant in a different output lists. But this can easily be O(1) by using either of the lists to store the result.\n\n# Code\n```\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n def addTwoNumbers(self, l1: Optional[ListNode], l2: Optional[ListNode]) -> Optional[ListNode]:\n def length(head):\n if not head:\n return 0\n return 1+length(head.next)\n len1=length(l1)\n len2=length(l2)\n if len1<len2:\n pad=l1\n no_pad=l2\n smaller=len1\n larger=len2\n else:\n pad=l2\n no_pad=l1\n larger=len1\n smaller=len2\n while smaller<larger:\n node=ListNode(0)\n node.next=pad\n pad=node\n smaller+=1\n l1,l2=pad,no_pad\n def rec(h1,h2):\n if h1.next and h2.next:\n carry,node=rec(h1.next,h2.next)\n else:\n carry,node=0,None\n n_node=ListNode((carry+h1.val+h2.val)%10)\n n_c=(carry+h1.val+h2.val)//10\n n_node.next=node\n return n_c,n_node \n carry,head=rec(l1,l2)\n if carry==1:\n n_h=ListNode(carry)\n n_h.next=head\n return n_h\n return head\n\n\n \n \n \n``` | 1 | You are given two **non-empty** linked lists representing two non-negative integers. The most significant digit comes first and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
You may assume the two numbers do not contain any leading zero, except the number 0 itself.
**Example 1:**
**Input:** l1 = \[7,2,4,3\], l2 = \[5,6,4\]
**Output:** \[7,8,0,7\]
**Example 2:**
**Input:** l1 = \[2,4,3\], l2 = \[5,6,4\]
**Output:** \[8,0,7\]
**Example 3:**
**Input:** l1 = \[0\], l2 = \[0\]
**Output:** \[0\]
**Constraints:**
* The number of nodes in each linked list is in the range `[1, 100]`.
* `0 <= Node.val <= 9`
* It is guaranteed that the list represents a number that does not have leading zeros.
**Follow up:** Could you solve it without reversing the input lists? | null |
✅Beat's 100% || 2 Method's || C++ || JAVA || PYTHON || Beginner Friendly🔥🔥🔥 | add-two-numbers-ii | 1 | 1 | # Intuition:\nThe stack-based approach for adding two numbers represented by linked lists involves using stacks to process the digits in reverse order. By pushing the digits of the linked lists onto separate stacks, we can simulate iterating through the numbers from the least significant digit to the most significant digit. We perform digit-wise addition, considering any carry-over, and construct a new linked list to represent the sum. This process continues until both input lists and the carry value are exhausted, resulting in a linked list that represents the sum of the input numbers in the correct order.\n\n# Approach 1: (Reverse LL):\n# Explanation:\n[2. Add Two Numbers](https://leetcode.com/problems/add-two-numbers/solutions/3675747/beats-100-c-java-python-beginner-friendly/)\n[206. Reverse Linked List](https://leetcode.com/problems/reverse-linked-list/solutions/3620367/best-method-100-c-java-python-beginner-friendly/)\n\n# Code\n```C++ []\nclass Solution {\npublic:\n ListNode* reverseList(ListNode* head) {\n ListNode* prev = NULL;\n\n while(head) {\n ListNode* nxt = head->next;\n head->next = prev;\n prev = head;\n head = nxt;\n }\n return prev;\n }\n\n ListNode* Helper(ListNode* l1, ListNode* l2) {\n ListNode* dummyHead = new ListNode(0);\n ListNode* tail = dummyHead;\n int carry = 0;\n\n while (l1 != nullptr || l2 != nullptr || carry != 0) {\n int digit1 = (l1 != nullptr) ? l1->val : 0;\n int digit2 = (l2 != nullptr) ? l2->val : 0;\n\n int sum = digit1 + digit2 + carry;\n int digit = sum % 10;\n carry = sum / 10;\n\n ListNode* newNode = new ListNode(digit);\n tail->next = newNode;\n tail = tail->next;\n\n l1 = (l1 != nullptr) ? l1->next : nullptr;\n l2 = (l2 != nullptr) ? l2->next : nullptr;\n }\n\n ListNode* result = dummyHead->next;\n delete dummyHead;\n return result;\n }\n\n ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {\n l1 = reverseList(l1);\n l2 = reverseList(l2);\n ListNode* ans = Helper(l1, l2);\n return reverseList(ans);\n }\n};\n```\n```Java []\nclass Solution {\n public ListNode reverseList(ListNode head) {\n ListNode prev = null;\n ListNode curr = head;\n\n while (curr != null) {\n ListNode next = curr.next;\n curr.next = prev;\n prev = curr;\n curr = next;\n }\n \n return prev;\n }\n\n public ListNode helper(ListNode l1, ListNode l2) {\n ListNode dummyHead = new ListNode(0);\n ListNode tail = dummyHead;\n int carry = 0;\n\n while (l1 != null || l2 != null || carry != 0) {\n int digit1 = (l1 != null) ? l1.val : 0;\n int digit2 = (l2 != null) ? l2.val : 0;\n\n int sum = digit1 + digit2 + carry;\n int digit = sum % 10;\n carry = sum / 10;\n\n ListNode newNode = new ListNode(digit);\n tail.next = newNode;\n tail = tail.next;\n\n l1 = (l1 != null) ? l1.next : null;\n l2 = (l2 != null) ? l2.next : null;\n }\n\n ListNode result = dummyHead.next;\n return result;\n }\n\n public ListNode addTwoNumbers(ListNode l1, ListNode l2) {\n l1 = reverseList(l1);\n l2 = reverseList(l2);\n ListNode ans = helper(l1, l2);\n return reverseList(ans);\n }\n}\n```\n```Python3 []\nclass Solution:\n def reverseList(self, head: ListNode) -> ListNode:\n prev = None\n curr = head\n\n while curr:\n nxt = curr.next\n curr.next = prev\n prev = curr\n curr = nxt\n \n return prev\n\n def helper(self, l1: ListNode, l2: ListNode) -> ListNode:\n dummyHead = ListNode(0)\n tail = dummyHead\n carry = 0\n\n while l1 or l2 or carry:\n digit1 = l1.val if l1 else 0\n digit2 = l2.val if l2 else 0\n\n total = digit1 + digit2 + carry\n digit = total % 10\n carry = total // 10\n\n newNode = ListNode(digit)\n tail.next = newNode\n tail = tail.next\n\n l1 = l1.next if l1 else None\n l2 = l2.next if l2 else None\n\n result = dummyHead.next\n return result\n\n def addTwoNumbers(self, l1: ListNode, l2: ListNode) -> ListNode:\n l1 = self.reverseList(l1)\n l2 = self.reverseList(l2)\n ans = self.helper(l1, l2)\n return self.reverseList(ans)\n```\n\n# Approach 2: (Using Stack)\n\n# Code\n```C++ []\nclass Solution {\npublic:\n ListNode* Helper(ListNode* l1, ListNode* l2) {\n stack<int> stack1, stack2;\n\n while (l1 != nullptr) {\n stack1.push(l1->val);\n l1 = l1->next;\n }\n\n while (l2 != nullptr) {\n stack2.push(l2->val);\n l2 = l2->next;\n }\n\n ListNode* result = nullptr;\n int carry = 0;\n\n while (!stack1.empty() || !stack2.empty() || carry != 0) {\n int digit1 = !stack1.empty() ? stack1.top() : 0;\n int digit2 = !stack2.empty() ? stack2.top() : 0;\n\n int sum = digit1 + digit2 + carry;\n int digit = sum % 10;\n carry = sum / 10;\n\n ListNode* newNode = new ListNode(digit);\n newNode->next = result;\n result = newNode;\n\n if (!stack1.empty())\n stack1.pop();\n if (!stack2.empty())\n stack2.pop();\n }\n\n return result;\n }\n\n ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) {\n ListNode* ans = Helper(l1, l2);\n return ans;\n }\n};\n```\n```Java []\nimport java.util.Stack;\n\nclass Solution {\n public ListNode helper(ListNode l1, ListNode l2) {\n Stack<Integer> stack1 = new Stack<>();\n Stack<Integer> stack2 = new Stack<>();\n\n while (l1 != null) {\n stack1.push(l1.val);\n l1 = l1.next;\n }\n\n while (l2 != null) {\n stack2.push(l2.val);\n l2 = l2.next;\n }\n\n ListNode result = null;\n int carry = 0;\n\n while (!stack1.empty() || !stack2.empty() || carry != 0) {\n int digit1 = !stack1.empty() ? stack1.pop() : 0;\n int digit2 = !stack2.empty() ? stack2.pop() : 0;\n\n int sum = digit1 + digit2 + carry;\n int digit = sum % 10;\n carry = sum / 10;\n\n ListNode newNode = new ListNode(digit);\n newNode.next = result;\n result = newNode;\n }\n\n return result;\n }\n\n public ListNode addTwoNumbers(ListNode l1, ListNode l2) {\n ListNode ans = helper(l1, l2);\n return ans;\n }\n}\n```\n```Python3 []\nclass Solution:\n def helper(self, l1: ListNode, l2: ListNode) -> ListNode:\n stack1 = []\n stack2 = []\n\n while l1:\n stack1.append(l1.val)\n l1 = l1.next\n\n while l2:\n stack2.append(l2.val)\n l2 = l2.next\n\n result = None\n carry = 0\n\n while stack1 or stack2 or carry:\n digit1 = stack1.pop() if stack1 else 0\n digit2 = stack2.pop() if stack2 else 0\n\n total = digit1 + digit2 + carry\n digit = total % 10\n carry = total // 10\n\n newNode = ListNode(digit)\n newNode.next = result\n result = newNode\n\n return result\n\n def addTwoNumbers(self, l1: ListNode, l2: ListNode) -> ListNode:\n ans = self.helper(l1, l2)\n return ans\n```\n\n**If you found my solution helpful, I would greatly appreciate your upvote, as it would motivate me to continue sharing more solutions.**\n\n | 85 | You are given two **non-empty** linked lists representing two non-negative integers. The most significant digit comes first and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
You may assume the two numbers do not contain any leading zero, except the number 0 itself.
**Example 1:**
**Input:** l1 = \[7,2,4,3\], l2 = \[5,6,4\]
**Output:** \[7,8,0,7\]
**Example 2:**
**Input:** l1 = \[2,4,3\], l2 = \[5,6,4\]
**Output:** \[8,0,7\]
**Example 3:**
**Input:** l1 = \[0\], l2 = \[0\]
**Output:** \[0\]
**Constraints:**
* The number of nodes in each linked list is in the range `[1, 100]`.
* `0 <= Node.val <= 9`
* It is guaranteed that the list represents a number that does not have leading zeros.
**Follow up:** Could you solve it without reversing the input lists? | null |
445: Solution with step by step explanation | add-two-numbers-ii | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Initialize two stacks stack1 and stack2 to store the values of each linked list.\n2. Traverse the first linked list l1 and push its values onto stack1.\n3. Traverse the second linked list l2 and push its values onto stack2.\n4. Initialize variables for sum and carry. Set result to None.\n5. Pop values from the stacks and add them together until both stacks are empty:\na. If stack1 is not empty, pop its top value as val1. Otherwise, set val1 to 0.\nb. If stack2 is not empty, pop its top value as val2. Otherwise, set val2 to 0.\nc. Calculate the sum of val1, val2, and carry and get the quotient and remainder using divmod(). Set carry to the quotient and val to the remainder.\nd. Create a new node to store the sum as new_node with value val and set its next to result.\ne. Update result to new_node.\n6. Return result or ListNode(0) if result is None.\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def addTwoNumbers(self, l1: ListNode, l2: ListNode) -> ListNode:\n # Create two stacks to store the values of each linked list\n stack1, stack2 = [], []\n\n # Traverse the first linked list and push its values onto stack1\n while l1:\n stack1.append(l1.val)\n l1 = l1.next\n\n # Traverse the second linked list and push its values onto stack2\n while l2:\n stack2.append(l2.val)\n l2 = l2.next\n\n # Initialize variables for sum and carry\n carry = 0\n result = None\n\n # Pop values from the stacks and add them together until both stacks are empty\n while stack1 or stack2 or carry:\n val1 = stack1.pop() if stack1 else 0\n val2 = stack2.pop() if stack2 else 0\n carry, val = divmod(val1 + val2 + carry, 10)\n\n # Create a new node to store the sum and add it to the front of the result linked list\n new_node = ListNode(val)\n new_node.next = result\n result = new_node\n\n return result or ListNode(0)\n\n``` | 3 | You are given two **non-empty** linked lists representing two non-negative integers. The most significant digit comes first and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
You may assume the two numbers do not contain any leading zero, except the number 0 itself.
**Example 1:**
**Input:** l1 = \[7,2,4,3\], l2 = \[5,6,4\]
**Output:** \[7,8,0,7\]
**Example 2:**
**Input:** l1 = \[2,4,3\], l2 = \[5,6,4\]
**Output:** \[8,0,7\]
**Example 3:**
**Input:** l1 = \[0\], l2 = \[0\]
**Output:** \[0\]
**Constraints:**
* The number of nodes in each linked list is in the range `[1, 100]`.
* `0 <= Node.val <= 9`
* It is guaranteed that the list represents a number that does not have leading zeros.
**Follow up:** Could you solve it without reversing the input lists? | null |
Easy python3 solution, no recursion, no reverse | add-two-numbers-ii | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n1. First convert the linkedlist 1 as an integer number.\n2. Again convert the linkedlist 2 as another integer number like step 1.\n3. Add both integer number and convert it as a string value.\n```\nSUM = str(int(val1) + int(val2))\n```\n4. Create a new linklist from the added string value.\n```\nhead = ListNode()\ncurr = head\nfor i in range(len(SUM)):\n curr.next = ListNode(SUM[i])\n curr = curr.next\nreturn head.next\n```\n\nHappy Leetcoding.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n$$O(n)$$\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n$$O(n)$$\n\n# Code\n```\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n def addTwoNumbers(self, l1: Optional[ListNode], l2: Optional[ListNode]) -> Optional[ListNode]:\n val1 = \'\'\n itr = l1\n while itr:\n val1 += str(itr.val)\n itr = itr.next\n val2 = \'\'\n itr = l2\n while itr:\n val2 += str(itr.val)\n itr = itr.next\n SUM = str(int(val1) + int(val2))\n\n head = ListNode()\n curr = head\n for i in range(len(SUM)):\n curr.next = ListNode(SUM[i])\n curr = curr.next\n return head.next\n``` | 3 | You are given two **non-empty** linked lists representing two non-negative integers. The most significant digit comes first and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
You may assume the two numbers do not contain any leading zero, except the number 0 itself.
**Example 1:**
**Input:** l1 = \[7,2,4,3\], l2 = \[5,6,4\]
**Output:** \[7,8,0,7\]
**Example 2:**
**Input:** l1 = \[2,4,3\], l2 = \[5,6,4\]
**Output:** \[8,0,7\]
**Example 3:**
**Input:** l1 = \[0\], l2 = \[0\]
**Output:** \[0\]
**Constraints:**
* The number of nodes in each linked list is in the range `[1, 100]`.
* `0 <= Node.val <= 9`
* It is guaranteed that the list represents a number that does not have leading zeros.
**Follow up:** Could you solve it without reversing the input lists? | null |
OMG binbin's best solution ever! Beats 98.5% for runtime and 66% for memory | add-two-numbers-ii | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n def addTwoNumbers(self, l1: Optional[ListNode], l2: Optional[ListNode]) -> Optional[ListNode]:\n # calculate number from each list \n # add two num, convert val into string\n #loop over string\'s each digit, create a new list\n def cal_num(node):\n num = 0\n while node:\n num = num*10 +(node.val)\n node = node.next\n return int(num)\n \n int_1 = cal_num(l1)\n int_2 = cal_num(l2)\n int_ret = str(int_1+int_2)\n\n node_list = []\n for dig in int_ret:\n new_node = ListNode(int(dig))\n node_list.append(new_node)\n \n head = node_list[0]\n for j in range(len(node_list)-1):\n node_list[j].next = node_list[j+1]\n \n return head\n \n``` | 2 | You are given two **non-empty** linked lists representing two non-negative integers. The most significant digit comes first and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
You may assume the two numbers do not contain any leading zero, except the number 0 itself.
**Example 1:**
**Input:** l1 = \[7,2,4,3\], l2 = \[5,6,4\]
**Output:** \[7,8,0,7\]
**Example 2:**
**Input:** l1 = \[2,4,3\], l2 = \[5,6,4\]
**Output:** \[8,0,7\]
**Example 3:**
**Input:** l1 = \[0\], l2 = \[0\]
**Output:** \[0\]
**Constraints:**
* The number of nodes in each linked list is in the range `[1, 100]`.
* `0 <= Node.val <= 9`
* It is guaranteed that the list represents a number that does not have leading zeros.
**Follow up:** Could you solve it without reversing the input lists? | null |
🔥🔥Easy Python and Java Solution with Explanation Beats 99% 🚀🚀 | add-two-numbers-ii | 1 | 1 | # Approach 1 => Using Stack\n- Create 2 stacks `s1` and `s2` for both the numbers and append the numbers in the respective stacks.\n- After that create a variable named `carry` which will take care of our carry values and one more variable as `root` which will be assigned to none so that we can return head of the list at the end.\n- Now use while loop and add values from both the stacks along with carry and append the `value` as a new node in our `ans` linked list.\n- At the end return `root`.\n\n# Approach 1 Code\n```python []\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n def addTwoNumbers(self, l1: Optional[ListNode], l2: Optional[ListNode]) -> Optional[ListNode]:\n s1, s2 =[], []\n while l1:\n s1.append(l1.val)\n l1 = l1.next\n \n while l2:\n s2.append(l2.val)\n l2 = l2.next\n root = None\n carry = 0\n while s1 or s2 or carry:\n v1,v2 = 0,0\n if s1:\n v1 = s1.pop()\n if s2:\n v2 = s2.pop()\n carry, value = divmod(v1+v2+carry, 10)\n ans = ListNode(value)\n ans.next = root\n root = ans\n return root\n \n```\n```java []\npublic class Solution {\n public ListNode addTwoNumbers(ListNode l1, ListNode l2) {\n Stack<Integer> s1 = new Stack<Integer>();\n Stack<Integer> s2 = new Stack<Integer>();\n \n while(l1 != null) {\n s1.push(l1.val);\n l1 = l1.next;\n };\n while(l2 != null) {\n s2.push(l2.val);\n l2 = l2.next;\n }\n \n int totalSum = 0, carry = 0;\n ListNode ans = new ListNode();\n while (!s1.empty() || !s2.empty()) {\n if (!s1.empty()) totalSum += s1.pop();\n if (!s2.empty()) totalSum += s2.pop();\n \n ans.val = totalSum % 10;\n carry = totalSum / 10;\n ListNode head = new ListNode(carry);\n head.next = ans;\n ans = head;\n totalSum = carry;\n }\n\n return carry == 0 ? ans.next: ans;\n }\n}\n```\n# Approach 2 => Reverse given linked list\n- Reverse both the linked list\n- After that create a variable named `carry` which will take care of our carry values and one more variable as `root` which will be assigned to none so that we can return head of the list at the end.\n- Now use while loop and add values from both the linked list along with carry and append the `value` as a new node in our `ans` linked list.\n- At the end return `root`.\n\n# Approach 2 Code\n```python []\n# Definition for singly-linked list.\n# class ListNode:\n# def __init__(self, val=0, next=None):\n# self.val = val\n# self.next = next\nclass Solution:\n def reverse(self, head: Optional[ListNode]) -> Optional[ListNode] :\n prev = None\n temp = None\n while head:\n temp = head.next\n head.next = prev\n prev = head\n head = temp\n return prev\n\n def addTwoNumbers(self, l1: Optional[ListNode], l2: Optional[ListNode]) -> Optional[ListNode]:\n rl1 = self.reverse(l1)\n rl2 = self.reverse(l2)\n root = None\n carry = 0\n while rl1 or rl2 or carry:\n v1,v2 = 0,0\n if rl1:\n v1 = rl1.val\n rl1 = rl1.next\n if rl2:\n v2 = rl2.val\n rl2 = rl2.next\n carry, value = divmod(v1+v2+carry, 10)\n ans = ListNode(value)\n ans.next = root\n root = ans\n return root\n \n\n```\n```java []\nclass Solution:\n def reverseList(self, head: Optional[ListNode]) -> Optional[ListNode]:\n prev = None\n temp = None\n while head:\n # Keep the next node\n temp = head.next\n # Reverse the link\n head.next = prev\n # Update the previous node and the current node.\n prev = head\n head = temp\n return prev\n\n def addTwoNumbers(self, l1: Optional[ListNode], l2: Optional[ListNode]) -> Optional[ListNode]:\n r1 = self.reverseList(l1)\n r2 = self.reverseList(l2)\n\n total_sum = 0\n carry = 0\n ans = ListNode()\n while r1 or r2:\n if r1:\n total_sum += r1.val\n r1 = r1.next\n if r2:\n total_sum += r2.val\n r2 = r2.next\n\n ans.val = total_sum % 10\n carry = total_sum // 10\n head = ListNode(carry)\n head.next = ans\n ans = head\n total_sum = carry\n\n return ans.next if carry == 0 else ans\n```\n# Video Explanation\nhttps://youtu.be/JX6NNkaUfQM\n\n# Complexity (For both approaches)\nwhere `m` is length of `l1` and `n` is length of `l2`\n- Time complexity:\nO(m+n)\n\n- Space complexity:\nO(m+n)\n | 4 | You are given two **non-empty** linked lists representing two non-negative integers. The most significant digit comes first and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
You may assume the two numbers do not contain any leading zero, except the number 0 itself.
**Example 1:**
**Input:** l1 = \[7,2,4,3\], l2 = \[5,6,4\]
**Output:** \[7,8,0,7\]
**Example 2:**
**Input:** l1 = \[2,4,3\], l2 = \[5,6,4\]
**Output:** \[8,0,7\]
**Example 3:**
**Input:** l1 = \[0\], l2 = \[0\]
**Output:** \[0\]
**Constraints:**
* The number of nodes in each linked list is in the range `[1, 100]`.
* `0 <= Node.val <= 9`
* It is guaranteed that the list represents a number that does not have leading zeros.
**Follow up:** Could you solve it without reversing the input lists? | null |
🔥[Python3] Using 2 stacks | add-two-numbers-ii | 0 | 1 | ```python3 []\nclass Solution:\n def addTwoNumbers(self, l1: Optional[ListNode], l2: Optional[ListNode]) -> Optional[ListNode]:\n st1, st2 = [], []\n\n while l1:\n st1.append(l1.val)\n l1 = l1.next\n while l2:\n st2.append(l2.val)\n l2 = l2.next\n\n nextNode, remainder = None, 0\n while st1 or st2 or remainder:\n v1 = st1.pop() if st1 else 0\n v2 = st2.pop() if st2 else 0\n remainder, val = divmod(v1 + v2 + remainder, 10)\n node = ListNode(val, nextNode)\n nextNode = node\n \n return node\n``` | 9 | You are given two **non-empty** linked lists representing two non-negative integers. The most significant digit comes first and each of their nodes contains a single digit. Add the two numbers and return the sum as a linked list.
You may assume the two numbers do not contain any leading zero, except the number 0 itself.
**Example 1:**
**Input:** l1 = \[7,2,4,3\], l2 = \[5,6,4\]
**Output:** \[7,8,0,7\]
**Example 2:**
**Input:** l1 = \[2,4,3\], l2 = \[5,6,4\]
**Output:** \[8,0,7\]
**Example 3:**
**Input:** l1 = \[0\], l2 = \[0\]
**Output:** \[0\]
**Constraints:**
* The number of nodes in each linked list is in the range `[1, 100]`.
* `0 <= Node.val <= 9`
* It is guaranteed that the list represents a number that does not have leading zeros.
**Follow up:** Could you solve it without reversing the input lists? | null |
99.41% faster solution | arithmetic-slices-ii-subsequence | 0 | 1 | ```\nclass Solution:\n def numberOfArithmeticSlices(self, nums: List[int]) -> int:\n res = 0\n dp = [defaultdict(int) for i in range(len(nums))]\n\t\t\n for i in range(1, len(nums)):\n for j in range(i):\n dif = nums[i]-nums[j]\n dp[i][dif] += 1\n if dif in dp[j]:\n dp[i][dif] += dp[j][dif]\n res += dp[j][dif]\n return res\n``` | 3 | Given an integer array `nums`, return _the number of all the **arithmetic subsequences** of_ `nums`.
A sequence of numbers is called arithmetic if it consists of **at least three elements** and if the difference between any two consecutive elements is the same.
* For example, `[1, 3, 5, 7, 9]`, `[7, 7, 7, 7]`, and `[3, -1, -5, -9]` are arithmetic sequences.
* For example, `[1, 1, 2, 5, 7]` is not an arithmetic sequence.
A **subsequence** of an array is a sequence that can be formed by removing some elements (possibly none) of the array.
* For example, `[2,5,10]` is a subsequence of `[1,2,1,**2**,4,1,**5**,**10**]`.
The test cases are generated so that the answer fits in **32-bit** integer.
**Example 1:**
**Input:** nums = \[2,4,6,8,10\]
**Output:** 7
**Explanation:** All arithmetic subsequence slices are:
\[2,4,6\]
\[4,6,8\]
\[6,8,10\]
\[2,4,6,8\]
\[4,6,8,10\]
\[2,4,6,8,10\]
\[2,6,10\]
**Example 2:**
**Input:** nums = \[7,7,7,7,7\]
**Output:** 16
**Explanation:** Any subsequence of this array is arithmetic.
**Constraints:**
* `1 <= nums.length <= 1000`
* `-231 <= nums[i] <= 231 - 1` | null |
446: Time 96.27% and Space 98.14%, Solution with step by step explanation | arithmetic-slices-ii-subsequence | 0 | 1 | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n1. Initialize a variable n to the length of the input array nums.\n\n2. Create an array dp of n empty dictionaries to store the number of arithmetic subsequences for each index.\n\n3. Initialize a variable res to 0 to store the total number of arithmetic subsequences.\n\n4. Iterate over each index i in the array nums.\n\n5. For each index i, iterate over all previous indexes j (i.e. j from 0 to i-1).\n\n6. Calculate the difference diff between nums[i] and nums[j].\n\n7. If the difference diff is outside the bounds of an integer, skip this index j.\n\n8. Otherwise, get the number of arithmetic subsequences for index j with the same difference diff from the dictionary at dp[j][diff]. If there is no such dictionary entry, set the count cnt to 0.\n\n9. Add the count cnt to the total count res.\n\n10. Add the count cnt + 1 to the dictionary at dp[i][diff] to store the number of arithmetic subsequences ending at index i with the same difference diff.\n\n11. After all iterations, return the total count res as the result.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def numberOfArithmeticSlices(self, nums: List[int]) -> int:\n n = len(nums)\n dp = [{} for _ in range(n)]\n res = 0\n # Iterate over each index in the array\n for i in range(n):\n # Check all previous indexes and calculate the difference\n for j in range(i):\n diff = nums[i] - nums[j]\n # If the difference is outside the bounds of an int, skip this index\n if diff > 2147483647 or diff < -2147483648:\n continue\n # If there is a subsequence with the same difference, add it to the count\n cnt = dp[j].get(diff, 0)\n res += cnt\n # If there is a subsequence with the same difference ending at index j, add it to the count\n dp[i][diff] = dp[i].get(diff, 0) + cnt + 1\n\n return res\n\n``` | 2 | Given an integer array `nums`, return _the number of all the **arithmetic subsequences** of_ `nums`.
A sequence of numbers is called arithmetic if it consists of **at least three elements** and if the difference between any two consecutive elements is the same.
* For example, `[1, 3, 5, 7, 9]`, `[7, 7, 7, 7]`, and `[3, -1, -5, -9]` are arithmetic sequences.
* For example, `[1, 1, 2, 5, 7]` is not an arithmetic sequence.
A **subsequence** of an array is a sequence that can be formed by removing some elements (possibly none) of the array.
* For example, `[2,5,10]` is a subsequence of `[1,2,1,**2**,4,1,**5**,**10**]`.
The test cases are generated so that the answer fits in **32-bit** integer.
**Example 1:**
**Input:** nums = \[2,4,6,8,10\]
**Output:** 7
**Explanation:** All arithmetic subsequence slices are:
\[2,4,6\]
\[4,6,8\]
\[6,8,10\]
\[2,4,6,8\]
\[4,6,8,10\]
\[2,4,6,8,10\]
\[2,6,10\]
**Example 2:**
**Input:** nums = \[7,7,7,7,7\]
**Output:** 16
**Explanation:** Any subsequence of this array is arithmetic.
**Constraints:**
* `1 <= nums.length <= 1000`
* `-231 <= nums[i] <= 231 - 1` | null |
🔥🔥 Easy, short, Fast Python/Swift DP | arithmetic-slices-ii-subsequence | 0 | 1 | **Python**\n```\nclass Solution:\n def numberOfArithmeticSlices(self, nums: List[int]) -> int:\n total, n = 0, len(nums)\n dp = [defaultdict(int) for _ in nums]\n for i in range(1, n):\n for j in range(i):\n diff = nums[j] - nums[i]\n dp[i][diff] += dp[j][diff] + 1\n total += dp[j][diff]\n return total\n```\n\n**Swift**\n```\nclass Solution {\n func numberOfArithmeticSlices(_ nums: [Int]) -> Int {\n var total = 0\n let n = nums.count\n var dp = Array(repeating: [Int: Int](), count: n)\n for i in 1..<n {\n for j in 0..<i {\n let diff = nums[j] - nums[i]\n dp[i][diff, default: 0] += dp[j][diff, default: 0] + 1\n total += dp[j][diff, default: 0]\n }\n }\n return total\n }\n}\n``` | 10 | Given an integer array `nums`, return _the number of all the **arithmetic subsequences** of_ `nums`.
A sequence of numbers is called arithmetic if it consists of **at least three elements** and if the difference between any two consecutive elements is the same.
* For example, `[1, 3, 5, 7, 9]`, `[7, 7, 7, 7]`, and `[3, -1, -5, -9]` are arithmetic sequences.
* For example, `[1, 1, 2, 5, 7]` is not an arithmetic sequence.
A **subsequence** of an array is a sequence that can be formed by removing some elements (possibly none) of the array.
* For example, `[2,5,10]` is a subsequence of `[1,2,1,**2**,4,1,**5**,**10**]`.
The test cases are generated so that the answer fits in **32-bit** integer.
**Example 1:**
**Input:** nums = \[2,4,6,8,10\]
**Output:** 7
**Explanation:** All arithmetic subsequence slices are:
\[2,4,6\]
\[4,6,8\]
\[6,8,10\]
\[2,4,6,8\]
\[4,6,8,10\]
\[2,4,6,8,10\]
\[2,6,10\]
**Example 2:**
**Input:** nums = \[7,7,7,7,7\]
**Output:** 16
**Explanation:** Any subsequence of this array is arithmetic.
**Constraints:**
* `1 <= nums.length <= 1000`
* `-231 <= nums[i] <= 231 - 1` | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.