
repo_name
stringlengths 4
136
| issue_id
stringlengths 5
10
| text
stringlengths 37
4.84M
|
|---|---|---|
kubernetes/kubernetes | 551698349 | Title: Failing test - ci-kubernetes-e2e-gci-gce-scalability
Question:
username_0: **Which jobs are failing**:
ci-kubernetes-e2e-gci-gce-scalability
**Which test(s) are failing**:
Stages: Overall
listResources After
listResources Before
**Since when has it been failing**:
1/16
**Testgrid link**:
https://testgrid.k8s.io/sig-release-master-blocking#gce-cos-master-scalability-100
**Reason for failure**:
Multiple occurrences of the following error messages,
W0118 00:01:50.100] - Invalid value for field 'zone': 'asia-northeast3-a'. Unknown zone.
W0118 00:01:50.100] - Invalid value for field 'zone': 'asia-northeast3-b'. Unknown zone.
W0118 00:01:50.101] - Invalid value for field 'zone': 'asia-northeast3-c'. Unknown zone.
**Anything else we need to know**:
Similar error was seen in the test failure mentioned in https://github.com/kubernetes/kubernetes/issues/87345
/priority critical-urgent
/sig scalability
Answers:
username_1: /close
The job is green now. The infrastructure problems seemed to be resolved. |
Norbert515/flutter_villains | 374118797 | Title: Should secondaryVillainAnimation be renamed to sidekickAnimation?
Question:
username_0: With enough documentation, obviously.
Answers:
username_0: A second poll has just started!
username_3: Every villain has his evil minions. Why only be limited to two if you can have many animations?
username_3: Yes, a list for the unstoppable villain!
Status: Issue closed
|
MicrosoftDocs/dynamics365smb-devitpro-pb | 707256953 | Title: Misc typo
Question:
username_0: // TextConst prefixed with Tok for Token
should be
// TextConst suffixed with Tok for Token
Incidentally, the Feedback buttons for this topic were not in English. They were German I think. Below is the page url I was on when I reported the above misc typo: https://docs.microsoft.com/de-de/dynamics365/business-central/dev-itpro/developer/analyzers/codecop-aa0074-textconstlabelvariablenamesshouldhaveapprovedsuffix
[Hier Feedback eingeben]
---
#### Dokumentdetails
⚠ *Bearbeiten Sie diesen Abschnitt nicht. Er ist für die Verknüpfung von docs.microsoft.com zum GitHub-Artikel erforderlich.*
* ID: b8e2178c-0742-1609-6373-4811a1968477
* Version Independent ID: 153d5502-ad26-e321-3c73-df9049553d66
* Content: [TextConst and Label variable names should have an approved suffix. - Business Central](https://docs.microsoft.com/de-de/dynamics365/business-central/dev-itpro/developer/analyzers/codecop-aa0074-textconstlabelvariablenamesshouldhaveapprovedsuffix)
* Content Source: [dev-itpro/developer/analyzers/codecop-aa0074-textconstlabelvariablenamesshouldhaveapprovedsuffix.md](https://github.com/MicrosoftDocs/dynamics365smb-devitpro-pb/blob/live/dev-itpro/developer/analyzers/codecop-aa0074-textconstlabelvariablenamesshouldhaveapprovedsuffix.md)
* Service: **dynamics365-business-central**
* GitHub Login: @username_1
* Microsoft Alias: **solsen**
Answers:
username_1: Thanks for the feedback - this will be fixed with the next doc refresh.
Regarding the URL - the /de-de/ part in this URL that you have submitted will give you a German version - this is picked up from the language that computer is set up to run. Or, if someone sent you a specific link with the /de-de/ set in the URL. If you remove that part from the URL, you get the English version.
Thanks!
Status: Issue closed
|
MicrosoftDocs/azure-docs | 380274228 | Title: service endpoint limits
Question:
username_0: Not one of those links has service limits in it for endpoints. Be nice to have an aggregation of endpoint limits for services in this. Or at least some links that don't send me down the R&D route to hades.
>> For an Azure service resource (such as, an Azure Storage account), services may enforce limits on the number of subnets used for securing the resource. Refer to the documentation for various services in Next steps for details.
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 1eb0407d-f4a5-6059-488d-fd082915c675
* Version Independent ID: 7c2fb429-743c-aea0-f1d5-de6dc2e62e8e
* Content: [Azure virtual network service endpoints](https://docs.microsoft.com/en-us/azure/virtual-network/virtual-network-service-endpoints-overview)
* Content Source: [articles/virtual-network/virtual-network-service-endpoints-overview.md](https://github.com/Microsoft/azure-docs/blob/master/articles/virtual-network/virtual-network-service-endpoints-overview.md)
* Service: **virtual-network**
* GitHub Login: @username_1
* Microsoft Alias: **sumeet.mittal**
Answers:
username_1: @username_0 - The reason why we don't want to publish all limits here is because each service have different limits and these can change based on service needs. Consolidating these on this overview pages can lead to content going out of sync and may cause confusion in future. But your feedback is deeply appreciated. I will find a way to link these limits to this page in next few weeks. Thanks
username_1: Added the limits to the FAQ section. Hope that is helpful. |
quentinhardy/odat | 499244846 | Title: passwordguesser failing
Question:
username_0: /opt/odat master ● ./odat.py passwordguesser -s 10.10.10.82 -d XE --accounts-file accounts/oracle_default_userpass.txt
[1] (10.10.10.82:1521): Searching valid accounts on the 10.10.10.82 server, port 1521
Traceback (most recent call last):
File "./odat.py", line 557, in <module>
main()
File "./odat.py", line 552, in main
arguments.func(args)
File "/opt/odat/PasswordGuesser.py", line 185, in runPasswordGuesserModule
passwordGuesser.searchValideAccounts()
File "/opt/odat/PasswordGuesser.py", line 98, in searchValideAccounts
pbar,nb = self.getStandardBarStarted(len(self.accounts)), 0
File "/opt/odat/OracleDatabase.py", line 261, in getStandardBarStarted
return ProgressBar(widgets=['', Percentage(), ' ', Bar(),' ', ETA(), ' ',''], maxval=maxvalue).start()
File "/opt/odat/progressbar.py", line 213, in __init__
assert (maxval > 0),'maxval <= 0'
AssertionError: maxval <= 0
Answers:
username_1: `oracle_default_userpass.txt` is not a default file of ODAT. I think your password file is empty. Put credentials in this file and it will work.
Status: Issue closed
|
grails/grails-core | 104445391 | Title: Repository archetype-catalog.xml issue
Question:
username_0: Dear team,
we're facing some issues trying to configure the Grails core repository in our Sonatype Nexus.
In fact, trying to browse the repository URL at http://repo.grails.org/grails/core/ the file archetype-catalog.xml appears like if it were a directory instead a file:
archetype-catalog.xml/ 18-Aug-2014 07:46 -
In some way, the resolution of this XML file seems corrupted and not usable.
Thanks in advance for your help, cheers
Answers:
username_1: I have sent an enquiry to Jfrog about this.
Status: Issue closed
|
NyxLang/string-utils | 863905139 | Title: Tests broken because Jest won't resolve imports
Question:
username_0: I'm opening an issue in case anyone comes across this who knows how to fix this problem.
I'm using Jest for testing and ES2015 modules to import and export internally. Unfortunately the one external dependency I have breaks Jest when I try to test any functions that use that dependency. Everything I'm importing as far as internal package code works fine, it's just when I try to import a dependency. It _works_, when I just use node to run the function everything does as expected. It's just that when I use Jest the tests break because it won't resolve the import for the external module.
Answers:
username_0: Yes, obviously this is a Jest issue, not an issue with my library, but I've scoured the interwebs as well as Jest's issues page and not found a working solution yet.
username_0: It is most inconvenient to have to go back and manually run test cases for every function that uses an internal function that imports the dependency that breaks Jest every time I change something in the internal API. 😑
username_0: Figured it out! I had to set it to un-ignore transforming the folder in `node_modules` that contained my dependency. Added `"/node_modules/(?!unicode-default-word-boundary).+\\.js$"` to the `transformIgnorePatterns` array in `jest.config.js`.
Maybe this will help someone else who's having a similar issue.
Status: Issue closed
|
espressif/esp32-camera | 1150152476 | Title: ../main/take_picture.c:46:10: fatal error: esp_camera.h: No such file or directory
Question:
username_0: ubuntu
idf
How to config code used in ubuntu with idf
```
../main/take_picture.c:46:10: fatal error: esp_camera.h: No such file or directory
#include "esp_camera.h"
^~~~~~~~~~~~~~
compilation terminated.
[5/257] Performing build step for 'bootloader'
[1/1] cd /home/pi/workspace/esp/esp32-camera/examples/build/bootloader/esp-idf/esptool_py && /home/pi/.espressif/python_env/idf4.4_py3.6_env/bin/python /home/pi/workspace/esp/esp-idf-v4.4/components/partition_table/check_sizes.py --offset 0x10000 bootloader 0x1000 /home/pi/workspace/esp/esp32-camera/examples/build/bootloader/bootloader.bin
Bootloader binary size 0x69a0 bytes. 0x8660 bytes (56%) free.
[6/255] Building C object esp-idf/esp_hid/CMakeFiles/__idf_esp_hid.dir/src/esp_hidh.c.obj
ninja: build stopped: subcommand failed.
ninja failed with exit code 1
``` |
biolink/biolink-model | 641693567 | Title: organize association_slot children
Question:
username_0: `association_slot` currently has the following children:
- association type
- association➞id
- change is catalyzed by
- clinical modifier qualifier
- edge label
- frequency qualifier
- has confidence level
- has evidence
- negated
- object
- onset qualifier
- provided by
- publications
- qualifiers
- quantifier qualifier
- relation
- sequence variant qualifier
- severity qualifier
- sex qualifier
- stage qualifier
- subject
@username_1's explanation on a Translator data modeling call I think helped me understand the role of `association_slot`. I think my prior confusion was due at least in part to the fact that many different types of things were included as children in a flat list. To make this more clear to people, I suggest adding a layer of grouping. Perhaps something like this:
- basic info
- association type
- edge label
- negated
- object
- relation
- subject
- provenance
- has confidence level
- has evidence
- provided by
- publications
- qualifiers
- clinical modifier qualifier
- frequency qualifier
- onset qualifier
- quantifier qualifier
- sequence variant qualifier
- severity qualifier
- sex qualifier
- stage qualifier
- not sure what to do with these
- association➞id
- change is catalyzed by
Anyway, I am not at all confident in the groupings I propose above, but am just suggesting that adding a level of grouping (even if it's only in the web documentation) would help new people understand its usage.
Answers:
username_1: I think this is a great start. I would name them something like 'basic info property slot' (maybe we can have a short label that is used in the html). These are more organizational groupings rather than something we would assign logical properties too, so I don't think it needs to be perfect, we can iterate
username_2: @TomConlin do you have what you need to work on this?
username_2: Should this be reassigned?
username_2: unassigned tom. is this something @sierra-moxon should take a look at? |
NeuralEnsemble/python-neo | 1100472977 | Title: Spike data support for OpenEphysBinaryRawIO
Question:
username_0: Hey,
I was looking for a neo IO class which supports a) lazy loading / memory efficient loading, and b) reading AND writing neo blocks. The openephysbinaryrawio class comes close, but is still missing support for spiking data (according to [this](https://github.com/NeuralEnsemble/python-neo/blob/34d4db8fb0dc950dbbc6defd7fb75e99ea877286/neo/rawio/openephysbinaryrawio.py#L143) line), which I definitely need. Is there any existing progress on this front? Would this issue count as a "user request" for the feature? 😄
Answers:
username_0: Noice, thanks Julia! I'll test and expand on your fork when I find some time.
username_0: Hey @JuliaSprenger and @samuelgarcia, I have been neck deep in experiments that leave me with barely any time to code. This will be the case at least until May, so that's probably the earliest that I can make any significant contributions on this front :( |
nodejs/node-gyp | 176002210 | Title: npm install Error failed to find python
Question:
username_0: I am getting error while installing npm packages and i have tried some online solutions. finnaly i am getting the error in the image attached.
Please refer the below screen for more info
https://cloud.githubusercontent.com/assets/10123941/18387393/0d72641c-76ba-11e6-81a5-b05436144f39.png
Answers:
username_1: What exactly is unclear? It's telling you that it can't find a python 2 executable. If you have it installed, point the PYTHON environment variable to it or pass `--python <path>` on the command line.
username_0: Yes i added a PYTHON variable to this "C:\Users\is4488\.windows-build-tools\python27\python.exe"
Still problem persist!!
Any Suggestions??
username_1: In the screenshot I don't see `\python.exe` in the printed path.
username_0: Hi username_1,
After setting python variable below error comes .Refer below screenshot
https://cloud.githubusercontent.com/assets/10123941/18408164/1cf9e604-7745-11e6-8bfa-7343f9cb9348.png
username_1: Do you have more than one version of Visual Studio or the Windows SDK installed? Try passing `--msvs_version=2015` on the command line.
username_0: Hi username_1,
No I have only one version of visual studio 2012 professional.
I tried like `--msvs_version=2015` this also,But same error comes
username_1: You are targeting node.js v4 so you need VS 2013 at the very least. Since you need to upgrade anyway, I'd skip 2013 and move to either VS 2015 or Visual C++ Build Tools.
Good luck. If you still have issues afterwards, holler and I'll reopen the issue.
Status: Issue closed
username_0: Hi username_1,
I installed Visual C++ Build Tools 2015 and installed and below error comes.
Please refer screen shot
`https://cloud.githubusercontent.com/assets/10123941/18583931/4d8ecdb2-7c2b-11e6-9fc1-af0e509d8887.png`
username_0: https://cloud.githubusercontent.com/assets/10123941/18583931/4d8ecdb2-7c2b-11e6-9fc1-af0e509d8887.png
username_1: I don't want to sound overly critical but it's rather obvious what is happening, isn't it?
Have you tried googling for 'C1060 error'? The first hit is https://msdn.microsoft.com/en-us/library/yz7kx3y2.aspx - it explains the compiler is out of memory and what you can do to remedy it. |
orchestral/testbench | 86970553 | Title: RuntimeException: No supported encrypter found. The cipher and / or key length are invalid.
Question:
username_0: Laravel's Encrypter class fails, because of too weak "random" string, in the app.php configuration (in fixtures), when the default AES-256-CBC cipher is being used.
In the current version, "SomeRandomString" is being used as the default APP_KEY value. This should be changed to something else...
Perhaps a key should / could be generated, before the application is created, if the default key is set to "SomeRandomString".
Additional information about this issue, can be found here: http://laravel.io/forum/06-09-2015-no-supported-encrypter-found-the-cipher-and-or-key-length-are-invalid
Answers:
username_1: You need a 32 byte encryption key, and you're sorted.
Status: Issue closed
username_2: See <https://github.com/orchestral/testbench#no-supported-encrypter-found-the-cipher-and--or-key-length-are-invalid>
Thank for the report.
username_3: I had this issue randomly, sometimes it worked, sometimes not.
Thanks to @username_1 for pointing me to the solution. ;)
https://github.com/laravel/framework/issues/13764#issuecomment-239349336
username_2: @username_3 I don't see how this is suitable for `orchestra/testbench`.
username_3: @username_2 yeah, sorry for crossing your path, I just wanted to point out how it helped me solve it on Laravel, so maybe that's gives a clue for anyone on this side. ;)
username_2: Testbench are used for purely for testing, therefore using `config:cache` would **JUST** cause more problem.
username_4: Hi guys! I have the same problem and I figured it out with this `tail -f storage/logs/laravel.log` because the error comes randomly and especially on ajax requests, but how to solve this one time and for ever?
username_2: Locking this issue since questions isn't related to Testbench |
ESMCI/cime | 173261221 | Title: Merge Mira and Cetus settings as much as possible in ACME configs
Question:
username_0: Mira and Cetus only need to differ, wrt configuration settings,
in the batch queue settings. We should merge the changes
in config_machines and config_compilers for Mira and Cetus
to a single entry. This change would make maintaining compiler
versions easier on these machines.
Answers:
username_1: On the CESM side (and this applies to cime2 as well as cime5) we do not have a separate definition for cetus, we identify that machine as mira as well.
username_2: The machine name, when used as an index in to the config files, is arbitrary and does not have to match the actual unix machine name (thanks to the regex ability). So we could collapse those in to one machine called "bgq" or similar.
username_2: Of course "-mach" is no longer a required argument so this could all be done under the hood.
username_0: We do want different settings for the batch queues on the two machines. The other places using "mira|cetus" should work, i think.
username_2: If you make the distinction in one file do you have to make it in all files?
username_1: It's going to use the machine identified by config_machines.xml so if that identifies the machine as mira then mira will be the identifier for all of the other files.
username_2: Sounds like we can't do this then: have one entry in config_compilers and machines then expand to 2 entries in config_batch.
username_0: I think this feature should be added to CIME. Machine name should not be set/derived from the MACH field, it should rather be matched with the MACH field (the machine name should be stored independently of this matching criterion).
We could be using two different rules (matching rules) in config_machines.xml and config_compilers.xml, for example.
username_2: @username_0 is this still a feature request? Can you explain?
username_2: telecon: closing.
Status: Issue closed
|
Nodejs-toulouse/meetup-01 | 234275104 | Title: [Framework Web] Express
Question:
username_0: :+1: pour voter pour Express !
- Orienté "code"
- Très léger
- Destiné à de petites à moyennes applications
- Fonctionne dans un grand nombre de situations
- Utilise des Middlewares
Answers:
username_1: +1
username_2: +1
username_3: +1
Avec l'étude d'une approche à la Hapi pour la définition des APIs (path, méthode HTTP et implémentation du handler au même endroit)
username_4: +1
username_5: 👍
username_6: +1
username_7: +1 |
nmxiaowei/avue | 615735160 | Title: 表单验证,自定义验证报错
Question:
username_0: https://avuejs.com/doc/form/form-rules
F12打开DevTools,可以看到自定义验证报错。无法验证。
TypeError: Cannot read property 'password' of undefined
at Object.validator (crud.47b9d39b.js:1)
at index.js:1
at s (index.js:1)
at za (index.js:1)
at index.js:1
at Array.forEach (<anonymous>)
at Ha (index.js:1)
at io.validate (index.js:1)
at i.validate (index.js:1)
at i.onFieldBlur (index.js:1)
Answers:
username_1: 已经修复文档错误
Status: Issue closed
|
biocatiit/musclex | 359573877 | Title: minor thing
Question:
username_0: IN projection trace, when a box is drawn, we were asked which background subtraction function we would like to use, either gaussian or convexhull. I would like add the third option NO background subtraction<issue_closed>
Status: Issue closed |
realestate-com-au/shush | 989513001 | Title: Provide arm64 build
Question:
username_0: Hey folks, i'm investigating moving some of our workload to AWS Graviton (aka arm64) instances, and we use Dockerised `shush` a lot.
I grabbed a checkout this repo `master` and did a `docker build .` on an arm64 instance, and it all worked perfectly. I could contribute a patch at some point but i thought i'd make this issue as a reminder/placeholder. Also, i'm unfamiliar with REA's build pipeline which makes it a bit harder since i think the big change will be there.
Thanks for providing this tool! 🙌
Answers:
username_1: Thanks for the report @username_0. We unfortunately didn't have any release automation in place for this tool.
I've generated some basic automation using our internal tooling here, and fired off a release of 1.5.1 which should habe the docker images you require.
Status: Issue closed
username_0: Ah, no problem – sorry for the hassle! Thank you! 🙏 |
StealthStop/DeepESM | 490023913 | Title: Bryan says there is an issue with memory and cuda errors
Question:
username_0: Possible solution:
It is also necessary to allocate VRam everytime you use tensorflow including when loading up a .pb tensor graph:
i do this by calling this function:
def AllocateVRam():
cfg = tf.ConfigProto()
cfg.gpu_options.allow_growth = True
cfg.gpu_options.per_process_gpu_memory_fraction = 0.5
k.tensorflow_backend.set_session(tf.Session(config=cfg))<issue_closed>
Status: Issue closed |
JuDFTteam/aiida-fleur | 1009432349 | Title: Expose ``clean_workdir`` input from Base workchains option to higher workchains
Question:
username_0: The ``BaseRestartWorkChain`` has the input ``clean_workdir`` to delete the contents of the remote folder after execution. However, at the moment it is not possible to use this option for example in the SCF workchain since it does not provide the inputs for it
This would be really useful to keep the memory usage on a remote machine down without manually cleaning up
Status: Issue closed
Answers:
username_0: Implemented in e7cf4a1. clean_workdir can now be entered in the add_comp_para section if the inputs are generated by ``get_inputs_fleur`` |
atoum/atoum | 264050699 | Title: Help text options are hard to read
Question:
username_0: I know this is my opinion, but I find the center-alignment of the help text options (when running `atoum --help`) difficult to read. It's also a pattern I've never seen in other CLI tools which are typically left-aligned and wrap in columns.
The CLI help text also has no maximum line-length and when it wraps it's hard to read. It would be better to wrap within columns.
Finally, the default colors for the options have poor contrast on a black background. The common pattern I've seen in other CLI tools is to not colorize the help text.
For example here's my help text:
<img width="1440" alt="screen shot 2017-10-09 at 7 00 45 pm" src="https://user-images.githubusercontent.com/2036909/31361988-2fd061b6-ad24-11e7-8b47-89d1ece11f3c.png">
Compared to, for example, Jest:
<img width="692" alt="screen shot 2017-10-09 at 7 01 40 pm" src="https://user-images.githubusercontent.com/2036909/31362019-53c9e754-ad24-11e7-95e8-89027b55738d.png">
Answers:
username_1: I totally agree with this, and it a discussion topic that came several times already.
@jubianchi, @Grummfy, @username_2 Do you agree to remove this mid-alignment?
username_2: If we adopt something which is readable and clean it's ok for me to change.
Status: Issue closed
|
rustwasm/wasm-bindgen | 439149539 | Title: Closures Example is not working.
Question:
username_0: link:
[https://rustwasm.github.io/wasm-bindgen/exbuild/closures/](url)
is not working.
It is showing the following error on console
```
RuntimeError: unreachable
at __rust_start_panic (wasm-function[673]:1)
at rust_panic (wasm-function[594]:31)
at std::panicking::rust_panic_with_hook::h5d8808384a53a826 (wasm-function[130]:304)
at std::panicking::continue_panic_fmt::h821bed92a14cf5d5 (wasm-function[324]:116)
at rust_begin_unwind (wasm-function[664]:3)
at core::panicking::panic_fmt::hfa7141b9630aa10b (wasm-function[487]:70)
at core::option::expect_failed::he814056c2f8215e8 (wasm-function[396]:91)
at <core::option::Option<T>>::expect::h33643d65ce465d73 (wasm-function[161]:170)
at closures::setup_clock::hcd8ed9afea8a32fa (wasm-function[44]:115)
at closures::run::h0707c66cb6048ff9 (wasm-function[31]:1014)
```
and a warning:
```
[Deprecation] Element.createShadowRoot is deprecated and will be removed in M73, around March 2019. Please use Element.attachShadow instead. See https://www.chromestatus.com/features/4507242028072960 for more details.
```
Answers:
username_1: cc @username_2 when trying to debug this with `--target web` it looks like the error goes away, so I'm curious if you know if this was an accidental regression in webpack?
username_2: I'm having an issue building the example locally, when running `wasm-pack`:
```
thread 'main' panicked at 'index 114 out of range for slice of length 39', src/libcore/slice/mod.rs:2413:5
stack backtrace:
0: std::sys::unix::backtrace::tracing::imp::unwind_backtrace
1: std::sys_common::backtrace::_print
2: std::panicking::default_hook::{{closure}}
3: std::panicking::default_hook
4: std::panicking::rust_panic_with_hook
5: std::panicking::continue_panic_fmt
6: rust_begin_unwind
7: core::panicking::panic_fmt
8: core::slice::slice_index_len_fail
9: <&'src str as wasm_bindgen_cli_support::decode::Decode<'src>>::decode
10: <alloc::vec::Vec<T> as wasm_bindgen_cli_support::decode::Decode<'src>>::decode
11: <wasm_bindgen_cli_support::decode::Export<'a> as wasm_bindgen_cli_support::decode::Decode<'a>>::decode
12: <alloc::vec::Vec<T> as wasm_bindgen_cli_support::decode::Decode<'src>>::decode
13: <wasm_bindgen_cli_support::decode::Program<'a> as wasm_bindgen_cli_support::decode::Decode<'a>>::decode
14: wasm_bindgen_cli_support::Bindgen::_generate
15: wasm_bindgen::main
16: std::rt::lang_start::{{closure}}
17: std::panicking::try::do_call
18: __rust_maybe_catch_panic
19: std::rt::lang_start_internal
20: main
Error: Running the wasm-bindgen CLI
```
Does it seems familiar to you @username_1?
wasm-pack 0.8.1. I'm unsure how I could get `wasm-bindgen`'s version.
username_1: Ah that's unfortunately expected from a few other bugs, but you can fix it by copying the example out to a separate directory and building from there
username_2: Indeed, I can build it now. It's quite hard to debug but it seems to be in the wasm binary itself. I'll keep trying.
username_2: Found the bug! Let me do a PR.
Status: Issue closed
|
google/paco | 98459387 | Title: Server UI: Action editor popup should be resizable
Question:
username_0: In general, any popup screen should be resizable to avoid keyhole problems, but this one particularly needs to be resizable given that it allows edit of scripts which might be lengthy.
Perhaps create separate bugs for other popups that need to be resized so that we can track them even if we don't do them now.
Answers:
username_1: I'm looking into this and it seems that ACE has no built-in way to support user resizing, only auto. I currently have the editor set to default to 10 lines and expand to as many as 20. So typing extra lines of code will expand the height of the editor. I could increase the 20. Another possibility would be some kind of toggle for some of the dialogs that expands them into a fullscreen mode.
username_0: Make it wider and taller
Status: Issue closed
|
macaullyjames/evabot | 163099259 | Title: Upgrade Rails
Question:
username_0: Rails 5.0.0.rc2 was released [a short while ago](http://weblog.rubyonrails.org/2016/6/22/Rails-5-0-rc2/). The deployment scripts will likely have to reworked, I don't think they take into account the fact that gems might need to be upgraded 🤔
Answers:
username_0: It's probably a good idea to stop using the global gemset ([relevant link](https://rvm.io/gemsets/creating)).
username_0: 5.0 was released [this week](http://weblog.rubyonrails.org/2016/6/30/Rails-5-0-final/), let's do this! 👌🏻
Status: Issue closed
username_0: This was resolved in 029bc830d690905fe7cb21b0933cb55a7ed5e9e3 🎉
For posterity: The upgrade process consisted of
- Setting the Rails version in the `Gemfile`
- Deleting `Gemfile.lock`
- `bundle install` |
aesara-devs/aesara | 1140127142 | Title: random_make_inplace assumes that RandomVariable Ops cannot have extra props
Question:
username_0: ## Description of your problem or feature request
I'm writing a new random variable Op, and I need to pass some shape related information to the op when it is created. This information should be stored in the `__props__` of the Op and that works fine. The problem is that when aesara tries to optimize the graph, and call `random_make_inplace` assumes that there are not any extra props, and raises an error.
**Please provide a minimal, self-contained, and reproducible example.**
```python
class Test(RandomVariable):
name = "test"
ndim_supp = 0
ndims_params = [0]
__props__ = ("name", "ndim_supp", "ndims_params", "dtype", "inplace", "extra")
dtype = "floatX"
_print_name = ("Test", "\\operatorname{Test}")
def __init__(self, extra, *args, **kwargs):
self.extra = extra
super().__init__(*args, **kwargs)
def make_node(self, rng, size, dtype, sigma):
return super().make_node(rng, size, dtype, sigma)
def rng_fn(self, rng, sigma, size):
return rng.normal(scale=sigma, size=size)
Test(extra="a")(sigma=1).eval()
```
**Please provide the full traceback of any errors.**
```python
ERROR (aesara.graph.opt): Optimization failure due to: random_make_inplace
ERROR (aesara.graph.opt): node: Test{name='test', ndim_supp=0, ndims_params=(0,), dtype='floatX', inplace=False, extra='a'}(RandomGeneratorSharedVariable(<Generator(PCG64) at 0x7FEB1976DE40>), TensorConstant{[]}, TensorConstant{11}, TensorConstant{1})
ERROR (aesara.graph.opt): TRACEBACK:
ERROR (aesara.graph.opt): Traceback (most recent call last):
File "/home/lpaz/anaconda3/lib/python3.8/site-packages/aesara/graph/opt.py", line 1994, in process_node
replacements = lopt.transform(fgraph, node)
File "/home/lpaz/anaconda3/lib/python3.8/site-packages/aesara/graph/opt.py", line 1204, in transform
return self.fn(fgraph, node)
File "/home/lpaz/anaconda3/lib/python3.8/site-packages/aesara/tensor/random/opt.py", line 47, in random_make_inplace
name, ndim_supp, ndims_params, dtype, _ = op._props()
ValueError: too many values to unpack (expected 5)
```
**Please provide any additional information below.**
I spoke with @username_1 and it seems like it should be easy to patch [this opt](https://github.com/aesara-devs/aesara/blob/main/aesara/tensor/random/opt.py#L42-L51) to consume any extra `__props__` and keep them when creating the inplace version of the Op
## Versions and main components
* Aesara version: 2.3.8
* Aesara config (`python -c "import aesara; print(aesara.config)"`)
* Python version: 3.8
* Operating system: Ubuntu 18.04
* How did you install Aesara: pip<issue_closed>
Status: Issue closed |
hangulize/hangulize | 533782845 | Title: 독일어 st sp 표기
Question:
username_0: 독일어에서 st와 sp에서 s는 어말에서는 /ʃ/로 그 외에는 /s/로 발음되는 것으로 배웠습니다.
https://blog.naver.com/bluett2/150128236355
https://www.google.com/search?q=german+st+sp+pronunciation
외래어표기법에 따로 이 내용이 적혀 있지는 않지만 다음 용례를 보면 외래어표기법도 이를 지킨다고 볼 수 있을 듯합니다(sp는 합성어 외에는 용례를 못 찾아 넘어갑니다).
Münster 뮌스터
Forster 포르스터
Fürstenberg 퓌르스텐베르크
Torsten 토르스텐
Carsten 카르스텐
한글라이즈에서는 이런 경우 '스'를 '슈'로 전사하는데, 이를 고쳐야 하지 않을까 싶습니다. 혹은 제가 모르는 근거가 있는 것일까요? |
ant-design/ant-design-pro | 372792463 | Title: 使用图表组件TimelineChart报错
Question:
username_0: bizcharts-plugin-slider.min.js?3768:1 Uncaught (in promise) TypeError: Cannot read property 'Group' of undefined
at Object.eval (bizcharts-plugin-slider.min.js?3768:1)
at e (bizcharts-plugin-slider.min.js?3768:1)
at Object.eval (bizcharts-plugin-slider.min.js?3768:1)
at e (bizcharts-plugin-slider.min.js?3768:1)
at Object.eval (bizcharts-plugin-slider.min.js?3768:1)
at e (bizcharts-plugin-slider.min.js?3768:1)
at eval (bizcharts-plugin-slider.min.js?3768:1)
at eval (bizcharts-plugin-slider.min.js?3768:1)
at eval (bizcharts-plugin-slider.min.js?3768:1)
at Object.eval (bizcharts-plugin-slider.min.js?3768:1)
Answers:
username_0: 我是在内网搞的,没办法给外网地址!我也更新了自己的版本库,还是报错!
开始报个警告:
BizCharts.js?7c2d:6950 There are multiple versions of G2. Version 3.2.8's reference is 'window.G2_3'
username_1: 没事的。我可以访问的,
钉钉联系我吧 花名: 期贤
username_0: 钉钉没用过,是加好友吗,好友要输入钉钉号或手机号!
username_1: 额 不是阿里内部用户吗?
codebox 上面也可以新建的
username_0: codebox也没用过!
username_1: 是时候学习一个了
username_0: 这个window.G2这个的版本是怎么决定,怎么搞都是2.3.12
username_0: BizCharts.js?7c2d:6950直接使用它自己定义的G2就没有问题,改一下这个代码,那是G2版本问题,但G2是最新版本了啊!
username_1: BizCharts 可能和 g2 的版本不一样
Status: Issue closed
|
Virtuoel/Pehkui | 868511194 | Title: immersive portals issue
Question:
username_0: when i use the 1.16.5 forge version with the immersive portals mod it doesnt resize the character
Answers:
username_1: It's because Immersive Portals' developer didn't add compatibility to the forge version of Pehkui
username_2: Duplicate of https://github.com/qouteall/ImmersivePortalsModForForge/issues/243
Status: Issue closed
|
mermaid-js/mermaid-live-editor | 1154745997 | Title: Mermaid support in something like draw.io or lucidchart
Question:
username_0: **Is your feature request related to a problem? Please describe.**
I would really like to extend mermaid support to something like lucidchart or drawio. I understand the complexity of representing things like layers (not going to happen) but even a solution like "are you sure?" with a preview of the rendered chart would go a long way. Simply scraping out the arrows as they connect shapes would be great! This is a follow up to [this discussion](https://news.ycombinator.com/item?id=30336368).
**Describe the solution you'd like**
I draw shapes from a pre-approved or limited shapes pallet. Call them something like "Mermaid-diamond" or whatever so I know they're something mermaid can understand. Then I make sure I draw arrows which connect at both ends to shapes. Mermaid should figure out how to render those, and any text labels attached to the shapes.
**Describe alternatives you've considered**
Write mermaid myself. It's OK but I find the syntax breaks my brain a bit. Alternately embed images but that's not nearly as nice.
**Additional context**
Nope. Thanks for letting me open this request! |
Flutterando/music_player_app | 646781837 | Title: Create reprodution bar
Question:
username_0: 
https://cdn.dribbble.com/users/121337/screenshots/12389575/media/746169132ec45b15992c0383745b6d2b.png<issue_closed>
Status: Issue closed |
jasonish/evebox | 327234980 | Title: Template file not found
Question:
username_0: Hello, I cloned the latest evebox and the dependencies and created a rpm. This rpm was added to a proprietory centos iso image along with elasticsearch 5.6.6 & suricata 4.0. Now when I am trying to bring up a VM with this image, the evebox esimport fails to execute with the error
_"Failed to install template: file does not exist
failed to install template for configured index"_
I see that the packr command[-v] is creating the box with all the resources.
_built box . with ["configdb/README.md" "configdb/V0.sql" "configdb/V1.sql" "elasticsearch/template-es5x.json" "elasticsearch/template-es6x.json" "favicon.ico" "postgres/V0.sql" "postgres/V1.sql" "postgres/V2.sql" "postgres/V3.sql" "postgres/examples.sql" "public/3rdpartylicenses.txt" "public/_done" "public/favicon.ico" "public/fontawesome-webfont.674f50d287a8c48dc19b.eot" "public/fontawesome-webfont.912ec66d7572ff821749.svg" "public/fontawesome-webfont.af7ae505a9eed503f8b8.woff2" "public/fontawesome-webfont.b06871f281fee6b241d6.ttf" "public/fontawesome-webfont.fee66e712a8a08eef580.woff" "public/index.html" "public/inline.7ad29852404a2889f74f.bundle.js" "public/main.9e188a1a67e840e8f653.bundle.js" "public/polyfills.9afba58cc5c5e906563e.bundle.js" "public/styles.63a57b75d0da691870af.bundle.css" "resources.go" "sqlite/V0.sql" "sqlite/V1.sql" "sqlite/V2.sql"]_
Would you know what is causing the command to fail at runtime? TIA.
Answers:
username_1: Actually my builds are fine. Can you test one of my binaries in your VM:
https://evebox.org/files/s3/release-staging/
If that works, but yours doesn't its something in the build process that isn't working out for you.
Thanks.
username_0: Thanks for checking this. I'll check my build process then.
Due to our requirement, we had to modify the vendor directory structure which might be causing the issue. I'll take a deeper look at how packr behaves. Thanks.
username_1: As a reference you might want to see "./docker.sh release" which does a release in a fresh docker instance, installs on deps and creating a linux release.
username_1: Closing for now as it doesn't seem to be an issue with the default build.
Let me know if you think I could be of help. Also note that as "vgo" becomes more stable I'll be switching to that, which looks like it will remove the vendor directory completely.
Status: Issue closed
|
SonarSonic/Practical-Logistics-2 | 321593854 | Title: 1.12.2 declare dependencies to SonarCore versions
Question:
username_0: It would be great if you declared the dependencies on sonarcore in your @Mod annotation to prevent crashes when using an older version. It then instead shows you the minimum version needed for PL to load in the dirt background screen thingy.<issue_closed>
Status: Issue closed |
NG-ZORRO/ng-zorro-antd | 780205867 | Title: form表单中属性设置为disabled之后,value中没有这个值
Question:
username_0: ## What problem does this feature solve?
1、在接口传递数据时,不需要另外拼凑数据。
2、方便了新增和编辑时使用数据
## What does the proposed API look like?
form表单中属性设置为disabled之后,value中有这个值<!-- generated by ng-zorro-issue-helper. DO NOT REMOVE -->
Status: Issue closed
Answers:
username_1: https://blog.kevinyang.net/2020/05/06/angular-formgroup-value/ |
fengyuanchen/cropperjs | 292633955 | Title: getCroppedCanvas无法完全按照宽高剪裁,有1像素偏差
Question:
username_0: getCroppedCanvas方法内同时传入宽高时,使用scaledRatio将宽高相除,再计算高度,会造成1像素的偏差。这个怎么解决?不能完全按照设置值进行剪裁吗?
Answers:
username_0: 主要因为canvas只支持math.floor剪裁像素,所以我的解决方法是通过默认只传width,出现误差则传height来解决。不知道是否正确呢~
if(this.props.canvasW && this.props.canvasH){
let d = this.cropper.getData(),
r = d.width / d.height,
w = this.props.canvasW,
h= this.props.canvasH,
realH = Math.floor(w/r);
if(h == realH){
return this.cropper.getCroppedCanvas({width: w});
}else{
return this.cropper.getCroppedCanvas({height: h});
}
}
username_0: 如果这种方式可以的话建议在getCroppedCanvas内部实现判断,如果width和height同时传入,需要做类似处理
username_1: 这个很难处理,如果不向下舍入,有时会多出1px黑线。建议可以到服务端裁剪。
Status: Issue closed
username_0: 通过我上面的写法,可以解决这个问题。还是做向下舍入,但是判断是否传入了width和height两个值,如果都有,就要保证传出的是这个值。实际上是对用户选择的区域做了微调,但是这个用户应该不可感知。建议可以在内部做这个处理。实际上我出现这个问题就是服务器做了严格的尺寸校验,这种需求还是蛮常见的。 |
zslayton/cron | 740685276 | Title: reject invalid cron values
Question:
username_0: I can use values greater than 59 for seconds and minutes, and greater than 24 for hours, in a cron expressions, and that gives surprising values without errors.
Example of accepted expressions...
```
0/100 0/100 0/100 * * *
Answers:
username_1: Quick thought, why don't you implement ScheduleFields like:
```rust
impl ScheduleFields {
pub(crate) fn new(
seconds: Seconds,
minutes: Minutes,
hours: Hours,
days_of_month: DaysOfMonth,
months: Months,
days_of_week: DaysOfWeek,
years: Years,
) -> Result<ScheduleFields, Error> {
if seconds.ordinals().difference((Seconds::inclusive_min()..=Seconds::inclusive_max()).iter()).collect().is_empty() {
return Err(Error::from(ErrorKind::Expression("Seconds out of range".to_owned())));
}
// etc. NB this is not working code yet
Ok(ScheduleFields {
years,
days_of_week,
months,
days_of_month,
hours,
minutes,
seconds,
})
}
}
```
This might also fix #11
username_1: I tried to make a draft, but it seems I was mistaken. The nom parser seems to filter the values somewhere(?) I'm not sure how it really works.
username_2: There's already code in `cron` that validates the ordinals themselves:
https://github.com/username_2/cron/blob/22ea6bcdb77f2b5d9e182df46a945d2867721d31/src/time_unit/mod.rs#L240-L260
The trouble in this example's case is that the divisor of the period is out of bounds:
```
0/100 0/100 0/100 * * *
```
To address this we'd need to bounds-check the variable `step` in the function `ordinals_from_root_specifier`:
https://github.com/username_2/cron/blob/22ea6bcdb77f2b5d9e182df46a945d2867721d31/src/time_unit/mod.rs#L310 |
skupperproject/skupper | 827642717 | Title: console link on docker desktop
Question:
username_0: Docker desktop now offers an easy way to start a k8s instance.
As part of recent improvements to the cli, the `status` option now presents a link to the console, however on this k8s instance, the link presented is localhost:8080.
This is probably a restriction of the k8s instance, but noting here as it might be confusing to some users.
Answers:
username_1: I assume that doesn't work?
What does `kubectl get services` show?
username_0: ```
% kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
skupper-controller LoadBalancer 10.109.231.124 localhost 8080:31232/TCP 79m
skupper-internal LoadBalancer 10.101.74.12 localhost 55671:31029/TCP,45671:30094/TCP 79m
skupper-messaging ClusterIP 10.111.221.202 <none> 5671/TCP 79m
```
username_0: BTW localhost:8080 works now, maybe i just didn't wait long enough.
I created another site in a separate namespace (east) and that reports
```
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
skupper-controller ClusterIP 10.110.155.86 <none> 8080/TCP 84m
skupper-internal ClusterIP 10.101.88.102 <none> 55671/TCP,45671/TCP 84m
skupper-messaging ClusterIP 10.101.144.70 <none> 5671/TCP 84m
```
no console url offered after `status` so I think i can close this? everything works as expected.
Status: Issue closed
|
TalkyTeam/TalkyTalky | 1051383543 | Title: Documentation
Question:
username_0: Could you add instructions on how to use TalkyTalky? I've been using [aeneas](https://github.com/readbeyond/aeneas) but it's having issues with a certain book. I'd very much love to try TalkyTalky. (What a name!) |
Traeger-GmbH/release-server | 577834316 | Title: Check filesystem permissions during startup
Question:
username_0: In order to avoid errors during runtime that result from wrong filesystem permissions these permissions shall be checked during the server startup.
To keep the logic of checking the permissions inside the `FsReleaseArtifactRepository` class, one can implement the check inside its constructor and create the singleton instances of `FsReleaseArtifactService` and `FsReleaseArtifactRepository` during startup.
This can be encapsulated in an extension method on IServiceCollection:
```
namespace Microsoft.Extensions.DependencyInjection
{
public static class ReleaseServerServiceCollectionExtensions
{
public static IServiceCollection AddReleaseArtifactService(this IServiceCollection services)
{
services.AddSingleton<IReleaseArtifactService>(serviceProvider =>
{
var releaseArtifactRepository = new FsReleaseArtifactRepository(
serviceProvider.GetRequiredService<Logging.ILogger<FsReleaseArtifactRepository>>(),
serviceProvider.GetRequiredService<IConfiguration>()
);
return new FsReleaseArtifactService(
releaseArtifactRepository,
serviceProvider.GetRequiredService<Logging.ILogger<FsReleaseArtifactService>>()
);
});
return services;
}
}
}
```
To add the services on startup just `services.AddReleaseArtifactService()` would have to be called in `ConfigureServices()` method of class `Startup`
Answers:
username_1: @username_0 do you have packages / functions in your mind, how to check the directory permissions?
Windows permissions are not the same like Linux.
A simple check could also be done as follows (pseudo code):
```
private void CheckPermissions(string directoryToCheck)
{
File.Create(Path.Combine(directoryToCheck, "testFile"));
File.ReadAllBytes(Path.Combine(directoryToCheck, "testFile"));
File.Delete(Path.Combine(directoryToCheck, "testFile"));
}
```
So, you can test the **read** and **write** access permission for Windows & Linux in one function (if you don't have the permission -> an exception will be thrown & the application does not start).
What do you think about this proposal? Or do you know more convenient possibilities.
username_0: I think there is a more convenient way to do this. @username_2 do you have any ideas how to achieve this?
username_2: This is not a good approach, because of an application shall not driven by exceptions. Always prefer return values instead of exceptions. Exceptions shall avoided as often as possible. An exception shall only be thrown in case of an issue in your code / use of an API, such as invalid parameters.
We already had such a requirement in one of our products as well. Here you will find the implementation I'd like to recommend:
```csharp
public static bool CanWriteDirectory(string path)
{
bool writable = false;
try {
path = Path.GetFullPath(path);
if (Directory.Exists(path)) {
// Generate a file name to reduce the risk of a file that might already exist.
path = Path.Combine(path, Guid.NewGuid().ToString("N") + "_test.file");
// It is important that we use FileMode.CreateNew instead of Create; otherwise
// we might overwrite an already existing file. Also, we need to use
// FileShare.Delete() so that we can delete the file while we have opened it,
// to ensure no other process can write data to that file between the time when
// we close it and then delete it.
using (var stream = new FileStream(
path,
FileMode.CreateNew,
FileAccess.ReadWrite,
FileShare.Delete)) {
// Delete it before closing it, to ensure no other process can access it.
File.Delete(path);
}
writable = true;
}
}
#pragma warning disable CA1031 // Do not catch general exception types
catch {
// Ignore.
}
#pragma warning restore CA1031 // Do not catch general exception types
return writable;
}
```
Instead of "killing" your application in case there a desired/required/configured directory is not writable you shall give the user of your application a more professional feedback using console outputs and/or logging. An application which crashes is by default not a quite kind application regarding its mediated user experience.
username_1: Thank you @username_2 ! :)
The snippet was only a draft and not meant as "productive" code. Also a simple exception throwing is not a final approach for an application. With this, I'm absolutely with you.
Your implementation snippet is exactly doing, what i meant (incl the productivity behaviour) :)
I will take this for the implementation.
username_1: @username_0 i implemented the check of the filesystem permission.
Your suggestion of the extension method of `IServiceCollection` didn't work. That's because if you add services as singelton, they will only then instanced, when you neet them (after firing a request).
Instead of this, i used a kind of "warmup" in the `Configure` function:
```csharp
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
//Warmup the ReleaseArtifactRepository to check the file permissions before continuing
app.ApplicationServices.GetService<IReleaseArtifactRepository>();
....
}
```
This kind of "warmup" instantiates the FsReleaseArtifactRepository, that runs the permission checks. For the permission check, i used the code snippet above (thanks @username_2).
username_0: I suppose that you misunderstood my proposal where to put the code for checking the permissions.
I would not check the permissions inside the constructor of `FsReleaseArtifactRepository` but in the extension method `AddFsReleaseArtifactService()` of IServiceCollection:
```cs
namespace Microsoft.Extensions.DependencyInjection
{
public static class ReleaseServerServiceCollectionExtensions
{
public static IServiceCollection AddFsReleaseArtifactService(this IServiceCollection services)
{
//
// Check filesystem permissions here.
//
services.AddSingleton<IReleaseArtifactService>(serviceProvider =>
{
var releaseArtifactRepository = new FsReleaseArtifactRepository(
serviceProvider.GetRequiredService<Logging.ILogger<FsReleaseArtifactRepository>>(),
serviceProvider.GetRequiredService<IConfiguration>()
);
return new FsReleaseArtifactService(
releaseArtifactRepository,
serviceProvider.GetRequiredService<Logging.ILogger<FsReleaseArtifactService>>()
);
});
return services;
}
}
}
```
Furthermore it is not good practice to just kill the running process from inside any component. It leads to unexpected behavior and is not predictable if the application is killed on different locations of the code.
Just log the error and throw a `System.UnauthorizedAccessException` if the permissions do not match the requirements. The callee then has the choice if he wants to handle this kind of exception.
username_1: As discussed with @username_0 the following changes were made:
- CanWriteDirectory() is now a DirectoryInfo extension method
- The permission check is now handled in the IServiceCollection extension method (see snippet above)
- If the permissions are not set as supposed, the application throws a `System.UnauthorizedException` that will be catched in the main method.
- Because of the missing ability to use a logger in the `ConfigureServices()` function (Startup.cs), we decided to log the Exception message in the catch block to the console.
Status: Issue closed
|
jline/jline3 | 558605796 | Title: Attempt to complete filename option value by using the whole option expression "--option=value"
Question:
username_0: Hello.
I have a command with an option named `"--path"` which is completed by a `FileNameCompleter`.
If I type `"--[TAB]"` the option name is completed to "--path=".
If I press `[TAB]` again, the content of the current working directory is displayed as completions. If I pick a subdirectory name "folder", the option is completed to `--path=folder/`. Then `[TAB]` stops working. If I set a breakpoint inside `FileNameCompleter`'s code, I see that the it is attempting to complete "--path=folder" instead of "folder", but there is no subdirectory called "--path=folder" in the current working directory, so no candidates are displayed.
Why is that happening?
If I remove the "=" sign, there is no autocompletion at all. Does _jline3_ only accept "--option=value" and not "--option value"?
Status: Issue closed
Answers:
username_1: Yes, for long options jline3 accept only "--option=value"
username_0: Ok, this is even more puzzling, then. Why is `FileNameCompleter` trying to complete the string "--path=folder" instead of "folder"?
username_1: That has been fixed in [Completers.java#L795](https://github.com/jline/jline3/blob/58c385801d6beabab8c6bb504736122ee18feb6f/builtins/src/main/java/org/jline/builtins/Completers.java#L795).
username_0: Oh, I missed that. Thanks, username_1!
When will this appear on mvm?
username_1: I think the next release will be done in February or at the beginning of March. I do not know if you can download 13.3.4-SNAPSHOT jars somewhere. |
kelumkps/git-crucible-review-creator | 196378980 | Title: Nice to have an auto installer for the script
Question:
username_0: It's nice to have an auto installer for the script. Right now user has to manually edit below properties on the script and copy it to .git/hooks directory. We should introduce a tool to automate these steps.
```
crucible_url="#HOST:PORT"
project_key="#PROJECT_KEY"
username="#USERNAME"
password="<PASSWORD>"
reviewers="#COMMA_SEPERATED_USERNAMES"
```
Answers:
username_0: Proposing below type of commands for the tool.
```
cli install
git directory
crucible url
username
password
project key
reviwers
cli uninstall
git directory
cli disable
git directory
cli enable
git directory
cli reviwers add <>
cli reviwers remove <>
cli update --all
git directory
```
username_0: An interactive command-line tool was developed as a complementary project for this and available as [git-crucible-cli](https://github.com/username_0/git-crucible-cli). It also available on [npm](https://www.npmjs.com/package/git-crucible) to install as a command line tool.
Status: Issue closed
|
MicrosoftDocs/azure-docs | 353621404 | Title: TLS settings are missing from documentation
Question:
username_0: The option to configure the minimum TLS version has been added to Redis Cache, however it is not mentioned above and the screen shots are out of date.
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 900d60f8-f8b4-bf7b-a7de-79828cf779ae
* Version Independent ID: 1b15867b-ff1a-c3cd-208e-6a818641e94a
* Content: [How to configure Azure Redis Cache](https://docs.microsoft.com/en-us/azure/redis-cache/cache-configure#access-ports)
* Content Source: [articles/redis-cache/cache-configure.md](https://github.com/Microsoft/azure-docs/blob/master/articles/redis-cache/cache-configure.md)
* Service: **cache**
* GitHub Login: @wesmc7777
* Microsoft Alias: **wesmc**
Answers:
username_1: @username_0 Thanks for the feedback! I have assigned the issue to the content author to evaluate and update as appropriate. |
lawchihon/TipCalculator | 196679445 | Title: Project Feedback!
Question:
username_0: Hello Chi.
Looks good, this exercise is intended in part to give you an introduction to the general rhythm of this course. The course is entirely project-based with an app being assigned each week and then due the following week. Each project builds on the last to help each engineer learn the practical elements of iOS development and best practices as quickly as possible. We also do a code review for each submitted project once the program begins.
The next step is to continue working on [optional features](https://courses.codepath.com/snippets/ios_university/prework_university.md#heading-5-optional-add-a-settings-screen-to-the-tip-calculator) and [extending](https://courses.codepath.com/snippets/ios_university/prework_university.md#heading-6-optional-extend-your-app-improve-ui-add-features) your tip calculator. With regards to extensions to implement, we are looking for developers with an interest in user experience and product development so be sure to focus on additional functional enhancements and/or improving the user interface of the app.
Check out some [past excellent submissions here](https://courses.codepath.com/snippets/ios_university/prework_university.md#heading-excellent-past-submissions). You can update your submission at any time [here](https://apply.codepath.com/dashboard/), and it will notify us to review again.
We'll be following up with you again shortly to outline the next steps in the admissions process.
Answers:
username_0: Hello Chi.
Great work!! This exercise is intended in part to give you an introduction to the general rhythm of this course. The course is entirely project-based with an app being assigned each week and then due the following week. Each project builds on the last to help each engineer learn the practical elements of iOS development and best practices as quickly as possible. We also do a code review for each submitted project once the program begins.
Great to see you were able to complete a large number of optional features to your app already. Your project looks great. As you can probably tell, the optional features available on each project are a great vehicle for exploring the iOS framework deeper.
We'll be following up with you again shortly to outline the next steps in the admissions process. |
twilio/twilio-python | 128775156 | Title: ImportError: No module named rest.ip_messaging
Question:
username_0: Hi,
The first example I try to copy+paste from [your docs](https://www.twilio.com/docs/api/ip-messaging/rest/channels) does not seem to work. Looks like the imports are not working.
```python
from twilio.rest.ip_messaging import TwilioIpMessagingClient
```
```
ImportError: No module named rest.ip_messaging
```
Answers:
username_1: Are you sure you are on the latest version of the library?
username_2: i'm having a similar problem. Running the most update twilio version as well.
username_1: @username_2 what extact version are you on?
username_1: @username_2 which exact version are you using?
username_3: Possibly related, I couldn't find any reference in the docs (http://twilio-python.readthedocs.org/en/release-6x/) as to how to deal with access tokens for IPM?
The previous "from twilio.access_token import AccessToken, IpMessagingGrant" now returns:
ImportError: No module named access_token
Mac OS X 10.11 Beta (15A279b)
Python 2.7.10
pip 8.0.2
twilio (6.0.0rc2)
Apols in advance if numpty question.
Rgds, Mick
username_1: @username_3 oh, are you using the 6.x release candidate? That library has different import directives. Check out https://github.com/twilio/twilio-python/wiki/Python-Version-6.x-Upgrade-Guide .
username_1: @username_3 sorry, that's our bad, a release candidate was mis-versioned and made the default download. You should download a 5.x version, unless you want to upgrade to the pre-release.
username_1: @username_0 @username_2 ^ that might be your issue as well
username_3: I'm awarding myself a "No-Prize"! So basically IPM not supported yet in 6.0.0rc2? No biggie, like you say, I can rollback, was just keen to checkout the new secret sauce!
username_1: @username_3 it is, it's just all the subdomains in the new version are under twilio.rest.Client, so there isn't 1 client per subdomain now.
It's us that get no-prize, the RC shouldn't have been the default version =P
username_3: Ok, so what's the solution to my problem statement/error msg above. Again I can't see any reference to Access Tokens in the upgrade guide or v6 docs?
username_1: @username_3 you know what, I don't think access tokens have been merged into the RC yet. I'll get that out for RC4 (RC3 is a small release today that makes auth more efficient). thanks!
username_3: This is getting a bit frustrating. Please actually read my comments before replying.
I repeat:
"So what's the solution to my problem statement/error msg above."
Hint: don't refer people to documentation before checking yourself that said documentation does actually contain the answer (or even exists).
Access Tokens clearly don't work "just as before" or I presumably wouldn't be getting the err msg. My code is based on https://www.twilio.com/docs/api/rest/access-tokens & https://www.twilio.com/docs/api/ip-messaging/guides/identity#create-token (pretty much the only documentation I can find)
username_1: @username_3 I apologize, when I originally directed you to the docs, I thought access tokens were in the RC and worked just as before. I've since noted that they are not in the 6.x.rc release candidate at the moment, that's a pre-release that still has a few kinks in it. If you need to use access tokens right now, you need to downgrade to a 5.x version or wait for the rc3 release.
So again, the solution is either downgrade to 5.x and use it exactly as you were trying to use it or wait for 6.0.rc3 and use it exactly as you were trying to use it.
username_3: So (as I said 3 hrs ago) IPM, of which Access Tokens is an instrinsic part, is NOT currently supported in v6!
I implore you, for future reference, when responding to a customer "get it right first time, every time".
Looking fwd to your talk at Signal on this, expect some mild heckling (kidding, we'll laugh about it over a beer!).
Signing off & rolling back to v5... :'-(
username_4: Hey @username_3, @username_0,
Sorry this has been quiet for such a long time. I've just taken a look through the repo and it looks like IP Messaging access tokens were added in v6 rc3 here: https://github.com/twilio/twilio-python/commit/3<PASSWORD>5584c<PASSWORD>fc228666<PASSWORD>286571<PASSWORD>9.
Have you tried using the latest release candidate with this? Can we close this issue?
Thanks!
Status: Issue closed
username_5: hey @username_3 @username_0!
Twilio Programmable Chat has been added in the latest release of the library! |
longhorn/longhorn | 613663338 | Title: [BUG] Failure under sustained write load
Question:
username_0: **Describe the bug**
I have a relatively large number of replica failures during sustained write operations (measured in minutes or tens of minutes)
**To Reproduce**
Steps to reproduce the behavior:
1. Run a MinIO cluster using minio operator
2. wait for cluster to come up
3. Using the mc client (`mc cp *files* host/bucket`), try to send around 20GB, broken into files of around 100MB each
4. See replica failure
**Expected behavior**
Replicas should stay up
**Log**
```
root@instance-manager-r-cc03c099:/var/log/instances# cat pvc-04a60ec8-16f3-400d-841d-6f2911e23630-r-ca01d6ee.log
time="2020-05-06T15:38:22Z" level=info msg="Creating volume /host/var/lib/longhorn/replicas/pvc-04a60ec8-16f3-400d-841d-6f2911e23630-25d075e0, size 42949672960/512"
time="2020-05-06T15:38:22Z" level=info msg="Listening on data server 0.0.0.0:10091"
time="2020-05-06T15:38:22Z" level=info msg="Listening on sync agent server 0.0.0.0:10092"
time="2020-05-06T15:38:22Z" level=info msg="Listening on gRPC Replica server 0.0.0.0:10090"
time="2020-05-06T15:38:22Z" level=info msg="Listening on sync 0.0.0.0:10092"
time="2020-05-06T15:38:25Z" level=info msg="New connection from: 10.244.12.196:50926"
time="2020-05-06T15:38:25Z" level=info msg="Opening volume /host/var/lib/longhorn/replicas/pvc-04a60ec8-16f3-400d-841d-6f2911e23630-25d075e0, size 42949672960/512"
time="2020-05-06T15:48:58Z" level=info msg="Closing volume"
time="2020-05-06T15:48:59Z" level=warning msg="Received signal interrupt to shutdown"
time="2020-05-06T15:48:59Z" level=warning msg="Starting to execute registered shutdown func github.com/longhorn/longhorn-engine/app/cmd.startReplica.func4"
time="2020-05-06T15:49:01Z" level=info msg="Listening on gRPC Replica server 0.0.0.0:10090"
time="2020-05-06T15:49:01Z" level=info msg="Listening on data server 0.0.0.0:10091"
time="2020-05-06T15:49:01Z" level=info msg="Listening on sync agent server 0.0.0.0:10092"
time="2020-05-06T15:49:01Z" level=info msg="Listening on sync 0.0.0.0:10092"
time="2020-05-06T15:49:04Z" level=info msg="New connection from: 10.244.10.198:46818"
time="2020-05-06T15:49:04Z" level=info msg="Opening volume /host/var/lib/longhorn/replicas/pvc-04a60ec8-16f3-400d-841d-6f2911e23630-25d075e0, size 42949672960/512"
time="2020-05-06T21:08:10Z" level=info msg="Replica server starts to snapshot [1a6e785c-e0e8-4f4b-b929-e66b11f6a88e] volume, user created false, created time 2020-05-06T21:08:10Z, labels map[]"
time="2020-05-06T21:08:10Z" level=info msg="Sending file volume-snap-1a6e785c-e0e8-4f4b-b929-e66b11f6a88e.img to 10.244.11.226:10259"
time="2020-05-06T21:08:10Z" level=info msg="source file size: 42949672960, setting up directIo: true"
time="2020-05-06T21:40:07Z" level=warning msg="Received signal interrupt to shutdown"
time="2020-05-06T21:40:07Z" level=warning msg="Starting to execute registered shutdown func github.com/longhorn/longhorn-engine/app/cmd.startReplica.func4"
```
**Environment:**
- Longhorn version: 0.8.0
- Kubernetes version: 1.16.0
- Node OS type and version: Alpine Linux 3.10
**Additional context**
Add any other context about the problem here.
Answers:
username_0: Log from a second failed replica:
```
root@instance-manager-r-cc03c099:/var/log/instances# cat pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-r-031a913c.log
time="2020-05-06T15:38:19Z" level=info msg="Creating volume /host/var/lib/longhorn/replicas/pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-d7f36a6c, size 42949672960/512"
time="2020-05-06T15:38:19Z" level=info msg="Listening on gRPC Replica server 0.0.0.0:10015"
time="2020-05-06T15:38:19Z" level=info msg="Listening on data server 0.0.0.0:10016"
time="2020-05-06T15:38:19Z" level=info msg="Listening on sync agent server 0.0.0.0:10017"
time="2020-05-06T15:38:19Z" level=info msg="Listening on sync 0.0.0.0:10017"
time="2020-05-06T15:38:21Z" level=info msg="New connection from: 10.244.10.198:34326"
time="2020-05-06T15:38:21Z" level=info msg="Opening volume /host/var/lib/longhorn/replicas/pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-d7f36a6c, size 42949672960/512"
time="2020-05-06T15:39:15Z" level=info msg="Closing volume"
time="2020-05-06T15:39:17Z" level=warning msg="Received signal interrupt to shutdown"
time="2020-05-06T15:39:17Z" level=warning msg="Starting to execute registered shutdown func github.com/longhorn/longhorn-engine/app/cmd.startReplica.func4"
time="2020-05-06T15:39:19Z" level=info msg="Listening on gRPC Replica server 0.0.0.0:10015"
time="2020-05-06T15:39:19Z" level=info msg="Listening on data server 0.0.0.0:10016"
time="2020-05-06T15:39:19Z" level=info msg="Listening on sync agent server 0.0.0.0:10017"
time="2020-05-06T15:39:19Z" level=info msg="Listening on sync 0.0.0.0:10017"
time="2020-05-06T15:39:20Z" level=info msg="New connection from: 10.244.8.95:41292"
time="2020-05-06T15:39:20Z" level=info msg="Opening volume /host/var/lib/longhorn/replicas/pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-d7f36a6c, size 42949672960/512"
time="2020-05-06T21:03:05Z" level=info msg="Replica server starts to snapshot [3bf81894-b5c6-4053-bec1-930b36583af6] volume, user created false, created time 2020-05-06T21:03:05Z, labels map[]"
time="2020-05-06T21:03:09Z" level=info msg="Sending file volume-snap-3bf81894-b5c6-4053-bec1-930b36583af6.img to 10.244.12.195:10229"
time="2020-05-06T21:03:09Z" level=info msg="source file size: 42949672960, setting up directIo: true"
time="2020-05-06T21:03:28Z" level=info msg="Replica server starts to snapshot [7cac0aa1-316f-4fdf-82dd-2d71c610ae1c] volume, user created false, created time 2020-05-06T21:03:27Z, labels map[]"
time="2020-05-06T21:03:35Z" level=error msg="writeData for batchInterval: [ 12320: 12352]( 32) failed, err: writeData failed, err: Post http://10.244.12.195:10229/v1-ssync/writeData?begin=50462720&end=50593792: EOF"
time="2020-05-06T21:03:35Z" level=error msg="syncFileContent failed: syncDataInterval [ 12288: 14336](2048) failed, err: writeData failed, err: Post http://10.244.12.195:10229/v1-ssync/writeData?begin=50462720&end=50593792: EOF"
time="2020-05-06T21:04:31Z" level=info msg="Replica server starts to snapshot [5e0b7541-c642-4597-964f-a69d0ec2cb17] volume, user created false, created time 2020-05-06T21:04:31Z, labels map[]"
time="2020-05-06T21:04:34Z" level=info msg="Sending file volume-snap-3bf81894-b5c6-4053-bec1-930b36583af6.img to 10.244.8.96:10199"
time="2020-05-06T21:04:34Z" level=info msg="source file size: 42949672960, setting up directIo: true"
time="2020-05-06T21:40:27Z" level=warning msg="Received signal interrupt to shutdown"
time="2020-05-06T21:40:27Z" level=warning msg="Starting to execute registered shutdown func github.com/longhorn/longhorn-engine/app/cmd.startReplica.func4"
root@instance-manager-r-cc03c099:/var/log/instances#
```
username_0: Another failed replica from the same host. I've got failure on mutliple hosts, it's just easier to pull multiple logs from the same host
```
root@instance-manager-r-cc03c099:/var/log/instances# cat pvc-e0ec00cd-1120-46d3-9776-8b033fbaa9e7-r-0897b768.log
time="2020-05-06T15:38:30Z" level=info msg="Creating volume /host/var/lib/longhorn/replicas/pvc-e0ec00cd-1120-46d3-9776-8b033fbaa9e7-e9650f59, size 42949672960/512"
time="2020-05-06T15:38:30Z" level=info msg="Listening on gRPC Replica server 0.0.0.0:10105"
time="2020-05-06T15:38:30Z" level=info msg="Listening on sync agent server 0.0.0.0:10107"
time="2020-05-06T15:38:30Z" level=info msg="Listening on data server 0.0.0.0:10106"
time="2020-05-06T15:38:30Z" level=info msg="Listening on sync 0.0.0.0:10107"
time="2020-05-06T15:38:32Z" level=info msg="New connection from: 10.244.11.227:51314"
time="2020-05-06T15:38:32Z" level=info msg="Opening volume /host/var/lib/longhorn/replicas/pvc-e0ec00cd-1120-46d3-9776-8b033fbaa9e7-e9650f59, size 42949672960/512"
time="2020-05-06T21:40:02Z" level=warning msg="Received signal interrupt to shutdown"
time="2020-05-06T21:40:02Z" level=warning msg="Starting to execute registered shutdown func github.com/longhorn/longhorn-engine/app/cmd.startReplica.func4"
```
username_0: From another host and replica:
```
root@instance-manager-r-4371052c:/var/log/instances# cat pvc-e0ec00cd-1120-46d3-9776-8b033fbaa9e7-r-7ddb32cf.log
time="2020-05-06T15:38:30Z" level=info msg="Creating volume /host/var/lib/longhorn/replicas/pvc-e0ec00cd-1120-46d3-9776-8b033fbaa9e7-7048c3f7, size 42949672960/512"
time="2020-05-06T15:38:30Z" level=info msg="Listening on gRPC Replica server 0.0.0.0:10255"
time="2020-05-06T15:38:30Z" level=info msg="Listening on data server 0.0.0.0:10256"
time="2020-05-06T15:38:30Z" level=info msg="Listening on sync agent server 0.0.0.0:10257"
time="2020-05-06T15:38:30Z" level=info msg="Listening on sync 0.0.0.0:10257"
time="2020-05-06T15:38:32Z" level=info msg="New connection from: 10.244.11.227:48978"
time="2020-05-06T15:38:32Z" level=info msg="Opening volume /host/var/lib/longhorn/replicas/pvc-e0ec00cd-1120-46d3-9776-8b033fbaa9e7-7048c3f7, size 42949672960/512"
time="2020-05-06T21:40:42Z" level=info msg="Replica server starts to snapshot [790b7ad7-4b7b-4c84-9a09-17f59bbe35be] volume, user created false, created time 2020-05-06T21:40:42Z, labels map[]"
time="2020-05-06T21:40:42Z" level=info msg="Sending file volume-snap-790b7ad7-4b7b-4c84-9a09-17f59bbe35be.img to 10.244.10.197:10004"
time="2020-05-06T21:40:42Z" level=info msg="source file size: 42949672960, setting up directIo: true"
time="2020-05-06T21:53:18Z" level=warning msg="Received signal interrupt to shutdown"
time="2020-05-06T21:53:18Z" level=warning msg="Starting to execute registered shutdown func github.com/longhorn/longhorn-engine/app/cmd.startReplica.func4"
```
This is the replica manager log during the first event:
```
[longhorn-instance-manager] time="2020-05-06T15:38:19Z" level=info msg="Process Manager: prepare to create process pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-r-86408dd5"
[longhorn-instance-manager] time="2020-05-06T15:38:19Z" level=info msg="Process Manager: created process pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-r-86408dd5"
[pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-r-86408dd5] time="2020-05-06T15:38:19Z" level=info msg="Creating volume /host/var/lib/longhorn/replicas/pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-f9c9edc2, size 42949672960/512"
[pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-r-86408dd5] time="2020-05-06T15:38:19Z" level=info msg="Listening on gRPC Replica server 0.0.0.0:10225"
[pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-r-86408dd5] time="2020-05-06T15:38:19Z" level=info msg="Listening on data server 0.0.0.0:10226"
[pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-r-86408dd5] time="2020-05-06T15:38:19Z" level=info msg="Listening on sync agent server 0.0.0.0:10227"
[longhorn-instance-manager] time="2020-05-06T15:38:20Z" level=info msg="Process pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-r-86408dd5 has started at localhost:10225"
[pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-r-86408dd5] time="2020-05-06T15:38:20Z" level=info msg="Listening on sync 0.0.0.0:10227"
[pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-r-86408dd5] time="2020-05-06T15:38:21Z" level=info msg="New connection from: 10.244.10.198:56460"
[pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-r-86408dd5] time="2020-05-06T15:38:21Z" level=info msg="Opening volume /host/var/lib/longhorn/replicas/pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-f9c9edc2, size 42949672960/512"
[longhorn-instance-manager] time="2020-05-06T15:38:22Z" level=info msg="Process Manager: prepare to create process pvc-04a60ec8-16f3-400d-841d-6f2911e23630-r-db38aad2"
[longhorn-instance-manager] time="2020-05-06T15:38:22Z" level=info msg="Process Manager: created process pvc-04a60ec8-16f3-400d-841d-6f2911e23630-r-db38aad2"
[pvc-04a60ec8-16f3-400d-841d-6f2911e23630-r-db38aad2] time="2020-05-06T15:38:22Z" level=info msg="Creating volume /host/var/lib/longhorn/replicas/pvc-04a60ec8-16f3-400d-841d-6f2911e23630-5975bc62, size 42949672960/512"
[pvc-04a60ec8-16f3-400d-841d-6f2911e23630-r-db38aad2] time="2020-05-06T15:38:22Z" level=info msg="Listening on sync agent server 0.0.0.0:10242"
[pvc-04a60ec8-16f3-400d-841d-6f2911e23630-r-db38aad2] time="2020-05-06T15:38:22Z" level=info msg="Listening on gRPC Replica server 0.0.0.0:10240"
time="2020-05-06T15:38:22Z" level=info msg="Listening on data server 0.0.0.0:10241"
[pvc-04a60ec8-16f3-400d-841d-6f2911e23630-r-db38aad2] time="2020-05-06T15:38:22Z" level=info msg="Listening on sync 0.0.0.0:10242"
[longhorn-instance-manager] time="2020-05-06T15:38:22Z" level=info msg="Process pvc-04a60ec8-16f3-400d-841d-6f2911e23630-r-db38aad2 has started at localhost:10240"
[pvc-04a60ec8-16f3-400d-841d-6f2911e23630-r-db38aad2] time="2020-05-06T15:38:25Z" level=info msg="New connection from: 10.244.12.196:49362"
[pvc-04a60ec8-16f3-400d-841d-6f2911e23630-r-db38aad2] time="2020-05-06T15:38:25Z" level=info msg="Opening volume /host/var/lib/longhorn/replicas/pvc-04a60ec8-16f3-400d-841d-6f2911e23630-5975bc62, size 42949672960/512"
[longhorn-instance-manager] time="2020-05-06T15:38:30Z" level=info msg="Process Manager: prepare to create process pvc-e0ec00cd-1120-46d3-9776-8b033fbaa9e7-r-7ddb32cf"
[longhorn-instance-manager] time="2020-05-06T15:38:30Z" level=info msg="Process Manager: created process pvc-e0ec00cd-1120-46d3-9776-8b033fbaa9e7-r-7ddb32cf"
[pvc-e0ec00cd-1120-46d3-9776-8b033fbaa9e7-r-7ddb32cf] time="2020-05-06T15:38:30Z" level=info msg="Creating volume /host/var/lib/longhorn/replicas/pvc-e0ec00cd-1120-46d3-9776-8b033fbaa9e7-7048c3f7, size 42949672960/512"
[pvc-e0ec00cd-1120-46d3-9776-8b033fbaa9e7-r-7ddb32cf] time="2020-05-06T15:38:30Z" level=info msg="Listening on gRPC Replica server 0.0.0.0:10255"
[pvc-e0ec00cd-1120-46d3-9776-8b033fbaa9e7-r-7ddb32cf] time="2020-05-06T15:38:30Z" level=info msg="Listening on data server 0.0.0.0:10256"
time="2020-05-06T15:38:30Z" level=info msg="Listening on sync agent server 0.0.0.0:10257"
[longhorn-instance-manager] time="2020-05-06T15:38:30Z" level=info msg="Process pvc-e0ec00cd-1120-46d3-9776-8b033fbaa9e7-r-7ddb32cf has started at localhost:10255"
[pvc-e0ec00cd-1120-46d3-9776-8b033fbaa9e7-r-7ddb32cf] time="2020-05-06T15:38:30Z" level=info msg="Listening on sync 0.0.0.0:10257"
[pvc-e0ec00cd-1120-46d3-9776-8b033fbaa9e7-r-7ddb32cf] time="2020-05-06T15:38:32Z" level=info msg="New connection from: 10.244.11.227:48978"
[pvc-e0ec00cd-1120-46d3-9776-8b033fbaa9e7-r-7ddb32cf] time="2020-05-06T15:38:32Z" level=info msg="Opening volume /host/var/lib/longhorn/replicas/pvc-e0ec00cd-1120-46d3-9776-8b033fbaa9e7-7048c3f7, size 42949672960/512"
[pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-r-86408dd5] time="2020-05-06T15:39:15Z" level=info msg="Closing volume"
[longhorn-instance-manager] time="2020-05-06T15:39:17Z" level=debug msg="Process Manager: prepare to delete process pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-r-86408dd5"
[longhorn-instance-manager] time="2020-05-06T15:39:17Z" level=debug msg="Process Manager: deleted process pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-r-86408dd5"
[longhorn-instance-manager] time="2020-05-06T15:39:17Z" level=debug msg="Process Manager: wait for process pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-r-86408dd5 to shutdown before unregistering process"
[longhorn-instance-manager] time="2020-05-06T15:39:17Z" level=debug msg="Process Manager: trying to stop process pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-r-86408dd5"
[longhorn-instance-manager] time="2020-05-06T15:39:17Z" level=info msg="wait for process pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-r-86408dd5 to shutdown"
[pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-r-86408dd5] time="2020-05-06T15:39:17Z" level=warning msg="Received signal interrupt to shutdown"
time="2020-05-06T15:39:17Z" level=warning msg="Starting to execute registered shutdown func github.com/longhorn/longhorn-engine/app/cmd.startReplica.func4"
[longhorn-instance-manager] time="2020-05-06T15:39:17Z" level=info msg="Process Manager: process pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-r-86408dd5 error out, error msg: exit status 1"
[longhorn-instance-manager] time="2020-05-06T15:39:17Z" level=debug msg="Process update: pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-r-86408dd5: state error: Error: exit status 1"
[longhorn-instance-manager] time="2020-05-06T15:39:17Z" level=debug msg="Process update: pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-r-86408dd5: state error: Error: exit status 1"
[longhorn-instance-manager] time="2020-05-06T15:39:17Z" level=info msg="Process Manager: successfully unregistered process pvc-17c3dfaa-b1a3-441b-b16d-a84a53f69805-r-86408dd5"
[Truncated]
[pvc-7d5ffcc2-0128-470a-9ad2-aea706ba48e7-r-2b39b4ed] time="2020-05-06T21:53:26Z" level=info msg="Replica server starts to snapshot [635df2d3-0e9f-4e70-b948-f5b192bf4f0d] volume, user created false, created time 2020-05-06T21:53:26Z, labels map[]"
[pvc-7d5ffcc2-0128-470a-9ad2-aea706ba48e7-r-2b39b4ed] time="2020-05-06T21:53:26Z" level=info msg="Launching receiver for file volume-head-001.img.meta"
[pvc-7d5ffcc2-0128-470a-9ad2-aea706ba48e7-r-2b39b4ed] time="2020-05-06T21:53:26Z" level=info msg="Running ssync server for file volume-head-001.img.meta at port 10033"
time="2020-05-06T21:53:26Z" level=info msg="Creating Ssync service"
[pvc-7d5ffcc2-0128-470a-9ad2-aea706ba48e7-r-2b39b4ed] time="2020-05-06T21:53:26Z" level=info msg="open: receiving fileSize: 178, setting up directIo: false"
time="2020-05-06T21:53:26Z" level=info msg="Ssync server opened and ready"
[pvc-7d5ffcc2-0128-470a-9ad2-aea706ba48e7-r-2b39b4ed] time="2020-05-06T21:53:26Z" level=info msg="Closing ssync server"
[pvc-7d5ffcc2-0128-470a-9ad2-aea706ba48e7-r-2b39b4ed] time="2020-05-06T21:53:26Z" level=info msg="Running ssync server for file volume-snap-03ba5c91-8a3c-4d07-830b-35f87e489fdb.img at port 10034"
time="2020-05-06T21:53:26Z" level=info msg="Creating Ssync service"
time="2020-05-06T21:53:26Z" level=info msg="Done running ssync server for file volume-head-001.img.meta at port 10033"
[pvc-7d5ffcc2-0128-470a-9ad2-aea706ba48e7-r-2b39b4ed] time="2020-05-06T21:53:26Z" level=info msg="open: receiving fileSize: 42949672960, setting up directIo: true"
[pvc-7d5ffcc2-0128-470a-9ad2-aea706ba48e7-r-2b39b4ed] time="2020-05-06T21:53:26Z" level=info msg="Ssync server opened and ready"
[longhorn-instance-manager] time="2020-05-06T21:54:25Z" level=info msg="Process Manager: prepare to create process pvc-04a60ec8-16f3-400d-841d-6f2911e23630-r-db38aad2"
[longhorn-instance-manager] time="2020-05-06T21:54:25Z" level=info msg="Process Manager: created process pvc-04a60ec8-16f3-400d-841d-6f2911e23630-r-db38aad2"
[pvc-04a60ec8-16f3-400d-841d-6f2911e23630-r-db38aad2] time="2020-05-06T21:54:25Z" level=info msg="Listening on data server 0.0.0.0:10196"
[pvc-04a60ec8-16f3-400d-841d-6f2911e23630-r-db38aad2] time="2020-05-06T21:54:25Z" level=info msg="Listening on gRPC Replica server 0.0.0.0:10195"
time="2020-05-06T21:54:25Z" level=info msg="Listening on sync agent server 0.0.0.0:10197"
[pvc-04a60ec8-16f3-400d-841d-6f2911e23630-r-db38aad2] time="2020-05-06T21:54:25Z" level=info msg="Listening on sync 0.0.0.0:10197"
```
username_1: @username_0 Can you send us a support bundle at `<EMAIL>`? We want to take a look. Also, can you make sure you have enough spaces on the disks used by Longhorn? It's maybe due to network or disk.
username_0: @username_1 while all of this was going on, my NFS backup server went bye-bye (see Issue #1306 ), so I'm busy trying to restore my cluster. Once that happens, I'm going to try and re-create this issue in my dev cluster, and then I'll send a support bundle.
username_1: Thanks @username_0 . It looks like a network issue so far. If that's the case, next time you should see something happening in `instance-manager-e-`, in which engine will disconnect the replica. It should also log why it happened.
username_0: I've just rebuilt a mini cluster for the sole purpose of reproducing this, and I've managed to do it. I'm attaching a support bundle now
username_0: [longhorn-support-bundle_9ca2e2f6-baff-4cea-a99d-3e0965aaea75_2020-06-03T18-52-43Z.zip](https://github.com/longhorn/longhorn/files/4725571/longhorn-support-bundle_9ca2e2f6-baff-4cea-a99d-3e0965aaea75_2020-06-03T18-52-43Z.zip)
username_0: Second failure in the transfer, I'm 9GB into a 20GB transfer:
[longhorn-support-bundle_9ca2e2f6-baff-4cea-a99d-3e0965aaea75_2020-06-03T19-09-52Z.zip](https://github.com/longhorn/longhorn/files/4725672/longhorn-support-bundle_9ca2e2f6-baff-4cea-a99d-3e0965aaea75_2020-06-03T19-09-52Z.zip)
username_1: Thanks @username_0
I've check the support bundle and seen the problem with `pvc-f24ee6ba-ad71-42f8-bf02-70cc779146e5`. It still looks like a CPU resource or network issue. More likely CPU resource issue. Can you try the option `Guaranteed Engine CPU`? This will guarantee the CPU for the engine, which can be the reason the data failed to be processed in time. We've set this option to `0.25` by default in v1.0.0. You can read more at https://longhorn.io/docs/1.0.0/references/settings/#guaranteed-engine-cpu . You can try v1.0.0 on the new cluster if it's possible.
For v0.8.0, the updated setting only applies to the new instance managers. so in order to change it, you need to:
1. Detach all the volumes (scale down the workload)
1. Change the setting to e.g. `0.25`
1. run `kubectl -n longhorn-system delete instancemanagers.longhorn.io --all`
1. Wait for the instance manager to get back to running.
For v1.0.0, updating the setting will automatically result in the restarting of instance managers, so you shouldn't change it when there are volumes attached.
username_0: I've done this, and here's the support bundle on first failure:
[longhorn-support-bundle_9ca2e2f6-baff-4cea-a99d-3e0965aaea75_2020-06-03T19-36-24Z.zip](https://github.com/longhorn/longhorn/files/4725820/longhorn-support-bundle_9ca2e2f6-baff-4cea-a99d-3e0965aaea75_2020-06-03T19-36-24Z.zip)
username_1: @username_0 From the support bundle, I don't see the setting on the pod been set. For example, when the setting was set, the instance manager pod should have something like this:
```
name: engine-manager
resources:
requests:
cpu: 250m
```
But in the support bundle I saw nothing set for the requests:
```
resources:
limits: {}
requests:
cpu:
format: DecimalSI
```
Also, when the setting took effect, we should see the following from `kubectl describe nodes`
```
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE
--------- ---- ------------ ---------- --------------- ------------- ---
...
longhorn-system instance-manager-e-9ef5a300 250m (12%) 0 (0%) 0 (0%) 0 (0%) 33m
longhorn-system instance-manager-r-1a18c62d 250m (12%) 0 (0%) 0 (0%) 0 (0%) 33m
```
Can you check if you've seen the setting been applied successfully?
username_0: I've checked the pods, the CPU request has been applied. I've attached the latest support bundle and the YAML from one of the instance manager pods.
[longhorn-support-bundle_9ca2e2f6-baff-4cea-a99d-3e0965aaea75_2020-06-03T19-47-50Z.zip](https://github.com/longhorn/longhorn/files/4725900/longhorn-support-bundle_9ca2e2f6-baff-4cea-a99d-3e0965aaea75_2020-06-03T19-47-50Z.zip)
```
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: "2020-06-03T19:21:45Z"
labels:
longhorn.io/component: instance-manager
longhorn.io/instance-manager-image: longhornio-longhorn-instance-manager-v1_20200301
longhorn.io/instance-manager-type: replica
longhorn.io/node: dev03
name: instance-manager-r-02acd9bc
namespace: longhorn-system
ownerReferences:
- apiVersion: longhorn.io/v1beta1
kind: InstanceManager
name: instance-manager-r-02acd9bc
uid: 62166847-1e15-498b-bef7-ce0b3946dc23
resourceVersion: "69837"
selfLink: /api/v1/namespaces/longhorn-system/pods/instance-manager-r-02acd9bc
uid: 997646e5-8c16-4eaa-81de-a692eca0680d
spec:
containers:
- args:
- longhorn-instance-manager
- --debug
- daemon
- --listen
- 0.0.0.0:8500
image: longhornio/longhorn-instance-manager:v1_20200301
imagePullPolicy: IfNotPresent
livenessProbe:
exec:
command:
- /usr/local/bin/grpc_health_probe
- -addr=:8500
failureThreshold: 3
initialDelaySeconds: 3
periodSeconds: 5
successThreshold: 1
timeoutSeconds: 1
name: replica-manager
resources:
requests:
cpu: 250m
securityContext:
privileged: true
terminationMessagePath: /dev/termination-log
terminationMessagePolicy: File
volumeMounts:
- mountPath: /host
mountPropagation: HostToContainer
name: host
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: longhorn-service-account-token-x6tq2
readOnly: true
dnsPolicy: ClusterFirst
enableServiceLinks: true
[Truncated]
containerStatuses:
- containerID: containerd://1f5a0468c34394931c1867a08048cb8f46e993b6ced3dd03b504c39650a16bfa
image: registry.devcluster.ecedge.net/longhornio/longhorn-instance-manager:v1_20200301
imageID: docker.io/longhornio/longhorn-instance-manager@sha256:a20ba6cdb4f1770aa85302a929a83bdcbc258fe78318ba7b5ca9561986dacc3e
lastState: {}
name: replica-manager
ready: true
restartCount: 0
started: true
state:
running:
startedAt: "2020-06-03T19:21:48Z"
hostIP: 192.168.18.103
phase: Running
podIP: 10.244.5.10
podIPs:
- ip: 10.244.5.10
qosClass: Burstable
startTime: "2020-06-03T19:21:45Z"
```
username_0: ```
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE
--------- ---- ------------ ---------- --------------- ------------- ---
argocd argocd-dex-server-7bccc4747d-gn6rc 10m (0%) 0 (0%) 20Mi (0%) 0 (0%) 4h31m
default image-puller-dx895 1m (0%) 50m (2%) 2Mi (0%) 10Mi (0%) 3h39m
edt edt-3 50m (2%) 0 (0%) 100Mi (2%) 0 (0%) 33m
external-dns cluster-dns-6db55975c8-c7gs9 10m (0%) 0 (0%) 20Mi (0%) 0 (0%) 3h51m
external-dns external-dns-6b9d49cc5f-749wd 20m (1%) 0 (0%) 40Mi (1%) 0 (0%) 3h41m
kube-system kube-flannel-ds-amd64-2kc56 100m (5%) 100m (5%) 50Mi (1%) 50Mi (1%) 4h32m
kube-system kube-proxy-kn5dh 0 (0%) 0 (0%) 0 (0%) 0 (0%) 4h32m
kube-system sealed-secrets-controller-64ff79df68-rxjng 10m (0%) 0 (0%) 15Mi (0%) 0 (0%) 4h3m
longhorn-system csi-attacher-78bf9b9898-dw9cb 0 (0%) 0 (0%) 0 (0%) 0 (0%) 3h56m
longhorn-system csi-resizer-586665f745-rc6bx 0 (0%) 0 (0%) 0 (0%) 0 (0%) 3h56m
longhorn-system engine-image-ei-e10d6bf5-t94qm 0 (0%) 0 (0%) 0 (0%) 0 (0%) 3h56m
longhorn-system instance-manager-e-ea2533eb 250m (12%) 0 (0%) 0 (0%) 0 (0%) 37m
longhorn-system instance-manager-r-e1a5c938 250m (12%) 0 (0%) 0 (0%) 0 (0%) 37m
longhorn-system longhorn-csi-plugin-tnljd 0 (0%) 0 (0%) 0 (0%) 0 (0%) 3h56m
longhorn-system longhorn-manager-h8q6p 300m (15%) 0 (0%) 300Mi (7%) 0 (0%) 3h57m
metallb-system controller-787d74cc8f-6shz8 10m (0%) 100m (5%) 20Mi (0%) 100Mi (2%) 4h31m
metallb-system speaker-hjtmb 20m (1%) 100m (5%) 30Mi (0%) 100Mi (2%) 4h31m
minio-operator-ns minio-operator-746b575b4f-lclm4 10m (0%) 0 (0%) 15Mi (0%) 0 (0%) 3h38m
Allocated resources:
```
username_1: Thanks @username_0 , the last support bundle has it enabled. What's the CPU utilization on the nodes? You can check it using `kubectl top nodes`. From the log it still looks like the engine cannot keep up with the requests.
username_0: This cluster is very minimal and so I don't have what I need to run `kubectl top nodes` running on it. I've connected to the two two nodes and grabbed snapshots of htop, and they're running around 50% CPU while both the 20GB transfer and rebuilds are in progress.
These are bare-metal clusters, and this one is a bit out of date. I rebuilt the kubernetes cluster, but not the base. Tomorrow, I'm going to fully rebuild the clusters on latest versions and I'll bring up 1.0 to see how it fares.
```
[0/1417]
1 [|||||||||||||||||||||||||||| 49.7%] Tasks: 108, 745 thr; 2 running
2 [|||||||||||||||||||||||||||||| 51.9%] Load average: 1.00 2.13 5.82
Mem[|||||||||||||||||||||||||||||||||||||||||||||1.33G/3.77G] Uptime: 05:29:26
Swp[ 0K/0K]
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
3106 root 20 0 262M 132M 31736 S 9.1 3.4 18:56.24 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kub
2559 root 20 0 164M 74984 28732 S 4.5 1.9 10:50.50 /usr/bin/containerd
14980 root 20 0 2480 2232 976 R 4.5 0.1 0:00.45 htop
11064 root 20 0 135M 56472 20900 S 3.9 1.4 5:42.67 longhorn-manager -d daemon --engine-image longhornio/longhorn-engine:
18718 root 20 0 164M 74984 28732 S 3.9 1.9 0:15.23 /usr/bin/containerd
13986 root 20 0 839M 19832 13972 S 3.2 0.5 0:18.45 /engine-binaries/longhornio-longhorn-engine-v0.8.0/longhorn controlle
3125 root 20 0 262M 132M 31736 S 3.2 3.4 0:50.56 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kub
3121 root 20 0 262M 132M 31736 S 2.6 3.4 1:55.09 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kub
```
```
[0/1431]
1 [|||||||||||||||||||||||||||||||||| 60.2%] Tasks: 104, 633 thr, 63 kthr; 2 running
2 [||||||||||||||||||||||||||||||| 55.0%] Load average: 1.62 3.29 4.37
Mem[|||||||||||||||||||||||||||||||||||||||||| 1.19G/3.77G] Uptime: 05:30:01
Swp[ 0K/0K]
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
1310 root 20 0 839M 25580 13896 S 29.3 0.6 4:10.21 /host/var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v0.
2932 root 20 0 262M 126M 27636 S 8.7 3.3 19:55.82 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kub
25914 root 20 0 839M 25580 13896 S 5.6 0.6 0:27.00 /host/var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v0.
1311 root 20 0 839M 25580 13896 S 4.4 0.6 0:36.08 /host/var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v0.
32211 root 20 0 2392 1944 960 R 4.4 0.0 0:00.35 htop
1990 root 20 0 839M 25580 13896 S 4.4 0.6 0:30.84 /host/var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v0.
2010 root 20 0 839M 25580 13896 S 3.7 0.6 0:31.11 /host/var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v0.
19076 root 20 0 108M 12596 3036 S 3.7 0.3 1:09.02 containerd-shim -namespace k8s.io -workdir /var/lib/containerd/io.con
1313 root 20 0 839M 25580 13896 S 3.1 0.6 0:34.09 /host/var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v0.
1994 root 20 0 839M 25580 13896 S 3.1 0.6 0:32.50 /host/var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v0.
2941 root 20 0 262M 126M 27636 S 2.5 3.3 2:22.08 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-ku
```
username_1: The load average is a bit disturbing here:
```
Load average: 1.00 2.13 5.82
Load average: 1.62 3.29 4.37
```
The load average for the last 5 minutes and 15 minutes exceeds the CPU numbers (which I assume is 2). It sounds like a CPU issue.
If it's two nodes cluster, you can change the replica count to 2 instead of 3, since the additional replica won't be useful if it landed on the same node. `hard anti-affinity` is enabled by default in v1.0.0.
username_0: @username_1 It's 3 leaders and 5 worker nodes. The load numbers don't have anything to do with CPU starvation, because these machines never peg the CPUs. I think it's mostly kernel contention due to some process accounting that should have been turned off for containerd. I'm going to rebuild these machines today, which will solve that problem and run them again.
username_0: @username_1 good news! I rebuilt the base, re-imaging all the machines, and brought up the exact same cluster (with Longhorn 0.8) and this time I've got no failures. The write load is even bigger than it was before (I'm sustaining 10-11 MB/s of S3 object storage on this cluster instead of the 7MB/s I was getting before), and there are no failures.
This time around, the process accounting if fixed, but I don't think that's the problem, because I had these same machines with the process accounting fix before experiencing the same problem.
I'm also on a newer kernel, which might be the case. I'm also including an htop snapshot like above, because I've brought some of these machines to 20 load and they're still surviving, as they should:
P.S. This is 0.8 *wihtout* the guaranteed CPU assignment.
```
[0/0]
1 [|||||||||||||||||||||||||||||||||||||||||||||||||||||||99.4%] Tasks: 111, 749 thr; 2 running
2 [|||||||||||||||||||||||||||||||||||||||||||||||||||||||98.8%] Load average: 21.91 21.34 16.79
Mem[|||||||||||||||||||||||||||||||||||||||||||||||||1.37G/3.76G] Uptime: 01:54:55
Swp[ 0K/0K]
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
22201 root 20 0 415M 331M 36272 D 97.9 8.6 20:18.92 minio server https://edt-{0...3}.edt.devcluster.ecedge.net/export
26575 root 20 0 415M 331M 36272 D 25.2 8.6 1:11.11 minio server https://edt-{0...3}.edt.devcluster.ecedge.net/export
23755 root 20 0 415M 331M 36272 R 11.4 8.6 1:20.51 minio server https://edt-{0...3}.edt.devcluster.ecedge.net/export
23628 root 20 0 415M 331M 36272 R 9.6 8.6 1:18.33 minio server https://edt-{0...3}.edt.devcluster.ecedge.net/export
18991 root 20 0 1199M 61304 13540 S 7.2 1.6 1:56.21 /engine-binaries/longhornio-longhorn-engine-v0.8.0/longhorn controller pvc-ab7
23478 root 20 0 415M 331M 36272 D 6.6 8.6 0:59.65 minio server https://edt-{0...3}.edt.devcluster.ecedge.net/export
3039 root 20 0 253M 109M 26404 S 4.8 2.9 4:56.45 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-kubelet.conf
29107 root 20 0 5148 3944 1000 R 4.2 0.1 0:01.69 htop
22229 root 20 0 415M 331M 36272 S 3.6 8.6 1:21.70 minio server https://edt-{0...3}.edt.devcluster.ecedge.net/export
23827 root 20 0 415M 331M 36272 S 3.0 8.6 1:16.68 minio server https://edt-{0...3}.edt.devcluster.ecedge.net/export
8696 root 20 0 1137M 10240 3304 R 3.0 0.3 0:58.15 tgtd -f
18902 root 20 0 1255M 58284 13704 S 2.4 1.5 0:42.13 /host/var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v0.8.0/longh
2726 root 20 0 226M 78972 7652 S 1.8 2.0 8:43.72 /usr/bin/containerd
19346 root 20 0 1199M 61304 13540 S 1.8 1.6 0:07.22 /engine-binaries/longhornio-longhorn-engine-v0.8.0/longhorn controller pvc-ab7
24649 root 20 0 1199M 61304 13540 S 1.8 1.6 0:07.91 /engine-binaries/longhornio-longhorn-engine-v0.8.0/longhorn controller pvc-ab7
23476 root 20 0 415M 331M 36272 D 1.8 8.6 1:09.09 minio server https://edt-{0...3}.edt.devcluster.ecedge.net/export
22231 root 20 0 415M 331M 36272 S 1.8 8.6 1:10.82 minio server https://edt-{0...3}.edt.devcluster.ecedge.net/export
22228 root 20 0 415M 331M 36272 R 1.2 8.6 0:23.07 minio server https://edt-{0...3}.edt.devcluster.ecedge.net/export
```
Status: Issue closed
username_0: I spoke too soon. After transferring about 27GB (first transfer I stopped at 17GB and then I restarted and got 10GB into the second transfer), I hit my first replica failure. I'm attaching the support bundle here:
[longhorn-support-bundle_10aadefb-36e0-4534-a6b1-d94da01ce37f_2020-06-04T10-33-47Z.zip](https://github.com/longhorn/longhorn/files/4729395/longhorn-support-bundle_10aadefb-36e0-4534-a6b1-d94da01ce37f_2020-06-04T10-33-47Z.zip)
username_0: **Describe the bug**
I have a relatively large number of replica failures during sustained write operations (measured in minutes or tens of minutes)
**To Reproduce**
Steps to reproduce the behavior:
1. Run a MinIO cluster using minio operator
2. wait for cluster to come up
3. Using the mc client (`mc cp *files* host/bucket`), try to send around 20GB, broken into files of around 100MB each
4. See replica failure
**Expected behavior**
Replicas should stay up
**Log**
```
root@instance-manager-r-cc03c099:/var/log/instances# cat pvc-04a60ec8-16f3-400d-841d-6f2911e23630-r-ca01d6ee.log
time="2020-05-06T15:38:22Z" level=info msg="Creating volume /host/var/lib/longhorn/replicas/pvc-04a60ec8-16f3-400d-841d-6f2911e23630-25d075e0, size 42949672960/512"
time="2020-05-06T15:38:22Z" level=info msg="Listening on data server 0.0.0.0:10091"
time="2020-05-06T15:38:22Z" level=info msg="Listening on sync agent server 0.0.0.0:10092"
time="2020-05-06T15:38:22Z" level=info msg="Listening on gRPC Replica server 0.0.0.0:10090"
time="2020-05-06T15:38:22Z" level=info msg="Listening on sync 0.0.0.0:10092"
time="2020-05-06T15:38:25Z" level=info msg="New connection from: 10.244.12.196:50926"
time="2020-05-06T15:38:25Z" level=info msg="Opening volume /host/var/lib/longhorn/replicas/pvc-04a60ec8-16f3-400d-841d-6f2911e23630-25d075e0, size 42949672960/512"
time="2020-05-06T15:48:58Z" level=info msg="Closing volume"
time="2020-05-06T15:48:59Z" level=warning msg="Received signal interrupt to shutdown"
time="2020-05-06T15:48:59Z" level=warning msg="Starting to execute registered shutdown func github.com/longhorn/longhorn-engine/app/cmd.startReplica.func4"
time="2020-05-06T15:49:01Z" level=info msg="Listening on gRPC Replica server 0.0.0.0:10090"
time="2020-05-06T15:49:01Z" level=info msg="Listening on data server 0.0.0.0:10091"
time="2020-05-06T15:49:01Z" level=info msg="Listening on sync agent server 0.0.0.0:10092"
time="2020-05-06T15:49:01Z" level=info msg="Listening on sync 0.0.0.0:10092"
time="2020-05-06T15:49:04Z" level=info msg="New connection from: 10.244.10.198:46818"
time="2020-05-06T15:49:04Z" level=info msg="Opening volume /host/var/lib/longhorn/replicas/pvc-04a60ec8-16f3-400d-841d-6f2911e23630-25d075e0, size 42949672960/512"
time="2020-05-06T21:08:10Z" level=info msg="Replica server starts to snapshot [1a6e785c-e0e8-4f4b-b929-e66b11f6a88e] volume, user created false, created time 2020-05-06T21:08:10Z, labels map[]"
time="2020-05-06T21:08:10Z" level=info msg="Sending file volume-snap-1a6e785c-e0e8-4f4b-b929-e66b11f6a88e.img to 10.244.11.226:10259"
time="2020-05-06T21:08:10Z" level=info msg="source file size: 42949672960, setting up directIo: true"
time="2020-05-06T21:40:07Z" level=warning msg="Received signal interrupt to shutdown"
time="2020-05-06T21:40:07Z" level=warning msg="Starting to execute registered shutdown func github.com/longhorn/longhorn-engine/app/cmd.startReplica.func4"
```
**Environment:**
- Longhorn version: 0.8.0
- Kubernetes version: 1.16.0
- Node OS type and version: Alpine Linux 3.10
**Additional context**
Add any other context about the problem here.
username_0: The machine which had the replica failure doesn't even have a very high load. (And yes, these are dual-core machines)
```
[0/0]
1 [||||||||||||| 22.1%] Tasks: 78, 498 thr; 1 running
2 [|||||||||||||| 23.4%] Load average: 1.12 2.56 2.33
Mem[||||||||||||||||||||||||||||||||||||||||||||1.13G/3.76G] Uptime: 02:20:21
Swp[ 0K/0K]
PID USER PRI NI VIRT RES SHR S CPU% MEM% TIME+ Command
3039 root 20 0 252M 105M 25084 S 5.2 2.7 5:31.92 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-k
11496 root 20 0 1442M 89440 13752 S 2.6 2.3 2:49.69 /host/var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v
11558 root 20 0 1327M 69592 13560 S 2.0 1.8 2:50.09 /host/var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v
2730 root 20 0 158M 88584 8152 S 2.6 2.2 8:27.42 /usr/bin/containerd
32006 root 20 0 2988 2804 992 R 3.3 0.1 0:00.56 htop
1456 root 20 0 128M 25180 17356 S 1.3 0.6 0:41.76 /speaker --port=7472 --config=config
7818 root 20 0 111M 14764 4900 S 0.0 0.4 0:32.02 /usr/bin/containerd-shim-runc-v1 -namespace k8s.io -id 3cda69449d7b
3064 root 20 0 252M 105M 25084 S 1.3 2.7 0:45.43 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-k
3059 root 20 0 252M 105M 25084 S 0.7 2.7 0:45.29 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-k
3053 root 20 0 252M 105M 25084 S 0.7 2.7 0:39.05 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-k
28211 root 20 0 1327M 69592 13560 S 0.0 1.8 0:00.67 /host/var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v
1480 root 20 0 128M 25180 17356 S 0.0 0.6 0:06.37 /speaker --port=7472 --config=config
14697 root 20 0 1442M 89440 13752 S 0.0 2.3 0:07.78 /host/var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v
9356 root 20 0 1327M 69592 13560 S 0.7 1.8 0:02.04 /host/var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v
11498 root 20 0 1442M 89440 13752 S 0.7 2.3 0:37.23 /host/var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v
11825 root 20 0 1442M 89440 13752 S 0.0 2.3 0:07.78 /host/var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v
7010 999 20 0 1067M 383M 33276 S 1.3 10.0 1:56.64 argocd-application-controller --status-processors 4 --operation-pro
7967 root 20 0 158M 88584 8152 S 2.0 2.2 0:28.80 /usr/bin/containerd
11535 root 20 0 1442M 89440 13752 S 1.3 2.3 0:08.75 /host/var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v
6519 root 20 0 135M 52616 19628 S 0.7 1.3 1:25.82 longhorn-manager -d daemon --engine-image longhornio/longhorn-engin
11571 root 20 0 1327M 69592 13560 S 0.7 1.8 0:04.96 /host/var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v
3052 root 20 0 252M 105M 25084 S 2.0 2.7 0:47.58 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-k
11867 root 20 0 1442M 89440 13752 S 0.0 2.3 0:06.54 /host/var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v
7871 root 20 0 1120M 17740 7732 S 0.7 0.5 0:13.82 longhorn-instance-manager --debug daemon --listen 0.0.0.0:8500
7870 root 20 0 1120M 17740 7732 S 0.7 0.5 0:27.98 longhorn-instance-manager --debug daemon --listen 0.0.0.0:8500
3046 root 20 0 252M 105M 25084 S 0.7 2.7 0:27.34 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-k
11559 root 20 0 1327M 69592 13560 S 0.7 1.8 0:36.67 /host/var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v
24792 root 20 0 158M 88584 8152 S 0.0 2.2 0:15.48 /usr/bin/containerd
7823 root 20 0 111M 14764 4900 S 0.0 0.4 0:02.40 /usr/bin/containerd-shim-runc-v1 -namespace k8s.io -id 3cda69449d7b
14600 root 20 0 1327M 69592 13560 S 0.0 1.8 0:07.23 /host/var/lib/longhorn/engine-binaries/longhornio-longhorn-engine-v
3483 root 20 0 252M 105M 25084 S 0.7 2.7 0:40.27 /usr/bin/kubelet --bootstrap-kubeconfig=/etc/kubernetes/bootstrap-k
1472 root 20 0 128M 25180 17356 S 0.0 0.6 0:06.77 /speaker --port=7472 --config=config
16227 root 20 0 4380 3540 3000 S 0.0 0.1 0:00.26 sshd: root@pts/0
1479 root 20 0 128M 25180 17356 S 0.0 0.6 0:05.83 /speaker --port=7472 --config=config
3114 root 20 0 158M 88584 8152 S 0.0 2.2 0:57.97 /usr/bin/containerd
6686 root 20 0 111M 14384 4892 S 0.7 0.4 0:16.87 /usr/bin/containerd-shim-runc-v1 -namespace k8s.io -id a9c5cda99abc
1475 root 20 0 128M 25180 17356 S 0.7 0.6 0:05.98 /speaker --port=7472 --config=config
```
username_0: After lunch, I'm going to upgrade this cluster to 0.8.1 and then to 1.0 and rerun this test.
username_0: Final support bundle of 0.8, I had a total of four replica failures across three of my five volumes
[longhorn-support-bundle_10aadefb-36e0-4534-a6b1-d94da01ce37f_2020-06-04T11-17-19Z.zip](https://github.com/longhorn/longhorn/files/4729590/longhorn-support-bundle_10aadefb-36e0-4534-a6b1-d94da01ce37f_2020-06-04T11-17-19Z.zip)
username_0: I finally get everything up to 1.0 today, and I started up the test only to get my first failures about 12GB into the transfer. Under 1.0, I'm seeing 8MB/s of S3 throughput on the cluster.
[longhorn-support-bundle_10aadefb-36e0-4534-a6b1-d94da01ce37f_2020-06-04T16-19-42Z.zip](https://github.com/longhorn/longhorn/files/4731379/longhorn-support-bundle_10aadefb-36e0-4534-a6b1-d94da01ce37f_2020-06-04T16-19-42Z.zip)
username_0: This is with 0.25 (250m) CPU requests
username_0: And another bundle after another 10GB or so:
[longhorn-support-bundle_10aadefb-36e0-4534-a6b1-d94da01ce37f_2020-06-04T18-27-50Z.zip](https://github.com/longhorn/longhorn/files/4732059/longhorn-support-bundle_10aadefb-36e0-4534-a6b1-d94da01ce37f_2020-06-04T18-27-50Z.zip)
username_1: @username_0 A few observation from the support bundle:
1. I might be looking into the wrong support bundle (or it might be a Longhorn bug), but I didn't see the CPU requests were set on the pods, though the setting indeed specified `0.25`.
2. And there are only 4 of 5 nodes shows up in the log, seems dev05 has disk pressure per reporting of Longhorn (but not reported Kubernetes)
```
Ready:
type: Ready
status: "False"
lastprobetime: ""
lasttransitiontime: "2020-06-04T18:13:46Z"
reason: KubernetesNodePressure
message: 'Kubernetes node dev05 has pressure: KubeletHasDiskPressure, kubelet
has disk pressure'
```
And all the pods running on the dev05 failed to generate the log.
3. I still think the CPU is likely the root cause here. Longhorn engine runs as a userspace program, it doesn't have higher priority over other processes (maybe it should). The process didn't peg the CPU but if the load is high enough to starve all the processes, then the Longhorn engine will get impacted and delayed the response, thus resulting in the replica disconnection. Another possible reason will be the network. The network can be too slow between the nodes to sustain the high bandwidth. The load average for the failed node is `Load average: 1.12 2.56 2.33 `, which means the workload is more than 2 cores can handle at the time.
username_0: @username_1 I've pulled the YAML on the pods, and they're showing the CPU request, so there might be something off with the logs.
I'm going to load in prometheus so I can get a better look at what is going on during a failure, and rerun the tests. I've watched the nodes live, I don't think it's flat out CPU starvation. I think it's much more likely a problem with kernel overhead. These are not huge machines, and I think that the number of forked processes for communicating with the binary is contributing. (the pid wraps around every 30 seconds or so, which just seems crazy to me). Hopefully the switch to GRPC will help here.
After that, I'm going to swap out the hardware for something much beefier... about 3x the performance of these machines, which are old, 10x the disk space. Once I've done that, I'll run these tests again.
I understand your point about CPU starvation, but I'd like to ask you to think about what that means for Longhorn in general (and machines running at capacity). Personally, I think that I'd much rather see the write speeds drop than have disk failure under load.
username_1: @username_0 understand. That would require automatically throttling when CPU is a problem. In fact you remind me of one thing, can you check and reduce `node.session.queue_depth` in ` /etc/iscsi/iscsid.conf` on each node? It will result in lower bandwidth of course, but it will limit the request to the backend, thus might fix the issue.
username_0: I figured it out! The high load was interfering with the NFS mount, and because on Linux write operations to NFS never fail, they just hang, and the freezing filesystem operations caused Longhorn on those nodes to lock up, causing replica failures.
I actually got pretty lucky here, you mentioned disk pressure, so I SSH'ed into the box to check out the space on the filesystem, but `df` just hung the shell. A quick look into the kernel logs showed NFS not responding messages.
From there, I switched to an S3 backup target and re-ran the tests. 30+ GB into transfer tests and no issues whatsoever.
Status: Issue closed
username_1: hmm, normally the NFS server/client shouldn't have able to interfere with Longhorn's data path. They might cause a delay in the disk information (which probably answered the question of why Longhorn's node update is slower than the Kubernetes's), but data plane is operating separately.
username_0: I ran the test again with Prometheus installed in the cluster (restoring my NFS settings), and I dumped the output of `dmesg` before the test, during, and again after (appending to the same file each time). The cluster never went about 60% CPU utilization. The failure happened on dev02, where the machine was consistently at about 90% CPU utilization. The CPU pegged to 100% on dev04, but that's not where the failure happened.


[longhorn-support-bundle_10aadefb-36e0-4534-a6b1-d94da01ce37f_2020-06-05T12-13-30Z.zip](https://github.com/longhorn/longhorn/files/4736041/longhorn-support-bundle_10aadefb-36e0-4534-a6b1-d94da01ce37f_2020-06-05T12-13-30Z.zip)
[dmesg.zip](https://github.com/longhorn/longhorn/files/4736054/dmesg.zip)
username_0: Also, don't be fooled by the earlier error messages in dmesg.log. There don't seem to be any NFS-related errors on dev02
username_0: I ran the test again, after having switched back to an S3 backup target. I may have been wrong about the mecahanism, but I am not wrong about the culprit. With an S3 backup target, I don't have unexplained replica failures under load. Everything works as it should.
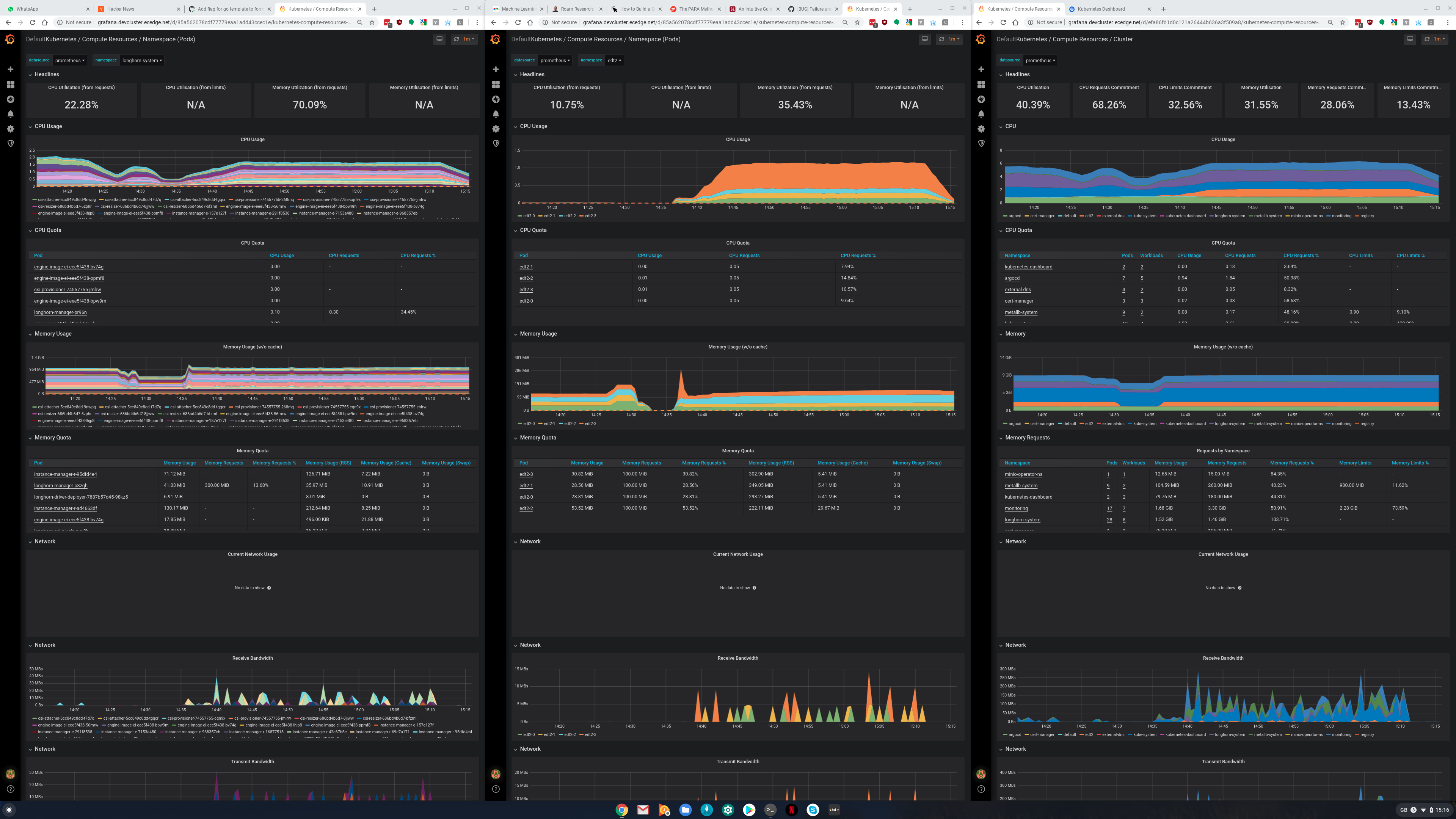

[dmesg.zip](https://github.com/longhorn/longhorn/files/4736320/dmesg.zip)
username_0: One last set of screenshots, the 3 hour view showing both the original transfer with failure and the successful transfer. The failure happens at about 13:57-13:58, you can see in the dev02 Disk I/O graph. sda io time splits from sda write patterns, with write suddenly dropping, and io time going back up again.


username_1: Thanks @username_0 for such a detailed explanation. I am surprised when I saw in the S3 case, CPU utilization is near 100% and the load is above 15, but it's still working fine for you. There must be something I don't fully understand yet. Given the evidence, I am sure the culprit is the NFS server as you said. I just hope I can make more sense of this.
Thanks again for digging into this issue! |
graphql-dotnet/graphql-client | 491093360 | Title: how do you get the fully rendered query?
Question:
username_0: Hi folks, I'm debugging a feature and I'd like to be able to grab the query as it's been rendered by this line of code
`response = client.Execute(query, operationName, variables);`
Having a query with the data all filled out by the code removes guess work in case of error. Is there a way to do this? It would be ideal to be able to see the query before it's sent in a debugging context. Thanks folks :)
Status: Issue closed
Answers:
username_1: This is not related to the client library |
open-policy-agent/kube-mgmt | 843145995 | Title: Availability of metrics for kube-mgmt
Question:
username_0: This is a question, not an issue.
I am trying to monitor the OPA running on my K8s cluster via prometheus and grafana. Can you please tell me if there are metrics for kube-mgmt? Are they exposed on the metrics endpoint to be scraped by Prometheus?
Answers:
username_1: Hi @username_0, let me better understand, do you mean you are already aware of the `/metrics` endpoint exposed by open-policy-agent and would like to know if kube-mgmt is exposing its own metrics at some endpoint or via the same endpoint in some way?
username_0: Yes, I am aware of the /metrics endpoint at which OPA exposes its metrics. I want to know if kube-mgmt also exposes its own metrics on the same endpoint or some endpoint. Please clarify on this.
username_1: AFAIK there is none and after a quick search, I couldn't find any reference to metrics being exposed by kube-mgmt directly. Maybe @username_2 could help.
What kind of metrics would you be interested in kube-mgmt exposing?
username_2: kube-mgmt doesn't expose a /metrics endpoint because it's essentially stateless and just watches configmaps and other kubernetes resources and replicates them into OPA. It doesn't even expose an HTTP server today.
Status: Issue closed
username_1: That was my understanding and expectation, thanks @username_2.
@username_0 I think we can close this issue, if you have any suggestion about metrics you'd like to have exposed by kube-mgmt feel free to write them down here.
username_0: Thanks for the clarification @username_1 and @username_2 . |
zhuhanyi/baoxian | 727858601 | Title: 宜利挑保险:为何有老人家反对子女为他们买保险?
Question:
username_0: # 为何有老人家反对子女为他们买保险?
1. 年轻时听多了保险骗人,这不赔那不赔的故事,对保险的反感深入意识。实际上2019年保司理赔率在97%以上,比如国寿赔付率为 99.40%,默默无闻的国宝人寿理赔率为 99.57%。
2. 觉得身体硬朗,不会得什么病。这显然是过度自信,国家癌症中心发布的《2019年全国癌症报告》显示:恶性肿瘤发病率随年龄增加逐渐上升,到80岁年龄组达到发病高峰。还有老人行动不便导致的意外摔倒等。
3. 不想让子女破费。这个想法充满了爱,但好心却可能增加子女的负担,保费是可控可负担的,而如果发生意外,生场大病,支出是不可控的,或超出子女能力范围。本来一年几千块的支出,到时可能变成几十万。
所以老人家们,主动提出让子女帮你买保险,才是真爱。
宜利挑保险,挑出好保险。 |
doctrine/cache | 354771280 | Title: getFunctionMock of PHPMock does not work anymore
Question:
username_0: When using `\phpmock\phpunit\PHPMock` trait `$this->getFunctionMock('\Doctrine\Common\Cache', 'apcu_fetch')` cannot mock `apcu_fetch` anymore because of function import in https://github.com/doctrine/cache/blob/d768d58baee9a4862ca783840eca1b9add7a7f57/lib/Doctrine/Common/Cache/ApcuCache.php#L9
Status: Issue closed
Answers:
username_1: This is expected and wanted: you are mocking details inside a third-party component, don't do that.
If you need to mock something, mock the `Cache` interface, and rely on that.
Closing as `invalid`.
username_2: This is also part of [Doctrine Coding Standard](https://github.com/doctrine/coding-standard). |
actor-framework/actor-framework | 42144726 | Title: Complete quoting for parameters of some CMake commands
Question:
username_0: Some parameters (like "[${DOXYGEN_EXECUTABLE}](https://github.com/actor-framework/actor-framework/blob/8de46283fd3037a92b797b2572aea3de6bed77a3/CMakeLists.txt#L194)" and "[${CMAKE_CURRENT_SOURCE_DIR}](https://github.com/actor-framework/actor-framework/blob/e1643bbb13309e5db95fc0c12d49feaf7e4b6c61/libcaf_core/CMakeLists.txt#L4)") are passed to CMake commands in your build scripts without enclosing them by quotation marks. I see that these places will result in build difficulties if the contents of the used variables will contain special characters like semicolons.
I would recommend to apply [advices from a wiki article](http://cmake.org/Wiki/CMake/Language_Syntax#CMake_splits_arguments_unless_you_use_quotation_marks_or_escapes. "CMake splits arguments unless you use quotation marks or escapes.").
Answers:
username_1: I'll close this since there wasn't any activity on this recently.
Status: Issue closed
|
pagekit/pagekit | 52625107 | Title: RuntimeException: Failed to start the session because headers have already been sent by .../app/app.php" at line 12.
Question:
username_0: After installation I receive the following statement using php 5.5 and Apache.
Does someone know how to handle this?
I am trying to evaluate pagekit as an alternative to my wordpress photographers webpage.
RuntimeException: Failed to start the session because headers have already been sent by "/var/www/vhosts/slyzza.de/pagekit.slyzza.de/app/app.php" at line 12.
It seems there are problems with the time setting in the app.php..
Answers:
username_1: We released the [Pagekit Beta](http://www.pagekit.com/blog/2015/09/10/pagekit-beta-released) today. I close this issue because the code base completely changed. Please open a new issue if it still exists.
Status: Issue closed
|
dotnet/aspnetcore | 877008542 | Title: Add default global using to Microsoft.NET.Sdk.Web for .NET 6
Question:
username_0: This is one of the bullet points from #30580. A long list of mostly the same `using` statements at the top of every ASP.NET Core is intimidating and ultimately unhelpful noise for the most point.
We should consider a set of name spaces that will be imported by default into all cs file in `net6.0` projects targeting `Microsoft.NET.Sdk.Web`.
Here's a strawman proposal for the possible default namespaces to use:
```c#
global using System;
global using System.Net.Http;
global using System.Net.Http.Json;
global using System.Threading.Tasks;
global using System.Collections.Generic;
global using System.Linq;
global using System.Threading.Tasks;
global using Microsoft.AspNetCore.Builder;
global using Microsoft.AspNetCore.Http;
global using Microsoft.AspNetCore.Mvc;
global using Microsoft.AspNetCore.Hosting;
global using Microsoft.AspNetCore.Routing;
global using Microsoft.EntityFrameworkCore;
global using Microsoft.Extensions.DependencyInjection;
global using Microsoft.Extensions.Hosting;
global using Microsoft.Extensions.Logging;
global using Microsoft.Extensions.Configuration;
```
It's kinda crazy seeing .cs files without usings but I [like it](https://github.com/username_2/CommunityStandUpMinimalAPI/blob/5f8044f9a6973a5bec8b200bf02c253d01c93028/Sample/TodoApi.cs) a lot.
We of course do need to be careful not to overdo this and introduce a bunch of conflicts or make intellisense too confusing. It's possible the strawman proposal is already a bit much, but I need to play with it more to get a good feeling for how convenient and/or annoying it is.
Answers:
username_1: `global using System.Linq;` 🙄
Also `global using Microsoft.EntityFrameworkCore;` could that be added to subpackages in some way instead? So its included *if* you add a provider to your project rather than by default if you are going another way (which could even be EF6 since that now runs on .NET6.0 and I assume most of the types will conflict and lead to much confusion)
username_2: Those shouldn't be in the ASP.NET one.
username_2: cc @username_4
username_3: Do these play well if a file already includes these usings?
username_2: Not yet (https://github.com/username_2/CommunityStandUpMinimalAPI/blob/386a0c1fef756e55a999429b8f8cba400ff3f4ca/Sample/Sample.csproj#L6).
I think it's interesting to discuss whether we want this in each project on on by default. Assuming we can stop the warning, I think we'd want a subset of namespaces in there by default.
username_4: Are we attempting to optimize for the top-level statements file or all files in the project? Today I feel the most friction is the amount of namespaces needed just to bootstrap a basic app in its `Program`/`Startup` classes and of course over time more instances of those will become merged into the top-level statements file using the minimal hosting API.
We also need to consider how this impacts existing apps that are simply used with the new SDK or just updated to narget `net6.0` without necessarily changing to use top-level statements or the minimal hosting API.
username_0: I would like to optimize for all files in a common ASP.NET Core project. I don't think there's a way to limit it to certain files.
username_5: Triage: We should consider having an msbuild property you can put in your csproj to disable the default usings.
username_6: In the meeting we also discussed the idea of an extensibility model. There would be a mechanism in the SDK, likely a well known item group, that specifies additional global usings which will be added by the SDK to the project's obj directory. This way, additional packages, such as EF can opt into adding global usings to a project directory when the package is referenced by including a props/target file.
username_6: I've added a POC for this at https://github.com/dotnet/sdk/pull/18459. To see how this looks in a Minimal API web app, checkout https://github.com/username_6/GlobalUsings.
One of the annoying things is that the global using now conflicts with other generated cs files and create these warnings:
```
C:\gh\tp\GlobalUsing\App\obj\Debug\net6.0\.NETCoreApp,Version=v6.0.AssemblyAttributes.cs(2,7): warning CS0105: The using directive for 'System' appeared previously in this namespace [C:\gh\tp\GlobalUsing\App\App.csproj]
C:\gh\tp\GlobalUsing\App\obj\Debug\net6.0\App.AssemblyInfo.cs(10,7): warning CS0105: The using directive for 'System' appeared previously in this namespace [C:\gh\tp\GlobalUsing\App\App.csproj]
```
I'm not sure the best way to get rid of these warnings. I'm not a fan of ignoring all CS0105 warnings.
username_2: It's going to be fixed by the compiler.
username_6: Also, I'm a little concerned with the serviceability of this feature. After we ship the first set of global usings, any addition or removal of using statements will be breaking right?
username_2: Removal is adding isn't
username_6: Adding could introduce type conflicts no?
username_2: Yes that is a good point, though there's [guidance](https://docs.microsoft.com/en-us/dotnet/standard/design-guidelines/names-of-namespaces#namespaces-and-type-name-conflicts) on how to avoid that generally. This could make the problem worse.
username_4: As discussed today in sync, any changes in the future should be behind a TFM version check so that simply getting a new SDK would not introduce issues. New platform (TFM) versions for apps typically involve changes and caveats beyond the TFM change itself which is why there are migration docs for each version change and a change to default global usings would be one such change that's called out, with mitigations detailed such as disabling the feature via an MSBuild property, etc.
username_2: Current list of usings:
```C#
global using global::System;
global using global::System.Collections.Generic;
global using global::System.Linq;
global using global::System.Net.Http;
global using global::System.Net.Http.Json;
global using global::System.Threading.Tasks;
global using global::Microsoft.AspNetCore.Builder;
global using global::Microsoft.AspNetCore.Hosting;
global using global::Microsoft.AspNetCore.Http;
global using global::Microsoft.AspNetCore.Mvc;
global using global::Microsoft.AspNetCore.Routing;
global using global::Microsoft.Extensions.Configuration;
global using global::Microsoft.Extensions.DependencyInjection;
global using global::Microsoft.Extensions.Hosting;
global using global::Microsoft.Extensions.Logging;
```
username_7: I suggest making this set an `ItemGroup` in MSBuild so that people can use `Remove` to remove individual items if they cause type conflicts. Visual Basic has this concept (though as command line arguments, instead of in source), and they represent them as Items, with a property for a global switch.
See https://github.com/dotnet/sdk/blob/cfc3463578c94dba51115d8fc218a4a7d96281c2/src/Tasks/Microsoft.NET.Build.Tasks/targets/Microsoft.NET.Sdk.VisualBasic.targets#L13-L39
username_6: For API review:
Current list of global usings:
```c#
//Sdk.Web
global using global::System;
global using global::System.Collections.Generic;
global using global::System.Linq;
global using global::System.Net.Http;
global using global::System.Net.Http.Json;
global using global::Microsoft.AspNetCore.Builder;
global using global::Microsoft.AspNetCore.Hosting;
global using global::Microsoft.AspNetCore.Http;
global using global::Microsoft.AspNetCore.Routing;
global using global::Microsoft.Extensions.Configuration;
global using global::Microsoft.Extensions.DependencyInjection;
global using global::Microsoft.Extensions.Hosting;
global using global::Microsoft.Extensions.Logging;
```
```c#
//Sdk.Worker
global using global::Microsoft.Extensions.Configuration;
global using global::Microsoft.Extensions.DependencyInjection;
global using global::Microsoft.Extensions.Hosting;
global using global::Microsoft.Extensions.Logging;
```
These usings will be generated by the .NET SDK in the obj folder by default for C# projects > net6.0. This feature can be disabled completely via `EnableDefaultGlobalUsings` or selectively via `EnableDefaultGlobalUsings_Web`/`EnableDefaultGlobalUsings_Worker`.
Status: Issue closed
|
google/re2 | 599298302 | Title: arg_test failing under glibc
Question:
username_0: ```
FAILED: re2_arg_test
: && /home/mangix/devstuff/openwrt/staging_dir/toolchain-mipsel_24kc_gcc-9.3.0_glibc/bin/g++-libcxx -Os -pipe -mno-branch-likely -mips32r2 -mtune=24kc -fno-caller-saves -fno-plt -fhonour-copts -Wno-error=unused-but-set-variable -Wno-error=unused-result -msoft-float -mips16 -minterlink-mips16 -ffile-prefix-map=/home/mangix/devstuff/openwrt/build_dir/target-mipsel_24kc_glibc/re2-2020-04-01=re2-2020-04-01 -Wformat -Werror=format-security -D_FORTIFY_SOURCE=1 -Wl,-z,now -Wl,-z,relro -std=c++2a -DNDEBUG -L/home/mangix/devstuff/openwrt/staging_dir/target-mipsel_24kc_glibc/usr/lib -L/home/mangix/devstuff/openwrt/staging_dir/target-mipsel_24kc_glibc/lib -L/home/mangix/devstuff/openwrt/staging_dir/toolchain-mipsel_24kc_gcc-9.3.0_glibc/usr/lib -L/home/mangix/devstuff/openwrt/staging_dir/toolchain-mipsel_24kc_gcc-9.3.0_glibc/lib -znow -zrelro CMakeFiles/re2_arg_test.dir/re2/testing/re2_arg_test.cc.o CMakeFiles/re2_arg_test.dir/util/test.cc.o -o re2_arg_test libtesting.a libre2.so -pthread && :
/home/mangix/devstuff/openwrt/staging_dir/toolchain-mipsel_24kc_gcc-9.3.0_glibc/lib/gcc/mipsel-openwrt-linux-gnu/9.3.0/../../../../mipsel-openwrt-linux-gnu/bin/ld: libre2.so: undefined reference to `ceilf'
```
I cannot find anywhere in the code ceilf being used. Nor in libcxx.
Answers:
username_1: You could try adding `-lm` to the linker flags for the RE2 tests. Defining `CMAKE_EXE_LINKER_FLAGS` at https://github.com/openwrt/packages/blob/master/libs/libre2/Makefile#L20-L21 might work.
Status: Issue closed
|
jquense/yup | 788535470 | Title: Allow empty string for certain tests
Question:
username_0: I'm stumbling on just one use case so far which I'd imagine must be common and there must be a way in yup.
I have a password. It must be required() and it also must be min(8). This yields two error messages when the password is an empty string. Since both errors are about the same issue I'd like to have min() allow an empty string as a valid value.
Schema for example:
``` js
const schema = yup.object().shape({
password: yup.string().min(8).required()
})
```
I've tried nullable() and defined() but didn't seem to have any affect. I thought maybe when() could help, but it can't self reference (understandably).
I've decided that using only min(8) covers both cases well enough for now. But, is there a way to make a particular test, such as min(), allow or ignore empty strings?
Thanks
Status: Issue closed
Answers:
username_1: There isn't any way to have the built-in `min` method ignore empty strings. You can either transform empty strings to another empty value like `null` or write a custom min test that does exactly what you want
username_0: After piecing some clues together I landed on this which seems to work for me. Creating a custom method allows for reusing it for multiple parameters.
``` js
yup.addMethod(yup.string, 'allowEmpty', function (formats, parseStrict) {
return this.transform(v => v === '' ? null : v).nullable()
})
const schema = yup.object().shape({
password: yup.string().min(8).required().allowEmpty()
})
``` |
RasaHQ/rasa | 794110308 | Title: Add integration test for Rasa Chat Channel (Rasa X)
Question:
username_0: **Description of Problem**:
We should add integration tests for the `Rasa Chat` channel which test the entire roundtrip of sending a message, processing it via Rasa Open Source and receiving the bot's response.
**Overview of the Solution**:
TBD
**Blockers**
* This task is dependent on https://github.com/RasaHQ/rasa/issues/7804.
* we need some Rasa X deployment to test against which could make this test a little bit different than the other integration tests
**Definition of Done**:
- [ ] Tests are added |
drawrowfly/tiktok-scraper | 602804738 | Title: Scrape popular hashtags and music
Question:
username_0: **Is your feature request related to a problem? Please describe.**
Scrape popular hashtags and music from https://www.tiktok.com/discover
**Describe the solution you'd like**
Like "trendEvent" method
Status: Issue closed
Answers:
username_0: Duplicate #21 |
1adrianb/face-alignment | 1094303818 | Title: It seems a bug in function "get_landmarks_from_directory( )"
Question:
username_0: Hi there,
**When I used the _get_landmarks_from_directory( )_ function as recommended [here](https://github.com/1adrianb/face-alignment#process-an-entire-directory-in-one-go), it was strange that the detected results of some images were wrong. Please check the images below:**

**While when I used the _get_landmarks( )_ function to process each image, it turn out that all detected results seems good.**
```
def get_landmarks_from_directory(fa, path):
img_list_raw = glob.glob(os.path.join(path, '*'))
img_list = [p for p in img_list_raw if is_image(p)]
predictions, no_face_detected = {}, []
for p in tqdm(img_list):
input = cv2.imread(p)
preds = fa.get_landmarks(input[..., ::-1])
if preds is None:
no_face_detected.append(p)
predictions[p] = preds if preds is None else preds[0].tolist()
return predictions, no_face_detected
```

**I tried to dive into the source code to figure out if there were any bugs in _get_landmarks_from_directory( )_ function but everything seems good, which made me confused. I attach two images in which I got wrong results when using _get_landmarks_from_directory( )_. Please test them. Thanks a lot.**

 |
forcedotcom/salesforcedx-vscode | 728504444 | Title: Variable does not exist: Schema.SObjectType.Case
Question:
username_0: ### Summary
Any time I have references to `Schema.SObjectType.SObject.method()`, where SObject is the API name of any object in the environment, VS Code reports the following problem:
```Variable does not exist: Schema.SObjectType.SObject```
One example is when trying to retrieve RecordTypeId by Name using `Schema.SObjectType.SObject.getRecordTypeInfosByName()`

### Steps To Reproduce:
1. Make any functioning reference to `Schema.SObjectType.SObject`, where `SObject` is the API name of an object
1. Deploy the code to the environment
1. Note a successful deployment
1. Note the Problem panel and the problem `Schema.SObjectType.SObjectType`
### Expected result
This should not be reported as a problem.
### Actual result
The reference to `Schema.SObjectType.SObject` is reported as a problem.

### Additional information
**VS Code Version**: 1.50.1
**SFDX CLI Version**: sfdx-cli/7.74.1-32db2396ed win32-x64 node-v12.18.3
**OS and version**: Windows 10 Enterprise, Version 1803
Answers:
username_1: Thanks for logging this @username_0 . Can you confirm if you have enabled the setting `salesforcedx-vscode-apex.enable-semantic-errors` ? I can't replicate this behavior without enabling that.
username_0: Indeed, I have.
username_2: If I have `Account.SObjectType` in the code with the aforementioned setting disabled it does not have yellow squiggles, but also it does not have any tip on hovering and will not bring up and other code information after hitting `.`
If I go to definition on `Account` I can see that it does not have the `SObjectType` member obviously as it is coming from somewhere else.
username_3: Thanks for confirming @username_0 . The semantic errors are bugging and I'm linking this one back to #1331.
@username_2 - It sounds like you are missing code smartness. Perhaps because you haven't refreshed SObject definitions or maybe java is missing? Here's a couple resources that can help. Please log a new issue with details if you still have trouble. We seek to keep one discussion per issue so we can keep everything straight.
[Code smartness](https://developer.salesforce.com/tools/vscode/en/apex/writing/#code-smartness-for-sobjects)
[Java setup](https://developer.salesforce.com/tools/vscode/en/getting-started/java-setup)
Status: Issue closed
|
blasedef/eu.quanticol.caspa | 55750332 | Title: Validation Check Error
Question:
username_0: Action pairs - there must exist the opposite named action
If there exist:
`a[True]<1>`
There must exist its partner
`a[True]<1>`
Answers:
username_0: However, there are some actions that do not need partners - so far this validation only covers unicast actions. |
godotengine/godot-proposals | 718215683 | Title: Add a signal to AudioStreamPlayer that indicates that the loop has started again
Question:
username_0: <!--
Please fill in *all* the questions below and don't remove any of them.
Proposals not following the template below will be closed immediately.
-->
**Describe the project you are working on:**
Projects with a dynamic music system.
**Describe the problem or limitation you are having in your project:**
There's no easy way to trigger actions when an AudioStream loops.
**Describe the feature / enhancement and how it helps to overcome the problem or limitation:**
Another signal should be added to the AudioStream indicating that it has finished the loop and it has started again.
**Describe how your proposal will work, with code, pseudocode, mockups, and/or diagrams:**
It's just another signal.
**If this enhancement will not be used often, can it be worked around with a few lines of script?:**
It can currently be worked around by setting the Stream to not loop automatically and playing the stream again when the `finished` signal is emitted.
**Is there a reason why this should be core and not an add-on in the asset library?:**
AudioStreamPlayer is a core feature.
**Related issues:**
https://github.com/godotengine/godot/issues/30737
https://github.com/godotengine/godot/issues/33579 |
epam/NGB | 1027184271 | Title: BUG: A space appears after the highlighted search match in file names in the dataset tree.
Question:
username_0: **To Reproduce**
1. Open NGB
2. Go to **DATASETS** panel
3. Enter any value in search field (e.d. te)
4. Look at search result in the dataset tree
**Expected behavior**
All search matches should be highlighted without spaces after in the word
**Actual result**
Matches for the searched value is highlighted.
Displays a space after matched value in the word. (e.g. Te st)
This behavior is relevant for files only
**Screenshots:**
<img src="https://user-images.githubusercontent.com/83421565/137454331-1912ceb1-5919-4548-b04a-c5eeebf0adae.png" width="200" />
**Environment:**
- NGB version: 2.6.1.3063
- Browser: Chrome Version 94.0.4606.81
Answers:
username_1: @username_0 should be fixed by 650e500cc2af495296e69543d3cec4710d86b4d9 |
bolt/bolt | 47833759 | Title: [RFE] Use require.js to manage javascript includes
Question:
username_0: See #1030.
**Goal**: clean up the mess that is Bolt's current javascript inclusion
management, and provide a sane framework for require.js-based script loading.
This takes care of:
* loading javascript files on-the-fly, as needed
* modularity
* avoiding duplicate includes
* avoiding version conflicts (different versions of the same module can
coexist)
**How to get there**.
The first thing we'll need is a generated requirejs configuration. Because
require.js uses JSON for its configuration, this is a matter of keeping a list
of javascript includes, massaging it into the right format, json_encode()ing
it, and serving it as a javascript file. Since that file will also act as our
main js entry point, it will also need to contain some bootstrapping
boilerplate. Requirejs doesn't run anything but the main entry point directly,
so when things register scripts, they need a way to hook themselves into the
main entry point. This can be done by generating a list of calls in the
generated main.js directly, or we can just generate a simple list of modules
that expect to be hooked up, and then the hard-coded bootstrapping part would
go through that list and set up all the hooks. This is what I imagine the
generated main.js might look like:
requirejs.config({
// json dump of config as collected by Bolt's javascript manager, e.g.:
paths: {
app: '/js/app',
extensions: '/js/extensions'
}
// etc. yadda yadda
});
(function(){
var __startup_scripts = [
// json dump of the module names of all the modules that have
// registered themselves as having a startup hook, e.g.:
'foobar',
'baz'
];
require(__startup_scripts, function(){
// Using 'magic' arguments array here so we can just iterate over
// the required modules.
// Note that all entry point modules are loaded asynchronously (and
// thus in parallel) before the iteration begins; order of
// execution, however, is determined by the order in which they are
// declared.
var modules = arguments;
for (var i = 0; i < modules.length; ++i) {
modules[i].run();
}
});
)();
This script needs to be generated on the fly, and hooked up to a silex route;
[Truncated]
* require-aware entry point (to be added to the startup scripts, and
facilitated in the require config with the assumption that it is an AMD
module)
* require-aware module (only added to require config)
* non-AMD script with extra options controlling import behavior. This is needed
for scripts that aren't AMD aware, or that don't play 100% nice with AMD
(such as jQuery).
We also need to distinguish between frontend- and backend scripts here, either
by passing an extra parameter to the registration methods, or by having two
completely independent script managers.
The final bit we need is something that injects a `<script>` tag into our page to
bootstrap require.js; this is pretty much a one-liner, but it needs to be
somewhat dynamic in that it needs to point to the correct URL for require.js
and main.js. Not rocket science though.
Finally, existing javascript will need to be converted, or we need to come up
with some sort of compatibility shimming to keep those scripts working.
Answers:
username_1: Let's not forget that the same applies to CSS loading, and RequireJS does not support CSS.. IMHO that would make RequireJS less than ideal. We should get one solution that will fix this for both JS and CSS
username_2: I don't know if this is closed.
How about a php task-runner like Taskphp [http://taskphp.github.io/ ] or Robo [http://codegyre.github.io/Robo/tasks/Assets/] ?
That way there is no need for Grunt or Gulp. Maybe port as a bolt extension ?
That way bolt community can avoid this: https://www.happyassassin.net/2014/12/29/adventures-in-php-web-asset-minimization/
username_0: It's not really the same problem though.
Requirejs addresses the fact that browser-based JS implementations provide insufficient support for modular code and lazy-loading includes. Assetic provides a framework for managing and pre-processing static assets. There are contact points between the two areas, but they are really separate problems.
username_0: This is basically grunt implemented in PHP; I don't see a significant advantage there, and meanwhile grunt enjoys a much larger user base...
username_2: That was an answer for username_1 : [Let's not forget that the same applies to CSS loading, and RequireJS does not support CSS.. IMHO that would make RequireJS less than ideal. We should get one solution that will fix this for both JS and CSS]. Sorry for that
username_1: This one supports CSS as well: http://webpack.github.io/
username_3: The only issue I see with webpack is if you were to give this functionality to template/theme authors, extension authors or even the end user who edits their own temples then node js / iojs become a dependency for everyone to install on their server (I'm not overtly familiar with webpack but this is my understanding... Am I wrong?). Once a file were to change the whole this would probably need to be rebuilt it it affects something higher/lower in the chain (ie JavaScript and jquery order)
Which is why I mentioned assetic. It's php. Does js,CSS, images cache busting all this stuff we are talking about and if you're advanced enough to know you have imagmagick on your system you can enable it through a yaml setting
username_4: Tagging this for closing on the 8th if no more info comes in since it's been stagnant for a year and no real progress. If anyone feels it would be productive to open the discussion after that feel free to reopen the issue!
Status: Issue closed
username_4: Closing per my comment on the 5th. Feel free to reopen if anyone feels productive in this area :) |
jenkins-x/jx | 304164566 | Title: Missing draft pack?
Question:
username_0: Actions:
Upgrade jx to 1.0.135
Running `jx import` now results in:
```
➜ jx import
error: could not load /Users/terry/.draft/packs/github.com/jenkins-x/draft-packs/packs/java: error reading /Users/terry/.draft/packs/github.com/jenkins-x/draft-packs/packs/java: open /Users/terry/.draft/packs/github.com/jenkins-x/draft-packs/packs/java: no such file or directory
```
Answers:
username_0: Whole folder missing:
```
➜ ls /Users/terry/.draft/packs/github.com/jenkins-x/
draft-repo
```
Not fixed by `draft pack-repo update` or running `jx init`
username_1: We’re currently in the middle of a release which involves multiple repos and we don’t yet have the gates in place to avoid this situation. This should be sorted soon and will update this issue but for today stick to the previous jx version.
username_2: @username_0 think this is fixed now
Status: Issue closed
|
KnpLabs/KnpPaginatorBundle | 305106165 | Title: knppaginatorbundle in a service
Question:
username_0: Hi,
Is there an example of a service, where i can pass into a parameter an Entity(findAll...) or repository(findByType...) query to a service that use knppaginator and return the paginator ?
Thanks a lot
I've tried without success, here is my service config:
```
admin.paginator:
class: AdminBundle\Services\AdminPaginator
arguments: ["@request_stack"]
tags:
- {name: "knp_paginator.injectable", paginator:"knp_paginator" }
```
my class doesn't work :
<?php
namespace AdminBundle\Services;
use Knp\Bundle\PaginatorBundle\DependencyInjection\KnpPaginatorExtension;
use Knp\Bundle\PaginatorBundle\KnpPaginatorBundle;
use Knp\Component\Pager\Paginator;
use Symfony\Component\HttpFoundation\Request;
use Doctrine\ORM\Mapping\Entity;
use Knp\Bundle\PaginatorBundle\Definition\PaginatorAwareInterface;
class AdminPaginator implements PaginatorAwareInterface {
private $request;
public function __construct(Request $request)
{
$this->request = $request;
}
public function paginator($entity)
{
$paginator = $this->get('knp_paginator');
$pageParam = $this->getParameter('page_name');
$page = $this->request->query->getInt($pageParam, 1);
$limitParam = $this->getParameter('limit');
$pagination = $paginator->paginate(
$entity,
$page,
$limitParam
);
return $pagination;
}
/**
* Sets the KnpPaginator instance.
*
* @param Paginator $paginator
*
* @return mixed
*/
public function setPaginator(Paginator $paginator)
{
// TODO: Implement setPaginator() method.
}
}
Answers:
username_1: Hello, you can simply inject the `@knp_paginator` in your service and get in in the constructor :
```php
public function __construct(PaginatorInterface $paginator)
{
$this->paginator = $paginator;
}
```
There should not be any need for tagging your service!
username_0: cool thanks a lot
Status: Issue closed
username_0: ```
<?php
namespace AdminBundle\Services;
use Doctrine\ORM\Mapping\Entity;
use Symfony\Component\HttpFoundation\RequestStack;
use Symfony\Component\DependencyInjection\ContainerInterface;
use Knp\Bundle\PaginatorBundle\DependencyInjection\KnpPaginatorExtension;
use Knp\Bundle\PaginatorBundle\KnpPaginatorBundle;
use Knp\Component\Pager\PaginatorInterface;
class AdminPaginator implements PaginatorAwareInterface {
private $request;
private $container;
private $paginator;
public function __construct(RequestStack $request, ContainerInterface $container, PaginatorInterface $paginator)
{
/**
* @var $request \Symfony\Component\HttpFoundation\RequestStack
*/
$this->request = $request;
$this->container = $container;
/**
* @var $paginator \Knp\Component\Pager\Paginator
*/
$this->paginator = $paginator;
}
/**
* @param \Doctrine\ORM\LazyCriteriaCollection $entity
* @return \Knp\Component\Pager\Pagination\PaginationInterface
*/
public function GetPagination(\Doctrine\ORM\LazyCriteriaCollection $entity)
{
$pageParam = $this->container->getParameter('page_name');
$limitParam = $this->request->getCurrentRequest()->query->getInt('limit', 10);
$page = $this->request->getCurrentRequest()->query->getInt($pageParam, 1);
$pagination = $this->paginator->paginate(
$entity,
$page,
$limitParam
);
return $pagination;
}
}
``` |
danmarsden/moodle-mod_attendance | 825819028 | Title: Missing text wrapping
Question:
username_0: Ionic columns should include the text-wrap attribute to avoid the text overlay the next column in mobile devices:
https://github.com/username_1/moodle-mod_attendance/blob/3420afac37573c621df17a365ca4cc2933fe837e/templates/mobile_view_page.mustache#L77
See example:
<img width="202" alt="imagen" src="https://user-images.githubusercontent.com/615556/110467997-fc0d8300-80d7-11eb-8ec7-335ada7b1381.png">
Answers:
username_1: cool - thanks @username_0
Status: Issue closed
|
alibaba/tsar | 27940080 | Title: mac os 10.9.1安装失败
Question:
username_0: make的时候报了如下错误
```
for i in modules src; do make -C $i; done
gcc -I../include -Wall -fPIC --shared -g -O2 -Wno-strict-aliasing mod_swap.c -o mod_swap.so
Undefined symbols for architecture x86_64:
"_register_mod_fileds", referenced from:
_mod_register in mod_swap-Pp8E05.o
"_set_mod_record", referenced from:
_read_vmstat_swap in mod_swap-Pp8E05.o
ld: symbol(s) not found for architecture x86_64
clang: error: linker command failed with exit code 1 (use -v to see invocation)
make[1]: *** [mod_swap.so] Error 1
```
Answers:
username_1: ...
"_lua_typename", referenced from:
_json_append_data in lua_cjson.o
_json_append_number in lua_cjson.o
ld: symbol(s) not found for architecture x86_64
clang: error: linker command failed with exit code 1 (use -v to see invocation)
make[2]: *** [cjson.so] Error 1
make[1]: *** [all] Error 2
make: *** [all] Error 2 |
jotegui/statReports | 152781950 | Title: Monthly VertNet data use report for 2016-3, resource nysm_birds
Question:
username_0: Your monthly VertNet data use report is ready!
You can see the HTML rendered version of the reports with this link:
http://dev.tools-usagestats.vertnet-portal.appspot.com/reports/5345b34d-82a4-44b7-9d82-5109df1ca243/201603/
Raw text and JSON-formatted versions of the report are also available for
download from this link. In addition, a copy of the text version has been
uploaded to your GitHub repository, under the "Reports" folder. Also, a full
list of all reports can be accessed here:
http://dev.tools-usagestats.vertnet-portal.appspot.com/reports/5345b34d-82a4-44b7-9d82-5109df1ca243/
You can find more information on the reporting system, along with an
explanation of each metric, here:
http://www.vertnet.org/resources/usagereportingguide.html
Please post any comments or questions to:
http://www.vertnet.org/feedback/contact.html
Thank you for being a part of VertNet. |
handy-pandas/bangazon_orientation_api | 223162278 | Title: Create a Category SQL table
Question:
username_0: # Issue Template for Bangazon Orientation API
1. Product Ticket Title: Bangazon Category table
2. Proposed Feature Title: Create a Category SQL table
3. Description of the feature:
* What: Create a Category table with the CategoryId primary key and the Name column.
* Where (when the feature would show up): This table will be exposed to the API.
* How (what implementation is needed): I will be implementing this task through SQL.
4. What files will be created or edited (where, file path): models/category.py
5. Potential Impact on the Project (possible conflicts with other features, hierarchy of feature completion):
6. Estimated time of completion: 15 minutes
7. Actual time of completion (added when moved to Done column):
Answers:
username_1: Good job
username_2: Actual time of completion (added when moved to Done column): 2 hours
Status: Issue closed
|
cryptomator/siv-mode | 574057863 | Title: S2V operation
Question:
username_0: I'm writing my own implementation of Cryptomator based on [Architecture - Cryptomator](https://docs.cryptomator.org/en/latest/security/architecture/) and I've noticed that there's a difference in S2V operation in your code and the reference specification provided by [RFC 5297](https://tools.ietf.org/html/rfc5297#section-2.4)
Is there a specific reason why you ignore a case when n is equal to zero
```
if n = 0 then
return V = AES-CMAC(K, <one>)
fi
```
Thanks
Answers:
username_1: You might be right, it seems to be missing. I'll have to take a closer look. Wondering why there is not test vector in the RFC for n=0.
username_0: Thanks for the quick response, my main concern is, that fixing this will cause problems with internal file structure(e.g. root directory encrypted name will differ)
username_1: I will not affect file names (even in the root dir, the empty string will be passed as AD to SIV), but it would affect the mapping between directory IDs and directory names.
However, neither the iOS app (which uses an independent implementation) nor our test cases (more than 60k tests) report any difference. Note that the [test cases](https://github.com/cryptomator/siv-mode/blob/develop/src/test/go/siv-test-vectors.go) are generated using [this library](/jacobsa/crypto).
Also, the linked section 2.4 or RFC 5297 doesn't mention n = 0 being special (other than in the pseudocode).
username_1: Ok I found it!
What the RFC calls `Sn` is in our case `plaintext`. Therefore n is _always_ greater than 0.
s2v is only used by encrypt and decrypt. In both cases plaintext will be passed to s2v.
Strictly speaking, s2v isn't implemented correctly, but we would just add dead code. I'll add a comment instead.
Status: Issue closed
username_0: _Is it?_
When you create a vault you need to get encrypted root directory ID, which is 0 bytes, making n = 0. That’s why I specifically mentioned root directory being “broken”. For example, when performing `aesSiv(dirId, null, encryptionMasterKey, macMasterKey)`, where:
encryptionMasterKey = `<KEY>`
macMasterKey = `<KEY>`
dirId = `empty data` (root directory ID is a special case and is empty, according to the documentation)
My implementation, if I ignore `n == 0` case, would give
`SQG3NEP3MYX5XUAGQ633E5HLOI7CFOMO`
The result matches with your implementation because Cryptomator recognises that vault and is able to work with it w/o a problem.
Obviously, if I uncomment a part that handles `n == 0`, the output would be
`XGTUM3VSORABP4VFX4LPTYJ7PKCZDYZ3`
So if someone like me decides to make his own implementation using the documentation, it won't be compatible(basically the implementation won't work) with Cryptomator app, that you provide
username_0: I think not being able to reproduce functionality described in the documentation by using only technical specification is a big problem. Basically that means your app does not behave like it supposed to, so to speak.
username_1: The length of the input values doesn't affect the number of input values. Even if the root dir id is an empty string, it is still passed to s2v.
username_1: It is technically impossible for n to be 0, as plaintext is parameter that is used as `Sn`. I don't know what language you're using, but in Java it is impossible for this parameter to "stop existing".
username_0: Yeah, I misunderstood your comment about Sn being a plaintext. I somehow assumed, that n would correspond to a length of Sn, not the input with associated data 🤦♂️
Thanks again for your response. |
MEASHY/Mahjong-Solitaire | 299670521 | Title: Create translated UI
Question:
username_0: Ken will provide a translated set of instructions based on our set of English instructions.
We will integrate this into Mahjong.
Answers:
username_1: Won't be implemented. See [UC30](https://github.com/MEASHY/Mahjong-Solitaire/wiki/Use-Cases#30-select-ui-language)
Status: Issue closed
|
verbb/knock-knock | 556899532 | Title: Craft 3.4 breaks CSS layout
Question:
username_0: ### Description
Craft 3.4 updates the layout of the control panel, meaning the styling of Knock Knock is now off
<img width="1279" alt="Screenshot 2020-01-29 at 14 29 17" src="https://user-images.githubusercontent.com/615149/73365174-be6ae380-42a3-11ea-91ad-fcab3091ed39.png">
### Steps to reproduce
1. Update to Craft 3.4
2. View lock-screen
### Additional info
- Plugin version: 1.1.2
- Craft version: 3.4
Status: Issue closed
Answers:
username_1: Fixed in [1.2.0](https://github.com/verbb/knock-knock/releases/tag/1.2.0) |
dart-lang/source_gen | 257981787 | Title: analyzer not updated for 2nd builder
Question:
username_0: I have a built_value class

and build it with
```dart
/// builder phases for built_value
List<BuildAction> phases() => [
new BuildAction(
new PartBuilder([
new BuiltValueGenerator(),
new BuiltReduxGenerator(),
]),
'my_proj_shared',
inputs: const ['lib/**/*.dart'])
];
```
In the `BuiltReduxGenerator` I get

instead of
```dart
ActionDispatcher<Thunk<RxApp, RxAppBuilder, RxAppActions>> get request;
```
I get
```dart
ActionDispatcher<Thunk<RxApp, dynamic, RxAppActions>> get request;
```
Is there something I can do, or is this a bug/missing feature?
Answers:
username_0: I haven't found a workaround.
Using the string doesn't work because it resolves the function typedef and makes it unusable for this purpose

username_1: All the generators in the same part builder run concurrently, they can't resolve the code output by each other. In order to resolve the build value code in the other generator it will need to be in a different build action, which also means it'll need to output a different file
Status: Issue closed
username_0: I see. Thanks for the info.
In the meantime I found a way to get the name of a typedef type parameter. |
kubernetes/website | 575838865 | Title: Volume snapshot restore feature still marked as alpha
Question:
username_0: **This is a Bug Report**
<!-- Thanks for filing an issue! Before submitting, please fill in the following information. -->
<!-- See https://kubernetes.io/docs/contribute/start/ for guidance on writing an actionable issue description. -->
<!--Required Information-->
**Problem:**
https://kubernetes.io/docs/concepts/storage/persistent-volumes/#volume-snapshot-and-restore-volume-from-snapshot-support
This page lists the "restore from volume snapshot" feature as alpha, but it should be beta in k8s 1.17.
**Proposed Solution:**
Update section to mark feature as beta. And make sure that the beta API is used in the example.
**Page to Update:**
https://kubernetes.io/docs/concepts/storage/persistent-volumes/#volume-snapshot-and-restore-volume-from-snapshot-support
<!--Optional Information (remove the comment tags around information you would like to include)-->
<!--Kubernetes Version:-->
The volume snapshot stuff went beta in k8s 1.17
<!--Additional Information:-->
Answers:
username_0: /assign @username_1
/sig storage
/cc @saad-ali
username_1: Looks like this one fell through the cracks. I think this is because we don't need to change the example so I forgot to update this page. I'll update it.
username_2: /kind bug
/priority important-longterm |
soimort/translate-shell | 339200016 | Title: trans is slow in bash
Question:
username_0: This is a continuation of issue 236.
I built translate for gawk (set target in Makefile to gawk) and execution speed is fast.
So it's bash that is slowing things down.
I looked at the trans file (built for bash) and I noticed that there're are return statments in bash functions that seem to be returning non 0-255 values.
AFAIK bash doesn't support this (e.g., https://stackoverflow.com/questions/17336915/return-value-in-a-bash-function)
Please advise.
Answers:
username_1: Please be more specific about where things go wrong, especially since I can't observe any substantial performance degradation on other platforms.
If most time is spent reading in the program, then this inefficiency is actually about bash, in particular, your bash port on WSL or Cygwin. I'm afraid there's nothing I can do about it.
Status: Issue closed
|
tensorflow/tensorflow | 248942321 | Title: I‘ve trained my CNN in win7 anaconda and get ckpt, but cannot use the ckpt in
Question:
username_0: Please go to Stack Overflow for help and support:
https://stackoverflow.com/questions/tagged/tensorflow
If you open a GitHub issue, here is our policy:
1. It must be a bug or a feature request.
2. The form below must be filled out.
3. It shouldn't be a TensorBoard issue. Those go [here](https://github.com/tensorflow/tensorboard/issues).
**Here's why we have that policy**: TensorFlow developers respond to issues. We want to focus on work that benefits the whole community, e.g., fixing bugs and adding features. Support only helps individuals. GitHub also notifies thousands of people when issues are filed. We want them to see you communicating an interesting problem, rather than being redirected to Stack Overflow.
------------------------
### System information
- **Have I written custom code (as opposed to using a stock example script provided in TensorFlow)**:
- **OS Platform and Distribution (e.g., Linux Ubuntu 16.04)**:
- **TensorFlow installed from (source or binary)**:
- **TensorFlow version (use command below)**:
- **Python version**:
- **Bazel version (if compiling from source)**:
- **CUDA/cuDNN version**:
- **GPU model and memory**:
- **Exact command to reproduce**:
You can collect some of this information using our environment capture script:
https://github.com/tensorflow/tensorflow/tree/master/tools/tf_env_collect.sh
You can obtain the TensorFlow version with
python -c "import tensorflow as tf; print(tf.GIT_VERSION, tf.VERSION)"
### Describe the problem
Describe the problem clearly here. Be sure to convey here why it's a bug in TensorFlow or a feature request.
### Source code / logs
Include any logs or source code that would be helpful to diagnose the problem. If including tracebacks, please include the full traceback. Large logs and files should be attached. Try to provide a reproducible test case that is the bare minimum necessary to generate the problem.
Answers:
username_1: _Warning: As you've not filled in the required info above you may not get the support you're looking for from the devs. Perhaps this is an issue for Stack Overflow?_
Without you filling in the template above there is no way anyone can help you. If the **only** difference is the OS then i'm surprised that the ckpt's don't work. They should work fine. Are you using any LSTM cells or different versions of Tensorflow. Please fill in the issue template above.
Status: Issue closed
username_2: This question is better asked on [StackOverflow](http://stackoverflow.com/questions/tagged/tensorflow) since it is not a bug or feature request. There is also a larger community that reads questions there. Thanks! |
Alderon-Games/pathoftitans-bugs | 1185408453 | Title: Megalania neck bugged
Question:
username_0: ## Expected Behavior
Meglania neck should be smooth
## Current Behavior
This bug is only visible when you are looking at other megs, it does not work with your own Meg. The megs neck on the + defense model is really bugged as it sometimes bends down to create a weird fold with a sharp corner instead of a normal smooth neck.
## Reproduction Steps
- have a friend be a Meg
- become something else and stand next to them
- watch as their neck becomes buggy and shoots up and down and then gets into this weird pose
## Evidence (Screenshots & Videos)

## Crash Logs
N/A
(If Applicable. No logs needed if there is no crash.)
## Build Information
**Game Version:** 0.0.0.18253
**Operating System & Version:**
Ipad9 or IPadOS 15.3.1
**Alderon Games ID:** 745-052-641 |
cccm-gis/Ciclo-2 | 416129204 | Title: Actualizar, publicar y actualizar base de datos del Gran Putumayo
Question:
username_0: Datos de San Miguel con estado de sectores y areas actualizados
- [ ] Actualizados al corte ciclo 2
- [ ] Publicados en Google Drive
- [ ] Compartidos con equipos relevantes
Datos de <NAME> con estado de sectores y areas actualizados
- [ ] Actualizados al corte ciclo 2
- [ ] Publicados en Google Drive
- [ ] Compartidos con equipos relevantes
Datos de Puerto Leguizamo con estado de sectores y areas actualizados
- [ ] Actualizados al corte ciclo 2
- [ ] Publicados en Google Drive
- [ ] Compartidos con equipos relevantes
Datos de Puerto Asis Zona 2 con estado de sectores y areas actualizados
- [ ] Actualizados al corte ciclo 2
- [ ] Publicados en Google Drive
- [ ] Compartidos con equipos relevantes |
LNRBHAW/lnrbhaw.github.io | 383994799 | Title: Hello World | LNRBHAW
Question:
username_0: https://lnrbhaw.github.io/2018/11/22/hello-world/
搞了三四天终于搭出了自己的博客,OI不一定能够成功,但至少留下这个博客可以怀念
Answers:
username_1: ##临江仙·一川绿
暖涨一川春雾绿,潇湘一川新绿,三十六峰横一川,一川草长绿,正浓一川绿
尽日一川侵草绿,满意一川平绿,南浦春来绿一川,一川芳草绿,冥冥一川绿
username_3: ## 临江仙·一川绿
暖涨一川春雾绿,潇湘一川新绿,三十六峰横一川,一川草长绿,正浓一川绿
尽日一川侵草绿,满意一川平绿,南浦春来绿一川,一川芳草绿,冥冥一川绿 |
pytorch/pytorch | 500999381 | Title: Nondeterminism in ROCm RNNs
Question:
username_0: ## 🐛 Bug
In this commit https://github.com/pytorch/pytorch/pull/26791/commits/2c83237d2fddded85774c9ac07e267985b2fe62f the sizes used in test_rnn_retain_variables were increased x10. This caused the corresponding ROCm build to fail (https://ci.pytorch.org/jenkins/job/pytorch-builds/job/py2-clang7-rocmdeb-ubuntu16.04-test1/2418/console).
Are ROCm RNNs nondeterministic?
## To Reproduce
See commit. test_rnn_retain_variables needs its sizes increased by 10x.
## Expected behavior
Test passes.
cc @username_1 @ngimel
Answers:
username_1: thanks for filing!
username_1: This issue is FBA-130 in the AMD jira system.
Status: Issue closed
username_2: FBA-130 has been closed. Closing this, too. |
jlippold/tweakCompatible | 339253135 | Title: `Badger 7` not working on iOS 11.3.1
Question:
username_0: ```
{
"packageId": "com.bflatstudios.badger7",
"action": "notworking",
"userInfo": {
"arch32": false,
"packageId": "com.bflatstudios.badger7",
"deviceId": "iPhone9,2",
"url": "http://cydia.saurik.com/package/com.bflatstudios.badger7/",
"iOSVersion": "11.3.1",
"packageVersionIndexed": false,
"packageName": "Badger 7",
"category": "Tweaks",
"repository": "BigBoss",
"name": "Badger 7",
"packageIndexed": false,
"packageStatusExplaination": "This tweak has not been reviewed. Please submit a review if you choose to install.",
"id": "com.bflatstudios.badger7",
"commercial": true,
"packageInstalled": false,
"tweakCompatVersion": "0.0.7",
"shortDescription": "interact with Notifications on the homescreen",
"latest": "1.1-1",
"author": "bFlat <NAME>",
"packageStatus": "Unknown"
},
"base64": "<KEY>",
"chosenStatus": "not working",
"notes": "Causes springboard crash "
}
``` |
image-rs/image | 766894946 | Title: Please Make 16 Bit Version accessible outside of the crate!
Question:
username_0: I would like to be able
Use Gray16Image type in my project
My specific use case for this functionality is
to load depth images
This is more generally applicable to
computer vision
## Draft
remove the "(crate)" option from pub(crate)
Answers:
username_1: [That's just a typedef](https://github.com/image-rs/image/blob/c0cc1383ea650a437ff94522d4a5e138515f3734/src/buffer.rs#L1307), you replace their use with `ImageBuffer<Luma<u16>, Vec<u16>>`. That being said, the inconsistency with other typdefs seems like an oversight. I think we didn't finisht the discussion on where they should be exported.
username_0: Yes thats what im doing now. But as you said it inconsistent. Would be nice to have it fixed. Thanks!
username_2: +1
I want to encode a 16bit PNG. Unless I miss something I am forced to take `image` as a dependency instead on just `png`.
From `png`:
```
pub enum ColorType {
Grayscale,
RGB,
Indexed,
GrayscaleAlpha,
RGBA,
}
```
Whereas `image::ColorType` has what I need – `Rgba16`. Also note the capitalization inconsistencies between `image::ColorType` and `png::ColorType` variants (`Rgba` vs `RGBA`).
A related issue is API ergonomics.
The `PngEncoder::encode()` has no variants for different buffer depths – it only takes `[u8]`.
In my case the input should be a `[u16]` (In below code `quantized_pixel_data` is a `Vec<u16>`):
```rust
image::png::PngEncoder::new(&mut buffer)
.encode(
// Woot?
unsafe {
&*core::ptr::slice_from_raw_parts(
quantized_pixel_data.as_ptr() as *const u8,
quantized_pixel_data.len() * 2,
)
},
width as _,
height as _,
image::ColorType::Rgba16,
)
.unwrap();
```
But I guess that maybe warrants its own ticket? Question is if this should be opened on this tracker or the one for the `png` crate?
username_2: Edit: I saw `png` has `BitDepth` separate (which is probably a good idea. However, the `write_image_data()` method there has the same issue: it only takes `[u8]` data.
username_1: Moderator note: Yes, please open separate issues for separate issues. Specifically it doesn't help the `png` crate to have an issue floating around here. I'm going to hide the comments in a day.
username_2: The issue is still for `image`'s `encode()`, *not* `png`. The latter would still need a third issue for `write_image_data()`.
I'll copy the comments over into a new issue and delete them here. |
markusfisch/BinaryEye | 737131217 | Title: Not scan big QR
Question:
username_0: I scan from the monitor screen.
your application cannot scan this code. SecScanQR - this application a competitor can scan.
the problem seems to be different pixel widths for squares. 1 pixel difference.

Answers:
username_1: Sorry for the late answer, and sorry for the inconvenience 😬
Unfortunately, I cannot reproduce this problem as I can read this image with Binary Eye without problems:
<img src="https://user-images.githubusercontent.com/485246/98470887-ea2ed880-21e8-11eb-8c5c-ad66a007207a.png" width="320" alt="scan"/> <img src="https://user-images.githubusercontent.com/485246/98470892-eef38c80-21e8-11eb-9b88-2637d7e72c08.png" width="320" alt="read"/>
Or did you mean scanning this QR Code with the camera? If so, please try again in landscape mode without restricting scanning area to make the most out of the camera image. I was able to scan this code this way without too much hassle.
username_0: I cannot scan from the monitor screen. it always shows me different numbers, but not the code
username_1: The reason for this is that the QR Code you try to read has so many tiny modules (dots) that they blur together in the camera frame which accidentally makes a simpler, random one-dimensional barcode 😬 Binary Eye tries to read all the different types of barcodes in the camera frame and so this can happen if the odds are just right. Which isn't very likely usually - you just seem to hit a rare case in which this isn't so unlikely it seems.
Now, there are two things you can do:
First, you could remove the cropping limiter and make Binary Eye scan the _whole_ screen. This means there are more pixels in the camera frame what makes a correct detection more likely.
Next, you could tap in the middle of the QR Code when scanning to make the camera focus on that spot. This will result in a sharp image what's also good for detection.
For demonstration, here I scan the code from above with my old Fairphone 2 (because it really hasn't a great camera):

username_0: if I scan without cropping the image then it turns out to recognize the full text. It is very strange that the image is the same, but if you crop the view then the QR code cannot be recognized. you can check the code and fix the problem. The scan should be the same. cropping the image is just a more convenient way for me. The scan should be the same.
username_1: Well, the reason the QR Code is recognized _without_ cropping is that the QR Code covers more pixels in the full camera frame as opposed to just a section of it.
For example, if a camera frame has a width of 100 pixels, and a code has 100 dots in one direction, then we can read this code only if the code covers the full width of the camera frame. Only then every dot is represented in the pictures.
Now, if we move back a bit so that the code covers only 80 pixels of our camera frame, we cannot decode the code because 20 of the dots of the code are missing from the input image.
So the problem is not really the cropping but that if we use just a section of the camera image we have less resolution what means less information. And so, there's nothing I could fix in the code 😉
Status: Issue closed
|
s-u/RJDBC | 344076311 | Title: dbReadTable says “invalid object name” but can select from with dbGetQuery
Question:
username_0: The following code fails at the second to last line but retrieves the correct result set on the last line:
```
library(RJDBC)
drv <- JDBC("com.microsoft.sqlserver.jdbc.SQLServerDriver","D:/sqljdbc4.jar")
conn <- dbConnect(drv,
'jdbc:sqlserver://[servername];databaseName=[databasename]',
'[username]', '[password]'
)
new_records_table <- 'dbo.new_dummy'
try(dbRemoveTable(conn, new_records_table), silent=T) # in case the table was already there
input_table <- data.frame(col1=c('A'))
dbWriteTable(conn, new_records_table, input_table)
dbReadTable(conn, new_records_table) # fails
dbGetQuery(conn, paste('SELECT * FROM', new_records_table)) # succeeds
```
(where [servername], [databasename], [username], and [password] were suppressed).
The error at the second to last line is
```
Error in .verify.JDBC.result(r, "Unable to retrieve JDBC result set for ", :
Unable to retrieve JDBC result set for SELECT * FROM "dbo.new_dummy" (Invalid object name 'dbo.new_dummy'.)
```
If I do `dbReadTable(conn, 'new_dummy')` instead, then there is no error and the correct result is retrieved. However, the problem remains for tables part of a non-dbo schema.
I'm on Windows 7 64-bit using R version 3.5.1, and output from sessionInfo() shows "RJDBC_0.2-7.1", "rJava_0.9-10", and "DBI_1.0.0" as the other attached packages. For the SQL server, it's SQL Server 2016.
Answers:
username_1: This is actually a bug in DBI - the full output is actually:
```
Note: method with signature ‘DBIConnection#character’ chosen for function ‘dbReadTable’,
target signature ‘JDBCConnection#character’.
"JDBCConnection#ANY" would also be valid
```
As you can see it was overriding our implementation with one that use invalid SQL syntax. I have added a work-around in 18953dc so our method is now used. Also note that you may have to specify the character used for quoting in your DBMS depending on the names you use (see the documentation).
Status: Issue closed
|
vuestorefront/storefront-ui | 1091058571 | Title: [FEATURE] MinifiedHero - new component
Question:
username_0: **Describe how this feature will help us improve**
To improve performance we can add a new Hero component without a third-party library (Glide.js) and has only basic CSS animations. This component is usually on the top of home page so it's important to keep it simple and without unnecessary JS.<issue_closed>
Status: Issue closed |
swagger-api/swagger-ui | 217653959 | Title: swagger-ui 'Try it' creating curl commands with '//' at start of path
Question:
username_0: I'm using http://petstore.swagger.io/ and testing https://github.com/username_0/swagger-akka-http-sample.
I've maintained this sample for a while but haven't checked it recently.
The `Try It` option now generates a URL with `//add` and this fails But `/add` works.
`curl -X POST http://localhost:12345//add -H "accept: application/json" -H "content-type: application/json" -d "{ \"numbers\": [ 0 ]}"`
The swagger.json is
```
{
"swagger" : "2.0",
"info" : {
"description" : "",
"version" : "1.0",
"title" : "",
"termsOfService" : ""
},
"host" : "localhost:12345",
"basePath" : "/",
"tags" : [ {
"name" : "add"
}, {
"name" : "hello"
} ],
"schemes" : [ "http" ],
"paths" : {
"/add" : {
"post" : {
"tags" : [ "add" ],
"summary" : "Add integers",
"description" : "",
"operationId" : "addIntegers",
"produces" : [ "application/json" ],
"parameters" : [ {
"in" : "body",
"name" : "body",
"description" : "\"numbers\" to sum",
"required" : true,
"schema" : {
"$ref" : "#/definitions/AddRequest"
}
} ],
"responses" : {
"200" : {
"description" : "Return sum",
"schema" : {
"$ref" : "#/definitions/AddResponse"
}
},
"500" : {
"description" : "Internal server error"
}
}
}
},
"/hello" : {
"get" : {
"tags" : [ "hello" ],
"summary" : "Return Hello greeting",
"description" : "",
"operationId" : "anonymousHello",
"produces" : [ "application/json" ],
[Truncated]
}
}
}
},
"Greeting" : {
"type" : "object",
"required" : [ "greeting" ],
"properties" : {
"greeting" : {
"type" : "string"
}
}
}
},
"externalDocs" : {
"description" : "Core Docs",
"url" : "http://acme.com/docs"
}
}
```
Answers:
username_1: @username_3 - this is an edge case when the `basePath` ends with a `\`. Since all paths must start with a `\` and they are appended to the `basePath`, the safe solution would be to remove the trailing `\` from the basePath if one exists.
username_2: @username_1 same issue here. The extra / is making my api not recognize the path and returning a 404 in Node.js. Do you guys have a way to reference ealier version of swagger.io petstore in the meantime? The immediate impact is that users are no longer to use Swagger UI to explore the API.
`curl -X GET http://localhost:3030//accounts/{account_id}/business-dashboard/map`
Thanks!
username_1: @username_2 - all the older versions are here in the repo, you can just use any of those...
username_2: Thanks @username_1 for the workaround. Will do.
I liked you that guys had been serving the UI and support URL query param. So, I just stuck my OpenAPI spec to it without hosting the UI and passed it around. But I know, hosting the app is not biggie.
username_3: Hi everyone- I've just opened a PR that fixes this in swagger-js.
I'm anticipating having the fix for this released in JS and UI on Friday evening.
Status: Issue closed
username_3: I'm using http://petstore.swagger.io/ and testing https://github.com/username_0/swagger-akka-http-sample.
I've maintained this sample for a while but haven't checked it recently.
The `Try It` option now generates a URL with `//add` and this fails But `/add` works.
`curl -X POST http://localhost:12345//add -H "accept: application/json" -H "content-type: application/json" -d "{ \"numbers\": [ 0 ]}"`
The swagger.json is
```
{
"swagger" : "2.0",
"info" : {
"description" : "",
"version" : "1.0",
"title" : "",
"termsOfService" : ""
},
"host" : "localhost:12345",
"basePath" : "/",
"tags" : [ {
"name" : "add"
}, {
"name" : "hello"
} ],
"schemes" : [ "http" ],
"paths" : {
"/add" : {
"post" : {
"tags" : [ "add" ],
"summary" : "Add integers",
"description" : "",
"operationId" : "addIntegers",
"produces" : [ "application/json" ],
"parameters" : [ {
"in" : "body",
"name" : "body",
"description" : "\"numbers\" to sum",
"required" : true,
"schema" : {
"$ref" : "#/definitions/AddRequest"
}
} ],
"responses" : {
"200" : {
"description" : "Return sum",
"schema" : {
"$ref" : "#/definitions/AddResponse"
}
},
"500" : {
"description" : "Internal server error"
}
}
}
},
"/hello" : {
"get" : {
"tags" : [ "hello" ],
"summary" : "Return Hello greeting",
"description" : "",
"operationId" : "anonymousHello",
"produces" : [ "application/json" ],
[Truncated]
}
}
}
},
"Greeting" : {
"type" : "object",
"required" : [ "greeting" ],
"properties" : {
"greeting" : {
"type" : "string"
}
}
}
},
"externalDocs" : {
"description" : "Core Docs",
"url" : "http://acme.com/docs"
}
}
```
username_3: Confirmed fixed- will be pushing the release to Git and NPM momentarily.
Status: Issue closed
username_2: Thanks @username_3. Has it been pushed to the site http://petstore.swagger.io? I've just tried it and I'm still seeing the the double slash today. I thought I saw it yesterday fixed.
username_3: @username_2, doesn't look like it- the [test spec](https://gist.github.com/username_3/ddbbdf9c4fbd5c7a4299d0a2c36b3502) I created for this issue is creating a double slash on petstore.swagger.io, but works for me with Swagger-UI 3.0.5 locally.
@username_5, can you advise on when the site will be updated?
username_1: The process it not automated yet.
username_5: It's updated now
username_2: It works! Thank you! |
hedgestudios/SearchForOmen | 417546625 | Title: There is no instruction of how to use stretch hog (map: Path_to_Forest)
Question:
username_0: **Description:**
There is no instruction of how to use stretch hog.
**Environment:**
macOS, version #93Jack
**Expected vs Actual:**
Expected: NPC to provide the information of key to use.
Actual: No instruction provided
Answers:
username_1: Now tells the player the controls to use stretch-hog when the player retrieves sebastian
Status: Issue closed
|
spring-projects/spring-shell | 1107798483 | Title: Please upgrade hibernate-validator(6.0.18.Final) to latest or any non-vulnerable version, as its coming as transitive dependency of it.
Question:
username_0: 
I have checked for “spring-shell-starter – 2.0.1-RELEASE” also that if there is any scope of upgrading this. But we can’t do any upgrade there because we are already on latest.

Status: Issue closed
Answers:
username_0: 
I have checked for “spring-shell-starter – 2.0.1-RELEASE” also that if there is any scope of upgrading this. But we can’t do any upgrade there because we are already on latest.

username_0: we are using the below plugin to combine all the dependencies regarding spring-shell-starter-2.0.1.RELEASE. So please tell me how can we overwrite this hibernate-validator jar version in this.
Status: Issue closed
username_1: This is resolved in `3.0.x` line which gets deps from latest Boot versions and we just got first milestone out. `2.0.x` line is not maintained anymore but you can do normal maven/gradle dance to force that validator version. |
kubernetes-sigs/aws-load-balancer-controller | 733119674 | Title: The Deployment "aws-load-balancer-controller" is invalid
Question:
username_0: I have run
`kubectl apply -f v2_0_0_full.yaml`
Here is the output with error,
```
customresourcedefinition.apiextensions.k8s.io/targetgroupbindings.elbv2.k8s.aws configured
mutatingwebhookconfiguration.admissionregistration.k8s.io/aws-load-balancer-webhook configured
serviceaccount/aws-load-balancer-controller unchanged
role.rbac.authorization.k8s.io/aws-load-balancer-controller-leader-election-role unchanged
clusterrole.rbac.authorization.k8s.io/aws-load-balancer-controller-role configured
rolebinding.rbac.authorization.k8s.io/aws-load-balancer-controller-leader-election-rolebinding unchanged
clusterrolebinding.rbac.authorization.k8s.io/aws-load-balancer-controller-rolebinding unchanged
service/aws-load-balancer-webhook-service unchanged
Warning: kubectl apply should be used on resource created by either kubectl create --save-config or kubectl apply
certificate.cert-manager.io/aws-load-balancer-serving-cert unchanged
issuer.cert-manager.io/aws-load-balancer-selfsigned-issuer unchanged
validatingwebhookconfiguration.admissionregistration.k8s.io/aws-load-balancer-webhook configured
The Deployment "aws-load-balancer-controller" is invalid: spec.selector: Invalid value: v1.LabelSelector{MatchLabels:map[string]string{"app.kubernetes.io/component":"controller", "app.kubernetes.io/instance":"aws-load-balancer-controller", "app.kubernetes.io/name":"aws-load-balancer-controller"}, MatchExpressions:[]v1.LabelSelectorRequirement(nil)}: field is immutable
```
I haven't modified anything but still the error came. the alb is working fine for now, but not sure how this error will impact. Please elaborate
Answers:
username_1: What does the current selector on your deployment look like?
```
$ kubectl describe deployments.apps -n kube-system aws-load-balancer-controller |grep Selector
```
The label selector field is immutable for Deployment object in API version apps/v1.
It seems as though you have had the helm installation at some point, and then applied the yaml manifests. If you would like to install yaml manifest, you'd need to first uninstall the helm chart completely.
To delete the helm chart,
```
helm delete aws-load-balancer-controller -n kube-system
```
username_0: Thank you. This is the output for the selector
`
Selector: app.kubernetes.io/instance=aws-load-balancer-controller,app.kubernetes.io/name=aws-load-balancer-controller`
sorry, do you mean the helm installation as mentioned in this official page which I have followed
[aws alb ingress](https://docs.aws.amazon.com/eks/latest/userguide/alb-ingress.html
)
By the way, the target groups for multiple apps is not being created with Ingress resource which worked fine with previously created cluster which is of seperate VPC, but in the same VPC situation that's not working.
username_0: Sorry, I have read this in the process, so I don't need to run the command at all.
"If you already installed the controller using the previous step, then don't complete this step."
It's my mistake. I m closing this. thanks a lot @username_1
Status: Issue closed
|
ory/ladon | 214862171 | Title: New custom StringPairsEqual condition rejects valid input
Question:
username_0: When using the most recent version of ladon (which includes the new StringPairsEqualCondition) in a fork of Hydra, the warden was incorrectly denying requests when given valid contexts.
A sample policy to be tested against:
```
{
"description": "Allow account admins full access to account resources.",
"subjects": [
"account-admin"
],
"effect": "allow",
"resources": [
"rn:accounts:<[A-z0-9_-]+(:.+)?>"
],
"actions": [
"create", "read", "update", "delete"
],
"conditions": {
"account-ids": {
"type": "StringPairsEqualCondition"
}
}
}
```
A sample context to test against:
```
{
"resource": "rn:accounts:1",
"action": "read",
"subject": "<SUBJECT_WITH_ABOVE_POLICY>",
"context": {
"account-ids": [
["1", "1"]
]
}
}
```
I'm wondering if this can be recreated by others. I believe the following line is failing to coerce properly, https://github.com/ory/ladon/blob/master/condition_string_pairs_equal.go#L11.
I am currently using the following implementation for this condition's `Fufills` function:
```
func (c *StringPairsEqualCondition) Fulfills(value interface{}, _ *Request) bool {
pairs, PairsOk := value.([]interface{})
if PairsOk {
for _, v := range pairs {
pair, PairOk := v.([]interface{})
if !PairOk || (len(pair) != 2) {
return false
}
a, AOk := pair[0].(string)
b, BOk := pair[1].(string)
if !AOk || !BOk || (a != b) {
return false
}
}
return true
}
return false
}
```
It seems Hydra was able to process the type coercion `[]interface{}` but not `[][]interface{}`. Not sure if this is because Hydra is doing something with the input or if it is ladon specific so I created the issue here.
Answers:
username_1: hm that looks weird, does it work with
```
pairs, PairsOk := value.([][]string)
```
?
username_1: The only thing hydra is doing is decode the JSON data, that should work with nested arrays
username_0: I don't believe the coercion `value.([][]string)` is working either. That is a little strange since its just JSON decoded.
username_0: When using the `reflect` package, and `reflect.GetType` function on the input `value`, the type `[]interface{}` is returned. Is this just the mechanism of the library doing the JSON decoding?
username_1: The http payload is decoded [here](https://github.com/ory/hydra/blob/master/warden/handler.go#L74-L84), [this](https://github.com/ory/hydra/blob/master/firewall/warden.go#L48) and [this](https://github.com/ory/hydra/blob/master/firewall/warden.go#L59) are the context types. Maybe just add a test that reproduces the case with json and try to fix it that way quickly?
username_0: I'll open a new branch with a coercion in the condition that will work with `[]interface{}`. I'll update tests to respect the new implementation.
username_0: PR #54 addresses this issue and should respect the `[]interface{}` type.
Status: Issue closed
|
BookStackApp/BookStack | 458005462 | Title: Login by name
Question:
username_0: I don't know if this has already been discussed anywhere here, but is there a reason why one has to login by email and not by name? Many tools use the same form field ("put in your name or your email address") which is much more convenient.
Answers:
username_1: Yeah, There are a few reasons:
- Having one system is easier to maintain (Especially since I bet people would then want this to be togglable).
- Names in BookStack are non-unique, for display, whereas email addresses are unique.
- Although convenient for some, multiple options can cause confusion for others.
- Using email to login reinforces the fact that the account is tied to that email, in the event of needing to reset the password.
To be honest, I can't think of any platforms I use where you can use name to login. Many allow login via username or email but BookStack does not really store a username (Unless LDAP is in use).
username_2: I understand the reasoning here. But I'm a teacher and want to publish materials for them om my wiki. Just for them, not public, protected by a password. So I want to create a "student" account and have them login with the name "student" with a password.
username_3: I would like to bump this feature request. For the home-user it would be very helpful, so I don't have to have the family have to remember multiple login methods for the local network services I have going, and they could just remember their one user-pass.
username_4: +1 for a simple username + password login.
username_5: I hope display name can be unique. Some feature will need unique name.
For example, somebody need to notify the page editor `JohnDoe`, they might type `@JohnDoe` in comment. But if display name is not unique, notification can not be done. More then one person will be notified.
username_0: I dont know @username_1 `s plans here, but there are solutions in other tools, where you can have a unique username and a display name and you can use both to @mention someone
username_6: I‘d like to see this, too.
Are there any workarounds to achieve that? I just want to host a simple wiki with predefined usernames and passwords which I give to my users, so there is no mail validity needed at all.
When using ldap there still is a need of an email address I guess? |
twosigma/beakerx-www | 281526431 | Title: unclear css
Question:
username_0: While looking at the code for beakerx.com, I discovered that the CSS could be cleaner. For example, there are 3 separate declarations for `body` and two `body:before` declarations that say the same thing. The `body` declaration is just one example. There are two `html` declarations.
The output looks like multiple CSS files concatenated into one, making it unclear where changes should be made.
```
body{
margin:0
}
body{
-webkit-font-smoothing:antialiased;
-moz-osx-font-smoothing:grayscale;
-webkit-text-size-adjust:100%;
font-family:"Lato",sans-serif;
font-weight:400
}
body{
background-color:#e44f0c;
color:#FFF
}
body:before{display:none}
body:before{display:none}
```<issue_closed>
Status: Issue closed |
kingcony/tweetsmple | 533231005 | Title: 質問させていただきます
Question:
username_0: はじめまして、質問させていただきます。
こちらのサンプルコードをクローンして、コンシューマキーとシークレットの部分のみ書き換えた状態でインストールしたアプリで確認したのですが。
Twitterアプリがインストールされている端末で認証すると、アプリで認証後にWebの認証画面が表示されて(アプリとWebで二重で認証される形)しまうのですが、そのような挙動は正しいでしょうか?
ご教授いただけると幸いです。<issue_closed>
Status: Issue closed |
clearlinux/distribution | 620922260 | Title: Gnome keyring issues at boot
Question:
username_0: This is going to be a pain in the rear to track down, but on my current install of Clear (about 4 days old) I have already had about 5-10 boots where the keyring fails to start and my desktop gets taken over by the keyring password prompt - several times in succession if I try to cancel.
Probably relevant:
- Using the Wayland session and GDM auto-login.
- Typically goes away after a reboot or two.
- Seems completely random, so it is likely that it is a problem of timing of services startup in systemd.
I would speculate that systemd might be attempting to start the keyring independently of some other service the keyring depends on. And sometimes that service is started before the keyring, as is necessary, but sometimes is started only after. I'm by no means an expert in systemd, but given the randomness, a service dependency issue seems to be the most likely cause.
Answers:
username_1: Are you really using the Wayland session? Since the 3.36 upgrade I don't have a Wayland option in the greeter?
username_0: Will do.
Has not happened in the past two days, and there have been a couple of updates since. I'm keeping the tab with this open, and if it does not happen again in the next two weeks, I will close the issue.
Status: Issue closed
username_0: Okay, so I have not had the issue again for about a week and through 3ish system updates. Very puzzling behaviour, but I will close this issue for now and only re-open it if it pops up again. |
lydiafork/lynn-blog | 681901094 | Title: 微信小程序recycle-view虚拟列表实现
Question:
username_0: 微信官方提供了长列表组件recycle-view,因此我们就来看一下这个recycle-view是如何实现的。
具体实现原理如下:
1、把整个页面分为200x200的方格
2、循环列表数据, 假设我们的数据项宽高为187.5x160,那么排列如下,
第一行的方格可以放第0, 1, 2, 3条数据(如下图)
第二行的方格可以接着放4, 5条数据
以此类推, 数据循环结束后,我们将会得到一个map
```
{
1. 0.0: [0, 1, 2, 3]
2. 1.0: [4, 5]
3. 2.0: [6, 7, 7]
4. 3.0: [8, 9, 9]
5. 4.0: [10, 11, 12, 13, 13]
6. 5.0: [14, 15, 15]
7. 6.0: [16, 17, 17]
8. 7.0: [18, 19, 19]
}
```

3、获取当前要显示的屏幕高度,初始化下是 0 - (展示几屏 * 屏幕高度)
4、计算minTop: 0 和 maxTop: 展示几屏 * 屏幕高度 之间需要渲染的数据
具体算法:
1: 计算startLine = minTop / 200
2: 计算endLine = maxTop / 200
3: 计算rectEachLine = 屏幕宽度 / 200, 在我们的例子中 rectEachLine = 1
4: 循环startLine - endLine之间, map对应的最小和最大数值

5: 调用setData更新列表数据
在我看来,以这种方式实现的原因主要是为了兼容多种多样的列表项(比如瀑布流),假如对于长宽固定的列表项来说其实变得更加复杂了,多了一次O(n)的循环。
当然具体代码中还有很多细节的优化,比如滚动事件增加节流。
具体代码在这~ 欢迎交流探讨
https://github.com/wechat-miniprogram/recycle-view |
wailsapp/wails | 859203236 | Title: i'm getting an error on Linux
Question:
username_0: I just installed wails on POPOS and tried to create a project with CLI but I'm getting the below error. Can someone plz tell me how to fix it. Thank You.
```The name of the project (My Project): y
Project Name: y
The output binary name (y):
Output binary Name: y
Project directory name (y):
Project Directory: y
Please select a template (* means unsupported on current platform):
1: Angular - Angular 8 template (Requires node 10.8+)
2: React JS - Create React App v4 template
3: Svelte - A basic Svelte template
4: Vanilla - A Vanilla HTML/JS template
5: Vue3 Full - Vue 3, Vuex, Vue-router, and Webpack4
6: Vue2/Webpack Basic - A basic Vue2/WebPack4 template
7: Vuetify1.5/Webpack Basic - A basic Vuetify1.5/Webpack4 template
8: Vuetify2/Webpack Basic - A basic Vuetify2/Webpack4 template
Please choose an option [1]: 5
Template: Vue3 Full
✓ Generating project...
⣽ Building project (this may take a while)...
Wails v1.16.3 - Building Application
⡿ Ensuring frontend dependencies are up to date (This may take a while)npm WARN deprecated [email protected]: request-promise-native has been deprecated because it extends the now deprecated request package, see https://github.com/request/request/issues/3142
npm WARN deprecated @hapi/[email protected]: This version has been deprecated and is no longer supported or maintained
npm WARN deprecated @hapi/[email protected]: This version has been deprecated and is no longer supported or maintained
npm WARN deprecated [email protected]: Please see https://github.com/lydell/urix#deprecated
npm WARN deprecated [email protected]: this library is no longer supported
npm WARN deprecated [email protected]: Legacy versions of mkdirp are no longer supported. Please update to mkdirp 1.x. (Note that the API surface has changed to use Promises in 1.x.)
npm WARN deprecated [email protected]: This loader has been deprecated. Please use eslint-webpack-plugin
npm WARN deprecated [email protected]: https://github.com/lydell/resolve-url#deprecated
npm WARN deprecated [email protected]: Debug versions >=3.2.0 <3.2.7 || >=4 <4.3.1 have a low-severity ReDos regression when used in a Node.js environment. It is recommended you upgrade to 3.2.7 or 4.3.1. (https://github.com/visionmedia/debug/issues/797)
npm WARN deprecated [email protected]: Chokidar 2 will break on node v14+. Upgrade to chokidar 3 with 15x less dependencies.
npm WARN deprecated [email protected]: Chokidar 2 will break on node v14+. Upgrade to chokidar 3 with 15x less dependencies.
npm WARN deprecated [email protected]: Chokidar 2 will break on node v14+. Upgrade to chokidar 3 with 15x less dependencies.
npm WARN deprecated [email protected]: 3.x is no longer supported
npm WARN deprecated @hapi/[email protected]: Moved to 'npm install @sideway/address'
npm WARN deprecated [email protected]: request has been deprecated, see https://github.com/request/request/issues/3142
npm WARN deprecated @hapi/[email protected]: This version has been deprecated and is no longer supported or maintained
npm WARN deprecated @hapi/[email protected]: Switch to 'npm install joi'
npm WARN deprecated [email protected]: core-js@<3 is no longer maintained and not recommended for usage due to the number of issues. Please, upgrade your dependencies to the actual version of core-js@3.
npm ERR! code 1
npm ERR! path /home/nani/work/wails/y/frontend/node_modules/node-sass
npm ERR! command failed
npm ERR! command sh -c node scripts/build.js
npm ERR! Building: /usr/local/bin/node /home/nani/work/wails/y/frontend/node_modules/node-gyp/bin/node-gyp.js rebuild --verbose --libsass_ext= --libsass_cflags= --libsass_ldflags= --libsass_library=
npm ERR! gyp info it worked if it ends with ok
npm ERR! gyp verb cli [
npm ERR! gyp verb cli '/usr/local/bin/node',
npm ERR! gyp verb cli '/home/nani/work/wails/y/frontend/node_modules/node-gyp/bin/node-gyp.js',
npm ERR! gyp verb cli 'rebuild',
npm ERR! gyp verb cli '--verbose',
npm ERR! gyp verb cli '--libsass_ext=',
npm ERR! gyp verb cli '--libsass_cflags=',
npm ERR! gyp verb cli '--libsass_ldflags=',
npm ERR! gyp verb cli '--libsass_library='
npm ERR! gyp verb cli ]
npm ERR! gyp info using [email protected]
npm ERR! gyp info using [email protected] | linux | x64
npm ERR! gyp verb command rebuild []
[Truncated]
npm ERR! gyp ERR! stack at /home/nani/work/wails/y/frontend/node_modules/isexe/index.js:42:5
npm ERR! gyp ERR! stack at /home/nani/work/wails/y/frontend/node_modules/isexe/mode.js:8:5
npm ERR! gyp ERR! stack at FSReqCallback.oncomplete (node:fs:193:21)
npm ERR! gyp ERR! System Linux 5.11.0-7612-generic
npm ERR! gyp ERR! command "/usr/local/bin/node" "/home/nani/work/wails/y/frontend/node_modules/node-gyp/bin/node-gyp.js" "rebuild" "--verbose" "--libsass_ext=" "--libsass_cflags=" "--libsass_ldflags=" "--libsass_library="
npm ERR! gyp ERR! cwd /home/nani/work/wails/y/frontend/node_modules/node-sass
npm ERR! gyp ERR! node -v v15.14.0
npm ERR! gyp ERR! node-gyp -v v3.8.0
npm ERR! gyp ERR! not ok
npm ERR! Build failed with error code: 1
npm ERR! A complete log of this run can be found in:
npm ERR! /home/nani/.npm/_logs/2021-04-15T19_50_44_445Z-debug.log
✗ Ensuring frontend dependencies are up to date (This may take a while)
Error: exit status 1
✗ exit status 1
Error: exit status 1```
Answers:
username_1: Looks like your npm setup is amiss. Looks like a dependency needs python?
username_0: I'll need python2 for this?
username_0: @username_1 just installed python2 and it seems to be working fine. But I'm not sure why python2 is used here, can you tell me why python2 is being used for?
Status: Issue closed
username_1: Glad it was sorted. Looks like it's a dependency of a vue3 dependency. |
department-of-veterans-affairs/caseflow | 196118780 | Title: End Product: Decision Date: Change to be editable value
Question:
username_0: As a Caseworker, I would like to be able to change the defaulted _"Decision Date"_ so that it contains the correct value since sometimes the VACOLS Decision Date is not accurate.
# Acceptance Criteria
1. Verify that the field _“Decision Date”_ defaults to the VACOLS decision date.
1. Verify that field _"Decision Date"_ can be edited.
### Mockups

# Related Stories
End Product: Collect information for creating an End Product https://github.com/department-of-veterans-affairs/caseflow/issues/416
Status: Issue closed
Answers:
username_1: As a Caseworker, I would like to be able to change the defaulted _"Decision Date"_ so that it contains the correct value since sometimes the VACOLS Decision Date is not accurate.
# Acceptance Criteria
1. Verify that the field _“Decision Date”_ defaults to the VACOLS decision date.
1. Verify that field _"Decision Date"_ can be edited.
### Mockups

# Related Stories
End Product: Collect information for creating an End Product https://github.com/department-of-veterans-affairs/caseflow/issues/416
username_2: Done.
Checked to be editable; (can be edited to an invalid date e.g. 14/33/0109)
Status: Issue closed
|
simon-wh/PAYDAY-2-BeardLib | 691634789 | Title: Weapons with custom underbarrels can crash other players
Question:
username_0: Switching to and firing a custom underbarrel will crash other players in the lobby.
`lib/units/weapons/newnpcraycastweaponbase` calls a function named `_sound_singleshot` to get the sound to play for the gun, leading to the crash.
Normally this would work fine as the game usually looks for the `_crew` variant of the gun to get the sounds, but underbarrels look for an `_npc` variant instead.
I'm not sure how to implement this in BeardLib, but this is how we fixed it in Restoration Mod:
- Add the following to `WeaponTweakData:_create_table_structure()`
```
self.[custom_underbarrel_name]_npc = {
usage = "is_rifle",
sounds = {},
use_data = {},
auto = {}
}
```
- Add the rest of the necessary definitions to `WeaponTweakData:init`:
```
self.[custom_underbarrel_name]_npc.sounds.prefix = "contrabandm203_npc"
self.[custom_underbarrel_name]_npc.use_data.selection_index = 2
self.[custom_underbarrel_name]_npc.DAMAGE = 2
self.[custom_underbarrel_name]_npc.muzzleflash = "effects/payday2/particles/weapons/9mm_auto"
self.[custom_underbarrel_name]_npc.shell_ejection = "effects/payday2/particles/weapons/shells/shell_9mm"
self.[custom_underbarrel_name]_npc.no_trail = true
self.[custom_underbarrel_name]_npc.CLIP_AMMO_MAX = 3
self.[custom_underbarrel_name]_npc.NR_CLIPS_MAX = 1
self.[custom_underbarrel_name]_npc.auto.fire_rate = 0.1
self.[custom_underbarrel_name]_npc.hold = "rifle"
self.[custom_underbarrel_name]_npc.alert_size = 2800
self.[custom_underbarrel_name]_npc.suppression = 1
self.[custom_underbarrel_name]_npc.FIRE_MODE = "auto"
```
Only the first line with the sound prefix should be necessary, though the rest were included to be safe.
To fix it for clients that don't have the underbarrel, you would likely have to spoof it as `contraband_m203_npc`.
Status: Issue closed
Answers:
username_1: Switching to and firing a custom underbarrel will crash other players in the lobby.
`lib/units/weapons/newnpcraycastweaponbase` calls a function named `_sound_singleshot` to get the sound to play for the gun, leading to the crash.
Normally this would work fine as the game usually looks for the `_crew` variant of the gun to get the sounds, but underbarrels look for an `_npc` variant instead.
I'm not sure how to implement this in BeardLib, but this is how we fixed it in Restoration Mod:
- Add the following to `WeaponTweakData:_create_table_structure()`
```
self.[custom_underbarrel_name]_npc = {
usage = "is_rifle",
sounds = {},
use_data = {},
auto = {}
}
```
- Add the rest of the necessary definitions to `WeaponTweakData:init`:
```
self.[custom_underbarrel_name]_npc.sounds.prefix = "contrabandm203_npc"
self.[custom_underbarrel_name]_npc.use_data.selection_index = 2
self.[custom_underbarrel_name]_npc.DAMAGE = 2
self.[custom_underbarrel_name]_npc.muzzleflash = "effects/payday2/particles/weapons/9mm_auto"
self.[custom_underbarrel_name]_npc.shell_ejection = "effects/payday2/particles/weapons/shells/shell_9mm"
self.[custom_underbarrel_name]_npc.no_trail = true
self.[custom_underbarrel_name]_npc.CLIP_AMMO_MAX = 3
self.[custom_underbarrel_name]_npc.NR_CLIPS_MAX = 1
self.[custom_underbarrel_name]_npc.auto.fire_rate = 0.1
self.[custom_underbarrel_name]_npc.hold = "rifle"
self.[custom_underbarrel_name]_npc.alert_size = 2800
self.[custom_underbarrel_name]_npc.suppression = 1
self.[custom_underbarrel_name]_npc.FIRE_MODE = "auto"
```
Only the first line with the sound prefix should be necessary, though the rest were included to be safe.
To fix it for clients that don't have the underbarrel, you would likely have to spoof it as `contraband_m203_npc`.
username_1: GitHub, when I say I attempt to fix, I meant I **ATTEMPT** to fix not I **fixed**.
username_1: Can you confirm if this happens as of the last commit? |
danisonfire/teacozy | 308680589 | Title: body looks good
Question:
username_0: Good job catching that default body margin and setting it to 0. Later we will learn about reset.css files which will handle that for us. Also good job using the body to inherit down opacity, font-family etc. CSS looks good.
https://github.com/username_1/teacozy/blob/master/resources/css/style.css#L3-L13<issue_closed>
Status: Issue closed |
hsimah/PoshScripts | 155634328 | Title: Write-Output colour extension
Question:
username_0: See proxy functions here: https://blogs.technet.microsoft.com/heyscriptingguy/2011/03/01/proxy-functions-spice-up-your-powershell-core-cmdlets/
Write-Output doesn't support colours like Write-Host does. |
legokor/FPGA-Utils | 816666752 | Title: Clock domain crossing
Question:
username_0: Synchronize a signal to a clock.
The width and the synchronization stages should be parameters of the module.
Answers:
username_0: example: (* ASYNC_REG="true" *) reg [31:0] foo;
username_0: It's good, but let's change the default `WIDTH` to 1, because that's the most common use case.
Status: Issue closed
|
nasa/osal | 810381641 | Title: Minor redundancy cleanup from static analysis warnings
Question:
username_0: **Is your feature request related to a problem? Please describe.**
Two minor redundant logic/checks:
https://github.com/nasa/osal/blob/ff4f52312297a3cdf3ddc0cf5ead95f27954630b/src/os/vxworks/src/os-impl-timebase.c#L397-L411
https://github.com/nasa/osal/blob/ff4f52312297a3cdf3ddc0cf5ead95f27954630b/src/os/vxworks/src/os-impl-network.c#L88
No actual issues, just minor cleanup.
**Describe the solution you'd like**
Remove first, refactor second so the bound is just checked in one place
**Describe alternatives you've considered**
None
**Additional context**
Static analysis warnings
**Requester Info**
<NAME> - NASA<issue_closed>
Status: Issue closed |
apache/cordova-android | 400580582 | Title: I have a question about development with android stuido 3.2 and higher
Question:
username_0: When opening the `platform / android` project created after executing the following command with android studio 3.2 or later, the following error occurs and it can not be built.
Does this have problems with my environment? Or is it that it does not correspond to android stuido 3.2 or higher with correct behavior?
create android project
```
$ cordova create test com.example.test Test && cd $_
$ cordova platform add [email protected]
```
error
```
ERROR: The minSdk version should not be declared in the android manifest file. You can move the version from the manifest to the defaultConfig in the build.gradle file.
Move minSdkVersion to build files and sync project
Affected Modules: CordovaLib, app
WARNING: The targetSdk version should not be declared in the android manifest file. You can move the version from the manifest to the defaultConfig in the build.gradle file.
Move targetSdkVersion to build file and sync project
Affected Modules: app
```
Answers:
username_0: sorry...
There was no error in ver 7.1.4 (@ latest). Was it a resolved issue?
username_1: I spotted similar error messages with android@nightly (8.0.0-dev) on Android Studio 3.3. Android Studio 3.3 offered me an option to fix the project automatically.
If I would accept the option to fix the project, Android Studio 3.3 would automatically update the following files to define minSdk and targetSdk values in Gradle instead of AndroidManifest.xml:
- `platforms/android/CordovaLib/AndroidManifest.xml`
- `platforms/android/CordovaLib/build.gradle`
- `platforms/android/app/build.gradle`
- `platforms/android/app/src/main/AndroidManifest.xml`
I think a similar kind of a solution would be needed to resolve the issue discussed in #508 (inconsistent handling of min/target SDK values), but may need some rework to respect the Gradle properties documented in <https://cordova.apache.org/docs/en/latest/guide/platforms/android/#setting-gradle-properties>.
Marked as a bug, hope we can resolve it before the major release for Cordova 9 (apache/cordova#10).
username_0: Thank you very much. Would you please tell me where this option can be set
username_2: In android studio let the gradle build run and fail. In the error log it will have a message about auto fixing/refactoring the issue. Click the message then hit refactor in the bottom left.
Status: Issue closed
username_3: Is this really fixed by this PR merge @username_1?
username_1: Should be
username_1: When opening the `platform / android` project created after executing the following command with android studio 3.2 or later, the following error occurs and it can not be built.
Does this have problems with my environment? Or is it that it does not correspond to android stuido 3.2 or higher with correct behavior?
create android project
```
$ cordova create test com.example.test Test && cd $_
$ cordova platform add [email protected]
```
error
```
ERROR: The minSdk version should not be declared in the android manifest file. You can move the version from the manifest to the defaultConfig in the build.gradle file.
Move minSdkVersion to build files and sync project
Affected Modules: CordovaLib, app
WARNING: The targetSdk version should not be declared in the android manifest file. You can move the version from the manifest to the defaultConfig in the build.gradle file.
Move targetSdkVersion to build file and sync project
Affected Modules: app
```
environment
```
npm 6.4.1
node v10.15.0
cordova 8.1.2
```
username_1: I would like to reopen this issue until we get a chance to actually test it and ensure the resulting issue #666 is resolved.
username_4: @username_1 I specify the min SDK version like so:
```
<platform name="android">
<preference name="android-minSdkVersion" value="21" />
</platform>
```
Does your PR also respect this preference? And if yes: Do you when your enhancement is released? Using cordova-android v8 atm
username_1: This should be resolved in [email protected]. If not then please
provide https://stackoverflow.com/help/mcve demo of the issue.
username_4: @username_1 I just created a brand new cordova app like described here: https://cordova.apache.org/docs/en/latest/guide/cli/index.html
Configured the android platform to v8.0.0
Ran `cordova platform add android` and `cordova build android`. When opening the project with android studio I get this notification:

So I click "update" and then I get this error:

The app still runs and it works when I click then on "move" in android studio. But it would be nice not to need to do that
username_5: I'm running android 8.0 and received this same error about the minsdk location and did the Refactor to fix option too...
username_6: Fix has been reverted by https://github.com/apache/cordova-android/issues/666
username_7: This should have be resolved with PR #699 and is now merged into master. It will be available in the next release.
Status: Issue closed
username_4: Thanks for the update @username_7
Do you know when the next release will happen?
username_8: 8.1.0 is out today! I can confirm this issue is now fixed! Awesome work guys!
username_9: so it's like cat-and-mouse. If you upgrade to 8.1.0 you get Can't install plugin: Cannot read property '0' of undefined #581
So you upgrade Branch to 4.0.0. Then another error (check "Branch.h missing") on iOS when on 4.0.0.
username_10: Sounds like a plugin problem, not a cordova-android problem.
username_9: @username_10 accurate. 🙏 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.