
repo_name
stringlengths 4
136
| issue_id
stringlengths 5
10
| text
stringlengths 37
4.84M
|
|---|---|---|
Opentrons/opentrons | 302944353 | Title: Robot Wifi Not Appearing on Windows
Question:
username_0: PLACEHOLDER - getting details.
## Expected: Wifi networks should appear in networks dropdown
## Observed: Wifi networks do not appear in windows machines
## Steps To Recreate
Note: Have not recreated this one yet; reported by @Laura-Danielle
1. Open run app on Windows (version >= 2018-03-06)
2. Open robot settings tab
3. Not wifi networks not visible in dropdown?
Answers:
username_0: @username_1 @Kadee80
Just an FYI -- not sure if this is related to any ongoing connectivity work.
username_1: @username_0 ongoing connectivity work as not touched existing discovery logic. @Laura-Danielle what version of Windows and which exact build did you see this behavior on?
I'm unable to reproduce this on my Windows 10 (v10.0.16299) with latest `edge` (commit 148d316 at time of writing)
username_0: @username_1 Reproduced this again on @Carlos-fernandez laptop:
- Last stable build: https://s3.amazonaws.com/opentrons-app/builds/Opentrons-v3.0.0-beta.2-win-b3193.exe
- PP2 Robot: OPENTRONS-OT2P20180327A04
- Was able to successfully connect on my mac
Status: Issue closed
|
scikit-mobility/scikit-mobility | 729020079 | Title: Add hexagonal tessellation with H3
Question:
username_0: Create a new tiler builder, based on H3, to enable the creation of hexagonal tessellation.
Answers:
username_1: @username_0 Is this being worked on? Happy to give it a shot if not.
username_0: Currently this issue is already taken from another contributor. We are planning to further expand the tessellation module by adding a method to create triangle tessellation. Do you want to contribute to that?
username_2: we just added the H3TessellationTiler in branch 1.2.x
Status: Issue closed
|
vtex-apps/store-discussion | 1025529588 | Title: Order by discount
Question:
username_0: **Describe the bug**
The filter `orderBy discount` don't work correctly. Currently the order by is this parameter on link `order=OrderByBestDiscountDESC` but this `orderBy` don't work how expected
**To Reproduce**
Currently -> https://www.medicalshop.pt/vida-diaria?order=OrderByBestDiscountDESC
**Expected behavior**
The filter expected is how this parameter on link `O=OrderByBestDiscountDESC` where products with more discount filtered first
**To Reproduce**
Expected -> https://www.medicalshop.pt/vida-diaria?O=OrderByBestDiscountDESC
**Screenshots**
Currently Image

Expected Image

** Component Used **
https://github.com/vtex-apps/search-result -> `order-by.v2`
Answers:
username_1: @username_0 could you give more details about what is wrong in the search result? for me the order is correct: first items with discount (descending) and then items with no discount
username_0: @username_1 Items with the lowest value and not the items with the highest discount first are showing.
username_1: hello @username_0, I investigated it with my team and we noticed that this store has not been reindexed since August.
During that time there have been some changes in how our sort boosts are calculated, so this store ended up with old values but applying the new sorting logic.
We've run an indexing for the entire store and soon the problem should be solved.
Thank you very much for your patience and any questions you can open a new issue or @ me here again. See you! 👋 🙂
Status: Issue closed
|
centreon/centreon | 121303371 | Title: [2.7.0-RC2] Centreon Engine stats
Question:
username_0: On the previous version, we were not able to scroll, it was better because we can see all details. Now.. it's too small! We don't see latency part, etc...
My point of view :-)
thanks
<issue_closed>
Status: Issue closed |
11ty/eleventy | 718357313 | Title: top-level svg in .html include fails to render when opening tag split into multiple lines
Question:
username_0: **Describe the bug**
When:
- you have an included `.html` file, and
- the top-level tag of the file is `svg`, and
- the _opening tag_ is _spread over multiple lines_, then
...the SVG fails to render in the browser.
**To Reproduce**
Steps to reproduce the behavior:
1. Go to https://gist.github.com/username_0/390aaea1c837188ae84e3a7b5ef0829e
2. Grab `include-ok.html` add to 11ty site, and include it in a layout
3. Build site; see it renders similarly to: 
4. Replace `include-ok.html` with `include-broken.html`, build site and refresh
5. See something broken like:

You can then see the problem is fixed by trying `include-ok-wrapped.html`, which wraps the `svg` in a `div` tag. It doesn't even need to be wrapped; the first tag can be an empty div like `<div></div>` followed by `<svg ..>`, and it will render properly.
**Screenshots**
See above
**Environment:**
- OS and Version: macOS 10.15.7
- Eleventy Version: v0.11.0
**Additional context**
may be the fault of something else in our configuration (it's in the gist).
Ref: https://github.com/mochajs/mocha/pull/4440
Answers:
username_1: @username_0 sorry for the wait. I'll try to take a look within 24 hours.
username_0: no rush, it's a corner case w/ a trivial workaround.
username_1: Test results:
- Breaks with markdown+liquid
- Does not break with nunjucks
- Does not break with just liquid
The problem may actually be with [markdown-it](https://github.com/markdown-it/markdown-it), which Eleventy uses under the hood. I'd open an issue there. Be sure to mention that the svg include works when wrapped in a div.
In the meantime, you could always try using a different markdown parser.
username_2: If you want to change the markdown parser, this section in the docs explain how to do that:
https://www.11ty.dev/docs/languages/markdown/#optional-set-your-own-library-instance
(Eleventy doesn't care, whether the set library is still `markdown-it`). |
eai04191/my-manjaro-way | 425212784 | Title: GRUBのコマンドラインメッセージ?が表示されない
Question:
username_0: なんかBIOSのスプラッシュがずっと写っててキモい
ログやメッセージが見えたほうが嬉しい
Answers:
username_0: [ubuntuでブートプロセスを表示 - 超ウィザード級ハッカーのたのしみ](http://fj.hatenablog.jp/entry/2016/04/01/004620)
`sudo vim /etc/default/grub`
`GRUB_CMDLINE_LINUX_DEFAULT="nosplash"`
`sudo update-grub`
Status: Issue closed
|
open-telemetry/opentelemetry-js | 1130390849 | Title: Pika build monorepo crush because requiere install unused dependencies
Question:
username_0: Please answer these questions before submitting a bug report.
When I try to complie my monorepo it crush because need some dependecies that I not use.

### What version of OpenTelemetry are you using?
0.27.0
```typescript
"dependencies": {
"@opentelemetry/api": "^1.0.4",
"@opentelemetry/auto-instrumentations-node": "^0.27.3",
"@opentelemetry/core": "^1.0.1",
"@opentelemetry/exporter-collector": "^0.25.0",
"@opentelemetry/exporter-collector-grpc": "^0.25.0",
"@opentelemetry/exporter-jaeger": "^1.0.1",
"@opentelemetry/exporter-prometheus": "^0.27.0",
"@opentelemetry/host-metrics": "^0.27.1",
"@opentelemetry/propagator-b3": "^1.0.1",
"@opentelemetry/propagator-jaeger": "^1.0.1",
"@opentelemetry/sdk-metrics-base": "^0.27.0",
"@opentelemetry/sdk-node": "^0.27.0",
"@opentelemetry/sdk-trace-base": "^1.0.1",
"@opentelemetry/semantic-conventions": "^1.0.1",
},
```
### What version of Node are you using?
14.17.0
### Please provide the code you used to setup the OpenTelemetry SDK
```typescript
import {
CompositePropagator,
W3CBaggagePropagator,
W3CTraceContextPropagator,
} from '@opentelemetry/core';
import { BatchSpanProcessor } from '@opentelemetry/sdk-trace-base';
import { JaegerExporter } from '@opentelemetry/exporter-jaeger';
import { getNodeAutoInstrumentations } from '@opentelemetry/auto-instrumentations-node';
import { JaegerPropagator } from '@opentelemetry/propagator-jaeger';
import { B3InjectEncoding, B3Propagator } from '@opentelemetry/propagator-b3';
import { PrometheusExporter } from '@opentelemetry/exporter-prometheus';
import { NodeSDK } from '@opentelemetry/sdk-node';
import { AsyncLocalStorageContextManager } from '@opentelemetry/context-async-hooks';
import { Resource } from '@opentelemetry/resources';
import { SemanticResourceAttributes } from '@opentelemetry/semantic-conventions';
import { HttpInstrumentation } from '@opentelemetry/instrumentation-http';
import { OpenTelemetryConfiguration } from '../interfaces/tracing.interface';
import * as _ from 'lodash';
import { defaultTraceExcludePaths } from './tracing.constants';
export const otelSDK = (options: OpenTelemetryConfiguration) => {
return new NodeSDK({
metricExporter: new PrometheusExporter({
...options.prometheusExporterConfig,
}),
metricInterval: options.metricInterval || 1000,
spanProcessor: new BatchSpanProcessor(
new JaegerExporter({
...options.jaegerExporterConfig,
}),
),
contextManager: new AsyncLocalStorageContextManager(),
textMapPropagator: new CompositePropagator({
[Truncated]
});
};
```
### What did you do?
1. git clone https://github.com/tresdoce/nestjs-tracing.git
2. git checkout feat/opentelemetry
2. npm install
3. npm run build
4. see the error
### What did you expect to see?
Complete building of the project
### What did you see instead?
The error says that I have to install this dependencies:
OS: Windows, MacOS
### Additional context
I think that problem is in @opentelemetry/auto-instrumentations-node dependency
Answers:
username_1: I guess that's a similar problem then https://github.com/open-telemetry/opentelemetry-js-contrib/issues/802
As workaround you can set `skipLibCheck: true` in your tsconfig.json file.
username_2: Another workaround is to use only the instrumentation packages for the modules you are using rather than the auto-instrumentations-node dependency.
I think this is because the types are a devDependency https://github.com/open-telemetry/opentelemetry-js-contrib/blob/main/plugins/node/opentelemetry-instrumentation-aws-sdk/package.json#L59
It seems like this is happening more for some reason. We should probably try to address this in a more systemic way. I can think of some possible solutions:
1. add the instrumented module to the dependencies of the instrumentation module
2. add the instrumented module to the peerDependencies of the instrumentation module
- NPM 7.x+ has [peerDependenciesMeta](https://docs.npmjs.com/cli/v7/configuring-npm/package-json#peerdependenciesmeta) which allows us to define these as optional so they are not automatically installed. NPM <7.x will not automatically install peer dependencies, but will warn in the console at install time.
3. Vendor all types in the instrumentation module
- This obviously increases the maintenance burden and chance for failures, but removes all external dependencies |
plotly/plotly.py | 1113840322 | Title: With newer versions of orjson, users need to specify the json engine explicitly (bug?)
Question:
username_0: Hey
I found out I get an
`AttributeError: partially initialized module 'orjson' has no attribute 'OPT_NON_STR_KEYS'`
if I don't specify this
`plotly.io.json.config.default_engine = 'orjson'`
when using orjson v3.6.6 (latest as of 25jan2022)
Also, additional note for whoever might have this issue: you don't need to uninstall orjson if you don't want to use it. just set the engine to 'json' explicitly.
I'm using orjson because of the performance claims, although I ran some tests switching between the 2 engines and they seem to yield the same results: using go.Candlestick with 10000 candlesticks and some 4-5 indicators, getting ~0.8sec in each case for creating the plot. My purpose is to improve the dash server performace, but it seems it makes no difference (the web page still renders slower than the ticker even with 600 candles) |
jesseduffield/lazygit | 631567588 | Title: Starting lazygit in a git directory and pressing "p" rapidly causes a panic
Question:
username_0: **Describe the bug**
Lazygit panics if "p" is pressed immediately after starting.
**To Reproduce**
Start lazygit and then press rapidly "p". I think lazygit did not finish to initialize it's internal data and pressing "p" causes some kind of error.
➜ ansible2 git:(master) lazygit
panic: runtime error: invalid memory address or nil pointer dereference
[signal SIGSEGV: segmentation violation code=0x1 addr=0x40 pc=0xa7d07f]
goroutine 1 [running]:
github.com/username_1/lazygit/pkg/gui.(*Gui).handlePullFiles(0xc000250a90, 0xc000270000, 0xc0000b29a0, 0x2, 0x100c00029fa08)
github.com/username_1/lazygit/pkg/gui/files_panel.go:404 +0x4f
github.com/username_1/lazygit/vendor/github.com/username_1/gocui.(*Gui).execKeybinding(...)
github.com/username_1/lazygit/vendor/github.com/username_1/gocui/gui.go:898
github.com/username_1/lazygit/vendor/github.com/username_1/gocui.(*Gui).execKeybindings(0xc000270000, 0xc0000b29a0, 0xc00029fb08, 0xc000305aa0, 0xc000000208, 0xc0000002b8)
github.com/username_1/lazygit/vendor/github.com/username_1/gocui/gui.go:891 +0x213
github.com/username_1/lazygit/vendor/github.com/username_1/gocui.(*Gui).onKey(0xc000270000, 0xc00029fb08, 0x2, 0x0)
github.com/username_1/lazygit/vendor/github.com/username_1/gocui/gui.go:809 +0x281
github.com/username_1/lazygit/vendor/github.com/username_1/gocui.(*Gui).handleEvent(...)
github.com/username_1/lazygit/vendor/github.com/username_1/gocui/gui.go:497
github.com/username_1/lazygit/vendor/github.com/username_1/gocui.(*Gui).MainLoop(0xc000270000, 0xc000000003, 0xc00029fc80)
github.com/username_1/lazygit/vendor/github.com/username_1/gocui/gui.go:457 +0x1f2
github.com/username_1/lazygit/pkg/gui.(*Gui).Run(0xc000250a90, 0x0, 0x0)
github.com/username_1/lazygit/pkg/gui/gui.go:363 +0x65a
github.com/username_1/lazygit/pkg/gui.(*Gui).RunWithSubprocesses(0xc000250a90, 0x0, 0x0)
github.com/username_1/lazygit/pkg/gui/gui.go:372 +0x40
github.com/username_1/lazygit/pkg/app.(*App).Run(0xc00018f420, 0xc0000cc980, 0x0)
github.com/username_1/lazygit/pkg/app/app.go:158 +0x6b
main.main()
github.com/username_1/lazygit/main.go:70 +0x811
**Expected behavior**
A clear and concise description of what you expected to happen.
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Desktop (please complete the following information):**
- OS: Linux
- Lazygit Version commit=, build date=2020-05-19, build source=debian, version=0.20.4, os=linux, arch=amd64
Answers:
username_1: thanks for raising this issue, this makes it very easy to replicate the problem :) It looks like we have a concurrency issue that might call for a mutex |
bazelbuild/continuous-integration | 447893731 | Title: Request to add new project codelabs
Question:
username_0: - I want to test the following project on Bazel CI: [https://github.com/bazelbuild/codelabs]
- I confirm that the project has a `.bazelci/presubmit.yml` file.
Answers:
username_1: Done!
Your project currently fails on Windows, because there are no tests: https://buildkite.com/bazel/bazel-codelabs/builds/1#d832f7f5-8073-4a8d-ac62-ffe8577267c5
Could you have a look at that?
Green Team: Feel free to remove the disable_reason once the project has been green in the disabled downstream pipeline.
Status: Issue closed
|
amuguna6/LEADERBOARD | 699304674 | Title: GADS LEADERBOARD 2020 SCREENSHOTS
Question:
username_0: 



 |
watson-developer-cloud/node-sdk | 170510664 | Title: [alchemy_language] Uncaught undefined Error
Question:
username_0: - node 6.3.4
- node-sdk 2.0.2
I have a couple of integration tests which use the alchemy api. Those tests sometimes run into the following error:
Uncaught Error: Uncaught, unspecified "error" event. ([object Object])
at classification-engine.js:208:26
at node_modules/async/lib/async.js:726:13
at node_modules/async/lib/async.js:52:16
at done (node_modules/async/lib/async.js:241:17)
at node_modules/async/lib/async.js:44:16
at node_modules/async/lib/async.js:723:17
at node_modules/async/lib/async.js:167:37
at classification-engine.js:197:25
at node_modules/watson-developer-cloud/alchemy-language/v1.js:33:7
at Request._callback (node_modules/watson-developer-cloud/lib/requestwrapper.js:69:5)
at Request.self.callback (node_modules/request/request.js:187:22)
at Request.<anonymous> (node_modules/request/request.js:1044:10)
at Gunzip.<anonymous> (node_modules/request/request.js:965:12)
at endReadableNT (_stream_readable.js:913:12)
at _combinedTickCallback (internal/process/next_tick.js:74:11)
at process._tickCallback (internal/process/next_tick.js:98:9)
Answers:
username_1: Hi @username_0,
Any chance you could get a prettyprint of that `[object Object]`? My guess is that the service itself hit some kind of error and the library passed it allong as the error object in your callback function at `classification-engine.js:197:25`. (Although, right now the library sometimes returns regular objects rather than Error instances right now. Let me see if I can change that real quick...)
username_1: I just pushed `v2.0.3` with a small change to ensure `error` objects passed to callbacks are always `instanceof Error`, which may help getting clearer messages out of your tests when something fails.
It should be up on npm as soon as the CI loop finishes.
username_0: Hi, thanks for the quick response. I haven't been able to reproduce the error (at least after I upgraded to the latest version):
I actually don't no where the [object Object] comes from. I have printed all errors to a log file. But it didn't catch this.
As a follow up, I've been extending my test coverage and found another "Uncaught Error". I simply left the password blank. Although it's pretty obvious, I guess this should be covered, right?
Uncaught Error: Unauthorized: Access is denied due to invalid credentials.
<HTML><HEAD><meta content="text/html; charset=UTF-8" http-equiv="Content-Type"><TITLE>Watson Error</TITLE></HEAD><BODY><HR><p>Invalid access to resource - /natural-language-classifier/api/v1/classifiers/33fffex86-nlc-188/classify</p><p>User access not Authorized.</p><p>Gateway Error Code : ERCD04-NOAUTHHDR-PLTFRMREQ</p><p>Unable to communicate with Watson.</p><p>Request URL : https://192.168.3.11:443/natural-language-classifier/api/v1/classifiers/33fffex86-nlc-188/classify</p><p>Error Id : gateway-dp01-180383972</p><p>Date-Time : 2016-08-11T06:28:09-04:00</p></BODY></HTML>
at Request._callback (node_modules/watson-developer-cloud/lib/requestwrapper.js:68:15)
at Request.self.callback (node_modules/request/request.js:187:22)
at Request.<anonymous> (node_modules/request/request.js:1044:10)
at IncomingMessage.<anonymous> (node_modules/request/request.js:965:12)
at endReadableNT (_stream_readable.js:913:12)
at _combinedTickCallback (internal/process/next_tick.js:74:11)
at process._tickCallback (internal/process/next_tick.js:98:9)
username_1: Yea, that makes sense, although I probably shouldn't stuff the HTML into the error message.
For the "uncaught" part, does your code look something like this:
```js
watson.do_whatever({/*...*/}, function(err, res) {
if (err) {
throw err; // <-- this line in particular
}
// do stuff with result
});
```
The SDK should not be `throw`ing errors, just returning them to the callback. So I don't think it would get the "uncaught error" prefix unless your code was doing the `throw` (?)
username_1: Closing for now, please re-open or file a new ticket if you're still experiencing this issue.
Status: Issue closed
|
NotSoSecure/Blacklist3r | 538966053 | Title: Option 'valalgo' is unknown.
Question:
username_0: Hello,
After compiling the tool in visual studio I don't have the same option as you :
From the readme:

On my side:
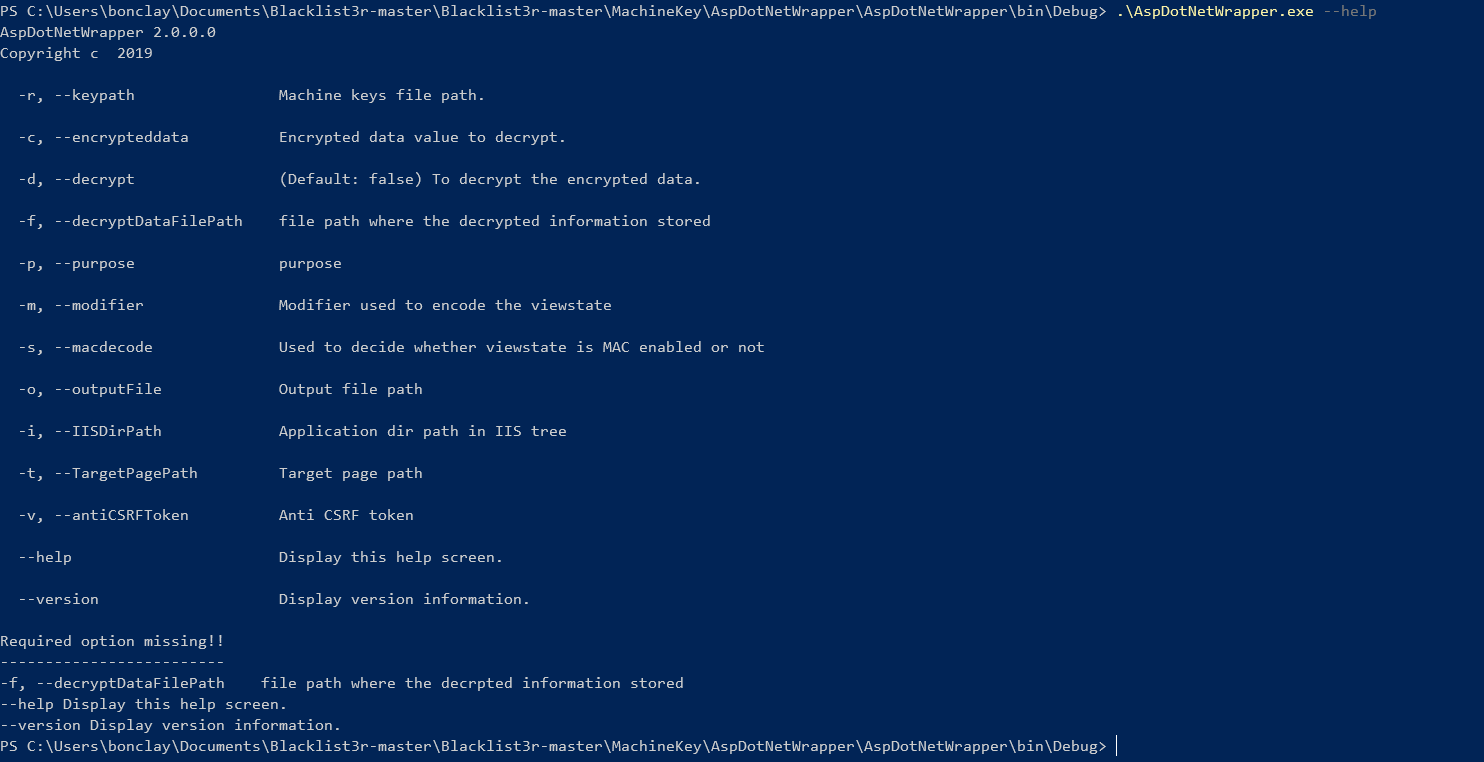
So of course, when I try with a sample command like
```
`AspDotNetWrapper.exe --keypath MachineKeys.txt --encrypteddata <KEY> --decrypt --purpose=owin.cookie --valalgo=hmacsha512 --decalgo=aes
```
I have this error:
```
ERROR(S):
Option 'valalgo' is unknown.
Option 'decalgo' is unknown.
Option 'legacy' is unknown.
```
We use the same version, any idea why I didn't have all options available ?
Answers:
username_0: If this is related you the version of .net I have (>4.5) It's means we can use `valalgo` only on a old version of .net ?
username_1: @username_0 did you manage to make it work? I am experiencing the same issue
username_0: Use the release version https://github.com/NotSoSecure/Blacklist3r/releases
username_2: The issue is fixed in AspDotNetWrapper v3.0
Status: Issue closed
|
researchgate/gradle-release | 330317148 | Title: Custom version property
Question:
username_0: I figured problem was on git repo hosting side, which resulted in this weird behaviour. Sorry for the noise.
Status: Issue closed
Answers:
username_1: Hm for me it works. Is it an error and the build breaks up or just a message? If it's an error it would be nice to get the stacktrace otherwise a debug run would be good to check where that message comes from because it could be possible that something else relies on that property that is not part of the release plugin
username_0: I figured problem was on git repo hosting side, which resulted in this weird behaviour. Sorry for the noise.
Status: Issue closed
username_2: * Try:
Run with --info or --debug option to get more log output. Run with --scan to get full insights.
* Exception is:
org.gradle.api.tasks.TaskExecutionException: Execution failed for task ':http-request-recorder:unSnapshotVersion'.
at org.gradle.api.internal.tasks.execution.ExecuteActionsTaskExecuter.executeActions(ExecuteActionsTaskExecuter.java:110)
at org.gradle.api.internal.tasks.execution.ExecuteActionsTaskExecuter.execute(ExecuteActionsTaskExecuter.java:77)
at org.gradle.api.internal.tasks.execution.OutputDirectoryCreatingTaskExecuter.execute(OutputDirectoryCreatingTaskExecuter.java:51)
at org.gradle.api.internal.tasks.execution.SkipUpToDateTaskExecuter.execute(SkipUpToDateTaskExecuter.java:59)
at org.gradle.api.internal.tasks.execution.ResolveTaskOutputCachingStateExecuter.execute(ResolveTaskOutputCachingStateExecuter.java:54)
at org.gradle.api.internal.tasks.execution.ValidatingTaskExecuter.execute(ValidatingTaskExecuter.java:59)
at org.gradle.api.internal.tasks.execution.SkipEmptySourceFilesTaskExecuter.execute(SkipEmptySourceFilesTaskExecuter.java:101)
at org.gradle.api.internal.tasks.execution.FinalizeInputFilePropertiesTaskExecuter.execute(FinalizeInputFilePropertiesTaskExecuter.java:44)
at org.gradle.api.internal.tasks.execution.CleanupStaleOutputsExecuter.execute(CleanupStaleOutputsExecuter.java:91)
at org.gradle.api.internal.tasks.execution.ResolveTaskArtifactStateTaskExecuter.execute(ResolveTaskArtifactStateTaskExecuter.java:62)
at org.gradle.api.internal.tasks.execution.SkipTaskWithNoActionsExecuter.execute(SkipTaskWithNoActionsExecuter.java:59)
at org.gradle.api.internal.tasks.execution.SkipOnlyIfTaskExecuter.execute(SkipOnlyIfTaskExecuter.java:54)
at org.gradle.api.internal.tasks.execution.ExecuteAtMostOnceTaskExecuter.execute(ExecuteAtMostOnceTaskExecuter.java:43)
at org.gradle.api.internal.tasks.execution.CatchExceptionTaskExecuter.execute(CatchExceptionTaskExecuter.java:34)
at org.gradle.api.internal.tasks.execution.EventFiringTaskExecuter$1.run(EventFiringTaskExecuter.java:51)
at org.gradle.internal.operations.DefaultBuildOperationExecutor$RunnableBuildOperationWorker.execute(DefaultBuildOperationExecutor.java:300)
at org.gradle.internal.operations.DefaultBuildOperationExecutor$RunnableBuildOperationWorker.execute(DefaultBuildOperationExecutor.java:292)
at org.gradle.internal.operations.DefaultBuildOperationExecutor.execute(DefaultBuildOperationExecutor.java:174)
at org.gradle.internal.operations.DefaultBuildOperationExecutor.run(DefaultBuildOperationExecutor.java:90)
at org.gradle.internal.operations.DelegatingBuildOperationExecutor.run(DelegatingBuildOperationExecutor.java:31)
at org.gradle.api.internal.tasks.execution.EventFiringTaskExecuter.execute(EventFiringTaskExecuter.java:46)
at org.gradle.execution.taskgraph.LocalTaskInfoExecutor.execute(LocalTaskInfoExecutor.java:42)
at org.gradle.execution.taskgraph.DefaultTaskExecutionGraph$BuildOperationAwareWorkItemExecutor.execute(DefaultTaskExecutionGraph.java:277)
at org.gradle.execution.taskgraph.DefaultTaskExecutionGraph$BuildOperationAwareWorkItemExecutor.execute(DefaultTaskExecutionGraph.java:262)
at org.gradle.execution.taskgraph.DefaultTaskPlanExecutor$ExecutorWorker$1.execute(DefaultTaskPlanExecutor.java:135)
at org.gradle.execution.taskgraph.DefaultTaskPlanExecutor$ExecutorWorker$1.execute(DefaultTaskPlanExecutor.java:130)
at org.gradle.execution.taskgraph.DefaultTaskPlanExecutor$ExecutorWorker.execute(DefaultTaskPlanExecutor.java:200)
at org.gradle.execution.taskgraph.DefaultTaskPlanExecutor$ExecutorWorker.executeWithWork(DefaultTaskPlanExecutor.java:191)
at org.gradle.execution.taskgraph.DefaultTaskPlanExecutor$ExecutorWorker.run(DefaultTaskPlanExecutor.java:130)
at org.gradle.internal.concurrent.ExecutorPolicy$CatchAndRecordFailures.onExecute(ExecutorPolicy.java:63)
at org.gradle.internal.concurrent.ManagedExecutorImpl$1.run(ManagedExecutorImpl.java:46)
at org.gradle.internal.concurrent.ThreadFactoryImpl$ManagedThreadRunnable.run(ThreadFactoryImpl.java:55)
Caused by: java.lang.AssertionError: [___/gradle.properties] contains no 'version' property. Expression: properties.version
at net.researchgate.release.ReleasePlugin.checkPropertiesFile(ReleasePlugin.groovy:278)
at net.researchgate.release.ReleasePlugin.unSnapshotVersion(ReleasePlugin.groovy:197)
at org.gradle.api.internal.AbstractTask$ClosureTaskAction.execute(AbstractTask.java:737)
at org.gradle.api.internal.AbstractTask$ClosureTaskAction.execute(AbstractTask.java:712)
at org.gradle.api.internal.tasks.execution.ExecuteActionsTaskExecuter$1.run(ExecuteActionsTaskExecuter.java:131)
at org.gradle.internal.operations.DefaultBuildOperationExecutor$RunnableBuildOperationWorker.execute(DefaultBuildOperationExecutor.java:300)
at org.gradle.internal.operations.DefaultBuildOperationExecutor$RunnableBuildOperationWorker.execute(DefaultBuildOperationExecutor.java:292)
at org.gradle.internal.operations.DefaultBuildOperationExecutor.execute(DefaultBuildOperationExecutor.java:174)
at org.gradle.internal.operations.DefaultBuildOperationExecutor.run(DefaultBuildOperationExecutor.java:90)
at org.gradle.internal.operations.DelegatingBuildOperationExecutor.run(DelegatingBuildOperationExecutor.java:31)
at org.gradle.api.internal.tasks.execution.ExecuteActionsTaskExecuter.executeAction(ExecuteActionsTaskExecuter.java:120)
at org.gradle.api.internal.tasks.execution.ExecuteActionsTaskExecuter.executeActions(ExecuteActionsTaskExecuter.java:99)
... 31 more
```
----
As a workaround, I now have a `version` entry in my `gradle.properties`:
```
version=1.0.1-SNAPSHOT
projectversion=1.0.1-SNAPSHOT
```
and this configuration `build.gradle`:
```
release {
versionPropertyFile = 'gradle.properties'
versionProperties = ['version', 'projectversion']
}
```
Thank you in advance for your feedback.
username_1: True it's a bug https://github.com/researchgate/gradle-release/blob/master/src/main/groovy/net/researchgate/release/ReleasePlugin.groovy#L319
username_3: @username_1 is there an update on this Issue?
I tried to use the custom Version property and i get the same Error as username_2.
username_1: I tried setting this:
```
versionProperties = ['myVersion']
```
But plugin seems to still require 'version' to be defined:
```
contains no 'version' property. Expression: 'properties.version'
```
Is there a way to use custom version property?
username_1: @username_3 No update on this from my side. But I will reopen this. |
Atlantiss/NetherwingBugtracker | 395384936 | Title: [Rogue][Spell] Vanish + Combat
Question:
username_0: **Description**: https://gfycat.com/EagerConcreteCrossbill The rogue vanishes my kidney shot and is supposed to be out of combat but isn't so I wasn't able to sap him after vanishing myself. This is pretty important interaction in rogue vs rogue as to how you should be able to reliably sap the other rogue if you both just vanished an ability.
**Expected behaviour**: Shouldn't be in combat after vanishing an ability.
**Server Revision**: 2555
Answers:
username_1: Are you sure it's the kidney shot that prolonged combat on him?
username_0: Nothing else hit him except kidney shot when he vanished. What I think happened is he vanished, lost combat but the kidney came at same time so he got in combat. I don't know how all the interaction with batching and stuff should work though
username_1: Please retest in rev 2564.
Status: Issue closed
|
kadena-io/chainweb-node | 432620217 | Title: Create type for query arguments in TreeDB
Question:
username_0: Create a type for the common query arguments:
```haskell
-> Maybe (NextItem (DbKey db))
-> Maybe Limit
-> Maybe MinRank
-> Maybe MaxRank
```
cf. https://github.com/kadena-io/chainweb/pull/78/files#diff-2d86eb70515a06a3479275ea4c5c9a6bR373
Answers:
username_0: ➤ <NAME> commented:
Since each field of our hypothetical wrapper type is itself wrapped in Maybe, a Monoid instance is an easy win. There are a number of places in the code base where:
entries db Nothing Nothing Nothing Nothingcould just as easily be
entries db mempty
Status: Issue closed
username_0: Moved issue over to chainweb-node (111)
username_0: Create a type for the common query arguments:
```haskell
-> Maybe (NextItem (DbKey db))
-> Maybe Limit
-> Maybe MinRank
-> Maybe MaxRank
```
cf. https://github.com/kadena-io/chainweb/pull/78/files#diff-2d86eb70515a06a3479275ea4c5c9a6bR373
Status: Issue closed
|
mapbox/mapbox-gl-js | 473581703 | Title: IE11 does not support `Object.includes()`
Question:
username_0: <!--
Hello! Thanks for contributing. For the fastest response and resolution, please:
- Make the issue title a succinct but specific description of the unexpected behavior. Bad: "Map rotation is broken". Good: "map.setBearing(...) throws a TypeError for negative values"
- Include a link to a minimal demonstration of the bug. We recommend using https://jsbin.com.
- Ensure you can reproduce the bug using the latest release.
- Check the console for relevant errors and warnings
- Only post to report a bug. For feature requests, please use https://github.com/mapbox/mapbox-gl-js/issues/new?template=Feature_request.md instead. Direct all other questions to https://stackoverflow.com/questions/tagged/mapbox-gl-js
-->
[This PR](https://github.com/mapbox/mapbox-gl-js/pull/8466) introduces an `includes` method (https://github.com/mapbox/mapbox-gl-js/pull/8466/files#diff-3bdcadb35be47763a1abccc9707d22e0R181) that IE11 does not support.
**mapbox-gl-js version**: 1.2.0-beta.1
**browser**: IE11
### Steps to Trigger Behavior
1. Errors on startup
Answers:
username_1: Fixed by #8565
Status: Issue closed
|
zio/zio-prelude | 748342341 | Title: Add forany1 and foranyPar1 to NonEmptyTraversable
Question:
username_0: Analogous to https://github.com/zio/zio-prelude/issues/392
But it should be able to return `G[B]` straight, without wrapping it in an Option.
Answers:
username_1: I think if we went with my proposal in #424 we wouldn't need this because `None` would represent there not being any "successful" value, which could occur if either the collection is empty or if all of the results are "failures". |
wso2/product-apim | 752011381 | Title: A duplicate permission error thrown when starts up in APIM Analytics 3.2.0
Question:
username_0: ### Description:
The following error thrown with APIM Analytics 3.2.0 pack at starts up.
`ERROR {org.wso2.carbon.kernel.internal.startupresolver.StartupComponentManager} - Runtime Exception occurred while calling onAllRequiredCapabilitiesAvailable of component carbon-deployment-service org.wso2.carbon.analytics.permissions.exceptions.PermissionException: Unable to add permission.
at org.wso2.carbon.analytics.permissions.internal.dao.PermissionsDAO.addPermission(PermissionsDAO.java:209)
at org.wso2.carbon.analytics.permissions.internal.impl.DefaultPermissionProvider.addPermission(DefaultPermissionProvider.java:83)
at org.wso2.carbon.dashboards.core.internal.DashboardMetadataProviderImpl.add(DashboardMetadataProviderImpl.java:174)
at org.wso2.carbon.dashboards.core.internal.DashboardImporter.importDashboards(DashboardImporter.java:78)
at org.wso2.carbon.dashboards.core.internal.DashboardMetadataProviderImpl.init(DashboardMetadataProviderImpl.java:111)
at org.wso2.carbon.dashboards.api.internal.DashboardRestApiProvider.getMicroservices(DashboardRestApiProvider.java:83)
at org.wso2.carbon.uiserver.internal.deployment.listener.RestApiDeployer.collectMicroservices(RestApiDeployer.java:127)
at org.wso2.carbon.uiserver.internal.deployment.listener.RestApiDeployer.appDeploymentEvent(RestApiDeployer.java:86)
at org.wso2.carbon.uiserver.internal.io.deployment.ArtifactAppDeployer.publishAppDeploymentEvent(ArtifactAppDeployer.java:154)
at org.wso2.carbon.uiserver.internal.io.deployment.ArtifactAppDeployer.deploy(ArtifactAppDeployer.java:103)
at org.wso2.carbon.deployment.engine.internal.DeploymentEngine.lambda$deployArtifacts$0(DeploymentEngine.java:291)
at java.util.ArrayList.forEach(ArrayList.java:1257)
at org.wso2.carbon.deployment.engine.internal.DeploymentEngine.deployArtifacts(DeploymentEngine.java:282)
at org.wso2.carbon.deployment.engine.internal.RepositoryScanner.sweep(RepositoryScanner.java:112)
at org.wso2.carbon.deployment.engine.internal.RepositoryScanner.scan(RepositoryScanner.java:68)
at org.wso2.carbon.deployment.engine.internal.DeploymentEngine.start(DeploymentEngine.java:121)
at org.wso2.carbon.deployment.engine.internal.DeploymentEngineListenerComponent.onAllRequiredCapabilitiesAvailable(DeploymentEngineListenerComponent.java:216)
at org.wso2.carbon.kernel.internal.startupresolver.StartupComponentManager.lambda$notifySatisfiableComponents$7(StartupComponentManager.java:266)
at java.util.ArrayList.forEach(ArrayList.java:1257)
at org.wso2.carbon.kernel.internal.startupresolver.StartupComponentManager.notifySatisfiableComponents(StartupComponentManager.java:252)
at org.wso2.carbon.kernel.internal.startupresolver.StartupOrderResolver$1.run(StartupOrderResolver.java:204)
at java.util.TimerThread.mainLoop(Timer.java:555)
at java.util.TimerThread.run(Timer.java:505)
Caused by: java.sql.SQLIntegrityConstraintViolationException: Duplicate entry 'DASH-apis.owner' for key 'PRIMARY'
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:117)
at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:97)
at com.mysql.cj.jdbc.exceptions.SQLExceptionsMapping.translateException(SQLExceptionsMapping.java:122)
at com.mysql.cj.jdbc.ClientPreparedStatement.executeInternal(ClientPreparedStatement.java:953)
at com.mysql.cj.jdbc.ClientPreparedStatement.executeUpdateInternal(ClientPreparedStatement.java:1092)
at com.mysql.cj.jdbc.ClientPreparedStatement.executeUpdateInternal(ClientPreparedStatement.java:1040)
at com.mysql.cj.jdbc.ClientPreparedStatement.executeLargeUpdate(ClientPreparedStatement.java:1347)
at com.mysql.cj.jdbc.ClientPreparedStatement.executeUpdate(ClientPreparedStatement.java:1025)
at com.zaxxer.hikari.proxy.PreparedStatementProxy.executeUpdate(PreparedStatementProxy.java:61)
at com.zaxxer.hikari.proxy.HikariPreparedStatementProxy.executeUpdate(HikariPreparedStatementProxy.java)
at org.wso2.carbon.analytics.permissions.internal.dao.PermissionsDAO.addPermission(PermissionsDAO.java:205)
... 22 more`
### Affected Product Version:
APIM Analytics 3.2.0
Answers:
username_1: i have the same issue
username_2: Related issue: https://github.com/wso2/carbon-dashboards/issues/1223 |
trufflesuite/truffle | 530509699 | Title: Upgrade contracts using unstructured storage method
Question:
username_0: It would be really useful if we could make use of [unstructured storage upgradeability](https://blog.openzeppelin.com/upgradeability-using-unstructured-storage/) similarly to how OpenZeppelin has set it up in their [SDK](https://docs.openzeppelin.com/sdk/2.6/). That way developers don't have to go through the arduous process of managing upgradeability manually, and it could make the whole process a whole lot more secure. |
jenkins-zh/jenkins-zh | 743442464 | Title: [教程大纲] Jenkins 流水线 milestone
Question:
username_0: ### 标题一
```
pipeline {
agent any
stages {
stage('Stop Old Build') {
steps {
milestone label: '', ordinal: Integer.parseInt(env.BUILD_ID) - 1
milestone label: '', ordinal: Integer.parseInt(env.BUILD_ID)
}
}
}
}
```
### 标题一
### 标题
### 参考资料
无。 |
asdf-vm/asdf-ruby | 251883683 | Title: Use all available cores
Question:
username_0: `make` should be run with `-j $NUMBER_OF_CORES`. Unless someone beats me to it, I will work on this.
Answers:
username_1: asdf provides `ASDF_CONCURRENCY` env variable to the install script, and it should be set to the number of cores.
Status: Issue closed
|
gatsbyjs/gatsby | 470321979 | Title: dangerouslySetInnerHTML behaviour different in develop vs build
Question:
username_0: ## Description
HTML passed to a component through props and rendered with `dangerouslySetInnerHTML` is rendered as expected with `gatsby develop` but not present with `gatsby build`.
### Steps to reproduce
HTML is passed here:
https://github.com/username_0/signalmark-landing/blob/0f03b01304e90c2656f495cb2a3dd1a07b55f005/src/pages/index.js#L48
HTML is rendered here:
https://github.com/username_0/signalmark-landing/blob/0f03b01304e90c2656f495cb2a3dd1a07b55f005/src/components/FeatureBlock.js#L28
### Expected result
A screenshot of the HTML being rendered with gatsby develop:

### Actual result
A screenshot of the behaviour with gatsby build. Notice that only the first line of the html is rendered.

### Environment
```
System:
OS: macOS 10.14.5
CPU: (4) x64 Intel(R) Core(TM) m3-6Y30 CPU @ 0.90GHz
Shell: 3.2.57 - /bin/bash
Binaries:
Node: 10.14.2 - ~/.nvm/versions/node/v10.14.2/bin/node
Yarn: 1.12.3 - /usr/local/bin/yarn
npm: 6.4.1 - ~/.nvm/versions/node/v10.14.2/bin/npm
Languages:
Python: 2.7.14 - /anaconda/bin/python
Browsers:
Chrome: 75.0.3770.142
Firefox: 65.0.1
Safari: 12.1.1
npmPackages:
gatsby: ^2.13.23 => 2.13.28
gatsby-cli: ^2.7.15 => 2.7.15
gatsby-image: ^2.2.6 => 2.2.6
gatsby-plugin-emotion: ^4.1.2 => 4.1.2
gatsby-plugin-google-analytics: ^2.1.4 => 2.1.4
gatsby-plugin-mailchimp: ^5.1.2 => 5.1.2
gatsby-plugin-manifest: ^2.2.3 => 2.2.3
gatsby-plugin-offline: ^2.2.4 => 2.2.4
gatsby-plugin-react-helmet: ^3.1.2 => 3.1.2
gatsby-plugin-sharp: ^2.2.7 => 2.2.8
gatsby-plugin-typography: ^2.3.2 => 2.3.2
gatsby-source-filesystem: ^2.1.5 => 2.1.5
gatsby-transformer-sharp: ^2.2.3 => 2.2.4
npmGlobalPackages:
gatsby-cli: 2.7.15
``` |
bom-radar/rapic | 133109325 | Title: Corrupt ODIM conversion when rapic moments within tilt have differing range bin counts
Question:
username_0: As reported by JS, the attached rapic scan produced corrupted VRAD and WRAD moments when converted to ODIM using the `rapic_to_odim` converter utility.
[201512152330Kurnell.rapic.zip](https://github.com/bom-radar/rapic/files/127234/201512152330Kurnell.rapic.zip)
Preliminary analysis reveals the corruption occurs only when the moments of a rapic tilt are sent with differing numbers of range bins. In the attached case the doppler moments contain fewer range bins that the reflectivity moment.
Answers:
username_0: Problem was caused by incorrectly referencing moment bin count during odim conversion when tilt bin count (max of all moment bin counts) was intended. This regression was introduced during the activity to remove the dependency on the Rainfields 3 utility library (`rainutil`).
Tested against rapic file attached to issue. Correct conversion is now observed.
Status: Issue closed
username_1: Thanks username_0, much appreciate the quick response. Tested on my end and everything is working fine :+1: |
github/VisualStudio | 233865922 | Title: Right hand of PR file diff sometimes comes up empty
Question:
username_0: - GitHub Extension for Visual Studio version: 2.2.1.100 (dev)
- Visual Studio version: 2015
__What happened__ (with steps, logs and screenshots, if possible)
I opened a PR without checking it out and double clicked on a file.

The right hand file came up as empty (deleted?). All other files in this PR appeared the same.
I later had some issues with Git moving between branches, which might be related. `git reset --hard` did however seem to fix it. Unfortunately I don't have a consistent repro for this. 😕
Answers:
username_0: It's doing it again and I've got the debugger attached this time. 😄
This task will return `null`:

Resulting in this:

username_0: It seems it can't find the commit. 😕

username_0: This was happening when viewing a file from a branch what wasn't already in the local repro. This explains why checking out a PR fixed it and make it difficult to repro!
Fixed by https://github.com/github/VisualStudio/compare/d4ed72773487...7559733297b2
Status: Issue closed
|
DanAndAlexMakeApps/PedometerGame | 134749206 | Title: Organization Created
Question:
username_0: We made stuff!
/cc @codepathreview
Answers:
username_1: :+1: Great to see your GitHub repository setup and user stories defined! The user stories are a key piece of the group project. They help you prioritize the most important parts of the app to build. It's particularly important that you've split the user stories into "Required" and "Optional" stories so your team can focus on the most important aspects of the app first and then add in the optionals as time permits toward the end of the project.
Next week we'll move on to the next step of the group project by doing something called wireframing, which is creating a blueprint for the app.
Status: Issue closed
|
MatthewRamirez/spaghettiprogramming.com | 174928450 | Title: Deal with static page for compression calculator
Question:
username_0: Either change the provisioning to set up this static site or maybe we can have https://spaghettiprogramming.com/compression_calculator redirect to a github static page or something
Status: Issue closed
Answers:
username_0: Now redirecting to github page via cname on `compression-calculator.spaghettiprogramming.com`. |
ANXS/postgresql | 485658597 | Title: Fedora 27 EOL
Question:
username_0: Fedora 27 is EOL so I'm getting build errors on PR. I suggest that only LTR distros are checked by version, and short term release distros like Fedora use 'latest' image.
Status: Issue closed
Answers:
username_0: Ok, now I see that Dockrfile contains fedora:latest. The issue is with python2-dnf package. |
apache/royale-compiler | 337228389 | Title: "assets" folder is not created in release mode
Question:
username_0: Hi,
just notice that when compiling in release mode, the "assets" folder is not copied like in debug mode.
Answers:
username_0: I fixed something related to this (copying assets from themes to release folder), but not yet for assets in main project.
Status: Issue closed
username_0: fixed in royale-asjs. Since this is managed in pom.xml where all resources and assets are copied.
I created a multiple execution so it was copied not only to js-debug, but to js-release as well, but only "assets" folder since, we don't want in release the rest of intermediate files (i.e: like a custom html template) |
HeberonYT/MultiMinecraft | 283399296 | Title: error de launcher
Question:
username_0: ayuda por favor quiero jugar pero cuando le doy jugar me manda al launcher y no cargan los perfiles y por lo tanto no me deja entrar, antes estaba bien pero ahora que se actualizo esto paso
Answers:
username_1: Lo mismo me sucede :v
Es un bugs con los perfiles.. A espera que heberon lo solucione!...
username_1: Mirad! encontre la solucion! aparece los achivos de los perfiles esta corruptos! :O
Solo hay que borralo y ejecutar el launcher y te creo uno nuevo.
;)
-VG
username_2: @username_0 @username_1
Efectivamente, los perfiles no cargan cuando se corrompen, eso sucede solo a los usuarios No Premium y es causado por que el perfil es leído por diferentes lanzadores No Premium y eso hace que se corrompan.
La solución es ir a la ubicación de la instancia, abrir la carpeta .minecraft y borrar el archivo "launcher_profiles.json".
Después ejecutar el lanzador de su preferencia y crea un nuevo perfil para arrancar el juego.
Status: Issue closed
|
Invalid-Entry/Nativity2020 | 769073657 | Title: None of the images are in the assets folder
Question:
username_0: objects.append(Background("assets/BG_04/Layers/Sky.png", 1))
there is no folder called BG_04 in the assets folder
Also in the parallax.py it references a image_file but the path for this isnt declared
self._asset = pygame.image.load(**image_file**).convert_alpha() |
bincrafters/community | 595344260 | Title: sfml/2.5.1: [bug] Problems with armv8 and armv7 (android)
Question:
username_0: <!--
Please don't forget to update the issue title.
Include all applicable information to help us reproduce your problem.
To help us debug your issue please explain:
-->
### Environment Details (include every applicable attribute)
* Operating System+version: Windows 10
* Compiler+version: clang 8.0.7 (provided by android_ndk_installer/r20@bincrafters/stable)
* Conan version: 1.22.3
* Python version: 3.8.1
### Steps to reproduce (Include if Applicable)
I used this profile:
```
include(default)
[settings]
arch=armv8
build_type=Release
compiler=clang
compiler.libcxx=libc++
compiler.version=8
os=Android
os.api_level=21
[build_requires]
android_ndk_installer/r20@bincrafters/stable
make/4.2.1
[options]
[env]
```
and this conanfile.py:
```python
from conans import ConanFile, CMake, tools
class AndroidtestConan(ConanFile):
name = "AndroidTest"
version = "0.1"
license = "<Put the package license here>"
author = "<Put your name here> <And your email here>"
url = "<Package recipe repository url here, for issues about the package>"
description = "<Description of Androidtest here>"
topics = ("<Put some tag here>", "<here>", "<and here>")
settings = "os", "compiler", "build_type", "arch"
options = {"shared": [True, False]}
default_options = {"shared": False}
generators = "cmake"
requires = "sfml/2.5.1@bincrafters/stable"
def build(self):
cmake = CMake(self)
cmake.configure()
cmake.build()
def package(self):
self.copy("*.h", dst="include")
self.copy("*hello.lib", dst="lib", keep_path=False)
self.copy("*.dll", dst="bin", keep_path=False)
self.copy("*.so", dst="lib", keep_path=False)
[Truncated]
-- Installing: D:/conan_stuff/.conan/data/sfml/2.5.1/bincrafters/stable/package/d6e0179ce95dbd07756cbd2cf2969c9500cfe501/./include/SFML/Window/WindowStyle.hpp
-- Installing: D:/conan_stuff/.conan/data/sfml/2.5.1/bincrafters/stable/package/d6e0179ce95dbd07756cbd2cf2969c9500cfe501/./include/SFML/Window.hpp
-- Installing: D:/conan_stuff/.conan/data/sfml/2.5.1/bincrafters/stable/package/d6e0179ce95dbd07756cbd2cf2969c9500cfe501/license.md
-- Installing: D:/conan_stuff/.conan/data/sfml/2.5.1/bincrafters/stable/package/d6e0179ce95dbd07756cbd2cf2969c9500cfe501/readme.md
CMake Error at source_subfolder/cmake_install.cmake:69 (file):
file INSTALL cannot find
"D:/conan_stuff/.conan/data/sfml/2.5.1/bincrafters/stable/build/d6e0179ce95dbd07756cbd2cf2969c9500cfe501/source_subfolder/extlibs/libs-android/arm64-v8a":
No such file or directory.
Call Stack (most recent call first):
cmake_install.cmake:42 (include)
gnumake: *** [Makefile:73: install] Error 1
sfml/2.5.1@bincrafters/stable: WARN: Package is corrupted, removing folder: D:\conan_stuff\.conan\data\sfml\2.5.1\bincrafters\stable\package\d6e0179ce95dbd07756cbd2cf2969c9500cfe501
ERROR: sfml/2.5.1@bincrafters/stable: Error in package() method, line 112
cmake.install()
ConanException: Error 2 while executing D:\.conan\b314cc\1\cmake-wrapper.cmd --build D:\conan_stuff\.conan\data\sfml\2.5.1\bincrafters\stable\build\d6e0179ce95dbd07756cbd2cf2969c9500cfe501\build_subfolder --target install -- -j8
```
</details>
Answers:
username_0: (by logs you can see I'm also installing "enet/1.3.14", "spdlog/1.5.0", "CLI11/1.9.0@cliutils/stable", "nlohmann_json/3.7.3", but everything OK with them)
Status: Issue closed
username_1: This recipe is now in the Conan Center Index.
Please migrate to the recipe version there.
If this is still an issue, please create a new issue in the Conan Center Index issue tracker.
Thanks!
https://conan.io/center/sfml |
bootstrapworld/codemirror-blocks | 433431511 | Title: Cannot drag blocks to some lines in `new-editor.html`
Question:
username_0: On master (https://github.com/bootstrapworld/codemirror-blocks/commit/7c8e22ab81b7ac90680107b707db4f0161d89745), I cannot drag blocks or function names to certain locations.

<issue_closed>
Status: Issue closed |
kubernetes-sigs/controller-tools | 350547607 | Title: The OWNERS_ALIASES file is invalid.
Question:
username_0: The OWNERS_ALIASES file in this repo cannot be loaded by Prow because it is not in the correct format.
https://github.com/kubernetes-sigs/controller-tools/blob/master/OWNERS_ALIASES
The `aliases` field should be a `map[string][]string` so the `-`s in front of the alias identifiers need to be removed. [Example.](https://github.com/kubernetes/kubernetes/blob/master/OWNERS_ALIASES)
/assign @pwittrock |
AzureAD/microsoft-authentication-library-for-python | 1158535815 | Title: acquire_token_silent hangs when switching between scopes - how do I fix this?
Question:
username_0: We use AD auth to connect to various databases used by our application, one Postgres, one MSSQL.
We're experiencing issues when running our application in an EC2 container, when trying to acquire a token via `acquire_token_silent` as the function appears to hang ad infinitum, no response at all, not even an error/stacktrace (N.B. it seems to work absolutely fine when running locally).
Important point to note is that when we get a token for the first DB connection, the below code works fine, however it's the second connection where the connection issues arise - we use a different scope in this instance, could this be causing issues?
The code:
```
scopes = [
scope
]
if not credential_manager:
credential_manager = msal.ConfidentialClientApplication(
os.environ["AZURE_CLIENT_ID"],
authority=f'https://login.microsoftonline.com/{os.environ["AZURE_TENANT_ID"]}',
client_credential=os.environ["AZURE_SECRET"],
)
result = None
result = credential_manager.acquire_token_silent(scopes, account=None)
if not result:
LOGGER.debug("No suitable token exists in cache. Let's get a new one from AAD.")
result = credential_manager.acquire_token_for_client(scopes=scopes)
else:
LOGGER.debug("Token found in cache.")
```
We've tried the approach of creating a `ConfidentialClientApplication` object both during initialisation and at the point at which we are trying to acquire the token - is there a best practice or can either be approach work?
Finally, we are running v1.14.0 of the MSAL library.
Any help would be much appreciated!
Answers:
username_1: If at all possible, you may try our latest MSAL 1.17. There will be no breaking change among MSAL 1.x series. And, there is no known [issue between 1.14 and 1.17](https://github.com/AzureAD/microsoft-authentication-library-for-python/releases) that would affect the behavior that you observed. You will likely still observe the same issue when using MSAL 1.17, but that will at least give us a more recent base to work with.
username_0: Hi Ray, thanks for the quick response!
So after exec'ing into the ECS container, we've managed to find out that it's not hanging afterall. Instead we're actually experiencing a seg fault:
`Segmentation fault (core dumped)`
Is this something you've ever experienced before? Everything runs smoothly when we run locally, so looks to be an issue with the way the server is set up potentially.
We've tried updating to 1.17 as well, but unfortunately no luck.
Status: Issue closed
username_0: Hi Ray, just to say we've found the issue and it's actually unrelated to MSAL so sorry for the inconvenience! We are running a multithreaded program which is causing some issues with pyodbc which is in turn struggling to make a connection to our MSSQL db. We incorrectly thought the issue was at the get auth stage - a good lesson to be better with our logging in the future!
Thanks for your help anyway and have a great weekend!
username_1: Good to know. At least we still learn something from it. :-) I hope you will start reusing the `ConfidentialClientApplication` object, and enjoying MSAL 1.17. :-)
username_0: Indeed we will, it works well! |
vega/vega-embed | 1109667944 | Title: How to Overcome CommonJS Dependencies by ECMA Script Module for Vega-Embed package
Question:
username_0: Hi,
As in Angular v'13 was causing trouble with vega-embed package, I downgraded to Angular version 10.1.2 with 'vega-embed' package of version 3.0.0-beta.19. Here I got warning message for CommonJS Dependencies. After googling out, I could stop that warning message on my console, but the bundlers became so huge in size. I am very new working with Vega-Lite along with Angular, I can't get it that which ECMA script module should I prefer in my app.component.ts file.
Currently I wrote this for importing vega-embed package.
" import embed from 'vega-embed'; ".
Answers:
username_1: We ship both a umd and a an esm bundle in the npm package. I don't fully understand what the problem with Vega Embed is. Can you describe the issue again?
username_0: The Common JS Bundle size is so big that compilation time is higher. In Angular 10, it is advisable to use ECMA script modules instead of Common JS. As currently I am importing the vega-embed module like this 1st picture.
What should (in ECMA script module) I write now ?
also I get some error message in VS studio editor like 2nd pic.

<img width="960" alt="ss2" src="https://user-images.githubusercontent.com/34280693/150436961-6b640aea-5e43-40d1-b299-1bbdaa030c22.png">
username_1: Hmm, I can't debug your build system but we do have `build/vega-embed.module.js`, which uses ESM. `build/vega-embed.module.d.ts` has the types. Both of them seem to be correctly specifies in the package.json at https://github.com/vega/vega-embed/blob/bb0f5a6161b401e869ace082d4fa84e6a767443c/package.json#L32-L35. What do you think is the bug with Vega-Embed?
username_0: e.g [https://stackoverflow.com/questions/62589229/angular-10-upgrade-fix-commonjs-or-amd-dependencies-can-cause-optimization-bai](here ) they mentioned for ECMA script how to use/import lodash via lodash-es. Similarly, for importing vega embed, what should I follow?
username_1: You could whitelist embed as suggested. Another option is to make sure that your bundler is actually using the esm module.
I'm not convinced that this is an angular issue and not Vega embed. You can ask on stack overflow for other ideas.
Status: Issue closed
|
dj-stripe/dj-stripe | 509765582 | Title: Add products/plan from django admin
Question:
username_0: I was trying to add plans from django admin. I could not see that plan being added in stripe account.
**Expected behavior**
Normally i hope stripe plans or data can be added from django admin also. Both the data should be synced
**Environment**
- dj-stripe version: [2.37.2]
- Database: [e.g. MySQL 5.7.25]
- Python version: [3.6.8]
- Django version: [2.2.5]
Answers:
username_1: Hi, currently we just use admin as a way of browsing the stripe data, it doesn't write back to stripe.
To add plans you can either use the stripe dashboard and receive that data via a webhook, or create them in your code with either stripe python api or dj-stripe.
username_1: Closing this because it's not a bug, but feel free to comment if you need more help.
Status: Issue closed
|
plusvic/yara | 109263572 | Title: Thread-safe setting of variables
Question:
username_0: If I read `libyara/rules.c` correctly, when there are multiple threads
sharing a ruleset for scanning, there is no way to safely define
external variables.
I use variable definition to pass trivial information such as file or
process names that are used within some of my rules. Of course, I
could use one copy of the ruleset per thread, but in my use case that
would mean a much larger memory footprint. (Also, this would defeat
the purpose of YARA's support for multiple threads.)
The `yr_rules_define_*_variable` functions operate on a global
structure hanging off the `YR_RULES` struct without any locking. Even
though `yr_rules_scan_mem_blocks` eventually copies everything into
`context.objects_table` before starting the actual scan, I see no way
to ensure that the variables hanging off `rules->externals_list_head`
are concsistent -- even if I protect the individual
`yr_rules_define_*_variable` calls with a mutex.
Am I missing something?
Answers:
username_1: You are right, yr_rules_define_*_variable aren't thread-safe. You can't assign a thread-specific value to a given variable, all threads share the same value which should be assigned by a single thread and shared by all threads calling yr_rules_scan_*.
As you said, the most important limitation here is that you can't pass values that depends on the file being scanned, like filename, or whatever. This could be solved by providing a separate structure to each thread to store variable values, but that would break existing code that assumes that once the main thread assigns value to a variable all other threads inherit that value.
username_2: I have hit this issue as well and will likely just be making multiple copies of the rules. Is there any chance the yr_rules_scan_* functions can be extended to include an (optional) variable list? Under the hood it may be possible to keep the calls the same and point this new argument to the rules/compiler structure's external variable list when it isn't present. The thinking being this might avoid breaking existing code while allowing an additional path to be added where variables could be defined per scan call. Yes this means that all variables would need to be defined at all times even if not in use but I see this as a issue for the caller and not an issue for yara to solve.
Thoughts? If this sounds like a possible approach I'd be willing to try and code some of this up but not sure how successful I'd be.
username_0: @username_2 What you describe is pretty much the path I had in mind.
username_2: @username_0 I think I have something, I'm just now starting to test things using the new functions and providing the vars to the scan function.
Status: Issue closed
|
bryanmylee/vim-colorscheme-icons | 961085028 | Title: Lightline tab icon color
Question:
username_0: Hey, nice plugin.
There is a way to make tab icons with different colors?
I'm using vim-devicons, onedark colorscheme and lightline.vim with this function:
```
function! LightlineWebDevIcons(n)
let l:bufnr = tabpagebuflist(a:n)[tabpagewinnr(a:n) - 1]
return WebDevIconsGetFileTypeSymbol(bufname(l:bufnr))
endfunction
```

Answers:
username_1: Hi, I'm not too sure about customizing the colors for `lightline.vim`.
This plugin specifically only targets the font color of the Nerd font icons. You will have to ask the developers at `lightline.vim`.
Status: Issue closed
|
algorithm005-class02/algorithm005-class02 | 562162308 | Title: 【0067-Week07】学习总结
Question:
username_0: 位运算
程序中的所有计数在计算机内存中都是以二进制的形式存储的,位运算就是直接对整数在内存中的二进制位进行操作
左移(<<)、右移(>>)、按位或(|)、按位与(&)、按位取反(~)、按位异或(^)
XOR - 异或
异或:相同为 0,不同为 1。也可用“不进位加法”来理解。 异或操作的一些特点:
x ^ 0 =x
x ^ 1s = ~x // 注意 1s = ~0
x ^ (~x) = 1s
x ^ x= 0
c = a ^ b => a ^ c = b, b ^ c = a a ^ b ^ c = a ^ (b ^ c) = (a ^ b) ^
LRU
最近最少使用策略
Answers:
username_1: c = a ^ b => a ^ c = b, b ^ c = a a ^ b ^ c = a ^ (b ^ c) = (a ^ b) ^
--最后少了一个 c |
mcneel/rhino.inside-revit | 613583819 | Title: Load Error
Question:
username_0: # Ticket Info
[Support Ticket](https://mcneel.supportbee.com/tickets/27983039)
# Host Info
- Environment.OSVersion: Microsoft Windows NT 10.0.17763.0
- SystemInformation.TerminalServerSession: False
- Environment.Version: 4.0.30319.42000 (4.8.03761)
- Autodesk Revit 2020
- VersionBuild: 20200206_0915(x64)
- SubVersionNumber: 2020.2
- ProductType: Revit
- Language: English_USA
- Rhino: 7.0.20084.11445 (Public Build)
- Rhino.Inside Revit: 0.0.7384.17360 (3/20/2020 9:38:40 AM)
# Journal Report
Section of journal after loading Rhino.Inside.Revit
```
Jrn.RibbonEvent "Execute external command:CustomCtrl_%CustomCtrl_%Add-Ins%Rhinoceros%CommandRhinoInside:RhinoInside.Revit.UI.CommandRhinoInside"
' 1:< fd00:c2b6:b24b:be67:2827:688d:e6a1:6a3b:: Delta VM: Avail -7 -> 134177030 MB, Used 1081 MB, Peak +24 -> 1108 MB; RAM: Avail +23 -> 23370 MB, Used +51 -> 546 MB
' 1:< GUI Resource Usage GDI: Avail 9104, Used 896, User: Used 455
'C 22-Apr-2020 16:31:57.202; 1:< Managed exception caught from external API application 'RhinoCommon' in method 'IntPtr ON_StringArray_New()' Exception type: '<System.DllNotFoundException>,' Exception method: '<Unable to load DLL 'rhcommon_c': The specified procedure could not be found. (Exception from HRESULT: 0x8007007F)>,' Stack trace ' at UnsafeNativeMethods.ON_StringArray_New()
'' at Rhino.RhinoApp.CapturedCommandWindowStrings(Boolean clearBuffer)
'' at RhinoInside.Revit.Rhinoceros.Startup()
'' at RhinoInside.Revit.Revit.OnStartup(UIControlledApplication applicationUI)
'' at RhinoInside.Revit.UI.CommandRhinoInside.Execute(ExternalCommandData data, String& message, ElementSet elements)
'' at RhinoInside.Revit.External.ActivationGate.Open[T](Func`1 func, Object state)
'' at RhinoInside.Revit.External.UI.Command.Autodesk.Revit.UI.IExternalCommand.Execute(ExternalCommandData data, String& message, ElementSet elements)
'C 22-Apr-2020 16:32:49.148; 0:< LicenseUpd(1)
```
# Console Log
```
```
# Third-party Addons
Addon data not collected
Status: Issue closed
Answers:
username_0: Moved to https://github.com/mcneel/rhino.inside-revit/issues/220 |
MyEtherWallet/MyEtherWallet | 278221619 | Title: Release Management Tooling
Question:
username_0: ### Why?
Releases should largely be automated, however due to security related concerns about completely automatic releases, I would like to propose a system that automates the boring parts while still allowing us to validate builds before release.
This release management process would be completed via several components:
Component 1: Release Bot
Handles building and PRing `dist` patches to a (new) repo that will be used exclusively for GitHub static site hosting (so that the existing strategy w/ CloudFront can continue to function).
Integrate with sentry bot to provide a method of inputting expected changes that will occur in some timespan, and alert on all non-expected changes (includes both a release that is unexpected, as well as unexpected diff on an expected release)
Note: We will likely have a separate repo for staging, so this bot should be configurable to handle building against multiple repos.
In total:
- MyEtherWallet (current)
- MyEtherWallet-Prod
- MyEtherWallet-Staging
Component 2: Verification Bot
By sharing logic from the release bot, this script will build locally and compare against change-set described above to ensure the diff is identical.
Will be used to validate bot-created PRs against staging and production to ensure the expected diff is correct. Because the build is minified/mangled, human verification is not possible.
Answers:
username_1: Researching and thinking on this issue, I think we can start with a CLI app that could both serve as a foundation for bot creation & allow for greater developer interaction. Here's a rough outline:
- CLI app would take a MEWv4 release tag as input, pull down the corresponding repo, and build the project.
- Depending on the CLI flags specified, it can then either:
- (1) calculate and report a unified hash of all the built dist files
- (2) hash another target directory and throw if the hash from (1) doesn't match
- (3) hash the staging/prod dist files in a PR and throw if the hash from (1) doesn't match
- (4) create and submit a pull request to the staging / production environments
Some key features this structure would enable:
- Developers could independently run the app in mode (1) or (3) to verify that the hash & version reported in any PRs is correct. This would allow for 'reviews' to take place, despite the minified code -- devs would reject the PR if the hashes can't be verified.
- Travis could be integrated with (2), such that the CI in the staging / prod repos will throw if a PR's calculated hash/version differ from the reported hash/version. This would essentially assume the 'Verification Bot' role described above
- The automated PR creation of (4) would serve as a basis for 'PR Bot' also previously described
So this would allow us to start off with a manual process that's still largely automated. Longer term, I think we can generalize Site Sentry bot so that it could assume various modes of task running. The 'PR Bot' would be one such mode, and the the CLI app would serve as the basis for this functionality.
Status: Issue closed
|
MicrosoftDocs/windowsserverdocs | 376947409 | Title: Needs to be updated for Ubuntu 18.10
Question:
username_0: Perhaps it all works fine out of the box, but it would be good to have that confirmed, and the documentation updated for the latest tools / features such as xRDP (on Server 2016, 2019, etc).
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: c07bfc89-b3b5-7090-768b-75412724e1c2
* Version Independent ID: 72e55502-a116-a71c-a9b2-a65c3f74b27c
* Content: [Feature Descriptions for Linux and FreeBSD virtual machines on Hyper-V](https://docs.microsoft.com/en-us/windows-server/virtualization/hyper-v/feature-descriptions-for-linux-and-freebsd-virtual-machines-on-hyper-v)
* Content Source: [WindowsServerDocs/virtualization/hyper-v/Feature-Descriptions-for-Linux-and-FreeBSD-virtual-machines-on-Hyper-V.md](https://github.com/MicrosoftDocs/windowsserverdocs/blob/master/WindowsServerDocs/virtualization/hyper-v/Feature-Descriptions-for-Linux-and-FreeBSD-virtual-machines-on-Hyper-V.md)
* Service: **na**
* Product: **windows-server-threshold**
* GitHub Login: @username_1
* Microsoft Alias: **kathydav**
Answers:
username_1: We are in the process of updating this with PR https://github.com/MicrosoftDocs/windowsserverdocs/pull/1958
Be aware that there's a known issue with SRIOV and Ubuntu 18.10
username_2: Is the issue resolved now? Can this ticket be closed?
Status: Issue closed
username_3: Perhaps it all works fine out of the box, but it would be good to have that confirmed, and the documentation updated for the latest tools / features such as xRDP (on Server 2016, 2019, etc).
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: c07bfc89-b3b5-7090-768b-75412724e1c2
* Version Independent ID: 72e55502-a116-a71c-a9b2-a65c3f74b27c
* Content: [Feature Descriptions for Linux and FreeBSD virtual machines on Hyper-V](https://docs.microsoft.com/en-us/windows-server/virtualization/hyper-v/feature-descriptions-for-linux-and-freebsd-virtual-machines-on-hyper-v)
* Content Source: [WindowsServerDocs/virtualization/hyper-v/Feature-Descriptions-for-Linux-and-FreeBSD-virtual-machines-on-Hyper-V.md](https://github.com/MicrosoftDocs/windowsserverdocs/blob/master/WindowsServerDocs/virtualization/hyper-v/Feature-Descriptions-for-Linux-and-FreeBSD-virtual-machines-on-Hyper-V.md)
* Service: **na**
* Product: **windows-server-threshold**
* GitHub Login: @username_1
* Microsoft Alias: **kathydav**
username_2: #please-close
Status: Issue closed
|
auth0/docs | 107803896 | Title: Missing doc on how device credentials works
Question:
username_0: https://auth0.com/docs/api/v2#!/Device_Credentials/post_device_credentials
Answers:
username_1: What is missing?
username_0: there is any doc about it, just the api which is not enough.
username_1: Gotcha. Thanks!
username_2: +1. We could really use some information on this as well. For example, is it possible to authenticate the device with this? How would something like that be done?
I was planning to implement some authentication scheme based on jwt tokens for my devices, but then I came across this endpoint in the api. No information to be found except for some issue reports.
Would really appreciate some guidance here.
Thanks again for a great product!
username_3: A new doc request was registered at our Docs trello board for this.
Status: Issue closed
username_4: Hsa this been addressed yet?
username_5: Any updates on this? :) |
facebook/flow | 152809657 | Title: no save downcast for generics
Question:
username_0: code:
```
type A = {foo : number};
type B = A & {bar : number};
let b : B = {foo : 1, bar : 2};
let a : A = b;
```
This will work, cause `B` extends `A`.
But then, if you write:
```
type G<T> = {t : T};
let gB : G<B> = {t : {foo : 1, bar: 2}};
let gA : G<A> = gB;
```
this will throw:
```
4: type B = A & {bar : number};
^^^^^^^^^^^^^^ property `bar`. Property not found in
10: let gA : G<A> = gB;
^ object type
```
So `G<B>` can't be downcasted to `G<A>`, even with:
```
let gA : G<A> = (gB : G<A>);
```<issue_closed>
Status: Issue closed |
laravel/nova-issues | 363015214 | Title: File Download from Storage
Question:
username_0: Hi team,
I am using S3 as storage for file uploads. I am able to upload files to s3 by using File Field. But I can not able to show this on download list with download link. Please guide me how to show download list in listing.
```
File::make('File Path')
->disk('s3')
->path('/allfiles/'.Auth::id())
->storeAs(function (Request $request) {
return $request->file_path->getClientOriginalName();
}),
```
Status: Issue closed
Answers:
username_1: File fields are set to not show on index using `public $showOnIndex = false;`. If you want to show them, the only way to do that right now is to either create a custom field and override `Laravel/Nova/Fields/File.php` to change that property, or show the download link in a computed Text field: https://nova.laravel.com/docs/1.0/resources/fields.html#computed-fields |
JuliaOpt/juliaopt.github.io | 201129477 | Title: a "get started" guide for Julia/IJulia/JuMP
Question:
username_0: I'm teaching a class using Julia + IJulia + JuMP and I struggled to find a good guide for students to get up and running. This is what I used last year: [http://www.juliaopt.org/install.pdf](http://www.juliaopt.org/install.pdf) but it's quite out-of-date now and I wanted something current for my students.
I took the above document and modified it -- here is the [Google Doc version](https://docs.google.com/document/d/1nv6bvzbcBDRnVjxPusiTMXdwo7Ywooggp_o2W0IZuTg/edit?usp=sharing) I'll share with my students so I can make changes throughout the semester as necessary.
Not sure what to do with this... I'm sure others would find the guide useful, but I'm not sure if this is the best format for it. Perhaps a wiki? Thoughts and suggestions are welcome.
Answers:
username_1: I'd be happy to replace the install.pdf with your version since it's more recent. Making the google docs link public might also be useful for others who might want to tweak the instructions for their own course.
@username_2, what do you think?
username_2: It looks pretty good. And I agree that making Google docs public would work out well. Wiki-like approach!
If we actually make a wiki page at https://github.com/JuliaOpt/juliaopt.github.io/wiki, who will be able to make changes? Only JuliaOpt members, or anyone?
username_2: It seems like we can allow any GitHub users edit wiki pages. But it looks quite painful to upload images. (need to upload images somewhere else)
I think public Google doc would be the best option for now.
username_2: I forgot about mentioning Chapter 1 of my book. I actually share Chapter 1 publicly.
http://www.username_2.net/julia/book/juliabook-preview.pdf
This explains how to install Julia, JuMP, IJulia for Windows and Mac users. It's quite wordier than the Google doc version of @username_0. Perhaps we can link to my chapter as well.
Status: Issue closed
|
JianweiCxyz/UIL_webpages | 301973306 | Title: Google Maps Browser compatibility
Question:
username_0: Desktop
- Firefox: all fine.
- Chrome: all fine.
- IE: cannot display legends
- Edge: cannot display legends
Mobile (ios)
- Safari / Chrome: cannot display maps
Mobile (Android)
- Unknown
Answers:
username_0: Legends fixed.
username_1: Android has sizing/scaling issues
username_0: Fixed with https://github.com/username_0/UIL_webpages/commit/c16948b514cd60c07872530a4d26c9bc60335f57
username_0: @username_1 See if Android works.
username_0: @username_1 Check this link: http://utw10792.utweb.utexas.edu/test3/ on Android.
username_1: Works fine on Android. Closing for now as this issue has been fixed sufficiently for soft launch.
Status: Issue closed
username_1: Android has issues with latest version. The header runs over on to over parts of the page.
username_1: Desktop
- Firefox: all fine.
- Chrome: all fine.
- IE: cannot display legends
- Edge: cannot display legends
Mobile (ios)
- Safari / Chrome: cannot display maps
Mobile (Android)
- Unknown
username_0: This issue is temporally fixed by https://github.com/username_0/UIL_webpages/commit/37d595dbe6334c79e8e4d67b74a030ca2c89e0a8
I hide the LOGO in phone size screens. Let me know if you think hiding title is better.
username_0: Fixed with b69b446
Status: Issue closed
|
wstrange/asn1lib | 514148623 | Title: Tag 20 (T61String) not implemented - seeking to send PR
Question:
username_0: Hi, and thanks for this package. It's just what I was looking for. I'm writing some code that can parse PEM certificate chains (I'll probably work into a PR for `asn1lib` when it's done) so I can verify some signatures for an Alexa skill.
It seems, though, that tag 20 is unimplemented, which is preventing me from decoding the signature from Amazon.
This is no problem - I can send a PR in - but I was wondering, which documents did you reference when writing this library? I'm not super familiar with BER/DER/etc., so I'm a bit at a loss as to where to start (the spec looks massive).
Thanks!
Answers:
username_1: Hey Tobe
Yea - this asn1 stuff is quite opaque.
I used this http://luca.ntop.org/Teaching/Appunti/asn1.html as a reference.
See section 5.16.
I *think* (but am not sure) that the PEM format would use DER encoding. See that sample from 5.16. Note the first two bytes are the length encoding - which the library will calculate for you.
You can probably just clone one of the existing string methods (maybe the ASN1IA5String ?)
I'm taking a guess that most of the chars in that encoding are just plain old 8 bit ascii. The official encoding is https://en.wikipedia.org/wiki/ITU_T.61
username_0: Sounds good, thanks. I'll get hacking right away...
username_1: My hunch: If you clone ASN1IA5String and change the tag to 20 - it will unblock you. That is probably not spec compliant - but if they stick to ascii chars, it probably works.
username_2: @username_0
Hello, please check out my util package at https://github.com/username_2/Dart-Basic-Utils
It already contains a util class for parsing PEM data. Maybe your usecase is already covered by this package.
```dart
AsymmetricKeyPair generateKeyPair({int keySize = 2048});
String formatKeyString(String key, String begin, String end,{int chunkSize = 64, String lineDelimiter = "\n"});
String generateRsaCsrPem(Map<String, String> attributes,RSAPrivateKey privateKey, RSAPublicKey publicKey);
String encodeASN1ObjectToPem(ASN1Object asn1Object, String begin, String end);
String encodeRSAPublicKeyToPem(RSAPublicKey publicKey);
String encodeRSAPrivateKeyToPem(RSAPrivateKey rsaPrivateKey);
RSAPrivateKey privateKeyFromPem(String pem);
RSAPublicKey publicKeyFromPem(String pem);
Uint8List getBytesFromPEMString(String pem);
RSAPrivateKey privateKeyFromDERBytes(Uint8List bytes);
RSAPrivateKey privateKeyFromASN1Sequence(ASN1Sequence asnSequence);
Uint8List rsaPublicKeyModulusToBytes(RSAPublicKey publicKey);
Uint8List rsaPublicKeyExponentToBytes(RSAPublicKey publicKey);
Uint8List rsaPrivateKeyToBytes(RSAPrivateKey privateKey);
ASN1Object encodeDN(Map<String, String> dn);
X509CertificateData x509CertificateFromPem(String pem);
String getSha1ThumbprintFromCertBytes(Uint8List bytes);
String getMd5ThumbprintFromCertBytes(Uint8List bytes);
```
username_1: Closing as stale for now. Please feel to re-open if this becomes a priority
Status: Issue closed
|
jantimon/html-webpack-plugin | 250660434 | Title: Using bluebird's Promises to init Webpack config with HtmlWebpackPlugin triggers a warning
Question:
username_0: ### Error Message & Stack Trace
Not a severe error, everything works fine, but it's semi-annoying to see this pop up every time I relaunch Webpack (plus I guess it could be masking a nastier bug)
```
(node:21434) Warning: a promise was created in a handler at /Users/username_0/Desktop/test/node_modules/webpack/bin/webpack.js:383:13 but was not returned from it, see http://goo.gl/rRqMUw
at new Promise (/Users/username_0/Desktop/test/node_modules/bluebird/js/release/promise.js:79:10)
```
Unfortunately the stack trace is not useful :(
### Config
```js
'use strict';
const Promise = require('bluebird'); // <-- removing this line to use native Promise will fix the issue
const HtmlWebpackPlugin = require('html-webpack-plugin');
module.exports = Promise.resolve({
entry: './app',
output: {
path: '/tmp/',
filename: '[name]',
},
plugins: [
new HtmlWebpackPlugin(), // <-- or this
],
});
```
The issue only happens if I use bluebird's Promise to init my Webpack config and HtmlWebpackPlugin together.
## Relevant Links
https://github.com/username_0/html-webpack-plugin-bug-demo
## Environment
```
$ node -e "var os=require('os');console.log('Node.js ' + process.version + '\n' + os.platform() + ' ' + os.release())"
Node.js v8.3.0
darwin 16.7.0
$ npm --version
5.3.0
$ npm ls webpack
/Users/username_0/Desktop/test
└── [email protected]
$ npm ls html-webpack-plugin
/Users/username_0/Desktop/test
└── [email protected]
```
Answers:
username_1: I think it's because we are mixing `Promise` and callback
Unless the above statement is wrong, I don't think, if will ever be fixed
username_1: Actually, I was wrong we are already using `bluebird`, maybe it's because the two version are different: https://github.com/username_2/html-webpack-plugin/blob/master/index.js#L5
username_2: Node was required for node 0.10 but now for webpack 2 we can probably drop that dependency
username_0: v3.0.0 no longer uses bluebird
https://github.com/username_2/html-webpack-plugin/pull/861/files#diff-b9cfc7f2cdf78a7f4b91a753d10865a2L46
Status: Issue closed
|
soosyze/soosyze | 781517171 | Title: Uniformisation des interfaces utilisateurs de suppression de données.
Question:
username_0: ## Titre
Le titre de l'interface de suppression doit afficher explicitement la ressource (contenu, menu, lien, utilisateur...)
Et peut inclure le nom de la ressource s'il est humainement lisible.
Exemple : Supprimer le {type_data} {name_data}
- Supprimer le compte utilisateur John,
- Supprimer le menu documentation...
## Fieldset
Le fieldset de l'interface de suppression doit afficher explicitement la ressource.
## Info
Un message d'information doit avertir l'utilisateur si la ressource est supprimée définitivement ou non.
Et avertir l'utilisateur de la portée de la suppression lorsque c'est possible.
## Options
Des options peuvent réduire la portée de la suppression.
## Validation
Le bouton de soumission doit se nommer **Supprimer** est possède la classe CSS `btn btn-danger`.
Ce bouton doit s'accompagner d'un bouton d'annulation sauf dans le cas ou l'interface est utilisé dans une API (fenêtre modale, drawer...)<issue_closed>
Status: Issue closed |
custom-components/ble_monitor | 1094234221 | Title: Configure Oral B 7000
Question:
username_0: Hello,
How we can configure Oral B device ?
I get only two sensors

Answers:
username_1: You can find additional info about the state when you select the toothbrush sensor and look at the sensor attributes.
What do you want to "configure", things like turning it on? That won't be possible, as BLE monitor is a passive component, only listening to data that is send by the toothbrush. However, you can use automations in HA to automate other things, like turn the light off, 2 minutes after the toothbrush became "Inactif"
Status: Issue closed
|
square/wire | 708877152 | Title: Allow `service` for enum name
Question:
username_0: Service could not be declared inside enum block, but proto parser fails when encountering `service` as enum entry decalration.
Example:
```
enum ServiceType {
service = 0; // parser fails, as it expects service declaration
external = 1;
mysql = 2;
mdb_mysql = 3;
conductor = 4;
jenkins = 5;
}
```<issue_closed>
Status: Issue closed |
kezong/fat-aar-android | 817816488 | Title: Could not find matching constructor for: org.gradle.api.internal.artifacts.DefaultResolvedArtifact
Question:
username_0: when git clone the example, just met the issue:
Caused by: groovy.lang.GroovyRuntimeException: Could not find matching constructor for: org.gradle.api.internal.artifacts.DefaultResolvedArtifact(org.gradle.api.internal.artifacts.DefaultModuleVersionIdentifier, org.gradle.internal.component.model.DefaultIvyArtifactName, com.kezong.fataar.FlavorArtifact$4, com.kezong.fataar.FlavorArtifact$2, com.kezong.fataar.FlavorArtifact$1, null)
at com.kezong.fataar.FlavorArtifact.createFlavorArtifact(FlavorArtifact.groovy:87)
at com.kezong.fataar.FlavorArtifact$createFlavorArtifact.call(Unknown Source)
at com.kezong.fataar.FatAarPlugin$_dealUnResolveArtifacts_closure7.doCall(FatAarPlugin.groovy:143)
at com.kezong.fataar.FatAarPlugin.dealUnResolveArtifacts(FatAarPlugin.groovy:137)
at com.kezong.fataar.FatAarPlugin$_doAfterEvaluate_closure3$_closure8.doCall(FatAarPlugin.groovy:67)
at com.kezong.fataar.FatAarPlugin$_doAfterEvaluate_closure3.doCall(FatAarPlugin.groovy:60)
at org.gradle.util.ClosureBackedAction.execute(ClosureBackedAction.java:71)
at org.gradle.util.ConfigureUtil.configureTarget(ConfigureUtil.java:154)
at org.gradle.util.ConfigureUtil.configure(ConfigureUtil.java:105)
at org.gradle.util.ConfigureUtil$WrappedConfigureAction.execute(ConfigureUtil.java:166)
at org.gradle.api.internal.DefaultCollectionCallbackActionDecorator$BuildOperationEmittingAction$1$1.run(DefaultCollectionCallbackActionDecorator.java:100)
at org.gradle.configuration.internal.DefaultUserCodeApplicationContext.reapply(DefaultUserCodeApplicationContext.java:60)
at org.gradle.api.internal.DefaultCollectionCallbackActionDecorator$BuildOperationEmittingAction$1.run(DefaultCollectionCallbackActionDecorator.java:97)
at org.gradle.internal.operations.DefaultBuildOperationExecutor$RunnableBuildOperationWorker.execute(DefaultBuildOperationExecutor.java:395)
at org.gradle.internal.operations.DefaultBuildOperationExecutor$RunnableBuildOperationWorker.execute(DefaultBuildOperationExecutor.java:387)
at org.gradle.internal.operations.DefaultBuildOperationExecutor$1.execute(DefaultBuildOperationExecutor.java:157)
at org.gradle.internal.operations.DefaultBuildOperationExecutor.execute(DefaultBuildOperationExecutor.java:242)
at org.gradle.internal.operations.DefaultBuildOperationExecutor.execute(DefaultBuildOperationExecutor.java:150)
at org.gradle.internal.operations.DefaultBuildOperationExecutor.run(DefaultBuildOperationExecutor.java:84)
at org.gradle.api.internal.DefaultCollectionCallbackActionDecorator$BuildOperationEmittingAction.execute(DefaultCollectionCallbackActionDecorator.java:94)
at org.gradle.api.internal.DefaultDomainObjectCollection.all(DefaultDomainObjectCollection.java:163)
at org.gradle.api.internal.DefaultDomainObjectCollection.all(DefaultDomainObjectCollection.java:198)
at org.gradle.api.DomainObjectCollection$all.call(Unknown Source)
at com.kezong.fataar.FatAarPlugin.doAfterEvaluate(FatAarPlugin.groovy:57)
at com.kezong.fataar.FatAarPlugin$_apply_closure1.doCall(FatAarPlugin.groovy:40)
at org.gradle.configuration.internal.DefaultListenerBuildOperationDecorator$BuildOperationEmittingClosure$1.lambda$run$0(DefaultListenerBuildOperationDecorator.java:180)
at org.gradle.configuration.internal.DefaultUserCodeApplicationContext.reapply(DefaultUserCodeApplicationContext.java:60)
at org.gradle.configuration.internal.DefaultListenerBuildOperationDecorator$BuildOperationEmittingClosure$1.run(DefaultListenerBuildOperationDecorator.java:177)
at org.gradle.internal.operations.DefaultBuildOperationExecutor$RunnableBuildOperationWorker.execute(DefaultBuildOperationExecutor.java:395)
at org.gradle.internal.operations.DefaultBuildOperationExecutor$RunnableBuildOperationWorker.execute(DefaultBuildOperationExecutor.java:387)
at org.gradle.internal.operations.DefaultBuildOperationExecutor$1.execute(DefaultBuildOperationExecutor.java:157)
at org.gradle.internal.operations.DefaultBuildOperationExecutor.execute(DefaultBuildOperationExecutor.java:242)
at org.gradle.internal.operations.DefaultBuildOperationExecutor.execute(DefaultBuildOperationExecutor.java:150)
at org.gradle.internal.operations.DefaultBuildOperationExecutor.run(DefaultBuildOperationExecutor.java:84)
at org.gradle.configuration.internal.DefaultListenerBuildOperationDecorator$BuildOperationEmittingClosure.doCall(DefaultListenerBuildOperationDecorator.java:174)
at org.gradle.listener.ClosureBackedMethodInvocationDispatch.dispatch(ClosureBackedMethodInvocationDispatch.java:41)
at org.gradle.listener.ClosureBackedMethodInvocationDispatch.dispatch(ClosureBackedMethodInvocationDispatch.java:25)
at org.gradle.internal.event.AbstractBroadcastDispatch.dispatch(AbstractBroadcastDispatch.java:42)
at org.gradle.internal.event.BroadcastDispatch$SingletonDispatch.dispatch(BroadcastDispatch.java:245)
at org.gradle.internal.event.BroadcastDispatch$SingletonDispatch.dispatch(BroadcastDispatch.java:157)
at org.gradle.internal.event.AbstractBroadcastDispatch.dispatch(AbstractBroadcastDispatch.java:58)
at org.gradle.internal.event.BroadcastDispatch$CompositeDispatch.dispatch(BroadcastDispatch.java:346)
at org.gradle.internal.event.BroadcastDispatch$CompositeDispatch.dispatch(BroadcastDispatch.java:249)
at org.gradle.internal.event.ListenerBroadcast.dispatch(ListenerBroadcast.java:141)
at org.gradle.internal.event.ListenerBroadcast.dispatch(ListenerBroadcast.java:37)
at org.gradle.internal.dispatch.ProxyDispatchAdapter$DispatchingInvocationHandler.invoke(ProxyDispatchAdapter.java:94)
at com.sun.proxy.$Proxy44.afterEvaluate(Unknown Source)
at org.gradle.configuration.project.LifecycleProjectEvaluator$NotifyAfterEvaluate$1.execute(LifecycleProjectEvaluator.java:186)
at org.gradle.configuration.project.LifecycleProjectEvaluator$NotifyAfterEvaluate$1.execute(LifecycleProjectEvaluator.java:183)
at org.gradle.api.internal.project.DefaultProject.stepEvaluationListener(DefaultProject.java:1454)
at org.gradle.configuration.project.LifecycleProjectEvaluator$NotifyAfterEvaluate.run(LifecycleProjectEvaluator.java:192)
at org.gradle.internal.operations.DefaultBuildOperationExecutor$RunnableBuildOperationWorker.execute(DefaultBuildOperationExecutor.java:395)
at org.gradle.internal.operations.DefaultBuildOperationExecutor$RunnableBuildOperationWorker.execute(DefaultBuildOperationExecutor.java:387)
at org.gradle.internal.operations.DefaultBuildOperationExecutor$1.execute(DefaultBuildOperationExecutor.java:157)
at org.gradle.internal.operations.DefaultBuildOperationExecutor.execute(DefaultBuildOperationExecutor.java:242)
at org.gradle.internal.operations.DefaultBuildOperationExecutor.execute(DefaultBuildOperationExecutor.java:150)
at org.gradle.internal.operations.DefaultBuildOperationExecutor.run(DefaultBuildOperationExecutor.java:84)
[Truncated]
at org.gradle.launcher.daemon.server.api.DaemonCommandExecution.proceed(DaemonCommandExecution.java:104)
at org.gradle.launcher.daemon.server.exec.LogAndCheckHealth.execute(LogAndCheckHealth.java:55)
at org.gradle.launcher.daemon.server.api.DaemonCommandExecution.proceed(DaemonCommandExecution.java:104)
at org.gradle.launcher.daemon.server.exec.LogToClient.doBuild(LogToClient.java:63)
at org.gradle.launcher.daemon.server.exec.BuildCommandOnly.execute(BuildCommandOnly.java:37)
at org.gradle.launcher.daemon.server.api.DaemonCommandExecution.proceed(DaemonCommandExecution.java:104)
at org.gradle.launcher.daemon.server.exec.EstablishBuildEnvironment.doBuild(EstablishBuildEnvironment.java:82)
at org.gradle.launcher.daemon.server.exec.BuildCommandOnly.execute(BuildCommandOnly.java:37)
at org.gradle.launcher.daemon.server.api.DaemonCommandExecution.proceed(DaemonCommandExecution.java:104)
at org.gradle.launcher.daemon.server.exec.StartBuildOrRespondWithBusy$1.run(StartBuildOrRespondWithBusy.java:52)
at org.gradle.launcher.daemon.server.DaemonStateCoordinator$1.run(DaemonStateCoordinator.java:297)
at org.gradle.internal.concurrent.ExecutorPolicy$CatchAndRecordFailures.onExecute(ExecutorPolicy.java:64)
at org.gradle.internal.concurrent.ManagedExecutorImpl$1.run(ManagedExecutorImpl.java:48)
at org.gradle.internal.concurrent.ThreadFactoryImpl$ManagedThreadRunnable.run(ThreadFactoryImpl.java:56)
**Build Environment**
- Operating System: [MacOS]
- Gradle Plugin Version: [4.1.0]
- Gradle Version: [6.5]
- Fat-aar Version: [1.3.1]
Answers:
username_1: you can change your gradle version to solve it
1、
dependencies {
classpath "com.android.tools.build:gradle:3.6.3"
classpath 'com.kezong:fat-aar:1.3.4'
// NOTE: Do not place your application dependencies here; they belong
// in the individual module build.gradle files
}
2、
distributionBase=GRADLE_USER_HOME
distributionPath=wrapper/dists
zipStoreBase=GRADLE_USER_HOME
zipStorePath=wrapper/dists
distributionUrl=https\://services.gradle.org/distributions/gradle-5.6.4-all.zip |
joemaidman/wedmin | 342165483 | Title: about the readme.
Question:
username_0: Would you mind explain what the meaning of wedmin (the database?), if wedmin is a database. what the postgres is ?
Answers:
username_1: Hey , wedmin is my attempt at a hilarious repo name, combining the words wedding and administration. It is also the name of the postgres database that the project expects to connect to so you will need to create a postgres database called wedmin locally for it to work.
FYI I have only just started created this project and it is nowhere near ready/complete (although it will run). I will be adding the key models/features over the next month.
username_0: Got that thanks for hard working~ |
Azure/azure-cosmos-dotnet-v3 | 554463387 | Title: Use AccountProperties for configurations reads dynamically
Question:
username_0: **Describe the bug**
Currently AccountProperties used to read several configurations example maxReplicacount on read calls is the snapshot during app initialization.
**To Reproduce**
Make some change in database account , and after periodic cache refresh these configuration wont get picked by sdk
**Expected behavior**
AccountProperties configuration reads should be dynamic from the cache instead of snapshot during initialization
**Actual behavior**
AccountProperties should get refresh with GlobalEnpointManager cache |
facebook/flow | 307679077 | Title: Flow is unable to infer return type, loops forever
Question:
username_0: Hey there, we have noticed a pattern where some combination of inferred return types and conditional recursion cause Flow to seemingly loop forever.
An example is here: https://goo.gl/fDQ4mc
Because Flow will loop forever, I went ahead and placed a return type annotation on the function. If the annotation is removed, Flow will analyze forever. Be careful with your browser tabs!
Answers:
username_1: this does not happen on flow 70, can u test again?
username_0: I made a screencast:
[flow-screen2.zip](https://github.com/facebook/flow/files/1939535/flow-screen2.zip)
GH won't let me upload the video file, so I had to put it in a zip, but it's there.
username_1: no errors on flow 77
you can type like this
`type Payload = string | Payload[]` |
platformio/platformio-home | 752778210 | Title: Could not load mDNS services
Question:
username_0: PIO Core Call Error: "b''\n\nError: Traceback (most recent call last):\r\n File \"d:\\users\\louis\\.platformio\\penv\\lib\\site-packages\\platformio\\__main__.py\", line 109, in main\r\n cli() # pylint: disable=no-value-for-parameter\r\n File \"d:\\users\\louis\\.platformio\\penv\\lib\\site-packages\\click\\core.py\", line 829, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"d:\\users\\louis\\.platformio\\penv\\lib\\site-packages\\click\\core.py\", line 782, in main\r\n rv = self.invoke(ctx)\r\n File \"d:\\users\\louis\\.platformio\\penv\\lib\\site-packages\\platformio\\commands\\__init__.py\", line 44, in invoke\r\n return super(PlatformioCLI, self).invoke(ctx)\r\n File \"d:\\users\\louis\\.platformio\\penv\\lib\\site-packages\\click\\core.py\", line 1259, in invoke\r\n return _process_result(sub_ctx.command.invoke(sub_ctx))\r\n File \"d:\\users\\louis\\.platformio\\penv\\lib\\site-packages\\click\\core.py\", line 1259, in invoke\r\n return _process_result(sub_ctx.command.invoke(sub_ctx))\r\n File \"d:\\users\\louis\\.platformio\\penv\\lib\\site-packages\\click\\core.py\", line 1066, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"d:\\users\\louis\\.platformio\\penv\\lib\\site-packages\\click\\core.py\", line 610, in invoke\r\n return callback(*args, **kwargs)\r\n File \"d:\\users\\louis\\.platformio\\penv\\lib\\site-packages\\platformio\\commands\\device\\command.py\", line 50, in device_list\r\n data[\"mdns\"] = util.get_mdns_services()\r\n File \"d:\\users\\louis\\.platformio\\penv\\lib\\site-packages\\platformio\\util.py\", line 208, in get_mdns_services\r\n with mDNSListener() as mdns:\r\n File \"d:\\users\\louis\\.platformio\\penv\\lib\\site-packages\\platformio\\util.py\", line 176, in __init__\r\n self._zc = zeroconf.Zeroconf(interfaces=zeroconf.InterfaceChoice.All)\r\n File \"D:\\Users\\louis\\.platformio\\packages\\contrib-pysite\\zeroconf.py\", line 1817, in __init__\r\n self._listen_socket.setsockopt(socket.IPPROTO_IP, socket.IP_ADD_MEMBERSHIP, _value)\r\nOSError: [WinError 10022] An invalid argument was supplied\r\n\r\n============================================================\r\n\r\nAn unexpected error occurred. Further steps:\r\n\r\n* Verify that you have the latest version of PlatformIO using\r\n `pip install -U platformio` command\r\n\r\n* Try to find answer in FAQ Troubleshooting section\r\n https://docs.platformio.org/page/faq.html\r\n\r\n* Report this problem to the developers\r\n https://github.com/platformio/platformio-core/issues\r\n\r\n============================================================"<issue_closed>
Status: Issue closed |
kernelci/kernel-bugs | 66261317 | Title: ICE regression in next (29 mar 2015)
Question:
username_0: ../mm/migrate.c: In function 'migrate_pages':
../mm/migrate.c:1148:1: internal compiler error: in push_minipool_fix, at config/arm/arm.c:13101
Please submit a full bug report,
with preprocessed source if appropriate.
See <file:///usr/share/doc/gcc-4.7/README.Bugs> for instructions.
Preprocessed source stored into /tmp/ccO1Nz1m.out file, please attach
this to your bugreport.
make[2]: *** [mm/migrate.o] Error 1
make[2]: Target `__build' not remade because of errors.
make[1]: *** [mm] Error 2
Thread with pending fix:
https://lkml.org/lkml/2015/4/1/171
Answers:
username_1: <NAME> picked up the fixes for this, and should be in linux-next starting with 20150406.
To be verified.
username_0: next-20150408 LGTM.
http://kernelci.org/boot/all/job/next/kernel/next-20150408/
Status: Issue closed
|
sabbelasichon/typo3-rector | 517386985 | Title: Important: #87028 - Access objects from `ObjectStorage` using numeric value
Question:
username_0: Important: #87028 - Access objects from `ObjectStorage` using numeric value
https://docs.typo3.org/c/typo3/cms-core/master/en-us/Changelog/9.5.x/Important-87028-AccessObjectsFromObjectStorageUsingNumericValue.html
.. include:: ../../Includes.txt
===========================================================================
Important: #87028 - Access objects from `ObjectStorage` using numeric value
===========================================================================
See :issue:`87028`
Description
===========
It is now possible to access the objects of an instance of :php:`TYPO3\CMS\Extbase\Persistence\ObjectStorage` using a numeric value.
The following code now works:
.. code-block:: php
$objectStorage = new \TYPO3\CMS\Extbase\Persistence\ObjectStorage();
$objectStorage->attach(new \stdClass());
$myObject = $objectStorage->offsetGet(0);
And more importantly, the following Fluid code works as well:
.. code-block:: html
<f:image image="{myObject.resources.0}" alt="My image!" />
Impact
======
The old way of getting information of an object in the storage still works as before.
.. index:: Fluid, PHP-API, ext:extbase<issue_closed>
Status: Issue closed |
couchbase/couchbase-lite-ios | 22773040 | Title: shorthand API for sync
Question:
username_0: So after beating myself up all day over how hard it is to configure synchronization, I came to the conclusion that the only thing for it, is to wrap it up in a tight API, something like this on iOS:
``` Objective-C
[CBLSocialSync syncDatabase: database withURL: remoteURL usingFacebookAppID: kFBAppID];
[CBLSocialSync syncDatabase: database withURL: remoteURL usingTwitterAPIKey: kTwitterAPIKey andSecret: kTwitterAPISecret];
[CBLSocialSync syncDatabase: database withURL: remoteURL usingPersona: YES];
```

This CBLSocialSync module I'm considering would be a wrapper around ALL the complexity in the picture above.
The only clean way to do that, is to give it responsibility both for getting the user logged into the service indicated (it might have to draw some UI...), and for getting the right access tokens / assertions / etc we need from the authentication services. It will also cover the details of installing the authentication into the sync session (pull and push) as well as detecting and handling the sort of errors that might be remedied by getting a new assertion and using it to start a new session with the remoteURL. So that aside from that one line of code, the developer is basically done thinking about sync for their app.
The goal would be to deliver this as a source add-on module (in the Extras folder with CBLUICollectionSource etc) so instead of trying to build a comprehensive library of social sync helpers, we can illustrate the common patterns, and let the community fill them out over time.
Answers:
username_1: Closing 1.x issue!
Status: Issue closed
|
stripe/react-stripe-js | 559730919 | Title: "Add Payment" with PaymentRequestButton
Question:
username_0: From what I can see from current implementation, you can have the PaymentRequestButton's canMakePayment method return non-null if you're on a supported browser with a payment method already loaded. Is it possible to support _adding_ a payment method if you're on a supported browser but don't have one integrated yet? On our site, it feels like we're missing a subset of people who would happily do a faster checkout with GooglePay but we don't even have a button to display to them if they haven't loaded a card before. I know there are ways to do this when inegrateing with GooglePay and ApplePay directly, is this something Stripe's wrapper can also support?
Answers:
username_1: Hi @username_0,
On-boarding a wallet is generally _more_ friction than just checking out with Elements, so we don't get a lot of asks for this. That said, I don't see why we couldn't support something like this as an opt-in API. I will add this to our feature requests for Stripe.js.
I am going to close this issue though. We can't really add support for this at the React Stripe.js level.
Status: Issue closed
|
ingbrzy/MA-XML-8.0-TURKISH | 188691029 | Title: Sürüm 6.11.10 Hakkında Problemler vb.
Question:
username_0: 6.11.10 hakkında bilgileri buraya bildirebilirsiniz. Gemini modeldeki Personal Assist ve bazı yerlerdeki Çince çeviriler Türkçeye çevrilmedi, çünkü ilerideki sürümde İngilizce hale getirilecek. Malum bazı modellerde 6.11.10 sürümü daha geç geliyor. vb...
Answers:
username_0: Beyler;
6.11.10 sürümündeki tüm içeriği PCye aktarıp dosyaların içeriklerini decompiler ettim. Sonuç şu: Bize kaynak dosya -çevrilecek dosyalar- diye verilen ingilizce ile telefondaki ingilizce dosyalar arasında bayağı farklar var. Şu an bir dosyayı derleyip ekliyeceğim. Şimdi bazı arkadaşların benim telefonda çoğu yer ingilizce demesinin sırrı ortaya çıktı. Kaynak dosyalardaki satırlar eksik. Farklı modellerde satırlarında farklı olabileceğini düşünürsek... Ben Note 4 içeriğini çıkardım. En azından birde Qualcomm işlemci bir başka modelin içeriğini de çıkarmak lazım. Bu konuda bir yazı yetkiliye göndereceğim. Aksi takdirde hiç bir zaman telefonlar tam Türkçe olmayacak. Çünkü kaynak dosyada çok çok eksiklik var. Sadece mediatek-res dosyasında 100e yakın satır eklenmemiş.
username_1: kaptan. bu miui 8 için lg klavye gibi bi klavye entegre edilemezmi
username_0: @username_1
Neden olmasın, yapacak biri lazım :)
username_0: Beyler; Google hizmetleri eklendi. Ayrıca şu an bazı Mi uygulamalarını çevirip ekleyeceğim. Mi VR gibi.
username_0: <NAME> adlı arkadaşın söylediği hatalar düzeltilip, eklendi.
username_0: Mi Band Tools adlı güzel bir yazılım var, bunu Türkçeleştirip (2.4 en son sürüm) sisteme ekledim. Üreticiye de çeviriyi gönderdim. Mi Fit yazılımından daha güzel.
username_0: 6.11.13/6.11.14/6.11.15/6.11.16 ve 6.11.17 sürümlerinde elen yeni satırlar ve değişiklikler eklendi. Kullandığı modelde halen İngilizce ve Çince yerler olana arkadaşlar var galiba. Note 4 modelinde sadece paylaşım yapılınca 1 connected 0 blocked denilen yer var kaynak dosyada böyle bir yer yok. Kaynak dosyada yok. Türkeçe çeviride ise bir kaç satır çevrilmedi onlarda Çince ve ay adları. Eğer böyle sorunu olanlar varsa bana apk dosyalarını göndersinler. O dosyaları açıp içlerine bakalım. Sitede verilen kaynak dosyaları hem eksik hemde satırların çoğu yok. Geçen hafta 5-6 dosya ben çevirip ekledim, bu hafta kaynak dosyaya eklediler. Kaynak dosyalar tam olsa kimse şikayet etmez. Şikayet sadece çeviri hataları ile uygulama hatalarından kaynaklanır.
username_2: Redmi note 3 (hennessy) mediatek işlemcili model için kamera galeri geçişi için herhangi bir çözüm yok mu? Sizdeki redmi note 4 mediatek işlemcili acaba onda da aynı sorun varmı?
username_0: @username_2
Evet bende de sorun devam ediyor. Ama bazı modellerde sorun yok. Bu hafta Resmi sürümü kurup orada sorun var mı diye bakacağım. Geçen baktığımda sorun orada da devam ediyordu.
username_0: MiVR dosyasını çevirip ekledim
username_3: bak şekil oldu :) genel olarak bir problem göremedim. 8.1.2 stabil olanı kurdum gayet güzel uzun kullanımda birşey görürsem paylaşırım
[](http://hizliresim.com/bk8mQG)
username_0: Qualcomm tabanlı bir modelin içindeki tüm apk dosyalarını alıp bana gönderecek arkadaş var mıdır? Zannedersem Qualcomm tabanlı ürünlerde ing. yerler kalmış. Kaynak dosyada olmayan satırlar. ES File Explorer içinden dosyalara ulaşabilirsiniz.
username_3: deniycem becerebilirsem göndereyim
username_3: https://mega.nz/#!pRw3garB!ZBjyTu5YGLOUFbGWaPZQ_NHTu5pQlWQDODEKccPoJGA
minote pro 8.1.2 işine yararmı bilmiyorum developer değil çünkü :)
username_0: @username_3
<NAME>; ne kadar çok kaynak dosya o kadar çok düzeltme demektir. Adını altın harfle yazacağım :) Teşekkürler
username_4: şekil diyorsunuzda bence bilakis rezil gözüküyor acı ama gerçek. Kilit ekranını görmek istemiyorum sayenizde bakmayın ses çıkartmıyorumda için kan ağlıyor
username_0: Aykut senin şu yazılıma katkın inkar edilemez. Yukarı işaretlerini kaldırıyorum
username_4: hocam ben orjinale en yakın ve basit olması taraftarıyım. elimde olsa '' yukari kaydır'' der gecerim yada acmak icin yukari kaydirin gibi. ama bu benim fikrim kimse katilmak zorunda değil
username_4: ayrica hocam apk dosyalari gonderirdim ama 300-400 mb dosya yapiyor romu direk indirsin ayni hesaba gelir
username_0: romdan dosyaları alamıyorum, bütün gün şu internet paylaşımını açınca çıkan X connected x blocked nerede diye harcadım halen bulamadım. Dili değiştirince de diğerlerinde ing. çıkıyor kaynak dosyaya koymamışlar resmide var
username_4: romu bununla parçalarsan istediğini alabilirsin.
[SystemExtract-support_5.1.zip](https://github.com/ingbrzy/MA-XML-8.0-TURKISH/files/600912/SystemExtract-support_5.1.zip)
username_1: ama dili ingilizce yapinca problem yok
username_5: Merhabalar Hocam. Oneplus3 Kullanıyorum miui8 port rom kurdum türkçe yok yani morelocate den turkce seciyorum çşı gibi harfler gözükmüyor mesela Facebook ta veya system de popup ekranında bisim karakterler yok. ingilizce de de Facebook ta insanların adlarındaki ıçş ler eksik Jbart ile denedim ama bootlop oldu yardımcı olurmusunuz Lütfen? burda da Log.https://mega.nz/#!sZF2yJyJ!eyTGlVWz9YASbNC6155VDgXr5Fc3oFi_OcMRp9LqYWc
Saygılar.
Status: Issue closed
|
vindevoy/cherryblog | 596775496 | Title: Number of posts per type are hardcoded
Question:
username_0: Number of posts per type are hardcoded. For now, this was not a problem, but with the number of releases, this will make a lot of pages. Better to get this straight from the settings as it should so we can adapt in the near future.
Solution:
- Change the python code not to hard code this
- Put it in a settings file
Answers:
username_0: Fixed with change in python code and an extra settings yaml file
Status: Issue closed
|
naser44/1 | 115486584 | Title: نوافذ الأجور يوم الجمعة دائما متسعة افتـح نوافذك..
Question:
username_0: <a href="http://ift.tt/1Q88p01">نوافِذ الأجور يومَ الجمعة دائمًا مُتسعة افتـح نوافُذك..</a> |
AdguardTeam/AdguardForAndroid | 425433655 | Title: Support common VPN protocols.
Question:
username_0: I don't talk about real VPN service by AdGuard.
Such like the option of outgoing proxy.
Is it possible to support common VPN protocols, like L2TP/IPSec, OpenVPN, SSTP...etc.?
Answers:
username_1: +1 for OpenVPN
username_2: +1 for WireGuard ;-)
username_3: Yes, I also want this feature
Please Adguard Team Do Something About It.
username_4: is there any news about it?
username_5: @username_4 @username_3
But we decide to go ahead and make our own real VPN service.
- Its features include its own protocol for encrypting VPN traffic.
- The VPN works seamlessly with AdGuard's main app in compatibility mode and requires no additional settings.
- Two operating modes and much more
AdGuard VPN is available on PlayStore (Free 3GB trial)
username_4: Too bad, I wanted to use my own VPN. So that I can access my home network, among other things. |
hanskorg/google-authenticator-rust | 479284424 | Title: rm println
Question:
username_0: thank you for this project, it helps me a lot
can you remove `println` code or replace it with [log](https://github.com/rust-lang-nursery/log)?
https://github.com/username_1/google-authenticator-rust/blob/d4e3baf83dfde11dbb9e854ae1bb8564df0235a4/src/google_authenticator.rs#L152-L153
Answers:
username_1: so sorry for that, new version(v0.1.8) later.
Status: Issue closed
|
DistanceDevelopment/distance-bugs | 141895867 | Title: Post-stratification abundance estimate incorrect
Question:
username_0: Distance project to combine several strata into a single stratum. Created new field in stratum layer upon which to perform post-stratification.
e.g.
Strat1 (area 720) merged with Strat2 (area 372) merged with Strat3 (area 736). When abundance is calculated, the area of Strat1 is used, rather than the combined area of 3 strata.
This is a problem when post-stratifying, but of course, not when doing a 'normal stratification.' |
dart-lang/sdk | 84559811 | Title: continue to support --no-minify for a short period
Question:
username_0: We discussed this offline, but here are some details.
While we debug issue:
https://code.google.com/p/dart/issues/detail?id=14720
it will helpful to keep the --no-minify flag and use it in the editor to build polymer apps. It's ok if we want to keep it undocumented and remove it soon as soon as we fix that bug. |
kubernetes-sigs/krew | 1040428518 | Title: Krew is not working after same plugin get installed and uninstalled twice
Question:
username_0: Hi, I was trying to automate the kubectl plugin releasing process within a custom krew-index repo, thus I need to test plugin installation as a part of the automation process to make sure everything's working.
## Environment
Host OS: `ubuntu-20.04` (github actions)
Krew version:
```
+ /opt/hostedtoolcache/krew/v0.4.2/amd64/krew version
OPTION VALUE
GitTag v0.4.2
GitCommit <PASSWORD>
IndexURI https://github.com/kubernetes-sigs/krew-index.git
BasePath /home/runner/.krew
IndexPath /home/runner/.krew/index/default
InstallPath /home/runner/.krew/store
BinPath /home/runner/.krew/bin
DetectedPlatform linux/amd64
```
Could not reproduce this on local macOS.
## What you did?
Run krew install and krew uninstall for every os/arch set of a kubectl plugin (`kubectl-convert` in the following example)
```bash
krew uninstall convert >/dev/null 2>&1 || true
KREW_OS="linux" \
KREW_ARCH="amd64" \
krew install \
--manifest="plugins/convert.yaml" \
--archive="build/archive/kubectl-convert.linux.amd64.tar.gz"
krew uninstall {{ trimPrefix "kubectl-" $v }}
```
## Expected behavior
krew only raise error when manifest or plugin package is invalid.
## What went wrong?
krew stopped working after two installation & uninstallation of the same plugin:
```log
--- :local: [ ] { arch: amd64, kernel: windows }
WARNING: Detected stdin, but discarding it because of --manifest or args
Installing plugin: convert
Installed plugin: convert
\
| Use this plugin:
| kubectl convert
| Documentation:
| https://github.com/kubernetes/kubernetes
/
Uninstalled plugin: convert
DONE :local: [ ] { arch: amd64, kernel: windows }
[Truncated]
/opt/hostedtoolcache/go/1.16.8/x64/src/net/http/client.go:251 +0x454
net/http.(*Client).send(0xea54e0, 0xc000074100, 0x0, 0x0, 0x0, 0xc00000e020, 0x0, 0x1, 0xc000074100)
/opt/hostedtoolcache/go/1.16.8/x64/src/net/http/client.go:175 +0xff
net/http.(*Client).do(0xea54e0, 0xc000074100, 0x0, 0x0, 0x0)
/opt/hostedtoolcache/go/1.16.8/x64/src/net/http/client.go:717 +0x45f
net/http.(*Client).Do(...)
/opt/hostedtoolcache/go/1.16.8/x64/src/net/http/client.go:585
net/http.(*Client).Get(0xea54e0, 0xaab711, 0x41, 0x0, 0x0, 0x0)
/opt/hostedtoolcache/go/1.16.8/x64/src/net/http/client.go:474 +0xbe
net/http.Get(...)
/opt/hostedtoolcache/go/1.16.8/x64/src/net/http/client.go:446
sigs.k8s.io/krew/cmd/krew/cmd/internal.FetchLatestTag(0x0, 0x0, 0x0, 0x0)
/home/runner/work/krew/krew/cmd/krew/cmd/internal/fetch_tag.go:35 +0xf2
sigs.k8s.io/krew/cmd/krew/cmd.preRun.func1()
/home/runner/work/krew/krew/cmd/krew/cmd/root.go:133 +0x1cf
created by sigs.k8s.io/krew/cmd/krew/cmd.preRun
/home/runner/work/krew/krew/cmd/krew/cmd/root.go:124 +0x445
```
full logs: [logs_22.zip](https://github.com/kubernetes-sigs/krew/files/7448505/logs_22.zip)
Answers:
username_1: I've looked at the logs (specifically `9_Build and Push kubectl-convert.txt`) and nothing jumps to me. I've also tested this locally as follows:
```
cd krew-index/plugins
KREW_OS="linux" KREW_ARCH="amd64" kubectl krew install --manifest=ctx.yaml
kubectl krew uninstall ctx
KREW_OS="linux" KREW_ARCH="amd64" kubectl krew install --manifest=ctx.yaml
kubectl krew uninstall ctx
KREW_OS="linux" KREW_ARCH="amd64" kubectl krew install --manifest=ctx.yaml
kubectl krew uninstall ctx
```
and it does not reproduce for me. Does it only happen on your build environment? Or can you also locally reproduce this issue? I don't have a theory on what would cause this other than something's messing with the filesystem somehow.
username_0: I cannot reproduce this on my local machine as well, only github actions have this issue.
Wild guess: one possible cause of this is the timing jitter in github virtual environment, as to my very limited experience, that's far more significant than the usual case.
username_0: I wish I could say yes, but there is no parallel job in my pipeline, to make sure they are sequential commands, I created a github action to run krew install/uninstall in script, but still no luck: https://github.com/arhat-dev/krew-index/runs/4170194680
Action logs:
[10_Test krew redundent installuninstall.txt](https://github.com/kubernetes-sigs/krew/files/7515719/10_Test.krew.redundent.installuninstall.txt)
username_1: I think I have a theory.
https://github.com/kubernetes-sigs/krew/blob/master/internal/receiptsmigration/migration.go
If there are plugins installed (maybe krew itself!) but there are no installation receipts, we give that "krew home outdated" error.
Is it possible to run "tree $HOME/.krew" before the failing command on GitHub actions? That would _greatly_ help us debug how your setup got into that situation.
username_0: You are right, the receipts dir is always empty before and after the crash, and the plugin is not removed after `krew uninstall`.
```
+ krew -v 10 uninstall convert
I1111 05:05:55.291830 21668 root.go:221] Ensure creating dir: "/home/runner/.krew"
I1111 05:05:55.291873 21668 root.go:221] Ensure creating dir: "/home/runner/.krew/store"
I1111 05:05:55.291879 21668 root.go:221] Ensure creating dir: "/home/runner/.krew/bin"
I1111 05:05:55.291883 21668 root.go:221] Ensure creating dir: "/home/runner/.krew/index"
I1111 05:05:55.291905 21668 root.go:221] Ensure creating dir: "/home/runner/.krew/receipts"
I1111 05:05:55.291998 21668 migration.go:30] Checking if index migration is needed.
I1111 05:05:55.292006 21668 migration.go:33] Index already migrated.
I1111 05:05:55.292024 21668 uninstall.go:47] Going to uninstall plugin convert
I1111 05:05:55.292052 21668 install.go:163] Finding installed version to delete
I1111 05:05:55.293208 21668 root.go:128] skipping upgrade check
I1111 05:05:55.293370 21668 install.go:172] Deleting plugin convert
I1111 05:05:55.293511 21668 install.go:175] Unlink "/home/runner/.krew/bin/kubectl-convert"
I1111 05:05:55.293531 21668 install.go:215] No file found at "/home/runner/.krew/bin/kubectl-convert"
I1111 05:05:55.293538 21668 install.go:181] Deleting path "/home/runner/.krew/store/convert"
I1111 05:05:55.302120 21668 install.go:186] Deleting plugin receipt "/home/runner/.krew/receipts/convert.yaml"
Uninstalled plugin: convert
I1111 05:05:55.302378 21668 root.go:176] Upgrade check was skipped or has not finished
+ krew -v 10 uninstall convert
+ tree /home/runner/.krew
/home/runner/.krew
├── bin
│ └── kubectl-convert.exe -> /home/runner/.krew/store/convert/v1.22.2/kubectl-convert
├── index
│ └── default
│ ├── CONTRIBUTING.md
│ ├── LICENSE
│ ├── OWNERS
│ ├── OWNERS_ALIASES
│ ├── README.md
│ ├── SECURITY_CONTACTS
│ ├── code-of-conduct.md
│ ├── plugins
... omitted ...
│ │ └── whoami.yaml
│ └── plugins.md
├── receipts
└── store
```
I tried removing windows installation test (on linux) and everything's working (for linux and darwin), and also tried testing windows installation on windows, worked as well.
So I guess it's something related to the `KREW_OS` env, and probably it's caused by the cleanup behavior that only happens on windows platform: https://github.com/kubernetes-sigs/krew/blob/master/cmd/krew/cmd/root.go#L165 .
Maybe a quick fix for this would be using runtime.GOOS rather than KREW_OS env to determine host os in this case?
username_1: I agree with your findings, although we need to look closely into implications of that (we might be relying on usage of KREW_OS for testing etc). |
ssborbis/ContextSearch-web-ext | 600131867 | Title: Question?
Question:
username_0: When I click on the CSE icon in the Chrome toolbar, the CSE search box with the search engines usually pops up, but not always. Sometimes a much smaller popup is displayed instead which has a magnifying glass and an options icon.
If I click the magnifying glass in the smaller popup, my previous searches are displayed. From there I can select a previous search if I want.
The problem is I cannot find a way to control which of the 2 popups will come up. Once in awhile I want to use the smaller popup, but can't get it come up. Sometimes when I don't want the small popup it comes up anyway, instead of the usual search box.
Is there a setting or some way to control which of these 2 popups comes up?
Answers:
username_1: This sounds like the same bug addressed in #241 The popup should always be full-sized.
A fix is in the repo, but no new release yet. If you can, you could try sideloading and testing the repo code to see if that fixes the issue. Otherwise, wait for the next release. It shouldn't be long.
username_0: How do you bring up the small menu when you want to use it instead of the full size menu?
Not familiar with sideloading, but if its easy I can give it a try.
Status: Issue closed
username_1: You can't, currently. I could add an option I suppose.
So, normal behavior should be - you click the icon and a full menu opens with menu bar ( close, options), search bar, tools bar (optionally), and search engine icons.
You want to be able to open the menu in a smaller form by not displaying the search engine icons? What would your workflow be from there vs the larger menu? Using the history? Pressing {ENTER} and using your default search engine? I'm trying to understand the benefit a menu without search engine icons would be.
username_0: If the user wants to use the small menu to access his previous searches he may have to click a lot of times before the small menu pops up.
Rather than removing the small menu from CSE maybe it would be better to just let users choose whether to bring up the large menu or the small menu, ie a right click option that includes a choice for the small menu; a left click that always brings up only the large menu.
As it is now, the small menu comes up randomly. Apparently the user has no way to select which of the 2 menus will pop up.
As far as I can see there is no way to access search history from the large menu; only the small menu gives access to search history.
The benefit of the small menu which doesn't have search engine icons might be best explained by whoever developed it that way. Using the search history is the only benefit I know that the small menu offers.
username_1: Just a quick sanity check. You're saying you only can access the search history if the menu is glitching? ( small, no search engines). That's definitely not right. Here's a gif of proper behavior. The search history should be displayed in all menus ( toolbar, quick menu, sidebar menu ) when you click the magnifying glass. If you're not seeing it, and you do have the option enabled, it could be because of the bug in #241 .

username_1: Ignore the green garbage in that gif. I don't think the image processed properly.
username_1: I pushed a release to AMO and Chromestore. Google has changed their privacy policy on submissions, so there will be a review process before the update shows. Might be a while. Once you get v1.20, see if the issues resolve.
username_0: After reading your sanity check comment and seeing your graphic showing how to access history from the large menu I realized I could access history from the large menu. Before this I didn't know history could be accessed from the large menu.
Now that you've shown me a way to access history from the large menu, the small menu seems redundant, less useful, without purpose. But it may have uses that I dont know about.
Is this history feature you explained in your sanity check comment documented at the Chrome webstore or anywhere ? There may be other features I haven't discovered. Are there any instructions that list all the features and explain how to use everything?
I'm tempted to suggest better documentation for CSE, better instructions, more explanation of its features, and how to use them. But maybe instructions are already available and I just haven't been able to find them.
Just now I checked for the latest version of CSE at the Chrome Webstore, but it still shows version 1.19.2 What does AMO stand for ?
username_1: 1.20 is still "Pending Review". Sometimes the system glitches and I have to resubmit to get it to go through.
AMO is the Mozilla Firefox version of ChromeStore. |
ruanyf/weekly | 810742348 | Title: [自荐][学习][摸鱼] 为Coder设计的摸鱼🐟单词记忆与输入练习的vsc插件
Question:
username_0: <p align="center">
为键盘工作者设计的单词记忆与英语肌肉记忆锻炼软件 VSCode 摸🐟版
</p>
<div align=center>
<img src="https://imgur.com/YozF2Tw.png"/>
</div>
## 💡 演示
<div align=center>
<img src="https://imgur.com/CBxwOnz.png"/>
</div>
## 📸 安装
VSCode 插件安装:[VSCode Plugin Market](https://marketplace.visualstudio.com/items?itemName=Kaiyi.qwerty-learner)
Github 项目: https://github.com/username_0/qwerty-learner-vscode
<br/>
本项目为 [Qwerty Learner](https://github.com/username_0/qwerty-learner) 的 VSCode 插件版本,访问原始项目获得更好的体验。
## ✨ 实现原理
因为 VSC 没有提供对 Keypress 的回调,所以实现上使用了较为取巧的方式,监听用户当前输入文档的改变,然后删除用户输入。 用户可以在任意代码、文档页面开启软件进行英语打字练习,插件会自动删除用户输入的问题,不会对文档内容造成影响。
## 🎛 使用说明
### 一键启动
**Mac** `Control + Shift + Q`
**Win** `Shift + Alt + Q`
可以在任意文档中使用快捷键启动,启动后插件将屏蔽用户对文档的输入,只需关注状态栏上的单词即可。
**⚠️ 切记需关闭中文输入法**,目前插件在开启中文输入法会有 Bug,待修复
### 章节、词典选择
打开 VSCode 命令面板,通过 “Qwerty” 前缀过滤,即可发现插件内置的命令。
<div align=center>
<img src="https://imgur.com/9O4hb6S.png"/>
</div>
- Change Chapter 可以切换章节
- Change Dictionary 可以切换字典
- Start/Pause 可以开关插件,功能等价于一键启动快捷键
命令面板快捷键
Mac: `cmd + shift + p`
Win: `ctrl + shift + p`
## 📕 词库列表
- CET-4
- CET-6
- GMAT
- GRE
- IELTS
- SAT
- TOEFL
- 考研英语
- 专业四级英语
- 专业八级英语
- Coder Dict 程序员常用词 |
ben18785/distribution-zoo | 779835190 | Title: Inconsistency between Student Guide and Distribution Zoo
Question:
username_0: Figure 8.27 shows 3 Gamma distributions ... (1,10) ... (4,2.5) ... and (10,1)
The zoo makes plotting of 2 of these impossible, because of limits on the sliders.
When I plot these distributions with R (using my own code for gamma because the built-in R code has different
parameterisation), the graph is rather different.

Here's my gamma function R code ...
makegamma<-function(a,b) {
g<-function(x) {
(b^a)/gamma(a) * x^(a-1) * exp(-b*x)
}
}
Answers:
username_1: @username_2 I've just come across this: any thoughts?
username_2: I completely missed this, sorry. @username_0 this just because the distribution zoo matches the R parameterisation. Hence why the results differ from your own code.
Status: Issue closed
|
mozartdiniz/Roads | 59322458 | Title: Name conflict in NPM
Question:
username_0: There's a [Roads package in NPM](https://www.npmjs.com/package/roads), and it may be a future issue for the project. I understand that when talking about naming JavaScript packages, life becames very hard! But, to avoid name colision, I advise you to better name it.
- https://github.com/Dashron/roads
- https://www.npmjs.com/package/roads |
toggl/toggldesktop | 490928784 | Title: Newly created project is cleared
Question:
username_0: ### 💻 Environment
Platform: macOS
OS Version: macOS 10.14
Toggl Version: 7.4.484
### 🐞 Actual behavior
The newly created project is cleared from the Project field:

### 💯 Expected behavior
The project should be selected
### 🔨 Steps to reproduce
See gif
### 📦 Additional info
[User report](https://app.intercom.io/a/apps/ayixs927/inbox/inbox/2931915/conversations/23581530568)
Answers:
username_1: Related to https://github.com/toggl/toggldesktop/pull/3215 I believe
username_0: Oops, sorry 👀
Status: Issue closed
|
inaka/katana-code | 604664214 | Title: ktn_dodger cannot parse macro functions in function clauses
Question:
username_0: Given the following module
```
-module(macros).
-define(MATCH_NAME(), #{name := "Per"}).
is_adult(?MATCH_NAME()) ->
false.
```
```
1> File = "path/to/macros.erl".
"path/to/macros.erl"
2> {ok, Dev} = file:open(File, [read]).
{ok, <0.328.0>}.
3> ktn_dodger:parse_form(Dev, 1, [{scan_opts, [text]}]).
{ok,{tree,attribute,
{attr,[{text,"module"},{location,1}],[],none},
{attribute,{tree,atom,
{attr,[{text,"module"},{location,1}],[],none},
module},
[{tree,atom,
{attr,[{text,"module"},{location,1}],[],none},
macros}]}},
2}
4> ktn_dodger:parse_form(Dev, 2, [{scan_opts, [text]}]).
{ok,{tree,attribute,
{attr,[{text,"define"},{location,2}],[],none},
{attribute,{atom,[{text,"define"},{location,2}],define},
[{tree,application,
{attr,[{text,"MATCH_NAME"},{location,2}],[],none},
{application,{var,[{text,"MATCH_NAME"},{location,2}],
'MATCH_NAME'},
[]}},
{tree,map_expr,
{attr,[{text,"#"},{location,2}],[],none},
{map_expr,none,
[{tree,map_field_exact,
{attr,[{text,"name"},{location,2}],[],none},
{map_field_exact,{atom,[{text,...},{...}],name},
{string,[{...}|...],[...]}}}]}}]}},
3}
5> ktn_dodger:parse_form(Dev, 2, [{scan_opts, [text]}]).
{error,{3,erl_parse,["syntax error before: ","?"]},5}
```
Problem seems to reside in ktn_dodger:scan_form which does not send correct thing to erl_parse:parse_form.
```
6> file:close(Dev), f(Dev), {ok, Dev} = file:open(File, [read]).
{ok, <0.333.0>}
7> c(ktn_dodger, [export_all]).
{ok, ktn_dodger}
8> {ok, Ts1, _} = io:scan_erl_form(Dev, "", 1, [{scan_opts, [text]}]).
{ok,[{'-',1},
{atom,1,module},
{'(',1},
{atom,1,macros},
{')',1},
{dot,1}],
2}
9> S1 = ktn_dodger:scan_form(Ts1, {opt, false}).
[{'-',1},
[Truncated]
{'->',3},
{atom,4,false},
{dot,4}],
5}
15> S3 = ktn_dodger:scan_form(Ts3, {opt, false}).
[{atom,3,is_adult},
{'(',3},
{'(',0},
{atom,3,'? <macro> ('},
{'(',3},
{var,3,'MATCH_NAME'},
{')',3},
{')',0},
{')',3},
{'->',3},
{atom,4,false},
{dot,4}]
16> erl_parse:parse_form(S3).
{error,{3,erl_parse,["syntax error before: ","'('"]}}
```
Answers:
username_1: You should try with `ktn_dodger:parse_form(Dev, 1, [{scan_opts, [text]}, no_fail]).`
Status: Issue closed
username_0: haven't been able to look at it yet, but you suggest opening a PR changing this row?
https://github.com/inaka/katana-code/blob/9ae6f99ac8709f576bdf3f4a1ff638e307765f48/src/ktn_code.erl#L96
```
{ok, Forms} = ktn_dodger:parse( IoString
- , {1, 1}
+ , 1
, [{scan_opts, [text]}]
+ , no_fail
),
```
username_1: Yeah, exactly. Sorry I closed the issue, I thought the usage of `ktn_dodger` was from another library not this one.
username_1: Given the following module
```
-module(macros).
-define(MATCH_NAME(), #{name := "Per"}).
is_adult(?MATCH_NAME()) ->
false.
```
```
1> File = "path/to/macros.erl".
"path/to/macros.erl"
2> {ok, Dev} = file:open(File, [read]).
{ok, <0.328.0>}.
3> ktn_dodger:parse_form(Dev, 1, [{scan_opts, [text]}]).
{ok,{tree,attribute,
{attr,[{text,"module"},{location,1}],[],none},
{attribute,{tree,atom,
{attr,[{text,"module"},{location,1}],[],none},
module},
[{tree,atom,
{attr,[{text,"module"},{location,1}],[],none},
macros}]}},
2}
4> ktn_dodger:parse_form(Dev, 2, [{scan_opts, [text]}]).
{ok,{tree,attribute,
{attr,[{text,"define"},{location,2}],[],none},
{attribute,{atom,[{text,"define"},{location,2}],define},
[{tree,application,
{attr,[{text,"MATCH_NAME"},{location,2}],[],none},
{application,{var,[{text,"MATCH_NAME"},{location,2}],
'MATCH_NAME'},
[]}},
{tree,map_expr,
{attr,[{text,"#"},{location,2}],[],none},
{map_expr,none,
[{tree,map_field_exact,
{attr,[{text,"name"},{location,2}],[],none},
{map_field_exact,{atom,[{text,...},{...}],name},
{string,[{...}|...],[...]}}}]}}]}},
3}
5> ktn_dodger:parse_form(Dev, 2, [{scan_opts, [text]}]).
{error,{3,erl_parse,["syntax error before: ","?"]},5}
```
Problem seems to reside in ktn_dodger:scan_form which does not send correct thing to erl_parse:parse_form.
```
6> file:close(Dev), f(Dev), {ok, Dev} = file:open(File, [read]).
{ok, <0.333.0>}
7> c(ktn_dodger, [export_all]).
{ok, ktn_dodger}
8> {ok, Ts1, _} = io:scan_erl_form(Dev, "", 1, [{scan_opts, [text]}]).
{ok,[{'-',1},
{atom,1,module},
{'(',1},
{atom,1,macros},
{')',1},
{dot,1}],
2}
9> S1 = ktn_dodger:scan_form(Ts1, {opt, false}).
[{'-',1},
[Truncated]
{'->',3},
{atom,4,false},
{dot,4}],
5}
15> S3 = ktn_dodger:scan_form(Ts3, {opt, false}).
[{atom,3,is_adult},
{'(',3},
{'(',0},
{atom,3,'? <macro> ('},
{'(',3},
{var,3,'MATCH_NAME'},
{')',3},
{')',0},
{')',3},
{'->',3},
{atom,4,false},
{dot,4}]
16> erl_parse:parse_form(S3).
{error,{3,erl_parse,["syntax error before: ","'('"]}}
``` |
santigarcor/laratrust | 248183641 | Title: Couldn't create seeder. Check the write permissions within the database/seeds directory.
Question:
username_0: - Laravel Version: 5.4.*
- Laratrust Version: 4.0.*
### Description:
When running the command to generate the seeders (php artisan laratrust:seeder), I get this error :
"Couldn't create seeder.
Check the write permissions within the database/seeds directory."
I have full permissions on the directories as you can see here

Answers:
username_1: What user runs your php-cli?
username_2: Hello,
I am in the same situation as leif0, same problem and the same permissions, what is the solution please?
username_3: Maybe the `LaratrustSeeder.php` file already exists. It seems the command doesn't differentiate these cases.
username_2: Thanks for your feedback
there is a laratrust_seeder.php file in the config folder. What should be done to remove it?
username_3: The `config/laratrust_seeder.php` file is just a configuration for how the seeder should be set up and it was created there with `php artisan vendor:publish` command. It doesn't affect the `database/seeds/LaratrustSeeder.php` file generation.
I was asking if there is a `database/seeds/LaratrustSeeder.php` file.
username_2: Sorry,
yes, there is a LaratrustSeeder.php file
username_3: @username_2 Delete it if it's incorrect. If it's what you wanted just leave it there and use it.
@username_1 Maybe we should differentiate these cases and display a different error message when the file already exists and when the script doesn't have write permission in the directory.
username_2: thank you for your answer, it works
username_1: I'll make that change
Status: Issue closed
|
grasshopper-cms/grasshopper-cms | 207370540 | Title: Grasshopper core should be a dependency of grasshopper CMS
Question:
username_0: A problem with GH api is that every time GH Core changes, GH api needs to be updated. This is because GH core is a direct dependency of GH api.
This relationship is not necessary. Usually there are many updates to GH core, while few real update to GH api.
A solution is to pass the version of GH core you wish to use into GH api. This will allow updates to GH Core without update GH api.
The side effect of this is that GH-CMS will have to depend on both GH API and Core.
This involves modifying both GH Core and GH Api. These modification should cause a bump to the major version numbers.
These changes should be added to the READMES of Core, API, and CMS.
A general overview of this should be added to docs.grasshopper.ws - https://github.com/grasshopper-cms/grasshopper-docs |
cunninghamge/whether-sweater | 823548532 | Title: road trip
Question:
username_0: Request:
```
POST /api/v1/road_trip
Content-Type: application/json
Accept: application/json
body:
{
"origin": "Denver,CO",
"destination": "Pueblo,CO",
"api_key": "jgn983hy48thw9begh98h4539h4"
}
```
- API key must be sent
- If no API key is given, or an incorrect key is provided, return 401 (Unauthorized)
- You will use MapQuest’s Directions API: https://developer.mapquest.com/documentation/directions-api/
- The structure of the response should be JSON API 1.0 Compliant.
- Your code should allow for the following:
- Traveling from New York, NY to Los Angeles, CA, with appropriate weather in L.A. when you arrive 40 hours later
- Traveling from New York, NY to London, UK, weather block should be empty and travel time should be “impossible”<issue_closed>
Status: Issue closed |
OctopusDeploy/Issues | 181590553 | Title: Add Tenant Icons to machines in environment view
Question:
username_0: We are using Tenants in our Octo setup.
From the environment screen we can see which labels are assigned to a machine, but not which tenant.
In our case, a machine can be shared by multiple tenants.
Due to the fact that adding mutiple labels against machines restricts the targeted tentants to those that have all labels for the machine (rather than any label for a machine), we can't use labels for targeting deployment hosts. We need to add all Tenants individually - which is fine, however it is difficult to tell which tenants are assigned to a machine from the environments screen.
To alleviate this issue, I have developed a tampermonkey script that shows a tenants logo as a 25x25 icon on the environment screen. It has turned out to be an effective use of real estate and make it visually very easy to identify tenants.
I thought I would suggest that this should be an option in the default interface. Here is an example screenshot from our environment.

Status: Issue closed
Answers:
username_1: Hi, thanks for getting in touch with us. The best way to do this is add a suggestion to our UserVoice site: https://octopusdeploy.uservoice.com
We have had a few suggestions like this, but nothing official - so tracking some votes would give us an indication how strongly people feel about it.
We don't actively monitor this backlog for new issues as per our [contributing guide](https://github.com/OctopusDeploy/Issues/blob/master/CONTRIBUTING.md).
[Why was this closed?](https://octopus.com/company/roadmap/why-was-this-closed) |
usnistgov/iheos-toolkit2 | 204982107 | Title: Add FindDocumentsByReferenceID to Conformance Test
Question:
username_0: Would it be possible to add the FindDocumentsByReferenceID query as an option for Registry conformance testing?
Answers:
username_1: Yes, that can be added. I cannot right now estimate which release it will
go into.
bill
username_2: I've just find that "FindDocumentsByRefId" is already added under the "Queries & Retrieves" section in the toolkit v6.1, but it seems it's not yet supported by the Repository/Registry simulator. Whenever I try to send this query to the RepReg simulator I always receive the following error:
XDSRegistryError : Unknown Stored Query query id = urn:uuid:12941a89-e02e-4be5-967c-ce4bfc8fe492 : (stepId=FindDocumentsbyRefId)
--
XDSRegistryError : Do not understand query [urn:uuid:12941a89-e02e-4be5-967c-ce4bfc8fe492] : (stepId=FindDocumentsbyRefId)
username_1: Yes, that is missing. I will schedule the work.
username_3: I am also facing similar issue. I tried with XDS Tool version 6.5.0. could you please tell me, is this issue already resolved? if yes could you please share the version that I can refer.
Error details:
RAN QueryRequest [QueryRequestMessageValidator] VC: [Request;SQ;HTTP;SOAP;xds.b]
Query ID is urn:uuid:12941a89-e02e-4be5-967c-ce4bfc8fe492[OK]
Query Name is[OK]
Query Parameters are:[OK]
ERROR
XDSRegistryError : Unknown Stored Query query id = urn:uuid:12941a89-e02e-4be5-967c-ce4bfc8fe492[ERROR]
ERROR
XDSRegistryError : Do not understand query [urn:uuid:12941a89-e02e-4be5-967c-ce4bfc8fe492][ERROR]
1 steps with errors[OK]
username_1: This is fixed in the current build. The next release, to be labeled 7.0.0,
will include it. We are working now to get that release out.
username_3: Hi Team, is FindDocumentsByRefId issue is resolved? i didnt get the option in 7.2.8 release. |
BogBel/telegram-bidthdays | 382168114 | Title: Tests Configuring
Question:
username_0: Write one test which should create db objects, save them to database, receive them and assert that data is stored correctly.
For each test running session should be created sqlite database with all tables which will be removed after test-session in both success or error test-result.
Pytest should be used to write and run tests. |
numpy/numpy | 124363328 | Title: Dead link in 'Building from source' doc
Question:
username_0: Under the [Basic installation](https://docs.scipy.org/doc/numpy-dev/user/building.html#basic-installation) section, there is a literal
```
:ref:`development-environment`
```
under `NOTE` just before the next subsection.
Answers:
username_0: Update: the reference interferes with the emphasis `*NOTE: ...*`. When the asterisks are removed, the link appears as desired (I tested it). Looks like a Sphinx bug.
Maybe something like `**NOTE:** ...` can work around the issue in the meanwhile.
username_1: Thanks @username_0. Sent a PR to fix this: gh-6914.
Status: Issue closed
|
spacetelescope/jwst | 859872888 | Title: overzealous outlier detection for NIRSpec IFU
Question:
username_0: _Issue [JP-2050](https://jira.stsci.edu/browse/JP-2050) was created on JIRA by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=muzerol):_
In the course of processing simulated IFU exposures of a dithered point source, we're encountering problems with the outlier detection step. A majority of usable pixels are being flagged as outliers, despite the source being bright and no cosmic rays were included. As a result, the output combined cube is mostly zero. For the full set of 4 dithered exposures, cube_build actually crashes because there is no unflagged data. We used only the default parameters for outlier_detection; it's not clear if this is just a matter of tuning them, or if there's a bug in the code.
Answers:
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=jdavies) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=521899#comment-521899):_
This looks like simulated data? Are the error arrays in the rate file realistic?
Would be useful to have the _rate and _cal files in the above data dump as well.
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=muzerol) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=522065#comment-522065):_
[<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=jdavies) cal files are now in the directory, along with one of the original count rate inputs. I don't know the details of what exactly went into the simulations, but it looks like the input err arrays contain some estimate of the photon noise and possibly read noise. If anything, they are probably underestimated, mostly ~0.1%, so that doesn't jive with the outlier flagging. Another possibility might be that the pointing is slightly off, so that the PSF pattern doesn't exactly overlap from dither to dither; however, I did a run with 2 dithers skipping outlier rejection, and the combined product qualitatively looks reasonable.
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=bushouse) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=538645#comment-538645):_
Looking at the values in the SCI and ERR arrays of the cal files indicates an SNR ~1000, which seems unrealistically high for data with relatively low signal levels. I found an old IFU exposure with actual lamp signal in it (from CV3?) and reprocessed from scratch, so that all of the variance and error arrays would be recomputed properly. This exposure, with LOTS of signal from the lamp, yields SCI/ERR ratios in the cal file ~100. So if high levels of signal give you SNR~100, this simulation of low to moderate signal with SNR~1000 is clearly unrealistic. So I'm guessing the overzealous CR flagging is due to the fact that the use of the low ERR values is making everything look like an outlier. I'm rerunning outlier_detection using much higher values of params like "snr" and "scale", to see if this helps to make up for the unrealistically low ERR values.
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=bushouse) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=539986#comment-539986):_
[<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=muzerol) could you put the original rate (cts) files into the data directory listed above, so that I can rerun them through calwebb_spec2 and try to generate more realistic error estimates? I'm sure that this problem with outlier_detection is simply due to the fact that the existing ERR values in the cal files are way too low. They imply a SNR~1000, whereas when I use the 1 cts file that had been provided and manually calculate VAR_RNOISE and VAR_POISSON arrays (using the same formulae as in the ramp_fit step) and then run through calwebb_spec2, which also then computes VAR_FLAT, I get cal files with implied SNR more in the 30-40 range.
Given the existing (very low) ERR values, I have to set the outlier_detection snr parameter to ~1000 in order to prevent it from flagging everything in sight. The detection threshold uses the ERR values as the noise estimate, so if those aren't realistic, you don't get reliable outlier detection.
P.S. the outlier_detection code seems to work fine on simulated MIRI MRS data, because it has more realistic ERR estimates.
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=muzerol) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=540051#comment-540051):_
[<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=bushouse) done.
Do you happen to have a script for the manual noise term calculations? We'll need to do the same thing for our other simulations, since all of them start at level 2a.
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=morrison) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=545056#comment-545056):_
[<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=bushouse) can you remind me how outlier detection is supposed to work when we cover more than 1 band of data. This NIRSpec data covers NRS1 and NRS2. I thought it worked on each band individually. So take all the NRS1 data - build single type cubes so they cover the same wavelength range and then build a median cube from these singles cubes again covering the same wavelength range. When the median cube is blotted back it covers only the range of wavelengths on NRS1. But when I run calspec3 on this data it creates single type cubes covering the wavelength range of NRS1 and NRS2. I am not sure how the median cube would be made from this data because 1/2 of single type cubes have 0's in the non covered wavelength. Then I am not sure how the median cube covering the wavelength range of NRS1 and NRS2 should be blotted back to just one detector. I am a little confused how this is supposed to work. Is the way calspec3 is working on this set set up correctly - or should it split outlier detection into at least 2 parts - one for each detector ?
The same is true about MIRI data that cover all 12 bands. I think I have some Miri data covering all 12 bands I will see how it does outlier detection.
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=bushouse) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=545058#comment-545058):_
Not sure how it was **supposed** to be doing things for NIRSpec IFU, but from what you describe it does in fact sound like it should be working on only 1 band of data at a time, as it does for MRS. There's no point in having the median constructed from the entire wavelength range, since only half the data contribute, which will affect the median. So I'm guessing the NIRSpec side needs some "hooks" like the MRS side, so that outlier_detection works on data from just one detector (wavelength range) at a time. The associations are already setup to restrict the data to just one grating/filter, so you shouldn't need to worry about that domain.
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=morrison) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=545074#comment-545074):_
Looking at outlier_detection_ifu.py the hooks for MIRI are setup on channel. I am running a test case of 12 bands of data and it works on the channels separately - building a median for each channel. For NIRSpec the hook is on grating. But that is not fine enough it should be grating and detector.
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=morrison) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=545126#comment-545126):_
[<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=dlaw)
This ticket is about a NIRSpec outlier detection problem but I am not sure that outlier detection is working correctly for MIRI. You have more experience than I do with testing MIRI MRS and outlier detection. So maybe you can set me straight. I have an association that covers the full wavelength of MIRI. I have 3 dithers of each data - so I have a total of 18 files. To be very clear 3 files for: IFULONG_LONG, IFULONG_MEDIUM, IFULONG_SHORT, IFUSHORT_LONG, IFUSHORT_MEDIUM, IFUSHORT_SHORT.
The first step is to create single type ifu cubes. These have a size of the entire 18 exposures on the sky - but are for each band. So with 18 files I get 36 single IFU cubes. Next a median cube is created that will be blotted back to the detector. MY CONFUSSION is that currently there is a median cube created for each channel. CHANNEL ? So for channel 1 it is a median of channel 1 Short, Channel 1 Medium and Channel 1 Long. Should it not be a median of each band - so a median of channel 1 short, another one for channel 1 medium and a third for channel 1 long. Currently I just have 4 median fits files.
The output names from using --steps.outlier_detection.save_intermiedate_results = TRUE are just plain confusing. I really think this needs improvement. For example I get a file
det_image_seq1_MIRIFUSHORT_12MEDIUMexp1_cal_ch1-mediumshortlong-_single_a3001__outlier_s3d.fits.fits
I find it confusing that mediumshortlong is in the name. I think that is not correct. Single IFU cube have just 1 band, so either I am very confused or those extra bands in the name really should not be there.
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=morrison) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=545268#comment-545268):_
[<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=dlaw) I tracked down 1 error for MIRI MRS outlier detection. The set of input_images needs to be consistent between outlier_detection and blot_cube. Blot_cube was redefining the list of images to be only those contained on the channel that is being blotted. This results in incorrect data arrays being added together in outlier_detection. I want to fix some of the output name strangeness and also FIX NIRSPEC and then I will put in a pr for you to look at.
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=morrison) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=545309#comment-545309):_
[<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=bushouse) I want to update how the names for some intermediate files are formed in outlier_detection. The name of median of the single IFU cubes is formed by the first name in the association. For MIRI a median image is formed for each channel. If the association contains multiple channels then the output median name is confusing. For example - I have an association for containing all four channels. The output medians names are:
det_image_seq1_MIRIFULONG_34MEDIUMexp1_a3001_band1_median.fits - this is for channel 1
det_image_seq1_MIRIFULONG_34MEDIUMexp1_a3001_band2_median.fits- this is for channel 2
det_image_seq1_MIRIFULONG_34MEDIUMexp1_a3001_band3_median.fits - this is for channel 3
det_image_seq1_MIRIFULONG_34MEDIUMexp1_a3001_band4_median.fits - this is for channel 4
Is there some requirement that the median contain the initial part of the first file. Or can I change to just
a3001_ch1_median.fits .... a3001_ch4_median.fits - where a3001 is in the association.
username_1: The median is not standard output, just optional, right?
So probably not super important, but it should probably follow the same pattern as for general spectral products in level 3. There's a product name, and an association name that get folded into the final name.
So the following NIRCam imaging _cal files
```
jw42424001001_01101_0000?_nrc?5_cal.fits
```
get combined into a final
```
jw42424-o002_t001_nircam_clear-f444w_i2d.fits
```
which is a product name generated by the association.
```
"products": [{
"name": "jw42424-o002_t001_nircam_clear-f444w",
"members": [{
"expname": "jw42424001001_01101_00001_nrca5_cal.fits",
"exptype": "science"
},
{
"expname": "jw42424001001_01101_00001_nrcb5_cal.fits",
"exptype": "science"
},
{
"expname": "jw42424001001_01101_00002_nrca5_cal.fits",
"exptype": "science"
},
{
"expname": "jw42424001001_01101_00002_nrcb5_cal.fits",
"exptype": "science"
},
{
"expname": "jw42424001001_01101_00003_nrca5_cal.fits",
"exptype": "science"
},
{
"expname": "jw42424001001_01101_00003_nrcb5_cal.fits",
"exptype": "science"
}
]
}]
}
```
And ideally the median output name would also be
```
jw42424-o002_t001_nircam_clear-f444w_median.fits
```
indicating it is a median made from combined images in that same association. Though maybe the things that get recorded by default in the product name are probably different for MIRI MRS than for NIRCam imaging? For NIRCam imaging it is the pupil and filter (clear and f444w).
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=bushouse) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=545376#comment-545376):_
I agree with [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=jdavies) that the file names of the intermediate products (single s3d cubes, median cube, blotted 2d images) should at least contain some of the original programmatic info from the input cal files. Remember that the names being used in your test ("det_image_seq1...") are totally bogus relative what actually gets used in normal ops processing. Normal input cal file names for MIRI MRS are going to be something like "jw00623036001_02105_00001_mirifushort_cal.fits", where the "02105" and "00001" fields are going to vary across the multiple inputs that go into a given median cube. Meanwhile, the output product root name defined in the spec3 ASN file will be a succinct value like "jw00623-o036_t008_miri" (no additional detector, filter, pupil, channel, band info, because we know the final spec3 product will cover multiple settings of all of those). So you could start with the ASN product root name and append something like "ch[n]_median.fits". Will a given median cube also be restricted to one band or could it cover multiple bands for the given channel? If restricted to one band, you could indicate both the channel and band in the appended suffix.
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=morrison) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=545633#comment-545633):_
[<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=dlaw)
General question. Outlier detection is currently organizing data by channel. It gathers all the exposures according to the channel number and first creates the "single" mode ifu cubes. Let me explain this using an example. If we have data for channel 1 and channel 2 that covers sub channels short, medium and long. The outlier detection would first gather all the data from channel 1 - the size of the single mode IFU cube would be that covered by channel 1, sub-channel short, medium, long. But when building 'single mode' ifus for outlier detection each exposure of channel 1 would create a separate single IFU file. Then all the channel 1 single IFU cubes are combined together to give us the median image that will be blotted back to each exposure and used for flagging outliers.
At the edges between short- medium- long the wavelengths overlap a little. Do you think this is beneficial - when creating the medium images if some wavelengths are a median of 2 bands (will it help flag outliers) or since the resolution is just slightly different - will it create a problem of flagging too many outliers ?
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=dlaw) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=545697#comment-545697):_
Hm, tricky. I'm inclined to say that outlier detection **should** work only on a per-band basis. I.e., the only information used to determined whether to flag things as an outlier in 1A should be other 1A data. That also avoid the complication of what to do when using crossed-band observations, in which case you **really** don't want to be combining bands to identify things to reject. Requiring the same band/channel for outlier detection seems like a clean solution to avoid potentially introducing problems.
Things like residual background matching should certainly look across bands to ensure continuity, but that's a different issue.
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=morrison) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=545705#comment-545705):_
[<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=jdavies) I can not figure out how to form the median name from the association Product name.
outlier_detection uses self.make_output_path (first defined in outlier_detection_step.py) to set up the names of the files. I don't really get how make_output_path is working.
The association I have is given below. The name of the association is 'asn_all.json'. When I try to form the name of the median files as follows
median_model.meta.filename = self.make_output_path(
suffix='ch{}_median_s3d'.format(band)
)
I get median files like this: asn_all_a3001_ch1_median_s3d.fits,.... asn_all_a3001_ch4_median_s3d.fits
So it is forming the name from the association name and not the Product name. Do I need to set the thee
'basepath' in self.make_output_path to something ? I don't understand how to pull out the product name down in outlier_detection_ifu.py - maybe I need to add something in outlier_detection_step.py ?
Association:
{"asn_rule": "Asn_MIRIFU_Dither", "targname": "MYTarget",
"asn_pool": "jw00024_001_01_pool", "program": "00024","asn_type":"dither",
"asn_id": "a3001",
"target": "1",
"products": [
{"name": "det_image",
"members": [
{"exptype": "SCIENCE", "expname": "det_image_seq1_MIRIFULONG_34MEDIUMexp1_cal.fits"},
{"exptype": "SCIENCE", "expname": "det_image_seq2_MIRIFULONG_34MEDIUMexp1_cal.fits"},
{"exptype": "SCIENCE", "expname": "det_image_seq3_MIRIFULONG_34MEDIUMexp1_cal.fits"},
{"exptype": "SCIENCE", "expname": "det_image_seq1_MIRIFULONG_34SHORTexp1_cal.fits"},
{"exptype": "SCIENCE", "expname": "det_image_seq2_MIRIFULONG_34SHORTexp1_cal.fits"},
{"exptype": "SCIENCE", "expname": "det_image_seq3_MIRIFULONG_34SHORTexp1_cal.fits"},
{"exptype": "SCIENCE", "expname": "det_image_seq1_MIRIFULONG_34LONGexp1_cal.fits"},
{"exptype": "SCIENCE", "expname": "det_image_seq2_MIRIFULONG_34LONGexp1_cal.fits"},
{"exptype": "SCIENCE", "expname": "det_image_seq3_MIRIFULONG_34LONGexp1_cal.fits"},
{"exptype": "SCIENCE", "expname": "det_image_seq1_MIRIFUSHORT_12MEDIUMexp1_cal.fits"},
{"exptype": "SCIENCE", "expname": "det_image_seq2_MIRIFUSHORT_12MEDIUMexp1_cal.fits"},
{"exptype": "SCIENCE", "expname": "det_image_seq3_MIRIFUSHORT_12MEDIUMexp1_cal.fits"},
{"exptype": "SCIENCE", "expname": "det_image_seq1_MIRIFUSHORT_12SHORTexp1_cal.fits"},
{"exptype": "SCIENCE", "expname": "det_image_seq2_MIRIFUSHORT_12SHORTexp1_cal.fits"},
{"exptype": "SCIENCE", "expname": "det_image_seq3_MIRIFUSHORT_12SHORTexp1_cal.fits"},
{"exptype": "SCIENCE", "expname": "det_image_seq1_MIRIFUSHORT_12LONGexp1_cal.fits"},
{"exptype": "SCIENCE", "expname": "det_image_seq2_MIRIFUSHORT_12LONGexp1_cal.fits"},
{"exptype": "SCIENCE", "expname": "det_image_seq3_MIRIFUSHORT_12LONGexp1_cal.fits"}
]
}
]
}
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=morrison) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=545723#comment-545723):_
[<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=jdavies)
ok I think I figured it out.
If I do this in outlier_detection_ifu.py
median_model.meta.filename = self.make_output_path(
basepath=self.input_models.meta.asn_table.products[0].name,
suffix='ch{}_median_s3d'.format(band)
The median file names are:
det_image_a3001_ch1_median_s3d.fits, ... det_image_a3001_ch4_median_s3d.fits
I am not sure how that works because the product name is 'det_image'. Somehow the asn id is added to the median file name, but think that is ok
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=morrison) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=545887#comment-545887):_
[<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=muzerol)
In working on this ticket I have found an oversight in both cube_build and outlier detection. IFU cubes are built in the spec3 pipeline by combining data from the same band - which for NIRSpec we defined as the same grating and same filter. However we did not select on detector. The data that was for this ticket contains NRS1, NRS2 exposures for grating G140H and filter F100LP. The default IFU cube for spec3 is one IFU cube containing NRS1 and NRS2. Is that what is desired ? Or should it be two IFU cubes covering the wavelength region covered by each detector ?
For outlier detection to we make 'single' type IFU cubes. These are IFU cubes for a single band. Each exposure for the band is mapped to the entire sky covered by the data but the single IFU only contains the data from a single exposure. All the single IFUs are combined together to create a median IFU cube. This median IFU cube is mapped back (blotted) to the detector space to flag outliers. The problem is that since we only look at the grating and the filter the 3D region the single IFUs cover include both NRS1 and NRS2. This results in a problem. When we take each exposure and mapped it to this single 3d IFU region the NRS1 exposures have data for the ~first 1/2 of the wavelengths while the NRS2 exposures have data for the ~second 1/2 of the wavelengths. Combining all the single IFU cubes into a median image is not correct. So we need to create single IFU cube for NIRSPec also looking at the detector. As I am making this change I wanted to see if we need to also look at the detector when making the default spec3 IFU cubes . I think we do - but I wanted to confirm with you.
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=dlaw) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=545899#comment-545899):_
Jumping in with an opinion quickly, though of course I defer to James on NIRSpec issues. It seems overly complicated for cube building to have to worry about splitting data coming from NRS1 and NRS2, especially since the wavelength transition between the detectors changes as a function of location in the FOV. Adding such a split would introduce quite a bit of extra complexity in the files that needed to be handled in many different places.
Rather, I would think that the median combination of the single IFU cubes should be able to handle cases like the one described above. It shouldn't matter if NRS1 exposures only have data for the first 1/2 of the wavelength range, as these spaxels should be flagged with NODATA (or the equivalent) and ignored by the median routine. The median combination shouldn't just bring in a zero when there is no data (or bad data), it should be respecting the DQ cube in determining what goes into the median for each spaxel.
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=muzerol) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=545908#comment-545908):_
[<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=morrison) we do want a single cube including data from both detectors, when applicable - note that only this is only relevant for the high-resolution gratings (except for the specific combination G140H+F070LP). In those cases, there is some overlap in the wavelength coverage on both detectors among some of the slices because of the wavelength tilt, so from a resampling standpoint, it's preferable to include input pixels from both detectors. It's also preferable from a science standpoint, so that there is always a single level 3 cube regardless of which disperser was used.
I'm not sure I understand the problem with outlier detection; is it that you can't determine the mapping back to detector space when both detectors are included? I wouldn't have expected any ambiguity as long as you can tell the IFU slice correspondence for a given output spaxel.
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=muzerol) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=545909#comment-545909):_
Just saw David's last comment, I agree with the reasoning in his first paragraph.
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=dlaw) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=545921#comment-545921):_
Interesting- it looks like the DQ array is entirely zero for intermediate-stage outlier detection products. That would need to be fixed before we could use such information of course.
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=jdavies) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=545928#comment-545928):_
When making a median cube, the input median cubes need not have fill values of zero. They can have fill values of `np.nan` where there is no input data maps onto the cube and then `np.nanmedian` can be used to create the median.
Spaxels themselves cannot actually have DQ values, right? There's no way to map a partial DQ or distribute input DQ values amongst adjacent spaxels.
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=morrison) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=545933#comment-545933):_
James ok great news on the default IFU cubes for NRS1 and NRS2 - so no change to cube build.
On outlier detection - one solution is to enhance the median combination routine. I will look into this. For single mode IFU cubes the DQ array was set to zero - mainly because it was not being used for these special type of cubes and since it was not being used I did not want to waste the time to set up the DQ plane. It takes a rather long time to set the DQ plane for NIRSpec. We could also use the weight map instead. I think it might be a better plane to use to create the median. The DQ plane setting for NIRSpec really needs more testing. I will need to explain sometime in detail what I did so you can critique the algorithm. One MORE THING - if the some of the wavelength slices overlap between the NRS1 and NRS2 - it could confuse the outlier detection algorithm. The blotted image that mapped back to the detector will be a combination of both detections for these wavelengths. Will this be a problem ?
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=dlaw) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=545934#comment-545934):_
Edit: Just realized that this comment crossed with Jane's, in which she answers why the extension is zero.
The data cube files have a DQ extension that's 3 dimensional, and contain information about the quality of individual spaxels. Generally you're right, and it's non-trivial to figure out how to map detector-based DQ values to DQ cubes, but the cubes do at least flag spaxels outside the footprint of the input data with a 513 value \{'DO_NOT_USE', 'NON_SCIENCE'}
At least, the cubes that I'm used to looking at do- for some reason the cubes that outlier detection is creating do not contain anything except zeros in the DQ extension.
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=dlaw) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=545936#comment-545936):_
[<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=morrison) Using the weight map to select what goes into the median could work too since this array is already being populated. Anything with non-zero WMAP would be a good starting point.
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=morrison) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=545941#comment-545941):_
[<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=muzerol) The issue about having the median cube being made from both NRS1 and NRS2 is not a problem when it comes to mapping (blotting) back to the two detectors. The only issue I think is for those wavelengths that overlap between NRS1 and NRS2. The median cube will be a combination of data from both detectors (which could be a good think since I think the resolution is the same since it is the same grating). These overlap regions will be backed back to both detectors and outlier detection will then be performed. Are there any differences in the data in these overlap regions from one detector to another. Are the noise properties between the detectors that same ? If not then it I will just improve the way the median image is created and not worry about separating the single mode IFU by detector.
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=muzerol) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=545955#comment-545955):_
[<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=morrison) are you able to back out the IFU slice (i.e., in the slicer plane, not cube wavelength slice) to which a spaxel corresponds? That would break the wavelength degeneracy with detector since the overlap occurs between different slices.
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=morrison) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=545958#comment-545958):_
[<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=muzerol) Ok what am I concerned about is the MEDIAN image for the the wavelengths that are found on both NRS1 and NRS2. This median in this wavelength region is will be derived using data from both detectors. This median image will be mapped back to every exposure that is was created from (this results in blot images).
There is no problem blotting it to NRS 1 or NRS2 that works fine. The blotting images are used to flag outliers. I just want to make sure that having a median image created using data from 2 different detectors (in the small overlap region) is not going cause the outlier detection any problems. I think if the noise properties of one detector was much different than the other one - it might. But It sounds like this may not be the case. - so I will just go with that and we can test it and see what happens.
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=muzerol) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=546049#comment-546049):_
[<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=morrison) ok, I think I understand now. The median cube spaxels with wavelengths in the overlap region were calculated using pixels from both detectors, so there may be some inconsistencies in flagging outliers compared to the rest of the pixels. I suspect this shouldn't be a problem since the detectors have similar total noise (NRS2 is ~15-25% higher, depending on the readout pattern). Also, the number of spaxels involved is relatively small, conservatively maybe 0.1%, and again this is only relevant for the high-resolution gratings.
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=bushouse) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=551865#comment-551865):_
[<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=muzerol) After fixing the blotting algorithm used in outlier_detection for NIRSpec IFU data and computing estimated variances/errors from the original countrate images that I hope is closer to what would be coming out of the ramp_fit step for real exposures, I think we're very close to reasonable results. When using the default outlier_detection `snr` and `scale` param values, there are still quite a few pixels flagged as outliers along the centers of the spectral traces in many slices, but I believe this is due to 2 things. 1) the estimated errors are still not quite realistic and 2) possible slight mismatches between the simulated data in each dither position and the assigned pointing information. If I raise the `snr` and `scale` param values, the number of flagged pixels decreases accordingly. Also, when doing a close inspection of the blotted image for each exposure against the original sci image, I can often see what appear to be slight offsets in the spectral trace in the areas where a lot of outlier flags occur (the offset causes the difference between the original and blotted data to exceed the detection threshold). This could be due to slight inconsistencies between the pointing information for each exposure and the actual location of the spectral data in the images.
I've attached some images showing the blotted, original sci, and resulting DQ map for part of one exposure. You probably can't see it from these images, but blinking the blotted and sci images shows a small, but distinct, offset in the centroid of the spectral trace in some slices, right where the most pixels are flagged in the DQ array. [Note that in the DQ image the "outlier" flag values show up as grey; the brighter pixels are very high DQ values, such as those pixels affected by stuck open shutters.]
So overall, I think we've done as much as we can do for now to the actual code, based on testing with the simulated data. Also, if the NGROUPS=80 value used in these simulated images is representative of the way real observations will be taken, I don't think you'll need to be relying on the outlier_detection step in level 3 at all to catch remaining CR's. With such a large value of NGROUPS, the jump step in calwebb_detector1 should have no problem at all catching pretty much everything. !blot_image.png|thumbnail! !sci_image.png|thumbnail! !crf_dq_image.png|thumbnail!
Status: Issue closed
username_0: _Comment by [<NAME>](https://jira.stsci.edu/secure/ViewProfile.jspa?name=muzerol) on [JIRA](https://jira.stsci.edu/browse/JP-2050?focusedCommentId=565082#comment-565082):_
Verified using the simulations and high numbers for the snr and scale parameters. We will need to do more analysis using real data to determine the optimum values for these parameters, especially for point sources. |
evancohen/smart-mirror | 196304033 | Title: angular.js TypeError: Cannot read property
Question:
username_0: Hi,
I've been working on adding traffic map support to the smart mirror. To do this I am using the Bing Maps API. I can ask the smart mirror to show traffic and it will return a static map with traffic in my area. I also wanted to be able to ask it to show traffic in different locations or zoom in and out. The problem is I cannot get it to zoom in or out unless the map URL is using the location coordinates. I've tried following [Microsoft's instructions](https://msdn.microsoft.com/en-us/library/ff701724.aspx) for adding zoom (using zoomLevel=15 or lvl=15), but it doesn't work with a static map. For example, I doesn't matter what the zoomLevel is set with this URL, it will always show the same area:
`http://dev.virtualearth.net/REST/V1/Imagery/Map/Road/Seattle%20Washington?mapLayer=TrafficFlow&mapSize=990,1200&zoomLevel=15&key=Bing_Map_API_Key`
But if I use the location coordinates, zoom can be set:
`http://dev.virtualearth.net/REST/V1/Imagery/Map/Road/47.605893,-122.334950/14?mapLayer=TrafficFlow&mapSize=1200,1200&key=Bing_Map_API_Key`
The easiest way to get the coordinates seems to be using this Google Maps API:
`$http.get("https://maps.googleapis.com/maps/api/geocode/json?address=" + local)`
This returns a JSON file similar to the one Evan uses to get the users geolocation, but the lat and lng coords are located at "results.geometry.location.lat" and "results.geometry.location.lng" instead of "location.lat" and "location.lng". I added the below code to the 'geolocation.js' and when I ask the smart mirror to "show traffic in Seattle Washington" I get an angular error.
Code:
```
service.getTrafficLocation = function(local) {
console.log("In getTrafficlocation-geolocation.js");
var trafficMapArea = {} ;
$http.get("https://maps.googleapis.com/maps/api/geocode/json?address=" + local).then(
function (result) {
console.log("Get requested location")
var coordLocation = angular.fromJson(result).data.location
deferred.resolve({ 'coords': { 'latitude': 'results.geometry.location.lat', 'longitude': 'results.geometry.location.lng' } })
var lat, lng;
console.log("Geo: done getting coords: " + coordLocation.coords.latitude);
//Note: This is how Google suggested to parse the JSON file but there is also a angular error at “result.results.length”
/*
for (var i = 0; i < result.results.length; i++) {
console.log("getting lat");
lat = result.results[i].lat ;
console.log("lat: " + lat) ;
trafficMapArea[0] = lat ;
}
for (var j = 0; j < result.results.length; j++) {
lng = result.results[j].lng ;
console.log("lng: " + lng) ;
trafficMapArea[1] = lng ;
}
*/
//console.log("coordLocation: " + trafficMapArea[0] + ", " + trafficMapArea[1]) ;
},
function (err) {
console.debug("Failed to retrieve geolocation.")
deferred.reject("Failed to retrieve geolocation.")
});
trafficLoc = deferred.promise ;
return deferred.promise ;
//return trafficMapArea ;
}
```
This is the error:
`angular.js:13236 TypeError: Cannot read property 'coords' of undefined
at geolocation.js:65
at processQueue (angular.js:15552)
at angular.js:15568
at Scope.$eval (angular.js:16820)
at Scope.$digest (angular.js:16636)
at Scope.$apply (angular.js:16928)
at done (angular.js:11266)
at completeRequest (angular.js:11464)
at XMLHttpRequest.requestLoaded (angular.js:11405)`
Any help figuring out what is causing the angular error would be greatly appreciated!
Answers:
username_1: Looks like the response doesn't contain a location. You should try to debug this and look at the full response you're getting from the google maps api.
Try it like this:
```console.log(angular.fromJson(result).data)```
or start your mirror using ```npm start dev``` and look in the network tab for the google maps api call. There you should be able to see the full response you're getting. (or the http error code)
username_0: Thank you for the help!
I looked in the network tab and can see the google api call does return the area I'm looking for, in this case I said Redmond, WA:
<img width="320" alt="screen shot 2016-12-19 at 8 20 34 am" src="https://cloud.githubusercontent.com/assets/24350171/21320003/5699ffde-c5c4-11e6-8912-32b771058ceb.png">
Full Result:
`{results: [{,…}], status: "OK"}
results
:
[{,…}]
0
:
{,…}
address_components
:
[{long_name: "Redmond", short_name: "Redmond", types: ["locality", "political"]},…]
formatted_address
:
"Redmond, WA, USA"
geometry
:
{bounds: {northeast: {lat: 47.7171189, lng: -122.036733},…},…}
bounds
:
{northeast: {lat: 47.7171189, lng: -122.036733},…}
location
:
{lat: 47.6739881, lng: -122.121512}
lat
:
47.6739881
lng
:
-122.121512
location_type
:
"APPROXIMATE"
viewport
:
{northeast: {lat: 47.71239, lng: -122.078646}, southwest: {lat: 47.627058, lng: -122.1645101}}
place_id
:
"ChIJI-4AIK0MkFQR8gTYxeqQA14"
types
:
["locality", "political"]
status
:
"OK" `
If I hover over 'lat' in the Network tab with the mouse it shows the location as:
`.results["0"].geometry.location.lat`
I changed the code in the geolocation.js file to:
`deferred.resolve({ 'coords': { 'latitude': 'result.results["0"].geometry.location.lat', 'longitude': 'results["0"].geometry.location.lng' } })
var lat, lng;`
And:
`deferred.resolve({ 'coords': { 'latitude': 'result.results[0].geometry.location.lat', 'longitude': 'results[0].geometry.location.lng' } })
var lat, lng;`
But still get the same error. I am not sure I am pulling the lat and lng data from the result correctly. Or is it something else?
Thanks again for the help
username_2: I suppose it's possible that their API has changed since this was first implemented. Can you provide a full stack trace for this error? I should have some time in the next few days to investigate.
username_1: You're actually reading the JSON in an incorrect way: you don't have any location element inside a data element.
I'm guessing this should work:
```var coordLocation = angular.fromJson(result).results[0].geometry.location```
username_0: Thanks again for the help!
@username_1
I tried your suggestion and I get this error:
angular.js:13236 TypeError: Cannot read property '0' of undefined
at geolocation.js:68
at processQueue (angular.js:15552)
at angular.js:15568
at Scope.$eval (angular.js:16820)
at Scope.$digest (angular.js:16636)
at Scope.$apply (angular.js:16928)
at done (angular.js:11266)
at completeRequest (angular.js:11464)
at XMLHttpRequest.requestLoaded
(angular.js:11405)(anonymous function) @ angular.js:13236
(anonymous function) @ angular.js:9965processQueue @ angular.js:15560
(anonymous function) @ angular.js:15568
$eval @ angular.js:16820
$digest @ angular.js:16636
$apply @ angular.js:16928
done @ angular.js:11266
completeRequest @ angular.js:11464
requestLoaded @ angular.js:11405
Also tried this:
`var coordLocation = angular.fromJson(result).results.0.geometry.location`
And the smart mirror crashed right away with this error:
Uncaught SyntaxError: Unexpected number
angular.js:13236 Error: [$injector:unpr] Unknown provider: GeolocationServiceProvider <- GeolocationService <- MirrorCtrl
http://errors.angularjs.org/1.5.0/$injector/unpr?p0=GeolocationServiceProvider%20%3C-%20GeolocationService%20%3C-%20MirrorCtrl
at angular.js:68
at angular.js:4397
at Object.getService [as get] (angular.js:4550)
at angular.js:4402
at getService (angular.js:4550)
at injectionArgs (angular.js:4574)
at Object.invoke (angular.js:4596)
at extend.instance (angular.js:9855)
at nodeLinkFn (angular.js:8927)
at compositeLinkFn (angular.js:8226)
(anonymous function) @ angular.js:13236
I've never done anything in java script before, so figuring out these little syntax errors has been a little of a pain, so I appreciate your help.
@username_2
This is a great project. I've had fun tinkering with it. Thanks for putting it out in the world!
Is the above error information enough or do you need more? I don't know how to pull a full stack trace, so please let me know.
Thank you
username_2: Usually `$http()` can figure out the data type. Do you actually need to use `angular.fromJson()`?
Or can you just use `result.results[0].geometry.location`?
username_3: @username_0 is this now resolved?
If not please update us and let us know how we can help. If it is please comment what solved the issue and then close the issue. thank you.
Also, we're available on [discord chat](https://discord.gg/EMb4ynW) to help assist you in real time.
username_0: Hi,
Sorry it took so long to respond. Yes, I was able to resolve this by accessing the location with:
`var coordLocation = angular.fromJson(result).data.results[0].geometry.location ;`
Before I was missing the ".data."
Thanks for the help and quick responses!
Status: Issue closed
|
ModelSEED/ModelSEED-UI | 169249872 | Title: Custom media compositions for peptides
Question:
username_0: Hi,
I am trying to create new media compositions that include dipeptides and tripeptides but can't find any of these compounds within Model Seed to add to the media.
Would you be able to help us with this please? Is there a way to add new dipeptides and tripeptides compounds with the corresponding ID, Formula, deltaG, detalGerr and charge for each peptide?
Many thanks
Anna
Answers:
username_1: Hi Anna,
I will let someone else who knows better provide the details, but the biochemistry file is available in the github repository. You should be able to and feel free to take out a branch and add any missing metabolites and reactions you need for your model. After that we should be able to merge the changes if all went well with the changes.
Or if you are running independently, you should be able to launch ModelSeed with your biochemistry file.
Hope that helps!
Best,
Nick
Sent from my iPhone
>
username_0: Hi Nick,
Thanks for your email.
Would you be able to send me the biochemistry file please? I can't seem to find it in the repository.
Many thanks
Anna
username_2: Hi Anna,
This is our biochemistry repo: https://github.com/ModelSEED/ModelSEEDDatabase/tree/master/Biochemistry
You can checkout the repo add your cpds and then submit a pull request.
username_0: Hi Nick,
I previously had annotated genomes imported from RAST into the "genome" and "mine" folder within Model Seed but these have suddenly disappeared. I can still see the annotated genomes in RAST and in the "all my files" folder but i can't see them in the "mine" genomes folder.
Please advise,
Many thanks.
Anna
username_1: Anna,
This is going to have to be a @username_3 question.
Best,
Nick
Sent from my iPhone
> On Aug 4, 2016, at 7:28 AM, username_0 <<EMAIL>> wrote:
>
> Hi Nick,
>
>
> I previously had annotated genomes imported from RAST into the "genome" and "mine" folder within Model Seed but these have suddenly disappeared. I can still see the annotated genomes in RAST and in the "all my files" folder but i can't see them in the "mine" genomes folder.
>
>
> Please advise,
>
>
> Many thanks.
>
>
> Anna
>
>
>
>
username_0: Hi Nick,
Sorry to keep emailing you. Do you have the email address for @username_3?
Many thanks
Anna
Get Outlook for iOS<https://aka.ms/o0ukef>
From: username_1 <<EMAIL><mailto:<EMAIL>>>
Sent: Thursday, August 4, 2016 4:45 pm
Subject: Re: [ModelSEED/ModelSEED-UI] Custom media compositions for peptides (#49)
To: ModelSEED/ModelSEED-UI <<EMAIL><mailto:<EMAIL>>>
Cc: <NAME> (MED) <<EMAIL><mailto:<EMAIL>>>, Author <<EMAIL><mailto:<EMAIL>>>
Anna,
This is going to have to be a @username_3 question.
Best,
Nick
Sent from my iPhone
> On Aug 4, 2016, at 7:28 AM, username_0 <<EMAIL><mailto:<EMAIL>>> wrote:
>
> Hi Nick,
>
>
> I previously had annotated genomes imported from RAST into the "genome" and "mine" folder within Model Seed but these have suddenly disappeared. I can still see the annotated genomes in RAST and in the "all my files" folder but i can't see them in the "mine" genomes folder.
>
>
> Please advise,
>
>
> Many thanks.
>
>
> Anna
>
>
>
>
username_1: Anna,
Not a problem. The communications are great. I like seeing the broader involvement we've gotten recently!
I've cc'd <NAME>. Feel free to email again if you don't get a reply.
Best,
Nick
Sent from my iPhone
> On Aug 4, 2016, at 12:42 PM, username_0 <<EMAIL>> wrote:
>
> Hi Nick,
>
> Sorry to keep emailing you. Do you have the email address for @username_3?
>
> Many thanks
>
> Anna
>
> Get Outlook for iOS<https://aka.ms/o0ukef>
>
>
> From: username_1 <<EMAIL><mailto:<EMAIL>>>
> Sent: Thursday, August 4, 2016 4:45 pm
> Subject: Re: [ModelSEED/ModelSEED-UI] Custom media compositions for peptides (#49)
> To: ModelSEED/ModelSEED-UI <<EMAIL><mailto:<EMAIL>>>
> Cc: <NAME> (MED) <<EMAIL><mailto:<EMAIL>>>, Author <<EMAIL><mailto:<EMAIL>>>
>
>
> Anna,
>
> This is going to have to be a @username_3 question.
>
> Best,
> Nick
>
> Sent from my iPhone
>
> > On Aug 4, 2016, at 7:28 AM, username_0 <<EMAIL><mailto:<EMAIL>>> wrote:
> >
> > Hi Nick,
> >
> >
> > I previously had annotated genomes imported from RAST into the "genome" and "mine" folder within Model Seed but these have suddenly disappeared. I can still see the annotated genomes in RAST and in the "all my files" folder but i can't see them in the "mine" genomes folder.
> >
> >
> > Please advise,
> >
> >
> > Many thanks.
> >
> >
> > Anna
> >
> >
> >
> >
username_3: Hi @username_1. As I am the wrong <NAME>, I don't think I'll be able to help with your annotated genome files.
However, I would recommend minifying and concat'ing your JS, as it looks like you have quite a large payload.
Best of luck!
username_4: Hi @username_0, the rast-annotated genomes list issue (under "mine") was fixed earlier today. There was a power outage causing the server to go down for some time.
@username_3, I am minifying and concat'ing JS with https://github.com/ModelSEED/ModelSEED-UI#build for the time being. Sorry for mixup.
username_0: Hello,
I am trying to add new compounds (dipeptides and tripeptides) to the model seed database so I can perform metabolic reconstructions. Do I just need to modify the compounds.master.tsv file or do I also need to modify the compartments.master.tsv and reactions.master.tsv files as well? I ask as I cant seem to find any information on dipeptides and tripeptides with regards to reaction pathways (rxns) and compartment data.
Many thanks
Anna
username_1: Anna,
You'll have to modify all of those to get the right reactions in the right places. Otherwise the compounds will have no attachment to any other reaction/compounds in the model.
Best,
Nick
Sent from my iPhone
> On Aug 8, 2016, at 9:15 AM, username_0 <<EMAIL>> wrote:
>
>
> Hello,
>
>
> I am trying to add new compounds (dipeptides and tripeptides) to the model seed database so I can perform metabolic reconstructions. Do I just need to modify the compounds.master.tsv file or do I also need to modify the compartments.master.tsv and reactions.master.tsv files as well? I ask as I cant seem to find any information on dipeptides and tripeptides with regards to reaction pathways (rxns) and compartment data.
>
>
> Many thanks
>
>
> Anna
>
>
>
>
>
username_0: Thanks Nick,
I'll start modifying the files. I've tried adding some new media to the "my media" folder but it doesn't seem to be working. I'm guessing the server isn't working well right now?
Anna
From: username_1 <<EMAIL>>
Sent: 08 August 2016 20:23
To: ModelSEED/ModelSEED-UI
Cc: Annapaula Correia (MED); Mention
Subject: Re: [ModelSEED/ModelSEED-UI] Custom media compositions for peptides (#49)
Anna,
You'll have to modify all of those to get the right reactions in the right places. Otherwise the compounds will have no attachment to any other reaction/compounds in the model.
Best,
Nick
Sent from my iPhone
> On Aug 8, 2016, at 9:15 AM, username_0 <<EMAIL>> wrote:
>
>
> Hello,
>
>
> I am trying to add new compounds (dipeptides and tripeptides) to the model seed database so I can perform metabolic reconstructions. Do I just need to modify the compounds.master.tsv file or do I also need to modify the compartments.master.tsv and reactions.master.tsv files as well? I ask as I cant seem to find any information on dipeptides and tripeptides with regards to reaction pathways (rxns) and compartment data.
>
>
> Many thanks
>
>
> Anna
>
>
>
>
>
username_5: Anna,
Here are some more details for you. You'll need to add new compounds and reactions in https://github.com/ModelSEED/ModelSEEDDatabase. The first step is update the master biochemistry files. Look in https://github.com/ModelSEED/ModelSEEDDatabase/blob/master/Biochemistry/README.md for information on the format of the files. The reaction and compound IDs need to be unique.
The second step is to update the templates that are used for reconstructing models of your organisms. Look in https://github.com/ModelSEED/ModelSEEDDatabase/blob/master/Templates/README.md for information on the format of the files and directions for building a template.
If the README files don't make sense, post an issue in the ModelSEEDDatabase repo and I can try to clarify.
username_0: Thanks Mike,
I am trying to perform reconstructions with custom modified media but it keeps failing. I have substituted glucose with succinate. Attached is an example of a file I am working with. Please advise
Thanks
Anna
username_5: Anna, I don't see a file attached. If it is small, can you paste the contents in a comment?
username_0: id name concentration minflux maxflux
cpd00001 H2O 0.001 -100 100
cpd00007 O2 0.001 -100 100
cpd00011 CO2 0.001 -100 0
cpd00013 NH3 0.001 -100 5
cpd00030 Mn2+ 0.001 -100 100
cpd00034 Zn2+ 0.001 -100 100
cpd00036 Succinate 0.001 -100 100
cpd00048 Sulfate 0.001 -100 5
cpd00058 Cu2+ 0.001 -100 100
cpd00063 Ca2+ 0.001 -100 100
cpd00067 H+ 0.001 -100 100
cpd00099 Cl- 0.001 -100 100
cpd00149 Co2+ 0.001 -100 100
cpd00205 K+ 0.001 -100 100
cpd00254 Mg 0.001 -100 100
cpd00971 Na+ 0.001 -100 100
cpd01665 D-O-Phosphoserine 0.001 -100 5
cpd10515 Fe2+ 0.001 -100 100
cpd10516 fe3 0.001 -100 100
I've substituted Succinate with Glucose in the Phosphate-O-Phospho-D-Serine media. Hope that helps.
Status: Issue closed
username_6: @username_0 I'm closing without comment. We've made significant changes to the website, so if you encounter any new problems, do let us know. |
expertiza/expertiza | 389936613 | Title: Reviewers don't get e-mailed when their authors resubmit
Question:
username_0: This is what the E1864 project team told me during their demo.
Answers:
username_1: I also couldn't find any code related to that. Could you please point me to a file or a project where I can find the code for the same.
username_1: Send the link mentioned in #1565 via email.
Status: Issue closed
|
codebuddies/DailyAlgorithms | 386440336 | Title: [Leetcode] Valid Parentheses
Question:
username_0: https://repl.it/@username_0/ExcellentBlandAutocad
Javascript:
```
/**
* @param {string} s
* @return {boolean}
*/
var isValid = function(s) {
if (s.length === 0) {
return true;
}
//create new string
//once you find a character that's open bracket, add that to new string
//if you find a closing bracket, compare that to most recent element in string
// if they match, you remove that element from string
// if they don't match, return false.
//at the end of it, if string is empty, return true
var stack = ""
var opening = "{(["
var closing = "})]"
for (var i = 0; i < s.length; i++) { // looping through
if (opening.indexOf(s[i]) > -1) { //if we find an opening bracket
stack += s[i]; //add to "stack"
} else if (stack.length === 0) { //if the element is a closing bracket, AND no opening brackets exist for it to compare to, return false
return false;
} else {
//find index of closing bracket, compare to index of opening
//check if the closing bracket matches w/ the last element of the "stack"
if (closing.indexOf(s[i]) === opening.indexOf(stack[stack.length-1])) {
stack = stack.slice(0, stack.length-1); //if there is a match, pop the stack
} else {
return false;
}
}
}
return stack.length === 0;
};```
Answers:
username_0: https://repl.it/@username_0/ExcellentBlandAutocad
Javascript:
```js
/**
* @param {string} s
* @return {boolean}
*/
var isValid = function(s) {
if (s.length === 0) {
return true;
}
//create new string
//once you find a character that's open bracket, add that to new string
//if you find a closing bracket, compare that to most recent element in string
// if they match, you remove that element from string
// if they don't match, return false.
//at the end of it, if string is empty, return true
var stack = ""
var opening = "{(["
var closing = "})]"
for (var i = 0; i < s.length; i++) { // looping through
if (opening.indexOf(s[i]) > -1) { //if we find an opening bracket
stack += s[i]; //add to "stack"
} else if (stack.length === 0) { //if the element is a closing bracket, AND no opening brackets exist for it to compare to, return false
return false;
} else {
//find index of closing bracket, compare to index of opening
//check if the closing bracket matches w/ the last element of the "stack"
if (closing.indexOf(s[i]) === opening.indexOf(stack[stack.length-1])) {
stack = stack.slice(0, stack.length-1); //if there is a match, pop the stack
} else {
return false;
}
}
}
return stack.length === 0;
}; |
codalab/codalab-competitions | 472548552 | Title: Weird Time limit exceeded
Question:
username_0: hello,
after running for a couple of hours all my submissions failed due to "time limit exceeded" i don't know exactly what is the origin of this error ! some people told me that they faced this problem before and they just got it fixed by resubmitting ! i believe that the problem is not in my submission and might be a server issue or a heavy load ! also i calculate the running time of each of my submissions from the scoring output log and they are as follows **(16955.6, 17310.1, 17900.1, 15630.2)** as you can see they are different
by the way the execution always stop at a specific step! do you have any idea about this issue ? the time of submitting is it important ?
Status: Issue closed
Answers:
username_0: The true elapsed time can be found in the metadata |
Trivadis/plsql-and-sql-coding-guidelines | 971549929 | Title: Automatically format all code in this repository
Question:
username_0: We could provide code in this repo to allow code to be automatically formatted before committing it. This could be done by using SQLcl and tvdformat.js or the standalone CLI provided in [this repo](https://github.com/Trivadis/plsql-formatter-settings).
Technically every client needs to enable the appropriate Git hook(s). We should just provide the necessary install procedure to simplify that set up process. This could be use as example to set up something similar in other Git repos using SQL and PL/SQL code.
Some code blocks are marked as `sql`, but contain more than SQL and PL/SQL commands. E.g. output of an execution in SQL*Plus, SQLcl or similar. These code blocks are not amended based on this issue. Instead the default logic will apply. There are simply not formatted due to parse errors. To fix that a dedicate issue can be created (once all these code blocks are identified). |
kastnerkyle/todo | 180183099 | Title: Constraint Markov Chain Papers and Links
Question:
username_0: The Continuator: Musical Interaction with Style
https://www.csl.sony.fr/downloads/papers/uploads/pachet-02f.pdf
Continuator code:
https://github.com/username_0/vlmc
Max patch with diagram, explanation
https://cycling74.com/project/variable-order-markov-model/#.V-2W6TMrLC0
Markov Constraints: Steerable generation of Markov sequences
https://www.csl.sony.fr/downloads/papers/2011/pachet-09c.pdf
Finite Length Markov Processes With Constraints
https://www.csl.sony.fr/downloads/papers/2011/pachet-11b.pdf
Self-learning Control of Constrained Markov Chains - A Gradient Approach
https://www.ece.ubc.ca/~vikramk/cdc.pdf
Exact Sampling for Regular and Markov Constraints with Belief Propagation
https://www.csl.sony.fr/downloads/papers/2015/papadopoulos-15b.pdf
Thesis on Constrained Markov Decision Processes
http://www-sop.inria.fr/members/Eitan.Altman/TEMP/h.pdf
Background on Belief Propagation
http://nghiaho.com/?page_id=1366
http://www.nowozin.net/sebastian/papers/nowozin2011structured-tutorial.pdf
http://sigpromu.org/reports/Field65_382.pdf
http://computerrobotvision.org/2009/tutorial_day/crv09_belief_propagation_v2.pdf
https://docs.google.com/presentation/d/17pblLQ8gsgLCQo9Ghre1zD_RlzQdEqwFPyr0afREXyI/edit?usp=sharing
Lecture on CSP
http://web.stanford.edu/class/cs227/Lectures/lec14.pdf
CSP in Python by Norvig
http://aima.cs.berkeley.edu/python/csp.html |
flathub/com.grangerhub.Tremulous | 497958947 | Title: Clicking Browse Folders menu buttons does nothing
Question:
username_0: Clicking the Homepath/Demos/Screen Shots folder buttons in Browse Folders menu does nothing.
Answers:
username_1: Howdy @username_0 ! Do you get any error messages in the console? Also which distro and desktop environment are you testing on? What is suppose to happen is your default file manager should open in a separate window with the corresponding folder. I have noticed that sometimes if you already have your default file manager open in an existing window, it might open the folder there without bringing that window into focus.
This is the main commit for this feature: https://github.com/GrangerHub/tremulous/commit/271734ff5a067fe513d6a530c5f91022b2f4ffd7
We have previously tested it successfully on Ubuntu with Gnome Shell, Windows 10, and a recent version of macos.
username_0: I am using Fedora 30 with GNOME Shell.
There is nothing in the log, just: `^7Sys_OpenWithDefault: opening /home/asciiwolf/.tremulous .....`
For screenshots/demos folders, there is also an i/o error, but I suspect it being there because the folders do not exist yet. |
im/im.github.io | 944081485 | Title: git submodule - 糖小米 · 笔记
Question:
username_0: https://tangxiaomi.top/2019/04/09/git/38399f8bee/
添加git submodule add -b [指定分支] [仓库地址] [路径] example: git submodule add -b icarus https://github.com/username_0/hexo-theme.git themes/icarus 命令执行完成,会在当前工程根路径下生成一个名为 .gitmodules 的文件,其中记录了子模块的信息。 .gitmodules[su |
ClickHouse/ClickHouse | 612800230 | Title: Add a setting 'input_format_enum_as_number'
Question:
username_0: **Use case**
https://github.com/ClickHouse/ClickHouse/issues/7971
Answers:
username_0: We can recognize numbers and check for symbolic values if the value is not a number.
It can be done even automatically without any settings if the Enum type does not have any symbolic values that can be ambiguously parsed as numbers.
username_1: Will this setting added in the near future?
username_0: This task is on hold. It's easy to implement, it's open to take for community members.
If you are interested implementing this, there is a green light, we will help to review as quick as possible.
username_2: https://github.com/ClickHouse/ClickHouse/pull/15685
username_3: This task has been done in [#15685](https://github.com/ClickHouse/ClickHouse/pull/15685) @username_0
Status: Issue closed
|
OpenNebula/one | 309366126 | Title: setuid/setgid for VM Templates
Question:
username_0: <!--////////////////////////////////////////////-->
<!-- COMPLETE THIS SECTION FOR FEATURE REQUESTS -->
<!--////////////////////////////////////////////-->
# Enhancement Request
## Description
This feature intends to enhance the user and group ownership of a VM instantiated from a particular VM Template.
This entails the creation of a new way of defining special permission for owners (similar to setuid in unix filesystems) and groups (similar to setgid in unix filesystems).
This feature enables the use case of a VM Template that will get instantiated always under a particular username or group, inheriting the permissions and visibility of those users/groups.
## Interface Changes
This new setting would be available through special attributes in the VM Template, that will be made available in Sunstone in the VM Template editions and VM instantiation from VM Template dialogs, as well as in the CLI “onetemplate instantiate” command
<!--////////////////////////////////////////////-->
<!-- THIS SECTION IS FOR THE DEVELOPMENT TEAM -->
<!-- BOTH FOR BUGS AND ENHANCEMENT REQUESTS -->
<!-- PROGRESS WILL BE REFLECTED HERE -->
<!--////////////////////////////////////////////-->
# Progress Status
- [ ] Branch created
- [ ] Code committed to development branch
- [ ] Testing - QA
- [ ] Documentation
- [ ] Release notes - resolved issues, compatibility, known issues
- [ ] Code committed to upstream release/hotfix branches
- [ ] Documentation committed to upstream release/hotfix branches
Status: Issue closed
Answers:
username_2: <!--////////////////////////////////////////////-->
<!-- COMPLETE THIS SECTION FOR FEATURE REQUESTS -->
<!--////////////////////////////////////////////-->
# Enhancement Request
## Description
This feature intends to enhance the user and group ownership of a VM instantiated from a particular VM Template.
This entails the creation of a new way of defining special permission for owners (similar to setuid in unix filesystems) and groups (similar to setgid in unix filesystems).
This feature enables the use case of a VM Template that will get instantiated always under a particular username or group, inheriting the permissions and visibility of those users/groups.
## Interface Changes
This new setting would be available through special attributes in the VM Template, that will be made available in Sunstone in the VM Template editions and VM instantiation from VM Template dialogs, as well as in the CLI “onetemplate instantiate” command
<!--////////////////////////////////////////////-->
<!-- THIS SECTION IS FOR THE DEVELOPMENT TEAM -->
<!-- BOTH FOR BUGS AND ENHANCEMENT REQUESTS -->
<!-- PROGRESS WILL BE REFLECTED HERE -->
<!--////////////////////////////////////////////-->
# Progress Status
- [x] Branch created
- [x] Code committed to development branch
- [x] Testing - QA
- [x] Documentation
- [x] Release notes - resolved issues, compatibility, known issues
- [x] Code committed to upstream release/hotfix branches
- [x] Documentation committed to upstream release/hotfix branches
username_2: # VM Instantiation
- [ ] Modular advanced options
# Template upgrade
- [ ] PCI -> Input / Output
- [ ] Rename tab 'Other' to 'Tags'
- [ ] Instantiate as user/group into tab 'General' as advaced options
Status: Issue closed
|
pulibrary/figgy | 377897224 | Title: Find missing numismatics images
Question:
username_0: A quick survey shows there are at least some images of coins not in the puld0049 directory. It would be useful to have a list of the missing images so we can track them down.
Child of #2025
Answers:
username_1: Alan said that Roel has been copying them from their hard drive, and returning the drive empty.
username_1: I asked Roel if there were other images beyond what we see in pudl0049 (which are a few years old), and he said he hadn't done anything since then, and any other images are on their hard drive in RBSC. So when we get ready to migrate data, we should ask Roel to copy all of their files to the Isilon again, so we have the most recent images.
username_0: Will need to be done right before migration.
username_2: The image files have been copied, but there still must be resources created in response to these new assets within Figgy (I believe that this is a CLI Rake task or something similar).
Status: Issue closed
username_0: Images ingested and linked to Coin records. |
AnsenYu/ENU-mainnet-contract-upgrade | 377145385 | Title: ENU mainnet enu.msig contract upgrade signatures collection
Question:
username_0: I'll release the transaction file at about Beijing 2018.11.05 12:00:00 (UTC 2018.11.05 04:00:00). Please sign the contract before Beijing 2018.11.05 21:00:00 (UTC 2018.11.05 13:00:00), due the expiration limitation of ENU transaction.
Let's make ENU great!
Answers:
username_1: username_1:
http://enumivo.qsx.io/transactions/ac0fa3c8c1ad76a0c7fb6cbd1e9f1a7d1be50fe55927f068e70d06f3dd2efb00
username_2: enumivotyler:
http://enumivo.qsx.io/search?q=3f9f6abd240b4be0c349be4f8cbe0757f42615801b36d02b144e2c12716f00d0
username_3: enumivoqsxio:
http://enumivo.qsx.io/transactions/5aef41c4e77327c16c0286b3c826bc4d80c28d1bc47cc5085d87f41138ebf542
SIG_K1_KWDNiKyJnbbczWp65P3wZdFfhVfwMCnnPb7yPcrX316ujCoPXGaw8JRNUVogYhNxZRL7Cr7ow6Y2VgxjeUoC11p66vhzdo
username_0: gamevcfundbp:
http://enumivo.qsx.io/transactions/7a3d67a70684ed31e9b31a0b8d31f46b31a74a2d6a058aa6f83ee7c251eb8e9b
SIG_K1_KkXdmdVGdMGSFq6K9RpkEkLroB1i1WLfSMrSaoavA79cKXsYiYLpqaAwUcVm4KVyRPNrnQamHkqdt1R5k9QZ1ti9osGmQq
username_0: enuhlawapiti:
http://enumivo.qsx.io/transactions/8324ec54d1cd45de40e0a887abf7ab31aef33e0da73763d643fcf67de96df27d
SIG_K1_JvG1aZZZVVXbm7NfXgeDip7pHoApXzvUaLcn1QNrmp8riJjfMpyZsdsinfA7HoUAtw7xgimBsyin6c93cE1DiGc7qLXM4R
username_0: enudavidfnck:
http://enumivo.qsx.io/search?q=aea7d2c2be82a28ca31dffb94780c98d96084a2667e6143496cd8e7c3c92714f
SIG_K1_JyuRFqdz27etLHGPfyFoHvdwLEf472BcETGiCHnu5VtVHrSXWPX8CV8g8SNdGXTLJtJY57Fm2sE7BC9vwHrVwYrPoZVCJw
username_4: hzchenforenu:
http://enumivo.qsx.io/search?q=ca762f75fd760b030d711e3de70479049d1c269ef39d36d9996bae71d0a9141f
SIG_K1_KgLKW8GpcWzoTGtReRxfawn4pgxWTDxaVWu8mqNXyDoimntegNGq9yAsFS73xta1GVZwSNNCcdmi69fNRiJySXTyGv738d
username_5: username_5zzzz
http://enumivo.qsx.io/transactions/cb5e130b9b77329da2a3a5e2e194e4e4b9a1a2f7e73cd565a8d7433bd1e623a3
SIG_K1_K72FvbXvN2MRvuRCQvRVNS8ZroUWf4dg47mBrnRTCgwATdaEdY9sk5e8CaEQPSWrMy8RPoD7ch9C4ztV7uCxiwv2NLyYj2
username_6: enubifreedom
http://enumivo.qsx.io/transactions/341076081345916eaf8feb1f8b63cd96b625ea5dd0cd53278be272e103f3c516
SIG_K1_KbysFkpNaGUL6zAbbwvivMAG2B36sTsecG6DBhMAGARK7wk6faMGGA9fyBWvkfkS8dHBUVq7Gq63dusWoTaf2ocbqASbp4
username_7: username_7forenu
http://enumivo.qsx.io/transactions/f727a38c5deb9c0d13f1f345ec419b5e24973adda1d9ec1fc530d1d862bad9f5
SIG_K1_K9pLeLpAaTMfG49Qix7R5ZfJtYXVhk3PDM1x9nsEpypu12QLRbwhETJgSCdvdX1bQiN2idVniTFtnhZssDau6RjKkSgCHX
username_8: funkydaifuku
http://enumivo.qsx.io/transactions/bd2001398ca4cde68b3cf6fa5cd4d52463ce5c06769f8d9e2dcd3b3e75edc1cc
SIG_K1_KcaHCxb4im7N3VGx3sJjDQSFH5MPhEEiqE615SsqjYnnGWgigH5mMGULLKLAHoiRaa5GptHgWDtjg2XxfNHCKfVnjwW2gG
username_9: dragosvlaicu
"SIG_K1_KYcgHQm7r4M5ZmtumT41Jaga4Ap95KxGr8UgqkP33jVPTbHidMoqHjFAvobR5eL8nszhZv92GbcrudcBLJMN8jcgtAon4r"
username_0: enudonnysong
http://enumivo.qsx.io/transactions/dc61dc2443406098ab381e661ff501d25c7cc4d648ad645eb4464b24ab9105cc
SIG_K1_Jx6BmCnvZjcuWHbiHWJ6U66CzACYsGcQVeWX9z7o27YGLw2he9c98Vhk5KX6LvDnopTHvNrvemrbU6rd9SbdkRjpgH6phP
username_10: eurnoproject
SIG_K1_Kgs5YJpVsf8ScrUQs328WrPWPCYRPTP9rs4p6xXvxBjpJKLvU7GaKdgap4SHGCJaY8ZQs5ZyVe72EFQKqgxd85xyGbeTez
username_0: enupeacelove
http://enumivo.qsx.io/transactions/3cebf23d273579872958a2c34c366e99fbebf46209bd7eb10d9c96a4321a88c8
SIG_K1_K92vepsbxUiUEYUBPxLqHVqTdQ5aq5dL3Vm73i8M7UWmXD3vLX3b3uYMv47XUXP8N4YsqSS9shDtUG8wbyE9rg8qq4vDnZ
username_0: A signed transaction with 15 BP's signatures is generated here:
https://github.com/username_0/ENU-mainnet-contract-upgrade/blob/master/enumsig/upgrade_enumsig_contract_signed_trx.json
I'll push it to the blockchain in about 2018.11.05 20:00:00 Beijing. |
google/xls | 855234128 | Title: DSLX interpreter hangs in simple loop
Question:
username_0: Minimal-ish example [here](https://github.com/username_0/xls_regex/commit/bdf4bb7e738d4d8c5e1b7d8bad33acb2cde2f998#diff-bb82a0d97b75e2d5bf227f22b5dfcc9502e9fc15fde0aa81cab832ba96e06262R46).
`interpreter_main donut.x` will hang after the loop finishes all 256 iterations (last trace print statement shows the value of `i` as 0xff).
When I replace `update(result_, u8:0, report_t:0)` (line 49) with `report_t[MAX_CYCLES]:[report_t:0, ...]`, the program finishes executing.
Answers:
username_0: XLS git hash is 14d5f6e7ba1fd553cdfc9a0d5cb772c1c3ea75cf |
davecparker/code12 | 345098398 | Title: Support += operator for Strings
Question:
username_0: Located within checkJava.lua, function canOpAssign +=
Also determine all types that use += with strings on right hand side of expression
Answers:
username_0: Located within checkJava.lua, function canOpAssign +=
Also determine all types that use += with strings on right hand side of expression
username_0: Also located in CodeGenJava.lua, function generateAssign
username_0: When applied to strings, the += operator can be used with strings, ints, doubles, booleans, and even null values with Java.
```
String s = "hello world";
s += "!"; // => "hello world!"
s += 4; // => "hello world!4"
s += 3.14; // => "hello world!43.14"
s += true; // => "hello world!43.14true"
s += false; // => "hello world!43.14truefalse"
s += null; // => "hello world!43.14truefalsenull"
``` |
microsoft/appcenter | 520942571 | Title: Suggestion for custom event log improvement
Question:
username_0: **Describe the solution you'd like**
The user can be able to see fully printed JSON output in the custom event log UI. Because currently, AppCenter is not supported to read the whole JSON output string:
[https://docs.microsoft.com/en-us/appcenter/sdk/analytics/android](https://docs.microsoft.com/en-us/appcenter/sdk/analytics/android)
**Describe alternatives you've considered**
If it's not possible, can we have at least one function which can track down what information belongs to which user?
Currently, the event format in AppCenter is like:
**With the current custom event log structure, it's impossible to indetify the indivedual information from each user**
_________________
- UserID
- Message
- Name
- Age
__________________
**Here is the format which I would like to see in this AppCenter**
__________________
- UserID
- Message
- Name
- Age
___________________
**With this format, it's very easy to track the information from each user and it will help the developer a lot to track down bugs.**
**Additional context**
This function will help me a lot with bug tracking. Because In some of these cases, I have to put a lot of time effort to make sure the function is working in every type of device. With this custom event log improvement, it will reduce the time spent during the bug fix test case scenario.
Answers:
username_1: Thank you for the feature request, I've assigned colleagues who can investigate it further. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.