
repo_name
stringlengths 4
136
| issue_id
stringlengths 5
10
| text
stringlengths 37
4.84M
|
|---|---|---|
introlab/rtabmap | 708779965 | Title: Add color to costmap/occupancy grid
Question:
username_0: Hi, I was reading #526 and I read that it would be possible that "the resulting points in obstacle and ground can have colors". Where should I edit the code to have something like this? I want to differentiate between different obstacles, hence for each obstacle cell I may want a different color in the map and this should be rectified every time is necessary. The faster way would be just to add this color encoding to every obstacle cell clearly (without having to create another costmap) and to add this information to the database. This would mean to create a new list for each signature (along empty, obstacle, ground) as long as obstacle where for each element I have the corresponding color value (so that the system is able to recreate it)
Answers:
username_1: For example with this [demo](http://wiki.ros.org/rtabmap_ros/#Robot_mapping_with_RVIZ), if you modify the the launch file as follows:
- Set Grid/FromDepth to true [here](https://github.com/introlab/rtabmap_ros/blob/58dd3134be6f2ccc81f998df4e258354f0071e44/launch/demo/demo_robot_mapping.launch#L53)
- Add:
```xml
<param name="Grid/3D" type="string" value="true"/>
<param name="Grid/RayTracing" type="string" value="false"/>
<param name="Grid/MaxObstacleHeight" type="string" value="2"/>
```
Launch the demo and add /rtabmap/cloud_obstacles to rviz:
```bash
roslaunch rtabmap_ros demo_robot_mapping.launch rviz:=true rtabmapviz:=false
rosbag play --clock demo_mapping.bag
```

The obstacles have the color of the RGB image. When visualizing individual local grids in DatabaseViewer:

The colors are added implicitly here when creating the cloud to segment from RGB-D or Stereo data contained in the node: https://github.com/introlab/rtabmap/blob/e8e3649f249382a790968ecbfa1dd9f32606d7d4/corelib/src/OccupancyGrid.cpp#L368-L369
As pointed out in the referred [post](https://github.com/introlab/rtabmap/issues/526#issuecomment-611011740), the `obstacles` [here](https://github.com/introlab/rtabmap/blob/cdff33b1c2bd04ea6a203824b18de631ba06f72d/corelib/src/Memory.cpp#L5102) would contain a RGB channel if `Grid/FromDepth` is true and `Grid/3D` is true. Before making any modifications, how are obstacles semantic computed in your approach? Is it image-based segmentation or pointcloud-based segmentation? For image-based segmentation, one could feed the segmented image instead of the RGB image to rtabmap, but loop closure detection won't work anymore (can be ok if you are using a lidar for localization though). With more deep modifications, using the multi-cameras approach already in rtabmap, would be to feed the segmented image along the RGB images (like if it was a two cameras setup), but we should add parameters to rtabmap to tell it to do loop closure detection on the first camera, but grid segmentation with the second camera.
cheers,
Mathieu
username_0: Actually, I'd like to color/create a 2D map. Each cell will be colored based either on the kind of obstacle that it represent/of there's a feature above that.
For example if I have a feature in world coordinates in (3,3,3) the 2D map in that point will be "colored" or marked. Same happens if I decide to use segmentation (that I don't have rn) but still I'm interested in the creation of a 2D map. Most probably, I'll use features. My idea was to have on the end a map, like the costmap that has probability values, with a value (between 0,100) that represent the number of features in that column. We already have the features in the base frame if I'm correct, so the work would be just to create another layer of costmaps correct?
username_0: So I thought about that during the last few days: the best way for this to work for me would be creating a matrix where for each cell I can have an "array" of values. Much like a 2D map but for each cell instead of having a value like [this](https://github.com/introlab/rtabmap/blob/e8e3649f249382a790968ecbfa1dd9f32606d7d4/corelib/src/OccupancyGrid.cpp#L647) I can have a list of values (int would be good). Then the structure would be the same (centering, resolution, etc).
In this way for example if I query (0.1, 0.1) I will have [1, 2, 5, 7] as result not just a single value.
I think that this would be possible if I can:
- add my custom structure in createLocalMap
- understand how to edit the code in the update such that the same cell viewed by two viewpoints is correctly merged
- write my caller/publisher following my custom structure/L647 and subsequents [easiest part]
username_1: This is quite specific to your application. One way would be to subscribe to data you want and reconstruct a map layer as you want. For example subscribing to /rtabmap/mapData to get features, transform them in map frame and project them in the occupancy grid map. The problem is when a loop closure happens, the whole occupancy grip has to be regenerated, you would need to update your structure too.
username_0: Yup, I know but to avoid unneccessary override and information flow I'd like to integrate that within your system. Each time a new node is added you use [this](https://github.com/introlab/rtabmap/blob/cdff33b1c2bd04ea6a203824b18de631ba06f72d/corelib/src/Memory.cpp#L764) method, right? If that returns true the node is correctly added. So I could directly edit my structure there while adding information where nodes are being added to the graph. Then when a loop closure is detected I can directly edit such information. That means that [here](https://github.com/introlab/rtabmap/blob/bedc771fa4acde22c1497811a88de50c42a248e8/corelib/src/Rtabmap.cpp#L2962) I will have my new poses in the new locations and I can then edit (by moving around and eventually delete) my information placing myself [here](https://github.com/introlab/rtabmap/blob/bedc771fa4acde22c1497811a88de50c42a248e8/corelib/src/Rtabmap.cpp#L3064) by working in a custom else (so it won't be updated if the LC is rejected). Any comment/suggestion/thought about this? Is this correct? |
microsoft/PowerToys | 681022755 | Title: [Issue] Setting reset
Question:
username_0: After updating to a newer version of PowerToys, some settings got reset, like the background of the shortcut guide.
Answers:
username_1: verified opacity didn't carry over from a 0.19 to .20 install. we (chances are me) did touch some json stuff and could be one of the settings that didn't get the attribute flag set correctly. Going from 0.20 to 0.20 upgrade, the settings did save.
Sadly, this will be a won't-fix as it would break then any 0.20. We're also building in more unit tests to verify this type of breaking change won't happen in the future
Status: Issue closed
|
veerendra2/funmotd | 626421251 | Title: Change wieghts variable name
Question:
username_0: https://github.com/username_0/funmotd/blob/master/funmotd/__init__.py#L95
```
$ funmotd --help
usage: funmotd [-h] [-l] [-e MODIFY MODIFY] [-n NSFW] [-v]
Displays TV Show and Movie Quotes as 'motd' on Terminal
optional arguments:
-h, --help show this help message and exit
-l View Available TV Show/Movies & Configuration
-e MODIFY MODIFY Modify Weights <<<<<<<<<<<<<<<<<<<<<<<<
-n NSFW Enable/Disable NSFW Quotes
-v Version and author information
``` |
umijs/qiankun | 601783354 | Title: 关于打包的疑问
Question:
username_0: <!--
感谢您向我们反馈问题,为了高效的解决问题,我们期望你能提供以下信息:
-->
## What happens?
我基于 umi-plugin-qiankun 的 examples 在本地跑,没问题;现在想把子应用打包下,然后再在父应用里去加载,结果子应用的资源就一直报404
<!-- 清晰的描述下遇到的问题。-->
## 最小可复现仓库
https://github.com/umijs/umi-plugin-qiankun
<!-- 为节约大家的时间,无复现步骤的 ISSUE 会被关闭,提供之后再 REOPEN -->
<!-- https://github.com/YOUR_REPOSITORY_URL -->
## 复现步骤,错误日志以及相关配置
1. clone 以上仓库, 安装依赖,
2. 进到exapmles目录
3. 打包app1,然后cd dist,通过 `http-server -p 8001 --cors` 启动本地服务
4. cd master 然后 npm start 启动 master 访问 /app1
5. 控制台报错资源 404

我个人感觉应该去加载 localhost:8001/app1/xx.js ,不知道为何少了 **app1** 这个前缀
<!-- 请提供复现步骤,错误日志以及相关配置 -->
<!-- 可以尝试不要锁版本,重新安装依赖试试先 -->
## 相关环境信息
- **qiankun 版本**: 1.4.5
- **浏览器版本**:chrome: 81.0.4044.113(正式版本) (64 位)
- **操作系统**:macos: 10.14.6 (18G95)
Answers:
username_1: entry 配置成 `localhost:8001/app1/index.html`
Status: Issue closed
|
cityofaustin/atd-data-tech | 1158635397 | Title: Investigate inclusion of Microsoft Projects data in dashboard
Question:
username_0: Whaaa... MPXJ??
@dianamartin - what is the process for getting a license? We would want one for Fernando, too.
Answers:
username_1: The Microsoft Project file (.mpp) I received from Fernando cannot be read by PowerBI but they do support loading in data from Microsoft Project Online. I currently don't have a license but @dianamartin says I can get one. I'm not exactly sure wha the difference is between the desktop and online versions of Project are but I hope that Fernando could move over to the online one easily?
[Docs about loading Project Online files into Power BI.](https://docs.microsoft.com/en-us/power-bi/connect-data/desktop-project-online-connect-to-data)
[Gantt charts in Power BI tutorial](https://www.youtube.com/watch?v=cdUg8LfarCg)
username_1: Also wanted to point out the MPXJ library that should allow us to read in the data and export over to CSV which could potentially allow us to cut MS Project out of the process entirely.
[MPXJ](https://pypi.org/project/mpxj/)
username_0: Whaaa... MPXJ??
@dianamartin - what is the process for getting a license? We would want one for Fernando, too.
username_1: Sorry should have CC'd you but Scott got me a MS Project license. I assume Fernando already has one since he's been working in MS Project. |
DestinyItemManager/DIM | 1024511274 | Title: Max Power not calculated correctly
Question:
username_0: ### DIM Version
Version 6.86.0 (release), built on 10/10/2021, 9:08:06 PM
### Browser Details
Version 94.0.4606.81 (Official Build) (64-bit)
### OS Details
Windows 10
### Describe the bug
The maximum power score on my Titan and Hunter is being calculated incorrectly, while it is logged correctly on my Warlock. DIM was reporting my max power as `1342 1/8`, but when I applied maximize power function, I noticed my Titan's power in-game was over 1343, despite DIM still reporting `1342 1/8`
When I hover over the details to describe the max power, there is a `modifiers -7` in the popover, and the popup with item details shows my energy weapon at `1320` instead of it's actual power level of `1329`.
### Logs
_No response_<issue_closed>
Status: Issue closed |
Swarbricklab-code/BrCa_cell_atlas | 1038347718 | Title: missing h5 files from Zenodo
Question:
username_0: Hi,
I would like to have a look at your spatial data, however the h5 files are missing.
Could you please add it ?
Thank you
Answers:
username_1: Apologies for the slow response.
Unfortunately we can't add `h5` files to the Zenodo repo without breaking the doi link to the paper. However, `h5` files are available on request. Please reach out if you still need these files.
You may also be able to create a Seurat spatial object from scratch using the publicly available data using the suggestions in this thread: https://github.com/satijalab/seurat/issues/2790
username_2: Hi,
I would have exactly the same request.
I'm wondering if there is a way to recover the h5 files somewhere ?
Tks !
username_1: Hi. I have searched high and low, but only found the `.h5` files for two samples and it appears that we did not consistently archive the `.h5` files. I think the rationale was that they were redundant because they contain exactly the same information as their MEX format equivalents. I'm curious if there are use cases where only HDF5 format will do?
In the meantime, you can load the counts and images via either Seurat's [Load10X_Spatial()](https://satijalab.org/seurat/reference/load10x_spatial) or Scanpy's [sc.read_visium()](https://scanpy.readthedocs.io/en/stable/generated/scanpy.read_visium.html).
If you really, really need `.h5` files in HDF5 format then you might be able to recreate them via `pandas.HDFStore` (see [this tutorial](https://riptutorial.com/pandas/example/9812/using-hdfstore), for example) and following the file hierarchy described here: https://support.10xgenomics.com/single-cell-atac/software/pipelines/latest/advanced/h5_matrices
Status: Issue closed
username_2: You can 't load counts with [Load10X_Spatial()](https://satijalab.org/seurat/reference/load10x_spatial) without h5 files.
Almost sure that the same with Scanpy's but can't tell 100%, not a scanpy user... Because they are based on a strict directory content.
h5 files for two samples it's fine.
My bet is that you have the Two TNBCs (1142243F and 1160920F) processed by independant lab... and that is exactly what I'm looking for. So I'm still interested to grap this two if possible.
Thank you
username_1: You're right -- `Load10X_Spatial()` requires a `.h5` file and this is probably the easiest way to load Visium data into Seurat.
Without the `.h5` files I think you can still get the data into Seurat doing something like the following:
```
my_object <- CreateSeuratObject(
counts = Read10X( data.dir = '/path/to/directory/containing/matrix.mtx/etc'),
assay = 'Spatial'
)
my_image <- Read10X_Image( image.dir = 'path/to/spatial/images' )
my_image <- image[Cells(x = my_object)]
DefaultAssay(object = my_image) <- 'Spatial'
my_object[['Slice1']] <- my_image
```
This is approach is appropriated from the code for `Load10X_Spatial()` here: https://github.com/satijalab/seurat/blob/master/R/preprocessing.R
I'll send the two `h5` files that we do have via email.
username_2: You were absolutely right.
I think here there is a mistake but the whole idea is good :
```
my_image <- Read10X_Image( image.dir = 'path/to/spatial/images' )
my_image <- image[Cells(x = my_object)]
```
I ended up with :
`
```
print(as.character(dirname(file_tisspos)))
print(as.character(dirname(file_features)))
"/home/docker/LR/LR/bench//spatial/BreastVisiumNoH5/spatial/1160920F_spatial"
"/home/docker/LR/LR/bench//spatial/BreastVisiumNoH5/filtered_count_matrices//1160920F_filtered_count_matrix"
X <- Read10X_Image(
as.character(dirname(file_tisspos)),
image.name = "tissue_lowres_image.png",
filter.matrix = TRUE
)
# gene.column = 2 by default and that was causing an error, update to 1 for last version with gziped
my_object <- CreateSeuratObject(
counts = Read10X( data.dir = as.character(dirname(file_features)) , gene.column = 1),
assay = 'Spatial'
)
my_image <- Read10X_Image( image.dir = as.character(dirname(file_tisspos)))
image <- my_image[Cells(x = my_object)]
DefaultAssay(object = image) <- 'Spatial'
my_object[['Slice1']] <- image
```
Juste note that the gz in /path/to/directory/containing/matrix.mtx are not really gziped. They have the extension but are just simple file...
Thanks for your help, and the files. :)
username_1: You're welcome, and thanks for the feedback on loading the Zenodo data.
I'll make a note in the readme pointing people to this code snippet.
I'll also make a feature request for the Seurat developers to make a wrapper function that does basically this. |
picqer/exact-php-client | 448899888 | Title: Change orderstatus for existing salesorder
Question:
username_0: I want to change the orderstatus of a salesorder to 20 after i retrieve it from the administration with status 12. I use the follwing php-code. I get no error but the change is not done.
What am i doing wrong?
try
{
$l_salesorders = new \Picqer\Financials\Exact\SalesOrder($connection);
$result = $l_salesorders->filter("Status eq 12");
foreach ($result as $salesorder)
{
echo 'salesorder: ' . $salesorder->Description . ' ordernummer ' . $salesorder->OrderNumber . ' status ' . $salesorder->Status . ' ' . $salesorder->DeliveryStatus . '<br>';
echo 'bijwerken<br>';
$salesorder->Status = '20';
$l_save_result = $salesorder->save();
echo 'save resultaat ' . $l_save_result->Status . ' ' . $l_save_result->DeliveryStatus . '<br>';
}
}
catch (\Exception $e)
{
echo get_class($e) . ' : ' . $e->getMessage();
}
Answers:
username_1: If you check the [SalesOrders API documentation](https://start.exactonline.nl/docs/HlpRestAPIResourcesDetails.aspx?name=SalesOrderSalesOrders), you'll see it's not possible to update (PUT) the `Status` property.
As far as I know, the `Status` of a SalesOrder is a dynamic representation of the linked SalesOrderLines (and PurchaseOrderLines), delivery data, invoices, and more. Even in the Exact Online front-end, it's impossible to directly set a specific status for a SalesOrder.
username_0: OK. Thanks.
Now i see how the documentation works. You only see the attributes which can be changed when you press the put/post buttons.
I already suspected it wasn't possible.
username_2: @username_0 this means your issue is solved and can be closed?
Status: Issue closed
|
DriveTimeInc/cordova-plugin-cookie-persistence | 305728090 | Title: Method to Cause Cookies to be Persisted
Question:
username_0: From @username_1 in #3
If you can expose a method to call the storage logic from JS at anytime - we can then call the code to refresh the Cookies details whenever we make a HTTPs call to the server. That way we will not need to worry about Exit/Closing of the app as the developer can manage the cookie refresh as they are loaded from the the web server.
Answers:
username_0: Are you thinking a method like:
```
void storeCookies() {
//retrieve cookies from view
//store cookies in txt file
}
```
Or where the app would supply the cookies to store?
```
void storeCookies(cookies) {
//store cookies in txt file
}
```
I'd think we'd want the first to maintain control.
Might also be worth adding a `clearCookies()` method that would wipe the persisted cookies.
username_1: Let me test the updated Android code first - as I thought there are a technical issue with the exiting of the app. It may not be necessary (for Android) to interact with Javascript at all if the code works as expected....
username_1: log data from Android simulator
V/FA: Session started, time: 854861
D/FA: Logging event (FE): session_start(_s), Bundle[{firebase_event_origin(_o)=auto, firebase_screen_class(_sc)=MainActivity, firebase_screen_id(_si)=394842885034794583}]
V/FA: Connecting to remote service
D/FA: Connected to remote service
V/FA: Processing queued up service tasks: 1
V/FA: Inactivity, disconnecting from the service
D/CordovaActivity: Paused the activity.
W/com.facebook.appevents.AppEventsLogger: deactivateApp events are being logged automatically. There's no need to call deactivateApp, this is safe to remove.
D/CookiePersistenceCordovaPlugin: Paused the activity.
D/CookiePersistenceCordovaPlugin: Paused the activity.
**D/CookiePersistenceCordovaPlugin: Write File - Contents: magical_device=c29<PASSWORD>; csrf_token=<PASSWORD>; magical=ee2242767a8f446eb29dbb292e606edf-18337; sess_user=c8bd3fc49baa0ae933bee23ea2a53f76-18337; magical_device=c2933b5e1d59497b881abfd9e7688421-18337; magicaltourstop=1; magical-friendProfileLikeCount=406
D/CookiePersistenceCordovaPlugin: storeCookies - Complete**
V/FA: Recording user engagement, ms: 19030
V/FA: Connecting to remote service
V/FA: Activity paused, time: 863894
D/FA: Logging event (FE): user_engagement(_e), Bundle[{firebase_event_origin(_o)=auto, engagement_time_msec(_et)=19030, firebase_screen_class(_sc)=MainActivity, firebase_screen_id(_si)=394842885034794583}]
V/FA: Connection attempt already in progress
[ 03-16 08:47:26.675 1697: 2045 D/ ]
HostConnection::get() New Host Connection established 0x83523940, tid 2045
D/EGL_emulation: eglMakeCurrent: 0xaa805fc0: ver 2 0 (tinfo 0xaa8038b0)
D/CordovaActivity: Stopped the activity.
D/FA: Connected to remote service
V/FA: Processing queued up service tasks: 2
username_1: Perfect !
username_1: Will test on a Samsung Galaxy S8 now
username_0: That looks great. Yea its debatable whether this is needed.
username_1: I have tested on my S8, the cookies do not seem to be getting passed to the web server - I have to login again. To test I clear all data, including the cookies and then start the app - login - then hardware show all apps. Close the app and start in again. Would expect to see the app in the logged in state. However asks for the login again.
If I login again - the app behaves oddly and does not render data correctly. I'll get some info from the server logs and see what the application server received.
username_0: Look for `Cookie File Content: <COOKIE STRING>` in the Android log. Also see if one of these exists: `UpdateCookies - Complete` or `UpdateCookies - Failed`
username_1: The app serverr is receiving the cookies from the saved session - might be a bug in our code... checking.
One thing to consider - duplicate cookies. If the restart of the app add the same cookie - the developer will need to check for that in the JS code...
username_1: another idea is have a option / config that indicates which cookies to store and re-store as it may not be appropriate to restore all the cookies on resume...
username_1: Have done a set of tests and seems to be working correctly. I get another developer to do what I am doing. Start app, Login, Hardware Show all app, close app, restart the app from desktop.,,,
Status: Issue closed
|
opendistro-for-elasticsearch/sql | 589441390 | Title: Aggregating over nested field doesn't work for default format
Question:
username_0: Test data: https://github.com/opendistro-for-elasticsearch/sql/issues/397#issuecomment-604719065
Query:
```
POST _opendistro/_sql
{
"query":
"""
SELECT
e.name AS employeeName,
COUNT(p) AS cnt
FROM employees_nested AS e,
e.projects AS p
WHERE p.name LIKE '%security%'
GROUP BY e.id, e.name
"""
}
{
"error": {
"reason": "There was internal problem at backend",
"details": "Aggregation type nested is not yet implemented",
"type": "SqlFeatureNotImplementedException"
},
"status": 500
}
```
Log:
```
[2020-03-27T15:19:21,742][WARN ][c.a.o.s.e.f.PrettyFormatRestExecutor] [186590df9563.ant.amazon.com] Error happened in pretty formatter
com.amazon.opendistroforelasticsearch.sql.exception.SqlFeatureNotImplementedException: Aggregation type nested is not yet implemented
at com.amazon.opendistroforelasticsearch.sql.executor.format.SelectResultSet.addNumericAggregation(SelectResultSet.java:659) ~[opendistro_sql-1.6.0.0.jar:1.6.0.0]
at com.amazon.opendistroforelasticsearch.sql.executor.format.SelectResultSet.getAggsData(SelectResultSet.java:616) ~[opendistro_sql-1.6.0.0.jar:1.6.0.0]
at com.amazon.opendistroforelasticsearch.sql.executor.format.SelectResultSet.getAggsData(SelectResultSet.java:612) ~[opendistro_sql-1.6.0.0.jar:1.6.0.0]
at com.amazon.opendistroforelasticsearch.sql.executor.format.SelectResultSet.populateRows(SelectResultSet.java:584) ~[opendistro_sql-1.6.0.0.jar:1.6.0.0]
at com.amazon.opendistroforelasticsearch.sql.executor.format.SelectResultSet.extractData(SelectResultSet.java:535) ~[opendistro_sql-1.6.0.0.jar:1.6.0.0]
at com.amazon.opendistroforelasticsearch.sql.executor.format.SelectResultSet.<init>(SelectResultSet.java:108) ~[opendistro_sql-1.6.0.0.jar:1.6.0.0]
at com.amazon.opendistroforelasticsearch.sql.executor.format.Protocol.loadResultSet(Protocol.java:83) ~[opendistro_sql-1.6.0.0.jar:1.6.0.0]
at com.amazon.opendistroforelasticsearch.sql.executor.format.Protocol.<init>(Protocol.java:65) ~[opendistro_sql-1.6.0.0.jar:1.6.0.0]
at com.amazon.opendistroforelasticsearch.sql.executor.format.PrettyFormatRestExecutor.execute(PrettyFormatRestExecutor.java:71) [opendistro_sql-1.6.0.0.jar:1.6.0.0]
at com.amazon.opendistroforelasticsearch.sql.executor.format.PrettyFormatRestExecutor.execute(PrettyFormatRestExecutor.java:47) [opendistro_sql-1.6.0.0.jar:1.6.0.0]
at com.amazon.opendistroforelasticsearch.sql.executor.AsyncRestExecutor.doExecuteWithTimeMeasured(AsyncRestExecutor.java:161) [opendistro_sql-1.6.0.0.jar:1.6.0.0]
at com.amazon.opendistroforelasticsearch.sql.executor.AsyncRestExecutor.lambda$async$1(AsyncRestExecutor.java:121) [opendistro_sql-1.6.0.0.jar:1.6.0.0]
at com.amazon.opendistroforelasticsearch.sql.utils.LogUtils.lambda$withCurrentContext$0(LogUtils.java:72) [opendistro_sql-1.6.0.0.jar:1.6.0.0]
at org.elasticsearch.common.util.concurrent.ThreadContext$ContextPreservingRunnable.run(ThreadContext.java:633) [elasticsearch-7.6.1.jar:7.6.1]
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128) [?:?]
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628) [?:?]
at java.lang.Thread.run(Thread.java:830) [?:?]
``` |
cdhart/cdhart-html | 688123666 | Title: colorschemez August 28 2020 at 05:14AM
Question:
username_0: <blockquote class="twitter-tweet">
<p lang="en" dir="ltr" xml:lang="en">undesired eggshell blue<br>
seamless celery<br>
boding darkish pink <a href="https://t.co/e5gNudkoT9">pic.twitter.com/e5gNudkoT9</a></p>
— colorschemer (@colorschemez) <a href="https://twitter.com/colorschemez/status/1299289322852478981?ref_src=twsrc%5Etfw">August 28, 2020</a>
</blockquote>
<br>
<br>
August 28, 2020 at 05:14AM<br>
via Twitter |
traveller59/spconv | 668343882 | Title: Build failure: recipe for target hash_table.cu.o failed
Question:
username_0: I am trying to build this on a Ubuntu 18.04 machine. But, it is failing. The build output is pasted below. The error I see is: "recipe for target 'src/cuhash/CMakeFiles/cuhash.dir/hash_table.cu.o' failed".
Any idea about the cause/fix?
Thanks!
=============================
running bdist_wheel
running build
running build_py
creating build
creating build/lib.linux-x86_64-3.8
creating build/lib.linux-x86_64-3.8/spconv
copying spconv/modules.py -> build/lib.linux-x86_64-3.8/spconv
copying spconv/identity.py -> build/lib.linux-x86_64-3.8/spconv
copying spconv/test_utils.py -> build/lib.linux-x86_64-3.8/spconv
copying spconv/tables.py -> build/lib.linux-x86_64-3.8/spconv
copying spconv/__init__.py -> build/lib.linux-x86_64-3.8/spconv
copying spconv/ops.py -> build/lib.linux-x86_64-3.8/spconv
copying spconv/functional.py -> build/lib.linux-x86_64-3.8/spconv
copying spconv/pool.py -> build/lib.linux-x86_64-3.8/spconv
copying spconv/conv.py -> build/lib.linux-x86_64-3.8/spconv
creating build/lib.linux-x86_64-3.8/spconv/utils
copying spconv/utils/__init__.py -> build/lib.linux-x86_64-3.8/spconv/utils
running build_ext
-- The CXX compiler identification is GNU 7.5.0
-- The CUDA compiler identification is NVIDIA 9.1.85
-- Check for working CXX compiler: /usr/bin/c++
-- Check for working CXX compiler: /usr/bin/c++ -- works
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Check for working CUDA compiler: /usr/bin/nvcc
-- Check for working CUDA compiler: /usr/bin/nvcc -- works
-- Detecting CUDA compiler ABI info
-- Detecting CUDA compiler ABI info - done
-- Looking for C++ include pthread.h
-- Looking for C++ include pthread.h - found
-- Looking for pthread_create
-- Looking for pthread_create - not found
-- Looking for pthread_create in pthreads
-- Looking for pthread_create in pthreads - not found
-- Looking for pthread_create in pthread
-- Looking for pthread_create in pthread - found
-- Found Threads: TRUE
-- Found CUDA: /usr (found version "9.1")
-- Caffe2: CUDA detected: 9.1
-- Caffe2: CUDA nvcc is: /usr/bin/nvcc
-- Caffe2: CUDA toolkit directory: /usr
-- Caffe2: Header version is: 9.1
-- Found CUDNN: /usr/local/cuda/lib64/libcudnn.so
-- Found cuDNN: v8.0.2 (include: /usr/local/cuda/include, library: /usr/local/cuda/lib64/libcudnn.so)
-- Autodetected CUDA architecture(s): 6.1
-- Added CUDA NVCC flags for: -gencode;arch=compute_61,code=sm_61
-- Found Torch: /home/username_0/anaconda3/envs/instseg/lib/python3.8/site-packages/torch/lib/libtorch.so
-- Autodetected CUDA architecture(s): 6.1
-- Found PythonInterp: /home/username_0/anaconda3/envs/instseg/bin/python3.8 (found suitable version "3.8.3", minimum required is "3.8")
-- Found PythonLibs: /home/username_0/anaconda3/envs/instseg/lib/libpython3.8.so
-- Performing Test HAS_CPP14_FLAG
-- Performing Test HAS_CPP14_FLAG - Success
-- pybind11 v2.5.0
-- Found OpenMP_CXX: -fopenmp (found version "4.5")
[Truncated]
-- Build files have been written to: /home/username_0/projects/detect3d/instseg/spconv/build/temp.linux-x86_64-3.8
Scanning dependencies of target spconv_nms
[ 4%] Building CUDA object src/utils/CMakeFiles/spconv_nms.dir/nms.cu.o
Scanning dependencies of target cuhash
[ 8%] Building CUDA object src/cuhash/CMakeFiles/cuhash.dir/hash_functions.cu.o
[ 12%] Building CXX object src/cuhash/CMakeFiles/cuhash.dir/hash_table.cpp.o
[ 16%] Building CUDA object src/cuhash/CMakeFiles/cuhash.dir/hash_table.cu.o
[ 20%] Building CXX object src/cuhash/CMakeFiles/cuhash.dir/hash_functions.cpp.o
src/cuhash/CMakeFiles/cuhash.dir/build.make:88: recipe for target 'src/cuhash/CMakeFiles/cuhash.dir/hash_table.cu.o' failed
[ 24%] Linking CUDA static library libspconv_nms.a
[ 24%] Built target spconv_nms
Scanning dependencies of target spconv_utils
[ 28%] Building CXX object src/utils/CMakeFiles/spconv_utils.dir/all.cc.o
CMakeFiles/Makefile2:108: recipe for target 'src/cuhash/CMakeFiles/cuhash.dir/all' failed
[ 32%] Linking CUDA device code CMakeFiles/spconv_utils.dir/cmake_device_link.o
[ 36%] Linking CXX shared library ../../../lib.linux-x86_64-3.8/spconv/spconv_utils.cpython-38-x86_64-linux-gnu.so
[ 36%] Built target spconv_utils
Makefile:129: recipe for target 'all' failed
Release
|||||CMAKE ARGS||||| ['-DCMAKE_PREFIX_PATH=/home/username_0/anaconda3/envs/instseg/lib/python3.8/site-packages/torch', '-DPYBIND11_PYTHON_VERSION=3.8', '-DSPCONV_BuildTests=OFF', '-DPYTORCH_VERSION=10600', '-DCMAKE_CUDA_FLAGS="--expt-relaxed-constexpr" -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__', '-DCMAKE_LIBRARY_OUTPUT_DIRECTORY=/home/username_0/projects/detect3d/instseg/spconv/build/lib.linux-x86_64-3.8/spconv', '-DCMAKE_BUILD_TYPE=Release'] |
Homebrew/install | 760411807 | Title: Install script fails on ubuntu 20.04 on AWS
Question:
username_0: # Please note we will close your issue without comment if you delete, do not read or do not fill out the issue checklist below and provide ALL the requested information. If you repeatedly fail to use the issue template, we will block you from ever submitting issues to Homebrew again.
- [ ] your problem was from running the official `install` or `uninstall` script?
- [ ] after installation: ran `brew config` and `brew doctor` and included their output with your issue? If you couldn't install: provided your OS version with the output of your issue?
<!-- To help us debug your issue, please complete these sections: -->
I deployed an Ubuntu 20.04 instance on AWS; these instances has one sudoer user called _ubuntu_ and it has no password.
I tried to running
```
ubuntu@ip-172-31-17-172:~$ /bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)"
==> Select the Homebrew installation directory
- Enter your password to install to /home/linuxbrew/.linuxbrew (recommended)
- Press Control-D to install to /home/ubuntu/.linuxbrew
- Press Control-C to cancel installation
[sudo] password for ubuntu:
Sorry, try again.
```
As the user does not have any password, I was unable to install to _/home/linuxbrew/.linuxbrew_.
Installing to /home/ubuntu/ succeeds but as you guys know there are many other issues with installing into this location.
The last commit that is working in is 08ee636817bb5113de259ce2d72e2628a8e8909b.
Answers:
username_1: Adding here that his change has also completely broken installs on Crostini / Chromebooks.
username_2: I suspect the changes with the INTERACTIVE check are causing this https://github.com/Homebrew/install/commit/342253e5bad2a86d82e08823cce0a57e8a4cf3d9#diff-043df5bdbf6639d7a77e1d44c5226fd7371e5259a1e4df3a0dd5d64c30dca44f
username_3: @username_2 Yes, that will be the case. We'll review PRs to address this. Note we do not support non-interactive installs outside of `/home/linuxbrew/.linuxbrew`.
username_2: Are you sure? The comments specifically mention `~/.linuxbrew`
```
# On Linux, it installs to /home/linuxbrew/.linuxbrew if you have sudo access
# and ~/.linuxbrew otherwise.
```
But this change: https://github.com/Homebrew/install/commit/6f37ca94af073c2971efbed8aa293322aa171f26 seems to have broken that behaviour
The if statement is now true once NONINTERACTIVE = true. Meaning it will always go to /home/linuxbrew
```
if [[ -n "${NONINTERACTIVE-}" ]] ||
[[ -w "$HOMEBREW_PREFIX_DEFAULT" ]] ||
[[ -w "/home/linuxbrew" ]] ||
[[ -w "/home" ]]; then
```
I believe that should be
```
if [[ -n "${NONINTERACTIVE-}" ]] &&
[[ -w "$HOMEBREW_PREFIX_DEFAULT" ]] &&
[[ -w "/home/linuxbrew" ]] &&
[[ -w "/home" ]]; then
```
I made a PR for it, if you agree https://github.com/Homebrew/install/pull/508
username_3: I'm sure that that's the intention, yes.
username_2: I don't mean to sound harsh, just trying to understand here but why?
What is the upside that I'm currently missing that justifies the breaking of existing workflows. Is there a security risk in allowing it to go to `~/.linuxbrew` ?
username_3: No security risk but most binary packages will not work and `brew doctor` will tell you not to file issues. We don't "support" it, as a result, and most users should avoid it.
username_2: I don't understand. Why would binary packages not work? Do they hardcode /home/linuxbrew in the compiled code ?
username_3: Yup, exactly.
username_2: Mike,
Ok, understood. Thanks for taking the time to explain.
What is the proper way to dispute that decision? I understand why we wouldn't want users to file tickets for binary packages not working. But not allowing an alternate home folder seems a bit overkill.
The result is that instead of having a homebrew that doesn't work for _some_ binary packages, we now have a homebrew that simply doesn't work _at all_ for some users, even if they're not using binaries.
Would you accept a PullRequest that adds a parameter to the install script that allows you to specify a home folder? That would give users a way to work around the brick wall they are facing at the moment.
username_3: No, sorry.
username_2: Ok, Clear communication. Thank you.
username_4: Try setting up sudo password.
username_1: I think that might make sense for the Ubuntu issue to set a sudo password, but I feel the Homebrew script should be written to work out of the box on a Chrome OS Crostini install. Especially when it worked before, it's just the new dialog system that breaks it. Perhaps I should open the Chromebook issue as a new, separate ticket.
username_4: Chrome OS? He has problem with sudo on Ubuntu.
username_1: Ya sorry my second comment was saying the exact same change is breaking Crostini as well.
username_5: Reading package lists... Done
Building dependency tree
Reading state information... Done
Note, selecting 'zlib1g-dev' instead of 'libz-dev'
bzip2 is already the newest version (1.0.8-2).
ca-certificates is already the newest version (20210119~20.04.1).
ca-certificates set to manually installed.
tzdata is already the newest version (2021a-0ubuntu0.20.04).
tzdata set to manually installed.
The following additional packages will be installed:
binutils binutils-common binutils-x86-64-linux-gnu cpp cpp-9 g++-9 gcc gcc-9 gcc-9-base git-man libasan5 libasn1-8-heimdal libatomic1 libbinutils
libbsd0 libc-dev-bin libc6 libc6-dev libcbor0.6 libcc1-0 libcrypt-dev libctf-nobfd0 libctf0 libcurl3-gnutls libcurl4 libedit2 liberror-perl
libfido2-1 libgcc-9-dev libgdbm-compat4 libgdbm6 libgomp1 libgssapi3-heimdal libhcrypto4-heimdal libheimbase1-heimdal libheimntlm0-heimdal
libhx509-5-heimdal libisl22 libitm1 libkrb5-26-heimdal libldap-2.4-2 libldap-common liblsan0 libmagic-mgc libmagic1 libmpc3 libmpfr6 libnghttp2-14
libperl5.30 libquadmath0 libroken18-heimdal librtmp1 libsasl2-2 libsasl2-modules-db libsigsegv2 libssh-4 libstdc++-9-dev libtsan0 libubsan1
libwind0-heimdal linux-libc-dev perl perl-modules-5.30
Suggested packages:
binutils-doc cpp-doc gcc-9-locales g++-multilib g++-9-multilib gcc-9-doc gawk-doc gcc-multilib manpages-dev autoconf automake libtool flex bison
gdb gcc-doc gcc-9-multilib gettext-base git-daemon-run | git-daemon-sysvinit git-doc git-el git-email git-gui gitk gitweb git-cvs git-mediawiki
git-svn glibc-doc gdbm-l10n libstdc++-9-doc make-doc keychain libpam-ssh monkeysphere ssh-askpass ed diffutils-doc perl-doc
libterm-readline-gnu-perl | libterm-readline-perl-perl libb-debug-perl liblocale-codes-perl
Recommended packages:
manpages manpages-dev libsasl2-modules xauth
The following NEW packages will be installed:
binutils binutils-common binutils-x86-64-linux-gnu cpp cpp-9 curl file fonts-dejavu-core g++ g++-9 gawk gcc gcc-9 gcc-9-base git git-man less
libasan5 libasn1-8-heimdal libatomic1 libbinutils libbsd0 libc-dev-bin libc6-dev libcbor0.6 libcc1-0 libcrypt-dev libctf-nobfd0 libctf0
libcurl3-gnutls libcurl4 libedit2 liberror-perl libfido2-1 libgcc-9-dev libgdbm-compat4 libgdbm6 libgomp1 libgssapi3-heimdal libhcrypto4-heimdal
libheimbase1-heimdal libheimntlm0-heimdal libhx509-5-heimdal libisl22 libitm1 libkrb5-26-heimdal libldap-2.4-2 libldap-common liblsan0 libmagic-mgc
libmagic1 libmpc3 libmpfr6 libnghttp2-14 libperl5.30 libquadmath0 libroken18-heimdal librtmp1 libsasl2-2 libsasl2-modules-db libsigsegv2 libssh-4
libstdc++-9-dev libtsan0 libubsan1 libwind0-heimdal linux-libc-dev locales make netbase openssh-client patch perl perl-modules-5.30 sudo
uuid-runtime zlib1g-dev
The following packages will be upgraded:
libc6
1 upgraded, 77 newly installed, 0 to remove and 15 not upgraded.
Need to get 63.3 MB of archives.
After this operation, 295 MB of additional disk space will be used.
Get:1 http://archive.ubuntu.com/ubuntu focal-updates/main amd64 libc6 amd64 2.31-0ubuntu9.2 [2715 kB]
Get:2 http://ppa.launchpad.net/git-core/ppa/ubuntu focal/main amd64 git-man all 1:2.31.1-0ppa1~ubuntu20.04.1 [1847 kB]
Get:3 http://archive.ubuntu.com/ubuntu focal-updates/main amd64 uuid-runtime amd64 2.34-0.1ubuntu9.1 [35.1 kB]
Get:4 http://ppa.launchpad.net/git-core/ppa/ubuntu focal/main amd64 git amd64 1:2.31.1-0ppa1~ubuntu20.04.1 [5439 kB]
Get:5 http://archive.ubuntu.com/ubuntu focal/main amd64 libmpfr6 amd64 4.0.2-1 [240 kB]
Get:6 http://archive.ubuntu.com/ubuntu focal/main amd64 libsigsegv2 amd64 2.12-2 [13.9 kB]
Get:7 http://archive.ubuntu.com/ubuntu focal/main amd64 gawk amd64 1:5.0.1+dfsg-1 [418 kB]
Get:8 http://archive.ubuntu.com/ubuntu focal-updates/main amd64 perl-modules-5.30 all 5.30.0-9ubuntu0.2 [2738 kB]
Get:9 http://archive.ubuntu.com/ubuntu focal/main amd64 libgdbm6 amd64 1.18.1-5 [27.4 kB]
Get:10 http://archive.ubuntu.com/ubuntu focal/main amd64 libgdbm-compat4 amd64 1.18.1-5 [6244 B]
Get:11 http://archive.ubuntu.com/ubuntu focal-updates/main amd64 libperl5.30 amd64 5.30.0-9ubuntu0.2 [3952 kB]
Get:12 http://archive.ubuntu.com/ubuntu focal-updates/main amd64 perl amd64 5.30.0-9ubuntu0.2 [224 kB]
Get:13 http://archive.ubuntu.com/ubuntu focal/main amd64 libmagic-mgc amd64 1:5.38-4 [218 kB]
Get:14 http://archive.ubuntu.com/ubuntu focal/main amd64 libmagic1 amd64 1:5.38-4 [75.9 kB]
Get:15 http://archive.ubuntu.com/ubuntu focal/main amd64 file amd64 1:5.38-4 [23.3 kB]
Get:16 http://archive.ubuntu.com/ubuntu focal-updates/main amd64 less amd64 551-1ubuntu0.1 [123 kB]
Get:17 http://archive.ubuntu.com/ubuntu focal/main amd64 libbsd0 amd64 0.10.0-1 [45.4 kB]
Get:18 http://archive.ubuntu.com/ubuntu focal-updates/main amd64 locales all 2.31-0ubuntu9.2 [3872 kB]
Get:19 http://archive.ubuntu.com/ubuntu focal/main amd64 netbase all 6.1 [13.1 kB]
Get:20 http://archive.ubuntu.com/ubuntu focal-updates/main amd64 sudo amd64 1.8.31-1ubuntu1.2 [514 kB]
Get:21 http://archive.ubuntu.com/ubuntu focal/main amd64 libcbor0.6 amd64 0.6.0-0ubuntu1 [21.1 kB]
Get:22 http://archive.ubuntu.com/ubuntu focal/main amd64 libedit2 amd64 3.1-20191231-1 [87.0 kB]
Get:23 http://archive.ubuntu.com/ubuntu focal/main amd64 libfido2-1 amd64 1.3.1-1ubuntu2 [47.9 kB]
Get:24 http://archive.ubuntu.com/ubuntu focal-updates/main amd64 openssh-client amd64 1:8.2p1-4ubuntu0.2 [671 kB]
[Truncated]
https://docs.brew.sh/Analytics
No analytics data has been sent yet (or will be during this `install` run).
==> Homebrew is run entirely by unpaid volunteers. Please consider donating:
https://github.com/Homebrew/brew#donations
==> Next steps:
- Add Homebrew to your PATH in /home/ubuntu/.profile:
echo 'eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)"' >> /home/ubuntu/.profile
eval "$(/home/linuxbrew/.linuxbrew/bin/brew shellenv)"
- Run `brew help` to get started
- Further documentation:
https://docs.brew.sh
- Install the Homebrew dependencies if you have sudo access:
sudo apt-get install build-essential
See https://docs.brew.sh/linux for more information
- We recommend that you install GCC:
brew install gcc
```
</details>
username_1: @username_5 Awesome! That does appear to fix the issue with installing Homebrew on Chromebooks! Thanks so much for the tip!
username_6: The install script does not account for password-less `sudo`...
Using `CI=1` does indeed work, but this shouldn't be broken out-of-the-box.
username_7: This has been open for quite some time now and some of the discussion seems to be a little misguided.
One of the main problems seems to be the entanglement of the `NONINTERACTIVE` flag with installation in `~/.linuxbrew` vs. `/home/linuxbrew/.linuxbrew`.
The other problem is that `sudo` makes it kind of hard to detect password-less `sudo` functionality.
I see 3 main, non-exclusive parts to solving that:
1. report the problem to all the upstreams with password-less sudoers configuration and reference this: https://askubuntu.com/a/1211226 solution (add `Defaults verifypw = any` to sudoers file)
2. report the problem to upstream `sudo` and request an amended `sudo -v`
3. Go the extra mile inside the install.sh script and try to detect the situation
- e.g. when the user hits `<CTRL-D>` at the sudo prompt, ask if they really meant `CI=1` |
cybozu-go/neco | 500144163 | Title: [neco-apps] Wait for gatekeeper policy to be created to stabilize test
Question:
username_0: ## What
When gatekeeper policy is applied, there is a slight delay before the policy is created.
This causes instability of gatekeeper test in neco-apps, so changes are needed to wait until the policy is created.
https://circleci.com/gh/cybozu-go/neco-apps/3682
## How
https://github.com/open-policy-agent/gatekeeper/blob/cb9c40032948de1de1170be7be37c24c244964e2/test/bats/test.bats#L48
## Checklist
- [ ] Finish implementation of the issue
- [ ] Test all functions
- [ ] Have enough logs to trace activities
- [ ] Notify developers of necessary actions<issue_closed>
Status: Issue closed |
dotnet/dotnet-api-docs | 387959712 | Title: Dead link
Question:
username_0: Look, EF docs at this level are almost nonexistent. And here you are, tempting me with a link to a "Metadata Workspace Overview." I practically broke my finger clicking that link, and it leads to
``` text
We're no longer updating this content regularly. Check the Microsoft Product Lifecycle for information about how this product, service, technology, or API is supported.
```
Why do you hate me? What did I do to you?
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 50fce505-544f-66d2-5322-1f9b7901c775
* Version Independent ID: 7125aaf3-74fa-f1d2-1489-f555648cc5a8
* Content: [DataSpace Enum (System.Data.Metadata.Edm)](https://docs.microsoft.com/en-us/dotnet/api/system.data.metadata.edm.dataspace?view=netframework-4.7.2)
* Content Source: [xml/System.Data.Metadata.Edm/DataSpace.xml](https://github.com/dotnet/dotnet-api-docs/blob/master/xml/System.Data.Metadata.Edm/DataSpace.xml)
* Product: **dotnet-api**
* GitHub Login: @douglaslMS
* Microsoft Alias: **douglasl**
Answers:
username_1: Thanks for your feedback @username_0. We're facing some redirections issues as we retire the MSDN content.
I'll update that link to go to https://docs.microsoft.com/en-us/previous-versions/bb399600(v=vs.90) for now.
@username_2 do you have any suggestions on a better link inside the EF docs?
username_2: @username_1 I don't have a better suggestion.
Things are complicated because several versions of EF exist.
That particular page about MetadataWorkspace seems to be from a very old EF documentation set and not part of the set we ported to https://docs.microsoft.com/ef/ef6.
In fact, the source of the link is the API reference docs from the legacy version of EF that ships in .NET Framework (aka EF4).
The EF6 API reference at https://docs.microsoft.com/dotnet/api/system.data.entity.core.metadata.edm.dataspace?view=entity-framework-6.2.0 doesn't have the link.
Any time I run into one of those loose pages, I add to a list I am tracking at https://github.com/aspnet/EntityFramework.Docs/issues/668. It may make sense to consolidate at least some of those into the EF6 docs.
Let me know if you have any thoughts.
username_2: I think it make sense to point customers doing active development on EF4 to at least upgrade to EF6. That gives them great compatibility, lots of improvements, and a path to .NET Core 3.0. So if something like this can be done, that would be great.
username_0: Sorry, there was no indication of the version it was covering (am 6.x, thought the docs were recent enough). Am here because I'm in the process of rewriting the query tree via an interceptor and omg the lack of docs on the subject... The ultimate goal is more complex row level filtering (aka where tenantId = derp is for wimps). Not much docs on the subject. Interception whether it is in Core or in 6.x is, if they are designed similarly, the goal is rewriting the query tree.
username_2: @username_0 in case you haven't found it, @rowanmiller has an example of a soft delete query interceptor at https://github.com/rowanmiller/Demo-TechEd2014/tree/master/FakeEstate.ListingManager/Models/EFHelpers.
The command trees from EF are indeed a complex area that never git a lot of documentation, mainly because it was designed only to be used in extremely advanced scenarios and we didn't see much demand. However a good understanding of LINQ expression trees should give you a good head start.
EF Core doesn't have an interception features like EF6, but you can use service replacement and intercept diagnostic events to accomplish similar tasks. Instead of having its own expression trees, EF Core uses LINQ expressions and Relinq query models.
username_0: I've pretty much looked everywhere and have seen everything online that's available. I'm old hat with Expressions, so I was able to pick up enough to get simple rewriting working. Now I'm stuck trying to figure out what the heck is up with TypeUsage and how to get from Type => DbExpressionBuilder.Parameter.
I am in an extremely advanced scenario, trying to rewrite queries to include row level filtering (and I don't mean these simple scenarios that every single example or filtering framework supports). I'm not that far off; once I get my parameter I'm pretty much done.
username_0: NVM that last bit, I figured out the beauty of binding in order to get variables.
Status: Issue closed
|
ContinuumIO/anaconda-issues | 140323195 | Title: Intel MKL FATAL ERROR: Cannot load libmkl_avx.so or libmkl_def.so.
Question:
username_0: _From @username_1 on February 10, 2016 2:20_
Seeing this on Travis CI (Linux) and in Docker containers during install. ( https://travis-ci.org/username_1/nanshe/builds/108187039#L749 )
_Copied from original issue: conda/conda#2048_
Answers:
username_0: _From @bilderbuchi on February 10, 2016 12:22_
I just encountered a similar/equivalent one (on Windows): `Intel MKL FATAL ERROR: Cannot load mkl_avx.dll or mkl_def.dll.
`
username_0: _From @username_1 on February 10, 2016 2:20_
Seeing this on Travis CI (Linux) and in Docker containers during install. ( https://travis-ci.org/username_1/nanshe/builds/108187039#L749 )
_Copied from original issue: conda/conda#2048_
username_0: _From @username_1 on February 10, 2016 15:34_
FWIW, this problem does not occur on Mac. So, it is only Linux and Windows.
username_0: _From @bilderbuchi on February 10, 2016 15:11_
[Here](https://github.com/astropy/ci-helpers/pull/67#issue-132452942) is another instance of this error, apparently. It provides a repro procedure (which doesn't repro on my side, though), and hints that maybe scipy 0.17 is the culprit, and downgrading to 0.15 could circumvent it?
username_0: _From @msarahan on February 10, 2016 13:50_
Pinging @ilanschnell
username_0: _From @username_1 on February 10, 2016 15:39_
It appears like the libraries are in the packages.
@bilderbuchi, are using Windows natively or are using it in a VM? If the latter what are you using for virtualization? If the former, do you know what architecture you have?
username_0: _From @bilderbuchi on February 11, 2016 6:59_
natively, 64bit, Windows 8.1.
username_0: _From @desilinguist on February 11, 2016 18:15_
Yes, I am having the same issue on my RHEL box. Works fine on my Mac. Seems like `scipy` is the culprit but all the paths seem so the set correctly when I run `show_config()` and all the libraries seem to be there under `$PREFIX/lib`.
username_0: _From @username_1 on February 11, 2016 18:17_
Sorry, by architecture, @bilderbuchi, I was meaning what kind of processor are you using?
username_0: _From @bilderbuchi on February 12, 2016 7:45_
An Intel(R) Xeon(R) CPU E3-1225 V2 @ 3.20GHz
username_0: Does this issue still exist? Regardless, going to kick it over to anaconda-issues. Pretty sure it's packaging-related.
username_1: This was a problem on Linux. I spun up a docker container and install `numpy`, `scipy`, and `mkl`. I tried importing `numpy` and `scipy`, which did not fail indicating this is probably fixed. Also, I tried using `numpy.dot`, which uses the BLAS if available, and imported/used a few functions from `scipy.linalg.blas`, which only use the BLAS. These seem to work and give results. So, I believe this is fixed and can be closed.
Status: Issue closed
username_0: Cool!
username_2: I have some Travis builds failing with the same error: https://travis-ci.org/colour-science/colour/builds/118175098
username_2: @username_0: Is it possible to re-open that issue please, it is not fixed or there are no clear step-by-step info to correct the problem.
username_1: Why do you need to pin the patch number for NumPy in your builds?
username_2: @username_1: It is a good point, back then I think we had specific requirements (especially for Scipy). I will try a build without specifying any version. Thanks!
username_2: Seems like it was that, for my curiosity any specific reason why this problem happened? Cheers,
username_1: There were some issues with the first MKL package released as you have seen. In this case, missing libraries on Linux. I expect (though have not checked) that NumPy 1.10.1 was pinned to a certain version of the MKL package. However, this was fixed in a later version of the MKL package and I believe the next NumPy package (think 1.10.2) changed its pinning to this new version.
username_2: Excellent makes sense! Thanks for the help, appreciated :+1:
username_3: ...
mkl 11.3.1 0
mkl-service 1.1.2 py27_0
...
numpy 1.10.4 py27_1
...
scikit-learn 0.17.1 np110py27_0
...
scipy 0.17.0 np110py27_2
```
username_4: I had the same problem, despite using the latest available packages. Turns out the solution was easier than I thought: for whatever reason Anaconda installed the MKL-enabled versions of the numpy/scipy stack, but did not actually install `mkl` itself. I have seen this when building Docker images based on the [Jupyter minimal notebook stack](https://github.com/jupyter/docker-stacks/tree/master/minimal-notebook).
A simple `conda install --yes mkl mkl-service` solved it for me.
username_5: Updating via
`conda install mkl`
solved it for me. It seems to have updated several modules including mkl, mkl-service and numpy.
username_6: Intel MKL FATAL ERROR: Cannot load libmkl_def.so.
```
Is there any workaround or suggested action?
username_7: I got also the following error:
python: symbol lookup error: /home/username/anaconda2/lib/libmkl_core.so: undefined symbol: mkl_blas_dtrsm
username_7: I finally solved this problem using two steps for my deep learning applications with Keras/Theano. Notice that I am using Ubuntu 14.04.
First, I removed mkl with the following two commands.
$ [sudo] conda install nomkl numpy scipy scikit-learn numexpr
$ [sudo] conda remove mkl mkl-service
Although mkl is removed from my anaconda python 3, LinearRegression fit in skearn still makes error related to scipy. During I am searching Web. Some brilliants said to remove python-scipy but install pip based way. So, I applied this solution to my case. I removed conda scipy and install pip sciy py as follows:
$ [sudo] conda remove scipy
$ [sudo] pip install scipy
while scipy was removed from conda, it also took his followers such as sklearn. Hence, I installed sklearn again using the pip tool such as.
$ [sudo] pip install sklearn
Now everything works perfectly. I am very fine without invoking mkl.
username_6: Following the instructions of @username_7 worked for me.
Thanks @username_7 . 👍
username_8: Also had to use @username_7 's solution on a fresh anaconda install on Ubuntu 16.04. The other upvoted methods didn't work for me. I'm hoping to be able to use MKL in the future.
username_9: I came across the same error while building `cvxopt` with `mkl:11.3.3` and `mkl:2017.0.0`, separately. I got around it by linking `libmkl_rt.so` and now no `LD_PRELOAD` trick is required. The linking order used by me was: `-lmkl_rt -lmkl_core -lmkl_intel_lp64 -lmkl_sequential`
username_10: @username_7 solution indeed do work and don't know why.
**Thanks mate!**
username_11: Occurs when using python 3.5 but not in python 3.6
username_12: I am using Anaconda 2 on Centos 7, I also met this issue. Following @username_7 's solution, the problem disappeared. Thanks!
username_13: I am using Anaconda3-4.3.0 on Ubuntu16.04, also met this issue and solved by following @username_7 's solution.
Thanks!
username_14: For me the problem was resolved by removing numpy from `~/.local/...`. If any `pip install --user <package>` command dragged numpy to install in `~/.local/lib/pythonX.Y/site-packages/numpy/` it will always use *that* numpy, and `conda list` will not show it, so you may thing you don't have that installed. `pip uninstall numpy` fixed it. I think that explains many of the issues, for instance switching to 3.6, since numpy for 3.5 won't be found anymore. Possibly similar issues exists for scipy, I didn't check.
username_15: For me (on Ubuntu 14.04, python 3.6.1) it started working after installing numexpr (conda install numexpr). No paths specified.
username_16: For me problems started appearing after installing a `Python 2.7` with corresponding `numpy` alongside `root` env. Creating a new env with python 3 and numpy helped and none of suggestions above did not.
username_17: This issue still exists.
My environment configs are:
**VM: {gues_os: Ubutu 14.04 64, anaconda2: 4.4.0}**
And I can assure both mkl and mkl-service are installed, and resides at '/opt/anaconda2/lib/'.
However, when I fire *python -c "import gensim"*, the exact error msg is:
**Intel MKL FATAL ERROR: Cannot load libmkl_avx.so or libmkl_def.so**
Using *LD_PRELOAD=...* does not help me out either.
Using *LD_DEBUG=symbol python -c 'import gensim'* does give me details, and found 4 places for ****
<pre>
1. 9582: symbol=mkl_dft_avx_xs_f32_1df; lookup in file=/opt/anaconda2/lib/python2.7/site-packages/scipy/special/../../../../libmkl_avx.so [0]
9582: symbol=mkl_sparse_optimize_bsr_trsm_i8; lookup in file=python [0]
9582: symbol=mkl_sparse_optimize_bsr_trsm_i8; lookup in file=/opt/anaconda2/bin/../lib/libpython2.7.so.1.0 [0]
9582: symbol=mkl_sparse_optimize_bsr_trsm_i8; lookup in file=/lib/x86_64-linux-gnu/libpthread.so.0 [0]
9582: symbol=mkl_sparse_optimize_bsr_trsm_i8; lookup in file=/lib/x86_64-linux-gnu/libdl.so.2 [0]
9582: symbol=mkl_sparse_optimize_bsr_trsm_i8; lookup in file=/lib/x86_64-linux-gnu/libutil.so.1 [0]
9582: symbol=mkl_sparse_optimize_bsr_trsm_i8; lookup in file=/lib/x86_64-linux-gnu/libm.so.6 [0]
9582: symbol=mkl_sparse_optimize_bsr_trsm_i8; lookup in file=/lib/x86_64-linux-gnu/libc.so.6 [0]
9582: symbol=mkl_sparse_optimize_bsr_trsm_i8; lookup in file=/lib64/ld-linux-x86-64.so.2 [0]
9582: symbol=mkl_sparse_optimize_bsr_trsm_i8; lookup in file=/opt/anaconda2/lib/python2.7/site-packages/scipy/special/../../../../libmkl_avx.so [0]
9582: symbol=mkl_sparse_optimize_bsr_trsm_i8; lookup in file=/lib/x86_64-linux-gnu/libdl.so.2 [0]
9582: symbol=mkl_sparse_optimize_bsr_trsm_i8; lookup in file=/lib/x86_64-linux-gnu/libc.so.6 [0]
9582: symbol=mkl_sparse_optimize_bsr_trsm_i8; lookup in file=/lib64/ld-linux-x86-64.so.2 [0]
**9582: /opt/anaconda2/lib/python2.7/site-packages/scipy/special/../../../../libmkl_avx.so**: error: symbol lookup error: undefined symbol: mkl_sparse_optimize_bsr_trsm_i8 (fatal)
2. 9582: symbol=mkl_sparse_optimize_bsr_trsm_i8; lookup in file=/opt/anaconda2/bin/../lib/libpython2.7.so.1.0 [0]
9582: symbol=mkl_sparse_optimize_bsr_trsm_i8; lookup in file=/lib/x86_64-linux-gnu/libpthread.so.0 [0]
9582: symbol=mkl_sparse_optimize_bsr_trsm_i8; lookup in file=/lib/x86_64-linux-gnu/libdl.so.2 [0]
9582: symbol=mkl_sparse_optimize_bsr_trsm_i8; lookup in file=/lib/x86_64-linux-gnu/libutil.so.1 [0]
9582: symbol=mkl_sparse_optimize_bsr_trsm_i8; lookup in file=/lib/x86_64-linux-gnu/libm.so.6 [0]
9582: symbol=mkl_sparse_optimize_bsr_trsm_i8; lookup in file=/lib/x86_64-linux-gnu/libc.so.6 [0]
9582: symbol=mkl_sparse_optimize_bsr_trsm_i8; lookup in file=/lib64/ld-linux-x86-64.so.2 [0]
9582: symbol=mkl_sparse_optimize_bsr_trsm_i8; lookup in file=/opt/anaconda2/lib/python2.7/site-packages/scipy/special/../../../../libmkl_def.so [0]
9582: symbol=mkl_sparse_optimize_bsr_trsm_i8; lookup in file=/lib/x86_64-linux-gnu/libdl.so.2 [0]
9582: symbol=mkl_sparse_optimize_bsr_trsm_i8; lookup in file=/lib/x86_64-linux-gnu/libc.so.6 [0]
9582: symbol=mkl_sparse_optimize_bsr_trsm_i8; lookup in file=/lib64/ld-linux-x86-64.so.2 [0]
** 9582: /opt/anaconda2/lib/python2.7/site-packages/scipy/special/../../../../libmkl_def.so**: error: symbol lookup error: undefined symbol: mkl_sparse_optimize_bsr_trsm_i8 (fatal)
</pre>
It reveals that the installed scipy is referencing MKL libs. But the installed MKL coming along with anaconda is located at **'/opt/anaconda2/lib/libmkl_{core,avx,def}.so'**.
And for aforementioned solutions, I believe either to uninstall mkl or to install nomkl is not solving this issue.
If understand correctly, *nomkl* is NON-MKL version for originally mkl-relavant packages such as scipy, numpy. Therefore installing nomkl will not give us MKL's benefit for later use while mkl- relevant boosting was assumed in MKL-verion of numpy/scipy/etc, right?
I tried to find which file is referencing these so file with **grep -r lmkl_avx** and **grep -r lmkl_def**, but no result returned.
I also installed Intel MKL package downloaded from Intel's site. Similar error log apears, but in addition I found:
<pre>
9517: symbol=COIProcessLoadSinkLibraryFromFile; lookup in file=/opt/anaconda2/lib/python2.7/site-packages/scipy/special/../../../../libmkl_intel_lp64.so [0]
9517: symbol=COIProcessLoadSinkLibraryFromFile; lookup in file=/opt/anaconda2/lib/python2.7/site-packages/scipy/special/../../../../libmkl_intel_thread.so [0]
9517: symbol=COIProcessLoadSinkLibraryFromFile; lookup in file=/opt/anaconda2/lib/python2.7/site-packages/scipy/special/../../../../libmkl_core.so [0]
9517: symbol=COIProcessLoadSinkLibraryFromFile; lookup in file=/opt/anaconda2/lib/python2.7/site-packages/scipy/special/../../../../libiomp5.so [0]
........
</pre>
The problem, I guess, is how to correctly link the **/opt/anaconda2/lib/liblmk_{core|avx|def}.so** for scipy or gensim, by hard code or dynamic way *-ld*.
I will continuing working and the post a solution, if no one solves.
username_17: In my *problematic* Ubuntu vbox, this issue is solved by using:
<pre>
LD_PRELOAD=/opt/anaconda2/lib/libmkl_core.so:/opt/anaconda2/lib/libmkl_sequential.so python -c 'import gensim'
</pre>
Also, in another copy of Ubuntu vbox as well as Centos vbox, I can do **python -c "import gensim"** after installing the same version of anaconda and gensim in my *problematic* Ubuntu without any additional settings. So the problem is relevant to system and.
username_18: On my scientific linux box, I fixed this issue by pinning mkl to version 11.3.3
```conda install mkl=11.3.3```
username_19: Nothing seems to work for me here. I am getting this from a VirtualEnv set up for django. Any help is appreciated,
username_19: This did the trick when everything else failed -
sudo cp /home/akshay/anaconda2/pkgs/mkl-2017.0.1-0/lib/* /usr/lib
username_20: run the following before other imports solve similar problem for me:
sys.setdlopenflags(sys.getdlopenflags() | ctypes.RTLD_GLOBAL)
username_21: I was having this error inside a conda environment. My problem was resolved by executing `conda install mkl` inside the environment.
username_22: I had the "Intel MKL FATAL ERROR: Error on loading function mkl_blas_avx_xdcopy". It was resolved by executing `conda update mkl`.
username_23: This issue is still persisting for me
username_24: I solved it by adding the two lines to the beginning of my code:
"""
import mkl
mkl.get_max_threads()
""" |
tensorflow/tensorflow | 916873047 | Title: How to use TF.data.Dataset for relational database like nuScenes
Question:
username_0: **System information**
- TensorFlow version (you are using): tensorflow==2.5.0 (pip installed, Ubuntu 20.04, CUDA 11.)
**Describe the feature and the current behavior/state.**
tf.data.Dataset is excellent while implementing the data-pipeline . But currently the relational database like nuScenes (https://www.nuscenes.org/nuscenes#data-format). has difficulty to implement. Please guide or inform the steps to be taken, with examples.
**Will this change the current api? How?**
**Who will benefit with this feature?**
All relational database like nuScenes can use the tf.data.Dataset and also perform better while using the distributed training. |
python-visualization/folium | 254425120 | Title: On The Fly Marker return geolocation?
Question:
username_0: I am new to Folium and saw the feature for on-the-fly placement of markers. Is it possible to return those values in Folium?
What I am trying to do is if a person creates a region defined by markers, to return those values and then run a query against that particular area?
Answers:
username_1: That is possible but not implemented. Take a look at ipyleaflet which I believe has that feature. |
primefaces/primefaces | 70106341 | Title: When modal is true, close icon doesn't apply focus with tab key on Dialog
Question:
username_0: When modal is true, close icon doesn't apply focus with tab key on Dialog.
Status: Issue closed
Answers:
username_1: A workaround:
jQuery(document).ready(function() {
var $uiIconClose = $('.ui-icon-close');
if ($uiIconClose[0]) {
$uiIconClose.attr('tabindex', 0);
}
}
username_1: Oh, and to close it when you have focus and hit enter:
```
$uiIconClose.keydown(function (e) {
var key = e.which;
if(key == 13) // the enter key code
{
$uiIconClose.click();
return true;
}
});
``` |
laravelista/comments | 895669006 | Title: error in redirect
Question:
username_0: whaen i try to create a new comment he try to redirect my to /home
i try to change it but sill redirect my to /home
Answers:
username_1: When the comment is created it tries to redirect you to the previous URL appended with a hash which points the browser to the newly created comment:
```
return Redirect::to(URL::previous() . '#comment-' . $comment->getKey());
``` |
ValveSoftware/steam-for-linux | 180517096 | Title: Steam messages slow down the computer display
Question:
username_0: #### Your system information
* Steam client version: Latest stable as of today
* Distribution (e.g. Ubuntu): UBuntu gnome 16.10
* Opted into Steam client beta?: [Yes/No] No
* Have you checked for system updates?: [Yes/No] Yes
#### Please describe your issue in as much detail as possible:
Steam message notification is very slow and slows down the computer.
#### Steps for reproducing this issue:
1. Wait to receive a message from a friend in chat<issue_closed>
Status: Issue closed |
forelleblau/ioBroker.forecastsolar | 499957859 | Title: Think about to fix the issues found by adapter checker
Question:
username_0: I am an automatic service that looks for possible errors in ioBroker and creates an issue for it. The link below leads directly to the test:
https://adapter-check.iobroker.in/?q=https://raw.githubusercontent.com/forelleblau/ioBroker.forecastsolar
- [ ] [E112] extIcon must be the same as an icon but with github path
- [ ] [E201] Bluefox was not found in the collaborators on NPM!. Please execute in adapter directory: "npm owner add bluefox iobroker.forecastsolar"
- [ ] [E300] Not found on travis. Please setup travis
I have also found warnings that may be fixed if possible.
- [ ] [W400] Cannot find "forecastsolar" in latest repository
Thanks,
your automatic adapter checker.
P.S.: There is a community in Github, which supports the maintenance and further development of adapters. There you will find many experienced developers who are always ready to assist anyone. New developers are always welcome there. For more informations visit: https://github.com/iobroker-community-adapters/info
Answers:
username_0: Do you need help fixing the bugs?
username_0: Do you need help fixing the bugs? |
alexhude/alfredworkflow-zsh-calculator | 194824815 | Title: Alfred 2 Compatibility
Question:
username_0: I tried to import this workflow with my copy of Alfred 2 but I get this error:

Would be cool to add Alfred 2 support.
Thanks!
Answers:
username_1: I have added Alfred2 version. However, I would recommend you to switch to Alfred3 since it is lot more powerful. Also it is unlikely I will support Alfred2 workflows for a long time.
Status: Issue closed
username_1: I have added Alfred2 version. However, I would recommend you to switch to Alfred3 since it is lot more powerful. Also it is unlikely I will support Alfred2 workflows for a long time.
username_0: I'll definitely consider to upgrade 👍 Thanks! |
DeanCording/node-red-contrib-ecolect | 460972121 | Title: I've solve all you're problem juste check you're pull request
Question:
username_0: ### I've solve all you're problem juste check you're pull request
Answers:
username_1: It looks like this project is abandoned! :(
username_2: Sorry, I haven't abandoned it, I just have some more pressing matters to attend to at the moment.
Thanks,
Dean
Status: Issue closed
|
uniVocity/univocity-parsers | 306666951 | Title: Trim quoted columns
Question:
username_0: In a CSV export, the column value is quoted with spaces; e.g. `" 1"`.
During import, this fails when read with `record.getInt` with a `NumberFormatException`. The default setting of trimming whitespace is enabled.
It looks like the quoted input is not trimmed, and the setting only trims whitespace surrounding it. It seems counter-intuitive that I would need to do my own conversion logic to handle this case.
Answers:
username_1: Thanks for the suggestion, I'm not even sure how we got this far without this as it can obviously affect a lot of people.
I'll add an option to trim spaces inside quotes in version 2.6.2, i.e. very soon
Status: Issue closed
username_1: All done, now you can use:
* `trimQuotedValues`
* `setIgnoreLeadingWhitespacesInQuotes`
* `setIgnoreTrailingWhitespacesInQuotes`
I've released a 2.6.2-SNAPSHOT version which includes these. Let me know if you find any issues.
Thank you for using our parsers!
username_1: Version 2.6.2 released. Thanks again for the suggestion |
pytorch/pytorch | 577516332 | Title: Query padding mask for nn.MultiheadAttention
Question:
username_0: nn.MultiheadAttention already have key_padding_mask, which is fine and easy to use, it would be useful to have query_padding_mask argument.
My attention alignments looks like this and i do not like it. Probably it decreese model performance.

Probably, I can make a length mask with attn_mask argument, but not sure how.
Answers:
username_1: Hi,
Could you please use the template provided to explain in more details what you want and why?
Thanks
username_0: @username_1
## 🚀 Feature
Len mask argument for query in nn.MultiheadAttention
## Motivation
Its easy to use key_padding_mask for key argument, and not obvious how to do same for query.
## Pitch
It would be cool and useful to have a padding mask the same as for key argument.
## Alternatives
Probably, I can make a length mask with attn_mask argument, but not sure how.
## Additional context
Image for attention alignments without query but with key padding mask.
 |
corona-warn-app/cwa-documentation | 812668678 | Title: Wie speichert man einen Eintrag im Kontakttagebuch?
Question:
username_0: Bei meinem Android-Handy erscheint kein Speicherbutton, wenn ich versuche, eine neue Person ins Kontakttagebuch einzutragen.
Answers:
username_1: Hi @username_0,
maybe this helps: https://www.coronawarn.app/de/blog/2020-12-28-corona-warn-app-version-1-10/
If you have more questions, please, let us know.
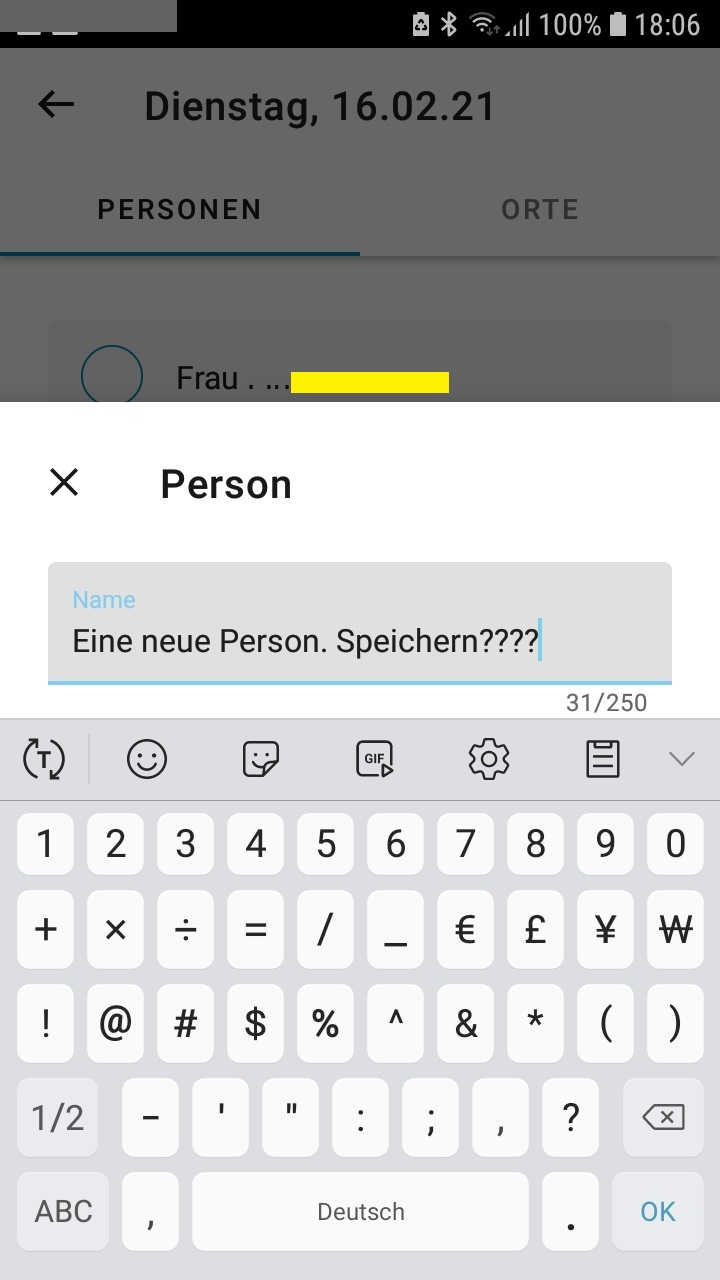
username_0: Thanks for the link. However, it is different on my phone: In the screenshot in the link, the "Speichern" button is just above the keyboard, but on my phone it looks like this: (yellow ribbon added over older entry for privacy reasons)
ut on my phone the "Speichern" button does not appear.
username_2: @username_0
What happens when you press "OK"?
username_0: Thanks, pressing OK (tiny) works - but it's not obvious enough for me
username_2: I really don't know what the behavior on Androids should be, @username_1 maybe transfer this to the Android repo for further investigation?
username_3: For Android German the keyboard shows "OK", for English it shows "Done". That may depend on exactly which Android keyboard is enabled though.
The screen shots and instructions on https://www.coronawarn.app/de/blog/2020-12-28-corona-warn-app-version-1-10/ seem to be from iOS, whereas the screen shots on https://www.coronawarn.app/en/blog/2020-12-28-corona-warn-app-version-1-10/ look like they are from Android.
username_4: For me, the keyboard shows a blue checkmark instead of an OK button (Android 10). Maybe this needs an additional explanatory sentence in the blogpost.
@username_0 If you are satisfied with the answers, you can close the issue :)
----
Corona-Warn-App Open Source Team
Status: Issue closed
username_3: The layout on Android differs from the layout on iOS shown in https://www.coronawarn.app/de/blog/2020-12-28-corona-warn-app-version-1-10/
Here is an example on a Google Pixel 3a phone with Android 11:

Google Pixel phones use the Gboard keyboard which offers the tick button ✅ to complete an entry.
Samsung phones use the Samsung keyboard with 🆗 (German) and Done (English).
username_3: It is now more obvious how to save the data for a person in CWA 1.14. In addition to the person's name, the data stored has new fields for telephone number and e-mail address. To store a new or edited person, there is a separate button, labelled "Speichern" in German or "Save" in English.
The screenshot below is again from a Google Pixel 3a phone with Android 11:
 |
mozilla/application-services-bug-mirror | 540612882 | Title: Firefox sync error message "Your email was just returned"
Question:
username_0: User Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0
Steps to reproduce:
Try to synchronize firefox sync.
Actual results:
I can't sync firefox sync.
Expected results:
I should be able to sync with my email account.
<EMAIL>
---
🐞 Issue is synchronized with Bugzilla [Bug 1605249](https://bugzilla.mozilla.org/show_bug.cgi?id=1605249) |
Nocommas555/TurtlePatformer | 818817252 | Title: create a basic sprite renderer class
Question:
username_0: It should include:
- animation handling
- custom data format that includes positional data about the center of the sprite to scale it
- z-layering support
Answers:
username_0: - Custom data format not needed anymore due to changing graphical lib from turtle to tkinter
username_0: animations and z-layering are done in the first iteration of our engine
username_0: The class is done. Loading screen not implemented, but the picture loader that caches info for multiple objects is.
Status: Issue closed
|
geneontology/go-annotation | 851033241 | Title: incorrect IDA annotation of 'plasmalogen synthase activity' to the Arabidopsis LPEAT1 and LPEAT2 genes
Question:
username_0: The GO term 'plasmalogen synthase activity' describes the attachment of an acyl-CoA to 1-O-alk-1-enyl-glycero-3-phosphocholine.
There is no experiment evidence suggests that the Arabidopsis genes LPEAT1 and LPEAT2 have such enzyme activity. The cited paper (PMID:19445718) does not support it. The substrates tested in the paper (in Methods section) included 1-palmitoyl-2-hydroxy-sn-glycero-3-phosphocholine, 1-oleoyl-2-hydroxy-sn-glycero-3-phosphocholine, and other lipids. None of them are 1-O-alk-1-enyl-glycero-3-phosphocholines.
Here is a screen shot of the incorrect GO annotation to LPEAT1:
<img width="1612" alt="Screen Shot 2021-03-30 at 9 34 16 PM" src="https://user-images.githubusercontent.com/36932254/113092196-5f07ac80-91a2-11eb-8895-1e2b05966496.png">
Answers:
username_1: Hi @username_2
Should we close this ticket? Or will you come back to close it when it's done locally?
username_2: Hi Pascale, <NAME> and <NAME> are going to take care of the fixes - Emmanuel will close the ticket when done.
username_3: Hi Peifen, Alan and Pascale,
We have updated GO annotation for LEAPT1 and LEAPT2 and added the correct reactions in the corresponding UniProt entries.
Best, Damien
username_3: The UniProtKB/Swiss-Prot updates of LEAPT1 and LEAPT2 should be freezed on May 12 (Freeze 2021_04) and publicly released on July 28 (Release 2021_04). For GOA, I do not have the release calendar.
Damien
username_1: Thanks !!
Status: Issue closed
|
fh1ch/node-bacstack | 275078866 | Title: writeProperty throws Exception when writing null to presentValue
Question:
username_0: tried to use
`writeProperty (address, 4, objectInstance, 85, 12, [{ type: 9, value: null }], (err, val) => {}
`
in order to reset entry in priority Array and got an Exception **'buffer.Add is not a function'**
(yes I know that the type of BACNET_APPLICATION_TAG_NULL is 0, but this doesn't matter here)
this is at line 431 of master/lib/bacnet-asn1.js:
snip >>>>
```
var bacappEncodeApplicationData = module.exports.bacappEncodeApplicationData = function(buffer, value) {
if (value.value === null) {
buffer.Add(baEnum.BacnetApplicationTags.BACNET_APPLICATION_TAG_NULL);
return;
}
```
<<<< snip
Status: Issue closed
Answers:
username_1: Hi @username_0
Thank you very much for reporting this issue. I really appreciate this 👍
Sorry for the delay on this, I don't have too much time working on such topics lately...
However, this issue has been fixed in PR #67 and is now available as release `0.0.1-beta.12`.
Happy coding 🍻 |
Facepunch/garrysmod-issues | 495547321 | Title: Nav mesh generation seems to consistently crash the game
Question:
username_0: ### Details
Been messing with nextbots again, but wanted a better test map than gm_construct. It's been some time since I generated one, but every time I enable cheats and run nav_generate it starts computing walkable space and eventually crashes failing to generate the .nav file.
_Todo: Upload dumps._
### Steps to reproduce
_Commands executed:_
1. `sv_cheats 1`
2. `nav_generate`
_Maps I've tried on:_
* dm_runoff _(HL2DM)_
* Custom test map that is a bland cube with a skybox
_Things I tried to make it work:_
* Disabled all workshop addons
* Deleted `./lua` and `./addons`
* Removing any existing map related files and started with a .bsp by itself
* If I reduce the incremental mesh generation distance to 500 I can get it to not crash the first couple times. Once the mesh reaches a certain size it crashes.
Answers:
username_1: Fixed in Dev, unfortunately had to disable the hull trace surface prop fix, it was causing this crash and I can't figure out why.
Status: Issue closed
|
cometkim/gatsby-plugin-typegen | 788962175 | Title: tagName option seems to be ignored
Question:
username_0: I've both `gql` and `graphql` tag in my project and I want to generate only `graphql` because are the ones used by gatsby.
Still I got some error relative to `gql` queries.
Moreover, looking at the source of this plugin it seems to me that this option is never managed, am I wrong?
Thanks
Answers:
username_1: As I mentioned from [README](https://github.com/username_1/gatsby-plugin-typegen/tree/master/plugin#disclaimer) this plugin support only graphql tag from gatsby, so you would need additional codegen config for graphql-tag or something.
and there was an issue from tag pluck
https://github.com/username_1/gatsby-plugin-typegen/issues/99
I'm not sure this has been resolved from upstream.
username_0: I actually need only graphql tag but other tag are included too if some file use both. I temporary solved removing `gql` from the file that use `graphql`, but it seems a but to me.
Status: Issue closed
username_1: This is fixed in v3 (current RC)
v3 relies on Gatsby's `SET_GRAPHQL_DEFINITIONS` API instead of graphql-tools. so It would not break again.
If you need a separate gql tag for non-gatsby env, you may still need graphql-tools. |
GoogleCloudPlatform/grpc-gcp-go | 418422553 | Title: Unbounded options
Question:
username_0: - When ChannelPoolConfig.MaxSize == 0, it should be treated as "unbounded". (Currently it's treated as 10](https://github.com/GoogleCloudPlatform/grpc-gcp-go/blob/master/grpcgcp/gcp_balancer.go#L36-L38).
- When ChannelPoolConfig.MaxConcurrentStreamsLowWatermark == 0, it should be treated as "unbounded". (Currently it's treated as 100](https://github.com/GoogleCloudPlatform/grpc-gcp-go/blob/master/grpcgcp/gcp_balancer.go#L36-L38). That is: channels should be spun up based on network signals, such as MAX_CONCURRENT_STREAMS.
- ChannelPoolConfig.MaxConcurrentStreamsLowWatermark == 0 (unbounded) should explicitly be the recommended default. There is no technical reason to my knowledge that <MAX_CONCURRENT_STREAMS should be on a single TCP connection.
Answers:
username_1: Thanks for bringing that up. The checker for https://github.com/GoogleCloudPlatform/grpc-gcp-go/blob/master/grpcgcp/gcp_picker.go#L69 and https://github.com/GoogleCloudPlatform/grpc-gcp-go/blob/master/grpcgcp/gcp_picker.go#L76 is just to cover the cases where user doesn't specify anything for those two values, because the generated proto class by default returns '0' for both GetMaxSize() and GetMaxConcurrentStreamsLowWatermark(), and honestly I don't know how I can check whether the '0' is specified by user or it's just come from the default unset value.
For MaxConcurrentStreamsLowWatermark, I made this default as 100 is just because of the max 100 concurrent streams bottleneck caused by GFE configuration. But if there's no consideration other than that, I can make it unbounded as default.
For MaxSize, is there any potential memory concerns if we set this as "unbounded"? And if '0' is treated as "unbounded", I'm not sure how to differentiate whether this is the default unset "0", or is specified by the user.
Looking forward to hear your thoughts:)
username_0: I don't think so. Ideally MaxConcurrentStreamsLowWatermark would be 0 (unbounded) and we'd just create new streams when we reach MAX_CONCURRENT_STREAMS. That is, the number should be very low in a normal case.
In the non-normal case, there's still not really any problems. Spinning up a bunch of connections is kind of unfortunate in terms of allocations (in-program and in kernel) but certainly isn't illegal.
username_2: It depends on what you're looking to do. We respect the server's max concurrent streams setting in accordance with the HTTP/2 spec. However, we will block an RPC if the transport picked would exceed its allowable stream count limit. There's no way for a balancer to choose a different transport if the preferred transport is already at its maximum, and there is currently no mechanism for conveying the maximum count back to the balancer.
username_1: So in https://github.com/GoogleCloudPlatform/grpc-gcp-go/blob/master/grpcgcp/grpc_gcp/grpc_gcp.pb.go#L144 the method will always return non-nil values (if unset 0 will be returned), so if user doesn't set the maxSize, then it will be read as 0, which means the maxSize will be "unbounded" by default. But I think it's fine as long as I document it, and you are right, 0 is totally meaningless.
username_2: FWIW, the proto3 workaround for this problem is boxed types, e.g. https://developers.google.com/protocol-buffers/docs/reference/google.protobuf#google.protobuf.Int32Value. The wrapping message can be unset, so you can distinguish between unset and set-to-default.
username_0: Gotcha. 100 as the default makes sense to me then.
@username_1 what happens if a user sets value >100? Maybe it's good to bound it to 100 and document the bound. "Any value over 100 will be rounded down to 100", or something?
username_1: I believe if the concurrent streams reach 100 or more in one connection, any new rpc request on that connection will just hang there. I'm not sure whether we want to round down 100+ to 100 for this value, since this value anyway is a soft limit. WDYT?
username_0: My feeling is that nobody would want their requests to hang in lieu of spinning out a new connection. There's little downside to spinning out a new connection (TCP init and warm up, which isn't that big of a deal if infrequent) compared to potentially building up a large backlog of requests. So, I'm in favour of rounding down.
username_1: Sounds good. So to confirm:
MaxSize: default is 0, and 0 means unbounded.
MaxStreamsLowWatermark: default is 100 (and 100+ will be rounded down to 100), and also 0 means unbounded.
Does that look good?
username_0: I had originally thought that this could result in letting something like MAX_CONCURRENT_STREAMS take over. Basically to let the transport figure it out. It _sounds_ like Doug's saying that's not possible. If that's the case, I would default to 100 if users set any value outside [1, 100].
My interpretation of @username_2 answer might be wrong, though, so would be good to double check.
username_1: I feel like rounding down the value in our code has some limitations. Since the current 100 maximum value is also a configurable value on GFE side, if somehow GFE changes this limit, then this round down logic also needs to be updated. Do you think it would be better for the service owner (e.g. spanner, bigtable) to have more flexibility when setting this MaxStreamsLowWatermark value? For example, they can decide to increase this value if they are aware that GFE somehow supports more concurrent streams.
username_0: I don't think service owners should ever adjust this value, since the GFE is cross services. Currently this default / max lives in grpc-gcp (this repo), which means you+grpc team own it. I actually think that's as close as you can get to the right canonical owner if you're unable to use MAX_CONCURRENT_STREAMS.
The actually correct solution, though, is to somehow use MAX_CONCURRENT_STREAMS.
Status: Issue closed
|
redhat-cop/openshift-templates | 661771623 | Title: CatalogSourceConfig used by operatorhub template is deprecated
Question:
username_0: https://github.com/redhat-cop/openshift-templates/tree/master/operatorhub uses `CatalogSourceConfig` which is now deprecated:
- https://docs.openshift.com/container-platform/4.2/release_notes/ocp-4-2-release-notes.html#ocp-4-2-deprecated-features
Answers:
username_1: Closed by #83
Status: Issue closed
|
filecoin-project/lotus | 761113998 | Title: ChainGetTipSetByHeight “looking for tipset with height greater than start point”
Question:
username_0: How to solve this problem?
Use the API `cli.ChainGetTipSetByHeight(context.Background(), abi.ChainEpoch(blockNo), types.EmptyTSK)` to get the same error。
<img width="1666" alt="WeChat6b2944fd2ec05ad4f88d2138b8af8c91" src="https://user-images.githubusercontent.com/18685332/101759867-1950a680-3b15-11eb-9fc0-c5b1f1bce5dc.png">
Status: Issue closed
Answers:
username_0: node error
username_1: set latest chain head block cid |
jitbit/AspNetSaml | 264386932 | Title: [Question] Single Logout
Question:
username_0: Hi,
Do you have a way to manage the single logout?
https://developers.onelogin.com/saml/examples/logout-request
I tried to create the request (following your example) but then it has to be signed and I don't know how to do that (I was trying to do the HTTP-Redirect)
Answers:
username_1: Sorry, it currently has no way of sending a "logout" request.
I don't think its gonna work with redirect, you have to send POST data to the provider server.
Status: Issue closed
|
dotnet/try-convert | 792617281 | Title: Missing space or newline after warning message
Question:
username_0: Attempt to convert an old Framework console app results in the following:
<pathname> contains an App.config file. App.config is replaced by appsettings.json in .NET Core. You will need to delete App.config and migrate to appsettings.json if it's applicable to your project.Conversion complete!
A newline after the last period would be nice.<issue_closed>
Status: Issue closed |
angular/angular | 816662810 | Title: [CDK TABLE] sticky directive causes problems with more than one mat-header-row
Question:
username_0: # 🐞 bug report
### Affected Package
The issue is caused by package @angular/material
### Is this a regression?
No idea
### Description
It is known that you can set `sticky` directive for more than one `matColumnDef`. It is also known that you can have more than one row of table heading (`mat-header-row`). However, with more than one `mat-header-row` the `sticky` feature breaks the table layout.
## 🔬 Minimal Reproduction
[https://stackblitz.com/edit/cdk-table-multi-row-heading-sticky-column](https://stackblitz.com/edit/cdk-table-multi-row-heading-sticky-column?file=src%2Fapp%2Fapp.component.html)
On the exaple you can see that two first columns are `sticky`. Also there is additional `mat-header-row` that groups more than one clumn.
## 🔥 Exception or Error
You can see how `2nd` column has moved to the right, covering another column named `id`. This problem makes it impossible to build more complex tables for our clients.
## 🌍 Your Environment
**Angular Version:**
<pre><code>
11.2.3 / 11.2.2
</code></pre>
**Anything else relevant?**
Nope |
Aldaviva/eircd | 247972032 | Title: commands:NAMES Zero argument client crash
Question:
username_0: Fix: file eircd_commands.erl line 152
```
eircd_connector:send_server_message(User, ?IRC_NAMES_END, "#"++ChannelName++" :End of /NAMES list.");
_ ->
eircd_connector:send_server_message(User, ?IRC_ERROR, ":/NAMES: No channel defined.")
```
Fixed file (+ code 421 is replaced with ?IRC_ERROR): [eircd_commands.zip](https://github.com/username_1/eircd/files/1200074/eircd_commands.zip)
Answers:
username_1: Hi @username_0,
Thanks for contributing this fix!
Can you submit your changes as a [pull request](https://help.github.com/articles/creating-a-pull-request/)?
Thanks,
Ben
username_1: Merged Pull Request #2.
Status: Issue closed
|
ipython/ipyparallel | 211985292 | Title: Boost python exceptions crashing engines
Question:
username_0: ```
Everything seems to work properly in my initial testing, until I try to distribute a task in which C++ code throws an exception (FYI, Boost.Python has a mechanism in which C++ exceptions are caught at the boundary between C++ and Python, and re-thrown in Python as Python exceptions -- in many years of using Boost Python, this mechanism has always been working flawlessly for my use cases).
When I try to distribute a task that throws from C++, I can see the following happening in the debug output of ipcluster:
```console
2017-03-05 22:07:17.940 [IPClusterStart] Process '/usr/bin/python3.5' stopped: {'pid': 18580, 'exit_code': -6}
2017-03-05 22:07:21.520 [IPClusterStart] b"2017-03-05 22:07:21.520 [IPControllerApp] heartbeat::missed b'af9a4de7-e140-4a91-b4bb-c7089b04adc9' : 1"
2017-03-05 22:07:24.520 [IPClusterStart] b"2017-03-05 22:07:24.520 [IPControllerApp] heartbeat::missed b'af9a4de7-e140-4a91-b4bb-c7089b04adc9' : 2"
2017-03-05 22:07:27.520 [IPClusterStart] b"2017-03-05 22:07:27.520 [IPControllerApp] heartbeat::missed b'af9a4de7-e140-4a91-b4bb-c7089b04adc9' : 3"
2017-03-05 22:07:30.520 [IPClusterStart] b"2017-03-05 22:07:30.520 [IPControllerApp] heartbeat::missed b'af9a4de7-e140-4a91-b4bb-c7089b04adc9' : 4"
2017-03-05 22:07:33.520 [IPClusterStart] b"2017-03-05 22:07:33.520 [IPControllerApp] heartbeat::missed b'af9a4de7-e140-4a91-b4bb-c7089b04adc9' : 5"
2017-03-05 22:07:36.520 [IPClusterStart] b"2017-03-05 22:07:36.520 [IPControllerApp] heartbeat::missed b'af9a4de7-e140-4a91-b4bb-c7089b04adc9' : 6"
2017-03-05 22:07:39.520 [IPClusterStart] b"2017-03-05 22:07:39.520 [IPControllerApp] heartbeat::missed b'af9a4de7-e140-4a91-b4bb-c7089b04adc9' : 7"
2017-03-05 22:07:42.520 [IPClusterStart] b"2017-03-05 22:07:42.520 [IPControllerApp] heartbeat::missed b'af9a4de7-e140-4a91-b4bb-c7089b04adc9' : 8"
2017-03-05 22:07:45.520 [IPClusterStart] b"2017-03-05 22:07:45.520 [IPControllerApp] heartbeat::missed b'af9a4de7-e140-4a91-b4bb-c7089b04adc9' : 9"
2017-03-05 22:07:48.520 [IPClusterStart] b"2017-03-05 22:07:48.520 [IPControllerApp] heartbeat::missed b'af9a4de7-e140-4a91-b4bb-c7089b04adc9' : 10"
2017-03-05 22:07:51.520 [IPClusterStart] b"2017-03-05 22:07:51.520 [IPControllerApp] heartbeat::missed b'af9a4de7-e140-4a91-b4bb-c7089b04adc9' : 11"
2017-03-05 22:07:51.521 [IPClusterStart] b'2017-03-05 22:07:51.520 [IPControllerApp] registration::unregister_engine(3)'
2017-03-05 22:07:56.531 [IPClusterStart] b'ERROR:tornado.application:Exception in callback functools.partial(<function wrap.<locals>.null_wrapper at 0x7f3ce0377598>)'
2017-03-05 22:07:56.535 [IPClusterStart] b'Traceback (most recent call last):'
2017-03-05 22:07:56.535 [IPClusterStart] b' File "/usr/lib64/python3.5/site-packages/tornado/ioloop.py", line 604, in _run_callback'
2017-03-05 22:07:56.535 [IPClusterStart] b' ret = callback()'
2017-03-05 22:07:56.536 [IPClusterStart] b' File "/usr/lib64/python3.5/site-packages/tornado/stack_context.py", line 275, in null_wrapper'
2017-03-05 22:07:56.536 [IPClusterStart] b' return fn(*args, **kwargs)'
2017-03-05 22:07:56.536 [IPClusterStart] b' File "/usr/lib64/python3.5/site-packages/ipyparallel/controller/scheduler.py", line 325, in <lambda>'
2017-03-05 22:07:56.536 [IPClusterStart] b' lambda : self.handle_stranded_tasks(uid),'
2017-03-05 22:07:56.536 [IPClusterStart] b' File "/usr/lib64/python3.5/site-packages/ipyparallel/controller/scheduler.py", line 335, in handle_stranded_tasks'
2017-03-05 22:07:56.536 [IPClusterStart] b' for msg_id in lost.keys():'
2017-03-05 22:07:56.537 [IPClusterStart] b'RuntimeError: dictionary changed size during iteration'
2017-03-05 22:07:56.537 [IPClusterStart] b"2017-03-05 22:07:56.534 [IPControllerApp] task::task '61317ff8-c759-4faa-aebb-2fd57595c586' finished on 3"
```
On the ipython side, when I try to ``.get()`` the result from the future, the interpreter waits for a bit and then says:
```console
In [14]: ar.get()
Traceback (most recent call last):
File "/usr/lib64/python3.5/site-packages/ipyparallel/controller/scheduler.py", line 347, in handle_stranded_tasks
raise error.EngineError("Engine %r died while running task %r"%(engine, msg_id))
ipyparallel.error.EngineError: Engine b'af9a4de7-e140-4a91-b4bb-c7089b04adc9' died while running task '61317ff8-c759-4faa-aebb-2fd57595c586'
```
I am able to reproduce the problem with a minimal Boost.Python module consisting of a single class with a single method which throws an ``std::invalid`` exception, which normally is translated into a ``ValueError`` python exception. I can make this minimal example available in a github repo if it can help to debug the issue. The exception translation works fine from the ipython prompt:
```console
In [1]: import ipy_testmod
In [2]: s = ipy_testmod.my_struct()
In [3]: s.my_method(123)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-3-ba5412712f47> in <module>()
----> 1 s.my_method(123)
ValueError: error!
In [4]:
[Truncated]
```console
In [10]: def func(x, n):
...: try:
...: return x.my_method(n)
...: except:
...: return 23
...:
In [11]: ar = lview.apply(func, s, 123)
In [12]: ar.get()
Traceback (most recent call last):
File "/usr/lib64/python3.5/site-packages/ipyparallel/controller/scheduler.py", line 347, in handle_stranded_tasks
raise error.EngineError("Engine %r died while running task %r"%(engine, msg_id))
ipyparallel.error.EngineError: Engine b'91e8abe8-2371-469c-af4b-f6d376ed3e5e' died while running task '3b1e0902-a321-4d06-affa-d9417c18b2d4'
In [13]:
```
It seems like just the act of throwing from C++ brings down the engine.
Answers:
username_1: I don't know about the objects you are using, but the only thing I see is that the object is pickled and sent to the engine before calling `.my_method()`. Do you see the same error if you create the function and call the failing method entirely on the engine (i.e. never pass the object itself to apply)?
I don't know how boost's exception wrapping works, but I could imagine either some local initialization isn't getting triggered in the remote environment and/or when the object is serialized / deserialized with pickle, it somehow gets detached from whatever does this.
username_0: @username_1 Thanks for the reply!
How would I create the object and run the offending function directly on the engine? Can I somehow connect to the engines after they have been started with ipcluster?
username_0: @username_1 just a wild guess, but is it possible that ipyparallel or some of its dependencies have been compiled with ``-fno-exceptions`` or similar flags?
username_0: @username_1 I just converted my minimal C++ module to use pybind11 (https://github.com/pybind/pybind11) instead of Boost.Python for the exposition. I have exactly the same behaviour: exception conversion from C++ to Python works as expected in the ipython prompt, from a script, etc., but it crashes the ipyparallel engine in exactly the same way as Boost.Python does.
This seems to be more of a fundamental problem with C++ exceptions rather than specifically with Boost.Python or pybind11.
username_1: I don't think so. IPython Parallel isn't compiled at all (it's Python), and there aren't any dependencies on the engines that aren't also present in the client, so if you can call it locally just before submitting it with apply, I don't think that would be it.
Are you running a local cluster (engines and client on the same machine), or are the engines remote?
username_0: @username_1 Skipping the serialization bit still results in the engine crashing:
```console
In [1]: import ipyparallel
In [2]: rc = ipyparallel.Client()
In [3]: lview = rc.load_balanced_view()
In [4]: def func():
...: import ipy_testmod
...: ipy_testmod.my_struct().my_method(123)
...:
In [5]: ar = lview.apply(func)
In [6]: ar.get()
Traceback (most recent call last):
File "/usr/lib64/python3.5/site-packages/ipyparallel/controller/scheduler.py", line 347, in handle_stranded_tasks
raise error.EngineError("Engine %r died while running task %r"%(engine, msg_id))
ipyparallel.error.EngineError: Engine b'f7d939fe-8260-4888-b5e7-0398d512617d' died while running task 'b9dfa4ce-2c41-4e56-a08e-56da13a54875'
In [7]: func() # NOTE: this works as expected, translates the C++ exception into ValueError
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-7-08a2da4138f6> in <module>()
----> 1 func()
<ipython-input-4-985d7752d976> in func()
1 def func():
2 import ipy_testmod
----> 3 ipy_testmod.my_struct().my_method(123)
4
ValueError: error!
In [8]:
```
The output of ipcluster:
```console
2017-03-06 17:10:38.326 [IPClusterStart] b'2017-03-06 17:10:38.326 [IPControllerApp] registration::finished registering engine 0:6763df59-10aa-456d-88ed-22a18a5c71c4'
2017-03-06 17:10:38.328 [IPClusterStart] b'2017-03-06 17:10:38.327 [IPControllerApp] engine::Engine Connected: 0'
2017-03-06 17:10:38.328 [IPClusterStart] b'2017-03-06 17:10:38.328 [IPControllerApp] registration::finished registering engine 3:30661364-375c-4827-92a8-cf0abb6409eb'
2017-03-06 17:10:38.329 [IPClusterStart] b'2017-03-06 17:10:38.328 [IPControllerApp] engine::Engine Connected: 3'
2017-03-06 17:10:38.329 [IPClusterStart] b'2017-03-06 17:10:38.329 [IPControllerApp] registration::finished registering engine 2:71319e88-8f8e-47f7-94fc-cdf2979ef70f'
2017-03-06 17:10:38.330 [IPClusterStart] b'2017-03-06 17:10:38.330 [IPControllerApp] engine::Engine Connected: 2'
2017-03-06 17:10:38.330 [IPClusterStart] b'2017-03-06 17:10:38.330 [IPControllerApp] registration::finished registering engine 1:f7d939fe-8260-4888-b5e7-0398d512617d'
2017-03-06 17:10:38.331 [IPClusterStart] b'2017-03-06 17:10:38.331 [IPControllerApp] engine::Engine Connected: 1'
2017-03-06 17:10:42.966 [IPClusterStart] b"2017-03-06 17:10:42.965 [IPControllerApp] client::client b'\\x00k\\x8bEh' requested 'connection_request'"
2017-03-06 17:10:42.966 [IPClusterStart] b"2017-03-06 17:10:42.965 [IPControllerApp] client::client [b'\\x00k\\x8bEh'] connected"
2017-03-06 17:11:02.652 [IPClusterStart] Engines appear to have started successfully
2017-03-06 17:11:08.010 [IPClusterStart] b"2017-03-06 17:11:08.009 [IPControllerApp] task::task 'b9dfa4ce-2c41-4e56-a08e-56da13a54875' arrived on 1"
2017-03-06 17:11:08.106 [IPClusterStart] Process '/usr/bin/python3.5' stopped: {'exit_code': -6, 'pid': 26654}
2017-03-06 17:11:11.326 [IPClusterStart] b"2017-03-06 17:11:11.326 [IPControllerApp] heartbeat::missed b'f7d939fe-8260-4888-b5e7-0398d512617d' : 1"
2017-03-06 17:11:14.326 [IPClusterStart] b"2017-03-06 17:11:14.326 [IPControllerApp] heartbeat::missed b'f7d939fe-8260-4888-b5e7-0398d512617d' : 2"
2017-03-06 17:11:17.327 [IPClusterStart] b"2017-03-06 17:11:17.326 [IPControllerApp] heartbeat::missed b'f7d939fe-8260-4888-b5e7-0398d512617d' : 3"
2017-03-06 17:11:20.326 [IPClusterStart] b"2017-03-06 17:11:20.326 [IPControllerApp] heartbeat::missed b'f7d939fe-8260-4888-b5e7-0398d512617d' : 4"
2017-03-06 17:11:23.326 [IPClusterStart] b"2017-03-06 17:11:23.326 [IPControllerApp] heartbeat::missed b'f7d939fe-8260-4888-b5e7-0398d512617d' : 5"
[Truncated]
2017-03-06 17:11:46.341 [IPClusterStart] b'Traceback (most recent call last):'
2017-03-06 17:11:46.342 [IPClusterStart] b' File "/usr/lib64/python3.5/site-packages/tornado/ioloop.py", line 604, in _run_callback'
2017-03-06 17:11:46.342 [IPClusterStart] b' ret = callback()'
2017-03-06 17:11:46.342 [IPClusterStart] b' File "/usr/lib64/python3.5/site-packages/tornado/stack_context.py", line 275, in null_wrapper'
2017-03-06 17:11:46.342 [IPClusterStart] b' return fn(*args, **kwargs)'
2017-03-06 17:11:46.342 [IPClusterStart] b' File "/usr/lib64/python3.5/site-packages/ipyparallel/controller/scheduler.py", line 325, in <lambda>'
2017-03-06 17:11:46.342 [IPClusterStart] b' lambda : self.handle_stranded_tasks(uid),'
2017-03-06 17:11:46.342 [IPClusterStart] b' File "/usr/lib64/python3.5/site-packages/ipyparallel/controller/scheduler.py", line 335, in handle_stranded_tasks'
2017-03-06 17:11:46.343 [IPClusterStart] b' for msg_id in lost.keys():'
2017-03-06 17:11:46.343 [IPClusterStart] b'RuntimeError: dictionary changed size during iteration'
2017-03-06 17:11:46.343 [IPClusterStart] b"2017-03-06 17:11:46.341 [IPControllerApp] task::task 'b9dfa4ce-2c41-4e56-a08e-56da13a54875' finished on 1"
```
(I have included some extra debug output before the failure, just in case)
I am running a local cluster, same machine:
```console
ipcluster start -n 4 --debug
```
username_0: And here is a gist with my minimal pybind11 module:
https://gist.github.com/username_0/49cea7bc085e72863ebd47b91344ba0a
username_0: @username_1 How would I hook up GDB to the ipyparallel engines? I'd like to try to see if I can get any additional clues about what is going on, but I rarely use GDB and all my attempts so far have not been fruitful.
username_0: @username_1 This is interesting: if I launch ``ipcluster`` like this:
```console
LD_PRELOAD=/usr/lib/gcc/x86_64-pc-linux-gnu/6.3.0/libstdc++.so.6 ipcluster start -n 4 --debug
```
it seems like everything works as intended. So it seems like something is somehow wrong with the C++ runtime inside the engine?
username_1: If you skip ipcluster, you can run with gdb:
```bash
[shell 1] $ ipcontroller
[shell 2] $ gdb --args ipengine
```
Even without gdb, running the engine directly might be informative.
Are your engines on the same machine running in the same env as your client?
username_0: @username_1 yes everything happens on the same machine in the same environment. The packages are installed via the distribution's package manager.
I just tried my minimal module on another linux system, an Arch Linux installation, and I did not have any issue. At this point I am positive that the problem is specific to my Gentoo system, probably something to do either with installation paths or maybe due to the fact that I am using the gold linker instead of the standard binutils linker.
If you don't need me to investigate further, I can close the ticket.
username_1: OK, thanks for digging in! Feel free to post here if you do find a solution.
Status: Issue closed
|
wso2/analytics-apim | 566727961 | Title: API AVAILABILITY pie chart legend text is huge compare to other charts
Question:
username_0: **Description:**
<img width="1618" alt="Screen Shot 2020-02-18 at 1 59 57 PM" src="https://user-images.githubusercontent.com/1552869/74717925-42870a00-5257-11ea-9055-da464829a337.png">
**Suggested Labels:**
<!-- Optional comma separated list of suggested labels. Non committers can’t assign labels to issues, so this will help issue creators who are not a committer to suggest possible labels-->
**Suggested Assignees:**
<!--Optional comma separated list of suggested team members who should attend the issue. Non committers can’t assign issues to assignees, so this will help issue creators who are not a committer to suggest possible assignees-->
**Affected Product Version:**
**OS, DB, other environment details and versions:**
**Steps to reproduce:**
**Related Issues:**
<!-- Any related issues such as sub tasks, issues reported in other repositories (e.g component repositories), similar problems, etc. --><issue_closed>
Status: Issue closed |
google/ExoPlayer | 1007657846 | Title: How to get the real playback address before player start play
Question:
username_0: What should i do if i want to send a network request to get the real playback address before playing.
My music App will load the playlist, but the playlist isn't have the playback address, i need to send a request to get the real address to play.
I create music source and register callback to let the player update playlist when the request is finish , but I don’t think this is a good way to deal with it.<issue_closed>
Status: Issue closed |
mkeeter/antimony | 99461951 | Title: error: converting to 'std::tuple<int, int, int>'
Question:
username_0: Hi all,
```antimony 0.9.0``` build stops with this error:
```
../../../lib/fab/inc/fab/types/shape.h:19:50: error: converting to 'std::tuple<int, int, int>' from initializer list would use explicit constructor 'constexpr std::tuple< <template-parameter-1-1> >::tuple(_UElements&& ...) [with _UElements = {int, int, int}; <template-parameter-2-2> = void; _Elements = {int, int, int}]'
std::tuple<int,int,int> color={-1,-1,-1});
```
gcc (GCC) 5.1.1 20150618 (Red Hat 5.1.1-4) on Fedora 22 64bit.
Full log: http://fpaste.org/252268/
Why does happen?
Thanks.
Answers:
username_1: Yes: there's an issue with type inference in gcc. It was fixed in 42b49fbd0a1714f118e63107103d435fadb561bc but I didn't merge that into master; folks that are building their own Antimony are encouraged to work from the `develop` branch.
Can you update to the latest `develop` commit and see if that solves your problem?
username_0: Thanks.
Status: Issue closed
|
mirage/mirage-net-xen | 58943988 | Title: Amazon EC2 instance crashes when connecting to an interface with numeric id
Question:
username_0: Error:
```
Netif.connect 1
Fatal error: exception Failure("net_1")
```
It doesn't crash with alphanumeric ids. But Interfaces with alphanumeric ids always map to the first device (see implementation of connect), hence preventing TCP stack to work properly.
Answers:
username_1: do you have the code that causes this crash? (`main.ml` or `lib/main.ml` perhaps?)
username_0: ```netif-forward``` in ```mirage-skeleton``` repo.
username_0: Can anyone compile and run ```netif-forward``` on a Xen machine? I am now having the same problem on Xen after recent updates.
@username_3 @samoht @username_1
username_1: am building a xen virtualbox right now (as part of tidying up
`mirage-vagrant-vms`). will hopefully be able to try in that context this
afternoon...
username_2: Hi Masoud,
I'm able to run netif-forward (with a few changes, since `id` is no
longer part of the DEVICE signature and ETHIF doesn't expose it
directly) with alphanumeric interface names, although what the unikernel
in fact receives is two netifs with the same MAC as you've reported. If
I change config.ml to ask for (netif "0") and (netif "1") instead of
(netif "tap1") and (netif "tap2"), I get two working interfaces on the
bridges specified.
This is on Xen x86 4.4, specifically the version packaged for Ubuntu
14.04 (dpkg -s reports version 4.4.1-0ubuntu0.14.04.3 ).
Thanks,
Mindy
On 03/19/2015 12:19 PM, <NAME> wrote:
> am building a xen virtualbox right now (as part of tidying up
> `mirage-vagrant-vms`). will hopefully be able to try in that context this
> afternoon...
>
>
username_0: Thanks, I thought that my pull request that works with latest signatures is already merged.
@username_1: please use the code here:
https://github.com/mirage/mirage-skeleton/pull/78
username_3: @username_0 -- that pull is waiting on a Travis pass, so you need to merge it back to the master branch and push the result to trigger it off.
username_4: Can this be closed? I think @username_2's patch in 1.6.0 means the mistake will be detected in now.
username_1: Yes; closing
Status: Issue closed
|
facebook/react-native | 83193564 | Title: When using a 'column' flexBox layout for a view, child views of that view do not stretch to fit.
Question:
username_0: In standard w3c html/css flexbox layout, you can declare a div with a `column` `flex-direction`, and have children with `flex-grow`, and those children will stretch to the desired proportions to fit the parent with the `column` `flex-direction`.
See the jsfiddle [here](https://jsfiddle.net/8dLt71j4/1/) - The first column has its two child elements appropriately stretching to fit it.
With `react-native`, `flex` is ignored for views within a view that has `flexDirection: 'column'`. It also ignores `alignItems: 'stretch'` for that view. You can see an example in a react playground [here](https://rnplay.org/plays/qO-EvA/edit).
Answers:
username_1: Thanks for the repro case, I need to investigate what's going on.
username_0: @username_1 I have some time to work on this. Want me to take a stab?
username_1: @username_0: would be awesome yeah!
username_0: :+1:
username_0: @username_1 I believe I figured out why this was happening in my repo case - I need to specify the height of the wrapper element. When I do, the views within that view **do** get stretched vertically to fit.
See the react-playground [here](https://rnplay.org/apps/TLwBCQ/) - where all I changed was setting the height of the row element.
Not sure if this is really a bug then!
username_2: @username_0 - you can actually avoid setting an explicit height at all.
The problem seems to be this: if a parent does not have flex, this doesn't work.
[Simplified example **with flex: 1** on container](https://rnplay.org/apps/6xdsLA)
[Same example **without flex: 1** on container](https://rnplay.org/apps/hnymjw)
You'll notice that this is **very** similar to the following change:

So this behaviour is a bit different in that we can't just say `display: flex` on the parent container and make it work, we have to give it a height or flex value, and then that stretches to the full available container size.
username_0: @username_2 you're totally right - that is what's going on.
username_3: +1 Facing the exact same issue. I don't believe that a fixed height should need to be set for the child to fill its parent.
username_3: Am I also right in saying that `justifyContent: 'center'` also seems to get ignored?
username_4: I think I am seeing a similar issue with (RN `0.13.2`):
```jsx
<View style={{paddingTop: 165, flexDirection: 'row', backgroundColor: 'red', alignItems: 'stretch'}}>
<View style={{backgroundColor: 'green'}}>
<Text>Name:</Text>
<Text>Description:</Text>
<Text>Tags:</Text>
</View>
<View style={{flex: 1}}>
<TextInput style={{height: 40, borderColor: 'gray', borderWidth: 1}}/>
<TextInput style={{height: 40, borderColor: 'gray', borderWidth: 1}}/>
<TextInput style={{height: 40, borderColor: 'gray', borderWidth: 1}}/>
</View>
</View>
```

username_5: Hi there! This issue is being closed because it has been inactive for a while.
But don't worry, it will live on with ProductPains! Check out its new home: https://productpains.com/post/react-native/layout-when-using-a-column-flexbox-layout-for-a-view-child-views-of-that-view-do-not-stretch-to-fit
ProductPains helps the community prioritize the most important issues thanks to its voting feature.
It is easy to use - just login with GitHub.
Also, if this issue is a bug, please consider sending a PR with a fix.
We're a small team and rely on the community for bug fixes of issues that don't affect fb apps.
Status: Issue closed
|
anthonyraymond/joal | 499850746 | Title: [Docker image joal:arm] Support for Raspberry Pi Zero (linux/arm/v6)
Question:
username_0: Hello,
First of all, thanks for this great software.
I intended to run joal on an old RPI Zero (without wireless, or anything). It's an ARMv6 CPU. Nothing happens when i'm trying to run `joal:arm` using docker on the Pi Zero (no output, nothing in the logs, nothing in the docker log, container not running). Even a `docker run --entrypoint /bin/sh ...` was just returning without giving me a shell prompt.
Joal's docker images are based on [maven:3.6-jdk-8](https://hub.docker.com/_/maven?tab=tags&page=1&name=3.6-jdk-8) and [openjdk:8u181-jre](https://hub.docker.com/_/openjdk?tab=tags&page=1&name=8u181-jre). When i'm trying to run those images on the Pi Zero with a custom `--entrypoint`, they don't run, as the main image. For the `maven:3.6-jdk-8` image, that's not surprising since this image is only for `amd64`. That only matters if you intend to build the image directly on your Pi Zero (which i was able to do then...and it took more than 2 hours, so i won't try that again).
But, more importantly, i noticed `openjdk:8u181-jre` supports only `arm/v5`, `arm/v7`, and `arm64/v8` according to [Docker Hub](https://hub.docker.com/_/openjdk?tab=tags&page=1&name=8u181-jre). On the other hand, `openjdk:8u181-jre-alpine` supports `arm/v6` and `arm64/v8`. After checking, the Pi Zero was able to run this image. I rebuilt a custom joal image on my laptop based on the alpine version of `openjdk` and the alpine version of `maven` (to be consistent), pushed it to the Pi Zero, and voilà ! The JVM takes a good 15 minutes to start, but then, it becomes very usable.
Now the problem is, those images don't support `arm/v5` and `arm/v7`. I guess there is a way to do that with [buildx ACLs](https://github.com/docker/buildx). You would have 1 Dockerfile for `arm/v6` and another one for `others`. But this would mean a tag for `arm/v6`, and another one for all others...not exactly "pretty".
In case you want to check what i did exactly, [here is my fork](https://github.com/username_0/joal/tree/armv6_pizero_alpine), i only changed the Dockerfile. Thanks in advance.
Answers:
username_1: Hello @username_0,
Thats unfortunate you are on the only arm arch which is not supported x)
I'm not quite into havng multiple Dockerfile for the reasons you well explained, more than that i'm hesitating between two options at the moment:
- Recoding the joal project with Golang (wich will solve the problem whatsoever a simple debian will run a golang compiled project)
- Upgrading to Java 11 (at the same time switching to adoptopenjdk images). which will result in loosing support for `arm/v5` and `arm/v6`, seems like the only supported arm version for these new images is `arm64/v8`
At the moment i'm not coding for this project but i'm likely to reboot the project as Golang in the future.
For the time being and for the futures releases i think you'll have to have your own fork of Joal to run it on the `arm/v6`.
Anyway thanks for the investigation :) and GG for the fix.
I'll keep you updated about the "maybe" Golang reboot.
username_0: @username_1
All right, thanks for your feedback and your clarifications. For now, I'm just going to keep using my own Dockerfile.
Using Golang would probably make the whole thing faster, I support the idea. I actually thought myself about rewriting to Node (because running a JVM on the Pi Zero is not exactly a great idea), but that's neither a short nor an easy task. Anyway, I'll be happy to hear about it if you eventually do it.
username_1: @username_0 The golang port is on the way ^^ i've just started working on it. |
OpenMined/PySyft | 288331250 | Title: Implement the inline Gather function for IntTensor on the CPU
Question:
username_0: As a Data Scientist using PySyft's IntTensor type, I want to leverage a wide range of methods which use our new Unity backend. For this ticket to be complete, the inline gather() should be added to our IntTensor class with the appropriate functionality.
If you want to take it to the next level, boost it implementing the operation on the GPU: Search for an issue titled like this but with "on the GPU" on the title!
HLSL (GPU language) tutorial here: [Direct Compute Programming Guide](https://github.com/OpenMined/OpenMined/blob/master/tutorials/DirectCompute_Programming_Guide.md)
Note, it is possible that when you look in the code you'll find that parts of this issue were completed on the backend while implementing another issue. This is normal as features do not live in isolation. If this is the case, just take it as a convenience that someone already built that part and press on!
### Every Reference You Might Need for this Issue:
- For a reference on the operation this performs check out [PyTorch](http://pytorch.org/docs/master/tensors.html)'s documentation.
- For a reference on how to program in Unity, check out [this basic tutorial](https://unity3d.com/learn/tutorials/projects/roll-ball-tutorial)
- For a reference on how to write HLSL code, check out [this basic tutorial](http://kylehalladay.com/blog/tutorial/2014/06/27/Compute-Shaders-Are-Nifty.html)
- For a complete tutorial on how to add functions to FloatTensor (step by step guide) see [this Google Document](https://docs.google.com/document/d/1WRd7gGLFN0Awtf86AICYIHtg3gfFWLBa5wYTthsB3i0/edit)
- For a reference on how other functions like this have been implemented check out the functions in [this notebook](https://github.com/OpenMined/OpenMined/blob/master/notebooks/Syft%20Tensor%20Example%20Notebook.ipynb) as well as the corresponding files that made it possible ([SyftController](https://github.com/OpenMined/OpenMined/blob/master/UnityProject/Assets/OpenMined/Network/Controllers/SyftController.cs), [FloatTensor.Ops](https://github.com/OpenMined/OpenMined/blob/master/UnityProject/Assets/OpenMined/Syft/Tensor/FloatTensor.Ops.cs), [FloatTensorShaders](https://github.com/OpenMined/OpenMined/blob/master/UnityProject/Assets/OpenMined/Syft/Tensor/Ops/Shaders/FloatTensorShaders.compute), [TensorOpsShaders](https://github.com/OpenMined/OpenMined/blob/master/UnityProject/Assets/OpenMined/Syft/Tensor/Ops/Shaders/TensorOpsShaders.compute), [FloatTensorTest](https://github.com/OpenMined/OpenMined/blob/master/UnityProject/Assets/OpenMined.Tests/Editor/FloatTensor/FloatTensorTest.cs) and [FloatTensorGpuTest](https://github.com/OpenMined/OpenMined/blob/master/UnityProject/Assets/OpenMined.Tests/Editor/FloatTensor/FloatTensorGpuTest.cs)).
- And of course, please consider our [Contributor Guidelines](https://github.com/OpenMined/Docs/blob/master/contributing/guidelines.md) for all contributions.
### Acceptance Criteria:
- [ ] comment below that you're picking up this project
- [ ] an example in a notebook in our [tests folder](https://github.com/OpenMined/OpenMined/tree/master/notebooks/tests) showing how to use the functionality from PySyft
- [ ] an integration test in PySyft demonstrating the correct CPU operation implemented over an IntTensor while connected to a Unity backend
- [ ] a Unit Test in OpenMined/OpenMined demonstrating the correct operation on a FloatTensor
- [ ] [inline](http://pytorch.org/docs/master/tensors.html) documentation in the python code. For inspiration on inline documentation, please check out PyTorch's documentation for this operator.
- [ ] Link your Pull Request back to this Issue so that it gets closed appropriately when the PR is merged.<issue_closed>
Status: Issue closed |
Wybxc/wybxc.github.io | 318732327 | Title: 精准空降?不存在的!——视频编码的一些小知识
Question:
username_0: https://wybxc.github.io/2017/12/24/%E7%B2%BE%E5%87%86%E7%A9%BA%E9%99%8D-%E4%B8%8D%E5%AD%98%E5%9C%A8%E7%9A%84-%E8%A7%86%E9%A2%91%E7%BC%96%E7%A0%81%E7%9A%84%E4%B8%80%E4%BA%9B%E5%B0%8F%E7%9F%A5%E8%AF%86/ |
getkuby/kuby-core | 730677740 | Title: Refresh kubeconfig if kuby config changes
Question:
username_0: A number of the provider gems will attempt to use old kubeconfig files created for other clusters if the config parameters in kuby.rb change. One possible solution would be to use a hashed version of things like the cluster ID, access token, tenant ID, etc in the file path so any config changes will force a kubeconfig refresh. See: https://github.com/getkuby/kuby-digitalocean/issues/2
Answers:
username_1: Hello, @username_0, I can work on this.
As I see now in kuby-core repo we have abstract method
```ruby
def kubeconfig_path
raise NotImplementedError, "please define #{__method__} in #{self.class.name}"
end
```
and particular provider should implements it (example from digital ocean)
```ruby
def kubeconfig_path
@kubeconfig_path ||= File.join(
kubeconfig_dir, "#{environment.app_name.downcase}-kubeconfig.yaml"
)
end
```
So should I implement fix for kuby-core (if so we anyways in need to rewrite this piece in every provider) or we can implement change for all providers in particular?
username_0: @username_1 awesome, thank you for volunteering! I think it would be best to implement specific changes per provider gem, since each provider accepts a different set of configuration parameters. For example, Linode and DigitalOcean require a cluster ID and access token, but Azure requires a tenant ID, client ID, client secret, subscription ID, resource name, and resource group name.
username_1: Implemented for all providers
https://github.com/getkuby/kuby-digitalocean/pull/3
https://github.com/getkuby/kuby-eks/pull/3
https://github.com/getkuby/kuby-azure/pull/1
username_0: All merged and new versions released. Thank you!
Status: Issue closed
|
bonigarcia/webdrivermanager | 1086611357 | Title: WebDriverManager is identified as consumer of log4j. Is Log4j used in WebDriverManager(or its dependencies) package? If so, what is the impact of Log4j vulnerability on WebDriverManager?
Question:
username_0: **Description of the problem**: I am using WebDriverManager.2.2.7 and AngleSharp.0.9.10 in test automation with Selenium. And these two packages reported to remediate as because of log4j vulnerability. I would like to know are these packages really dependent on log4j/log4j2? If yes, what is the Log4j vulnerability impact? And how to remediate?
**Operating system**: Win10
**WebDriverManager version**: 2.2.7
AngleSharp got installed when WebDriverManager installed. That means WebDriverManager has the dependency on AngleSharp. So how to remediate the log4j vulnerability for WebDriverManager and AngleSharp? |
asdf-vm/asdf-plugin-template | 772708978 | Title: Update workflow files for asdf action v1.1.0
Question:
username_0: https://github.com/asdf-vm/actions/releases/tag/v1.1.0
Answers:
username_0: CC: @username_1
username_1: The template references `@v1` which I understand pulls the latest minor.patch at the time the workflow runs, no?
https://github.com/asdf-vm/asdf-plugin-template/blob/8f51de0cc2ed8a663bf7d1628beb184eb9afe60d/template/.github/workflows/build.yml#L21
username_0: Yes, that's correct! But what I wanted to say is that we can remove the `env` field.
username_1: Ah yes, a good addition to the Actions :pray:
Status: Issue closed
|
judah4/HSV-Color-Picker-Unity | 106532216 | Title: Unity 5.1/5.2 Hex Text not updating/working
Question:
username_0: I found that to get the hex text color to work I had to switch the public "Text" item over to be an actual "InputField" item and then access its .text component.
Examples:
// Unity 5.1/2 needs an InputFiled vs grabbing the text component
public InputField hexInput;
public void ManipulateViaHex2RGB()
{
string hex = hexInput.text;
...
Answers:
username_1: Fixed in v2
Status: Issue closed
|
dotnet/docs | 958060677 | Title: Following the instructions did not yield a service I could actually start. I had to invoke `UseWindowsService` on the `IHostBuilder` in `Program.CreateHostBuilder`.
Question:
username_0: [Enter feedback here]
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: ed148088-4550-2788-0756-390eab15e3f6
* Version Independent ID: 64d5cdf8-e50f-0c89-7f16-82645ba6383e
* Content: [Create a Windows Service using BackgroundService](https://docs.microsoft.com/en-us/dotnet/core/extensions/windows-service)
* Content Source: [docs/core/extensions/windows-service.md](https://github.com/dotnet/docs/blob/main/docs/core/extensions/windows-service.md)
* Product: **dotnet-fundamentals**
* GitHub Login: @username_1
* Microsoft Alias: **dapine**
Answers:
username_1: Hi @username_0 - I'm sorry that you had a bad experience, but this step is right there in the article. You must have skimmed past this or something?

To help improve its visibility I'm adding another heading to help with discoverability. Instead of being nested under the **Rewrite the Worker class** heading, it will be under a new heading called **Rewrite the Program class**.
Status: Issue closed
username_0: Ah, yes, I must have. Thank you! |
youzan/vant-weapp | 368472804 | Title: dialog正文支持换行
Question:
username_0: **描述一下问题**
关于dialog支持换行,我看到有支持 [#174](https://github.com/youzan/vant-weapp/pull/174)
但是在0.3.8版本上 message并没有被text包裹
```
<view class="van-dialog__content" wx:if="{{ message || useSlot }}">
<slot wx:if="{{ useSlot }}" />
<view wx:elif="{{ message }}" class="van-dialog__message {{ title ? 'van-dialog__message--has-title' : '' }}">
{{ message }}
</view>
</view>
```
请问下 是什么回事
**环境**
- 设备:
- 基础库版本:
- Vant Weapp 版本:0.3.8
Answers:
username_1: 已在 0.4.0 版本支持
Status: Issue closed
|
intellij-solidity/intellij-solidity | 679714844 | Title: Cannot cast to payable()
Question:
username_0: When I do something like:
```
_transferETH(payable(target), value);
```
it gives me an error:
```
')', ',', <expression> or '{' expected, got 'payable'
```
in the position of `payable` keyword.
<img width="374" alt="스크린샷 2020-08-16 오후 5 29 34" src="https://user-images.githubusercontent.com/68796029/90330220-15d56480-dfe6-11ea-9b95-e60a4fa0554d.png">
FYI, payable() is used to convert an `address` to `address payable` type (supported >= 0.6.0)<issue_closed>
Status: Issue closed |
Ylianst/MeshCentral | 899402746 | Title: Capture is stopped after local user consents to UAC prompt
Question:
username_0: Hello,
Using meshcentral for a while to help family and friends.
I noticed twice that the captured desktop stops refreshing after a local UAC prompt showed up and the local user allowed it.
Last time I noticed this was with meshcentral `v0.8.32`, hosted on CentOS 8.3 x64, client computer was Win10 x64 1909.
Steps to reproduce:
On a Windows 10 computer, run the agent as temporary agent using 'connect' button as local administrator.
Once you're connected to the remote screen, run let's say `cmd.exe`, then right click on the cmd program icon and click `run as administrator`
On the windows 10 computer, consent to the UAC prompt locally.
Now the server does not have any remote desktop updates anymore and is stuck with the "pre UAC prompt screen". Clicking 'refresh' button does not help.
Disconnect and reconnect to the desktop solves the issue.
I do understand that the UAC prompt cannot be captured in temporary non privelege execution, but when the UAC prompt is locally accepted, it should resume the desktop capture process IMHO.
Best regards.
Answers:
username_1: If the agent running in interactive mode (You run the agent and hit the "Connect" button?) or is the agent running as a background Windows service?
If running as the local user, it does not have the rights to capture the UAC screen and so, this is normal. If running as a background service with higher privileges, it should be able to capture UAC.
username_0: @username_1 Please read my report again, it's stated.
Agent runs in interactive mode. I get it that the UAC prompt won't be captured since it's on secure desktop, but once a local user accepted an UAC prompt, the desktop capture should resume, which it doesn't.
username_1: Oh! Got it. Sorry. Your right, it should resume capture. This is an issue for Bryan.
username_0: Any news for this ?
username_2: The easiest workaround for this, is to run this console command, from the console tab:
`uac interactive`
This will make it so you can see the UAC prompt. (It won't let you interact with it directly, unless the agent is running as background service. However, the screen capture will continue to work correctly.
The reason for the problem before, is that if UAC is set to secure, which is the default, and the agent is running as interactive, when the UAC prompt pops up, the screen capture process exits, and the agent tries to respawn the capture process as a different user, but becuase the agent was not running as LocalSystem, it lacks permission to do that, so the capture process is lost.
username_0: Related to #3167 |
TrackTech/ActivityList | 241551785 | Title: DB connection Failure
Question:
username_0: Application should close gracefully.
Status: Issue closed
Answers:
username_0: - Application checks if mongoclient returns an error and returns 503 http code in case it does.
- function(err,result) is the standard used by callback function in node js |
rust-lang/rustfmt | 410041650 | Title: [unstable option] unstable option: control_brace_style
Question:
username_0: Tracking issue for unstable option: control_brace_style
Answers:
username_1: Would love to have this feature stabilized. Having `else` statements on the same line as the closing brace of an `if` block is the only thing about rustfmt that bothers me, so this is the only setting I have in my rustfmt.toml file.
username_2: Does anyone know what's holding this up from being stabilized? Any information would be appreciated. Thank you!
username_3: Is there a reason this still isn't stabilized? |
scullxbones/akka-persistence-mongo | 257757587 | Title: java.lang.NoClassDefFoundError: reactivemongo/akkastream/package$
Question:
username_0: Hey guys I'am getting the stranges error while settingup the project with the package from this repo.
My build.sbt
`libraryDependencies ++= {
val akkaV = "2.5.4"
val akkaHttpV = "10.0.10"
val reactiveMongoV = "0.12.6"
Seq(
"com.typesafe.akka" % "akka-slf4j_2.11" % akkaV,
"org.slf4j" % "slf4j-simple" % "1.7.25",
"com.typesafe.akka" %% "akka-actor" % akkaV,
"com.typesafe.akka" %% "akka-stream" % akkaV,
"com.typesafe.akka" %% "akka-http" % akkaHttpV,
"com.typesafe.akka" %% "akka-slf4j" % akkaV,
"com.typesafe.akka" %% "akka-persistence" % akkaV,
"com.github.username_1" %% "akka-persistence-mongo-rxmongo" % "2.0.3",
"org.reactivemongo" %% "reactivemongo" % reactiveMongoV
)
}`
and here is my error:
`project_name[ERROR] java.lang.NoClassDefFoundError: reactivemongo/akkastream/package$
project_name[ERROR] at akka.contrib.persistence.mongodb.RxMongoJournaller$$anonfun$maxSequenceNr$1.apply(RxMongoJournaller.scala:197)
project_name[ERROR] at akka.contrib.persistence.mongodb.RxMongoJournaller$$anonfun$maxSequenceNr$1.apply(RxMongoJournaller.scala:201)
project_name[ERROR] at scala.concurrent.Future$$anonfun$flatMap$1.apply(Future.scala:253)
project_name[ERROR] at scala.concurrent.Future$$anonfun$flatMap$1.apply(Future.scala:251)
project_name[ERROR] at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:32)
project_name[ERROR] at akka.dispatch.BatchingExecutor$AbstractBatch.processBatch(BatchingExecutor.scala:55)
project_name[ERROR] at akka.dispatch.BatchingExecutor$BlockableBatch$$anonfun$run$1.apply$mcV$sp(BatchingExecutor.scala:91)
project_name[ERROR] at akka.dispatch.BatchingExecutor$BlockableBatch$$anonfun$run$1.apply(BatchingExecutor.scala:91)
project_name[ERROR] at akka.dispatch.BatchingExecutor$BlockableBatch$$anonfun$run$1.apply(BatchingExecutor.scala:91)
project_name[ERROR] at scala.concurrent.BlockContext$.withBlockContext(BlockContext.scala:72)
project_name[ERROR] at akka.dispatch.BatchingExecutor$BlockableBatch.run(BatchingExecutor.scala:90)
project_name[ERROR] at akka.dispatch.TaskInvocation.run(AbstractDispatcher.scala:40)
project_name[ERROR] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
project_name[ERROR] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
project_name[ERROR] at java.lang.Thread.run(Thread.java:745)
project_name[ERROR] Caused by: java.lang.ClassNotFoundException: reactivemongo.akkastream.package$
project_name[ERROR] at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
project_name[ERROR] at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
project_name[ERROR] at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:331)
project_name[ERROR] at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
project_name[ERROR] ... 15 more`
Any idea what is going on? I've read the Readme a couple of times already.
Answers:
username_1: @username_0 - i'm seeing on `reactivemongo.org` that there's a new dependency, I think this was included before:
```
libraryDependencies += "org.reactivemongo" %% "reactivemongo-akkastream" % "0.12.6"
```
Can you confirm if adding this dependency fixes the issue for you? If so, I can update the docs.
Thanks!
Status: Issue closed
username_1: My mistake, I added this dependency but didn't document it. Documentation is fixed now.
Thanks for the report! |
firebase/firebase-functions | 895426853 | Title: Firebase Environment Config removes characters from values
Question:
username_0: I had an API key "<KEY>" when set an environment config functions:config:set the value was converted to "s&#hs*#hkfgG". The "$318" was removed from the value. Was fun discovering this :)
NOTE: This API key is changed :)
Answers:
username_1: The $ character may be having conflicts with environment variables. Can you verify that your variables are printing correctly when you run `firebase functions:config:get`? If not, make sure you use single quote marks (`'`) when setting the param in your terminal to turn off string interpolation.
If that doesn't reveal a problem we can dive deeper to see where we're accidentally performing string substitution.
username_2: I tried replicating the issue without success:
```
$ firebase functions:config:get
{
"foo": {
"bar": "s&#h$318s*#hkfgG"
},
"someservice": {
"key": "THE API KEY"
}
}
// index.js
functions.logger.info(functions.config().foo.bar);
```
Deployed and executed the function, and here's what I get on the logs:
```
2021-05-24 14:53:31.162 PDT helloWorld mgr3eiwb91hq s&#h$318s*#hkfgG
```
@username_0 Can you help us clarify what's going wrong? |
GMOD/Apollo | 608521423 | Title: remove extra queries
Question:
username_0: a lot of extra queries:
Answers:
username_0: When clicking on a single details we get a lot of extra unnecessary queries:

username_0: when clicking back and forth between a gene and a transcript, we get the right # of clicks.
When I change the selected gene we get:

- 1 availablestatuses
- 2 getAttributes, get Comments, get DbXrefs
- 2 gene products, provenance, go annotations
- 2 getCannedKeys, values, Comments
Status: Issue closed
|
daviseford/aos-reminders | 724998353 | Title: Importing Saurus Scar-veteran on Cold One, parsed as Carnosaur
Question:
username_0: If I import [this list](https://drive.google.com/file/d/1ElatR9-3UnlOo5Q_3EzBlWqBKt9X25w7/view?usp=sharing), the Scar-veteran is parsed as being on Carnosaur, although in the list, it's riding a Cold one.
Answers:
username_1: Great report.
So, I think I know what's going on here. Whichever version you add, it lists it only with its warscroll name, and not its subtitle. So we can't actually tell which one it is, because either one would show up the same in the Azyr export (we're not parsing either points or pictures 😅)
The only way around this at the moment is to include it in the [`AzyrAmbiguousNamesMap`](https://github.com/username_2/aos-reminders/blob/2b9c7be21cc8cd03a3543703101beaa22dd776c5/src/utils/import/options.ts#L414-L444) so the user gets a warning when importing either from Azyr, so that they might be able to spot and fix it themselves.
Not sure when I'll get to this, so if anyone else wants to, that's the fix.
username_0: Hadn't noticed that the mount didn't even show up on the PDF. Good catch! The Azyr app is sooo full of things that are either buggy or badly done, that it's surprising how a high-revenue company like GW didn't come up with something better... Oh well... /shrug
Don't worry about this one. It's a quick fix after importing the list. Just added it in here so you're aware. ;)
username_1: Cool, glad the solution makes sense to you. We'll get the warning in there, as you say it's then a quick fix for the user, but without the warning it's really hard to notice it's even done it. Fortunately it's a one-liner, I just need to remember the confusing way around to write it.
And yeah, it's pretty wild some of the stuff aosr has to put up with from Azyr 😅
username_0: I would argue that it might make sense to drop the support for Azyr... I would guess that most of AOSR users, don't mind redoing a finalized list on Warscroll Builder (I wouldn't at least). Azyr is good to do lists on-the-go. But after a list is completed, it should be quick to just copy it to Warscroll Builder.
This would free your time up to focus on more important stuff related to Warscroll Builder imports, which is, I guess, the main source of your imports, as well as other improvements. (I would love to help with code contributions, but JavaScript and Scala are my nemeses. I'm more of a Java and Apache Cassandra guy. :) )
@username_2 , just out of curiosity, do you know the ratio of format imports (Azyr vs Warscroll Builder)?
username_2: Warscroll Builder accounts for most of the imports.

That's data from the last 30 days.
I won't drop Azyr support unless it goes lower. Now Battlescribe on the other hand... that's becoming a real chore to maintain.
username_2: There _is_ a decent correlation between people who use the Import features, and people who subscribe. So I definitely don't want to take any import functionality away :)
Status: Issue closed
username_0: Holy guacamole! I was pleasantly surprised by this today. If half the apps in the world had this kind of fixes and improvements, people would be blissful (ok, maybe that's a stretch... :))!
Kudos for all your work guys. You ROCK!
 |
karabiner-inc/materia_commerce | 437477192 | Title: change contract/contract_details relation
Question:
username_0: contract entity reration change be able to multi type histories management.
eg: contract and contract change requests
add columns
- history_type :string
- history_number :integer
change relation
contract -|----<contract_no, history_type, history_number >----|<
contract_details |
microsoft/FluidFramework | 975936865 | Title: Add options to turn GC sweep on / off
Question:
username_0: Add a container runtime option to turn sweep on / off. Also, add a local storage flag to override it.
Initially, we will ship sweep disabled. We can use the local storage flag to enable it for selected documents and test. Once we are reasonably confident in the process, we will enable it.<issue_closed>
Status: Issue closed |
typeorm/typeorm | 392350429 | Title: Migration generate continuously repeats entries
Question:
username_0: **Issue type:**
[ ] question
[ X] bug report
[ ] feature request
[ ] documentation issue
**Database system/driver:**
[ ] `cordova`
[ ] `mongodb`
[ ] `mssql`
[X ] `mysql` / `mariadb`
[ ] `oracle`
[ ] `postgres`
[ ] `sqlite`
[ ] `sqljs`
[ ] `react-native`
[ ] `expo`
**TypeORM version:**
[X ] `latest`
[ ] `@next`
[ ] `0.x.x` (or put your version here)
**Steps to reproduce or a small repository showing the problem:**
When building model files and relying on building and running migrations, TypeORM will constantly drop and add the same indexes over and over.
Table A:
```import { Entity, Column, ManyToOne, JoinColumn, PrimaryColumn } from 'typeorm';
import { TableB } from './table-b';
@Entity('table_a')
export class TableA {
@PrimaryColumn('uuid')
id: string;
@Column({ nullable: true })
etag: string;
@ManyToOne(type => TableB, item => item.id)
@JoinColumn({name: 'category_id'})
category: TableB;
@Column({ nullable: true })
file_name: string;
}
```
Table B:
```import { Entity, PrimaryGeneratedColumn, Column, Index } from 'typeorm';
@Entity('table_b')
export class TableB {
[Truncated]
Instead:
A new migration file is generated dropping and adding indexes. This actually happens on indexes and foreign keys. It makes no difference whether you try to name the IDX/FK yourself or let TypeOrm do it. On my 30 table database, I get a huge list of every index and foreign keys being removed and added, it never recognizes nothing has changed.
```import {MigrationInterface, QueryRunner} from "typeorm";
export class mySql1545169077016 implements MigrationInterface {
public async up(queryRunner: QueryRunner): Promise<any> {
await queryRunner.query("DROP INDEX `IDX_2a8279b83232e2243609048a69` ON `table_b`");
await queryRunner.query("CREATE INDEX `IDX_2a8279b83232e2243609048a69` ON `table_b`(`uuid`)");
}
public async down(queryRunner: QueryRunner): Promise<any> {
await queryRunner.query("DROP INDEX `IDX_2a8279b83232e2243609048a69` ON `table_b`");
await queryRunner.query("CREATE INDEX `IDX_2a8279b83232e2243609048a69` ON `table_b`(`site_id`, `uuid`)");
}
}
Answers:
username_0: I saw the comment on https://github.com/typeorm/typeorm/issues/3277 but even if you are not naming things, every new migration file will drop and readd things that are already there. Even using @Index() the type hint shows you can provide a name, i.e. @Index("my_index_name") but it will always be dropped and readded whenever you make a new migration file.
With a list of 30 tables, every time I run a new build migration, I get a huge list of changes I have to delete most of them to find my the one I want.
username_1: Would be helpful if you put all this code into minimal possible reproduction repository and let us check it.
username_2: New to typeorm here, it looks like when i run migration:generate the newly generated migrations includes CREATE TABLE queries in the up function, which obviously will fail since they've already been created before. Is this the expected behavior? Or should TypeOrm only create new migrations for altering the table to add the column I added?
username_3: I don't know if it was caused by the same issue as @username_0 was having, but I also ran into the issue of TypeORM generating these migrations endlessly. My issue turned out to be that I named the class of the entity differently from the filename. Perhaps TypeORM could ensure that the exported class names match the filenames and throw an error otherwise?
username_4: I seem to be having a similar issue where I have a view entity for a postgres view and whenever I try to generate a migration, the migration wants to drop the view twice, and the revert wants to put it back twice.
username_5: I'm having this same issue, but only with mysql/mariadb, tested on a postgres db and It works. You can recreate this just by creating an entity and generating a migration, then run the migration and generate again, it gonna be the same code from the first migration. Hope this can get some attention... :(
username_6: The same issue here, typeorm version 0.2.24, connection type MySQL, generate migration creates the same entities over and over again, it doesn't produce diff
username_7: Same here. Connection type is postgres (pg v12), was working fine with 0.2.22, upgrading to 0.2.24 causes generate to generate migrations every time it is run, w/o any changes to the entities themselves.
The bulk of generated migrations is dropping FK and recreating them.
This is a real blocker for moving to 0.2.24
username_7: @username_1 here is a PR with testcase https://github.com/typeorm/typeorm/pull/5869
username_8: +1
Status: Issue closed
username_9: :tada: Code was merged in so I'll be closing this out.
username_10: This is issue is still present when using mariadb with typeorm version 0.2.31.
Steps to reproduce:
* Empty database schema
* Generate migration for entities
* Run the migration
* Generate the migrations again -> Queries altering the columns, droping and recreating the FK-s etc.
I don't think this is supposed to happen.
username_11: Not sure if our case is related to this.
Looks like there will be two DDL queries generated for joining table when using ManyToMany annotation.
Here's a sample repository.
https://github.com/username_11/typeorm-repeated-migrations
I put three commits for different ways to define entities and joining tables.
We could see migration files in the first two commits.
There are two DDL queries for joining table but the table names are different.
One is `post_to_tag` and the other is `tag_to_post`.
The differences are 1) order of FKs and 2) PK configuration.
### Entity definition demonstrated from Typeorm doc.
https://github.com/username_11/typeorm-repeated-migrations/commit/0814ffc7fd863b1c715c4101a9ac35bf7c829d60#diff-0e61419b393c2da56e1d2f8cb965d9c8d735dcd4b345be31def32c3a5e69d2e5
### Define joining table with naming convention demonstrated in Typeorm doc.
https://github.com/username_11/typeorm-repeated-migrations/commit/955f6c04d63c9f1eeba783f4468ca81f6b93ac07#diff-89cfe6f26ee888bc22c677a1900978475e7757912418630f8179ec2a238a5640
### Self-defined joining table and specify name in JoinTable annotation.
https://github.com/username_11/typeorm-repeated-migrations/commit/87ff51d0b59edef54e4e28c1cba8fbafe713ab55#diff-1de678b75047b2292793a36c1a20ecf68ac9b218d34142f8506eb1e96580bb9f
username_11: Please ignore my above comment since I found another issue related to it.
https://github.com/typeorm/typeorm/issues/5688 |
michaellwest/sitecore-codeeditor | 51510144 | Title: Add text/scss mimetype
Question:
username_0: ```xml
<mediaType name="SASS" extensions="scss">
<mimeType>text/scss</mimeType>
<forceDownload>false</forceDownload>
<sharedTemplate>system/media/unversioned/code</sharedTemplate>
<versionedTemplate>system/media/versioned/code</versionedTemplate>
</mediaType>
```
Status: Issue closed
Answers:
username_0: Implemented. @username_1 sorry it took so long to get this out the door. Hope it meets your business needs.
username_1: Thanks Michael. I’ll install it tomorrow. Looking forward to it. |
warint/covid19_article | 753708196 | Title: Repository needs a tagged release.
Question:
username_0: The version you indicate in the submission does not match any versions here. You need to make a GitHub tagged release.
Linking to Review Tssue: https://github.com/openjournals/jose-reviews/issues/101 |
lirantal/dockly | 434391582 | Title: Extra green lines
Question:
username_0: ## Actual Behavior
I have 5 extra green lines at the bottom of the window.

## Steps to Re-produce the Problem
1. Install Dockly.
2. Run Dockly from cmd.exe.
## Context
- Operating System: Windows 10
- Node.js version (run `node --version`): v10.15.2
- Package version: 3.10.5
- Docker version (run `docker --version`): Docker version 18.03.0-ce, build 0520e24302
- Is docker installed locally? Yes.
- Does this file exists `/var/run/docker.sock` ? No.
Answers:
username_1: I have that too (as in, it's expected :))

username_0: Can I remove it to increase logs box?
Like this:

username_1: I see what you mean but for the new version we use a layout system which really has just one block set for the toolbar but due to automatic positioning it's taking up the relevant space.
See:
```
const CONTAINERS_GRID_LAYOUT = {
'actionsMenu': [4, 4, 4, 4],
'searchInput': [11, 0, 1, 12],
'actionStatus': [6, 0, 1, 10],
'containerInfo': [2, 2, 8, 8],
'containerList': [0, 0, 6, 10],
'containerLogs': [7, 0, 4, 12],
'containerStatus': [0, 10, 2, 2],
'containerUtilization': [2, 10, 3, 2],
'containerVsImages': [5, 10, 2, 2],
'help': [4, 4, 4, 4],
'toolbar': [11, 0, 1, 12]
}
```
If you're able to figure out better spacing I'm happy to merge a PR
Status: Issue closed
username_1: @username_0 I'll close this issue out due to inactivity and currently no action planned on it. I'm also happy if you want to re-open and re-engage in the conversation on this! |
OpenVidu/openvidu | 392615116 | Title: Ionic 3 manual install required of dependency of openvidu-browser.
Question:
username_0: I create a fresh ionic 3 application using ionic cli 4.5.0
ionic (Ionic CLI) : 4.5.0 (/usr/local/lib/node_modules/ionic)
Ionic Framework : ionic-angular 3.9.2
and then run `npm install openvidu-browser --save` (2.7.0)
then run the application in `serve` mode. its given error of `freeice` `platform` etc js not found which is dependency of `openvidu-browser`
after that I run this command `npm i freeice platform uuid ..... --save` like all the dependency of openvidu-browser then only it works. However, it not required for only Angular 7 application.
Answers:
username_1: Hi,
Be aware that only Ionic v4 is offically supported (still in beta, but first stable version will be officialy released in a few weeks)
username_0: Hi @username_1
I tested openvidu in ionic 3 and its fully working. except the above-mentioned configuration issue.
username_2: Hello, I wanted to know if the Ionic 3 tutorials are still planned or not, Thank you
(also @username_0 , if possible, would you be willing to explain how did you manage to make openvidu work in ionic 3 ? that would be a really big help, my app stops working when I import hark from the dependencies... Thank you very much in advance )
username_0: Hi @username_2
For Ionic 3, only you need to install all dependency of "openvidu-browser" along with the openvidu-browser with proper version. No need to import those dependencies into the application except openvidu-browser. you can see the dependencies [here](https://github.com/OpenVidu/openvidu/blob/master/openvidu-browser/package.json#L6-L10).
So, only you need run like
`npm i [email protected] --save`
`npm i [email protected] --save` and so on
then `ionic serve` or build
username_2: So you mean I have to place myself into the openvidu-browser module itself and there install the dependencies ?
username_1: Hi,
[openvidu-ionic](https://openvidu.io/docs/tutorials/openvidu-ionic/) tutorial is now officially using **Ionic 5**. We still support Ionic 4, but no official support will be given for Ionic 3. That doesn't mean it won't work (in fact it should work just fine), but if you are using Ionic 3 version, we strongly recommend to update to a more recent version.
Regards.
Status: Issue closed
|
betagouv/mon-entreprise | 1015078041 | Title: Ajouter l'assurance maladie dans la liste des partenaire pour les pharmaciens
Question:
username_0: Comme pour les autres professions libérales PAM conventionnées :
Avant :

Après :

Answers:
username_0: cc @bobylito |
geoladris/core | 177788412 | Title: Refactor packages
Question:
username_0: Separate classes in different meaningful packages instead of everything in the same one.
Answers:
username_0: Mainly I refactored the `core` project packages to `org.geoladris`, `org.geoladris.config` and `org.geoladris.servlet`. Please, check if you agree with it.
username_0: I assume you agree with it.
Status: Issue closed
|
kordlib/kord | 833053589 | Title: Add builder functions at rest level
Question:
username_0: This is a reminder to add missing higher order functions for rest module and embed request transformers (Embed -> EmbedRequest)
Answers:
username_1: There are probably more transformers needed than just embed right?
username_0: That's a sure thing. that's why the issue is made. List anything you feel that it needs a builder or a transformer here
username_2: I'd like to be able to subclass some entities as well as replacing them in some events and such.
My use-case is basically for people that make use of PluralKit, which is basically an accessibility tool for people that are plural - it allows every member of a plural system to interact separately by deleting messages from the account and resending them as webhook messages.
I'd like to be able to add this metadata to events and entities, based on extensions to my framework. This means that subclassing is vital, as the extra context may not always be available, and the extension may not always be loaded. |
TNRIS/tnris.org | 708396728 | Title: Information Architecture / Navigation Bar Revisions
Question:
username_0: There are some inconsistencies with the information architecture that could be hindering navigation.
1.) Some tabs on the primary navigation bar are dropdowns to secondary navigation options while others (Events, Geographic Information Offices) are direct links to pages. We should add chevrons to give users a visual symbol to know whether they will see a dropdown or be taken to a new page.
**It looks like Chris has already started working on implementing this in the latest update. We discussed potentially enhancing this in the future to highlight the active tab and flip the chevron.
ex)

2.) Some pages (Education and Training, Geographic Information Office) have navigation levels that are not accessible via the primary navigation header. Unless these are intentionally more hidden, they should be added as dropdown options so users can navigate to these pages from anywhere on the site.

3.) Data from Google Analytics suggests some users could be having difficulty navigating to Stratmaps (and Stratmaps sub-pages)
While /stratmap/land-parcels is the most visited page (behind the home page), only 16%* of users navigate there directly from the home page
*excluding direct visits (typing URL, bookmark, clicking link on other site, etc.)
For comparison: (% of visits preceded directly by home page visit):
/maps/ - 51%
/geographic-information-office/ - 41%
/Texas-imagery-service/ - 38%
/research-distribution-center/ - 36%
/events/ - 36%
/applications-and-utilities/ - 31%
**/stratmap/stratmap-contracts/ - 22%
/stratmap/elevation-lidar – 22%
/stratmap/hydrography/ 13%
/stratmap/orthoimagery/ - 10%
/stratmap/address-points/ - 8%**
*Stats from Jan 1, 2020 - Sep 15, 2020
Hypothesis: Some users that want Stratmaps don’t immediately know to look under Programs.
7-10% navigate from Maps to Stratmaps
only 1-2% navigate from Stratmaps to Maps
If we give Stratmaps its own tab, then more users will get to their desired destination in fewer steps
How it could be structured:

Answers:
username_0: *Research & Distribution Center also has secondary navigation options. This is still a relevant issue as we want to provide navigation paths that are easy and obvious, but this may require further thought so we don't clutter the nav bar.
username_1: nice work @username_0 👍🏻 🚀 💯
Status: Issue closed
|
manijak/nativescript-carousel | 287734796 | Title: cannot read property 'setOnTouchListener' on Android 8.0
Question:
username_0: On Android 8.0+ i receive this error: cannot read property 'setOnTouchListener'
Where is the problem?
Answers:
username_1: Tested the plugin on both sdk 26 and 27, works fine. Check your installation and setup.
Try nuking platforms, node_modules and hooks folders, and rebuild.
Status: Issue closed
|
lambdalisue/jupyter-vim-binding | 146469799 | Title: ESC takes you to Jupyter's command mode in Safari.
Question:
username_0: ### Summary
Hitting `<Esc>` takes me to Jupyter's command mode in Safari, Chrome however works just fine.
### Environment
- Operating system : (e.g. Mac OS X 10.11.3)
- Web browser : (e.g. Safari 9.0.3)
- Version or revision of Jupyter Notebook : (e.g. 4.1)
- Revision of jupyter-vim-binding : (e.g. 3e4030da4d23094840baa6967b99b965bea4144b)
### Behavior
Hitting `<Esc>` takes me to Jupyter's command mode in Safari, Chrome however works just fine.
#### Expected
It shouldn't take me to Jupyter's command mode.
#### Actual
It takes me to Jupyter's command mode.
### Step by step procedure
1. Start local Jupyter Notebook by `jupyter notebook`
2. Access http://localhost:xxxx/ in Safari
3. Enter insert mode in a cell, then hit `<Esc>`, you will be taken to Jupyter's command mode.
### What you have done to solve the issue
For example, the behavior is confirmed with Safari 9.0.3 and could not be reproduced in Firefox but Chrome.
Answers:
username_1: Thanks! ok, I'll check it prob next week. ping me if no further responce after next week :-)
username_0: Friendly *ping*.
username_1: Thanks and sorry for late reply.
I tried with Safari Version 9.0.3 (11601.4.4) on OS X El Capitan (10.11.3) + jupyter-vim-binding ad4e35e on Jupyter 4.2 and found:
- `<Esc>` does nothing in *Command mode* but `<S-Esc>` (An expected behavior)
- **None of Vim mappings worked** in *Command mode* (Unexpected behavior)
So it seems that the situation is a bit different from yours. In my case, none of Vim mappings worked even in [CodeMirror's Vim mode](https://codemirror.net/demo/vim.html) it self, mean that jupyter-vim-binding can not support Safari somehow.
Which exact version of Safari did you use? Not sure why CodeMirror's Vim mode itself does not work in my Safari...
username_1: I see. Then jupyter-vim-binding does not work in Safari.
username_0: Thanks for looking into this.
Status: Issue closed
username_0: Just FYI, I finally figured it out, another plugin was interfering with bindings, I deactivated it and it was all good. |
Azure/azure-cli | 529752603 | Title: az storage share create fail
Question:
username_0: ### **This is autogenerated. Please review and update as needed.**
## Describe the bug
**Command Name**
`az storage share create`
**Errors:**
```
The specified resource does not exist. ErrorCode: ResourceNotFound
<?xml version="1.0" encoding="utf-8"?><Error><Code>ResourceNotFound</Code><Message>The specified resource does not exist.
RequestId:ca46e34d-101a-0053-57c1-a5a32f000000
Time:2019-11-28T08:00:32.7138918Z</Message></Error>
Traceback (most recent call last):
python3.7/site-packages/knack/cli.py, ln 206, in invoke
cmd_result = self.invocation.execute(args)
cli/core/commands/__init__.py, ln 603, in execute
raise ex
...
storage/v2018_11_09/common/_error.py, ln 115, in _http_error_handler
raise ex
azure.common.AzureMissingResourceHttpError: The specified resource does not exist. ErrorCode: ResourceNotFound
<?xml version="1.0" encoding="utf-8"?><Error><Code>ResourceNotFound</Code><Message>The specified resource does not exist.
RequestId:ca46e34d-101a-0053-57c1-a5a32f000000
Time:2019-11-28T08:00:32.7138918Z</Message></Error>
```
## To Reproduce:
Steps to reproduce the behavior. Note that argument values have been redacted, as they may contain sensitive information.
- _Put any pre-requisite steps here..._
- `az storage share create -n {} --account-name {} --account-key {} --debug`
## Expected Behavior
## Environment Summary
```
Darwin-17.7.0-x86_64-i386-64bit
Python 3.7.5
Shell: bash
azure-cli 2.0.71
```
## Additional Context
<!--Please don't remove this:-->
<!--auto-generated-->
Answers:
username_1: @username_2 Please take a look
username_2: Hi @username_0, could you please share me more debug information? I cannot reproduce your issue in my windows machine.
username_3: Hi @username_0 any update?
Status: Issue closed
username_2: Given no response, I cannot reproduce your issue. Close it now and if you still have problems, feel free to create a new issue. |
coronasafe/care_fe | 980260527 | Title: patient list loop !!!!!!
Question:
username_0: * logged in as staff
* selected a patient from patient list and update anything
* when trying to go back to patient list its not happening
* its came to consultation page
* after click 'back' its going to patient page and its happening like a loop ( patient card page and consultation page)<issue_closed>
Status: Issue closed |
DeskDirector/UserVoice | 449368245 | Title: DD Tech: Ability to Edit Note or Time Entry
Question:
username_0: Can we please have a feature that allows a technician to edit their time entry or note in DD Tech? Sometimes the wrong date or length of time may be inputted, and it would be unfortunate to have to log into CW just to edit a recent entry.
Answers:
username_1: Yes, this is needed. Sometimes information that's put in needs to be removed later out of a ticket, or something was mistyped.
username_2: Related request: Ticket #26962 |
gahansen/Albany | 286035625 | Title: Trilinos for Albany build error on Ride with CUDA KokkosNode
Question:
username_0: Last night's Albany build on Ride did not go through due to a build error in Trilinos coming from TpetraExt_MatrixMatrix_def.hpp:
http://cdash.sandia.gov/CDash-2-3-0/viewBuildError.php?buildid=64991
@username_1, any thoughts?
Answers:
username_1: @username_0 @username_2 would know what's going on with that thing :-) . He's been working on the CUDA and OpenMP specializations.
username_2: Working on fixing it.
username_0: Thanks @username_2 . I'm happy to test the fix once it's ready.
username_2: Checkin script is running.
username_2: Checked in. @username_0 please close this bug if the Albany nightlies are clean tonight.
username_1: Thanks @username_2 ! :D
Status: Issue closed
username_0: Appears to be resolved now. Thanks @username_2 ! |
kenberkeley/life-in-australia | 394793849 | Title: [20181229] 澳洲的物价为什么贵?揭秘澳洲经济运行模式
Question:
username_0: 请注意:这里的“物价”,泛指进口或使用进口原料的商品价格。澳洲本土自产的商品价格还是相对公道的。
具体表象是:除澳洲本土自产外的其他商品一般都比国内要贵。
这里“贵”的定义是因人而异的,主要表现在货币汇率差。
例如,对于瑞士人而言,澳洲物价可能也就那样。
当然,对于某些土豪国人而言,这根本不算事儿,随手就买几栋别墅压压惊。
### 地理隔离
在这方面,澳大利亚和新西兰是“难兄难弟”,均处遥远的南半球。
与世界上其他主流工业国家的地理隔离,导致高昂的航运成本。
也因为如此,很多跨国公司都不倾向于在澳洲设厂生产。
这也意味着澳洲强依赖于进口,进口可都是要缴税的。
同时,澳洲小宗货物铁路运输不发达,境内长途运输多用空运或公路。
澳洲的油费可不便宜,而货车司机的加班费也相当可观。
这些成本最终都会转嫁到消费者的头上(羊毛出在羊身上)。
地理隔离也导致缺乏廉价劳动力(黑工)。
美国境内有很多偷渡客,他们是支撑资本主义市场强劲的廉价劳动力。
### 人口
澳大利亚全国的人口才刚超过上海,除几个大城市外,人口分布稀疏。
这就意味着“薄利多销”在这里行不通,因为压根没有那么多的销量。
在澳洲做生意的资本家们一般都喜欢走极端:
既然不能“薄利多销”,那就按人头狠狠地一次赚个够吧!
所以他们就简单粗暴地以土澳市场的承受能力来定价,
这就是著名的 “Charge what the market will bear”。
不过呢,澳洲人民比较懒,不像中国人那样货比三家。
商家们的高定价,大伙儿貌似都比较无所谓。
久而久之这就成了一种税,戏称为“澳洲税”。
商家们一般认为能讹多少纯靠本事,靠本事讹的钱凭什么要害臊?
当然了,人口少还会导致其他问题。
例如基建,无论是政府出资还是民间投资,由于回本周期太长,都觉得不划算,还不如不建或者慢慢来吧。
这就直接导致了基础设施相对落后,大城市基本就是在啃工业革命时代的老本,偏远地区也可以有借口继续保持原生态。
人口少也导致了劳动力稀缺,人们不愁找工作。
即便是找不到工作,也有政府的各种福利加持。
所以,土澳人民普遍安逸,这对于正在创业的雇主可能会比较抓狂。
### 政府财政支出
上面提到了福利,在此详细展开。
澳洲是一个高福利国家,从出生到退休的教育医疗养老,为每一个个体全程提供一条龙福利。
这的确很不错,但实际上羊毛永远都是出在羊身上,能量永远都是守恒的,不可能凭空产生。
同时也注定了澳洲政府是强政府,奉行公有制,与美国不一样。但目前坑太大,已经逐渐向美国靠拢。
澳洲政府本身不仅不负责赚钱,而且还要养活很多公仆。
这庞大的财政支出都是平摊到大家的头上,主要表现为沉重的税收。
而且,这里的“大家”得排除儿童、退休老人、失业者、残疾人、原土著以及滥领福利钻空子的人等。
雇员要上缴高昂的个人所得税,稍高收入者还要交 [Medicare Levy Surcharge](https://www.privatehealth.gov.au/healthinsurance/incentivessurcharges/mls.htm)
雇主要上缴各项经营税
大家的日常消费还有 [10% 的 GST](https://www.ato.gov.au/Business/GST)
公费医疗坑太大了,公立医院排队的时间都可以环游世界了,政府又开始给补贴鼓励大伙儿买私人保险,否则超龄参保还要额外收你 [Lifetime Health Cover (LHC) loading](https://www.privatehealth.gov.au/healthinsurance/incentivessurcharges)
[Truncated]
所以大家相对都比较安分。
而且,人力成本如此高昂,会导致非澳洲企业不倾向于在澳洲投资设厂生产,澳洲本土企业也会倾向于把生产线转移到劳动力更为廉价的亚洲。
这就意味着工作岗位的流失。
但是,也只有这样,才能保证企业员工的高收入,产生良性循环;而不是薄利多销,靠剥削员工为生!
好处就是,商品以及服务都含税,美国就可能是分开的(导致最后给的钱超过原价很多),而且美国要给小费哦(美国的最低工资标准真的令人发指,所以给小费真的可以帮到服务生们!!!)!
单 GST 就很高了(10%+),还有其他杂七杂八的税款!
【这是一个循环!!!高消费高收入的循环!!!能量肯定是守恒的!!!】
但是也得想想:不用给员工买医疗保险,是不是算是省了一笔钱?这笔钱给员工,由政府扣,貌似也差不多哈哈哈!只是效率有点低
### 房地产泡沫
澳洲的土地泡沫也很大哈哈哈哈!!!!!!!!!!房地产的泡沫导致啥都贵!!!因为做生意离不开地!(网购落后的情况下!)
做生意的租金贼贵!!!所以商品也贵!土地所有者没有动力降租金,跟卖商品一个道理!高租金,真的租不出去再说!根本不考虑可持续!
土地使用成本很高很高!!!!!!!!!!!
(有待整理) |
dataabc/weiboSpider | 1138734529 | Title: 包引用问题
Question:
username_0: 感谢您申报bug,为了表示感谢,如果bug确实存在,您将出现在本项目的贡献者列表里;如果您不但发现了bug,还提供了很好的解决方案,我们会邀请您以pull request的方式成为本项目的代码贡献者(Contributor);如果您多次提供很好的pull request,我们将邀请您成为本项目的协助者(Collaborator)。当然,是否提供解决方按都是自愿的。不管是否是真正的bug、是否提供解决方案,我们都感谢您对本项目的帮助。
- 问:请您指明哪个版本出了bug(github版/PyPi版/全部)?
答:github
- 问:您使用的是否是最新的程序(是/否)?
答:是
- 问:爬取任意用户都会复现此bug吗(是/否)?
答:是
- 问:如果方便,请您描述bug详情,如果代码报错,最好附上错误提示。
答:无法运行

Answers:
username_0: 不好意思是运行错了文件
Status: Issue closed
|
power-assert-js/babel-plugin-espower | 396403357 | Title: Detecting the spread operator
Question:
username_0: From https://github.com/avajs/ava/issues/2004:
```js
test("example1", t => {
t.true(...[false, "bad!"]);
})
```
Currently this crashes. Implementing this fully seems like a stretch, but it'd be good if the plugin didn't crash.
Answers:
username_1: @username_0 Thank you for reporting and finding edge case. Now I'm working on this issue.
Status: Issue closed
username_1: @username_0 Fixed by #29 and released as [3.0.1](https://github.com/power-assert-js/babel-plugin-espower/blob/master/CHANGELOG.md#301-2019-01-08). Thank you for using and reporting 😃 |
digidem/mapeo-core | 1066643351 | Title: (Back) `DELETE` Api
Question:
username_0: Using the new [CRUD documentation](https://mapeo-core-docs-git-first-draft-digidem.vercel.app/docs/concepts/client/crud) create the following functions, and adapt the current mapeo core structures to return the desired types:
Delete Functions:
- [ ] Delete Observation |
smartinez87/exception_notification | 23089219 | Title: Delayed::Job Notification
Question:
username_0: Can anyone point me to better instructions for sending out exception notifications when delayed::jobs fail? I can't seem to get it to work on Rails 4 following an approach similar to:
http://stackoverflow.com/questions/5972903/how-to-make-exceptionnotifier-work-with-delayed-job-in-rails-3
I've also posted this issue here:
http://stackoverflow.com/questions/18777746/configuring-exception-notification-with-delayed-jobs-in-rails-4
Answers:
username_1: I am using @lucerion's method, but I am getting the same (useless framework) trace. I just get notified about the error. No details I get.
Mail and implementation: https://gist.github.com/username_1/4cb391c4151b07310bed
username_2: To get notified only at the last attempt I added ` if job.attempts == Delayed::Worker.max_attempts` to the original code of @lucerion .
The full fledged notification code (improved by from http://stackoverflow.com/a/6967915/930720) is:
# Optional but recommended for less future surprises.
# Fail at startup if method does not exist instead of later in a background job
[[ExceptionNotifier::Notifier, :background_exception_notification]].each do |object, method_name|
raise NoMethodError, "undefined method `#{method_name}' for #{object.inspect}" unless object.respond_to?(method_name, true)
end
# Chain delayed job's handle_failed_job method to do exception notification
Delayed::Worker.class_eval do
def handle_failed_job_with_notification(job, error)
handle_failed_job_without_notification(job, error)
# rescue if ExceptionNotifier fails for some reason
begin
ExceptionNotifier.notify_exception(error) if job.attempts == Delayed::Worker.max_attempts
rescue Exception => e
Rails.logger.error "ExceptionNotifier failed: #{e.class.name}: #{e.message}"
e.backtrace.each do |f|
Rails.logger.error " #{f}"
end
Rails.logger.flush
end
end
alias_method_chain :handle_failed_job, :notification
end
username_3: For Rails 5+
```
# in config/initializers/delayed_job.rb
module CustomFailedJob
def handle_failed_job(job, error)
super
ExceptionNotifier.notify_exception(error, data: {job: job})
end
end
class Delayed::Worker
prepend CustomFailedJob
end
```
username_4: And to send it only on the last attempt for Rails +5:
```
# Send emails with exceptions
module CustomFailedJob
def handle_failed_job(job, error)
super
if job.attempts == Delayed::Worker.max_attempts
ExceptionNotifier.notify_exception(error, data: {job: job})
end
end
end
class Delayed::Worker
prepend CustomFailedJob
end
```
username_5: In case it helps anyone else that finds this through google, I've found this works well for me.
From https://stackoverflow.com/questions/5972903/how-to-make-exceptionnotifier-work-with-delayed-job-in-rails-3
```
class DelayedJobExceptionNotification < Delayed::Plugin
callbacks do |lifecycle|
lifecycle.around(:invoke_job) do |job, *args, &block|
begin
block.call(job, *args)
rescue StandardError => error
ExceptionNotifier.notify_exception(error, data: {job: job})
raise error
end
end
end
end
Delayed::Worker.plugins << DelayedJobExceptionNotification
``` |
JabRef/jabref | 469427847 | Title: Import of abbreviation list with umlauts no correctly read in
Question:
username_0: JabRef version JabRef 5.0-dev--snapshot--2019-07-17--master--b094bc6ab
Windows 10 10.0 amd64
Java 1.8.0_211
- [x] I have tested the latest development version from http://builds.jabref.org/master/ and the problem persists
Importing or adding a Journal name with umlauts is scrambled and not correctly saved
Steps to reproduce the behavior:
1. Open "Manage abbreviations" menu
2. create a new list or import an existing one with journal names having umlauts
3. "Save changes"
4. reopen menu and have a look at the entry (also doesnt abbreviate it because not found)
Answers:
username_1: Thank you for your report :+1:
This should be fixed in current `journal-abbrev-encoding`. Please try the latest build from http://builds.jabref.org/journal-abbrev-encoding.
Status: Issue closed
|
RethinkRobotics-opensource/rosnodejs | 424542417 | Title: Is this being maintained post-shutdown?
Question:
username_0: I'm currently using rosnodejs in a number of nodes, but is there someone who is taking charge of maintaining rosnodejs after the Rethink shutdown?
Answers:
username_1: I'm continuing to maintain rosnodejs. I don't have any plans to stop, but am happy for help if there's updates people are looking for - I haven't seen much in the way of requests so it's been relatively quiet.
username_0: This @username_1 for maintaining this! Are there plans for an "official" ROS 2 version?
username_1: @minggangw and Intel already have one over [here](https://github.com/RobotWebTools/rclnodejs)!
username_0: Thanks!
Status: Issue closed
|
ValveSoftware/steam-for-linux | 17891666 | Title: Steam seems to download client updates while game is running
Question:
username_0: I don't have a good connection. Often while playing CS: Source, my ping will suddenly jump up and I can see that my bandwidth is saturated.
Nethogs says that the steam client is downloading something, but no game is updating and no network usage is shown in the client's Library/Downloads page.
Once the bandwidth use has stopped, the problem doesn't recur for the rest of the session.
Game updates do suspend correctly when other games are running. Since nothing else is downloading, I'm just guessing but I think that the steam client might be downloading client updates in the background, to be applied next time the app is started.
Status: Issue closed
Answers:
username_1: Closing as a duplicate of #2003. |
strawberry-graphql/strawberry | 878602569 | Title: Proposal: Custom fields
Question:
username_0: ## Objective
Allow developers to create custom fields to encapsulate common resolver logic, allow modification of field arguments and return types.
## Motivation
At the moment the only way to define a field is to use the `strawberry.field` function. There is no ability to modify arguments or types programmatically so defining common patterns in a schema means duplicating logic throughout the code base.
@username_3 work on refactoring StrawberryField into a proper class has now provided us with a stable foundation on which to provide an API for developers to extend the default StrawberryField class to define their own custom fields.
## Benefit
Custom fields will allow developers to create fields to abstract away common patterns in their schema and make it more maintainable. Strawberry can also provide common custom fields to help with things like pagination, permissions and validation.
## API design
```python
from strawberry import StrawberryField
class MyCustomField(StrawberryField):
def process_type(self, type_: Type) -> Type:
...
def process_arguments(self, arguments: Dict[str, Type]) -> Dict[str, Type]:
...
def get_result(self, source: Any, info: Info, arguments: Dict[str, Any]) -> Union[Awaitable[Any], Any]:
...
```
### Examples
#### Simple upper case field
```python
class UpperCaseField(StrawberryField):
def process_type(self, type_: Type) -> Type:
# Make sure that this field is only used on str fields
assert type_ is str
return type_
def get_result(
self, kwargs: Dict[str, Any], source: Any, info: Any
) -> Union[Awaitable[Any], Any]:
result = super().get_result(kwargs, source, info)
return cast(str, result).upper()
@strawberry.type
class Query:
name: str = UpperCaseField(default="Jonathan")
@UpperCaseField()
def alt_name() -> str:
return "username_0"
schema = strawberry.Schema(query=Query)
result = schema.execute_sync("{ name, altName }", root_value=Query())
[Truncated]
"Pride and Prejudice",
"Sense and Sensibility",
"Persuasion",
"Mansfield Park",
]
schema = strawberry.Schema(query=Query)
result = schema.execute_sync("{ books(first: 2) }")
assert result.data["books"] == ["Pride and Prejudice", "Sense and Sensibility"]
```
## Alternatives
Allowing the usage of decorators (#473) would allow you to encapsulate resolver logic but it wouldn’t let you modify the arguments for a field or the return type. Custom fields allow both of those things at the expense of being more verbose and not as obvious. Decorators are still possibly a good thing to support for the more limited use cases.
## Questions
- Should we treat mutations and subscriptions differently?
- Should we provide examples/helpers on how to test custom fields?
- How can you compose multiple custom fields?
Answers:
username_1: I like this concept. I'm already using this approach in `strawberry-graphql-django` package. I'm pretty sure other users may want to do the same :)
### Field composition
Would it make sense to use class inheritance in a such way that arguments, types and results of super class are all accessed through super object? This would allow composition and inheritance from multiple classes like this.
```python
class PaginationMixin:
def get_arguments(self):
return {
'pagination': PaginationInput
} | super().get_arguments()
def get_result(self, source, info, pagination, **kwargs):
result = super().get_result(source, info, **kwargs)
return apply_pagination(result, pagination)
class FilteringMixin:
def get_arguments(self):
return {
'filtering': FilteringInput
} | super().get_arguments()
def get_result(self, source, info, filtering, **kwargs):
result = super().get_result(source, info, **kwargs)
return apply_filtering(result, filtering)
class CustomField(
FilteringMixing,
PaginationMixing,
StrawberryField,
):
pass
```
I'm not sure which one, `process_arguments` or `get_arguments`, would be better name.
### kwargs of get_result
You had argument called `arguments` in first example but other examples had `kwargs`. Which one would you propose?
Currenly `kwargs` is passed as an dict to `get_result` method. Would it make sense to change `kwargs` to `**kwargs`? After that it would be a bit cleaner to "pop" arguments from kwargs before passing rest of the kwargs to `get_result` of inherited class.
```python
def get_result(self, my_argument, **kwargs):
return super().get_result(**kwargs)
# vs
def get_result(self, kwargs):
my_argument = kwargs.pop('my_argument')
return super().get_result(**kwargs)
```
### post_init
In Django integration I'm missing some kind of `post_init` method which is called as soon as type and arguments have been resolved. We need to check there that output and input types are both from the same model like this:
```python
class DjangoField:
def post_init(self):
assert self.arguments['input']._django_model == self.type._django_model
```
It's possible that types are still forward references (strings) when types and arguments are processed which means that it is not be possible to do validation there until forward references have been resolved.
username_0: @username_1 very sorry I haven't replied to you! I think I must have just done it in my head and not actually written it down 🤦
Status: Issue closed
username_0: ## Objective
Allow developers to create custom fields to encapsulate common resolver logic, allow modification of field arguments and return types.
## Motivation
At the moment the only way to define a field is to use the `strawberry.field` function. There is no ability to modify arguments or types programmatically so defining common patterns in a schema means duplicating logic throughout the code base.
@username_3 work on refactoring StrawberryField into a proper class has now provided us with a stable foundation on which to provide an API for developers to extend the default StrawberryField class to define their own custom fields.
## Benefit
Custom fields will allow developers to create fields to abstract away common patterns in their schema and make it more maintainable. Strawberry can also provide common custom fields to help with things like pagination, permissions and validation.
## API design
```python
from strawberry import StrawberryField
class MyCustomField(StrawberryField):
def process_type(self, type_: Type) -> Type:
...
def process_arguments(self, arguments: Dict[str, Type]) -> Dict[str, Type]:
...
def get_result(self, source: Any, info: Info, arguments: Dict[str, Any]) -> Union[Awaitable[Any], Any]:
...
```
### Examples
#### Simple upper case field
```python
class UpperCaseField(StrawberryField):
def process_type(self, type_: Type) -> Type:
# Make sure that this field is only used on str fields
assert type_ is str
return type_
def get_result(
self, kwargs: Dict[str, Any], source: Any, info: Any
) -> Union[Awaitable[Any], Any]:
result = super().get_result(kwargs, source, info)
return cast(str, result).upper()
@strawberry.type
class Query:
name: str = UpperCaseField(default="Jonathan")
@UpperCaseField()
def alt_name() -> str:
return "username_0"
schema = strawberry.Schema(query=Query)
result = schema.execute_sync("{ name, altName }", root_value=Query())
[Truncated]
"Pride and Prejudice",
"Sense and Sensibility",
"Persuasion",
"Mansfield Park",
]
schema = strawberry.Schema(query=Query)
result = schema.execute_sync("{ books(first: 2) }")
assert result.data["books"] == ["Pride and Prejudice", "Sense and Sensibility"]
```
## Alternatives
Allowing the usage of decorators (#473) would allow you to encapsulate resolver logic but it wouldn’t let you modify the arguments for a field or the return type. Custom fields allow both of those things at the expense of being more verbose and not as obvious. Decorators are still possibly a good thing to support for the more limited use cases.
## Questions
- Should we treat mutations and subscriptions differently?
- Should we provide examples/helpers on how to test custom fields?
- How can you compose multiple custom fields?
username_2: I mostly like this, the only two things I don't like are, from this example:
```python
@strawberry.type
class Query:
@PaginatedField()
def books() -> List[str]:
return [
"Pride and Prejudice",
"Sense and Sensibility",
"Persuasion",
"Mansfield Park",
]
```
1. `@PaginatedField()` this is mostly a personal preference, but I don't like using classes as decorators (mostly because it looks odd)
2. `List[str]` we are changing the field type, but we still use the old type in the method (which is fine); my only concern on this is that we are hiding the new field type
Have you considered an API like this:
```python
@strawberry.type
class Query:
@strawberry.field
def books() -> PaginatedField[List[str]]:
return [
"Pride and Prejudice",
"Sense and Sensibility",
"Persuasion",
"Mansfield Park",
]
```
?
username_0: That is an interesting alternative API but wouldn't that require more mypy plugin magic and extra IDE integration? Also I'm not sure it's as obvious that you're potentially modifying the arguments to the field and the resolver logic when you're just wrapping the return type.
username_2: don't really like this option
```python
@strawberry.type
class Query:
@strawberry.field(implementation=PaginatedField)
def books() -> List[str]:
return [
"Pride and Prejudice",
"Sense and Sensibility",
"Persuasion",
"Mansfield Park",
]
```
maybe we can do what asgi ref does with sync_to_async? :D
https://github.com/django/asgiref/blob/main/asgiref/sync.py#L511-L512
username_0: Sure thats fine. I think the built in custom fields we should expose as lower case but people are free to define their own custom fields with any kind of naming convention.
username_2: Yes, that works for me :D
username_3: This is also something the Python standard library does. Easiest example is `@property` (although it's implemented in C, not pure Python)
username_4: Hello, what's the status of this proposal?
username_0: @username_4 unfortunately the PR that I created is pretty out of date at this point and needs updating. I still think the proposal is a good idea though. I might be able to find time to update it but if anyone else wants to pick this up that would be very helpful!
username_4: I can do it when i have some free time, but i'd like to know if it's still regarded as a proposal subject to approval or a feature that still needs to be added.
In other words, given a working implementation of this, is there a chance is not merged because it's deemed not useful?
username_0: @strawberry-graphql/core what do you think? Any objections to this feature? |
runelite/runelite | 577272435 | Title: Arceuus Library Varlamore Envoy suggestion
Question:
username_0: Varlamore Envoy can only ever be used in a quest, and never be requested. Currently, there is a way to toggle off the Varlamore Envoy book in the UI, but without proper foreknowledge about this book and what it's used for it appears to just be a normal library book, which can cause confusion and needless support requests due to the fact that searching for and not finding the book will reset your library plugin layout.
I would suggest one or more of these changes:
A) Exclude the Varlamore Envoy book from resetting the plugin's library layout, as well as from contributing to finding the current layout
B) Visually differentiate between the Varlamore Envoy and every other book, thus encouraging users to look into the book more if they encounter an issue.
C) Warn the user in some way that Varlamore Envoy is ONLY used during a quest, and make them aware of the option to disable it.
Status: Issue closed
Answers:
username_1: This is mostly a duplicate of #10296 in that we need better handling of the Varlamore Envoy--both in tracking it for the layout and in how and when it is shown in the overlay. |
easylist/easylist | 781002595 | Title: techcpl.com (exe.app)
Question:
username_0: <!--
Note: If you're a website owner that has been specifically targeted, fix the site before reporting.
Remove revolving ad servers, popup ads, adblock countering etc. Only then will this request be reviewed. -->
<!-- Any additions, changes or removals is at the Authors discretion.
You're free to counterargue (to a certain point) if you disagree with the decision.
To avoid being banned, don't constantly re-open or create new (related) issue reports.
-->
<!-- Just include the website URL in the Title line of this issue report -->
### List the website(s) you're having issues:
```
techcpl.com
Which is a part of the exe.app and exe.io sites.
```
### What happens?
A lot of times it will not load the content displaying " Please disable Adblock to proceed to the destination page.".
### List Subscriptions you're using:
UBlock Builtins
EasyList
Ublock Malware
Peter Lowe’s Ad and tracking server list
Greek AdBlock Filter
### Your settings
Disabled other extensions to retest.
Specs:
Latest Firefox
Latest UBlock Origin
Windows 10 (1909)
Status: Issue closed
Answers:
username_1: This won't be fixed in Easylist, report to uBO |
screeps/screeps | 192276533 | Title: cpu load
Question:
username_0: Hi,
I run a server for multiple days, and the longer I run the server, the more rise the cpu usage and load (up to 100% of one core I think).
And because it used that much cpu, I deleted the bots on the server and restarted it, and the load is rising again, but not that fast as with the bots.
My setup:
Node 7.2.0
Python 2.7.12
2 User on the server
2 Cores of a Xeon E3-1220
8 GB RAM
Answers:
username_1: Same here. Tickrate gets really slow and that on a 3 cpu server with only 1 player with 1 room playing :/
username_2: As said elsewhere, the issue appears to be node 7. Downgrade to node 6 (which is the stable long term support version) and the issue disappears. At least, I have been running all day with consistent CPU load anyway (which is a first, before with node 7 CPU reaches 100% within an hour or two).
When you downgrade node, make sure to rebuild npm packages with `npm rebuild` or the server will crash. You might need `npm rebuild -g` if you installed screeps globally.
username_0: I can confirm that.
But the issue still exists and the [package.json line 25](https://github.com/screeps/screeps/blob/master/package.json#L25) should also be changed:
NodeJS >= 6.5.0 but < 7 (don't know the exact string).
Status: Issue closed
|
towerofpower256/DavesSNBulkDataExportTool | 1112068156 | Title: New feature: auth details from file
Question:
username_0: I'd like to be able to pull authentication details from a file, instead of requiring them to be entered in the console.
This will prevent usernames, passwords, and tokens:
- Being visible in the terminal where people can look over your shoulder and see them.
- Being saved in the terminal history in plain text.
I'm thinking of a plain text file containing a JSON payload, and being able to specify the file as a command line parameter.
E.g.
```json
{
"basic_username":"admin",
"basic_password":"<PASSWORD>",
"oauth_clientid":"aksdjhaskdjh",
"oauth_secret":"<KEY>"
}
```
While this won't store auth details securely, it will prevent them from being visible on the terminal and visible in the terminal history. |
cssstats/cssstats | 64613929 | Title: CSS import is included twice in stats
Question:
username_0: I've noticed that if page uses @imports in CSS the imported file gets to be included twice in statistics.
You can test it from here: http://import.meetpollux.com/
Result: http://cssstats.com/stats?url=http://import.meetpollux.com/
See the content of imported style1.css file:
body {
color: black;
}
Maybe the content is included once as "part" of original CSS request and then second time as standalone file request detected from the code?
Answers:
username_1: Thanks for reporting this! I will do a bit of digging to see what's happening here.
username_1: This is now resolved in the `[email protected]`. Now, cssstats just needs a redeploy with:
```
npm cache clean
npm i get-css@latest --save
```
To ensure the latest version of `get-css` is installed. cc/ @username_2
username_2: Will this up when I get home and have access to my non-work cpu machine.
Status: Issue closed
username_2: Fixed on production. |
Botasha/prj-rev-bwfs-dasmoto | 268907093 | Title: headings
Question:
username_0: https://github.com/Botasha/prj-rev-bwfs-dasmoto/blob/master/Dasmoto's%20Art%20%26%20Craft/index.html#L11
It's considered poor organization to use a heading _before_ you've used the previous level heading.
So, before using an `h3`, you should already have an `h2` on the page. If the size of the heading is not exactly to your liking, you can change in the stylesheet.
https://github.com/Botasha/prj-rev-bwfs-dasmoto/blob/master/Dasmoto's%20Art%20%26%20Craft/index.html#L13
This should probably be an `h3`. |
kubesphere/kubesphere | 851143057 | Title: on the create deployment page, does not display quota prompt information for all clusters
Question:
username_0: **Environment**
multi-cluster:
host clustere : v 3.1
member cluster: v 3.1
**steps:**
1. there exists a multi-cluster workspace 'm-ws', and the workspace quota information for the Host and Membere clusters is set
2. there exists a multi-cluster project 'm-ws' under workspace 'm-ws', and the project quota information for host and member clusters is set
3. enter project 'm-p', create Deployment, and on the create page, view the quota prompt
Expected results:
The quota information for the host cluster and member is displayed
Actual results:
Only the quota information for the Host cluster is displayed

/kind bug
/assign @leoendless
/priority Medium
/milestone 3.1.0
/area console
Answers:
username_1: Quota information removed when creating multicluster deployment, I think we can close this issue now.
username_1: /close |
pykeen/pykeen | 973479794 | Title: RuntimeError: CUDA out of memory when training with a large file
Question:
username_0: I am facing `CUDA out of memory` when training with a large file. I have changed the batch size to 16 but it does not works. Could you please help? Thanks.
```
DATA_PATH = A_FILE_OF_1.18GB
tfac = TriplesFactory.from_path(DATA_PATH)
training, testing, validation = tfac.split([.8, .1, .1])
result = pipeline(
training=training,
testing=testing,
validation=validation,
model='TransE',
stopper='early',
training_kwargs=dict(num_epochs=5, batch_size=16),
)
```
Answers:
username_1: 16 might still be too big depending on your hyperparameters. Before specifying at 16, did you use automatic memory optimization (this is invoked by default if no batch size is given)?
username_0: Thank you for your reply.
Yes, the reason I set 16 is that I find the default value of batch size in the source code is 256. I did not set any batch size before, but there was the same issue.
username_1: Hmm, well it's tough to say just from the code you've given. Maybe you can share the output of `pykeen.env()` and the full error stack trace?
username_0: Here there are.
···
| Key | Value |
|-----------------|--------------------------|
| OS | posix |
| Platform | Linux |
| Release | 4.4.0-142-generic |
| User | XXX |
| Time | Wed Aug 18 21:13:03 2021 |
| Python | 3.8.10 |
| PyKEEN | 1.5.0 |
| PyKEEN Hash | UNHASHED |
| PyKEEN Branch | |
| PyTorch | 1.6.0 |
| CUDA Available? | true |
| CUDA Version | 10.2 |
| cuDNN Version | 7605 |
···
Stack
```
Traceback (most recent call last):
File "trainkge.py", line 38, in <module>
mpk = MyPyKeen(temp)
File "/XXX/my/xmunlp-ndap-common-data/kg//../kg/mypykeen.py", line 20, in __init__
result = pipeline(
File "/XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/pykeen/pipeline/api.py", line 1016, in pipeline
losses = training_loop_instance.train(
File "/XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/pykeen/training/training_loop.py", line 301, in train
result = self._train(
File "/XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/pykeen/training/training_loop.py", line 689, in _train
raise e
File "/XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/pykeen/training/training_loop.py", line 598, in _train
batch_loss = self._forward_pass(
File "/XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/pykeen/training/training_loop.py", line 760, in _forward_pass
loss.backward()
File "/XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/tensor.py", line 185, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/autograd/__init__.py", line 125, in backward
Variable._execution_engine.run_backward(
RuntimeError: CUDA out of memory. Tried to allocate 1.40 GiB (GPU 0; 10.76 GiB total capacity; 8.59 GiB already allocated; 173.12 MiB free; 9.82 GiB reserved in total by PyTorch)
Exception raised from malloc at /opt/conda/conda-bld/pytorch_1595629395347/work/c10/cuda/CUDACachingAllocator.cpp:272 (most recent call first):
frame #0: c10::Error::Error(c10::SourceLocation, std::string) + 0x4d (0x7fa1cb6b977d in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libc10.so)
frame #1: <unknown function> + 0x20626 (0x7fa1cb911626 in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libc10_cuda.so)
frame #2: <unknown function> + 0x214f4 (0x7fa1cb9124f4 in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libc10_cuda.so)
frame #3: <unknown function> + 0x21b81 (0x7fa1cb912b81 in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libc10_cuda.so)
frame #4: at::native::empty_cuda(c10::ArrayRef<long>, c10::TensorOptions const&, c10::optional<c10::MemoryFormat>) + 0x249 (0x7fa1ce813e39 in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libtorch_cuda.so)
frame #5: <unknown function> + 0xd15c49 (0x7fa1cc834c49 in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libtorch_cuda.so)
frame #6: <unknown function> + 0xd2fa77 (0x7fa1cc84ea77 in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libtorch_cuda.so)
frame #7: <unknown function> + 0xe450dd (0x7fa202c590dd in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libtorch_cpu.so)
frame #8: <unknown function> + 0xe453f7 (0x7fa202c593f7 in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libtorch_cpu.so)
frame #9: at::empty(c10::ArrayRef<long>, c10::TensorOptions const&, c10::optional<c10::MemoryFormat>) + 0xfa (0x7fa202d63e7a in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libtorch_cpu.so)
frame #10: at::TensorIterator::fast_set_up(at::TensorIteratorConfig const&) + 0x56a (0x7fa2029f13ea in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libtorch_cpu.so)
frame #11: at::TensorIterator::build(at::TensorIteratorConfig&) + 0x76 (0x7fa2029f5456 in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libtorch_cpu.so)
frame #12: at::TensorIterator::TensorIterator(at::TensorIteratorConfig&) + 0xdd (0x7fa2029f5abd in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libtorch_cpu.so)
frame #13: at::TensorIterator::binary_op(at::Tensor&, at::Tensor const&, at::Tensor const&, bool) + 0x14a (0x7fa2029f5c6a in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libtorch_cpu.so)
frame #14: at::native::add(at::Tensor const&, at::Tensor const&, c10::Scalar) + 0x47 (0x7fa202732b77 in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libtorch_cpu.so)
frame #15: <unknown function> + 0xd001c0 (0x7fa1cc81f1c0 in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libtorch_cuda.so)
frame #16: <unknown function> + 0x7f66b4 (0x7fa20260a6b4 in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libtorch_cpu.so)
frame #17: at::add(at::Tensor const&, at::Tensor const&, c10::Scalar) + 0x183 (0x7fa202d3a9e3 in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libtorch_cpu.so)
frame #18: <unknown function> + 0x2be54e1 (0x7fa2049f94e1 in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libtorch_cpu.so)
frame #19: <unknown function> + 0x7f66b4 (0x7fa20260a6b4 in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libtorch_cpu.so)
frame #20: at::Tensor::add(at::Tensor const&, c10::Scalar) const + 0x183 (0x7fa202eae3d3 in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libtorch_cpu.so)
frame #21: <unknown function> + 0x30dd790 (0x7fa204ef1790 in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libtorch_cpu.so)
frame #22: <unknown function> + 0x30de4e3 (0x7fa204ef24e3 in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libtorch_cpu.so)
frame #23: torch::autograd::Engine::evaluate_function(std::shared_ptr<torch::autograd::GraphTask>&, torch::autograd::Node*, torch::autograd::InputBuffer&, std::shared_ptr<torch::autograd::ReadyQueue> const&) + 0xb80 (0x7fa204edffe0 in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libtorch_cpu.so)
frame #24: torch::autograd::Engine::thread_main(std::shared_ptr<torch::autograd::GraphTask> const&) + 0x451 (0x7fa204ee1401 in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libtorch_cpu.so)
frame #25: torch::autograd::Engine::thread_init(int, std::shared_ptr<torch::autograd::ReadyQueue> const&, bool) + 0x89 (0x7fa204ed9579 in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libtorch_cpu.so)
frame #26: torch::autograd::python::PythonEngine::thread_init(int, std::shared_ptr<torch::autograd::ReadyQueue> const&, bool) + 0x4a (0x7fa2092031ba in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/torch/lib/libtorch_python.so)
frame #27: <unknown function> + 0xc9067 (0x7fa21ffa0067 in /XXX/miniconda3/envs/py38ndap/lib/python3.8/site-packages/pandas/_libs/window/../../../../../libstdc++.so.6)
frame #28: <unknown function> + 0x76ba (0x7fa23606d6ba in /lib/x86_64-linux-gnu/libpthread.so.0)
frame #29: clone + 0x6d (0x7fa23548b4dd in /lib/x86_64-linux-gnu/libc.so.6)
```
username_1: Are you sharing your GPU with other students?
username_0: I had checked that no one used GPU before I ran the script.
username_2: @username_0
You can also try to reduce the embedding dimension, which defaults to 50.
https://github.com/pykeen/pykeen/blob/8405d82db33e6a6cda2d237ed8d2b719c578483e/src/pykeen/models/unimodal/trans_e.py#L58
To do so, use the `model_kwargs`, e.g.,
```python
result = pipeline(
...,
model_kwargs=dict(embedding_dim=16),
)
```
From my experience, L2 norm is more efficient memory-wise, while by default L1 is used for TransE. This can be changed by
```python
result = pipeline(
...,
model_kwargs=dict(scoring_fct_norm=2),
)
```
username_0: The solution works for me. Thank you @username_2 , @username_1
Status: Issue closed
|
pytest-dev/pytest-twisted | 399181904 | Title: What is the public interface? (let me know what you actually use)
Question:
username_0: With everything in one file, being a module distribution (rather than package), and having only the readme as documentation I'm left a little unclear about what is 'public interface' and what isn't. I'd like to make this more explicit so that going forward we don't have to think about this on a case by case basis every time we feel like tweaking something. (also, maybe I want a package with versioneer and explicit public interface and tests inside like I'm used to...)
The readme references:
- pytest options
- `-p no:twisted`
- `--reactor`
- pytest fixtures
- `twisted_greenlet`
- `import pytest`
- Not in the readme anymore but they were as of [v1.6](https://github.com/pytest-dev/pytest-twisted/tree/1.6) (2018.01.11) and have no deprecation notices
- `@inlineCallbacks`
- `blockon()`
- `import pytest_twisted`
- `init_default_reactor()`
- `init_qt5_reactor()`
- `@pytest_twisted.inlineCallbacks`
- `blockon()`
The remaining items are:
- 'public'
- `blockon_default`
- `block_from_thread`
- `init_twisted_greenlet`
- `stop_twisted_greenlet`
- `twisted_greenlet`
- `reactor_installers`
- 'private'
- `_config`
- `_instances`
- `_install_reactor`
- `pytest_`*
- `pytest_pyfunc_call`
- `pytest_addoption`
- `pytest_configure`
- `_pytest_pyfunc_call`
Answers:
username_0: https://github.com/glyph/publication/
username_1: I use
```
from pytest_twisted import inlineCallbacks
```
username_2: I use `@pytest_twisted.inlineCallbacks` and `pytest_twisted.blockon(deferred)` |
cmv/cmv-app | 216201594 | Title: Start the app with panes closed
Question:
username_0: This is maybe not a bug so sorry if this is not the right place to ask but
Could anyone tell me if there is a way to "Start the app with panes closed" on pc
I noticed it alreay happens in mobile size screen.
Thanks
Answers:
username_1: @username_0 To have the left pane closed when the application starts, you can change the pane configuration in `viewer.js`:
``` javascript
panes: {
left: {
open: false
}
},
```
With the default css, the above configuration will cause the pane to open for a split second, then collapse. To override this, you can include the style parameter below:
``` javascript
panes: {
left: {
open: false,
style: 'display:none'
}
},
```
username_0: Thanks a lot.
I tried it for left pane and it was a success but since i am using bottom pane for attributetable widget it doesnt work
I tried borh with style parameter and without it and The table doesnt appear although the query in the widget works and result is displayed in the map.
username_1: Sounds like the panes are working as I would expect but the attribute tables widget is not configured properly.
Your bottom pane should be configured like [this](https://github.com/username_1/cmv-widgets/blob/master/config/search.js#L29-L40) and then your attributes table widget should have [these properties](https://github.com/username_1/cmv-widgets/blob/master/config/search.js#L106-L107) in the configuration.
username_0: Yes thank you it worked fine.
In viewer.js in panes i put none instead of false and it worked.
Status: Issue closed
|
jsonrpcx/json-rpc-cxx | 782482260 | Title: Question about invoking a method in typemapper.hpp
Question:
username_0: Hi,
I am enjoying your library, so first of all, thank you.
I am running into an issue invoking a function which accepts a struct that includes only two simple enums classes:
```
enum class A {
a1 = 0,
a2
};
enum class B {
b1 = 0,
b2
};
struct some_struct {
A a;
B b;
}
```
I can see the correct conversion happening in my custom typemapper: `void from_json(const nlohmann::json& j, some_struct str)`, however, when the handler then invokes the function which was bound (happens in typemapper.hpp in: ` method(params[index].get<typename std::decay<ParamTypes>::type>()...);`) , the argument struct appears uninitialized, as if a copy didn't execute.
Can you suggest what is going wrong?
Answers:
username_0: Disregard.
I didn't pay attention and provided a value type argument instead of a reference type argument for `some_struct` in the typemapper.
`void from_json(const nlohmann::json& j, some_struct str)` should be `void from_json(const nlohmann::json& j, some_struct& str)`
Status: Issue closed
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.