
repo_name
stringlengths 4
136
| issue_id
stringlengths 5
10
| text
stringlengths 37
4.84M
|
|---|---|---|
OpenHFT/Zero-Allocation-Hashing | 579899839 | Title: Fatal crash on Samsung Galaxy J5 (SM-J530F)
Question:
username_0: Hi,
Only on android device: Samsung Galaxy J5 (SM-J530F), but possibly there are other devices affected.
We have fatal crash that always happens when trying to hash byte array (contents does not seem to matter) using xxHash:
```kotlin
LongHashFunction
.xx().hashBytes(value)
```
Taken from LogCat:
```
--------- beginning of crash
2020-03-12 12:07:08.966 16010-16280/? A/libc: Fatal signal 7 (SIGBUS), code 1, fault addr 0x1338520c in tid 16280 (.pl/...), pid 16010 ()
2020-03-12 12:07:09.051 16283-16283/? A/DEBUG: *** *** *** *** *** *** *** *** *** *** *** *** *** *** *** ***
2020-03-12 12:07:09.051 16283-16283/? A/DEBUG: Build fingerprint: 'samsung/j5y17ltexx/j5y17lte:8.1.0/M1AJQ/J530FXXU3BRJ2:user/release-keys'
2020-03-12 12:07:09.052 16283-16283/? A/DEBUG: Revision: '7'
2020-03-12 12:07:09.052 16283-16283/? A/DEBUG: ABI: 'arm'
2020-03-12 12:07:09.052 16283-16283/? A/DEBUG: pid: 16010, tid: 16280, name: .pl/... >>> com.erfg.music <<<
2020-03-12 12:07:09.052 16283-16283/? A/DEBUG: signal 7 (SIGBUS), code 1 (BUS_ADRALN), fault addr 0x1338520c
2020-03-12 12:07:09.052 16283-16283/? A/DEBUG: r0 1338520c r1 0000000c r2 ca9e95cc r3 0000000c
2020-03-12 12:07:09.052 16283-16283/? A/DEBUG: r4 6f31be58 r5 00000004 r6 00000000 r7 ca9e98c8
2020-03-12 12:07:09.052 16283-16283/? A/DEBUG: r8 00000000 r9 cb5f2c00 sl ca9e96c8 fp ca9e9654
2020-03-12 12:07:09.052 16283-16283/? A/DEBUG: ip eae9fced sp ca9e95a8 lr eae9fcf7 pc eae9fcfa cpsr 600d0030
2020-03-12 12:07:09.185 16283-16283/? A/DEBUG: backtrace:
2020-03-12 12:07:09.185 16283-16283/? A/DEBUG: #00 pc 00310cfa /system/lib/libart.so (art::Unsafe_getLong(_JNIEnv*, _jobject*, _jobject*, long long)+13)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #01 pc 005db08f /system/framework/arm/boot.oat (offset 0x1cb000) (sun.misc.Unsafe.getLong [DEDUPED]+110)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #02 pc 0040c575 /system/lib/libart.so (art_quick_invoke_stub_internal+68)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #03 pc 004116e5 /system/lib/libart.so (art_quick_invoke_stub+228)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #04 pc 000b0227 /system/lib/libart.so (art::ArtMethod::Invoke(art::Thread*, unsigned int*, unsigned int, art::JValue*, char const*)+138)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #05 pc 00204005 /system/lib/libart.so (art::interpreter::ArtInterpreterToCompiledCodeBridge(art::Thread*, art::ArtMethod*, art::ShadowFrame*, unsigned short, art::JValue*)+224)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #06 pc 001ff54d /system/lib/libart.so (_ZN3art11interpreter6DoCallILb0ELb0EEEbPNS_9ArtMethodEPNS_6ThreadERNS_11ShadowFrameEPKNS_11InstructionEtPNS_6JValueE+588)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #07 pc 003f8c87 /system/lib/libart.so (MterpInvokeVirtualQuick+598)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #08 pc 00402714 /system/lib/libart.so (ExecuteMterpImpl+29972)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #09 pc 001e6bc1 /system/lib/libart.so (art::interpreter::Execute(art::Thread*, art::DexFile::CodeItem const*, art::ShadowFrame&, art::JValue, bool)+340)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #10 pc 001eb36f /system/lib/libart.so (art::interpreter::ArtInterpreterToInterpreterBridge(art::Thread*, art::DexFile::CodeItem const*, art::ShadowFrame*, art::JValue*)+142)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #11 pc 001ff535 /system/lib/libart.so (_ZN3art11interpreter6DoCallILb0ELb0EEEbPNS_9ArtMethodEPNS_6ThreadERNS_11ShadowFrameEPKNS_11InstructionEtPNS_6JValueE+564)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #12 pc 003f8c87 /system/lib/libart.so (MterpInvokeVirtualQuick+598)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #13 pc 00402714 /system/lib/libart.so (ExecuteMterpImpl+29972)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #14 pc 001e6bc1 /system/lib/libart.so (art::interpreter::Execute(art::Thread*, art::DexFile::CodeItem const*, art::ShadowFrame&, art::JValue, bool)+340)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #15 pc 001eb36f /system/lib/libart.so (art::interpreter::ArtInterpreterToInterpreterBridge(art::Thread*, art::DexFile::CodeItem const*, art::ShadowFrame*, art::JValue*)+142)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #16 pc 001ff535 /system/lib/libart.so (_ZN3art11interpreter6DoCallILb0ELb0EEEbPNS_9ArtMethodEPNS_6ThreadERNS_11ShadowFrameEPKNS_11InstructionEtPNS_6JValueE+564)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #17 pc 003f8c87 /system/lib/libart.so (MterpInvokeVirtualQuick+598)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #18 pc 00402714 /system/lib/libart.so (ExecuteMterpImpl+29972)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #19 pc 001e6bc1 /system/lib/libart.so (art::interpreter::Execute(art::Thread*, art::DexFile::CodeItem const*, art::ShadowFrame&, art::JValue, bool)+340)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #20 pc 001eb36f /system/lib/libart.so (art::interpreter::ArtInterpreterToInterpreterBridge(art::Thread*, art::DexFile::CodeItem const*, art::ShadowFrame*, art::JValue*)+142)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #21 pc 00200159 /system/lib/libart.so (_ZN3art11interpreter6DoCallILb1ELb0EEEbPNS_9ArtMethodEPNS_6ThreadERNS_11ShadowFrameEPKNS_11InstructionEtPNS_6JValueE+444)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #22 pc 003f8fa5 /system/lib/libart.so (MterpInvokeVirtualQuickRange+472)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #23 pc 00402794 /system/lib/libart.so (ExecuteMterpImpl+30100)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #24 pc 001e6bc1 /system/lib/libart.so (art::interpreter::Execute(art::Thread*, art::DexFile::CodeItem const*, art::ShadowFrame&, art::JValue, bool)+340)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #25 pc 001eb36f /system/lib/libart.so (art::interpreter::ArtInterpreterToInterpreterBridge(art::Thread*, art::DexFile::CodeItem const*, art::ShadowFrame*, art::JValue*)+142)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #26 pc 001ff535 /system/lib/libart.so (_ZN3art11interpreter6DoCallILb0ELb0EEEbPNS_9ArtMethodEPNS_6ThreadERNS_11ShadowFrameEPKNS_11InstructionEtPNS_6JValueE+564)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #27 pc 003f8c87 /system/lib/libart.so (MterpInvokeVirtualQuick+598)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #28 pc 00402714 /system/lib/libart.so (ExecuteMterpImpl+29972)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #29 pc 001e6bc1 /system/lib/libart.so (art::interpreter::Execute(art::Thread*, art::DexFile::CodeItem const*, art::ShadowFrame&, art::JValue, bool)+340)
2020-03-12 12:07:09.186 16283-16283/? A/DEBUG: #30 pc 001eb36f /system/lib/libart.so (art::interpreter::ArtInterpreterToInterpreterBridge(art::Thread*, art::DexFile::CodeItem const*, art::ShadowFrame*, art::JValue*)+142)
2020-03-12 12:07:09.187 16283-16283/? A/DEBUG: #31 pc 001ff535 /system/lib/libart.so (_ZN3art11interpreter6DoCallILb0ELb0EEEbPNS_9ArtMethodEPNS_6ThreadERNS_11ShadowFrameEPKNS_11InstructionEtPNS_6JValueE+564)
2020-03-12 12:07:09.187 16283-16283/? A/DEBUG: #32 pc 003f77b9 /system/lib/libart.so (MterpInvokeStatic+184)
2020-03-12 12:07:09.187 16283-16283/? A/DEBUG: #33 pc 003feb14 /system/lib/libart.so (ExecuteMterpImpl+14612)
2020-03-12 12:07:09.187 16283-16283/? A/DEBUG: #34 pc 001e6bc1 /system/lib/libart.so (art::interpreter::Execute(art::Thread*, art::DexFile::CodeItem const*, art::ShadowFrame&, art::JValue, bool)+340)
[Truncated]
2020-03-12 12:07:09.187 16283-16283/? A/DEBUG: #53 pc 003feb94 /system/lib/libart.so (ExecuteMterpImpl+14740)
2020-03-12 12:07:09.187 16283-16283/? A/DEBUG: #54 pc 001e6bc1 /system/lib/libart.so (art::interpreter::Execute(art::Thread*, art::DexFile::CodeItem const*, art::ShadowFrame&, art::JValue, bool)+340)
2020-03-12 12:07:09.187 16283-16283/? A/DEBUG: #55 pc 001eb36f /system/lib/libart.so (art::interpreter::ArtInterpreterToInterpreterBridge(art::Thread*, art::DexFile::CodeItem const*, art::ShadowFrame*, art::JValue*)+142)
2020-03-12 12:07:09.187 16283-16283/? A/DEBUG: #56 pc 001ff535 /system/lib/libart.so (_ZN3art11interpreter6DoCallILb0ELb0EEEbPNS_9ArtMethodEPNS_6ThreadERNS_11ShadowFrameEPKNS_11InstructionEtPNS_6JValueE+564)
2020-03-12 12:07:09.188 16283-16283/? A/DEBUG: #57 pc 003f7391 /system/lib/libart.so (MterpInvokeInterface+1080)
2020-03-12 12:07:09.188 16283-16283/? A/DEBUG: #58 pc 003feb94 /system/lib/libart.so (ExecuteMterpImpl+14740)
2020-03-12 12:07:09.188 16283-16283/? A/DEBUG: #59 pc 001e6bc1 /system/lib/libart.so (art::interpreter::Execute(art::Thread*, art::DexFile::CodeItem const*, art::ShadowFrame&, art::JValue, bool)+340)
2020-03-12 12:07:09.188 16283-16283/? A/DEBUG: #60 pc 001eb36f /system/lib/libart.so (art::interpreter::ArtInterpreterToInterpreterBridge(art::Thread*, art::DexFile::CodeItem const*, art::ShadowFrame*, art::JValue*)+142)
2020-03-12 12:07:09.188 16283-16283/? A/DEBUG: #61 pc 001ff535 /system/lib/libart.so (_ZN3art11interpreter6DoCallILb0ELb0EEEbPNS_9ArtMethodEPNS_6ThreadERNS_11ShadowFrameEPKNS_11InstructionEtPNS_6JValueE+564)
2020-03-12 12:07:09.188 16283-16283/? A/DEBUG: #62 pc 003f7391 /system/lib/libart.so (MterpInvokeInterface+1080)
2020-03-12 12:07:09.188 16283-16283/? A/DEBUG: #63 pc 003feb94 /system/lib/libart.so (ExecuteMterpImpl+14740)
2020-03-12 12:07:11.258 2748-2748/? E//system/bin/tombstoned: Tombstone written to: /data/tombstones/tombstone_07
2020-03-12 12:07:11.266 2693-2693/? E/audit: type=1701 audit(1584011231.251:1220): auid=4294967295 uid=10219 gid=10219 ses=4294967295 subj=u:r:untrusted_app:s0:c512,c768 pid=16280 comm=".pl/..." exe="/system/bin/app_process32" sig=7
2020-03-12 12:07:11.301 2962-16284/? E/ActivityManager: Found activity ActivityRecord{dc4c01c u0 com.efgd.music/.MainActivity t-1 f} in proc activity list using null instead of expected ProcessRecord{ca03534 16010:com.efgd.music/u0a219}
2020-03-12 12:07:11.398 3338-3338/? E/SKBD: bbw getInstance start
2020-03-12 12:07:11.398 3338-3338/? E/SKBD: bbw sendSIPInformation state: 6 isAbstractKeyboardView : true
2020-03-12 12:07:11.404 3338-16293/? E/SKBD: bbw sending null keyboardInfo as SIP is closed
2020-03-12 12:07:11.419 5224-5254/? E/PBSessionCacheImpl: sessionId[22976978907188413] not persisted.
```
Answers:
username_1: @username_2 I remember you looked at some other Android-related issues, would you be able to check this one out?
Thanks
username_2: are other hash functions than xx() produce the same crash? does `value` equal to null? what is the length of `value`? hashBytes(new byte[0-16]) always produce the same crash?
username_0: I have no physical access to this device now, since all our work is remote due to covid spread. All information i have is from QA team in my company, so i have limited options here.
We are using xxHash to generate HMAC for requests. So value is mostly around 200-300 bytes long UTF-8 encoded string. It can never be null (it's kotlin, value is based on NonNullable string). If you need more data on that i try to get this device somehow.
username_2: how can relate this stack to hash function?
username_0: That's the weird part. There is no my code on the stack. But if I remove call to hash function - everything else runs just fine. Add this to only one device it happens on - i think this might be some framework issue. And it's Samsung, which have a long history of breaking Android framework in many ways..
I know that this might be impossible to fix, but I hoped somebody might have some idea
username_2: sorry, i have no idea~
need more info, so better to get the device for debugging and test some other hash methods.
username_2: @username_0 can u try to catch exceptions when call hash method:
```java
LongHashFunction h = null;
long v= 0;
try {
h = LongHashFunction.xx();
} catch (Throwable e) { throw new Exception(e); }
try {
v = h.hashBytes(value);
} catch (Throwable e) { throw new Exception(e); }
```
username_0: I tried to capture exception, but it's fatal crash so nothing was caught. It just crashes the process entirely, bypassing even global exception handlers.
I will try more as soon as I will get the device |
fedspendingtransparency/usaspending-api | 985846576 | Title: REST GET request that returns award details using agency codes
Question:
username_0: The only way to get award details via agency identifier as far as I know is to call `https://api.usaspending.gov/api/v2/bulk_download/awards/`. It would be nice if a json response was returned. I looked through the documentation for quite some time. But it is very possible I missed something. If I did not miss the call I need, would it be possible to return this data via json? I am more than happy to contribute if this team does not deem this as a high priority task and/or does not have the time. Thank you. |
jOOQ/jOOQ | 245057401 | Title: Add Clock Configuration.clock()
Question:
username_0: Some jOOQ features depend on a clock. Currently, the optimistic locking feature is hard-wired to a call to `System.currentTimeMillis()`, which cannot be overridden by users for testing purposes.
With a `Configuration.clock()`, we could allow users to override this behaviour. (see https://github.com/jOOQ/jOOQ/issues/6445).
Another feature that could depend on overrideable timestamps is the transaction timestamp feature (not yet implemented: https://github.com/jOOQ/jOOQ/issues/5096)<issue_closed>
Status: Issue closed |
Azure/azure-cli | 899928463 | Title: Is it possible to add new baked script in the list of commands?
Question:
username_0: [Enter feedback here]
Is it possible to add new baked script in the list of commands?
If I have a list of commands I want to run, it would be very helpful if I can have them in the list and execute later to do some diagnostics. The reason of having a list is that we don't want support engineers being able to run anything on the VM, only in allowed list.
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: f04b196d-7d11-7213-f037-f12b85b19c52
* Version Independent ID: adc05d8e-b13b-134b-5f61-42aaf23666df
* Content: [az vm run-command](https://docs.microsoft.com/en-us/cli/azure/vm/run-command?view=azure-cli-latest)
* Content Source: [latest/docs-ref-autogen/vm/run-command.yml](https://github.com/MicrosoftDocs/azure-docs-cli/blob/master/latest/docs-ref-autogen/vm/run-command.yml)
* Service: **virtual-machines**
* GitHub Login: @rloutlaw
* Microsoft Alias: **routlaw**
Answers:
username_1: Compute
username_2: @username_0 Could you help to explain what `baked script` is? What features does it need to support?
username_0: It means as an owner of the VM, I can define a couple of .sh scripts (e.x. a.sh, b.sh...)which is deployed on the VM, and I can run CLI command like this:
`az vm run-command invoke a.sh`
`az vm run-command invoke b.sh`.
This can help to run duplicate shell commands one by one. Also it can reduce the possible human error when support engineers are working on the VMs.
username_2: @username_0 In fact, at present, the parameter `--scripts` of command `az vm run-command invoke` can support inputing script.
Such as:
```sh
az vm run-command invoke -g MyResourceGroup -n MyVm --command-id RunShellScript --scripts @scripts_file
```
May I ask what's the difference between this `baked script` and `az vm run-command invoke -g MyResourceGroup -n MyVm --command-id RunShellScript --scripts @scripts_file`?
username_0: I assume `script_file` has to be on the local machine, instead of the remote VM.
My scenario is that a developer can author a list of script files gathering diagnostic information and check-in in the source repo. These script eventually get deployed on the VMs via release pipeline. These scripts are reviewed and well written so it is trusted with high quality.
Then some day an issue got reported on the service, and the SRE run these scripts on the remote VM to gather diagnostic information, instead of invoking some ad-hoc scripts which have a relatively low quality and a higher risk of damage. |
EarthMC/Issue-Tracker | 436465507 | Title: When 1.14?
Question:
username_0: I get it's probably gonna be a while until all the plugins work with 1.14, but I thought I might as well check.
Answers:
username_1: Me knowing how long plugins take to update id give it 2 weeks to 3 months
username_2: or a year
username_3: probably a year
username_4: likely a year
Status: Issue closed
|
frontendbr/forum | 163265542 | Title: Onde conseguir Freeman?
Question:
username_0: Eu estou começando na área e gostaria de dicas para conseguir Freelas.
Quais sites eu devo me cadastrar ou com mensagens quem falar?
Preciso ter um portfólio?
É como eu tenho 16 anos, perante a lei é permitido eu fazer Freelance?
Obrigado desde já!!!
Answers:
username_1: Não é ilegal, mas pode ter dificuldades se não emitir NF. Para emitir NF você precisa ao menos ser MEI (Micro Empreendedor Individual), para ser MEI você precisa ser de maior ou emancipado. Com 16 anos eu emancipei e consegui abrir MEI e emitir NF sem problemas.
Entretanto, gostaria de te dar uma dica baseado em minha experiência: freela não vale a pena, pelo menos para quem está no começo da carreira (que parece o seu caso). Se puder encontrar um estágio ou um emprego fixo com um mentor com mais experiência que você seria ótimo! Você poderá aprender muito e conseguirá sentir uma curva de aprendizado muito boa.
Fazer freela sem experiência pode ser ruim pra você, pode ser ruim para seu cliente, e pode ser ruim para outros desenvolvedores.
username_2: Faço das palavras do amigo acima as minhas, mas caso não queira se emancipar, pode abrir no nome de algum parente que não trabalha assinar sua carteira como aprendiz e pronto. Mas teria que ler muito, acredito que possa pegar jobs pequenos em sua cidade e coisas do tipo.
Dificilmente uma empresa vai contratar um menor aprendiz pra essa área, é o que acredito, ainda mais dependendo de onde mora (interior no caso). Acredito que com 16 anos ainda esteja com seus pais, relativamente sem custo de vida, aproveitaria esse tempo ao máximo para me especializar, não ter problemas pessoas tais como (divida, sustento próprio, família pra sustentar) isso freia seu desenvolvimento, aproveita que ta sem essa carga, com muito tempo disponível e mete a cara nos estudos.
username_0: @username_1 e @username_2 muito obrigado pelas dicas!!!!
Eu já pensei em pegar um estágio em uma empresa mas a questão é o tempo perdido em trânsito e como eu estou no ensino médio ainda, não sobraria tempo para estudar. Por isso a ideia de pegar Freelas, posso conciliar o tempo estudando, ganhando experiência e ganhando um trocados de extra.
username_3: concordo com @username_1 Muitos clientes são exigentes com a qualidade de produtos e principalmente com os prazos, se você for um desenvolvedor inexperiente, isso pode comprometer você como profissional e os outros profissionais que perderam uma oportunidade de freela, por conta disto. Acredito que seria melhor um estagio, não ocupa tanto tempo, mesmo porque estagio dura no maximo 6 horas.
username_4: @username_0 "Ter um portfólio" sempre ajuda, mas acredito que o portfólio de qualquer desenvolvedor hoje em dia é o Github.
Por isso participe de projetos open source, crie seu próprio, mostre seu trabalho com "sites demo" ou no codepen (que funciona muito pra frontend).
Quanto a onde buscar trabalhos, existem vários lugares pra pegar freelas. Eu particularmente uso o [Upwork](http://www.upwork.com). Como funciona por "bids" e recomendações, no ínicio eu adotei a estratégia de fazer preços mais baratos para ter um histórico no site e hoje em dia já consigo contratos de valor hora acima de $35 usd, o que é relativamente alto se vc morar aqui no Brasil.
Ah, mas no caso do Upwork o ingles é necessário, sempre rola entrevista, algumas vezes por chat e outras por Skype call (inclusive com camera).
username_5: @username_4 boa dica sobre o Upwork, eu utilizava muito quando era odesk.
@username_0 tem esse repo no github que contém uma lista de empresas que disponibilizam trabalho remoto. https://github.com/lerrua/remote-jobs-brazil
username_0: @username_5 @username_4 @username_3 obrigado pela ajuda!!!
Faz nove meses que eu venho estudando Front-end e acredito que está na hora de ganhar mas um pouco de experiência. E @username_4 vou procurar investir mais tempo em projetos open source.
username_4: @username_0 se quiser uma dica por onde começar, https://github.com/username_4/react-hot-redux-firebase-starter, eu to precisando de uma ajudinha lá. Já separei as issues e acredito que seja fácil mandar uns PR pra fecha-las.
username_6: Como a maioria já comentou, eu reforço que como você está ainda sem cargas de responsabilidades ainda, aproveite ao máximo para estudar e se dedicar.
Utilize bastante o Github, escreva um blog talvez, faça experimentos para ir criando um portfólio. Assim vai ser muito mais proveitoso. Além disso, recomendo começar a se movimentar, ir em eventos, conversar com as pessoas da comunidade, o network é muito importante para quem deseja freelas, pois muitas vezes funciona por recomendação =)
Status: Issue closed
|
pachyderm/pachyderm | 187513576 | Title: Pachctl doc links are broken
Question:
username_0: http://docs.pachyderm.io/en/latest/pachctl/pachctl.html
The links to each command are broken
Answers:
username_1: pachctl.md is autogenerated. All the links need ../pachctl/ in front of them. I think this needs to be added to `make assets` or whatever we use to autogenerate the pachctl docs. I could obviously change the links in the md file, but that doesn't solve the problem and I probably shouldn't be the one to futz with the `make` file.
username_0: Its more than just that prefix. The links right now point to `somecommand.md` when they should point to `somecommand.html`
There is a problem with how we're rendering markdown on RTD.
This was working in the past because we had a manually updated `doc/pachctl/pachctl.rst` file that mimicked the auto-generated one.
[I've opened an issue on RTD](https://github.com/rtfd/readthedocs.org/issues/2520) so we'll see what they say. Hopefully I'm just doing something silly. If not, we'll probably just run with the manual curation of the rst file.
username_1: adding an rst file for now. I'll touch up the rst to include 1-liner cmd summaries.
Status: Issue closed
|
mgsx-dev/gdx-gltf | 895695892 | Title: Why texture incomplete when camera move faraway ?
Question:
username_0: I download the model from sketchfab,the model's texture incomplete when camera move faraway, but it's ok when camera close to the model. I'm not writing any code, just using the release jar.
Answers:
username_1: which model? which jar release? which texture?
username_0: I used the jar both "gdx-gltf-demo-desktop-2.0.0-preview.jar" and "gdx-gltf-demo-desktop-1.0.0-patch1.jar".
The model have tested is :
1. https://sketchfab.com/3d-models/forest-warrior-527429928e0349168aa7c29e14a8c1c8 , the texture for hair and cloth goes wrong.
2. https://sketchfab.com/3d-models/motelsign-post-apo-170f5144a7544fabbf203199a72e3cc8 , the texture for wood goes wrong.
Camera moving faraway will lead to the problem, if you check it very closely, it' ok.
I'm using AMD's display card now, the screen monitor could blink sometimes . I will test it on Intel's integrated graphics card and report again.
username_0: I‘ve imported the models to Blender, also bad when camera faraway in this computer(Windows, AMD WX4100 graphics card).
But !!! The models work well in another computer(Linux, Intel integrate graphics card) with Blender .
I don't know what happed, and i think your code and jar may working well, perhaps my computer's ENV not good...
Status: Issue closed
username_1: yeah, it sounds like an issue with your driver, maybe try to upgrade them on your machine.
I'm closing now since it's not an issue with the library. |
zkSNACKs/WalletWasabi | 931680517 | Title: Start Wasabi with the OS
Question:
username_0: ### General Description
We want to make an opportunity to put Wasabi into the Startup folder to make it run when the OS starts. (Mainly on Win and Mac).
Part of Wasabi2.0 PREVIEW version.
Complexity | Priority |
--- | --- |
5 | 2 |
@username_2 , @username_0 , @username_3 and @username_1 should look into this and find a sollution for this.
Answers:
username_1: I modified the description a bit - nothing cardinal.
username_2: I have started researching this a bit. I'm not familiar too much with WiX though, so I've read some basic documentation and I can work on making this happen on Windows. Does it sound good or does @username_3 have a better idea how to move this forward?
username_3: I found the same answer as @username_2, we need to place the WW shortcut icon into the `Startup` folder.
I found a code snippet for this, and I will test it later with a dummy project to see if it's works or not.
username_2: @username_3 This may be a good start: https://github.com/username_2/WalletWasabi/tree/feature/2021-06-29-wix
username_3: I made a little project for testing.
```
Console.WriteLine("Hello World!");
string pathToExe = Assembly.GetExecutingAssembly().Location;
pathToExe = pathToExe.Remove(pathToExe.Length - 3);
pathToExe += "exe";
RegistryKey rkApp = Registry.CurrentUser.OpenSubKey("SOFTWARE\\Microsoft\\Windows\\CurrentVersion\\Run", true);
rkApp.SetValue("FinalApp", pathToExe.Trim());
Thread.Sleep(2000);
Console.WriteLine("Done.");
```
With this we can write to the registry only for the current user, and we don't even have to copy anything to the shortcut folder.
Note: This is for Windows only!
username_3: With a little modification we could do something like this:
```
string keyName = @"Software\Microsoft\Windows\CurrentVersion\Run";
using (RegistryKey key = Registry.CurrentUser.OpenSubKey(keyName, true))
{
if (key == null)
{
// Key doesn't exist. Create it.
}
else
{
key.DeleteValue("MyApp");
}
}
```
Maybe in the Options of the UI we could have a boolean to controll this.
username_2: I, for one, would say that it's nicer to use the startup folder. One can just simply open a folder and knows what's inside. But I say that as a poweruser probably.
username_2: @username_1 A decision should be made whether the startup feature is supposed to be an install-only one or whether WW settings should contain a checkbox for this as proposed by Adam's #5956.
username_1: Yes.
Status: Issue closed
username_3: Windows: #5960
macOS: #6041
Linux: #6080 |
bincrafters/community | 563482989 | Title: [question][qt] why does qt package do not append bin folder to PATH
Question:
username_0: <!-- What is your question? Please be as specific as possible! -->
I have tried to use `qt 5.14.1` conan package and noticed that the only env variable it creates is `CMAKE_PREFIX_PATH`. This works perfect when project is being built with cmake.
But this doesn't work if there is a need to use same qt binaries, e.g. for test automation. I have tried to generate conan virtual environment and again it provides me only the `CMAKE_PREFIX_PATH` that contains root folder of the package. I can use that, but I also expected that package should append qt `bin` folder to the `PATH` variable. Is there any reason of not doing so?
Answers:
username_1: Hi. Conan is able to add the bin folder to the PATH without setting it explicitely in package_info. You can either use tools.RunEnvironment, or the run_environment argument of self.run, or conan virtual environment generator.
username_0: @username_1 I have just installed qt 5.14.1 on both osx and windows with virtual environment generated:
`conan install qt/5.14.1@bincrafters/stable -g=virtualenv --build=missing`
I have received generated virtual env files, but when I open the `environment.sh.env` file it mentions qt only in `CMAKE_PREFIX_PATH` . variable. Also trying to use qmake with activated env does not find `qmake` binary. Could you, please, let me know what am I doing wrong?
username_1: I was not being precise enough: you need to use [virtualrunenv generator](https://docs.conan.io/en/latest/mastering/virtualenv.html#virtualrunenv-generator)
username_0: @username_1 yes, that does work. Thanks for quick support
Status: Issue closed
|
Azure/autorest.java | 461045169 | Title: Import cut off half way during generation of network v2019_02_01
Question:
username_0: Import statement is cut off half way in SubnetImpl. No type depends on this import.
```java
import com.microsoft.azure.management.network.v2019_02_01.InterfaceEndpoint;
import com.microsoft.azure.management.network.v2019_02_01.NetworkSecurityGroup;
import com.microsoft.azure.management.network.v2019_02_01.;
import com.microsoft.azure.management.network.v2019_02_01.RouteTable;
import com.microsoft.azure.management.network.v2019_02_01.ServiceEndpointPolicy;
```
Answers:
username_1: Please reopen if this is still an issue for v4 generator.
Status: Issue closed
|
TheBusyBiscuit/builds | 1086080273 | Title: LuckyPandas not showing up on the build page
Question:
username_0: <!-- FILL IN THE FORM BELOW -->
## :round_pushpin: Description (REQUIRED)
<!-- A clear and detailed description of what went wrong. -->
<!-- The more information you can provide, the easier we can handle this problem. -->
<!-- Start writing below this line -->
Luckypandas isnt showing up on the builds page for some reason
## :bookmark_tabs: Steps to reproduce the Issue (REQUIRED)
<!-- Tell us the exact steps to reproduce this issue, the more detailed the easier we can reproduce it. -->
<!-- A link to the site in question is required! -->
<!-- Screenshots help us a lot too!-->
<!-- Start writing below this line -->
1. Open your preferred web browser (Google Chome, Microsoft Edge, Mozilla Firefox or any other Web Browser)
2. Go to the URL https://thebusybiscuit.github.io/builds/
3. Search for j3fftw1
4. Then you will see there is no LuckyPandas
## :bulb: Expected behavior (REQUIRED)
<!-- What were you expecting to happen? -->
<!-- What do you think would have been the correct behaviour? -->
<!-- Start writing below this line -->
When going to the builds page i expect LuckyPandas to show with multiple builds.
Answers:
username_1: Turns out that commit 87c5a1c88a7ddd653f8efcb779c10d1fd6d3844b was pushed by the builds program the exact same time that pull request #145 was merged, making it override the PR :LUL:
Never happened before, but just make a new PR and it will make it this time
Status: Issue closed
|
dt222cc/1dv450-dt222cc | 137542888 | Title: If-satser och undantag
Question:
username_0: Det sparar en rad kod att göra en tilldelning i en if-sats som du gör många gånger i dina controllers, t.ex. [här](https://github.com/username_1/1dv450-username_1/blob/master/2-api/app/controllers/api/v1/events_controller.rb#L65). Men jag tycker att det blir svårare att förstå.
Jag föredrar användningen av ´find´ istället för ´find_by_id´. Visst, den kommer att kasta ett exception vid fel id. Men genom att ha en funktion som räddar t.ex. alla `RecordNotFound` exceptions minskar både komplexiteten och antalet rader kod. Ett exempel på vad jag menar finns [här](https://github.com/thajo/1dv450_demo/blob/master/app/controllers/teams_controller.rb#L6).
Answers:
username_1: Noterat
Status: Issue closed
|
LiveSplit/livesplit-core | 314794503 | Title: C API Segment History Iterator seems to be broken
Question:
username_0: When trying to figure out #120 I updated livesplit-core in LiveSplit and it seems to panic on Option::unwrap() on SegmentHistoryIter::next, which doesn't seem to make sense, but so far I couldn't figure out what is going on there, especially with Debug Mode not working #121<issue_closed>
Status: Issue closed |
truedread/netflix-1080p | 471874829 | Title: Unexpended Error(opera&win) 1.14&1.15
Question:
username_0: O7111-1003 error code and i try look console and i see
```
chrome-extension://nmfikcpmiiikoaokjcpjngkbandapkcp/get_manifest.js net::ERR_FILE_NOT_FOUND
(anonymous) @ content_script.js:43
```
Before i installed 1.13 and thats work perfectly.
Status: Issue closed
Answers:
username_0: O7111-1003 error code and i try look console and i see
```
chrome-extension://nmfikcpmiiikoaokjcpjngkbandapkcp/get_manifest.js net::ERR_FILE_NOT_FOUND
(anonymous) @ content_script.js:43
```
Before i installed 1.13 and thats work perfectly.
username_1: Update to the latest version.
username_0: i tried already lastest version not work with opera
Status: Issue closed
username_1: Closing as major changes have been made that have probably fixed this. |
dyatchenko/ServiceBrokerListener | 438598384 | Title: Why 'insert' trigger three TableChangedEvent?
Question:
username_0: I use the example code, but when i insert data in SSMS, the TableChangedEvent trigger three times in this order --- NotificationType.None, NotificationTypes.Update, NotificationTypes.Insert.
I want to monitor update, insert, delete event, when I delete and update data in SSMS it works perfectly. Just the insert trigger three times...
`var listener = new SqlDependencyEx(connectionString, "DatabaseName", "TableName");
listener.TableChanged += (o, e) =>
{
//logic code
};
listener.Start();
`
Thanks for any reply! |
Nervengift/kvvliveapi | 347482511 | Title: 'kvvliveapi' has no attribute 'search_by_name'
Question:
username_0: Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: module 'kvvliveapi' has no attribute 'search_by_name'
```
- Tested on Python 3.6 and Python 3.7.
- Installed via pip, Version 0.1.1<issue_closed>
Status: Issue closed |
jhipster/jhipster-registry | 265004849 | Title: JHipster registry docker image doesn't work on OpenShift
Question:
username_0: <!--
- Please follow the issue template below for bug reports and feature requests.
- If you have a support request rather than a bug, please use [Stack Overflow](http://stackoverflow.com/questions/tagged/jhipster) with the JHipster tag.
- For bug reports it is mandatory to run the command `jhipster info` in your project's root folder, and paste the result here.
- Tickets opened without any of these pieces of information will be **closed** without any explanation.
-->
##### **Overview of the issue**
JHipster registry docker image (on DockerHub) needs to have root access.
It need to write in /target directory for logs.
This directory is not created in the dockerfile
<!-- Explain the bug or feature request, if an error is being thrown a stack trace helps -->
##### **Motivation for or Use Case**
I need to maintain an override of image :
`FROM jhipster/jhipster-registry:v3.1.2
RUN mkdir /target && chmod g+rwx /target
`
It's a bad pratice that docker image needs to be root...
<!-- Explain why this is a bug or a new feature for you -->
##### **Reproduce the error**
Just deploy hipster/jhipster-registry on minishift
You'll get a "Could not write to /target/...." error
<!-- For bug reports, an unambiguous set of steps to reproduce the error -->
##### **Related issues**
<!-- Has a similar issue been reported before? Please search both closed & open issues -->
##### **Suggest a Fix**
Just add
RUN mkdir /target && chmod g+rwx /target
In the https://hub.docker.com/r/jhipster/jhipster-registry/~/dockerfile/
<!-- For bug reports, if you can't fix the bug yourself, perhaps you can point to what might be
causing the problem (line of code or commit) -->
##### **JHipster Registry Version(s)**
latest : v3.1.2
<!--
Which version of JHipster Registry are you using, is it a regression?
-->
##### **Browsers and Operating System**
<!-- What OS are you on? is this a problem with all browsers or only IE8? -->
- [X] Checking this box is mandatory (this is just to show you read everything)
Answers:
username_1: Did you use our Openshift sub-generator? I'm pretty sure it works, it's made by Red Hat
username_0: Yes i use it.
And when using it, (without touching anything else) jhipster registry refuse to start

username_0: The jhipster registry part is not running with the jhispter service account which has right for anyuid.
But if we modify the dockerfile as i suggested, all would be right!
username_0: The problem comes from this commit : https://github.com/jhipster/jhipster-registry/commit/085439b9c33c5a84746d39c473f1ec8c10b78a63#diff-285a2da9b966f929edc1374c522a0449
So, this is a regression, it use to work with 3.1.1
username_2: Creating the `target` folder should be OK
@username_0 : do you want to PR ?
username_0: Hi, i don't know where is the https://hub.docker.com/r/jhipster/jhipster-registry/~/dockerfile/ Dockerfile,
It's not the same as the one in https://github.com/jhipster/jhipster-registry/blob/master/src/main/docker/Dockerfile
username_2: It's this file https://github.com/jhipster/jhipster-registry/blob/master/Dockerfile in the root folder
username_0: Ah, ok, btw why two versions?
I'll do the pull request
username_2: The Dockerfile inside `src/main/docker` is used in development only.
For Docker Hub, it's the `Dockerfile` in the root folder which is used
username_0: PR done.
There's still another problem with environment variables like ${GIT_URI} not evaluated in this version of Dockerfiles (you've to create an entrypoint) but i will open a new issue if i have time...
username_2: Thanks for PR, I will have a look when I have time
And yes, if you have another issue, plz open a new one, so it's clear
username_1: Thanks @username_0 for the bug report, the explanation, and the PR! You rock :-)
Status: Issue closed
username_0: No, the bug is not fixed...
```
docker run jhipster/jhipster-registry:master /bin/sh -c 'ls -la /target'
ls: /target: No such file or directory
```
apparently this dockerfile is used to compile and build the image and not for running
username_3: @username_0 Yes the lines were not added at the right place: the correct fix is:. https://github.com/jhipster/jhipster-registry/pull/192
username_3: <!--
- Please follow the issue template below for bug reports and feature requests.
- If you have a support request rather than a bug, please use [Stack Overflow](http://stackoverflow.com/questions/tagged/jhipster) with the JHipster tag.
- For bug reports it is mandatory to run the command `jhipster info` in your project's root folder, and paste the result here.
- Tickets opened without any of these pieces of information will be **closed** without any explanation.
-->
##### **Overview of the issue**
JHipster registry docker image (on DockerHub) needs to have root access.
It need to write in /target directory for logs.
This directory is not created in the dockerfile
<!-- Explain the bug or feature request, if an error is being thrown a stack trace helps -->
##### **Motivation for or Use Case**
I need to maintain an override of image :
`FROM jhipster/jhipster-registry:v3.1.2
RUN mkdir /target && chmod g+rwx /target
`
It's a bad pratice that docker image needs to be root...
<!-- Explain why this is a bug or a new feature for you -->
##### **Reproduce the error**
Just deploy hipster/jhipster-registry on minishift
You'll get a "Could not write to /target/...." error
<!-- For bug reports, an unambiguous set of steps to reproduce the error -->
##### **Related issues**
<!-- Has a similar issue been reported before? Please search both closed & open issues -->
##### **Suggest a Fix**
Just add
RUN mkdir /target && chmod g+rwx /target
In the https://hub.docker.com/r/jhipster/jhipster-registry/~/dockerfile/
<!-- For bug reports, if you can't fix the bug yourself, perhaps you can point to what might be
causing the problem (line of code or commit) -->
##### **JHipster Registry Version(s)**
latest : v3.1.2
<!--
Which version of JHipster Registry are you using, is it a regression?
-->
##### **Browsers and Operating System**
<!-- What OS are you on? is this a problem with all browsers or only IE8? -->
- [X] Checking this box is mandatory (this is just to show you read everything)
Status: Issue closed
username_0: I confirm it works!
Thanks! |
bitfocus/companion-module-renewedvision-propresenter | 968749234 | Title: Is there any other way to do this ???
Question:
username_0: 1. Next Previous item in Current PlayList or Library.
2. Next Previous Background in current Media List.
3. Next previous Media List in Media.
4. Custom Action how to ???
how can I this ???
Answers:
username_1: Hello!
We can only send commands to Pro7 that Pro7 understands in it's remote protocol.
There are no commands in the remote protocol for those items you listed in 1. 2. and 3.
You can however, send MIDI notes to Pro7 to achieve much of what you are wanting.....(using MIDI relay Companion module and with MIDI-relay listener program installed and running on machine with Pro7.)

The custom action does NO magic - you can make up new features/actions that Pro7 does not already do.
The reason I have added that to the module is so that there is a way to make buttons that support any NEW features that get added to Pro7 remote protocol *before* the Companion module is updated to support those new features.
It took me acouple of weeks to update the module to add triggering macros and looks - all that time, anyone could have used custom action to trigger macros and looks (if they asked me what is the custom action to type there).
It's really a support option for me to help people if they want a new feature in a rush before the Companiopn app is updated.
Status: Issue closed
|
8bitPit/Niagara-Issues | 799818187 | Title: Sort Favourites my most used (Like Alphabets)
Question:
username_0: I am suggesting an option be added to allow favourites to be sorted by most used. I understand there is a feature to add suggested apps below favourites but this is not enough. First problem is it takes a while to suggest. The bigger issue is if you have a lot of favourites there are no suggestions. I used to have a app called "app swap" and it was a simple concept that would sort your drawer by most used. It was genius
Likewise I would love to see my favorites sorted by most used because right now I have to manually do this and it's extremely time consuming and annoying. The suggestions feature as stated above doesn't show suggestions with lots of favourites so what's the point?
Status: Issue closed
Answers:
username_1: I'm sorry, but we don't have plans to make the maximum number of suggestions customizable: https://github.com/username_1/Niagara-Issues/issues/454. We believe the most efficient way to set up Niagara Launcher is by having 8 favorites and accessing the rest of the apps via the alphabet (its sub-sections are sorted by usage) and with swipe actions: https://help.niagaralauncher.app/article/38-folders. |
GoogleCloudPlatform/flink-on-k8s-operator | 598791603 | Title: chart installed failed in flink-operator-v1beta1
Question:
username_0: version: flink-operator-v1beta1
I try to install the flinkoperator with helm3 and get the following errors:
helm3 install flinkoperator ./flink-operator/
Error: parse error at (flink-operator/templates/flink-operator.yaml:2756): undefined variable "$clusterName"
I changed the $clusterName to "clusterName" mananly and tried anagin:
helm3 install flinkoperator ./flink-operator/
Error: unable to build kubernetes objects from release manifest: [unable to recognize "": no matches for kind "Certificate" in version "certmanager.k8s.io/v1alpha1", unable to recognize "": no matches for kind "Issuer" in version "certmanager.k8s.io/v1alpha1"]
Answers:
username_1: Please try helm install with [instruction](helm repo add flink-operator-repo https://googlecloudplatform.github.io/flink-on-k8s-operator/) again. Just update with new release hosted by helm server.
Status: Issue closed
username_0: It works now, thanks. |
syndesisio/syndesis | 300260403 | Title: Order of items in FTP connection configuration form
Question:
username_0: I think items in FTP configuration form should be listed/sorted in more user friendly way. see picture.

Answers:
username_1: @seanforyou23 how is the ordering enforced, just by the ordering of parameters in connector?
username_1: @sunilmeddr fyi
username_2: So yeah, the forms should be rendered in whatever order the fields come back from the backend. We've a [client-side hack](https://github.com/syndesisio/syndesis/blob/master/app/ui/src/app/connections/common/configuration/configuration.service.ts#L35-L42) at the moment that we can use to specify an exact order, and then there's an open issue to either add support at the backend for an additional attribute or an `index` property to fields: #1204
username_3: @username_2 @username_1 can you tell me which is the order you whant them to be displayed ? I'm working on some connectors stuffs so I can take it
username_4: I think we implemented this.
Status: Issue closed
|
Dwarf-Therapist/Dwarf-Therapist | 648079297 | Title: Missing goal/dream in 47.04 (attaining rank in society)
Question:
username_0: I've got a dwarf with the goal: "She dreams of attaining rank in society."
This isn't recognised by Dwarf Therapist and doesn't appear in the personality tooltip for that dwarf.
It looks like it just needs to be added to the [goals] list in [/resources/game_data.ini](https://github.com/Dwarf-Therapist/Dwarf-Therapist/blob/v41.1.7/resources/game_data.ini#L1392) but I don't know how to find out its ID number.
Answers:
username_0: I managed to find out its ID by trial-and-error modifications to game_data.ini. The following works:
14\id=13
14\name="rank"
14\desc="dreams of attaining rank in society"
username_1: There is actually two new goals according to dfhack: https://github.com/DFHack/df-structures/blob/b67b3fa4b02f834dc76a2e1eae21136e0be089f7/df.units.xml#L198-L199
The best way to find new values is looking at them using dfhack (either command line or gui/gm-editor).
username_2: This should be fixed now. I've added the three missing goals in PR #224 among with ability to group dwarfs by their goal.
Status: Issue closed
|
OpenEmu/OpenEmu | 1046649875 | Title: Flickering screen when in a full screen game and using eGPU
Question:
username_0: # Summary of issue
When I'm using my [Blackmagic eGPU](https://www.apple.com/shop/product/HM8Y2VC/A/blackmagic-egpu), the screen flickers most of the time. I can occasionally get the screen not to flicker while using the eGPU, but it is not clear what does that. All it takes to fully fix it is to switch my HDMI cable directly into my mac instead of the eGPU.

## Notes:
* Does not appear to happen while the in-game menu (with the pause, reset, save state functions, etc) is showing up
* Does not appear to be something that the OS built in screen-capturing can capture. I had to record my screen with a video camera for the above video. Not sure how the rendering stack works, but I thought this might be relevant.
# Steps to reproduce
1. Use a Mac Mini with a Blackmagic eGPU
2. Plug monitor HDMI cable into eGPU port
3. Launch a game (works on multiple emulators)
4. Make the game full screen
5. Wait for the in-game menu to fade away
4. Observe flickering
# Expected Behavior
Games work without flickering while using eGPU HDMI port in full screen
# Observed Behavior
Games flicker while using eGPU HDMI port in full screen
# Debugging Information
- OpenEmu Version: v2.3.3
- macOS Version: 11.6
- Mac Mini 2018 (no built in GPU) |
sw6y15/HKEvent | 398926214 | Title: Could I replace anchors parameter in tiny-yolo-voc.cfg?
Question:
username_0: Hi, could I replace anchors parameters in tiny-yolo-voc.cfg by the output of `darknet.exe detector calc_anchors` command?


as well as in the ObjectDetection.cs of sample code in section 4?

The output of `darknet.exe detector calc_anchors` command is quite different from default value in tiny-yolo-voc.cfg. Is that related to the pixel resolution of fruit images?
Answers:
username_1: I have the same concern, when running `darknet.exe detector calc_anchors`, output value seems very large compared to the default value for voc.
username_2: Yep. **calc_anchors** uses k-mean method to cluster bounding box in your training data. For more strategies, you can refer to [Link](https://github.com/AlexeyAB/darknet#how-to-improve-object-detection)
username_2: It's correct step. Replace the anchors calculate from calc_anchors.
Status: Issue closed
|
influxdata/helm-charts | 926872091 | Title: Telegraf: no way to specify loadBalancerIP in service
Question:
username_0: Currently telegraf chart does not provide way to specify static IP address for LoadBalancer type of service. Which is trivial if You need to run it as LoadBalancer.
Service should contain additional value i.e. extraSpec which should allow setting any custom variable to service spec.
link: https://github.com/influxdata/helm-charts/blob/master/charts/telegraf/templates/service.yaml
eg.
```
{{- if .Values.service.loadBalancerIP }}
loadBalancerIP: {{ .Values.service.loadBalancerIP }}
``` |
dart-lang/language | 573802539 | Title: For loop specification needs total rewrite
Question:
username_0: Section `\ref{forLoop}` in the language specification needs to be completely rewritten: It specifies a highly incomplete set of static analysis rules, and it only specifies the dynamic semantics for one form of the statement (in particular, it does not cover the case where the iteration variable has a declared type).
Furthermore, it uses a very unusual approach to specify that there is a fresh iteration variable for each iteration of the loop, involving substitutions of variable names on the entire body of the loop.
It may work better to specify this kind of for loop in terms of a desugaring step where the fresh variable for each iteration is achieved by introducing regular local variable declaration in a nested block, and relying on the standard semantics of such declarations.
Answers:
username_1: Hear, hear!
The variable issue for `for (D id = e; test; inc) b` is currently rewritten into something which does an `if (first) ...` to separate the initialization from the increment.
That's important only in the case where the `inc` contains a closure capturing the loop variable.
That's something like
```dart
bool first = true;
D tmp = e;
while (true) {
D id = tmp;
if (first) {
first = false;
} else {
inc; // Can capture id.
}
if (!test) break;
{ b } // Can refer to capture of id, must be same variable as id.
tmp = id;
}
```
This ensures that the loop variable captured in `inc` is the loop variable of the following iteration, and there is only one variable per iteration.
(It also means that you can have a final loop variable, but then you can't modify it in the `inc` part).
This is not a particularly *efficient* desugaring. If we know that the `inc` does not capture the variable, we can desugar to the simpler:
``dart
D tmp = e;
while (true) {
D id = tmp;
if (!test) break
{b};
tmp = id;
inc[tmp/id];
}
```
If `test` and/or` b` does not capture the `id` variable either, we can simplify even further, like (no capture in test):
```dart
D tmp = e;
while (test[tmp/id]) {
D id = tmp;
{ b }
tmp = id;
inc[tmp/id];
}
```
or (no capture at all):
```dart
D id = e;
while (test) {
{ b }
inc;
}
```
The issue here is that we *have* to do this optimization in order to get an efficient for loop, with the default implementation being quite inefficient. |
HERA-Team/hera_cal | 424552652 | Title: Spectral Structure in Omnical Solutions due to lack of Firstcal Offset Solving
Question:
username_0: In our most recent attempt at running IDR2.2, I found considerable and worrisome new spectral structure introduced into our pipeline relative to IDR2.1.
Looking at `abscal` phases over a couple of hours, we found:

We did not observe anything like this in IDR2.1:
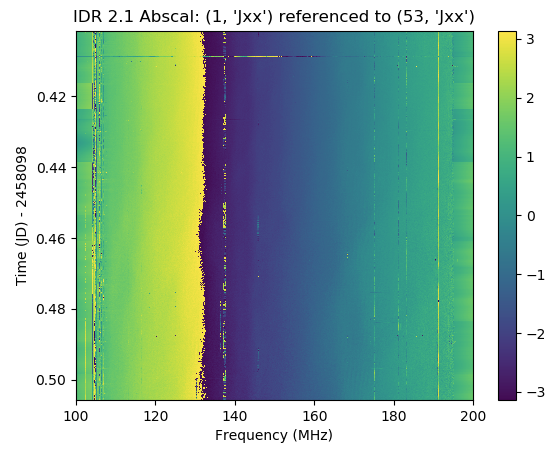
I believe this is traceable to issues in `redcal` and in particular to `firstcal`. In IDR2.1, we employed an iterative algorithm in `firstcal` to identify antennas there were 180 degrees rotated, effectively introducing a pi phase offset. This step was removed from the recent `firstcal` overhaul because we didn't think it was necessary. I now believe that it is (which is why I'm writing all this up!).
Digging into `redcal` results from this failed IDR2.2 candidate, we found evidence for complicated spectral structure:

Now compare this to IDR2.1:

I believe that this is due to bad `logcal` or `omnical` solutions that result from `firstcal` not getting close enough to the truth. We see something similar in simulations. For example, here is a simulated 19 element array where the gains are perfectly characterized by a single delay and offset (and all have amplitude of 1):

Using `redcal` on the current master branch, we get a very similar pathology:

The error in phase and delay is expected, since both of those terms are affected by degeneracies, and can be fixed later in `abscal`. However, the spectral structure is not expected. Moreover, if we force the phase offsets (phi) to be small (rather than letting them range from 0 to 2pi), the effect goes away. It therefore appears necessary to add the ability for `firstcal` to solve for phases offsets in addition to delays.
This is what I'm doing in #453.
Answers:
username_0: As I noted in #453, this problem is basically fixed with the new iterative firstcal offset solving.
Here's the result:
<img width="608" alt="Screen Shot 2019-03-23 at 4 55 13 PM" src="https://user-images.githubusercontent.com/5281139/54873101-c6f1b400-4d8c-11e9-9f2f-c2c39b933050.png">
Looks just like IDR2.1!
username_0: One more update:
I have verified that this vastly improves the abscal result. Here's the same comparison again, but now for a single run of abscal.

Status: Issue closed
|
PaddlePaddle/Paddle | 509609738 | Title: DynamicRNN中对hidden嵌套循环
Question:
username_0: - paddle 1.5, python3.6
seq2seq自定义解码过程遇到问题:
我希望实现如下操作:给定m*n的矩阵X,将X中的m个**独立同质**的n维向量用**共享参数**的方式与DynamicRNN 的 hidden 状态为 S分别进行计算。最后得到m个结果,进而求出m个概率值。
尝试了两种方法:
一是复制hidden,二是DynamicRNN里面嵌套循环,结果都是报错如下
Exception: /paddle/paddle/fluid/memory/detail/meta_cache.cc:33 Assertion `desc->check_guards()` failed.
Traceback (most recent call last):
File "./train.py", line 187, in <module>
cli()
File "/home/wangxin/tools/py367gcc48_paddle15/lib/python3.6/site-packages/click/core.py", line 764, in __call__
return self.main(*args, **kwargs)
File "/home/wangxin/tools/py367gcc48_paddle15/lib/python3.6/site-packages/click/core.py", line 717, in main
rv = self.invoke(ctx)
File "/home/wangxin/tools/py367gcc48_paddle15/lib/python3.6/site-packages/click/core.py", line 1137, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/home/wangxin/tools/py367gcc48_paddle15/lib/python3.6/site-packages/click/core.py", line 956, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/home/wangxin/tools/py367gcc48_paddle15/lib/python3.6/site-packages/click/core.py", line 555, in invoke
return callback(*args, **kwargs)
File "/home/wangxin/tools/py367gcc48_paddle15/lib/python3.6/site-packages/click_config/__init__.py", line 45, in wrapper
return fn(**kwargs_to_forward)
File "./train.py", line 151, in train
return_numpy=False)
File "/home/wangxin/tools/py367gcc48_paddle15/lib/python3.6/site-packages/paddle/fluid/executor.py", line 650, in run
use_program_cache=use_program_cache)
File "/home/wangxin/tools/py367gcc48_paddle15/lib/python3.6/site-packages/paddle/fluid/executor.py", line 748, in _run
exe.run(program.desc, scope, 0, True, True, fetch_var_name)
RuntimeError: Exception encounter.
Exception: /paddle/paddle/fluid/memory/detail/meta_cache.cc:33 Assertion `desc->check_guards()` failed.
terminate called after throwing an instance of 'std::runtime_error'
what(): Exception encounter.
train_old.sh: line 6: 28038 Aborted
- DynamicRNN中复制hidden方式:
DynamicRNN外定义
```
param = self.helper.create_parameter(
attr=self.helper.param_attr, shape=[256, 1],
dtype="float32", is_bias=False)
```
DynamicRNN中
```
state = fluid.layers.fc(input=state, size=256)
state = fluid.layers.squeeze(state, axes=[0])
z1 = fluid.layers.elementwise_mul(X, state)
z2 = fluid.layers.mul(z1, param)
z3 = fluid.layers.squeeze(z2, axes=[-1])
prob = fluid.layers.softmax(input=z3, axis=-1)
prob = fluid.layers.reshape(prob, shape=[-1, 58])
```
- DynamicRNN中嵌套循环的方式:
```
y_array = fluid.layers.create_array('float32')
i = fluid.layers.fill_constant(shape=[1], dtype='int64', value=0)
i.stop_gradient = True
limit = fluid.layers.fill_constant(shape=[1], dtype='int64', value=58)
limit.stop_gradient = True
cond = fluid.layers.less_than(x=i, y=limit)
while_op = fluid.layers.While(cond=cond)
with while_op.block():
activation = fluid.layers.gather(X, i)
activation = fluid.layers.reshape(activation, shape=[-1, 256])
activation = fluid.layers.fc(input=activation, size=64,
param_attr='pre_y_pr', bias_attr='pre_y_bs')
z = fluid.layers.elementwise_mul(activation, state)
y = fluid.layers.fc(input=z, size=1,
param_attr='y_pr', bias_attr='y_bs')
fluid.layers.array_write(y, i=i, array=y_array)
fluid.layers.increment(x=i, value=1, in_place=True)
fluid.layers.less_than(x=i, y=limit, cond=cond)
y_array, y_array_index = fluid.layers.tensor_array_to_tensor(y_array)
y_array = fluid.layers.reshape(y_array, shape=[-1, 58])
y_array = fluid.layers.softmax(input=y_array, axis=-1)
prob = fluid.layers.softmax(input=y_array, axis=-1)
```
两种写法报错一致,请问是什么原因导致的?
Answers:
username_0: 尝试在DynamicRNN外定义。
```
param0 = self.helper.create_parameter(
attr=self.helper.param_attr, shape=[256],
dtype="float32", is_bias=False)
param = self.helper.create_parameter(
attr=self.helper.param_attr, shape=[256, 1],
dtype="float32", is_bias=False)
z1 = fluid.layers.elementwise_mul(X, param0)
z2 = fluid.layers.mul(z1, param)
z3 = fluid.layers.concat(z2, axis=-1)
z3 = fluid.layers.squeeze(z2, axes=[-1])
prob = fluid.layers.softmax(input=z3, axis=-1)
```
代码可以运行。但DynamicRNN里面state做输入则有问题,请问是什么原因?
username_1: 请问m*n的矩阵X中m和n分别代表什么呢,看到贴的代码里有`z1 = fluid.layers.elementwise_mul(X, state)` 这个在DynamicRNN中可能会有问题,因为`state`(形状为`[batch_size, hidden_size]`)的batch_size会动态的变小(这个是DynamicRNN针对变长数据的特殊设计,一个batch的不等长样本若某些已经到达其长度,则会去掉),因而将一个固定大小的X和state做elementwise的乘法是可能有问题的
username_0: m是候选(比如字符串)的个数,n是候选的向量表示的维度。需要m个候选的向量表示分别与state做运算,可能是但不限于elementwise_mul。请问有无方法实现单个time step中若干个不同元素与state做运算?
username_0: m是候选(比如字符串)的个数,n是候选的向量表示的维度。需要m个候选的向量表示分别与state做运算,可能是但不限于elementwise_mul。请问有无方法实现单个time step中若干个不同元素与state做运算?
username_0: DynamicRNN的设计是这样,while_op的batch size也会变吗?请问while_op是否有希望实现预期功能?
username_1: 如果没有特别的性能要求,可以考虑不用变长数据和DynamicRNN这个接口,改用padding的数据,这样的话seq2seq可以参考这里 https://github.com/PaddlePaddle/book/blob/for_paddle1.6/08.machine_translation/README.cn.md |
CaoZ/JD-Coin | 340857816 | Title: 并不跳出登陆用的浏览器
Question:
username_0: 我安装require之后直接运行main.py并没有跳出浏览器登陆
Answers:
username_1: 你好,是每次都这样吗?是什么系统呢?有完整日志可以提供下吗?
username_0: (base) C:\Users\11034\Desktop\JD-Coin-browser>pip install -r requirements.txt
Requirement already satisfied: requests in c:\programdata\anaconda3\lib\site-packages (from -r requirements.txt (line 1)) (2.18.4)
Requirement already satisfied: PyQT5 in c:\programdata\anaconda3\lib\site-packages (from -r requirements.txt (line 2)) (5.11.2)
Requirement already satisfied: pyquery in c:\programdata\anaconda3\lib\site-packages (from -r requirements.txt (line 3)) (1.4.0)
Requirement already satisfied: chardet<3.1.0,>=3.0.2 in c:\programdata\anaconda3\lib\site-packages (from requests->-r requirements.txt (line 1)) (3.0.4)
Requirement already satisfied: idna<2.7,>=2.5 in c:\programdata\anaconda3\lib\site-packages (from requests->-r requirements.txt (line 1)) (2.6)
Requirement already satisfied: urllib3<1.23,>=1.21.1 in c:\programdata\anaconda3\lib\site-packages (from requests->-r requirements.txt (line 1)) (1.22)
Requirement already satisfied: certifi>=2017.4.17 in c:\programdata\anaconda3\lib\site-packages (from requests->-r requirements.txt (line 1)) (2018.4.16)
Requirement already satisfied: PyQt5_sip<4.20,>=4.19.11 in c:\programdata\anaconda3\lib\site-packages (from PyQT5->-r requirements.txt (line 2)) (4.19.12)
Requirement already satisfied: cssselect>0.7.9 in c:\programdata\anaconda3\lib\site-packages (from pyquery->-r requirements.txt (line 3)) (1.0.3)
Requirement already satisfied: lxml>=2.1 in c:\programdata\anaconda3\lib\site-packages (from pyquery->-r requirements.txt (line 3)) (4.2.1)
(base) C:\Users\11034\Desktop\JD-Coin-browser>python app/main.py
2018-07-13 11:02:38,504 root[config] INFO: 使用配置文件 "config.json".
2018-07-13 11:02:38,504 root[config] WARNING: 配置文件不存在, 使用默认配置文件 "config.default.json".
2018-07-13 11:02:38,504 root[config] INFO: 用户名/密码未找到, 自动登录功能将不可用.
2018-07-13 11:02:38,692 jobs[daka] INFO: Job Start: 京东客户端钢镚打卡
2018-07-13 11:02:38,973 jobs[daka] INFO: 登录状态: False
2018-07-13 11:02:38,973 jobs[daka] INFO: 进行登录...
[14532:4932:0713/110240.678:ERROR:instance.cc(49)] Unable to locate service manifest for proxy_resolver
[14532:4932:0713/110240.678:ERROR:service_manager.cc(930)] Failed to resolve service name: proxy_resolver
[2032:692:0713/110241.983:ERROR:adm_helpers.cc(73)] Failed to query stereo recording.
[2032:11536:0713/110242.739:ERROR:BudgetService.cpp(160)] Unable to connect to the Mojo BudgetService.
[14532:4932:0713/110248.716:ERROR:instance.cc(49)] Unable to locate service manifest for proxy_resolver
[14532:4932:0713/110248.716:ERROR:service_manager.cc(930)] Failed to resolve service name: proxy_resolver
username_0: win10
username_0: 之后就循环出现之前发的那一条
username_1: 如果使用普通的 Python, 不使用 Anaconda 呢?会不会是 Anaconda 安装 lib 的原因?
username_0: 不知道,之前我开启pac模式的shadowsocks,跳出那个,现在我关掉shadowsocks之后显示这个
[10124:6948:0716/055115.170:ERROR:adm_helpers.cc(73)] Failed to query stereo recording.
[10124:15616:0716/055115.834:ERROR:BudgetService.cpp(160)] Unable to connect to the Mojo BudgetService.
username_0: 是不是我只能通过配置文件而不是浏览器登陆了emmm
username_2: 我也碰到了相同的问题,我用的是mac,python3.6.4, 请问有什么解决办法吗?
username_3: 一模一样的问题,Anaconda装的3.6环境
username_4: Mac , pyenv安装的3.6.5 同样的问题
2018-07-17 20:51:24,376 jobs[daka] INFO: 登录状态: False
2018-07-17 20:51:24,377 jobs[daka] INFO: 进行登录...
[45427:86019:0717/205125.660066:ERROR:adm_helpers.cc(73)] Failed to query stereo recording.
2018-07-17 20:51:25.838 QtWebEngineProcess[45427:7054525] NSColorList could not parse color list file /System/Library/Colors/System.clr
2018-07-17 20:51:25.838 QtWebEngineProcess[45427:7054525] Couldn't set selectedTextBackgroundColor from default ()
2018-07-17 20:51:25.838 QtWebEngineProcess[45427:7054525] Couldn't set selectedTextColor from default ()
[45427:775:0717/205125.980140:ERROR:BudgetService.cpp(160)] Unable to connect to the Mojo BudgetService.
[45427:86019:0717/205205.516720:ERROR:stunport.cc(88)] Binding request timed out from 0.0.0.x:50771 (any)
username_5: mac, 同样的问题
username_6: 我win10,官网下载安装的py3.7 64位版本,同样问题
username_7: mac, 同样的问题😩尝试了代理也没用
username_8: 应该是python版本的问题,我之前用3.6.3的python 没问题 昨天升级了之后就无法打开了
username_9: 我是把 browser 下的 MobileBrowser.__init__ 里的self.show() self.raise_()self.activateWindow()改到了get_cookies(url) 下,可以正常跳转。 python 3.6.6
username_10: PyQT5==5.10.1
PyQT5有新版释出,没有适配吧
username_11: 我不用pyqt登录了,我用无头浏览器登录
username_12: pyqt5 5.11.2的也不能出现登录窗口,PyQT5==5.10.1 这个可用。
Status: Issue closed
username_1: 感谢各位,问题已修复~
username_13: PyQt5 5.11.3 下也不能跳出浏览器,改成 PyQT5==5.10.1 才行 |
spring-projects/spring-integration | 264730557 | Title: Channel name being passed instead of actual channel
Question:
username_0: I have had trouble getting access to the actual gatherResultChannel using just the name, unlike the replyChannel (which is the object itself).
https://github.com/spring-projects/spring-integration/blob/00807d47e2880e780b1430c3aba3a588490572da/spring-integration-core/src/main/java/org/springframework/integration/scattergather/ScatterGatherHandler.java#L140
Wouldn't it be better to just do:
```
Message<?> scatterMessage = getMessageBuilderFactory()
.fromMessage(requestMessage)
.setHeader(GATHER_RESULT_CHANNEL, gatherResultChannel)
.setReplyChannel(this.gatherChannel)
.build();
```
so the actual channel is accessible to each subscriber to put their result into?
Answers:
username_1: This is an internal channel for bridging logic from the gatherer to the output:
```
PollableChannel gatherResultChannel = new QueueChannel();
Object gatherResultChannelName = this.replyChannelRegistry.channelToChannelName(gatherResultChannel);
Message<?> scatterMessage = getMessageBuilderFactory()
.fromMessage(requestMessage)
.setHeader(GATHER_RESULT_CHANNEL, gatherResultChannelName)
.setReplyChannel(this.gatherChannel)
.build();
this.messagingTemplate.send(this.scatterChannel, scatterMessage);
Message<?> gatherResult = gatherResultChannel.receive(this.gatherTimeout);
if (gatherResult != null) {
return gatherResult;
}
```
Not sure why would someone deal with that...
You can restore it into the object via that `HeaderChannelRegistry` though.
Its conversion to string is done intentionally because of serialization issue during network communication to let end-developer to avoid `header-channels-to-string` step: https://docs.spring.io/spring-integration/docs/4.3.12.RELEASE/reference/html/messaging-transformation-chapter.html#header-channel-registry
That is done intentionally because
username_1: Closed as "Works as Designed" after reporter reaction to the answer.
Status: Issue closed
|
AlexsLemonade/resources-portal | 853578012 | Title: Allow bulk add of resources
Question:
username_0: ### Problem or idea
It is frustrating to fill out the form if they are adding multiple resources. We can
- provide template spreadsheet/csv which they can populate with their data and upload.
Considerations:
- How will linking with grants/ team work?
- How will specifying requirements work?
### Solution or next step
Consider this for future iterations and spec out the details (requirements) for the feature then. |
MSRDL/TSA | 333861154 | Title: Initial Benchmarking Results
Question:
username_0: I have got some benchmarking results from 4 baseline algorithms and compared it with the SLS. I have computed both Mean Average Precision and AUC score for all the algorithms on a single dataset. Please find the observations attached here: [Initial Results](https://github.com/MSRDL/TSA/files/2117138/benchmarking.pdf)
Status: Issue closed
Answers:
username_1: I have got some benchmarking results from 4 baseline algorithms and compared it with the SLS. I have computed both Mean Average Precision and AUC score for all the algorithms on a single dataset. Please find the observations attached here: [Initial Results](https://github.com/MSRDL/TSA/files/2117138/benchmarking.pdf)
username_1: Let's redo the benchmarking on new algorithms |
symfony/symfony | 482714759 | Title: [phpunit-bridge] Too few arguments to function PHPUnit\Runner\TestSuiteSorter::reorderTestsInSuite()
Question:
username_0: **Symfony version affected**: 4.3.2
**Description**
I'm trying to run single test with `php bin/phpunit tests/path/to/test/file.php`.
I get an error:
```
PHP Fatal error: Uncaught ArgumentCountError: Too few arguments to function PHPUnit\Runner\TestSuiteSorter::reorderTestsInSuite(), 3 passed in /code/vendor/phpunit/phpunit/src/TextUI/TestRunner.php on line 180 and at least 4 expected in /code/bin/.phpunit/phpunit-8/src/Runner/TestSuiteSorter.php:126
Stack trace:
#0 /code/vendor/phpunit/phpunit/src/TextUI/TestRunner.php(180): PHPUnit\Runner\TestSuiteSorter->reorderTestsInSuite(Object(PHPUnit\Framework\TestSuite), 0, true)
#1 /code/bin/.phpunit/phpunit-8/src/TextUI/Command.php(201): PHPUnit\TextUI\TestRunner->doRun(Object(PHPUnit\Framework\TestSuite), Array, true)
#2 /code/bin/.phpunit/phpunit-8/src/TextUI/Command.php(160): PHPUnit\TextUI\Command->run(Array, true)
#3 /code/bin/.phpunit/phpunit-8/phpunit(17): PHPUnit\TextUI\Command::main()
#4 /code/vendor/symfony/phpunit-bridge/bin/simple-phpunit.php(259): include('/code/bin/.phpu...')
#5 /code/vendor/symfony/phpunit-bridge/bin/simple-phpunit(13): require('/code/vendor/sy...')
#6 /code/bin/phpunit(13): require('/code/vendor/sy.. in /code/bin/.phpunit/phpunit-8/src/Runner/TestSuiteSorter.php on line 126
```
**Additional context**
```
$ composer show symfony/phpunit-bridge
name : symfony/phpunit-bridge
descrip. : Symfony PHPUnit Bridge
keywords :
versions : * v4.3.3
```
```
$ php bin/phpunit --version
#!/usr/bin/env php
PHPUnit 8.3.4 by <NAME> and contributors.
```
`phpunit.xml`:
```xml
<?xml version="1.0" encoding="UTF-8"?>
<phpunit xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="https://schema.phpunit.de/8.3/phpunit.xsd"
bootstrap="config/bootstrap.php"
executionOrder="depends,defects"
forceCoversAnnotation="true"
beStrictAboutCoversAnnotation="true"
beStrictAboutOutputDuringTests="true"
beStrictAboutTodoAnnotatedTests="true"
verbose="true">
<testsuites>
<testsuite name="default">
<directory suffix="Test.php">tests</directory>
</testsuite>
</testsuites>
<filter>
<whitelist processUncoveredFilesFromWhitelist="true">
<directory suffix=".php">src</directory>
</whitelist>
</filter>
</phpunit>
```
Thanks in advance!<issue_closed>
Status: Issue closed |
Azure/autorest | 193640685 | Title: Latest 1.0.0 AutoRest does not ifdef System.Security.Permissions
Question:
username_0: In the latest 1.0.0 version of AutoRest, custom exceptions do not properly wrap the using for System.Security.Permissions, which is not supported in CoreCLR (portable). In previous versions, this generated code looked like this:
```
#if !PORTABLE
using System.Security.Permissions;
#endif
```
Now it is simply this:
`using System.Security.Permissions;`
Which results in the following exception when building for portable/CoreCLR:
```
The type or namespace name 'Permissions' does not exist in the namespace 'System.Security' (are you missing an assembly reference?)
```
Answers:
username_1: Ach!
This turns out to be a side effect of the C# simplifier. I will look into this today.
G
username_1: @username_0 you should be able to disable the c# simplifier step with `-DisableSimplifier ` ... could you try that?
Status: Issue closed
|
kubernetes/kubernetes | 701790359 | Title: api/core/v1: The default PV Reclaim Policy is different with the document
Question:
username_0: <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
Change the default PV Reclaim Policy in the codebase or the document
**Why is this needed**:
Really misunderstanding when we just read the document and use the api package .
### The main issue
The default PV Reclaim Policy documented [here](https://kubernetes.io/docs/tasks/administer-cluster/change-pv-reclaim-policy/#why-change-reclaim-policy-of-a-persistentvolume) is `Delete` , but the real default Reclaim Policy we use is `Retain` which defined [here](https://github.com/kubernetes/kubernetes/blob/master/staging/src/k8s.io/api/core/v1/types.go#L386). It seems that the document is not correct anymore ?
Answers:
username_0: /sig docs
username_1: This should refer to dynamic-provisioning
https://kubernetes.io/blog/2017/03/dynamic-provisioning-and-storage-classes-kubernetes/
username_0: Still `Delete` not `Retain`?
username_2: According to the comment here: https://github.com/kubernetes/kubernetes/blob/e36e68f5f6964a3e612b36bfea0bb17c8f05e083/staging/src/k8s.io/api/core/v1/types.go#L343-L349
The default policy is `Retain` when pv is manually created and `Delete` when dynamically provisioned.
/remove-kind feature
username_0: OK , docs here https://kubernetes.io/docs/concepts/storage/persistent-volumes/#delete is correct , thanks for your time @username_2 .
Status: Issue closed
|
kapsakcj/nanoporeWorkflow | 640607328 | Title: remove git-lfs requirement & alter test data format
Question:
username_0: Currently, simply downloading the scripts with `git clone` results in errors due to git-lfs. This is frustrating, but I think it is important to keep test data in the repo somehow.
One possible workaround is split the 3 fast5 files (each are ~240-362MB in size) into individual fast5 files. Right now there are a total of 9576 reads within these 3 fast5s, and we may be able to split them into have 1 fast5 for every read. File sizes would be MUCH smaller and would likely avoid having to use git-lfs.
I think the github limit is 100MB/file. 100GB/repository.
SciComp has a module `fast5/2.0.1` for running `ont_fast5_api` which should allow us to split the fast5s. https://github.com/nanoporetech/ont_fast5_api#multi_to_single_fast5
Answers:
username_0: It was pretty easy to split the batch fast5s into single-read fast5s
```
ml fast5/2.0.1
cd github/nanoporeWorkflow/t/data
multi_to_single_fast5 --input_path SalmonellaLitchfield.FAST5 --save_path single-read-fast5s/ -t 16
```
Haven't commited/pushed these files to GitHub yet, still in progress on M3
username_0: This commit added the single-read fast5s. Still need to remove multi-read fast5s and overhaul TravisCI tests.
https://github.com/username_0/nanoporeWorkflow/commit/c7def8f5d3bbd2056ed67109eb225e72cb646e5a |
bnicenboim/eeguana | 709562761 | Title: More control over plot_components()
Question:
username_0: R version 4.0.2 (2020-06-22)
Platform: x86_64-w64-mingw32/x64 (64-bit)
Running under: Windows 10 x64 (build 19041)
Matrix products: default
locale:
[1] LC_COLLATE=English_United States.1252 LC_CTYPE=English_United States.1252 LC_MONETARY=English_United States.1252 LC_NUMERIC=C
[5] LC_TIME=English_United States.1252
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] stringr_1.4.0 data.table_1.13.0 ggplot2_3.3.2 dplyr_1.0.2 eeguana_0.1.4.9000
loaded via a namespace (and not attached):
[1] Rcpp_1.0.5 prettyunits_1.1.1 ps_1.3.4 assertthat_0.2.1 rprojroot_1.3-2 digest_0.6.25 utf8_1.1.4 R6_2.4.1
[9] cellranger_1.1.0 backports_1.1.10 pillar_1.4.6 rlang_0.4.7 curl_4.3 readxl_1.3.1 rstudioapi_0.11 car_3.0-9
[17] callr_3.4.4 desc_1.2.0 labeling_0.3 devtools_2.3.2 foreign_0.8-80 bit_4.0.4 munsell_0.5.0 MBA_0.0-9
[25] compiler_4.0.2 pkgconfig_2.0.3 pkgbuild_1.1.0 tidyselect_1.1.0 tibble_3.0.3 rio_0.5.16 fansi_0.4.1 crayon_1.3.4
[33] withr_2.3.0 grid_4.0.2 gtable_0.3.0 lifecycle_0.2.0 magrittr_1.5 scales_1.1.1 zip_2.1.1 cli_2.0.2
[41] stringi_1.5.3 carData_3.0-4 farver_2.0.3 fs_1.5.0 remotes_2.2.0 testthat_2.3.2 ini_0.3.1 ellipsis_0.3.1
[49] generics_0.0.2 vctrs_0.3.4 openxlsx_4.2.2 RColorBrewer_1.1-2 tools_4.0.2 forcats_0.5.0 bit64_4.0.5 glue_1.4.2
[57] purrr_0.3.4 hms_0.5.3 processx_3.4.4 abind_1.4-5 pkgload_1.1.0 colorspace_1.4-1 sessioninfo_1.1.1 isoband_0.2.2
[65] memoise_1.1.0 haven_2.3.1 usethis_1.6.3
```
Answers:
username_1: yeah, I didn't have time to work a lot on the plotting of ICA. (I'd like to eventually use shiny for this... ).
Would you mind sharing the data (or a subset of it)?
username_0: This is absolutely not a priority, I usually draw ICs directly from EEGLAB when generating them with AMICA. I just thought I'd report those issues in case you weren't aware of them.
Here are the files I used to generate the figure above:
https://web.tresorit.com/l/0YncD#agxGH_S1oGXgxONvmAVvxQ
username_1: thanks!
I'll look at it in the next weeks.
username_1: ok, if I get it, you want that plot_components would behave like plot_topo, right?
where you can do the following:
```
dat_bline_ica %>%
plot_topo() +
# add a head and nose shape
annotate_head() +
# add contour lines
geom_contour() +
# add electrode labels
geom_text(color = "black") +
facet_grid(~condition)
```
is this right?
username_0: Exactly, this sounds like a simple solution that would make things much easier because plot_topo() is much more configurable.
Status: Issue closed
username_1: I fixed this, but I also did some changes that break things: changed a lot of arguments names. I'll need to test more and verify that I'm being consistent before I release a new version.
BTW, really cool that you're using the method function in "eeg_ica" :+1:
If you're using the package, and you want to collaborate, drop me a line by email. I'm really busy now, and I'm doing basic maintenance, until we get new EEG data (from a pre-registration), and I doubt that will happen before March next year. |
doo/scanbot-sdk-example-react-native | 303909903 | Title: Crash using onPolygonDetected
Question:
username_0: When I add `onPolygonDetected` to `ScanbotCameraView` it crashes immediately. I just added:
```JS
onPolygonDetected={this.onPolygonDetected}
...
onPolygonDetected = (event: Event) => {
console.log(event);
};
```
```
2018-03-09 08:57:27.874448-0800 ScanbotSDKDemo[1382:1283189] *** Terminating app due to uncaught exception 'NSInvalidArgumentException', reason: '*** -[__NSPlaceholderDictionary initWithObjects:forKeys:count:]: attempt to insert nil object from objects[0]'
```
<img width="1512" alt="screen shot 2018-03-09 at 8 58 04 am" src="https://user-images.githubusercontent.com/32274158/37219399-1c9e268a-2378-11e8-8913-d453de9c51eb.png">
Status: Issue closed
Answers:
username_1: Hey @username_0, thanks for your report!
We have fixed this issue and just published `[email protected]`.
Eddy |
WASdev/ci.docker | 722876927 | Title: Missing third-party libraries in current 192.168.127.12 image
Question:
username_0: Using kernel-java8-ibmjava-ubi, Running applications using third-party API seems to be throwing errors due to the fact that some jars are now missing after RUN configure.sh
For example with server.xml:
```
<server>
<featureManager>
<feature>localConnector-1.0</feature>
<feature>jaxrs-1.1</feature>
<feature>servlet-3.1</feature>
<feature>transportSecurity-1.0</feature>
<feature>appSecurity-2.0</feature>
<feature>ldapRegistry-3.0</feature>
<feature>jsp-2.3</feature>
<feature>distributedMap-1.0</feature>
<feature>javaMail-1.5</feature>
</featureManager>
<enterpriseApplication id="my-EAR" location="my-EAR.ear" name="my-EAR">
<classloader apiTypeVisibility="spec,ibm-api,api,stable,third-party" delegation="parentLast"/>
</enterpriseApplication>
</server>
```
and Dockerfile:
```
FROM ibmcom/websphere-liberty:kernel-java8-ibmjava-ubi as JAVA_BUILD
USER root
# configure to get liberty jar libraries
COPY server.xml /config/
RUN configure.sh
```
jars like `./api/third-party/com.ibm.websphere.appserver.thirdparty.jaxrs_1.0.44.jar` seems to be missing now from directory.
These seem to be working fine on 172.16.58.3-kernel-java8-ibmjava-ubi
Answers:
username_0: Turning on VERBOSE gave me this:
```
CWWKF1219E: The IBM WebSphere Liberty Repository cannot be reached. Verify that your computer has network access and firewalls are configured correctly, then try the action again. If the connection still fails, the repository server might be temporarily unavailable.
+ '[' 33 -ne 22 ']'
+ exit 0
```
Not sure what the actual URL is to actually verify
Status: Issue closed
username_0: Closing for now as this seems to be network-related. |
LedgerHQ/ledgerjs | 504053109 | Title: How to get the same BItcoin address by the path,
Question:
username_0: ```
And here's the address I'm expecting to see:

Why am I getting different addresses?
Answers:
username_0: Answering my own question - actually, the addresses in the output and at the screenshot are the same. The reason why them look different is the encoding. Just add the `format` option:
```javascript
const result = await btc.getWalletPublicKey(path, { format: 'bech32' });
```
Status: Issue closed
|
vbence/stream-m | 71829899 | Title: Connection reset
Question:
username_0: Connect RTMP from Wirecast
Exception in thread "Thread-2" java.lang.RuntimeException: java.net.SocketException: Connection reset
at org.czentral.util.stream.Feeder.feedTo(Feeder.java:78)
at org.czentral.minirtmp.MiniRTMP$Worker.run(MiniRTMP.java:95)
Caused by: java.net.SocketException: Connection reset
at java.net.SocketInputStream.read(SocketInputStream.java:196)
at java.net.SocketInputStream.read(SocketInputStream.java:122)
at org.czentral.util.stream.Feeder.feedTo(Feeder.java:70)
... 1 more
Answers:
username_1: The RTMP implementation in Stream-m is by far not complete. Wirecast must be more squeamish with the protocol. I will do some wiresharking and get back to you on the weekend.
username_1: Can you please check if the issue is still present in the latest version?
username_0: Issuse don't solved problem:
Exception in thread "Thread-19" java.lang.RuntimeException: java.net.SocketException: Connection reset
at org.czentral.util.stream.Feeder.feedTo(Feeder.java:78)
at org.czentral.minirtmp.MiniRTMP$Worker.run(MiniRTMP.java:95)
Caused by: java.net.SocketException: Connection reset
at java.net.SocketInputStream.read(SocketInputStream.java:196)
at java.net.SocketInputStream.read(SocketInputStream.java:122)
at org.czentral.util.stream.Feeder.feedTo(Feeder.java:70)
... 1 more
username_1: Confirmed. It seems like I uploaded the wrong version. Please stand by for a re-uploaded version.
username_0: Good now wirecast can connect but i have another problem, if i start watching then server is crash.
metadata: [@setDataFrame, onMetaData, {audiocodecid=mp4a, videokeyframe_frequency=240.0, audiodatarate=192.0, height=720.0, audiosamplerate=44100.0, audiochannels=2.0, width=1280.0, videodatarate=2025.0, videocodecid=avc1, framerate=30.0}]
Exception in thread "Thread-6" java.lang.NullPointerException
at org.czentral.minihttp.MiniHTTP$Worker.run(MiniHTTP.java:108)
Exception in thread "Thread-8" java.lang.NullPointerException
at org.czentral.minihttp.MiniHTTP$Worker.run(MiniHTTP.java:108)
metadata: [@setDataFrame, onMetaData, {audiocodecid=mp4a, videokeyframe_frequency=240.0, audiodatarate=192.0, height=720.0, audiosamplerate=44100.0, audiochannels=2.0, width=1280.0, videodatarate=2025.0, videocodecid=avc1, framerate=30.0}]
Exception in thread "Thread-11" java.lang.NullPointerException
at org.czentral.minihttp.MiniHTTP$Worker.run(MiniHTTP.java:108)
Exception in thread "Thread-9" java.lang.ArrayIndexOutOfBoundsException
at java.lang.System.arraycopy(Native Method)
at org.czentral.minirtmp.ApplicationContext.processChunk(ApplicationContext.java:118)
at org.czentral.minirtmp.RTMPStreamProcessor.processPacket(RTMPStreamProcessor.java:206)
at org.czentral.minirtmp.RTMPStreamProcessor.process(RTMPStreamProcessor.java:75)
at org.czentral.util.stream.Feeder.feedTo(Feeder.java:56)
at org.czentral.minirtmp.MiniRTMP$Worker.run(MiniRTMP.java:95)
Exception in thread "Thread-13" java.lang.NullPointerException
at org.czentral.minihttp.MiniHTTP$Worker.run(MiniHTTP.java:108)
metadata: [@setDataFrame, onMetaData, {audiocodecid=mp4a, videokeyframe_frequency=240.0, audiodatarate=128.0, height=576.0, audiosamplerate=44100.0, audiochannels=2.0, width=1024.0, videodatarate=1500.0, videocodecid=avc1, framerate=25.0}]
Exception in thread "Thread-16" java.lang.NullPointerException
at org.czentral.minihttp.MiniHTTP$Worker.run(MiniHTTP.java:108)
username_1: The error message is quite cryptic - sorry for that. You have to use a smaller keyframe interval, please try 60 (instead of the current 240).
username_0: I'm testing on different options, but it does not work when I start to play. I run stream-m on linux debian if you want i can send you a pass to testing account.
Exception in thread "Thread-2" java.lang.RuntimeException: java.net.SocketException: Connection reset
at org.czentral.util.stream.Feeder.feedTo(Feeder.java:78)
at org.czentral.minirtmp.MiniRTMP$Worker.run(MiniRTMP.java:95)
Caused by: java.net.SocketException: Connection reset
at java.net.SocketInputStream.read(SocketInputStream.java:196)
at java.net.SocketInputStream.read(SocketInputStream.java:122)
at org.czentral.util.stream.Feeder.feedTo(Feeder.java:70)
... 1 more
metadata: [@setDataFrame, onMetaData, {audiocodecid=mp4a, videokeyframe_frequency=240.0, audiodatarate=192.0, height=720.0, audiosamplerate=44100.0, audiochannels=2.0, width=1280.0, videodatarate=2025.0, videocodecid=avc1, framerate=30.0}]
Exception in thread "Thread-3" java.lang.ArrayIndexOutOfBoundsException
at java.lang.System.arraycopy(Native Method)
at org.czentral.minirtmp.ApplicationContext.processChunk(ApplicationContext.java:118)
at org.czentral.minirtmp.RTMPStreamProcessor.processPacket(RTMPStreamProcessor.java:206)
at org.czentral.minirtmp.RTMPStreamProcessor.process(RTMPStreamProcessor.java:75)
at org.czentral.util.stream.Feeder.feedTo(Feeder.java:56)
at org.czentral.minirtmp.MiniRTMP$Worker.run(MiniRTMP.java:95)
metadata: [@setDataFrame, onMetaData, {audiocodecid=mp4a, videokeyframe_frequency=60.0, audiodatarate=96.0, height=600.0, audiosamplerate=44100.0, audiochannels=2.0, width=800.0, videodatarate=1024.0, videocodecid=avc1, framerate=30.0}]
Exception in thread "Thread-7" java.lang.NullPointerException
at org.czentral.minihttp.MiniHTTP$Worker.run(MiniHTTP.java:108)
Exception in thread "Thread-5" java.lang.ArrayIndexOutOfBoundsException
at java.lang.System.arraycopy(Native Method)
at org.czentral.minirtmp.ApplicationContext.processChunk(ApplicationContext.java:118)
at org.czentral.minirtmp.RTMPStreamProcessor.processPacket(RTMPStreamProcessor.java:206)
at org.czentral.minirtmp.RTMPStreamProcessor.process(RTMPStreamProcessor.java:75)
at org.czentral.util.stream.Feeder.feedTo(Feeder.java:56)
at org.czentral.minirtmp.MiniRTMP$Worker.run(MiniRTMP.java:95)
metadata: [@setDataFrame, onMetaData, {audiocodecid=mp4a, videokeyframe_frequency=50.0, audiodatarate=96.0, height=600.0, audiosamplerate=44100.0, audiochannels=2.0, width=800.0, videodatarate=640.0, videocodecid=avc1, framerate=30.0}]
Exception in thread "Thread-14" java.lang.NullPointerException
at org.czentral.minihttp.MiniHTTP$Worker.run(MiniHTTP.java:108)
Exception in thread "Thread-12" java.lang.ArrayIndexOutOfBoundsException
at java.lang.System.arraycopy(Native Method)
at org.czentral.minirtmp.ApplicationContext.processChunk(ApplicationContext.java:118)
at org.czentral.minirtmp.RTMPStreamProcessor.processPacket(RTMPStreamProcessor.java:206)
at org.czentral.minirtmp.RTMPStreamProcessor.process(RTMPStreamProcessor.java:75)
at org.czentral.util.stream.Feeder.feedTo(Feeder.java:56)
at org.czentral.minirtmp.MiniRTMP$Worker.run(MiniRTMP.java:95)
Exception in thread "Thread-2" java.lang.RuntimeException: java.net.SocketException: Connection reset
at org.czentral.util.stream.Feeder.feedTo(Feeder.java:78)
at org.czentral.minirtmp.MiniRTMP$Worker.run(MiniRTMP.java:95)
Caused by: java.net.SocketException: Connection reset
at java.net.SocketInputStream.read(SocketInputStream.java:196)
at java.net.SocketInputStream.read(SocketInputStream.java:122)
at org.czentral.util.stream.Feeder.feedTo(Feeder.java:70)
... 1 more
metadata: [@setDataFrame, onMetaData, {audiocodecid=mp4a, videokeyframe_frequency=240.0, audiodatarate=192.0, height=720.0, audiosamplerate=44100.0, audiochannels=2.0, width=1280.0, videodatarate=2025.0, videocodecid=avc1, framerate=30.0}]
Exception in thread "Thread-3" java.lang.ArrayIndexOutOfBoundsException
at java.lang.System.arraycopy(Native Method)
at org.czentral.minirtmp.ApplicationContext.processChunk(ApplicationContext.java:118)
at org.czentral.minirtmp.RTMPStreamProcessor.processPacket(RTMPStreamProcessor.java:206)
at org.czentral.minirtmp.RTMPStreamProcessor.process(RTMPStreamProcessor.java:75)
at org.czentral.util.stream.Feeder.feedTo(Feeder.java:56)
at org.czentral.minirtmp.MiniRTMP$Worker.run(MiniRTMP.java:95)
metadata: [@setDataFrame, onMetaData, {audiocodecid=mp4a, videokeyframe_frequency=60.0, audiodatarate=96.0, height=600.0, audiosamplerate=44100.0, audiochannels=2.0, width=800.0, videodatarate=1024.0, videocodecid=avc1, framerate=30.0}]
Exception in thread "Thread-7" java.lang.NullPointerException
at org.czentral.minihttp.MiniHTTP$Worker.run(MiniHTTP.java:108)
Exception in thread "Thread-5" java.lang.ArrayIndexOutOfBoundsException
at java.lang.System.arraycopy(Native Method)
at org.czentral.minirtmp.ApplicationContext.processChunk(ApplicationContext.java:118)
at org.czentral.minirtmp.RTMPStreamProcessor.processPacket(RTMPStreamProcessor.java:206)
at org.czentral.minirtmp.RTMPStreamProcessor.process(RTMPStreamProcessor.java:75)
at org.czentral.util.stream.Feeder.feedTo(Feeder.java:56)
at org.czentral.minirtmp.MiniRTMP$Worker.run(MiniRTMP.java:95)
metadata: [@setDataFrame, onMetaData, {audiocodecid=mp4a, videokeyframe_frequency=50.0, audiodatarate=96.0, height=600.0, audiosamplerate=44100.0, audiochannels=2.0, width=800.0, videodatarate=640.0, videocodecid=avc1, framerate=30.0}]
Exception in thread "Thread-14" java.lang.NullPointerException
at org.czentral.minihttp.MiniHTTP$Worker.run(MiniHTTP.java:108)
Exception in thread "Thread-12" java.lang.ArrayIndexOutOfBoundsException
at java.lang.System.arraycopy(Native Method)
at org.czentral.minirtmp.ApplicationContext.processChunk(ApplicationContext.java:118)
at org.czentral.minirtmp.RTMPStreamProcessor.processPacket(RTMPStreamProcessor.java:206)
at org.czentral.minirtmp.RTMPStreamProcessor.process(RTMPStreamProcessor.java:75)
at org.czentral.util.stream.Feeder.feedTo(Feeder.java:56)
at org.czentral.minirtmp.MiniRTMP$Worker.run(MiniRTMP.java:95)
username_1: Your snippet shows the keyframe interval is still too high. Please see Step 4 in this article:
http://support.metacdn.com/hc/en-us/articles/204513925-How-To-Broadcast-A-Live-Stream-Using-Telestream-Wirecast
Setting it to 60 should solve the issue.
Status: Issue closed
|
elementary/website | 377147236 | Title: Clicking Code icon on homepage breaks the slideshow
Question:
username_0: ### Expected behavior
To show the code preview
### Actual behavior
Breaks slideshow and shows all arrows for all apps and puts preview images of all the apps on top of each other
### Steps to reproduce the behavior
1. Go to the main website
2. Scroll to area that lists the apps
3. Click Code app
4. BOOM
Example screenshot attached:
<img width="1626" alt="screen shot 2018-11-04 at 12 19 26" src="https://user-images.githubusercontent.com/105126/47964070-2fcdcf00-e02c-11e8-8016-c7da8d587c53.png">
### System information
- **Operating system**: Mac OS
- **Operating system version**: 10.12.6
- **Browser**: Chrome
- **Browser version**: 69
- **Enabled Browser Extensions**:
<bountysource-plugin>
---
Want to back this issue? **[Post a bounty on it!](https://www.bountysource.com/issues/65398225-clicking-code-icon-on-homepage-breaks-the-slideshow?utm_campaign=plugin&utm_content=tracker%2F10548672&utm_medium=issues&utm_source=github)** We accept bounties via [Bountysource](https://www.bountysource.com/?utm_campaign=plugin&utm_content=tracker%2F10548672&utm_medium=issues&utm_source=github).
</bountysource-plugin>
Answers:
username_1: Thanks for the report! This is actually a duplicate of https://github.com/elementary/website/issues/2081
Status: Issue closed
|
ProtoSchool/munich | 402910872 | Title: Add your chapter to our listings
Question:
username_0: Once issues #1, #2, and #3 are complete, please complete Step 5 in the [chapter setup instructions](https://github.com/ProtoSchool/organizing#how-to-start-a-new-protoschool-chapter) by opening a pull request to have your chapter included in the [list of ProtoSchool chapters](https://proto.school/#/chapters).
Please be sure to include the `repo` field so that your listing will link to this chapter repo. Should you decide that you'd like your listing to go to a website instead (now or in the future), you can add an additional `website` field with the appropriate URL, which will update the link.
Answers:
username_0: @username_1 @rklaehn Just popping in with a reminder that your chapter isn't yet listed on our main website, although you've done a ton to prepare your repo. Please let me know if you have any questions about the process of getting it added.
username_1: I was waiting for @rklaehn to check the CoC. I will close the issue and
list the chapter today.
username_1: PR committed and all checks passed
Status: Issue closed
|
grpc/grpc | 1004294681 | Title: [Python install] Build Failure
Question:
username_0: System: Windows 10
Python 2.7.3
Running setup.py install for grpcio ... error
ERROR: Command errored out with exit status 1:
command: 'c:\python27\python.exe' -u -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'c:\\users\\joaog\\appdata\\local\\temp\\pip-install-xenxc7\\grpcio\\setup.py'"'"'; __file__='"'"'c:\\users\\joaog\\appdata\\local\\temp\\pip-install-xenxc7\\grpcio\\setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' install --record 'c:\users\joaog\appdata\local\temp\pip-record-xfyp5n\install-record.txt' --single-version-externally-managed --compile
cwd: c:\users\joaog\appdata\local\temp\pip-install-xenxc7\grpcio\
Complete output (150 lines):
('ASM Builds for BoringSSL currently not supported on:', 'win-amd64')
Found cython-generated files...
running install
running build
running build_py
running build_project_metadata
creating python_build
creating python_build\lib.win-amd64-2.7
creating python_build\lib.win-amd64-2.7\grpc
copying src\python\grpcio\grpc\_auth.py -> python_build\lib.win-amd64-2.7\grpc
copying src\python\grpcio\grpc\_channel.py -> python_build\lib.win-amd64-2.7\grpc
copying src\python\grpcio\grpc\_common.py -> python_build\lib.win-amd64-2.7\grpc
copying src\python\grpcio\grpc\_compression.py -> python_build\lib.win-amd64-2.7\grpc
copying src\python\grpcio\grpc\_grpcio_metadata.py -> python_build\lib.win-amd64-2.7\grpc
copying src\python\grpcio\grpc\_interceptor.py -> python_build\lib.win-amd64-2.7\grpc
copying src\python\grpcio\grpc\_plugin_wrapping.py -> python_build\lib.win-amd64-2.7\grpc
copying src\python\grpcio\grpc\_runtime_protos.py -> python_build\lib.win-amd64-2.7\grpc
copying src\python\grpcio\grpc\_server.py -> python_build\lib.win-amd64-2.7\grpc
copying src\python\grpcio\grpc\_simple_stubs.py -> python_build\lib.win-amd64-2.7\grpc
copying src\python\grpcio\grpc\_utilities.py -> python_build\lib.win-amd64-2.7\grpc
copying src\python\grpcio\grpc\__init__.py -> python_build\lib.win-amd64-2.7\grpc
creating python_build\lib.win-amd64-2.7\grpc\aio
copying src\python\grpcio\grpc\aio\_base_call.py -> python_build\lib.win-amd64-2.7\grpc\aio
copying src\python\grpcio\grpc\aio\_base_channel.py -> python_build\lib.win-amd64-2.7\grpc\aio
copying src\python\grpcio\grpc\aio\_base_server.py -> python_build\lib.win-amd64-2.7\grpc\aio
copying src\python\grpcio\grpc\aio\_call.py -> python_build\lib.win-amd64-2.7\grpc\aio
copying src\python\grpcio\grpc\aio\_channel.py -> python_build\lib.win-amd64-2.7\grpc\aio
copying src\python\grpcio\grpc\aio\_interceptor.py -> python_build\lib.win-amd64-2.7\grpc\aio
copying src\python\grpcio\grpc\aio\_metadata.py -> python_build\lib.win-amd64-2.7\grpc\aio
copying src\python\grpcio\grpc\aio\_server.py -> python_build\lib.win-amd64-2.7\grpc\aio
copying src\python\grpcio\grpc\aio\_typing.py -> python_build\lib.win-amd64-2.7\grpc\aio
copying src\python\grpcio\grpc\aio\_utils.py -> python_build\lib.win-amd64-2.7\grpc\aio
copying src\python\grpcio\grpc\aio\__init__.py -> python_build\lib.win-amd64-2.7\grpc\aio
creating python_build\lib.win-amd64-2.7\grpc\beta
copying src\python\grpcio\grpc\beta\implementations.py -> python_build\lib.win-amd64-2.7\grpc\beta
copying src\python\grpcio\grpc\beta\interfaces.py -> python_build\lib.win-amd64-2.7\grpc\beta
copying src\python\grpcio\grpc\beta\utilities.py -> python_build\lib.win-amd64-2.7\grpc\beta
copying src\python\grpcio\grpc\beta\_client_adaptations.py -> python_build\lib.win-amd64-2.7\grpc\beta
copying src\python\grpcio\grpc\beta\_metadata.py -> python_build\lib.win-amd64-2.7\grpc\beta
copying src\python\grpcio\grpc\beta\_server_adaptations.py -> python_build\lib.win-amd64-2.7\grpc\beta
copying src\python\grpcio\grpc\beta\__init__.py -> python_build\lib.win-amd64-2.7\grpc\beta
creating python_build\lib.win-amd64-2.7\grpc\experimental
copying src\python\grpcio\grpc\experimental\gevent.py -> python_build\lib.win-amd64-2.7\grpc\experimental
copying src\python\grpcio\grpc\experimental\session_cache.py -> python_build\lib.win-amd64-2.7\grpc\experimental
copying src\python\grpcio\grpc\experimental\__init__.py -> python_build\lib.win-amd64-2.7\grpc\experimental
creating python_build\lib.win-amd64-2.7\grpc\framework
copying src\python\grpcio\grpc\framework\__init__.py -> python_build\lib.win-amd64-2.7\grpc\framework
creating python_build\lib.win-amd64-2.7\grpc\_cython
copying src\python\grpcio\grpc\_cython\__init__.py -> python_build\lib.win-amd64-2.7\grpc\_cython
creating python_build\lib.win-amd64-2.7\grpc\experimental\aio
copying src\python\grpcio\grpc\experimental\aio\__init__.py -> python_build\lib.win-amd64-2.7\grpc\experimental\aio
creating python_build\lib.win-amd64-2.7\grpc\framework\common
[Truncated]
File "c:\python27\lib\distutils\command\build_ext.py", line 499, in build_extension
depends=ext.depends)
File "c:\python27\lib\distutils\msvc9compiler.py", line 473, in compile
self.initialize()
File "c:\python27\lib\distutils\msvc9compiler.py", line 383, in initialize
vc_env = query_vcvarsall(VERSION, plat_spec)
File "c:\python27\lib\site-packages\setuptools\msvc.py", line 139, in msvc9_query_vcvarsall
return EnvironmentInfo(arch, ver).return_env()
File "c:\python27\lib\site-packages\setuptools\msvc.py", line 1590, in return_env
[self.VCIncludes,
File "c:\python27\lib\site-packages\setuptools\msvc.py", line 1135, in VCIncludes
return [join(self.si.VCInstallDir, 'Include'),
File "c:\python27\lib\site-packages\setuptools\msvc.py", line 693, in VCInstallDir
raise distutils.errors.DistutilsPlatformError(msg)
DistutilsPlatformError: Microsoft Visual C++ 9.0 is required. Get it from http://aka.ms/vcpython27
----------------------------------------
ERROR: Command errored out with exit status 1: 'c:\python27\python.exe' -u -c 'import sys, setuptools, tokenize; sys.argv[0] = '"'"'c:\\users\\joaog\\appdata\\local\\temp\\pip-install-xenxc7\\grpcio\\setup.py'"'"'; __file__='"'"'c:\\users\\joaog\\appdata\\local\\temp\\pip-install-xenxc7\\grpcio\\setup.py'"'"';f=getattr(tokenize, '"'"'open'"'"', open)(__file__);code=f.read().replace('"'"'\r\n'"'"', '"'"'\n'"'"');f.close();exec(compile(code, __file__, '"'"'exec'"'"'))' install --record 'c:\users\joaog\appdata\local\temp\pip-record-xfyp5n\install-record.txt' --single-version-externally-managed --compile Check the logs for full command output.
WARNING: You are using pip version 19.2.3, however version 20.3.4 is available.
You should consider upgrading via the 'python -m pip install --upgrade pip' command
Answers:
username_1: I see
```DistutilsPlatformError: Microsoft Visual C++ 9.0 is required. Get it from http://aka.ms/vcpython27
```
Status: Issue closed
username_0: Yeah, the vcpython27 doesn't have support anymore on the Windows 10. So, it's officially dead. |
jlippold/tweakCompatible | 660213083 | Title: `AppStore++` working on iOS 13.6
Question:
username_0: ```
{
"packageId": "com.cokepokes.appstoreplusplus",
"action": "working",
"userInfo": {
"arch32": false,
"packageId": "com.cokepokes.appstoreplusplus",
"deviceId": "iPhone10,5",
"url": "http://cydia.saurik.com/package/com.cokepokes.appstoreplusplus/",
"iOSVersion": "13.6",
"packageVersionIndexed": false,
"packageName": "AppStore++",
"category": "Tweaks",
"repository": "(null)",
"name": "AppStore++",
"installed": "0.9.12",
"packageIndexed": true,
"packageStatusExplaination": "A matching version of this tweak for this iOS version could not be found. Please submit a review if you choose to install.",
"id": "com.cokepokes.appstoreplusplus",
"commercial": false,
"packageInstalled": true,
"tweakCompatVersion": "0.1.5",
"shortDescription": "Allows you to downgrade/upgrade apps in the AppStore on iOS 11-13.whatever",
"latest": "0.9.12",
"author": "CokePokes",
"packageStatus": "Unknown"
},
"base64": "<KEY>
"chosenStatus": "working",
"notes": ""
}
```
Answers:
username_1: This issue is being closed because your review was accepted into the tweakCompatible website.
Tweak developers do not monitor or fix issues submitted via this repo.
If you have an issue with a tweak, contact the developer via another method.
Status: Issue closed
|
kubernetes/kubernetes | 127826347 | Title: should introduce a knob to enable quorum read of etcd for HA
Question:
username_0: Almost immediately, a read request(?key=hello) was forward to etcd-3, if api-server doesn't enable quorum read, this read request will failed(key not found) since the data has not been synced to etcd-3.
Answers:
username_1: /cc @username_6
username_2: @username_3 what's the scale of your cluster?(`how much nodes?`)
username_3: @ username_2 currently ~500
username_4: I agree that we need this knob and I'd be happy to accept a PR adding it.
username_5: As a stop gap to a future client enhancement to accept read horizons, this seems ok to me.
username_5: We think we may be seeing this in a customer environment with a large cluster, where monitorNodeStatus() gets the List of nodes and doesn't get all of them. That raises the concern of why monitorNodeStatus isn't using a cache store and list watcher (which is going to have the same behavior, except it will now start seeing its own watch events, but practically that's not a real issue). The node controller would have to guarantee that it doesn't "walk back in time" on a relist - I don't know that list watcher has that check today.
username_6: I think that list watcher doesn't have such check, but it's highly unprobably for it to "walk back in time". And it should be very straighforward to add a check for it.
username_5: I would probably like the client even to have that logic - however we would
have to deserialize the body today for that so it's probably more complex
than not. In the future we discussed returning a header always that
represented the resource version of the resource, which would be easier for
a client to indicate.
username_7: This topic seems to repeatedly surprise people when setting up HA cluster. Compare https://github.com/coreos/tectonic-installer/issues/400 and https://github.com/openshift/origin/issues/14520. We know that `--enable-quorum-read` causes performance problems, leaving it out in HA leads to wrong behaviour. What's our plan? Should we address this in 1.8? /cc @kubernetes/sig-api-machinery-misc
Just a possible way forward we could switch to opt-out for quorum reads (via `GetOptions`) and address performance bottlenecks with e.g. informers. Is that feasible?
username_8: There is ongoing discussion at openshift/origin#14520 but we should try to consolidate it here.
So I was under the assumption that nothing in Kube used quorum and only the OAuth tokens in Origin used it. Not sure about the former.
That being said a conversation I had with @username_10 recently made me think that we could enable quorum for everything with etcd v3 and not kill performance.
username_7: @username_6 @username_11 can you comment on quorum+etcd3?
username_8: https://github.com/coreos/etcd/issues/6829#issuecomment-259564546 and https://coreos.com/blog/etcd-3-1-announcement.html seem relevant.
username_1: quorum read is the default for v3, and v3.1 has helped the iop issue. There were several issues opened about this a while ago and the plan of record is to update to 3.1.X in 1.8.
username_5: Does anyone have experience running very large clusters with quorum read on
and HA? We realized in openshift we only had quorum reads on for 1
specific resource, and even that was a massive spike in IO. Turning on
quorum for everything will at least double the number of quorum reads
(25-50% of reads on those very large clusters were quorum, there rest were
not).
My concern is anyone at scale who doesn't have this on already is going to
see a significant change in workload, even on etcd v3, unless they've
tested.
username_1: @mffiedler had the experimental data and can compare against an upstream deploy. We had seen a very large drop when running the same experiment against 3.1.X months ago.
/cc @rrati @username_9
username_5: There are two angles to this:
1. anyone who needs to do a "live read" in order to get causal consistency
is unlikely to know that they need to ask for a quorum read (it's very
common to not think about this when designing code) - that's 5-10% of
actual controllers
2. GC needs causal reads for everything, but if we turn it on for
everything that's a big hammer, but it might be the right default for small
- medium clusters
There's also the angle that changing the cluster default to quorum on
changes the behavior of the system in failures - if you have 3 etcd members
but are in partition, and quorum reads for endpoints are off, a kube-proxy
that gets restarted is going to coast. If quorum reads are on, the
kube-proxy will start back up and serve nothing. The error behavior of
quorum read changes as well - you get hard errors which change how
controllers react. At some point we'll have checkpointing, but not yet.
Can we make "resourceVersion=latest" have meaning and force a quorum read?
username_9: Very large was still 2x what it was in the prior tests...
username_1: What are the results for disabling multi-tenant sdn?
username_9: Not sure -- we don't run without it. Does the multi-tenant SDN hit oauth tokens? @username_10
username_10: shouldn't... it runs with infrastructure credentials which are cert-based
username_11: 3.1's q-read does not touch disk at all. It is also faster than pervious non-q-read under heavy load. I strongly suggest to give etcd 3.1 a try.
username_5: I did a quick prototype of letting the GC controller indicate it wants a Live read (which is what it's actually doing). But I think it is probably just simpler to turn on quorum reads for everything and introduce a way to opt out (which technically we already have with `ResourceVersion: "0"`).
username_7: Where do you want to opt-out? |
MegatronKing/HttpCanary | 558150696 | Title: Export Full Log in one go
Question:
username_0: For applications that send lots of small messages it is rather annyoing to click on every part of the conversation and save request&response manually. A simple Export everything in my view button would help greatly in Analisys.
Answers:
username_1: Thanks, a nice suggestion!
Status: Issue closed
username_1: The latest version supports batch OP. |
ctf0/Seti_UX | 307712290 | Title: Problem with Diff color
Question:
username_0: Hey!
Diff used to look like this:

But now they look like this:

I'm a little bit confused, since the Repo says that the last commit is from 22 Sep 2017, but the files were modified 7 days ago.
I'm not versed enough in Sublime themes to know how to fix the problem. Do you have an idea what changes could have caused this?
Answers:
username_1: np,i will fix it, btw do u have something to test with ?
username_0: Paste [this](https://github.com/username_1/Seti_UX/commit/73ae84ae8c059abf7750f824874d216a1717f250.diff) in a new sublime file to test. Select `diff` as syntax if it doesn't automatically.
username_1: yea i understand, thats mostly because am refactoring the colors pallet of the scheme so its easier to maintain , also what version of ST r u using ? and isnt it possible to send the same text in the ss above ?
username_0: I'm running `Dev Channel, Build 3157` on OS X. The screenshot is a part of a rather large diff from a private project. I would prefer not to put it on the internet unless it's absolutely necessary.
username_0: ```diff
diff --git a/app/services/import_users.rb b/app/services/import_users.rb
index 343446424..1bd696438 100644
--- a/app/services/import_users.rb
+++ b/app/services/import_users.rb
@@ -1,7 +1,7 @@
# frozen_string_literal: true
class ImportUsers
- BASE_HEADERS = %w[first_name last_name email occurrence_ids country_code state_code
+ BASE_HEADERS = %w[first_name last_name email locale occurrence_ids country_code state_code
taxon_ids invite_message invite_skip identity bio].freeze
# Expect a CSV with headers included in BASE_HEADERS or keys in user profile schema.
```
username_1: thanx, i will try to push the fix today
username_1: try the latest commit, tell me if u want the bg color back
username_0: Looking good to me! No need to bring back the background color, since it was not really different from the normal brackground, and I see you're trying to reduce the number of colors.
Status: Issue closed
username_1: awesome. |
Nethereum/Nethereum | 339750917 | Title: ContractDeployment -- Contract definition additions and inclusion when generating code.
Question:
username_0: * Include swarm bzz (for verification) (using dec storage)
* Include runtime bytecode (excluding constructor etc) (for verification) (for verification with deployed code)
* ABI definition string for info
* ... |
BIDMCDigitalPsychiatry/LAMP-platform | 821273195 | Title: Incorrect Steps data
Question:
username_0: Hi,
We are using mindLAMP 2 mobile app from Apple Store released on Dec 3 2020. We are noticing the steps data value is carried forward to next day in couchdb.
Here is one of the test participant data
```
{
"data": [
{
"timestamp": 1614607053358,
"sensor": "lamp.steps",
"data": {
"value": 34710
}
},
{
"timestamp": 1614553344962,
"sensor": "lamp.steps",
"data": {
"value": 35279
}
},
{
"timestamp": 1614553342403,
"sensor": "lamp.steps",
"data": {
"value": 35279
}
},
{
"timestamp": 1614553339842,
"sensor": "lamp.steps",
"data": {
"value": 35279
}
}
],
}
```
Answers:
username_1: @username_2 Currently for step count, we are getting value from the time of (start-time is) first login to the app. Can we set the start-time as the day beginning time in device's timezone ?
username_2: @username_1 I believe we discussed that the step count samples should be queried using a start time equivalent to the last access time? Then, after querying the data, the access time should be saved for the next check.
username_1: @username_2 [this](https://github.com/BIDMCDigitalPsychiatry/LAMP-platform/issues/56 So for pedometer) was the last changes we done with step count as per the suggestion of consultant.
.Now we are using [listener](https://developer.apple.com/documentation/coremotion/cmpedometer/1613950-startupdates) for the changes rather than querying. And for HealthKit steps, we are using statistical query to get the cumulative data.
If we don't need cumulative result, we can do the same old [querying](https://developer.apple.com/documentation/coremotion/cmpedometer/1613946-querypedometerdata) pedometer and (HKSampleQuery)HealthKit data. Also we can test is there any chance to skip overlapping data!. We have done the same with sleep data and verified that we are able to get all overlapped data.
username_2: [Can you see if switching to this method improves things?](https://developer.apple.com/documentation/coremotion/cmpedometer/1778437-starteventupdates)
username_1: @username_2 this is an observer and we have to query the pedometer data using one of the above methods.. Let me try some and will update here.
username_2: We would like to get step count changes as they occur. (For example, 30 steps at 3pm, 12 steps at 6pm, etc.) They will be coalesced into day blocks or week blocks by client code during data analysis.
username_1: @username_2
I thought it can be do like getting the difference with previous. so in the same way we can can find the step count in a day. [From pedometer, didn't find a way to getting like 30 steps at 3 pm]
System is auto correcting the step count if there is multiple occurrences of step count from watch and mobile at same time.
So recommending to fetch the statistics data (cumulative result) even if we are able to get count changes (30 steps at 3 pm) from HealthKit.
----------------------------
Still if we need 'count changes' (30 steps at 3 pm), for Pedometer, we can query data using custom time span using the last accessed time which we did at initial time. Also for HealthKit, we can use statistical query by changing the `start time` when fetch on each interval. But this may mismatch with the data with device when system auto correcting the counts. Also for health kit step count, if we change the `start time` for the statistical result, we may be miss the watch step count, because the watch data will take some time to sync with the device.
username_2: Yes, this is a tricky one - do you have any ideas on how to solve this because I was under the impression that the query method we were using should do this automatically from Apple's end. And we can't filter the data because like you said, generated timestamp is different than the timestamp when the data was synchronized.
Do we potentially submit all data for a whole day at the end of the day instead of as soon as we receive them? I feel like this is not an optimal solution.
username_3: @username_1, is it possible to get similar data and format as your mindlamp android app?
username_1: @username_3 I will check and update here.
username_1: @username_2
1. For pedometer step count, we can collect daily steps. (we can get it by setting the start time as 'start of the day').
2. And for health kit steps, we can collect step count changes as they occur. (we can fix the 'missing steps' by keeping last saved timestamp per the source identifier) So we will get like e.g: 10 steps at 1 pm, 8 steps at 2 pm, 12 steps at 2:15pm etc).
username_2: This makes sense as well - sounds like a good plan!
Status: Issue closed
|
RikvanToor/BMN | 353484682 | Title: Add nice 404 page
Question:
username_0: Currenly, it defaults to the Lumen page
Answers:
username_1: Dit :) Ook als je sessie verlopen is krijg je deze pagina, wat verwarrend kan zijn. Misschien een idee om gewoon een simpele pagina-niet-gevonden pagina te maken met een link naar de inlogpagina?
username_0: Je zou in principe geen 404 pagina's moeten krijgen als je sessie verloopt. Weet je op welke pagina dit was?
username_1: Ook bij https://bmn.rikvantoor.nl/homeParticipant (de pagina met "<NAME>"), in Chrome op Windows 10 |
JetBrains/Exposed | 392987410 | Title: Any way to make Exposed work with Proguard?
Question:
username_0: Hi there,
I tried optimizing/shrinking my application that works with Exposed with Proguard but I can't seem to get it to work. I added this to my config:
```
-keep class org.jetbrains.exposed.** { *; }
-keep class * extends org.jetbrains.exposed.dao.IntIdTable { *; }
```
But no luck. Adding:
```
-dontoptimize
-dontobfuscate
-dontshrink
```
Works, but that's not very helpful to begin with :) Anyone who knows what filters might work? Thanks!
Answers:
username_1: @username_0, could you provide a simple project with proguard setup to check what doesn't work?
Status: Issue closed
username_0: @username_1 I don't know what happened here, but I got it working at some point... I'm sorry if I let this open for too long. I guess it was unrelated to Exposed.
Feel free to reopen if someone else still has this problem, I'm willing to help in that case.
username_2: Hey @username_0 how did you get it work? Please share your proguard rules
username_3: Hi @username_2 Any idea about how to fix this issue? |
StoneCypher/fsl | 440484361 | Title: Colors that were string prefixes were sniping each other
Question:
username_0: You couldn't make something `goldenrod` because `gold` would catch it then `enrod` was a syntax error. Nine other color pairs (aqua/aquamarine, lime/limegreen, orange/orangered, white/whitesmoke, olive/olivedrab, lavender/lavenderblush, green/greenyellow, yellow/yellowgreen, blue/blueviolet) were also affected.<issue_closed>
Status: Issue closed |
mariotoffia/FluentDocker | 564762639 | Title: Compose Dispose always throws exception
Question:
username_0: https://github.com/username_1/FluentDocker/blob/9c4bbcafe1f5fcc70bc11d4c64b4aec138dbf5bc/Ductus.FluentDocker/Services/Impl/DockerComposeCompositeService.cs#L50
This line is always called even though the docker-compose down is successful. I do not know how can I debug this, so i just catch the exception. Let me know if there is more information i can provide
Answers:
username_1: Can you provide with a simple test si I can recreate it?
username_1: @username_0 Hi, since I haven't heard from you and not able to reproduce on my side. I will close this issue tomorrow. If you still have problem, can you please assemble a little test so I may debug and solve your problem.
username_0: Hello @username_1 today when i get home i will try to provide it. You can close it until i do so it does not mess the bug tracker. Thanks for the support
Status: Issue closed
|
mjaschen/collmex | 417153888 | Title: Update PHPUnit to Version 7.x
Question:
username_0: After changing the minimum required PHP version to 7.1 (#111), PHPUnit should be updated too. [PHPUnit 7.x](https://phpunit.de/getting-started/phpunit-7.html) is the highest version which supports PHP 7.1.
Answers:
username_1: I can take care of this.
username_0: I suggest I give you commit rights - that would make things a little easier. Does that sound okay to you?
username_1: Yes, that sounds okay if you still are willing to review my PRs. (I'm a big proponent of peer review. And of automated tests. And of static code analysis.)
username_0: Yes, I'd definitively take a look at changes. After all, there is still my name in the library title ;-)
Status: Issue closed
|
qlcchain/QWallet-Android | 589741336 | Title: [2020] Week #14
Question:
username_0: #45 Interface change on Neo chain, claim function change in wallet
#46 Manage multiple chain wallets with the same mnemonic
#47 Buried points of main functional modules
#48 The display speed of the home page is optimized, and the related content of the home page is loaded in advance or the configuration file is loaded
Status: Issue closed
Answers:
username_1: 1, Interface change on Neo chain, claim function change in wallet
2, Manage multiple chain wallets with the same mnemonic
3, Buried points of main functional modules (Android and IOS use the same configuration file to communicate where the burying point is)
4, The display speed of the home page is optimized, and the related content of the home page is loaded in advance or the configuration file is loaded
username_1: #45
#46
#47
#50
#51
username_1: #45
#46
#47
#50
#51
Status: Issue closed
username_0: #45 Interface change on Neo chain, claim function change in wallet
#46 Manage multiple chain wallets with the same mnemonic
#47 Buried points of main functional modules
#48 The display speed of the home page is optimized, and the related content of the home page is loaded in advance or the configuration file is loaded
Status: Issue closed
|
MikeWarren2014/GroupManagementAppServer | 197973007 | Title: create "Maintenance" page
Question:
username_0: Just like with software written by any other entity, there exist periods during which, due to issues that will unavoidably come up, or changes in requirements (or whatever else), the server will need to be down for maintenance and the software features will become inaccessible to the end users. One such page needs to be created. I already implemented a 404.html page, and some node.js logic that sends a `{ "status" : "ok" }` to the client upon requesting `/serverTest`. Problem is, it may be that the end user is not trying to access a page outside the de-facto sandbox (i.e. a resource on the server they're not supposed to), but the node.js server may be just down. Maintenance page should be served for this case. |
raml-org/datatype-expansion | 271101374 | Title: Canonicalization adds undefined required property to array of union
Question:
username_0: Take the following type:
```js
{
type: 'array',
items: {
type: 'union',
anyOf: ['string', 'number']
}
}
```
The expanded form is:
```js
{
type: 'array',
items: {
type: 'union',
anyOf: [{ type: 'string' }, { type: 'number' }]
}
}
```
The canonical form incorrectly includes a `required` property with the value `undefined`:
```js
{
type: 'union',
anyOf: [{
type: 'array',
items: {
type: 'string'
}
}, {
type: 'array',
items: {
type: 'number'
}
}],
required: undefined
}
```
Algorithm step 3.4 should propagate the `required` property to `items` only if specified in `form` (i.e. for cases where `form` is a `property-value`).<issue_closed>
Status: Issue closed |
jenkins-zh/jenkins-cli | 789670389 | Title: How to config jenkins Pipeline Job details ?
Question:
username_0: **Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
Many times we want to add or fix an parametes to an job. Job may hava many parametes. A prodcution has many jobs . adding or fixing a parametes is a repeating work and useless.
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
jcli job parametes fix or add an map like
--stringParas env=qa
--stringParas port=3212
--passwrodPara xxx=xxx
**Describe alternatives you've considered**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
Add any other context or screenshots about the feature request here.
Noting
Answers:
username_1: hi @username_0 , I was wondering if you'd like to help to test #513. Let's see if it can help you out of the repeating work.
username_0: wow, thank you for your help~ . i will try it ~
username_1: Please don't forget the install the latest of [pipeline-restful-api-plugin](https://github.com/jenkinsci/pipeline-restful-api-plugin/)
Status: Issue closed
|
CocoaPods/CocoaPods | 506956623 | Title: XCode11.1 crash after pod install or pod update, macOS Catalina
Question:
username_0: XCode11.1 will crash after pod install or pod update, tried to degrade CocoaPods from v1.8.3 to v1.7.0, still crash.
Answers:
username_1: This is an incomplete bug report. Please re-open a new issue by filling in the template, provide steps to reproduce and/or a sample app.
Status: Issue closed
|
remote-job-boards/software-engineering | 863349272 | Title: First + Third: Contract Front End Engineer
Question:
username_0: **Tags:** #javascript #wordpress #shopify #html #css #gutenberg #react #ecommerce #front-end #engineer #css #html
**Published on:** April 14, 2021
**Original Job Post:** https://remoteOK.io/remote-jobs/103577-remote-contract-front-end-engineer-first-third

**Overview Of Role: **
We're a fully remote web development agency looking for a contract Front-end Engineer. This position should have an attention to detail and love to develop interactive and engaging web experiences. This person should have a keen eye for engaging animations and clean code.
**Our mission:**
At First + Third, it is our mission to outperform average agencies. We believe that when an agency only thinks about how to get a project done and not enough about the client’s goals, it becomes impossible for the project to be a success.
As an organization we are obsessed with helping our clients understand and achieve their objectives through thoughtful, well-executed web design and development. We are relentless in our pursuit of the very best solution for each individual client and work tirelessly until the desired results are achieved.
As a team, we invest ourselves fully in meeting our client’s goals as if they were our own because when they succeed, we do too.
**Responsibilities:**
**Execute** - Be able to take visual designs in sketch and written specifications and turn those into semantic html/css/js that is reusable, scalable, performant, accessible and work on all major browsers
**Make it move** - We love to create experiences on our pages. We leverage CSS and JavaScript animation to make our pages come alive
**Components** - Be able to create reusable Gutenberg blocks that allow clients and product team to enter content and customize the components.
Reuse - Develop a reusable component/block library for WordPress that is reusable across client projects
**Requirements:**
* 2+ years of experience as a front-end developer.
* Strong understanding of HTML and CSS including cross-browser compatibility and performance.
* Ability to write modern and performant JavaScript using latest technologies.
* We expect you to know your way around git and Github
* Experience with front-end building tools (such as Webpack).
* Experience working remotely.
* Comfortable interpreting designs and/or specifications and thinking through the best approach to adapting it to code.
* A solid understanding of good UX and UI practices for websites.
* Familiarity with Sketch and Adobe XD.
* Experience with WordPress and Gutenberg with building out custom blocks.
* Experience working with component systems.
* Estimating work for a project and taking specs and turning into clearly defined, executable tasks.
**Nice to haves:**
* Experience with React
* Experience with Node.js
* Experience with Shopify
* Understanding of WCAG accessibility compliance. Ability to implement accessibility standards as well as audit existing websites.
#Salary or Compensation
$50,000 — $90,000/year
### Location
United States, Europe, Canada<br><issue_closed>
Status: Issue closed |
rust-cli/book | 808166862 | Title: Add appendix of relevant crates
Question:
username_0: I think it would be helpful to list some useful CLI crates in an appendix including those used in the book.
Answers:
username_1: PR welcome! Adding the ones mentioned in the book with some comment would be a great start. I would be hesitant to make this too extensive as it can quickly become outdated. It needs to offer a significant benefit over a page like https://lib.rs/command-line-interface or one of the blog posts that people post about this topic every couple of months :)
username_0: Just made a PR with a list of crates used in the book and a list of relevant lib.rs categories
username_2: Generally we didn't want to add crates to the book because we didn't want to be biased towards certain crates. But i guess this is fine
Status: Issue closed
|
dotnet/cli | 329250096 | Title: Use RID-specific restore output folder for self-contained publish
Question:
username_0: As described in https://github.com/dotnet/designs/pull/36/files, we should use a separate restore output folder (and hence a separate assets file) for self-contained publish. This will avoid the non-rid-specific assets file from being invalidated, and may prevent issues with VS where it picks up the updated RID-specific output file.
Note that publish from VS is already specifying a separate restore output folder for self-contained publish. The command line should use the same folder. It will also be necessary to use the same two properties to override the output path to prevent the override from affecting referenced projects (see https://github.com/dotnet/sdk/pull/2195). |
phpstan/phpstan | 968746863 | Title: Array unpacking on constants after upgrade to PHP 8 - false positives
Question:
username_0: # Bug report
<!-- Before reporting an issue please check that you are using the latest PHPStan version! -->
<!-- Please describe your problem here. -->
After upgrading from PHP 7.4 to PHP 8, we encountered an issue with array unpacking of class constants - while the case with global constants works as expected, the type is wrongly inferred for class constant `Foo::B` -> `array(array('a', 'b', 'c'))` instead of `array('a', 'b', 'c')`
We do not see the same issue with PHP 7.4.
### Code snippet that reproduces the problem
https://phpstan.org/r/7fc3ec28-1ba8-4409-9e3d-634b67c6a98d#
<!-- Try to reproduce the issue you are facing using https://phpstan.org/ and post the unique URL here -->
### Expected output
Call to function in_array() with arguments 'c', array('a', 'b', 'c') and true will always evaluate to true.
<!-- Was the issue reported incorrectly? Or should PHPStan detect an issue with the code but doesn't? -->
### Did PHPStan help you today? Did it make you happy in any way?
<!--
Answering this question is not required, but if you have anything positive to share, please do so here!
Sometimes we get tired of reading bug reports all day and a little positive end note does wonders.
Idea by <NAME>, https://joeyh.name/blog/entry/two_holiday_stories/
--> |
Dart-Code/Dart-Code | 294401792 | Title: Crash in closing labels provider
Question:
username_0: Hit after opening `flutter_tools` package code.

```text
/C:/Program Files (x86)/Microsoft VS Code/resources/app/out/vs/workbench/workbench.main.js:4056 TypeError: Cannot read property 'document' of undefined
at ClosingLabelsDecorations.setTrackingFile (C:\Users\danny\.vscode\extensions\Dart-Code.dart-code-2.7.3\out\src\decorations\closing_labels_decorations.js:58:40)
at ClosingLabelsDecorations.subscriptions.push.vs.window.onDidChangeActiveTextEditor (C:\Users\danny\.vscode\extensions\Dart-Code.dart-code-2.7.3\out\src\decorations\closing_labels_decorations.js:24:83)
at e.fire (c:\Program Files (x86)\Microsoft VS Code\resources\app\out\vs\workbench\node\extensionHostProcess.js:87:218)
at c:\Program Files (x86)\Microsoft VS Code\resources\app\out\vs\workbench\node\extensionHostProcess.js:485:858
at e.fire (c:\Program Files (x86)\Microsoft VS Code\resources\app\out\vs\workbench\node\extensionHostProcess.js:87:218)
at e.$acceptDocumentsAndEditorsDelta (c:\Program Files (x86)\Microsoft VS Code\resources\app\out\vs\workbench\node\extensionHostProcess.js:435:723)
at t.e.invoke (c:\Program Files (x86)\Microsoft VS Code\resources\app\out\vs\workbench\node\extensionHostProcess.js:516:87)
at e._invokeHandler (c:\Program Files (x86)\Microsoft VS Code\resources\app\out\vs\workbench\node\extensionHostProcess.js:357:580)
at e._receiveOneMessage (c:\Program Files (x86)\Microsoft VS Code\resources\app\out\vs\workbench\node\extensionHostProcess.js:357:270)
at c:\Program Files (x86)\Microsoft VS Code\resources\app\out\vs\workbench\node\extensionHostProcess.js:356:206
```<issue_closed>
Status: Issue closed |
pulumi/pulumi-terraform | 484157767 | Title: Intellisense docs missing for resource types
Question:
username_0: We had this problem in Kubernetes too. The culprit seems to be these [`__init__.py` files](https://github.com/pulumi/pulumi-aws/blob/d42f7d16700e2cd9b68264cd4135b7de6f37af25/sdk/python/pulumi_aws/cloudfront/__init__.py). We're doing something like this:
```python
# coding=utf-8
# *** WARNING: this file was generated by the Pulumi Kubernetes codegen tool. ***
# *** Do not edit by hand unless you're certain you know what you are doing! ***
# Export this package's modules as members:
from .DaemonSet import *
from .Deployment import *
```
but we should be doing something like this:
```python
# coding=utf-8
# *** WARNING: this file was generated by the Pulumi Kubernetes codegen tool. ***
# *** Do not edit by hand unless you're certain you know what you are doing! ***
# Export this package's modules as members:
from .DaemonSet import (DaemonSet)
from .Deployment import (Deployment)
```
cc @lukehoban @stack72 @jen20 also see our fix here https://github.com/pulumi/pulumi-kubernetes/pull/635 |
lmrodriguezr/nonpareil | 513277490 | Title: Paired end reads (again!)
Question:
username_0: Can I asked again about paired end reads. I have followed the advice to use only one mate pair. However, it leaves me with a challenge of interpretation. Say I determine that 1e10 bases gives 95% coverage, and this is what I wish to achieve, do I decide:
- I need 2e10 bases to achieve this coverage (seems unlikely, since the second mate pair not analysed by nonpareil will contribute more coverage)
- I need 1e10 bases (but second mate pair perhaps won't double coverage?)
- Something in between
You warned in #8 that if paired end reads are analysed together, the coverage may be underestimated. Having tested this (with the kmer approach), this does not seem to be the case. Perhaps it's because of the kmer approach:

Is there a way to consider even non-overlapping paired reads as a single unit (e.g. concatenate with NNNN between), and would this be desirable?
Thanks for your help,
Andrew<issue_closed>
Status: Issue closed |
deanilvincent/check-password-strength | 578168557 | Title: Wrong default value
Question:
username_0: According to Readme you have wrong default value for password strength.
Right now it is `{ id: 2, value: 'Weak }`. Should be `Strong`. Add some test to it please :)
Answers:
username_1: Oh thanks for your contribution. I appreciate it! :) Bug fixes in version [1.0.8 ](https://www.npmjs.com/package/check-password-strength/v/1.0.8)
Status: Issue closed
|
MassTransit/MassTransit | 757232223 | Title: Exception "The connection was inactive for more than the allowed 60000 milliseconds"
Question:
username_0: Earlier today, I received exceptions like these for all of my services connected to a particular Azure Service Bus. Some of the services experienced this a handful of times over a couple hundred milliseconds.
Since it happened at the same time for all my services, I guess the root cause was something on the Azure end. This has only happened once before, quite a while ago, and is therefore not reproducible. I'm posting it here in case you want to know about this happening. Maybe there's something MassTransit could do regarding logging or general resiliency.
This happened with v7.0.6. I haven't been able to upgrade yet. If you think this is fixed in a later version (or is not useful to do anything about in MT), feel free to close. (Again, this happens very rarely, so even after upgrading I could never say with certainty that it's fixed. So I'm reporting it just in case.)
```
Exception on Receiver "sb://my-service-name.servicebus.windows.net/api-project" during Receive ActiveDispatchCount(0) ErrorRequiresRecycle(false)
Microsoft.Azure.ServiceBus.ServiceBusCommunicationException: The connection was inactive for more than the allowed 60000 milliseconds and is closed by container '97e4f072-4e55-45cc-8308-d6858130b2a0'.
---> Microsoft.Azure.ServiceBus.ServiceBusException: The connection was inactive for more than the allowed 60000 milliseconds and is closed by container '97e4f072-4e55-45cc-8308-d6858130b2a0'.
at async Task<IList<Message>> Microsoft.Azure.ServiceBus.Core.MessageReceiver.OnReceiveAsync(int maxMessageCount, TimeSpan serverWaitTime)
--- End of inner exception stack trace ---
at async Task<IList<Message>> Microsoft.Azure.ServiceBus.Core.MessageReceiver.OnReceiveAsync(int maxMessageCount, TimeSpan serverWaitTime)
at void Microsoft.Azure.ServiceBus.Core.MessageReceiver+<>c__DisplayClass65_0+<<ReceiveAsync>b__0>d.MoveNext()
at async Task Microsoft.Azure.ServiceBus.RetryPolicy.RunOperation(Func<Task> operation, TimeSpan operationTimeout)
at async Task Microsoft.Azure.ServiceBus.RetryPolicy.RunOperation(Func<Task> operation, TimeSpan operationTimeout)
at async Task<IList<Message>> Microsoft.Azure.ServiceBus.Core.MessageReceiver.ReceiveAsync(int maxMessageCount, TimeSpan operationTimeout)
at async Task<Message> Microsoft.Azure.ServiceBus.Core.MessageReceiver.ReceiveAsync(TimeSpan operationTimeout)
at async Task Microsoft.Azure.ServiceBus.MessageReceivePump.MessagePumpTaskAsync()+(?) => { }
```
Answers:
username_1: It recovered though, right? The log entry was reduced to Warning in 7.0.7 for these transient errors.
https://github.com/MassTransit/MassTransit/commit/67e2e1c96ed923373d6577b76d763a79a98bd5db
username_0: Thanks. I guess it's working fine, or I would be swimming in exceptions or bug reports now.
username_1: From researching, it's expected behavior when there is no traffic, and MassTransit will reconnect. Is there any reason for this issue to stay open?
username_0: Thanks for the clarification. From your description, it sounds as if this should happen every time there has been no traffic for 60 seconds; that is not the case for me. In many months of running a low-traffic dev environment, I have almost never encountered this exception. (I would also find it a bit annoying to get an error or a warning logged every time there was no traffic for 60 seconds, were that the case.) Furthermore, it happened for all my different services simultaneously.
Does the issue make any sense to you in light of the above?
I guess my concrete questions for this issue (and #2148) would be (sorry for not making this clear right away):
* What is actually happening here? Should I be concerned?
* If it is expected to happen regularly and does *not* constitute any operational breakage or other concern (because MassTransit will immediately recover on its own, with no impact to end users), should it perhaps be logged as information or lower? Or at least be configurable to do so? (I try to keep my warning logs clear of stuff I don't need to concern myself with; otherwise the important stuff drowns in a lot of noise.)
* If it is expected to happen regularly and *does* constitute some kind of concern, well, it shouldn't be expected to happen regularly and steps should be taken to remediate the situation. Whether on Azure, in MT, or on my end, I don't know; that would depend on the source of the issue.
username_1: I don't think it's a common thing, since there is usually some type of traffic on the wire. This error in particular seems like one that should not be logged at all (imho) though the debug logs will show a disconnect and reconnect.
username_0: I see. Does that mean that you will make a change to MT so that this exception is no longer logged? (To be clear, I am in favor of that.)
Status: Issue closed
|
syuilo/logica | 241877954 | Title: Tickを進める際更新対象を処理する順番により1Tickぶん遅延が発生することがある
Question:
username_0: 必ず更新を要求した時点でのTickの状態を取得するようにすれば解決するかもしれない
Answers:
username_0: 必ず更新を要求した時点でのTickの状態を取得するようにすれば解決するかもしれない
username_0: というよりTickする際の更新対象を更新して捌いていく作業の前に一旦現時点でのノードの状態を全部コピーしておいて、ノードを更新していくときにそっちのコピーしておいた方のデータを見せれば良いのかも
それなら捌いていく中でノードの状態が変わってもコピーした方には影響がないから更新する順番とか関係なしに常に正しい情報が取得される(どんな順番で更新したとしても結果が同じ)
…はず
username_0: まあこれは論理的な話であって実際に実装するときは全部コピーなんてしてたら負荷がかかりそうだからもっとスマートな方法を探す必要はある
username_0: 例えば捌く前に更新対象の各ノードの入力をすべて取得しておいて捌いていくときはその入力を渡していくとか…
username_0: NodeのgetInputメソッドは廃止か…?
username_0: 代わりにサーキット側から受け取った入力情報を見る事になる
username_0: これは例えば、画像をガウスブラーするときの処理と似ている。
ガウスブラーをかけるとき、各ピクセルについて周りのnピクセルの平均値をとる事になるけど、その周りのピクセルとはブラー処理前のピクセルであって、処理済みのピクセルは含まれない
Status: Issue closed
|
APynnaert/prj-rev-bwfs-dasmoto | 253454178 | Title: SUMMARY: Satisfactory
Question:
username_0: Nice job on this project! I really liked your usage of divs, and how you used IDs to select the headings. I recommend removing the font-weight:bold on your h1 and h2s, deleting repetitive stylings in the CSS and removing the quotes around lightcoral.
If you’re in the mood for a challenge...I would look into adding more items under each section and finding a nice way to lay them out. Here's a link to get you started - https://www.w3schools.com/css/css_rwd_grid.asp. Keep up the fantastic work! ^_^ |
ajaxorg/ace | 75241808 | Title: How to bind ACE content to a model ?
Question:
username_0: Hi,
is there a slightest possibility to create a binding between text-dom-nodes created in ACE and an external model, so that I can setup a sync? For instance:

shows a dual editor, when a user changes/selects a node in the upper editor, these changes would go into ACE without going over a brutal setValue.
I know there are other complications but I would be happy already to get a little glue where to start.
thank you!
g
Answers:
username_1: You can use `editor.session.insert({row, column}, text)` `editor.session.remove(range)` methods to modify only part of the text in the editor.
It mostly depends on what events you get from the graphical editor above.
But the easiest solution might be to use diff and apply changes using insert,remove methods.
Status: Issue closed
username_0: Ok, I think I will go the diff route. Thank you! |
fordhurley/atom-glsl-preview | 255339408 | Title: Extension directive should occur before any non-preprocessor tokens
Question:
username_0: ```
WARNING: 0:108: ' ' : extension directive should occur before any non-preprocessor tokens
```
It seems like it doesn't like:
```
#extension GL_OES_standard_derivatives : enable
```
Answers:
username_1: Yes, the reason for this is that the package adds some code to the shader _before_ your code. Namely, the built in uniforms. There are a few ways that we could support enabling extensions, but it would require some thinking.
I'm not totally clear on the value of the derivatives extension in this case, though. As I understand it, the derivative functions only work on `varying` values from the vertex shader, and our vertex shader produces none. Do you want to be able to write the vertex shader code?
username_1: This is now possible by writing a "bare" shader. See `examples/bare.glsl`.
Status: Issue closed
|
florence/cover | 65352196 | Title: Fix byte/char offset
Question:
username_0: Instead of the horrible byte/char offset stuff we do, we should use `port-count-lines!` to force the lexers to report in characters.
This needs to go into version 2, because it will require an API change.
Answers:
username_0: This turned out to be a giant mess because of dynamic-require not calling port-count-lines! (I think...?)
Status: Issue closed
|
biopython/biopython | 136745598 | Title: bug while parsing mmCif files
Question:
username_0: Hi,
I am getting an exception while parsing a bunch of mmcif files. I get the error when using 1.66, and actually I do not get the error when using 1.65.
the error appears when doing:
MMCIF_parser = MMCIFParser()
MMCIF_structure = MMCIF_parser.get_structure(pdbid, filename)
for example for structures: 4P9S, 4ZHL, 2IGM, 4ZHA, 3N0S
If it is a feature rather than a bug, would it be possible to get something like PERMISSIVE=1 like for the pdb parser, to ignore this?
os: linux and windows, both 64 bit
Python version : 2.7.10 (anaconda)
Biopython version: 1.66
Traceback that occurs (the full error message): when trying to parse 4P9S
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "C:\Anaconda\lib\site-packages\Bio\PDB\MMCIFParser.py", line 61, in get_structure
self._build_structure(structure_id)
File "C:\Anaconda\lib\site-packages\Bio\PDB\MMCIFParser.py", line 179, in _build_structure
name, element=element)
File "C:\Anaconda\lib\site-packages\Bio\PDB\StructureBuilder.py", line 241, in init_atom
residue.add(self.atom)
File "C:\Anaconda\lib\site-packages\Bio\PDB\Residue.py", line 80, in add
"Atom %s defined twice in residue %s" % (atom_id, self))
Bio.PDB.PDBExceptions.PDBConstructionException: Atom PA defined twice in residue <Residue FAD het=H_FAD resseq=901 icode= >
Answers:
username_1: Thanks for reporting this. The MMCIFParser wasn't correctly initiating new residues when the chain was changing. I'll submit a pull request to fix this shortly.
username_2: This is probably fixed now, but ideally we'd like you to confirm this @username_0. Are you able to try the changes fro @username_1 on #776 which I just merged? i.e. Are you comfortable getting Biopython from GitHub and reinstalling from source? Thanks!
username_0: Hi,
Yes, I will do. I will run my programs first with 1.65 and then with the
new version to be sure. It will take a couple of days to get everything
done. Should I expect other changes compared to 1.65?
username_1: Thanks @username_2 ! @username_0 I don't think there were major changes, although 1.65 is over a year old.
username_0: Hi,
Thanks a lot Joao and Peter for the wornderful and extremely quick support!.
The situation has dramatically improved regarding 1.66 and it is even better than in 1.65! However, it is not 100 % perfect. I have a sample of ~4600 cif files which pdb counterpart are correctly processed by biopython. In 1.66 there were around 650 cif files not processed, as I reported in this ticket, in 1.65 it was 379. Now with the latest code it is only 2 which is excellent! However, I think that it should be 0 failures ... so here I put the two failures for your consideration. The error message is a bit different this time, so we can open a new ticket if you prefer. Do you think it is something fixable? If yes, I would be happy to test again.
**Structure: 4Q96**
traceback: Traceback (most recent call last):
File "/apps64/bidev/pdbw/python/PdbWorkflow/PDB_convert_embl.py", line 307, in get_atom_sequence_mmcif
MMCIF_structure = MMCIF_parser.get_structure(protein_ID, pdb_file_path)
File "/homebasel/biocomp/fajardoo/python_test_modules/biopython_repo/Bio/PDB/MMCIFParser.py", line 65, in get_structure
self._build_structure(structure_id)
File "/homebasel/biocomp/fajardoo/python_test_modules/biopython_repo/Bio/PDB/MMCIFParser.py", line 181, in _build_structure
structure_builder.init_residue(resname, hetatm_flag, int_resseq, icode)
File "/homebasel/biocomp/fajardoo/python_test_modules/biopython_repo/Bio/PDB/StructureBuilder.py", line 157, in init_residue
% (resname, field, resseq, icode))
PDBConstructionException: Blank altlocs in duplicate residue ARG (' ', 55, ' ')
**Structure 4Q94**
traceback: Traceback (most recent call last):
File "/apps64/bidev/pdbw/python/PdbWorkflow/PDB_convert_embl.py", line 307, in get_atom_sequence_mmcif
MMCIF_structure = MMCIF_parser.get_structure(protein_ID, pdb_file_path)
File "/homebasel/biocomp/fajardoo/python_test_modules/biopython_repo/Bio/PDB/MMCIFParser.py", line 65, in get_structure
self._build_structure(structure_id)
File "/homebasel/biocomp/fajardoo/python_test_modules/biopython_repo/Bio/PDB/MMCIFParser.py", line 181, in _build_structure
structure_builder.init_residue(resname, hetatm_flag, int_resseq, icode)
File "/homebasel/biocomp/fajardoo/python_test_modules/biopython_repo/Bio/PDB/StructureBuilder.py", line 157, in init_residue
% (resname, field, resseq, icode))
PDBConstructionException: Blank altlocs in duplicate residue SER (' ', 2, ' ')
Status: Issue closed
username_2: Thanks for verifying the fix. Could you file a new issue for the blank altlocs issue? |
fable-compiler/ts2fable | 408364700 | Title: Duplicated modules are not merged
Question:
username_0: 
<issue_closed>
Status: Issue closed |
GNiklasch/formic-windmill | 267148941 | Title: UMs at rail head confused by black cell ahead
Question:
username_0: UMs extending or repairing a rail seem to have difficulties when they encounter a black cell ahead in the RM1 (normally blue) position.
(I'm not yet sure why - spectrum mismatch?)
This is a bit of a problem because the first mine shaft off rail2 may wrap around onto the head of rail3, and create black cells in exactly this context. Surprisingly the shaft turns out to be stronger than the rail and even multiple UMs at the rail head are unable to resist a single drilling UM. (But the scenario can arise in other ways, too - recognising this kind of wraparound from the shaft side would be a separate topic, and would not suffice to fix this.)
Answers:
username_0: Laden miners already repaint RM1 cells from `LCL_RM1_WRP` (black) to `LCL_RM1` (blue) as they encounter them. Unladen miners didn't do this because it had not been thought necessary and because I had believed it added some redundancy beyond keeping the shaft-exhausted marking in RR1. (It doesn't add much redundancy. Chances are when RR1 gets erased by an enemy, RM1 would also get wiped out.)
There is no issue in `runUMAtHomeStrategy()` (queen in view) nor in `runUMFreshCenterRailTactic()` (engineer in view); in both cases a UM on RM0 would already force the RM1 cell ahead to `LCL_RM1` before advancing.
The bug can bite us, however, when `runUMCenterRailTactic()` accepts `LCL_RM1_WRP` as a good match and the UM advances from RM0 to this RM1 cell, and only then discovers that the rail ahead (RL2, RM2, RR2) isn't in good shape. Usually the UM, failing to recognize the surroundings, would next step from RM1 onto the (green) RL1 cell, find herself still lost, paint RL1 white, and move on to the (red) RM0 cell - thus going round in a circle. More complex dances would occur when two or more UMs are at the site.
The fix is to have `runUMCenterRailTactic()` force the `LCL_RM1` color before stepping onto this cell, provided that there isn't a friend already on this cell who might still need it to propagate its state as a shaft-wrapped marker to RR1.
Once this has been corrected, we can risk addressing #7, too.
Status: Issue closed
username_0: Fixed in v1.2 by 3b945de. |
clash-lang/clash-compiler | 558681455 | Title: Simulation performance of `Unsigned n` for special values of `n`
Question:
username_0: Could `Unsigned 8` be represented as a `Word8`, with a no-op `bitCoerce` both ways? Similarly for `Signed 16` and `Int16` etc.? I am currently writing some Clash code that I'd like to simulate interactively as well, writing RGB color values into an SDL texture. If I use `Unsigned 8` in my code and convert to `Word8` on the edges, it is much slower than using `Word8` through and through internally.
Answers:
username_1: Myeah... I don't know how. Sadly the following isn't allowed:
```haskell
module Test where
import Clash.Prelude
import Data.Word
class UnsignedX (n :: Nat) where
data UnsignedN n
instance {-# OVERLAPPING #-} UnsignedX 8 where
data UnsignedN 8 = U8 Word8
instance {-# OVERLAPPING #-} UnsignedX 16 where
data UnsignedN 16 = U16 Word16
instance {-# OVERLAPPING #-} UnsignedX 32 where
data UnsignedN 32 = U32 Word32
instance {-# OVERLAPPING #-} UnsignedX 64 where
data UnsignedN 64 = U64 Word64
instance {-# OVERLAPPABLE #-} UnsignedX n where
data UnsignedN n = UN (Unsigned n)
instance Num (UnsignedN 8) where
fromInteger = U8 . fromInteger
instance Num (UnsignedN 16) where
fromInteger = U16 . fromInteger
instance Num (UnsignedN 32) where
fromInteger = U32 . fromInteger
instance Num (UnsignedN 64) where
fromInteger = U64 . fromInteger
```
```
[1 of 1] Compiling Test ( Test.hs, interpreted )
Test.hs:10:8: error:
Conflicting family instance declarations:
UnsignedN 8 -- Defined at Test.hs:10:8
UnsignedN n -- Defined at Test.hs:22:8
|
10 | data UnsignedN 8 = U8 Word8
| ^^^^^^^^^
Test.hs:13:8: error:
Conflicting family instance declarations:
UnsignedN 16 -- Defined at Test.hs:13:8
UnsignedN n -- Defined at Test.hs:22:8
|
13 | data UnsignedN 16 = U16 Word16
| ^^^^^^^^^
Test.hs:16:8: error:
Conflicting family instance declarations:
UnsignedN 32 -- Defined at Test.hs:16:8
UnsignedN n -- Defined at Test.hs:22:8
|
16 | data UnsignedN 32 = U32 Word32
| ^^^^^^^^^
Test.hs:19:8: error:
Conflicting family instance declarations:
UnsignedN 64 -- Defined at Test.hs:19:8
UnsignedN n -- Defined at Test.hs:22:8
|
19 | data UnsignedN 64 = U64 Word64
| ^^^^^^^^^
Failed, no modules loaded.
```
username_2: Could backpack be used for this?
username_3: Not without breaking compatibility with `stack`, and thus Windows IIRC
username_0: https://stackoverflow.com/q/60057227/477476
username_4: It would be cool if we could get something like this to work.
But isn't the much simpler option to just use the `Word*` or `Int*` types directly?
And if you need to write any generic functions for them, use a constraint like `(Num n, BitPack n) => ...`
username_0: Maybe?
But in some situations, I'd like to enforce unsignedness at least. For example, for a VGA output with `r`, `g` and `b` bits of red/green/blue DAC depth, it'd feel weird to allow `Signed r` as the red channel.
username_0: Based on https://stackoverflow.com/a/60059575/477476 I think we can do this with quite nice ergonomics actually.
The individual instances can be lifted as follows:
```
instance (KnownNat n) => Show (Unsigned n) where
show = unary show show show show show
instance (KnownNat n) => Eq (Unsigned n) where
(==) = bin (==) (==) (==) (==) (==)
(/=) = bin (/=) (/=) (/=) (/=) (/=)
instance (KnownNat n) => Ord (Unsigned n) where
compare = bin compare compare compare compare compare
instance (KnownNat n) => Num (Unsigned n) where
fromInteger = con fromInteger fromInteger fromInteger fromInteger fromInteger
(+) = binOp (+) (+) (+) (+) (+)
(-) = binOp (-) (-) (-) (-) (-)
(*) = binOp (*) (*) (*) (*) (*)
abs = unOp abs abs abs abs abs
signum = unOp signum signum signum signum signum
```
And turns out the margin of this Github issue is *not* too small to show the full infrastructure needed!
```
{-# LANGUAGE DataKinds, TypeFamilies, GADTs, RankNTypes #-}
{-# LANGUAGE TypeOperators, TypeApplications, ScopedTypeVariables #-}
{-# LANGUAGE RecordWildCards #-}
import Data.Word
import GHC.TypeLits (KnownNat, Nat)
import Data.Proxy
import Data.Type.Equality
import GHC.TypeNats (sameNat)
import Data.Singletons.Prelude.Bool
import Unsafe.Coerce
eqNat :: forall n m. (KnownNat n, KnownNat m) => Either ((n == m) :~: 'False) (n :~: m)
eqNat =
case sameNat @n @m Proxy Proxy of
Just r -> Right r
Nothing -> Left (unsafeCoerce (Refl :: 'False :~: 'False))
type IsSpecialSize (n :: Nat) = (n == 8) || (n == 16) || (n == 32) || (n == 64)
data SSize (n :: Nat) where
SSize8 :: SSize 8
SSize16 :: SSize 16
SSize32 :: SSize 32
SSize64 :: SSize 64
SSizeOther :: (IsSpecialSize n ~ False) => SSize n
sSize :: forall n. (KnownNat n) => SSize n
sSize =
case eqNat @n @8 of
Right Refl -> SSize8
Left Refl -> case eqNat @n @16 of
Right Refl -> SSize16
[Truncated]
unOp :: forall n. (KnownNat n) => Kit n (UnOp Word8) (UnOp Word16) (UnOp Word32) (UnOp Word64) (UnOp Integer) (UnOp (Unsigned n))
unOp f8 f16 f32 f64 f0 = unary (U8 . f8) (U16 . f16) (U32 . f32) (U64 . f64) (U . f0)
type Bin a r = a -> a -> r
bin :: forall n a. (KnownNat n) => Kit n (Bin Word8 a) (Bin Word16 a) (Bin Word32 a) (Bin Word64 a) (Bin Integer a) (Bin (Unsigned n) a)
bin f8 f16 f32 f64 f0 = case sSize @n of
SSize8 -> \ (U8 x) (U8 y) -> f8 x y
SSize16 -> \ (U16 x) (U16 y) -> f16 x y
SSizeOther -> \ (U x) (U y) -> f0 x y
type BinOp a = a -> a -> a
(...) :: (r -> r') -> (a -> b -> r) -> (a -> b -> r')
f ... g = \x y -> f (g x y)
binOp :: forall n. (KnownNat n) => Kit n (BinOp Word8) (BinOp Word16) (BinOp Word32) (BinOp Word64) (BinOp Integer) (BinOp (Unsigned n))
binOp f8 f16 f32 f64 f0 = bin (U8 ... f8) (U16 ... f16) (U32 ... f32) (U64 ... f64) (U ... f0)
```
username_0: I strongly suspect that `con`, `unary` and `bin` can be unified somehow, but that's now an internal implementation detail.
username_0: In fact, we might even use `Word8` for `Unsigned n` if `n <= 8`, if only we do sufficient truncation on results before converting to something else. Just a thought; this could get ugly fast.
username_1: But is it actually faster? Since it seems to suggest that a lot of constant folding and specialization needs to happen at compile-time; otherwise we're doing those `eqNat` things at runtime, and also still pattern-match on the constructor of this new `Unsigned` instead of the constructor of `Integer` which is used by the current version of `Unsigned`.
It would be interesting to see the results of the clash-prelude benchmark (https://github.com/clash-lang/clash-compiler/blob/master/clash-prelude/clash-prelude.cabal#L370) for this new representation of `Unsigned`
username_0: Running the full benchmark would require putting in the full work, before we even know if it is worth it. However, I have now run parts of the benchmark that didn't require me to do any thinking :) I'd say the numbers are very promising for arithmetic performance. All tests are with `WORD_SIZE_IN_BITS` set to 64.
With `Integer` as the underlying representation (i.e., before my changes):
```
benchmarking Signed/fromInteger# WORD_SIZE_IN_BITS
time 75.14 ns (74.89 ns .. 75.38 ns)
1.000 R² (1.000 R² .. 1.000 R²)
mean 75.35 ns (75.13 ns .. 75.67 ns)
std dev 849.4 ps (635.4 ps .. 1.220 ns)
variance introduced by outliers: 11% (moderately inflated)
benchmarking Signed/+# WORD_SIZE_IN_BITS
time 64.08 ns (63.86 ns .. 64.35 ns)
1.000 R² (1.000 R² .. 1.000 R²)
mean 64.21 ns (64.05 ns .. 64.40 ns)
std dev 614.2 ps (513.8 ps .. 746.6 ps)
benchmarking Signed/negate# WORD_SIZE_IN_BITS
time 50.00 ns (49.67 ns .. 50.57 ns)
0.997 R² (0.993 R² .. 0.999 R²)
mean 51.53 ns (50.40 ns .. 53.67 ns)
std dev 4.981 ns (2.986 ns .. 6.960 ns)
variance introduced by outliers: 91% (severely inflated)
benchmarking Signed/abs# WORD_SIZE_IN_BITS
time 50.04 ns (49.82 ns .. 50.22 ns)
1.000 R² (1.000 R² .. 1.000 R²)
mean 49.97 ns (49.85 ns .. 50.13 ns)
std dev 465.5 ps (375.0 ps .. 638.3 ps)
benchmarking Signed/-# WORD_SIZE_IN_BITS
time 65.74 ns (65.52 ns .. 66.01 ns)
1.000 R² (1.000 R² .. 1.000 R²)
mean 65.75 ns (65.56 ns .. 66.03 ns)
std dev 772.2 ps (586.0 ps .. 1.054 ns)
variance introduced by outliers: 12% (moderately inflated)
benchmarking Signed/*# WORD_SIZE_IN_BITS
time 101.9 ns (101.4 ns .. 102.4 ns)
0.999 R² (0.996 R² .. 1.000 R²)
mean 104.4 ns (102.0 ns .. 113.9 ns)
std dev 15.31 ns (1.095 ns .. 32.56 ns)
variance introduced by outliers: 95% (severely inflated)
benchmarking Signed/pack# WORD_SIZE_IN_BITS
time 12.11 ns (12.07 ns .. 12.15 ns)
1.000 R² (1.000 R² .. 1.000 R²)
mean 12.08 ns (12.05 ns .. 12.13 ns)
std dev 145.4 ps (114.3 ps .. 217.8 ps)
variance introduced by outliers: 14% (moderately inflated)
```
With `Int64` representation (i.e. with my changes):
```
benchmarking Signed/fromInteger# WORD_SIZE_IN_BITS
time 49.32 ns (49.01 ns .. 49.69 ns)
1.000 R² (0.999 R² .. 1.000 R²)
mean 49.68 ns (49.37 ns .. 50.11 ns)
[Truncated]
mean 30.37 ns (29.78 ns .. 31.88 ns)
std dev 2.766 ns (513.8 ps .. 4.893 ns)
variance introduced by outliers: 90% (severely inflated)
benchmarking Signed/*# WORD_SIZE_IN_BITS
time 29.11 ns (29.00 ns .. 29.25 ns)
1.000 R² (1.000 R² .. 1.000 R²)
mean 29.32 ns (29.20 ns .. 29.46 ns)
std dev 437.1 ps (367.7 ps .. 530.3 ps)
variance introduced by outliers: 19% (moderately inflated)
benchmarking Signed/pack# WORD_SIZE_IN_BITS
time 13.55 ns (13.49 ns .. 13.60 ns)
1.000 R² (1.000 R² .. 1.000 R²)
mean 13.50 ns (13.43 ns .. 13.55 ns)
std dev 199.8 ps (163.7 ps .. 235.6 ps)
variance introduced by outliers: 19% (moderately inflated)
```
Code is at https://github.com/username_0/clash-compiler/tree/signed-int
username_1: Those number are indeed very encouraging! Especially since I see that those functions are still marked `NOINLINE` i.e. stopping GHC dead in its tracks to do any kind of specialization. It would be interesting to extend the benchmark with explicitly polymorphic with NOINLINEs (to simulate "library" code where the `Num (Signed n)` dictionary still takes a `KnownNat n` argument:
```haskell
multBenchPoly :: Benchmark
multBenchPoly = env setup $ \m ->
bench "*# WORD_SIZE_IN_BITS" $ nf (uncurry (polyMultSigned)) m
where
setup = return (smallValue_pos1,smallValue_pos2)
polyMultSigned :: KnownNat n => Signed n -> Signed n -> Signed n
polyMultSigned = (*#)
{-# NOINLINE #-}
```
as this would also stop GHC from doing specialization on the `Num (Signed n)` dictionary and eliminating those `eqNat`s.
username_0: It doesn't seem to change anything:
```
benchmarking Signed/Mono *# WORD_SIZE_IN_BITS
time 29.79 ns (29.61 ns .. 29.98 ns)
1.000 R² (1.000 R² .. 1.000 R²)
mean 29.66 ns (29.53 ns .. 29.81 ns)
std dev 466.3 ps (362.1 ps .. 619.3 ps)
variance introduced by outliers: 20% (moderately inflated)
```
vs.
```
benchmarking Signed/Poly *# WORD_SIZE_IN_BITS
time 29.40 ns (29.28 ns .. 29.53 ns)
1.000 R² (1.000 R² .. 1.000 R²)
mean 29.44 ns (29.29 ns .. 29.58 ns)
std dev 472.3 ps (400.0 ps .. 553.3 ps)
variance introduced by outliers: 21% (moderately inflated)
```
username_1: Perhaps we can take some of the code from https://github.com/Bodigrim/mod, at least for `Unsigned`.
username_0: I'm not giving up on this idea. I think a good next step would be to finish the implementation for `Signed` so that I can run the test suites (you guys have test suites, right?).
I'm publishing my work as I go to https://github.com/username_0/clash-compiler/tree/signed-int in case anyone wants to help out.
username_0: The functions that are slower (MUCH slower) are the extending ones, where there is no easy way to exploit the special cases... E.g. for `plus#`:
Before:
```
benchmarking Signed/plus# WORD_SIZE_IN_BITS
time 15.84 ns (15.75 ns .. 16.00 ns)
0.998 R² (0.997 R² .. 1.000 R²)
mean 16.23 ns (16.00 ns .. 16.74 ns)
std dev 1.123 ns (596.4 ps .. 1.863 ns)
variance introduced by outliers: 84% (severely inflated)
```
With a naive implementation via `Integer`:
```
benchmarking Signed/plus# WORD_SIZE_IN_BITS
time 76.22 ns (75.69 ns .. 76.83 ns)
0.999 R² (0.999 R² .. 1.000 R²)
mean 75.60 ns (75.05 ns .. 76.31 ns)
std dev 2.061 ns (1.562 ns .. 2.779 ns)
variance introduced by outliers: 42% (moderately inflated)
```
by naive implementation, I mean the following:
```
plus# a b = fromInteger_INLINE $ toInteger_INLINE a + toInteger_INLINE b
```
username_0: I'm withdrawing from this one because it seems like a red herring. I have manually changed my Bounce example to use `Int`s everywhere, and there is not much improvement to the simulation time for a single frame.
I think I initially misunderstood the timing figures I saw. It is true that using `Word8` instead of `Unsigned 8` for the VGA color channels improved end-to-end simulation performance tremendously, but that is because ultimately I am shoving everything into an SDL texture which is a `Ptr Word8`; so the real overhead is in the `bitCoerce :: Unsigned 8 -> Word8` conversion before writing to the texture.
Of course, if we had `Unsigned 8` represented as `Word8`, it could still be that this could be compiled to a zero-cost `coerce` instead...
username_1: @username_0 Although it doesn't help with the `bitCoerce`, I have been able to speed up the numeric operators (without changing the underlying data representation too much: Natural instead of Integer) at: https://github.com/clash-lang/clash-compiler/pull/1132
username_1: Also by adding:
```haskell
unsigned8toWord8 :: Unsigned 8 -> Word8
unsigned8toWord8 (U (NatS# u#)) = W8# (narrow8Word# u#)
unsigned8toWord8 (U (NatJ# u#)) = W8# (narrow8Word# (bigNatToWord u#))
{-# NOINLINE unsigned8toWord8 #-}
{-# RULES
"bitCoerce/Unsigned 8 -> Word8" bitCoerce = unsigned8toWord8
#-}
```
I can make bitCoerce for those types go from:
```
time 22.08 ns (22.05 ns .. 22.11 ns)
1.000 R² (1.000 R² .. 1.000 R²)
mean 22.10 ns (22.07 ns .. 22.13 ns)
std dev 96.59 ps (78.29 ps .. 129.6 ps
```
to:
```
time 4.572 ns (4.566 ns .. 4.585 ns)
1.000 R² (0.999 R² .. 1.000 R²)
mean 4.594 ns (4.570 ns .. 4.667 ns)
std dev 150.1 ps (11.44 ps .. 289.1 ps)
```
Of course I'd have to add a primitive for the HDL backends; But that's probably worth it.
username_1: Fast conversions added at: https://github.com/clash-lang/clash-compiler/pull/1144 |
IFRCGo/go-api | 630296966 | Title: Fix permissions for private field reports on event API
Question:
username_0: https://github.com/IFRCGo/go-frontend/pull/1302 hides private field reports tied to emergencies when the user is not logged in. However, this is a style fix that does not deal with the underlying issue of permissions to the event API:
When a user is not authenticated, the event API will currently related field report data tied to the event. If a field report is marked as private, this does not affect the data returned from the API. A fix was proposed https://github.com/IFRCGo/go-api/pull/748 but rolled back because, to my understanding, it broke aggregations of the field report data displayed on the frontend.
The proper fix would be to:
1. rethink how the aggregations are calculated on the event, maybe moving them from the frontend to the backend
2. re-implement the permissions on field reports as demonstrated by @GregoryHorvath
cc @username_1
Answers:
username_1: Thanks @username_0 -
Currently, there are a number of values that get displayed on the frontend, that are all pulled from the "latest" field report submitted:
So, we need to:
- enumerate what all these fields we need from the "latest" field report
- have the backend return these fields under `latest_field_report` or so, and hide any other details about the field report, and not return information for any other field reports
- switch the frontend to use these fields from `latest_field_report` (should be fairly straightforward)
@username_2 @mmusori - the business question here is - "Do we want to continue displaying these figures on the Emergency page from the 'latest' Field Report, or do we want to change the logic of how these figures are aggregated / displayed on the Emergency page?" - if it makes sense to go ahead with implementing the current logic, but have the data returned by the backend, we can go ahead with the steps outlined above, else we will need a separate ticket that defines how we want to change how we aggregate data from Field Reports onto Emergencies.
username_2: @mmusori personally I think the above proposed approach sounds good - but obvs you would need to confirm if happy. Also may need to check with our various external API consumers?
@username_1 the page would need to of course also keep the existing logic to only show the recent FR fields if "hide attached FRs" is not ticked for that emergency!
@username_1 I suspect the above proposed changes would go a long way towards solving the 3000 column issue in https://github.com/IFRCGo/go-api/issues/758#issuecomment-638637260 - so should presumably be worked on in conjunction! Cheers |
betagouv/mon-entreprise | 761067065 | Title: Ajouter une section : À quoi servent mes impôts ?
Question:
username_0: On présente actuellement une section « À quoi servent mes cotisations ? ». On pourrait sur le même modèle ajouter une section « À quoi servent mes impôts ? » en reprenant par exemple les proportions de https://www.aquoiserventmesimpots.gouv.fr/depenses-publics


Answers:
username_0: On peut potentiellement ajouter un lien vers http://www.aquoiserventlescotisations.urssaf.fr au niveau de cette section "à quoi servent mes cotisations ?" « en savoir plus »
username_0: Bon ils ont refait le site « à quoi servent mes impôts » mais c'est pas génial... https://www.economie.gouv.fr/aqsmi
username_1: (ah oui, l'idée est bonne, mais c'est moche :p)
Status: Issue closed
username_0: Hors sujet pour le moment. |
alerta/docker-alerta | 411490209 | Title: 404 errors when running mailer integration
Question:
username_0: I've custom built a docker container containing the mailer integration:
**alerta-mailer-DockerFile**
```
FROM alerta/alerta-web
USER root
RUN apt-get update
RUN apt-get -y upgrade
RUN apt-get autoclean
RUN apt-get clean
USER 1001
RUN /venv/bin/pip install --upgrade pip
RUN /venv/bin/pip install git+https://github.com/alerta/alerta-contrib.git#subdirectory=integrations/mailer
```
I've spun up the new image in a container and everything works from the web gui.
I exec into the alerta container and run: alerta-mailer
I see the following output:
```
DEBUG:mailer:Looking for rules files in /app/alerta.rules.d
Python dns.resolver unavailable. The skip_mta option will be forced to FalseError 99 connecting to localhost:6379. Cannot assign requested address.
DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): localhost:8080
Starting new HTTP connection (1): localhost:8080
DEBUG:urllib3.connectionpool:http://localhost:8080 "POST /heartbeat HTTP/1.1" 404 None
http://localhost:8080 "POST /heartbeat HTTP/1.1" 404 None
DEBUG:urllib3.connectionpool:http://localhost:8080 "POST /heartbeat HTTP/1.1" 404 None
http://localhost:8080 "POST /heartbeat HTTP/1.1" 404 None
```
This looks like it's trying to post to the heartbeats page in alerta but failing as the path is incorrect.
I've run:
curl http://localhost:8080 and can confirm the page is returned. However, running http://localhost:8080/heartbeat fails with a 404 error which I expect is what I'm seeing from alerta-mailer.
`curl -X POST http://localhost:8080/heartbeat`
I get a 404 Not Found.
Answers:
username_1: The API endpoint is at:
http://<docker>:<port>/api
username_0: That gets around the issue but still, running alerta-mailer causes the above error. I'm assuming that this should just run without needing additional switches and just pull it's config from the alerta.conf file then send emails to the configured recipients. When you run it, it just loops with this error message.
username_1: You created a rules file, right? As the error message suggested. And you're still getting an error??? I'm very confused.
Status: Issue closed
username_1: Closing due to inactivity. If you believe this issue has been closed prematurely please provide more information to help progress the issue. If you do not know what is expected you can ask on [Gitter chat](https://gitter.im/alerta/chat).
username_0: I think my problem is that the Readme reads (to me at least), that the JSON alert-rules are optional and is used for additional emails you want to email to.
In my alerta.conf config file I have:
```
[alerta-mailer]
key = <KEY>
mail_to = <EMAIL>
mail_from = <EMAIL>
mail_localhost = alerta.mydomain.com # fqdn to use in the HELO/EHLO command
smtp_host = myalertaserver.myserver.com
smtp_username =
smtp_password =
smtp_port = 21
smtp_use_ssl = False
smtp_starttls = False
dashboard_url = http://myalertaserver.myserver.com:8080
debug = True
```
I exec onto my alerta instance with mailer already installed and run `alertamailer`. My assumption here is that it will look in the alerta.conf config file, see the settings and mail the only email I have entered under the mail_to variable. It doesn't. It just repeats the
```
DEBUG:urllib3.connectionpool:http://localhost:8080 "POST /heartbeat HTTP/1.1" 404 None
http://localhost:8080 "POST /heartbeat HTTP/1.1" 404 None
```
error. I'm assuming I've misunderstood the way to set it up?
username_1: I've custom built a docker container containing the mailer integration:
**alerta-mailer-DockerFile**
```
FROM alerta/alerta-web
USER root
RUN apt-get update
RUN apt-get -y upgrade
RUN apt-get autoclean
RUN apt-get clean
USER 1001
RUN /venv/bin/pip install --upgrade pip
RUN /venv/bin/pip install git+https://github.com/alerta/alerta-contrib.git#subdirectory=integrations/mailer
```
I've spun up the new image in a container and everything works from the web gui.
I exec into the alerta container and run: alerta-mailer
I see the following output:
```
DEBUG:mailer:Looking for rules files in /app/alerta.rules.d
Python dns.resolver unavailable. The skip_mta option will be forced to FalseError 99 connecting to localhost:6379. Cannot assign requested address.
DEBUG:urllib3.connectionpool:Starting new HTTP connection (1): localhost:8080
Starting new HTTP connection (1): localhost:8080
DEBUG:urllib3.connectionpool:http://localhost:8080 "POST /heartbeat HTTP/1.1" 404 None
http://localhost:8080 "POST /heartbeat HTTP/1.1" 404 None
DEBUG:urllib3.connectionpool:http://localhost:8080 "POST /heartbeat HTTP/1.1" 404 None
http://localhost:8080 "POST /heartbeat HTTP/1.1" 404 None
```
This looks like it's trying to post to the heartbeats page in alerta but failing as the path is incorrect.
I've run:
curl http://localhost:8080 and can confirm the page is returned. However, running http://localhost:8080/heartbeat fails with a 404 error which I expect is what I'm seeing from alerta-mailer.
`curl -X POST http://localhost:8080/heartbeat`
I get a 404 Not Found.
username_1: So does it work if you create a rules file?
username_0: That's my question then I guess. Is the rules file compulsory? If so, what are the parameters in alerta.conf used for?
username_1: The README explains that `alerta.conf` is used to configure the mail transport and `alerta.rules.d/*` rules files configure emails destinations according regexp criteria.
username_0: Then I'm confused what the mail_to variable is for in the alerta.conf mailer section. I assumed all alerts would go to the emails specified here.
username_1: I quick glance at the code revealed that the `mail_to` setting provides the default list of contacts which can be supplemented by a specific mail rule. https://github.com/alerta/alerta-contrib/blob/master/integrations/mailer/mailer.py#L251-L252
username_0: So I'm understanding it correctly then? It provides a default list of contacts which can be supplemented (not has to be). So shouldn't it then email the email addresses under mail_to with alerts by default without the need for an additional mail rule as soon as I run alertamailer?
Status: Issue closed
username_1: Sounds right. Let me know if you need any more info.
username_2: I get the following error when I try to run the mailer:
File "/usr/local/lib/python3.6/threading.py", line 916, in _bootstrap_inner
self.run()
File "/venv/lib/python3.6/site-packages/mailer.py", line 185, in run
self.send_email(alert)
File "/venv/lib/python3.6/site-packages/mailer.py", line 271, in send_email
self._template_name).render(**template_vars)
File "/venv/lib/python3.6/site-packages/jinja2/environment.py", line 830, in get_template
return self._load_template(name, self.make_globals(globals))
File "/venv/lib/python3.6/site-packages/jinja2/environment.py", line 804, in _load_template
template = self.loader.load(self, name, globals)
File "/venv/lib/python3.6/site-packages/jinja2/loaders.py", line 113, in load
source, filename, uptodate = self.get_source(environment, name)
File "/venv/lib/python3.6/site-packages/jinja2/loaders.py", line 187, in get_source
raise TemplateNotFound(template)
jinja2.exceptions.TemplateNotFound: email.tmpl
Do I need to explicitly create email.tmp?
username_1: I don't think so. An `email.tmpl` is included in the package.
We ask users to not comment on closed/resolved issues. If you have an issue please raise a new bug report and ensure you provide as much information as possible relevant to your particular issue and environment. |
rstudio/distill | 629485306 | Title: Non-English characters
Question:
username_0: Hi,
I'm new to Distill, and I'm trying to convert an R Markdown site of my own to Distill. But I getting this error:
pandoc.exe: Cannot decode byte '\xed': Data.Text.Internal.Encoding.decodeUtf8: Invalid UTF-8 stream
Erro: pandoc document conversion failed with error 1
Can't you use non-english characters on Distill' YALM?? It works fine on R Markdown.
Answers:
username_1: I've just tested this with the \xed character ("í"), as well as with Cyrillic characters, and the article knits without errors.
Since this issue has been open for almost 3 months, can one issue you no longer experience this problem, or have you abandoned distill altogether?
What version of Pandoc are you using?
username_1: I think this issue can be closed?
username_2: i have same error:
```
pandoc.exe: Cannot decode byte '\xc8': Data.Text.Internal.Encoding.decodeUtf8: Invalid UTF-8 stream
Error: pandoc document conversion failed with error 1
Execution halted
Exited with status 1.
```
when have cyrilic characters in _site.yml
```
name: "statiecon_"
title: "statiecon"
description: |
statiecon
output_dir: "docs"
navbar:
right:
- text: "Home"
href: index.html
- text: "ИМБФГЖ"
href: about.html
output: distill::distill_article
```
username_2: [1] ‘2.7.3’
```
username_3: +1
same problem on Korean version
username_4: Seems like an issue with UTF8 and Pandoc.
What is the encoding of your site.yml file ? Is it UTF-8 ?
If not, can you try convert the file to UTF-8, then retry. (You can use `File > Save with encoding` in RStudio)
username_4: @username_2 @rpmeira we've made some improvements regarding encoding while fixing other issues.
Do you still have your issues with last dev version of **distill** ?
Thanks.
username_2: I updated distill to 1.2. Also, i checked encoding of site.yml file in RStudio, it’s UTF-8. But same error is appears when add Cyrillic symbol in navbar> text tag.
```
pandoc.exe: Cannot decode byte '\xd4': Data.Text.Internal.Encoding.decodeUtf8: Invalid UTF-8 stream
Error: pandoc document conversion failed with error 1
```
You can reproduce problem if create new distill website and only change content in navbar> text on the site.yml file with cyrillic symbol. For example: "ТестЯ"
username_4: Thanks for the check and information, I'll look into it. We may have missed something.
username_4: @username_2 I can't reproduce with last version of **distill** and **rmarkdown**. Which version of Pandoc do you have ? `rmarkdown::pandoc_version()`
username_2: [1] ‘2.11.2’
username_4: @username_2 I have Pandoc 2.11.4
Would you be willing to try with this one ?
* Either by using RStudio daily (https://dailies.rstudio.com/) which comes bundle with Pandoc 2.11.4
* Or by installing the latest Pandoc version (https://bookdown.org/yihui/rmarkdown-cookbook/install-pandoc.html)
As the error is a Pandoc error in the first place I want to check if everything is ok on Pandoc's side.
Thank you!
username_2: The same error with RStudio daily and Pandoc 2.11.4.

username_4: @username_2 as I cannot reproduce so I can't test myself: Pandoc 2.12 is now out and it seems they fixed an issue regarding encoding again: https://github.com/jgm/pandoc/releases
Are you able to try ?
Also, could you share a reproducible example of this issue, in a github repo maybe so that we are not dependant on copy pasting. I tried again with https://github.com/rstudio/distill/issues/137#issuecomment-727016091 and it works for me with no issue.
username_5: Hi,
I have the same issue when editing the YAML file in pt-BR. I have Pandoc v. 2.13 and RStudio v, 1.4.1106 installed.
I don´t know if it will help, but the files I am using are available here: https://github.com/username_5/site_comcorp
username_2: The problem is still appearing at the RStudio 1.4.17.17 (Pandoc bundled version) and Pandoc 2.14.0.1. Reproducible code example is publish on gitub.
https://github.com/username_2/statiecon_reproducible_example |
datamolecule/letsencrypt_http_challenge | 164274871 | Title: Rails 5 support
Question:
username_0: Dependency to rails version has to be updated to support Rails 5.
Answers:
username_1: Thanks for pointing this out, I will release a 1.0.0 version of the gem for Rails 5 shortly.
username_1: Version 0.0.3 released that remove Rails 4 dependency.
Status: Issue closed
|
JuliaGizmos/Interact.jl | 456450488 | Title: Filepicker Widget in Mux?
Question:
username_0: I'm trying to use `filepicker` with Mux, and haven't been able to get it to work. I just noticed this line in the Tutorial, however:
```
Important note: this app needs to run in Blink, as the browser doesn't allow us to get access to the local path of a file.
```
Does this mean that the `filepicker` widget only works with Blink, or am I misunderstanding what the limitations are?
Answers:
username_1: That is correct, browsers don't have access to the local file system, so the "Blink" filepicker that returns the path to the selected file is not possible (normally this is handled server side). I'm not sure what's the best way to handle this in the Interact framework.
username_0: Is there a way to load and cache that file into the server rather than a reference to the local file system? |
PermutaTriangle/Tilings | 646383113 | Title: AssertionError: parameters did not match comb_class for the rule
Question:
username_0: To replicate:
```python
from tilings.tilescope import TileScope, TileScopePack
basis = '0123_0213_0231_0312'
pack = TileScopePack.insertion_row_and_col_placements(row_only=True).make_fusion(apply_first=True)
css = TileScope(basis, pack)
spec = css.auto_search()
counts = [spec.count_objects_of_size(n) for n in range(11)]
```
Traceback:
```python
---------------------------------------------------------------------------
AssertionError Traceback (most recent call last)
<ipython-input-1-8721081a5bfa> in <module>
5 css = TileScope(basis, pack)
6 spec = css.auto_search()
----> 7 counts = [spec.count_objects_of_size(n) for n in range(11)]
<ipython-input-1-8721081a5bfa> in <listcomp>(.0)
5 css = TileScope(basis, pack)
6 spec = css.auto_search()
----> 7 counts = [spec.count_objects_of_size(n) for n in range(11)]
~/Dropbox/Research/Active/2017-44-ATRAP/repos/comb_spec_searcher/comb_spec_searcher/specification.py in count_objects_of_size(self, n, **parameters)
347 limit = n * self.number_of_rules()
348 with RecursionLimit(limit):
--> 349 return self.root_rule.count_objects_of_size(n, **parameters)
350
351 def generate_objects_of_size(
~/Dropbox/Research/Active/2017-44-ATRAP/repos/comb_spec_searcher/comb_spec_searcher/strategies/rule.py in count_objects_of_size(self, n, **parameters)
378 self.subrecs is not None
379 ), "you must call the set_subrecs function first"
--> 380 res = self.constructor.get_recurrence(self.subrecs, n, **parameters)
381 self.count_cache[key] = res
382 # # THE FOLLOWING CODE SNIPPET IS FOR DEBUGGING PURPOSES
~/Dropbox/Research/Active/2017-44-ATRAP/repos/comb_spec_searcher/comb_spec_searcher/strategies/constructor.py in get_recurrence(self, subrecs, n, **parameters)
336 def get_recurrence(self, subrecs: SubRecs, n: int, **parameters: int) -> int:
337 if not parameters:
--> 338 return sum(rec(n) for rec in subrecs)
339 res = 0
340 for (idx, rec), extra_params in zip(
~/Dropbox/Research/Active/2017-44-ATRAP/repos/comb_spec_searcher/comb_spec_searcher/strategies/constructor.py in <genexpr>(.0)
336 def get_recurrence(self, subrecs: SubRecs, n: int, **parameters: int) -> int:
337 if not parameters:
--> 338 return sum(rec(n) for rec in subrecs)
339 res = 0
340 for (idx, rec), extra_params in zip(
~/Dropbox/Research/Active/2017-44-ATRAP/repos/comb_spec_searcher/comb_spec_searcher/strategies/rule.py in count_objects_of_size(self, n, **parameters)
378 self.subrecs is not None
379 ), "you must call the set_subrecs function first"
--> 380 res = self.constructor.get_recurrence(self.subrecs, n, **parameters)
381 self.count_cache[key] = res
382 # # THE FOLLOWING CODE SNIPPET IS FOR DEBUGGING PURPOSES
[Truncated]
--> 372 self, list(parameters), self.comb_class.extra_parameters,
373 )
374 )
AssertionError: parameters did not match comb_class for the rule
placing the leftmost point in cell (0, 0) but only the child at index 1 is non-empty
+-+ +-+-+
|\| = |●| |
+-+ +-+-+
\: Av+(01) | |\|
Requirement 0: +-+-+
0: (0, 0) \: Av(01)
Assumption 0: ●: point
can count points in cell (0, 0) Requirement 0:
0: (0, 1)
Assumption 0:
can count points in cells (0, 1), (1, 0)
parameters given: ['k_1']
comb_class_parameters: ('k_0',)
``` |
w3c/specberus | 159044811 | Title: Bug in rule “sotd.group-homepage”: [Unable to find the deliverer]
Question:
username_0: [Unable to find the deliverer]
Found [while checking `https://www.w3.org/TR/worklets-1/`](https://www.w3.org/pubrules/?url=https%3A%2F%2Fwww.w3.org%2FTR%2Fworklets-1%2F&profile=FPWD&validation=simple-validation&noRecTrack=false&informativeOnly=false&echidnaReady=false&patentPolicy=pp2004).
This is a joint TAG-CSS publication, which I suspect is the cause of this issue. There is a link to the CSS WG home page, but specberus does not find it.
Answers:
username_1: Closing as it's related to #411
Status: Issue closed
|
theCrag/website | 169997592 | Title: In manual account creation, password is shown on screen
Question:
username_0: Don't know if [it was intentional](http://www.lukew.com/ff/entry.asp?1941), but when I created my account, my password was visible in the password field. Made me anxious and look over my shoulder. I suppose it is less trouble for the user than typing in the password twice to make sure it is consistent without seeing it - but since the user is giving their email anyway, if they mistype in a single hidden-password field and find they can't log in with that password, password reset should be no big deal anyway. At least, it would be nice if there was a "Show Password" checkbox that was unchecked by default.
Example: http://imgur.com/a/hHORt
Answers:
username_1: @username_0 we should probably fix that as it seems to be standard to have it hidden by default.
From a personal security note it is far more secure if you create a unique password for every site, in which case it would not matter.
username_2: No this was an explicit decision, pretty well every usability study for the last 10 years has consistently found that showing password at creation time (but obviously not later when entering them) improves the usability of the page, reduces the change of typos and so the end result is actually better security. This is in the same category as duplicating the email (or password) field which lots of sites still do because they think they should, but it's a horrible user experience.
This has been in place for a couple year but very occasionally we do get concerned people asking about it. I do agree that the show password checkbox would make some people more comfortable so I'll add that to the todo list and rename this issue accordingly.
username_3: 
has been implemented
Status: Issue closed
|
space-wizards/space-station-14 | 1126590105 | Title: Clientside movement
Question:
username_0: We agreed to try it, mainly for people with Argentinian levels of internet.
I had a potential idea on implementing it:
- Subscribe to ComponentGetStateAttemptEvent for transforms + physics and where the entity has a specific component (e.g. clientauthrotiativecomponent) then ignore them for netsync. This is mainly because we can use it for their own actor entity + stuff like board games. Main thing is to work out how expensive this may be given it's adding a HasComp to every time transform is dirty (probably nowhere near as bad as MoveEvent itself) and means they always have to use the slow path for PVS.
- Whenever the client moves during IsFirstTimePredicted have them send a message with their new position
Answers:
username_1: Allowing the client to inform the server where the player is positioned is how you get speed and teleport hacks.
username_0: another another conversation if we can make pushing not bad
https://discord.com/channels/310555209753690112/310555209753690112/940387150111858768
Status: Issue closed
|
smaranjitghose/DeepPixel | 596262665 | Title: GitHub Actions for this project
Question:
username_0: # Task:
Create custom GitHub Actions or use pre-existing ones to automate the workflow for this project
Answers:
username_1: I would like to work on this @username_0
username_0: Minoli before giving PRs, please have a discussion with me or the other mentors in the respective channel on Slack, so that we can figure the most appropriate actions for this project and also analyze the tradeoff for using similar GitHub apps from the GitHub marketplace. If you need to experiment this, feel free to give a PR to any of my repos like ```DeepHoli```
username_1: Yes👍
Status: Issue closed
|
ARMmbed/mbed-os-example-lorawan | 369416042 | Title: ACK_TIMEOUT ELAPSE and ERROR CODE -1010
Question:
username_0: I am using X-NUCLEO-53L0A1 and NUCLEOF401RE with the SX1272 shield.
I try to send the proximity sensor data to the gateway but it keeps showing ack_timeout and finally a send error code -1010.




I only added the sensor data into the send message function

Answers:
username_1: Does it work if you remove all sensor code and *physically* disconnect the sensor board? It could be that your sensors are wired to pins that are also used by the LoRa shield - although doesn't look like it from first glance.
Note that you're initializing objects on every call to `send_message` now so you're leaking memory and probably introducing bugs in the sensor code.
username_0: @username_1 thanks for your reply.
I've changed the pins for the sensor so there will be no collision.
Actually, even if I remove the sensor code and the sensor, and simply run the example which with the dummy sensor code, the trace log shows similar.
I can join the network successfully, and the sensor data can be received from the LORA gateway, but only can receive no more than twice. After that, the board keeps sending empty message. It seems it will not entering the send_message loop after two times.
username_2: ARM Internal Ref: IOTCELL-1467
username_1: @username_3 Could this be an uncalibrated crystal?
username_3: @username_0 It's hard to pin down what is going on at your end. It could be uncaliberated crystals on board. However, I can notice something peculiar from your trace. You are probably located in China or US and your PHY layer is picking up channels from full range. Are you sure that the base station in your vicinity is capable of handling these many channels ? Most base stations in production can support only 8 channels, and if you haven't configured FSB mask for your PHY, you may be swinging into channels where nobody is listening to you.
username_1: @username_0 Those are warnings, not errors.
username_3: @username_0 How many channels does your base station supports ?
username_0: @username_3 it supports 8 channels. I updated the code to the latest one and it works fine now though still not find where the problem is. Thanks for your help anyway. |
py-suruga/pycon-jp-2020-tutorial | 675972991 | Title: 公開ライセンスを変更する
Question:
username_0: 利用しているライブラリの考慮をしていなかったため、変更の必要があるため検討し直す
- MIT
- BSD
Answers:
username_0: 利用しているライブラリのライセンス
- python:PSFL(BSDスタイル)
- requests:apache2.0
- bs4:MIT
- slackclient:MIT
- slackeventsapi:MIT
- sphinx:BSD
- pytest:MIT
継承の条件はないものの、BSDかMITあたりにし直した方が良いと考えてる。理由は以下
- CC1 は著作権放棄となるが、上記のライセンスは著作権放棄にはならない
- このプロジェクト上の成果物(サンプルコードを改変したり、sphinxのビルド内容に含まれるコード)は元となるライセンスを準拠する必要がある。
Status: Issue closed
|
Signbank/Global-signbank | 349539933 | Title: Add a flag 'Accessible for other users' to datasets
Question:
username_0: * On the 'metadata' page for each dataset, allow for dataset managers to indicate that their dataset is available for access by others (upon request, and following the conditions specified in the field that is already there) --> create a binary field, with a checkbox on the dataset page that by default is not checked
* When new users register, only list the datasets for which they can apply for access to that have value 'true' for this new binary field
[sorry @username_1 if it all sounds a bit clumsy , but it's Friday afternoon...]
Answers:
username_1: Should this be different than the is_public field? That's not currently visible in the detail view.
The glosses have an inWeb field.
There is a method get_selected_datasets_for_user that, if the user is anonymous, sets the selected_datasets to the public_datasets, if any are available, otherwise to the DEFAULT_DATASET
Does there need to be any change to this?
Is Accessible to others different than is_public? Does it need to be?
Does the setting of selected_datasets to public_datasets for anonymous users make sense?
There aren't very many inWeb glosses, so in a way it doesn't do anything.
From your description above, it seems like is_public can be used for Accessible by others.
And then just leave the selected_datasets as the DEFAULT for anonymous users, filtered by the inWeb setting.
username_2: What's the status of this @username_1 ? Still waiting for input form Onno?
username_2: Okay, does that mean this issue is done, @username_1 ?
username_1: Yes
Status: Issue closed
|
ken310sato1203/todaysdog | 63348447 | Title: String.formatが正しく処理されない
Question:
username_0: Titaniumのバージョンアップ後に、String.formatが正しく処理されなくなった。
二つ目以降の引数が処理されない。
String.format("%04.0f-%02.0f-%02.0f %02.0f:%02.0f:%02.0f +0000", 2014, 9, 21, 10, 32, 20);
↓
"2014--0-00 -0:-0:00 +0000"
Answers:
username_0: 各項目で0埋めして文字列を結合して対応 |
MIC-DKFZ/medicaldetectiontoolkit | 892826606 | Title: Batch generation error on my customized dataset
Question:
username_0: Thanks for the very helpful repo!
First, I got the code running on the example LIDC data and the training looked fine. Then I switched to my customized dataset , which looks like the following snapshot:

Each patient has only one segmented ROI, so the class_target only has one value while the total number of foreground is 5 (larger than 2).
At the beginning, the training was stuck in the get_class_balanced_patients, so I switched to the random sample "batch_ixs = np.random.choice(len(class_targets_list), self.batch_size)".
However, I got the following errors from the batch generator. Would you have any comment on how to get rid of this error? Thank a lot!!
data set loaded with: 118 train / 40 val / 40 test patients
starting training epoch 1
Exception in worker 4
Traceback (most recent call last):
File "/opt/conda/lib/python3.6/site-packages/batchgenerators/dataloading/multi_threaded_augmenter.py", line 48, in producer
item = transform(**item)
File "/opt/conda/lib/python3.6/site-packages/batchgenerators/transforms/abstract_transforms.py", line 88, in __call__
data_dict = t(**data_dict)
File "/opt/conda/lib/python3.6/site-packages/batchgenerators/transforms/utility_transforms.py", line 225, in __call__
data_dict = convert_seg_to_bounding_box_coordinates(data_dict, self.dim, self.get_rois_from_seg_flag, class_specific_seg_flag=self.class_specific_seg_flag)
File "/opt/conda/lib/python3.6/site-packages/batchgenerators/augmentations/utils.py", line 522, in convert_seg_to_bounding_box_coordinates
p_roi_labels_list.append(data_dict['class_target'][b][rix] + 1)
IndexError: index 4 is out of bounds for axis 0 with size 1
Traceback (most recent call last):
File "exec.py", line 176, in <module>
train(logger)
File "exec.py", line 68, in train
batch = next(batch_gen['train'])
File "/opt/conda/lib/python3.6/site-packages/batchgenerators/dataloading/multi_threaded_augmenter.py", line 190, in __next__
item = self.__get_next_item()
File "/opt/conda/lib/python3.6/site-packages/batchgenerators/dataloading/multi_threaded_augmenter.py", line 172, in __get_next_item
raise RuntimeError("MultiThreadedAugmenter.abort_event was set, something went wrong. Maybe one of "
RuntimeError: MultiThreadedAugmenter.abort_event was set, something went wrong. Maybe one of your workers crashed |
EvertonQuadros/br.edu.ifrs.restinga.Evoevent | 185649140 | Title: RF011_T07: Realizar validações
Question:
username_0: A exibição da opção de submissão deve estar condicionada a validações da mesma forma que o preenchimento do formulário. Por exemplo, não podemos exibir a opção de submissão de inscrição para um usuário que está inscrito no evento ou em um evento que não recebe mais inscrições. |
EDDiscovery/EDDiscovery | 221372121 | Title: EDDiscovery ver 7.0 crashing elite and dangerous
Question:
username_0: Before the update of 7.0 version everything was working fine and with 7.0 it makes the game come to a complete standstill it just locks up the game and computer up is there a way of installing the older ver before 7.0?
Answers:
username_1: Please provide more details on how it is locking up the whole computer.
Yes you can use a previous version, but it won't know about any 2.3 features
username_2: Unable to Sync with EDSM, has been working to till last update I keep getting ( date is not in the format yyyy-mm-dd hh:mm:ss )
username_0: Hi thank you for getting to me well eddiscovery when i run it alone it takes up about 4,350 mb and it starts to slow down the computer can't even move the mouse to click on elite and if already running elite it be working fine but once i start eddiscovery it all comes to a standstill. I didn't have that problem with the other version before 7.0. I also used an unstaller program to wipe the program and the Windows registry setting and did a clean installation and still having the problem
Is there a way to restall the older version of eddiscovery? I really like the program
Felipe
username_0: Kinda sounds what is happening with me too i lift it on all night and still it was taking so much ram out of my computer 4,350 mb or more and if i startup elite the computer comes to a crawl
Felipe
username_3: When it is taking 4GB of RAM, do you have the 3D map open?
username_0: No nothing is open but the Journal
Sent from my iPhone
username_3: When you say it's taking 4350MB, is this from Task Manager, or is it from the disk usage in `%LOCALAPPDATA%\EDDiscovery`?
After a sync, the `%LOCALAPPDATA%\EDDiscovery` directory is about 3GB in size, with 99% of that taken by EDSM data.
Without the 3D map having been opened, I got a peak working set size of 548MB, and a peak private bytes size (what task manager shows) of 416MB. After completing the EDSM sync, this fell to about 270MB.

This is with about 15k entries in my travel history.
Once the 3D map was opened, the peak memory usage increased to 1.5GB.

If you click S-Panel and click Statistics, how many jumps does it say you have made?

If you go to `%USERPROFILE%\Saved Games\Frontier Developments\Elite Dangerous`, and get the folder properties, how many MB do all the files in it take up?

Status: Issue closed
username_1: Closed, no response from user.. |
m88i/nexus-operator | 1164031035 | Title: Support for external DB
Question:
username_0: Nexus has support for external DB since 3.31.0 https://help.sonatype.com/repomanager3/planning-your-implementation/sql-database-options.
Might be interesting to add this option as it's useful for resilience. |
swoole/swoole-src | 414536729 | Title: swoole_event_dispatch在定时器存在时执行一次后并没有让出控制权
Question:
username_0: Please answer these questions before submitting your issue. Thanks!
1. What did you do? If possible, provide a simple script for reproducing the error.
`<?php
class Process extends Swoole\Process
{
public function __construct()
{
parent::__construct([$this, 'run']);
}
public function run()
{
swoole_set_process_name("process");
swoole_timer_tick(800, function () {
echo "Tick\n";
});
while(1) {
echo "loop\n";
sleep(1);
swoole_event_dispatch();
}
}
}
$server = new Swoole\Server('0.0.0.0', 12341, SWOOLE_PROCESS, SWOOLE_SOCK_UDP);
$server->set(['log_file' => '/dev/null']);
$server->on('packet', function () { });
$server->addProcess(new Process);
$server->start();
`
2. What did you expect to see?
loop
Tick
loop
Tick
...
3. What did you see instead?
loop
Tick
Tick
Tick
...
4. What version of Swoole are you using (show your `php --ri swoole`)?
master
5. What is your machine environment used (including version of kernel & php & gcc) ?
php:7.0.32
centos 7
Answers:
username_0: 我看了源码,应该是swReactorEpoll_wait(我现在系统用的epoll,其他IO多路复用应该存在同样问题),当`n = epoll_wait(epoll_fd, events, max_event_num, msec);`这里返回0时(因为只要定时器),那么走这个分支:
`else if (n == 0)
{
if (reactor->onTimeout != NULL)
{
reactor->onTimeout(reactor);
}
continue;
}`
没有判断reactor->once,所以没有break跳出循环
username_1: 感谢反馈,确实存在问题,已经修复。
Status: Issue closed
|
Benlitz/AudioController | 73594511 | Title: Display the correct screen name in the settings menu
Question:
username_0: Currently the name of the driver is displayed, most of the time it's just the default windows driver so there's no way to make a distinction between monitors.
See http://stackoverflow.com/questions/4958683/how-do-i-get-the-actual-monitor-name-as-seen-in-the-resolution-dialog |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.