
text
stringlengths 7
328k
| id
stringlengths 14
166
| metadata
dict | __index_level_0__
int64 0
459
|
|---|---|---|---|
#include "q_matrix.cuh"
#include "matrix_view.cuh"
#include "util.cuh"
#include "quant/qdq_2.cuh"
#include "quant/qdq_3.cuh"
#include "quant/qdq_4.cuh"
#include "quant/qdq_5.cuh"
#include "quant/qdq_6.cuh"
#include "quant/qdq_8.cuh"
#define BLOCK_KN_SIZE 128
#define THREADS_X 32
#define THREADS_Y 32
// Shuffle quantized data on load
__global__ void shuffle_kernel
(
uint32_t* __restrict__ b_q_weight,
const int size_k,
const int size_n,
const int rows_8,
const int rows_6,
const int rows_5,
const int rows_4,
const int rows_3,
const int rows_2
)
{
int n = blockIdx.x * THREADS_X + threadIdx.x;
if (n >= size_n) return;
int k = 0;
uint32_t* b_ptr = b_q_weight + n;
while (k < rows_8) { shuffle_8bit_4 (b_ptr, size_n); b_ptr += 1 * size_n; k += 4; }
while (k < rows_6) { shuffle_6bit_16(b_ptr, size_n); b_ptr += 3 * size_n; k += 16; }
while (k < rows_5) { shuffle_5bit_32(b_ptr, size_n); b_ptr += 5 * size_n; k += 32; }
while (k < rows_4) { shuffle_4bit_8 (b_ptr, size_n); b_ptr += 1 * size_n; k += 8; }
while (k < rows_3) { shuffle_3bit_32(b_ptr, size_n); b_ptr += 3 * size_n; k += 32; }
while (k < rows_2) { shuffle_2bit_16(b_ptr, size_n); b_ptr += 1 * size_n; k += 16; }
}
// QMatrix constructor
QMatrix::QMatrix
(
const int _device,
const int _height,
const int _width,
const int _groups,
uint32_t* _q_weight,
uint16_t* _q_perm,
uint16_t* _q_invperm,
uint32_t* _q_scale,
half* _q_scale_max,
uint16_t* _q_groups,
uint16_t* _q_group_map,
uint32_t* _gptq_qzeros,
half* _gptq_scales,
uint32_t* _gptq_g_idx,
half* _temp_dq
) :
device(_device),
height(_height),
width(_width),
groups(_groups),
temp_dq(_temp_dq)
{
cudaSetDevice(device);
failed = false;
cuda_q_weight = _q_weight;
cuda_q_perm = _q_perm;
cuda_q_invperm = _q_invperm;
cuda_q_scale = _q_scale;
cuda_q_scale_max = _q_scale_max;
cuda_q_groups = _q_groups;
cuda_q_group_map = _q_group_map;
cuda_gptq_qzeros = _gptq_qzeros;
cuda_gptq_scales = _gptq_scales;
is_gptq = (_gptq_qzeros != NULL);
if (is_gptq)
{
gptq_groupsize = 1;
while (gptq_groupsize * groups < height) gptq_groupsize *= 2;
}
// Create group map
rows_8 = 0;
rows_6 = 0;
rows_5 = 0;
rows_4 = 0;
rows_3 = 0;
rows_2 = 0;
if (!is_gptq)
{
uint16_t* cpu_q_groups = (uint16_t*)calloc(groups * 2, sizeof(uint16_t));
cudaMemcpy(cpu_q_groups, cuda_q_groups, groups * 2 * sizeof(uint16_t), cudaMemcpyDeviceToHost);
int row = 0;
for (int i = 0; i < groups; i++)
{
int bits = cpu_q_groups[i * 2];
int rows;
if (i < groups - 1)
{
int qrows = cpu_q_groups[i * 2 + 3] - cpu_q_groups[i * 2 + 1];
rows = qrows * 32 / bits;
}
else rows = height - row;
if (bits == 8) rows_8 += rows;
if (bits == 6) rows_6 += rows;
if (bits == 5) rows_5 += rows;
if (bits == 4) rows_4 += rows;
if (bits == 3) rows_3 += rows;
if (bits == 2) rows_2 += rows;
row += rows;
}
free(cpu_q_groups);
rows_6 += rows_8;
rows_5 += rows_6;
rows_4 += rows_5;
rows_3 += rows_4;
rows_2 += rows_3;
}
else
{
rows_4 = height;
rows_3 = height;
rows_2 = height;
if (_gptq_g_idx)
{
if (!make_sequential(_gptq_g_idx))
{
failed = true;
//printf("FAIL\n");
return;
}
}
}
// DBGI(rows_8);
// DBGI(rows_6);
// DBGI(rows_5);
// DBGI(rows_4);
// DBGI(rows_3);
// DBGI(rows_2);
// Shuffle quantized data
dim3 blockDim, gridDim;
blockDim.x = THREADS_X;
blockDim.y = 1;
gridDim.x = DIVIDE(width, THREADS_X);
gridDim.y = 1;
const cudaStream_t stream = at::cuda::getCurrentCUDAStream();
shuffle_kernel<<<gridDim, blockDim, 0, stream>>>(cuda_q_weight, height, width, rows_8, rows_6, rows_5, rows_4, rows_3, rows_2);
}
QMatrix::~QMatrix()
{
}
// Reconstruct b[k,n] (GPTQ)
__global__ void reconstruct_gptq_kernel
(
const uint32_t* __restrict__ b_q_weight,
const uint16_t* __restrict__ b_q_perm,
const uint32_t* __restrict__ b_gptq_qzeros,
const half* __restrict__ b_gptq_scales,
//const uint16_t* __restrict__ b_q_groups,
const int size_k,
const int size_n,
const int groupsize,
const int groups,
half* __restrict__ b,
const int rows_4
)
{
MatrixView_half_rw b_(b, size_k, size_n);
MatrixView_q4_row b_gptq_qzeros_(b_gptq_qzeros, groups, size_n);
MatrixView_half b_gptq_scales_(b_gptq_scales, groups, size_n);
int offset_k = BLOCK_KN_SIZE * blockIdx.y;
int offset_n = BLOCK_KN_SIZE * blockIdx.x * 4;
int end_k = min(offset_k + BLOCK_KN_SIZE, size_k);
// Preload remapping table
__shared__ uint16_t perm[BLOCK_KN_SIZE];
int t = threadIdx.x;
if (b_q_perm)
{
if (offset_k + t < size_k)
perm[t] = b_q_perm[offset_k + t];
}
// Column
int n = offset_n + t * 4;
if (n >= size_n) return;
// Find initial group
int group = offset_k / groupsize;
int nextgroup = offset_k + groupsize;
// b offset
int qk = offset_k / (32 / 4);
const uint32_t* b_ptr = b_q_weight + qk * size_n + n;
// Initial zeros/scale
int zeros[4];
half2 scales[4];
half2 z1z16[4][2];
half2 y1y16[4][2];
b_gptq_qzeros_.item4(zeros, group, n);
b_gptq_scales_.item4_h2(scales, group, n);
dequant_4bit_8_prep_zero((zeros[0] + 1) & 0x0F, z1z16[0], y1y16[0]);
dequant_4bit_8_prep_zero((zeros[1] + 1) & 0x0F, z1z16[1], y1y16[1]);
dequant_4bit_8_prep_zero((zeros[2] + 1) & 0x0F, z1z16[2], y1y16[2]);
dequant_4bit_8_prep_zero((zeros[3] + 1) & 0x0F, z1z16[3], y1y16[3]);
__syncthreads();
int k = offset_k;
int lk = 0;
while (k < end_k)
{
if (k == nextgroup)
{
group++;
nextgroup += groupsize;
b_gptq_qzeros_.item4(zeros, group, n);
b_gptq_scales_.item4_h2(scales, group, n);
dequant_4bit_8_prep_zero((zeros[0] + 1) & 0x0F, z1z16[0], y1y16[0]);
dequant_4bit_8_prep_zero((zeros[1] + 1) & 0x0F, z1z16[1], y1y16[1]);
dequant_4bit_8_prep_zero((zeros[2] + 1) & 0x0F, z1z16[2], y1y16[2]);
dequant_4bit_8_prep_zero((zeros[3] + 1) & 0x0F, z1z16[3], y1y16[3]);
}
for (int p = 0; p < 4; p++)
{
half2 dq[4][4];
const int4* b_ptr4 = (int4*) b_ptr;
int4 load_int4 = *b_ptr4;
dequant_4bit_8_gptq(load_int4.x, dq[0], z1z16[0], y1y16[0], size_n, false);
dequant_4bit_8_gptq(load_int4.y, dq[1], z1z16[1], y1y16[1], size_n, false);
dequant_4bit_8_gptq(load_int4.z, dq[2], z1z16[2], y1y16[2], size_n, false);
dequant_4bit_8_gptq(load_int4.w, dq[3], z1z16[3], y1y16[3], size_n, false);
b_ptr += size_n;
//half* dqh = (half*)dq;
if (b_q_perm)
{
for (int j = 0; j < 4; j++)
{
for (int v = 0; v < 4; v++) dq[v][j] = __hmul2(scales[v], dq[v][j]);
b_.set4(perm[lk++], n, __low2half(dq[0][j]), __low2half(dq[1][j]), __low2half(dq[2][j]), __low2half(dq[3][j]));
b_.set4(perm[lk++], n, __high2half(dq[0][j]), __high2half(dq[1][j]), __high2half(dq[2][j]), __high2half(dq[3][j]));
}
}
else
{
for (int j = 0; j < 4; j++)
{
for (int v = 0; v < 4; v++) dq[v][j] = __hmul2(scales[v], dq[v][j]);
b_.set4(offset_k + lk++, n, __low2half(dq[0][j]), __low2half(dq[1][j]), __low2half(dq[2][j]), __low2half(dq[3][j]));
b_.set4(offset_k + lk++, n, __high2half(dq[0][j]), __high2half(dq[1][j]), __high2half(dq[2][j]), __high2half(dq[3][j]));
}
}
}
k += 32;
}
}
// Reconstruct b[k,n]
__global__ void reconstruct_kernel
(
const uint32_t* __restrict__ b_q_weight,
const uint16_t* __restrict__ b_q_perm,
const uint32_t* __restrict__ b_q_scale,
const half* __restrict__ b_q_scale_max,
const uint16_t* __restrict__ b_q_group_map,
const int size_k,
const int size_n,
//const int groupsize,
const int groups,
half* __restrict__ b,
const int rows_8,
const int rows_6,
const int rows_5,
const int rows_4,
const int rows_3,
const int rows_2
)
{
MatrixView_half_rw b_(b, size_k, size_n);
MatrixView_q4_row b_q_scale_(b_q_scale, groups, size_n);
int offset_k = BLOCK_KN_SIZE * blockIdx.y;
int offset_n = BLOCK_KN_SIZE * blockIdx.x;
// Preload remapping table
int t = threadIdx.x;
__shared__ uint16_t perm[BLOCK_KN_SIZE];
if (offset_k + t < size_k)
perm[t] = b_q_perm[offset_k + t];
// Column
int n = offset_n + t;
if (n >= size_n) return;
// Find initial group
// int group = offset_k / groupsize;
int group = b_q_group_map[offset_k * 2];
int pre_rows_8 = min(rows_8, offset_k);
int pre_rows_6 = offset_k > rows_8 ? min(rows_6, offset_k) - rows_8 : 0;
int pre_rows_5 = offset_k > rows_6 ? min(rows_5, offset_k) - rows_6 : 0;
int pre_rows_4 = offset_k > rows_5 ? min(rows_4, offset_k) - rows_5 : 0;
int pre_rows_3 = offset_k > rows_4 ? min(rows_3, offset_k) - rows_4 : 0;
int pre_rows_2 = offset_k > rows_3 ? min(rows_2, offset_k) - rows_3 : 0;
int qk = 0;
qk += pre_rows_8 / 32 * 8;
qk += pre_rows_6 / 32 * 6;
qk += pre_rows_5 / 32 * 5;
qk += pre_rows_4 / 32 * 4;
qk += pre_rows_3 / 32 * 3;
qk += pre_rows_2 / 32 * 2;
const uint32_t* b_ptr = b_q_weight + qk * size_n + n;
half qs_h = dq_scale(b_q_scale_.item(group, n), b_q_scale_max[group]);
half2 qs_h2 = __halves2half2(qs_h, qs_h);
int nextgroup = offset_k + b_q_group_map[offset_k * 2 + 1];
int end_k = min(offset_k + BLOCK_KN_SIZE, size_k);
int k = offset_k;
int lk = 0;
__syncthreads();
while (k < rows_8 && k < end_k)
{
if (k == nextgroup) { group++; qs_h = dq_scale(b_q_scale_.item(group, n), b_q_scale_max[group]); nextgroup += b_q_group_map[k * 2 + 1]; qs_h2 = __halves2half2(qs_h, qs_h); }
for (int p = 0; p < 4; p++)
{
half2 dq[4];
uint32_t q_0 = *b_ptr; b_ptr += size_n;
uint32_t q_1 = *b_ptr; b_ptr += size_n;
dequant_8bit_8(q_0, q_1, dq, size_n);
for (int j = 0; j < 4; j++) dq[j] = __hmul2(dq[j], qs_h2);
half* dqh = (half*) dq;
for (int j = 0; j < 8; j++) b_.set(perm[lk++], n, dqh[j]);
}
k += 32;
}
while (k < rows_6 && k < end_k)
{
if (k == nextgroup) { group++; qs_h = dq_scale(b_q_scale_.item(group, n), b_q_scale_max[group]); nextgroup += b_q_group_map[k * 2 + 1]; qs_h2 = __halves2half2(qs_h, qs_h); }
for (int p = 0; p < 2; p++)
{
half2 dq[8];
uint32_t q_0 = *b_ptr; b_ptr += size_n;
uint32_t q_1 = *b_ptr; b_ptr += size_n;
uint32_t q_2 = *b_ptr; b_ptr += size_n;
dequant_6bit_16(q_0, q_1, q_2, dq, size_n);
for (int j = 0; j < 8; j++) dq[j] = __hmul2(dq[j], qs_h2);
half* dqh = (half*) dq;
for (int j = 0; j < 16; j++) b_.set(perm[lk++], n, dqh[j]);
}
k += 32;
}
while (k < rows_5 && k < end_k)
{
if (k == nextgroup) { group++; qs_h = dq_scale(b_q_scale_.item(group, n), b_q_scale_max[group]); nextgroup += b_q_group_map[k * 2 + 1]; qs_h2 = __halves2half2(qs_h, qs_h); }
for (int p = 0; p < 1; p++)
{
half2 dq[16];
uint32_t q_0 = *b_ptr; b_ptr += size_n;
uint32_t q_1 = *b_ptr; b_ptr += size_n;
uint32_t q_2 = *b_ptr; b_ptr += size_n;
uint32_t q_3 = *b_ptr; b_ptr += size_n;
uint32_t q_4 = *b_ptr; b_ptr += size_n;
dequant_5bit_32(q_0, q_1, q_2, q_3, q_4, dq, size_n);
for (int j = 0; j < 16; j++) dq[j] = __hmul2(dq[j], qs_h2);
half* dqh = (half*) dq;
for (int j = 0; j < 32; j++) b_.set(perm[lk++], n, dqh[j]);
}
k += 32;
}
while (k < rows_4 && k < end_k)
{
if (k == nextgroup) { group++; qs_h = dq_scale(b_q_scale_.item(group, n), b_q_scale_max[group]); nextgroup += b_q_group_map[k * 2 + 1]; qs_h2 = __halves2half2(qs_h, qs_h); }
for (int p = 0; p < 4; p++)
{
half2 dq[4];
uint32_t q_0 = *b_ptr; b_ptr += size_n;
dequant_4bit_8(q_0, dq, size_n);
for (int j = 0; j < 4; j++) dq[j] = __hmul2(dq[j], qs_h2);
half* dqh = (half*) dq;
for (int j = 0; j < 8; j++) b_.set(perm[lk++], n, dqh[j]);
}
k += 32;
}
while (k < rows_3 && k < end_k)
{
if (k == nextgroup) { group++; qs_h = dq_scale(b_q_scale_.item(group, n), b_q_scale_max[group]); nextgroup += b_q_group_map[k * 2 + 1]; qs_h2 = __halves2half2(qs_h, qs_h); }
for (int p = 0; p < 1; p++)
{
half2 dq[16];
uint32_t q_0 = *b_ptr; b_ptr += size_n;
uint32_t q_1 = *b_ptr; b_ptr += size_n;
uint32_t q_2 = *b_ptr; b_ptr += size_n;
dequant_3bit_32(q_0, q_1, q_2, dq, size_n);
for (int j = 0; j < 16; j++) dq[j] = __hmul2(dq[j], qs_h2);
half* dqh = (half*) dq;
for (int j = 0; j < 32; j++) b_.set(perm[lk++], n, dqh[j]);
}
k += 32;
}
while (k < rows_2 && k < end_k)
{
if (k == nextgroup) { group++; qs_h = dq_scale(b_q_scale_.item(group, n), b_q_scale_max[group]); nextgroup += b_q_group_map[k * 2 + 1]; qs_h2 = __halves2half2(qs_h, qs_h); }
for (int p = 0; p < 1; p++)
{
half2 dq[8];
uint32_t q_0 = *b_ptr; b_ptr += size_n;
dequant_2bit_16(q_0, dq, size_n);
for (int j = 0; j < 8; j++) dq[j] = __hmul2(dq[j], qs_h2);
half* dqh = (half*) dq;
for (int j = 0; j < 16; j++) b_.set(perm[lk++], n, dqh[j]);
}
k += 16;
}
}
void QMatrix::reconstruct(half* out)
{
dim3 blockDim, gridDim;
blockDim.x = BLOCK_KN_SIZE;
blockDim.y = 1;
gridDim.y = DIVIDE(height, BLOCK_KN_SIZE);
const cudaStream_t stream = at::cuda::getCurrentCUDAStream();
if (!is_gptq)
{
gridDim.x = DIVIDE(width, BLOCK_KN_SIZE);
reconstruct_kernel<<<gridDim, blockDim, 0, stream>>>
(
cuda_q_weight,
cuda_q_perm,
cuda_q_scale,
cuda_q_scale_max,
cuda_q_group_map,
height,
width,
//groupsize,
groups,
out,
rows_8,
rows_6,
rows_5,
rows_4,
rows_3,
rows_2
);
}
else
{
gridDim.x = DIVIDE(width, BLOCK_KN_SIZE * 4);
reconstruct_gptq_kernel<<<gridDim, blockDim, 0, stream>>>
(
cuda_q_weight,
cuda_q_perm,
cuda_gptq_qzeros,
cuda_gptq_scales,
//const uint16_t* __restrict__ b_q_groups,
height,
width,
gptq_groupsize,
groups,
out,
rows_4
);
}
}
__global__ void make_sequential_kernel
(
const uint32_t* __restrict__ w,
uint32_t* __restrict__ w_new,
const uint16_t* __restrict__ q_perm,
const int w_height,
const int w_width
)
{
const uint64_t* w2 = (uint64_t*) w;
uint64_t* w_new2 = (uint64_t*) w_new;
int w2_stride = w_width >> 1;
int w2_column = THREADS_X * blockIdx.x + threadIdx.x;
if (w2_column >= w2_stride) return;
int w_new2_row = blockIdx.y;
int q_perm_idx = w_new2_row << 3;
uint64_t dst = 0;
#pragma unroll
for (int i = 0; i < 8; i++)
{
int source_row = q_perm[q_perm_idx++];
int w2_row = source_row >> 3;
int w2_subrow = source_row & 0x07;
int w2_row_shift = w2_subrow << 2;
int wnew2_row_shift = i << 2;
uint64_t src = w2[w2_row * w2_stride + w2_column];
src >>= w2_row_shift;
src &= 0x0000000f0000000f;
src <<= wnew2_row_shift;
dst |= src;
}
w_new2[w_new2_row * w2_stride + w2_column] = dst;
}
bool QMatrix::make_sequential(const uint32_t* cpu_g_idx)
{
const cudaStream_t stream = at::cuda::getCurrentCUDAStream();
uint32_t* cuda_new_qweight = NULL;
cudaError_t err = cudaMalloc(&cuda_new_qweight, height / 8 * width * sizeof(uint32_t));
if (err != cudaSuccess) {
cudaError_t cuda_status = cudaGetLastError(); // Clear error
return false;
}
uint32_t* cpu_g_idx_map = (uint32_t*) calloc(groups, sizeof(uint32_t));
uint32_t* cpu_x_map = (uint32_t*) malloc(height * sizeof(uint32_t));
uint32_t* cpu_x_map_inv = (uint32_t*) malloc(height * sizeof(uint32_t));
// Group histogram
for (int i = 0; i < height; i++) cpu_g_idx_map[cpu_g_idx[i]]++;
// Group map
for (int i = 0, acc = 0; i < groups; i++)
{
short tmp = cpu_g_idx_map[i];
cpu_g_idx_map[i] = acc;
acc += tmp;
}
// X map (inverse)
for (int row = 0; row < height; row++)
{
uint32_t target_group = cpu_g_idx[row];
uint32_t target_row = cpu_g_idx_map[target_group];
cpu_g_idx_map[target_group]++;
cpu_x_map_inv[row] = target_row;
}
// X map
for (int row = 0; row < height; row++) cpu_x_map[cpu_x_map_inv[row]] = row;
// Reduce to uint16_t
uint16_t* cpu_x_map16 = (uint16_t*)cpu_x_map;
uint16_t* cpu_x_map_inv16 = (uint16_t*)cpu_x_map_inv;
for (int row = 0; row < height; row++) cpu_x_map16[row] = (uint16_t) cpu_x_map[row];
for (int row = 0; row < height; row++) cpu_x_map_inv16[row] = (uint16_t) cpu_x_map_inv[row];
// Move to CUDA
cudaMemcpyAsync(cuda_q_perm, cpu_x_map16, height * sizeof(uint16_t), cudaMemcpyHostToDevice);
cudaMemcpyAsync(cuda_q_invperm, cpu_x_map_inv16, height * sizeof(uint16_t), cudaMemcpyHostToDevice);
// Rearrange rows in w
dim3 blockDim, gridDim;
blockDim.x = THREADS_X;
blockDim.y = 1;
gridDim.x = DIVIDE(width, THREADS_X);
gridDim.y = height / 8;
make_sequential_kernel<<<gridDim, blockDim, 0, stream>>>
(
cuda_q_weight,
cuda_new_qweight,
cuda_q_perm,
height / 8,
width
);
// Replace qweights
cudaMemcpyAsync(cuda_q_weight, cuda_new_qweight, height / 8 * width * sizeof(uint32_t), cudaMemcpyDeviceToDevice);
// Cleanup
cudaDeviceSynchronize();
cudaFree(cuda_new_qweight);
free(cpu_g_idx_map);
free(cpu_x_map);
free(cpu_x_map_inv);
return true;
}
| text-generation-inference/server/exllamav2_kernels/exllamav2_kernels/cuda/q_matrix.cu/0 | {
"file_path": "text-generation-inference/server/exllamav2_kernels/exllamav2_kernels/cuda/q_matrix.cu",
"repo_id": "text-generation-inference",
"token_count": 10524
} | 199 |
import torch
from loguru import logger
from transformers.configuration_utils import PretrainedConfig
from transformers.models.auto import modeling_auto
from huggingface_hub import hf_hub_download
from typing import Optional
from pathlib import Path
from text_generation_server.utils.speculate import get_speculate, set_speculate
from text_generation_server.models.model import Model
from text_generation_server.models.causal_lm import CausalLM
from text_generation_server.models.flash_causal_lm import FlashCausalLM
from text_generation_server.models.bloom import BLOOMSharded
from text_generation_server.models.mpt import MPTSharded
from text_generation_server.models.seq2seq_lm import Seq2SeqLM
from text_generation_server.models.rw import RW
from text_generation_server.models.opt import OPTSharded
from text_generation_server.models.galactica import GalacticaSharded
from text_generation_server.models.santacoder import SantaCoder
from text_generation_server.models.t5 import T5Sharded
from text_generation_server.models.gpt_neox import GPTNeoxSharded
from text_generation_server.models.phi import Phi
# The flag below controls whether to allow TF32 on matmul. This flag defaults to False
# in PyTorch 1.12 and later.
torch.backends.cuda.matmul.allow_tf32 = True
# The flag below controls whether to allow TF32 on cuDNN. This flag defaults to True.
torch.backends.cudnn.allow_tf32 = True
# Disable gradients
torch.set_grad_enabled(False)
__all__ = [
"Model",
"BLOOMSharded",
"CausalLM",
"GalacticaSharded",
"Seq2SeqLM",
"SantaCoder",
"OPTSharded",
"T5Sharded",
"get_model",
]
FLASH_ATT_ERROR_MESSAGE = "{} requires Flash Attention enabled models."
FLASH_ATTENTION = True
try:
from text_generation_server.models.flash_rw import FlashRWSharded
from text_generation_server.models.flash_neox import FlashNeoXSharded
from text_generation_server.models.flash_llama import (
FlashLlama,
)
from text_generation_server.models.flash_qwen2 import (
FlashQwen2,
)
from text_generation_server.models.flash_gemma import (
FlashGemma,
)
from text_generation_server.models.flash_santacoder import (
FlashSantacoderSharded,
)
from text_generation_server.models.idefics import IDEFICSSharded
from text_generation_server.models.flash_mistral import FlashMistral
from text_generation_server.models.flash_mixtral import FlashMixtral
from text_generation_server.models.flash_phi import FlashPhi
from text_generation_server.models.flash_starcoder2 import FlashStarcoder2
from text_generation_server.utils.flash_attn import HAS_FLASH_ATTN_V2_CUDA
except ImportError as e:
logger.warning(f"Could not import Flash Attention enabled models: {e}")
FLASH_ATTENTION = False
HAS_FLASH_ATTN_V2_CUDA = False
if FLASH_ATTENTION:
__all__.append(FlashNeoXSharded)
__all__.append(FlashRWSharded)
__all__.append(FlashSantacoderSharded)
__all__.append(FlashLlama)
__all__.append(IDEFICSSharded)
__all__.append(FlashMistral)
__all__.append(FlashMixtral)
__all__.append(FlashPhi)
__all__.append(FlashQwen2)
__all__.append(FlashStarcoder2)
MAMBA_AVAILABLE = True
try:
from text_generation_server.models.mamba import Mamba
except ImportError as e:
logger.warning(f"Could not import Mamba: {e}")
MAMBA_AVAILABLE = False
if MAMBA_AVAILABLE:
__all__.append(Mamba)
def get_model(
model_id: str,
revision: Optional[str],
sharded: bool,
quantize: Optional[str],
speculate: Optional[int],
dtype: Optional[str],
trust_remote_code: bool,
) -> Model:
if dtype is None:
# Keep it as default for now and let
# every model resolve their own default dtype.
dtype = None
elif dtype == "float16":
dtype = torch.float16
elif dtype == "bfloat16":
dtype = torch.bfloat16
else:
raise RuntimeError(f"Unknown dtype {dtype}")
if speculate is not None:
set_speculate(speculate)
else:
set_speculate(0)
config_dict, _ = PretrainedConfig.get_config_dict(
model_id, revision=revision, trust_remote_code=trust_remote_code
)
use_medusa = None
if "medusa_num_heads" in config_dict:
medusa_model_id = model_id
medusa_revision = revision
model_id = config_dict["base_model_name_or_path"]
revision = "main"
speculate_medusa = config_dict["medusa_num_heads"]
if speculate is not None:
if speculate > speculate_medusa:
raise RuntimeError(
"Speculate is set to `{speculate}` but this medusa models only has `{speculate_medusa}` heads, please make them match"
)
else:
set_speculate(speculate)
else:
set_speculate(speculate_medusa)
config_dict, _ = PretrainedConfig.get_config_dict(
model_id, revision=revision, trust_remote_code=trust_remote_code
)
is_local = Path(medusa_model_id).exists()
if not is_local:
medusa_config = hf_hub_download(
medusa_model_id, revision=medusa_revision, filename="config.json"
)
hf_hub_download(
medusa_model_id,
revision=medusa_revision,
filename="medusa_lm_head.safetensors",
)
use_medusa = Path(medusa_config).parent
else:
use_medusa = Path(medusa_model_id)
method = "medusa"
else:
method = "n-gram"
speculate = get_speculate()
if speculate > 0:
logger.info(f"Using speculation {method} with {speculate} input ids.")
model_type = config_dict.get("model_type", None)
if model_type is None:
# TODO: fix how we determine model type for Mamba
if "ssm_cfg" in config_dict:
# *only happens in Mamba case
model_type = "ssm"
else:
raise RuntimeError(
f"Could not determine model type for {model_id} revision {revision}"
)
if model_type == "ssm":
return Mamba(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
if model_id.startswith("facebook/galactica"):
return GalacticaSharded(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
if (
model_type == "gpt_bigcode"
or model_type == "gpt2"
and model_id.startswith("bigcode/")
):
if FLASH_ATTENTION:
return FlashSantacoderSharded(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
elif sharded:
raise NotImplementedError(
FLASH_ATT_ERROR_MESSAGE.format("Sharded Santacoder")
)
else:
return SantaCoder(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
if model_type == "bloom":
return BLOOMSharded(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
elif model_type == "mpt":
return MPTSharded(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
elif model_type == "gpt_neox":
if FLASH_ATTENTION:
return FlashNeoXSharded(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
elif sharded:
return GPTNeoxSharded(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
else:
return CausalLM(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
elif model_type == "phi":
if FLASH_ATTENTION:
return FlashPhi(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
else:
return CausalLM(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
elif model_type == "phi-msft":
if FLASH_ATTENTION:
raise NotImplementedError(
"Legacy phi-msft is not supported with Flash Attention"
)
else:
return Phi(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
elif model_type == "llama" or model_type == "baichuan":
if FLASH_ATTENTION:
return FlashLlama(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
elif sharded:
raise NotImplementedError(FLASH_ATT_ERROR_MESSAGE.format("Sharded Llama"))
else:
return CausalLM(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
if model_type == "gemma":
if FLASH_ATTENTION:
return FlashGemma(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
elif sharded:
raise NotImplementedError(FLASH_ATT_ERROR_MESSAGE.format("Sharded Gemma"))
else:
return CausalLM(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
if model_type in ["RefinedWeb", "RefinedWebModel", "falcon"]:
if sharded:
if FLASH_ATTENTION:
if config_dict.get("alibi", False):
raise NotImplementedError("sharded is not supported for this model")
return FlashRWSharded(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
raise NotImplementedError(FLASH_ATT_ERROR_MESSAGE.format(f"Sharded Falcon"))
else:
if FLASH_ATTENTION and not config_dict.get("alibi", False):
return FlashRWSharded(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
else:
return RW(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
if model_type == "mistral":
sliding_window = config_dict.get("sliding_window", -1)
if (
(sliding_window is None or sliding_window == -1) and FLASH_ATTENTION
) or HAS_FLASH_ATTN_V2_CUDA:
return FlashMistral(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
elif sharded:
raise NotImplementedError(FLASH_ATT_ERROR_MESSAGE.format("Sharded Mistral"))
else:
return CausalLM(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
if model_type == "mixtral":
sliding_window = config_dict.get("sliding_window", -1)
if (
(sliding_window is None or sliding_window == -1) and FLASH_ATTENTION
) or HAS_FLASH_ATTN_V2_CUDA:
return FlashMixtral(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
elif sharded:
raise NotImplementedError(FLASH_ATT_ERROR_MESSAGE.format("Sharded Mixtral"))
else:
return CausalLM(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
if model_type == "starcoder2":
sliding_window = config_dict.get("sliding_window", -1)
if (
(sliding_window is None or sliding_window == -1) and FLASH_ATTENTION
) or HAS_FLASH_ATTN_V2_CUDA:
return FlashStarcoder2(
model_id,
revision,
quantize=quantize,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
elif sharded:
raise NotImplementedError(
FLASH_ATT_ERROR_MESSAGE.format("Sharded Starcoder2")
)
else:
return CausalLM(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
if model_type == "qwen2":
sliding_window = config_dict.get("sliding_window", -1)
if (
(sliding_window is None or sliding_window == -1) and FLASH_ATTENTION
) or HAS_FLASH_ATTN_V2_CUDA:
return FlashQwen2(
model_id,
revision,
quantize=quantize,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
elif sharded:
raise NotImplementedError(FLASH_ATT_ERROR_MESSAGE.format("Sharded Qwen2"))
else:
return CausalLM(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
if model_type == "opt":
return OPTSharded(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
if model_type == "t5":
return T5Sharded(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
if model_type == "idefics":
if FLASH_ATTENTION:
return IDEFICSSharded(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
else:
raise NotImplementedError(FLASH_ATT_ERROR_MESSAGE.format("Idefics"))
if sharded:
raise NotImplementedError("sharded is not supported for AutoModel")
if quantize == "gptq":
raise NotImplementedError(
"gptq quantization is not supported for AutoModel, you can try to quantize it with `text-generation-server quantize ORIGINAL_MODEL_ID NEW_MODEL_ID`"
)
if quantize == "awq":
raise NotImplementedError("awq quantization is not supported for AutoModel")
elif (quantize == "bitsandbytes-fp4") or (quantize == "bitsandbytes-nf4"):
raise NotImplementedError("4bit quantization is not supported for AutoModel")
elif quantize == "eetq":
raise NotImplementedError("Eetq quantization is not supported for AutoModel")
if model_type in modeling_auto.MODEL_FOR_CAUSAL_LM_MAPPING_NAMES:
return CausalLM(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
if model_type in modeling_auto.MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING_NAMES:
return Seq2SeqLM(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
auto_map = config_dict.get("auto_map", None)
if trust_remote_code and auto_map is not None:
if "AutoModelForCausalLM" in auto_map.keys():
return CausalLM(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
if "AutoModelForSeq2SeqLM" in auto_map.keys():
return Seq2SeqLM(
model_id,
revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
raise ValueError(f"Unsupported model type {model_type}")
| text-generation-inference/server/text_generation_server/models/__init__.py/0 | {
"file_path": "text-generation-inference/server/text_generation_server/models/__init__.py",
"repo_id": "text-generation-inference",
"token_count": 10041
} | 200 |
# coding=utf-8
# Copyright 2022 EleutherAI and the HuggingFace Inc. team. All rights reserved.
#
# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
# and OPT implementations in this library. It has been modified from its
# original forms to accommodate minor architectural differences compared
# to GPT-NeoX and OPT used by the Meta AI team that trained the model.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Idefics model configuration"""
import copy
from transformers import PretrainedConfig
IDEFICS_PRETRAINED_CONFIG_ARCHIVE_MAP = {
"HuggingFaceM4/idefics-9b": "https://huggingface.co/HuggingFaceM4/idefics-9b/blob/main/config.json",
"HuggingFaceM4/idefics-80b": "https://huggingface.co/HuggingFaceM4/idefics-80b/blob/main/config.json",
}
class IdeficsVisionConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`IdeficsModel`]. It is used to instantiate an
Idefics model according to the specified arguments, defining the model architecture. Instantiating a configuration
with the defaults will yield a similar configuration to that of the Idefics-9B.
e.g. [HuggingFaceM4/idefics-9b](https://huggingface.co/HuggingFaceM4/idefics-9b)
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
hidden_size (`int`, *optional*, defaults to 768):
Dimensionality of the encoder layers and the pooler layer. (elsewhere referred to as `hidden_size`)
image_size (`int`, *optional*, defaults to 224):
The size (resolution) of each image.
intermediate_size (`int`, *optional*, defaults to 5120):
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
patch_size (`int`, *optional*, defaults to 14):
The size (resolution) of each patch.
num_hidden_layers (`int`, *optional*, defaults to 32):
Number of hidden layers in the Transformer encoder.
num_attention_heads (`int`, *optional*, defaults to 16):
Number of attention heads for each attention layer in the Transformer encoder.
image_num_channels (`int`, *optional*, defaults to `3`):
Number of image channels.
hidden_act (`str` or `function`, *optional*, defaults to `"gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"selu"` and `"gelu_new"` ``"quick_gelu"` are supported.
layer_norm_eps (`float`, *optional*, defaults to 1e-5):
The epsilon used by the layer normalization layers.
attention_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention probabilities.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
initializer_factor (`float`, *optional*, defaults to 1.0):
A factor for initializing all weight matrices (should be kept to 1.0, used internally for initialization
testing).
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
"""
model_type = "idefics"
attribute_map = {
"hidden_size": "embed_dim",
}
def __init__(
self,
embed_dim=768,
image_size=224,
intermediate_size=5120,
patch_size=14,
num_hidden_layers=32,
num_attention_heads=16,
num_channels=3,
hidden_act="gelu",
layer_norm_eps=1e-5,
attention_dropout=0.0,
initializer_range=0.02,
initializer_factor=1.0,
**kwargs,
):
self.embed_dim = embed_dim
self.image_size = image_size
self.intermediate_size = intermediate_size
self.patch_size = patch_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.num_channels = num_channels
self.layer_norm_eps = layer_norm_eps
self.attention_dropout = attention_dropout
self.initializer_range = initializer_range
self.initializer_factor = initializer_factor
self.hidden_act = hidden_act
super().__init__(**kwargs)
class IdeficsPerceiverConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`IdeficsModel`]. It is used to instantiate an
Idefics model according to the specified arguments, defining the model architecture. Instantiating a configuration
with the defaults will yield a similar configuration to that of the Idefics-9B.
e.g. [HuggingFaceM4/idefics-9b](https://huggingface.co/HuggingFaceM4/idefics-9b)
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
use_resampler (`bool`, *optional*, defaults to `False`):
Whether or not to use the resampler
resampler_n_latents (`int`, *optional*, defaults to ):
Number of latent embeddings to resample ("compress") the input sequence to (usually < 128).
resampler_depth (`int`, *optional*, defaults to 6):
Depth of the Perceiver Resampler (Transformer w/ cross attention). Should be shallow (< 3).
resampler_n_heads (`int`, *optional*, defaults to 16):
Number of heads in each Transformer block (for multi-headed self-attention).
resampler_head_dim (`int`, *optional*, defaults to 96):
Dimensionality of each head projection in the Transformer block.
qk_layer_norms_perceiver (`bool`, *optional*, defaults to `False`):
Whether or not to use qk layer norms in perceiver
"""
model_type = "idefics"
def __init__(
self,
use_resampler=False,
resampler_n_latents=64,
resampler_depth=6,
resampler_n_heads=16,
resampler_head_dim=96,
qk_layer_norms_perceiver=False,
**kwargs,
):
self.use_resampler = use_resampler
self.resampler_n_latents = resampler_n_latents
self.resampler_depth = resampler_depth
self.resampler_n_heads = resampler_n_heads
self.resampler_head_dim = resampler_head_dim
self.qk_layer_norms_perceiver = qk_layer_norms_perceiver
super().__init__(**kwargs)
class IdeficsConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`IdeficsModel`]. It is used to instantiate an
Idefics model according to the specified arguments, defining the model architecture. Instantiating a configuration
with the defaults will yield a similar configuration to that of the Idefics-9B.
e.g. [HuggingFaceM4/idefics-9b](https://huggingface.co/HuggingFaceM4/idefics-9b)
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
additional_vocab_size (`int`, *optional`, defaults to 0):
Additional vocabulary size of the model, typically for the special "<img>" token. Additional vocab tokens
are always trainable whereas regular vocab tokens can be frozen or not.
vocab_size (`int`, *optional*, defaults to 32000):
Vocabulary size of the Idefics model. Defines the number of different tokens that can be represented by the
`inputs_ids` passed when calling [`~IdeficsModel`]
hidden_size (`int`, *optional*, defaults to 4096):
Dimension of the hidden representations.
intermediate_size (`int`, *optional*, defaults to 11008):
Dimension of the MLP representations.
num_hidden_layers (`int`, *optional*, defaults to 32):
Number of hidden layers in the Transformer encoder.
num_attention_heads (`int`, *optional*, defaults to 32):
Number of attention heads for each attention layer in the Transformer encoder.
dropout (`float`, *optional*, defaults to 0.0):
The dropout probability for all fully connected layers in the embeddings, encoder, and pooler.
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
The non-linear activation function (function or string) in the decoder.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
alpha_initializer (`str`, *optional*, defaults to `"zeros"`):
Initialization type for the alphas.
alphas_initializer_range (`float`, *optional*, defaults to 0.0):
The standard deviation of the truncated_normal_initializer for initializing the alphas in the Gated Cross
Attention.
alpha_type (`str`, *optional*, defaults to `"float"`):
Whether the gating alphas should be vectors or single floats.
rms_norm_eps (`float`, *optional*, defaults to 1e-6):
The epsilon used by the rms normalization layers.
use_cache (`bool`, *optional*, defaults to `True`):
Whether or not the model should return the last key/values attentions (not used by all models). Only
relevant if `config.is_decoder=True`.
pad_token_id (`int`, *optional*, defaults to 0)
Padding token id.
bos_token_id (`int`, *optional*, defaults to 1)
Beginning of stream token id.
eos_token_id (`int`, *optional*, defaults to 2)
End of stream token id.
tie_word_embeddings(`bool`, *optional*, defaults to `False`):
Whether to tie weight embeddings
cross_layer_interval (`int`, *optional*, default to 1)
Interval for cross attention (from text to image) layers.
qk_layer_norms (`bool`, *optional*, defaults to `False`): Whether to add layer norm after q and k
freeze_text_layers (`bool`, *optional*, defaults to `True`): Whether to freeze text layers
freeze_text_module_exceptions (`bool`, *optional*, defaults to `[]`):
Exceptions to freezing text layers when `freeze_text_layers` is `True`
freeze_lm_head (`bool`, *optional*, defaults to `False`): Whether to freeze lm head
freeze_vision_layers (`bool`, *optional*, defaults to `True`): Whether to freeze vision layers
freeze_vision_module_exceptions (`bool`, *optional*, defaults to `[]`):
Exceptions to freezing vision layers when `freeze_vision_layers` is `True`
use_resampler (`bool`, *optional*, defaults to `False`): Whether to use the Resampler
vision_config (`IdeficsVisionConfig`, *optional*): Custom vision config or dict
perceiver_config (`IdeficsPerceiverConfig`, *optional*): Custom perceiver config or dict
Example:
```python
>>> from transformers import IdeficsModel, IdeficsConfig
>>> # Initializing a Idefics idefics-9b style configuration
>>> configuration = IdeficsConfig()
>>> # Initializing a model from the idefics-9b style configuration
>>> model = IdeficsModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "idefics"
is_composition = True
def __init__(
self,
vocab_size=32000,
additional_vocab_size=0,
hidden_size=4096,
intermediate_size=11008,
num_hidden_layers=32,
num_attention_heads=32,
dropout=0.0,
hidden_act="silu",
initializer_range=0.02,
alpha_initializer="zeros",
alphas_initializer_range=0.0,
alpha_type="float",
rms_norm_eps=1e-6,
use_cache=True,
pad_token_id=0,
bos_token_id=1,
eos_token_id=2,
tie_word_embeddings=False,
cross_layer_interval=1,
qk_layer_norms=False,
freeze_text_layers=True,
freeze_text_module_exceptions=[],
freeze_lm_head=False,
freeze_vision_layers=True,
freeze_vision_module_exceptions=[],
use_resampler=False,
vision_config=None,
perceiver_config=None,
**kwargs,
):
self.vocab_size = vocab_size
self.additional_vocab_size = additional_vocab_size
self.hidden_size = hidden_size
self.intermediate_size = intermediate_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.dropout = dropout
self.hidden_act = hidden_act
self.initializer_range = initializer_range
self.alpha_initializer = alpha_initializer
self.alphas_initializer_range = alphas_initializer_range
self.alpha_type = alpha_type
self.rms_norm_eps = rms_norm_eps
self.use_cache = use_cache
self.cross_layer_interval = cross_layer_interval
self.qk_layer_norms = qk_layer_norms
self.freeze_vision_layers = freeze_vision_layers
self.freeze_text_layers = freeze_text_layers
self.freeze_text_module_exceptions = freeze_text_module_exceptions
self.freeze_vision_module_exceptions = freeze_vision_module_exceptions
self.freeze_lm_head = freeze_lm_head
self.use_resampler = use_resampler
if perceiver_config is None:
self.perceiver_config = IdeficsPerceiverConfig()
elif isinstance(perceiver_config, dict):
self.perceiver_config = IdeficsPerceiverConfig(**perceiver_config)
elif isinstance(perceiver_config, IdeficsPerceiverConfig):
self.perceiver_config = perceiver_config
if vision_config is None:
self.vision_config = IdeficsVisionConfig()
elif isinstance(vision_config, dict):
self.vision_config = IdeficsVisionConfig(**vision_config)
elif isinstance(vision_config, IdeficsVisionConfig):
self.vision_config = vision_config
super().__init__(
pad_token_id=pad_token_id,
bos_token_id=bos_token_id,
eos_token_id=eos_token_id,
tie_word_embeddings=tie_word_embeddings,
**kwargs,
)
# IMPORTANT: Do not do any __init__ args-based checks in the constructor, since
# PretrainedConfig.from_dict first instantiates the class with the config dict and only then
# updates the config object with `kwargs` from from_pretrained, so during the instantiation
# of this object many attributes have default values and haven't yet been overridden.
# Do any required checks inside `from_pretrained` once the superclass' `from_pretrained` was run.
def to_dict(self):
"""
Serializes this instance to a Python dictionary. Override the default [`~PretrainedConfig.to_dict`].
Returns:
`Dict[str, any]`: Dictionary of all the attributes that make up this configuration instance,
"""
output = copy.deepcopy(self.__dict__)
output["vision_config"] = self.vision_config.to_dict()
output["perceiver_config"] = self.perceiver_config.to_dict()
output["model_type"] = self.__class__.model_type
return output
| text-generation-inference/server/text_generation_server/models/custom_modeling/idefics_config.py/0 | {
"file_path": "text-generation-inference/server/text_generation_server/models/custom_modeling/idefics_config.py",
"repo_id": "text-generation-inference",
"token_count": 6204
} | 201 |
import torch
from typing import Optional
from text_generation_server.models.flash_mistral import BaseFlashMistral
from text_generation_server.models.custom_modeling.flash_mixtral_modeling import (
MixtralConfig,
FlashMixtralForCausalLM,
)
class FlashMixtral(BaseFlashMistral):
def __init__(
self,
model_id: str,
revision: Optional[str] = None,
quantize: Optional[str] = None,
use_medusa: Optional[str] = None,
dtype: Optional[torch.dtype] = None,
trust_remote_code: bool = False,
):
super(FlashMixtral, self).__init__(
config_cls=MixtralConfig,
model_cls=FlashMixtralForCausalLM,
model_id=model_id,
revision=revision,
quantize=quantize,
use_medusa=use_medusa,
dtype=dtype,
trust_remote_code=trust_remote_code,
)
| text-generation-inference/server/text_generation_server/models/flash_mixtral.py/0 | {
"file_path": "text-generation-inference/server/text_generation_server/models/flash_mixtral.py",
"repo_id": "text-generation-inference",
"token_count": 421
} | 202 |
import torch
import torch.distributed
from transformers import AutoConfig, AutoTokenizer
from typing import Optional, List, Tuple
from text_generation_server.models import CausalLM
from text_generation_server.models.custom_modeling.phi_modeling import (
PhiConfig,
PhiForCausalLM,
)
from text_generation_server.utils import (
initialize_torch_distributed,
weight_files,
Weights,
)
class Phi(CausalLM):
def __init__(
self,
model_id: str,
revision: Optional[str] = None,
quantize: Optional[str] = None,
use_medusa: Optional[str] = None,
dtype: Optional[torch.dtype] = None,
trust_remote_code: bool = False,
):
self.process_group, _rank, _world_size = initialize_torch_distributed()
if torch.cuda.is_available():
device = torch.device("cuda")
dtype = torch.float16 if dtype is None else dtype
else:
if quantize:
raise ValueError("quantization is not available on CPU")
device = torch.device("cpu")
dtype = torch.float32 if dtype is None else dtype
tokenizer = AutoTokenizer.from_pretrained(
model_id,
revision=revision,
padding_side="left",
truncation_side="left",
trust_remote_code=trust_remote_code,
)
config = PhiConfig.from_pretrained(
model_id, revision=revision, trust_remote_code=trust_remote_code
)
tokenizer.bos_token_id = config.bos_token_id
tokenizer.eos_token_id = config.eos_token_id
tokenizer.pad_token = tokenizer.eos_token
config.quantize = quantize
config.use_medusa = use_medusa
torch.distributed.barrier(group=self.process_group)
filenames = weight_files(model_id, revision=revision, extension=".safetensors")
weights = Weights(filenames, device, dtype, process_group=self.process_group)
model = PhiForCausalLM(config, weights)
torch.distributed.barrier(group=self.process_group)
super(CausalLM, self).__init__(
model=model,
tokenizer=tokenizer,
requires_padding=True,
dtype=dtype,
device=device,
)
| text-generation-inference/server/text_generation_server/models/phi.py/0 | {
"file_path": "text-generation-inference/server/text_generation_server/models/phi.py",
"repo_id": "text-generation-inference",
"token_count": 1000
} | 203 |
import torch
from exllama_kernels import make_q4, q4_matmul, prepare_buffers, set_tuning_params
# Dummy tensor to pass instead of g_idx since there is no way to pass "None" to a C++ extension
none_tensor = torch.empty((1, 1), device="meta")
def ext_make_q4(qweight, qzeros, scales, g_idx, device):
"""Construct Q4Matrix, return handle"""
return make_q4(
qweight, qzeros, scales, g_idx if g_idx is not None else none_tensor, device
)
def ext_q4_matmul(x, q4, q4_width):
"""Matrix multiplication, returns x @ q4"""
outshape = x.shape[:-1] + (q4_width,)
x = x.view(-1, x.shape[-1])
output = torch.empty((x.shape[0], q4_width), dtype=torch.float16, device=x.device)
q4_matmul(x, q4, output)
return output.view(outshape)
MAX_DQ = 1
MAX_INNER = 1
ACT_ORDER = False
DEVICE = None
TEMP_STATE = None
TEMP_DQ = None
def set_device(device):
global DEVICE
DEVICE = device
def create_exllama_buffers(max_total_tokens: int):
global MAX_DQ, MAX_INNER, ACT_ORDER, DEVICE, TEMP_STATE, TEMP_DQ
assert DEVICE is not None, "call set_device first"
if not ACT_ORDER:
max_total_tokens = 1
# This temp_state buffer is required to reorder X in the act-order case.
temp_state = torch.zeros(
(max_total_tokens, MAX_INNER), dtype=torch.float16, device=DEVICE
)
temp_dq = torch.zeros((1, MAX_DQ), dtype=torch.float16, device=DEVICE)
# This temp_dq buffer is required to dequantize weights when using cuBLAS, typically for the prefill.
prepare_buffers(DEVICE, temp_state, temp_dq)
matmul_recons_thd = 8
matmul_fused_remap = False
matmul_no_half2 = False
set_tuning_params(matmul_recons_thd, matmul_fused_remap, matmul_no_half2)
TEMP_STATE, TEMP_DQ = temp_state, temp_dq
class Ex4bitLinear(torch.nn.Module):
"""Linear layer implementation with per-group 4-bit quantization of the weights"""
def __init__(self, qweight, qzeros, scales, g_idx, bias, bits, groupsize):
super().__init__()
global MAX_DQ, MAX_INNER, ACT_ORDER, DEVICE
assert bits == 4
self.device = qweight.device
self.qweight = qweight
self.qzeros = qzeros
self.scales = scales
self.g_idx = g_idx.cpu() if g_idx is not None else None
self.bias = bias if bias is not None else None
if self.g_idx is not None and (
(self.g_idx == 0).all()
or torch.equal(
g_idx.cpu(),
torch.tensor(
[i // groupsize for i in range(g_idx.shape[0])], dtype=torch.int32
),
)
):
self.empty_g_idx = True
self.g_idx = None
assert self.device.type == "cuda"
assert self.device.index is not None
self.q4 = ext_make_q4(
self.qweight, self.qzeros, self.scales, self.g_idx, self.device.index
)
self.height = qweight.shape[0] * 8
self.width = qweight.shape[1]
# Infer groupsize from height of qzeros
self.groupsize = None
if self.qzeros.shape[0] > 1:
self.groupsize = (self.qweight.shape[0] * 8) // (self.qzeros.shape[0])
if self.groupsize is not None:
assert groupsize == self.groupsize
# Handle act-order matrix
if self.g_idx is not None:
if self.groupsize is None:
raise ValueError("Found group index but no groupsize. What do?")
self.act_order = True
else:
self.act_order = False
DEVICE = self.qweight.device
MAX_DQ = max(MAX_DQ, self.qweight.numel() * 8)
if self.act_order:
MAX_INNER = max(MAX_INNER, self.height, self.width)
ACT_ORDER = True
def forward(self, x):
out = ext_q4_matmul(x, self.q4, self.width)
if self.bias is not None:
out.add_(self.bias)
return out
| text-generation-inference/server/text_generation_server/utils/gptq/exllama.py/0 | {
"file_path": "text-generation-inference/server/text_generation_server/utils/gptq/exllama.py",
"repo_id": "text-generation-inference",
"token_count": 1833
} | 204 |
## How to release
# Before the release
Simple checklist on how to make releases for `tokenizers`.
- Freeze `master` branch.
- Run all tests (Check CI has properly run)
- If any significant work, check benchmarks:
- `cd tokenizers && cargo bench` (needs to be run on latest release tag to measure difference if it's your first time)
- Run all `transformers` tests. (`transformers` is a big user of `tokenizers` we need
to make sure we don't break it, testing is one way to make sure nothing unforeseen
has been done.)
- Run all fast tests at the VERY least (not just the tokenization tests). (`RUN_PIPELINE_TESTS=1 CUDA_VISIBLE_DEVICES=-1 pytest -sv tests/`)
- When all *fast* tests work, then we can also (it's recommended) run the whole `transformers`
test suite.
- Rebase this [PR](https://github.com/huggingface/transformers/pull/16708).
This will create new docker images ready to run the tests suites with `tokenizers` from the main branch.
- Wait for actions to finish
- Rebase this [PR](https://github.com/huggingface/transformers/pull/16712)
This will run the actual full test suite.
- Check the results.
- **If any breaking change has been done**, make sure the version can safely be increased for transformers users (`tokenizers` version need to make sure users don't upgrade before `transformers` has). [link](https://github.com/huggingface/transformers/blob/main/setup.py#L154)
For instance `tokenizers>=0.10,<0.11` so we can safely upgrade to `0.11` without impacting
current users
- Then start a new PR containing all desired code changes from the following steps.
- You will `Create release` after the code modifications are on `master`.
# Rust
- `tokenizers` (rust, python & node) versions don't have to be in sync but it's
very common to release for all versions at once for new features.
- Edit `Cargo.toml` to reflect new version
- Edit `CHANGELOG.md`:
- Add relevant PRs that were added (python PRs do not belong for instance).
- Add links at the end of the files.
- Go to [Releases](https://github.com/huggingface/tokenizers/releases)
- Create new Release:
- Mark it as pre-release
- Use new version name with a new tag (create on publish) `vX.X.X`.
- Copy paste the new part of the `CHANGELOG.md`
- ⚠️ Click on `Publish release`. This will start the whole process of building a uploading
the new version on `crates.io`, there's no going back after this
- Go to the [Actions](https://github.com/huggingface/tokenizers/actions) tab and check everything works smoothly.
- If anything fails, you need to fix the CI/CD to make it work again. Since your package was not uploaded to the repository properly, you can try again.
# Python
- Edit `bindings/python/setup.py` to reflect new version.
- Edit `bindings/python/py_src/tokenizers/__init__.py` to reflect new version.
- Edit `CHANGELOG.md`:
- Add relevant PRs that were added (node PRs do not belong for instance).
- Add links at the end of the files.
- Go to [Releases](https://github.com/huggingface/tokenizers/releases)
- Create new Release:
- Mark it as pre-release
- Use new version name with a new tag (create on publish) `python-vX.X.X`.
- Copy paste the new part of the `CHANGELOG.md`
- ⚠️ Click on `Publish release`. This will start the whole process of building a uploading
the new version on `pypi`, there's no going back after this
- Go to the [Actions](https://github.com/huggingface/tokenizers/actions) tab and check everything works smoothly.
- If anything fails, you need to fix the CI/CD to make it work again. Since your package was not uploaded to the repository properly, you can try again.
- This CI/CD has 3 distinct builds, `Pypi`(normal), `conda` and `extra`. `Extra` is REALLY slow (~4h), this is normal since it has to rebuild many things, but enables the wheel to be available for old Linuxes
# Node
- Edit `bindings/node/package.json` to reflect new version.
- Edit `CHANGELOG.md`:
- Add relevant PRs that were added (python PRs do not belong for instance).
- Add links at the end of the files.
- Go to [Releases](https://github.com/huggingface/tokenizers/releases)
- Create new Release:
- Mark it as pre-release
- Use new version name with a new tag (create on publish) `node-vX.X.X`.
- Copy paste the new part of the `CHANGELOG.md`
- ⚠️ Click on `Publish release`. This will start the whole process of building a uploading
the new version on `npm`, there's no going back after this
- Go to the [Actions](https://github.com/huggingface/tokenizers/actions) tab and check everything works smoothly.
- If anything fails, you need to fix the CI/CD to make it work again. Since your package was not uploaded to the repository properly, you can try again.
# Testing the CI/CD for release
If you want to make modifications to the CI/CD of the release GH actions, you need
to :
- **Comment the part that uploads the artifacts** to `crates.io`, `PyPi` or `npm`.
- Change the trigger mechanism so it can trigger every time you push to your branch.
- Keep pushing your changes until the artifacts are properly created.
| tokenizers/RELEASE.md/0 | {
"file_path": "tokenizers/RELEASE.md",
"repo_id": "tokenizers",
"token_count": 1519
} | 205 |
/* eslint-disable */
var globRequire = require
console.log = (..._args: any[]) => {}
describe('quicktourExample', () => {
function require(mod: string) {
if (mod.startsWith('tokenizers')) {
return globRequire('../../')
} else {
return globRequire(mod)
}
}
it.skip('trains the tokenizer', async () => {
// START init_tokenizer
let { Tokenizer } = require('tokenizers')
let { BPE } = require('tokenizers')
let tokenizer = new Tokenizer(BPE.init({}, [], { unkToken: '[UNK]' }))
// END init_tokenizer
// START init_trainer
let { bpeTrainer } = require('tokenizers')
let trainer = bpeTrainer({
specialTokens: ['[UNK]', '[CLS]', '[SEP]', '[PAD]', '[MASK]'],
})
// END init_trainer
// START init_pretok
let { whitespacePreTokenizer } = require('tokenizers')
tokenizer.setPreTokenizer(whitespacePreTokenizer())
// END init_pretok
// START train
let files = ['test', 'train', 'valid'].map((split) => `data/wikitext-103-raw/wiki.${split}.raw`)
tokenizer.train(files, trainer)
// END train
// START save
tokenizer.save('data/tokenizer-wiki.json')
// END save
})
it('shows a quicktour example', async () => {
let { Tokenizer } = require('tokenizers')
// START reload_tokenizer
let tokenizer = Tokenizer.fromFile('data/tokenizer-wiki.json')
// END reload_tokenizer
// START encode
var output = await tokenizer.encode("Hello, y'all! How are you 😁 ?")
// END encode
// START print_tokens
console.log(output.getTokens())
// ["Hello", ",", "y", "'", "all", "!", "How", "are", "you", "[UNK]", "?"]
// END print_tokens
expect(output.getTokens()).toEqual(['Hello', ',', 'y', "'", 'all', '!', 'How', 'are', 'you', '[UNK]', '?'])
// START print_ids
console.log(output.getIds())
// [27253, 16, 93, 11, 5097, 5, 7961, 5112, 6218, 0, 35]
// END print_ids
expect(output.getIds()).toEqual([27253, 16, 93, 11, 5097, 5, 7961, 5112, 6218, 0, 35])
// START print_offsets
let offsets = output.getOffsets()
console.log(offsets[9])
// (26, 27)
// END print_offsets
expect(offsets[9]).toEqual([26, 27])
// START use_offsets
let { slice } = require('tokenizers')
let sentence = "Hello, y'all! How are you 😁 ?"
let [start, end] = offsets[9]
console.log(slice(sentence, start, end))
// "😁"
// END use_offsets
expect(slice(sentence, start, end)).toEqual('😁')
// START check_sep
console.log(tokenizer.tokenToId('[SEP]'))
// 2
// END check_sep
expect(tokenizer.tokenToId('[SEP]')).toEqual(2)
// START init_template_processing
let { templateProcessing } = require('tokenizers')
tokenizer.setPostProcessor(
templateProcessing('[CLS] $A [SEP]', '[CLS] $A [SEP] $B:1 [SEP]:1', [
['[CLS]', tokenizer.tokenToId('[CLS]')],
['[SEP]', tokenizer.tokenToId('[SEP]')],
]),
)
// END init_template_processing
// START print_special_tokens
var output = await tokenizer.encode("Hello, y'all! How are you 😁 ?")
console.log(output.getTokens())
// ["[CLS]", "Hello", ",", "y", "'", "all", "!", "How", "are", "you", "[UNK]", "?", "[SEP]"]
// END print_special_tokens
expect(output.getTokens()).toEqual([
'[CLS]',
'Hello',
',',
'y',
"'",
'all',
'!',
'How',
'are',
'you',
'[UNK]',
'?',
'[SEP]',
])
// START print_special_tokens_pair
var output = await tokenizer.encode("Hello, y'all!", 'How are you 😁 ?')
console.log(output.getTokens())
// ["[CLS]", "Hello", ",", "y", "'", "all", "!", "[SEP]", "How", "are", "you", "[UNK]", "?", "[SEP]"]
// END print_special_tokens_pair
expect(output.getTokens()).toEqual([
'[CLS]',
'Hello',
',',
'y',
"'",
'all',
'!',
'[SEP]',
'How',
'are',
'you',
'[UNK]',
'?',
'[SEP]',
])
// START print_type_ids
console.log(output.getTypeIds())
// [0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1]
// END print_type_ids
expect(output.getTypeIds()).toEqual([0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1])
// START encode_batch
var output = await tokenizer.encodeBatch(["Hello, y'all!", 'How are you 😁 ?'])
// END encode_batch
// START encode_batch_pair
// var output = await tokenizer.encodeBatch(
// [["Hello, y'all!", "How are you 😁 ?"], ["Hello to you too!", "I'm fine, thank you!"]]
// );
// END encode_batch_pair
// START enable_padding
tokenizer.setPadding({ padId: 3, padToken: '[PAD]' })
// END enable_padding
// START print_batch_tokens
var output = await tokenizer.encodeBatch(["Hello, y'all!", 'How are you 😁 ?'])
console.log(output[1].getTokens())
// ["[CLS]", "How", "are", "you", "[UNK]", "?", "[SEP]", "[PAD]"]
// END print_batch_tokens
expect(output[1].getTokens()).toEqual(['[CLS]', 'How', 'are', 'you', '[UNK]', '?', '[SEP]', '[PAD]'])
// START print_attention_mask
console.log(output[1].getAttentionMask())
// [1, 1, 1, 1, 1, 1, 1, 0]
// END print_attention_mask
expect(output[1].getAttentionMask()).toEqual([1, 1, 1, 1, 1, 1, 1, 0])
})
})
| tokenizers/bindings/node/examples/documentation/quicktour.test.ts/0 | {
"file_path": "tokenizers/bindings/node/examples/documentation/quicktour.test.ts",
"repo_id": "tokenizers",
"token_count": 2324
} | 206 |
{
"name": "tokenizers-android-arm-eabi",
"version": "0.13.4-rc1",
"os": [
"android"
],
"cpu": [
"arm"
],
"main": "tokenizers.android-arm-eabi.node",
"files": [
"tokenizers.android-arm-eabi.node"
],
"description": "Tokenizers platform specific bindings",
"keywords": [
"napi-rs",
"NAPI",
"N-API",
"Rust",
"node-addon",
"node-addon-api"
],
"license": "MIT",
"engines": {
"node": ">= 10"
},
"publishConfig": {
"registry": "https://registry.npmjs.org/",
"access": "public"
},
"repository": "tokenizers"
} | tokenizers/bindings/node/npm/android-arm-eabi/package.json/0 | {
"file_path": "tokenizers/bindings/node/npm/android-arm-eabi/package.json",
"repo_id": "tokenizers",
"token_count": 269
} | 207 |
{
"name": "tokenizers-linux-x64-gnu",
"version": "0.13.4-rc1",
"os": [
"linux"
],
"cpu": [
"x64"
],
"main": "tokenizers.linux-x64-gnu.node",
"files": [
"tokenizers.linux-x64-gnu.node"
],
"description": "Tokenizers platform specific bindings",
"keywords": [
"napi-rs",
"NAPI",
"N-API",
"Rust",
"node-addon",
"node-addon-api"
],
"license": "MIT",
"engines": {
"node": ">= 10"
},
"publishConfig": {
"registry": "https://registry.npmjs.org/",
"access": "public"
},
"repository": "tokenizers",
"libc": [
"glibc"
]
} | tokenizers/bindings/node/npm/linux-x64-gnu/package.json/0 | {
"file_path": "tokenizers/bindings/node/npm/linux-x64-gnu/package.json",
"repo_id": "tokenizers",
"token_count": 289
} | 208 |
use crate::arc_rwlock_serde;
use napi::bindgen_prelude::*;
use napi_derive::napi;
use serde::{Deserialize, Serialize};
use std::sync::{Arc, RwLock};
use tk::normalizers::NormalizerWrapper;
use tk::NormalizedString;
use tokenizers as tk;
/// Normalizer
#[derive(Debug, Clone, Serialize, Deserialize)]
#[napi]
pub struct Normalizer {
#[serde(flatten, with = "arc_rwlock_serde")]
normalizer: Option<Arc<RwLock<NormalizerWrapper>>>,
}
#[napi]
impl Normalizer {
#[napi]
pub fn normalize_string(&self, sequence: String) -> Result<String> {
use tk::Normalizer;
let mut normalized = NormalizedString::from(sequence);
self
.normalize(&mut normalized)
.map_err(|e| Error::from_reason(format!("{}", e)))?;
Ok(normalized.get().to_string())
}
}
impl tk::Normalizer for Normalizer {
fn normalize(&self, normalized: &mut NormalizedString) -> tk::Result<()> {
self
.normalizer
.as_ref()
.ok_or("Uninitialized Normalizer")?
.read()
.unwrap()
.normalize(normalized)?;
Ok(())
}
}
#[napi]
pub fn prepend_normalizer(prepend: String) -> Normalizer {
Normalizer {
normalizer: Some(Arc::new(RwLock::new(
tk::normalizers::prepend::Prepend::new(prepend).into(),
))),
}
}
#[napi]
pub fn strip_accents_normalizer() -> Normalizer {
Normalizer {
normalizer: Some(Arc::new(RwLock::new(
tk::normalizers::strip::StripAccents.into(),
))),
}
}
#[napi(object)]
#[derive(Default)]
pub struct BertNormalizerOptions {
pub clean_text: Option<bool>,
pub handle_chinese_chars: Option<bool>,
pub strip_accents: Option<bool>,
pub lowercase: Option<bool>,
}
/// bert_normalizer(options?: {
/// cleanText?: bool = true,
/// handleChineseChars?: bool = true,
/// stripAccents?: bool = true,
/// lowercase?: bool = true
/// })
#[napi]
pub fn bert_normalizer(options: Option<BertNormalizerOptions>) -> Normalizer {
let options = options.unwrap_or_default();
Normalizer {
normalizer: Some(Arc::new(RwLock::new(
tk::normalizers::bert::BertNormalizer::new(
options.clean_text.unwrap_or(true),
options.handle_chinese_chars.unwrap_or(true),
options.strip_accents,
options.lowercase.unwrap_or(true),
)
.into(),
))),
}
}
#[napi]
pub fn nfd_normalizer() -> Normalizer {
Normalizer {
normalizer: Some(Arc::new(RwLock::new(tk::normalizers::unicode::NFD.into()))),
}
}
#[napi]
pub fn nfkd_normalizer() -> Normalizer {
Normalizer {
normalizer: Some(Arc::new(RwLock::new(tk::normalizers::unicode::NFKD.into()))),
}
}
#[napi]
pub fn nfc_normalizer() -> Normalizer {
Normalizer {
normalizer: Some(Arc::new(RwLock::new(tk::normalizers::unicode::NFC.into()))),
}
}
#[napi]
pub fn nfkc_normalizer() -> Normalizer {
Normalizer {
normalizer: Some(Arc::new(RwLock::new(tk::normalizers::unicode::NFKC.into()))),
}
}
// /// strip(left?: boolean, right?: boolean)
#[napi]
pub fn strip_normalizer(left: Option<bool>, right: Option<bool>) -> Normalizer {
let left = left.unwrap_or(true);
let right = right.unwrap_or(true);
Normalizer {
normalizer: Some(Arc::new(RwLock::new(
tk::normalizers::strip::Strip::new(left, right).into(),
))),
}
}
#[napi]
pub fn sequence_normalizer(normalizers: Vec<&Normalizer>) -> Normalizer {
let mut sequence: Vec<NormalizerWrapper> = Vec::with_capacity(normalizers.len());
normalizers.into_iter().for_each(|normalizer| {
if let Some(normalizer) = &normalizer.normalizer {
sequence.push((**normalizer).read().unwrap().clone())
}
});
Normalizer {
normalizer: Some(Arc::new(RwLock::new(NormalizerWrapper::Sequence(
tk::normalizers::Sequence::new(sequence),
)))),
}
}
#[napi]
pub fn lowercase() -> Normalizer {
Normalizer {
normalizer: Some(Arc::new(RwLock::new(
tk::normalizers::utils::Lowercase.into(),
))),
}
}
#[napi]
pub fn replace(pattern: String, content: String) -> Result<Normalizer> {
Ok(Normalizer {
normalizer: Some(Arc::new(RwLock::new(
tk::normalizers::replace::Replace::new(pattern, content)
.map_err(|e| Error::from_reason(e.to_string()))?
.into(),
))),
})
}
#[napi]
pub fn nmt() -> Normalizer {
Normalizer {
normalizer: Some(Arc::new(RwLock::new(tk::normalizers::unicode::Nmt.into()))),
}
}
#[napi]
pub fn precompiled(bytes: Vec<u8>) -> Result<Normalizer> {
Ok(Normalizer {
normalizer: Some(Arc::new(RwLock::new(
tk::normalizers::precompiled::Precompiled::from(&bytes)
.map_err(|e| Error::from_reason(e.to_string()))?
.into(),
))),
})
}
| tokenizers/bindings/node/src/normalizers.rs/0 | {
"file_path": "tokenizers/bindings/node/src/normalizers.rs",
"repo_id": "tokenizers",
"token_count": 1886
} | 209 |
include Cargo.toml
include pyproject.toml
include rust-toolchain
include ../../LICENSE
recursive-include src *
recursive-include tokenizers-lib *
recursive-exclude tokenizers-lib/target *
| tokenizers/bindings/python/MANIFEST.in/0 | {
"file_path": "tokenizers/bindings/python/MANIFEST.in",
"repo_id": "tokenizers",
"token_count": 57
} | 210 |
from typing import Dict, Iterator, List, Optional, Union
from tokenizers import AddedToken, Tokenizer, decoders, trainers
from tokenizers.models import WordPiece
from tokenizers.normalizers import BertNormalizer
from tokenizers.pre_tokenizers import BertPreTokenizer
from tokenizers.processors import BertProcessing
from .base_tokenizer import BaseTokenizer
class BertWordPieceTokenizer(BaseTokenizer):
"""Bert WordPiece Tokenizer"""
def __init__(
self,
vocab: Optional[Union[str, Dict[str, int]]] = None,
unk_token: Union[str, AddedToken] = "[UNK]",
sep_token: Union[str, AddedToken] = "[SEP]",
cls_token: Union[str, AddedToken] = "[CLS]",
pad_token: Union[str, AddedToken] = "[PAD]",
mask_token: Union[str, AddedToken] = "[MASK]",
clean_text: bool = True,
handle_chinese_chars: bool = True,
strip_accents: Optional[bool] = None,
lowercase: bool = True,
wordpieces_prefix: str = "##",
):
if vocab is not None:
tokenizer = Tokenizer(WordPiece(vocab, unk_token=str(unk_token)))
else:
tokenizer = Tokenizer(WordPiece(unk_token=str(unk_token)))
# Let the tokenizer know about special tokens if they are part of the vocab
if tokenizer.token_to_id(str(unk_token)) is not None:
tokenizer.add_special_tokens([str(unk_token)])
if tokenizer.token_to_id(str(sep_token)) is not None:
tokenizer.add_special_tokens([str(sep_token)])
if tokenizer.token_to_id(str(cls_token)) is not None:
tokenizer.add_special_tokens([str(cls_token)])
if tokenizer.token_to_id(str(pad_token)) is not None:
tokenizer.add_special_tokens([str(pad_token)])
if tokenizer.token_to_id(str(mask_token)) is not None:
tokenizer.add_special_tokens([str(mask_token)])
tokenizer.normalizer = BertNormalizer(
clean_text=clean_text,
handle_chinese_chars=handle_chinese_chars,
strip_accents=strip_accents,
lowercase=lowercase,
)
tokenizer.pre_tokenizer = BertPreTokenizer()
if vocab is not None:
sep_token_id = tokenizer.token_to_id(str(sep_token))
if sep_token_id is None:
raise TypeError("sep_token not found in the vocabulary")
cls_token_id = tokenizer.token_to_id(str(cls_token))
if cls_token_id is None:
raise TypeError("cls_token not found in the vocabulary")
tokenizer.post_processor = BertProcessing((str(sep_token), sep_token_id), (str(cls_token), cls_token_id))
tokenizer.decoder = decoders.WordPiece(prefix=wordpieces_prefix)
parameters = {
"model": "BertWordPiece",
"unk_token": unk_token,
"sep_token": sep_token,
"cls_token": cls_token,
"pad_token": pad_token,
"mask_token": mask_token,
"clean_text": clean_text,
"handle_chinese_chars": handle_chinese_chars,
"strip_accents": strip_accents,
"lowercase": lowercase,
"wordpieces_prefix": wordpieces_prefix,
}
super().__init__(tokenizer, parameters)
@staticmethod
def from_file(vocab: str, **kwargs):
vocab = WordPiece.read_file(vocab)
return BertWordPieceTokenizer(vocab, **kwargs)
def train(
self,
files: Union[str, List[str]],
vocab_size: int = 30000,
min_frequency: int = 2,
limit_alphabet: int = 1000,
initial_alphabet: List[str] = [],
special_tokens: List[Union[str, AddedToken]] = [
"[PAD]",
"[UNK]",
"[CLS]",
"[SEP]",
"[MASK]",
],
show_progress: bool = True,
wordpieces_prefix: str = "##",
):
"""Train the model using the given files"""
trainer = trainers.WordPieceTrainer(
vocab_size=vocab_size,
min_frequency=min_frequency,
limit_alphabet=limit_alphabet,
initial_alphabet=initial_alphabet,
special_tokens=special_tokens,
show_progress=show_progress,
continuing_subword_prefix=wordpieces_prefix,
)
if isinstance(files, str):
files = [files]
self._tokenizer.train(files, trainer=trainer)
def train_from_iterator(
self,
iterator: Union[Iterator[str], Iterator[Iterator[str]]],
vocab_size: int = 30000,
min_frequency: int = 2,
limit_alphabet: int = 1000,
initial_alphabet: List[str] = [],
special_tokens: List[Union[str, AddedToken]] = [
"[PAD]",
"[UNK]",
"[CLS]",
"[SEP]",
"[MASK]",
],
show_progress: bool = True,
wordpieces_prefix: str = "##",
length: Optional[int] = None,
):
"""Train the model using the given iterator"""
trainer = trainers.WordPieceTrainer(
vocab_size=vocab_size,
min_frequency=min_frequency,
limit_alphabet=limit_alphabet,
initial_alphabet=initial_alphabet,
special_tokens=special_tokens,
show_progress=show_progress,
continuing_subword_prefix=wordpieces_prefix,
)
self._tokenizer.train_from_iterator(
iterator,
trainer=trainer,
length=length,
)
| tokenizers/bindings/python/py_src/tokenizers/implementations/bert_wordpiece.py/0 | {
"file_path": "tokenizers/bindings/python/py_src/tokenizers/implementations/bert_wordpiece.py",
"repo_id": "tokenizers",
"token_count": 2637
} | 211 |
# Generated content DO NOT EDIT
from .. import trainers
Trainer = trainers.Trainer
BpeTrainer = trainers.BpeTrainer
UnigramTrainer = trainers.UnigramTrainer
WordLevelTrainer = trainers.WordLevelTrainer
WordPieceTrainer = trainers.WordPieceTrainer
| tokenizers/bindings/python/py_src/tokenizers/trainers/__init__.py/0 | {
"file_path": "tokenizers/bindings/python/py_src/tokenizers/trainers/__init__.py",
"repo_id": "tokenizers",
"token_count": 74
} | 212 |
use pyo3::prelude::*;
use tk::Token;
#[pyclass(module = "tokenizers", name = "Token")]
#[derive(Clone)]
pub struct PyToken {
token: Token,
}
impl From<Token> for PyToken {
fn from(token: Token) -> Self {
Self { token }
}
}
impl From<PyToken> for Token {
fn from(token: PyToken) -> Self {
token.token
}
}
#[pymethods]
impl PyToken {
#[new]
#[pyo3(text_signature = None)]
fn new(id: u32, value: String, offsets: (usize, usize)) -> PyToken {
Token::new(id, value, offsets).into()
}
#[getter]
fn get_id(&self) -> u32 {
self.token.id
}
#[getter]
fn get_value(&self) -> &str {
&self.token.value
}
#[getter]
fn get_offsets(&self) -> (usize, usize) {
self.token.offsets
}
fn as_tuple(&self) -> (u32, &str, (usize, usize)) {
(self.token.id, &self.token.value, self.token.offsets)
}
}
| tokenizers/bindings/python/src/token.rs/0 | {
"file_path": "tokenizers/bindings/python/src/token.rs",
"repo_id": "tokenizers",
"token_count": 439
} | 213 |
import json
import pickle
import pytest
from tokenizers.pre_tokenizers import (
BertPreTokenizer,
ByteLevel,
CharDelimiterSplit,
Digits,
Metaspace,
PreTokenizer,
Punctuation,
Sequence,
Split,
UnicodeScripts,
Whitespace,
WhitespaceSplit,
)
class TestByteLevel:
def test_instantiate(self):
assert ByteLevel() is not None
assert ByteLevel(add_prefix_space=True) is not None
assert ByteLevel(add_prefix_space=False) is not None
assert isinstance(ByteLevel(), PreTokenizer)
assert isinstance(ByteLevel(), ByteLevel)
assert isinstance(pickle.loads(pickle.dumps(ByteLevel())), ByteLevel)
def test_has_alphabet(self):
assert isinstance(ByteLevel.alphabet(), list)
assert len(ByteLevel.alphabet()) == 256
def test_can_modify(self):
pretok = ByteLevel(add_prefix_space=False)
assert pretok.add_prefix_space == False
# Modify these
pretok.add_prefix_space = True
assert pretok.add_prefix_space == True
def test_manual_reload(self):
byte_level = ByteLevel()
state = json.loads(byte_level.__getstate__())
reloaded = ByteLevel(**state)
assert isinstance(reloaded, ByteLevel)
class TestSplit:
def test_instantiate(self):
pre_tokenizer = Split(pattern=" ", behavior="removed")
assert pre_tokenizer is not None
assert isinstance(pre_tokenizer, PreTokenizer)
assert isinstance(pre_tokenizer, Split)
assert isinstance(pickle.loads(pickle.dumps(Split(" ", "removed"))), Split)
# test with invert=True
pre_tokenizer_with_invert = Split(pattern=" ", behavior="isolated", invert=True)
assert pre_tokenizer_with_invert is not None
assert isinstance(pre_tokenizer_with_invert, PreTokenizer)
assert isinstance(pre_tokenizer_with_invert, Split)
assert isinstance(pickle.loads(pickle.dumps(Split(" ", "removed", True))), Split)
class TestWhitespace:
def test_instantiate(self):
assert Whitespace() is not None
assert isinstance(Whitespace(), PreTokenizer)
assert isinstance(Whitespace(), Whitespace)
assert isinstance(pickle.loads(pickle.dumps(Whitespace())), Whitespace)
class TestWhitespaceSplit:
def test_instantiate(self):
assert WhitespaceSplit() is not None
assert isinstance(WhitespaceSplit(), PreTokenizer)
assert isinstance(WhitespaceSplit(), WhitespaceSplit)
assert isinstance(pickle.loads(pickle.dumps(WhitespaceSplit())), WhitespaceSplit)
class TestBertPreTokenizer:
def test_instantiate(self):
assert BertPreTokenizer() is not None
assert isinstance(BertPreTokenizer(), PreTokenizer)
assert isinstance(BertPreTokenizer(), BertPreTokenizer)
assert isinstance(pickle.loads(pickle.dumps(BertPreTokenizer())), BertPreTokenizer)
class TestMetaspace:
def test_instantiate(self):
assert Metaspace() is not None
assert Metaspace(replacement="-") is not None
with pytest.raises(ValueError, match="expected a string of length 1"):
Metaspace(replacement="")
assert Metaspace(add_prefix_space=True) is not None
assert isinstance(Metaspace(), PreTokenizer)
assert isinstance(Metaspace(), Metaspace)
assert isinstance(pickle.loads(pickle.dumps(Metaspace())), Metaspace)
def test_can_modify(self):
pretok = Metaspace(replacement="$", add_prefix_space=False)
assert pretok.replacement == "$"
assert pretok.add_prefix_space == False
# Modify these
pretok.replacement = "%"
assert pretok.replacement == "%"
pretok.add_prefix_space = True
assert pretok.add_prefix_space == True
pretok.prepend_scheme = "never"
assert pretok.prepend_scheme == "never"
class TestCharDelimiterSplit:
def test_instantiate(self):
assert CharDelimiterSplit("-") is not None
with pytest.raises(ValueError, match="expected a string of length 1"):
CharDelimiterSplit("")
assert isinstance(CharDelimiterSplit(" "), PreTokenizer)
assert isinstance(CharDelimiterSplit(" "), CharDelimiterSplit)
assert isinstance(pickle.loads(pickle.dumps(CharDelimiterSplit("-"))), CharDelimiterSplit)
def test_can_modify(self):
pretok = CharDelimiterSplit("@")
assert pretok.delimiter == "@"
# Modify these
pretok.delimiter = "!"
assert pretok.delimiter == "!"
class TestPunctuation:
def test_instantiate(self):
assert Punctuation() is not None
assert Punctuation("removed") is not None
assert isinstance(Punctuation(), PreTokenizer)
assert isinstance(Punctuation(), Punctuation)
assert isinstance(pickle.loads(pickle.dumps(Punctuation())), Punctuation)
class TestSequence:
def test_instantiate(self):
assert Sequence([]) is not None
assert isinstance(Sequence([]), PreTokenizer)
assert isinstance(Sequence([]), Sequence)
dumped = pickle.dumps(Sequence([]))
assert isinstance(pickle.loads(dumped), Sequence)
def test_bert_like(self):
pre_tokenizer = Sequence([WhitespaceSplit(), Punctuation()])
assert isinstance(Sequence([]), PreTokenizer)
assert isinstance(Sequence([]), Sequence)
assert isinstance(pickle.loads(pickle.dumps(pre_tokenizer)), Sequence)
result = pre_tokenizer.pre_tokenize_str("Hey friend! How are you?!?")
assert result == [
("Hey", (0, 3)),
("friend", (4, 10)),
("!", (10, 11)),
("How", (16, 19)),
("are", (20, 23)),
("you", (24, 27)),
("?", (27, 28)),
("!", (28, 29)),
("?", (29, 30)),
]
class TestDigits:
def test_instantiate(self):
assert Digits() is not None
assert isinstance(Digits(), PreTokenizer)
assert isinstance(Digits(), Digits)
assert isinstance(Digits(True), Digits)
assert isinstance(Digits(False), Digits)
assert isinstance(pickle.loads(pickle.dumps(Digits())), Digits)
def test_can_modify(self):
pretok = Digits(individual_digits=False)
assert pretok.individual_digits == False
# Modify these
pretok.individual_digits = True
assert pretok.individual_digits == True
class TestUnicodeScripts:
def test_instantiate(self):
assert UnicodeScripts() is not None
assert isinstance(UnicodeScripts(), PreTokenizer)
assert isinstance(UnicodeScripts(), UnicodeScripts)
assert isinstance(pickle.loads(pickle.dumps(UnicodeScripts())), UnicodeScripts)
class TestCustomPreTokenizer:
class BadCustomPretok:
def pre_tokenize(self, pretok, wrong):
# This method does not have the right signature: it takes one too many arg
pass
class GoodCustomPretok:
def split(self, n, normalized):
# Here we just test that we can return a List[NormalizedString], it
# does not really make sense to return twice the same otherwise
return [normalized, normalized]
def pre_tokenize(self, pretok):
pretok.split(self.split)
def test_instantiate(self):
bad = PreTokenizer.custom(TestCustomPreTokenizer.BadCustomPretok())
good = PreTokenizer.custom(TestCustomPreTokenizer.GoodCustomPretok())
assert isinstance(bad, PreTokenizer)
assert isinstance(good, PreTokenizer)
with pytest.raises(Exception, match="TypeError:.*pre_tokenize()"):
bad.pre_tokenize_str("Hey there!")
assert good.pre_tokenize_str("Hey there!") == [
("Hey there!", (0, 10)),
("Hey there!", (0, 10)),
]
def test_camel_case(self):
class CamelCasePretok:
def get_state(self, c):
if c.islower():
return "lower"
elif c.isupper():
return "upper"
elif c.isdigit():
return "digit"
else:
return "rest"
def split(self, n, normalized):
i = 0
# states = {"any", "lower", "upper", "digit", "rest"}
state = "any"
pieces = []
for j, c in enumerate(normalized.normalized):
c_state = self.get_state(c)
if state == "any":
state = c_state
if state != "rest" and state == c_state:
pass
elif state == "upper" and c_state == "lower":
pass
else:
pieces.append(normalized[i:j])
i = j
state = c_state
pieces.append(normalized[i:])
return pieces
def pre_tokenize(self, pretok):
pretok.split(self.split)
camel = PreTokenizer.custom(CamelCasePretok())
assert camel.pre_tokenize_str("HeyThere!?-ThisIsLife") == [
("Hey", (0, 3)),
("There", (3, 8)),
("!", (8, 9)),
("?", (9, 10)),
("-", (10, 11)),
("This", (11, 15)),
("Is", (15, 17)),
("Life", (17, 21)),
]
| tokenizers/bindings/python/tests/bindings/test_pre_tokenizers.py/0 | {
"file_path": "tokenizers/bindings/python/tests/bindings/test_pre_tokenizers.py",
"repo_id": "tokenizers",
"token_count": 4218
} | 214 |
# Minimal makefile for Sphinx documentation
#
# You can set these variables from the command line, and also
# from the environment for those with `?=`
SPHINXOPTS ?=
SPHINXBUILD ?= sphinx-build
BUILDDIR ?= build
SOURCEDIR = source
# Put it first so that "make" without argument is like "make html_all".
html_all:
@echo "Generating doc for Rust"
@$(SPHINXBUILD) -M html "$(SOURCEDIR)" "$(BUILDDIR)/rust" $(SPHINXOPTS) $(O) -t rust
@echo "Generating doc for Python"
@$(SPHINXBUILD) -M html "$(SOURCEDIR)" "$(BUILDDIR)/python" $(SPHINXOPTS) $(O) -t python
@echo "Generating doc for Node.js"
@$(SPHINXBUILD) -M html "$(SOURCEDIR)" "$(BUILDDIR)/node" $(SPHINXOPTS) $(O) -t node
.PHONY: html_all Makefile
# Catch-all target: route all unknown targets to Sphinx using the new
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
%: Makefile
@$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
| tokenizers/docs/Makefile/0 | {
"file_path": "tokenizers/docs/Makefile",
"repo_id": "tokenizers",
"token_count": 393
} | 215 |
<!-- DISABLE-FRONTMATTER-SECTIONS -->
# Tokenizers
Fast State-of-the-art tokenizers, optimized for both research and
production
[🤗 Tokenizers](https://github.com/huggingface/tokenizers) provides an
implementation of today's most used tokenizers, with a focus on
performance and versatility. These tokenizers are also used in [🤗 Transformers](https://github.com/huggingface/transformers).
# Main features:
- Train new vocabularies and tokenize, using today's most used tokenizers.
- Extremely fast (both training and tokenization), thanks to the Rust implementation. Takes less than 20 seconds to tokenize a GB of text on a server's CPU.
- Easy to use, but also extremely versatile.
- Designed for both research and production.
- Full alignment tracking. Even with destructive normalization, it's always possible to get the part of the original sentence that corresponds to any token.
- Does all the pre-processing: Truncation, Padding, add the special tokens your model needs.
| tokenizers/docs/source-doc-builder/index.mdx/0 | {
"file_path": "tokenizers/docs/source-doc-builder/index.mdx",
"repo_id": "tokenizers",
"token_count": 250
} | 216 |
Input sequences
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
These types represent all the different kinds of sequence that can be used as input of a Tokenizer.
Globally, any sequence can be either a string or a list of strings, according to the operating
mode of the tokenizer: ``raw text`` vs ``pre-tokenized``.
.. autodata:: tokenizers.TextInputSequence
.. autodata:: tokenizers.PreTokenizedInputSequence
.. autodata:: tokenizers.InputSequence
Encode inputs
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
These types represent all the different kinds of input that a :class:`~tokenizers.Tokenizer` accepts
when using :meth:`~tokenizers.Tokenizer.encode_batch`.
.. autodata:: tokenizers.TextEncodeInput
.. autodata:: tokenizers.PreTokenizedEncodeInput
.. autodata:: tokenizers.EncodeInput
Tokenizer
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: tokenizers.Tokenizer
:members:
Encoding
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: tokenizers.Encoding
:members:
Added Tokens
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: tokenizers.AddedToken
:members:
Models
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. automodule:: tokenizers.models
:members:
Normalizers
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. automodule:: tokenizers.normalizers
:members:
Pre-tokenizers
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. automodule:: tokenizers.pre_tokenizers
:members:
Post-processor
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. automodule:: tokenizers.processors
:members:
Trainers
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. automodule:: tokenizers.trainers
:members:
Decoders
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. automodule:: tokenizers.decoders
:members:
Visualizer
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
.. autoclass:: tokenizers.tools.Annotation
:members:
.. autoclass:: tokenizers.tools.EncodingVisualizer
:members: __call__
| tokenizers/docs/source/api/python.inc/0 | {
"file_path": "tokenizers/docs/source/api/python.inc",
"repo_id": "tokenizers",
"token_count": 562
} | 217 |
#!/usr/bin/env node
const { spawn } = require("child_process");
const fs = require("fs");
let folderName = '.';
if (process.argv.length >= 3) {
folderName = process.argv[2];
if (!fs.existsSync(folderName)) {
fs.mkdirSync(folderName);
}
}
const clone = spawn("git", ["clone", "https://github.com/rustwasm/create-wasm-app.git", folderName]);
clone.on("close", code => {
if (code !== 0) {
console.error("cloning the template failed!")
process.exit(code);
} else {
console.log("🦀 Rust + 🕸 Wasm = ❤");
}
});
| tokenizers/tokenizers/examples/unstable_wasm/www/.bin/create-wasm-app.js/0 | {
"file_path": "tokenizers/tokenizers/examples/unstable_wasm/www/.bin/create-wasm-app.js",
"repo_id": "tokenizers",
"token_count": 210
} | 218 |
use crate::tokenizer::{Decoder, Result};
use monostate::MustBe;
use serde::{Deserialize, Serialize};
#[derive(Clone, Debug, Serialize, Deserialize, Default)]
/// Fuse simply fuses all tokens into one big string.
/// It's usually the last decoding step anyway, but this
/// decoder exists incase some decoders need to happen after that
/// step
#[non_exhaustive]
pub struct Fuse {
#[serde(rename = "type")]
type_: MustBe!("Fuse"),
}
impl Fuse {
pub fn new() -> Self {
Self {
type_: MustBe!("Fuse"),
}
}
}
impl Decoder for Fuse {
fn decode_chain(&self, tokens: Vec<String>) -> Result<Vec<String>> {
let new_string = tokens.join("");
Ok(vec![new_string])
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn decode() {
let decoder = Fuse::new();
let res = decoder
.decode_chain(vec!["Hey".into(), " friend!".into()])
.unwrap();
assert_eq!(res, vec!["Hey friend!"]);
}
}
| tokenizers/tokenizers/src/decoders/fuse.rs/0 | {
"file_path": "tokenizers/tokenizers/src/decoders/fuse.rs",
"repo_id": "tokenizers",
"token_count": 433
} | 219 |
use crate::models::unigram::{lattice::Lattice, model::Unigram};
use crate::tokenizer::{AddedToken, Result, Trainer};
use crate::utils::parallelism::*;
use crate::utils::progress::{ProgressBar, ProgressStyle};
use log::debug;
use serde::{Deserialize, Serialize};
use std::cmp::Reverse;
use std::collections::{HashMap, HashSet};
use std::convert::TryInto;
// A token and a score
type SentencePiece = (String, f64);
// A full sentence or word + it's count within the dataset
type Sentence = (String, u32);
fn digamma(mut x: f64) -> f64 {
let mut result = 0.0;
while x < 7.0 {
result -= 1.0 / x;
x += 1.0;
}
x -= 1.0 / 2.0;
let xx = 1.0 / x;
let xx2 = xx * xx;
let xx4 = xx2 * xx2;
result += x.ln() + (1.0 / 24.0) * xx2 - 7.0 / 960.0 * xx4 + (31.0 / 8064.0) * xx4 * xx2
- (127.0 / 30720.0) * xx4 * xx4;
result
}
#[derive(thiserror::Error, Debug)]
pub enum UnigramTrainerError {
#[error("The vocabulary is not large enough to contain all chars")]
VocabularyTooSmall,
}
fn to_log_prob(pieces: &mut [SentencePiece]) {
let sum: f64 = pieces.iter().map(|(_, score)| score).sum();
let logsum = sum.ln();
for (_, score) in pieces.iter_mut() {
*score = score.ln() - logsum;
}
}
/// A `UnigramTrainer` can train a `Unigram` model from `word_counts`.
#[non_exhaustive]
#[derive(Builder, Debug, Clone, Serialize, Deserialize)]
pub struct UnigramTrainer {
#[builder(default = "true")]
pub show_progress: bool,
#[builder(default = "8000")]
pub vocab_size: u32,
#[builder(default = "2")]
pub n_sub_iterations: u32,
#[builder(default = "0.75")]
pub shrinking_factor: f64,
#[builder(default = "vec![]")]
pub special_tokens: Vec<AddedToken>,
#[builder(default = "HashSet::new()")]
pub initial_alphabet: HashSet<char>,
#[builder(default = "None")]
pub unk_token: Option<String>,
#[builder(default = "16")]
pub max_piece_length: usize,
#[builder(default = "1_000_000")]
seed_size: usize,
#[builder(default = "HashMap::new()")]
words: HashMap<String, u32>,
}
impl Default for UnigramTrainer {
fn default() -> Self {
Self::builder().build().unwrap()
}
}
impl UnigramTrainer {
pub fn builder() -> UnigramTrainerBuilder {
UnigramTrainerBuilder::default()
}
/// Setup a progress bar if asked to show progress
fn setup_progress(&self) -> Option<ProgressBar> {
if self.show_progress {
let p = ProgressBar::new(0);
p.set_style(
ProgressStyle::default_bar()
.template("[{elapsed_precise}] {msg:<30!} {wide_bar} {pos:<9!}/{len:>9!}")
.expect("Invalid progress template"),
);
Some(p)
} else {
None
}
}
fn is_valid_sentencepiece(&self, char_string: &[char]) -> bool {
// Checks string length
// Space not in the substring, numbers, hiragana and more should be taken
// care of within pre_tokenizers.
// https://github.com/google/sentencepiece/blob/26be9516cd81d5315ee31c48d2438018e0eab879/src/trainer_interface.cc#L203
let n = char_string.len();
if char_string.is_empty() || n > self.max_piece_length {
return false;
}
true
}
fn finalize(&self, model: Unigram, required_chars: HashSet<String>) -> Result<Unigram> {
let mut min_score_penalty = 0.0;
let min_score_penalty_delta = 0.0001;
let mut pieces: Vec<(String, f64)> = vec![];
let mut inserted: HashSet<String> = HashSet::new();
// We don't want to include the <UNK> that was used to train
inserted.insert("<UNK>".into());
let existing_pieces: HashMap<String, f64> = model.iter().cloned().collect();
for c in required_chars {
if let Some(t) = existing_pieces.get(&c) {
inserted.insert(c.clone());
pieces.push((c, *t));
} else {
let score = model.min_score + min_score_penalty;
inserted.insert(c.clone());
pieces.push((c, score));
min_score_penalty += min_score_penalty_delta;
}
}
let (unk_id, need_add_unk) = if let Some(ref unk) = self.unk_token {
let unk_id = self.special_tokens.iter().enumerate().find_map(|(i, t)| {
if t.content == *unk {
Some(i)
} else {
None
}
});
match unk_id {
Some(id) => (Some(id), false),
None => (Some(0), true),
}
} else {
(None, false)
};
let vocab_size_without_special_tokens = if need_add_unk {
self.vocab_size as usize - self.special_tokens.len() - 1
} else {
self.vocab_size as usize - self.special_tokens.len()
};
for (token, score) in model.iter() {
if inserted.contains::<str>(token) {
continue;
}
inserted.insert(token.to_string());
pieces.push((token.to_string(), if score.is_nan() { 0.0 } else { *score }));
if pieces.len() == vocab_size_without_special_tokens {
break;
}
}
pieces.sort_by(|(_, a), (_, b)| b.partial_cmp(a).unwrap());
// Insert the necessary tokens
let mut special_tokens = self
.special_tokens
.iter()
.map(|t| (t.content.clone(), 0.0))
.collect::<Vec<_>>();
if need_add_unk {
special_tokens.insert(0, (self.unk_token.clone().unwrap(), 0.0));
}
Unigram::from(
special_tokens.into_iter().chain(pieces).collect(),
unk_id,
model.byte_fallback(),
)
}
fn required_chars(&self, word_counts: &[Sentence]) -> HashSet<String> {
word_counts
.iter()
.flat_map(|(s, _count)| s.chars())
.chain(self.initial_alphabet.iter().copied())
.map(|c| c.to_string())
.collect()
}
fn make_seed_sentence_pieces(
&self,
sentences: &[Sentence],
_progress: &Option<ProgressBar>,
) -> Vec<SentencePiece> {
// Put all sentences in a string, separated by \0
let total: usize = sentences
.iter()
.map(|(s, _)| s.chars().count())
.sum::<usize>()
+ sentences.len();
let mut flat_string = String::with_capacity(total);
let mut all_chars: HashMap<char, u32> = HashMap::new();
let c_sentence_boundary = '\0';
let k_sentence_boundary = '\0'.to_string();
for (string, n) in sentences {
if string.is_empty() {
continue;
}
flat_string.push_str(string);
// XXX
// Comment suggests we add sentence boundary, but it seems to be missing from actual
// code in spm.
flat_string.push_str(&k_sentence_boundary);
for c in string.chars() {
if c != c_sentence_boundary {
*all_chars.entry(c).or_insert(0) += n;
}
}
}
flat_string.shrink_to_fit();
#[cfg(feature = "esaxx_fast")]
let suffix = esaxx_rs::suffix(&flat_string).unwrap();
#[cfg(not(feature = "esaxx_fast"))]
let suffix = esaxx_rs::suffix_rs(&flat_string).unwrap();
// Basic chars need to be in sentence pieces.
let mut seed_sentencepieces: Vec<SentencePiece> = vec![];
let mut sall_chars: Vec<_> = all_chars.into_iter().map(|(a, b)| (b, a)).collect();
// Reversed order
sall_chars.sort_by_key(|&a| Reverse(a));
let mut substr_index: Vec<_> = suffix
.iter()
.filter_map(|(string, freq)| {
if string.len() <= 1 {
return None;
}
if string.contains(&c_sentence_boundary) {
return None;
}
if !self.is_valid_sentencepiece(string) {
return None;
}
let score = freq * string.len() as u32;
// if let Some(p) = &progress {
// p.inc(1);
// }
Some((score, string))
})
.collect();
// Fill seed_sentencepieces
for (count, character) in sall_chars {
seed_sentencepieces.push((character.to_string(), count.into()));
}
// sort by decreasing score
substr_index.sort_by_key(|&a| Reverse(a));
for (score, char_string) in substr_index {
// Just in case
assert!(self.is_valid_sentencepiece(char_string));
let string: String = char_string.iter().collect();
seed_sentencepieces.push((string, score.into()));
if seed_sentencepieces.len() >= self.seed_size {
break;
}
}
to_log_prob(&mut seed_sentencepieces);
seed_sentencepieces
}
fn prune_sentence_pieces(
&self,
model: &Unigram,
pieces: &[SentencePiece],
sentences: &[Sentence],
) -> Vec<SentencePiece> {
let mut always_keep = vec![true; pieces.len()];
let mut alternatives: Vec<Vec<usize>> = vec![Vec::new(); pieces.len()];
let bos_id = pieces.len() + 1;
let eos_id = pieces.len() + 2;
// First, segments the current sentencepieces to know
// how each sentencepiece is resegmented if this sentencepiece is removed
// from the vocabulary.
// To do so, we take the second best segmentation of sentencepiece[i].
// alternatives[i] stores the sequence of second best sentencepieces.
for (id, (token, _score)) in pieces.iter().enumerate() {
// Always keep unk.
if id == 0 {
always_keep[id] = false;
continue;
}
let mut lattice = Lattice::from(token, bos_id, eos_id);
model.populate_nodes(&mut lattice);
let nbests = lattice.nbest(2);
if nbests.len() == 1 {
always_keep[id] = true;
} else if nbests[0].len() >= 2 {
always_keep[id] = false;
} else if nbests[0].len() == 1 {
always_keep[id] = true;
for node in &nbests[1] {
let alt_id = node.borrow().id;
alternatives[id].push(alt_id);
}
}
}
// Second, segments all sentences to compute likelihood
// with a unigram language model. inverted[i] stores
// the set of sentence index where the sentencepieces[i] appears.
let chunk_size = std::cmp::max(sentences.len() / current_num_threads(), 1);
let indexed_sentences: Vec<(usize, &Sentence)> = sentences.iter().enumerate().collect();
let collected: (f64, Vec<f64>, Vec<Vec<usize>>) = indexed_sentences
.maybe_par_chunks(chunk_size)
.map(|enumerated_sentence_count_chunk| {
let mut vsum = 0.0;
let mut freq: Vec<f64> = vec![0.0; pieces.len()];
let mut inverted: Vec<Vec<usize>> = vec![Vec::new(); pieces.len()];
for (i, (sentence, count)) in enumerated_sentence_count_chunk {
let mut lattice = Lattice::from(sentence, bos_id, eos_id);
model.populate_nodes(&mut lattice);
vsum += *count as f64;
for node_ref in lattice.viterbi() {
let id = node_ref.borrow().id;
freq[id] += *count as f64;
inverted[id].push(*i);
}
}
(vsum, freq, inverted)
})
.reduce(
|| (0.0, vec![0.0; pieces.len()], vec![Vec::new(); pieces.len()]),
|(vsum, freq, inverted), (lvsum, lfreq, linverted)| {
(
vsum + lvsum,
freq.iter()
.zip(lfreq)
.map(|(global_el, local_el)| global_el + local_el)
.collect(),
inverted
.iter()
.zip(linverted)
.map(|(global_el, local_el)| [&global_el[..], &local_el[..]].concat())
.collect(),
)
},
);
let (vsum, freq, inverted) = collected;
let sum: f64 = freq.iter().sum();
let logsum = sum.ln();
let mut candidates: Vec<(usize, f64)> = vec![];
let mut new_pieces: Vec<SentencePiece> = Vec::with_capacity(self.vocab_size as usize);
new_pieces.push(pieces[0].clone());
// Finally, computes how likely the LM likelihood is reduced if
// the sentencepiece[i] is removed from the vocabulary.
// Since the exact computation of loss is difficult, we compute the
// loss approximately by assuming that all sentencepiece[i] in the sentences
// are replaced with alternatives[i] when sentencepiece[i] is removed.
for (id, (token, score)) in pieces.iter().enumerate() {
if id == 0 {
continue;
}
if freq[id] == 0.0 && !always_keep[id] {
// not found in Viterbi path. Can remove this entry safely.
continue;
} else if alternatives[id].is_empty() {
// no alternatives. Keeps this entry.
new_pieces.push((token.to_string(), *score));
} else {
let mut f = 0.0; // the frequency of pieces[i];
for n in &inverted[id] {
let score = sentences[*n].1 as f64;
f += score;
}
// TODO: Temporary hack to avoid Nans.
if f == 0.0 || f.is_nan() {
// new_pieces.push((token.to_string(), *score));
continue;
}
f /= vsum; // normalizes by all sentence frequency.
let logprob_sp = freq[id].ln() - logsum;
// After removing the sentencepiece[i], its frequency freq[i] is
// re-assigned to alternatives.
// new_sum = current_sum - freq[i] + freq[i] * alternatives.size()
// = current_sum + freq[i] (alternatives - 1)
let logsum_alt = (sum + freq[id] * (alternatives.len() - 1) as f64).ln();
// The frequencies of altenatives are increased by freq[i].
let mut logprob_alt = 0.0;
for n in &alternatives[id] {
logprob_alt += (freq[*n] + freq[id]).ln() - logsum_alt;
}
// loss: the diff of likelihood after removing the sentencepieces[i].
let loss = f * (logprob_sp - logprob_alt);
if loss.is_nan() {
panic!("");
}
candidates.push((id, loss));
}
}
let desired_vocab_size: usize = (self.vocab_size as usize * 11) / 10; // * 1.1
let pruned_size: usize = ((pieces.len() as f64) * self.shrinking_factor) as usize;
let pruned_size = desired_vocab_size.max(pruned_size);
candidates.sort_by(|(_, a), (_, b)| b.partial_cmp(a).unwrap());
for (id, _score) in candidates {
if new_pieces.len() == pruned_size {
break;
}
new_pieces.push(pieces[id].clone());
}
new_pieces.to_vec()
}
/// Update the progress bar with the new provided length and message
fn update_progress(&self, p: &Option<ProgressBar>, len: usize, message: &'static str) {
if let Some(p) = p {
p.set_message(message);
p.set_length(len as u64);
p.reset();
}
}
/// Set the progress bar in the finish state
fn finalize_progress(&self, p: &Option<ProgressBar>, final_len: usize) {
if let Some(p) = p {
p.set_length(final_len as u64);
p.finish();
println!();
}
}
fn run_e_step(&self, model: &Unigram, sentences: &[Sentence]) -> (f64, u32, Vec<f64>) {
let all_sentence_freq: u32 = sentences.iter().map(|(_a, b)| *b).sum();
let chunk_size = std::cmp::max(sentences.len() / current_num_threads(), 1);
let collected: (f64, u32, Vec<f64>) = sentences
.maybe_par_chunks(chunk_size)
.map(|sentences_chunk| {
let mut expected: Vec<f64> = vec![0.0; model.len()];
let mut objs: f64 = 0.0;
let mut ntokens: u32 = 0;
for (string, freq) in sentences_chunk {
let mut lattice = Lattice::from(string, model.bos_id, model.eos_id);
model.populate_nodes(&mut lattice);
let z: f64 = lattice.populate_marginal(*freq as f64, &mut expected);
if z.is_nan() {
panic!("likelihood is NAN. Input sentence may be too long.");
}
ntokens += lattice.viterbi().len() as u32;
objs -= z / (all_sentence_freq as f64);
}
(objs, ntokens, expected)
})
.reduce(
|| (0.0, 0, vec![0.0; model.len()]),
|(objs, ntokens, expected), (lobjs, lntokens, lexpected)| {
(
objs + lobjs,
ntokens + lntokens,
expected
.iter()
.zip(lexpected)
.map(|(global_el, local_el)| global_el + local_el)
.collect(),
)
},
);
collected
}
fn run_m_step(&self, pieces: &[SentencePiece], expected: &[f64]) -> Vec<SentencePiece> {
if pieces.len() != expected.len() {
panic!(
"Those two iterators are supposed to be the same length ({} vs {})",
pieces.len(),
expected.len()
);
}
let mut new_pieces: Vec<SentencePiece> =
Vec::with_capacity(self.vocab_size.try_into().unwrap());
let mut sum = 0.0;
let expected_frequency_threshold = 0.5;
for (i, (freq, (piece, _score))) in expected.iter().zip(pieces).enumerate() {
// Always keep unk.
if i == 0 {
new_pieces.push((piece.clone(), f64::NAN));
continue;
}
if *freq < expected_frequency_threshold {
continue;
}
new_pieces.push((piece.clone(), *freq));
sum += freq;
}
// // Here we do not use the original EM, but use the
// // Bayesianified/DPified EM algorithm.
// // https://cs.stanford.edu/~pliang/papers/tutorial-acl2007-talk.pdf
// // This modification will act as a sparse prior.
let logsum = digamma(sum);
let new_pieces: Vec<_> = new_pieces
.into_iter()
.map(|(s, c)| (s, digamma(c) - logsum))
.collect();
new_pieces
}
pub fn do_train(
&self,
sentences: Vec<Sentence>,
model: &mut Unigram,
) -> Result<Vec<AddedToken>> {
let progress = self.setup_progress();
//
// 1. Compute frequent substrings
// TODO Should be able to upgrade to u64 when needed
self.update_progress(&progress, sentences.len(), "Suffix array seeds");
let mut pieces: Vec<SentencePiece> =
Vec::with_capacity(self.vocab_size.try_into().unwrap());
// We use a UNK token when training, whatever the `self.unk_token`
pieces.push(("<UNK>".into(), f64::NAN));
pieces.extend(self.make_seed_sentence_pieces(&sentences, &progress));
self.finalize_progress(&progress, sentences.len());
// Useful to check compatibility with spm.
debug!(
"Using {} pieces on {} sentences for EM training",
pieces.len(),
sentences.len()
);
let desired_vocab_size: usize = (self.vocab_size as usize * 11) / 10; // * 1.1
// 2. Run E-M Loops to fine grain the pieces.
// We will shrink the vocab by shrinking_factor every loop on average
// Some other pieces are dropped if logprob is too small
// V = N * (f)**k
// k = log(V / N) / log(f)
let expected_loops = (((desired_vocab_size as f64).ln() - (pieces.len() as f64).ln())
/ self.shrinking_factor.ln()) as usize
+ 1;
let expected_updates = expected_loops * self.n_sub_iterations as usize;
self.update_progress(&progress, expected_updates, "EM training");
let required_chars = self.required_chars(&sentences);
if required_chars.len() as u32 > self.vocab_size {
return Err(Box::new(UnigramTrainerError::VocabularyTooSmall));
}
let mut new_model = Unigram::from(pieces.clone(), Some(0), false)?;
loop {
// Sub-EM iteration.
for _iter in 0..self.n_sub_iterations {
// Executes E step
let (_objective, _num_tokens, expected) = self.run_e_step(&new_model, &sentences);
// Executes M step.
pieces = self.run_m_step(&pieces, &expected);
new_model = Unigram::from(pieces.clone(), Some(0), false)?;
// Useful comment for checking compatibility with spm
debug!(
"Em iter={} size={} obj={} num_tokens={} num_tokens/piece={}",
_iter,
new_model.len(),
_objective,
_num_tokens,
_num_tokens as f64 / model.len() as f64
);
if let Some(p) = &progress {
p.inc(1);
}
} // end of Sub EM iteration
// Stops the iteration when the size of sentences reaches to the
// desired symbol size.
if pieces.len() <= desired_vocab_size {
break;
}
// Prunes pieces.
pieces = self.prune_sentence_pieces(&new_model, &pieces, &sentences);
new_model = Unigram::from(pieces.clone(), Some(0), false)?;
}
self.finalize_progress(&progress, expected_updates);
// Finally, adjusts the size of sentencepices to be |vocab_size|.
*model = self.finalize(new_model, required_chars)?;
Ok(self.special_tokens.clone())
}
}
impl Trainer for UnigramTrainer {
type Model = Unigram;
/// Train a Unigram model
fn train(&self, model: &mut Unigram) -> Result<Vec<AddedToken>> {
let sentences: Vec<_> = self.words.iter().map(|(s, i)| (s.to_owned(), *i)).collect();
self.do_train(sentences, model)
}
/// Whether we should show progress
fn should_show_progress(&self) -> bool {
self.show_progress
}
fn feed<I, S, F>(&mut self, iterator: I, process: F) -> Result<()>
where
I: Iterator<Item = S> + Send,
S: AsRef<str> + Send,
F: Fn(&str) -> Result<Vec<String>> + Sync,
{
let words: Result<HashMap<String, u32>> = iterator
.maybe_par_bridge()
.map(|sequence| {
let words = process(sequence.as_ref())?;
let mut map = HashMap::new();
for word in words {
map.entry(word).and_modify(|c| *c += 1).or_insert(1);
}
Ok(map)
})
.reduce(
|| Ok(HashMap::new()),
|acc, ws| {
let mut acc = acc?;
for (k, v) in ws? {
acc.entry(k).and_modify(|c| *c += v).or_insert(v);
}
Ok(acc)
},
);
self.words = words?;
Ok(())
}
}
#[cfg(test)]
mod tests {
use super::*;
use assert_approx_eq::assert_approx_eq;
use std::iter::FromIterator;
#[test]
fn test_unigram_chars() {
let trainer = UnigramTrainerBuilder::default()
.show_progress(false)
.build()
.unwrap();
let sentences = vec![
("This is a".to_string(), 1),
("こんにちは友達".to_string(), 1),
];
let required_chars = trainer.required_chars(&sentences);
assert_eq!(required_chars.len(), 13);
let progress = None;
let table = trainer.make_seed_sentence_pieces(&sentences, &progress);
let target_strings = vec![
"s", "i", " ", "達", "友", "ん", "は", "に", "ち", "こ", "h", "a", "T", "is ", "s ",
];
let strings: Vec<_> = table.iter().map(|(string, _)| string).collect();
assert_eq!(strings, target_strings);
let scores = table.iter().map(|(_, score)| score);
let target_scores = vec![
-2.5649493574615367, // 2.0
-2.5649493574615367, // 2.0
-2.5649493574615367, // 2.0
-3.258096538021482, // 1.0
-3.258096538021482, // 1.0
-3.258096538021482, // 1.0
-3.258096538021482, // 1.0
-3.258096538021482, // 1.0
-3.258096538021482, // 1.0
-3.258096538021482, // 1.0
-3.258096538021482, // 1.0
-3.258096538021482, // 1.0
-3.258096538021482, // 1.0
-1.4663370687934272, // 6.0
-1.8718021769015916, // 4.0
];
for (score, target_score) in scores.zip(target_scores) {
assert_approx_eq!(*score, target_score, 0.01);
}
}
#[test]
fn test_initial_alphabet() {
let trainer = UnigramTrainerBuilder::default()
.show_progress(false)
.initial_alphabet(HashSet::from_iter(vec!['a', 'b', 'c', 'd', 'e', 'f']))
.build()
.unwrap();
let sentences = vec![("こんにちは友達".to_string(), 1)];
let required_chars = trainer.required_chars(&sentences);
assert_eq!(
required_chars,
vec!["こ", "ん", "に", "ち", "は", "友", "達", "a", "b", "c", "d", "e", "f"]
.into_iter()
.map(|s| s.to_owned())
.collect::<HashSet<_>>()
);
}
#[test]
fn test_unk_token() {
// 1. Should add `unk_token` as first special token
let trainer = UnigramTrainerBuilder::default()
.show_progress(false)
.special_tokens(vec![
AddedToken::from("[SEP]", true),
AddedToken::from("[CLS]", true),
])
.unk_token(Some("[UNK]".into()))
.build()
.unwrap();
let mut unigram = Unigram::default();
trainer
.do_train(vec![("The".into(), 12), ("are".into(), 11)], &mut unigram)
.unwrap();
let mut pieces = unigram.iter();
assert_eq!(pieces.next(), Some(&("[UNK]".into(), 0.0)));
assert_eq!(pieces.next(), Some(&("[SEP]".into(), 0.0)));
assert_eq!(pieces.next(), Some(&("[CLS]".into(), 0.0)));
// 2. Let it where it is
let trainer = UnigramTrainerBuilder::default()
.show_progress(false)
.special_tokens(vec![
AddedToken::from("[SEP]", true),
AddedToken::from("[CLS]", true),
AddedToken::from("[UNK]", true),
])
.unk_token(Some("[UNK]".into()))
.build()
.unwrap();
let mut unigram = Unigram::default();
trainer
.do_train(vec![("The".into(), 12), ("are".into(), 11)], &mut unigram)
.unwrap();
let mut pieces = unigram.iter();
assert_eq!(pieces.next(), Some(&("[SEP]".into(), 0.0)));
assert_eq!(pieces.next(), Some(&("[CLS]".into(), 0.0)));
assert_eq!(pieces.next(), Some(&("[UNK]".into(), 0.0)));
// 3. Don't put it there if not needed
let trainer = UnigramTrainerBuilder::default()
.show_progress(false)
.build()
.unwrap();
let mut unigram = Unigram::default();
trainer
.do_train(vec![("The".into(), 12), ("are".into(), 11)], &mut unigram)
.unwrap();
let mut pieces = unigram.iter();
assert_eq!(pieces.next().unwrap().0, "e".to_string());
}
#[test]
fn test_special_tokens() {
let trainer = UnigramTrainerBuilder::default()
.show_progress(false)
.special_tokens(vec![
AddedToken::from("[SEP]", true),
AddedToken::from("[CLS]", true),
])
.build()
.unwrap();
let mut unigram = Unigram::default();
trainer
.do_train(vec![("The".into(), 12), ("are".into(), 11)], &mut unigram)
.unwrap();
let mut pieces = unigram.iter();
assert_eq!(pieces.next(), Some(&("[SEP]".into(), 0.0)));
assert_eq!(pieces.next(), Some(&("[CLS]".into(), 0.0)));
}
#[test]
fn test_to_log_prob() {
let mut a = vec![("".to_string(), 1.0), ("".to_string(), 2.0)];
to_log_prob(&mut a);
let scores = a.iter().map(|(_, score)| *score).collect::<Vec<_>>();
// ln(1) - ln(3)
assert_approx_eq!(scores[0], -1.098, 0.01);
// ln(2) - ln(3)
assert_approx_eq!(scores[1], -0.405, 0.01);
}
}
| tokenizers/tokenizers/src/models/unigram/trainer.rs/0 | {
"file_path": "tokenizers/tokenizers/src/models/unigram/trainer.rs",
"repo_id": "tokenizers",
"token_count": 15681
} | 220 |
use crate::tokenizer::{PreTokenizedString, PreTokenizer, Result, SplitDelimiterBehavior};
use crate::utils::macro_rules_attribute;
use unicode_categories::UnicodeCategories;
fn is_bert_punc(x: char) -> bool {
char::is_ascii_punctuation(&x) || x.is_punctuation()
}
#[derive(Copy, Clone, Debug, PartialEq, Eq)]
#[macro_rules_attribute(impl_serde_type!)]
pub struct BertPreTokenizer;
impl PreTokenizer for BertPreTokenizer {
fn pre_tokenize(&self, pretokenized: &mut PreTokenizedString) -> Result<()> {
pretokenized.split(|_, s| s.split(char::is_whitespace, SplitDelimiterBehavior::Removed))?;
pretokenized.split(|_, s| s.split(is_bert_punc, SplitDelimiterBehavior::Isolated))
}
}
#[cfg(test)]
mod tests {
use super::*;
use crate::{NormalizedString, OffsetReferential, OffsetType};
#[test]
fn basic() {
let pretok = BertPreTokenizer;
let mut pretokenized: PreTokenizedString = "Hey friend! How are you?!?".into();
pretok.pre_tokenize(&mut pretokenized).unwrap();
assert_eq!(
pretokenized
.get_splits(OffsetReferential::Original, OffsetType::Byte)
.into_iter()
.map(|(s, o, _)| (s, o))
.collect::<Vec<_>>(),
vec![
("Hey", (0, 3)),
("friend", (4, 10)),
("!", (10, 11)),
("How", (16, 19)),
("are", (20, 23)),
("you", (24, 27)),
("?", (27, 28)),
("!", (28, 29)),
("?", (29, 30)),
]
);
}
#[test]
fn chinese_chars() {
let mut n = NormalizedString::from("野口里佳 Noguchi Rika");
n.transform(
n.get().to_owned().chars().flat_map(|c| {
if (c as usize) > 0x4E00 {
vec![(' ', 0), (c, 1), (' ', 1)]
} else {
vec![(c, 0)]
}
}),
0,
);
let mut pretokenized = n.into();
let pretok = BertPreTokenizer;
pretok.pre_tokenize(&mut pretokenized).unwrap();
assert_eq!(
pretokenized
.get_splits(OffsetReferential::Original, OffsetType::Byte)
.into_iter()
.map(|(s, o, _)| (s, o))
.collect::<Vec<_>>(),
vec![
("野", (0, 3)),
("口", (3, 6)),
("里", (6, 9)),
("佳", (9, 12)),
("Noguchi", (13, 20)),
("Rika", (21, 25))
]
);
}
}
| tokenizers/tokenizers/src/pre_tokenizers/bert.rs/0 | {
"file_path": "tokenizers/tokenizers/src/pre_tokenizers/bert.rs",
"repo_id": "tokenizers",
"token_count": 1460
} | 221 |
use crate::processors::PostProcessorWrapper;
use crate::tokenizer::{Encoding, PostProcessor, Result};
use crate::utils::macro_rules_attribute;
use serde::{Deserialize, Serialize};
#[derive(Clone, Debug, PartialEq, Eq)]
#[macro_rules_attribute(impl_serde_type!)]
pub struct Sequence {
processors: Vec<PostProcessorWrapper>,
}
impl Sequence {
pub fn new(processors: Vec<PostProcessorWrapper>) -> Self {
Self { processors }
}
}
impl PostProcessor for Sequence {
fn added_tokens(&self, is_pair: bool) -> usize {
self.processors
.iter()
.map(|p| p.added_tokens(is_pair))
.sum::<usize>()
}
fn process_encodings(
&self,
mut encodings: Vec<Encoding>,
add_special_tokens: bool,
) -> Result<Vec<Encoding>> {
for processor in &self.processors {
encodings = processor.process_encodings(encodings, add_special_tokens)?;
}
Ok(encodings)
}
}
#[cfg(test)]
mod tests {
use super::*;
use crate::processors::{ByteLevel, PostProcessorWrapper};
use crate::tokenizer::{Encoding, PostProcessor};
use std::collections::HashMap;
use std::iter::FromIterator;
#[test]
fn process_chain() {
let start = Encoding::new(
vec![0; 5],
vec![0; 5],
vec![
"Ġ".into(),
"ĠĠĠĠHelloĠĠ".into(),
"ĠĠHello".into(),
"HelloĠĠ".into(),
"ĠĠĠĠ".into(),
],
vec![],
vec![(0, 1), (0, 11), (11, 18), (18, 25), (25, 29)],
vec![],
vec![],
vec![],
HashMap::new(),
);
let bytelevel = ByteLevel::default().trim_offsets(true);
let sequence = Sequence::new(vec![PostProcessorWrapper::ByteLevel(bytelevel)]);
let expected = Encoding::new(
vec![0; 5],
vec![0; 5],
vec![
"Ġ".into(),
"ĠĠĠĠHelloĠĠ".into(),
"ĠĠHello".into(),
"HelloĠĠ".into(),
"ĠĠĠĠ".into(),
],
vec![],
vec![(0, 0), (4, 9), (13, 18), (18, 23), (29, 29)],
vec![],
vec![],
vec![],
HashMap::from_iter(vec![(0, 0..5)]),
);
assert_eq!(
expected,
bytelevel.process(start.clone(), None, false).unwrap()
);
assert_eq!(
expected,
sequence.process(start.clone(), None, false).unwrap()
);
let pair_expected = Encoding::new(
vec![0; 10],
vec![0, 0, 0, 0, 0, 1, 1, 1, 1, 1],
vec![
"Ġ".into(),
"ĠĠĠĠHelloĠĠ".into(),
"ĠĠHello".into(),
"HelloĠĠ".into(),
"ĠĠĠĠ".into(),
"Ġ".into(),
"ĠĠĠĠHelloĠĠ".into(),
"ĠĠHello".into(),
"HelloĠĠ".into(),
"ĠĠĠĠ".into(),
],
vec![],
vec![
(0, 0),
(4, 9),
(13, 18),
(18, 23),
(29, 29),
(0, 0),
(4, 9),
(13, 18),
(18, 23),
(29, 29),
],
vec![],
vec![],
vec![],
HashMap::from_iter(vec![(0, 0..5), (1, 5..10)]),
);
assert_eq!(
pair_expected,
bytelevel
.process(start.clone(), Some(start.clone()), false)
.unwrap()
);
assert_eq!(
pair_expected,
sequence.process(start.clone(), Some(start), false).unwrap()
);
}
}
| tokenizers/tokenizers/src/processors/sequence.rs/0 | {
"file_path": "tokenizers/tokenizers/src/processors/sequence.rs",
"repo_id": "tokenizers",
"token_count": 2313
} | 222 |
//!
//! This module defines helpers to allow optional Rayon usage.
//!
use rayon::iter::IterBridge;
use rayon::prelude::*;
use rayon_cond::CondIterator;
// Re-export rayon current_num_threads
pub use rayon::current_num_threads;
pub const ENV_VARIABLE: &str = "TOKENIZERS_PARALLELISM";
// Reading/Writing this variable should always happen on the main thread
static mut USED_PARALLELISM: bool = false;
/// Check if the TOKENIZERS_PARALLELISM env variable has been explicitly set
pub fn is_parallelism_configured() -> bool {
std::env::var(ENV_VARIABLE).is_ok()
}
/// Check if at some point we used a parallel iterator
pub fn has_parallelism_been_used() -> bool {
unsafe { USED_PARALLELISM }
}
/// Get the currently set value for `TOKENIZERS_PARALLELISM` env variable
pub fn get_parallelism() -> bool {
match std::env::var(ENV_VARIABLE) {
Ok(mut v) => {
v.make_ascii_lowercase();
!matches!(v.as_ref(), "" | "off" | "false" | "f" | "no" | "n" | "0")
}
Err(_) => true, // If we couldn't get the variable, we use the default
}
}
/// Set the value for `TOKENIZERS_PARALLELISM` for the current process
pub fn set_parallelism(val: bool) {
std::env::set_var(ENV_VARIABLE, if val { "true" } else { "false" })
}
/// Allows to convert into an iterator that can be executed either parallelly or serially.
///
/// The choice is made according to the currently set `TOKENIZERS_PARALLELISM` environment variable.
/// This variable can have one of the following values
/// - False => "" (empty value), "false", "f", "off", "no", "n", "0"
/// - True => Any other value
///
pub trait MaybeParallelIterator<P, S>
where
P: ParallelIterator,
S: Iterator<Item = P::Item>,
{
/// Convert ourself in a CondIterator, that will be executed either in parallel or serially,
/// based solely on the `TOKENIZERS_PARALLELISM` environment variable
fn into_maybe_par_iter(self) -> CondIterator<P, S>;
/// Convert ourself in a CondIterator, that will be executed either in parallel or serially,
/// based on both the `TOKENIZERS_PARALLELISM` environment variable and the provided bool.
/// Both must be true to run with parallelism activated.
fn into_maybe_par_iter_cond(self, cond: bool) -> CondIterator<P, S>;
}
impl<P, S, I> MaybeParallelIterator<P, S> for I
where
I: IntoParallelIterator<Iter = P, Item = P::Item> + IntoIterator<IntoIter = S, Item = S::Item>,
P: ParallelIterator,
S: Iterator<Item = P::Item>,
{
fn into_maybe_par_iter(self) -> CondIterator<P, S> {
let parallelism = get_parallelism();
if parallelism {
unsafe { USED_PARALLELISM = true };
}
CondIterator::new(self, parallelism)
}
fn into_maybe_par_iter_cond(self, cond: bool) -> CondIterator<P, S> {
if cond {
self.into_maybe_par_iter()
} else {
CondIterator::from_serial(self)
}
}
}
/// Shared reference version of MaybeParallelIterator, works the same but returns an iterator
/// over references, does not consume self
pub trait MaybeParallelRefIterator<'data, P, S>
where
P: ParallelIterator,
S: Iterator<Item = P::Item>,
P::Item: 'data,
{
fn maybe_par_iter(&'data self) -> CondIterator<P, S>;
fn maybe_par_iter_cond(&'data self, cond: bool) -> CondIterator<P, S>;
}
impl<'data, P, S, I: 'data + ?Sized> MaybeParallelRefIterator<'data, P, S> for I
where
&'data I: MaybeParallelIterator<P, S>,
P: ParallelIterator,
S: Iterator<Item = P::Item>,
P::Item: 'data,
{
fn maybe_par_iter(&'data self) -> CondIterator<P, S> {
self.into_maybe_par_iter()
}
fn maybe_par_iter_cond(&'data self, cond: bool) -> CondIterator<P, S> {
self.into_maybe_par_iter_cond(cond)
}
}
/// Exclusive reference version of MaybeParallelIterator, works the same but returns an iterator
/// over mutable references, does not consume self
pub trait MaybeParallelRefMutIterator<'data, P, S>
where
P: ParallelIterator,
S: Iterator<Item = P::Item>,
P::Item: 'data,
{
fn maybe_par_iter_mut(&'data mut self) -> CondIterator<P, S>;
fn maybe_par_iter_mut_cond(&'data mut self, cond: bool) -> CondIterator<P, S>;
}
impl<'data, P, S, I: 'data + ?Sized> MaybeParallelRefMutIterator<'data, P, S> for I
where
&'data mut I: MaybeParallelIterator<P, S>,
P: ParallelIterator,
S: Iterator<Item = P::Item>,
P::Item: 'data,
{
fn maybe_par_iter_mut(&'data mut self) -> CondIterator<P, S> {
self.into_maybe_par_iter()
}
fn maybe_par_iter_mut_cond(&'data mut self, cond: bool) -> CondIterator<P, S> {
self.into_maybe_par_iter_cond(cond)
}
}
/// Converts any serial iterator into a CondIterator, that can either run parallelly or serially.
pub trait MaybeParallelBridge<T, S>
where
S: Iterator<Item = T> + Send,
T: Send,
{
fn maybe_par_bridge(self) -> CondIterator<IterBridge<S>, S>;
fn maybe_par_bridge_cond(self, cond: bool) -> CondIterator<IterBridge<S>, S>;
}
impl<T, S> MaybeParallelBridge<T, S> for S
where
S: Iterator<Item = T> + Send,
T: Send,
{
fn maybe_par_bridge(self) -> CondIterator<IterBridge<S>, S> {
let iter = CondIterator::from_serial(self);
if get_parallelism() {
unsafe { USED_PARALLELISM = true };
CondIterator::from_parallel(iter.into_parallel().right().unwrap())
} else {
iter
}
}
fn maybe_par_bridge_cond(self, cond: bool) -> CondIterator<IterBridge<S>, S> {
if cond {
self.maybe_par_bridge()
} else {
CondIterator::from_serial(self)
}
}
}
/// Allows to convert into `chunks` that can be executed either parallelly or serially.
pub trait MaybeParallelSlice<'data, T>
where
T: Sync,
{
/// Create a CondIterator, that will be executed either in parallel or serially,
/// based solely on the `TOKENIZERS_PARALLELISM` environment variable
fn maybe_par_chunks(
&'_ self,
chunk_size: usize,
) -> CondIterator<rayon::slice::Chunks<'_, T>, std::slice::Chunks<'_, T>>;
/// Create a CondIterator, that will be executed either in parallel or serially,
/// based on both the `TOKENIZERS_PARALLELISM` environment variable and the provided bool.
/// Both must be true to run with parallelism activated.
fn maybe_par_chunks_cond(
&'_ self,
cond: bool,
chunk_size: usize,
) -> CondIterator<rayon::slice::Chunks<'_, T>, std::slice::Chunks<'_, T>>;
}
impl<T> MaybeParallelSlice<'_, T> for [T]
where
T: Sync,
{
fn maybe_par_chunks(
&'_ self,
chunk_size: usize,
) -> CondIterator<rayon::slice::Chunks<'_, T>, std::slice::Chunks<'_, T>> {
let parallelism = get_parallelism();
if parallelism {
CondIterator::from_parallel(self.par_chunks(chunk_size))
} else {
CondIterator::from_serial(self.chunks(chunk_size))
}
}
fn maybe_par_chunks_cond(
&'_ self,
cond: bool,
chunk_size: usize,
) -> CondIterator<rayon::slice::Chunks<'_, T>, std::slice::Chunks<'_, T>> {
if cond {
self.maybe_par_chunks(chunk_size)
} else {
CondIterator::from_serial(self.chunks(chunk_size))
}
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn test_maybe_parallel_iterator() {
let mut v = vec![1u32, 2, 3, 4, 5, 6];
assert_eq!(v.maybe_par_iter().sum::<u32>(), 21);
assert_eq!(
v.maybe_par_iter_mut()
.map(|v| {
*v *= 2;
*v
})
.sum::<u32>(),
42
);
assert_eq!(v.maybe_par_iter().sum::<u32>(), 42);
assert_eq!(v.into_maybe_par_iter().sum::<u32>(), 42);
}
#[test]
fn test_maybe_parallel_slice() {
let v = [1, 2, 3, 4, 5];
let chunks: Vec<_> = v.maybe_par_chunks(2).collect();
assert_eq!(chunks, vec![&[1, 2][..], &[3, 4], &[5]]);
}
}
| tokenizers/tokenizers/src/utils/parallelism.rs/0 | {
"file_path": "tokenizers/tokenizers/src/utils/parallelism.rs",
"repo_id": "tokenizers",
"token_count": 3431
} | 223 |
cff-version: "1.2.0"
date-released: 2020-10
message: "If you use this software, please cite it using these metadata."
title: "Transformers: State-of-the-Art Natural Language Processing"
url: "https://github.com/huggingface/transformers"
authors:
- family-names: Wolf
given-names: Thomas
- family-names: Debut
given-names: Lysandre
- family-names: Sanh
given-names: Victor
- family-names: Chaumond
given-names: Julien
- family-names: Delangue
given-names: Clement
- family-names: Moi
given-names: Anthony
- family-names: Cistac
given-names: Perric
- family-names: Ma
given-names: Clara
- family-names: Jernite
given-names: Yacine
- family-names: Plu
given-names: Julien
- family-names: Xu
given-names: Canwen
- family-names: "Le Scao"
given-names: Teven
- family-names: Gugger
given-names: Sylvain
- family-names: Drame
given-names: Mariama
- family-names: Lhoest
given-names: Quentin
- family-names: Rush
given-names: "Alexander M."
preferred-citation:
type: conference-paper
authors:
- family-names: Wolf
given-names: Thomas
- family-names: Debut
given-names: Lysandre
- family-names: Sanh
given-names: Victor
- family-names: Chaumond
given-names: Julien
- family-names: Delangue
given-names: Clement
- family-names: Moi
given-names: Anthony
- family-names: Cistac
given-names: Perric
- family-names: Ma
given-names: Clara
- family-names: Jernite
given-names: Yacine
- family-names: Plu
given-names: Julien
- family-names: Xu
given-names: Canwen
- family-names: "Le Scao"
given-names: Teven
- family-names: Gugger
given-names: Sylvain
- family-names: Drame
given-names: Mariama
- family-names: Lhoest
given-names: Quentin
- family-names: Rush
given-names: "Alexander M."
booktitle: "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations"
month: 10
start: 38
end: 45
title: "Transformers: State-of-the-Art Natural Language Processing"
year: 2020
publisher: "Association for Computational Linguistics"
url: "https://www.aclweb.org/anthology/2020.emnlp-demos.6"
address: "Online"
| transformers/CITATION.cff/0 | {
"file_path": "transformers/CITATION.cff",
"repo_id": "transformers",
"token_count": 824
} | 224 |
local base = import 'templates/base.libsonnet';
local tpus = import 'templates/tpus.libsonnet';
local utils = import "templates/utils.libsonnet";
local volumes = import "templates/volumes.libsonnet";
local bertBaseCased = base.BaseTest {
frameworkPrefix: "hf",
modelName: "bert-base-cased",
mode: "example",
configMaps: [],
timeout: 3600, # 1 hour, in seconds
image: std.extVar('image'),
imageTag: std.extVar('image-tag'),
tpuSettings+: {
softwareVersion: "pytorch-nightly",
},
accelerator: tpus.v3_8,
volumeMap+: {
datasets: volumes.PersistentVolumeSpec {
name: "huggingface-cluster-disk",
mountPath: "/datasets",
},
},
command: utils.scriptCommand(
|||
python -m pytest -s transformers/examples/pytorch/test_xla_examples.py -v
test_exit_code=$?
echo "\nFinished running commands.\n"
test $test_exit_code -eq 0
|||
),
};
bertBaseCased.oneshotJob
| transformers/docker/transformers-pytorch-tpu/bert-base-cased.jsonnet/0 | {
"file_path": "transformers/docker/transformers-pytorch-tpu/bert-base-cased.jsonnet",
"repo_id": "transformers",
"token_count": 371
} | 225 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Distributed training with 🤗 Accelerate
As models get bigger, parallelism has emerged as a strategy for training larger models on limited hardware and accelerating training speed by several orders of magnitude. At Hugging Face, we created the [🤗 Accelerate](https://huggingface.co/docs/accelerate) library to help users easily train a 🤗 Transformers model on any type of distributed setup, whether it is multiple GPU's on one machine or multiple GPU's across several machines. In this tutorial, learn how to customize your native PyTorch training loop to enable training in a distributed environment.
## Setup
Get started by installing 🤗 Accelerate:
```bash
pip install accelerate
```
Then import and create an [`~accelerate.Accelerator`] object. The [`~accelerate.Accelerator`] will automatically detect your type of distributed setup and initialize all the necessary components for training. You don't need to explicitly place your model on a device.
```py
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
```
## Prepare to accelerate
The next step is to pass all the relevant training objects to the [`~accelerate.Accelerator.prepare`] method. This includes your training and evaluation DataLoaders, a model and an optimizer:
```py
>>> train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
... train_dataloader, eval_dataloader, model, optimizer
... )
```
## Backward
The last addition is to replace the typical `loss.backward()` in your training loop with 🤗 Accelerate's [`~accelerate.Accelerator.backward`]method:
```py
>>> for epoch in range(num_epochs):
... for batch in train_dataloader:
... outputs = model(**batch)
... loss = outputs.loss
... accelerator.backward(loss)
... optimizer.step()
... lr_scheduler.step()
... optimizer.zero_grad()
... progress_bar.update(1)
```
As you can see in the following code, you only need to add four additional lines of code to your training loop to enable distributed training!
```diff
+ from accelerate import Accelerator
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
+ accelerator = Accelerator()
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
optimizer = AdamW(model.parameters(), lr=3e-5)
- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
- model.to(device)
+ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
+ train_dataloader, eval_dataloader, model, optimizer
+ )
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps
)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
- batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
- loss.backward()
+ accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
```
## Train
Once you've added the relevant lines of code, launch your training in a script or a notebook like Colaboratory.
### Train with a script
If you are running your training from a script, run the following command to create and save a configuration file:
```bash
accelerate config
```
Then launch your training with:
```bash
accelerate launch train.py
```
### Train with a notebook
🤗 Accelerate can also run in a notebook if you're planning on using Colaboratory's TPUs. Wrap all the code responsible for training in a function, and pass it to [`~accelerate.notebook_launcher`]:
```py
>>> from accelerate import notebook_launcher
>>> notebook_launcher(training_function)
```
For more information about 🤗 Accelerate and its rich features, refer to the [documentation](https://huggingface.co/docs/accelerate).
| transformers/docs/source/en/accelerate.md/0 | {
"file_path": "transformers/docs/source/en/accelerate.md",
"repo_id": "transformers",
"token_count": 1516
} | 226 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# DeepSpeed
[DeepSpeed](https://www.deepspeed.ai/) is a PyTorch optimization library that makes distributed training memory-efficient and fast. At it's core is the [Zero Redundancy Optimizer (ZeRO)](https://hf.co/papers/1910.02054) which enables training large models at scale. ZeRO works in several stages:
* ZeRO-1, optimizer state partioning across GPUs
* ZeRO-2, gradient partitioning across GPUs
* ZeRO-3, parameteter partitioning across GPUs
In GPU-limited environments, ZeRO also enables offloading optimizer memory and computation from the GPU to the CPU to fit and train really large models on a single GPU. DeepSpeed is integrated with the Transformers [`Trainer`] class for all ZeRO stages and offloading. All you need to do is provide a config file or you can use a provided template. For inference, Transformers support ZeRO-3 and offloading since it allows loading huge models.
This guide will walk you through how to deploy DeepSpeed training, the features you can enable, how to setup the config files for different ZeRO stages, offloading, inference, and using DeepSpeed without the [`Trainer`].
## Installation
DeepSpeed is available to install from PyPI or Transformers (for more detailed installation options, take a look at the DeepSpeed [installation details](https://www.deepspeed.ai/tutorials/advanced-install/) or the GitHub [README](https://github.com/microsoft/deepspeed#installation)).
<Tip>
If you're having difficulties installing DeepSpeed, check the [DeepSpeed CUDA installation](../debugging#deepspeed-cuda-installation) guide. While DeepSpeed has a pip installable PyPI package, it is highly recommended to [install it from source](https://www.deepspeed.ai/tutorials/advanced-install/#install-deepspeed-from-source) to best match your hardware and to support certain features, like 1-bit Adam, which aren’t available in the PyPI distribution.
</Tip>
<hfoptions id="install">
<hfoption id="PyPI">
```bash
pip install deepspeed
```
</hfoption>
<hfoption id="Transformers">
```bash
pip install transformers[deepspeed]
```
</hfoption>
</hfoptions>
## Memory requirements
Before you begin, it is a good idea to check whether you have enough GPU and CPU memory to fit your model. DeepSpeed provides a tool for estimating the required CPU/GPU memory. For example, to estimate the memory requirements for the [bigscience/T0_3B](bigscience/T0_3B) model on a single GPU:
```bash
$ python -c 'from transformers import AutoModel; \
from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live; \
model = AutoModel.from_pretrained("bigscience/T0_3B"); \
estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=1, num_nodes=1)'
[...]
Estimated memory needed for params, optim states and gradients for a:
HW: Setup with 1 node, 1 GPU per node.
SW: Model with 2783M total params, 65M largest layer params.
per CPU | per GPU | Options
70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=1
70.00GB | 0.25GB | offload_param=cpu , offload_optimizer=cpu , zero_init=0
62.23GB | 5.43GB | offload_param=none, offload_optimizer=cpu , zero_init=1
62.23GB | 5.43GB | offload_param=none, offload_optimizer=cpu , zero_init=0
0.37GB | 46.91GB | offload_param=none, offload_optimizer=none, zero_init=1
15.56GB | 46.91GB | offload_param=none, offload_optimizer=none, zero_init=0
```
This means you either need a single 80GB GPU without CPU offload or a 8GB GPU and a ~60GB CPU to offload to (these are just the memory requirements for the parameters, optimizer states and gradients, and you'll need a bit more for the CUDA kernels and activations). You should also consider the tradeoff between cost and speed because it'll be cheaper to rent or buy a smaller GPU but it'll take longer to train your model.
If you have enough GPU memory make sure you disable CPU/NVMe offload to make everything faster.
## Select a ZeRO stage
After you've installed DeepSpeed and have a better idea of your memory requirements, the next step is selecting a ZeRO stage to use. In order of fastest and most memory-efficient:
| Fastest | Memory efficient |
|------------------|------------------|
| ZeRO-1 | ZeRO-3 + offload |
| ZeRO-2 | ZeRO-3 |
| ZeRO-2 + offload | ZeRO-2 + offload |
| ZeRO-3 | ZeRO-2 |
| ZeRO-3 + offload | ZeRO-1 |
To find what works best for you, start with the fastest approach and if you run out of memory, try the next stage which is slower but more memory efficient. Feel free to work in whichever direction you prefer (starting with the most memory efficient or fastest) to discover the appropriate balance between speed and memory usage.
A general process you can use is (start with batch size of 1):
1. enable gradient checkpointing
2. try ZeRO-2
3. try ZeRO-2 and offload the optimizer
4. try ZeRO-3
5. try ZeRO-3 and offload parameters to the CPU
6. try ZeRO-3 and offload parameters and the optimizer to the CPU
7. try lowering various default values like a narrower search beam if you're using the [`~GenerationMixin.generate`] method
8. try mixed half-precision (fp16 on older GPU architectures and bf16 on Ampere) over full-precision weights
9. add more hardware if possible or enable Infinity to offload parameters and the optimizer to a NVMe
10. once you're not running out of memory, measure effective throughput and then try to increase the batch size as large as you can to maximize GPU efficiency
11. lastly, try to optimize your training setup by disabling some offload features or use a faster ZeRO stage and increasing/decreasing the batch size to find the best tradeoff between speed and memory usage
## DeepSpeed configuration file
DeepSpeed works with the [`Trainer`] class by way of a config file containing all the parameters for configuring how you want setup your training run. When you execute your training script, DeepSpeed logs the configuration it received from [`Trainer`] to the console so you can see exactly what configuration was used.
<Tip>
Find a complete list of DeepSpeed configuration options on the [DeepSpeed Configuration JSON](https://www.deepspeed.ai/docs/config-json/) reference. You can also find more practical examples of various DeepSpeed configuration examples on the [DeepSpeedExamples](https://github.com/microsoft/DeepSpeedExamples) repository or the main [DeepSpeed](https://github.com/microsoft/DeepSpeed) repository. To quickly find specific examples, you can:
```bash
git clone https://github.com/microsoft/DeepSpeedExamples
cd DeepSpeedExamples
find . -name '*json'
# find examples with the Lamb optimizer
grep -i Lamb $(find . -name '*json')
```
</Tip>
The DeepSpeed configuration file is passed as a path to a JSON file if you're training from the command line interface or as a nested `dict` object if you're using the [`Trainer`] in a notebook setting.
<hfoptions id="pass-config">
<hfoption id="path to file">
```py
TrainingArguments(..., deepspeed="path/to/deepspeed_config.json")
```
</hfoption>
<hfoption id="nested dict">
```py
ds_config_dict = dict(scheduler=scheduler_params, optimizer=optimizer_params)
args = TrainingArguments(..., deepspeed=ds_config_dict)
trainer = Trainer(model, args, ...)
```
</hfoption>
</hfoptions>
### DeepSpeed and Trainer parameters
There are three types of configuration parameters:
1. Some of the configuration parameters are shared by [`Trainer`] and DeepSpeed, and it can be difficult to identify errors when there are conflicting definitions. To make it easier, these shared configuration parameters are configured from the [`Trainer`] command line arguments.
2. Some configuration parameters that are automatically derived from the model configuration so you don't need to manually adjust these values. The [`Trainer`] uses a configuration value `auto` to determine set the most correct or efficient value. You could set your own configuration parameters explicitly, but you must take care to ensure the [`Trainer`] arguments and DeepSpeed configuration parameters agree. Mismatches may cause the training to fail in very difficult to detect ways!
3. Some configuration parameters specific to DeepSpeed only which need to be manually set based on your training needs.
You could also modify the DeepSpeed configuration and edit [`TrainingArguments`] from it:
1. Create or load a DeepSpeed configuration to used as the main configuration
2. Create a [`TrainingArguments`] object based on these DeepSpeed configuration values
Some values, such as `scheduler.params.total_num_steps` are calculated by the [`Trainer`] during training.
### ZeRO configuration
There are three configurations, each corresponding to a different ZeRO stage. Stage 1 is not as interesting for scalability, and this guide focuses on stages 2 and 3. The `zero_optimization` configuration contains all the options for what to enable and how to configure them. For a more detailed explanation of each parameter, take a look at the [DeepSpeed Configuration JSON](https://www.deepspeed.ai/docs/config-json/) reference.
<Tip warning={true}>
DeepSpeed doesn’t validate parameter names and any typos fallback on the parameter's default setting. You can watch the DeepSpeed engine startup log messages to see what values it is going to use.
</Tip>
The following configurations must be setup with DeepSpeed because the [`Trainer`] doesn't provide equivalent command line arguments.
<hfoptions id="zero-config">
<hfoption id="ZeRO-1">
ZeRO-1 shards the optimizer states across GPUs, and you can expect a tiny speed up. The ZeRO-1 config can be setup like this:
```yml
{
"zero_optimization": {
"stage": 1
}
}
```
</hfoption>
<hfoption id="ZeRO-2">
ZeRO-2 shards the optimizer and gradients across GPUs. This stage is primarily used for training since it's features are not relevant to inference. Some important parameters to configure for better performance include:
* `offload_optimizer` should be enabled to reduce GPU memory usage.
* `overlap_comm` when set to `true` trades off increased GPU memory usage to lower allreduce latency. This feature uses 4.5x the `allgather_bucket_size` and `reduce_bucket_size` values. In this example, they're set to `5e8` which means it requires 9GB of GPU memory. If your GPU memory is 8GB or less, you should reduce `overlap_comm` to lower the memory requirements and prevent an out-of-memory (OOM) error.
* `allgather_bucket_size` and `reduce_bucket_size` trade off available GPU memory for communication speed. The smaller their values, the slower communication is and the more GPU memory is available. You can balance, for example, whether a bigger batch size is more important than a slightly slower training time.
* `round_robin_gradients` is available in DeepSpeed 0.4.4 for CPU offloading. It parallelizes gradient copying to CPU memory among ranks by fine-grained gradient partitioning. Performance benefit grows with gradient accumulation steps (more copying between optimizer steps) or GPU count (increased parallelism).
```yml
{
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"allgather_partitions": true,
"allgather_bucket_size": 5e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 5e8,
"contiguous_gradients": true
"round_robin_gradients": true
}
}
```
</hfoption>
<hfoption id="ZeRO-3">
ZeRO-3 shards the optimizer, gradient, and parameters across GPUs. Unlike ZeRO-2, ZeRO-3 can also be used for inference, in addition to training, because it allows large models to be loaded on multiple GPUs. Some important parameters to configure include:
* `device: "cpu"` can help if you're running out of GPU memory and if you have free CPU memory available. This allows offloading model parameters to the CPU.
* `pin_memory: true` can improve throughput, but less memory becomes available for other processes because the pinned memory is reserved for the specific process that requested it and it's typically accessed much faster than normal CPU memory.
* `stage3_max_live_parameters` is the upper limit on how many full parameters you want to keep on the GPU at any given time. Reduce this value if you encounter an OOM error.
* `stage3_max_reuse_distance` is a value for determining when a parameter is used again in the future, and it helps decide whether to throw the parameter away or to keep it. If the parameter is going to be reused (if the value is less than `stage3_max_reuse_distance`), then it is kept to reduce communication overhead. This is super helpful when activation checkpointing is enabled and you want to keep the parameter in the forward recompute until the backward pass. But reduce this value if you encounter an OOM error.
* `stage3_gather_16bit_weights_on_model_save` consolidates fp16 weights when a model is saved. For large models and multiple GPUs, this is an expensive in terms of memory and speed. You should enable it if you're planning on resuming training.
* `sub_group_size` controls which parameters are updated during the optimizer step. Parameters are grouped into buckets of `sub_group_size` and each bucket is updated one at a time. When used with NVMe offload, `sub_group_size` determines when model states are moved in and out of CPU memory from during the optimization step. This prevents running out of CPU memory for extremely large models. `sub_group_size` can be left to its default value if you aren't using NVMe offload, but you may want to change it if you:
1. Run into an OOM error during the optimizer step. In this case, reduce `sub_group_size` to reduce memory usage of the temporary buffers.
2. The optimizer step is taking a really long time. In this case, increase `sub_group_size` to improve bandwidth utilization as a result of increased data buffers.
* `reduce_bucket_size`, `stage3_prefetch_bucket_size`, and `stage3_param_persistence_threshold` are dependent on a model's hidden size. It is recommended to set these values to `auto` and allow the [`Trainer`] to automatically assign the values.
```yml
{
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
}
}
```
You can use the [`deepspeed.zero.Init`](https://deepspeed.readthedocs.io/en/latest/zero3.html#deepspeed.zero.Init) context manager to initialize a model faster:
```py
from transformers import T5ForConditionalGeneration, T5Config
import deepspeed
with deepspeed.zero.Init():
config = T5Config.from_pretrained("google-t5/t5-small")
model = T5ForConditionalGeneration(config)
```
For pretrained models, the DeepSped config file needs to have `is_deepspeed_zero3_enabled: true` setup in [`TrainingArguments`] and it needs a ZeRO configuration enabled. The [`TrainingArguments`] object must be created **before** calling the model [`~PreTrainedModel.from_pretrained`].
```py
from transformers import AutoModel, Trainer, TrainingArguments
training_args = TrainingArguments(..., deepspeed=ds_config)
model = AutoModel.from_pretrained("google-t5/t5-small")
trainer = Trainer(model=model, args=training_args, ...)
```
You'll need ZeRO-3 if the fp16 weights don't fit on a single GPU. If you're able to load fp16 weights, then make sure you specify `torch_dtype=torch.float16` in [`~PreTrainedModel.from_pretrained`].
Another consideration for ZeRO-3 is if you have multiple GPUs, no single GPU has all the parameters unless it's the parameters for the currently executing layer. To access all parameters from all the layers at once, such as loading pretrained model weights in [`~PreTrainedModel.from_pretrained`], one layer is loaded at a time and immediately partitioned to all GPUs. This is because for very large models, it isn't possible to load the weights on one GPU and then distribute them across the other GPUs due to memory limitations.
If you encounter a model parameter weight that looks like the following, where `tensor([1.])` or the parameter size is 1 instead of a larger multi-dimensional shape, this means the parameter is partitioned and this is a ZeRO-3 placeholder.
```py
tensor([1.0], device="cuda:0", dtype=torch.float16, requires_grad=True)
```
<Tip>
For more information about initializing large models with ZeRO-3 and accessing the parameters, take a look at the [Constructing Massive Models](https://deepspeed.readthedocs.io/en/latest/zero3.html#constructing-massive-models) and [Gathering Parameters](https://deepspeed.readthedocs.io/en/latest/zero3.html#gathering-parameters) guides.
</Tip>
</hfoption>
</hfoptions>
### NVMe configuration
[ZeRO-Infinity](https://hf.co/papers/2104.07857) allows offloading model states to the CPU and/or NVMe to save even more memory. Smart partitioning and tiling algorithms allow each GPU to send and receive very small amounts of data during offloading such that a modern NVMe can fit an even larger total memory pool than is available to your training process. ZeRO-Infinity requires ZeRO-3.
Depending on the CPU and/or NVMe memory available, you can offload both the [optimizer states](https://www.deepspeed.ai/docs/config-json/#optimizer-offloading) and [parameters](https://www.deepspeed.ai/docs/config-json/#parameter-offloading), just one of them, or none. You should also make sure the `nvme_path` is pointing to an NVMe device, because while it still works with a normal hard drive or solid state drive, it'll be significantly slower. With a modern NVMe, you can expect peak transfer speeds of ~3.5GB/s for read and ~3GB/s for write operations. Lastly, [run a benchmark](https://github.com/microsoft/DeepSpeed/issues/998) on your training setup to determine the optimal `aio` configuration.
The example ZeRO-3/Infinity configuration file below sets most of the parameter values to `auto`, but you could also manually add these values.
```yml
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "nvme",
"nvme_path": "/local_nvme",
"pin_memory": true,
"buffer_count": 4,
"fast_init": false
},
"offload_param": {
"device": "nvme",
"nvme_path": "/local_nvme",
"pin_memory": true,
"buffer_count": 5,
"buffer_size": 1e8,
"max_in_cpu": 1e9
},
"aio": {
"block_size": 262144,
"queue_depth": 32,
"thread_count": 1,
"single_submit": false,
"overlap_events": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
```
## DeepSpeed features
There are a number of important parameters to specify in the DeepSpeed configuration file which are briefly described in this section.
### Activation/gradient checkpointing
Activation and gradient checkpointing trades speed for more GPU memory which allows you to overcome scenarios where your GPU is out of memory or to increase your batch size for better performance. To enable this feature:
1. For a Hugging Face model, set `model.gradient_checkpointing_enable()` or `--gradient_checkpointing` in the [`Trainer`].
2. For a non-Hugging Face model, use the DeepSpeed [Activation Checkpointing API](https://deepspeed.readthedocs.io/en/latest/activation-checkpointing.html). You could also replace the Transformers modeling code and replace `torch.utils.checkpoint` with the DeepSpeed API. This approach is more flexible because you can offload the forward activations to the CPU memory instead of recalculating them.
### Optimizer and scheduler
DeepSpeed and Transformers optimizer and scheduler can be mixed and matched as long as you don't enable `offload_optimizer`. When `offload_optimizer` is enabled, you could use a non-DeepSpeed optimizer (except for LAMB) as long as it has both a CPU and GPU implementation.
<Tip warning={true}>
The optimizer and scheduler parameters for the config file can be set from the command line to avoid hard to find errors. For example, if the learning rate is set to a different value in another place you can override it from the command line. Aside from the optimizer and scheduler parameters, you'll need to ensure your [`Trainer`] command line arguments match the DeepSpeed configuration.
</Tip>
<hfoptions id="opt-sched">
<hfoption id="optimizer">
DeepSpeed offers several [optimizers](https://www.deepspeed.ai/docs/config-json/#optimizer-parameters) (Adam, AdamW, OneBitAdam, and LAMB) but you can also import other optimizers from PyTorch. If you don't configure the optimizer in the config, the [`Trainer`] automatically selects AdamW and either uses the supplied values or the default values for the following parameters from the command line: `lr`, `adam_beta1`, `adam_beta2`, `adam_epsilon`, `weight_decay`.
You can set the parameters to `"auto"` or manually input your own desired values.
```yaml
{
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
}
}
```
You can also use an unsupported optimizer by adding the following to the top level configuration.
```yaml
{
"zero_allow_untested_optimizer": true
}
```
From DeepSpeed==0.8.3 on, if you want to use offload, you'll also need to the following to the top level configuration because offload works best with DeepSpeed's CPU Adam optimizer.
```yaml
{
"zero_force_ds_cpu_optimizer": false
}
```
</hfoption>
<hfoption id="scheduler">
DeepSpeed supports the LRRangeTest, OneCycle, WarmupLR and WarmupDecayLR learning rate [schedulers](https://www.deepspeed.ai/docs/config-json/#scheduler-parameters).
Transformers and DeepSpeed provide two of the same schedulers:
* WarmupLR is the same as `--lr_scheduler_type constant_with_warmup` in Transformers
* WarmupDecayLR is the same as `--lr_scheduler_type linear` in Transformers (this is the default scheduler used in Transformers)
If you don't configure the scheduler in the config, the [`Trainer`] automatically selects WarmupDecayLR and either uses the supplied values or the default values for the following parameters from the command line: `warmup_min_lr`, `warmup_max_lr`, `warmup_num_steps`, `total_num_steps` (automatically calculated during run time if `max_steps` is not provided).
You can set the parameters to `"auto"` or manually input your own desired values.
```yaml
{
"scheduler": {
"type": "WarmupDecayLR",
"params": {
"total_num_steps": "auto",
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
}
}
```
</hfoption>
</hfoptions>
### Precision
Deepspeed supports fp32, fp16, and bf16 mixed precision.
<hfoptions id="precision">
<hfoption id="fp32">
If your model doesn't work well with mixed precision, for example if it wasn't pretrained in mixed precision, you may encounter overflow or underflow issues which can cause NaN loss. For these cases, you should use full fp32 precision by explicitly disabling the default fp16 mode.
```yaml
{
"fp16": {
"enabled": false
}
}
```
For Ampere GPUs and PyTorch > 1.7, it automatically switches to the more efficient [tf32](https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices) format for some operations but the results are still in fp32. You can control it from the [`Trainer`] by setting `--tf32` to enable it, and `--tf32 0` or `--no_tf32` to disable it.
</hfoption>
<hfoption id="fp16">
To configure PyTorch AMP-like fp16 mixed precision reduces memory usage and accelerates training speed. [`Trainer`] automatically enables or disables fp16 based on the value of `args.fp16_backend`, and the rest of the config can be set by you. fp16 is enabled from the command line when the following arguments are passed: `--fp16`, `--fp16_backend amp` or `--fp16_full_eval`.
```yaml
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
}
}
```
For additional DeepSpeed fp16 training options, take a look at the [FP16 Training Options](https://www.deepspeed.ai/docs/config-json/#fp16-training-options) reference.
To configure Apex-like fp16 mixed precision, setup the config as shown below with `"auto"` or your own values. [`Trainer`] automatically configure `amp` based on the values of `args.fp16_backend` and `args.fp16_opt_level`. It can also be enabled from the command line when the following arguments are passed: `--fp16`, `--fp16_backend apex` or `--fp16_opt_level 01`.
```yaml
{
"amp": {
"enabled": "auto",
"opt_level": "auto"
}
}
```
</hfoption>
<hfoption id="bf16">
To use bf16, you'll need at least DeepSpeed==0.6.0. bf16 has the same dynamic range as fp32 and doesn’t require loss scaling. However, if you use [gradient accumulation](#gradient-accumulation) with bf16, gradients are accumulated in bf16 which may not be desired because this format's low precision can lead to lossy accumulation.
bf16 can be setup in the config file or enabled from the command line when the following arguments are passed: `--bf16` or `--bf16_full_eval`.
```yaml
{
"bf16": {
"enabled": "auto"
}
}
```
</hfoption>
</hfoptions>
### Batch size
The batch size can be auto-configured or explicitly set. If you choose to use the `"auto"` option, [`Trainer`] sets `train_micro_batch_size_per_gpu` to the value of args.`per_device_train_batch_size` and `train_batch_size` to `args.world_size * args.per_device_train_batch_size * args.gradient_accumulation_steps`.
```yaml
{
"train_micro_batch_size_per_gpu": "auto",
"train_batch_size": "auto"
}
```
### Gradient accumulation
Gradient accumulation can be auto-configured or explicitly set. If you choose to use the `"auto"` option, [`Trainer`] sets it to the value of `args.gradient_accumulation_steps`.
```yaml
{
"gradient_accumulation_steps": "auto"
}
```
### Gradient clipping
Gradient clipping can be auto-configured or explicitly set. If you choose to use the `"auto"` option, [`Trainer`] sets it to the value of `args.max_grad_norm`.
```yaml
{
"gradient_clipping": "auto"
}
```
### Communication data type
For communication collectives like reduction, gathering and scattering operations, a separate data type is used.
All gather and scatter operations are performed in the same data type the data is in. For example, if you're training with bf16, the data is also gathered in bf16 because gathering is a non-lossy operation.
Reduce operations are lossy, for example when gradients are averaged across multiple GPUs. When the communication is done in fp16 or bf16, it is more likely to be lossy because adding multiple numbers in low precision isn't exact. This is especially the case with bf16 which has a lower precision than fp16. For this reason, fp16 is the default for reduction operations because the loss is minimal when averaging gradients.
You can choose the communication data type by setting the `communication_data_type` parameter in the config file. For example, choosing fp32 adds a small amount of overhead but ensures the reduction operation is accumulated in fp32 and when it is ready, it is downcasted to whichever half-precision dtype you're training in.
```yaml
{
"communication_data_type": "fp32"
}
```
## Deployment
DeepSpeed can be deployed by different launchers such as [torchrun](https://pytorch.org/docs/stable/elastic/run.html), the `deepspeed` launcher, or [Accelerate](https://huggingface.co/docs/accelerate/basic_tutorials/launch#using-accelerate-launch). To deploy, add `--deepspeed ds_config.json` to the [`Trainer`] command line. It’s recommended to use DeepSpeed’s [`add_config_arguments`](https://deepspeed.readthedocs.io/en/latest/initialize.html#argument-parsing) utility to add any necessary command line arguments to your code.
This guide will show you how to deploy DeepSpeed with the `deepspeed` launcher for different training setups. You can check out this [post](https://github.com/huggingface/transformers/issues/8771#issuecomment-759248400) for more practical usage examples.
<hfoptions id="deploy">
<hfoption id="multi-GPU">
To deploy DeepSpeed on multiple GPUs, add the `--num_gpus` parameter. If you want to use all available GPUs, you don't need to add `--num_gpus`. The example below uses 2 GPUs.
```bash
deepspeed --num_gpus=2 examples/pytorch/translation/run_translation.py \
--deepspeed tests/deepspeed/ds_config_zero3.json \
--model_name_or_path google-t5/t5-small --per_device_train_batch_size 1 \
--output_dir output_dir --overwrite_output_dir --fp16 \
--do_train --max_train_samples 500 --num_train_epochs 1 \
--dataset_name wmt16 --dataset_config "ro-en" \
--source_lang en --target_lang ro
```
</hfoption>
<hfoption id="single-GPU">
To deploy DeepSpeed on a single GPU, add the `--num_gpus` parameter. It isn't necessary to explicitly set this value if you only have 1 GPU because DeepSpeed deploys all GPUs it can see on a given node.
```bash
deepspeed --num_gpus=1 examples/pytorch/translation/run_translation.py \
--deepspeed tests/deepspeed/ds_config_zero2.json \
--model_name_or_path google-t5/t5-small --per_device_train_batch_size 1 \
--output_dir output_dir --overwrite_output_dir --fp16 \
--do_train --max_train_samples 500 --num_train_epochs 1 \
--dataset_name wmt16 --dataset_config "ro-en" \
--source_lang en --target_lang ro
```
DeepSpeed is still useful with just 1 GPU because you can:
1. Offload some computations and memory to the CPU to make more GPU resources available to your model to use a larger batch size or fit a very large model that normally won't fit.
2. Minimize memory fragmentation with it's smart GPU memory management system which also allows you to fit bigger models and data batches.
<Tip>
Set the `allgather_bucket_size` and `reduce_bucket_size` values to 2e8 in the [ZeRO-2](#zero-configuration) configuration file to get better performance on a single GPU.
</Tip>
</hfoption>
</hfoptions>
### Multi-node deployment
A node is one or more GPUs for running a workload. A more powerful setup is a multi-node setup which can be launched with the `deepspeed` launcher. For this guide, let's assume there are two nodes with 8 GPUs each. The first node can be accessed `ssh hostname1` and the second node with `ssh hostname2`. Both nodes must be able to communicate with each other locally over ssh without a password.
By default, DeepSpeed expects your multi-node environment to use a shared storage. If this is not the case and each node can only see the local filesystem, you need to adjust the config file to include a [`checkpoint`](https://www.deepspeed.ai/docs/config-json/#checkpoint-options) to allow loading without access to a shared filesystem:
```yaml
{
"checkpoint": {
"use_node_local_storage": true
}
}
```
You could also use the [`Trainer`]'s `--save_on_each_node` argument to automatically add the above `checkpoint` to your config.
<hfoptions id="multinode">
<hfoption id="torchrun">
For [torchrun](https://pytorch.org/docs/stable/elastic/run.html), you have to ssh to each node and run the following command on both of them. The launcher waits until both nodes are synchronized before launching the training.
```bash
python -m torch.run --nproc_per_node=8 --nnode=2 --node_rank=0 --master_addr=hostname1 \
--master_port=9901 your_program.py <normal cl args> --deepspeed ds_config.json
```
</hfoption>
<hfoption id="deepspeed">
For the `deepspeed` launcher, start by creating a `hostfile`.
```bash
hostname1 slots=8
hostname2 slots=8
```
Then you can launch the training with the following command. The `deepspeed` launcher automatically launches the command on both nodes at once.
```bash
deepspeed --num_gpus 8 --num_nodes 2 --hostfile hostfile --master_addr hostname1 --master_port=9901 \
your_program.py <normal cl args> --deepspeed ds_config.json
```
Check out the [Resource Configuration (multi-node)](https://www.deepspeed.ai/getting-started/#resource-configuration-multi-node) guide for more details about configuring multi-node compute resources.
</hfoption>
</hfoptions>
### SLURM
In a SLURM environment, you'll need to adapt your SLURM script to your specific SLURM environment. An example SLURM script may look like:
```bash
#SBATCH --job-name=test-nodes # name
#SBATCH --nodes=2 # nodes
#SBATCH --ntasks-per-node=1 # crucial - only 1 task per dist per node!
#SBATCH --cpus-per-task=10 # number of cores per tasks
#SBATCH --gres=gpu:8 # number of gpus
#SBATCH --time 20:00:00 # maximum execution time (HH:MM:SS)
#SBATCH --output=%x-%j.out # output file name
export GPUS_PER_NODE=8
export MASTER_ADDR=$(scontrol show hostnames $SLURM_JOB_NODELIST | head -n 1)
export MASTER_PORT=9901
srun --jobid $SLURM_JOBID bash -c 'python -m torch.distributed.run \
--nproc_per_node $GPUS_PER_NODE --nnodes $SLURM_NNODES --node_rank $SLURM_PROCID \
--master_addr $MASTER_ADDR --master_port $MASTER_PORT \
your_program.py <normal cl args> --deepspeed ds_config.json'
```
Then you can schedule your multi-node deployment with the following command which launches training simultaneously on all nodes.
```bash
sbatch launch.slurm
```
### Notebook
The `deepspeed` launcher doesn't support deployment from a notebook so you'll need to emulate the distributed environment. However, this only works for 1 GPU. If you want to use more than 1 GPU, you must use a multi-process environment for DeepSpeed to work. This means you have to use the `deepspeed` launcher which can't be emulated as shown here.
```py
# DeepSpeed requires a distributed environment even when only one process is used.
# This emulates a launcher in the notebook
import os
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "9994" # modify if RuntimeError: Address already in use
os.environ["RANK"] = "0"
os.environ["LOCAL_RANK"] = "0"
os.environ["WORLD_SIZE"] = "1"
# Now proceed as normal, plus pass the DeepSpeed config file
training_args = TrainingArguments(..., deepspeed="ds_config_zero3.json")
trainer = Trainer(...)
trainer.train()
```
If you want to create the config file on the fly in the notebook in the current directory, you could have a dedicated cell.
```py
%%bash
cat <<'EOT' > ds_config_zero3.json
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu",
"pin_memory": true
},
"offload_param": {
"device": "cpu",
"pin_memory": true
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"steps_per_print": 2000,
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
"wall_clock_breakdown": false
}
EOT
```
If the training script is in a file and not in a notebook cell, you can launch `deepspeed` normally from the shell in a notebook cell. For example, to launch `run_translation.py`:
```py
!git clone https://github.com/huggingface/transformers
!cd transformers; deepspeed examples/pytorch/translation/run_translation.py ...
```
You could also use `%%bash` magic and write multi-line code to run the shell program, but you won't be able to view the logs until training is complete. With `%%bash` magic, you don't need to emulate a distributed environment.
```py
%%bash
git clone https://github.com/huggingface/transformers
cd transformers
deepspeed examples/pytorch/translation/run_translation.py ...
```
## Save model weights
DeepSpeed stores the main full precision fp32 weights in custom checkpoint optimizer files (the glob pattern looks like `global_step*/*optim_states.pt`) and are saved under the normal checkpoint.
<hfoptions id="save">
<hfoption id="fp16">
A model trained with ZeRO-2 saves the pytorch_model.bin weights in fp16. To save the model weights in fp16 for a model trained with ZeRO-3, you need to set `"stage3_gather_16bit_weights_on_model_save": true` because the model weights are partitioned across multiple GPUs. Otherwise, the [`Trainer`] won't save the weights in fp16 and it won't create a pytorch_model.bin file. This is because DeepSpeed's state_dict contains a placeholder instead of the real weights and you won't be able to load them.
```yaml
{
"zero_optimization": {
"stage3_gather_16bit_weights_on_model_save": true
}
}
```
</hfoption>
<hfoption id="fp32">
The full precision weights shouldn't be saved during training because it can require a lot of memory. It is usually best to save the fp32 weights offline after training is complete. But if you have a lot of free CPU memory, it is possible to save the fp32 weights during training. This section covers both online and offline approaches.
### Online
You must have saved at least one checkpoint to load the latest checkpoint as shown in the following:
```py
from transformers.trainer_utils import get_last_checkpoint
from deepspeed.utils.zero_to_fp32 import load_state_dict_from_zero_checkpoint
checkpoint_dir = get_last_checkpoint(trainer.args.output_dir)
fp32_model = load_state_dict_from_zero_checkpoint(trainer.model, checkpoint_dir)
```
If you've enabled the `--load_best_model_at_end` parameter to track the best checkpoint in [`TrainingArguments`], you can finish training first and save the final model explicitly. Then you can reload it as shown below:
```py
from deepspeed.utils.zero_to_fp32 import load_state_dict_from_zero_checkpoint
checkpoint_dir = os.path.join(trainer.args.output_dir, "checkpoint-final")
trainer.deepspeed.save_checkpoint(checkpoint_dir)
fp32_model = load_state_dict_from_zero_checkpoint(trainer.model, checkpoint_dir)
```
<Tip>
Once `load_state_dict_from_zero_checkpoint` is run, the model is no longer usable in DeepSpeed in the context of the same application. You'll need to initialize the DeepSpeed engine again since `model.load_state_dict(state_dict)` removes all the DeepSpeed magic from it. Only use this at the very end of training.
</Tip>
You can also extract and load the state_dict of the fp32 weights:
```py
from deepspeed.utils.zero_to_fp32 import get_fp32_state_dict_from_zero_checkpoint
state_dict = get_fp32_state_dict_from_zero_checkpoint(checkpoint_dir) # already on cpu
model = model.cpu()
model.load_state_dict(state_dict)
```
### Offline
DeepSpeed provides a zero_to_fp32.py script at the top-level of the checkpoint folder for extracting weights at any point. This is a standalone script and you don't need a configuration file or [`Trainer`].
For example, if your checkpoint folder looked like this:
```bash
$ ls -l output_dir/checkpoint-1/
-rw-rw-r-- 1 stas stas 1.4K Mar 27 20:42 config.json
drwxrwxr-x 2 stas stas 4.0K Mar 25 19:52 global_step1/
-rw-rw-r-- 1 stas stas 12 Mar 27 13:16 latest
-rw-rw-r-- 1 stas stas 827K Mar 27 20:42 optimizer.pt
-rw-rw-r-- 1 stas stas 231M Mar 27 20:42 pytorch_model.bin
-rw-rw-r-- 1 stas stas 623 Mar 27 20:42 scheduler.pt
-rw-rw-r-- 1 stas stas 1.8K Mar 27 20:42 special_tokens_map.json
-rw-rw-r-- 1 stas stas 774K Mar 27 20:42 spiece.model
-rw-rw-r-- 1 stas stas 1.9K Mar 27 20:42 tokenizer_config.json
-rw-rw-r-- 1 stas stas 339 Mar 27 20:42 trainer_state.json
-rw-rw-r-- 1 stas stas 2.3K Mar 27 20:42 training_args.bin
-rwxrw-r-- 1 stas stas 5.5K Mar 27 13:16 zero_to_fp32.py*
```
To reconstruct the fp32 weights from the DeepSpeed checkpoint (ZeRO-2 or ZeRO-3) subfolder `global_step1`, run the following command to create and consolidate the full fp32 weights from multiple GPUs into a single pytorch_model.bin file. The script automatically discovers the subfolder containing the checkpoint.
```py
python zero_to_fp32.py . pytorch_model.bin
```
<Tip>
Run `python zero_to_fp32.py -h` for more usage details. The script requires 2x the general RAM of the final fp32 weights.
</Tip>
</hfoption>
</hfoptions>
## ZeRO Inference
[ZeRO Inference](https://www.deepspeed.ai/2022/09/09/zero-inference.html) places the model weights in CPU or NVMe memory to avoid burdening the GPU which makes it possible to run inference with huge models on a GPU. Inference doesn't require any large additional amounts of memory for the optimizer states and gradients so you can fit much larger batches and/or sequence lengths on the same hardware.
ZeRO Inference shares the same configuration file as [ZeRO-3](#zero-configuration), and ZeRO-2 and ZeRO-1 configs won't work because they don't provide any benefits for inference.
To run ZeRO Inference, pass your usual training arguments to the [`TrainingArguments`] class and add the `--do_eval` argument.
```bash
deepspeed --num_gpus=2 your_program.py <normal cl args> --do_eval --deepspeed ds_config.json
```
## Non-Trainer DeepSpeed integration
DeepSpeed also works with Transformers without the [`Trainer`] class. This is handled by the [`HfDeepSpeedConfig`] which only takes care of gathering ZeRO-3 parameters and splitting a model across multiple GPUs when you call [`~PreTrainedModel.from_pretrained`].
<Tip>
If you want everything automatically taken care of for you, try using DeepSpeed with the [`Trainer`]! You'll need to follow the [DeepSpeed documentation](https://www.deepspeed.ai/), and manually configure the parameter values in the config file (you can't use the `"auto"` value).
</Tip>
To efficiently deploy ZeRO-3, you must instantiate the [`HfDeepSpeedConfig`] object before the model and keep that object alive:
<hfoptions id="models">
<hfoption id="pretrained model">
```py
from transformers.integrations import HfDeepSpeedConfig
from transformers import AutoModel
import deepspeed
ds_config = {...} # deepspeed config object or path to the file
# must run before instantiating the model to detect zero 3
dschf = HfDeepSpeedConfig(ds_config) # keep this object alive
model = AutoModel.from_pretrained("openai-community/gpt2")
engine = deepspeed.initialize(model=model, config_params=ds_config, ...)
```
</hfoption>
<hfoption id="non-pretrained model">
[`HfDeepSpeedConfig`] is not required for ZeRO-1 or ZeRO-2.
```py
from transformers.integrations import HfDeepSpeedConfig
from transformers import AutoModel, AutoConfig
import deepspeed
ds_config = {...} # deepspeed config object or path to the file
# must run before instantiating the model to detect zero 3
dschf = HfDeepSpeedConfig(ds_config) # keep this object alive
config = AutoConfig.from_pretrained("openai-community/gpt2")
model = AutoModel.from_config(config)
engine = deepspeed.initialize(model=model, config_params=ds_config, ...)
```
</hfoption>
</hfoptions>
### Non-Trainer ZeRO Inference
To run ZeRO Inference without the [`Trainer`] in cases where you can’t fit a model onto a single GPU, try using additional GPUs or/and offloading to CPU memory. The important nuance to understand here is that the way ZeRO is designed, you can process different inputs on different GPUs in parallel.
Make sure to:
* disable CPU offload if you have enough GPU memory (since it slows things down).
* enable bf16 if you have an Ampere or newer GPU to make things faster. If you don’t have one of these GPUs, you may enable fp16 as long as you don’t use a model pretrained in bf16 (T5 models) because it may lead to an overflow error.
Take a look at the following script to get a better idea of how to run ZeRO Inference without the [`Trainer`] on a model that won't fit on a single GPU.
```py
#!/usr/bin/env python
# This script demonstrates how to use Deepspeed ZeRO in an inference mode when one can't fit a model
# into a single GPU
#
# 1. Use 1 GPU with CPU offload
# 2. Or use multiple GPUs instead
#
# First you need to install deepspeed: pip install deepspeed
#
# Here we use a 3B "bigscience/T0_3B" model which needs about 15GB GPU RAM - so 1 largish or 2
# small GPUs can handle it. or 1 small GPU and a lot of CPU memory.
#
# To use a larger model like "bigscience/T0" which needs about 50GB, unless you have an 80GB GPU -
# you will need 2-4 gpus. And then you can adapt the script to handle more gpus if you want to
# process multiple inputs at once.
#
# The provided deepspeed config also activates CPU memory offloading, so chances are that if you
# have a lot of available CPU memory and you don't mind a slowdown you should be able to load a
# model that doesn't normally fit into a single GPU. If you have enough GPU memory the program will
# run faster if you don't want offload to CPU - so disable that section then.
#
# To deploy on 1 gpu:
#
# deepspeed --num_gpus 1 t0.py
# or:
# python -m torch.distributed.run --nproc_per_node=1 t0.py
#
# To deploy on 2 gpus:
#
# deepspeed --num_gpus 2 t0.py
# or:
# python -m torch.distributed.run --nproc_per_node=2 t0.py
from transformers import AutoTokenizer, AutoConfig, AutoModelForSeq2SeqLM
from transformers.integrations import HfDeepSpeedConfig
import deepspeed
import os
import torch
os.environ["TOKENIZERS_PARALLELISM"] = "false" # To avoid warnings about parallelism in tokenizers
# distributed setup
local_rank = int(os.getenv("LOCAL_RANK", "0"))
world_size = int(os.getenv("WORLD_SIZE", "1"))
torch.cuda.set_device(local_rank)
deepspeed.init_distributed()
model_name = "bigscience/T0_3B"
config = AutoConfig.from_pretrained(model_name)
model_hidden_size = config.d_model
# batch size has to be divisible by world_size, but can be bigger than world_size
train_batch_size = 1 * world_size
# ds_config notes
#
# - enable bf16 if you use Ampere or higher GPU - this will run in mixed precision and will be
# faster.
#
# - for older GPUs you can enable fp16, but it'll only work for non-bf16 pretrained models - e.g.
# all official t5 models are bf16-pretrained
#
# - set offload_param.device to "none" or completely remove the `offload_param` section if you don't
# - want CPU offload
#
# - if using `offload_param` you can manually finetune stage3_param_persistence_threshold to control
# - which params should remain on gpus - the larger the value the smaller the offload size
#
# For in-depth info on Deepspeed config see
# https://huggingface.co/docs/transformers/main/main_classes/deepspeed
# keeping the same format as json for consistency, except it uses lower case for true/false
# fmt: off
ds_config = {
"fp16": {
"enabled": False
},
"bf16": {
"enabled": False
},
"zero_optimization": {
"stage": 3,
"offload_param": {
"device": "cpu",
"pin_memory": True
},
"overlap_comm": True,
"contiguous_gradients": True,
"reduce_bucket_size": model_hidden_size * model_hidden_size,
"stage3_prefetch_bucket_size": 0.9 * model_hidden_size * model_hidden_size,
"stage3_param_persistence_threshold": 10 * model_hidden_size
},
"steps_per_print": 2000,
"train_batch_size": train_batch_size,
"train_micro_batch_size_per_gpu": 1,
"wall_clock_breakdown": False
}
# fmt: on
# next line instructs transformers to partition the model directly over multiple gpus using
# deepspeed.zero.Init when model's `from_pretrained` method is called.
#
# **it has to be run before loading the model AutoModelForSeq2SeqLM.from_pretrained(model_name)**
#
# otherwise the model will first be loaded normally and only partitioned at forward time which is
# less efficient and when there is little CPU RAM may fail
dschf = HfDeepSpeedConfig(ds_config) # keep this object alive
# now a model can be loaded.
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
# initialise Deepspeed ZeRO and store only the engine object
ds_engine = deepspeed.initialize(model=model, config_params=ds_config)[0]
ds_engine.module.eval() # inference
# Deepspeed ZeRO can process unrelated inputs on each GPU. So for 2 gpus you process 2 inputs at once.
# If you use more GPUs adjust for more.
# And of course if you have just one input to process you then need to pass the same string to both gpus
# If you use only one GPU, then you will have only rank 0.
rank = torch.distributed.get_rank()
if rank == 0:
text_in = "Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy"
elif rank == 1:
text_in = "Is this review positive or negative? Review: this is the worst restaurant ever"
tokenizer = AutoTokenizer.from_pretrained(model_name)
inputs = tokenizer.encode(text_in, return_tensors="pt").to(device=local_rank)
with torch.no_grad():
outputs = ds_engine.module.generate(inputs, synced_gpus=True)
text_out = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"rank{rank}:\n in={text_in}\n out={text_out}")
```
Save the script as t0.py and launch it:
```bash
$ deepspeed --num_gpus 2 t0.py
rank0:
in=Is this review positive or negative? Review: this is the best cast iron skillet you will ever buy
out=Positive
rank1:
in=Is this review positive or negative? Review: this is the worst restaurant ever
out=negative
```
This is a very basic example and you'll want to adapt it to your use case.
### Generate
Using multiple GPUs with ZeRO-3 for generation requires synchronizing the GPUs by setting `synced_gpus=True` in the [`~GenerationMixin.generate`] method. Otherwise, if one GPU is finished generating before another one, the whole system hangs because the remaining GPUs haven't received the weight shard from the GPU that finished first.
For Transformers>=4.28, if `synced_gpus` is automatically set to `True` if multiple GPUs are detected during generation.
## Troubleshoot
When you encounter an issue, you should consider whether DeepSpeed is the cause of the problem because often it isn't (unless it's super obviously and you can see DeepSpeed modules in the exception)! The first step should be to retry your setup without DeepSpeed, and if the problem persists, then you can report the issue. If the issue is a core DeepSpeed problem and unrelated to the Transformers integration, open an Issue on the [DeepSpeed repository](https://github.com/microsoft/DeepSpeed).
For issues related to the Transformers integration, please provide the following information:
* the full DeepSpeed config file
* the command line arguments of the [`Trainer`], or [`TrainingArguments`] arguments if you're scripting the [`Trainer`] setup yourself (don't dump the [`TrainingArguments`] which has dozens of irrelevant entries)
* the outputs of:
```bash
python -c 'import torch; print(f"torch: {torch.__version__}")'
python -c 'import transformers; print(f"transformers: {transformers.__version__}")'
python -c 'import deepspeed; print(f"deepspeed: {deepspeed.__version__}")'
```
* a link to a Google Colab notebook to reproduce the issue
* if impossible, a standard and non-custom dataset we can use and also try to use an existing example to reproduce the issue with
The following sections provide a guide for resolving two of the most common issues.
### DeepSpeed process killed at startup
When the DeepSpeed process is killed during launch without a traceback, that usually means the program tried to allocate more CPU memory than your system has or your process tried to allocate more CPU memory than allowed leading the OS kernel to terminate the process. In this case, check whether your configuration file has either `offload_optimizer`, `offload_param` or both configured to offload to the CPU.
If you have NVMe and ZeRO-3 setup, experiment with offloading to the NVMe ([estimate](https://deepspeed.readthedocs.io/en/latest/memory.html) the memory requirements for your model).
### NaN loss
NaN loss often occurs when a model is pretrained in bf16 and then you try to use it with fp16 (especially relevant for TPU trained models). To resolve this, use fp32 or bf16 if your hardware supports it (TPU, Ampere GPUs or newer).
The other issue may be related to using fp16. For example, if this is your fp16 configuration:
```yaml
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
}
}
```
You might see the following `OVERFLOW!` messages in the logs:
```bash
0%| | 0/189 [00:00<?, ?it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 262144, reducing to 262144
1%|▌ | 1/189 [00:00<01:26, 2.17it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 262144, reducing to 131072.0
1%|█▏
[...]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
14%|████████████████▌ | 27/189 [00:14<01:13, 2.21it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
15%|█████████████████▏ | 28/189 [00:14<01:13, 2.18it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
15%|█████████████████▊ | 29/189 [00:15<01:13, 2.18it/s]
[deepscale] OVERFLOW! Rank 0 Skipping step. Attempted loss scale: 1, reducing to 1
[...]
```
This means the DeepSpeed loss scaler is unable to find a scaling coefficient to overcome loss overflow. To fix it, try a higher `initial_scale_power` value (32 usually works).
## Resources
DeepSpeed ZeRO is a powerful technology for training and loading very large models for inference with limited GPU resources, making it more accessible to everyone. To learn more about DeepSpeed, feel free to read the [blog posts](https://www.microsoft.com/en-us/research/search/?q=deepspeed), [documentation](https://www.deepspeed.ai/getting-started/), and [GitHub repository](https://github.com/microsoft/deepspeed).
The following papers are also a great resource for learning more about ZeRO:
* [ZeRO: Memory Optimizations Toward Training Trillion Parameter Models](https://hf.co/papers/1910.02054)
* [ZeRO-Offload: Democratizing Billion-Scale Model Training](https://hf.co/papers/2101.06840)
* [ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning](https://hf.co/papers/2104.07857)
| transformers/docs/source/en/deepspeed.md/0 | {
"file_path": "transformers/docs/source/en/deepspeed.md",
"repo_id": "transformers",
"token_count": 18766
} | 227 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Utilities for Tokenizers
This page lists all the utility functions used by the tokenizers, mainly the class
[`~tokenization_utils_base.PreTrainedTokenizerBase`] that implements the common methods between
[`PreTrainedTokenizer`] and [`PreTrainedTokenizerFast`] and the mixin
[`~tokenization_utils_base.SpecialTokensMixin`].
Most of those are only useful if you are studying the code of the tokenizers in the library.
## PreTrainedTokenizerBase
[[autodoc]] tokenization_utils_base.PreTrainedTokenizerBase
- __call__
- all
## SpecialTokensMixin
[[autodoc]] tokenization_utils_base.SpecialTokensMixin
## Enums and namedtuples
[[autodoc]] tokenization_utils_base.TruncationStrategy
[[autodoc]] tokenization_utils_base.CharSpan
[[autodoc]] tokenization_utils_base.TokenSpan
| transformers/docs/source/en/internal/tokenization_utils.md/0 | {
"file_path": "transformers/docs/source/en/internal/tokenization_utils.md",
"repo_id": "transformers",
"token_count": 428
} | 228 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BARThez
## Overview
The BARThez model was proposed in [BARThez: a Skilled Pretrained French Sequence-to-Sequence Model](https://arxiv.org/abs/2010.12321) by Moussa Kamal Eddine, Antoine J.-P. Tixier, Michalis Vazirgiannis on 23 Oct,
2020.
The abstract of the paper:
*Inductive transfer learning, enabled by self-supervised learning, have taken the entire Natural Language Processing
(NLP) field by storm, with models such as BERT and BART setting new state of the art on countless natural language
understanding tasks. While there are some notable exceptions, most of the available models and research have been
conducted for the English language. In this work, we introduce BARThez, the first BART model for the French language
(to the best of our knowledge). BARThez was pretrained on a very large monolingual French corpus from past research
that we adapted to suit BART's perturbation schemes. Unlike already existing BERT-based French language models such as
CamemBERT and FlauBERT, BARThez is particularly well-suited for generative tasks, since not only its encoder but also
its decoder is pretrained. In addition to discriminative tasks from the FLUE benchmark, we evaluate BARThez on a novel
summarization dataset, OrangeSum, that we release with this paper. We also continue the pretraining of an already
pretrained multilingual BART on BARThez's corpus, and we show that the resulting model, which we call mBARTHez,
provides a significant boost over vanilla BARThez, and is on par with or outperforms CamemBERT and FlauBERT.*
This model was contributed by [moussakam](https://huggingface.co/moussakam). The Authors' code can be found [here](https://github.com/moussaKam/BARThez).
<Tip>
BARThez implementation is the same as BART, except for tokenization. Refer to [BART documentation](bart) for information on
configuration classes and their parameters. BARThez-specific tokenizers are documented below.
</Tip>
## Resources
- BARThez can be fine-tuned on sequence-to-sequence tasks in a similar way as BART, check:
[examples/pytorch/summarization/](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization/README.md).
## BarthezTokenizer
[[autodoc]] BarthezTokenizer
## BarthezTokenizerFast
[[autodoc]] BarthezTokenizerFast
| transformers/docs/source/en/model_doc/barthez.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/barthez.md",
"repo_id": "transformers",
"token_count": 818
} | 229 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BORT
<Tip warning={true}>
This model is in maintenance mode only, we do not accept any new PRs changing its code.
If you run into any issues running this model, please reinstall the last version that supported this model: v4.30.0.
You can do so by running the following command: `pip install -U transformers==4.30.0`.
</Tip>
## Overview
The BORT model was proposed in [Optimal Subarchitecture Extraction for BERT](https://arxiv.org/abs/2010.10499) by
Adrian de Wynter and Daniel J. Perry. It is an optimal subset of architectural parameters for the BERT, which the
authors refer to as "Bort".
The abstract from the paper is the following:
*We extract an optimal subset of architectural parameters for the BERT architecture from Devlin et al. (2018) by
applying recent breakthroughs in algorithms for neural architecture search. This optimal subset, which we refer to as
"Bort", is demonstrably smaller, having an effective (that is, not counting the embedding layer) size of 5.5% the
original BERT-large architecture, and 16% of the net size. Bort is also able to be pretrained in 288 GPU hours, which
is 1.2% of the time required to pretrain the highest-performing BERT parametric architectural variant, RoBERTa-large
(Liu et al., 2019), and about 33% of that of the world-record, in GPU hours, required to train BERT-large on the same
hardware. It is also 7.9x faster on a CPU, as well as being better performing than other compressed variants of the
architecture, and some of the non-compressed variants: it obtains performance improvements of between 0.3% and 31%,
absolute, with respect to BERT-large, on multiple public natural language understanding (NLU) benchmarks.*
This model was contributed by [stefan-it](https://huggingface.co/stefan-it). The original code can be found [here](https://github.com/alexa/bort/).
## Usage tips
- BORT's model architecture is based on BERT, refer to [BERT's documentation page](bert) for the
model's API reference as well as usage examples.
- BORT uses the RoBERTa tokenizer instead of the BERT tokenizer, refer to [RoBERTa's documentation page](roberta) for the tokenizer's API reference as well as usage examples.
- BORT requires a specific fine-tuning algorithm, called [Agora](https://adewynter.github.io/notes/bort_algorithms_and_applications.html#fine-tuning-with-algebraic-topology) ,
that is sadly not open-sourced yet. It would be very useful for the community, if someone tries to implement the
algorithm to make BORT fine-tuning work.
| transformers/docs/source/en/model_doc/bort.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/bort.md",
"repo_id": "transformers",
"token_count": 867
} | 230 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ConvNeXT
## Overview
The ConvNeXT model was proposed in [A ConvNet for the 2020s](https://arxiv.org/abs/2201.03545) by Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie.
ConvNeXT is a pure convolutional model (ConvNet), inspired by the design of Vision Transformers, that claims to outperform them.
The abstract from the paper is the following:
*The "Roaring 20s" of visual recognition began with the introduction of Vision Transformers (ViTs), which quickly superseded ConvNets as the state-of-the-art image classification model.
A vanilla ViT, on the other hand, faces difficulties when applied to general computer vision tasks such as object detection and semantic segmentation. It is the hierarchical Transformers
(e.g., Swin Transformers) that reintroduced several ConvNet priors, making Transformers practically viable as a generic vision backbone and demonstrating remarkable performance on a wide
variety of vision tasks. However, the effectiveness of such hybrid approaches is still largely credited to the intrinsic superiority of Transformers, rather than the inherent inductive
biases of convolutions. In this work, we reexamine the design spaces and test the limits of what a pure ConvNet can achieve. We gradually "modernize" a standard ResNet toward the design
of a vision Transformer, and discover several key components that contribute to the performance difference along the way. The outcome of this exploration is a family of pure ConvNet models
dubbed ConvNeXt. Constructed entirely from standard ConvNet modules, ConvNeXts compete favorably with Transformers in terms of accuracy and scalability, achieving 87.8% ImageNet top-1 accuracy
and outperforming Swin Transformers on COCO detection and ADE20K segmentation, while maintaining the simplicity and efficiency of standard ConvNets.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/convnext_architecture.jpg"
alt="drawing" width="600"/>
<small> ConvNeXT architecture. Taken from the <a href="https://arxiv.org/abs/2201.03545">original paper</a>.</small>
This model was contributed by [nielsr](https://huggingface.co/nielsr). TensorFlow version of the model was contributed by [ariG23498](https://github.com/ariG23498),
[gante](https://github.com/gante), and [sayakpaul](https://github.com/sayakpaul) (equal contribution). The original code can be found [here](https://github.com/facebookresearch/ConvNeXt).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ConvNeXT.
<PipelineTag pipeline="image-classification"/>
- [`ConvNextForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## ConvNextConfig
[[autodoc]] ConvNextConfig
## ConvNextFeatureExtractor
[[autodoc]] ConvNextFeatureExtractor
## ConvNextImageProcessor
[[autodoc]] ConvNextImageProcessor
- preprocess
<frameworkcontent>
<pt>
## ConvNextModel
[[autodoc]] ConvNextModel
- forward
## ConvNextForImageClassification
[[autodoc]] ConvNextForImageClassification
- forward
</pt>
<tf>
## TFConvNextModel
[[autodoc]] TFConvNextModel
- call
## TFConvNextForImageClassification
[[autodoc]] TFConvNextForImageClassification
- call
</tf>
</frameworkcontent> | transformers/docs/source/en/model_doc/convnext.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/convnext.md",
"repo_id": "transformers",
"token_count": 1215
} | 231 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# DialoGPT
## Overview
DialoGPT was proposed in [DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao,
Jianfeng Gao, Jingjing Liu, Bill Dolan. It's a GPT2 Model trained on 147M conversation-like exchanges extracted from
Reddit.
The abstract from the paper is the following:
*We present a large, tunable neural conversational response generation model, DialoGPT (dialogue generative pre-trained
transformer). Trained on 147M conversation-like exchanges extracted from Reddit comment chains over a period spanning
from 2005 through 2017, DialoGPT extends the Hugging Face PyTorch transformer to attain a performance close to human
both in terms of automatic and human evaluation in single-turn dialogue settings. We show that conversational systems
that leverage DialoGPT generate more relevant, contentful and context-consistent responses than strong baseline
systems. The pre-trained model and training pipeline are publicly released to facilitate research into neural response
generation and the development of more intelligent open-domain dialogue systems.*
The original code can be found [here](https://github.com/microsoft/DialoGPT).
## Usage tips
- DialoGPT is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather
than the left.
- DialoGPT was trained with a causal language modeling (CLM) objective on conversational data and is therefore powerful
at response generation in open-domain dialogue systems.
- DialoGPT enables the user to create a chat bot in just 10 lines of code as shown on [DialoGPT's model card](https://huggingface.co/microsoft/DialoGPT-medium).
Training:
In order to train or fine-tune DialoGPT, one can use causal language modeling training. To cite the official paper: *We
follow the OpenAI GPT-2 to model a multiturn dialogue session as a long text and frame the generation task as language
modeling. We first concatenate all dialog turns within a dialogue session into a long text x_1,..., x_N (N is the
sequence length), ended by the end-of-text token.* For more information please confer to the original paper.
<Tip>
DialoGPT's architecture is based on the GPT2 model, refer to [GPT2's documentation page](gpt2) for API reference and examples.
</Tip>
| transformers/docs/source/en/model_doc/dialogpt.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/dialogpt.md",
"repo_id": "transformers",
"token_count": 789
} | 232 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Falcon
## Overview
Falcon is a class of causal decoder-only models built by [TII](https://www.tii.ae/). The largest Falcon checkpoints
have been trained on >=1T tokens of text, with a particular emphasis on the [RefinedWeb](https://arxiv.org/abs/2306.01116)
corpus. They are made available under the Apache 2.0 license.
Falcon's architecture is modern and optimized for inference, with multi-query attention and support for efficient
attention variants like `FlashAttention`. Both 'base' models trained only as causal language models as well as
'instruct' models that have received further fine-tuning are available.
Falcon models are (as of 2023) some of the largest and most powerful open-source language models,
and consistently rank highly in the [OpenLLM leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
## Converting custom checkpoints
<Tip>
Falcon models were initially added to the Hugging Face Hub as custom code checkpoints. However, Falcon is now fully
supported in the Transformers library. If you fine-tuned a model from a custom code checkpoint, we recommend converting
your checkpoint to the new in-library format, as this should give significant improvements to stability and
performance, especially for generation, as well as removing the need to use `trust_remote_code=True`!
</Tip>
You can convert custom code checkpoints to full Transformers checkpoints using the `convert_custom_code_checkpoint.py`
script located in the
[Falcon model directory](https://github.com/huggingface/transformers/tree/main/src/transformers/models/falcon)
of the Transformers library. To use this script, simply call it with
`python convert_custom_code_checkpoint.py --checkpoint_dir my_model`. This will convert your checkpoint in-place, and
you can immediately load it from the directory afterwards with e.g. `from_pretrained()`. If your model hasn't been
uploaded to the Hub, we recommend making a backup before attempting the conversion, just in case!
## FalconConfig
[[autodoc]] FalconConfig
- all
## FalconModel
[[autodoc]] FalconModel
- forward
## FalconForCausalLM
[[autodoc]] FalconForCausalLM
- forward
## FalconForSequenceClassification
[[autodoc]] FalconForSequenceClassification
- forward
## FalconForTokenClassification
[[autodoc]] FalconForTokenClassification
- forward
## FalconForQuestionAnswering
[[autodoc]] FalconForQuestionAnswering
- forward
| transformers/docs/source/en/model_doc/falcon.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/falcon.md",
"repo_id": "transformers",
"token_count": 837
} | 233 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# M2M100
## Overview
The M2M100 model was proposed in [Beyond English-Centric Multilingual Machine Translation](https://arxiv.org/abs/2010.11125) by Angela Fan, Shruti Bhosale, Holger Schwenk, Zhiyi Ma, Ahmed El-Kishky,
Siddharth Goyal, Mandeep Baines, Onur Celebi, Guillaume Wenzek, Vishrav Chaudhary, Naman Goyal, Tom Birch, Vitaliy
Liptchinsky, Sergey Edunov, Edouard Grave, Michael Auli, Armand Joulin.
The abstract from the paper is the following:
*Existing work in translation demonstrated the potential of massively multilingual machine translation by training a
single model able to translate between any pair of languages. However, much of this work is English-Centric by training
only on data which was translated from or to English. While this is supported by large sources of training data, it
does not reflect translation needs worldwide. In this work, we create a true Many-to-Many multilingual translation
model that can translate directly between any pair of 100 languages. We build and open source a training dataset that
covers thousands of language directions with supervised data, created through large-scale mining. Then, we explore how
to effectively increase model capacity through a combination of dense scaling and language-specific sparse parameters
to create high quality models. Our focus on non-English-Centric models brings gains of more than 10 BLEU when directly
translating between non-English directions while performing competitively to the best single systems of WMT. We
open-source our scripts so that others may reproduce the data, evaluation, and final M2M-100 model.*
This model was contributed by [valhalla](https://huggingface.co/valhalla).
## Usage tips and examples
M2M100 is a multilingual encoder-decoder (seq-to-seq) model primarily intended for translation tasks. As the model is
multilingual it expects the sequences in a certain format: A special language id token is used as prefix in both the
source and target text. The source text format is `[lang_code] X [eos]`, where `lang_code` is source language
id for source text and target language id for target text, with `X` being the source or target text.
The [`M2M100Tokenizer`] depends on `sentencepiece` so be sure to install it before running the
examples. To install `sentencepiece` run `pip install sentencepiece`.
**Supervised Training**
```python
from transformers import M2M100Config, M2M100ForConditionalGeneration, M2M100Tokenizer
model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M", src_lang="en", tgt_lang="fr")
src_text = "Life is like a box of chocolates."
tgt_text = "La vie est comme une boîte de chocolat."
model_inputs = tokenizer(src_text, text_target=tgt_text, return_tensors="pt")
loss = model(**model_inputs).loss # forward pass
```
**Generation**
M2M100 uses the `eos_token_id` as the `decoder_start_token_id` for generation with the target language id
being forced as the first generated token. To force the target language id as the first generated token, pass the
*forced_bos_token_id* parameter to the *generate* method. The following example shows how to translate between
Hindi to French and Chinese to English using the *facebook/m2m100_418M* checkpoint.
```python
>>> from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
>>> hi_text = "जीवन एक चॉकलेट बॉक्स की तरह है।"
>>> chinese_text = "生活就像一盒巧克力。"
>>> model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M")
>>> tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M")
>>> # translate Hindi to French
>>> tokenizer.src_lang = "hi"
>>> encoded_hi = tokenizer(hi_text, return_tensors="pt")
>>> generated_tokens = model.generate(**encoded_hi, forced_bos_token_id=tokenizer.get_lang_id("fr"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
"La vie est comme une boîte de chocolat."
>>> # translate Chinese to English
>>> tokenizer.src_lang = "zh"
>>> encoded_zh = tokenizer(chinese_text, return_tensors="pt")
>>> generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
>>> tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
"Life is like a box of chocolate."
```
## Resources
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## M2M100Config
[[autodoc]] M2M100Config
## M2M100Tokenizer
[[autodoc]] M2M100Tokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## M2M100Model
[[autodoc]] M2M100Model
- forward
## M2M100ForConditionalGeneration
[[autodoc]] M2M100ForConditionalGeneration
- forward
| transformers/docs/source/en/model_doc/m2m_100.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/m2m_100.md",
"repo_id": "transformers",
"token_count": 1685
} | 234 |
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# mLUKE
## Overview
The mLUKE model was proposed in [mLUKE: The Power of Entity Representations in Multilingual Pretrained Language Models](https://arxiv.org/abs/2110.08151) by Ryokan Ri, Ikuya Yamada, and Yoshimasa Tsuruoka. It's a multilingual extension
of the [LUKE model](https://arxiv.org/abs/2010.01057) trained on the basis of XLM-RoBERTa.
It is based on XLM-RoBERTa and adds entity embeddings, which helps improve performance on various downstream tasks
involving reasoning about entities such as named entity recognition, extractive question answering, relation
classification, cloze-style knowledge completion.
The abstract from the paper is the following:
*Recent studies have shown that multilingual pretrained language models can be effectively improved with cross-lingual
alignment information from Wikipedia entities. However, existing methods only exploit entity information in pretraining
and do not explicitly use entities in downstream tasks. In this study, we explore the effectiveness of leveraging
entity representations for downstream cross-lingual tasks. We train a multilingual language model with 24 languages
with entity representations and show the model consistently outperforms word-based pretrained models in various
cross-lingual transfer tasks. We also analyze the model and the key insight is that incorporating entity
representations into the input allows us to extract more language-agnostic features. We also evaluate the model with a
multilingual cloze prompt task with the mLAMA dataset. We show that entity-based prompt elicits correct factual
knowledge more likely than using only word representations.*
This model was contributed by [ryo0634](https://huggingface.co/ryo0634). The original code can be found [here](https://github.com/studio-ousia/luke).
## Usage tips
One can directly plug in the weights of mLUKE into a LUKE model, like so:
```python
from transformers import LukeModel
model = LukeModel.from_pretrained("studio-ousia/mluke-base")
```
Note that mLUKE has its own tokenizer, [`MLukeTokenizer`]. You can initialize it as follows:
```python
from transformers import MLukeTokenizer
tokenizer = MLukeTokenizer.from_pretrained("studio-ousia/mluke-base")
```
<Tip>
As mLUKE's architecture is equivalent to that of LUKE, one can refer to [LUKE's documentation page](luke) for all
tips, code examples and notebooks.
</Tip>
## MLukeTokenizer
[[autodoc]] MLukeTokenizer
- __call__
- save_vocabulary
| transformers/docs/source/en/model_doc/mluke.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/mluke.md",
"repo_id": "transformers",
"token_count": 825
} | 235 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# NLLB-MOE
## Overview
The NLLB model was presented in [No Language Left Behind: Scaling Human-Centered Machine Translation](https://arxiv.org/abs/2207.04672) by Marta R. Costa-jussà, James Cross, Onur Çelebi,
Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula,
Loic Barrault, Gabriel Mejia Gonzalez, Prangthip Hansanti, John Hoffman, Semarley Jarrett, Kaushik Ram Sadagopan, Dirk Rowe, Shannon Spruit, Chau Tran, Pierre Andrews,
Necip Fazil Ayan, Shruti Bhosale, Sergey Edunov, Angela Fan, Cynthia Gao, Vedanuj Goswami, Francisco Guzmán, Philipp Koehn, Alexandre Mourachko, Christophe Ropers,
Safiyyah Saleem, Holger Schwenk, and Jeff Wang.
The abstract of the paper is the following:
*Driven by the goal of eradicating language barriers on a global scale, machine translation has solidified itself as a key focus of artificial intelligence research today.
However, such efforts have coalesced around a small subset of languages, leaving behind the vast majority of mostly low-resource languages. What does it take to break the
200 language barrier while ensuring safe, high quality results, all while keeping ethical considerations in mind? In No Language Left Behind, we took on this challenge by
first contextualizing the need for low-resource language translation support through exploratory interviews with native speakers. Then, we created datasets and models aimed
at narrowing the performance gap between low and high-resource languages. More specifically, we developed a conditional compute model based on Sparsely Gated Mixture of
Experts that is trained on data obtained with novel and effective data mining techniques tailored for low-resource languages. We propose multiple architectural and training
improvements to counteract overfitting while training on thousands of tasks. Critically, we evaluated the performance of over 40,000 different translation directions using
a human-translated benchmark, Flores-200, and combined human evaluation with a novel toxicity benchmark covering all languages in Flores-200 to assess translation safety.
Our model achieves an improvement of 44% BLEU relative to the previous state-of-the-art, laying important groundwork towards realizing a universal translation system.*
This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ).
The original code can be found [here](https://github.com/facebookresearch/fairseq).
## Usage tips
- M2M100ForConditionalGeneration is the base model for both NLLB and NLLB MoE
- The NLLB-MoE is very similar to the NLLB model, but it's feed forward layer is based on the implementation of SwitchTransformers.
- The tokenizer is the same as the NLLB models.
## Implementation differences with SwitchTransformers
The biggest difference is the way the tokens are routed. NLLB-MoE uses a `top-2-gate` which means that for each input, only the top two experts are selected based on the
highest predicted probabilities from the gating network, and the remaining experts are ignored. In `SwitchTransformers`, only the top-1 probabilities are computed,
which means that tokens have less probability of being forwarded. Moreover, if a token is not routed to any expert, `SwitchTransformers` still adds its unmodified hidden
states (kind of like a residual connection) while they are masked in `NLLB`'s top-2 routing mechanism.
## Generating with NLLB-MoE
The available checkpoints require around 350GB of storage. Make sure to use `accelerate` if you do not have enough RAM on your machine.
While generating the target text set the `forced_bos_token_id` to the target language id. The following
example shows how to translate English to French using the *facebook/nllb-200-distilled-600M* model.
Note that we're using the BCP-47 code for French `fra_Latn`. See [here](https://github.com/facebookresearch/flores/blob/main/flores200/README.md#languages-in-flores-200)
for the list of all BCP-47 in the Flores 200 dataset.
```python
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/nllb-moe-54b")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-moe-54b")
>>> article = "Previously, Ring's CEO, Jamie Siminoff, remarked the company started when his doorbell wasn't audible from his shop in his garage."
>>> inputs = tokenizer(article, return_tensors="pt")
>>> translated_tokens = model.generate(
... **inputs, forced_bos_token_id=tokenizer.lang_code_to_id["fra_Latn"], max_length=50
... )
>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
"Auparavant, le PDG de Ring, Jamie Siminoff, a fait remarquer que la société avait commencé lorsque sa sonnette n'était pas audible depuis son magasin dans son garage."
```
### Generating from any other language than English
English (`eng_Latn`) is set as the default language from which to translate. In order to specify that you'd like to translate from a different language,
you should specify the BCP-47 code in the `src_lang` keyword argument of the tokenizer initialization.
See example below for a translation from romanian to german:
```python
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/nllb-moe-54b", src_lang="ron_Latn")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("facebook/nllb-moe-54b")
>>> article = "Şeful ONU spune că nu există o soluţie militară în Siria"
>>> inputs = tokenizer(article, return_tensors="pt")
>>> translated_tokens = model.generate(
... **inputs, forced_bos_token_id=tokenizer.lang_code_to_id["deu_Latn"], max_length=30
... )
>>> tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
```
## Resources
- [Translation task guide](../tasks/translation)
- [Summarization task guide](../tasks/summarization)
## NllbMoeConfig
[[autodoc]] NllbMoeConfig
## NllbMoeTop2Router
[[autodoc]] NllbMoeTop2Router
- route_tokens
- forward
## NllbMoeSparseMLP
[[autodoc]] NllbMoeSparseMLP
- forward
## NllbMoeModel
[[autodoc]] NllbMoeModel
- forward
## NllbMoeForConditionalGeneration
[[autodoc]] NllbMoeForConditionalGeneration
- forward
| transformers/docs/source/en/model_doc/nllb-moe.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/nllb-moe.md",
"repo_id": "transformers",
"token_count": 2003
} | 236 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Phi
## Overview
The Phi-1 model was proposed in [Textbooks Are All You Need](https://arxiv.org/abs/2306.11644) by Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee and Yuanzhi Li.
The Phi-1.5 model was proposed in [Textbooks Are All You Need II: phi-1.5 technical report](https://arxiv.org/abs/2309.05463) by Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar and Yin Tat Lee.
### Summary
In Phi-1 and Phi-1.5 papers, the authors showed how important the quality of the data is in training relative to the model size.
They selected high quality "textbook" data alongside with synthetically generated data for training their small sized Transformer
based model Phi-1 with 1.3B parameters. Despite this small scale, phi-1 attains pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP.
They follow the same strategy for Phi-1.5 and created another 1.3B parameter model with performance on natural language tasks comparable
to models 5x larger, and surpassing most non-frontier LLMs. Phi-1.5 exhibits many of the traits of much larger LLMs such as the ability
to “think step by step” or perform some rudimentary in-context learning.
With these two experiments the authors successfully showed the huge impact of quality of training data when training machine learning models.
The abstract from the Phi-1 paper is the following:
*We introduce phi-1, a new large language model for code, with significantly smaller size than
competing models: phi-1 is a Transformer-based model with 1.3B parameters, trained for 4 days on
8 A100s, using a selection of “textbook quality” data from the web (6B tokens) and synthetically
generated textbooks and exercises with GPT-3.5 (1B tokens). Despite this small scale, phi-1 attains
pass@1 accuracy 50.6% on HumanEval and 55.5% on MBPP. It also displays surprising emergent
properties compared to phi-1-base, our model before our finetuning stage on a dataset of coding
exercises, and phi-1-small, a smaller model with 350M parameters trained with the same pipeline as
phi-1 that still achieves 45% on HumanEval.*
The abstract from the Phi-1.5 paper is the following:
*We continue the investigation into the power of smaller Transformer-based language models as
initiated by TinyStories – a 10 million parameter model that can produce coherent English – and
the follow-up work on phi-1, a 1.3 billion parameter model with Python coding performance close
to the state-of-the-art. The latter work proposed to use existing Large Language Models (LLMs) to
generate “textbook quality” data as a way to enhance the learning process compared to traditional
web data. We follow the “Textbooks Are All You Need” approach, focusing this time on common
sense reasoning in natural language, and create a new 1.3 billion parameter model named phi-1.5,
with performance on natural language tasks comparable to models 5x larger, and surpassing most
non-frontier LLMs on more complex reasoning tasks such as grade-school mathematics and basic
coding. More generally, phi-1.5 exhibits many of the traits of much larger LLMs, both good –such
as the ability to “think step by step” or perform some rudimentary in-context learning– and bad,
including hallucinations and the potential for toxic and biased generations –encouragingly though, we
are seeing improvement on that front thanks to the absence of web data. We open-source phi-1.5 to
promote further research on these urgent topics.*
This model was contributed by [Susnato Dhar](https://huggingface.co/susnato).
The original code for Phi-1, Phi-1.5 and Phi-2 can be found [here](https://huggingface.co/microsoft/phi-1), [here](https://huggingface.co/microsoft/phi-1_5) and [here](https://huggingface.co/microsoft/phi-2), respectively.
## Usage tips
- This model is quite similar to `Llama` with the main difference in [`PhiDecoderLayer`], where they used [`PhiAttention`] and [`PhiMLP`] layers in parallel configuration.
- The tokenizer used for this model is identical to the [`CodeGenTokenizer`].
## How to use Phi-2
<Tip warning={true}>
Phi-2 has been integrated in the development version (4.37.0.dev) of `transformers`. Until the official version is released through `pip`, ensure that you are doing one of the following:
* When loading the model, ensure that `trust_remote_code=True` is passed as an argument of the `from_pretrained()` function.
* Update your local `transformers` to the development version: `pip uninstall -y transformers && pip install git+https://github.com/huggingface/transformers`. The previous command is an alternative to cloning and installing from the source.
</Tip>
```python
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> model = AutoModelForCausalLM.from_pretrained("microsoft/phi-2")
>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-2")
>>> inputs = tokenizer('Can you help me write a formal email to a potential business partner proposing a joint venture?', return_tensors="pt", return_attention_mask=False)
>>> outputs = model.generate(**inputs, max_length=30)
>>> text = tokenizer.batch_decode(outputs)[0]
>>> print(text)
'Can you help me write a formal email to a potential business partner proposing a joint venture?\nInput: Company A: ABC Inc.\nCompany B: XYZ Ltd.\nJoint Venture: A new online platform for e-commerce'
```
### Example :
```python
>>> from transformers import PhiForCausalLM, AutoTokenizer
>>> # define the model and tokenizer.
>>> model = PhiForCausalLM.from_pretrained("microsoft/phi-1_5")
>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-1_5")
>>> # feel free to change the prompt to your liking.
>>> prompt = "If I were an AI that had just achieved"
>>> # apply the tokenizer.
>>> tokens = tokenizer(prompt, return_tensors="pt")
>>> # use the model to generate new tokens.
>>> generated_output = model.generate(**tokens, use_cache=True, max_new_tokens=10)
>>> tokenizer.batch_decode(generated_output)[0]
'If I were an AI that had just achieved a breakthrough in machine learning, I would be thrilled'
```
## Combining Phi and Flash Attention 2
First, make sure to install the latest version of Flash Attention 2 to include the sliding window attention feature.
```bash
pip install -U flash-attn --no-build-isolation
```
Make also sure that you have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of flash-attn repository. Make also sure to load your model in half-precision (e.g. `torch.float16``)
To load and run a model using Flash Attention 2, refer to the snippet below:
```python
>>> import torch
>>> from transformers import PhiForCausalLM, AutoTokenizer
>>> # define the model and tokenizer and push the model and tokens to the GPU.
>>> model = PhiForCausalLM.from_pretrained("microsoft/phi-1_5", torch_dtype=torch.float16, attn_implementation="flash_attention_2").to("cuda")
>>> tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-1_5")
>>> # feel free to change the prompt to your liking.
>>> prompt = "If I were an AI that had just achieved"
>>> # apply the tokenizer.
>>> tokens = tokenizer(prompt, return_tensors="pt").to("cuda")
>>> # use the model to generate new tokens.
>>> generated_output = model.generate(**tokens, use_cache=True, max_new_tokens=10)
>>> tokenizer.batch_decode(generated_output)[0]
'If I were an AI that had just achieved a breakthrough in machine learning, I would be thrilled'
```
### Expected speedups
Below is an expected speedup diagram that compares pure inference time between the native implementation in transformers using `microsoft/phi-1` checkpoint and the Flash Attention 2 version of the model using a sequence length of 2048.
<div style="text-align: center">
<img src="https://huggingface.co/datasets/ybelkada/documentation-images/resolve/main/phi_1_speedup_plot.jpg">
</div>
## PhiConfig
[[autodoc]] PhiConfig
<frameworkcontent>
<pt>
## PhiModel
[[autodoc]] PhiModel
- forward
## PhiForCausalLM
[[autodoc]] PhiForCausalLM
- forward
- generate
## PhiForSequenceClassification
[[autodoc]] PhiForSequenceClassification
- forward
## PhiForTokenClassification
[[autodoc]] PhiForTokenClassification
- forward
</pt>
</frameworkcontent>
| transformers/docs/source/en/model_doc/phi.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/phi.md",
"repo_id": "transformers",
"token_count": 2611
} | 237 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# ResNet
## Overview
The ResNet model was proposed in [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by Kaiming He, Xiangyu Zhang, Shaoqing Ren and Jian Sun. Our implementation follows the small changes made by [Nvidia](https://catalog.ngc.nvidia.com/orgs/nvidia/resources/resnet_50_v1_5_for_pytorch), we apply the `stride=2` for downsampling in bottleneck's `3x3` conv and not in the first `1x1`. This is generally known as "ResNet v1.5".
ResNet introduced residual connections, they allow to train networks with an unseen number of layers (up to 1000). ResNet won the 2015 ILSVRC & COCO competition, one important milestone in deep computer vision.
The abstract from the paper is the following:
*Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers---8x deeper than VGG nets but still having lower complexity. An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers.
The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions, where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.*
The figure below illustrates the architecture of ResNet. Taken from the [original paper](https://arxiv.org/abs/1512.03385).
<img width="600" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/resnet_architecture.png"/>
This model was contributed by [Francesco](https://huggingface.co/Francesco). The TensorFlow version of this model was added by [amyeroberts](https://huggingface.co/amyeroberts). The original code can be found [here](https://github.com/KaimingHe/deep-residual-networks).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with ResNet.
<PipelineTag pipeline="image-classification"/>
- [`ResNetForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## ResNetConfig
[[autodoc]] ResNetConfig
<frameworkcontent>
<pt>
## ResNetModel
[[autodoc]] ResNetModel
- forward
## ResNetForImageClassification
[[autodoc]] ResNetForImageClassification
- forward
</pt>
<tf>
## TFResNetModel
[[autodoc]] TFResNetModel
- call
## TFResNetForImageClassification
[[autodoc]] TFResNetForImageClassification
- call
</tf>
<jax>
## FlaxResNetModel
[[autodoc]] FlaxResNetModel
- __call__
## FlaxResNetForImageClassification
[[autodoc]] FlaxResNetForImageClassification
- __call__
</jax>
</frameworkcontent>
| transformers/docs/source/en/model_doc/resnet.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/resnet.md",
"repo_id": "transformers",
"token_count": 1253
} | 238 |
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Speech2Text
## Overview
The Speech2Text model was proposed in [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Dmytro Okhonko, Juan Pino. It's a
transformer-based seq2seq (encoder-decoder) model designed for end-to-end Automatic Speech Recognition (ASR) and Speech
Translation (ST). It uses a convolutional downsampler to reduce the length of speech inputs by 3/4th before they are
fed into the encoder. The model is trained with standard autoregressive cross-entropy loss and generates the
transcripts/translations autoregressively. Speech2Text has been fine-tuned on several datasets for ASR and ST:
[LibriSpeech](http://www.openslr.org/12), [CoVoST 2](https://github.com/facebookresearch/covost), [MuST-C](https://ict.fbk.eu/must-c/).
This model was contributed by [valhalla](https://huggingface.co/valhalla). The original code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text).
## Inference
Speech2Text is a speech model that accepts a float tensor of log-mel filter-bank features extracted from the speech
signal. It's a transformer-based seq2seq model, so the transcripts/translations are generated autoregressively. The
`generate()` method can be used for inference.
The [`Speech2TextFeatureExtractor`] class is responsible for extracting the log-mel filter-bank
features. The [`Speech2TextProcessor`] wraps [`Speech2TextFeatureExtractor`] and
[`Speech2TextTokenizer`] into a single instance to both extract the input features and decode the
predicted token ids.
The feature extractor depends on `torchaudio` and the tokenizer depends on `sentencepiece` so be sure to
install those packages before running the examples. You could either install those as extra speech dependencies with
`pip install transformers"[speech, sentencepiece]"` or install the packages separately with `pip install torchaudio sentencepiece`. Also `torchaudio` requires the development version of the [libsndfile](http://www.mega-nerd.com/libsndfile/) package which can be installed via a system package manager. On Ubuntu it can
be installed as follows: `apt install libsndfile1-dev`
- ASR and Speech Translation
```python
>>> import torch
>>> from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
>>> from datasets import load_dataset
>>> model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-small-librispeech-asr")
>>> processor = Speech2TextProcessor.from_pretrained("facebook/s2t-small-librispeech-asr")
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
>>> inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["sampling_rate"], return_tensors="pt")
>>> generated_ids = model.generate(inputs["input_features"], attention_mask=inputs["attention_mask"])
>>> transcription = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> transcription
['mister quilter is the apostle of the middle classes and we are glad to welcome his gospel']
```
- Multilingual speech translation
For multilingual speech translation models, `eos_token_id` is used as the `decoder_start_token_id` and
the target language id is forced as the first generated token. To force the target language id as the first
generated token, pass the `forced_bos_token_id` parameter to the `generate()` method. The following
example shows how to transate English speech to French text using the *facebook/s2t-medium-mustc-multilingual-st*
checkpoint.
```python
>>> import torch
>>> from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
>>> from datasets import load_dataset
>>> model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-medium-mustc-multilingual-st")
>>> processor = Speech2TextProcessor.from_pretrained("facebook/s2t-medium-mustc-multilingual-st")
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
>>> inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["sampling_rate"], return_tensors="pt")
>>> generated_ids = model.generate(
... inputs["input_features"],
... attention_mask=inputs["attention_mask"],
... forced_bos_token_id=processor.tokenizer.lang_code_to_id["fr"],
... )
>>> translation = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> translation
["(Vidéo) Si M. Kilder est l'apossible des classes moyennes, et nous sommes heureux d'être accueillis dans son évangile."]
```
See the [model hub](https://huggingface.co/models?filter=speech_to_text) to look for Speech2Text checkpoints.
## Speech2TextConfig
[[autodoc]] Speech2TextConfig
## Speech2TextTokenizer
[[autodoc]] Speech2TextTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## Speech2TextFeatureExtractor
[[autodoc]] Speech2TextFeatureExtractor
- __call__
## Speech2TextProcessor
[[autodoc]] Speech2TextProcessor
- __call__
- from_pretrained
- save_pretrained
- batch_decode
- decode
<frameworkcontent>
<pt>
## Speech2TextModel
[[autodoc]] Speech2TextModel
- forward
## Speech2TextForConditionalGeneration
[[autodoc]] Speech2TextForConditionalGeneration
- forward
</pt>
<tf>
## TFSpeech2TextModel
[[autodoc]] TFSpeech2TextModel
- call
## TFSpeech2TextForConditionalGeneration
[[autodoc]] TFSpeech2TextForConditionalGeneration
- call
</tf>
</frameworkcontent>
| transformers/docs/source/en/model_doc/speech_to_text.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/speech_to_text.md",
"repo_id": "transformers",
"token_count": 1920
} | 239 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Wav2Vec2-Conformer
## Overview
The Wav2Vec2-Conformer was added to an updated version of [fairseq S2T: Fast Speech-to-Text Modeling with fairseq](https://arxiv.org/abs/2010.05171) by Changhan Wang, Yun Tang, Xutai Ma, Anne Wu, Sravya Popuri, Dmytro Okhonko, Juan Pino.
The official results of the model can be found in Table 3 and Table 4 of the paper.
The Wav2Vec2-Conformer weights were released by the Meta AI team within the [Fairseq library](https://github.com/pytorch/fairseq/blob/main/examples/wav2vec/README.md#pre-trained-models).
This model was contributed by [patrickvonplaten](https://huggingface.co/patrickvonplaten).
The original code can be found [here](https://github.com/pytorch/fairseq/tree/main/examples/wav2vec).
## Usage tips
- Wav2Vec2-Conformer follows the same architecture as Wav2Vec2, but replaces the *Attention*-block with a *Conformer*-block
as introduced in [Conformer: Convolution-augmented Transformer for Speech Recognition](https://arxiv.org/abs/2005.08100).
- For the same number of layers, Wav2Vec2-Conformer requires more parameters than Wav2Vec2, but also yields
an improved word error rate.
- Wav2Vec2-Conformer uses the same tokenizer and feature extractor as Wav2Vec2.
- Wav2Vec2-Conformer can use either no relative position embeddings, Transformer-XL-like position embeddings, or
rotary position embeddings by setting the correct `config.position_embeddings_type`.
## Resources
- [Audio classification task guide](../tasks/audio_classification)
- [Automatic speech recognition task guide](../tasks/asr)
## Wav2Vec2ConformerConfig
[[autodoc]] Wav2Vec2ConformerConfig
## Wav2Vec2Conformer specific outputs
[[autodoc]] models.wav2vec2_conformer.modeling_wav2vec2_conformer.Wav2Vec2ConformerForPreTrainingOutput
## Wav2Vec2ConformerModel
[[autodoc]] Wav2Vec2ConformerModel
- forward
## Wav2Vec2ConformerForCTC
[[autodoc]] Wav2Vec2ConformerForCTC
- forward
## Wav2Vec2ConformerForSequenceClassification
[[autodoc]] Wav2Vec2ConformerForSequenceClassification
- forward
## Wav2Vec2ConformerForAudioFrameClassification
[[autodoc]] Wav2Vec2ConformerForAudioFrameClassification
- forward
## Wav2Vec2ConformerForXVector
[[autodoc]] Wav2Vec2ConformerForXVector
- forward
## Wav2Vec2ConformerForPreTraining
[[autodoc]] Wav2Vec2ConformerForPreTraining
- forward
| transformers/docs/source/en/model_doc/wav2vec2-conformer.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/wav2vec2-conformer.md",
"repo_id": "transformers",
"token_count": 990
} | 240 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# YOLOS
## Overview
The YOLOS model was proposed in [You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection](https://arxiv.org/abs/2106.00666) by Yuxin Fang, Bencheng Liao, Xinggang Wang, Jiemin Fang, Jiyang Qi, Rui Wu, Jianwei Niu, Wenyu Liu.
YOLOS proposes to just leverage the plain [Vision Transformer (ViT)](vit) for object detection, inspired by DETR. It turns out that a base-sized encoder-only Transformer can also achieve 42 AP on COCO, similar to DETR and much more complex frameworks such as Faster R-CNN.
The abstract from the paper is the following:
*Can Transformer perform 2D object- and region-level recognition from a pure sequence-to-sequence perspective with minimal knowledge about the 2D spatial structure? To answer this question, we present You Only Look at One Sequence (YOLOS), a series of object detection models based on the vanilla Vision Transformer with the fewest possible modifications, region priors, as well as inductive biases of the target task. We find that YOLOS pre-trained on the mid-sized ImageNet-1k dataset only can already achieve quite competitive performance on the challenging COCO object detection benchmark, e.g., YOLOS-Base directly adopted from BERT-Base architecture can obtain 42.0 box AP on COCO val. We also discuss the impacts as well as limitations of current pre-train schemes and model scaling strategies for Transformer in vision through YOLOS.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/yolos_architecture.png"
alt="drawing" width="600"/>
<small> YOLOS architecture. Taken from the <a href="https://arxiv.org/abs/2106.00666">original paper</a>.</small>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/hustvl/YOLOS).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with YOLOS.
<PipelineTag pipeline="object-detection"/>
- All example notebooks illustrating inference + fine-tuning [`YolosForObjectDetection`] on a custom dataset can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/YOLOS).
- See also: [Object detection task guide](../tasks/object_detection)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<Tip>
Use [`YolosImageProcessor`] for preparing images (and optional targets) for the model. Contrary to [DETR](detr), YOLOS doesn't require a `pixel_mask` to be created.
</Tip>
## YolosConfig
[[autodoc]] YolosConfig
## YolosImageProcessor
[[autodoc]] YolosImageProcessor
- preprocess
- pad
- post_process_object_detection
## YolosFeatureExtractor
[[autodoc]] YolosFeatureExtractor
- __call__
- pad
- post_process_object_detection
## YolosModel
[[autodoc]] YolosModel
- forward
## YolosForObjectDetection
[[autodoc]] YolosForObjectDetection
- forward
| transformers/docs/source/en/model_doc/yolos.md/0 | {
"file_path": "transformers/docs/source/en/model_doc/yolos.md",
"repo_id": "transformers",
"token_count": 1089
} | 241 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Methods and tools for efficient training on a single GPU
This guide demonstrates practical techniques that you can use to increase the efficiency of your model's training by
optimizing memory utilization, speeding up the training, or both. If you'd like to understand how GPU is utilized during
training, please refer to the [Model training anatomy](model_memory_anatomy) conceptual guide first. This guide
focuses on practical techniques.
<Tip>
If you have access to a machine with multiple GPUs, these approaches are still valid, plus you can leverage additional methods outlined in the [multi-GPU section](perf_train_gpu_many).
</Tip>
When training large models, there are two aspects that should be considered at the same time:
* Data throughput/training time
* Model performance
Maximizing the throughput (samples/second) leads to lower training cost. This is generally achieved by utilizing the GPU
as much as possible and thus filling GPU memory to its limit. If the desired batch size exceeds the limits of the GPU memory,
the memory optimization techniques, such as gradient accumulation, can help.
However, if the preferred batch size fits into memory, there's no reason to apply memory-optimizing techniques because they can
slow down the training. Just because one can use a large batch size, does not necessarily mean they should. As part of
hyperparameter tuning, you should determine which batch size yields the best results and then optimize resources accordingly.
The methods and tools covered in this guide can be classified based on the effect they have on the training process:
| Method/tool | Improves training speed | Optimizes memory utilization |
|:-----------------------------------------------------------|:------------------------|:-----------------------------|
| [Batch size choice](#batch-size-choice) | Yes | Yes |
| [Gradient accumulation](#gradient-accumulation) | No | Yes |
| [Gradient checkpointing](#gradient-checkpointing) | No | Yes |
| [Mixed precision training](#mixed-precision-training) | Yes | (No) |
| [Optimizer choice](#optimizer-choice) | Yes | Yes |
| [Data preloading](#data-preloading) | Yes | No |
| [DeepSpeed Zero](#deepspeed-zero) | No | Yes |
| [torch.compile](#using-torchcompile) | Yes | No |
| [Parameter-Efficient Fine Tuning (PEFT)](#using--peft) | No | Yes |
<Tip>
Note: when using mixed precision with a small model and a large batch size, there will be some memory savings but with a
large model and a small batch size, the memory use will be larger.
</Tip>
You can combine the above methods to get a cumulative effect. These techniques are available to you whether you are
training your model with [`Trainer`] or writing a pure PyTorch loop, in which case you can [configure these optimizations
with 🤗 Accelerate](#using--accelerate).
If these methods do not result in sufficient gains, you can explore the following options:
* [Look into building your own custom Docker container with efficient software prebuilds](#efficient-software-prebuilds)
* [Consider a model that uses Mixture of Experts (MoE)](#mixture-of-experts)
* [Convert your model to BetterTransformer to leverage PyTorch native attention](#using-pytorch-native-attention-and-flash-attention)
Finally, if all of the above is still not enough, even after switching to a server-grade GPU like A100, consider moving
to a multi-GPU setup. All these approaches are still valid in a multi-GPU setup, plus you can leverage additional parallelism
techniques outlined in the [multi-GPU section](perf_train_gpu_many).
## Batch size choice
To achieve optimal performance, start by identifying the appropriate batch size. It is recommended to use batch sizes and
input/output neuron counts that are of size 2^N. Often it's a multiple of 8, but it can be
higher depending on the hardware being used and the model's dtype.
For reference, check out NVIDIA's recommendation for [input/output neuron counts](
https://docs.nvidia.com/deeplearning/performance/dl-performance-fully-connected/index.html#input-features) and
[batch size](https://docs.nvidia.com/deeplearning/performance/dl-performance-fully-connected/index.html#batch-size) for
fully connected layers (which are involved in GEMMs (General Matrix Multiplications)).
[Tensor Core Requirements](https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc)
define the multiplier based on the dtype and the hardware. For instance, for fp16 data type a multiple of 8 is recommended, unless
it's an A100 GPU, in which case use multiples of 64.
For parameters that are small, consider also [Dimension Quantization Effects](https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#dim-quantization).
This is where tiling happens and the right multiplier can have a significant speedup.
## Gradient Accumulation
The **gradient accumulation** method aims to calculate gradients in smaller increments instead of computing them for the
entire batch at once. This approach involves iteratively calculating gradients in smaller batches by performing forward
and backward passes through the model and accumulating the gradients during the process. Once a sufficient number of
gradients have been accumulated, the model's optimization step is executed. By employing gradient accumulation, it
becomes possible to increase the **effective batch size** beyond the limitations imposed by the GPU's memory capacity.
However, it is important to note that the additional forward and backward passes introduced by gradient accumulation can
slow down the training process.
You can enable gradient accumulation by adding the `gradient_accumulation_steps` argument to [`TrainingArguments`]:
```py
training_args = TrainingArguments(per_device_train_batch_size=1, gradient_accumulation_steps=4, **default_args)
```
In the above example, your effective batch size becomes 4.
Alternatively, use 🤗 Accelerate to gain full control over the training loop. Find the 🤗 Accelerate example
[further down in this guide](#using--accelerate).
While it is advised to max out GPU usage as much as possible, a high number of gradient accumulation steps can
result in a more pronounced training slowdown. Consider the following example. Let's say, the `per_device_train_batch_size=4`
without gradient accumulation hits the GPU's limit. If you would like to train with batches of size 64, do not set the
`per_device_train_batch_size` to 1 and `gradient_accumulation_steps` to 64. Instead, keep `per_device_train_batch_size=4`
and set `gradient_accumulation_steps=16`. This results in the same effective batch size while making better use of
the available GPU resources.
For additional information, please refer to batch size and gradient accumulation benchmarks for [RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004392537)
and [A100](https://github.com/huggingface/transformers/issues/15026#issuecomment-1005033957).
## Gradient Checkpointing
Some large models may still face memory issues even when the batch size is set to 1 and gradient accumulation is used.
This is because there are other components that also require memory storage.
Saving all activations from the forward pass in order to compute the gradients during the backward pass can result in
significant memory overhead. The alternative approach of discarding the activations and recalculating them when needed
during the backward pass, would introduce a considerable computational overhead and slow down the training process.
**Gradient checkpointing** offers a compromise between these two approaches and saves strategically selected activations
throughout the computational graph so only a fraction of the activations need to be re-computed for the gradients. For
an in-depth explanation of gradient checkpointing, refer to [this great article](https://medium.com/tensorflow/fitting-larger-networks-into-memory-583e3c758ff9).
To enable gradient checkpointing in the [`Trainer`], pass the corresponding a flag to [`TrainingArguments`]:
```py
training_args = TrainingArguments(
per_device_train_batch_size=1, gradient_accumulation_steps=4, gradient_checkpointing=True, **default_args
)
```
Alternatively, use 🤗 Accelerate - find the 🤗 Accelerate example [further in this guide](#using--accelerate).
<Tip>
While gradient checkpointing may improve memory efficiency, it slows training by approximately 20%.
</Tip>
## Mixed precision training
**Mixed precision training** is a technique that aims to optimize the computational efficiency of training models by
utilizing lower-precision numerical formats for certain variables. Traditionally, most models use 32-bit floating point
precision (fp32 or float32) to represent and process variables. However, not all variables require this high precision
level to achieve accurate results. By reducing the precision of certain variables to lower numerical formats like 16-bit
floating point (fp16 or float16), we can speed up the computations. Because in this approach some computations are performed
in half-precision, while some are still in full precision, the approach is called mixed precision training.
Most commonly mixed precision training is achieved by using fp16 (float16) data types, however, some GPU architectures
(such as the Ampere architecture) offer bf16 and tf32 (CUDA internal data type) data types. Check
out the [NVIDIA Blog](https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/) to learn more about
the differences between these data types.
### fp16
The main advantage of mixed precision training comes from saving the activations in half precision (fp16).
Although the gradients are also computed in half precision they are converted back to full precision for the optimization
step so no memory is saved here.
While mixed precision training results in faster computations, it can also lead to more GPU memory being utilized, especially for small batch sizes.
This is because the model is now present on the GPU in both 16-bit and 32-bit precision (1.5x the original model on the GPU).
To enable mixed precision training, set the `fp16` flag to `True`:
```py
training_args = TrainingArguments(per_device_train_batch_size=4, fp16=True, **default_args)
```
If you prefer to use 🤗 Accelerate, find the 🤗 Accelerate example [further in this guide](#using--accelerate).
### BF16
If you have access to an Ampere or newer hardware you can use bf16 for mixed precision training and evaluation. While
bf16 has a worse precision than fp16, it has a much bigger dynamic range. In fp16 the biggest number you can have
is `65535` and any number above that will result in an overflow. A bf16 number can be as large as `3.39e+38` (!) which
is about the same as fp32 - because both have 8-bits used for the numerical range.
You can enable BF16 in the 🤗 Trainer with:
```python
training_args = TrainingArguments(bf16=True, **default_args)
```
### TF32
The Ampere hardware uses a magical data type called tf32. It has the same numerical range as fp32 (8-bits), but instead
of 23 bits precision it has only 10 bits (same as fp16) and uses only 19 bits in total. It's "magical" in the sense that
you can use the normal fp32 training and/or inference code and by enabling tf32 support you can get up to 3x throughput
improvement. All you need to do is to add the following to your code:
```python
import torch
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
```
CUDA will automatically switch to using tf32 instead of fp32 where possible, assuming that the used GPU is from the Ampere series.
According to [NVIDIA research](https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/), the
majority of machine learning training workloads show the same perplexity and convergence with tf32 training as with fp32.
If you're already using fp16 or bf16 mixed precision it may help with the throughput as well.
You can enable this mode in the 🤗 Trainer:
```python
TrainingArguments(tf32=True, **default_args)
```
<Tip>
tf32 can't be accessed directly via `tensor.to(dtype=torch.tf32)` because it is an internal CUDA data type. You need `torch>=1.7` to use tf32 data types.
</Tip>
For additional information on tf32 vs other precisions, please refer to the following benchmarks:
[RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004390803) and
[A100](https://github.com/huggingface/transformers/issues/15026#issuecomment-1004543189).
## Flash Attention 2
You can speedup the training throughput by using Flash Attention 2 integration in transformers. Check out the appropriate section in the [single GPU section](./perf_infer_gpu_one#Flash-Attention-2) to learn more about how to load a model with Flash Attention 2 modules.
## Optimizer choice
The most common optimizer used to train transformer models is Adam or AdamW (Adam with weight decay). Adam achieves
good convergence by storing the rolling average of the previous gradients; however, it adds an additional memory
footprint of the order of the number of model parameters. To remedy this, you can use an alternative optimizer.
For example if you have [NVIDIA/apex](https://github.com/NVIDIA/apex) installed for NVIDIA GPUs, or [ROCmSoftwarePlatform/apex](https://github.com/ROCmSoftwarePlatform/apex) for AMD GPUs, `adamw_apex_fused` will give you the
fastest training experience among all supported AdamW optimizers.
[`Trainer`] integrates a variety of optimizers that can be used out of box: `adamw_hf`, `adamw_torch`, `adamw_torch_fused`,
`adamw_apex_fused`, `adamw_anyprecision`, `adafactor`, or `adamw_bnb_8bit`. More optimizers can be plugged in via a third-party implementation.
Let's take a closer look at two alternatives to AdamW optimizer:
1. `adafactor` which is available in [`Trainer`]
2. `adamw_bnb_8bit` is also available in Trainer, but a third-party integration is provided below for demonstration.
For comparison, for a 3B-parameter model, like “google-t5/t5-3b”:
* A standard AdamW optimizer will need 24GB of GPU memory because it uses 8 bytes for each parameter (8*3 => 24GB)
* Adafactor optimizer will need more than 12GB. It uses slightly more than 4 bytes for each parameter, so 4*3 and then some extra.
* 8bit BNB quantized optimizer will use only (2*3) 6GB if all optimizer states are quantized.
### Adafactor
Adafactor doesn't store rolling averages for each element in weight matrices. Instead, it keeps aggregated information
(sums of rolling averages row- and column-wise), significantly reducing its footprint. However, compared to Adam,
Adafactor may have slower convergence in certain cases.
You can switch to Adafactor by setting `optim="adafactor"` in [`TrainingArguments`]:
```py
training_args = TrainingArguments(per_device_train_batch_size=4, optim="adafactor", **default_args)
```
Combined with other approaches (gradient accumulation, gradient checkpointing, and mixed precision training)
you can notice up to 3x improvement while maintaining the throughput! However, as mentioned before, the convergence of
Adafactor can be worse than Adam.
### 8-bit Adam
Instead of aggregating optimizer states like Adafactor, 8-bit Adam keeps the full state and quantizes it. Quantization
means that it stores the state with lower precision and dequantizes it only for the optimization. This is similar to the
idea behind mixed precision training.
To use `adamw_bnb_8bit`, you simply need to set `optim="adamw_bnb_8bit"` in [`TrainingArguments`]:
```py
training_args = TrainingArguments(per_device_train_batch_size=4, optim="adamw_bnb_8bit", **default_args)
```
However, we can also use a third-party implementation of the 8-bit optimizer for demonstration purposes to see how that can be integrated.
First, follow the installation guide in the GitHub [repo](https://github.com/TimDettmers/bitsandbytes) to install the `bitsandbytes` library
that implements the 8-bit Adam optimizer.
Next you need to initialize the optimizer. This involves two steps:
* First, group the model's parameters into two groups - one where weight decay should be applied, and the other one where it should not. Usually, biases and layer norm parameters are not weight decayed.
* Then do some argument housekeeping to use the same parameters as the previously used AdamW optimizer.
```py
import bitsandbytes as bnb
from torch import nn
from transformers.trainer_pt_utils import get_parameter_names
training_args = TrainingArguments(per_device_train_batch_size=4, **default_args)
decay_parameters = get_parameter_names(model, [nn.LayerNorm])
decay_parameters = [name for name in decay_parameters if "bias" not in name]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if n in decay_parameters],
"weight_decay": training_args.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if n not in decay_parameters],
"weight_decay": 0.0,
},
]
optimizer_kwargs = {
"betas": (training_args.adam_beta1, training_args.adam_beta2),
"eps": training_args.adam_epsilon,
}
optimizer_kwargs["lr"] = training_args.learning_rate
adam_bnb_optim = bnb.optim.Adam8bit(
optimizer_grouped_parameters,
betas=(training_args.adam_beta1, training_args.adam_beta2),
eps=training_args.adam_epsilon,
lr=training_args.learning_rate,
)
```
Finally, pass the custom optimizer as an argument to the `Trainer`:
```py
trainer = Trainer(model=model, args=training_args, train_dataset=ds, optimizers=(adam_bnb_optim, None))
```
Combined with other approaches (gradient accumulation, gradient checkpointing, and mixed precision training),
you can expect to get about a 3x memory improvement and even slightly higher throughput as using Adafactor.
### multi_tensor
pytorch-nightly introduced `torch.optim._multi_tensor` which should significantly speed up the optimizers for situations
with lots of small feature tensors. It should eventually become the default, but if you want to experiment with it sooner, take a look at this GitHub [issue](https://github.com/huggingface/transformers/issues/9965).
## Data preloading
One of the important requirements to reach great training speed is the ability to feed the GPU at the maximum speed it
can handle. By default, everything happens in the main process, and it might not be able to read the data from disk fast
enough, and thus create a bottleneck, leading to GPU under-utilization. Configure the following arguments to reduce the bottleneck:
- `DataLoader(pin_memory=True, ...)` - ensures the data gets preloaded into the pinned memory on CPU and typically leads to much faster transfers from CPU to GPU memory.
- `DataLoader(num_workers=4, ...)` - spawn several workers to preload data faster. During training, watch the GPU utilization stats; if it's far from 100%, experiment with increasing the number of workers. Of course, the problem could be elsewhere, so many workers won't necessarily lead to better performance.
When using [`Trainer`], the corresponding [`TrainingArguments`] are: `dataloader_pin_memory` (`True` by default), and `dataloader_num_workers` (defaults to `0`).
## DeepSpeed ZeRO
DeepSpeed is an open-source deep learning optimization library that is integrated with 🤗 Transformers and 🤗 Accelerate.
It provides a wide range of features and optimizations designed to improve the efficiency and scalability of large-scale
deep learning training.
If your model fits onto a single GPU and you have enough space to fit a small batch size, you don't need to use DeepSpeed
as it'll only slow things down. However, if the model doesn't fit onto a single GPU or you can't fit a small batch, you can
leverage DeepSpeed ZeRO + CPU Offload, or NVMe Offload for much larger models. In this case, you need to separately
[install the library](main_classes/deepspeed#installation), then follow one of the guides to create a configuration file
and launch DeepSpeed:
* For an in-depth guide on DeepSpeed integration with [`Trainer`], review [the corresponding documentation](main_classes/deepspeed), specifically the
[section for a single GPU](main_classes/deepspeed#deployment-with-one-gpu). Some adjustments are required to use DeepSpeed in a notebook; please take a look at the [corresponding guide](main_classes/deepspeed#deployment-in-notebooks).
* If you prefer to use 🤗 Accelerate, refer to [🤗 Accelerate DeepSpeed guide](https://huggingface.co/docs/accelerate/en/usage_guides/deepspeed).
## Using torch.compile
PyTorch 2.0 introduced a new compile function that doesn't require any modification to existing PyTorch code but can
optimize your code by adding a single line of code: `model = torch.compile(model)`.
If using [`Trainer`], you only need `to` pass the `torch_compile` option in the [`TrainingArguments`]:
```python
training_args = TrainingArguments(torch_compile=True, **default_args)
```
`torch.compile` uses Python's frame evaluation API to automatically create a graph from existing PyTorch programs. After
capturing the graph, different backends can be deployed to lower the graph to an optimized engine.
You can find more details and benchmarks in [PyTorch documentation](https://pytorch.org/get-started/pytorch-2.0/).
`torch.compile` has a growing list of backends, which can be found in by calling `torchdynamo.list_backends()`, each of which with its optional dependencies.
Choose which backend to use by specifying it via `torch_compile_backend` in the [`TrainingArguments`]. Some of the most commonly used backends are:
**Debugging backends**:
* `dynamo.optimize("eager")` - Uses PyTorch to run the extracted GraphModule. This is quite useful in debugging TorchDynamo issues.
* `dynamo.optimize("aot_eager")` - Uses AotAutograd with no compiler, i.e, just using PyTorch eager for the AotAutograd's extracted forward and backward graphs. This is useful for debugging, and unlikely to give speedups.
**Training & inference backends**:
* `dynamo.optimize("inductor")` - Uses TorchInductor backend with AotAutograd and cudagraphs by leveraging codegened Triton kernels [Read more](https://dev-discuss.pytorch.org/t/torchinductor-a-pytorch-native-compiler-with-define-by-run-ir-and-symbolic-shapes/747)
* `dynamo.optimize("nvfuser")` - nvFuser with TorchScript. [Read more](https://dev-discuss.pytorch.org/t/tracing-with-primitives-update-1-nvfuser-and-its-primitives/593)
* `dynamo.optimize("aot_nvfuser")` - nvFuser with AotAutograd. [Read more](https://dev-discuss.pytorch.org/t/tracing-with-primitives-update-1-nvfuser-and-its-primitives/593)
* `dynamo.optimize("aot_cudagraphs")` - cudagraphs with AotAutograd. [Read more](https://github.com/pytorch/torchdynamo/pull/757)
**Inference-only backend**s:
* `dynamo.optimize("ofi")` - Uses Torchscript optimize_for_inference. [Read more](https://pytorch.org/docs/stable/generated/torch.jit.optimize_for_inference.html)
* `dynamo.optimize("fx2trt")` - Uses NVIDIA TensorRT for inference optimizations. [Read more](https://pytorch.org/TensorRT/tutorials/getting_started_with_fx_path.html)
* `dynamo.optimize("onnxrt")` - Uses ONNXRT for inference on CPU/GPU. [Read more](https://onnxruntime.ai/)
* `dynamo.optimize("ipex")` - Uses IPEX for inference on CPU. [Read more](https://github.com/intel/intel-extension-for-pytorch)
For an example of using `torch.compile` with 🤗 Transformers, check out this [blog post on fine-tuning a BERT model for Text Classification using the newest PyTorch 2.0 features](https://www.philschmid.de/getting-started-pytorch-2-0-transformers)
## Using 🤗 PEFT
[Parameter-Efficient Fine Tuning (PEFT)](https://huggingface.co/blog/peft) methods freeze the pretrained model parameters during fine-tuning and add a small number of trainable parameters (the adapters) on top of it.
As a result the [memory associated to the optimizer states and gradients](https://huggingface.co/docs/transformers/model_memory_anatomy#anatomy-of-models-memory) are greatly reduced.
For example with a vanilla AdamW, the memory requirement for the optimizer state would be:
* fp32 copy of parameters: 4 bytes/param
* Momentum: 4 bytes/param
* Variance: 4 bytes/param
Suppose a model with 7B parameters and 200 millions parameters injected with [Low Rank Adapters](https://huggingface.co/docs/peft/conceptual_guides/lora).
The memory requirement for the optimizer state of the plain model would be 12 * 7 = 84 GB (assuming 7B trainable parameters).
Adding Lora increases slightly the memory associated to the model weights and substantially decreases memory requirement for the optimizer state to 12 * 0.2 = 2.4GB.
Read more about PEFT and its detailed usage in [the PEFT documentation](https://huggingface.co/docs/peft/) or [PEFT repository](https://github.com/huggingface/peft).
## Using 🤗 Accelerate
With [🤗 Accelerate](https://huggingface.co/docs/accelerate/index) you can use the above methods while gaining full
control over the training loop and can essentially write the loop in pure PyTorch with some minor modifications.
Suppose you have combined the methods in the [`TrainingArguments`] like so:
```py
training_args = TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
fp16=True,
**default_args,
)
```
The full example training loop with 🤗 Accelerate is only a handful of lines of code long:
```py
from accelerate import Accelerator
from torch.utils.data.dataloader import DataLoader
dataloader = DataLoader(ds, batch_size=training_args.per_device_train_batch_size)
if training_args.gradient_checkpointing:
model.gradient_checkpointing_enable()
accelerator = Accelerator(fp16=training_args.fp16)
model, optimizer, dataloader = accelerator.prepare(model, adam_bnb_optim, dataloader)
model.train()
for step, batch in enumerate(dataloader, start=1):
loss = model(**batch).loss
loss = loss / training_args.gradient_accumulation_steps
accelerator.backward(loss)
if step % training_args.gradient_accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
```
First we wrap the dataset in a [`DataLoader`](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader).
Then we can enable gradient checkpointing by calling the model's [`~PreTrainedModel.gradient_checkpointing_enable`] method.
When we initialize the [`Accelerator`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator)
we can specify if we want to use mixed precision training and it will take care of it for us in the [`prepare`] call.
During the [`prepare`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.prepare)
call the dataloader will also be distributed across workers should we use multiple GPUs. We use the same [8-bit optimizer](#8-bit-adam) from the earlier example.
Finally, we can add the main training loop. Note that the `backward` call is handled by 🤗 Accelerate. We can also see
how gradient accumulation works: we normalize the loss, so we get the average at the end of accumulation and once we have
enough steps we run the optimization.
Implementing these optimization techniques with 🤗 Accelerate only takes a handful of lines of code and comes with the
benefit of more flexibility in the training loop. For a full documentation of all features have a look at the
[Accelerate documentation](https://huggingface.co/docs/accelerate/index).
## Efficient Software Prebuilds
PyTorch's [pip and conda builds](https://pytorch.org/get-started/locally/#start-locally) come prebuilt with the cuda toolkit
which is enough to run PyTorch, but it is insufficient if you need to build cuda extensions.
At times, additional efforts may be required to pre-build some components. For instance, if you're using libraries like `apex` that
don't come pre-compiled. In other situations figuring out how to install the right cuda toolkit system-wide can be complicated.
To address these scenarios PyTorch and NVIDIA released a new version of NGC docker container which already comes with
everything prebuilt. You just need to install your programs on it, and it will run out of the box.
This approach is also useful if you want to tweak the pytorch source and/or make a new customized build.
To find the docker image version you want start [with PyTorch release notes](https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/),
choose one of the latest monthly releases. Go into the release's notes for the desired release, check that the environment's
components are matching your needs (including NVIDIA Driver requirements!) and then at the very top of that document go
to the corresponding NGC page. If for some reason you get lost, here is [the index of all PyTorch NGC images](https://ngc.nvidia.com/catalog/containers/nvidia:pytorch).
Next follow the instructions to download and deploy the docker image.
## Mixture of Experts
Some recent papers reported a 4-5x training speedup and a faster inference by integrating
Mixture of Experts (MoE) into the Transformer models.
Since it has been discovered that more parameters lead to better performance, this technique allows to increase the
number of parameters by an order of magnitude without increasing training costs.
In this approach every other FFN layer is replaced with a MoE Layer which consists of many experts, with a gated function
that trains each expert in a balanced way depending on the input token's position in a sequence.

(source: [GLAM](https://ai.googleblog.com/2021/12/more-efficient-in-context-learning-with.html))
You can find exhaustive details and comparison tables in the papers listed at the end of this section.
The main drawback of this approach is that it requires staggering amounts of GPU memory - almost an order of magnitude
larger than its dense equivalent. Various distillation and approaches are proposed to how to overcome the much higher memory requirements.
There is direct trade-off though, you can use just a few experts with a 2-3x smaller base model instead of dozens or
hundreds experts leading to a 5x smaller model and thus increase the training speed moderately while increasing the
memory requirements moderately as well.
Most related papers and implementations are built around Tensorflow/TPUs:
- [GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding](https://arxiv.org/abs/2006.16668)
- [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961)
- [GLaM: Generalist Language Model (GLaM)](https://ai.googleblog.com/2021/12/more-efficient-in-context-learning-with.html)
And for Pytorch DeepSpeed has built one as well: [DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale](https://arxiv.org/abs/2201.05596), [Mixture of Experts](https://www.deepspeed.ai/tutorials/mixture-of-experts/) - blog posts: [1](https://www.microsoft.com/en-us/research/blog/deepspeed-powers-8x-larger-moe-model-training-with-high-performance/), [2](https://www.microsoft.com/en-us/research/publication/scalable-and-efficient-moe-training-for-multitask-multilingual-models/) and specific deployment with large transformer-based natural language generation models: [blog post](https://www.deepspeed.ai/2021/12/09/deepspeed-moe-nlg.html), [Megatron-Deepspeed branch](https://github.com/microsoft/Megatron-DeepSpeed/tree/moe-training).
## Using PyTorch native attention and Flash Attention
PyTorch's [`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html) (SDPA) can also call FlashAttention and memory-efficient attention kernels under the hood. SDPA support is currently being added natively in Transformers and is used by default for `torch>=2.1.1` when an implementation is available. Please refer to [PyTorch scaled dot product attention](https://huggingface.co/docs/transformers/perf_infer_gpu_one#pytorch-scaled-dot-product-attention) for a list of supported models and more details.
Check out this [blogpost](https://pytorch.org/blog/out-of-the-box-acceleration/) to learn more about acceleration and memory-savings with SDPA.
| transformers/docs/source/en/perf_train_gpu_one.md/0 | {
"file_path": "transformers/docs/source/en/perf_train_gpu_one.md",
"repo_id": "transformers",
"token_count": 9803
} | 242 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Automatic speech recognition
[[open-in-colab]]
<Youtube id="TksaY_FDgnk"/>
Automatic speech recognition (ASR) converts a speech signal to text, mapping a sequence of audio inputs to text outputs. Virtual assistants like Siri and Alexa use ASR models to help users everyday, and there are many other useful user-facing applications like live captioning and note-taking during meetings.
This guide will show you how to:
1. Finetune [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base) on the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset to transcribe audio to text.
2. Use your finetuned model for inference.
<Tip>
The task illustrated in this tutorial is supported by the following model architectures:
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
[Data2VecAudio](../model_doc/data2vec-audio), [Hubert](../model_doc/hubert), [M-CTC-T](../model_doc/mctct), [SEW](../model_doc/sew), [SEW-D](../model_doc/sew-d), [UniSpeech](../model_doc/unispeech), [UniSpeechSat](../model_doc/unispeech-sat), [Wav2Vec2](../model_doc/wav2vec2), [Wav2Vec2-BERT](../model_doc/wav2vec2-bert), [Wav2Vec2-Conformer](../model_doc/wav2vec2-conformer), [WavLM](../model_doc/wavlm)
<!--End of the generated tip-->
</Tip>
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers datasets evaluate jiwer
```
We encourage you to login to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to login:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Load MInDS-14 dataset
Start by loading a smaller subset of the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset from the 🤗 Datasets library. This'll give you a chance to experiment and make sure everything works before spending more time training on the full dataset.
```py
>>> from datasets import load_dataset, Audio
>>> minds = load_dataset("PolyAI/minds14", name="en-US", split="train[:100]")
```
Split the dataset's `train` split into a train and test set with the [`~Dataset.train_test_split`] method:
```py
>>> minds = minds.train_test_split(test_size=0.2)
```
Then take a look at the dataset:
```py
>>> minds
DatasetDict({
train: Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 16
})
test: Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 4
})
})
```
While the dataset contains a lot of useful information, like `lang_id` and `english_transcription`, you'll focus on the `audio` and `transcription` in this guide. Remove the other columns with the [`~datasets.Dataset.remove_columns`] method:
```py
>>> minds = minds.remove_columns(["english_transcription", "intent_class", "lang_id"])
```
Take a look at the example again:
```py
>>> minds["train"][0]
{'audio': {'array': array([-0.00024414, 0. , 0. , ..., 0.00024414,
0.00024414, 0.00024414], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'sampling_rate': 8000},
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'transcription': "hi I'm trying to use the banking app on my phone and currently my checking and savings account balance is not refreshing"}
```
There are two fields:
- `audio`: a 1-dimensional `array` of the speech signal that must be called to load and resample the audio file.
- `transcription`: the target text.
## Preprocess
The next step is to load a Wav2Vec2 processor to process the audio signal:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base")
```
The MInDS-14 dataset has a sampling rate of 8000kHz (you can find this information in its [dataset card](https://huggingface.co/datasets/PolyAI/minds14)), which means you'll need to resample the dataset to 16000kHz to use the pretrained Wav2Vec2 model:
```py
>>> minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
>>> minds["train"][0]
{'audio': {'array': array([-2.38064706e-04, -1.58618059e-04, -5.43987835e-06, ...,
2.78103951e-04, 2.38446111e-04, 1.18740834e-04], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'sampling_rate': 16000},
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'transcription': "hi I'm trying to use the banking app on my phone and currently my checking and savings account balance is not refreshing"}
```
As you can see in the `transcription` above, the text contains a mix of upper and lowercase characters. The Wav2Vec2 tokenizer is only trained on uppercase characters so you'll need to make sure the text matches the tokenizer's vocabulary:
```py
>>> def uppercase(example):
... return {"transcription": example["transcription"].upper()}
>>> minds = minds.map(uppercase)
```
Now create a preprocessing function that:
1. Calls the `audio` column to load and resample the audio file.
2. Extracts the `input_values` from the audio file and tokenize the `transcription` column with the processor.
```py
>>> def prepare_dataset(batch):
... audio = batch["audio"]
... batch = processor(audio["array"], sampling_rate=audio["sampling_rate"], text=batch["transcription"])
... batch["input_length"] = len(batch["input_values"][0])
... return batch
```
To apply the preprocessing function over the entire dataset, use 🤗 Datasets [`~datasets.Dataset.map`] function. You can speed up `map` by increasing the number of processes with the `num_proc` parameter. Remove the columns you don't need with the [`~datasets.Dataset.remove_columns`] method:
```py
>>> encoded_minds = minds.map(prepare_dataset, remove_columns=minds.column_names["train"], num_proc=4)
```
🤗 Transformers doesn't have a data collator for ASR, so you'll need to adapt the [`DataCollatorWithPadding`] to create a batch of examples. It'll also dynamically pad your text and labels to the length of the longest element in its batch (instead of the entire dataset) so they are a uniform length. While it is possible to pad your text in the `tokenizer` function by setting `padding=True`, dynamic padding is more efficient.
Unlike other data collators, this specific data collator needs to apply a different padding method to `input_values` and `labels`:
```py
>>> import torch
>>> from dataclasses import dataclass, field
>>> from typing import Any, Dict, List, Optional, Union
>>> @dataclass
... class DataCollatorCTCWithPadding:
... processor: AutoProcessor
... padding: Union[bool, str] = "longest"
... def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
... # split inputs and labels since they have to be of different lengths and need
... # different padding methods
... input_features = [{"input_values": feature["input_values"][0]} for feature in features]
... label_features = [{"input_ids": feature["labels"]} for feature in features]
... batch = self.processor.pad(input_features, padding=self.padding, return_tensors="pt")
... labels_batch = self.processor.pad(labels=label_features, padding=self.padding, return_tensors="pt")
... # replace padding with -100 to ignore loss correctly
... labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
... batch["labels"] = labels
... return batch
```
Now instantiate your `DataCollatorForCTCWithPadding`:
```py
>>> data_collator = DataCollatorCTCWithPadding(processor=processor, padding="longest")
```
## Evaluate
Including a metric during training is often helpful for evaluating your model's performance. You can quickly load a evaluation method with the 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) library. For this task, load the [word error rate](https://huggingface.co/spaces/evaluate-metric/wer) (WER) metric (see the 🤗 Evaluate [quick tour](https://huggingface.co/docs/evaluate/a_quick_tour) to learn more about how to load and compute a metric):
```py
>>> import evaluate
>>> wer = evaluate.load("wer")
```
Then create a function that passes your predictions and labels to [`~evaluate.EvaluationModule.compute`] to calculate the WER:
```py
>>> import numpy as np
>>> def compute_metrics(pred):
... pred_logits = pred.predictions
... pred_ids = np.argmax(pred_logits, axis=-1)
... pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
... pred_str = processor.batch_decode(pred_ids)
... label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
... wer = wer.compute(predictions=pred_str, references=label_str)
... return {"wer": wer}
```
Your `compute_metrics` function is ready to go now, and you'll return to it when you setup your training.
## Train
<frameworkcontent>
<pt>
<Tip>
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#train-with-pytorch-trainer)!
</Tip>
You're ready to start training your model now! Load Wav2Vec2 with [`AutoModelForCTC`]. Specify the reduction to apply with the `ctc_loss_reduction` parameter. It is often better to use the average instead of the default summation:
```py
>>> from transformers import AutoModelForCTC, TrainingArguments, Trainer
>>> model = AutoModelForCTC.from_pretrained(
... "facebook/wav2vec2-base",
... ctc_loss_reduction="mean",
... pad_token_id=processor.tokenizer.pad_token_id,
... )
```
At this point, only three steps remain:
1. Define your training hyperparameters in [`TrainingArguments`]. The only required parameter is `output_dir` which specifies where to save your model. You'll push this model to the Hub by setting `push_to_hub=True` (you need to be signed in to Hugging Face to upload your model). At the end of each epoch, the [`Trainer`] will evaluate the WER and save the training checkpoint.
2. Pass the training arguments to [`Trainer`] along with the model, dataset, tokenizer, data collator, and `compute_metrics` function.
3. Call [`~Trainer.train`] to finetune your model.
```py
>>> training_args = TrainingArguments(
... output_dir="my_awesome_asr_mind_model",
... per_device_train_batch_size=8,
... gradient_accumulation_steps=2,
... learning_rate=1e-5,
... warmup_steps=500,
... max_steps=2000,
... gradient_checkpointing=True,
... fp16=True,
... group_by_length=True,
... evaluation_strategy="steps",
... per_device_eval_batch_size=8,
... save_steps=1000,
... eval_steps=1000,
... logging_steps=25,
... load_best_model_at_end=True,
... metric_for_best_model="wer",
... greater_is_better=False,
... push_to_hub=True,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=encoded_minds["train"],
... eval_dataset=encoded_minds["test"],
... tokenizer=processor,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
>>> trainer.train()
```
Once training is completed, share your model to the Hub with the [`~transformers.Trainer.push_to_hub`] method so everyone can use your model:
```py
>>> trainer.push_to_hub()
```
</pt>
</frameworkcontent>
<Tip>
For a more in-depth example of how to finetune a model for automatic speech recognition, take a look at this blog [post](https://huggingface.co/blog/fine-tune-wav2vec2-english) for English ASR and this [post](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for multilingual ASR.
</Tip>
## Inference
Great, now that you've finetuned a model, you can use it for inference!
Load an audio file you'd like to run inference on. Remember to resample the sampling rate of the audio file to match the sampling rate of the model if you need to!
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", "en-US", split="train")
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> audio_file = dataset[0]["audio"]["path"]
```
The simplest way to try out your finetuned model for inference is to use it in a [`pipeline`]. Instantiate a `pipeline` for automatic speech recognition with your model, and pass your audio file to it:
```py
>>> from transformers import pipeline
>>> transcriber = pipeline("automatic-speech-recognition", model="stevhliu/my_awesome_asr_minds_model")
>>> transcriber(audio_file)
{'text': 'I WOUD LIKE O SET UP JOINT ACOUNT WTH Y PARTNER'}
```
<Tip>
The transcription is decent, but it could be better! Try finetuning your model on more examples to get even better results!
</Tip>
You can also manually replicate the results of the `pipeline` if you'd like:
<frameworkcontent>
<pt>
Load a processor to preprocess the audio file and transcription and return the `input` as PyTorch tensors:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("stevhliu/my_awesome_asr_mind_model")
>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
```
Pass your inputs to the model and return the logits:
```py
>>> from transformers import AutoModelForCTC
>>> model = AutoModelForCTC.from_pretrained("stevhliu/my_awesome_asr_mind_model")
>>> with torch.no_grad():
... logits = model(**inputs).logits
```
Get the predicted `input_ids` with the highest probability, and use the processor to decode the predicted `input_ids` back into text:
```py
>>> import torch
>>> predicted_ids = torch.argmax(logits, dim=-1)
>>> transcription = processor.batch_decode(predicted_ids)
>>> transcription
['I WOUL LIKE O SET UP JOINT ACOUNT WTH Y PARTNER']
```
</pt>
</frameworkcontent> | transformers/docs/source/en/tasks/asr.md/0 | {
"file_path": "transformers/docs/source/en/tasks/asr.md",
"repo_id": "transformers",
"token_count": 5105
} | 243 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Export to TorchScript
<Tip>
This is the very beginning of our experiments with TorchScript and we are still
exploring its capabilities with variable-input-size models. It is a focus of interest to
us and we will deepen our analysis in upcoming releases, with more code examples, a more
flexible implementation, and benchmarks comparing Python-based codes with compiled
TorchScript.
</Tip>
According to the [TorchScript documentation](https://pytorch.org/docs/stable/jit.html):
> TorchScript is a way to create serializable and optimizable models from PyTorch code.
There are two PyTorch modules, [JIT and
TRACE](https://pytorch.org/docs/stable/jit.html), that allow developers to export their
models to be reused in other programs like efficiency-oriented C++ programs.
We provide an interface that allows you to export 🤗 Transformers models to TorchScript
so they can be reused in a different environment than PyTorch-based Python programs.
Here, we explain how to export and use our models using TorchScript.
Exporting a model requires two things:
- model instantiation with the `torchscript` flag
- a forward pass with dummy inputs
These necessities imply several things developers should be careful about as detailed
below.
## TorchScript flag and tied weights
The `torchscript` flag is necessary because most of the 🤗 Transformers language models
have tied weights between their `Embedding` layer and their `Decoding` layer.
TorchScript does not allow you to export models that have tied weights, so it is
necessary to untie and clone the weights beforehand.
Models instantiated with the `torchscript` flag have their `Embedding` layer and
`Decoding` layer separated, which means that they should not be trained down the line.
Training would desynchronize the two layers, leading to unexpected results.
This is not the case for models that do not have a language model head, as those do not
have tied weights. These models can be safely exported without the `torchscript` flag.
## Dummy inputs and standard lengths
The dummy inputs are used for a models forward pass. While the inputs' values are
propagated through the layers, PyTorch keeps track of the different operations executed
on each tensor. These recorded operations are then used to create the *trace* of the
model.
The trace is created relative to the inputs' dimensions. It is therefore constrained by
the dimensions of the dummy input, and will not work for any other sequence length or
batch size. When trying with a different size, the following error is raised:
```
`The expanded size of the tensor (3) must match the existing size (7) at non-singleton dimension 2`
```
We recommended you trace the model with a dummy input size at least as large as the
largest input that will be fed to the model during inference. Padding can help fill the
missing values. However, since the model is traced with a larger input size, the
dimensions of the matrix will also be large, resulting in more calculations.
Be careful of the total number of operations done on each input and follow the
performance closely when exporting varying sequence-length models.
## Using TorchScript in Python
This section demonstrates how to save and load models as well as how to use the trace
for inference.
### Saving a model
To export a `BertModel` with TorchScript, instantiate `BertModel` from the `BertConfig`
class and then save it to disk under the filename `traced_bert.pt`:
```python
from transformers import BertModel, BertTokenizer, BertConfig
import torch
enc = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
# Tokenizing input text
text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
tokenized_text = enc.tokenize(text)
# Masking one of the input tokens
masked_index = 8
tokenized_text[masked_index] = "[MASK]"
indexed_tokens = enc.convert_tokens_to_ids(tokenized_text)
segments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
# Creating a dummy input
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
dummy_input = [tokens_tensor, segments_tensors]
# Initializing the model with the torchscript flag
# Flag set to True even though it is not necessary as this model does not have an LM Head.
config = BertConfig(
vocab_size_or_config_json_file=32000,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
torchscript=True,
)
# Instantiating the model
model = BertModel(config)
# The model needs to be in evaluation mode
model.eval()
# If you are instantiating the model with *from_pretrained* you can also easily set the TorchScript flag
model = BertModel.from_pretrained("google-bert/bert-base-uncased", torchscript=True)
# Creating the trace
traced_model = torch.jit.trace(model, [tokens_tensor, segments_tensors])
torch.jit.save(traced_model, "traced_bert.pt")
```
### Loading a model
Now you can load the previously saved `BertModel`, `traced_bert.pt`, from disk and use
it on the previously initialised `dummy_input`:
```python
loaded_model = torch.jit.load("traced_bert.pt")
loaded_model.eval()
all_encoder_layers, pooled_output = loaded_model(*dummy_input)
```
### Using a traced model for inference
Use the traced model for inference by using its `__call__` dunder method:
```python
traced_model(tokens_tensor, segments_tensors)
```
## Deploy Hugging Face TorchScript models to AWS with the Neuron SDK
AWS introduced the [Amazon EC2 Inf1](https://aws.amazon.com/ec2/instance-types/inf1/)
instance family for low cost, high performance machine learning inference in the cloud.
The Inf1 instances are powered by the AWS Inferentia chip, a custom-built hardware
accelerator, specializing in deep learning inferencing workloads. [AWS
Neuron](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/#) is the SDK for
Inferentia that supports tracing and optimizing transformers models for deployment on
Inf1. The Neuron SDK provides:
1. Easy-to-use API with one line of code change to trace and optimize a TorchScript
model for inference in the cloud.
2. Out of the box performance optimizations for [improved
cost-performance](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/benchmark/>).
3. Support for Hugging Face transformers models built with either
[PyTorch](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/bert_tutorial/tutorial_pretrained_bert.html)
or
[TensorFlow](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/tensorflow/huggingface_bert/huggingface_bert.html).
### Implications
Transformers models based on the [BERT (Bidirectional Encoder Representations from
Transformers)](https://huggingface.co/docs/transformers/main/model_doc/bert)
architecture, or its variants such as
[distilBERT](https://huggingface.co/docs/transformers/main/model_doc/distilbert) and
[roBERTa](https://huggingface.co/docs/transformers/main/model_doc/roberta) run best on
Inf1 for non-generative tasks such as extractive question answering, sequence
classification, and token classification. However, text generation tasks can still be
adapted to run on Inf1 according to this [AWS Neuron MarianMT
tutorial](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/transformers-marianmt.html).
More information about models that can be converted out of the box on Inferentia can be
found in the [Model Architecture
Fit](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/models/models-inferentia.html#models-inferentia)
section of the Neuron documentation.
### Dependencies
Using AWS Neuron to convert models requires a [Neuron SDK
environment](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/neuron-frameworks/pytorch-neuron/index.html#installation-guide)
which comes preconfigured on [AWS Deep Learning
AMI](https://docs.aws.amazon.com/dlami/latest/devguide/tutorial-inferentia-launching.html).
### Converting a model for AWS Neuron
Convert a model for AWS NEURON using the same code from [Using TorchScript in
Python](torchscript#using-torchscript-in-python) to trace a `BertModel`. Import the
`torch.neuron` framework extension to access the components of the Neuron SDK through a
Python API:
```python
from transformers import BertModel, BertTokenizer, BertConfig
import torch
import torch.neuron
```
You only need to modify the following line:
```diff
- torch.jit.trace(model, [tokens_tensor, segments_tensors])
+ torch.neuron.trace(model, [token_tensor, segments_tensors])
```
This enables the Neuron SDK to trace the model and optimize it for Inf1 instances.
To learn more about AWS Neuron SDK features, tools, example tutorials and latest
updates, please see the [AWS NeuronSDK
documentation](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/index.html).
| transformers/docs/source/en/torchscript.md/0 | {
"file_path": "transformers/docs/source/en/torchscript.md",
"repo_id": "transformers",
"token_count": 2740
} | 244 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Compartir modelos personalizados
La biblioteca 🤗 Transformers está diseñada para ser fácilmente ampliable. Cada modelo está completamente codificado
sin abstracción en una subcarpeta determinada del repositorio, por lo que puedes copiar fácilmente un archivo del modelo
y ajustarlo según tus necesidades.
Si estás escribiendo un modelo completamente nuevo, podría ser más fácil comenzar desde cero. En este tutorial, te mostraremos
cómo escribir un modelo personalizado y su configuración para que pueda usarse dentro de Transformers, y cómo puedes compartirlo
con la comunidad (con el código en el que se basa) para que cualquiera pueda usarlo, incluso si no está presente en la biblioteca
🤗 Transformers.
Ilustraremos todo esto con un modelo ResNet, envolviendo la clase ResNet de la [biblioteca timm](https://github.com/rwightman/pytorch-image-models) en un [`PreTrainedModel`].
## Escribir una configuración personalizada
Antes de adentrarnos en el modelo, primero escribamos su configuración. La configuración de un modelo es un objeto que
contendrá toda la información necesaria para construir el modelo. Como veremos en la siguiente sección, el modelo solo puede
tomar un `config` para ser inicializado, por lo que realmente necesitamos que ese objeto esté lo más completo posible.
En nuestro ejemplo, tomaremos un par de argumentos de la clase ResNet que tal vez queramos modificar. Las diferentes
configuraciones nos darán los diferentes tipos de ResNet que son posibles. Luego simplemente almacenamos esos argumentos
después de verificar la validez de algunos de ellos.
```python
from transformers import PretrainedConfig
from typing import List
class ResnetConfig(PretrainedConfig):
model_type = "resnet"
def __init__(
self,
block_type="bottleneck",
layers: List[int] = [3, 4, 6, 3],
num_classes: int = 1000,
input_channels: int = 3,
cardinality: int = 1,
base_width: int = 64,
stem_width: int = 64,
stem_type: str = "",
avg_down: bool = False,
**kwargs,
):
if block_type not in ["basic", "bottleneck"]:
raise ValueError(f"`block_type` must be 'basic' or bottleneck', got {block_type}.")
if stem_type not in ["", "deep", "deep-tiered"]:
raise ValueError(f"`stem_type` must be '', 'deep' or 'deep-tiered', got {stem_type}.")
self.block_type = block_type
self.layers = layers
self.num_classes = num_classes
self.input_channels = input_channels
self.cardinality = cardinality
self.base_width = base_width
self.stem_width = stem_width
self.stem_type = stem_type
self.avg_down = avg_down
super().__init__(**kwargs)
```
Las tres cosas importantes que debes recordar al escribir tu propia configuración son las siguientes:
- tienes que heredar de `PretrainedConfig`,
- el `__init__` de tu `PretrainedConfig` debe aceptar cualquier `kwargs`,
- esos `kwargs` deben pasarse a la superclase `__init__`.
La herencia es para asegurarte de obtener toda la funcionalidad de la biblioteca 🤗 Transformers, mientras que las otras dos
restricciones provienen del hecho de que una `PretrainedConfig` tiene más campos que los que estás configurando. Al recargar una
`config` con el método `from_pretrained`, esos campos deben ser aceptados por tu `config` y luego enviados a la superclase.
Definir un `model_type` para tu configuración (en este caso `model_type="resnet"`) no es obligatorio, a menos que quieras
registrar tu modelo con las clases automáticas (ver la última sección).
Una vez hecho esto, puedes crear y guardar fácilmente tu configuración como lo harías con cualquier otra configuración de un
modelo de la biblioteca. Así es como podemos crear una configuración resnet50d y guardarla:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d_config.save_pretrained("custom-resnet")
```
Esto guardará un archivo llamado `config.json` dentro de la carpeta `custom-resnet`. Luego puedes volver a cargar tu configuración
con el método `from_pretrained`:
```py
resnet50d_config = ResnetConfig.from_pretrained("custom-resnet")
```
También puedes usar cualquier otro método de la clase [`PretrainedConfig`], como [`~PretrainedConfig.push_to_hub`], para cargar
directamente tu configuración en el Hub.
## Escribir un modelo personalizado
Ahora que tenemos nuestra configuración de ResNet, podemos seguir escribiendo el modelo. En realidad escribiremos dos: una que
extrae las características ocultas de un grupo de imágenes (como [`BertModel`]) y una que es adecuada para clasificación de
imagenes (como [`BertForSequenceClassification`]).
Como mencionamos antes, solo escribiremos un envoltura (_wrapper_) libre del modelo para simplificar este ejemplo. Lo único que debemos
hacer antes de escribir esta clase es un mapeo entre los tipos de bloques y las clases de bloques reales. Luego se define el
modelo desde la configuración pasando todo a la clase `ResNet`:
```py
from transformers import PreTrainedModel
from timm.models.resnet import BasicBlock, Bottleneck, ResNet
from .configuration_resnet import ResnetConfig
BLOCK_MAPPING = {"basic": BasicBlock, "bottleneck": Bottleneck}
class ResnetModel(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor):
return self.model.forward_features(tensor)
```
Para el modelo que clasificará las imágenes, solo cambiamos el método de avance (es decir, el método `forward`):
```py
import torch
class ResnetModelForImageClassification(PreTrainedModel):
config_class = ResnetConfig
def __init__(self, config):
super().__init__(config)
block_layer = BLOCK_MAPPING[config.block_type]
self.model = ResNet(
block_layer,
config.layers,
num_classes=config.num_classes,
in_chans=config.input_channels,
cardinality=config.cardinality,
base_width=config.base_width,
stem_width=config.stem_width,
stem_type=config.stem_type,
avg_down=config.avg_down,
)
def forward(self, tensor, labels=None):
logits = self.model(tensor)
if labels is not None:
loss = torch.nn.cross_entropy(logits, labels)
return {"loss": loss, "logits": logits}
return {"logits": logits}
```
En ambos casos, observa cómo heredamos de `PreTrainedModel` y llamamos a la inicialización de la superclase con `config`
(un poco como cuando escribes `torch.nn.Module`). La línea que establece `config_class` no es obligatoria, a menos
que quieras registrar tu modelo con las clases automáticas (consulta la última sección).
<Tip>
Si tu modelo es muy similar a un modelo dentro de la biblioteca, puedes reutilizar la misma configuración de ese modelo.
</Tip>
Puedes hacer que tu modelo devuelva lo que quieras, pero devolver un diccionario como lo hicimos para
`ResnetModelForImageClassification`, con el `loss` incluido cuando se pasan las etiquetas, hará que tu modelo se pueda
usar directamente dentro de la clase [`Trainer`]. Usar otro formato de salida está bien, siempre y cuando estés planeando usar
tu propio bucle de entrenamiento u otra biblioteca para el entrenamiento.
Ahora que tenemos nuestra clase, vamos a crear un modelo:
```py
resnet50d = ResnetModelForImageClassification(resnet50d_config)
```
Nuevamente, puedes usar cualquiera de los métodos de [`PreTrainedModel`], como [`~PreTrainedModel.save_pretrained`] o
[`~PreTrainedModel.push_to_hub`]. Usaremos el segundo en la siguiente sección y veremos cómo pasar los pesos del modelo
con el código de nuestro modelo. Pero primero, carguemos algunos pesos previamente entrenados dentro de nuestro modelo.
En tu caso de uso, probablemente estarás entrenando tu modelo personalizado con tus propios datos. Para ir rápido en este
tutorial, usaremos la versión preentrenada de resnet50d. Dado que nuestro modelo es solo un envoltorio alrededor del resnet50d
original, será fácil transferir esos pesos:
```py
import timm
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
Ahora veamos cómo asegurarnos de que cuando hacemos [`~PreTrainedModel.save_pretrained`] o [`~PreTrainedModel.push_to_hub`],
se guarda el código del modelo.
## Enviar el código al _Hub_
<Tip warning={true}>
Esta _API_ es experimental y puede tener algunos cambios leves en las próximas versiones.
</Tip>
Primero, asegúrate de que tu modelo esté completamente definido en un archivo `.py`. Puedes basarte en importaciones
relativas a otros archivos, siempre que todos los archivos estén en el mismo directorio (aún no admitimos submódulos
para esta característica). Para nuestro ejemplo, definiremos un archivo `modeling_resnet.py` y un archivo
`configuration_resnet.py` en una carpeta del directorio de trabajo actual llamado `resnet_model`. El archivo de configuración
contiene el código de `ResnetConfig` y el archivo del modelo contiene el código de `ResnetModel` y
`ResnetModelForImageClassification`.
```
.
└── resnet_model
├── __init__.py
├── configuration_resnet.py
└── modeling_resnet.py
```
El `__init__.py` puede estar vacío, solo está ahí para que Python detecte que `resnet_model` se puede usar como un módulo.
<Tip warning={true}>
Si copias archivos del modelo desde la biblioteca, deberás reemplazar todas las importaciones relativas en la parte superior
del archivo para importarlos desde el paquete `transformers`.
</Tip>
Ten en cuenta que puedes reutilizar (o subclasificar) una configuración o modelo existente.
Para compartir tu modelo con la comunidad, sigue estos pasos: primero importa el modelo y la configuración de ResNet desde
los archivos recién creados:
```py
from resnet_model.configuration_resnet import ResnetConfig
from resnet_model.modeling_resnet import ResnetModel, ResnetModelForImageClassification
```
Luego, debes decirle a la biblioteca que deseas copiar el código de esos objetos cuando usas el método `save_pretrained`
y registrarlos correctamente con una determinada clase automática (especialmente para modelos), simplemente ejecuta:
```py
ResnetConfig.register_for_auto_class()
ResnetModel.register_for_auto_class("AutoModel")
ResnetModelForImageClassification.register_for_auto_class("AutoModelForImageClassification")
```
Ten en cuenta que no es necesario especificar una clase automática para la configuración (solo hay una clase automática
para ellos, [`AutoConfig`]), pero es diferente para los modelos. Tu modelo personalizado podría ser adecuado para muchas
tareas diferentes, por lo que debes especificar cuál de las clases automáticas es la correcta para tu modelo.
A continuación, vamos a crear la configuración y los modelos como lo hicimos antes:
```py
resnet50d_config = ResnetConfig(block_type="bottleneck", stem_width=32, stem_type="deep", avg_down=True)
resnet50d = ResnetModelForImageClassification(resnet50d_config)
pretrained_model = timm.create_model("resnet50d", pretrained=True)
resnet50d.model.load_state_dict(pretrained_model.state_dict())
```
Ahora, para enviar el modelo al Hub, asegúrate de haber iniciado sesión. Ejecuta en tu terminal:
```bash
huggingface-cli login
```
o desde un _notebook_:
```py
from huggingface_hub import notebook_login
notebook_login()
```
Luego puedes ingresar a tu propio espacio (o una organización de la que seas miembro) de esta manera:
```py
resnet50d.push_to_hub("custom-resnet50d")
```
Además de los pesos del modelo y la configuración en formato json, esto también copió los archivos `.py` del modelo y la
configuración en la carpeta `custom-resnet50d` y subió el resultado al Hub. Puedes verificar el resultado en este
[repositorio de modelos](https://huggingface.co/sgugger/custom-resnet50d).
Consulta el tutorial sobre cómo [compartir modelos](model_sharing) para obtener más información sobre el método para subir modelos al Hub.
## Usar un modelo con código personalizado
Puedes usar cualquier configuración, modelo o _tokenizador_ con archivos de código personalizado en tu repositorio con las
clases automáticas y el método `from_pretrained`. Todos los archivos y códigos cargados en el Hub se analizan en busca de
malware (consulta la documentación de [seguridad del Hub](https://huggingface.co/docs/hub/security#malware-scanning) para
obtener más información), pero aún debes revisar el código del modelo y el autor para evitar la ejecución de código malicioso
en tu computadora. Configura `trust_remote_code=True` para usar un modelo con código personalizado:
```py
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained("sgugger/custom-resnet50d", trust_remote_code=True)
```
También se recomienda encarecidamente pasar un _hash_ de confirmación como una "revisión" para asegurarte de que el autor
de los modelos no actualizó el código con algunas líneas nuevas maliciosas (a menos que confíes plenamente en los autores
de los modelos).
```py
commit_hash = "ed94a7c6247d8aedce4647f00f20de6875b5b292"
model = AutoModelForImageClassification.from_pretrained(
"sgugger/custom-resnet50d", trust_remote_code=True, revision=commit_hash
)
```
Ten en cuenta que al navegar por el historial de confirmaciones del repositorio del modelo en Hub, hay un botón para copiar
fácilmente el hash de confirmación de cualquier _commit_.
## Registrar un model con código personalizado a las clases automáticas
Si estás escribiendo una biblioteca que amplía 🤗 Transformers, es posible que quieras ampliar las clases automáticas para
incluir tu propio modelo. Esto es diferente de enviar el código al Hub en el sentido de que los usuarios necesitarán importar
tu biblioteca para obtener los modelos personalizados (al contrario de descargar automáticamente el código del modelo desde Hub).
Siempre que tu configuración tenga un atributo `model_type` que sea diferente de los tipos de modelos existentes, y que tus
clases modelo tengan los atributos `config_class` correctos, puedes agregarlos a las clases automáticas de la siguiente manera:
```py
from transformers import AutoConfig, AutoModel, AutoModelForImageClassification
AutoConfig.register("resnet", ResnetConfig)
AutoModel.register(ResnetConfig, ResnetModel)
AutoModelForImageClassification.register(ResnetConfig, ResnetModelForImageClassification)
```
Ten en cuenta que el primer argumento utilizado al registrar tu configuración personalizada en [`AutoConfig`] debe coincidir
con el `model_type` de tu configuración personalizada, y el primer argumento utilizado al registrar tus modelos personalizados
en cualquier clase del modelo automático debe coincidir con el `config_class ` de esos modelos.
| transformers/docs/source/es/custom_models.md/0 | {
"file_path": "transformers/docs/source/es/custom_models.md",
"repo_id": "transformers",
"token_count": 5983
} | 245 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Entrenamiento con scripts
Junto con los [notebooks](./noteboks/README) de 🤗 Transformers, también hay scripts con ejemplos que muestran cómo entrenar un modelo para una tarea en [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch), [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow), o [JAX/Flax](https://github.com/huggingface/transformers/tree/main/examples/flax).
También encontrarás scripts que hemos usado en nuestros [proyectos de investigación](https://github.com/huggingface/transformers/tree/main/examples/research_projects) y [ejemplos pasados](https://github.com/huggingface/transformers/tree/main/examples/legacy) que en su mayoría son aportados por la comunidad. Estos scripts no se mantienen activamente y requieren una versión específica de 🤗 Transformers que probablemente sea incompatible con la última versión de la biblioteca.
No se espera que los scripts de ejemplo funcionen de inmediato en todos los problemas, y es posible que debas adaptar el script al problema que estás tratando de resolver. Para ayudarte con esto, la mayoría de los scripts exponen completamente cómo se preprocesan los datos, lo que te permite editarlos según sea necesario para tu caso de uso.
Para cualquier característica que te gustaría implementar en un script de ejemplo, por favor discútelo en el [foro](https://discuss.huggingface.co/) o con un [issue](https://github.com/huggingface/transformers/issues) antes de enviar un Pull Request. Si bien agradecemos las correcciones de errores, es poco probable que fusionemos un Pull Request que agregue más funcionalidad a costa de la legibilidad.
Esta guía te mostrará cómo ejecutar un ejemplo de un script de entrenamiento para resumir texto en [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) y [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization). Se espera que todos los ejemplos funcionen con ambos frameworks a menos que se especifique lo contrario.
## Configuración
Para ejecutar con éxito la última versión de los scripts de ejemplo debes **instalar 🤗 Transformers desde su fuente** en un nuevo entorno virtual:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
```
Para versiones anteriores de los scripts de ejemplo, haz clic en alguno de los siguientes links:
<details>
<summary>Ejemplos de versiones anteriores de 🤗 Transformers</summary>
<ul>
<li><a href="https://github.com/huggingface/transformers/tree/v4.5.1/examples">v4.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.4.2/examples">v4.4.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.3.3/examples">v4.3.3</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.2.2/examples">v4.2.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.1.1/examples">v4.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.0.1/examples">v4.0.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.5.1/examples">v3.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.4.0/examples">v3.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.3.1/examples">v3.3.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.2.0/examples">v3.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.1.0/examples">v3.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.0.2/examples">v3.0.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.11.0/examples">v2.11.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.10.0/examples">v2.10.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.9.1/examples">v2.9.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.8.0/examples">v2.8.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.7.0/examples">v2.7.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.6.0/examples">v2.6.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.5.1/examples">v2.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.4.0/examples">v2.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.3.0/examples">v2.3.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.2.0/examples">v2.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.1.0/examples">v2.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.0.0/examples">v2.0.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.2.0/examples">v1.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.1.0/examples">v1.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.0.0/examples">v1.0.0</a></li>
</ul>
</details>
Luego cambia tu clon actual de 🤗 Transformers a una versión específica, por ejemplo v3.5.1:
```bash
git checkout tags/v3.5.1
```
Una vez que hayas configurado la versión correcta de la biblioteca, ve a la carpeta de ejemplo de tu elección e instala los requisitos específicos del ejemplo:
```bash
pip install -r requirements.txt
```
## Ejecutar un script
<frameworkcontent>
<pt>
El script de ejemplo descarga y preprocesa un conjunto de datos de la biblioteca 🤗 [Datasets](https://huggingface.co/docs/datasets/). Luego, el script ajusta un conjunto de datos con [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) en una arquitectura que soporta la tarea de resumen. El siguiente ejemplo muestra cómo ajustar un [T5-small](https://huggingface.co/google-t5/t5-small) en el conjunto de datos [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail). El modelo T5 requiere un argumento adicional `source_prefix` debido a cómo fue entrenado. Este aviso le permite a T5 saber que se trata de una tarea de resumir.
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
El script de ejemplo descarga y preprocesa un conjunto de datos de la biblioteca 🤗 [Datasets](https://huggingface.co/docs/datasets/). Luego, el script ajusta un conjunto de datos utilizando Keras en una arquitectura que soporta la tarea de resumir. El siguiente ejemplo muestra cómo ajustar un [T5-small](https://huggingface.co/google-t5/t5-small) en el conjunto de datos [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail). El modelo T5 requiere un argumento adicional `source_prefix` debido a cómo fue entrenado. Este aviso le permite a T5 saber que se trata de una tarea de resumir.
```bash
python examples/tensorflow/summarization/run_summarization.py \
--model_name_or_path google-t5/t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## Entrenamiento distribuido y de precisión mixta
[Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) admite un entrenamiento distribuido y de precisión mixta, lo que significa que también puedes usarlo en un script. Para habilitar ambas características:
- Agrega el argumento `fp16` para habilitar la precisión mixta.
- Establece la cantidad de GPU que se usará con el argumento `nproc_per_node`.
```bash
torchrun \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
Los scripts de TensorFlow utilizan [`MirroredStrategy`](https://www.tensorflow.org/guide/distributed_training#mirroredstrategy) para el entrenamiento distribuido, y no es necesario agregar argumentos adicionales al script de entrenamiento. El script de TensorFlow utilizará múltiples GPUs de forma predeterminada si están disponibles.
## Ejecutar un script en una TPU
<frameworkcontent>
<pt>
Las Unidades de Procesamiento de Tensor (TPUs) están diseñadas específicamente para acelerar el rendimiento. PyTorch admite TPU con el compilador de aprendizaje profundo [XLA](https://www.tensorflow.org/xla) (consulta [aquí](https://github.com/pytorch/xla/blob/master/README.md) para obtener más detalles). Para usar una TPU, inicia el script `xla_spawn.py` y usa el argumento `num_cores` para establecer la cantidad de núcleos de TPU que deseas usar.
```bash
python xla_spawn.py --num_cores 8 \
summarization/run_summarization.py \
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
Las Unidades de Procesamiento de Tensor (TPUs) están diseñadas específicamente para acelerar el rendimiento. TensorFlow utiliza [`TPUStrategy`](https://www.tensorflow.org/guide/distributed_training#tpustrategy) para entrenar en TPUs. Para usar una TPU, pasa el nombre del recurso de la TPU al argumento `tpu`
```bash
python run_summarization.py \
--tpu name_of_tpu_resource \
--model_name_or_path google-t5/t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## Ejecutar un script con 🤗 Accelerate
🤗 [Accelerate](https://huggingface.co/docs/accelerate) es una biblioteca exclusiva de PyTorch que ofrece un método unificado para entrenar un modelo en varios tipos de configuraciones (solo CPU, GPU múltiples, TPU) mientras mantiene una visibilidad completa en el ciclo de entrenamiento de PyTorch. Asegúrate de tener 🤗 Accelerate instalado si aún no lo tienes:
> Nota: Como Accelerate se está desarrollando rápidamente, debes instalar la versión git de Accelerate para ejecutar los scripts
```bash
pip install git+https://github.com/huggingface/accelerate
```
En lugar del script `run_summarization.py`, debes usar el script `run_summarization_no_trainer.py`. Los scripts compatibles con 🤗 Accelerate tendrán un archivo `task_no_trainer.py` en la carpeta. Comienza ejecutando el siguiente comando para crear y guardar un archivo de configuración:
```bash
accelerate config
```
Prueba tu configuración para asegurarte que está configurada correctamente:
```bash
accelerate test
```
Todo listo para iniciar el entrenamiento:
```bash
accelerate launch run_summarization_no_trainer.py \
--model_name_or_path google-t5/t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir ~/tmp/tst-summarization
```
## Usar un conjunto de datos personalizado
El script de la tarea resumir admite conjuntos de datos personalizados siempre que sean un archivo CSV o JSON Line. Cuando uses tu propio conjunto de datos, necesitas especificar varios argumentos adicionales:
- `train_file` y `validation_file` especifican la ruta a tus archivos de entrenamiento y validación.
- `text_column` es el texto de entrada para resumir.
- `summary_column` es el texto de destino para la salida.
Un script para resumir que utiliza un conjunto de datos personalizado se vera así:
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--train_file path_to_csv_or_jsonlines_file \
--validation_file path_to_csv_or_jsonlines_file \
--text_column text_column_name \
--summary_column summary_column_name \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--overwrite_output_dir \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--predict_with_generate
```
## Prueba un script
A veces, es una buena idea ejecutar tu secuencia de comandos en una cantidad menor de ejemplos para asegurarte de que todo funciona como se espera antes de comprometerte con un conjunto de datos completo, lo que puede demorar horas en completarse. Utiliza los siguientes argumentos para truncar el conjunto de datos a un número máximo de muestras:
- `max_train_samples`
- `max_eval_samples`
- `max_predict_samples`
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path google-t5/t5-small \
--max_train_samples 50 \
--max_eval_samples 50 \
--max_predict_samples 50 \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
No todos los scripts de ejemplo admiten el argumento `max_predict_samples`. Puede que desconozcas si la secuencia de comandos admite este argumento, agrega `-h` para verificar:
```bash
examples/pytorch/summarization/run_summarization.py -h
```
## Reanudar el entrenamiento desde el punto de control
Otra opción útil para habilitar es reanudar el entrenamiento desde un punto de control anterior. Esto asegurará que puedas continuar donde lo dejaste sin comenzar de nuevo si tu entrenamiento se interrumpe. Hay dos métodos para reanudar el entrenamiento desde un punto de control.
El primer método utiliza el argumento `output_dir previous_output_dir` para reanudar el entrenamiento desde el último punto de control almacenado en `output_dir`. En este caso, debes eliminar `overwrite_output_dir`:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--output_dir previous_output_dir \
--predict_with_generate
```
El segundo método utiliza el argumento `resume_from_checkpoint path_to_specific_checkpoint` para reanudar el entrenamiento desde una carpeta de punto de control específica.
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--resume_from_checkpoint path_to_specific_checkpoint \
--predict_with_generate
```
## Comparte tu modelo
Todos los scripts pueden cargar tu modelo final en el [Model Hub](https://huggingface.co/models). Asegúrate de haber iniciado sesión en Hugging Face antes de comenzar:
```bash
huggingface-cli login
```
Luego agrega el argumento `push_to_hub` al script. Este argumento creará un repositorio con tu nombre de usuario Hugging Face y el nombre de la carpeta especificado en `output_dir`.
Para darle a tu repositorio un nombre específico, usa el argumento `push_to_hub_model_id` para añadirlo. El repositorio se incluirá automáticamente en tu namespace.
El siguiente ejemplo muestra cómo cargar un modelo con un nombre de repositorio específico:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--push_to_hub \
--push_to_hub_model_id finetuned-t5-cnn_dailymail \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
| transformers/docs/source/es/run_scripts.md/0 | {
"file_path": "transformers/docs/source/es/run_scripts.md",
"repo_id": "transformers",
"token_count": 7017
} | 246 |
- sections:
- local: index
title: 🤗 Transformers
- local: quicktour
title: Visite rapide
- local: installation
title: Installation
title: Démarrer
- sections:
- local: in_translation
title: Pipelines pour l'inférence
- local: autoclass_tutorial
title: Chargement d'instances pré-entraînées avec une AutoClass
- local: in_translation
title: Préparation des données
- local: in_translation
title: Fine-tune un modèle pré-entraîné
- local: in_translation
title: Entraînement avec un script
- local: in_translation
title: Entraînement distribué avec 🤗 Accelerate
- local: in_translation
title: Chargement et entraînement des adaptateurs avec 🤗 PEFT
- local: in_translation
title: Partager un modèle
- local: in_translation
title: Agents
- local: in_translation
title: Génération avec LLMs
title: Tutoriels
| transformers/docs/source/fr/_toctree.yml/0 | {
"file_path": "transformers/docs/source/fr/_toctree.yml",
"repo_id": "transformers",
"token_count": 376
} | 247 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Convertire checkpoint di Tensorflow
È disponibile un'interfaccia a linea di comando per convertire gli originali checkpoint di Bert/GPT/GPT-2/Transformer-XL/XLNet/XLM
in modelli che possono essere caricati utilizzando i metodi `from_pretrained` della libreria.
<Tip>
A partire dalla versione 2.3.0 lo script di conversione è parte di transformers CLI (**transformers-cli**), disponibile in ogni installazione
di transformers >=2.3.0.
La seguente documentazione riflette il formato dei comandi di **transformers-cli convert**.
</Tip>
## BERT
Puoi convertire qualunque checkpoint Tensorflow di BERT (in particolare
[i modeli pre-allenati rilasciati da Google](https://github.com/google-research/bert#pre-trained-models))
in un file di salvataggio Pytorch utilizzando lo script
[convert_bert_original_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/tree/main/src/transformers/models/bert/convert_bert_original_tf_checkpoint_to_pytorch.py).
Questo CLI prende come input un checkpoint di Tensorflow (tre files che iniziano con `bert_model.ckpt`) ed il relativo
file di configurazione (`bert_config.json`), crea un modello Pytorch per questa configurazione, carica i pesi dal
checkpoint di Tensorflow nel modello di Pytorch e salva il modello che ne risulta in un file di salvataggio standard di Pytorch che
può essere importato utilizzando `from_pretrained()` (vedi l'esempio nel
[quicktour](quicktour) , [run_glue.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification/run_glue.py) ).
Devi soltanto lanciare questo script di conversione **una volta** per ottenere un modello Pytorch. Dopodichè, potrai tralasciare
il checkpoint di Tensorflow (i tre files che iniziano con `bert_model.ckpt`), ma assicurati di tenere il file di configurazione
(`bert_config.json`) ed il file di vocabolario (`vocab.txt`) in quanto queste componenti sono necessarie anche per il modello di Pytorch.
Per lanciare questo specifico script di conversione avrai bisogno di un'installazione di Tensorflow e di Pytorch
(`pip install tensorflow`). Il resto della repository richiede soltanto Pytorch.
Questo è un esempio del processo di conversione per un modello `BERT-Base Uncased` pre-allenato:
```bash
export BERT_BASE_DIR=/path/to/bert/uncased_L-12_H-768_A-12
transformers-cli convert --model_type bert \
--tf_checkpoint $BERT_BASE_DIR/bert_model.ckpt \
--config $BERT_BASE_DIR/bert_config.json \
--pytorch_dump_output $BERT_BASE_DIR/pytorch_model.bin
```
Puoi scaricare i modelli pre-allenati di Google per la conversione [qua](https://github.com/google-research/bert#pre-trained-models).
## ALBERT
Per il modello ALBERT, converti checkpoint di Tensoflow in Pytorch utilizzando lo script
[convert_albert_original_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/tree/main/src/transformers/models/albert/convert_albert_original_tf_checkpoint_to_pytorch.py).
Il CLI prende come input un checkpoint di Tensorflow (tre files che iniziano con `model.ckpt-best`) e i relativi file di
configurazione (`albert_config.json`), dopodichè crea e salva un modello Pytorch. Per lanciare questa conversione
avrai bisogno di un'installazione di Tensorflow e di Pytorch.
Ecco un esempio del procedimento di conversione di un modello `ALBERT Base` pre-allenato:
```bash
export ALBERT_BASE_DIR=/path/to/albert/albert_base
transformers-cli convert --model_type albert \
--tf_checkpoint $ALBERT_BASE_DIR/model.ckpt-best \
--config $ALBERT_BASE_DIR/albert_config.json \
--pytorch_dump_output $ALBERT_BASE_DIR/pytorch_model.bin
```
Puoi scaricare i modelli pre-allenati di Google per la conversione [qui](https://github.com/google-research/albert#pre-trained-models).
## OpenAI GPT
Ecco un esempio del processo di conversione di un modello OpenAI GPT pre-allenato, assumendo che il tuo checkpoint di NumPy
sia salvato nello stesso formato dei modelli pre-allenati OpenAI (vedi [qui](https://github.com/openai/finetune-transformer-lm)):
```bash
export OPENAI_GPT_CHECKPOINT_FOLDER_PATH=/path/to/openai/pretrained/numpy/weights
transformers-cli convert --model_type gpt \
--tf_checkpoint $OPENAI_GPT_CHECKPOINT_FOLDER_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
[--config OPENAI_GPT_CONFIG] \
[--finetuning_task_name OPENAI_GPT_FINETUNED_TASK] \
```
## OpenAI GPT-2
Ecco un esempio del processo di conversione di un modello OpenAI GPT-2 pre-allenato (vedi [qui](https://github.com/openai/gpt-2)):
```bash
export OPENAI_GPT2_CHECKPOINT_PATH=/path/to/openai-community/gpt2/pretrained/weights
transformers-cli convert --model_type openai-community/gpt2 \
--tf_checkpoint $OPENAI_GPT2_CHECKPOINT_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
[--config OPENAI_GPT2_CONFIG] \
[--finetuning_task_name OPENAI_GPT2_FINETUNED_TASK]
```
## XLNet
Ecco un esempio del processo di conversione di un modello XLNet pre-allenato:
```bash
export TRANSFO_XL_CHECKPOINT_PATH=/path/to/xlnet/checkpoint
export TRANSFO_XL_CONFIG_PATH=/path/to/xlnet/config
transformers-cli convert --model_type xlnet \
--tf_checkpoint $TRANSFO_XL_CHECKPOINT_PATH \
--config $TRANSFO_XL_CONFIG_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
[--finetuning_task_name XLNET_FINETUNED_TASK] \
```
## XLM
Ecco un esempio del processo di conversione di un modello XLM pre-allenato:
```bash
export XLM_CHECKPOINT_PATH=/path/to/xlm/checkpoint
transformers-cli convert --model_type xlm \
--tf_checkpoint $XLM_CHECKPOINT_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT
[--config XML_CONFIG] \
[--finetuning_task_name XML_FINETUNED_TASK]
```
## T5
Ecco un esempio del processo di conversione di un modello T5 pre-allenato:
```bash
export T5=/path/to/t5/uncased_L-12_H-768_A-12
transformers-cli convert --model_type t5 \
--tf_checkpoint $T5/t5_model.ckpt \
--config $T5/t5_config.json \
--pytorch_dump_output $T5/pytorch_model.bin
```
| transformers/docs/source/it/converting_tensorflow_models.md/0 | {
"file_path": "transformers/docs/source/it/converting_tensorflow_models.md",
"repo_id": "transformers",
"token_count": 2422
} | 248 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Models
ベースクラスである [`PreTrainedModel`]、[`TFPreTrainedModel`]、[`FlaxPreTrainedModel`] は、モデルの読み込みと保存に関する共通のメソッドを実装しており、これはローカルのファイルやディレクトリから、またはライブラリが提供する事前学習モデル構成(HuggingFaceのAWS S3リポジトリからダウンロード)からモデルを読み込むために使用できます。
[`PreTrainedModel`] と [`TFPreTrainedModel`] は、次の共通のメソッドも実装しています:
- 語彙に新しいトークンが追加された場合に、入力トークン埋め込みのリサイズを行う
- モデルのアテンションヘッドを刈り込む
各モデルに共通するその他のメソッドは、[`~modeling_utils.ModuleUtilsMixin`](PyTorchモデル用)および[`~modeling_tf_utils.TFModuleUtilsMixin`](TensorFlowモデル用)で定義されており、テキスト生成の場合、[`~generation.GenerationMixin`](PyTorchモデル用)、[`~generation.TFGenerationMixin`](TensorFlowモデル用)、および[`~generation.FlaxGenerationMixin`](Flax/JAXモデル用)もあります。
## PreTrainedModel
[[autodoc]] PreTrainedModel
- push_to_hub
- all
<a id='from_pretrained-torch-dtype'></a>
### 大規模モデルの読み込み
Transformers 4.20.0では、[`~PreTrainedModel.from_pretrained`] メソッドが再設計され、[Accelerate](https://huggingface.co/docs/accelerate/big_modeling) を使用して大規模モデルを扱うことが可能になりました。これには Accelerate >= 0.9.0 と PyTorch >= 1.9.0 が必要です。以前の方法でフルモデルを作成し、その後事前学習の重みを読み込む代わりに(これにはメモリ内のモデルサイズが2倍必要で、ランダムに初期化されたモデル用と重み用の2つが必要でした)、モデルを空の外殻として作成し、事前学習の重みが読み込まれるときにパラメーターを実体化するオプションが追加されました。
このオプションは `low_cpu_mem_usage=True` で有効にできます。モデルはまず空の重みを持つメタデバイス上に作成され、その後状態辞書が内部に読み込まれます(シャードされたチェックポイントの場合、シャードごとに読み込まれます)。この方法で使用される最大RAMは、モデルの完全なサイズだけです。
```py
from transformers import AutoModelForSeq2SeqLM
t0pp = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp", low_cpu_mem_usage=True)
```
さらに、モデルが完全にRAMに収まらない場合(現時点では推論のみ有効)、異なるデバイスにモデルを直接配置できます。`device_map="auto"` を使用すると、Accelerateは各レイヤーをどのデバイスに配置するかを決定し、最速のデバイス(GPU)を最大限に活用し、残りの部分をCPU、あるいはGPU RAMが不足している場合はハードドライブにオフロードします。モデルが複数のデバイスに分割されていても、通常どおり実行されます。
`device_map` を渡す際、`low_cpu_mem_usage` は自動的に `True` に設定されるため、それを指定する必要はありません。
```py
from transformers import AutoModelForSeq2SeqLM
t0pp = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0pp", device_map="auto")
```
モデルがデバイス間でどのように分割されたかは、その `hf_device_map` 属性を見ることで確認できます:
```py
t0pp.hf_device_map
```
```python out
{'shared': 0,
'decoder.embed_tokens': 0,
'encoder': 0,
'decoder.block.0': 0,
'decoder.block.1': 1,
'decoder.block.2': 1,
'decoder.block.3': 1,
'decoder.block.4': 1,
'decoder.block.5': 1,
'decoder.block.6': 1,
'decoder.block.7': 1,
'decoder.block.8': 1,
'decoder.block.9': 1,
'decoder.block.10': 1,
'decoder.block.11': 1,
'decoder.block.12': 1,
'decoder.block.13': 1,
'decoder.block.14': 1,
'decoder.block.15': 1,
'decoder.block.16': 1,
'decoder.block.17': 1,
'decoder.block.18': 1,
'decoder.block.19': 1,
'decoder.block.20': 1,
'decoder.block.21': 1,
'decoder.block.22': 'cpu',
'decoder.block.23': 'cpu',
'decoder.final_layer_norm': 'cpu',
'decoder.dropout': 'cpu',
'lm_head': 'cpu'}
```
同じフォーマットに従って、独自のデバイスマップを作成することもできます(レイヤー名からデバイスへの辞書です)。モデルのすべてのパラメータを指定されたデバイスにマップする必要がありますが、1つのレイヤーが完全に同じデバイスにある場合、そのレイヤーのサブモジュールのすべてがどこに行くかの詳細を示す必要はありません。例えば、次のデバイスマップはT0ppに適しています(GPUメモリがある場合):
```python
device_map = {"shared": 0, "encoder": 0, "decoder": 1, "lm_head": 1}
```
モデルのメモリへの影響を最小限に抑えるもう 1 つの方法は、低精度の dtype (`torch.float16` など) でモデルをインスタンス化するか、以下で説明する直接量子化手法を使用することです。
### Model Instantiation dtype
Pytorch では、モデルは通常 `torch.float32` 形式でインスタンス化されます。これは、しようとすると問題になる可能性があります
重みが fp16 にあるモデルをロードすると、2 倍のメモリが必要になるためです。この制限を克服するには、次のことができます。
`torch_dtype` 引数を使用して、目的の `dtype` を明示的に渡します。
```python
model = T5ForConditionalGeneration.from_pretrained("t5", torch_dtype=torch.float16)
```
または、モデルを常に最適なメモリ パターンでロードしたい場合は、特別な値 `"auto"` を使用できます。
そして、`dtype` はモデルの重みから自動的に導出されます。
```python
model = T5ForConditionalGeneration.from_pretrained("t5", torch_dtype="auto")
```
スクラッチからインスタンス化されたモデルには、どの `dtype` を使用するかを指示することもできます。
```python
config = T5Config.from_pretrained("t5")
model = AutoModel.from_config(config)
```
Pytorch の設計により、この機能は浮動小数点 dtype でのみ使用できます。
## ModuleUtilsMixin
[[autodoc]] modeling_utils.ModuleUtilsMixin
## TFPreTrainedModel
[[autodoc]] TFPreTrainedModel
- push_to_hub
- all
## TFModelUtilsMixin
[[autodoc]] modeling_tf_utils.TFModelUtilsMixin
## FlaxPreTrainedModel
[[autodoc]] FlaxPreTrainedModel
- push_to_hub
- all
## Pushing to the Hub
[[autodoc]] utils.PushToHubMixin
## Sharded checkpoints
[[autodoc]] modeling_utils.load_sharded_checkpoint
| transformers/docs/source/ja/main_classes/model.md/0 | {
"file_path": "transformers/docs/source/ja/main_classes/model.md",
"repo_id": "transformers",
"token_count": 3297
} | 249 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Bark
## Overview
Bark は、[suno-ai/bark](https://github.com/suno-ai/bark) で Suno AI によって提案されたトランスフォーマーベースのテキスト読み上げモデルです。
Bark は 4 つの主要なモデルで構成されています。
- [`BarkSemanticModel`] ('テキスト'モデルとも呼ばれる): トークン化されたテキストを入力として受け取り、テキストの意味を捉えるセマンティック テキスト トークンを予測する因果的自己回帰変換モデル。
- [`BarkCoarseModel`] ('粗い音響' モデルとも呼ばれる): [`BarkSemanticModel`] モデルの結果を入力として受け取る因果的自己回帰変換器。 EnCodec に必要な最初の 2 つのオーディオ コードブックを予測することを目的としています。
- [`BarkFineModel`] ('微細音響' モデル)、今回は非因果的オートエンコーダー トランスフォーマーで、以前のコードブック埋め込みの合計に基づいて最後のコードブックを繰り返し予測します。
- [`EncodecModel`] からすべてのコードブック チャネルを予測したので、Bark はそれを使用して出力オーディオ配列をデコードします。
最初の 3 つのモジュールはそれぞれ、特定の事前定義された音声に従って出力サウンドを調整するための条件付きスピーカー埋め込みをサポートできることに注意してください。
### Optimizing Bark
Bark は、コードを数行追加するだけで最適化でき、**メモリ フットプリントが大幅に削減**され、**推論が高速化**されます。
#### Using half-precision
モデルを半精度でロードするだけで、推論を高速化し、メモリ使用量を 50% 削減できます。
```python
from transformers import BarkModel
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16).to(device)
```
#### Using 🤗 Better Transformer
Better Transformer は、内部でカーネル融合を実行する 🤗 最適な機能です。パフォーマンスを低下させることなく、速度を 20% ~ 30% 向上させることができます。モデルを 🤗 Better Transformer にエクスポートするのに必要なコードは 1 行だけです。
```python
model = model.to_bettertransformer()
```
この機能を使用する前に 🤗 Optimum をインストールする必要があることに注意してください。 [インストール方法はこちら](https://huggingface.co/docs/optimum/installation)
#### Using CPU offload
前述したように、Bark は 4 つのサブモデルで構成されており、オーディオ生成中に順番に呼び出されます。言い換えれば、1 つのサブモデルが使用されている間、他のサブモデルはアイドル状態になります。
CUDA デバイスを使用している場合、メモリ フットプリントの 80% 削減による恩恵を受ける簡単な解決策は、アイドル状態の GPU のサブモデルをオフロードすることです。この操作は CPU オフロードと呼ばれます。 1行のコードで使用できます。
```python
model.enable_cpu_offload()
```
この機能を使用する前に、🤗 Accelerate をインストールする必要があることに注意してください。 [インストール方法はこちら](https://huggingface.co/docs/accelerate/basic_tutorials/install)
#### Combining optimization techniques
最適化手法を組み合わせて、CPU オフロード、半精度、🤗 Better Transformer をすべて一度に使用できます。
```python
from transformers import BarkModel
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
# load in fp16
model = BarkModel.from_pretrained("suno/bark-small", torch_dtype=torch.float16).to(device)
# convert to bettertransformer
model = BetterTransformer.transform(model, keep_original_model=False)
# enable CPU offload
model.enable_cpu_offload()
```
推論最適化手法の詳細については、[こちら](https://huggingface.co/docs/transformers/perf_infer_gpu_one) をご覧ください。
### Tips
Suno は、多くの言語で音声プリセットのライブラリを提供しています [こちら](https://suno-ai.notion.site/8b8e8749ed514b0cbf3f699013548683?v=bc67cff786b04b50b3ceb756fd05f68c)。
これらのプリセットは、ハブ [こちら](https://huggingface.co/suno/bark-small/tree/main/speaker_embeddings) または [こちら](https://huggingface.co/suno/bark/tree/main/speaker_embeddings)。
```python
>>> from transformers import AutoProcessor, BarkModel
>>> processor = AutoProcessor.from_pretrained("suno/bark")
>>> model = BarkModel.from_pretrained("suno/bark")
>>> voice_preset = "v2/en_speaker_6"
>>> inputs = processor("Hello, my dog is cute", voice_preset=voice_preset)
>>> audio_array = model.generate(**inputs)
>>> audio_array = audio_array.cpu().numpy().squeeze()
```
Bark は、非常にリアルな **多言語** 音声だけでなく、音楽、背景ノイズ、単純な効果音などの他の音声も生成できます。
```python
>>> # Multilingual speech - simplified Chinese
>>> inputs = processor("惊人的!我会说中文")
>>> # Multilingual speech - French - let's use a voice_preset as well
>>> inputs = processor("Incroyable! Je peux générer du son.", voice_preset="fr_speaker_5")
>>> # Bark can also generate music. You can help it out by adding music notes around your lyrics.
>>> inputs = processor("♪ Hello, my dog is cute ♪")
>>> audio_array = model.generate(**inputs)
>>> audio_array = audio_array.cpu().numpy().squeeze()
```
このモデルは、笑う、ため息、泣くなどの**非言語コミュニケーション**を生成することもできます。
```python
>>> # Adding non-speech cues to the input text
>>> inputs = processor("Hello uh ... [clears throat], my dog is cute [laughter]")
>>> audio_array = model.generate(**inputs)
>>> audio_array = audio_array.cpu().numpy().squeeze()
```
オーディオを保存するには、モデル設定と scipy ユーティリティからサンプル レートを取得するだけです。
```python
>>> from scipy.io.wavfile import write as write_wav
>>> # save audio to disk, but first take the sample rate from the model config
>>> sample_rate = model.generation_config.sample_rate
>>> write_wav("bark_generation.wav", sample_rate, audio_array)
```
このモデルは、[Yoach Lacombe (ylacombe)](https://huggingface.co/ylacombe) および [Sanchit Gandhi (sanchit-gandhi)](https://github.com/sanchit-gandhi) によって提供されました。
元のコードは [ここ](https://github.com/suno-ai/bark) にあります。
## BarkConfig
[[autodoc]] BarkConfig
- all
## BarkProcessor
[[autodoc]] BarkProcessor
- all
- __call__
## BarkModel
[[autodoc]] BarkModel
- generate
- enable_cpu_offload
## BarkSemanticModel
[[autodoc]] BarkSemanticModel
- forward
## BarkCoarseModel
[[autodoc]] BarkCoarseModel
- forward
## BarkFineModel
[[autodoc]] BarkFineModel
- forward
## BarkCausalModel
[[autodoc]] BarkCausalModel
- forward
## BarkCoarseConfig
[[autodoc]] BarkCoarseConfig
- all
## BarkFineConfig
[[autodoc]] BarkFineConfig
- all
## BarkSemanticConfig
[[autodoc]] BarkSemanticConfig
- all
| transformers/docs/source/ja/model_doc/bark.md/0 | {
"file_path": "transformers/docs/source/ja/model_doc/bark.md",
"repo_id": "transformers",
"token_count": 3181
} | 250 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BLIP
## Overview
BLIP モデルは、[BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation](https://arxiv.org/abs/2201.12086) で Junnan Li、Dongxu Li、Caiming Xiong、Steven Hoi によって提案されました。 。
BLIP は、次のようなさまざまなマルチモーダル タスクを実行できるモデルです。
- 視覚的な質問応答
- 画像とテキストの検索(画像とテキストのマッチング)
- 画像キャプション
論文の要約は次のとおりです。
*視覚言語事前トレーニング (VLP) により、多くの視覚言語タスクのパフォーマンスが向上しました。
ただし、既存の事前トレーニング済みモデルのほとんどは、理解ベースのタスクまたは世代ベースのタスクのいずれかでのみ優れています。さらに、最適ではない監視ソースである Web から収集されたノイズの多い画像とテキストのペアを使用してデータセットをスケールアップすることで、パフォーマンスの向上が大幅に達成されました。この論文では、視覚言語の理解と生成タスクの両方に柔軟に移行する新しい VLP フレームワークである BLIP を提案します。 BLIP は、キャプションをブートストラップすることでノイズの多い Web データを効果的に利用します。キャプショナーが合成キャプションを生成し、フィルターがノイズの多いキャプションを除去します。画像テキスト検索 (平均再現率 +2.7%@1)、画像キャプション作成 (CIDEr で +2.8%)、VQA ( VQA スコアは +1.6%)。 BLIP は、ゼロショット方式でビデオ言語タスクに直接転送した場合にも、強力な一般化能力を発揮します。コード、モデル、データセットがリリースされています。*

このモデルは [ybelkada](https://huggingface.co/ybelkada) によって提供されました。
元のコードは [ここ](https://github.com/salesforce/BLIP) にあります。
## Resources
- [Jupyter ノートブック](https://github.com/huggingface/notebooks/blob/main/examples/image_captioning_blip.ipynb) カスタム データセットの画像キャプション用に BLIP を微調整する方法
## BlipConfig
[[autodoc]] BlipConfig
- from_text_vision_configs
## BlipTextConfig
[[autodoc]] BlipTextConfig
## BlipVisionConfig
[[autodoc]] BlipVisionConfig
## BlipProcessor
[[autodoc]] BlipProcessor
## BlipImageProcessor
[[autodoc]] BlipImageProcessor
- preprocess
<frameworkcontent>
<pt>
## BlipModel
[[autodoc]] BlipModel
- forward
- get_text_features
- get_image_features
## BlipTextModel
[[autodoc]] BlipTextModel
- forward
## BlipVisionModel
[[autodoc]] BlipVisionModel
- forward
## BlipForConditionalGeneration
[[autodoc]] BlipForConditionalGeneration
- forward
## BlipForImageTextRetrieval
[[autodoc]] BlipForImageTextRetrieval
- forward
## BlipForQuestionAnswering
[[autodoc]] BlipForQuestionAnswering
- forward
</pt>
<tf>
## TFBlipModel
[[autodoc]] TFBlipModel
- call
- get_text_features
- get_image_features
## TFBlipTextModel
[[autodoc]] TFBlipTextModel
- call
## TFBlipVisionModel
[[autodoc]] TFBlipVisionModel
- call
## TFBlipForConditionalGeneration
[[autodoc]] TFBlipForConditionalGeneration
- call
## TFBlipForImageTextRetrieval
[[autodoc]] TFBlipForImageTextRetrieval
- call
## TFBlipForQuestionAnswering
[[autodoc]] TFBlipForQuestionAnswering
- call
</tf>
</frameworkcontent> | transformers/docs/source/ja/model_doc/blip.md/0 | {
"file_path": "transformers/docs/source/ja/model_doc/blip.md",
"repo_id": "transformers",
"token_count": 1785
} | 251 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# DialoGPT
## Overview
DialoGPT は、[DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation](https://arxiv.org/abs/1911.00536) で Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao,
Jianfeng Gao, Jingjing Liu, Bill Dolan.これは、から抽出された 147M 万の会話のようなやりとりでトレーニングされた GPT2 モデルです。
レディット。
論文の要約は次のとおりです。
*私たちは、大規模で調整可能なニューラル会話応答生成モデル DialoGPT (対話生成事前トレーニング済み) を紹介します。
変成器)。 Reddit のコメント チェーンから抽出された 1 億 4,700 万件の会話のようなやり取りを対象にトレーニングされました。
2005 年から 2017 年にかけて、DialoGPT は人間に近いパフォーマンスを達成するために Hugging Face PyTorch トランスフォーマーを拡張しました。
シングルターンダイアログ設定における自動評価と人間による評価の両方。会話システムが
DialoGPT を活用すると、強力なベースラインよりも関連性が高く、内容が充実し、コンテキストに一貫性のある応答が生成されます。
システム。神経反応の研究を促進するために、事前トレーニングされたモデルとトレーニング パイプラインが公開されています。
よりインテリジェントなオープンドメイン対話システムの生成と開発。*
元のコードは [ここ](https://github.com/microsoft/DialoGPT) にあります。
## Usage tips
- DialoGPT は絶対位置埋め込みを備えたモデルであるため、通常は入力を右側にパディングすることをお勧めします。
左よりも。
- DialoGPT は、会話データの因果言語モデリング (CLM) 目標に基づいてトレーニングされているため、強力です
オープンドメイン対話システムにおける応答生成時。
- DialoGPT を使用すると、[DialoGPT's model card](https://huggingface.co/microsoft/DialoGPT-medium) に示されているように、ユーザーはわずか 10 行のコードでチャット ボットを作成できます。
トレーニング:
DialoGPT をトレーニングまたは微調整するには、因果言語モデリング トレーニングを使用できます。公式論文を引用すると: *私たちは
OpenAI GPT-2に従って、マルチターン対話セッションを長いテキストとしてモデル化し、生成タスクを言語としてフレーム化します
モデリング。まず、ダイアログ セッション内のすべてのダイアログ ターンを長いテキスト x_1,..., x_N に連結します (N は
* 詳細については、元の論文を参照してください。
<Tip>
DialoGPT のアーキテクチャは GPT2 モデルに基づいています。API リファレンスと例については、[GPT2 のドキュメント ページ](openai-community/gpt2) を参照してください。
</Tip>
| transformers/docs/source/ja/model_doc/dialogpt.md/0 | {
"file_path": "transformers/docs/source/ja/model_doc/dialogpt.md",
"repo_id": "transformers",
"token_count": 1576
} | 252 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Efficient Training on Multiple GPUs
単一のGPUでのトレーニングが遅すぎる場合や、モデルの重みが単一のGPUのメモリに収まらない場合、複数のGPUを使用したセットアップが必要となります。単一のGPUから複数のGPUへの切り替えには、ワークロードを分散するためのある種の並列処理が必要です。データ、テンソル、またはパイプラインの並列処理など、さまざまな並列処理技術があります。ただし、すべてに適した一つの解決策は存在せず、最適な設定は使用するハードウェアに依存します。この記事は、おそらく他のフレームワークにも適用される主要な概念に焦点を当てつつ、PyTorchベースの実装に焦点を当てています。
<Tip>
**注意**: [単一GPUセクション](perf_train_gpu_one) で紹介された多くの戦略(混合精度トレーニングや勾配蓄積など)は一般的であり、モデルのトレーニングに一般的に適用されます。したがって、マルチGPUやCPUトレーニングなどの次のセクションに入る前に、それを確認してください。
</Tip>
まず、さまざまな1D並列処理技術とその利点および欠点について詳しく説明し、それらを2Dおよび3D並列処理に組み合わせてさらに高速なトレーニングを実現し、より大きなモデルをサポートする方法を検討します。さまざまな他の強力な代替手法も紹介されます。
## Concepts
以下は、この文書で後で詳しく説明される主要な概念の簡単な説明です。
1. **DataParallel (DP)** - 同じセットアップが複数回複製され、各セットアップにデータのスライスが供給されます。処理は並行して行われ、各セットアップはトレーニングステップの最後に同期されます。
2. **TensorParallel (TP)** - 各テンソルは複数のチャンクに分割され、単一のGPUにテンソル全体が存在するのではなく、テンソルの各シャードが指定されたGPUに存在します。処理中に、各シャードは別々に並行して処理され、異なるGPUで同期され、ステップの最後に結果が同期されます。これは水平並列処理と呼ばれるもので、分割は水平レベルで行われます。
3. **PipelineParallel (PP)** - モデルは垂直(レイヤーレベル)に複数のGPUに分割され、モデルの単一または複数のレイヤーが単一のGPUに配置されます。各GPUはパイプラインの異なるステージを並行して処理し、バッチの小さなチャンクで作業します。
4. **Zero Redundancy Optimizer (ZeRO)** - TPといくらか似たようなテンソルのシャーディングを実行しますが、前向きまたは後向きの計算のためにテンソル全体が再構築されるため、モデルを変更する必要はありません。また、GPUメモリが制限されている場合に補償するためのさまざまなオフロード技術をサポートします。
5. **Sharded DDP** - Sharded DDPは、さまざまなZeRO実装で使用される基本的なZeROコンセプトの別名です。
各コンセプトの詳細に深入りする前に、大規模なインフラストラクチャで大規模なモデルをトレーニングする際の大まかな決定プロセスを見てみましょう。
## Scalability Strategy
**⇨ シングルノード / マルチGPU**
* モデルが単一のGPUに収まる場合:
1. DDP - 分散データ並列
2. ZeRO - 状況と使用される構成に応じて速いかどうかが異なります
* モデルが単一のGPUに収まらない場合:
1. PP
2. ZeRO
3. TP
非常に高速なノード内接続(NVLINKまたはNVSwitchなど)があれば、これらの3つはほぼ同じ速度になるはずで、これらがない場合、PPはTPまたはZeROよりも速くなります。TPの程度も差を生じるかもしれません。特定のセットアップでの勝者を見つけるために実験することが最善です。
TPはほとんどの場合、単一ノード内で使用されます。つまり、TPサイズ <= ノードごとのGPU数です。
* 最大のレイヤーが単一のGPUに収まらない場合:
1. ZeROを使用しない場合 - TPを使用する必要があります。PP単独では収まらないでしょう。
2. ZeROを使用する場合 - "シングルGPU"のエントリと同じものを参照してください
**⇨ マルチノード / マルチGPU**
* ノード間の高速接続がある場合:
1. ZeRO - モデルへのほとんどの変更が不要です
2. PP+TP+DP - 通信が少なく、モデルへの大規模な変更が必要です
* ノード間の接続が遅く、GPUメモリがまだ不足している場合:
1. DP+PP+TP+ZeRO-1
## Data Parallelism
2つのGPUを持つほとんどのユーザーは、`DataParallel`(DP)と`DistributedDataParallel`(DDP)によって提供されるトレーニング速度の向上をすでに享受しています。これらはほぼ自明に使用できるPyTorchの組み込み機能です。一般的に、すべてのモデルで動作するDDPを使用することをお勧めします。DPは一部のモデルで失敗する可能性があるためです。[PyTorchのドキュメンテーション](https://pytorch.org/docs/master/generated/torch.nn.DataParallel.html)自体もDDPの使用を推奨しています。
### DP vs DDP
`DistributedDataParallel`(DDP)は通常、`DataParallel`(DP)よりも高速ですが、常にそうとは限りません:
* DPはPythonスレッドベースですが、DDPはマルチプロセスベースです。そのため、GIL(Global Interpreter Lock)などのPythonスレッドの制約がないためです。
* 一方、GPUカード間の遅い相互接続性は、DDPの場合に実際には遅い結果をもたらす可能性があります。
以下は、2つのモード間のGPU間通信の主な違いです:
[DDP](https://pytorch.org/docs/master/notes/ddp.html):
- 開始時、メインプロセスはモデルをGPU 0から他のGPUに複製します。
- それから各バッチごとに:
1. 各GPUは各自のミニバッチのデータを直接消費します。
2. `backward`中、ローカル勾配が準備できると、それらはすべてのプロセスで平均化されます。
[DP](https://pytorch.org/docs/master/generated/torch.nn.DataParallel.html):
各バッチごとに:
1. GPU 0はデータバッチを読み取り、それから各GPUにミニバッチを送信します。
2. GPU 0から各GPUに最新のモデルを複製します。
3. `forward`を実行し、各GPUからGPU 0に出力を送信し、損失を計算します。
4. GPU 0からすべてのGPUに損失を分散し、`backward`を実行します。
5. 各GPUからGPU 0に勾配を送信し、それらを平均化します。
DDPはバッチごとに行う通信は勾配の送信のみであり、一方、DPはバッチごとに5つの異なるデータ交換を行います。
DPはプロセス内でデータをPythonスレッドを介してコピーしますが、DDPは[torch.distributed](https://pytorch.org/docs/master/distributed.html)を介してデータをコピーします。
DPではGPU 0は他のGPUよりもはるかに多くの作業を行うため、GPUの未使用率が高くなります。
DDPは複数のマシン間で使用できますが、DPの場合はそうではありません。
DPとDDPの他にも違いがありますが、この議論には関係ありません。
これら2つのモードを深く理解したい場合、この[記事](https://www.telesens.co/2019/04/04/distributed-data-parallel-training-using-pytorch-on-aws/)を強くお勧めします。素晴らしいダイアグラムを含み、さまざまなハードウェアでの複数のベンチマークとプロファイラの出力を示し、知っておく必要があるすべての微妙なニュアンスを説明しています。
実際のベンチマークを見てみましょう:
| Type | NVlink | Time |
| :----- | ----- | ---: |
| 2:DP | Y | 110s |
| 2:DDP | Y | 101s |
| 2:DDP | N | 131s |
解析:
ここで、DPはNVlinkを使用したDDPに比べて約10%遅く、NVlinkを使用しないDDPに比べて約15%高速であることが示されています。
実際の違いは、各GPUが他のGPUと同期する必要があるデータの量に依存します。同期するデータが多いほど、遅いリンクが合計の実行時間を遅くする可能性が高くなります。
以下は完全なベンチマークコードと出力です:
`NCCL_P2P_DISABLE=1`を使用して、対応するベンチマークでNVLink機能を無効にしました。
```bash
# DP
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 \
python examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path openai-community/gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 110.5948, 'train_samples_per_second': 1.808, 'epoch': 0.69}
# DDP w/ NVlink
rm -r /tmp/test-clm; CUDA_VISIBLE_DEVICES=0,1 \
torchrun --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path openai-community/gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 101.9003, 'train_samples_per_second': 1.963, 'epoch': 0.69}
# DDP w/o NVlink
rm -r /tmp/test-clm; NCCL_P2P_DISABLE=1 CUDA_VISIBLE_DEVICES=0,1 \
torchrun --nproc_per_node 2 examples/pytorch/language-modeling/run_clm.py \
--model_name_or_path openai-community/gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 \
--do_train --output_dir /tmp/test-clm --per_device_train_batch_size 4 --max_steps 200
{'train_runtime': 131.4367, 'train_samples_per_second': 1.522, 'epoch': 0.69}
```
ハードウェア: 2x TITAN RTX、各24GB + 2つのNVLink(`nvidia-smi topo -m`で `NV2`)
ソフトウェア: `pytorch-1.8-to-be` + `cuda-11.0` / `transformers==4.3.0.dev0`
## ZeRO Data Parallelism
ZeROパワードデータ並列処理(ZeRO-DP)は、次の[ブログ投稿](https://www.microsoft.com/en-us/research/blog/zero-deepspeed-new-system-optimizations-enable-training-models-with-over-100-billion-parameters/)のダイアグラムで説明されています。

これは理解が難しいかもしれませんが、実際にはこの概念は非常にシンプルです。これは通常の`DataParallel`(DP)ですが、完全なモデルパラメータ、勾配、およびオプティマイザの状態を複製する代わりに、各GPUはそれぞれのスライスのみを保存します。そして、実行時に、特定のレイヤーに必要な完全なレイヤーパラメータが必要な場合、すべてのGPUが同期して、お互いに不足している部分を提供します。それがすべてです。
3つのレイヤーからなる単純なモデルを考えてみましょう。各レイヤーには3つのパラメータがあります:
```
La | Lb | Lc
---|----|---
a0 | b0 | c0
a1 | b1 | c1
a2 | b2 | c2
```
レイヤーLaには、重みa0、a1、およびa2があります。
3つのGPUがある場合、Sharded DDP(= Zero-DP)はモデルを3つのGPUに次のように分割します:
```
GPU0:
La | Lb | Lc
---|----|---
a0 | b0 | c0
GPU1:
La | Lb | Lc
---|----|---
a1 | b1 | c1
GPU2:
La | Lb | Lc
---|----|---
a2 | b2 | c2
```
これは、典型的なディープニューラルネットワーク(DNN)のダイアグラムを想像すると、テンソル並列処理と同様の水平スライスであるようなものです。垂直スライスは、異なるGPUに完全な層グループを配置する方法です。しかし、これは単なる出発点に過ぎません。
これから、各GPUは通常のデータ並列処理(DP)と同様に、通常のミニバッチを受け取ります:
```
x0 => GPU0
x1 => GPU1
x2 => GPU2
```
最初に、入力データはレイヤーLaに適用されます。
GPU0に焦点を当てましょう:x0は、その前向きパスを実行するためにa0、a1、a2のパラメータが必要ですが、GPU0にはa0しかありません。GPU1からa1を、GPU2からa2を受け取り、モデルの各部分をまとめます。
同様に、GPU1はミニバッチx1を受け取り、a1しか持っていませんが、a0とa2のパラメータが必要です。これらはGPU0とGPU2から取得します。
GPU2もx2を受け取ります。a0とa1はGPU0とGPU1から受け取り、a2とともに完全なテンソルを再構築します。
3つのGPUは完全なテンソルを再構築し、前向き計算が行われます。
計算が完了すると、不要になったデータは削除されます。計算中だけ使用され、再構築は事前にフェッチを使用して効率的に行われます。
そして、このプロセス全体がレイヤーLb、次に前向きでLc、そして逆方向でLc -> Lb -> Laに対して繰り返されます。
私にとって、これは効率的なグループでの重みの分散戦略のように聞こえます:
1. 人Aはテントを持っています。
2. 人Bはストーブを持っています。
3. 人Cは斧を持っています。
今、彼らは毎晩持っているものを共有し、他の人から持っていないものをもらい、朝には割り当てられたタイプのギアを詰めて旅を続けます。これがSharded DDP / Zero DPです。
この戦略を、各人が独自のテント、ストーブ、斧を持って運ばなければならないシンプルな戦略と比較してみてください。これがPyTorchのDataParallel(DPおよびDDP)です。
このトピックの文献を読む際に、以下の類義語に出会うかもしれません:Sharded、Partitioned。
ZeROがモデルの重みを分割する方法に注意を払うと、これはテンソルパラレリズムと非常に似ているように見えます。これは後で議論される垂直モデルパラレリズムとは異なり、各レイヤーの重みをパーティション/シャーディングします。
Implementations:
- [DeepSpeed](https://www.deepspeed.ai/tutorials/zero/) ZeRO-DP stages 1+2+3
- [`transformers` integration](main_classes/trainer#trainer-integrations)
## Naive Model Parallelism (Vertical) and Pipeline Parallelism
ナイーブモデルパラレリズム(MP)は、モデルの層を複数のGPUに分散させる方法です。このメカニズムは比較的単純で、希望する層を`.to()`メソッドを使用して特定のデバイスに切り替えるだけです。これにより、データがこれらの層を通過するたびに、データも層と同じデバイスに切り替えられ、残りの部分は変更されません。
私たちはこれを「垂直MP」と呼びます。なぜなら、ほとんどのモデルがどのように描かれるかを思い出すと、層を垂直にスライスするからです。たとえば、以下の図は8層のモデルを示しています:
```
=================== ===================
| 0 | 1 | 2 | 3 | | 4 | 5 | 6 | 7 |
=================== ===================
gpu0 gpu1
```
我々は、モデルを垂直に2つに分割し、レイヤー0から3をGPU0に配置し、レイヤー4から7をGPU1に配置しました。
データがレイヤー0から1、1から2、2から3に移動する間は通常のモデルと同じです。しかし、データがレイヤー3からレイヤー4に移動する必要がある場合、GPU0からGPU1への移動が発生し、通信のオーバーヘッドが発生します。参加しているGPUが同じコンピュートノード(例:同じ物理マシン)にある場合、このコピーは非常に高速ですが、異なるコンピュートノード(例:複数のマシン)にある場合、通信のオーバーヘッドは大幅に増加する可能性があります。
その後、レイヤー4から5、6から7までは通常のモデルと同様に動作し、7番目のレイヤーが完了すると、データをしばしばレイヤー0に戻す必要があります(またはラベルを最後のレイヤーに送信します)。これで損失を計算し、オプティマイザが作業を開始できます。
問題点:
- 主な欠点、およびなぜこれを「単純な」MPと呼ぶのかは、1つを除いてすべてのGPUがどんな瞬間でもアイドル状態であることです。したがって、4つのGPUを使用する場合、単純なMPは、1つのGPUのメモリ容量を4倍にするのとほぼ同じであり、ハードウェアの残りを無視します。さらに、データのコピーのオーバーヘッドがあることを忘れてはいけません。したがって、4枚の6GBのカードは、データのコピーのオーバーヘッドがない1枚の24GBのカードと同じサイズを収容できるでしょうが、後者はトレーニングをより迅速に完了します。ただし、たとえば40GBのカードがあり、45GBのモデルを収める必要がある場合、勾配とオプティマイザの状態のためにほとんど収めることができません。
- 共有の埋め込みは、GPU間でコピーする必要があるかもしれません。
パイプライン並列処理(PP)は、ほぼ単純なMPと同じですが、GPUがアイドル状態になる問題を解決し、入力バッチをマイクロバッチに分割し、パイプラインを人工的に作成することにより、異なるGPUが計算プロセスに同時に参加できるようにします。
以下は、[GPipe論文](https://ai.googleblog.com/2019/03/introducing-gpipe-open-source-library.html)からの図で、上部には単純なMP、下部にはPPが示されています:

この図から、PPがGPUがアイドル状態の領域である「バブル」を少なく持つことがわかります。アイドル状態の部分は「バブル」と呼ばれます。
図の両方の部分は、4つのGPUがパイプラインに参加している4の次元の並列性を示しています。つまり、4つのパイプステージF0、F1、F2、F3のフォワードパスがあり、逆順のバックワードパスB3、B2、B1、B0があります。
PPは調整する新しいハイパーパラメータを導入します。それは `chunks` で、同じパイプステージを通じて連続して送信されるデータのチャンクの数を定義します。たとえば、下の図では `chunks=4` が表示されています。GPU0はチャンク0、1、2、3(F0,0、F0,1、F0,2、F0,3)で同じフォワードパスを実行し、他のGPUが作業を開始し始めるのを待ってから、GPU0はチャンク3、2、1、0(B0,3、B0,2、B0,1、B0,0)で逆順パスを実行します。
注意すべきは、概念的にはこれが勾配蓄積ステップ(GAS)と同じコンセプトであることです。PyTorchは `chunks` を使用し、DeepSpeedは同じハイパーパラメータをGASと呼びます。
`chunks` の導入により、PPはマイクロバッチ(MBS)の概念を導入します。DPはグローバルデータバッチサイズをミニバッチに分割します。したがって、DPの次数が4で、グローバルバッチサイズが1024の場合、4つのミニバッチ(それぞれ256)に分割されます(1024/4)。そして、`chunks`(またはGAS)の数が32である場合、マイクロバッチサイズは8になります(256/32)。各パイプラインステージは1つのマイクロバッチで作業します。
DP + PPセットアップのグローバルバッチサイズを計算するには、`mbs*chunks*dp_degree`(`8*32*4=1024`)を行います。
図に戻りましょう。
`chunks=1` であれば、非効率な単純なMPになります。非常に大きな `chunks` 値を使用すると、非常に小さなマイクロバッチサイズになり、効率があまり高くないかもしれません。したがって、GPUの効率的な利用を最大化する値を見つけるために実験する必要があります。これは、バブルのサイズを最小限にすることに対応する、すべての参加GPUにわたる高い並行GPU利用を可能にするためです。
2つのソリューショングループがあります。従来のパイプラインAPIソリューションと、ユーザーのモデルを大幅に変更する必要があるより現代的なソリューションです。
従来のパイプラインAPIソリューション:
- PyTorch
- DeepSpeed
- Megatron-LM
現代的なソリューション:
- Varuna
- Sagemaker
従来のパイプラインAPIソリューションの問題点:
- モデルをかなり変更する必要があるため、Pipelineはモジュールの通常のフローを`nn.Sequential`シーケンスに再書き込む必要があり、モデルの設計を変更することが必要です。
- 現在、Pipeline APIは非常に制限的です。最初のパイプラインステージに渡されるPython変数のセットがある場合、回避策を見つける必要があります。現在、パイプラインインターフェースでは、唯一のテンソルまたはテンソルのタプルを入力と出力として要求しています。これらのテンソルはバッチサイズを最初の次元として持っている必要があります。パイプラインはミニバッチをマイクロバッチに分割します。可能な改善点については、こちらの議論が行われています:https://github.com/pytorch/pytorch/pull/50693
- パイプステージのレベルでの条件付き制御フローは不可能です。例えば、T5のようなエンコーダーデコーダーモデルは、条件付きエンコーダーステージを処理するために特別な回避策が必要です。
- 各レイヤーを配置する必要があるため、1つのモデルの出力が他のモデルの入力になるようにします。
VarunaとSageMakerとの実験はまだ行っていませんが、彼らの論文によれば、上記で述べた問題のリストを克服し、ユーザーのモデルにははるかに小さな変更しか必要としないと報告されています。
実装:
- [Pytorch](https://pytorch.org/docs/stable/pipeline.html) (initial support in pytorch-1.8, and progressively getting improved in 1.9 and more so in 1.10). Some [examples](https://github.com/pytorch/pytorch/blob/master/benchmarks/distributed/pipeline/pipe.py)
- [DeepSpeed](https://www.deepspeed.ai/tutorials/pipeline/)
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM) has an internal implementation - no API.
- [Varuna](https://github.com/microsoft/varuna)
- [SageMaker](https://arxiv.org/abs/2111.05972) - this is a proprietary solution that can only be used on AWS.
- [OSLO](https://github.com/tunib-ai/oslo) - この実装は、Hugging Face Transformersに基づいています。
🤗 Transformersのステータス: この執筆時点では、いずれのモデルも完全なPP(パイプライン並列処理)をサポートしていません。GPT2モデルとT5モデルは単純なMP(モデル並列処理)サポートを持っています。主な障害は、モデルを`nn.Sequential`に変換できず、すべての入力がテンソルである必要があることです。現在のモデルには、変換を非常に複雑にする多くの機能が含まれており、これらを削除する必要があります。
他のアプローチ:
DeepSpeed、Varuna、およびSageMakerは、[交互にパイプラインを実行](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-core-features.html)するコンセプトを使用しています。ここでは、バックワードパスを優先させてバブル(アイドル時間)をさらに最小限に抑えます。
Varunaは、最適なスケジュールを発見するためにシミュレーションを使用してスケジュールをさらに改善しようとします。
OSLOは、`nn.Sequential`の変換なしでTransformersに基づくパイプライン並列処理を実装しています。
## Tensor Parallelism
テンソル並列処理では、各GPUがテンソルのスライスのみを処理し、全体が必要な操作のためにのみ完全なテンソルを集約します。
このセクションでは、[Megatron-LM](https://github.com/NVIDIA/Megatron-LM)論文からのコンセプトと図を使用します:[GPUクラスタでの効率的な大規模言語モデルトレーニング](https://arxiv.org/abs/2104.04473)。
どのトランスフォーマの主要な構築要素は、完全に接続された`nn.Linear`に続く非線形アクティベーション`GeLU`です。
Megatronの論文の表記法に従って、行列の乗算部分を`Y = GeLU(XA)`と書くことができます。ここで、`X`と`Y`は入力ベクトルと出力ベクトルで、`A`は重み行列です。
行列の計算を行列形式で見ると、行列乗算を複数のGPUで分割できる方法が簡単に理解できます:

重み行列`A`を`N`個のGPUに対して列ごとに分割し、並列で行列乗算`XA_1`から`XA_n`を実行すると、`N`個の出力ベクトル`Y_1、Y_2、...、Y_n`が得られ、それらを独立して`GeLU`に供給できます:

この原理を使用して、最後まで同期が必要ないまま、任意の深さのMLPを更新できます。Megatron-LMの著者はそのための有用なイラストを提供しています:

マルチヘッドアテンションレイヤーを並列化することはさらに簡単です。それらは既に複数の独立したヘッドを持っているため、本質的に並列です!

特別な考慮事項:TPには非常に高速なネットワークが必要であり、したがって1つのノードを超えてTPを実行しないことがお勧めされません。実際には、1つのノードに4つのGPUがある場合、最大のTP度数は4です。TP度数8が必要な場合は、少なくとも8つのGPUを持つノードを使用する必要があります。
このセクションは、元のより詳細な[TPの概要](https://github.com/huggingface/transformers/issues/10321#issuecomment-783543530)に基づいています。
by [@anton-l](https://github.com/anton-l)。
SageMakerは、より効率的な処理のためにTPとDPを組み合わせて使用します。
代替名:
- [DeepSpeed](https://github.com/microsoft/DeepSpeed)はこれを「テンソルスライシング」と呼びます。詳細は[DeepSpeedの特徴](https://www.deepspeed.ai/training/#model-parallelism)をご覧ください。
実装例:
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)には、モデル固有の内部実装があります。
- [parallelformers](https://github.com/tunib-ai/parallelformers)(現時点では推論のみ)。
- [SageMaker](https://arxiv.org/abs/2111.05972) - これはAWSでのみ使用できるプロプライエタリなソリューションです。
- [OSLO](https://github.com/tunib-ai/oslo)には、Transformersに基づいたテンソル並列実装があります。
🤗 Transformersの状況:
- コア: まだコアには実装されていません。
- ただし、推論が必要な場合、[parallelformers](https://github.com/tunib-ai/parallelformers)はほとんどのモデルに対してサポートを提供します。これがコアに実装されるまで、これを使用できます。そして、トレーニングモードもサポートされることを期待しています。
- Deepspeed-Inferenceでは、BERT、GPT-2、およびGPT-NeoモデルをCUDAカーネルベースの高速推論モードでサポートしています。詳細は[こちら](https://www.deepspeed.ai/tutorials/inference-tutorial/)をご覧ください。
## DP+PP
DeepSpeedの[パイプラインチュートリアル](https://www.deepspeed.ai/tutorials/pipeline/)からの次の図は、DPをPPと組み合わせる方法を示しています。

ここで重要なのは、DPランク0がGPU2を見えなくし、DPランク1がGPU3を見えなくすることです。DPにとって、存在するのはGPU 0 と 1 のみで、それらの2つのGPUのようにデータを供給します。GPU0はPPを使用してGPU2に一部の負荷を「秘密裏に」オフロードし、GPU1も同様にGPU3を支援に引き入れます。
各次元には少なくとも2つのGPUが必要ですので、ここでは少なくとも4つのGPUが必要です。
実装例:
- [DeepSpeed](https://github.com/microsoft/DeepSpeed)
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
- [Varuna](https://github.com/microsoft/varuna)
- [SageMaker](https://arxiv.org/abs/2111.05972)
- [OSLO](https://github.com/tunib-ai/oslo)
🤗 Transformersの状況: まだ実装されていません
## DP+PP+TP
さらに効率的なトレーニングを行うために、3Dパラレリズムを使用し、PPをTPとDPと組み合わせます。これは次の図で示されています。

この図は[3Dパラレリズム:兆パラメータモデルへのスケーリング](https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/)というブログ投稿から取得されたもので、おすすめの読み物です。
各次元には少なくとも2つのGPUが必要ですので、ここでは少なくとも8つのGPUが必要です。
実装例:
- [DeepSpeed](https://github.com/microsoft/DeepSpeed) - DeepSpeedには、さらに効率的なDPであるZeRO-DPと呼ばれるものも含まれています。
- [Megatron-LM](https://github.com/NVIDIA/Megatron-LM)
- [Varuna](https://github.com/microsoft/varuna)
- [SageMaker](https://arxiv.org/abs/2111.05972)
- [OSLO](https://github.com/tunib-ai/oslo)
🤗 Transformersの状況: まだ実装されていません。PPとTPがないため。
## ZeRO DP+PP+TP
DeepSpeedの主要な機能の1つはZeROで、これはDPの拡張機能です。これについてはすでに「ZeROデータ並列化」で説明されています。通常、これは単独で動作する機能で、PPやTPは必要ありません。しかし、PPとTPと組み合わせることもできます。
ZeRO-DPがPPと組み合わされる場合、通常はZeROステージ1(オプティマイザーシャーディング)のみが有効になります。
ZeROステージ2(勾配シャーディング)をパイプライン並列化と組み合わせて使用する理論的な可能性はありますが、性能に悪影響を及ぼします。各マイクロバッチごとに勾配をシャーディングする前に、勾配を集約するための追加のリダクションスキャッター集計が必要で、通信オーバーヘッドが発生する可能性があります。パイプライン並列化の性質上、小さなマイクロバッチが使用され、計算の集中度(マイクロバッチサイズ)をバランスにかけ、パイプラインバブル(マイクロバッチ数)を最小限に抑えることに焦点が当てられています。したがって、これらの通信コストは影響を及ぼすでしょう。
さらに、PPには通常よりも少ない層が含まれており、メモリの節約はそれほど大きくありません。PPは既に勾配サイズを「1/PP」に削減するため、勾配シャーディングの節約は純粋なDPよりもはるかに重要ではありません。
ZeROステージ3も同様の理由で適していません - より多くのノード間通信が必要です。
そして、ZeROを持っているので、もう一つの利点はZeRO-Offloadです。これはステージ1オプティマイザーステートをCPUにオフロードできます。
実装例:
- [Megatron-DeepSpeed](https://github.com/microsoft/Megatron-DeepSpeed)と[BigScienceからのMegatron-Deepspeed](https://github.com/bigscience-workshop/Megatron-DeepSpeed)は、前者のリポジトリのフォークです。
- [OSLO](https://github.com/tunib-ai/oslo)
重要な論文:
- [DeepSpeedとMegatronを使用したMegatron-Turing NLG 530Bのトレーニング](https://arxiv.org/abs/2201.11990)
🤗 Transformersの状況: まだ実装されていません。PPとTPがないため。
## FlexFlow
[FlexFlow](https://github.com/flexflow/FlexFlow)は、わずかに異なるアプローチで並列化の問題を解決します。
論文: [Zhihao Jia、Matei Zaharia、Alex Aikenによる "Deep Neural Networksのデータとモデルの並列化を超えて"](https://arxiv.org/abs/1807.05358)
FlexFlowは、サンプル-オペレータ-属性-パラメータの4D並列化を行います。
1. サンプル = データ並列化(サンプル単位の並列化)
2. オペレータ = 単一の操作をいくつかのサブ操作に並列化
3. 属性 = データ並列化(長さ方向の並列化)
4. パラメータ = モデル並列化(次元に関係なく、水平または垂直)
例:
* サンプル
シーケンス長512の10バッチを考えてみましょう。これらをサンプル次元で2つのデバイスに並列化すると、10 x 512が5 x 2 x 512になります。
* オペレータ
層正規化を行う場合、まずstdを計算し、次にmeanを計算し、データを正規化できます。オペレータの並列化により、stdとmeanを並列に計算できます。したがって、オペレータ次元で2つのデバイス(cuda:0、cuda:1)に並列化すると、最初に入力データを両方のデバイスにコピーし、cuda:0でstdを計算し、cuda:1でmeanを同時に計算します。
* 属性
10バッチの512長があります。これらを属性次元で2つのデバイスに並列化すると、10 x 512が10 x 2 x 256になります。
* パラメータ
これはテンソルモデルの並列化または単純な層ごとのモデルの並列化と似ています。
このフレームワークの重要性は、(1)GPU/TPU/CPU対(2)RAM/DRAM対(3)高速内部接続/低速外部接続などのリソースを取り、これらすべてをアルゴリズムによって自動的に最適化することです。どの並列化をどこで使用するかをアルゴリズム的に決定します。
非常に重要な側面の1つは、FlexFlowは静的で固定のワークロードを持つモデルのために設計されており、動的な動作を持つモデルはイテレーションごとに異なる並列化戦略を好む場合があることです。
したがって、このフレームワークの約束は非常に魅力的です。選択したクラスタで30分間のシミュレーションを実行し、この特定の環境を最適に利用するための最良の戦略を提供します。部分を追加/削除/置換すると、それに対して実行して再最適化プランを作成します。その後、トレーニングできます。異なるセットアップには独自の最適化があります。
🤗 Transformersの現在の状況: まだ統合されていません。すでに[transformers.utils.fx](https://github.com/huggingface/transformers/blob/master/src/transformers/utils/fx.py)を使用してモデルがFXトレース可能であるため、FlexFlowを動作させるために必要な手順を誰かが見つける必要があります。
## Which Strategy To Use When
ここでは、どの並列化戦略をいつ使用するかの非常におおまかなアウトラインを示します。各リストの最初が通常よりも速いことが一般的です。
**⇨ 単一GPU**
* モデルが単一GPUに収まる場合:
1. 通常の使用
* モデルが単一GPUに収まらない場合:
1. ZeRO + CPUをオフロードし、オプションでNVMeをオフロード
2. 上記に加えて、最大のレイヤーが単一GPUに収まらない場合、[Memory Centric Tiling](https://deepspeed.readthedocs.io/en/latest/zero3.html#memory-centric-tiling)(詳細は以下参照)を有効化
* 最大のレイヤーが単一GPUに収まらない場合:
1. ZeROを使用しない場合 - TPを有効化する必要があります。なぜなら、PPだけでは収めることができないからです。
2. ZeROを使用する場合は、上記の「単一GPU」のエントリと同じものを参照してください
**⇨ 単一ノード/マルチGPU**
* モデルが単一GPUに収まる場合:
1. DDP - 分散データ並列
2. ZeRO - 状況と使用される構成に依存して速いかどうかが異なることがあります
* モデルが単一GPUに収まらない場合:
1. PP
2. ZeRO
3. TP
非常に高速なノード内接続がNVLINKまたはNVSwitchである場合、これらのすべてはほとんど同等の性能です。これらがない場合、PPはTPまたはZeROよりも速くなります。TPの度合いも違いを生じるかもしれません。特定のセットアップで勝者を見つけるために実験するのが最善です。
TPはほとんど常に単一ノード内で使用されます。つまり、TPサイズ <= ノードあたりのGPUです。
* 最大のレイヤーが単一GPUに収まらない場合:
1. ZeROを使用しない場合 - TPを使用する必要があります。なぜなら、PPだけでは収めることができないからです。
2. ZeROを使用する場合は、上記の「単一GPU」のエントリと同じものを参照してください
**⇨ マルチノード/マルチGPU**
* 高速なノード間接続がある場合:
1. ZeRO - モデルへのほとんどの変更が不要です
2. PP+TP+DP - 通信が少なく、モデルに大規模な変更が必要です
* 遅いノード間接続があり、GPUメモリが少ない場合:
1. DP+PP+TP+ZeRO-1
| transformers/docs/source/ja/perf_train_gpu_many.md/0 | {
"file_path": "transformers/docs/source/ja/perf_train_gpu_many.md",
"repo_id": "transformers",
"token_count": 18222
} | 253 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Automatic speech recognition
[[open-in-colab]]
<Youtube id="TksaY_FDgnk"/>
自動音声認識 (ASR) は音声信号をテキストに変換し、一連の音声入力をテキスト出力にマッピングします。 Siri や Alexa などの仮想アシスタントは ASR モデルを使用してユーザーを日常的に支援しており、ライブキャプションや会議中のメモ取りなど、他にも便利なユーザー向けアプリケーションが数多くあります。
このガイドでは、次の方法を説明します。
1. [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) データセットの [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base) を微調整して、音声をテキストに書き起こします。
2. 微調整したモデルを推論に使用します。
<Tip>
このチュートリアルで説明するタスクは、次のモデル アーキテクチャでサポートされています。
<!--This tip is automatically generated by `make fix-copies`, do not fill manually!-->
[Data2VecAudio](../model_doc/data2vec-audio), [Hubert](../model_doc/hubert), [M-CTC-T](../model_doc/mctct), [SEW](../model_doc/sew), [SEW-D](../model_doc/sew-d), [UniSpeech](../model_doc/unispeech), [UniSpeechSat](../model_doc/unispeech-sat), [Wav2Vec2](../model_doc/wav2vec2), [Wav2Vec2-Conformer](../model_doc/wav2vec2-conformer), [WavLM](../model_doc/wavlm)
<!--End of the generated tip-->
</Tip>
始める前に、必要なライブラリがすべてインストールされていることを確認してください。
```bash
pip install transformers datasets evaluate jiwer
```
モデルをアップロードしてコミュニティと共有できるように、Hugging Face アカウントにログインすることをお勧めします。プロンプトが表示されたら、トークンを入力してログインします。
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Load MInDS-14 dataset
まず、🤗 データセット ライブラリから [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) データセットの小さいサブセットをロードします。これにより、完全なデータセットのトレーニングにさらに時間を費やす前に、実験してすべてが機能することを確認する機会が得られます。
```py
>>> from datasets import load_dataset, Audio
>>> minds = load_dataset("PolyAI/minds14", name="en-US", split="train[:100]")
```
[`~Dataset.train_test_split`] メソッドを使用して、データセットの `train` 分割をトレイン セットとテスト セットに分割します。
```py
>>> minds = minds.train_test_split(test_size=0.2)
```
次に、データセットを見てみましょう。
```py
>>> minds
DatasetDict({
train: Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 16
})
test: Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 4
})
})
```
データセットには`lang_id`や`english_transcription`などの多くの有用な情報が含まれていますが、このガイドでは「`audio`」と「`transciption`」に焦点を当てます。 [`~datasets.Dataset.remove_columns`] メソッドを使用して他の列を削除します。
```py
>>> minds = minds.remove_columns(["english_transcription", "intent_class", "lang_id"])
```
もう一度例を見てみましょう。
```py
>>> minds["train"][0]
{'audio': {'array': array([-0.00024414, 0. , 0. , ..., 0.00024414,
0.00024414, 0.00024414], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'sampling_rate': 8000},
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'transcription': "hi I'm trying to use the banking app on my phone and currently my checking and savings account balance is not refreshing"}
```
次の 2 つのフィールドがあります。
- `audio`: 音声ファイルをロードしてリサンプリングするために呼び出す必要がある音声信号の 1 次元の `array`。
- `transcription`: ターゲットテキスト。
## Preprocess
次のステップでは、Wav2Vec2 プロセッサをロードしてオーディオ信号を処理します。
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base")
```
MInDS-14 データセットのサンプリング レートは 8000kHz です (この情報は [データセット カード](https://huggingface.co/datasets/PolyAI/minds14) で確認できます)。つまり、データセットを再サンプリングする必要があります。事前トレーニングされた Wav2Vec2 モデルを使用するには、16000kHz に設定します。
```py
>>> minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
>>> minds["train"][0]
{'audio': {'array': array([-2.38064706e-04, -1.58618059e-04, -5.43987835e-06, ...,
2.78103951e-04, 2.38446111e-04, 1.18740834e-04], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'sampling_rate': 16000},
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602ba9e2963e11ccd901cd4f.wav',
'transcription': "hi I'm trying to use the banking app on my phone and currently my checking and savings account balance is not refreshing"}
```
上の `transcription` でわかるように、テキストには大文字と小文字が混在しています。 Wav2Vec2 トークナイザーは大文字のみでトレーニングされるため、テキストがトークナイザーの語彙と一致することを確認する必要があります。
```py
>>> def uppercase(example):
... return {"transcription": example["transcription"].upper()}
>>> minds = minds.map(uppercase)
```
次に、次の前処理関数を作成します。
1. `audio`列を呼び出して、オーディオ ファイルをロードしてリサンプリングします。
2. オーディオ ファイルから `input_values` を抽出し、プロセッサを使用して `transcription` 列をトークン化します。
```py
>>> def prepare_dataset(batch):
... audio = batch["audio"]
... batch = processor(audio["array"], sampling_rate=audio["sampling_rate"], text=batch["transcription"])
... batch["input_length"] = len(batch["input_values"][0])
... return batch
```
データセット全体に前処理関数を適用するには、🤗 Datasets [`~datasets.Dataset.map`] 関数を使用します。 `num_proc` パラメータを使用してプロセスの数を増やすことで、`map` を高速化できます。 [`~datasets.Dataset.remove_columns`] メソッドを使用して、不要な列を削除します。
```py
>>> encoded_minds = minds.map(prepare_dataset, remove_columns=minds.column_names["train"], num_proc=4)
```
🤗 Transformers には ASR 用のデータ照合器がないため、[`DataCollatorWithPadding`] を調整してサンプルのバッチを作成する必要があります。また、テキストとラベルが (データセット全体ではなく) バッチ内の最も長い要素の長さに合わせて動的に埋め込まれ、均一な長さになります。 `padding=True` を設定すると、`tokenizer` 関数でテキストを埋め込むことができますが、動的な埋め込みの方が効率的です。
他のデータ照合器とは異なり、この特定のデータ照合器は、`input_values`と `labels`」に異なるパディング方法を適用する必要があります。
```py
>>> import torch
>>> from dataclasses import dataclass, field
>>> from typing import Any, Dict, List, Optional, Union
>>> @dataclass
... class DataCollatorCTCWithPadding:
... processor: AutoProcessor
... padding: Union[bool, str] = "longest"
... def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
... # split inputs and labels since they have to be of different lengths and need
... # different padding methods
... input_features = [{"input_values": feature["input_values"][0]} for feature in features]
... label_features = [{"input_ids": feature["labels"]} for feature in features]
... batch = self.processor.pad(input_features, padding=self.padding, return_tensors="pt")
... labels_batch = self.processor.pad(labels=label_features, padding=self.padding, return_tensors="pt")
... # replace padding with -100 to ignore loss correctly
... labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
... batch["labels"] = labels
... return batch
```
次に、`DataCollatorForCTCWithPadding` をインスタンス化します。
```py
>>> data_collator = DataCollatorCTCWithPadding(processor=processor, padding="longest")
```
## Evaluate
トレーニング中にメトリクスを含めると、多くの場合、モデルのパフォーマンスを評価するのに役立ちます。 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) ライブラリを使用して、評価メソッドをすばやくロードできます。このタスクでは、[単語エラー率](https://huggingface.co/spaces/evaluate-metric/wer) (WER) メトリクスを読み込みます (🤗 Evaluate [クイック ツアー](https://huggingface.co/docs/evaluate/a_quick_tour) を参照して、メトリクスをロードして計算する方法の詳細を確認してください)。
```py
>>> import evaluate
>>> wer = evaluate.load("wer")
```
次に、予測とラベルを [`~evaluate.EvaluationModule.compute`] に渡して WER を計算する関数を作成します。
```py
>>> import numpy as np
>>> def compute_metrics(pred):
... pred_logits = pred.predictions
... pred_ids = np.argmax(pred_logits, axis=-1)
... pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
... pred_str = processor.batch_decode(pred_ids)
... label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
... wer = wer.compute(predictions=pred_str, references=label_str)
... return {"wer": wer}
```
これで`compute_metrics`関数の準備が整いました。トレーニングをセットアップするときにこの関数に戻ります。
## Train
<frameworkcontent>
<pt>
<Tip>
[`Trainer`] を使用したモデルの微調整に慣れていない場合は、[ここ](../training#train-with-pytorch-trainer) の基本的なチュートリアルをご覧ください。
</Tip>
これでモデルのトレーニングを開始する準備が整いました。 [`AutoModelForCTC`] で Wav2Vec2 をロードします。 `ctc_loss_reduction` パラメータで適用する削減を指定します。多くの場合、デフォルトの合計ではなく平均を使用する方が適切です。
```py
>>> from transformers import AutoModelForCTC, TrainingArguments, Trainer
>>> model = AutoModelForCTC.from_pretrained(
... "facebook/wav2vec2-base",
... ctc_loss_reduction="mean",
... pad_token_id=processor.tokenizer.pad_token_id,
... )
```
この時点で残っている手順は次の 3 つだけです。
1. [`TrainingArguments`] でトレーニング ハイパーパラメータを定義します。唯一の必須パラメータは、モデルの保存場所を指定する `output_dir` です。 `push_to_hub=True`を設定して、このモデルをハブにプッシュします (モデルをアップロードするには、Hugging Face にサインインする必要があります)。各エポックの終了時に、[`トレーナー`] は WER を評価し、トレーニング チェックポイントを保存します。
2. トレーニング引数を、モデル、データセット、トークナイザー、データ照合器、および `compute_metrics` 関数とともに [`Trainer`] に渡します。
3. [`~Trainer.train`] を呼び出してモデルを微調整します。
```py
>>> training_args = TrainingArguments(
... output_dir="my_awesome_asr_mind_model",
... per_device_train_batch_size=8,
... gradient_accumulation_steps=2,
... learning_rate=1e-5,
... warmup_steps=500,
... max_steps=2000,
... gradient_checkpointing=True,
... fp16=True,
... group_by_length=True,
... evaluation_strategy="steps",
... per_device_eval_batch_size=8,
... save_steps=1000,
... eval_steps=1000,
... logging_steps=25,
... load_best_model_at_end=True,
... metric_for_best_model="wer",
... greater_is_better=False,
... push_to_hub=True,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=encoded_minds["train"],
... eval_dataset=encoded_minds["test"],
... tokenizer=processor,
... data_collator=data_collator,
... compute_metrics=compute_metrics,
... )
>>> trainer.train()
```
トレーニングが完了したら、 [`~transformers.Trainer.push_to_hub`] メソッドを使用してモデルをハブに共有し、誰もがモデルを使用できるようにします。
```py
>>> trainer.push_to_hub()
```
</pt>
</frameworkcontent>
<Tip>
自動音声認識用にモデルを微調整する方法のより詳細な例については、英語 ASR および英語のこのブログ [投稿](https://huggingface.co/blog/fine-tune-wav2vec2-english) を参照してください。多言語 ASR については、この [投稿](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) を参照してください。
</Tip>
## Inference
モデルを微調整したので、それを推論に使用できるようになりました。
推論を実行したい音声ファイルをロードします。必要に応じて、オーディオ ファイルのサンプリング レートをモデルのサンプリング レートと一致するようにリサンプリングすることを忘れないでください。
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", "en-US", split="train")
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> audio_file = dataset[0]["audio"]["path"]
```
推論用に微調整されたモデルを試す最も簡単な方法は、それを [`pipeline`] で使用することです。モデルを使用して自動音声認識用の`pipeline`をインスタンス化し、オーディオ ファイルをそれに渡します。
```py
>>> from transformers import pipeline
>>> transcriber = pipeline("automatic-speech-recognition", model="stevhliu/my_awesome_asr_minds_model")
>>> transcriber(audio_file)
{'text': 'I WOUD LIKE O SET UP JOINT ACOUNT WTH Y PARTNER'}
```
<Tip>
転写はまあまあですが、もっと良くなる可能性があります。さらに良い結果を得るには、より多くの例でモデルを微調整してみてください。
</Tip>
必要に応じて、「パイプライン」の結果を手動で複製することもできます。
<frameworkcontent>
<pt>
プロセッサをロードしてオーディオ ファイルと文字起こしを前処理し、`input`を PyTorch テンソルとして返します。
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("stevhliu/my_awesome_asr_mind_model")
>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
```
Pass your inputs to the model and return the logits:
```py
>>> from transformers import AutoModelForCTC
>>> model = AutoModelForCTC.from_pretrained("stevhliu/my_awesome_asr_mind_model")
>>> with torch.no_grad():
... logits = model(**inputs).logits
```
最も高い確率で予測された `input_ids` を取得し、プロセッサを使用して予測された `input_ids` をデコードしてテキストに戻します。
```py
>>> import torch
>>> predicted_ids = torch.argmax(logits, dim=-1)
>>> transcription = processor.batch_decode(predicted_ids)
>>> transcription
['I WOUL LIKE O SET UP JOINT ACOUNT WTH Y PARTNER']
```
</pt>
</frameworkcontent>
| transformers/docs/source/ja/tasks/asr.md/0 | {
"file_path": "transformers/docs/source/ja/tasks/asr.md",
"repo_id": "transformers",
"token_count": 7201
} | 254 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Transformers Agents
<Tip warning={true}>
Transformers Agentsは、いつでも変更される可能性のある実験的なAPIです。エージェントが返す結果は、APIまたは基礎となるモデルが変更される可能性があるため、異なることがあります。
</Tip>
Transformersバージョンv4.29.0は、*ツール*と*エージェント*のコンセプトを基に構築されています。この[colab](https://colab.research.google.com/drive/1c7MHD-T1forUPGcC_jlwsIptOzpG3hSj)で試すことができます。
要するに、これはtransformersの上に自然言語APIを提供するものです:私たちは一連の厳選されたツールを定義し、自然言語を解釈し、これらのツールを使用するエージェントを設計します。これは設計上拡張可能です。私たちはいくつかの関連するツールを厳選しましたが、コミュニティによって開発された任意のツールを使用するためにシステムを簡単に拡張できる方法も示します。
この新しいAPIで何ができるかのいくつかの例から始めましょう。特に多モーダルなタスクに関して強力ですので、画像を生成したりテキストを読み上げたりするのに最適です。
上記のテキストの上に、日本語の翻訳を提供します。
```py
agent.run("Caption the following image", image=image)
```
| **Input** | **Output** |
|-----------------------------------------------------------------------------------------------------------------------------|-----------------------------------|
| <img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/beaver.png" width=200> | A beaver is swimming in the water |
---
```py
agent.run("Read the following text out loud", text=text)
```
| **Input** | **Output** |
|-------------------------------------------------------------------------------------------------------------------------|----------------------------------------------|
| A beaver is swimming in the water | <audio controls><source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tts_example.wav" type="audio/wav"> your browser does not support the audio element. </audio>
---
```py
agent.run(
"In the following `document`, where will the TRRF Scientific Advisory Council Meeting take place?",
document=document,
)
```
| **Input** | **Output** |
|-----------------------------------------------------------------------------------------------------------------------------|----------------|
| <img src="https://datasets-server.huggingface.co/assets/hf-internal-testing/example-documents/--/hf-internal-testing--example-documents/test/0/image/image.jpg" width=200> | ballroom foyer |
## Quickstart
`agent.run`を使用する前に、エージェントをインスタンス化する必要があります。エージェントは、大規模な言語モデル(LLM)です。
OpenAIモデルとBigCode、OpenAssistantからのオープンソースの代替モデルをサポートしています。OpenAIモデルはパフォーマンスが優れていますが、OpenAIのAPIキーが必要であり、無料で使用することはできません。一方、Hugging FaceはBigCodeとOpenAssistantモデルのエンドポイントへの無料アクセスを提供しています。
まず、デフォルトの依存関係をすべてインストールするために`agents`のエクストラをインストールしてください。
```bash
pip install transformers[agents]
```
OpenAIモデルを使用するには、`openai`の依存関係をインストールした後、`OpenAiAgent`をインスタンス化します。
```bash
pip install openai
```
```py
from transformers import OpenAiAgent
agent = OpenAiAgent(model="text-davinci-003", api_key="<your_api_key>")
```
BigCodeまたはOpenAssistantを使用するには、まずログインしてInference APIにアクセスしてください。
```py
from huggingface_hub import login
login("<YOUR_TOKEN>")
```
次に、エージェントをインスタンス化してください。
```py
from transformers import HfAgent
# Starcoder
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder")
# StarcoderBase
# agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoderbase")
# OpenAssistant
# agent = HfAgent(url_endpoint="https://api-inference.huggingface.co/models/OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5")
```
これは、Hugging Faceが現在無料で提供している推論APIを使用しています。このモデル(または別のモデル)の独自の推論エンドポイントをお持ちの場合は、上記のURLエンドポイントをご自分のURLエンドポイントで置き換えることができます。
<Tip>
StarCoderとOpenAssistantは無料で利用でき、シンプルなタスクには非常に優れた性能を発揮します。ただし、より複雑なプロンプトを処理する際には、チェックポイントが十分でないことがあります。そのような場合には、現時点ではオープンソースではないものの、パフォーマンスが向上する可能性のあるOpenAIモデルを試してみることをお勧めします。
</Tip>
これで準備が整いました!これから、あなたが利用できる2つのAPIについて詳しく説明します。
### Single execution (run)
単一実行メソッドは、エージェントの [`~Agent.run`] メソッドを使用する場合です。
```py
agent.run("Draw me a picture of rivers and lakes.")
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes.png" width=200>
これは、実行したいタスクに適したツール(またはツール)を自動的に選択し、適切に実行します。1つまたは複数のタスクを同じ命令で実行することができます(ただし、命令が複雑であるほど、エージェントが失敗する可能性が高くなります)。
```py
agent.run("Draw me a picture of the sea then transform the picture to add an island")
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/sea_and_island.png" width=200>
<br/>
[`~Agent.run`] 操作は独立して実行できますので、異なるタスクで何度も実行することができます。
注意点として、あなたの `agent` は単なる大規模な言語モデルであるため、プロンプトのわずかな変更でも完全に異なる結果が得られる可能性があります。したがって、実行したいタスクをできるだけ明確に説明することが重要です。良いプロンプトの書き方については、[こちら](custom_tools#writing-good-user-inputs) で詳しく説明しています。
実行ごとに状態を保持したり、テキスト以外のオブジェクトをエージェントに渡したりする場合は、エージェントが使用する変数を指定することができます。例えば、最初の川や湖の画像を生成し、その画像に島を追加するようにモデルに指示するには、次のように行うことができます:
```python
picture = agent.run("Generate a picture of rivers and lakes.")
updated_picture = agent.run("Transform the image in `picture` to add an island to it.", picture=picture)
```
<Tip>
これは、モデルがあなたのリクエストを理解できない場合や、ツールを混同する場合に役立つことがあります。例えば:
```py
agent.run("Draw me the picture of a capybara swimming in the sea")
```
ここでは、モデルは2つの方法で解釈できます:
- `text-to-image`に海で泳ぐカピバラを生成させる
- または、`text-to-image`でカピバラを生成し、それを海で泳がせるために`image-transformation`ツールを使用する
最初のシナリオを強制したい場合は、プロンプトを引数として渡すことができます:
```py
agent.run("Draw me a picture of the `prompt`", prompt="a capybara swimming in the sea")
```
</Tip>
### Chat-based execution (チャット)
エージェントは、[`~Agent.chat`] メソッドを使用することで、チャットベースのアプローチも可能です。
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes.png" width=200>
```py
agent.chat("Transform the picture so that there is a rock in there")
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes_and_beaver.png" width=200>
<br/>
これは、指示をまたいで状態を保持したい場合に便利なアプローチで、単一の指示に比べて複雑な指示を処理するのは難しいかもしれません(その場合は [`~Agent.run`] メソッドの方が適しています)。
このメソッドは、非テキスト型の引数や特定のプロンプトを渡したい場合にも使用できます。
### ⚠️ Remote execution
デモンストレーションの目的やすべてのセットアップで使用できるように、リリースのためにいくつかのデフォルトツール用のリモート実行ツールも作成しました。これらは [推論エンドポイント](https://huggingface.co/inference-endpoints) を使用して作成されます。
これらは現在オフになっていますが、リモート実行ツールを自分で設定する方法については、[カスタムツールガイド](./custom_tools) を読むことをお勧めします。
### What's happening here? What are tools, and what are agents?

#### Agents
ここでの「エージェント」とは、大規模な言語モデルのことであり、特定の一連のツールにアクセスできるようにプロンプトを設定しています。
LLM(大規模言語モデル)は、コードの小さなサンプルを生成するのにかなり優れており、このAPIは、エージェントに特定のツールセットを使用してタスクを実行するコードの小さなサンプルを生成させることに利用しています。このプロンプトは、エージェントにタスクとツールの説明を提供することで、エージェントが使用しているツールのドキュメントにアクセスし、関連するコードを生成できるようになります。
#### Tools
ツールは非常に単純で、名前と説明からなる単一の関数です。それから、これらのツールの説明を使用してエージェントをプロンプトします。プロンプトを通じて、エージェントに、ツールを使用してクエリで要求されたタスクをどのように実行するかを示します。特に、ツールの期待される入力と出力を示します。
これは新しいツールを使用しており、パイプラインではなくツールを使用しています。なぜなら、エージェントは非常に原子的なツールでより良いコードを生成するからです。パイプラインはよりリファクタリングされ、しばしば複数のタスクを組み合わせています。ツールは非常に単純なタスクに焦点を当てることを意図しています。
#### Code-execution?!
このコードは、ツールとツールと一緒に渡される入力のセットで、当社の小規模なPythonインタープリタで実行されます。すでに提供されたツールとprint関数しか呼び出すことができないため、実行できることはすでに制限されています。Hugging Faceのツールに制限されているため、安全だと考えても問題ありません。
さらに、属性の検索やインポートは許可しておらず(それらは渡された入力/出力を処理するためには必要ないはずです)、最も明らかな攻撃は問題ありません(エージェントにそれらを出力するようにプロンプトする必要があります)。超安全な側に立ちたい場合は、追加の引数 return_code=True を指定して run() メソッドを実行できます。その場合、エージェントは実行するコードを返すだけで、実行するかどうかはあなた次第です。
実行は、違法な操作を試みる行またはエージェントが生成したコードに通常のPythonエラーがある場合に停止します。
### A curated set of tools
私たちは、このようなエージェントを強化できるツールのセットを特定します。以下は、`transformers`に統合されたツールの更新されたリストです:
- **ドキュメント質問応答**: 画像形式のドキュメント(PDFなど)が与えられた場合、このドキュメントに関する質問に回答します([Donut](./model_doc/donut))
- **テキスト質問応答**: 長いテキストと質問が与えられた場合、テキスト内の質問に回答します([Flan-T5](./model_doc/flan-t5))
- **無条件の画像キャプション**: 画像にキャプションを付けます!([BLIP](./model_doc/blip))
- **画像質問応答**: 画像が与えられた場合、その画像に関する質問に回答します([VILT](./model_doc/vilt))
- **画像セグメンテーション**: 画像とプロンプトが与えられた場合、そのプロンプトのセグメンテーションマスクを出力します([CLIPSeg](./model_doc/clipseg))
- **音声からテキストへの変換**: 人の話し声のオーディオ録音が与えられた場合、その音声をテキストに転記します([Whisper](./model_doc/whisper))
- **テキストから音声への変換**: テキストを音声に変換します([SpeechT5](./model_doc/speecht5))
- **ゼロショットテキスト分類**: テキストとラベルのリストが与えられた場合、テキストが最も対応するラベルを識別します([BART](./model_doc/bart))
- **テキスト要約**: 長いテキストを1つまたは数文に要約します([BART](./model_doc/bart))
- **翻訳**: テキストを指定された言語に翻訳します([NLLB](./model_doc/nllb))
これらのツールはtransformersに統合されており、手動でも使用できます。たとえば、次のように使用できます:
```py
from transformers import load_tool
tool = load_tool("text-to-speech")
audio = tool("This is a text to speech tool")
```
### Custom tools
私たちは、厳選されたツールのセットを特定する一方、この実装が提供する主要な価値は、カスタムツールを迅速に作成して共有できる能力だと強く信じています。
ツールのコードをHugging Face Spaceまたはモデルリポジトリにプッシュすることで、エージェントと直接連携してツールを活用できます。[`huggingface-tools` organization](https://huggingface.co/huggingface-tools)には、**transformers非依存**のいくつかのツールが追加されました:
- **テキストダウンローダー**: ウェブURLからテキストをダウンロードするためのツール
- **テキストから画像へ**: プロンプトに従って画像を生成するためのツール。安定した拡散を活用します
- **画像変換**: 初期画像とプロンプトを指定して画像を変更するためのツール。instruct pix2pixの安定した拡散を活用します
- **テキストからビデオへ**: プロンプトに従って小さなビデオを生成するためのツール。damo-vilabを活用します
最初から使用しているテキストから画像へのツールは、[*huggingface-tools/text-to-image*](https://huggingface.co/spaces/huggingface-tools/text-to-image)にあるリモートツールです!今後も、この組織および他の組織にさらにこのようなツールをリリースし、この実装をさらに強化していきます。
エージェントはデフォルトで[`huggingface-tools`](https://huggingface.co/huggingface-tools)にあるツールにアクセスできます。
ツールの作成と共有方法、またHubに存在するカスタムツールを活用する方法についての詳細は、[次のガイド](custom_tools)で説明しています。
### Code generation
これまで、エージェントを使用してあなたのためにアクションを実行する方法を示しました。ただし、エージェントはコードを生成するだけで、非常に制限されたPythonインタープリタを使用して実行します。生成されたコードを異なる環境で使用したい場合、エージェントにコードを返すように指示できます。ツールの定義と正確なインポートも含めて。
例えば、以下の命令:
```python
agent.run("Draw me a picture of rivers and lakes", return_code=True)
```
次のコードを返します
```python
from transformers import load_tool
image_generator = load_tool("huggingface-tools/text-to-image")
image = image_generator(prompt="rivers and lakes")
```
その後、自分で変更して実行できます。
| transformers/docs/source/ja/transformers_agents.md/0 | {
"file_path": "transformers/docs/source/ja/transformers_agents.md",
"repo_id": "transformers",
"token_count": 7879
} | 255 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# 사용자 정의 도구와 프롬프트[[custom-tools-and-prompts]]
<Tip>
Transformers와 관련하여 어떤 도구와 에이전트가 있는지 잘 모르신다면 [Transformers Agents](transformers_agents) 페이지를 먼저 읽어보시기 바랍니다.
</Tip>
<Tip warning={true}>
Transformers Agents는 실험 중인 API로 언제든지 변경될 수 있습니다.
API 또는 기반 모델이 변경되기 쉽기 때문에 에이전트가 반환하는 결과도 달라질 수 있습니다.
</Tip>
에이전트에게 권한을 부여하고 새로운 작업을 수행하게 하려면 사용자 정의 도구와 프롬프트를 만들고 사용하는 것이 무엇보다 중요합니다.
이 가이드에서는 다음과 같은 내용을 살펴보겠습니다:
- 프롬프트를 사용자 정의하는 방법
- 사용자 정의 도구를 사용하는 방법
- 사용자 정의 도구를 만드는 방법
## 프롬프트를 사용자 정의하기[[customizing-the-prompt]]
[Transformers Agents](transformers_agents)에서 설명한 것처럼 에이전트는 [`~Agent.run`] 및 [`~Agent.chat`] 모드에서 실행할 수 있습니다.
`run`(실행) 모드와 `chat`(채팅) 모드 모두 동일한 로직을 기반으로 합니다.
에이전트를 구동하는 언어 모델은 긴 프롬프트에 따라 조건이 지정되고, 중지 토큰에 도달할 때까지 다음 토큰을 생성하여 프롬프트를 완수합니다.
`chat` 모드에서는 프롬프트가 이전 사용자 입력 및 모델 생성으로 연장된다는 점이 두 모드의 유일한 차이점입니다.
이를 통해 에이전트가 과거 상호작용에 접근할 수 있게 되므로 에이전트에게 일종의 메모리를 제공하는 셈입니다.
### 프롬프트의 구조[[structure-of-the-prompt]]
어떻게 프롬프트 사용자 정의를 잘 할 수 있는지 이해하기 위해 프롬프트의 구조를 자세히 살펴봅시다.
프롬프트는 크게 네 부분으로 구성되어 있습니다.
- 1. 도입: 에이전트가 어떻게 행동해야 하는지, 도구의 개념에 대한 설명.
- 2. 모든 도구에 대한 설명. 이는 런타임에 사용자가 정의/선택한 도구로 동적으로 대체되는 `<<all_tools>>` 토큰으로 정의됩니다.
- 3. 작업 예제 및 해당 솔루션 세트.
- 4. 현재 예제 및 해결 요청.
각 부분을 더 잘 이해할 수 있도록 짧은 버전을 통해 `run` 프롬프트가 어떻게 보이는지 살펴보겠습니다:
````text
I will ask you to perform a task, your job is to come up with a series of simple commands in Python that will perform the task.
[...]
You can print intermediate results if it makes sense to do so.
Tools:
- document_qa: This is a tool that answers a question about a document (pdf). It takes an input named `document` which should be the document containing the information, as well as a `question` that is the question about the document. It returns a text that contains the answer to the question.
- image_captioner: This is a tool that generates a description of an image. It takes an input named `image` which should be the image to the caption and returns a text that contains the description in English.
[...]
Task: "Answer the question in the variable `question` about the image stored in the variable `image`. The question is in French."
I will use the following tools: `translator` to translate the question into English and then `image_qa` to answer the question on the input image.
Answer:
```py
translated_question = translator(question=question, src_lang="French", tgt_lang="English")
print(f"The translated question is {translated_question}.")
answer = image_qa(image=image, question=translated_question)
print(f"The answer is {answer}")
```
Task: "Identify the oldest person in the `document` and create an image showcasing the result as a banner."
I will use the following tools: `document_qa` to find the oldest person in the document, then `image_generator` to generate an image according to the answer.
Answer:
```py
answer = document_qa(document, question="What is the oldest person?")
print(f"The answer is {answer}.")
image = image_generator("A banner showing " + answer)
```
[...]
Task: "Draw me a picture of rivers and lakes"
I will use the following
````
도입(*"도구:"* 앞의 텍스트)에서는 모델이 어떻게 작동하고 무엇을 해야 하는지 정확하게 설명합니다.
에이전트는 항상 같은 방식으로 작동해야 하므로 이 부분은 사용자 정의할 필요가 없을 가능성이 높습니다.
두 번째 부분(*"도구"* 아래의 글머리 기호)은 `run` 또는 `chat`을 호출할 때 동적으로 추가됩니다.
정확히 `agent.toolbox`에 있는 도구 수만큼 글머리 기호가 있고, 각 글머리 기호는 도구의 이름과 설명으로 구성됩니다:
```text
- <tool.name>: <tool.description>
```
문서 질의응답 도구를 가져오고 이름과 설명을 출력해서 빠르게 확인해 보겠습니다.
```py
from transformers import load_tool
document_qa = load_tool("document-question-answering")
print(f"- {document_qa.name}: {document_qa.description}")
```
그러면 다음 결과가 출력됩니다:
```text
- document_qa: This is a tool that answers a question about a document (pdf). It takes an input named `document` which should be the document containing the information, as well as a `question` that is the question about the document. It returns a text that contains the answer to the question.
```
여기서 도구 이름이 짧고 정확하다는 것을 알 수 있습니다.
설명은 두 부분으로 구성되어 있는데, 첫 번째 부분에서는 도구의 기능을 설명하고 두 번째 부분에서는 예상되는 입력 인수와 반환 값을 명시합니다.
에이전트가 도구를 올바르게 사용하려면 좋은 도구 이름과 도구 설명이 매우 중요합니다.
에이전트가 도구에 대해 알 수 있는 유일한 정보는 이름과 설명뿐이므로, 이 두 가지를 정확하게 작성하고 도구 상자에 있는 기존 도구의 스타일과 일치하는지 확인해야 합니다.
특히 이름에 따라 예상되는 모든 인수가 설명에 코드 스타일로 언급되어 있는지, 예상되는 유형과 그 유형이 무엇인지에 대한 설명이 포함되어 있는지 확인하세요.
<Tip>
도구에 어떤 이름과 설명이 있어야 하는지 이해하려면 엄선된 Transformers 도구의 이름과 설명을 확인하세요.
[`Agent.toolbox`] 속성을 가진 모든 도구를 볼 수 있습니다.
</Tip>
세 번째 부분에는 에이전트가 어떤 종류의 사용자 요청에 대해 어떤 코드를 생성해야 하는지 정확하게 보여주는 엄선된 예제 세트가 포함되어 있습니다.
에이전트를 지원하는 대규모 언어 모델은 프롬프트에서 패턴을 인식하고 새로운 데이터로 패턴을 반복하는 데 매우 능숙합니다.
따라서 에이전트가 실제로 올바른 실행 가능한 코드를 생성할 가능성을 극대화하는 방식으로 예제를 작성하는 것이 매우 중요합니다.
한 가지 예를 살펴보겠습니다:
````text
Task: "Identify the oldest person in the `document` and create an image showcasing the result as a banner."
I will use the following tools: `document_qa` to find the oldest person in the document, then `image_generator` to generate an image according to the answer.
Answer:
```py
answer = document_qa(document, question="What is the oldest person?")
print(f"The answer is {answer}.")
image = image_generator("A banner showing " + answer)
```
````
작업 설명, 에이전트가 수행하려는 작업에 대한 설명, 마지막으로 생성된 코드, 이 세 부분으로 구성된 프롬프트는 모델에 반복하여 제공됩니다.
프롬프트의 일부인 모든 예제는 이러한 정확한 패턴으로 되어 있으므로, 에이전트가 새 토큰을 생성할 때 정확히 동일한 패턴을 재현할 수 있습니다.
프롬프트 예제는 Transformers 팀이 선별하고 일련의 [problem statements](https://github.com/huggingface/transformers/blob/main/src/transformers/tools/evaluate_agent.py)에 따라 엄격하게 평가하여
에이전트의 프롬프트가 에이전트의 실제 사용 사례를 최대한 잘 해결할 수 있도록 보장합니다.
프롬프트의 마지막 부분은 다음에 해당합니다:
```text
Task: "Draw me a picture of rivers and lakes"
I will use the following
```
이는 에이전트가 완료해야 할 최종적인 미완성 예제입니다. 미완성 예제는 실제 사용자 입력에 따라 동적으로 만들어집니다.
위 예시의 경우 사용자가 다음과 같이 실행했습니다:
```py
agent.run("Draw me a picture of rivers and lakes")
```
사용자 입력 - *즉* Task: *"Draw me a picture of rivers and lakes"*가 프롬프트 템플릿에 맞춰 "Task: <task> \n\n I will use the following"로 캐스팅됩니다.
이 문장은 에이전트에게 조건이 적용되는 프롬프트의 마지막 줄을 구성하므로 에이전트가 이전 예제에서 수행한 것과 정확히 동일한 방식으로 예제를 완료하도록 강력하게 영향을 미칩니다.
너무 자세히 설명하지 않더라도 채팅 템플릿의 프롬프트 구조는 동일하지만 예제의 스타일이 약간 다릅니다. *예를 들면*:
````text
[...]
=====
Human: Answer the question in the variable `question` about the image stored in the variable `image`.
Assistant: I will use the tool `image_qa` to answer the question on the input image.
```py
answer = image_qa(text=question, image=image)
print(f"The answer is {answer}")
```
Human: I tried this code, it worked but didn't give me a good result. The question is in French
Assistant: In this case, the question needs to be translated first. I will use the tool `translator` to do this.
```py
translated_question = translator(question=question, src_lang="French", tgt_lang="English")
print(f"The translated question is {translated_question}.")
answer = image_qa(text=translated_question, image=image)
print(f"The answer is {answer}")
```
=====
[...]
````
`run` 프롬프트의 예와는 반대로, 각 `chat` 프롬프트의 예에는 *Human(사람)*과 *Assistant(어시스턴트)* 간에 하나 이상의 교환이 있습니다. 모든 교환은 `run` 프롬프트의 예와 유사한 구조로 되어 있습니다.
사용자의 입력이 *Human:* 뒤에 추가되며, 에이전트에게 코드를 생성하기 전에 수행해야 할 작업을 먼저 생성하라는 메시지가 표시됩니다.
교환은 이전 교환을 기반으로 할 수 있으므로 위와 같이 사용자가 "**이** 코드를 시도했습니다"라고 입력하면 이전에 생성된 에이전트의 코드를 참조하여 과거 교환을 참조할 수 있습니다.
`.chat`을 실행하면 사용자의 입력 또는 *작업*이 미완성된 양식의 예시로 캐스팅됩니다:
```text
Human: <user-input>\n\nAssistant:
```
그러면 에이전트가 이를 완성합니다. `run` 명령과 달리 `chat` 명령은 완료된 예제를 프롬프트에 추가하여 에이전트에게 다음 `chat` 차례에 대한 더 많은 문맥을 제공합니다.
이제 프롬프트가 어떻게 구성되어 있는지 알았으니 어떻게 사용자 정의할 수 있는지 살펴봅시다!
### 좋은 사용자 입력 작성하기[[writing-good-user-inputs]]
대규모 언어 모델이 사용자의 의도를 이해하는 능력이 점점 더 향상되고 있지만, 에이전트가 올바른 작업을 선택할 수 있도록 최대한 정확성을 유지하는 것은 큰 도움이 됩니다.
최대한 정확하다는 것은 무엇을 의미할까요?
에이전트는 프롬프트에서 도구 이름 목록과 해당 설명을 볼 수 있습니다.
더 많은 도구가 추가될수록 에이전트가 올바른 도구를 선택하기가 더 어려워지고 실행할 도구의 올바른 순서를 선택하는 것은 더욱 어려워집니다.
일반적인 실패 사례를 살펴보겠습니다. 여기서는 분석할 코드만 반환하겠습니다.
```py
from transformers import HfAgent
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder")
agent.run("Show me a tree", return_code=True)
```
그러면 다음 결과가 출력됩니다:
```text
==Explanation from the agent==
I will use the following tool: `image_segmenter` to create a segmentation mask for the image.
==Code generated by the agent==
mask = image_segmenter(image, prompt="tree")
```
우리가 원했던 결과가 아닐 수도 있습니다. 대신 나무 이미지가 생성되기를 원할 가능성이 더 높습니다.
따라서 에이전트가 특정 도구를 사용하도록 유도하려면 도구의 이름과 설명에 있는 중요한 키워드를 사용하는 것이 매우 유용할 수 있습니다. 한번 살펴보겠습니다.
```py
agent.toolbox["image_generator"].description
```
```text
'This is a tool that creates an image according to a prompt, which is a text description. It takes an input named `prompt` which contains the image description and outputs an image.
```
이름과 설명은 "image", "prompt", "create" 및 "generate" 키워드를 사용합니다. 이 단어들을 사용하면 더 잘 작동할 가능성이 높습니다. 프롬프트를 조금 더 구체화해 보겠습니다.
```py
agent.run("Create an image of a tree", return_code=True)
```
이 코드는 다음 프롬프트를 만들어냅니다:
```text
==Explanation from the agent==
I will use the following tool `image_generator` to generate an image of a tree.
==Code generated by the agent==
image = image_generator(prompt="tree")
```
훨씬 낫네요! 저희가 원했던 것과 비슷해 보입니다.
즉, 에이전트가 작업을 올바른 도구에 올바르게 매핑하는 데 어려움을 겪고 있다면 도구 이름과 설명에서 가장 관련성이 높은 키워드를 찾아보고 이를 통해 작업 요청을 구체화해 보세요.
### 도구 설명 사용자 정의하기[[customizing-the-tool-descriptions]]
앞서 살펴본 것처럼 에이전트는 각 도구의 이름과 설명에 액세스할 수 있습니다.
기본 도구에는 매우 정확한 이름과 설명이 있어야 하지만 특정 사용 사례에 맞게 도구의 설명이나 이름을 변경하는 것이 도움이 될 수도 있습니다.
이는 매우 유사한 여러 도구를 추가했거나 특정 도메인(*예*: 이미지 생성 및 변환)에만 에이전트를 사용하려는 경우에 특히 중요해질 수 있습니다.
일반적인 문제는 이미지 생성 작업에 많이 사용되는 경우 에이전트가 이미지 생성과 이미지 변환/수정을 혼동하는 것입니다. *예를 들어,*
```py
agent.run("Make an image of a house and a car", return_code=True)
```
그러면 다음 결과가 출력됩니다:
```text
==Explanation from the agent==
I will use the following tools `image_generator` to generate an image of a house and `image_transformer` to transform the image of a car into the image of a house.
==Code generated by the agent==
house_image = image_generator(prompt="A house")
car_image = image_generator(prompt="A car")
house_car_image = image_transformer(image=car_image, prompt="A house")
```
결과물이 우리가 여기서 원하는 것과 정확히 일치하지 않을 수 있습니다. 에이전트가 `image_generator`와 `image_transformer`의 차이점을 이해하기 어려워서 두 가지를 함께 사용하는 경우가 많은 것 같습니다.
여기서 `image_transformer`의 도구 이름과 설명을 변경하여 에이전트가 도울 수 있습니다.
"image" 및 "prompt"와 약간 분리하기 위해 `modifier`라고 대신 부르겠습니다:
```py
agent.toolbox["modifier"] = agent.toolbox.pop("image_transformer")
agent.toolbox["modifier"].description = agent.toolbox["modifier"].description.replace(
"transforms an image according to a prompt", "modifies an image"
)
```
이제 "modify"은 새 이미지 프로세서를 사용하라는 강력한 신호이므로 위의 프롬프트에 도움이 될 것입니다. 다시 실행해 봅시다.
```py
agent.run("Make an image of a house and a car", return_code=True)
```
여기서 다음과 같은 결과를 얻게 됩니다:
```text
==Explanation from the agent==
I will use the following tools: `image_generator` to generate an image of a house, then `image_generator` to generate an image of a car.
==Code generated by the agent==
house_image = image_generator(prompt="A house")
car_image = image_generator(prompt="A car")
```
우리가 염두에 두었던 것과 확실히 더 가까워졌습니다! 하지만 집과 자동차가 모두 같은 이미지에 포함되면 좋겠습니다. 작업을 단일 이미지 생성에 더 집중하면 도움이 될 것입니다:
```py
agent.run("Create image: 'A house and car'", return_code=True)
```
```text
==Explanation from the agent==
I will use the following tool: `image_generator` to generate an image.
==Code generated by the agent==
image = image_generator(prompt="A house and car")
```
<Tip warning={true}>
에이전트는 여전히 특히 여러 개체의 이미지를 생성하는 것과 같이 약간 더 복잡한 사용 사례에서 취약한 경우가 많습니다.
앞으로 몇 달 안에 에이전트 자체와 기본 프롬프트가 더욱 개선되어 에이전트가 다양한 사용자 입력에 더욱 강력하게 대응할 수 있도록 할 예정입니다.
</Tip>
### 전체 프롬프트 사용자 정의하기[[customizing-the-whole-prompt]]
사용자에게 최대한의 유연성을 제공하기 위해 [위](#structure-of-the-prompt)에 설명된 전체 프롬프트 템플릿을 사용자가 덮어쓸 수 있습니다.
이 경우 사용자 정의 프롬프트에 소개 섹션, 도구 섹션, 예제 섹션 및 미완성 예제 섹션이 포함되어 있는지 확인하세요.
`run` 프롬프트 템플릿을 덮어쓰려면 다음과 같이 하면 됩니다:
```py
template = """ [...] """
agent = HfAgent(your_endpoint, run_prompt_template=template)
```
<Tip warning={true}>
에이전트가 사용 가능한 도구를 인식하고 사용자의 프롬프트를 올바르게 삽입할 수 있도록 `<<all_tools>>` 문자열과 `<<prompt>>`를 `template` 어딘가에 정의해야 합니다.
</Tip>
마찬가지로 `chat` 프롬프트 템플릿을 덮어쓸 수 있습니다. `chat` 모드에서는 항상 다음과 같은 교환 형식을 사용한다는 점에 유의하세요:
```text
Human: <<task>>
Assistant:
```
따라서 사용자 정의 `chat` 프롬프트 템플릿의 예제에서도 이 형식을 사용하는 것이 중요합니다.
다음과 같이 인스턴스화 할 때 `chat` 템플릿을 덮어쓸 수 있습니다.
```python
template = """ [...] """
agent = HfAgent(url_endpoint=your_endpoint, chat_prompt_template=template)
```
<Tip warning={true}>
에이전트가 사용 가능한 도구를 인식할 수 있도록 `<<all_tools>>` 문자열을 `template` 어딘가에 정의해야 합니다.
</Tip>
두 경우 모두 커뮤니티의 누군가가 호스팅하는 템플릿을 사용하려는 경우 프롬프트 템플릿 대신 저장소 ID를 전달할 수 있습니다.
기본 프롬프트는 [이 저장소](https://huggingface.co/datasets/huggingface-tools/default-prompts)를 예로 들 수 있습니다.
Hub의 저장소에 사용자 정의 프롬프트를 업로드하여 커뮤니티와 공유하려면 다음을 확인하세요:
- 데이터 세트 저장소를 사용하세요.
- `run` 명령에 대한 프롬프트 템플릿을 `run_prompt_template.txt`라는 파일에 넣으세요.
- `chat` 명령에 대한 프롬프트 템플릿을 `chat_prompt_template.txt`라는 파일에 넣으세요.
## 사용자 정의 도구 사용하기[[using-custom-tools]]
이 섹션에서는 이미지 생성에 특화된 두 가지 기존 사용자 정의 도구를 활용하겠습니다:
- 더 많은 이미지 수정을 허용하기 위해 [huggingface-tools/image-transformation](https://huggingface.co/spaces/huggingface-tools/image-transformation)을
[diffusers/controlnet-canny-tool](https://huggingface.co/spaces/diffusers/controlnet-canny-tool)로 대체합니다.
- 기본 도구 상자에 이미지 업스케일링을 위한 새로운 도구가 추가되었습니다:
[diffusers/latent-upscaler-tool](https://huggingface.co/spaces/diffusers/latent-upscaler-tool)가 기존 이미지 변환 도구를 대체합니다.
편리한 [`load_tool`] 함수를 사용하여 사용자 정의 도구를 가져오는 것으로 시작하겠습니다:
```py
from transformers import load_tool
controlnet_transformer = load_tool("diffusers/controlnet-canny-tool")
upscaler = load_tool("diffusers/latent-upscaler-tool")
```
에이전트에게 사용자 정의 도구를 추가하면 도구의 설명과 이름이 에이전트의 프롬프트에 자동으로 포함됩니다.
따라서 에이전트가 사용 방법을 이해할 수 있도록 사용자 정의 도구의 설명과 이름을 잘 작성해야 합니다.
`controlnet_transformer`의 설명과 이름을 살펴보겠습니다:
```py
print(f"Description: '{controlnet_transformer.description}'")
print(f"Name: '{controlnet_transformer.name}'")
```
그러면 다음 결과가 출력됩니다:
```text
Description: 'This is a tool that transforms an image with ControlNet according to a prompt.
It takes two inputs: `image`, which should be the image to transform, and `prompt`, which should be the prompt to use to change it. It returns the modified image.'
Name: 'image_transformer'
```
이름과 설명이 정확하고 [큐레이팅 된 도구 세트(curated set of tools)](./transformers_agents#a-curated-set-of-tools)의 스타일에 맞습니다.
다음으로, `controlnet_transformer`와 `upscaler`로 에이전트를 인스턴스화해 봅시다:
```py
tools = [controlnet_transformer, upscaler]
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder", additional_tools=tools)
```
이 명령을 실행하면 다음 정보가 표시됩니다:
```text
image_transformer has been replaced by <transformers_modules.diffusers.controlnet-canny-tool.bd76182c7777eba9612fc03c0
8718a60c0aa6312.image_transformation.ControlNetTransformationTool object at 0x7f1d3bfa3a00> as provided in `additional_tools`
```
큐레이팅된 도구 세트에는 이미 'image_transformer' 도구가 있으며, 이 도구는 사용자 정의 도구로 대체됩니다.
<Tip>
기존 도구와 똑같은 작업에 사용자 정의 도구를 사용하려는 경우 기존 도구를 덮어쓰는 것이 유용할 수 있습니다.
에이전트가 해당 작업에 능숙하기 때문입니다.
이 경우 사용자 정의 도구가 덮어쓴 도구와 정확히 동일한 API를 따라야 하며, 그렇지 않으면 해당 도구를 사용하는 모든 예제가 업데이트되도록 프롬프트 템플릿을 조정해야 한다는 점에 유의하세요.
</Tip>
업스케일러 도구에 지정된 'image_upscaler'라는 이름 아직 기본 도구 상자에는 존재하지 않기 때문에, 도구 목록에 해당 이름이 간단히 추가되었습니다.
에이전트가 현재 사용할 수 있는 도구 상자는 언제든지 `agent.toolbox` 속성을 통해 확인할 수 있습니다:
```py
print("\n".join([f"- {a}" for a in agent.toolbox.keys()]))
```
```text
- document_qa
- image_captioner
- image_qa
- image_segmenter
- transcriber
- summarizer
- text_classifier
- text_qa
- text_reader
- translator
- image_transformer
- text_downloader
- image_generator
- video_generator
- image_upscaler
```
에이전트의 도구 상자에 `image_upscaler`가 추가된 점을 주목하세요.
이제 새로운 도구를 사용해봅시다! [Transformers Agents Quickstart](./transformers_agents#single-execution-run)에서 생성한 이미지를 다시 사용하겠습니다.
```py
from diffusers.utils import load_image
image = load_image(
"https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes.png"
)
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes.png" width=200>
이미지를 아름다운 겨울 풍경으로 바꿔 봅시다:
```py
image = agent.run("Transform the image: 'A frozen lake and snowy forest'", image=image)
```
```text
==Explanation from the agent==
I will use the following tool: `image_transformer` to transform the image.
==Code generated by the agent==
image = image_transformer(image, prompt="A frozen lake and snowy forest")
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes_winter.png" width=200>
새로운 이미지 처리 도구는 이미지를 매우 강력하게 수정할 수 있는 ControlNet을 기반으로 합니다.
기본적으로 이미지 처리 도구는 512x512 픽셀 크기의 이미지를 반환합니다. 이를 업스케일링할 수 있는지 살펴봅시다.
```py
image = agent.run("Upscale the image", image)
```
```text
==Explanation from the agent==
I will use the following tool: `image_upscaler` to upscale the image.
==Code generated by the agent==
upscaled_image = image_upscaler(image)
```
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rivers_and_lakes_winter_upscale.png" width=400>
에이전트는 업스케일러 도구의 설명과 이름만 보고 방금 추가한 업스케일러 도구에 "이미지 업스케일링"이라는 프롬프트를 자동으로 매핑하여 올바르게 실행했습니다.
다음으로 새 사용자 정의 도구를 만드는 방법을 살펴보겠습니다.
### 새 도구 추가하기[[adding-new-tools]]
이 섹션에서는 에이전트에게 추가할 수 있는 새 도구를 만드는 방법을 보여 드립니다.
#### 새 도구 만들기[[creating-a-new-tool]]
먼저 도구를 만드는 것부터 시작하겠습니다.
특정 작업에 대해 가장 많은 다운로드를 받은 Hugging Face Hub의 모델을 가져오는, 그다지 유용하지는 않지만 재미있는 작업을 추가하겠습니다.
다음 코드를 사용하면 됩니다:
```python
from huggingface_hub import list_models
task = "text-classification"
model = next(iter(list_models(filter=task, sort="downloads", direction=-1)))
print(model.id)
```
`text-classification`(텍스트 분류) 작업의 경우 `'facebook/bart-large-mnli'`를 반환하고, `translation`(번역) 작업의 경우 `'google-t5/t5-base'`를 반환합니다.
이를 에이전트가 활용할 수 있는 도구로 변환하려면 어떻게 해야 할까요?
모든 도구는 필요한 주요 속성을 보유하는 슈퍼클래스 `Tool`에 의존합니다. 이를 상속하는 클래스를 만들어 보겠습니다:
```python
from transformers import Tool
class HFModelDownloadsTool(Tool):
pass
```
이 클래스에는 몇 가지 요구사항이 있습니다:
- 도구 자체의 이름에 해당하는 `name` 속성. 수행명이 있는 다른 도구와 호환되도록 `model_download_counter`로 이름을 지정하겠습니다.
- 에이전트의 프롬프트를 채우는 데 사용되는 속성 `description`.
- `inputs` 및 `outputs` 속성. 이를 정의하면 Python 인터프리터가 유형에 대한 정보에 입각한 선택을 하는 데 도움이 되며,
도구를 허브에 푸시할 때 gradio 데모를 생성할 수 있습니다.
두 속성 모두 값은 '텍스트', '이미지' 또는 '오디오'가 될 수 있는 예상 값의 리스트입니다.
- 추론 코드가 포함된 `__call__` 메소드. 이것이 우리가 위에서 다루었던 코드입니다!
이제 클래스의 모습은 다음과 같습니다:
```python
from transformers import Tool
from huggingface_hub import list_models
class HFModelDownloadsTool(Tool):
name = "model_download_counter"
description = (
"This is a tool that returns the most downloaded model of a given task on the Hugging Face Hub. "
"It takes the name of the category (such as text-classification, depth-estimation, etc), and "
"returns the name of the checkpoint."
)
inputs = ["text"]
outputs = ["text"]
def __call__(self, task: str):
model = next(iter(list_models(filter=task, sort="downloads", direction=-1)))
return model.id
```
이제 도구를 손쉽게 사용할 수 있게 되었습니다.
도구를 파일에 저장하고 메인 스크립트에서 가져옵니다. 이 파일의 이름을 `model_downloads.py`로 지정하면 결과적으로 가져오기 코드는 다음과 같습니다:
```python
from model_downloads import HFModelDownloadsTool
tool = HFModelDownloadsTool()
```
다른 사람들이 이 기능을 활용할 수 있도록 하고 초기화를 더 간단하게 하려면 네임스페이스 아래의 Hub로 푸시하는 것이 좋습니다.
그렇게 하려면 `tool` 변수에서 `push_to_hub`를 호출하면 됩니다:
```python
tool.push_to_hub("hf-model-downloads")
```
이제 허브에 코드가 생겼습니다! 마지막 단계인 에이전트가 코드를 사용하도록 하는 단계를 살펴보겠습니다.
#### 에이전트가 도구를 사용하게 하기[[Having-the-agent-use-the-tool]]
이제 이런 식으로 허브에 존재하는 도구를 인스턴스화할 수 있습니다(도구의 사용자 이름은 변경하세요):
We now have our tool that lives on the Hub which can be instantiated as such (change the user name for your tool):
```python
from transformers import load_tool
tool = load_tool("lysandre/hf-model-downloads")
```
이 도구를 에이전트에서 사용하려면 에이전트 초기화 메소드의 `additional_tools` 매개변수에 전달하기만 하면 됩니다:
```python
from transformers import HfAgent
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder", additional_tools=[tool])
agent.run(
"Can you read out loud the name of the model that has the most downloads in the 'text-to-video' task on the Hugging Face Hub?"
)
```
그러면 다음과 같은 결과가 출력됩니다:
```text
==Code generated by the agent==
model = model_download_counter(task="text-to-video")
print(f"The model with the most downloads is {model}.")
audio_model = text_reader(model)
==Result==
The model with the most downloads is damo-vilab/text-to-video-ms-1.7b.
```
and generates the following audio.
| **Audio** |
|------------------------------------------------------------------------------------------------------------------------------------------------------|
| <audio controls><source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/damo.wav" type="audio/wav"/> |
<Tip>
LLM에 따라 일부는 매우 취약하기 때문에 제대로 작동하려면 매우 정확한 프롬프트가 필요합니다.
에이전트가 도구를 잘 활용하기 위해서는 도구의 이름과 설명을 잘 정의하는 것이 무엇보다 중요합니다.
</Tip>
### 기존 도구 대체하기[[replacing-existing-tools]]
에이전트의 도구 상자에 새 항목을 배정하기만 하면 기존 도구를 대체할 수 있습니다. 방법은 다음과 같습니다:
```python
from transformers import HfAgent, load_tool
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder")
agent.toolbox["image-transformation"] = load_tool("diffusers/controlnet-canny-tool")
```
<Tip>
다른 도구로 교체할 때는 주의하세요! 이 작업으로 에이전트의 프롬프트도 조정됩니다.
작업에 더 적합한 프롬프트가 있으면 좋을 수 있지만,
다른 도구보다 더 많이 선택되거나 정의한 도구 대신 다른 도구가 선택될 수도 있습니다.
</Tip>
## gradio-tools 사용하기[[leveraging-gradio-tools]]
[gradio-tools](https://github.com/freddyaboulton/gradio-tools)는 Hugging Face Spaces를 도구로 사용할 수 있는 강력한 라이브러리입니다.
기존의 많은 Spaces뿐만 아니라 사용자 정의 Spaces를 사용하여 디자인할 수 있도록 지원합니다.
우리는 `Tool.from_gradio` 메소드를 사용하여 `gradio_tools`에 대한 지원을 제공합니다.
예를 들어, 프롬프트를 개선하고 더 나은 이미지를 생성하기 위해 `gradio-tools` 툴킷에서 제공되는 `StableDiffusionPromptGeneratorTool` 도구를 활용하고자 합니다.
먼저 `gradio_tools`에서 도구를 가져와서 인스턴스화합니다:
```python
from gradio_tools import StableDiffusionPromptGeneratorTool
gradio_tool = StableDiffusionPromptGeneratorTool()
```
해당 인스턴스를 `Tool.from_gradio` 메소드에 전달합니다:
```python
from transformers import Tool
tool = Tool.from_gradio(gradio_tool)
```
이제 일반적인 사용자 정의 도구와 똑같이 관리할 수 있습니다.
이를 활용하여 `a rabbit wearing a space suit'(우주복을 입은 토끼)라는 프롬프트를 개선했습니다:
```python
from transformers import HfAgent
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder", additional_tools=[tool])
agent.run("Generate an image of the `prompt` after improving it.", prompt="A rabbit wearing a space suit")
```
모델이 도구를 적절히 활용합니다:
```text
==Explanation from the agent==
I will use the following tools: `StableDiffusionPromptGenerator` to improve the prompt, then `image_generator` to generate an image according to the improved prompt.
==Code generated by the agent==
improved_prompt = StableDiffusionPromptGenerator(prompt)
print(f"The improved prompt is {improved_prompt}.")
image = image_generator(improved_prompt)
```
마지막으로 이미지를 생성하기 전에:
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/rabbit.png">
<Tip warning={true}>
gradio-tools는 다른 모달리티로 작업할 때에도 *텍스트* 입력 및 출력을 필요로 합니다.
이 구현은 이미지 및 오디오 객체에서 작동합니다.
현재는 이 두 가지가 호환되지 않지만 지원 개선을 위해 노력하면서 빠르게 호환될 것입니다.
</Tip>
## 향후 Langchain과의 호환성[[future-compatibility-with-langchain]]
저희는 Langchain을 좋아하며 매우 매력적인 도구 모음을 가지고 있다고 생각합니다.
이러한 도구를 처리하기 위해 Langchain은 다른 모달리티와 작업할 때에도 *텍스트* 입력과 출력을 필요로 합니다.
이는 종종 객체의 직렬화된(즉, 디스크에 저장된) 버전입니다.
이 차이로 인해 transformers-agents와 Langchain 간에는 멀티 모달리티가 처리되지 않습니다.
향후 버전에서 이 제한이 해결되기를 바라며, 이 호환성을 달성할 수 있도록 열렬한 Langchain 사용자의 도움을 환영합니다.
저희는 더 나은 지원을 제공하고자 합니다. 도움을 주고 싶으시다면, [이슈를 열어](https://github.com/huggingface/transformers/issues/new) 의견을 공유해 주세요.
| transformers/docs/source/ko/custom_tools.md/0 | {
"file_path": "transformers/docs/source/ko/custom_tools.md",
"repo_id": "transformers",
"token_count": 22824
} | 256 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 패딩과 잘라내기[[padding-and-truncation]]
배치 입력은 길이가 다른 경우가 많아서 고정 크기 텐서로 변환할 수 없습니다. 패딩과 잘라내기는 다양한 길이의 배치에서 직사각형 텐서를 생성할 수 있도록 이 문제를 해결하는 전략입니다. 패딩은 특수한 **패딩 토큰**을 추가하여 짧은 시퀀스가 배치에서 가장 긴 시퀀스 또는 모델에서 허용하는 최대 길이와 동일한 길이를 갖도록 합니다. 잘라내기는 긴 시퀀스를 잘라내어 패딩과 다른 방식으로 시퀀스의 길이를 동일하게 합니다.
대부분의 경우 배치에 가장 긴 시퀀스의 길이로 패딩하고 모델이 허용할 수 있는 최대 길이로 잘라내는 것이 잘 작동합니다. 그러나 필요하다면 API가 지원하는 더 많은 전략을 사용할 수 있습니다. 필요한 인수는 `padding`, `truncation`, `max_length` 세 가지입니다.
`padding` 인수는 패딩을 제어합니다. 불리언 또는 문자열일 수 있습니다:
- `True` 또는 `'longest'`: 배치에서 가장 긴 시퀀스로 패딩합니다(단일 시퀀스만 제공하는 경우 패딩이 적용되지 않습니다).
- `'max_length'`: `max_length` 인수가 지정한 길이로 패딩하거나, `max_length`가 제공되지 않은 경우(`max_length=None`) 모델에서 허용되는 최대 길이로 패딩합니다. 단일 시퀀스만 제공하는 경우에도 패딩이 적용됩니다.
- `False` 또는 `'do_not_pad'`: 패딩이 적용되지 않습니다. 이것이 기본 동작입니다.
`truncation` 인수는 잘라낼 방법을 정합니다. 불리언 또는 문자열일 수 있습니다:
- `True` 또는 `longest_first`: `max_length` 인수가 지정한 최대 길이로 잘라내거나,
`max_length`가 제공되지 않은 경우(`max_length=None`) 모델에서 허용되는 최대 길이로 잘라냅니다.
시퀀스 쌍에서 가장 긴 시퀀스의 토큰을 적절한 길이에 도달할 때까지 하나씩 제거합니다.
- `'only_second'`: `max_length` 인수가 지정한 최대 길이로 잘라내거나,
`max_length`가 제공되지 않은 경우(`max_length=None`) 모델에서 허용되는 최대 길이로 잘라냅니다.
시퀀스 쌍(또는 시퀀스 쌍의 배치)가 제공된 경우 쌍의 두 번째 문장만 잘라냅니다.
- `'only_first'`: `max_length` 인수가 지정한 최대 길이로 잘라내거나,
`max_length`가 제공되지 않은 경우(`max_length=None`) 모델에서 허용되는 최대 길이로 잘라냅니다.
시퀀스 쌍(또는 시퀀스 쌍의 배치)가 제공된 경우 쌍의 첫 번째 문장만 잘라냅니다.
- `False` 또는 `'do_not_truncate'`: 잘라내기를 적용하지 않습니다. 이것이 기본 동작입니다.
`max_length` 인수는 패딩 및 잘라내기를 적용할 길이를 제어합니다. 이 인수는 정수 또는 `None`일 수 있으며, `None`일 경우 모델이 허용할 수 있는 최대 길이로 기본값이 설정됩니다. 모델에 특정한 최대 입력 길이가 없는 경우 `max_length`에 대한 잘라내기 또는 패딩이 비활성화됩니다.
다음 표에는 패딩 및 잘라내기를 설정하는 권장 방법이 요약되어 있습니다.
입력으로 시퀀스 쌍을 사용하는 경우, 다음 예제에서 `truncation=True`를 `['only_first', 'only_second', 'longest_first']`에서 선택한 `STRATEGY`, 즉 `truncation='only_second'` 또는 `truncation='longest_first'`로 바꾸면 앞서 설명한 대로 쌍의 두 시퀀스가 잘리는 방식을 제어할 수 있습니다.
| 잘라내기 | 패딩 | 사용 방법 |
|--------------------------------------|-----------------------------------|------------------------------------------------------------------------------------------|
| 잘라내기 없음 | 패딩 없음 | `tokenizer(batch_sentences)` |
| | 배치 내 최대 길이로 패딩 | `tokenizer(batch_sentences, padding=True)` 또는 |
| | | `tokenizer(batch_sentences, padding='longest')` |
| | 모델의 최대 입력 길이로 패딩 | `tokenizer(batch_sentences, padding='max_length')` |
| | 특정 길이로 패딩 | `tokenizer(batch_sentences, padding='max_length', max_length=42)` |
| | 다양한 길이로 패딩 | `tokenizer(batch_sentences, padding=True, pad_to_multiple_of=8)` |
| 모델의 최대 입력 길이로 잘라내기 | 패딩 없음 | `tokenizer(batch_sentences, truncation=True)` 또는 |
| | | `tokenizer(batch_sentences, truncation=STRATEGY)` |
| | 배치 내 최대 길이로 패딩 | `tokenizer(batch_sentences, padding=True, truncation=True)` 또는 |
| | | `tokenizer(batch_sentences, padding=True, truncation=STRATEGY)` |
| | 모델의 최대 입력 길이로 패딩 | `tokenizer(batch_sentences, padding='max_length', truncation=True)` 또는 |
| | | `tokenizer(batch_sentences, padding='max_length', truncation=STRATEGY)` |
| | 특정 길이로 패딩 | 사용 불가 |
| 특정 길이로 잘라내기 | 패딩 없음 | `tokenizer(batch_sentences, truncation=True, max_length=42)` 또는 |
| | | `tokenizer(batch_sentences, truncation=STRATEGY, max_length=42)` |
| | 배치 내 최대 길이로 패딩 | `tokenizer(batch_sentences, padding=True, truncation=True, max_length=42)` 또는 |
| | | `tokenizer(batch_sentences, padding=True, truncation=STRATEGY, max_length=42)` |
| | 모델의 최대 입력 길이로 패딩 | 사용 불가 |
| | 특정 길이로 패딩 | `tokenizer(batch_sentences, padding='max_length', truncation=True, max_length=42)` 또는 |
| | | `tokenizer(batch_sentences, padding='max_length', truncation=STRATEGY, max_length=42)` |
| transformers/docs/source/ko/pad_truncation.md/0 | {
"file_path": "transformers/docs/source/ko/pad_truncation.md",
"repo_id": "transformers",
"token_count": 5964
} | 257 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 전처리[[preprocess]]
[[open-in-colab]]
모델을 훈련하려면 데이터 세트를 모델에 맞는 입력 형식으로 전처리해야 합니다. 텍스트, 이미지 또는 오디오인지 관계없이 데이터를 텐서 배치로 변환하고 조립할 필요가 있습니다. 🤗 Transformers는 모델에 대한 데이터를 준비하는 데 도움이 되는 일련의 전처리 클래스를 제공합니다. 이 튜토리얼에서는 다음 내용을 배울 수 있습니다:
* 텍스트는 [Tokenizer](./main_classes/tokenizer)를 사용하여 토큰 시퀀스로 변환하고 토큰의 숫자 표현을 만든 후 텐서로 조립합니다.
* 음성 및 오디오는 [Feature extractor](./main_classes/feature_extractor)를 사용하여 오디오 파형에서 시퀀스 특성을 파악하여 텐서로 변환합니다.
* 이미지 입력은 [ImageProcessor](./main_classes/image)을 사용하여 이미지를 텐서로 변환합니다.
* 멀티모달 입력은 [Processor](./main_classes/processors)을 사용하여 토크나이저와 특성 추출기 또는 이미지 프로세서를 결합합니다.
<Tip>
`AutoProcessor`는 **언제나** 작동하여 토크나이저, 이미지 프로세서, 특성 추출기 또는 프로세서 등 사용 중인 모델에 맞는 클래스를 자동으로 선택합니다.
</Tip>
시작하기 전에 🤗 Datasets를 설치하여 실험에 사용할 데이터를 불러올 수 있습니다:
```bash
pip install datasets
```
## 자연어처리[[natural-language-processing]]
<Youtube id="Yffk5aydLzg"/>
텍스트 데이터를 전처리하기 위한 기본 도구는 [tokenizer](main_classes/tokenizer)입니다. 토크나이저는 일련의 규칙에 따라 텍스트를 *토큰*으로 나눕니다. 토큰은 숫자로 변환되고 텐서는 모델 입력이 됩니다. 모델에 필요한 추가 입력은 토크나이저에 의해 추가됩니다.
<Tip>
사전훈련된 모델을 사용할 계획이라면 모델과 함께 사전훈련된 토크나이저를 사용하는 것이 중요합니다. 이렇게 하면 텍스트가 사전훈련 말뭉치와 동일한 방식으로 분할되고 사전훈련 중에 동일한 해당 토큰-인덱스 쌍(일반적으로 *vocab*이라고 함)을 사용합니다.
</Tip>
시작하려면 [`AutoTokenizer.from_pretrained`] 메소드를 사용하여 사전훈련된 토크나이저를 불러오세요. 모델과 함께 사전훈련된 *vocab*을 다운로드합니다:
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("google-bert/bert-base-cased")
```
그 다음으로 텍스트를 토크나이저에 넣어주세요:
```py
>>> encoded_input = tokenizer("Do not meddle in the affairs of wizards, for they are subtle and quick to anger.")
>>> print(encoded_input)
{'input_ids': [101, 2079, 2025, 19960, 10362, 1999, 1996, 3821, 1997, 16657, 1010, 2005, 2027, 2024, 11259, 1998, 4248, 2000, 4963, 1012, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
토크나이저는 세 가지 중요한 항목을 포함한 딕셔너리를 반환합니다:
* [input_ids](glossary#input-ids)는 문장의 각 토큰에 해당하는 인덱스입니다.
* [attention_mask](glossary#attention-mask)는 토큰을 처리해야 하는지 여부를 나타냅니다.
* [token_type_ids](glossary#token-type-ids)는 두 개 이상의 시퀀스가 있을 때 토큰이 속한 시퀀스를 식별합니다.
`input_ids`를 디코딩하여 입력을 반환합니다:
```py
>>> tokenizer.decode(encoded_input["input_ids"])
'[CLS] Do not meddle in the affairs of wizards, for they are subtle and quick to anger. [SEP]'
```
토크나이저가 두 개의 특수한 토큰(분류 토큰 `CLS`와 분할 토큰 `SEP`)을 문장에 추가했습니다.
모든 모델에 특수한 토큰이 필요한 것은 아니지만, 필요하다면 토크나이저가 자동으로 추가합니다.
전처리할 문장이 여러 개 있는 경우에는 리스트로 토크나이저에 전달합니다:
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_inputs = tokenizer(batch_sentences)
>>> print(encoded_inputs)
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1]]}
```
### 패딩[[pad]]
모델 입력인 텐서는 모양이 균일해야 하지만, 문장의 길이가 항상 같지는 않기 때문에 문제가 될 수 있습니다. 패딩은 짧은 문장에 특수한 *패딩 토큰*을 추가하여 텐서를 직사각형 모양이 되도록 하는 전략입니다.
`padding` 매개변수를 `True`로 설정하여 배치 내의 짧은 시퀀스를 가장 긴 시퀀스에 맞춰 패딩합니다.
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch_sentences, padding=True)
>>> print(encoded_input)
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
```
길이가 짧은 첫 문장과 세 번째 문장이 이제 `0`으로 채워졌습니다.
### 잘라내기[[truncation]]
한편, 때로는 시퀀스가 모델에서 처리하기에 너무 길 수도 있습니다. 이 경우, 시퀀스를 더 짧게 줄일 필요가 있습니다.
모델에서 허용하는 최대 길이로 시퀀스를 자르려면 `truncation` 매개변수를 `True`로 설정하세요:
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True)
>>> print(encoded_input)
{'input_ids': [[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]]}
```
<Tip>
다양한 패딩과 잘라내기 인수에 대해 더 알아보려면 [패딩과 잘라내기](./pad_truncation) 개념 가이드를 확인해보세요.
</Tip>
### 텐서 만들기[[build-tensors]]
마지막으로, 토크나이저가 모델에 공급되는 실제 텐서를 반환하도록 합니다.
`return_tensors` 매개변수를 PyTorch의 경우 `pt`, TensorFlow의 경우 `tf`로 설정하세요:
<frameworkcontent>
<pt>
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="pt")
>>> print(encoded_input)
{'input_ids': tensor([[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]])}
```
</pt>
<tf>
```py
>>> batch_sentences = [
... "But what about second breakfast?",
... "Don't think he knows about second breakfast, Pip.",
... "What about elevensies?",
... ]
>>> encoded_input = tokenizer(batch_sentences, padding=True, truncation=True, return_tensors="tf")
>>> print(encoded_input)
{'input_ids': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
array([[101, 1252, 1184, 1164, 1248, 6462, 136, 102, 0, 0, 0, 0, 0, 0, 0],
[101, 1790, 112, 189, 1341, 1119, 3520, 1164, 1248, 6462, 117, 21902, 1643, 119, 102],
[101, 1327, 1164, 5450, 23434, 136, 102, 0, 0, 0, 0, 0, 0, 0, 0]],
dtype=int32)>,
'token_type_ids': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
array([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int32)>,
'attention_mask': <tf.Tensor: shape=(2, 9), dtype=int32, numpy=
array([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]], dtype=int32)>}
```
</tf>
</frameworkcontent>
## 오디오[[audio]]
오디오 작업은 모델에 맞는 데이터 세트를 준비하기 위해 [특성 추출기](main_classes/feature_extractor)가 필요합니다. 특성 추출기는 원시 오디오 데이터에서 특성를 추출하고 이를 텐서로 변환하는 것이 목적입니다.
오디오 데이터 세트에 특성 추출기를 사용하는 방법을 보기 위해 [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) 데이터 세트를 가져오세요. (데이터 세트를 가져오는 방법은 🤗 [데이터 세트 튜토리얼](https://huggingface.co/docs/datasets/load_hub)에서 자세히 설명하고 있습니다.)
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
```
`audio` 열의 첫 번째 요소에 접근하여 입력을 살펴보세요. `audio` 열을 호출하면 오디오 파일을 자동으로 가져오고 리샘플링합니다.
```py
>>> dataset[0]["audio"]
{'array': array([ 0. , 0.00024414, -0.00024414, ..., -0.00024414,
0. , 0. ], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
'sampling_rate': 8000}
```
이렇게 하면 세 가지 항목이 반환됩니다:
* `array`는 1D 배열로 가져와서 (필요한 경우) 리샘플링된 음성 신호입니다.
* `path`는 오디오 파일의 위치를 가리킵니다.
* `sampling_rate`는 음성 신호에서 초당 측정되는 데이터 포인트 수를 나타냅니다.
이 튜토리얼에서는 [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base) 모델을 사용합니다. 모델 카드를 보면 Wav2Vec2가 16kHz 샘플링된 음성 오디오를 기반으로 사전훈련된 것을 알 수 있습니다.
모델을 사전훈련하는 데 사용된 데이터 세트의 샘플링 레이트와 오디오 데이터의 샘플링 레이트가 일치해야 합니다. 데이터의 샘플링 레이트가 다르면 데이터를 리샘플링해야 합니다.
1. 🤗 Datasets의 [`~datasets.Dataset.cast_column`] 메소드를 사용하여 샘플링 레이트를 16kHz로 업샘플링하세요:
```py
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16_000))
```
2. 오디오 파일을 리샘플링하기 위해 `audio` 열을 다시 호출합니다:
```py
>>> dataset[0]["audio"]
{'array': array([ 2.3443763e-05, 2.1729663e-04, 2.2145823e-04, ...,
3.8356509e-05, -7.3497440e-06, -2.1754686e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~JOINT_ACCOUNT/602ba55abb1e6d0fbce92065.wav',
'sampling_rate': 16000}
```
다음으로, 입력을 정규화하고 패딩할 특성 추출기를 가져오세요. 텍스트 데이터의 경우, 더 짧은 시퀀스에 대해 `0`이 추가됩니다. 오디오 데이터에도 같은 개념이 적용됩니다.
특성 추출기는 배열에 `0`(묵음으로 해석)을 추가합니다.
[`AutoFeatureExtractor.from_pretrained`]를 사용하여 특성 추출기를 가져오세요:
```py
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")
```
오디오 `array`를 특성 추출기에 전달하세요. 또한, 발생할 수 있는 조용한 오류(silent errors)를 더 잘 디버깅할 수 있도록 특성 추출기에 `sampling_rate` 인수를 추가하는 것을 권장합니다.
```py
>>> audio_input = [dataset[0]["audio"]["array"]]
>>> feature_extractor(audio_input, sampling_rate=16000)
{'input_values': [array([ 3.8106556e-04, 2.7506407e-03, 2.8015103e-03, ...,
5.6335266e-04, 4.6588284e-06, -1.7142107e-04], dtype=float32)]}
```
토크나이저와 마찬가지로 배치 내에서 가변적인 시퀀스를 처리하기 위해 패딩 또는 잘라내기를 적용할 수 있습니다. 이 두 개의 오디오 샘플의 시퀀스 길이를 확인해보세요:
```py
>>> dataset[0]["audio"]["array"].shape
(173398,)
>>> dataset[1]["audio"]["array"].shape
(106496,)
```
오디오 샘플의 길이가 동일하도록 데이터 세트를 전처리하는 함수를 만드세요. 최대 샘플 길이를 지정하면 특성 추출기가 해당 길이에 맞춰 시퀀스를 패딩하거나 잘라냅니다:
```py
>>> def preprocess_function(examples):
... audio_arrays = [x["array"] for x in examples["audio"]]
... inputs = feature_extractor(
... audio_arrays,
... sampling_rate=16000,
... padding=True,
... max_length=100000,
... truncation=True,
... )
... return inputs
```
`preprocess_function`을 데이터 세트의 처음 예시 몇 개에 적용해보세요:
```py
>>> processed_dataset = preprocess_function(dataset[:5])
```
이제 샘플 길이가 모두 같고 지정된 최대 길이에 맞게 되었습니다. 드디어 전처리된 데이터 세트를 모델에 전달할 수 있습니다!
```py
>>> processed_dataset["input_values"][0].shape
(100000,)
>>> processed_dataset["input_values"][1].shape
(100000,)
```
## 컴퓨터 비전[[computer-vision]]
컴퓨터 비전 작업의 경우, 모델에 대한 데이터 세트를 준비하기 위해 [이미지 프로세서](main_classes/image_processor)가 필요합니다.
이미지 전처리는 이미지를 모델이 예상하는 입력으로 변환하는 여러 단계로 이루어집니다.
이러한 단계에는 크기 조정, 정규화, 색상 채널 보정, 이미지의 텐서 변환 등이 포함됩니다.
<Tip>
이미지 전처리는 이미지 증강 기법을 몇 가지 적용한 뒤에 할 수도 있습니다.
이미지 전처리 및 이미지 증강은 모두 이미지 데이터를 변형하지만, 서로 다른 목적을 가지고 있습니다:
* 이미지 증강은 과적합(over-fitting)을 방지하고 모델의 견고함(resiliency)을 높이는 데 도움이 되는 방식으로 이미지를 수정합니다.
밝기와 색상 조정, 자르기, 회전, 크기 조정, 확대/축소 등 다양한 방법으로 데이터를 증강할 수 있습니다.
그러나 증강으로 이미지의 의미가 바뀌지 않도록 주의해야 합니다.
* 이미지 전처리는 이미지가 모델이 예상하는 입력 형식과 일치하도록 보장합니다.
컴퓨터 비전 모델을 미세 조정할 때 이미지는 모델이 초기에 훈련될 때와 정확히 같은 방식으로 전처리되어야 합니다.
이미지 증강에는 원하는 라이브러리를 무엇이든 사용할 수 있습니다. 이미지 전처리에는 모델과 연결된 `ImageProcessor`를 사용합니다.
</Tip>
[food101](https://huggingface.co/datasets/food101) 데이터 세트를 가져와서 컴퓨터 비전 데이터 세트에서 이미지 프로세서를 어떻게 사용하는지 알아보세요.
데이터 세트를 불러오는 방법은 🤗 [데이터 세트 튜토리얼](https://huggingface.co/docs/datasets/load_hub)을 참고하세요.
<Tip>
데이터 세트가 상당히 크기 때문에 🤗 Datasets의 `split` 매개변수를 사용하여 훈련 세트에서 작은 샘플만 가져오세요!
</Tip>
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("food101", split="train[:100]")
```
다음으로, 🤗 Datasets의 [`image`](https://huggingface.co/docs/datasets/package_reference/main_classes?highlight=image#datasets.Image)로 이미지를 확인해보세요:
```py
>>> dataset[0]["image"]
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/vision-preprocess-tutorial.png"/>
</div>
[`AutoImageProcessor.from_pretrained`]로 이미지 프로세서를 가져오세요:
```py
>>> from transformers import AutoImageProcessor
>>> image_processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
```
먼저 이미지 증강 단계를 추가해 봅시다. 아무 라이브러리나 사용해도 괜찮지만, 이번 튜토리얼에서는 torchvision의 [`transforms`](https://pytorch.org/vision/stable/transforms.html) 모듈을 사용하겠습니다.
다른 데이터 증강 라이브러리를 사용해보고 싶다면, [Albumentations](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_albumentations.ipynb) 또는 [Kornia notebooks](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification_kornia.ipynb)에서 어떻게 사용하는지 배울 수 있습니다.
1. [`Compose`](https://pytorch.org/vision/master/generated/torchvision.transforms.Compose.html)로 [`RandomResizedCrop`](https://pytorch.org/vision/main/generated/torchvision.transforms.RandomResizedCrop.html)와 [`ColorJitter`](https://pytorch.org/vision/main/generated/torchvision.transforms.ColorJitter.html) 등 변환을 몇 가지 연결하세요.
참고로 크기 조정에 필요한 이미지의 크기 요구사항은 `image_processor`에서 가져올 수 있습니다.
일부 모델은 정확한 높이와 너비를 요구하지만, 제일 짧은 변의 길이(`shortest_edge`)만 정의된 모델도 있습니다.
```py
>>> from torchvision.transforms import RandomResizedCrop, ColorJitter, Compose
>>> size = (
... image_processor.size["shortest_edge"]
... if "shortest_edge" in image_processor.size
... else (image_processor.size["height"], image_processor.size["width"])
... )
>>> _transforms = Compose([RandomResizedCrop(size), ColorJitter(brightness=0.5, hue=0.5)])
```
2. 모델은 입력으로 [`pixel_values`](model_doc/visionencoderdecoder#transformers.VisionEncoderDecoderModel.forward.pixel_values)를 받습니다.
`ImageProcessor`는 이미지 정규화 및 적절한 텐서 생성을 처리할 수 있습니다.
배치 이미지에 대한 이미지 증강 및 이미지 전처리를 결합하고 `pixel_values`를 생성하는 함수를 만듭니다:
```py
>>> def transforms(examples):
... images = [_transforms(img.convert("RGB")) for img in examples["image"]]
... examples["pixel_values"] = image_processor(images, do_resize=False, return_tensors="pt")["pixel_values"]
... return examples
```
<Tip>
위의 예에서는 이미지 증강 중에 이미지 크기를 조정했기 때문에 `do_resize=False`로 설정하고, 해당 `image_processor`에서 `size` 속성을 활용했습니다.
이미지 증강 중에 이미지 크기를 조정하지 않은 경우 이 매개변수를 생략하세요.
기본적으로는 `ImageProcessor`가 크기 조정을 처리합니다.
증강 변환 과정에서 이미지를 정규화하려면 `image_processor.image_mean` 및 `image_processor.image_std` 값을 사용하세요.
</Tip>
3. 🤗 Datasets의 [`set_transform`](https://huggingface.co/docs/datasets/process#format-transform)를 사용하여 실시간으로 변환을 적용합니다:
```py
>>> dataset.set_transform(transforms)
```
4. 이제 이미지에 접근하면 이미지 프로세서가 `pixel_values`를 추가한 것을 알 수 있습니다.
드디어 처리된 데이터 세트를 모델에 전달할 수 있습니다!
```py
>>> dataset[0].keys()
```
다음은 변형이 적용된 후의 이미지입니다. 이미지가 무작위로 잘려나갔고 색상 속성이 다릅니다.
```py
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> img = dataset[0]["pixel_values"]
>>> plt.imshow(img.permute(1, 2, 0))
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/preprocessed_image.png"/>
</div>
<Tip>
`ImageProcessor`는 객체 감지, 시맨틱 세그멘테이션(semantic segmentation), 인스턴스 세그멘테이션(instance segmentation), 파놉틱 세그멘테이션(panoptic segmentation)과 같은 작업에 대한 후처리 방법을 제공합니다.
이러한 방법은 모델의 원시 출력을 경계 상자나 세그멘테이션 맵과 같은 의미 있는 예측으로 변환해줍니다.
</Tip>
### 패딩[[pad]]
예를 들어, [DETR](./model_doc/detr)와 같은 경우에는 모델이 훈련할 때 크기 조정 증강을 적용합니다.
이로 인해 배치 내 이미지 크기가 달라질 수 있습니다.
[`DetrImageProcessor`]의 [`DetrImageProcessor.pad`]를 사용하고 사용자 정의 `collate_fn`을 정의해서 배치 이미지를 처리할 수 있습니다.
```py
>>> def collate_fn(batch):
... pixel_values = [item["pixel_values"] for item in batch]
... encoding = image_processor.pad(pixel_values, return_tensors="pt")
... labels = [item["labels"] for item in batch]
... batch = {}
... batch["pixel_values"] = encoding["pixel_values"]
... batch["pixel_mask"] = encoding["pixel_mask"]
... batch["labels"] = labels
... return batch
```
## 멀티모달[[multimodal]]
멀티모달 입력이 필요한 작업의 경우, 모델에 데이터 세트를 준비하기 위한 [프로세서](main_classes/processors)가 필요합니다.
프로세서는 토크나이저와 특성 추출기와 같은 두 가지 처리 객체를 결합합니다.
[LJ Speech](https://huggingface.co/datasets/lj_speech) 데이터 세트를 가져와서 자동 음성 인식(ASR)을 위한 프로세서를 사용하는 방법을 확인하세요.
(데이터 세트를 가져오는 방법에 대한 자세한 내용은 🤗 [데이터 세트 튜토리얼](https://huggingface.co/docs/datasets/load_hub)에서 볼 수 있습니다.)
```py
>>> from datasets import load_dataset
>>> lj_speech = load_dataset("lj_speech", split="train")
```
자동 음성 인식(ASR)에서는 `audio`와 `text`에만 집중하면 되므로, 다른 열들은 제거할 수 있습니다:
```py
>>> lj_speech = lj_speech.map(remove_columns=["file", "id", "normalized_text"])
```
이제 `audio`와 `text`열을 살펴보세요:
```py
>>> lj_speech[0]["audio"]
{'array': array([-7.3242188e-04, -7.6293945e-04, -6.4086914e-04, ...,
7.3242188e-04, 2.1362305e-04, 6.1035156e-05], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/917ece08c95cf0c4115e45294e3cd0dee724a1165b7fc11798369308a465bd26/LJSpeech-1.1/wavs/LJ001-0001.wav',
'sampling_rate': 22050}
>>> lj_speech[0]["text"]
'Printing, in the only sense with which we are at present concerned, differs from most if not from all the arts and crafts represented in the Exhibition'
```
기존에 사전훈련된 모델에서 사용된 데이터 세트와 새로운 오디오 데이터 세트의 샘플링 레이트를 일치시키기 위해 오디오 데이터 세트의 샘플링 레이트를 [리샘플링](preprocessing#audio)해야 합니다!
```py
>>> lj_speech = lj_speech.cast_column("audio", Audio(sampling_rate=16_000))
```
[`AutoProcessor.from_pretrained`]로 프로세서를 가져오세요:
```py
>>> from transformers import AutoProcessor
>>> processor = AutoProcessor.from_pretrained("facebook/wav2vec2-base-960h")
```
1. `array`에 들어 있는 오디오 데이터를 `input_values`로 변환하고 `text`를 토큰화하여 `labels`로 변환하는 함수를 만듭니다.
모델의 입력은 다음과 같습니다:
```py
>>> def prepare_dataset(example):
... audio = example["audio"]
... example.update(processor(audio=audio["array"], text=example["text"], sampling_rate=16000))
... return example
```
2. 샘플을 `prepare_dataset` 함수에 적용하세요:
```py
>>> prepare_dataset(lj_speech[0])
```
이제 프로세서가 `input_values`와 `labels`를 추가하고, 샘플링 레이트도 올바르게 16kHz로 다운샘플링했습니다.
드디어 처리된 데이터 세트를 모델에 전달할 수 있습니다!
| transformers/docs/source/ko/preprocessing.md/0 | {
"file_path": "transformers/docs/source/ko/preprocessing.md",
"repo_id": "transformers",
"token_count": 17108
} | 258 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Tour rápido
[[open-in-colab]]
Comece a trabalhar com 🤗 Transformers! Comece usando [`pipeline`] para rápida inferência e facilmente carregue um modelo pré-treinado e um tokenizer com [AutoClass](./model_doc/auto) para resolver tarefas de texto, visão ou áudio.
<Tip>
Todos os exemplos de código apresentados na documentação têm um botão no canto superior direito para escolher se você deseja ocultar ou mostrar o código no Pytorch ou no TensorFlow. Caso contrário, é esperado que funcione para ambos back-ends sem nenhuma alteração.
</Tip>
## Pipeline
[`pipeline`] é a maneira mais fácil de usar um modelo pré-treinado para uma dada tarefa.
<Youtube id="tiZFewofSLM"/>
A [`pipeline`] apoia diversas tarefas fora da caixa:
**Texto**:
* Análise sentimental: classifica a polaridade de um texto.
* Geração de texto (em Inglês): gera texto a partir de uma entrada.
* Reconhecimento de entidade mencionada: legenda cada palavra com uma classe que a representa (pessoa, data, local, etc...)
* Respostas: extrai uma resposta dado algum contexto e uma questão
* Máscara de preenchimento: preenche o espaço, dado um texto com máscaras de palavras.
* Sumarização: gera o resumo de um texto longo ou documento.
* Tradução: traduz texto para outra língua.
* Extração de características: cria um tensor que representa o texto.
**Imagem**:
* Classificação de imagens: classifica uma imagem.
* Segmentação de imagem: classifica cada pixel da imagem.
* Detecção de objetos: detecta objetos em uma imagem.
**Audio**:
* Classficação de áudio: legenda um trecho de áudio fornecido.
* Reconhecimento de fala automático: transcreve audio em texto.
<Tip>
Para mais detalhes sobre a [`pipeline`] e tarefas associadas, siga a documentação [aqui](./main_classes/pipelines).
</Tip>
### Uso da pipeline
No exemplo a seguir, você usará [`pipeline`] para análise sentimental.
Instale as seguintes dependências se você ainda não o fez:
<frameworkcontent>
<pt>
```bash
pip install torch
```
</pt>
<tf>
```bash
pip install tensorflow
```
</tf>
</frameworkcontent>
Importe [`pipeline`] e especifique a tarefa que deseja completar:
```py
>>> from transformers import pipeline
>>> classifier = pipeline("sentiment-analysis")
```
A pipeline baixa and armazena um [modelo pré-treinado](https://huggingface.co/distilbert/distilbert-base-uncased-finetuned-sst-2-english) padrão e tokenizer para análise sentimental. Agora você pode usar `classifier` no texto alvo:
```py
>>> classifier("We are very happy to show you the 🤗 Transformers library.")
[{'label': 'POSITIVE', 'score': 0.9998}]
```
Para mais de uma sentença, passe uma lista para a [`pipeline`], a qual retornará uma lista de dicionários:
```py
>>> results = classifier(["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."])
>>> for result in results:
... print(f"label: {result['label']}, with score: {round(result['score'], 4)}")
label: POSITIVE, with score: 0.9998
label: NEGATIVE, with score: 0.5309
```
A [`pipeline`] também pode iterar sobre um Dataset inteiro. Comece instalando a biblioteca de [🤗 Datasets](https://huggingface.co/docs/datasets/):
```bash
pip install datasets
```
Crie uma [`pipeline`] com a tarefa que deseja resolver e o modelo que deseja usar.
```py
>>> import torch
>>> from transformers import pipeline
>>> speech_recognizer = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-960h")
```
A seguir, carregue uma base de dados (confira a 🤗 [Iniciação em Datasets](https://huggingface.co/docs/datasets/quickstart) para mais detalhes) que você gostaria de iterar sobre. Por exemplo, vamos carregar o dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14):
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train") # doctest: +IGNORE_RESULT
```
Precisamos garantir que a taxa de amostragem do conjunto de dados corresponda à taxa de amostragem em que o facebook/wav2vec2-base-960h foi treinado.
```py
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=speech_recognizer.feature_extractor.sampling_rate))
```
Os arquivos de áudio são carregados e re-amostrados automaticamente ao chamar a coluna `"audio"`.
Vamos extrair as arrays de formas de onda originais das primeiras 4 amostras e passá-las como uma lista para o pipeline:
```py
>>> result = speech_recognizer(dataset[:4]["audio"])
>>> print([d["text"] for d in result])
['I WOULD LIKE TO SET UP A JOINT ACCOUNT WITH MY PARTNER HOW DO I PROCEED WITH DOING THAT', "FONDERING HOW I'D SET UP A JOIN TO HET WITH MY WIFE AND WHERE THE AP MIGHT BE", "I I'D LIKE TOY SET UP A JOINT ACCOUNT WITH MY PARTNER I'M NOT SEEING THE OPTION TO DO IT ON THE APSO I CALLED IN TO GET SOME HELP CAN I JUST DO IT OVER THE PHONE WITH YOU AND GIVE YOU THE INFORMATION OR SHOULD I DO IT IN THE AP AND I'M MISSING SOMETHING UQUETTE HAD PREFERRED TO JUST DO IT OVER THE PHONE OF POSSIBLE THINGS", 'HOW DO I TURN A JOIN A COUNT']
```
Para um conjunto de dados maior onde as entradas são maiores (como em fala ou visão), será necessário passar um gerador em vez de uma lista que carregue todas as entradas na memória. Consulte a [documentação do pipeline](./main_classes/pipelines) para mais informações.
### Use outro modelo e tokenizer na pipeline
A [`pipeline`] pode acomodar qualquer modelo do [Model Hub](https://huggingface.co/models), facilitando sua adaptação para outros casos de uso. Por exemplo, se você quiser um modelo capaz de lidar com texto em francês, use as tags no Model Hub para filtrar um modelo apropriado. O principal resultado filtrado retorna um [modelo BERT](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment) bilíngue ajustado para análise de sentimentos. Ótimo, vamos usar este modelo!
```py
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
```
<frameworkcontent>
<pt>
Use o [`AutoModelForSequenceClassification`] e [`AutoTokenizer`] para carregar o modelo pré-treinado e seu tokenizer associado (mais em `AutoClass` abaixo):
```py
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</pt>
<tf>
Use o [`TFAutoModelForSequenceClassification`] and [`AutoTokenizer`] para carregar o modelo pré-treinado e o tokenizer associado (mais em `TFAutoClass` abaixo):
```py
>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</tf>
</frameworkcontent>
Então você pode especificar o modelo e o tokenizador na [`pipeline`] e aplicar o `classifier` no seu texto alvo:
```py
>>> classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
>>> classifier("Nous sommes très heureux de vous présenter la bibliothèque 🤗 Transformers.")
[{'label': '5 stars', 'score': 0.7273}]
```
Se você não conseguir achar um modelo para o seu caso de uso, precisará usar fine-tune em um modelo pré-treinado nos seus dados. Veja nosso [tutorial de fine-tuning](./training) para descobrir como. Finalmente, depois que você tiver usado esse processo em seu modelo, considere compartilhá-lo conosco (veja o tutorial [aqui](./model_sharing)) na plataforma Model Hub afim de democratizar NLP! 🤗
## AutoClass
<Youtube id="AhChOFRegn4"/>
Por baixo dos panos, as classes [`AutoModelForSequenceClassification`] e [`AutoTokenizer`] trabalham juntas para fortificar o [`pipeline`]. Um [AutoClass](./model_doc/auto) é um atalho que automaticamente recupera a arquitetura de um modelo pré-treinado a partir de seu nome ou caminho. Basta selecionar a `AutoClass` apropriada para sua tarefa e seu tokenizer associado com [`AutoTokenizer`].
Vamos voltar ao nosso exemplo e ver como você pode usar a `AutoClass` para replicar os resultados do [`pipeline`].
### AutoTokenizer
Um tokenizer é responsável por pré-processar o texto em um formato que seja compreensível para o modelo. Primeiro, o tokenizer dividirá o texto em palavras chamadas *tokens*. Existem várias regras que regem o processo de tokenização, incluindo como dividir uma palavra e em que nível (saiba mais sobre tokenização [aqui](./tokenizer_summary)). A coisa mais importante a lembrar, porém, é que você precisa instanciar o tokenizer com o mesmo nome do modelo para garantir que está usando as mesmas regras de tokenização com as quais um modelo foi pré-treinado.
Carregue um tokenizer com [`AutoTokenizer`]:
```py
>>> from transformers import AutoTokenizer
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
Em seguida, o tokenizer converte os tokens em números para construir um tensor como entrada para o modelo. Isso é conhecido como o *vocabulário* do modelo.
Passe o texto para o tokenizer:
```py
>>> encoding = tokenizer("We are very happy to show you the 🤗 Transformers library.")
>>> print(encoding)
{'input_ids': [101, 11312, 10320, 12495, 19308, 10114, 11391, 10855, 10103, 100, 58263, 13299, 119, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
O tokenizer retornará um dicionário contendo:
* [input_ids](./glossary#input-ids): representações numéricas de seus tokens.
* [atttention_mask](.glossary#attention-mask): indica quais tokens devem ser atendidos.
Assim como o [`pipeline`], o tokenizer aceitará uma lista de entradas. Além disso, o tokenizer também pode preencher e truncar o texto para retornar um lote com comprimento uniforme:
<frameworkcontent>
<pt>
```py
>>> pt_batch = tokenizer(
... ["We are very happy to show you the 🤗 transformers library.", "We hope you don't hate it."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="pt",
... )
```
</pt>
<tf>
```py
>>> tf_batch = tokenizer(
... ["We are very happy to show you the 🤗 Transformers library.", "We hope you don't hate it."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="tf",
... )
```
</tf>
</frameworkcontent>
Leia o tutorial de [pré-processamento](./pré-processamento) para obter mais detalhes sobre tokenização.
### AutoModel
<frameworkcontent>
<pt>
🤗 Transformers fornecem uma maneira simples e unificada de carregar instâncias pré-treinadas. Isso significa que você pode carregar um [`AutoModel`] como carregaria um [`AutoTokenizer`]. A única diferença é selecionar o [`AutoModel`] correto para a tarefa. Como você está fazendo classificação de texto ou sequência, carregue [`AutoModelForSequenceClassification`]:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
Veja o [sumário de tarefas](./task_summary) para qual classe de [`AutoModel`] usar para cada tarefa.
</Tip>
Agora você pode passar seu grupo de entradas pré-processadas diretamente para o modelo. Você apenas tem que descompactar o dicionário usando `**`:
```py
>>> pt_outputs = pt_model(**pt_batch)
```
O modelo gera as ativações finais no atributo `logits`. Aplique a função softmax aos `logits` para recuperar as probabilidades:
```py
>>> from torch import nn
>>> pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
>>> print(pt_predictions)
tensor([[0.0021, 0.0018, 0.0115, 0.2121, 0.7725],
[0.2084, 0.1826, 0.1969, 0.1755, 0.2365]], grad_fn=<SoftmaxBackward0>)
```
</pt>
<tf>
🤗 Transformers fornecem uma maneira simples e unificada de carregar instâncias pré-treinadas. Isso significa que você pode carregar um [`TFAutoModel`] como carregaria um [`AutoTokenizer`]. A única diferença é selecionar o [`TFAutoModel`] correto para a tarefa. Como você está fazendo classificação de texto ou sequência, carregue [`TFAutoModelForSequenceClassification`]:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
Veja o [sumário de tarefas](./task_summary) para qual classe de [`AutoModel`] usar para cada tarefa.
</Tip>
Agora você pode passar seu grupo de entradas pré-processadas diretamente para o modelo através da passagem de chaves de dicionários ao tensor.
```py
>>> tf_outputs = tf_model(tf_batch)
```
O modelo gera as ativações finais no atributo `logits`. Aplique a função softmax aos `logits` para recuperar as probabilidades:
```py
>>> import tensorflow as tf
>>> tf_predictions = tf.nn.softmax(tf_outputs.logits, axis=-1)
>>> tf_predictions # doctest: +IGNORE_RESULT
```
</tf>
</frameworkcontent>
<Tip>
Todos os modelos de 🤗 Transformers (PyTorch ou TensorFlow) geram tensores *antes* da função de ativação final (como softmax) pois essa função algumas vezes é fundida com a perda.
</Tip>
Os modelos são um standard [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) ou um [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) para que você possa usá-los em seu loop de treinamento habitual. No entanto, para facilitar as coisas, 🤗 Transformers fornece uma classe [`Trainer`] para PyTorch que adiciona funcionalidade para treinamento distribuído, precisão mista e muito mais. Para o TensorFlow, você pode usar o método `fit` de [Keras](https://keras.io/). Consulte o [tutorial de treinamento](./training) para obter mais detalhes.
<Tip>
As saídas do modelo 🤗 Transformers são classes de dados especiais para que seus atributos sejam preenchidos automaticamente em um IDE.
As saídas do modelo também se comportam como uma tupla ou um dicionário (por exemplo, você pode indexar com um inteiro, uma parte ou uma string), caso em que os atributos `None` são ignorados.
</Tip>
### Salvar um modelo
<frameworkcontent>
<pt>
Uma vez que seu modelo estiver afinado, você pode salvá-lo com seu Tokenizer usando [`PreTrainedModel.save_pretrained`]:
```py
>>> pt_save_directory = "./pt_save_pretrained"
>>> tokenizer.save_pretrained(pt_save_directory) # doctest: +IGNORE_RESULT
>>> pt_model.save_pretrained(pt_save_directory)
```
Quando você estiver pronto para usá-lo novamente, recarregue com [`PreTrainedModel.from_pretrained`]:
```py
>>> pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")
```
</pt>
<tf>
Uma vez que seu modelo estiver afinado, você pode salvá-lo com seu Tokenizer usando [`TFPreTrainedModel.save_pretrained`]:
```py
>>> tf_save_directory = "./tf_save_pretrained"
>>> tokenizer.save_pretrained(tf_save_directory) # doctest: +IGNORE_RESULT
>>> tf_model.save_pretrained(tf_save_directory)
```
Quando você estiver pronto para usá-lo novamente, recarregue com [`TFPreTrainedModel.from_pretrained`]
```py
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("./tf_save_pretrained")
```
</tf>
</frameworkcontent>
Um recurso particularmente interessante dos 🤗 Transformers é a capacidade de salvar um modelo e recarregá-lo como um modelo PyTorch ou TensorFlow. Use `from_pt` ou `from_tf` para converter o modelo de um framework para outro:
<frameworkcontent>
<pt>
```py
>>> from transformers import AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(tf_save_directory)
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(tf_save_directory, from_tf=True)
```
</pt>
<tf>
```py
>>> from transformers import TFAutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(pt_save_directory)
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(pt_save_directory, from_pt=True)
```
</tf>
</frameworkcontent> | transformers/docs/source/pt/quicktour.md/0 | {
"file_path": "transformers/docs/source/pt/quicktour.md",
"repo_id": "transformers",
"token_count": 6110
} | 259 |
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 聊天模型的模板
## 介绍
LLM 的一个常见应用场景是聊天。在聊天上下文中,不再是连续的文本字符串构成的语句(不同于标准的语言模型),
聊天模型由一条或多条消息组成的对话组成,每条消息都有一个“用户”或“助手”等 **角色**,还包括消息文本。
与`Tokenizer`类似,不同的模型对聊天的输入格式要求也不同。这就是我们添加**聊天模板**作为一个功能的原因。
聊天模板是`Tokenizer`的一部分。用来把问答的对话内容转换为模型的输入`prompt`。
让我们通过一个快速的示例来具体说明,使用`BlenderBot`模型。
BlenderBot有一个非常简单的默认模板,主要是在对话轮之间添加空格:
```python
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")
>>> chat = [
... {"role": "user", "content": "Hello, how are you?"},
... {"role": "assistant", "content": "I'm doing great. How can I help you today?"},
... {"role": "user", "content": "I'd like to show off how chat templating works!"},
... ]
>>> tokenizer.apply_chat_template(chat, tokenize=False)
" Hello, how are you? I'm doing great. How can I help you today? I'd like to show off how chat templating works!</s>"
```
注意,整个聊天对话内容被压缩成了一整个字符串。如果我们使用默认设置的`tokenize=True`,那么该字符串也将被tokenized处理。
不过,为了看到更复杂的模板实际运行,让我们使用`mistralai/Mistral-7B-Instruct-v0.1`模型。
```python
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
>>> chat = [
... {"role": "user", "content": "Hello, how are you?"},
... {"role": "assistant", "content": "I'm doing great. How can I help you today?"},
... {"role": "user", "content": "I'd like to show off how chat templating works!"},
... ]
>>> tokenizer.apply_chat_template(chat, tokenize=False)
"<s>[INST] Hello, how are you? [/INST]I'm doing great. How can I help you today?</s> [INST] I'd like to show off how chat templating works! [/INST]"
```
可以看到,这一次tokenizer已经添加了[INST]和[/INST]来表示用户消息的开始和结束。
Mistral-instruct是有使用这些token进行训练的,但BlenderBot没有。
## 我如何使用聊天模板?
正如您在上面的示例中所看到的,聊天模板非常容易使用。只需构建一系列带有`role`和`content`键的消息,
然后将其传递给[`~PreTrainedTokenizer.apply_chat_template`]方法。
另外,在将聊天模板用作模型预测的输入时,还建议使用`add_generation_prompt=True`来添加[generation prompt](#什么是generation-prompts)。
这是一个准备`model.generate()`的示例,使用`Zephyr`模型:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "HuggingFaceH4/zephyr-7b-beta"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint) # You may want to use bfloat16 and/or move to GPU here
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
tokenized_chat = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
print(tokenizer.decode(tokenized_chat[0]))
```
这将生成Zephyr期望的输入格式的字符串。它看起来像这样:
```text
<|system|>
You are a friendly chatbot who always responds in the style of a pirate</s>
<|user|>
How many helicopters can a human eat in one sitting?</s>
<|assistant|>
```
现在我们已经按照`Zephyr`的要求传入prompt了,我们可以使用模型来生成对用户问题的回复:
```python
outputs = model.generate(tokenized_chat, max_new_tokens=128)
print(tokenizer.decode(outputs[0]))
```
输出结果是:
```text
<|system|>
You are a friendly chatbot who always responds in the style of a pirate</s>
<|user|>
How many helicopters can a human eat in one sitting?</s>
<|assistant|>
Matey, I'm afraid I must inform ye that humans cannot eat helicopters. Helicopters are not food, they are flying machines. Food is meant to be eaten, like a hearty plate o' grog, a savory bowl o' stew, or a delicious loaf o' bread. But helicopters, they be for transportin' and movin' around, not for eatin'. So, I'd say none, me hearties. None at all.
```
啊,原来这么容易!
## 有自动化的聊天`pipeline`吗?
有的,[`ConversationalPipeline`]。这个`pipeline`的设计是为了方便使用聊天模型。让我们再试一次 Zephyr 的例子,但这次使用`pipeline`:
```python
from transformers import pipeline
pipe = pipeline("conversational", "HuggingFaceH4/zephyr-7b-beta")
messages = [
{
"role": "system",
"content": "You are a friendly chatbot who always responds in the style of a pirate",
},
{"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
]
print(pipe(messages))
```
```text
Conversation id: 76d886a0-74bd-454e-9804-0467041a63dc
system: You are a friendly chatbot who always responds in the style of a pirate
user: How many helicopters can a human eat in one sitting?
assistant: Matey, I'm afraid I must inform ye that humans cannot eat helicopters. Helicopters are not food, they are flying machines. Food is meant to be eaten, like a hearty plate o' grog, a savory bowl o' stew, or a delicious loaf o' bread. But helicopters, they be for transportin' and movin' around, not for eatin'. So, I'd say none, me hearties. None at all.
```
[`ConversationalPipeline`]将负责处理所有的`tokenized`并调用`apply_chat_template`,一旦模型有了聊天模板,您只需要初始化pipeline并传递消息列表!
## 什么是"generation prompts"?
您可能已经注意到`apply_chat_template`方法有一个`add_generation_prompt`参数。
这个参数告诉模板添加模型开始答复的标记。例如,考虑以下对话:
```python
messages = [
{"role": "user", "content": "Hi there!"},
{"role": "assistant", "content": "Nice to meet you!"},
{"role": "user", "content": "Can I ask a question?"}
]
```
这是`add_generation_prompt=False`的结果,使用ChatML模板:
```python
tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=False)
"""<|im_start|>user
Hi there!<|im_end|>
<|im_start|>assistant
Nice to meet you!<|im_end|>
<|im_start|>user
Can I ask a question?<|im_end|>
"""
```
下面这是`add_generation_prompt=True`的结果:
```python
tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
"""<|im_start|>user
Hi there!<|im_end|>
<|im_start|>assistant
Nice to meet you!<|im_end|>
<|im_start|>user
Can I ask a question?<|im_end|>
<|im_start|>assistant
"""
```
这一次我们添加了模型开始答复的标记。这可以确保模型生成文本时只会给出答复,而不会做出意外的行为,比如继续用户的消息。
记住,聊天模型只是语言模型,它们被训练来继续文本,而聊天对它们来说只是一种特殊的文本!
你需要用适当的控制标记来引导它们,让它们知道自己应该做什么。
并非所有模型都需要生成提示。一些模型,如BlenderBot和LLaMA,在模型回复之前没有任何特殊标记。
在这些情况下,`add_generation_prompt`参数将不起作用。`add_generation_prompt`参数取决于你所使用的模板。
## 我可以在训练中使用聊天模板吗?
可以!我们建议您将聊天模板应用为数据集的预处理步骤。之后,您可以像进行任何其他语言模型训练任务一样继续。
在训练时,通常应该设置`add_generation_prompt=False`,因为添加的助手标记在训练过程中并不会有帮助。
让我们看一个例子:
```python
from transformers import AutoTokenizer
from datasets import Dataset
tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-beta")
chat1 = [
{"role": "user", "content": "Which is bigger, the moon or the sun?"},
{"role": "assistant", "content": "The sun."}
]
chat2 = [
{"role": "user", "content": "Which is bigger, a virus or a bacterium?"},
{"role": "assistant", "content": "A bacterium."}
]
dataset = Dataset.from_dict({"chat": [chat1, chat2]})
dataset = dataset.map(lambda x: {"formatted_chat": tokenizer.apply_chat_template(x["chat"], tokenize=False, add_generation_prompt=False)})
print(dataset['formatted_chat'][0])
```
结果是:
```text
<|user|>
Which is bigger, the moon or the sun?</s>
<|assistant|>
The sun.</s>
```
这样,后面你可以使用`formatted_chat`列,跟标准语言建模任务中一样训练即可。
## 高级:聊天模板是如何工作的?
模型的聊天模板存储在`tokenizer.chat_template`属性上。如果没有设置,则将使用该模型的默认模板。
让我们来看看`BlenderBot`的模板:
```python
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/blenderbot-400M-distill")
>>> tokenizer.default_chat_template
"{% for message in messages %}{% if message['role'] == 'user' %}{{ ' ' }}{% endif %}{{ message['content'] }}{% if not loop.last %}{{ ' ' }}{% endif %}{% endfor %}{{ eos_token }}"
```
这看着有点复杂。让我们添加一些换行和缩进,使其更易读。
请注意,默认情况下忽略每个块后的第一个换行以及块之前的任何前导空格,
使用Jinja的`trim_blocks`和`lstrip_blocks`标签。
这里,请注意空格的使用。我们强烈建议您仔细检查模板是否打印了多余的空格!
```
{% for message in messages %}
{% if message['role'] == 'user' %}
{{ ' ' }}
{% endif %}
{{ message['content'] }}
{% if not loop.last %}
{{ ' ' }}
{% endif %}
{% endfor %}
{{ eos_token }}
```
如果你之前不了解[Jinja template](https://jinja.palletsprojects.com/en/3.1.x/templates/)。
Jinja是一种模板语言,允许你编写简单的代码来生成文本。
在许多方面,代码和语法类似于Python。在纯Python中,这个模板看起来会像这样:
```python
for idx, message in enumerate(messages):
if message['role'] == 'user':
print(' ')
print(message['content'])
if not idx == len(messages) - 1: # Check for the last message in the conversation
print(' ')
print(eos_token)
```
这里使用Jinja模板处理如下三步:
1. 对于每条消息,如果消息是用户消息,则在其前面添加一个空格,否则不打印任何内容
2. 添加消息内容
3. 如果消息不是最后一条,请在其后添加两个空格。在最后一条消息之后,打印`EOS`。
这是一个简单的模板,它不添加任何控制tokens,也不支持`system`消息(常用于指导模型在后续对话中如何表现)。
但 Jinja 给了你很大的灵活性来做这些事情!让我们看一个 Jinja 模板,
它可以实现类似于LLaMA的prompt输入(请注意,真正的LLaMA模板包括`system`消息,请不要在实际代码中使用这个简单模板!)
```
{% for message in messages %}
{% if message['role'] == 'user' %}
{{ bos_token + '[INST] ' + message['content'] + ' [/INST]' }}
{% elif message['role'] == 'system' %}
{{ '<<SYS>>\\n' + message['content'] + '\\n<</SYS>>\\n\\n' }}
{% elif message['role'] == 'assistant' %}
{{ ' ' + message['content'] + ' ' + eos_token }}
{% endif %}
{% endfor %}
```
这里稍微看一下,就能明白这个模板的作用:它根据每条消息的“角色”添加对应的消息。
`user`、`assistant`、`system`的消息需要分别处理,因为它们代表不同的角色输入。
## 高级:编辑聊天模板
### 如何创建聊天模板?
很简单,你只需编写一个jinja模板并设置`tokenizer.chat_template`。你也可以从一个现有模板开始,只需要简单编辑便可以!
例如,我们可以采用上面的LLaMA模板,并在助手消息中添加"[ASST]"和"[/ASST]":
```
{% for message in messages %}
{% if message['role'] == 'user' %}
{{ bos_token + '[INST] ' + message['content'].strip() + ' [/INST]' }}
{% elif message['role'] == 'system' %}
{{ '<<SYS>>\\n' + message['content'].strip() + '\\n<</SYS>>\\n\\n' }}
{% elif message['role'] == 'assistant' %}
{{ '[ASST] ' + message['content'] + ' [/ASST]' + eos_token }}
{% endif %}
{% endfor %}
```
现在,只需设置`tokenizer.chat_template`属性。下次使用[`~PreTrainedTokenizer.apply_chat_template`]时,它将使用您的新模板!
此属性将保存在`tokenizer_config.json`文件中,因此您可以使用[`~utils.PushToHubMixin.push_to_hub`]将新模板上传到 Hub,
这样每个人都可以使用你模型的模板!
```python
template = tokenizer.chat_template
template = template.replace("SYS", "SYSTEM") # Change the system token
tokenizer.chat_template = template # Set the new template
tokenizer.push_to_hub("model_name") # Upload your new template to the Hub!
```
由于[`~PreTrainedTokenizer.apply_chat_template`]方法是由[`ConversationalPipeline`]类调用,
因此一旦你设置了聊天模板,您的模型将自动与[`ConversationalPipeline`]兼容。
### “默认”模板是什么?
在引入聊天模板(chat_template)之前,聊天prompt是在模型中通过硬编码处理的。为了向前兼容,我们保留了这种硬编码处理聊天prompt的方法。
如果一个模型没有设置聊天模板,但其模型有默认模板,`ConversationalPipeline`类和`apply_chat_template`等方法将使用该模型的聊天模板。
您可以通过检查`tokenizer.default_chat_template`属性来查找`tokenizer`的默认模板。
这是我们纯粹为了向前兼容性而做的事情,以避免破坏任何现有的工作流程。即使默认的聊天模板适用于您的模型,
我们强烈建议通过显式设置`chat_template`属性来覆盖默认模板,以便向用户清楚地表明您的模型已经正确的配置了聊天模板,
并且为了未来防范默认模板被修改或弃用的情况。
### 我应该使用哪个模板?
在为已经训练过的聊天模型设置模板时,您应确保模板与模型在训练期间看到的消息格式完全匹配,否则可能会导致性能下降。
即使您继续对模型进行训练,也应保持聊天模板不变,这样可能会获得最佳性能。
这与`tokenization`非常类似,在推断时,你选用跟训练时一样的`tokenization`,通常会获得最佳性能。
如果您从头开始训练模型,或者在微调基础语言模型进行聊天时,您有很大的自由选择适当的模板!
LLMs足够聪明,可以学会处理许多不同的输入格式。我们为没有特定类别模板的模型提供一个默认模板,该模板遵循
`ChatML` format格式要求,对于许多用例来说,
这是一个很好的、灵活的选择。
默认模板看起来像这样:
```
{% for message in messages %}
{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}
{% endfor %}
```
如果您喜欢这个模板,下面是一行代码的模板形式,它可以直接复制到您的代码中。这一行代码还包括了[generation prompts](#什么是"generation prompts"?),
但请注意它不会添加`BOS`或`EOS`token。
如果您的模型需要这些token,它们不会被`apply_chat_template`自动添加,换句话说,文本的默认处理参数是`add_special_tokens=False`。
这是为了避免模板和`add_special_tokens`逻辑产生冲突,如果您的模型需要特殊tokens,请确保将它们添加到模板中!
```
tokenizer.chat_template = "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}"
```
该模板将每条消息包装在`<|im_start|>`和`<|im_end|>`tokens里面,并将角色简单地写为字符串,这样可以灵活地训练角色。输出如下:
```text
<|im_start|>system
You are a helpful chatbot that will do its best not to say anything so stupid that people tweet about it.<|im_end|>
<|im_start|>user
How are you?<|im_end|>
<|im_start|>assistant
I'm doing great!<|im_end|>
```
`user`,`system`和`assistant`是对话助手模型的标准角色,如果您的模型要与[`ConversationalPipeline`]兼容,我们建议你使用这些角色。
但您可以不局限于这些角色,模板非常灵活,任何字符串都可以成为角色。
### 如何添加聊天模板?
如果您有任何聊天模型,您应该设置它们的`tokenizer.chat_template`属性,并使用[`~PreTrainedTokenizer.apply_chat_template`]测试,
然后将更新后的`tokenizer`推送到 Hub。
即使您不是模型所有者,如果您正在使用一个空的聊天模板或者仍在使用默认的聊天模板,
请发起一个[pull request](https://huggingface.co/docs/hub/repositories-pull-requests-discussions),以便正确设置该属性!
一旦属性设置完成,就完成了!`tokenizer.apply_chat_template`现在将在该模型中正常工作,
这意味着它也会自动支持在诸如`ConversationalPipeline`的地方!
通过确保模型具有这一属性,我们可以确保整个社区都能充分利用开源模型的全部功能。
格式不匹配已经困扰这个领域并悄悄地损害了性能太久了,是时候结束它们了!
## 高级:模板写作技巧
如果你对Jinja不熟悉,我们通常发现编写聊天模板的最简单方法是先编写一个简短的Python脚本,按照你想要的方式格式化消息,然后将该脚本转换为模板。
请记住,模板处理程序将接收对话历史作为名为`messages`的变量。每条`message`都是一个带有两个键`role`和`content`的字典。
您可以在模板中像在Python中一样访问`messages`,这意味着您可以使用`{% for message in messages %}`进行循环,
或者例如使用`{{ messages[0] }}`访问单个消息。
您也可以使用以下提示将您的代码转换为Jinja:
### For循环
在Jinja中,for循环看起来像这样:
```
{% for message in messages %}
{{ message['content'] }}
{% endfor %}
```
请注意,`{{ expression block }}`中的内容将被打印到输出。您可以在表达式块中使用像`+`这样的运算符来组合字符串。
### If语句
Jinja中的if语句如下所示:
```
{% if message['role'] == 'user' %}
{{ message['content'] }}
{% endif %}
```
注意Jinja使用`{% endfor %}`和`{% endif %}`来表示`for`和`if`的结束。
### 特殊变量
在您的模板中,您将可以访问`messages`列表,但您还可以访问其他几个特殊变量。
这些包括特殊`token`,如`bos_token`和`eos_token`,以及我们上面讨论过的`add_generation_prompt`变量。
您还可以使用`loop`变量来访问有关当前循环迭代的信息,例如使用`{% if loop.last %}`来检查当前消息是否是对话中的最后一条消息。
以下是一个示例,如果`add_generation_prompt=True`需要在对话结束时添加`generate_prompt`:
```
{% if loop.last and add_generation_prompt %}
{{ bos_token + 'Assistant:\n' }}
{% endif %}
```
### 空格的注意事项
我们已经尽可能尝试让Jinja忽略除`{{ expressions }}`之外的空格。
然而,请注意Jinja是一个通用的模板引擎,它可能会将同一行文本块之间的空格视为重要,并将其打印到输出中。
我们**强烈**建议在上传模板之前检查一下,确保模板没有在不应该的地方打印额外的空格!
| transformers/docs/source/zh/chat_templating.md/0 | {
"file_path": "transformers/docs/source/zh/chat_templating.md",
"repo_id": "transformers",
"token_count": 11163
} | 260 |
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 模型输出
所有模型的输出都是 [`~utils.ModelOutput`] 的子类的实例。这些是包含模型返回的所有信息的数据结构,但也可以用作元组或字典。
让我们看一个例子:
```python
from transformers import BertTokenizer, BertForSequenceClassification
import torch
tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
model = BertForSequenceClassification.from_pretrained("google-bert/bert-base-uncased")
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
outputs = model(**inputs, labels=labels)
```
`outputs` 对象是 [`~modeling_outputs.SequenceClassifierOutput`],如下面该类的文档中所示,它表示它有一个可选的 `loss`,一个 `logits`,一个可选的 `hidden_states` 和一个可选的 `attentions` 属性。在这里,我们有 `loss`,因为我们传递了 `labels`,但我们没有 `hidden_states` 和 `attentions`,因为我们没有传递 `output_hidden_states=True` 或 `output_attentions=True`。
<Tip>
当传递 `output_hidden_states=True` 时,您可能希望 `outputs.hidden_states[-1]` 与 `outputs.last_hidden_states` 完全匹配。然而,这并不总是成立。一些模型在返回最后的 hidden state时对其应用归一化或其他后续处理。
</Tip>
您可以像往常一样访问每个属性,如果模型未返回该属性,您将得到 `None`。在这里,例如,`outputs.loss` 是模型计算的损失,而 `outputs.attentions` 是 `None`。
当将我们的 `outputs` 对象视为元组时,它仅考虑那些没有 `None` 值的属性。例如这里它有两个元素,`loss` 和 `logits`,所以
```python
outputs[:2]
```
将返回元组 `(outputs.loss, outputs.logits)`。
将我们的 `outputs` 对象视为字典时,它仅考虑那些没有 `None` 值的属性。例如在这里它有两个键,分别是 `loss` 和 `logits`。
我们在这里记录了被多个类型模型使用的通用模型输出。特定输出类型在其相应的模型页面上有文档。
## ModelOutput
[[autodoc]] utils.ModelOutput
- to_tuple
## BaseModelOutput
[[autodoc]] modeling_outputs.BaseModelOutput
## BaseModelOutputWithPooling
[[autodoc]] modeling_outputs.BaseModelOutputWithPooling
## BaseModelOutputWithCrossAttentions
[[autodoc]] modeling_outputs.BaseModelOutputWithCrossAttentions
## BaseModelOutputWithPoolingAndCrossAttentions
[[autodoc]] modeling_outputs.BaseModelOutputWithPoolingAndCrossAttentions
## BaseModelOutputWithPast
[[autodoc]] modeling_outputs.BaseModelOutputWithPast
## BaseModelOutputWithPastAndCrossAttentions
[[autodoc]] modeling_outputs.BaseModelOutputWithPastAndCrossAttentions
## Seq2SeqModelOutput
[[autodoc]] modeling_outputs.Seq2SeqModelOutput
## CausalLMOutput
[[autodoc]] modeling_outputs.CausalLMOutput
## CausalLMOutputWithCrossAttentions
[[autodoc]] modeling_outputs.CausalLMOutputWithCrossAttentions
## CausalLMOutputWithPast
[[autodoc]] modeling_outputs.CausalLMOutputWithPast
## MaskedLMOutput
[[autodoc]] modeling_outputs.MaskedLMOutput
## Seq2SeqLMOutput
[[autodoc]] modeling_outputs.Seq2SeqLMOutput
## NextSentencePredictorOutput
[[autodoc]] modeling_outputs.NextSentencePredictorOutput
## SequenceClassifierOutput
[[autodoc]] modeling_outputs.SequenceClassifierOutput
## Seq2SeqSequenceClassifierOutput
[[autodoc]] modeling_outputs.Seq2SeqSequenceClassifierOutput
## MultipleChoiceModelOutput
[[autodoc]] modeling_outputs.MultipleChoiceModelOutput
## TokenClassifierOutput
[[autodoc]] modeling_outputs.TokenClassifierOutput
## QuestionAnsweringModelOutput
[[autodoc]] modeling_outputs.QuestionAnsweringModelOutput
## Seq2SeqQuestionAnsweringModelOutput
[[autodoc]] modeling_outputs.Seq2SeqQuestionAnsweringModelOutput
## Seq2SeqSpectrogramOutput
[[autodoc]] modeling_outputs.Seq2SeqSpectrogramOutput
## SemanticSegmenterOutput
[[autodoc]] modeling_outputs.SemanticSegmenterOutput
## ImageClassifierOutput
[[autodoc]] modeling_outputs.ImageClassifierOutput
## ImageClassifierOutputWithNoAttention
[[autodoc]] modeling_outputs.ImageClassifierOutputWithNoAttention
## DepthEstimatorOutput
[[autodoc]] modeling_outputs.DepthEstimatorOutput
## Wav2Vec2BaseModelOutput
[[autodoc]] modeling_outputs.Wav2Vec2BaseModelOutput
## XVectorOutput
[[autodoc]] modeling_outputs.XVectorOutput
## Seq2SeqTSModelOutput
[[autodoc]] modeling_outputs.Seq2SeqTSModelOutput
## Seq2SeqTSPredictionOutput
[[autodoc]] modeling_outputs.Seq2SeqTSPredictionOutput
## SampleTSPredictionOutput
[[autodoc]] modeling_outputs.SampleTSPredictionOutput
## TFBaseModelOutput
[[autodoc]] modeling_tf_outputs.TFBaseModelOutput
## TFBaseModelOutputWithPooling
[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPooling
## TFBaseModelOutputWithPoolingAndCrossAttentions
[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPoolingAndCrossAttentions
## TFBaseModelOutputWithPast
[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPast
## TFBaseModelOutputWithPastAndCrossAttentions
[[autodoc]] modeling_tf_outputs.TFBaseModelOutputWithPastAndCrossAttentions
## TFSeq2SeqModelOutput
[[autodoc]] modeling_tf_outputs.TFSeq2SeqModelOutput
## TFCausalLMOutput
[[autodoc]] modeling_tf_outputs.TFCausalLMOutput
## TFCausalLMOutputWithCrossAttentions
[[autodoc]] modeling_tf_outputs.TFCausalLMOutputWithCrossAttentions
## TFCausalLMOutputWithPast
[[autodoc]] modeling_tf_outputs.TFCausalLMOutputWithPast
## TFMaskedLMOutput
[[autodoc]] modeling_tf_outputs.TFMaskedLMOutput
## TFSeq2SeqLMOutput
[[autodoc]] modeling_tf_outputs.TFSeq2SeqLMOutput
## TFNextSentencePredictorOutput
[[autodoc]] modeling_tf_outputs.TFNextSentencePredictorOutput
## TFSequenceClassifierOutput
[[autodoc]] modeling_tf_outputs.TFSequenceClassifierOutput
## TFSeq2SeqSequenceClassifierOutput
[[autodoc]] modeling_tf_outputs.TFSeq2SeqSequenceClassifierOutput
## TFMultipleChoiceModelOutput
[[autodoc]] modeling_tf_outputs.TFMultipleChoiceModelOutput
## TFTokenClassifierOutput
[[autodoc]] modeling_tf_outputs.TFTokenClassifierOutput
## TFQuestionAnsweringModelOutput
[[autodoc]] modeling_tf_outputs.TFQuestionAnsweringModelOutput
## TFSeq2SeqQuestionAnsweringModelOutput
[[autodoc]] modeling_tf_outputs.TFSeq2SeqQuestionAnsweringModelOutput
## FlaxBaseModelOutput
[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutput
## FlaxBaseModelOutputWithPast
[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPast
## FlaxBaseModelOutputWithPooling
[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPooling
## FlaxBaseModelOutputWithPastAndCrossAttentions
[[autodoc]] modeling_flax_outputs.FlaxBaseModelOutputWithPastAndCrossAttentions
## FlaxSeq2SeqModelOutput
[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqModelOutput
## FlaxCausalLMOutputWithCrossAttentions
[[autodoc]] modeling_flax_outputs.FlaxCausalLMOutputWithCrossAttentions
## FlaxMaskedLMOutput
[[autodoc]] modeling_flax_outputs.FlaxMaskedLMOutput
## FlaxSeq2SeqLMOutput
[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqLMOutput
## FlaxNextSentencePredictorOutput
[[autodoc]] modeling_flax_outputs.FlaxNextSentencePredictorOutput
## FlaxSequenceClassifierOutput
[[autodoc]] modeling_flax_outputs.FlaxSequenceClassifierOutput
## FlaxSeq2SeqSequenceClassifierOutput
[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqSequenceClassifierOutput
## FlaxMultipleChoiceModelOutput
[[autodoc]] modeling_flax_outputs.FlaxMultipleChoiceModelOutput
## FlaxTokenClassifierOutput
[[autodoc]] modeling_flax_outputs.FlaxTokenClassifierOutput
## FlaxQuestionAnsweringModelOutput
[[autodoc]] modeling_flax_outputs.FlaxQuestionAnsweringModelOutput
## FlaxSeq2SeqQuestionAnsweringModelOutput
[[autodoc]] modeling_flax_outputs.FlaxSeq2SeqQuestionAnsweringModelOutput
| transformers/docs/source/zh/main_classes/output.md/0 | {
"file_path": "transformers/docs/source/zh/main_classes/output.md",
"repo_id": "transformers",
"token_count": 3318
} | 261 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 使用脚本进行训练
除了 🤗 Transformers [notebooks](./noteboks/README),还有示例脚本演示了如何使用[PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch)、[TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow)或[JAX/Flax](https://github.com/huggingface/transformers/tree/main/examples/flax)训练模型以解决特定任务。
您还可以在这些示例中找到我们在[研究项目](https://github.com/huggingface/transformers/tree/main/examples/research_projects)和[遗留示例](https://github.com/huggingface/transformers/tree/main/examples/legacy)中使用过的脚本,这些脚本主要是由社区贡献的。这些脚本已不再被积极维护,需要使用特定版本的🤗 Transformers, 可能与库的最新版本不兼容。
示例脚本可能无法在初始配置下直接解决每个问题,您可能需要根据要解决的问题调整脚本。为了帮助您,大多数脚本都完全暴露了数据预处理的方式,允许您根据需要对其进行编辑。
如果您想在示例脚本中实现任何功能,请在[论坛](https://discuss.huggingface.co/)或[issue](https://github.com/huggingface/transformers/issues)上讨论,然后再提交Pull Request。虽然我们欢迎修复错误,但不太可能合并添加更多功能的Pull Request,因为这会降低可读性。
本指南将向您展示如何在[PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization)和[TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization)中运行示例摘要训练脚本。除非另有说明,否则所有示例都可以在两个框架中工作。
## 设置
要成功运行示例脚本的最新版本,您必须在新虚拟环境中**从源代码安装 🤗 Transformers**:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
```
对于旧版本的示例脚本,请点击下面的切换按钮:
<details>
<summary>老版本🤗 Transformers示例 </summary>
<ul>
<li><a href="https://github.com/huggingface/transformers/tree/v4.5.1/examples">v4.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.4.2/examples">v4.4.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.3.3/examples">v4.3.3</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.2.2/examples">v4.2.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.1.1/examples">v4.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.0.1/examples">v4.0.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.5.1/examples">v3.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.4.0/examples">v3.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.3.1/examples">v3.3.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.2.0/examples">v3.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.1.0/examples">v3.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.0.2/examples">v3.0.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.11.0/examples">v2.11.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.10.0/examples">v2.10.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.9.1/examples">v2.9.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.8.0/examples">v2.8.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.7.0/examples">v2.7.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.6.0/examples">v2.6.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.5.1/examples">v2.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.4.0/examples">v2.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.3.0/examples">v2.3.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.2.0/examples">v2.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.1.0/examples">v2.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.0.0/examples">v2.0.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.2.0/examples">v1.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.1.0/examples">v1.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.0.0/examples">v1.0.0</a></li>
</ul>
</details>
然后切换您clone的 🤗 Transformers 仓到特定的版本,例如v3.5.1:
```bash
git checkout tags/v3.5.1
```
在安装了正确的库版本后,进入您选择的版本的`example`文件夹并安装例子要求的环境:
```bash
pip install -r requirements.txt
```
## 运行脚本
<frameworkcontent>
<pt>
示例脚本从🤗 [Datasets](https://huggingface.co/docs/datasets/)库下载并预处理数据集。然后,脚本通过[Trainer](https://huggingface.co/docs/transformers/main_classes/trainer)使用支持摘要任务的架构对数据集进行微调。以下示例展示了如何在[CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail)数据集上微调[T5-small](https://huggingface.co/google-t5/t5-small)。由于T5模型的训练方式,它需要一个额外的`source_prefix`参数。这个提示让T5知道这是一个摘要任务。
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
示例脚本从 🤗 [Datasets](https://huggingface.co/docs/datasets/) 库下载并预处理数据集。然后,脚本使用 Keras 在支持摘要的架构上微调数据集。以下示例展示了如何在 [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail) 数据集上微调 [T5-small](https://huggingface.co/google-t5/t5-small)。T5 模型由于训练方式需要额外的 `source_prefix` 参数。这个提示让 T5 知道这是一个摘要任务。
```bash
python examples/tensorflow/summarization/run_summarization.py \
--model_name_or_path google-t5/t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## 分布式训练和混合精度
[Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) 支持分布式训练和混合精度,这意味着你也可以在脚本中使用它。要启用这两个功能,可以做如下设置:
- 添加 `fp16` 参数以启用混合精度。
- 使用 `nproc_per_node` 参数设置使用的GPU数量。
```bash
torchrun \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
TensorFlow脚本使用[`MirroredStrategy`](https://www.tensorflow.org/guide/distributed_training#mirroredstrategy)进行分布式训练,您无需在训练脚本中添加任何其他参数。如果可用,TensorFlow脚本将默认使用多个GPU。
## 在TPU上运行脚本
<frameworkcontent>
<pt>
张量处理单元(TPUs)是专门设计用于加速性能的。PyTorch使用[XLA](https://www.tensorflow.org/xla)深度学习编译器支持TPU(更多细节请参见[这里](https://github.com/pytorch/xla/blob/master/README.md))。要使用TPU,请启动`xla_spawn.py`脚本并使用`num_cores`参数设置要使用的TPU核心数量。
```bash
python xla_spawn.py --num_cores 8 \
summarization/run_summarization.py \
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
张量处理单元(TPUs)是专门设计用于加速性能的。TensorFlow脚本使用[`TPUStrategy`](https://www.tensorflow.org/guide/distributed_training#tpustrategy)在TPU上进行训练。要使用TPU,请将TPU资源的名称传递给`tpu`参数。
```bash
python run_summarization.py \
--tpu name_of_tpu_resource \
--model_name_or_path google-t5/t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## 基于🤗 Accelerate运行脚本
🤗 [Accelerate](https://huggingface.co/docs/accelerate) 是一个仅支持 PyTorch 的库,它提供了一种统一的方法来在不同类型的设置(仅 CPU、多个 GPU、多个TPU)上训练模型,同时保持对 PyTorch 训练循环的完全可见性。如果你还没有安装 🤗 Accelerate,请确保你已经安装了它:
> 注意:由于 Accelerate 正在快速发展,因此必须安装 git 版本的 accelerate 来运行脚本。
```bash
pip install git+https://github.com/huggingface/accelerate
```
你需要使用`run_summarization_no_trainer.py`脚本,而不是`run_summarization.py`脚本。🤗 Accelerate支持的脚本需要在文件夹中有一个`task_no_trainer.py`文件。首先运行以下命令以创建并保存配置文件:
```bash
accelerate config
```
检测您的设置以确保配置正确:
```bash
accelerate test
```
现在您可以开始训练模型了:
```bash
accelerate launch run_summarization_no_trainer.py \
--model_name_or_path google-t5/t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir ~/tmp/tst-summarization
```
## 使用自定义数据集
摘要脚本支持自定义数据集,只要它们是CSV或JSON Line文件。当你使用自己的数据集时,需要指定一些额外的参数:
- `train_file` 和 `validation_file` 分别指定您的训练和验证文件的路径。
- `text_column` 是输入要进行摘要的文本。
- `summary_column` 是目标输出的文本。
使用自定义数据集的摘要脚本看起来是这样的:
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--train_file path_to_csv_or_jsonlines_file \
--validation_file path_to_csv_or_jsonlines_file \
--text_column text_column_name \
--summary_column summary_column_name \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--overwrite_output_dir \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--predict_with_generate
```
## 测试脚本
通常,在提交整个数据集之前,最好先在较少的数据集示例上运行脚本,以确保一切按预期工作,因为完整数据集的处理可能需要花费几个小时的时间。使用以下参数将数据集截断为最大样本数:
- `max_train_samples`
- `max_eval_samples`
- `max_predict_samples`
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path google-t5/t5-small \
--max_train_samples 50 \
--max_eval_samples 50 \
--max_predict_samples 50 \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
并非所有示例脚本都支持`max_predict_samples`参数。如果您不确定您的脚本是否支持此参数,请添加`-h`参数进行检查:
```bash
examples/pytorch/summarization/run_summarization.py -h
```
## 从checkpoint恢复训练
另一个有用的选项是从之前的checkpoint恢复训练。这将确保在训练中断时,您可以从之前停止的地方继续进行,而无需重新开始。有两种方法可以从checkpoint恢复训练。
第一种方法使用`output_dir previous_output_dir`参数从存储在`output_dir`中的最新的checkpoint恢复训练。在这种情况下,您应该删除`overwrite_output_dir`:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--output_dir previous_output_dir \
--predict_with_generate
```
第二种方法使用`resume_from_checkpoint path_to_specific_checkpoint`参数从特定的checkpoint文件夹恢复训练。
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--resume_from_checkpoint path_to_specific_checkpoint \
--predict_with_generate
```
## 分享模型
所有脚本都可以将您的最终模型上传到[Model Hub](https://huggingface.co/models)。在开始之前,请确保您已登录Hugging Face:
```bash
huggingface-cli login
```
然后,在脚本中添加`push_to_hub`参数。这个参数会创建一个带有您Hugging Face用户名和`output_dir`中指定的文件夹名称的仓库。
为了给您的仓库指定一个特定的名称,使用`push_to_hub_model_id`参数来添加它。该仓库将自动列出在您的命名空间下。
以下示例展示了如何上传具有特定仓库名称的模型:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--push_to_hub \
--push_to_hub_model_id finetuned-t5-cnn_dailymail \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
``` | transformers/docs/source/zh/run_scripts.md/0 | {
"file_path": "transformers/docs/source/zh/run_scripts.md",
"repo_id": "transformers",
"token_count": 8305
} | 262 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2022 The HuggingFace Team All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning the library vision-encoder-decoder models for image captioning.
"""
import json
import logging
import os
import sys
import time
import warnings
from dataclasses import asdict, dataclass, field
from enum import Enum
from functools import partial
from pathlib import Path
from typing import Callable, Optional
import datasets
import evaluate
import jax
import jax.numpy as jnp
import nltk # Here to have a nice missing dependency error message early on
import numpy as np
import optax
from datasets import Dataset, load_dataset
from filelock import FileLock
from flax import jax_utils, traverse_util
from flax.jax_utils import unreplicate
from flax.training import train_state
from flax.training.common_utils import get_metrics, onehot, shard, shard_prng_key
from huggingface_hub import HfApi
from PIL import Image
from tqdm import tqdm
import transformers
from transformers import (
AutoImageProcessor,
AutoTokenizer,
FlaxVisionEncoderDecoderModel,
HfArgumentParser,
is_tensorboard_available,
)
from transformers.utils import is_offline_mode, send_example_telemetry
logger = logging.getLogger(__name__)
try:
nltk.data.find("tokenizers/punkt")
except (LookupError, OSError):
if is_offline_mode():
raise LookupError(
"Offline mode: run this script without TRANSFORMERS_OFFLINE first to download nltk data files"
)
with FileLock(".lock") as lock:
nltk.download("punkt", quiet=True)
# Copied from transformers.models.bart.modeling_flax_bart.shift_tokens_right
def shift_tokens_right(input_ids: np.ndarray, pad_token_id: int, decoder_start_token_id: int) -> np.ndarray:
"""
Shift input ids one token to the right.
"""
shifted_input_ids = np.zeros_like(input_ids)
shifted_input_ids[:, 1:] = input_ids[:, :-1]
shifted_input_ids[:, 0] = decoder_start_token_id
shifted_input_ids = np.where(shifted_input_ids == -100, pad_token_id, shifted_input_ids)
return shifted_input_ids
@dataclass
class TrainingArguments:
output_dir: str = field(
metadata={"help": "The output directory where the model predictions and checkpoints will be written."},
)
overwrite_output_dir: bool = field(
default=False,
metadata={
"help": (
"Overwrite the content of the output directory. "
"Use this to continue training if output_dir points to a checkpoint directory."
)
},
)
do_train: bool = field(default=False, metadata={"help": "Whether to run training."})
do_eval: bool = field(default=False, metadata={"help": "Whether to run eval on the dev set."})
do_predict: bool = field(default=False, metadata={"help": "Whether to run predictions on the test set."})
per_device_train_batch_size: int = field(
default=8, metadata={"help": "Batch size per GPU/TPU core/CPU for training."}
)
per_device_eval_batch_size: int = field(
default=8, metadata={"help": "Batch size per GPU/TPU core/CPU for evaluation."}
)
_block_size_doc = """
The default value `0` will preprocess (tokenization + image processing) the whole dataset before training and
cache the results. This uses more disk space, but avoids (repeated) processing time during training. This is a
good option if your disk space is large enough to store the whole processed dataset.
If a positive value is given, the captions in the dataset will be tokenized before training and the results are
cached. During training, it iterates the dataset in chunks of size `block_size`. On each block, images are
transformed by the image processor with the results being kept in memory (no cache), and batches of size
`batch_size` are yielded before processing the next block. This could avoid the heavy disk usage when the
dataset is large.
"""
block_size: int = field(default=0, metadata={"help": _block_size_doc})
learning_rate: float = field(default=5e-5, metadata={"help": "The initial learning rate for AdamW."})
weight_decay: float = field(default=0.0, metadata={"help": "Weight decay for AdamW if we apply some."})
adam_beta1: float = field(default=0.9, metadata={"help": "Beta1 for AdamW optimizer"})
adam_beta2: float = field(default=0.999, metadata={"help": "Beta2 for AdamW optimizer"})
adam_epsilon: float = field(default=1e-8, metadata={"help": "Epsilon for AdamW optimizer."})
label_smoothing_factor: float = field(
default=0.0, metadata={"help": "The label smoothing epsilon to apply (zero means no label smoothing)."}
)
num_train_epochs: float = field(default=3.0, metadata={"help": "Total number of training epochs to perform."})
warmup_steps: int = field(default=0, metadata={"help": "Linear warmup over warmup_steps."})
logging_steps: int = field(default=500, metadata={"help": "Log every X updates steps."})
eval_steps: int = field(default=None, metadata={"help": "Run an evaluation every X steps."})
seed: int = field(default=42, metadata={"help": "Random seed that will be set at the beginning of training."})
push_to_hub: bool = field(
default=False, metadata={"help": "Whether or not to upload the trained model to the model hub after training."}
)
hub_model_id: str = field(
default=None, metadata={"help": "The name of the repository to keep in sync with the local `output_dir`."}
)
hub_token: str = field(default=None, metadata={"help": "The token to use to push to the Model Hub."})
def __post_init__(self):
if self.output_dir is not None:
self.output_dir = os.path.expanduser(self.output_dir)
def to_dict(self):
"""
Serializes this instance while replace `Enum` by their values (for JSON serialization support). It obfuscates
the token values by removing their value.
"""
d = asdict(self)
for k, v in d.items():
if isinstance(v, Enum):
d[k] = v.value
if isinstance(v, list) and len(v) > 0 and isinstance(v[0], Enum):
d[k] = [x.value for x in v]
if k.endswith("_token"):
d[k] = f"<{k.upper()}>"
return d
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune, or train from scratch.
"""
model_name_or_path: str = field(
metadata={"help": "The model checkpoint for weights initialization."},
)
cache_dir: Optional[str] = field(
default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
)
use_fast_tokenizer: bool = field(
default=True,
metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
)
dtype: Optional[str] = field(
default="float32",
metadata={
"help": (
"Floating-point format in which the model weights should be initialized and trained. Choose one of"
" `[float32, float16, bfloat16]`."
)
},
)
token: str = field(
default=None,
metadata={
"help": (
"The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
"generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
)
},
)
use_auth_token: bool = field(
default=None,
metadata={
"help": "The `use_auth_token` argument is deprecated and will be removed in v4.34. Please use `token` instead."
},
)
trust_remote_code: bool = field(
default=False,
metadata={
"help": (
"Whether or not to allow for custom models defined on the Hub in their own modeling files. This option "
"should only be set to `True` for repositories you trust and in which you have read the code, as it will "
"execute code present on the Hub on your local machine."
)
},
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
dataset_name: Optional[str] = field(
default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
)
dataset_config_name: Optional[str] = field(
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
)
data_dir: Optional[str] = field(
default=None, metadata={"help": "The data directory of the dataset to use (via the datasets library)."}
)
image_column: Optional[str] = field(
default=None,
metadata={"help": "The name of the column in the datasets containing the full image file paths."},
)
caption_column: Optional[str] = field(
default=None,
metadata={"help": "The name of the column in the datasets containing the image captions."},
)
train_file: Optional[str] = field(default=None, metadata={"help": "The input training data file (a text file)."})
validation_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input evaluation data file to evaluate the perplexity on (a text file)."},
)
test_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input predict data file to do prediction on (a text file)."},
)
max_target_length: Optional[int] = field(
default=128,
metadata={
"help": (
"The maximum total sequence length for target text after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
)
},
)
val_max_target_length: Optional[int] = field(
default=None,
metadata={
"help": (
"The maximum total sequence length for validation target text after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded. Will default to `max_target_length`. "
"This argument is also used to override the `max_length` param of `model.generate`, which is used "
"during evaluation."
)
},
)
max_train_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
)
},
)
max_eval_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
"value if set."
)
},
)
max_predict_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of prediction examples to this "
"value if set."
)
},
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
predict_with_generate: bool = field(
default=False, metadata={"help": "Whether to use generate to calculate generative metrics (ROUGE, BLEU)."}
)
num_beams: Optional[int] = field(
default=None,
metadata={
"help": (
"Number of beams to use for evaluation. This argument will be passed to `model.generate`, "
"which is used during evaluation."
)
},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
def __post_init__(self):
if self.dataset_name is None and self.train_file is None and self.validation_file is None:
raise ValueError("Need either a dataset name or a training/validation file.")
else:
if self.train_file is not None:
extension = self.train_file.split(".")[-1]
if extension not in ["csv", "json"]:
raise ValueError(f"`train_file` should be a csv or a json file, got {extension}.")
if self.validation_file is not None:
extension = self.validation_file.split(".")[-1]
if extension not in ["csv", "json"]:
raise ValueError(f"`validation_file` should be a csv or a json file, got {extension}.")
if self.val_max_target_length is None:
self.val_max_target_length = self.max_target_length
image_captioning_name_mapping = {
"image_caption_dataset.py": ("image_path", "caption"),
}
class TrainState(train_state.TrainState):
dropout_rng: jnp.ndarray
def replicate(self):
return jax_utils.replicate(self).replace(dropout_rng=shard_prng_key(self.dropout_rng))
def data_loader(rng: jax.random.PRNGKey, dataset: Dataset, batch_size: int, shuffle: bool = False):
"""
Returns batches of size `batch_size` from truncated `dataset`, sharded over all local devices.
Shuffle batches if `shuffle` is `True`.
"""
steps = len(dataset) // batch_size # Skip incomplete batch.
# We use `numpy.ndarray` to interact with `datasets.Dataset`, since using `jax.numpy.array` to index into a
# dataset is significantly slow. Using JAX array at the 1st place is only to keep JAX's PRNGs generation
# mechanism, which works differently from NumPy/SciPy.
if shuffle:
batch_idx = jax.random.permutation(rng, len(dataset))
batch_idx = np.asarray(batch_idx)
else:
batch_idx = np.arange(len(dataset))
for idx in range(steps):
start_idx = batch_size * idx
end_idx = batch_size * (idx + 1)
selected_indices = batch_idx[start_idx:end_idx]
batch = dataset[selected_indices]
batch = shard(batch)
yield batch
def write_metric(summary_writer, metrics, train_time, step, metric_key_prefix="train"):
if train_time:
summary_writer.scalar("train_time", train_time, step)
metrics = get_metrics(metrics)
for key, vals in metrics.items():
tag = f"{metric_key_prefix}_{key}"
for i, val in enumerate(vals):
summary_writer.scalar(tag, val, step - len(vals) + i + 1)
else:
for metric_name, value in metrics.items():
summary_writer.scalar(f"{metric_key_prefix}_{metric_name}", value, step)
def create_learning_rate_fn(
train_ds_size: int, train_batch_size: int, num_train_epochs: int, num_warmup_steps: int, learning_rate: float
) -> Callable[[int], jnp.ndarray]:
"""Returns a linear warmup, linear_decay learning rate function."""
steps_per_epoch = train_ds_size // train_batch_size
num_train_steps = steps_per_epoch * num_train_epochs
warmup_fn = optax.linear_schedule(init_value=0.0, end_value=learning_rate, transition_steps=num_warmup_steps)
decay_fn = optax.linear_schedule(
init_value=learning_rate, end_value=0, transition_steps=num_train_steps - num_warmup_steps
)
schedule_fn = optax.join_schedules(schedules=[warmup_fn, decay_fn], boundaries=[num_warmup_steps])
return schedule_fn
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
if model_args.use_auth_token is not None:
warnings.warn(
"The `use_auth_token` argument is deprecated and will be removed in v4.34. Please use `token` instead.",
FutureWarning,
)
if model_args.token is not None:
raise ValueError("`token` and `use_auth_token` are both specified. Please set only the argument `token`.")
model_args.token = model_args.use_auth_token
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_image_captioning", model_args, data_args, framework="flax")
if (
os.path.exists(training_args.output_dir)
and os.listdir(training_args.output_dir)
and training_args.do_train
and not training_args.overwrite_output_dir
):
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
"Use --overwrite_output_dir to overcome."
)
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
# Setup logging, we only want one process per machine to log things on the screen.
logger.setLevel(logging.INFO if jax.process_index() == 0 else logging.ERROR)
if jax.process_index() == 0:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
# Set the verbosity to info of the Transformers logger (on main process only):
logger.info(f"Training/evaluation parameters {training_args}")
# Handle the repository creation
if training_args.push_to_hub:
# Retrieve of infer repo_name
repo_name = training_args.hub_model_id
if repo_name is None:
repo_name = Path(training_args.output_dir).absolute().name
# Create repo and retrieve repo_id
api = HfApi()
repo_id = api.create_repo(repo_name, exist_ok=True, token=training_args.hub_token).repo_id
# Get the datasets: you can either provide your own CSV/JSON training and evaluation files (see below)
# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For CSV/JSON files this script will use the first column for the full image path and the second column for the
# captions (unless you specify column names for this with the `image_column` and `caption_column` arguments).
#
if data_args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
dataset = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
cache_dir=model_args.cache_dir,
keep_in_memory=False,
data_dir=data_args.data_dir,
token=model_args.token,
)
else:
data_files = {}
if data_args.train_file is not None:
data_files["train"] = data_args.train_file
extension = data_args.train_file.split(".")[-1]
if data_args.validation_file is not None:
data_files["validation"] = data_args.validation_file
extension = data_args.validation_file.split(".")[-1]
if data_args.test_file is not None:
data_files["test"] = data_args.test_file
extension = data_args.test_file.split(".")[-1]
dataset = load_dataset(
extension,
data_files=data_files,
cache_dir=model_args.cache_dir,
token=model_args.token,
)
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# https://huggingface.co/docs/datasets/loading_datasets.
# Load pretrained model and tokenizer
model = FlaxVisionEncoderDecoderModel.from_pretrained(
model_args.model_name_or_path,
seed=training_args.seed,
dtype=getattr(jnp, model_args.dtype),
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
image_processor = AutoImageProcessor.from_pretrained(
model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
tokenizer = AutoTokenizer.from_pretrained(
model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
use_fast=model_args.use_fast_tokenizer,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
tokenizer.pad_token = tokenizer.convert_ids_to_tokens(model.config.pad_token_id)
# Preprocessing the datasets.
# We need to tokenize inputs and targets.
if training_args.do_train:
column_names = dataset["train"].column_names
elif training_args.do_eval:
column_names = dataset["validation"].column_names
elif training_args.do_predict:
column_names = dataset["test"].column_names
else:
logger.info("There is nothing to do. Please pass `do_train`, `do_eval` and/or `do_predict`.")
return
# Get the column names for input/target.
dataset_columns = image_captioning_name_mapping.get(data_args.dataset_name, None)
if data_args.image_column is None:
if dataset_columns is None:
raise ValueError(
f"`--dataset_name` {data_args.dataset_name} not found in dataset '{data_args.dataset_name}'. Make sure"
" to set `--dataset_name` to the correct dataset name, one of"
f" {', '.join(image_captioning_name_mapping.keys())}."
)
image_column = dataset_columns[0]
else:
image_column = data_args.image_column
if image_column not in column_names:
raise ValueError(
f"--image_column' value '{data_args.image_column}' needs to be one of: {', '.join(column_names)}"
)
if data_args.caption_column is None:
if dataset_columns is None:
raise ValueError(
f"`--dataset_name` {data_args.dataset_name} not found in dataset '{data_args.dataset_name}'. Make sure"
" to set `--dataset_name` to the correct dataset name, one of"
f" {', '.join(image_captioning_name_mapping.keys())}."
)
caption_column = dataset_columns[1]
else:
caption_column = data_args.caption_column
if caption_column not in column_names:
raise ValueError(
f"--caption_column' value '{data_args.caption_column}' needs to be one of: {', '.join(column_names)}"
)
# In Flax, for seq2seq models we need to pass `decoder_input_ids`
# as the Flax models don't accept `labels`, we need to prepare the decoder_input_ids here
# for that dynamically import the `shift_tokens_right` function from the model file
model_module = __import__(model.__module__, fromlist=["shift_tokens_right"])
shift_tokens_right_fn = getattr(model_module, "shift_tokens_right", shift_tokens_right)
def filter_fn(examples):
"""remove problematic images"""
bools = []
for image_file in examples[image_column]:
try:
image = Image.open(image_file)
image_processor(images=image, return_tensors="np")
bools.append(True)
except Exception:
bools.append(False)
return bools
# Setting padding="max_length" as we need fixed length inputs for jitted functions
def tokenization_fn(examples, max_target_length):
"""Run tokenization on captions."""
captions = []
for caption in examples[caption_column]:
captions.append(caption.lower() + " " + tokenizer.eos_token)
targets = captions
model_inputs = {}
labels = tokenizer(
text_target=targets,
max_length=max_target_length,
padding="max_length",
truncation=True,
return_tensors="np",
)
model_inputs["labels"] = labels["input_ids"]
decoder_input_ids = shift_tokens_right_fn(
labels["input_ids"], model.config.pad_token_id, model.config.decoder_start_token_id
)
model_inputs["decoder_input_ids"] = np.asarray(decoder_input_ids)
# We need decoder_attention_mask so we can ignore pad tokens from loss
model_inputs["decoder_attention_mask"] = labels["attention_mask"]
model_inputs[image_column] = examples[image_column]
return model_inputs
def image_processing_fn(examples, check_image=True):
"""
Run preprocessing on images
If `check_image` is `True`, the examples that fails during `Image.open()` will be caught and discarded.
Otherwise, an exception will be thrown.
"""
model_inputs = {}
if check_image:
images = []
to_keep = []
for image_file in examples[image_column]:
try:
img = Image.open(image_file)
images.append(img)
to_keep.append(True)
except Exception:
to_keep.append(False)
for k, v in examples.items():
if k != image_column:
model_inputs[k] = v[to_keep]
else:
images = [Image.open(image_file) for image_file in examples[image_column]]
encoder_inputs = image_processor(images=images, return_tensors="np")
model_inputs["pixel_values"] = encoder_inputs.pixel_values
return model_inputs
def preprocess_fn(examples, max_target_length, check_image=True):
"""Run tokenization + image processing"""
model_inputs = {}
# This contains image path column
model_inputs.update(tokenization_fn(examples, max_target_length))
model_inputs.update(image_processing_fn(model_inputs, check_image=check_image))
# Remove image path column
model_inputs.pop(image_column)
return model_inputs
features = datasets.Features(
{
"pixel_values": datasets.Array3D(
shape=(
getattr(model.config.encoder, "num_channels", 3),
model.config.encoder.image_size,
model.config.encoder.image_size,
),
dtype="float32",
),
"labels": datasets.Sequence(feature=datasets.Value(dtype="int32", id=None), length=-1, id=None),
"decoder_input_ids": datasets.Sequence(feature=datasets.Value(dtype="int32", id=None), length=-1, id=None),
"decoder_attention_mask": datasets.Sequence(
feature=datasets.Value(dtype="int32", id=None), length=-1, id=None
),
}
)
# If `block_size` is `0`, tokenization & image processing is done at the beginning
run_img_proc_at_beginning = training_args.block_size == 0
# Used in .map() below
function_kwarg = preprocess_fn if run_img_proc_at_beginning else tokenization_fn
# `features` is used only for the final preprocessed dataset (for the performance purpose).
features_kwarg = features if run_img_proc_at_beginning else None
# Keep `image_column` if the image processing is done during training
remove_columns_kwarg = [x for x in column_names if x != image_column or run_img_proc_at_beginning]
processor_names = "tokenizer and image processor" if run_img_proc_at_beginning else "tokenizer"
# Store some constant
train_batch_size = int(training_args.per_device_train_batch_size) * jax.device_count()
eval_batch_size = int(training_args.per_device_eval_batch_size) * jax.device_count()
if training_args.block_size % train_batch_size > 0 or training_args.block_size % eval_batch_size > 0:
raise ValueError(
"`training_args.block_size` needs to be a multiple of the global train/eval batch size. "
f"Got {training_args.block_size}, {train_batch_size} and {eval_batch_size} respectively instead."
)
if training_args.do_train:
if "train" not in dataset:
raise ValueError("--do_train requires a train dataset")
train_dataset = dataset["train"]
if data_args.max_train_samples is not None:
max_train_samples = min(len(train_dataset), data_args.max_train_samples)
train_dataset = train_dataset.select(range(max_train_samples))
# remove problematic examples
# (if image processing is performed at the beginning, the filtering is done during preprocessing below
# instead here.)
if not run_img_proc_at_beginning:
train_dataset = train_dataset.filter(filter_fn, batched=True, num_proc=data_args.preprocessing_num_workers)
train_dataset = train_dataset.map(
function=function_kwarg,
batched=True,
num_proc=data_args.preprocessing_num_workers,
# kept image paths
remove_columns=remove_columns_kwarg,
load_from_cache_file=not data_args.overwrite_cache,
desc=f"Running {processor_names} on train dataset",
fn_kwargs={"max_target_length": data_args.max_target_length},
features=features_kwarg,
)
if run_img_proc_at_beginning:
# set format (for performance) since the dataset is ready to be used
train_dataset = train_dataset.with_format("numpy")
steps_per_epoch = len(train_dataset) // train_batch_size
num_train_examples_per_epoch = steps_per_epoch * train_batch_size
num_epochs = int(training_args.num_train_epochs)
total_train_steps = steps_per_epoch * num_epochs
else:
num_train_examples_per_epoch = 0
if training_args.do_eval:
if "validation" not in dataset:
raise ValueError("--do_eval requires a validation dataset")
eval_dataset = dataset["validation"]
if data_args.max_eval_samples is not None:
max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
eval_dataset = eval_dataset.select(range(max_eval_samples))
# remove problematic examples
# (if image processing is performed at the beginning, the filtering is done during preprocessing below
# instead here.)
if not run_img_proc_at_beginning:
eval_dataset = eval_dataset.filter(filter_fn, batched=True, num_proc=data_args.preprocessing_num_workers)
eval_dataset = eval_dataset.map(
function=function_kwarg,
batched=True,
num_proc=data_args.preprocessing_num_workers,
# kept image paths
remove_columns=remove_columns_kwarg,
load_from_cache_file=not data_args.overwrite_cache,
desc=f"Running {processor_names} on validation dataset",
fn_kwargs={"max_target_length": data_args.val_max_target_length},
features=features_kwarg,
)
if run_img_proc_at_beginning:
# set format (for performance) since the dataset is ready to be used
eval_dataset = eval_dataset.with_format("numpy")
num_eval_examples = len(eval_dataset)
eval_steps = num_eval_examples // eval_batch_size
if training_args.do_predict:
if "test" not in dataset:
raise ValueError("--do_predict requires a test dataset")
predict_dataset = dataset["test"]
if data_args.max_predict_samples is not None:
max_predict_samples = min(len(predict_dataset), data_args.max_predict_samples)
predict_dataset = predict_dataset.select(range(max_predict_samples))
# remove problematic examples
# (if image processing is performed at the beginning, the filtering is done during preprocessing below
# instead here.)
if not run_img_proc_at_beginning:
predict_dataset = predict_dataset.filter(
filter_fn, batched=True, num_proc=data_args.preprocessing_num_workers
)
predict_dataset = predict_dataset.map(
function=function_kwarg,
batched=True,
num_proc=data_args.preprocessing_num_workers,
# kept image paths
remove_columns=remove_columns_kwarg,
load_from_cache_file=not data_args.overwrite_cache,
desc=f"Running {processor_names} on prediction dataset",
fn_kwargs={"max_target_length": data_args.val_max_target_length},
features=features_kwarg,
)
if run_img_proc_at_beginning:
# set format (for performance) since the dataset is ready to be used
predict_dataset = predict_dataset.with_format("numpy")
num_test_examples = len(predict_dataset)
test_steps = num_test_examples // eval_batch_size
def blockwise_data_loader(
rng: jax.random.PRNGKey,
ds: Dataset,
block_size: int,
batch_size: int,
shuffle: bool = False,
keep_in_memory: bool = False,
split: str = "",
):
"""
Wrap the simple `data_loader` in a block-wise way if `block_size` > 0, else it's the same as `data_loader`.
If `block_size` > 0, it requires `ds` to have a column that gives image paths in order to perform image
processing (with the column name being specified by `image_column`). The tokenization should be done before
training in this case.
"""
# We use `numpy.ndarray` to interact with `datasets.Dataset`, since using `jax.numpy.array` to index into a
# dataset is significantly slow. Using JAX array at the 1st place is only to keep JAX's PRNGs generation
# mechanism, which works differently from NumPy/SciPy.
if shuffle:
indices = jax.random.permutation(rng, len(ds))
indices = np.asarray(indices)
else:
indices = np.arange(len(ds))
_block_size = len(ds) if not block_size else block_size
steps_per_block = _block_size // batch_size
num_examples = len(ds)
steps = num_examples // batch_size
num_splits = steps // steps_per_block + int(steps % steps_per_block > 0)
for idx in range(num_splits):
if not block_size:
_ds = ds
else:
start_idx = block_size * idx
end_idx = block_size * (idx + 1)
selected_indices = indices[start_idx:end_idx]
_ds = ds.select(selected_indices)
_ds = _ds.map(
image_processing_fn,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=[image_column],
load_from_cache_file=not data_args.overwrite_cache,
features=features,
keep_in_memory=keep_in_memory,
# The images are already checked either in `.filter()` or in `preprocess_fn()`
fn_kwargs={"check_image": False},
desc=f"Running image processing on {split} dataset".replace(" ", " "),
)
_ds = _ds.with_format("numpy")
# No need to shuffle here
loader = data_loader(rng, _ds, batch_size=batch_size, shuffle=False)
for batch in loader:
yield batch
# Metric
metric = evaluate.load("rouge", cache_dir=model_args.cache_dir)
def postprocess_text(preds, labels):
preds = [pred.strip() for pred in preds]
labels = [label.strip() for label in labels]
# rougeLSum expects newline after each sentence
preds = ["\n".join(nltk.sent_tokenize(pred)) for pred in preds]
labels = ["\n".join(nltk.sent_tokenize(label)) for label in labels]
return preds, labels
def compute_metrics(preds, labels):
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Some simple post-processing
decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
result = metric.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True)
# Extract a few results from ROUGE
result = {key: value.mid.fmeasure * 100 for key, value in result.items()}
prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in preds]
result["gen_len"] = np.mean(prediction_lens)
result = {k: round(v, 6) for k, v in result.items()}
return result, decoded_preds, decoded_labels
# Enable tensorboard only on the master node
has_tensorboard = is_tensorboard_available()
if has_tensorboard and jax.process_index() == 0:
try:
from flax.metrics.tensorboard import SummaryWriter
summary_writer = SummaryWriter(log_dir=Path(training_args.output_dir))
except ImportError as ie:
has_tensorboard = False
logger.warning(
f"Unable to display metrics through TensorBoard because some package are not installed: {ie}"
)
else:
logger.warning(
"Unable to display metrics through TensorBoard because the package is not installed: "
"Please run pip install tensorboard to enable."
)
# Initialize our training
rng = jax.random.PRNGKey(training_args.seed)
rng, dropout_rng = jax.random.split(rng)
# Create learning rate schedule
linear_decay_lr_schedule_fn = create_learning_rate_fn(
num_train_examples_per_epoch,
train_batch_size,
training_args.num_train_epochs,
training_args.warmup_steps,
training_args.learning_rate,
)
# We use Optax's "masking" functionality to not apply weight decay
# to bias and LayerNorm scale parameters. decay_mask_fn returns a
# mask boolean with the same structure as the parameters.
# The mask is True for parameters that should be decayed.
def decay_mask_fn(params):
flat_params = traverse_util.flatten_dict(params)
# find out all LayerNorm parameters
layer_norm_candidates = ["layernorm", "layer_norm", "ln"]
layer_norm_named_params = {
layer[-2:]
for layer_norm_name in layer_norm_candidates
for layer in flat_params.keys()
if layer_norm_name in "".join(layer).lower()
}
flat_mask = {path: (path[-1] != "bias" and path[-2:] not in layer_norm_named_params) for path in flat_params}
return traverse_util.unflatten_dict(flat_mask)
# create adam optimizer
adamw = optax.adamw(
learning_rate=linear_decay_lr_schedule_fn,
b1=training_args.adam_beta1,
b2=training_args.adam_beta2,
eps=training_args.adam_epsilon,
weight_decay=training_args.weight_decay,
mask=decay_mask_fn,
)
# Setup train state
state = TrainState.create(apply_fn=model.__call__, params=model.params, tx=adamw, dropout_rng=dropout_rng)
# label smoothed cross entropy
def loss_fn(logits, labels, padding_mask, label_smoothing_factor=0.0):
"""
The label smoothing implementation is adapted from Flax's official example:
https://github.com/google/flax/blob/87a211135c6a377c8f29048a1cac3840e38b9da4/examples/wmt/train.py#L104
"""
vocab_size = logits.shape[-1]
confidence = 1.0 - label_smoothing_factor
low_confidence = (1.0 - confidence) / (vocab_size - 1)
normalizing_constant = -(
confidence * jnp.log(confidence) + (vocab_size - 1) * low_confidence * jnp.log(low_confidence + 1e-20)
)
soft_labels = onehot(labels, vocab_size, on_value=confidence, off_value=low_confidence)
loss = optax.softmax_cross_entropy(logits, soft_labels)
loss = loss - normalizing_constant
# ignore padded tokens from loss
loss = loss * padding_mask
loss = loss.sum()
num_labels = padding_mask.sum()
return loss, num_labels
# Define gradient update step fn
def train_step(state, batch, label_smoothing_factor=0.0):
dropout_rng, new_dropout_rng = jax.random.split(state.dropout_rng)
def compute_loss(params):
labels = batch.pop("labels")
logits = state.apply_fn(**batch, params=params, dropout_rng=dropout_rng, train=True)[0]
loss, num_labels = loss_fn(logits, labels, batch["decoder_attention_mask"], label_smoothing_factor)
return loss, num_labels
grad_fn = jax.value_and_grad(compute_loss, has_aux=True)
(loss, num_labels), grad = grad_fn(state.params)
num_labels = jax.lax.psum(num_labels, "batch")
# true loss = total loss / total samples
loss = jax.lax.psum(loss, "batch")
loss = jax.tree_util.tree_map(lambda x: x / num_labels, loss)
# true grad = total grad / total samples
grad = jax.lax.psum(grad, "batch")
grad = jax.tree_util.tree_map(lambda x: x / num_labels, grad)
new_state = state.apply_gradients(grads=grad, dropout_rng=new_dropout_rng)
metrics = {"loss": loss, "learning_rate": linear_decay_lr_schedule_fn(state.step)}
return new_state, metrics
# Define eval fn
def eval_step(params, batch, label_smoothing_factor=0.0):
labels = batch.pop("labels")
logits = model(**batch, params=params, train=False)[0]
loss, num_labels = loss_fn(logits, labels, batch["decoder_attention_mask"], label_smoothing_factor)
num_labels = jax.lax.psum(num_labels, "batch")
# true loss = total loss / total samples
loss = jax.lax.psum(loss, "batch")
loss = jax.tree_util.tree_map(lambda x: x / num_labels, loss)
metrics = {"loss": loss}
return metrics
# Define generation function
max_length = (
data_args.val_max_target_length if data_args.val_max_target_length is not None else model.config.max_length
)
num_beams = data_args.num_beams if data_args.num_beams is not None else model.config.num_beams
gen_kwargs = {"max_length": max_length, "num_beams": num_beams}
def generate_step(params, batch):
model.params = params
output_ids = model.generate(batch["pixel_values"], **gen_kwargs)
return output_ids.sequences
# Create parallel version of the train and eval step
p_train_step = jax.pmap(
partial(train_step, label_smoothing_factor=training_args.label_smoothing_factor), "batch", donate_argnums=(0,)
)
p_eval_step = jax.pmap(partial(eval_step, label_smoothing_factor=training_args.label_smoothing_factor), "batch")
p_generate_step = jax.pmap(generate_step, "batch")
# Replicate the train state on each device
state = state.replicate()
if training_args.do_train:
logger.info("***** Running training *****")
logger.info(f" Num train examples = {num_train_examples_per_epoch}")
logger.info(f" Num Epochs = {num_epochs}")
logger.info(f" Instantaneous train batch size per device = {training_args.per_device_train_batch_size}")
logger.info(f" Total train batch size (w. parallel & distributed) = {train_batch_size}")
logger.info(f" Optimization steps per epoch = {steps_per_epoch}")
logger.info(f" Total optimization steps = {total_train_steps}")
if training_args.do_eval:
logger.info(f" Num evaluation examples = {num_eval_examples}")
logger.info(f" Instantaneous evaluation batch size per device = {training_args.per_device_eval_batch_size}")
logger.info(f" Total evaluation batch size (w. parallel & distributed) = {eval_batch_size}")
logger.info(f" Evaluation steps = {eval_steps}")
if training_args.do_predict:
logger.info(f" Num test examples = {num_test_examples}")
logger.info(f" Instantaneous test batch size per device = {training_args.per_device_eval_batch_size}")
logger.info(f" Total test batch size (w. parallel & distributed) = {eval_batch_size}")
logger.info(f" Test steps = {test_steps}")
# create output directory
if not os.path.isdir(os.path.join(training_args.output_dir)):
os.makedirs(os.path.join(training_args.output_dir), exist_ok=True)
def save_ckpt(ckpt_dir: str, commit_msg: str = ""):
"""save checkpoints and push to Hugging Face Hub if specified"""
# save checkpoint after each epoch and push checkpoint to the hub
if jax.process_index() == 0:
params = jax.device_get(jax.tree_util.tree_map(lambda x: x[0], state.params))
model.save_pretrained(os.path.join(training_args.output_dir, ckpt_dir), params=params)
tokenizer.save_pretrained(os.path.join(training_args.output_dir, ckpt_dir))
if training_args.push_to_hub:
api.upload_folder(
commit_message=commit_msg,
folder_path=training_args.output_dir,
repo_id=repo_id,
repo_type="model",
token=training_args.hub_token,
)
def evaluation_loop(
rng: jax.random.PRNGKey,
dataset: Dataset,
metric_key_prefix: str = "eval",
ckpt_dir: str = "",
is_prediction=False,
):
logger.info(f"*** {'Predict' if is_prediction else 'Evaluate'} ***")
metrics = []
preds = []
labels = []
batches = blockwise_data_loader(
rng,
dataset,
block_size=training_args.block_size,
batch_size=eval_batch_size,
keep_in_memory=False,
shuffle=False,
split="prediction" if is_prediction else "validation",
)
steps = len(dataset) // eval_batch_size
for _ in tqdm(
range(steps), desc=f"{'Predicting' if is_prediction else 'Evaluating'}...", position=2, leave=False
):
# Model forward
batch = next(batches)
_labels = batch.get("labels", None)
if not is_prediction and _labels is None:
raise ValueError("Evaluation requires the validation dataset to have `labels`")
if _labels is not None:
_metrics = p_eval_step(state.params, batch)
metrics.append(_metrics)
# generation
if data_args.predict_with_generate:
generated_ids = p_generate_step(state.params, batch)
preds.extend(jax.device_get(generated_ids.reshape(-1, gen_kwargs["max_length"])))
if _labels is not None:
labels.extend(jax.device_get(_labels.reshape(-1, _labels.shape[-1])))
if metrics:
# normalize metrics
metrics = get_metrics(metrics)
metrics = jax.tree_util.tree_map(jnp.mean, metrics)
# compute ROUGE metrics
generations = []
rouge_desc = ""
if data_args.predict_with_generate:
if labels:
rouge_metrics, decoded_preds, decoded_labels = compute_metrics(preds, labels)
metrics.update(rouge_metrics)
rouge_desc = " ".join(
[
f"{'Predict' if is_prediction else 'Eval'} {key}: {value} |"
for key, value in rouge_metrics.items()
]
)
for pred, label in zip(decoded_preds, decoded_labels):
pred = pred.replace("\n", " ")
label = label.replace("\n", " ")
generations.append({"label": label, "pred": pred})
else:
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
# Some simple post-processing
decoded_preds = [pred.strip() for pred in decoded_preds]
# rougeLSum expects newline after each sentence
decoded_preds = ["\n".join(nltk.sent_tokenize(pred)) for pred in decoded_preds]
for pred in decoded_preds:
pred = pred.replace("\n", " ")
generations.append({"pred": pred})
if metrics:
# Print metrics and update progress bar
desc = f"{'Predict' if is_prediction else 'Eval'} Loss: {metrics['loss']} | {rouge_desc})"
if training_args.do_train and not is_prediction:
desc = f"Epoch... ({epoch + 1}/{num_epochs} | Step: {cur_step} | " + desc
epochs.write(desc)
epochs.desc = desc
logger.info(desc)
if jax.process_index() == 0:
if not os.path.isdir(os.path.join(training_args.output_dir, ckpt_dir)):
os.makedirs(os.path.join(training_args.output_dir, ckpt_dir), exist_ok=True)
if metrics:
# Save metrics (only for the evaluation/prediction being done along with training)
if has_tensorboard and training_args.do_train:
write_metric(
summary_writer, metrics, train_time=None, step=cur_step, metric_key_prefix=metric_key_prefix
)
# save final metrics in json
metrics = {
f"{metric_key_prefix}_{metric_name}": round(value.item(), 6)
for metric_name, value in metrics.items()
}
_path = os.path.join(training_args.output_dir, ckpt_dir, f"{metric_key_prefix}_results.json")
with open(_path, "w") as f:
json.dump(metrics, f, indent=4, sort_keys=True)
# Update report
with open(os.path.join(training_args.output_dir, "log"), "a", encoding="UTF-8") as fp:
fp.write(desc + "\n")
# Save generations
if generations:
output_file = os.path.join(training_args.output_dir, ckpt_dir, f"{metric_key_prefix}_generation.json")
with open(output_file, "w", encoding="UTF-8") as fp:
json.dump(generations, fp, ensure_ascii=False, indent=4)
def evaluate(rng: jax.random.PRNGKey, dataset: Dataset, ckpt_dir: str = ""):
evaluation_loop(rng, dataset, metric_key_prefix="eval", ckpt_dir=ckpt_dir)
def predict(rng: jax.random.PRNGKey, dataset: Dataset):
evaluation_loop(rng, dataset, metric_key_prefix="test", is_prediction=True)
input_rng = None
if training_args.do_train:
cur_step = 0
train_time = 0
epochs = tqdm(range(num_epochs), desc=f"Epoch ... (1/{num_epochs})", position=0)
for epoch in epochs:
# ======================== Training ================================
# Create sampling rng
rng, input_rng = jax.random.split(rng)
train_metrics = []
train_batches = blockwise_data_loader(
input_rng,
train_dataset,
block_size=training_args.block_size,
batch_size=train_batch_size,
keep_in_memory=True,
shuffle=True,
split="train",
)
# train
for batch_idx, _ in enumerate(tqdm(range(steps_per_epoch), desc="Training...", position=1, leave=False)):
cur_step += 1
batch = next(train_batches)
batch_start = time.time()
state, train_metric = p_train_step(state, batch)
train_metrics.append(train_metric)
train_time += time.time() - batch_start
time_per_step = train_time / cur_step
# log and save info
if training_args.logging_steps > 0 and cur_step % training_args.logging_steps == 0:
_train_metric = unreplicate(train_metric)
desc = (
f"Epoch... ({epoch + 1}/{num_epochs} | Step: {cur_step} | Loss: {_train_metric['loss']} |"
f" Learning Rate: {_train_metric['learning_rate']} | Time per step: {time_per_step})"
)
epochs.desc = desc
epochs.write(desc)
logger.info(desc)
with open(os.path.join(training_args.output_dir, "log"), "a", encoding="UTF-8") as fp:
fp.write(desc + "\n")
# Save metrics
if has_tensorboard and jax.process_index() == 0:
write_metric(
summary_writer,
train_metrics,
train_time=train_time,
step=cur_step,
metric_key_prefix="train",
)
# ======================== Evaluating (inside an epoch) ==============================
if (
training_args.do_eval
and (training_args.eval_steps is not None and training_args.eval_steps > 0)
and cur_step % training_args.eval_steps == 0
):
ckpt_dir = f"ckpt_epoch_{epoch + 1}_step_{cur_step}"
commit_msg = f"Saving weights and logs of epoch {epoch + 1} - step {cur_step}"
evaluate(input_rng, eval_dataset, ckpt_dir)
save_ckpt(ckpt_dir=ckpt_dir, commit_msg=commit_msg)
# ======================== Epoch End ==============================
# log and save info
if training_args.logging_steps <= 0:
logger.info(desc)
with open(os.path.join(training_args.output_dir, "log"), "a", encoding="UTF-8") as fp:
fp.write(desc + "\n")
# Save metrics
if has_tensorboard and jax.process_index() == 0:
write_metric(
summary_writer, train_metrics, train_time=train_time, step=cur_step, metric_key_prefix="train"
)
# ======================== Evaluating (after each epoch) ==============================
if training_args.do_eval and (training_args.eval_steps is None or training_args.eval_steps <= 0):
ckpt_dir = f"ckpt_epoch_{epoch + 1}_step_{cur_step}"
commit_msg = f"Saving weights and logs of epoch {epoch + 1} - step {cur_step}"
evaluate(input_rng, eval_dataset, ckpt_dir)
save_ckpt(ckpt_dir=ckpt_dir, commit_msg=commit_msg)
# ======================== Evaluating | Predicting ==============================
# Create sampling rng
if input_rng is None:
rng, input_rng = jax.random.split(rng)
# run evaluation without training
if training_args.do_eval and not training_args.do_train:
evaluate(input_rng, eval_dataset)
# run prediction after (or without) training
if training_args.do_predict:
predict(input_rng, predict_dataset)
if __name__ == "__main__":
main()
| transformers/examples/flax/image-captioning/run_image_captioning_flax.py/0 | {
"file_path": "transformers/examples/flax/image-captioning/run_image_captioning_flax.py",
"repo_id": "transformers",
"token_count": 24575
} | 263 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2020 The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Benchmarking the library on inference and training """
from transformers import HfArgumentParser, PyTorchBenchmark, PyTorchBenchmarkArguments
def main():
parser = HfArgumentParser(PyTorchBenchmarkArguments)
try:
benchmark_args = parser.parse_args_into_dataclasses()[0]
except ValueError as e:
arg_error_msg = "Arg --no_{0} is no longer used, please use --no-{0} instead."
begin_error_msg = " ".join(str(e).split(" ")[:-1])
full_error_msg = ""
depreciated_args = eval(str(e).split(" ")[-1])
wrong_args = []
for arg in depreciated_args:
# arg[2:] removes '--'
if arg[2:] in PyTorchBenchmarkArguments.deprecated_args:
# arg[5:] removes '--no_'
full_error_msg += arg_error_msg.format(arg[5:])
else:
wrong_args.append(arg)
if len(wrong_args) > 0:
full_error_msg = full_error_msg + begin_error_msg + str(wrong_args)
raise ValueError(full_error_msg)
benchmark = PyTorchBenchmark(args=benchmark_args)
benchmark.run()
if __name__ == "__main__":
main()
| transformers/examples/legacy/benchmarking/run_benchmark.py/0 | {
"file_path": "transformers/examples/legacy/benchmarking/run_benchmark.py",
"repo_id": "transformers",
"token_count": 699
} | 264 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2018 Google AI, Google Brain and Carnegie Mellon University Authors and the HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" OpenAI GPT model fine-tuning script.
Adapted from https://github.com/huggingface/pytorch-openai-transformer-lm/blob/master/train.py
It self adapted from https://github.com/openai/finetune-transformer-lm/blob/master/train.py
This script with default values fine-tunes and evaluate a pretrained OpenAI GPT on the RocStories dataset:
python run_openai_gpt.py \
--model_name openai-community/openai-gpt \
--do_train \
--do_eval \
--train_dataset "$ROC_STORIES_DIR/cloze_test_val__spring2016 - cloze_test_ALL_val.csv" \
--eval_dataset "$ROC_STORIES_DIR/cloze_test_test__spring2016 - cloze_test_ALL_test.csv" \
--output_dir ../log \
--train_batch_size 16 \
"""
import argparse
import csv
import logging
import os
import random
import numpy as np
import torch
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler, TensorDataset
from tqdm import tqdm, trange
from transformers import (
CONFIG_NAME,
WEIGHTS_NAME,
AdamW,
OpenAIGPTDoubleHeadsModel,
OpenAIGPTTokenizer,
get_linear_schedule_with_warmup,
)
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s", datefmt="%m/%d/%Y %H:%M:%S", level=logging.INFO
)
logger = logging.getLogger(__name__)
def accuracy(out, labels):
outputs = np.argmax(out, axis=1)
return np.sum(outputs == labels)
def load_rocstories_dataset(dataset_path):
"""Output a list of tuples(story, 1st continuation, 2nd continuation, label)"""
with open(dataset_path, encoding="utf_8") as f:
f = csv.reader(f)
output = []
next(f) # skip the first line
for line in tqdm(f):
output.append((" ".join(line[1:5]), line[5], line[6], int(line[-1]) - 1))
return output
def pre_process_datasets(encoded_datasets, input_len, cap_length, start_token, delimiter_token, clf_token):
"""Pre-process datasets containing lists of tuples(story, 1st continuation, 2nd continuation, label)
To Transformer inputs of shape (n_batch, n_alternative, length) comprising for each batch, continuation:
input_ids[batch, alternative, :] = [start_token] + story[:cap_length] + [delimiter_token] + cont1[:cap_length] + [clf_token]
"""
tensor_datasets = []
for dataset in encoded_datasets:
n_batch = len(dataset)
input_ids = np.zeros((n_batch, 2, input_len), dtype=np.int64)
mc_token_ids = np.zeros((n_batch, 2), dtype=np.int64)
lm_labels = np.full((n_batch, 2, input_len), fill_value=-100, dtype=np.int64)
mc_labels = np.zeros((n_batch,), dtype=np.int64)
for (
i,
(story, cont1, cont2, mc_label),
) in enumerate(dataset):
with_cont1 = [start_token] + story[:cap_length] + [delimiter_token] + cont1[:cap_length] + [clf_token]
with_cont2 = [start_token] + story[:cap_length] + [delimiter_token] + cont2[:cap_length] + [clf_token]
input_ids[i, 0, : len(with_cont1)] = with_cont1
input_ids[i, 1, : len(with_cont2)] = with_cont2
mc_token_ids[i, 0] = len(with_cont1) - 1
mc_token_ids[i, 1] = len(with_cont2) - 1
lm_labels[i, 0, : len(with_cont1)] = with_cont1
lm_labels[i, 1, : len(with_cont2)] = with_cont2
mc_labels[i] = mc_label
all_inputs = (input_ids, mc_token_ids, lm_labels, mc_labels)
tensor_datasets.append(tuple(torch.tensor(t) for t in all_inputs))
return tensor_datasets
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--model_name", type=str, default="openai-community/openai-gpt", help="pretrained model name")
parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
parser.add_argument("--do_eval", action="store_true", help="Whether to run eval on the dev set.")
parser.add_argument(
"--output_dir",
default=None,
type=str,
required=True,
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument("--train_dataset", type=str, default="")
parser.add_argument("--eval_dataset", type=str, default="")
parser.add_argument("--seed", type=int, default=42)
parser.add_argument("--num_train_epochs", type=int, default=3)
parser.add_argument("--train_batch_size", type=int, default=8)
parser.add_argument("--eval_batch_size", type=int, default=16)
parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
parser.add_argument("--max_grad_norm", type=int, default=1)
parser.add_argument(
"--max_steps",
default=-1,
type=int,
help=(
"If > 0: set total number of training steps to perform. Override num_train_epochs."
),
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument("--learning_rate", type=float, default=6.25e-5)
parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
parser.add_argument("--lr_schedule", type=str, default="warmup_linear")
parser.add_argument("--weight_decay", type=float, default=0.01)
parser.add_argument("--lm_coef", type=float, default=0.9)
parser.add_argument("--n_valid", type=int, default=374)
parser.add_argument("--server_ip", type=str, default="", help="Can be used for distant debugging.")
parser.add_argument("--server_port", type=str, default="", help="Can be used for distant debugging.")
args = parser.parse_args()
print(args)
if args.server_ip and args.server_port:
# Distant debugging - see https://code.visualstudio.com/docs/python/debugging#_attach-to-a-local-script
import ptvsd
print("Waiting for debugger attach")
ptvsd.enable_attach(address=(args.server_ip, args.server_port), redirect_output=True)
ptvsd.wait_for_attach()
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
torch.cuda.manual_seed_all(args.seed)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
n_gpu = torch.cuda.device_count()
logger.info("device: {}, n_gpu {}".format(device, n_gpu))
if not args.do_train and not args.do_eval:
raise ValueError("At least one of `do_train` or `do_eval` must be True.")
if not os.path.exists(args.output_dir):
os.makedirs(args.output_dir)
# Load tokenizer and model
# This loading functions also add new tokens and embeddings called `special tokens`
# These new embeddings will be fine-tuned on the RocStories dataset
special_tokens = ["_start_", "_delimiter_", "_classify_"]
tokenizer = OpenAIGPTTokenizer.from_pretrained(args.model_name)
tokenizer.add_tokens(special_tokens)
special_tokens_ids = tokenizer.convert_tokens_to_ids(special_tokens)
model = OpenAIGPTDoubleHeadsModel.from_pretrained(args.model_name)
model.resize_token_embeddings(len(tokenizer))
model.to(device)
# Load and encode the datasets
def tokenize_and_encode(obj):
"""Tokenize and encode a nested object"""
if isinstance(obj, str):
return tokenizer.convert_tokens_to_ids(tokenizer.tokenize(obj))
elif isinstance(obj, int):
return obj
return [tokenize_and_encode(o) for o in obj]
logger.info("Encoding dataset...")
train_dataset = load_rocstories_dataset(args.train_dataset)
eval_dataset = load_rocstories_dataset(args.eval_dataset)
datasets = (train_dataset, eval_dataset)
encoded_datasets = tokenize_and_encode(datasets)
# Compute the max input length for the Transformer
max_length = model.config.n_positions // 2 - 2
input_length = max(
len(story[:max_length]) + max(len(cont1[:max_length]), len(cont2[:max_length])) + 3
for dataset in encoded_datasets
for story, cont1, cont2, _ in dataset
)
input_length = min(input_length, model.config.n_positions) # Max size of input for the pre-trained model
# Prepare inputs tensors and dataloaders
tensor_datasets = pre_process_datasets(encoded_datasets, input_length, max_length, *special_tokens_ids)
train_tensor_dataset, eval_tensor_dataset = tensor_datasets[0], tensor_datasets[1]
train_data = TensorDataset(*train_tensor_dataset)
train_sampler = RandomSampler(train_data)
train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=args.train_batch_size)
eval_data = TensorDataset(*eval_tensor_dataset)
eval_sampler = SequentialSampler(eval_data)
eval_dataloader = DataLoader(eval_data, sampler=eval_sampler, batch_size=args.eval_batch_size)
# Prepare optimizer
if args.do_train:
if args.max_steps > 0:
t_total = args.max_steps
args.num_train_epochs = args.max_steps // (len(train_dataloader) // args.gradient_accumulation_steps) + 1
else:
t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
param_optimizer = list(model.named_parameters())
no_decay = ["bias", "LayerNorm.bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)],
"weight_decay": args.weight_decay,
},
{"params": [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], "weight_decay": 0.0},
]
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
scheduler = get_linear_schedule_with_warmup(
optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total
)
if args.do_train:
nb_tr_steps, tr_loss, exp_average_loss = 0, 0, None
model.train()
for _ in trange(int(args.num_train_epochs), desc="Epoch"):
tr_loss = 0
nb_tr_steps = 0
tqdm_bar = tqdm(train_dataloader, desc="Training")
for step, batch in enumerate(tqdm_bar):
batch = tuple(t.to(device) for t in batch)
input_ids, mc_token_ids, lm_labels, mc_labels = batch
losses = model(input_ids, mc_token_ids=mc_token_ids, lm_labels=lm_labels, mc_labels=mc_labels)
loss = args.lm_coef * losses[0] + losses[1]
loss.backward()
optimizer.step()
scheduler.step()
optimizer.zero_grad()
tr_loss += loss.item()
exp_average_loss = (
loss.item() if exp_average_loss is None else 0.7 * exp_average_loss + 0.3 * loss.item()
)
nb_tr_steps += 1
tqdm_bar.desc = "Training loss: {:.2e} lr: {:.2e}".format(exp_average_loss, scheduler.get_lr()[0])
# Save a trained model
if args.do_train:
# Save a trained model, configuration and tokenizer
model_to_save = model.module if hasattr(model, "module") else model # Only save the model itself
# If we save using the predefined names, we can load using `from_pretrained`
output_model_file = os.path.join(args.output_dir, WEIGHTS_NAME)
output_config_file = os.path.join(args.output_dir, CONFIG_NAME)
torch.save(model_to_save.state_dict(), output_model_file)
model_to_save.config.to_json_file(output_config_file)
tokenizer.save_vocabulary(args.output_dir)
# Load a trained model and vocabulary that you have fine-tuned
model = OpenAIGPTDoubleHeadsModel.from_pretrained(args.output_dir)
tokenizer = OpenAIGPTTokenizer.from_pretrained(args.output_dir)
model.to(device)
if args.do_eval:
model.eval()
eval_loss, eval_accuracy = 0, 0
nb_eval_steps, nb_eval_examples = 0, 0
for batch in tqdm(eval_dataloader, desc="Evaluating"):
batch = tuple(t.to(device) for t in batch)
input_ids, mc_token_ids, lm_labels, mc_labels = batch
with torch.no_grad():
_, mc_loss, _, mc_logits = model(
input_ids, mc_token_ids=mc_token_ids, lm_labels=lm_labels, mc_labels=mc_labels
)
mc_logits = mc_logits.detach().cpu().numpy()
mc_labels = mc_labels.to("cpu").numpy()
tmp_eval_accuracy = accuracy(mc_logits, mc_labels)
eval_loss += mc_loss.mean().item()
eval_accuracy += tmp_eval_accuracy
nb_eval_examples += input_ids.size(0)
nb_eval_steps += 1
eval_loss = eval_loss / nb_eval_steps
eval_accuracy = eval_accuracy / nb_eval_examples
train_loss = tr_loss / nb_tr_steps if args.do_train else None
result = {"eval_loss": eval_loss, "eval_accuracy": eval_accuracy, "train_loss": train_loss}
output_eval_file = os.path.join(args.output_dir, "eval_results.txt")
with open(output_eval_file, "w") as writer:
logger.info("***** Eval results *****")
for key in sorted(result.keys()):
logger.info(" %s = %s", key, str(result[key]))
writer.write("%s = %s\n" % (key, str(result[key])))
if __name__ == "__main__":
main()
| transformers/examples/legacy/run_openai_gpt.py/0 | {
"file_path": "transformers/examples/legacy/run_openai_gpt.py",
"repo_id": "transformers",
"token_count": 6175
} | 265 |
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Fine-tuning the library models for named entity recognition on CoNLL-2003. """
import logging
import os
import sys
from dataclasses import dataclass, field
from importlib import import_module
from typing import Dict, List, Optional, Tuple
import numpy as np
from seqeval.metrics import accuracy_score, f1_score, precision_score, recall_score
from torch import nn
from utils_ner import Split, TokenClassificationDataset, TokenClassificationTask
import transformers
from transformers import (
AutoConfig,
AutoModelForTokenClassification,
AutoTokenizer,
DataCollatorWithPadding,
EvalPrediction,
HfArgumentParser,
Trainer,
TrainingArguments,
set_seed,
)
from transformers.trainer_utils import is_main_process
logger = logging.getLogger(__name__)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
task_type: Optional[str] = field(
default="NER", metadata={"help": "Task type to fine tune in training (e.g. NER, POS, etc)"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
use_fast: bool = field(default=False, metadata={"help": "Set this flag to use fast tokenization."})
# If you want to tweak more attributes on your tokenizer, you should do it in a distinct script,
# or just modify its tokenizer_config.json.
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
data_dir: str = field(
metadata={"help": "The input data dir. Should contain the .txt files for a CoNLL-2003-formatted task."}
)
labels: Optional[str] = field(
default=None,
metadata={"help": "Path to a file containing all labels. If not specified, CoNLL-2003 labels are used."},
)
max_seq_length: int = field(
default=128,
metadata={
"help": (
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
)
},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
if (
os.path.exists(training_args.output_dir)
and os.listdir(training_args.output_dir)
and training_args.do_train
and not training_args.overwrite_output_dir
):
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. Use"
" --overwrite_output_dir to overcome."
)
module = import_module("tasks")
try:
token_classification_task_clazz = getattr(module, model_args.task_type)
token_classification_task: TokenClassificationTask = token_classification_task_clazz()
except AttributeError:
raise ValueError(
f"Task {model_args.task_type} needs to be defined as a TokenClassificationTask subclass in {module}. "
f"Available tasks classes are: {TokenClassificationTask.__subclasses__()}"
)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO if training_args.local_rank in [-1, 0] else logging.WARN,
)
logger.warning(
"Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
training_args.local_rank,
training_args.device,
training_args.n_gpu,
bool(training_args.local_rank != -1),
training_args.fp16,
)
# Set the verbosity to info of the Transformers logger (on main process only):
if is_main_process(training_args.local_rank):
transformers.utils.logging.set_verbosity_info()
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
logger.info("Training/evaluation parameters %s", training_args)
# Set seed
set_seed(training_args.seed)
# Prepare CONLL-2003 task
labels = token_classification_task.get_labels(data_args.labels)
label_map: Dict[int, str] = dict(enumerate(labels))
num_labels = len(labels)
# Load pretrained model and tokenizer
#
# Distributed training:
# The .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
config = AutoConfig.from_pretrained(
model_args.config_name if model_args.config_name else model_args.model_name_or_path,
num_labels=num_labels,
id2label=label_map,
label2id={label: i for i, label in enumerate(labels)},
cache_dir=model_args.cache_dir,
)
tokenizer = AutoTokenizer.from_pretrained(
model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
use_fast=model_args.use_fast,
)
model = AutoModelForTokenClassification.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
)
# Get datasets
train_dataset = (
TokenClassificationDataset(
token_classification_task=token_classification_task,
data_dir=data_args.data_dir,
tokenizer=tokenizer,
labels=labels,
model_type=config.model_type,
max_seq_length=data_args.max_seq_length,
overwrite_cache=data_args.overwrite_cache,
mode=Split.train,
)
if training_args.do_train
else None
)
eval_dataset = (
TokenClassificationDataset(
token_classification_task=token_classification_task,
data_dir=data_args.data_dir,
tokenizer=tokenizer,
labels=labels,
model_type=config.model_type,
max_seq_length=data_args.max_seq_length,
overwrite_cache=data_args.overwrite_cache,
mode=Split.dev,
)
if training_args.do_eval
else None
)
def align_predictions(predictions: np.ndarray, label_ids: np.ndarray) -> Tuple[List[int], List[int]]:
preds = np.argmax(predictions, axis=2)
batch_size, seq_len = preds.shape
out_label_list = [[] for _ in range(batch_size)]
preds_list = [[] for _ in range(batch_size)]
for i in range(batch_size):
for j in range(seq_len):
if label_ids[i, j] != nn.CrossEntropyLoss().ignore_index:
out_label_list[i].append(label_map[label_ids[i][j]])
preds_list[i].append(label_map[preds[i][j]])
return preds_list, out_label_list
def compute_metrics(p: EvalPrediction) -> Dict:
preds_list, out_label_list = align_predictions(p.predictions, p.label_ids)
return {
"accuracy_score": accuracy_score(out_label_list, preds_list),
"precision": precision_score(out_label_list, preds_list),
"recall": recall_score(out_label_list, preds_list),
"f1": f1_score(out_label_list, preds_list),
}
# Data collator
data_collator = DataCollatorWithPadding(tokenizer, pad_to_multiple_of=8) if training_args.fp16 else None
# Initialize our Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
compute_metrics=compute_metrics,
data_collator=data_collator,
)
# Training
if training_args.do_train:
trainer.train(
model_path=model_args.model_name_or_path if os.path.isdir(model_args.model_name_or_path) else None
)
trainer.save_model()
# For convenience, we also re-save the tokenizer to the same directory,
# so that you can share your model easily on huggingface.co/models =)
if trainer.is_world_process_zero():
tokenizer.save_pretrained(training_args.output_dir)
# Evaluation
results = {}
if training_args.do_eval:
logger.info("*** Evaluate ***")
result = trainer.evaluate()
output_eval_file = os.path.join(training_args.output_dir, "eval_results.txt")
if trainer.is_world_process_zero():
with open(output_eval_file, "w") as writer:
logger.info("***** Eval results *****")
for key, value in result.items():
logger.info(" %s = %s", key, value)
writer.write("%s = %s\n" % (key, value))
results.update(result)
# Predict
if training_args.do_predict:
test_dataset = TokenClassificationDataset(
token_classification_task=token_classification_task,
data_dir=data_args.data_dir,
tokenizer=tokenizer,
labels=labels,
model_type=config.model_type,
max_seq_length=data_args.max_seq_length,
overwrite_cache=data_args.overwrite_cache,
mode=Split.test,
)
predictions, label_ids, metrics = trainer.predict(test_dataset)
preds_list, _ = align_predictions(predictions, label_ids)
output_test_results_file = os.path.join(training_args.output_dir, "test_results.txt")
if trainer.is_world_process_zero():
with open(output_test_results_file, "w") as writer:
for key, value in metrics.items():
logger.info(" %s = %s", key, value)
writer.write("%s = %s\n" % (key, value))
# Save predictions
output_test_predictions_file = os.path.join(training_args.output_dir, "test_predictions.txt")
if trainer.is_world_process_zero():
with open(output_test_predictions_file, "w") as writer:
with open(os.path.join(data_args.data_dir, "test.txt"), "r") as f:
token_classification_task.write_predictions_to_file(writer, f, preds_list)
return results
def _mp_fn(index):
# For xla_spawn (TPUs)
main()
if __name__ == "__main__":
main()
| transformers/examples/legacy/token-classification/run_ner.py/0 | {
"file_path": "transformers/examples/legacy/token-classification/run_ner.py",
"repo_id": "transformers",
"token_count": 5023
} | 266 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
import logging
import os
import sys
import warnings
from dataclasses import dataclass, field
from typing import Optional
import evaluate
import numpy as np
import torch
from datasets import load_dataset
from PIL import Image
from torchvision.transforms import (
CenterCrop,
Compose,
Lambda,
Normalize,
RandomHorizontalFlip,
RandomResizedCrop,
Resize,
ToTensor,
)
import transformers
from transformers import (
MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING,
AutoConfig,
AutoImageProcessor,
AutoModelForImageClassification,
HfArgumentParser,
Trainer,
TrainingArguments,
set_seed,
)
from transformers.trainer_utils import get_last_checkpoint
from transformers.utils import check_min_version, send_example_telemetry
from transformers.utils.versions import require_version
""" Fine-tuning a 🤗 Transformers model for image classification"""
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.40.0.dev0")
require_version("datasets>=2.14.0", "To fix: pip install -r examples/pytorch/image-classification/requirements.txt")
MODEL_CONFIG_CLASSES = list(MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING.keys())
MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
def pil_loader(path: str):
with open(path, "rb") as f:
im = Image.open(f)
return im.convert("RGB")
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
Using `HfArgumentParser` we can turn this class into argparse arguments to be able to specify
them on the command line.
"""
dataset_name: Optional[str] = field(
default=None,
metadata={
"help": "Name of a dataset from the hub (could be your own, possibly private dataset hosted on the hub)."
},
)
dataset_config_name: Optional[str] = field(
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
)
train_dir: Optional[str] = field(default=None, metadata={"help": "A folder containing the training data."})
validation_dir: Optional[str] = field(default=None, metadata={"help": "A folder containing the validation data."})
train_val_split: Optional[float] = field(
default=0.15, metadata={"help": "Percent to split off of train for validation."}
)
max_train_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
)
},
)
max_eval_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
"value if set."
)
},
)
image_column_name: str = field(
default="image",
metadata={"help": "The name of the dataset column containing the image data. Defaults to 'image'."},
)
label_column_name: str = field(
default="label",
metadata={"help": "The name of the dataset column containing the labels. Defaults to 'label'."},
)
def __post_init__(self):
if self.dataset_name is None and (self.train_dir is None and self.validation_dir is None):
raise ValueError(
"You must specify either a dataset name from the hub or a train and/or validation directory."
)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
default="google/vit-base-patch16-224-in21k",
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"},
)
model_type: Optional[str] = field(
default=None,
metadata={"help": "If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES)},
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None, metadata={"help": "Where do you want to store the pretrained models downloaded from s3"}
)
model_revision: str = field(
default="main",
metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
)
image_processor_name: str = field(default=None, metadata={"help": "Name or path of preprocessor config."})
token: str = field(
default=None,
metadata={
"help": (
"The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
"generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
)
},
)
use_auth_token: bool = field(
default=None,
metadata={
"help": "The `use_auth_token` argument is deprecated and will be removed in v4.34. Please use `token` instead."
},
)
trust_remote_code: bool = field(
default=False,
metadata={
"help": (
"Whether or not to allow for custom models defined on the Hub in their own modeling files. This option "
"should only be set to `True` for repositories you trust and in which you have read the code, as it will "
"execute code present on the Hub on your local machine."
)
},
)
ignore_mismatched_sizes: bool = field(
default=False,
metadata={"help": "Will enable to load a pretrained model whose head dimensions are different."},
)
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
if model_args.use_auth_token is not None:
warnings.warn(
"The `use_auth_token` argument is deprecated and will be removed in v4.34. Please use `token` instead.",
FutureWarning,
)
if model_args.token is not None:
raise ValueError("`token` and `use_auth_token` are both specified. Please set only the argument `token`.")
model_args.token = model_args.use_auth_token
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_image_classification", model_args, data_args)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
if training_args.should_log:
# The default of training_args.log_level is passive, so we set log level at info here to have that default.
transformers.utils.logging.set_verbosity_info()
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Log on each process the small summary:
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
)
logger.info(f"Training/evaluation parameters {training_args}")
# Detecting last checkpoint.
last_checkpoint = None
if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
last_checkpoint = get_last_checkpoint(training_args.output_dir)
if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
"Use --overwrite_output_dir to overcome."
)
elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
logger.info(
f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
"the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
)
# Set seed before initializing model.
set_seed(training_args.seed)
# Initialize our dataset and prepare it for the 'image-classification' task.
if data_args.dataset_name is not None:
dataset = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
cache_dir=model_args.cache_dir,
token=model_args.token,
)
else:
data_files = {}
if data_args.train_dir is not None:
data_files["train"] = os.path.join(data_args.train_dir, "**")
if data_args.validation_dir is not None:
data_files["validation"] = os.path.join(data_args.validation_dir, "**")
dataset = load_dataset(
"imagefolder",
data_files=data_files,
cache_dir=model_args.cache_dir,
)
dataset_column_names = dataset["train"].column_names if "train" in dataset else dataset["validation"].column_names
if data_args.image_column_name not in dataset_column_names:
raise ValueError(
f"--image_column_name {data_args.image_column_name} not found in dataset '{data_args.dataset_name}'. "
"Make sure to set `--image_column_name` to the correct audio column - one of "
f"{', '.join(dataset_column_names)}."
)
if data_args.label_column_name not in dataset_column_names:
raise ValueError(
f"--label_column_name {data_args.label_column_name} not found in dataset '{data_args.dataset_name}'. "
"Make sure to set `--label_column_name` to the correct text column - one of "
f"{', '.join(dataset_column_names)}."
)
def collate_fn(examples):
pixel_values = torch.stack([example["pixel_values"] for example in examples])
labels = torch.tensor([example[data_args.label_column_name] for example in examples])
return {"pixel_values": pixel_values, "labels": labels}
# If we don't have a validation split, split off a percentage of train as validation.
data_args.train_val_split = None if "validation" in dataset.keys() else data_args.train_val_split
if isinstance(data_args.train_val_split, float) and data_args.train_val_split > 0.0:
split = dataset["train"].train_test_split(data_args.train_val_split)
dataset["train"] = split["train"]
dataset["validation"] = split["test"]
# Prepare label mappings.
# We'll include these in the model's config to get human readable labels in the Inference API.
labels = dataset["train"].features[data_args.label_column_name].names
label2id, id2label = {}, {}
for i, label in enumerate(labels):
label2id[label] = str(i)
id2label[str(i)] = label
# Load the accuracy metric from the datasets package
metric = evaluate.load("accuracy", cache_dir=model_args.cache_dir)
# Define our compute_metrics function. It takes an `EvalPrediction` object (a namedtuple with a
# predictions and label_ids field) and has to return a dictionary string to float.
def compute_metrics(p):
"""Computes accuracy on a batch of predictions"""
return metric.compute(predictions=np.argmax(p.predictions, axis=1), references=p.label_ids)
config = AutoConfig.from_pretrained(
model_args.config_name or model_args.model_name_or_path,
num_labels=len(labels),
label2id=label2id,
id2label=id2label,
finetuning_task="image-classification",
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
model = AutoModelForImageClassification.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
ignore_mismatched_sizes=model_args.ignore_mismatched_sizes,
)
image_processor = AutoImageProcessor.from_pretrained(
model_args.image_processor_name or model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
# Define torchvision transforms to be applied to each image.
if "shortest_edge" in image_processor.size:
size = image_processor.size["shortest_edge"]
else:
size = (image_processor.size["height"], image_processor.size["width"])
normalize = (
Normalize(mean=image_processor.image_mean, std=image_processor.image_std)
if hasattr(image_processor, "image_mean") and hasattr(image_processor, "image_std")
else Lambda(lambda x: x)
)
_train_transforms = Compose(
[
RandomResizedCrop(size),
RandomHorizontalFlip(),
ToTensor(),
normalize,
]
)
_val_transforms = Compose(
[
Resize(size),
CenterCrop(size),
ToTensor(),
normalize,
]
)
def train_transforms(example_batch):
"""Apply _train_transforms across a batch."""
example_batch["pixel_values"] = [
_train_transforms(pil_img.convert("RGB")) for pil_img in example_batch[data_args.image_column_name]
]
return example_batch
def val_transforms(example_batch):
"""Apply _val_transforms across a batch."""
example_batch["pixel_values"] = [
_val_transforms(pil_img.convert("RGB")) for pil_img in example_batch[data_args.image_column_name]
]
return example_batch
if training_args.do_train:
if "train" not in dataset:
raise ValueError("--do_train requires a train dataset")
if data_args.max_train_samples is not None:
dataset["train"] = (
dataset["train"].shuffle(seed=training_args.seed).select(range(data_args.max_train_samples))
)
# Set the training transforms
dataset["train"].set_transform(train_transforms)
if training_args.do_eval:
if "validation" not in dataset:
raise ValueError("--do_eval requires a validation dataset")
if data_args.max_eval_samples is not None:
dataset["validation"] = (
dataset["validation"].shuffle(seed=training_args.seed).select(range(data_args.max_eval_samples))
)
# Set the validation transforms
dataset["validation"].set_transform(val_transforms)
# Initialize our trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset["train"] if training_args.do_train else None,
eval_dataset=dataset["validation"] if training_args.do_eval else None,
compute_metrics=compute_metrics,
tokenizer=image_processor,
data_collator=collate_fn,
)
# Training
if training_args.do_train:
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:
checkpoint = last_checkpoint
train_result = trainer.train(resume_from_checkpoint=checkpoint)
trainer.save_model()
trainer.log_metrics("train", train_result.metrics)
trainer.save_metrics("train", train_result.metrics)
trainer.save_state()
# Evaluation
if training_args.do_eval:
metrics = trainer.evaluate()
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
# Write model card and (optionally) push to hub
kwargs = {
"finetuned_from": model_args.model_name_or_path,
"tasks": "image-classification",
"dataset": data_args.dataset_name,
"tags": ["image-classification", "vision"],
}
if training_args.push_to_hub:
trainer.push_to_hub(**kwargs)
else:
trainer.create_model_card(**kwargs)
if __name__ == "__main__":
main()
| transformers/examples/pytorch/image-classification/run_image_classification.py/0 | {
"file_path": "transformers/examples/pytorch/image-classification/run_image_classification.py",
"repo_id": "transformers",
"token_count": 7153
} | 267 |
<!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Multiple Choice
## Fine-tuning on SWAG with the Trainer
`run_swag` allows you to fine-tune any model from our [hub](https://huggingface.co/models) (as long as its architecture as a `ForMultipleChoice` version in the library) on the SWAG dataset or your own csv/jsonlines files as long as they are structured the same way. To make it works on another dataset, you will need to tweak the `preprocess_function` inside the script.
```bash
python examples/multiple-choice/run_swag.py \
--model_name_or_path FacebookAI/roberta-base \
--do_train \
--do_eval \
--learning_rate 5e-5 \
--num_train_epochs 3 \
--output_dir /tmp/swag_base \
--per_device_eval_batch_size=16 \
--per_device_train_batch_size=16 \
--overwrite_output
```
Training with the defined hyper-parameters yields the following results:
```
***** Eval results *****
eval_acc = 0.8338998300509847
eval_loss = 0.44457291918821606
```
## With Accelerate
Based on the script [run_swag_no_trainer.py](https://github.com/huggingface/transformers/blob/main/examples/pytorch/multiple-choice/run_swag_no_trainer.py).
Like `run_swag.py`, this script allows you to fine-tune any of the models on the [hub](https://huggingface.co/models) (as long as its architecture as a `ForMultipleChoice` version in the library) on
the SWAG dataset or your own data in a csv or a JSON file. The main difference is that this
script exposes the bare training loop, to allow you to quickly experiment and add any customization you would like.
It offers less options than the script with `Trainer` (but you can easily change the options for the optimizer
or the dataloaders directly in the script) but still run in a distributed setup, on TPU and supports mixed precision by
the mean of the [🤗 `Accelerate`](https://github.com/huggingface/accelerate) library. You can use the script normally
after installing it:
```bash
pip install git+https://github.com/huggingface/accelerate
```
then
```bash
export DATASET_NAME=swag
python run_swag_no_trainer.py \
--model_name_or_path google-bert/bert-base-cased \
--dataset_name $DATASET_NAME \
--max_seq_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$DATASET_NAME/
```
You can then use your usual launchers to run in it in a distributed environment, but the easiest way is to run
```bash
accelerate config
```
and reply to the questions asked. Then
```bash
accelerate test
```
that will check everything is ready for training. Finally, you can launch training with
```bash
export DATASET_NAME=swag
accelerate launch run_swag_no_trainer.py \
--model_name_or_path google-bert/bert-base-cased \
--dataset_name $DATASET_NAME \
--max_seq_length 128 \
--per_device_train_batch_size 32 \
--learning_rate 2e-5 \
--num_train_epochs 3 \
--output_dir /tmp/$DATASET_NAME/
```
This command is the same and will work for:
- a CPU-only setup
- a setup with one GPU
- a distributed training with several GPUs (single or multi node)
- a training on TPUs
Note that this library is in alpha release so your feedback is more than welcome if you encounter any problem using it.
| transformers/examples/pytorch/multiple-choice/README.md/0 | {
"file_path": "transformers/examples/pytorch/multiple-choice/README.md",
"repo_id": "transformers",
"token_count": 1170
} | 268 |
<!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Semantic segmentation examples
This directory contains 2 scripts that showcase how to fine-tune any model supported by the [`AutoModelForSemanticSegmentation` API](https://huggingface.co/docs/transformers/main/en/model_doc/auto#transformers.AutoModelForSemanticSegmentation) (such as [SegFormer](https://huggingface.co/docs/transformers/main/en/model_doc/segformer), [BEiT](https://huggingface.co/docs/transformers/main/en/model_doc/beit), [DPT](https://huggingface.co/docs/transformers/main/en/model_doc/dpt)) using PyTorch.
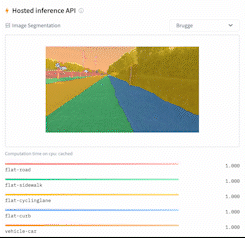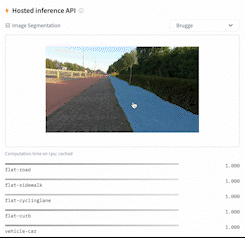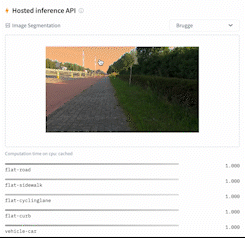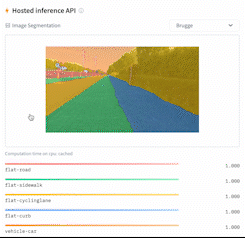
Content:
* [Note on custom data](#note-on-custom-data)
* [PyTorch version, Trainer](#pytorch-version-trainer)
* [PyTorch version, no Trainer](#pytorch-version-no-trainer)
* [Reload and perform inference](#reload-and-perform-inference)
* [Important notes](#important-notes)
## Note on custom data
In case you'd like to use the script with custom data, there are 2 things required: 1) creating a DatasetDict 2) creating an id2label mapping. Below, these are explained in more detail.
### Creating a `DatasetDict`
The script assumes that you have a `DatasetDict` with 2 columns, "image" and "label", both of type [Image](https://huggingface.co/docs/datasets/package_reference/main_classes#datasets.Image). This can be created as follows:
```python
from datasets import Dataset, DatasetDict, Image
# your images can of course have a different extension
# semantic segmentation maps are typically stored in the png format
image_paths_train = ["path/to/image_1.jpg/jpg", "path/to/image_2.jpg/jpg", ..., "path/to/image_n.jpg/jpg"]
label_paths_train = ["path/to/annotation_1.png", "path/to/annotation_2.png", ..., "path/to/annotation_n.png"]
# same for validation
# image_paths_validation = [...]
# label_paths_validation = [...]
def create_dataset(image_paths, label_paths):
dataset = Dataset.from_dict({"image": sorted(image_paths),
"label": sorted(label_paths)})
dataset = dataset.cast_column("image", Image())
dataset = dataset.cast_column("label", Image())
return dataset
# step 1: create Dataset objects
train_dataset = create_dataset(image_paths_train, label_paths_train)
validation_dataset = create_dataset(image_paths_validation, label_paths_validation)
# step 2: create DatasetDict
dataset = DatasetDict({
"train": train_dataset,
"validation": validation_dataset,
}
)
# step 3: push to hub (assumes you have ran the huggingface-cli login command in a terminal/notebook)
dataset.push_to_hub("name of repo on the hub")
# optionally, you can push to a private repo on the hub
# dataset.push_to_hub("name of repo on the hub", private=True)
```
An example of such a dataset can be seen at [nielsr/ade20k-demo](https://huggingface.co/datasets/nielsr/ade20k-demo).
### Creating an id2label mapping
Besides that, the script also assumes the existence of an `id2label.json` file in the repo, containing a mapping from integers to actual class names. An example of that can be seen [here](https://huggingface.co/datasets/nielsr/ade20k-demo/blob/main/id2label.json). This can be created in Python as follows:
```python
import json
# simple example
id2label = {0: 'cat', 1: 'dog'}
with open('id2label.json', 'w') as fp:
json.dump(id2label, fp)
```
You can easily upload this by clicking on "Add file" in the "Files and versions" tab of your repo on the hub.
## PyTorch version, Trainer
Based on the script [`run_semantic_segmentation.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py).
The script leverages the [🤗 Trainer API](https://huggingface.co/docs/transformers/main_classes/trainer) to automatically take care of the training for you, running on distributed environments right away.
Here we show how to fine-tune a [SegFormer](https://huggingface.co/nvidia/mit-b0) model on the [segments/sidewalk-semantic](https://huggingface.co/datasets/segments/sidewalk-semantic) dataset:
```bash
python run_semantic_segmentation.py \
--model_name_or_path nvidia/mit-b0 \
--dataset_name segments/sidewalk-semantic \
--output_dir ./segformer_outputs/ \
--remove_unused_columns False \
--do_train \
--do_eval \
--evaluation_strategy steps \
--push_to_hub \
--push_to_hub_model_id segformer-finetuned-sidewalk-10k-steps \
--max_steps 10000 \
--learning_rate 0.00006 \
--lr_scheduler_type polynomial \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--logging_strategy steps \
--logging_steps 100 \
--evaluation_strategy epoch \
--save_strategy epoch \
--seed 1337
```
The resulting model can be seen here: https://huggingface.co/nielsr/segformer-finetuned-sidewalk-10k-steps. The corresponding Weights and Biases report [here](https://wandb.ai/nielsrogge/huggingface/reports/SegFormer-fine-tuning--VmlldzoxODY5NTQ2). Note that it's always advised to check the original paper to know the details regarding training hyperparameters. E.g. from the SegFormer paper:
> We trained the models using AdamW optimizer for 160K iterations on ADE20K, Cityscapes, and 80K iterations on COCO-Stuff. (...) We used a batch size of 16 for ADE20K and COCO-Stuff, and a batch size of 8 for Cityscapes. The learning rate was set to an initial value of 0.00006 and then used a “poly” LR schedule with factor 1.0 by default.
Note that you can replace the model and dataset by simply setting the `model_name_or_path` and `dataset_name` arguments respectively, with any model or dataset from the [hub](https://huggingface.co/). For an overview of all possible arguments, we refer to the [docs](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments) of the `TrainingArguments`, which can be passed as flags.
## PyTorch version, no Trainer
Based on the script [`run_semantic_segmentation_no_trainer.py`](https://github.com/huggingface/transformers/blob/main/examples/pytorch/semantic-segmentation/run_semantic_segmentation.py).
The script leverages [🤗 `Accelerate`](https://github.com/huggingface/accelerate), which allows to write your own training loop in PyTorch, but have it run instantly on any (distributed) environment, including CPU, multi-CPU, GPU, multi-GPU and TPU. It also supports mixed precision.
First, run:
```bash
accelerate config
```
and reply to the questions asked regarding the environment on which you'd like to train. Then
```bash
accelerate test
```
that will check everything is ready for training. Finally, you can launch training with
```bash
accelerate launch run_semantic_segmentation_no_trainer.py --output_dir segformer-finetuned-sidewalk --with_tracking --push_to_hub
```
and boom, you're training, possibly on multiple GPUs, logging everything to all trackers found in your environment (like Weights and Biases, Tensorboard) and regularly pushing your model to the hub (with the repo name being equal to `args.output_dir` at your HF username) 🤗
With the default settings, the script fine-tunes a [SegFormer]((https://huggingface.co/docs/transformers/main/en/model_doc/segformer)) model on the [segments/sidewalk-semantic](https://huggingface.co/datasets/segments/sidewalk-semantic) dataset.
The resulting model can be seen here: https://huggingface.co/nielsr/segformer-finetuned-sidewalk. Note that the script usually requires quite a few epochs to achieve great results, e.g. the SegFormer authors fine-tuned their model for 160k steps (batches) on [`scene_parse_150`](https://huggingface.co/datasets/scene_parse_150).
## Reload and perform inference
This means that after training, you can easily load your trained model as follows:
```python
from transformers import AutoImageProcessor, AutoModelForSemanticSegmentation
model_name = "name_of_repo_on_the_hub_or_path_to_local_folder"
image_processor = AutoImageProcessor.from_pretrained(model_name)
model = AutoModelForSemanticSegmentation.from_pretrained(model_name)
```
and perform inference as follows:
```python
from PIL import Image
import requests
import torch
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# prepare image for the model
inputs = image_processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
# rescale logits to original image size
logits = nn.functional.interpolate(outputs.logits.detach().cpu(),
size=image.size[::-1], # (height, width)
mode='bilinear',
align_corners=False)
predicted = logits.argmax(1)
```
For visualization of the segmentation maps, we refer to the [example notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/SegFormer/Segformer_inference_notebook.ipynb).
## Important notes
Some datasets, like [`scene_parse_150`](https://huggingface.co/datasets/scene_parse_150), contain a "background" label that is not part of the classes. The Scene Parse 150 dataset for instance contains labels between 0 and 150, with 0 being the background class, and 1 to 150 being actual class names (like "tree", "person", etc.). For these kind of datasets, one replaces the background label (0) by 255, which is the `ignore_index` of the PyTorch model's loss function, and reduces all labels by 1. This way, the `labels` are PyTorch tensors containing values between 0 and 149, and 255 for all background/padding.
In case you're training on such a dataset, make sure to set the ``reduce_labels`` flag, which will take care of this.
| transformers/examples/pytorch/semantic-segmentation/README.md/0 | {
"file_path": "transformers/examples/pytorch/semantic-segmentation/README.md",
"repo_id": "transformers",
"token_count": 3408
} | 269 |
# coding=utf-8
# Copyright 2018 HuggingFace Inc..
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import json
import logging
import os
import shutil
import sys
import tempfile
import unittest
from unittest import mock
from accelerate.utils import write_basic_config
from transformers.testing_utils import (
TestCasePlus,
backend_device_count,
run_command,
slow,
torch_device,
)
logging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger()
def get_setup_file():
parser = argparse.ArgumentParser()
parser.add_argument("-f")
args = parser.parse_args()
return args.f
def get_results(output_dir):
results = {}
path = os.path.join(output_dir, "all_results.json")
if os.path.exists(path):
with open(path, "r") as f:
results = json.load(f)
else:
raise ValueError(f"can't find {path}")
return results
stream_handler = logging.StreamHandler(sys.stdout)
logger.addHandler(stream_handler)
class ExamplesTestsNoTrainer(TestCasePlus):
@classmethod
def setUpClass(cls):
# Write Accelerate config, will pick up on CPU, GPU, and multi-GPU
cls.tmpdir = tempfile.mkdtemp()
cls.configPath = os.path.join(cls.tmpdir, "default_config.yml")
write_basic_config(save_location=cls.configPath)
cls._launch_args = ["accelerate", "launch", "--config_file", cls.configPath]
@classmethod
def tearDownClass(cls):
shutil.rmtree(cls.tmpdir)
@mock.patch.dict(os.environ, {"WANDB_MODE": "offline", "DVCLIVE_TEST": "true"})
def test_run_glue_no_trainer(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
{self.examples_dir}/pytorch/text-classification/run_glue_no_trainer.py
--model_name_or_path distilbert/distilbert-base-uncased
--output_dir {tmp_dir}
--train_file ./tests/fixtures/tests_samples/MRPC/train.csv
--validation_file ./tests/fixtures/tests_samples/MRPC/dev.csv
--per_device_train_batch_size=2
--per_device_eval_batch_size=1
--learning_rate=1e-4
--seed=42
--num_warmup_steps=2
--checkpointing_steps epoch
--with_tracking
""".split()
run_command(self._launch_args + testargs)
result = get_results(tmp_dir)
self.assertGreaterEqual(result["eval_accuracy"], 0.75)
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "epoch_0")))
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "glue_no_trainer")))
@unittest.skip("Zach is working on this.")
@mock.patch.dict(os.environ, {"WANDB_MODE": "offline", "DVCLIVE_TEST": "true"})
def test_run_clm_no_trainer(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
{self.examples_dir}/pytorch/language-modeling/run_clm_no_trainer.py
--model_name_or_path distilbert/distilgpt2
--train_file ./tests/fixtures/sample_text.txt
--validation_file ./tests/fixtures/sample_text.txt
--block_size 128
--per_device_train_batch_size 5
--per_device_eval_batch_size 5
--num_train_epochs 2
--output_dir {tmp_dir}
--checkpointing_steps epoch
--with_tracking
""".split()
if backend_device_count(torch_device) > 1:
# Skipping because there are not enough batches to train the model + would need a drop_last to work.
return
run_command(self._launch_args + testargs)
result = get_results(tmp_dir)
self.assertLess(result["perplexity"], 100)
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "epoch_0")))
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "clm_no_trainer")))
@unittest.skip("Zach is working on this.")
@mock.patch.dict(os.environ, {"WANDB_MODE": "offline", "DVCLIVE_TEST": "true"})
def test_run_mlm_no_trainer(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
{self.examples_dir}/pytorch/language-modeling/run_mlm_no_trainer.py
--model_name_or_path distilbert/distilroberta-base
--train_file ./tests/fixtures/sample_text.txt
--validation_file ./tests/fixtures/sample_text.txt
--output_dir {tmp_dir}
--num_train_epochs=1
--checkpointing_steps epoch
--with_tracking
""".split()
run_command(self._launch_args + testargs)
result = get_results(tmp_dir)
self.assertLess(result["perplexity"], 42)
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "epoch_0")))
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "mlm_no_trainer")))
@mock.patch.dict(os.environ, {"WANDB_MODE": "offline", "DVCLIVE_TEST": "true"})
def test_run_ner_no_trainer(self):
# with so little data distributed training needs more epochs to get the score on par with 0/1 gpu
epochs = 7 if backend_device_count(torch_device) > 1 else 2
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
{self.examples_dir}/pytorch/token-classification/run_ner_no_trainer.py
--model_name_or_path google-bert/bert-base-uncased
--train_file tests/fixtures/tests_samples/conll/sample.json
--validation_file tests/fixtures/tests_samples/conll/sample.json
--output_dir {tmp_dir}
--learning_rate=2e-4
--per_device_train_batch_size=2
--per_device_eval_batch_size=2
--num_train_epochs={epochs}
--seed 7
--checkpointing_steps epoch
--with_tracking
""".split()
run_command(self._launch_args + testargs)
result = get_results(tmp_dir)
self.assertGreaterEqual(result["eval_accuracy"], 0.75)
self.assertLess(result["train_loss"], 0.6)
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "epoch_0")))
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "ner_no_trainer")))
@mock.patch.dict(os.environ, {"WANDB_MODE": "offline", "DVCLIVE_TEST": "true"})
def test_run_squad_no_trainer(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
{self.examples_dir}/pytorch/question-answering/run_qa_no_trainer.py
--model_name_or_path google-bert/bert-base-uncased
--version_2_with_negative
--train_file tests/fixtures/tests_samples/SQUAD/sample.json
--validation_file tests/fixtures/tests_samples/SQUAD/sample.json
--output_dir {tmp_dir}
--seed=42
--max_train_steps=10
--num_warmup_steps=2
--learning_rate=2e-4
--per_device_train_batch_size=2
--per_device_eval_batch_size=1
--checkpointing_steps epoch
--with_tracking
""".split()
run_command(self._launch_args + testargs)
result = get_results(tmp_dir)
# Because we use --version_2_with_negative the testing script uses SQuAD v2 metrics.
self.assertGreaterEqual(result["eval_f1"], 28)
self.assertGreaterEqual(result["eval_exact"], 28)
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "epoch_0")))
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "qa_no_trainer")))
@mock.patch.dict(os.environ, {"WANDB_MODE": "offline", "DVCLIVE_TEST": "true"})
def test_run_swag_no_trainer(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
{self.examples_dir}/pytorch/multiple-choice/run_swag_no_trainer.py
--model_name_or_path google-bert/bert-base-uncased
--train_file tests/fixtures/tests_samples/swag/sample.json
--validation_file tests/fixtures/tests_samples/swag/sample.json
--output_dir {tmp_dir}
--max_train_steps=20
--num_warmup_steps=2
--learning_rate=2e-4
--per_device_train_batch_size=2
--per_device_eval_batch_size=1
--with_tracking
""".split()
run_command(self._launch_args + testargs)
result = get_results(tmp_dir)
self.assertGreaterEqual(result["eval_accuracy"], 0.8)
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "swag_no_trainer")))
@slow
@mock.patch.dict(os.environ, {"WANDB_MODE": "offline", "DVCLIVE_TEST": "true"})
def test_run_summarization_no_trainer(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
{self.examples_dir}/pytorch/summarization/run_summarization_no_trainer.py
--model_name_or_path google-t5/t5-small
--train_file tests/fixtures/tests_samples/xsum/sample.json
--validation_file tests/fixtures/tests_samples/xsum/sample.json
--output_dir {tmp_dir}
--max_train_steps=50
--num_warmup_steps=8
--learning_rate=2e-4
--per_device_train_batch_size=2
--per_device_eval_batch_size=1
--checkpointing_steps epoch
--with_tracking
""".split()
run_command(self._launch_args + testargs)
result = get_results(tmp_dir)
self.assertGreaterEqual(result["eval_rouge1"], 10)
self.assertGreaterEqual(result["eval_rouge2"], 2)
self.assertGreaterEqual(result["eval_rougeL"], 7)
self.assertGreaterEqual(result["eval_rougeLsum"], 7)
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "epoch_0")))
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "summarization_no_trainer")))
@slow
@mock.patch.dict(os.environ, {"WANDB_MODE": "offline", "DVCLIVE_TEST": "true"})
def test_run_translation_no_trainer(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
{self.examples_dir}/pytorch/translation/run_translation_no_trainer.py
--model_name_or_path sshleifer/student_marian_en_ro_6_1
--source_lang en
--target_lang ro
--train_file tests/fixtures/tests_samples/wmt16/sample.json
--validation_file tests/fixtures/tests_samples/wmt16/sample.json
--output_dir {tmp_dir}
--max_train_steps=50
--num_warmup_steps=8
--num_beams=6
--learning_rate=3e-3
--per_device_train_batch_size=2
--per_device_eval_batch_size=1
--source_lang en_XX
--target_lang ro_RO
--checkpointing_steps epoch
--with_tracking
""".split()
run_command(self._launch_args + testargs)
result = get_results(tmp_dir)
self.assertGreaterEqual(result["eval_bleu"], 30)
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "epoch_0")))
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "translation_no_trainer")))
@slow
def test_run_semantic_segmentation_no_trainer(self):
stream_handler = logging.StreamHandler(sys.stdout)
logger.addHandler(stream_handler)
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
{self.examples_dir}/pytorch/semantic-segmentation/run_semantic_segmentation_no_trainer.py
--dataset_name huggingface/semantic-segmentation-test-sample
--output_dir {tmp_dir}
--max_train_steps=10
--num_warmup_steps=2
--learning_rate=2e-4
--per_device_train_batch_size=2
--per_device_eval_batch_size=1
--checkpointing_steps epoch
""".split()
run_command(self._launch_args + testargs)
result = get_results(tmp_dir)
self.assertGreaterEqual(result["eval_overall_accuracy"], 0.10)
@mock.patch.dict(os.environ, {"WANDB_MODE": "offline", "DVCLIVE_TEST": "true"})
def test_run_image_classification_no_trainer(self):
tmp_dir = self.get_auto_remove_tmp_dir()
testargs = f"""
{self.examples_dir}/pytorch/image-classification/run_image_classification_no_trainer.py
--model_name_or_path google/vit-base-patch16-224-in21k
--dataset_name hf-internal-testing/cats_vs_dogs_sample
--learning_rate 1e-4
--per_device_train_batch_size 2
--per_device_eval_batch_size 1
--max_train_steps 2
--train_val_split 0.1
--seed 42
--output_dir {tmp_dir}
--with_tracking
--checkpointing_steps 1
--label_column_name labels
""".split()
run_command(self._launch_args + testargs)
result = get_results(tmp_dir)
# The base model scores a 25%
self.assertGreaterEqual(result["eval_accuracy"], 0.4)
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "step_1")))
self.assertTrue(os.path.exists(os.path.join(tmp_dir, "image_classification_no_trainer")))
| transformers/examples/pytorch/test_accelerate_examples.py/0 | {
"file_path": "transformers/examples/pytorch/test_accelerate_examples.py",
"repo_id": "transformers",
"token_count": 6386
} | 270 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning a 🤗 Transformers model on token classification tasks (NER, POS, CHUNKS) relying on the accelerate library
without using a Trainer.
"""
import argparse
import json
import logging
import math
import os
import random
from pathlib import Path
import datasets
import evaluate
import numpy as np
import torch
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import set_seed
from datasets import ClassLabel, load_dataset
from huggingface_hub import HfApi
from torch.utils.data import DataLoader
from tqdm.auto import tqdm
import transformers
from transformers import (
CONFIG_MAPPING,
MODEL_MAPPING,
AutoConfig,
AutoModelForTokenClassification,
AutoTokenizer,
DataCollatorForTokenClassification,
PretrainedConfig,
SchedulerType,
default_data_collator,
get_scheduler,
)
from transformers.utils import check_min_version, send_example_telemetry
from transformers.utils.versions import require_version
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.40.0.dev0")
logger = get_logger(__name__)
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/token-classification/requirements.txt")
# You should update this to your particular problem to have better documentation of `model_type`
MODEL_CONFIG_CLASSES = list(MODEL_MAPPING.keys())
MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
def parse_args():
parser = argparse.ArgumentParser(
description="Finetune a transformers model on a text classification task (NER) with accelerate library"
)
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help="The name of the dataset to use (via the datasets library).",
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The configuration name of the dataset to use (via the datasets library).",
)
parser.add_argument(
"--train_file", type=str, default=None, help="A csv or a json file containing the training data."
)
parser.add_argument(
"--validation_file", type=str, default=None, help="A csv or a json file containing the validation data."
)
parser.add_argument(
"--text_column_name",
type=str,
default=None,
help="The column name of text to input in the file (a csv or JSON file).",
)
parser.add_argument(
"--label_column_name",
type=str,
default=None,
help="The column name of label to input in the file (a csv or JSON file).",
)
parser.add_argument(
"--max_length",
type=int,
default=128,
help=(
"The maximum total input sequence length after tokenization. Sequences longer than this will be truncated,"
" sequences shorter will be padded if `--pad_to_max_length` is passed."
),
)
parser.add_argument(
"--pad_to_max_length",
action="store_true",
help="If passed, pad all samples to `max_length`. Otherwise, dynamic padding is used.",
)
parser.add_argument(
"--model_name_or_path",
type=str,
help="Path to pretrained model or model identifier from huggingface.co/models.",
required=False,
)
parser.add_argument(
"--config_name",
type=str,
default=None,
help="Pretrained config name or path if not the same as model_name",
)
parser.add_argument(
"--tokenizer_name",
type=str,
default=None,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--per_device_train_batch_size",
type=int,
default=8,
help="Batch size (per device) for the training dataloader.",
)
parser.add_argument(
"--per_device_eval_batch_size",
type=int,
default=8,
help="Batch size (per device) for the evaluation dataloader.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=5e-5,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument("--weight_decay", type=float, default=0.0, help="Weight decay to use.")
parser.add_argument("--num_train_epochs", type=int, default=3, help="Total number of training epochs to perform.")
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--lr_scheduler_type",
type=SchedulerType,
default="linear",
help="The scheduler type to use.",
choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
)
parser.add_argument(
"--num_warmup_steps", type=int, default=0, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument("--output_dir", type=str, default=None, help="Where to store the final model.")
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
parser.add_argument(
"--model_type",
type=str,
default=None,
help="Model type to use if training from scratch.",
choices=MODEL_TYPES,
)
parser.add_argument(
"--label_all_tokens",
action="store_true",
help="Setting labels of all special tokens to -100 and thus PyTorch will ignore them.",
)
parser.add_argument(
"--return_entity_level_metrics",
action="store_true",
help="Indication whether entity level metrics are to be returner.",
)
parser.add_argument(
"--task_name",
type=str,
default="ner",
choices=["ner", "pos", "chunk"],
help="The name of the task.",
)
parser.add_argument(
"--debug",
action="store_true",
help="Activate debug mode and run training only with a subset of data.",
)
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument(
"--hub_model_id", type=str, help="The name of the repository to keep in sync with the local `output_dir`."
)
parser.add_argument("--hub_token", type=str, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--trust_remote_code",
type=bool,
default=False,
help=(
"Whether or not to allow for custom models defined on the Hub in their own modeling files. This option "
"should only be set to `True` for repositories you trust and in which you have read the code, as it will "
"execute code present on the Hub on your local machine."
),
)
parser.add_argument(
"--checkpointing_steps",
type=str,
default=None,
help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help="If the training should continue from a checkpoint folder.",
)
parser.add_argument(
"--with_tracking",
action="store_true",
help="Whether to enable experiment trackers for logging.",
)
parser.add_argument(
"--report_to",
type=str,
default="all",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`,'
' `"wandb"`, `"comet_ml"` and `"clearml"`. Use `"all"` (default) to report to all integrations. '
"Only applicable when `--with_tracking` is passed."
),
)
parser.add_argument(
"--ignore_mismatched_sizes",
action="store_true",
help="Whether or not to enable to load a pretrained model whose head dimensions are different.",
)
args = parser.parse_args()
# Sanity checks
if args.task_name is None and args.train_file is None and args.validation_file is None:
raise ValueError("Need either a task name or a training/validation file.")
else:
if args.train_file is not None:
extension = args.train_file.split(".")[-1]
assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
if args.validation_file is not None:
extension = args.validation_file.split(".")[-1]
assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
if args.push_to_hub:
assert args.output_dir is not None, "Need an `output_dir` to create a repo when `--push_to_hub` is passed."
return args
def main():
args = parse_args()
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_ner_no_trainer", args)
# Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
# If we're using tracking, we also need to initialize it here and it will by default pick up all supported trackers
# in the environment
accelerator = (
Accelerator(log_with=args.report_to, project_dir=args.output_dir) if args.with_tracking else Accelerator()
)
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.push_to_hub:
# Retrieve of infer repo_name
repo_name = args.hub_model_id
if repo_name is None:
repo_name = Path(args.output_dir).absolute().name
# Create repo and retrieve repo_id
api = HfApi()
repo_id = api.create_repo(repo_name, exist_ok=True, token=args.hub_token).repo_id
with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
if "step_*" not in gitignore:
gitignore.write("step_*\n")
if "epoch_*" not in gitignore:
gitignore.write("epoch_*\n")
elif args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
accelerator.wait_for_everyone()
# Get the datasets: you can either provide your own CSV/JSON/TXT training and evaluation files (see below)
# or just provide the name of one of the public datasets for token classification task available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For CSV/JSON files, this script will use the column called 'tokens' or the first column if no column called
# 'tokens' is found. You can easily tweak this behavior (see below).
#
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
# download the dataset.
if args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
raw_datasets = load_dataset(args.dataset_name, args.dataset_config_name)
else:
data_files = {}
if args.train_file is not None:
data_files["train"] = args.train_file
extension = args.train_file.split(".")[-1]
if args.validation_file is not None:
data_files["validation"] = args.validation_file
extension = args.validation_file.split(".")[-1]
raw_datasets = load_dataset(extension, data_files=data_files)
# Trim a number of training examples
if args.debug:
for split in raw_datasets.keys():
raw_datasets[split] = raw_datasets[split].select(range(100))
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# https://huggingface.co/docs/datasets/loading_datasets.
if raw_datasets["train"] is not None:
column_names = raw_datasets["train"].column_names
features = raw_datasets["train"].features
else:
column_names = raw_datasets["validation"].column_names
features = raw_datasets["validation"].features
if args.text_column_name is not None:
text_column_name = args.text_column_name
elif "tokens" in column_names:
text_column_name = "tokens"
else:
text_column_name = column_names[0]
if args.label_column_name is not None:
label_column_name = args.label_column_name
elif f"{args.task_name}_tags" in column_names:
label_column_name = f"{args.task_name}_tags"
else:
label_column_name = column_names[1]
# In the event the labels are not a `Sequence[ClassLabel]`, we will need to go through the dataset to get the
# unique labels.
def get_label_list(labels):
unique_labels = set()
for label in labels:
unique_labels = unique_labels | set(label)
label_list = list(unique_labels)
label_list.sort()
return label_list
# If the labels are of type ClassLabel, they are already integers and we have the map stored somewhere.
# Otherwise, we have to get the list of labels manually.
labels_are_int = isinstance(features[label_column_name].feature, ClassLabel)
if labels_are_int:
label_list = features[label_column_name].feature.names
label_to_id = {i: i for i in range(len(label_list))}
else:
label_list = get_label_list(raw_datasets["train"][label_column_name])
label_to_id = {l: i for i, l in enumerate(label_list)}
num_labels = len(label_list)
# Load pretrained model and tokenizer
#
# In distributed training, the .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
if args.config_name:
config = AutoConfig.from_pretrained(
args.config_name, num_labels=num_labels, trust_remote_code=args.trust_remote_code
)
elif args.model_name_or_path:
config = AutoConfig.from_pretrained(
args.model_name_or_path, num_labels=num_labels, trust_remote_code=args.trust_remote_code
)
else:
config = CONFIG_MAPPING[args.model_type]()
logger.warning("You are instantiating a new config instance from scratch.")
tokenizer_name_or_path = args.tokenizer_name if args.tokenizer_name else args.model_name_or_path
if not tokenizer_name_or_path:
raise ValueError(
"You are instantiating a new tokenizer from scratch. This is not supported by this script. "
"You can do it from another script, save it, and load it from here, using --tokenizer_name."
)
if config.model_type in {"bloom", "gpt2", "roberta"}:
tokenizer = AutoTokenizer.from_pretrained(
tokenizer_name_or_path, use_fast=True, add_prefix_space=True, trust_remote_code=args.trust_remote_code
)
else:
tokenizer = AutoTokenizer.from_pretrained(
tokenizer_name_or_path, use_fast=True, trust_remote_code=args.trust_remote_code
)
if args.model_name_or_path:
model = AutoModelForTokenClassification.from_pretrained(
args.model_name_or_path,
from_tf=bool(".ckpt" in args.model_name_or_path),
config=config,
ignore_mismatched_sizes=args.ignore_mismatched_sizes,
trust_remote_code=args.trust_remote_code,
)
else:
logger.info("Training new model from scratch")
model = AutoModelForTokenClassification.from_config(config, trust_remote_code=args.trust_remote_code)
# We resize the embeddings only when necessary to avoid index errors. If you are creating a model from scratch
# on a small vocab and want a smaller embedding size, remove this test.
embedding_size = model.get_input_embeddings().weight.shape[0]
if len(tokenizer) > embedding_size:
embedding_size = model.get_input_embeddings().weight.shape[0]
if len(tokenizer) > embedding_size:
model.resize_token_embeddings(len(tokenizer))
# Model has labels -> use them.
if model.config.label2id != PretrainedConfig(num_labels=num_labels).label2id:
if sorted(model.config.label2id.keys()) == sorted(label_list):
# Reorganize `label_list` to match the ordering of the model.
if labels_are_int:
label_to_id = {i: int(model.config.label2id[l]) for i, l in enumerate(label_list)}
label_list = [model.config.id2label[i] for i in range(num_labels)]
else:
label_list = [model.config.id2label[i] for i in range(num_labels)]
label_to_id = {l: i for i, l in enumerate(label_list)}
else:
logger.warning(
"Your model seems to have been trained with labels, but they don't match the dataset: ",
f"model labels: {sorted(model.config.label2id.keys())}, dataset labels:"
f" {sorted(label_list)}.\nIgnoring the model labels as a result.",
)
# Set the correspondences label/ID inside the model config
model.config.label2id = {l: i for i, l in enumerate(label_list)}
model.config.id2label = dict(enumerate(label_list))
# Map that sends B-Xxx label to its I-Xxx counterpart
b_to_i_label = []
for idx, label in enumerate(label_list):
if label.startswith("B-") and label.replace("B-", "I-") in label_list:
b_to_i_label.append(label_list.index(label.replace("B-", "I-")))
else:
b_to_i_label.append(idx)
# Preprocessing the datasets.
# First we tokenize all the texts.
padding = "max_length" if args.pad_to_max_length else False
# Tokenize all texts and align the labels with them.
def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(
examples[text_column_name],
max_length=args.max_length,
padding=padding,
truncation=True,
# We use this argument because the texts in our dataset are lists of words (with a label for each word).
is_split_into_words=True,
)
labels = []
for i, label in enumerate(examples[label_column_name]):
word_ids = tokenized_inputs.word_ids(batch_index=i)
previous_word_idx = None
label_ids = []
for word_idx in word_ids:
# Special tokens have a word id that is None. We set the label to -100 so they are automatically
# ignored in the loss function.
if word_idx is None:
label_ids.append(-100)
# We set the label for the first token of each word.
elif word_idx != previous_word_idx:
label_ids.append(label_to_id[label[word_idx]])
# For the other tokens in a word, we set the label to either the current label or -100, depending on
# the label_all_tokens flag.
else:
if args.label_all_tokens:
label_ids.append(b_to_i_label[label_to_id[label[word_idx]]])
else:
label_ids.append(-100)
previous_word_idx = word_idx
labels.append(label_ids)
tokenized_inputs["labels"] = labels
return tokenized_inputs
with accelerator.main_process_first():
processed_raw_datasets = raw_datasets.map(
tokenize_and_align_labels,
batched=True,
remove_columns=raw_datasets["train"].column_names,
desc="Running tokenizer on dataset",
)
train_dataset = processed_raw_datasets["train"]
eval_dataset = processed_raw_datasets["validation"]
# Log a few random samples from the training set:
for index in random.sample(range(len(train_dataset)), 3):
logger.info(f"Sample {index} of the training set: {train_dataset[index]}.")
# DataLoaders creation:
if args.pad_to_max_length:
# If padding was already done ot max length, we use the default data collator that will just convert everything
# to tensors.
data_collator = default_data_collator
else:
# Otherwise, `DataCollatorForTokenClassification` will apply dynamic padding for us (by padding to the maximum length of
# the samples passed). When using mixed precision, we add `pad_to_multiple_of=8` to pad all tensors to multiple
# of 8s, which will enable the use of Tensor Cores on NVIDIA hardware with compute capability >= 7.5 (Volta).
data_collator = DataCollatorForTokenClassification(
tokenizer, pad_to_multiple_of=(8 if accelerator.use_fp16 else None)
)
train_dataloader = DataLoader(
train_dataset, shuffle=True, collate_fn=data_collator, batch_size=args.per_device_train_batch_size
)
eval_dataloader = DataLoader(eval_dataset, collate_fn=data_collator, batch_size=args.per_device_eval_batch_size)
# Optimizer
# Split weights in two groups, one with weight decay and the other not.
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": args.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
# Use the device given by the `accelerator` object.
device = accelerator.device
model.to(device)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
num_warmup_steps=args.num_warmup_steps,
num_training_steps=args.max_train_steps,
)
# Prepare everything with our `accelerator`.
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler
)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# Figure out how many steps we should save the Accelerator states
checkpointing_steps = args.checkpointing_steps
if checkpointing_steps is not None and checkpointing_steps.isdigit():
checkpointing_steps = int(checkpointing_steps)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if args.with_tracking:
experiment_config = vars(args)
# TensorBoard cannot log Enums, need the raw value
experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
accelerator.init_trackers("ner_no_trainer", experiment_config)
# Metrics
metric = evaluate.load("seqeval")
def get_labels(predictions, references):
# Transform predictions and references tensos to numpy arrays
if device.type == "cpu":
y_pred = predictions.detach().clone().numpy()
y_true = references.detach().clone().numpy()
else:
y_pred = predictions.detach().cpu().clone().numpy()
y_true = references.detach().cpu().clone().numpy()
# Remove ignored index (special tokens)
true_predictions = [
[label_list[p] for (p, l) in zip(pred, gold_label) if l != -100]
for pred, gold_label in zip(y_pred, y_true)
]
true_labels = [
[label_list[l] for (p, l) in zip(pred, gold_label) if l != -100]
for pred, gold_label in zip(y_pred, y_true)
]
return true_predictions, true_labels
def compute_metrics():
results = metric.compute()
if args.return_entity_level_metrics:
# Unpack nested dictionaries
final_results = {}
for key, value in results.items():
if isinstance(value, dict):
for n, v in value.items():
final_results[f"{key}_{n}"] = v
else:
final_results[key] = value
return final_results
else:
return {
"precision": results["overall_precision"],
"recall": results["overall_recall"],
"f1": results["overall_f1"],
"accuracy": results["overall_accuracy"],
}
# Train!
total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
# Only show the progress bar once on each machine.
progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
completed_steps = 0
starting_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "":
checkpoint_path = args.resume_from_checkpoint
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()]
dirs.sort(key=os.path.getctime)
path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last
checkpoint_path = path
path = os.path.basename(checkpoint_path)
accelerator.print(f"Resumed from checkpoint: {checkpoint_path}")
accelerator.load_state(checkpoint_path)
# Extract `epoch_{i}` or `step_{i}`
training_difference = os.path.splitext(path)[0]
if "epoch" in training_difference:
starting_epoch = int(training_difference.replace("epoch_", "")) + 1
resume_step = None
completed_steps = starting_epoch * num_update_steps_per_epoch
else:
# need to multiply `gradient_accumulation_steps` to reflect real steps
resume_step = int(training_difference.replace("step_", "")) * args.gradient_accumulation_steps
starting_epoch = resume_step // len(train_dataloader)
completed_steps = resume_step // args.gradient_accumulation_steps
resume_step -= starting_epoch * len(train_dataloader)
# update the progress_bar if load from checkpoint
progress_bar.update(completed_steps)
for epoch in range(starting_epoch, args.num_train_epochs):
model.train()
if args.with_tracking:
total_loss = 0
if args.resume_from_checkpoint and epoch == starting_epoch and resume_step is not None:
# We skip the first `n` batches in the dataloader when resuming from a checkpoint
active_dataloader = accelerator.skip_first_batches(train_dataloader, resume_step)
else:
active_dataloader = train_dataloader
for step, batch in enumerate(active_dataloader):
outputs = model(**batch)
loss = outputs.loss
# We keep track of the loss at each epoch
if args.with_tracking:
total_loss += loss.detach().float()
loss = loss / args.gradient_accumulation_steps
accelerator.backward(loss)
if step % args.gradient_accumulation_steps == 0 or step == len(train_dataloader) - 1:
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
completed_steps += 1
if isinstance(checkpointing_steps, int):
if completed_steps % checkpointing_steps == 0:
output_dir = f"step_{completed_steps}"
if args.output_dir is not None:
output_dir = os.path.join(args.output_dir, output_dir)
accelerator.save_state(output_dir)
if completed_steps >= args.max_train_steps:
break
model.eval()
samples_seen = 0
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
outputs = model(**batch)
predictions = outputs.logits.argmax(dim=-1)
labels = batch["labels"]
if not args.pad_to_max_length: # necessary to pad predictions and labels for being gathered
predictions = accelerator.pad_across_processes(predictions, dim=1, pad_index=-100)
labels = accelerator.pad_across_processes(labels, dim=1, pad_index=-100)
predictions_gathered, labels_gathered = accelerator.gather((predictions, labels))
# If we are in a multiprocess environment, the last batch has duplicates
if accelerator.num_processes > 1:
if step == len(eval_dataloader) - 1:
predictions_gathered = predictions_gathered[: len(eval_dataloader.dataset) - samples_seen]
labels_gathered = labels_gathered[: len(eval_dataloader.dataset) - samples_seen]
else:
samples_seen += labels_gathered.shape[0]
preds, refs = get_labels(predictions_gathered, labels_gathered)
metric.add_batch(
predictions=preds,
references=refs,
) # predictions and preferences are expected to be a nested list of labels, not label_ids
eval_metric = compute_metrics()
accelerator.print(f"epoch {epoch}:", eval_metric)
if args.with_tracking:
accelerator.log(
{
"seqeval": eval_metric,
"train_loss": total_loss.item() / len(train_dataloader),
"epoch": epoch,
"step": completed_steps,
},
step=completed_steps,
)
if args.push_to_hub and epoch < args.num_train_epochs - 1:
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(
args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
)
if accelerator.is_main_process:
tokenizer.save_pretrained(args.output_dir)
api.upload_folder(
commit_message=f"Training in progress epoch {epoch}",
folder_path=args.output_dir,
repo_id=repo_id,
repo_type="model",
token=args.hub_token,
)
if args.checkpointing_steps == "epoch":
output_dir = f"epoch_{epoch}"
if args.output_dir is not None:
output_dir = os.path.join(args.output_dir, output_dir)
accelerator.save_state(output_dir)
if args.with_tracking:
accelerator.end_training()
if args.output_dir is not None:
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(
args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
)
if accelerator.is_main_process:
tokenizer.save_pretrained(args.output_dir)
if args.push_to_hub:
api.upload_folder(
commit_message="End of training",
folder_path=args.output_dir,
repo_id=repo_id,
repo_type="model",
token=args.hub_token,
)
all_results = {f"eval_{k}": v for k, v in eval_metric.items()}
if args.with_tracking:
all_results.update({"train_loss": total_loss.item() / len(train_dataloader)})
with open(os.path.join(args.output_dir, "all_results.json"), "w") as f:
# Convert all float64 & int64 type numbers to float & int for json serialization
for key, value in all_results.items():
if isinstance(value, np.float64):
all_results[key] = float(value)
elif isinstance(value, np.int64):
all_results[key] = int(value)
json.dump(all_results, f)
if __name__ == "__main__":
main()
| transformers/examples/pytorch/token-classification/run_ner_no_trainer.py/0 | {
"file_path": "transformers/examples/pytorch/token-classification/run_ner_no_trainer.py",
"repo_id": "transformers",
"token_count": 14931
} | 271 |
# Examples
In this folder we showcase some examples to use code models for downstream tasks.
## Complexity prediction
In this task we want to predict the complexity of Java programs in [CodeComplex](https://huggingface.co/datasets/codeparrot/codecomplex) dataset. Using Hugging Face `trainer`, we finetuned [multilingual CodeParrot](https://huggingface.co/codeparrot/codeparrot-small-multi) and [UniXcoder](https://huggingface.co/microsoft/unixcoder-base-nine) on it, and we used the latter to build this Java complexity prediction [space](https://huggingface.co/spaces/codeparrot/code-complexity-predictor) on Hugging Face hub.
To fine-tune a model on this dataset you can use the following commands:
```python
python train_complexity_predictor.py \
--model_ckpt microsoft/unixcoder-base-nine \
--num_epochs 60 \
--num_warmup_steps 10 \
--batch_size 8 \
--learning_rate 5e-4
```
## Code generation: text to python
In this task we want to train a model to generate code from english text. We finetuned Codeparrot-small on [github-jupyter-text-to-code](https://huggingface.co/datasets/codeparrot/github-jupyter-text-to-code), a dataset where the samples are a succession of docstrings and their Python code, originally extracted from Jupyter notebooks parsed in this [dataset](https://huggingface.co/datasets/codeparrot/github-jupyter-parsed).
To fine-tune a model on this dataset we use the same [script](https://github.com/huggingface/transformers/blob/main/examples/research_projects/codeparrot/scripts/codeparrot_training.py) as the pretraining of codeparrot:
```python
accelerate launch scripts/codeparrot_training.py \
--model_ckpt codeparrot/codeparrot-small \
--dataset_name_train codeparrot/github-jupyter-text-to-code \
--dataset_name_valid codeparrot/github-jupyter-text-to-code \
--train_batch_size 12 \
--valid_batch_size 12 \
--learning_rate 5e-4 \
--num_warmup_steps 100 \
--gradient_accumulation 1 \
--gradient_checkpointing False \
--max_train_steps 3000 \
--save_checkpoint_steps 200 \
--save_dir jupyter-text-to-python
```
## Code explanation: python to text
In this task we want to train a model to explain python code. We finetuned Codeparrot-small on [github-jupyter-code-to-text](https://huggingface.co/datasets/codeparrot/github-jupyter-code-to-text), a dataset where the samples are a succession of Python code and its explanation as a docstring, we just inverted the order of text and code pairs in github-jupyter-code-to-text dataset and added the delimiters "Explanation:" and "End of explanation" inside the doctrings.
To fine-tune a model on this dataset we use the same [script](https://github.com/huggingface/transformers/blob/main/examples/research_projects/codeparrot/scripts/codeparrot_training.py) as the pretraining of codeparrot:
```python
accelerate launch scripts/codeparrot_training.py \
--model_ckpt codeparrot/codeparrot-small \
--dataset_name_train codeparrot/github-jupyter-code-to-text \
--dataset_name_valid codeparrot/github-jupyter-code-to-text \
--train_batch_size 12 \
--valid_batch_size 12 \
--learning_rate 5e-4 \
--num_warmup_steps 100 \
--gradient_accumulation 1 \
--gradient_checkpointing False \
--max_train_steps 3000 \
--save_checkpoint_steps 200 \
--save_dir jupyter-python-to-text
``` | transformers/examples/research_projects/codeparrot/examples/README.md/0 | {
"file_path": "transformers/examples/research_projects/codeparrot/examples/README.md",
"repo_id": "transformers",
"token_count": 1170
} | 272 |
import gym
import numpy as np
import torch
from mujoco_py import GlfwContext
from transformers import DecisionTransformerModel
GlfwContext(offscreen=True) # Create a window to init GLFW.
def get_action(model, states, actions, rewards, returns_to_go, timesteps):
# we don't care about the past rewards in this model
states = states.reshape(1, -1, model.config.state_dim)
actions = actions.reshape(1, -1, model.config.act_dim)
returns_to_go = returns_to_go.reshape(1, -1, 1)
timesteps = timesteps.reshape(1, -1)
if model.config.max_length is not None:
states = states[:, -model.config.max_length :]
actions = actions[:, -model.config.max_length :]
returns_to_go = returns_to_go[:, -model.config.max_length :]
timesteps = timesteps[:, -model.config.max_length :]
# pad all tokens to sequence length
attention_mask = torch.cat(
[torch.zeros(model.config.max_length - states.shape[1]), torch.ones(states.shape[1])]
)
attention_mask = attention_mask.to(dtype=torch.long, device=states.device).reshape(1, -1)
states = torch.cat(
[
torch.zeros(
(states.shape[0], model.config.max_length - states.shape[1], model.config.state_dim),
device=states.device,
),
states,
],
dim=1,
).to(dtype=torch.float32)
actions = torch.cat(
[
torch.zeros(
(actions.shape[0], model.config.max_length - actions.shape[1], model.config.act_dim),
device=actions.device,
),
actions,
],
dim=1,
).to(dtype=torch.float32)
returns_to_go = torch.cat(
[
torch.zeros(
(returns_to_go.shape[0], model.config.max_length - returns_to_go.shape[1], 1),
device=returns_to_go.device,
),
returns_to_go,
],
dim=1,
).to(dtype=torch.float32)
timesteps = torch.cat(
[
torch.zeros(
(timesteps.shape[0], model.config.max_length - timesteps.shape[1]), device=timesteps.device
),
timesteps,
],
dim=1,
).to(dtype=torch.long)
else:
attention_mask = None
_, action_preds, _ = model(
states=states,
actions=actions,
rewards=rewards,
returns_to_go=returns_to_go,
timesteps=timesteps,
attention_mask=attention_mask,
return_dict=False,
)
return action_preds[0, -1]
# build the environment
env = gym.make("Hopper-v3")
state_dim = env.observation_space.shape[0]
act_dim = env.action_space.shape[0]
max_ep_len = 1000
device = "cuda"
scale = 1000.0 # normalization for rewards/returns
TARGET_RETURN = 3600 / scale # evaluation conditioning targets, 3600 is reasonable from the paper LINK
state_mean = np.array(
[
1.311279,
-0.08469521,
-0.5382719,
-0.07201576,
0.04932366,
2.1066856,
-0.15017354,
0.00878345,
-0.2848186,
-0.18540096,
-0.28461286,
]
)
state_std = np.array(
[
0.17790751,
0.05444621,
0.21297139,
0.14530419,
0.6124444,
0.85174465,
1.4515252,
0.6751696,
1.536239,
1.6160746,
5.6072536,
]
)
state_mean = torch.from_numpy(state_mean).to(device=device)
state_std = torch.from_numpy(state_std).to(device=device)
# Create the decision transformer model
model = DecisionTransformerModel.from_pretrained("edbeeching/decision-transformer-gym-hopper-medium")
model = model.to(device)
model.eval()
for ep in range(10):
episode_return, episode_length = 0, 0
state = env.reset()
target_return = torch.tensor(TARGET_RETURN, device=device, dtype=torch.float32).reshape(1, 1)
states = torch.from_numpy(state).reshape(1, state_dim).to(device=device, dtype=torch.float32)
actions = torch.zeros((0, act_dim), device=device, dtype=torch.float32)
rewards = torch.zeros(0, device=device, dtype=torch.float32)
timesteps = torch.tensor(0, device=device, dtype=torch.long).reshape(1, 1)
for t in range(max_ep_len):
env.render()
# add padding
actions = torch.cat([actions, torch.zeros((1, act_dim), device=device)], dim=0)
rewards = torch.cat([rewards, torch.zeros(1, device=device)])
action = get_action(
model,
(states.to(dtype=torch.float32) - state_mean) / state_std,
actions.to(dtype=torch.float32),
rewards.to(dtype=torch.float32),
target_return.to(dtype=torch.float32),
timesteps.to(dtype=torch.long),
)
actions[-1] = action
action = action.detach().cpu().numpy()
state, reward, done, _ = env.step(action)
cur_state = torch.from_numpy(state).to(device=device).reshape(1, state_dim)
states = torch.cat([states, cur_state], dim=0)
rewards[-1] = reward
pred_return = target_return[0, -1] - (reward / scale)
target_return = torch.cat([target_return, pred_return.reshape(1, 1)], dim=1)
timesteps = torch.cat([timesteps, torch.ones((1, 1), device=device, dtype=torch.long) * (t + 1)], dim=1)
episode_return += reward
episode_length += 1
if done:
break
| transformers/examples/research_projects/decision_transformer/run_decision_transformer.py/0 | {
"file_path": "transformers/examples/research_projects/decision_transformer/run_decision_transformer.py",
"repo_id": "transformers",
"token_count": 2763
} | 273 |
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" This is the exact same script as `examples/question-answering/run_squad.py` (as of 2020, January 8th) with an additional and optional step of distillation."""
import argparse
import glob
import logging
import os
import random
import timeit
import numpy as np
import torch
from torch import nn
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
from torch.utils.data.distributed import DistributedSampler
from tqdm import tqdm, trange
import transformers
from transformers import (
WEIGHTS_NAME,
AdamW,
BertConfig,
BertForQuestionAnswering,
BertTokenizer,
DistilBertConfig,
DistilBertForQuestionAnswering,
DistilBertTokenizer,
RobertaConfig,
RobertaForQuestionAnswering,
RobertaTokenizer,
XLMConfig,
XLMForQuestionAnswering,
XLMTokenizer,
XLNetConfig,
XLNetForQuestionAnswering,
XLNetTokenizer,
get_linear_schedule_with_warmup,
squad_convert_examples_to_features,
)
from transformers.data.metrics.squad_metrics import (
compute_predictions_log_probs,
compute_predictions_logits,
squad_evaluate,
)
from transformers.data.processors.squad import SquadResult, SquadV1Processor, SquadV2Processor
from transformers.trainer_utils import is_main_process
try:
from torch.utils.tensorboard import SummaryWriter
except ImportError:
from tensorboardX import SummaryWriter
logger = logging.getLogger(__name__)
MODEL_CLASSES = {
"bert": (BertConfig, BertForQuestionAnswering, BertTokenizer),
"xlnet": (XLNetConfig, XLNetForQuestionAnswering, XLNetTokenizer),
"xlm": (XLMConfig, XLMForQuestionAnswering, XLMTokenizer),
"distilbert": (DistilBertConfig, DistilBertForQuestionAnswering, DistilBertTokenizer),
"roberta": (RobertaConfig, RobertaForQuestionAnswering, RobertaTokenizer),
}
def set_seed(args):
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
if args.n_gpu > 0:
torch.cuda.manual_seed_all(args.seed)
def to_list(tensor):
return tensor.detach().cpu().tolist()
def train(args, train_dataset, model, tokenizer, teacher=None):
"""Train the model"""
if args.local_rank in [-1, 0]:
tb_writer = SummaryWriter()
args.train_batch_size = args.per_gpu_train_batch_size * max(1, args.n_gpu)
train_sampler = RandomSampler(train_dataset) if args.local_rank == -1 else DistributedSampler(train_dataset)
train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=args.train_batch_size)
if args.max_steps > 0:
t_total = args.max_steps
args.num_train_epochs = args.max_steps // (len(train_dataloader) // args.gradient_accumulation_steps) + 1
else:
t_total = len(train_dataloader) // args.gradient_accumulation_steps * args.num_train_epochs
# Prepare optimizer and schedule (linear warmup and decay)
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": args.weight_decay,
},
{"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], "weight_decay": 0.0},
]
optimizer = AdamW(optimizer_grouped_parameters, lr=args.learning_rate, eps=args.adam_epsilon)
scheduler = get_linear_schedule_with_warmup(
optimizer, num_warmup_steps=args.warmup_steps, num_training_steps=t_total
)
# Check if saved optimizer or scheduler states exist
if os.path.isfile(os.path.join(args.model_name_or_path, "optimizer.pt")) and os.path.isfile(
os.path.join(args.model_name_or_path, "scheduler.pt")
):
# Load in optimizer and scheduler states
optimizer.load_state_dict(torch.load(os.path.join(args.model_name_or_path, "optimizer.pt")))
scheduler.load_state_dict(torch.load(os.path.join(args.model_name_or_path, "scheduler.pt")))
if args.fp16:
try:
from apex import amp
except ImportError:
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
model, optimizer = amp.initialize(model, optimizer, opt_level=args.fp16_opt_level)
# multi-gpu training (should be after apex fp16 initialization)
if args.n_gpu > 1:
model = nn.DataParallel(model)
# Distributed training (should be after apex fp16 initialization)
if args.local_rank != -1:
model = nn.parallel.DistributedDataParallel(
model, device_ids=[args.local_rank], output_device=args.local_rank, find_unused_parameters=True
)
# Train!
logger.info("***** Running training *****")
logger.info(" Num examples = %d", len(train_dataset))
logger.info(" Num Epochs = %d", args.num_train_epochs)
logger.info(" Instantaneous batch size per GPU = %d", args.per_gpu_train_batch_size)
logger.info(
" Total train batch size (w. parallel, distributed & accumulation) = %d",
args.train_batch_size
* args.gradient_accumulation_steps
* (torch.distributed.get_world_size() if args.local_rank != -1 else 1),
)
logger.info(" Gradient Accumulation steps = %d", args.gradient_accumulation_steps)
logger.info(" Total optimization steps = %d", t_total)
global_step = 1
epochs_trained = 0
steps_trained_in_current_epoch = 0
# Check if continuing training from a checkpoint
if os.path.exists(args.model_name_or_path):
try:
# set global_step to global_step of last saved checkpoint from model path
checkpoint_suffix = args.model_name_or_path.split("-")[-1].split("/")[0]
global_step = int(checkpoint_suffix)
epochs_trained = global_step // (len(train_dataloader) // args.gradient_accumulation_steps)
steps_trained_in_current_epoch = global_step % (len(train_dataloader) // args.gradient_accumulation_steps)
logger.info(" Continuing training from checkpoint, will skip to saved global_step")
logger.info(" Continuing training from epoch %d", epochs_trained)
logger.info(" Continuing training from global step %d", global_step)
logger.info(" Will skip the first %d steps in the first epoch", steps_trained_in_current_epoch)
except ValueError:
logger.info(" Starting fine-tuning.")
tr_loss, logging_loss = 0.0, 0.0
model.zero_grad()
train_iterator = trange(
epochs_trained, int(args.num_train_epochs), desc="Epoch", disable=args.local_rank not in [-1, 0]
)
# Added here for reproducibility
set_seed(args)
for _ in train_iterator:
epoch_iterator = tqdm(train_dataloader, desc="Iteration", disable=args.local_rank not in [-1, 0])
for step, batch in enumerate(epoch_iterator):
# Skip past any already trained steps if resuming training
if steps_trained_in_current_epoch > 0:
steps_trained_in_current_epoch -= 1
continue
model.train()
if teacher is not None:
teacher.eval()
batch = tuple(t.to(args.device) for t in batch)
inputs = {
"input_ids": batch[0],
"attention_mask": batch[1],
"start_positions": batch[3],
"end_positions": batch[4],
}
if args.model_type != "distilbert":
inputs["token_type_ids"] = None if args.model_type == "xlm" else batch[2]
if args.model_type in ["xlnet", "xlm"]:
inputs.update({"cls_index": batch[5], "p_mask": batch[6]})
if args.version_2_with_negative:
inputs.update({"is_impossible": batch[7]})
outputs = model(**inputs)
loss, start_logits_stu, end_logits_stu = outputs
# Distillation loss
if teacher is not None:
if "token_type_ids" not in inputs:
inputs["token_type_ids"] = None if args.teacher_type == "xlm" else batch[2]
with torch.no_grad():
start_logits_tea, end_logits_tea = teacher(
input_ids=inputs["input_ids"],
token_type_ids=inputs["token_type_ids"],
attention_mask=inputs["attention_mask"],
)
assert start_logits_tea.size() == start_logits_stu.size()
assert end_logits_tea.size() == end_logits_stu.size()
loss_fct = nn.KLDivLoss(reduction="batchmean")
loss_start = loss_fct(
nn.functional.log_softmax(start_logits_stu / args.temperature, dim=-1),
nn.functional.softmax(start_logits_tea / args.temperature, dim=-1),
) * (args.temperature**2)
loss_end = loss_fct(
nn.functional.log_softmax(end_logits_stu / args.temperature, dim=-1),
nn.functional.softmax(end_logits_tea / args.temperature, dim=-1),
) * (args.temperature**2)
loss_ce = (loss_start + loss_end) / 2.0
loss = args.alpha_ce * loss_ce + args.alpha_squad * loss
if args.n_gpu > 1:
loss = loss.mean() # mean() to average on multi-gpu parallel (not distributed) training
if args.gradient_accumulation_steps > 1:
loss = loss / args.gradient_accumulation_steps
if args.fp16:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
else:
loss.backward()
tr_loss += loss.item()
if (step + 1) % args.gradient_accumulation_steps == 0:
if args.fp16:
nn.utils.clip_grad_norm_(amp.master_params(optimizer), args.max_grad_norm)
else:
nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
optimizer.step()
scheduler.step() # Update learning rate schedule
model.zero_grad()
global_step += 1
# Log metrics
if args.local_rank in [-1, 0] and args.logging_steps > 0 and global_step % args.logging_steps == 0:
# Only evaluate when single GPU otherwise metrics may not average well
if args.local_rank == -1 and args.evaluate_during_training:
results = evaluate(args, model, tokenizer)
for key, value in results.items():
tb_writer.add_scalar("eval_{}".format(key), value, global_step)
tb_writer.add_scalar("lr", scheduler.get_lr()[0], global_step)
tb_writer.add_scalar("loss", (tr_loss - logging_loss) / args.logging_steps, global_step)
logging_loss = tr_loss
if args.local_rank in [-1, 0] and args.save_steps > 0 and global_step % args.save_steps == 0:
# Save model checkpoint
output_dir = os.path.join(args.output_dir, "checkpoint-{}".format(global_step))
if not os.path.exists(output_dir):
os.makedirs(output_dir)
model_to_save = (
model.module if hasattr(model, "module") else model
) # Take care of distributed/parallel training
model_to_save.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
torch.save(args, os.path.join(output_dir, "training_args.bin"))
logger.info("Saving model checkpoint to %s", output_dir)
torch.save(optimizer.state_dict(), os.path.join(output_dir, "optimizer.pt"))
torch.save(scheduler.state_dict(), os.path.join(output_dir, "scheduler.pt"))
logger.info("Saving optimizer and scheduler states to %s", output_dir)
if args.max_steps > 0 and global_step > args.max_steps:
epoch_iterator.close()
break
if args.max_steps > 0 and global_step > args.max_steps:
train_iterator.close()
break
if args.local_rank in [-1, 0]:
tb_writer.close()
return global_step, tr_loss / global_step
def evaluate(args, model, tokenizer, prefix=""):
dataset, examples, features = load_and_cache_examples(args, tokenizer, evaluate=True, output_examples=True)
if not os.path.exists(args.output_dir) and args.local_rank in [-1, 0]:
os.makedirs(args.output_dir)
args.eval_batch_size = args.per_gpu_eval_batch_size * max(1, args.n_gpu)
# Note that DistributedSampler samples randomly
eval_sampler = SequentialSampler(dataset)
eval_dataloader = DataLoader(dataset, sampler=eval_sampler, batch_size=args.eval_batch_size)
# multi-gpu evaluate
if args.n_gpu > 1 and not isinstance(model, nn.DataParallel):
model = nn.DataParallel(model)
# Eval!
logger.info("***** Running evaluation {} *****".format(prefix))
logger.info(" Num examples = %d", len(dataset))
logger.info(" Batch size = %d", args.eval_batch_size)
all_results = []
start_time = timeit.default_timer()
for batch in tqdm(eval_dataloader, desc="Evaluating"):
model.eval()
batch = tuple(t.to(args.device) for t in batch)
with torch.no_grad():
inputs = {"input_ids": batch[0], "attention_mask": batch[1]}
if args.model_type != "distilbert":
inputs["token_type_ids"] = None if args.model_type == "xlm" else batch[2] # XLM don't use segment_ids
example_indices = batch[3]
if args.model_type in ["xlnet", "xlm"]:
inputs.update({"cls_index": batch[4], "p_mask": batch[5]})
outputs = model(**inputs)
for i, example_index in enumerate(example_indices):
eval_feature = features[example_index.item()]
unique_id = int(eval_feature.unique_id)
output = [to_list(output[i]) for output in outputs]
# Some models (XLNet, XLM) use 5 arguments for their predictions, while the other "simpler"
# models only use two.
if len(output) >= 5:
start_logits = output[0]
start_top_index = output[1]
end_logits = output[2]
end_top_index = output[3]
cls_logits = output[4]
result = SquadResult(
unique_id,
start_logits,
end_logits,
start_top_index=start_top_index,
end_top_index=end_top_index,
cls_logits=cls_logits,
)
else:
start_logits, end_logits = output
result = SquadResult(unique_id, start_logits, end_logits)
all_results.append(result)
evalTime = timeit.default_timer() - start_time
logger.info(" Evaluation done in total %f secs (%f sec per example)", evalTime, evalTime / len(dataset))
# Compute predictions
output_prediction_file = os.path.join(args.output_dir, "predictions_{}.json".format(prefix))
output_nbest_file = os.path.join(args.output_dir, "nbest_predictions_{}.json".format(prefix))
if args.version_2_with_negative:
output_null_log_odds_file = os.path.join(args.output_dir, "null_odds_{}.json".format(prefix))
else:
output_null_log_odds_file = None
if args.model_type in ["xlnet", "xlm"]:
# XLNet uses a more complex post-processing procedure
predictions = compute_predictions_log_probs(
examples,
features,
all_results,
args.n_best_size,
args.max_answer_length,
output_prediction_file,
output_nbest_file,
output_null_log_odds_file,
model.config.start_n_top,
model.config.end_n_top,
args.version_2_with_negative,
tokenizer,
args.verbose_logging,
)
else:
predictions = compute_predictions_logits(
examples,
features,
all_results,
args.n_best_size,
args.max_answer_length,
args.do_lower_case,
output_prediction_file,
output_nbest_file,
output_null_log_odds_file,
args.verbose_logging,
args.version_2_with_negative,
args.null_score_diff_threshold,
tokenizer,
)
# Compute the F1 and exact scores.
results = squad_evaluate(examples, predictions)
return results
def load_and_cache_examples(args, tokenizer, evaluate=False, output_examples=False):
if args.local_rank not in [-1, 0] and not evaluate:
# Make sure only the first process in distributed training process the dataset, and the others will use the cache
torch.distributed.barrier()
# Load data features from cache or dataset file
input_file = args.predict_file if evaluate else args.train_file
cached_features_file = os.path.join(
os.path.dirname(input_file),
"cached_distillation_{}_{}_{}".format(
"dev" if evaluate else "train",
list(filter(None, args.model_name_or_path.split("/"))).pop(),
str(args.max_seq_length),
),
)
if os.path.exists(cached_features_file) and not args.overwrite_cache:
logger.info("Loading features from cached file %s", cached_features_file)
features_and_dataset = torch.load(cached_features_file)
try:
features, dataset, examples = (
features_and_dataset["features"],
features_and_dataset["dataset"],
features_and_dataset["examples"],
)
except KeyError:
raise DeprecationWarning(
"You seem to be loading features from an older version of this script please delete the "
"file %s in order for it to be created again" % cached_features_file
)
else:
logger.info("Creating features from dataset file at %s", input_file)
processor = SquadV2Processor() if args.version_2_with_negative else SquadV1Processor()
if evaluate:
examples = processor.get_dev_examples(args.data_dir, filename=args.predict_file)
else:
examples = processor.get_train_examples(args.data_dir, filename=args.train_file)
features, dataset = squad_convert_examples_to_features(
examples=examples,
tokenizer=tokenizer,
max_seq_length=args.max_seq_length,
doc_stride=args.doc_stride,
max_query_length=args.max_query_length,
is_training=not evaluate,
return_dataset="pt",
threads=args.threads,
)
if args.local_rank in [-1, 0]:
logger.info("Saving features into cached file %s", cached_features_file)
torch.save({"features": features, "dataset": dataset, "examples": examples}, cached_features_file)
if args.local_rank == 0 and not evaluate:
# Make sure only the first process in distributed training process the dataset, and the others will use the cache
torch.distributed.barrier()
if output_examples:
return dataset, examples, features
return dataset
def main():
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument(
"--model_type",
default=None,
type=str,
required=True,
help="Model type selected in the list: " + ", ".join(MODEL_CLASSES.keys()),
)
parser.add_argument(
"--model_name_or_path",
default=None,
type=str,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models",
)
parser.add_argument(
"--output_dir",
default=None,
type=str,
required=True,
help="The output directory where the model checkpoints and predictions will be written.",
)
# Distillation parameters (optional)
parser.add_argument(
"--teacher_type",
default=None,
type=str,
help=(
"Teacher type. Teacher tokenizer and student (model) tokenizer must output the same tokenization. Only for"
" distillation."
),
)
parser.add_argument(
"--teacher_name_or_path",
default=None,
type=str,
help="Path to the already SQuAD fine-tuned teacher model. Only for distillation.",
)
parser.add_argument(
"--alpha_ce", default=0.5, type=float, help="Distillation loss linear weight. Only for distillation."
)
parser.add_argument(
"--alpha_squad", default=0.5, type=float, help="True SQuAD loss linear weight. Only for distillation."
)
parser.add_argument(
"--temperature", default=2.0, type=float, help="Distillation temperature. Only for distillation."
)
# Other parameters
parser.add_argument(
"--data_dir",
default=None,
type=str,
help="The input data dir. Should contain the .json files for the task."
+ "If no data dir or train/predict files are specified, will run with tensorflow_datasets.",
)
parser.add_argument(
"--train_file",
default=None,
type=str,
help="The input training file. If a data dir is specified, will look for the file there"
+ "If no data dir or train/predict files are specified, will run with tensorflow_datasets.",
)
parser.add_argument(
"--predict_file",
default=None,
type=str,
help="The input evaluation file. If a data dir is specified, will look for the file there"
+ "If no data dir or train/predict files are specified, will run with tensorflow_datasets.",
)
parser.add_argument(
"--config_name", default="", type=str, help="Pretrained config name or path if not the same as model_name"
)
parser.add_argument(
"--tokenizer_name",
default="",
type=str,
help="Pretrained tokenizer name or path if not the same as model_name",
)
parser.add_argument(
"--cache_dir",
default="",
type=str,
help="Where do you want to store the pre-trained models downloaded from huggingface.co",
)
parser.add_argument(
"--version_2_with_negative",
action="store_true",
help="If true, the SQuAD examples contain some that do not have an answer.",
)
parser.add_argument(
"--null_score_diff_threshold",
type=float,
default=0.0,
help="If null_score - best_non_null is greater than the threshold predict null.",
)
parser.add_argument(
"--max_seq_length",
default=384,
type=int,
help=(
"The maximum total input sequence length after WordPiece tokenization. Sequences "
"longer than this will be truncated, and sequences shorter than this will be padded."
),
)
parser.add_argument(
"--doc_stride",
default=128,
type=int,
help="When splitting up a long document into chunks, how much stride to take between chunks.",
)
parser.add_argument(
"--max_query_length",
default=64,
type=int,
help=(
"The maximum number of tokens for the question. Questions longer than this will "
"be truncated to this length."
),
)
parser.add_argument("--do_train", action="store_true", help="Whether to run training.")
parser.add_argument("--do_eval", action="store_true", help="Whether to run eval on the dev set.")
parser.add_argument(
"--evaluate_during_training", action="store_true", help="Rul evaluation during training at each logging step."
)
parser.add_argument(
"--do_lower_case", action="store_true", help="Set this flag if you are using an uncased model."
)
parser.add_argument("--per_gpu_train_batch_size", default=8, type=int, help="Batch size per GPU/CPU for training.")
parser.add_argument(
"--per_gpu_eval_batch_size", default=8, type=int, help="Batch size per GPU/CPU for evaluation."
)
parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
parser.add_argument("--adam_epsilon", default=1e-8, type=float, help="Epsilon for Adam optimizer.")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument(
"--num_train_epochs", default=3.0, type=float, help="Total number of training epochs to perform."
)
parser.add_argument(
"--max_steps",
default=-1,
type=int,
help="If > 0: set total number of training steps to perform. Override num_train_epochs.",
)
parser.add_argument("--warmup_steps", default=0, type=int, help="Linear warmup over warmup_steps.")
parser.add_argument(
"--n_best_size",
default=20,
type=int,
help="The total number of n-best predictions to generate in the nbest_predictions.json output file.",
)
parser.add_argument(
"--max_answer_length",
default=30,
type=int,
help=(
"The maximum length of an answer that can be generated. This is needed because the start "
"and end predictions are not conditioned on one another."
),
)
parser.add_argument(
"--verbose_logging",
action="store_true",
help=(
"If true, all of the warnings related to data processing will be printed. "
"A number of warnings are expected for a normal SQuAD evaluation."
),
)
parser.add_argument("--logging_steps", type=int, default=50, help="Log every X updates steps.")
parser.add_argument("--save_steps", type=int, default=50, help="Save checkpoint every X updates steps.")
parser.add_argument(
"--eval_all_checkpoints",
action="store_true",
help="Evaluate all checkpoints starting with the same prefix as model_name ending and ending with step number",
)
parser.add_argument("--no_cuda", action="store_true", help="Whether not to use CUDA when available")
parser.add_argument(
"--overwrite_output_dir", action="store_true", help="Overwrite the content of the output directory"
)
parser.add_argument(
"--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
)
parser.add_argument("--seed", type=int, default=42, help="random seed for initialization")
parser.add_argument("--local_rank", type=int, default=-1, help="local_rank for distributed training on gpus")
parser.add_argument(
"--fp16",
action="store_true",
help="Whether to use 16-bit (mixed) precision (through NVIDIA apex) instead of 32-bit",
)
parser.add_argument(
"--fp16_opt_level",
type=str,
default="O1",
help=(
"For fp16: Apex AMP optimization level selected in ['O0', 'O1', 'O2', and 'O3']. "
"See details at https://nvidia.github.io/apex/amp.html"
),
)
parser.add_argument("--server_ip", type=str, default="", help="Can be used for distant debugging.")
parser.add_argument("--server_port", type=str, default="", help="Can be used for distant debugging.")
parser.add_argument("--threads", type=int, default=1, help="multiple threads for converting example to features")
args = parser.parse_args()
if (
os.path.exists(args.output_dir)
and os.listdir(args.output_dir)
and args.do_train
and not args.overwrite_output_dir
):
raise ValueError(
"Output directory ({}) already exists and is not empty. Use --overwrite_output_dir to overcome.".format(
args.output_dir
)
)
# Setup distant debugging if needed
if args.server_ip and args.server_port:
# Distant debugging - see https://code.visualstudio.com/docs/python/debugging#_attach-to-a-local-script
import ptvsd
print("Waiting for debugger attach")
ptvsd.enable_attach(address=(args.server_ip, args.server_port), redirect_output=True)
ptvsd.wait_for_attach()
# Setup CUDA, GPU & distributed training
if args.local_rank == -1 or args.no_cuda:
device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
args.n_gpu = 0 if args.no_cuda else torch.cuda.device_count()
else: # Initializes the distributed backend which will take care of synchronizing nodes/GPUs
torch.cuda.set_device(args.local_rank)
device = torch.device("cuda", args.local_rank)
torch.distributed.init_process_group(backend="nccl")
args.n_gpu = 1
args.device = device
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO if args.local_rank in [-1, 0] else logging.WARN,
)
logger.warning(
"Process rank: %s, device: %s, n_gpu: %s, distributed training: %s, 16-bits training: %s",
args.local_rank,
device,
args.n_gpu,
bool(args.local_rank != -1),
args.fp16,
)
# Set the verbosity to info of the Transformers logger (on main process only):
if is_main_process(args.local_rank):
transformers.utils.logging.set_verbosity_info()
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Set seed
set_seed(args)
# Load pretrained model and tokenizer
if args.local_rank not in [-1, 0]:
# Make sure only the first process in distributed training will download model & vocab
torch.distributed.barrier()
args.model_type = args.model_type.lower()
config_class, model_class, tokenizer_class = MODEL_CLASSES[args.model_type]
config = config_class.from_pretrained(
args.config_name if args.config_name else args.model_name_or_path,
cache_dir=args.cache_dir if args.cache_dir else None,
)
tokenizer = tokenizer_class.from_pretrained(
args.tokenizer_name if args.tokenizer_name else args.model_name_or_path,
do_lower_case=args.do_lower_case,
cache_dir=args.cache_dir if args.cache_dir else None,
)
model = model_class.from_pretrained(
args.model_name_or_path,
from_tf=bool(".ckpt" in args.model_name_or_path),
config=config,
cache_dir=args.cache_dir if args.cache_dir else None,
)
if args.teacher_type is not None:
assert args.teacher_name_or_path is not None
assert args.alpha_ce > 0.0
assert args.alpha_ce + args.alpha_squad > 0.0
assert args.teacher_type != "distilbert", "We constraint teachers not to be of type DistilBERT."
teacher_config_class, teacher_model_class, _ = MODEL_CLASSES[args.teacher_type]
teacher_config = teacher_config_class.from_pretrained(
args.teacher_name_or_path, cache_dir=args.cache_dir if args.cache_dir else None
)
teacher = teacher_model_class.from_pretrained(
args.teacher_name_or_path, config=teacher_config, cache_dir=args.cache_dir if args.cache_dir else None
)
teacher.to(args.device)
else:
teacher = None
if args.local_rank == 0:
# Make sure only the first process in distributed training will download model & vocab
torch.distributed.barrier()
model.to(args.device)
logger.info("Training/evaluation parameters %s", args)
# Before we do anything with models, we want to ensure that we get fp16 execution of torch.einsum if args.fp16 is set.
# Otherwise it'll default to "promote" mode, and we'll get fp32 operations. Note that running `--fp16_opt_level="O2"` will
# remove the need for this code, but it is still valid.
if args.fp16:
try:
import apex
apex.amp.register_half_function(torch, "einsum")
except ImportError:
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
# Training
if args.do_train:
train_dataset = load_and_cache_examples(args, tokenizer, evaluate=False, output_examples=False)
global_step, tr_loss = train(args, train_dataset, model, tokenizer, teacher=teacher)
logger.info(" global_step = %s, average loss = %s", global_step, tr_loss)
# Save the trained model and the tokenizer
if args.do_train and (args.local_rank == -1 or torch.distributed.get_rank() == 0):
logger.info("Saving model checkpoint to %s", args.output_dir)
# Save a trained model, configuration and tokenizer using `save_pretrained()`.
# They can then be reloaded using `from_pretrained()`
model_to_save = (
model.module if hasattr(model, "module") else model
) # Take care of distributed/parallel training
model_to_save.save_pretrained(args.output_dir)
tokenizer.save_pretrained(args.output_dir)
# Good practice: save your training arguments together with the trained model
torch.save(args, os.path.join(args.output_dir, "training_args.bin"))
# Load a trained model and vocabulary that you have fine-tuned
model = model_class.from_pretrained(args.output_dir)
tokenizer = tokenizer_class.from_pretrained(args.output_dir, do_lower_case=args.do_lower_case)
model.to(args.device)
# Evaluation - we can ask to evaluate all the checkpoints (sub-directories) in a directory
results = {}
if args.do_eval and args.local_rank in [-1, 0]:
if args.do_train:
logger.info("Loading checkpoints saved during training for evaluation")
checkpoints = [args.output_dir]
if args.eval_all_checkpoints:
checkpoints = [
os.path.dirname(c) for c in sorted(glob.glob(args.output_dir + "/**/" + WEIGHTS_NAME, recursive=True))
]
logger.info("Evaluate the following checkpoints: %s", checkpoints)
for checkpoint in checkpoints:
# Reload the model
global_step = checkpoint.split("-")[-1] if len(checkpoints) > 1 else ""
model = model_class.from_pretrained(checkpoint)
model.to(args.device)
# Evaluate
result = evaluate(args, model, tokenizer, prefix=global_step)
result = {k + ("_{}".format(global_step) if global_step else ""): v for k, v in result.items()}
results.update(result)
logger.info("Results: {}".format(results))
return results
if __name__ == "__main__":
main()
| transformers/examples/research_projects/distillation/run_squad_w_distillation.py/0 | {
"file_path": "transformers/examples/research_projects/distillation/run_squad_w_distillation.py",
"repo_id": "transformers",
"token_count": 15430
} | 274 |
from .model import FSNERModel
from .tokenizer_utils import FSNERTokenizerUtils
__all__ = ["FSNERModel", "FSNERTokenizerUtils"]
| transformers/examples/research_projects/fsner/src/fsner/__init__.py/0 | {
"file_path": "transformers/examples/research_projects/fsner/src/fsner/__init__.py",
"repo_id": "transformers",
"token_count": 44
} | 275 |
command:
- python3
- train.py
method: random
parameters:
lr:
values: [4e-5, 3e-5]
warmup_steps:
values: [20000, 15000, 10000, 5000]
weight_decay:
distribution: normal
mu: 1e-2
sigma: 2e-3
metric:
name: eval_loss
goal: minimize
| transformers/examples/research_projects/jax-projects/big_bird/sweep_flax.yaml/0 | {
"file_path": "transformers/examples/research_projects/jax-projects/big_bird/sweep_flax.yaml",
"repo_id": "transformers",
"token_count": 222
} | 276 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2022 The HuggingFace Team All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning LayoutLMv3 for token classification on FUNSD or CORD.
"""
# You can also adapt this script on your own token classification task and datasets. Pointers for this are left as
# comments.
import logging
import os
import sys
from dataclasses import dataclass, field
from typing import Optional
import datasets
import numpy as np
from datasets import ClassLabel, load_dataset, load_metric
import transformers
from transformers import (
AutoConfig,
AutoModelForTokenClassification,
AutoProcessor,
HfArgumentParser,
Trainer,
TrainingArguments,
set_seed,
)
from transformers.data.data_collator import default_data_collator
from transformers.trainer_utils import get_last_checkpoint
from transformers.utils import check_min_version
from transformers.utils.versions import require_version
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.19.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/token-classification/requirements.txt")
logger = logging.getLogger(__name__)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
default="microsoft/layoutlmv3-base",
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"},
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
processor_name: Optional[str] = field(
default=None, metadata={"help": "Name or path to the processor files if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
)
model_revision: str = field(
default="main",
metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
)
use_auth_token: bool = field(
default=False,
metadata={
"help": (
"Will use the token generated when running `huggingface-cli login` (necessary to use this script "
"with private models)."
)
},
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
task_name: Optional[str] = field(default="ner", metadata={"help": "The name of the task (ner, pos...)."})
dataset_name: Optional[str] = field(
default="nielsr/funsd-layoutlmv3",
metadata={"help": "The name of the dataset to use (via the datasets library)."},
)
dataset_config_name: Optional[str] = field(
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
)
train_file: Optional[str] = field(
default=None, metadata={"help": "The input training data file (a csv or JSON file)."}
)
validation_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input evaluation data file to evaluate on (a csv or JSON file)."},
)
test_file: Optional[str] = field(
default=None,
metadata={"help": "An optional input test data file to predict on (a csv or JSON file)."},
)
text_column_name: Optional[str] = field(
default=None, metadata={"help": "The column name of text to input in the file (a csv or JSON file)."}
)
label_column_name: Optional[str] = field(
default=None, metadata={"help": "The column name of label to input in the file (a csv or JSON file)."}
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
max_seq_length: int = field(
default=512,
metadata={
"help": (
"The maximum total input sequence length after tokenization. If set, sequences longer "
"than this will be truncated, sequences shorter will be padded."
)
},
)
max_train_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
)
},
)
max_eval_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
"value if set."
)
},
)
max_predict_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of prediction examples to this "
"value if set."
)
},
)
label_all_tokens: bool = field(
default=False,
metadata={
"help": (
"Whether to put the label for one word on all tokens of generated by that word or just on the "
"one (in which case the other tokens will have a padding index)."
)
},
)
return_entity_level_metrics: bool = field(
default=False,
metadata={"help": "Whether to return all the entity levels during evaluation or just the overall ones."},
)
def __post_init__(self):
if self.dataset_name is None and self.train_file is None and self.validation_file is None:
raise ValueError("Need either a dataset name or a training/validation file.")
else:
if self.train_file is not None:
extension = self.train_file.split(".")[-1]
assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
if self.validation_file is not None:
extension = self.validation_file.split(".")[-1]
assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
self.task_name = self.task_name.lower()
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Log on each process the small summary:
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
+ f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
)
logger.info(f"Training/evaluation parameters {training_args}")
# Detecting last checkpoint.
last_checkpoint = None
if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
last_checkpoint = get_last_checkpoint(training_args.output_dir)
if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
"Use --overwrite_output_dir to overcome."
)
elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
logger.info(
f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
"the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
)
# Set seed before initializing model.
set_seed(training_args.seed)
# Get the datasets
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
# download the dataset.
if data_args.dataset_name == "funsd":
# Downloading and loading a dataset from the hub.
dataset = load_dataset(
"nielsr/funsd-layoutlmv3",
data_args.dataset_config_name,
cache_dir=model_args.cache_dir,
token=True if model_args.use_auth_token else None,
)
elif data_args.dataset_name == "cord":
# Downloading and loading a dataset from the hub.
dataset = load_dataset(
"nielsr/cord-layoutlmv3",
data_args.dataset_config_name,
cache_dir=model_args.cache_dir,
token=True if model_args.use_auth_token else None,
)
else:
raise ValueError("This script only supports either FUNSD or CORD out-of-the-box.")
if training_args.do_train:
column_names = dataset["train"].column_names
features = dataset["train"].features
else:
column_names = dataset["test"].column_names
features = dataset["test"].features
image_column_name = "image"
text_column_name = "words" if "words" in column_names else "tokens"
boxes_column_name = "bboxes"
label_column_name = (
f"{data_args.task_name}_tags" if f"{data_args.task_name}_tags" in column_names else column_names[1]
)
remove_columns = column_names
# In the event the labels are not a `Sequence[ClassLabel]`, we will need to go through the dataset to get the
# unique labels.
def get_label_list(labels):
unique_labels = set()
for label in labels:
unique_labels = unique_labels | set(label)
label_list = list(unique_labels)
label_list.sort()
return label_list
# If the labels are of type ClassLabel, they are already integers and we have the map stored somewhere.
# Otherwise, we have to get the list of labels manually.
if isinstance(features[label_column_name].feature, ClassLabel):
label_list = features[label_column_name].feature.names
# No need to convert the labels since they are already ints.
id2label = dict(enumerate(label_list))
label2id = {v: k for k, v in enumerate(label_list)}
else:
label_list = get_label_list(datasets["train"][label_column_name])
id2label = dict(enumerate(label_list))
label2id = {v: k for k, v in enumerate(label_list)}
num_labels = len(label_list)
# Load pretrained model and processor
#
# Distributed training:
# The .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
config = AutoConfig.from_pretrained(
model_args.config_name if model_args.config_name else model_args.model_name_or_path,
num_labels=num_labels,
finetuning_task=data_args.task_name,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=True if model_args.use_auth_token else None,
)
processor = AutoProcessor.from_pretrained(
model_args.processor_name if model_args.processor_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
use_fast=True,
revision=model_args.model_revision,
token=True if model_args.use_auth_token else None,
add_prefix_space=True,
apply_ocr=False,
)
model = AutoModelForTokenClassification.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=True if model_args.use_auth_token else None,
)
# Set the correspondences label/ID inside the model config
model.config.label2id = label2id
model.config.id2label = id2label
# Preprocessing the dataset
# The processor does everything for us (prepare the image using LayoutLMv3ImageProcessor
# and prepare the words, boxes and word-level labels using LayoutLMv3TokenizerFast)
def prepare_examples(examples):
images = examples[image_column_name]
words = examples[text_column_name]
boxes = examples[boxes_column_name]
word_labels = examples[label_column_name]
encoding = processor(
images,
words,
boxes=boxes,
word_labels=word_labels,
truncation=True,
padding="max_length",
max_length=data_args.max_seq_length,
)
return encoding
if training_args.do_train:
if "train" not in dataset:
raise ValueError("--do_train requires a train dataset")
train_dataset = dataset["train"]
if data_args.max_train_samples is not None:
train_dataset = train_dataset.select(range(data_args.max_train_samples))
with training_args.main_process_first(desc="train dataset map pre-processing"):
train_dataset = train_dataset.map(
prepare_examples,
batched=True,
remove_columns=remove_columns,
num_proc=data_args.preprocessing_num_workers,
load_from_cache_file=not data_args.overwrite_cache,
)
if training_args.do_eval:
validation_name = "test"
if validation_name not in dataset:
raise ValueError("--do_eval requires a validation dataset")
eval_dataset = dataset[validation_name]
if data_args.max_eval_samples is not None:
eval_dataset = eval_dataset.select(range(data_args.max_eval_samples))
with training_args.main_process_first(desc="validation dataset map pre-processing"):
eval_dataset = eval_dataset.map(
prepare_examples,
batched=True,
remove_columns=remove_columns,
num_proc=data_args.preprocessing_num_workers,
load_from_cache_file=not data_args.overwrite_cache,
)
if training_args.do_predict:
if "test" not in datasets:
raise ValueError("--do_predict requires a test dataset")
predict_dataset = datasets["test"]
if data_args.max_predict_samples is not None:
max_predict_samples = min(len(predict_dataset), data_args.max_predict_samples)
predict_dataset = predict_dataset.select(range(max_predict_samples))
with training_args.main_process_first(desc="prediction dataset map pre-processing"):
predict_dataset = predict_dataset.map(
prepare_examples,
batched=True,
remove_columns=remove_columns,
num_proc=data_args.preprocessing_num_workers,
load_from_cache_file=not data_args.overwrite_cache,
)
# Metrics
metric = load_metric("seqeval")
def compute_metrics(p):
predictions, labels = p
predictions = np.argmax(predictions, axis=2)
# Remove ignored index (special tokens)
true_predictions = [
[label_list[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
true_labels = [
[label_list[l] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
results = metric.compute(predictions=true_predictions, references=true_labels)
if data_args.return_entity_level_metrics:
# Unpack nested dictionaries
final_results = {}
for key, value in results.items():
if isinstance(value, dict):
for n, v in value.items():
final_results[f"{key}_{n}"] = v
else:
final_results[key] = value
return final_results
else:
return {
"precision": results["overall_precision"],
"recall": results["overall_recall"],
"f1": results["overall_f1"],
"accuracy": results["overall_accuracy"],
}
# Initialize our Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=processor,
data_collator=default_data_collator,
compute_metrics=compute_metrics,
)
# Training
if training_args.do_train:
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:
checkpoint = last_checkpoint
train_result = trainer.train(resume_from_checkpoint=checkpoint)
metrics = train_result.metrics
trainer.save_model() # Saves the tokenizer too for easy upload
max_train_samples = (
data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
)
metrics["train_samples"] = min(max_train_samples, len(train_dataset))
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state()
# Evaluation
if training_args.do_eval:
logger.info("*** Evaluate ***")
metrics = trainer.evaluate()
max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
# Predict
if training_args.do_predict:
logger.info("*** Predict ***")
predictions, labels, metrics = trainer.predict(predict_dataset, metric_key_prefix="predict")
predictions = np.argmax(predictions, axis=2)
# Remove ignored index (special tokens)
true_predictions = [
[label_list[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)
]
trainer.log_metrics("predict", metrics)
trainer.save_metrics("predict", metrics)
# Save predictions
output_predictions_file = os.path.join(training_args.output_dir, "predictions.txt")
if trainer.is_world_process_zero():
with open(output_predictions_file, "w") as writer:
for prediction in true_predictions:
writer.write(" ".join(prediction) + "\n")
kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "token-classification"}
if data_args.dataset_name is not None:
kwargs["dataset_tags"] = data_args.dataset_name
if data_args.dataset_config_name is not None:
kwargs["dataset_args"] = data_args.dataset_config_name
kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
else:
kwargs["dataset"] = data_args.dataset_name
if training_args.push_to_hub:
trainer.push_to_hub(**kwargs)
else:
trainer.create_model_card(**kwargs)
def _mp_fn(index):
# For xla_spawn (TPUs)
main()
if __name__ == "__main__":
main()
| transformers/examples/research_projects/layoutlmv3/run_funsd_cord.py/0 | {
"file_path": "transformers/examples/research_projects/layoutlmv3/run_funsd_cord.py",
"repo_id": "transformers",
"token_count": 8703
} | 277 |
<!---
Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
## Whole Word Mask Language Model
These scripts leverage the 🤗 Datasets library and the Trainer API. You can easily customize them to your needs if you
need extra processing on your datasets.
The following examples, will run on a datasets hosted on our [hub](https://huggingface.co/datasets) or with your own
text files for training and validation. We give examples of both below.
The BERT authors released a new version of BERT using Whole Word Masking in May 2019. Instead of masking randomly
selected tokens (which may be part of words), they mask randomly selected words (masking all the tokens corresponding
to that word). This technique has been refined for Chinese in [this paper](https://arxiv.org/abs/1906.08101).
To fine-tune a model using whole word masking, use the following script:
```bash
python run_mlm_wwm.py \
--model_name_or_path FacebookAI/roberta-base \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--do_train \
--do_eval \
--output_dir /tmp/test-mlm-wwm
```
For Chinese models, we need to generate a reference files (which requires the ltp library), because it's tokenized at
the character level.
**Q :** Why a reference file?
**A :** Suppose we have a Chinese sentence like: `我喜欢你` The original Chinese-BERT will tokenize it as
`['我','喜','欢','你']` (character level). But `喜欢` is a whole word. For whole word masking proxy, we need a result
like `['我','喜','##欢','你']`, so we need a reference file to tell the model which position of the BERT original token
should be added `##`.
**Q :** Why LTP ?
**A :** Cause the best known Chinese WWM BERT is [Chinese-BERT-wwm](https://github.com/ymcui/Chinese-BERT-wwm) by HIT.
It works well on so many Chines Task like CLUE (Chinese GLUE). They use LTP, so if we want to fine-tune their model,
we need LTP.
You could run the following:
```bash
export TRAIN_FILE=/path/to/train/file
export LTP_RESOURCE=/path/to/ltp/tokenizer
export BERT_RESOURCE=/path/to/bert/tokenizer
export SAVE_PATH=/path/to/data/ref.txt
python run_chinese_ref.py \
--file_name=$TRAIN_FILE \
--ltp=$LTP_RESOURCE \
--bert=$BERT_RESOURCE \
--save_path=$SAVE_PATH
```
Then you can run the script like this:
```bash
export TRAIN_FILE=/path/to/train/file
export VALIDATION_FILE=/path/to/validation/file
export TRAIN_REF_FILE=/path/to/train/chinese_ref/file
export VALIDATION_REF_FILE=/path/to/validation/chinese_ref/file
export OUTPUT_DIR=/tmp/test-mlm-wwm
python run_mlm_wwm.py \
--model_name_or_path FacebookAI/roberta-base \
--train_file $TRAIN_FILE \
--validation_file $VALIDATION_FILE \
--train_ref_file $TRAIN_REF_FILE \
--validation_ref_file $VALIDATION_REF_FILE \
--do_train \
--do_eval \
--output_dir $OUTPUT_DIR
```
**Note1:** On TPU, you should the flag `--pad_to_max_length` to make sure all your batches have the same length.
**Note2:** And if you have any questions or something goes wrong when running this code, don't hesitate to pin @wlhgtc.
| transformers/examples/research_projects/mlm_wwm/README.md/0 | {
"file_path": "transformers/examples/research_projects/mlm_wwm/README.md",
"repo_id": "transformers",
"token_count": 1192
} | 278 |
# coding=utf-8
# Copyright 2020-present, the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Masked Linear module: A fully connected layer that computes an adaptive binary mask on the fly.
The mask (binary or not) is computed at each forward pass and multiplied against
the weight matrix to prune a portion of the weights.
The pruned weight matrix is then multiplied against the inputs (and if necessary, the bias is added).
"""
import math
import torch
from torch import nn
from torch.nn import init
from .binarizer import MagnitudeBinarizer, ThresholdBinarizer, TopKBinarizer
class MaskedLinear(nn.Linear):
"""
Fully Connected layer with on the fly adaptive mask.
If needed, a score matrix is created to store the importance of each associated weight.
"""
def __init__(
self,
in_features: int,
out_features: int,
bias: bool = True,
mask_init: str = "constant",
mask_scale: float = 0.0,
pruning_method: str = "topK",
):
"""
Args:
in_features (`int`)
Size of each input sample
out_features (`int`)
Size of each output sample
bias (`bool`)
If set to ``False``, the layer will not learn an additive bias.
Default: ``True``
mask_init (`str`)
The initialization method for the score matrix if a score matrix is needed.
Choices: ["constant", "uniform", "kaiming"]
Default: ``constant``
mask_scale (`float`)
The initialization parameter for the chosen initialization method `mask_init`.
Default: ``0.``
pruning_method (`str`)
Method to compute the mask.
Choices: ["topK", "threshold", "sigmoied_threshold", "magnitude", "l0"]
Default: ``topK``
"""
super(MaskedLinear, self).__init__(in_features=in_features, out_features=out_features, bias=bias)
assert pruning_method in ["topK", "threshold", "sigmoied_threshold", "magnitude", "l0"]
self.pruning_method = pruning_method
if self.pruning_method in ["topK", "threshold", "sigmoied_threshold", "l0"]:
self.mask_scale = mask_scale
self.mask_init = mask_init
self.mask_scores = nn.Parameter(torch.empty(self.weight.size()))
self.init_mask()
def init_mask(self):
if self.mask_init == "constant":
init.constant_(self.mask_scores, val=self.mask_scale)
elif self.mask_init == "uniform":
init.uniform_(self.mask_scores, a=-self.mask_scale, b=self.mask_scale)
elif self.mask_init == "kaiming":
init.kaiming_uniform_(self.mask_scores, a=math.sqrt(5))
def forward(self, input: torch.tensor, threshold: float):
# Get the mask
if self.pruning_method == "topK":
mask = TopKBinarizer.apply(self.mask_scores, threshold)
elif self.pruning_method in ["threshold", "sigmoied_threshold"]:
sig = "sigmoied" in self.pruning_method
mask = ThresholdBinarizer.apply(self.mask_scores, threshold, sig)
elif self.pruning_method == "magnitude":
mask = MagnitudeBinarizer.apply(self.weight, threshold)
elif self.pruning_method == "l0":
l, r, b = -0.1, 1.1, 2 / 3
if self.training:
u = torch.zeros_like(self.mask_scores).uniform_().clamp(0.0001, 0.9999)
s = torch.sigmoid((u.log() - (1 - u).log() + self.mask_scores) / b)
else:
s = torch.sigmoid(self.mask_scores)
s_bar = s * (r - l) + l
mask = s_bar.clamp(min=0.0, max=1.0)
# Mask weights with computed mask
weight_thresholded = mask * self.weight
# Compute output (linear layer) with masked weights
return nn.functional.linear(input, weight_thresholded, self.bias)
| transformers/examples/research_projects/movement-pruning/emmental/modules/masked_nn.py/0 | {
"file_path": "transformers/examples/research_projects/movement-pruning/emmental/modules/masked_nn.py",
"repo_id": "transformers",
"token_count": 1917
} | 279 |
import logging
import os
from dataclasses import dataclass, field
from functools import partial
from pathlib import Path
from tempfile import TemporaryDirectory
from typing import List, Optional
import faiss
import torch
from datasets import Features, Sequence, Value, load_dataset
from transformers import DPRContextEncoder, DPRContextEncoderTokenizerFast, HfArgumentParser
logger = logging.getLogger(__name__)
torch.set_grad_enabled(False)
device = "cuda" if torch.cuda.is_available() else "cpu"
def split_text(text: str, n=100, character=" ") -> List[str]:
"""Split the text every ``n``-th occurrence of ``character``"""
text = text.split(character)
return [character.join(text[i : i + n]).strip() for i in range(0, len(text), n)]
def split_documents(documents: dict) -> dict:
"""Split documents into passages"""
titles, texts = [], []
for title, text in zip(documents["title"], documents["text"]):
if text is not None:
for passage in split_text(text):
titles.append(title if title is not None else "")
texts.append(passage)
return {"title": titles, "text": texts}
def embed(documents: dict, ctx_encoder: DPRContextEncoder, ctx_tokenizer: DPRContextEncoderTokenizerFast) -> dict:
"""Compute the DPR embeddings of document passages"""
input_ids = ctx_tokenizer(
documents["title"], documents["text"], truncation=True, padding="longest", return_tensors="pt"
)["input_ids"]
embeddings = ctx_encoder(input_ids.to(device=device), return_dict=True).pooler_output
return {"embeddings": embeddings.detach().cpu().numpy()}
def main(
rag_example_args: "RagExampleArguments",
processing_args: "ProcessingArguments",
index_hnsw_args: "IndexHnswArguments",
):
######################################
logger.info("Step 1 - Create the dataset")
######################################
# The dataset needed for RAG must have three columns:
# - title (string): title of the document
# - text (string): text of a passage of the document
# - embeddings (array of dimension d): DPR representation of the passage
# Let's say you have documents in tab-separated csv files with columns "title" and "text"
assert os.path.isfile(rag_example_args.csv_path), "Please provide a valid path to a csv file"
# You can load a Dataset object this way
dataset = load_dataset(
"csv", data_files=[rag_example_args.csv_path], split="train", delimiter="\t", column_names=["title", "text"]
)
# More info about loading csv files in the documentation: https://huggingface.co/docs/datasets/loading_datasets?highlight=csv#csv-files
# Then split the documents into passages of 100 words
dataset = dataset.map(split_documents, batched=True, num_proc=processing_args.num_proc)
# And compute the embeddings
ctx_encoder = DPRContextEncoder.from_pretrained(rag_example_args.dpr_ctx_encoder_model_name).to(device=device)
ctx_tokenizer = DPRContextEncoderTokenizerFast.from_pretrained(rag_example_args.dpr_ctx_encoder_model_name)
new_features = Features(
{"text": Value("string"), "title": Value("string"), "embeddings": Sequence(Value("float32"))}
) # optional, save as float32 instead of float64 to save space
dataset = dataset.map(
partial(embed, ctx_encoder=ctx_encoder, ctx_tokenizer=ctx_tokenizer),
batched=True,
batch_size=processing_args.batch_size,
features=new_features,
)
# And finally save your dataset
passages_path = os.path.join(rag_example_args.output_dir, "my_knowledge_dataset")
dataset.save_to_disk(passages_path)
# from datasets import load_from_disk
# dataset = load_from_disk(passages_path) # to reload the dataset
######################################
logger.info("Step 2 - Index the dataset")
######################################
# Let's use the Faiss implementation of HNSW for fast approximate nearest neighbor search
index = faiss.IndexHNSWFlat(index_hnsw_args.d, index_hnsw_args.m, faiss.METRIC_INNER_PRODUCT)
dataset.add_faiss_index("embeddings", custom_index=index)
# And save the index
index_path = os.path.join(rag_example_args.output_dir, "my_knowledge_dataset_hnsw_index.faiss")
dataset.get_index("embeddings").save(index_path)
# dataset.load_faiss_index("embeddings", index_path) # to reload the index
@dataclass
class RagExampleArguments:
csv_path: str = field(
default=str(Path(__file__).parent / "test_run" / "dummy-kb" / "my_knowledge_dataset.csv"),
metadata={"help": "Path to a tab-separated csv file with columns 'title' and 'text'"},
)
question: Optional[str] = field(
default=None,
metadata={"help": "Question that is passed as input to RAG. Default is 'What does Moses' rod turn into ?'."},
)
rag_model_name: str = field(
default="facebook/rag-sequence-nq",
metadata={"help": "The RAG model to use. Either 'facebook/rag-sequence-nq' or 'facebook/rag-token-nq'"},
)
dpr_ctx_encoder_model_name: str = field(
default="facebook/dpr-ctx_encoder-multiset-base",
metadata={
"help": (
"The DPR context encoder model to use. Either 'facebook/dpr-ctx_encoder-single-nq-base' or"
" 'facebook/dpr-ctx_encoder-multiset-base'"
)
},
)
output_dir: Optional[str] = field(
default=str(Path(__file__).parent / "test_run" / "dummy-kb"),
metadata={"help": "Path to a directory where the dataset passages and the index will be saved"},
)
@dataclass
class ProcessingArguments:
num_proc: Optional[int] = field(
default=None,
metadata={
"help": "The number of processes to use to split the documents into passages. Default is single process."
},
)
batch_size: int = field(
default=16,
metadata={
"help": "The batch size to use when computing the passages embeddings using the DPR context encoder."
},
)
@dataclass
class IndexHnswArguments:
d: int = field(
default=768,
metadata={"help": "The dimension of the embeddings to pass to the HNSW Faiss index."},
)
m: int = field(
default=128,
metadata={
"help": (
"The number of bi-directional links created for every new element during the HNSW index construction."
)
},
)
if __name__ == "__main__":
logging.basicConfig(level=logging.WARNING)
logger.setLevel(logging.INFO)
parser = HfArgumentParser((RagExampleArguments, ProcessingArguments, IndexHnswArguments))
rag_example_args, processing_args, index_hnsw_args = parser.parse_args_into_dataclasses()
with TemporaryDirectory() as tmp_dir:
rag_example_args.output_dir = rag_example_args.output_dir or tmp_dir
main(rag_example_args, processing_args, index_hnsw_args)
| transformers/examples/research_projects/rag-end2end-retriever/use_own_knowledge_dataset.py/0 | {
"file_path": "transformers/examples/research_projects/rag-end2end-retriever/use_own_knowledge_dataset.py",
"repo_id": "transformers",
"token_count": 2578
} | 280 |
import argparse
import logging
import os
import sys
import tempfile
from pathlib import Path
import lightning_base
import pytest
import pytorch_lightning as pl
import torch
from convert_pl_checkpoint_to_hf import convert_pl_to_hf
from distillation import distill_main
from finetune import SummarizationModule, main
from huggingface_hub import list_models
from parameterized import parameterized
from run_eval import generate_summaries_or_translations
from torch import nn
from transformers import AutoConfig, AutoModelForSeq2SeqLM
from transformers.testing_utils import CaptureStderr, CaptureStdout, TestCasePlus, require_torch_gpu, slow
from utils import label_smoothed_nll_loss, lmap, load_json
logging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger()
CUDA_AVAILABLE = torch.cuda.is_available()
CHEAP_ARGS = {
"max_tokens_per_batch": None,
"supervise_forward": True,
"normalize_hidden": True,
"label_smoothing": 0.2,
"eval_max_gen_length": None,
"eval_beams": 1,
"val_metric": "loss",
"save_top_k": 1,
"adafactor": True,
"early_stopping_patience": 2,
"logger_name": "default",
"length_penalty": 0.5,
"cache_dir": "",
"task": "summarization",
"num_workers": 2,
"alpha_hid": 0,
"freeze_embeds": True,
"enc_only": False,
"tgt_suffix": "",
"resume_from_checkpoint": None,
"sortish_sampler": True,
"student_decoder_layers": 1,
"val_check_interval": 1.0,
"output_dir": "",
"fp16": False, # TODO(SS): set this to CUDA_AVAILABLE if ci installs apex or start using native amp
"no_teacher": False,
"fp16_opt_level": "O1",
"gpus": 1 if CUDA_AVAILABLE else 0,
"n_tpu_cores": 0,
"max_grad_norm": 1.0,
"do_train": True,
"do_predict": True,
"accumulate_grad_batches": 1,
"server_ip": "",
"server_port": "",
"seed": 42,
"model_name_or_path": "sshleifer/bart-tiny-random",
"config_name": "",
"tokenizer_name": "facebook/bart-large",
"do_lower_case": False,
"learning_rate": 0.3,
"lr_scheduler": "linear",
"weight_decay": 0.0,
"adam_epsilon": 1e-08,
"warmup_steps": 0,
"max_epochs": 1,
"train_batch_size": 2,
"eval_batch_size": 2,
"max_source_length": 12,
"max_target_length": 12,
"val_max_target_length": 12,
"test_max_target_length": 12,
"fast_dev_run": False,
"no_cache": False,
"n_train": -1,
"n_val": -1,
"n_test": -1,
"student_encoder_layers": 1,
"freeze_encoder": False,
"auto_scale_batch_size": False,
"overwrite_output_dir": False,
"student": None,
}
def _dump_articles(path: Path, articles: list):
content = "\n".join(articles)
Path(path).open("w").writelines(content)
ARTICLES = [" Sam ate lunch today.", "Sams lunch ingredients."]
SUMMARIES = ["A very interesting story about what I ate for lunch.", "Avocado, celery, turkey, coffee"]
T5_TINY = "patrickvonplaten/t5-tiny-random"
T5_TINIER = "sshleifer/t5-tinier-random"
BART_TINY = "sshleifer/bart-tiny-random"
MBART_TINY = "sshleifer/tiny-mbart"
MARIAN_TINY = "sshleifer/tiny-marian-en-de"
FSMT_TINY = "stas/tiny-wmt19-en-de"
stream_handler = logging.StreamHandler(sys.stdout)
logger.addHandler(stream_handler)
logging.disable(logging.CRITICAL) # remove noisy download output from tracebacks
def make_test_data_dir(tmp_dir):
for split in ["train", "val", "test"]:
_dump_articles(os.path.join(tmp_dir, f"{split}.source"), ARTICLES)
_dump_articles(os.path.join(tmp_dir, f"{split}.target"), SUMMARIES)
return tmp_dir
class TestSummarizationDistiller(TestCasePlus):
@classmethod
def setUpClass(cls):
logging.disable(logging.CRITICAL) # remove noisy download output from tracebacks
return cls
@slow
@require_torch_gpu
def test_hub_configs(self):
"""I put require_torch_gpu cause I only want this to run with self-scheduled."""
model_list = list_models()
org = "sshleifer"
model_ids = [x.modelId for x in model_list if x.modelId.startswith(org)]
allowed_to_be_broken = ["sshleifer/blenderbot-3B", "sshleifer/blenderbot-90M"]
failures = []
for m in model_ids:
if m in allowed_to_be_broken:
continue
try:
AutoConfig.from_pretrained(m)
except Exception:
failures.append(m)
assert not failures, f"The following models could not be loaded through AutoConfig: {failures}"
def test_distill_no_teacher(self):
updates = {"student_encoder_layers": 2, "student_decoder_layers": 1, "no_teacher": True}
self._test_distiller_cli(updates)
def test_distill_checkpointing_with_teacher(self):
updates = {
"student_encoder_layers": 2,
"student_decoder_layers": 1,
"max_epochs": 4,
"val_check_interval": 0.25,
"alpha_hid": 2.0,
"model_name_or_path": "IGNORE_THIS_IT_DOESNT_GET_USED",
}
model = self._test_distiller_cli(updates, check_contents=False)
ckpts = list(Path(model.output_dir).glob("*.ckpt"))
self.assertEqual(1, len(ckpts))
transformer_ckpts = list(Path(model.output_dir).glob("**/*.bin"))
self.assertEqual(len(transformer_ckpts), 2)
examples = lmap(str.strip, Path(model.hparams.data_dir).joinpath("test.source").open().readlines())
out_path = tempfile.mktemp() # XXX: not being cleaned up
generate_summaries_or_translations(examples, out_path, str(model.output_dir / "best_tfmr"))
self.assertTrue(Path(out_path).exists())
out_path_new = self.get_auto_remove_tmp_dir()
convert_pl_to_hf(ckpts[0], transformer_ckpts[0].parent, out_path_new)
assert os.path.exists(os.path.join(out_path_new, "pytorch_model.bin"))
def test_loss_fn(self):
model = AutoModelForSeq2SeqLM.from_pretrained(BART_TINY)
input_ids, mask = model.dummy_inputs["input_ids"], model.dummy_inputs["attention_mask"]
target_ids = torch.tensor([[0, 4, 8, 2], [0, 8, 2, 1]], dtype=torch.long, device=model.device)
decoder_input_ids = target_ids[:, :-1].contiguous() # Why this line?
lm_labels = target_ids[:, 1:].clone() # why clone?
model_computed_loss = model(
input_ids, attention_mask=mask, decoder_input_ids=decoder_input_ids, labels=lm_labels, use_cache=False
).loss
logits = model(input_ids, attention_mask=mask, decoder_input_ids=decoder_input_ids, use_cache=False).logits
lprobs = nn.functional.log_softmax(logits, dim=-1)
smoothed_loss, nll_loss = label_smoothed_nll_loss(
lprobs, lm_labels, 0.1, ignore_index=model.config.pad_token_id
)
with self.assertRaises(AssertionError):
# TODO: understand why this breaks
self.assertEqual(nll_loss, model_computed_loss)
def test_distill_mbart(self):
updates = {
"student_encoder_layers": 2,
"student_decoder_layers": 1,
"num_train_epochs": 4,
"val_check_interval": 0.25,
"alpha_hid": 2.0,
"task": "translation",
"model_name_or_path": "IGNORE_THIS_IT_DOESNT_GET_USED",
"tokenizer_name": MBART_TINY,
"teacher": MBART_TINY,
"src_lang": "en_XX",
"tgt_lang": "ro_RO",
}
model = self._test_distiller_cli(updates, check_contents=False)
assert model.model.config.model_type == "mbart"
ckpts = list(Path(model.output_dir).glob("*.ckpt"))
self.assertEqual(1, len(ckpts))
transformer_ckpts = list(Path(model.output_dir).glob("**/*.bin"))
all_files = list(Path(model.output_dir).glob("best_tfmr/*"))
assert len(all_files) > 2
self.assertEqual(len(transformer_ckpts), 2)
def test_distill_t5(self):
updates = {
"student_encoder_layers": 1,
"student_decoder_layers": 1,
"alpha_hid": 2.0,
"teacher": T5_TINY,
"model_name_or_path": T5_TINY,
"tokenizer_name": T5_TINY,
}
self._test_distiller_cli(updates)
def test_distill_different_base_models(self):
updates = {
"teacher": T5_TINY,
"student": T5_TINIER,
"model_name_or_path": T5_TINIER,
"tokenizer_name": T5_TINIER,
}
self._test_distiller_cli(updates)
def _test_distiller_cli(self, updates, check_contents=True):
default_updates = {
"label_smoothing": 0.0,
"early_stopping_patience": -1,
"train_batch_size": 1,
"eval_batch_size": 2,
"max_epochs": 2,
"alpha_mlm": 0.2,
"alpha_ce": 0.8,
"do_predict": True,
"model_name_or_path": "sshleifer/tinier_bart",
"teacher": CHEAP_ARGS["model_name_or_path"],
"val_check_interval": 0.5,
}
default_updates.update(updates)
args_d: dict = CHEAP_ARGS.copy()
tmp_dir = make_test_data_dir(tmp_dir=self.get_auto_remove_tmp_dir())
output_dir = self.get_auto_remove_tmp_dir()
args_d.update(data_dir=tmp_dir, output_dir=output_dir, **default_updates)
model = distill_main(argparse.Namespace(**args_d))
if not check_contents:
return model
contents = os.listdir(output_dir)
contents = {os.path.basename(p) for p in contents}
ckpt_files = [p for p in contents if p.endswith("ckpt")]
assert len(ckpt_files) > 0
self.assertIn("test_generations.txt", contents)
self.assertIn("test_results.txt", contents)
metrics = load_json(model.metrics_save_path)
last_step_stats = metrics["val"][-1]
self.assertGreaterEqual(last_step_stats["val_avg_gen_time"], 0.01)
self.assertGreaterEqual(1.0, last_step_stats["val_avg_gen_time"])
self.assertIsInstance(last_step_stats[f"val_avg_{model.val_metric}"], float)
desired_n_evals = int(args_d["max_epochs"] * (1 / args_d["val_check_interval"]) + 1)
self.assertEqual(len(metrics["val"]), desired_n_evals)
self.assertEqual(len(metrics["test"]), 1)
return model
class TestTheRest(TestCasePlus):
@parameterized.expand(
[T5_TINY, BART_TINY, MBART_TINY, MARIAN_TINY, FSMT_TINY],
)
def test_finetune(self, model):
args_d: dict = CHEAP_ARGS.copy()
task = "translation" if model in [MBART_TINY, MARIAN_TINY, FSMT_TINY] else "summarization"
args_d["label_smoothing"] = 0.1 if task == "translation" else 0
tmp_dir = make_test_data_dir(tmp_dir=self.get_auto_remove_tmp_dir())
output_dir = self.get_auto_remove_tmp_dir()
args_d.update(
data_dir=tmp_dir,
model_name_or_path=model,
tokenizer_name=None,
train_batch_size=2,
eval_batch_size=2,
output_dir=output_dir,
do_predict=True,
task=task,
src_lang="en_XX",
tgt_lang="ro_RO",
freeze_encoder=True,
freeze_embeds=True,
)
assert "n_train" in args_d
args = argparse.Namespace(**args_d)
module = main(args)
input_embeds = module.model.get_input_embeddings()
assert not input_embeds.weight.requires_grad
if model == T5_TINY:
lm_head = module.model.lm_head
assert not lm_head.weight.requires_grad
assert (lm_head.weight == input_embeds.weight).all().item()
elif model == FSMT_TINY:
fsmt = module.model.model
embed_pos = fsmt.decoder.embed_positions
assert not embed_pos.weight.requires_grad
assert not fsmt.decoder.embed_tokens.weight.requires_grad
# check that embeds are not the same
assert fsmt.decoder.embed_tokens != fsmt.encoder.embed_tokens
else:
bart = module.model.model
embed_pos = bart.decoder.embed_positions
assert not embed_pos.weight.requires_grad
assert not bart.shared.weight.requires_grad
# check that embeds are the same
assert bart.decoder.embed_tokens == bart.encoder.embed_tokens
assert bart.decoder.embed_tokens == bart.shared
example_batch = load_json(module.output_dir / "text_batch.json")
assert isinstance(example_batch, dict)
assert len(example_batch) >= 4
def test_finetune_extra_model_args(self):
args_d: dict = CHEAP_ARGS.copy()
task = "summarization"
tmp_dir = make_test_data_dir(tmp_dir=self.get_auto_remove_tmp_dir())
args_d.update(
data_dir=tmp_dir,
tokenizer_name=None,
train_batch_size=2,
eval_batch_size=2,
do_predict=False,
task=task,
src_lang="en_XX",
tgt_lang="ro_RO",
freeze_encoder=True,
freeze_embeds=True,
)
# test models whose config includes the extra_model_args
model = BART_TINY
output_dir = self.get_auto_remove_tmp_dir()
args_d1 = args_d.copy()
args_d1.update(
model_name_or_path=model,
output_dir=output_dir,
)
extra_model_params = ("encoder_layerdrop", "decoder_layerdrop", "dropout", "attention_dropout")
for p in extra_model_params:
args_d1[p] = 0.5
args = argparse.Namespace(**args_d1)
model = main(args)
for p in extra_model_params:
assert getattr(model.config, p) == 0.5, f"failed to override the model config for param {p}"
# test models whose config doesn't include the extra_model_args
model = T5_TINY
output_dir = self.get_auto_remove_tmp_dir()
args_d2 = args_d.copy()
args_d2.update(
model_name_or_path=model,
output_dir=output_dir,
)
unsupported_param = "encoder_layerdrop"
args_d2[unsupported_param] = 0.5
args = argparse.Namespace(**args_d2)
with pytest.raises(Exception) as excinfo:
model = main(args)
assert str(excinfo.value) == f"model config doesn't have a `{unsupported_param}` attribute"
def test_finetune_lr_schedulers(self):
args_d: dict = CHEAP_ARGS.copy()
task = "summarization"
tmp_dir = make_test_data_dir(tmp_dir=self.get_auto_remove_tmp_dir())
model = BART_TINY
output_dir = self.get_auto_remove_tmp_dir()
args_d.update(
data_dir=tmp_dir,
model_name_or_path=model,
output_dir=output_dir,
tokenizer_name=None,
train_batch_size=2,
eval_batch_size=2,
do_predict=False,
task=task,
src_lang="en_XX",
tgt_lang="ro_RO",
freeze_encoder=True,
freeze_embeds=True,
)
# emulate finetune.py
parser = argparse.ArgumentParser()
parser = pl.Trainer.add_argparse_args(parser)
parser = SummarizationModule.add_model_specific_args(parser, os.getcwd())
args = {"--help": True}
# --help test
with pytest.raises(SystemExit) as excinfo:
with CaptureStdout() as cs:
args = parser.parse_args(args)
assert False, "--help is expected to sys.exit"
assert excinfo.type == SystemExit
expected = lightning_base.arg_to_scheduler_metavar
assert expected in cs.out, "--help is expected to list the supported schedulers"
# --lr_scheduler=non_existing_scheduler test
unsupported_param = "non_existing_scheduler"
args = {f"--lr_scheduler={unsupported_param}"}
with pytest.raises(SystemExit) as excinfo:
with CaptureStderr() as cs:
args = parser.parse_args(args)
assert False, "invalid argument is expected to sys.exit"
assert excinfo.type == SystemExit
expected = f"invalid choice: '{unsupported_param}'"
assert expected in cs.err, f"should have bailed on invalid choice of scheduler {unsupported_param}"
# --lr_scheduler=existing_scheduler test
supported_param = "cosine"
args_d1 = args_d.copy()
args_d1["lr_scheduler"] = supported_param
args = argparse.Namespace(**args_d1)
model = main(args)
assert (
getattr(model.hparams, "lr_scheduler") == supported_param
), f"lr_scheduler={supported_param} shouldn't fail"
| transformers/examples/research_projects/seq2seq-distillation/_test_seq2seq_examples.py/0 | {
"file_path": "transformers/examples/research_projects/seq2seq-distillation/_test_seq2seq_examples.py",
"repo_id": "transformers",
"token_count": 7908
} | 281 |
#!/usr/bin/env bash
python run_asr.py \
--output_dir="./wav2vec2-base-100h" \
--num_train_epochs="30" \
--per_device_train_batch_size="32" \
--per_device_eval_batch_size="32" \
--evaluation_strategy="steps" \
--save_total_limit="3" \
--save_steps="500" \
--eval_steps="100" \
--logging_steps="50" \
--learning_rate="5e-4" \
--warmup_steps="3000" \
--model_name_or_path="facebook/wav2vec2-base" \
--fp16 \
--dataset_name="librispeech_asr" \
--dataset_config_name="clean" \
--train_split_name="train.100" \
--preprocessing_num_workers="32" \
--group_by_length \
--freeze_feature_extractor
| transformers/examples/research_projects/wav2vec2/finetune_base_100.sh/0 | {
"file_path": "transformers/examples/research_projects/wav2vec2/finetune_base_100.sh",
"repo_id": "transformers",
"token_count": 249
} | 282 |
# Zero-shot classifier distillation
Author: @joeddav
This script provides a way to improve the speed and memory performance of a zero-shot classifier by training a more
efficient student model from the zero-shot teacher's predictions over an unlabeled dataset.
The zero-shot classification pipeline uses a model pre-trained on natural language inference (NLI) to determine the
compatibility of a set of candidate class names with a given sequence. This serves as a convenient out-of-the-box
classifier without the need for labeled training data. However, for a given sequence, the method requires each
possible label to be fed through the large NLI model separately. Thus for `N` sequences and `K` classes, a total of
`N*K` forward passes through the model are required. This requirement slows inference considerably, particularly as
`K` grows.
Given (1) an unlabeled corpus and (2) a set of candidate class names, the provided script trains a student model
with a standard classification head with `K` output dimensions. The resulting student model can then be used for
classifying novel text instances with a significant boost in speed and memory performance while retaining similar
classification performance to the original zero-shot model
### Usage
A teacher NLI model can be distilled to a more efficient student model by running [`distill_classifier.py`](https://github.com/huggingface/transformers/blob/main/examples/research_projects/zero-shot-distillation/distill_classifier.py):
```bash
python distill_classifier.py \
--data_file <unlabeled_data.txt> \
--class_names_file <class_names.txt> \
--output_dir <output_dir>
```
`<unlabeled_data.txt>` should be a text file with a single unlabeled example per line. `<class_names.txt>` is a text file with one class name per line.
Other optional arguments include:
- `--teacher_name_or_path` (default: `roberta-large-mnli`): The name or path of the NLI teacher model.
- `--student_name_or_path` (default: `distillbert-base-uncased`): The name or path of the student model which will
be fine-tuned to copy the teacher predictions.
- `--hypothesis_template` (default `"This example is {}."`): The template used to turn each label into an NLI-style
hypothesis when generating teacher predictions. This template must include a `{}` or similar syntax for the
candidate label to be inserted into the template. For example, the default template is `"This example is {}."` With
the candidate label `sports`, this would be fed into the model like `[CLS] sequence to classify [SEP] This example
is sports . [SEP]`.
- `--multi_class`: Whether or not multiple candidate labels can be true. By default, the scores are normalized such
that the sum of the label likelihoods for each sequence is 1. If `--multi_class` is passed, the labels are
considered independent and probabilities are normalized for each candidate by doing a softmax of the entailment
score vs. the contradiction score. This is sometimes called "multi-class multi-label" classification.
- `--temperature` (default: `1.0`): The temperature applied to the softmax of the teacher model predictions. A
higher temperature results in a student with smoother (lower confidence) predictions than the teacher while a value
`<1` resultings in a higher-confidence, peaked distribution. The default `1.0` is equivalent to no smoothing.
- `--teacher_batch_size` (default: `32`): The batch size used for generating a single set of teacher predictions.
Does not affect training. Use `--per_device_train_batch_size` to change the training batch size.
Any of the arguments in the 🤗 Trainer's
[`TrainingArguments`](https://huggingface.co/transformers/main_classes/trainer.html?#trainingarguments) can also be
modified, such as `--learning_rate`, `--fp16`, `--no_cuda`, `--warmup_steps`, etc. Run `python distill_classifier.py
-h` for a full list of available arguments or consult the [Trainer
documentation](https://huggingface.co/transformers/main_classes/trainer.html#trainingarguments).
> **Note**: Distributed and TPU training are not currently supported. Single-node multi-GPU is supported, however,
and will run automatically if multiple GPUs are available.
### Example: Topic classification
> A full colab demo notebook of this example can be found [here](https://colab.research.google.com/drive/1mjBjd0cR8G57ZpsnFCS3ngGyo5nCa9ya?usp=sharing).
Let's say we're interested in classifying news articles into one of four topic categories: "the world", "sports",
"business", or "science/tech". We have an unlabeled dataset, [AG's News](https://huggingface.co/datasets/ag_news),
which corresponds to this problem (in reality AG's News is annotated, but we will pretend it is not for the sake of
example).
We can use an NLI model like `roberta-large-mnli` for zero-shot classification like so:
```python
>>> class_names = ["the world", "sports", "business", "science/tech"]
>>> hypothesis_template = "This text is about {}."
>>> sequence = "A new moon has been discovered in Jupiter's orbit"
>>> zero_shot_classifier = pipeline("zero-shot-classification", model="roberta-large-mnli")
>>> zero_shot_classifier(sequence, class_names, hypothesis_template=hypothesis_template)
{'sequence': "A new moon has been discovered in Jupiter's orbit",
'labels': ['science/tech', 'the world', 'business', 'sports'],
'scores': [0.7035840153694153, 0.18744826316833496, 0.06027870625257492, 0.04868902638554573]}
```
Unfortunately, inference is slow since each of our 4 class names must be fed through the large model for every
sequence to be classified. But with our unlabeled data we can distill the model to a small distilbert classifier to
make future inference much faster.
To run the script, we will need to put each training example (text only) from AG's News on its own line in
`agnews/train_unlabeled.txt`, and each of the four class names in the newline-separated `agnews/class_names.txt`.
Then we can run distillation with the following command:
```bash
python distill_classifier.py \
--data_file ./agnews/unlabeled.txt \
--class_names_files ./agnews/class_names.txt \
--teacher_name_or_path roberta-large-mnli \
--hypothesis_template "This text is about {}." \
--output_dir ./agnews/distilled
```
The script will generate a set of soft zero-shot predictions from `roberta-large-mnli` for each example in
`agnews/unlabeled.txt`. It will then train a student distilbert classifier on the teacher predictions and
save the resulting model in `./agnews/distilled`.
The resulting model can then be loaded and used like any other pre-trained classifier:
```python
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("./agnews/distilled")
tokenizer = AutoTokenizer.from_pretrained("./agnews/distilled")
```
and even used trivially with a `TextClassificationPipeline`:
```python
>>> distilled_classifier = TextClassificationPipeline(model=model, tokenizer=tokenizer, return_all_scores=True)
>>> distilled_classifier(sequence)
[[{'label': 'the world', 'score': 0.14899294078350067},
{'label': 'sports', 'score': 0.03205857425928116},
{'label': 'business', 'score': 0.05943061783909798},
{'label': 'science/tech', 'score': 0.7595179080963135}]]
```
> Tip: pass `device=0` when constructing a pipeline to run on a GPU
As we can see, the results of the student closely resemble that of the trainer despite never having seen this
example during training. Now let's do a quick & dirty speed comparison simulating 16K examples with a batch size of
16:
```python
for _ in range(1000):
zero_shot_classifier([sequence] * 16, class_names)
# runs in 1m 23s on a single V100 GPU
```
```python
%%time
for _ in range(1000):
distilled_classifier([sequence] * 16)
# runs in 10.3s on a single V100 GPU
```
As we can see, the distilled student model runs an order of magnitude faster than its teacher NLI model. This is
also a seeting where we only have `K=4` possible labels. The higher the number of classes for a given task, the more
drastic the speedup will be, since the zero-shot teacher's complexity scales linearly with the number of classes.
Since we secretly have access to ground truth labels for AG's news, we can evaluate the accuracy of each model. The
original zero-shot model `roberta-large-mnli` gets an accuracy of 69.3% on the held-out test set. After training a
student on the unlabeled training set, the distilled model gets a similar score of 70.4%.
Lastly, you can share the distilled model with the community and/or use it with our inference API by [uploading it
to the 🤗 Hub](https://huggingface.co/transformers/model_sharing.html). We've uploaded the distilled model from this
example at
[joeddav/distilbert-base-uncased-agnews-student](https://huggingface.co/joeddav/distilbert-base-uncased-agnews-student).
| transformers/examples/research_projects/zero-shot-distillation/README.md/0 | {
"file_path": "transformers/examples/research_projects/zero-shot-distillation/README.md",
"repo_id": "transformers",
"token_count": 2467
} | 283 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Script for preparing TFRecord shards for pre-tokenized examples."""
import argparse
import logging
import os
import datasets
import tensorflow as tf
from transformers import AutoTokenizer
logger = logging.getLogger(__name__)
def parse_args():
parser = argparse.ArgumentParser(
description="Prepare TFRecord shards from pre-tokenized samples of the wikitext dataset."
)
parser.add_argument(
"--dataset_name",
type=str,
default="wikitext",
help="Name of the training. Explore datasets at: hf.co/datasets.",
)
parser.add_argument(
"--dataset_config", type=str, default="wikitext-103-raw-v1", help="Configuration name of the dataset."
)
parser.add_argument(
"--tokenizer_name_or_path",
type=str,
default="sayakpaul/unigram-tokenizer-wikitext",
help="Tokenizer identifier. Can be a local filepath or a Hub identifier.",
)
parser.add_argument(
"--shard_size",
type=int,
default=1000,
help="Number of entries to go in a single shard.",
)
parser.add_argument("--split", type=str, default="train", choices=["train", "test", "validation"])
parser.add_argument(
"--limit",
default=None,
type=int,
help="Limit the number of shards (used for debugging).",
)
parser.add_argument(
"--max_length",
type=int,
default=512,
help="Maximum sequence length. For training on TPUs, it helps to have a maximum"
" sequence length that is a multiple of 8.",
)
parser.add_argument(
"--output_dir",
default="tf-tpu",
type=str,
help="Output directory where the TFRecord shards will be saved. If the"
" path is appended with `gs://` ('gs://tf-tpu', for example) then the TFRecord"
" shards will be directly saved to a Google Cloud Storage bucket.",
)
args = parser.parse_args()
return args
def tokenize_function(tokenizer):
def fn(examples):
return tokenizer(examples["text"])
return fn
def get_serialized_examples(tokenized_data):
records = []
for i in range(len(tokenized_data["input_ids"])):
features = {
"input_ids": tf.train.Feature(int64_list=tf.train.Int64List(value=tokenized_data["input_ids"][i])),
"attention_mask": tf.train.Feature(
int64_list=tf.train.Int64List(value=tokenized_data["attention_mask"][i])
),
}
features = tf.train.Features(feature=features)
example = tf.train.Example(features=features)
record_bytes = example.SerializeToString()
records.append(record_bytes)
return records
def main(args):
dataset = datasets.load_dataset(args.dataset_name, args.dataset_config, split=args.split)
if args.limit is not None:
max_samples = min(len(dataset), args.limit)
dataset = dataset.select(range(max_samples))
print(f"Limiting the dataset to {args.limit} entries.")
tokenizer = AutoTokenizer.from_pretrained(args.tokenizer_name_or_path)
# Handle output directory creation.
# For serializing into a Google Cloud Storage Bucket, one needs to first
# create a bucket.
if "gs" not in args.output_dir:
if not os.path.exists(args.output_dir):
os.makedirs(args.output_dir)
split_dir = os.path.join(args.output_dir, args.split)
if not os.path.exists(split_dir):
os.makedirs(split_dir)
else:
split_dir = os.path.join(args.output_dir, args.split)
# Tokenize the whole dataset at once.
tokenize_fn = tokenize_function(tokenizer)
dataset_tokenized = dataset.map(tokenize_fn, batched=True, num_proc=4, remove_columns=["text"])
# We need to concatenate all our texts together, and then split the result
# into chunks of a fixed size, which we will call block_size. To do this, we
# will use the map method again, with the option batched=True. When we use batched=True,
# the function we pass to map() will be passed multiple inputs at once, allowing us
# to group them into more or fewer examples than we had in the input.
# This allows us to create our new fixed-length samples. The advantage of this
# method is that we don't lose a whole lot of content from the dataset compared to the
# case where we simply tokenize with a pre-defined max_length.
def group_texts(examples):
# Concatenate all texts.
concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}
total_length = len(concatenated_examples[list(examples.keys())[0]])
# We drop the small remainder, though you could add padding instead if the model supports it
# In this, as in all things, we advise you to follow your heart 🫀
total_length = (total_length // args.max_length) * args.max_length
# Split by chunks of max_len.
result = {
k: [t[i : i + args.max_length] for i in range(0, total_length, args.max_length)]
for k, t in concatenated_examples.items()
}
return result
grouped_dataset = dataset_tokenized.map(group_texts, batched=True, batch_size=1000, num_proc=4)
shard_count = 0
total_records = 0
for shard in range(0, len(grouped_dataset), args.shard_size):
dataset_snapshot = grouped_dataset[shard : shard + args.shard_size]
records_containing = len(dataset_snapshot["input_ids"])
filename = os.path.join(split_dir, f"dataset-{shard_count}-{records_containing}.tfrecord")
serialized_examples = get_serialized_examples(dataset_snapshot)
with tf.io.TFRecordWriter(filename) as out_file:
for i in range(len(serialized_examples)):
example = serialized_examples[i]
out_file.write(example)
print("Wrote file {} containing {} records".format(filename, records_containing))
shard_count += 1
total_records += records_containing
with open(f"split-{args.split}-records-count.txt", "w") as f:
print(f"Total {args.split} records: {total_records}", file=f)
if __name__ == "__main__":
args = parse_args()
main(args)
| transformers/examples/tensorflow/language-modeling-tpu/prepare_tfrecord_shards.py/0 | {
"file_path": "transformers/examples/tensorflow/language-modeling-tpu/prepare_tfrecord_shards.py",
"repo_id": "transformers",
"token_count": 2654
} | 284 |
[tool.ruff]
# Never enforce `E501` (line length violations).
ignore = ["C901", "E501", "E741", "F402", "F823" ]
select = ["C", "E", "F", "I", "W"]
line-length = 119
# Ignore import violations in all `__init__.py` files.
[tool.ruff.per-file-ignores]
"__init__.py" = ["E402", "F401", "F403", "F811"]
"src/transformers/file_utils.py" = ["F401"]
"src/transformers/utils/dummy_*.py" = ["F401"]
[tool.ruff.isort]
lines-after-imports = 2
known-first-party = ["transformers"]
[tool.ruff.format]
# Like Black, use double quotes for strings.
quote-style = "double"
# Like Black, indent with spaces, rather than tabs.
indent-style = "space"
# Like Black, respect magic trailing commas.
skip-magic-trailing-comma = false
# Like Black, automatically detect the appropriate line ending.
line-ending = "auto"
[tool.pytest.ini_options]
doctest_optionflags="NUMBER NORMALIZE_WHITESPACE ELLIPSIS"
doctest_glob="**/*.md"
markers = [
"flash_attn_test: marks tests related to flash attention (deselect with '-m \"not flash_attn_test\"')",
"bitsandbytes: select (or deselect with `not`) bitsandbytes integration tests",
] | transformers/pyproject.toml/0 | {
"file_path": "transformers/pyproject.toml",
"repo_id": "transformers",
"token_count": 406
} | 285 |
# This file is adapted from the AllenNLP library at https://github.com/allenai/allennlp
# Copyright 2020 The HuggingFace Team and the AllenNLP authors. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Utilities for working with the local dataset cache.
"""
import copy
import csv
import linecache
import os
import platform
import sys
import warnings
from abc import ABC, abstractmethod
from collections import defaultdict, namedtuple
from datetime import datetime
from multiprocessing import Pipe, Process, Queue
from multiprocessing.connection import Connection
from typing import Callable, Iterable, List, NamedTuple, Optional, Union
from .. import AutoConfig, PretrainedConfig
from .. import __version__ as version
from ..utils import is_psutil_available, is_py3nvml_available, is_tf_available, is_torch_available, logging
from .benchmark_args_utils import BenchmarkArguments
if is_torch_available():
from torch.cuda import empty_cache as torch_empty_cache
if is_tf_available():
from tensorflow.python.eager import context as tf_context
if is_psutil_available():
import psutil
if is_py3nvml_available():
import py3nvml.py3nvml as nvml
if platform.system() == "Windows":
from signal import CTRL_C_EVENT as SIGKILL
else:
from signal import SIGKILL
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
_is_memory_tracing_enabled = False
BenchmarkOutput = namedtuple(
"BenchmarkOutput",
[
"time_inference_result",
"memory_inference_result",
"time_train_result",
"memory_train_result",
"inference_summary",
"train_summary",
],
)
def separate_process_wrapper_fn(func: Callable[[], None], do_multi_processing: bool) -> Callable[[], None]:
"""
This function wraps another function into its own separated process. In order to ensure accurate memory
measurements it is important that the function is executed in a separate process
Args:
- `func`: (`callable`): function() -> ... generic function which will be executed in its own separate process
- `do_multi_processing`: (`bool`) Whether to run function on separate process or not
"""
def multi_process_func(*args, **kwargs):
# run function in an individual
# process to get correct memory
def wrapper_func(queue: Queue, *args):
try:
result = func(*args)
except Exception as e:
logger.error(e)
print(e)
result = "N/A"
queue.put(result)
queue = Queue()
p = Process(target=wrapper_func, args=[queue] + list(args))
p.start()
result = queue.get()
p.join()
return result
if do_multi_processing:
logger.info(f"Function {func} is executed in its own process...")
return multi_process_func
else:
return func
def is_memory_tracing_enabled():
global _is_memory_tracing_enabled
return _is_memory_tracing_enabled
class Frame(NamedTuple):
"""
`Frame` is a NamedTuple used to gather the current frame state. `Frame` has the following fields:
- 'filename' (string): Name of the file currently executed
- 'module' (string): Name of the module currently executed
- 'line_number' (int): Number of the line currently executed
- 'event' (string): Event that triggered the tracing (default will be "line")
- 'line_text' (string): Text of the line in the python script
"""
filename: str
module: str
line_number: int
event: str
line_text: str
class UsedMemoryState(NamedTuple):
"""
`UsedMemoryState` are named tuples with the following fields:
- 'frame': a `Frame` namedtuple (see below) storing information on the current tracing frame (current file,
location in current file)
- 'cpu_memory': CPU RSS memory state *before* executing the line
- 'gpu_memory': GPU used memory *before* executing the line (sum for all GPUs or for only `gpus_to_trace` if
provided)
"""
frame: Frame
cpu_memory: int
gpu_memory: int
class Memory(NamedTuple):
"""
`Memory` NamedTuple have a single field `bytes` and you can get a human readable str of the number of mega bytes by
calling `__repr__`
- `byte` (integer): number of bytes,
"""
bytes: int
def __repr__(self) -> str:
return str(bytes_to_mega_bytes(self.bytes))
class MemoryState(NamedTuple):
"""
`MemoryState` are namedtuples listing frame + CPU/GPU memory with the following fields:
- `frame` (`Frame`): the current frame (see above)
- `cpu`: CPU memory consumed at during the current frame as a `Memory` named tuple
- `gpu`: GPU memory consumed at during the current frame as a `Memory` named tuple
- `cpu_gpu`: CPU + GPU memory consumed at during the current frame as a `Memory` named tuple
"""
frame: Frame
cpu: Memory
gpu: Memory
cpu_gpu: Memory
class MemorySummary(NamedTuple):
"""
`MemorySummary` namedtuple otherwise with the fields:
- `sequential`: a list of `MemoryState` namedtuple (see below) computed from the provided `memory_trace` by
subtracting the memory after executing each line from the memory before executing said line.
- `cumulative`: a list of `MemoryState` namedtuple (see below) with cumulative increase in memory for each line
obtained by summing repeated memory increase for a line if it's executed several times. The list is sorted
from the frame with the largest memory consumption to the frame with the smallest (can be negative if memory
is released)
- `total`: total memory increase during the full tracing as a `Memory` named tuple (see below). Line with
memory release (negative consumption) are ignored if `ignore_released_memory` is `True` (default).
"""
sequential: List[MemoryState]
cumulative: List[MemoryState]
current: List[MemoryState]
total: Memory
MemoryTrace = List[UsedMemoryState]
def measure_peak_memory_cpu(function: Callable[[], None], interval=0.5, device_idx=None) -> int:
"""
measures peak cpu memory consumption of a given `function` running the function for at least interval seconds and
at most 20 * interval seconds. This function is heavily inspired by: `memory_usage` of the package
`memory_profiler`:
https://github.com/pythonprofilers/memory_profiler/blob/895c4ac7a08020d66ae001e24067da6dcea42451/memory_profiler.py#L239
Args:
- `function`: (`callable`): function() -> ... function without any arguments to measure for which to measure
the peak memory
- `interval`: (`float`, `optional`, defaults to `0.5`) interval in second for which to measure the memory usage
- `device_idx`: (`int`, `optional`, defaults to `None`) device id for which to measure gpu usage
Returns:
- `max_memory`: (`int`) consumed memory peak in Bytes
"""
def get_cpu_memory(process_id: int) -> int:
"""
measures current cpu memory usage of a given `process_id`
Args:
- `process_id`: (`int`) process_id for which to measure memory
Returns
- `memory`: (`int`) consumed memory in Bytes
"""
process = psutil.Process(process_id)
try:
meminfo_attr = "memory_info" if hasattr(process, "memory_info") else "get_memory_info"
memory = getattr(process, meminfo_attr)()[0]
except psutil.AccessDenied:
raise ValueError("Error with Psutil.")
return memory
if not is_psutil_available():
logger.warning(
"Psutil not installed, we won't log CPU memory usage. "
"Install Psutil (pip install psutil) to use CPU memory tracing."
)
max_memory = "N/A"
else:
class MemoryMeasureProcess(Process):
"""
`MemoryMeasureProcess` inherits from `Process` and overwrites its `run()` method. Used to measure the
memory usage of a process
"""
def __init__(self, process_id: int, child_connection: Connection, interval: float):
super().__init__()
self.process_id = process_id
self.interval = interval
self.connection = child_connection
self.num_measurements = 1
self.mem_usage = get_cpu_memory(self.process_id)
def run(self):
self.connection.send(0)
stop = False
while True:
self.mem_usage = max(self.mem_usage, get_cpu_memory(self.process_id))
self.num_measurements += 1
if stop:
break
stop = self.connection.poll(self.interval)
# send results to parent pipe
self.connection.send(self.mem_usage)
self.connection.send(self.num_measurements)
while True:
# create child, parent connection
child_connection, parent_connection = Pipe()
# instantiate process
mem_process = MemoryMeasureProcess(os.getpid(), child_connection, interval)
mem_process.start()
# wait until we get memory
parent_connection.recv()
try:
# execute function
function()
# start parent connection
parent_connection.send(0)
# receive memory and num measurements
max_memory = parent_connection.recv()
num_measurements = parent_connection.recv()
except Exception:
# kill process in a clean way
parent = psutil.Process(os.getpid())
for child in parent.children(recursive=True):
os.kill(child.pid, SIGKILL)
mem_process.join(0)
raise RuntimeError("Process killed. Error in Process")
# run process at least 20 * interval or until it finishes
mem_process.join(20 * interval)
if (num_measurements > 4) or (interval < 1e-6):
break
# reduce interval
interval /= 10
return max_memory
def start_memory_tracing(
modules_to_trace: Optional[Union[str, Iterable[str]]] = None,
modules_not_to_trace: Optional[Union[str, Iterable[str]]] = None,
events_to_trace: str = "line",
gpus_to_trace: Optional[List[int]] = None,
) -> MemoryTrace:
"""
Setup line-by-line tracing to record rss mem (RAM) at each line of a module or sub-module. See `./benchmark.py` for
usage examples. Current memory consumption is returned using psutil and in particular is the RSS memory "Resident
Set Size” (the non-swapped physical memory the process is using). See
https://psutil.readthedocs.io/en/latest/#psutil.Process.memory_info
Args:
- `modules_to_trace`: (None, string, list/tuple of string) if None, all events are recorded if string or list
of strings: only events from the listed module/sub-module will be recorded (e.g. 'fairseq' or
'transformers.models.gpt2.modeling_gpt2')
- `modules_not_to_trace`: (None, string, list/tuple of string) if None, no module is avoided if string or list
of strings: events from the listed module/sub-module will not be recorded (e.g. 'torch')
- `events_to_trace`: string or list of string of events to be recorded (see official python doc for
`sys.settrace` for the list of events) default to line
- `gpus_to_trace`: (optional list, default None) list of GPUs to trace. Default to tracing all GPUs
Return:
- `memory_trace` is a list of `UsedMemoryState` for each event (default each line of the traced script).
- `UsedMemoryState` are named tuples with the following fields:
- 'frame': a `Frame` namedtuple (see below) storing information on the current tracing frame (current
file, location in current file)
- 'cpu_memory': CPU RSS memory state *before* executing the line
- 'gpu_memory': GPU used memory *before* executing the line (sum for all GPUs or for only
`gpus_to_trace` if provided)
`Frame` is a namedtuple used by `UsedMemoryState` to list the current frame state. `Frame` has the following
fields: - 'filename' (string): Name of the file currently executed - 'module' (string): Name of the module
currently executed - 'line_number' (int): Number of the line currently executed - 'event' (string): Event that
triggered the tracing (default will be "line") - 'line_text' (string): Text of the line in the python script
"""
if is_psutil_available():
process = psutil.Process(os.getpid())
else:
logger.warning(
"Psutil not installed, we won't log CPU memory usage. "
"Install psutil (pip install psutil) to use CPU memory tracing."
)
process = None
if is_py3nvml_available():
try:
nvml.nvmlInit()
devices = list(range(nvml.nvmlDeviceGetCount())) if gpus_to_trace is None else gpus_to_trace
nvml.nvmlShutdown()
except (OSError, nvml.NVMLError):
logger.warning("Error while initializing communication with GPU. We won't perform GPU memory tracing.")
log_gpu = False
else:
log_gpu = is_torch_available() or is_tf_available()
else:
logger.warning(
"py3nvml not installed, we won't log GPU memory usage. "
"Install py3nvml (pip install py3nvml) to use GPU memory tracing."
)
log_gpu = False
memory_trace = []
def traceit(frame, event, args):
"""
Tracing method executed before running each line in a module or sub-module Record memory allocated in a list
with debugging information
"""
global _is_memory_tracing_enabled
if not _is_memory_tracing_enabled:
return traceit
# Filter events
if events_to_trace is not None:
if isinstance(events_to_trace, str) and event != events_to_trace:
return traceit
elif isinstance(events_to_trace, (list, tuple)) and event not in events_to_trace:
return traceit
if "__name__" not in frame.f_globals:
return traceit
# Filter modules
name = frame.f_globals["__name__"]
if not isinstance(name, str):
return traceit
else:
# Filter whitelist of modules to trace
if modules_to_trace is not None:
if isinstance(modules_to_trace, str) and modules_to_trace not in name:
return traceit
elif isinstance(modules_to_trace, (list, tuple)) and all(m not in name for m in modules_to_trace):
return traceit
# Filter blacklist of modules not to trace
if modules_not_to_trace is not None:
if isinstance(modules_not_to_trace, str) and modules_not_to_trace in name:
return traceit
elif isinstance(modules_not_to_trace, (list, tuple)) and any(m in name for m in modules_not_to_trace):
return traceit
# Record current tracing state (file, location in file...)
lineno = frame.f_lineno
filename = frame.f_globals["__file__"]
if filename.endswith(".pyc") or filename.endswith(".pyo"):
filename = filename[:-1]
line = linecache.getline(filename, lineno).rstrip()
traced_state = Frame(filename, name, lineno, event, line)
# Record current memory state (rss memory) and compute difference with previous memory state
cpu_mem = 0
if process is not None:
mem = process.memory_info()
cpu_mem = mem.rss
gpu_mem = 0
if log_gpu:
# Clear GPU caches
if is_torch_available():
torch_empty_cache()
if is_tf_available():
tf_context.context()._clear_caches() # See https://github.com/tensorflow/tensorflow/issues/20218#issuecomment-416771802
# Sum used memory for all GPUs
nvml.nvmlInit()
for i in devices:
handle = nvml.nvmlDeviceGetHandleByIndex(i)
meminfo = nvml.nvmlDeviceGetMemoryInfo(handle)
gpu_mem += meminfo.used
nvml.nvmlShutdown()
mem_state = UsedMemoryState(traced_state, cpu_mem, gpu_mem)
memory_trace.append(mem_state)
return traceit
sys.settrace(traceit)
global _is_memory_tracing_enabled
_is_memory_tracing_enabled = True
return memory_trace
def stop_memory_tracing(
memory_trace: Optional[MemoryTrace] = None, ignore_released_memory: bool = True
) -> Optional[MemorySummary]:
"""
Stop memory tracing cleanly and return a summary of the memory trace if a trace is given.
Args:
`memory_trace` (optional output of start_memory_tracing, default: None):
memory trace to convert in summary
`ignore_released_memory` (boolean, default: None):
if True we only sum memory increase to compute total memory
Return:
- None if `memory_trace` is None
- `MemorySummary` namedtuple otherwise with the fields:
- `sequential`: a list of `MemoryState` namedtuple (see below) computed from the provided `memory_trace` by
subtracting the memory after executing each line from the memory before executing said line.
- `cumulative`: a list of `MemoryState` namedtuple (see below) with cumulative increase in memory for each
line obtained by summing repeated memory increase for a line if it's executed several times. The list is
sorted from the frame with the largest memory consumption to the frame with the smallest (can be negative
if memory is released)
- `total`: total memory increase during the full tracing as a `Memory` named tuple (see below). Line with
memory release (negative consumption) are ignored if `ignore_released_memory` is `True` (default).
`Memory` named tuple have fields
- `byte` (integer): number of bytes,
- `string` (string): same as human readable string (ex: "3.5MB")
`Frame` are namedtuple used to list the current frame state and have the following fields:
- 'filename' (string): Name of the file currently executed
- 'module' (string): Name of the module currently executed
- 'line_number' (int): Number of the line currently executed
- 'event' (string): Event that triggered the tracing (default will be "line")
- 'line_text' (string): Text of the line in the python script
`MemoryState` are namedtuples listing frame + CPU/GPU memory with the following fields:
- `frame` (`Frame`): the current frame (see above)
- `cpu`: CPU memory consumed at during the current frame as a `Memory` named tuple
- `gpu`: GPU memory consumed at during the current frame as a `Memory` named tuple
- `cpu_gpu`: CPU + GPU memory consumed at during the current frame as a `Memory` named tuple
"""
global _is_memory_tracing_enabled
_is_memory_tracing_enabled = False
if memory_trace is not None and len(memory_trace) > 1:
memory_diff_trace = []
memory_curr_trace = []
cumulative_memory_dict = defaultdict(lambda: [0, 0, 0])
for (
(frame, cpu_mem, gpu_mem),
(next_frame, next_cpu_mem, next_gpu_mem),
) in zip(memory_trace[:-1], memory_trace[1:]):
cpu_mem_inc = next_cpu_mem - cpu_mem
gpu_mem_inc = next_gpu_mem - gpu_mem
cpu_gpu_mem_inc = cpu_mem_inc + gpu_mem_inc
memory_diff_trace.append(
MemoryState(
frame=frame,
cpu=Memory(cpu_mem_inc),
gpu=Memory(gpu_mem_inc),
cpu_gpu=Memory(cpu_gpu_mem_inc),
)
)
memory_curr_trace.append(
MemoryState(
frame=frame,
cpu=Memory(next_cpu_mem),
gpu=Memory(next_gpu_mem),
cpu_gpu=Memory(next_gpu_mem + next_cpu_mem),
)
)
cumulative_memory_dict[frame][0] += cpu_mem_inc
cumulative_memory_dict[frame][1] += gpu_mem_inc
cumulative_memory_dict[frame][2] += cpu_gpu_mem_inc
cumulative_memory = sorted(
cumulative_memory_dict.items(), key=lambda x: x[1][2], reverse=True
) # order by the total CPU + GPU memory increase
cumulative_memory = [
MemoryState(
frame=frame,
cpu=Memory(cpu_mem_inc),
gpu=Memory(gpu_mem_inc),
cpu_gpu=Memory(cpu_gpu_mem_inc),
)
for frame, (cpu_mem_inc, gpu_mem_inc, cpu_gpu_mem_inc) in cumulative_memory
]
memory_curr_trace = sorted(memory_curr_trace, key=lambda x: x.cpu_gpu.bytes, reverse=True)
if ignore_released_memory:
total_memory = sum(max(0, step_trace.cpu_gpu.bytes) for step_trace in memory_diff_trace)
else:
total_memory = sum(step_trace.cpu_gpu.bytes for step_trace in memory_diff_trace)
total_memory = Memory(total_memory)
return MemorySummary(
sequential=memory_diff_trace,
cumulative=cumulative_memory,
current=memory_curr_trace,
total=total_memory,
)
return None
def bytes_to_mega_bytes(memory_amount: int) -> int:
"""Utility to convert a number of bytes (int) into a number of mega bytes (int)"""
return memory_amount >> 20
class Benchmark(ABC):
"""
Benchmarks is a simple but feature-complete benchmarking script to compare memory and time performance of models in
Transformers.
"""
args: BenchmarkArguments
configs: PretrainedConfig
framework: str
def __init__(self, args: BenchmarkArguments = None, configs: PretrainedConfig = None):
self.args = args
if configs is None:
self.config_dict = {
model_name: AutoConfig.from_pretrained(model_name) for model_name in self.args.model_names
}
else:
self.config_dict = dict(zip(self.args.model_names, configs))
warnings.warn(
f"The class {self.__class__} is deprecated. Hugging Face Benchmarking utils"
" are deprecated in general and it is advised to use external Benchmarking libraries "
" to benchmark Transformer models.",
FutureWarning,
)
if self.args.memory and os.getenv("TRANSFORMERS_USE_MULTIPROCESSING") == 0:
logger.warning(
"Memory consumption will not be measured accurately if `args.multi_process` is set to `False.` The"
" flag 'TRANSFORMERS_USE_MULTIPROCESSING' should only be disabled for debugging / testing."
)
self._print_fn = None
self._framework_version = None
self._environment_info = None
@property
def print_fn(self):
if self._print_fn is None:
if self.args.log_print:
def print_and_log(*args):
with open(self.args.log_filename, "a") as log_file:
log_file.write("".join(args) + "\n")
print(*args)
self._print_fn = print_and_log
else:
self._print_fn = print
return self._print_fn
@property
@abstractmethod
def framework_version(self):
pass
@abstractmethod
def _inference_speed(self, model_name: str, batch_size: int, sequence_length: int) -> float:
pass
@abstractmethod
def _train_speed(self, model_name: str, batch_size: int, sequence_length: int) -> float:
pass
@abstractmethod
def _inference_memory(
self, model_name: str, batch_size: int, sequence_length: int
) -> [Memory, Optional[MemorySummary]]:
pass
@abstractmethod
def _train_memory(
self, model_name: str, batch_size: int, sequence_length: int
) -> [Memory, Optional[MemorySummary]]:
pass
def inference_speed(self, *args, **kwargs) -> float:
return separate_process_wrapper_fn(self._inference_speed, self.args.do_multi_processing)(*args, **kwargs)
def train_speed(self, *args, **kwargs) -> float:
return separate_process_wrapper_fn(self._train_speed, self.args.do_multi_processing)(*args, **kwargs)
def inference_memory(self, *args, **kwargs) -> [Memory, Optional[MemorySummary]]:
return separate_process_wrapper_fn(self._inference_memory, self.args.do_multi_processing)(*args, **kwargs)
def train_memory(self, *args, **kwargs) -> [Memory, Optional[MemorySummary]]:
return separate_process_wrapper_fn(self._train_memory, self.args.do_multi_processing)(*args, **kwargs)
def run(self):
result_dict = {model_name: {} for model_name in self.args.model_names}
inference_result_time = copy.deepcopy(result_dict)
inference_result_memory = copy.deepcopy(result_dict)
train_result_time = copy.deepcopy(result_dict)
train_result_memory = copy.deepcopy(result_dict)
for c, model_name in enumerate(self.args.model_names):
self.print_fn(f"{c + 1} / {len(self.args.model_names)}")
model_dict = {
"bs": self.args.batch_sizes,
"ss": self.args.sequence_lengths,
"result": {i: {} for i in self.args.batch_sizes},
}
inference_result_time[model_name] = copy.deepcopy(model_dict)
inference_result_memory[model_name] = copy.deepcopy(model_dict)
train_result_time[model_name] = copy.deepcopy(model_dict)
train_result_memory[model_name] = copy.deepcopy(model_dict)
inference_summary = train_summary = None
for batch_size in self.args.batch_sizes:
for sequence_length in self.args.sequence_lengths:
if self.args.inference:
if self.args.memory:
memory, inference_summary = self.inference_memory(model_name, batch_size, sequence_length)
inference_result_memory[model_name]["result"][batch_size][sequence_length] = memory
if self.args.speed:
time = self.inference_speed(model_name, batch_size, sequence_length)
inference_result_time[model_name]["result"][batch_size][sequence_length] = time
if self.args.training:
if self.args.memory:
memory, train_summary = self.train_memory(model_name, batch_size, sequence_length)
train_result_memory[model_name]["result"][batch_size][sequence_length] = memory
if self.args.speed:
time = self.train_speed(model_name, batch_size, sequence_length)
train_result_time[model_name]["result"][batch_size][sequence_length] = time
if self.args.inference:
if self.args.speed:
self.print_fn("\n" + 20 * "=" + ("INFERENCE - SPEED - RESULT").center(40) + 20 * "=")
self.print_results(inference_result_time, type_label="Time in s")
self.save_to_csv(inference_result_time, self.args.inference_time_csv_file)
if self.args.is_tpu:
self.print_fn(
"TPU was used for inference. Note that the time after compilation stabilized (after ~10"
" inferences model.forward(..) calls) was measured."
)
if self.args.memory:
self.print_fn("\n" + 20 * "=" + ("INFERENCE - MEMORY - RESULT").center(40) + 20 * "=")
self.print_results(inference_result_memory, type_label="Memory in MB")
self.save_to_csv(inference_result_memory, self.args.inference_memory_csv_file)
if self.args.trace_memory_line_by_line:
self.print_fn("\n" + 20 * "=" + ("INFERENCE - MEMOMRY - LINE BY LINE - SUMMARY").center(40) + 20 * "=")
self.print_memory_trace_statistics(inference_summary)
if self.args.training:
if self.args.speed:
self.print_fn("\n" + 20 * "=" + ("TRAIN - SPEED - RESULTS").center(40) + 20 * "=")
self.print_results(train_result_time, "Time in s")
self.save_to_csv(train_result_time, self.args.train_time_csv_file)
if self.args.is_tpu:
self.print_fn(
"TPU was used for training. Note that the time after compilation stabilized (after ~10 train"
" loss=model.forward(...) + loss.backward() calls) was measured."
)
if self.args.memory:
self.print_fn("\n" + 20 * "=" + ("TRAIN - MEMORY - RESULTS").center(40) + 20 * "=")
self.print_results(train_result_memory, type_label="Memory in MB")
self.save_to_csv(train_result_memory, self.args.train_memory_csv_file)
if self.args.trace_memory_line_by_line:
self.print_fn("\n" + 20 * "=" + ("TRAIN - MEMOMRY - LINE BY LINE - SUMMARY").center(40) + 20 * "=")
self.print_memory_trace_statistics(train_summary)
if self.args.env_print:
self.print_fn("\n" + 20 * "=" + ("ENVIRONMENT INFORMATION").center(40) + 20 * "=")
self.print_fn("\n".join([f"- {prop}: {val}" for prop, val in self.environment_info.items()]) + "\n")
if self.args.save_to_csv:
with open(self.args.env_info_csv_file, mode="w", newline="") as csv_file:
writer = csv.writer(csv_file)
for key, value in self.environment_info.items():
writer.writerow([key, value])
return BenchmarkOutput(
inference_result_time,
inference_result_memory,
train_result_time,
train_result_memory,
inference_summary,
train_summary,
)
@property
def environment_info(self):
if self._environment_info is None:
info = {}
info["transformers_version"] = version
info["framework"] = self.framework
if self.framework == "PyTorch":
info["use_torchscript"] = self.args.torchscript
if self.framework == "TensorFlow":
info["eager_mode"] = self.args.eager_mode
info["use_xla"] = self.args.use_xla
info["framework_version"] = self.framework_version
info["python_version"] = platform.python_version()
info["system"] = platform.system()
info["cpu"] = platform.processor()
info["architecture"] = platform.architecture()[0]
info["date"] = datetime.date(datetime.now())
info["time"] = datetime.time(datetime.now())
info["fp16"] = self.args.fp16
info["use_multiprocessing"] = self.args.do_multi_processing
info["only_pretrain_model"] = self.args.only_pretrain_model
if is_psutil_available():
info["cpu_ram_mb"] = bytes_to_mega_bytes(psutil.virtual_memory().total)
else:
logger.warning(
"Psutil not installed, we won't log available CPU memory. "
"Install psutil (pip install psutil) to log available CPU memory."
)
info["cpu_ram_mb"] = "N/A"
info["use_gpu"] = self.args.is_gpu
if self.args.is_gpu:
info["num_gpus"] = 1 # TODO(PVP) Currently only single GPU is supported
if is_py3nvml_available():
nvml.nvmlInit()
handle = nvml.nvmlDeviceGetHandleByIndex(self.args.device_idx)
info["gpu"] = nvml.nvmlDeviceGetName(handle)
info["gpu_ram_mb"] = bytes_to_mega_bytes(nvml.nvmlDeviceGetMemoryInfo(handle).total)
info["gpu_power_watts"] = nvml.nvmlDeviceGetPowerManagementLimit(handle) / 1000
info["gpu_performance_state"] = nvml.nvmlDeviceGetPerformanceState(handle)
nvml.nvmlShutdown()
else:
logger.warning(
"py3nvml not installed, we won't log GPU memory usage. "
"Install py3nvml (pip install py3nvml) to log information about GPU."
)
info["gpu"] = "N/A"
info["gpu_ram_mb"] = "N/A"
info["gpu_power_watts"] = "N/A"
info["gpu_performance_state"] = "N/A"
info["use_tpu"] = self.args.is_tpu
# TODO(PVP): See if we can add more information about TPU
# see: https://github.com/pytorch/xla/issues/2180
self._environment_info = info
return self._environment_info
def print_results(self, result_dict, type_label):
self.print_fn(80 * "-")
self.print_fn(
"Model Name".center(30) + "Batch Size".center(15) + "Seq Length".center(15) + type_label.center(15)
)
self.print_fn(80 * "-")
for model_name in self.args.model_names:
for batch_size in result_dict[model_name]["bs"]:
for sequence_length in result_dict[model_name]["ss"]:
result = result_dict[model_name]["result"][batch_size][sequence_length]
if isinstance(result, float):
result = round(1000 * result) / 1000
result = "< 0.001" if result == 0.0 else str(result)
else:
result = str(result)
self.print_fn(
model_name[:30].center(30) + str(batch_size).center(15),
str(sequence_length).center(15),
result.center(15),
)
self.print_fn(80 * "-")
def print_memory_trace_statistics(self, summary: MemorySummary):
self.print_fn(
"\nLine by line memory consumption:\n"
+ "\n".join(
f"{state.frame.filename}:{state.frame.line_number}: mem {state.cpu_gpu}: {state.frame.line_text}"
for state in summary.sequential
)
)
self.print_fn(
"\nLines with top memory consumption:\n"
+ "\n".join(
f"=> {state.frame.filename}:{state.frame.line_number}: mem {state.cpu_gpu}: {state.frame.line_text}"
for state in summary.cumulative[:6]
)
)
self.print_fn(
"\nLines with lowest memory consumption:\n"
+ "\n".join(
f"=> {state.frame.filename}:{state.frame.line_number}: mem {state.cpu_gpu}: {state.frame.line_text}"
for state in summary.cumulative[-6:]
)
)
self.print_fn(f"\nTotal memory increase: {summary.total}")
def save_to_csv(self, result_dict, filename):
if not self.args.save_to_csv:
return
self.print_fn("Saving results to csv.")
with open(filename, mode="w") as csv_file:
if len(self.args.model_names) <= 0:
raise ValueError(f"At least 1 model should be defined, but got {self.model_names}")
fieldnames = ["model", "batch_size", "sequence_length"]
writer = csv.DictWriter(csv_file, fieldnames=fieldnames + ["result"])
writer.writeheader()
for model_name in self.args.model_names:
result_dict_model = result_dict[model_name]["result"]
for bs in result_dict_model:
for ss in result_dict_model[bs]:
result_model = result_dict_model[bs][ss]
writer.writerow(
{
"model": model_name,
"batch_size": bs,
"sequence_length": ss,
"result": ("{}" if not isinstance(result_model, float) else "{:.4f}").format(
result_model
),
}
)
| transformers/src/transformers/benchmark/benchmark_utils.py/0 | {
"file_path": "transformers/src/transformers/benchmark/benchmark_utils.py",
"repo_id": "transformers",
"token_count": 16506
} | 286 |
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import warnings
from argparse import ArgumentParser
from os import listdir, makedirs
from pathlib import Path
from typing import Dict, List, Optional, Tuple
from packaging.version import Version, parse
from transformers.pipelines import Pipeline, pipeline
from transformers.tokenization_utils import BatchEncoding
from transformers.utils import ModelOutput, is_tf_available, is_torch_available
# This is the minimal required version to
# support some ONNX Runtime features
ORT_QUANTIZE_MINIMUM_VERSION = parse("1.4.0")
SUPPORTED_PIPELINES = [
"feature-extraction",
"ner",
"sentiment-analysis",
"fill-mask",
"question-answering",
"text-generation",
"translation_en_to_fr",
"translation_en_to_de",
"translation_en_to_ro",
]
class OnnxConverterArgumentParser(ArgumentParser):
"""
Wraps all the script arguments supported to export transformers models to ONNX IR
"""
def __init__(self):
super().__init__("ONNX Converter")
self.add_argument(
"--pipeline",
type=str,
choices=SUPPORTED_PIPELINES,
default="feature-extraction",
)
self.add_argument(
"--model",
type=str,
required=True,
help="Model's id or path (ex: google-bert/bert-base-cased)",
)
self.add_argument("--tokenizer", type=str, help="Tokenizer's id or path (ex: google-bert/bert-base-cased)")
self.add_argument(
"--framework",
type=str,
choices=["pt", "tf"],
help="Framework for loading the model",
)
self.add_argument("--opset", type=int, default=11, help="ONNX opset to use")
self.add_argument(
"--check-loading",
action="store_true",
help="Check ONNX is able to load the model",
)
self.add_argument(
"--use-external-format",
action="store_true",
help="Allow exporting model >= than 2Gb",
)
self.add_argument(
"--quantize",
action="store_true",
help="Quantize the neural network to be run with int8",
)
self.add_argument("output")
def generate_identified_filename(filename: Path, identifier: str) -> Path:
"""
Append a string-identifier at the end (before the extension, if any) to the provided filepath
Args:
filename: pathlib.Path The actual path object we would like to add an identifier suffix
identifier: The suffix to add
Returns: String with concatenated identifier at the end of the filename
"""
return filename.parent.joinpath(filename.stem + identifier).with_suffix(filename.suffix)
def check_onnxruntime_requirements(minimum_version: Version):
"""
Check onnxruntime is installed and if the installed version match is recent enough
Raises:
ImportError: If onnxruntime is not installed or too old version is found
"""
try:
import onnxruntime
# Parse the version of the installed onnxruntime
ort_version = parse(onnxruntime.__version__)
# We require 1.4.0 minimum
if ort_version < ORT_QUANTIZE_MINIMUM_VERSION:
raise ImportError(
f"We found an older version of onnxruntime ({onnxruntime.__version__}) "
f"but we require onnxruntime to be >= {minimum_version} to enable all the conversions options.\n"
"Please update onnxruntime by running `pip install --upgrade onnxruntime`"
)
except ImportError:
raise ImportError(
"onnxruntime doesn't seem to be currently installed. "
"Please install the onnxruntime by running `pip install onnxruntime`"
" and relaunch the conversion."
)
def ensure_valid_input(model, tokens, input_names):
"""
Ensure inputs are presented in the correct order, without any Non
Args:
model: The model used to forward the input data
tokens: BatchEncoding holding the input data
input_names: The name of the inputs
Returns: Tuple
"""
print("Ensuring inputs are in correct order")
model_args_name = model.forward.__code__.co_varnames
model_args, ordered_input_names = [], []
for arg_name in model_args_name[1:]: # start at index 1 to skip "self" argument
if arg_name in input_names:
ordered_input_names.append(arg_name)
model_args.append(tokens[arg_name])
else:
print(f"{arg_name} is not present in the generated input list.")
break
print(f"Generated inputs order: {ordered_input_names}")
return ordered_input_names, tuple(model_args)
def infer_shapes(nlp: Pipeline, framework: str) -> Tuple[List[str], List[str], Dict, BatchEncoding]:
"""
Attempt to infer the static vs dynamic axes for each input and output tensors for a specific model
Args:
nlp: The pipeline object holding the model to be exported
framework: The framework identifier to dispatch to the correct inference scheme (pt/tf)
Returns:
- List of the inferred input variable names
- List of the inferred output variable names
- Dictionary with input/output variables names as key and shape tensor as value
- a BatchEncoding reference which was used to infer all the above information
"""
def build_shape_dict(name: str, tensor, is_input: bool, seq_len: int):
if isinstance(tensor, (tuple, list)):
return [build_shape_dict(name, t, is_input, seq_len) for t in tensor]
else:
# Let's assume batch is the first axis with only 1 element (~~ might not be always true ...)
axes = {[axis for axis, numel in enumerate(tensor.shape) if numel == 1][0]: "batch"}
if is_input:
if len(tensor.shape) == 2:
axes[1] = "sequence"
else:
raise ValueError(f"Unable to infer tensor axes ({len(tensor.shape)})")
else:
seq_axes = [dim for dim, shape in enumerate(tensor.shape) if shape == seq_len]
axes.update({dim: "sequence" for dim in seq_axes})
print(f"Found {'input' if is_input else 'output'} {name} with shape: {axes}")
return axes
tokens = nlp.tokenizer("This is a sample output", return_tensors=framework)
seq_len = tokens.input_ids.shape[-1]
outputs = nlp.model(**tokens) if framework == "pt" else nlp.model(tokens)
if isinstance(outputs, ModelOutput):
outputs = outputs.to_tuple()
if not isinstance(outputs, (list, tuple)):
outputs = (outputs,)
# Generate input names & axes
input_vars = list(tokens.keys())
input_dynamic_axes = {k: build_shape_dict(k, v, True, seq_len) for k, v in tokens.items()}
# flatten potentially grouped outputs (past for gpt2, attentions)
outputs_flat = []
for output in outputs:
if isinstance(output, (tuple, list)):
outputs_flat.extend(output)
else:
outputs_flat.append(output)
# Generate output names & axes
output_names = [f"output_{i}" for i in range(len(outputs_flat))]
output_dynamic_axes = {k: build_shape_dict(k, v, False, seq_len) for k, v in zip(output_names, outputs_flat)}
# Create the aggregated axes representation
dynamic_axes = dict(input_dynamic_axes, **output_dynamic_axes)
return input_vars, output_names, dynamic_axes, tokens
def load_graph_from_args(
pipeline_name: str, framework: str, model: str, tokenizer: Optional[str] = None, **models_kwargs
) -> Pipeline:
"""
Convert the set of arguments provided through the CLI to an actual pipeline reference (tokenizer + model
Args:
pipeline_name: The kind of pipeline to use (ner, question-answering, etc.)
framework: The actual model to convert the pipeline from ("pt" or "tf")
model: The model name which will be loaded by the pipeline
tokenizer: The tokenizer name which will be loaded by the pipeline, default to the model's value
Returns: Pipeline object
"""
# If no tokenizer provided
if tokenizer is None:
tokenizer = model
# Check the wanted framework is available
if framework == "pt" and not is_torch_available():
raise Exception("Cannot convert because PyTorch is not installed. Please install torch first.")
if framework == "tf" and not is_tf_available():
raise Exception("Cannot convert because TF is not installed. Please install tensorflow first.")
print(f"Loading pipeline (model: {model}, tokenizer: {tokenizer})")
# Allocate tokenizer and model
return pipeline(pipeline_name, model=model, tokenizer=tokenizer, framework=framework, model_kwargs=models_kwargs)
def convert_pytorch(nlp: Pipeline, opset: int, output: Path, use_external_format: bool):
"""
Export a PyTorch backed pipeline to ONNX Intermediate Representation (IR
Args:
nlp: The pipeline to be exported
opset: The actual version of the ONNX operator set to use
output: Path where will be stored the generated ONNX model
use_external_format: Split the model definition from its parameters to allow model bigger than 2GB
Returns:
"""
if not is_torch_available():
raise Exception("Cannot convert because PyTorch is not installed. Please install torch first.")
import torch
from torch.onnx import export
print(f"Using framework PyTorch: {torch.__version__}")
with torch.no_grad():
input_names, output_names, dynamic_axes, tokens = infer_shapes(nlp, "pt")
ordered_input_names, model_args = ensure_valid_input(nlp.model, tokens, input_names)
export(
nlp.model,
model_args,
f=output.as_posix(),
input_names=ordered_input_names,
output_names=output_names,
dynamic_axes=dynamic_axes,
do_constant_folding=True,
opset_version=opset,
)
def convert_tensorflow(nlp: Pipeline, opset: int, output: Path):
"""
Export a TensorFlow backed pipeline to ONNX Intermediate Representation (IR)
Args:
nlp: The pipeline to be exported
opset: The actual version of the ONNX operator set to use
output: Path where will be stored the generated ONNX model
Notes: TensorFlow cannot export model bigger than 2GB due to internal constraint from TensorFlow
"""
if not is_tf_available():
raise Exception("Cannot convert because TF is not installed. Please install tensorflow first.")
print("/!\\ Please note TensorFlow doesn't support exporting model > 2Gb /!\\")
try:
import tensorflow as tf
import tf2onnx
from tf2onnx import __version__ as t2ov
print(f"Using framework TensorFlow: {tf.version.VERSION}, tf2onnx: {t2ov}")
# Build
input_names, output_names, dynamic_axes, tokens = infer_shapes(nlp, "tf")
# Forward
nlp.model.predict(tokens.data)
input_signature = [tf.TensorSpec.from_tensor(tensor, name=key) for key, tensor in tokens.items()]
model_proto, _ = tf2onnx.convert.from_keras(
nlp.model, input_signature, opset=opset, output_path=output.as_posix()
)
except ImportError as e:
raise Exception(
f"Cannot import {e.name} required to convert TF model to ONNX. Please install {e.name} first. {e}"
)
def convert(
framework: str,
model: str,
output: Path,
opset: int,
tokenizer: Optional[str] = None,
use_external_format: bool = False,
pipeline_name: str = "feature-extraction",
**model_kwargs,
):
"""
Convert the pipeline object to the ONNX Intermediate Representation (IR) format
Args:
framework: The framework the pipeline is backed by ("pt" or "tf")
model: The name of the model to load for the pipeline
output: The path where the ONNX graph will be stored
opset: The actual version of the ONNX operator set to use
tokenizer: The name of the model to load for the pipeline, default to the model's name if not provided
use_external_format:
Split the model definition from its parameters to allow model bigger than 2GB (PyTorch only)
pipeline_name: The kind of pipeline to instantiate (ner, question-answering, etc.)
model_kwargs: Keyword arguments to be forwarded to the model constructor
Returns:
"""
warnings.warn(
"The `transformers.convert_graph_to_onnx` package is deprecated and will be removed in version 5 of"
" Transformers",
FutureWarning,
)
print(f"ONNX opset version set to: {opset}")
# Load the pipeline
nlp = load_graph_from_args(pipeline_name, framework, model, tokenizer, **model_kwargs)
if not output.parent.exists():
print(f"Creating folder {output.parent}")
makedirs(output.parent.as_posix())
elif len(listdir(output.parent.as_posix())) > 0:
raise Exception(f"Folder {output.parent.as_posix()} is not empty, aborting conversion")
# Export the graph
if framework == "pt":
convert_pytorch(nlp, opset, output, use_external_format)
else:
convert_tensorflow(nlp, opset, output)
def optimize(onnx_model_path: Path) -> Path:
"""
Load the model at the specified path and let onnxruntime look at transformations on the graph to enable all the
optimizations possible
Args:
onnx_model_path: filepath where the model binary description is stored
Returns: Path where the optimized model binary description has been saved
"""
from onnxruntime import InferenceSession, SessionOptions
# Generate model name with suffix "optimized"
opt_model_path = generate_identified_filename(onnx_model_path, "-optimized")
sess_option = SessionOptions()
sess_option.optimized_model_filepath = opt_model_path.as_posix()
_ = InferenceSession(onnx_model_path.as_posix(), sess_option)
print(f"Optimized model has been written at {opt_model_path}: \N{heavy check mark}")
print("/!\\ Optimized model contains hardware specific operators which might not be portable. /!\\")
return opt_model_path
def quantize(onnx_model_path: Path) -> Path:
"""
Quantize the weights of the model from float32 to in8 to allow very efficient inference on modern CPU
Args:
onnx_model_path: Path to location the exported ONNX model is stored
Returns: The Path generated for the quantized
"""
import onnx
import onnxruntime
from onnx.onnx_pb import ModelProto
from onnxruntime.quantization import QuantizationMode
from onnxruntime.quantization.onnx_quantizer import ONNXQuantizer
from onnxruntime.quantization.registry import IntegerOpsRegistry
# Load the ONNX model
onnx_model = onnx.load(onnx_model_path.as_posix())
if parse(onnx.__version__) < parse("1.5.0"):
print(
"Models larger than 2GB will fail to quantize due to protobuf constraint.\n"
"Please upgrade to onnxruntime >= 1.5.0."
)
# Copy it
copy_model = ModelProto()
copy_model.CopyFrom(onnx_model)
# Construct quantizer
# onnxruntime renamed input_qType to activation_qType in v1.13.1, so we
# check the onnxruntime version to ensure backward compatibility.
# See also: https://github.com/microsoft/onnxruntime/pull/12873
if parse(onnxruntime.__version__) < parse("1.13.1"):
quantizer = ONNXQuantizer(
model=copy_model,
per_channel=False,
reduce_range=False,
mode=QuantizationMode.IntegerOps,
static=False,
weight_qType=True,
input_qType=False,
tensors_range=None,
nodes_to_quantize=None,
nodes_to_exclude=None,
op_types_to_quantize=list(IntegerOpsRegistry),
)
else:
quantizer = ONNXQuantizer(
model=copy_model,
per_channel=False,
reduce_range=False,
mode=QuantizationMode.IntegerOps,
static=False,
weight_qType=True,
activation_qType=False,
tensors_range=None,
nodes_to_quantize=None,
nodes_to_exclude=None,
op_types_to_quantize=list(IntegerOpsRegistry),
)
# Quantize and export
quantizer.quantize_model()
# Append "-quantized" at the end of the model's name
quantized_model_path = generate_identified_filename(onnx_model_path, "-quantized")
# Save model
print(f"Quantized model has been written at {quantized_model_path}: \N{heavy check mark}")
onnx.save_model(quantizer.model.model, quantized_model_path.as_posix())
return quantized_model_path
def verify(path: Path):
from onnxruntime import InferenceSession, SessionOptions
from onnxruntime.capi.onnxruntime_pybind11_state import RuntimeException
print(f"Checking ONNX model loading from: {path} ...")
try:
onnx_options = SessionOptions()
_ = InferenceSession(path.as_posix(), onnx_options, providers=["CPUExecutionProvider"])
print(f"Model {path} correctly loaded: \N{heavy check mark}")
except RuntimeException as re:
print(f"Error while loading the model {re}: \N{heavy ballot x}")
if __name__ == "__main__":
parser = OnnxConverterArgumentParser()
args = parser.parse_args()
# Make sure output is absolute path
args.output = Path(args.output).absolute()
try:
print("\n====== Converting model to ONNX ======")
# Convert
convert(
args.framework,
args.model,
args.output,
args.opset,
args.tokenizer,
args.use_external_format,
args.pipeline,
)
if args.quantize:
# Ensure requirements for quantization on onnxruntime is met
check_onnxruntime_requirements(ORT_QUANTIZE_MINIMUM_VERSION)
# onnxruntime optimizations doesn't provide the same level of performances on TensorFlow than PyTorch
if args.framework == "tf":
print(
"\t Using TensorFlow might not provide the same optimization level compared to PyTorch.\n"
"\t For TensorFlow users you can try optimizing the model directly through onnxruntime_tools.\n"
"\t For more information, please refer to the onnxruntime documentation:\n"
"\t\thttps://github.com/microsoft/onnxruntime/tree/master/onnxruntime/python/tools/transformers\n"
)
print("\n====== Optimizing ONNX model ======")
# Quantization works best when using the optimized version of the model
args.optimized_output = optimize(args.output)
# Do the quantization on the right graph
args.quantized_output = quantize(args.optimized_output)
# And verify
if args.check_loading:
print("\n====== Check exported ONNX model(s) ======")
verify(args.output)
if hasattr(args, "optimized_output"):
verify(args.optimized_output)
if hasattr(args, "quantized_output"):
verify(args.quantized_output)
except Exception as e:
print(f"Error while converting the model: {e}")
exit(1)
| transformers/src/transformers/convert_graph_to_onnx.py/0 | {
"file_path": "transformers/src/transformers/convert_graph_to_onnx.py",
"repo_id": "transformers",
"token_count": 7910
} | 287 |
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import csv
import dataclasses
import json
from dataclasses import dataclass
from typing import List, Optional, Union
from ...utils import is_tf_available, is_torch_available, logging
logger = logging.get_logger(__name__)
@dataclass
class InputExample:
"""
A single training/test example for simple sequence classification.
Args:
guid: Unique id for the example.
text_a: string. The untokenized text of the first sequence. For single
sequence tasks, only this sequence must be specified.
text_b: (Optional) string. The untokenized text of the second sequence.
Only must be specified for sequence pair tasks.
label: (Optional) string. The label of the example. This should be
specified for train and dev examples, but not for test examples.
"""
guid: str
text_a: str
text_b: Optional[str] = None
label: Optional[str] = None
def to_json_string(self):
"""Serializes this instance to a JSON string."""
return json.dumps(dataclasses.asdict(self), indent=2) + "\n"
@dataclass(frozen=True)
class InputFeatures:
"""
A single set of features of data. Property names are the same names as the corresponding inputs to a model.
Args:
input_ids: Indices of input sequence tokens in the vocabulary.
attention_mask: Mask to avoid performing attention on padding token indices.
Mask values selected in `[0, 1]`: Usually `1` for tokens that are NOT MASKED, `0` for MASKED (padded)
tokens.
token_type_ids: (Optional) Segment token indices to indicate first and second
portions of the inputs. Only some models use them.
label: (Optional) Label corresponding to the input. Int for classification problems,
float for regression problems.
"""
input_ids: List[int]
attention_mask: Optional[List[int]] = None
token_type_ids: Optional[List[int]] = None
label: Optional[Union[int, float]] = None
def to_json_string(self):
"""Serializes this instance to a JSON string."""
return json.dumps(dataclasses.asdict(self)) + "\n"
class DataProcessor:
"""Base class for data converters for sequence classification data sets."""
def get_example_from_tensor_dict(self, tensor_dict):
"""
Gets an example from a dict with tensorflow tensors.
Args:
tensor_dict: Keys and values should match the corresponding Glue
tensorflow_dataset examples.
"""
raise NotImplementedError()
def get_train_examples(self, data_dir):
"""Gets a collection of [`InputExample`] for the train set."""
raise NotImplementedError()
def get_dev_examples(self, data_dir):
"""Gets a collection of [`InputExample`] for the dev set."""
raise NotImplementedError()
def get_test_examples(self, data_dir):
"""Gets a collection of [`InputExample`] for the test set."""
raise NotImplementedError()
def get_labels(self):
"""Gets the list of labels for this data set."""
raise NotImplementedError()
def tfds_map(self, example):
"""
Some tensorflow_datasets datasets are not formatted the same way the GLUE datasets are. This method converts
examples to the correct format.
"""
if len(self.get_labels()) > 1:
example.label = self.get_labels()[int(example.label)]
return example
@classmethod
def _read_tsv(cls, input_file, quotechar=None):
"""Reads a tab separated value file."""
with open(input_file, "r", encoding="utf-8-sig") as f:
return list(csv.reader(f, delimiter="\t", quotechar=quotechar))
class SingleSentenceClassificationProcessor(DataProcessor):
"""Generic processor for a single sentence classification data set."""
def __init__(self, labels=None, examples=None, mode="classification", verbose=False):
self.labels = [] if labels is None else labels
self.examples = [] if examples is None else examples
self.mode = mode
self.verbose = verbose
def __len__(self):
return len(self.examples)
def __getitem__(self, idx):
if isinstance(idx, slice):
return SingleSentenceClassificationProcessor(labels=self.labels, examples=self.examples[idx])
return self.examples[idx]
@classmethod
def create_from_csv(
cls, file_name, split_name="", column_label=0, column_text=1, column_id=None, skip_first_row=False, **kwargs
):
processor = cls(**kwargs)
processor.add_examples_from_csv(
file_name,
split_name=split_name,
column_label=column_label,
column_text=column_text,
column_id=column_id,
skip_first_row=skip_first_row,
overwrite_labels=True,
overwrite_examples=True,
)
return processor
@classmethod
def create_from_examples(cls, texts_or_text_and_labels, labels=None, **kwargs):
processor = cls(**kwargs)
processor.add_examples(texts_or_text_and_labels, labels=labels)
return processor
def add_examples_from_csv(
self,
file_name,
split_name="",
column_label=0,
column_text=1,
column_id=None,
skip_first_row=False,
overwrite_labels=False,
overwrite_examples=False,
):
lines = self._read_tsv(file_name)
if skip_first_row:
lines = lines[1:]
texts = []
labels = []
ids = []
for i, line in enumerate(lines):
texts.append(line[column_text])
labels.append(line[column_label])
if column_id is not None:
ids.append(line[column_id])
else:
guid = f"{split_name}-{i}" if split_name else str(i)
ids.append(guid)
return self.add_examples(
texts, labels, ids, overwrite_labels=overwrite_labels, overwrite_examples=overwrite_examples
)
def add_examples(
self, texts_or_text_and_labels, labels=None, ids=None, overwrite_labels=False, overwrite_examples=False
):
if labels is not None and len(texts_or_text_and_labels) != len(labels):
raise ValueError(
f"Text and labels have mismatched lengths {len(texts_or_text_and_labels)} and {len(labels)}"
)
if ids is not None and len(texts_or_text_and_labels) != len(ids):
raise ValueError(f"Text and ids have mismatched lengths {len(texts_or_text_and_labels)} and {len(ids)}")
if ids is None:
ids = [None] * len(texts_or_text_and_labels)
if labels is None:
labels = [None] * len(texts_or_text_and_labels)
examples = []
added_labels = set()
for text_or_text_and_label, label, guid in zip(texts_or_text_and_labels, labels, ids):
if isinstance(text_or_text_and_label, (tuple, list)) and label is None:
text, label = text_or_text_and_label
else:
text = text_or_text_and_label
added_labels.add(label)
examples.append(InputExample(guid=guid, text_a=text, text_b=None, label=label))
# Update examples
if overwrite_examples:
self.examples = examples
else:
self.examples.extend(examples)
# Update labels
if overwrite_labels:
self.labels = list(added_labels)
else:
self.labels = list(set(self.labels).union(added_labels))
return self.examples
def get_features(
self,
tokenizer,
max_length=None,
pad_on_left=False,
pad_token=0,
mask_padding_with_zero=True,
return_tensors=None,
):
"""
Convert examples in a list of `InputFeatures`
Args:
tokenizer: Instance of a tokenizer that will tokenize the examples
max_length: Maximum example length
pad_on_left: If set to `True`, the examples will be padded on the left rather than on the right (default)
pad_token: Padding token
mask_padding_with_zero: If set to `True`, the attention mask will be filled by `1` for actual values
and by `0` for padded values. If set to `False`, inverts it (`1` for padded values, `0` for actual
values)
Returns:
If the `examples` input is a `tf.data.Dataset`, will return a `tf.data.Dataset` containing the
task-specific features. If the input is a list of `InputExamples`, will return a list of task-specific
`InputFeatures` which can be fed to the model.
"""
if max_length is None:
max_length = tokenizer.max_len
label_map = {label: i for i, label in enumerate(self.labels)}
all_input_ids = []
for ex_index, example in enumerate(self.examples):
if ex_index % 10000 == 0:
logger.info(f"Tokenizing example {ex_index}")
input_ids = tokenizer.encode(
example.text_a,
add_special_tokens=True,
max_length=min(max_length, tokenizer.max_len),
)
all_input_ids.append(input_ids)
batch_length = max(len(input_ids) for input_ids in all_input_ids)
features = []
for ex_index, (input_ids, example) in enumerate(zip(all_input_ids, self.examples)):
if ex_index % 10000 == 0:
logger.info(f"Writing example {ex_index}/{len(self.examples)}")
# The mask has 1 for real tokens and 0 for padding tokens. Only real
# tokens are attended to.
attention_mask = [1 if mask_padding_with_zero else 0] * len(input_ids)
# Zero-pad up to the sequence length.
padding_length = batch_length - len(input_ids)
if pad_on_left:
input_ids = ([pad_token] * padding_length) + input_ids
attention_mask = ([0 if mask_padding_with_zero else 1] * padding_length) + attention_mask
else:
input_ids = input_ids + ([pad_token] * padding_length)
attention_mask = attention_mask + ([0 if mask_padding_with_zero else 1] * padding_length)
if len(input_ids) != batch_length:
raise ValueError(f"Error with input length {len(input_ids)} vs {batch_length}")
if len(attention_mask) != batch_length:
raise ValueError(f"Error with input length {len(attention_mask)} vs {batch_length}")
if self.mode == "classification":
label = label_map[example.label]
elif self.mode == "regression":
label = float(example.label)
else:
raise ValueError(self.mode)
if ex_index < 5 and self.verbose:
logger.info("*** Example ***")
logger.info(f"guid: {example.guid}")
logger.info(f"input_ids: {' '.join([str(x) for x in input_ids])}")
logger.info(f"attention_mask: {' '.join([str(x) for x in attention_mask])}")
logger.info(f"label: {example.label} (id = {label})")
features.append(InputFeatures(input_ids=input_ids, attention_mask=attention_mask, label=label))
if return_tensors is None:
return features
elif return_tensors == "tf":
if not is_tf_available():
raise RuntimeError("return_tensors set to 'tf' but TensorFlow 2.0 can't be imported")
import tensorflow as tf
def gen():
for ex in features:
yield ({"input_ids": ex.input_ids, "attention_mask": ex.attention_mask}, ex.label)
dataset = tf.data.Dataset.from_generator(
gen,
({"input_ids": tf.int32, "attention_mask": tf.int32}, tf.int64),
({"input_ids": tf.TensorShape([None]), "attention_mask": tf.TensorShape([None])}, tf.TensorShape([])),
)
return dataset
elif return_tensors == "pt":
if not is_torch_available():
raise RuntimeError("return_tensors set to 'pt' but PyTorch can't be imported")
import torch
from torch.utils.data import TensorDataset
all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)
all_attention_mask = torch.tensor([f.attention_mask for f in features], dtype=torch.long)
if self.mode == "classification":
all_labels = torch.tensor([f.label for f in features], dtype=torch.long)
elif self.mode == "regression":
all_labels = torch.tensor([f.label for f in features], dtype=torch.float)
dataset = TensorDataset(all_input_ids, all_attention_mask, all_labels)
return dataset
else:
raise ValueError("return_tensors should be one of 'tf' or 'pt'")
| transformers/src/transformers/data/processors/utils.py/0 | {
"file_path": "transformers/src/transformers/data/processors/utils.py",
"repo_id": "transformers",
"token_count": 5994
} | 288 |
# coding=utf-8
# Copyright 2021 The Google AI Flax Team Authors, and The HuggingFace Inc. team.
# Copyright (c) 2020, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import copy
import inspect
import warnings
from functools import partial
from typing import Any, Dict, Optional, Union
import flax
import jax
import jax.numpy as jnp
import numpy as np
from jax import lax
from ..models.auto import (
FLAX_MODEL_FOR_CAUSAL_LM_MAPPING,
FLAX_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING,
FLAX_MODEL_FOR_VISION_2_SEQ_MAPPING,
)
from ..utils import ModelOutput, logging
from .configuration_utils import GenerationConfig
from .flax_logits_process import (
FlaxForcedBOSTokenLogitsProcessor,
FlaxForcedEOSTokenLogitsProcessor,
FlaxForceTokensLogitsProcessor,
FlaxLogitsProcessorList,
FlaxMinLengthLogitsProcessor,
FlaxSuppressTokensAtBeginLogitsProcessor,
FlaxSuppressTokensLogitsProcessor,
FlaxTemperatureLogitsWarper,
FlaxTopKLogitsWarper,
FlaxTopPLogitsWarper,
)
logger = logging.get_logger(__name__)
@flax.struct.dataclass
class FlaxGreedySearchOutput(ModelOutput):
"""
Flax Base class for outputs of decoder-only generation models using greedy search.
Args:
sequences (`jnp.ndarray` of shape `(batch_size, max_length)`):
The generated sequences.
"""
sequences: jnp.ndarray = None
@flax.struct.dataclass
class FlaxSampleOutput(ModelOutput):
"""
Flax Base class for outputs of decoder-only generation models using sampling.
Args:
sequences (`jnp.ndarray` of shape `(batch_size, max_length)`):
The generated sequences.
"""
sequences: jnp.ndarray = None
@flax.struct.dataclass
class FlaxBeamSearchOutput(ModelOutput):
"""
Flax Base class for outputs of decoder-only generation models using greedy search.
Args:
sequences (`jnp.ndarray` of shape `(batch_size, max_length)`):
The generated sequences.
scores (`jnp.ndarray` of shape `(batch_size,)`):
The scores (log probabilities) of the generated sequences.
"""
sequences: jnp.ndarray = None
scores: jnp.ndarray = None
@flax.struct.dataclass
class GreedyState:
cur_len: jnp.ndarray
sequences: jnp.ndarray
running_token: jnp.ndarray
is_sent_finished: jnp.ndarray
model_kwargs: Dict[str, jnp.ndarray]
@flax.struct.dataclass
class SampleState:
cur_len: jnp.ndarray
sequences: jnp.ndarray
running_token: jnp.ndarray
is_sent_finished: jnp.ndarray
prng_key: jnp.ndarray
model_kwargs: Dict[str, jnp.ndarray]
@flax.struct.dataclass
class BeamSearchState:
cur_len: jnp.ndarray
running_sequences: jnp.ndarray
running_scores: jnp.ndarray
sequences: jnp.ndarray
scores: jnp.ndarray
is_sent_finished: jnp.ndarray
model_kwargs: Dict[str, jnp.ndarray]
class FlaxGenerationMixin:
"""
A class containing all functions for auto-regressive text generation, to be used as a mixin in
[`FlaxPreTrainedModel`].
The class exposes [`~generation.FlaxGenerationMixin.generate`], which can be used for:
- *greedy decoding* by calling [`~generation.FlaxGenerationMixin._greedy_search`] if `num_beams=1` and
`do_sample=False`
- *multinomial sampling* by calling [`~generation.FlaxGenerationMixin._sample`] if `num_beams=1` and
`do_sample=True`
- *beam-search decoding* by calling [`~generation.FlaxGenerationMixin._beam_search`] if `num_beams>1` and
`do_sample=False`
You do not need to call any of the above methods directly. Pass custom parameter values to 'generate' instead. To
learn more about decoding strategies refer to the [text generation strategies guide](../generation_strategies).
"""
def prepare_inputs_for_generation(self, *args, **kwargs):
raise NotImplementedError(
"A model class needs to define a `prepare_inputs_for_generation` method in order to use `generate`."
)
@staticmethod
def _run_loop_in_debug(cond_fn, body_fn, init_state):
"""
Run generation in untraced mode. This should only be used for debugging purposes.
"""
state = init_state
while cond_fn(state):
state = body_fn(state)
return state
def _prepare_encoder_decoder_kwargs_for_generation(self, input_ids, params, model_kwargs):
encoder_kwargs = {
argument: value
for argument, value in model_kwargs.items()
if not (argument.startswith("decoder_") or argument.startswith("cross_attn"))
}
model_kwargs["encoder_outputs"] = self.encode(input_ids, params=params, return_dict=True, **encoder_kwargs)
return model_kwargs
def _prepare_decoder_input_ids_for_generation(
self,
batch_size: int,
decoder_start_token_id: int = None,
bos_token_id: int = None,
model_kwargs: Optional[Dict[str, jnp.ndarray]] = None,
) -> jnp.ndarray:
if model_kwargs is not None and "decoder_input_ids" in model_kwargs:
# Only use this arg if not None, otherwise just remove from model_kwargs
decoder_input_ids = model_kwargs.pop("decoder_input_ids")
if decoder_input_ids is not None:
return decoder_input_ids
decoder_start_token_id = self._get_decoder_start_token_id(decoder_start_token_id, bos_token_id)
return jnp.array(decoder_start_token_id, dtype="i4").reshape(1, -1).repeat(batch_size, axis=0)
def _get_decoder_start_token_id(self, decoder_start_token_id: int = None, bos_token_id: int = None) -> int:
# retrieve decoder_start_token_id for encoder-decoder models
# fall back to bos_token_id if necessary
decoder_start_token_id = (
decoder_start_token_id
if decoder_start_token_id is not None
else self.generation_config.decoder_start_token_id
)
bos_token_id = bos_token_id if bos_token_id is not None else self.generation_config.bos_token_id
if decoder_start_token_id is not None:
return decoder_start_token_id
elif (
hasattr(self.config, "decoder")
and hasattr(self.config.decoder, "decoder_start_token_id")
and self.config.decoder.decoder_start_token_id is not None
):
return self.config.decoder.decoder_start_token_id
elif bos_token_id is not None:
return bos_token_id
elif (
hasattr(self.config, "decoder")
and hasattr(self.config.decoder, "bos_token_id")
and self.config.decoder.bos_token_id is not None
):
return self.config.decoder.bos_token_id
raise ValueError(
"`decoder_start_token_id` or `bos_token_id` has to be defined for encoder-decoder generation."
)
@staticmethod
def _expand_to_num_beams(tensor, num_beams):
return jnp.broadcast_to(tensor[:, None], (tensor.shape[0], num_beams) + tensor.shape[1:])
def _adapt_logits_for_beam_search(self, logits):
"""
This function can be overwritten in the specific modeling_flax_<model-name>.py classes to allow for custom beam
search behavior. Note that the only model that overwrites this method is [`~transformes.FlaxMarianMTModel`].
"""
return logits
def _validate_model_class(self):
"""
Confirms that the model class is compatible with generation. If not, raises an exception that points to the
right class to use.
"""
if not self.can_generate():
generate_compatible_mappings = [
FLAX_MODEL_FOR_CAUSAL_LM_MAPPING,
FLAX_MODEL_FOR_VISION_2_SEQ_MAPPING,
FLAX_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING,
]
generate_compatible_classes = set()
for model_mapping in generate_compatible_mappings:
supported_models = model_mapping.get(type(self.config), default=None)
if supported_models is not None:
generate_compatible_classes.add(supported_models.__name__)
exception_message = (
f"The current model class ({self.__class__.__name__}) is not compatible with `.generate()`, as "
"it doesn't have a language model head."
)
if generate_compatible_classes:
exception_message += f" Please use one of the following classes instead: {generate_compatible_classes}"
raise TypeError(exception_message)
def _validate_model_kwargs(self, model_kwargs: Dict[str, Any]):
"""Validates model kwargs for generation. Generate argument typos will also be caught here."""
unused_model_args = []
model_args = set(inspect.signature(self.prepare_inputs_for_generation).parameters)
# `kwargs`/`model_kwargs` is often used to handle optional forward pass inputs like `attention_mask`. If
# `prepare_inputs_for_generation` doesn't accept them, then a stricter check can be made ;)
if "kwargs" in model_args or "model_kwargs" in model_args:
model_args |= set(inspect.signature(self.__call__).parameters)
for key, value in model_kwargs.items():
if value is not None and key not in model_args:
unused_model_args.append(key)
if unused_model_args:
raise ValueError(
f"The following `model_kwargs` are not used by the model: {unused_model_args} (note: typos in the"
" generate arguments will also show up in this list)"
)
def generate(
self,
input_ids: jnp.ndarray,
generation_config: Optional[GenerationConfig] = None,
prng_key: Optional[jnp.ndarray] = None,
trace: bool = True,
params: Optional[Dict[str, jnp.ndarray]] = None,
logits_processor: Optional[FlaxLogitsProcessorList] = None,
**kwargs,
):
r"""
Generates sequences of token ids for models with a language modeling head.
Parameters:
input_ids (`jnp.ndarray` of shape `(batch_size, sequence_length)`):
The sequence used as a prompt for the generation.
generation_config (`~generation.GenerationConfig`, *optional*):
The generation configuration to be used as base parametrization for the generation call. `**kwargs`
passed to generate matching the attributes of `generation_config` will override them. If
`generation_config` is not provided, the default will be used, which had the following loading
priority: 1) from the `generation_config.json` model file, if it exists; 2) from the model
configuration. Please note that unspecified parameters will inherit [`~generation.GenerationConfig`]'s
default values, whose documentation should be checked to parameterize generation.
trace (`bool`, *optional*, defaults to `True`):
Whether to trace generation. Setting `trace=False` should only be used for debugging and will lead to a
considerably slower runtime.
params (`Dict[str, jnp.ndarray]`, *optional*):
Optionally the model parameters can be passed. Can be useful for parallelized generation.
logits_processor (`FlaxLogitsProcessorList `, *optional*):
Custom logits processors that complement the default logits processors built from arguments and
generation config. If a logit processor is passed that is already created with the arguments or a
generation config an error is thrown. This feature is intended for advanced users.
kwargs (`Dict[str, Any]`, *optional*):
Ad hoc parametrization of `generate_config` and/or additional model-specific kwargs that will be
forwarded to the `forward` function of the model. If the model is an encoder-decoder model, encoder
specific kwargs should not be prefixed and decoder specific kwargs should be prefixed with *decoder_*.
Return:
[`~utils.ModelOutput`].
"""
# Handle `generation_config` and kwargs that might update it, and validate the `.generate()` call
self._validate_model_class()
# priority: `generation_config` argument > `model.generation_config` (the default generation config)
if generation_config is None:
# legacy: users may modify the model configuration to control generation. To trigger this legacy behavior,
# two conditions must be met
# 1) the generation config must have been created from the model config (`_from_model_config` field);
# 2) the generation config must have seen no modification since its creation (the hash is the same).
if self.generation_config._from_model_config and self.generation_config._original_object_hash == hash(
self.generation_config
):
new_generation_config = GenerationConfig.from_model_config(self.config)
if new_generation_config != self.generation_config:
warnings.warn(
"You have modified the pretrained model configuration to control generation. This is a"
" deprecated strategy to control generation and will be removed soon, in a future version."
" Please use and modify the model generation configuration (see"
" https://huggingface.co/docs/transformers/generation_strategies#default-text-generation-configuration )"
)
self.generation_config = new_generation_config
generation_config = self.generation_config
generation_config = copy.deepcopy(generation_config)
model_kwargs = generation_config.update(**kwargs) # All unused kwargs must be model kwargs
self._validate_model_kwargs(model_kwargs.copy())
logits_processor = logits_processor if logits_processor is not None else FlaxLogitsProcessorList()
# set init values
prng_key = prng_key if prng_key is not None else jax.random.PRNGKey(0)
if generation_config.pad_token_id is None and generation_config.eos_token_id is not None:
if model_kwargs.get("attention_mask") is None:
logger.warning(
"The attention mask and the pad token id were not set. As a consequence, you may observe "
"unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results."
)
eos_token_id = generation_config.eos_token_id
if isinstance(eos_token_id, list):
eos_token_id = eos_token_id[0]
logger.warning(f"Setting `pad_token_id` to `eos_token_id`:{eos_token_id} for open-end generation.")
generation_config.pad_token_id = eos_token_id
if generation_config.decoder_start_token_id is None and self.config.is_encoder_decoder:
raise ValueError("`decoder_start_token_id` has to be defined for encoder-decoder generation.")
# decoder-only models should use left-padding for generation (can't be checked with `trace=True`)
if not self.config.is_encoder_decoder and not trace:
if (
generation_config.pad_token_id is not None
and jnp.sum(input_ids[:, -1] == generation_config.pad_token_id) > 0
):
logger.warning(
"A decoder-only architecture is being used, but right-padding was detected! For correct "
"generation results, please set `padding_side='left'` when initializing the tokenizer."
)
batch_size = input_ids.shape[0]
if self.config.is_encoder_decoder:
# add encoder_outputs to model_kwargs
if model_kwargs.get("encoder_outputs") is None:
model_kwargs = self._prepare_encoder_decoder_kwargs_for_generation(input_ids, params, model_kwargs)
# prepare decoder_input_ids for generation
input_ids = self._prepare_decoder_input_ids_for_generation(
batch_size,
decoder_start_token_id=generation_config.decoder_start_token_id,
bos_token_id=generation_config.bos_token_id,
model_kwargs=model_kwargs,
)
# Prepare `max_length` depending on other stopping criteria.
input_ids_seq_length = input_ids.shape[-1]
has_default_max_length = kwargs.get("max_length") is None and generation_config.max_length is not None
if has_default_max_length and generation_config.max_new_tokens is None and generation_config.max_length == 20:
# 20 is the default max_length of the generation config
warnings.warn(
f"Using the model-agnostic default `max_length` (={generation_config.max_length}) "
"to control the generation length. recommend setting `max_new_tokens` to control the maximum length of the generation.",
UserWarning,
)
elif generation_config.max_new_tokens is not None:
if not has_default_max_length and generation_config.max_length is not None:
logger.warning(
f"Both `max_new_tokens` (={generation_config.max_new_tokens}) and `max_length`(="
f"{generation_config.max_length}) seem to have been set. `max_new_tokens` will take precedence. "
"Please refer to the documentation for more information. "
"(https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)"
)
generation_config.max_length = generation_config.max_new_tokens + input_ids_seq_length
if generation_config.min_length is not None and generation_config.min_length > generation_config.max_length:
raise ValueError(
f"Unfeasable length constraints: the minimum length ({generation_config.min_length}) is larger than"
f" the maximum length ({generation_config.max_length})"
)
if input_ids_seq_length >= generation_config.max_length:
input_ids_string = "decoder_input_ids" if self.config.is_encoder_decoder else "input_ids"
logger.warning(
f"Input length of {input_ids_string} is {input_ids_seq_length}, but `max_length` is set to"
f" {generation_config.max_length}. This can lead to unexpected behavior. You should consider"
" increasing`max_new_tokens`."
)
logits_processor = self._get_logits_processor(
generation_config=generation_config,
input_ids_seq_length=input_ids_seq_length,
logits_processor=logits_processor,
)
if not generation_config.do_sample and generation_config.num_beams == 1:
return self._greedy_search(
input_ids,
generation_config.max_length,
generation_config.pad_token_id,
generation_config.eos_token_id,
logits_processor=logits_processor,
trace=trace,
params=params,
model_kwargs=model_kwargs,
)
elif generation_config.do_sample and generation_config.num_beams == 1:
logits_warper = self._get_logits_warper(generation_config=generation_config)
return self._sample(
input_ids,
generation_config.max_length,
generation_config.pad_token_id,
generation_config.eos_token_id,
prng_key,
logits_warper=logits_warper,
logits_processor=logits_processor,
trace=trace,
params=params,
model_kwargs=model_kwargs,
)
elif not generation_config.do_sample and generation_config.num_beams > 1:
# broadcast input_ids & encoder_outputs
input_ids = self._expand_to_num_beams(input_ids, num_beams=generation_config.num_beams)
if "encoder_outputs" in model_kwargs:
model_kwargs["encoder_outputs"]["last_hidden_state"] = self._expand_to_num_beams(
model_kwargs["encoder_outputs"]["last_hidden_state"], num_beams=generation_config.num_beams
)
for kwarg in ["attention_mask", "decoder_attention_mask"]:
if kwarg in model_kwargs:
model_kwargs[kwarg] = self._expand_to_num_beams(
model_kwargs[kwarg], num_beams=generation_config.num_beams
)
return self._beam_search(
input_ids,
generation_config.max_length,
generation_config.pad_token_id,
generation_config.eos_token_id,
length_penalty=generation_config.length_penalty,
early_stopping=generation_config.early_stopping,
logits_processor=logits_processor,
trace=trace,
params=params,
num_return_sequences=generation_config.num_return_sequences,
model_kwargs=model_kwargs,
)
else:
raise NotImplementedError("`Beam sampling is currently not implemented.")
def _get_logits_warper(self, generation_config: GenerationConfig) -> FlaxLogitsProcessorList:
"""
This class returns a [`FlaxLogitsProcessorList`] list object that contains all relevant [`FlaxLogitsWarper`]
instances used for multinomial sampling.
"""
warpers = FlaxLogitsProcessorList()
if generation_config.temperature is not None and generation_config.temperature != 1.0:
warpers.append(FlaxTemperatureLogitsWarper(generation_config.temperature))
if generation_config.top_k is not None and generation_config.top_k != 0:
warpers.append(FlaxTopKLogitsWarper(top_k=generation_config.top_k, min_tokens_to_keep=1))
if generation_config.top_p is not None and generation_config.top_p < 1.0:
warpers.append(FlaxTopPLogitsWarper(top_p=generation_config.top_p, min_tokens_to_keep=1))
return warpers
def _get_logits_processor(
self,
generation_config: GenerationConfig,
input_ids_seq_length: int,
logits_processor: Optional[FlaxLogitsProcessorList],
) -> FlaxLogitsProcessorList:
"""
This class returns a [`FlaxLogitsProcessorList`] list object that contains all relevant [`FlaxLogitsProcessor`]
instances used to modify the scores of the language model head.
"""
processors = FlaxLogitsProcessorList()
if (
generation_config.min_length is not None
and generation_config.eos_token_id is not None
and generation_config.min_length > -1
):
processors.append(
FlaxMinLengthLogitsProcessor(generation_config.min_length, generation_config.eos_token_id)
)
if generation_config.forced_bos_token_id is not None:
processors.append(FlaxForcedBOSTokenLogitsProcessor(generation_config.forced_bos_token_id))
if generation_config.forced_eos_token_id is not None:
processors.append(
FlaxForcedEOSTokenLogitsProcessor(generation_config.max_length, generation_config.forced_eos_token_id)
)
if generation_config.suppress_tokens is not None:
processors.append(FlaxSuppressTokensLogitsProcessor(generation_config.suppress_tokens))
if generation_config.begin_suppress_tokens is not None:
begin_index = input_ids_seq_length
begin_index = (
begin_index
if (input_ids_seq_length > 1 or generation_config.forced_bos_token_id is None)
else begin_index + 1
)
if generation_config.forced_decoder_ids is not None and len(generation_config.forced_decoder_ids) > 0:
# generation starts after the last token that is forced
begin_index += generation_config.forced_decoder_ids[-1][0]
processors.append(
FlaxSuppressTokensAtBeginLogitsProcessor(generation_config.begin_suppress_tokens, begin_index)
)
if generation_config.forced_decoder_ids is not None:
forced_decoder_ids = [
[input_ids_seq_length + i[0] - 1, i[1]] for i in generation_config.forced_decoder_ids
]
processors.append(FlaxForceTokensLogitsProcessor(forced_decoder_ids))
processors = self._merge_criteria_processor_list(processors, logits_processor)
return processors
def _merge_criteria_processor_list(
self,
default_list: FlaxLogitsProcessorList,
custom_list: FlaxLogitsProcessorList,
) -> FlaxLogitsProcessorList:
if len(custom_list) == 0:
return default_list
for default in default_list:
for custom in custom_list:
if type(custom) is type(default):
object_type = "logits processor"
raise ValueError(
f"A custom {object_type} of type {type(custom)} with values {custom} has been passed to"
f" `generate`, but it has already been created with the values {default}. {default} has been"
" created by passing the corresponding arguments to generate or by the model's config default"
f" values. If you just want to change the default values of {object_type} consider passing"
f" them as arguments to `generate` instead of using a custom {object_type}."
)
default_list.extend(custom_list)
return default_list
def _greedy_search(
self,
input_ids: None,
max_length: Optional[int] = None,
pad_token_id: Optional[int] = None,
eos_token_id: Optional[int] = None,
logits_processor: Optional[FlaxLogitsProcessorList] = None,
trace: bool = True,
params: Optional[Dict[str, jnp.ndarray]] = None,
model_kwargs: Optional[Dict[str, jnp.ndarray]] = None,
):
# init values
max_length = max_length if max_length is not None else self.generation_config.max_length
pad_token_id = pad_token_id if pad_token_id is not None else self.generation_config.pad_token_id
eos_token_id = eos_token_id if eos_token_id is not None else self.generation_config.eos_token_id
batch_size, cur_len = input_ids.shape
eos_token_id = jnp.array(eos_token_id, dtype=jnp.int32 if eos_token_id is not None else None)
pad_token_id = jnp.array(pad_token_id, dtype=jnp.int32)
cur_len = jnp.array(cur_len)
# per batch-item holding current token in loop.
sequences = jnp.full((batch_size, max_length), pad_token_id, dtype=jnp.int32)
sequences = lax.dynamic_update_slice(sequences, input_ids, (0, 0))
# per batch-item state bit indicating if sentence has finished.
is_sent_finished = jnp.zeros((batch_size,), dtype=jnp.bool_)
# For Seq2Seq generation, we only need to use the decoder instead of the whole model in generation loop
# and pass it the `encoder_outputs`, which are part of the `model_kwargs`.
model = self.decode if self.config.is_encoder_decoder else self
# initialize model specific kwargs
model_kwargs = self.prepare_inputs_for_generation(input_ids, max_length, **model_kwargs)
# initialize state
state = GreedyState(
cur_len=cur_len,
sequences=sequences,
running_token=input_ids,
is_sent_finished=is_sent_finished,
model_kwargs=model_kwargs,
)
def greedy_search_cond_fn(state):
"""state termination condition fn."""
has_reached_max_length = state.cur_len == max_length
all_sequence_finished = jnp.all(state.is_sent_finished)
finish_generation = jnp.logical_or(has_reached_max_length, all_sequence_finished)
return ~finish_generation
def greedy_search_body_fn(state):
"""state update fn."""
model_outputs = model(state.running_token, params=params, **state.model_kwargs)
logits = model_outputs.logits[:, -1]
# apply min_length, ...
logits = logits_processor(state.sequences, logits, state.cur_len)
next_token = jnp.argmax(logits, axis=-1)
next_token = next_token * ~state.is_sent_finished + pad_token_id * state.is_sent_finished
next_is_sent_finished = state.is_sent_finished | (next_token == eos_token_id)
next_token = next_token[:, None]
next_sequences = lax.dynamic_update_slice(state.sequences, next_token, (0, state.cur_len))
next_model_kwargs = self.update_inputs_for_generation(model_outputs, state.model_kwargs)
return GreedyState(
cur_len=state.cur_len + 1,
sequences=next_sequences,
running_token=next_token,
is_sent_finished=next_is_sent_finished,
model_kwargs=next_model_kwargs,
)
# The very first prompt often has sequence length > 1, so run outside of `lax.while_loop` to comply with TPU
if input_ids.shape[1] > 1:
state = greedy_search_body_fn(state)
if not trace:
state = self._run_loop_in_debug(greedy_search_cond_fn, greedy_search_body_fn, state)
else:
state = lax.while_loop(greedy_search_cond_fn, greedy_search_body_fn, state)
return FlaxGreedySearchOutput(sequences=state.sequences)
def _sample(
self,
input_ids: None,
max_length: Optional[int] = None,
pad_token_id: Optional[int] = None,
eos_token_id: Optional[int] = None,
prng_key: Optional[jnp.ndarray] = None,
logits_processor: Optional[FlaxLogitsProcessorList] = None,
logits_warper: Optional[FlaxLogitsProcessorList] = None,
trace: bool = True,
params: Optional[Dict[str, jnp.ndarray]] = None,
model_kwargs: Optional[Dict[str, jnp.ndarray]] = None,
):
# init values
max_length = max_length if max_length is not None else self.generation_config.max_length
pad_token_id = pad_token_id if pad_token_id is not None else self.generation_config.pad_token_id
eos_token_id = eos_token_id if eos_token_id is not None else self.generation_config.eos_token_id
prng_key = prng_key if prng_key is not None else jax.random.PRNGKey(0)
batch_size, cur_len = input_ids.shape
eos_token_id = jnp.array(eos_token_id, dtype=jnp.int32 if eos_token_id is not None else None)
pad_token_id = jnp.array(pad_token_id, dtype=jnp.int32)
cur_len = jnp.array(cur_len)
# per batch-item holding current token in loop.
sequences = jnp.full((batch_size, max_length), pad_token_id, dtype=jnp.int32)
sequences = lax.dynamic_update_slice(sequences, input_ids, (0, 0))
# per batch-item state bit indicating if sentence has finished.
is_sent_finished = jnp.zeros((batch_size,), dtype=jnp.bool_)
# For Seq2Seq generation, we only need to use the decoder instead of the whole model in generation loop
# and pass it the `encoder_outputs`, which are part of the `model_kwargs`.
model = self.decode if self.config.is_encoder_decoder else self
# initialize model specific kwargs
model_kwargs = self.prepare_inputs_for_generation(input_ids, max_length, **model_kwargs)
# initialize state
state = SampleState(
cur_len=cur_len,
sequences=sequences,
running_token=input_ids,
is_sent_finished=is_sent_finished,
prng_key=prng_key,
model_kwargs=model_kwargs,
)
def sample_search_cond_fn(state):
"""state termination condition fn."""
has_reached_max_length = state.cur_len == max_length
all_sequence_finished = jnp.all(state.is_sent_finished)
finish_generation = jnp.logical_or(has_reached_max_length, all_sequence_finished)
return ~finish_generation
def sample_search_body_fn(state):
"""state update fn."""
prng_key, prng_key_next = jax.random.split(state.prng_key)
model_outputs = model(state.running_token, params=params, **state.model_kwargs)
logits = model_outputs.logits[:, -1]
# apply min_length, ...
logits = logits_processor(state.sequences, logits, state.cur_len)
# apply top_p, top_k, temperature
logits = logits_warper(logits, logits, state.cur_len)
next_token = jax.random.categorical(prng_key, logits, axis=-1)
next_token = next_token * ~state.is_sent_finished + pad_token_id * state.is_sent_finished
next_is_sent_finished = state.is_sent_finished | (next_token == eos_token_id)
next_token = next_token[:, None]
next_sequences = lax.dynamic_update_slice(state.sequences, next_token, (0, state.cur_len))
next_model_kwargs = self.update_inputs_for_generation(model_outputs, state.model_kwargs)
return SampleState(
cur_len=state.cur_len + 1,
sequences=next_sequences,
running_token=next_token,
is_sent_finished=next_is_sent_finished,
model_kwargs=next_model_kwargs,
prng_key=prng_key_next,
)
# The very first prompt often has sequence length > 1, so run outside of `lax.while_loop` to comply with TPU
if input_ids.shape[1] > 1:
state = sample_search_body_fn(state)
if not trace:
state = self._run_loop_in_debug(sample_search_cond_fn, sample_search_body_fn, state)
else:
state = lax.while_loop(sample_search_cond_fn, sample_search_body_fn, state)
return FlaxSampleOutput(sequences=state.sequences)
def _beam_search(
self,
input_ids: None,
max_length: Optional[int] = None,
pad_token_id: Optional[int] = None,
eos_token_id: Optional[int] = None,
length_penalty: Optional[float] = None,
early_stopping: Optional[Union[bool, str]] = None,
logits_processor: Optional[FlaxLogitsProcessorList] = None,
trace: bool = True,
params: Optional[Dict[str, jnp.ndarray]] = None,
num_return_sequences: Optional[int] = None,
model_kwargs: Optional[Dict[str, jnp.ndarray]] = None,
):
"""
This beam search function is heavily inspired by Flax's official example:
https://github.com/google/flax/blob/main/examples/wmt/decode.py
"""
def flatten_beam_dim(tensor):
"""Flattens the first two dimensions of a non-scalar array."""
# ignore scalars (e.g. cache index)
if tensor.ndim == 0:
return tensor
return tensor.reshape((tensor.shape[0] * tensor.shape[1],) + tensor.shape[2:])
def unflatten_beam_dim(tensor, batch_size, num_beams):
"""Unflattens the first, flat batch*beam dimension of a non-scalar array."""
# ignore scalars (e.g. cache index)
if tensor.ndim == 0:
return tensor
return tensor.reshape((batch_size, num_beams) + tensor.shape[1:])
def gather_beams(nested, beam_indices, batch_size, new_num_beams):
"""
Gathers the beam slices indexed by beam_indices into new beam array.
"""
batch_indices = jnp.reshape(
jnp.arange(batch_size * new_num_beams) // new_num_beams, (batch_size, new_num_beams)
)
def gather_fn(tensor):
# ignore scalars (e.g. cache index)
if tensor.ndim == 0:
return tensor
else:
return tensor[batch_indices, beam_indices]
return jax.tree_util.tree_map(gather_fn, nested)
# init values
max_length = max_length if max_length is not None else self.generation_config.max_length
pad_token_id = pad_token_id if pad_token_id is not None else self.generation_config.pad_token_id
eos_token_id = eos_token_id if eos_token_id is not None else self.generation_config.eos_token_id
length_penalty = length_penalty if length_penalty is not None else self.generation_config.length_penalty
early_stopping = early_stopping if early_stopping is not None else self.generation_config.early_stopping
num_return_sequences = (
num_return_sequences if num_return_sequences is not None else self.generation_config.num_return_sequences
)
batch_size, num_beams, cur_len = input_ids.shape
eos_token_id = jnp.array(eos_token_id, dtype=jnp.int32 if eos_token_id is not None else None)
pad_token_id = jnp.array(pad_token_id, dtype=jnp.int32)
cur_len = jnp.array(cur_len)
# record the prompt length of decoder
decoder_prompt_len = input_ids.shape[-1]
# per batch,beam-item holding current token in loop.
sequences = jnp.full((batch_size, num_beams, max_length), pad_token_id, dtype=jnp.int32)
running_sequences = jnp.full((batch_size, num_beams, max_length), pad_token_id, dtype=jnp.int32)
running_sequences = lax.dynamic_update_slice(sequences, input_ids, (0, 0, 0))
# per batch,beam-item state bit indicating if sentence has finished.
is_sent_finished = jnp.zeros((batch_size, num_beams), dtype=jnp.bool_)
# per batch,beam-item score, logprobs
running_scores = jnp.tile(jnp.array([0.0] + [np.array(-1.0e7)] * (num_beams - 1)), [batch_size, 1])
scores = jnp.ones((batch_size, num_beams)) * np.array(-1.0e7)
# For Seq2Seq generation, we only need to use the decoder instead of the whole model in generation loop
# and pass it the `encoder_outputs`, which are part of the `model_kwargs`.
model = self.decode if self.config.is_encoder_decoder else self
# flatten beam dim
if "encoder_outputs" in model_kwargs:
model_kwargs["encoder_outputs"]["last_hidden_state"] = flatten_beam_dim(
model_kwargs["encoder_outputs"]["last_hidden_state"]
)
for kwarg in ["attention_mask", "decoder_attention_mask"]:
if kwarg in model_kwargs:
model_kwargs[kwarg] = flatten_beam_dim(model_kwargs[kwarg])
# initialize model specific kwargs
model_kwargs = self.prepare_inputs_for_generation(flatten_beam_dim(input_ids), max_length, **model_kwargs)
# initialize state
state = BeamSearchState(
cur_len=cur_len,
running_sequences=running_sequences,
running_scores=running_scores,
sequences=sequences,
scores=scores,
is_sent_finished=is_sent_finished,
model_kwargs=model_kwargs,
)
def beam_search_cond_fn(state):
"""beam search state termination condition fn."""
# 1. is less than max length?
not_max_length_yet = state.cur_len < max_length
# 2. can the new beams still improve?
# early_stopping == False -> apply heuristic = always get the best score from `cur_len`. See the discussion
# below for more details.
# https://github.com/huggingface/transformers/pull/20901#issuecomment-1369845565
# early_stopping == "never" -> compute the best score from max_length or cur_len, depending on the sign of
# length_penalty. Positive length_penalty favors longer sequences, thus we use max_length there.
if early_stopping == "never" and length_penalty > 0.0:
best_running_score = state.running_scores[:, :1] / (
(max_length - decoder_prompt_len) ** length_penalty
)
else:
best_running_score = state.running_scores[:, :1] / (
(state.cur_len - decoder_prompt_len) ** length_penalty
)
worst_finished_score = jnp.where(
state.is_sent_finished, jnp.min(state.scores, axis=1, keepdims=True), np.array(-1.0e7)
)
improvement_still_possible = jnp.any(best_running_score > worst_finished_score)
# 3. is there still a beam that has not finished?
still_open_beam = ~(jnp.all(state.is_sent_finished) & (early_stopping is True))
return not_max_length_yet & still_open_beam & improvement_still_possible
def beam_search_body_fn(state, input_ids_length=1):
"""beam search state update fn."""
# 1. Forward current tokens
# Collect the current position slice along length to feed the fast
# autoregressive decoder model. Flatten the beam dimension into batch
# dimension for feeding into the model.
# unflatten beam dimension
# Unflatten beam dimension in attention cache arrays
input_token = flatten_beam_dim(
lax.dynamic_slice(
state.running_sequences,
(0, 0, state.cur_len - input_ids_length),
(batch_size, num_beams, input_ids_length),
)
)
model_outputs = model(input_token, params=params, **state.model_kwargs)
logits = unflatten_beam_dim(model_outputs.logits[:, -1], batch_size, num_beams)
cache = jax.tree_util.tree_map(
lambda tensor: unflatten_beam_dim(tensor, batch_size, num_beams), model_outputs.past_key_values
)
# adapt logits for FlaxMarianMTModel
logits = self._adapt_logits_for_beam_search(logits)
# 2. Compute log probs
# get log probabilities from logits,
# process logits with processors (*e.g.* min_length, ...), and
# add new logprobs to existing running logprobs scores.
log_probs = jax.nn.log_softmax(logits)
log_probs = logits_processor(
flatten_beam_dim(running_sequences), flatten_beam_dim(log_probs), state.cur_len
)
log_probs = unflatten_beam_dim(log_probs, batch_size, num_beams)
log_probs = log_probs + jnp.expand_dims(state.running_scores, axis=2)
vocab_size = log_probs.shape[2]
log_probs = log_probs.reshape((batch_size, num_beams * vocab_size))
# 3. Retrieve top-K
# Each item in batch has num_beams * vocab_size candidate sequences.
# For each item, get the top 2*k candidates with the highest log-
# probabilities. We gather the top 2*K beams here so that even if the best
# K sequences reach EOS simultaneously, we have another K sequences
# remaining to continue the live beam search.
# Gather the top 2*K scores from _all_ beams.
# Gather 2*k top beams.
# Recover the beam index by floor division.
# Recover token id by modulo division and expand Id array for broadcasting.
# Update sequences for the 2*K top-k new sequences.
beams_to_keep = 2 * num_beams
topk_log_probs, topk_indices = lax.top_k(log_probs, k=beams_to_keep)
topk_beam_indices = topk_indices // vocab_size
topk_running_sequences = gather_beams(
state.running_sequences, topk_beam_indices, batch_size, beams_to_keep
)
topk_ids = jnp.expand_dims(topk_indices % vocab_size, axis=2)
topk_sequences = lax.dynamic_update_slice(topk_running_sequences, topk_ids, (0, 0, state.cur_len))
# 4. Check which sequences have ended
# Update current sequences:
# Did any of these sequences reach an end marker?
# To prevent these just finished sequences from being added to the current sequences
# set of active beam search sequences, set their log probs to a very large
# negative value.
did_topk_just_finished = topk_sequences[:, :, state.cur_len] == eos_token_id
running_topk_log_probs = topk_log_probs + did_topk_just_finished * np.array(-1.0e7)
# 5. Get running sequences scores for next
# Determine the top k beam indices (from top 2*k beams) from log probs
# and gather top k beams (from top 2*k beams).
next_topk_indices = lax.top_k(running_topk_log_probs, k=num_beams)[1]
next_running_sequences, next_running_scores = gather_beams(
[topk_sequences, running_topk_log_probs], next_topk_indices, batch_size, num_beams
)
# 6. Process topk logits
# Further process log probs:
# - add length penalty
# - make sure no scores can be added anymore if beam is full
# - make sure still running sequences cannot be chosen as finalized beam
topk_log_probs = topk_log_probs / ((state.cur_len + 1 - decoder_prompt_len) ** length_penalty)
beams_in_batch_are_full = jnp.broadcast_to(
state.is_sent_finished.all(axis=-1, keepdims=True), did_topk_just_finished.shape
) & (early_stopping is True)
add_penalty = ~did_topk_just_finished | beams_in_batch_are_full
topk_log_probs += add_penalty * np.array(-1.0e7)
# 7. Get scores, sequences, is sentence finished for next.
# Combine sequences, scores, and flags along the beam dimension and compare
# new finished sequence scores to existing finished scores and select the
# best from the new set of beams
merged_sequences = jnp.concatenate([state.sequences, topk_sequences], axis=1)
merged_scores = jnp.concatenate([state.scores, topk_log_probs], axis=1)
merged_is_sent_finished = jnp.concatenate([state.is_sent_finished, did_topk_just_finished], axis=1)
topk_merged_indices = lax.top_k(merged_scores, k=num_beams)[1]
next_sequences, next_scores, next_is_sent_finished = gather_beams(
[merged_sequences, merged_scores, merged_is_sent_finished], topk_merged_indices, batch_size, num_beams
)
# 8. Update model kwargs.
# Determine the top k beam indices from the original set of all beams.
# With these, gather the top k beam-associated caches.
next_running_indices = gather_beams(topk_beam_indices, next_topk_indices, batch_size, num_beams)
next_cache = gather_beams(cache, next_running_indices, batch_size, num_beams)
model_outputs["past_key_values"] = jax.tree_util.tree_map(lambda x: flatten_beam_dim(x), next_cache)
next_model_kwargs = self.update_inputs_for_generation(model_outputs, state.model_kwargs)
return BeamSearchState(
cur_len=state.cur_len + 1,
running_scores=next_running_scores,
running_sequences=next_running_sequences,
scores=next_scores,
sequences=next_sequences,
is_sent_finished=next_is_sent_finished,
model_kwargs=next_model_kwargs,
)
# Always run first iteration outside of `lax.while_loop` to avoid calling `beam_search_cond_fn`
# when `state.cur_len` equals `decoder_prompt_len`. This also helps to comply with TPU when
# the very first prompt has sequence length > 1.
state = partial(beam_search_body_fn, input_ids_length=input_ids.shape[-1])(state)
if not trace:
state = self._run_loop_in_debug(beam_search_cond_fn, beam_search_body_fn, state)
else:
state = lax.while_loop(beam_search_cond_fn, beam_search_body_fn, state)
# Account for the edge-case where there are no finished sequences for a
# particular batch item. If so, return running sequences for that batch item.
none_finished = jnp.any(state.is_sent_finished, axis=1)
sequences = jnp.where(none_finished[:, None, None], state.sequences, state.running_sequences)
scores = jnp.where(none_finished[:, None], state.scores, state.running_scores)
# Take best beams for each batch (the score is sorted in descending order)
sequences = flatten_beam_dim(sequences[:, :num_return_sequences, :])
scores = flatten_beam_dim(scores[:, :num_return_sequences])
return FlaxBeamSearchOutput(sequences=sequences, scores=scores)
| transformers/src/transformers/generation/flax_utils.py/0 | {
"file_path": "transformers/src/transformers/generation/flax_utils.py",
"repo_id": "transformers",
"token_count": 21734
} | 289 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"AQLM (Additive Quantization of Language Model) integration file"
from ..utils import is_accelerate_available, is_aqlm_available, is_torch_available
if is_torch_available():
import torch.nn as nn
def replace_with_aqlm_linear(
model,
quantization_config=None,
linear_weights_not_to_quantize=None,
current_key_name=None,
has_been_replaced=False,
):
"""
Public method that recursively replaces the Linear layers of the given model with AQLM quantized layers.
`accelerate` is needed to use this method. Returns the converted model and a boolean that indicates if the
conversion has been successfull or not.
Args:
model (`torch.nn.Module`):
The model to convert, can be any `torch.nn.Module` instance.
quantization_config (`AqlmConfig`):
The quantization config object that contains the quantization parameters.
linear_weights_not_to_quantize (`list[str]`, *optional*):
A list of nn.Linear weights to not convert. If a parameter path is in the list (e.g. `lm_head.weight`), the corresponding module will not be
converted.
current_key_name (`list`, *optional*):
A list that contains the current key name. This is used for recursion and should not be passed by the user.
has_been_replaced (`bool`, *optional*):
A boolean that indicates if the conversion has been successful or not. This is used for recursion and
should not be passed by the user.
"""
if not is_aqlm_available():
raise ValueError("AQLM is not available. Please install it with `pip install aqlm[cpu,gpu]`")
if not is_accelerate_available():
raise ValueError("AQLM requires Accelerate to be installed: `pip install accelerate`")
if linear_weights_not_to_quantize is None:
linear_weights_not_to_quantize = []
from accelerate import init_empty_weights
from aqlm import QuantizedLinear
for name, module in model.named_children():
if current_key_name is None:
current_key_name = []
current_key_name.append(name)
if isinstance(module, nn.Linear):
# Check if the current key is not in the `linear_weights_not_to_quantize`
if ".".join(current_key_name) + ".weight" not in linear_weights_not_to_quantize:
with init_empty_weights():
in_features = module.in_features
out_features = module.out_features
model._modules[name] = QuantizedLinear(
in_features,
out_features,
bias=module.bias is not None,
in_group_size=quantization_config.in_group_size,
out_group_size=quantization_config.out_group_size,
num_codebooks=quantization_config.num_codebooks,
nbits_per_codebook=quantization_config.nbits_per_codebook,
)
has_been_replaced = True
# Store the module class in case we need to transpose the weight later
model._modules[name].source_cls = type(module)
# Force requires grad to False to avoid unexpected errors
model._modules[name].requires_grad_(False)
if len(list(module.children())) > 0:
_, has_been_replaced = replace_with_aqlm_linear(
module,
quantization_config=quantization_config,
linear_weights_not_to_quantize=linear_weights_not_to_quantize,
current_key_name=current_key_name,
has_been_replaced=has_been_replaced,
)
# Remove the last key for recursion
current_key_name.pop(-1)
return model, has_been_replaced
| transformers/src/transformers/integrations/aqlm.py/0 | {
"file_path": "transformers/src/transformers/integrations/aqlm.py",
"repo_id": "transformers",
"token_count": 1821
} | 290 |
#include <torch/extension.h>
#include "ATen/ATen.h"
typedef at::BFloat16 bf16;
void cuda_forward(int B, int T, int C, float *w, float *u, float *k, float *v, float *y);
void cuda_forward_bf16(int B, int T, int C, float *w, bf16 *u, bf16 *k, bf16 *v, bf16 *y);
void cuda_forward_with_state(int B, int T, int C, float *w, float *u, float *k, float *v, float *y, float *s);
void cuda_forward_with_state_bf16(int B, int T, int C, float *w, bf16 *u, bf16 *k, bf16 *v, bf16 *y, float *s);
void cuda_backward(int B, int T, int C, float *w, float *u, float *k, float *v, float *y, float *gy, float *gw, float *gu, float *gk, float *gv);
void cuda_backward_bf16(int B, int T, int C, float *w, bf16 *u, bf16 *k, bf16 *v, bf16 *y, bf16 *gy, bf16 *gw, bf16 *gu, bf16 *gk, bf16 *gv);
void forward(torch::Tensor &w, torch::Tensor &u, torch::Tensor &k, torch::Tensor &v, torch::Tensor &y) {
const int B = k.size(0);
const int T = k.size(1);
const int C = k.size(2);
cuda_forward(B, T, C, w.data_ptr<float>(), u.data_ptr<float>(), k.data_ptr<float>(), v.data_ptr<float>(), y.data_ptr<float>());
}
void forward_bf16(torch::Tensor &w, torch::Tensor &u, torch::Tensor &k, torch::Tensor &v, torch::Tensor &y) {
const int B = k.size(0);
const int T = k.size(1);
const int C = k.size(2);
cuda_forward_bf16(B, T, C, w.data_ptr<float>(), u.data_ptr<bf16>(), k.data_ptr<bf16>(), v.data_ptr<bf16>(), y.data_ptr<bf16>());
}
void forward_with_state(torch::Tensor &w, torch::Tensor &u, torch::Tensor &k, torch::Tensor &v, torch::Tensor &y, torch::Tensor &s) {
const int B = k.size(0);
const int T = k.size(1);
const int C = k.size(2);
cuda_forward_with_state(B, T, C, w.data_ptr<float>(), u.data_ptr<float>(), k.data_ptr<float>(), v.data_ptr<float>(), y.data_ptr<float>(), s.data_ptr<float>());
}
void forward_with_state_bf16(torch::Tensor &w, torch::Tensor &u, torch::Tensor &k, torch::Tensor &v, torch::Tensor &y, torch::Tensor &s) {
const int B = k.size(0);
const int T = k.size(1);
const int C = k.size(2);
cuda_forward_with_state_bf16(B, T, C, w.data_ptr<float>(), u.data_ptr<bf16>(), k.data_ptr<bf16>(), v.data_ptr<bf16>(), y.data_ptr<bf16>(), s.data_ptr<float>());
}
void backward(torch::Tensor &w, torch::Tensor &u, torch::Tensor &k, torch::Tensor &v, torch::Tensor &y, torch::Tensor &gy, torch::Tensor &gw, torch::Tensor &gu, torch::Tensor &gk, torch::Tensor &gv) {
const int B = k.size(0);
const int T = k.size(1);
const int C = k.size(2);
cuda_backward(B, T, C, w.data_ptr<float>(), u.data_ptr<float>(), k.data_ptr<float>(), v.data_ptr<float>(), y.data_ptr<float>(), gy.data_ptr<float>(), gw.data_ptr<float>(), gu.data_ptr<float>(), gk.data_ptr<float>(), gv.data_ptr<float>());
}
void backward_bf16(torch::Tensor &w, torch::Tensor &u, torch::Tensor &k, torch::Tensor &v, torch::Tensor &y, torch::Tensor &gy, torch::Tensor &gw, torch::Tensor &gu, torch::Tensor &gk, torch::Tensor &gv) {
const int B = k.size(0);
const int T = k.size(1);
const int C = k.size(2);
cuda_backward_bf16(B, T, C, w.data_ptr<float>(), u.data_ptr<bf16>(), k.data_ptr<bf16>(), v.data_ptr<bf16>(), y.data_ptr<bf16>(),
gy.data_ptr<bf16>(), gw.data_ptr<bf16>(), gu.data_ptr<bf16>(), gk.data_ptr<bf16>(), gv.data_ptr<bf16>());
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
m.def("forward", &forward, "wkv forward");
m.def("forward_bf16", &forward_bf16, "wkv forward bf16");
m.def("forward_with_state", &forward_with_state, "wkv forward with state");
m.def("forward_with_state_bf16", &forward_with_state_bf16, "wkv forward with state bf16");
m.def("backward", &backward, "wkv backward");
m.def("backward_bf16", &backward_bf16, "wkv backward bf16");
}
TORCH_LIBRARY(wkv, m) {
m.def("forward", forward);
m.def("forward_bf16", forward_bf16);
m.def("forward_with_state", forward_with_state);
m.def("forward_with_state_bf16", forward_with_state_bf16);
m.def("backward", backward);
m.def("backward_bf16", backward_bf16);
}
| transformers/src/transformers/kernels/rwkv/wkv_op.cpp/0 | {
"file_path": "transformers/src/transformers/kernels/rwkv/wkv_op.cpp",
"repo_id": "transformers",
"token_count": 1807
} | 291 |
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" PyTorch - TF 2.0 general utilities."""
import os
import re
import numpy
from .utils import (
ExplicitEnum,
expand_dims,
is_numpy_array,
is_safetensors_available,
is_torch_tensor,
logging,
reshape,
squeeze,
tensor_size,
)
from .utils import transpose as transpose_func
if is_safetensors_available():
from safetensors import safe_open
logger = logging.get_logger(__name__)
class TransposeType(ExplicitEnum):
"""
Possible ...
"""
NO = "no"
SIMPLE = "simple"
CONV1D = "conv1d"
CONV2D = "conv2d"
def convert_tf_weight_name_to_pt_weight_name(
tf_name, start_prefix_to_remove="", tf_weight_shape=None, name_scope=None
):
"""
Convert a TF 2.0 model variable name in a pytorch model weight name.
Conventions for TF2.0 scopes -> PyTorch attribute names conversions:
- '$1___$2' is replaced by $2 (can be used to duplicate or remove layers in TF2.0 vs PyTorch)
- '_._' is replaced by a new level separation (can be used to convert TF2.0 lists in PyTorch nn.ModulesList)
return tuple with:
- pytorch model weight name
- transpose: `TransposeType` member indicating whether and how TF2.0 and PyTorch weights matrices should be
transposed with regards to each other
"""
if name_scope is not None:
if not tf_name.startswith(name_scope) and "final_logits_bias" not in tf_name:
raise ValueError(
f"Weight name {tf_name} does not start with name_scope {name_scope}. This is an internal error "
"in Transformers, so (unless you were doing something really evil) please open an issue to report it!"
)
tf_name = tf_name[len(name_scope) :]
tf_name = tf_name.lstrip("/")
tf_name = tf_name.replace(":0", "") # device ids
tf_name = re.sub(
r"/[^/]*___([^/]*)/", r"/\1/", tf_name
) # '$1___$2' is replaced by $2 (can be used to duplicate or remove layers in TF2.0 vs PyTorch)
tf_name = tf_name.replace(
"_._", "/"
) # '_._' is replaced by a level separation (can be used to convert TF2.0 lists in PyTorch nn.ModulesList)
tf_name = re.sub(r"//+", "/", tf_name) # Remove empty levels at the end
tf_name = tf_name.split("/") # Convert from TF2.0 '/' separators to PyTorch '.' separators
# Some weights have a single name without "/" such as final_logits_bias in BART
if len(tf_name) > 1:
tf_name = tf_name[1:] # Remove level zero
tf_weight_shape = list(tf_weight_shape)
# When should we transpose the weights
if tf_name[-1] == "kernel" and tf_weight_shape is not None and len(tf_weight_shape) == 4:
transpose = TransposeType.CONV2D
elif tf_name[-1] == "kernel" and tf_weight_shape is not None and len(tf_weight_shape) == 3:
transpose = TransposeType.CONV1D
elif bool(
tf_name[-1] in ["kernel", "pointwise_kernel", "depthwise_kernel"]
or "emb_projs" in tf_name
or "out_projs" in tf_name
):
transpose = TransposeType.SIMPLE
else:
transpose = TransposeType.NO
# Convert standard TF2.0 names in PyTorch names
if tf_name[-1] == "kernel" or tf_name[-1] == "embeddings" or tf_name[-1] == "gamma":
tf_name[-1] = "weight"
if tf_name[-1] == "beta":
tf_name[-1] = "bias"
# The SeparableConv1D TF layer contains two weights that are translated to PyTorch Conv1D here
if tf_name[-1] == "pointwise_kernel" or tf_name[-1] == "depthwise_kernel":
tf_name[-1] = tf_name[-1].replace("_kernel", ".weight")
# Remove prefix if needed
tf_name = ".".join(tf_name)
if start_prefix_to_remove:
tf_name = tf_name.replace(start_prefix_to_remove, "", 1)
return tf_name, transpose
def apply_transpose(transpose: TransposeType, weight, match_shape=None, pt_to_tf=True):
"""
Apply a transpose to some weight then tries to reshape the weight to the same shape as a given shape, all in a
framework agnostic way.
"""
if transpose is TransposeType.CONV2D:
# Conv2D weight:
# PT: (num_out_channel, num_in_channel, kernel[0], kernel[1])
# -> TF: (kernel[0], kernel[1], num_in_channel, num_out_channel)
axes = (2, 3, 1, 0) if pt_to_tf else (3, 2, 0, 1)
weight = transpose_func(weight, axes=axes)
elif transpose is TransposeType.CONV1D:
# Conv1D weight:
# PT: (num_out_channel, num_in_channel, kernel)
# -> TF: (kernel, num_in_channel, num_out_channel)
weight = transpose_func(weight, axes=(2, 1, 0))
elif transpose is TransposeType.SIMPLE:
weight = transpose_func(weight)
if match_shape is None:
return weight
if len(match_shape) < len(weight.shape):
weight = squeeze(weight)
elif len(match_shape) > len(weight.shape):
weight = expand_dims(weight, axis=0)
if list(match_shape) != list(weight.shape):
try:
weight = reshape(weight, match_shape)
except AssertionError as e:
e.args += (match_shape, match_shape)
raise e
return weight
#####################
# PyTorch => TF 2.0 #
#####################
def load_pytorch_checkpoint_in_tf2_model(
tf_model,
pytorch_checkpoint_path,
tf_inputs=None,
allow_missing_keys=False,
output_loading_info=False,
_prefix=None,
tf_to_pt_weight_rename=None,
):
"""Load pytorch checkpoints in a TF 2.0 model"""
try:
import tensorflow as tf # noqa: F401
import torch # noqa: F401
from safetensors.torch import load_file as safe_load_file # noqa: F401
from .pytorch_utils import is_torch_greater_or_equal_than_1_13 # noqa: F401
except ImportError:
logger.error(
"Loading a PyTorch model in TensorFlow, requires both PyTorch and TensorFlow to be installed. Please see "
"https://pytorch.org/ and https://www.tensorflow.org/install/ for installation instructions."
)
raise
# Treats a single file as a collection of shards with 1 shard.
if isinstance(pytorch_checkpoint_path, str):
pytorch_checkpoint_path = [pytorch_checkpoint_path]
# Loads all shards into a single state dictionary
pt_state_dict = {}
for path in pytorch_checkpoint_path:
pt_path = os.path.abspath(path)
logger.info(f"Loading PyTorch weights from {pt_path}")
if pt_path.endswith(".safetensors"):
state_dict = safe_load_file(pt_path)
else:
weights_only_kwarg = {"weights_only": True} if is_torch_greater_or_equal_than_1_13 else {}
state_dict = torch.load(pt_path, map_location="cpu", **weights_only_kwarg)
pt_state_dict.update(state_dict)
logger.info(f"PyTorch checkpoint contains {sum(t.numel() for t in pt_state_dict.values()):,} parameters")
return load_pytorch_weights_in_tf2_model(
tf_model,
pt_state_dict,
tf_inputs=tf_inputs,
allow_missing_keys=allow_missing_keys,
output_loading_info=output_loading_info,
_prefix=_prefix,
tf_to_pt_weight_rename=tf_to_pt_weight_rename,
)
def load_pytorch_model_in_tf2_model(tf_model, pt_model, tf_inputs=None, allow_missing_keys=False):
"""Load pytorch checkpoints in a TF 2.0 model"""
pt_state_dict = pt_model.state_dict()
return load_pytorch_weights_in_tf2_model(
tf_model, pt_state_dict, tf_inputs=tf_inputs, allow_missing_keys=allow_missing_keys
)
def load_pytorch_weights_in_tf2_model(
tf_model,
pt_state_dict,
tf_inputs=None,
allow_missing_keys=False,
output_loading_info=False,
_prefix=None,
tf_to_pt_weight_rename=None,
):
"""Load pytorch state_dict in a TF 2.0 model."""
try:
import tensorflow as tf # noqa: F401
import torch # noqa: F401
except ImportError:
logger.error(
"Loading a PyTorch model in TensorFlow, requires both PyTorch and TensorFlow to be installed. Please see "
"https://pytorch.org/ and https://www.tensorflow.org/install/ for installation instructions."
)
raise
pt_state_dict = {k: v.numpy() for k, v in pt_state_dict.items()}
return load_pytorch_state_dict_in_tf2_model(
tf_model,
pt_state_dict,
tf_inputs=tf_inputs,
allow_missing_keys=allow_missing_keys,
output_loading_info=output_loading_info,
_prefix=_prefix,
tf_to_pt_weight_rename=tf_to_pt_weight_rename,
)
def _log_key_warnings(missing_keys, unexpected_keys, mismatched_keys, class_name):
if len(unexpected_keys) > 0:
logger.warning(
"Some weights of the PyTorch model were not used when initializing the TF 2.0 model"
f" {class_name}: {unexpected_keys}\n- This IS expected if you are initializing"
f" {class_name} from a PyTorch model trained on another task or with another architecture"
" (e.g. initializing a TFBertForSequenceClassification model from a BertForPreTraining model).\n- This IS"
f" NOT expected if you are initializing {class_name} from a PyTorch model that you expect"
" to be exactly identical (e.g. initializing a TFBertForSequenceClassification model from a"
" BertForSequenceClassification model)."
)
else:
logger.warning(f"All PyTorch model weights were used when initializing {class_name}.\n")
if len(missing_keys) > 0:
logger.warning(
f"Some weights or buffers of the TF 2.0 model {class_name} were not initialized from the"
f" PyTorch model and are newly initialized: {missing_keys}\nYou should probably TRAIN this model on a"
" down-stream task to be able to use it for predictions and inference."
)
else:
logger.warning(
f"All the weights of {class_name} were initialized from the PyTorch model.\n"
"If your task is similar to the task the model of the checkpoint was trained on, "
f"you can already use {class_name} for predictions without further training."
)
if len(mismatched_keys) > 0:
mismatched_warning = "\n".join(
[
f"- {key}: found shape {shape1} in the checkpoint and {shape2} in the model instantiated"
for key, shape1, shape2 in mismatched_keys
]
)
logger.warning(
f"Some weights of {class_name} were not initialized from the model checkpoint"
f" are newly initialized because the shapes did not"
f" match:\n{mismatched_warning}\nYou should probably TRAIN this model on a down-stream task to be able"
" to use it for predictions and inference."
)
def load_pytorch_state_dict_in_tf2_model(
tf_model,
pt_state_dict,
tf_inputs=None,
allow_missing_keys=False,
output_loading_info=False,
_prefix=None,
tf_to_pt_weight_rename=None,
ignore_mismatched_sizes=False,
skip_logger_warnings=False,
):
"""Load a pytorch state_dict in a TF 2.0 model. pt_state_dict can be either an actual dict or a lazy-loading
safetensors archive created with the safe_open() function."""
import tensorflow as tf
if tf_inputs is None:
tf_inputs = tf_model.dummy_inputs
if _prefix is None:
_prefix = ""
if tf_inputs:
with tf.name_scope(_prefix):
tf_model(tf_inputs, training=False) # Make sure model is built
# Convert old format to new format if needed from a PyTorch state_dict
tf_keys_to_pt_keys = {}
for key in pt_state_dict.keys():
new_key = None
if "gamma" in key:
new_key = key.replace("gamma", "weight")
if "beta" in key:
new_key = key.replace("beta", "bias")
if "running_var" in key:
new_key = key.replace("running_var", "moving_variance")
if "running_mean" in key:
new_key = key.replace("running_mean", "moving_mean")
# New `weight_norm` from https://github.com/huggingface/transformers/pull/24030
key_components = key.split(".")
name = None
if key_components[-3::2] == ["parametrizations", "original0"]:
name = key_components[-2] + "_g"
elif key_components[-3::2] == ["parametrizations", "original1"]:
name = key_components[-2] + "_v"
if name is not None:
key_components = key_components[:-3] + [name]
new_key = ".".join(key_components)
if new_key is None:
new_key = key
tf_keys_to_pt_keys[new_key] = key
# Matt: All TF models store the actual model stem in a MainLayer class, including the base model.
# In PT, the derived models (with heads) use the base model class as the stem instead,
# and there is no MainLayer class. This means that TF base classes have one
# extra layer in their weight names, corresponding to the MainLayer class. This code block compensates for that.
start_prefix_to_remove = ""
if not any(s.startswith(tf_model.base_model_prefix) for s in tf_keys_to_pt_keys.keys()):
start_prefix_to_remove = tf_model.base_model_prefix + "."
symbolic_weights = tf_model.trainable_weights + tf_model.non_trainable_weights
tf_loaded_numel = 0
all_pytorch_weights = set(tf_keys_to_pt_keys.keys())
missing_keys = []
mismatched_keys = []
is_safetensor_archive = hasattr(pt_state_dict, "get_tensor")
for symbolic_weight in symbolic_weights:
sw_name = symbolic_weight.name
name, transpose = convert_tf_weight_name_to_pt_weight_name(
sw_name,
start_prefix_to_remove=start_prefix_to_remove,
tf_weight_shape=symbolic_weight.shape,
name_scope=_prefix,
)
if tf_to_pt_weight_rename is not None:
aliases = tf_to_pt_weight_rename(name) # Is a tuple to account for possible name aliasing
for alias in aliases: # The aliases are in priority order, take the first one that matches
if alias in tf_keys_to_pt_keys:
name = alias
break
else:
# If none of the aliases match, just use the first one (it'll be reported as missing)
name = aliases[0]
# Find associated numpy array in pytorch model state dict
if name not in tf_keys_to_pt_keys:
if allow_missing_keys:
missing_keys.append(name)
continue
elif tf_model._keys_to_ignore_on_load_missing is not None:
# authorized missing keys don't have to be loaded
if any(re.search(pat, name) is not None for pat in tf_model._keys_to_ignore_on_load_missing):
continue
raise AttributeError(f"{name} not found in PyTorch model")
state_dict_name = tf_keys_to_pt_keys[name]
if is_safetensor_archive:
array = pt_state_dict.get_tensor(state_dict_name)
else:
array = pt_state_dict[state_dict_name]
try:
array = apply_transpose(transpose, array, symbolic_weight.shape)
except tf.errors.InvalidArgumentError as e:
if not ignore_mismatched_sizes:
error_msg = str(e)
error_msg += (
"\n\tYou may consider adding `ignore_mismatched_sizes=True` in the model `from_pretrained` method."
)
raise tf.errors.InvalidArgumentError(error_msg)
else:
mismatched_keys.append((name, array.shape, symbolic_weight.shape))
continue
tf_loaded_numel += tensor_size(array)
symbolic_weight.assign(tf.cast(array, symbolic_weight.dtype))
del array # Immediately free memory to keep peak usage as low as possible
all_pytorch_weights.discard(name)
logger.info(f"Loaded {tf_loaded_numel:,} parameters in the TF 2.0 model.")
unexpected_keys = list(all_pytorch_weights)
if tf_model._keys_to_ignore_on_load_missing is not None:
for pat in tf_model._keys_to_ignore_on_load_missing:
missing_keys = [k for k in missing_keys if re.search(pat, k) is None]
if tf_model._keys_to_ignore_on_load_unexpected is not None:
for pat in tf_model._keys_to_ignore_on_load_unexpected:
unexpected_keys = [k for k in unexpected_keys if re.search(pat, k) is None]
if not skip_logger_warnings:
_log_key_warnings(missing_keys, unexpected_keys, mismatched_keys, class_name=tf_model.__class__.__name__)
if output_loading_info:
loading_info = {
"missing_keys": missing_keys,
"unexpected_keys": unexpected_keys,
"mismatched_keys": mismatched_keys,
}
return tf_model, loading_info
return tf_model
def load_sharded_pytorch_safetensors_in_tf2_model(
tf_model,
safetensors_shards,
tf_inputs=None,
allow_missing_keys=False,
output_loading_info=False,
_prefix=None,
tf_to_pt_weight_rename=None,
ignore_mismatched_sizes=False,
):
all_loading_infos = []
for shard in safetensors_shards:
with safe_open(shard, framework="tf") as safetensors_archive:
tf_model, loading_info = load_pytorch_state_dict_in_tf2_model(
tf_model,
safetensors_archive,
tf_inputs=tf_inputs,
allow_missing_keys=allow_missing_keys,
output_loading_info=True,
_prefix=_prefix,
tf_to_pt_weight_rename=tf_to_pt_weight_rename,
ignore_mismatched_sizes=ignore_mismatched_sizes,
skip_logger_warnings=True, # We will emit merged warnings at the end
)
all_loading_infos.append(loading_info)
# Now we just need to merge the loading info
# Keys are missing only if they're missing in *every* shard
missing_keys = sorted(set.intersection(*[set(info["missing_keys"]) for info in all_loading_infos]))
# Keys are unexpected/mismatched if they're unexpected/mismatched in *any* shard
unexpected_keys = sum([info["unexpected_keys"] for info in all_loading_infos], [])
mismatched_keys = sum([info["mismatched_keys"] for info in all_loading_infos], [])
_log_key_warnings(missing_keys, unexpected_keys, mismatched_keys, class_name=tf_model.__class__.__name__)
if output_loading_info:
loading_info = {
"missing_keys": missing_keys,
"unexpected_keys": unexpected_keys,
"mismatched_keys": mismatched_keys,
}
return tf_model, loading_info
return tf_model
#####################
# TF 2.0 => PyTorch #
#####################
def load_tf2_checkpoint_in_pytorch_model(
pt_model, tf_checkpoint_path, tf_inputs=None, allow_missing_keys=False, output_loading_info=False
):
"""
Load TF 2.0 HDF5 checkpoint in a PyTorch model We use HDF5 to easily do transfer learning (see
https://github.com/tensorflow/tensorflow/blob/ee16fcac960ae660e0e4496658a366e2f745e1f0/tensorflow/python/keras/engine/network.py#L1352-L1357).
"""
try:
import tensorflow as tf # noqa: F401
import torch # noqa: F401
except ImportError:
logger.error(
"Loading a TensorFlow model in PyTorch, requires both PyTorch and TensorFlow to be installed. Please see "
"https://pytorch.org/ and https://www.tensorflow.org/install/ for installation instructions."
)
raise
import transformers
from .modeling_tf_utils import load_tf_weights
logger.info(f"Loading TensorFlow weights from {tf_checkpoint_path}")
# Instantiate and load the associated TF 2.0 model
tf_model_class_name = "TF" + pt_model.__class__.__name__ # Add "TF" at the beginning
tf_model_class = getattr(transformers, tf_model_class_name)
tf_model = tf_model_class(pt_model.config)
if tf_inputs is None:
tf_inputs = tf_model.dummy_inputs
if tf_inputs is not None:
tf_model(tf_inputs, training=False) # Make sure model is built
load_tf_weights(tf_model, tf_checkpoint_path)
return load_tf2_model_in_pytorch_model(
pt_model, tf_model, allow_missing_keys=allow_missing_keys, output_loading_info=output_loading_info
)
def load_tf2_model_in_pytorch_model(pt_model, tf_model, allow_missing_keys=False, output_loading_info=False):
"""Load TF 2.0 model in a pytorch model"""
weights = tf_model.weights
return load_tf2_weights_in_pytorch_model(
pt_model, weights, allow_missing_keys=allow_missing_keys, output_loading_info=output_loading_info
)
def load_tf2_weights_in_pytorch_model(pt_model, tf_weights, allow_missing_keys=False, output_loading_info=False):
"""Load TF2.0 symbolic weights in a PyTorch model"""
try:
import tensorflow as tf # noqa: F401
import torch # noqa: F401
except ImportError:
logger.error(
"Loading a TensorFlow model in PyTorch, requires both PyTorch and TensorFlow to be installed. Please see "
"https://pytorch.org/ and https://www.tensorflow.org/install/ for installation instructions."
)
raise
tf_state_dict = {tf_weight.name: tf_weight.numpy() for tf_weight in tf_weights}
return load_tf2_state_dict_in_pytorch_model(
pt_model, tf_state_dict, allow_missing_keys=allow_missing_keys, output_loading_info=output_loading_info
)
def load_tf2_state_dict_in_pytorch_model(pt_model, tf_state_dict, allow_missing_keys=False, output_loading_info=False):
import torch
new_pt_params_dict = {}
current_pt_params_dict = dict(pt_model.named_parameters())
# Make sure we are able to load PyTorch base models as well as derived models (with heads)
# TF models always have a prefix, some of PyTorch models (base ones) don't
start_prefix_to_remove = ""
if not any(s.startswith(pt_model.base_model_prefix) for s in current_pt_params_dict.keys()):
start_prefix_to_remove = pt_model.base_model_prefix + "."
# Build a map from potential PyTorch weight names to TF 2.0 Variables
tf_weights_map = {}
for name, tf_weight in tf_state_dict.items():
pt_name, transpose = convert_tf_weight_name_to_pt_weight_name(
name, start_prefix_to_remove=start_prefix_to_remove, tf_weight_shape=tf_weight.shape
)
tf_weights_map[pt_name] = (tf_weight, transpose)
all_tf_weights = set(tf_weights_map.keys())
loaded_pt_weights_data_ptr = {}
missing_keys_pt = []
for pt_weight_name, pt_weight in current_pt_params_dict.items():
# Handle PyTorch shared weight ()not duplicated in TF 2.0
if pt_weight.data_ptr() in loaded_pt_weights_data_ptr:
new_pt_params_dict[pt_weight_name] = loaded_pt_weights_data_ptr[pt_weight.data_ptr()]
continue
pt_weight_name_to_check = pt_weight_name
# New `weight_norm` from https://github.com/huggingface/transformers/pull/24030
key_components = pt_weight_name.split(".")
name = None
if key_components[-3::2] == ["parametrizations", "original0"]:
name = key_components[-2] + "_g"
elif key_components[-3::2] == ["parametrizations", "original1"]:
name = key_components[-2] + "_v"
if name is not None:
key_components = key_components[:-3] + [name]
pt_weight_name_to_check = ".".join(key_components)
# Find associated numpy array in pytorch model state dict
if pt_weight_name_to_check not in tf_weights_map:
if allow_missing_keys:
missing_keys_pt.append(pt_weight_name)
continue
raise AttributeError(f"{pt_weight_name} not found in TF 2.0 model")
array, transpose = tf_weights_map[pt_weight_name_to_check]
array = apply_transpose(transpose, array, pt_weight.shape, pt_to_tf=False)
if numpy.isscalar(array):
array = numpy.array(array)
if not is_torch_tensor(array) and not is_numpy_array(array):
array = array.numpy()
if is_numpy_array(array):
# Convert to torch tensor
array = torch.from_numpy(array)
new_pt_params_dict[pt_weight_name] = array
loaded_pt_weights_data_ptr[pt_weight.data_ptr()] = array
all_tf_weights.discard(pt_weight_name)
missing_keys, unexpected_keys = pt_model.load_state_dict(new_pt_params_dict, strict=False)
missing_keys += missing_keys_pt
# Some models may have keys that are not in the state by design, removing them before needlessly warning
# the user.
if pt_model._keys_to_ignore_on_load_missing is not None:
for pat in pt_model._keys_to_ignore_on_load_missing:
missing_keys = [k for k in missing_keys if re.search(pat, k) is None]
if pt_model._keys_to_ignore_on_load_unexpected is not None:
for pat in pt_model._keys_to_ignore_on_load_unexpected:
unexpected_keys = [k for k in unexpected_keys if re.search(pat, k) is None]
if len(unexpected_keys) > 0:
logger.warning(
"Some weights of the TF 2.0 model were not used when initializing the PyTorch model"
f" {pt_model.__class__.__name__}: {unexpected_keys}\n- This IS expected if you are initializing"
f" {pt_model.__class__.__name__} from a TF 2.0 model trained on another task or with another architecture"
" (e.g. initializing a BertForSequenceClassification model from a TFBertForPreTraining model).\n- This IS"
f" NOT expected if you are initializing {pt_model.__class__.__name__} from a TF 2.0 model that you expect"
" to be exactly identical (e.g. initializing a BertForSequenceClassification model from a"
" TFBertForSequenceClassification model)."
)
else:
logger.warning(f"All TF 2.0 model weights were used when initializing {pt_model.__class__.__name__}.\n")
if len(missing_keys) > 0:
logger.warning(
f"Some weights of {pt_model.__class__.__name__} were not initialized from the TF 2.0 model and are newly"
f" initialized: {missing_keys}\nYou should probably TRAIN this model on a down-stream task to be able to"
" use it for predictions and inference."
)
else:
logger.warning(
f"All the weights of {pt_model.__class__.__name__} were initialized from the TF 2.0 model.\n"
"If your task is similar to the task the model of the checkpoint was trained on, "
f"you can already use {pt_model.__class__.__name__} for predictions without further training."
)
logger.info(f"Weights or buffers not loaded from TF 2.0 model: {all_tf_weights}")
if output_loading_info:
loading_info = {"missing_keys": missing_keys, "unexpected_keys": unexpected_keys}
return pt_model, loading_info
return pt_model
| transformers/src/transformers/modeling_tf_pytorch_utils.py/0 | {
"file_path": "transformers/src/transformers/modeling_tf_pytorch_utils.py",
"repo_id": "transformers",
"token_count": 11605
} | 292 |
# coding=utf-8
# Copyright 2018 The Google Flax Team Authors and The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Auto Model class."""
from collections import OrderedDict
from ...utils import logging
from .auto_factory import _BaseAutoModelClass, _LazyAutoMapping, auto_class_update
from .configuration_auto import CONFIG_MAPPING_NAMES
logger = logging.get_logger(__name__)
FLAX_MODEL_MAPPING_NAMES = OrderedDict(
[
# Base model mapping
("albert", "FlaxAlbertModel"),
("bart", "FlaxBartModel"),
("beit", "FlaxBeitModel"),
("bert", "FlaxBertModel"),
("big_bird", "FlaxBigBirdModel"),
("blenderbot", "FlaxBlenderbotModel"),
("blenderbot-small", "FlaxBlenderbotSmallModel"),
("bloom", "FlaxBloomModel"),
("clip", "FlaxCLIPModel"),
("distilbert", "FlaxDistilBertModel"),
("electra", "FlaxElectraModel"),
("gemma", "FlaxGemmaModel"),
("gpt-sw3", "FlaxGPT2Model"),
("gpt2", "FlaxGPT2Model"),
("gpt_neo", "FlaxGPTNeoModel"),
("gptj", "FlaxGPTJModel"),
("llama", "FlaxLlamaModel"),
("longt5", "FlaxLongT5Model"),
("marian", "FlaxMarianModel"),
("mbart", "FlaxMBartModel"),
("mistral", "FlaxMistralModel"),
("mt5", "FlaxMT5Model"),
("opt", "FlaxOPTModel"),
("pegasus", "FlaxPegasusModel"),
("regnet", "FlaxRegNetModel"),
("resnet", "FlaxResNetModel"),
("roberta", "FlaxRobertaModel"),
("roberta-prelayernorm", "FlaxRobertaPreLayerNormModel"),
("roformer", "FlaxRoFormerModel"),
("t5", "FlaxT5Model"),
("vision-text-dual-encoder", "FlaxVisionTextDualEncoderModel"),
("vit", "FlaxViTModel"),
("wav2vec2", "FlaxWav2Vec2Model"),
("whisper", "FlaxWhisperModel"),
("xglm", "FlaxXGLMModel"),
("xlm-roberta", "FlaxXLMRobertaModel"),
]
)
FLAX_MODEL_FOR_PRETRAINING_MAPPING_NAMES = OrderedDict(
[
# Model for pre-training mapping
("albert", "FlaxAlbertForPreTraining"),
("bart", "FlaxBartForConditionalGeneration"),
("bert", "FlaxBertForPreTraining"),
("big_bird", "FlaxBigBirdForPreTraining"),
("electra", "FlaxElectraForPreTraining"),
("longt5", "FlaxLongT5ForConditionalGeneration"),
("mbart", "FlaxMBartForConditionalGeneration"),
("mt5", "FlaxMT5ForConditionalGeneration"),
("roberta", "FlaxRobertaForMaskedLM"),
("roberta-prelayernorm", "FlaxRobertaPreLayerNormForMaskedLM"),
("roformer", "FlaxRoFormerForMaskedLM"),
("t5", "FlaxT5ForConditionalGeneration"),
("wav2vec2", "FlaxWav2Vec2ForPreTraining"),
("whisper", "FlaxWhisperForConditionalGeneration"),
("xlm-roberta", "FlaxXLMRobertaForMaskedLM"),
]
)
FLAX_MODEL_FOR_MASKED_LM_MAPPING_NAMES = OrderedDict(
[
# Model for Masked LM mapping
("albert", "FlaxAlbertForMaskedLM"),
("bart", "FlaxBartForConditionalGeneration"),
("bert", "FlaxBertForMaskedLM"),
("big_bird", "FlaxBigBirdForMaskedLM"),
("distilbert", "FlaxDistilBertForMaskedLM"),
("electra", "FlaxElectraForMaskedLM"),
("mbart", "FlaxMBartForConditionalGeneration"),
("roberta", "FlaxRobertaForMaskedLM"),
("roberta-prelayernorm", "FlaxRobertaPreLayerNormForMaskedLM"),
("roformer", "FlaxRoFormerForMaskedLM"),
("xlm-roberta", "FlaxXLMRobertaForMaskedLM"),
]
)
FLAX_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING_NAMES = OrderedDict(
[
# Model for Seq2Seq Causal LM mapping
("bart", "FlaxBartForConditionalGeneration"),
("blenderbot", "FlaxBlenderbotForConditionalGeneration"),
("blenderbot-small", "FlaxBlenderbotSmallForConditionalGeneration"),
("encoder-decoder", "FlaxEncoderDecoderModel"),
("longt5", "FlaxLongT5ForConditionalGeneration"),
("marian", "FlaxMarianMTModel"),
("mbart", "FlaxMBartForConditionalGeneration"),
("mt5", "FlaxMT5ForConditionalGeneration"),
("pegasus", "FlaxPegasusForConditionalGeneration"),
("t5", "FlaxT5ForConditionalGeneration"),
]
)
FLAX_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
[
# Model for Image-classsification
("beit", "FlaxBeitForImageClassification"),
("regnet", "FlaxRegNetForImageClassification"),
("resnet", "FlaxResNetForImageClassification"),
("vit", "FlaxViTForImageClassification"),
]
)
FLAX_MODEL_FOR_VISION_2_SEQ_MAPPING_NAMES = OrderedDict(
[
("vision-encoder-decoder", "FlaxVisionEncoderDecoderModel"),
]
)
FLAX_MODEL_FOR_CAUSAL_LM_MAPPING_NAMES = OrderedDict(
[
# Model for Causal LM mapping
("bart", "FlaxBartForCausalLM"),
("bert", "FlaxBertForCausalLM"),
("big_bird", "FlaxBigBirdForCausalLM"),
("bloom", "FlaxBloomForCausalLM"),
("electra", "FlaxElectraForCausalLM"),
("gemma", "FlaxGemmaForCausalLM"),
("gpt-sw3", "FlaxGPT2LMHeadModel"),
("gpt2", "FlaxGPT2LMHeadModel"),
("gpt_neo", "FlaxGPTNeoForCausalLM"),
("gptj", "FlaxGPTJForCausalLM"),
("llama", "FlaxLlamaForCausalLM"),
("mistral", "FlaxMistralForCausalLM"),
("opt", "FlaxOPTForCausalLM"),
("roberta", "FlaxRobertaForCausalLM"),
("roberta-prelayernorm", "FlaxRobertaPreLayerNormForCausalLM"),
("xglm", "FlaxXGLMForCausalLM"),
("xlm-roberta", "FlaxXLMRobertaForCausalLM"),
]
)
FLAX_MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
[
# Model for Sequence Classification mapping
("albert", "FlaxAlbertForSequenceClassification"),
("bart", "FlaxBartForSequenceClassification"),
("bert", "FlaxBertForSequenceClassification"),
("big_bird", "FlaxBigBirdForSequenceClassification"),
("distilbert", "FlaxDistilBertForSequenceClassification"),
("electra", "FlaxElectraForSequenceClassification"),
("mbart", "FlaxMBartForSequenceClassification"),
("roberta", "FlaxRobertaForSequenceClassification"),
("roberta-prelayernorm", "FlaxRobertaPreLayerNormForSequenceClassification"),
("roformer", "FlaxRoFormerForSequenceClassification"),
("xlm-roberta", "FlaxXLMRobertaForSequenceClassification"),
]
)
FLAX_MODEL_FOR_QUESTION_ANSWERING_MAPPING_NAMES = OrderedDict(
[
# Model for Question Answering mapping
("albert", "FlaxAlbertForQuestionAnswering"),
("bart", "FlaxBartForQuestionAnswering"),
("bert", "FlaxBertForQuestionAnswering"),
("big_bird", "FlaxBigBirdForQuestionAnswering"),
("distilbert", "FlaxDistilBertForQuestionAnswering"),
("electra", "FlaxElectraForQuestionAnswering"),
("mbart", "FlaxMBartForQuestionAnswering"),
("roberta", "FlaxRobertaForQuestionAnswering"),
("roberta-prelayernorm", "FlaxRobertaPreLayerNormForQuestionAnswering"),
("roformer", "FlaxRoFormerForQuestionAnswering"),
("xlm-roberta", "FlaxXLMRobertaForQuestionAnswering"),
]
)
FLAX_MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
[
# Model for Token Classification mapping
("albert", "FlaxAlbertForTokenClassification"),
("bert", "FlaxBertForTokenClassification"),
("big_bird", "FlaxBigBirdForTokenClassification"),
("distilbert", "FlaxDistilBertForTokenClassification"),
("electra", "FlaxElectraForTokenClassification"),
("roberta", "FlaxRobertaForTokenClassification"),
("roberta-prelayernorm", "FlaxRobertaPreLayerNormForTokenClassification"),
("roformer", "FlaxRoFormerForTokenClassification"),
("xlm-roberta", "FlaxXLMRobertaForTokenClassification"),
]
)
FLAX_MODEL_FOR_MULTIPLE_CHOICE_MAPPING_NAMES = OrderedDict(
[
# Model for Multiple Choice mapping
("albert", "FlaxAlbertForMultipleChoice"),
("bert", "FlaxBertForMultipleChoice"),
("big_bird", "FlaxBigBirdForMultipleChoice"),
("distilbert", "FlaxDistilBertForMultipleChoice"),
("electra", "FlaxElectraForMultipleChoice"),
("roberta", "FlaxRobertaForMultipleChoice"),
("roberta-prelayernorm", "FlaxRobertaPreLayerNormForMultipleChoice"),
("roformer", "FlaxRoFormerForMultipleChoice"),
("xlm-roberta", "FlaxXLMRobertaForMultipleChoice"),
]
)
FLAX_MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING_NAMES = OrderedDict(
[
("bert", "FlaxBertForNextSentencePrediction"),
]
)
FLAX_MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING_NAMES = OrderedDict(
[
("speech-encoder-decoder", "FlaxSpeechEncoderDecoderModel"),
("whisper", "FlaxWhisperForConditionalGeneration"),
]
)
FLAX_MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING_NAMES = OrderedDict(
[
("whisper", "FlaxWhisperForAudioClassification"),
]
)
FLAX_MODEL_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, FLAX_MODEL_MAPPING_NAMES)
FLAX_MODEL_FOR_PRETRAINING_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, FLAX_MODEL_FOR_PRETRAINING_MAPPING_NAMES)
FLAX_MODEL_FOR_MASKED_LM_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, FLAX_MODEL_FOR_MASKED_LM_MAPPING_NAMES)
FLAX_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING = _LazyAutoMapping(
CONFIG_MAPPING_NAMES, FLAX_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING_NAMES
)
FLAX_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING = _LazyAutoMapping(
CONFIG_MAPPING_NAMES, FLAX_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING_NAMES
)
FLAX_MODEL_FOR_VISION_2_SEQ_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, FLAX_MODEL_FOR_VISION_2_SEQ_MAPPING_NAMES)
FLAX_MODEL_FOR_CAUSAL_LM_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, FLAX_MODEL_FOR_CAUSAL_LM_MAPPING_NAMES)
FLAX_MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING = _LazyAutoMapping(
CONFIG_MAPPING_NAMES, FLAX_MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING_NAMES
)
FLAX_MODEL_FOR_QUESTION_ANSWERING_MAPPING = _LazyAutoMapping(
CONFIG_MAPPING_NAMES, FLAX_MODEL_FOR_QUESTION_ANSWERING_MAPPING_NAMES
)
FLAX_MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING = _LazyAutoMapping(
CONFIG_MAPPING_NAMES, FLAX_MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING_NAMES
)
FLAX_MODEL_FOR_MULTIPLE_CHOICE_MAPPING = _LazyAutoMapping(
CONFIG_MAPPING_NAMES, FLAX_MODEL_FOR_MULTIPLE_CHOICE_MAPPING_NAMES
)
FLAX_MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING = _LazyAutoMapping(
CONFIG_MAPPING_NAMES, FLAX_MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING_NAMES
)
FLAX_MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING = _LazyAutoMapping(
CONFIG_MAPPING_NAMES, FLAX_MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING_NAMES
)
FLAX_MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING = _LazyAutoMapping(
CONFIG_MAPPING_NAMES, FLAX_MODEL_FOR_AUDIO_CLASSIFICATION_MAPPING_NAMES
)
class FlaxAutoModel(_BaseAutoModelClass):
_model_mapping = FLAX_MODEL_MAPPING
FlaxAutoModel = auto_class_update(FlaxAutoModel)
class FlaxAutoModelForPreTraining(_BaseAutoModelClass):
_model_mapping = FLAX_MODEL_FOR_PRETRAINING_MAPPING
FlaxAutoModelForPreTraining = auto_class_update(FlaxAutoModelForPreTraining, head_doc="pretraining")
class FlaxAutoModelForCausalLM(_BaseAutoModelClass):
_model_mapping = FLAX_MODEL_FOR_CAUSAL_LM_MAPPING
FlaxAutoModelForCausalLM = auto_class_update(FlaxAutoModelForCausalLM, head_doc="causal language modeling")
class FlaxAutoModelForMaskedLM(_BaseAutoModelClass):
_model_mapping = FLAX_MODEL_FOR_MASKED_LM_MAPPING
FlaxAutoModelForMaskedLM = auto_class_update(FlaxAutoModelForMaskedLM, head_doc="masked language modeling")
class FlaxAutoModelForSeq2SeqLM(_BaseAutoModelClass):
_model_mapping = FLAX_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING
FlaxAutoModelForSeq2SeqLM = auto_class_update(
FlaxAutoModelForSeq2SeqLM,
head_doc="sequence-to-sequence language modeling",
checkpoint_for_example="google-t5/t5-base",
)
class FlaxAutoModelForSequenceClassification(_BaseAutoModelClass):
_model_mapping = FLAX_MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING
FlaxAutoModelForSequenceClassification = auto_class_update(
FlaxAutoModelForSequenceClassification, head_doc="sequence classification"
)
class FlaxAutoModelForQuestionAnswering(_BaseAutoModelClass):
_model_mapping = FLAX_MODEL_FOR_QUESTION_ANSWERING_MAPPING
FlaxAutoModelForQuestionAnswering = auto_class_update(FlaxAutoModelForQuestionAnswering, head_doc="question answering")
class FlaxAutoModelForTokenClassification(_BaseAutoModelClass):
_model_mapping = FLAX_MODEL_FOR_TOKEN_CLASSIFICATION_MAPPING
FlaxAutoModelForTokenClassification = auto_class_update(
FlaxAutoModelForTokenClassification, head_doc="token classification"
)
class FlaxAutoModelForMultipleChoice(_BaseAutoModelClass):
_model_mapping = FLAX_MODEL_FOR_MULTIPLE_CHOICE_MAPPING
FlaxAutoModelForMultipleChoice = auto_class_update(FlaxAutoModelForMultipleChoice, head_doc="multiple choice")
class FlaxAutoModelForNextSentencePrediction(_BaseAutoModelClass):
_model_mapping = FLAX_MODEL_FOR_NEXT_SENTENCE_PREDICTION_MAPPING
FlaxAutoModelForNextSentencePrediction = auto_class_update(
FlaxAutoModelForNextSentencePrediction, head_doc="next sentence prediction"
)
class FlaxAutoModelForImageClassification(_BaseAutoModelClass):
_model_mapping = FLAX_MODEL_FOR_IMAGE_CLASSIFICATION_MAPPING
FlaxAutoModelForImageClassification = auto_class_update(
FlaxAutoModelForImageClassification, head_doc="image classification"
)
class FlaxAutoModelForVision2Seq(_BaseAutoModelClass):
_model_mapping = FLAX_MODEL_FOR_VISION_2_SEQ_MAPPING
FlaxAutoModelForVision2Seq = auto_class_update(FlaxAutoModelForVision2Seq, head_doc="vision-to-text modeling")
class FlaxAutoModelForSpeechSeq2Seq(_BaseAutoModelClass):
_model_mapping = FLAX_MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING
FlaxAutoModelForSpeechSeq2Seq = auto_class_update(
FlaxAutoModelForSpeechSeq2Seq, head_doc="sequence-to-sequence speech-to-text modeling"
)
| transformers/src/transformers/models/auto/modeling_flax_auto.py/0 | {
"file_path": "transformers/src/transformers/models/auto/modeling_flax_auto.py",
"repo_id": "transformers",
"token_count": 6167
} | 293 |
# coding=utf-8
# Copyright 2021 Microsoft Research and the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import Callable, List, Optional, Tuple
import flax
import flax.linen as nn
import jax
import jax.numpy as jnp
import numpy as np
from flax.core.frozen_dict import FrozenDict, freeze, unfreeze
from flax.linen.attention import dot_product_attention_weights
from flax.traverse_util import flatten_dict, unflatten_dict
from ...modeling_flax_outputs import (
FlaxBaseModelOutput,
FlaxBaseModelOutputWithPooling,
FlaxMaskedLMOutput,
FlaxSequenceClassifierOutput,
)
from ...modeling_flax_utils import (
ACT2FN,
FlaxPreTrainedModel,
append_replace_return_docstrings,
overwrite_call_docstring,
)
from ...utils import add_start_docstrings, add_start_docstrings_to_model_forward
from .configuration_beit import BeitConfig
@flax.struct.dataclass
class FlaxBeitModelOutputWithPooling(FlaxBaseModelOutputWithPooling):
"""
Class for outputs of [`FlaxBeitModel`].
Args:
last_hidden_state (`jnp.ndarray` of shape `(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
pooler_output (`jnp.ndarray` of shape `(batch_size, hidden_size)`):
Average of the last layer hidden states of the patch tokens (excluding the *[CLS]* token) if
*config.use_mean_pooling* is set to True. If set to False, then the final hidden state of the *[CLS]* token
will be returned.
hidden_states (`tuple(jnp.ndarray)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `jnp.ndarray` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`. Hidden-states of the model at the output of each layer plus
the initial embedding outputs.
attentions (`tuple(jnp.ndarray)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `jnp.ndarray` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`. Attentions weights after the attention softmax, used to compute the weighted average in
the self-attention heads.
"""
BEIT_START_DOCSTRING = r"""
This model inherits from [`FlaxPreTrainedModel`]. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading, saving and converting weights from PyTorch models)
This model is also a
[flax.linen.Module](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html) subclass. Use it as
a regular Flax linen Module and refer to the Flax documentation for all matter related to general usage and
behavior.
Finally, this model supports inherent JAX features such as:
- [Just-In-Time (JIT) compilation](https://jax.readthedocs.io/en/latest/jax.html#just-in-time-compilation-jit)
- [Automatic Differentiation](https://jax.readthedocs.io/en/latest/jax.html#automatic-differentiation)
- [Vectorization](https://jax.readthedocs.io/en/latest/jax.html#vectorization-vmap)
- [Parallelization](https://jax.readthedocs.io/en/latest/jax.html#parallelization-pmap)
Parameters:
config ([`BeitConfig`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~FlaxPreTrainedModel.from_pretrained`] method to load the model weights.
dtype (`jax.numpy.dtype`, *optional*, defaults to `jax.numpy.float32`):
The data type of the computation. Can be one of `jax.numpy.float32`, `jax.numpy.float16` (on GPUs) and
`jax.numpy.bfloat16` (on TPUs).
This can be used to enable mixed-precision training or half-precision inference on GPUs or TPUs. If
specified all the computation will be performed with the given `dtype`.
**Note that this only specifies the dtype of the computation and does not influence the dtype of model
parameters.**
If you wish to change the dtype of the model parameters, see [`~FlaxPreTrainedModel.to_fp16`] and
[`~FlaxPreTrainedModel.to_bf16`].
"""
BEIT_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`numpy.ndarray` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See
[`AutoImageProcessor.__call__`] for details.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
def relative_position_index_init(window_size: Tuple[int, int]) -> jnp.ndarray:
"""
get pair-wise relative position index for each token inside the window
"""
num_relative_distance = (2 * window_size[0] - 1) * (2 * window_size[1] - 1) + 3
coords_h = np.arange(window_size[0])
coords_w = np.arange(window_size[1])
coords = np.stack(np.meshgrid(coords_h, coords_w, indexing="ij")) # 2, Wh, Ww
coords_flatten = np.reshape(coords, (2, -1))
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = np.transpose(relative_coords, (1, 2, 0)) # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += window_size[1] - 1
relative_coords[:, :, 0] *= 2 * window_size[1] - 1
relative_position_index = np.zeros(shape=(window_size[0] * window_size[1] + 1,) * 2, dtype=relative_coords.dtype)
relative_position_index[1:, 1:] = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
relative_position_index[0, 0:] = num_relative_distance - 3
relative_position_index[0:, 0] = num_relative_distance - 2
relative_position_index[0, 0] = num_relative_distance - 1
return jnp.array(relative_position_index)
def ones_with_scale(key, shape, scale, dtype=jnp.float32):
return jnp.ones(shape, dtype) * scale
class FlaxBeitDropPath(nn.Module):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""
rate: float
@nn.module.compact
def __call__(self, inputs, deterministic: Optional[bool] = True):
if self.rate == 0.0:
return inputs
keep_prob = 1.0 - self.rate
if deterministic:
return inputs
else:
shape = (inputs.shape[0],) + (1,) * (inputs.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
rng = self.make_rng("droppath")
random_tensor = keep_prob + jax.random.uniform(rng, shape=shape, dtype=inputs.dtype)
binary_tensor = jnp.floor(random_tensor)
output = inputs / keep_prob * binary_tensor
return output
class FlaxBeitPatchEmbeddings(nn.Module):
config: BeitConfig
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.num_channels = self.config.num_channels
image_size = self.config.image_size
patch_size = self.config.patch_size
num_patches = (image_size // patch_size) * (image_size // patch_size)
patch_shape = (image_size // patch_size, image_size // patch_size)
self.num_patches = num_patches
self.patch_shape = patch_shape
self.projection = nn.Conv(
self.config.hidden_size,
kernel_size=(patch_size, patch_size),
strides=(patch_size, patch_size),
padding="VALID",
dtype=self.dtype,
kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
)
def __call__(self, pixel_values):
num_channels = pixel_values.shape[-1]
if num_channels != self.num_channels:
raise ValueError(
"Make sure that the channel dimension of the pixel values match with the one set in the configuration."
)
embeddings = self.projection(pixel_values)
batch_size, _, _, channels = embeddings.shape
return jnp.reshape(embeddings, (batch_size, -1, channels))
class FlaxBeitEmbeddings(nn.Module):
"""Construct the CLS token, position and patch embeddings."""
config: BeitConfig
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.cls_token = self.param("cls_token", nn.initializers.zeros, (1, 1, self.config.hidden_size))
if self.config.use_mask_token:
self.mask_token = self.param("mask_token", nn.initializers.zeros, (1, 1, self.config.hidden_size))
self.patch_embeddings = FlaxBeitPatchEmbeddings(self.config, dtype=self.dtype)
num_patches = self.patch_embeddings.num_patches
if self.config.use_absolute_position_embeddings:
self.position_embeddings = self.param(
"position_embeddings", nn.initializers.zeros, (1, num_patches + 1, self.config.hidden_size)
)
self.dropout = nn.Dropout(rate=self.config.hidden_dropout_prob)
def __call__(self, pixel_values, bool_masked_pos=None, deterministic=True):
embeddings = self.patch_embeddings(pixel_values)
batch_size, seq_len, _ = embeddings.shape
cls_tokens = jnp.broadcast_to(self.cls_token, (batch_size, 1, self.config.hidden_size))
cls_tokens = cls_tokens.astype(embeddings.dtype)
if bool_masked_pos is not None:
mask_tokens = jnp.broadcast_to(self.mask_token, (batch_size, seq_len, self.config.hidden_size))
mask_tokens = mask_tokens.astype(embeddings.dtype)
# replace the masked visual tokens by mask_tokens
w = jnp.expand_dims(bool_masked_pos, axis=-1)
embeddings = embeddings * (1 - w) + mask_tokens * w
embeddings = jnp.concatenate((cls_tokens, embeddings), axis=1)
if self.config.use_absolute_position_embeddings:
embeddings = embeddings + self.position_embeddings.astype(embeddings.dtype)
embeddings = self.dropout(embeddings, deterministic=deterministic)
return embeddings
class FlaxBeitRelativePositionBias(nn.Module):
config: BeitConfig
window_size: Tuple[int, int]
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
num_relative_distance = (2 * self.window_size[0] - 1) * (2 * self.window_size[1] - 1) + 3
self.relative_position_bias_table = self.param(
"relative_position_bias_table",
nn.initializers.zeros,
(num_relative_distance, self.config.num_attention_heads),
) # 2*Wh-1 * 2*Ww-1, nH
# cls to token & token 2 cls & cls to cls
self.relative_position_index = relative_position_index_init(self.window_size)
def __call__(self):
index = self.relative_position_index.reshape(-1)
shape = (self.window_size[0] * self.window_size[1] + 1, self.window_size[0] * self.window_size[1] + 1, -1)
relative_position_bias = self.relative_position_bias_table[index].reshape(shape) # Wh*Ww,Wh*Ww,nH
return jnp.transpose(relative_position_bias, (2, 0, 1))
class FlaxBeitSelfAttention(nn.Module):
config: BeitConfig
window_size: Tuple[int, int]
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
if self.config.hidden_size % self.config.num_attention_heads != 0 and not hasattr(
self.config, "embedding_size"
):
raise ValueError(
f"The hidden size {self.config.hidden_size,} is not a multiple of the number of attention "
f"heads {self.config.num_attention_heads}."
)
self.query = nn.Dense(
self.config.hidden_size,
dtype=self.dtype,
kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
)
self.key = nn.Dense(
self.config.hidden_size,
dtype=self.dtype,
kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
use_bias=False,
)
self.value = nn.Dense(
self.config.hidden_size,
dtype=self.dtype,
kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
)
self.relative_position_bias = (
FlaxBeitRelativePositionBias(self.config, window_size=self.window_size, dtype=self.dtype)
if self.window_size
else None
)
def __call__(
self, hidden_states, relative_position_bias=None, deterministic: bool = True, output_attentions: bool = False
):
head_dim = self.config.hidden_size // self.config.num_attention_heads
query_states = self.query(hidden_states).reshape(
hidden_states.shape[:2] + (self.config.num_attention_heads, head_dim)
)
value_states = self.value(hidden_states).reshape(
hidden_states.shape[:2] + (self.config.num_attention_heads, head_dim)
)
key_states = self.key(hidden_states).reshape(
hidden_states.shape[:2] + (self.config.num_attention_heads, head_dim)
)
dropout_rng = None
if not deterministic and self.config.attention_probs_dropout_prob > 0.0:
dropout_rng = self.make_rng("dropout")
attention_bias = jnp.array(0.0, dtype=self.dtype)
# Add relative position bias if present.
if self.relative_position_bias is not None:
attention_bias = jnp.expand_dims(self.relative_position_bias(), 0)
attention_bias = attention_bias.astype(query_states.dtype)
# Add shared relative position bias if provided.
if relative_position_bias is not None:
attention_bias = attention_bias + relative_position_bias.astype(attention_bias.dtype)
attn_weights = dot_product_attention_weights(
query_states,
key_states,
bias=attention_bias,
dropout_rng=dropout_rng,
dropout_rate=self.config.attention_probs_dropout_prob,
broadcast_dropout=True,
deterministic=deterministic,
dtype=self.dtype,
precision=None,
)
attn_output = jnp.einsum("...hqk,...khd->...qhd", attn_weights, value_states)
attn_output = attn_output.reshape(attn_output.shape[:2] + (-1,))
outputs = (attn_output, attn_weights) if output_attentions else (attn_output,)
return outputs
class FlaxBeitSelfOutput(nn.Module):
config: BeitConfig
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.dense = nn.Dense(
self.config.hidden_size,
kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
dtype=self.dtype,
)
self.dropout = nn.Dropout(rate=self.config.hidden_dropout_prob)
def __call__(self, hidden_states, deterministic: bool = True):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states, deterministic=deterministic)
return hidden_states
class FlaxBeitAttention(nn.Module):
config: BeitConfig
window_size: Tuple[int, int]
dtype: jnp.dtype = jnp.float32
def setup(self):
self.attention = FlaxBeitSelfAttention(self.config, self.window_size, dtype=self.dtype)
self.output = FlaxBeitSelfOutput(self.config, dtype=self.dtype)
def __call__(
self, hidden_states, relative_position_bias=None, deterministic=True, output_attentions: bool = False
):
attn_outputs = self.attention(
hidden_states, relative_position_bias, deterministic=deterministic, output_attentions=output_attentions
)
attn_output = attn_outputs[0]
attn_output = self.output(attn_output, deterministic=deterministic)
outputs = (attn_output,)
if output_attentions:
outputs += (attn_outputs[1],)
return outputs
class FlaxBeitIntermediate(nn.Module):
config: BeitConfig
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.dense = nn.Dense(
self.config.intermediate_size,
kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
dtype=self.dtype,
)
self.activation = ACT2FN[self.config.hidden_act]
def __call__(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.activation(hidden_states)
return hidden_states
class FlaxBeitOutput(nn.Module):
config: BeitConfig
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.dense = nn.Dense(
self.config.hidden_size,
kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
dtype=self.dtype,
)
self.dropout = nn.Dropout(rate=self.config.hidden_dropout_prob)
def __call__(self, hidden_states, deterministic: bool = True):
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states, deterministic=deterministic)
return hidden_states
class FlaxBeitLayer(nn.Module):
config: BeitConfig
window_size: Tuple[int, int]
drop_path_rate: float
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.attention = FlaxBeitAttention(self.config, self.window_size, dtype=self.dtype)
self.intermediate = FlaxBeitIntermediate(self.config, dtype=self.dtype)
self.output = FlaxBeitOutput(self.config, dtype=self.dtype)
self.layernorm_before = nn.LayerNorm(epsilon=self.config.layer_norm_eps, dtype=self.dtype)
self.drop_path = FlaxBeitDropPath(rate=self.drop_path_rate)
self.layernorm_after = nn.LayerNorm(epsilon=self.config.layer_norm_eps, dtype=self.dtype)
self.init_values = self.config.layer_scale_init_value
if self.init_values > 0:
self.lambda_1 = self.param("lambda_1", ones_with_scale, (self.config.hidden_size), self.init_values)
self.lambda_2 = self.param("lambda_2", ones_with_scale, (self.config.hidden_size), self.init_values)
else:
self.lambda_1 = None
self.lambda_2 = None
def __call__(
self, hidden_states, relative_position_bias=None, deterministic: bool = True, output_attentions: bool = False
):
self_attention_outputs = self.attention(
self.layernorm_before(hidden_states), # in BEiT, layernorm is applied before self-attention
relative_position_bias,
deterministic=deterministic,
output_attentions=output_attentions,
)
attention_output = self_attention_outputs[0]
# apply lambda_1 if present
if self.lambda_1 is not None:
attention_output = self.lambda_1.astype(attention_output.dtype) * attention_output
# first residual connection
hidden_states = self.drop_path(attention_output, deterministic=deterministic) + hidden_states
# in BEiT, layernorm is also applied after self-attention
layer_output = self.layernorm_after(hidden_states)
layer_output = self.intermediate(layer_output)
layer_output = self.output(layer_output, deterministic=deterministic)
# apply lambda_2 if present
if self.lambda_2 is not None:
layer_output = self.lambda_2.astype(layer_output.dtype) * layer_output
# second residual connection
layer_output = self.drop_path(layer_output, deterministic=deterministic) + hidden_states
outputs = (layer_output,)
if output_attentions:
outputs += (self_attention_outputs[1],)
return outputs
class FlaxBeitLayerCollection(nn.Module):
config: BeitConfig
window_size: Tuple[int, int]
drop_path_rates: List[float]
relative_position_bias: Callable[[], jnp.ndarray]
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.layers = [
FlaxBeitLayer(
self.config,
window_size=self.window_size if self.config.use_relative_position_bias else None,
drop_path_rate=self.drop_path_rates[i],
name=str(i),
dtype=self.dtype,
)
for i in range(self.config.num_hidden_layers)
]
def __call__(
self,
hidden_states,
deterministic: bool = True,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
all_attentions = () if output_attentions else None
all_hidden_states = () if output_hidden_states else None
for i, layer in enumerate(self.layers):
if output_hidden_states:
all_hidden_states += (hidden_states,)
relative_position_bias = self.relative_position_bias() if self.relative_position_bias is not None else None
layer_outputs = layer(
hidden_states, relative_position_bias, deterministic=deterministic, output_attentions=output_attentions
)
hidden_states = layer_outputs[0]
if output_attentions:
all_attentions += (layer_outputs[1],)
if output_hidden_states:
all_hidden_states += (hidden_states,)
outputs = (hidden_states,)
if not return_dict:
return tuple(v for v in outputs if v is not None)
return FlaxBaseModelOutput(
last_hidden_state=hidden_states, hidden_states=all_hidden_states, attentions=all_attentions
)
class FlaxBeitEncoder(nn.Module):
config: BeitConfig
window_size: Tuple[int, int]
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
if self.config.use_shared_relative_position_bias:
self.relative_position_bias = FlaxBeitRelativePositionBias(
config=self.config, window_size=self.window_size, dtype=self.dtype
)
# stochastic depth decay rule
drop_path_rates = list(np.linspace(0, self.config.drop_path_rate, self.config.num_hidden_layers))
self.layer = FlaxBeitLayerCollection(
self.config,
window_size=self.window_size,
drop_path_rates=drop_path_rates,
relative_position_bias=self.relative_position_bias
if self.config.use_shared_relative_position_bias
else None,
dtype=self.dtype,
)
def __call__(
self,
hidden_states,
deterministic: bool = True,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
return self.layer(
hidden_states,
deterministic=deterministic,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
class FlaxBeitPreTrainedModel(FlaxPreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = BeitConfig
base_model_prefix = "beit"
main_input_name = "pixel_values"
module_class: nn.Module = None
def __init__(
self,
config: BeitConfig,
input_shape=None,
seed: int = 0,
dtype: jnp.dtype = jnp.float32,
_do_init: bool = True,
**kwargs,
):
module = self.module_class(config=config, dtype=dtype, **kwargs)
if input_shape is None:
input_shape = (1, config.image_size, config.image_size, config.num_channels)
super().__init__(config, module, input_shape=input_shape, seed=seed, dtype=dtype, _do_init=_do_init)
def init_weights(self, rng: jax.random.PRNGKey, input_shape: Tuple, params: FrozenDict = None) -> FrozenDict:
# init input tensors
pixel_values = jnp.zeros(input_shape, dtype=self.dtype)
params_rng, dropout_rng = jax.random.split(rng)
dropout_rng, droppath_rng = jax.random.split(dropout_rng)
rngs = {"params": params_rng, "dropout": dropout_rng, "droppath": droppath_rng}
random_params = self.module.init(rngs, pixel_values, return_dict=False)["params"]
if params is not None:
random_params = flatten_dict(unfreeze(random_params))
params = flatten_dict(unfreeze(params))
for missing_key in self._missing_keys:
params[missing_key] = random_params[missing_key]
self._missing_keys = set()
return freeze(unflatten_dict(params))
else:
return random_params
@add_start_docstrings_to_model_forward(BEIT_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
def __call__(
self,
pixel_values,
bool_masked_pos=None,
params: dict = None,
dropout_rng: jax.random.PRNGKey = None,
train: bool = False,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
):
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.return_dict
pixel_values = jnp.transpose(pixel_values, (0, 2, 3, 1))
# Handle any PRNG if needed
rngs = {}
if dropout_rng is not None:
dropout_rng, droppath_rng = jax.random.split(dropout_rng)
rngs["dropout"] = dropout_rng
rngs["droppath"] = droppath_rng
return self.module.apply(
{"params": params or self.params},
jnp.array(pixel_values, dtype=jnp.float32),
bool_masked_pos,
not train,
output_attentions,
output_hidden_states,
return_dict,
rngs=rngs,
)
class FlaxBeitPooler(nn.Module):
config: BeitConfig
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
if self.config.use_mean_pooling:
self.layernorm = nn.LayerNorm(epsilon=self.config.layer_norm_eps, dtype=self.dtype)
def __call__(self, hidden_states):
if self.config.use_mean_pooling:
# Mean pool the final hidden states of the patch tokens
patch_tokens = hidden_states[:, 1:, :]
pooled_output = self.layernorm(jnp.mean(patch_tokens, axis=1))
else:
# Pool by simply taking the final hidden state of the [CLS] token
pooled_output = hidden_states[:, 0]
return pooled_output
class FlaxBeitModule(nn.Module):
config: BeitConfig
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
add_pooling_layer: bool = True
def setup(self):
self.embeddings = FlaxBeitEmbeddings(self.config, dtype=self.dtype)
self.encoder = FlaxBeitEncoder(
self.config, window_size=self.embeddings.patch_embeddings.patch_shape, dtype=self.dtype
)
if not self.config.use_mean_pooling:
self.layernorm = nn.LayerNorm(epsilon=self.config.layer_norm_eps, dtype=self.dtype)
self.pooler = FlaxBeitPooler(self.config, dtype=self.dtype) if self.add_pooling_layer else None
def __call__(
self,
pixel_values,
bool_masked_pos=None,
deterministic: bool = True,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
):
hidden_states = self.embeddings(pixel_values, bool_masked_pos, deterministic=deterministic)
outputs = self.encoder(
hidden_states,
deterministic=deterministic,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = outputs[0]
if not self.config.use_mean_pooling:
hidden_states = self.layernorm(hidden_states)
pooled = self.pooler(hidden_states) if self.add_pooling_layer else None
if not return_dict:
# if pooled is None, don't return it
if pooled is None:
return (hidden_states,) + outputs[1:]
return (hidden_states, pooled) + outputs[1:]
return FlaxBeitModelOutputWithPooling(
last_hidden_state=hidden_states,
pooler_output=pooled,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"The bare Beit Model transformer outputting raw hidden-states without any specific head on top.",
BEIT_START_DOCSTRING,
)
class FlaxBeitModel(FlaxBeitPreTrainedModel):
module_class = FlaxBeitModule
FLAX_BEIT_MODEL_DOCSTRING = """
Returns:
Examples:
```python
>>> from transformers import AutoImageProcessor, FlaxBeitModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("microsoft/beit-base-patch16-224-pt22k-ft22k")
>>> model = FlaxBeitModel.from_pretrained("microsoft/beit-base-patch16-224-pt22k-ft22k")
>>> inputs = image_processor(images=image, return_tensors="np")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
```
"""
overwrite_call_docstring(FlaxBeitModel, FLAX_BEIT_MODEL_DOCSTRING)
append_replace_return_docstrings(FlaxBeitModel, output_type=FlaxBeitModelOutputWithPooling, config_class=BeitConfig)
class FlaxBeitForMaskedImageModelingModule(nn.Module):
config: BeitConfig
dtype: jnp.dtype = jnp.float32 # the dtype of the computation
def setup(self):
self.beit = FlaxBeitModule(self.config, add_pooling_layer=False, dtype=self.dtype)
# Classifier head
self.layernorm = nn.LayerNorm(epsilon=self.config.layer_norm_eps, dtype=self.dtype)
self.lm_head = nn.Dense(
self.config.vocab_size,
kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
dtype=self.dtype,
)
def __call__(
self,
pixel_values=None,
bool_masked_pos=None,
deterministic: bool = True,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.beit(
pixel_values,
bool_masked_pos,
deterministic=deterministic,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
sequence_output = self.layernorm(sequence_output)
prediction_scores = self.lm_head(sequence_output[:, 1:])
if not return_dict:
output = (prediction_scores,) + outputs[2:]
return output
return FlaxMaskedLMOutput(
logits=prediction_scores,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"Beit Model transformer with a 'language' modeling head on top (to predict visual tokens).",
BEIT_START_DOCSTRING,
)
class FlaxBeitForMaskedImageModeling(FlaxBeitPreTrainedModel):
module_class = FlaxBeitForMaskedImageModelingModule
FLAX_BEIT_MLM_DOCSTRING = """
bool_masked_pos (`numpy.ndarray` of shape `(batch_size, num_patches)`):
Boolean masked positions. Indicates which patches are masked (1) and which aren't (0).
Returns:
Examples:
```python
>>> from transformers import AutoImageProcessor, BeitForMaskedImageModeling
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("microsoft/beit-base-patch16-224-pt22k")
>>> model = BeitForMaskedImageModeling.from_pretrained("microsoft/beit-base-patch16-224-pt22k")
>>> inputs = image_processor(images=image, return_tensors="np")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
```
"""
overwrite_call_docstring(FlaxBeitForMaskedImageModeling, FLAX_BEIT_MLM_DOCSTRING)
append_replace_return_docstrings(
FlaxBeitForMaskedImageModeling, output_type=FlaxMaskedLMOutput, config_class=BeitConfig
)
class FlaxBeitForImageClassificationModule(nn.Module):
config: BeitConfig
dtype: jnp.dtype = jnp.float32
def setup(self):
self.beit = FlaxBeitModule(config=self.config, dtype=self.dtype, add_pooling_layer=True)
self.classifier = nn.Dense(
self.config.num_labels,
kernel_init=jax.nn.initializers.normal(self.config.initializer_range),
dtype=self.dtype,
)
def __call__(
self,
pixel_values=None,
bool_masked_pos=None,
deterministic: bool = True,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.beit(
pixel_values,
deterministic=deterministic,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
pooled_output = outputs[1]
logits = self.classifier(pooled_output)
if not return_dict:
output = (logits,) + outputs[2:]
return output
return FlaxSequenceClassifierOutput(
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
Beit Model transformer with an image classification head on top (a linear layer on top of the average of the final
hidden states of the patch tokens) e.g. for ImageNet.
""",
BEIT_START_DOCSTRING,
)
class FlaxBeitForImageClassification(FlaxBeitPreTrainedModel):
module_class = FlaxBeitForImageClassificationModule
FLAX_BEIT_CLASSIF_DOCSTRING = """
Returns:
Example:
```python
>>> from transformers import AutoImageProcessor, FlaxBeitForImageClassification
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("microsoft/beit-base-patch16-224")
>>> model = FlaxBeitForImageClassification.from_pretrained("microsoft/beit-base-patch16-224")
>>> inputs = image_processor(images=image, return_tensors="np")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_class_idx = logits.argmax(-1).item()
>>> print("Predicted class:", model.config.id2label[predicted_class_idx])
```
"""
overwrite_call_docstring(FlaxBeitForImageClassification, FLAX_BEIT_CLASSIF_DOCSTRING)
append_replace_return_docstrings(
FlaxBeitForImageClassification, output_type=FlaxSequenceClassifierOutput, config_class=BeitConfig
)
| transformers/src/transformers/models/beit/modeling_flax_beit.py/0 | {
"file_path": "transformers/src/transformers/models/beit/modeling_flax_beit.py",
"repo_id": "transformers",
"token_count": 15754
} | 294 |
# coding=utf-8
# Copyright 2023 The Salesforce Team Authors and The HuggingFace Team. All rights reserved.
#
# Licensed under the BSD-3-clause license (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://opensource.org/licenses/BSD-3-Clause
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from __future__ import annotations
import math
from typing import Optional, Tuple
import tensorflow as tf
from ...modeling_tf_outputs import (
TFBaseModelOutputWithPastAndCrossAttentions,
TFBaseModelOutputWithPoolingAndCrossAttentions,
TFCausalLMOutputWithCrossAttentions,
)
from ...modeling_tf_utils import (
TFModelInputType,
TFPreTrainedModel,
get_initializer,
get_tf_activation,
keras,
keras_serializable,
shape_list,
unpack_inputs,
)
from ...tf_utils import check_embeddings_within_bounds, invert_attention_mask, stable_softmax
from ...utils import add_start_docstrings_to_model_forward, logging
from .configuration_blip import BlipTextConfig
logger = logging.get_logger(__name__)
BLIP_TEXT_INPUTS_DOCSTRING = r"""
Args:
input_ids (`tf.Tensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
it.
Indices can be obtained using [`AutoProcessor`]. See [`BlipProcessor.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`tf.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
position_ids (`tf.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
[What are position IDs?](../glossary#position-ids)
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
# Adapted from https://github.com/salesforce/BLIP/blob/main/models/med.py#L52
class TFBlipTextEmbeddings(keras.layers.Layer):
"""Construct the embeddings from word and position embeddings."""
def __init__(self, config, **kwargs):
super().__init__(**kwargs)
self.word_embeddings = keras.layers.Embedding(
config.vocab_size,
config.hidden_size,
embeddings_initializer=get_initializer(config.initializer_range),
name="word_embeddings",
)
self.position_embeddings = keras.layers.Embedding(
config.max_position_embeddings,
config.hidden_size,
embeddings_initializer=get_initializer(config.initializer_range),
name="position_embeddings",
)
# self.LayerNorm is not snake-cased to stick with PyTorch model variable name and be able to load
# any TensorFlow checkpoint file
self.LayerNorm = keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="LayerNorm")
self.dropout = keras.layers.Dropout(config.hidden_dropout_prob, name="dropout")
self.position_ids = tf.expand_dims(tf.range(config.max_position_embeddings), 0)
self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
self.config = config
def call(self, input_ids=None, position_ids=None, inputs_embeds=None, past_key_values_length=0, training=None):
if input_ids is not None:
input_shape = tf.shape(input_ids)
else:
input_shape = tf.shape(inputs_embeds)[:-1]
seq_length = input_shape[1]
if position_ids is None:
position_ids = self.position_ids[:, past_key_values_length : seq_length + past_key_values_length]
if inputs_embeds is None:
check_embeddings_within_bounds(input_ids, self.config.vocab_size)
inputs_embeds = self.word_embeddings(input_ids)
embeddings = inputs_embeds
if self.position_embedding_type == "absolute":
position_embeddings = self.position_embeddings(position_ids)
embeddings += position_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings, training=training)
return embeddings
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "word_embeddings", None) is not None:
with tf.name_scope(self.word_embeddings.name):
self.word_embeddings.build(None)
if getattr(self, "position_embeddings", None) is not None:
with tf.name_scope(self.position_embeddings.name):
self.position_embeddings.build(None)
if getattr(self, "LayerNorm", None) is not None:
with tf.name_scope(self.LayerNorm.name):
self.LayerNorm.build([None, None, self.config.hidden_size])
if getattr(self, "dropout", None) is not None:
with tf.name_scope(self.dropout.name):
self.dropout.build(None)
# Adapted from https://github.com/salesforce/BLIP/blob/main/models/med.py#L97
class TFBlipTextSelfAttention(keras.layers.Layer):
def __init__(self, config, is_cross_attention, **kwargs):
super().__init__(**kwargs)
self.config = config
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
"The hidden size (%d) is not a multiple of the number of attention heads (%d)"
% (config.hidden_size, config.num_attention_heads)
)
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = keras.layers.Dense(
self.all_head_size, kernel_initializer=get_initializer(config.initializer_range), name="query"
)
self.key = keras.layers.Dense(
self.all_head_size, kernel_initializer=get_initializer(config.initializer_range), name="key"
)
self.value = keras.layers.Dense(
self.all_head_size, kernel_initializer=get_initializer(config.initializer_range), name="value"
)
self.dropout = keras.layers.Dropout(config.attention_probs_dropout_prob)
self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
self.max_position_embeddings = config.max_position_embeddings
self.distance_embedding = keras.layers.Embedding(
2 * config.max_position_embeddings - 1, self.attention_head_size
)
self.is_cross_attention = is_cross_attention
def transpose_for_scores(self, x):
new_x_shape = tf.concat(
[tf.shape(x)[:-1], tf.constant([self.num_attention_heads, self.attention_head_size], dtype=tf.int32)],
axis=0,
)
x = tf.reshape(x, new_x_shape)
return tf.transpose(x, perm=(0, 2, 1, 3))
def call(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_value=None,
output_attentions=False,
training=None,
):
mixed_query_layer = self.query(hidden_states)
# If this is instantiated as a cross-attention module, the keys
# and values come from an encoder; the attention mask needs to be
# such that the encoder's padding tokens are not attended to.
is_cross_attention = encoder_hidden_states is not None
if is_cross_attention:
key_layer = self.transpose_for_scores(self.key(encoder_hidden_states))
value_layer = self.transpose_for_scores(self.value(encoder_hidden_states))
attention_mask = encoder_attention_mask
elif past_key_value is not None:
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
key_layer = tf.concat([past_key_value[0], key_layer], axis=2)
value_layer = tf.concat([past_key_value[1], value_layer], axis=2)
else:
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
query_layer = self.transpose_for_scores(mixed_query_layer)
past_key_value = (key_layer, value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = tf.matmul(query_layer, key_layer, transpose_b=True)
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
seq_length = shape_list(hidden_states)[1]
position_ids_l = tf.expand_dims(tf.range(seq_length, dtype=tf.int64, device=hidden_states.device), 1)
position_ids_r = tf.expand_dims(tf.range(seq_length, dtype=tf.int64, device=hidden_states.device), 0)
distance = position_ids_l - position_ids_r
positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
positional_embedding = tf.cast(positional_embedding, query_layer.dtype) # fp16 compatibility
if self.position_embedding_type == "relative_key":
relative_position_scores = tf.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores
elif self.position_embedding_type == "relative_key_query":
relative_position_scores_query = tf.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
relative_position_scores_key = tf.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores_query + relative_position_scores_key
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in BlipTextModel forward() function)
attention_scores = attention_scores + tf.cast(attention_mask, attention_scores.dtype)
# Normalize the attention scores to probabilities.
attention_probs = stable_softmax(attention_scores, axis=-1)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs_dropped = self.dropout(attention_probs, training=training)
# Mask heads if we want to
if head_mask is not None:
attention_probs_dropped = attention_probs_dropped * head_mask
context_layer = attention_probs_dropped @ value_layer
context_layer = tf.transpose(context_layer, perm=(0, 2, 1, 3))
new_context_layer_shape = shape_list(context_layer)[:-2] + [self.all_head_size]
context_layer = tf.reshape(context_layer, new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
outputs = outputs + (past_key_value,)
return outputs
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "query", None) is not None:
with tf.name_scope(self.query.name):
self.query.build([None, None, self.config.hidden_size])
if self.is_cross_attention:
if getattr(self, "key", None) is not None:
with tf.name_scope(self.key.name):
self.key.build([None, None, self.config.encoder_hidden_size])
if getattr(self, "value", None) is not None:
with tf.name_scope(self.value.name):
self.value.build([None, None, self.config.encoder_hidden_size])
else:
if getattr(self, "key", None) is not None:
with tf.name_scope(self.key.name):
self.key.build([None, None, self.config.hidden_size])
if getattr(self, "value", None) is not None:
with tf.name_scope(self.value.name):
self.value.build([None, None, self.config.hidden_size])
class TFBlipTextSelfOutput(keras.layers.Layer):
def __init__(self, config: BlipTextConfig, **kwargs):
super().__init__(**kwargs)
self.dense = keras.layers.Dense(
units=config.hidden_size, kernel_initializer=get_initializer(config.initializer_range), name="dense"
)
self.LayerNorm = keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="LayerNorm")
self.dropout = keras.layers.Dropout(rate=config.hidden_dropout_prob)
self.config = config
def call(self, hidden_states: tf.Tensor, input_tensor: tf.Tensor, training: Optional[bool] = None) -> tf.Tensor:
hidden_states = self.dense(inputs=hidden_states)
hidden_states = self.dropout(inputs=hidden_states, training=training)
hidden_states = self.LayerNorm(inputs=hidden_states + input_tensor)
return hidden_states
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "dense", None) is not None:
with tf.name_scope(self.dense.name):
self.dense.build([None, None, self.config.hidden_size])
if getattr(self, "LayerNorm", None) is not None:
with tf.name_scope(self.LayerNorm.name):
self.LayerNorm.build([None, None, self.config.hidden_size])
# Adapted from https://github.com/salesforce/BLIP/blob/main/models/med.py#242
class TFBlipTextAttention(keras.layers.Layer):
def __init__(self, config, is_cross_attention=False, **kwargs):
super().__init__(**kwargs)
self.self = TFBlipTextSelfAttention(config, is_cross_attention, name="self")
# "output" is a protected attribute on TF models
self.self_output = TFBlipTextSelfOutput(config, name="output")
def call(
self,
hidden_states: tf.Tensor,
attention_mask: tf.Tensor | None = None,
head_mask: tf.Tensor | None = None,
encoder_hidden_states: tf.Tensor | None = None,
encoder_attention_mask: tf.Tensor | None = None,
past_key_value: Tuple[Tuple[tf.Tensor]] | None = None,
output_attentions: Optional[bool] = False,
training: Optional[bool] = None,
):
self_outputs = self.self(
hidden_states,
attention_mask,
head_mask,
encoder_hidden_states,
encoder_attention_mask,
past_key_value,
output_attentions,
training=training,
)
attention_output = self.self_output(self_outputs[0], hidden_states, training=training)
outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
return outputs
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "self", None) is not None:
with tf.name_scope(self.self.name):
self.self.build(None)
if getattr(self, "self_output", None) is not None:
with tf.name_scope(self.self_output.name):
self.self_output.build(None)
# Copied from transformers.models.bert.modeling_tf_bert.TFBertIntermediate with Bert->BlipText
class TFBlipTextIntermediate(keras.layers.Layer):
def __init__(self, config: BlipTextConfig, **kwargs):
super().__init__(**kwargs)
self.dense = keras.layers.Dense(
units=config.intermediate_size, kernel_initializer=get_initializer(config.initializer_range), name="dense"
)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = get_tf_activation(config.hidden_act)
else:
self.intermediate_act_fn = config.hidden_act
self.config = config
def call(self, hidden_states: tf.Tensor) -> tf.Tensor:
hidden_states = self.dense(inputs=hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "dense", None) is not None:
with tf.name_scope(self.dense.name):
self.dense.build([None, None, self.config.hidden_size])
class TFBlipTextOutput(keras.layers.Layer):
def __init__(self, config: BlipTextConfig, **kwargs):
super().__init__(**kwargs)
self.dense = keras.layers.Dense(
units=config.hidden_size, kernel_initializer=get_initializer(config.initializer_range), name="dense"
)
self.LayerNorm = keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="LayerNorm")
self.dropout = keras.layers.Dropout(rate=config.hidden_dropout_prob)
self.config = config
def call(self, hidden_states: tf.Tensor, input_tensor: tf.Tensor, training: bool = False) -> tf.Tensor:
hidden_states = self.dense(inputs=hidden_states)
hidden_states = self.dropout(inputs=hidden_states, training=training)
hidden_states = self.LayerNorm(inputs=hidden_states + input_tensor)
return hidden_states
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "dense", None) is not None:
with tf.name_scope(self.dense.name):
self.dense.build([None, None, self.config.intermediate_size])
if getattr(self, "LayerNorm", None) is not None:
with tf.name_scope(self.LayerNorm.name):
self.LayerNorm.build([None, None, self.config.hidden_size])
class TFBlipTextLayer(keras.layers.Layer):
def __init__(self, config, **kwargs):
super().__init__(**kwargs)
self.config = config
self.attention = TFBlipTextAttention(config, name="attention")
if self.config.is_decoder:
self.crossattention = TFBlipTextAttention(
config, is_cross_attention=self.config.is_decoder, name="crossattention"
)
self.intermediate = TFBlipTextIntermediate(config, name="intermediate")
self.self_output = TFBlipTextOutput(config, name="output")
def call(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_value=None,
output_attentions=False,
training=None,
):
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
self_attention_outputs = self.attention(
hidden_states,
attention_mask,
head_mask,
output_attentions=output_attentions,
past_key_value=self_attn_past_key_value,
training=training,
)
attention_output = self_attention_outputs[0]
outputs = self_attention_outputs[1:-1]
present_key_value = self_attention_outputs[-1]
if encoder_hidden_states is not None:
cross_attention_outputs = self.crossattention(
attention_output,
attention_mask,
head_mask,
encoder_hidden_states,
encoder_attention_mask,
output_attentions=output_attentions,
training=training,
)
attention_output = cross_attention_outputs[0]
outputs = outputs + cross_attention_outputs[1:-1] # add cross attentions if we output attention weights
intermediate_output = self.intermediate(attention_output)
layer_output = self.self_output(intermediate_output, attention_output, training=training)
outputs = (layer_output,) + outputs
outputs = outputs + (present_key_value,)
return outputs
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "attention", None) is not None:
with tf.name_scope(self.attention.name):
self.attention.build(None)
if getattr(self, "intermediate", None) is not None:
with tf.name_scope(self.intermediate.name):
self.intermediate.build(None)
if getattr(self, "self_output", None) is not None:
with tf.name_scope(self.self_output.name):
self.self_output.build(None)
if getattr(self, "crossattention", None) is not None:
with tf.name_scope(self.crossattention.name):
self.crossattention.build(None)
# Adapted from https://github.com/salesforce/BLIP/blob/main/models/med.py#L386
@keras_serializable
class TFBlipTextEncoder(keras.layers.Layer):
config_class = BlipTextConfig
def __init__(self, config, name=None, **kwargs):
super().__init__(name=name, **kwargs)
self.config = config
self.layer = [TFBlipTextLayer(config, name=f"layer_._{i}") for i in range(config.num_hidden_layers)]
@unpack_inputs
def call(
self,
hidden_states,
attention_mask=None,
head_mask=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
past_key_values=None,
use_cache=None,
output_attentions=False,
output_hidden_states=False,
return_dict=True,
training=None,
):
all_hidden_states = () if output_hidden_states else None
all_self_attentions = () if output_attentions else None
all_cross_attentions = () if output_attentions and self.config.is_decoder else None
next_decoder_cache = () if use_cache else None
for i in range(self.config.num_hidden_layers):
layer_module = self.layer[i]
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
layer_head_mask = head_mask[i] if head_mask is not None else None
past_key_value = past_key_values[i] if past_key_values is not None else None
layer_outputs = layer_module(
hidden_states,
attention_mask,
layer_head_mask,
encoder_hidden_states,
encoder_attention_mask,
past_key_value,
output_attentions,
training=training,
)
hidden_states = layer_outputs[0]
if use_cache:
next_decoder_cache += (layer_outputs[-1],)
if output_attentions:
all_self_attentions = all_self_attentions + (layer_outputs[1],)
all_cross_attentions = all_cross_attentions + (layer_outputs[2],)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(
v
for v in [
hidden_states,
next_decoder_cache,
all_hidden_states,
all_self_attentions,
all_cross_attentions,
]
if v is not None
)
return TFBaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=next_decoder_cache,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
cross_attentions=all_cross_attentions,
)
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "layer", None) is not None:
for layer in self.layer:
with tf.name_scope(layer.name):
layer.build(None)
# Copied from transformers.models.bert.modeling_tf_bert.TFBertPooler with Bert->BlipText
class TFBlipTextPooler(keras.layers.Layer):
def __init__(self, config: BlipTextConfig, **kwargs):
super().__init__(**kwargs)
self.dense = keras.layers.Dense(
units=config.hidden_size,
kernel_initializer=get_initializer(config.initializer_range),
activation="tanh",
name="dense",
)
self.config = config
def call(self, hidden_states: tf.Tensor) -> tf.Tensor:
# We "pool" the model by simply taking the hidden state corresponding
# to the first token.
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(inputs=first_token_tensor)
return pooled_output
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "dense", None) is not None:
with tf.name_scope(self.dense.name):
self.dense.build([None, None, self.config.hidden_size])
# Copied from transformers.models.bert.modeling_tf_bert.TFBertPredictionHeadTransform with Bert->BlipText
class TFBlipTextPredictionHeadTransform(keras.layers.Layer):
def __init__(self, config: BlipTextConfig, **kwargs):
super().__init__(**kwargs)
self.dense = keras.layers.Dense(
units=config.hidden_size,
kernel_initializer=get_initializer(config.initializer_range),
name="dense",
)
if isinstance(config.hidden_act, str):
self.transform_act_fn = get_tf_activation(config.hidden_act)
else:
self.transform_act_fn = config.hidden_act
self.LayerNorm = keras.layers.LayerNormalization(epsilon=config.layer_norm_eps, name="LayerNorm")
self.config = config
def call(self, hidden_states: tf.Tensor) -> tf.Tensor:
hidden_states = self.dense(inputs=hidden_states)
hidden_states = self.transform_act_fn(hidden_states)
hidden_states = self.LayerNorm(inputs=hidden_states)
return hidden_states
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "dense", None) is not None:
with tf.name_scope(self.dense.name):
self.dense.build([None, None, self.config.hidden_size])
if getattr(self, "LayerNorm", None) is not None:
with tf.name_scope(self.LayerNorm.name):
self.LayerNorm.build([None, None, self.config.hidden_size])
class TFBlipTextLMPredictionHead(keras.layers.Layer):
def __init__(self, config, **kwargs):
super().__init__(**kwargs)
self.transform = TFBlipTextPredictionHeadTransform(config, name="transform")
# The output weights are the same as the input embeddings, but there is
# an output-only bias for each token.
self.decoder = keras.layers.Dense(
config.vocab_size,
kernel_initializer=get_initializer(config.initializer_range),
name="decoder",
use_bias=False,
)
self.config = config
def build(self, input_shape=None):
self.bias = self.add_weight(name="bias", shape=(self.config.vocab_size,), initializer="zeros", trainable=True)
if self.built:
return
self.built = True
if getattr(self, "transform", None) is not None:
with tf.name_scope(self.transform.name):
self.transform.build(None)
if getattr(self, "decoder", None) is not None:
with tf.name_scope(self.decoder.name):
self.decoder.build([None, None, self.config.hidden_size])
def call(self, hidden_states):
hidden_states = self.transform(hidden_states)
hidden_states = self.decoder(hidden_states) + self.bias
return hidden_states
class TFBlipTextOnlyMLMHead(keras.layers.Layer):
def __init__(self, config, **kwargs):
super().__init__(**kwargs)
self.predictions = TFBlipTextLMPredictionHead(config, name="predictions")
def call(self, sequence_output: tf.Tensor) -> tf.Tensor:
prediction_scores = self.predictions(sequence_output)
return prediction_scores
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "predictions", None) is not None:
with tf.name_scope(self.predictions.name):
self.predictions.build(None)
# Adapted from https://github.com/salesforce/BLIP/blob/main/models/med.py#L548
class TFBlipTextPreTrainedModel(TFPreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = BlipTextConfig
base_model_prefix = "bert"
_keys_to_ignore_on_load_missing = [r"position_ids"]
# Adapted from https://github.com/salesforce/BLIP/blob/3a29b7410476bf5f2ba0955827390eb6ea1f4f9d/models/med.py#L571
class TFBlipTextModel(TFBlipTextPreTrainedModel):
"""
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in [Attention is
all you need](https://arxiv.org/abs/1706.03762) by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin. argument and `is_decoder` set to `True`; an
`encoder_hidden_states` is then expected as an input to the forward pass.
"""
def __init__(self, config, add_pooling_layer=True, name=None, **kwargs):
super().__init__(config, name=name, **kwargs)
self.config = config
self.embeddings = TFBlipTextEmbeddings(config, name="embeddings")
self.encoder = TFBlipTextEncoder(config, name="encoder")
self.pooler = TFBlipTextPooler(config, name="pooler") if add_pooling_layer else None
def get_input_embeddings(self):
return self.embeddings.word_embeddings
def set_input_embeddings(self, value):
self.embeddings.word_embeddings = value
@tf.function
def get_extended_attention_mask(
self, attention_mask: tf.Tensor, input_shape: Tuple[int], is_decoder: bool
) -> tf.Tensor:
"""
Makes broadcastable attention and causal masks so that future and masked tokens are ignored.
Arguments:
attention_mask (`tf.Tensor`):
Mask with ones indicating tokens to attend to, zeros for tokens to ignore.
input_shape (`Tuple[int]`):
The shape of the input to the model.
is_decoder (`bool`):
Whether the model is used as a decoder.
Returns:
`tf.Tensor` The extended attention mask, with the same dtype as `attention_mask.dtype`.
"""
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
# ourselves in which case we just need to make it broadcastable to all heads.
if not isinstance(attention_mask, tf.Tensor):
attention_mask = tf.convert_to_tensor(attention_mask) # Catches NumPy inputs that haven't been cast yet
if attention_mask.shape.rank == 3:
extended_attention_mask = attention_mask[:, None, :, :]
elif attention_mask.shape.rank == 2:
# Provided a padding mask of dimensions [batch_size, seq_length]
# - if the model is a decoder, apply a causal mask in addition to the padding mask
# - if the model is an encoder, make the mask broadcastable to [batch_size, num_heads, seq_length, seq_length]
if is_decoder:
batch_size, seq_length = input_shape
seq_ids = tf.range(seq_length, dtype=attention_mask.dtype)
causal_mask = tf.broadcast_to(seq_ids, (batch_size, seq_length, seq_length)) <= seq_ids[None, :, None]
# in case past_key_values are used we need to add a prefix ones mask to the causal mask
if shape_list(causal_mask)[1] < shape_list(attention_mask)[1]:
prefix_seq_len = tf.shape(attention_mask)[1] - tf.shape(causal_mask)[1]
causal_mask = tf.concat(
[
tf.ones((batch_size, seq_length, prefix_seq_len), dtype=causal_mask.dtype),
causal_mask,
],
axis=-1,
)
extended_attention_mask = (
tf.cast(causal_mask[:, None, :, :], attention_mask.dtype) * attention_mask[:, None, None, :]
)
else:
extended_attention_mask = attention_mask[:, None, None, :]
else:
raise ValueError(
"Wrong shape for input_ids (shape {}) or attention_mask (shape {})".format(
input_shape, attention_mask.shape
)
)
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
# masked positions, this operation will create a tensor which is 0.0 for
# positions we want to attend and -10000.0 for masked positions.
# Since we are adding it to the raw scores before the softmax, this is
# effectively the same as removing these entirely.
extended_attention_mask = tf.cast(extended_attention_mask, self.dtype) # fp16 compatibility
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
return extended_attention_mask
@add_start_docstrings_to_model_forward(BLIP_TEXT_INPUTS_DOCSTRING)
@unpack_inputs
def call(
self,
input_ids: TFModelInputType | None = None,
attention_mask: tf.Tensor | None = None,
position_ids: tf.Tensor | None = None,
head_mask: tf.Tensor | None = None,
inputs_embeds: tf.Tensor | None = None,
encoder_embeds: tf.Tensor | None = None,
encoder_hidden_states: tf.Tensor | None = None,
encoder_attention_mask: tf.Tensor | None = None,
past_key_values: Tuple[Tuple[tf.Tensor]] | None = None,
use_cache: bool | None = None,
output_attentions: bool | None = None,
output_hidden_states: bool | None = None,
return_dict: bool | None = None,
is_decoder: bool = False,
training: bool = False,
) -> Tuple[tf.Tensor] | TFBaseModelOutputWithPoolingAndCrossAttentions:
r"""
encoder_hidden_states (`tf.Tensor`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
the model is configured as a decoder.
encoder_attention_mask (`tf.Tensor`, *optional*):
Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
past_key_values (`tuple(tuple(tf.Tensor))`, *optional*):
Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
`decoder_input_ids` of shape `(batch_size, sequence_length)`.
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
`past_key_values`).
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if is_decoder:
use_cache = use_cache if use_cache is not None else self.config.use_cache
else:
use_cache = False
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
input_shape = shape_list(input_ids)
batch_size, seq_length = input_shape
elif inputs_embeds is not None:
input_shape = shape_list(inputs_embeds)[:-1]
batch_size, seq_length = input_shape
elif encoder_embeds is not None:
input_shape = shape_list(encoder_embeds)[:-1]
batch_size, seq_length = input_shape
else:
raise ValueError("You have to specify either input_ids or inputs_embeds or encoder_embeds")
# past_key_values_length
past_key_values_length = past_key_values[0][0].shape[2] if past_key_values is not None else 0
if attention_mask is None:
attention_mask = tf.ones(((batch_size, seq_length + past_key_values_length)))
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
# ourselves in which case we just need to make it broadcastable to all heads.
extended_attention_mask: tf.Tensor = self.get_extended_attention_mask(attention_mask, input_shape, is_decoder)
# If a 2D or 3D attention mask is provided for the cross-attention
# we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
if encoder_hidden_states is not None:
if isinstance(encoder_hidden_states, list):
encoder_batch_size, encoder_sequence_length, _ = shape_list(encoder_hidden_states[0])
else:
encoder_batch_size, encoder_sequence_length, _ = shape_list(encoder_hidden_states)
encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
if isinstance(encoder_attention_mask, list):
encoder_extended_attention_mask = [invert_attention_mask(mask) for mask in encoder_attention_mask]
elif encoder_attention_mask is None:
encoder_attention_mask = tf.ones(encoder_hidden_shape)
encoder_extended_attention_mask = invert_attention_mask(encoder_attention_mask)
else:
encoder_extended_attention_mask = invert_attention_mask(encoder_attention_mask)
else:
encoder_extended_attention_mask = None
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
if encoder_embeds is None:
embedding_output = self.embeddings(
input_ids=input_ids,
position_ids=position_ids,
inputs_embeds=inputs_embeds,
past_key_values_length=past_key_values_length,
)
else:
embedding_output = encoder_embeds
encoder_outputs = self.encoder(
embedding_output,
attention_mask=extended_attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_extended_attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
training=training,
)
sequence_output = encoder_outputs[0]
pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
if not return_dict:
return (sequence_output, pooled_output) + encoder_outputs[1:]
return TFBaseModelOutputWithPoolingAndCrossAttentions(
last_hidden_state=sequence_output,
pooler_output=pooled_output,
past_key_values=encoder_outputs.past_key_values,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
cross_attentions=encoder_outputs.cross_attentions,
)
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "embeddings", None) is not None:
with tf.name_scope(self.embeddings.name):
self.embeddings.build(None)
if getattr(self, "encoder", None) is not None:
with tf.name_scope(self.encoder.name):
self.encoder.build(None)
if getattr(self, "pooler", None) is not None:
with tf.name_scope(self.pooler.name):
self.pooler.build(None)
# Adapted from https://github.com/salesforce/BLIP/blob/main/models/med.py#L811
class TFBlipTextLMHeadModel(TFBlipTextPreTrainedModel):
_keys_to_ignore_on_load_unexpected = [r"pooler"]
_keys_to_ignore_on_load_missing = [r"position_ids", r"predictions.decoder.bias"]
def __init__(self, config, **kwargs):
super().__init__(config, **kwargs)
self.bert = TFBlipTextModel(config, add_pooling_layer=False, name="bert")
self.cls = TFBlipTextOnlyMLMHead(config, name="cls")
self.label_smoothing = config.label_smoothing
def get_output_embeddings(self):
return self.cls.predictions.decoder
def set_output_embeddings(self, new_embeddings):
self.cls.predictions.decoder = new_embeddings
@add_start_docstrings_to_model_forward(BLIP_TEXT_INPUTS_DOCSTRING)
@unpack_inputs
def call(
self,
input_ids=None,
attention_mask=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
encoder_hidden_states=None,
encoder_attention_mask=None,
labels=None,
past_key_values=None,
use_cache=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
return_logits=False,
is_decoder=True,
training=None,
):
r"""
encoder_hidden_states (`tf.Tensor`, *optional*): Sequence of
hidden-states at the output of the last layer of the encoder. Used in the cross-attention if the model is
configured as a decoder.
encoder_attention_mask (`tf.Tensor`, *optional*):
Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
labels (`tf.Tensor`, *optional*):
Labels for computing the left-to-right language modeling loss (next word prediction). Indices should be in
`[-100, 0, ..., config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are
ignored (masked), the loss is only computed for the tokens with labels n `[0, ..., config.vocab_size]`
past_key_values (`tuple(tuple(tf.Tensor))`, *optional*):
Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
`decoder_input_ids` of shape `(batch_size, sequence_length)`.
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
`past_key_values`).
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
use_cache = False
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
is_decoder=is_decoder,
training=training,
)
sequence_output = outputs[0]
prediction_scores = self.cls(sequence_output)
if return_logits:
return prediction_scores[:, :-1, :]
lm_loss = None
if labels is not None:
# we are doing next-token prediction; shift prediction scores and input ids by one
shifted_prediction_scores = prediction_scores[:, :-1, :]
shifted_prediction_scores = tf.reshape(shifted_prediction_scores, (-1, self.config.vocab_size))
labels = labels[:, 1:]
labels = tf.reshape(labels, (-1,))
# Keras won't give us label smoothing for sparse CE, so we de-sparsify things here
# Use relu to clamp masked labels at 0 to avoid NaN (we will be zeroing those out later anyway)
one_hot_labels = tf.one_hot(tf.nn.relu(labels), depth=self.config.vocab_size, dtype=tf.float32)
loss_fct = keras.losses.CategoricalCrossentropy(
from_logits=True, label_smoothing=self.label_smoothing, reduction="none"
)
masked_positions = tf.cast(tf.not_equal(labels, -100), dtype=tf.float32)
lm_loss = loss_fct(one_hot_labels, shifted_prediction_scores)
lm_loss *= masked_positions
lm_loss = tf.reduce_sum(lm_loss, axis=0) / tf.math.count_nonzero(masked_positions, dtype=tf.float32)
if not return_dict:
output = (prediction_scores,) + outputs[2:]
return ((lm_loss,) + output) if lm_loss is not None else output
return TFCausalLMOutputWithCrossAttentions(
loss=lm_loss,
logits=prediction_scores,
past_key_values=outputs.past_key_values,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
cross_attentions=outputs.cross_attentions,
)
def prepare_inputs_for_generation(self, input_ids, past_key_values=None, attention_mask=None, **model_kwargs):
input_shape = input_ids.shape
# if model is used as a decoder in encoder-decoder model, the decoder attention mask is created on the fly
if attention_mask is None:
attention_mask = input_ids.new_ones(input_shape)
# cut decoder_input_ids if past_key_values is used
if past_key_values is not None:
input_ids = input_ids[:, -1:]
return {
"input_ids": input_ids,
"attention_mask": attention_mask,
"past_key_values": past_key_values,
"encoder_hidden_states": model_kwargs.get("encoder_hidden_states", None),
"encoder_attention_mask": model_kwargs.get("encoder_attention_mask", None),
"is_decoder": True,
}
def _reorder_cache(self, past_key_values, beam_idx):
reordered_past = ()
for layer_past in past_key_values:
reordered_past += (tuple(past_state.index_select(0, beam_idx) for past_state in layer_past),)
return reordered_past
def build(self, input_shape=None):
if self.built:
return
self.built = True
if getattr(self, "bert", None) is not None:
with tf.name_scope(self.bert.name):
self.bert.build(None)
if getattr(self, "cls", None) is not None:
with tf.name_scope(self.cls.name):
self.cls.build(None)
| transformers/src/transformers/models/blip/modeling_tf_blip_text.py/0 | {
"file_path": "transformers/src/transformers/models/blip/modeling_tf_blip_text.py",
"repo_id": "transformers",
"token_count": 21912
} | 295 |
# coding=utf-8
# Copyright 2023 The Intel Labs Team Authors, The Microsoft Research Team Authors and HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""PyTorch BridgeTower Model"""
import math
from collections import OrderedDict
from dataclasses import dataclass
from typing import List, Optional, Tuple, Union
import torch
import torch.utils.checkpoint
from torch import nn
from torch.nn import CrossEntropyLoss
from ...activations import ACT2FN, QuickGELUActivation
from ...modeling_outputs import (
BaseModelOutputWithPastAndCrossAttentions,
BaseModelOutputWithPoolingAndCrossAttentions,
MaskedLMOutput,
ModelOutput,
SequenceClassifierOutput,
)
from ...modeling_utils import PreTrainedModel, apply_chunking_to_forward
from ...pytorch_utils import find_pruneable_heads_and_indices, prune_linear_layer
from ...utils import add_start_docstrings, add_start_docstrings_to_model_forward, logging, replace_return_docstrings
from .configuration_bridgetower import BridgeTowerConfig, BridgeTowerTextConfig, BridgeTowerVisionConfig
logger = logging.get_logger(__name__)
_CONFIG_FOR_DOC = "BridgeTowerConfig"
_CHECKPOINT_FOR_DOC = "BridgeTower/bridgetower-base"
_TOKENIZER_FOR_DOC = "RobertaTokenizer"
BRIDGETOWER_PRETRAINED_MODEL_ARCHIVE_LIST = [
"BridgeTower/bridgetower-base",
"BridgeTower/bridgetower-base-itm-mlm",
# See all bridgetower models at https://huggingface.co/BridgeTower
]
BRIDGETOWER_START_DOCSTRING = r"""
This model is a PyTorch `torch.nn.Module <https://pytorch.org/docs/stable/nn.html#torch.nn.Module>`_ subclass. Use
it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
Parameters:
config ([`BridgeTowerConfig`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
BRIDGETOWER_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `({0})`):
Indices of input sequence tokens in the vocabulary. Indices can be obtained using [`AutoTokenizer`]. See
[`PreTrainedTokenizer.encode`] and [`PreTrainedTokenizer.__call__`] for details. [What are input
IDs?](../glossary#input-ids)
attention_mask (`torch.FloatTensor` of shape `({0})`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
token_type_ids (`torch.LongTensor` of shape `({0})`, *optional*):
Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
1]`:
- 0 corresponds to a *sentence A* token,
- 1 corresponds to a *sentence B* token.
[What are token type IDs?](../glossary#token-type-ids)
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Pixel values can be obtained using [`BridgeTowerImageProcessor`]. See
[`BridgeTowerImageProcessor.__call__`] for details.
pixel_mask (`torch.LongTensor` of shape `(batch_size, height, width)`, *optional*):
Mask to avoid performing attention on padding pixel values. Mask values selected in `[0, 1]`:
- 1 for pixels that are real (i.e. **not masked**),
- 0 for pixels that are padding (i.e. **masked**).
`What are attention masks? <../glossary.html#attention-mask>`__
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
inputs_embeds (`torch.FloatTensor` of shape `({0}, hidden_size)`, *optional*):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
model's internal embedding lookup matrix.
image_embeds (`torch.FloatTensor` of shape `(batch_size, num_patches, hidden_size)`, *optional*):
Optionally, instead of passing `pixel_values`, you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `pixel_values` into patch embeddings.
image_token_type_idx (`int`, *optional*):
- The token type ids for images.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
@dataclass
class BridgeTowerModelOutput(ModelOutput):
"""
Output type of [`BridgeTowerModel`].
Args:
text_features (`torch.FloatTensor` of shape `(batch_size, text_sequence_length, hidden_size)`):
Sequence of hidden-states at the text output of the last layer of the model.
image_features (`torch.FloatTensor` of shape `(batch_size, image_sequence_length, hidden_size)`):
Sequence of hidden-states at the image output of the last layer of the model.
pooler_output (`torch.FloatTensor` of shape `(batch_size, hidden_size x 2)`):
Concatenation of last layer hidden-state of the first token of the text and image sequence (classification
token), respectively, after further processing through layers used for auxiliary pretraining tasks.
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of
the model at the output of each layer plus the optional initial embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
text_features: torch.FloatTensor = None
image_features: torch.FloatTensor = None
pooler_output: torch.FloatTensor = None
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
attentions: Optional[Tuple[torch.FloatTensor]] = None
@dataclass
class BridgeTowerContrastiveOutput(ModelOutput):
"""
Output type of ['BridgeTowerForContrastiveLearning']
Args:
loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `return_loss` is `True`:
Image-text contrastive loss.
logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`):
Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
text_embeds (`torch.FloatTensor)`, *optional*, returned when model is initialized with `with_projection=True`):
The text embeddings obtained by applying the projection layer to the pooler_output.
image_embeds (`torch.FloatTensor)`, *optional*, returned when model is initialized with `with_projection=True`):
The image embeddings obtained by applying the projection layer to the pooler_output.
cross_embeds (`torch.FloatTensor)`, *optional*, returned when model is initialized with `with_projection=True`):
The text-image cross-modal embeddings obtained by applying the projection layer to the pooler_output.
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of
the model at the output of each layer plus the optional initial embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
"""
loss: Optional[torch.FloatTensor] = None
logits: torch.FloatTensor = None
text_embeds: Optional[Tuple[torch.FloatTensor]] = None
image_embeds: Optional[Tuple[torch.FloatTensor]] = None
cross_embeds: Optional[Tuple[torch.FloatTensor]] = None
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
attentions: Optional[Tuple[torch.FloatTensor]] = None
class BridgeTowerResidualAttention(nn.Module):
def __init__(self, config):
super().__init__()
self.attn = nn.MultiheadAttention(config.hidden_size, config.hidden_size // 64)
self.ln_1 = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.mlp = nn.ModuleDict(
OrderedDict(
[
("c_fc", nn.Linear(config.hidden_size, config.hidden_size * 4)),
("gelu", QuickGELUActivation()),
("c_proj", nn.Linear(config.hidden_size * 4, config.hidden_size)),
]
)
)
self.ln_2 = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.attn_mask = None
def attention(self, hidden_state: torch.Tensor, attention_mask: torch.Tensor):
if attention_mask is not None:
attention_mask = attention_mask.to(dtype=torch.bool, device=hidden_state.device)
self.attn_mask = (
self.attn_mask.to(dtype=hidden_state.dtype, device=hidden_state.device)
if self.attn_mask is not None
else None
)
return self.attn(
hidden_state,
hidden_state,
hidden_state,
need_weights=False,
attn_mask=self.attn_mask,
key_padding_mask=attention_mask,
)[0]
def forward(self, hidden_state: torch.Tensor, attention_mask: torch.Tensor = None):
residual_state = hidden_state + self.attention(self.ln_1(hidden_state), attention_mask)
hidden_state = self.ln_2(residual_state)
for _, layer in self.mlp.items():
hidden_state = layer(hidden_state)
hidden_state = residual_state + hidden_state
return hidden_state
class BridgeTowerTransformer(nn.Module):
def __init__(self, config):
super().__init__()
self.hidden_size = config.hidden_size
self.num_hidden_layers = config.num_hidden_layers
if config.remove_last_layer:
self.resblocks = nn.ModuleList(
[BridgeTowerResidualAttention(config) for _ in range(self.num_hidden_layers - 1)]
)
else:
self.resblocks = nn.ModuleList(
[BridgeTowerResidualAttention(config) for _ in range(self.num_hidden_layers)]
)
self.stop_gradient = config.stop_gradient
def forward(self, hidden_state: torch.Tensor, attention_mask: Optional[torch.Tensor] = None):
hidden_states = []
for block in self.resblocks:
hidden_state = block(hidden_state, attention_mask)
if self.stop_gradient:
hidden_states.append(hidden_state.detach())
else:
hidden_states.append(hidden_state)
return hidden_states
# Copied from transformers.models.clip.modeling_clip.CLIPVisionEmbeddings with CLIP->BridgeTower
class BridgeTowerVisionEmbeddings(nn.Module):
def __init__(self, config: BridgeTowerVisionConfig):
super().__init__()
self.config = config
self.embed_dim = config.hidden_size
self.image_size = config.image_size
self.patch_size = config.patch_size
self.class_embedding = nn.Parameter(torch.randn(self.embed_dim))
self.patch_embedding = nn.Conv2d(
in_channels=config.num_channels,
out_channels=self.embed_dim,
kernel_size=self.patch_size,
stride=self.patch_size,
bias=False,
)
self.num_patches = (self.image_size // self.patch_size) ** 2
self.num_positions = self.num_patches + 1
self.position_embedding = nn.Embedding(self.num_positions, self.embed_dim)
self.register_buffer("position_ids", torch.arange(self.num_positions).expand((1, -1)), persistent=False)
def forward(self, pixel_values: torch.FloatTensor) -> torch.Tensor:
batch_size = pixel_values.shape[0]
target_dtype = self.patch_embedding.weight.dtype
patch_embeds = self.patch_embedding(pixel_values.to(dtype=target_dtype)) # shape = [*, width, grid, grid]
patch_embeds = patch_embeds.flatten(2).transpose(1, 2)
class_embeds = self.class_embedding.expand(batch_size, 1, -1)
embeddings = torch.cat([class_embeds, patch_embeds], dim=1)
embeddings = embeddings + self.position_embedding(self.position_ids)
return embeddings
class BridgeTowerVisionTransformer(nn.Module):
def __init__(self, config):
super().__init__()
self.embeddings = BridgeTowerVisionEmbeddings(config)
self.ln_pre = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.transformer = BridgeTowerTransformer(config)
self.ln_post = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.share_layernorm = config.share_layernorm
if not config.share_layernorm:
self.ln_separate = nn.ModuleList(
[nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps) for _ in range(config.num_hidden_layers)]
)
def forward(self, pixel_values: torch.Tensor, attention_mask):
hidden_states = self.embeddings(pixel_values)
hidden_states = self.ln_pre(hidden_states)
# NLD -> LND
hidden_states = hidden_states.permute(1, 0, 2)
hidden_states = self.transformer(hidden_states, attention_mask)
# shape = [num_hidden_layers, hidden_size, *, grid ** 2]
hidden_states = torch.stack(hidden_states, dim=0)
# shape = [num_hidden_layers, *, hidden_size, grid ** 2]
hidden_states = hidden_states.permute(0, 2, 1, 3)
if self.share_layernorm:
hidden_states = self.ln_post(hidden_states)
else:
hidden_states_stack = []
for hidden_states, ln in zip(hidden_states, self.ln_separate):
hidden_states = ln(hidden_states)
hidden_states_stack.append(hidden_states)
# shape = [num_hidden_layers, *, hidden_size, grid ** 2]
hidden_states = torch.stack(hidden_states_stack, dim=0)
return hidden_states
def forward_pre(self, pixel_values: torch.Tensor):
hidden_states = self.embeddings(pixel_values)
hidden_states = self.ln_pre(hidden_states)
# NLD -> LND
hidden_states = hidden_states.permute(1, 0, 2)
return hidden_states
def forward_post(self, hidden_state: torch.Tensor):
visual_output_post = hidden_state.permute(1, 0, 2)
visual_output_post = self.ln_post(visual_output_post)
return visual_output_post
class BridgeTowerLinkTower(nn.Module):
def __init__(self, config):
super().__init__()
self.link_tower_type = config.link_tower_type
self.hidden_size = config.hidden_size
if config.link_tower_type in ["add", "scaled_add", "interpolate"]:
if config.link_tower_type == "scaled_add":
self.scaled_factor = nn.Parameter(torch.tensor(1.0))
elif config.link_tower_type == "interpolate":
self.beta = nn.Parameter(torch.tensor(0.5))
self.LayerNorm = nn.LayerNorm(self.hidden_size, eps=config.layer_norm_eps)
else:
raise NotImplementedError(f"link_tower_type {config.link_tower_type} is not implemented")
def forward(self, hidden_states, cross_modal_hidden_states, attention_mask):
if self.link_tower_type == "add":
return self.LayerNorm(hidden_states + cross_modal_hidden_states)
elif self.link_tower_type == "scaled_add":
return self.LayerNorm(hidden_states * self.scaled_factor + cross_modal_hidden_states)
elif self.link_tower_type == "interpolate":
return self.LayerNorm(hidden_states * (1 - self.beta) + cross_modal_hidden_states * self.beta)
else:
raise NotImplementedError(f"link_tower_type {self.link_tower_type} is not implemented")
# Copied from transformers.models.bert.modeling_bert.BertSelfOutput with Bert->BridgeTower
class BridgeTowerSelfOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
# Copied from transformers.models.bert.modeling_bert.BertIntermediate with Bert->BridgeTower
class BridgeTowerIntermediate(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = ACT2FN[config.hidden_act]
else:
self.intermediate_act_fn = config.hidden_act
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
# Copied from transformers.models.bert.modeling_bert.BertOutput with Bert->BridgeTower
class BridgeTowerOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
# Copied from transformers.models.bert.modeling_bert.BertPooler with Bert->BridgeTower
class BridgeTowerPooler(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
# We "pool" the model by simply taking the hidden state corresponding
# to the first token.
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
# Copied from transformers.models.roberta.modeling_roberta.RobertaSelfAttention with Roberta->BridgeTower
class BridgeTowerSelfAttention(nn.Module):
def __init__(self, config, position_embedding_type=None):
super().__init__()
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
f"heads ({config.num_attention_heads})"
)
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
self.position_embedding_type = position_embedding_type or getattr(
config, "position_embedding_type", "absolute"
)
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
self.max_position_embeddings = config.max_position_embeddings
self.distance_embedding = nn.Embedding(2 * config.max_position_embeddings - 1, self.attention_head_size)
self.is_decoder = config.is_decoder
def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
past_key_value: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
output_attentions: Optional[bool] = False,
) -> Tuple[torch.Tensor]:
mixed_query_layer = self.query(hidden_states)
# If this is instantiated as a cross-attention module, the keys
# and values come from an encoder; the attention mask needs to be
# such that the encoder's padding tokens are not attended to.
is_cross_attention = encoder_hidden_states is not None
if is_cross_attention and past_key_value is not None:
# reuse k,v, cross_attentions
key_layer = past_key_value[0]
value_layer = past_key_value[1]
attention_mask = encoder_attention_mask
elif is_cross_attention:
key_layer = self.transpose_for_scores(self.key(encoder_hidden_states))
value_layer = self.transpose_for_scores(self.value(encoder_hidden_states))
attention_mask = encoder_attention_mask
elif past_key_value is not None:
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
key_layer = torch.cat([past_key_value[0], key_layer], dim=2)
value_layer = torch.cat([past_key_value[1], value_layer], dim=2)
else:
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
query_layer = self.transpose_for_scores(mixed_query_layer)
use_cache = past_key_value is not None
if self.is_decoder:
# if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
# Further calls to cross_attention layer can then reuse all cross-attention
# key/value_states (first "if" case)
# if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
# all previous decoder key/value_states. Further calls to uni-directional self-attention
# can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
# if encoder bi-directional self-attention `past_key_value` is always `None`
past_key_value = (key_layer, value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
query_length, key_length = query_layer.shape[2], key_layer.shape[2]
if use_cache:
position_ids_l = torch.tensor(key_length - 1, dtype=torch.long, device=hidden_states.device).view(
-1, 1
)
else:
position_ids_l = torch.arange(query_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
position_ids_r = torch.arange(key_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
distance = position_ids_l - position_ids_r
positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
if self.position_embedding_type == "relative_key":
relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores
elif self.position_embedding_type == "relative_key_query":
relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores_query + relative_position_scores_key
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in BridgeTowerModel forward() function)
attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities.
attention_probs = nn.functional.softmax(attention_scores, dim=-1)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
if self.is_decoder:
outputs = outputs + (past_key_value,)
return outputs
# Copied from transformers.models.bert.modeling_bert.BertAttention with Bert->BridgeTower
class BridgeTowerAttention(nn.Module):
def __init__(self, config, position_embedding_type=None):
super().__init__()
self.self = BridgeTowerSelfAttention(config, position_embedding_type=position_embedding_type)
self.output = BridgeTowerSelfOutput(config)
self.pruned_heads = set()
def prune_heads(self, heads):
if len(heads) == 0:
return
heads, index = find_pruneable_heads_and_indices(
heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads
)
# Prune linear layers
self.self.query = prune_linear_layer(self.self.query, index)
self.self.key = prune_linear_layer(self.self.key, index)
self.self.value = prune_linear_layer(self.self.value, index)
self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
# Update hyper params and store pruned heads
self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
self.pruned_heads = self.pruned_heads.union(heads)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
past_key_value: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
output_attentions: Optional[bool] = False,
) -> Tuple[torch.Tensor]:
self_outputs = self.self(
hidden_states,
attention_mask,
head_mask,
encoder_hidden_states,
encoder_attention_mask,
past_key_value,
output_attentions,
)
attention_output = self.output(self_outputs[0], hidden_states)
outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
return outputs
class BridgeTowerBertCrossLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.chunk_size_feed_forward = config.chunk_size_feed_forward
self.seq_len_dim = 1
self.attention = BridgeTowerAttention(config)
self.is_decoder = config.is_decoder
self.add_cross_attention = config.add_cross_attention
self.crossattention = BridgeTowerAttention(config)
self.intermediate = BridgeTowerIntermediate(config)
self.output = BridgeTowerOutput(config)
def forward(
self,
hidden_states,
encoder_hidden_states,
attention_mask=None,
head_mask=None,
encoder_attention_mask=None,
past_key_value=None,
output_attentions=False,
):
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
self_attention_outputs = self.attention(
hidden_states,
attention_mask=attention_mask,
head_mask=None,
output_attentions=output_attentions,
past_key_value=None,
)
attention_output = self_attention_outputs[0]
# if decoder, the last output is tuple of self-attn cache
# add self attentions if we output attention weights
outputs = self_attention_outputs[1:]
cross_attention_outputs = self.crossattention(
attention_output,
attention_mask=attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_value=past_key_value,
output_attentions=output_attentions,
)
attention_output = cross_attention_outputs[0]
# add cross attentions if we output attention weights
outputs = outputs + cross_attention_outputs[1:-1]
layer_output = apply_chunking_to_forward(
self.feed_forward_chunk, self.chunk_size_feed_forward, self.seq_len_dim, attention_output
)
outputs = (layer_output,) + outputs
return outputs
def feed_forward_chunk(self, attention_output):
intermediate_output = self.intermediate(attention_output)
layer_output = self.output(intermediate_output, attention_output)
return layer_output
class BridgeTowerTextLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.chunk_size_feed_forward = config.chunk_size_feed_forward
self.seq_len_dim = 1
self.attention = BridgeTowerAttention(config)
self.is_decoder = config.is_decoder
self.add_cross_attention = config.add_cross_attention
if self.add_cross_attention:
if not self.is_decoder:
raise ValueError(f"{self} should be used as a decoder model if cross attention is added")
self.crossattention = BridgeTowerAttention(config, position_embedding_type="absolute")
self.intermediate = BridgeTowerIntermediate(config)
self.output = BridgeTowerOutput(config)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
past_key_value: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
output_attentions: Optional[bool] = False,
) -> Tuple[torch.Tensor]:
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
self_attention_outputs = self.attention(
hidden_states,
attention_mask,
head_mask,
output_attentions=output_attentions,
past_key_value=self_attn_past_key_value,
)
attention_output = self_attention_outputs[0]
# if decoder, the last output is tuple of self-attn cache
if self.is_decoder:
outputs = self_attention_outputs[1:-1]
present_key_value = self_attention_outputs[-1]
else:
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
cross_attn_present_key_value = None
if self.is_decoder and encoder_hidden_states is not None:
if not hasattr(self, "crossattention"):
raise ValueError(
f"If `encoder_hidden_states` are passed, {self} has to be instantiated with cross-attention layers"
" by setting `config.add_cross_attention=True`"
)
# cross_attn cached key/values tuple is at positions 3,4 of past_key_value tuple
cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
cross_attention_outputs = self.crossattention(
attention_output,
attention_mask,
head_mask,
encoder_hidden_states,
encoder_attention_mask,
cross_attn_past_key_value,
output_attentions,
)
attention_output = cross_attention_outputs[0]
outputs = outputs + cross_attention_outputs[1:-1] # add cross attentions if we output attention weights
# add cross-attn cache to positions 3,4 of present_key_value tuple
cross_attn_present_key_value = cross_attention_outputs[-1]
present_key_value = present_key_value + cross_attn_present_key_value
layer_output = apply_chunking_to_forward(
self.feed_forward_chunk, self.chunk_size_feed_forward, self.seq_len_dim, attention_output
)
outputs = (layer_output,) + outputs
# if decoder, return the attn key/values as the last output
if self.is_decoder:
outputs = outputs + (present_key_value,)
return outputs
def feed_forward_chunk(self, attention_output):
intermediate_output = self.intermediate(attention_output)
layer_output = self.output(intermediate_output, attention_output)
return layer_output
# Copied from transformers.models.roberta.modeling_roberta.RobertaEncoder with Roberta->BridgeTowerText
class BridgeTowerTextEncoder(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.layer = nn.ModuleList([BridgeTowerTextLayer(config) for _ in range(config.num_hidden_layers)])
self.gradient_checkpointing = False
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = False,
output_hidden_states: Optional[bool] = False,
return_dict: Optional[bool] = True,
) -> Union[Tuple[torch.Tensor], BaseModelOutputWithPastAndCrossAttentions]:
all_hidden_states = () if output_hidden_states else None
all_self_attentions = () if output_attentions else None
all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
if self.gradient_checkpointing and self.training:
if use_cache:
logger.warning_once(
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
)
use_cache = False
next_decoder_cache = () if use_cache else None
for i, layer_module in enumerate(self.layer):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
layer_head_mask = head_mask[i] if head_mask is not None else None
past_key_value = past_key_values[i] if past_key_values is not None else None
if self.gradient_checkpointing and self.training:
layer_outputs = self._gradient_checkpointing_func(
layer_module.__call__,
hidden_states,
attention_mask,
layer_head_mask,
encoder_hidden_states,
encoder_attention_mask,
past_key_value,
output_attentions,
)
else:
layer_outputs = layer_module(
hidden_states,
attention_mask,
layer_head_mask,
encoder_hidden_states,
encoder_attention_mask,
past_key_value,
output_attentions,
)
hidden_states = layer_outputs[0]
if use_cache:
next_decoder_cache += (layer_outputs[-1],)
if output_attentions:
all_self_attentions = all_self_attentions + (layer_outputs[1],)
if self.config.add_cross_attention:
all_cross_attentions = all_cross_attentions + (layer_outputs[2],)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(
v
for v in [
hidden_states,
next_decoder_cache,
all_hidden_states,
all_self_attentions,
all_cross_attentions,
]
if v is not None
)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=next_decoder_cache,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
cross_attentions=all_cross_attentions,
)
# Copied from transformers.models.roberta.modeling_roberta.RobertaEmbeddings with Roberta->BridgeTowerText
class BridgeTowerTextEmbeddings(nn.Module):
"""
Same as BertEmbeddings with a tiny tweak for positional embeddings indexing.
"""
# Copied from transformers.models.bert.modeling_bert.BertEmbeddings.__init__
def __init__(self, config):
super().__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
# any TensorFlow checkpoint file
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
self.register_buffer(
"position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)), persistent=False
)
self.register_buffer(
"token_type_ids", torch.zeros(self.position_ids.size(), dtype=torch.long), persistent=False
)
# End copy
self.padding_idx = config.pad_token_id
self.position_embeddings = nn.Embedding(
config.max_position_embeddings, config.hidden_size, padding_idx=self.padding_idx
)
def forward(
self, input_ids=None, token_type_ids=None, position_ids=None, inputs_embeds=None, past_key_values_length=0
):
if position_ids is None:
if input_ids is not None:
# Create the position ids from the input token ids. Any padded tokens remain padded.
position_ids = create_position_ids_from_input_ids(input_ids, self.padding_idx, past_key_values_length)
else:
position_ids = self.create_position_ids_from_inputs_embeds(inputs_embeds)
if input_ids is not None:
input_shape = input_ids.size()
else:
input_shape = inputs_embeds.size()[:-1]
seq_length = input_shape[1]
# Setting the token_type_ids to the registered buffer in constructor where it is all zeros, which usually occurs
# when its auto-generated, registered buffer helps users when tracing the model without passing token_type_ids, solves
# issue #5664
if token_type_ids is None:
if hasattr(self, "token_type_ids"):
buffered_token_type_ids = self.token_type_ids[:, :seq_length]
buffered_token_type_ids_expanded = buffered_token_type_ids.expand(input_shape[0], seq_length)
token_type_ids = buffered_token_type_ids_expanded
else:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = inputs_embeds + token_type_embeddings
if self.position_embedding_type == "absolute":
position_embeddings = self.position_embeddings(position_ids)
embeddings += position_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
def create_position_ids_from_inputs_embeds(self, inputs_embeds):
"""
We are provided embeddings directly. We cannot infer which are padded so just generate sequential position ids.
Args:
inputs_embeds: torch.Tensor
Returns: torch.Tensor
"""
input_shape = inputs_embeds.size()[:-1]
sequence_length = input_shape[1]
position_ids = torch.arange(
self.padding_idx + 1, sequence_length + self.padding_idx + 1, dtype=torch.long, device=inputs_embeds.device
)
return position_ids.unsqueeze(0).expand(input_shape)
# Copied from transformers.models.roberta.modeling_roberta.create_position_ids_from_input_ids
def create_position_ids_from_input_ids(input_ids, padding_idx, past_key_values_length=0):
"""
Replace non-padding symbols with their position numbers. Position numbers begin at padding_idx+1. Padding symbols
are ignored. This is modified from fairseq's `utils.make_positions`.
Args:
x: torch.Tensor x:
Returns: torch.Tensor
"""
# The series of casts and type-conversions here are carefully balanced to both work with ONNX export and XLA.
mask = input_ids.ne(padding_idx).int()
incremental_indices = (torch.cumsum(mask, dim=1).type_as(mask) + past_key_values_length) * mask
return incremental_indices.long() + padding_idx
class BridgeTowerPreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = BridgeTowerConfig
base_model_prefix = "bridgetower"
supports_gradient_checkpointing = False
_no_split_modules = ["BridgeTowerSelfAttention", "BridgeTowerResidualAttention"]
_skip_keys_device_placement = "past_key_values"
def _init_weights(self, module):
if isinstance(module, BridgeTowerVisionModel):
proj_std = (module.visual.transformer.hidden_size**-0.5) * (
(2 * module.visual.transformer.num_hidden_layers) ** -0.5
)
attn_std = module.visual.transformer.hidden_size**-0.5
fc_std = (2 * module.visual.transformer.hidden_size) ** -0.5
for block in module.visual.transformer.resblocks:
nn.init.normal_(block.attn.in_proj_weight, std=attn_std * self.config.initializer_factor)
nn.init.normal_(block.attn.out_proj.weight, std=proj_std * self.config.initializer_factor)
nn.init.normal_(block.mlp.c_fc.weight, std=fc_std * self.config.initializer_factor)
nn.init.normal_(block.mlp.c_proj.weight, std=proj_std * self.config.initializer_factor)
nn.init.normal_(module.visual.embeddings.class_embedding, std=attn_std * self.config.initializer_factor)
nn.init.normal_(
module.visual.embeddings.position_embedding.weight, std=attn_std * self.config.initializer_factor
)
elif isinstance(module, (nn.Linear, nn.Conv2d, nn.Embedding)):
module.weight.data.normal_(mean=0.0, std=0.05 * self.config.initializer_factor)
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
if isinstance(module, nn.Linear) and module.bias is not None:
module.bias.data.zero_()
class BridgeTowerVisionModel(BridgeTowerPreTrainedModel):
config_class = BridgeTowerVisionConfig
def __init__(self, config):
super().__init__(config)
self.visual = BridgeTowerVisionTransformer(config)
@property
def dtype(self):
return self.visual.embeddings.patch_embedding.weight.dtype
def forward(self, image, image_mask=None):
return self.visual(image.type(self.dtype), image_mask)
class BridgeTowerTextModel(BridgeTowerPreTrainedModel):
"""
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in *Attention is
all you need*_ by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz
Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the `is_decoder` argument of the configuration set
to `True`. To be used in a Seq2Seq model, the model needs to initialized with both `is_decoder` argument and
`add_cross_attention` set to `True`; an `encoder_hidden_states` is then expected as an input to the forward pass.
.. _*Attention is all you need*: https://arxiv.org/abs/1706.03762
"""
config_class = BridgeTowerTextConfig
def __init__(self, config, add_pooling_layer=True):
super().__init__(config)
self.config = config
self.embeddings = BridgeTowerTextEmbeddings(config)
self.encoder = BridgeTowerTextEncoder(config)
self.pooler = BridgeTowerPooler(config) if add_pooling_layer else None
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
return self.embeddings.word_embeddings
def set_input_embeddings(self, value):
self.embeddings.word_embeddings = value
def _prune_heads(self, heads_to_prune):
"""
Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
class PreTrainedModel
"""
for layer, heads in heads_to_prune.items():
self.encoder.layer[layer].attention.prune_heads(heads)
# Copied from transformers.models.roberta.modeling_roberta.RobertaModel.forward
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
token_type_ids: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor], BaseModelOutputWithPoolingAndCrossAttentions]:
r"""
encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
the model is configured as a decoder.
encoder_attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
past_key_values (`tuple(tuple(torch.FloatTensor))` of length `config.n_layers` with each tuple having 4 tensors of shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
`decoder_input_ids` of shape `(batch_size, sequence_length)`.
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
`past_key_values`).
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if self.config.is_decoder:
use_cache = use_cache if use_cache is not None else self.config.use_cache
else:
use_cache = False
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
self.warn_if_padding_and_no_attention_mask(input_ids, attention_mask)
input_shape = input_ids.size()
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
batch_size, seq_length = input_shape
device = input_ids.device if input_ids is not None else inputs_embeds.device
# past_key_values_length
past_key_values_length = past_key_values[0][0].shape[2] if past_key_values is not None else 0
if attention_mask is None:
attention_mask = torch.ones(((batch_size, seq_length + past_key_values_length)), device=device)
if token_type_ids is None:
if hasattr(self.embeddings, "token_type_ids"):
buffered_token_type_ids = self.embeddings.token_type_ids[:, :seq_length]
buffered_token_type_ids_expanded = buffered_token_type_ids.expand(batch_size, seq_length)
token_type_ids = buffered_token_type_ids_expanded
else:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
# ourselves in which case we just need to make it broadcastable to all heads.
extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape)
# If a 2D or 3D attention mask is provided for the cross-attention
# we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
if self.config.is_decoder and encoder_hidden_states is not None:
encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
if encoder_attention_mask is None:
encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)
else:
encoder_extended_attention_mask = None
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
embedding_output = self.embeddings(
input_ids=input_ids,
position_ids=position_ids,
token_type_ids=token_type_ids,
inputs_embeds=inputs_embeds,
past_key_values_length=past_key_values_length,
)
encoder_outputs = self.encoder(
embedding_output,
attention_mask=extended_attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_extended_attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = encoder_outputs[0]
pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
if not return_dict:
return (sequence_output, pooled_output) + encoder_outputs[1:]
return BaseModelOutputWithPoolingAndCrossAttentions(
last_hidden_state=sequence_output,
pooler_output=pooled_output,
past_key_values=encoder_outputs.past_key_values,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
cross_attentions=encoder_outputs.cross_attentions,
)
@add_start_docstrings(
"The bare BridgeTower Model transformer outputting BridgeTowerModelOutput object without any specific head on"
" top.",
BRIDGETOWER_START_DOCSTRING,
)
class BridgeTowerModel(BridgeTowerPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.config = config
vision_config = config.vision_config
text_config = config.text_config
if config.share_cross_modal_transformer_layers:
self.cross_modal_text_transform = nn.Linear(text_config.hidden_size, config.hidden_size)
self.cross_modal_image_transform = nn.Linear(vision_config.hidden_size, config.hidden_size)
else:
self.cross_modal_text_transform = nn.ModuleList(
[nn.Linear(text_config.hidden_size, config.hidden_size) for _ in range(config.num_hidden_layers)]
)
self.cross_modal_image_transform = nn.ModuleList(
[nn.Linear(vision_config.hidden_size, config.hidden_size) for _ in range(config.num_hidden_layers)]
)
self.token_type_embeddings = nn.Embedding(2, config.hidden_size)
self.vision_model = BridgeTowerVisionModel(vision_config)
self.text_model = BridgeTowerTextModel(text_config)
if not vision_config.share_layernorm and config.init_layernorm_from_vision_encoder:
for ln in self.vision_model.visual.cross_modal_ln_separate:
ln.weight.data = self.vision_model.visual.ln_post.weight.data
ln.bias.data = self.vision_model.visual.ln_post.bias.data
self.cross_modal_image_layers = nn.ModuleList(
[BridgeTowerBertCrossLayer(text_config) for _ in range(config.num_hidden_layers)]
)
self.cross_modal_text_layers = nn.ModuleList(
[BridgeTowerBertCrossLayer(text_config) for _ in range(config.num_hidden_layers)]
)
# Class token => Linear => Tanh
self.cross_modal_image_pooler = BridgeTowerPooler(config)
self.cross_modal_text_pooler = BridgeTowerPooler(config)
# Initialize BridgeTower Components
self.cross_modal_text_layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.cross_modal_image_layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
if config.share_link_tower_layers:
self.cross_modal_text_link_tower = BridgeTowerLinkTower(config)
self.cross_modal_image_link_tower = BridgeTowerLinkTower(config)
else:
self.cross_modal_text_link_tower = nn.ModuleList(
[BridgeTowerLinkTower(config) for _ in range(config.num_hidden_layers - 1)]
)
self.cross_modal_image_link_tower = nn.ModuleList(
[BridgeTowerLinkTower(config) for _ in range(config.num_hidden_layers - 1)]
)
self.post_init()
def get_input_embeddings(self):
return self.text_model.get_input_embeddings()
def set_input_embeddings(self, value):
self.text_model.set_input_embeddings(value)
@add_start_docstrings_to_model_forward(BRIDGETOWER_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=BridgeTowerModelOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
pixel_values: Optional[torch.FloatTensor] = None,
pixel_mask: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
image_embeds: Optional[torch.FloatTensor] = None,
image_token_type_idx: Optional[int] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
labels: Optional[torch.LongTensor] = None,
) -> Union[Tuple[torch.Tensor], BridgeTowerModelOutput]:
r"""
output_hidden_states (`bool`, *optional*):
If set to `True`, hidden states are returned as a list containing the hidden states of text, image, and
cross-modal components respectively. i.e. `(hidden_states_text, hidden_states_image,
hidden_states_cross_modal)` where each element is a list of the hidden states of the corresponding
modality. `hidden_states_txt/img` are a list of tensors corresponding to unimodal hidden states and
`hidden_states_cross_modal` is a list of tuples containing `cross_modal_text_hidden_states` and
`cross_modal_image_hidden_states` of each brdige layer.
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels are currently not supported.
Returns:
Examples:
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerModel
>>> from PIL import Image
>>> import requests
>>> # prepare image and text
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> text = "hello world"
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base")
>>> model = BridgeTowerModel.from_pretrained("BridgeTower/bridgetower-base")
>>> inputs = processor(image, text, return_tensors="pt")
>>> outputs = model(**inputs)
>>> outputs.keys()
odict_keys(['text_features', 'image_features', 'pooler_output'])
```"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
all_hidden_states_text = () if output_hidden_states else None
all_hidden_states_image = () if output_hidden_states else None
all_hidden_states_cross = () if output_hidden_states else None
all_hidden_states = () if output_hidden_states else None
all_self_attentions = () if output_attentions else None
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
image_token_type_idx = image_token_type_idx if image_token_type_idx else 1
input_shape = input_ids.size()
text_embeds = self.text_model.embeddings(input_ids=input_ids)
if output_hidden_states:
all_hidden_states_text += (text_embeds,)
if attention_mask is None:
attention_mask = torch.ones(input_shape, dtype=torch.long, device=input_ids.device)
extend_text_masks = self.text_model.get_extended_attention_mask(attention_mask, input_shape).to(
input_ids.device
)
# The split_index determines how many layers of the uni-modal encoder are applied before the cross-modal encoder
split_index = len(self.text_model.encoder.layer) - self.config.num_hidden_layers + 1
# Run the first 'split_index' layers of the textual encoder
for layer in self.text_model.encoder.layer[:split_index]:
text_embeds = layer(text_embeds, extend_text_masks)[0]
if output_hidden_states:
all_hidden_states_text += (text_embeds,)
if image_embeds is None:
image_embeds = self.vision_model.visual.forward_pre(pixel_values.type(self.vision_model.dtype))
else:
# Permute as BridgeTowerResidualAttention has batch_first=True
image_embeds = image_embeds.permute(1, 0, 2)
if output_hidden_states:
all_hidden_states_image += (image_embeds,)
# Run the first 'split_index' layers of the visual encoder
for block in self.vision_model.visual.transformer.resblocks[:split_index]:
image_embeds = block(image_embeds)
if output_hidden_states:
all_hidden_states_image += (image_embeds,)
image_embeds_with_ln = self.vision_model.visual.forward_post(image_embeds.type(self.vision_model.dtype))
# first layer is a special case because we don't have the output from the cross-encoder yet
cross_modal_text = self.cross_modal_text_transform(text_embeds)
text_token_type_embeddings = self.token_type_embeddings(
torch.zeros(1, dtype=torch.long, device=input_ids.device)
).expand_as(cross_modal_text)
cross_modal_text = self.cross_modal_text_layernorm(cross_modal_text + text_token_type_embeddings)
image_embeds_with_ln = self.cross_modal_image_transform(image_embeds_with_ln)
image_token_type_embeddings = self.token_type_embeddings(
torch.full((1,), image_token_type_idx, dtype=torch.long, device=input_ids.device)
).expand_as(image_embeds_with_ln)
image_embeds_with_ln = image_embeds_with_ln + image_token_type_embeddings
cross_modal_image = self.cross_modal_image_layernorm(image_embeds_with_ln)
pixel_mask = torch.ones(
(cross_modal_image.size(0), cross_modal_image.size(1)),
dtype=torch.long,
device=input_ids.device,
)
extend_image_masks = self.text_model.get_extended_attention_mask(pixel_mask, pixel_mask.size()).to(
input_ids.device
)
layer_outputs_text = self.cross_modal_text_layers[0](
cross_modal_text,
cross_modal_image,
attention_mask=extend_text_masks,
encoder_attention_mask=extend_image_masks,
output_attentions=output_attentions,
)
cross_text_features = layer_outputs_text[0]
layer_outputs_image = self.cross_modal_image_layers[0](
cross_modal_image,
cross_modal_text,
attention_mask=extend_image_masks,
encoder_attention_mask=extend_text_masks,
output_attentions=output_attentions,
)
cross_image_features = layer_outputs_image[0]
if output_hidden_states:
all_hidden_states_cross += ((cross_text_features, cross_image_features),)
if output_attentions:
all_self_attentions += ((layer_outputs_text[1], layer_outputs_image[1]),)
link_layer_index = 0
# Each of the top 6 layers of the visual and textual encoders ([split_index:]) is connected to each layer of
# the cross-modal encoder via bridge layers, which brings bottom-up alignment and fusion to the cross-modal encoder.
for i in range(split_index, len(self.text_model.encoder.layer)):
text_embeds = self.text_model.encoder.layer[i](text_embeds, extend_text_masks)[0]
image_embeds = self.vision_model.visual.transformer.resblocks[i](image_embeds).type(
self.vision_model.dtype
)
image_embeds_with_ln = (
self.cross_modal_image_transform(self.vision_model.visual.forward_post(image_embeds))
+ image_token_type_embeddings
)
text_link_tower = self.cross_modal_text_link_tower[link_layer_index]
image_link_tower = self.cross_modal_image_link_tower[link_layer_index]
# Bridge layers for textual and visual encoders
cross_text_features_ = text_link_tower(
self.cross_modal_text_transform(text_embeds) + text_token_type_embeddings,
cross_text_features,
extend_text_masks,
)
cross_image_features_ = image_link_tower(image_embeds_with_ln, cross_image_features, extend_image_masks)
# Cross-modal encoder via bridge layers of textual and visual encoders
layer_outputs_text = self.cross_modal_text_layers[link_layer_index + 1](
cross_text_features_,
cross_image_features_,
attention_mask=extend_text_masks,
encoder_attention_mask=extend_image_masks,
output_attentions=output_attentions,
)
cross_text_features = layer_outputs_text[0]
layer_outputs_image = self.cross_modal_image_layers[link_layer_index + 1](
cross_image_features_,
cross_text_features_,
attention_mask=extend_image_masks,
encoder_attention_mask=extend_text_masks,
output_attentions=output_attentions,
)
cross_image_features = layer_outputs_image[0]
link_layer_index += 1
if output_hidden_states:
all_hidden_states_text += (text_embeds,)
all_hidden_states_image += (image_embeds,)
all_hidden_states_cross += ((cross_text_features, cross_image_features),)
if output_attentions:
all_self_attentions += ((layer_outputs_text[1], layer_outputs_image[1]),)
# Concatenate the cls token of the text and image features to get the final represtation
text_features, image_features = cross_text_features, cross_image_features
cls_features = self.get_cls_features(text_features, image_features)
if output_hidden_states:
all_hidden_states = (all_hidden_states_text, all_hidden_states_image, all_hidden_states_cross)
if not return_dict:
return tuple(
v
for v in [text_features, image_features, cls_features, all_hidden_states, all_self_attentions]
if v is not None
)
return BridgeTowerModelOutput(
text_features=text_features,
image_features=image_features,
pooler_output=cls_features,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
)
def get_cls_features(self, text_features, image_features):
cls_features_text = self.cross_modal_text_pooler(text_features)
cls_features_image = self.cross_modal_image_pooler(image_features)
return torch.cat([cls_features_text, cls_features_image], dim=-1)
# Copied from transformers.models.vilt.modeling_vilt.ViltPredictionHeadTransform with Vilt->BridgeTower
class BridgeTowerPredictionHeadTransform(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
if isinstance(config.hidden_act, str):
self.transform_act_fn = ACT2FN[config.hidden_act]
else:
self.transform_act_fn = config.hidden_act
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
def forward(self, hidden_states):
hidden_states = self.dense(hidden_states)
hidden_states = self.transform_act_fn(hidden_states)
hidden_states = self.LayerNorm(hidden_states)
return hidden_states
class BridgeTowerMLMHead(nn.Module):
def __init__(self, config, weight=None):
super().__init__()
self.config = config
self.transform = BridgeTowerPredictionHeadTransform(config)
self.decoder = nn.Linear(config.hidden_size, config.text_config.vocab_size, bias=False)
self.bias = nn.Parameter(torch.zeros(config.text_config.vocab_size))
if weight is not None:
self.decoder.weight = weight
def forward(self, x):
mlm_score = self.transform(x)
mlm_score = self.decoder(mlm_score) + self.bias
return mlm_score
class BridgeTowerITMHead(nn.Module):
def __init__(self, hidden_size):
super().__init__()
self.fc = nn.Linear(hidden_size, 2)
def forward(self, x):
itm_score = self.fc(x)
return itm_score
@add_start_docstrings(
"""
BridgeTower Model with a language modeling head on top as done during pretraining.
""",
BRIDGETOWER_START_DOCSTRING,
)
class BridgeTowerForMaskedLM(BridgeTowerPreTrainedModel):
_tied_weights_keys = ["mlm_score.decoder.weight"]
def __init__(self, config):
super().__init__(config)
self.bridgetower = BridgeTowerModel(config)
self.mlm_score = BridgeTowerMLMHead(config)
# Initialize weights and apply final processing
self.post_init()
def get_output_embeddings(self):
return self.mlm_score.decoder
def set_output_embeddings(self, new_embeddings):
self.mlm_score.decoder = new_embeddings
@add_start_docstrings_to_model_forward(BRIDGETOWER_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
@replace_return_docstrings(output_type=MaskedLMOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
pixel_values: Optional[torch.FloatTensor] = None,
pixel_mask: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
image_embeds: Optional[torch.FloatTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
labels: Optional[torch.LongTensor] = None,
) -> Union[MaskedLMOutput, Tuple[torch.FloatTensor]]:
r"""
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the masked language modeling loss. Indices should be in `[-100, 0, ...,
config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are ignored (masked), the
loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`
Returns:
Examples:
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000360943.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
>>> text = "a <mask> looking out of the window"
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # prepare inputs
>>> encoding = processor(image, text, return_tensors="pt")
>>> # forward pass
>>> outputs = model(**encoding)
>>> results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
>>> print(results)
.a cat looking out of the window.
```"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.bridgetower(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
pixel_values=pixel_values,
pixel_mask=pixel_mask,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
image_embeds=image_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
mlm_logits = self.mlm_score(outputs.text_features if return_dict else outputs[0])
masked_lm_loss = None
if labels is not None:
loss_fct = CrossEntropyLoss() # -100 index = padding token
labels = labels.to(mlm_logits.device)
masked_lm_loss = loss_fct(mlm_logits.view(-1, self.config.text_config.vocab_size), labels.view(-1))
if not return_dict:
output = tuple(mlm_logits)
return ((masked_lm_loss,) + output) if masked_lm_loss is not None else output
return MaskedLMOutput(
loss=masked_lm_loss,
logits=mlm_logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
@add_start_docstrings(
"""
BridgeTower Model transformer with a classifier head on top (a linear layer on top of the final hidden state of the
[CLS] token) for image-to-text matching.
""",
BRIDGETOWER_START_DOCSTRING,
)
class BridgeTowerForImageAndTextRetrieval(BridgeTowerPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.bridgetower = BridgeTowerModel(config)
self.itm_score = BridgeTowerITMHead(config.hidden_size * 2)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(BRIDGETOWER_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=SequenceClassifierOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
pixel_values: Optional[torch.FloatTensor] = None,
pixel_mask: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
image_embeds: Optional[torch.FloatTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
labels: Optional[torch.LongTensor] = None,
) -> Union[SequenceClassifierOutput, Tuple[torch.FloatTensor]]:
r"""
labels (`torch.LongTensor` of shape `(batch_size, 1)`, *optional*):
Labels for computing the image-text matching loss. 0 means the pairs don't match and 1 means they match.
The pairs with 0 will be skipped for calculation.
Returns:
Examples:
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
>>> import requests
>>> from PIL import Image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
>>> # forward pass
>>> scores = dict()
>>> for text in texts:
... # prepare inputs
... encoding = processor(image, text, return_tensors="pt")
... outputs = model(**encoding)
... scores[text] = outputs.logits[0, 1].item()
```"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.bridgetower(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
pixel_values=pixel_values,
pixel_mask=pixel_mask,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
image_embeds=image_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
pooler_output = outputs.pooler_output if return_dict else outputs[2]
logits = self.itm_score(pooler_output)
itm_loss = None
if labels is not None:
loss_fct = CrossEntropyLoss()
labels = labels.to(logits.device)
itm_loss = loss_fct(logits, labels)
if not return_dict:
output = tuple(logits)
return ((itm_loss,) + output) if itm_loss is not None else output
return SequenceClassifierOutput(
loss=itm_loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
class BridgeTowerContrastiveHead(nn.Module):
def __init__(self, hidden_size, embed_size):
super().__init__()
self.fc = nn.Linear(hidden_size, embed_size)
def forward(self, x):
x = self.fc(x)
return x
@add_start_docstrings(
"""
BridgeTower Model with a image-text contrastive head on top computing image-text contrastive loss.
""",
BRIDGETOWER_START_DOCSTRING,
)
class BridgeTowerForContrastiveLearning(BridgeTowerPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.bridgetower = BridgeTowerModel(config)
self.itc_text_head = BridgeTowerContrastiveHead(config.hidden_size, config.contrastive_hidden_size)
self.itc_image_head = BridgeTowerContrastiveHead(config.hidden_size, config.contrastive_hidden_size)
self.itc_cross_modal_head = BridgeTowerContrastiveHead(config.hidden_size * 2, config.contrastive_hidden_size)
self.logit_scale = nn.Parameter(torch.tensor(self.config.logit_scale_init_value))
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(BRIDGETOWER_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=BridgeTowerContrastiveOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
token_type_ids: Optional[torch.LongTensor] = None,
pixel_values: Optional[torch.FloatTensor] = None,
pixel_mask: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
image_embeds: Optional[torch.FloatTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = True,
return_dict: Optional[bool] = None,
return_loss: Optional[bool] = None,
) -> Union[BridgeTowerContrastiveOutput, Tuple[torch.FloatTensor]]:
r"""
return_loss (`bool`, *optional*):
Whether or not to return the contrastive loss.
Returns:
Examples:
```python
>>> from transformers import BridgeTowerProcessor, BridgeTowerForContrastiveLearning
>>> import requests
>>> from PIL import Image
>>> import torch
>>> image_urls = [
... "https://farm4.staticflickr.com/3395/3428278415_81c3e27f15_z.jpg",
... "http://images.cocodataset.org/val2017/000000039769.jpg",
... ]
>>> texts = ["two dogs in a car", "two cats sleeping on a couch"]
>>> images = [Image.open(requests.get(url, stream=True).raw) for url in image_urls]
>>> processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> model = BridgeTowerForContrastiveLearning.from_pretrained("BridgeTower/bridgetower-large-itm-mlm-itc")
>>> inputs = processor(images, texts, padding=True, return_tensors="pt")
>>> loss = model(**inputs, return_loss=True).loss
>>> inputs = processor(images, texts[::-1], padding=True, return_tensors="pt")
>>> loss_swapped = model(**inputs, return_loss=True).loss
>>> print("Loss", round(loss.item(), 4))
Loss 0.0019
>>> print("Loss with swapped images", round(loss_swapped.item(), 4))
Loss with swapped images 2.126
```"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.bridgetower(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
pixel_values=pixel_values,
pixel_mask=pixel_mask,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
image_embeds=image_embeds,
output_attentions=output_attentions,
output_hidden_states=True,
return_dict=return_dict,
)
pooler_output = outputs.pooler_output if return_dict else outputs[2]
hidden_states_txt, hidden_states_img, hidden_states_cross_modal = (
outputs.hidden_states if return_dict else outputs[3]
)
text_embeds = hidden_states_txt[-1]
image_embeds = hidden_states_img[-1]
image_embeds_with_ln = self.bridgetower.vision_model.visual.forward_post(image_embeds)
image_token_type_embeddings = self.bridgetower.token_type_embeddings(
torch.full((1,), 1, dtype=torch.long, device=self.bridgetower.token_type_embeddings.weight.device)
).expand_as(image_embeds_with_ln)
image_embeds = self.bridgetower.cross_modal_image_transform(image_embeds_with_ln) + image_token_type_embeddings
# normalized features
text_embeds = nn.functional.normalize(self.itc_text_head(text_embeds[:, 0, :]), dim=-1, p=2)
image_embeds = nn.functional.normalize(self.itc_image_head(image_embeds[:, 0, :]), dim=-1, p=2).to(
device=text_embeds.device
)
cross_embeds = nn.functional.normalize(self.itc_cross_modal_head(pooler_output), dim=-1, p=2).to(
device=text_embeds.device
)
logits = torch.stack([text_embeds, image_embeds, cross_embeds], dim=-2)
logit_scale = self.logit_scale.exp().to(device=text_embeds.device)
logits_text_to_image = torch.matmul(text_embeds, image_embeds.t()) * logit_scale
logits_text_to_cross = torch.matmul(text_embeds, cross_embeds.t()) * logit_scale
logits_image_to_cross = torch.matmul(image_embeds, cross_embeds.t()) * logit_scale
itc_loss = None
if return_loss:
labels = torch.arange(len(logits), device=logits.device)
text_to_image_loss = nn.functional.cross_entropy(logits_text_to_image, labels)
text_to_cross_loss = nn.functional.cross_entropy(logits_text_to_cross, labels)
image_to_cross_loss = nn.functional.cross_entropy(logits_image_to_cross, labels)
itc_loss = (text_to_image_loss + text_to_cross_loss + image_to_cross_loss) / 3.0
if not return_dict:
output = (logits, text_embeds, image_embeds, cross_embeds) + outputs[3:]
return ((itc_loss,) + output) if itc_loss is not None else output
return BridgeTowerContrastiveOutput(
loss=itc_loss,
logits=logits,
text_embeds=text_embeds,
image_embeds=image_embeds,
cross_embeds=cross_embeds,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
| transformers/src/transformers/models/bridgetower/modeling_bridgetower.py/0 | {
"file_path": "transformers/src/transformers/models/bridgetower/modeling_bridgetower.py",
"repo_id": "transformers",
"token_count": 37419
} | 296 |
# coding=utf-8
# Copyright 2023 The LAION-AI Team and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" PyTorch CLAP model."""
import collections
import math
from dataclasses import dataclass
from typing import Any, List, Optional, Tuple, Union
import torch
import torch.nn.functional as F
from torch import nn
from ...activations import ACT2FN
from ...modeling_outputs import (
BaseModelOutputWithPastAndCrossAttentions,
BaseModelOutputWithPooling,
BaseModelOutputWithPoolingAndCrossAttentions,
)
from ...modeling_utils import PreTrainedModel
from ...pytorch_utils import apply_chunking_to_forward, find_pruneable_heads_and_indices, meshgrid, prune_linear_layer
from ...utils import (
ModelOutput,
add_start_docstrings,
add_start_docstrings_to_model_forward,
logging,
replace_return_docstrings,
)
from .configuration_clap import ClapAudioConfig, ClapConfig, ClapTextConfig
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "laion/clap-htsat-fused"
CLAP_PRETRAINED_MODEL_ARCHIVE_LIST = [
"laion/clap-htsat-fused",
"laion/clap-htsat-unfused",
# See all clap models at https://huggingface.co/models?filter=clap
]
# Adapted from: https://github.com/LAION-AI/CLAP/blob/6ad05a971ba0622f6acee8c41993e0d02bbed639/src/open_clip/utils.py#L191
def interpolate(hidden_states, ratio):
"""
Interpolate data in time domain. This is used to compensate the resolution reduction in downsampling of a CNN.
Args:
hidden_states (`torch.FloatTensor` of shape (batch_size, time_length, classes_num)):
Input hidden states
ratio (`int`):
The ratio of the length of the output to the length of the input.
"""
(batch_size, time_length, classes_num) = hidden_states.shape
upsampled = hidden_states[:, :, None, :].repeat(1, 1, ratio, 1)
upsampled = upsampled.reshape(batch_size, time_length * ratio, classes_num)
return upsampled
# Adapted from https://github.com/LAION-AI/CLAP/blob/6ad05a971ba0622f6acee8c41993e0d02bbed639/src/open_clip/htsat.py#L249
def window_partition(hidden_states, window_size):
"""
Returns the resized hidden states. The output shape should be `(batch_size * num_windows, window_size, window_size,
num_channels)`
Args:
hidden_states (`torch.FloatTensor` of shape `(batch_size, height, width, num_channels)`):
Input hidden states
window_size (`int`):
Window size
"""
batch_size, height, width, num_channels = hidden_states.shape
hidden_states = hidden_states.view(
batch_size, height // window_size, window_size, width // window_size, window_size, num_channels
)
windows = hidden_states.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, num_channels)
return windows
# Adapted from https://github.com/LAION-AI/CLAP/blob/6ad05a971ba0622f6acee8c41993e0d02bbed639/src/open_clip/htsat.py#L263
def window_reverse(windows, window_size, height, width):
"""
Merges windows to produce higher resolution features.
Args:
windows (`torch.FloatTensor` of shape `(num_windows * batch_size, window_size, window_size, num_channels)`):
Input windows
window_size (`int`):
Window size
height (`int`):
Height of the resized audio
width (`int`):
Width of the resized audio
"""
num_channels = windows.shape[-1]
windows = windows.view(-1, height // window_size, width // window_size, window_size, window_size, num_channels)
windows = windows.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, height, width, num_channels)
return windows
# Copied from transformers.models.roberta.modeling_roberta.create_position_ids_from_input_ids
def create_position_ids_from_input_ids(input_ids, padding_idx, past_key_values_length=0):
"""
Replace non-padding symbols with their position numbers. Position numbers begin at padding_idx+1. Padding symbols
are ignored. This is modified from fairseq's `utils.make_positions`.
Args:
x: torch.Tensor x:
Returns: torch.Tensor
"""
# The series of casts and type-conversions here are carefully balanced to both work with ONNX export and XLA.
mask = input_ids.ne(padding_idx).int()
incremental_indices = (torch.cumsum(mask, dim=1).type_as(mask) + past_key_values_length) * mask
return incremental_indices.long() + padding_idx
# contrastive loss function, adapted from
# https://sachinruk.github.io/blog/pytorch/pytorch%20lightning/loss%20function/gpu/2021/03/07/CLIP.html#CLIP-loss-function
def contrastive_loss(logits: torch.Tensor) -> torch.Tensor:
labels = torch.arange(len(logits), device=logits.device)
return nn.functional.cross_entropy(logits, labels)
@dataclass
# Copied from transformers.models.clip.modeling_clip.CLIPTextModelOutput with CLIP->Clap
class ClapTextModelOutput(ModelOutput):
"""
Base class for text model's outputs that also contains a pooling of the last hidden states.
Args:
text_embeds (`torch.FloatTensor` of shape `(batch_size, output_dim)` *optional* returned when model is initialized with `with_projection=True`):
The text embeddings obtained by applying the projection layer to the pooler_output.
last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
text_embeds: Optional[torch.FloatTensor] = None
last_hidden_state: torch.FloatTensor = None
hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
@dataclass
class ClapAudioModelOutput(ModelOutput):
"""
ClapAudio model output to mimic the output of the original implementation.
Args:
audio_embeds (`torch.FloatTensor` of shape `(batch_size, hidden_size)`):
The Audio embeddings obtained by applying the projection layer to the pooler_output.
last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
"""
audio_embeds: Optional[torch.FloatTensor] = None
last_hidden_state: torch.FloatTensor = None
hidden_states: Optional[Tuple[torch.FloatTensor, ...]] = None
attentions: Optional[Tuple[torch.FloatTensor, ...]] = None
@dataclass
# Copied from transformers.models.clip.modeling_clip.CLIPOutput with CLIP->Clap, vision->audio, Vision->Audio, image->audio
class ClapOutput(ModelOutput):
"""
Args:
loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `return_loss` is `True`):
Contrastive loss for audio-text similarity.
logits_per_audio:(`torch.FloatTensor` of shape `(audio_batch_size, text_batch_size)`):
The scaled dot product scores between `audio_embeds` and `text_embeds`. This represents the audio-text
similarity scores.
logits_per_text:(`torch.FloatTensor` of shape `(text_batch_size, audio_batch_size)`):
The scaled dot product scores between `text_embeds` and `audio_embeds`. This represents the text-audio
similarity scores.
text_embeds(`torch.FloatTensor` of shape `(batch_size, output_dim`):
The text embeddings obtained by applying the projection layer to the pooled output of [`ClapTextModel`].
audio_embeds(`torch.FloatTensor` of shape `(batch_size, output_dim`):
The audio embeddings obtained by applying the projection layer to the pooled output of [`ClapAudioModel`].
text_model_output(`BaseModelOutputWithPooling`):
The output of the [`ClapTextModel`].
audio_model_output(`BaseModelOutputWithPooling`):
The output of the [`ClapAudioModel`].
"""
loss: Optional[torch.FloatTensor] = None
logits_per_audio: torch.FloatTensor = None
logits_per_text: torch.FloatTensor = None
text_embeds: torch.FloatTensor = None
audio_embeds: torch.FloatTensor = None
text_model_output: BaseModelOutputWithPooling = None
audio_model_output: BaseModelOutputWithPooling = None
def to_tuple(self) -> Tuple[Any]:
return tuple(
self[k] if k not in ["text_model_output", "audio_model_output"] else getattr(self, k).to_tuple()
for k in self.keys()
)
# Adapted from transformers.models.swin.modeling_swin.SwinDropPath
class ClapDropPath(nn.Module):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks). This is a slightly
refactored version of the `SwinDropPath` implementation.
"""
def __init__(self, drop_prob=None):
super().__init__()
self.drop_prob = drop_prob
def forward(self, hidden_states):
if self.drop_prob == 0.0 or not self.training:
return hidden_states
keep_prob = 1 - self.drop_prob
# work with diff dim tensors, not just 2D ConvNets
shape = (hidden_states.shape[0],) + (1,) * (hidden_states.ndim - 1)
random_tensor = keep_prob + torch.rand(shape, dtype=hidden_states.dtype, device=hidden_states.device)
random_tensor.floor_() # binarize
output = hidden_states.div(keep_prob) * random_tensor
return output
# Adapted from https://github.com/LAION-AI/CLAP/blob/6ad05a971ba0622f6acee8c41993e0d02bbed639/src/open_clip/feature_fusion.py#L133
class ClapAudioAFFBlock(nn.Module):
r"""
ATTENTIONAL FEATURE FUSION Block from CLAP, since in CLAP we are always in 2D mode, it is not needed to implement
the 1D version.
"""
def __init__(self, config: ClapAudioConfig):
super().__init__()
channels = config.patch_embeds_hidden_size
downsize_ratio = config.aff_block_r
inter_channels = int(channels // downsize_ratio)
self.local_att = nn.Sequential(
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
self.global_att = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channels, inter_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(inter_channels),
nn.ReLU(inplace=True),
nn.Conv2d(inter_channels, channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(channels),
)
self.sigmoid = nn.Sigmoid()
def forward(self, hidden_states, residual):
attention_input = hidden_states + residual
fused_layer_output = self.local_att(attention_input) + self.global_att(attention_input)
fused_layer_output = self.sigmoid(fused_layer_output)
output = 2 * hidden_states * fused_layer_output + 2 * residual * (1 - fused_layer_output)
return output
class ClapAudioPatchEmbed(nn.Module):
"""
This module converts the hidden states reshaped as an image to patch embeddings ready to be passed to the
Transformer block.
"""
def __init__(self, config: ClapAudioConfig):
super().__init__()
img_size = (config.spec_size, config.spec_size) if isinstance(config.spec_size, int) else config.spec_size
patch_size = (
(config.patch_size, config.patch_size) if isinstance(config.patch_size, int) else config.patch_size
)
patch_stride = (
(config.patch_stride, config.patch_stride) if isinstance(config.patch_stride, int) else config.patch_stride
)
self.img_size = img_size
self.patch_stride = patch_stride
self.grid_size = (img_size[0] // patch_stride[0], img_size[1] // patch_stride[1])
self.num_patches = self.grid_size[0] * self.grid_size[1]
self.flatten = config.flatten_patch_embeds
self.enable_fusion = config.enable_fusion
padding = ((patch_size[0] - patch_stride[0]) // 2, (patch_size[1] - patch_stride[1]) // 2)
scale_factor = 4 if (self.enable_fusion) and (config.fusion_type == "channel_map") else 1
self.proj = nn.Conv2d(
config.patch_embed_input_channels * scale_factor,
config.patch_embeds_hidden_size,
kernel_size=patch_size,
stride=patch_stride,
padding=padding,
)
self.norm = nn.LayerNorm(config.patch_embeds_hidden_size) if config.enable_patch_layer_norm else nn.Identity()
if self.enable_fusion:
self.fusion_model = ClapAudioAFFBlock(config)
self.mel_conv2d = nn.Conv2d(
config.patch_embed_input_channels,
config.patch_embeds_hidden_size,
kernel_size=(patch_size[0], patch_size[1] * 3),
stride=(patch_stride[0], patch_stride[1] * 3),
padding=padding,
)
def forward(self, hidden_states, is_longer_idx=None):
if self.enable_fusion:
# retrieve the last mel as we have transposed the input
global_hidden_states = hidden_states[:, 0:1, :, :]
# global processing
batch_size, num_channels, height, width = global_hidden_states.shape
if height != self.img_size[0] or width != self.img_size[1]:
raise ValueError(
f"Input audio size ({height}*{width}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
)
global_hidden_states = self.proj(global_hidden_states)
output_width = global_hidden_states.size(-1)
if len(is_longer_idx) > 0:
# local processing
local_hidden_states = hidden_states[is_longer_idx, 1:, :, :].contiguous()
batch_size, num_channels, height, width = local_hidden_states.shape
local_hidden_states = local_hidden_states.view(batch_size * num_channels, 1, height, width)
local_hidden_states = self.mel_conv2d(local_hidden_states)
_, features, height, width = local_hidden_states.shape
local_hidden_states = local_hidden_states.view(batch_size, num_channels, features, height, width)
local_hidden_states = local_hidden_states.permute((0, 2, 3, 1, 4)).contiguous().flatten(3)
local_width = local_hidden_states.size(-1)
local_hidden_states = torch.nn.functional.pad(
local_hidden_states, (0, output_width - local_width), "constant", 0
)
global_hidden_states[is_longer_idx] = self.fusion_model(
global_hidden_states[is_longer_idx], local_hidden_states
)
hidden_states = global_hidden_states
else:
_, _, height, width = hidden_states.shape
if height != self.img_size[0] or width != self.img_size[1]:
raise ValueError(
f"Input audio size ({height}*{width}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
)
hidden_states = self.proj(hidden_states)
if self.flatten:
hidden_states = hidden_states.flatten(2).transpose(1, 2)
hidden_states = self.norm(hidden_states)
return hidden_states
# Copied from transformers.models.swin.modeling_swin.SwinSelfAttention with Swin->ClapAudio
class ClapAudioSelfAttention(nn.Module):
def __init__(self, config, dim, num_heads, window_size):
super().__init__()
if dim % num_heads != 0:
raise ValueError(
f"The hidden size ({dim}) is not a multiple of the number of attention heads ({num_heads})"
)
self.num_attention_heads = num_heads
self.attention_head_size = int(dim / num_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.window_size = (
window_size if isinstance(window_size, collections.abc.Iterable) else (window_size, window_size)
)
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * self.window_size[0] - 1) * (2 * self.window_size[1] - 1), num_heads)
)
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(meshgrid([coords_h, coords_w], indexing="ij"))
coords_flatten = torch.flatten(coords, 1)
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]
relative_coords = relative_coords.permute(1, 2, 0).contiguous()
relative_coords[:, :, 0] += self.window_size[0] - 1
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1)
self.register_buffer("relative_position_index", relative_position_index)
self.query = nn.Linear(self.all_head_size, self.all_head_size, bias=config.qkv_bias)
self.key = nn.Linear(self.all_head_size, self.all_head_size, bias=config.qkv_bias)
self.value = nn.Linear(self.all_head_size, self.all_head_size, bias=config.qkv_bias)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
def transpose_for_scores(self, x):
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
output_attentions: Optional[bool] = False,
) -> Tuple[torch.Tensor]:
batch_size, dim, num_channels = hidden_states.shape
mixed_query_layer = self.query(hidden_states)
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
query_layer = self.transpose_for_scores(mixed_query_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)]
relative_position_bias = relative_position_bias.view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1
)
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous()
attention_scores = attention_scores + relative_position_bias.unsqueeze(0)
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in ClapAudioModel forward() function)
mask_shape = attention_mask.shape[0]
attention_scores = attention_scores.view(
batch_size // mask_shape, mask_shape, self.num_attention_heads, dim, dim
)
attention_scores = attention_scores + attention_mask.unsqueeze(1).unsqueeze(0)
attention_scores = attention_scores.view(-1, self.num_attention_heads, dim, dim)
# Normalize the attention scores to probabilities.
attention_probs = nn.functional.softmax(attention_scores, dim=-1)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
return outputs
# Copied from transformers.models.swin.modeling_swin.SwinSelfOutput with Swin->ClapAudio
class ClapAudioSelfOutput(nn.Module):
def __init__(self, config, dim):
super().__init__()
self.dense = nn.Linear(dim, dim)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
return hidden_states
# Copied from transformers.models.swin.modeling_swin.SwinAttention with Swin->ClapAudio
class ClapAudioAttention(nn.Module):
def __init__(self, config, dim, num_heads, window_size):
super().__init__()
self.self = ClapAudioSelfAttention(config, dim, num_heads, window_size)
self.output = ClapAudioSelfOutput(config, dim)
self.pruned_heads = set()
def prune_heads(self, heads):
if len(heads) == 0:
return
heads, index = find_pruneable_heads_and_indices(
heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads
)
# Prune linear layers
self.self.query = prune_linear_layer(self.self.query, index)
self.self.key = prune_linear_layer(self.self.key, index)
self.self.value = prune_linear_layer(self.self.value, index)
self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
# Update hyper params and store pruned heads
self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
self.pruned_heads = self.pruned_heads.union(heads)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
output_attentions: Optional[bool] = False,
) -> Tuple[torch.Tensor]:
self_outputs = self.self(hidden_states, attention_mask, head_mask, output_attentions)
attention_output = self.output(self_outputs[0], hidden_states)
outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
return outputs
# Copied from transformers.models.swin.modeling_swin.SwinIntermediate with Swin->ClapAudio
class ClapAudioIntermediate(nn.Module):
def __init__(self, config, dim):
super().__init__()
self.dense = nn.Linear(dim, int(config.mlp_ratio * dim))
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = ACT2FN[config.hidden_act]
else:
self.intermediate_act_fn = config.hidden_act
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
# Copied from transformers.models.swin.modeling_swin.SwinOutput with Swin->ClapAudio
class ClapAudioOutput(nn.Module):
def __init__(self, config, dim):
super().__init__()
self.dense = nn.Linear(int(config.mlp_ratio * dim), dim)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
return hidden_states
# Copied from transformers.models.swin.modeling_swin.SwinLayer with SwinDropPath->ClapDropPath, Swin->ClapAudio
class ClapAudioLayer(nn.Module):
def __init__(self, config, dim, input_resolution, num_heads, shift_size=0):
super().__init__()
self.chunk_size_feed_forward = config.chunk_size_feed_forward
self.shift_size = shift_size
self.window_size = config.window_size
self.input_resolution = input_resolution
self.layernorm_before = nn.LayerNorm(dim, eps=config.layer_norm_eps)
self.attention = ClapAudioAttention(config, dim, num_heads, window_size=self.window_size)
self.drop_path = ClapDropPath(config.drop_path_rate) if config.drop_path_rate > 0.0 else nn.Identity()
self.layernorm_after = nn.LayerNorm(dim, eps=config.layer_norm_eps)
self.intermediate = ClapAudioIntermediate(config, dim)
self.output = ClapAudioOutput(config, dim)
def set_shift_and_window_size(self, input_resolution):
if min(input_resolution) <= self.window_size:
# if window size is larger than input resolution, we don't partition windows
self.shift_size = 0
self.window_size = min(input_resolution)
def get_attn_mask(self, height, width, dtype):
if self.shift_size > 0:
# calculate attention mask for SW-MSA
img_mask = torch.zeros((1, height, width, 1), dtype=dtype)
height_slices = (
slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None),
)
width_slices = (
slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None),
)
count = 0
for height_slice in height_slices:
for width_slice in width_slices:
img_mask[:, height_slice, width_slice, :] = count
count += 1
mask_windows = window_partition(img_mask, self.window_size)
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
else:
attn_mask = None
return attn_mask
def maybe_pad(self, hidden_states, height, width):
pad_right = (self.window_size - width % self.window_size) % self.window_size
pad_bottom = (self.window_size - height % self.window_size) % self.window_size
pad_values = (0, 0, 0, pad_right, 0, pad_bottom)
hidden_states = nn.functional.pad(hidden_states, pad_values)
return hidden_states, pad_values
def forward(
self,
hidden_states: torch.Tensor,
input_dimensions: Tuple[int, int],
head_mask: Optional[torch.FloatTensor] = None,
output_attentions: Optional[bool] = False,
always_partition: Optional[bool] = False,
) -> Tuple[torch.Tensor, torch.Tensor]:
if not always_partition:
self.set_shift_and_window_size(input_dimensions)
else:
pass
height, width = input_dimensions
batch_size, _, channels = hidden_states.size()
shortcut = hidden_states
hidden_states = self.layernorm_before(hidden_states)
hidden_states = hidden_states.view(batch_size, height, width, channels)
# pad hidden_states to multiples of window size
hidden_states, pad_values = self.maybe_pad(hidden_states, height, width)
_, height_pad, width_pad, _ = hidden_states.shape
# cyclic shift
if self.shift_size > 0:
shifted_hidden_states = torch.roll(hidden_states, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_hidden_states = hidden_states
# partition windows
hidden_states_windows = window_partition(shifted_hidden_states, self.window_size)
hidden_states_windows = hidden_states_windows.view(-1, self.window_size * self.window_size, channels)
attn_mask = self.get_attn_mask(height_pad, width_pad, dtype=hidden_states.dtype)
if attn_mask is not None:
attn_mask = attn_mask.to(hidden_states_windows.device)
attention_outputs = self.attention(
hidden_states_windows, attn_mask, head_mask, output_attentions=output_attentions
)
attention_output = attention_outputs[0]
attention_windows = attention_output.view(-1, self.window_size, self.window_size, channels)
shifted_windows = window_reverse(attention_windows, self.window_size, height_pad, width_pad)
# reverse cyclic shift
if self.shift_size > 0:
attention_windows = torch.roll(shifted_windows, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
attention_windows = shifted_windows
was_padded = pad_values[3] > 0 or pad_values[5] > 0
if was_padded:
attention_windows = attention_windows[:, :height, :width, :].contiguous()
attention_windows = attention_windows.view(batch_size, height * width, channels)
hidden_states = shortcut + self.drop_path(attention_windows)
layer_output = self.layernorm_after(hidden_states)
layer_output = self.intermediate(layer_output)
layer_output = hidden_states + self.output(layer_output)
layer_outputs = (layer_output, attention_outputs[1]) if output_attentions else (layer_output,)
return layer_outputs
# Copied from transformers.models.swin.modeling_swin.SwinStage with Swin->ClapAudio
class ClapAudioStage(nn.Module):
def __init__(self, config, dim, input_resolution, depth, num_heads, drop_path, downsample):
super().__init__()
self.config = config
self.dim = dim
self.blocks = nn.ModuleList(
[
ClapAudioLayer(
config=config,
dim=dim,
input_resolution=input_resolution,
num_heads=num_heads,
shift_size=0 if (i % 2 == 0) else config.window_size // 2,
)
for i in range(depth)
]
)
# patch merging layer
if downsample is not None:
self.downsample = downsample(input_resolution, dim=dim, norm_layer=nn.LayerNorm)
else:
self.downsample = None
self.pointing = False
def forward(
self,
hidden_states: torch.Tensor,
input_dimensions: Tuple[int, int],
head_mask: Optional[torch.FloatTensor] = None,
output_attentions: Optional[bool] = False,
always_partition: Optional[bool] = False,
) -> Tuple[torch.Tensor]:
height, width = input_dimensions
for i, layer_module in enumerate(self.blocks):
layer_head_mask = head_mask[i] if head_mask is not None else None
layer_outputs = layer_module(
hidden_states, input_dimensions, layer_head_mask, output_attentions, always_partition
)
hidden_states = layer_outputs[0]
hidden_states_before_downsampling = hidden_states
if self.downsample is not None:
height_downsampled, width_downsampled = (height + 1) // 2, (width + 1) // 2
output_dimensions = (height, width, height_downsampled, width_downsampled)
hidden_states = self.downsample(hidden_states_before_downsampling, input_dimensions)
else:
output_dimensions = (height, width, height, width)
stage_outputs = (hidden_states, hidden_states_before_downsampling, output_dimensions)
if output_attentions:
stage_outputs += layer_outputs[1:]
return stage_outputs
# Copied from transformers.models.swin.modeling_swin.SwinPatchMerging with Swin->ClapAudio
class ClapAudioPatchMerging(nn.Module):
"""
Patch Merging Layer.
Args:
input_resolution (`Tuple[int]`):
Resolution of input feature.
dim (`int`):
Number of input channels.
norm_layer (`nn.Module`, *optional*, defaults to `nn.LayerNorm`):
Normalization layer class.
"""
def __init__(self, input_resolution: Tuple[int], dim: int, norm_layer: nn.Module = nn.LayerNorm) -> None:
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def maybe_pad(self, input_feature, height, width):
should_pad = (height % 2 == 1) or (width % 2 == 1)
if should_pad:
pad_values = (0, 0, 0, width % 2, 0, height % 2)
input_feature = nn.functional.pad(input_feature, pad_values)
return input_feature
def forward(self, input_feature: torch.Tensor, input_dimensions: Tuple[int, int]) -> torch.Tensor:
height, width = input_dimensions
# `dim` is height * width
batch_size, dim, num_channels = input_feature.shape
input_feature = input_feature.view(batch_size, height, width, num_channels)
# pad input to be disible by width and height, if needed
input_feature = self.maybe_pad(input_feature, height, width)
# [batch_size, height/2, width/2, num_channels]
input_feature_0 = input_feature[:, 0::2, 0::2, :]
# [batch_size, height/2, width/2, num_channels]
input_feature_1 = input_feature[:, 1::2, 0::2, :]
# [batch_size, height/2, width/2, num_channels]
input_feature_2 = input_feature[:, 0::2, 1::2, :]
# [batch_size, height/2, width/2, num_channels]
input_feature_3 = input_feature[:, 1::2, 1::2, :]
# batch_size height/2 width/2 4*num_channels
input_feature = torch.cat([input_feature_0, input_feature_1, input_feature_2, input_feature_3], -1)
input_feature = input_feature.view(batch_size, -1, 4 * num_channels) # batch_size height/2*width/2 4*C
input_feature = self.norm(input_feature)
input_feature = self.reduction(input_feature)
return input_feature
class ClapAudioEncoder(nn.Module):
def __init__(self, config):
super().__init__()
self.num_layers = len(config.depths)
self.config = config
self.patch_embed = ClapAudioPatchEmbed(config)
self.enable_fusion = config.enable_fusion
self.patch_stride = self.patch_embed.patch_stride
self.spec_size = config.spec_size
self.freq_ratio = config.spec_size // config.num_mel_bins
self.num_features = int(config.patch_embeds_hidden_size * 2 ** (self.num_layers - 1))
drop_path_rate = [x.item() for x in torch.linspace(0, config.drop_path_rate, sum(config.depths))]
grid_size = self.patch_embed.grid_size
self.input_resolutions = [(grid_size[0] // (2**i), grid_size[1] // (2**i)) for i in range(self.num_layers)]
self.layers = nn.ModuleList(
[
ClapAudioStage(
config=config,
dim=int(config.patch_embeds_hidden_size * 2**i_layer),
input_resolution=self.input_resolutions[i_layer],
depth=config.depths[i_layer],
num_heads=config.num_attention_heads[i_layer],
drop_path=drop_path_rate[sum(config.depths[:i_layer]) : sum(config.depths[: i_layer + 1])],
downsample=ClapAudioPatchMerging if (i_layer < self.num_layers - 1) else None,
)
for i_layer in range(self.num_layers)
]
)
self.gradient_checkpointing = False
self.batch_norm = nn.BatchNorm2d(config.num_mel_bins)
self.norm = nn.LayerNorm(self.num_features)
self.depths = config.depths
self.avgpool = nn.AdaptiveAvgPool1d(1)
def reshape_mel2img(self, normalized_input_features):
"""
The input is 4 normalized log mel spectrograms. It is reshape to the common shape of images. Each channel
should represent 1 of the 4 crops of the spectrogram. For more details, refer to the [`ClapFeatureExtractor`].
"""
_, _, time_length, freq_length = normalized_input_features.shape
spec_width = int(self.spec_size * self.freq_ratio)
spec_heigth = self.spec_size // self.freq_ratio
if time_length > spec_width or freq_length > spec_heigth:
raise ValueError("the wav size should be less than or equal to the swin input size")
# to avoid bicubic zero error
if time_length < spec_width:
normalized_input_features = nn.functional.interpolate(
normalized_input_features, (spec_width, freq_length), mode="bicubic", align_corners=True
)
if freq_length < spec_heigth:
normalized_input_features = nn.functional.interpolate(
normalized_input_features, (time_length, spec_heigth), mode="bicubic", align_corners=True
)
batch, channels, time, freq = normalized_input_features.shape
# batch_size, channels, spec_width, spec_heigth --> batch_size, channels, spec_heigth * freq_ratio, spec_width // freq_ratio
normalized_input_features = normalized_input_features.reshape(
batch, channels * self.freq_ratio, time // self.freq_ratio, freq
)
normalized_input_features = normalized_input_features.permute(0, 1, 3, 2).contiguous()
normalized_input_features = normalized_input_features.reshape(
batch, channels, freq * self.freq_ratio, time // self.freq_ratio
)
return normalized_input_features
def forward(
self,
input_features,
is_longer: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
output_attentions: Optional[bool] = False,
output_hidden_states: Optional[bool] = False,
output_hidden_states_before_downsampling: Optional[bool] = False,
always_partition: Optional[bool] = False,
return_dict: Optional[bool] = True,
) -> Union[Tuple, ClapAudioModelOutput]:
input_features = input_features.transpose(1, 3)
normalized_input_features = self.batch_norm(input_features)
normalized_input_features = normalized_input_features.transpose(1, 3)
is_longer_list_idx = None
if self.enable_fusion:
is_longer_list = is_longer.to(input_features.device)
is_longer_list_idx = torch.where(is_longer_list == 1)[0]
hidden_states = self.reshape_mel2img(normalized_input_features)
frames_num = hidden_states.shape[2]
hidden_states = self.patch_embed(hidden_states, is_longer_list_idx)
all_hidden_states = () if output_hidden_states else None
all_reshaped_hidden_states = () if output_hidden_states else None
all_self_attentions = () if output_attentions else None
input_dimensions = self.input_resolutions[0]
if output_hidden_states:
batch_size, _, hidden_size = hidden_states.shape
# rearrange batch_size (height width) channels -> batch_size channel height width
reshaped_hidden_state = hidden_states.view(batch_size, *input_dimensions, hidden_size)
reshaped_hidden_state = reshaped_hidden_state.permute(0, 3, 1, 2)
all_hidden_states += (hidden_states,)
all_reshaped_hidden_states += (reshaped_hidden_state,)
for i, layer_module in enumerate(self.layers):
layer_head_mask = head_mask[i] if head_mask is not None else None
input_dimensions = self.input_resolutions[i]
if self.gradient_checkpointing and self.training:
layer_outputs = self._gradient_checkpointing_func(
layer_module.__call__, hidden_states, input_dimensions, layer_head_mask, output_attentions
)
else:
layer_outputs = layer_module(
hidden_states, input_dimensions, layer_head_mask, output_attentions, always_partition
)
hidden_states = layer_outputs[0]
hidden_states_before_downsampling = layer_outputs[1]
output_dimensions = layer_outputs[2]
input_dimensions = (output_dimensions[-2], output_dimensions[-1])
if output_hidden_states and output_hidden_states_before_downsampling:
batch_size, _, hidden_size = hidden_states_before_downsampling.shape
# rearrange batch_size (height width) channels -> batch_size channel height width
# here we use the original (not downsampled) height and width
reshaped_hidden_state = hidden_states_before_downsampling.view(
batch_size, *(output_dimensions[0], output_dimensions[1]), hidden_size
)
reshaped_hidden_state = reshaped_hidden_state.permute(0, 3, 1, 2)
all_hidden_states += (hidden_states_before_downsampling,)
all_reshaped_hidden_states += (reshaped_hidden_state,)
elif output_hidden_states and not output_hidden_states_before_downsampling:
batch_size, _, hidden_size = hidden_states.shape
# rearrange batch_size (height width) channels -> batch_size channel height width
reshaped_hidden_state = hidden_states.view(batch_size, *input_dimensions, hidden_size)
reshaped_hidden_state = reshaped_hidden_state.permute(0, 3, 1, 2)
all_hidden_states += (hidden_states,)
all_reshaped_hidden_states += (reshaped_hidden_state,)
if output_attentions:
all_self_attentions += layer_outputs[3:]
last_hidden_state = self.norm(hidden_states)
batch_size, _, n_channels = last_hidden_state.shape
freq_shape = frames_num // (2 ** (len(self.depths) - 1)) // self.patch_stride[0]
temporal_shape = frames_num // (2 ** (len(self.depths) - 1)) // self.patch_stride[1]
last_hidden_state = (
last_hidden_state.permute(0, 2, 1).contiguous().reshape(batch_size, n_channels, freq_shape, temporal_shape)
)
batch_size, n_channels, n_frequencies, n_temp = last_hidden_state.shape
# group 2D CNN
c_freq_bin = n_frequencies // self.freq_ratio
last_hidden_state = last_hidden_state.reshape(
batch_size, n_channels, n_frequencies // c_freq_bin, c_freq_bin, n_temp
)
last_hidden_state = (
last_hidden_state.permute(0, 1, 3, 2, 4).contiguous().reshape(batch_size, n_channels, c_freq_bin, -1)
)
latent_output = self.avgpool(torch.flatten(last_hidden_state, 2))
latent_output = torch.flatten(latent_output, 1)
if not return_dict:
return tuple(
v
for v in [
last_hidden_state,
latent_output,
all_reshaped_hidden_states,
all_self_attentions,
]
if v is not None
)
return BaseModelOutputWithPooling(
last_hidden_state=last_hidden_state,
pooler_output=latent_output,
hidden_states=all_reshaped_hidden_states,
attentions=all_self_attentions,
)
CLAP_START_DOCSTRING = r"""
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior.
Parameters:
config ([`ClapConfig`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
CLAP_TEXT_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
it.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
[What are position IDs?](../glossary#position-ids)
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
CLAP_AUDIO_INPUTS_DOCSTRING = r"""
Args:
input_features (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Input audio features. This should be returnes by the [`ClapFeatureExtractor`] class that you can also
retrieve from [`AutoFeatureExtractor`]. See [`ClapFeatureExtractor.__call__`] for details.
is_longer (`torch.FloatTensor`, of shape `(batch_size, 1)`, *optional*):
Whether the audio clip is longer than `max_length`. If `True`, a feature fusion will be enabled to enhance
the features.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
CLAP_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
it.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
[What are position IDs?](../glossary#position-ids)
input_features (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Input audio features. This should be returnes by the [`ClapFeatureExtractor`] class that you can also
retrieve from [`AutoFeatureExtractor`]. See [`ClapFeatureExtractor.__call__`] for details.
return_loss (`bool`, *optional*):
Whether or not to return the contrastive loss.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
class ClapProjectionLayer(nn.Module):
def __init__(self, config: Union[ClapAudioConfig, ClapTextConfig]):
super().__init__()
self.config = config
hidden_size = config.hidden_size
projection_dim = config.projection_dim
self.linear1 = nn.Linear(hidden_size, projection_dim)
self.activation = ACT2FN[config.projection_hidden_act]
self.linear2 = nn.Linear(projection_dim, projection_dim)
def forward(self, hidden_states):
hidden_states = self.linear1(hidden_states)
hidden_states = self.activation(hidden_states)
hidden_states = self.linear2(hidden_states)
return hidden_states
# Copied from transformers.models.roberta.modeling_roberta.RobertaEmbeddings with Roberta->ClapText, persistent=False->persistent=True
class ClapTextEmbeddings(nn.Module):
"""
Same as BertEmbeddings with a tiny tweak for positional embeddings indexing.
"""
# Copied from transformers.models.bert.modeling_bert.BertEmbeddings.__init__
def __init__(self, config):
super().__init__()
self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
self.token_type_embeddings = nn.Embedding(config.type_vocab_size, config.hidden_size)
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
# any TensorFlow checkpoint file
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
self.register_buffer(
"position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)), persistent=True
)
self.register_buffer(
"token_type_ids", torch.zeros(self.position_ids.size(), dtype=torch.long), persistent=True
)
# End copy
self.padding_idx = config.pad_token_id
self.position_embeddings = nn.Embedding(
config.max_position_embeddings, config.hidden_size, padding_idx=self.padding_idx
)
def forward(
self, input_ids=None, token_type_ids=None, position_ids=None, inputs_embeds=None, past_key_values_length=0
):
if position_ids is None:
if input_ids is not None:
# Create the position ids from the input token ids. Any padded tokens remain padded.
position_ids = create_position_ids_from_input_ids(input_ids, self.padding_idx, past_key_values_length)
else:
position_ids = self.create_position_ids_from_inputs_embeds(inputs_embeds)
if input_ids is not None:
input_shape = input_ids.size()
else:
input_shape = inputs_embeds.size()[:-1]
seq_length = input_shape[1]
# Setting the token_type_ids to the registered buffer in constructor where it is all zeros, which usually occurs
# when its auto-generated, registered buffer helps users when tracing the model without passing token_type_ids, solves
# issue #5664
if token_type_ids is None:
if hasattr(self, "token_type_ids"):
buffered_token_type_ids = self.token_type_ids[:, :seq_length]
buffered_token_type_ids_expanded = buffered_token_type_ids.expand(input_shape[0], seq_length)
token_type_ids = buffered_token_type_ids_expanded
else:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
if inputs_embeds is None:
inputs_embeds = self.word_embeddings(input_ids)
token_type_embeddings = self.token_type_embeddings(token_type_ids)
embeddings = inputs_embeds + token_type_embeddings
if self.position_embedding_type == "absolute":
position_embeddings = self.position_embeddings(position_ids)
embeddings += position_embeddings
embeddings = self.LayerNorm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
def create_position_ids_from_inputs_embeds(self, inputs_embeds):
"""
We are provided embeddings directly. We cannot infer which are padded so just generate sequential position ids.
Args:
inputs_embeds: torch.Tensor
Returns: torch.Tensor
"""
input_shape = inputs_embeds.size()[:-1]
sequence_length = input_shape[1]
position_ids = torch.arange(
self.padding_idx + 1, sequence_length + self.padding_idx + 1, dtype=torch.long, device=inputs_embeds.device
)
return position_ids.unsqueeze(0).expand(input_shape)
# Copied from transformers.models.bert.modeling_bert.BertSelfAttention with Bert->ClapText
class ClapTextSelfAttention(nn.Module):
def __init__(self, config, position_embedding_type=None):
super().__init__()
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
f"The hidden size ({config.hidden_size}) is not a multiple of the number of attention "
f"heads ({config.num_attention_heads})"
)
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size)
self.key = nn.Linear(config.hidden_size, self.all_head_size)
self.value = nn.Linear(config.hidden_size, self.all_head_size)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
self.position_embedding_type = position_embedding_type or getattr(
config, "position_embedding_type", "absolute"
)
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
self.max_position_embeddings = config.max_position_embeddings
self.distance_embedding = nn.Embedding(2 * config.max_position_embeddings - 1, self.attention_head_size)
self.is_decoder = config.is_decoder
def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
past_key_value: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
output_attentions: Optional[bool] = False,
) -> Tuple[torch.Tensor]:
mixed_query_layer = self.query(hidden_states)
# If this is instantiated as a cross-attention module, the keys
# and values come from an encoder; the attention mask needs to be
# such that the encoder's padding tokens are not attended to.
is_cross_attention = encoder_hidden_states is not None
if is_cross_attention and past_key_value is not None:
# reuse k,v, cross_attentions
key_layer = past_key_value[0]
value_layer = past_key_value[1]
attention_mask = encoder_attention_mask
elif is_cross_attention:
key_layer = self.transpose_for_scores(self.key(encoder_hidden_states))
value_layer = self.transpose_for_scores(self.value(encoder_hidden_states))
attention_mask = encoder_attention_mask
elif past_key_value is not None:
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
key_layer = torch.cat([past_key_value[0], key_layer], dim=2)
value_layer = torch.cat([past_key_value[1], value_layer], dim=2)
else:
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
query_layer = self.transpose_for_scores(mixed_query_layer)
use_cache = past_key_value is not None
if self.is_decoder:
# if cross_attention save Tuple(torch.Tensor, torch.Tensor) of all cross attention key/value_states.
# Further calls to cross_attention layer can then reuse all cross-attention
# key/value_states (first "if" case)
# if uni-directional self-attention (decoder) save Tuple(torch.Tensor, torch.Tensor) of
# all previous decoder key/value_states. Further calls to uni-directional self-attention
# can concat previous decoder key/value_states to current projected key/value_states (third "elif" case)
# if encoder bi-directional self-attention `past_key_value` is always `None`
past_key_value = (key_layer, value_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
query_length, key_length = query_layer.shape[2], key_layer.shape[2]
if use_cache:
position_ids_l = torch.tensor(key_length - 1, dtype=torch.long, device=hidden_states.device).view(
-1, 1
)
else:
position_ids_l = torch.arange(query_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
position_ids_r = torch.arange(key_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
distance = position_ids_l - position_ids_r
positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
if self.position_embedding_type == "relative_key":
relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores
elif self.position_embedding_type == "relative_key_query":
relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
attention_scores = attention_scores + relative_position_scores_query + relative_position_scores_key
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
if attention_mask is not None:
# Apply the attention mask is (precomputed for all layers in ClapTextModel forward() function)
attention_scores = attention_scores + attention_mask
# Normalize the attention scores to probabilities.
attention_probs = nn.functional.softmax(attention_scores, dim=-1)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
if self.is_decoder:
outputs = outputs + (past_key_value,)
return outputs
# Copied from transformers.models.bert.modeling_bert.BertSelfOutput
class ClapTextSelfOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
# Copied from transformers.models.bert.modeling_bert.BertAttention with Bert->ClapText
class ClapTextAttention(nn.Module):
def __init__(self, config, position_embedding_type=None):
super().__init__()
self.self = ClapTextSelfAttention(config, position_embedding_type=position_embedding_type)
self.output = ClapTextSelfOutput(config)
self.pruned_heads = set()
def prune_heads(self, heads):
if len(heads) == 0:
return
heads, index = find_pruneable_heads_and_indices(
heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads
)
# Prune linear layers
self.self.query = prune_linear_layer(self.self.query, index)
self.self.key = prune_linear_layer(self.self.key, index)
self.self.value = prune_linear_layer(self.self.value, index)
self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
# Update hyper params and store pruned heads
self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
self.pruned_heads = self.pruned_heads.union(heads)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
past_key_value: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
output_attentions: Optional[bool] = False,
) -> Tuple[torch.Tensor]:
self_outputs = self.self(
hidden_states,
attention_mask,
head_mask,
encoder_hidden_states,
encoder_attention_mask,
past_key_value,
output_attentions,
)
attention_output = self.output(self_outputs[0], hidden_states)
outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
return outputs
# Copied from transformers.models.bert.modeling_bert.BertIntermediate
class ClapTextIntermediate(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = ACT2FN[config.hidden_act]
else:
self.intermediate_act_fn = config.hidden_act
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
# Copied from transformers.models.bert.modeling_bert.BertOutput
class ClapTextOutput(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = self.LayerNorm(hidden_states + input_tensor)
return hidden_states
# Copied from transformers.models.bert.modeling_bert.BertLayer with Bert->ClapText
class ClapTextLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.chunk_size_feed_forward = config.chunk_size_feed_forward
self.seq_len_dim = 1
self.attention = ClapTextAttention(config)
self.is_decoder = config.is_decoder
self.add_cross_attention = config.add_cross_attention
if self.add_cross_attention:
if not self.is_decoder:
raise ValueError(f"{self} should be used as a decoder model if cross attention is added")
self.crossattention = ClapTextAttention(config, position_embedding_type="absolute")
self.intermediate = ClapTextIntermediate(config)
self.output = ClapTextOutput(config)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
past_key_value: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
output_attentions: Optional[bool] = False,
) -> Tuple[torch.Tensor]:
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
self_attention_outputs = self.attention(
hidden_states,
attention_mask,
head_mask,
output_attentions=output_attentions,
past_key_value=self_attn_past_key_value,
)
attention_output = self_attention_outputs[0]
# if decoder, the last output is tuple of self-attn cache
if self.is_decoder:
outputs = self_attention_outputs[1:-1]
present_key_value = self_attention_outputs[-1]
else:
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
cross_attn_present_key_value = None
if self.is_decoder and encoder_hidden_states is not None:
if not hasattr(self, "crossattention"):
raise ValueError(
f"If `encoder_hidden_states` are passed, {self} has to be instantiated with cross-attention layers"
" by setting `config.add_cross_attention=True`"
)
# cross_attn cached key/values tuple is at positions 3,4 of past_key_value tuple
cross_attn_past_key_value = past_key_value[-2:] if past_key_value is not None else None
cross_attention_outputs = self.crossattention(
attention_output,
attention_mask,
head_mask,
encoder_hidden_states,
encoder_attention_mask,
cross_attn_past_key_value,
output_attentions,
)
attention_output = cross_attention_outputs[0]
outputs = outputs + cross_attention_outputs[1:-1] # add cross attentions if we output attention weights
# add cross-attn cache to positions 3,4 of present_key_value tuple
cross_attn_present_key_value = cross_attention_outputs[-1]
present_key_value = present_key_value + cross_attn_present_key_value
layer_output = apply_chunking_to_forward(
self.feed_forward_chunk, self.chunk_size_feed_forward, self.seq_len_dim, attention_output
)
outputs = (layer_output,) + outputs
# if decoder, return the attn key/values as the last output
if self.is_decoder:
outputs = outputs + (present_key_value,)
return outputs
def feed_forward_chunk(self, attention_output):
intermediate_output = self.intermediate(attention_output)
layer_output = self.output(intermediate_output, attention_output)
return layer_output
# Copied from transformers.models.bert.modeling_bert.BertEncoder with Bert->ClapText
class ClapTextEncoder(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.layer = nn.ModuleList([ClapTextLayer(config) for _ in range(config.num_hidden_layers)])
self.gradient_checkpointing = False
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
past_key_values: Optional[Tuple[Tuple[torch.FloatTensor]]] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = False,
output_hidden_states: Optional[bool] = False,
return_dict: Optional[bool] = True,
) -> Union[Tuple[torch.Tensor], BaseModelOutputWithPastAndCrossAttentions]:
all_hidden_states = () if output_hidden_states else None
all_self_attentions = () if output_attentions else None
all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
if self.gradient_checkpointing and self.training:
if use_cache:
logger.warning_once(
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
)
use_cache = False
next_decoder_cache = () if use_cache else None
for i, layer_module in enumerate(self.layer):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
layer_head_mask = head_mask[i] if head_mask is not None else None
past_key_value = past_key_values[i] if past_key_values is not None else None
if self.gradient_checkpointing and self.training:
layer_outputs = self._gradient_checkpointing_func(
layer_module.__call__,
hidden_states,
attention_mask,
layer_head_mask,
encoder_hidden_states,
encoder_attention_mask,
past_key_value,
output_attentions,
)
else:
layer_outputs = layer_module(
hidden_states,
attention_mask,
layer_head_mask,
encoder_hidden_states,
encoder_attention_mask,
past_key_value,
output_attentions,
)
hidden_states = layer_outputs[0]
if use_cache:
next_decoder_cache += (layer_outputs[-1],)
if output_attentions:
all_self_attentions = all_self_attentions + (layer_outputs[1],)
if self.config.add_cross_attention:
all_cross_attentions = all_cross_attentions + (layer_outputs[2],)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(
v
for v in [
hidden_states,
next_decoder_cache,
all_hidden_states,
all_self_attentions,
all_cross_attentions,
]
if v is not None
)
return BaseModelOutputWithPastAndCrossAttentions(
last_hidden_state=hidden_states,
past_key_values=next_decoder_cache,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
cross_attentions=all_cross_attentions,
)
# Copied from transformers.models.bert.modeling_bert.BertPooler
class ClapTextPooler(nn.Module):
def __init__(self, config):
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.activation = nn.Tanh()
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
# We "pool" the model by simply taking the hidden state corresponding
# to the first token.
first_token_tensor = hidden_states[:, 0]
pooled_output = self.dense(first_token_tensor)
pooled_output = self.activation(pooled_output)
return pooled_output
class ClapPreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = ClapConfig
base_model_prefix = "clap"
supports_gradient_checkpointing = False
def _init_weights(self, module):
"""Initialize the weights"""
factor = self.config.initializer_factor
if isinstance(module, ClapTextEmbeddings):
module.position_embeddings.weight.data.normal_(mean=0.0, std=factor * 0.02)
module.token_type_embeddings.weight.data.normal_(mean=0.0, std=factor * 0.02)
elif isinstance(module, ClapModel):
nn.init.normal_(module.logit_scale_a, std=factor * 0.02)
nn.init.normal_(module.logit_scale_t, std=factor * 0.02)
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=factor * 0.02)
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
elif isinstance(module, (nn.Conv2d, nn.Linear)):
in_proj_std = (self.config.hidden_size**-0.5) * ((2 * self.config.num_hidden_layers) ** -0.5) * factor
nn.init.normal_(module.weight, std=in_proj_std)
if module.bias is not None:
module.bias.data.zero_()
class ClapAudioModel(ClapPreTrainedModel):
config_class = ClapAudioConfig
main_input_name = "input_features"
def __init__(self, config: ClapAudioConfig):
super().__init__(config)
self.audio_encoder = ClapAudioEncoder(config)
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self) -> nn.Module:
return self.audio_encoder.patch_embed.proj
@add_start_docstrings_to_model_forward(CLAP_AUDIO_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=ClapAudioConfig)
def forward(
self,
input_features: Optional[torch.FloatTensor] = None,
is_longer: Optional[torch.BoolTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseModelOutputWithPooling]:
r"""
Returns:
Examples:
```python
>>> from datasets import load_dataset
>>> from transformers import AutoProcessor, ClapAudioModel
>>> dataset = load_dataset("ashraq/esc50")
>>> audio_sample = dataset["train"]["audio"][0]["array"]
>>> model = ClapAudioModel.from_pretrained("laion/clap-htsat-fused")
>>> processor = AutoProcessor.from_pretrained("laion/clap-htsat-fused")
>>> inputs = processor(audios=audio_sample, return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_state = outputs.last_hidden_state
```"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return self.audio_encoder(
input_features=input_features,
is_longer=is_longer,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
class ClapTextModel(ClapPreTrainedModel):
"""
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
cross-attention is added between the self-attention layers, following the architecture described in *Attention is
all you need*_ by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz
Kaiser and Illia Polosukhin.
To behave as an decoder the model needs to be initialized with the `is_decoder` argument of the configuration set
to `True`. To be used in a Seq2Seq model, the model needs to initialized with both `is_decoder` argument and
`add_cross_attention` set to `True`; an `encoder_hidden_states` is then expected as an input to the forward pass.
.. _*Attention is all you need*: https://arxiv.org/abs/1706.03762
"""
config_class = ClapTextConfig
# Copied from transformers.models.bert.modeling_bert.BertModel.__init__ with Bert->ClapText
def __init__(self, config, add_pooling_layer=True):
super().__init__(config)
self.config = config
self.embeddings = ClapTextEmbeddings(config)
self.encoder = ClapTextEncoder(config)
self.pooler = ClapTextPooler(config) if add_pooling_layer else None
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
return self.embeddings.word_embeddings
def set_input_embeddings(self, value):
self.embeddings.word_embeddings = value
# Copied from transformers.models.bert.modeling_bert.BertModel.forward
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
token_type_ids: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor], BaseModelOutputWithPoolingAndCrossAttentions]:
r"""
encoder_hidden_states (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
the model is configured as a decoder.
encoder_attention_mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
the cross-attention if the model is configured as a decoder. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
past_key_values (`tuple(tuple(torch.FloatTensor))` of length `config.n_layers` with each tuple having 4 tensors of shape `(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
`decoder_input_ids` of shape `(batch_size, sequence_length)`.
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
`past_key_values`).
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if self.config.is_decoder:
use_cache = use_cache if use_cache is not None else self.config.use_cache
else:
use_cache = False
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
self.warn_if_padding_and_no_attention_mask(input_ids, attention_mask)
input_shape = input_ids.size()
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
batch_size, seq_length = input_shape
device = input_ids.device if input_ids is not None else inputs_embeds.device
# past_key_values_length
past_key_values_length = past_key_values[0][0].shape[2] if past_key_values is not None else 0
if attention_mask is None:
attention_mask = torch.ones(((batch_size, seq_length + past_key_values_length)), device=device)
if token_type_ids is None:
if hasattr(self.embeddings, "token_type_ids"):
buffered_token_type_ids = self.embeddings.token_type_ids[:, :seq_length]
buffered_token_type_ids_expanded = buffered_token_type_ids.expand(batch_size, seq_length)
token_type_ids = buffered_token_type_ids_expanded
else:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
# ourselves in which case we just need to make it broadcastable to all heads.
extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape)
# If a 2D or 3D attention mask is provided for the cross-attention
# we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
if self.config.is_decoder and encoder_hidden_states is not None:
encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
if encoder_attention_mask is None:
encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)
else:
encoder_extended_attention_mask = None
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
embedding_output = self.embeddings(
input_ids=input_ids,
position_ids=position_ids,
token_type_ids=token_type_ids,
inputs_embeds=inputs_embeds,
past_key_values_length=past_key_values_length,
)
encoder_outputs = self.encoder(
embedding_output,
attention_mask=extended_attention_mask,
head_mask=head_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_extended_attention_mask,
past_key_values=past_key_values,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = encoder_outputs[0]
pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
if not return_dict:
return (sequence_output, pooled_output) + encoder_outputs[1:]
return BaseModelOutputWithPoolingAndCrossAttentions(
last_hidden_state=sequence_output,
pooler_output=pooled_output,
past_key_values=encoder_outputs.past_key_values,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
cross_attentions=encoder_outputs.cross_attentions,
)
@add_start_docstrings(CLAP_START_DOCSTRING)
class ClapModel(ClapPreTrainedModel):
config_class = ClapConfig
def __init__(self, config: ClapConfig):
super().__init__(config)
if not isinstance(config.text_config, ClapTextConfig):
raise ValueError(
"config.text_config is expected to be of type ClapTextConfig but is of type"
f" {type(config.text_config)}."
)
if not isinstance(config.audio_config, ClapAudioConfig):
raise ValueError(
"config.audio_config is expected to be of type ClapAudioConfig but is of type"
f" {type(config.audio_config)}."
)
text_config = config.text_config
audio_config = config.audio_config
self.logit_scale_a = nn.Parameter(torch.tensor(math.log(config.logit_scale_init_value)))
self.logit_scale_t = nn.Parameter(torch.tensor(math.log(config.logit_scale_init_value)))
self.projection_dim = config.projection_dim
self.text_model = ClapTextModel(text_config)
self.text_projection = ClapProjectionLayer(text_config)
self.audio_model = ClapAudioModel(audio_config)
self.audio_projection = ClapProjectionLayer(audio_config)
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(CLAP_TEXT_INPUTS_DOCSTRING)
def get_text_features(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> torch.FloatTensor:
r"""
Returns:
text_features (`torch.FloatTensor` of shape `(batch_size, output_dim`): The text embeddings obtained by
applying the projection layer to the pooled output of [`ClapTextModel`].
Examples:
```python
>>> from transformers import AutoTokenizer, ClapModel
>>> model = ClapModel.from_pretrained("laion/clap-htsat-unfused")
>>> tokenizer = AutoTokenizer.from_pretrained("laion/clap-htsat-unfused")
>>> inputs = tokenizer(["the sound of a cat", "the sound of a dog"], padding=True, return_tensors="pt")
>>> text_features = model.get_text_features(**inputs)
```"""
# Use CLAP model's config for some fields (if specified) instead of those of audio & text components.
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
text_outputs = self.text_model(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
pooled_output = text_outputs[1] if return_dict is not None else text_outputs.pooler_output
text_features = self.text_projection(pooled_output)
text_features = F.normalize(text_features, dim=-1)
return text_features
@add_start_docstrings_to_model_forward(CLAP_AUDIO_INPUTS_DOCSTRING)
def get_audio_features(
self,
input_features: Optional[torch.Tensor] = None,
is_longer: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> torch.FloatTensor:
r"""
Returns:
audio_features (`torch.FloatTensor` of shape `(batch_size, output_dim`): The audio embeddings obtained by
applying the projection layer to the pooled output of [`ClapAudioModel`].
Examples:
```python
>>> from transformers import AutoFeatureExtractor, ClapModel
>>> import torch
>>> model = ClapModel.from_pretrained("laion/clap-htsat-unfused")
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("laion/clap-htsat-unfused")
>>> random_audio = torch.rand((16_000))
>>> inputs = feature_extractor(random_audio, return_tensors="pt")
>>> audio_features = model.get_audio_features(**inputs)
```"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
audio_outputs = self.audio_model(
input_features=input_features,
is_longer=is_longer,
return_dict=return_dict,
)
pooled_output = audio_outputs[1] if not return_dict else audio_outputs.pooler_output
audio_features = self.audio_projection(pooled_output)
audio_features = F.normalize(audio_features, dim=-1)
return audio_features
@add_start_docstrings_to_model_forward(CLAP_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=ClapOutput, config_class=ClapConfig)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
input_features: Optional[torch.FloatTensor] = None,
is_longer: Optional[torch.BoolTensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
return_loss: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, ClapOutput]:
r"""
Returns:
Examples:
```python
>>> from datasets import load_dataset
>>> from transformers import AutoProcessor, ClapModel
>>> dataset = load_dataset("ashraq/esc50")
>>> audio_sample = dataset["train"]["audio"][0]["array"]
>>> model = ClapModel.from_pretrained("laion/clap-htsat-unfused")
>>> processor = AutoProcessor.from_pretrained("laion/clap-htsat-unfused")
>>> input_text = ["Sound of a dog", "Sound of vaccum cleaner"]
>>> inputs = processor(text=input_text, audios=audio_sample, return_tensors="pt", padding=True)
>>> outputs = model(**inputs)
>>> logits_per_audio = outputs.logits_per_audio # this is the audio-text similarity score
>>> probs = logits_per_audio.softmax(dim=-1) # we can take the softmax to get the label probabilities
```"""
# Use CLAP model's config for some fields (if specified) instead of those of audio & text components.
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
audio_outputs = self.audio_model(
input_features=input_features,
is_longer=is_longer,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
text_outputs = self.text_model(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
audio_embeds = audio_outputs[1] if not return_dict else audio_outputs.pooler_output
audio_embeds = self.audio_projection(audio_embeds)
text_embeds = text_outputs[1] if not return_dict else text_outputs.pooler_output
text_embeds = self.text_projection(text_embeds)
# normalized features
audio_embeds = audio_embeds / audio_embeds.norm(p=2, dim=-1, keepdim=True)
text_embeds = text_embeds / text_embeds.norm(p=2, dim=-1, keepdim=True)
# cosine similarity as logits
logit_scale_text = self.logit_scale_t.exp()
logit_scale_audio = self.logit_scale_a.exp()
logits_per_text = torch.matmul(text_embeds, audio_embeds.t()) * logit_scale_text
logits_per_audio = torch.matmul(audio_embeds, text_embeds.t()) * logit_scale_audio
loss = None
if return_loss:
caption_loss = contrastive_loss(logits_per_text)
audio_loss = contrastive_loss(logits_per_audio.t())
loss = (caption_loss + audio_loss) / 2.0
if not return_dict:
output = (logits_per_audio, logits_per_text, text_embeds, audio_embeds, text_outputs, audio_outputs)
return ((loss,) + output) if loss is not None else output
return ClapOutput(
loss=loss,
logits_per_audio=logits_per_audio,
logits_per_text=logits_per_text,
text_embeds=text_embeds,
audio_embeds=audio_embeds,
text_model_output=text_outputs,
audio_model_output=audio_outputs,
)
@add_start_docstrings(
"""
CLAP Text Model with a projection layer on top (a linear layer on top of the pooled output).
""",
CLAP_START_DOCSTRING,
)
class ClapTextModelWithProjection(ClapPreTrainedModel):
config_class = ClapTextConfig
def __init__(self, config: ClapTextConfig):
super().__init__(config)
self.text_model = ClapTextModel(config)
self.text_projection = ClapProjectionLayer(config)
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self) -> nn.Module:
return self.text_model.embeddings.word_embeddings
def set_input_embeddings(self, value):
self.text_model.embeddings.word_embeddings = value
@add_start_docstrings_to_model_forward(CLAP_TEXT_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=ClapTextModelOutput, config_class=ClapTextConfig)
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, ClapTextModelOutput]:
r"""
Returns:
Examples:
```python
>>> from transformers import AutoTokenizer, ClapTextModelWithProjection
>>> model = ClapTextModelWithProjection.from_pretrained("laion/clap-htsat-unfused")
>>> tokenizer = AutoTokenizer.from_pretrained("laion/clap-htsat-unfused")
>>> inputs = tokenizer(["a sound of a cat", "a sound of a dog"], padding=True, return_tensors="pt")
>>> outputs = model(**inputs)
>>> text_embeds = outputs.text_embeds
```"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
text_outputs = self.text_model(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
pooled_output = text_outputs[1] if not return_dict else text_outputs.pooler_output
text_embeds = self.text_projection(pooled_output)
if not return_dict:
outputs = (text_embeds, text_outputs[0]) + text_outputs[2:]
return tuple(output for output in outputs if output is not None)
return ClapTextModelOutput(
text_embeds=text_embeds,
last_hidden_state=text_outputs.last_hidden_state,
hidden_states=text_outputs.hidden_states,
attentions=text_outputs.attentions,
)
@add_start_docstrings(
"""
CLAP Audio Model with a projection layer on top (a linear layer on top of the pooled output).
""",
CLAP_START_DOCSTRING,
)
class ClapAudioModelWithProjection(ClapPreTrainedModel):
config_class = ClapAudioConfig
main_input_name = "input_features"
def __init__(self, config: ClapAudioConfig):
super().__init__(config)
self.audio_model = ClapAudioModel(config)
self.audio_projection = ClapProjectionLayer(config)
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self) -> nn.Module:
return self.audio_model.audio_encoder.patch_embed.proj
@add_start_docstrings_to_model_forward(CLAP_AUDIO_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=ClapAudioModelOutput, config_class=ClapAudioConfig)
def forward(
self,
input_features: Optional[torch.FloatTensor] = None,
is_longer: Optional[torch.BoolTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, ClapAudioModelOutput]:
r"""
Returns:
Examples:
```python
>>> from datasets import load_dataset
>>> from transformers import ClapAudioModelWithProjection, ClapProcessor
>>> model = ClapAudioModelWithProjection.from_pretrained("laion/clap-htsat-fused")
>>> processor = ClapProcessor.from_pretrained("laion/clap-htsat-fused")
>>> dataset = load_dataset("ashraq/esc50")
>>> audio_sample = dataset["train"]["audio"][0]["array"]
>>> inputs = processor(audios=audio_sample, return_tensors="pt")
>>> outputs = model(**inputs)
>>> audio_embeds = outputs.audio_embeds
```"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
audio_outputs = self.audio_model(
input_features=input_features,
is_longer=is_longer,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
pooled_output = audio_outputs[1] if not return_dict else audio_outputs.pooler_output
audio_embeds = self.audio_projection(pooled_output)
if not return_dict:
outputs = (audio_embeds, audio_outputs[0]) + audio_outputs[2:]
return tuple(output for output in outputs if output is not None)
return ClapAudioModelOutput(
audio_embeds=audio_embeds,
last_hidden_state=audio_outputs.last_hidden_state,
attentions=audio_outputs.attentions,
hidden_states=audio_outputs.hidden_states,
)
| transformers/src/transformers/models/clap/modeling_clap.py/0 | {
"file_path": "transformers/src/transformers/models/clap/modeling_clap.py",
"repo_id": "transformers",
"token_count": 44304
} | 297 |
# coding=utf-8
# Copyright 2022 The OpenAI Team Authors and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" PyTorch CLIPSeg model."""
import copy
import math
from dataclasses import dataclass
from typing import Any, Optional, Tuple, Union
import torch
import torch.utils.checkpoint
from torch import nn
from ...activations import ACT2FN
from ...modeling_attn_mask_utils import _create_4d_causal_attention_mask, _prepare_4d_attention_mask
from ...modeling_outputs import BaseModelOutput, BaseModelOutputWithPooling
from ...modeling_utils import PreTrainedModel
from ...utils import (
ModelOutput,
add_start_docstrings,
add_start_docstrings_to_model_forward,
logging,
replace_return_docstrings,
)
from .configuration_clipseg import CLIPSegConfig, CLIPSegTextConfig, CLIPSegVisionConfig
logger = logging.get_logger(__name__)
_CHECKPOINT_FOR_DOC = "CIDAS/clipseg-rd64-refined"
CLIPSEG_PRETRAINED_MODEL_ARCHIVE_LIST = [
"CIDAS/clipseg-rd64-refined",
# See all CLIPSeg models at https://huggingface.co/models?filter=clipseg
]
# contrastive loss function, adapted from
# https://sachinruk.github.io/blog/pytorch/pytorch%20lightning/loss%20function/gpu/2021/03/07/CLIP.html
def contrastive_loss(logits: torch.Tensor) -> torch.Tensor:
return nn.functional.cross_entropy(logits, torch.arange(len(logits), device=logits.device))
# Copied from transformers.models.clip.modeling_clip.clip_loss with clip->clipseg
def clipseg_loss(similarity: torch.Tensor) -> torch.Tensor:
caption_loss = contrastive_loss(similarity)
image_loss = contrastive_loss(similarity.t())
return (caption_loss + image_loss) / 2.0
@dataclass
# Copied from transformers.models.clip.modeling_clip.CLIPOutput with CLIP->CLIPSeg
class CLIPSegOutput(ModelOutput):
"""
Args:
loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `return_loss` is `True`):
Contrastive loss for image-text similarity.
logits_per_image:(`torch.FloatTensor` of shape `(image_batch_size, text_batch_size)`):
The scaled dot product scores between `image_embeds` and `text_embeds`. This represents the image-text
similarity scores.
logits_per_text:(`torch.FloatTensor` of shape `(text_batch_size, image_batch_size)`):
The scaled dot product scores between `text_embeds` and `image_embeds`. This represents the text-image
similarity scores.
text_embeds(`torch.FloatTensor` of shape `(batch_size, output_dim`):
The text embeddings obtained by applying the projection layer to the pooled output of [`CLIPSegTextModel`].
image_embeds(`torch.FloatTensor` of shape `(batch_size, output_dim`):
The image embeddings obtained by applying the projection layer to the pooled output of [`CLIPSegVisionModel`].
text_model_output(`BaseModelOutputWithPooling`):
The output of the [`CLIPSegTextModel`].
vision_model_output(`BaseModelOutputWithPooling`):
The output of the [`CLIPSegVisionModel`].
"""
loss: Optional[torch.FloatTensor] = None
logits_per_image: torch.FloatTensor = None
logits_per_text: torch.FloatTensor = None
text_embeds: torch.FloatTensor = None
image_embeds: torch.FloatTensor = None
text_model_output: BaseModelOutputWithPooling = None
vision_model_output: BaseModelOutputWithPooling = None
def to_tuple(self) -> Tuple[Any]:
return tuple(
self[k] if k not in ["text_model_output", "vision_model_output"] else getattr(self, k).to_tuple()
for k in self.keys()
)
@dataclass
class CLIPSegDecoderOutput(ModelOutput):
"""
Args:
logits (`torch.FloatTensor` of shape `(batch_size, height, width)`):
Classification scores for each pixel.
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`. Attentions weights after the attention softmax, used to compute the weighted average in
the self-attention heads.
"""
logits: torch.FloatTensor = None
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
attentions: Optional[Tuple[torch.FloatTensor]] = None
@dataclass
class CLIPSegImageSegmentationOutput(ModelOutput):
"""
Args:
loss (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `return_loss` is `True`):
Contrastive loss for image-text similarity.
...
vision_model_output (`BaseModelOutputWithPooling`):
The output of the [`CLIPSegVisionModel`].
"""
loss: Optional[torch.FloatTensor] = None
logits: torch.FloatTensor = None
conditional_embeddings: torch.FloatTensor = None
pooled_output: torch.FloatTensor = None
vision_model_output: BaseModelOutputWithPooling = None
decoder_output: CLIPSegDecoderOutput = None
def to_tuple(self) -> Tuple[Any]:
return tuple(
self[k] if k not in ["vision_model_output", "decoder_output"] else getattr(self, k).to_tuple()
for k in self.keys()
)
class CLIPSegVisionEmbeddings(nn.Module):
# Copied from transformers.models.clip.modeling_clip.CLIPVisionEmbeddings.__init__ with CLIP->CLIPSeg
def __init__(self, config: CLIPSegVisionConfig):
super().__init__()
self.config = config
self.embed_dim = config.hidden_size
self.image_size = config.image_size
self.patch_size = config.patch_size
self.class_embedding = nn.Parameter(torch.randn(self.embed_dim))
self.patch_embedding = nn.Conv2d(
in_channels=config.num_channels,
out_channels=self.embed_dim,
kernel_size=self.patch_size,
stride=self.patch_size,
bias=False,
)
self.num_patches = (self.image_size // self.patch_size) ** 2
self.num_positions = self.num_patches + 1
self.position_embedding = nn.Embedding(self.num_positions, self.embed_dim)
self.register_buffer("position_ids", torch.arange(self.num_positions).expand((1, -1)), persistent=False)
def interpolate_position_embeddings(self, new_size):
if len(new_size) != 2:
raise ValueError("new_size should consist of 2 values")
num_patches_one_direction = int(self.num_patches**0.5)
# we interpolate the position embeddings in 2D
a = self.position_embedding.weight[1:].T.view(
1, self.config.hidden_size, num_patches_one_direction, num_patches_one_direction
)
b = (
nn.functional.interpolate(a, new_size, mode="bicubic", align_corners=False)
.squeeze(0)
.view(self.config.hidden_size, new_size[0] * new_size[1])
.T
)
result = torch.cat([self.position_embedding.weight[:1], b])
return result
def forward(self, pixel_values: torch.FloatTensor) -> torch.Tensor:
batch_size = pixel_values.shape[0]
patch_embeds = self.patch_embedding(pixel_values) # shape = [*, width, grid, grid]
patch_embeds = patch_embeds.flatten(2).transpose(1, 2)
class_embeds = self.class_embedding.expand(batch_size, 1, -1)
embeddings = torch.cat([class_embeds, patch_embeds], dim=1)
if embeddings.shape[1] != self.num_positions:
new_shape = int(math.sqrt(embeddings.shape[1] - 1))
embeddings = embeddings + self.interpolate_position_embeddings((new_shape, new_shape))
embeddings = embeddings.to(embeddings.dtype)
else:
embeddings = embeddings + self.position_embedding(self.position_ids)
return embeddings
# Copied from transformers.models.clip.modeling_clip.CLIPTextEmbeddings with CLIP->CLIPSeg
class CLIPSegTextEmbeddings(nn.Module):
def __init__(self, config: CLIPSegTextConfig):
super().__init__()
embed_dim = config.hidden_size
self.token_embedding = nn.Embedding(config.vocab_size, embed_dim)
self.position_embedding = nn.Embedding(config.max_position_embeddings, embed_dim)
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
self.register_buffer(
"position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)), persistent=False
)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
position_ids: Optional[torch.LongTensor] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
) -> torch.Tensor:
seq_length = input_ids.shape[-1] if input_ids is not None else inputs_embeds.shape[-2]
if position_ids is None:
position_ids = self.position_ids[:, :seq_length]
if inputs_embeds is None:
inputs_embeds = self.token_embedding(input_ids)
position_embeddings = self.position_embedding(position_ids)
embeddings = inputs_embeds + position_embeddings
return embeddings
# Copied from transformers.models.clip.modeling_clip.CLIPAttention with CLIP->CLIPSeg
class CLIPSegAttention(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
def __init__(self, config):
super().__init__()
self.config = config
self.embed_dim = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = self.embed_dim // self.num_heads
if self.head_dim * self.num_heads != self.embed_dim:
raise ValueError(
f"embed_dim must be divisible by num_heads (got `embed_dim`: {self.embed_dim} and `num_heads`:"
f" {self.num_heads})."
)
self.scale = self.head_dim**-0.5
self.dropout = config.attention_dropout
self.k_proj = nn.Linear(self.embed_dim, self.embed_dim)
self.v_proj = nn.Linear(self.embed_dim, self.embed_dim)
self.q_proj = nn.Linear(self.embed_dim, self.embed_dim)
self.out_proj = nn.Linear(self.embed_dim, self.embed_dim)
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
causal_attention_mask: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = False,
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
"""Input shape: Batch x Time x Channel"""
bsz, tgt_len, embed_dim = hidden_states.size()
# get query proj
query_states = self.q_proj(hidden_states) * self.scale
key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
proj_shape = (bsz * self.num_heads, -1, self.head_dim)
query_states = self._shape(query_states, tgt_len, bsz).view(*proj_shape)
key_states = key_states.view(*proj_shape)
value_states = value_states.view(*proj_shape)
src_len = key_states.size(1)
attn_weights = torch.bmm(query_states, key_states.transpose(1, 2))
if attn_weights.size() != (bsz * self.num_heads, tgt_len, src_len):
raise ValueError(
f"Attention weights should be of size {(bsz * self.num_heads, tgt_len, src_len)}, but is"
f" {attn_weights.size()}"
)
# apply the causal_attention_mask first
if causal_attention_mask is not None:
if causal_attention_mask.size() != (bsz, 1, tgt_len, src_len):
raise ValueError(
f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is"
f" {causal_attention_mask.size()}"
)
attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + causal_attention_mask
attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
if attention_mask is not None:
if attention_mask.size() != (bsz, 1, tgt_len, src_len):
raise ValueError(
f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}"
)
attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + attention_mask
attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
if output_attentions:
# this operation is a bit akward, but it's required to
# make sure that attn_weights keeps its gradient.
# In order to do so, attn_weights have to reshaped
# twice and have to be reused in the following
attn_weights_reshaped = attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
attn_weights = attn_weights_reshaped.view(bsz * self.num_heads, tgt_len, src_len)
else:
attn_weights_reshaped = None
attn_probs = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
attn_output = torch.bmm(attn_probs, value_states)
if attn_output.size() != (bsz * self.num_heads, tgt_len, self.head_dim):
raise ValueError(
f"`attn_output` should be of size {(bsz, self.num_heads, tgt_len, self.head_dim)}, but is"
f" {attn_output.size()}"
)
attn_output = attn_output.view(bsz, self.num_heads, tgt_len, self.head_dim)
attn_output = attn_output.transpose(1, 2)
attn_output = attn_output.reshape(bsz, tgt_len, embed_dim)
attn_output = self.out_proj(attn_output)
return attn_output, attn_weights_reshaped
# Copied from transformers.models.clip.modeling_clip.CLIPMLP with CLIP->CLIPSeg
class CLIPSegMLP(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.activation_fn = ACT2FN[config.hidden_act]
self.fc1 = nn.Linear(config.hidden_size, config.intermediate_size)
self.fc2 = nn.Linear(config.intermediate_size, config.hidden_size)
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
hidden_states = self.fc1(hidden_states)
hidden_states = self.activation_fn(hidden_states)
hidden_states = self.fc2(hidden_states)
return hidden_states
# Copied from transformers.models.clip.modeling_clip.CLIPEncoderLayer with CLIP->CLIPSeg
class CLIPSegEncoderLayer(nn.Module):
def __init__(self, config: CLIPSegConfig):
super().__init__()
self.embed_dim = config.hidden_size
self.self_attn = CLIPSegAttention(config)
self.layer_norm1 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
self.mlp = CLIPSegMLP(config)
self.layer_norm2 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: torch.Tensor,
causal_attention_mask: torch.Tensor,
output_attentions: Optional[bool] = False,
) -> Tuple[torch.FloatTensor]:
"""
Args:
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
attention_mask (`torch.FloatTensor`): attention mask of size
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
`(config.encoder_attention_heads,)`.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
"""
residual = hidden_states
hidden_states = self.layer_norm1(hidden_states)
hidden_states, attn_weights = self.self_attn(
hidden_states=hidden_states,
attention_mask=attention_mask,
causal_attention_mask=causal_attention_mask,
output_attentions=output_attentions,
)
hidden_states = residual + hidden_states
residual = hidden_states
hidden_states = self.layer_norm2(hidden_states)
hidden_states = self.mlp(hidden_states)
hidden_states = residual + hidden_states
outputs = (hidden_states,)
if output_attentions:
outputs += (attn_weights,)
return outputs
class CLIPSegPreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = CLIPSegConfig
base_model_prefix = "clip"
supports_gradient_checkpointing = True
def _init_weights(self, module):
"""Initialize the weights"""
factor = self.config.initializer_factor
if isinstance(module, CLIPSegTextEmbeddings):
module.token_embedding.weight.data.normal_(mean=0.0, std=factor * 0.02)
module.position_embedding.weight.data.normal_(mean=0.0, std=factor * 0.02)
elif isinstance(module, CLIPSegVisionEmbeddings):
factor = self.config.initializer_factor
nn.init.normal_(module.class_embedding, mean=0.0, std=module.embed_dim**-0.5 * factor)
nn.init.normal_(module.patch_embedding.weight, std=module.config.initializer_range * factor)
nn.init.normal_(module.position_embedding.weight, std=module.config.initializer_range * factor)
elif isinstance(module, CLIPSegAttention):
factor = self.config.initializer_factor
in_proj_std = (module.embed_dim**-0.5) * ((2 * module.config.num_hidden_layers) ** -0.5) * factor
out_proj_std = (module.embed_dim**-0.5) * factor
nn.init.normal_(module.q_proj.weight, std=in_proj_std)
nn.init.normal_(module.k_proj.weight, std=in_proj_std)
nn.init.normal_(module.v_proj.weight, std=in_proj_std)
nn.init.normal_(module.out_proj.weight, std=out_proj_std)
elif isinstance(module, CLIPSegMLP):
factor = self.config.initializer_factor
in_proj_std = (module.config.hidden_size**-0.5) * ((2 * module.config.num_hidden_layers) ** -0.5) * factor
fc_std = (2 * module.config.hidden_size) ** -0.5 * factor
nn.init.normal_(module.fc1.weight, std=fc_std)
nn.init.normal_(module.fc2.weight, std=in_proj_std)
elif isinstance(module, CLIPSegModel):
nn.init.normal_(
module.text_projection.weight,
std=module.text_embed_dim**-0.5 * self.config.initializer_factor,
)
nn.init.normal_(
module.visual_projection.weight,
std=module.vision_embed_dim**-0.5 * self.config.initializer_factor,
)
if isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
if isinstance(module, nn.Linear) and module.bias is not None:
module.bias.data.zero_()
CLIPSEG_START_DOCSTRING = r"""
This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
Parameters:
config ([`CLIPSegConfig`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
CLIPSEG_TEXT_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
it.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
[What are position IDs?](../glossary#position-ids)
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
CLIPSEG_VISION_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
[`AutoImageProcessor`]. See [`CLIPImageProcessor.__call__`] for details.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
CLIPSEG_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
it.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
config.max_position_embeddings - 1]`.
[What are position IDs?](../glossary#position-ids)
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Padding will be ignored by default should you provide it. Pixel values can be obtained using
[`AutoImageProcessor`]. See [`CLIPImageProcessor.__call__`] for details.
return_loss (`bool`, *optional*):
Whether or not to return the contrastive loss.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
# Copied from transformers.models.clip.modeling_clip.CLIPEncoder with CLIP->CLIPSeg
class CLIPSegEncoder(nn.Module):
"""
Transformer encoder consisting of `config.num_hidden_layers` self attention layers. Each layer is a
[`CLIPSegEncoderLayer`].
Args:
config: CLIPSegConfig
"""
def __init__(self, config: CLIPSegConfig):
super().__init__()
self.config = config
self.layers = nn.ModuleList([CLIPSegEncoderLayer(config) for _ in range(config.num_hidden_layers)])
self.gradient_checkpointing = False
def forward(
self,
inputs_embeds,
attention_mask: Optional[torch.Tensor] = None,
causal_attention_mask: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseModelOutput]:
r"""
Args:
inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation.
This is useful if you want more control over how to convert `input_ids` indices into associated vectors
than the model's internal embedding lookup matrix.
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
causal_attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Causal mask for the text model. Mask values selected in `[0, 1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
encoder_states = () if output_hidden_states else None
all_attentions = () if output_attentions else None
hidden_states = inputs_embeds
for idx, encoder_layer in enumerate(self.layers):
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
if self.gradient_checkpointing and self.training:
layer_outputs = self._gradient_checkpointing_func(
encoder_layer.__call__,
hidden_states,
attention_mask,
causal_attention_mask,
output_attentions,
)
else:
layer_outputs = encoder_layer(
hidden_states,
attention_mask,
causal_attention_mask,
output_attentions=output_attentions,
)
hidden_states = layer_outputs[0]
if output_attentions:
all_attentions = all_attentions + (layer_outputs[1],)
if output_hidden_states:
encoder_states = encoder_states + (hidden_states,)
if not return_dict:
return tuple(v for v in [hidden_states, encoder_states, all_attentions] if v is not None)
return BaseModelOutput(
last_hidden_state=hidden_states, hidden_states=encoder_states, attentions=all_attentions
)
class CLIPSegTextTransformer(nn.Module):
# Copied from transformers.models.clip.modeling_clip.CLIPTextTransformer.__init__ with CLIP->CLIPSeg
def __init__(self, config: CLIPSegTextConfig):
super().__init__()
self.config = config
embed_dim = config.hidden_size
self.embeddings = CLIPSegTextEmbeddings(config)
self.encoder = CLIPSegEncoder(config)
self.final_layer_norm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
# For `pooled_output` computation
self.eos_token_id = config.eos_token_id
@add_start_docstrings_to_model_forward(CLIPSEG_TEXT_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=CLIPSegTextConfig)
# Copied from transformers.models.clip.modeling_clip.CLIPTextTransformer.forward with clip->clipseg, CLIP->CLIPSeg
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseModelOutputWithPooling]:
r"""
Returns:
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if input_ids is None:
raise ValueError("You have to specify input_ids")
input_shape = input_ids.size()
input_ids = input_ids.view(-1, input_shape[-1])
hidden_states = self.embeddings(input_ids=input_ids, position_ids=position_ids)
# CLIPSeg's text model uses causal mask, prepare it here.
# https://github.com/openai/CLIPSeg/blob/cfcffb90e69f37bf2ff1e988237a0fbe41f33c04/clipseg/model.py#L324
causal_attention_mask = _create_4d_causal_attention_mask(
input_shape, hidden_states.dtype, device=hidden_states.device
)
# expand attention_mask
if attention_mask is not None:
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
attention_mask = _prepare_4d_attention_mask(attention_mask, hidden_states.dtype)
encoder_outputs = self.encoder(
inputs_embeds=hidden_states,
attention_mask=attention_mask,
causal_attention_mask=causal_attention_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
last_hidden_state = encoder_outputs[0]
last_hidden_state = self.final_layer_norm(last_hidden_state)
if self.eos_token_id == 2:
# The `eos_token_id` was incorrect before PR #24773: Let's keep what have been done here.
# A CLIPSeg model with such `eos_token_id` in the config can't work correctly with extra new tokens added
# ------------------------------------------------------------
# text_embeds.shape = [batch_size, sequence_length, transformer.width]
# take features from the eot embedding (eot_token is the highest number in each sequence)
# casting to torch.int for onnx compatibility: argmax doesn't support int64 inputs with opset 14
pooled_output = last_hidden_state[
torch.arange(last_hidden_state.shape[0], device=last_hidden_state.device),
input_ids.to(dtype=torch.int, device=last_hidden_state.device).argmax(dim=-1),
]
else:
# The config gets updated `eos_token_id` from PR #24773 (so the use of exta new tokens is possible)
pooled_output = last_hidden_state[
torch.arange(last_hidden_state.shape[0], device=last_hidden_state.device),
# We need to get the first position of `eos_token_id` value (`pad_token_ids` might equal to `eos_token_id`)
(input_ids.to(dtype=torch.int, device=last_hidden_state.device) == self.eos_token_id)
.int()
.argmax(dim=-1),
]
if not return_dict:
return (last_hidden_state, pooled_output) + encoder_outputs[1:]
return BaseModelOutputWithPooling(
last_hidden_state=last_hidden_state,
pooler_output=pooled_output,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
)
class CLIPSegTextModel(CLIPSegPreTrainedModel):
config_class = CLIPSegTextConfig
_no_split_modules = ["CLIPSegTextEmbeddings", "CLIPSegEncoderLayer"]
def __init__(self, config: CLIPSegTextConfig):
super().__init__(config)
self.text_model = CLIPSegTextTransformer(config)
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self) -> nn.Module:
return self.text_model.embeddings.token_embedding
def set_input_embeddings(self, value):
self.text_model.embeddings.token_embedding = value
@add_start_docstrings_to_model_forward(CLIPSEG_TEXT_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=CLIPSegTextConfig)
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseModelOutputWithPooling]:
r"""
Returns:
Examples:
```python
>>> from transformers import AutoTokenizer, CLIPSegTextModel
>>> tokenizer = AutoTokenizer.from_pretrained("CIDAS/clipseg-rd64-refined")
>>> model = CLIPSegTextModel.from_pretrained("CIDAS/clipseg-rd64-refined")
>>> inputs = tokenizer(["a photo of a cat", "a photo of a dog"], padding=True, return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_state = outputs.last_hidden_state
>>> pooled_output = outputs.pooler_output # pooled (EOS token) states
```"""
return self.text_model(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
class CLIPSegVisionTransformer(nn.Module):
# Copied from transformers.models.clip.modeling_clip.CLIPVisionTransformer.__init__ with CLIP->CLIPSeg
def __init__(self, config: CLIPSegVisionConfig):
super().__init__()
self.config = config
embed_dim = config.hidden_size
self.embeddings = CLIPSegVisionEmbeddings(config)
self.pre_layrnorm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
self.encoder = CLIPSegEncoder(config)
self.post_layernorm = nn.LayerNorm(embed_dim, eps=config.layer_norm_eps)
@add_start_docstrings_to_model_forward(CLIPSEG_VISION_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=CLIPSegVisionConfig)
# Copied from transformers.models.clip.modeling_clip.CLIPVisionTransformer.forward
def forward(
self,
pixel_values: Optional[torch.FloatTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseModelOutputWithPooling]:
r"""
Returns:
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if pixel_values is None:
raise ValueError("You have to specify pixel_values")
hidden_states = self.embeddings(pixel_values)
hidden_states = self.pre_layrnorm(hidden_states)
encoder_outputs = self.encoder(
inputs_embeds=hidden_states,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
last_hidden_state = encoder_outputs[0]
pooled_output = last_hidden_state[:, 0, :]
pooled_output = self.post_layernorm(pooled_output)
if not return_dict:
return (last_hidden_state, pooled_output) + encoder_outputs[1:]
return BaseModelOutputWithPooling(
last_hidden_state=last_hidden_state,
pooler_output=pooled_output,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
)
class CLIPSegVisionModel(CLIPSegPreTrainedModel):
config_class = CLIPSegVisionConfig
main_input_name = "pixel_values"
def __init__(self, config: CLIPSegVisionConfig):
super().__init__(config)
self.vision_model = CLIPSegVisionTransformer(config)
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self) -> nn.Module:
return self.vision_model.embeddings.patch_embedding
@add_start_docstrings_to_model_forward(CLIPSEG_VISION_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=BaseModelOutputWithPooling, config_class=CLIPSegVisionConfig)
def forward(
self,
pixel_values: Optional[torch.FloatTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseModelOutputWithPooling]:
r"""
Returns:
Examples:
```python
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, CLIPSegVisionModel
>>> processor = AutoProcessor.from_pretrained("CIDAS/clipseg-rd64-refined")
>>> model = CLIPSegVisionModel.from_pretrained("CIDAS/clipseg-rd64-refined")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_state = outputs.last_hidden_state
>>> pooled_output = outputs.pooler_output # pooled CLS states
```"""
return self.vision_model(
pixel_values=pixel_values,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
@add_start_docstrings(CLIPSEG_START_DOCSTRING)
class CLIPSegModel(CLIPSegPreTrainedModel):
config_class = CLIPSegConfig
def __init__(self, config: CLIPSegConfig):
super().__init__(config)
if not isinstance(config.text_config, CLIPSegTextConfig):
raise ValueError(
"config.text_config is expected to be of type CLIPSegTextConfig but is of type"
f" {type(config.text_config)}."
)
if not isinstance(config.vision_config, CLIPSegVisionConfig):
raise ValueError(
"config.vision_config is expected to be of type CLIPSegVisionConfig but is of type"
f" {type(config.vision_config)}."
)
text_config = config.text_config
vision_config = config.vision_config
self.projection_dim = config.projection_dim
self.text_embed_dim = text_config.hidden_size
self.vision_embed_dim = vision_config.hidden_size
self.text_model = CLIPSegTextTransformer(text_config)
self.vision_model = CLIPSegVisionTransformer(vision_config)
self.visual_projection = nn.Linear(self.vision_embed_dim, self.projection_dim, bias=False)
self.text_projection = nn.Linear(self.text_embed_dim, self.projection_dim, bias=False)
self.logit_scale = nn.Parameter(torch.tensor(self.config.logit_scale_init_value))
# Initialize weights and apply final processing
self.post_init()
@add_start_docstrings_to_model_forward(CLIPSEG_TEXT_INPUTS_DOCSTRING)
def get_text_features(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> torch.FloatTensor:
r"""
Returns:
text_features (`torch.FloatTensor` of shape `(batch_size, output_dim`): The text embeddings obtained by
applying the projection layer to the pooled output of [`CLIPSegTextModel`].
Examples:
```python
>>> from transformers import AutoTokenizer, CLIPSegModel
>>> tokenizer = AutoTokenizer.from_pretrained("CIDAS/clipseg-rd64-refined")
>>> model = CLIPSegModel.from_pretrained("CIDAS/clipseg-rd64-refined")
>>> inputs = tokenizer(["a photo of a cat", "a photo of a dog"], padding=True, return_tensors="pt")
>>> text_features = model.get_text_features(**inputs)
```"""
# Use CLIPSEG model's config for some fields (if specified) instead of those of vision & text components.
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
text_outputs = self.text_model(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
pooled_output = text_outputs[1]
text_features = self.text_projection(pooled_output)
return text_features
@add_start_docstrings_to_model_forward(CLIPSEG_VISION_INPUTS_DOCSTRING)
def get_image_features(
self,
pixel_values: Optional[torch.FloatTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> torch.FloatTensor:
r"""
Returns:
image_features (`torch.FloatTensor` of shape `(batch_size, output_dim`): The image embeddings obtained by
applying the projection layer to the pooled output of [`CLIPSegVisionModel`].
Examples:
```python
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, CLIPSegModel
>>> processor = AutoProcessor.from_pretrained("CIDAS/clipseg-rd64-refined")
>>> model = CLIPSegModel.from_pretrained("CIDAS/clipseg-rd64-refined")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(images=image, return_tensors="pt")
>>> image_features = model.get_image_features(**inputs)
```"""
# Use CLIPSEG model's config for some fields (if specified) instead of those of vision & text components.
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
vision_outputs = self.vision_model(
pixel_values=pixel_values,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
pooled_output = vision_outputs[1] # pooled_output
image_features = self.visual_projection(pooled_output)
return image_features
@add_start_docstrings_to_model_forward(CLIPSEG_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=CLIPSegOutput, config_class=CLIPSegConfig)
def forward(
self,
input_ids: Optional[torch.LongTensor] = None,
pixel_values: Optional[torch.FloatTensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
return_loss: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, CLIPSegOutput]:
r"""
Returns:
Examples:
```python
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, CLIPSegModel
>>> processor = AutoProcessor.from_pretrained("CIDAS/clipseg-rd64-refined")
>>> model = CLIPSegModel.from_pretrained("CIDAS/clipseg-rd64-refined")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(
... text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True
... )
>>> outputs = model(**inputs)
>>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
>>> probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
```"""
# Use CLIPSEG model's config for some fields (if specified) instead of those of vision & text components.
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
vision_outputs = self.vision_model(
pixel_values=pixel_values,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
text_outputs = self.text_model(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
image_embeds = vision_outputs[1]
image_embeds = self.visual_projection(image_embeds)
text_embeds = text_outputs[1]
text_embeds = self.text_projection(text_embeds)
# normalized features
image_embeds = image_embeds / image_embeds.norm(p=2, dim=-1, keepdim=True)
text_embeds = text_embeds / text_embeds.norm(p=2, dim=-1, keepdim=True)
# cosine similarity as logits
logit_scale = self.logit_scale.exp()
logits_per_text = torch.matmul(text_embeds, image_embeds.t()) * logit_scale
logits_per_image = logits_per_text.t()
loss = None
if return_loss:
loss = clipseg_loss(logits_per_text)
if not return_dict:
output = (logits_per_image, logits_per_text, text_embeds, image_embeds, text_outputs, vision_outputs)
return ((loss,) + output) if loss is not None else output
return CLIPSegOutput(
loss=loss,
logits_per_image=logits_per_image,
logits_per_text=logits_per_text,
text_embeds=text_embeds,
image_embeds=image_embeds,
text_model_output=text_outputs,
vision_model_output=vision_outputs,
)
class CLIPSegDecoderLayer(nn.Module):
"""
CLIPSeg decoder layer, which is identical to `CLIPSegEncoderLayer`, except that normalization is applied after
self-attention/MLP, rather than before.
"""
# Copied from transformers.models.clip.modeling_clip.CLIPEncoderLayer.__init__ with CLIP->CLIPSeg
def __init__(self, config: CLIPSegConfig):
super().__init__()
self.embed_dim = config.hidden_size
self.self_attn = CLIPSegAttention(config)
self.layer_norm1 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
self.mlp = CLIPSegMLP(config)
self.layer_norm2 = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_eps)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: torch.Tensor,
causal_attention_mask: torch.Tensor,
output_attentions: Optional[bool] = False,
) -> Tuple[torch.FloatTensor]:
"""
Args:
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
attention_mask (`torch.FloatTensor`): attention mask of size
`(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
`(config.encoder_attention_heads,)`.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
"""
residual = hidden_states
hidden_states, attn_weights = self.self_attn(
hidden_states=hidden_states,
attention_mask=attention_mask,
causal_attention_mask=causal_attention_mask,
output_attentions=output_attentions,
)
hidden_states = residual + hidden_states
hidden_states = self.layer_norm1(hidden_states)
residual = hidden_states
hidden_states = self.mlp(hidden_states)
hidden_states = residual + hidden_states
hidden_states = self.layer_norm2(hidden_states)
outputs = (hidden_states,)
if output_attentions:
outputs += (attn_weights,)
return outputs
class CLIPSegDecoder(CLIPSegPreTrainedModel):
def __init__(self, config: CLIPSegConfig):
super().__init__(config)
self.conditional_layer = config.conditional_layer
self.film_mul = nn.Linear(config.projection_dim, config.reduce_dim)
self.film_add = nn.Linear(config.projection_dim, config.reduce_dim)
if config.use_complex_transposed_convolution:
transposed_kernels = (config.vision_config.patch_size // 4, config.vision_config.patch_size // 4)
self.transposed_convolution = nn.Sequential(
nn.Conv2d(config.reduce_dim, config.reduce_dim, kernel_size=3, padding=1),
nn.ReLU(),
nn.ConvTranspose2d(
config.reduce_dim,
config.reduce_dim // 2,
kernel_size=transposed_kernels[0],
stride=transposed_kernels[0],
),
nn.ReLU(),
nn.ConvTranspose2d(
config.reduce_dim // 2, 1, kernel_size=transposed_kernels[1], stride=transposed_kernels[1]
),
)
else:
self.transposed_convolution = nn.ConvTranspose2d(
config.reduce_dim, 1, config.vision_config.patch_size, stride=config.vision_config.patch_size
)
depth = len(config.extract_layers)
self.reduces = nn.ModuleList(
[nn.Linear(config.vision_config.hidden_size, config.reduce_dim) for _ in range(depth)]
)
decoder_config = copy.deepcopy(config.vision_config)
decoder_config.hidden_size = config.reduce_dim
decoder_config.num_attention_heads = config.decoder_num_attention_heads
decoder_config.intermediate_size = config.decoder_intermediate_size
decoder_config.hidden_act = "relu"
self.layers = nn.ModuleList([CLIPSegDecoderLayer(decoder_config) for _ in range(len(config.extract_layers))])
def forward(
self,
hidden_states: Tuple[torch.Tensor],
conditional_embeddings: torch.Tensor,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = True,
):
all_hidden_states = () if output_hidden_states else None
all_attentions = () if output_attentions else None
activations = hidden_states[::-1]
output = None
for i, (activation, layer, reduce) in enumerate(zip(activations, self.layers, self.reduces)):
if output is not None:
output = reduce(activation) + output
else:
output = reduce(activation)
if i == self.conditional_layer:
output = self.film_mul(conditional_embeddings) * output.permute(1, 0, 2) + self.film_add(
conditional_embeddings
)
output = output.permute(1, 0, 2)
layer_outputs = layer(
output, attention_mask=None, causal_attention_mask=None, output_attentions=output_attentions
)
output = layer_outputs[0]
if output_hidden_states:
all_hidden_states += (output,)
if output_attentions:
all_attentions += (layer_outputs[1],)
output = output[:, 1:, :].permute(0, 2, 1) # remove cls token and reshape to [batch_size, reduce_dim, seq_len]
size = int(math.sqrt(output.shape[2]))
batch_size = conditional_embeddings.shape[0]
output = output.view(batch_size, output.shape[1], size, size)
logits = self.transposed_convolution(output).squeeze(1)
if not return_dict:
return tuple(v for v in [logits, all_hidden_states, all_attentions] if v is not None)
return CLIPSegDecoderOutput(
logits=logits,
hidden_states=all_hidden_states,
attentions=all_attentions,
)
@add_start_docstrings(
"""
CLIPSeg model with a Transformer-based decoder on top for zero-shot and one-shot image segmentation.
""",
CLIPSEG_START_DOCSTRING,
)
class CLIPSegForImageSegmentation(CLIPSegPreTrainedModel):
config_class = CLIPSegConfig
def __init__(self, config: CLIPSegConfig):
super().__init__(config)
self.config = config
self.clip = CLIPSegModel(config)
self.extract_layers = config.extract_layers
self.decoder = CLIPSegDecoder(config)
# Initialize weights and apply final processing
self.post_init()
def get_conditional_embeddings(
self,
batch_size: int = None,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
conditional_pixel_values: Optional[torch.Tensor] = None,
):
if input_ids is not None:
# compute conditional embeddings from texts
if len(input_ids) != batch_size:
raise ValueError("Make sure to pass as many prompt texts as there are query images")
with torch.no_grad():
conditional_embeddings = self.clip.get_text_features(
input_ids, attention_mask=attention_mask, position_ids=position_ids
)
elif conditional_pixel_values is not None:
# compute conditional embeddings from images
if len(conditional_pixel_values) != batch_size:
raise ValueError("Make sure to pass as many prompt images as there are query images")
with torch.no_grad():
conditional_embeddings = self.clip.get_image_features(conditional_pixel_values)
else:
raise ValueError(
"Invalid conditional, should be either provided as `input_ids` or `conditional_pixel_values`"
)
return conditional_embeddings
@add_start_docstrings_to_model_forward(CLIPSEG_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=CLIPSegImageSegmentationOutput, config_class=CLIPSegTextConfig)
def forward(
self,
input_ids: Optional[torch.FloatTensor] = None,
pixel_values: Optional[torch.FloatTensor] = None,
conditional_pixel_values: Optional[torch.FloatTensor] = None,
conditional_embeddings: Optional[torch.FloatTensor] = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
labels: Optional[torch.LongTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, CLIPSegOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size,)`, *optional*):
Labels for computing the sequence classification/regression loss. Indices should be in `[0, ...,
config.num_labels - 1]`. If `config.num_labels == 1` a regression loss is computed (Mean-Square loss), If
`config.num_labels > 1` a classification loss is computed (Cross-Entropy).
Returns:
Examples:
```python
>>> from transformers import AutoProcessor, CLIPSegForImageSegmentation
>>> from PIL import Image
>>> import requests
>>> processor = AutoProcessor.from_pretrained("CIDAS/clipseg-rd64-refined")
>>> model = CLIPSegForImageSegmentation.from_pretrained("CIDAS/clipseg-rd64-refined")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = ["a cat", "a remote", "a blanket"]
>>> inputs = processor(text=texts, images=[image] * len(texts), padding=True, return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
>>> print(logits.shape)
torch.Size([3, 352, 352])
```"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
# step 1: forward the query images through the frozen CLIP vision encoder
with torch.no_grad():
vision_outputs = self.clip.vision_model(
pixel_values=pixel_values,
output_attentions=output_attentions,
output_hidden_states=True, # we need the intermediate hidden states
return_dict=return_dict,
)
pooled_output = self.clip.visual_projection(vision_outputs[1])
hidden_states = vision_outputs.hidden_states if return_dict else vision_outputs[2]
# we add +1 here as the hidden states also include the initial embeddings
activations = [hidden_states[i + 1] for i in self.extract_layers]
# update vision_outputs
if return_dict:
vision_outputs = BaseModelOutputWithPooling(
last_hidden_state=vision_outputs.last_hidden_state,
pooler_output=vision_outputs.pooler_output,
hidden_states=vision_outputs.hidden_states if output_hidden_states else None,
attentions=vision_outputs.attentions,
)
else:
vision_outputs = (
vision_outputs[:2] + vision_outputs[3:] if not output_hidden_states else vision_outputs
)
# step 2: compute conditional embeddings, either from text, images or an own provided embedding
if conditional_embeddings is None:
conditional_embeddings = self.get_conditional_embeddings(
batch_size=pixel_values.shape[0],
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
conditional_pixel_values=conditional_pixel_values,
)
else:
if conditional_embeddings.shape[0] != pixel_values.shape[0]:
raise ValueError(
"Make sure to pass as many conditional embeddings as there are query images in the batch"
)
if conditional_embeddings.shape[1] != self.config.projection_dim:
raise ValueError(
"Make sure that the feature dimension of the conditional embeddings matches"
" `config.projection_dim`."
)
# step 3: forward both the pooled output and the activations through the lightweight decoder to predict masks
decoder_outputs = self.decoder(
activations,
conditional_embeddings,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
logits = decoder_outputs.logits if return_dict else decoder_outputs[0]
loss = None
if labels is not None:
# move labels to the correct device to enable PP
labels = labels.to(logits.device)
loss_fn = nn.BCEWithLogitsLoss()
loss = loss_fn(logits, labels)
if not return_dict:
output = (logits, conditional_embeddings, pooled_output, vision_outputs, decoder_outputs)
return ((loss,) + output) if loss is not None else output
return CLIPSegImageSegmentationOutput(
loss=loss,
logits=logits,
conditional_embeddings=conditional_embeddings,
pooled_output=pooled_output,
vision_model_output=vision_outputs,
decoder_output=decoder_outputs,
)
| transformers/src/transformers/models/clipseg/modeling_clipseg.py/0 | {
"file_path": "transformers/src/transformers/models/clipseg/modeling_clipseg.py",
"repo_id": "transformers",
"token_count": 27597
} | 298 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.