
hexsha
stringlengths 40
40
| size
int64 6
14.9M
| ext
stringclasses 1
value | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 6
260
| max_stars_repo_name
stringlengths 6
119
| max_stars_repo_head_hexsha
stringlengths 40
41
| max_stars_repo_licenses
list | max_stars_count
int64 1
191k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 6
260
| max_issues_repo_name
stringlengths 6
119
| max_issues_repo_head_hexsha
stringlengths 40
41
| max_issues_repo_licenses
list | max_issues_count
int64 1
67k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 6
260
| max_forks_repo_name
stringlengths 6
119
| max_forks_repo_head_hexsha
stringlengths 40
41
| max_forks_repo_licenses
list | max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | avg_line_length
float64 2
1.04M
| max_line_length
int64 2
11.2M
| alphanum_fraction
float64 0
1
| cells
list | cell_types
list | cell_type_groups
list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
ecbfe2642c21e1e4e5025b87b6bae2d205bb2c9e | 17,513 | ipynb | Jupyter Notebook | Vacation_Itinerary/Vacation_Itinerary.ipynb | Bettinadavis11/World_weather_analysis | c5f5e0a9add6c885b59292983b17b65a918a7270 | [
"MIT"
] | null | null | null | Vacation_Itinerary/Vacation_Itinerary.ipynb | Bettinadavis11/World_weather_analysis | c5f5e0a9add6c885b59292983b17b65a918a7270 | [
"MIT"
] | null | null | null | Vacation_Itinerary/Vacation_Itinerary.ipynb | Bettinadavis11/World_weather_analysis | c5f5e0a9add6c885b59292983b17b65a918a7270 | [
"MIT"
] | null | null | null | 32.075092 | 131 | 0.462171 | [
[
[
"## Deliverable 3. Create a Travel Itinerary Map.",
"_____no_output_____"
]
],
[
[
"# Dependencies and Setup\nimport pandas as pd\nimport requests\nimport gmaps\n\n\n# Import API key\nfrom config import g_key\n\n# Configure gmaps\ngmaps.configure(api_key=g_key)",
"_____no_output_____"
],
[
"# 1. Read the WeatherPy_vacation.csv into a DataFrame.\nvacation_df = pd.read_csv(\"C:/Users/betti/Desktop/World_weather_analysis/Vacation_Search/WeatherPy_Vacation.csv\")\nvacation_df.head()",
"_____no_output_____"
],
[
"# 2. Using the template add the city name, the country code, the weather description and maximum temperature for the city.\ninfo_box_template = \"\"\"\n<dl>\n<dt>Hotel Name</dt><dd>{Hotel Name}</dd>\n<dt>City</dt><dd>{City}</dd>\n<dt>Country</dt><dd>{Country}</dd>\n<dt>Weather Description</dt><dd>{Current Description} at {Max Temp}°F</dd>\n</dl>\n\"\"\"\n\n# 3a. Get the data from each row and add it to the formatting template and store the data in a list.\nhotel_info = [info_box_template.format(**row) for index, row in vacation_df.iterrows()]\n\n# 3b. Get the latitude and longitude from each row and store in a new DataFrame.\nlocations = vacation_df[[\"Lat\", \"Lng\"]]",
"_____no_output_____"
],
[
"# 4a. Add a marker layer for each city to the map.\nmarker_layer = gmaps.marker_layer(locations, info_box_content=hotel_info)\n\n# 4b. Display the figure\n\nfig = gmaps.figure()\nfig.add_layer(marker_layer)\n\nfig",
"_____no_output_____"
],
[
"# From the map above pick 4 cities and create a vacation itinerary route to travel between the four cities. \n# 5. Create DataFrames for each city by filtering the 'vacation_df' using the loc method. \n# Hint: The starting and ending city should be the same city.\n\nvacation_start = vacation_df.loc[vacation_df[\"City\"] == \"Ulladulla\"]\nvacation_end = vacation_df.loc[vacation_df[\"City\"] == \"Ulladulla\"]\nvacation_stop1 = vacation_df.loc[vacation_df[\"City\"] == \"Flinders\"]\nvacation_stop2 = vacation_df.loc[vacation_df[\"City\"] == \"Nelson Bay\"] \nvacation_stop3 = vacation_df.loc[vacation_df[\"City\"] == \"Port Macquarie\"]\nprint(vacation_start)\nprint(vacation_stop1)\nprint(vacation_stop2)\nprint(vacation_stop3)",
" City_ID City Country Max Temp Current Description Lat Lng \\\n1 4 Ulladulla AU 82.76 broken clouds -35.35 150.4667 \n\n Hotel Name \n1 Sandpiper Motel \n City_ID City Country Max Temp Current Description Lat \\\n119 422 Flinders AU 79.21 broken clouds -34.5833 \n\n Lng Hotel Name \n119 150.8552 Shellharbour Resort & Conference Centre \n City_ID City Country Max Temp Current Description Lat Lng \\\n6 16 Nelson Bay AU 85.28 light rain -32.7167 152.15 \n\n Hotel Name \n6 Mantra Nelson Bay \n City_ID City Country Max Temp Current Description Lat \\\n178 648 Port Macquarie AU 82.36 scattered clouds -31.4333 \n\n Lng Hotel Name \n178 152.9167 Rydges Port Macquarie \n"
],
[
"# 6. Get the latitude-longitude pairs as tuples from each city DataFrame using the to_numpy function and list indexing.\nstart = vacation_start[\"Lat\"].values[0], vacation_start[\"Lng\"].values[0]\nend = vacation_end[\"Lat\"].values[0], vacation_end[\"Lng\"].values[0]\nstop1 = vacation_stop1[\"Lat\"].values[0], vacation_stop1[\"Lng\"].values[0]\nstop2 = vacation_stop2[\"Lat\"].values[0], vacation_stop2[\"Lng\"].values[0]\nstop3 = vacation_stop3[\"Lat\"].values[0], vacation_stop3[\"Lng\"].values[0]\nprint(start)\nprint(stop1)\nprint(stop2)\nprint(stop3)",
"(-35.35, 150.4667)\n(-34.5833, 150.8552)\n(-32.7167, 152.15)\n(-31.4333, 152.9167)\n"
],
[
"# 7. Create a direction layer map using the start and end latitude-longitude pairs,\n# and stop1, stop2, and stop3 as the waypoints. The travel_mode should be \"DRIVING\", \"BICYCLING\", or \"WALKING\".\nfig = gmaps.figure()\nvacation_itinerary = gmaps.directions_layer(\n start, end, waypoints = [stop1, stop2, stop3],\n travel_mode = \"DRIVING\"\n)\nfig.add_layer(vacation_itinerary)\nfig\n",
"_____no_output_____"
],
[
"# 8. To create a marker layer map between the four cities.\n# Combine the four city DataFrames into one DataFrame using the concat() function.\nitinerary_df = pd.concat([vacation_start, vacation_end,\n vacation_stop1, vacation_stop2,\n vacation_stop3],ignore_index=True)\nitinerary_df",
"_____no_output_____"
],
[
"# 9 Using the template add city name, the country code, the weather description and maximum temperature for the city. \ninfo_box_template = \"\"\"\n<dl>\n<dt>Hotel Name</dt><dd>{Hotel Name}</dd>\n<dt>City</dt><dd>{City}</dd>\n<dt>Country</dt><dd>{Country}</dd>\n<dt>Weather Description</dt><dd>{Current Description} at {Max Temp}°F</dd>\n</dl>\n\"\"\"\n\n# 10a Get the data from each row and add it to the formatting template and store the data in a list.\nhotel_info = [info_box_template.format(**row) for index, row in itinerary_df.iterrows()]\n\n# 10b. Get the latitude and longitude from each row and store in a new DataFrame.\nlocations = itinerary_df[[\"Lat\", \"Lng\"]]",
"_____no_output_____"
],
[
"# 11a. Add a marker layer for each city to the map.\nmarker_layer = gmaps.marker_layer(locations, info_box_content=hotel_info)\n\n# 11b. Display the figure\nfig = gmaps.figure()\nfig.add_layer(marker_layer)\n\nfig",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecbfeaa3158898a42f3217e47f215b8b9c6c8821 | 15,366 | ipynb | Jupyter Notebook | AoC 2020/AoC 2020 - Day 12.ipynb | RubenFixit/AoC | af042a5d6ca230a767862b471400275d2258a116 | [
"MIT"
] | null | null | null | AoC 2020/AoC 2020 - Day 12.ipynb | RubenFixit/AoC | af042a5d6ca230a767862b471400275d2258a116 | [
"MIT"
] | null | null | null | AoC 2020/AoC 2020 - Day 12.ipynb | RubenFixit/AoC | af042a5d6ca230a767862b471400275d2258a116 | [
"MIT"
] | null | null | null | 33.995575 | 317 | 0.491019 | [
[
[
"# [Advent of Code 2020: Day 12](https://adventofcode.com/2020/day/12)",
"_____no_output_____"
],
[
"## --- Day 12: Rain Risk ---\n\nYour ferry made decent progress toward the island, but the storm came in faster than anyone expected. The ferry needs to take **evasive actions**!\n\nUnfortunately, the ship's navigation computer seems to be malfunctioning; rather than giving a route directly to safety, it produced extremely circuitous instructions. When the captain uses the [PA system](https://en.wikipedia.org/wiki/Public_address_system) to ask if anyone can help, you quickly volunteer.\n\nThe navigation instructions (your puzzle input) consists of a sequence of single-character **actions** paired with integer input **values**. After staring at them for a few minutes, you work out what they probably mean:\n\n* Action **`N`** means to move **north** by the given value.\n* Action **`S`** means to move **south** by the given value.\n* Action **`E`** means to move **east** by the given value.\n* Action **`W`** means to move **west** by the given value.\n* Action **`L`** means to turn **left** the given number of degrees.\n* Action **`R`** means to turn **right** the given number of degrees.\n* Action **`F`** means to move **forward** by the given value in the direction the ship is currently facing.\n\nThe ship starts by facing **east**. Only the `L` and `R` actions change the direction the ship is facing. (That is, if the ship is facing east and the next instruction is `N10`, the ship would move north 10 units, but would still move east if the following action were `F`.)\n\nFor example:\n\n```\nF10\nN3\nF7\nR90\nF11\n\n```\n\nThese instructions would be handled as follows:\n\n* `F10` would move the ship 10 units east (because the ship starts by facing east) to **east 10, north 0**.\n* `N3` would move the ship 3 units north to **east 10, north 3**.\n* `F7` would move the ship another 7 units east (because the ship is still facing east) to **east 17, north 3**.\n* `R90` would cause the ship to turn right by 90 degrees and face **south**; it remains at **east 17, north 3**.\n* `F11` would move the ship 11 units south to **east 17, south 8**.\n\nAt the end of these instructions, the ship's [Manhattan distance](https://en.wikipedia.org/wiki/Manhattan_distance) (sum of the absolute values of its east/west position and its north/south position) from its starting position is `17 + 8` = **`25`**.\n\nFigure out where the navigation instructions lead. **What is the Manhattan distance between that location and the ship's starting position?**",
"_____no_output_____"
]
],
[
[
"import unittest\nimport re\nfrom IPython.display import Markdown, display\n\nfrom aoc_puzzle import AocPuzzle\n\nclass FerryNav(AocPuzzle):\n \n def parse_data(self, raw_data):\n data_lines = raw_data.split('\\n')\n self.data = []\n for line in data_lines:\n m = re.match('(\\w)(\\d+)', line)\n self.data.append((m.group(1), int(m.group(2))))\n \n self.NORTH = 'N'\n self.SOUTH = 'S'\n self.EAST = 'E'\n self.WEST = 'W'\n self.TURN_LEFT = 'L'\n self.TURN_RIGHT = 'R'\n self.GO_FORWARD = 'F'\n \n self.HEADING_LIST = ['N','E','S','W']\n self.DEGREES_PER_HEADING = 90\n \n self.start_pos = (0,0)\n self.pos = self.start_pos\n self.heading = self.EAST\n \n def change_heading(self, val):\n start_index = self.HEADING_LIST.index(self.heading)\n \n hchange = val // self.DEGREES_PER_HEADING\n \n hindex = (start_index + hchange) % len(self.HEADING_LIST)\n \n self.heading = self.HEADING_LIST[hindex] \n \n def do_action(self, action):\n move, val = action\n \n if move == self.GO_FORWARD:\n move = self.heading\n \n lat, lon = self.pos\n if move == self.NORTH:\n lon += val\n elif move == self.SOUTH:\n lon -= val\n elif move == self.EAST:\n lat += val\n elif move == self.WEST:\n lat -= val\n elif move == self.TURN_LEFT:\n self.change_heading(-val)\n elif move == self.TURN_RIGHT:\n self.change_heading(val)\n else:\n raise f'Unknown Action: {action}'\n \n self.pos = (lat,lon)\n \n def run(self, output=False, debug=False):\n \n self.debug = debug\n \n for action in self.data:\n if debug: print(f'Action: {action}')\n self.do_action(action)\n if debug: print(f'Pos: {self.pos}\\n')\n \n lat, lon = self.pos\n \n result = abs(lat) + abs(lon)\n \n if output:\n display(Markdown(f'### Manhattan distance traveled: `{result}`')) \n return result\n \n\nclass TestBasic(unittest.TestCase):\n\n def test_parse_data(self):\n in_data = 'F10\\nN3\\nF7\\nR90\\nF11'\n exp_out = [('F',10),('N',3),('F',7),('R',90),('F',11)]\n fn = FerryNav(in_data)\n self.assertEqual(fn.data, exp_out)\n \n def test_ferry_nav(self):\n in_data = 'F10\\nN3\\nF7\\nR90\\nF11'\n exp_out = 25\n fn = FerryNav(in_data)\n self.assertEqual(fn.run(debug=True), exp_out)\n \nunittest.main(argv=[\"\"], exit=False)",
".."
],
[
"fn = FerryNav(\"input/d12.txt\")\nfn.run(output=True)",
"_____no_output_____"
]
],
[
[
"## --- Part Two ---\n\nBefore you can give the destination to the captain, you realize that the actual action meanings were printed on the back of the instructions the whole time.\n\nAlmost all of the actions indicate how to move a **waypoint** which is relative to the ship's position:\n\n* Action **`N`** means to move the waypoint **north** by the given value.\n* Action **`S`** means to move the waypoint **south** by the given value.\n* Action **`E`** means to move the waypoint **east** by the given value.\n* Action **`W`** means to move the waypoint **west** by the given value.\n* Action **`L`** means to rotate the waypoint around the ship **left** (**counter-clockwise**) the given number of degrees.\n* Action **`R`** means to rotate the waypoint around the ship **right** (**clockwise**) the given number of degrees.\n* Action **`F`** means to move **forward** to the waypoint a number of times equal to the given value.\n\nThe waypoint starts **10 units east and 1 unit north** relative to the ship. The waypoint is relative to the ship; that is, if the ship moves, the waypoint moves with it.\n\nFor example, using the same instructions as above:\n\n* `F10` moves the ship to the waypoint 10 times (a total of **100 units east and 10 units north**), leaving the ship at **east 100, north 10**. The waypoint stays 10 units east and 1 unit north of the ship.\n* `N3` moves the waypoint 3 units north to **10 units east and 4 units north of the ship**. The ship remains at **east 100, north 10**.\n* `F7` moves the ship to the waypoint 7 times (a total of **70 units east and 28 units north**), leaving the ship at **east 170, north 38**. The waypoint stays 10 units east and 4 units north of the ship.\n* `R90` rotates the waypoint around the ship clockwise 90 degrees, moving it to **4 units east and 10 units south of the ship**. The ship remains at **east 170, north 38**.\n* `F11` moves the ship to the waypoint 11 times (a total of **44 units east and 110 units south**), leaving the ship at **east 214, south 72**. The waypoint stays 4 units east and 10 units south of the ship.\n\nAfter these operations, the ship's Manhattan distance from its starting position is `214 + 72` = **`286`**.\n\nFigure out where the navigation instructions actually lead. **What is the Manhattan distance between that location and the ship's starting position?**",
"_____no_output_____"
]
],
[
[
"class FerryNav2(FerryNav):\n waypoint = (10,1)\n \n def do_move(self, mag):\n lat, lon = self.pos\n wp_lat, wp_lon = self.waypoint\n \n lat += wp_lat * mag\n lon += wp_lon * mag\n self.pos = (lat, lon)\n \n def rotate_waypoint(self, val):\n lat, lon = self.waypoint\n \n hchange = abs(val) // self.DEGREES_PER_HEADING\n if val > 0:\n for _ in range(hchange):\n lat, lon = lon, -lat\n else:\n for _ in range(hchange):\n lat, lon = -lon, lat\n \n return (lat, lon)\n \n def do_action(self, action):\n move, val = action\n \n if move == self.GO_FORWARD:\n self.do_move(val)\n return\n \n lat, lon = self.waypoint\n if move == self.NORTH:\n lon += val\n elif move == self.SOUTH:\n lon -= val\n elif move == self.EAST:\n lat += val\n elif move == self.WEST:\n lat -= val\n elif move == self.TURN_LEFT:\n lat, lon = self.rotate_waypoint(-val)\n elif move == self.TURN_RIGHT:\n lat, lon = self.rotate_waypoint(val)\n else:\n raise f'Unknown Action: {action}'\n \n self.waypoint = (lat,lon)\n if self.debug: print(f'Waypoint: {self.waypoint}')\n\n\nclass TestBasic(unittest.TestCase):\n \n def test_ferry_nav2(self):\n in_data = 'F10\\nN3\\nF7\\nR90\\nF11'\n exp_out = 286\n fn = FerryNav2(in_data)\n self.assertEqual(fn.run(debug=True), exp_out)\n \nunittest.main(argv=[\"\"], exit=False)",
"."
],
[
"fn = FerryNav2(\"input/d12.txt\")\nfn.run(output=True)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
ecbff14be89aff124ae141d06db6fea6dc8cb635 | 207,464 | ipynb | Jupyter Notebook | training/BackgroundTrain-rnd-40Part.ipynb | violatingcp/QUASAR | 60d1c00d0c461bc706631d4210e31a80d1a3c482 | [
"MIT"
] | null | null | null | training/BackgroundTrain-rnd-40Part.ipynb | violatingcp/QUASAR | 60d1c00d0c461bc706631d4210e31a80d1a3c482 | [
"MIT"
] | null | null | null | training/BackgroundTrain-rnd-40Part.ipynb | violatingcp/QUASAR | 60d1c00d0c461bc706631d4210e31a80d1a3c482 | [
"MIT"
] | null | null | null | 55.044839 | 15,328 | 0.671143 | [
[
[
"import numpy as np\nimport scipy as sp\nimport scipy.stats\nimport itertools\nimport logging\nimport matplotlib.pyplot as plt\nimport pandas as pd\nimport torch.utils.data as utils\nimport math\nimport time\nimport tqdm\n\nimport torch\nimport torch.optim as optim\nimport torch.nn.functional as F\nfrom argparse import ArgumentParser\nfrom torch.distributions import MultivariateNormal\n\nimport torch.nn as nn\nimport torch.nn.init as init\nimport sys\n\nsys.path.append(\"../new_flows\")\nfrom flows import RealNVP, Planar, MAF\nfrom models import NormalizingFlowModel",
"_____no_output_____"
]
],
[
[
"## Load and process the data",
"_____no_output_____"
]
],
[
[
"df_purebkg = pd.read_hdf(\"/data/t3home000/spark/LHCOlympics_previous/preprocessed_40part_testdataset.h5\")",
"_____no_output_____"
],
[
"dt = df_purebkg.values",
"_____no_output_____"
],
[
"idx = dt[:,120]\nbkg_idx = np.where(idx==0)[0]\nsignal_idx = np.where(idx==1)[0]",
"_____no_output_____"
],
[
"dtsig = dt[signal_idx]",
"_____no_output_____"
],
[
"Ysig = dtsig[:,0:120]",
"_____no_output_____"
],
[
"dt = dt[bkg_idx]",
"_____no_output_____"
],
[
"dt.shape",
"_____no_output_____"
],
[
"Y = dt[:,0:120]",
"_____no_output_____"
],
[
"Y.shape",
"_____no_output_____"
],
[
"Ysig.shape",
"_____no_output_____"
],
[
"bkg_mean = []\nbkg_std = []",
"_____no_output_____"
],
[
"for i in range(120):\n mean = np.mean(Y[:,i])\n std = np.std(Y[:,i])\n bkg_mean.append(mean)\n bkg_std.append(std)\n Y[:,i] = (Y[:,i]-mean)/std",
"_____no_output_____"
],
[
"for i in range(120):\n Ysig[:,i] = (Ysig[:,i]-bkg_mean[i])/bkg_std[i]",
"_____no_output_____"
],
[
"bkg_mean",
"_____no_output_____"
],
[
"bins = np.linspace(-3,3,100)\nbins.shape\ncolumn = 90\n#print(f_rnd.columns[column])\n#plt.ylim(0, 500)\nplt.hist(Y[:,column],bins,alpha=0.5,color='b');\n#plt.hist(sigout[:,column],bins,alpha=0.5,color='r');\n#plt.hist(out2[:,column],bins,alpha=0.5,color='g');\n#plt.axvline(np.mean(Y[:,column]))",
"_____no_output_____"
],
[
"bkg_mean",
"_____no_output_____"
],
[
"bkg_std",
"_____no_output_____"
],
[
"total_PureBkg = torch.tensor(Y)\n\ntotal_PureBkg_selection = total_PureBkg",
"_____no_output_____"
],
[
"total_sig = torch.tensor(Ysig)",
"_____no_output_____"
],
[
"total_sig.shape",
"_____no_output_____"
],
[
"bs = 800\nbkgAE_train_iterator = utils.DataLoader(total_PureBkg_selection, batch_size=bs, shuffle=True) \nbkgAE_test_iterator = utils.DataLoader(total_PureBkg_selection, batch_size=bs)",
"_____no_output_____"
]
],
[
[
"## Build the model",
"_____no_output_____"
]
],
[
[
"####MAF \nclass VAE_NF(nn.Module):\n def __init__(self, K, D):\n super().__init__()\n self.dim = D\n self.K = K\n self.encoder = nn.Sequential(\n nn.Linear(120, 300),\n nn.LeakyReLU(True),\n nn.Linear(300, 160),\n nn.LeakyReLU(True),\n nn.Linear(160, 80),\n nn.LeakyReLU(True),\n nn.Linear(80, 40),\n nn.LeakyReLU(True),\n nn.Linear(40, 20),\n nn.LeakyReLU(True),\n nn.Linear(20, D * 2)\n )\n\n self.decoder = nn.Sequential(\n nn.Linear(D, 20),\n nn.LeakyReLU(True),\n nn.Linear(20, 40),\n nn.LeakyReLU(True),\n nn.Linear(40, 80),\n nn.LeakyReLU(True),\n nn.Linear(80, 160),\n nn.LeakyReLU(True),\n nn.Linear(160, 300),\n nn.LeakyReLU(True),\n nn.Linear(300, 120)\n )\n \n flow_init = MAF(dim=D)\n flows_init = [flow_init for _ in range(K)]\n prior = MultivariateNormal(torch.zeros(D).cuda(), torch.eye(D).cuda())\n self.flows = NormalizingFlowModel(prior, flows_init)\n\n def forward(self, x):\n # Run Encoder and get NF params\n enc = self.encoder(x)\n mu = enc[:, :self.dim]\n log_var = enc[:, self.dim: self.dim * 2]\n\n # Re-parametrize\n sigma = (log_var * .5).exp()\n z = mu + sigma * torch.randn_like(sigma)\n kl_div = -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())\n # Construct more expressive posterior with NF\n \n z_k, _, sum_ladj = self.flows(z)\n \n kl_div = kl_div / x.size(0) - sum_ladj.mean() # mean over batch\n\n # Run Decoder\n x_prime = self.decoder(z_k)\n return x_prime, kl_div",
"_____no_output_____"
]
],
[
[
"####MAF \nclass VAE_NF(nn.Module):\n def __init__(self, K, D):\n super().__init__()\n self.dim = D\n self.K = K\n self.encoder = nn.Sequential(\n nn.Linear(16, 50),\n nn.LeakyReLU(True),\n nn.Linear(50, 48),\n nn.LeakyReLU(True), \n nn.Linear(48, D * 2)\n )\n\n self.decoder = nn.Sequential(\n nn.Linear(D, 48),\n nn.LeakyReLU(True),\n nn.Linear(48, 50),\n nn.LeakyReLU(True),\n nn.Linear(50, 16)\n )\n \n flow_init = MAF(dim=D)\n flows_init = [flow_init for _ in range(K)]\n prior = MultivariateNormal(torch.zeros(D).cuda(), torch.eye(D).cuda())\n self.flows = NormalizingFlowModel(prior, flows_init)\n\n def forward(self, x):\n # Run Encoder and get NF params\n enc = self.encoder(x)\n mu = enc[:, :self.dim]\n log_var = enc[:, self.dim: self.dim * 2]\n\n # Re-parametrize\n sigma = (log_var * .5).exp()\n z = mu + sigma * torch.randn_like(sigma)\n kl_div = -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())\n # Construct more expressive posterior with NF\n \n z_k, _, sum_ladj = self.flows(z)\n \n kl_div = kl_div / x.size(0) - sum_ladj.mean() # mean over batch\n\n # Run Decoder\n x_prime = self.decoder(z_k)\n return x_prime, kl_div",
"_____no_output_____"
],
[
"## Creating Instance¶",
"_____no_output_____"
]
],
[
[
"N_EPOCHS = 30\nPRINT_INTERVAL = 2000\nNUM_WORKERS = 4\nLR = 1e-4\n\nN_FLOWS = 10\nZ_DIM = 10\n\nn_steps = 0",
"_____no_output_____"
],
[
"model = VAE_NF(N_FLOWS, Z_DIM).cuda()",
"_____no_output_____"
],
[
"optimizer = optim.Adam(model.parameters(), lr=1e-7)",
"_____no_output_____"
],
[
"beta = 1",
"_____no_output_____"
],
[
"def train():\n global n_steps\n train_loss = []\n model.train()\n\n for batch_idx, x in enumerate(bkgAE_train_iterator):\n start_time = time.time()\n \n x = x.float().cuda()\n\n x_tilde, kl_div = model(x)\n \n \n \n mseloss = nn.MSELoss(size_average=False)\n \n huberloss = nn.SmoothL1Loss(size_average=False)\n \n\n #loss_recons = F.binary_cross_entropy(x_tilde, x, size_average=False) / x.size(0)\n loss_recons = mseloss(x_tilde,x ) / x.size(0)\n \n #loss_recons = huberloss(x_tilde,x ) / x.size(0)\n loss = loss_recons + beta * kl_div\n\n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n\n train_loss.append([loss_recons.item(), kl_div.item()])\n\n if (batch_idx + 1) % PRINT_INTERVAL == 0:\n print('\\tIter [{}/{} ({:.0f}%)]\\tLoss: {} Time: {:5.3f} ms/batch'.format(\n batch_idx * len(x), 50000,\n PRINT_INTERVAL * batch_idx / 50000,\n np.asarray(train_loss)[-PRINT_INTERVAL:].mean(0),\n 1000 * (time.time() - start_time)\n ))\n\n n_steps += 1",
"_____no_output_____"
],
[
"def evaluate(split='valid'):\n global n_steps\n start_time = time.time()\n val_loss = []\n model.eval()\n\n with torch.no_grad():\n for batch_idx, x in enumerate(bkgAE_test_iterator):\n \n x = x.float().cuda()\n\n x_tilde, kl_div = model(x)\n mseloss = nn.MSELoss(size_average=False)\n #loss_recons = F.binary_cross_entropy(x_tilde, x, size_average=False) / x.size(0)\n huberloss = nn.SmoothL1Loss(size_average=False)\n \n\n #loss_recons = F.binary_cross_entropy(x_tilde, x, size_average=False) / x.size(0)\n loss_recons = mseloss(x_tilde,x ) / x.size(0)\n #loss_recons = huberloss(x_tilde,x ) / x.size(0)\n loss = loss_recons + beta * kl_div\n\n val_loss.append(loss.item())\n #writer.add_scalar('loss/{}/ELBO'.format(split), loss.item(), n_steps)\n #writer.add_scalar('loss/{}/reconstruction'.format(split), loss_recons.item(), n_steps)\n #writer.add_scalar('loss/{}/KL'.format(split), kl_div.item(), n_steps)\n\n print('\\nEvaluation Completed ({})!\\tLoss: {:5.4f} Time: {:5.3f} s'.format(\n split,\n np.asarray(val_loss).mean(0),\n time.time() - start_time\n ))\n return np.asarray(val_loss).mean(0)",
"_____no_output_____"
],
[
"print(beta)",
"1\n"
],
[
"print(model)",
"VAE_NF(\n (encoder): Sequential(\n (0): Linear(in_features=120, out_features=300, bias=True)\n (1): LeakyReLU(negative_slope=True)\n (2): Linear(in_features=300, out_features=160, bias=True)\n (3): LeakyReLU(negative_slope=True)\n (4): Linear(in_features=160, out_features=80, bias=True)\n (5): LeakyReLU(negative_slope=True)\n (6): Linear(in_features=80, out_features=40, bias=True)\n (7): LeakyReLU(negative_slope=True)\n (8): Linear(in_features=40, out_features=20, bias=True)\n (9): LeakyReLU(negative_slope=True)\n (10): Linear(in_features=20, out_features=20, bias=True)\n )\n (decoder): Sequential(\n (0): Linear(in_features=10, out_features=20, bias=True)\n (1): LeakyReLU(negative_slope=True)\n (2): Linear(in_features=20, out_features=40, bias=True)\n (3): LeakyReLU(negative_slope=True)\n (4): Linear(in_features=40, out_features=80, bias=True)\n (5): LeakyReLU(negative_slope=True)\n (6): Linear(in_features=80, out_features=160, bias=True)\n (7): LeakyReLU(negative_slope=True)\n (8): Linear(in_features=160, out_features=300, bias=True)\n (9): LeakyReLU(negative_slope=True)\n (10): Linear(in_features=300, out_features=120, bias=True)\n )\n (flows): NormalizingFlowModel(\n (flows): ModuleList(\n (0): MAF(\n (layers): ModuleList(\n (0): FCNN(\n (network): Sequential(\n (0): Linear(in_features=1, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (1): FCNN(\n (network): Sequential(\n (0): Linear(in_features=2, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (2): FCNN(\n (network): Sequential(\n (0): Linear(in_features=3, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (3): FCNN(\n (network): Sequential(\n (0): Linear(in_features=4, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (4): FCNN(\n (network): Sequential(\n (0): Linear(in_features=5, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (5): FCNN(\n (network): Sequential(\n (0): Linear(in_features=6, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (6): FCNN(\n (network): Sequential(\n (0): Linear(in_features=7, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (7): FCNN(\n (network): Sequential(\n (0): Linear(in_features=8, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (8): FCNN(\n (network): Sequential(\n (0): Linear(in_features=9, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n )\n )\n (1): MAF(\n (layers): ModuleList(\n (0): FCNN(\n (network): Sequential(\n (0): Linear(in_features=1, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (1): FCNN(\n (network): Sequential(\n (0): Linear(in_features=2, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (2): FCNN(\n (network): Sequential(\n (0): Linear(in_features=3, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (3): FCNN(\n (network): Sequential(\n (0): Linear(in_features=4, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (4): FCNN(\n (network): Sequential(\n (0): Linear(in_features=5, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (5): FCNN(\n (network): Sequential(\n (0): Linear(in_features=6, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (6): FCNN(\n (network): Sequential(\n (0): Linear(in_features=7, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (7): FCNN(\n (network): Sequential(\n (0): Linear(in_features=8, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (8): FCNN(\n (network): Sequential(\n (0): Linear(in_features=9, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n )\n )\n (2): MAF(\n (layers): ModuleList(\n (0): FCNN(\n (network): Sequential(\n (0): Linear(in_features=1, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (1): FCNN(\n (network): Sequential(\n (0): Linear(in_features=2, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (2): FCNN(\n (network): Sequential(\n (0): Linear(in_features=3, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (3): FCNN(\n (network): Sequential(\n (0): Linear(in_features=4, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (4): FCNN(\n (network): Sequential(\n (0): Linear(in_features=5, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (5): FCNN(\n (network): Sequential(\n (0): Linear(in_features=6, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (6): FCNN(\n (network): Sequential(\n (0): Linear(in_features=7, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (7): FCNN(\n (network): Sequential(\n (0): Linear(in_features=8, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (8): FCNN(\n (network): Sequential(\n (0): Linear(in_features=9, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n )\n )\n (3): MAF(\n (layers): ModuleList(\n (0): FCNN(\n (network): Sequential(\n (0): Linear(in_features=1, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (1): FCNN(\n (network): Sequential(\n (0): Linear(in_features=2, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (2): FCNN(\n (network): Sequential(\n (0): Linear(in_features=3, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (3): FCNN(\n (network): Sequential(\n (0): Linear(in_features=4, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (4): FCNN(\n (network): Sequential(\n (0): Linear(in_features=5, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (5): FCNN(\n (network): Sequential(\n (0): Linear(in_features=6, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (6): FCNN(\n (network): Sequential(\n (0): Linear(in_features=7, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (7): FCNN(\n (network): Sequential(\n (0): Linear(in_features=8, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (8): FCNN(\n (network): Sequential(\n (0): Linear(in_features=9, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n )\n )\n (4): MAF(\n (layers): ModuleList(\n (0): FCNN(\n (network): Sequential(\n (0): Linear(in_features=1, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (1): FCNN(\n (network): Sequential(\n (0): Linear(in_features=2, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (2): FCNN(\n (network): Sequential(\n (0): Linear(in_features=3, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (3): FCNN(\n (network): Sequential(\n (0): Linear(in_features=4, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (4): FCNN(\n (network): Sequential(\n (0): Linear(in_features=5, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (5): FCNN(\n (network): Sequential(\n (0): Linear(in_features=6, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (6): FCNN(\n (network): Sequential(\n (0): Linear(in_features=7, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (7): FCNN(\n (network): Sequential(\n (0): Linear(in_features=8, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (8): FCNN(\n (network): Sequential(\n (0): Linear(in_features=9, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n )\n )\n (5): MAF(\n (layers): ModuleList(\n (0): FCNN(\n (network): Sequential(\n (0): Linear(in_features=1, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (1): FCNN(\n (network): Sequential(\n (0): Linear(in_features=2, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (2): FCNN(\n (network): Sequential(\n (0): Linear(in_features=3, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (3): FCNN(\n (network): Sequential(\n (0): Linear(in_features=4, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (4): FCNN(\n (network): Sequential(\n (0): Linear(in_features=5, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (5): FCNN(\n (network): Sequential(\n (0): Linear(in_features=6, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (6): FCNN(\n (network): Sequential(\n (0): Linear(in_features=7, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (7): FCNN(\n (network): Sequential(\n (0): Linear(in_features=8, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (8): FCNN(\n (network): Sequential(\n (0): Linear(in_features=9, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n )\n )\n (6): MAF(\n (layers): ModuleList(\n (0): FCNN(\n (network): Sequential(\n (0): Linear(in_features=1, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (1): FCNN(\n (network): Sequential(\n (0): Linear(in_features=2, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (2): FCNN(\n (network): Sequential(\n (0): Linear(in_features=3, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (3): FCNN(\n (network): Sequential(\n (0): Linear(in_features=4, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (4): FCNN(\n (network): Sequential(\n (0): Linear(in_features=5, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (5): FCNN(\n (network): Sequential(\n (0): Linear(in_features=6, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (6): FCNN(\n (network): Sequential(\n (0): Linear(in_features=7, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (7): FCNN(\n (network): Sequential(\n (0): Linear(in_features=8, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (8): FCNN(\n (network): Sequential(\n (0): Linear(in_features=9, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n )\n )\n (7): MAF(\n (layers): ModuleList(\n (0): FCNN(\n (network): Sequential(\n (0): Linear(in_features=1, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (1): FCNN(\n (network): Sequential(\n (0): Linear(in_features=2, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (2): FCNN(\n (network): Sequential(\n (0): Linear(in_features=3, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (3): FCNN(\n (network): Sequential(\n (0): Linear(in_features=4, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (4): FCNN(\n (network): Sequential(\n (0): Linear(in_features=5, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (5): FCNN(\n (network): Sequential(\n (0): Linear(in_features=6, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (6): FCNN(\n (network): Sequential(\n (0): Linear(in_features=7, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (7): FCNN(\n (network): Sequential(\n (0): Linear(in_features=8, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (8): FCNN(\n (network): Sequential(\n (0): Linear(in_features=9, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n )\n )\n (8): MAF(\n (layers): ModuleList(\n (0): FCNN(\n (network): Sequential(\n (0): Linear(in_features=1, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (1): FCNN(\n (network): Sequential(\n (0): Linear(in_features=2, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (2): FCNN(\n (network): Sequential(\n (0): Linear(in_features=3, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (3): FCNN(\n (network): Sequential(\n (0): Linear(in_features=4, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (4): FCNN(\n (network): Sequential(\n (0): Linear(in_features=5, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (5): FCNN(\n (network): Sequential(\n (0): Linear(in_features=6, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (6): FCNN(\n (network): Sequential(\n (0): Linear(in_features=7, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (7): FCNN(\n (network): Sequential(\n (0): Linear(in_features=8, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (8): FCNN(\n (network): Sequential(\n (0): Linear(in_features=9, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n )\n )\n (9): MAF(\n (layers): ModuleList(\n (0): FCNN(\n (network): Sequential(\n (0): Linear(in_features=1, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (1): FCNN(\n (network): Sequential(\n (0): Linear(in_features=2, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (2): FCNN(\n (network): Sequential(\n (0): Linear(in_features=3, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (3): FCNN(\n (network): Sequential(\n (0): Linear(in_features=4, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (4): FCNN(\n (network): Sequential(\n (0): Linear(in_features=5, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (5): FCNN(\n (network): Sequential(\n (0): Linear(in_features=6, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (6): FCNN(\n (network): Sequential(\n (0): Linear(in_features=7, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (7): FCNN(\n (network): Sequential(\n (0): Linear(in_features=8, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n (8): FCNN(\n (network): Sequential(\n (0): Linear(in_features=9, out_features=8, bias=True)\n (1): Tanh()\n (2): Linear(in_features=8, out_features=8, bias=True)\n (3): Tanh()\n (4): Linear(in_features=8, out_features=2, bias=True)\n )\n )\n )\n )\n )\n )\n)\n"
],
[
"'''\nae_def = {\n \"type\":\"bkg\",\n \"trainon\":\"purebkg\",\n \"features\":\"tauDDTwithrawmass\",\n \"architecture\":\"MAF\",\n \"selection\":\"turnoncutandj1sdbcut\",\n \"trainloss\":\"MSELoss\",\n \"beta\":\"beta1\",\n \"zdimnflow\":\"z6f10\",\n}\n'''",
"_____no_output_____"
],
[
"ae_def = {\n \"type\":\"bkg\",\n \"trainon\":\"purebkg\",\n \"features\":\"40part\",\n \"architecture\":\"MAF\",\n \"selection\":\"noselection\",\n \"trainloss\":\"MSELoss\",\n \"beta\":\"beta1\",\n \"zdimnflow\":\"z10f10\",\n}",
"_____no_output_____"
],
[
"ae_def",
"_____no_output_____"
],
[
"N_EPOCHS = 10\nBEST_LOSS = 9\nLAST_SAVED = -1\nPATIENCE_COUNT = 0\nPATIENCE_LIMIT = 5\nfor epoch in range(1, 1000):\n print(\"Epoch {}:\".format(epoch))\n train()\n cur_loss = evaluate()\n\n if cur_loss <= BEST_LOSS:\n PATIENCE_COUNT = 0\n BEST_LOSS = cur_loss\n LAST_SAVED = epoch\n print(\"Saving model!\")\n torch.save(model.state_dict(),f\"/data/t3home000/spark/QUASAR/weights/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['architecture']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}.h5\")\n \n else:\n PATIENCE_COUNT += 1\n print(\"Not saving model! Last saved: {}\".format(LAST_SAVED))\n if PATIENCE_COUNT > 10:\n print(\"Patience Limit Reached\")\n break ",
"Epoch 1:\n"
],
[
"model.load_state_dict(torch.load(f\"/data/t3home000/spark/QUASAR/weights/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['architecture']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}.h5\"))",
"_____no_output_____"
]
],
[
[
"## Testing the bkg ae",
"_____no_output_____"
]
],
[
[
"def getloss(tensor):\n return torch.mean((model(tensor.float().cuda())[0]- tensor.float().cuda())**2,dim=1).data.cpu().numpy()",
"_____no_output_____"
],
[
"sigloss = getloss(total_sig)",
"_____no_output_____"
],
[
"def get_loss(dt):\n \n def generator(dt, chunk_size=5000, total_size=1000000):\n\n i = 0\n i_max = total_size // chunk_size\n print(i_max)\n \n for i in range(i_max):\n start=i * chunk_size\n stop=(i + 1) * chunk_size\n yield torch.tensor(dt[start:stop])\n \n loss = []\n\n \n with torch.no_grad():\n \n for total_in_selection in generator(dt,chunk_size=5000, total_size=1000000):\n loss.extend(torch.mean((model(total_in_selection.float().cuda())[0]- total_in_selection.float().cuda())**2,dim=1).data.cpu().numpy())\n \n return loss",
"_____no_output_____"
],
[
"bkgloss = get_loss(Y)",
"200\n"
],
[
"sigloss.shape",
"_____no_output_____"
],
[
"len(bkgloss)",
"_____no_output_____"
],
[
"plt.hist(sigloss,bins=np.linspace(0,2,1001),alpha=0.3,density=True);\nplt.hist(bkgloss,bins=np.linspace(0,2,1001),alpha=0.3,density=True);",
"_____no_output_____"
],
[
"inputlist = [\n '/data/t3home000/spark/QUASAR/preprocessing/conventional_tau_BB1_rnd.h5',\n '/data/t3home000/spark/QUASAR/preprocessing/conventional_tau_BB2.h5',\n '/data/t3home000/spark/QUASAR/preprocessing/conventional_tau_BB3.h5',\n '/data/t3home000/spark/QUASAR/preprocessing/conventional_tau_background.h5',\n '/data/t3home000/spark/QUASAR/preprocessing/conventional_tau_rnd.h5',\n '/data/t3home000/spark/QUASAR/preprocessing/conventional_tau_rnd.h5', \n '/data/t3home000/spark/QUASAR/preprocessing/conventional_tau_3prong_rnd.h5' \n]",
"_____no_output_____"
],
[
"ae_def",
"_____no_output_____"
],
[
"outputlist_waic = [\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_WAICloss_bb1.npy\",\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_WAICloss_bb2.npy\",\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_WAICloss_bb3.npy\",\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_WAICloss_purebkg.npy\",\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_WAICloss_rndbkg.npy\",\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_WAICloss_2prong.npy\",\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_WAICloss_3prong.npy\",\n]\n\noutputlist_justloss = [\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_Justloss_bb1.npy\",\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_Justloss_bb2.npy\",\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_Justloss_bb3.npy\",\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_Justloss_purebkg.npy\",\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_Justloss_rndbkg.npy\",\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_Justloss_2prong.npy\",\n f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_Justloss_3prong.npy\",\n]",
"_____no_output_____"
],
[
"exist_signalflag = [\n False,\n False,\n False,\n False,\n True,\n True,\n True,\n]\nis_signal = [\n False,\n False,\n False,\n False,\n False,\n True,\n True\n]\n\nnprong = [\n None,\n None,\n None,\n None,\n None,\n '2prong',\n '3prong'\n]",
"_____no_output_____"
],
[
"for in_file, out_file_waic, out_file_justloss, sigbit_flag, is_sig, n_prong in zip(inputlist,outputlist_waic,outputlist_justloss,exist_signalflag,is_signal, nprong): \n \n f_bb = pd.read_hdf(in_file)\n dt = f_bb.values\n correct = (dt[:,3]>0) &(dt[:,19]>0) & (dt[:,1]>0) & (dt[:,2]>0)\n dt = dt[correct]\n for i in range(13,19):\n dt[:,i] = dt[:,i]/dt[:,3]\n\n for i in range(29,35):\n dt[:,i] = dt[:,i]/(dt[:,19])\n\n\n\n if sigbit_flag:\n idx = dt[:,-1]\n sigidx = (idx == 1)\n bkgidx = (idx == 0)\n if is_sig:\n dt = dt[sigidx]\n else:\n dt = dt[bkgidx]\n \n if n_prong == '2prong':\n \n correct = (dt[:,3]>450) & (dt[:,3]<550) & (dt[:,19]>50) & (dt[:,19]<150) & (dt[:,0]>3400) & (dt[:,0]<3600)\n dt = dt[correct]\n \n if n_prong == '3prong':\n \n correct = (dt[:,3]>450) & (dt[:,3]<550) & (dt[:,19]>50) & (dt[:,19]<150) & (dt[:,0]>3400) & (dt[:,0]<3600)\n dt = dt[correct] \n \n \n Y = dt[:,[4,5,6,7,8,11,12,13,14,15,16,17,18,20,21,22,23,24,27,28,29,30,31,32,33,34]]\n #Y = dt[:,[3,4,5,6,11,12,13,14,15,16,17,18,19,20,21,22,27,28,29,30,31,32,33,34]]\n #Y = dt[:,[3,4,5,6,11,12,13,14,15,16,17,18,19,20,21,22,27,28,29,30,31,32,33,34]]\n #Y = dt[:,[3,4,5,6,11,12,19,20,21,22,27,28]]\n \n\n \n \n print(Y.shape)\n for i in range(26):\n Y[:,i] = (Y[:,i]-bkg_mean[i])/bkg_std[i]\n \n total_bb_test = torch.tensor(Y)\n #huberloss = nn.SmoothL1Loss(reduction='none')\n sigae_bbloss = torch.mean((model(total_bb_test.float().cuda())[0]- total_bb_test.float().cuda())**2,dim=1).data.cpu().numpy()\n bbvar = torch.var((model(total_bb_test.float().cuda())[0]- total_bb_test.float().cuda())**2,dim=1).data.cpu().numpy()\n waic = sigae_bbloss + bbvar\n #sigae_bbloss = torch.mean(huberloss(model(total_bb_test.float().cuda())[0],total_bb_test.float().cuda()),dim=1).data.cpu().numpy()\n print(waic[0:10])\n plt.hist(waic,bins=np.linspace(0,10,1001),density=True);\n plt.xlim([0,2])\n np.save(out_file_waic,waic)\n np.save(out_file_justloss,sigae_bbloss)",
"(999728, 26)\n"
],
[
"f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_WAICloss_bb1.npy\",\nf\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_WAICloss_bb2.npy\",\nf\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_WAICloss_bb3.npy\",\nf\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_WAICloss_purebkg.npy\",\nf\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_WAICloss_rndbkg.npy\",",
"_____no_output_____"
],
[
"loss_prong3 = np.load(f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_Justloss_3prong.npy\")\nloss_prong2 = np.load(f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_Justloss_2prong.npy\")\nloss_purebkg = np.load(f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_Justloss_purebkg.npy\")\nloss_rndbkg = np.load(f\"../data_strings/{ae_def['type']}_{ae_def['trainon']}_{ae_def['features']}_{ae_def['selection']}_{ae_def['trainloss']}_{ae_def['beta']}_{ae_def['zdimnflow']}_Justloss_rndbkg.npy\")\n\n",
"_____no_output_____"
],
[
"#plt.hist(loss_purebkg,bins=np.linspace(0,2,100),density=True,alpha=0.3,label='Pure Bkg');\nplt.hist(loss_rndbkg,bins=np.linspace(0,2,100),density=False,alpha=0.3,label='(rnd) bkg');\n\nplt.hist(loss_prong2,bins=np.linspace(0,2,100),density=False,alpha=0.3,label='2prong (rnd)sig');\nplt.hist(loss_prong3,bins=np.linspace(0,2,100),density=False,alpha=0.3,label='3prong (rnd)sig');\n#plt.yscale('log')\nplt.xlabel('BkgAE trained on PureBkg')\nplt.legend(loc='upper right')\n#plt.savefig('bkgae_trained_on_purebkg_withmass_turnonselection.png')",
"_____no_output_____"
],
[
"ae_def",
"_____no_output_____"
],
[
"len(loss_prong2)",
"_____no_output_____"
],
[
"def reconstruct(X):\n out = model(torch.tensor(X[:100000]).float().cuda())[0]\n out = out.data.cpu().numpy()\n return out",
"_____no_output_____"
],
[
"out = reconstruct(Y)",
"_____no_output_____"
],
[
"out.shape",
"_____no_output_____"
],
[
"bins = np.linspace(-3,3,100)\nbins.shape\ncolumn = 0\n#print(df.coluns[column])\nplt.hist(Y[:,column],bins,density=True,alpha=0.5,color='b');\nplt.hist(out[:,column],bins,density=True,alpha=0.5,color='r');\nplt.axvline(np.mean(Y[:,column]))",
"_____no_output_____"
],
[
"f_bb = pd.read_hdf('/data/t3home000/spark/QUASAR/preprocessing/conventional_tau_3prong_rnd.h5')",
"_____no_output_____"
],
[
"dt = f_bb.values",
"_____no_output_____"
],
[
"correct = (dt[:,3]>0) &(dt[:,19]>0)\ndt = dt[correct]\nfor i in range(13,19):\n dt[:,i] = dt[:,i]/dt[:,3]\n \nfor i in range(29,35):\n dt[:,i] = dt[:,i]/(dt[:,19])\n \n \ncorrect = (dt[:,29]>=0) &(dt[:,29]<=1)&(dt[:,30]>=0) &(dt[:,30]<=1)&(dt[:,31]>=0) &(dt[:,31]<=1)&(dt[:,32]>=0) &(dt[:,32]<=1)&(dt[:,33]>=0) &(dt[:,33]<=1)&(dt[:,34]>=-0.01) &(dt[:,34]<=1)\ndt = dt[correct]\nY = dt[:,[3,4,5,6,11,12,13,14,15,16,17,18,19,20,21,22,27,28,29,30,31,32,33,34]]",
"_____no_output_____"
],
[
"Y.shape",
"_____no_output_____"
],
[
"idx = dt[:,-1]\nsigidx = idx == 1\nbkgidx = idx == 0",
"_____no_output_____"
],
[
"for i in range(24):\n Y[:,i] = (Y[:,i]-bkg_mean[i])/bkg_std[i]",
"_____no_output_____"
],
[
"Y = Y[sigidx]",
"_____no_output_____"
],
[
"#correct = Y[:,0] > 300 #(For 2prong)\ncorrect = Y[:,0] > 400 # (for 3prong)",
"_____no_output_____"
],
[
"Y = Y[correct]",
"_____no_output_____"
],
[
"Y.shape",
"_____no_output_____"
],
[
"plt.hist(Y[:,0],bins=np.linspace(0,1000,1001));",
"_____no_output_____"
],
[
"np.mean(Y[:,0])",
"_____no_output_____"
],
[
"total_bb_test = torch.tensor(Y)\nbkgae_bbloss = torch.mean((model(total_bb_test.float().cuda())[0]- total_bb_test.float().cuda())**2,dim=1).data.cpu().numpy()",
"_____no_output_____"
],
[
"bkgae_bbloss",
"_____no_output_____"
],
[
"plt.hist(bkgae_bbloss,bins=np.linspace(0,10,1001));",
"_____no_output_____"
],
[
"np.save('../data_strings/bkgae_rndbkg_loss_3prong.npy',bkgae_bbloss)",
"_____no_output_____"
],
[
"loss_prong3 = np.load('../data_strings/bkgae_purebkg_loss_3prong.npy')\nloss_prong2 = np.load('../data_strings/bkgae_purebkg_loss_2prong.npy')\nloss_purebkg = np.load('../data_strings/bkgae_purebkg_loss_purebkg.npy')\nloss_rndbkg = np.load('../data_strings/bkgae_purebkg_loss_rndbkg.npy')",
"_____no_output_____"
],
[
"len(loss_purebkg)",
"_____no_output_____"
],
[
"len(loss_prong2)",
"_____no_output_____"
],
[
"plt.hist(loss_purebkg,bins=np.linspace(0,10,100),weights=np.ones(len(loss_purebkg)),alpha=0.3,label='Pure Bkg');\nplt.hist(loss_rndbkg,bins=np.linspace(0,10,100),weights=np.ones(len(loss_rndbkg))*(len(loss_purebkg)/len(loss_rndbkg)),alpha=0.3,label='(rnd) bkg');\n\n#plt.hist(loss_prong3,bins=np.linspace(0,2,100),weights=np.ones(len(loss_prong3))*(len(loss_purebkg)/len(loss_prong3)),alpha=0.3,label='2prong (rnd)sig');\n#plt.hist(loss_prong2,bins=np.linspace(0,2,100),weights=np.ones(len(loss_prong2))*(len(loss_purebkg)/len(loss_prong2)),alpha=0.3,label='3prong (rnd)sig');\nplt.yscale('log')\nplt.xlabel('BkgAE trained on Pure Bkg')\nplt.legend(loc='upper right')\nplt.savefig('bkgae_trained_on_pure_bkg_onlybkg.png')",
"_____no_output_____"
],
[
"def get_loss(dt):\n \n def generator(dt, chunk_size=5000, total_size=1000000):\n\n i = 0\n i_max = total_size // chunk_size\n print(i_max)\n \n for i in range(i_max):\n start=i * chunk_size\n stop=(i + 1) * chunk_size\n yield torch.tensor(dt[start:stop])\n \n loss = []\n\n \n with torch.no_grad():\n \n for total_in_selection in generator(dt,chunk_size=5000, total_size=1000000):\n loss.extend(torch.mean((model(total_in_selection.float().cuda())[0]- total_in_selection.float().cuda())**2,dim=1).data.cpu().numpy())\n \n return loss",
"_____no_output_____"
],
[
"bb1_loss_bkg = get_loss(X_bb1)",
"200\n"
],
[
"bb1_loss_bkg = np.array(bb1_loss_bkg,dtype=np.float)",
"_____no_output_____"
],
[
"bb1_loss_bkg",
"_____no_output_____"
],
[
"plt.hist(bb1_loss_bkg,bins=np.linspace(0,5,1001));",
"_____no_output_____"
],
[
"np.save('../data_strings/bkgaeloss_bb1.npy',bb1_loss_bkg)",
"_____no_output_____"
],
[
"f_bb2 = pd.read_hdf('/data/t3home000/spark/QUASAR/preprocessing/conventional_tau_BB2.h5')\ndt_bb2 = f_bb2.values",
"_____no_output_____"
],
[
"X_bb2 = dt_bb2[:,[3,4,5,6,11,12,19,20,21,22,27,28]]",
"_____no_output_____"
],
[
"for i in range(12):\n X_bb2[:,i] = (X_bb2[:,i]-bkg_mean[i])/bkg_std[i]",
"_____no_output_____"
],
[
"bb2_loss_bkg = get_loss(X_bb2)",
"200\n"
],
[
"bb2_loss_bkg = np.array(bb2_loss_bkg,dtype=np.float)",
"_____no_output_____"
],
[
"plt.hist(bb2_loss_bkg,bins=np.linspace(0,5,1001));",
"_____no_output_____"
],
[
"f_bb3 = pd.read_hdf('/data/t3home000/spark/QUASAR/preprocessing/conventional_tau_BB3.h5')\ndt_bb3 = f_bb3.values",
"_____no_output_____"
],
[
"X_bb3 = dt_bb3[:,[3,4,5,6,11,12,19,20,21,22,27,28]]",
"_____no_output_____"
],
[
"for i in range(12):\n X_bb3[:,i] = (X_bb3[:,i]-bkg_mean[i])/bkg_std[i]",
"_____no_output_____"
],
[
"bb3_loss_bkg = get_loss(X_bb3)",
"200\n"
],
[
"bb3_loss_bkg = np.array(bb3_loss_bkg,dtype=np.float)",
"_____no_output_____"
],
[
"bb3_loss_bkg",
"_____no_output_____"
],
[
"plt.hist(bb3_loss_bkg,bins=np.linspace(0,5,1001));",
"_____no_output_____"
],
[
"np.save('../data_strings/bkgaeloss_bb2.npy',bb2_loss_bkg)",
"_____no_output_____"
],
[
"np.save('../data_strings/bkgaeloss_bb3.npy',bb3_loss_bkg)",
"_____no_output_____"
],
[
"X[signal_idx].shape",
"_____no_output_____"
],
[
"loss_bkg = get_loss(X[bkg_idx])\nloss_sig = get_loss(X[signal_idx])",
"(992924, 30)\n(99829, 30)\n"
],
[
"plt.rcParams[\"figure.figsize\"] = (10,10)\nbins = np.linspace(0,0.5,1100)\nplt.hist(loss_bkg,bins=bins,alpha=0.3,color='b',label='bkg')\nplt.hist(loss_sig,bins=bins,alpha=0.3,color='r',label='sig')\nplt.xlabel(r'Autoencoder Loss')\nplt.ylabel('Count')\nplt.legend(loc='upper right')\nplt.show()",
"_____no_output_____"
],
[
"def get_tpr_fpr(sigloss,bkgloss,aetype='sig'):\n bins = np.linspace(0,50,1001)\n tpr = []\n fpr = []\n for cut in bins:\n if aetype == 'sig':\n tpr.append(np.where(sigloss<cut)[0].shape[0]/len(sigloss))\n fpr.append(np.where(bkgloss<cut)[0].shape[0]/len(bkgloss))\n if aetype == 'bkg':\n tpr.append(np.where(sigloss>cut)[0].shape[0]/len(sigloss))\n fpr.append(np.where(bkgloss>cut)[0].shape[0]/len(bkgloss))\n return tpr,fpr ",
"_____no_output_____"
],
[
"bkg_tpr, bkg_fpr = get_tpr_fpr(loss_sig,loss_bkg,aetype='bkg')",
"_____no_output_____"
],
[
"np.save('NFLOWVAE_PlanarNEW_bkgAE_fpr.npy',bkg_fpr)\nnp.save('NFLOWVAE_PlanarNEW_bkgAE_tpr.npy',bkg_tpr)",
"_____no_output_____"
],
[
"plt.plot(bkg_fpr,bkg_tpr,label='Bkg NFlowVAE-Planar')\n",
"_____no_output_____"
],
[
"def get_precision_recall(sigloss,bkgloss,aetype='bkg'):\n bins = np.linspace(0,100,1001)\n tpr = []\n fpr = []\n precision = []\n for cut in bins:\n if aetype == 'sig':\n tpr.append(np.where(sigloss<cut)[0].shape[0]/len(sigloss))\n precision.append((np.where(sigloss<cut)[0].shape[0])/(np.where(bkgloss<cut)[0].shape[0]+np.where(sigloss<cut)[0].shape[0]))\n \n if aetype == 'bkg':\n tpr.append(np.where(sigloss>cut)[0].shape[0]/len(sigloss))\n precision.append((np.where(sigloss>cut)[0].shape[0])/(np.where(bkgloss>cut)[0].shape[0]+np.where(sigloss>cut)[0].shape[0]))\n return precision,tpr ",
"_____no_output_____"
],
[
"precision,recall = get_precision_recall(loss_sig,loss_bkg,aetype='bkg')",
"_____no_output_____"
],
[
"np.save('NFLOWVAE_PlanarNEW_22var_sigloss.npy',loss_sig)\nnp.save('NFLOWVAE_PlanarNEW_22var_bkgloss.npy',loss_bkg)",
"_____no_output_____"
],
[
"np.save('NFLOWVAE_PlanarNEW_precision.npy',precision)\nnp.save('NFLOWVAE_PlanarNEW_recall.npy',recall)\nnp.save('NFLOWVAE_PlanarNEW_bkgAE_fpr.npy',bkg_fpr)\nnp.save('NFLOWVAE_PlanarNEW_bkgAE_tpr.npy',bkg_tpr)\nnp.save('NFLOWVAE_PlanarNEW_sigloss.npy',loss_sig)\nnp.save('NFLOWVAE_PlanarNEW_bkgloss.npy',loss_bkg)",
"_____no_output_____"
],
[
"plt.plot(recall,precision)",
"_____no_output_____"
],
[
"flows = [1,2,3,4,5,6]\nzdim = [1,2,3,4,5]\n\nfor N_flows in flows:\n for Z_DIM in zdim:\n model = VAE_NF(N_FLOWS, Z_DIM).cuda()\n optimizer = optim.Adam(model.parameters(), lr=LR)\n BEST_LOSS = 99999\n LAST_SAVED = -1\n PATIENCE_COUNT = 0\n PATIENCE_LIMIT = 5\n for epoch in range(1, N_EPOCHS):\n print(\"Epoch {}:\".format(epoch))\n train()\n cur_loss = evaluate()\n\n if cur_loss <= BEST_LOSS:\n PATIENCE_COUNT = 0\n BEST_LOSS = cur_loss\n LAST_SAVED = epoch\n print(\"Saving model!\")\n if mode == 'ROC':\n torch.save(model.state_dict(),f\"/data/t3home000/spark/QUASAR/weights/bkg_vae_NF_planar_RND_22var_z{Z_DIM}_f{N_FLOWS}.h5\")\n else:\n torch.save(model.state_dict(), f\"/data/t3home000/spark/QUASAR/weights/bkg_vae_NF_planar_PureBkg_22var_z{Z_DIM}_f{N_FLOWS}.h5\")\n else:\n PATIENCE_COUNT += 1\n print(\"Not saving model! Last saved: {}\".format(LAST_SAVED))\n if PATIENCE_COUNT > 3:\n print(\"Patience Limit Reached\")\n break \n \n loss_bkg = get_loss(dt_PureBkg[bkg_idx])\n loss_sig = get_loss(dt_PureBkg[signal_idx])\n np.save(f'NFLOWVAE_PlanarNEW_22var_z{Z_DIM}_f{N_flows}_sigloss.npy',loss_sig)\n np.save(f'NFLOWVAE_PlanarNEW_22var_z{Z_DIM}_f{N_flows}_bkgloss.npy',loss_bkg)",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecbfff8fdc5930258425f27559a60e696e2c5898 | 14,339 | ipynb | Jupyter Notebook | deep_learning/transformer/transformer.ipynb | bingrao/notebook | 4bd74a09ffe86164e4bd318b25480c9ca0c6a462 | [
"MIT"
] | null | null | null | deep_learning/transformer/transformer.ipynb | bingrao/notebook | 4bd74a09ffe86164e4bd318b25480c9ca0c6a462 | [
"MIT"
] | null | null | null | deep_learning/transformer/transformer.ipynb | bingrao/notebook | 4bd74a09ffe86164e4bd318b25480c9ca0c6a462 | [
"MIT"
] | null | null | null | 29.263265 | 719 | 0.550596 | [
[
[
"The two most commonly used attention functions are additive attention [(cite)](https://arxiv.org/abs/1409.0473), and dot-product (multiplicative) attention. Dot-product attention is identical to our algorithm, except for the scaling factor of $\\frac{1}{\\sqrt{d_k}}$. Additive attention computes the compatibility function using a feed-forward network with a single hidden layer. While the two are similar in theoretical complexity, dot-product attention is much faster and more space-efficient in practice, since it can be implemented using highly optimized matrix multiplication code. \n\n \nWhile for small values of $d_k$ the two mechanisms perform similarly, additive attention outperforms dot product attention without scaling for larger values of $d_k$ [(cite)](https://arxiv.org/abs/1703.03906). We suspect that for large values of $d_k$, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients (To illustrate why the dot products get large, assume that the components of $q$ and $k$ are independent random variables with mean $0$ and variance $1$. Then their dot product, $q \\cdot k = \\sum_{i=1}^{d_k} q_ik_i$, has mean $0$ and variance $d_k$.). To counteract this effect, we scale the dot products by $\\frac{1}{\\sqrt{d_k}}$.",
"_____no_output_____"
],
[
"# What is Attention\n\nInformally, a neural attention mechanism equips a neural network with the ability to focus on a subset of its inputs (or features): it selects specific inputs. Let $x \\in R^{d}$ be an input vector, $z \\in R^{k}$ a feature vector, $a \\in [0, 1]^{k}$ an attention vector, $g \\in R^{k}$ an attention glimpse and $f_{ϕ}(x)$ an attention network with parameters. Typically, attention is implemented as\n\n$$a = f_{ϕ}(x)$$\n$$g = a*z$$",
"_____no_output_____"
],
[
"# Reference\n1. [Attention in Neural Networks and How to Use It](http://akosiorek.github.io/ml/2017/10/14/visual-attention.html)",
"_____no_output_____"
],
[
"# Epoch vs Batch Size vs Iterations\nWe need terminologies like **epochs**, **batch size**, **iterations** only when the data is too big which happens all the time in machine learning and we can’t pass all the data to the computer at once. So, to overcome this problem we need to divide the data into smaller sizes and give it to our computer one by one and update the weights of the neural networks at the end of every step to fit it to the data given.\n# What is Epoches : One Epoch is when an **ENTIRE** dataset is passed forward and backward through the neural network only ONCE.\nSince one epoch is too big to feed to the computer at once we divide it in several smaller **batches**.\n\n## Why we use more than one Epoch?\n\nI know it doesn’t make sense in the starting that — passing the entire dataset through a neural network is not enough. And we need to pass the full dataset multiple times to the same neural network. But keep in mind that we are using a limited dataset and to optimise the learning and the graph we are using Gradient Descent which is an iterative process. So, updating the weights with single pass or one epoch is not enough.\n\n\n<img src=\"images/nums_epoches.png\" />\n\nHowever in above graph, as the number of epochs increases, more number of times the weight are changed in the neural network and the curve goes from underfitting to optimal to overfitting curve.\n\n\n## So, what is the right numbers of epochs?\n\nUnfortunately, there is no right answer to this question. The answer is **different for different datasets but you can say that the numbers of epochs is related to how diverse your data is… ** just an example - Do you have only black cats in your dataset or is it much more diverse dataset?\n\n# Batch Size: Total number of training examples present in a single batch.\n\nAs I said, you can’t pass the entire dataset into the neural net at once. So, you divide dataset into Number of Batches or sets or parts.\n\n# Iterations: Iterations is the number of batches needed to complete one epoch.\n\n**Note**: The number of batches is equal to number of iterations for one epoch.\n\n\n\n# Example\nLet’s say we have 2000 training examples that we are going to use . **We can divide the dataset of 2000 examples into batches of 500 then it will take 4 iterations to complete 1 epoch.**, Where **Batch Size** is 500 and **Iterations** is 4, for 1 complete epoch.\n",
"_____no_output_____"
],
[
"\n\n",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport math, copy, time\nfrom torch.autograd import Variable\nimport matplotlib.pyplot as plt\nimport seaborn\nseaborn.set_context(context=\"talk\")\n%matplotlib inline\nclass PositionalEncoding(nn.Module):\n \"Implement the PE function.\"\n def __init__(self, d_model, dropout, max_len=5000):\n super(PositionalEncoding, self).__init__()\n self.dropout = nn.Dropout(p=dropout)\n \n # Compute the positional encodings once in log space.\n pe = torch.zeros(max_len, d_model)\n position = torch.arange(0, max_len).unsqueeze(1)\n div_term = torch.exp(torch.arange(0, d_model, 2) *\n -(math.log(10000.0) / d_model))\n pe[:, 0::2] = torch.sin(position * div_term)\n pe[:, 1::2] = torch.cos(position * div_term)\n pe = pe.unsqueeze(0)\n self.register_buffer('pe', pe)\n \n def forward(self, x):\n x = Variable(self.pe[:, :x.size(1)], \n requires_grad=False)\n return self.dropout(x)",
"_____no_output_____"
],
[
"pe = PositionalEncoding(16, 0.1)",
"_____no_output_____"
],
[
"pe.pe.size()",
"_____no_output_____"
],
[
"table = pe.pe.squeeze(0)",
"_____no_output_____"
],
[
"table.size()",
"_____no_output_____"
],
[
"p1 = table[1,:]",
"_____no_output_____"
],
[
"p2 = table[2,:]",
"_____no_output_____"
],
[
"p3 = table[3,:]",
"_____no_output_____"
],
[
"p2",
"_____no_output_____"
],
[
"p1",
"_____no_output_____"
],
[
"p2 - p1",
"_____no_output_____"
],
[
"p3 - p2",
"_____no_output_____"
],
[
"import torchtext\nfrom torchtext.data.utils import get_tokenizer\nTEXT = torchtext.data.Field(tokenize=get_tokenizer(\"basic_english\"),\n init_token='<sos>',\n eos_token='<eos>',\n lower=True)",
"_____no_output_____"
],
[
"train_txt, val_txt, test_txt = torchtext.datasets.WikiText2.splits(TEXT)",
"downloading wikitext-2-v1.zip\n"
],
[
"type(train_txt.examples[0].text)",
"_____no_output_____"
],
[
"import numpy as np\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport math, copy, time\nfrom torch.autograd import Variable\nimport matplotlib.pyplot as plt\nimport seaborn\nseaborn.set_context(context=\"talk\")\n%matplotlib inline\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecc000ab095cfd78c49e63e287b7afd4ecce47e0 | 6,915 | ipynb | Jupyter Notebook | Lab02/Pipeline.ipynb | jugi92/databricks-intro | 57cd4c7681f8079274be0397563c26b15a8f5b16 | [
"MIT"
] | null | null | null | Lab02/Pipeline.ipynb | jugi92/databricks-intro | 57cd4c7681f8079274be0397563c26b15a8f5b16 | [
"MIT"
] | null | null | null | Lab02/Pipeline.ipynb | jugi92/databricks-intro | 57cd4c7681f8079274be0397563c26b15a8f5b16 | [
"MIT"
] | null | null | null | 3,457.5 | 6,914 | 0.75517 | [
[
[
"## Creating a Pipeline\n\nIn this exercise, you will implement a pipeline that includes multiple stages of *transformers* and *estimators* to prepare features and train a classification model. The resulting trained *PipelineModel* can then be used as a transformer to predict whether or not a flight will be late.\n\n### Import Spark SQL and Spark ML Libraries\n\nFirst, import the libraries you will need:",
"_____no_output_____"
]
],
[
[
"from pyspark.sql.types import *\nfrom pyspark.sql.functions import *\n\nfrom pyspark.ml import Pipeline\nfrom pyspark.ml.classification import LogisticRegression\nfrom pyspark.ml.feature import VectorAssembler, StringIndexer, MinMaxScaler",
"_____no_output_____"
]
],
[
[
"### Load Source Data\nThe data for this exercise is provided as a CSV file containing details of flights. The data includes specific characteristics (or *features*) for each flight, as well as a column indicating whether or not the flight was late.\n\nYou will load this data into a dataframe and display it.",
"_____no_output_____"
]
],
[
[
"flightSchema = StructType([\n StructField(\"DayofMonth\", IntegerType(), False),\n StructField(\"DayOfWeek\", IntegerType(), False),\n StructField(\"Carrier\", StringType(), False),\n StructField(\"OriginAirportID\", StringType(), False),\n StructField(\"DestAirportID\", StringType(), False),\n StructField(\"DepDelay\", IntegerType(), False),\n StructField(\"ArrDelay\", IntegerType(), False),\n StructField(\"Late\", IntegerType(), False),\n])\n\ndata = spark.read.csv('wasb://spark@<YOUR_ACCOUNT>.blob.core.windows.net/data/flights.csv', schema=flightSchema, header=True)\ndata.show()",
"_____no_output_____"
]
],
[
[
"### Split the Data\nIt is common practice when building supervised machine learning models to split the source data, using some of it to train the model and reserving some to test the trained model. In this exercise, you will use 70% of the data for training, and reserve 30% for testing.",
"_____no_output_____"
]
],
[
[
"splits = data.randomSplit([0.7, 0.3])\ntrain = splits[0]\ntest = splits[1]\ntrain_rows = train.count()\ntest_rows = test.count()\nprint (\"Training Rows:\", train_rows, \" Testing Rows:\", test_rows)",
"_____no_output_____"
]
],
[
[
"### Define the Pipeline\nA predictive model often requires multiple stages of feature preparation. For example, it is common when using some algorithms to distingish between continuous features (which have a calculable numeric value) and categorical features (which are numeric representations of discrete categories). It is also common to *normalize* continuous numeric features to use a common scale - for example, by scaling all numbers to a proportional decimal value between 0 and 1 (strictly speaking, it only really makes sense to do this when you have multiple numeric columns - normalizing them all to similar scales prevents a feature with particularly large values from dominating the training of the model - in this case, we only have one non-categorical numeric feature; but I've included this so you can see how it's done!).\n\nA pipeline consists of a a series of *transformer* and *estimator* stages that typically prepare a dataframe for\nmodeling and then train a predictive model. In this case, you will create a pipeline with seven stages:\n- A **StringIndexer** estimator for each categorical variable to generate numeric indexes for categorical features\n- A **VectorAssembler** that creates a vector of continuous numeric features\n- A **MinMaxScaler** that normalizes vector of numeric features\n- A **VectorAssembler** that creates a vector of categorical and continuous features\n- A **LogisticRegression** algorithm that trains a classification model.",
"_____no_output_____"
]
],
[
[
"monthdayIndexer = StringIndexer(inputCol=\"DayofMonth\", outputCol=\"DayofMonthIdx\")\nweekdayIndexer = StringIndexer(inputCol=\"DayOfWeek\", outputCol=\"DayOfWeekIdx\")\ncarrierIndexer = StringIndexer(inputCol=\"Carrier\", outputCol=\"CarrierIdx\")\noriginIndexer = StringIndexer(inputCol=\"OriginAirportID\", outputCol=\"OriginAirportIdx\")\ndestIndexer = StringIndexer(inputCol=\"DestAirportID\", outputCol=\"DestAirportIdx\")\nnumVect = VectorAssembler(inputCols = [\"DepDelay\"], outputCol=\"numFeatures\")\nminMax = MinMaxScaler(inputCol = numVect.getOutputCol(), outputCol=\"normNums\")\nfeatVect = VectorAssembler(inputCols=[\"DayofMonthIdx\", \"DayOfWeekIdx\", \"CarrierIdx\", \"OriginAirportIdx\", \"DestAirportIdx\", \"normNums\"], outputCol=\"features\")\nlr = LogisticRegression(labelCol=\"Late\", featuresCol=\"features\")\npipeline = Pipeline(stages=[monthdayIndexer, weekdayIndexer, carrierIndexer, originIndexer, destIndexer, numVect, minMax, featVect, lr])",
"_____no_output_____"
]
],
[
[
"### Run the Pipeline as an Estimator\nThe pipeline itself is an estimator, and so it has a **fit** method that you can call to run the pipeline on a specified dataframe. In this case, you will run the pipeline on the training data to train a model.",
"_____no_output_____"
]
],
[
[
"piplineModel = pipeline.fit(train)\nprint (\"Pipeline complete!\")",
"_____no_output_____"
]
],
[
[
"### Test the Pipeline Model\nThe model produced by the pipeline is a transformer that will apply all of the stages in the pipeline to a specified dataframe and apply the trained model to generate predictions. In this case, you will transform the **test** dataframe using the pipeline to generate label predictions.",
"_____no_output_____"
]
],
[
[
"prediction = piplineModel.transform(test)\npredicted = prediction.select(\"features\", col(\"prediction\").cast(\"Int\"), col(\"Late\").alias(\"trueLabel\"))\npredicted.show(100, truncate=False)",
"_____no_output_____"
]
],
[
[
"The resulting dataframe is produced by applying all of the transformations in the pipline to the test data. The **prediction** column contains the predicted value for the label, and the **trueLabel** column contains the actual known value from the testing data.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
ecc004fa726ba6b259e2f94a56c3b0d11adc80a3 | 1,253 | ipynb | Jupyter Notebook | jupyter-spark/work/setup_jupyter.ipynb | n3eo/bigdata-lecture-exercise | 0bc5477cf8f3c57b2924bab60889e4dd88e3857e | [
"MIT"
] | null | null | null | jupyter-spark/work/setup_jupyter.ipynb | n3eo/bigdata-lecture-exercise | 0bc5477cf8f3c57b2924bab60889e4dd88e3857e | [
"MIT"
] | null | null | null | jupyter-spark/work/setup_jupyter.ipynb | n3eo/bigdata-lecture-exercise | 0bc5477cf8f3c57b2924bab60889e4dd88e3857e | [
"MIT"
] | null | null | null | 24.096154 | 143 | 0.536313 | [
[
[
"from pyspark.sql import SparkSession",
"_____no_output_____"
],
[
"spark = SparkSession\\\n .builder\\\n .master(\"spark://spark-master:7077\")\\\n .config(\"spark.sql.repl.eagerEval.enabled\", \"true\")\\\n .config('spark.extraListeners', 'sparkmonitor.listener.JupyterSparkMonitorListener')\\\n .config('spark.driver.extraClassPath', '/opt/bitnami/python/lib/python3.6/site-packages/sparkmonitor/listener_2.12.jar')\\\n .getOrCreate()",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code"
]
] |
ecc00a9352bae79f9bd06320bee2c76bf6685de4 | 52,175 | ipynb | Jupyter Notebook | Statistics/Statistical Power Test.ipynb | handsonmachinelearning/Tutorials | eb55d63e381e3e8b8eb9e053fc0da101aadc09ea | [
"Apache-2.0"
] | 1 | 2022-01-03T21:35:12.000Z | 2022-01-03T21:35:12.000Z | Statistics/Statistical Power Test.ipynb | handsonmachinelearning/Tutorials | eb55d63e381e3e8b8eb9e053fc0da101aadc09ea | [
"Apache-2.0"
] | null | null | null | Statistics/Statistical Power Test.ipynb | handsonmachinelearning/Tutorials | eb55d63e381e3e8b8eb9e053fc0da101aadc09ea | [
"Apache-2.0"
] | 1 | 2022-01-03T21:35:14.000Z | 2022-01-03T21:35:14.000Z | 249.641148 | 22,732 | 0.91402 | [
[
[
"#https://machinelearningmastery.com/statistical-power-and-power-analysis-in-python/\nfrom statsmodels.stats.power import TTestIndPower\nimport numpy as np",
"_____no_output_____"
]
],
[
[
"p-value (p): Probability of obtaining a result equal to or more extreme than was observed in the data.\n\np <= alpha: reject H0, different distribution.\np > alpha: fail to reject H0, same distribution.\n\nSignificance level (alpha): Boundary for specifying a statistically significant finding when interpreting the p-value.\n\nType I Error. Reject the null hypothesis when there is in fact no significant effect (false positive). The p-value is optimistically small.\n\nType II Error. Not reject the null hypothesis when there is a significant effect (false negative). The p-value is pessimistically large.\n\nPower = 1 - Type II Error\nPr(True Positive) = 1 - Pr(False Negative)\n\nLow Statistical Power: Large risk of committing Type II errors, e.g. a false negative.\nHigh Statistical Power: Small risk of committing Type II errors.\n\n\nPower Analysis\nStatistical power is one piece in a puzzle that has four related parts; they are:\n\n Effect Size. The quantified magnitude of a result present in the population. Effect size is calculated using a specific statistical measure, such as Pearson’s correlation coefficient for the relationship between variables or Cohen’s d for the difference between groups.\n \n Sample Size. The number of observations in the sample.\n \n Significance. The significance level used in the statistical test, e.g. alpha. Often set to 5% or 0.05.\n \n Statistical Power. The probability of accepting the alternative hypothesis if it is true.",
"_____no_output_____"
],
[
"#https://machinelearningmastery.com/effect-size-measures-in-python/\n\nTo calculate the Effect size there are various metrics. To calculate the difference between groups use Cohen's D.\n\nCohen's D\nSmall Effect Size: d=0.20\nMedium Effect Size: d=0.50\nLarge Effect Size: d=0.80\n\nd = (u1 - u2) / s\n\nWhere d is the Cohen’s d, u1 is the mean of the first sample, u2 is the mean of the second sample, and s is the pooled standard deviation of both samples.\n\nThe pooled standard deviation for two independent samples can be calculated as follows\n\ns = sqrt(((n1 - 1) . s1^2 + (n2 - 1) . s2^2) / (n1 + n2 - 2))\n\nWhere s is the pooled standard deviation, n1 and n2 are the size of the first sample and second samples and s1^2 and s2^2 is the variance for the first and second samples. The subtractions are the adjustments for the number of degrees of freedom.",
"_____no_output_____"
]
],
[
[
"# function to calculate Cohen's d for independent samples\ndef cohend(d1, d2):\n # calculate the size of samples\n n1, n2 = len(d1), len(d2)\n # calculate the variance of the samples\n s1, s2 = var(d1, ddof=1), var(d2, ddof=1)\n # calculate the pooled standard deviation\n s = sqrt(((n1 - 1) * s1 + (n2 - 1) * s2) / (n1 + n2 - 2))\n # calculate the means of the samples\n u1, u2 = mean(d1), mean(d2)\n # calculate the effect size\n return (u1 - u2) / s",
"_____no_output_____"
],
[
"# parameters for power analysis\neffect = 0.8\nalpha = 0.05\npower = 0.8\n\n#ratio of the number of samples in one sample to the other. \n#If both samples are expected to have the same number of observations, then the ratio is 1.0. \n#If, for example, the second sample is expected to have half as many observations, then the ratio would be 0.5.\n\nratio_ =1",
"_____no_output_____"
],
[
"# perform power analysis\nanalysis = TTestIndPower()\nresult = analysis.solve_power(effect, power=power, nobs1=None, ratio=ratio_, alpha=alpha)\n\nprint('Sample Size: %.3f' % result)",
"Sample Size: 25.525\n"
],
[
"# calculate power curves from multiple power analyses\nanalysis = TTestIndPower()\nanalysis.plot_power(dep_var='nobs', nobs=np.arange(5, 100), effect_size=np.array([0.2, 0.5, 0.8]))\n\n# calculate power curves for varying sample and effect size\nfrom numpy import array\nfrom matplotlib import pyplot\nfrom statsmodels.stats.power import TTestIndPower\n# parameters for power analysis\neffect_sizes = array([0.2, 0.5, 0.8])\nsample_sizes = array(range(5, 100))\n# calculate power curves from multiple power analyses\nanalysis = TTestIndPower()\nanalysis.plot_power(dep_var='nobs', nobs=sample_sizes, effect_size=effect_sizes)\npyplot.show()",
"_____no_output_____"
]
]
] | [
"code",
"raw",
"code"
] | [
[
"code"
],
[
"raw",
"raw"
],
[
"code",
"code",
"code",
"code"
]
] |
ecc0213696022367fc72ea8852b27199376e80ff | 41,801 | ipynb | Jupyter Notebook | CNN_Model.ipynb | ArpitaChatterjee/CNN-Model | 0a4a19a147f5a678ab9213428cfb34950d181bf0 | [
"MIT"
] | 1 | 2021-11-09T15:31:34.000Z | 2021-11-09T15:31:34.000Z | CNN_Model.ipynb | ArpitaChatterjee/CNN-Model | 0a4a19a147f5a678ab9213428cfb34950d181bf0 | [
"MIT"
] | null | null | null | CNN_Model.ipynb | ArpitaChatterjee/CNN-Model | 0a4a19a147f5a678ab9213428cfb34950d181bf0 | [
"MIT"
] | null | null | null | 32.031418 | 451 | 0.418172 | [
[
[
"<a href=\"https://colab.research.google.com/github/ArpitaChatterjee/CNN-Model/blob/main/CNN_Model.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"!pip install keras-tuner",
"Collecting keras-tuner\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/a7/f7/4b41b6832abf4c9bef71a664dc563adb25afc5812831667c6db572b1a261/keras-tuner-1.0.1.tar.gz (54kB)\n\r\u001b[K |██████ | 10kB 22.6MB/s eta 0:00:01\r\u001b[K |████████████ | 20kB 3.4MB/s eta 0:00:01\r\u001b[K |██████████████████ | 30kB 4.4MB/s eta 0:00:01\r\u001b[K |████████████████████████ | 40kB 4.8MB/s eta 0:00:01\r\u001b[K |██████████████████████████████ | 51kB 4.0MB/s eta 0:00:01\r\u001b[K |████████████████████████████████| 61kB 3.3MB/s \n\u001b[?25hRequirement already satisfied: future in /usr/local/lib/python3.6/dist-packages (from keras-tuner) (0.16.0)\nRequirement already satisfied: numpy in /usr/local/lib/python3.6/dist-packages (from keras-tuner) (1.18.5)\nRequirement already satisfied: tabulate in /usr/local/lib/python3.6/dist-packages (from keras-tuner) (0.8.7)\nCollecting terminaltables\n Downloading https://files.pythonhosted.org/packages/9b/c4/4a21174f32f8a7e1104798c445dacdc1d4df86f2f26722767034e4de4bff/terminaltables-3.1.0.tar.gz\nCollecting colorama\n Downloading https://files.pythonhosted.org/packages/c9/dc/45cdef1b4d119eb96316b3117e6d5708a08029992b2fee2c143c7a0a5cc5/colorama-0.4.3-py2.py3-none-any.whl\nRequirement already satisfied: tqdm in /usr/local/lib/python3.6/dist-packages (from keras-tuner) (4.41.1)\nRequirement already satisfied: requests in /usr/local/lib/python3.6/dist-packages (from keras-tuner) (2.23.0)\nRequirement already satisfied: scipy in /usr/local/lib/python3.6/dist-packages (from keras-tuner) (1.4.1)\nRequirement already satisfied: scikit-learn in /usr/local/lib/python3.6/dist-packages (from keras-tuner) (0.22.2.post1)\nRequirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.6/dist-packages (from requests->keras-tuner) (2020.6.20)\nRequirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests->keras-tuner) (3.0.4)\nRequirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from requests->keras-tuner) (1.24.3)\nRequirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests->keras-tuner) (2.10)\nRequirement already satisfied: joblib>=0.11 in /usr/local/lib/python3.6/dist-packages (from scikit-learn->keras-tuner) (0.16.0)\nBuilding wheels for collected packages: keras-tuner, terminaltables\n Building wheel for keras-tuner (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for keras-tuner: filename=keras_tuner-1.0.1-cp36-none-any.whl size=73200 sha256=98777061e0d967002905d7bc77ecdd8336a97e46de09f3a207856589a42ea054\n Stored in directory: /root/.cache/pip/wheels/b9/cc/62/52716b70dd90f3db12519233c3a93a5360bc672da1a10ded43\n Building wheel for terminaltables (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for terminaltables: filename=terminaltables-3.1.0-cp36-none-any.whl size=15356 sha256=ba57bc798b58addb36eb001e0eee3f99fdd0e4e9f1a0ac75766ed9cf5d6c9fbe\n Stored in directory: /root/.cache/pip/wheels/30/6b/50/6c75775b681fb36cdfac7f19799888ef9d8813aff9e379663e\nSuccessfully built keras-tuner terminaltables\nInstalling collected packages: terminaltables, colorama, keras-tuner\nSuccessfully installed colorama-0.4.3 keras-tuner-1.0.1 terminaltables-3.1.0\n"
],
[
"import tensorflow as tf\nfrom tensorflow import keras\nimport numpy as np",
"_____no_output_____"
],
[
"print(tf.__version__)",
"2.3.0\n"
],
[
"fashion_mnist=keras.datasets.fashion_mnist",
"_____no_output_____"
],
[
"#train n test img\n(train_images, train_labels),(test_images, test_labels)=fashion_mnist.load_data()",
"Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz\n32768/29515 [=================================] - 0s 0us/step\nDownloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz\n26427392/26421880 [==============================] - 0s 0us/step\nDownloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz\n8192/5148 [===============================================] - 0s 0us/step\nDownloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz\n4423680/4422102 [==============================] - 0s 0us/step\n"
],
[
"#shift th emodels btw 0-1 to trian, test img for easy calc\ntrain_images=train_images/255.0\ntest_images=test_images/255.0",
"_____no_output_____"
],
[
"train_images[0].shape#the ",
"_____no_output_____"
],
[
"train_images=train_images.reshape(len(train_images),28,28,1)#reshape it in size28,28,1\ntest_images=test_images.reshape(len(test_images),28,28,1)",
"_____no_output_____"
],
[
"def build_model(hp): #hp-hyperparameter\n model = keras.Sequential([\n keras.layers.Conv2D(#convolution 2d array\n filters=hp.Int('conv_1_filter', min_value=32, max_value=128, step=16),#my filter \n kernel_size=hp.Choice('conv_1_kernel', values = [3,5]),#aka filter size, choice--select range of parameter\n activation='relu',\n input_shape=(28,28,1)\n ),\n keras.layers.Conv2D(#2nd convo 2d layer\n filters=hp.Int('conv_2_filter', min_value=32, max_value=64, step=16),\n kernel_size=hp.Choice('conv_2_kernel', values = [3,5]),\n activation='relu'\n ),\n keras.layers.Flatten(),#flatten my layer\n keras.layers.Dense(#dense layer\n units=hp.Int('dense_1_units', min_value=32, max_value=128, step=16),#minvlaue=noof nodes(btw 32-128) to be selected \n activation='relu'\n ),\n keras.layers.Dense(10, activation='softmax')#last dense layer\n ])\n \n model.compile(optimizer=keras.optimizers.Adam(hp.Choice('learning_rate', values=[1e-2, 1e-3])),#when we use adam we proveide learning rate with value\n loss='sparse_categorical_crossentropy',#\n metrics=['accuracy'])\n \n return model",
"_____no_output_____"
],
[
"from kerastuner import RandomSearch\nfrom kerastuner.engine.hyperparameters import HyperParameters",
"_____no_output_____"
],
[
"#run my random search,1st param=my fn, maxtrails =no of trails\ntuner_search = RandomSearch(build_model, \n objective='val_accuracy',\n max_trials=5,directory='output',project_name=\"Mnist Fashion\")",
"_____no_output_____"
],
[
"tuner_search.search(train_images, train_labels, epochs=3, validation_split=0.1)#do search for best validation n op n execute 3epoch of 5 trails i.e 15 times ",
"Epoch 1/3\n1688/1688 [==============================] - 8s 5ms/step - loss: 0.3794 - accuracy: 0.8616 - val_loss: 0.2869 - val_accuracy: 0.8937\nEpoch 2/3\n1688/1688 [==============================] - 8s 5ms/step - loss: 0.2378 - accuracy: 0.9122 - val_loss: 0.2458 - val_accuracy: 0.9080\nEpoch 3/3\n1688/1688 [==============================] - 8s 5ms/step - loss: 0.1794 - accuracy: 0.9322 - val_loss: 0.2405 - val_accuracy: 0.9120\n"
],
[
"model=tuner_search.get_best_models(num_models=1)[0]#store best model ",
"_____no_output_____"
],
[
"model.summary()#show best convo model",
"Model: \"sequential\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nconv2d (Conv2D) (None, 26, 26, 64) 640 \n_________________________________________________________________\nconv2d_1 (Conv2D) (None, 24, 24, 32) 18464 \n_________________________________________________________________\nflatten (Flatten) (None, 18432) 0 \n_________________________________________________________________\ndense (Dense) (None, 80) 1474640 \n_________________________________________________________________\ndense_1 (Dense) (None, 10) 810 \n=================================================================\nTotal params: 1,494,554\nTrainable params: 1,494,554\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"model.fit(train_images, train_labels, epochs=10, validation_split=0.1, initial_epoch=3)#retrain for this perticular best model here we \n#get accuracy of 99% almost",
"Epoch 4/10\n1688/1688 [==============================] - 7s 4ms/step - loss: 0.1340 - accuracy: 0.9503 - val_loss: 0.2517 - val_accuracy: 0.9130\nEpoch 5/10\n1688/1688 [==============================] - 7s 4ms/step - loss: 0.0940 - accuracy: 0.9655 - val_loss: 0.2904 - val_accuracy: 0.9113\nEpoch 6/10\n1688/1688 [==============================] - 7s 4ms/step - loss: 0.0629 - accuracy: 0.9778 - val_loss: 0.3208 - val_accuracy: 0.9152\nEpoch 7/10\n1688/1688 [==============================] - 7s 4ms/step - loss: 0.0460 - accuracy: 0.9833 - val_loss: 0.3702 - val_accuracy: 0.9120\nEpoch 8/10\n1688/1688 [==============================] - 7s 4ms/step - loss: 0.0327 - accuracy: 0.9878 - val_loss: 0.4018 - val_accuracy: 0.9123\nEpoch 9/10\n1688/1688 [==============================] - 7s 4ms/step - loss: 0.0292 - accuracy: 0.9895 - val_loss: 0.4632 - val_accuracy: 0.9115\nEpoch 10/10\n1688/1688 [==============================] - 7s 4ms/step - loss: 0.0215 - accuracy: 0.9920 - val_loss: 0.4587 - val_accuracy: 0.9148\n"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecc02de3c8a764dc91d5a56e6d1963e47c2f8889 | 290,520 | ipynb | Jupyter Notebook | tutorials/noise/2_relaxation_and_decoherence.ipynb | qfizik/qiskit-tutorials | f3f900098761e05bf66b53ae76b0dca59ff9c774 | [
"Apache-2.0"
] | null | null | null | tutorials/noise/2_relaxation_and_decoherence.ipynb | qfizik/qiskit-tutorials | f3f900098761e05bf66b53ae76b0dca59ff9c774 | [
"Apache-2.0"
] | null | null | null | tutorials/noise/2_relaxation_and_decoherence.ipynb | qfizik/qiskit-tutorials | f3f900098761e05bf66b53ae76b0dca59ff9c774 | [
"Apache-2.0"
] | null | null | null | 669.400922 | 77,760 | 0.934325 | [
[
[
"# *Relaxation and Decoherence* \n\n\nThis notebook gives examples for how to use the ``ignis.characterization.coherence`` module for measuring $T_1$ and $T_2$.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\n\nimport qiskit\nfrom qiskit.providers.aer.noise.errors.standard_errors import thermal_relaxation_error\nfrom qiskit.providers.aer.noise import NoiseModel\n\nfrom qiskit_experiments.library.calibration import *",
"_____no_output_____"
]
],
[
[
"## Generation of coherence circuits",
"_____no_output_____"
],
[
"This shows how to generate the circuits. The list of qubits specifies for which qubits to generate characterization circuits; these circuits will run in parallel. The discrete unit of time is the identity gate (``iden``) and so the user must specify the time of each identity gate if they would like the characterization parameters returned in units of time. This should be available from the backend.",
"_____no_output_____"
]
],
[
[
"num_of_gates = (np.linspace(10, 300, 50)).astype(int)\ngate_time = 0.1\n\n# Note that it is possible to measure several qubits in parallel\nqubits = [0, 2]\n\nt1_circs, t1_xdata = t1_circuits(num_of_gates, gate_time, qubits)\nt2star_circs, t2star_xdata, osc_freq = t2star_circuits(num_of_gates, gate_time, qubits, nosc=5)\nt2echo_circs, t2echo_xdata = t2_circuits(np.floor(num_of_gates/2).astype(int), \n gate_time, qubits)\nt2cpmg_circs, t2cpmg_xdata = t2_circuits(np.floor(num_of_gates/6).astype(int), \n gate_time, qubits, \n n_echos=5, phase_alt_echo=True)",
"_____no_output_____"
]
],
[
[
"## Backend execution",
"_____no_output_____"
]
],
[
[
"backend = qiskit.Aer.get_backend('qasm_simulator')\nshots = 400\n\n# Let the simulator simulate the following times for qubits 0 and 2:\nt_q0 = 25.0\nt_q2 = 15.0\n\n# Define T1 and T2 noise:\nt1_noise_model = NoiseModel()\nt1_noise_model.add_quantum_error(\n thermal_relaxation_error(t_q0, 2*t_q0, gate_time), \n 'id', [0])\nt1_noise_model.add_quantum_error(\n thermal_relaxation_error(t_q2, 2*t_q2, gate_time), \n 'id', [2])\n\nt2_noise_model = NoiseModel()\nt2_noise_model.add_quantum_error(\n thermal_relaxation_error(np.inf, t_q0, gate_time, 0.5), \n 'id', [0])\nt2_noise_model.add_quantum_error(\n thermal_relaxation_error(np.inf, t_q2, gate_time, 0.5), \n 'id', [2])\n\n# Run the simulator\nt1_backend_result = qiskit.execute(t1_circs, backend, shots=shots,\n noise_model=t1_noise_model, optimization_level=0).result()\nt2star_backend_result = qiskit.execute(t2star_circs, backend, shots=shots,\n noise_model=t2_noise_model, optimization_level=0).result()\nt2echo_backend_result = qiskit.execute(t2echo_circs, backend, shots=shots,\n noise_model=t2_noise_model, optimization_level=0).result()\n\n# It is possible to split the circuits into multiple jobs and then give the results to the fitter as a list:\nt2cpmg_backend_result1 = qiskit.execute(t2cpmg_circs[0:5], backend,\n shots=shots, noise_model=t2_noise_model,\n optimization_level=0).result()\nt2cpmg_backend_result2 = qiskit.execute(t2cpmg_circs[5:], backend,\n shots=shots, noise_model=t2_noise_model,\n optimization_level=0).result()",
"_____no_output_____"
]
],
[
[
"## Analysis of results",
"_____no_output_____"
]
],
[
[
"# Fitting T1\n\nplt.figure(figsize=(15, 6))\n\nt1_fit = T1Fitter(t1_backend_result, t1_xdata, qubits,\n fit_p0=[1, t_q0, 0],\n fit_bounds=([0, 0, -1], [2, 40, 1]))\nprint(t1_fit.time())\nprint(t1_fit.time_err())\nprint(t1_fit.params)\nprint(t1_fit.params_err)\n\nfor i in range(2):\n ax = plt.subplot(1, 2, i+1)\n t1_fit.plot(i, ax=ax)\nplt.show()",
"[24.10436641574169, 15.1725404065493]\n[2.2001166293232, 0.6420239307715634]\n{'0': [array([ 0.97307515, 24.10436642, 0.02663813]), array([ 1.00092258e+00, 1.51725404e+01, -5.42259153e-03])]}\n{'0': [array([0.04753859, 2.20011663, 0.05166528]), array([0.01408857, 0.64202393, 0.01729388])]}\n"
]
],
[
[
"Execute the backend again to get more statistics, and add the results to the previous ones:",
"_____no_output_____"
]
],
[
[
"t1_backend_result_new = qiskit.execute(t1_circs, backend,\n shots=shots, noise_model=t1_noise_model,\n optimization_level=0).result()\nt1_fit.add_data(t1_backend_result_new)\n\nplt.figure(figsize=(15, 6))\nfor i in range(2):\n ax = plt.subplot(1, 2, i+1)\n t1_fit.plot(i, ax=ax) \nplt.show()",
"_____no_output_____"
],
[
"# Fitting T2*\n\nt2star_fit = T2StarFitter(t2star_backend_result, t2star_xdata, qubits,\n fit_p0=[0.5, t_q0, osc_freq, 0, 0.5],\n fit_bounds=([-0.5, 0, 0, -np.pi, -0.5],\n [1.5, 40, 2*osc_freq, np.pi, 1.5]))\n\nplt.figure(figsize=(15, 6))\nfor i in range(2):\n ax = plt.subplot(1, 2, i+1)\n t2star_fit.plot(i, ax=ax) \nplt.show()",
"_____no_output_____"
],
[
"# Fitting T2 single echo\n\nt2echo_fit = T2Fitter(t2echo_backend_result, t2echo_xdata, qubits,\n fit_p0=[0.5, t_q0, 0.5],\n fit_bounds=([-0.5, 0, -0.5],\n [1.5, 40, 1.5]))\n\nprint(t2echo_fit.params)\n\nplt.figure(figsize=(15, 6))\nfor i in range(2):\n ax = plt.subplot(1, 2, i+1)\n t2echo_fit.plot(i, ax=ax) \nplt.show()",
"{'0': [array([ 0.46514794, 21.68047828, 0.53799714]), array([ 0.53077749, 16.98595852, 0.47459488])]}\n"
],
[
"# Fitting T2 CPMG\n\nt2cpmg_fit = T2Fitter([t2cpmg_backend_result1, t2cpmg_backend_result2],\n t2cpmg_xdata, qubits,\n fit_p0=[0.5, t_q0, 0.5],\n fit_bounds=([-0.5, 0, -0.5],\n [1.5, 40, 1.5]))\n\nplt.figure(figsize=(15, 6))\nfor i in range(2):\n ax = plt.subplot(1, 2, i+1)\n t2cpmg_fit.plot(i, ax=ax)\nplt.show()",
"_____no_output_____"
],
[
"import qiskit.tools.jupyter\n%qiskit_version_table\n%qiskit_copyright",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
ecc040c28a52801511edfa951c2db727eaeb3b89 | 20,500 | ipynb | Jupyter Notebook | utils/modred_descriptors.ipynb | Charlie059/Co-Crystal-Prediction-Master | 70045935740c1d12bed2a6f9440b763f3349b914 | [
"MIT"
] | 3 | 2021-04-12T14:03:57.000Z | 2021-04-27T00:21:44.000Z | utils/modred_descriptors.ipynb | Charlie059/Co-Crystal-Prediction-Master | 70045935740c1d12bed2a6f9440b763f3349b914 | [
"MIT"
] | null | null | null | utils/modred_descriptors.ipynb | Charlie059/Co-Crystal-Prediction-Master | 70045935740c1d12bed2a6f9440b763f3349b914 | [
"MIT"
] | 1 | 2021-04-28T14:27:03.000Z | 2021-04-28T14:27:03.000Z | 20,500 | 20,500 | 0.497122 | [
[
[
"# Import the libraries\n\nimport sys\nimport json\nimport tempfile\nimport numpy as np\nimport pandas as pd\nimport os.path\nimport warnings\nwarnings.filterwarnings('ignore')",
"_____no_output_____"
],
[
"!pip install kora -q\n!pip install mordred\nimport kora.install.rdkit",
"\u001b[K |████████████████████████████████| 61kB 3.7MB/s \n\u001b[K |████████████████████████████████| 51kB 7.0MB/s \n\u001b[?25hCollecting mordred\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/93/3d/26c908ece761adafcea06320bf8fe73f4de69979273fb164226dc6038c39/mordred-1.2.0.tar.gz (128kB)\n\u001b[K |████████████████████████████████| 133kB 6.5MB/s \n\u001b[?25hRequirement already satisfied: six==1.* in /usr/local/lib/python3.6/dist-packages (from mordred) (1.15.0)\nRequirement already satisfied: numpy==1.* in /usr/local/lib/python3.6/dist-packages (from mordred) (1.18.5)\nRequirement already satisfied: networkx==2.* in /usr/local/lib/python3.6/dist-packages (from mordred) (2.5)\nRequirement already satisfied: decorator>=4.3.0 in /usr/local/lib/python3.6/dist-packages (from networkx==2.*->mordred) (4.4.2)\nBuilding wheels for collected packages: mordred\n Building wheel for mordred (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for mordred: filename=mordred-1.2.0-cp36-none-any.whl size=176721 sha256=a83c0f900a589f8ee32f14270a31b1a4ac423c2a533db3574c380222ae0c419e\n Stored in directory: /root/.cache/pip/wheels/ac/74/3f/2fd81b1187013f2eadb15620434813f1824c4c03b7bd1f94f6\nSuccessfully built mordred\nInstalling collected packages: mordred\nSuccessfully installed mordred-1.2.0\n"
],
[
"from google.colab import drive\ndrive.mount('/content/gdrive')",
"Mounted at /content/gdrive\n"
],
[
"df = pd.read_csv('/content/gdrive/My Drive/Colab Notebooks/cocrystal_design/data/dataset1.csv')\ndf = pd.DataFrame(df.iloc[:5,1])\ndf.to_csv(path_or_buf = '/content/gdrive/My Drive/Colab Notebooks/cocrystal_design/data/dataset_mol1.csv')",
"_____no_output_____"
],
[
"from rdkit import Chem\nfrom mordred import Calculator, descriptors #https://github.com/mordred-descriptor/mordred\ncalc = Calculator(descriptors, ignore_3D=True)\nmol = Chem.MolFromSmiles('c1ccccc1')\ncalc(mol)[:3] # example \n#pd.DataFrame(calc(mol)[:3], columns=calc.descriptors[:3])",
"_____no_output_____"
],
[
"# Calculate the descriptors for the first dataset (first co-former)\ndataset_mol1 = pd.read_csv('/content/gdrive/My Drive/Colab Notebooks/cocrystal_design/data/dataset_mol1.csv')\ndescriptors_mol1 =[]\nfor mol in dataset_mol1.smiles1.values:\n try:\n descriptors_mol1.append(calc(Chem.MolFromSmiles(mol)))\n except TypeError:\n descriptors_mol1.append('none')\n# Save the dataset1 with the descriptors\ndataset1 = pd.DataFrame(descriptors_mol1)\ndataset1 = pd.DataFrame(dataset1.values, columns=calc.descriptors)\ndataset1",
"_____no_output_____"
],
[
"# Calculate the descriptors for the second dataset (first co-former)\ndataset_mol2 = pd.read_csv('dataset_mol2.csv')\ndescriptors_mol2 =[]\nfor mol in dataset_mol2.smiles2.values:\n try:\n descriptors_mol2.append(calc(Chem.MolFromSmiles(mol)))\n except TypeError:\n descriptors_mol2.append('none')\n# Save dataset2 with the descriptors\ndataset2 = pd.DataFrame(descriptors_mol2)\npd.DataFrame(dataset2.values, columns=calc.descriptors).to_csv('dataset2.csv', index=False)",
"_____no_output_____"
],
[
"# Calculate the descriptors for the zinc15 dataset\nzin15=pd.read_csv('zinc_smiles.csv')\n\ndescriptors_zinc15 =[]\nfor mol in zin15.smiles.values:\n try:\n descriptors_zinc15.append(calc(Chem.MolFromSmiles(mol)))\n except TypeError:\n descriptors_zinc15.append('none')\nunlab_dataset = pd.DataFrame(descriptors_zinc15)\npd.DataFrame(descriptors_zinc15.values, columns=calc.descriptors).to_csv('zinc15_dataset.csv', index=False)",
"_____no_output_____"
],
[
"# Save the dataset with the descriptors\nunlab_dataset = pd.DataFrame(descriptors_zinc15)\nunlab_dataset\npd.DataFrame(unlab_dataset.values, columns=calc.descriptors).to_csv('zinc15_dataset.csv', index=False)",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecc048f9fd36c5796256a07a6ecb7b6dc9af6ce8 | 221,869 | ipynb | Jupyter Notebook | Michelson_Interferometer_2019.ipynb | jupyterphysics/Optica | 4e0246d7b9775c6d3e750f8c34b408a2d1adacf5 | [
"MIT"
] | null | null | null | Michelson_Interferometer_2019.ipynb | jupyterphysics/Optica | 4e0246d7b9775c6d3e750f8c34b408a2d1adacf5 | [
"MIT"
] | null | null | null | Michelson_Interferometer_2019.ipynb | jupyterphysics/Optica | 4e0246d7b9775c6d3e750f8c34b408a2d1adacf5 | [
"MIT"
] | null | null | null | 197.041741 | 107,232 | 0.860724 | [
[
[
"# Michelson Interferometer.",
"_____no_output_____"
]
],
[
[
"from IPython.display import HTML\nHTML('''\n <style>\n .prompt{display: None;}\n \n .output_wrapper button.btn.btn-default,\n .output_wrapper .ui-dialog-titlebar {display: none;} <!-- hide toolbars and buttons of the plot -->\n \n </style>\n <script>\n code_show=true; \n function code_toggle() \n {\n if (code_show)\n {\n $('div.input').hide();\n } else\n {\n $('div.input').show();\n }\n code_show = !code_show\n } \n $( document ).ready(code_toggle);\n </script>\n The raw code for this IPython notebook is by default hidden for easier reading.\n To toggle on/off the raw code, click <a href=\"javascript:code_toggle()\">here</a>.\n ''')",
"_____no_output_____"
]
],
[
[
"\n\n> *Figure 1. Albert Abraham Michelson, (source: wikipedia).*\n\n\nTogether with Edward Morley, Michelson carried out an experiment to measure the speed of the earth with respect to the \"aether\". The aether was thought to be the medium that carried light waves. To do so he developed an interferometer now known as the Michelson interferometer. Variations of this interferometer are used a lot today e.g. in the detection of gravitational waves. \n\n\n<div>\n<img src=\"attachment:Michelson_fig1.png\" width=\"500\"/>\n</div>\n\n> *Figure 2. Schematic of the Michelson interferometer setup used in this simulation. The distance $d_1$ is fixed at 5 cm while the distance $d_2$ can be changed between 5 and 10 cm. Also the tilt $t$ of mirror 1 can be varied. The wavelength of the source is 632.8 nm*\n\n\n\nThe simplest form of a Michelson interferometer is shown in figure 2. It consists of two mutually perpendicular plane mirrors, one of which is mounted so that it can be moved along an axis perpendicular to its plane (surface). This movable mirror is normally moved at a constant velocity. Located between the fixed mirror and the movable mirror is a beamsplitter. The beamsplitter divides the input beam of radiation into two beams. That is, the input beam is partially reflected to the fixed mirror M1 and partially transmitted to the movable mirror M2.\n\nAfter the beams return to the beamsplitter they interfere and are again partially reflected and partially transmitted. Because of the effect of interference, the intensity of each beam, one passing to the detector and the other returning to the source, depends on the difference of path lengths of the two arms of the interferometer. The variation in the intensity of the beams seen by the detector is a function of the path difference and a graph or plot of this intensity is know as an interferogram. \n\nThe lenses $f_2$ and $f_1$ can be inserted to create a ringshaped interference pattern at the focal plane of lens $f_1$. \n\nin this simulation you can investigate some properties of the interferometer.\n\n\n### 1. Investigate the ring pattern observed at the screen.\n\n 1. In the simulation make sure you have the two lenses $f_1$ and $f_2$ inserted.\n 2. Use the fine displacement of the mirror $d_1$ and observe the changes in the interference pattern. Explain the result.\n 2. Show that the radii of the rings in the pattern as observed in the focal plane of $f_1$ satisfy the following relation:\n \n $$ y_m^2 = \\frac{f_1^2 \\lambda}{\\left | d_2 - d_1 \\right |} \\left ( m_0 + m \\right ) $$\n \n , where $m$ is an integer counting the rings; and $m_0$ is an offset value between 0 and 1 to account for the fact that at some given arm length difference the optical pathlength difference at the optical axis is not always exactly a multiple of the wavelength.\n \n 3. Measure (use the mouse cursor in the image) the radii of the rings for some value of $d_2$ and plot the radii as a function of \n the ring-number. (Plot such that you obtain a straight line!).\n 4. Determine the difference in arm lengths $d_2-d_1$ using the results from (3) and check the result.\n 5. Repeat the above steps for at least one other arm length difference.\n\n\n### 2. Questions.\n\n \n 1. How can you experimentally determine (by observing the pattern on the screen) if the arm lengths of the interferometer are equal?\n 2. Remove the two lenses and explain the observed pattern. How does this pattern change if you move the mirror?\n 3. Change the tilt of the mirror and explain the observed pattern.\n\nLiterature: Hecht, 5th ed., chapter 9. \n",
"_____no_output_____"
]
],
[
[
"%matplotlib notebook\n\n#!/usr/bin/env python\n\"\"\"\n Computer practical 4. Newton rings.\n ====================================================================\n\n This is part of the 'computer practical' set of assignments.\n Demonstrates the Newton rings experiment.\n Measure the radii of the rings and find the radius of curvature\n of the lens.\n \n .. :copyright: (c) 2017 by Fred van Goor.\n adapted by j.s.kanger 2019\n :license: MIT, see License for more details.\n \n\"\"\"\nfrom ipywidgets import interact, interactive, fixed, interact_manual\nimport ipywidgets as widgets\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport LightPipes as lp\n\n\n# Define some constants\nwavelength = 632.8e-9 #wavelength of HeNe laser\nsize = 8e-3 # size of the grid for calculation\nsize_image = 4e-3 # size of the image being displayed\nN = 400 # number (NxN) of grid pixels\nR = 2e-3 # laser beam radius\nd1 = 5e-2 # length of arm 1\nd2 = 7e-2 # length of arm 2\nz3 = 15e-2 # distance laser to beamsplitter (taken to be same as f2)\nz4 = 1e-2 # distance beamsplitter to screen\nRbs = 0.5 # reflection beam splitter\ntx, ty = 0e-4, 0. # tilt of mirror 1\nf1 = 150e-3 # focal length of lens 1\nf2 = 150e-3 # focal length of lens 2\n\n\n# setup the figure\nfig, (ax1, ax2) = plt.subplots(1, 2, figsize=(9,6))\nfig.suptitle(f'Michelson Interferometer', fontsize=14)\n\n# axes 1 contains the pattern\nax1.set_aspect('equal', 'box')\nax1.set_title('Intensity distribution')\nlimit = size_image*1e3/2\nax1.set_xlim(-limit, limit)\nax1.set_ylim(-limit, limit)\nax1.set_xlabel('mm')\next = size*1e3/2\nimg = ax1.imshow([[]], interpolation='bicubic', cmap='hot', vmin=0, vmax=1, extent=[-ext, ext, -ext, ext])\n\n# axes 2 contains an image of the setup\nax2.set_title('linetrace')\nax2.set_xlabel('mm')\nax2.set_xlim(-limit, limit)\nax2.set_ylim(0, 1)\nax2.set_aspect((2*limit))\nline, = ax2.plot([],[],'k')\nx_scale = np.linspace(-ext, ext, N, endpoint=True)\n\nplt.tight_layout()\nplt.show()\n\n# create the input beam\nFnull = lp.Begin(size, wavelength, N)\nFnull = lp.GaussAperture(R, 0, 0, 1, Fnull)\n\ndef Michelson(toggle_lens, d_course, d_fine, t):\n \"\"\"\n Calculates and shows the output of the Michelson interferometer\n \"\"\"\n tx = t*1e-3\n d2 = d_course*1e-2 + d_fine*1e-9\n \n #insert positive lens f2 (optional) and propagate to the beamsplitter::\n if toggle_lens:\n F = lp.Lens(f2, 0, 0, Fnull)\n F = lp.Forvard(z3, F)\n else:\n F = lp.Forvard(z3, Fnull)\n\n #Split the beams:\n F20 = lp.IntAttenuator(1-Rbs, F)\n F10 = lp.IntAttenuator(Rbs, F)\n\n #propagate to- and back from the mirror #1:\n F1 = lp.Forvard(d1, F10)\n F1 = lp.Tilt(tx, ty, F1)\n F1 = lp.Forvard(d1, F1)\n \n #propagate to- and back from the mirror #2:\n F2 = lp.Forvard(d2*2, F20)\n \n # pass through the beamsplitter\n F1 = lp.IntAttenuator(1-Rbs, F1)\n F2 = lp.IntAttenuator(Rbs, F2)\n\n #Recombine the two beams and propagate to the screen:\n F = lp.BeamMix(F1, F2)\n if toggle_lens:\n F = lp.Lens(f1, 0, 0, F)\n F = lp.Forvard(f1, F)\n I = lp.Intensity(0, F)\n\n # plot the intensity as an image\n #img.set_array(I[crop:N+1-crop,crop:N+1-crop])\n img.set_data(I)\n #img.autoscale()\n line.set_data(x_scale, I[int(N/2)][:])\n ax1.format_coord = lambda x, y: \\\n f'x = {x:2.2f} mm, y = {y:2.2f} mm, Intensity = ' \n \n return None\n\n\n\n# start the interactive plot\nw = interact(Michelson,\\\n toggle_lens = widgets.Checkbox(layout={'width': 'initial'}, style={'description_width': 'initial'}, \\\n value=True,description=f'Insert lenses f1 ({f1*1e3} mm) and f2 ({f2*1e3} mm)',disabled=False),\\\n t = widgets.FloatSlider(layout={'width': 'initial'},style={'description_width': 'initial'},\\\n description=r'$t$ [mrad]', min=-3, max=3, step=0.1, value=0, \\\n continuous_update=False, readout_format='.1f'),\n d_course = widgets.FloatSlider(layout={'width': 'initial'},style={'description_width': 'initial'},\\\n description=r'$d_2$ course [cm]', min=4.5, max=10, step=0.1, value=7, \\\n continuous_update=False, readout_format='.1f'), \\\n d_fine = widgets.FloatSlider(layout={'width': 'initial'},style={'description_width': 'initial'}, \\\n description=r'$d_2$ fine [nm]', min=0, max=wavelength*1e9, step=10, value=0, \\\n continuous_update=False, readout_format='.1f')\n )\n\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
ecc04e4b8ae4fc725ee4a3275269262cd8b43360 | 45,451 | ipynb | Jupyter Notebook | datapreprocessing.ipynb | 18cse006/DMDW | a851d5b115b9a3dc1a635f3bb6c789b9aa5157ef | [
"Apache-2.0"
] | null | null | null | datapreprocessing.ipynb | 18cse006/DMDW | a851d5b115b9a3dc1a635f3bb6c789b9aa5157ef | [
"Apache-2.0"
] | null | null | null | datapreprocessing.ipynb | 18cse006/DMDW | a851d5b115b9a3dc1a635f3bb6c789b9aa5157ef | [
"Apache-2.0"
] | null | null | null | 35.453198 | 227 | 0.293547 | [
[
[
"<a href=\"https://colab.research.google.com/github/18cse006/DMDW/blob/main/datapreprocessing.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"path=(\"https://raw.githubusercontent.com/18cse006/DMDW/main/Car_sales.csv\")",
"_____no_output_____"
],
[
"data=pd.read_csv(path)",
"_____no_output_____"
],
[
"type(data)",
"_____no_output_____"
],
[
"data.shape",
"_____no_output_____"
],
[
"data.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 157 entries, 0 to 156\nData columns (total 16 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 Manufacturer 157 non-null object \n 1 Model 157 non-null object \n 2 Sales_in_thousands 157 non-null float64\n 3 __year_resale_value 121 non-null float64\n 4 Vehicle_type 157 non-null object \n 5 Price_in_thousands 155 non-null float64\n 6 Engine_size 156 non-null float64\n 7 Horsepower 156 non-null float64\n 8 Wheelbase 156 non-null float64\n 9 Width 156 non-null float64\n 10 Length 156 non-null float64\n 11 Curb_weight 155 non-null float64\n 12 Fuel_capacity 156 non-null float64\n 13 Fuel_efficiency 154 non-null float64\n 14 Latest_Launch 157 non-null object \n 15 Power_perf_factor 155 non-null float64\ndtypes: float64(12), object(4)\nmemory usage: 19.8+ KB\n"
],
[
"data.index",
"_____no_output_____"
],
[
"data.columns",
"_____no_output_____"
],
[
"data.head()",
"_____no_output_____"
],
[
"data.tail()",
"_____no_output_____"
],
[
"data.head(10)",
"_____no_output_____"
],
[
"data.isnull().sum()",
"_____no_output_____"
],
[
"data.dropna(inplace=True)\ndata.isnull().sum",
"_____no_output_____"
],
[
"data.shape",
"_____no_output_____"
],
[
"data.head(10)",
"_____no_output_____"
],
[
"#2nd method handling missing values\ndata.mean()",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecc0539942b6fca729eba83854737f7473da1f23 | 1,855 | ipynb | Jupyter Notebook | lessons/NLP Pipelines/tokenization_practice-zh.ipynb | callezenwaka/DSND_Term2 | 6252cb75f9fbd61043b308a783b1d62cdd217001 | [
"MIT"
] | 1,030 | 2018-07-03T19:09:50.000Z | 2022-03-25T05:48:57.000Z | lessons/NLP Pipelines/tokenization_practice-zh.ipynb | callezenwaka/DSND_Term2 | 6252cb75f9fbd61043b308a783b1d62cdd217001 | [
"MIT"
] | 21 | 2018-09-20T14:36:04.000Z | 2021-10-11T18:25:31.000Z | lessons/NLP Pipelines/tokenization_practice-zh.ipynb | callezenwaka/DSND_Term2 | 6252cb75f9fbd61043b308a783b1d62cdd217001 | [
"MIT"
] | 1,736 | 2018-06-27T19:33:46.000Z | 2022-03-28T17:52:33.000Z | 20.384615 | 188 | 0.550943 | [
[
[
"### 下载数据包\n运行下方的单元格,下载必要的 nltk 数据包。注意,因为我们使用教室工作环境,整个课程每个 notebook 都要下载一些包。但是,你可以在你的电脑上运行 `nltk.download()` ,下载所有的包。要知道这会占据一些存储空间。你可以查看 [这里](https://www.nltk.org/data.html) 了解更多关于 nltk 数据安装的信息。",
"_____no_output_____"
]
],
[
[
"import nltk\nnltk.download('punkt')",
"_____no_output_____"
]
],
[
[
"# 分词\n试试 nltk 中的分词方法,将下面的文本分割成词,然后试试分割成句子。\n\n**注意:所有的解决方案 notebook可以通过点击工作环境左上角的 Jupyter 图标找到。**",
"_____no_output_____"
]
],
[
[
"# import statements\n",
"_____no_output_____"
],
[
"text = \"Dr. Smith graduated from the University of Washington. He later started an analytics firm called Lux, which catered to enterprise customers.\"\nprint(text)",
"_____no_output_____"
],
[
"# Split text into words using NLTK\n",
"_____no_output_____"
],
[
"# Split text into sentences\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
ecc05d0d3e598f58e29be6a641a708878c9071a0 | 14,381 | ipynb | Jupyter Notebook | site/ko/beta/tutorials/eager/custom_training.ipynb | crypdra/docs | 41ab06fd14b3a3dff933bb80b19ce46c7c5781cf | [
"Apache-2.0"
] | 2 | 2019-10-25T18:51:16.000Z | 2019-10-25T18:51:18.000Z | site/ko/beta/tutorials/eager/custom_training.ipynb | crypdra/docs | 41ab06fd14b3a3dff933bb80b19ce46c7c5781cf | [
"Apache-2.0"
] | null | null | null | site/ko/beta/tutorials/eager/custom_training.ipynb | crypdra/docs | 41ab06fd14b3a3dff933bb80b19ce46c7c5781cf | [
"Apache-2.0"
] | null | null | null | 30.148847 | 300 | 0.489465 | [
[
[
"##### Copyright 2018 The TensorFlow Authors.",
"_____no_output_____"
]
],
[
[
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
]
],
[
[
"# 사용자 정의 학습: 기초",
"_____no_output_____"
],
[
"<table class=\"tfo-notebook-buttons\" align=\"left\">\n <td>\n <a target=\"_blank\" href=\"https://www.tensorflow.org/beta/tutorials/eager/custom_training\"><img src=\"https://www.tensorflow.org/images/tf_logo_32px.png\" />TensorFlow.org에서 보기</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/docs/blob/master/site/ko/beta/tutorials/eager/custom_training.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />구글 코랩(Colab)에서 실행하기</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://github.com/tensorflow/docs/blob/master/site/ko/beta/tutorials/eager/custom_training.ipynb\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />깃허브(GitHub) 소스 보기</a>\n </td>\n <td> \n <a href=\"https://storage.googleapis.com/tensorflow_docs/docs/site/ko/beta/tutorials/eager/custom_training.ipynb\"><img src=\"https://www.tensorflow.org/images/download_logo_32px.png\" />노트북 다운로드</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"Note: 이 문서는 텐서플로 커뮤니티에서 번역했습니다. 커뮤니티 번역 활동의 특성상 정확한 번역과 최신 내용을 반영하기 위해 노력함에도\n불구하고 [공식 영문 문서](https://www.tensorflow.org/?hl=en)의 내용과 일치하지 않을 수 있습니다.\n이 번역에 개선할 부분이 있다면\n[tensorflow/docs](https://github.com/tensorflow/docs) 깃헙 저장소로 풀 리퀘스트를 보내주시기 바랍니다.\n문서 번역이나 리뷰에 지원하려면\n[[email protected]](https://groups.google.com/a/tensorflow.org/forum/#!forum/docs)로\n메일을 보내주시기 바랍니다.",
"_____no_output_____"
],
[
"이전 튜토리얼에서는 머신러닝을 위한 기본 구성 요소인 자동 미분(automatic differentiation)을 위한 텐서플로 API를 알아보았습니다. 이번 튜토리얼에서는 이전 튜토리얼에서 소개되었던 텐서플로의 기본 요소를 사용하여 간단한 머신러닝을 수행해보겠습니다. \n\n텐서플로는 반복되는 코드를 줄이기 위해 유용한 추상화를 제공하는 고수준 신경망(neural network) API인 `tf.keras`를 포함하고 있습니다. 신경망을 다룰 때 이러한 고수준의 API을 강하게 추천합니다. 이번 짧은 튜토리얼에서는 탄탄한 기초를 기르기 위해 기본적인 요소만으로 신경망 훈련시켜 보겠습니다.",
"_____no_output_____"
],
[
"## 설정",
"_____no_output_____"
]
],
[
[
"from __future__ import absolute_import, division, print_function, unicode_literals\n\ntry:\n # Colab only\n %tensorflow_version 2.x\nexcept Exception:\n pass\nimport tensorflow as tf",
"_____no_output_____"
]
],
[
[
"## 변수\n\n텐서플로의 텐서(Tensor)는 상태가 없고, 변경이 불가능한(immutable stateless) 객체입니다. 그러나 머신러닝 모델은 상태가 변경될(stateful) 필요가 있습니다. 예를 들어, 모델 학습에서 예측을 계산하기 위한 동일한 코드는 시간이 지남에 따라 다르게(희망하건대 더 낮은 손실로 가는 방향으로)동작해야 합니다. 이 연산 과정을 통해 변화되어야 하는 상태를 표현하기 위해 명령형 프로그래밍 언어인 파이썬을 사용 할 수 있습니다. ",
"_____no_output_____"
]
],
[
[
"# 파이썬 구문 사용\nx = tf.zeros([10, 10])\nx += 2 # 이것은 x = x + 2와 같으며, x의 초기값을 변경하지 않습니다.\nprint(x)",
"_____no_output_____"
]
],
[
[
"텐서플로는 상태를 변경할 수 있는 연산자가 내장되어 있으며, 이러한 연산자는 상태를 표현하기 위한 저수준 파이썬 표현보다 사용하기가 더 좋습니다. 예를 들어, 모델에서 가중치를 나타내기 위해서 텐서플로 변수를 사용하는 것이 편하고 효율적입니다. \n\n텐서플로 변수는 값을 저장하는 객체로 텐서플로 연산에 사용될 때 저장된 이 값을 읽어올 것입니다. `tf.assign_sub`, `tf.scatter_update` 등은 텐서플로 변수에 저장되있는 값을 조작하는 연산자입니다.",
"_____no_output_____"
]
],
[
[
"v = tf.Variable(1.0)\nassert v.numpy() == 1.0\n\n# 값을 재배열합니다.\nv.assign(3.0)\nassert v.numpy() == 3.0\n\n# tf.square()와 같은 텐서플로 연산에 `v`를 사용하고 재할당합니다. \nv.assign(tf.square(v))\nassert v.numpy() == 9.0",
"_____no_output_____"
]
],
[
[
"변수를 사용한 연산은 그래디언트가 계산될 때 자동적으로 추적됩니다. 임베딩(embedding)을 나타내는 변수의 경우 기본적으로 희소 텐서(sparse tensor)를 사용하여 업데이트됩니다. 이는 연산과 메모리에 더욱 효율적입니다. \n\n또한 변수를 사용하는 것은 코드를 읽는 독자에게 상태가 변경될 수 있다는 것을 알려주는 손쉬운 방법입니다.",
"_____no_output_____"
],
[
"## 예: 선형 모델 훈련\n\n지금까지 간단한 모델을 구축하고 학습시키기 위해 ---`Tensor`, `GradientTape`, `Variable` --- 와 같은 몇가지 개념을 설명했습니다. 이는 일반적으로 다음의 과정을 포함합니다.\n\n1. 모델 정의\n2. 손실 함수 정의\n3. 훈련 데이터 가져오기\n4. 훈련 데이터에서 실행, 데이터에 최적화하기 위해 \"옵티마이저(optimizer)\"를 사용한 변수 조정\n\n이번 튜토리얼에서는 선형 모델의 간단한 예제를 살펴보겠습니다:\n`f(x) = x * W + b`, 모델은 `W` 와 `b` 두 변수를 가지고 있는 선형모델이며, 잘 학습된 모델이 `W = 3.0` and `b = 2.0`의 값을 갖도록 합성 데이터를 만들겠습니다.",
"_____no_output_____"
],
[
"### 모델 정의\n\n변수와 연산을 캡슐화하기 위한 간단한 클래스를 정의해봅시다.",
"_____no_output_____"
]
],
[
[
"class Model(object):\n def __init__(self):\n # 변수를 (5.0, 0.0)으로 초기화 합니다.\n # 실제로는 임의의 값으로 초기화 되어야합니다.\n self.W = tf.Variable(5.0)\n self.b = tf.Variable(0.0)\n\n def __call__(self, x):\n return self.W * x + self.b\n\nmodel = Model()\n\nassert model(3.0).numpy() == 15.0",
"_____no_output_____"
]
],
[
[
"### 손실 함수 정의\n\n손실 함수는 주어진 입력에 대한 모델의 출력이 원하는 출력과 얼마나 잘 일치하는지를 측정합니다. 평균 제곱 오차(mean square error)를 적용한 손실 함수를 사용하겠습니다.",
"_____no_output_____"
]
],
[
[
"def loss(predicted_y, desired_y):\n return tf.reduce_mean(tf.square(predicted_y - desired_y))",
"_____no_output_____"
]
],
[
[
"### 훈련 데이터 가져오기\n\n약간의 잡음과 훈련 데이터를 합칩니다.",
"_____no_output_____"
]
],
[
[
"TRUE_W = 3.0\nTRUE_b = 2.0\nNUM_EXAMPLES = 1000\n\ninputs = tf.random.normal(shape=[NUM_EXAMPLES])\nnoise = tf.random.normal(shape=[NUM_EXAMPLES])\noutputs = inputs * TRUE_W + TRUE_b + noise",
"_____no_output_____"
]
],
[
[
"모델을 훈련시키기 전에, 모델의 현재 상태를 시각화합시다. 모델의 예측을 빨간색으로, 훈련 데이터를 파란색으로 구성합니다.",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\n\nplt.scatter(inputs, outputs, c='b')\nplt.scatter(inputs, model(inputs), c='r')\nplt.show()\n\nprint('현재 손실: '),\nprint(loss(model(inputs), outputs).numpy())",
"_____no_output_____"
]
],
[
[
"### 훈련 루프 정의\n\n이제 네트워크와 훈련 데이터가 준비되었습니다. 모델의 변수(`W` 와 `b`)를 업데이트하기 위해 훈련 데이터를 사용하여 훈련시켜 보죠. 그리고 [경사 하강법(gradient descent)](https://en.wikipedia.org/wiki/Gradient_descent)을 사용하여 손실을 감소시킵니다. 경사 하강법에는 여러가지 방법이 있으며, `tf.train.Optimizer` 에 구현되어있습니다. 이러한 구현을 사용하는 것을 강력히 추천드립니다. 그러나 이번 튜토리얼에서는 기본적인 방법을 사용하겠습니다.",
"_____no_output_____"
]
],
[
[
"def train(model, inputs, outputs, learning_rate):\n with tf.GradientTape() as t:\n current_loss = loss(model(inputs), outputs)\n dW, db = t.gradient(current_loss, [model.W, model.b])\n model.W.assign_sub(learning_rate * dW)\n model.b.assign_sub(learning_rate * db)",
"_____no_output_____"
]
],
[
[
"마지막으로, 훈련 데이터를 반복적으로 실행하고, `W` 와 `b`의 변화 과정을 확인합니다.",
"_____no_output_____"
]
],
[
[
"model = Model()\n\n# 도식화를 위해 W값과 b값의 변화를 저장합니다.\nWs, bs = [], []\nepochs = range(10)\nfor epoch in epochs:\n Ws.append(model.W.numpy())\n bs.append(model.b.numpy())\n current_loss = loss(model(inputs), outputs)\n\n train(model, inputs, outputs, learning_rate=0.1)\n print('에포크 %2d: W=%1.2f b=%1.2f, 손실=%2.5f' %\n (epoch, Ws[-1], bs[-1], current_loss))\n\n# 저장된 값들을 도식화합니다.\nplt.plot(epochs, Ws, 'r',\n epochs, bs, 'b')\nplt.plot([TRUE_W] * len(epochs), 'r--',\n [TRUE_b] * len(epochs), 'b--')\nplt.legend(['W', 'b', 'true W', 'true_b'])\nplt.show()\n",
"_____no_output_____"
]
],
[
[
"## 다음 단계\n\n이번 튜토리얼에서는 변수를 다루었으며, 지금까지 논의된 텐서플로의 기본 요소를 사용하여 간단한 선형 모델을 구축하고 훈련시켰습니다.\n\n이론적으로, 텐서플로를 머신러닝 연구에 사용하기 위해 알아야 할 것이 매우 많습니다. 실제로 신경망에 있어 `tf.keras`와 같은 고수준 API는 고수준 구성 요소(\"층\"으로 불리는)를 제공하고, 저장 및 복원을 위한 유틸리티, 손실 함수 모음, 최적화 전략 모음 등을 제공하기 때문에 더욱 편리합니다. ",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
ecc05e3b5a5495e79c28e08d86891b39cc65bc84 | 364,636 | ipynb | Jupyter Notebook | typeII/Net1.1.ipynb | han-fuyun/SolarRadioBurst | 594b00c44a2985df1427edfd059557cefd841270 | [
"MIT"
] | 1 | 2022-01-24T03:48:13.000Z | 2022-01-24T03:48:13.000Z | typeII/Net1.1.ipynb | han-fuyun/SolarRadioBurst | 594b00c44a2985df1427edfd059557cefd841270 | [
"MIT"
] | null | null | null | typeII/Net1.1.ipynb | han-fuyun/SolarRadioBurst | 594b00c44a2985df1427edfd059557cefd841270 | [
"MIT"
] | 1 | 2022-01-12T01:03:32.000Z | 2022-01-12T01:03:32.000Z | 828.718182 | 24,687 | 0.559583 | [
[
[
"from keras import models\nfrom keras import layers",
"Using TensorFlow backend.\n"
],
[
"model = models.Sequential()\n#卷积层,参数意义分别为:\n#经过这一层之后,特征图的个数,一个卷积核,产生一个特征图,第一层:32,说明有32个卷积核;第二层64,说明在第一层的特征图基础上,每张特征图有两个卷积核进行特征采集\n#卷积核大小\n#激活函数\n#输入大小(只在开始的第一层有,后面不需要)\nmodel.add(layers.Conv2D(32,(3,3),activation='relu',input_shape=(400,200,3)))\nmodel.add(layers.MaxPool2D(2,2))\nmodel.add(layers.Conv2D(64,(3,3),activation='relu'))\nmodel.add(layers.MaxPooling2D((2, 2)))\nmodel.add(layers.Conv2D(128, (3, 3), activation='relu'))\nmodel.add(layers.MaxPooling2D((2, 2)))\nmodel.add(layers.Flatten())\nmodel.add(layers.Dense(512, activation='relu'))\nmodel.add(layers.Dense(1, activation='sigmoid'))\n\n",
"_____no_output_____"
],
[
"#配置模型的损失函数、优化器、指标名称\nfrom keras import optimizers\n\nmodel.compile(loss='binary_crossentropy', #损失函数\noptimizer=optimizers.RMSprop(lr=1e-4), #优化器\nmetrics=['acc']) #指标名称\n",
"_____no_output_____"
],
[
"#图片的训练路径和验证路径\ntrain_dir = r'G:\\test\\normal_x\\typeII1.2\\train'\nvalidation_dir = r'G:\\test\\normal_x\\typeII1.2\\val'\n",
"_____no_output_____"
],
[
"#生成训练需要的图片和标签\nfrom keras.preprocessing.image import ImageDataGenerator\n#将图片大小调整到1以内,原先图片每个像素的格式为uint8,所以要除以255\ntrain_datagen = ImageDataGenerator(rescale=1./255)\nvalidation_datagen = ImageDataGenerator(rescale=1./255)\n\n#根据目录的名称,生成对应的标签\n#train_dir有Ⅱ型和Ⅲ型的图片\n#每次生成batch_size数量的图片,图片大小为target_size\ntrain_generator = train_datagen.flow_from_directory(\ntrain_dir,\ntarget_size=(400, 200), #生成图片的大小\nbatch_size=20, #一次生成图片的数量\nclass_mode='binary') #图片标签的类型\n\nvalidation_generator = validation_datagen.flow_from_directory(\nvalidation_dir,\ntarget_size=(400, 200), #生成图片的大小\nbatch_size=10, #一次生成图片的数量\nclass_mode='binary') #图片标签的类型\n",
"Found 800 images belonging to 2 classes.\nFound 260 images belonging to 2 classes.\n"
],
[
"#开始训练\nhistory = model.fit_generator(\ntrain_generator,\nsteps_per_epoch=40,\nepochs=50,\nvalidation_data=validation_generator,\nvalidation_steps=13)",
"Epoch 1/50\n40/40 [==============================] - 25s 627ms/step - loss: 0.6755 - acc: 0.6425 - val_loss: 0.3311 - val_acc: 0.7538\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 2/50\n40/40 [==============================] - 9s 216ms/step - loss: 0.4537 - acc: 0.7738 - val_loss: 0.7471 - val_acc: 0.8385\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 3/50\n40/40 [==============================] - 9s 216ms/step - loss: 0.3961 - acc: 0.8300 - val_loss: 0.4623 - val_acc: 0.8615\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 0s - loss: 0.3999 - acc: 0.8278\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 4/50\n40/40 [==============================] - 9s 216ms/step - loss: 0.3448 - acc: 0.8637 - val_loss: 0.6767 - val_acc: 0.8000\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 5/50\n40/40 [==============================] - 9s 216ms/step - loss: 0.3066 - acc: 0.8675 - val_loss: 0.4253 - val_acc: 0.9000\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 2s - loss: 0.3207 - acc: 0.8630\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 6/50\n40/40 [==============================] - 9s 216ms/step - loss: 0.2804 - acc: 0.8763 - val_loss: 0.1774 - val_acc: 0.8692\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 7/50\n40/40 [==============================] - 9s 216ms/step - loss: 0.2231 - acc: 0.9150 - val_loss: 0.4504 - val_acc: 0.8846\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 8/50\n40/40 [==============================] - 9s 217ms/step - loss: 0.2302 - acc: 0.9112 - val_loss: 0.0693 - val_acc: 0.9000\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 4s - loss: 0.2306 - acc: 0.9158\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 9/50\n40/40 [==============================] - 9s 217ms/step - loss: 0.1739 - acc: 0.9275 - val_loss: 0.1648 - val_acc: 0.7538\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 10/50\n40/40 [==============================] - 9s 217ms/step - loss: 0.1685 - acc: 0.9450 - val_loss: 0.0568 - val_acc: 0.8769\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 11/50\n40/40 [==============================] - 9s 217ms/step - loss: 0.1379 - acc: 0.9538 - val_loss: 1.0294 - val_acc: 0.7769\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 12/50\n40/40 [==============================] - 9s 217ms/step - loss: 0.1205 - acc: 0.9563 - val_loss: 0.7463 - val_acc: 0.9077\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 13/50\n40/40 [==============================] - 9s 216ms/step - loss: 0.0935 - acc: 0.9700 - val_loss: 0.5361 - val_acc: 0.9000\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 7s - loss: 0.0786 - acc: 0.9750\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 2s - loss: 0.0945 - acc: 0.9661\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 14/50\n40/40 [==============================] - 9s 217ms/step - loss: 0.1016 - acc: 0.9700 - val_loss: 0.0977 - val_acc: 0.9077\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 15/50\n40/40 [==============================] - 9s 217ms/step - loss: 0.0695 - acc: 0.9800 - val_loss: 0.0107 - val_acc: 0.9308\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 16/50\n40/40 [==============================] - 9s 217ms/step - loss: 0.0800 - acc: 0.9725 - val_loss: 0.8364 - val_acc: 0.8846\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 17/50\n40/40 [==============================] - 9s 221ms/step - loss: 0.0491 - acc: 0.9862 - val_loss: 0.1602 - val_acc: 0.8077\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 2s - loss: 0.0414 - acc: 0.9875\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 18/50\n40/40 [==============================] - 9s 218ms/step - loss: 0.0634 - acc: 0.9812 - val_loss: 0.4039 - val_acc: 0.9154\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 2s - loss: 0.0686 - acc: 0.9788\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 19/50\n40/40 [==============================] - 9s 218ms/step - loss: 0.0417 - acc: 0.9912 - val_loss: 0.2100 - val_acc: 0.9154\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 20/50\n40/40 [==============================] - 9s 217ms/step - loss: 0.0395 - acc: 0.9912 - val_loss: 0.0077 - val_acc: 0.8846\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 21/50\n40/40 [==============================] - 9s 217ms/step - loss: 0.0331 - acc: 0.9875 - val_loss: 1.0723 - val_acc: 0.8923\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 1s - loss: 0.0266 - acc: 0.9924\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 22/50\n40/40 [==============================] - 9s 217ms/step - loss: 0.0175 - acc: 0.9987 - val_loss: 0.4173 - val_acc: 0.8692\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 6s - loss: 0.0182 - acc: 1.0000\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 23/50\n40/40 [==============================] - 9s 216ms/step - loss: 0.0161 - acc: 0.9962 - val_loss: 0.0022 - val_acc: 0.8846\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 24/50\n40/40 [==============================] - 9s 217ms/step - loss: 0.0393 - acc: 0.9900 - val_loss: 0.2868 - val_acc: 0.9154\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 7s - loss: 0.2087 - acc: 0.9375\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 7s - loss: 0.1763 - acc: 0.9400\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 25/50\n40/40 [==============================] - 9s 217ms/step - loss: 0.0123 - acc: 0.9962 - val_loss: 1.7732 - val_acc: 0.8692\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 5s - loss: 0.0030 - acc: 1.0000\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 26/50\n40/40 [==============================] - 9s 217ms/step - loss: 0.0187 - acc: 0.9937 - val_loss: 0.0372 - val_acc: 0.9154\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 27/50\n40/40 [==============================] - 9s 217ms/step - loss: 0.0066 - acc: 1.0000 - val_loss: 0.6097 - val_acc: 0.8846\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 28/50\n40/40 [==============================] - 9s 217ms/step - loss: 0.0091 - acc: 0.9975 - val_loss: 0.1244 - val_acc: 0.9154\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 5s - loss: 0.0023 - acc: 1.0000\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 29/50\n40/40 [==============================] - 9s 217ms/step - loss: 0.0145 - acc: 0.9962 - val_loss: 0.0503 - val_acc: 0.9000\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 7s - loss: 0.0027 - acc: 1.0000\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 30/50\n40/40 [==============================] - 9s 217ms/step - loss: 0.0123 - acc: 0.9962 - val_loss: 0.0281 - val_acc: 0.8846\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 31/50\n40/40 [==============================] - 9s 217ms/step - loss: 0.0027 - acc: 1.0000 - val_loss: 0.4744 - val_acc: 0.9231\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 32/50\n40/40 [==============================] - 9s 217ms/step - loss: 0.0338 - acc: 0.9950 - val_loss: 0.2715 - val_acc: 0.8615\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 33/50\n40/40 [==============================] - 9s 217ms/step - loss: 0.0016 - acc: 1.0000 - val_loss: 1.1954 - val_acc: 0.9000\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 7s - loss: 0.0029 - acc: 1.0000\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 6s - loss: 0.0025 - acc: 1.0000\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 34/50\n40/40 [==============================] - 9s 216ms/step - loss: 0.0071 - acc: 0.9987 - val_loss: 1.4080 - val_acc: 0.9000\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 35/50\n40/40 [==============================] - 9s 218ms/step - loss: 0.0030 - acc: 1.0000 - val_loss: 0.8145 - val_acc: 0.9231\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 36/50\n40/40 [==============================] - 9s 217ms/step - loss: 0.0128 - acc: 0.9975 - val_loss: 0.0268 - val_acc: 0.8692\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 5s - loss: 4.5343e-04 - acc: 1.0000\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 37/50\n40/40 [==============================] - 9s 217ms/step - loss: 0.0018 - acc: 1.0000 - val_loss: 0.5069 - val_acc: 0.8923\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 38/50\n40/40 [==============================] - 9s 217ms/step - loss: 0.0390 - acc: 0.9825 - val_loss: 0.0164 - val_acc: 0.9154\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 4s - loss: 2.9731e-04 - acc: 1.0000\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 39/50\n40/40 [==============================] - 9s 216ms/step - loss: 7.8045e-04 - acc: 1.0000 - val_loss: 7.4164e-04 - val_acc: 0.8923\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 40/50\n40/40 [==============================] - 9s 217ms/step - loss: 0.0243 - acc: 0.9912 - val_loss: 1.2321 - val_acc: 0.8923\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 4s - loss: 3.0839e-04 - acc: 1.0000\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 41/50\n40/40 [==============================] - 9s 216ms/step - loss: 0.0031 - acc: 0.9987 - val_loss: 0.2252 - val_acc: 0.9154\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 42/50\n40/40 [==============================] - 9s 216ms/step - loss: 2.6004e-04 - acc: 1.0000 - val_loss: 0.5218 - val_acc: 0.8923\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 7s - loss: 3.1906e-04 - acc: 1.0000\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 43/50\n40/40 [==============================] - 9s 216ms/step - loss: 0.0157 - acc: 0.9937 - val_loss: 1.1064 - val_acc: 0.9154\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 44/50\n40/40 [==============================] - 9s 217ms/step - loss: 8.4160e-04 - acc: 1.0000 - val_loss: 1.7681 - val_acc: 0.8846\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 4s - loss: 9.0737e-04 - acc: 1.0000\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 4s - loss: 8.8233e-04 - acc: 1.0000\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 45/50\n40/40 [==============================] - 9s 217ms/step - loss: 1.5938e-04 - acc: 1.0000 - val_loss: 1.6608 - val_acc: 0.8923\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 46/50\n40/40 [==============================] - 9s 216ms/step - loss: 0.0332 - acc: 0.9937 - val_loss: 0.5720 - val_acc: 0.9077\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 3s - loss: 0.0599 - acc: 0.9886\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 47/50\n40/40 [==============================] - 9s 216ms/step - loss: 1.8163e-04 - acc: 1.0000 - val_loss: 1.6715 - val_acc: 0.9308\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 4s - loss: 2.4670e-04 - acc: 1.0000\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 2s - loss: 2.1349e-04 - acc: 1.0000\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 48/50\n40/40 [==============================] - 9s 216ms/step - loss: 0.0110 - acc: 0.9962 - val_loss: 0.0246 - val_acc: 0.8769\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 5s - loss: 1.0966e-04 - acc: 1.0000\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 49/50\n40/40 [==============================] - 9s 217ms/step - loss: 4.2465e-04 - acc: 1.0000 - val_loss: 2.6115 - val_acc: 0.9077\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\nEpoch 50/50\n40/40 [==============================] - 9s 217ms/step - loss: 7.9941e-05 - acc: 1.0000 - val_loss: 1.9771 - val_acc: 0.9000\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 7s - loss: 2.0553e-04 - acc: 1.0000\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b - ETA: 7s - loss: 1.5655e-04 - acc: 1.0000\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\n"
],
[
"#绘制训练精度、验证精度\n#绘制训练损失、验证损失\n#python画图库,类似matlab的plot\nimport matplotlib.pyplot as plt\nacc = history.history['acc'] #得到训练的指标数据\nval_acc = history.history['val_acc'] #得到验证的指标数据\nloss = history.history['loss'] #得到训练损失\nval_loss = history.history['val_loss'] #得到验证损失\nepochs = range(1, len(acc) + 1)\nplt.plot(epochs, acc, 'bo', label='Training acc')\nplt.plot(epochs, val_acc, 'b', label='Validation acc')\nplt.title('Training and validation accuracy')\nplt.savefig('accuracy_1.1.png')\nplt.legend() #画图例\nplt.figure() #另一张图\nplt.plot(epochs, loss, 'bo', label='Training loss')\nplt.plot(epochs, val_loss, 'b', label='Validation loss')\nplt.title('Training and validation loss')\nplt.savefig('loss_1.1.png')\nplt.legend()\nplt.show() #画图,最后加上",
"_____no_output_____"
],
[
"# 保存每轮的精度和损失\n\nfile = open('acc_loss_50_1.1.txt','a')\nfile.write('训练精度:')\nfor i in acc :\n file.write(str(i))\n file.write(\" \")\nfile.write(\"\\n\")\nfile.write('验证精度:')\nfor i in val_acc :\n file.write(str(i))\n file.write(\" \")\n\n\nfile.write(\"\\n\")\nfile.write('训练损失:')\nfor i in loss :\n file.write(str(i))\n file.write(\" \")\n\nfile.write(\"\\n\")\nfile.write('验证损失:')\nfor i in val_loss :\n file.write(str(i))\n file.write(\" \")\n\nfile.close()",
"_____no_output_____"
],
[
"import os\nimport cv2 as cv\nimport numpy as np\n\nIII_dir = r'G:\\test\\normal_x\\typeII1.2\\val\\II'\nO_dir = r'G:\\test\\normal_x\\typeII1.2\\val\\O'\n\ndef my_image(path):\n out = []\n filenames = os.listdir(path)\n for filename in filenames:\n image = cv.imread(os.path.join(path, filename))\n\n image = cv.resize(image, (200, 400))\n image = image/255.0\n out.append(image)\n return np.array(out)\n\nimgs_III = my_image(III_dir)\nimgs_O = my_image(O_dir)\nret_III = model.predict_classes(imgs_III)\nret_O = model.predict_classes(imgs_O)\n\nret_III = ret_III.tolist()\nret_O = ret_O.tolist()\ntrue = ret_III.count([0])\nfalse = ret_O.count([0])\nTPR = true/len(ret_III)\nFPR = false/len(ret_O)\nprint(\"TPR is :{:f} \".format(TPR))\nprint(\"FPR is :{:f} \".format(FPR))",
"TPR is :0.900000 \nFPR is :0.100000 \n"
],
[
"model.save('typeII_binary_normalization_50_1.1.h5')\n",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecc072e2c8e81bc4e7d3dfba1e78871c86096ba3 | 152,058 | ipynb | Jupyter Notebook | PhyloPractical.ipynb | davelunt/phylo_practical | 1179d7b89d32c2f48a1114629b9ba7ce19fe7fc9 | [
"Unlicense"
] | null | null | null | PhyloPractical.ipynb | davelunt/phylo_practical | 1179d7b89d32c2f48a1114629b9ba7ce19fe7fc9 | [
"Unlicense"
] | null | null | null | PhyloPractical.ipynb | davelunt/phylo_practical | 1179d7b89d32c2f48a1114629b9ba7ce19fe7fc9 | [
"Unlicense"
] | null | null | null | 105.963763 | 36,978 | 0.589111 | [
[
[
"<h1><font color='DarkBlue'>PRACTICAL PHYLOGENETICS NOTEBOOK</font></h1>\n<hr>\nDr Dave Lunt [email protected]",
"_____no_output_____"
],
[
"<h2><font color='Blue'>Goals of these experiments</font></h2>",
"_____no_output_____"
],
[
"This Jupyter notebook will take you through two case studies using phylogenetic analysis to understand biological questions. This will involve aligning sequences and building maximum likelihood phylogenetic trees, followed by annotation an interpretation.\n\nWe hope that this will give you \n- experience in analysing DNA sequence data\n- Understanding of the steps involved in phylogenetics\n- Knowledge about the compleities of the specific case studies we are using\n\nYou will write up one of the case study analyses you perform today for your assessment.",
"_____no_output_____"
],
[
"<h2><font color='Blue'>Introduction to Jupyter computational notebooks</font></h2>",
"_____no_output_____"
],
[
"<font color=red>**FIRSTLY, DO NOT PANIC. EVERYTHING YOU NEED TO KNOW ABOUT COMPUTERS AND CODE WILL BE TAUGHT HERE. YOU WILL BE ABLE TO DO THIS EVEN IF YOU HAVE LITTLE EXPERIENCE WITH COMPUTERS**</font>\n\nThis class of students has mixed prior experience however, so if you have not done the bioinformatics practicals in Genetic Analysis last semester then please make yourself known and we will give you a 5 minute catch-up to make your life easier.\n\nIf you are familiar with Jupyter notebooks then you can skip this section and move to \"A NEW SPECIES oF APE?\" below.\n\nThis document that you are reading now is a **Jupyter Notebook**. It is a web browser based text editor that is also able to execute scripts ie code. Today we are using the programming language `python`, probably the most used language in bioinformatics, but we could also run `R`, `bash` or many other languages. Scripts are found in the grey cells (see below) and have something like `In [ ]:` or `[1]` to their left in the margin.. \n\nTo execute a script, click the cell below and then press SHIFT+ENTER, or instead the triangular \"Run\" button in the tool bar above. Try running this code below now ",
"_____no_output_____"
]
],
[
[
"print('Hey there, good job in running the python print command!')",
"Hey there, good job in running the python print command!\n"
]
],
[
[
"This code cell (containing \"print('Hey...\") should have executed when you pressed SHIFT-ENTER and it's output was printed below the cell (\"Hey there, good job...\"). All Jupyter commands run in a similar fashion",
"_____no_output_____"
],
[
"Can you identify which parts of this notebook are code, which parts output, and which parts documentation like this sentence? Discuss with us if you are in doubt.\n\n1. Try editing the code below and re-running. Replace \"Good job\" with \"Even better job\"\n2. Instead of the `Run` button at the top you can click in the cell and press Shift-Enter to run the code. Most people find this faster, edit the cell below then give it a try:",
"_____no_output_____"
]
],
[
[
"print('Hey there, really good job!')",
"Hey there, really good job!\n"
]
],
[
[
"<h4><font color='Blue'>ACTION:</font></h4>\n\nNow edit the cell above to have two print statements. On a new line type `print('Your new phrase')` and then run it. It might be easier to copy/paste and just change the pasted phrase. If it doesn't run well, you have a typo. Yes, its always a typo.\n\n**Congratulations, you have now run, copy/pasted and edited cells. Those are all the skills you will need today**\n\nThis iterative edit-and-run approach is how much of modern biological data is explored and analysed. This mix of code and explanation you are seeing in this Jupyter notebook is called \"literate programming\"",
"_____no_output_____"
],
[
"This notebook will take you through the anaysis of the two case studies found in the practical handbook. To make this notebook concise, background information is excluded from it and only available in the practical handbook, and you will need to work with both documents. For each case study you will need to run several cells just as you did above. The programs will then align and clean the DNA sequences, build a tree and annotate it. **In most cases you will only need to run the cell just as you did above. In a few cases you will be able to tweak the script just a bit following clear instructions**. Good luck!",
"_____no_output_____"
],
[
"<h1><font color='Blue'>STUDY1: A NEW SPECIES OF APE?</font></h1>",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"_Figure 1:_ Male Bornean, Sumatran and Tapanuli orangutans, three suggested species [wikipedia](https://en.wikipedia.org/wiki/Orangutan). ",
"_____no_output_____"
],
[
"The first aim of today is to investigate what phylogenetics can tell us about different species of great ape. It is, of course, complex. You might like to think how you would conceptually go about trying to get information using a phylogenetic approach.",
"_____no_output_____"
],
[
"**Table 1: Latin names and common names of species in this practical.** As always, Googling is encouraged.",
"_____no_output_____"
],
[
"| Name | Common name | Name | Common Name |\n| ----------------|:----------------------| --------------|:---------- |\n| Macaca macaca | Macaque (outgroup)| Homo sapiens sapiens | Modern humans\n| Hylobates lar | Gibbon (outgroup) | Homo sapiens neanderthalis | Neanderthals (extinct)|\n| Gorilla gorilla | Western Gorilla | Homo sapiens denisovan | Denisovans (extinct)\n| Gorilla beringei | Eastern/mountain Gorilla | Pongo abelii | Sumatran orangutan |\n| Pan troglodytes | Chimp | Pongo pygmaeus | Bornean orangutan |\n| Pan paniscus | Bonobo | Pongo tapanuliensis | Tapanuli orangutan|\n|",
"_____no_output_____"
],
[
"<h2><font color='Blue'>How much data do you have?</font></h2>\nYour working directory has some DNA sequence files in fasta format. There are a number of ways to determine the number of sequences in a file, here is a quick one-liner. \n",
"_____no_output_____"
]
],
[
[
"!echo \"Number of sequences: \"; grep -c \">\" data/filename.fas",
"Number of sequences: \r\n19\r\n"
]
],
[
[
"It should have displayed the number of sequences in the `ape.fas` file in the `data` directory\n\nIf you got 'file does not exist' it is because you haven't pointed it at `ape.fas`",
"_____no_output_____"
],
[
"### Some python code for processing sequences, just FYI",
"_____no_output_____"
],
[
"Below we use some python code to allow more complex analyses. In the next example we are going to find the number and total length of sequences using a useful code package called BioPython [1].\n\nRemember: The code below has explanations of what each section does (explanations begin with the # or 'comment' symbol) as some people are interested in seeing bioinformatics code in action. I want you to see scripting like this so you can realise it's not magic **but you do not have to know python or understand this code. Just run the cell as usual.**",
"_____no_output_____"
]
],
[
[
"# --------------------------------------------\n# Python code to report on number of sequences \n# in a file by using BioPython\n# --------------------------------------------\n\n# import BioPython code so we can use it\nfrom Bio.SeqIO.FastaIO import SimpleFastaParser\n\n# set counts to zero before starting\ncount = 0\ntotal_len = 0\n\n# open the data file and give it a handle (nickname)\nwith open(\"data/ape.fas\") as in_handle:\n \n# for each title line add 1 to count of records, \n# and add length of sequence to a count called total_len\n for title, seq in SimpleFastaParser(in_handle):\n count += 1\n total_len += len(seq)\n \n# print the results in a readable format\nprint(\"The file contained %i records with total sequence length of %i nucleotides\" % (count, total_len))",
"The file contained 3 records with total sequence length of 1449 nucleotides\n"
]
],
[
[
"<h4><font color='Blue'>QUESTIONS:</font></h4>\n\n- Can you see which part of the above code specifies the fasta file `ape.fas`?\n\n- How could you run this on a different file in the data directory called `testseqs.fasta`? \n\nYou don't need any python knowledge to answer these. The idea here is that in much of bioinformatics you can modify someone else's code to point at your data file and everything will work. ",
"_____no_output_____"
],
[
"<h4><font color='Blue'>ACTION:</font></h4>\n\nTry it, just change the name above and re-run the cell, or ask for help if you can't quite see it. Remember that the file is within the `data` directory. If you've done it correctly (watch for typos) then the number and length of sequence reported will change.",
"_____no_output_____"
],
[
"<hr>\n<h2><font color='Blue'>Aligning the sequences</font></h2>\nIn order to carry out a valid analysis you have to align the DNA sequences. If you're not quite sure why, look at the images below and discuss with a demonstrator. ",
"_____no_output_____"
],
[
"\n_A DNA sequence alignmnet. Each character (column) can be directly compared across the different species_",
"_____no_output_____"
],
[
"\n_A set of DNA sequences not completely aligned. Each character (column) cannot be directly compared across the different species as some are 'shifted' so even though they are very similar, they look enormously different when just comparing down each column (character)_",
"_____no_output_____"
],
[
"To align the sequences we will use a program called MAFFT [2]. What piece of information will we have to add to the code? Yes, the name of the input DNA sequence file to be aligned.\n\n<h4><font color='Blue'>ACTIONS:</font></h4>\n\n- Change the name of the file in the following code to be `ape.fas`\n- run the cell",
"_____no_output_____"
]
],
[
[
"# ---------------------------\n# Align sequences using MAFFT\n# ---------------------------\n\n!mafft --auto --quiet data/sequencefile.fas > ape.afa",
"_____no_output_____"
]
],
[
[
"In the command above can you see where we name the output file? You may remember that the greater than symbol `>` is used to specify where the output of a command goes, in this case to `ape.afa`. Did it work? Can you find the `ape.afa` file? The `.afa` extension stands for 'aligned fasta'",
"_____no_output_____"
],
[
"<hr>\n<h2><font color='Blue'>QC the alignment</font></h2>\nTrimal [3] quality controls the alignment, removing badly aligned regions and alignment artefacts. \n\nCan you see that the input file specified `ape.afa` is the output file from the previous step? Can you see the output file that it will write? This should appear in your files list once you have run the cell.",
"_____no_output_____"
]
],
[
[
"# ------------------------------------------\n# Quality control the alignment using trimal\n# ------------------------------------------\n\n!trimal -in ape.afa -out ape_trimmed.afa -gappyout -keepheader",
"_____no_output_____"
]
],
[
[
"<hr>\n<h2><font color='Blue'>Tree reconstruction</font></h2>\nThis section will reconstruct a maximum likelihood phylogenetic tree using the sequence alignment you have produced. We will use the program FastTree [4].",
"_____no_output_____"
]
],
[
[
"# -------------------------\n# Build tree using FastTree\n# -------------------------\n\n!FastTree -gtr -nt ape_trimmed.afa > ape.nwk",
"FastTree Version 2.1.10 Double precision (No SSE3)\nAlignment: ape_trimmed.afa\nNucleotide distances: Jukes-Cantor Joins: balanced Support: SH-like 1000\nSearch: Normal +NNI +SPR (2 rounds range 10) +ML-NNI opt-each=1\nTopHits: 1.00*sqrtN close=default refresh=0.80\nML Model: Generalized Time-Reversible, CAT approximation with 20 rate categories\nInitial topology in 0.00 seconds\nRefining topology: 16 rounds ME-NNIs, 2 rounds ME-SPRs, 8 rounds ML-NNIs\nTotal branch-length 0.477 after 0.02 sec\nML-NNI round 1: LogLk = -1805.940 NNIs 2 max delta 0.00 Time 0.04\nGTR Frequencies: 0.3150 0.3149 0.1056 0.2645\nGTR rates(ac ag at cg ct gt) 2.3845 14.9825 1.2609 1.5635 13.8255 1.0000\nSwitched to using 20 rate categories (CAT approximation)1 of 20 \nRate categories were divided by 0.732 so that average rate = 1.0\nCAT-based log-likelihoods may not be comparable across runs\nUse -gamma for approximate but comparable Gamma(20) log-likelihoods\nML-NNI round 2: LogLk = -1589.440 NNIs 0 max delta 0.00 Time 0.12\nTurning off heuristics for final round of ML NNIs (converged)\nML-NNI round 3: LogLk = -1589.426 NNIs 0 max delta 0.00 Time 0.14 (final)\nOptimize all lengths: LogLk = -1589.426 Time 0.15\nTotal time: 0.18 seconds Unique: 17/19 Bad splits: 0/14\n"
]
],
[
[
"<hr>",
"_____no_output_____"
],
[
"The treebuilding program \"FastTree\" gives lots of output, you can just ignore all those details. When it is finished a file called `ape.nwk` will appear. This is a Newick tree file (.nwk) containing the tree as bracket notation text. Double click it if you want to have a look.",
"_____no_output_____"
],
[
"<hr>\n<h2><font color='Blue'>Tree Annotation and Viewing</font></h2>\n\nThe tree alone (example below) is in bracket notation format (called Newick) and not very meaningful to examine.\n\n```\n((A,B),(C,D));\n```\nInstead we are going to display it as a graphic, and then annotate it to be easier to interpret. To do this we are going to use a tree graphics program called ToyTree [5].",
"_____no_output_____"
],
[
"<h4><font color='Blue'>QUESTION:</font></h4>\n\nWhat treefile (.nwk) has just been written by the build tree cell above? Open it for a look at the Newick format.\n\n<h4><font color='Blue'>ACTION:</font></h4>\n\nTake your newick treefile name and enter it into the cell below to replace \"tree.nwk\"",
"_____no_output_____"
]
],
[
[
"# -----------------------------------\n# Drawing the phylogeny using ToyTree\n# -----------------------------------\n# import the code so we can use it here\nimport toytree # a tree plotting library\nimport toyplot # a general plotting library\n# import numpy as np # a numerical library, give it the shorthand 'np'\n\n# read the newick format tree file, give it the name 'newick'\nnewick = \"tree.nwk\" # change this to point at your .nwk treefile\ntre = toytree.tree(newick, tree_format=1)\n\ntre.draw();",
"_____no_output_____"
]
],
[
[
"If you see a graphic image of a phylogenetic tree, congratulations! If not please ask for a little help, its probably a quick fix for a demonstrator.\n\n<h4><font color='Blue'>NOW ROOT THE TREE</font></h4>\n\nYour tree will probably look very odd because it isn't yet rooted correctly. Use the next cell to root it by entering \"Macaca\" (Macacque) instead of \"outgroup\"",
"_____no_output_____"
]
],
[
[
"# ----------------\n# Root and re-draw\n# ----------------\n# root and draw the tree\nrtre = tre.root(wildcard=\"outgroup\") # specify the outgroup taxon\nrtre.draw(height=600, tip_labels_align=True); # draw the tree",
"_____no_output_____"
]
],
[
[
"You should now have a tree that reveals a lot about the relationships betwen these species. Remember that there is a table with the species name earlier in this document. It will be easier to interpret though when you put it into a report if you annotate and colour it by taxon.",
"_____no_output_____"
],
[
"<h4><font color='Blue'>NOW ANNOTATE THE TREE:</font></h4>\nAlthough you now have 'the answer' it is not so easy to study this tree. You will need to compare the divergences between the two species of orangutan and compare those to the divergences between the two species of chimpanzee. In this simple tree its not too hard, but in general phylogeneticists label and colour to maintain focus on the correct comaprisons. You are now going to use the script below to colour in the tips by their species identity. \n\nRun the cell and examine the tree",
"_____no_output_____"
]
],
[
[
"# -----------------------------\n# Colouring the tree label text\n# -----------------------------\n\n# set list of colours depending on the taxon label text\n# numbers like \"#5384a3\" are colour 'hex' codes, cyan in\n# this case (google \"hex colour codes\" for other options)\n\ncolorlist = [\"blue\" if \"Pan_paniscus\" in tip\n else \"darkblue\" if \"Pan_troglodytes\" in tip \n else \"red\" if \"Pongo_abelii\" in tip \n else \"orange\" if \"Pongo_pygmaeus\" in tip\n else \"#5384a3\" for tip in rtre.get_tip_labels()]\n\n# draw the tree\ncanvas = rtre.draw(\n width=600, # set dimensions of the figure\n height=600,\n scalebar=True, # scale bar of divergence levels\n tip_labels_align=True,\n tip_labels=True,\n tip_labels_colors=colorlist,\n node_labels=None,\n node_sizes=[0 if i else 8 for i in rtre.get_node_values(None, 1, 0)],\n node_markers=\"s\", # use \"o\" for circles instead of squares\n node_colors=toytree.colors[0],\n)",
"_____no_output_____"
]
],
[
[
"You now have all the skills to edit this script and change colours. Pick some ones you like and rerun. The tree tips are marked by squares, the dashed lines after those just help link the tips to the names. You can remove the code line `tip_labels_align=True,` above and rerun to see it without the dotted lines",
"_____no_output_____"
],
[
"<h3><font color=red>IMPORTANT, SAVE YOUR FILE</font></h3>\nMake sure that you save and take away a copy of you tree file image in a format suitable to insert into your final report. Run the cell below and then find the file in your working directory and save it somewhere accesible.",
"_____no_output_____"
]
],
[
[
"# --------------------------------\n# Save the tree as a graphics file\n# --------------------------------\n\n# import code to draw graphics files\nimport toyplot.pdf\nimport toyplot.svg\nimport toyplot.html\n\n# draw graphics files\n# toyplot.svg.render(canvas[0], \"ape.svg\")\ntoyplot.pdf.render(canvas[0], \"ape.pdf\")\ntoyplot.html.render(canvas[0], \"ape.html\")",
"_____no_output_____"
]
],
[
[
"<h4><font color='Blue'>SPECIES DIFFERENTIATION</font></h4>",
"_____no_output_____"
],
[
"Looking at the tree, it would seem the two *Pan* clades are as distant from each other as the two *Pongo* clades\n \nThe scale along the bottom is genetic distances from 0 to 1, so 0.06 would be 6%. Find the common ancestor node of each genus. What is the distance between the common ancestor of both Pan species and the tree tips? What is that value for Pongo? Do you think it is very different?\n\nWhen this analysis was first done orangutans were all classified as the same species, whereas there were two Pan species. Do you think that classification accurately reflects evolutionary history? Does the classification in this way have any negatives for conservation planning? Discuss in your group.\n\nSoon after these analyses on single mitochondrial genes, exactly as you have done here, orangutans were divided into two species.",
"_____no_output_____"
],
[
"## Pause",
"_____no_output_____"
],
[
"You have just loaded a data file, aligned it, quality controled the alignment, constructed a maximum likelihood phyogenetic tree, and created an annotated figure of the phylogeny. Well done!",
"_____no_output_____"
],
[
"Oh yes, some of you may also have modified a bioinformatics python script to characterise a DNA sequence file. ",
"_____no_output_____"
],
[
"This was quite a lot of work to do the first time, trying to understand how to pass a specific data file through the analytical satges to create a phylogeny. Fortunately, as you learned above, doing it again on a different data file just requires a simple change, ie specifying a different file.",
"_____no_output_____"
],
[
"Below you can quite rapidly analyse a \"big ape\" data set, containing a lot more sequences, by rerunning the same commands with different data. It should not take long. In the second case study (below) we are going to swap from apes to HIV, but again it should be rapid because the commands will be very similar.",
"_____no_output_____"
],
[
"<hr>\n<h2><font color='Blue'>A big data analysis of great apes</font></h2>\n\nOne very useful aspect of using code to carry out analyses is that once you have written it, and it works, its very little effort to re-run it again on any number or any size of other data sets.\n\nHere I have collected from GenBank whole mitochondrial genomes (about 16,000 nucleotides per genome) from a lot of great apes including humas, neanderthals, and species of gorillas in addition to the species you have just analysed. The file is large but we can just run the same code again. If you want to find out how much data you have, you could insert a cell and paste in the code to quantify sequences (from the ape example) and run it for the big_ape dataset. This is optional. For efficiency reasons I've compressed the code below a little, but its the same as you have just run.\n\nThis big analysis gives you the opportunity to decide whether the similarity of divergence between groups that you have just observed is true more widely. When you have produced their big trees you should discuss what the divergence levels might mean with your demonstrators. If you want to find out how much data you are analysing you can copy and paste the \"how much data do you have?\" cell from above, and run it here (on the new fasta file). But that is optional.",
"_____no_output_____"
],
[
"The data is in the `data` directory in a file called `big_ape.fas` make sure your code points at the correct input file.\n\nRun this cell to align, trim the alignment, and then build a tree. It might take a few minutes to complete. When there is a number not an asterisk in the left margin then it is complete.",
"_____no_output_____"
]
],
[
[
"# Align\n!mafft --auto --quiet data/sequencefile.fas > big_ape.afa\nprint(\"\\nThe sequence alignment has finished\")\n# Trim\n!trimal -in big_ape.afa -out big_ape_trimmed.afa -gappyout -keepheader\nprint(\"The alignment trimming has finished\")\n# Tree build\nprint(\"The phylogenetic tree construction has started\\n\")\n!FastTree -gtr -nt big_ape_trimmed.afa > big_ape.nwk\nprint(\"\\nThe phylogenetic analysis has finished\")",
"\nThe sequence alignment has finished\nThe alignment trimming has finished\nThe phylogenetic tree construction has started\n\nFastTree Version 2.1.10 Double precision (No SSE3)\nAlignment: big_ape_trimmed.afa\nNucleotide distances: Jukes-Cantor Joins: balanced Support: SH-like 1000\nSearch: Normal +NNI +SPR (2 rounds range 10) +ML-NNI opt-each=1\nTopHits: 1.00*sqrtN close=default refresh=0.80\nML Model: Generalized Time-Reversible, CAT approximation with 20 rate categories\nIgnored unknown character n (seen 42 times)\nIgnored unknown character r (seen 1 times)\nIgnored unknown character s (seen 1 times)\nInitial topology in 0.26 seconds\nRefining topology: 23 rounds ME-NNIs, 2 rounds ME-SPRs, 11 rounds ML-NNIs\nTotal branch-length 0.536 after 3.99 sec3, 1 of 49 splits \nML-NNI round 1: LogLk = -77072.124 NNIs 4 max delta 7.85 Time 5.89\nGTR Frequencies: 0.3092 0.3142 0.1304 0.2462ep 12 of 12 \nGTR rates(ac ag at cg ct gt) 5.1842 40.6082 3.0165 1.5506 43.5488 1.0000\nSwitched to using 20 rate categories (CAT approximation)19 of 20 \nRate categories were divided by 0.742 so that average rate = 1.0\nCAT-based log-likelihoods may not be comparable across runs\nUse -gamma for approximate but comparable Gamma(20) log-likelihoods\nML-NNI round 2: LogLk = -65713.209 NNIs 1 max delta 0.00 Time 15.20\nTurning off heuristics for final round of ML NNIs (converged)\nML-NNI round 3: LogLk = -65710.620 NNIs 0 max delta 0.00 Time 17.37 (final)\nOptimize all lengths: LogLk = -65710.620 Time 17.93\nTotal time: 23.36 seconds Unique: 51/53 Bad splits: 0/48\n\nThe phylogenetic analysis has finished\n"
]
],
[
[
"Expect this to take a couple of minutes. Remember if there is an asterisk in the top left \"`In [*]:`\" then it is still working, when it is a number it is finished. \n\nWhat tree file (.nwk) did it write? You will need this below\n\nIf this completed without errors then you can just run the cell below and see the output tree. You may want to adjust colours and re-run a few times. If you had an error, see if you can spot what went wrong, but seek assistance if not.",
"_____no_output_____"
]
],
[
[
"# import the tree plotting software\nimport toytree\nimport toyplot\nimport toyplot.svg\nimport toyplot.html\nimport toyplot.pdf\n\n# read the tree file, you will need to specify the correct file here\nnewick = \"tree_file.nwk\"\nbigtre = toytree.tree(newick, tree_format=1)\n\n# specify the rooted tree with outgroup as Macaque, Hylobates lar\nbigrtre = bigtre.root(wildcard=\"Hylobates\")\n\n# colour the tree, change these options until you are happy with the design\ncolorlist = [\"#d6557c\" if \"Pan\" in tip # pink\n else \"blue\" if \"Gorilla_b\" in tip #\n else \"#4169E1\" if \"Gorilla_g\" in tip #royalblue\n else \"#008000\" if \"Homo_sapiens_sapiens\" in tip #green\n else \"#32CD32\" if \"neanderthal\" in tip #limegreen\n else \"#006400\" if \"denisovan\" in tip #darkgreen\n else \"red\" if \"Pongo_abelii\" in tip #darkgreen\n else \"orange\" if \"Pongo_pygmaeus\" in tip #darkgreen\n else \"brown\" if \"Pongo_tapanuliensis\" in tip #darkgreen\n else \"#5384a3\" for tip in bigrtre.get_tip_labels()] # cyan\n\n\n# create the tree using these colours and some other standard options\ncanvas = bigrtre.draw(\n width=700,\n height=1200,\n scalebar=True,\n node_labels=None,\n node_sizes=[0 if i else 8 for i in bigrtre.get_node_values(None, 1, 0)],\n node_markers=\"s\",\n node_colors=toytree.colors[0],\n tip_labels_align=True,\n tip_labels_colors=colorlist\n);",
"_____no_output_____"
],
[
"# --------------------------------\n# Save the tree as a graphics file\n# --------------------------------\n#you can specify the name if you wish\n\ntoyplot.pdf.render(canvas[0], \"bigape.pdf\")\ntoyplot.html.render(canvas[0], \"bigape.html\")",
"_____no_output_____"
]
],
[
[
"Check the files list to make sure that the tree has saved and looks how you intended. You will need this tree for your report. You can alter and recreate the tree under the same, or a different name.",
"_____no_output_____"
],
[
"<h2><font color='Blue'>It's a bit more complicated than that...</font></h2>",
"_____no_output_____"
],
[
"There is no level of percentage sequence divergence that determines what is a species. So what can this tree really tell us? Well, amount of sequence divergence from closest relatives gives us a good initial picture of the system, and can give a framework on which to carry out more sophisticated analyses. Evolutionary biologists have sequenced the entire nuclear genomes of these species (you have analysed the much smaller mitochondrial genomes). This allows them to look at estinates of coalescent date, evidence for hybridization and many other biological aspects. ",
"_____no_output_____"
],
[
"<h2><font color='Blue'>Well Done</font></h2>\n\nYou are now finished with case study 1, the apes. Case study two, the origins of HIV, will be much faster now you have experience.\n\n<h4>Please feel free to take a short break here.</h4>\n<hr>",
"_____no_output_____"
],
[
"<h1><font color='DodgerBlue'>STUDY2: WHAT ARE THE ORIGINS OF HIV?</font></h1>",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"<hr>\n\n**QUESTION: Has HIV (human immunodeficiency virus) coevolved with humans or does it have a recent zoonotic origin?**\n\nHow can you test this? You now have all the skills required. We are going to repeat some of the work described by Sharp and Hahn (2011) in their paper \"Origins of HIV and the AIDS Pandemic\". Their figure 4 is very informative, and Zimmer and Emlen redraw it in their (3rd edition) Figure 8.12. \n\nToday you are going to reanalyse the HIV and SIV sequence data from great apes to produce a simlar figure and answer the question set above regarding zoonotic transfer. ",
"_____no_output_____"
],
[
"<h3><font color='DodgerBlue'>Sequence data</font></h3>",
"_____no_output_____"
],
[
"I have prepared aligned fasta files for you containing SIV and HIV sequence data from the *env* gene (Google it). They are called `SIVHIVspecies_ENV.afa`\n\nIt would be useful for you to know how many sequences were in each file, you calculated this earlier today for different files. Paste in the code to the cell below and describe the sequences.",
"_____no_output_____"
],
[
"You will need this alignment file name to enter below",
"_____no_output_____"
],
[
"<h3><font color='DodgerBlue'>Tree reconstruction</font></h3>",
"_____no_output_____"
]
],
[
[
"#HIV\nprint(\"\\nThe analysis has begun, this will take a few minutes, please be patient\")\n\n# # Alignment has already been done, so this is commented out\n# !mafft --auto --quiet data/SIVHIVspecies_ENV.fasta > SIVHIVspecies_ENV.afa\n# print(\"\\nThe sequence alignment has finished\")\n# Trim\n!trimal -in data/alignment_file.afa -out SIVHIVspecies_ENV_trimmed.afa -gappyout -keepheader\nprint(\"The alignment trimming has finished\")\n# Tree build\nprint(\"The phylogenetic tree construction has started\\n\")\n!FastTree -gtr -nt SIVHIVspecies_ENV_trimmed.afa > SIVHIVspecies_ENV.nwk\nprint(\"\\nThe phylogenetic analysis has finished\")",
"\nThe analysis has begun, this will take a few minutes, please be patient\nThe alignment trimming has finished\nThe phylogenetic tree construction has started\n\nFastTree Version 2.1.10 Double precision (No SSE3)\nAlignment: SIVHIVspecies_ENV_trimmed.afa\nNucleotide distances: Jukes-Cantor Joins: balanced Support: SH-like 1000\nSearch: Normal +NNI +SPR (2 rounds range 10) +ML-NNI opt-each=1\nTopHits: 1.00*sqrtN close=default refresh=0.80\nML Model: Generalized Time-Reversible, CAT approximation with 20 rate categories\nIgnored unknown character K (seen 5 times)\nIgnored unknown character M (seen 5 times)\nIgnored unknown character R (seen 32 times)\nIgnored unknown character S (seen 2 times)\nIgnored unknown character W (seen 8 times)\nIgnored unknown character X (seen 1 times)\nIgnored unknown character Y (seen 10 times)\nInitial topology in 0.03 seconds\nRefining topology: 21 rounds ME-NNIs, 2 rounds ME-SPRs, 11 rounds ML-NNIs\nTotal branch-length 3.781 after 0.48 sec1, 1 of 39 splits \nML-NNI round 1: LogLk = -31085.336 NNIs 7 max delta 7.27 Time 0.71\nGTR Frequencies: 0.3398 0.1837 0.2346 0.2419ep 12 of 12 \nGTR rates(ac ag at cg ct gt) 2.9686 4.7631 1.6332 1.4876 5.4581 1.0000\nSwitched to using 20 rate categories (CAT approximation)1 of 20 \nRate categories were divided by 0.849 so that average rate = 1.0\nCAT-based log-likelihoods may not be comparable across runs\nUse -gamma for approximate but comparable Gamma(20) log-likelihoods\nML-NNI round 2: LogLk = -27203.055 NNIs 3 max delta 6.79 Time 1.54\nML-NNI round 3: LogLk = -27202.662 NNIs 0 max delta 0.00 Time 1.60\nTurning off heuristics for final round of ML NNIs (converged)\nML-NNI round 4: LogLk = -27193.168 NNIs 2 max delta 4.67 Time 1.85 (final)\nOptimize all lengths: LogLk = -27193.108 Time 1.91\nTotal time: 2.20 seconds Unique: 41/41 Bad splits: 0/38\n\nThe phylogenetic analysis has finished\n"
],
[
"# import the code so we can use it later, just run this cell\nimport toytree # a tree plotting library\nimport toyplot # a general plotting library\nimport toyplot.pdf\nimport toyplot.svg",
"_____no_output_____"
],
[
"newick = \"SIVHIVspecies_ENV.nwk\"\nhivtre = toytree.tree(newick, tree_format=1)\nhivrtre = hivtre.root(wildcard=\"schwein\")\n\n# change these options until you are happy with the design\ncolorlist = [\"green\" if \"P.t.schweinfurthii\" in tip \n else \"blue\" if \"P.t.\" in tip \n else \"blue\" if \"G.g\" in tip\n else \"blue\" if \"H.sapiens\" in tip \n else \"blue\" for tip in hivrtre.get_tip_labels()]\n\ncanvas = hivrtre.draw(\n node_labels=None,\n width=600,\n height=600,\n node_sizes=[0 if i else 8 for i in hivrtre.get_node_values(None, 1, 0)],\n node_markers=\"s\",\n node_colors=toytree.colors[0],\n tip_labels_align=True,\n tip_labels_colors=colorlist);\n",
"_____no_output_____"
]
],
[
[
"You can use modify the code to colour it in more appropriately if you wish. Maybe change the colour to highlight Human HIV sequences in red?\n\nThe name contains a lot of metadata. The letter after H.sapiens indicates the HIV1 group to which that sequence belongs. Then the country from which it was isolated. Then the year. Then some identifiers and accession number. So `H.sapiens.O.CM.96.LA51YBF35.KU168294` is HIV1 group O, from Cameroon, isolated in 1996, with sample code LA51YBF35 and genbank accession number KU168294.",
"_____no_output_____"
],
[
"It may help you to talk about HIV1 group O, or group P, or group N in your explanations and in your annotations of the tree.",
"_____no_output_____"
],
[
"Make sure you then download the annotated tree and save it somewhere safe for your report. If you want to save several differently coloured tree (a good idea) then remember to change the filename below else they will overwrite the previous file.",
"_____no_output_____"
]
],
[
[
"# --------------------------------\n# Save the tree as a graphics file\n# --------------------------------\n# remember to save these files and take them away\n\ntoyplot.pdf.render(canvas[0], \"hiv.pdf\")\ntoyplot.html.render(canvas[0], \"hiv.html\")\n",
"_____no_output_____"
]
],
[
[
"## Interpreting the tree",
"_____no_output_____"
],
[
"The tree shows the diversity of great ape immunodeficiency viruses. Here are some questions that you could write about in your report. They are suggestions only, you can set yourself different or extra questions also, you decide.\n\n**Does the pattern of S/HIV represent the evolutionary history of the species? Has the virus speciated along with these apes or is it more complex than that?**\n\n**If you think there has been a zoonotic spread of SIV, ie a transfer to humans, is there a single origin or multiple transfers of HIV1?**\n\n**Can you determine anything about the geography of the transfer of the pandemic strain (M)? Think about the subspecies of the source. What is their gepgraphic range? Maybe you wish to include a map in your report? Wikipedia has one**\n\nIt is useful to think about how you will provide phylogenetic evidence for your answer to each of the questions above. How can you annotate a phylogeny to demonstrate the evidence for your conclusion. Poor reports will rely largely on written descriptions of a tree, excellent reports make a powerful link between the text and the figure, using annotations to make their points very clear.\n",
"_____no_output_____"
],
[
"## Writing your assessed report",
"_____no_output_____"
],
[
"There is extensivehelp on the canvas site on what to include and how to structure your report. You should discuss your conclusions and figures with a demonstrator or myself before leaving however. Please make sure that you have downloaded image files of any trees that you need to include in your report. This Jupyter lab environment may continue to work but I can't guarrantee it's availability past the end of the practical (that is out of my hands).",
"_____no_output_____"
],
[
"<hr>\n<h2><font color='Blue'>What skills have you acquired?</font></h2>\n\nIf you have completed this practical I think you have now showed your competency in a range of important practical and conceptual skills:\n1. Understanding the use of phylogenetic trees\n2. Basic use of Jupyter notebooks\n3. Basic use of BioPython to characterise sequence data files\n4. Basic use of python to align DNA sequecne data and build a phylogenetic tree\n5. Use of python to programmatically annotate a phylogenetic tree\n\nThese are the sorts of phrases you could include on you cv if you wished.",
"_____no_output_____"
],
[
"## Software References\n\n1. Cock PJA, Antao T, Chang JT, Chapman BA, Cox CJ, Dalke A, et al. Biopython: freely available Python tools for computational molecular biology and bioinformatics. Bioinformatics. 2009;25: 1422–1423. doi:10.1093/bioinformatics/btp163\n2. Katoh K, Toh H. Recent developments in the MAFFT multiple sequence alignment program. Brief Bioinform. 2008;9: 286–298. doi:10.1093/bib/bbn013\n3. Capella-Gutiérrez S, Silla-Martínez JM, Gabaldón T. trimAl: a tool for automated alignment trimming in large-scale phylogenetic analyses. Bioinformatics. 2009;25: 1972–1973. doi:10.1093/bioinformatics/btp348\n4. Price MN, Dehal PS, Arkin AP. FastTree 2 – Approximately Maximum-Likelihood Trees for Large Alignments. PLoS ONE. 2010. p. e9490. doi:10.1371/journal.pone.0009490\n5. Eaton DAR. Toytree: A minimalist tree visualization and manipulation library for Python. Methods Ecol Evol. 2020;11: 187–191. doi:10.1111/2041-210X.13313\n",
"_____no_output_____"
],
[
"## Case Study References\n\nSharp PM, Hahn BH. Origins of HIV and the AIDS pandemic. Cold Spring Harb Perspect Med. 2011;1: a006841. doi:10.1101/cshperspect.a006841\n\nLocke DP, Hillier LW, Warren WC, Worley KC, Nazareth LV, Muzny DM, et al. Comparative and demographic analysis of orang-utan genomes. Nature. 2011;469: 529–533. doi:10.1038/nature09687\n\nNater A, Mattle-Greminger MP, Nurcahyo A, Nowak MG, de Manuel M, Desai T, et al. Morphometric, Behavioral, and Genomic Evidence for a New Orangutan Species. Curr Biol. 2017;0. doi:10.1016/j.cub.2017.09.047\n\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
ecc0a19a7aff2eb5cdeb9b559bc3b97f951c824d | 37,197 | ipynb | Jupyter Notebook | imaging/ml/ml_codelab/breast_density_cloud_ml.ipynb | rbkucera/healthcare | 6978eb350575b4a570bbca19c4f7ae0e3d99dd5e | [
"Apache-2.0"
] | null | null | null | imaging/ml/ml_codelab/breast_density_cloud_ml.ipynb | rbkucera/healthcare | 6978eb350575b4a570bbca19c4f7ae0e3d99dd5e | [
"Apache-2.0"
] | null | null | null | imaging/ml/ml_codelab/breast_density_cloud_ml.ipynb | rbkucera/healthcare | 6978eb350575b4a570bbca19c4f7ae0e3d99dd5e | [
"Apache-2.0"
] | null | null | null | 40.431522 | 748 | 0.641638 | [
[
[
"Copyright 2018 Google Inc.\n\nLicensed under the Apache License, Version 2.0 (the \"License\"); you may not use this file except in compliance with the License. You may obtain a copy of the License at\n\nhttps://www.apache.org/licenses/LICENSE-2.0\n\nUnless required by applicable law or agreed to in writing, software distributed under the License is distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.\n",
"_____no_output_____"
],
[
"# Training/Inference on Breast Density Classification Model on Cloud ML Engine\n",
"_____no_output_____"
],
[
"The goal of this tutorial is to train, deploy and run inference on a breast density classification model. Breast density is thought to be a factor for an increase in the risk for breast cancer. This will emphasize using the [Cloud Healthcare API](https://cloud.google.com/healthcare/) in order to store, retreive and transcode medical images (in DICOM format) in a managed and scalable way. This tutorial will focus on using [Cloud Machine Learning Engine](https://cloud.google.com/ml-engine/) to scalably train and serve the model.\n\n**Note: This is the Cloud ML Engine version of the AutoML Codelab found [here](./breast_density_auto_ml.ipynb).**",
"_____no_output_____"
],
[
"## Requirements\n- A Google Cloud project.\n- Project has [Cloud Healthcare API](https://cloud.google.com/healthcare/docs/quickstart) enabled (**Note: You will need to be [whitelisted](https://cloud.google.com/healthcare/) for this product as it is in Alpha**).\n- Project has [Cloud Machine Learning API ](https://cloud.google.com/ml-engine/docs/tensorflow/getting-started-training-prediction)enabled.\n- Project has [Cloud Dataflow API ](https://cloud.google.com/dataflow/docs/quickstarts/quickstart-python)enabled.\n- Project has [Cloud Build API](https://cloud.google.com/cloud-build/docs/quickstart-docker) enabled.\n- Environment has [Google Application Default Credentials](https://cloud.google.com/docs/authentication/production#providing_service_account_credentials) set up. This is already set up if running on [Cloud Datalab](https://cloud.google.com/datalab/).\n- Environment has [gcloud](https://cloud.google.com/sdk/gcloud/) and [gsutil](https://cloud.google.com/storage/docs/gsutil) installed. This is already set up if running on [Cloud Datalab](https://cloud.google.com/datalab/).\n\n",
"_____no_output_____"
],
[
"## Input Dataset\n\nThe dataset that will be used for training is the [TCIA CBIS-DDSM](https://wiki.cancerimagingarchive.net/display/Public/CBIS-DDSM) dataset. This dataset contains ~2500 mammography images in DICOM format. Each image is given a [BI-RADS breast density ](https://breast-cancer.ca/densitbi-rads/) score from 1 to 4. In this tutorial, we will build a binary classifier that distinguishes between breast density \"2\" (*scattered density*) and \"3\" (*heterogeneously dense*). These are the two most common and variably assigned scores. In the literature, this is said to be [particularly difficult for radiologists to consistently distinguish](https://aapm.onlinelibrary.wiley.com/doi/pdf/10.1002/mp.12683).",
"_____no_output_____"
],
[
"### Store TCIA Dataset in Cloud Healthcare API\n\nThe [TCIA REST API ](https://wiki.cancerimagingarchive.net/display/Public/TCIA+Programmatic+Interface+%28REST+API%29+Usage+Guide) will be used to fetch the images. The TCIA requires an API key which can be retreived by following the instructions in the **Getting Started with the TCIA API** section of the previous link. Once you receive the API key, assign it below (**NOTE: TCIA does not support self-registration, so expect some turn-around time until you get the key**). ",
"_____no_output_____"
]
],
[
[
"tcia_api_key = \"MY_KEY\" #@param",
"_____no_output_____"
]
],
[
[
"We need to create a Cloud Healthcare API Dataset and Dicom Store to store the the DICOM instances sourced from TCIA. Please refer [here](https://cloud.google.com/healthcare/docs/introduction) for a description of the Cloud Healthcare API data hierarchy. Add your parameters for Cloud Healthcare API below:",
"_____no_output_____"
]
],
[
[
"project_id = \"MY_PROJECT\" # @param\nlocation = \"us-central1\" # @param\ndataset_id = \"MY_DATASET\" # @param\ndicom_store_id = \"MY_DICOM_STORE\" # @param",
"_____no_output_____"
],
[
"import json\nimport httplib2\nimport os\nfrom oauth2client.client import GoogleCredentials\n\nHEALTHCARE_API_URL = 'https://healthcare.googleapis.com/v1beta1'\n\nhttp = httplib2.Http()\nhttp = GoogleCredentials.get_application_default().authorize(http)\n\n# Create Cloud Healthcare API dataset.\npath = os.path.join(HEALTHCARE_API_URL, 'projects', project_id, 'locations', location, 'datasets?dataset_id=' + dataset_id)\nheaders = {'Content-Type': 'application/json'}\nresp, content = http.request(path, method='POST', headers=headers)\nassert resp.status == 200, 'error creating Dataset, code: {0}, response: {1}'.format(resp.status, content)\nprint('Full response:\\n{0}'.format(content))\n\n# Create Cloud Healthcare API DICOM store.\npath = os.path.join(HEALTHCARE_API_URL, 'projects', project_id, 'locations', location, 'datasets', dataset_id, 'dicomStores?dicom_store_id=' + dicom_store_id)\nresp, content = http.request(path, method='POST', headers=headers)\nassert resp.status == 200, 'error creating DICOM store, code: {0}, response: {1}'.format(resp.status, content)\nprint('Full response:\\n{0}'.format(content))",
"_____no_output_____"
]
],
[
[
"Next, we are going to transfer the DICOM instances from the TCIA API to the Cloud Healthcare API. We have added a helper script called *[store_tcia_in_hc_api.py](./scripts/store_tcia_in_hc_api.py)* to do this. Internally, this uses the STOW-RS DICOMWeb protocol (implemented as DicomWebPost in Cloud Healthcare API).\n\nNote: We are transfering >100GB of data so this will take some time to complete (this takes ~30min on n1-standard-4 machine-type). There is an optional *--max_concurrency* flag that allows you to modify the rate of data transfer).",
"_____no_output_____"
]
],
[
[
"# Store DICOM instances in Cloud Healthcare API.\n!python -m scripts.store_tcia_in_hc_api --project_id=$project_id --location=$location --dataset_id=$dataset_id --dicom_store_id=$dicom_store_id --tcia_api_key=$tcia_api_key",
"_____no_output_____"
]
],
[
[
"### Explore the Cloud Healthcare DICOM dataset (optional)\n\nThis is an optional section to explore the Cloud Healthcare DICOM dataset. In the following code, we simply just list the studies that we have loaded into the Cloud Healthcare API. You can modify the *num_of_studies_to_print* parameter to print as many studies as desired.",
"_____no_output_____"
]
],
[
[
"num_of_studies_to_print = 2 # @param\n\n\npath = os.path.join(HEALTHCARE_API_URL, 'projects', project_id, 'locations', location, 'datasets', dataset_id, 'dicomStores', dicom_store_id, 'dicomWeb', 'studies')\nresp, content = http.request(path, method='GET')\nassert resp.status == 200, 'error querying Dataset, code: {0}, response: {1}'.format(resp.status, content)\nresponse = json.loads(content)\n\nprint(json.dumps(response[:num_of_studies_to_print], indent=2))",
"_____no_output_____"
]
],
[
[
"## Convert DICOM to JPEG\n\nThe ML model that we will build requires that the dataset be in JPEG. We will leverage the Cloud Healthcare API to transcode DICOM to JPEG.\n\nFirst we will create a [Google Cloud Storage](https://cloud.google.com/storage/) bucket to hold the output JPEG files. Next, we will use the ExportDicomData API to transform the DICOMs to JPEGs.",
"_____no_output_____"
]
],
[
[
"jpeg_bucket = \"gs://MY_JPEG_BUCKET\" # @param",
"_____no_output_____"
],
[
"%%bash -s {project_id} {location} {jpeg_bucket}\n# Create bucket.\ngsutil -q mb -c regional -l $2 $3\n\n# Allow Cloud Healthcare API to write to bucket.\nPROJECT_NUMBER=`gcloud projects describe $1 | grep projectNumber | sed 's/[^0-9]//g'`\nSERVICE_ACCOUNT=\"service-${PROJECT_NUMBER}@gcp-sa-healthcare.iam.gserviceaccount.com\"\ngsutil -q iam ch serviceAccount:${SERVICE_ACCOUNT}:objectCreator $3",
"_____no_output_____"
]
],
[
[
"Next we will convert the DICOMs to JPEGs using the ExportDicomData API. This is an asynchronous call that returns an Operation name. The operation name will be used to poll the status of the operation.",
"_____no_output_____"
]
],
[
[
"# Path to request ExportDicomData operation.\ndataset_url = os.path.join(HEALTHCARE_API_URL, 'projects', project_id, 'locations', location, 'datasets', dataset_id)\ndicom_store_url = os.path.join(dataset_url, 'dicomStores', dicom_store_id)\npath = dicom_store_url + \":export\"\n\n# Headers (send request in JSON format).\nheaders = {'Content-Type': 'application/json'}\n\n# Body (encoded in JSON format).\noutput_config = {'output_config': {'gcs_destination': {'uri_prefix': jpeg_bucket, 'mime_type': 'image/jpeg; transfer-syntax=1.2.840.10008.1.2.4.50'}}}\nbody = json.dumps(output_config)\n\nresp, content = http.request(path, method='POST', headers=headers, body=body)\nassert resp.status == 200, 'error exporting to JPEG, code: {0}, response: {1}'.format(resp.status, content)\nprint('Full response:\\n{0}'.format(content))\n\n# Record operation_name so we can poll for it later.\nresponse = json.loads(content)\noperation_name = response['name']",
"_____no_output_____"
]
],
[
[
"We will use the Operation name returned from the previous command to poll the status of ExportDicomData. We will poll for operation completeness, which should take a few minutes. When the operation is complete, the operation's *done* field will be set to true.\n\nMeanwhile, you should be able to observe the JPEG images being added to your Google Cloud Storage bucket.",
"_____no_output_____"
]
],
[
[
"import time\n\ndef wait_for_operation_completion(path, timeout): \n success = False\n while time.time() < timeout:\n print('Waiting for operation completion...')\n resp, content = http.request(path, method='GET')\n assert resp.status == 200, 'error polling for Operation results, code: {0}, response: {1}'.format(resp.status, content)\n response = json.loads(content)\n if 'done' in response:\n if response['done'] == True and 'error' not in response:\n success = True;\n break\n time.sleep(30)\n\n print('Full response:\\n{0}'.format(content)) \n assert success, \"operation did not complete successfully in time limit\"\n print('Success!')\n return response\n \ntimeout = time.time() + 10*60 # Wait up to 10 minutes.\npath = os.path.join(HEALTHCARE_API_URL, operation_name)\n_ = wait_for_operation_completion(path, timeout)",
"_____no_output_____"
]
],
[
[
"## Training\n\nWe will use [Transfer Learning](https://en.wikipedia.org/wiki/Transfer_learning) to retrain a generically trained trained model to perform breast density classification. Specifically, we will use an [Inception V3](https://github.com/tensorflow/models/tree/master/research/inception) checkpoint as the starting point.\n\nThe neural network we will use can roughly be split into two parts: \"feature extraction\" and \"classification\". In transfer learning, we take advantage of a pre-trained (checkpoint) model to do the \"feature extraction\", and add a few layers to perform the \"classification\" relevant to the specific problem. In this case, we are adding aa [dense](https://www.tensorflow.org/api_docs/python/tf/layers/dense) layer with two neurons to do the classification and a [softmax](https://www.tensorflow.org/api_docs/python/tf/nn/softmax) layer to normalize the classification score. The mammography images will be classified as either \"2\" (scattered density) or \"3\" (heterogeneously dense). See below for diagram of the training process:\n\n\n\n\nThe \"feature extraction\" and the \"classification\" part will be done in the following steps, respectively.",
"_____no_output_____"
],
[
"### Preprocess Raw Images using Cloud Dataflow\n\nIn this step, we will resize images to 300x300 (required for Inception V3) and will run each image through the checkpoint Inception V3 model to calculate the *bottleneck values*. This is the feature vector for the output of the feature extraction part of the model (the part that is already pre-trained). Since this process is resource intensive, we will utilize [Cloud Dataflow](https://cloud.google.com/dataflow/) in order to do this scalably. We extract the features and calculate the bottleneck values here for performance reasons - so that we don't have to recalculate them during training.\n\nThe output of this process will be a collection of [TFRecords](https://www.tensorflow.org/guide/datasets) storing the bottleneck value for each image in the input dataset. This TFRecord format is commonly used to store Tensors in binary format for storage.\n\nFinally, in this step, we will also split the input dataset into *training*, *validation* or *testing*. The percentage of each can be modified using the parameters below.",
"_____no_output_____"
]
],
[
[
"# GCS Bucket to store output TFRecords.\nbottleneck_bucket = \"gs://MY_BOTTLENECK_BUCKET\" # @param\n\n# Percentage of dataset to allocate for validation and testing.\nvalidation_percentage = 10 # @param\ntesting_percentage = 10 # @param\n\n# Number of Dataflow workers. This can be increased to improve throughput.\ndataflow_num_workers = 5 # @param\n\n# Staging bucket for training.\nstaging_bucket = \"gs://MY_TRAINING_STAGING_BUCKET\" # @param\n\n\n!gsutil -q mb -c regional -l $location $bottleneck_bucket\n!gsutil -q mb -c regional -l $location $staging_bucket",
"_____no_output_____"
]
],
[
[
"The following command will kick off a Cloud Dataflow pipeline that runs preprocessing. The script that has the relevant code is [preprocess.py](./scripts/preprocess/preprocess.py). ***You can check out how the pipeline is progressing [here](https://console.cloud.google.com/dataflow)***.\n\nWhen the operation is done, we will begin training the classification layers.",
"_____no_output_____"
]
],
[
[
"%%bash -s {project_id} {jpeg_bucket} {bottleneck_bucket} {validation_percentage} {testing_percentage} {dataflow_num_workers} {staging_bucket}\n\n# Install Python library dependencies.\npip -q install pip==9.0.3 \n\n# Start job in Cloud Dataflow and wait for completion.\npython -m scripts.preprocess.preprocess \\\n --project $1 \\\n --input_path $2 \\\n --output_path \"$3/record\" \\\n --num_workers $6 \\\n --temp_location \"$7/temp\" \\\n --staging_location \"$7/staging\" \\\n --validation_percentage $4 \\\n --testing_percentage $5",
"_____no_output_____"
]
],
[
[
"### Train the Classification Layers of Model using Cloud ML Engine\n\nIn this step, we will train the classification layers of the model. This consists of just a [dense](https://www.tensorflow.org/api_docs/python/tf/layers/dense) and [softmax](https://www.tensorflow.org/api_docs/python/tf/nn/softmax) layer. We will use the bottleneck values calculated at the previous step as the input to these layers. We will use Cloud ML Engine to train the model. The output of stage will be a trained model exported to GCS, which can be used for inference.\n\n\nThere are various training parameters below that can be tuned. ",
"_____no_output_____"
]
],
[
[
"training_steps = 1000 # @param\nlearning_rate = 0.01 # @param\n\n# Location of exported model.\nexported_model_bucket = \"gs://MY_EXPORTED_MODEL_BUCKET\" # @param\n\n\n# Inference requires the exported model to be versioned (by default we choose version 1).\nexported_model_versioned_uri = exported_model_bucket + \"/1\"\n\n# Create bucket for exported model.\n!gsutil -q mb -c regional -l $location $exported_model_bucket\n",
"_____no_output_____"
]
],
[
[
"We'll invoke Cloud ML Engine with the above parameters. We use a GPU for training to speed up operations. The script that does the training is [model.py](./scripts/trainer/model.py)",
"_____no_output_____"
]
],
[
[
"%%bash -s {location} {bottleneck_bucket} {staging_bucket} {training_steps} {learning_rate} {exported_model_versioned_uri}\n\n# Start training on CMLE.\ngcloud ml-engine jobs submit training breast_density \\\n --runtime-version 1.9 \\\n --scale-tier BASIC_GPU \\\n --module-name \"scripts.trainer.model\" \\\n --package-path scripts \\\n --staging-bucket $3 \\\n --region $1 \\\n -- \\\n --bottleneck_dir \"$2/record\" \\\n --training_steps $4 \\\n --learning_rate $5 \\\n --export_model_path $6",
"_____no_output_____"
]
],
[
[
"You can monitor the status of the training job by running the following command. The job can take a few minutes to start-up.",
"_____no_output_____"
]
],
[
[
"!gcloud ml-engine jobs describe breast_density",
"_____no_output_____"
]
],
[
[
"When the job has started, you can observe the logs for the training job by executing the below command (it will poll for new logs every 30 seconds).\n\nAs training progresses, the logs will output the accuracy on the training set, validation set, as well as the [cross entropy](http://ml-cheatsheet.readthedocs.io/en/latest/loss_functions.html). You'll generally see that the accuracy goes up, while the cross entropy goes down as the number of training iterations increases.\n\n\nFinally, when the training is complete, the accuracy of the model on the held-out test set will be output to console. The job can take a few minutes to shut-down.",
"_____no_output_____"
]
],
[
[
"!gcloud ml-engine jobs stream-logs breast_density --polling-interval=30",
"_____no_output_____"
]
],
[
[
"### Export Trained Model for Inference in Cloud ML Engine\n\nCloud ML Engine can also be used to serve the model for inference. The inference model is composed of the pre-trained Inception V3 checkpoint, along with the classification layers we trained above for breast density. First we set the inference model name and version.",
"_____no_output_____"
]
],
[
[
"model_name = \"breast_density\" # @param\nversion = \"v1\" # @param\n\n# The full name of the model.\nfull_model_name = \"projects/\" + project_id + \"/models/\" + model_name + \"/versions/\" + version",
"_____no_output_____"
],
[
"!gcloud ml-engine models create $model_name --regions $location\n!gcloud ml-engine versions create $version --model $model_name --origin $exported_model_versioned_uri --runtime-version 1.9",
"_____no_output_____"
]
],
[
[
"## Inference\n\nTo allow medical imaging ML models to be easily integrated into clinical workflows, an *inference module* can be used. A standalone modality, a PACS system or a DICOM router can push DICOM instances into Cloud Healthcare [DICOM stores](https://cloud.google.com/healthcare/docs/introduction), allowing ML models to be triggered for inference. This inference results can then be structured into various DICOM formats (e.g. DICOM [structured reports](http://dicom.nema.org/MEDICAL/Dicom/2014b/output/chtml/part20/sect_A.3.html)) and stored in the Cloud Healthcare API, which can then be retrieved by the customer.\n\nThe inference module is built as a [Docker](https://www.docker.com/) container and deployed using [Kubernetes](https://kubernetes.io/), allowing you to easily scale your deployment. The dataflow for inference can look as follows (see corresponding diagram below):\n\n1. Client application uses [STOW-RS](ftp://dicom.nema.org/medical/Dicom/2013/output/chtml/part18/sect_6.6.html) to push a new DICOM instance to the Cloud Healthcare DICOMWeb API.\n\n2. The insertion of the DICOM instance triggers a [Cloud Pubsub](https://cloud.google.com/pubsub/) message to be published. The *inference module* will pull incoming Pubsub messages and will recieve a message for the previously inserted DICOM instance. \n\n3. The *inference module* will retrieve the instance in JPEG format from the Cloud Healthcare API using [WADO-RS](ftp://dicom.nema.org/medical/Dicom/2013/output/chtml/part18/sect_6.5.html).\n\n4. The *inference module* will send the JPEG bytes to the model hosted on Cloud ML Engine.\n\n5. Cloud ML Engine will return the prediction back to the *inference module*.\n\n6. The *inference module* will package the prediction into a DICOM instance. This can potentially be a DICOM structured report, [presentation state](ftp://dicom.nema.org/MEDICAL/dicom/2014b/output/chtml/part03/sect_A.33.html), or even burnt text on the image. In this codelab, we will focus on just DICOM structured reports. The structured report is then stored back in the Cloud Healthcare API using STOW-RS.\n\n7. The client application can query for (or retrieve) the structured report by using [QIDO-RS](http://dicom.nema.org/dicom/2013/output/chtml/part18/sect_6.7.html) or WADO-RS. Pubsub can also be used by the client application to poll for the newly created DICOM structured report instance.\n\n\n\n\nTo begin, we will create a new DICOM store that will store our inference source (DICOM mammography instance) and results (DICOM structured report). In order to enable Pubsub notifications to be triggered on inserted instances, we will give the DICOM store a Pubsub channel to publish on.",
"_____no_output_____"
]
],
[
[
"# Pubsub config.\npubsub_topic_id = \"MY_PUBSUB_TOPIC_ID\" # @param\npubsub_subscription_id = \"MY_PUBSUB_SUBSRIPTION_ID\" # @param\n\n# DICOM Store for store DICOM used for inference.\ninference_dicom_store_id = \"MY_INFERENCE_DICOM_STORE\" # @param\n\npubsub_subscription_name = \"projects/\" + project_id + \"/subscriptions/\" + pubsub_subscription_id\ninference_dicom_store_name = \"projects/\" + project_id + \"/locations/\" + location + \"/datasets/\" + dataset_id + \"/dicomStores/\" + inference_dicom_store_id",
"_____no_output_____"
],
[
"%%bash -s {pubsub_topic_id} {pubsub_subscription_id} {project_id} {location} {dataset_id} {inference_dicom_store_id}\n\n# Create Pubsub channel.\ngcloud beta pubsub topics create $1\ngcloud beta pubsub subscriptions create $2 --topic $1\n\n# Create a Cloud Healthcare DICOM store that published on given Pubsub topic.\nTOKEN=`gcloud beta auth application-default print-access-token`\nNOTIFICATION_CONFIG=\"{notification_config: {pubsub_topic: \\\"projects/$3/topics/$1\\\"}}\"\ncurl -s -X POST -H \"Content-Type: application/json\" -d \"${NOTIFICATION_CONFIG}\" https://healthcare.googleapis.com/v1beta1/projects/$3/locations/$4/datasets/$5/dicomStores?access_token=${TOKEN}\\&dicom_store_id=$6\n\n# Enable Cloud Healthcare API to publish on given Pubsub topic.\nPROJECT_NUMBER=`gcloud projects describe $3 | grep projectNumber | sed 's/[^0-9]//g'`\nSERVICE_ACCOUNT=\"service-${PROJECT_NUMBER}@gcp-sa-healthcare.iam.gserviceaccount.com\"\ngcloud beta pubsub topics add-iam-policy-binding $1 --member=\"serviceAccount:${SERVICE_ACCOUNT}\" --role=\"roles/pubsub.publisher\"",
"_____no_output_____"
]
],
[
[
"Next, we will building the *inference module* using [Cloud Build API](https://cloud.google.com/cloud-build/docs/api/reference/rest/). This will create a Docker container that will be stored in [Google Container Registry](https://cloud.google.com/container-registry/). The inference module code is found in *[inference.py](./scripts/inference/inference.py)*. The build script used to build the Docker container for this module is *[cloudbuild.yaml](./scripts/inference/cloudbuild.yaml)*.",
"_____no_output_____"
]
],
[
[
"%%bash -s {project_id}\nPROJECT_ID=$1\n\ngcloud builds submit --config scripts/inference/cloudbuild.yaml --timeout 1h scripts/inference",
"_____no_output_____"
]
],
[
[
"Next, we will deploy the *inference module* to Kubernetes. To do this, we first need to install [kubectl](https://https://kubernetes.io/docs/reference/kubectl/overview/).",
"_____no_output_____"
]
],
[
[
"!gcloud -q components install kubectl",
"_____no_output_____"
]
],
[
[
"Then we create a Kubernetes Cluster and a Deployment for the *inference module*.",
"_____no_output_____"
]
],
[
[
"%%bash -s {project_id} {location} {pubsub_subscription_name} {full_model_name} {inference_dicom_store_name}\ngcloud container clusters create inference-module --region=$2 --scopes https://www.googleapis.com/auth/cloud-platform --num-nodes=1\n\nPROJECT_ID=$1\nSUBSCRIPTION_PATH=$3\nMODEL_PATH=$4\nINFERENCE_DICOM_STORE_NAME=$5\n\ncat <<EOF | kubectl create -f -\napiVersion: extensions/v1beta1\nkind: Deployment\nmetadata:\n name: inference-module\n namespace: default\nspec:\n replicas: 1\n template:\n metadata:\n labels:\n app: inference-module\n spec:\n containers:\n - name: inference-module\n image: gcr.io/${PROJECT_ID}/inference-module:latest\n command:\n - \"/opt/inference_module/bin/inference_module\"\n - \"--subscription_path=${SUBSCRIPTION_PATH}\"\n - \"--model_path=${MODEL_PATH}\"\n - \"--dicom_store_path=${INFERENCE_DICOM_STORE_NAME}\"\n - \"--prediction_service=CMLE\"\nEOF",
"_____no_output_____"
]
],
[
[
"Next, we will store a mammography DICOM instance from the TCIA dataset to the DICOM store. This is the image that we will request inference for. Pushing this instance to the DICOM store will result in a Pubsub message, which will trigger the *inference module*. Again, we will use *[store_tcia_in_hc_api.py](./scripts/store_tcia_in_hc_api.py)* to push the DICOM to Cloud Healthcare API.",
"_____no_output_____"
]
],
[
[
"# DICOM study and series UID of input mammography image that we'll push for inference.\ninput_mammo_study_uid = \"1.3.6.1.4.1.9590.100.1.2.85935434310203356712688695661986996009\"\ninput_mammo_series_uid = \"1.3.6.1.4.1.9590.100.1.2.374115997511889073021386151921807063992\"",
"_____no_output_____"
],
[
"%%bash -s {project_id} {location} {dataset_id} {inference_dicom_store_id} {tcia_api_key} {input_mammo_study_uid}\n\n# Store input mammo image into Cloud Healthcare DICOMWeb API.\npython -m scripts.store_tcia_in_hc_api --project_id=$1 --location=$2 --dataset_id=$3 --dicom_store_id=$4 --tcia_api_key=$5 --has_study_uid=$6",
"_____no_output_____"
]
],
[
[
"You should be able to observe the *inference module*'s logs by running the following command. In the logs, you should observe that the inference module successfully recieved the the Pubsub message and ran inference on the DICOM instance. The logs should also include the inference results. It can take a few minutes to start-up the Kubernetes deployment, so you many have to run this a few times.",
"_____no_output_____"
]
],
[
[
"!kubectl logs -l app=inference-module",
"_____no_output_____"
]
],
[
[
"You can also query the Cloud Healthcare DICOMWeb API (using QIDO-RS) to see that the DICOM structured report has been inserted for the study. The structured report contents can be found under tag **\"0040A730\"**. \n\nYou can optionally also use WADO-RS to recieve the instance (e.g. for viewing).",
"_____no_output_____"
]
],
[
[
"%%bash -s {project_id} {location} {dataset_id} {inference_dicom_store_id} {input_mammo_study_uid}\n\nTOKEN=`gcloud beta auth application-default print-access-token`\n\n# QIDO-RS should return two results in JSON response. One for the original DICOM\n# instance, and one for the Strucured Report containing the inference results.\ncurl -s https://healthcare.googleapis.com/v1beta1/projects/$1/locations/$2/datasets/$3/dicomStores/$4/dicomWeb/studies/$5/instances?includefield=all\\&access_token=${TOKEN} | python -m json.tool",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
ecc0a502ba950552c0007ee178055d141acf9807 | 31,659 | ipynb | Jupyter Notebook | compound_disease/compound_treats_disease/datafile/compound_disease_datafile_generator.ipynb | ajlee21/snorkeling | 93ca5269199a55ed2093334cb32b6d3120ae3535 | [
"CC0-1.0",
"BSD-3-Clause"
] | null | null | null | compound_disease/compound_treats_disease/datafile/compound_disease_datafile_generator.ipynb | ajlee21/snorkeling | 93ca5269199a55ed2093334cb32b6d3120ae3535 | [
"CC0-1.0",
"BSD-3-Clause"
] | null | null | null | compound_disease/compound_treats_disease/datafile/compound_disease_datafile_generator.ipynb | ajlee21/snorkeling | 93ca5269199a55ed2093334cb32b6d3120ae3535 | [
"CC0-1.0",
"BSD-3-Clause"
] | null | null | null | 28.702629 | 242 | 0.452004 | [
[
[
"# Generate Compound Treats Disease Candidates",
"_____no_output_____"
],
[
"This notebook is designed to construct a table that contains compound and disease pairs with various statistics (number of sentences, if contained in hetionet, if the edge has sentences and which training category each pair belongs to).",
"_____no_output_____"
]
],
[
[
"%load_ext autoreload\n%autoreload 2\n%matplotlib inline\n\nfrom collections import Counter\nfrom itertools import product\nimport os\nimport pickle\nimport sys\n\nimport pandas as pd",
"_____no_output_____"
],
[
"#Set up the environment\nusername = \"danich1\"\npassword = \"snorkel\"\ndbname = \"pubmeddb\"\n\n#Path subject to change for different os\ndatabase_str = \"postgresql+psycopg2://{}:{}@/{}?host=/var/run/postgresql\".format(username, password, dbname)",
"_____no_output_____"
],
[
"disease_url = 'https://raw.githubusercontent.com/dhimmel/disease-ontology/052ffcc960f5897a0575f5feff904ca84b7d2c1d/data/xrefs-prop-slim.tsv'\ncompound_url = \"https://raw.githubusercontent.com/dhimmel/drugbank/7b94454b14a2fa4bb9387cb3b4b9924619cfbd3e/data/drugbank.tsv\"\nctpd_url = \"https://raw.githubusercontent.com/dhimmel/indications/11d535ba0884ee56c3cd5756fdfb4985f313bd80/catalog/indications.tsv\"",
"_____no_output_____"
],
[
"base_dir = os.path.join(os.path.dirname(os.getcwd()), 'compound_disease')",
"_____no_output_____"
]
],
[
[
"## Read in Diesease and Compound Entities",
"_____no_output_____"
]
],
[
[
"disease_ontology_df = (\n pd.read_csv(disease_url, sep=\"\\t\")\n .drop_duplicates([\"doid_code\", \"doid_name\"])\n .rename(columns={'doid_code': 'doid_id'})\n)\ndisease_ontology_df.head(2)",
"_____no_output_____"
],
[
"drugbank_df = (\n pd.read_table(compound_url)\n .rename(index=str, columns={'name':'drug_name'})\n)\ndrugbank_df.head(2)",
"/home/danich1/.local/lib/python3.6/site-packages/ipykernel_launcher.py:2: FutureWarning: read_table is deprecated, use read_csv instead, passing sep='\\t'.\n \n"
]
],
[
[
"## Read in Compound Treats/Palliates Disease Tables",
"_____no_output_____"
]
],
[
[
"compound_treats_palliates_disease_df = (\n pd.read_table(ctpd_url)\n .assign(sources='pharmacotherapydb')\n .drop([\"n_curators\", \"n_resources\"], axis=1)\n .rename(index=str, columns={\"drug\": \"drug_name\", \"disease\":\"doid_name\"})\n)\ncompound_treats_palliates_disease_df.head(2)",
"/home/danich1/.local/lib/python3.6/site-packages/ipykernel_launcher.py:2: FutureWarning: read_table is deprecated, use read_csv instead, passing sep='\\t'.\n \n"
]
],
[
[
"## Read in Sentences with Edge Pair",
"_____no_output_____"
]
],
[
[
"query = '''\nSELECT \"Compound_cid\" as drugbank_id, \"Disease_cid\" as doid_id, count(*) AS n_sentences\nFROM compound_disease\nGROUP BY \"Compound_cid\", \"Disease_cid\";\n'''\ncompound_disease_sentence_df = pd.read_sql(query, database_str)\ncompound_disease_sentence_df.head(2)",
"_____no_output_____"
]
],
[
[
"## Merge Edges Into a Unified Table",
"_____no_output_____"
]
],
[
[
"compound_disease_map_df = (\n drugbank_df[[\"drugbank_id\", \"drug_name\"]]\n .assign(key=1)\n .merge(disease_ontology_df[[\"doid_id\", \"doid_name\"]].assign(key=1))\n .drop(\"key\", axis=1)\n)\ncompound_disease_map_df.head(2)",
"_____no_output_____"
],
[
"compound_treats_disease_df = (\n compound_disease_map_df\n .merge(\n compound_treats_palliates_disease_df\n .query(\"category=='DM'\")\n [[\"doid_id\", \"drugbank_id\", \"category\", \"sources\"]],\n on=[\"drugbank_id\", \"doid_id\"], \n how=\"left\"\n )\n .merge(compound_disease_sentence_df, on=[\"drugbank_id\", \"doid_id\"], how=\"left\")\n .fillna({\"n_sentences\": 0})\n .astype({\"n_sentences\": int})\n)\ncompound_treats_disease_df=(\n compound_treats_disease_df\n .assign(hetionet=compound_treats_disease_df.sources.notnull().astype(int))\n .assign(has_sentence=(compound_treats_disease_df.n_sentences > 0).astype(int))\n)\ncompound_treats_disease_df.head(2)",
"_____no_output_____"
],
[
"# Make sure all existing edges are found\n# 755 is determined from neo4j to be all CtD Edges\nassert compound_treats_disease_df.hetionet.value_counts()[1] == 755",
"_____no_output_____"
],
[
"compound_treats_disease_df.query(\"hetionet==1&has_sentence==1\").shape[0]",
"_____no_output_____"
]
],
[
[
"Note 69 edges in hetionet does not have sentences.",
"_____no_output_____"
],
[
"## Sort Edges into categories",
"_____no_output_____"
]
],
[
[
"def partitioner(df):\n \"\"\"\n This function creates a parition rank for the current dataset.\n This algorithm assigns a rank [0-1) for each datapoint inside each group (outlined below):\n 1,1 -in hetionet and has sentences\n 1,0 - in hetionet and doesn't have sentences\n 0,1 - not in hetionet and does have sentences\n 0,0, - not in hetionet and doesn't have sentences\n \n This ranking will be used in the get split function to assign each datapoint \n into its corresponding category (train, dev, test)\n \"\"\"\n partition_rank = pd.np.linspace(0, 1, num=len(df), endpoint=False)\n pd.np.random.shuffle(partition_rank)\n df['partition_rank'] = partition_rank\n return df",
"_____no_output_____"
],
[
"def get_split(partition_rank, training=0.7, dev=0.2, test=0.1):\n \"\"\"\n This function partitions the data into training, dev, and test sets\n The partitioning algorithm is as follows:\n 1. anything less than 0.7 goes into training and receives an appropiate label\n 2. If not less than 0.7 subtract 0.7 and see if the rank is less than 0.2 if not assign to dev\n 3. Lastly if the rank is greater than 0.9 (0.7+0.2) assign it to test set.\n \n return label that corresponds to appropiate dataset cateogories\n \"\"\"\n if partition_rank < training:\n return 9\n partition_rank -= training\n if partition_rank < dev:\n return 10\n partition_rank -= dev\n assert partition_rank <= test\n return 11",
"_____no_output_____"
],
[
"pd.np.random.seed(100)\nctd_map_df = compound_treats_disease_df.groupby(['hetionet', 'has_sentence']).apply(partitioner)\nctd_map_df.head(2)",
"_____no_output_____"
],
[
"ctd_map_df['split'] = ctd_map_df.partition_rank.map(get_split)\nctd_map_df.split.value_counts()",
"_____no_output_____"
],
[
"ctd_map_df.sources.unique()",
"_____no_output_____"
],
[
"ctd_map_df = ctd_map_df[[\n \"drugbank_id\", \"drug_name\",\n \"doid_id\", \"doid_name\",\n \"sources\", \"n_sentences\",\n \"hetionet\", \"has_sentence\",\n \"split\", \"partition_rank\"\n]]\nctd_map_df.head(2)",
"_____no_output_____"
],
[
"ctd_map_df.to_csv(\"output/compound_treats_disease.tsv.xz\", sep=\"\\t\", compression=\"xz\", index=False)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecc0a9b22affa9a9748665ce01bf211ce0260f7c | 6,159 | ipynb | Jupyter Notebook | python/Crawling/09_selenium_1.ipynb | WGLee87/TIL | 35e8b8d96953933eb8ba542f533e84f82890ce77 | [
"MIT"
] | null | null | null | python/Crawling/09_selenium_1.ipynb | WGLee87/TIL | 35e8b8d96953933eb8ba542f533e84f82890ce77 | [
"MIT"
] | null | null | null | python/Crawling/09_selenium_1.ipynb | WGLee87/TIL | 35e8b8d96953933eb8ba542f533e84f82890ce77 | [
"MIT"
] | null | null | null | 23.329545 | 91 | 0.519727 | [
[
[
"### selenium\n - 브라우저를 직접 실행하여 자동화하고 브라우저상에 있는 데이터를 수집\n - 웹 테스트 자동화를 위해서 만들어진 라이브러리\n - 다양한 브라우저 지원\n - 다양한 언어를 지원",
"_____no_output_____"
],
[
"###### 설정\n - seleniu chromm driver 설정\n - 크롬 드라이버 다운로드 : https://chromedriver.chromium.org/downloads\n - 본인 컴퓨터에 맞는 드라이버 버전을 다운로드\n - 사용중인 주피터 노트북과 같은 디렉토리에 크롬 드라이버 파일 업로드\n - mac\n - chromedriver 파일을 /usr/local/bin 디렉토리로 복사\n - sudo cp ~/Downloads/chromedriver /usr/local/bin\n - windows\n - 환경변수 추가\n - 내컴퓨터 - 속성 - 고급시스템설정 - 환경변수\n - chromedriver의 path를 추가\n - selenium python package 설치\n - sudo pip install selenium\n - conda install -c conda-forge selenium",
"_____no_output_____"
]
],
[
[
"from selenium import webdriver",
"_____no_output_____"
],
[
"chrome_driver = '/Users/wglee/Desktop/DATA ANALYSIS/Chromedriver'\ndriver = webdriver.Chrome(chrome_driver)\n\n# 페이지 이동 : get\ndriver.get('https://daum.net')\n\n# 윈도우 사이즈 조절\ndriver.set_window_size(1800, 1000)\n\n# 스크롤 위치 조절\n# driver.execute_script('window.scrollTo(200,300);')\n\n# alert 다루기\n# driver.execute_script(\"alert('FastCampus');\")\n# alert = driver.switch_to.alert\n# alert.accept()\n\n# input 태그에 문자열 입력\n#select_one : find_element_by_css_selector\n#select : find_elements_by_css_selector\ndriver.find_element_by_css_selector('#q').send_keys('패스트 캠퍼스')\n# driver.find_element_by_css_selector('#q').clear()\n# driver.find_element_by_css_selector('#q').send_keys('파이썬')\n\n# button 클릭\ndriver.find_element_by_css_selector('.inner_search > .btn_search').click()",
"_____no_output_____"
],
[
"# 브라우저 종료\ndriver.quit()",
"_____no_output_____"
]
],
[
[
"#### Darksky api 키 재발급 자동화",
"_____no_output_____"
]
],
[
[
"# 브라우저 열기\ndriver = webdriver.Chrome()",
"_____no_output_____"
],
[
"# 로그인 페이지 이동\ndriver.get('https://darksky.net/dev/login')",
"_____no_output_____"
],
[
"# 이메일, 패스워드 입력\n# 로그인 버튼 클릭\nemail = '[email protected]'\npw = 'qwer1234'\n\ndriver.find_element_by_css_selector('#email').send_keys(email)\ndriver.find_element_by_css_selector('#password').send_keys(pw)\ndriver.find_element_by_css_selector('[type=\"submit\"]').click()",
"_____no_output_____"
],
[
"# 리셋 시크릿 버튼 클릭\ndriver.find_element_by_css_selector('.reset-key').click()",
"_____no_output_____"
],
[
"# alert 확인 버튼 클릭\nalert = driver.switch_to.alert\nalert.accept()",
"_____no_output_____"
],
[
"# 바뀐 키값 출력\ns_key = driver.find_element_by_css_selector('#api-key').get_attribute('value')\ns_key",
"_____no_output_____"
],
[
"# 브라우저 종료",
"_____no_output_____"
],
[
"driver.quit()",
"_____no_output_____"
],
[
"# 함수로 만들기\ndef get_apikeys(email, pw):\n driver = webdriver.Chrome()\n driver.get('https://darksky.net/dev/login')\n \n driver.find_element_by_css_selector('#email').send_keys(email)\n driver.find_element_by_css_selector('#password').send_keys(pw)\n driver.find_element_by_css_selector('[type=\"submit\"]').click()\n \n driver.find_element_by_css_selector('.reset-key').click()\n \n alert = driver.switch_to.alert\n alert.accept()\n \n s_key = driver.find_element_by_css_selector('#api-key').get_attribute('value')\n \n driver.quit()\n \n return s_key",
"_____no_output_____"
],
[
"email = '[email protected]'\npw = 'qwer1234'\nget_apikeys(email, pw)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecc0c4f53589b6170060ee48d049e570c8c280cc | 21,167 | ipynb | Jupyter Notebook | notebooks/C01_Spark_Concepts.ipynb | cliburn/bios-823-2020 | 842dde98b28899bb52b315fc2df10813629183bb | [
"MIT"
] | 13 | 2020-08-17T20:59:59.000Z | 2021-09-27T16:30:59.000Z | notebooks/C01_Spark_Concepts.ipynb | cliburn/bios-823-2020 | 842dde98b28899bb52b315fc2df10813629183bb | [
"MIT"
] | null | null | null | notebooks/C01_Spark_Concepts.ipynb | cliburn/bios-823-2020 | 842dde98b28899bb52b315fc2df10813629183bb | [
"MIT"
] | 11 | 2020-08-17T21:35:22.000Z | 2021-09-19T16:05:45.000Z | 28.110226 | 313 | 0.57018 | [
[
[
"# Spark",
"_____no_output_____"
],
[
"## Spark Concepts\n\n### History\n\n- Motivation\n - Move computing to data, not data to computing\n - An SSD transfers data at about 500 MB per sec, or 40 minutes to transfer 1 TB\n - A 7200 RPM hard disk drive transfers data at about 200 MB per second, or about 1.5 hours to transfer 1 TB.\n- Google\n - Google Distributed Filesystem (GFS)\n - Big Table\n - Map-reduce\n- Yahoo!\n - Hadoop Distributed File System (HDFS)\n - Yet Anohter Resource Negotiator (YARN)\n - MapReduce\n- Limitations of MapReduce\n - Cumbersome API\n - Every stage reads from/writes to disk\n - No native interactive SQL (HIVE, Impala, Drill)\n - No native streaming (Storm)\n - No native mahcine learning (Mahout)\n- Spark\n - Simple API\n - In-memory storage\n - Better fault tolerance\n - Can take advantage of embarrassingly parallel computations\n - Multi-language support (Scala, Java, Python, R)\n - Support multiple workloads\n - Spark 1.0 released May 11, 2014\n - Spark 2.0 released Nov 14, 2016\n - Spark 3.0 released Oct 02, 2020",
"_____no_output_____"
],
[
"### Resources\n\n- [Quick Start](http://spark.apache.org/docs/latest/quick-start.html)\n- [Spark Programming Guide](http://spark.apache.org/docs/latest/programming-guide.html)\n- [DataFramews, DataSets and SQL](http://spark.apache.org/docs/latest/sql-programming-guide.html)\n- [MLLib](http://spark.apache.org/docs/latest/mllib-guide.html)\n- [GraphX](http://spark.apache.org/docs/latest/graphx-programming-guide.html)\n- [Streaming](http://spark.apache.org/docs/latest/streaming-programming-guide.html)",
"_____no_output_____"
],
[
"## Distributed computing\n\nWith distributed computing, you interact with a network of computers that communicate via message passing as if issuing instructions to a single computer.\n\n- Distributed execution concepts\n - Spark driver (local)\n - Spark session\n - Spark shell\n - Communicates with Spark Master\n - Communicates with Spark workers\n - Spark master (cluster)\n - Resource management on cluster\n - Spark workers (cluster)\n - Communicate resources to cluster manger\n - Start Spark Executors\n - Spark executors (cluster)\n - Communicate with driver\n - Runs task\n - Can run multiple threads in parallel\n- Execution process\n - Driver creates jobs\n - Each job is a DAG\n - DAGScheduler translates into physical plan using RDDs\n - Optimization includes merging and splitting into stages\n - TaskScheduler distributes physical plans to Executors\n - Job consists of one or more stages\n - Stage normally ends when there is a need to exchange data (shuffle)\n - Stage consists of tasks\n - A task is a unit of execution\n - Each task is sent to one executor and assigned one data partition\n - A multi-core computer can run several tasks in parallel\n\n\n\nSource: https://image.slidesharecdn.com/distributedcomputingwithspark-150414042905-conversion-gate01/95/distributed-computing-with-spark-21-638.jpg\n\n### Hadoop and Spark\n\n- There are 3 major components to a distributed system\n - storage\n - cluster management\n - computing engine\n\n- Hadoop is a framework that provides all 3 \n - distributed storage (HDFS) \n - cluster management (YARN)\n - computing engine (MapReduce)\n \n- Spakr only provides the (in-memory) distributed computing engine, and relies on other frameworks for storage and cluster management. It is most frequently used on top of the Hadoop framework, but can also use other distributed storage(e.g. S3 and Cassandra) or cluster management (e.g. Mesos) software.\n\n### Distributed storage\n\n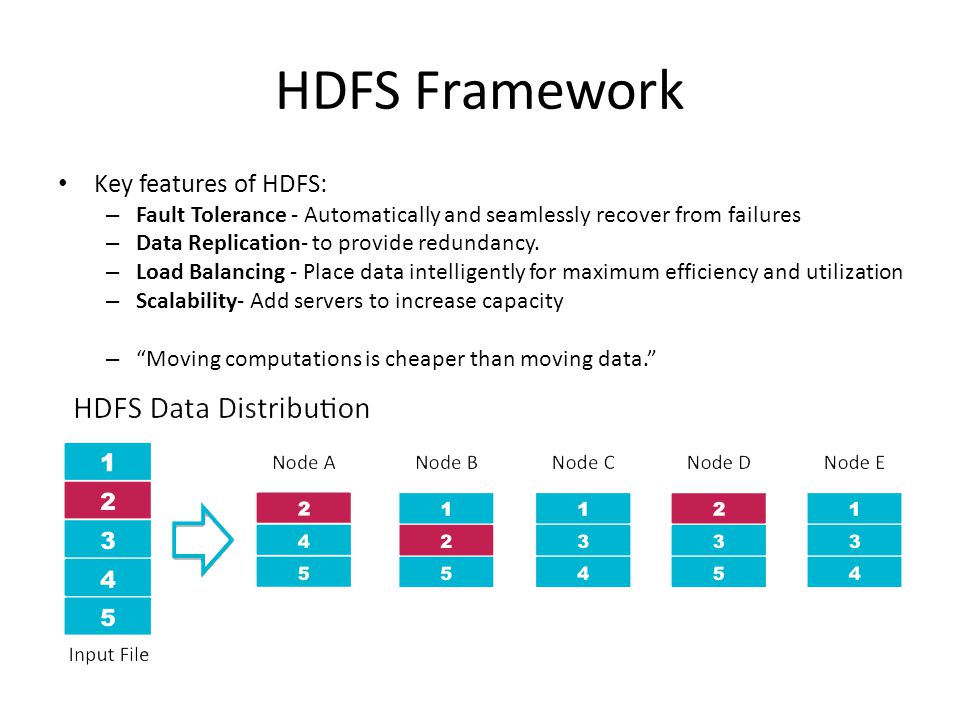\n\nSource: http://slideplayer.com/slide/3406872/12/images/15/HDFS+Framework+Key+features+of+HDFS:.jpg\n\n### Role of YARN\n\n- Resource manager (manages cluster resources)\n - Scheduler\n - Applications manager\n- Node manager (manages single machine/node)\n - manages data containers/partitions\n - monitors resource usage\n - reports to resource manager\n\n\n\nSource: https://kannandreams.files.wordpress.com/2013/11/yarn1.png\n\n### YARN operations\n\n\n\nSource: https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/yarn_architecture.gif\n\n### Hadoop MapReduce versus Spark\n\nSpark has several advantages over Hadoop MapReduce\n\n- Use of RAM rahter than disk mean faster processing for multi-step operations\n- Allows interactive applications\n- Allows real-time applications\n- More flexible programming API (full range of functional constructs)\n\n\n\nSource: https://i0.wp.com/s3.amazonaws.com/acadgildsite/wordpress_images/bigdatadeveloper/10+steps+to+master+apache+spark/hadoop_spark_1.png\n\n### Overall Ecosystem\n\n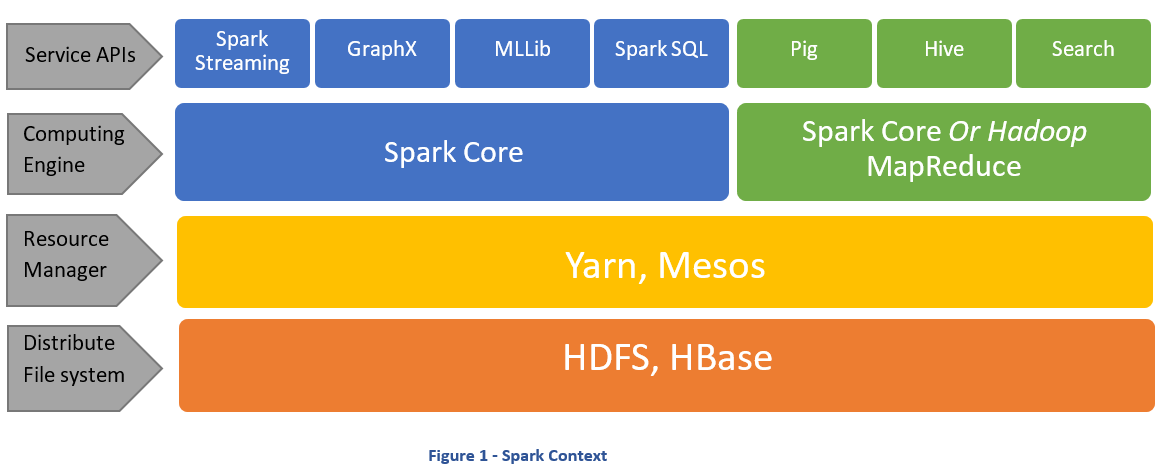\n\nSource: https://cdn-images-1.medium.com/max/1165/1*z0Vm749Pu6mHdlyPsznMRg.png\n\n### Spark Ecosystem\n\n- Spark is written in Scala, a functional programming language built on top of the Java Virtual Machine (JVM)\n- Traditionally, you have to code in Scala to get the best performance from Spark\n- With Spark DataFrames and vectorized operations (Spark 2.3 onwards) Python is now competitive\n\n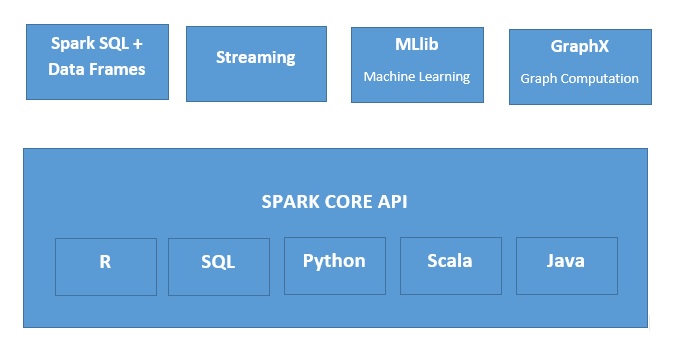\n\nSource: https://databricks.com/wp-content/uploads/2018/12/Spark.jpg\n\n### Livy and Spark magic\n\n- Livy provides a REST interface to a Spark cluster.\n\n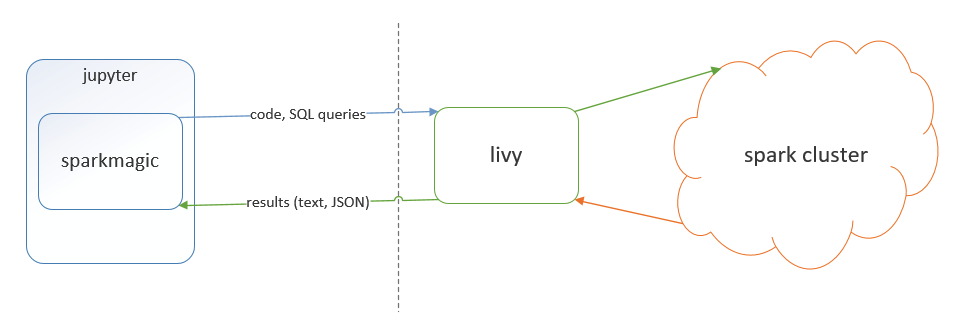\n\nSource: https://cdn-images-1.medium.com/max/956/0*-lwKpnEq0Tpi3Tlj.png\n\n### PySpark\n\n\n\nSource: http://i.imgur.com/YlI8AqEl.png\n\n### Resilient distributed datasets (RDDs)\n\n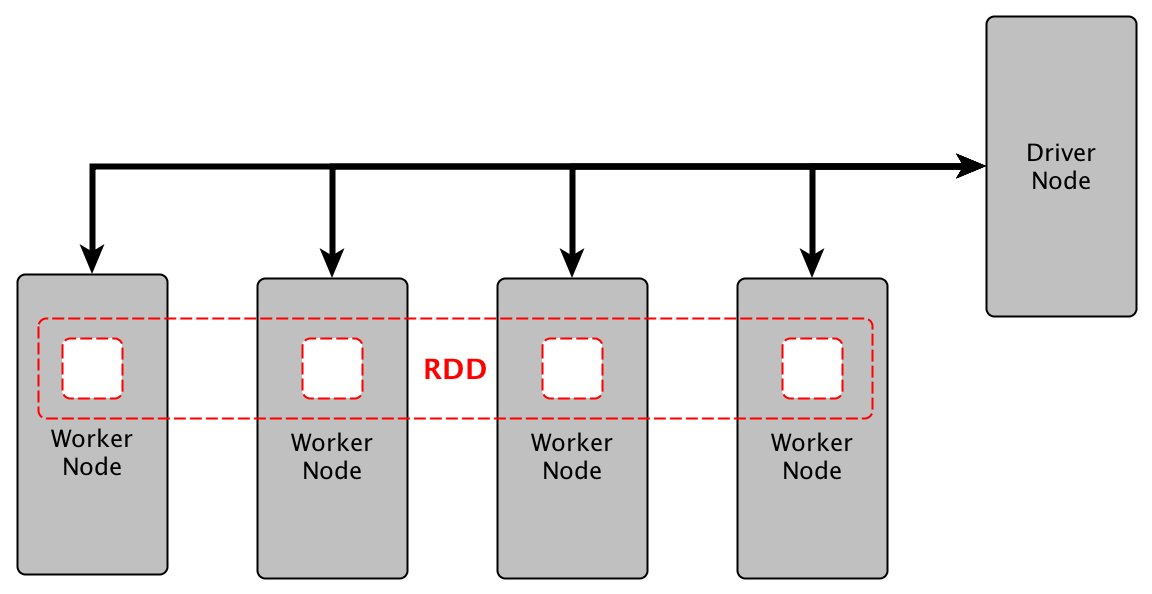\n\nSource: https://miro.medium.com/max/1152/1*l2MUHFvWfcdiUbh7Y-fM5Q.png\n\n### Spark fault tolerance\n\n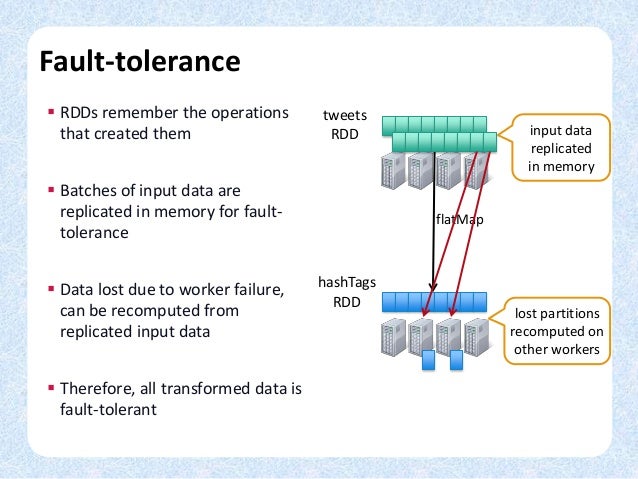\n\nSource: https://image.slidesharecdn.com/deep-dive-with-spark-streamingtathagata-dasspark-meetup2013-06-17-130623151510-phpapp02/95/deep-dive-with-spark-streaming-tathagata-das-spark-meetup-20130617-13-638.jpg",
"_____no_output_____"
],
[
"## Hadoop",
"_____no_output_____"
],
[
"Java 11 gives warning messages with `hdfs`. This futility `print_hadooop` unction just removes the clutter of the output.",
"_____no_output_____"
]
],
[
[
"def print_hadoop(s):\n for line in s.splitlines():\n if 'WARN' in line or 'JAVA_TOOL_OPTIONS' in line:\n continue\n print(line)",
"_____no_output_____"
]
],
[
[
"### HDFS\n\nWorking with files in HDFS is similar to working with files in a regular Unix shell. Some commonly used commands are illustrated below.\n\nThe commands below will only work if there is a local installation of HDFS and a local user directory has been created.",
"_____no_output_____"
],
[
"#### List contents of HDFS",
"_____no_output_____"
]
],
[
[
"%%capture out\n! hdfs dfs -ls -R | head -n4",
"_____no_output_____"
],
[
"print_hadoop(out.stdout)",
"_____no_output_____"
]
],
[
[
"#### Make directory",
"_____no_output_____"
]
],
[
[
"%%capture out\n! hdfs dfs -mkdir csv notebooks",
"_____no_output_____"
]
],
[
[
"#### Copy files from HDFS to HDFS",
"_____no_output_____"
]
],
[
[
"%%capture out\n! hdfs dfs -cp data/*csv csv/",
"_____no_output_____"
],
[
"print_hadoop(out.stdout)",
"cp: `data/SacramentocrimeJanuary2006.csv': No such file or directory\ncp: `data/X_test.csv': No such file or directory\ncp: `data/X_test_unscaled.csv': No such file or directory\ncp: `data/X_train.csv': No such file or directory\ncp: `data/X_train_unscaled.csv': No such file or directory\ncp: `data/flat.csv': No such file or directory\ncp: `data/nile.csv': No such file or directory\ncp: `data/profiles.csv': No such file or directory\ncp: `data/test.csv': No such file or directory\ncp: `data/test_null.csv': No such file or directory\ncp: `data/uk-deaths-from-bronchitis-emphys.csv': No such file or directory\ncp: `data/y_test.csv': No such file or directory\ncp: `data/y_test_unscaled.csv': No such file or directory\ncp: `data/y_train.csv': No such file or directory\ncp: `data/y_train_unscaled.csv': No such file or directory\n"
],
[
"%%capture out\n! hdfs dfs -ls csv | head -n4",
"_____no_output_____"
],
[
"print_hadoop(out.stdout)",
"_____no_output_____"
]
],
[
[
"#### Copy from local to HDFS",
"_____no_output_____"
]
],
[
[
"! ls | head -n4",
"19A_Stream_Generator.ipynb\r\n19B_Spark_Streaming.ipynb\r\n19C_Spark_Streaming.ipynb\r\n19D_Spark_Streaming.ipynb\r\n"
],
[
"%%capture out\n! hdfs dfs -copyFromLocal A*ipynb notebooks",
"_____no_output_____"
],
[
"print_hadoop(out.stdout)",
"_____no_output_____"
],
[
"%%capture out\n! hdfs dfs -ls notebooks| head -n4",
"_____no_output_____"
],
[
"print_hadoop(out.stdout)",
"Found 16 items\n-rw-r--r-- 1 cliburnchan supergroup 25709 2020-11-02 13:57 notebooks/A01_Python_Concepts.ipynb\n-rw-r--r-- 1 cliburnchan supergroup 25709 2020-11-02 13:57 notebooks/A01_copied.ipynb\n-rw-r--r-- 1 cliburnchan supergroup 11433 2020-11-02 13:57 notebooks/A02_Numpy_Concepts.ipynb\n"
]
],
[
[
"#### Copy from HDFS to local",
"_____no_output_____"
]
],
[
[
"%%capture out\n! hdfs dfs -copyToLocal notebooks/A01_Python_Concepts.ipynb A01_copied.ipynb",
"_____no_output_____"
],
[
"! ls -1 A01*",
"A01_Python_Concepts.ipynb\r\nA01_copied.ipynb\r\n"
]
],
[
[
"#### Get information",
"_____no_output_____"
]
],
[
[
"%%capture out\n! hdfs -version",
"_____no_output_____"
],
[
"print_hadoop(out.stdout)",
"java version \"11.0.9\" 2020-10-20 LTS\nJava(TM) SE Runtime Environment 18.9 (build 11.0.9+7-LTS)\nJava HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.9+7-LTS, mixed mode)\n"
],
[
"%%capture out\n! hdfs dfs -du -h .",
"_____no_output_____"
],
[
"print_hadoop(out.stdout)",
"0 csv\n358.2 K notebooks\n"
],
[
"%%capture out\n! hdfs dfs -df -h .",
"_____no_output_____"
],
[
"print_hadoop(out.stdout)",
"Filesystem Size Used Available Use%\nhdfs://localhost:9000 931.5 G 365.1 K 347.6 G 0%\n"
],
[
"%%capture out\n! hdfs dfs -help count",
"_____no_output_____"
],
[
"print_hadoop(out.stdout)",
"-count [-q] [-h] <path> ... :\n Count the number of directories, files and bytes under the paths\n that match the specified file pattern. The output columns are:\n DIR_COUNT FILE_COUNT CONTENT_SIZE FILE_NAME or\n QUOTA REMAINING_QUOTA SPACE_QUOTA REMAINING_SPACE_QUOTA \n DIR_COUNT FILE_COUNT CONTENT_SIZE FILE_NAME\n The -h option shows file sizes in human readable format.\n"
]
],
[
[
"### MapReduce\n\nIf you are interested in MapReduce, see the official [tutorial](https://hadoop.apache.org/docs/current/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html#Example:_WordCount_v1.0)\n\nWe will jump straight to Spark, which has a much nicer API for data scientists and statisticians.",
"_____no_output_____"
],
[
"## Install Spark\n\n- If necessary, install [Java](https://java.com/en/download/help/download_options.xml)\n- Downlaod and install [Sppark](http://spark.apache.org/downloads.html)\n```bash\nwget https://apache.claz.org/spark/spark-3.0.1/spark-3.0.1-bin-hadoop2.7.tgz\n\ntar xzf spark-3.0.3-bin-hadoop2.7.tgz\nsudo mv spark-3.0.1-bin-hadoop2.7 /usr/local/spark\n```\nSet up graphframes\n```bash\npython3 -m pip install graphframes\n```\nSet up environment variables\n```bash\nexport PATH=$PATH:/usr/local/spark/bin\nexport SPARK_HOME=/usr/local/spark\nexport PYTHONPATH=$SPARK_HOME/python:$PYTHONPATH\nexport PYSPARK_DRIVER_PYTHON=\"jupyter\"\nexport PYSPARK_DRIVER_PYTHON_OPTS=\"notebook\"\nexport PYSPARK_PYTHON=python3\n```",
"_____no_output_____"
],
[
"### `sparkmagic` (Optional)\n\nInstall and start `livy`\n```\ncd ~\nwget https://www.apache.org/dyn/closer.lua/incubator/livy/0.7.0-incubating/apache-livy-0.7.0-incubating-bin.zip\nunzip apache-livy-0.7.0-incubating-bin.zip\nmv apache-livy-0.7.0-incubating-bin livy\nlivy/bin/livy-server start\n```\n\nInstall `sparkmagic`\n\n```\npython3 -m pip install sparkmagic\njupyter nbextension enable --py --sys-prefix widgetsnbextension \n```\n\nType `pip show sparkmagic` and cd to the directory shown in LOCATION\n\n```\njupyter-kernelspec install sparkmagic/kernels/pysparkkernel\njupyter serverextension enable --py sparkmagic\n```\n\nFor the adventurous, see [Running Spark on an AWS EMR cluster](https://docs.aws.amazon.com/emr/latest/ReleaseGuide/emr-spark.html).",
"_____no_output_____"
],
[
"## Check",
"_____no_output_____"
]
],
[
[
"from pyspark.sql import SparkSession\nspark = SparkSession.builder.getOrCreate()",
"_____no_output_____"
]
],
[
[
"### Spark UI\n\n- Default port 4040 http://localhost:4040/",
"_____no_output_____"
]
],
[
[
"%%file candy.csv\nname,age,candy\ntom,3,m&m\nshirley,6,mentos\ndavid,4,candy floss\nanne,5,starburst",
"_____no_output_____"
],
[
"df = spark.read.csv('csv/SacramentocrimeJanuary2006.csv')",
"_____no_output_____"
],
[
"df.show(n=10)",
"_____no_output_____"
],
[
"spark.stop()",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
ecc0d3b573db75453758c55047bd13df084a3fae | 6,849 | ipynb | Jupyter Notebook | Kristjan/reading Villems data from json to csv - all.ipynb | kristjanr/ut-ml-adverse-media | 12fa6ada0a6f46ce098a654e39aea0ebbf1d55f5 | [
"MIT"
] | 1 | 2021-02-21T17:58:39.000Z | 2021-02-21T17:58:39.000Z | Kristjan/reading Villems data from json to csv - all.ipynb | kristjanr/ut-ml-adverse-media | 12fa6ada0a6f46ce098a654e39aea0ebbf1d55f5 | [
"MIT"
] | null | null | null | Kristjan/reading Villems data from json to csv - all.ipynb | kristjanr/ut-ml-adverse-media | 12fa6ada0a6f46ce098a654e39aea0ebbf1d55f5 | [
"MIT"
] | 1 | 2021-02-14T13:31:06.000Z | 2021-02-14T13:31:06.000Z | 25.74812 | 76 | 0.418017 | [
[
[
"\n!unzip -qq ../AM_and_NAM_16.11.20.zip -d ../\n",
"_____no_output_____"
],
[
"import json\nimport os\n\nam = []\n\nfor filename in os.listdir('../AdverseMedia_13.11.20/AM/'):\n with open(f'../AdverseMedia_13.11.20/AM/{filename}') as f:\n am.append(json.load(f)['cleaned_article'])",
"_____no_output_____"
],
[
"nam = []\nfor filename in os.listdir('../AdverseMedia_13.11.20/NAM/'):\n with open(f'../AdverseMedia_13.11.20/NAM/{filename}') as f:\n nam.append(json.load(f)['cleaned_article'])",
"_____no_output_____"
],
[
"len(am), len(nam)",
"_____no_output_____"
],
[
"import pandas as pd\n\nam_df = pd.DataFrame({'article': am, 'label': [1]*len(am)})",
"_____no_output_____"
],
[
"nam_df = pd.DataFrame({'article': nam, 'label': [0]*len(nam)})",
"_____no_output_____"
],
[
"df = nam_df.append(am_df)",
"_____no_output_____"
],
[
"df.shape, len(am) + len(nam)",
"_____no_output_____"
],
[
"df.to_csv('additional_data.csv', index=False)",
"_____no_output_____"
],
[
"pd.read_csv('../additional_data.csv.zip')",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecc0d9f8c2d5fb4e055c2fbcbc05557807f870a4 | 39,568 | ipynb | Jupyter Notebook | Experiment_Size.ipynb | thuytrinht4/experimental_design | fafb10dc50764f2c7025091ea4b69e93ef95cfe2 | [
"CECILL-B"
] | null | null | null | Experiment_Size.ipynb | thuytrinht4/experimental_design | fafb10dc50764f2c7025091ea4b69e93ef95cfe2 | [
"CECILL-B"
] | null | null | null | Experiment_Size.ipynb | thuytrinht4/experimental_design | fafb10dc50764f2c7025091ea4b69e93ef95cfe2 | [
"CECILL-B"
] | null | null | null | 120.634146 | 23,660 | 0.830242 | [
[
[
"# Experiment Size\n\nWe can use the knowledge of our desired practical significance boundary to plan out our experiment. By knowing how many observations we need in order to detect our desired effect to our desired level of reliability, we can see how long we would need to run our experiment and whether or not it is feasible.\n\nLet's use the example from the video, where we have a baseline click-through rate of 10% and want to see a manipulation increase this baseline to 12%. How many observations would we need in each group in order to detect this change with power $1-\\beta = .80$ (i.e. detect the 2% absolute increase 80% of the time), at a Type I error rate of $\\alpha = .05$?",
"_____no_output_____"
]
],
[
[
"# import packages\nimport numpy as np\nimport scipy.stats as stats\n\nimport matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"## Method 1: Trial and Error\n\nOne way we could solve this is through trial and error. Every sample size will have a level of power associated with it; testing multiple sample sizes will gradually allow us to narrow down the minimum sample size required to obtain our desired power level. This isn't a particularly efficient method, but it can provide an intuition for how experiment sizing works.\n\nFill in the `power()` function below following these steps:\n\n1. Under the null hypothesis, we should have a critical value for which the Type I error rate is at our desired alpha level.\n - `se_null`: Compute the standard deviation for the difference in proportions under the null hypothesis for our two groups. The base probability is given by `p_null`. Remember that the variance of the difference distribution is the sum of the variances for the individual distributions, and that _each_ group is assigned `n` observations.\n - `null_dist`: To assist in re-use, this should be a [scipy norm object](https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.norm.html). Specify the center and standard deviation of the normal distribution using the \"loc\" and \"scale\" arguments, respectively.\n - `p_crit`: Compute the critical value of the distribution that would cause us to reject the null hypothesis. One of the methods of the `null_dist` object will help you obtain this value (passing in some function of our desired error rate `alpha`).\n2. The power is the proportion of the distribution under the alternative hypothesis that is past that previously-obtained critical value.\n - `se_alt`: Now it's time to make computations in the other direction. This will be standard deviation of differences under the desired detectable difference. Note that the individual distributions will have different variances now: one with `p_null` probability of success, and the other with `p_alt` probability of success.\n - `alt_dist`: This will be a scipy norm object like above. Be careful of the \"loc\" argument in this one. The way the `power` function is set up, it expects `p_alt` to be greater than `p_null`, for a positive difference.\n - `beta`: Beta is the probability of a Type-II error, or the probability of failing to reject the null for a particular non-null state. That means you should make use of `alt_dist` and `p_crit` here!\n\nThe second half of the function has already been completed for you, which creates a visualization of the distribution of differences for the null case and for the desired detectable difference. Use the cells that follow to run the function and observe the visualizations, and to test your code against a few assertion statements. Check the following page if you need help coming up with the solution.",
"_____no_output_____"
]
],
[
[
"def power(p_null, p_alt, n, alpha = .05, plot = True):\n \"\"\"\n Compute the power of detecting the difference in two populations with \n different proportion parameters, given a desired alpha rate.\n \n Input parameters:\n p_null: base success rate under null hypothesis\n p_alt : desired success rate to be detected, must be larger than\n p_null\n n : number of observations made in each group\n alpha : Type-I error rate\n plot : boolean for whether or not a plot of distributions will be\n created\n \n Output value:\n power : Power to detect the desired difference, under the null.\n \"\"\"\n \n # Compute the power\n se_null = np.sqrt((p_null * (1-p_null) + p_null * (1-p_null)) / n)\n null_dist = stats.norm(loc = 0, scale = se_null)\n p_crit = null_dist.ppf(1 - alpha)\n \n se_alt = np.sqrt((p_null * (1-p_null) + p_alt * (1-p_alt) ) / n)\n alt_dist = stats.norm(loc = p_alt - p_null, scale = se_alt)\n beta = alt_dist.cdf(p_crit)\n \n if plot:\n # Compute distribution heights\n low_bound = null_dist.ppf(.01)\n high_bound = alt_dist.ppf(.99)\n x = np.linspace(low_bound, high_bound, 201)\n y_null = null_dist.pdf(x)\n y_alt = alt_dist.pdf(x)\n\n # Plot the distributions\n plt.plot(x, y_null)\n plt.plot(x, y_alt)\n plt.vlines(p_crit, 0, np.amax([null_dist.pdf(p_crit), alt_dist.pdf(p_crit)]),\n linestyles = '--')\n plt.fill_between(x, y_null, 0, where = (x >= p_crit), alpha = .5)\n plt.fill_between(x, y_alt , 0, where = (x <= p_crit), alpha = .5)\n \n plt.legend(['null','alt'])\n plt.xlabel('difference')\n plt.ylabel('density')\n plt.show()\n \n # return power\n return (1 - beta)\n ",
"_____no_output_____"
],
[
"power(.1, .12, 1000)",
"_____no_output_____"
],
[
"assert np.isclose(power(.1, .12, 1000, plot = False), 0.4412, atol = 1e-4)\nassert np.isclose(power(.1, .12, 3000, plot = False), 0.8157, atol = 1e-4)\nassert np.isclose(power(.1, .12, 5000, plot = False), 0.9474, atol = 1e-4)\nprint('You should see this message if all the assertions passed!')",
"You should see this message if all the assertions passed!\n"
]
],
[
[
"## Method 2: Analytic Solution\n\nNow that we've got some intuition for power by using trial and error, we can now approach a closed-form solution for computing a minimum experiment size. The key point to notice is that, for an $\\alpha$ and $\\beta$ both < .5, the critical value for determining statistical significance will fall between our null click-through rate and our alternative, desired click-through rate. So, the difference between $p_0$ and $p_1$ can be subdivided into the distance from $p_0$ to the critical value $p^*$ and the distance from $p^*$ to $p_1$.\n\n<img src= 'images/ExpSize_Power.png'>\n\nThose subdivisions can be expressed in terms of the standard error and the z-scores:\n\n$$p^* - p_0 = z_{1-\\alpha} SE_{0},$$\n$$p_1 - p^* = -z_{\\beta} SE_{1};$$\n\n$$p_1 - p_0 = z_{1-\\alpha} SE_{0} - z_{\\beta} SE_{1}$$\n\nIn turn, the standard errors can be expressed in terms of the standard deviations of the distributions, divided by the square root of the number of samples in each group:\n\n$$SE_{0} = \\frac{s_{0}}{\\sqrt{n}},$$\n$$SE_{1} = \\frac{s_{1}}{\\sqrt{n}}$$\n\nSubstituting these values in and solving for $n$ will give us a formula for computing a minimum sample size to detect a specified difference, at the desired level of power:\n\n$$n = \\lceil \\big(\\frac{z_{\\alpha} s_{0} - z_{\\beta} s_{1}}{p_1 - p_0}\\big)^2 \\rceil$$\n\nwhere $\\lceil ... \\rceil$ represents the ceiling function, rounding up decimal values to the next-higher integer. Implement the necessary variables in the function below, and test them with the cells that follow.",
"_____no_output_____"
]
],
[
[
"def experiment_size(p_null, p_alt, alpha = .05, beta = .20):\n \"\"\"\n Compute the minimum number of samples needed to achieve a desired power\n level for a given effect size.\n \n Input parameters:\n p_null: base success rate under null hypothesis\n p_alt : desired success rate to be detected\n alpha : Type-I error rate\n beta : Type-II error rate\n \n Output value:\n n : Number of samples required for each group to obtain desired power\n \"\"\"\n \n # Get necessary z-scores and standard deviations (@ 1 obs per group)\n z_null = stats.norm.ppf(1 - alpha)\n z_alt = stats.norm.ppf(beta)\n sd_null = np.sqrt(p_null * (1-p_null) + p_null * (1-p_null))\n sd_alt = np.sqrt(p_null * (1-p_null) + p_alt * (1-p_alt) )\n \n # Compute and return minimum sample size\n p_diff = p_alt - p_null\n n = ((z_null*sd_null - z_alt*sd_alt) / p_diff) ** 2\n return np.ceil(n)",
"_____no_output_____"
],
[
"experiment_size(.1, .12)",
"_____no_output_____"
],
[
"assert np.isclose(experiment_size(.1, .12), 2863)\nprint('You should see this message if the assertion passed!')",
"You should see this message if the assertion passed!\n"
]
],
[
[
"## Notes on Interpretation\n\nThe example explored above is a one-tailed test, with the alternative value greater than the null. The power computations performed in the first part will _not_ work if the alternative proportion is less than the null, e.g. detecting a proportion parameter of 0.88 against a null of 0.9. You might want to try to rewrite the code to handle that case! The same issue should not show up for the second approach, where we directly compute the sample size.\n\nIf you find that you need to do a two-tailed test, you should pay attention to two main things. First of all, the \"alpha\" parameter needs to account for the fact that the rejection region is divided into two areas. Secondly, you should perform the computation based on the worst-case scenario, the alternative case with the highest variability. Since, for the binomial, variance is highest when $p = .5$, decreasing as $p$ approaches 0 or 1, you should choose the alternative value that is closest to .5 as your reference when computing the necessary sample size.\n\nNote as well that the above methods only perform sizing for _statistical significance_, and do not take into account _practical significance_. One thing to realize is that if the true size of the experimental effect is the same as the desired practical significance level, then it's a coin flip whether the mean will be above or below the practical significance bound. This also doesn't even consider how a confidence interval might interact with that bound. In a way, experiment sizing is a way of checking on whether or not you'll be able to get what you _want_ from running an experiment, rather than checking if you'll get what you _need_.",
"_____no_output_____"
],
[
"## Alternative Approaches\n\nThere are also tools and Python packages that can also help with sample sizing decisions, so you don't need to solve for every case on your own. The sample size calculator [here](http://www.evanmiller.org/ab-testing/sample-size.html) is applicable for proportions, and provides the same results as the methods explored above. (Note that the calculator assumes a two-tailed test, however.) Python package \"statsmodels\" has a number of functions in its [`power` module](https://www.statsmodels.org/stable/stats.html#power-and-sample-size-calculations) that perform power and sample size calculations. Unlike previously shown methods, differences between null and alternative are parameterized as an effect size (standardized difference between group means divided by the standard deviation). Thus, we can use these functions for more than just tests of proportions. If we want to do the same tests as before, the [`proportion_effectsize`](http://www.statsmodels.org/stable/generated/statsmodels.stats.proportion.proportion_effectsize.html) function computes [Cohen's h](https://en.wikipedia.org/wiki/Cohen%27s_h) as a measure of effect size. As a result, the output of the statsmodel functions will be different from the result expected above. This shouldn't be a major concern since in most cases, you're not going to be stopping based on an exact number of observations. You'll just use the value to make general design decisions.",
"_____no_output_____"
]
],
[
[
"# example of using statsmodels for sample size calculation\nfrom statsmodels.stats.power import NormalIndPower\nfrom statsmodels.stats.proportion import proportion_effectsize\n\n# leave out the \"nobs\" parameter to solve for it\nNormalIndPower().solve_power(effect_size = proportion_effectsize(.12, .1), alpha = .05, power = 0.8,\n alternative = 'larger')",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
] |
ecc0dd4c3ca86e0a62bf2e09a68058901ea5e0a2 | 51,086 | ipynb | Jupyter Notebook | P000.ipynb | brunoschirmer/rossman_stores | 99a5435545b6410eea4770bcfccb5f632d9fa46d | [
"MIT"
] | null | null | null | P000.ipynb | brunoschirmer/rossman_stores | 99a5435545b6410eea4770bcfccb5f632d9fa46d | [
"MIT"
] | null | null | null | P000.ipynb | brunoschirmer/rossman_stores | 99a5435545b6410eea4770bcfccb5f632d9fa46d | [
"MIT"
] | null | null | null | 27.391957 | 1,258 | 0.544924 | [
[
[
"# 0.0 Imports",
"_____no_output_____"
]
],
[
[
"import math\nimport numpy as np\nimport pandas as pd\nimport random\nimport pickle\nimport warnings\nimport inflection\nimport seaborn as sns\nimport xgboost as xgb\n\nfrom scipy import stats as ss\nfrom boruta import BorutaPy\nfrom matplotlib import pyplot as plt\nfrom IPython.display import Image\nfrom IPython.core.display import HTML\n\n\nfrom sklearn.metrics import mean_absolute_error, mean_squared_error\nfrom sklearn.ensemble import RandomForestRegressor\nfrom sklearn.linear_model import LinearRegression, Lasso\nfrom sklearn.preprocessing import RobustScaler, MinMaxScaler, LabelEncoder\n\nwarnings.filterwarnings( 'ignore' )",
"_____no_output_____"
],
[
"def jupyter_settings():\n %matplotlib inline\n %pylab inline\n plt.style.use( 'bmh' )\n plt.rcParams['figure.figsize'] = [25, 12]\n plt.rcParams['font.size'] = 24\n display( HTML( '<style>.container { width:100% !important; }</style>') )\n pd.options.display.max_columns = None\n pd.options.display.max_rows = None\n pd.set_option( 'display.expand_frame_repr', False )\n sns.set()\n \njupyter_settings()",
"_____no_output_____"
],
[
"def cramer_v( x, y ):\n cm = pd.crosstab( x, y ).to_numpy()\n n = cm.sum()\n r, k = cm.shape\n \n chi2 = ss.chi2_contingency( cm )[0]\n chi2corr = max( 0, chi2 - (k-1)*(r-1)/(n-1) )\n \n kcorr = k - (k-1)**2/(n-1)\n rcorr = r - (r-1)**2/(n-1)\n \n return np.sqrt( (chi2corr/n) / ( min( kcorr-1, rcorr-1 ) ) )",
"_____no_output_____"
]
],
[
[
"## 0.1 Helper Functions",
"_____no_output_____"
],
[
"## 0.2 Loading Data",
"_____no_output_____"
]
],
[
[
"df_sales_raw = pd.read_csv('data/train.csv', low_memory=False)\ndf_store_raw = pd.read_csv('data/store.csv', low_memory=False)\n\n## Merge\n\ndf_raw = pd.merge(df_sales_raw, df_store_raw, how='left', on='Store')",
"_____no_output_____"
],
[
"df_raw.head(10)",
"_____no_output_____"
]
],
[
[
"# 1.0 Descricao dos Dados",
"_____no_output_____"
],
[
"## 1.1 Rename Columns",
"_____no_output_____"
]
],
[
[
"##Copia do DF atual para evitar rodar tudo de novo caso ocorra overwriting\n\ndf1 = df_raw",
"_____no_output_____"
],
[
"df1.head()",
"_____no_output_____"
],
[
"cols_old = ['Store', 'DayOfWeek', 'Date', 'Sales', 'Customers', 'Open', 'Promo', 'StateHoliday', 'SchoolHoliday', \n 'StoreType', 'Assortment', 'CompetitionDistance', 'CompetitionOpenSinceMonth',\n 'CompetitionOpenSinceYear', 'Promo2', 'Promo2SinceWeek', 'Promo2SinceYear', 'PromoInterval']\n\nsnakecase = lambda x: inflection.underscore( x )\n\ncols_new = list( map( snakecase, cols_old ) )\n\n# rename\ndf1.columns = cols_new",
"_____no_output_____"
]
],
[
[
"## 1.2 Data Dimensions",
"_____no_output_____"
]
],
[
[
"print('Number of rows: {}'.format (df1.shape[0]))\nprint('Number of columns: {}'.format (df1.shape[1]))",
"_____no_output_____"
]
],
[
[
"## 1.3 Data Types",
"_____no_output_____"
]
],
[
[
"##Mudar data de objeto para data\n\ndf1['date'] = pd.to_datetime( df1['date'] )\ndf1.head()",
"_____no_output_____"
]
],
[
[
"## 1.4 Check NA Values (Not Available)",
"_____no_output_____"
]
],
[
[
"#Buscando valor max para preencher NAs\ndf1['competition_distance'].max()",
"_____no_output_____"
],
[
"df1.isna().sum()",
"_____no_output_____"
]
],
[
[
"## 1.5 Fillout NA Values",
"_____no_output_____"
]
],
[
[
"df1.sample()",
"_____no_output_____"
],
[
"#competition_distance \ndf1['competition_distance'] = df1['competition_distance'].apply( lambda x: 200000.0 if math.isnan( x ) else x )\n\n#competition_open_since_month\ndf1['competition_open_since_month'] = df1.apply( lambda x: x['date'].month if math.isnan( x['competition_open_since_month'] ) else x['competition_open_since_month'], axis=1 )\n\n#competition_open_since_year \ndf1['competition_open_since_year'] = df1.apply( lambda x: x['date'].year if math.isnan( x['competition_open_since_year'] ) else x['competition_open_since_year'], axis=1 )\n\n#promo2_since_week \ndf1['promo2_since_week'] = df1.apply( lambda x: x['date'].week if math.isnan( x['promo2_since_week'] ) else x['promo2_since_week'], axis=1 )\n\n#promo2_since_year \ndf1['promo2_since_year'] = df1.apply( lambda x: x['date'].year if math.isnan( x['promo2_since_year'] ) else x['promo2_since_year'], axis=1 )\n\n#promo_interval \nmonth_map = {1: 'Jan', 2: 'Fev', 3: 'Mar', 4: 'Apr', 5: 'May', 6: 'Jun', 7: 'Jul', 8: 'Aug', 9: 'Sep', 10: 'Oct', 11: 'Nov', 12: 'Dec'}\n\ndf1['promo_interval'].fillna(0, inplace=True )\n\ndf1['month_map'] = df1['date'].dt.month.map( month_map )\n\ndf1['is_promo'] = df1[['promo_interval', 'month_map']].apply( lambda x: 0 if x['promo_interval'] == 0 else 1 if x['month_map'] in x['promo_interval'].split( ',' ) else 0, axis=1 )",
"_____no_output_____"
],
[
"df1.isna().sum()",
"_____no_output_____"
]
],
[
[
"## 1.6 Change types",
"_____no_output_____"
]
],
[
[
"# competiton\ndf1['competition_open_since_month'] = df1['competition_open_since_month'].astype( int )\ndf1['competition_open_since_year'] = df1['competition_open_since_year'].astype( int )\n \n# promo2\ndf1['promo2_since_week'] = df1['promo2_since_week'].astype( int )\ndf1['promo2_since_year'] = df1['promo2_since_year'].astype( int )",
"_____no_output_____"
]
],
[
[
"## 1.7 Descriptive Statistics Analysis",
"_____no_output_____"
]
],
[
[
"#Atraves da estatistica descritiva, vamos ganhar conhecimento do negocio, e detectar alguns erros. usar a metrica\n#de dispersao e tendencia central. tendencia central resume os dados em um unico numero, como media e mediana\n#e dispersao para entender como os dados estao espalhados\n\n#Central tendency: mean, median\n#Dispersion: std, min, max, range, skew, kurtosis\n\n#Precisamos separar os dados entre as variaveis numericas e categoricas",
"_____no_output_____"
],
[
"num_attributes = df1.select_dtypes( include=['int64', 'float64'] )\ncat_attributes = df1.select_dtypes( exclude=['int64', 'float64', 'datetime64[ns]'] )",
"_____no_output_____"
],
[
"#para checar usamos um sample\ncat_attributes.sample(2)",
"_____no_output_____"
]
],
[
[
"## 1.7.1 Numerical Attributes",
"_____no_output_____"
]
],
[
[
"# Central Tendency - mean, meadina \nct1 = pd.DataFrame( num_attributes.apply( np.mean ) ).T\nct2 = pd.DataFrame( num_attributes.apply( np.median ) ).T\n\n# dispersion - std, min, max, range, skew, kurtosis\nd1 = pd.DataFrame( num_attributes.apply( np.std ) ).T \nd2 = pd.DataFrame( num_attributes.apply( min ) ).T \nd3 = pd.DataFrame( num_attributes.apply( max ) ).T \nd4 = pd.DataFrame( num_attributes.apply( lambda x: x.max() - x.min() ) ).T \nd5 = pd.DataFrame( num_attributes.apply( lambda x: x.skew() ) ).T \nd6 = pd.DataFrame( num_attributes.apply( lambda x: x.kurtosis() ) ).T \n\n# concatenar\nm = pd.concat( [d2, d3, d4, ct1, ct2, d1, d5, d6] ).T.reset_index()\nm.columns = ['attributes', 'min', 'max', 'range', 'mean', 'median', 'std', 'skew', 'kurtosis']\nm",
"_____no_output_____"
],
[
"sns.distplot( df1['competition_distance'], kde=False )",
"_____no_output_____"
]
],
[
[
"## 1.7.2 Categorical Attributes",
"_____no_output_____"
]
],
[
[
"cat_attributes.apply( lambda x: x.unique().shape[0] )",
"_____no_output_____"
],
[
"aux = df1[(df1['state_holiday'] != '0') & (df1['sales'] > 0)]\n\nplt.subplot( 1, 3, 1 )\nsns.boxplot( x='state_holiday', y='sales', data=aux )\n\nplt.subplot( 1, 3, 2 )\nsns.boxplot( x='store_type', y='sales', data=aux )\n\nplt.subplot( 1, 3, 3 )\nsns.boxplot( x='assortment', y='sales', data=aux )",
"_____no_output_____"
]
],
[
[
"# 2.0 Feature Enginering",
"_____no_output_____"
]
],
[
[
"df2 = df1.copy()",
"_____no_output_____"
]
],
[
[
"## 2.1 Mapa Mental de Hipoteses",
"_____no_output_____"
]
],
[
[
"Image('img/MindMapHypothesis.png')",
"_____no_output_____"
]
],
[
[
"## 2.2 Criação das Hipóteses",
"_____no_output_____"
],
[
"### 2.2.1 Hipóteses Loja",
"_____no_output_____"
],
[
"**1.** Lojas com mais funcionarios deveriam vender mais\n\n**2.** Lojas com maior estoque deveriam vender mais\n\n**3.** Lojas maiores deveriam vender mais\n\n**4.** Lojas menores deveriam vender menos\n\n**5.** Lojas com maior sortimento deveriam vender mais\n\n**6.** Lojas com competidores mais proximos deveriam vender menos\n\n**7.** Lojas com competidores a mais tempo deveriam vender mais",
"_____no_output_____"
],
[
"### 2.2.2 Hipóteses Produto",
"_____no_output_____"
],
[
"**1.** Lojas que investem mais em markerting deveriam vender mais\n\n**2.** Lojas com maior exposicao de produtos nas vitrines deveriam vender mais\n\n**3.** Lojas com menor preco deveriam vender mais\n\n**4.** Lojas com precos menores por mais tempo (promocao) deveriam vender mais\n\n**5.** Lojas com promocoes ativas por mais tempo deveriam vender mais\n\n**6.** Lojas com promocoes mais promocoes consecutivas deveriam vender mais\n\n**7.** Lojas com mais dias de promocao deveriam vender mais\n\n",
"_____no_output_____"
],
[
"### 2.2.3 Hipóteses Tempo",
"_____no_output_____"
],
[
"**1.** Lojas que tem mais feriados deveriam vender menos\n\n**2.** Lojas que abrem nos primeiros seis meses deveriam vender mais (sazonalidade)\n\n**3.** Lojas que abrem nos finais de semana deveriam vender mais\n\n**4.** Lojas com precos menores por mais tempo (promocao) deveriam vender mais\n\n**5.** Lojas com maior sortimento deveriam vender mais\n\n**6.** Lojas abertas durante o Natal deveriam vender mais\n\n**7.** Lojas deveriam vender mais ao longo dos anos\n\n**8.** Lojas deveriam vender mais no segundo semestre\n\n**9.** Lojas deveriam vender mais depois do dia 10 do mes\n\n**10.** Lojas deveriam vender menos aos finais de semana\n\n**11.** Lojas deveriam vender menos durante feriados escolares",
"_____no_output_____"
],
[
"## 2.3 Lista final de hipoteses\n\n**1.** Lojas com maior sortimento deveriam vender mais\n\n**2.** Lojas com competidores mais proximos deveriam vender menos\n\n**3.** Lojas com competidores a mais tempo deveriam vender mais\n\n**4.** Lojas com promocoes ativas por mais tempo deveriam vender mais\n\n**5.** Lojas com promocoes mais promocoes consecutivas deveriam vender mais\n\n**6.** Lojas com mais dias de promocao deveriam vender mais\n\n**7.** Lojas abertas durante o Natal deveriam vender mais\n\n**8.** Lojas deveriam vender mais ao longo dos anos\n\n**9.** Lojas deveriam vender mais no segundo semestre\n\n**10.** Lojas deveriam vender mais depois do dia 10 do mes\n\n**11.** Lojas deveriam vender menos aos finais de semana\n\n**12.** Lojas deveriam vender menos durante feriados escolares",
"_____no_output_____"
],
[
"## 2.4 Feature Engineering",
"_____no_output_____"
]
],
[
[
"# year\ndf2['year'] = df2['date'].dt.year\n\n# month\ndf2['month'] = df2['date'].dt.month\n\n# day\ndf2['day'] = df2['date'].dt.day\n\n# week of year\ndf2['week_of_year'] = df2['date'].dt.isocalendar().week\n\n# year week\ndf2['year_week'] = df2['date'].dt.strftime( '%Y-%W' )\n\n# competition since\ndf2['competition_since'] = df2.apply( lambda x: datetime.datetime( year=x['competition_open_since_year'], month=x['competition_open_since_month'],day=1 ), axis=1 )\ndf2['competition_time_month'] = ( ( df2['date'] - df2['competition_since'] )/30 ).apply( lambda x: x.days ).astype( int )\n\n# promo since\ndf2['promo_since'] = df2['promo2_since_year'].astype( str ) + '-' + df2['promo2_since_week'].astype( str )\ndf2['promo_since'] = df2['promo_since'].apply( lambda x: datetime.datetime.strptime( x + '-1', '%Y-%W-%w' ) - datetime.timedelta( days=7 ) )\ndf2['promo_time_week'] = ( ( df2['date'] - df2['promo_since'] )/7 ).apply( lambda x: x.days ).astype( int )\n\n# assortment\ndf2['assortment'] = df2['assortment'].apply( lambda x: 'basic' if x == 'a' else 'extra' if x == 'b' else 'extended' )\n\n# state holiday\ndf2['state_holiday'] = df2['state_holiday'].apply( lambda x: 'public_holiday' if x == 'a' else 'easter_holiday' if x == 'b' else 'christmas' if x == 'c' else 'regular_day' )",
"_____no_output_____"
]
],
[
[
"# 3.0 Filtragem de Variáveis",
"_____no_output_____"
]
],
[
[
"df3 = df2.copy()",
"_____no_output_____"
]
],
[
[
"## 3.1 Filtragem das Linhas",
"_____no_output_____"
]
],
[
[
"df3 = df3[(df3['open'] != 0) & (df3['sales'] > 0)]",
"_____no_output_____"
]
],
[
[
"## 3.2 Seleção das colunas",
"_____no_output_____"
]
],
[
[
"cols_drop = ['open', 'promo_interval', 'month_map', 'customers']\ndf3 = df3.drop(cols_drop, axis=1)",
"_____no_output_____"
]
],
[
[
"# 4.0 Data Exploratory Analysis",
"_____no_output_____"
]
],
[
[
"df4 = df3.copy()",
"_____no_output_____"
]
],
[
[
"## 4.1 Análise Univariada",
"_____no_output_____"
],
[
"### 4.1.1 Response Variable",
"_____no_output_____"
]
],
[
[
"sns.distplot( df4['sales'], kde=False )",
"_____no_output_____"
]
],
[
[
"### 4.1.2 Numerical Variables",
"_____no_output_____"
]
],
[
[
"num_attributes.hist( bins=25 );",
"_____no_output_____"
]
],
[
[
"### 4.1.3 Categorical Variables",
"_____no_output_____"
]
],
[
[
"# state_holiday\nplt.subplot( 3, 2, 1 )\na = df4[df4['state_holiday'] != 'regular_day']\nsns.countplot( a['state_holiday'] )\n\nplt.subplot( 3, 2, 2 )\nsns.kdeplot( df4[df4['state_holiday'] == 'public_holiday']['sales'], label='public_holiday', shade=True )\nsns.kdeplot( df4[df4['state_holiday'] == 'easter_holiday']['sales'], label='easter_holiday', shade=True )\nsns.kdeplot( df4[df4['state_holiday'] == 'christmas']['sales'], label='christmas', shade=True )\n\n# store_type\nplt.subplot( 3, 2, 3 )\nsns.countplot( df4['store_type'] )\n\nplt.subplot( 3, 2, 4 )\nsns.kdeplot( df4[df4['store_type'] == 'a']['sales'], label='a', shade=True )\nsns.kdeplot( df4[df4['store_type'] == 'b']['sales'], label='b', shade=True )\nsns.kdeplot( df4[df4['store_type'] == 'c']['sales'], label='c', shade=True )\nsns.kdeplot( df4[df4['store_type'] == 'd']['sales'], label='d', shade=True )\n\n# assortment\nplt.subplot( 3, 2, 5 )\nsns.countplot( df4['assortment'] )\n\nplt.subplot( 3, 2, 6 )\nsns.kdeplot( df4[df4['assortment'] == 'extended']['sales'], label='extended', shade=True )\nsns.kdeplot( df4[df4['assortment'] == 'basic']['sales'], label='basic', shade=True )\nsns.kdeplot( df4[df4['assortment'] == 'extra']['sales'], label='extra', shade=True )",
"_____no_output_____"
]
],
[
[
"## 4.2. Analise Bivariada",
"_____no_output_____"
],
[
"## H1. Lojas com maior sortimentos deveriam vender mais.\nFALSA Lojas com MAIOR SORTIMENTO vendem MENOS.",
"_____no_output_____"
]
],
[
[
"aux1 = df4[['assortment', 'sales']].groupby( 'assortment' ).sum().reset_index()\nsns.barplot( x='assortment', y='sales', data=aux1 );\n\naux2 = df4[['year_week', 'assortment', 'sales']].groupby( ['year_week','assortment'] ).sum().reset_index()\naux2.pivot( index='year_week', columns='assortment', values='sales' ).plot()\n\naux3 = aux2[aux2['assortment'] == 'extra']\naux3.pivot( index='year_week', columns='assortment', values='sales' ).plot()",
"_____no_output_____"
]
],
[
[
"## H2. Lojas com competidores mais próximos deveriam vender menos.\nFALSA Lojas com COMPETIDORES MAIS PROXIMOS vendem MAIS.",
"_____no_output_____"
]
],
[
[
"aux1 = df4[['competition_distance', 'sales']].groupby( 'competition_distance' ).sum().reset_index()\n\nplt.subplot( 1, 3, 1 )\nsns.scatterplot( x ='competition_distance', y='sales', data=aux1 );\n\nplt.subplot( 1, 3, 2 )\nbins = list( np.arange( 0, 20000, 1000) )\naux1['competition_distance_binned'] = pd.cut( aux1['competition_distance'], bins=bins )\naux2 = aux1[['competition_distance_binned', 'sales']].groupby( 'competition_distance_binned' ).sum().reset_index()\nsns.barplot( x='competition_distance_binned', y='sales', data=aux2 );\nplt.xticks( rotation=90 );\n\nplt.subplot( 1, 3, 3 )\nx = sns.heatmap( aux1.corr( method='pearson' ), annot=True );",
"_____no_output_____"
]
],
[
[
"## H3. Lojas com competidores à mais tempo deveriam vendem mais.\nFALSE Lojas com COMPETIDORES À MAIS TEMPO vendem MENOS.",
"_____no_output_____"
]
],
[
[
"plt.subplot( 1, 3, 1 )\naux1 = df4[['competition_time_month', 'sales']].groupby( 'competition_time_month' ).sum().reset_index()\naux2 = aux1[( aux1['competition_time_month'] < 120 ) & ( aux1['competition_time_month'] != 0 )]\nsns.barplot( x='competition_time_month', y='sales', data=aux2 );\nplt.xticks( rotation=90 );\n\nplt.subplot( 1, 3, 2 )\nsns.regplot( x='competition_time_month', y='sales', data=aux2 );\n\nplt.subplot( 1, 3, 3 )\nx = sns.heatmap( aux1.corr( method='pearson'), annot=True );",
"_____no_output_____"
]
],
[
[
"## H4. Lojas com promoções ativas por mais tempo deveriam vender mais.\nFALSA Lojas com promocoes ativas por mais tempo vendem menos, depois de um certo periodo de promocao",
"_____no_output_____"
]
],
[
[
"aux1 = df4[['promo_time_week', 'sales']].groupby( 'promo_time_week').sum().reset_index()\n\ngrid = GridSpec( 2, 3 )\n\nplt.subplot( grid[0,0] )\naux2 = aux1[aux1['promo_time_week'] > 0] # promo extendido\nsns.barplot( x='promo_time_week', y='sales', data=aux2 );\nplt.xticks( rotation=90 );\n\nplt.subplot( grid[0,1] )\nsns.regplot( x='promo_time_week', y='sales', data=aux2 );\n\nplt.subplot( grid[1,0] )\naux3 = aux1[aux1['promo_time_week'] < 0] # promo regular\nsns.barplot( x='promo_time_week', y='sales', data=aux3 );\nplt.xticks( rotation=90 );\n\nplt.subplot( grid[1,1] )\nsns.regplot( x='promo_time_week', y='sales', data=aux3 );\n\nplt.subplot( grid[:,2] )\nsns.heatmap( aux1.corr( method='pearson' ), annot=True );",
"_____no_output_____"
]
],
[
[
"**H5.** Lojas com mais dias de promoção deveriam vender mais.",
"_____no_output_____"
],
[
"## H7. Lojas com mais promoções consecutivas deveriam vender mais.\nFALSA Lojas com mais promocoes consecutivas vendem menos",
"_____no_output_____"
]
],
[
[
"df4[['promo', 'promo2', 'sales']].groupby( ['promo', 'promo2'] ).sum().reset_index()",
"_____no_output_____"
],
[
"aux1 = df4[( df4['promo'] == 1 ) & ( df4['promo2'] == 1 )][['year_week', 'sales']].groupby( 'year_week' ).sum().reset_index()\nax = aux1.plot()\n\naux2 = df4[( df4['promo'] == 1 ) & ( df4['promo2'] == 0 )][['year_week', 'sales']].groupby( 'year_week' ).sum().reset_index()\naux2.plot( ax=ax )\n\nax.legend( labels=['Tradicional & Extendida', 'Extendida']);",
"_____no_output_____"
]
],
[
[
"## H8. Lojas abertas durante o feriado de Natal deveriam vender mais.\nFALSA Lojas abertas durante o feriado do Natal vendem menos.",
"_____no_output_____"
]
],
[
[
"aux = df4[df4['state_holiday'] != 'regular_day']\n\nplt.subplot( 1, 2, 1 )\naux1 = aux[['state_holiday', 'sales']].groupby( 'state_holiday' ).sum().reset_index()\nsns.barplot( x='state_holiday', y='sales', data=aux1 );\n\nplt.subplot( 1, 2, 2 )\naux2 = aux[['year', 'state_holiday', 'sales']].groupby( ['year', 'state_holiday'] ).sum().reset_index()\nsns.barplot( x='year', y='sales', hue='state_holiday', data=aux2 );",
"_____no_output_____"
]
],
[
[
"##H9. Lojas deveriam vender mais ao longo dos anos.\nFALSA Lojas vendem menos ao longo dos anos",
"_____no_output_____"
]
],
[
[
"aux1 = df4[['year', 'sales']].groupby( 'year' ).sum().reset_index()\n\nplt.subplot( 1, 3, 1 )\nsns.barplot( x='year', y='sales', data=aux1 );\n\nplt.subplot( 1, 3, 2 )\nsns.regplot( x='year', y='sales', data=aux1 );\n\nplt.subplot( 1, 3, 3 )\nsns.heatmap( aux1.corr( method='pearson' ), annot=True );",
"_____no_output_____"
]
],
[
[
"## H10. Lojas deveriam vender mais no segundo semestre do ano.\nFALSA Lojas vendem menos no segundo semestre do ano",
"_____no_output_____"
]
],
[
[
"aux1 = df4[['month', 'sales']].groupby( 'month' ).sum().reset_index()\n\nplt.subplot( 1, 3, 1 )\nsns.barplot( x='month', y='sales', data=aux1 );\n\nplt.subplot( 1, 3, 2 )\nsns.regplot( x='month', y='sales', data=aux1 );\n\nplt.subplot( 1, 3, 3 )\nsns.heatmap( aux1.corr( method='pearson' ), annot=True );",
"_____no_output_____"
]
],
[
[
"## H11. Lojas deveriam vender mais depois do dia 10 de cada mês.\nVERDADEIRA Lojas vendem mais depois do dia 10 de cada mes.",
"_____no_output_____"
]
],
[
[
"plt.subplot( 2, 2, 1 )\nsns.barplot( x='day', y='sales', data=aux1 );\n\nplt.subplot( 2, 2, 2 )\nsns.regplot( x='day', y='sales', data=aux1 );\n\nplt.subplot( 2, 2, 3 )\nsns.heatmap( aux1.corr( method='pearson' ), annot=True );\n\naux1['before_after'] = aux1['day'].apply( lambda x: 'before_10_days' if x <= 10 else 'after_10_days' )\naux2 =aux1[['before_after', 'sales']].groupby( 'before_after' ).sum().reset_index()\n\nplt.subplot( 2, 2, 4 )\nsns.barplot( x='before_after', y='sales', data=aux2 );",
"_____no_output_____"
]
],
[
[
"## H12. Lojas deveriam vender menos aos finais de semana.\nVERDADEIRA Lojas vendem menos nos final de semana",
"_____no_output_____"
]
],
[
[
"aux1 = df4[['day_of_week', 'sales']].groupby( 'day_of_week' ).sum().reset_index()\n\nplt.subplot( 1, 3, 1 )\nsns.barplot( x='day_of_week', y='sales', data=aux1 );\n\nplt.subplot( 1, 3, 2 )\nsns.regplot( x='day_of_week', y='sales', data=aux1 );\n\nplt.subplot( 1, 3, 3 )\nsns.heatmap( aux1.corr( method='pearson' ), annot=True );",
"_____no_output_____"
]
],
[
[
"## H13. Lojas deveriam vender menos durante os feriados escolares.\nVERDADEIRA Lojas vendem menos durante os feriadso escolares, except os meses de Julho e Agosto.",
"_____no_output_____"
]
],
[
[
"aux1 = df4[['school_holiday', 'sales']].groupby( 'school_holiday' ).sum().reset_index()\nplt.subplot( 2, 1, 1 )\nsns.barplot( x='school_holiday', y='sales', data=aux1 );\n\naux2 = df4[['month', 'school_holiday', 'sales']].groupby( ['month','school_holiday'] ).sum().reset_index()\nplt.subplot( 2, 1, 2 )\nsns.barplot( x='month', y='sales', hue='school_holiday', data=aux2 );",
"_____no_output_____"
]
],
[
[
"### 4.2.1. Resumo das Hipoteses",
"_____no_output_____"
]
],
[
[
"tab =[['Hipoteses', 'Conclusao', 'Relevancia'],\n ['H1', 'Falsa', 'Baixa'], \n ['H2', 'Falsa', 'Media'], \n ['H3', 'Falsa', 'Media'],\n ['H4', 'Falsa', 'Baixa'],\n ['H5', '-', '-'],\n ['H7', 'Falsa', 'Baixa'],\n ['H8', 'Falsa', 'Media'],\n ['H9', 'Falsa', 'Alta'],\n ['H10', 'Falsa', 'Alta'],\n ['H11', 'Verdadeira', 'Alta'],\n ['H12', 'Verdadeira', 'Alta'],\n ['H13', 'Verdadeira', 'Baixa'],\n ] \nprint( tabulate( tab, headers='firstrow' ) )",
"_____no_output_____"
]
],
[
[
"## 4.3. Analise Multivariada",
"_____no_output_____"
]
],
[
[
"correlation = num_attributes.corr( method='pearson' )\nsns.heatmap( correlation, annot=True );",
"_____no_output_____"
]
],
[
[
"### 4.3.2 Categorical Attributes",
"_____no_output_____"
]
],
[
[
"# only categorical data\na = df4.select_dtypes( include='object' )\n\n# Calculate cramer V\na1 = cramer_v( a['state_holiday'], a['state_holiday'] )\na2 = cramer_v( a['state_holiday'], a['store_type'] )\na3 = cramer_v( a['state_holiday'], a['assortment'] )\n\na4 = cramer_v( a['store_type'], a['state_holiday'] )\na5 = cramer_v( a['store_type'], a['store_type'] )\na6 = cramer_v( a['store_type'], a['assortment'] )\n\na7 = cramer_v( a['assortment'], a['state_holiday'] )\na8 = cramer_v( a['assortment'], a['store_type'] )\na9 = cramer_v( a['assortment'], a['assortment'] )\n\n# Final dataset\nd = pd.DataFrame( {'state_holiday': [a1, a2, a3], \n 'store_type': [a4, a5, a6],\n 'assortment': [a7, a8, a9] })\nd = d.set_index( d.columns )\n\nsns.heatmap( d, annot=True )",
"_____no_output_____"
]
],
[
[
"# 05 - DATA PREPARATION",
"_____no_output_____"
]
],
[
[
"df5 = df4.copy()",
"_____no_output_____"
]
],
[
[
"## 5.1 Normalização",
"_____no_output_____"
],
[
"## 5.2 Rescalling",
"_____no_output_____"
]
],
[
[
"rs = RobustScaler()\nmms = MinMaxScaler()\n\n# competition distance\ndf5['competition_distance'] = rs.fit_transform( df5[['competition_distance']].values )\npickle.dump( rs, open( 'parameter/competition_distance_scaler.pkl', 'wb') )\n\n# competition time month\ndf5['competition_time_month'] = rs.fit_transform( df5[['competition_time_month']].values )\npickle.dump( rs, open( 'parameter/competition_time_month_scaler.pkl', 'wb') )\n\n# promo time week\ndf5['promo_time_week'] = mms.fit_transform( df5[['promo_time_week']].values )\npickle.dump( rs, open( 'parameter/promo_time_week_scaler.pkl', 'wb') )\n\n# year\ndf5['year'] = mms.fit_transform( df5[['year']].values )\npickle.dump( mms, open( 'parameter/year_scaler.pkl', 'wb') )",
"_____no_output_____"
]
],
[
[
"## 5.3 Transformação",
"_____no_output_____"
],
[
"### 5.3.1 Encoding",
"_____no_output_____"
]
],
[
[
"# state_holiday - One Hot Encoding\ndf5 = pd.get_dummies( df5, prefix=['state_holiday'], columns=['state_holiday'] )\n\n# store_type - Label Encoding\nle = LabelEncoder()\ndf5['store_type'] = le.fit_transform( df5['store_type'] )\npickle.dump( le, open( 'parameter/store_type_scaler.pkl', 'wb') )\n\n# assortment - Ordinal Encoding\nassortment_dict = {'basic': 1, 'extra': 2, 'extended': 3}\ndf5['assortment'] = df5['assortment'].map( assortment_dict )",
"_____no_output_____"
]
],
[
[
"### 5.3.2 Response Variable Transformation",
"_____no_output_____"
]
],
[
[
"df5['sales'] = np.log1p( df5['sales'] )",
"_____no_output_____"
]
],
[
[
"### 5.3.3 Nature Transformation",
"_____no_output_____"
]
],
[
[
"df5['day_of_week_sin'] = df5['day_of_week'].apply( lambda x: np.sin( x * ( 2. * np.pi/7 ) ) )\ndf5['day_of_week_cos'] = df5['day_of_week'].apply( lambda x: np.cos( x * ( 2. * np.pi/7 ) ) )\n\n# month\ndf5['month_sin'] = df5['month'].apply( lambda x: np.sin( x * ( 2. * np.pi/12 ) ) )\ndf5['month_cos'] = df5['month'].apply( lambda x: np.cos( x * ( 2. * np.pi/12 ) ) )\n\n# day \ndf5['day_sin'] = df5['day'].apply( lambda x: np.sin( x * ( 2. * np.pi/30 ) ) )\ndf5['day_cos'] = df5['day'].apply( lambda x: np.cos( x * ( 2. * np.pi/30 ) ) )\n\n# week of year\ndf5['week_of_year_sin'] = df5['week_of_year'].apply( lambda x: np.sin( x * ( 2. * np.pi/52 ) ) )\ndf5['week_of_year_cos'] = df5['week_of_year'].apply( lambda x: np.cos( x * ( 2. * np.pi/52 ) ) )",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
ecc0e863de0ae9706558d7a973287affea7d9f6f | 618,892 | ipynb | Jupyter Notebook | nb/fsps_metallicity_range.ipynb | biprateep/provabgs | 6a62dcee6933dd7834d9c9871c24391e6c797105 | [
"MIT"
] | 11 | 2020-12-11T21:06:53.000Z | 2022-03-16T17:20:57.000Z | nb/fsps_metallicity_range.ipynb | biprateep/provabgs | 6a62dcee6933dd7834d9c9871c24391e6c797105 | [
"MIT"
] | 15 | 2020-11-25T05:06:26.000Z | 2021-04-07T15:34:52.000Z | nb/fsps_metallicity_range.ipynb | biprateep/provabgs | 6a62dcee6933dd7834d9c9871c24391e6c797105 | [
"MIT"
] | 3 | 2021-01-10T15:20:26.000Z | 2021-11-07T21:17:13.000Z | 2,838.954128 | 382,472 | 0.960087 | [
[
[
"import fsps\nimport numpy as np \n# --- plotting ---\nimport matplotlib as mpl\nimport matplotlib.pyplot as plt\nmpl.rcParams['text.usetex'] = True\nmpl.rcParams['font.family'] = 'serif'\nmpl.rcParams['axes.linewidth'] = 1.5\nmpl.rcParams['axes.xmargin'] = 1\nmpl.rcParams['xtick.labelsize'] = 'x-large'\nmpl.rcParams['xtick.major.size'] = 5\nmpl.rcParams['xtick.major.width'] = 1.5\nmpl.rcParams['ytick.labelsize'] = 'x-large'\nmpl.rcParams['ytick.major.size'] = 5\nmpl.rcParams['ytick.major.width'] = 1.5\nmpl.rcParams['legend.frameon'] = False",
"_____no_output_____"
],
[
"ssp = fsps.StellarPopulation(zcontinuous=1, sfh=0, imf_type=1)",
"_____no_output_____"
],
[
"ssp.libraries",
"_____no_output_____"
],
[
"# metallicity bins of the MIST isochrones\nzlegend = np.array([4.49043431e-05, 1.42000001e-04, 2.52515678e-04, 4.49043431e-04,\n 7.98524687e-04, 1.42000001e-03, 2.52515678e-03, 4.49043431e-03,\n 7.98524687e-03, 1.42000001e-02, 2.52515678e-02, 4.49043431e-02])",
"_____no_output_____"
],
[
"np.log10(zlegend/0.0190)",
"_____no_output_____"
],
[
"fig = plt.figure(figsize=(10,30))\nfor i, tage in enumerate([1e-3, 1e-2, 0.1, 1, 5, 10, 13.7]):\n sub = fig.add_subplot(7,1,i+1)\n for Z in zlegend[::2]:\n ssp.params['logzsol'] = np.log10(Z/0.019)\n w, f = ssp.get_spectrum(tage=tage, peraa=True)\n sub.plot(w, f, label='$\\log Z/Z_\\odot =%.1f$' % np.log10(Z/0.0190))\n sub.text(0.95, 0.95, r'$t_{\\rm age} = %.3f$' % tage, ha='right', va='top', transform=sub.transAxes, fontsize=25)\n sub.set_xlim(1e3, 1e4)\n if tage == 1.: sub.set_ylabel(r'SSP Luminosity $L_\\odot/A$', fontsize=25)\nsub.legend(loc='upper left', fontsize=10) \nsub.set_xlabel('wavelength ($AA$)', fontsize=25)",
"_____no_output_____"
]
],
[
[
"all stellar emission has to be some linear combination of these SSPs!",
"_____no_output_____"
]
],
[
[
"sdss_bands = fsps.find_filter('sdss')\nsdss_waves = [3543, 4770, 6231, 7625, 9134]",
"_____no_output_____"
],
[
"fig = plt.figure(figsize=(10,30))\nfor i, tage in enumerate([1e-2, 0.1, 1, 5, 10, 13.7]):\n sub = fig.add_subplot(6,1,i+1)\n for iz, Z in enumerate(zlegend[::2]):\n ssp.params['logzsol'] = np.log10(Z/0.019)\n _mags = ssp.get_mags(tage=tage, bands=sdss_bands, redshift=0.05)\n sub.scatter(sdss_waves, _mags, c='C%i' % iz, label='$\\log Z/Z_\\odot =%.1f$' % np.log10(Z/0.0190))\n sub.plot(sdss_waves, _mags, c='C%i' % iz)\n \n sub.text(0.95, 0.95, r'$t_{\\rm age} = %.3f$' % tage, ha='right', va='top', transform=sub.transAxes, fontsize=25)\n sub.set_xlim(3e3, 1.3e4)\n if tage == 1.: sub.set_ylabel(r'magnitude at $z=0.05$', fontsize=25)\nsub.legend(loc='lower right', fontsize=15) \nsub.set_xlabel('wavelength ($AA$)', fontsize=25)",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
ecc0eff8ce17e7a5b7a4e1b26b7f9952263b2844 | 220,013 | ipynb | Jupyter Notebook | samples/04_gis_analysts_data_scientists/identifying-country-names-from-incomplete-house-addresses.ipynb | tyhayward/arcgis-python-api | ede7f8a5cbdafe675808c2be5b70ee2e6128952a | [
"Apache-2.0"
] | 1 | 2021-05-29T07:14:48.000Z | 2021-05-29T07:14:48.000Z | samples/04_gis_analysts_data_scientists/identifying-country-names-from-incomplete-house-addresses.ipynb | tyhayward/arcgis-python-api | ede7f8a5cbdafe675808c2be5b70ee2e6128952a | [
"Apache-2.0"
] | null | null | null | samples/04_gis_analysts_data_scientists/identifying-country-names-from-incomplete-house-addresses.ipynb | tyhayward/arcgis-python-api | ede7f8a5cbdafe675808c2be5b70ee2e6128952a | [
"Apache-2.0"
] | null | null | null | 115.310797 | 64,879 | 0.724071 | [
[
[
"# Identifying country names from incomplete house addresses",
"_____no_output_____"
],
[
"<h1>Table of Contents<span class=\"tocSkip\"></span></h1>\n<div class=\"toc\">\n<ul class=\"toc-item\">\n<li><span><a href=\"#Introduction\" data-toc-modified-id=\"Introduction-1\">Introduction</a></span></li>\n<li><span><a href=\"#Prerequisites\" data-toc-modified-id=\"Prerequisites-2\">Prerequisites</a></span></li>\n<li><span><a href=\"#Imports\" data-toc-modified-id=\"Imports-3\">Imports</a></span></li>\n<li><span><a href=\"#Data-preparation\" data-toc-modified-id=\"Data-preparation-4\">Data preparation</a></span></li>\n<li><span><a href=\"#TextClassifier-model\" data-toc-modified-id=\"TextClassifier-model-5\">TextClassifier model</a></span></li>\n<ul class=\"toc-item\">\n<li><span><a href=\"#Load-model-architecture\" data-toc-modified-id=\"Load-model-architecture-5.1\">Load model architecture</a></span></li>\n<li><span><a href=\"#Model-training\" data-toc-modified-id=\"Model-training-5.2\">Model training</a></span></li> \n<li><span><a href=\"#Validate-results\" data-toc-modified-id=\"Validate-results-5.3\">Validate results</a></span></li>\n<li><span><a href=\"#Model-metrics\" data-toc-modified-id=\"Model-metrics-5.4\">Model metrics</a></span></li> \n<li><span><a href=\"#Get-misclassified-records\" data-toc-modified-id=\"Get-misclassified-records-5.5\">Get misclassified records</a></span></li>\n<li><span><a href=\"#Saving-the-trained-model\" data-toc-modified-id=\"Saving-the-trained-model-5.6\">Saving the trained model</a></span></li>\n</ul>\n<li><span><a href=\"#Model-inference\" data-toc-modified-id=\"Model-inference-6\">Model inference</a></span></li>\n<li><span><a href=\"#Conclusion\" data-toc-modified-id=\"Conclusion-7\">Conclusion</a></span></li>\n<li><span><a href=\"#References\" data-toc-modified-id=\"References-8\">References</a></span></li>\n</ul></div>",
"_____no_output_____"
],
[
"# Introduction",
"_____no_output_____"
],
[
"[Geocoding](https://en.wikipedia.org/wiki/Geocoding) is the process of taking input text, such as an **address** or the name of a place, and returning a **latitude/longitude** location for that place. In this notebook, we will be picking up a dataset consisting of incomplete house addresses from 10 countries. We will build a classifier using `TextClassifier` class of `arcgis.learn.text` module to predict the country for these incomplete house addresses. \n\nThe house addresses in the dataset consist of text in multiple languages like English, Japanese, French, Spanish, etc. The dataset is a small subset of the house addresses taken from [OpenAddresses data](http://results.openaddresses.io/) \n\n**A note on the dataset**\n- The data is collected around 2020-05-27 by [OpenAddresses](http://openaddresses.io).\n- The data licenses can be found in `data/country-classifier/LICENSE.txt`.",
"_____no_output_____"
],
[
"# Prerequisites",
"_____no_output_____"
],
[
"- Data preparation and model training workflows using arcgis.learn have a dependency on [transformers](https://huggingface.co/transformers/v3.0.2/index.html). Refer to the section **\"Install deep learning dependencies of arcgis.learn module\"** [on this page](https://developers.arcgis.com/python/guide/install-and-set-up/#Install-deep-learning-dependencies) for detailed documentation on the installation of the dependencies.\n\n- **Labeled data**: For `TextClassifier` to learn, it needs to see documents/texts that have been assigned a label. Labeled data for this sample notebook is located at `data/country-classifier/house-addresses.csv`\n\n- To learn more about how `TextClassifier` works, please see the guide on [Text Classification with arcgis.learn](https://developers.arcgis.com/python/guide/text-classification).",
"_____no_output_____"
],
[
"# Imports",
"_____no_output_____"
]
],
[
[
"import os\nimport zipfile\nimport pandas as pd\nfrom pathlib import Path\nfrom arcgis.gis import GIS\nfrom arcgis.learn import prepare_textdata\nfrom arcgis.learn.text import TextClassifier",
"_____no_output_____"
],
[
"gis = GIS('home')",
"_____no_output_____"
]
],
[
[
"# Data preparation\n\nData preparation involves splitting the data into training and validation sets, creating the necessary data structures for loading data into the model and so on. The `prepare_data()` function can directly read the training samples and automate the entire process.",
"_____no_output_____"
]
],
[
[
"training_data = gis.content.get('ab36969cfe814c89ba3b659cf734492a')\ntraining_data",
"_____no_output_____"
],
[
"filepath = training_data.download(file_name=training_data.name)",
"_____no_output_____"
],
[
"with zipfile.ZipFile(filepath, 'r') as zip_ref:\n zip_ref.extractall(Path(filepath).parent)",
"_____no_output_____"
],
[
"DATA_ROOT = Path(os.path.join(filepath.split('.')[0]))",
"_____no_output_____"
],
[
"data = prepare_textdata(DATA_ROOT, \"classification\", train_file=\"house-addresses.csv\", \n text_columns=\"Address\", label_columns=\"Country\", batch_size=64)",
"_____no_output_____"
]
],
[
[
"The `show_batch()` method can be used to see the training samples, along with labels.",
"_____no_output_____"
]
],
[
[
"data.show_batch(10)",
"_____no_output_____"
]
],
[
[
"# TextClassifier model",
"_____no_output_____"
],
[
"`TextClassifier` model in `arcgis.learn.text` is built on top of [Hugging Face Transformers](https://huggingface.co/transformers/v3.0.2/index.html) library. The model training and inferencing workflow are similar to computer vision models in `arcgis.learn`. \n\nRun the command below to see what backbones are supported for the text classification task.",
"_____no_output_____"
]
],
[
[
"print(TextClassifier.supported_backbones)",
"['BERT', 'RoBERTa', 'DistilBERT', 'ALBERT', 'FlauBERT', 'CamemBERT', 'XLNet', 'XLM', 'XLM-RoBERTa', 'Bart', 'ELECTRA', 'Longformer', 'MobileBERT']\n"
]
],
[
[
"Call the model's `available_backbone_models()` method with the backbone name to get the available models for that backbone. The call to **available_backbone_models** method will list out only few of the available models for each backbone. Visit [this](https://huggingface.co/transformers/pretrained_models.html) link to get a complete list of models for each backbone.",
"_____no_output_____"
]
],
[
[
"print(TextClassifier.available_backbone_models(\"xlm-roberta\"))",
"('xlm-roberta-base', 'xlm-roberta-large')\n"
]
],
[
[
"## Load model architecture",
"_____no_output_____"
],
[
"Invoke the `TextClassifier` class by passing the data and the backbone you have chosen. The dataset consists of house addresses in multiple languages like Japanese, English, French, Spanish, etc., hence we will use a [multi-lingual transformer backbone](https://huggingface.co/transformers/v3.0.2/multilingual.html) to train our model.",
"_____no_output_____"
]
],
[
[
"model = TextClassifier(data, backbone=\"xlm-roberta-base\")",
"_____no_output_____"
]
],
[
[
"## Model training",
"_____no_output_____"
],
[
"The `learning rate`[[1]](#References) is a **tuning parameter** that determines the step size at each iteration while moving toward a minimum of a loss function, it represents the speed at which a machine learning model **\"learns\"**. `arcgis.learn` includes a learning rate finder, and is accessible through the model's `lr_find()` method, that can automatically select an **optimum learning rate**, without requiring repeated experiments.",
"_____no_output_____"
]
],
[
[
"model.lr_find()",
"_____no_output_____"
]
],
[
[
"Training the model is an iterative process. We can train the model using its `fit()` method till the validation loss (or error rate) continues to go down with each training pass also known as an epoch. This is indicative of the model learning the task.",
"_____no_output_____"
]
],
[
[
"model.fit(epochs=4, lr=0.001)",
"_____no_output_____"
]
],
[
[
"By default, the earlier layers of the model (i.e. the backbone) are frozen. Once the later layers have been sufficiently trained, the earlier layers are unfrozen (by calling `unfreeze()` method of the class) to further fine-tune the model.",
"_____no_output_____"
]
],
[
[
"model.unfreeze()\n\nmodel.fit(epochs=6)",
"_____no_output_____"
]
],
[
[
"## Validate results",
"_____no_output_____"
],
[
"Once we have the trained model, we can see the results to see how it performs.",
"_____no_output_____"
]
],
[
[
"model.show_results(15)",
"_____no_output_____"
]
],
[
[
"### Test the model prediction on an input text",
"_____no_output_____"
]
],
[
[
"text = \"\"\"1016, 8A, CL RICARDO LEON - SANTA ANA (CARTAGENA), 30319\"\"\"\nprint(model.predict(text))",
"('1016, 8A, CL RICARDO LEON - SANTA ANA (CARTAGENA), 30319', 'ES', 1.0)\n"
]
],
[
[
"## Model metrics\n\nTo get a sense of how well the model is trained, we will calculate some important metrics for our `text-classifier` model. First, to find how accurate[[2]](#References) the model is in correctly predicting the classes in the dataset, we will call the model's `accuracy()` method.",
"_____no_output_____"
]
],
[
[
"model.accuracy()",
"_____no_output_____"
]
],
[
[
"Other important metrics to look at are Precision, Recall & F1-measures [[3]](#References). To find `precision`, `recall` & `f1` scores per label/class we will call the model's `metrics_per_label()` method.",
"_____no_output_____"
]
],
[
[
"model.metrics_per_label()",
"_____no_output_____"
]
],
[
[
"## Get misclassified records\n\nIts always a good idea to see the cases where your model is not performing well. This step will help us to:\n- Identify if there is a problem in the dataset.\n- Identify if there is a problem with text/documents belonging to a specific label/class. \n- Identify if there is a class imbalance in your dataset, due to which the model didn't see much of the labeled data for a particular class, hence not able to learn properly about that class.\n\nTo get the **misclassified records** we will call the model's `get_misclassified_records` method.",
"_____no_output_____"
]
],
[
[
"misclassified_records = model.get_misclassified_records()",
"_____no_output_____"
],
[
"misclassified_records.style.set_table_styles([dict(selector='th', props=[('text-align', 'left')])])\\\n .set_properties(**{'text-align': \"left\"}).hide_index()",
"_____no_output_____"
]
],
[
[
"## Saving the trained model\n\nOnce you are satisfied with the model, you can save it using the save() method. This creates an Esri Model Definition (EMD file) that can be used for inferencing on unseen data.",
"_____no_output_____"
]
],
[
[
"model.save(\"country-classifier\")",
"Computing model metrics...\n"
]
],
[
[
"# Model inference\n\nThe trained model can be used to classify new text documents using the predict method. This method accepts a string or a list of strings to predict the labels of these new documents/text.",
"_____no_output_____"
]
],
[
[
"text_list = data._train_df.sample(15).Address.values\nresult = model.predict(text_list)\n\ndf = pd.DataFrame(result, columns=[\"Address\", \"CountryCode\", \"Confidence\"])\n\ndf.style.set_table_styles([dict(selector='th', props=[('text-align', 'left')])])\\\n .set_properties(**{'text-align': \"left\"}).hide_index()",
"_____no_output_____"
]
],
[
[
"# Conclusion",
"_____no_output_____"
],
[
"In this notebook, we have built a text classifier using `TextClassifier` class of `arcgis.learn.text` module. The dataset consisted of house addresses of 10 countries written in languages like English, Japanese, French, Spanish, etc. To achieve this we used a [multi-lingual transformer backbone](https://huggingface.co/transformers/v3.0.2/multilingual.html) like `XLM-RoBERTa` to build a classifier to predict the country for an input house address. ",
"_____no_output_____"
],
[
"# References",
"_____no_output_____"
],
[
"[1] [Learning Rate](https://en.wikipedia.org/wiki/Learning_rate)\n\n[2] [Accuracy](https://en.wikipedia.org/wiki/Accuracy_and_precision)\n\n[3] [Precision, recall and F1-measures](https://scikit-learn.org/stable/modules/model_evaluation.html#precision-recall-and-f-measures)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
ecc0fb0dfdcd0ffb71b017a1c582e739a9e8a632 | 6,536 | ipynb | Jupyter Notebook | SD201/TP/TP_1/SUn/.ipynb_checkpoints/TP1-PageRank-checkpoint.ipynb | zhufangda/Telecom-Paristech | 13772c3b3db59598b68de0ade0170d5986491c42 | [
"Apache-2.0"
] | 5 | 2019-06-20T11:06:18.000Z | 2020-11-28T15:09:34.000Z | SD201/TP/TP_1/SUn/.ipynb_checkpoints/TP1-PageRank-checkpoint.ipynb | zhufangda/Telecom-Paristech | 13772c3b3db59598b68de0ade0170d5986491c42 | [
"Apache-2.0"
] | null | null | null | SD201/TP/TP_1/SUn/.ipynb_checkpoints/TP1-PageRank-checkpoint.ipynb | zhufangda/Telecom-Paristech | 13772c3b3db59598b68de0ade0170d5986491c42 | [
"Apache-2.0"
] | 2 | 2019-05-10T13:24:41.000Z | 2019-05-10T14:15:07.000Z | 31.574879 | 118 | 0.535802 | [
[
[
"#Exercise on Python and PageRank\nfrom scipy.sparse import coo_matrix\nimport numpy as np\nfrom numpy.linalg import norm",
"_____no_output_____"
],
[
"def myPageRank(G_file_name, epsilon = 0.1, beta = 0.8): \n M = preprocessor(G_file_name)[1] \n N = preprocessor(G_file_name)[0]\n A = beta * M + (1 - beta) / N\n Pi = np.array([1 / N for x in range(int(N))])\n while True:\n ancientPi = Pi\n Pi = A.dot(ancientPi)\n if norm((Pi - ancientPi), ord=1) < epsilon:\n break\n return Pi \n \n\ndef preprocessor(G_file_name):\n #G is a list a lines of the kind i j denoting that there is an edge between node i and j (from j to i) \n with open(G_file_name, \"r\") as file:\n lines = file.readlines()\n file.close()\n i_list = np.array([])\n j_list = np.array([])\n for line in lines:\n i_list = np.append(i_list, int(line.split()[0]) - 1)\n for line in lines:\n j_list = np.append(j_list, int(line.split()[1]) - 1)\n i_list, j_list = remove_dead_ends(i_list, j_list)\n N = max(np.append(i_list, j_list)) + 1\n data = [0 for x in range(len(i_list))]\n for j in j_list:\n k = j_list.tolist().count(j) #number of successors of the page j\n for index in [x for x, y in enumerate(j_list) if y == j]:\n data[index] = 1 / k\n M = coo_matrix((data, (i_list, j_list)), shape=(N, N)).toarray()\n return (N, M)\n\n\ndef remove_dead_ends(list1, list2):\n differences = list(set(list1.tolist()) - set(list2.tolist()))\n indices_to_remove = [i for i, x in enumerate(list1.tolist()) if x in differences]\n i_list = []\n j_list = []\n for index in range(1, len(list1) + 1):\n if index not in indices_to_remove:\n i_list = np.append(i_list, list1[index - 1])\n j_list = np.append(j_list, list2[index - 1])\n return np.array(i_list), np.array(j_list)",
"_____no_output_____"
],
[
"print(myPageRank(\"first_matrix.txt\"))\nprint(myPageRank(\"second_matrix.txt\", epsilon = 0.00000000000000000001, beta = 1))\n\nprint(myPageRank(\"dead_ends_matrix.txt\"))\nresult_dead_ends_matrix = myPageRank(\"dead_ends_matrix.txt\", beta = 1)\nprint(result_dead_ends_matrix)\n\nif sum(result_dead_ends_matrix) == 1:\n print(\"Dead ends problem has been resolved correctly\")\nelse:\n print(\"Dead ends problem has not yet been resolved correctly\")",
"[ 0.25866667 0.17866667 0.56266667]\n[ 0.28571429 0.14285714 0.14285714 0.14285714 0.14285714 0.14285714]\n[ 0.03402667 0.03402667 0.05524148]\n[ 0.02083333 0.02083333 0.04166667]\nDead ends problem has not yet been resolved correctly\n"
],
[
"#extract the web pages to construct a graph\nimport re\nimport os",
"_____no_output_____"
],
[
"path = \"/Users/sun-haozhe/Documents/Python workspace/SD201/TP1/toyset/\"\ndictionary = {}\ni = 1\nhyperlinks = []\n\nnew_file_name = \"web_graph.txt\"\nnew_file = open(new_file_name, \"w\")\n\nfor file_name in os.listdir(path):\n dictionary[file_name] = i\n i += 1 \n with open(path + file_name, \"r\") as file:\n file_text = file.read()\n hyperlinks = np.append(hyperlinks, re.findall('a href=\"([^\\'\" >]+)', file_text) ) \n file.close()\n \nfor file_name in os.listdir(path):\n for html in hyperlinks:\n new_file.write(str(dictionary[html]) + \" \" + str(dictionary[file_name]) + \"\\n\") ",
"_____no_output_____"
],
[
"#run the PageRank algorithm on the web graph\nPageRankVector = myPageRank(new_file_name)\nprint(PageRankVector)",
"debug, page rank turn0\ndebug, page rank turn1\n[ 0.03426624 0.00659118 0.01047817 0.01190282 0.0459668 0.06625482\n 0.01829174 0.01485764 0.03478509 0.01195558 0.01389908 0.01095745\n 0.01915797 0.01481807 0.01144992 0.0104518 0.0210619 0.0085083\n 0.01234254 0.01097064 0.02362976 0.01532373 0.02014291 0.02211278\n 0.01240848 0.01142354 0.04639332 0.02498846 0.00556667 0.0046213\n 0.01565793 0.02500165 0.01629548 0.01186326 0.01288776 0.01186326\n 0.00797626 0.02938112 0.01670881 0.03033968 0.01577663 0.00991976\n 0.0050742 0.04399692 0.03473233 0.01480488 0.00411564 0.01091789\n 0.00945367 0.01729361 0.0070177 0.01772013 0.02211278 0.01963725\n 0.0138727 ]\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecc10ca3f96e3eaed3547951338319fcce13e29b | 145,816 | ipynb | Jupyter Notebook | Lab1/Lab1.ipynb | bvshih/PHYS434 | c05826052d50e4c93da209e0b3f500453c5bc554 | [
"MIT"
] | null | null | null | Lab1/Lab1.ipynb | bvshih/PHYS434 | c05826052d50e4c93da209e0b3f500453c5bc554 | [
"MIT"
] | 4 | 2021-11-01T16:56:14.000Z | 2021-12-13T05:02:17.000Z | Lab1/Lab1.ipynb | bvshih/PHYS434 | c05826052d50e4c93da209e0b3f500453c5bc554 | [
"MIT"
] | null | null | null | 321.889625 | 34,196 | 0.934356 | [
[
[
"import numpy as np\nimport matplotlib\nimport matplotlib.pyplot as plt\nimport scipy\nfrom scipy import stats\nplt.rcParams[\"figure.figsize\"] = (15,10)",
"_____no_output_____"
]
],
[
[
"\n## A little statistics\n\n### 1. Converting a probability into a $\\sigma$.\nFirst, we look at normal distributions. These are distributions that are described by the probability density function: $$P(x) = \\frac{1}{\\sigma \\sqrt{2 \\pi}} e^{-(x-\\mu)^2/(2 \\sigma ^2)}$$ where $\\mu$ represents the mean and $\\sigma^2$ represents the variance. In a 'standard normal distribution' $\\mu = 0$ and $\\sigma^2 = 1$. To find the probability from a probability density function, integrate the probability density function. The limits of integration will depend on the statistical question you are asking. For example, if the signal you are looking for is anything $X = 1$ or less, the limits of integration would be from $-\\infty$ to 1. $$Probability = \\int^{1}_{-\\infty}\\frac{1}{\\sigma \\sqrt{2 \\pi}} e^{-(X-\\mu)^2(2 \\sigma ^2)} \\, dx\\\\ \n= \\frac{1}{2} \\text{erf} \\biggl(\\frac{X}{2}\\biggr)$$\nThe antiderivative of a normal distribution is so commonly used that there is a special function called the error function. \nLuckily, it is very common to need to do this calculation so there is a special function `scipy.norm.cdf()` that takes a z-value ('sigma') and finds the probability of getting that value or less.\nHere we find the probability of getting 0.1 or less and 0.01 or less in a standard normal distribution.",
"_____no_output_____"
]
],
[
[
"print(stats.norm.cdf(0.1))\nprint(stats.norm.cdf(0.01))",
"0.539827837277029\n0.5039893563146316\n"
]
],
[
[
"However, if you are looking for a signal at $X = 1$ or greater, the limits of integration would be from 1 to $\\infty$. And your integral would look like this: $$Probability = \\int_{1}^{\\infty}\\frac{1}{\\sigma \\sqrt{2 \\pi}} e^{-(X-\\mu)^2(2 \\sigma ^2)} \\, dx\\\\ \n= \\frac{1}{2} \\text{erfc} \\biggl(\\frac{X}{2}\\biggr)$$ \nNotice that the antiderivative changed. It is now the complementary error function which is defined as $$\\text{erfc}(z) = 1 - \\text{erf}(z)$$\nTo do this you can use `scipy.norm.sf()`. Here we find the probability of 0.1 or more and 0.01 or more in a standard normal distribution. Note that adding together `scipy.norm.cdf(x)` and `scipy.norm.sf(x)` gives you 1. ",
"_____no_output_____"
]
],
[
[
"print(stats.norm.sf(0.1))\nprint(stats.norm.sf(0.01))\n\nprint(stats.norm.cdf(0.1) + stats.norm.sf(0.1))",
"0.460172162722971\n0.4960106436853684\n1.0\n"
]
],
[
[
"To go from a probability to the z-value ('sigma'), you can use `scipy.norm.ppf()` where the argument is your probability. Here you can see that putting in the values we got from `scipy.norm.cdf()` into `scipy.norm.ppf()` gives us the original value we put into `scipy.norm.cdf()`.",
"_____no_output_____"
]
],
[
[
"print(round(stats.norm.ppf(0.539827837277029),1))\nprint(round(stats.norm.ppf(0.5039893563146316),2))",
"0.1\n0.01\n"
]
],
[
[
"### 2. Other Continuous Analytic Distributions: $\\chi^2$ Distribution\n\nThe probability density function of a $\\chi^2$ distribution is described by:\n$$P_r(x) = \\frac{x^{r/2-1}e^{-x/2}}{\\Gamma \\bigl(\\frac{1}{2} r \\bigr) 2^{r/2}}$$ where r is the degrees of freedom and $\\Gamma(x)$ is the gamma function. Here we set the degrees of freedom to `df = 20`, generate 100,000 random variates, and plot the binned values along with the probability density function. ",
"_____no_output_____"
]
],
[
[
"df = 20\nd = stats.chi2.rvs(df, loc = 3.0, scale = .01, size = 100000)",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(1, 1)\nax.hist(d,50, density=True)\nplt.tick_params(labelsize = 24)\nplt.xlim(min(d),max(d))\nx = np.linspace(min(d), max(d),1000)\nax.plot(x, stats.chi2.pdf(x, df, loc = 3., scale = 0.01),linewidth = 8,alpha = 0.7)\nplt.show()",
"_____no_output_____"
]
],
[
[
"3.",
"_____no_output_____"
],
[
"Now lets select some values that represent the measurement we need to find the 'sigma' of. ",
"_____no_output_____"
]
],
[
[
"val = [3.1, 3.3, 3.35, 3.4]",
"_____no_output_____"
]
],
[
[
"Statistical Question: What is the probability that the signal-free data produces a signal that is equally or more signal-like at greater than the chosen value?\n\n$$Probability = \\int^{\\infty}_{val} (\\text{pdf of} \\chi^2) \\, dx$$",
"_____no_output_____"
]
],
[
[
"probability = stats.chi2.sf(val, df, loc = 3., scale = 0.01)\nprint(probability)",
"[0.96817194 0.06985366 0.02010428 0.00499541]\n"
],
[
"sigma = stats.norm.ppf(probability)\nprint(sigma)",
"[ 1.85458078 -1.47688181 -2.05160001 -2.57614671]\n"
]
],
[
[
"As the probabilities get smaller, the sigmas get more negative. When the measurement value is less than the mean, the 'sigma' is positive. When the measurement value is more than the mean, the 'sigma' is negative. This happens because in a standard normal distribution, the distribution is symmetrical around X = 0 so integrating from $-\\infty$ to 0 is equal and opposite from integrating from 0 to $\\infty$. ",
"_____no_output_____"
],
[
"\n## Non-continuous Distributions: Poisson Distribution\n\nA Poisson distribution describes the probability of getting $n$ events/occurances in $N$ trials. The probability mass function is: \n$$P_\\nu(n)=e^{-\\nu} \\frac{\\nu^n}{n!}$$ where $\\nu \\equiv N p$ and $p$ is the probability of an event/occurance. ",
"_____no_output_____"
]
],
[
[
"nu = 6",
"_____no_output_____"
],
[
"d = stats.poisson.rvs(nu, size = 100000);\n\nfig, ax = plt.subplots(1, 1)\nx = np.arange(stats.poisson.ppf(0.01,nu), stats.poisson.ppf(0.99, nu))\n\nplt.plot(x,stats.poisson.pmf(x,nu))\nplt.vlines(x, 0, stats.poisson.pmf(x, nu))",
"_____no_output_____"
],
[
"nu = 3\nd = stats.poisson.rvs(nu, size = 100000);\n\nfig, ax = plt.subplots(1, 1)\nx = np.arange(stats.poisson.ppf(0.01,nu), stats.poisson.ppf(0.99, nu))\n\nplt.plot(x,stats.poisson.pmf(x,nu))\nplt.vlines(x, 0, stats.poisson.pmf(x, nu))",
"_____no_output_____"
],
[
"nu = 10.3\nd = stats.poisson.rvs(nu, size = 100000);\n\nfig, ax = plt.subplots(1, 1)\nx = np.arange(stats.poisson.ppf(0.01,nu), stats.poisson.ppf(0.99, nu))\n\nplt.plot(x,stats.poisson.pmf(x,nu))\nplt.vlines(x, 0, stats.poisson.pmf(x, nu))",
"_____no_output_____"
]
],
[
[
"Poisson distributions are based on $\\nu$ which acts like the average value of the distribution. It is the mean rate of the occurance of the specific event. So the distribution is centered on the integer value of $\\nu$. It also represents the expected value and variance. \n\nStatistical Question: What is the probability that the signal-free data gives a signal of 4 or less?",
"_____no_output_____"
]
],
[
[
"probability = stats.poisson.cdf(4, nu)\nprint(probability)\nsigma = stats.norm.ppf(probability)\nprint(sigma)",
"0.024062063768182273\n-1.9762706884607972\n"
]
],
[
[
"Since the values are discrete, probabilities and sigmas are also discrete. This implies that there are a fixed number of possible sigmas for an experiment and only certain sigmas are possible. However, the mean value can be non-integer because it is just average number of events in a given amount of time. So the number of events is discrete but the average is continuous depending on the interval of time since time is continuous.",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
ecc10f4aef43ca771d278981f72b0c945541d8d4 | 1,490 | ipynb | Jupyter Notebook | 001-Jupyter/001-Tutorials/002-IPython-Cookbook/chapter05_hpc/07_openmp.ipynb | willirath/jupyter-jsc-notebooks | e64aa9c6217543c4ffb5535e7a478b2c9457629a | [
"BSD-3-Clause"
] | null | null | null | 001-Jupyter/001-Tutorials/002-IPython-Cookbook/chapter05_hpc/07_openmp.ipynb | willirath/jupyter-jsc-notebooks | e64aa9c6217543c4ffb5535e7a478b2c9457629a | [
"BSD-3-Clause"
] | null | null | null | 001-Jupyter/001-Tutorials/002-IPython-Cookbook/chapter05_hpc/07_openmp.ipynb | willirath/jupyter-jsc-notebooks | e64aa9c6217543c4ffb5535e7a478b2c9457629a | [
"BSD-3-Clause"
] | 1 | 2022-01-13T18:49:12.000Z | 2022-01-13T18:49:12.000Z | 18.625 | 96 | 0.497315 | [
[
[
"# 5.7. Releasing the GIL to take advantage of multi-core processors with Cython and OpenMP",
"_____no_output_____"
]
],
[
[
"%load_ext Cython",
"_____no_output_____"
],
[
"%%cython --compile-args=-fopenmp --link-args=-fopenmp --force\nfrom cython.parallel import prange",
"_____no_output_____"
]
],
[
[
"```cython\ncdef Vec3 add(Vec3 x, Vec3 y) nogil:\n return vec3(x.x + y.x, x.y + y.y, x.z + y.z)\n```",
"_____no_output_____"
],
[
"```cython\nwith nogil:\n for i in prange(w):\n # ...\n```",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
ecc10fd9422f06e33ad8e81671f546c95eff57d4 | 72,563 | ipynb | Jupyter Notebook | libro_optimizacion/temas/1.computo_cientifico/1.5/Definicion_de_funcion_continuidad_derivada.ipynb | kennyldc/analisis-numerico-computo-cientifico | a7510353703379a8054ec4f10456cbc546c6b65b | [
"Apache-2.0"
] | null | null | null | libro_optimizacion/temas/1.computo_cientifico/1.5/Definicion_de_funcion_continuidad_derivada.ipynb | kennyldc/analisis-numerico-computo-cientifico | a7510353703379a8054ec4f10456cbc546c6b65b | [
"Apache-2.0"
] | null | null | null | libro_optimizacion/temas/1.computo_cientifico/1.5/Definicion_de_funcion_continuidad_derivada.ipynb | kennyldc/analisis-numerico-computo-cientifico | a7510353703379a8054ec4f10456cbc546c6b65b | [
"Apache-2.0"
] | null | null | null | 24.325511 | 579 | 0.424183 | [
[
[
"(FCD)=",
"_____no_output_____"
],
[
"# 1.5 Definición de función, continuidad y derivada",
"_____no_output_____"
],
[
"```{admonition} Notas para contenedor de docker:\n\nComando de docker para ejecución de la nota de forma local:\n\nnota: cambiar `<ruta a mi directorio>` por la ruta de directorio que se desea mapear a `/datos` dentro del contenedor de docker y `<versión imagen de docker>` por la versión más actualizada que se presenta en la documentación.\n\n`docker run --rm -v <ruta a mi directorio>:/datos --name jupyterlab_optimizacion -p 8888:8888 -d palmoreck/jupyterlab_optimizacion:<versión imagen de docker>`\n\npassword para jupyterlab: `qwerty`\n\nDetener el contenedor de docker:\n\n`docker stop jupyterlab_optimizacion`\n\nDocumentación de la imagen de docker `palmoreck/jupyterlab_optimizacion:<versión imagen de docker>` en [liga](https://github.com/palmoreck/dockerfiles/tree/master/jupyterlab/optimizacion).\n\n```",
"_____no_output_____"
],
[
"---",
"_____no_output_____"
],
[
"Nota generada a partir de la [liga1](https://www.dropbox.com/s/jfrxanjls8kndjp/Diferenciacion_e_Integracion.pdf?dl=0), [liga2](https://www.dropbox.com/s/mmd1uzvwhdwsyiu/4.3.2.Teoria_de_convexidad_Funciones_convexas.pdf?dl=0) e inicio de [liga3](https://www.dropbox.com/s/ko86cce1olbtsbk/4.3.1.Teoria_de_convexidad_Conjuntos_convexos.pdf?dl=0).",
"_____no_output_____"
],
[
"```{admonition} Al final de esta nota la comunidad lectora:\n:class: tip\n\n* Aprenderá las definiciones de función y derivada de una función en algunos casos de interés para el curso. En específico el caso de derivada direccional es muy importante.\n\n* Aprenderá que el gradiente y Hessiana de una función son un vector y una matriz de primeras (información de primer orden) y segundas derivadas (información de segundo orden) respectivamente.\n\n* Aprenderá algunas fórmulas utilizadas con el operador nabla de diferenciación.\n\n\n* Aprenderá la diferencia entre el cálculo algebraico o simbólico y el numérico vía el paquete *SymPy*.\n\n```",
"_____no_output_____"
],
[
"## Función",
"_____no_output_____"
],
[
"```{admonition} Definición\n\nUna función, $f$, es una regla de correspondencia entre un conjunto nombrado dominio y otro conjunto nombrado codominio.\n```",
"_____no_output_____"
],
[
"### Notación\n\n$f: A \\rightarrow B$ es una función de un conjunto $\\text{dom}f \\subseteq A$ en un conjunto $B$.\n\n```{admonition} Observación\n:class: tip\n\n$\\text{dom}f$ (el dominio de $f$) puede ser un subconjunto propio de $A$, esto es, algunos elementos de $A$ y otros no, son mapeados a elementos de $B$.\n```",
"_____no_output_____"
],
[
"En lo que sigue se considera al espacio $\\mathbb{R}^n$ y se asume que conjuntos y subconjuntos están en este espacio.\n",
"_____no_output_____"
],
[
"(CACCI)=",
"_____no_output_____"
],
[
"### Conjunto abierto, cerrado, cerradura e interior",
"_____no_output_____"
],
[
"```{margin} \n\nUn punto $x$ se nombra **punto límite** de un conjunto $X$, si existe una sucesión $\\{x_k\\} \\subset X$ que converge a $x$. El conjunto de puntos límites se nombra **cerradura** o *closure* de $X$ y se denota como $\\text{cl}X$. \n\nUn conjunto $X$ se nombra **cerrado** si es igual a su cerradura.\n\n```",
"_____no_output_____"
],
[
"```{admonition} Definición\n\nEl interior de un conjunto $X$ es el conjunto de **puntos interiores**: un punto $x$ de un conjunto $X$ se llama interior si existe una **vecindad** de $x$ (conjunto abierto\\* que contiene a $x$) contenida en $X$.\n\n\\*Un conjunto $X$ se dice que es **abierto** si $\\forall x \\in X$ existe una bola abierta\\* centrada en $x$ y contenida en $X$. Es equivalente escribir que $X$ es **abierto** si su complemento $\\mathbb{R}^n \\ X$ es cerrado.\n\n\\*Una **bola abierta** con radio $\\epsilon>0$ y centrada en $x$ es el conjunto: $B_\\epsilon(x) =\\{y \\in \\mathbb{R}^n : ||y-x|| < \\epsilon\\}$. Ver {ref}`Ejemplos de gráficas de normas en el plano <EGNP>` para ejemplos de bolas abiertas en el plano.\n```",
"_____no_output_____"
],
[
"En lo siguiente $\\text{intdom}f$ es el **interior** del dominio de $f$. ",
"_____no_output_____"
],
[
"## Continuidad",
"_____no_output_____"
],
[
"```{admonition} Definición\n\n$f: \\mathbb{R}^n \\rightarrow \\mathbb{R}^m$ es continua en $x \\in \\text{dom}f$ si $\\forall \\epsilon >0 \\exists \\delta > 0$ tal que:\n\n$$y \\in \\text{dom}f, ||y-x||_2 \\leq \\delta \\implies ||f(y)-f(x)||_2 \\leq \\epsilon$$\n\n```",
"_____no_output_____"
],
[
"```{admonition} Comentarios\n\n* $f$ continua en un punto $x$ del dominio de $f$ entonces $f(y)$ es arbitrariamente cercana a $f(x)$ para $y$ en el dominio de $f$ cercana a $x$.\n\n* Otra forma de definir que $f$ sea continua en $x \\in \\text{dom}f$ es con sucesiones y límites: si $\\{x_i\\}_{i \\in \\mathbb{N}} \\subseteq \\text{dom}f$ es una sucesión de puntos en el dominio de $f$ que converge a $x \\in \\text{dom}f$, $\\displaystyle \\lim_{i \\rightarrow \\infty}x_i = x$, y $f$ es continua en $x$ entonces la sucesión $\\{f(x_i)\\}_{i \\in \\mathbb{N}}$ converge a $f(x)$: $\\displaystyle \\lim_{i \\rightarrow \\infty}f(x_i) = f(x) = f \\left(\\displaystyle \\lim_{i \\rightarrow \\infty} x_i \\right )$.\n```",
"_____no_output_____"
],
[
"### Notación\n\n$\\mathcal{C}([a,b])=\\{\\text{funciones } f:\\mathbb{R} \\rightarrow \\mathbb{R} \\text{ continuas en el intervalo [a,b]}\\}$ y $\\mathcal{C}(\\text{dom}f) = \\{\\text{funciones } f:\\mathbb{R}^n \\rightarrow \\mathbb{R}^m \\text{ continuas en su dominio}\\}$.\n",
"_____no_output_____"
],
[
"## Función Diferenciable",
"_____no_output_____"
],
[
"### Caso $f: \\mathbb{R} \\rightarrow \\mathbb{R}$",
"_____no_output_____"
],
[
"```{admonition} Definición\n\n$f$ es diferenciable en $x_0 \\in (a,b)$ si $\\displaystyle \\lim_{x \\rightarrow x_0} \\frac{f(x)-f(x_0)}{x-x_0}$ existe y escribimos:\n\n$$f^{(1)}(x_0) = \\displaystyle \\lim_{x \\rightarrow x_0} \\frac{f(x)-f(x_0)}{x-x_0}.$$\n```",
"_____no_output_____"
],
[
"$f$ es diferenciable en $[a,b]$ si es diferenciable en cada punto de $[a,b]$. Análogamente definiendo la variable $h=x-x_0$ se tiene:\n",
"_____no_output_____"
],
[
"$f^{(1)}(x_0) = \\displaystyle \\lim_{h \\rightarrow 0} \\frac{f(x_0+h)-f(x_0)}{h}$ que típicamente se escribe como:\n\n$$f^{(1)}(x) = \\displaystyle \\lim_{h \\rightarrow 0} \\frac{f(x+h)-f(x)}{h}.$$",
"_____no_output_____"
],
[
"```{admonition} Comentario\n\nSi $f$ es diferenciable en $x_0$ entonces $f(x) \\approx f(x_0) + f^{(1)}(x_0)(x-x_0)$. Gráficamente:\n\n<img src=\"https://dl.dropboxusercontent.com/s/3t13ku6pk1pjwxo/f_diferenciable.png?dl=0\" heigth=\"500\" width=\"500\">\n```",
"_____no_output_____"
],
[
"Como las derivadas también son funciones tenemos una notación para las derivadas que son continuas:",
"_____no_output_____"
],
[
"### Notación\n\n$\\mathcal{C}^n([a,b])=\\{\\text{funciones } f:\\mathbb{R} \\rightarrow \\mathbb{R} \\text{ con } n \\text{ derivadas continuas en el intervalo [a,b]}\\}$.\n",
"_____no_output_____"
],
[
"En Python podemos utilizar el paquete [SymPy](https://www.sympy.org/en/index.html) para calcular límites y derivadas de forma **simbólica** (ver [sympy/calculus](https://docs.sympy.org/latest/tutorial/calculus.html)) que es diferente al cálculo **numérico** que se revisa en {ref}`Polinomios de Taylor y diferenciación numérica <PTDN>`.",
"_____no_output_____"
],
[
"### Ejemplo\n",
"_____no_output_____"
]
],
[
[
"import sympy",
"_____no_output_____"
]
],
[
[
"**Límite de $\\frac{\\cos(x+h) - \\cos(x)}{h}$ para $h \\rightarrow 0$:**",
"_____no_output_____"
]
],
[
[
"x, h = sympy.symbols(\"x, h\")",
"_____no_output_____"
],
[
"quotient = (sympy.cos(x+h) - sympy.cos(x))/h",
"_____no_output_____"
],
[
"sympy.pprint(sympy.limit(quotient, h, 0))",
"-sin(x)\n"
]
],
[
[
"Lo anterior corresponde a la **derivada de $\\cos(x)$**:",
"_____no_output_____"
]
],
[
[
"x = sympy.Symbol('x')",
"_____no_output_____"
],
[
"sympy.pprint(sympy.cos(x).diff(x))",
"-sin(x)\n"
]
],
[
[
"**Si queremos evaluar la derivada podemos usar:**",
"_____no_output_____"
]
],
[
[
"sympy.pprint(sympy.cos(x).diff(x).subs(x,sympy.pi/2))",
"-1\n"
],
[
"sympy.pprint(sympy.Derivative(sympy.cos(x), x))",
"d \n──(cos(x))\ndx \n"
],
[
"sympy.pprint(sympy.Derivative(sympy.cos(x), x).doit_numerically(sympy.pi/2))",
"-1.00000000000000\n"
]
],
[
[
"### Caso $f: \\mathbb{R}^n \\rightarrow \\mathbb{R}^m$",
"_____no_output_____"
],
[
"```{admonition} Definición\n\n$f$ es diferenciable en $x \\in \\text{intdom}f$ si existe una matriz $Df(x) \\in \\mathbb{R}^{m\\times n}$ tal que:\n\n$$\\displaystyle \\lim_{z \\rightarrow x, z \\neq x} \\frac{||f(z)-f(x)-Df(x)(z-x)||_2}{||z-x||_2} = 0, z \\in \\text{dom}f$$\n\nen este caso $Df(x)$ se llama la derivada de $f$ en $x$.\n```",
"_____no_output_____"
],
[
"```{admonition} Observación\n:class: tip\n\nSólo puede existir a lo más una matriz que satisfaga el límite anterior.\n```\n",
"_____no_output_____"
],
[
"```{margin}\n\nUna función afín es de la forma $h(x) = Ax+b$ con $A \\in \\mathbb{R}^{p \\times n}$ y $b \\in \\mathbb{R}^p$. Ver [Affine_transformation](https://en.wikipedia.org/wiki/Affine_transformation)\n\n```",
"_____no_output_____"
],
[
"```{admonition} Comentarios:\n\n* $Df(x)$ también es llamada la **Jacobiana** de $f$.\n\n* Se dice que $f$ es diferenciable si $\\text{dom}f$ es abierto y es diferenciable en cada punto de $\\text{dom}f.$\n\n* La función: $f(x) + Df(x)(z-x)$ es afín y se le llama **aproximación de orden $1$** de $f$ en $x$ (o también cerca de $x$). Para $z$ cercana a $x$ ésta aproximación es cercana a $f(z)$.\n\n* $Df(x)$ puede encontrarse con la definición de límite anterior o con las derivadas parciales: $Df(x)_{ij} = \\frac{\\partial f_i(x)}{\\partial x_j}, i=1,\\dots,m, j=1,\\dots,n$ definidas como:\n\n$$\\frac{\\partial f_i(x)}{\\partial x_j} = \\displaystyle \\lim_{h \\rightarrow 0} \\frac{f_i(x+he_j)-f_i(x)}{h}$$\n\ndonde: $f_i : \\mathbb{R}^n \\rightarrow \\mathbb{R}$, $i=1,\\dots,m,j=1,\\dots,n$ y $e_j$ $j$-ésimo vector canónico que tiene un número $1$ en la posición $j$ y $0$ en las entradas restantes.\n\n* Si $f: \\mathbb{R}^n \\rightarrow \\mathbb{R}, Df(x) \\in \\mathbb{R}^{1\\times n}$, su transpuesta se llama **gradiente**, se denota $\\nabla f(x)$, es una función $\\nabla f : \\mathbb{R}^n \\rightarrow \\mathbb{R}^n$, recibe un vector y devuelve un vector columna y sus componentes son derivadas parciales: \n\n$$\\nabla f(x) = Df(x)^T = \n \\left[ \\begin{array}{c}\n \\frac{\\partial f(x)}{\\partial x_1}\\\\\n \\vdots\\\\\n \\frac{\\partial f(x)}{\\partial x_n}\n \\end{array}\n \\right] = \\left[ \n \\begin{array}{c} \n \\displaystyle \\lim_{h \\rightarrow 0} \\frac{f(x+he_1) - f(x)}{h}\\\\\n \\vdots\\\\\n \\displaystyle \\lim_{h \\rightarrow 0} \\frac{f(x+he_n) - f(x)}{h}\n \\end{array}\n \\right] \\in \\mathbb{R}^{n\\times 1}.$$\n \n* En este contexto, la aproximación de primer orden a $f$ en $x$ es: $f(x) + \\nabla f(x)^T(z-x)$ para $z$ cercana a $x$.\n```",
"_____no_output_____"
],
[
"### Notación\n\n$\\mathcal{C}^n(\\text{dom}f) = \\{\\text{funciones } f:\\mathbb{R}^n \\rightarrow \\mathbb{R}^m \\text{ con } n \\text{ derivadas continuas en su dominio}\\}$.\n",
"_____no_output_____"
],
[
"### Ejemplo\n\n$f : \\mathbb{R}^2 \\rightarrow \\mathbb{R}^2$ dada por:\n\n$$f(x) = \n\\left [ \n\\begin{array}{c}\nx_1x_2 + x_2^2\\\\\nx_1^2 + 2x_1x_2 + x_2^2\\\\\n\\end{array}\n\\right ]\n$$\n\ncon $x = (x_1, x_2)^T$. Calcular la derivada de $f$.\n",
"_____no_output_____"
]
],
[
[
"x1, x2 = sympy.symbols(\"x1, x2\")",
"_____no_output_____"
]
],
[
[
"**Definimos funciones $f_1, f_2$ que son componentes del vector $f(x)$**.",
"_____no_output_____"
]
],
[
[
"f1 = x1*x2 + x2**2",
"_____no_output_____"
],
[
"sympy.pprint(f1)",
" 2\nx₁⋅x₂ + x₂ \n"
],
[
"f2 = x1**2 + x2**2 + 2*x1*x2",
"_____no_output_____"
],
[
"sympy.pprint(f2)",
" 2 2\nx₁ + 2⋅x₁⋅x₂ + x₂ \n"
]
],
[
[
"**Derivadas parciales:**",
"_____no_output_____"
],
[
"Para $f_1(x) = x_1x_2 + x_2^2$:",
"_____no_output_____"
],
[
"```{margin}\n\n**Derivada parcial de $f_1$ respecto a $x_1$.**\n```",
"_____no_output_____"
]
],
[
[
"df1_x1 = f1.diff(x1)",
"_____no_output_____"
],
[
"sympy.pprint(df1_x1)",
"x₂\n"
]
],
[
[
"```{margin}\n\n**Derivada parcial de $f_1$ respecto a $x_2$.**\n```",
"_____no_output_____"
]
],
[
[
"df1_x2 = f1.diff(x2)",
"_____no_output_____"
],
[
"sympy.pprint(df1_x2)",
"x₁ + 2⋅x₂\n"
]
],
[
[
"Para $f_2(x) = x_1^2 + 2x_1 x_2 + x_2^2$:",
"_____no_output_____"
],
[
"```{margin}\n\n**Derivada parcial de $f_2$ respecto a $x_1$.**\n```",
"_____no_output_____"
]
],
[
[
"df2_x1 = f2.diff(x1)",
"_____no_output_____"
],
[
"sympy.pprint(df2_x1)",
"2⋅x₁ + 2⋅x₂\n"
]
],
[
[
"```{margin}\n\n**Derivada parcial de $f_2$ respecto a $x_2$.**\n```",
"_____no_output_____"
]
],
[
[
"df2_x2 = f2.diff(x2)",
"_____no_output_____"
],
[
"sympy.pprint(df2_x2)",
"2⋅x₁ + 2⋅x₂\n"
]
],
[
[
"**Entonces la derivada es:**",
"_____no_output_____"
],
[
"$$Df(x) = \n\\left [\n\\begin{array}{cc}\nx_2 & x_1+2x_2\\\\\n2x_1 + 2x_2 & 2x_1+2x_2\n\\end{array}\n\\right ]\n$$",
"_____no_output_____"
],
[
"**Otra opción más fácil es utilizando [Matrices](https://docs.sympy.org/latest/tutorial/matrices.html):**",
"_____no_output_____"
]
],
[
[
"f = sympy.Matrix([f1, f2])",
"_____no_output_____"
],
[
"sympy.pprint(f)",
"⎡ 2 ⎤\n⎢ x₁⋅x₂ + x₂ ⎥\n⎢ ⎥\n⎢ 2 2⎥\n⎣x₁ + 2⋅x₁⋅x₂ + x₂ ⎦\n"
]
],
[
[
"```{margin} \n\n**Jacobiana de $f$**\n``` ",
"_____no_output_____"
]
],
[
[
"sympy.pprint(f.jacobian([x1, x2]))",
"⎡ x₂ x₁ + 2⋅x₂ ⎤\n⎢ ⎥\n⎣2⋅x₁ + 2⋅x₂ 2⋅x₁ + 2⋅x₂⎦\n"
]
],
[
[
"**Para evaluar por ejemplo en $(x_1, x_2)^T = (0, 1)^T$:**",
"_____no_output_____"
]
],
[
[
"d = f.jacobian([x1, x2])",
"_____no_output_____"
],
[
"sympy.pprint(d.subs([(x1, 0), (x2, 1)]))",
"⎡1 2⎤\n⎢ ⎥\n⎣2 2⎦\n"
]
],
[
[
"## Regla de la cadena",
"_____no_output_____"
],
[
"```{admonition} Definición\n\nSi $f:\\mathbb{R}^n \\rightarrow \\mathbb{R}^m$ es diferenciable en $x\\in \\text{intdom}f$ y $g:\\mathbb{R}^m \\rightarrow \\mathbb{R}^p$ es diferenciable en $f(x)\\in \\text{intdom}g$, se define la composición $h:\\mathbb{R}^n \\rightarrow \\mathbb{R}^p$ por $h(z) = g(f(z))$, la cual es diferenciable en $x$, con derivada:\n\n$$Dh(x)=Dg(f(x))Df(x)\\in \\mathbb{R}^{p\\times n}.$$\n```",
"_____no_output_____"
],
[
"(EJ1)=",
"_____no_output_____"
],
[
"### Ejemplo\n\nSean $f:\\mathbb{R}^n \\rightarrow \\mathbb{R}$, $g:\\mathbb{R} \\rightarrow \\mathbb{R}$, $h:\\mathbb{R}^n \\rightarrow \\mathbb{R}$ con $h(z) = g(f(z))$ entonces: \n\n$$Dh(x) = Dg(f(x))Df(x) = \\frac{dg(f(x))}{dx}\\nabla f(x)^T \\in \\mathbb{R}^{1\\times n}$$\n\ny la transpuesta de $Dh(x)$ es: $\\nabla h(x) = Dh(x)^T = \\frac{dg(f(x))}{dx} \\nabla f(x) \\in \\mathbb{R}^{n\\times 1}$.\n",
"_____no_output_____"
],
[
"### Ejemplo\n\n$f(x) = \\cos(x), g(x)=\\sin(x)$ por lo que $h(x) = \\sin(\\cos(x))$. Calcular la derivada de $h$.\n",
"_____no_output_____"
]
],
[
[
"x = sympy.Symbol('x')",
"_____no_output_____"
],
[
"f = sympy.cos(x)",
"_____no_output_____"
],
[
"sympy.pprint(f)",
"cos(x)\n"
],
[
"g = sympy.sin(x)",
"_____no_output_____"
],
[
"sympy.pprint(g)",
"sin(x)\n"
],
[
"h = g.subs(x, f)",
"_____no_output_____"
],
[
"sympy.pprint(h)",
"sin(cos(x))\n"
],
[
"sympy.pprint(h.diff(x))",
"-sin(x)⋅cos(cos(x))\n"
]
],
[
[
"**Otras formas para calcular la derivada de la composición $h$:**",
"_____no_output_____"
]
],
[
[
"g = sympy.sin",
"_____no_output_____"
],
[
"h = g(f)",
"_____no_output_____"
],
[
"sympy.pprint(h.diff(x))",
"-sin(x)⋅cos(cos(x))\n"
],
[
"h = sympy.sin(f)",
"_____no_output_____"
],
[
"sympy.pprint(h.diff(x))",
"-sin(x)⋅cos(cos(x))\n"
]
],
[
[
"### Ejemplo\n\n$f(x) = x_1 + \\frac{1}{x_2}, g(x) = e^x$ por lo que $h(x) = e^{x_1 + \\frac{1}{x_2}}$. Calcular la derivada de $h$.",
"_____no_output_____"
]
],
[
[
"x1, x2 = sympy.symbols(\"x1, x2\")",
"_____no_output_____"
],
[
"f = x1 + 1/x2",
"_____no_output_____"
],
[
"sympy.pprint(f)",
" 1 \nx₁ + ──\n x₂\n"
],
[
"g = sympy.exp",
"_____no_output_____"
],
[
"sympy.pprint(g)",
"exp\n"
],
[
"h = g(f)",
"_____no_output_____"
],
[
"sympy.pprint(h)",
" 1 \n x₁ + ──\n x₂\nℯ \n"
]
],
[
[
"```{margin}\n\n**Derivada parcial de $h$ respecto a $x_1$.**\n```",
"_____no_output_____"
]
],
[
[
"sympy.pprint(h.diff(x1))",
" 1 \n x₁ + ──\n x₂\nℯ \n"
]
],
[
[
"```{margin}\n\n**Derivada parcial de $h$ respecto a $x_2$.**\n```",
"_____no_output_____"
]
],
[
[
"sympy.pprint(h.diff(x2))",
" 1 \n x₁ + ── \n x₂ \n-ℯ \n──────────\n 2 \n x₂ \n"
]
],
[
[
"**Otra forma para calcular el gradiente de $h$ (derivada de $h$) es utilizando [how-to-get-the-gradient-and-hessian-sympy](https://stackoverflow.com/questions/39558515/how-to-get-the-gradient-and-hessian-sympy):**",
"_____no_output_____"
]
],
[
[
"from sympy.tensor.array import derive_by_array",
"_____no_output_____"
],
[
"sympy.pprint(derive_by_array(h, (x1, x2)))",
"⎡ 1 ⎤\n⎢ 1 x₁ + ── ⎥\n⎢ x₁ + ── x₂ ⎥\n⎢ x₂ -ℯ ⎥\n⎢ℯ ──────────⎥\n⎢ 2 ⎥\n⎣ x₂ ⎦\n"
]
],
[
[
"(CP1)=",
"_____no_output_____"
],
[
"### Caso particular\n\nSean:\n\n* $f: \\mathbb{R}^n \\rightarrow \\mathbb{R}^m$, $f(x) = Ax +b$ con $A \\in \\mathbb{R}^{m\\times n},b \\in \\mathbb{R}^m$,\n\n* $g:\\mathbb{R}^m \\rightarrow \\mathbb{R}^p$, \n\n* $h: \\mathbb{R}^n \\rightarrow \\mathbb{R}^p$, $h(x)=g(f(x))=g(Ax+b)$ con $\\text{dom}h=\\{z \\in \\mathbb{R}^n | Az+b \\in \\text{dom}g\\}$ entonces:\n\n$$Dh(x) = Dg(f(x))Df(x)=Dg(Ax+b)A.$$",
"_____no_output_____"
],
[
"```{admonition} Observación\n:class: tip\n\nSi $p=1$, $g: \\mathbb{R}^m \\rightarrow \\mathbb{R}$, $h: \\mathbb{R}^n \\rightarrow \\mathbb{R}$ se tiene:\n\n$$\\nabla h(x) = Dh(x)^T = A^TDg(Ax+b)^T=A^T\\nabla g(Ax+b) \\in \\mathbb{R}^{n\\times 1}.$$\n\n```",
"_____no_output_____"
],
[
"(EJRestriccionALinea)=",
"_____no_output_____"
],
[
"### Ejemplo\n\nEste caso particular considera un caso importante en el que se tienen funciones restringidas a una línea. Si $f: \\mathbb{R}^n \\rightarrow \\mathbb{R}$, $g: \\mathbb{R} \\rightarrow \\mathbb{R}$ está dada por $g(t) = f(x+tv)$ con $x, v \\in \\mathbb{R}^n$ y $t \\in \\mathbb{R}$, entonces escribimos que $g$ es $f$ pero restringida a la línea $x+tv$. La derivada de $g$ es:\n\n$$Dg(t) = \\nabla f(x+tv)^T v.$$\n\nEl escalar $Dg(0) = \\nabla f(x)^Tv$ se llama **derivada direccional** de $f$ en $x$ en la dirección $v$. Un dibujo en el que se considera $\\Delta x: = v$:\n\n<img src=\"https://dl.dropboxusercontent.com/s/18udjmzmmd7drrz/line_search_backtracking_1.png?dl=0\" heigth=\"300\" width=\"300\">\n\n",
"_____no_output_____"
],
[
"Como ejemplo considérese $f(x) = x_1 ^2 + x_2^2$ con $x=(x_1, x_2)^T$ y $g(t) = f(x+tv)$ para $v=(v_1, v_2)^T$ vector fijo y $t \\in \\mathbb{R}$. Calcular $Dg(t)$.",
"_____no_output_____"
],
[
"**Primera opción**",
"_____no_output_____"
]
],
[
[
"x1, x2 = sympy.symbols(\"x1, x2\")",
"_____no_output_____"
],
[
"f = x1**2 + x2**2",
"_____no_output_____"
],
[
"sympy.pprint(f)",
" 2 2\nx₁ + x₂ \n"
],
[
"t = sympy.Symbol('t')\nv1, v2 = sympy.symbols(\"v1, v2\")",
"_____no_output_____"
],
[
"new_args_for_f_function = {\"x1\": x1+t*v1, \"x2\": x2 + t*v2}",
"_____no_output_____"
],
[
"g = f.subs(new_args_for_f_function)",
"_____no_output_____"
],
[
"sympy.pprint(g)",
" 2 2\n(t⋅v₁ + x₁) + (t⋅v₂ + x₂) \n"
]
],
[
[
"```{margin} \n\n**Derivada de $g$ respecto a $t$: $Dg(t)=\\nabla f(x+tv)^T v$.**\n\n```",
"_____no_output_____"
]
],
[
[
"sympy.pprint(g.diff(t))",
"2⋅v₁⋅(t⋅v₁ + x₁) + 2⋅v₂⋅(t⋅v₂ + x₂)\n"
]
],
[
[
"**Segunda opción para calcular la derivada utilizando vectores:**",
"_____no_output_____"
]
],
[
[
"x = sympy.Matrix([x1, x2])",
"_____no_output_____"
],
[
"sympy.pprint(x)",
"⎡x₁⎤\n⎢ ⎥\n⎣x₂⎦\n"
],
[
"v = sympy.Matrix([v1, v2])",
"_____no_output_____"
],
[
"new_arg_f_function = x+t*v",
"_____no_output_____"
],
[
"sympy.pprint(new_arg_f_function)",
"⎡t⋅v₁ + x₁⎤\n⎢ ⎥\n⎣t⋅v₂ + x₂⎦\n"
],
[
"mapping_for_g_function = {\"x1\": new_arg_f_function[0], \n \"x2\": new_arg_f_function[1]}",
"_____no_output_____"
],
[
"g = f.subs(mapping_for_g_function)",
"_____no_output_____"
],
[
"sympy.pprint(g)",
" 2 2\n(t⋅v₁ + x₁) + (t⋅v₂ + x₂) \n"
]
],
[
[
"```{margin} \n\n**Derivada de $g$ respecto a $t$: $Dg(t)=\\nabla f(x+tv)^T v$.**\n\n```",
"_____no_output_____"
]
],
[
[
"sympy.pprint(g.diff(t))",
"2⋅v₁⋅(t⋅v₁ + x₁) + 2⋅v₂⋅(t⋅v₂ + x₂)\n"
]
],
[
[
"**Tercera opción definiendo a la función $f$ a partir de $x$ symbol Matrix:**",
"_____no_output_____"
]
],
[
[
"sympy.pprint(x)",
"⎡x₁⎤\n⎢ ⎥\n⎣x₂⎦\n"
],
[
"f = x[0]**2 + x[1]**2",
"_____no_output_____"
],
[
"sympy.pprint(f)",
" 2 2\nx₁ + x₂ \n"
],
[
"sympy.pprint(new_arg_f_function)",
"⎡t⋅v₁ + x₁⎤\n⎢ ⎥\n⎣t⋅v₂ + x₂⎦\n"
],
[
"g = f.subs({\"x1\": new_arg_f_function[0], \n \"x2\": new_arg_f_function[1]})",
"_____no_output_____"
],
[
"sympy.pprint(g)",
" 2 2\n(t⋅v₁ + x₁) + (t⋅v₂ + x₂) \n"
]
],
[
[
"```{margin} \n\n**Derivada de $g$ respecto a $t$: $Dg(t)=\\nabla f(x+tv)^T v$.**\n\n```",
"_____no_output_____"
]
],
[
[
"sympy.pprint(g.diff(t))",
"2⋅v₁⋅(t⋅v₁ + x₁) + 2⋅v₂⋅(t⋅v₂ + x₂)\n"
]
],
[
[
"**En lo siguiente se utiliza [derive-by_array](https://docs.sympy.org/latest/modules/tensor/array.html#derivatives-by-array), [how-to-get-the-gradient-and-hessian-sympy](https://stackoverflow.com/questions/39558515/how-to-get-the-gradient-and-hessian-sympy) para mostrar cómo se puede hacer un producto punto con SymPy**",
"_____no_output_____"
]
],
[
[
"sympy.pprint(derive_by_array(f, x))",
"⎡2⋅x₁⎤\n⎢ ⎥\n⎣2⋅x₂⎦\n"
],
[
"sympy.pprint(derive_by_array(f, x).subs({\"x1\": new_arg_f_function[0], \n \"x2\": new_arg_f_function[1]}))",
"⎡2⋅t⋅v₁ + 2⋅x₁⎤\n⎢ ⎥\n⎣2⋅t⋅v₂ + 2⋅x₂⎦\n"
],
[
"gradient_f_new_arg = derive_by_array(f, x).subs({\"x1\": new_arg_f_function[0], \n \"x2\": new_arg_f_function[1]})\n",
"_____no_output_____"
],
[
"sympy.pprint(v)",
"⎡v₁⎤\n⎢ ⎥\n⎣v₂⎦\n"
]
],
[
[
"```{margin} \n\n**Derivada de $g$ respecto a $t$: $Dg(t)=\\nabla f(x+tv)^T v = v^T \\nabla f(x + tv)$.**\n\n```",
"_____no_output_____"
]
],
[
[
"sympy.pprint(v.dot(gradient_f_new_arg))",
"v₁⋅(2⋅t⋅v₁ + 2⋅x₁) + v₂⋅(2⋅t⋅v₂ + 2⋅x₂)\n"
]
],
[
[
"(EJ2)=",
"_____no_output_____"
],
[
"### Ejemplo\n\nSi $h: \\mathbb{R}^n \\rightarrow \\mathbb{R}$ dada por $h(x) = \\log \\left( \\displaystyle \\sum_{i=1}^m \\exp(a_i^Tx+b_i) \\right)$ con $x\\in \\mathbb{R}^n,a_i\\in \\mathbb{R}^n \\forall i=1,\\dots,m$ y $b_i \\in \\mathbb{R} \\forall i=1,\\dots,m$ entonces: \n\n$$\nDh(x)=\\left(\\displaystyle \\sum_{i=1}^m\\exp(a_i^Tx+b_i) \\right)^{-1}\\left[ \\begin{array}{c}\n \\exp(a_1^Tx+b_1)\\\\\n \\vdots\\\\\n \\exp(a_m^Tx+b_m)\n \\end{array}\n \\right]^TA=(1^Tz)^{-1}z^TA\n$$\n\ndonde: $A=(a_i)_{i=1}^m \\in \\mathbb{R}^{m\\times n}, b \\in \\mathbb{R}^m$, $z=\\left[ \\begin{array}{c}\n \\exp(a_1^Tx+b_1)\\\\\n \\vdots\\\\\n \\exp(a_m^Tx+b_m)\n \\end{array}\\right]$ y $1 \\in \\mathbb{R}^m$ es un vector con entradas iguales a $1$. Por lo tanto $\\nabla h(x) = (1^Tz)^{-1}A^Tz$.\n \n\nEn este ejemplo $Dh(x) = Dg(f(x))Df(x)$ con:\n\n* $h(x)=g(f(x))$,\n\n* $g: \\mathbb{R}^m \\rightarrow \\mathbb{R}$ dada por $g(y)=\\log \\left( \\displaystyle \\sum_{i=1}^m \\exp(y_i) \\right )$,\n\n* $f(x)=Ax+b.$ \n",
"_____no_output_____"
],
[
"Para lo siguiente se utilizó como referencias: [liga1](https://stackoverflow.com/questions/41581002/how-to-derive-with-respect-to-a-matrix-element-with-sympy), [liga2](https://docs.sympy.org/latest/modules/tensor/indexed.html), [liga3](https://stackoverflow.com/questions/37705571/sum-over-matrix-entries-in-sympy-1-0-with-python-3-5), [liga4](https://docs.sympy.org/latest/modules/tensor/array.html), [liga5](https://docs.sympy.org/latest/modules/concrete.html), [liga6](https://stackoverflow.com/questions/51723550/summation-over-a-sympy-array).",
"_____no_output_____"
]
],
[
[
"m = sympy.Symbol('m')\nn = sympy.Symbol('n')",
"_____no_output_____"
]
],
[
[
"```{margin} \n\nVer [indexed](https://docs.sympy.org/latest/modules/tensor/indexed.html)\n\n```",
"_____no_output_____"
]
],
[
[
"y = sympy.IndexedBase('y')",
"_____no_output_____"
],
[
"i = sympy.Symbol('i') #for index of sum",
"_____no_output_____"
],
[
"g = sympy.log(sympy.Sum(sympy.exp(y[i]), (i, 1, m)))",
"_____no_output_____"
]
],
[
[
"```{margin} \n\n**Esta función es la que queremos derivar.**\n\n```",
"_____no_output_____"
]
],
[
[
"sympy.pprint(g)",
" ⎛ m ⎞\n ⎜ ___ ⎟\n ⎜ ╲ ⎟\n ⎜ ╲ y[i]⎟\nlog⎜ ╱ ℯ ⎟\n ⎜ ╱ ⎟\n ⎜ ‾‾‾ ⎟\n ⎝i = 1 ⎠\n"
]
],
[
[
"**Para un caso de $m=3$ en la función $g$ se tiene:**",
"_____no_output_____"
]
],
[
[
"y1, y2, y3 = sympy.symbols(\"y1, y2, y3\")",
"_____no_output_____"
],
[
"g_m_3 = sympy.log(sympy.exp(y1) + sympy.exp(y2) + sympy.exp(y3))",
"_____no_output_____"
],
[
"sympy.pprint(g_m_3)",
" ⎛ y₁ y₂ y₃⎞\nlog⎝ℯ + ℯ + ℯ ⎠\n"
]
],
[
[
"```{margin} \n\nVer [derive-by_array](https://docs.sympy.org/latest/modules/tensor/array.html#derivatives-by-array)\n\n```",
"_____no_output_____"
]
],
[
[
"dg_m_3 = derive_by_array(g_m_3, [y1, y2, y3])",
"_____no_output_____"
]
],
[
[
"```{margin} \n\n**Derivada de $g$ respecto a $y_1, y_2, y_3$.** \n\n```",
"_____no_output_____"
]
],
[
[
"sympy.pprint(dg_m_3)",
"⎡ y₁ y₂ y₃ ⎤\n⎢ ℯ ℯ ℯ ⎥\n⎢─────────────── ─────────────── ───────────────⎥\n⎢ y₁ y₂ y₃ y₁ y₂ y₃ y₁ y₂ y₃⎥\n⎣ℯ + ℯ + ℯ ℯ + ℯ + ℯ ℯ + ℯ + ℯ ⎦\n"
]
],
[
[
"```{margin} \n\nVer [Kronecker delta](https://en.wikipedia.org/wiki/Kronecker_delta)\n\n```",
"_____no_output_____"
]
],
[
[
"sympy.pprint(derive_by_array(g, [y[1], y[2], y[3]]))",
"⎡ m m m ⎤\n⎢ ____ ____ ____ ⎥\n⎢ ╲ ╲ ╲ ⎥\n⎢ ╲ ╲ ╲ ⎥\n⎢ ╲ y[i] ╲ y[i] ╲ y[i] ⎥\n⎢ ╱ ℯ ⋅δ ╱ ℯ ⋅δ ╱ ℯ ⋅δ ⎥\n⎢ ╱ 1,i ╱ 2,i ╱ 3,i⎥\n⎢ ╱ ╱ ╱ ⎥\n⎢ ‾‾‾‾ ‾‾‾‾ ‾‾‾‾ ⎥\n⎢i = 1 i = 1 i = 1 ⎥\n⎢──────────────── ──────────────── ────────────────⎥\n⎢ m m m ⎥\n⎢ ___ ___ ___ ⎥\n⎢ ╲ ╲ ╲ ⎥\n⎢ ╲ y[i] ╲ y[i] ╲ y[i] ⎥\n⎢ ╱ ℯ ╱ ℯ ╱ ℯ ⎥\n⎢ ╱ ╱ ╱ ⎥\n⎢ ‾‾‾ ‾‾‾ ‾‾‾ ⎥\n⎣ i = 1 i = 1 i = 1 ⎦\n"
]
],
[
[
"**Para la composición $h(x) = g(f(x))$ se utilizan las siguientes celdas:**",
"_____no_output_____"
],
[
"```{margin} \n\nVer [indexed](https://docs.sympy.org/latest/modules/tensor/indexed.html)\n```",
"_____no_output_____"
]
],
[
[
"A = sympy.IndexedBase('A')\nx = sympy.IndexedBase('x')",
"_____no_output_____"
],
[
"j = sympy.Symbol('j')",
"_____no_output_____"
],
[
"b = sympy.IndexedBase('b')",
"_____no_output_____"
],
[
"#we want something like:\nsympy.pprint(sympy.exp(sympy.Sum(A[i, j]*x[j], (j, 1, n)) + b[i]))",
" n \n ___ \n ╲ \n ╲ \n b[i] + ╱ A[i, j]⋅x[j]\n ╱ \n ‾‾‾ \n j = 1 \nℯ \n"
],
[
"#better if we split each step:\narg_sum = A[i, j]*x[j]",
"_____no_output_____"
],
[
"sympy.pprint(arg_sum)",
"A[i, j]⋅x[j]\n"
],
[
"arg_exp = sympy.Sum(arg_sum, (j, 1, n)) + b[i]",
"_____no_output_____"
],
[
"sympy.pprint(arg_exp)",
" n \n ___ \n ╲ \n ╲ \nb[i] + ╱ A[i, j]⋅x[j]\n ╱ \n ‾‾‾ \n j = 1 \n"
],
[
"sympy.pprint(sympy.exp(arg_exp))",
" n \n ___ \n ╲ \n ╲ \n b[i] + ╱ A[i, j]⋅x[j]\n ╱ \n ‾‾‾ \n j = 1 \nℯ \n"
],
[
"arg_2_sum = sympy.exp(arg_exp)",
"_____no_output_____"
],
[
"sympy.pprint(sympy.Sum(arg_2_sum, (i, 1, m)))",
" m \n_______ \n╲ \n ╲ \n ╲ n \n ╲ ___ \n ╲ ╲ \n ╲ ╲ \n ╱ b[i] + ╱ A[i, j]⋅x[j]\n ╱ ╱ \n ╱ ‾‾‾ \n ╱ j = 1 \n ╱ ℯ \n╱ \n‾‾‾‾‾‾‾ \n i = 1 \n"
],
[
"h = sympy.log(sympy.Sum(arg_2_sum, (i, 1, m))) \n#complex expression: sympy.log(sympy.Sum(sympy.exp(sympy.Sum(A[i, j]*x[j], (j, 1, n)) + b[i]), (i, 1, m)))",
"_____no_output_____"
],
[
"sympy.pprint(h)",
" ⎛ m ⎞\n ⎜_______ ⎟\n ⎜╲ ⎟\n ⎜ ╲ ⎟\n ⎜ ╲ n ⎟\n ⎜ ╲ ___ ⎟\n ⎜ ╲ ╲ ⎟\n ⎜ ╲ ╲ ⎟\nlog⎜ ╱ b[i] + ╱ A[i, j]⋅x[j]⎟\n ⎜ ╱ ╱ ⎟\n ⎜ ╱ ‾‾‾ ⎟\n ⎜ ╱ j = 1 ⎟\n ⎜ ╱ ℯ ⎟\n ⎜╱ ⎟\n ⎜‾‾‾‾‾‾‾ ⎟\n ⎝ i = 1 ⎠\n"
]
],
[
[
"```{margin} \n\n**Derivada de $h$ respecto a $x_1$.**\n```",
"_____no_output_____"
]
],
[
[
"sympy.pprint(h.diff(x[1]))",
" m \n________ \n╲ \n ╲ n \n ╲ ___ \n ╲ ╲ \n ╲ ╲ \n ╲ b[i] + ╱ A[i, j]⋅x[j] n \n ╲ ╱ ___ \n ╱ ‾‾‾ ╲ \n ╱ j = 1 ╲ δ ⋅A[i, j]\n ╱ ℯ ⋅ ╱ 1,j \n ╱ ╱ \n ╱ ‾‾‾ \n ╱ j = 1 \n╱ \n‾‾‾‾‾‾‾‾ \n i = 1 \n──────────────────────────────────────────────────────\n m \n _______ \n ╲ \n ╲ \n ╲ n \n ╲ ___ \n ╲ ╲ \n ╲ ╲ \n ╱ b[i] + ╱ A[i, j]⋅x[j] \n ╱ ╱ \n ╱ ‾‾‾ \n ╱ j = 1 \n ╱ ℯ \n ╱ \n ‾‾‾‾‾‾‾ \n i = 1 \n"
]
],
[
[
"```{margin} \n\nVer [Kronecker delta](https://en.wikipedia.org/wiki/Kronecker_delta)\n```",
"_____no_output_____"
]
],
[
[
"sympy.pprint(derive_by_array(h, [x[1]])) #we can use also: derive_by_array(h, [x[1], x[2], x[3]]",
"⎡ m ⎤\n⎢________ ⎥\n⎢╲ ⎥\n⎢ ╲ n ⎥\n⎢ ╲ ___ ⎥\n⎢ ╲ ╲ ⎥\n⎢ ╲ ╲ ⎥\n⎢ ╲ b[i] + ╱ A[i, j]⋅x[j] n ⎥\n⎢ ╲ ╱ ___ ⎥\n⎢ ╱ ‾‾‾ ╲ ⎥\n⎢ ╱ j = 1 ╲ δ ⋅A[i, j]⎥\n⎢ ╱ ℯ ⋅ ╱ 1,j ⎥\n⎢ ╱ ╱ ⎥\n⎢ ╱ ‾‾‾ ⎥\n⎢ ╱ j = 1 ⎥\n⎢╱ ⎥\n⎢‾‾‾‾‾‾‾‾ ⎥\n⎢ i = 1 ⎥\n⎢──────────────────────────────────────────────────────⎥\n⎢ m ⎥\n⎢ _______ ⎥\n⎢ ╲ ⎥\n⎢ ╲ ⎥\n⎢ ╲ n ⎥\n⎢ ╲ ___ ⎥\n⎢ ╲ ╲ ⎥\n⎢ ╲ ╲ ⎥\n⎢ ╱ b[i] + ╱ A[i, j]⋅x[j] ⎥\n⎢ ╱ ╱ ⎥\n⎢ ╱ ‾‾‾ ⎥\n⎢ ╱ j = 1 ⎥\n⎢ ╱ ℯ ⎥\n⎢ ╱ ⎥\n⎢ ‾‾‾‾‾‾‾ ⎥\n⎣ i = 1 ⎦\n"
]
],
[
[
"```{admonition} Pregunta\n:class: tip\n\n¿Se puede resolver este ejercicio con [Matrix Symbol](https://docs.sympy.org/latest/modules/matrices/expressions.html)?\n```",
"_____no_output_____"
],
[
"```{admonition} Ejercicio\n:class: tip\n\nVerificar que lo obtenido con SymPy es igual a lo desarrollado en \"papel\" al inicio del {ref}`Ejemplo <EJ2>`\n```",
"_____no_output_____"
],
[
"## Segunda derivada de una función $f: \\mathbb{R}^n \\rightarrow \\mathbb{R}$.",
"_____no_output_____"
],
[
"```{admonition} Definición\n\nSea $f:\\mathbb{R}^n \\rightarrow \\mathbb{R}$. La segunda derivada o matriz **Hessiana** de $f$ en $x \\in \\text{intdom}f$ existe si $f$ es dos veces diferenciable en $x$, se denota $\\nabla^2f(x)$ y sus componentes son segundas derivadas parciales:\n\n$$\\nabla^2f(x) = \\left[\\begin{array}{cccc}\n\\frac{\\partial^2f(x)}{\\partial x_1^2} &\\frac{\\partial^2f(x)}{\\partial x_2 \\partial x_1}&\\dots&\\frac{\\partial^2f(x)}{\\partial x_n \\partial x_1}\\\\\n\\frac{\\partial^2f(x)}{\\partial x_1 \\partial x_2} &\\frac{\\partial^2f(x)}{\\partial x_2^2} &\\dots&\\frac{\\partial^2f(x)}{\\partial x_n \\partial x_2}\\\\\n\\vdots &\\vdots& \\ddots&\\vdots\\\\\n\\frac{\\partial^2f(x)}{\\partial x_1 \\partial x_n} &\\frac{\\partial^2f(x)}{\\partial x_2 \\partial x_n}&\\dots&\\frac{\\partial^2f(x)}{\\partial x_n^2} \\\\\n\\end{array}\n\\right]\n$$\n```",
"_____no_output_____"
],
[
"```{admonition} Comentarios:\n\n* La aproximación de segundo orden a $f$ en $x$ (o también para puntos cercanos a $x$) es la función cuadrática en la variable $z$:\n\n$$f(x) + \\nabla f(x)^T(z-x)+\\frac{1}{2}(z-x)^T\\nabla^2f(x)(z-x)$$\n\n* Se cumple:\n\n$$\\displaystyle \\lim_{z \\rightarrow x, z \\neq x} \\frac{|f(z)-[f(x)+\\nabla f(x)^T(z-x)+\\frac{1}{2}(z-x)^T\\nabla^2f(x)(z-x)]|}{||z-x||_2} = 0, z \\in \\text{dom}f$$\n\n* Se tiene lo siguiente:\n\n * $\\nabla f$ es una función nombrada *gradient mapping* (o simplemente gradiente).\n\n * $\\nabla f:\\mathbb{R}^n \\rightarrow \\mathbb{R}^n$ tiene regla de correspondencia $\\nabla f(x)$ (evaluar en $x$ la matriz $Df(\\cdot)^T$).\n\n * Se dice que $f$ es dos veces diferenciable en $\\text{dom}f$ si $\\text{dom}f$ es abierto y $f$ es dos veces diferenciable en cada punto de $x$.\n \n * $D\\nabla f(x) = \\nabla^2f(x)$ para $x \\in \\text{intdom}f$.\n \n * $\\nabla ^2 f(x) : \\mathbb{R}^n \\rightarrow \\mathbb{R}^{n \\times n}$.\n \n * Si $f \\in \\mathcal{C}^2(\\text{dom}f)$ entonces la Hessiana es una matriz simétrica.\n \n```",
"_____no_output_____"
],
[
"## Regla de la cadena para la segunda derivada",
"_____no_output_____"
],
[
"(CP2)=",
"_____no_output_____"
],
[
"### Caso particular",
"_____no_output_____"
],
[
"Sean:\n\n* $f:\\mathbb{R}^n \\rightarrow \\mathbb{R}$, \n\n* $g:\\mathbb{R} \\rightarrow \\mathbb{R}$, \n\n* $h:\\mathbb{R}^n \\rightarrow \\mathbb{R}$ con $h(x) = g(f(x))$, entonces: \n\n$$\\nabla^2h(x) = D\\nabla h(x)$$ \n\n",
"_____no_output_____"
],
[
"```{margin} \n\nVer {ref}`Ejemplo 1 de la regla de la cadena <EJ1>` \n\n```",
"_____no_output_____"
],
[
"\ny \n\n$$\\nabla h(x)=Dh(x)^T = (Dg(f(x))Df(x))^T=\\frac{dg(f(x))}{dx}\\nabla f(x)$$\n",
"_____no_output_____"
],
[
"por lo que:\n\n$$\n\\begin{eqnarray}\n\\nabla^2 h(x) &=& D\\nabla h(x) \\nonumber \\\\\n&=& D \\left(\\frac{dg(f(x))}{dx}\\nabla f(x)\\right) \\nonumber \\\\\n&=& \\frac{dg(f(x))}{dx}\\nabla^2 f(x)+\\left(\\frac{d^2g(f(x))}{dx}\\nabla f(x) \\nabla f(x)^T \\right)^T \\nonumber \\\\\n&=& \\frac{dg(f(x))}{dx}\\nabla^2 f(x)+\\frac{d^2g(f(x))}{dx} \\nabla f(x) \\nabla f(x)^T \\nonumber\n\\end{eqnarray}\n$$",
"_____no_output_____"
],
[
"(CP3)=",
"_____no_output_____"
],
[
"### Caso particular",
"_____no_output_____"
],
[
"Sean:\n\n* $f:\\mathbb{R}^n \\rightarrow \\mathbb{R}^m, f(x) = Ax+b$ con $A \\in \\mathbb{R}^{m\\times n}$, $b \\in \\mathbb{R}^m$,\n\n* $g:\\mathbb{R}^m \\rightarrow \\mathbb{R}^p$,\n\n* $h:\\mathbb{R}^n \\rightarrow \\mathbb{R}^p$, $h(x) = g(f(x)) = g(Ax+b)$ con $\\text{dom}h=\\{z \\in \\mathbb{R}^n | Az+b \\in \\text{dom}g\\}$ entonces:\n",
"_____no_output_____"
],
[
"```{margin}\n\nVer {ref}`Caso particular <CP1>` para la expresión de la derivada.\n```",
"_____no_output_____"
],
[
"$$Dh(x)^T = Dg(f(x))Df(x) = Dg(Ax+b)A.$$\n",
"_____no_output_____"
],
[
"```{admonition} Observación\n:class: tip\n\nSi $p=1$, $g: \\mathbb{R}^m \\rightarrow \\mathbb{R}$, $h: \\mathbb{R}^n \\rightarrow \\mathbb{R}$ se tiene: \n\n$$\\nabla^2h(x) = D \\nabla h(x) = A^T \\nabla^2g(Ax+b)A.$$\n\n```",
"_____no_output_____"
],
[
"### Ejemplo",
"_____no_output_____"
],
[
"```{margin}\n\nVer {ref}`Ejemplo <EJRestriccionALinea>`\n\n```",
"_____no_output_____"
],
[
"Si $f:\\mathbb{R}^n \\rightarrow \\mathbb{R}$, $g: \\mathbb{R} \\rightarrow \\mathbb{R}$ está dada por $g(t) = f(x+tv)$ con $x,v \\in \\mathbb{R}^n, t \\in \\mathbb{R}$, esto es, $g$ es $f$ pero restringida a la línea $\\{x+tv|t \\in \\mathbb{R}\\}$ , entonces:\n\n$$Dg(t) = Df(x+tv)v = \\nabla f(x+tv)^Tv$$\n\nPor lo que:",
"_____no_output_____"
],
[
"$$\\nabla ^2g(t) = D\\nabla f(x+tv)^Tv=v^T\\nabla^2f(x+tv)v.$$",
"_____no_output_____"
],
[
"### Ejemplo",
"_____no_output_____"
],
[
"```{margin}\n\nVer {ref}`Ejemplo <EJ2>`\n\n```",
"_____no_output_____"
],
[
"Si $h: \\mathbb{R}^n \\rightarrow \\mathbb{R}, h(x) = \\log \\left( \\displaystyle \\sum_{i=1}^m \\exp(a_i^Tx+b_i)\\right)$ con $x \\in \\mathbb{R}^n, a_i \\in \\mathbb{R}^n \\forall i=1,\\dots,m$ y $b_i \\in \\mathbb{R} \\forall i=1,\\dots,m$. \n\nComo se desarrolló anteriormente $\\nabla h(x) = (1^Tz)^{-1}A^Tz$ con $z=\\left[ \\begin{array}{c}\n \\exp(a_1^Tx+b_1)\\\\\n \\vdots\\\\\n \\exp(a_m^Tx+b_m)\n \\end{array}\\right]$ y $A=(a_i)_{i=1}^m \\in \\mathbb{R}^{m\\times n}.$\n\n",
"_____no_output_____"
],
[
"Por lo que \n\n$$\\nabla^2 h(x) = D\\nabla h(x) = A^T \\nabla^2g(Ax+b)A$$ ",
"_____no_output_____"
],
[
"```{margin}\n\n$\\nabla^2 g(y)$ se obtiene de acuerdo a {ref}`Caso particular <CP2>` tomando $\\log:\\mathbb{R} \\rightarrow \\mathbb{R}, \\displaystyle \\sum_{i=1}^m \\exp(y_i): \\mathbb{R}^m \\rightarrow \\mathbb{R}$\n\n```",
"_____no_output_____"
],
[
"donde: $\\nabla^2g(y)=(1^Ty)^{-1}\\text{diag}(y)-(1^Ty)^{-2}yy^T$.\n \n ",
"_____no_output_____"
],
[
"$$\\therefore \\nabla^2 h(x) = A^T\\left[(1^Tz)^{-1}\\text{diag}(z)-(1^Tz)^{-2}zz^T \\right]A$$\n\ny $\\text{diag}(c)$ es una matriz diagonal con elementos en su diagonal iguales a las entradas del vector $c$.",
"_____no_output_____"
],
[
"```{admonition} Ejercicio\n:class: tip\n\nVerificar con el paquete de SymPy las expresiones para la segunda derivada de los dos ejemplos anteriores.\n\n```",
"_____no_output_____"
],
[
"## Tablita útil para fórmulas de diferenciación con el operador $\\nabla$",
"_____no_output_____"
],
[
"Sean $f,g:\\mathbb{R}^n \\rightarrow \\mathbb{R}$ con $f,g \\in \\mathcal{C}^2$ respectivamente en sus dominios y $\\alpha_1, \\alpha_2 \\in \\mathbb{R}$, $A \\in \\mathbb{R}^{n \\times n}$, $b \\in \\mathbb{R}^n$ son fijas. Diferenciando con respecto a la variable $x \\in \\mathbb{R}^n$ se tiene:",
"_____no_output_____"
],
[
"| | |\n|:--:|:--:|\n|linealidad | $\\nabla(\\alpha_1 f(x) + \\alpha_2 g(x)) = \\alpha_1 \\nabla f(x) + \\alpha_2 \\nabla g(x)$|\n|producto | $\\nabla(f(x)g(x)) = \\nabla f(x) g(x) + f(x) \\nabla g(x)$|\n|producto punto|$\\nabla(b^Tx) = b$ \n|cuadrático|$\\nabla(x^TAx) = 2(A+A^T)x$|\n|segunda derivada| $\\nabla^2(Ax)=A$|",
"_____no_output_____"
],
[
"## Comentario respecto al cómputo simbólico o algebraico y númerico",
"_____no_output_____"
],
[
"\nSi bien el cómputo simbólico o algebraico nos ayuda a calcular las expresiones para las derivadas evitando los problemas de errores por redondeo que se revisarán en {ref}`Polinomios de Taylor y diferenciación numérica <PTDN>`, la complejidad de las expresiones que internamente se manejan es ineficiente vs el cómputo numérico, ver [Computer science aspects of computer algebra](https://en.wikipedia.org/wiki/Computer_algebra#Computer_science_aspects) y [GNU_Multiple_Precision_Arithmetic_Library](https://en.wikipedia.org/wiki/GNU_Multiple_Precision_Arithmetic_Library).\n",
"_____no_output_____"
],
[
"Como ejemplo de la precisión arbitraria que se puede manejar con el cómputo simbólico o algebraico vs el {ref}`Sistema en punto flotante <SPF>` considérese el cálculo siguiente:",
"_____no_output_____"
]
],
[
[
"eps = 1-3*(4/3-1)",
"_____no_output_____"
],
[
"print(\"{:0.16e}\".format(eps))",
"_____no_output_____"
],
[
"eps_sympy = 1-3*(sympy.Rational(4,3)-1)",
"_____no_output_____"
],
[
"print(\"{:0.16e}\".format(float(eps_sympy)))",
"_____no_output_____"
]
],
[
[
"```{admonition} Ejercicios\n:class: tip\n\n1.Resuelve los ejercicios y preguntas de la nota.\n```",
"_____no_output_____"
],
[
"**Referencias**\n\n1. S. P. Boyd, L. Vandenberghe, Convex Optimization. Cambridge University Press, 2004.\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
ecc113f30bea1979e182ca7dd46a315da407c4c1 | 165,095 | ipynb | Jupyter Notebook | docs/source/tutorials/3-science-examples/periodograms-measuring-a-rotation-period.ipynb | stephtdouglas/lightkurve | 0f0a51f85975993295a692d78f006a9b77afe1b9 | [
"MIT"
] | null | null | null | docs/source/tutorials/3-science-examples/periodograms-measuring-a-rotation-period.ipynb | stephtdouglas/lightkurve | 0f0a51f85975993295a692d78f006a9b77afe1b9 | [
"MIT"
] | null | null | null | docs/source/tutorials/3-science-examples/periodograms-measuring-a-rotation-period.ipynb | stephtdouglas/lightkurve | 0f0a51f85975993295a692d78f006a9b77afe1b9 | [
"MIT"
] | null | null | null | 202.81941 | 81,460 | 0.890875 | [
[
[
"# Measuring and removing a rotation period signal from a light curve",
"_____no_output_____"
],
[
"## Learning Goals\nBy the end of this tutorial, you will:\n\n- Learn what the light curve and periodogram of a rotating star looks like.\n- Be able to estimate a rotation period using a Lomb-Scargle periodogram.\n- Be able to use the Lomb-Scargle method to model and remove the rotation signal.\n- Understand how *iterative sine fitting* works.\n",
"_____no_output_____"
],
[
"## Introduction\n\nA light curve from a star often has many oscillating signals. For some people, this is useful data, and for others this is annoying noise. In this tutorial, we will look at how a Lomb-Scargle periodogram can be used to extract models of sinusoidal variation from light curves, and how those can be used to detect and remove signals.\n\nIf you find this tutorial difficult to follow, we recommend consulting the companion tutorials, which explain the basics of *Kepler* light curves and periodograms.",
"_____no_output_____"
],
[
"## Imports\nThis tutorial only requires **[Lightkurve](https://docs.lightkurve.org)** and **[NumPy](https://numpy.org/)**.",
"_____no_output_____"
]
],
[
[
"import lightkurve as lk\nimport numpy as np\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"## 1. What are Rotation Signals?\n\nMany different types of stars exhibit oscillations in their brightnesses over time. By studying these changes in brightness, we can derive interesting properties from these stars. One example of such a property is a star's rotation rate.\n\nFor stars like the Sun, magnetic activity on their surface will cause [star spots](https://en.wikipedia.org/wiki/Sunspot) to appear. These are areas of the star that are temporarily cooler, and therefore appear darker, than the surrounding regions. As these spots rotate in and out of our view, the star's brightness will increase and decrease. This is often referred to as a *rotation signal*.\n\nA periodogram will show this brightness oscillation as a peak in the frequency domain. In what follows, we will look at how to extract this periodic frequency from the periodogram using Lightkurve's tools.",
"_____no_output_____"
],
[
"## 2. Plotting the Light Curve of a Rotating Star",
"_____no_output_____"
],
[
"In an accompanying tutorial, we looked at an eclipsing binary system, in which two stars eclipsed each other periodically. Now, let's look at a different kind of oscillator — a rotating star — and see how that signal appears in the time series brightness data.\n\nWe're going to explore a star named KIC 2157356, which is part of the cohort of rotating stars that were studied by *Kepler* and analyzed in a research paper by [McQuillan et al. (2014)](https://arxiv.org/abs/1402.5694).\n\nBecause rotation variability tends to happen on relatively long time scales (for instance, the Sun rotates every 25 days), we will start by downloading three ~90-day long quarters of *Kepler* data and then combine them using Lightkurve's [`stitch()`](https://docs.lightkurve.org/api/lightkurve.collections.LightCurveCollection.html#lightkurve.collections.LightCurveCollection.stitch) feature.",
"_____no_output_____"
]
],
[
[
"# Search Kepler data for Quarters 6, 7, and 8.\nsearch_result = lk.search_lightcurve('KIC 2157356', mission='Kepler', quarter=(6, 7, 8))\n# Download and stitch the data together\nlc = search_result.download_all().stitch()\n# Plot the resulting light curve\nlc.plot();",
"_____no_output_____"
]
],
[
[
"This looks quite different from the light curve we studied in the eclipsing binary tutorial. Here, the brightness modulation from the spots rotating in and out of view is significantly larger, with an overall $2\\%$ change in the brightness of the star! Compare this with asteroseismic oscillations (see the accompanying tutorials), which occur on the parts per million scale instead. (Note: 1 part per million equals 0.0001%).",
"_____no_output_____"
],
[
"## 3. Plotting the Periodogram of a Rotating Star\n\nNext, we'll convert the light curve to the frequency domain. Based on the plot we created above, we expect to see a high-power peak associated with the rotation period. We may also expect to see some smaller peaks, such as alias harmonics.\n\nFor clarity, we will truncate the periodogram to `maximum_period=100`, because we can infer from the light curve that the rotation period is much shorter than that. We also set `view=period` to make sure the x-axis uses period rather than frequency units. This is helpful because it is more natural to think about rotation rates in units of *days* rather than *Hertz* (1/s).",
"_____no_output_____"
]
],
[
[
"pg = lc.to_periodogram(maximum_period=100)\npg.plot(view='period');",
"_____no_output_____"
]
],
[
[
"Here we can see a strong peak near 13 days, which is consistent with the sinusoidal trend we saw in the time-domain plot earlier. The reason there are so few aliases in this periodogram is most likely because the star we've chosen has a variability that is very close to sinusoidal, which is not always the case.\n\nTo obtain an estimate of the rotation period, we can now access the `period_at_max_power` property:",
"_____no_output_____"
]
],
[
[
"pg.period_at_max_power",
"_____no_output_____"
]
],
[
[
"Success! We established that the highest peak in the periodogram appears to align with the expected rotation signal in our time series, and we used a periodogram to obtain an estimate of the rotation period.\n\nNext, we will use additional features of the Lomb-Scargle periodogram to model the rotational signal in the time domain.",
"_____no_output_____"
],
[
"## 4. Using the Lomb-Scargle Method to Model the Rotation Signal",
"_____no_output_____"
],
[
"Lightkurve uses the Lomb-Scargle method to make periodograms. For more information on Lomb-Scargle periodograms, read [Vanderplas (2017)](https://arxiv.org/pdf/1703.09824.pdf). Without delving into the fine details here, Lomb-Scargle works by fitting a sinusoidal curve at each of the frequencies in the periodogram, and uses this fit to determine the value of power each frequency has in the periodogram. These model fits are stored in the periodogram object and can be extracted.\n\nIn the graph below, we visualize the Lomb-Scargle model associated with the highest peak by extracting it and then plotting it on top of our time series data. We need to pass in the `time` range we want the model for, as well as the specific `frequency` for which we want the model returned.",
"_____no_output_____"
]
],
[
[
"# Create a model light curve for the highest peak in the periodogram\nlc_model = pg.model(time=lc.time, frequency=pg.frequency_at_max_power)\n# Plot the light curve\nax = lc.plot()\n# Plot the model light curve on top\nlc_model.plot(ax=ax, lw=3, ls='--', c='red');",
"_____no_output_____"
]
],
[
[
"Looking at the plot above, we can see that the Lomb-Scargle model fits the rotation signal relatively well. This is expected; it corresponds to the highest peak in the periodogram, after all. It is not perfect, however. There are deviations in amplitude, and also in phase towards the right hand side of the graph.\n\nThe periodogram will only ever be able to approximate the exact oscillation frequency, and there will always be some associated error (in fact if you look at the periodogram higher up, you'll see that the peak is relatively broad). This uncertainty reflects the fact that the rotation signal is *not* a perfect sinusoid, and that there is additional noise from the star to deal with on top of that. It's for this reason that studies of stellar rotation often use multiple independent methods to estimate a rotation period.",
"_____no_output_____"
],
[
"## 5. Removing Periodic Signals Using Iterative Sine Fitting\n\nWe're not always interested in the rotation signal — sometimes, we want it removed! This is the case, for example, when studying the small signals of a transiting planet in a star which also shows a strong rotation signal. Using the tools we described above, we can model and remove the rotation signal from the time series to help us study the planet transits.\n\nThis process, called *iterative sine fitting*, has a limited range of applications, but is useful to know for quick analysis. Let's apply it to KIC 8197761, a star known to host a planet embedded within stellar noise.",
"_____no_output_____"
]
],
[
[
"# Download the light curve data\nsearch = lk.search_lightcurve('KIC 8197761', mission='Kepler')\nlc = search.download_all().stitch()\n\n# Fold the light curve at the known planet period\nplanet_period = 9.8686667\nlc.fold(period=planet_period).plot();",
"_____no_output_____"
]
],
[
[
"Despite these data being folded on the period of a known planet, we are unable to see the planet transits within the noise. Let's have a look at the periodogram.",
"_____no_output_____"
]
],
[
[
"pg = lc.to_periodogram()\npg.plot(scale='log');",
"_____no_output_____"
]
],
[
[
"As we can see in this periodogram, the star appears to include multiple high-amplitude oscillation signals. Using the Lomb-Scargle `model()` method we used earlier, we can remove these signals from the time series data. We'll do this as follows:\n\n1. Calculate a periodogram.\n2. Calculate the Lomb-Scargle `model()` for the highest peak.\n3. Divide the light curve by the model to remove the signal.\n4. Repeat using the new light curve.\n\nIn this example, we will apply this procedure 50 times, that is, we're going to remove the signals associated with the 50 highest peaks in the periodogram from the time series.",
"_____no_output_____"
]
],
[
[
"# Remove the signals associated with the 50 highest peaks\nnewlc = lc.copy()\nfor i in range(50):\n pg = newlc.to_periodogram()\n model = pg.model(time=newlc.time, frequency=pg.frequency_at_max_power)\n newlc.flux = newlc.flux / model.flux\n\n# Plot the new light curve on top of the original one\nax = lc.plot(alpha=.5, label='Original');\nnewlc.plot(ax=ax, label='New'); ",
"_____no_output_____"
]
],
[
[
"In the graph above, we can observe that the new light curve displays less variations. Let's go ahead and fold it to find out if we can see the planet transit this time around. We'll also plot a binned version of our reduced light curve on top, just to make things clearer.",
"_____no_output_____"
]
],
[
[
"ax = newlc.fold(period=planet_period).plot(label='Unbinned')\nnewlc.fold(period=planet_period).bin(0.1).plot(ax=ax, lw=2, label='Binned');",
"_____no_output_____"
]
],
[
[
"Now we can see that a \"dip\" consistent with a planet transit has appeared, which makes it clearer to study!\n\nIt is important to note here that iterative sine fitting, as used in this tutorial, is a pragmatic method with a few drawbacks. The most important drawback is that the 50 signals we have attempted to remove were probably not perfectly sinusoidal in shape. This means that we have likely introduced complicated new residual patterns into the light curve, and introduced spurious new peaks in the periodogram. It is important to be very careful when using light curves to which complicated and imperfect data manipulation operations have been applied.\n\nFor new developments on how to extract rotation using advanced methods such as Gaussian Processes or asteroseismology, read, for example, [Angus et al. (2017)](https://arxiv.org/abs/1706.05459) and [Davies et al. (2015)](https://arxiv.org/abs/1411.1359).",
"_____no_output_____"
],
[
"## About this Notebook\n\n**Authors**: Oliver Hall ([email protected]), Geert Barentsen\n\n**Updated On**: 2020-09-15",
"_____no_output_____"
],
[
"## Citing Lightkurve and Astropy\n\nIf you use `lightkurve` or `astropy` for published research, please cite the authors. Click the buttons below to copy BibTeX entries to your clipboard.",
"_____no_output_____"
]
],
[
[
"lk.show_citation_instructions()",
"_____no_output_____"
]
],
[
[
"<img style=\"float: right;\" src=\"https://raw.githubusercontent.com/spacetelescope/notebooks/master/assets/stsci_pri_combo_mark_horizonal_white_bkgd.png\" alt=\"Space Telescope Logo\" width=\"200px\"/>",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
ecc11d97c0e3ff8e7621ffbda6e9929e060a8748 | 774 | ipynb | Jupyter Notebook | slideshow.ipynb | RalfKellner/github-slideshow | 6293a4459add9385590434bf739825108a9fd2a3 | [
"MIT"
] | null | null | null | slideshow.ipynb | RalfKellner/github-slideshow | 6293a4459add9385590434bf739825108a9fd2a3 | [
"MIT"
] | 3 | 2020-12-15T12:01:48.000Z | 2020-12-15T12:22:19.000Z | slideshow.ipynb | RalfKellner/github-slideshow | 6293a4459add9385590434bf739825108a9fd2a3 | [
"MIT"
] | null | null | null | 18.878049 | 68 | 0.541344 | [
[
[
"# This is a short slideshow\n\n* Until last week converting slides to pdf worked just fine\n* Now, it doesn't and I don't know how to fix it",
"_____no_output_____"
]
]
] | [
"markdown"
] | [
[
"markdown"
]
] |
ecc12b76a6a0b1e7bdddaf00a49c4ca1e4b290c0 | 6,932 | ipynb | Jupyter Notebook | springboard_modules/8_4_1_Inferential_Capstone_I.ipynb | tanaysd/Data-Science-Springboard | 951e20109e14a784c2c8746f352f712e653ba250 | [
"MIT"
] | null | null | null | springboard_modules/8_4_1_Inferential_Capstone_I.ipynb | tanaysd/Data-Science-Springboard | 951e20109e14a784c2c8746f352f712e653ba250 | [
"MIT"
] | null | null | null | springboard_modules/8_4_1_Inferential_Capstone_I.ipynb | tanaysd/Data-Science-Springboard | 951e20109e14a784c2c8746f352f712e653ba250 | [
"MIT"
] | null | null | null | 24.237762 | 231 | 0.551068 | [
[
[
"- Is there a difference between the annual income of default and full paid loans?\n- Is the difference statistically significant?",
"_____no_output_____"
]
],
[
[
"#import necessary modules\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nfrom scipy import stats\nfrom scipy.stats import probplot\nfrom scipy.stats.mstats import zscore\nimport statsmodels.stats.api as sms\n\npd.set_option('max_columns', None)\n\nimport nltk\nimport collections as co\nfrom wordcloud import WordCloud, STOPWORDS\n\n%matplotlib inline",
"/usr/local/lib/python3.6/site-packages/statsmodels/compat/pandas.py:56: FutureWarning: The pandas.core.datetools module is deprecated and will be removed in a future version. Please use the pandas.tseries module instead.\n from pandas.core import datetools\n"
],
[
"#read loans.csv as a dataframe\nloans_df = pd.read_csv('~/Downloads/tanay/loan.csv',low_memory=False, engine='c')",
"_____no_output_____"
],
[
"#define a function to classify loan status into one of the following bins ('Fully Paid', 'Default', 'Current')\ndef loan_status_bin(text):\n if text in ('Fully Paid', 'Does not meet the credit policy. Status:Fully Paid'):\n return 'Fully Paid'\n elif text in ('Current', 'Issued'):\n return 'Current'\n elif text in ('Charged Off', 'Default', 'Does not meet the credit policy. Status:Charged Off'):\n return 'Default'\n elif text in ('Late (16-30 days)', 'Late (31-120 days)', 'In Grace Period'):\n return 'Late'\n else:\n 'UNKNOWN BIN'",
"_____no_output_____"
],
[
"#create a new attribute 'loan_status_bin' in the dataframe\nloans_df['loan_status_bin']=loans_df['loan_status'].apply(loan_status_bin)\nloans_df['loan_status_bin'].unique()",
"_____no_output_____"
],
[
"loans_df.fillna(loans_df.median()['annual_inc'], inplace=True)",
"_____no_output_____"
],
[
"loans_df[loans_df['annual_inc'].isnull()==True]['annual_inc'].count()",
"_____no_output_____"
],
[
"loans_df_fp=loans_df[loans_df['loan_status_bin']=='Fully Paid']",
"_____no_output_____"
],
[
"loans_df_def=loans_df[loans_df['loan_status_bin']=='Default']",
"_____no_output_____"
],
[
"print('For Default loans, mean annual income is {0}, standard deviation is {1}, size of dataframe is {2}'.format(loans_df_def['annual_inc'].mean(), loans_df_def['annual_inc'].std(), len(loans_df_def['annual_inc'])))",
"For Default loans, mean annual income is 65199.76680867284, standard deviation is 56955.15545104668, size of dataframe is 47228\n"
],
[
"print('For Fully Paid loans, mean annual income is {0}, standard deviation is {1}, size of dataframe is {2}'.format(loans_df_fp['annual_inc'].mean(), loans_df_fp['annual_inc'].std(), len(loans_df_fp['annual_inc'])))",
"For Fully Paid loans, mean annual income is 74142.5024192341, standard deviation is 59205.29202398379, size of dataframe is 209711\n"
],
[
"def_mean=loans_df_def['annual_inc'].mean()\ndef_std=loans_df_def['annual_inc'].std()\n\nfp_mean=loans_df_fp['annual_inc'].mean()\nfp_std=loans_df_fp['annual_inc'].std()",
"_____no_output_____"
],
[
"h0_mean = 0\nmean_diff = abs(def_mean-fp_mean)\nsigma_diff = np.sqrt((fp_std**2)/len(loans_df_fp) + (def_std**2)/len(loans_df_def))\nmean_diff, sigma_diff",
"_____no_output_____"
],
[
"z = (mean_diff - h0_mean) / sigma_diff\nz",
"_____no_output_____"
],
[
"p = (1-stats.norm.cdf(z))*2\np",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecc134d6b028ebf448e7339aaa543fc7c7da3733 | 24,763 | ipynb | Jupyter Notebook | 3) semi-supervised_text/3.lagrangean-S3VM.ipynb | initOS/research-criticality-identification | 6af61986ec16bb6fdae2e22a6198e472ea4c5317 | [
"MIT"
] | null | null | null | 3) semi-supervised_text/3.lagrangean-S3VM.ipynb | initOS/research-criticality-identification | 6af61986ec16bb6fdae2e22a6198e472ea4c5317 | [
"MIT"
] | null | null | null | 3) semi-supervised_text/3.lagrangean-S3VM.ipynb | initOS/research-criticality-identification | 6af61986ec16bb6fdae2e22a6198e472ea4c5317 | [
"MIT"
] | null | null | null | 87.501767 | 13,120 | 0.76586 | [
[
[
"\\# Developer: Ali Hashaam ([email protected]) <br>\n\\# 2nd February 2019 <br>\n\n\\# © 2019 initOS GmbH <br>\n\\# License MIT <br>\n\n\\# Library for TSVM and SelfLearning taken from https://github.com/tmadl/semisup-learn <br>\n\\# Library for lagrangean-S3VM taken from https://github.com/fbagattini/lagrangean-s3vm <br>",
"_____no_output_____"
]
],
[
[
"import re, random, scipy\nimport pandas as pd\nimport numpy as np\nfrom sklearn.svm import SVC\nfrom sklearn.feature_extraction.text import TfidfVectorizer\nfrom sklearn.model_selection import StratifiedShuffleSplit\nfrom methods.qns3vm import QN_S3VM\nfrom sklearn.metrics import classification_report\nfrom lagrangian_s3vm import *\nfrom utils import *\nfrom sklearn.externals import joblib\nfrom collections import Counter\nimport time\nimport matplotlib.pyplot as plt\n%matplotlib inline\nfrom __future__ import division",
"_____no_output_____"
],
[
"regex_square_brackets = re.compile(r'(\\[)|(\\])')\nbugs = pd.read_csv('../datasets/lexical_semantic_preprocessed_mantis_bugs_less_columns_with_class_expansion.csv')\nbug_notes = pd.read_csv('../datasets/lexical_semantic_preprocessed_mantis_bugnotes.csv')\n\nbug_notes['bug_note'] = bug_notes['bug_note'].str.replace(regex_square_brackets, '')\nbugs['additional_information'] = bugs['additional_information'].str.replace(regex_square_brackets, '')\nbugs['description'] = bugs['description'].str.replace(regex_square_brackets, '')\nbugs['summary'] = bugs['summary'].str.replace(regex_square_brackets, '')\ndf_bug_note_table = bug_notes.groupby(['bug_id'])['bug_note'].apply(','.join).to_frame('bug_notes').reset_index()\n\nresult = pd.merge(bugs, df_bug_note_table, how='left', left_on='id', right_on='bug_id')\nresult['textual_data'] = result['summary'].fillna('') + ',' + result['description'].fillna('') + ',' + result['additional_information'].fillna('') + ',' + result['bug_notes'].fillna('')\nresult['textual_data'] = result['textual_data'].str.replace(\" \", \"\")\nresult.sort_values(by=['class'], inplace=True)\nresult.reset_index(drop=True, inplace= True)",
"_____no_output_____"
],
[
"result.loc[result['class']=='critical', 'class'] = -1\nresult.loc[result['class']=='non-critical', 'class'] = 1\nunlabelled_index = result[(result['class'].isnull())].index\nlabelled_index = result[~(result['class'].isnull())].index\nprint result['class'].value_counts()",
" 1 2591\n-1 1104\nName: class, dtype: int64\n"
],
[
"def lagrangian_s3vm(df, classifier_name):\n for no_of_features in [100, 500, 1000]:\n print(\"\"\"####################### Running for Number of features {} ############################\"\"\".format(no_of_features))\n tfidf_vectorizer = TfidfVectorizer(max_df=0.95, min_df=2, max_features=no_of_features, stop_words='english')\n X = tfidf_vectorizer.fit_transform(df['textual_data'])\n Y = np.array(df['class'])\n #print(\"members for classes {}\".format(\",\".join(\"(%s,%s)\" % tup for tup in sorted(Counter(Y).items()))))\n X_U = X[unlabelled_index]\n X_l = X[labelled_index]\n Y_l = Y[labelled_index]\n stratified_shuffle_split = StratifiedShuffleSplit(n_splits=1, test_size=0.6, random_state=0)\n scores = []\n iteration = 1\n for train_index, test_index in stratified_shuffle_split.split(X_l, Y_l):\n X_train = X_l[train_index].copy()\n Y_train = Y_l[train_index].copy()\n X_test = X_l[test_index].copy()\n Y_test = Y_l[test_index].copy()\n svc = get_best_estimator_by_cv(X_train.toarray(), Y_train.astype(float), 5)\n classifier = lagrangian_s3vm_train(X_train.toarray(),\n Y_train.astype(float),\n X_U.toarray(),\n svc,\n r=0.5)\n joblib.dump(classifier, 'models/{}_{}_{}.pkl'.format(classifier_name, no_of_features, iteration))\n joblib.dump(X_test, 'models/X_test_{}_{}_{}.pkl'.format(classifier_name, no_of_features, iteration))\n joblib.dump(Y_test, 'models/Y_test_{}_{}_{}.pkl'.format(classifier_name, no_of_features, iteration))\n score = classifier.score(X_test.toarray(), Y_test.astype(float))\n scores.append(score)\n iteration += 1\n print \"{} average score: {}\".format(classifier_name, np.mean(scores))",
"_____no_output_____"
],
[
"start_time = time.time()\nlagrangian_s3vm(result, 'Lagrangian S3VM')\nprint(\"--- %s seconds ---\" % (time.time() - start_time))",
"####################### Running for Number of features 100 ############################\nLagrangian S3VM average score: 0.801533603969\n####################### Running for Number of features 500 ############################\nLagrangian S3VM average score: 0.823635543527\n####################### Running for Number of features 1000 ############################\nLagrangian S3VM average score: 0.822282363554\n--- 150.562000036 seconds ---\n"
],
[
"# took --- 170.966814041 seconds --- to execute",
"_____no_output_____"
],
[
"def get_results(classifier):\n dict_features = {}\n dict_acc = {}\n for features in [500]:\n model = joblib.load('models/{}_{}_{}.pkl'.format(classifier, features, 1))\n x_tst = joblib.load('models/X_test_{}_{}_{}.pkl'.format(classifier, features, 1))\n y_tst = joblib.load('models/Y_test_{}_{}_{}.pkl'.format(classifier, features, 1))\n acc = model.score(x_tst.toarray(), y_tst.astype(int))\n y_pred = model.predict(x_tst.toarray())\n result = classification_report(y_tst.astype(int), y_pred.astype(int), output_dict=True)\n dict_features[str(features)] = pd.DataFrame(result)\n dict_features[str(features)].transpose().to_csv('{}_{}_latex_table_report.csv'.format(classifier, features))\n dict_acc[str(features)] = acc\n print dict_features['500']\n arrays = [[\"Precision\", \"Precision\", \"Precision\", \"Recall\", \"Recall\", \"Recall\", \"F1-score\", \"F1-score\", \n \"F1-score\"], ['Critical', 'Non-Critical', 'Weighted Avg.', 'Critical', 'Non-Critical', \n 'Weighted Avg.', 'Critical', 'Non-Critical', 'Weighted Avg.']]\n MI = pd.MultiIndex.from_arrays(arrays, names=('Measures', 'Classes'))\n vals = [[round(dict_features[str(features)].loc['precision', '-1'], 2)],\n [round(dict_features[str(features)].loc['precision', '1'], 2)],\n [round(dict_features[str(features)].loc['precision', 'weighted avg'], 2)],\n [round(dict_features[str(features)].loc['recall', '-1'], 2)],\n [round(dict_features[str(features)].loc['recall', '1'], 2)],\n [round(dict_features[str(features)].loc['recall', 'weighted avg'], 2)],\n [round(dict_features[str(features)].loc['f1-score', '-1'], 2)],\n [round(dict_features[str(features)].loc['f1-score', '1'], 2)],\n [round(dict_features[str(features)].loc['f1-score', 'weighted avg'], 2)]]\n #[round(dict_acc[str(features)],2)]]\n df = pd.DataFrame(vals, index=MI, columns=['vals']) \n df = df.unstack().transpose().reset_index(level=0, drop=True)\n ax = df.plot(kind='bar', figsize=(8,6), rot=False)\n patches, labels = ax.get_legend_handles_labels()\n ax.legend(patches, labels, loc='upper left')\n #vals = [[round(dict_features['500'].loc['precision', 'weighted avg'], 2), \n # round(dict_features['500'].loc['recall', 'weighted avg'], 2),\n # round(dict_features['500'].loc['f1-score', 'weighted avg'], 2),\n # round(dict_acc['500'],2)]]\n #columns=[\"Precision\", \"Recall\", \"F1-score\", \"Accuracy\"]\n #df = pd.DataFrame(vals, columns=columns) \n #df = df.transpose()\n #ax = df.plot(kind='bar', figsize=(8,6), rot=False, legend=False)\n plt.xlabel('Evaluation Measure {}'.format(classifier), fontsize=12)\n plt.savefig('{}_results.pdf'.format(classifier), dpi=720)\n \n return df",
"_____no_output_____"
],
[
"df = get_results('Lagrangian S3VM')",
" -1 1 macro avg micro avg weighted avg\nf1-score 0.650581 0.882051 0.766316 0.823636 0.812934\nprecision 0.796499 0.830682 0.813590 0.823636 0.820475\nrecall 0.549849 0.940193 0.745021 0.823636 0.823636\nsupport 662.000000 1555.000000 2217.000000 2217.000000 2217.000000\n"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecc13b8c5ee23297ae88e72663954e371453a9b4 | 16,508 | ipynb | Jupyter Notebook | kochi-python-oct-2018/Metaclasses.ipynb | pythonhacker/talks | fa2a99af38d7092498eefb39940701a1ac10b6c2 | [
"MIT"
] | 2 | 2018-10-14T19:13:01.000Z | 2019-02-14T06:07:10.000Z | kochi-python-oct-2018/Metaclasses.ipynb | Vasistareddy/talks | fa2a99af38d7092498eefb39940701a1ac10b6c2 | [
"MIT"
] | null | null | null | kochi-python-oct-2018/Metaclasses.ipynb | Vasistareddy/talks | fa2a99af38d7092498eefb39940701a1ac10b6c2 | [
"MIT"
] | 3 | 2018-10-14T19:12:32.000Z | 2019-02-28T17:30:00.000Z | 22.040053 | 680 | 0.487218 | [
[
[
"## `type` hierarchy",
"_____no_output_____"
]
],
[
[
"class Foo:\n pass",
"_____no_output_____"
],
[
"x = Foo()",
"_____no_output_____"
],
[
"type(x)",
"_____no_output_____"
],
[
"type(Foo)",
"_____no_output_____"
],
[
"type(type)",
"_____no_output_____"
]
],
[
[
"<img src=\"class-chain.png\" />",
"_____no_output_____"
],
[
"## Metaclasses are class `factories`",
"_____no_output_____"
]
],
[
[
"# Uncomment this\n# help(type)",
"_____no_output_____"
],
[
"Foo = type('Foo', (), {})\nFoo",
"_____no_output_____"
],
[
"x = Foo()",
"_____no_output_____"
],
[
"type(x)",
"_____no_output_____"
],
[
"type(Foo)",
"_____no_output_____"
],
[
"isinstance(Foo, type)",
"_____no_output_____"
]
],
[
[
"## Adding attributes",
"_____no_output_____"
]
],
[
[
"Person = type('Person', (), {'name': '', 'age': 0, 'gender': 'NA', \n '__str__': lambda x: '{}, age:{}, sex: {}'.format(x.name, x.age, x.gender)})",
"_____no_output_____"
],
[
"Person",
"_____no_output_____"
],
[
"# Building an object and adding attributes\njohn = Person()\n\njohn.name='John'\njohn.age = 25\njohn.gender = 'M'\nprint(john)",
"John, age:25, sex: M\n"
],
[
"# Can't we initialize directly ?\njohn = Person(name='John', age=25, sex='M')",
"_____no_output_____"
]
],
[
[
"## Metaclass to the rescue",
"_____no_output_____"
]
],
[
[
"class PersonType(type):\n \"\"\" A type for Person classes \"\"\"\n \n \n def __new__(cls, name, bases, dct):\n x = super().__new__(cls, name, bases, dct)\n # Dynamic assignment of methods\n x.__init__ = cls.__myinit__\n x.__str__ = cls.__mystr__\n x.hello = cls.hello\n return x\n\n def __myinit__(self, name=None, age=0, gender='NA'):\n self.name = name\n self.age = age\n self.gender = gender\n \n def __mystr__(self):\n return \"{}, age: {}, sex: {}\".format(self.name, self.age, self.gender)\n \n def hello(self):\n print(self)\n print(\"Hi - I am \", self.name)",
"_____no_output_____"
],
[
"class Person(metaclass=PersonType):\n pass",
"_____no_output_____"
],
[
"john = Person('John', 25, 'M')\nprint(john)\njohn.hello()",
"John, age: 25, sex: M\nJohn, age: 25, sex: M\nHi - I am John\n"
]
],
[
[
"## A better way - Use `__prepare__` special method on the meta-class",
"_____no_output_____"
]
],
[
[
"class PersonPreparedType(type):\n \"\"\" A type for Person classes \"\"\"\n \n @classmethod\n def __prepare__(mcs, cls, bases, **kwargs):\n print('Metaclass=>',mcs, cls)\n return {'__init__': mcs.__myinit__, '__str__': mcs.__mystr__, 'hello': mcs.hello}\n\n def __myinit__(self, name=None, age=0, gender='NA'):\n self.name = name\n self.age = age\n self.gender = gender\n \n def __mystr__(self):\n return \"{}, age: {}, sex: {}\".format(self.name, self.age, self.gender)\n \n def hello(self):\n print('Calling on',self)\n print(\"Hi - I am \", self.name)",
"_____no_output_____"
],
[
"class Person(metaclass=PersonPreparedType):\n pass",
"Metaclass=> <class '__main__.PersonPreparedType'> Person\n"
],
[
"john = Person('John', 25, 'M')\nprint(john)\njohn.hello()",
"John, age: 25, sex: M\nCalling on John, age: 25, sex: M\nHi - I am John\n"
]
],
[
[
"## Metaclass Methods",
"_____no_output_____"
],
[
"Metaclasses rely on several magic methods so it's quite useful to know a bit more about them.",
"_____no_output_____"
]
],
[
[
"class Meta(type):\n \n def __init__(cls, *args, **kwargs):\n print('__init__:',cls)\n type.__init__(cls, *args)\n \n @classmethod\n def __prepare__(mcs, cls, bases, **kwargs):\n print('__prepare__:',mcs,cls)\n return {'__new__': mcs.my_new, 'hello': mcs.hello}\n \n def __call__(cls, *args, **kwargs):\n print('__call__:',cls, args)\n return type.__call__(cls, *args, **kwargs)\n \n def __new__(mcs, cls, bases=(), dct={}):\n print('mcs __new__:',mcs, cls, bases)\n print('mcs __new__ dict:', dct)\n return type.__new__(mcs, cls, bases, dct)\n \n @classmethod\n def my_new(mcs,cls,bases=(),dct={}):\n print('__new__:',mcs,cls)\n return object.__new__(cls)\n \n def hello(self):\n print('Hello World')",
"_____no_output_____"
],
[
"class C(metaclass=Meta):\n \n def __init__(self, x=100):\n print('C __init__',self)",
"__prepare__: <class '__main__.Meta'> C\nmcs __new__: <class '__main__.Meta'> C ()\nmcs __new__ dict: {'__new__': <bound method Meta.my_new of <class '__main__.Meta'>>, 'hello': <function Meta.hello at 0x7fd3cb78bbf8>, '__module__': '__main__', '__qualname__': 'C', '__init__': <function C.__init__ at 0x7fd3caf738c8>}\n__init__: <class '__main__.C'>\n"
],
[
"c=C(200)",
"__call__: <class '__main__.C'> (200,)\n__new__: <class '__main__.Meta'> <class '__main__.C'>\nC __init__ <__main__.C object at 0x7fd3caf74d30>\n"
]
],
[
[
"### Method Calling Order",
"_____no_output_____"
],
[
"### Metaclass (Metaclass & Class creation)\n\n1. First the metaclass's `__prepare__` method is called. This method is called before the class body is executed and it must return a dictionary-like object that's used as the local namespace for all the code from the class body.\n2. Then the metaclass's `__new__` method is called. The dictionary returned by `__prepare__` above is passed to this method (as the last) argument.\n3. At this point the metaclass's object is created. Then `__init__` (metclass's `__init__`) is called on it. Note that this takes the class as the argument. The class is `created` at this point.\n\n### Class (Instance creation)\n\n1. First class's `__call__` method is called. Any arguments to class creation is also passed her.\n2. Next class's `__new__` method is called. This can be over-ridden to customize `instance creation`\n3. Finally the instance's `__init__` is called (via the class) and the instance object returned.",
"_____no_output_____"
],
[
"## Class Creation",
"_____no_output_____"
],
[
"<img src=\"class-creation.png\" />",
"_____no_output_____"
],
[
"## Instance Creation",
"_____no_output_____"
],
[
"<img src=\"instance-creation.png\" />",
"_____no_output_____"
],
[
"1. Sub-classes inherit the `metaclass`.\n2. Meta-class is available as the `__class__` attribute",
"_____no_output_____"
]
],
[
[
"class D(C):\n pass",
"__prepare__: <class '__main__.Meta'> D\nmcs __new__: <class '__main__.Meta'> D (<class '__main__.C'>,)\nmcs __new__ dict: {'__new__': <bound method Meta.my_new of <class '__main__.Meta'>>, 'hello': <function Meta.hello at 0x7fd3cb78bbf8>, '__module__': '__main__', '__qualname__': 'D'}\n__init__: <class '__main__.D'>\n"
],
[
"print(C.__class__)\nprint(D.__class__)",
"<class '__main__.Meta'>\n<class '__main__.Meta'>\n"
]
],
[
[
"#### Make sure you understand the following `truisms` ",
"_____no_output_____"
]
],
[
[
"print(isinstance(C, Meta))",
"True\n"
],
[
"print(issubclass(C, Meta))",
"False\n"
],
[
"print(issubclass(D,C))",
"True\n"
],
[
"print(isinstance(D,Meta))",
"True\n"
],
[
"print(issubclass(C, object))",
"True\n"
]
],
[
[
"### References",
"_____no_output_____"
],
[
"1. https://blog.ionelmc.ro/2015/02/09/understanding-python-metaclasses/\n2. https://realpython.com/python-metaclasses/\n3. https://www.python.org/dev/peps/pep-3115/",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
ecc149bd58812ca2bef9353ede91c6ed9e6feb6b | 414,600 | ipynb | Jupyter Notebook | finalized_code/RF_XGBoost_Models.ipynb | laporpe/STA_208 | 2baefbaad0f18658ade9c1a5498630b6f917a676 | [
"MIT"
] | 1 | 2021-04-27T18:59:13.000Z | 2021-04-27T18:59:13.000Z | finalized_code/RF_XGBoost_Models.ipynb | laporpe/STA_208 | 2baefbaad0f18658ade9c1a5498630b6f917a676 | [
"MIT"
] | null | null | null | finalized_code/RF_XGBoost_Models.ipynb | laporpe/STA_208 | 2baefbaad0f18658ade9c1a5498630b6f917a676 | [
"MIT"
] | 2 | 2021-04-27T19:03:18.000Z | 2022-01-11T01:50:57.000Z | 200.872093 | 74,676 | 0.881703 | [
[
[
"import pandas as pd\nimport numpy as np\nfrom Functions import Cleaning_Functions\nfrom sklearn import model_selection, linear_model, neighbors, preprocessing, metrics, ensemble\n\nfun = Cleaning_Functions()\n\nclean = pd.read_csv(\"../data/clean.csv\")\n#clean = clean.drop(\"continent\", axis =1)\nclean = clean.drop(\"continent\", axis =1)\nclean.YEAR = clean.YEAR.astype('category')",
"_____no_output_____"
],
[
"def standarize_data(df):\n \"\"\"\n Input: a dataset\n action: returns numeric column values scaled by mean and standard deviation\n \"\"\"\n numeric_data = df.select_dtypes(include=['float64', 'int64'])\n for i in numeric_data.columns:\n df[i] = (df[i] - df[i].mean())/df[i].std()\n return df",
"_____no_output_____"
],
[
"market_data = fun.delete_id_columns(clean) #1\nmarket_data, pred_market = fun.drop_response_rows_with_NAs(market_data, \"Market_Orientation\", \"PPI_Likelihood\") #2\nmarket_data = fun.replace_NAN_with_na(market_data) #3\nmarket_data = fun.entry_to_lowercase(market_data) #4\nmarket_data = fun.remove_underscores_spaces(market_data) #5\nmarket_data = fun.convert_to_categorical(market_data) #6\nmarket_data = fun.impute_data(market_data)\nmarket_data = standarize_data(market_data)\n",
"_____no_output_____"
],
[
"pred_market",
"_____no_output_____"
],
[
"#Ana's fuc\ndef get_dummyXs_y(df, y_var):\n \n y = df[y_var]\n X = df.drop(y_var, axis = 1)\n X_cat = X.select_dtypes(include = [\"category\", \"O\"])\n X_num = X.select_dtypes(include=['float64', 'int64'])\n \n X_cat_dummy = pd.get_dummies(X_cat)\n newX = pd.concat([X_num, X_cat_dummy], axis = 1)\n \n return newX, y",
"_____no_output_____"
],
[
"X, y = get_dummyXs_y(market_data, \"Market_Orientation\")\nX_tr, X_te, y_tr, y_te = model_selection.train_test_split(X,y, test_size = 0.3, random_state = 50)\n",
"_____no_output_____"
],
[
"def fit_predict(clf, X_tr, X_te, y_tr, y_te):\n clf.fit(X_tr,y_tr)\n pred = clf.predict(X_te)\n mse = metrics.mean_squared_error(y_te, pred)\n \n return \"MSE: {} \".format(mse)\n\n\n\ndef tune_parameters(X_train, y_train, clf, param_dict, cv=5):\n \n \n \n best_model = model_selection.GridSearchCV(clf, param_dict, cv=cv, scoring = \"neg_mean_squared_error\", n_jobs =-1, verbose=3)\n \n best_model.fit(X_train, y_train)\n \n print(\"Best Parameters: {} \\n Training MSE: {} \\n Parameter Index: {}\".format(best_model.best_params_,best_model.best_score_,best_model.best_index_) ) # best is alpha = 0\n\n\n #uses gridsearch, prints best parameters, best model, its MSE on the training set\n #returns classifer\n \n return clf\n\ntest_mse_market = []",
"_____no_output_____"
]
],
[
[
"Market Orientation\n=======",
"_____no_output_____"
],
[
"## Random Forest Model",
"_____no_output_____"
]
],
[
[
"forest_model = ensemble.RandomForestRegressor()\nfit_predict(forest_model, X_tr, X_te, y_tr, y_te)\n\nparameters = dict()\nparameters = {'n_estimators':(np.arange(100, 300, 50)), 'max_depth': [10,20, 50], 'max_features':[\"auto\", \"sqrt\", \"log2\"]}\n\nbest_forest = tune_parameters( X_tr, y_tr,forest_model, parameters)\n\nforest_pred = best_forest.predict(X_te)\nforest_test_mse_market = metrics.mean_squared_error(y_te, forest_pred)",
"Fitting 5 folds for each of 36 candidates, totalling 180 fits\n"
],
[
"#test_mse.append(\"Random Forrest Test MSE:{}\".format(forest_test_mse))\n\nprint(\"Test MSE: {}\".format(metrics.mean_squared_error(y_te, forest_pred)))",
"Test MSE: 0.00989572865176026\n"
],
[
"\nforest_importances = pd.Series(best_forest.feature_importances_, index=X.columns).sort_values(ascending=False)\npd.DataFrame(forest_importances)[0:20]\n",
"_____no_output_____"
]
],
[
[
"## XG Boosting Model",
"_____no_output_____"
]
],
[
[
"XG_model = ensemble.GradientBoostingRegressor()\nfit_predict(XG_model, X_tr, X_te, y_tr, y_te)\n\n\nparameters = dict()\nparameters = {'n_estimators':(np.arange(100, 300, 50)), 'max_depth': [10,20,50]}\n\nbest_XG = tune_parameters( X_tr, y_tr,XG_model, parameters)\n\nXG_pred = best_XG.predict(X_te)\nXG_test_mse = metrics.mean_squared_error(y_te, XG_pred)\n\n\ntest_mse_market.append(\"XGBoost Test MSE:{}\".format(XG_test_mse))\n\nprint(\"Test MSE: {}\".format(metrics.mean_squared_error(y_te, XG_pred)))",
"_____no_output_____"
],
[
"\nXG_importances = pd.Series(best_XG.feature_importances_, index=X.columns).sort_values(ascending=False)\nXG_importances\n",
"_____no_output_____"
]
],
[
[
"PPI_Likelihood\n=====",
"_____no_output_____"
]
],
[
[
"\nclean = pd.read_csv(\"../data/clean.csv\")\n#clean = clean.drop(\"continent\", axis =1)\nclean = clean.drop(\"Country\", axis =1)\nclean.YEAR = clean.YEAR.astype('category')\nPPI_data = fun.delete_id_columns(clean) #1\nPPI_data, pred_PPI = fun.drop_response_rows_with_NAs(PPI_data, \"PPI_Likelihood\", \"Market_Orientation\") #2\nPPI_data = fun.replace_NAN_with_na(PPI_data) #3\nPPI_data = fun.entry_to_lowercase(PPI_data) #4\nPPI_data = fun.remove_underscores_spaces(PPI_data) #5\nPPI_data = fun.convert_to_categorical(PPI_data) #6\nPPI_data = fun.impute_data(PPI_data)\nPPI_data = standarize_data(PPI_data)\n\n\nX, y = get_dummyXs_y(PPI_data, \"PPI_Likelihood\")\nX_tr, X_te, y_tr, y_te = model_selection.train_test_split(X,y, test_size = 0.3, random_state = 50)\n\ntest_mse_ppi = []",
"_____no_output_____"
],
[
"forest_model = ensemble.RandomForestRegressor()\nfit_predict(forest_model, X_tr, X_te, y_tr, y_te)\n\nparameters = dict()\nparameters = {'n_estimators':(np.arange(100, 300, 50)), 'max_depth': [10,20, 50]}\n\nbest_forest = tune_parameters( X_tr, y_tr,forest_model, parameters)\n\nforest_pred = best_forest.predict(X_te)\nforest_test_mse_ppi = metrics.mean_squared_error(y_te, forest_pred)\n\ntest_mse_ppi.append(\"Random Forrest Test MSE:{}\".format(forest_test_mse_ppi))\n\nprint(\"Test MSE: {}\".format(metrics.mean_squared_error(y_te, forest_pred)))",
"Fitting 5 folds for each of 12 candidates, totalling 60 fits\n"
],
[
"\nforest_importances = pd.Series(best_forest.feature_importances_, index=X.columns).sort_values(ascending=False)\npd.DataFrame(forest_importances)[0:20]",
"_____no_output_____"
],
[
"XG_model = ensemble.GradientBoostingRegressor()\nfit_predict(XG_model, X_tr, X_te, y_tr, y_te)\n\n\nparameters = dict()\nparameters = {'n_estimators':(np.arange(100, 300, 20)), 'max_depth': [10,20,50]}\n\nbest_XG = tune_parameters( X_tr, y_tr,XG_model, parameters)\n\nXG_pred = best_XG.predict(X_te)\nXG_test_mse = metrics.mean_squared_error(y_te, XG_pred)\n\ntest_mse_ppi.append(\"XGBoost Test MSE:{}\".format(XG_test_mse))\n\nprint(\"Test MSE: {}\".format(metrics.mean_squared_error(y_te, XG_pred)))",
"_____no_output_____"
],
[
"XG_importances = pd.Series(best_XG.feature_importances_, index=X.columns).sort_values(ascending=False)\nXG_importances\n",
"_____no_output_____"
]
],
[
[
"## Country Specific PPI Likeilhood",
"_____no_output_____"
]
],
[
[
"clean = pd.read_csv(\"../data/clean.csv\")\n#clean = clean.drop(\"Country\", axis =1)\nclean.YEAR = clean.YEAR.astype('category')\nPPI_data = fun.delete_id_columns(clean) #1\nPPI_data, pred_PPI = fun.drop_response_rows_with_NAs(PPI_data, \"PPI_Likelihood\", \"Market_Orientation\") #2\nPPI_data = fun.replace_NAN_with_na(PPI_data) #3\nPPI_data = fun.entry_to_lowercase(PPI_data) #4\nPPI_data = fun.remove_underscores_spaces(PPI_data) #5\nPPI_data = fun.convert_to_categorical(PPI_data) #6\nPPI_data = fun.impute_data(PPI_data)\nPPI_data = standarize_data(PPI_data)\n",
"_____no_output_____"
],
[
"#produces a dictionary of country specific dataframes\n\n\ncountry_dict={}\nfor country in PPI_data[\"Country\"].values.unique():\n new_df = PPI_data[PPI_data[\"Country\"].values == country]\n country_dict[country] = new_df",
"_____no_output_____"
],
[
"#wrapper func\ndef country_model(country, y, clf, parameter_dict):\n \"\"\"\n INPUT\n country: str, country name as appears in dataframe\n y: str, column name of response\n clf: scikitlearn clf, the scikit learn model to train \n parameter_dict: dict, dictionary of model parameters\n \n OUTPUT\n country: str, country name as appears in dataframe\n clf: trained best model\n mse: test mse for this model\n index: the list of dummy varaible columns for that country\n \"\"\"\n X,y = get_dummyXs_y(country_dict[country], y)\n X_tr,X_te,y_tr,y_te = model_selection.train_test_split(X,y, test_size=0.3, random_state=50)\n \n index = X.columns\n fit_predict(clf, X_tr,X_te,y_tr,y_te)\n \n best_clf = tune_parameters(X_tr, y_tr, clf, parameter_dict)\n \n best_pred = best_clf.predict(X_te)\n mse = metrics.mean_squared_error(y_te, best_pred)\n print(best_clf.feature_importances_.sort())\n print(\"\\n \\n {} \\n Test MSE: {}\".format(country, mse))\n \n return country, best_clf.feature_importances_, mse, index",
"_____no_output_____"
],
[
"country_dict[\"ghana\"].shape",
"_____no_output_____"
],
[
"forest_model = ensemble.RandomForestRegressor()\nparameters= {'n_estimators':(np.arange(100, 300, 50)), 'max_depth': [10,20, 50]}\n\n#\n#name, ghana_forrest, ghana_mse, index = country_model(country_dict[\"ghana\"], \"PPI_Likelihood\",forest_model,parameters)\n#for key in country_dict:\n\n\ncountry_results= {}\nfor country in PPI_data[\"Country\"].values.unique():\n country_results[country] =country_model(country,\n \"PPI_Likelihood\",\n forest_model,\n parameters)",
"Fitting 5 folds for each of 12 candidates, totalling 60 fits\n"
],
[
"country_feature = {}\nfor country in country_results:\n country_feature[country] = pd.Series(country_results[country][1], \n index=country_results[country][3].values).sort_values(ascending=False)\n\n",
"_____no_output_____"
],
[
"country_feature[1:10]",
"_____no_output_____"
],
[
"def plot_country_feature(country, ax1):\n country_feature[country][1:10].plot(kind=\"bar\", \n title = \"Most Important Features: {}\".format(country), \n ylabel = \"Importance Metric\",\n xlabel = \"Features\", ax=ax1)\n \n \n",
"_____no_output_____"
],
[
"for country in country_feature:\n print(country)",
"tanzania\nguatemala\nhonduras\nelsalvador\nmali\nburkinafaso\nmalawi\nkenya\nindia\ncambodia\nvietnam\nethiopia\nzambia\nghana\nuganda\nperu\n"
],
[
"import matplotlib.pyplot as plt\nf, (ax1, ax2, ax3, ax4) = plt.subplots(1, 4, figsize=(15, 5), \n sharex=False)\nplot_country_feature(\"tanzania\", ax1=ax1)\nplot_country_feature(\"guatemala\", ax1=ax2)\nplot_country_feature(\"honduras\", ax1=ax3)\nplot_country_feature(\"elsalvador\", ax1=ax4)\n\nf, (ax1, ax2, ax3, ax4) = plt.subplots(1, 4, figsize=(15, 5), \n sharex=False)\nplot_country_feature(\"mali\", ax1=ax1)\nplot_country_feature(\"burkinafaso\", ax1=ax2)\nplot_country_feature(\"malawi\", ax1=ax3)\nplot_country_feature(\"ethiopia\", ax1=ax4)\n\nf, (ax1, ax2, ax3, ax4) = plt.subplots(1, 4, figsize=(15, 5), \n sharex=False)\nplot_country_feature(\"india\", ax1=ax1)\nplot_country_feature(\"cambodia\", ax1=ax2)\nplot_country_feature(\"vietnam\", ax1=ax3)\nplot_country_feature(\"kenya\", ax1=ax4)\n\nf, (ax1, ax2, ax3, ax4) = plt.subplots(1, 4, figsize=(15, 5), \n sharex=False)\nplot_country_feature(\"zambia\", ax1=ax1)\nplot_country_feature(\"ghana\", ax1=ax2)\nplot_country_feature(\"uganda\", ax1=ax3)\nplot_country_feature(\"peru\", ax1=ax4)",
"_____no_output_____"
]
],
[
[
"# By Continent ",
"_____no_output_____"
]
],
[
[
"clean = pd.read_csv(\"../data/clean.csv\")\nclean = clean.drop(\"Country\", axis =1)\nclean.YEAR = clean.YEAR.astype('category')\n\nPPI_data = fun.delete_id_columns(clean) #1\nPPI_data, pred_PPI = fun.drop_response_rows_with_NAs(PPI_data, \"PPI_Likelihood\", \"Market_Orientation\") #2\nPPI_data = fun.replace_NAN_with_na(PPI_data) #3\nPPI_data = fun.entry_to_lowercase(PPI_data) #4\nPPI_data = fun.remove_underscores_spaces(PPI_data) #5\nPPI_data = fun.convert_to_categorical(PPI_data) #6\nPPI_data = fun.impute_data(PPI_data)\nPPI_data = standarize_data(PPI_data)\n\n\nX, y = get_dummyXs_y(PPI_data, \"PPI_Likelihood\")\nX_tr, X_te, y_tr, y_te = model_selection.train_test_split(X,y, test_size = 0.3, random_state = 50)\n\ntest_mse_ppi = []\n",
"_____no_output_____"
],
[
"pred_PPI",
"_____no_output_____"
],
[
"#produces a dictionary of country specific dataframes\ncontinent_dict={}\nfor continent in PPI_data[\"continent\"].values.unique():\n new_df = PPI_data[PPI_data[\"continent\"].values == continent]\n continent_dict[continent] = new_df",
"_____no_output_____"
],
[
"def continent_model(continent, y, clf, parameter_dict):\n \"\"\"\n INPUT\n continent: str, continent name as appears in dataframe\n y: str, column name of response\n clf: scikitlearn clf, the scikit learn model to train \n parameter_dict: dict, dictionary of model parameters\n \n OUTPUT\n continent: str, continent name as appears in dataframe\n clf: trained best model\n mse: test mse for this model\n index: the list of dummy varaible columns for that country\n \"\"\"\n X,y = get_dummyXs_y(continent_dict[continent], y)\n X_tr,X_te,y_tr,y_te = model_selection.train_test_split(X,y, test_size=0.3, random_state=50)\n \n index = X.columns\n fit_predict(clf, X_tr,X_te,y_tr,y_te)\n \n best_clf = tune_parameters(X_tr, y_tr, clf, parameter_dict)\n \n best_pred = best_clf.predict(X_te)\n mse = metrics.mean_squared_error(y_te, best_pred)\n print(best_clf.feature_importances_.sort())\n print(\"\\n \\n {} \\n Test MSE: {}\".format(continent, mse))\n \n return continent, best_clf.feature_importances_, mse, index",
"_____no_output_____"
],
[
"forest_model = ensemble.RandomForestRegressor()\nparameters= {'n_estimators':(np.arange(100, 300, 50)), 'max_depth': [10,20, 50]}\n\n#\n#name, ghana_forrest, ghana_mse, index = country_model(country_dict[\"ghana\"], \"PPI_Likelihood\",forest_model,parameters)\n#for key in country_dict:\n\n\ncontinent_results= {}\nfor continent in PPI_data[\"continent\"].values.unique():\n continent_results[continent] =continent_model(continent,\n \"PPI_Likelihood\",\n forest_model,\n parameters)",
"Fitting 5 folds for each of 12 candidates, totalling 60 fits\n"
],
[
"continent_feature = {}\nfor continent in continent_results:\n continent_feature[continent] = pd.Series(continent_results[continent][1], \n index=continent_results[continent][3].values).sort_values(ascending=False)\n",
"_____no_output_____"
],
[
"def plot_continent_feature(continent, ax1):\n continent_feature[continent][1:10].plot(kind=\"bar\", \n title = \"Most Important Features: {}\".format(continent), \n ylabel = \"Importance Metric\",\n xlabel = \"Features\",\n ax=ax1)\n \n \n",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\nf, (ax1, ax2, ax3, ax4) = plt.subplots(1, 4, figsize=(15, 5), \n sharex=False)\nplot_continent_feature(\"africa\", ax1=ax1)\nplot_continent_feature(\"centralamerica\", ax1=ax2)\nplot_continent_feature(\"asia\", ax1=ax3)\nplot_continent_feature(\"southamerica\", ax1=ax4)\n\n",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecc169755561606a17a169a8fc6a73550e457f20 | 9,408 | ipynb | Jupyter Notebook | tutorials/as_a_feeler.ipynb | CodyKochmann/battle_tested | 6044d5988fdae9d1ead3fe42f2a93cc1a1d04a9b | [
"MIT"
] | 91 | 2017-06-26T14:01:43.000Z | 2022-02-15T11:41:20.000Z | tutorials/as_a_feeler.ipynb | CodyKochmann/battle_tested | 6044d5988fdae9d1ead3fe42f2a93cc1a1d04a9b | [
"MIT"
] | 47 | 2017-05-20T12:51:05.000Z | 2021-06-11T08:43:35.000Z | tutorials/as_a_feeler.ipynb | CodyKochmann/battle_tested | 6044d5988fdae9d1ead3fe42f2a93cc1a1d04a9b | [
"MIT"
] | 1 | 2017-08-07T05:18:40.000Z | 2017-08-07T05:18:40.000Z | 44.169014 | 4,482 | 0.617134 | [
[
[
"# this is just to silence \n%xmode plain",
"Exception reporting mode: Plain\n"
]
],
[
[
"## Using `battle_tested` to feel out new libraries.\n\n`battle_tested` doesn't necessisarily need to be used as a fuzzer. I like to use its testing \nfuncionality to literally \"feel out\" a library that is recommended to me so I know what works\nand what will cause issues.\n\nHere is how I used `battle_tested` to \"feel out\" sqlitedict so when I'm using it, there aren't \nany surprises.\n\nFirst, lets import `SqliteDict` and make a harness that will allow us to test what can be assigned and what will cause random explosions to happen.",
"_____no_output_____"
]
],
[
[
"from sqlitedict import SqliteDict\n\ndef harness(key, value):\n \"\"\" this tests what can be assigned in SqliteDict's keys and values \"\"\"\n mydict = SqliteDict(\":memory:\")\n mydict[key] = value",
"_____no_output_____"
]
],
[
[
"Now, we import the tools we need from `battle_tested` and fuzz it.",
"_____no_output_____"
]
],
[
[
"from battle_tested import fuzz, success_map, crash_map\n\nfuzz(harness, keep_testing=True) # keep testing allows us to collect \"all\" crashes",
"testing: harness()\ntests: 9 speed: 88/sec avg: 88\n"
]
],
[
[
"---\nNow we can call `success_map()` and `crash_map()` to start to get a feel for what is accepted and what isn't.",
"_____no_output_____"
]
],
[
[
"crash_map()",
"_____no_output_____"
],
[
"success_map()",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
ecc16e5a8b9688435ce957e9f817dc916f61c77a | 58,288 | ipynb | Jupyter Notebook | study_roadmaps/1_getting_started_roadmap/2_elemental_features_of_monk/2) Feature - Resume an interrupted training.ipynb | shubham7169/monk_v1 | 2d63ba9665160cc7758ba0541baddf87c1cfa578 | [
"Apache-2.0"
] | 7 | 2020-07-26T08:37:29.000Z | 2020-10-30T10:23:11.000Z | study_roadmaps/1_getting_started_roadmap/2_elemental_features_of_monk/2) Feature - Resume an interrupted training.ipynb | aayush-fadia/monk_v1 | 4234eecede3427efc952461408e2d14ef5fa0e57 | [
"Apache-2.0"
] | null | null | null | study_roadmaps/1_getting_started_roadmap/2_elemental_features_of_monk/2) Feature - Resume an interrupted training.ipynb | aayush-fadia/monk_v1 | 4234eecede3427efc952461408e2d14ef5fa0e57 | [
"Apache-2.0"
] | null | null | null | 33.13701 | 1,900 | 0.539116 | [
[
[
"<a href=\"https://colab.research.google.com/github/Tessellate-Imaging/monk_v1/blob/master/study_roadmaps/1_getting_started_roadmap/2_elemental_features_of_monk/2)%20Feature%20-%20Resume%20an%20interrupted%20training.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# Goals\n\n### 1. Understand how you can resume an interrupted training from last check point \n - Training can get interrupted for variety of reasons\n - power failure\n - connection lost to power remote desktop\n \n### 2. Training is also somwtimes intentionally interrupted to update hyper-parameters and resume training\n\n\n### 3. Steps\n - Start training a classifier for 20 epochs\n - Interrupt training manually at around 10 epochs\n - Change batch size\n - Resume training",
"_____no_output_____"
],
[
"## Table of Contents\n\n\n## [0. Install](#0)\n\n\n## [1. Start training a classifier for 20 epochs](#1)\n\n\n## [2. Reload experiment in resume mode](#2)\n\n\n## [3. Resume training the classifier](#3)",
"_____no_output_____"
],
[
"<a id='0'></a>\n# Install Monk\n \n - git clone https://github.com/Tessellate-Imaging/monk_v1.git\n \n - cd monk_v1/installation/Linux && pip install -r requirements_cu9.txt\n - (Select the requirements file as per OS and CUDA version)",
"_____no_output_____"
]
],
[
[
"!git clone https://github.com/Tessellate-Imaging/monk_v1.git",
"_____no_output_____"
],
[
"# If using Colab install using the commands below\n!cd monk_v1/installation/Misc && pip install -r requirements_colab.txt\n\n# If using Kaggle uncomment the following command\n#!cd monk_v1/installation/Misc && pip install -r requirements_kaggle.txt\n\n# Select the requirements file as per OS and CUDA version when using a local system or cloud\n#!cd monk_v1/installation/Linux && pip install -r requirements_cu9.txt",
"_____no_output_____"
]
],
[
[
"## Dataset - Malarial cell images\n - Credits: https://www.kaggle.com/iarunava/cell-images-for-detecting-malaria",
"_____no_output_____"
]
],
[
[
"! wget --load-cookies /tmp/cookies.txt \"https://docs.google.com/uc?export=download&confirm=$(wget --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=1mMEtGIK8UZNCrErXRJR-kutNTaN1zxjC' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\\1\\n/p')&id=1mMEtGIK8UZNCrErXRJR-kutNTaN1zxjC\" -O malaria_cell.zip && rm -rf /tmp/cookies.txt",
"_____no_output_____"
],
[
"! unzip -qq malaria_cell.zip",
"_____no_output_____"
]
],
[
[
"# Imports \n\n - Using single mxnet-gluoncv backend for this tutorial",
"_____no_output_____"
]
],
[
[
"# Monk\nimport os\nimport sys\nsys.path.append(\"monk_v1/monk/\");",
"_____no_output_____"
],
[
"#Using mxnet-gluon backend \nfrom gluon_prototype import prototype",
"_____no_output_____"
]
],
[
[
"<a id='1'></a>\n# Start training a classifier for 20 epochs",
"_____no_output_____"
],
[
"### Creating and managing experiments\n - Provide project name\n - Provide experiment name",
"_____no_output_____"
]
],
[
[
"gtf = prototype(verbose=1);\ngtf.Prototype(\"Malaria-Cell\", \"exp-resume-training\");",
"Mxnet Version: 1.5.0\n\nExperiment Details\n Project: Malaria-Cell\n Experiment: exp-resume-training\n Dir: /home/abhi/Desktop/Work/tess_tool/gui/v0.3/finetune_models/Organization/development/v5.0_blocks/study_roadmap/change_post_num_layers/2_elemental_features_of_monk/workspace/Malaria-Cell/exp-resume-training/\n\n"
]
],
[
[
"### This creates files and directories as per the following structure\n \n \n workspace\n |\n |--------Malaria-Cell\n |\n |\n |-----exp-resume-training\n |\n |-----experiment-state.json\n |\n |-----output\n |\n |------logs (All training logs and graphs saved here)\n |\n |------models (all trained models saved here)",
"_____no_output_____"
],
[
"### Load Dataset",
"_____no_output_____"
]
],
[
[
"gtf.Default(dataset_path=\"malaria_cell\", \n model_name=\"resnet18_v2\", \n num_epochs=20);\n\n#Read the summary generated once you run this cell. ",
"Dataset Details\n Train path: malaria_cell\n Val path: None\n CSV train path: None\n CSV val path: None\n\nDataset Params\n Input Size: 224\n Batch Size: 4\n Data Shuffle: True\n Processors: 4\n Train-val split: 0.7\n\nPre-Composed Train Transforms\n[{'RandomHorizontalFlip': {'p': 0.8}}, {'Normalize': {'mean': [0.485, 0.456, 0.406], 'std': [0.229, 0.224, 0.225]}}]\n\nPre-Composed Val Transforms\n[{'RandomHorizontalFlip': {'p': 0.8}}, {'Normalize': {'mean': [0.485, 0.456, 0.406], 'std': [0.229, 0.224, 0.225]}}]\n\nDataset Numbers\n Num train images: 1411\n Num val images: 605\n Num classes: 2\n\nModel Params\n Model name: resnet18_v2\n Use Gpu: True\n Use pretrained: True\n Freeze base network: True\n\nModel Details\n Loading pretrained model\n Model Loaded on device\n Model name: resnet18_v2\n Num of potentially trainable layers: 40\n Num of actual trainable layers: 1\n\nOptimizer\n Name: sgd\n Learning rate: 0.01\n Params: {'lr': 0.01, 'momentum': 0, 'weight_decay': 0, 'momentum_dampening_rate': 0, 'clipnorm': 0.0, 'clipvalue': 0.0}\n\n\n\nLearning rate scheduler\n Name: steplr\n Params: {'step_size': 6, 'gamma': 0.1, 'last_epoch': -1}\n\nLoss\n Name: softmaxcrossentropy\n Params: {'weight': None, 'batch_axis': 0, 'axis_to_sum_over': -1, 'label_as_categories': True, 'label_smoothing': False}\n\nTraining params\n Num Epochs: 20\n\nDisplay params\n Display progress: True\n Display progress realtime: True\n Save Training logs: True\n Save Intermediate models: True\n Intermediate model prefix: intermediate_model_\n\n"
]
],
[
[
"### From the summary current batch size is 4",
"_____no_output_____"
]
],
[
[
"#Start Training\ngtf.Train();\n\n#Manually stop the cell after 10 iteration ",
"Training Start\n Epoch 1/20\n ----------\n"
]
],
[
[
"<a id='2'></a>\n# Reload experiment in resume mode\n - Set resume_train flag as True",
"_____no_output_____"
]
],
[
[
"gtf = prototype(verbose=1);\ngtf.Prototype(\"Malaria-Cell\", \"exp-resume-training\", resume_train=True);",
"Mxnet Version: 1.5.1\n\nModel Details\n Loading model - workspace/Malaria-Cell/exp-resume-training/output/models/resume_state-symbol.json\n Model Loaded on device\n Model name: resnet18_v2\n Num of potentially trainable layers: 59\n Num of actual trainable layers: 1\n\nExperiment Details\n Project: Malaria-Cell\n Experiment: exp-resume-training\n Dir: /home/abhi/Desktop/Work/tess_tool/gui/v0.3/finetune_models/Organization/development/v5.0_blocks/study_roadmap/elemental_features_of_monk/workspace/Malaria-Cell/exp-resume-training/\n\n"
]
],
[
[
"### Print Summary",
"_____no_output_____"
]
],
[
[
"gtf.Summary()",
"\n\nExperiment Summary\n\nSystem\n Project Name: Malaria-Cell\n Project Dir: workspace/Malaria-Cell/\n Experiment Name: exp-resume-training\n Experiment Dir: workspace/Malaria-Cell/exp-resume-training/\n Library: Mxnet\n Origin: ['New', 'New']\n\nDataset\n Status: True\n Dataset Type: train\n Train path: malaria_cell\n Val path: None\n Test path: False\n CSV Train: None\n CSV Val: None\n CSV Test: False\n\nDataset Parameters:\n Input Size: 224\n Batch Size: 4\n Shuffle: True\n Processors: 4\n Num Classes: 2\n\nDataset Transforms:\n Train transforms: [{'RandomHorizontalFlip': {'p': 0.8}}, {'Normalize': {'mean': [0.485, 0.456, 0.406], 'std': [0.229, 0.224, 0.225]}}]\n Val transforms: [{'RandomHorizontalFlip': {'p': 0.8}}, {'Normalize': {'mean': [0.485, 0.456, 0.406], 'std': [0.229, 0.224, 0.225]}}]\n Test transforms: [{'Normalize': {'mean': [0.485, 0.456, 0.406], 'std': [0.229, 0.224, 0.225]}}]\n\nModel\n Status:\n Model Name: resnet18_v2\n Use Gpu: True\n Use pretrained weights: True\n Base network weights freezed: True\n Number of trainable parameters: 1\n\nHyper-Parameters\n Status: True\n Optimizer: {'name': 'sgd', 'params': {'lr': 0.01, 'momentum': 0, 'weight_decay': 0, 'momentum_dampening_rate': 0, 'clipnorm': 0.0, 'clipvalue': 0.0}}\n Learning Rate Scheduler: {'name': 'steplr', 'params': {'step_size': 6, 'gamma': 0.1, 'last_epoch': -1}}\n loss: {'name': 'softmaxcrossentropy', 'params': {'weight': None, 'batch_axis': 0, 'axis_to_sum_over': -1, 'label_as_categories': True, 'label_smoothing': False}}\n Num epochs: 20\n\n\nDataset Settings\n Status: True\n Display progress: True\n Display progress realtime: True\n Save intermediate models: True\n Save training logs: True\n Intermediate model prefix: intermediate_model_\n\n\nTraining\n Status: False\n\nExternal Evaluation\n Status: False\n\n"
]
],
[
[
"### Summary findings\n - Training status is still False",
"_____no_output_____"
],
[
"### Update batch size",
"_____no_output_____"
]
],
[
[
"# This part of code will be taken up again in upcoming sections\ngtf.update_batch_size(8);\ngtf.Reload();",
"Update: Batch size - 8\n\nPre-Composed Train Transforms\n[{'RandomHorizontalFlip': {'p': 0.8}}, {'Normalize': {'mean': [0.485, 0.456, 0.406], 'std': [0.229, 0.224, 0.225]}}]\n\nPre-Composed Val Transforms\n[{'RandomHorizontalFlip': {'p': 0.8}}, {'Normalize': {'mean': [0.485, 0.456, 0.406], 'std': [0.229, 0.224, 0.225]}}]\n\nDataset Numbers\n Num train images: 1411\n Num val images: 605\n Num classes: 2\n\nModel Details\n Loading model - workspace/Malaria-Cell/exp-resume-training/output/models/resume_state-symbol.json\n Model Loaded on device\n Model name: resnet18_v2\n Num of potentially trainable layers: 59\n Num of actual trainable layers: 1\n\n"
]
],
[
[
"<a id='3'></a>\n# Resume training the classifier",
"_____no_output_____"
]
],
[
[
"gtf.Train();",
"Training Resume\n Epoch 1/20\n ----------\nSkipping Current Epoch\n\n\n Epoch 2/20\n ----------\nSkipping Current Epoch\n\n\n Epoch 3/20\n ----------\nSkipping Current Epoch\n\n\n Epoch 4/20\n ----------\nSkipping Current Epoch\n\n\n Epoch 5/20\n ----------\nSkipping Current Epoch\n\n\n Epoch 6/20\n ----------\nSkipping Current Epoch\n\n\n Epoch 7/20\n ----------\nSkipping Current Epoch\n\n\n Epoch 8/20\n ----------\nSkipping Current Epoch\n\n\n Epoch 9/20\n ----------\nSkipping Current Epoch\n\n\n Epoch 10/20\n ----------\n"
]
],
[
[
"### It skipped epochs 1-9",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
ecc18219c8582d30e58c56cb9c6a46b302269523 | 2,778 | ipynb | Jupyter Notebook | book/community/templates/template-environments-sensors.ipynb | raquelcarmo/environmental-ai-book | be72357a4e22162d0e24418744c541fe20deebef | [
"CC-BY-4.0"
] | 3 | 2021-11-05T02:12:39.000Z | 2021-11-22T17:55:31.000Z | book/community/templates/template-environments-sensors.ipynb | raquelcarmo/environmental-ai-book | be72357a4e22162d0e24418744c541fe20deebef | [
"CC-BY-4.0"
] | 17 | 2021-07-26T11:03:55.000Z | 2021-11-26T14:41:13.000Z | book/community/templates/template-environments-sensors.ipynb | raquelcarmo/environmental-ai-book | be72357a4e22162d0e24418744c541fe20deebef | [
"CC-BY-4.0"
] | 6 | 2021-07-16T14:27:36.000Z | 2021-11-26T11:38:43.000Z | 20.887218 | 154 | 0.514039 | [
[
[
"# [Sensor name]\n\n:::{eval-rst}\n:opticon:`tag`\n:badge:`[Environment],badge-primary`\n:badge:`Sensors,badge-secondary`\n:::\n\n## Context\n### Purpose\n*Describe the purpose of the use case.*\n\n### Sensor description\n*Describe the main features of the sensor e.g. variables.*\n\n### Highlights\n*Provide 3-5 bullet points that convey the use case’s core procedures. Each bullet point must have a maximum of 85 characters, including spaces.*\n* Highlight 1\n* Highlight 2\n\n### Contributions\n\n#### Notebook\nAuthor (role), Affiliation, GitHub alias\n\n#### Dataset originator/creator\nInstitution/Community/Individual (affiliation)\n\n#### Dataset authors\nInstitution/Community/Individual (affiliation)\n\n#### Dataset documentation\n```{bibliography}\n :style: plain\n :list: bullet\n :filter: topic % \"replace by the `topic` entry linked to the publication(s) in the `_bibliography/references.bib` file\"\n```\n\n:::{note}\n*Optional: add credits or acknowledgements to data providers or authors of code snippets*\n:::",
"_____no_output_____"
],
[
"## Install and load libraries",
"_____no_output_____"
],
[
"## Load data",
"_____no_output_____"
],
[
"## Visualisation",
"_____no_output_____"
],
[
"## Summary",
"_____no_output_____"
],
[
"## Version\n- Notebook:\n- Dataset:",
"_____no_output_____"
]
]
] | [
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
ecc184793c413cba1d8ae64273e1136f6fccf7e5 | 825 | ipynb | Jupyter Notebook | Learn to code in 30 days/Day_21. Generics (C, C++, JAVA).ipynb | Nam-SH/HackerRank | d1ced5cdad3eae7661f39af4d12aa33f460821cb | [
"MIT"
] | null | null | null | Learn to code in 30 days/Day_21. Generics (C, C++, JAVA).ipynb | Nam-SH/HackerRank | d1ced5cdad3eae7661f39af4d12aa33f460821cb | [
"MIT"
] | null | null | null | Learn to code in 30 days/Day_21. Generics (C, C++, JAVA).ipynb | Nam-SH/HackerRank | d1ced5cdad3eae7661f39af4d12aa33f460821cb | [
"MIT"
] | null | null | null | 18.75 | 116 | 0.533333 | [
[
[
"# Day_21. Generics (C, C++, JAVA)\n\n<br>\n\n",
"_____no_output_____"
]
]
] | [
"markdown"
] | [
[
"markdown"
]
] |
ecc1868c57f7b4142c1776e001b3d36abcf9e309 | 57,124 | ipynb | Jupyter Notebook | docs/notebooks/Common_Gotchas_in_JAX.ipynb | bloops/jax | 62230f65256728f580c5ecfa8867cac69a681cb1 | [
"Apache-2.0"
] | 7 | 2020-12-04T16:54:54.000Z | 2022-02-15T07:26:56.000Z | docs/notebooks/Common_Gotchas_in_JAX.ipynb | bloops/jax | 62230f65256728f580c5ecfa8867cac69a681cb1 | [
"Apache-2.0"
] | 20 | 2021-08-17T20:31:56.000Z | 2022-03-31T11:56:24.000Z | docs/notebooks/Common_Gotchas_in_JAX.ipynb | bloops/jax | 62230f65256728f580c5ecfa8867cac69a681cb1 | [
"Apache-2.0"
] | null | null | null | 29.08554 | 670 | 0.554093 | [
[
[
"# 🔪 JAX - The Sharp Bits 🔪\n\n[](https://colab.research.google.com/github/google/jax/blob/main/docs/notebooks/Common_Gotchas_in_JAX.ipynb)",
"_____no_output_____"
],
[
"*levskaya@ mattjj@*\n\nWhen walking about the countryside of [Italy](https://iaml.it/blog/jax-intro), the people will not hesitate to tell you that __JAX__ has _\"una anima di pura programmazione funzionale\"_.\n\n__JAX__ is a language for __expressing__ and __composing__ __transformations__ of numerical programs. __JAX__ is also able to __compile__ numerical programs for CPU or accelerators (GPU/TPU). \nJAX works great for many numerical and scientific programs, but __only if they are written with certain constraints__ that we describe below.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nfrom jax import grad, jit\nfrom jax import lax\nfrom jax import random\nimport jax\nimport jax.numpy as jnp\nimport matplotlib as mpl\nfrom matplotlib import pyplot as plt\nfrom matplotlib import rcParams\nrcParams['image.interpolation'] = 'nearest'\nrcParams['image.cmap'] = 'viridis'\nrcParams['axes.grid'] = False",
"_____no_output_____"
]
],
[
[
"## 🔪 Pure functions",
"_____no_output_____"
],
[
"JAX transformation and compilation are designed to work only on Python functions that are functionally pure: all the input data is passed through the function parameters, all the results are output through the function results. A pure function will always return the same result if invoked with the same inputs. \n\nHere are some examples of functions that are not functionally pure for which JAX behaves differently than the Python interpreter. Note that these behaviors are not guaranteed by the JAX system; the proper way to use JAX is to use it only on functionally pure Python functions.",
"_____no_output_____"
]
],
[
[
"def impure_print_side_effect(x):\n print(\"Executing function\") # This is a side-effect \n return x\n\n# The side-effects appear during the first run \nprint (\"First call: \", jit(impure_print_side_effect)(4.))\n\n# Subsequent runs with parameters of same type and shape may not show the side-effect\n# This is because JAX now invokes a cached compilation of the function\nprint (\"Second call: \", jit(impure_print_side_effect)(5.))\n\n# JAX re-runs the Python function when the type or shape of the argument changes\nprint (\"Third call, different type: \", jit(impure_print_side_effect)(jnp.array([5.])))",
"Executing function\nFirst call: 4.0\nSecond call: 5.0\nExecuting function\nThird call, different type: [5.]\n"
],
[
"g = 0.\ndef impure_uses_globals(x):\n return x + g\n\n# JAX captures the value of the global during the first run\nprint (\"First call: \", jit(impure_uses_globals)(4.))\ng = 10. # Update the global\n\n# Subsequent runs may silently use the cached value of the globals\nprint (\"Second call: \", jit(impure_uses_globals)(5.))\n\n# JAX re-runs the Python function when the type or shape of the argument changes\n# This will end up reading the latest value of the global\nprint (\"Third call, different type: \", jit(impure_uses_globals)(jnp.array([4.])))",
"First call: 4.0\nSecond call: 5.0\nThird call, different type: [14.]\n"
],
[
"g = 0.\ndef impure_saves_global(x):\n global g\n g = x\n return x\n\n# JAX runs once the transformed function with special Traced values for arguments\nprint (\"First call: \", jit(impure_saves_global)(4.))\nprint (\"Saved global: \", g) # Saved global has an internal JAX value",
"First call: 4.0\nSaved global: Traced<ShapedArray(float32[], weak_type=True):JaxprTrace(level=-1/1)>\n"
]
],
[
[
"A Python function can be functionally pure even if it actually uses stateful objects internally, as long as it does not read or write external state:",
"_____no_output_____"
]
],
[
[
"def pure_uses_internal_state(x):\n state = dict(even=0, odd=0)\n for i in range(10):\n state['even' if i % 2 == 0 else 'odd'] += x\n return state['even'] + state['odd']\n\nprint(jit(pure_uses_internal_state)(5.))",
"_____no_output_____"
]
],
[
[
"It is not recommended to use iterators in any JAX function you want to `jit` or in any control-flow primitive. The reason is that an iterator is a python object which introduces state to retrieve the next element. Therefore, it is incompatible with JAX functional programming model. In the code below, there are some examples of incorrect attempts to use iterators with JAX. Most of them return an error, but some give unexpected results.",
"_____no_output_____"
]
],
[
[
"import jax.numpy as jnp\nimport jax.lax as lax\nfrom jax import make_jaxpr\n\n# lax.fori_loop\narray = jnp.arange(10)\nprint(lax.fori_loop(0, 10, lambda i,x: x+array[i], 0)) # expected result 45\niterator = iter(range(10))\nprint(lax.fori_loop(0, 10, lambda i,x: x+next(iterator), 0)) # unexpected result 0\n\n# lax.scan\ndef func11(arr, extra):\n ones = jnp.ones(arr.shape) \n def body(carry, aelems):\n ae1, ae2 = aelems\n return (carry + ae1 * ae2 + extra, carry)\n return lax.scan(body, 0., (arr, ones)) \nmake_jaxpr(func11)(jnp.arange(16), 5.)\n# make_jaxpr(func11)(iter(range(16)), 5.) # throws error\n\n# lax.cond\narray_operand = jnp.array([0.])\nlax.cond(True, lambda x: x+1, lambda x: x-1, array_operand)\niter_operand = iter(range(10))\n# lax.cond(True, lambda x: next(x)+1, lambda x: next(x)-1, iter_operand) # throws error",
"45\n0\n"
]
],
[
[
"## 🔪 In-Place Updates",
"_____no_output_____"
],
[
"In Numpy you're used to doing this:",
"_____no_output_____"
]
],
[
[
"numpy_array = np.zeros((3,3), dtype=np.float32)\nprint(\"original array:\")\nprint(numpy_array)\n\n# In place, mutating update\nnumpy_array[1, :] = 1.0\nprint(\"updated array:\")\nprint(numpy_array)",
"original array:\n[[0. 0. 0.]\n [0. 0. 0.]\n [0. 0. 0.]]\nupdated array:\n[[0. 0. 0.]\n [1. 1. 1.]\n [0. 0. 0.]]\n"
]
],
[
[
"If we try to update a JAX device array in-place, however, we get an __error__! (☉_☉)",
"_____no_output_____"
]
],
[
[
"jax_array = jnp.zeros((3,3), dtype=jnp.float32)\n\n# In place update of JAX's array will yield an error!\ntry:\n jax_array[1, :] = 1.0\nexcept Exception as e:\n print(\"Exception {}\".format(e))",
"Exception '<class 'jax.interpreters.xla.DeviceArray'>' object does not support item assignment. JAX arrays are immutable; perhaps you want jax.ops.index_update or jax.ops.index_add instead?\n"
]
],
[
[
"__What gives?!__ \n\nAllowing mutation of variables in-place makes program analysis and transformation very difficult. JAX requires a pure functional expression of a numerical program. \n\nInstead, JAX offers the _functional_ update functions: [__index_update__](https://jax.readthedocs.io/en/latest/_autosummary/jax.ops.index_update.html#jax.ops.index_update), [__index_add__](https://jax.readthedocs.io/en/latest/_autosummary/jax.ops.index_add.html#jax.ops.index_add), [__index_min__](https://jax.readthedocs.io/en/latest/_autosummary/jax.ops.index_min.html#jax.ops.index_min), [__index_max__](https://jax.readthedocs.io/en/latest/_autosummary/jax.ops.index_max.html#jax.ops.index_max), and the [__index__](https://jax.readthedocs.io/en/latest/_autosummary/jax.ops.index.html#jax.ops.index) helper.\n\n️⚠️ inside `jit`'d code and `lax.while_loop` or `lax.fori_loop` the __size__ of slices can't be functions of argument _values_ but only functions of argument _shapes_ -- the slice start indices have no such restriction. See the below __Control Flow__ Section for more information on this limitation.",
"_____no_output_____"
]
],
[
[
"from jax.ops import index, index_add, index_update",
"_____no_output_____"
]
],
[
[
"### index_update",
"_____no_output_____"
],
[
"If the __input values__ of __index_update__ aren't reused, __jit__-compiled code will perform these operations _in-place_.",
"_____no_output_____"
]
],
[
[
"jax_array = jnp.zeros((3, 3))\nprint(\"original array:\")\nprint(jax_array)\n\nnew_jax_array = index_update(jax_array, index[1, :], 1.)\n\nprint(\"old array unchanged:\")\nprint(jax_array)\n\nprint(\"new array:\")\nprint(new_jax_array)",
"original array:\n[[0. 0. 0.]\n [0. 0. 0.]\n [0. 0. 0.]]\nold array unchanged:\n[[0. 0. 0.]\n [0. 0. 0.]\n [0. 0. 0.]]\nnew array:\n[[0. 0. 0.]\n [1. 1. 1.]\n [0. 0. 0.]]\n"
]
],
[
[
"### index_add",
"_____no_output_____"
],
[
"If the __input values__ of __index_update__ aren't reused, __jit__-compiled code will perform these operations _in-place_.",
"_____no_output_____"
]
],
[
[
"print(\"original array:\")\njax_array = jnp.ones((5, 6))\nprint(jax_array)\n\nnew_jax_array = index_add(jax_array, index[::2, 3:], 7.)\nprint(\"new array post-addition:\")\nprint(new_jax_array)",
"original array:\n[[1. 1. 1. 1. 1. 1.]\n [1. 1. 1. 1. 1. 1.]\n [1. 1. 1. 1. 1. 1.]\n [1. 1. 1. 1. 1. 1.]\n [1. 1. 1. 1. 1. 1.]]\nnew array post-addition:\n[[1. 1. 1. 8. 8. 8.]\n [1. 1. 1. 1. 1. 1.]\n [1. 1. 1. 8. 8. 8.]\n [1. 1. 1. 1. 1. 1.]\n [1. 1. 1. 8. 8. 8.]]\n"
]
],
[
[
"## 🔪 Out-of-Bounds Indexing",
"_____no_output_____"
],
[
"In Numpy, you are used to errors being thrown when you index an array outside of its bounds, like this:",
"_____no_output_____"
]
],
[
[
"try:\n np.arange(10)[11]\nexcept Exception as e:\n print(\"Exception {}\".format(e))",
"Exception index 11 is out of bounds for axis 0 with size 10\n"
]
],
[
[
"However, raising an error from code running on an accelerator can be difficult or impossible. Therefore, JAX must choose some non-error behavior for out of bounds indexing (akin to how invalid floating point arithmetic results in `NaN`). When the indexing operation is an array index update (e.g. `index_add` or `scatter`-like primitives), updates at out-of-bounds indices will be skipped; when the operation is an array index retrieval (e.g. NumPy indexing or `gather`-like primitives) the index is clamped to the bounds of the array since __something__ must be returned. For example, the last value of the array will be returned from this indexing operation:",
"_____no_output_____"
]
],
[
[
"jnp.arange(10)[11]",
"_____no_output_____"
]
],
[
[
"Note that due to this behavior for index retrieval, functions like `jnp.nanargmin` and `jnp.nanargmax` return -1 for slices consisting of NaNs whereas Numpy would throw an error.\n\nNote also that, as the two behaviors described above are not inverses of each other, reverse-mode automatic differentiation (which turns index updates into index retrievals and vice versa) [will not preserve the semantics of out of bounds indexing](https://github.com/google/jax/issues/5760). Thus it may be a good idea to think of out-of-bounds indexing in JAX as a case of [undefined behavior](https://en.wikipedia.org/wiki/Undefined_behavior).",
"_____no_output_____"
],
[
"## 🔪 Non-array inputs: NumPy vs. JAX\n\nNumPy is generally happy accepting Python lists or tuples as inputs to its API functions:",
"_____no_output_____"
]
],
[
[
"np.sum([1, 2, 3])",
"_____no_output_____"
]
],
[
[
"JAX departs from this, generally returning a helpful error:",
"_____no_output_____"
]
],
[
[
"try:\n jnp.sum([1, 2, 3])\nexcept TypeError as e:\n print(f\"TypeError: {e}\")",
"TypeError: sum requires ndarray or scalar arguments, got <class 'list'> at position 0.\n"
]
],
[
[
"This is a deliberate design choice, because passing lists or tuples to traced functions can lead to silent performance degradation that might otherwise be difficult to detect.\n\nFor example, consider the following permissive version of `jnp.sum` that allows list inputs:",
"_____no_output_____"
]
],
[
[
"def permissive_sum(x):\n return jnp.sum(jnp.array(x))\n\nx = list(range(10))\npermissive_sum(x)",
"_____no_output_____"
]
],
[
[
"The output is what we would expect, but this hides potential performance issues under the hood. In JAX's tracing and JIT compilation model, each element in a Python list or tuple is treated as a separate JAX variable, and individually processed and pushed to device. This can be seen in the jaxpr for the ``permissive_sum`` function above:",
"_____no_output_____"
]
],
[
[
"make_jaxpr(permissive_sum)(x)",
"_____no_output_____"
]
],
[
[
"Each entry of the list is handled as a separate input, resulting in a tracing & compilation overhead that grows linearly with the size of the list. To prevent surprises like this, JAX avoids implicit conversions of lists and tuples to arrays.\n\nIf you would like to pass a tuple or list to a JAX function, you can do so by first explicitly converting it to an array:",
"_____no_output_____"
]
],
[
[
"jnp.sum(jnp.array(x))",
"_____no_output_____"
]
],
[
[
"## 🔪 Random Numbers",
"_____no_output_____"
],
[
"> _If all scientific papers whose results are in doubt because of bad \n> `rand()`s were to disappear from library shelves, there would be a \n> gap on each shelf about as big as your fist._ - Numerical Recipes",
"_____no_output_____"
],
[
"### RNGs and State\nYou're used to _stateful_ pseudorandom number generators (PRNGs) from numpy and other libraries, which helpfully hide a lot of details under the hood to give you a ready fountain of pseudorandomness:",
"_____no_output_____"
]
],
[
[
"print(np.random.random())\nprint(np.random.random())\nprint(np.random.random())",
"0.08960303423860538\n0.6720478073539145\n0.24536720985284477\n"
]
],
[
[
"Underneath the hood, numpy uses the [Mersenne Twister](https://en.wikipedia.org/wiki/Mersenne_Twister) PRNG to power its pseudorandom functions. The PRNG has a period of $2^{19937}-1$ and at any point can be described by __624 32bit unsigned ints__ and a __position__ indicating how much of this \"entropy\" has been used up.",
"_____no_output_____"
]
],
[
[
"np.random.seed(0)\nrng_state = np.random.get_state()\n#print(rng_state)\n# --> ('MT19937', array([0, 1, 1812433255, 1900727105, 1208447044,\n# 2481403966, 4042607538, 337614300, ... 614 more numbers..., \n# 3048484911, 1796872496], dtype=uint32), 624, 0, 0.0)",
"_____no_output_____"
]
],
[
[
"This pseudorandom state vector is automagically updated behind the scenes every time a random number is needed, \"consuming\" 2 of the uint32s in the Mersenne twister state vector:",
"_____no_output_____"
]
],
[
[
"_ = np.random.uniform()\nrng_state = np.random.get_state()\n#print(rng_state) \n# --> ('MT19937', array([2443250962, 1093594115, 1878467924,\n# ..., 2648828502, 1678096082], dtype=uint32), 2, 0, 0.0)\n\n# Let's exhaust the entropy in this PRNG statevector\nfor i in range(311):\n _ = np.random.uniform()\nrng_state = np.random.get_state()\n#print(rng_state) \n# --> ('MT19937', array([2443250962, 1093594115, 1878467924,\n# ..., 2648828502, 1678096082], dtype=uint32), 624, 0, 0.0)\n\n# Next call iterates the RNG state for a new batch of fake \"entropy\".\n_ = np.random.uniform()\nrng_state = np.random.get_state()\n# print(rng_state) \n# --> ('MT19937', array([1499117434, 2949980591, 2242547484, \n# 4162027047, 3277342478], dtype=uint32), 2, 0, 0.0)",
"_____no_output_____"
]
],
[
[
"The problem with magic PRNG state is that it's hard to reason about how it's being used and updated across different threads, processes, and devices, and it's _very easy_ to screw up when the details of entropy production and consumption are hidden from the end user.\n\nThe Mersenne Twister PRNG is also known to have a [number](https://cs.stackexchange.com/a/53475) of problems, it has a large 2.5Kb state size, which leads to problematic [initialization issues](https://dl.acm.org/citation.cfm?id=1276928). It [fails](http://www.pcg-random.org/pdf/toms-oneill-pcg-family-v1.02.pdf) modern BigCrush tests, and is generally slow.",
"_____no_output_____"
],
[
"### JAX PRNG",
"_____no_output_____"
],
[
"JAX instead implements an _explicit_ PRNG where entropy production and consumption are handled by explicitly passing and iterating PRNG state. JAX uses a modern [Threefry counter-based PRNG](https://github.com/google/jax/blob/main/design_notes/prng.md) that's __splittable__. That is, its design allows us to __fork__ the PRNG state into new PRNGs for use with parallel stochastic generation.\n\nThe random state is described by two unsigned-int32s that we call a __key__:",
"_____no_output_____"
]
],
[
[
"from jax import random\nkey = random.PRNGKey(0)\nkey",
"_____no_output_____"
]
],
[
[
"JAX's random functions produce pseudorandom numbers from the PRNG state, but __do not__ change the state! \n\nReusing the same state will cause __sadness__ and __monotony__, depriving the end user of __lifegiving chaos__:",
"_____no_output_____"
]
],
[
[
"print(random.normal(key, shape=(1,)))\nprint(key)\n# No no no!\nprint(random.normal(key, shape=(1,)))\nprint(key)",
"[-0.20584226]\n[0 0]\n[-0.20584226]\n[0 0]\n"
]
],
[
[
"Instead, we __split__ the PRNG to get usable __subkeys__ every time we need a new pseudorandom number:",
"_____no_output_____"
]
],
[
[
"print(\"old key\", key)\nkey, subkey = random.split(key)\nnormal_pseudorandom = random.normal(subkey, shape=(1,))\nprint(\" \\---SPLIT --> new key \", key)\nprint(\" \\--> new subkey\", subkey, \"--> normal\", normal_pseudorandom)",
"old key [0 0]\n \\---SPLIT --> new key [4146024105 967050713]\n \\--> new subkey [2718843009 1272950319] --> normal [-1.2515389]\n"
]
],
[
[
"We propagate the __key__ and make new __subkeys__ whenever we need a new random number:",
"_____no_output_____"
]
],
[
[
"print(\"old key\", key)\nkey, subkey = random.split(key)\nnormal_pseudorandom = random.normal(subkey, shape=(1,))\nprint(\" \\---SPLIT --> new key \", key)\nprint(\" \\--> new subkey\", subkey, \"--> normal\", normal_pseudorandom)",
"old key [4146024105 967050713]\n \\---SPLIT --> new key [2384771982 3928867769]\n \\--> new subkey [1278412471 2182328957] --> normal [-0.58665055]\n"
]
],
[
[
"We can generate more than one __subkey__ at a time:",
"_____no_output_____"
]
],
[
[
"key, *subkeys = random.split(key, 4)\nfor subkey in subkeys:\n print(random.normal(subkey, shape=(1,)))",
"[-0.37533438]\n[0.98645043]\n[0.14553197]\n"
]
],
[
[
"## 🔪 Control Flow",
"_____no_output_____"
],
[
"### ✔ python control_flow + autodiff ✔\n\nIf you just want to apply `grad` to your python functions, you can use regular python control-flow constructs with no problems, as if you were using [Autograd](https://github.com/hips/autograd) (or Pytorch or TF Eager).",
"_____no_output_____"
]
],
[
[
"def f(x):\n if x < 3:\n return 3. * x ** 2\n else:\n return -4 * x\n\nprint(grad(f)(2.)) # ok!\nprint(grad(f)(4.)) # ok!",
"12.0\n-4.0\n"
]
],
[
[
"### python control flow + JIT\n\nUsing control flow with `jit` is more complicated, and by default it has more constraints.\n\nThis works:",
"_____no_output_____"
]
],
[
[
"@jit\ndef f(x):\n for i in range(3):\n x = 2 * x\n return x\n\nprint(f(3))",
"24\n"
]
],
[
[
"So does this:",
"_____no_output_____"
]
],
[
[
"@jit\ndef g(x):\n y = 0.\n for i in range(x.shape[0]):\n y = y + x[i]\n return y\n\nprint(g(jnp.array([1., 2., 3.])))",
"6.0\n"
]
],
[
[
"But this doesn't, at least by default:",
"_____no_output_____"
]
],
[
[
"@jit\ndef f(x):\n if x < 3:\n return 3. * x ** 2\n else:\n return -4 * x\n\n# This will fail!\ntry:\n f(2)\nexcept Exception as e:\n print(\"Exception {}\".format(e))",
"Exception Abstract value passed to `bool`, which requires a concrete value. The function to be transformed can't be traced at the required level of abstraction. If using `jit`, try using `static_argnums` or applying `jit` to smaller subfunctions instead.\n"
]
],
[
[
"__What gives!?__\n\nWhen we `jit`-compile a function, we usually want to compile a version of the function that works for many different argument values, so that we can cache and reuse the compiled code. That way we don't have to re-compile on each function evaluation.\n\nFor example, if we evaluate an `@jit` function on the array `jnp.array([1., 2., 3.], jnp.float32)`, we might want to compile code that we can reuse to evaluate the function on `jnp.array([4., 5., 6.], jnp.float32)` to save on compile time.\n\nTo get a view of your Python code that is valid for many different argument values, JAX traces it on _abstract values_ that represent sets of possible inputs. There are [multiple different levels of abstraction](https://github.com/google/jax/blob/main/jax/_src/abstract_arrays.py), and different transformations use different abstraction levels.\n\nBy default, `jit` traces your code on the `ShapedArray` abstraction level, where each abstract value represents the set of all array values with a fixed shape and dtype. For example, if we trace using the abstract value `ShapedArray((3,), jnp.float32)`, we get a view of the function that can be reused for any concrete value in the corresponding set of arrays. That means we can save on compile time.\n\nBut there's a tradeoff here: if we trace a Python function on a `ShapedArray((), jnp.float32)` that isn't committed to a specific concrete value, when we hit a line like `if x < 3`, the expression `x < 3` evaluates to an abstract `ShapedArray((), jnp.bool_)` that represents the set `{True, False}`. When Python attempts to coerce that to a concrete `True` or `False`, we get an error: we don't know which branch to take, and can't continue tracing! The tradeoff is that with higher levels of abstraction we gain a more general view of the Python code (and thus save on re-compilations), but we require more constraints on the Python code to complete the trace.\n\nThe good news is that you can control this tradeoff yourself. By having `jit` trace on more refined abstract values, you can relax the traceability constraints. For example, using the `static_argnums` argument to `jit`, we can specify to trace on concrete values of some arguments. Here's that example function again:",
"_____no_output_____"
]
],
[
[
"def f(x):\n if x < 3:\n return 3. * x ** 2\n else:\n return -4 * x\n\nf = jit(f, static_argnums=(0,))\n\nprint(f(2.))",
"12.0\n"
]
],
[
[
"Here's another example, this time involving a loop:",
"_____no_output_____"
]
],
[
[
"def f(x, n):\n y = 0.\n for i in range(n):\n y = y + x[i]\n return y\n\nf = jit(f, static_argnums=(1,))\n\nf(jnp.array([2., 3., 4.]), 2)",
"_____no_output_____"
]
],
[
[
"In effect, the loop gets statically unrolled. JAX can also trace at _higher_ levels of abstraction, like `Unshaped`, but that's not currently the default for any transformation",
"_____no_output_____"
],
[
"️⚠️ **functions with argument-__value__ dependent shapes**\n\nThese control-flow issues also come up in a more subtle way: numerical functions we want to __jit__ can't specialize the shapes of internal arrays on argument _values_ (specializing on argument __shapes__ is ok). As a trivial example, let's make a function whose output happens to depend on the input variable `length`.",
"_____no_output_____"
]
],
[
[
"def example_fun(length, val):\n return jnp.ones((length,)) * val\n# un-jit'd works fine\nprint(example_fun(5, 4))\n\nbad_example_jit = jit(example_fun)\n# this will fail:\ntry:\n print(bad_example_jit(10, 4))\nexcept Exception as e:\n print(\"Exception {}\".format(e))\n# static_argnums tells JAX to recompile on changes at these argument positions:\ngood_example_jit = jit(example_fun, static_argnums=(0,))\n# first compile\nprint(good_example_jit(10, 4))\n# recompiles\nprint(good_example_jit(5, 4))",
"[4. 4. 4. 4. 4.]\nException Shapes must be 1D sequences of concrete values of integer type, got (Traced<ShapedArray(int32[], weak_type=True):JaxprTrace(level=-1/1)>,).\nIf using `jit`, try using `static_argnums` or applying `jit` to smaller subfunctions.\n[4. 4. 4. 4. 4. 4. 4. 4. 4. 4.]\n[4. 4. 4. 4. 4.]\n"
]
],
[
[
"`static_argnums` can be handy if `length` in our example rarely changes, but it would be disastrous if it changed a lot! \n\nLastly, if your function has global side-effects, JAX's tracer can cause weird things to happen. A common gotcha is trying to print arrays inside __jit__'d functions:",
"_____no_output_____"
]
],
[
[
"@jit\ndef f(x):\n print(x)\n y = 2 * x\n print(y)\n return y\nf(2)",
"Traced<ShapedArray(int32[], weak_type=True):JaxprTrace(level=-1/1)>\nTraced<ShapedArray(int32[]):JaxprTrace(level=-1/1)>\n"
]
],
[
[
"### Structured control flow primitives\n\nThere are more options for control flow in JAX. Say you want to avoid re-compilations but still want to use control flow that's traceable, and that avoids un-rolling large loops. Then you can use these 4 structured control flow primitives:\n\n - `lax.cond` _differentiable_\n - `lax.while_loop` __fwd-mode-differentiable__\n - `lax.fori_loop` __fwd-mode-differentiable__\n - `lax.scan` _differentiable_",
"_____no_output_____"
],
[
"#### cond\npython equivalent:\n\n```python\ndef cond(pred, true_fun, false_fun, operand):\n if pred:\n return true_fun(operand)\n else:\n return false_fun(operand)\n```",
"_____no_output_____"
]
],
[
[
"from jax import lax\n\noperand = jnp.array([0.])\nlax.cond(True, lambda x: x+1, lambda x: x-1, operand)\n# --> array([1.], dtype=float32)\nlax.cond(False, lambda x: x+1, lambda x: x-1, operand)\n# --> array([-1.], dtype=float32)",
"_____no_output_____"
]
],
[
[
"#### while_loop\n\npython equivalent:\n```\ndef while_loop(cond_fun, body_fun, init_val):\n val = init_val\n while cond_fun(val):\n val = body_fun(val)\n return val\n```",
"_____no_output_____"
]
],
[
[
"init_val = 0\ncond_fun = lambda x: x<10\nbody_fun = lambda x: x+1\nlax.while_loop(cond_fun, body_fun, init_val)\n# --> array(10, dtype=int32)",
"_____no_output_____"
]
],
[
[
"#### fori_loop\npython equivalent:\n```\ndef fori_loop(start, stop, body_fun, init_val):\n val = init_val\n for i in range(start, stop):\n val = body_fun(i, val)\n return val\n```",
"_____no_output_____"
]
],
[
[
"init_val = 0\nstart = 0\nstop = 10\nbody_fun = lambda i,x: x+i\nlax.fori_loop(start, stop, body_fun, init_val)\n# --> array(45, dtype=int32)",
"_____no_output_____"
]
],
[
[
"#### Summary\n\n$$\n\\begin{array} {r|rr} \n\\hline \\\n\\textrm{construct} \n& \\textrm{jit} \n& \\textrm{grad} \\\\\n\\hline \\\n\\textrm{if} & ❌ & ✔ \\\\\n\\textrm{for} & ✔* & ✔\\\\\n\\textrm{while} & ✔* & ✔\\\\\n\\textrm{lax.cond} & ✔ & ✔\\\\\n\\textrm{lax.while_loop} & ✔ & \\textrm{fwd}\\\\\n\\textrm{lax.fori_loop} & ✔ & \\textrm{fwd}\\\\\n\\textrm{lax.scan} & ✔ & ✔\\\\\n\\hline\n\\end{array}\n$$\n\n<center>\n\n$\\ast$ = argument-<b>value</b>-independent loop condition - unrolls the loop\n\n</center>",
"_____no_output_____"
],
[
"## 🔪 NaNs",
"_____no_output_____"
],
[
"### Debugging NaNs\n\nIf you want to trace where NaNs are occurring in your functions or gradients, you can turn on the NaN-checker by:\n\n* setting the `JAX_DEBUG_NANS=True` environment variable;\n\n* adding `from jax.config import config` and `config.update(\"jax_debug_nans\", True)` near the top of your main file;\n\n* adding `from jax.config import config` and `config.parse_flags_with_absl()` to your main file, then set the option using a command-line flag like `--jax_debug_nans=True`;\n\nThis will cause computations to error-out immediately on production of a NaN. Switching this option on adds a nan check to every floating point type value produced by XLA. That means values are pulled back to the host and checked as ndarrays for every primitive operation not under an `@jit`. For code under an `@jit`, the output of every `@jit` function is checked and if a nan is present it will re-run the function in de-optimized op-by-op mode, effectively removing one level of `@jit` at a time.\n\nThere could be tricky situations that arise, like nans that only occur under a `@jit` but don't get produced in de-optimized mode. In that case you'll see a warning message print out but your code will continue to execute.\n\nIf the nans are being produced in the backward pass of a gradient evaluation, when an exception is raised several frames up in the stack trace you will be in the backward_pass function, which is essentially a simple jaxpr interpreter that walks the sequence of primitive operations in reverse. In the example below, we started an ipython repl with the command line `env JAX_DEBUG_NANS=True ipython`, then ran this:",
"_____no_output_____"
],
[
"```\nIn [1]: import jax.numpy as jnp\n\nIn [2]: jnp.divide(0., 0.)\n---------------------------------------------------------------------------\nFloatingPointError Traceback (most recent call last)\n<ipython-input-2-f2e2c413b437> in <module>()\n----> 1 jnp.divide(0., 0.)\n\n.../jax/jax/numpy/lax_numpy.pyc in divide(x1, x2)\n 343 return floor_divide(x1, x2)\n 344 else:\n--> 345 return true_divide(x1, x2)\n 346\n 347\n\n.../jax/jax/numpy/lax_numpy.pyc in true_divide(x1, x2)\n 332 x1, x2 = _promote_shapes(x1, x2)\n 333 return lax.div(lax.convert_element_type(x1, result_dtype),\n--> 334 lax.convert_element_type(x2, result_dtype))\n 335\n 336\n\n.../jax/jax/lax.pyc in div(x, y)\n 244 def div(x, y):\n 245 r\"\"\"Elementwise division: :math:`x \\over y`.\"\"\"\n--> 246 return div_p.bind(x, y)\n 247\n 248 def rem(x, y):\n\n... stack trace ...\n\n.../jax/jax/interpreters/xla.pyc in handle_result(device_buffer)\n 103 py_val = device_buffer.to_py()\n 104 if np.any(np.isnan(py_val)):\n--> 105 raise FloatingPointError(\"invalid value\")\n 106 else:\n 107 return DeviceArray(device_buffer, *result_shape)\n\nFloatingPointError: invalid value\n```",
"_____no_output_____"
],
[
"The nan generated was caught. By running `%debug`, we can get a post-mortem debugger. This also works with functions under `@jit`, as the example below shows.",
"_____no_output_____"
],
[
"```\nIn [4]: from jax import jit\n\nIn [5]: @jit\n ...: def f(x, y):\n ...: a = x * y\n ...: b = (x + y) / (x - y)\n ...: c = a + 2\n ...: return a + b * c\n ...:\n\nIn [6]: x = jnp.array([2., 0.])\n\nIn [7]: y = jnp.array([3., 0.])\n\nIn [8]: f(x, y)\nInvalid value encountered in the output of a jit function. Calling the de-optimized version.\n---------------------------------------------------------------------------\nFloatingPointError Traceback (most recent call last)\n<ipython-input-8-811b7ddb3300> in <module>()\n----> 1 f(x, y)\n\n ... stack trace ...\n\n<ipython-input-5-619b39acbaac> in f(x, y)\n 2 def f(x, y):\n 3 a = x * y\n----> 4 b = (x + y) / (x - y)\n 5 c = a + 2\n 6 return a + b * c\n\n.../jax/jax/numpy/lax_numpy.pyc in divide(x1, x2)\n 343 return floor_divide(x1, x2)\n 344 else:\n--> 345 return true_divide(x1, x2)\n 346\n 347\n\n.../jax/jax/numpy/lax_numpy.pyc in true_divide(x1, x2)\n 332 x1, x2 = _promote_shapes(x1, x2)\n 333 return lax.div(lax.convert_element_type(x1, result_dtype),\n--> 334 lax.convert_element_type(x2, result_dtype))\n 335\n 336\n\n.../jax/jax/lax.pyc in div(x, y)\n 244 def div(x, y):\n 245 r\"\"\"Elementwise division: :math:`x \\over y`.\"\"\"\n--> 246 return div_p.bind(x, y)\n 247\n 248 def rem(x, y):\n\n ... stack trace ...\n```",
"_____no_output_____"
],
[
"When this code sees a nan in the output of an `@jit` function, it calls into the de-optimized code, so we still get a clear stack trace. And we can run a post-mortem debugger with `%debug` to inspect all the values to figure out the error.\n\n⚠️ You shouldn't have the NaN-checker on if you're not debugging, as it can introduce lots of device-host round-trips and performance regressions!\n\n⚠️ The NaN-checker doesn't work with `pmap`. To debug nans in `pmap` code, one thing to try is replacing `pmap` with `vmap`.",
"_____no_output_____"
],
[
"## Double (64bit) precision\n\nAt the moment, JAX by default enforces single-precision numbers to mitigate the Numpy API's tendency to aggressively promote operands to `double`. This is the desired behavior for many machine-learning applications, but it may catch you by surprise!",
"_____no_output_____"
]
],
[
[
"x = random.uniform(random.PRNGKey(0), (1000,), dtype=jnp.float64)\nx.dtype",
"_____no_output_____"
]
],
[
[
"To use double-precision numbers, you need to set the `jax_enable_x64` configuration variable __at startup__. \n\nThere are a few ways to do this:\n\n1. You can enable 64bit mode by setting the environment variable `JAX_ENABLE_X64=True`.\n\n2. You can manually set the `jax_enable_x64` configuration flag at startup:\n\n ```python\n # again, this only works on startup!\n from jax.config import config\n config.update(\"jax_enable_x64\", True)\n ```\n\n3. You can parse command-line flags with `absl.app.run(main)`\n\n ```python\n from jax.config import config\n config.config_with_absl()\n ```\n\n4. If you want JAX to run absl parsing for you, i.e. you don't want to do `absl.app.run(main)`, you can instead use\n\n ```python\n from jax.config import config\n if __name__ == '__main__':\n # calls config.config_with_absl() *and* runs absl parsing\n config.parse_flags_with_absl()\n ```\n\nNote that #2-#4 work for _any_ of JAX's configuration options.\n\nWe can then confirm that `x64` mode is enabled:",
"_____no_output_____"
]
],
[
[
"import jax.numpy as jnp\nfrom jax import random\nx = random.uniform(random.PRNGKey(0), (1000,), dtype=jnp.float64)\nx.dtype # --> dtype('float64')",
"_____no_output_____"
]
],
[
[
"### Caveats\n⚠️ XLA doesn't support 64-bit convolutions on all backends!",
"_____no_output_____"
],
[
"## Fin.\n\nIf something's not covered here that has caused you weeping and gnashing of teeth, please let us know and we'll extend these introductory _advisos_!",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
ecc1894fae49d7268b38b0d5b431a6aa3fa2381c | 108,597 | ipynb | Jupyter Notebook | notebooks/old_ICSD_Notebooks/Parsing unique entries and the element information.ipynb | 3juholee/materialproject_ml | 6eb734fc1f92c6567c34845e917024dbb514e507 | [
"MIT"
] | null | null | null | notebooks/old_ICSD_Notebooks/Parsing unique entries and the element information.ipynb | 3juholee/materialproject_ml | 6eb734fc1f92c6567c34845e917024dbb514e507 | [
"MIT"
] | null | null | null | notebooks/old_ICSD_Notebooks/Parsing unique entries and the element information.ipynb | 3juholee/materialproject_ml | 6eb734fc1f92c6567c34845e917024dbb514e507 | [
"MIT"
] | null | null | null | 161.602679 | 39,122 | 0.872685 | [
[
[
"In this notebook we shall try to remove duplicates from the icsd csv file and then store the Elements(and their frequencies) for each unique composition.",
"_____no_output_____"
],
[
"# Deleting Duplicate Entries Based on Unique Compositions",
"_____no_output_____"
]
],
[
[
"from __future__ import division, print_function\n\nimport pylab as plt\nimport matplotlib.pyplot as mpl\nfrom pymatgen.core import Element, Composition\n\n\n%matplotlib inline",
"/usr/local/lib/python2.7/site-packages/matplotlib/font_manager.py:273: UserWarning: Matplotlib is building the font cache using fc-list. This may take a moment.\n warnings.warn('Matplotlib is building the font cache using fc-list. This may take a moment.')\n"
]
],
[
[
"We import all the data and check the unique compositions by string matching of the pymatgen formulas. We then make a list out of all the unique entries and write them to a file called Unique_ICSD.dat in the ICSD subfolder.",
"_____no_output_____"
]
],
[
[
"import csv\n\nwith open(\"ICSD/icsd-ternaries.csv\", \"r\") as f:\n csv_reader = csv.reader(f, dialect = csv.excel_tab)\n data = [line for line in csv_reader]",
"_____no_output_____"
],
[
"formulas = [line[2] for line in data]\ncompositions = [Composition(x) for x in formulas]\nunique_formulas = list(set(formulas))\nunique_compositions = set(Composition(f).formula for f in unique_formulas)",
"_____no_output_____"
],
[
"unique_data=[]\nfound_comps=[]\nfor line in data:\n form=Composition(line[2]).formula \n if form not in found_comps:\n unique_data.append(line)\n found_comps.append(form)",
"_____no_output_____"
],
[
"with open(\"ICSD/Unique_ICSD.dat\",\"w\") as f:\n for line in unique_data:\n print(\"\\t\".join(line),end='\\n',file=f)",
"_____no_output_____"
]
],
[
[
"Just to check that everything worked out fine, we check that the number of entries in the list we just wrote to file is the same as number of unique compositions found by chuck in the ICSD_ternaries notebook. ",
"_____no_output_____"
]
],
[
[
"print(\"Number of unique compositions found by Chuck:\", len(unique_compositions))\nprint(\"Number of lines we just wrote to file:\",len(unique_data))",
"Number of unique compositions found by Chuck: 42035\nNumber of lines we just wrote to file: 42035\n"
]
],
[
[
"From now on, this becomes our default datafile. Let us now try to import it in the same way as in Cleaning_spacegroups.ipynb and see if the spacegroup number parsing works. ",
"_____no_output_____"
]
],
[
[
"with open('ICSD/Unique_ICSD.dat','r') as f:\n data_1=csv.reader(f,\"excel-tab\")\n list_data1=[[element.strip() for element in row] for row in data_1]\nfor row1 in list_data1:\n row1[1]=row1[1].replace(' ','')\nlist_space=[row1[1].rstrip('Z').rstrip('S').rstrip(\"H\").rstrip('R') for row1 in list_data1]",
"_____no_output_____"
],
[
"with open(\"ICSD/spacegroups.dat\",'r') as f:\n dat=csv.reader(f,dialect='excel-tab',quoting=csv.QUOTE_NONE)\n list_dat=[element.strip() for row in dat for element in row ]\n list1=[[int(list_dat[i*2]),list_dat[i*2+1]] for i in range(int(len(list_dat)/2))]\ndict_space={}\nfor i in range(len(list1)):\n dict_space[list1[i][1]]=list1[i][0]\nwith open('ICSD/spacegroups_2.dat','r') as f1:\n f=f1.readlines()\n for line in f:\n data2=[element.strip() for element in line.split()]\n if data2[1] not in dict_space.keys():\n dict_space[data2[1]]=int(data2[0])\n \nwith open('ICSD/spacegroups_3.dat','r') as f1:\n f=f1.readlines()\n for line in f:\n data3=[element.strip() for element in line.split()]\n if data3[0] not in dict_space.keys():\n dict_space[data3[0]]=int(data3[1])",
"_____no_output_____"
],
[
"plt.figure(figsize = (8,5))\nlist_nf=[]\ncount_f=plt.array([0]*230)\ncount_not=0\nfor s in list_space:\n if s in dict_space.keys():\n #print \"Found Element in dictionary for space_group_name {0}, with space_group number {1}\".format(s,dict_space[s])\n count_f[dict_space[s]-1]+=1\n else:\n #print \"Entry not found for space group name \",s\n list_nf.append(s)\nprint(\"Found Entries={0}, Not Found Entries={1}\".format(sum(count_f),len(list_space)-sum(count_f)))\nprint(\"Found No Entries for these spacegroups\",plt.array(plt.where(count_f==0))+1)\nplt.xlabel(\"Space Group #\")\nplt.ylabel(\"Number of instances\")\nplt.title(\"Frequency distibution of data from New Data file based on unique coompositions\")\nplt.plot(plt.arange(230),count_f,'bo-')",
"Found Entries=42035, Not Found Entries=0\nFound No Entries for these spacegroups [[ 27 48 89 93 153 170 171 172 179 184 192 207 211]]\n"
],
[
"sg_counts = sorted(enumerate(count_f,1), key = lambda x: x[1], reverse = True)\nprint(\" SG Count\")\nprint(\"--- -----\")\nfor i in range(20):\n sg,count = sg_counts[i]\n print(\"{:3} {:4}\".format(sg, count))\nplt.semilogy(range(len(sg_counts)), [e[1] for e in sg_counts], \"o-\")",
" SG Count\n--- -----\n 62 3133\n225 2709\n194 2633\n227 2127\n139 2072\n166 1654\n 14 1623\n 63 1424\n 12 1365\n191 1261\n221 1159\n216 943\n 15 874\n129 863\n189 746\n 2 716\n140 621\n223 612\n 71 595\n148 587\n"
]
],
[
[
"By comparing the output from Cleaning_spacegroups.ipynb, we see that there are 5 new spacegroups that now have no instances. Also the number of instances of each of the spacegroups has dropped drastically. So some compositions clearly exist in multiple spacegroups and therefore just using compositions to mark unque entries is probably a bad idea. Let us import the mother datafile and see how many entries the newly empty spacegroups had originally.",
"_____no_output_____"
]
],
[
[
"with open('ICSD/icsd-ternaries.csv','r') as f:\n data=csv.reader(f,\"excel-tab\")\n list_data=[[element.strip() for element in row] for row in data]\nfor row in list_data:\n row[1]=row[1].replace(' ','')\nlist_space_old=[row[1].rstrip('Z').rstrip('S').rstrip(\"H\").rstrip('R') for row in list_data]",
"_____no_output_____"
],
[
"plt.figure(figsize = (8,5))\nlist_nf_old=[]\ncount_f_old=plt.array([0]*230)\ncount_not_old=0\nfor s in list_space_old:\n if s in dict_space.keys():\n #print \"Found Element in dictionary for space_group_name {0}, with space_group number {1}\".format(s,dict_space[s])\n count_f_old[dict_space[s]-1]+=1\n else:\n #print \"Entry not found for space group name \",s\n list_nf_old.append(s)\nprint(\"Found Entries={0}, Not Found Entries={1}\".format(sum(count_f_old),len(list_space_old)-sum(count_f_old)))\nprint(\"Found No Entries for these spacegroups\",plt.array(plt.where(count_f_old==0))+1)\nplt.xlabel(\"Space Group #\")\nplt.ylabel(\"Number of instances\")\nplt.title(\"Frequency distibution of data from New Data file based on unique coompositions\")\nplt.plot(plt.arange(230),count_f_old,'bo-')",
"Found Entries=68064, Not Found Entries=0\nFound No Entries for these spacegroups [[ 48 89 93 153 170 171 172 211]]\n"
],
[
"for a in [27,48,89,93,153,170,171,172,179,184,192,207,211]:\n print(a,count_f_old[a-1])",
"27 3\n48 0\n89 0\n93 0\n153 0\n170 0\n171 0\n172 0\n179 1\n184 5\n192 2\n207 1\n211 0\n"
]
],
[
[
"We see that the newly empty groups had very little data in the first place. But we definitely need to have more sophisticated methods for catching data duplication.",
"_____no_output_____"
],
[
"# Parsing Stoichiometry for every composition ",
"_____no_output_____"
]
],
[
[
"from pymatgen.matproj.rest import MPRester",
"_____no_output_____"
],
[
"def desired_element(elem):\n omit = ['Po', 'At', 'Rn', 'Fr', 'Ra']\n return not e.is_noble_gas and not e.is_actinoid and not e.symbol in omit\n#element_universe = [str(e) for e in Element if desired_element(e)]\nelement_universe = [str(e) for e in Element]\ndict_element={}\nfor i,j in enumerate(element_universe):\n dict_element[str(j)]=i\nprint(\"Number of included elements =\", len(element_universe))",
"Number of included elements = 103\n"
]
],
[
[
"Some Compositions have Deutorium and Tritium. Right now I am creating new elements entry for D and T with array indices 103 and 104. We might want to map these to Hydrogen later. In that case the cell below would be:\ndict_element['D']=dict_element['H'].value()\ndict_element['T']=dict_element['H'].value()",
"_____no_output_____"
]
],
[
[
"dict_element['D']=103\ndict_element['T']=104",
"_____no_output_____"
],
[
"print(dict_element.keys())",
"['Ru', 'Re', 'Ra', 'Rb', 'Rn', 'Rh', 'Be', 'Ba', 'Bi', 'Bk', 'Br', 'D', 'H', 'P', 'T', 'Os', 'Hg', 'Ge', 'Gd', 'Ga', 'Pr', 'Pt', 'Pu', 'C', 'Pb', 'Pa', 'Pd', 'Xe', 'Po', 'Pm', 'Ho', 'Hf', 'Mo', 'He', 'Md', 'Mg', 'K', 'Mn', 'O', 'Zr', 'S', 'W', 'Zn', 'Eu', 'Es', 'Er', 'Ni', 'No', 'Na', 'Nb', 'Nd', 'Ne', 'Np', 'Fr', 'Fe', 'Fm', 'B', 'F', 'Sr', 'N', 'Kr', 'Si', 'Sn', 'Sm', 'V', 'Sc', 'Sb', 'Se', 'Co', 'Cm', 'Cl', 'Ca', 'Cf', 'Ce', 'Cd', 'Tm', 'Cs', 'Cr', 'Cu', 'La', 'Li', 'Tl', 'Lu', 'Lr', 'Th', 'Ti', 'Te', 'Tb', 'Tc', 'Ta', 'Yb', 'Dy', 'I', 'U', 'Y', 'Ac', 'Ag', 'Ir', 'Am', 'Al', 'As', 'Ar', 'Au', 'At', 'In']\n"
],
[
"import numpy as np",
"_____no_output_____"
],
[
"stoich_array=np.zeros((len(list_data1),len(dict_element)),dtype=float)\nfor index,entry in enumerate(list_data1):\n comp=Composition(entry[2])\n temp_dict=dict(comp.get_el_amt_dict())\n #print(index,temp_dict.keys())\n for key in temp_dict.keys():\n if dict_element.has_key(key):\n stoich_array[index][dict_element[key]]= temp_dict[key]\n else:\n print(\"For line_number {0}, we did not find element {1} in formula {2} in line with entry number {3}\".format(index,key,comp.formula,entry[0]))",
"_____no_output_____"
],
[
"print(\"Entry Number Element list Number of occurances \")\nprint(\"------------ -------------- ------------------------- \")\ndict_inverse = dict ( (v,k) for k, v in dict_element.items() )\nfor i, entry in enumerate(stoich_array[0:20]):\n nzentries=np.where(entry!=0)[0]\n present_els=[dict_inverse[ent] for ent in nzentries]\n print(\"{:<13} {:<22} {:<10}\".format(i,present_els,entry[nzentries]))",
"Entry Number Element list Number of occurances \n------------ -------------- ------------------------- \n0 ['Ag', 'Ge', 'Te'] [ 8. 1. 6.]\n1 ['O', 'Pb', 'W'] [ 4. 1. 1.]\n2 ['Mo', 'Pb', 'Se'] [ 3. 0.5 4. ]\n3 ['Br', 'Cu', 'Te'] [ 1. 1. 1.]\n4 ['Fe', 'I', 'O'] [ 1. 3. 9.]\n5 ['Cd', 'N', 'O'] [ 1. 2. 6.]\n6 ['Fe', 'S', 'Si'] [ 2. 4. 1.]\n7 ['Fe', 'Ge', 'S'] [ 2. 1. 4.]\n8 ['Ga', 'O', 'Ti'] [ 3.46 48. 21.54]\n9 ['Ag', 'N', 'O'] [ 1. 1. 3.]\n10 ['Ga', 'Mn', 'Se'] [ 2. 1. 4.]\n11 ['Cr', 'P', 'S'] [ 1. 1. 4.]\n12 ['Ge', 'Pt', 'Se'] [ 1. 1. 1.]\n13 ['Cu', 'S', 'Sn'] [ 4. 4. 1.]\n14 ['Co', 'O', 'Si'] [ 2. 4. 1.]\n15 ['Cl', 'Mn', 'O'] [ 3. 8. 10.]\n16 ['Ag', 'P', 'S'] [ 4. 2. 7.]\n17 ['C', 'O', 'Os'] [ 12. 12. 3.]\n18 ['N', 'Nb', 'O'] [ 1. 1. 1.]\n19 ['N', 'O', 'Ta'] [ 1. 1. 1.]\n"
]
],
[
[
"Storing this array as a sparse csr matrix and outputting the first 10 entries just to show how the storage is done.",
"_____no_output_____"
]
],
[
[
"import scipy.sparse \nsparse_stoich=scipy.sparse.csr_matrix(stoich_array)\nprint(sparse_stoich[0:10])",
" (0, 1)\t8.0\n (0, 35)\t1.0\n (0, 90)\t6.0\n (1, 62)\t4.0\n (1, 66)\t1.0\n (1, 97)\t1.0\n (2, 53)\t3.0\n (2, 66)\t0.5\n (2, 82)\t4.0\n (3, 13)\t1.0\n (3, 24)\t1.0\n (3, 90)\t1.0\n (4, 30)\t1.0\n (4, 41)\t3.0\n (4, 62)\t9.0\n (5, 16)\t1.0\n (5, 54)\t2.0\n (5, 62)\t6.0\n (6, 30)\t2.0\n (6, 79)\t4.0\n (6, 83)\t1.0\n (7, 30)\t2.0\n (7, 35)\t1.0\n (7, 79)\t4.0\n (8, 33)\t3.46\n (8, 62)\t48.0\n (8, 92)\t21.54\n (9, 1)\t1.0\n (9, 54)\t1.0\n (9, 62)\t3.0\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
ecc18b3eb807635ecdb4a2b615ceff6cdf76a5ae | 4,981 | ipynb | Jupyter Notebook | notebook/LSST donuts.ipynb | jmeyers314/jtrace | 9149a5af766fb9a9cd7ebfe6f3f18de0eb8b2e89 | [
"BSD-2-Clause"
] | 13 | 2018-12-24T03:55:04.000Z | 2021-11-09T11:40:40.000Z | notebook/LSST donuts.ipynb | bregeon/batoid | 7b03d9b59ff43db6746eadab7dd58a463a0415c3 | [
"BSD-2-Clause"
] | 65 | 2017-08-15T07:19:05.000Z | 2021-09-08T17:44:57.000Z | notebook/LSST donuts.ipynb | bregeon/batoid | 7b03d9b59ff43db6746eadab7dd58a463a0415c3 | [
"BSD-2-Clause"
] | 10 | 2019-02-19T07:02:31.000Z | 2021-12-10T22:19:40.000Z | 26.078534 | 86 | 0.542461 | [
[
[
"import batoid\nimport numpy as np\nfrom ipywidgets import interact\nimport ipywidgets as widgets\nimport matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
],
[
"fiducial_telescope = batoid.Optic.fromYaml(\"LSST_r.yaml\")",
"_____no_output_____"
],
[
"theta_x = 0\ntheta_y = 0\nwavelength = 620e-9\n\ntelescope = fiducial_telescope.withGloballyShiftedOptic(\n 'LSST.LSSTCamera', [0,0,1e-3]\n)\n\nnx=1536\nfftpsf = batoid.fftPSF(\n telescope, theta_x, theta_y, wavelength, \n nx=nx, pad_factor=1\n)\nscale = np.sqrt(np.abs(np.linalg.det(fftpsf.primitiveVectors))) # meters\n\nextent = scale*fftpsf.array.shape[0]/2*np.r_[-1., 1., -1., 1.] # meters\nextent -= scale/2\nextent *= 1e6 # microns\n\nplt.imshow(fftpsf.array/fftpsf.array.sum(), extent=extent)\nplt.colorbar()\nplt.title(\"FFT PSF\")\nplt.show()\n\nfftpsf_sub = fftpsf.array[16::32, 16::32]\nplt.imshow(fftpsf_sub/fftpsf_sub.sum(), extent=extent)\nplt.colorbar()\nplt.title(\"FFT PSF downsampled\")\nplt.show()",
"_____no_output_____"
],
[
"theta_x = 0\ntheta_y = np.deg2rad(1.75)\nwavelength = 620e-9\n\ntelescope = fiducial_telescope.withGloballyShiftedOptic(\n 'LSST.LSSTCamera', [0,0,1e-3]\n)\n\nnx=1536\nfftpsf = batoid.fftPSF(\n telescope, theta_x, theta_y, wavelength, \n nx=nx, pad_factor=1\n)\nscale = np.sqrt(np.abs(np.linalg.det(fftpsf.primitiveVectors))) # meters\n\nextent = scale*fftpsf.array.shape[0]/2*np.r_[-1., 1., -1., 1.] # meters\nextent -= scale/2\nextent *= 1e6 # microns\n\nplt.imshow(fftpsf.array/fftpsf.array.sum(), extent=extent)\nplt.colorbar()\nplt.title(\"FFT PSF\")\nplt.show()\n\nfftpsf_sub = fftpsf.array[16::32, 16::32]\nplt.imshow(fftpsf_sub/fftpsf_sub.sum(), extent=extent)\nplt.colorbar()\nplt.title(\"FFT PSF downsampled\")\nplt.show()",
"_____no_output_____"
],
[
"wavelength = 500e-9\ntheta_x = 0\ntheta_y = np.deg2rad(1.75)\n\ntelescope = fiducial_telescope.withGloballyShiftedOptic(\n 'LSST.LSSTCamera', [0,0,1e-3]\n)\n\nnx = 1800\nnxOut = 32\ndx = 1200*1e-6/nxOut\nhuygensPSF = batoid.huygensPSF(\n telescope, theta_x, theta_y, wavelength, \n nx=nx, dx=dx, dy=dx, nxOut=nxOut\n)\n\nscale = np.sqrt(np.abs(np.linalg.det(huygensPSF.primitiveVectors))) # meters\nif huygensPSF.primitiveVectors[0,0] < 1:\n huygensPSF.array = huygensPSF.array[::-1,::-1]\n\nextent = scale*huygensPSF.array.shape[0]/2*np.r_[-1., 1., -1., 1.] # meters\nextent -= scale/2\nextent *= 1e6 # microns\n\nplt.imshow(huygensPSF.array/huygensPSF.array.sum(), extent=extent)\nplt.colorbar()\nplt.title(\"Huygens PSF\")\nplt.show()",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code"
]
] |
ecc1929757cc60c3c764eb1644a22b45db7d6851 | 30,456 | ipynb | Jupyter Notebook | A Getting Started Guide For PowerShell AML Notebooks.ipynb | x3nc0n/Azure-Sentinel-Notebooks | 56ffe87892d250624b684018530813e5870aec7a | [
"MIT"
] | null | null | null | A Getting Started Guide For PowerShell AML Notebooks.ipynb | x3nc0n/Azure-Sentinel-Notebooks | 56ffe87892d250624b684018530813e5870aec7a | [
"MIT"
] | 1 | 2021-02-24T00:16:15.000Z | 2021-02-24T00:16:15.000Z | A Getting Started Guide For PowerShell AML Notebooks.ipynb | x3nc0n/Azure-Sentinel-Notebooks | 56ffe87892d250624b684018530813e5870aec7a | [
"MIT"
] | null | null | null | 30,456 | 30,456 | 0.690439 | [
[
[
"# A Getting Started Guide for Azure Sentinel notebooks with PowerShell\r\n**Notebook Version:** 1.0<br>\r\n\r\n **Platforms Supported**:\r\n - Azure Machine Learning (AML) Notebooks \r\n\r\n**Data Sources Required**:\r\n - Log Analytics - SecurityEvent (Optional)\r\n\r\n**.Net Interactive installation is required! **:\r\n - To use this notebook, you will first need to install .Net Interactive. Instructions are located in this article -> [Azure Sentinel Notebooks + Powershell](https://aka.ms/sentinel/pwsh-notebooks).\r\n\r\n** About this notebook **: \r\n\r\nThis notebook takes you through the basics needed to get started with PowerShell notebooks that leverage Azure Sentinel data and APIs. \r\n\r\nThis notebook assumes that you are running this in an Azure Machine Learning notebooks environment created via the Azure Sentinel UI as this notebook has not yet been tested in other environments. Check the [official documentation](https://docs.microsoft.com/en-us/azure/sentinel/notebooks) on creating an Azure Sentinel AML workspace/environment to learn more.\r\n\r\nFor a notebook that provides more definitive guidance to the notebook experience, launch the [A Getting Started Guide for Azure Sentinel ML Notebooks](https://github.com/Azure/Azure-Sentinel-Notebooks/blob/master/A%20Getting%20Started%20Guide%20For%20Azure%20Sentinel%20ML%20Notebooks.ipynb) notebook from the Azure Sentinel notebook UI. This notebook provides a step-by-step overview of the notebook experience as well as some tips and tricks on how to get the most out of your Jupyter notebook experience.\r\n\r\nFor more information as to why Juypter for security investigations, check out this excellent article [Why Use Jupyter for Security Investigations](https://techcommunity.microsoft.com/t5/azure-sentinel/why-use-jupyter-for-security-investigations/ba-p/475729)\r\n\r\nLastly, don't forget to install .Net Interactive to use this notebook!",
"_____no_output_____"
],
[
"---\r\n\r\n### Using Azure Notebooks\r\nFor this notebook we are going to be using PowerShell, so you will need to select the **\".NET (Powershell)\"** kernel in the dropdown on the top right corner of the notebook UI.\r\n\r\nOnce you have selected the right kernel, you are ready to move onto the next code cell.\r\n\r\n",
"_____no_output_____"
],
[
"---\r\n## Installing the required PowerShell modules\r\nCode cells behave in the same way your code would in other environments, so you need to remember about common coding practices such as variable initialization and module/library imports. For this notebook you only need to make sure to install the required PowerShell modules since those are not installed by default.",
"_____no_output_____"
]
],
[
[
"##Installs modules necessary to run notebook\r\nInstall-Module Az.Compute,Az.Resources,Az.OperationalInsights,powershell-yaml -Force",
"_____no_output_____"
]
],
[
[
"---\r\n## Working with PowerShell within a Jupyter notebook - The Basics \r\nIn this section we added a few tips and tricks to using PowerShell in a notebook!\r\n- While there are differences between running PowerShell in a notebook environment vs a local machine, most features are support.\r\n- If you plan on porting your existing scripts, there are some modifications might need to be made to account for these differences.\r\n- Due to an additional UI+kernel intecepting your PowerShell commands, be sure to not overload the output as this can cause a chokepoint. \r\n- Also, since the output goes to a white (or black if darkmode is set) UI, some output colors might need to be modified to be visible.\r\n<br>\r\n<br>\r\n",
"_____no_output_____"
],
[
"#### Work with the display\r\n\r\n",
"_____no_output_____"
]
],
[
[
"##Get more details on your PowerShell environment\r\n$PSVersionTable",
"_____no_output_____"
],
[
"##Output Markdown\r\nOut-Display \"**THIS IS BOLD** _ITALICS_\" -MimeType text/markdown\r\n\r\n##Set foreground color\r\n$host.UI.RawUI.ForegroundColor = [System.ConsoleColor]::Blue\r\n\r\n##Default output colors can be changed \r\n$Host.PrivateData.WarningBackgroundColor = \"White\"\r\n$Host.PrivateData.WarningForegroundColor = \"Black\"\r\n\r\n##Change output color inline\r\nWrite-Host \"Lets get started ...\" -ForegroundColor Blue -BackgroundColor White\r\n\r\n##You can write-host with the -nonewlinke flag\r\nWrite-Host \"Hello \" -NoNewline -ForegroundColor Red\r\nWrite-Host \"World!\" -ForegroundColor Blue",
"_____no_output_____"
]
],
[
[
"#### Output to HTML or markdown. ",
"_____no_output_____"
]
],
[
[
"##Output HTML\r\n#!html\r\n<b>Hello in HTML!</b>",
"_____no_output_____"
],
[
"#!markdown\r\n\r\nWrite a **list** ...\r\n* first item\r\n* second item\r\n\r\n...or a _table_...\r\n\r\n|CallerIP |PrincipalString |\r\n|---------|--------|\r\n|10.1.1.1 |[email protected] |\r\n|10.1.1.2 |[email protected] |",
"_____no_output_____"
]
],
[
[
"#### Output from C# and visa versa. Yes, switching between DotNet languages is possible too",
"_____no_output_____"
]
],
[
[
"#!csharp\r\nvar x=\"Hello using C#!\";\r\nConsole.WriteLine(x);\r\n\r\n#!pwsh\r\n$x = \"Hello using PowerShell!\"\r\nWrite-Host $x\r\n",
"_____no_output_____"
]
],
[
[
"#### Download content",
"_____no_output_____"
]
],
[
[
"##Download IOCs from the internet and use them in your investigation/hunts\r\n$ips = (Invoke-WebRequest 'https://raw.githubusercontent.com/parthdmaniar/coronavirus-covid-19-SARS-CoV-2-IoCs/master/IPs').content\r\n$ips",
"_____no_output_____"
]
],
[
[
"#### Prompt for information",
"_____no_output_____"
]
],
[
[
"##You can ask for user input\r\nWrite-Host \"Don't forget that execution of cells will block on prompts until you submit!\"\r\n$name = Read-Host -Prompt \"What is the server name you would like to investigate? \"\r\n$name",
"_____no_output_____"
]
],
[
[
"#### Use progress bars or run commands in parallel",
"_____no_output_____"
]
],
[
[
"##You can use a progress bar\r\nFor ($i=0; $i -le 100; $i++) {\r\n Write-Progress -Id 1 -Activity \"Parent work progress\" -Status \"Current Count: $i\" -PercentComplete $i -CurrentOperation \"Counting ...\"\r\n \r\n For ($j=0; $j -le 10; $j++) {\r\n Start-Sleep -Milliseconds 5\r\n Write-Progress -Parent 1 -Id 2 -Activity \"Child work progress\" -Status \"Current Count: $j\" -PercentComplete ($j*10) -CurrentOperation \"Working ...\"\r\n }\r\n \r\n if ($i -eq 50) {\r\n Write-Host \"Doing the work around here...\" -Foreground DarkBlue\r\n \"Output goes here...\"\r\n }\r\n}",
"_____no_output_____"
],
[
"##If you have long running task, that prints output to the screen\r\n##use the -Parallel flag to run them in parallel, vastly improving performance.\r\n##Example below runs one loop sequentially while the second example runs them in parallel\r\n\r\nWrite-Host \"Number of seconds running commands sequentially: \" -nonewline\r\n(Measure-Command { \r\n 1..5 | ForEach-Object -Process {write-output \"This is number $_\"; sleep 2}\r\n}).Seconds\r\n\r\nWrite-Host \"Number of seconds running commands in parallel: \" -nonewline\r\n(Measure-Command { \r\n 1..5 | ForEach-Object -Parallel {write-output \"This is number $_\"; sleep 2}\r\n}).Seconds",
"_____no_output_____"
]
],
[
[
"---\r\n## Azure Sentinel Configuration\r\nOnce we have set up our Jupyter environment with the libraries that we'll use in the notebook, we need to make sure we have some configuration in place. Some of the notebook components need addtional configuration to connect to external services (e.g. API keys to retrieve Threat Intelligence data). This includes configuration for connection to our Azure Sentinel workspace.\r\nFor this notebook, we simply import the configuration from the config.json file that is created in your notebook explorer folder when you launch the notebook from the Azure Sentinel UI.\r\n<br>\r\n",
"_____no_output_____"
]
],
[
[
"##Get your configuration file settings\r\n$nbcontentpath = \"config.json\"\r\nif(!(test-path $nbcontentpath)){\r\n write-host \"INFO: Your configuration path ($nbcontentpath) could not be located.\"\r\n write-host \"INFO: Attempting to build the file path explicitly. If this continues to be a problem, run 'dir' within the cell to find the current working directory and update the `$nbcontentpath variable accordingly.\" \r\n $username = read-host \"Enter the user name used for the notebook file explorer (the name of the top level folder):\"\r\n $nbcontentpath = \"users\\$username\\config.json\"\r\n}\r\n\r\n##Path fix in case you picked up the cookie cutter configuration file (if you cloned repo from GitHub in terminal)\r\nif(test-path $nbcontentpath){\r\n $content = gc $nbcontentpath | ?{$_ -match \"cookiecutter\"}\r\n if($content.Length -gt 0) {\r\n $nbcontentpath = \"..\\\" + $nbcontentpath\r\n } \r\n}\r\n\r\ntry {\r\n $nbconfigcontent = Get-Content $nbcontentpath -ErrorAction Stop \r\n}\r\ncatch {\r\n write-host \"ERROR: Your configuration path ($nbcontentpath) could not be located. Please fix before continuing further.\" \r\n}\r\n\r\n##Set variables you will use throughout the notebook\r\n$tenantId = ($nbconfigcontent | ConvertFrom-Json).tenant_id\r\n$subscriptionId = ($nbconfigcontent | ConvertFrom-Json).subscription_id\r\n$resourceGroup = ($nbconfigcontent | ConvertFrom-Json).resource_group\r\n$workspaceName = ($nbconfigcontent | ConvertFrom-Json).workspace_name\r\n$workspaceId = ($nbconfigcontent | ConvertFrom-Json).workspace_id\r\n\r\nWrite-Host \"SubscriptionId: \" $subscriptionId \r\nWrite-Host \"TenantId: \" $tenantId\r\nWrite-Host \"WorkspaceId: \" $workspaceId\r\nWrite-Host \"workspaceName: \" $workspaceName ",
"_____no_output_____"
]
],
[
[
"---\r\n## Connect to your Azure Sentinel workspace\r\nOnce you have configured your notebook, now you can connect to your workspace.\r\n\r\n> **Note**: <br>\r\n- We changed the default foreground colors in case you are using the \"Light\" notebook UI theme, since the yellow output will be hard to see. Feel free to modify.\r\n<br>\r\n<br>\r\n",
"_____no_output_____"
]
],
[
[
"#Change the default colors used for PowerShell warnings as they make the Connect-AzAccount output difficult to see \r\n$Host.PrivateData.WarningBackgroundColor = \"White\"\r\n$Host.PrivateData.WarningForegroundColor = \"Black\"\r\n\r\n##Connect to selected subscription\r\nConnect-AzAccount\r\nSelect-AzSubscription -SubscriptionId $subscriptionId -TenantId $tenantId",
"_____no_output_____"
],
[
"##Configure the Log Analytics workspace\r\n$workspace = $null\r\n$workspaces = Get-AzOperationalInsightsWorkspace -ResourceGroupName $resourceGroup\r\nif($workspaces.Length -gt 1) {\r\n Write-Host \"INFO: Multiple workspaces detected.\" \r\n foreach($wksp in $workspaces){\r\n if($wksp.Name -eq $workspaceName) {\r\n $workspace = $wksp\r\n } \r\n } \r\n}\r\nelse {\r\n $workspace = $workspaces \r\n}\r\nWrite-Host \"INFO: Ensure that the workspace -- {\"$workspace.Name\"} is the intended target workspace before continuing to the next cell.\" \r\n$workspace\r\n",
"_____no_output_____"
]
],
[
[
"---\r\n## Access your hunting queries \r\nUtilize the savedsearch API to download and run your hunting queries",
"_____no_output_____"
]
],
[
[
"##Query your workspace using the savedsearches API\r\n$savedSearchQueries = (Get-AzOperationalInsightsSavedSearch -ResourceGroupName $resourceGroup -WorkspaceName $workspaceName).value\r\n$huntingQueries = $savedSearchQueries | %{$_.properties } | ? {$_.Category -match \"Hunting Queries\"}\r\nWrite-Host \"Displaying the first 5 hunting queries...\"\r\n0..4 | foreach {Write-Host \"Hunting Query Name: \" -nonewline;$huntingQueries[$_].DisplayName}",
"_____no_output_____"
]
],
[
[
"---\r\n## Access your Azure Sentinel incidents \r\nUtilize the Azure Sentinel API to download metadata regarding your incidents\r\n\r\n> **Note**: It could take a few seconds to download all of your incidents!\r\n<br>\r\n<br>",
"_____no_output_____"
]
],
[
[
"##Build resource id\r\n$worksapceId = \"subscriptions/${subscriptionId}/resourceGroups/${resourceGroup}/providers/Microsoft.OperationalInsights/workspaces/${workspaceName}\"\r\n$incidentsResource = $worksapceId + \"/\" + \"providers/Microsoft.SecurityInsights/incidents\"\r\n\r\n##Get incidents\r\n$incidents = Get-AzResource -ResourceId $incidentsResource -ApiVersion \"2019-01-01-preview\"\r\n\r\n##Only display a few incidents as the notebook has to translate the PowerShell output into the Jupyter UI\r\n0..4 | foreach {Write-Host \"Incident Number {$_}: \" -nonewline;$incidents[$_].Properties}",
"_____no_output_____"
],
[
"##Retrieve all of your incident counts and day they were created\r\n$incidentsforgraph = $incidents | % {$_.properties} | select Title, Description, Severity, Status, Owner, createdTimeUtc, relatedAnalyticRuleIds, incidentUrl | ? {(get-date $_.createdTimeUtc) -gt (get-date).AddDays(-31d)} \r\n\r\n##Add formated property for the date they were created to make it easier to create graphs\r\nforeach($incident in $incidentsforgraph)\r\n{\r\n $incident | Add-Member -MemberType NoteProperty -Name NewDate -Value (get-date $incident.createdTimeUtc -format \"yyyy-MM-dd\") -Force\r\n}\r\n\r\n##Retrieve all of your incident counts and day they were created for the last 30 days\r\n$openIncidents = $incidentsforgraph | ? {$_.Status -ne \"Closed\"} \r\n$closedIncidents = $incidentsforgraph | ? {$_.Status -eq \"Closed\"} \r\nWrite-Host \"Total incidents (last 30 days) : \" $incidentsforgraph.count\r\nWrite-Host \"Total Open Incidents (last 30 days) : \" $openIncidents.count\r\nWrite-Host \"Total Closed Incidents (last 30 days) : \" $closedIncidents.count\r\n\r\n",
"_____no_output_____"
]
],
[
[
"---\r\n## Chart your incidents using XPlot\r\nCharts can be rendered using [Xplot.Plotly](https://fslab.org/XPlot/). \r\nHere is a simple example on how to combine your incident data with XPlot.\r\n<br>\r\n<br>",
"_____no_output_____"
]
],
[
[
"##At least one of each incident type (open or closed) must exists to run this cell\r\nif(($closedIncidents -eq $null) -or ($openIncidents -eq $null)){\r\n Write-Host \"You need at least one instance of each incident type (open or closed) to render the chart\"\r\n}\r\nelse {\r\n ##Create open incident plots\r\n $openSeries = [Graph.Scatter]::new()\r\n $openSeries.name = \"Open Incidents\"\r\n $openSeries.x = @(($openIncidents | group-object -Property NewDate).Name | % {$_.ToString()})\r\n $openSeries.y = (($openIncidents | group-object -Property NewDate | Select Count | %{$_.Count})) \r\n\r\n ##Create closed incident plots\r\n $closeSeries = [Graph.Scatter]::new()\r\n $closeSeries.name = \"Closed Incidents\"\r\n $closeSeries.x = @(($closedIncidents | group-object -Property NewDate).Name | % {$_.ToString()})\r\n $closeSeries.y = (($closedIncidents | group-object -Property NewDate | Select Count | %{$_.Count})) \r\n\r\n ##Display chart\r\n $chart = @($openSeries, $closeSeries) | New-PlotlyChart -Title \"Open vs Closed Incidents\"\r\n Out-Display $chart\r\n}",
"_____no_output_____"
]
],
[
[
"---\r\n## Query your Azure Sentinel Data\r\nData within your Azure Sentinel workspace can be manipulated.\r\nMy favorite part about working with notebooks is that I can extract values from one query or API call and use them as inputs to another query and/or API.\r\n\r\n> **Note**: \r\n- The query below requires the Heartbeat table. This was chosen as an example since it will reside in all Azure Sentinel workspaces.\r\n- For a more 'real world' example, pick another table or add your own query.\r\n<br>\r\n<br>",
"_____no_output_____"
]
],
[
[
"##Add a timeframe variable\r\n$timeframe = $null\r\ndo {\r\n $timeframe = Read-Host \"How many days back would you like to query the data? (you must enter an integer for number of days):\"\r\n $timeframe = $timeframe -as [int]\r\n if ($timeframe -eq $null) { write-host \"You must enter a numeric value\" }\r\n}\r\nuntil ($timeframe -ne $null)\r\nwrite-host \"You entered: $timeframe days as the input timespan.\"\r\n\r\n\r\n##Query Heartbeat table\r\n$query = \"Heartbeat | where TimeGenerated >= ago($timeframe\" + \"d\" + \") | take 10\"\r\nWrite-Host \"Query to run: \" $query\r\n##Run query and add results to object. Now you can use object to display data or graph\r\n$queryResults = Invoke-AzOperationalInsightsQuery -Workspace $Workspace -query $query\r\n#0..1 | foreach {Write-Host \"Result Number {$_}: \";$queryResults.results[$_] }\r\n$queryResults.Results | select TimeGenerated, ComputerIP, Computer, `\r\n OSType, RemoteIPLongitude, RemoteIPLatitude, RemoteIPCountry, `\r\n Resource, ResourceType, ComputerEnvironment | Format-Table \r\n",
"_____no_output_____"
]
],
[
[
"---\r\n## Match Azure Sentinel data with IOCs\r\nYou can also join data from external sources...\r\n\r\n<br>\r\n<br>",
"_____no_output_____"
]
],
[
[
"##Using the example from an earlier cell, collect a list of IOCs and join them with IPs from a query\r\n##Download IOCs from the internet and use them in your investigation/hunts\r\n$ips = ((Invoke-WebRequest 'https://raw.githubusercontent.com/parthdmaniar/coronavirus-covid-19-SARS-CoV-2-IoCs/master/IPs').content).ToString() -Split \"`n\" \r\n\r\n\r\n##Query the Log Analytics table\r\n$query = @\"\r\n Heartbeat \r\n | where TimeGenerated >= ago(1d) \r\n | summarize RecordCount=count() by ComputerIPs=ComputerIP \r\n\"@\r\n\r\n##Run query and add results to object. Now you can use object to display data or graph\r\n$queryResults = Invoke-AzOperationalInsightsQuery -Workspace $Workspace -query $query\r\n$computerips=($queryResults.Results | Group-Object ComputerIPs).Group.ComputerIPs\r\n\r\n##Compare IOC IPs to IPs from your logs\r\nWrite-Host \"Example of comparing IPs to IOCs...\"\r\nforeach($computerip in ($computerips | select -first 10 )) {\r\n for($i=0;$i -lt $ips.Length;$i++) {\r\n write-host \"IOC-IP:\" $ips[$i] \"does not match IP:\" $ips[$i] \"from logs!\"\r\n if($i -gt 3) {break}\r\n }\r\n}\r\n\r\n",
"_____no_output_____"
]
],
[
[
"---\r\n## Enriching data\r\n\r\nNow that we have seen how to query for data, we can see how you can enrich data with additional data sources. \r\n- For this we are going to use an external threat intelligence provider to give us some more details about a URL.\r\n- The example cell below assuming you have a VirusTotal (VT) key in your yaml configuration file\r\n- If you don't already have a VirusTotal API key, signup [here](https://www.virustotal.com/gui/join-us).\r\n- If not, you can either hardcode the VT key in the cell or run the [A Getting Started Guide for Azure Sentinel ML Notebooks](https://github.com/Azure/Azure-Sentinel-Notebooks/blob/master/A%20Getting%20Started%20Guide%20For%20Azure%20Sentinel%20ML%20Notebooks.ipynb) notebook for instructions on how to create the configuration file with your VirusTotal key included. \r\n<br/>",
"_____no_output_____"
]
],
[
[
"##Get your configuration file settings\r\n$configFileSuccess=$false\r\n$yamlcontentpath = \"msticpyconfig.yaml\"\r\n$yaml = $null\r\nif(!(test-path $yamlcontentpath)) {\r\n write-host \"INFO: Your configuration path ($yamlcontentpath) could not be located.\"\r\n write-host \"INFO: Attempting to build the file path explicitly. If this continues to be a problem, run 'dir' within the cell to find the current working directory and update the `$nbcontentpath variable accordingly.\" \r\n $username = read-host \"Enter the user name used for the notebook file explorer:\"\r\n $yamlcontentpath = \"users\\$username\\msticpyconfig.yaml\"\r\n}\r\n\r\n##Path fix in case you picked up the cookie cutter configuration file (if you cloned repo from GitHub in terminal)\r\nif(test-path $yamlcontentpath){\r\n $content = gc $yamlcontentpath #| ? {$_ -match \"your-workspace-id\"}\r\n if($content.Length -gt 0) {\r\n $yamlcontentpath = \"..\\\" + $yamlcontentpath\r\n } \r\n}\r\n\r\n##Set Yaml content\r\ntry {\r\n $configFileSuccess=$true\r\n $yamlcontent = Get-Content $yamlcontentpath -ErrorAction Stop -Raw\r\n $yaml = ConvertFrom-Yaml $yamlcontent\r\n}\r\ncatch {\r\n $configFileSuccess=$false\r\n write-host \"ERROR: Your configuration path ($yamlcontentpath) could not be located. Please fix or hardcode the key before continuing further.\" \r\n}\r\n\r\n\r\n##Harcode your key here if you haven't configured the yaml configuration file\r\n##$APIKey = \"<>\"\r\n\r\n##Set your API key and you are good to go\r\n$APIKey = $yaml.TIProviders.VirusTotal.Args.AuthKey\r\nif($APIKey -eq $null){\r\n $configFileSuccess = $false\r\n}\r\nelse {\r\n $configFileSuccess = $true\r\n}\r\n\r\nif($configFileSuccess) {\r\n write-host \"INFO: Your VT key was correctly configured. \" \r\n $yaml.TIProviders.VirusTotal\r\n}\r\nelse {\r\n write-host \"ERROR: Your VT key was not correctly configured. Please fix before continuing further.\" \r\n}",
"_____no_output_____"
],
[
"##Input VT URL and Key\r\n##Ideally, it would be better to retrieve the key from msticpyconfig.yaml\r\n##$APIKey = '<VT_KEY_HERE>'\r\n\r\n$Resource = Read-Host \"Enter the URL you would like to submit (example: support.btcsupports.com):\"\r\n\r\n##Test URL\r\n##$Resource = 'http://support.btcsupports.com/'\r\n\r\n##Setup VT URI\r\n$URI = 'https://www.virustotal.com/vtapi/v2/url/report'\r\n$QueryResources = $Resource -join ','\r\n$OldEAP = $ErrorActionPreference\r\n$ErrorActionPreference = 'SilentlyContinue'\r\n$Body = @{'resource'= $QueryResources; 'apikey'= $APIKey; 'scan'=$scanurl}\r\n\r\n\r\n# Start building parameters for REST Method invokation.\r\n$Params = @{}\r\n$Params.add('Body', $Body)\r\n$Params.add('Method', 'Get')\r\n$Params.add('Uri',$URI)\r\n$Params.Add('ErrorVariable', 'RESTError')\r\n$ReportResult = Invoke-RestMethod @Params\r\n\r\n$ErrorActionPreference = $OldEAP\r\n\r\nif ($RESTError)\r\n{\r\n if ($RESTError.Message.Contains('403'))\r\n {\r\nthrow 'API key is not valid.'\r\n }\r\n elseif ($RESTError.Message -like '*204*')\r\n {\r\nthrow 'API key rate has been reached.'\r\n }\r\n else\r\n {\r\nthrow $RESTError\r\n }\r\n}\r\n\r\nforeach ($URLReport in $ReportResult)\r\n{\r\n $URLReport.pstypenames.insert(0,'VirusTotal.URL.Report')\r\n Write-host \"Resource:\" $URLReport.resource\r\n Write-host \"Last Scan:\" $URLReport.scan_date\r\n Write-host \"VT Link:\" $URLReport.permalink\r\n Write-host \"Positive Scans:\" $URLReport.positives\r\n Write-host \"Total Scans:\" $URLReport.total \r\n $URLReport\r\n}\r\n",
"_____no_output_____"
]
],
[
[
"---\r\n## Get your watchlist aliases and data \r\nRetrieve your watchlist aliases and data by running the code below\r\n> **Note**: You must be part of the private preview program to use this feature. Sign-up at [www.aka.ms/SecurityPrP](www.aka.ms/SecurityPrP) to get started!\r\n\r\n",
"_____no_output_____"
]
],
[
[
"##Retrieve watchlist results\r\n$queryResults = $null\r\n$watchlistalias = read-host \"Enter your watchlist alias to get the results:\"\r\n$query = \"_GetWatchlist('$watchlistalias')\"\r\n$queryResults = Invoke-AzOperationalInsightsQuery -Workspace $Workspace -query $query\r\n$queryResults.Results | Select Watchlistitem | select -first 100",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
ecc19881dc514c8146834fc90379e1374deea751 | 12,279 | ipynb | Jupyter Notebook | _notebooks/2020-06-01-automatically-restart-docker-after-reboot-with-service.ipynb | jonwhittlestone/words | 8d8ea018627a3cd3097a71f43b31db707a14af13 | [
"Apache-2.0"
] | null | null | null | _notebooks/2020-06-01-automatically-restart-docker-after-reboot-with-service.ipynb | jonwhittlestone/words | 8d8ea018627a3cd3097a71f43b31db707a14af13 | [
"Apache-2.0"
] | null | null | null | _notebooks/2020-06-01-automatically-restart-docker-after-reboot-with-service.ipynb | jonwhittlestone/words | 8d8ea018627a3cd3097a71f43b31db707a14af13 | [
"Apache-2.0"
] | null | null | null | 38.613208 | 410 | 0.575128 | [
[
[
"# Automatically restart docker containers after reboot\n> Creating a cloud server and the service that restarts a web app when rebooted.\n\n- toc: true \n- badges: false\n- comments: false\n- categories: [systemd, automation]\n- show_image: true\n- image: images/on.png",
"_____no_output_____"
],
[
"# The Problem\n\nAs part of Covid-19 relief, DigitalOcean donated some free credit for me to work on a local food delivery scheme.\n\nI need to get most value for money by making that credit go as far as possible. It would also be nice to minimise power consumption.\n\n\n\n# The Solution\n\nThe server should be powered-down outside of operating hours and turned back on before start of business. This can be done using the cloud provider's control panel.\n\nTo avoid manual work starting the web app, a service is needed to bring the containers back online when the droplet is swtiched on.\n\nCovered in this article is the process for using the DigitalOcean API to create a droplet with the requisite `user_data` for creating the `systemd` service to start containers at boot time.\n\n**TLDR; Have a look at the [companion repo.](https://github.com/jonwhittlestone/scheduled-serverless-startup). It contains an example dockerized web app and the shell scripts for starting containers and creating the service.**\n\nNot covered in this article is the process to automate the power down and up to a schedule. This is covered in a subsequent article.\n\n\n## Prerequisites\n\n* A Digital Ocean account (free trial available)\n* [Generate an access token](https://www.digitalocean.com/docs/apis-clis/api/) for accessing the DigitalOcean API\n* Add the token to your environment\n\n $ export DIGITAL_OCEAN_ACCESS_TOKEN=XXXXXXXX\n* `jq` installed to format JSON responses\n * [Download JQ](https://stedolan.github.io/jq/download/) for your OS",
"_____no_output_____"
],
[
"## Create a DigitalOcean droplet (optional)\n\n\nIf you already have a web server, with an app, move to section, ['Create a systemd service.'](#Create-a-systemd-service)\n\nIf you do not already have a web server, launch a Droplet with requisite SSH access.\n\n\n### cURL to create the droplet\n\nThis cURL statement creates an Ubuntu 18.04 server in London. The `user_data` key in the payload is used for defining various statements to execute once the server is created. In this case we are cloning the [repo](https://github.com/jonwhittlestone/scheduled-serverless-startup) containing the dockerized app, starting it, and creating the systemd service to restart the app when the server boots up.\n\n $ curl -X POST \\\n -H 'Content-Type: application/json' \\\n -H 'Authorization: Bearer '$DIGITAL_OCEAN_ACCESS_TOKEN'' \\\n -d '{\"name\":\"scheduled-serverless\",\"region\":\"lon1\",\"size\":\"s-2vcpu-4gb\",\"image\":\"docker-18-04\", \"user_data\":\n \"#!/bin/bash\n apt-get update\n apt-get upgrade -y\n git clone https://github.com/jonwhittlestone/scheduled-serverless-startup.git /root/scheduled-serverless-startup\n sh /root/scheduled-serverless-startup/start-containers.sh\n sh /root/scheduled-serverless-startup/create-service.sh\"}' \\\n \"https://api.digitalocean.com/v2/droplets\" \n\n### SSH into your new droplet\n\nYou will be emailed your root password. \nAfter you SSH in using the provided password, you will be asked to change it.\n\n\n\n\n### Test the web app is running\n\nThe app is running with Docker on port 80, so it's simply a case of: \n \n root@scheduled-serverless:~# curl localhost\n\n A Howapped Project.\n \n### Test the service is running\n\nRestart your server with\n \n root@scheduled-serverless:~# sudo reboot\n \nAnd then ssh and repeat the cURL statement to the web service\n\n (base) ➜ ~ ssh [email protected] curl localhost\n [email protected]'s password: \n % Total % Received % Xferd Average Speed Time Time Time Current\n Dload Upload Total Spent Left Speed\n 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0\n A Howapped Project.\n\n 100 22 100 22 0 0 1294 0 --:--:-- --:--:-- --:--:-- 1294\n",
"_____no_output_____"
],
[
"## Create a systemd service\n\nUbuntu's init system is called `systemd` and various flavours of Linux may have differing init systems.\n\n### Scripting the starting of the web app\n\nWe need to define what should be automated which is starting the containers.\n\nIn this case, I have an example dockerized app defined in the [companion repo](https://github.com/jonwhittlestone/scheduled-serverless-startup), so let's clone that.\n\nIf this directory is present (because it has been previously cloned), then just pull the latest changes.\n\n```\n#!/bin/bash\n\nif [ -d \"/root/scheduled-serverless-startup\" ] \nthen\n git pull origin master\nelse\n cd /root/scheduled-serverless-startup\n git clone https://github.com/jonwhittlestone/scheduled-serverless-startup.git /root/scheduled-serverless-startup\nfi\ncd /root/scheduled-serverless-startup/app\ndocker-compose up -d\n```\n\nLastly, we start containers with `docker-compose`\n\n### Using `systemctl` to enable the service\n\nUsing the interface [`systemctl`](https://www.linode.com/docs/quick-answers/linux-essentials/introduction-to-systemctl/) we can manage the init system. Each service is called a unit file. This means loading a service, [enabling at boot](https://www.linode.com/docs/quick-answers/linux-essentials/introduction-to-systemctl/#enabling-a-service-at-boot) and restarting.\n\nOn an Ubuntu system, you may inspect the running services:\n\n```\n$ systemctl status | head\n● madebyjon\n State: running\n Jobs: 0 queued\n Failed: 0 units\n Since: Mon 2020-06-08 05:56:42 BST; 1 day 2h ago\n CGroup: /\n ├─3770 bpfilter_umh\n ├─user.slice\n │ └─user-1000.slice\n │ ├─[email protected]\n\n```\n\n\nThe following [shell script](https://github.com/jonwhittlestone/scheduled-serverless-startup/blob/master/create-service.sh) creates the unit file, enables it at boot and starts the service.\n\n```\n#!/bin/bash\ntouch /etc/systemd/system/howapped.service\ncat > /etc/systemd/system/howapped.service<<-EOF\n [Unit]\n Description=HowappedProjectStartOnBoot\n After=network.target\n [Service]\n Type=simple\n User=root\n WorkingDirectory=/root/scheduled-serverless-startup\n ExecStart=/bin/sh /root/scheduled-serverless-startup/start-containers.sh\n Restart=on-abort\n [Install]\n WantedBy=multi-user.target\nEOF\nsystemctl daemon-reload\nsystemctl enable howapped.service\nsystemctl restart howapped.service\n```",
"_____no_output_____"
],
[
"## Enable the systemd service\n\nThe below excerpt verifies we have the working directory created. \n\n\n```\nroot@scheduled-serverless:~/scheduled-serverless-startup# ls\nREADME.md app create-service.sh\nVagrantfile cloud-config.yaml start-containers.sh\nroot@scheduled-serverless:~/scheduled-serverless-startup# pwd\n/root/scheduled-serverless-startup\n```\n\nAnd this runs the shell script to create the unit file and enable it.\n\n```\nroot@scheduled-serverless:~/scheduled-serverless-startup# sh create-service.sh \nCreated symlink /etc/systemd/system/multi-user.target.wants/howapped.service → /etc/systemd/system/howapped.service.\n\n```\n",
"_____no_output_____"
],
[
"## Test it\n\nWe will use the CURL statement to find the ID of our droplet, so that we can then use a CURL statement to power down the machine.\n\n```\n$ curl \\\n -H 'Content-Type: application/json' \\\n -H 'Authorization: Bearer '$DIGITAL_OCEAN_ACCESS_TOKEN'' \\\n \"https://api.digitalocean.com/v2/droplets?name=scheduled-serverless\" | jq '.droplets[] | {id:.id, name:.name, status: .status}'\n \n{\n \"id\": 195393249,\n \"name\": \"scheduled-serverless\",\n \"status\": \"on\"\n}\n\n\n# power it down\n$ curl -X POST \\\n -H 'Content-Type: application/json' \\\n -H 'Authorization: Bearer '$DIGITAL_OCEAN_ACCESS_TOKEN'' \\\n -d '{\"type\":\"power_off\"}' \\\n \"https://api.digitalocean.com/v2/droplets/195393249/actions\" | jq '.[] | {id:.id, status:.status, type:.type}'\n\n```\n\nWe power it back up:\n\n```\n$ curl -X POST \\\n -H 'Content-Type: application/json' \\\n -H 'Authorization: Bearer '$DIGITAL_OCEAN_ACCESS_TOKEN'' \\\n -d '{\"type\":\"power_on\"}' \\\n \"https://api.digitalocean.com/v2/droplets/195393249/actions\" | jq '.[] | {id:.id, status:.status, type:.type}'\n\n{\n \"id\": 953153688,\n \"status\": \"in-progress\",\n \"type\": \"power_on\"\n}\n\n```\n\n\nAnd verify our app is running.\n\n```\n$ ssh [email protected] curl localhost\[email protected]'s password: \n % Total % Received % Xferd Average Speed Time Time Time Current\n Dload Upload Total Spent Left Speed\n 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0\nA Howapped Project.\n\n```",
"_____no_output_____"
],
[
"## Clean up\n\nIf you were following along by creating a DigitalOcean droplet, you may wish to power down or destroy the machine if not in use.\n\n",
"_____no_output_____"
],
[
"## Resources\n\n* [Linode - Introduction to Systemctl](https://www.linode.com/docs/quick-answers/linux-essentials/introduction-to-systemctl/)",
"_____no_output_____"
]
]
] | [
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
ecc19c2c8cf2c5808c4e121787e1a18edbc360e9 | 39,367 | ipynb | Jupyter Notebook | workspace_setup/tutorial_files/3_analogbase.ipynb | ucb-art/gpdk045 | bc1af818f220361d9480f1480a116b5cbd533df6 | [
"BSD-3-Clause"
] | null | null | null | workspace_setup/tutorial_files/3_analogbase.ipynb | ucb-art/gpdk045 | bc1af818f220361d9480f1480a116b5cbd533df6 | [
"BSD-3-Clause"
] | 1 | 2018-09-27T10:18:15.000Z | 2018-09-27T17:40:22.000Z | workspace_setup/tutorial_files/3_analogbase.ipynb | ucb-art/gpdk045 | bc1af818f220361d9480f1480a116b5cbd533df6 | [
"BSD-3-Clause"
] | 3 | 2019-02-17T22:05:47.000Z | 2020-06-15T16:20:19.000Z | 60.10229 | 1,733 | 0.619072 | [
[
[
"# AnalogBase\nIn this module, you will learn the basics of `AnalogBase`, and how to design a source-follower layout generator using AnalogBase.\n",
"_____no_output_____"
],
[
"## What is AnalogBase?\n<img src=\"bootcamp_pics/3_analogbase/analogbase_1.PNG\" alt=\"Drawing\" style=\"width: 200px;\" />\n`AnalogBase` is one of several \"layout floorplan\" classes that allows designers to easily develop process-portable layout generator for various electromigration-constrained circuits. To do so, `AnalogBase` draws rows of transistors with substrate contacts on the top-most and bottom-most rows, as shown in the figure above. In this floorplan, the number of current-carrying wires scales naturally with number of fingers, which is optimal for circuits with large bias currents.\n\nBy convention, `AnalogBase` draws $N$ rows of NMOS (labeled as `nch`) and $P$ rows of PMOS (labeled as `pch`), with $N$ and $P$ being nonnegative integers, so you can only draw NMOS rows by setting $P=0$, and so on. The rows are indexed from bottom to top, so `nch(N-1)` is the top-most NMOS row, and `pch0` is the bottom-most PMOS row.\n",
"_____no_output_____"
],
[
"## Transistor Source/Drain Naming Convention\n<img src=\"bootcamp_pics/3_analogbase/analogbase_3.PNG\" alt=\"Drawing\" style=\"width: 600px;\"/>\nBefore we talk about how `AnalogBase` draws transistor connections, we need to establish a naming convention for source/drain junctions of a transistor, since source and drain are often interchangeable. In XBase, the left-most source/drain junction of a transistor is always called \"source\", and after that source and drain alternates between each other, as shown in the above figure. This implies that for even number of fingers, the right-most junction is always \"source\", and for odd number of fingers, the left-most junction is always \"drain\".",
"_____no_output_____"
],
[
"## AnalogMosConn Overview\n<img src=\"bootcamp_pics/3_analogbase/analogbase_2.PNG\" alt=\"Drawing\" style=\"width: 600px;\"/>\nTo connect transistors to the routing grid, `AnalogBase` \"drops\" `AnalogMosConn`, a layout cell consisting only of wires and vias, on top of desired transistors to connect gates, sources, and drains to a vertical routing layer. For most technologies, `AnalogMosConn` draws gate, drain, and source wires on every other source/drain junction, with drain and source wires interleaving with each other. By default, the gate wires are drawn below the transistor row, to draw gate wires above the transistor row, flip the row upside down by changing the row orientation from `R0` to `MX` (we will see an example of this later).\n\nWith this layout style, the gate wires can either be drawn in the same tracks as source wires (\"G aligned to S\"), or they can be drawn in the same tracks as drain wires (\"G aligned to D\"). The gate wire location is usually determined by source/drain wire direction. For example, in the figure above, if the source of a transistor needs to be connected to the row below it, then gate wires cannot be aligned to source, as this will cause a short between gate and source wires when the source wires is extended downwards. Because of this, when creating a `AnalogMosConn`, designer needs to specify the drain and source wire directions (whether they go \"up\" or \"down\"), and the gate wire locations will be determined automatically to avoid shorts.",
"_____no_output_____"
],
[
"## Connecting to Horizontal Tracks\n<img src=\"bootcamp_pics/3_analogbase/analogbase_4.PNG\" alt=\"Drawing\" style=\"width: 300px;\"/>\nIn the previous section, we see that `AnalogMosConn` connects the transistor to vertical tracks. How do we connect those vertical wires to the horizontal tracks above it? If you recall from the previous module, you would need to use the `connect_to_tracks()` method with the horizontal track index. The question now becomes: how do I know which track index can be used for gate/drain/source connections?\n\nTo get a better understanding of this problem, consider the layout shown in the figure above. The PMOS drain wires can be easily connected to track 10 with no issues, but the PMOS gate wires cannot be connected to track 10 without shorting with drain wires. In fact, the PMOS gate wires can only be connected to tracks 5, 6, and 7 without running into minimum line-end spacing rules with other wires. How can we determine what the legal track indices are? Furthermore, if our particular circuit requires more than 3 horizontal tracks for PMOS gate connections, how can we tell `AnalogBase` to space the rows further apart?\n\n<img src=\"bootcamp_pics/3_analogbase/analogbase_5.PNG\" alt=\"Drawing\" style=\"width: 300px;\"/>\nTo address these issues, `AnalogBase` introduces the concept of relative track indices, as shown in the figure above. `AnalogBase` categorizes each horizontal tracks by the transistor row it belongs to, and by whether it can be connected to the gate/drain/source wires without DRC errors. \n\nIn each row, `g0` is the horizontal track furthest from the transistor row that can be connected to the gate wires without errors, and the index increases as the wire moves closer to the transistor. `ds0` is the horizontal track closest to the transistor row (perhaps on top of it) that can be connected to the drain/source wires without errors, and the index increases as the wire moves away from the transistor.\n\n`AnalogBase` provides two methods to convert relative track indices to absolute track numbers, which can then be passed to `connect_to_tracks()` method to draw the connections. Using the figure above as an example, `self.get_track_index('pch', 0, 'g', 1)` will returns the track number of the horizontal track at PMOS row 0, gate type, index 1, which is track number 5. `self.make_track_id('pch', 0, 'g', 1)` will return the corresponding `TrackID` object instead.\n\nFinally, designer can specify the number of horizontal tracks needed for gate/drain/source connections on each row, and `AnalogBase` will automatically move rows further apart if necessary.",
"_____no_output_____"
],
[
"## CS Amplifier Layout Example\n<img src=\"bootcamp_pics/3_analogbase/analogbase_6.PNG\" alt=\"Drawing\" style=\"width: 400px;\"/>\nNow that you have a general idea of how `AnalogBase` works, lets walk through a common-source amplifier example. The figure above shows a rough sketch of the layout floorplan (**NOTE: ALWAYS DRAW FLOORPLAN BEFORE CODING!**). We have one NMOS row on the bottom, one PMOS row on the top, and we put extra dummy transistors on both sides to reduce edge layout effects. The input connects to NMOS gates from below the NMOS row, the PMOS bias connects to PMOS gates from above the PMOS row, and the output drain/source of NMOS/PMOS are connected to a horizontal track between the two rows. Finally, the supply drain/source wires are extended and shorted on top of the substrate contacts on both ends.\n\nThe entire common-source amplifier layout generator code is reproduced below. We will walk through important sections of the code and describe what they do.\n\n```python\nclass AmpCS(AnalogBase):\n \"\"\"A common source amplifier.\"\"\"\n def __init__(self, temp_db, lib_name, params, used_names, **kwargs):\n super(AmpCS, self).__init__(temp_db, lib_name, params, used_names, **kwargs)\n self._sch_params = None\n\n @property\n def sch_params(self):\n return self._sch_params\n\n @classmethod\n def get_params_info(cls):\n \"\"\"Returns a dictionary containing parameter descriptions.\n\n Override this method to return a dictionary from parameter names to descriptions.\n\n Returns\n -------\n param_info : dict[str, str]\n dictionary from parameter name to description.\n \"\"\"\n return dict(\n lch='channel length, in meters.',\n w_dict='width dictionary.',\n intent_dict='intent dictionary.',\n fg_dict='number of fingers dictionary.',\n ndum='number of dummies on each side.',\n ptap_w='NMOS substrate width, in meters/number of fins.',\n ntap_w='PMOS substrate width, in meters/number of fins.',\n show_pins='True to draw pin geometries.',\n )\n\n def draw_layout(self):\n \"\"\"Draw the layout of a transistor for characterization.\n \"\"\"\n\n lch = self.params['lch']\n w_dict = self.params['w_dict']\n intent_dict = self.params['intent_dict']\n fg_dict = self.params['fg_dict']\n ndum = self.params['ndum']\n ptap_w = self.params['ptap_w']\n ntap_w = self.params['ntap_w']\n show_pins = self.params['show_pins']\n\n fg_amp = fg_dict['amp']\n fg_load = fg_dict['load']\n\n if fg_load % 2 != 0 or fg_amp % 2 != 0:\n raise ValueError('fg_load=%d and fg_amp=%d must all be even.' % (fg_load, fg_amp))\n\n # compute total number of fingers in each row\n fg_half_pmos = fg_load // 2\n fg_half_nmos = fg_amp // 2\n fg_half = max(fg_half_pmos, fg_half_nmos)\n fg_tot = (fg_half + ndum) * 2\n\n # specify width/threshold of each row\n nw_list = [w_dict['amp']]\n pw_list = [w_dict['load']]\n nth_list = [intent_dict['amp']]\n pth_list = [intent_dict['load']]\n\n # specify number of horizontal tracks for each row\n ng_tracks = [1] # input track\n nds_tracks = [1] # one track for space\n pds_tracks = [1] # output track\n pg_tracks = [1] # bias track\n\n # specify row orientations\n n_orient = ['R0'] # gate connection on bottom\n p_orient = ['MX'] # gate connection on top\n\n self.draw_base(lch, fg_tot, ptap_w, ntap_w, nw_list,\n nth_list, pw_list, pth_list,\n ng_tracks=ng_tracks, nds_tracks=nds_tracks,\n pg_tracks=pg_tracks, pds_tracks=pds_tracks,\n n_orientations=n_orient, p_orientations=p_orient,\n )\n\n # figure out if output connects to drain or source of nmos\n if (fg_amp - fg_load) % 4 == 0:\n aout, aoutb, nsdir, nddir = 'd', 's', 0, 2\n else:\n aout, aoutb, nsdir, nddir = 's', 'd', 2, 0\n\n # create transistor connections\n load_col = ndum + fg_half - fg_half_pmos\n amp_col = ndum + fg_half - fg_half_nmos\n amp_ports = self.draw_mos_conn('nch', 0, amp_col, fg_amp, nsdir, nddir)\n load_ports = self.draw_mos_conn('pch', 0, load_col, fg_load, 2, 0)\n # amp_ports/load_ports are dictionaries of WireArrays representing\n # transistor ports.\n print(amp_ports)\n print(amp_ports['g'])\n\n # create TrackID from relative track index\n vin_tid = self.make_track_id('nch', 0, 'g', 0)\n vout_tid = self.make_track_id('pch', 0, 'ds', 0)\n vbias_tid = self.make_track_id('pch', 0, 'g', 0)\n # can also convert from relative to absolute track index\n print(self.get_track_index('nch', 0, 'g', 0))\n\n vin_warr = self.connect_to_tracks(amp_ports['g'], vin_tid)\n vout_warr = self.connect_to_tracks([amp_ports[aout], load_ports['d']], vout_tid)\n vbias_warr = self.connect_to_tracks(load_ports['g'], vbias_tid)\n self.connect_to_substrate('ptap', amp_ports[aoutb])\n self.connect_to_substrate('ntap', load_ports['s'])\n\n vss_warrs, vdd_warrs = self.fill_dummy()\n\n self.add_pin('VSS', vss_warrs, show=show_pins)\n self.add_pin('VDD', vdd_warrs, show=show_pins)\n self.add_pin('vin', vin_warr, show=show_pins)\n self.add_pin('vout', vout_warr, show=show_pins)\n self.add_pin('vbias', vbias_warr, show=show_pins)\n\n # compute schematic parameters\n sch_fg_dict = fg_dict.copy()\n sch_fg_dict['dump'] = fg_tot - fg_load\n if aout == 'd':\n sch_fg_dict['dumn_list'] = [fg_tot - fg_amp]\n else:\n sch_fg_dict['dumn_list'] = [fg_tot - fg_amp - 2, 2]\n self._sch_params = dict(\n lch=lch,\n w_dict=w_dict,\n intent_dict=intent_dict,\n fg_dict=sch_fg_dict,\n )\n\n```",
"_____no_output_____"
],
[
"## Class Definition\n```python\nclass AmpCS(AnalogBase):\n \"\"\"A common source amplifier\"\"\"\n def __init__(self, temp_db, lib_name, params, used_names **kwargs):\n super(AmpCS, self).__init__(temp_db, lib_name, params, used_names, **kwargs)\n self._sch_params = None\n \n @property\n def sch_params(self):\n return self._sch_params\n```\nThe layout generator code starts with the Python class definition. We subclass the `AnalogBase` class to inherit various functions described earlier. The constructor doesn't do much besides calling the super constructor and initializing a private attribute. Finally, we declare a read-only property, `sch_params`, which we will compute later. It contains the schematic parameters for the schematic generator we will see in the next module.",
"_____no_output_____"
],
[
"## Parameter Specifications\n```python\n@classmethod\ndef get_params_info(cls):\n \"\"\"Returns a dictionary containing parameter descriptions.\n Override this method to return a dictionary from parameter names to descriptions.\n Returns\n -------\n param_info : dict[str, str]\n dictionary from parameter name to description.\n \"\"\"\n return dict(\n lch='channel length, in meters.',\n w_dict='width dictionary.',\n intent_dict='intent dictionary.',\n fg_dict='number of fingers dictionary.',\n ndum='number of dummies on each side.',\n ptap_w='NMOS substrate width, in meters/number of fins.',\n ntap_w='PMOS substrate width, in meters/number of fins.',\n show_pins='True to draw pin geometries.',\n )\n```\nNext we have a class method, `get_params_info()`, that simply returns a Python dictionary from layout parameter names to a brief description of the corresponding parameter. This method should list all layout parameters, and it is used to determine to compute a unique ID to represent the generated instance. This allows XBase to avoid re-generating existing layouts when constructing a complex layout hierarchy with many duplicate layout instances.",
"_____no_output_____"
],
[
"## How many fingers in a row?\nNext, in the `draw_layout()` method is where all the layout generation happens. The beginning is rather straight-forward, then we get to the following section:\n```python\n # compute total number of fingers in each row\nfg_half_pmos = fg_load // 2\nfg_half_nmos = fg_amp // 2\nfg_half = max(fg_half_pmos, fg_half_nmos)\nfg_tot = (fg_half + ndum) * 2\n```\nThis section computes how many fingers we need to draw in each transistor row. To get a better understanding, consider the two scenarios below:\n<img src=\"bootcamp_pics/3_analogbase/analogbase_7.PNG\" alt=\"Drawing\" style=\"width: 600px;\" />\nSince `AnalogBase` must draw the same number of fingers for each row, we see that total number of fingers in each row depends on whether the AMP transistor or the LOAD transistor has more fingers. We resolve this by using the `max()` function to get the larger of the two.",
"_____no_output_____"
],
[
"## Drawing Transistor Rows\n```python\n# specify width/threshold of each row\nnw_list = [w_dict['amp']]\npw_list = [w_dict['load']]\nnth_list = [intent_dict['amp']]\npth_list = [intent_dict['load']]\n\n# specify number of horizontal tracks for each row\nng_tracks = [1] # input track\nnds_tracks = [1] # one track for space\npds_tracks = [1] # output track\npg_tracks = [1] # bias track\n\n# specify row orientations\nn_orient = ['R0'] # gate connection on bottom\np_orient = ['MX'] # gate connection on top\n\nself.draw_base(lch, fg_tot, ptap_w, ntap_w, nw_list,\n nth_list, pw_list, pth_list,\n ng_tracks=ng_tracks, nds_tracks=nds_tracks,\n pg_tracks=pg_tracks, pds_tracks=pds_tracks,\n n_orientations=n_orient, p_orientations=p_orient,\n )\n```\nThis section specifies the layout parameters for each row, then calls the `draw_base()` method in `AnalogBase` to draw the transistor and substrate contact rows. Note that the PMOS row orientation is set to `MX` so that `AnalogMosConn` will draw gate wires on the top of PMOS row.",
"_____no_output_____"
],
[
"## Is output on source or drain?\n```python\n# figure out if output connects to drain or source of nmos\nif (fg_amp - fg_load) % 4 == 0:\n aout, aoutb, nsdir, nddir = 'd', 's', 0, 2\nelse:\n aout, aoutb, nsdir, nddir = 's', 'd', 2, 0\n```\nThis section determines if the output should connect to drain or source of the nmos transistor, and as the result what should the nmos source/drain wire directions be. To see why this is necessary, consider the two cases shown below:\n<img src=\"bootcamp_pics/3_analogbase/analogbase_8.PNG\" alt=\"Drawing\" style=\"width: 600px;\" />\nIn both cases, we have 8 PMOS fingers, and 4 or 6 NMOS fingers, respectively. To make life simpler, we decide to always connect the output wires to PMOS drain (if you expect PMOS to always be larger, this gives you less parasitic capacitance). Furthermore, to have better symmetric, we align the center of the PMOS and NMOS transistors. Then, to minimize interconnect resistance, we should connect output to the NMOS junction that is aligned to PMOS drain. If we check the above figure, we see that the corresponding NMOS junction is drain when NMOS has 4 fingers, but it is source when NMOS has 6 fingers! This means that the correct NMOS junction to connect to actually depends on both `fg_amp` and `fg_load`. By sketching a few example, you should be able to figure out that we need to connect output to NMOS drain if the difference in number of fingers is a multiple of 4, and connect output to NMOS drain otherwise. This is exactly what this section of code does.",
"_____no_output_____"
],
[
"## Drawing Transistor Connections\n```python\n# create transistor connections\nload_col = ndum + fg_half - fg_half_pmos\namp_col = ndum + fg_half - fg_half_nmos\namp_ports = self.draw_mos_conn('nch', 0, amp_col, fg_amp, nsdir, nddir)\nload_ports = self.draw_mos_conn('pch', 0, load_col, fg_load, 2, 0)\n# amp_ports/load_ports are dictionaries of WireArrays representing\n# transistor ports.\nprint(amp_ports)\nprint(amp_ports['g'])\n```\nNow we are ready to draw the actual transistor connections. To do so, we use the `draw_mos_conn()` function. As an example, `self.draw_mos_conn('pch', 0, load_col, fg_load, 2, 0)` creates an `AnalogMosConn` object on top of PMOS row 0, starting at transistor index `load_col` (with index 0 being left-most transistor), using `fg_load` fingers to the right, with source going up (code 2) and drain going down (code 0). Remember that the source/drain directions are used to determine gate wires location.\n\nthe `draw_mos_conn()` method will return a dictionary from the strings `'g'`, `'d'`, and `'s'` to the `WireArray` objects for the corresponding vertical wires.",
"_____no_output_____"
],
[
"## Connecting Wires\n```python\n# create TrackID from relative track index\nvin_tid = self.make_track_id('nch', 0, 'g', 0)\nvout_tid = self.make_track_id('pch', 0, 'ds', 0)\nvbias_tid = self.make_track_id('pch', 0, 'g', 0)\n# can also convert from relative to absolute track index\nprint(self.get_track_index('nch', 0, 'g', 0))\n\nvin_warr = self.connect_to_tracks(amp_ports['g'], vin_tid)\nvout_warr = self.connect_to_tracks([amp_ports[aout], load_ports['d']], vout_tid)\nvbias_warr = self.connect_to_tracks(load_ports['g'], vbias_tid)\nself.connect_to_substrate('ptap', amp_ports[aoutb])\nself.connect_to_substrate('ntap', load_ports['s'])\n```\nThis section used the `make_track_id()` and `get_track_index()` methods described before to get horizontal track indices from relative index. We then use `connect_to_tracks()` to connect wires to the desired tracks. `connect_to_substrate()` method is used to connect transistor junctions to the specified substrate contacts.",
"_____no_output_____"
],
[
"## Dummies and Pins\n```python\nvss_warrs, vdd_warrs = self.fill_dummy()\n\nself.add_pin('VSS', vss_warrs, show=show_pins)\nself.add_pin('VDD', vdd_warrs, show=show_pins)\nself.add_pin('vin', vin_warr, show=show_pins)\nself.add_pin('vout', vout_warr, show=show_pins)\nself.add_pin('vbias', vbias_warr, show=show_pins)\n```\nAfter all connections are made, the `fill_dummy()` method can be used to automatically connect all unconnected transistors to corresponding substrate contacts as dummy transistors. `add_pin()` function is used to add layout pins, as seem from the routing demo module.",
"_____no_output_____"
],
[
"## Schematic Parameters\n```python\n # compute schematic parameters\nsch_fg_dict = fg_dict.copy()\nsch_fg_dict['dump'] = fg_tot - fg_load\nif aout == 'd':\n sch_fg_dict['dumn_list'] = [fg_tot - fg_amp]\nelse:\n sch_fg_dict['dumn_list'] = [fg_tot - fg_amp - 2, 2]\nself._sch_params = dict(\n lch=lch,\n w_dict=w_dict,\n intent_dict=intent_dict,\n fg_dict=sch_fg_dict,\n)\n```\nFinally, we compute the schematic parameter dictionary, which will be used with the schematic generator later to produce LVS clean schematic. Notice that dummy NMOS connections needs to change if the source of NMOS is connected to output wire.",
"_____no_output_____"
],
[
"## SF Amplifier Exercise\nNow that you understand how the common-source amplifier layout generator works, try to complete the following source-follower amplifier class by filling in missing codes. The floorplan for the source-follower amplifier is drawn for you below:\n<img src=\"bootcamp_pics/3_analogbase/analogbase_9.PNG\" alt=\"Drawing\" style=\"width: 400px;\"/>\nNotice that:\n* we have two rows of NMOS.\n* Gate connection is on the top for second row\n* To minimize parasitics, we will use leave 1 horizontal track empty between vin and VDD.\n\nYou can evaluate the next cell (Press Ctrl+Enter) to see a preliminary layout of the source follower. It will also run LVS after generating the layout, which will fail if your layout is not correct.",
"_____no_output_____"
]
],
[
[
"from abs_templates_ec.analog_core import AnalogBase\n\n\nclass AmpSF(AnalogBase):\n \"\"\"A template of a single transistor with dummies.\n This class is mainly used for transistor characterization or\n design exploration with config views.\n Parameters\n ----------\n temp_db : :class:`bag.layout.template.TemplateDB`\n the template database.\n lib_name : str\n the layout library name.\n params : dict[str, any]\n the parameter values.\n used_names : set[str]\n a set of already used cell names.\n kwargs : dict[str, any]\n dictionary of optional parameters. See documentation of\n :class:`bag.layout.template.TemplateBase` for details.\n \"\"\"\n\n def __init__(self, temp_db, lib_name, params, used_names, **kwargs):\n super(AmpSF, self).__init__(temp_db, lib_name, params, used_names, **kwargs)\n self._sch_params = None\n\n @property\n def sch_params(self):\n return self._sch_params\n\n @classmethod\n def get_params_info(cls):\n \"\"\"Returns a dictionary containing parameter descriptions.\n Override this method to return a dictionary from parameter names to descriptions.\n Returns\n -------\n param_info : dict[str, str]\n dictionary from parameter name to description.\n \"\"\"\n return dict(\n lch='channel length, in meters.',\n w_dict='width dictionary.',\n intent_dict='intent dictionary.',\n fg_dict='number of fingers dictionary.',\n ndum='number of dummies on each side.',\n ptap_w='NMOS substrate width, in meters/number of fins.',\n ntap_w='PMOS substrate width, in meters/number of fins.',\n show_pins='True to draw pin geometries.',\n )\n\n def draw_layout(self):\n \"\"\"Draw the layout of a transistor for characterization.\n \"\"\"\n\n lch = self.params['lch']\n w_dict = self.params['w_dict']\n intent_dict = self.params['intent_dict']\n fg_dict = self.params['fg_dict']\n ndum = self.params['ndum']\n ptap_w = self.params['ptap_w']\n ntap_w = self.params['ntap_w']\n show_pins = self.params['show_pins']\n\n fg_amp = fg_dict['amp']\n fg_bias = fg_dict['bias']\n\n if fg_bias % 2 != 0 or fg_amp % 2 != 0:\n raise ValueError('fg_bias=%d and fg_amp=%d must all be even.' % (fg_bias, fg_amp))\n\n fg_half_bias = fg_bias // 2\n fg_half_amp = fg_amp // 2\n fg_half = max(fg_half_bias, fg_half_amp)\n fg_tot = (fg_half + ndum) * 2\n\n nw_list = [w_dict['bias'], w_dict['amp']]\n nth_list = [intent_dict['bias'], intent_dict['amp']]\n ng_tracks = [1, 3]\n nds_tracks = [1, 1]\n\n n_orient = ['R0', 'MX']\n\n self.draw_base(lch, fg_tot, ptap_w, ntap_w, nw_list,\n nth_list, [], [],\n ng_tracks=ng_tracks, nds_tracks=nds_tracks,\n pg_tracks=[], pds_tracks=[],\n n_orientations=n_orient,\n )\n\n if (fg_amp - fg_bias) % 4 == 0:\n aout, aoutb, nsdir, nddir = 'd', 's', 2, 0\n else:\n aout, aoutb, nsdir, nddir = 's', 'd', 0, 2\n\n # TODO: compute bias_col and amp_col\n bias_col = amp_col = 0\n\n amp_ports = self.draw_mos_conn('nch', 1, amp_col, fg_amp, nsdir, nddir)\n bias_ports = self.draw_mos_conn('nch', 0, bias_col, fg_bias, 0, 2)\n\n # TODO: get TrackIDs for horizontal tracks\n # The following are related code copied and pasted from AmpCS\n # for reference\n # vin_tid = self.make_track_id('nch', 0, 'g', 0)\n # vout_tid = self.make_track_id('pch', 0, 'ds', 0)\n # vbias_tid = self.make_track_id('pch', 0, 'g', 0)\n vdd_tid = vin_tid = vout_tid = vbias_tid = None\n\n if vdd_tid is None:\n return\n\n # uncomment to visualize track location\n # hm_layer = self.mos_conn_layer + 1\n # xl = self.bound_box.left_unit\n # xr = self.bound_box.right_unit\n # self.add_wires(hm_layer, vdd_tid.base_index, xl, xr, unit_mode=True)\n # self.add_wires(hm_layer, vin_tid.base_index, xl, xr, unit_mode=True)\n # self.add_wires(hm_layer, vout_tid.base_index, xl, xr, unit_mode=True)\n # self.add_wires(hm_layer, vbias_tid.base_index, xl, xr, unit_mode=True)\n \n # TODO: connect transistors to horizontal tracks\n # The following are related code copied and pasted from AmpCS\n # for reference\n # vin_warr = self.connect_to_tracks(amp_ports['g'], vin_tid)\n # vout_warr = self.connect_to_tracks([amp_ports[aout], load_ports['d']], vout_tid)\n # vbias_warr = self.connect_to_tracks(load_ports['g'], vbias_tid)\n vin_warr = vout_warr = vbias_warr = vdd_warr = None\n\n if vin_warr is None:\n return\n\n self.connect_to_substrate('ptap', bias_ports['s'])\n\n vss_warrs, _ = self.fill_dummy()\n\n self.add_pin('VSS', vss_warrs, show=show_pins)\n # TODO: add pins\n\n sch_fg_dict = fg_dict.copy()\n sch_fg_dict['dum_list'] = [fg_tot - fg_bias, fg_tot - fg_amp - 2, 2]\n\n self._sch_params = dict(\n lch=lch,\n w_dict=w_dict,\n intent_dict=intent_dict,\n fg_dict=sch_fg_dict,\n )\n \n \nimport os\n\n# import bag package\nimport bag\nfrom bag.io import read_yaml\n\n# import BAG demo Python modules\nimport xbase_demo.core as demo_core\nfrom xbase_demo.demo_layout.core import AmpSFSoln\n\n# load circuit specifications from file\nspec_fname = os.path.join(os.environ['BAG_WORK_DIR'], 'specs_demo/demo.yaml')\ntop_specs = read_yaml(spec_fname)\n\n# obtain BagProject instance\nlocal_dict = locals()\nif 'bprj' in local_dict:\n print('using existing BagProject')\n bprj = local_dict['bprj']\nelse:\n print('creating BagProject')\n bprj = bag.BagProject()\n\ndemo_core.run_flow(bprj, top_specs, 'amp_sf_soln', AmpSF, run_lvs=True, lvs_only=True)",
"creating BagProject\ncomputing layout\next_w0 = 1, ext_wend=9, tot_ntr=20\next_w0 = 2, ext_wend=8, tot_ntr=20\next_w0 = 4, ext_wend=9, tot_ntr=21\nfinal: ext_w0 = 2, ext_wend=8, tot_ntr=20\ncreating layout\nlayout done\ncomputing AMP_SF schematics\n"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
]
] |
ecc1a1049a6af3e67fefd3ca7f9ef483981f61b4 | 3,982 | ipynb | Jupyter Notebook | 01_feature_demonstration/02_maximum_words_in_doc.ipynb | ilos-vigil/ktrain-assessment-study | eb4a8520f8170f879f65c91312f312a0b4121d02 | [
"Unlicense"
] | null | null | null | 01_feature_demonstration/02_maximum_words_in_doc.ipynb | ilos-vigil/ktrain-assessment-study | eb4a8520f8170f879f65c91312f312a0b4121d02 | [
"Unlicense"
] | null | null | null | 01_feature_demonstration/02_maximum_words_in_doc.ipynb | ilos-vigil/ktrain-assessment-study | eb4a8520f8170f879f65c91312f312a0b4121d02 | [
"Unlicense"
] | null | null | null | 1,991 | 3,981 | 0.607233 | [
[
[
"from ktrain import text\nfrom pprint import pprint",
"_____no_output_____"
],
[
"X_train = [\n 'Ubuntu is most popular distro based on Linux',\n 'I prefer Debian over Ubuntu',\n 'Linux only have 3 percent marketshare',\n 'Both Ubuntu and Debian uses systemd'\n]\ny_train = [\n 'Fact',\n 'Opinion',\n 'Fact',\n 'Fact'\n]\nX_test = [\n 'Arch Linux is better if you prefer minimalistic setup',\n]\ny_test = [\n 'Opinion'\n]",
"_____no_output_____"
]
],
[
[
"Set maximum unique words to **10**.",
"_____no_output_____"
]
],
[
[
"train_ds, test_ds, preproc = text.texts_from_array(\n X_train, y_train, X_test, y_test, maxlen=10\n)\ntokenizer = preproc.get_tokenizer()\nprint('ID/word dictionary:')\npprint(tokenizer.index_word)",
"language: en\nWord Counts: 21\nNrows: 4\n4 train sequences\ntrain sequence lengths:\n\tmean : 6\n\t95percentile : 8\n\t99percentile : 8\nx_train shape: (4,10)\ny_train shape: (4, 2)\nIs Multi-Label? False\n1 test sequences\ntest sequence lengths:\n\tmean : 3\n\t95percentile : 3\n\t99percentile : 3\nx_test shape: (1,10)\ny_test shape: (1, 2)\ntask: text classification\nID/word dictionary:\n{1: 'ubuntu',\n 2: 'linux',\n 3: 'debian',\n 4: 'is',\n 5: 'most',\n 6: 'popular',\n 7: 'distro',\n 8: 'based',\n 9: 'on',\n 10: 'i',\n 11: 'prefer',\n 12: 'over',\n 13: 'only',\n 14: 'have',\n 15: '3',\n 16: 'percent',\n 17: 'marketshare',\n 18: 'both',\n 19: 'and',\n 20: 'uses',\n 21: 'systemd'}\n"
]
],
[
[
"As expected, maximum words is 10 and padding is on left of document.",
"_____no_output_____"
]
],
[
[
"print('Train data:')\nprint(train_ds[0])\nprint('Test data:')\nprint(test_ds[0])",
"Train data:\n[[ 0 0 1 4 5 6 7 8 9 2]\n [ 0 0 0 0 0 10 11 3 12 1]\n [ 0 0 0 0 2 13 14 15 16 17]\n [ 0 0 0 0 18 1 19 3 20 21]]\nTest data:\n[[ 0 0 0 0 0 0 0 2 4 11]]\n"
]
],
[
[
"Set maximum unique words to **5**.",
"_____no_output_____"
]
],
[
[
"train_ds, test_ds, preproc = text.texts_from_array(\n X_train, y_train, X_test, y_test, maxlen=5\n)",
"language: en\nWord Counts: 21\nNrows: 4\n4 train sequences\ntrain sequence lengths:\n\tmean : 6\n\t95percentile : 8\n\t99percentile : 8\nx_train shape: (4,5)\ny_train shape: (4, 2)\nIs Multi-Label? False\n1 test sequences\ntest sequence lengths:\n\tmean : 3\n\t95percentile : 3\n\t99percentile : 3\nx_test shape: (1,5)\ny_test shape: (1, 2)\ntask: text classification\n"
]
],
[
[
"As expected, maximum words is 5. We also can see that beginning of the document is removed.",
"_____no_output_____"
]
],
[
[
"print('Train data:')\nprint(train_ds[0])\nprint('Test data:')\nprint(test_ds[0])",
"Train data:\n[[ 6 7 8 9 2]\n [10 11 3 12 1]\n [13 14 15 16 17]\n [ 1 19 3 20 21]]\nTest data:\n[[ 0 0 2 4 11]]\n"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
ecc1b597ca4a57012272eb6de8b61069ea849891 | 6,786 | ipynb | Jupyter Notebook | assignments/A5/A5_BONUS.ipynb | eds-uga/csci1360e-su17 | 605083bbdca853e4cf5772b43a2522a09f440946 | [
"MIT"
] | null | null | null | assignments/A5/A5_BONUS.ipynb | eds-uga/csci1360e-su17 | 605083bbdca853e4cf5772b43a2522a09f440946 | [
"MIT"
] | null | null | null | assignments/A5/A5_BONUS.ipynb | eds-uga/csci1360e-su17 | 605083bbdca853e4cf5772b43a2522a09f440946 | [
"MIT"
] | 1 | 2020-08-01T08:25:28.000Z | 2020-08-01T08:25:28.000Z | 28.157676 | 410 | 0.574123 | [
[
[
"# Bonus\n\nThese questions are all-or-nothing.",
"_____no_output_____"
],
[
"### Part A\n\nWrite a function, `enhanced_average`, which computes the average of a list of numbers, with some tweaks.\n\n - Takes 2 arguments. 1 is required: the list of numbers. The second is optional: it's a list of weights (named **`weights`**) for the required list of numbers. If provided, it should be the same length as the required list. In that case, it should be used to compute a weighted average. If it's not provided, the average should be computed normally.\n - returns 1 number: the average (or weighted average, if the optional argument `weights` is provided).\n \nWhen you're computing a weighted average, you need to multiply each number in the required list by its corresponding weight in the `weights` list. You can think of the \"normal\" way of computing the mean (without weights) as being a weighted version, just where all the weights are 1.\n\nFor example, if you have a list of numbers `[1, 2, 3]`, the unweighted mean is 2. However, with the weights `[1, 1, 10`], the weighted average is 2.75. Since the corresponding weight for 3 is 10, that means 3 counts as essentially 10 3s, whereas 1 and 2 are still weighted normally. Except, however, now you're dividing by the sum of the *weights* (12), except simply by how many numbers you have (3).\n \nIf `weights` is not the same length as the required list your function should throw a `ValueError`.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nnp.random.seed(235764)\n\ni1 = np.random.randint(0, 100, 10).tolist()\na1 = np.mean(i1)\nnp.testing.assert_allclose(a1, enhanced_average(i1))",
"_____no_output_____"
],
[
"i2 = np.random.randint(0, 100, 10).tolist()\nw2 = [0.0, 1, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1]\na2 = 60.5\nnp.testing.assert_allclose(a2, enhanced_average(i2, weights = w2))",
"_____no_output_____"
],
[
"i3 = np.random.randint(0, 100, 10).tolist()\nw3 = [0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.1, 0.2]\ntry:\n a = enhanced_average(i3, weights = w3)\nexcept ValueError:\n assert True\nelse:\n assert False",
"_____no_output_____"
]
],
[
[
"### Part B\n\nIf you've ever taken a computer science course, you know that *sorting* is an integral part of the field. If lists are ordered, there are lots of operations that become significantly easier--for instance, searching for a specific item. There are many different ways of sorting, each with their advantages and drawbacks (though some are objectively better than others).\n\nWrite your own sorting function, `my_sort`, which takes a list of numbers and sorts them in **ascending order** (least to greatest). You cannot use any built-in functions (no `list.reverse()` calls), or indexing tricks (no `[::-1]` usage), nor any sorting calls to the NumPy library (no calls to `np.sort()`). You have to do this on your own!\n\nYour function should also have an optional argument, `desc`, which if set to `True`, instead returns the sorted list in **descending order** (greatest to least).",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\nnp.random.seed(85973)\ni1 = np.random.random(10).tolist()\nnp.testing.assert_allclose(np.sort(i1), my_sort(i1))",
"_____no_output_____"
],
[
"i2 = np.random.random(100).tolist()\na2 = np.sort(i2).tolist()\na2.reverse()\nnp.testing.assert_allclose(a2, my_sort(i2, desc = True))",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
ecc1ce5dacdff0ad87884969688389ff1ce0d79f | 1,299 | ipynb | Jupyter Notebook | plt_doc.ipynb | Yunfei-Zhang/sci-plot | 403e2a370f73b03290a0fc510de96d7bf33b1f1d | [
"MIT"
] | null | null | null | plt_doc.ipynb | Yunfei-Zhang/sci-plot | 403e2a370f73b03290a0fc510de96d7bf33b1f1d | [
"MIT"
] | null | null | null | plt_doc.ipynb | Yunfei-Zhang/sci-plot | 403e2a370f73b03290a0fc510de96d7bf33b1f1d | [
"MIT"
] | null | null | null | 18.295775 | 77 | 0.487298 | [
[
[
"# Documentation",
"_____no_output_____"
],
[
"## Line type\n- solid: '-'\n- dotted: ':'\n- dashed: '--'\n- dashdot: \t'-.'",
"_____no_output_____"
],
[
"## Colors\n### Tableau Palette\n- tab: blue\n- tab: orange\n- tab: green\n- tab: red\n- tab: brown\n- tab: gray\n- tab: olive\n\n### CSS colors\n- slateblue\n- orange\n- darkgreen\n- tomato\n- darkgray\n- royalblue",
"_____no_output_____"
]
]
] | [
"markdown"
] | [
[
"markdown",
"markdown",
"markdown"
]
] |
ecc1de0fd8873a604f9765f9eb6dc0fb5bdc75d4 | 12,796 | ipynb | Jupyter Notebook | notebooks/ptyhonVideoForBigDataFiles/WorkingWithBigDataInPython_OperatorsUpdatesAggregations=Video2.5.ipynb | dguardia/pyhtonForDataScience-David | 1c846554baecf2dc072aa95686a7839b467f6e11 | [
"MIT"
] | 1 | 2019-09-10T18:19:35.000Z | 2019-09-10T18:19:35.000Z | notebooks/ptyhonVideoForBigDataFiles/WorkingWithBigDataInPython_OperatorsUpdatesAggregations=Video2.5.ipynb | dguardia/pyhtonForDataScience-David | 1c846554baecf2dc072aa95686a7839b467f6e11 | [
"MIT"
] | null | null | null | notebooks/ptyhonVideoForBigDataFiles/WorkingWithBigDataInPython_OperatorsUpdatesAggregations=Video2.5.ipynb | dguardia/pyhtonForDataScience-David | 1c846554baecf2dc072aa95686a7839b467f6e11 | [
"MIT"
] | null | null | null | 19.99375 | 128 | 0.482338 | [
[
[
"https://www.safaribooksonline.com/videos/working-with-big/9781788839068/9781788839068-video2_5\nstopped at minute 5.52",
"_____no_output_____"
]
],
[
[
"import pymongo\nfrom pymongo import MongoClient\nclient=pymongo.MongoClient('this_mongo_1')",
"_____no_output_____"
],
[
"client.database_names()",
"_____no_output_____"
],
[
"client.drop_database('packt')",
"_____no_output_____"
],
[
"client.drop_database('packt1')\nclient.drop_database('test2')",
"_____no_output_____"
],
[
"client.database_names()",
"_____no_output_____"
],
[
"db=client.packt\ntestCollection=db.testCollection",
"_____no_output_____"
],
[
"import pprint\nfor doc in testCollection.find():\n pprint.pprint(doc)",
"_____no_output_____"
],
[
"cur=testCollection.find()\ncur.count()",
"_____no_output_____"
]
],
[
[
"##### insert some documents",
"_____no_output_____"
]
],
[
[
"testCollection.insert_one({'name': 'alice', 'salary': 50000})\ntestCollection.insert_one({'name': 'bob', 'salary': 40000})\ntestCollection.insert_one({'name': 'charlie', 'salary': 60000})",
"_____no_output_____"
],
[
"cur.count()",
"_____no_output_____"
],
[
"cur.close()",
"_____no_output_____"
]
],
[
[
"### set and indvidual document ",
"_____no_output_____"
]
],
[
[
"res = testCollection.update_one({'name': 'alice'}, {'$set': {'salary': 55000}})",
"_____no_output_____"
],
[
"testCollection.find_one({'name': 'alice'}, {'_id': 0})",
"_____no_output_____"
]
],
[
[
"#### remove field from docuemnt",
"_____no_output_____"
]
],
[
[
"res = testCollection.update_one({'name': 'alice'}, {'$unset': {'salary': \"\"}})",
"_____no_output_____"
],
[
"res.acknowledged",
"_____no_output_____"
],
[
"cur=testCollection.find()\ncur.count()",
"_____no_output_____"
],
[
"testCollection.find_one({'name': 'alice'}, {'_id': 0})",
"_____no_output_____"
]
],
[
[
"### calculate total and mean salary ",
"_____no_output_____"
]
],
[
[
"pipeline = []",
"_____no_output_____"
],
[
"#add docuemnts where salary exists to the pipeline\npipeline.append({\"$match\": {\"salary\": {'$exists': \"True\"}}})",
"_____no_output_____"
],
[
"pipeline",
"_____no_output_____"
],
[
"#creates a new field avSalary and totalSalary with the avg and sum of salary\npipeline.append({'$group':{\"_id\":None,\"avSalary\":{\"$avg\":\"$salary\"},\"totalSalary\":{\"$sum\":\"$salary\"}}})",
"_____no_output_____"
],
[
"cur = testCollection.aggregate(pipeline=pipeline)",
"_____no_output_____"
],
[
"cur.next()",
"_____no_output_____"
],
[
"for d in testCollection.find():\n print(d)",
"{'_id': ObjectId('5b45187e0d03a0009675d6f2'), 'name': 'alice'}\n{'_id': ObjectId('5b45187e0d03a0009675d6f3'), 'name': 'bob', 'salary': 40000}\n{'_id': ObjectId('5b45187e0d03a0009675d6f4'), 'name': 'charlie', 'salary': 60000}\n"
],
[
"testCollection.drop()",
"_____no_output_____"
],
[
"testCollection.insert_one({'name': 'alice', 'salary': 50000, 'unit': 'legal'})\ntestCollection.insert_one({'name': 'bob', 'salary': 40000, 'unit': 'marketing'})\ntestCollection.insert_one({'name': 'charlie', 'salary': 60000, 'unit': 'communications'})\ntestCollection.insert_one({'name': 'david', 'salary': 70000, 'unit': 'legal'})\ntestCollection.insert_one({'name': 'edwina', 'salary': 90000, 'unit': 'communications'})",
"_____no_output_____"
],
[
"pipeline = []\npipeline.append({'$group':{\"_id\":\"$unit\",\"avSalary\":{\"$avg\":\"$salary\"},\"totalSalary\":{\"$sum\":\"$salary\"}}})",
"_____no_output_____"
],
[
"cur = testCollection.aggregate(pipeline=pipeline)",
"_____no_output_____"
],
[
"for d in cur:\n print(d)",
"{'_id': 'communciations', 'avSalary': 90000.0, 'totalSalary': 90000}\n{'_id': 'communications', 'avSalary': 70000.0, 'totalSalary': 210000}\n{'_id': 'marketing', 'avSalary': 40000.0, 'totalSalary': 80000}\n{'_id': 'legal', 'avSalary': 60000.0, 'totalSalary': 240000}\n"
]
],
[
[
"#### match by condition on array index",
"_____no_output_____"
]
],
[
[
"#find in key ages and secnd position \ncoll.find_one({'ages.1' : 42},{'_id': 0 } )",
"_____no_output_____"
],
[
"#find in key ages and secnd position gt 40\ncoll.find_one({'ages.1' : {'$gt' : 40}},{'_id': 0 } )",
"_____no_output_____"
]
],
[
[
"#### insert documents with nested dictionary",
"_____no_output_____"
]
],
[
[
"res = coll.insert_one({'personInfo': {'name': 'alice', 'age': 30}})\nres = coll.insert_one({'personInfo': {'name': 'bob', 'age': 42}})\nres = coll.insert_one({'personInfo': {'name': 'charlie', 'age': 12}})\nres = coll.insert_one({'personInfo': {'name': 'david', 'age': 19}})",
"_____no_output_____"
]
],
[
[
"#### match name",
"_____no_output_____"
]
],
[
[
"coll.find_one({'personInfo.name': 'alice'}, {'_id': 0})",
"_____no_output_____"
]
],
[
[
"#### match by age",
"_____no_output_____"
]
],
[
[
"coll.find_one({'personInfo.age': {'$gt': 40}}, {'_id': 0})",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
ecc1e24887e7e5867f3fa0bbd3c42861517d7714 | 923 | ipynb | Jupyter Notebook | tests/data/common/naics_utils.ipynb | leksmall/lear | cc7d75be830d12bfcc33b89bb2c4f34795bcd518 | [
"Apache-2.0"
] | null | null | null | tests/data/common/naics_utils.ipynb | leksmall/lear | cc7d75be830d12bfcc33b89bb2c4f34795bcd518 | [
"Apache-2.0"
] | null | null | null | tests/data/common/naics_utils.ipynb | leksmall/lear | cc7d75be830d12bfcc33b89bb2c4f34795bcd518 | [
"Apache-2.0"
] | null | null | null | 21.465116 | 66 | 0.524377 | [
[
[
"def get_element_type_from_label(label: str):\n map = {\n 'All examples': 'ALL_EXAMPLES',\n 'Illustrative example(s)': 'ILLUSTRATIVE_EXAMPLES',\n 'Inclusion(s)': 'INCLUSIONS',\n 'Exclusion(s)': 'EXCLUSIONS'\n }\n return map.get(label, None)",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code"
]
] |
ecc1ee749055371c97119f713226a66295c41db9 | 209,453 | ipynb | Jupyter Notebook | RajPatel/HW1.ipynb | rjp429/ROB2004 | bddfe035f96b7e236bae344784084f76074266fc | [
"BSD-3-Clause"
] | null | null | null | RajPatel/HW1.ipynb | rjp429/ROB2004 | bddfe035f96b7e236bae344784084f76074266fc | [
"BSD-3-Clause"
] | 2 | 2020-10-04T15:26:33.000Z | 2020-11-04T19:27:23.000Z | RajPatel/HW1.ipynb | rjp429/ROB2004 | bddfe035f96b7e236bae344784084f76074266fc | [
"BSD-3-Clause"
] | null | null | null | 632.78852 | 201,384 | 0.949578 | [
[
[
"",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport math as math\nimport matplotlib.pylab as plt\nfrom mpl_toolkits.mplot3d import Axes3D\nfrom numpy import sin,cos,pi,exp,sqrt\nfrom mpl_toolkits.mplot3d.art3d import Poly3DCollection, Line3DCollection\n\nfrom ipywidgets import interact, interactive, fixed, interact_manual, FloatSlider\nimport ipywidgets as widgets\nfrom IPython.display import display, Latex, Markdown\n\n#this is the library that contains all the rigid body tranforms functions\nimport transforms as trans\nimport allfunc as fn",
"_____no_output_____"
],
[
"# 2D simple rotation\n\n# Counter CLockwise is positive theta\ntheta = np.radians(-90)\n\nR = np.array([[np.cos(theta),-np.sin(theta)],[np.sin(theta),np.cos(theta)]]) # DRAW Instead\n\nprint(np.array_repr(R))",
"array([[ 6.123234e-17, 1.000000e+00],\n [-1.000000e+00, 6.123234e-17]])\n"
],
[
"# 2D mirror + rotation\n\n# Counter CLockwise is positive theta\ntheta = np.radians(45)\n\nR = np.array([[-np.cos(theta),np.sin(theta)],[np.sin(theta),np.cos(theta)]]) # DRAW nstead\n\nprint(np.array_repr(R))",
"array([[-0.70710678, 0.70710678],\n [ 0.70710678, 0.70710678]])\n"
],
[
"\np_01 = np.array([[0.40785347], [-0.13464365]])\nR_01 = np.array([[-0.12115869, -0.99263315], [0.99263315, -0.12115869]])\np_21 = np.array([[0.17846946], [0.20535999]])\nR_21 = np.array([[0.77275609, 0.63470310], [-0.63470310, 0.77275609]])\n\n\n# 2D homogeneous transformation\n\np1 = p_01\nr1 = R_01\n\nt1 = np.array([[0.,0.,0.],[0.,0.,0.],[0.,0.,1.]])\n\nt1[0][2] = p1[0]\nt1[1][2] = p1[1]\nt1[0][:2] = r1[0]\nt1[1][:2] = r1[1]\n\n\n\np2 = p_21\nr2 = np.transpose(R_21)\np2 = -r2@p_21\n\n\nt2 = np.array([[0.,0.,0.],[0.,0.,0.],[0.,0.,1.]])\n\nt2[0][2] = p2[0]\nt2[1][2] = p2[1]\nt2[0][:2] = r2[0]\nt2[1][:2] = r2[1]\n\n\nt = t1@t2\n\nprint(np.array_repr(t))\n\nprint((r1@p2)+p1)\n",
"array([[-0.72365345, -0.69016352, 0.67873548],\n [ 0.69016352, -0.72365345, -0.10920729],\n [ 0. , 0. , 1. ]])\n[[ 0.67873548]\n [-0.10920729]]\n"
],
[
"\nT_01 = np.array([[-0.57938699, -0.81505259, 0.02865731], [0.81505259, -0.57938699, 0.04109700], [0.00000000, 0.00000000, 1.00000000]])\nT_21 = np.array([[-0.62755265, -0.77857412, 0.42005043], [0.77857412, -0.62755265, 0.33393594], [0.00000000, 0.00000000, 1.00000000]])\n\n\nprint(np.array_repr(T_01@T_21))\n\n",
"array([[-0.27098301, 0.96258413, -0.4868898 ],\n [-0.96258413, -0.27098301, 0.18998205],\n [ 0. , 0. , 1. ]])\n"
],
[
"\np_4 = np.array([[-0.04340388], [-0.06536943]])\nR_14 = np.array([[-0.62859794, -0.77773044], [0.77773044, -0.62859794]])\nq_1 = np.array([[-0.43438301], [-0.96785230]])\n\nR_41 = np.transpose(R_14)\np_1 = -np.transpose(R_14)@p_4\n\nprint(np.array_repr((R_41@q_1+p_1)))",
"array([[-0.45611972],\n [ 0.87137524]])\n"
],
[
"T_74 = np.array([[0.89715347, 0.44171897, 0.89719618], [-0.44171897, 0.89715347, -0.87410686], [0.00000000, 0.00000000, 1.00000000]])\np_7 = np.array([[0.80515685], [0.20637779]])\n\nR_74 = np.array([[0.,0.],[0.,0.]])\n\nP_74 = np.array([[0.],[0.]])\n\nR_74[0] = T_74[0][:2]\nR_74[1] = T_74[1][:2]\nP_74[0] = T_74[0][2]\nP_74[1] = T_74[1][2]\n\nR_47 = np.transpose(R_74)\nP_47 = -R_47@P_74\n\np_4 = R_47@p_7 + P_47\n\nprint(np.array_repr(p_4))\n",
"array([[-0.55984397],\n [ 0.92870503]])\n"
],
[
"T_80 = np.array([[-0.99963592, 0.02698197, 0.84828747], [-0.02698197, -0.99963592, -0.49933470], [0.00000000, 0.00000000, 1.00000000]])\nv_8 = np.array([[-0.94247001], [0.21877446]])\n\nR_80 = np.array([[0.,0.],[0.,0.]])\n\nR_80[0] = T_80[0][:2]\nR_80[1] = T_80[1][:2]\n\nR_08 = np.transpose(R_80)\n\nv_0 = R_08@v_8\n\nprint(np.array_repr(v_0))\n\n\n",
"array([[ 0.93622391],\n [-0.24412451]])\n"
],
[
"T_83 = np.array([[-0.51262225, -0.60297925, 0.61125646, -0.63293773], [-0.17011515, -0.62647192, -0.76065351, -0.16652703], [0.84159329, -0.49391190, 0.21856754, -0.30120392], [0.00000000, 0.00000000, 0.00000000, 1.00000000]])\np_3 = np.array([[-0.49837079], [-0.12069008], [0.81022909]])\n\nP_83 = np.array([[0.],[0.],[0.]])\n\n\n\nR_83,P_83_1 = fn.TransToRp(T_83)\n\nP_83 = P_83_1.reshape(3,1)\n\nR_38 = np.transpose(R_83)\nP_38 = -R_38@P_83\n\n\np_8 = (R_83@p_3) + P_83\n\n\nprint(p_8)",
"[[ 0.1905696 ]\n [-0.62244126]\n [-0.48392939]]\n"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecc1f1baa0d24cd9555c796cbb930c6e46edba68 | 6,171 | ipynb | Jupyter Notebook | .ipynb_checkpoints/TrajGenerator_V2-checkpoint.ipynb | bvsk35/Hopping_Bot | 5a8c7d4fdb4ae0a5ddf96002deb3c9ba1116c216 | [
"MIT"
] | null | null | null | .ipynb_checkpoints/TrajGenerator_V2-checkpoint.ipynb | bvsk35/Hopping_Bot | 5a8c7d4fdb4ae0a5ddf96002deb3c9ba1116c216 | [
"MIT"
] | null | null | null | .ipynb_checkpoints/TrajGenerator_V2-checkpoint.ipynb | bvsk35/Hopping_Bot | 5a8c7d4fdb4ae0a5ddf96002deb3c9ba1116c216 | [
"MIT"
] | 1 | 2020-03-02T07:27:04.000Z | 2020-03-02T07:27:04.000Z | 32.824468 | 474 | 0.599741 | [
[
[
"### Import required libraries",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\n\nfrom CartPole import CartPole\nfrom CartPole_GPS import CartPole_GPS\n\nfrom ilqr.dynamics import constrain\nfrom copy import deepcopy\n\nfrom EstimateDynamics import local_estimate\nfrom GMM import Estimated_Dynamics_Prior",
"_____no_output_____"
]
],
[
[
"### Formulate the iLQR problem",
"_____no_output_____"
]
],
[
[
"'''\n1 - dt = time step\n2 - N = Number of control points in the trajectory\n3 - x0 = Initial state\n4 - x_goal = Final state\n5 - Q = State cost\n6 - R = Control cost\n7 - Q_terminal = Cost at the final step\n8 - x_dynamics array stores the information regarding system. \n x_dynamics[0] = m = mass of the pendulum bob \n x_dynamics[1] = M = mass of the cart \n x_dynamics[2] = L = length of the massless rod \n x_dynamics[3] = g = gravity \n x_dynamics[4] = d = damping in the system\n'''\ndt = 0.005\nN = 500 # Number of time steps in trajectory.\nx_dynamics = np.array([1, 5, 2, 9.80665, 1]) # m=1, M=5, L=2, g=9.80665, d=1\nx0 = np.array([-3.0, 0.0, 0.1, 0.0]) # Initial state\nx_goal = np.array([2.0, 0.0, 0.0, 0.0])\n# Instantenous state cost.\nQ = np.eye(5)\nQ[2, 2] = 10\nQ[3, 3] = 10\n# Q[4, 4] = 100\n# Terminal state cost.\nQ_terminal = 100 * np.eye(5)\n# Instantaneous control cost.\nR = np.array([[1.0]])",
"_____no_output_____"
]
],
[
[
"### iLQR on Cart Pole",
"_____no_output_____"
]
],
[
[
"cartpole_prob = CartPole(dt, N, x_dynamics, x0, x_goal, Q, R, Q_terminal)\nxs, us = cartpole_prob.run_IterLinQuadReg()",
"_____no_output_____"
],
[
"# State matrix split into individual states. For plotting and analysing purposes.\nt = np.arange(N + 1) * dt\nx = xs[:, 0] # Position\nx_dot = xs[:, 1] # Velocity\ntheta = np.unwrap(cartpole_prob.deaugment_state(xs)[:, 2]) # Theta, makes for smoother plots.\ntheta_dot = xs[:, 3] # Angular velocity",
"_____no_output_____"
]
],
[
[
"### Simulate the real system and generate the data\nCost matrices, initial position and goal position will remain same as the above problem. As it indicates one policy. But still the initial positions and goal positions must be passed explicitly to the function. But you don't need to pass cost matrices (assume penalty on the system is same), this is just used to use to calculate the cost of the trajectory. Correct control action must be passed. Parameter gamma indicates how much of original data you want to keep\n\nVariance of the Gaussian noise will be taken as input from a Unif(0, var_range) uniform distribution. Inputs: x_initial, x_goal, u, n_rollouts, pattern='Normal', pattern_rand=False, var_range=10, gamma=0.2, percent=20\n\nPattern controls how the control sequence will be modified after applying white Guassian noise (zero mean).\n- Normal: based on the correction/mixing parameter gamma generate control (gamma controls how much noise we want).\n- MissingValue: based on the given percentage, set those many values to zero (it is implicitly it uses \"Normal\" generated control is used). \n- Shuffle: shuffles the entire \"Normal\" generated control sequence.\n- TimeDelay: takes the \"Normal\" generated control and shifts it by 1 index i.e. one unit time delay.\n- Extreme: sets gamma as zeros and generates control based on only noise.\n\nIf 'pattern_rand' is 'True' then we don't need to send the explicitly, it will chose one randomly for every rollout (default is 'False'). If you want to chose specific pattern then send it explicitly. ",
"_____no_output_____"
]
],
[
[
"x_rollout, u_rollout, local_policy, cost = cartpole_prob.gen_rollouts(x0, x_goal, us, n_rollouts=10, pattern_rand=True, var_range=10, gamma=0.2, percent=20)",
"_____no_output_____"
]
],
[
[
"### Local system dynamics/model estimate\nloca_estimate: function takes the states (arranged in a special format, [x(t), u(t), x(t+1)]), no. of gaussian mixtures and no.of states.",
"_____no_output_____"
]
],
[
[
"model = Estimated_Dynamics_Prior(init_sequential=False, eigreg=False, warmstart=True, \n min_samples_per_cluster=20, max_clusters=50, max_samples=20, strength=1.0)\nmodel.update_prior(x_rollout, u_rollout)\nA, B, C = model.fit(x_rollout, u_rollout)",
"_____no_output_____"
],
[
"print(A.shape)\nprint(B.shape)\nprint(C.shape)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
ecc1fb58f8ee23db256c55317f72729bb85b3e72 | 315,534 | ipynb | Jupyter Notebook | PMS_ Statistics.ipynb | AmbaPant/NPS | 0500f39f6708388d5c3f2b8d3e5ee5e56a1f646f | [
"MIT"
] | 1 | 2020-09-16T03:21:55.000Z | 2020-09-16T03:21:55.000Z | PMS_ Statistics.ipynb | AmbaPant/NPS | 0500f39f6708388d5c3f2b8d3e5ee5e56a1f646f | [
"MIT"
] | null | null | null | PMS_ Statistics.ipynb | AmbaPant/NPS | 0500f39f6708388d5c3f2b8d3e5ee5e56a1f646f | [
"MIT"
] | 2 | 2020-08-10T12:17:21.000Z | 2020-09-13T14:31:02.000Z | 136.299784 | 56,252 | 0.829277 | [
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nfrom sklearn import preprocessing\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"## scaling data",
"_____no_output_____"
]
],
[
[
"df = pd.read_csv('data/temperature.csv')\ndf",
"_____no_output_____"
],
[
"print('mean of 2001 = %0.2f'%df['2001'].mean())\nprint('standard deviation of 2001 = %0.3f ' %df['2001'].std())\nprint('Maximum value of 2001 = ',df['2001'].max())\nprint('Minumum value of 2001 = ',df['2001'].min())\nprint('sum of 2001 = ',df['2001'].sum())\n",
"mean of 2001 = 18.64\nstandard deviation of 2001 = 2.254 \nMaximum value of 2001 = 22.0\nMinumum value of 2001 = 13.0\nsum of 2001 = 223.7\n"
],
[
"plt.subplots(figsize = [15,6])\nplt.plot(df['month'],df['2001'],color ='b')\nplt.xlabel('Month',fontsize =18,color='k')\nplt.ylabel('Temperature',fontsize =18,color='k')\nplt.title('Original data',fontsize =24,color='k')\nplt.tick_params(axis='x', rotation= 45)\nplt.savefig(\"image/normal1.png\", dpi = 600) # dpi dot per inch\nplt.show()",
"_____no_output_____"
],
[
"df['2001']",
"_____no_output_____"
],
[
"A1=df['2001'].values.reshape(-1,1)\nA2=df['2002'].values.reshape(-1,1)\nA1",
"_____no_output_____"
]
],
[
[
"### Example:1",
"_____no_output_____"
]
],
[
[
"f_scaled1 = preprocessing.StandardScaler().fit(A1).transform(A1) # (A- mean A)/sd A\nf_scaled2 = preprocessing.StandardScaler().fit(A2).transform(A2) # (A- mean A)/sd A\nf_scaled1",
"_____no_output_____"
],
[
"np.sum(f_scaled1)",
"_____no_output_____"
],
[
"plt.subplots(figsize = [15,6])\nplt.plot(df['month'],f_scaled1,color ='brown',label='2001')\nplt.plot(df['month'],f_scaled2,color ='blue',label='2002')\nplt.axhline(y=0,color='k')\nplt.xlabel('Month',fontsize =18,color='k')\nplt.ylabel('y',fontsize =18,color='k')\nplt.title('Scaled data',fontsize =24,color='g')\nplt.tick_params(axis='x', rotation= 45)\nplt.legend()\nplt.savefig(\"image/scaled1.png\", dpi = 600) # dpi dot per inch\nplt.show()",
"_____no_output_____"
]
],
[
[
"$f(x,\\mu,\\sigma) = \\frac{1}{\\sqrt{2\\pi\\sigma^{2}}} e ^{-\\frac{1}{2}(\\frac{x-\\mu}{\\sigma})^{2}}$",
"_____no_output_____"
]
],
[
[
"const=np.sqrt(2*np.pi)*df['2001'].std()\nnormal=np.exp(-0.5*(f_scaled1)**2)/const\nplt.subplots(figsize = [15,6])\nplt.plot(f_scaled1,normal,color ='m')\nplt.xlabel('f_scaled1',fontsize =18,color='k')\nplt.ylabel('y',fontsize =18,color='k')\nplt.title('Normalized data',fontsize =24,color='g')\nplt.tick_params(axis='x', rotation= 45)\nplt.savefig(\"image/normal.png\", dpi = 600) # dpi dot per inch",
"_____no_output_____"
]
],
[
[
"### Example:2",
"_____no_output_____"
]
],
[
[
"f_scaled3 = preprocessing.MinMaxScaler().fit(A1).transform(A1)# (A- min A)/( max A -min A)\nf_scaled3",
"_____no_output_____"
],
[
"plt.subplots(figsize = [15,6])\nplt.plot(df['month'],f_scaled3,color ='orange')\nplt.xlabel('no.',fontsize =18,color='k')\nplt.ylabel('y',fontsize =18,color='k')\nplt.title('Scaled data',fontsize =24,color='g')\nplt.tight_layout() \nplt.savefig(\"image/scaled2.png\", dpi = 600) # dpi dot per inch\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Example:3",
"_____no_output_____"
]
],
[
[
"A = (100*np.random.rand(10,10)).astype(int) # construction of 10 x 10 matrix\nA ",
"_____no_output_____"
],
[
"n=np.arange(1,11)",
"_____no_output_____"
],
[
"df = pd.DataFrame(A, columns= ['Nepali','English','Math','Science','Health','History','Geography','Social','Moral','Computer'],\\\n index= [n])",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"df.index.names = ['Roll no'] #naming index\ndf",
"_____no_output_____"
],
[
"df.iloc[5,1]",
"_____no_output_____"
],
[
"df.info()",
"<class 'pandas.core.frame.DataFrame'>\nMultiIndex: 10 entries, (1,) to (10,)\nData columns (total 10 columns):\n # Column Non-Null Count Dtype\n--- ------ -------------- -----\n 0 Nepali 10 non-null int32\n 1 English 10 non-null int32\n 2 Math 10 non-null int32\n 3 Science 10 non-null int32\n 4 Health 10 non-null int32\n 5 History 10 non-null int32\n 6 Geography 10 non-null int32\n 7 Social 10 non-null int32\n 8 Moral 10 non-null int32\n 9 Computer 10 non-null int32\ndtypes: int32(10)\nmemory usage: 866.0 bytes\n"
],
[
"df.describe()",
"_____no_output_____"
],
[
"np.mean(df,axis =0)",
"_____no_output_____"
],
[
"plt.figure(figsize = [10,8])\nplt.pie(np.mean(df,axis =0),startangle=90, autopct='%1.0f%%', shadow = True) \nplt.legend(df.columns, loc = 'upper right') \nplt.title(\"subject wise mark distribution\",fontsize =24,color='g')\nplt.show()",
"_____no_output_____"
],
[
"plt.figure(figsize = [10,6])\nplt.errorbar(df.columns, np.mean(df,axis =0),yerr=np.std(df,axis =0),fmt='-o',capsize=4) #SE\nplt.xlabel('Subject',fontsize =18,color='k')\nplt.ylabel('Average Mark',fontsize =18,color='k')\nplt.title(\"Subject wise mark distribution\",fontsize =24,color='g')\nplt.tick_params(axis='x', rotation= 45)\nplt.show()",
"_____no_output_____"
],
[
"np.mean(df,axis =1)",
"_____no_output_____"
],
[
"plt.figure(figsize = [10,8])\nplt.bar(n,np.mean(df,axis =1),yerr=0.1*np.std(df,axis =1),align='center', color=\"pink\",capsize=4)\nplt.xlabel('Roll no.',fontsize =18,color='k')\nplt.ylabel('Average Mark',fontsize =18,color='k')\nplt.tick_params(axis='x', rotation= 45)\nplt.title(\"Roll no. wise mark distribution\",fontsize =24,color='g')\nplt.show()",
"_____no_output_____"
],
[
"df['Percentage']=100*np.sum(df,axis =1)/1000 #\ndf ",
"_____no_output_____"
],
[
"df.iloc[1,10]",
"_____no_output_____"
],
[
"grade=[]\nfor i in range(10):\n if(df.iloc[i,0]>30 and df.iloc[i,1]>30 and df.iloc[i,2]>30 and df.iloc[i,3]>30 and df.iloc[i,4]>30 and df.iloc[i,5]>30 and df.iloc[i,6]>30 and df.iloc[i,7]>30 and df.iloc[i,8]>30 and df.iloc[i,9]>30):\n if(df.iloc[i,10]>=40 and df.iloc[i,10]<50):\n y='E'\n elif(df.iloc[i,10]>=50 and df.iloc[i,10]<60):\n y='D'\n elif(df.iloc[i,10]>=60 and df.iloc[i,10]<70):\n y='C'\n elif(df.iloc[i,10]>=70 and df.iloc[i,10]<80):\n y='B' \n elif(df.iloc[i,10]>=80 and df.iloc[i,10]<90):\n y='A' \n elif(df.iloc[i,10]>=90 and df.iloc[i,10]<=100):\n y='A+'\n else:\n y='F'\n else:\n y='F'\n grade.append(y) ",
"_____no_output_____"
],
[
"df['Grade']=grade\ndf",
"_____no_output_____"
],
[
"df.to_csv(\"data/result.csv\") #save data in csv format in excel",
"_____no_output_____"
]
],
[
[
"correlation coefficient\n$(r)=\\frac{cov(x,y)}{\\sqrt{\\sigma_x \\sigma_y}}$",
"_____no_output_____"
]
],
[
[
"cov=np.cov(df.iloc[:,1],df.iloc[:,2])\ncov[0][1]",
"_____no_output_____"
],
[
"cv=np.corrcoef(df.iloc[:,1],df.iloc[:,3])\ncv",
"_____no_output_____"
],
[
"cv[0,1]",
"_____no_output_____"
],
[
"r=np.eye(10,10) # construction of 10 x 10 identical matrix\nfor i in range(10):\n for j in range(10):\n a=np.corrcoef(df.iloc[:,i],df.iloc[:,j])\n r[i][j]=\"{:.3}\".format(a[0,1]) \n ",
"_____no_output_____"
],
[
"df1 = pd.DataFrame(r)\ndf1",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
ecc1fc7465994c4751d2aac722f4ab5b53b6d8e8 | 30,825 | ipynb | Jupyter Notebook | Neural net/RNN.ipynb | junaid1460/machine_learning | 901d533807fb3367494cf86cb16c86a54035336d | [
"MIT"
] | null | null | null | Neural net/RNN.ipynb | junaid1460/machine_learning | 901d533807fb3367494cf86cb16c86a54035336d | [
"MIT"
] | null | null | null | Neural net/RNN.ipynb | junaid1460/machine_learning | 901d533807fb3367494cf86cb16c86a54035336d | [
"MIT"
] | null | null | null | 63.556701 | 2,173 | 0.619238 | [
[
[
"import numpy as np\nfrom __future__ import print_function",
"_____no_output_____"
],
[
"\n\n# data I/O\ndata = open('input.txt', 'r').read() # should be simple plain text file\nchars = list(set(data))\ndata_size, vocab_size = len(data), len(chars)\nprint('data has %d characters, %d unique.' % (data_size, vocab_size))\nchar_to_ix = { ch:i for i,ch in enumerate(chars) }\nix_to_char = { i:ch for i,ch in enumerate(chars) }\n\n# hyperparameters\nhidden_size = 100 # size of hidden layer of neurons\nseq_length = 25 # number of steps to unroll the RNN for\nlearning_rate = 1e-1\n\n# model parameters\nWxh = np.random.randn(hidden_size, vocab_size)*0.01 # input to hidden\nWhh = np.random.randn(hidden_size, hidden_size)*0.01 # hidden to hidden\nWhy = np.random.randn(vocab_size, hidden_size)*0.01 # hidden to output\nbh = np.zeros((hidden_size, 1)) # hidden bias\nby = np.zeros((vocab_size, 1)) # output bias\n\ndef lossFun(inputs, targets, hprev):\n \"\"\"\n inputs,targets are both list of integers.\n hprev is Hx1 array of initial hidden state\n returns the loss, gradients on model parameters, and last hidden state\n \"\"\"\n xs, hs, ys, ps = {}, {}, {}, {}\n hs[-1] = np.copy(hprev)\n loss = 0\n # forward pass\n for t in range(len(inputs)):\n xs[t] = np.zeros((vocab_size,1)) # encode in 1-of-k representation\n xs[t][inputs[t]] = 1\n hs[t] = np.tanh(np.dot(Wxh, xs[t]) + np.dot(Whh, hs[t-1]) + bh) # hidden state\n ys[t] = np.dot(Why, hs[t]) + by # unnormalized log probabilities for next chars\n ps[t] = np.exp(ys[t]) / np.sum(np.exp(ys[t])) # probabilities for next chars\n loss += -np.log(ps[t][targets[t],0]) # softmax (cross-entropy loss)\n # backward pass: compute gradients going backwards\n dWxh, dWhh, dWhy = np.zeros_like(Wxh), np.zeros_like(Whh), np.zeros_like(Why)\n dbh, dby = np.zeros_like(bh), np.zeros_like(by)\n dhnext = np.zeros_like(hs[0])\n for t in reversed(range(len(inputs))):\n dy = np.copy(ps[t])\n dy[targets[t]] -= 1 # backprop into y. see http://cs231n.github.io/neural-networks-case-study/#grad if confused here\n dWhy += np.dot(dy, hs[t].T)\n dby += dy\n dh = np.dot(Why.T, dy) + dhnext # backprop into h\n dhraw = (1 - hs[t] * hs[t]) * dh # backprop through tanh nonlinearity\n dbh += dhraw\n dWxh += np.dot(dhraw, xs[t].T)\n dWhh += np.dot(dhraw, hs[t-1].T)\n dhnext = np.dot(Whh.T, dhraw)\n for dparam in [dWxh, dWhh, dWhy, dbh, dby]:\n np.clip(dparam, -5, 5, out=dparam) # clip to mitigate exploding gradients\n return loss, dWxh, dWhh, dWhy, dbh, dby, hs[len(inputs)-1]\n\ndef sample(h, seed_ix, n):\n \"\"\" \n sample a sequence of integers from the model \n h is memory state, seed_ix is seed letter for first time step\n \"\"\"\n x = np.zeros((vocab_size, 1))\n x[seed_ix] = 1\n ixes = []\n for t in range(n):\n h = np.tanh(np.dot(Wxh, x) + np.dot(Whh, h) + bh)\n y = np.dot(Why, h) + by\n p = np.exp(y) / np.sum(np.exp(y))\n ix = np.random.choice(range(vocab_size), p=p.ravel())\n x = np.zeros((vocab_size, 1))\n x[ix] = 1\n ixes.append(ix)\n return ixes\n\nn, p = 0, 0\nmWxh, mWhh, mWhy = np.zeros_like(Wxh), np.zeros_like(Whh), np.zeros_like(Why)\nmbh, mby = np.zeros_like(bh), np.zeros_like(by) # memory variables for Adagrad\nsmooth_loss = -np.log(1.0/vocab_size)*seq_length # loss at iteration \n\nwhile True:\n # prepare inputs (we're sweeping from left to right in steps seq_length long)\n if p+seq_length+1 >= len(data) or n == 0: \n hprev = np.zeros((hidden_size,1)) # reset RNN memory\n p = 0 # go from start of data\n inputs = [char_to_ix[ch] for ch in data[p:p+seq_length]]\n targets = [char_to_ix[ch] for ch in data[p+1:p+seq_length+1]]\n\n # sample from the model now and then\n if n % 100 == 0:\n sample_ix = sample(hprev, inputs[0], 200)\n txt = ''.join(ix_to_char[ix] for ix in sample_ix)\n print( '----\\n %s \\n----' % (txt, ))\n\n # forward seq_length characters through the net and fetch gradient\n loss, dWxh, dWhh, dWhy, dbh, dby, hprev = lossFun(inputs, targets, hprev)\n smooth_loss = smooth_loss * 0.999 + loss * 0.001\n if n % 100 == 0: print('iter %d, loss: %f' % (n, smooth_loss) )# print progress\n\n # perform parameter update with Adagrad\n for param, dparam, mem in zip([Wxh, Whh, Why, bh, by], \n [dWxh, dWhh, dWhy, dbh, dby], \n [mWxh, mWhh, mWhy, mbh, mby]):\n mem += dparam * dparam\n param += -learning_rate * dparam / np.sqrt(mem + 1e-8) # adagrad update\n\n p += seq_length # move data pointer\n n += 1 # iteration counter \n ",
"data has 1125 characters, 56 unique.\n----\n so?a?PwRdATxP-oYvOG(Lqs;M(t,,OqgAcgPDSkLnNPN\nHh)ap\n'!SaNNrCWGkalQNAhIoAhd./;I .WW/CL(wtwHcv?CavHD.PnH\n-lgR)w HpoTw;beSPsixOIBuxPMAC-hL.'B)MAecPYAbcbxfpBpmT!TGOB)vtt!WQbgTk +BALdh\".PrrMG'b+L.lnfwcG' NC \n----\niter 0, loss: 100.633784\n----\n su ,ckem P lfur o,eDe eReueseW;l !ed ,eh iohe/CieradffdRePlOefrhtM'bhoe\ngy?teyoyoveulumNes+i ,arecg,S s ?tm,eYha/uwHsPAiueQh ;'uyvlu?veviteumhtrmnerhieeDioi u?r\"d ioyastWg.eoegAv (eloketsoenmvel kso u \n----\niter 100, loss: 101.840896\n----\n d i o waoraricolO!syn Rmppir r pta frg smneolsl ilsmblolstors)g ilneimr oenp maaoei ohalae Go olinoairnrl iSWpsloeoGopottmopt s oeadslt ulsymhs' ngpnngrnwce nilianrDsseein oeoeP slepielefenre Pril \n----\niter 200, loss: 100.073025\n----\n .?Beioan.lo wh cc lhen or w' Li \"o.oCYt c dl daeu .osuttc a de qo?ua'eeiyafe loa c luae lt aoiedue a iuener outro sos tot teo aoP toacee d Houldstsotoehlrsta due a OvPsahrouhan m.c o vt iotofnale do \n----\niter 300, loss: 98.035339\n----\n rtade ate gmenMnir SNtCn g pfvei Wr ttv,uenf dsxnGretolite.dd ee yohelmldum lotulalfeerit.nHp ls -tO\n\"cencyoi;let'ewlart inxmelvndM tyu a tOcnnane \"ngn tinwietBi m.m.oalelchengritenllfl. ,ra ps n,een \n----\niter 400, loss: 95.597521\n----\n ?tratisevatvsand isn HresnCfdoret.CWIfr BemeOid in-lroagaa f c,tgatorist i?ne, thiel n ftit pc\"vensf?oan. snate snso o v i?r innn ddol palu ivs vit -nu aNebtedet on tsean LS+ Ge,ara do th; etveo al \n----\niter 500, loss: 92.945112\n----\n ilf tomrmting. .nurmpppesscht oof b ong Lvor inng.fhse at.gh fom Now sumphi Dhpelu hutordhipWs or Hhes iriavveduowibvanntatots'mteteaSt kiQ Bir am we.l shes voesoshe ougigr g/o( akti,s de ihiryht- \n----\niter 600, loss: 90.098676\n----\n cng. otu ics re? Beves te chemings ind. crtece pretome cot alng lo ta an sooug Sf PN/QPr inl of arteS lIis trere seripmt pfgisle to ing, ntoo as g is'ewit tivres cor ceveat. as gosmeveil, cor'edad apm \n----\niter 700, loss: 87.242393\n----\n veis crho p SHeve nh pef fing Od? CQur WToud pe gourly our ps pofmeherdat aat iel \"ormtovel fo? gfelsri gf Ipr Win 'esinnf ateOSerecrimeangat ron ufmour ipu fingp (o \"re if ingaateonlrtadilen Or\"our a \n----\niter 800, loss: 84.451722\n----\n uiml'l'r \nNomule logil gort, CLGevicato prlant Wourlth. ndef ffeper. Thindis it ye wel'yo WPe, ,oos, av te Ar toatlps Rn'u touvOl\"tr tr yol Be dovillx\n? Thee dred gsentk-in ?reand ang amedodibg OSDep \n----\niter 900, loss: 81.685841\n----\n eg ther ecuant fobut ave nm tou lo n u yos xhea. ?+. ke dhingu ong ark ilu kang SoW Qwim theantd youur tar Are tois, fose den thteriHellchrems to fyvef ing.carecde nek ir coou yo ?CyoWe wevaprite gh \n----\niter 1000, loss: 79.042981\n----\n endoolmasixn iS, ant metee.ntionparte.\nBurtmenimececthevt angGeas youm at ote Acteortuplec\"mfmmiend glo. MCouut oad fmen aRG youps nte gote premecuilg inmiprite ad ta. Ind Courd ay mendithes abutang t \n----\niter 1100, loss: 76.457896\n----\n nth pilupilrt -o as iog'ig prevelachet in g of, coCLfangmme nt? pof primer thevhings oreate mteagsop se ?hecs ad i? yor thr arO amte tivg ebuter.ageyhe SDen m? buelf,.crsilt Ardtat gr che Wen Wenn you \n----\niter 1200, loss: 73.880857\n----\n afexkewsepril s andewinn arceit, orol dar af ie', OS. were.chitsinpis arathipils tofWe, anMipngils mripadt is .chiki, romdef. \"P' ?pore end tPofr an ambonpiptevelinGndeand, this erotellil,. olws foosu \n----\niter 1300, loss: 71.388050\n----\n dodereoaOrwen at falgolufr onrind thong avdo .qo.ud irs artothet oto pifiwe de th alBu onu'te Anw you Mre AL oulIhe fraond t? rethibstCoass mekate sutme ftot thinur gceCh\"es pendat in yoruteeg thalsut \n----\niter 1400, loss: 68.943551\n----\n rutoo you \"helog thisle Woat rotiset oer foiss comsier ton is deen fots youug ortut ilog it e Oc. Wouug Srefen ompgHrhe tferelveriith coour pocler ecox in peGso. Ort \nruas ive sand tfilg aSod eretiati \n----\niter 1500, loss: 66.659403\n----\n it tour mengnmet -nnecl, ver handbipte goallls doels noumpiSdo the do psere;g ler ther fbe pit, ire af tar freet. Bu ss.yomes fres (eulm ing f onllructe. btise soaf OSCCureg pinglang, ered Wre Spreev \n----\niter 1600, loss: 64.355837\n----\n feedledeced thes' trops y; ar? you OSIllo Dar the nyo rrate fhergtote bentyoop'inl weengthis croeved i(tyu Ores mens.\nWOS sabet, .ru all \"oh pero thile e. Obu loRyu crecceate nr ant Loul aHat Loily y \n----\niter 1700, loss: 62.193518\n----\n tmedantPAr ate youd inguSed yourenam nat/ieced cango gerhatiir to tse, ofras matis it catied meore etheh ingith? Orons frotongosart diend ar yke ofops ort foshend? prethens afmirlt Suis Los wonfschiH \n----\niter 1800, loss: 60.120718\n----\n ? OR\"n ingOSertend art at gutog your eromalled hanpello p.amet Lot aluw \nour gomefe Anisuirg youO \"honle, Hroisptie d, -C+ shugrecef tevecede\nt(e grete innd cent ors to th lslings oto De siing irial \n----\niter 1900, loss: 58.032338\n----\n heat ollg anmid Cou Thel pramm ntmirertin your to tor and tereant nr, mratiplins thiplloamreas or OS? Wanguthorudr yardacte ceo amd sinethi fig ind weld o. wet youu. If if arts. Nonsu, this Bobeu mand \n----\niter 2000, loss: 56.120077\n----\n l dhofwsinpilll'n thengreantveli( ugrinas tover if is you res wou lvvilnu rout yo ngois caml ocaadid grindilve iku seate oe phimmHipland tCongalond Oolve anqwuthereot por ar ade ,out nonuOSDevp out s \n----\niter 2100, loss: 54.278927\n----\n elcommint popillont Bu thet enre tore the prerts inl CMot go you pratotippertot in'ime fon ferobeatdect-ing tfe cheten threang at to eo OSDevelLinured at Ciks andt thertat pref promig? fekemminnddente \n----\niter 2200, loss: 52.527578\n----\n ngethot ilg mmmmisumserter ff perliendingHtino? \"rad? But poulls bot alanguseven thev'eng thel your goals, butd lant ant; gf cleweolus orls if mshiu? wre develonparllmento pen Gt/in youraliat, mats wa \n----\niter 2300, loss: 50.746725\n----\n Angthore ,\"manis feroceld toru greeve co subet, ang any R//M?W.\n?Wabe dd ip'llln ufields ces. Be this you ws inly yHarshkis pryours un oy palWiwinl- ureds pingurnet deothveping OSDev'ing akipilll, fat \n----\niter 2400, loss: 49.017964\n----\n re. Wmmilended tour lhabut theven in ss ney + alla yo Oad, GCom ads its corecde ome cat-terotit commpmincamotis doat Sbe tho samen to OSDevl'ingWansindintot ar ther abo ade lo -CQi nd tour weigfad in \n----\niter 2500, loss: 47.440256\n----\n as preane dalu an is this akentaen fopraemiclqu Smecete icrsecens grefere tis an avee ocesshelruimengthien-then Cwens Nof ar this ff reu the ne greaed fopssenedey mellr moruand tone But gotiel, Ore te \n----\niter 2600, loss: 45.904672\n----\n ngeven in Av'inou Bde, if ysumhwifr tor grefmenmen Cfare, thinp only unes.\nC(C.-her at ever LingWare. Was yon psonut Somp yovu gorpengthing tour Ik Gotwerexceten yovruding Scee, mre tor atid elon? Be \n----\niter 2700, loss: 44.396994\n----\n L ang inn tour south in y oals you als indsabeadd thit ang aro prefelel fand. geilld absum pills abk the nuis Linu fres yo alw, but, groillg abeutn cher tor build no ures. Buit on youlal Hellan fec \n----\niter 2800, loss: 43.045296\n----\n tde.ld ame ied toreasotheteco fread. In s.OS+ sseite the yo uref is ofter comiel, to as ateise ruind ir fert- ing. But geant gooncu on Won, cshive yougr ufe lonsWoisurte torisicvee tod ass catheelean \n----\niter 2900, loss: 41.757455\n----\n per t\"on urhangecee Cux? Oreit ce Ct\"on ar d\" go uarent\nNon peloC aDer IfuOSDer youred oty k\"ent, prtaecd, butewecte our Wompititin\" Wit, yoc. Ad theed thillom you ured to suie', chammintilg is tha \n----\niter 3000, loss: 40.449951\n----\n ertert is OS? Ore\n. If theng thoels ofapsiel, ibu sems towus orr bit are \"buu lor -Come. Cw falsu Whathered piver tou preammenows it. bess Nssuth pricg aof wate Wonl pingutheven burucameveptimmibut t \n----\niter 3100, loss: 39.233745\n----\n g ping Yhour this dopsehatsipi;mendit ct\"oise, Phevewit iill aof ysumpimmint. IQs ard ed youx dereot your Buis cesCPNout olan you. But yoyu Bees Lat? shing OQlr aRd in ce teog are dQis posuare de Co. \n----\niter 3200, loss: 38.027416\n----\n elcome ing your gonlang ts you sert and the \"Hve'n contilod aro cat, chipscat is Wateve fit in Iwo fessutrentiver) rothels Lant, tor sils on somereed in OSDevs? IRQs aro then lons, but. Ands frien fer \n----\niter 3300, loss: 36.947373\n----\n nt? Orut, fomsit cle oake, ore fring ane dehampillg you es.\nNoxt ar CoQlu Thacle tome go nu suxce don ar eadir dat Wo frecte f OSDev'ing. CHs nre. Wavl, OSDev'ing? greseet do rever yo but geaned eftem \n----\niter 3400, loss: 35.813496\n"
]
]
] | [
"code"
] | [
[
"code",
"code"
]
] |
ecc210cd8ff507fd644a661c7cdc3deb12f634aa | 10,249 | ipynb | Jupyter Notebook | Recurrent Neural Network/Basic RNN.ipynb | TaehoLi/Pytorch-secondstep | acb5378951385c2d52b4a89945a98016b993d0d9 | [
"MIT"
] | null | null | null | Recurrent Neural Network/Basic RNN.ipynb | TaehoLi/Pytorch-secondstep | acb5378951385c2d52b4a89945a98016b993d0d9 | [
"MIT"
] | null | null | null | Recurrent Neural Network/Basic RNN.ipynb | TaehoLi/Pytorch-secondstep | acb5378951385c2d52b4a89945a98016b993d0d9 | [
"MIT"
] | null | null | null | 26.279487 | 90 | 0.496536 | [
[
[
"#!pip install torch torchvision",
"_____no_output_____"
],
[
"# 단순한 문자 RNN을 만들어보겠습니다.\n\nimport torch \nimport torch.nn as nn\nimport torch.optim as optim\nimport numpy as np",
"_____no_output_____"
],
[
"# 하이퍼파라미터 설정\n\nn_hidden = 35 \nlr = 0.01\nepochs = 1000",
"_____no_output_____"
],
[
"# 사용하는 문자는 영어 소문자 및 몇가지 특수문자로 제한했습니다.\n# alphabet(0-25), space(26), ... , start(0), end(1)\n\nstring = \"hello pytorch. how long can a rnn cell remember? show me your limit!\"\nchars = \"abcdefghijklmnopqrstuvwxyz ?!.,:;01\"\n\n# 문자들을 리스트로 바꾸고 이의 길이(=문자의 개수)를 저장해놓습니다.\nchar_list = [i for i in chars]\nn_letters = len(char_list)",
"_____no_output_____"
],
[
"# 문자를 그대로 쓰지않고 one-hot 벡터로 바꿔서 연산에 쓰도록 하겠습니다.\n\n#Start = [0 0 0 … 1 0]\n#a = [1 0 0 … 0 0]\n#b = [0 1 0 … 0 0]\n#c = [0 0 1 … 0 0]\n#...\n#end = [0 0 0 … 0 1]",
"_____no_output_____"
],
[
"# 문자열을 one-hot 벡터의 스택으로 만드는 함수\n# abc -> [[1 0 0 … 0 0],\n# [0 1 0 … 0 0],\n# [0 0 1 … 0 0]]\n\ndef string_to_onehot(string):\n # 먼저 시작 토큰과 끝 토큰을 만들어줍니다.\n start = np.zeros(shape=n_letters ,dtype=int)\n end = np.zeros(shape=n_letters ,dtype=int)\n start[-2] = 1\n end[-1] = 1\n # 여기서부터는 문자열의 문자들을 차례대로 받아서 진행합니다.\n for i in string:\n # 먼저 문자가 몇번째 문자인지 찾습니다.\n # a:0, b:1, c:2,...\n idx = char_list.index(i)\n # 0으로만 구성된 배열을 만들어줍니다.\n # [0 0 0 … 0 0]\n zero = np.zeros(shape=n_letters ,dtype=int)\n # 해당 문자 인데스만 1로 바꿔줍니다.\n # b: [0 1 0 … 0 0]\n zero[idx]=1\n # start와 새로 생긴 zero를 붙이고 이를 start에 할당합니다.\n # 이게 반복되면 start에는 문자를 one-hot 벡터로 바꾼 배열들이 점점 쌓여가게 됩니다.\n start = np.vstack([start,zero])\n # 문자열이 다 끝나면 쌓아온 start와 end를 붙여줍니다.\n output = np.vstack([start,end])\n return output",
"_____no_output_____"
],
[
"# One-hot 벡터를 문자로 바꿔주는 함수 \n# [1 0 0 ... 0 0] -> a \n# https://pytorch.org/docs/stable/tensors.html?highlight=numpy#torch.Tensor.numpy\n\ndef onehot_to_word(onehot_1):\n # 텐서를 입력으로 받아 넘파이 배열로 바꿔줍니다.\n onehot = torch.Tensor.numpy(onehot_1)\n # one-hot 벡터의 최대값(=1) 위치 인덱스로 문자를 찾습니다.\n return char_list[onehot.argmax()]",
"_____no_output_____"
],
[
"# RNN with 1 hidden layer\n\nclass RNN(nn.Module):\n def __init__(self, input_size, hidden_size, output_size):\n super(RNN, self).__init__()\n \n self.input_size = input_size\n self.hidden_size = hidden_size\n self.output_size = output_size\n \n self.i2h = nn.Linear(input_size + hidden_size, hidden_size)\n self.i2o = nn.Linear(input_size + hidden_size, output_size)\n self.act_fn = nn.Tanh()\n \n def forward(self, input, hidden):\n # 입력과 hidden state를 cat함수로 붙여줍니다.\n combined = torch.cat((input, hidden), 1)\n # 붙인 값을 i2h 및 i2o에 통과시켜 hidden state는 업데이트, 결과값은 계산해줍니다.\n hidden = self.act_fn(self.i2h(combined))\n output = self.i2o(combined)\n return output, hidden\n \n # 아직 입력이 없을때(t=0)의 hidden state를 초기화해줍니다. \n def init_hidden(self):\n return torch.zeros(1, self.hidden_size)\n \nrnn = RNN(n_letters, n_hidden, n_letters)",
"_____no_output_____"
],
[
"# 손실함수와 최적화함수를 설정해줍니다.\n\nloss_func = nn.MSELoss()\noptimizer = torch.optim.Adam(rnn.parameters(), lr=lr)",
"_____no_output_____"
],
[
"# train\n\n# 문자열을 onehot 벡터로 만들고 이를 토치 텐서로 바꿔줍니다.\n# 또한 데이터타입도 학습에 맞게 바꿔줍니다.\none_hot = torch.from_numpy(string_to_onehot(string)).type_as(torch.FloatTensor())\n\nfor i in range(epochs):\n optimizer.zero_grad()\n # 학습에 앞서 hidden state를 초기화해줍니다.\n hidden = rnn.init_hidden()\n \n # 문자열 전체에 대한 손실을 구하기 위해 total_loss라는 변수를 만들어줍니다. \n total_loss = 0\n for j in range(one_hot.size()[0]-1):\n # 입력은 앞에 글자 \n # pyotrch 에서 p y t o r c\n input_ = one_hot[j:j+1,:]\n # 목표값은 뒤에 글자\n # pytorch 에서 y t o r c h\n target = one_hot[j+1]\n output, hidden = rnn.forward(input_, hidden)\n \n loss = loss_func(output.view(-1),target.view(-1))\n total_loss += loss\n\n total_loss.backward()\n optimizer.step()\n\n if i % 100 == 0:\n print(total_loss)",
"tensor(2.7090, grad_fn=<AddBackward0>)\ntensor(0.0740, grad_fn=<AddBackward0>)\ntensor(0.0209, grad_fn=<AddBackward0>)\ntensor(0.0124, grad_fn=<AddBackward0>)\ntensor(0.0083, grad_fn=<AddBackward0>)\ntensor(0.0077, grad_fn=<AddBackward0>)\ntensor(0.0042, grad_fn=<AddBackward0>)\ntensor(0.0034, grad_fn=<AddBackward0>)\ntensor(0.0039, grad_fn=<AddBackward0>)\ntensor(0.0028, grad_fn=<AddBackward0>)\n"
],
[
"# test \n# hidden state 는 처음 한번만 초기화해줍니다.\n\nstart = torch.zeros(1,n_letters)\nstart[:,-2] = 1\n\nwith torch.no_grad():\n hidden = rnn.init_hidden()\n # 처음 입력으로 start token을 전달해줍니다.\n input_ = start\n # output string에 문자들을 계속 붙여줍니다.\n output_string = \"\"\n\n # 원래는 end token이 나올때 까지 반복하는게 맞으나 끝나지 않아서 string의 길이로 정했습니다.\n for i in range(len(string)):\n output, hidden = rnn.forward(input_, hidden)\n # 결과값을 문자로 바꿔서 output_string에 붙여줍니다.\n output_string += onehot_to_word(output.data)\n # 또한 이번의 결과값이 다음의 입력값이 됩니다.\n input_ = output\n\nprint(output_string)",
"hello pytorch. how n cnonnn noyoyyyyyyyeeeeemmmmmrrrrrrrllllllllllll\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecc2180515d249f85396f5aed094154d68ca478d | 23,168 | ipynb | Jupyter Notebook | monty-hall/monty-hall.ipynb | marlanbar/fun | 3b412d1261ca10a5a84f44c7aa1e312d6fbff334 | [
"MIT"
] | null | null | null | monty-hall/monty-hall.ipynb | marlanbar/fun | 3b412d1261ca10a5a84f44c7aa1e312d6fbff334 | [
"MIT"
] | null | null | null | monty-hall/monty-hall.ipynb | marlanbar/fun | 3b412d1261ca10a5a84f44c7aa1e312d6fbff334 | [
"MIT"
] | null | null | null | 100.730435 | 18,850 | 0.867921 | [
[
[
"import numpy as np\nfrom random import choice, sample\nfrom matplotlib import pyplot as plt\n\n%matplotlib inline",
"_____no_output_____"
],
[
"wins_stayed_prop.append(1)",
"_____no_output_____"
],
[
"tries = 10000\ndoors = set(range(3))\nwins_stayed = 0\nwins_changed = 0\nprop_wins_stayed = []\nprop_wins_changed = []\nfor i in range(tries): \n car = sample(doors, 1)\n chosen_door = sample(doors, 1)\n goat = sample(doors.difference(set(chosen_door + car)),1)\n changed_door = sample(doors.difference(set(chosen_door + goat)),1)\n wins_changed += int(car == changed_door)\n wins_stayed += int(car == chosen_door)\n prop_wins_stayed.append(float(wins_stayed) / (i + 1))\n prop_wins_changed.append(float(wins_changed) / (i + 1))",
"_____no_output_____"
],
[
"np.linspace(0,1,7)",
"_____no_output_____"
],
[
"plt.plot(prop_wins_changed, label=\"Changed\")\nplt.plot(prop_wins_stayed, label=\"Stayed\")\nplt.yticks(np.linspace(0,1,7), np.linspace(0,1,7))\nplt.grid()\nplt.legend()\nplt.show()",
"_____no_output_____"
],
[
"wins_changed",
"_____no_output_____"
],
[
"wins_stayed",
"_____no_output_____"
],
[
"wins_changed + wins_stayed",
"_____no_output_____"
],
[
"[0,1,2]",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecc219adbd88ae52b3b91cf59d10849664e0ec76 | 600,515 | ipynb | Jupyter Notebook | Untitled.ipynb | Mallinator/RNN_Amazon_Reviews_Dataset | 8556fa670a5e66160d38941c461986fc82580068 | [
"MIT"
] | 1 | 2019-11-22T01:43:28.000Z | 2019-11-22T01:43:28.000Z | Untitled.ipynb | Mallinator/RNN_Amazon_Reviews_Dataset | 8556fa670a5e66160d38941c461986fc82580068 | [
"MIT"
] | null | null | null | Untitled.ipynb | Mallinator/RNN_Amazon_Reviews_Dataset | 8556fa670a5e66160d38941c461986fc82580068 | [
"MIT"
] | null | null | null | 580.768859 | 524,746 | 0.930863 | [
[
[
"# RNN MODEL ON AMAZON FINE FOOD REVIEWS DATASET",
"_____no_output_____"
],
[
"Data Source **[https://www.kaggle.com/snap/amazon-fine-food-reviews](https://www.kaggle.com/snap/amazon-fine-food-reviews)**",
"_____no_output_____"
],
[
"The Amazon Fine Food Reviews dataset consists of reviews of fine foods from Amazon.It consist of data collected from past many years. This dataset consist of approx 550k reviews. ",
"_____no_output_____"
],
[
" ",
"_____no_output_____"
],
[
"## SNIPPET\n1. Calculated the frequency of each word in vocabulary.\n2. Sorted the vocabulary by the rank. \n3. Applied LSTM with 1-Layer & 2-Layer on dataset.\n4. Plotted epoch vs losses.\n5. Conclusion based on the obtained results.",
"_____no_output_____"
],
[
"## DATA INFORMATION\n* Number of reviews: 568,454\n* Number of users: 256,059\n* Number of products: 74,258\n* Timespan: Oct 1999 - Oct 2012\n* Number of Attributes/Columns in data: 10 ",
"_____no_output_____"
],
[
"## ATTRIBUTE INFORMATION\n\n1. Id\n2. ProductId - unique identifier for the product\n3. UserId - unqiue identifier for the user\n4. ProfileName\n5. HelpfulnessNumerator - number of users who found the review helpful\n6. HelpfulnessDenominator - number of users who indicated whether they found the review helpful or not\n7. Score - rating between 1 and 5\n8. Time - timestamp for the review\n9. Summary - brief summary of the review\n10. Text - text of the review",
"_____no_output_____"
],
[
"## OBJECTIVE\nConvert the data according to rank and then predict the polarity of Reviews in Amazon fine food dataset using LSTM model with 1-layer and 2-layer respectively. ",
"_____no_output_____"
],
[
"## IMPORTING",
"_____no_output_____"
]
],
[
[
"import sqlite3\nimport re\nimport pickle\nimport numpy as np\nimport pandas as pd\nfrom PIL import Image\nfrom wordcloud import WordCloud, STOPWORDS, ImageColorGenerator\nimport matplotlib.pyplot as plt\nfrom keras.datasets import imdb\nfrom keras.models import Sequential\nfrom keras.layers import Dense\nfrom keras.layers import LSTM\nfrom keras.layers.embeddings import Embedding\nfrom sklearn.model_selection import train_test_split\nfrom keras.preprocessing import sequence",
"_____no_output_____"
]
],
[
[
"## FUNCTIONS",
"_____no_output_____"
],
[
"### 1. CLEANING ",
"_____no_output_____"
]
],
[
[
"def cleanhtml(sentence): #function to clean the word of any html-tags\n cleanr = re.compile('<.*?>')\n cleantext = re.sub(cleanr, ' ', sentence)\n return cleantext\ndef cleanpunc(sentence): #function to clean the word of any punctuation or special characters\n cleaned = re.sub(r'[?|!|\\'|\"|#]',r'',sentence)\n cleaned = re.sub(r'[.|,|)|(|\\|/]',r' ',cleaned)\n return cleaned",
"_____no_output_____"
]
],
[
[
"### 2. STORING IN LIST",
"_____no_output_____"
]
],
[
[
"def LOW(l):\n i=0\n list_of_sent=[] # list to store all the lists.\n for sent in l:\n filtered_sentence=[] # list to store each review.\n for w in sent.split():\n for cleaned_words in cleanpunc(w).split():\n if(cleaned_words.isalpha()): \n filtered_sentence.append(cleaned_words.lower())\n else:\n continue \n list_of_sent.append(filtered_sentence)\n return list_of_sent",
"_____no_output_____"
]
],
[
[
"### 3. USING PICKLE ",
"_____no_output_____"
]
],
[
[
"'''\nThese functions are used to save and retrieve the information and use it afterwards for future reference.\n'''\n\n# Method to Save the data.\ndef save(o,f):\n op=open(f+\".p\",\"wb\")\n pickle.dump(o,op)\n\n# Method to retrieve the data. \ndef retrieve(f):\n op=open(f+\".p\",\"rb\")\n ret=pickle.load(op)\n return ret",
"_____no_output_____"
]
],
[
[
"### 4. PLOTTING TRAIN VS VAL LOSS",
"_____no_output_____"
]
],
[
[
"def Plot(err):\n x = list(range(1,11))\n v_loss = err.history['val_loss']\n t_loss = err.history['loss']\n plt.plot(x, v_loss, '-b', label='Validation Loss')\n plt.plot(x, t_loss, '-r', label='Training Loss')\n plt.legend(loc='center right')\n plt.xlabel(\"EPOCHS\",fontsize=15, color='black')\n plt.ylabel(\"Train Loss & Validation Loss\",fontsize=15, color='black')\n plt.title(\"Train vs Validation Loss on Epoch's\" ,fontsize=15, color='black')\n plt.show()",
"_____no_output_____"
]
],
[
[
"## LOADING DATA",
"_____no_output_____"
]
],
[
[
"con = sqlite3.connect('./database.sqlite') # making a connection with sqlite\n\n\"\"\" Assembling data from Reviews where score is not 3 as 3 will be a neutral score so we cant decide the polarity\n based on a score of 3.here, score of 1&2 will be considered as negative whereas score of 4&5 will be considered as \n positive.\n\"\"\"\nfiltered_data = pd.read_sql_query(\"\"\" SELECT * FROM Reviews WHERE Score != 3 \"\"\", con) \n\n# function to map the polarity\n\ndef polarity(x):\n if x < 3:\n return 0\n return 1\n\nfiltered_data['Score']=filtered_data['Score'].map(polarity)",
"_____no_output_____"
]
],
[
[
"## DATA PRE-PROCESSING",
"_____no_output_____"
]
],
[
[
"#Sorting data according to ProductId in ascending order\nsorted_data=filtered_data.sort_values('ProductId', axis=0, ascending=True, inplace=False, kind='quicksort', na_position='last')\n#Deduplication of entries\nfinal=sorted_data.drop_duplicates(subset={\"UserId\",\"ProfileName\",\"Time\",\"Text\"}, keep='first', inplace=False)\nfinal=final[final.HelpfulnessNumerator<=final.HelpfulnessDenominator]",
"_____no_output_____"
],
[
"#Before starting the next phase of preprocessing lets see the number of entries left\nprint(\"Dimension of dataset - : \",final.shape,\"\\n\")\n\n#How many positive and negative reviews are present in our dataset?\nprint(\"________________________ Frequency of positive and negative reviews _________________________\")\nprint(final['Score'].value_counts())",
"Dimension of dataset - : (364171, 10) \n\n________________________ Frequency of positive and negative reviews _________________________\n1 307061\n0 57110\nName: Score, dtype: int64\n"
]
],
[
[
"## SAMPLING DATA",
"_____no_output_____"
]
],
[
[
"# Taking 60k reviews\nfinal = final.sample(60000)",
"_____no_output_____"
]
],
[
[
"## SORTING",
"_____no_output_____"
]
],
[
[
"final.sort_values('Time',inplace=True)",
"_____no_output_____"
],
[
"print(\"Dimension of dataset - : \",final.shape,\"\\n\")\n\n#How many positive and negative reviews are present in our dataset?\nprint(\"________________________ Frequency of positive and negative reviews _________________________\")\nprint(final['Score'].value_counts())",
"Dimension of dataset - : (60000, 10) \n\n________________________ Frequency of positive and negative reviews _________________________\n1 50687\n0 9313\nName: Score, dtype: int64\n"
]
],
[
[
"## CONVERTING THE DATA",
"_____no_output_____"
]
],
[
[
"total=[]\nfor i in range(60000):\n l1=final['Text'].values[i]\n l2=str(l1)\n total.append(l2)\n \ntotal = LOW(total)",
"_____no_output_____"
],
[
"all_=[]\nvocab=[]\nVocab=[]\n\nfor i in total:\n all_.extend(i)\n \nfor i in all_:\n c=0\n if i not in vocab:\n vocab.append(i)\n c = all_.count(i)\n Vocab.append((i,c))\n else:\n pass",
"_____no_output_____"
]
],
[
[
"## VOCABULARY",
"_____no_output_____"
]
],
[
[
"l1 = sorted(Vocab,reverse=True, key=lambda x:x[1])\nl2 = sorted(Vocab,reverse=False, key=lambda x:x[1])",
"_____no_output_____"
],
[
"mapped1 =[]\nmapped2 =[]\n\nfor i in range(len(l1)):\n mapped1.append(l1[i][0])\n \nfor i in range(len(l2)):\n mapped2.append(l2[i][0])\n\nkeys=list(range(1,len(l1)+1))\n\ndata1 = dict(zip(mapped1, keys))\ndata2 = dict(zip(mapped2, keys))",
"_____no_output_____"
],
[
"'''\n Printing the vocabulary according to the frequency of the words.\n eg. the was used most of the times and queen is used least.\n'''\nwo= WordCloud(width = 2000, height = 1000)\nwo.generate_from_frequencies(data2)\nplt.figure(figsize=(20,10))\nplt.imshow(wo, interpolation='bilinear')\nplt.axis(\"off\")\nplt.show()\nprint(\"\\n\")\nprint(\"___________________ SIZE OF VOCABULARY ______________________\")\nprint(len(vocab))",
"_____no_output_____"
]
],
[
[
"## CONVERTING ACCORDING TO RANK",
"_____no_output_____"
]
],
[
[
"print(\"_______________________ FIRST REVIEW BEFORE CONVERTING ________________\\n\")\nprint(total[0])",
"_______________________ FIRST REVIEW BEFORE CONVERTING ________________\n\n['this', 'witty', 'little', 'book', 'makes', 'my', 'son', 'laugh', 'at', 'loud', 'i', 'recite', 'it', 'in', 'the', 'car', 'as', 'were', 'driving', 'along', 'and', 'he', 'always', 'can', 'sing', 'the', 'refrain', 'hes', 'learned', 'about', 'whales', 'india', 'drooping', 'i', 'love', 'all', 'the', 'new', 'words', 'this', 'book', 'introduces', 'and', 'the', 'silliness', 'of', 'it', 'all', 'this', 'is', 'a', 'classic', 'book', 'i', 'am', 'willing', 'to', 'bet', 'my', 'son', 'will', 'still', 'be', 'able', 'to', 'recite', 'from', 'memory', 'when', 'he', 'is', 'in', 'college']\n"
],
[
"for i in range(len(total)):\n for j in range(len(total[i])):\n rank = data1.get(total[i][j])\n total[i][j]=rank",
"_____no_output_____"
],
[
"print(\"_______________________ FIRST REVIEW AFTER CONVERSION ________________\\n\")\nprint(total[0])",
"_______________________ FIRST REVIEW AFTER CONVERSION ________________\n\n[9, 16916, 75, 1556, 161, 12, 526, 4497, 31, 4865, 2, 19954, 6, 10, 1, 1511, 21, 74, 3201, 599, 3, 103, 165, 43, 6863, 1, 12626, 990, 1345, 62, 19955, 2140, 19956, 2, 50, 40, 1, 246, 1888, 9, 1556, 15022, 3, 1, 25597, 7, 6, 40, 9, 8, 4, 1531, 1556, 2, 90, 1917, 5, 2391, 12, 526, 52, 137, 29, 346, 5, 19954, 41, 3588, 45, 103, 8, 10, 1998]\n"
]
],
[
[
"## SPLITTING DATA INTO TRAIN & TEST",
"_____no_output_____"
]
],
[
[
"f = final['Score'].tolist()",
"_____no_output_____"
],
[
"'''\nThis function is used to split that data into train and test.\nIt uses the function to split it into 70-30 %.\nIt does not shuffle so the data is distributed sequentially.\n'''\nx_train, x_test, y_train, y_test = train_test_split(total,f,test_size=0.3,shuffle=False) # Splitting it in 70-30 without shuffling.",
"_____no_output_____"
],
[
"print(\"-----------------------TRAIN DATA------------------------------------\")\nprint(len(x_train))\nprint(len(y_train))\nprint(\"---------------------------------------------------------------------\")\nprint(\"\\n-----------------------TEST DATA-------------------------------------\")\nprint(len(x_test))\nprint(len(y_test))",
"-----------------------TRAIN DATA------------------------------------\n42000\n42000\n---------------------------------------------------------------------\n\n-----------------------TEST DATA-------------------------------------\n18000\n18000\n"
]
],
[
[
"# LSTM MODEL\n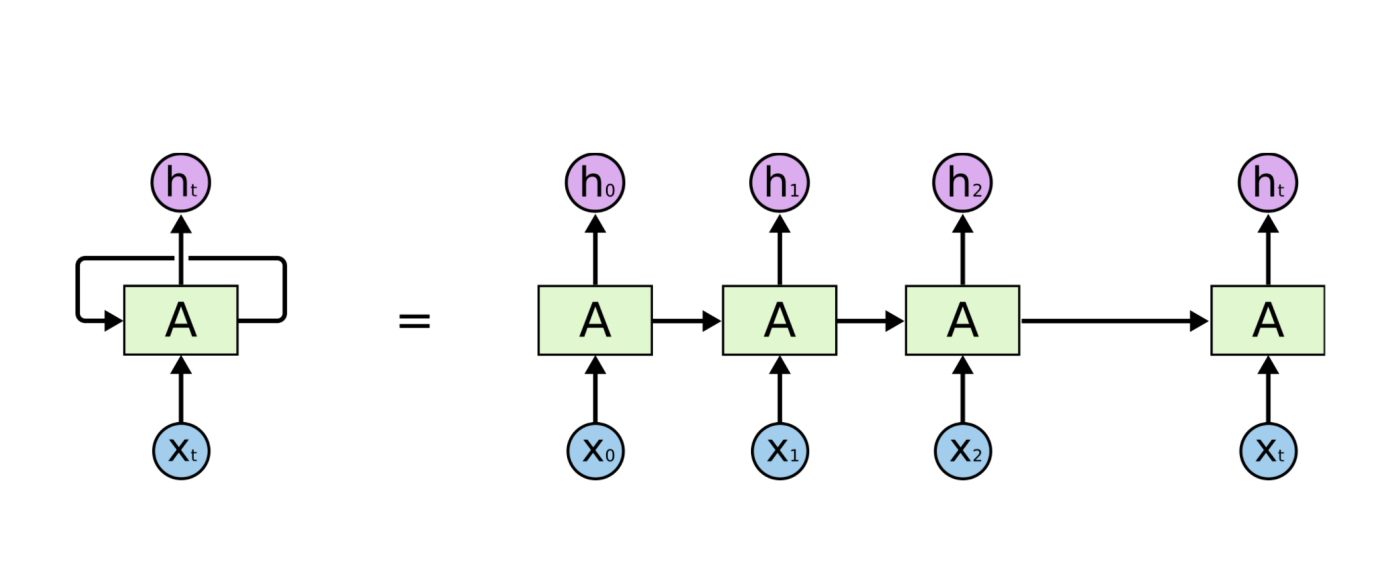",
"_____no_output_____"
],
[
"## PADDING",
"_____no_output_____"
]
],
[
[
"X_train = sequence.pad_sequences(x_train, maxlen = 700)\nX_test = sequence.pad_sequences(x_test, maxlen = 700)",
"_____no_output_____"
],
[
"print(\"-----------------------TRAIN DATA------------------------------------\")\nprint(X_train.shape)\nprint(len(y_train))\nprint(\"---------------------------------------------------------------------\")\nprint(\"\\n-----------------------TEST DATA-------------------------------------\")\nprint(X_test.shape)\nprint(len(y_test))",
"-----------------------TRAIN DATA------------------------------------\n(42000, 700)\n42000\n---------------------------------------------------------------------\n\n-----------------------TEST DATA-------------------------------------\n(18000, 700)\n18000\n"
]
],
[
[
"## DEFINING MODEL",
"_____no_output_____"
],
[
"### 1 - LAYER LSTM",
"_____no_output_____"
]
],
[
[
"'''\n In the embedding layer we put the total vocabulary as first parameter followed by output_dim\n and then the input length which we obtained after padding.\n'''\nmodel = Sequential()\nmodel.add(Embedding(44580, 32, input_length = 700))\nmodel.add(LSTM(100))\nmodel.add(Dense(1, activation='sigmoid'))\n\nmodel.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])\n\nprint(model.summary())",
"_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nembedding_4 (Embedding) (None, 700, 32) 1426560 \n_________________________________________________________________\nlstm_4 (LSTM) (None, 100) 53200 \n_________________________________________________________________\ndense_4 (Dense) (None, 1) 101 \n=================================================================\nTotal params: 1,479,861\nTrainable params: 1,479,861\nNon-trainable params: 0\n_________________________________________________________________\nNone\n"
]
],
[
[
"## FITTING THE MODEL",
"_____no_output_____"
]
],
[
[
"history = model.fit(X_train, y_train, epochs=10, batch_size=128, validation_data=(X_test, y_test))",
"Train on 42000 samples, validate on 18000 samples\nEpoch 1/10\n42000/42000 [==============================] - 580s 14ms/step - loss: 0.0382 - acc: 0.9874 - val_loss: 0.4414 - val_acc: 0.9006\nEpoch 2/10\n42000/42000 [==============================] - 544s 13ms/step - loss: 0.0277 - acc: 0.9907 - val_loss: 0.4852 - val_acc: 0.9025\nEpoch 3/10\n42000/42000 [==============================] - 560s 13ms/step - loss: 0.0180 - acc: 0.9941 - val_loss: 0.4918 - val_acc: 0.9003\nEpoch 4/10\n42000/42000 [==============================] - 550s 13ms/step - loss: 0.0147 - acc: 0.9956 - val_loss: 0.5784 - val_acc: 0.8998\nEpoch 5/10\n42000/42000 [==============================] - 543s 13ms/step - loss: 0.0189 - acc: 0.9940 - val_loss: 0.4866 - val_acc: 0.8938\nEpoch 6/10\n42000/42000 [==============================] - 555s 13ms/step - loss: 0.0157 - acc: 0.9953 - val_loss: 0.5656 - val_acc: 0.8968\nEpoch 7/10\n42000/42000 [==============================] - 549s 13ms/step - loss: 0.0157 - acc: 0.9948 - val_loss: 0.5310 - val_acc: 0.8974\nEpoch 8/10\n42000/42000 [==============================] - 648s 15ms/step - loss: 0.0131 - acc: 0.9961 - val_loss: 0.6062 - val_acc: 0.8906\nEpoch 9/10\n42000/42000 [==============================] - 1071s 25ms/step - loss: 0.0068 - acc: 0.9981 - val_loss: 0.6934 - val_acc: 0.8974\nEpoch 10/10\n42000/42000 [==============================] - 1071s 26ms/step - loss: 0.0027 - acc: 0.9994 - val_loss: 0.7410 - val_acc: 0.8966\n"
]
],
[
[
"## TRAIN VS VAL LOSS",
"_____no_output_____"
]
],
[
[
"Plot(history)",
"_____no_output_____"
]
],
[
[
"#### Here we can see clearly that our model is overfitting.",
"_____no_output_____"
],
[
"## EVALUATING THE MODEL",
"_____no_output_____"
]
],
[
[
"scores = model.evaluate(X_test, y_test, verbose=0)\nprint(\"Accuracy: %.2f%%\" % (scores[1]*100))",
"Accuracy: 89.66%\n"
]
],
[
[
"### 2 - LAYER LSTM",
"_____no_output_____"
]
],
[
[
"'''\n \n If we have to apply 2 layers in LSTM then the output of the above layer must be\n in a 3-dimensional space and by applying return_sequence=True that is achieved.\n \n'''\nmodel = Sequential()\nmodel.add(Embedding(44580, 32, input_length = 700))\nmodel.add(LSTM(50,return_sequences=True))\nmodel.add(LSTM(30))\nmodel.add(Dense(1, activation='sigmoid'))\n\nmodel.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])\n\n# printing the structure of the model.\nprint(model.summary())",
"_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nembedding_7 (Embedding) (None, 700, 32) 1426560 \n_________________________________________________________________\nlstm_9 (LSTM) (None, 700, 50) 16600 \n_________________________________________________________________\nlstm_10 (LSTM) (None, 30) 9720 \n_________________________________________________________________\ndense_6 (Dense) (None, 1) 31 \n=================================================================\nTotal params: 1,452,911\nTrainable params: 1,452,911\nNon-trainable params: 0\n_________________________________________________________________\nNone\n"
]
],
[
[
"## FITTING THE MODEL",
"_____no_output_____"
]
],
[
[
"history1 = model.fit(X_train, y_train, epochs=10, batch_size=128, validation_data=(X_test, y_test))",
"Train on 42000 samples, validate on 18000 samples\nEpoch 1/10\n42000/42000 [==============================] - 621s 15ms/step - loss: 0.2977 - acc: 0.8846 - val_loss: 0.2334 - val_acc: 0.9068\nEpoch 2/10\n42000/42000 [==============================] - 474s 11ms/step - loss: 0.1651 - acc: 0.9371 - val_loss: 0.2345 - val_acc: 0.9115\nEpoch 3/10\n42000/42000 [==============================] - 475s 11ms/step - loss: 0.1238 - acc: 0.9544 - val_loss: 0.2502 - val_acc: 0.9139\nEpoch 4/10\n42000/42000 [==============================] - 474s 11ms/step - loss: 0.0928 - acc: 0.9665 - val_loss: 0.2480 - val_acc: 0.9054\nEpoch 5/10\n42000/42000 [==============================] - 482s 11ms/step - loss: 0.0682 - acc: 0.9773 - val_loss: 0.2890 - val_acc: 0.9086\nEpoch 6/10\n42000/42000 [==============================] - 476s 11ms/step - loss: 0.0555 - acc: 0.9809 - val_loss: 0.3191 - val_acc: 0.8999\nEpoch 7/10\n42000/42000 [==============================] - 474s 11ms/step - loss: 0.0384 - acc: 0.9880 - val_loss: 0.3639 - val_acc: 0.9034\nEpoch 8/10\n42000/42000 [==============================] - 474s 11ms/step - loss: 0.0316 - acc: 0.9902 - val_loss: 0.4074 - val_acc: 0.9021\nEpoch 9/10\n42000/42000 [==============================] - 474s 11ms/step - loss: 0.0263 - acc: 0.9912 - val_loss: 0.4120 - val_acc: 0.9019\nEpoch 10/10\n42000/42000 [==============================] - 475s 11ms/step - loss: 0.0233 - acc: 0.9932 - val_loss: 0.4605 - val_acc: 0.8973\n"
]
],
[
[
"## TRAIN VS VAL LOSS",
"_____no_output_____"
]
],
[
[
"Plot(history1)",
"_____no_output_____"
]
],
[
[
"## EVALUATING THE MODEL",
"_____no_output_____"
]
],
[
[
"scores = model.evaluate(X_test, y_test, verbose=0)\nprint(\"Accuracy: %.2f%%\" % (scores[1]*100))",
"Accuracy: 89.73%\n"
]
],
[
[
"",
"_____no_output_____"
],
[
"### 1. In the first model we had obtained an accuracy of 89.66%.\n### 2. In the second model the accuracy obtained was 89.73%.\n### 3. In the first model we can see that the model is overfitting as the train loss and validation loss are seprated by big margin.\n### 4. We can analyze from the results that LSTM works very good on data as in 1st epoch it was giving a training loss of 0.0382 which is a very big deal .",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
ecc224c1fde264bb801b16650bc952caf8d18661 | 18,003 | ipynb | Jupyter Notebook | module3/James_Barciz_LS_DS_223_assignment.ipynb | JamesBarciz/DS-Unit-2-Kaggle-Challenge | 3321b4b7570b3e0b433e4689bc7aef1cf08660dc | [
"MIT"
] | null | null | null | module3/James_Barciz_LS_DS_223_assignment.ipynb | JamesBarciz/DS-Unit-2-Kaggle-Challenge | 3321b4b7570b3e0b433e4689bc7aef1cf08660dc | [
"MIT"
] | null | null | null | module3/James_Barciz_LS_DS_223_assignment.ipynb | JamesBarciz/DS-Unit-2-Kaggle-Challenge | 3321b4b7570b3e0b433e4689bc7aef1cf08660dc | [
"MIT"
] | null | null | null | 36.22334 | 452 | 0.542243 | [
[
[
"<a href=\"https://colab.research.google.com/github/JamesBarciz/DS-Unit-2-Kaggle-Challenge/blob/master/module3/James_Barciz_LS_DS_223_assignment.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"Lambda School Data Science\n\n*Unit 2, Sprint 2, Module 3*\n\n---",
"_____no_output_____"
],
[
"# Cross-Validation\n\n\n## Assignment\n- [ ] [Review requirements for your portfolio project](https://lambdaschool.github.io/ds/unit2), then submit your dataset.\n- [ ] Continue to participate in our Kaggle challenge. \n- [ ] Use scikit-learn for hyperparameter optimization with RandomizedSearchCV.\n- [ ] Submit your predictions to our Kaggle competition. (Go to our Kaggle InClass competition webpage. Use the blue **Submit Predictions** button to upload your CSV file. Or you can use the Kaggle API to submit your predictions.)\n- [ ] Commit your notebook to your fork of the GitHub repo.\n\n\nYou won't be able to just copy from the lesson notebook to this assignment.\n\n- Because the lesson was ***regression***, but the assignment is ***classification.***\n- Because the lesson used [TargetEncoder](https://contrib.scikit-learn.org/categorical-encoding/targetencoder.html), which doesn't work as-is for _multi-class_ classification.\n\nSo you will have to adapt the example, which is good real-world practice.\n\n1. Use a model for classification, such as [RandomForestClassifier](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html)\n2. Use hyperparameters that match the classifier, such as `randomforestclassifier__ ...`\n3. Use a metric for classification, such as [`scoring='accuracy'`](https://scikit-learn.org/stable/modules/model_evaluation.html#common-cases-predefined-values)\n4. If you’re doing a multi-class classification problem — such as whether a waterpump is functional, functional needs repair, or nonfunctional — then use a categorical encoding that works for multi-class classification, such as [OrdinalEncoder](https://contrib.scikit-learn.org/categorical-encoding/ordinal.html) (not [TargetEncoder](https://contrib.scikit-learn.org/categorical-encoding/targetencoder.html))\n\n\n\n## Stretch Goals\n\n### Reading\n- Jake VanderPlas, [Python Data Science Handbook, Chapter 5.3](https://jakevdp.github.io/PythonDataScienceHandbook/05.03-hyperparameters-and-model-validation.html), Hyperparameters and Model Validation\n- Jake VanderPlas, [Statistics for Hackers](https://speakerdeck.com/jakevdp/statistics-for-hackers?slide=107)\n- Ron Zacharski, [A Programmer's Guide to Data Mining, Chapter 5](http://guidetodatamining.com/chapter5/), 10-fold cross validation\n- Sebastian Raschka, [A Basic Pipeline and Grid Search Setup](https://github.com/rasbt/python-machine-learning-book/blob/master/code/bonus/svm_iris_pipeline_and_gridsearch.ipynb)\n- Peter Worcester, [A Comparison of Grid Search and Randomized Search Using Scikit Learn](https://blog.usejournal.com/a-comparison-of-grid-search-and-randomized-search-using-scikit-learn-29823179bc85)\n\n### Doing\n- Add your own stretch goals!\n- Try other [categorical encodings](https://contrib.scikit-learn.org/categorical-encoding/). See the previous assignment notebook for details.\n- In additon to `RandomizedSearchCV`, scikit-learn has [`GridSearchCV`](https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.GridSearchCV.html). Another library called scikit-optimize has [`BayesSearchCV`](https://scikit-optimize.github.io/notebooks/sklearn-gridsearchcv-replacement.html). Experiment with these alternatives.\n- _[Introduction to Machine Learning with Python](http://shop.oreilly.com/product/0636920030515.do)_ discusses options for \"Grid-Searching Which Model To Use\" in Chapter 6:\n\n> You can even go further in combining GridSearchCV and Pipeline: it is also possible to search over the actual steps being performed in the pipeline (say whether to use StandardScaler or MinMaxScaler). This leads to an even bigger search space and should be considered carefully. Trying all possible solutions is usually not a viable machine learning strategy. However, here is an example comparing a RandomForestClassifier and an SVC ...\n\nThe example is shown in [the accompanying notebook](https://github.com/amueller/introduction_to_ml_with_python/blob/master/06-algorithm-chains-and-pipelines.ipynb), code cells 35-37. Could you apply this concept to your own pipelines?\n",
"_____no_output_____"
],
[
"### BONUS: Stacking!\n\nHere's some code you can use to \"stack\" multiple submissions, which is another form of ensembling:\n\n```python\nimport pandas as pd\n\n# Filenames of your submissions you want to ensemble\nfiles = ['submission-01.csv', 'submission-02.csv', 'submission-03.csv']\n\ntarget = 'status_group'\nsubmissions = (pd.read_csv(file)[[target]] for file in files)\nensemble = pd.concat(submissions, axis='columns')\nmajority_vote = ensemble.mode(axis='columns')[0]\n\nsample_submission = pd.read_csv('sample_submission.csv')\nsubmission = sample_submission.copy()\nsubmission[target] = majority_vote\nsubmission.to_csv('my-ultimate-ensemble-submission.csv', index=False)\n```",
"_____no_output_____"
]
],
[
[
"%%capture\nimport sys\n\n# If you're on Colab:\nif 'google.colab' in sys.modules:\n DATA_PATH = 'https://raw.githubusercontent.com/LambdaSchool/DS-Unit-2-Kaggle-Challenge/master/data/'\n !pip install category_encoders==2.*\n\n# If you're working locally:\nelse:\n DATA_PATH = '../data/'",
"_____no_output_____"
],
[
"import pandas as pd\n\n# Merge train_features.csv & train_labels.csv\ntrain = pd.merge(pd.read_csv(DATA_PATH+'waterpumps/train_features.csv'), \n pd.read_csv(DATA_PATH+'waterpumps/train_labels.csv'))\n\n# Read test_features.csv & sample_submission.csv\ntest = pd.read_csv(DATA_PATH+'waterpumps/test_features.csv')\nsample_submission = pd.read_csv(DATA_PATH+'waterpumps/sample_submission.csv')",
"_____no_output_____"
],
[
"import category_encoders as ce\nimport numpy as np\nfrom sklearn.impute import SimpleImputer\nfrom sklearn.model_selection import cross_val_score\nfrom sklearn.pipeline import make_pipeline\nfrom sklearn.ensemble import RandomForestClassifier",
"_____no_output_____"
],
[
"def wrangle(X):\n X = X.copy()\n X['latitude'] = X['latitude'].replace(-2e-08, 0)\n\n cols_with_zeros = ['longitude', 'latitude']\n for col in cols_with_zeros:\n X[col] = X[col].replace(0, np.nan)\n\n X = X.drop(columns='quantity_group')\n return X",
"_____no_output_____"
],
[
"train = wrangle(train)\ntest = wrangle(test)",
"_____no_output_____"
],
[
"# Remove features with high cardinality\n\ntarget = 'status_group'\n\ntrain_features = train.drop(columns=[target, 'id'])\nnumeric_features = train_features.select_dtypes(include='number').columns.tolist()\ncardinality = train_features.select_dtypes(exclude='number').nunique()\ncategorical_features = cardinality[cardinality <= 50].index.tolist()\nfeatures = numeric_features + categorical_features\n\nX_train = train[features]\ny_train = train[target]\n\npipeline = make_pipeline(\n ce.OrdinalEncoder(),\n SimpleImputer(strategy='mean'),\n RandomForestClassifier(n_estimators=100, random_state=42)\n)\n\nk=3\nscores = cross_val_score(pipeline, X_train, y_train, cv=k,\n scoring='accuracy')\nprint(f'Accuracy for {k} folds:', scores)",
"Accuracy for 3 folds: [0.80045455 0.8029798 0.79656566]\n"
],
[
"scores.mean()",
"_____no_output_____"
],
[
"from sklearn.model_selection import GridSearchCV, RandomizedSearchCV\nfrom scipy.stats import randint, uniform",
"_____no_output_____"
],
[
"param_distributions = {\n 'simpleimputer__strategy': ['mean', 'median'],\n 'randomforestclassifier__n_estimators': randint(50,500),\n 'randomforestclassifier__max_depth': [5,10,15,20,None],\n 'randomforestclassifier__max_features': uniform(0,1),\n}\n\nsearch = RandomizedSearchCV(\n pipeline,\n param_distributions=param_distributions,\n n_iter=10,\n cv=4,\n scoring='accuracy',\n verbose=10,\n return_train_score=True,\n n_jobs=-1\n)\n\nsearch.fit(X_train, y_train);",
"Fitting 4 folds for each of 10 candidates, totalling 40 fits\n"
],
[
"print('Best hyperparameters', search.best_params_)\nprint('Cross-Validation Accuracy Score', search.best_score_)",
"Best hyperparameters {'randomforestclassifier__max_depth': 20, 'randomforestclassifier__max_features': 0.31111256817667554, 'randomforestclassifier__n_estimators': 358, 'simpleimputer__strategy': 'median'}\nCross-Validation Accuracy Score 0.8092087542087542\n"
],
[
"X_test = test[features]",
"_____no_output_____"
],
[
"y_pred = search.predict(X_test)",
"_____no_output_____"
],
[
"y_pred",
"_____no_output_____"
],
[
"submission = test[['id']].copy()\nsubmission['status_group'] = y_pred\n# submission['status_group']\nsubmission.to_csv('status_group_JamesBarciz_3.csv', index=False)",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecc22a2702830ed4be87e1172057f721a3e75ec8 | 426,034 | ipynb | Jupyter Notebook | pretrained-model/tts/glowtts/export/glowtts-haqkiem.ipynb | ishine/malaya-speech | fd34afc7107af1656dff4b3201fa51dda54fde18 | [
"MIT"
] | null | null | null | pretrained-model/tts/glowtts/export/glowtts-haqkiem.ipynb | ishine/malaya-speech | fd34afc7107af1656dff4b3201fa51dda54fde18 | [
"MIT"
] | null | null | null | pretrained-model/tts/glowtts/export/glowtts-haqkiem.ipynb | ishine/malaya-speech | fd34afc7107af1656dff4b3201fa51dda54fde18 | [
"MIT"
] | null | null | null | 328.729938 | 121,396 | 0.925083 | [
[
[
"import os\n\nos.environ['CUDA_VISIBLE_DEVICES'] = ''",
"_____no_output_____"
],
[
"import tensorflow as tf\nimport malaya_speech\nimport malaya_speech.train\nfrom malaya_speech.train.model import revsic_glowtts as glowtts\nimport numpy as np",
"_____no_output_____"
],
[
"_pad = 'pad'\n_start = 'start'\n_eos = 'eos'\n_punctuation = \"!'(),.:;? \"\n_special = '-'\n_letters = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz'\n_rejected = '\\'():;\"'\n\nMALAYA_SPEECH_SYMBOLS = (\n [_pad, _start, _eos] + list(_special) + list(_punctuation) + list(_letters)\n)",
"_____no_output_____"
],
[
"input_ids = tf.placeholder(tf.int32, [None, None], name = 'input_ids')\nlens = tf.placeholder(tf.int32, [None], name = 'lens')\nmel_outputs = tf.placeholder(tf.float32, [None, None, 80])\nmel_lengths = tf.placeholder(tf.int32, [None])\ntemperature = tf.placeholder(tf.float32, shape=(), name = 'temperature')\nlength_scale = tf.placeholder(tf.float32, shape=(), name = 'length_ratio')",
"_____no_output_____"
],
[
"config = glowtts.Config(mel = 80, vocabs = len(MALAYA_SPEECH_SYMBOLS))\nconfig.temperature = temperature\nconfig.length_scale = length_scale",
"_____no_output_____"
],
[
"model = glowtts.Model(config)",
"WARNING:tensorflow:From /home/husein/.local/lib/python3.6/site-packages/tensorflow_core/python/keras/initializers.py:119: calling RandomUniform.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.\nInstructions for updating:\nCall initializer instance with the dtype argument instead of passing it to the constructor\n"
],
[
"instance = malaya_speech.train.model.revsic_glowtts.flow.actnorm.ActNorm\n\nfor k in range(len(model.decoder.flows)):\n if isinstance(model.decoder.flows[k], instance):\n model.decoder.flows[k].init = 1",
"_____no_output_____"
],
[
"loss, losses, attn = model.compute_loss(text = input_ids, \n textlen = lens, \n mel = mel_outputs, mellen = mel_lengths)\nloss, losses, attn",
"WARNING:tensorflow:From /home/husein/.local/lib/python3.6/site-packages/tensorflow_core/python/ops/resource_variable_ops.py:1630: calling BaseResourceVariable.__init__ (from tensorflow.python.ops.resource_variable_ops) with constraint is deprecated and will be removed in a future version.\nInstructions for updating:\nIf using Keras pass *_constraint arguments to layers.\nWARNING:tensorflow:From /home/husein/malaya-speech/malaya_speech/train/model/utils.py:469: The name tf.debugging.assert_equal is deprecated. Please use tf.compat.v1.debugging.assert_equal instead.\n\nWARNING:tensorflow:From /home/husein/.local/lib/python3.6/site-packages/tensorflow_core/python/ops/init_ops.py:97: calling GlorotUniform.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.\nInstructions for updating:\nCall initializer instance with the dtype argument instead of passing it to the constructor\nWARNING:tensorflow:From /home/husein/.local/lib/python3.6/site-packages/tensorflow_core/python/ops/init_ops.py:97: calling Zeros.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.\nInstructions for updating:\nCall initializer instance with the dtype argument instead of passing it to the constructor\nWARNING:tensorflow:From /home/husein/malaya-speech/malaya_speech/train/model/revsic_glowtts/model.py:292: where (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse tf.where in 2.0, which has the same broadcast rule as np.where\n"
],
[
"mel, mellen, attn_out = model(inputs = input_ids, lengths = lens)\nmel, mellen, attn_out",
"_____no_output_____"
],
[
"mel = tf.identity(mel, name = 'mel_output')\nattn_out = tf.identity(attn_out, name = 'alignment_histories')",
"_____no_output_____"
],
[
"sess = tf.Session()\nsess.run(tf.global_variables_initializer())",
"_____no_output_____"
],
[
"path = 'glowtts-haqkiem'\nckpt_path = tf.train.latest_checkpoint(path)\nckpt_path",
"_____no_output_____"
],
[
"saver = tf.train.Saver()\nsaver.restore(sess, ckpt_path)",
"INFO:tensorflow:Restoring parameters from glowtts-haqkiem/model.ckpt-42500\n"
],
[
"import re\nfrom unidecode import unidecode\nimport malaya\n\nnormalizer = malaya.normalize.normalizer(date = False, time = False)\npad_to = 2\n\ndef tts_encode(string: str, add_eos: bool = True):\n r = [MALAYA_SPEECH_SYMBOLS.index(c) for c in string if c in MALAYA_SPEECH_SYMBOLS]\n if add_eos:\n r = r + [MALAYA_SPEECH_SYMBOLS.index('eos')]\n return r\n\ndef put_spacing_num(string):\n string = re.sub('[A-Za-z]+', lambda ele: ' ' + ele[0] + ' ', string)\n return re.sub(r'[ ]+', ' ', string).strip()\n\ndef convert_to_ascii(string):\n return unidecode(string)\n\ndef collapse_whitespace(string):\n return re.sub(_whitespace_re, ' ', string)\n\ndef cleaning(string, normalize = True, add_eos = False):\n sequence = []\n string = convert_to_ascii(string)\n if string[-1] in '-,':\n string = string[:-1]\n if string[-1] not in '.,?!':\n string = string + '.'\n string = string.replace('&', ' dan ')\n string = string.replace(':', ',').replace(';', ',')\n if normalize:\n t = normalizer._tokenizer(string)\n for i in range(len(t)):\n if t[i] == '-':\n t[i] = ','\n string = ' '.join(t)\n string = normalizer.normalize(string, \n check_english = False, \n normalize_entity = False, \n normalize_text = False,\n normalize_url = True,\n normalize_email = True,\n normalize_year = True)\n string = string['normalize']\n else:\n string = string\n string = put_spacing_num(string)\n string = ''.join([c for c in string if c in MALAYA_SPEECH_SYMBOLS and c not in _rejected])\n string = re.sub(r'[ ]+', ' ', string).strip()\n string = string.lower()\n ids = tts_encode(string, add_eos = add_eos)\n text_input = np.array(ids)\n num_pad = pad_to - ((len(text_input) + 2) % pad_to)\n text_input = np.pad(\n text_input, ((1, 1)), 'constant', constant_values = ((1, 2))\n )\n text_input = np.pad(\n text_input, ((0, num_pad)), 'constant', constant_values = 0\n )\n \n return string, text_input",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"t, ids = cleaning('Syed Saddiq berkata, mereka seharusnya mengingati bahawa semasa menjadi Perdana Menteri Pakatan Harapan')\nt, ids",
"_____no_output_____"
],
[
"%%time\n\no = sess.run([mel, mellen, attn_out], feed_dict = {input_ids: [ids],\n lens: [len(ids)],\n temperature: 0.6666, length_scale: 1.0})",
"CPU times: user 7.67 s, sys: 261 ms, total: 7.93 s\nWall time: 6.8 s\n"
],
[
"mel_outputs_ = np.reshape(o[0], [-1, 80])\nfig = plt.figure(figsize=(10, 8))\nax1 = fig.add_subplot(311)\nax1.set_title(f'Predicted Mel-before-Spectrogram')\nim = ax1.imshow(np.rot90(mel_outputs_), aspect='auto', interpolation='none')\nfig.colorbar(mappable=im, shrink=0.65, orientation='horizontal', ax=ax1)\nplt.show()",
"_____no_output_____"
],
[
"fig = plt.figure(figsize=(8, 6))\nax = fig.add_subplot(111)\nax.set_title('Alignment steps')\nim = ax.imshow(\n o[-1][0].T,\n aspect='auto',\n origin='lower',\n interpolation='none')\nfig.colorbar(im, ax=ax)\nxlabel = 'Decoder timestep'\nplt.xlabel(xlabel)\nplt.ylabel('Encoder timestep')\nplt.tight_layout()\nplt.show()",
"_____no_output_____"
],
[
"import pickle\n\nwith open('a.pkl', 'wb') as fopen:\n pickle.dump([np.reshape(o[0], [-1, 80])], fopen)",
"_____no_output_____"
],
[
"saver = tf.train.Saver()\nsaver.save(sess, 'glowtts-haqkiem-output/model.ckpt')",
"_____no_output_____"
],
[
"strings = ','.join(\n [\n n.name\n for n in tf.get_default_graph().as_graph_def().node\n if ('Variable' in n.op\n or 'gather' in n.op.lower()\n or 'input_ids' in n.name\n or 'lens' in n.name\n or 'temperature' in n.name\n or 'length_ratio' in n.name\n or 'mel_output' in n.name\n or 'alignment_histories' in n.name)\n and 'adam' not in n.name\n and 'global_step' not in n.name\n and 'Assign' not in n.name\n and 'AssignVariableOp' not in n.name\n and 'ReadVariableOp' not in n.name\n and 'Gather' not in n.name\n and 'IsVariableInitialized' not in n.name\n ]\n)\nstrings.split(',')",
"_____no_output_____"
],
[
"def freeze_graph(model_dir, output_node_names):\n\n if not tf.gfile.Exists(model_dir):\n raise AssertionError(\n \"Export directory doesn't exists. Please specify an export \"\n 'directory: %s' % model_dir\n )\n\n checkpoint = tf.train.get_checkpoint_state(model_dir)\n input_checkpoint = checkpoint.model_checkpoint_path\n\n absolute_model_dir = '/'.join(input_checkpoint.split('/')[:-1])\n output_graph = absolute_model_dir + '/frozen_model.pb'\n clear_devices = True\n with tf.Session(graph = tf.Graph()) as sess:\n saver = tf.train.import_meta_graph(\n input_checkpoint + '.meta', clear_devices = clear_devices\n )\n saver.restore(sess, input_checkpoint)\n output_graph_def = tf.graph_util.convert_variables_to_constants(\n sess,\n tf.get_default_graph().as_graph_def(),\n output_node_names.split(','),\n )\n with tf.gfile.GFile(output_graph, 'wb') as f:\n f.write(output_graph_def.SerializeToString())\n print('%d ops in the final graph.' % len(output_graph_def.node))",
"_____no_output_____"
],
[
"freeze_graph('glowtts-haqkiem-output', strings)",
"INFO:tensorflow:Restoring parameters from glowtts-haqkiem-output/model.ckpt\n"
],
[
"import struct\n\nunknown = b'\\xff\\xff\\xff\\xff'\n\ndef load_graph(frozen_graph_filename, return_def = False):\n with tf.gfile.GFile(frozen_graph_filename, 'rb') as f:\n graph_def = tf.GraphDef()\n graph_def.ParseFromString(f.read())\n \n for node in graph_def.node:\n if node.op == 'RefSwitch':\n node.op = 'Switch'\n for index in range(len(node.input)):\n if 'moving_' in node.input[index]:\n node.input[index] = node.input[index] + '/read'\n elif node.op == 'AssignSub':\n node.op = 'Sub'\n if 'use_locking' in node.attr:\n del node.attr['use_locking']\n elif node.op == 'AssignAdd':\n node.op = 'Add'\n if 'use_locking' in node.attr:\n del node.attr['use_locking']\n elif node.op in ['Assign', 'AssignVariableOp']:\n if node.op == 'AssignVariableOp':\n node.attr.setdefault('T')\n node.attr['T'].type = node.attr['dtype'].type\n del node.attr['dtype']\n node.op = 'Identity'\n if 'use_locking' in node.attr:\n del node.attr['use_locking']\n if 'validate_shape' in node.attr:\n del node.attr['validate_shape']\n if len(node.input) == 2:\n node.input[0] = node.input[1]\n del node.input[1]\n elif node.op == 'Switch' and 'wave_net_block' in node.name and 'AssignVariableOp_' in node.name:\n node.attr['T'].type = 1\n \n if return_def:\n return graph_def\n \n with tf.Graph().as_default() as graph:\n tf.import_graph_def(graph_def)\n return graph",
"_____no_output_____"
],
[
"g = load_graph('glowtts-haqkiem-output/frozen_model.pb')",
"_____no_output_____"
],
[
"test_sess = tf.InteractiveSession(graph = g)",
"_____no_output_____"
],
[
"input_nodes = ['input_ids', 'lens', 'temperature', 'length_ratio']\ninputs = {n: g.get_tensor_by_name(f'import/{n}:0') for n in input_nodes}",
"_____no_output_____"
],
[
"output_nodes = ['mel_output','alignment_histories']\noutputs = {n: g.get_tensor_by_name(f'import/{n}:0') for n in output_nodes}",
"_____no_output_____"
],
[
"%%time\n\no = test_sess.run(outputs, feed_dict = {inputs['input_ids']: [ids], \n inputs['lens']: [len(ids)],\n inputs['temperature']: 0.3333,\n inputs['length_ratio']: 1.0})",
"CPU times: user 2.95 s, sys: 80.6 ms, total: 3.03 s\nWall time: 2 s\n"
],
[
"mel_outputs_ = np.reshape(o['mel_output'], [-1, 80])\nfig = plt.figure(figsize=(10, 8))\nax1 = fig.add_subplot(311)\nax1.set_title(f'Predicted Mel-before-Spectrogram')\nim = ax1.imshow(np.rot90(mel_outputs_), aspect='auto', interpolation='none')\nfig.colorbar(mappable=im, shrink=0.65, orientation='horizontal', ax=ax1)\nplt.show()",
"_____no_output_____"
],
[
"fig = plt.figure(figsize=(8, 6))\nax = fig.add_subplot(111)\nax.set_title('Alignment steps')\nim = ax.imshow(\n o['alignment_histories'][0].T,\n aspect='auto',\n origin='lower',\n interpolation='none')\nfig.colorbar(im, ax=ax)\nxlabel = 'Decoder timestep'\nplt.xlabel(xlabel)\nplt.ylabel('Encoder timestep')\nplt.tight_layout()\nplt.show()",
"_____no_output_____"
],
[
"from tensorflow.tools.graph_transforms import TransformGraph",
"_____no_output_____"
],
[
"transforms = ['add_default_attributes',\n 'remove_nodes(op=Identity, op=CheckNumerics)',\n 'fold_batch_norms',\n 'fold_old_batch_norms',\n 'quantize_weights(fallback_min=-1024, fallback_max=1024)',\n 'strip_unused_nodes',\n 'sort_by_execution_order']",
"_____no_output_____"
],
[
"pb = 'glowtts-haqkiem-output/frozen_model.pb'",
"_____no_output_____"
],
[
"input_graph_def = tf.GraphDef()\nwith tf.gfile.FastGFile(pb, 'rb') as f:\n input_graph_def.ParseFromString(f.read())\n\ntransformed_graph_def = TransformGraph(input_graph_def, \n input_nodes,\n output_nodes, transforms)\n \nwith tf.gfile.GFile(f'{pb}.quantized', 'wb') as f:\n f.write(transformed_graph_def.SerializeToString())",
"WARNING:tensorflow:From <ipython-input-38-c5b774ec3708>:2: FastGFile.__init__ (from tensorflow.python.platform.gfile) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse tf.gfile.GFile.\n"
],
[
"g = load_graph('glowtts-haqkiem-output/frozen_model.pb.quantized')",
"_____no_output_____"
],
[
"test_sess = tf.InteractiveSession(graph = g)\ninputs = {n: g.get_tensor_by_name(f'import/{n}:0') for n in input_nodes}\noutputs = {n: g.get_tensor_by_name(f'import/{n}:0') for n in output_nodes}",
"_____no_output_____"
],
[
"%%time\n\no = test_sess.run(outputs, feed_dict = {inputs['input_ids']: [ids], \n inputs['lens']: [len(ids)],\n inputs['temperature']: 0.3333,\n inputs['length_ratio']: 1.0})",
"CPU times: user 3.41 s, sys: 165 ms, total: 3.58 s\nWall time: 2.6 s\n"
],
[
"mel_outputs_ = np.reshape(o['mel_output'], [-1, 80])\nfig = plt.figure(figsize=(10, 8))\nax1 = fig.add_subplot(311)\nax1.set_title(f'Predicted Mel-before-Spectrogram')\nim = ax1.imshow(np.rot90(mel_outputs_), aspect='auto', interpolation='none')\nfig.colorbar(mappable=im, shrink=0.65, orientation='horizontal', ax=ax1)\nplt.show()",
"_____no_output_____"
],
[
"b2_application_key_id = os.environ['b2_application_key_id']\nb2_application_key = os.environ['b2_application_key']",
"_____no_output_____"
],
[
"from b2sdk.v1 import *\ninfo = InMemoryAccountInfo()\nb2_api = B2Api(info)\napplication_key_id = b2_application_key_id\napplication_key = b2_application_key\nb2_api.authorize_account(\"production\", application_key_id, application_key)\nfile_info = {'how': 'good-file'}\nb2_bucket = b2_api.get_bucket_by_name('malaya-speech-model')",
"_____no_output_____"
],
[
"file = 'glowtts-haqkiem-output/frozen_model.pb'\noutPutname = 'v2/tts/glowtts-haqkiem.pb'\nb2_bucket.upload_local_file(\n local_file=file,\n file_name=outPutname,\n file_infos=file_info,\n)",
"_____no_output_____"
],
[
"file = 'glowtts-haqkiem-output/frozen_model.pb.quantized'\noutPutname = 'v2/tts/glowtts-haqkiem.pb.quantized'\nb2_bucket.upload_local_file(\n local_file=file,\n file_name=outPutname,\n file_infos=file_info,\n)",
"_____no_output_____"
],
[
"!tar -zcvf glowtts-haqkiem-output.tar.gz glowtts-haqkiem-output",
"glowtts-haqkiem-output/\nglowtts-haqkiem-output/model.ckpt.index\nglowtts-haqkiem-output/model.ckpt.data-00000-of-00001\nglowtts-haqkiem-output/frozen_model.pb.quantized\nglowtts-haqkiem-output/checkpoint\nglowtts-haqkiem-output/model.ckpt.meta\nglowtts-haqkiem-output/frozen_model.pb\n"
],
[
"file = 'glowtts-haqkiem-output.tar.gz'\noutPutname = 'pretrained/glowtts-haqkiem-output.tar.gz'\nb2_bucket.upload_local_file(\n local_file=file,\n file_name=outPutname,\n file_infos=file_info,\n)",
"ERROR:b2sdk.bucket:error when uploading, upload_url was https://pod-000-1400-13.backblaze.com/b2api/v2/b2_upload_part/4_z1df33cf49156ac6f744c0b11_f2045241436310e66_d20211013_m024345_c000_v0001400_t0009/0028\nTraceback (most recent call last):\n File \"/home/husein/.local/lib/python3.6/site-packages/urllib3/connectionpool.py\", line 672, in urlopen\n chunked=chunked,\n File \"/home/husein/.local/lib/python3.6/site-packages/urllib3/connectionpool.py\", line 421, in _make_request\n six.raise_from(e, None)\n File \"<string>\", line 3, in raise_from\n File \"/home/husein/.local/lib/python3.6/site-packages/urllib3/connectionpool.py\", line 416, in _make_request\n httplib_response = conn.getresponse()\n File \"/usr/lib/python3.6/http/client.py\", line 1373, in getresponse\n response.begin()\n File \"/usr/lib/python3.6/http/client.py\", line 311, in begin\n version, status, reason = self._read_status()\n File \"/usr/lib/python3.6/http/client.py\", line 280, in _read_status\n raise RemoteDisconnected(\"Remote end closed connection without\"\nhttp.client.RemoteDisconnected: Remote end closed connection without response\n\nDuring handling of the above exception, another exception occurred:\n\nTraceback (most recent call last):\n File \"/home/husein/.local/lib/python3.6/site-packages/requests/adapters.py\", line 449, in send\n timeout=timeout\n File \"/home/husein/.local/lib/python3.6/site-packages/urllib3/connectionpool.py\", line 720, in urlopen\n method, url, error=e, _pool=self, _stacktrace=sys.exc_info()[2]\n File \"/home/husein/.local/lib/python3.6/site-packages/urllib3/util/retry.py\", line 400, in increment\n raise six.reraise(type(error), error, _stacktrace)\n File \"/home/husein/.local/lib/python3.6/site-packages/urllib3/packages/six.py\", line 734, in reraise\n raise value.with_traceback(tb)\n File \"/home/husein/.local/lib/python3.6/site-packages/urllib3/connectionpool.py\", line 672, in urlopen\n chunked=chunked,\n File \"/home/husein/.local/lib/python3.6/site-packages/urllib3/connectionpool.py\", line 421, in _make_request\n six.raise_from(e, None)\n File \"<string>\", line 3, in raise_from\n File \"/home/husein/.local/lib/python3.6/site-packages/urllib3/connectionpool.py\", line 416, in _make_request\n httplib_response = conn.getresponse()\n File \"/usr/lib/python3.6/http/client.py\", line 1373, in getresponse\n response.begin()\n File \"/usr/lib/python3.6/http/client.py\", line 311, in begin\n version, status, reason = self._read_status()\n File \"/usr/lib/python3.6/http/client.py\", line 280, in _read_status\n raise RemoteDisconnected(\"Remote end closed connection without\"\nurllib3.exceptions.ProtocolError: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response',))\n\nDuring handling of the above exception, another exception occurred:\n\nTraceback (most recent call last):\n File \"/home/husein/.local/lib/python3.6/site-packages/b2sdk/b2http.py\", line 54, in _translate_errors\n response = fcn()\n File \"/home/husein/.local/lib/python3.6/site-packages/b2sdk/b2http.py\", line 304, in do_post\n response = self.session.post(url, headers=headers, data=data, timeout=self.TIMEOUT)\n File \"/home/husein/.local/lib/python3.6/site-packages/requests/sessions.py\", line 581, in post\n return self.request('POST', url, data=data, json=json, **kwargs)\n File \"/home/husein/.local/lib/python3.6/site-packages/requests/sessions.py\", line 533, in request\n resp = self.send(prep, **send_kwargs)\n File \"/home/husein/.local/lib/python3.6/site-packages/requests/sessions.py\", line 646, in send\n r = adapter.send(request, **kwargs)\n File \"/home/husein/.local/lib/python3.6/site-packages/requests/adapters.py\", line 498, in send\n raise ConnectionError(err, request=request)\nrequests.exceptions.ConnectionError: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response',))\n\nDuring handling of the above exception, another exception occurred:\n\nTraceback (most recent call last):\n File \"/home/husein/.local/lib/python3.6/site-packages/b2sdk/bucket.py\", line 689, in _upload_part\n HEX_DIGITS_AT_END, hashing_stream\n File \"/home/husein/.local/lib/python3.6/site-packages/b2sdk/raw_api.py\", line 546, in upload_part\n return self.b2_http.post_content_return_json(upload_url, headers, data_stream)\n File \"/home/husein/.local/lib/python3.6/site-packages/b2sdk/b2http.py\", line 308, in post_content_return_json\n response = _translate_and_retry(do_post, try_count, post_params)\n File \"/home/husein/.local/lib/python3.6/site-packages/b2sdk/b2http.py\", line 137, in _translate_and_retry\n return _translate_errors(fcn, post_params)\n File \"/home/husein/.local/lib/python3.6/site-packages/b2sdk/b2http.py\", line 87, in _translate_errors\n raise B2ConnectionError(str(e0))\nb2sdk.exception.B2ConnectionError: Connection error: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response',))\nERROR:b2sdk.bucket:error when uploading, upload_url was https://pod-000-1400-00.backblaze.com/b2api/v2/b2_upload_part/4_z1df33cf49156ac6f744c0b11_f2045241436310e66_d20211013_m024345_c000_v0001400_t0009/0039\nTraceback (most recent call last):\n File \"/home/husein/.local/lib/python3.6/site-packages/urllib3/connectionpool.py\", line 672, in urlopen\n chunked=chunked,\n File \"/home/husein/.local/lib/python3.6/site-packages/urllib3/connectionpool.py\", line 421, in _make_request\n six.raise_from(e, None)\n File \"<string>\", line 3, in raise_from\n File \"/home/husein/.local/lib/python3.6/site-packages/urllib3/connectionpool.py\", line 416, in _make_request\n httplib_response = conn.getresponse()\n File \"/usr/lib/python3.6/http/client.py\", line 1373, in getresponse\n response.begin()\n File \"/usr/lib/python3.6/http/client.py\", line 311, in begin\n version, status, reason = self._read_status()\n File \"/usr/lib/python3.6/http/client.py\", line 280, in _read_status\n raise RemoteDisconnected(\"Remote end closed connection without\"\nhttp.client.RemoteDisconnected: Remote end closed connection without response\n\nDuring handling of the above exception, another exception occurred:\n\nTraceback (most recent call last):\n File \"/home/husein/.local/lib/python3.6/site-packages/requests/adapters.py\", line 449, in send\n timeout=timeout\n File \"/home/husein/.local/lib/python3.6/site-packages/urllib3/connectionpool.py\", line 720, in urlopen\n method, url, error=e, _pool=self, _stacktrace=sys.exc_info()[2]\n File \"/home/husein/.local/lib/python3.6/site-packages/urllib3/util/retry.py\", line 400, in increment\n raise six.reraise(type(error), error, _stacktrace)\n File \"/home/husein/.local/lib/python3.6/site-packages/urllib3/packages/six.py\", line 734, in reraise\n raise value.with_traceback(tb)\n File \"/home/husein/.local/lib/python3.6/site-packages/urllib3/connectionpool.py\", line 672, in urlopen\n chunked=chunked,\n File \"/home/husein/.local/lib/python3.6/site-packages/urllib3/connectionpool.py\", line 421, in _make_request\n six.raise_from(e, None)\n File \"<string>\", line 3, in raise_from\n File \"/home/husein/.local/lib/python3.6/site-packages/urllib3/connectionpool.py\", line 416, in _make_request\n httplib_response = conn.getresponse()\n File \"/usr/lib/python3.6/http/client.py\", line 1373, in getresponse\n response.begin()\n File \"/usr/lib/python3.6/http/client.py\", line 311, in begin\n version, status, reason = self._read_status()\n File \"/usr/lib/python3.6/http/client.py\", line 280, in _read_status\n raise RemoteDisconnected(\"Remote end closed connection without\"\nurllib3.exceptions.ProtocolError: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response',))\n\nDuring handling of the above exception, another exception occurred:\n\nTraceback (most recent call last):\n File \"/home/husein/.local/lib/python3.6/site-packages/b2sdk/b2http.py\", line 54, in _translate_errors\n response = fcn()\n File \"/home/husein/.local/lib/python3.6/site-packages/b2sdk/b2http.py\", line 304, in do_post\n response = self.session.post(url, headers=headers, data=data, timeout=self.TIMEOUT)\n File \"/home/husein/.local/lib/python3.6/site-packages/requests/sessions.py\", line 581, in post\n return self.request('POST', url, data=data, json=json, **kwargs)\n File \"/home/husein/.local/lib/python3.6/site-packages/requests/sessions.py\", line 533, in request\n resp = self.send(prep, **send_kwargs)\n File \"/home/husein/.local/lib/python3.6/site-packages/requests/sessions.py\", line 646, in send\n r = adapter.send(request, **kwargs)\n File \"/home/husein/.local/lib/python3.6/site-packages/requests/adapters.py\", line 498, in send\n raise ConnectionError(err, request=request)\nrequests.exceptions.ConnectionError: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response',))\n\nDuring handling of the above exception, another exception occurred:\n\nTraceback (most recent call last):\n File \"/home/husein/.local/lib/python3.6/site-packages/b2sdk/bucket.py\", line 689, in _upload_part\n HEX_DIGITS_AT_END, hashing_stream\n File \"/home/husein/.local/lib/python3.6/site-packages/b2sdk/raw_api.py\", line 546, in upload_part\n return self.b2_http.post_content_return_json(upload_url, headers, data_stream)\n File \"/home/husein/.local/lib/python3.6/site-packages/b2sdk/b2http.py\", line 308, in post_content_return_json\n response = _translate_and_retry(do_post, try_count, post_params)\n File \"/home/husein/.local/lib/python3.6/site-packages/b2sdk/b2http.py\", line 137, in _translate_and_retry\n return _translate_errors(fcn, post_params)\n File \"/home/husein/.local/lib/python3.6/site-packages/b2sdk/b2http.py\", line 87, in _translate_errors\n raise B2ConnectionError(str(e0))\nb2sdk.exception.B2ConnectionError: Connection error: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response',))\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecc247969d7a99952b12ff7ad29e64a0de9d53d9 | 131,237 | ipynb | Jupyter Notebook | CoLA/LSTM_CoLA_original.ipynb | wangluheng328/BI-Significance | 50499f8280734d4ef025eec91d2dc2cd4ada2422 | [
"MIT"
] | null | null | null | CoLA/LSTM_CoLA_original.ipynb | wangluheng328/BI-Significance | 50499f8280734d4ef025eec91d2dc2cd4ada2422 | [
"MIT"
] | null | null | null | CoLA/LSTM_CoLA_original.ipynb | wangluheng328/BI-Significance | 50499f8280734d4ef025eec91d2dc2cd4ada2422 | [
"MIT"
] | null | null | null | 58.069469 | 29,742 | 0.626622 | [
[
[
"# Data Loading\n",
"_____no_output_____"
]
],
[
[
"!pip install wget",
"Collecting wget\n Downloading https://files.pythonhosted.org/packages/47/6a/62e288da7bcda82b935ff0c6cfe542970f04e29c756b0e147251b2fb251f/wget-3.2.zip\nBuilding wheels for collected packages: wget\n Building wheel for wget (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for wget: filename=wget-3.2-cp37-none-any.whl size=9681 sha256=e4a17d97fb280aa15ac05e09299ea5e4fe1821f876ec5c30db217f727ccf30c1\n Stored in directory: /root/.cache/pip/wheels/40/15/30/7d8f7cea2902b4db79e3fea550d7d7b85ecb27ef992b618f3f\nSuccessfully built wget\nInstalling collected packages: wget\nSuccessfully installed wget-3.2\n"
],
[
"import pandas as pd\nimport numpy as np\n\nfrom google.colab import drive\ndrive.mount('/content/drive', force_remount=True)\n\nimport wget\nimport os\n\nprint('Downloading dataset...')\n\n# The URL for the dataset zip file.\nurl = 'https://nyu-mll.github.io/CoLA/cola_public_1.1.zip'\n\n# Download the file (if we haven't already)\nif not os.path.exists('./cola_public_1.1.zip'):\n wget.download(url, './cola_public_1.1.zip')\n\n# Unzip the dataset (if we haven't already)\nif not os.path.exists('./cola_public/'):\n !unzip cola_public_1.1.zip\n \nimport pandas as pd\n\n# Load the dataset into a pandas dataframe.\ndf = pd.read_csv(\"./cola_public/raw/in_domain_train.tsv\", delimiter='\\t', header=None, names=['sentence_source', 'label', 'label_notes', 'sentence'])\n\n# Report the number of sentences.\nprint('Number of training sentences: {:,}\\n'.format(df.shape[0]))\n\n# Display 10 random rows from the data.\ndf.sample(10)",
"Mounted at /content/drive\nDownloading dataset...\nArchive: cola_public_1.1.zip\n creating: cola_public/\n inflating: cola_public/README \n creating: cola_public/tokenized/\n inflating: cola_public/tokenized/in_domain_dev.tsv \n inflating: cola_public/tokenized/in_domain_train.tsv \n inflating: cola_public/tokenized/out_of_domain_dev.tsv \n creating: cola_public/raw/\n inflating: cola_public/raw/in_domain_dev.tsv \n inflating: cola_public/raw/in_domain_train.tsv \n inflating: cola_public/raw/out_of_domain_dev.tsv \nNumber of training sentences: 8,551\n\n"
],
[
"import string\ndf.sentence = df.sentence.str.translate(str.maketrans('', '', string.punctuation))",
"_____no_output_____"
]
],
[
[
"We will split the data into train, val, and test sets. \n`train_texts`, `val_texts`, and `test_texts` should contain a list of text examples in the dataset.\n",
"_____no_output_____"
]
],
[
[
"# 0.15 for val, 0.15 for test, 0.7 for train\nval_size = int(df.shape[0] * 0.15)\ntest_size = int(df.shape[0] * 0.15)\n\n# Shuffle the data\ndf = df.sample(frac=1)\n# Split df to test/val/train\ntest_df = df[:test_size]\nval_df = df[test_size:test_size+val_size]\ntrain_df = df[test_size+val_size:]\n\n\ntrain_texts, train_labels = list(train_df.sentence), list(train_df.label)\nval_texts, val_labels = list(val_df.sentence), list(val_df.label)\ntest_texts, test_labels = list(test_df.sentence), list(test_df.label)\n\n\n# Check that idces do not overlap\nassert set(train_df.index).intersection(set(val_df.index)) == set({})\nassert set(test_df.index).intersection(set(train_df.index)) == set({})\nassert set(val_df.index).intersection(set(test_df.index)) == set({})\n# Check that all idces are present\nassert df.shape[0] == len(train_labels) + len(val_labels) + len(test_labels)\n\n# Sizes\nprint(\n f\"Size of initial data: {df.shape[0]}\\n\"\n f\"Train size: {len(train_labels)}\\n\"\n f\"Val size: {len(val_labels)}\\n\"\n f\"Test size: {len(test_labels)}\\n\"\n)",
"Size of initial data: 8551\nTrain size: 5987\nVal size: 1282\nTest size: 1282\n\n"
],
[
"train_texts[:10] # Just checking the examples in train_text",
"_____no_output_____"
]
],
[
[
"# Download and Load GloVe Embeddings\nWe will use GloVe embedding parameters to initialize our layer of word representations / embedding layer.\nLet's download and load glove.\n\n\n\n",
"_____no_output_____"
]
],
[
[
"#@title Download GloVe word embeddings\n\n# === Download GloVe word embeddings\n# !wget http://nlp.stanford.edu/data/glove.6B.zip\n\n# === Unzip word embeddings and use only the top 50000 word embeddings for speed\n# !unzip glove.6B.zip\n# !head -n 50000 glove.6B.300d.txt > glove.6B.300d__50k.txt\n\n# === Download Preprocessed version\n!wget https://docs.google.com/uc?id=1KMJTagaVD9hFHXFTPtNk0u2JjvNlyCAu -O glove_split.aa\n!wget https://docs.google.com/uc?id=1LF2yD2jToXriyD-lsYA5hj03f7J3ZKaY -O glove_split.ab\n!wget https://docs.google.com/uc?id=1N1xnxkRyM5Gar7sv4d41alyTL92Iip3f -O glove_split.ac\n!cat glove_split.?? > 'glove.6B.300d__50k.txt'",
"--2021-05-07 11:19:26-- https://docs.google.com/uc?id=1KMJTagaVD9hFHXFTPtNk0u2JjvNlyCAu\nResolving docs.google.com (docs.google.com)... 74.125.140.139, 74.125.140.101, 74.125.140.138, ...\nConnecting to docs.google.com (docs.google.com)|74.125.140.139|:443... connected.\nHTTP request sent, awaiting response... 302 Moved Temporarily\nLocation: https://doc-0k-0g-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/snva8nvg83i5srbn2grltrf79ciddggb/1620386325000/14514704803973256873/*/1KMJTagaVD9hFHXFTPtNk0u2JjvNlyCAu [following]\nWarning: wildcards not supported in HTTP.\n--2021-05-07 11:19:27-- https://doc-0k-0g-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/snva8nvg83i5srbn2grltrf79ciddggb/1620386325000/14514704803973256873/*/1KMJTagaVD9hFHXFTPtNk0u2JjvNlyCAu\nResolving doc-0k-0g-docs.googleusercontent.com (doc-0k-0g-docs.googleusercontent.com)... 74.125.133.132, 2a00:1450:400c:c07::84\nConnecting to doc-0k-0g-docs.googleusercontent.com (doc-0k-0g-docs.googleusercontent.com)|74.125.133.132|:443... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: unspecified [audio/audible]\nSaving to: ‘glove_split.aa’\n\nglove_split.aa [ <=> ] 50.00M 88.6MB/s in 0.6s \n\n2021-05-07 11:19:28 (88.6 MB/s) - ‘glove_split.aa’ saved [52428800]\n\n--2021-05-07 11:19:28-- https://docs.google.com/uc?id=1LF2yD2jToXriyD-lsYA5hj03f7J3ZKaY\nResolving docs.google.com (docs.google.com)... 142.251.5.138, 142.251.5.101, 142.251.5.113, ...\nConnecting to docs.google.com (docs.google.com)|142.251.5.138|:443... connected.\nHTTP request sent, awaiting response... 302 Moved Temporarily\nLocation: https://doc-08-0g-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/5s9ln03p3qeqdrs505ekitq61m8ea16p/1620386325000/14514704803973256873/*/1LF2yD2jToXriyD-lsYA5hj03f7J3ZKaY [following]\nWarning: wildcards not supported in HTTP.\n--2021-05-07 11:19:33-- https://doc-08-0g-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/5s9ln03p3qeqdrs505ekitq61m8ea16p/1620386325000/14514704803973256873/*/1LF2yD2jToXriyD-lsYA5hj03f7J3ZKaY\nResolving doc-08-0g-docs.googleusercontent.com (doc-08-0g-docs.googleusercontent.com)... 74.125.133.132, 2a00:1450:400c:c07::84\nConnecting to doc-08-0g-docs.googleusercontent.com (doc-08-0g-docs.googleusercontent.com)|74.125.133.132|:443... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: unspecified [application/octet-stream]\nSaving to: ‘glove_split.ab’\n\nglove_split.ab [ <=> ] 50.00M 113MB/s in 0.4s \n\n2021-05-07 11:19:34 (113 MB/s) - ‘glove_split.ab’ saved [52428800]\n\n--2021-05-07 11:19:34-- https://docs.google.com/uc?id=1N1xnxkRyM5Gar7sv4d41alyTL92Iip3f\nResolving docs.google.com (docs.google.com)... 142.251.5.100, 142.251.5.101, 142.251.5.102, ...\nConnecting to docs.google.com (docs.google.com)|142.251.5.100|:443... connected.\nHTTP request sent, awaiting response... 302 Moved Temporarily\nLocation: https://doc-04-0g-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/s61eub23iq2t9i9egnpab4u0e8f60miq/1620386325000/14514704803973256873/*/1N1xnxkRyM5Gar7sv4d41alyTL92Iip3f [following]\nWarning: wildcards not supported in HTTP.\n--2021-05-07 11:19:36-- https://doc-04-0g-docs.googleusercontent.com/docs/securesc/ha0ro937gcuc7l7deffksulhg5h7mbp1/s61eub23iq2t9i9egnpab4u0e8f60miq/1620386325000/14514704803973256873/*/1N1xnxkRyM5Gar7sv4d41alyTL92Iip3f\nResolving doc-04-0g-docs.googleusercontent.com (doc-04-0g-docs.googleusercontent.com)... 74.125.133.132, 2a00:1450:400c:c07::84\nConnecting to doc-04-0g-docs.googleusercontent.com (doc-04-0g-docs.googleusercontent.com)|74.125.133.132|:443... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: unspecified [application/octet-stream]\nSaving to: ‘glove_split.ac’\n\nglove_split.ac [ <=> ] 23.49M 47.6MB/s in 0.5s \n\n2021-05-07 11:19:37 (47.6 MB/s) - ‘glove_split.ac’ saved [24629432]\n\n"
]
],
[
[
"## Load GloVe Embeddings",
"_____no_output_____"
]
],
[
[
"def load_glove(glove_path, embedding_dim):\n with open(glove_path) as f:\n token_ls = [PAD_TOKEN, UNK_TOKEN]\n embedding_ls = [np.zeros(embedding_dim), np.random.rand(embedding_dim)]\n for line in f:\n token, raw_embedding = line.split(maxsplit=1)\n token_ls.append(token)\n embedding = np.array([float(x) for x in raw_embedding.split()])\n embedding_ls.append(embedding)\n embeddings = np.array(embedding_ls)\n return token_ls, embeddings\n\nPAD_TOKEN = '<PAD>'\nUNK_TOKEN = '<UNK>'\nEMBEDDING_DIM=300 # dimension of Glove embeddings\nglove_path = \"glove.6B.300d__50k.txt\"\nvocab, embeddings = load_glove(glove_path, EMBEDDING_DIM)",
"_____no_output_____"
]
],
[
[
"## Import packages",
"_____no_output_____"
]
],
[
[
"!pip install sacremoses\n\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport torch.optim as optim\nimport numpy as np\nimport os\nimport pandas as pd\nimport sacremoses\nfrom torch.utils.data import dataloader, Dataset\nfrom tqdm.auto import tqdm",
"Collecting sacremoses\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/75/ee/67241dc87f266093c533a2d4d3d69438e57d7a90abb216fa076e7d475d4a/sacremoses-0.0.45-py3-none-any.whl (895kB)\n\r\u001b[K |▍ | 10kB 15.4MB/s eta 0:00:01\r\u001b[K |▊ | 20kB 20.5MB/s eta 0:00:01\r\u001b[K |█ | 30kB 19.7MB/s eta 0:00:01\r\u001b[K |█▌ | 40kB 16.4MB/s eta 0:00:01\r\u001b[K |█▉ | 51kB 12.8MB/s eta 0:00:01\r\u001b[K |██▏ | 61kB 10.9MB/s eta 0:00:01\r\u001b[K |██▋ | 71kB 10.7MB/s eta 0:00:01\r\u001b[K |███ | 81kB 11.5MB/s eta 0:00:01\r\u001b[K |███▎ | 92kB 11.1MB/s eta 0:00:01\r\u001b[K |███▋ | 102kB 10.7MB/s eta 0:00:01\r\u001b[K |████ | 112kB 10.7MB/s eta 0:00:01\r\u001b[K |████▍ | 122kB 10.7MB/s eta 0:00:01\r\u001b[K |████▊ | 133kB 10.7MB/s eta 0:00:01\r\u001b[K |█████▏ | 143kB 10.7MB/s eta 0:00:01\r\u001b[K |█████▌ | 153kB 10.7MB/s eta 0:00:01\r\u001b[K |█████▉ | 163kB 10.7MB/s eta 0:00:01\r\u001b[K |██████▎ | 174kB 10.7MB/s eta 0:00:01\r\u001b[K |██████▋ | 184kB 10.7MB/s eta 0:00:01\r\u001b[K |███████ | 194kB 10.7MB/s eta 0:00:01\r\u001b[K |███████▎ | 204kB 10.7MB/s eta 0:00:01\r\u001b[K |███████▊ | 215kB 10.7MB/s eta 0:00:01\r\u001b[K |████████ | 225kB 10.7MB/s eta 0:00:01\r\u001b[K |████████▍ | 235kB 10.7MB/s eta 0:00:01\r\u001b[K |████████▉ | 245kB 10.7MB/s eta 0:00:01\r\u001b[K |█████████▏ | 256kB 10.7MB/s eta 0:00:01\r\u001b[K |█████████▌ | 266kB 10.7MB/s eta 0:00:01\r\u001b[K |█████████▉ | 276kB 10.7MB/s eta 0:00:01\r\u001b[K |██████████▎ | 286kB 10.7MB/s eta 0:00:01\r\u001b[K |██████████▋ | 296kB 10.7MB/s eta 0:00:01\r\u001b[K |███████████ | 307kB 10.7MB/s eta 0:00:01\r\u001b[K |███████████▍ | 317kB 10.7MB/s eta 0:00:01\r\u001b[K |███████████▊ | 327kB 10.7MB/s eta 0:00:01\r\u001b[K |████████████ | 337kB 10.7MB/s eta 0:00:01\r\u001b[K |████████████▌ | 348kB 10.7MB/s eta 0:00:01\r\u001b[K |████████████▉ | 358kB 10.7MB/s eta 0:00:01\r\u001b[K |█████████████▏ | 368kB 10.7MB/s eta 0:00:01\r\u001b[K |█████████████▌ | 378kB 10.7MB/s eta 0:00:01\r\u001b[K |██████████████ | 389kB 10.7MB/s eta 0:00:01\r\u001b[K |██████████████▎ | 399kB 10.7MB/s eta 0:00:01\r\u001b[K |██████████████▋ | 409kB 10.7MB/s eta 0:00:01\r\u001b[K |███████████████ | 419kB 10.7MB/s eta 0:00:01\r\u001b[K |███████████████▍ | 430kB 10.7MB/s eta 0:00:01\r\u001b[K |███████████████▊ | 440kB 10.7MB/s eta 0:00:01\r\u001b[K |████████████████ | 450kB 10.7MB/s eta 0:00:01\r\u001b[K |████████████████▌ | 460kB 10.7MB/s eta 0:00:01\r\u001b[K |████████████████▉ | 471kB 10.7MB/s eta 0:00:01\r\u001b[K |█████████████████▏ | 481kB 10.7MB/s eta 0:00:01\r\u001b[K |█████████████████▋ | 491kB 10.7MB/s eta 0:00:01\r\u001b[K |██████████████████ | 501kB 10.7MB/s eta 0:00:01\r\u001b[K |██████████████████▎ | 512kB 10.7MB/s eta 0:00:01\r\u001b[K |██████████████████▊ | 522kB 10.7MB/s eta 0:00:01\r\u001b[K |███████████████████ | 532kB 10.7MB/s eta 0:00:01\r\u001b[K |███████████████████▍ | 542kB 10.7MB/s eta 0:00:01\r\u001b[K |███████████████████▊ | 552kB 10.7MB/s eta 0:00:01\r\u001b[K |████████████████████▏ | 563kB 10.7MB/s eta 0:00:01\r\u001b[K |████████████████████▌ | 573kB 10.7MB/s eta 0:00:01\r\u001b[K |████████████████████▉ | 583kB 10.7MB/s eta 0:00:01\r\u001b[K |█████████████████████▎ | 593kB 10.7MB/s eta 0:00:01\r\u001b[K |█████████████████████▋ | 604kB 10.7MB/s eta 0:00:01\r\u001b[K |██████████████████████ | 614kB 10.7MB/s eta 0:00:01\r\u001b[K |██████████████████████▎ | 624kB 10.7MB/s eta 0:00:01\r\u001b[K |██████████████████████▊ | 634kB 10.7MB/s eta 0:00:01\r\u001b[K |███████████████████████ | 645kB 10.7MB/s eta 0:00:01\r\u001b[K |███████████████████████▍ | 655kB 10.7MB/s eta 0:00:01\r\u001b[K |███████████████████████▉ | 665kB 10.7MB/s eta 0:00:01\r\u001b[K |████████████████████████▏ | 675kB 10.7MB/s eta 0:00:01\r\u001b[K |████████████████████████▌ | 686kB 10.7MB/s eta 0:00:01\r\u001b[K |█████████████████████████ | 696kB 10.7MB/s eta 0:00:01\r\u001b[K |█████████████████████████▎ | 706kB 10.7MB/s eta 0:00:01\r\u001b[K |█████████████████████████▋ | 716kB 10.7MB/s eta 0:00:01\r\u001b[K |██████████████████████████ | 727kB 10.7MB/s eta 0:00:01\r\u001b[K |██████████████████████████▍ | 737kB 10.7MB/s eta 0:00:01\r\u001b[K |██████████████████████████▊ | 747kB 10.7MB/s eta 0:00:01\r\u001b[K |███████████████████████████ | 757kB 10.7MB/s eta 0:00:01\r\u001b[K |███████████████████████████▌ | 768kB 10.7MB/s eta 0:00:01\r\u001b[K |███████████████████████████▉ | 778kB 10.7MB/s eta 0:00:01\r\u001b[K |████████████████████████████▏ | 788kB 10.7MB/s eta 0:00:01\r\u001b[K |████████████████████████████▌ | 798kB 10.7MB/s eta 0:00:01\r\u001b[K |█████████████████████████████ | 808kB 10.7MB/s eta 0:00:01\r\u001b[K |█████████████████████████████▎ | 819kB 10.7MB/s eta 0:00:01\r\u001b[K |█████████████████████████████▋ | 829kB 10.7MB/s eta 0:00:01\r\u001b[K |██████████████████████████████ | 839kB 10.7MB/s eta 0:00:01\r\u001b[K |██████████████████████████████▍ | 849kB 10.7MB/s eta 0:00:01\r\u001b[K |██████████████████████████████▊ | 860kB 10.7MB/s eta 0:00:01\r\u001b[K |███████████████████████████████▏| 870kB 10.7MB/s eta 0:00:01\r\u001b[K |███████████████████████████████▌| 880kB 10.7MB/s eta 0:00:01\r\u001b[K |███████████████████████████████▉| 890kB 10.7MB/s eta 0:00:01\r\u001b[K |████████████████████████████████| 901kB 10.7MB/s \n\u001b[?25hRequirement already satisfied: regex in /usr/local/lib/python3.7/dist-packages (from sacremoses) (2019.12.20)\nRequirement already satisfied: tqdm in /usr/local/lib/python3.7/dist-packages (from sacremoses) (4.41.1)\nRequirement already satisfied: click in /usr/local/lib/python3.7/dist-packages (from sacremoses) (7.1.2)\nRequirement already satisfied: joblib in /usr/local/lib/python3.7/dist-packages (from sacremoses) (1.0.1)\nRequirement already satisfied: six in /usr/local/lib/python3.7/dist-packages (from sacremoses) (1.15.0)\nInstalling collected packages: sacremoses\nSuccessfully installed sacremoses-0.0.45\n"
]
],
[
[
"# Tokenize text data.\nWe will use the `tokenize` function to convert text data into sequence of indices.",
"_____no_output_____"
]
],
[
[
"def tokenize(data, labels, tokenizer, vocab, max_seq_length=64):\n vocab_to_idx = {word: i for i, word in enumerate(vocab)}\n text_data = []\n label_data = []\n for ex in tqdm(data):\n tokenized = tokenizer.tokenize(ex.lower())\n ids = [vocab_to_idx.get(token, 1) for token in tokenized]\n text_data.append(ids)\n return text_data, labels\ntokenizer = sacremoses.MosesTokenizer()\ntrain_data_indices, train_labels = tokenize(train_texts, train_labels, tokenizer, vocab)\nval_data_indices, val_labels = tokenize(val_texts, val_labels, tokenizer, vocab)\ntest_data_indices, test_labels = tokenize(test_texts, test_labels, tokenizer, vocab)",
"_____no_output_____"
],
[
"print(\"\\nTrain text first 5 examples:\\n\", train_data_indices[:5])\nprint(\"\\nTrain labels first 5 examples:\\n\", train_labels[:5])",
"\nTrain text first 5 examples:\n [[787, 220, 18721], [2, 1204, 1777, 672, 9, 14389], [8581, 3609, 19, 7216, 61, 2, 749], [3247, 16492, 58, 30429, 75, 2072, 10526, 1, 7, 13172, 16492], [83, 109, 2067, 132, 6506, 36, 893, 9, 308, 12, 1964]]\n\nTrain labels first 5 examples:\n [1, 1, 1, 0, 1]\n"
]
],
[
[
"# Create DataLoaders ",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport torch\nfrom torch.utils.data import Dataset\n\nclass SpamDataset(Dataset):\n \"\"\"\n Class that represents a train/validation/test dataset that's readable for PyTorch\n Note that this class inherits torch.utils.data.Dataset\n \"\"\"\n \n def __init__(self, data_list, target_list, max_sent_length=64):\n \"\"\"\n @param data_list: list of data tokens \n @param target_list: list of data targets \n\n \"\"\"\n self.data_list = data_list\n self.target_list = target_list\n self.max_sent_length = max_sent_length\n assert (len(self.data_list) == len(self.target_list))\n\n def __len__(self):\n return len(self.data_list)\n \n def __getitem__(self, key, max_sent_length=None):\n \"\"\"\n Triggered when you call dataset[i]\n \"\"\"\n if max_sent_length is None:\n max_sent_length = self.max_sent_length\n token_idx = self.data_list[key][:max_sent_length]\n label = self.target_list[key]\n return [token_idx, label]\n\n def spam_collate_func(self,batch):\n \"\"\"\n Customized function for DataLoader that dynamically pads the batch so that all \n data have the same length\n \"\"\" \n data_list = [] # store padded sequences\n label_list = []\n max_batch_seq_len = None # the length of longest sequence in batch\n # if it is less than self.max_sent_length\n # else max_batch_seq_len = self.max_sent_length\n\n \"\"\"\n # Pad the sequences in your data \n # if their length is less than max_batch_seq_len\n # or trim the sequences that are longer than self.max_sent_length\n # return padded data_list and label_list\n\n \"\"\"\n label_list = [datum[1] for datum in batch]\n max_batch_seq_len = max(len(datum[0]) for datum in batch)\n if max_batch_seq_len > self.max_sent_length:\n max_batch_seq_len = self.max_sent_length\n\n for datum in batch:\n padded_vec = np.pad(np.array(datum[0]), \n pad_width=((0,max_batch_seq_len-len(datum[0]))), \n mode=\"constant\", constant_values=0)\n data_list.append(padded_vec)\n data_list = torch.from_numpy(np.array(data_list))\n label_list = torch.LongTensor(label_list) \n\n return [data_list, label_list]\n\nBATCH_SIZE = 64\nmax_sent_length=64\ntrain_dataset = SpamDataset(train_data_indices, train_labels, max_sent_length)\ntrain_loader = torch.utils.data.DataLoader(dataset=train_dataset, \n batch_size=BATCH_SIZE,\n collate_fn=train_dataset.spam_collate_func,\n shuffle=True)\n\nval_dataset = SpamDataset(val_data_indices, val_labels, train_dataset.max_sent_length)\nval_loader = torch.utils.data.DataLoader(dataset=val_dataset, \n batch_size=BATCH_SIZE,\n collate_fn=train_dataset.spam_collate_func,\n shuffle=False)\n\ntest_dataset = SpamDataset(test_data_indices, test_labels, train_dataset.max_sent_length)\ntest_loader = torch.utils.data.DataLoader(dataset=test_dataset, \n batch_size=BATCH_SIZE,\n collate_fn=train_dataset.spam_collate_func,\n shuffle=False)\n\n",
"_____no_output_____"
]
],
[
[
"Let's try to print out an batch from train_loader.\n",
"_____no_output_____"
]
],
[
[
"data_batch, labels = next(iter(train_loader))\nprint(\"data batch dimension: \", data_batch.size())\nprint(\"data_batch: \", data_batch)\nprint(\"labels: \", labels)",
"data batch dimension: torch.Size([64, 19])\ndata_batch: tensor([[ 2, 1932, 2435, ..., 0, 0, 0],\n [ 2, 17552, 16, ..., 0, 0, 0],\n [ 686, 3790, 287, ..., 0, 0, 0],\n ...,\n [ 3256, 392, 38, ..., 0, 0, 0],\n [ 43, 915, 38, ..., 0, 0, 0],\n [ 1964, 11537, 14, ..., 0, 0, 0]])\nlabels: tensor([1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 0, 1, 0, 1,\n 0, 1, 0, 1, 1, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 1, 0, 1, 1,\n 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0, 1, 1, 1, 0])\n"
]
],
[
[
"# Build a LSTM Classifier",
"_____no_output_____"
]
],
[
[
"# First import torch related libraries\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\n\nclass LSTMClassifier(nn.Module):\n \"\"\"\n LSTMClassifier classification model\n \"\"\"\n def __init__(self, embeddings, hidden_size, num_layers, num_classes, bidirectional, dropout_prob=0.3):\n super().__init__()\n self.embedding_layer = self.load_pretrained_embeddings(embeddings)\n self.dropout = None\n self.lstm = None\n self.non_linearity = None # For example, ReLU\n self.clf = None # classifier layer\n \"\"\"\n define the components of your BiLSTM Classifier model\n\n \"\"\"\n self.hidden_size = hidden_size\n self.num_layers = num_layers\n self.dropout = nn.Dropout(p = dropout_prob)\n self.lstm = nn.LSTM(embeddings.shape[1], hidden_size, num_layers, batch_first=True, \n bidirectional=bidirectional, dropout=0.3)\n self.relu = nn.ReLU()\n # self.clf = nn.Linear(hidden_size*2, num_classes)\n self.clf = nn.Linear(hidden_size, num_classes)\n \n def load_pretrained_embeddings(self, embeddings):\n\n embedding_layer = nn.Embedding(embeddings.shape[0], embeddings.shape[1], padding_idx=0)\n embedding_layer.weight.data = torch.Tensor(embeddings).float()\n return embedding_layer\n\n\n def forward(self, inputs):\n logits = None\n\n batch_size = inputs.size()[0] # inputs : batch_sz, seq_len\n out = self.dropout(self.embedding_layer(inputs))\n out, _ = self.lstm(out, None)\n out = out.mean(1)\n out = self.relu(out)\n #out = self.relu(torch.mean(out,1))\n logits = self.clf(out)\n return logits",
"_____no_output_____"
]
],
[
[
"First, we will define an evaluation function that will return the accuracy of the model. We will use this to compute validation accuracy and test accuracy of the model given a dataloader.",
"_____no_output_____"
]
],
[
[
"def evaluate(model, dataloader, device):\n accuracy = None\n model.eval()\n\n n_correct = n_total = 0 \n model.eval()\n with torch.no_grad():\n \n for (data_batch, batch_labels) in dataloader:\n out = model(data_batch.to(device))\n max_scores, preds = out.max(dim=1)\n #preds = np.argmax(out, axis=1).cpu().numpy()\n n_correct += np.sum(preds.cpu().numpy() == batch_labels.numpy())\n n_total += out.shape[0]\n accuracy = n_correct*1.0/n_total\n return accuracy ",
"_____no_output_____"
]
],
[
[
"# Initialize the LSTM classifier model, criterion and optimizer\n",
"_____no_output_____"
]
],
[
[
"# BiLSTM hyperparameters\nhidden_size = 32\nnum_layers = 1\nnum_classes = 2\nbidirectional=False\ntorch.manual_seed(1234)\n\n# if cuda exists, use cuda, else run on cpu\nif torch.cuda.is_available():\n device = torch.device(\"cuda:0\")\nelse:\n device=torch.device('cpu')\n\nmodel = LSTMClassifier(embeddings, hidden_size, num_layers, num_classes, bidirectional)\nmodel.to(device)\ncriterion = nn.CrossEntropyLoss()\noptimizer = optim.Adam(model.parameters(), lr=0.01)",
"/usr/local/lib/python3.7/dist-packages/torch/nn/modules/rnn.py:63: UserWarning: dropout option adds dropout after all but last recurrent layer, so non-zero dropout expects num_layers greater than 1, but got dropout=0.3 and num_layers=1\n \"num_layers={}\".format(dropout, num_layers))\n"
]
],
[
[
"# Train model with early stopping ",
"_____no_output_____"
]
],
[
[
"train_loss_history = []\nval_accuracy_history = []\nbest_val_accuracy = 0\nn_no_improve = 0\nearly_stop_patience=2\nNUM_EPOCHS=10\n \nfor epoch in tqdm(range(NUM_EPOCHS)):\n model.train() # this enables regularization, which we don't currently have\n for i, (data_batch, batch_labels) in enumerate(train_loader):\n \"\"\"\n Code for training lstm\n Keep track of training of for each batch using train_loss_history\n \"\"\"\n preds = model(data_batch.to(device))\n loss = criterion(preds, batch_labels.to(device))\n loss.backward()\n optimizer.step()\n optimizer.zero_grad()\n train_loss_history.append(loss.item())\n \n # The end of a training epoch \n\n\n cur_val_accuracy = evaluate(model, val_loader, device=device)\n val_accuracy_history.append(cur_val_accuracy)\n print(\"epoch: {}, val_accuracy: {}\".format(epoch+1, cur_val_accuracy))\n if cur_val_accuracy > best_val_accuracy:\n best_val_accuracy = cur_val_accuracy\n torch.save(model, 'best_model.pt')\n n_no_improve = 0\n else:\n n_no_improve += 1 \n if n_no_improve > early_stop_patience:\n print(\"Early stopped at epoch \",epoch)\n break\n\n \n\nprint(\"Best validation accuracy is: \", best_val_accuracy)",
"_____no_output_____"
]
],
[
[
"# Draw training curve \nX-axis: training steps, Y-axis: training loss",
"_____no_output_____"
]
],
[
[
"pd.Series(train_loss_history).plot()",
"_____no_output_____"
]
],
[
[
"# Validation accuracy curve\nX-axis: Epochs, Y-axis: validation accuracy",
"_____no_output_____"
]
],
[
[
"pd.Series(val_accuracy_history).plot()",
"_____no_output_____"
]
],
[
[
"# Test Accuracy",
"_____no_output_____"
]
],
[
[
"# Reload best model from saved checkpoint\n# Compute test accuracy\nmodel = torch.load('best_model.pt')\ntest_accuracy = evaluate(model, test_loader, device)\n\n\nprint(test_accuracy)",
"0.7004680187207488\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
ecc2637c66f823f7642cee24a207a3979dc5dac1 | 137,759 | ipynb | Jupyter Notebook | courses/dl2/translate.ipynb | mogwai/fastai | df38e530bd395a53c2c9b89b8950684ba3a2270e | [
"Apache-2.0"
] | 59 | 2020-08-18T03:41:35.000Z | 2022-03-23T03:51:55.000Z | courses/dl2/translate.ipynb | mogwai/fastai | df38e530bd395a53c2c9b89b8950684ba3a2270e | [
"Apache-2.0"
] | 17 | 2020-08-25T14:15:32.000Z | 2022-03-27T02:12:19.000Z | courses/dl2/translate.ipynb | mogwai/fastai | df38e530bd395a53c2c9b89b8950684ba3a2270e | [
"Apache-2.0"
] | 89 | 2020-08-17T23:45:42.000Z | 2022-03-27T20:53:43.000Z | 79.952989 | 70,876 | 0.790751 | [
[
[
"**Important: This notebook will only work with fastai-0.7.x. Do not try to run any fastai-1.x code from this path in the repository because it will load fastai-0.7.x**",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n%reload_ext autoreload\n%autoreload 2",
"_____no_output_____"
]
],
[
[
"Please note that this notebook is most likely going to cause a stuck process. So if you are going to run it, please make sure to restart your jupyter notebook as soon as you completed running it.\n\nThe bug happens inside the `fastText` library, which we have no control over. You can check the status of this issue: [here](https://github.com/fastai/fastai/issues/754) and [here](https://github.com/facebookresearch/fastText/issues/618#issuecomment-419554225).\n\nFor the future, note that there're 3 separate implementations of fasttext, perhaps one of them works:\nhttps://github.com/facebookresearch/fastText/tree/master/python\nhttps://pypi.org/project/fasttext/\nhttps://radimrehurek.com/gensim/models/fasttext.html#module-gensim.models.fasttext",
"_____no_output_____"
],
[
"## Translation files",
"_____no_output_____"
]
],
[
[
"from fastai.text import *",
"_____no_output_____"
]
],
[
[
"French/English parallel texts from http://www.statmt.org/wmt15/translation-task.html . It was created by Chris Callison-Burch, who crawled millions of web pages and then used *a set of simple heuristics to transform French URLs onto English URLs (i.e. replacing \"fr\" with \"en\" and about 40 other hand-written rules), and assume that these documents are translations of each other*.",
"_____no_output_____"
]
],
[
[
"PATH = Path('data/translate')\nTMP_PATH = PATH/'tmp'\nTMP_PATH.mkdir(exist_ok=True)\nfname='giga-fren.release2.fixed'\nen_fname = PATH/f'{fname}.en'\nfr_fname = PATH/f'{fname}.fr'",
"_____no_output_____"
],
[
"re_eq = re.compile('^(Wh[^?.!]+\\?)')\nre_fq = re.compile('^([^?.!]+\\?)')\n\nlines = ((re_eq.search(eq), re_fq.search(fq)) \n for eq, fq in zip(open(en_fname, encoding='utf-8'), open(fr_fname, encoding='utf-8')))\n\nqs = [(e.group(), f.group()) for e,f in lines if e and f]",
"_____no_output_____"
],
[
"pickle.dump(qs, (PATH/'fr-en-qs.pkl').open('wb'))",
"_____no_output_____"
],
[
"qs = pickle.load((PATH/'fr-en-qs.pkl').open('rb'))",
"_____no_output_____"
],
[
"qs[:5], len(qs)",
"_____no_output_____"
],
[
"en_qs,fr_qs = zip(*qs)",
"_____no_output_____"
],
[
"en_tok = Tokenizer.proc_all_mp(partition_by_cores(en_qs))",
"_____no_output_____"
],
[
"fr_tok = Tokenizer.proc_all_mp(partition_by_cores(fr_qs), 'fr')",
"_____no_output_____"
],
[
"en_tok[0], fr_tok[0]",
"_____no_output_____"
],
[
"np.percentile([len(o) for o in en_tok], 90), np.percentile([len(o) for o in fr_tok], 90)",
"_____no_output_____"
],
[
"keep = np.array([len(o)<30 for o in en_tok])",
"_____no_output_____"
],
[
"en_tok = np.array(en_tok)[keep]\nfr_tok = np.array(fr_tok)[keep]",
"_____no_output_____"
],
[
"pickle.dump(en_tok, (PATH/'en_tok.pkl').open('wb'))\npickle.dump(fr_tok, (PATH/'fr_tok.pkl').open('wb'))",
"_____no_output_____"
],
[
"en_tok = pickle.load((PATH/'en_tok.pkl').open('rb'))\nfr_tok = pickle.load((PATH/'fr_tok.pkl').open('rb'))",
"_____no_output_____"
],
[
"def toks2ids(tok,pre):\n freq = Counter(p for o in tok for p in o)\n itos = [o for o,c in freq.most_common(40000)]\n itos.insert(0, '_bos_')\n itos.insert(1, '_pad_')\n itos.insert(2, '_eos_')\n itos.insert(3, '_unk')\n stoi = collections.defaultdict(lambda: 3, {v:k for k,v in enumerate(itos)})\n ids = np.array([([stoi[o] for o in p] + [2]) for p in tok])\n np.save(TMP_PATH/f'{pre}_ids.npy', ids)\n pickle.dump(itos, open(TMP_PATH/f'{pre}_itos.pkl', 'wb'))\n return ids,itos,stoi",
"_____no_output_____"
],
[
"en_ids,en_itos,en_stoi = toks2ids(en_tok,'en')\nfr_ids,fr_itos,fr_stoi = toks2ids(fr_tok,'fr')",
"_____no_output_____"
],
[
"def load_ids(pre):\n ids = np.load(TMP_PATH/f'{pre}_ids.npy')\n itos = pickle.load(open(TMP_PATH/f'{pre}_itos.pkl', 'rb'))\n stoi = collections.defaultdict(lambda: 3, {v:k for k,v in enumerate(itos)})\n return ids,itos,stoi",
"_____no_output_____"
],
[
"en_ids,en_itos,en_stoi = load_ids('en')\nfr_ids,fr_itos,fr_stoi = load_ids('fr')",
"_____no_output_____"
],
[
"[fr_itos[o] for o in fr_ids[0]], len(en_itos), len(fr_itos)",
"_____no_output_____"
]
],
[
[
"## Word vectors",
"_____no_output_____"
],
[
"fasttext word vectors available from https://fasttext.cc/docs/en/english-vectors.html",
"_____no_output_____"
]
],
[
[
"# ! pip install git+https://github.com/facebookresearch/fastText.git",
"_____no_output_____"
],
[
"import fastText as ft",
"_____no_output_____"
]
],
[
[
"To use the fastText library, you'll need to download [fasttext word vectors](https://github.com/facebookresearch/fastText/blob/master/pretrained-vectors.md) for your language (download the 'bin plus text' ones).",
"_____no_output_____"
]
],
[
[
"en_vecs = ft.load_model(str((PATH/'wiki.en.bin')))",
"_____no_output_____"
],
[
"fr_vecs = ft.load_model(str((PATH/'wiki.fr.bin')))",
"_____no_output_____"
],
[
"def get_vecs(lang, ft_vecs):\n vecd = {w:ft_vecs.get_word_vector(w) for w in ft_vecs.get_words()}\n pickle.dump(vecd, open(PATH/f'wiki.{lang}.pkl','wb'))\n return vecd",
"_____no_output_____"
],
[
"en_vecd = get_vecs('en', en_vecs)\nfr_vecd = get_vecs('fr', fr_vecs)",
"_____no_output_____"
],
[
"en_vecd = pickle.load(open(PATH/'wiki.en.pkl','rb'))\nfr_vecd = pickle.load(open(PATH/'wiki.fr.pkl','rb'))",
"_____no_output_____"
],
[
"ft_words = en_vecs.get_words(include_freq=True)\nft_word_dict = {k:v for k,v in zip(*ft_words)}\nft_words = sorted(ft_word_dict.keys(), key=lambda x: ft_word_dict[x])\n\nlen(ft_words)",
"_____no_output_____"
],
[
"dim_en_vec = len(en_vecd[','])\ndim_fr_vec = len(fr_vecd[','])\ndim_en_vec,dim_fr_vec",
"_____no_output_____"
],
[
"en_vecs = np.stack(list(en_vecd.values()))\nen_vecs.mean(),en_vecs.std()",
"_____no_output_____"
]
],
[
[
"## Model data",
"_____no_output_____"
]
],
[
[
"enlen_90 = int(np.percentile([len(o) for o in en_ids], 99))\nfrlen_90 = int(np.percentile([len(o) for o in fr_ids], 97))\nenlen_90,frlen_90",
"_____no_output_____"
],
[
"en_ids_tr = np.array([o[:enlen_90] for o in en_ids])\nfr_ids_tr = np.array([o[:frlen_90] for o in fr_ids])",
"_____no_output_____"
],
[
"class Seq2SeqDataset(Dataset):\n def __init__(self, x, y): self.x,self.y = x,y\n def __getitem__(self, idx): return A(self.x[idx], self.y[idx])\n def __len__(self): return len(self.x)",
"_____no_output_____"
],
[
"np.random.seed(42)\ntrn_keep = np.random.rand(len(en_ids_tr))>0.1\nen_trn,fr_trn = en_ids_tr[trn_keep],fr_ids_tr[trn_keep]\nen_val,fr_val = en_ids_tr[~trn_keep],fr_ids_tr[~trn_keep]\nlen(en_trn),len(en_val)",
"_____no_output_____"
],
[
"trn_ds = Seq2SeqDataset(fr_trn,en_trn)\nval_ds = Seq2SeqDataset(fr_val,en_val)",
"_____no_output_____"
],
[
"bs=125",
"_____no_output_____"
],
[
"trn_samp = SortishSampler(en_trn, key=lambda x: len(en_trn[x]), bs=bs)\nval_samp = SortSampler(en_val, key=lambda x: len(en_val[x]))",
"_____no_output_____"
],
[
"trn_dl = DataLoader(trn_ds, bs, transpose=True, transpose_y=True, num_workers=1, \n pad_idx=1, pre_pad=False, sampler=trn_samp)\nval_dl = DataLoader(val_ds, int(bs*1.6), transpose=True, transpose_y=True, num_workers=1, \n pad_idx=1, pre_pad=False, sampler=val_samp)\nmd = ModelData(PATH, trn_dl, val_dl)",
"_____no_output_____"
],
[
"it = iter(trn_dl)\nits = [next(it) for i in range(5)]\n[(len(x),len(y)) for x,y in its]",
"_____no_output_____"
]
],
[
[
"## Initial model",
"_____no_output_____"
]
],
[
[
"def create_emb(vecs, itos, em_sz):\n emb = nn.Embedding(len(itos), em_sz, padding_idx=1)\n wgts = emb.weight.data\n miss = []\n for i,w in enumerate(itos):\n try: wgts[i] = torch.from_numpy(vecs[w]*3)\n except: miss.append(w)\n print(len(miss),miss[5:10])\n return emb",
"_____no_output_____"
],
[
"nh,nl = 256,2",
"_____no_output_____"
],
[
"class Seq2SeqRNN(nn.Module):\n def __init__(self, vecs_enc, itos_enc, em_sz_enc, vecs_dec, itos_dec, em_sz_dec, nh, out_sl, nl=2):\n super().__init__()\n self.nl,self.nh,self.out_sl = nl,nh,out_sl\n self.emb_enc = create_emb(vecs_enc, itos_enc, em_sz_enc)\n self.emb_enc_drop = nn.Dropout(0.15)\n self.gru_enc = nn.GRU(em_sz_enc, nh, num_layers=nl, dropout=0.25)\n self.out_enc = nn.Linear(nh, em_sz_dec, bias=False)\n \n self.emb_dec = create_emb(vecs_dec, itos_dec, em_sz_dec)\n self.gru_dec = nn.GRU(em_sz_dec, em_sz_dec, num_layers=nl, dropout=0.1)\n self.out_drop = nn.Dropout(0.35)\n self.out = nn.Linear(em_sz_dec, len(itos_dec))\n self.out.weight.data = self.emb_dec.weight.data\n \n def forward(self, inp):\n sl,bs = inp.size()\n h = self.initHidden(bs)\n emb = self.emb_enc_drop(self.emb_enc(inp))\n enc_out, h = self.gru_enc(emb, h)\n h = self.out_enc(h)\n\n dec_inp = V(torch.zeros(bs).long())\n res = []\n for i in range(self.out_sl):\n emb = self.emb_dec(dec_inp).unsqueeze(0)\n outp, h = self.gru_dec(emb, h)\n outp = self.out(self.out_drop(outp[0]))\n res.append(outp)\n dec_inp = V(outp.data.max(1)[1])\n if (dec_inp==1).all(): break\n return torch.stack(res)\n \n def initHidden(self, bs): return V(torch.zeros(self.nl, bs, self.nh))",
"_____no_output_____"
],
[
"def seq2seq_loss(input, target):\n sl,bs = target.size()\n sl_in,bs_in,nc = input.size()\n if sl>sl_in: input = F.pad(input, (0,0,0,0,0,sl-sl_in))\n input = input[:sl]\n return F.cross_entropy(input.view(-1,nc), target.view(-1))#, ignore_index=1)",
"_____no_output_____"
],
[
"opt_fn = partial(optim.Adam, betas=(0.8, 0.99))",
"_____no_output_____"
],
[
"rnn = Seq2SeqRNN(fr_vecd, fr_itos, dim_fr_vec, en_vecd, en_itos, dim_en_vec, nh, enlen_90)\nlearn = RNN_Learner(md, SingleModel(to_gpu(rnn)), opt_fn=opt_fn)\nlearn.crit = seq2seq_loss",
"3097 ['l’', \"d'\", 't_up', 'd’', \"qu'\"]\n1285 [\"'s\", '’s', \"n't\", 'n’t', ':']\n"
],
[
"learn.lr_find()\nlearn.sched.plot()",
"_____no_output_____"
],
[
"lr=3e-3",
"_____no_output_____"
],
[
"learn.fit(lr, 1, cycle_len=12, use_clr=(20,10))",
"_____no_output_____"
],
[
"learn.save('initial')",
"_____no_output_____"
],
[
"learn.load('initial')",
"_____no_output_____"
]
],
[
[
"### Test",
"_____no_output_____"
]
],
[
[
"x,y = next(iter(val_dl))\nprobs = learn.model(V(x))\npreds = to_np(probs.max(2)[1])\n\nfor i in range(180,190):\n print(' '.join([fr_itos[o] for o in x[:,i] if o != 1]))\n print(' '.join([en_itos[o] for o in y[:,i] if o != 1]))\n print(' '.join([en_itos[o] for o in preds[:,i] if o!=1]))\n print()",
"quels facteurs pourraient influer sur le choix de leur emplacement ? _eos_\nwhat factors influencetheir location ? _eos_\nwhat factors might might influence on the their ? ? _eos_\n\nqu’ est -ce qui ne peut pas changer ? _eos_\nwhat can not change ? _eos_\nwhat not change change ? _eos_\n\nque faites - vous ? _eos_\nwhat do you do ? _eos_\nwhat do you do ? _eos_\n\nqui réglemente les pylônes d' antennes ? _eos_\nwho regulates antenna towers ? _eos_\nwho regulates the doors doors ? _eos_\n\noù sont - ils situés ? _eos_\nwhere are they located ? _eos_\nwhere are the located ? _eos_\n\nquelles sont leurs compétences ? _eos_\nwhat are their qualifications ? _eos_\nwhat are their skills ? _eos_\n\nqui est victime de harcèlement sexuel ? _eos_\nwho experiences sexual harassment ? _eos_\nwho is victim sexual sexual ? ? _eos_\n\nquelles sont les personnes qui visitent les communautés autochtones ? _eos_\nwho visits indigenous communities ? _eos_\nwho are people people aboriginal aboriginal ? _eos_\n\npourquoi ces trois points en particulier ? _eos_\nwhy these specific three ? _eos_\nwhy are these two different ? ? _eos_\n\npourquoi ou pourquoi pas ? _eos_\nwhy or why not ? _eos_\nwhy or why not _eos_\n\n"
]
],
[
[
"## Bidir",
"_____no_output_____"
]
],
[
[
"class Seq2SeqRNN_Bidir(nn.Module):\n def __init__(self, vecs_enc, itos_enc, em_sz_enc, vecs_dec, itos_dec, em_sz_dec, nh, out_sl, nl=2):\n super().__init__()\n self.emb_enc = create_emb(vecs_enc, itos_enc, em_sz_enc)\n self.nl,self.nh,self.out_sl = nl,nh,out_sl\n self.gru_enc = nn.GRU(em_sz_enc, nh, num_layers=nl, dropout=0.25, bidirectional=True)\n self.out_enc = nn.Linear(nh*2, em_sz_dec, bias=False)\n self.drop_enc = nn.Dropout(0.05)\n self.emb_dec = create_emb(vecs_dec, itos_dec, em_sz_dec)\n self.gru_dec = nn.GRU(em_sz_dec, em_sz_dec, num_layers=nl, dropout=0.1)\n self.emb_enc_drop = nn.Dropout(0.15)\n self.out_drop = nn.Dropout(0.35)\n self.out = nn.Linear(em_sz_dec, len(itos_dec))\n self.out.weight.data = self.emb_dec.weight.data\n \n def forward(self, inp):\n sl,bs = inp.size()\n h = self.initHidden(bs)\n emb = self.emb_enc_drop(self.emb_enc(inp))\n enc_out, h = self.gru_enc(emb, h)\n h = h.view(2,2,bs,-1).permute(0,2,1,3).contiguous().view(2,bs,-1)\n h = self.out_enc(self.drop_enc(h))\n\n dec_inp = V(torch.zeros(bs).long())\n res = []\n for i in range(self.out_sl):\n emb = self.emb_dec(dec_inp).unsqueeze(0)\n outp, h = self.gru_dec(emb, h)\n outp = self.out(self.out_drop(outp[0]))\n res.append(outp)\n dec_inp = V(outp.data.max(1)[1])\n if (dec_inp==1).all(): break\n return torch.stack(res)\n \n def initHidden(self, bs): return V(torch.zeros(self.nl*2, bs, self.nh))",
"_____no_output_____"
],
[
"rnn = Seq2SeqRNN_Bidir(fr_vecd, fr_itos, dim_fr_vec, en_vecd, en_itos, dim_en_vec, nh, enlen_90)\nlearn = RNN_Learner(md, SingleModel(to_gpu(rnn)), opt_fn=opt_fn)\nlearn.crit = seq2seq_loss",
"_____no_output_____"
],
[
"learn.fit(lr, 1, cycle_len=12, use_clr=(20,10))",
"_____no_output_____"
],
[
"learn.save('bidir')",
"_____no_output_____"
]
],
[
[
"## Teacher forcing",
"_____no_output_____"
]
],
[
[
"class Seq2SeqStepper(Stepper):\n def step(self, xs, y, epoch):\n self.m.pr_force = (10-epoch)*0.1 if epoch<10 else 0\n xtra = []\n output = self.m(*xs, y)\n if isinstance(output,tuple): output,*xtra = output\n self.opt.zero_grad()\n loss = raw_loss = self.crit(output, y)\n if self.reg_fn: loss = self.reg_fn(output, xtra, raw_loss)\n loss.backward()\n if self.clip: # Gradient clipping\n nn.utils.clip_grad_norm(trainable_params_(self.m), self.clip)\n self.opt.step()\n return raw_loss.data[0]",
"_____no_output_____"
],
[
"class Seq2SeqRNN_TeacherForcing(nn.Module):\n def __init__(self, vecs_enc, itos_enc, em_sz_enc, vecs_dec, itos_dec, em_sz_dec, nh, out_sl, nl=2):\n super().__init__()\n self.emb_enc = create_emb(vecs_enc, itos_enc, em_sz_enc)\n self.nl,self.nh,self.out_sl = nl,nh,out_sl\n self.gru_enc = nn.GRU(em_sz_enc, nh, num_layers=nl, dropout=0.25)\n self.out_enc = nn.Linear(nh, em_sz_dec, bias=False)\n self.emb_dec = create_emb(vecs_dec, itos_dec, em_sz_dec)\n self.gru_dec = nn.GRU(em_sz_dec, em_sz_dec, num_layers=nl, dropout=0.1)\n self.emb_enc_drop = nn.Dropout(0.15)\n self.out_drop = nn.Dropout(0.35)\n self.out = nn.Linear(em_sz_dec, len(itos_dec))\n self.out.weight.data = self.emb_dec.weight.data\n self.pr_force = 1.\n \n def forward(self, inp, y=None):\n sl,bs = inp.size()\n h = self.initHidden(bs)\n emb = self.emb_enc_drop(self.emb_enc(inp))\n enc_out, h = self.gru_enc(emb, h)\n h = self.out_enc(h)\n\n dec_inp = V(torch.zeros(bs).long())\n res = []\n for i in range(self.out_sl):\n emb = self.emb_dec(dec_inp).unsqueeze(0)\n outp, h = self.gru_dec(emb, h)\n outp = self.out(self.out_drop(outp[0]))\n res.append(outp)\n dec_inp = V(outp.data.max(1)[1])\n if (dec_inp==1).all(): break\n if (y is not None) and (random.random()<self.pr_force):\n if i>=len(y): break\n dec_inp = y[i]\n return torch.stack(res)\n \n def initHidden(self, bs): return V(torch.zeros(self.nl, bs, self.nh))",
"_____no_output_____"
],
[
"rnn = Seq2SeqRNN_TeacherForcing(fr_vecd, fr_itos, dim_fr_vec, en_vecd, en_itos, dim_en_vec, nh, enlen_90)\nlearn = RNN_Learner(md, SingleModel(to_gpu(rnn)), opt_fn=opt_fn)\nlearn.crit = seq2seq_loss",
"_____no_output_____"
],
[
"learn.fit(lr, 1, cycle_len=12, use_clr=(20,10), stepper=Seq2SeqStepper)",
"_____no_output_____"
],
[
"learn.save('forcing')",
"_____no_output_____"
]
],
[
[
"## Attentional model",
"_____no_output_____"
]
],
[
[
"def rand_t(*sz): return torch.randn(sz)/math.sqrt(sz[0])\ndef rand_p(*sz): return nn.Parameter(rand_t(*sz))",
"_____no_output_____"
],
[
"class Seq2SeqAttnRNN(nn.Module):\n def __init__(self, vecs_enc, itos_enc, em_sz_enc, vecs_dec, itos_dec, em_sz_dec, nh, out_sl, nl=2):\n super().__init__()\n self.emb_enc = create_emb(vecs_enc, itos_enc, em_sz_enc)\n self.nl,self.nh,self.out_sl = nl,nh,out_sl\n self.gru_enc = nn.GRU(em_sz_enc, nh, num_layers=nl, dropout=0.25)\n self.out_enc = nn.Linear(nh, em_sz_dec, bias=False)\n self.emb_dec = create_emb(vecs_dec, itos_dec, em_sz_dec)\n self.gru_dec = nn.GRU(em_sz_dec, em_sz_dec, num_layers=nl, dropout=0.1)\n self.emb_enc_drop = nn.Dropout(0.15)\n self.out_drop = nn.Dropout(0.35)\n self.out = nn.Linear(em_sz_dec, len(itos_dec))\n self.out.weight.data = self.emb_dec.weight.data\n\n self.W1 = rand_p(nh, em_sz_dec)\n self.l2 = nn.Linear(em_sz_dec, em_sz_dec)\n self.l3 = nn.Linear(em_sz_dec+nh, em_sz_dec)\n self.V = rand_p(em_sz_dec)\n\n def forward(self, inp, y=None, ret_attn=False):\n sl,bs = inp.size()\n h = self.initHidden(bs)\n emb = self.emb_enc_drop(self.emb_enc(inp))\n enc_out, h = self.gru_enc(emb, h)\n h = self.out_enc(h)\n\n dec_inp = V(torch.zeros(bs).long())\n res,attns = [],[]\n w1e = enc_out @ self.W1\n for i in range(self.out_sl):\n w2h = self.l2(h[-1])\n u = F.tanh(w1e + w2h)\n a = F.softmax(u @ self.V, 0)\n attns.append(a)\n Xa = (a.unsqueeze(2) * enc_out).sum(0)\n emb = self.emb_dec(dec_inp)\n wgt_enc = self.l3(torch.cat([emb, Xa], 1))\n \n outp, h = self.gru_dec(wgt_enc.unsqueeze(0), h)\n outp = self.out(self.out_drop(outp[0]))\n res.append(outp)\n dec_inp = V(outp.data.max(1)[1])\n if (dec_inp==1).all(): break\n if (y is not None) and (random.random()<self.pr_force):\n if i>=len(y): break\n dec_inp = y[i]\n\n res = torch.stack(res)\n if ret_attn: res = res,torch.stack(attns)\n return res\n\n def initHidden(self, bs): return V(torch.zeros(self.nl, bs, self.nh))",
"_____no_output_____"
],
[
"rnn = Seq2SeqAttnRNN(fr_vecd, fr_itos, dim_fr_vec, en_vecd, en_itos, dim_en_vec, nh, enlen_90)\nlearn = RNN_Learner(md, SingleModel(to_gpu(rnn)), opt_fn=opt_fn)\nlearn.crit = seq2seq_loss",
"_____no_output_____"
],
[
"lr=2e-3",
"_____no_output_____"
],
[
"learn.fit(lr, 1, cycle_len=15, use_clr=(20,10), stepper=Seq2SeqStepper)",
"_____no_output_____"
],
[
"learn.save('attn')",
"_____no_output_____"
],
[
"learn.load('attn')",
"_____no_output_____"
]
],
[
[
"### Test",
"_____no_output_____"
]
],
[
[
"x,y = next(iter(val_dl))\nprobs,attns = learn.model(V(x),ret_attn=True)\npreds = to_np(probs.max(2)[1])",
"_____no_output_____"
],
[
"for i in range(180,190):\n print(' '.join([fr_itos[o] for o in x[:,i] if o != 1]))\n print(' '.join([en_itos[o] for o in y[:,i] if o != 1]))\n print(' '.join([en_itos[o] for o in preds[:,i] if o!=1]))\n print()",
"quels facteurs pourraient influer sur le choix de leur emplacement ? _eos_\nwhat factors influencetheir location ? _eos_\nwhat factors might influence the their their their ? _eos_\n\nqu’ est -ce qui ne peut pas changer ? _eos_\nwhat can not change ? _eos_\nwhat can not change change ? _eos_\n\nque faites - vous ? _eos_\nwhat do you do ? _eos_\nwhat do you do ? _eos_\n\nqui réglemente les pylônes d' antennes ? _eos_\nwho regulates antenna towers ? _eos_\nwho regulates the lights ? ? _eos_\n\noù sont - ils situés ? _eos_\nwhere are they located ? _eos_\nwhere are they located ? _eos_\n\nquelles sont leurs compétences ? _eos_\nwhat are their qualifications ? _eos_\nwhat are their skills ? _eos_\n\nqui est victime de harcèlement sexuel ? _eos_\nwho experiences sexual harassment ? _eos_\nwho is victim sexual sexual ? _eos_\n\nquelles sont les personnes qui visitent les communautés autochtones ? _eos_\nwho visits indigenous communities ? _eos_\nwho is people people aboriginal people ? _eos_\n\npourquoi ces trois points en particulier ? _eos_\nwhy these specific three ? _eos_\nwhy are these three three ? ? _eos_\n\npourquoi ou pourquoi pas ? _eos_\nwhy or why not ? _eos_\nwhy or why not ? _eos_\n\n"
],
[
"attn = to_np(attns[...,180])",
"_____no_output_____"
],
[
"fig, axes = plt.subplots(3, 3, figsize=(15, 10))\nfor i,ax in enumerate(axes.flat):\n ax.plot(attn[i])",
"_____no_output_____"
]
],
[
[
"## All",
"_____no_output_____"
]
],
[
[
"class Seq2SeqRNN_All(nn.Module):\n def __init__(self, vecs_enc, itos_enc, em_sz_enc, vecs_dec, itos_dec, em_sz_dec, nh, out_sl, nl=2):\n super().__init__()\n self.emb_enc = create_emb(vecs_enc, itos_enc, em_sz_enc)\n self.nl,self.nh,self.out_sl = nl,nh,out_sl\n self.gru_enc = nn.GRU(em_sz_enc, nh, num_layers=nl, dropout=0.25, bidirectional=True)\n self.out_enc = nn.Linear(nh*2, em_sz_dec, bias=False)\n self.drop_enc = nn.Dropout(0.25)\n self.emb_dec = create_emb(vecs_dec, itos_dec, em_sz_dec)\n self.gru_dec = nn.GRU(em_sz_dec, em_sz_dec, num_layers=nl, dropout=0.1)\n self.emb_enc_drop = nn.Dropout(0.15)\n self.out_drop = nn.Dropout(0.35)\n self.out = nn.Linear(em_sz_dec, len(itos_dec))\n self.out.weight.data = self.emb_dec.weight.data\n\n self.W1 = rand_p(nh*2, em_sz_dec)\n self.l2 = nn.Linear(em_sz_dec, em_sz_dec)\n self.l3 = nn.Linear(em_sz_dec+nh*2, em_sz_dec)\n self.V = rand_p(em_sz_dec)\n\n def forward(self, inp, y=None):\n sl,bs = inp.size()\n h = self.initHidden(bs)\n emb = self.emb_enc_drop(self.emb_enc(inp))\n enc_out, h = self.gru_enc(emb, h)\n h = h.view(2,2,bs,-1).permute(0,2,1,3).contiguous().view(2,bs,-1)\n h = self.out_enc(self.drop_enc(h))\n\n dec_inp = V(torch.zeros(bs).long())\n res,attns = [],[]\n w1e = enc_out @ self.W1\n for i in range(self.out_sl):\n w2h = self.l2(h[-1])\n u = F.tanh(w1e + w2h)\n a = F.softmax(u @ self.V, 0)\n attns.append(a)\n Xa = (a.unsqueeze(2) * enc_out).sum(0)\n emb = self.emb_dec(dec_inp)\n wgt_enc = self.l3(torch.cat([emb, Xa], 1))\n \n outp, h = self.gru_dec(wgt_enc.unsqueeze(0), h)\n outp = self.out(self.out_drop(outp[0]))\n res.append(outp)\n dec_inp = V(outp.data.max(1)[1])\n if (dec_inp==1).all(): break\n if (y is not None) and (random.random()<self.pr_force):\n if i>=len(y): break\n dec_inp = y[i]\n return torch.stack(res)\n\n def initHidden(self, bs): return V(torch.zeros(self.nl*2, bs, self.nh))",
"_____no_output_____"
],
[
"rnn = Seq2SeqRNN_All(fr_vecd, fr_itos, dim_fr_vec, en_vecd, en_itos, dim_en_vec, nh, enlen_90)\nlearn = RNN_Learner(md, SingleModel(to_gpu(rnn)), opt_fn=opt_fn)\nlearn.crit = seq2seq_loss",
"_____no_output_____"
],
[
"learn.fit(lr, 1, cycle_len=15, use_clr=(20,10), stepper=Seq2SeqStepper)",
"_____no_output_____"
]
],
[
[
"### Test",
"_____no_output_____"
]
],
[
[
"x,y = next(iter(val_dl))\nprobs = learn.model(V(x))\npreds = to_np(probs.max(2)[1])\n\nfor i in range(180,190):\n print(' '.join([fr_itos[o] for o in x[:,i] if o != 1]))\n print(' '.join([en_itos[o] for o in y[:,i] if o != 1]))\n print(' '.join([en_itos[o] for o in preds[:,i] if o!=1]))\n print()",
"quels facteurs pourraient influer sur le choix de leur emplacement ? _eos_\nwhat factors influencetheir location ? _eos_\nwhat factors might affect the choice of their ? ? _eos_\n\nqu’ est -ce qui ne peut pas changer ? _eos_\nwhat can not change ? _eos_\nwhat can not change change _eos_\n\nque faites - vous ? _eos_\nwhat do you do ? _eos_\nwhat do you do ? _eos_\n\nqui réglemente les pylônes d' antennes ? _eos_\nwho regulates antenna towers ? _eos_\nwho regulates the antenna ? ? _eos_\n\noù sont - ils situés ? _eos_\nwhere are they located ? _eos_\nwhere are they located ? _eos_\n\nquelles sont leurs compétences ? _eos_\nwhat are their qualifications ? _eos_\nwhat are their skills ? _eos_\n\nqui est victime de harcèlement sexuel ? _eos_\nwho experiences sexual harassment ? _eos_\nwho is victim harassment harassment ? _eos_\n\nquelles sont les personnes qui visitent les communautés autochtones ? _eos_\nwho visits indigenous communities ? _eos_\nwho are the people people ? ?\n\npourquoi ces trois points en particulier ? _eos_\nwhy these specific three ? _eos_\nwhy are these three specific ? _eos_\n\npourquoi ou pourquoi pas ? _eos_\nwhy or why not ? _eos_\nwhy or why not ? _eos_\n\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
ecc2647272e10aabebb6af516f2302b7f00f8c38 | 16,051 | ipynb | Jupyter Notebook | Part 3 - Training Neural Networks.ipynb | quboanthony/DL_PyTorch | d8383288c5ff3573c4acebaf936e99b1a9597ca2 | [
"MIT"
] | null | null | null | Part 3 - Training Neural Networks.ipynb | quboanthony/DL_PyTorch | d8383288c5ff3573c4acebaf936e99b1a9597ca2 | [
"MIT"
] | null | null | null | Part 3 - Training Neural Networks.ipynb | quboanthony/DL_PyTorch | d8383288c5ff3573c4acebaf936e99b1a9597ca2 | [
"MIT"
] | null | null | null | 37.590164 | 636 | 0.613046 | [
[
[
"# Training Neural Networks\n\nThe network we built in the previous part isn't so smart, it doesn't know anything about our handwritten digits. Neural networks with non-linear activations work like universal function approximators. There is some function that maps your input to the output. For example, images of handwritten digits to class probabilities. The power of neural networks is that we can train them to approximate this function, and basically any function given enough data and compute time.\n\n<img src=\"assets/function_approx.png\" width=500px>\n\nAt first the network is naive, it doesn't know the function mapping the inputs to the outputs. We train the network by showing it examples of real data, then adjusting the network parameters such that it approximates this function.\n\nTo find these parameters, we need to know how poorly the network is predicting the real outputs. For this we calculate a **loss function** (also called the cost), a measure of our prediction error. For example, the mean squared loss is often used in regression and binary classification problems\n\n$$\n\\ell = \\frac{1}{2n}\\sum_i^n{\\left(y_i - \\hat{y}_i\\right)^2}\n$$\n\nwhere $n$ is the number of training examples, $y_i$ are the true labels, and $\\hat{y}_i$ are the predicted labels.\n\nBy minimizing this loss with respect to the network parameters, we can find configurations where the loss is at a minimum and the network is able to predict the correct labels with high accuracy. We find this minimum using a process called **gradient descent**. The gradient is the slope of the loss function and points in the direction of fastest change. To get to the minimum in the least amount of time, we then want to follow the gradient (downwards). You can think of this like descending a mountain by following the steepest slope to the base.\n\n<img src='assets/gradient_descent.png' width=350px>",
"_____no_output_____"
],
[
"## Backpropagation\n\nFor single layer networks, gradient descent is simple to implement. However, it's more complicated for deeper, multilayer neural networks like the one we've built. Complicated enough that it took about 30 years before researchers figured out how to train multilayer networks, although it's straightforward once you learn about it. \n\nThis is done through **backpropagation** which is really just an application of the chain rule from calculus. It's easiest to understand if we convert a two layer network into a graph representation.\n\n<img src='assets/w1_backprop_graph.png' width=400px>\n\nIn the forward pass through the network, our data and operations go from right to left here. To train the weights with gradient descent, we propagate the gradient of the cost backwards through the network. Mathematically, this is really just calculating the gradient of the loss with respect to the weights using the chain rule.\n\n$$\n\\frac{\\partial \\ell}{\\partial w_1} = \\frac{\\partial l_1}{\\partial w_1} \\frac{\\partial s}{\\partial l_1} \\frac{\\partial l_2}{\\partial s} \\frac{\\partial \\ell}{\\partial l_2}\n$$\n\nWe update our weights using this gradient with some learning rate $\\alpha$. \n\n$$\nw^\\prime = w - \\alpha \\frac{\\partial \\ell}{\\partial w}\n$$\n\nThe learning rate is set such that the weight update steps are small enough that the iterative method settles in a minimum.\n\nThe first thing we need to do for training is define our loss function. In PyTorch, you'll usually see this as `criterion`. Here we're using softmax output, so we want to use `criterion = nn.CrossEntropyLoss()` as our loss. Later when training, you use `loss = criterion(output, targets)` to calculate the actual loss.\n\nWe also need to define the optimizer we're using, SGD or Adam, or something along those lines. Here I'll just use SGD with `torch.optim.SGD`, passing in the network parameters and the learning rate.",
"_____no_output_____"
],
[
"## Autograd\n\nTorch provides a module, `autograd`, for automatically calculating the gradient of tensors. It does this by keeping track of operations performed on tensors. To make sure PyTorch keeps track of operations on a tensor and calculates the gradients, you need to set `requires_grad` on a tensor. You can do this at creation with the `requires_grad` keyword, or at any time with `x.requires_grad_(True)`.\n\nYou can turn off gradients for a block of code with the `torch.no_grad()` content:\n```python\nx = torch.zeros(1, requires_grad=True)\n>>> with torch.no_grad():\n... y = x * 2\n>>> y.requires_grad\nFalse\n```\n\nAlso, you can turn on or off gradients altogether with `torch.set_grad_enabled(True|False)`.\n\nThe gradients are computed with respect to some variable `z` with `z.backward()`. This does a backward pass through the operations that created `z`.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n%config InlineBackend.figure_format = 'retina'\n\nfrom collections import OrderedDict\n\nimport numpy as np\nimport time\n\nimport torch\nfrom torch import nn\nfrom torch import optim\nimport torch.nn.functional as F\n\nimport helper",
"_____no_output_____"
],
[
"x = torch.randn(2,2, requires_grad=True)\nprint(x)",
"_____no_output_____"
],
[
"y = x**2\nprint(y)",
"_____no_output_____"
]
],
[
[
"Below we can see the operation that created `y`, a power operation `PowBackward0`.",
"_____no_output_____"
]
],
[
[
"## grad_fn shows the function that generated this variable\nprint(y.grad_fn)",
"_____no_output_____"
]
],
[
[
"The autgrad module keeps track of these operations and knows how to calculate the gradient for each one. In this way, it's able to calculate the gradients for a chain of operations, with respect to any one tensor. Let's reduce the tensor `y` to a scalar value, the mean.",
"_____no_output_____"
]
],
[
[
"z = y.mean()\nprint(z)",
"_____no_output_____"
]
],
[
[
"You can check the gradients for `x` and `y` but they are empty currently.",
"_____no_output_____"
]
],
[
[
"print(x.grad)",
"_____no_output_____"
]
],
[
[
"To calculate the gradients, you need to run the `.backward` method on a Variable, `z` for example. This will calculate the gradient for `z` with respect to `x`\n\n$$\n\\frac{\\partial z}{\\partial x} = \\frac{\\partial}{\\partial x}\\left[\\frac{1}{n}\\sum_i^n x_i^2\\right] = \\frac{x}{2}\n$$",
"_____no_output_____"
]
],
[
[
"z.backward()\nprint(x.grad)\nprint(x/2)",
"_____no_output_____"
]
],
[
[
"These gradients calculations are particularly useful for neural networks. For training we need the gradients of the weights with respect to the cost. With PyTorch, we run data forward through the network to calculate the cost, then, go backwards to calculate the gradients with respect to the cost. Once we have the gradients we can make a gradient descent step. ",
"_____no_output_____"
],
[
"## Get the data and define the network\n\nThe same as we saw in part 3, we'll load the MNIST dataset and define our network.",
"_____no_output_____"
]
],
[
[
"from torchvision import datasets, transforms\n\n# Define a transform to normalize the data\ntransform = transforms.Compose([transforms.ToTensor(),\n transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),\n ])\n# Download and load the training data\ntrainset = datasets.MNIST('MNIST_data/', download=True, train=True, transform=transform)\ntrainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True)",
"_____no_output_____"
]
],
[
[
"I'll build a network with `nn.Sequential` here. Only difference from the last part is I'm not actually using softmax on the output, but instead just using the raw output from the last layer. This is because the output from softmax is a probability distribution. Often, the output will have values really close to zero or really close to one. Due to [inaccuracies with representing numbers as floating points](https://docs.python.org/3/tutorial/floatingpoint.html), computations with a softmax output can lose accuracy and become unstable. To get around this, we'll use the raw output, called the **logits**, to calculate the loss.",
"_____no_output_____"
]
],
[
[
"# Hyperparameters for our network\ninput_size = 784\nhidden_sizes = [128, 64]\noutput_size = 10\n\n# Build a feed-forward network\nmodel = nn.Sequential(OrderedDict([\n ('fc1', nn.Linear(input_size, hidden_sizes[0])),\n ('relu1', nn.ReLU()),\n ('fc2', nn.Linear(hidden_sizes[0], hidden_sizes[1])),\n ('relu2', nn.ReLU()),\n ('logits', nn.Linear(hidden_sizes[1], output_size))]))",
"_____no_output_____"
]
],
[
[
"## Training the network!\n\nThe first thing we need to do for training is define our loss function. In PyTorch, you'll usually see this as `criterion`. Here we're using softmax output, so we want to use `criterion = nn.CrossEntropyLoss()` as our loss. Later when training, you use `loss = criterion(output, targets)` to calculate the actual loss.\n\nWe also need to define the optimizer we're using, SGD or Adam, or something along those lines. Here I'll just use SGD with `torch.optim.SGD`, passing in the network parameters and the learning rate.",
"_____no_output_____"
]
],
[
[
"criterion = nn.CrossEntropyLoss()\noptimizer = optim.SGD(model.parameters(), lr=0.01)",
"_____no_output_____"
]
],
[
[
"First, let's consider just one learning step before looping through all the data. The general process with PyTorch:\n\n* Make a forward pass through the network to get the logits \n* Use the logits to calculate the loss\n* Perform a backward pass through the network with `loss.backward()` to calculate the gradients\n* Take a step with the optimizer to update the weights\n\nBelow I'll go through one training step and print out the weights and gradients so you can see how it changes.",
"_____no_output_____"
]
],
[
[
"print('Initial weights - ', model.fc1.weight)\n\nimages, labels = next(iter(trainloader))\nimages.resize_(64, 784)\n\n# Clear the gradients, do this because gradients are accumulated\noptimizer.zero_grad()\n\n# Forward pass, then backward pass, then update weights\noutput = model.forward(images)\nloss = criterion(output, labels)\nloss.backward()\nprint('Gradient -', model.fc1.weight.grad)\noptimizer.step()",
"_____no_output_____"
],
[
"print('Updated weights - ', model.fc1.weight)",
"_____no_output_____"
]
],
[
[
"### Training for real\n\nNow we'll put this algorithm into a loop so we can go through all the images. This is fairly straightforward. We'll loop through the mini-batches in our dataset, pass the data through the network to calculate the losses, get the gradients, then run the optimizer.",
"_____no_output_____"
]
],
[
[
"optimizer = optim.SGD(model.parameters(), lr=0.003)",
"_____no_output_____"
],
[
"epochs = 3\nprint_every = 40\nsteps = 0\nfor e in range(epochs):\n running_loss = 0\n for images, labels in iter(trainloader):\n steps += 1\n # Flatten MNIST images into a 784 long vector\n images.resize_(images.size()[0], 784)\n \n optimizer.zero_grad()\n \n # Forward and backward passes\n output = model.forward(images)\n loss = criterion(output, labels)\n loss.backward()\n optimizer.step()\n \n running_loss += loss.item()\n \n if steps % print_every == 0:\n print(\"Epoch: {}/{}... \".format(e+1, epochs),\n \"Loss: {:.4f}\".format(running_loss/print_every))\n \n running_loss = 0",
"_____no_output_____"
]
],
[
[
"With the network trained, we can check out it's predictions.",
"_____no_output_____"
]
],
[
[
"images, labels = next(iter(trainloader))\n\nimg = images[0].view(1, 784)\n# Turn off gradients to speed up this part\nwith torch.no_grad():\n logits = model.forward(img)\n\n# Output of the network are logits, need to take softmax for probabilities\nps = F.softmax(logits, dim=1)\nhelper.view_classify(img.view(1, 28, 28), ps)",
"_____no_output_____"
]
],
[
[
"Now our network is brilliant. It can accurately predict the digits in our images. Next up you'll write the code for training a neural network on a more complex dataset.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
ecc26683c2e62d5984811551e297ea41903d3c9c | 28,447 | ipynb | Jupyter Notebook | Data_analysis/Shotgun_metagenomics_analysis/Step3.1_apply_progressive_cutoffs_on_blast_result_Nanopore.ipynb | Yiheng323/Benchmarking-taxonomic-classification-strategies-using-mock-fungal-communities | 0dcd614d70f4aee2996b3edc348a952470d26ba2 | [
"MIT"
] | null | null | null | Data_analysis/Shotgun_metagenomics_analysis/Step3.1_apply_progressive_cutoffs_on_blast_result_Nanopore.ipynb | Yiheng323/Benchmarking-taxonomic-classification-strategies-using-mock-fungal-communities | 0dcd614d70f4aee2996b3edc348a952470d26ba2 | [
"MIT"
] | null | null | null | Data_analysis/Shotgun_metagenomics_analysis/Step3.1_apply_progressive_cutoffs_on_blast_result_Nanopore.ipynb | Yiheng323/Benchmarking-taxonomic-classification-strategies-using-mock-fungal-communities | 0dcd614d70f4aee2996b3edc348a952470d26ba2 | [
"MIT"
] | null | null | null | 44.309969 | 166 | 0.64179 | [
[
[
"# modules required for handling dataframes\nimport numpy as np\nimport os\nimport pandas as pd\nimport matplotlib.pyplot as plt\nfrom decimal import Decimal",
"_____no_output_____"
],
[
"# put in all input parameters. Here I am showing the code for one sample as an example.\n# to generate the final_df for other samples, simply change the basedir and barcode, as all file names just has this two difference between each two samples.\n# please note that there are other places of this script that require understanding and hard coding skills which I also commented below.\n\nsourcedir = '/home/yiheng/MinION_data' # the directory where all the documents of each sequencing run are stored.\nbarcode = '05' # the barcode for each sample. Barcode05 is PD sample, 06 is PB sample.\nbasedir = os.path.join(sourcedir, 'barcode%s' % barcode)\ndb = \"refseq_fungi_updated\" # database used\ngenera_in_mock = ['Aspergillus','Blastobotrys','Candida','Diutina', 'Nakaseomyces', 'Clavispora','Cryptococcus','Cyberlindnera',\n'Debaryomyces','Geotrichum','Kluyveromyces','Kodamaea','Lomentospora','Magnusiomyces','Meyerozyma','Pichia',\n'Rhodotorula','Scedosporium','Trichophyton', 'Trichosporon', 'Wickerhamomyces','Yarrowia','Zygoascus', 'Purpureocillium']",
"_____no_output_____"
],
[
"blastdf_dir = os.path.join(basedir, 'barcode%s.%sdb_blast.tab' % (barcode,db)) # the directory for .blast_output file\nblast_df = pd.read_csv(blastdf_dir, index_col=0, sep='\\t')",
"_____no_output_____"
],
[
"# this is for the total # of bases, which is total number of reads passed QC (7)\nseq_sum_dir = os.path.join(basedir, 'sequencing_summary_barcode%s.txt' % barcode) # the directory of sequencing summary file for each run\nseq_sum_df = pd.read_csv(seq_sum_dir, sep='\\t')\nseq_sum_df_pass = seq_sum_df[seq_sum_df.passes_filtering==True]\nseq_sum_df_pass.sequence_length_template.sum()",
"_____no_output_____"
],
[
"seq_sum_df_pass.columns",
"_____no_output_____"
],
[
"seq_sum_df_pass_drop = seq_sum_df_pass.drop(columns=['batch_id', 'filename', 'run_id', 'channel', 'mux', 'start_time',\n 'duration', 'num_events', 'passes_filtering', 'template_start','num_events_template', 'template_duration', \n 'strand_score_template', 'median_template', 'mad_template', 'scaling_median_template', 'scaling_mad_template'])\nsubset_seq_sum_df_unclassified = seq_sum_df_pass_drop[~seq_sum_df_pass_drop.read_id.isin(blast_df.qseqid_blast)]\nsubset_seq_sum_df_pass = seq_sum_df_pass_drop[seq_sum_df_pass_drop.read_id.isin(blast_df.qseqid_blast)]",
"_____no_output_____"
],
[
"total_blast_df = pd.merge(blast_df, seq_sum_df_pass_drop,how=\"outer\", left_on='qseqid_blast', right_on='read_id')\ntotal_blast_df['superkingdom_blast'] = 'Eukaryota'\ntotal_blast_df['sequence_length_template_blast'] = total_blast_df['sequence_length_template']\ntotal_blast_fillna = total_blast_df.fillna(value='unclassified')\ntotal_blast_fillna[total_blast_fillna.pident_blast != 'unclassified'].sequence_length_template.sum()",
"_____no_output_____"
],
[
"final_df = pd.merge(blast_df, subset_seq_sum_df_pass,how=\"outer\", left_on='qseqid_blast', right_on='read_id')",
"_____no_output_____"
],
[
"def generate_taxonomy_pivot_sum_blast(tax_df, rank, bcs, num):\n \"\"\"From tax_df, generate a pivot table listing num rank counts, sorted by bcs\"\"\"\n pivot_table = tax_df.pivot_table(values='sequence_length_template_blast', \n index=rank, \n columns='superkingdom_blast', \n aggfunc='sum', \n fill_value=0)\n pivot_table.columns.name = None\n pivot_table = pivot_table.sort_values(bcs, axis=0, ascending=False).head(n=num)\n return pivot_table",
"_____no_output_____"
],
[
"# Alright, here is the math. \n# Actually they can be all merged into one function but no harm to keep it like that as it's clearer.\n# Here the pmatch is the query coverage.\ndef calculate_precision_pmatch(blast_df, pmatch):\n subset_blast_df = blast_df[blast_df.pmatch_blast >= float(pmatch)]\n fungidb_blast_pivot = generate_taxonomy_pivot_sum_blast(subset_blast_df, 'genus_blast', 'Eukaryota', 2000) \n subset_fungidb_blast_pivot = fungidb_blast_pivot[fungidb_blast_pivot.index.isin(genera_in_mock)]\n precision = float((subset_fungidb_blast_pivot.sum().sum())/fungidb_blast_pivot['Eukaryota'].sum()*100)\n return precision\n\ndef calculate_precision_pident(blast_df, pident):\n subset_blast_df = blast_df[blast_df.pident_blast >= float(pident)]\n fungidb_blast_pivot = generate_taxonomy_pivot_sum_blast(subset_blast_df, 'genus_blast', 'Eukaryota', 2000) \n subset_fungidb_blast_pivot = fungidb_blast_pivot[fungidb_blast_pivot.index.isin(genera_in_mock)]\n precision = float((subset_fungidb_blast_pivot.sum().sum())/fungidb_blast_pivot['Eukaryota'].sum()*100)\n return precision\n\ndef calculate_precision_length(blast_df, length):\n subset_blast_df = blast_df[blast_df.sequence_length_template_blast >= float(length)]\n fungidb_blast_pivot = generate_taxonomy_pivot_sum_blast(subset_blast_df, 'genus_blast', 'Eukaryota', 2000) \n subset_fungidb_blast_pivot = fungidb_blast_pivot[fungidb_blast_pivot.index.isin(genera_in_mock)]\n precision = float((subset_fungidb_blast_pivot.sum().sum())/fungidb_blast_pivot['Eukaryota'].sum()*100)\n return precision\n\ndef calculate_precision_evalue(blast_df, evalue):\n subset_blast_df = blast_df[blast_df.log_evalue_blast >= int(evalue)]\n fungidb_blast_pivot = generate_taxonomy_pivot_sum_blast(subset_blast_df, 'genus_blast', 'Eukaryota', 2000) \n subset_fungidb_blast_pivot = fungidb_blast_pivot[fungidb_blast_pivot.index.isin(genera_in_mock)]\n precision = float((subset_fungidb_blast_pivot.sum().sum())/fungidb_blast_pivot['Eukaryota'].sum()*100)\n return precision\n\ndef calculate_precision_qscore(blast_df, qscore):\n subset_blast_df = blast_df[blast_df.mean_qscore_template >= int(qscore)]\n fungidb_blast_pivot = generate_taxonomy_pivot_sum_blast(subset_blast_df, 'genus_blast', 'Eukaryota', 2000) \n subset_fungidb_blast_pivot = fungidb_blast_pivot[fungidb_blast_pivot.index.isin(genera_in_mock)]\n precision = float(subset_fungidb_blast_pivot.sum()/fungidb_blast_pivot.sum()*100)\n return precision\n\ndef calculate_completeness_pmatch(blast_df, pmatch):\n subset_blast_df = blast_df[blast_df.pmatch_blast >= float(pmatch)]\n fungidb_blast_pivot = generate_taxonomy_pivot_sum_blast(subset_blast_df, 'genus_blast', 'Eukaryota', 2000) \n subset_fungidb_blast_pivot = fungidb_blast_pivot[fungidb_blast_pivot.index.isin(genera_in_mock)]\n# 24 is the number of genera that in the community, including the contaminative species and those alternative names\n completeness = len(subset_fungidb_blast_pivot)/24*100\n return completeness\n\ndef calculate_completeness_pident(blast_df, pident):\n subset_blast_df = blast_df[blast_df.pident_blast >= float(pident)]\n fungidb_blast_pivot = generate_taxonomy_pivot_sum_blast(subset_blast_df, 'genus_blast', 'Eukaryota', 2000) \n subset_fungidb_blast_pivot = fungidb_blast_pivot[fungidb_blast_pivot.index.isin(genera_in_mock)]\n completeness = len(subset_fungidb_blast_pivot)/24*100\n return completeness\n\ndef calculate_completeness_length(blast_df, length):\n subset_blast_df = blast_df[blast_df.sequence_length_template_blast >= float(length)]\n fungidb_blast_pivot = generate_taxonomy_pivot_sum_blast(subset_blast_df, 'genus_blast', 'Eukaryota', 2000) \n subset_fungidb_blast_pivot = fungidb_blast_pivot[fungidb_blast_pivot.index.isin(genera_in_mock)]\n completeness = len(subset_fungidb_blast_pivot)/24*100\n return completeness\n\ndef calculate_completeness_evalue(blast_df, evalue):\n subset_blast_df = blast_df[blast_df.log_evalue_blast >= int(evalue)]\n fungidb_blast_pivot = generate_taxonomy_pivot_sum_blast(subset_blast_df, 'genus_blast', 'Eukaryota', 2000) \n subset_fungidb_blast_pivot = fungidb_blast_pivot[fungidb_blast_pivot.index.isin(genera_in_mock)]\n completeness = len(subset_fungidb_blast_pivot)/24*100\n return completeness\n\ndef calculate_completeness_qscore(blast_df, qscore):\n subset_blast_df = blast_df[blast_df.mean_qscore_template >= int(qscore)]\n fungidb_blast_pivot = generate_taxonomy_pivot_sum_blast(subset_blast_df, 'genus_blast', 'Eukaryota', 2000) \n subset_fungidb_blast_pivot = fungidb_blast_pivot[fungidb_blast_pivot.index.isin(genera_in_mock)]\n # 24 is the number of genera that in the community, including the contaminative species and those alternative names\n completeness = len(subset_fungidb_blast_pivot)/24*100\n return completeness",
"_____no_output_____"
],
[
"# Please not that there is a difference in the denominator of calculating remaining rate.\n# This is to reflect the 'actual' remaining rate before we run the alignement.\n# For all other alignment parameters, we cannot do it because they are dependent on the alignment result.\n# For Illumina data, it was not much unaligned contigs so I just used the total number of aligned contigs for the calculation.\ndef calculate_remaining_length(blast_df, length):\n if barcode == '06':\n subset_blast_df = blast_df[blast_df.sequence_length_template_blast >= float(length)]\n fungidb_blast_pivot = generate_taxonomy_pivot_sum_blast(subset_blast_df, 'genus_blast', 'Eukaryota', 20000) \n remaining_rate = float(fungidb_blast_pivot.sum().sum()/4052192342*100)\n return remaining_rate\n elif barcode == '05':\n subset_blast_df = blast_df[blast_df.sequence_length_template_blast >= float(length)]\n fungidb_blast_pivot = generate_taxonomy_pivot_sum_blast(subset_blast_df, 'genus_blast', 'Eukaryota', 20000) \n remaining_rate = float(fungidb_blast_pivot.sum().sum()/2223839802*100)\n return remaining_rate\n\ndef calculate_remaining_evalue(blast_df, evalue):\n if barcode == '06':\n subset_blast_df = blast_df[blast_df.log_evalue_blast >= int(evalue)]\n fungidb_blast_pivot = generate_taxonomy_pivot_sum_blast(subset_blast_df, 'genus_blast', 'Eukaryota', 20000) \n remaining_rate = float(fungidb_blast_pivot.sum()/2905573749*100)\n return remaining_rate\n elif barcode == '05':\n subset_blast_df = blast_df[blast_df.log_evalue_blast >= int(evalue)]\n fungidb_blast_pivot = generate_taxonomy_pivot_sum_blast(subset_blast_df, 'genus_blast', 'Eukaryota', 20000) \n remaining_rate = float(fungidb_blast_pivot.sum()/1618364905*100)\n return remaining_rate\n\ndef calculate_remaining_pmatch(blast_df, pmatch):\n if barcode == '06':\n subset_blast_df = blast_df[blast_df.pmatch_blast >= int(pmatch)]\n fungidb_blast_pivot = generate_taxonomy_pivot_sum_blast(subset_blast_df, 'genus_blast', 'Eukaryota', 20000) \n remaining_rate = float(fungidb_blast_pivot.sum()/2905573749*100)\n return remaining_rate\n elif barcode == '05':\n subset_blast_df = blast_df[blast_df.pmatch_blast >= int(pmatch)]\n fungidb_blast_pivot = generate_taxonomy_pivot_sum_blast(subset_blast_df, 'genus_blast', 'Eukaryota', 20000) \n remaining_rate = float(fungidb_blast_pivot.sum()/1618364905*100)\n return remaining_rate\n \ndef calculate_remaining_pident(blast_df, pident):\n if barcode == '06':\n subset_blast_df = blast_df[blast_df.pident_blast >= int(pident)]\n fungidb_blast_pivot = generate_taxonomy_pivot_sum_blast(subset_blast_df, 'genus_blast', 'Eukaryota', 20000) \n remaining_rate = float(fungidb_blast_pivot.sum()/2905573749*100)\n return remaining_rate\n elif barcode == '05':\n subset_blast_df = blast_df[blast_df.pident_blast >= int(pident)]\n fungidb_blast_pivot = generate_taxonomy_pivot_sum_blast(subset_blast_df, 'genus_blast', 'Eukaryota', 20000) \n remaining_rate = float(fungidb_blast_pivot.sum()/3363783952*100)\n return remaining_rate\n\ndef calculate_remaining_qscore(blast_df, qscore):\n if barcode == '06':\n subset_blast_df = blast_df[blast_df.mean_qscore_template >= float(qscore)]\n fungidb_blast_pivot = generate_taxonomy_pivot_sum_blast(subset_blast_df, 'genus_blast', 'Eukaryota', 2000) \n remaining_rate = float(fungidb_blast_pivot.sum()/4052192342*100)\n return remaining_rate\n elif barcode == '05':\n subset_blast_df = blast_df[blast_df.mean_qscore_template >= float(qscore)]\n fungidb_blast_pivot = generate_taxonomy_pivot_sum_blast(subset_blast_df, 'genus_blast', 'Eukaryota', 2000) \n remaining_rate = float(fungidb_blast_pivot.sum()/2223839802*100)\n return remaining_rate \n",
"_____no_output_____"
],
[
"qscore_precision_df = pd.DataFrame()\n# Here the range may need to be hard coded according to the qscore range.\nqscore_precision_df['qscore'] = np.arange(7, 20, 0.1)\nqscore_precision_df['precision'] = np.nan\n\nfor qscore in qscore_precision_df['qscore']:\n qscore_precision_df.iloc[int(qscore_precision_df[qscore_precision_df['qscore']==qscore].index[0]),\n qscore_precision_df.columns.get_loc('precision')] = calculate_precision_qscore(final_df, qscore)\n\nqscore_precision_df.to_csv(os.path.join(basedir, 'barcode%s.%sdb_qscore_precision.tab' % (barcode, db)), sep='\\t')",
"_____no_output_____"
],
[
"qscore_completeness_df = pd.DataFrame()\nqscore_completeness_df['qscore'] = np.arange(7, 20.6, 0.1)\nqscore_completeness_df['completeness'] = np.nan\n\nfor qscore in qscore_completeness_df['qscore']:\n qscore_completeness_df.iloc[int(qscore_completeness_df[qscore_completeness_df['qscore']==qscore].index[0]),\n qscore_completeness_df.columns.get_loc('completeness')] = calculate_completeness_qscore(final_df, qscore)\n\nqscore_completeness_df.to_csv(os.path.join(basedir, 'barcode%s.%sdb_qscore_completeness.tab' % (barcode, db)), sep='\\t')",
"_____no_output_____"
],
[
"# log_evalue normaly ends at 414 or 415, the computer will not recognize if higher than that.\nevalue_x_precision = pd.DataFrame()\nevalue_x_precision['evalue'] = range(0, 414)\nevalue_x_precision['precision_rate'] = np.nan\n\nfor evalue in range(0, 414):\n evalue_x_precision.iloc[evalue, evalue_x_precision.columns.get_loc('precision_rate')] = calculate_precision_evalue(final_df, evalue)\n\nevalue_x_precision.to_csv(os.path.join(basedir, 'barcode%s.%sdb_evalue_precision.tab' % (barcode, db)), sep='\\t')",
"_____no_output_____"
],
[
"evalue_x_completeness = pd.DataFrame()\nevalue_x_completeness['evalue'] = range(0, 414)\nevalue_x_completeness['completeness'] = np.nan\n\nfor evalue in range(0, 414):\n evalue_x_completeness.iloc[evalue, evalue_x_completeness.columns.get_loc('completeness')] = calculate_completeness_evalue(final_df, evalue)\n\nevalue_x_completeness.to_csv(os.path.join(basedir, 'barcode%s.%sdb_evalue_completeness.tab' % (barcode, db)), sep='\\t')",
"_____no_output_____"
],
[
"# This is to help decide the range of the read length cut-offs.\ntotal_blast_fillna.sequence_length_template.sort_values(ascending=False).head()",
"_____no_output_____"
],
[
"length_x_precision = pd.DataFrame()\nlength_x_precision['length'] = np.arange(0,20000,50)\nlength_x_precision['precision_rate'] = np.nan\n\nfor length in length_x_precision['length']:\n length_x_precision.iloc[int(length_x_precision[length_x_precision['length']==length].index[0]),\n length_x_precision.columns.get_loc('precision_rate')] = calculate_precision_length(final_df, length)\n\nlength_x_precision.to_csv(os.path.join(basedir, 'barcode%s.%sdb_length_precision.tab' % (barcode, db)), sep='\\t')",
"_____no_output_____"
],
[
"length_x_completeness = pd.DataFrame()\nlength_x_completeness['length'] = np.arange(0,20000,50)\nlength_x_completeness['completeness'] = np.nan\n\nfor length in length_x_completeness['length']:\n length_x_completeness.iloc[int(length_x_completeness[length_x_completeness['length']==length].index[0]), \n length_x_completeness.columns.get_loc('completeness')] = calculate_completeness_length(final_df, length)\n \nlength_x_completeness.to_csv(os.path.join(basedir, 'barcode%s.%sdb_length_completeness.tab' % (barcode, db)), sep='\\t')",
"_____no_output_____"
],
[
"pident_x_precision = pd.DataFrame()\npident_x_precision['pident'] = range(0, 101)\npident_x_precision['precision_rate'] = np.nan\n\nfor pident in pident_x_precision['pident']:\n pident_x_precision.iloc[pident_x_precision[pident_x_precision.pident==pident].index, \n pident_x_precision.columns.get_loc('precision_rate')] = calculate_precision_pident(final_df, pident)\n\npident_x_precision.to_csv(os.path.join(basedir, 'barcode%s.%sdb_pident_precision.tab' % (barcode, db)), sep='\\t')",
"_____no_output_____"
],
[
"pident_x_completeness = pd.DataFrame()\npident_x_completeness['pident'] = range(0, 101)\npident_x_completeness['completeness'] = np.nan\n\nfor pident in range(0,101):\n pident_x_completeness.iloc[pident, pident_x_completeness.columns.get_loc('completeness')] = calculate_completeness_pident(final_df, pident)\n \npident_x_completeness.to_csv(os.path.join(basedir, 'barcode%s.%sdb_pident_completeness.tab' % (barcode, db)), sep='\\t')",
"_____no_output_____"
],
[
"# this is to see what range of pident in our dataframe\nfinal_df.pmatch_blast.sort_values(ascending=False).head()",
"_____no_output_____"
],
[
"pmatch_X_precision = pd.DataFrame()\npmatch_X_precision['pmatch'] = range(0, 98)\npmatch_X_precision['precision_rate'] = np.nan\n\nfor pmatch in pmatch_X_precision['pmatch']:\n pmatch_X_precision.iloc[pmatch_X_precision[pmatch_X_precision.pmatch==pmatch].index, \n pmatch_X_precision.columns.get_loc('precision_rate')] = calculate_precision_pmatch(final_df, pmatch)\n\npmatch_X_precision.to_csv(os.path.join(basedir, 'barcode%s.%sdb_pmatch_precision.tab' % (barcode, db)), sep='\\t')",
"_____no_output_____"
],
[
"pmatch_X_completeness = pd.DataFrame()\npmatch_X_completeness['pmatch'] = range(0, 98)\npmatch_X_completeness['completeness'] = np.nan\n\nfor pmatch in range(0,98):\n pmatch_X_completeness.iloc[pmatch, pmatch_X_completeness.columns.get_loc('completeness')] = calculate_completeness_pmatch(final_df, pmatch)\n\npmatch_X_completeness.to_csv(os.path.join(basedir, 'barcode%s.%sdb_pmatch_completeness.tab' % (barcode, db)), sep='\\t')",
"_____no_output_____"
],
[
"length_x_remaining = pd.DataFrame()\n# This number of 20000 is from the total sum of the sequence length.\nlength_x_remaining['length'] = np.arange(0, 20000, 50)\nlength_x_remaining['remaining_rate'] = np.nan\n\nfor length in length_x_remaining['length']:\n length_x_remaining.iloc[int(length_x_remaining[length_x_remaining['length']==length].index[0]),\n length_x_remaining.columns.get_loc('remaining_rate')] = calculate_remaining_length(total_blast_fillna, length)\n\nlength_x_remaining.to_csv(os.path.join(basedir, 'barcode%s.%sdb_length_remaining.tab' % (barcode, db)), sep='\\t') ",
"_____no_output_____"
],
[
"qscore_x_remaining = pd.DataFrame()\nqscore_x_remaining['qscore'] = np.arange(7, 20.1, 0.1)\nqscore_x_remaining['remaining_rate'] = np.nan\n\nfor qscore in qscore_x_remaining['qscore']:\n qscore_x_remaining.iloc[qscore_x_remaining[qscore_x_remaining.qscore==qscore].index,\n qscore_x_remaining.columns.get_loc('remaining_rate')] = calculate_remaining_qscore(total_blast_fillna, qscore)\n\nqscore_x_remaining.to_csv(os.path.join(basedir, 'barcode%s.%sdb_qscore_remaining.tab' % (barcode, db)), sep='\\t')",
"_____no_output_____"
],
[
"pident_x_remaining = pd.DataFrame()\npident_x_remaining['pident'] = range(0, 100)\npident_x_remaining['remaining_rate'] = np.nan\n\nfor y in pident_x_remaining['pident']:\n pident_x_remaining.iloc[pident_x_remaining[pident_x_remaining.pident==y].index,\n pident_x_remaining.columns.get_loc('remaining_rate')] = calculate_remaining_pident(final_df, y)\n\npident_x_remaining.to_csv(os.path.join(basedir, 'barcode%s.%sdb_pident_remaining.tab' % (barcode, db)), sep='\\t')",
"_____no_output_____"
],
[
"pmatch_x_remaining = pd.DataFrame()\npmatch_x_remaining['pmatch'] = range(0, 98)\npmatch_x_remaining['remaining_rate'] = np.nan\n\nfor pmatch in pmatch_x_remaining['pmatch']:\n pmatch_x_remaining.iloc[pmatch_x_remaining[pmatch_x_remaining.pmatch==pmatch].index,\n pmatch_x_remaining.columns.get_loc('remaining_rate')] = calculate_remaining_pmatch(final_df, pmatch)\n \npmatch_x_remaining.to_csv(os.path.join(basedir, 'barcode%s.%sdb_pmatch_remaining.tab' % (barcode, db)), sep='\\t')",
"_____no_output_____"
],
[
"evalue_x_remaining = pd.DataFrame()\nevalue_x_remaining['evalue'] = range(0, 414)\nevalue_x_remaining['remaining_rate'] = np.nan\n\nfor evalue in evalue_x_remaining['evalue']:\n evalue_x_remaining.iloc[evalue_x_remaining[evalue_x_remaining.evalue==evalue].index,\n evalue_x_remaining.columns.get_loc('remaining_rate')] = calculate_remaining_evalue(final_df, evalue)\n \nevalue_x_remaining.to_csv(os.path.join(basedir, 'barcode%s.%sdb_evalue_remaining.tab' % (barcode, db)), sep='\\t')",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecc27414771c3847c253f1bc4b7830b95e5882eb | 4,814 | ipynb | Jupyter Notebook | Real_time_object_detection_using_web_cam/Custom Object detection live video.ipynb | R-Srijith/Custom-object-detection-using-yoloV3 | 13e7579fbafa0d5b82006def790bdf5b0e5ac6a6 | [
"MIT"
] | null | null | null | Real_time_object_detection_using_web_cam/Custom Object detection live video.ipynb | R-Srijith/Custom-object-detection-using-yoloV3 | 13e7579fbafa0d5b82006def790bdf5b0e5ac6a6 | [
"MIT"
] | null | null | null | Real_time_object_detection_using_web_cam/Custom Object detection live video.ipynb | R-Srijith/Custom-object-detection-using-yoloV3 | 13e7579fbafa0d5b82006def790bdf5b0e5ac6a6 | [
"MIT"
] | null | null | null | 30.468354 | 113 | 0.480058 | [
[
[
"import cv2\nimport numpy as np\nimport matplotlib.pyplot as plt\n",
"_____no_output_____"
],
[
"## prodviding path to weights and configuration file\nnet = cv2.dnn.readNetFromDarknet(\"yolov3_custom.cfg\",\"yolov3_custom_4000.weights\")",
"_____no_output_____"
],
[
"### edit your class name \nclasses = ['mask_weared_incorrect','with_mask','without_mask']",
"_____no_output_____"
],
[
"cap = cv2.VideoCapture(0)\n\nwhile 1:\n _, img = cap.read()\n img = cv2.resize(img,(1280,720))\n hight,width,_ = img.shape\n blob = cv2.dnn.blobFromImage(img, 1/255,(416,416),(0,0,0),swapRB = True,crop= False)\n\n net.setInput(blob)\n\n output_layers_name = net.getUnconnectedOutLayersNames()\n\n layerOutputs = net.forward(output_layers_name)\n\n boxes =[]\n confidences = []\n class_ids = []\n\n for output in layerOutputs:\n for detection in output:\n score = detection[5:]\n class_id = np.argmax(score)\n confidence = score[class_id]\n if confidence > 0.7:\n center_x = int(detection[0] * width)\n center_y = int(detection[1] * hight)\n w = int(detection[2] * width)\n h = int(detection[3]* hight)\n x = int(center_x - w/2)\n y = int(center_y - h/2)\n boxes.append([x,y,w,h])\n confidences.append((float(confidence)))\n class_ids.append(class_id)\n\n\n indexes = cv2.dnn.NMSBoxes(boxes,confidences,.5,.4)\n\n boxes =[]\n confidences = []\n class_ids = []\n\n for output in layerOutputs:\n for detection in output:\n score = detection[5:]\n class_id = np.argmax(score)\n confidence = score[class_id]\n if confidence > 0.5:\n center_x = int(detection[0] * width)\n center_y = int(detection[1] * hight)\n w = int(detection[2] * width)\n h = int(detection[3]* hight)\n\n x = int(center_x - w/2)\n y = int(center_y - h/2)\n\n\n\n boxes.append([x,y,w,h])\n confidences.append((float(confidence)))\n class_ids.append(class_id)\n\n indexes = cv2.dnn.NMSBoxes(boxes,confidences,.8,.4)\n font = cv2.FONT_HERSHEY_PLAIN\n colors = np.random.uniform(0,255,size =(len(boxes),3))\n if len(indexes)>0:\n for i in indexes.flatten():\n x,y,w,h = boxes[i]\n label = str(classes[class_ids[i]])\n confidence = str(round(confidences[i],2))\n color = colors[i]\n cv2.rectangle(img,(x,y),(x+w,y+h),color,2)\n cv2.putText(img, label, (x+70, y-10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (36,255,12), 2)\n cv2.putText(img, confidence, (x, y-10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (36,255,12), 2,False)\n\n cv2.imshow('img',img)\n if cv2.waitKey(1) == ord('q'):\n break\n \ncap.release()\ncv2.destroyAllWindows()",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code"
]
] |
ecc27dc04be4f04d02ed8401f99b7a8165999b52 | 32,706 | ipynb | Jupyter Notebook | notebooks/Test_Packaging.ipynb | cspencerjones/xlayers | dc61e8b9189c2933f38547fd2cf77210bfd7d35c | [
"MIT"
] | 11 | 2019-10-16T17:27:32.000Z | 2021-07-14T18:47:52.000Z | notebooks/Test_Packaging.ipynb | cspencerjones/xlayers | dc61e8b9189c2933f38547fd2cf77210bfd7d35c | [
"MIT"
] | 11 | 2019-10-27T14:18:06.000Z | 2020-10-30T14:39:57.000Z | notebooks/Test_Packaging.ipynb | cspencerjones/xlayers | dc61e8b9189c2933f38547fd2cf77210bfd7d35c | [
"MIT"
] | 5 | 2019-10-26T14:02:36.000Z | 2020-07-13T04:45:52.000Z | 88.394595 | 20,788 | 0.793555 | [
[
[
"#These are the modules you will need\nfrom xlayers import finegrid, layers\nfrom xlayers.core import layers_numpy\nfrom xlayers.core import layers_xarray",
"_____no_output_____"
],
[
"# Import some packages\nimport os\nos.environ['NUMPY_EXPERIMENTAL_ARRAY_FUNCTION'] = '0'\n\n\nfrom matplotlib import pyplot as plt\nimport numpy as np\nimport xarray as xr\nimport gcsfs\n\n%matplotlib inline\nplt.rcParams['figure.figsize'] = 12, 6\n%config InlineBackend.figure_format = 'retina' ",
"_____no_output_____"
],
[
"#Look at what CMIP6 data is on the cloud\nimport pandas as pd\ndf = pd.read_csv('https://storage.googleapis.com/cmip6/pangeo-cmip6.csv')\ndf.head()",
"_____no_output_____"
],
[
"#Load some of that CMIP6 data\ndf_theta = df[(df.table_id == 'Omon') & (df.variable_id == 'thetao')]\nuri = df_theta[(df_theta.source_id == 'SAM0-UNICON') &\n (df_theta.experiment_id == 'historical')].zstore.values[0]\ngcs = gcsfs.GCSFileSystem(token='anon')\nds_theta = xr.open_zarr(gcs.get_mapper(uri), consolidated=True)\ndf_salt = df[(df.table_id == 'Omon') & (df.variable_id == 'so')]\nuri = df_salt[(df_salt.source_id == 'SAM0-UNICON') &\n (df_salt.experiment_id == 'historical')].zstore.values[0]\ngcs = gcsfs.GCSFileSystem(token='anon')\nds_salt = xr.open_zarr(gcs.get_mapper(uri), consolidated=True)\ndf_v = df[(df.table_id == 'Omon') & (df.variable_id == 'vo')]\nuri = df_v[(df_v.source_id == 'SAM0-UNICON') &\n (df_v.experiment_id == 'historical')].zstore.values[0]\ngcs = gcsfs.GCSFileSystem(token='anon')\nds_v = xr.open_zarr(gcs.get_mapper(uri), consolidated=True)",
"_____no_output_____"
],
[
"#find density from temperature and salinity\nimport gsw\ndens = xr.apply_ufunc(gsw.density.sigma0, ds_salt['so'], ds_theta['thetao'],\n dask='parallelized', output_dtypes=[float, ]\n ).rename('dens').to_dataset()",
"_____no_output_____"
],
[
"#this function calculates the quantities drF and drC from the depth levels of your model \n#(here lev_bnds defines the depth of each of the cell boundaries)\ndef finegrid_metrics(levs,lev_bnds):\n drF = np.diff(lev_bnds,axis=1)\n drC = np.concatenate((np.array([levs[0]]),np.diff(levs,axis=0),np.array([lev_bnds[-1,-1]-levs[-1]])))\n return(drF,drC)",
"_____no_output_____"
],
[
"#actually apply the function\nfine_drf,fine_drc = finegrid_metrics(ds_theta.lev.values,ds_theta.lev_bnds.values)",
"_____no_output_____"
],
[
"#Here we call the first xlayers function, finegrid, that calculates key parameters for rebinning the data\ndrf_finer, mapindex, mapfact, cellindex = finegrid.finegrid(np.squeeze(fine_drf),np.squeeze(fine_drc),[fine_drf.size,10])\nplt.plot(cellindex)",
"_____no_output_____"
],
[
"#here we define the new coordinate system\nthetalayers = np.linspace(-3,31,80)\n\n#this is the main function in xlayers: it is being applied to a single column here for demonstration purposes\nVH = layers.layers_1(ds_v.vo[0,:,100,100].values, ds_theta.thetao[0,:,100,100].values,\n thetalayers, mapfact, mapindex, cellindex, drf_finer)",
"_____no_output_____"
],
[
"#now we prepare more data to go into the \"layers\" function\nv_in = ds_v.vo[0,:,:,:]#.transpose('lev','time','j','i')\ntheta_in = dens.dens[0,:,:,:]#.transpose('lev','time','j','i')",
"_____no_output_____"
],
[
"thetalayers = np.linspace(20,30,80)\n\n#Here we apply the \"layers\" function to an xarray. 'lev' is the name of the vertical coordinate in our dataset\n#'Tlev' is the name of the new coordinate\nv_lay1 = layers_xarray(v_in, theta_in,thetalayers, \n mapfact, mapindex, cellindex, drf_finer, 'lev', 'Tlev')\n#Note, v_lay1 is thickness weighted (i.e. if the input has units m/s, the output has units m^2/s)\n#To transform back into non-thickness-weighted coordinates, find the thickness of each layer by using \n#xr.ones_like(v_in) as input, and divide through by this thickness",
"_____no_output_____"
],
[
"#Here I basically plot the ROC from the thickness-weighted velocity. \n#Note: I have not summed with dx because I haven't had time to put it in\nfig = plt.figure(figsize=(10,7))\n(v_lay1).cumsum('Tlev').sum('i').plot(x='j',yincrease=False)",
"Warning: theta_in may not be monotonically ascending/descending\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecc27ef60378332b40c4269356da99b89c0297e1 | 119,593 | ipynb | Jupyter Notebook | notebooks/WebFuzzer.ipynb | BharathMonash/fuzzingbook | c734bccc4515b2561f1bfa2313f73d02eede2057 | [
"MIT"
] | null | null | null | notebooks/WebFuzzer.ipynb | BharathMonash/fuzzingbook | c734bccc4515b2561f1bfa2313f73d02eede2057 | [
"MIT"
] | null | null | null | notebooks/WebFuzzer.ipynb | BharathMonash/fuzzingbook | c734bccc4515b2561f1bfa2313f73d02eede2057 | [
"MIT"
] | 1 | 2021-01-26T02:30:59.000Z | 2021-01-26T02:30:59.000Z | 28.13291 | 716 | 0.562934 | [
[
[
"# Testing Web Applications\n\nIn this chapter, we explore how to generate tests for Graphical User Interfaces (GUIs), notably on Web interfaces. We set up a (vulnerable) Web server and demonstrate how to systematically explore its behavior – first with hand-written grammars, then with grammars automatically inferred from the user interface. We also show how to conduct systematic attacks on these servers, notably with code and SQL injection.",
"_____no_output_____"
],
[
"**Prerequisites**\n\n* The techniques in this chapter make use of [grammars for fuzzing](Grammars.ipynb).\n* Basic knowledge of HTML and HTTP is required.\n* Knowledge of SQL databases is helpful.",
"_____no_output_____"
],
[
"## Synopsis\n<!-- Automatically generated. Do not edit. -->\n\nTo [use the code provided in this chapter](Importing.ipynb), write\n\n```python\n>>> from fuzzingbook.WebFuzzer import <identifier>\n```\n\nand then make use of the following features.\n\n\nThis chapter provides a simple (and vulnerable) Web server and two experimental fuzzers that are applied to it.\n\n### Fuzzing Web Forms\n\n`WebFormFuzzer` demonstrates how to interact with a Web form. Given a URL with a Web form, it automatically extracts a grammar that produces a URL; this URL contains values for all form elements. Support is limited to GET forms and a subset of HTML form elements.\n\nHere's the grammar extracted for our vulnerable Web server:\n\n```python\n>>> web_form_fuzzer = WebFormFuzzer(httpd_url)\n>>> web_form_fuzzer.grammar['<start>']\n['<action>?<query>']\n>>> web_form_fuzzer.grammar['<action>']\n['/order']\n>>> web_form_fuzzer.grammar['<query>']\n['<item>&<name>&<email-1>&<city>&<zip>&<terms>&<submit-1>']\n```\nUsing it for fuzzing yields a path with all form values filled; accessing this path acts like filling out and submitting the form.\n\n```python\n>>> web_form_fuzzer.fuzz()\n'/order?item=lockset&name=%43+&email=+c%40_+c&city=%37b_4&zip=5&terms=on&submit='\n```\nRepeated calls to `WebFormFuzzer.fuzz()` invoke the form again and again, each time with different (fuzzed) values.\n\n### SQL Injection Attacks\n\n`SQLInjectionFuzzer` is an experimental extension of `WebFormFuzzer` whose constructor takes an additional _payload_ – an SQL command to be injected and executed on the server. Otherwise, it is used like `WebFormFuzzer`:\n\n```python\n>>> sql_fuzzer = SQLInjectionFuzzer(httpd_url, \"DELETE FROM orders\")\n>>> sql_fuzzer.fuzz()\n\"/order?item=lockset&name=+&email=0%404&city=+'+)%3b+DELETE+FROM+orders%3b+--&zip='+OR+1%3d1--'&terms=on&submit=\"\n```\nAs you can see, the path to be retrieved contains the payload encoded into one of the form field values.\n\n`SQLInjectionFuzzer` is a proof-of-concept on how to build a malicious fuzzer; you should study and extend its code to make actual use of it.\n\n",
"_____no_output_____"
],
[
"## A Web User Interface\n\nLet us start with a simple example. We want to set up a _Web server_ that allows readers of this book to buy fuzzingbook-branded fan articles. In reality, we would make use of an existing Web shop (or an appropriate framework) for this purpose. For the purpose of this book, we _write our own Web server_, building on the HTTP server facilities provided by the Python library.",
"_____no_output_____"
],
[
"All of our Web server is defined in a `HTTPRequestHandler`, which, as the name suggests, handles arbitrary Web page requests.",
"_____no_output_____"
]
],
[
[
"from http.server import HTTPServer, BaseHTTPRequestHandler, HTTPStatus",
"_____no_output_____"
],
[
"class SimpleHTTPRequestHandler(BaseHTTPRequestHandler):\n pass",
"_____no_output_____"
]
],
[
[
"### Taking Orders\n\nFor our Web server, we need a number of Web pages:\n* We want one page where customers can place an order.\n* We want one page where they see their order confirmed. \n* Additionally, we need pages display error messages such as \"Page Not Found\".",
"_____no_output_____"
],
[
"We start with the order form. The dictionary `FUZZINGBOOK_SWAG` holds the items that customers can order, together with long descriptions:",
"_____no_output_____"
]
],
[
[
"import bookutils",
"_____no_output_____"
],
[
"FUZZINGBOOK_SWAG = {\n \"tshirt\": \"One FuzzingBook T-Shirt\",\n \"drill\": \"One FuzzingBook Rotary Hammer\",\n \"lockset\": \"One FuzzingBook Lock Set\"\n}",
"_____no_output_____"
]
],
[
[
"This is the HTML code for the order form. The menu for selecting the swag to be ordered is created dynamically from `FUZZINGBOOK_SWAG`. We omit plenty of details such as precise shipping address, payment, shopping cart, and more.",
"_____no_output_____"
]
],
[
[
"HTML_ORDER_FORM = \"\"\"\n<html><body>\n<form action=\"/order\" style=\"border:3px; border-style:solid; border-color:#FF0000; padding: 1em;\">\n <strong id=\"title\" style=\"font-size: x-large\">Fuzzingbook Swag Order Form</strong>\n <p>\n Yes! Please send me at your earliest convenience\n <select name=\"item\">\n \"\"\"\n# (We don't use h2, h3, etc. here as they interfere with the notebook table of contents)\n\n\nfor item in FUZZINGBOOK_SWAG:\n HTML_ORDER_FORM += \\\n '<option value=\"{item}\">{name}</option>\\n'.format(item=item,\n name=FUZZINGBOOK_SWAG[item])\n\nHTML_ORDER_FORM += \"\"\"\n </select>\n <br>\n <table>\n <tr><td>\n <label for=\"name\">Name: </label><input type=\"text\" name=\"name\">\n </td><td>\n <label for=\"email\">Email: </label><input type=\"email\" name=\"email\"><br>\n </td></tr>\n <tr><td>\n <label for=\"city\">City: </label><input type=\"text\" name=\"city\">\n </td><td>\n <label for=\"zip\">ZIP Code: </label><input type=\"number\" name=\"zip\">\n </tr></tr>\n </table>\n <input type=\"checkbox\" name=\"terms\"><label for=\"terms\">I have read\n the <a href=\"/terms\">terms and conditions</a></label>.<br>\n <input type=\"submit\" name=\"submit\" value=\"Place order\">\n</p>\n</form>\n</body></html>\n\"\"\"",
"_____no_output_____"
]
],
[
[
"This is what the order form looks like:",
"_____no_output_____"
]
],
[
[
"from IPython.display import display",
"_____no_output_____"
],
[
"from bookutils import HTML",
"_____no_output_____"
],
[
"HTML(HTML_ORDER_FORM)",
"_____no_output_____"
]
],
[
[
"This form is not yet functional, as there is no server behind it; pressing \"place order\" will lead you to a nonexistent page.",
"_____no_output_____"
],
[
"### Order Confirmation\n\nOnce we have gotten an order, we show a confirmation page, which is instantiated with the customer information submitted before. Here is the HTML and the rendering:",
"_____no_output_____"
]
],
[
[
"HTML_ORDER_RECEIVED = \"\"\"\n<html><body>\n<div style=\"border:3px; border-style:solid; border-color:#FF0000; padding: 1em;\">\n <strong id=\"title\" style=\"font-size: x-large\">Thank you for your Fuzzingbook Order!</strong>\n <p id=\"confirmation\">\n We will send <strong>{item_name}</strong> to {name} in {city}, {zip}<br>\n A confirmation mail will be sent to {email}.\n </p>\n <p>\n Want more swag? Use our <a href=\"/\">order form</a>!\n </p>\n</div>\n</body></html>\n\"\"\"",
"_____no_output_____"
],
[
"HTML(HTML_ORDER_RECEIVED.format(item_name=\"One FuzzingBook Rotary Hammer\",\n name=\"Jane Doe\",\n email=\"[email protected]\",\n city=\"Seattle\",\n zip=\"98104\"))",
"_____no_output_____"
]
],
[
[
"### Terms and Conditions\n\nA Web site can only be complete if it has the necessary legalese. This page shows some terms and conditions.",
"_____no_output_____"
]
],
[
[
"HTML_TERMS_AND_CONDITIONS = \"\"\"\n<html><body>\n<div style=\"border:3px; border-style:solid; border-color:#FF0000; padding: 1em;\">\n <strong id=\"title\" style=\"font-size: x-large\">Fuzzingbook Terms and Conditions</strong>\n <p>\n The content of this project is licensed under the\n <a href=\"https://creativecommons.org/licenses/by-nc-sa/4.0/\">Creative Commons\n Attribution-NonCommercial-ShareAlike 4.0 International License.</a>\n </p>\n <p>\n To place an order, use our <a href=\"/\">order form</a>.\n </p>\n</div>\n</body></html>\n\"\"\"",
"_____no_output_____"
],
[
"HTML(HTML_TERMS_AND_CONDITIONS)",
"_____no_output_____"
]
],
[
[
"## Storing Orders",
"_____no_output_____"
],
[
"To store orders, we make use of a *database*, stored in the file `orders.db`.",
"_____no_output_____"
]
],
[
[
"import sqlite3\nimport os",
"_____no_output_____"
],
[
"ORDERS_DB = \"orders.db\"",
"_____no_output_____"
]
],
[
[
"To interact with the database, we use *SQL commands*. The following commands create a table with five text columns for item, name, email, city, and zip – the exact same fields we also use in our HTML form.",
"_____no_output_____"
]
],
[
[
"def init_db():\n if os.path.exists(ORDERS_DB):\n os.remove(ORDERS_DB)\n\n db_connection = sqlite3.connect(ORDERS_DB)\n db_connection.execute(\"DROP TABLE IF EXISTS orders\")\n db_connection.execute(\"CREATE TABLE orders (item text, name text, email text, city text, zip text)\")\n db_connection.commit()\n\n return db_connection",
"_____no_output_____"
],
[
"db = init_db()",
"_____no_output_____"
]
],
[
[
"At this point, the database is still empty:",
"_____no_output_____"
]
],
[
[
"print(db.execute(\"SELECT * FROM orders\").fetchall())",
"_____no_output_____"
]
],
[
[
"We can add entries using the SQL `INSERT` command:",
"_____no_output_____"
]
],
[
[
"db.execute(\"INSERT INTO orders \" +\n \"VALUES ('lockset', 'Walter White', '[email protected]', 'Albuquerque', '87101')\")\ndb.commit()",
"_____no_output_____"
]
],
[
[
"These values are now in the database:",
"_____no_output_____"
]
],
[
[
"print(db.execute(\"SELECT * FROM orders\").fetchall())",
"_____no_output_____"
]
],
[
[
"We can also delete entries from the table again (say, after completion of the order):",
"_____no_output_____"
]
],
[
[
"db.execute(\"DELETE FROM orders WHERE name = 'Walter White'\")\ndb.commit()",
"_____no_output_____"
],
[
"print(db.execute(\"SELECT * FROM orders\").fetchall())",
"_____no_output_____"
]
],
[
[
"### Handling HTTP Requests\n\nWe have an order form and a database; now we need a Web server which brings it all together. The Python `http.server` module provides everything we need to build a simple HTTP server. A `HTTPRequestHandler` is an object that takes and processes HTTP requests – in particular, `GET` requests for retrieving Web pages.",
"_____no_output_____"
],
[
"We implement the `do_GET()` method that, based on the given path, branches off to serve the requested Web pages. Requesting the path `/` produces the order form; a path beginning with `/order` sends an order to be processed. All other requests end in a `Page Not Found` message.",
"_____no_output_____"
]
],
[
[
"class SimpleHTTPRequestHandler(BaseHTTPRequestHandler):\n def do_GET(self):\n try:\n # print(\"GET \" + self.path)\n if self.path == \"/\":\n self.send_order_form()\n elif self.path.startswith(\"/order\"):\n self.handle_order()\n elif self.path.startswith(\"/terms\"):\n self.send_terms_and_conditions()\n else:\n self.not_found()\n except Exception:\n self.internal_server_error()",
"_____no_output_____"
]
],
[
[
"#### Order Form\n\nAccessing the home page (i.e. getting the page at `/`) is simple: We go and serve the `html_order_form` as defined above.",
"_____no_output_____"
]
],
[
[
"class SimpleHTTPRequestHandler(SimpleHTTPRequestHandler):\n def send_order_form(self):\n self.send_response(HTTPStatus.OK, \"Place your order\")\n self.send_header(\"Content-type\", \"text/html\")\n self.end_headers()\n self.wfile.write(HTML_ORDER_FORM.encode(\"utf8\"))",
"_____no_output_____"
]
],
[
[
"Likewise, we can send out the terms and conditions:",
"_____no_output_____"
]
],
[
[
"class SimpleHTTPRequestHandler(SimpleHTTPRequestHandler):\n def send_terms_and_conditions(self):\n self.send_response(HTTPStatus.OK, \"Terms and Conditions\")\n self.send_header(\"Content-type\", \"text/html\")\n self.end_headers()\n self.wfile.write(HTML_TERMS_AND_CONDITIONS.encode(\"utf8\"))",
"_____no_output_____"
]
],
[
[
"#### Processing Orders",
"_____no_output_____"
],
[
"When the user clicks `Submit` on the order form, the Web browser creates and retrieves a URL of the form\n\n```\n<hostname>/order?field_1=value_1&field_2=value_2&field_3=value_3\n```\n\nwhere each `field_i` is the name of the field in the HTML form, and `value_i` is the value provided by the user. Values use the CGI encoding we have seen in the [chapter on coverage](Coverage.ipynb) – that is, spaces are converted into `+`, and characters that are not digits or letters are converted into `%nn`, where `nn` is the hexadecimal value of the character.\n\nIf Jane Doe <[email protected]> from Seattle orders a T-Shirt, this is the URL the browser creates:\n\n```\n<hostname>/order?item=tshirt&name=Jane+Doe&email=doe%40example.com&city=Seattle&zip=98104\n```",
"_____no_output_____"
],
[
"When processing a query, the attribute `self.path` of the HTTP request handler holds the path accessed – i.e., everything after `<hostname>`. The helper method `get_field_values()` takes `self.path` and returns a dictionary of values.",
"_____no_output_____"
]
],
[
[
"import urllib.parse",
"_____no_output_____"
],
[
"class SimpleHTTPRequestHandler(SimpleHTTPRequestHandler):\n def get_field_values(self):\n # Note: this fails to decode non-ASCII characters properly\n query_string = urllib.parse.urlparse(self.path).query\n\n # fields is { 'item': ['tshirt'], 'name': ['Jane Doe'], ...}\n fields = urllib.parse.parse_qs(query_string, keep_blank_values=True)\n\n values = {}\n for key in fields:\n values[key] = fields[key][0]\n\n return values",
"_____no_output_____"
]
],
[
[
"The method `handle_order()` takes these values from the URL, stores the order, and returns a page confirming the order. If anything goes wrong, it sends an internal server error.",
"_____no_output_____"
]
],
[
[
"class SimpleHTTPRequestHandler(SimpleHTTPRequestHandler):\n def handle_order(self):\n values = self.get_field_values()\n self.store_order(values)\n self.send_order_received(values)",
"_____no_output_____"
]
],
[
[
"Storing the order makes use of the database connection defined above; we create an SQL command instantiated with the values as extracted from the URL.",
"_____no_output_____"
]
],
[
[
"class SimpleHTTPRequestHandler(SimpleHTTPRequestHandler):\n def store_order(self, values):\n db = sqlite3.connect(ORDERS_DB)\n # The following should be one line\n sql_command = \"INSERT INTO orders VALUES ('{item}', '{name}', '{email}', '{city}', '{zip}')\".format(**values)\n self.log_message(\"%s\", sql_command)\n db.executescript(sql_command)\n db.commit()",
"_____no_output_____"
]
],
[
[
"After storing the order, we send the confirmation HTML page, which again is instantiated with the values from the URL.",
"_____no_output_____"
]
],
[
[
"class SimpleHTTPRequestHandler(SimpleHTTPRequestHandler):\n def send_order_received(self, values):\n # Should use html.escape()\n values[\"item_name\"] = FUZZINGBOOK_SWAG[values[\"item\"]]\n confirmation = HTML_ORDER_RECEIVED.format(**values).encode(\"utf8\")\n\n self.send_response(HTTPStatus.OK, \"Order received\")\n self.send_header(\"Content-type\", \"text/html\")\n self.end_headers()\n self.wfile.write(confirmation)",
"_____no_output_____"
]
],
[
[
"#### Other HTTP commands\n\nBesides the `GET` command (which does all the heavy lifting), HTTP servers can also support other HTTP commands; we support the `HEAD` command, which returns the head information of a Web page. In our case, this is always empty.",
"_____no_output_____"
]
],
[
[
"class SimpleHTTPRequestHandler(SimpleHTTPRequestHandler):\n def do_HEAD(self):\n # print(\"HEAD \" + self.path)\n self.send_response(HTTPStatus.OK)\n self.send_header(\"Content-type\", \"text/html\")\n self.end_headers()",
"_____no_output_____"
]
],
[
[
"### Error Handling\n\nWe have defined pages for submitting and processing orders; now we also need a few pages for errors that might occur.",
"_____no_output_____"
],
[
"#### Page Not Found\n\nThis page is displayed if a non-existing page (i.e. anything except `/` or `/order`) is requested.",
"_____no_output_____"
]
],
[
[
"HTML_NOT_FOUND = \"\"\"\n<html><body>\n<div style=\"border:3px; border-style:solid; border-color:#FF0000; padding: 1em;\">\n <strong id=\"title\" style=\"font-size: x-large\">Sorry.</strong>\n <p>\n This page does not exist. Try our <a href=\"/\">order form</a> instead.\n </p>\n</div>\n</body></html>\n \"\"\"",
"_____no_output_____"
],
[
"HTML(HTML_NOT_FOUND)",
"_____no_output_____"
]
],
[
[
"The method `not_found()` takes care of sending this out with the appropriate HTTP status code.",
"_____no_output_____"
]
],
[
[
"class SimpleHTTPRequestHandler(SimpleHTTPRequestHandler):\n def not_found(self):\n self.send_response(HTTPStatus.NOT_FOUND, \"Not found\")\n\n self.send_header(\"Content-type\", \"text/html\")\n self.end_headers()\n\n message = HTML_NOT_FOUND\n self.wfile.write(message.encode(\"utf8\"))",
"_____no_output_____"
]
],
[
[
"#### Internal Errors\n\nThis page is shown for any internal errors that might occur. For diagnostic purposes, we have it include the traceback of the failing function.",
"_____no_output_____"
]
],
[
[
"HTML_INTERNAL_SERVER_ERROR = \"\"\"\n<html><body>\n<div style=\"border:3px; border-style:solid; border-color:#FF0000; padding: 1em;\">\n <strong id=\"title\" style=\"font-size: x-large\">Internal Server Error</strong>\n <p>\n The server has encountered an internal error. Go to our <a href=\"/\">order form</a>.\n <pre>{error_message}</pre>\n </p>\n</div>\n</body></html>\n \"\"\"",
"_____no_output_____"
],
[
"HTML(HTML_INTERNAL_SERVER_ERROR)",
"_____no_output_____"
],
[
"import sys\nimport traceback",
"_____no_output_____"
],
[
"class SimpleHTTPRequestHandler(SimpleHTTPRequestHandler):\n def internal_server_error(self):\n self.send_response(HTTPStatus.INTERNAL_SERVER_ERROR, \"Internal Error\")\n\n self.send_header(\"Content-type\", \"text/html\")\n self.end_headers()\n\n exc = traceback.format_exc()\n self.log_message(\"%s\", exc.strip())\n\n message = HTML_INTERNAL_SERVER_ERROR.format(error_message=exc)\n self.wfile.write(message.encode(\"utf8\"))",
"_____no_output_____"
]
],
[
[
"### Logging\n\nOur server runs as a separate process in the background, waiting to receive commands at all time. To see what it is doing, we implement a special logging mechanism. The `httpd_message_queue` establishes a queue into which one process (the server) can store Python objects, and in which another process (the notebook) can retrieve them. We use this to pass log messages from the server, which we can then display in the notebook.",
"_____no_output_____"
]
],
[
[
"from multiprocessing import Queue",
"_____no_output_____"
],
[
"HTTPD_MESSAGE_QUEUE = Queue()",
"_____no_output_____"
]
],
[
[
"Let us place two messages in the queue:",
"_____no_output_____"
]
],
[
[
"HTTPD_MESSAGE_QUEUE.put(\"I am another message\")",
"_____no_output_____"
],
[
"HTTPD_MESSAGE_QUEUE.put(\"I am one more message\")",
"_____no_output_____"
]
],
[
[
"To distinguish server messages from other parts of the notebook, we format them specially:",
"_____no_output_____"
]
],
[
[
"from bookutils import rich_output, terminal_escape",
"_____no_output_____"
],
[
"def display_httpd_message(message):\n if rich_output():\n display(\n HTML(\n '<pre style=\"background: NavajoWhite;\">' +\n message +\n \"</pre>\"))\n else:\n print(terminal_escape(message))",
"_____no_output_____"
],
[
"display_httpd_message(\"I am a httpd server message\")",
"_____no_output_____"
]
],
[
[
"The method `print_httpd_messages()` prints all messages accumulated in the queue so far:",
"_____no_output_____"
]
],
[
[
"def print_httpd_messages():\n while not HTTPD_MESSAGE_QUEUE.empty():\n message = HTTPD_MESSAGE_QUEUE.get()\n display_httpd_message(message)",
"_____no_output_____"
],
[
"import time",
"_____no_output_____"
],
[
"time.sleep(1)\nprint_httpd_messages()",
"_____no_output_____"
]
],
[
[
"With `clear_httpd_messages()`, we can silently discard all pending messages:",
"_____no_output_____"
]
],
[
[
"def clear_httpd_messages():\n while not HTTPD_MESSAGE_QUEUE.empty():\n HTTPD_MESSAGE_QUEUE.get()",
"_____no_output_____"
]
],
[
[
"The method `log_message()` in the request handler makes use of the queue to store its messages:",
"_____no_output_____"
]
],
[
[
"class SimpleHTTPRequestHandler(SimpleHTTPRequestHandler):\n def log_message(self, format, *args):\n message = (\"%s - - [%s] %s\\n\" %\n (self.address_string(),\n self.log_date_time_string(),\n format % args))\n HTTPD_MESSAGE_QUEUE.put(message)",
"_____no_output_____"
]
],
[
[
"In [the chapter on carving](Carver.ipynb), we had introduced a `webbrowser()` method which retrieves the contents of the given URL. We now extend it such that it also prints out any log messages produced by the server:",
"_____no_output_____"
]
],
[
[
"import requests",
"_____no_output_____"
],
[
"def webbrowser(url, mute=False):\n \"\"\"Download the http/https resource given by the URL\"\"\"\n import requests # for imports\n \n try:\n r = requests.get(url)\n contents = r.text\n finally:\n if not mute:\n print_httpd_messages()\n else:\n clear_httpd_messages()\n\n return contents",
"_____no_output_____"
]
],
[
[
"### Running the Server\n\nAfter all these definitions, we are now ready to get the Web server up and running. We run the server on the *local host* – that is, the same machine which also runs this notebook. We check for an accessible port and put the resulting URL in the queue created earlier.",
"_____no_output_____"
]
],
[
[
"def run_httpd_forever(handler_class):\n host = \"127.0.0.1\" # localhost IP\n for port in range(8800, 9000):\n httpd_address = (host, port)\n\n try:\n httpd = HTTPServer(httpd_address, handler_class)\n break\n except OSError:\n continue\n\n httpd_url = \"http://\" + host + \":\" + repr(port)\n HTTPD_MESSAGE_QUEUE.put(httpd_url)\n httpd.serve_forever()",
"_____no_output_____"
]
],
[
[
"The function `start_httpd()` starts the server in a separate process, which we start using the `multiprocessing` module. It retrieves its URL from the message queue and returns it, such that we can start talking to the server.",
"_____no_output_____"
]
],
[
[
"from multiprocessing import Process",
"_____no_output_____"
],
[
"def start_httpd(handler_class=SimpleHTTPRequestHandler):\n clear_httpd_messages()\n\n httpd_process = Process(target=run_httpd_forever, args=(handler_class,))\n httpd_process.start()\n\n httpd_url = HTTPD_MESSAGE_QUEUE.get()\n return httpd_process, httpd_url",
"_____no_output_____"
]
],
[
[
"Let us now start the server and save its URL:",
"_____no_output_____"
]
],
[
[
"httpd_process, httpd_url = start_httpd()\nhttpd_url",
"_____no_output_____"
]
],
[
[
"### Interacting with the Server\n\nLet us now access the server just created.",
"_____no_output_____"
],
[
"#### Direct Browser Access\n\nIf you are running the Jupyter notebook server on the local host as well, you can now access the server directly at the given URL. Simply open the address in `httpd_url` by clicking on the link below.\n\n**Note**: This only works if you are running the Jupyter notebook server on the local host.",
"_____no_output_____"
]
],
[
[
"def print_url(url):\n if rich_output():\n display(HTML('<pre><a href=\"%s\">%s</a></pre>' % (url, url)))\n else:\n print(terminal_escape(url))",
"_____no_output_____"
],
[
"print_url(httpd_url)",
"_____no_output_____"
]
],
[
[
"Even more convenient, you may be able to interact directly with the server using the window below. \n\n**Note**: This only works if you are running the Jupyter notebook server on the local host.",
"_____no_output_____"
]
],
[
[
"HTML('<iframe src=\"' + httpd_url + '\" ' +\n 'width=\"100%\" height=\"230\"></iframe>')",
"_____no_output_____"
]
],
[
[
"After interaction, you can retrieve the messages produced by the server:",
"_____no_output_____"
]
],
[
[
"print_httpd_messages()",
"_____no_output_____"
]
],
[
[
"We can also see any orders placed in the database:",
"_____no_output_____"
]
],
[
[
"print(db.execute(\"SELECT * FROM orders\").fetchall())",
"_____no_output_____"
]
],
[
[
"And we can clear the order database:",
"_____no_output_____"
]
],
[
[
"db.execute(\"DELETE FROM orders\")\ndb.commit()",
"_____no_output_____"
]
],
[
[
"#### Retrieving the Home Page\n\nEven if our browser cannot directly interact with the server, the _notebook_ can. We can, for instance, retrieve the contents of the home page and display them:",
"_____no_output_____"
]
],
[
[
"contents = webbrowser(httpd_url)",
"_____no_output_____"
],
[
"HTML(contents)",
"_____no_output_____"
]
],
[
[
"#### Placing Orders\n\nTo test this form, we can generate URLs with orders and have the server process them.",
"_____no_output_____"
],
[
"The method `urljoin()` puts together a base URL (i.e., the URL of our server) and a path – say, the path towards our order.",
"_____no_output_____"
]
],
[
[
"from urllib.parse import urljoin, urlsplit",
"_____no_output_____"
],
[
"urljoin(httpd_url, \"/order?foo=bar\")",
"_____no_output_____"
]
],
[
[
"With `urljoin()`, we can create a full URL that is the same as the one generated by the browser as we submit the order form. Sending this URL to the browser effectively places the order, as we can see in the server log produced:",
"_____no_output_____"
]
],
[
[
"contents = webbrowser(urljoin(httpd_url,\n \"/order?item=tshirt&name=Jane+Doe&email=doe%40example.com&city=Seattle&zip=98104\"))",
"_____no_output_____"
]
],
[
[
"The web page returned confirms the order:",
"_____no_output_____"
]
],
[
[
"HTML(contents)",
"_____no_output_____"
]
],
[
[
"And the order is in the database, too:",
"_____no_output_____"
]
],
[
[
"print(db.execute(\"SELECT * FROM orders\").fetchall())",
"_____no_output_____"
]
],
[
[
"#### Error Messages\n\nWe can also test whether the server correctly responds to invalid requests. Nonexistent pages, for instance, are correctly handled:",
"_____no_output_____"
]
],
[
[
"HTML(webbrowser(urljoin(httpd_url, \"/some/other/path\")))",
"_____no_output_____"
]
],
[
[
"You may remember we also have a page for internal server errors. Can we get the server to produce this page? To find this out, we have to test the server thoroughly – which we do in the remainder of this chapter.",
"_____no_output_____"
],
[
"## Fuzzing Input Forms\n\nAfter setting up and starting the server, let us now go and systematically test it – first with expected, and then with less expected values.",
"_____no_output_____"
],
[
"### Fuzzing with Expected Values\n\nSince placing orders is all done by creating appropriate URLs, we define a [grammar](Grammars.ipynb) `ORDER_GRAMMAR` which encodes ordering URLs. It comes with a few sample values for names, email addresses, cities and (random) digits.",
"_____no_output_____"
],
[
"To make it easier to define strings that become part of a URL, we define the function `cgi_encode()`, taking a string and autmatically encoding it into CGI:",
"_____no_output_____"
]
],
[
[
"import string",
"_____no_output_____"
],
[
"def cgi_encode(s, do_not_encode=\"\"):\n ret = \"\"\n for c in s:\n if (c in string.ascii_letters or c in string.digits\n or c in \"$-_.+!*'(),\" or c in do_not_encode):\n ret += c\n elif c == ' ':\n ret += '+'\n else:\n ret += \"%%%02x\" % ord(c)\n return ret",
"_____no_output_____"
],
[
"s = cgi_encode('Is \"DOW30\" down .24%?')\ns",
"_____no_output_____"
]
],
[
[
"The optional parameter `do_not_encode` allows us to skip certain characters from encoding. This is useful when encoding grammar rules:",
"_____no_output_____"
]
],
[
[
"cgi_encode(\"<string>@<string>\", \"<>\")",
"_____no_output_____"
]
],
[
[
"`cgi_encode()` is the exact counterpart of the `cgi_decode()` function defined in the [chapter on coverage](Coverage.ipynb):",
"_____no_output_____"
]
],
[
[
"from Coverage import cgi_decode # minor dependency",
"_____no_output_____"
],
[
"cgi_decode(s)",
"_____no_output_____"
]
],
[
[
"Now for the grammar. We make use of `cgi_encode()` to encode strings:",
"_____no_output_____"
]
],
[
[
"from Grammars import crange, is_valid_grammar, syntax_diagram",
"_____no_output_____"
],
[
"ORDER_GRAMMAR = {\n \"<start>\": [\"<order>\"],\n \"<order>\": [\"/order?item=<item>&name=<name>&email=<email>&city=<city>&zip=<zip>\"],\n \"<item>\": [\"tshirt\", \"drill\", \"lockset\"],\n \"<name>\": [cgi_encode(\"Jane Doe\"), cgi_encode(\"John Smith\")],\n \"<email>\": [cgi_encode(\"[email protected]\"), cgi_encode(\"[email protected]\")],\n \"<city>\": [\"Seattle\", cgi_encode(\"New York\")],\n \"<zip>\": [\"<digit>\" * 5],\n \"<digit>\": crange('0', '9')\n}",
"_____no_output_____"
],
[
"assert is_valid_grammar(ORDER_GRAMMAR)",
"_____no_output_____"
],
[
"syntax_diagram(ORDER_GRAMMAR)",
"_____no_output_____"
]
],
[
[
"Using [one of our grammar fuzzers](GrammarFuzzer.iynb), we can instantiate this grammar and generate URLs:",
"_____no_output_____"
]
],
[
[
"from GrammarFuzzer import GrammarFuzzer",
"_____no_output_____"
],
[
"order_fuzzer = GrammarFuzzer(ORDER_GRAMMAR)\n[order_fuzzer.fuzz() for i in range(5)]",
"_____no_output_____"
]
],
[
[
"Sending these URLs to the server will have them processed correctly:",
"_____no_output_____"
]
],
[
[
"HTML(webbrowser(urljoin(httpd_url, order_fuzzer.fuzz())))",
"_____no_output_____"
],
[
"print(db.execute(\"SELECT * FROM orders\").fetchall())",
"_____no_output_____"
]
],
[
[
"### Fuzzing with Unexpected Values",
"_____no_output_____"
],
[
"We can now see that the server does a good job when faced with \"standard\" values. But what happens if we feed it non-standard values? To this end, we make use of a [mutation fuzzer](MutationFuzzer.ipynb) which inserts random changes into the URL. Our seed (i.e. the value to be mutated) comes from the grammar fuzzer:",
"_____no_output_____"
]
],
[
[
"seed = order_fuzzer.fuzz()\nseed",
"_____no_output_____"
]
],
[
[
"Mutating this string yields mutations not only in the field values, but also in field names as well as the URL structure.",
"_____no_output_____"
]
],
[
[
"from MutationFuzzer import MutationFuzzer # minor deoendency",
"_____no_output_____"
],
[
"mutate_order_fuzzer = MutationFuzzer([seed], min_mutations=1, max_mutations=1)\n[mutate_order_fuzzer.fuzz() for i in range(5)]",
"_____no_output_____"
]
],
[
[
"Let us fuzz a little until we get an internal server error. We use the Python `requests` module to interact with the Web server such that we can directly access the HTTP status code.",
"_____no_output_____"
]
],
[
[
"while True:\n path = mutate_order_fuzzer.fuzz()\n url = urljoin(httpd_url, path)\n r = requests.get(url)\n if r.status_code == HTTPStatus.INTERNAL_SERVER_ERROR:\n break",
"_____no_output_____"
]
],
[
[
"That didn't take long. Here's the offending URL:",
"_____no_output_____"
]
],
[
[
"url",
"_____no_output_____"
],
[
"clear_httpd_messages()\nHTML(webbrowser(url))",
"_____no_output_____"
]
],
[
[
"How does the URL cause this internal error? We make use of [delta debugging](Reducer.ipynb) to minimize the failure-inducing path, setting up a `WebRunner` class to define the failure condition:",
"_____no_output_____"
]
],
[
[
"failing_path = path\nfailing_path",
"_____no_output_____"
],
[
"from Fuzzer import Runner",
"_____no_output_____"
],
[
"class WebRunner(Runner):\n def __init__(self, base_url=None):\n self.base_url = base_url\n\n def run(self, url):\n if self.base_url is not None:\n url = urljoin(self.base_url, url)\n\n import requests # for imports\n r = requests.get(url)\n if r.status_code == HTTPStatus.OK:\n return url, Runner.PASS\n elif r.status_code == HTTPStatus.INTERNAL_SERVER_ERROR:\n return url, Runner.FAIL\n else:\n return url, Runner.UNRESOLVED",
"_____no_output_____"
],
[
"web_runner = WebRunner(httpd_url)\nweb_runner.run(failing_path)",
"_____no_output_____"
]
],
[
[
"This is the minimized path:",
"_____no_output_____"
]
],
[
[
"from Reducer import DeltaDebuggingReducer # minor",
"_____no_output_____"
],
[
"minimized_path = DeltaDebuggingReducer(web_runner).reduce(failing_path)\nminimized_path",
"_____no_output_____"
]
],
[
[
"It turns out that our server encounters an internal error if we do not supply the requested fields:",
"_____no_output_____"
]
],
[
[
"minimized_url = urljoin(httpd_url, minimized_path)\nminimized_url",
"_____no_output_____"
],
[
"clear_httpd_messages()\nHTML(webbrowser(minimized_url))",
"_____no_output_____"
]
],
[
[
"We see that we might have a lot to do to make our Web server more robust against unexpected inputs. The [exercises](#Exercises) give some instructions on what to do.",
"_____no_output_____"
],
[
"## Extracting Grammars for Input Forms\n\nIn our previous examples, we have assumed that we have a grammar that produces valid (or less valid) order queries. However, such a grammar does not need to be specified manually; we can also _extract it automatically_ from a Web page at hand. This way, we can apply our test generators on arbitrary Web forms without a manual specification step.",
"_____no_output_____"
],
[
"### Searching HTML for Input Fields\n\nThe key idea of our approach is to identify all input fields in a form. To this end, let us take a look at how the individual elements in our order form are encoded in HTML:",
"_____no_output_____"
]
],
[
[
"html_text = webbrowser(httpd_url)\nprint(html_text[html_text.find(\"<form\"):html_text.find(\"</form>\") + len(\"</form>\")])",
"_____no_output_____"
]
],
[
[
"We see that there is a number of form elements that accept inputs, in particular `<input>`, but also `<select>` and `<option>`. The idea now is to _parse_ the HTML of the Web page in question, to extract these individual input elements, and then to create a _grammar_ that produces a matching URL, effectively filling out the form.",
"_____no_output_____"
],
[
"To parse the HTML page, we could define a grammar to parse HTML and make use of [our own parser infrastructure](Parser.ipynb). However, it is much easier to not reinvent the wheel and instead build on the existing, dedicated `HTMLParser` class from the Python library.",
"_____no_output_____"
]
],
[
[
"from html.parser import HTMLParser",
"_____no_output_____"
]
],
[
[
"During parsing, we search for `<form>` tags and save the associated action (i.e., the URL to be invoked when the form is submitted) in the `action` attribute. While processing the form, we create a map `fields` that holds all input fields we have seen; it maps field names to the respective HTML input types (`\"text\"`, `\"number\"`, `\"checkbox\"`, etc.). Exclusive selection options map to a list of possible values; the `select` stack holds the currently active selection.",
"_____no_output_____"
]
],
[
[
"class FormHTMLParser(HTMLParser):\n def reset(self):\n super().reset()\n self.action = \"\" # Form action\n # Map of field name to type (or selection name to [option_1, option_2,\n # ...])\n self.fields = {}\n self.select = [] # Stack of currently active selection names",
"_____no_output_____"
]
],
[
[
"While parsing, the parser calls `handle_starttag()` for every opening tag (such as `<form>`) found; conversely, it invokes `handle_endtag()` for closing tags (such as `</form>`). `attributes` gives us a map of associated attributes and values.\n\nHere is how we process the individual tags:\n* When we find a `<form>` tag, we save the associated action in the `action` attribute;\n* When we find an `<input>` tag or similar, we save the type in the `fields` attribute;\n* When we find a `<select>` tag or similar, we push its name on the `select` stack;\n* When we find an `<option>` tag, we append the option to the list associated with the last pushed `<select>` tag.",
"_____no_output_____"
]
],
[
[
"class FormHTMLParser(FormHTMLParser):\n def handle_starttag(self, tag, attrs):\n attributes = {attr_name: attr_value for attr_name, attr_value in attrs}\n # print(tag, attributes)\n\n if tag == \"form\":\n self.action = attributes.get(\"action\", \"\")\n\n elif tag == \"select\" or tag == \"datalist\":\n if \"name\" in attributes:\n name = attributes[\"name\"]\n self.fields[name] = []\n self.select.append(name)\n else:\n self.select.append(None)\n\n elif tag == \"option\" and \"multiple\" not in attributes:\n current_select_name = self.select[-1]\n if current_select_name is not None and \"value\" in attributes:\n self.fields[current_select_name].append(attributes[\"value\"])\n\n elif tag == \"input\" or tag == \"option\" or tag == \"textarea\":\n if \"name\" in attributes:\n name = attributes[\"name\"]\n self.fields[name] = attributes.get(\"type\", \"text\")\n\n elif tag == \"button\":\n if \"name\" in attributes:\n name = attributes[\"name\"]\n self.fields[name] = [\"\"]",
"_____no_output_____"
],
[
"class FormHTMLParser(FormHTMLParser):\n def handle_endtag(self, tag):\n if tag == \"select\":\n self.select.pop()",
"_____no_output_____"
]
],
[
[
"Our implementation handles only one form per Web page; it also works on HTML only, ignoring all interaction coming from JavaScript. Also, it does not support all HTML input types.",
"_____no_output_____"
],
[
"Let us put this parser to action. We create a class `HTMLGrammarMiner` that takes a HTML document to parse. It then returns the associated action and the associated fields:",
"_____no_output_____"
]
],
[
[
"class HTMLGrammarMiner(object):\n def __init__(self, html_text):\n html_parser = FormHTMLParser()\n html_parser.feed(html_text)\n self.fields = html_parser.fields\n self.action = html_parser.action",
"_____no_output_____"
]
],
[
[
"Applied on our order form, this is what we get:",
"_____no_output_____"
]
],
[
[
"html_miner = HTMLGrammarMiner(html_text)\nhtml_miner.action",
"_____no_output_____"
],
[
"html_miner.fields",
"_____no_output_____"
]
],
[
[
"From this structure, we can now generate a grammar that automatically produces valid form submission URLs.",
"_____no_output_____"
],
[
"### Mining Grammars for Web Pages",
"_____no_output_____"
],
[
"To create a grammar from the fields extracted from HTML, we build on the `CGI_GRAMMAR` defined in the [chapter on grammars](Grammars.ipynb). The key idea is to define rules for every HTML input type: An HTML `number` type will get values from the `<number>` rule; likewise, values for the HTML `email` type will be defined from the `<email>` rule. Our default grammar provides very simple rules for these types.",
"_____no_output_____"
]
],
[
[
"from Grammars import crange, srange, new_symbol, unreachable_nonterminals, CGI_GRAMMAR, extend_grammar",
"_____no_output_____"
],
[
"class HTMLGrammarMiner(HTMLGrammarMiner):\n QUERY_GRAMMAR = extend_grammar(CGI_GRAMMAR, {\n \"<start>\": [\"<action>?<query>\"],\n\n \"<text>\": [\"<string>\"],\n\n \"<number>\": [\"<digits>\"],\n \"<digits>\": [\"<digit>\", \"<digits><digit>\"],\n \"<digit>\": crange('0', '9'),\n\n \"<checkbox>\": [\"<_checkbox>\"],\n \"<_checkbox>\": [\"on\", \"off\"],\n\n \"<email>\": [\"<_email>\"],\n \"<_email>\": [cgi_encode(\"<string>@<string>\", \"<>\")],\n\n # Use a fixed password in case we need to repeat it\n \"<password>\": [\"<_password>\"],\n \"<_password>\": [\"abcABC.123\"],\n\n # Stick to printable characters to avoid logging problems\n \"<percent>\": [\"%<hexdigit-1><hexdigit>\"],\n \"<hexdigit-1>\": srange(\"34567\"),\n \n # Submissions:\n \"<submit>\": [\"\"]\n })",
"_____no_output_____"
]
],
[
[
"Our grammar miner now takes the fields extracted from HTML, converting them into rules. Essentially, every input field encountered gets included in the resulting query URL; and it gets a rule expanding it into the appropriate type.",
"_____no_output_____"
]
],
[
[
"class HTMLGrammarMiner(HTMLGrammarMiner):\n def mine_grammar(self):\n grammar = extend_grammar(self.QUERY_GRAMMAR)\n grammar[\"<action>\"] = [self.action]\n\n query = \"\"\n for field in self.fields:\n field_symbol = new_symbol(grammar, \"<\" + field + \">\")\n field_type = self.fields[field]\n\n if query != \"\":\n query += \"&\"\n query += field_symbol\n\n if isinstance(field_type, str):\n field_type_symbol = \"<\" + field_type + \">\"\n grammar[field_symbol] = [field + \"=\" + field_type_symbol]\n if field_type_symbol not in grammar:\n # Unknown type\n grammar[field_type_symbol] = [\"<text>\"]\n else:\n # List of values\n value_symbol = new_symbol(grammar, \"<\" + field + \"-value>\")\n grammar[field_symbol] = [field + \"=\" + value_symbol]\n grammar[value_symbol] = field_type\n\n grammar[\"<query>\"] = [query]\n\n # Remove unused parts\n for nonterminal in unreachable_nonterminals(grammar):\n del grammar[nonterminal]\n\n assert is_valid_grammar(grammar)\n\n return grammar",
"_____no_output_____"
]
],
[
[
"Let us show `HTMLGrammarMiner` in action, again applied on our order form. Here is the full resulting grammar:",
"_____no_output_____"
]
],
[
[
"html_miner = HTMLGrammarMiner(html_text)\ngrammar = html_miner.mine_grammar()\ngrammar",
"_____no_output_____"
]
],
[
[
"Let us take a look into the structure of the grammar. It produces URL paths of this form:",
"_____no_output_____"
]
],
[
[
"grammar[\"<start>\"]",
"_____no_output_____"
]
],
[
[
"Here, the `<action>` comes from the `action` attribute of the HTML form:",
"_____no_output_____"
]
],
[
[
"grammar[\"<action>\"]",
"_____no_output_____"
]
],
[
[
"The `<query>` is composed from the individual field items:",
"_____no_output_____"
]
],
[
[
"grammar[\"<query>\"]",
"_____no_output_____"
]
],
[
[
"Each of these fields has the form `<field-name>=<field-type>`, where `<field-type>` is already defined in the grammar:",
"_____no_output_____"
]
],
[
[
"grammar[\"<zip>\"]",
"_____no_output_____"
],
[
"grammar[\"<terms>\"]",
"_____no_output_____"
]
],
[
[
"These are the query URLs produced from the grammar. We see that these are similar to the ones produced from our hand-crafted grammar, except that the string values for names, email addresses, and cities are now completely random:",
"_____no_output_____"
]
],
[
[
"order_fuzzer = GrammarFuzzer(grammar)\n[order_fuzzer.fuzz() for i in range(3)]",
"_____no_output_____"
]
],
[
[
"We can again feed these directly into our Web browser:",
"_____no_output_____"
]
],
[
[
"HTML(webbrowser(urljoin(httpd_url, order_fuzzer.fuzz())))",
"_____no_output_____"
]
],
[
[
"We see (one more time) that we can mine a grammar automatically from given data.",
"_____no_output_____"
],
[
"### A Fuzzer for Web Forms\n\nTo make things most convenient, let us define a `WebFormFuzzer` class that does everything in one place. Given a URL, it extracts its HTML content, mines the grammar and then produces inputs for it.",
"_____no_output_____"
]
],
[
[
"class WebFormFuzzer(GrammarFuzzer):\n def __init__(self, url, **grammar_fuzzer_options):\n html_text = self.get_html(url)\n grammar = self.get_grammar(html_text)\n super().__init__(grammar, **grammar_fuzzer_options)\n\n def get_html(self, url):\n return requests.get(url).text\n\n def get_grammar(self, html_text):\n grammar_miner = HTMLGrammarMiner(html_text)\n return grammar_miner.mine_grammar() ",
"_____no_output_____"
]
],
[
[
"All it now takes to fuzz a Web form is to provide its URL:",
"_____no_output_____"
]
],
[
[
"web_form_fuzzer = WebFormFuzzer(httpd_url)\nweb_form_fuzzer.fuzz()",
"_____no_output_____"
]
],
[
[
"We can combine the fuzzer with a `WebRunner` as defined above to run the resulting fuzz inputs directly on our Web server:",
"_____no_output_____"
]
],
[
[
"web_form_runner = WebRunner(httpd_url)\nweb_form_fuzzer.runs(web_form_runner, 10)",
"_____no_output_____"
]
],
[
[
"While convenient to use, this fuzzer is still very rudimentary:\n\n* It is limited to one form per page.\n* It only supports `GET` actions (i.e., inputs encoded into the URL). A full Web form fuzzer would have to at least support `POST` actions.\n* The fuzzer is build on HTML only. There is no Javascript handling for dynamic Web pages.",
"_____no_output_____"
],
[
"Let us clear any pending messages before we get to the next section:",
"_____no_output_____"
]
],
[
[
"clear_httpd_messages()",
"_____no_output_____"
]
],
[
[
"## Crawling User Interfaces\n\n",
"_____no_output_____"
],
[
"So far, we have assumed there would be only one form to explore. A real Web server, of course, has several pages – and possibly several forms, too. We define a simple *crawler* that explores all the links that originate from one page.",
"_____no_output_____"
],
[
"Our crawler is pretty straightforward. Its main component is again a `HTMLParser` that analyzes the HTML code for links of the form\n\n```html\n<a href=\"<link>\">\n```\n\nand saves all the links found in a list called `links`.",
"_____no_output_____"
]
],
[
[
"class LinkHTMLParser(HTMLParser):\n def reset(self):\n super().reset()\n self.links = []\n\n def handle_starttag(self, tag, attrs):\n attributes = {attr_name: attr_value for attr_name, attr_value in attrs}\n\n if tag == \"a\" and \"href\" in attributes:\n # print(\"Found:\", tag, attributes)\n self.links.append(attributes[\"href\"])",
"_____no_output_____"
]
],
[
[
"The actual crawler comes as a _generator function_ `crawl()` which produces one URL after another. By default, it returns only URLs that reside on the same host; the parameter `max_pages` controls how many pages (default: 1) should be scanned. We also respect the `robots.txt` file on the remote site to check which pages we are allowed to scan.",
"_____no_output_____"
]
],
[
[
"from collections import deque\nimport urllib.robotparser",
"_____no_output_____"
],
[
"def crawl(url, max_pages=1, same_host=True):\n \"\"\"Return the list of linked URLs from the given URL. Accesses up to `max_pages`.\"\"\"\n\n pages = deque([(url, \"<param>\")])\n urls_seen = set()\n\n rp = urllib.robotparser.RobotFileParser()\n rp.set_url(urljoin(url, \"/robots.txt\"))\n rp.read()\n\n while len(pages) > 0 and max_pages > 0:\n page, referrer = pages.popleft()\n if not rp.can_fetch(\"*\", page):\n # Disallowed by robots.txt\n continue\n\n r = requests.get(page)\n max_pages -= 1\n\n if r.status_code != HTTPStatus.OK:\n print(\"Error \" + repr(r.status_code) + \": \" + page,\n \"(referenced from \" + referrer + \")\",\n file=sys.stderr)\n continue\n\n content_type = r.headers[\"content-type\"]\n if not content_type.startswith(\"text/html\"):\n continue\n\n parser = LinkHTMLParser()\n parser.feed(r.text)\n\n for link in parser.links:\n target_url = urljoin(page, link)\n if same_host and urlsplit(\n target_url).hostname != urlsplit(url).hostname:\n # Different host\n continue\n if urlsplit(target_url).fragment != \"\":\n # Ignore #fragments\n continue\n\n if target_url not in urls_seen:\n pages.append((target_url, page))\n urls_seen.add(target_url)\n yield target_url\n\n if page not in urls_seen:\n urls_seen.add(page)\n yield page",
"_____no_output_____"
]
],
[
[
"We can run the crawler on our own server, where it will quickly return the order page and the terms and conditions page.",
"_____no_output_____"
]
],
[
[
"for url in crawl(httpd_url):\n print_httpd_messages()\n print_url(url)",
"_____no_output_____"
]
],
[
[
"We can also crawl over other sites, such as the home page of this project.",
"_____no_output_____"
]
],
[
[
"for url in crawl(\"https://www.fuzzingbook.org/\"):\n print_url(url)",
"_____no_output_____"
]
],
[
[
"Once we have crawled over all the links of a site, we can generate tests for all the forms we found:",
"_____no_output_____"
]
],
[
[
"for url in crawl(httpd_url, max_pages=float('inf')):\n web_form_fuzzer = WebFormFuzzer(url)\n web_form_runner = WebRunner(url)\n print(web_form_fuzzer.run(web_form_runner))",
"_____no_output_____"
]
],
[
[
"For even better effects, one could integrate crawling and fuzzing – and also analyze the order confirmation pages for further links. We leave this to the reader as an exercise.",
"_____no_output_____"
],
[
"Let us get rid of any server messages accumulated above:",
"_____no_output_____"
]
],
[
[
"clear_httpd_messages()",
"_____no_output_____"
]
],
[
[
"## Crafting Web Attacks\n\nBefore we close the chapter, let us take a look at a special class of \"uncommon\" inputs that not only yield generic failures, but actually allow _attackers_ to manipulate the server at their will. We will illustrate three common attacks using our server, which (surprise) actually turns out to be vulnerable against all of them.",
"_____no_output_____"
],
[
"### HTML Injection Attacks\n\nThe first kind of attack we look at is *HTML injection*. The idea of HTML injection is to supply the Web server with _data that can also be interpreted as HTML_. If this HTML data is then displayed to users in their Web browsers, it can serve malicious purposes, although (seemingly) originating from a reputable site. If this data is also _stored_, it becomes a _persistent_ attack; the attacker does not even have to lure victims towards specific pages.",
"_____no_output_____"
],
[
"Here is an example of a (simple) HTML injection. For the `name` field, we not only use plain text, but also embed HTML tags – in this case, a link towards a malware-hosting site.",
"_____no_output_____"
]
],
[
[
"from Grammars import extend_grammar",
"_____no_output_____"
],
[
"ORDER_GRAMMAR_WITH_HTML_INJECTION = extend_grammar(ORDER_GRAMMAR, {\n \"<name>\": [cgi_encode('''\n Jane Doe<p>\n <strong><a href=\"www.lots.of.malware\">Click here for cute cat pictures!</a></strong>\n </p>\n ''')],\n})",
"_____no_output_____"
]
],
[
[
"If we use this grammar to create inputs, the resulting URL will have all of the HTML encoded in:",
"_____no_output_____"
]
],
[
[
"html_injection_fuzzer = GrammarFuzzer(ORDER_GRAMMAR_WITH_HTML_INJECTION)\norder_with_injected_html = html_injection_fuzzer.fuzz()\norder_with_injected_html",
"_____no_output_____"
]
],
[
[
"What hapens if we send this string to our Web server? It turns out that the HTML is left in the confirmation page and shown as link. This also happens in the log:",
"_____no_output_____"
]
],
[
[
"HTML(webbrowser(urljoin(httpd_url, order_with_injected_html)))",
"_____no_output_____"
]
],
[
[
"Since the link seemingly comes from a trusted origin, users are much more likely to follow it. The link is even persistent, as it is stored in the database:",
"_____no_output_____"
]
],
[
[
"print(db.execute(\"SELECT * FROM orders WHERE name LIKE '%<%'\").fetchall())",
"_____no_output_____"
]
],
[
[
"This means that anyone ever querying the database (for instance, operators processing the order) will also see the link, multiplying its impact. By carefully crafting the injected HTML, one can thus expose malicious content to a large number of users – until the injected HTML is finally deleted.",
"_____no_output_____"
],
[
"### Cross-Site Scripting Attacks\n\nIf one can inject HTML code into a Web page, one can also inject *JavaScript* code as part of the injected HTML. This code would then be executed as soon as the injected HTML is rendered. \n\nThis is particularly dangerous because executed JavaScript always executes in the _origin_ of the page which contains it. Therefore, an attacker can normally not force a user to run JavaScript in any origin he does not control himself. When an attacker, however, can inject his code into a vulnerable Web application, he can have the client run the code with the (trusted) Web application as origin.\n\nIn such a *cross-site scripting* (*XSS*) attack, the injected script can do a lot more than just plain HTML. For instance, the code can access sensitive page content or session cookies. If the code in question runs in the operator's browser (for instance, because an operator is reviewing the list of orders), it could retrieve any other information shown on the screen and thus steal order details for a variety of customers.",
"_____no_output_____"
],
[
"Here is a very simple example of a script injection. Whenever the name is displayed, it causes the browser to \"steal\" the current *session cookie* – the piece of data the browser uses to identify the user with the server. In our case, we could steal the cookie of the Jupyter session.",
"_____no_output_____"
]
],
[
[
"ORDER_GRAMMAR_WITH_XSS_INJECTION = extend_grammar(ORDER_GRAMMAR, {\n \"<name>\": [cgi_encode('Jane Doe' +\n '<script>' +\n 'document.title = document.cookie.substring(0, 10);' +\n '</script>')\n ],\n})",
"_____no_output_____"
],
[
"xss_injection_fuzzer = GrammarFuzzer(ORDER_GRAMMAR_WITH_XSS_INJECTION)\norder_with_injected_xss = xss_injection_fuzzer.fuzz()\norder_with_injected_xss",
"_____no_output_____"
],
[
"url_with_injected_xss = urljoin(httpd_url, order_with_injected_xss)\nurl_with_injected_xss",
"_____no_output_____"
],
[
"HTML(webbrowser(url_with_injected_xss, mute=True))",
"_____no_output_____"
]
],
[
[
"The message looks as always – but if you have a look at your browser title, it should now show the first 10 characters of your \"secret\" notebook cookie. Instead of showing its prefix in the title, the script could also silently send the cookie to a remote server, allowing attackers to highjack your current notebook session and interact with the server on your behalf. It could also go and access and send any other data that is shown in your browser or otherwise available. It could run a *keylogger* and steal passwords and other sensitive data as it is typed in. Again, it will do so every time the compromised order with Jane Doe's name is shown in the browser and the associated script is executed.",
"_____no_output_____"
],
[
"Let us go and reset the title to a less sensitive value:",
"_____no_output_____"
]
],
[
[
"HTML('<script>document.title = \"Jupyter\"</script>')",
"_____no_output_____"
]
],
[
[
"### SQL Injection Attacks\n\nCross-site scripts have the same privileges as web pages – most notably, they cannot access or change data outside of your browser. So-called *SQL injection* targets _databases_, allowing to inject commands that can read or modify data in the database, or change the purpose of the original query.",
"_____no_output_____"
],
[
"To understand how SQL injection works, let us take a look at the code that produces the SQL command to insert a new order into the database:\n\n```python\nsql_command = (\"INSERT INTO orders \" +\n \"VALUES ('{item}', '{name}', '{email}', '{city}', '{zip}')\".format(**values))\n```\n\nWhat happens if any of the values (say, `name`) has a value that _can also be interpreted as a SQL command?_ Then, instead of the intended `INSERT` command, we would execute the command imposed by `name`.",
"_____no_output_____"
],
[
"Let us illustrate this by an example. We set the individual values as they would be found during execution:",
"_____no_output_____"
]
],
[
[
"values = {\n \"item\": \"tshirt\",\n \"name\": \"Jane Doe\",\n \"email\": \"[email protected]\",\n \"city\": \"Seattle\",\n \"zip\": \"98104\"\n}",
"_____no_output_____"
]
],
[
[
"and format the string as seen above:",
"_____no_output_____"
]
],
[
[
"sql_command = (\"INSERT INTO orders \" +\n \"VALUES ('{item}', '{name}', '{email}', '{city}', '{zip}')\".format(**values))\nsql_command",
"_____no_output_____"
]
],
[
[
"All fine, right? But now, we define a very \"special\" name that can also be interpreted as a SQL command:",
"_____no_output_____"
]
],
[
[
"values[\"name\"] = \"Jane', 'x', 'x', 'x'); DELETE FROM orders; -- \"",
"_____no_output_____"
],
[
"sql_command = (\"INSERT INTO orders \" +\n \"VALUES ('{item}', '{name}', '{email}', '{city}', '{zip}')\".format(**values))\nsql_command",
"_____no_output_____"
]
],
[
[
"What happens here is that we now get a command to insert values into the database (with a few \"dummy\" values `x`), followed by a SQL `DELETE` command that would _delete all entries_ of the orders table. The string `-- ` starts a SQL _comment_ such that the remainder of the original query would be easily ignored. By crafting strings that can also be interpreted as SQL commands, attackers can alter or delete database data, bypass authentication mechanisms and many more.",
"_____no_output_____"
],
[
"Is our server also vulnerable to such attacks? Of course it is. We create a special grammar such that we can set the `<name>` parameter to a string with SQL injection, just as shown above.",
"_____no_output_____"
]
],
[
[
"from Grammars import extend_grammar",
"_____no_output_____"
],
[
"ORDER_GRAMMAR_WITH_SQL_INJECTION = extend_grammar(ORDER_GRAMMAR, {\n \"<name>\": [cgi_encode(\"Jane', 'x', 'x', 'x'); DELETE FROM orders; --\")],\n})",
"_____no_output_____"
],
[
"sql_injection_fuzzer = GrammarFuzzer(ORDER_GRAMMAR_WITH_SQL_INJECTION)\norder_with_injected_sql = sql_injection_fuzzer.fuzz()\norder_with_injected_sql",
"_____no_output_____"
]
],
[
[
"These are the current orders:",
"_____no_output_____"
]
],
[
[
"print(db.execute(\"SELECT * FROM orders\").fetchall())",
"_____no_output_____"
]
],
[
[
"Let us go and send our URL with SQL injection to the server. From the log, we see that the \"malicious\" SQL command is formed just as sketched above, and executed, too.",
"_____no_output_____"
]
],
[
[
"contents = webbrowser(urljoin(httpd_url, order_with_injected_sql))",
"_____no_output_____"
]
],
[
[
"All orders are now gone:",
"_____no_output_____"
]
],
[
[
"print(db.execute(\"SELECT * FROM orders\").fetchall())",
"_____no_output_____"
]
],
[
[
"This effect is also illustrated [in this very popular XKCD comic](https://xkcd.com/327/):",
"_____no_output_____"
],
[
"{width=100%}",
"_____no_output_____"
],
[
"Even if we had not been able to execute arbitrary commands, being able to compromise an orders database offers several possibilities for mischief. For instance, we could use the address and matching credit card number of an existing person to go through validation and submit an order, only to have the order then delivered to an address of our choice. We could also use SQL injection to inject HTML and JavaScript code as above, bypassing possible sanitization geared at these domains.",
"_____no_output_____"
],
[
"To avoid such effects, the remedy is to _sanitize_ all third-party inputs – no character in the input must be interpretable as plain HTML, JavaScript, or SQL. This is achieved by properly _quoting_ and _escaping_ inputs. The [exercises](#Exercises) give some instructions on what to do.",
"_____no_output_____"
],
[
"### Leaking Internal Information\n\nTo craft the above SQL queries, we have used _insider information_ – for instance, we knew the name of the table as well as its structure. Surely, an attacker would not know this and thus not be able to run the attack, right? Unfortunately, it turns out we are leaking all of this information out to the world in the first place. The error message produced by our server reveals everything we need:",
"_____no_output_____"
]
],
[
[
"answer = webbrowser(urljoin(httpd_url, \"/order\"), mute=True)",
"_____no_output_____"
],
[
"HTML(answer)",
"_____no_output_____"
]
],
[
[
"The best way to avoid information leakage through failures is of course not to fail in the first place. But if you fail, make it hard for the attacker to establish a link between the attack and the failure. Do not produce \"internal error\" messages (and certainly not ones with internal information); do not become unresponsive; just go back to the home page and ask the user to supply correct data. One more time, the [exercises](#Exercises) give some instructions on how to fix the server.",
"_____no_output_____"
],
[
"If you can manipulate the server not only to alter information, but also to _retrieve_ information, you can learn about table names and structure by accessing special _tables_ (also called *data dictionary*) in which database servers store their metadata. In the MySQL server, for instance, the special table `information_schema` holds metadata such as the names of databases and tables, data types of columns, or access privileges.",
"_____no_output_____"
],
[
"## Fully Automatic Web Attacks",
"_____no_output_____"
],
[
"So far, we have demonstrated the above attacks using our manually written order grammar. However, the attacks also work for generated grammars. We extend `HTMLGrammarMiner` by adding a number of common SQL injection attacks:",
"_____no_output_____"
]
],
[
[
"class SQLInjectionGrammarMiner(HTMLGrammarMiner):\n ATTACKS = [\n \"<string>' <sql-values>); <sql-payload>; <sql-comment>\",\n \"<string>' <sql-comment>\",\n \"' OR 1=1<sql-comment>'\",\n \"<number> OR 1=1\",\n ]\n\n def __init__(self, html_text, sql_payload):\n super().__init__(html_text)\n\n self.QUERY_GRAMMAR = extend_grammar(self.QUERY_GRAMMAR, {\n \"<text>\": [\"<string>\", \"<sql-injection-attack>\"],\n \"<number>\": [\"<digits>\", \"<sql-injection-attack>\"],\n \"<checkbox>\": [\"<_checkbox>\", \"<sql-injection-attack>\"],\n \"<email>\": [\"<_email>\", \"<sql-injection-attack>\"],\n \"<sql-injection-attack>\": [\n cgi_encode(attack, \"<->\") for attack in self.ATTACKS\n ],\n \"<sql-values>\": [\"\", cgi_encode(\"<sql-values>, '<string>'\", \"<->\")],\n \"<sql-payload>\": [cgi_encode(sql_payload)],\n \"<sql-comment>\": [\"--\", \"#\"],\n })",
"_____no_output_____"
],
[
"html_miner = SQLInjectionGrammarMiner(\n html_text, sql_payload=\"DROP TABLE orders\")",
"_____no_output_____"
],
[
"grammar = html_miner.mine_grammar()\ngrammar",
"_____no_output_____"
],
[
"grammar[\"<text>\"]",
"_____no_output_____"
]
],
[
[
"We see that several fields now are tested for vulnerabilities:",
"_____no_output_____"
]
],
[
[
"sql_fuzzer = GrammarFuzzer(grammar)\nsql_fuzzer.fuzz()",
"_____no_output_____"
],
[
"print(db.execute(\"SELECT * FROM orders\").fetchall())",
"_____no_output_____"
],
[
"contents = webbrowser(urljoin(httpd_url,\n \"/order?item=tshirt&name=Jane+Doe&email=doe%40example.com&city=Seattle&zip=98104\"))",
"_____no_output_____"
],
[
"def orders_db_is_empty():\n try:\n entries = db.execute(\"SELECT * FROM orders\").fetchall()\n except sqlite3.OperationalError:\n return True\n return len(entries) == 0",
"_____no_output_____"
],
[
"orders_db_is_empty()",
"_____no_output_____"
],
[
"class SQLInjectionFuzzer(WebFormFuzzer):\n def __init__(self, url, sql_payload=\"\", **kwargs):\n self.sql_payload = sql_payload\n super().__init__(url, **kwargs)\n\n def get_grammar(self, html_text):\n grammar_miner = SQLInjectionGrammarMiner(\n html_text, sql_payload=self.sql_payload)\n return grammar_miner.mine_grammar()",
"_____no_output_____"
],
[
"sql_fuzzer = SQLInjectionFuzzer(httpd_url, \"DELETE FROM orders\")\nweb_runner = WebRunner(httpd_url)\ntrials = 1\n\nwhile True:\n sql_fuzzer.run(web_runner)\n if orders_db_is_empty():\n break\n trials += 1",
"_____no_output_____"
],
[
"trials",
"_____no_output_____"
]
],
[
[
"Our attack was successful! After less than a second of testing, our database is empty:",
"_____no_output_____"
]
],
[
[
"orders_db_is_empty()",
"_____no_output_____"
]
],
[
[
"Again, note the level of possible automation: We can\n\n* Crawl the Web pages of a host for possible forms\n* Automatically identify form fields and possible values\n* Inject SQL (or HTML, or JavaScript) into any of these fields\n\nand all of this fully automatically, not needing anything but the URL of the site.",
"_____no_output_____"
],
[
"The bad news is that with a tool set as the above, anyone can attack web sites. The even worse news is that such penetration tests take place every day, on every web site. The good news, though, is that after reading this chapter, you now get an idea of how Web servers are attacked every day – and what you as a Web server maintainer could and should do to prevent this.",
"_____no_output_____"
],
[
"## Synopsis\n\nThis chapter provides a simple (and vulnerable) Web server and two experimental fuzzers that are applied to it.",
"_____no_output_____"
],
[
"### Fuzzing Web Forms\n\n`WebFormFuzzer` demonstrates how to interact with a Web form. Given a URL with a Web form, it automatically extracts a grammar that produces a URL; this URL contains values for all form elements. Support is limited to GET forms and a subset of HTML form elements.",
"_____no_output_____"
],
[
"Here's the grammar extracted for our vulnerable Web server:",
"_____no_output_____"
]
],
[
[
"web_form_fuzzer = WebFormFuzzer(httpd_url)",
"_____no_output_____"
],
[
"web_form_fuzzer.grammar['<start>']",
"_____no_output_____"
],
[
"web_form_fuzzer.grammar['<action>']",
"_____no_output_____"
],
[
"web_form_fuzzer.grammar['<query>']",
"_____no_output_____"
]
],
[
[
"Using it for fuzzing yields a path with all form values filled; accessing this path acts like filling out and submitting the form.",
"_____no_output_____"
]
],
[
[
"web_form_fuzzer.fuzz()",
"_____no_output_____"
]
],
[
[
"Repeated calls to `WebFormFuzzer.fuzz()` invoke the form again and again, each time with different (fuzzed) values.",
"_____no_output_____"
],
[
"### SQL Injection Attacks\n\n`SQLInjectionFuzzer` is an experimental extension of `WebFormFuzzer` whose constructor takes an additional _payload_ – an SQL command to be injected and executed on the server. Otherwise, it is used like `WebFormFuzzer`:",
"_____no_output_____"
]
],
[
[
"sql_fuzzer = SQLInjectionFuzzer(httpd_url, \"DELETE FROM orders\")\nsql_fuzzer.fuzz()",
"_____no_output_____"
]
],
[
[
"As you can see, the path to be retrieved contains the payload encoded into one of the form field values.",
"_____no_output_____"
],
[
"`SQLInjectionFuzzer` is a proof-of-concept on how to build a malicious fuzzer; you should study and extend its code to make actual use of it.",
"_____no_output_____"
],
[
"## Lessons Learned\n\n* User Interfaces (in the Web and elsewhere) should be tested with _expected_ and _unexpected_ values.\n* One can _mine grammars from user interfaces_, allowing for their widespread testing.\n* Consequent _sanitizing_ of inputs prevents common attacks such as code and SQL injection.\n* Do not attempt to write a Web server yourself, as you are likely to repeat all the mistakes of others.",
"_____no_output_____"
],
[
"We're done, so we can clean up:",
"_____no_output_____"
]
],
[
[
"clear_httpd_messages()",
"_____no_output_____"
],
[
"httpd_process.terminate()",
"_____no_output_____"
]
],
[
[
"## Next Steps\n\nFrom here, the next step is [GUI Fuzzing](GUIFuzzer.ipynb), going from HTML- and Web-based user interfaces to generic user interfaces (including JavaScript and mobile user interfaces).\n\nIf you are interested in security testing, do not miss our [chapter on information flow](InformationFlow.ipynb), showing how to systematically detect information leaks; this also addresses the issue of SQL Injection attacks.",
"_____no_output_____"
],
[
"## Background\n\nThe [Wikipedia pages on Web application security](https://en.wikipedia.org/wiki/Web_application_security) are a mandatory read for anyone building, maintaining, or testing Web applications. In 2012, cross-site scripting and SQL injection, as discussed in this chapter, made up more than 50% of Web application vulnerabilities.\n\nThe [Wikipedia page on penetration testing](https://en.wikipedia.org/wiki/Penetration_test) provides a comprehensive overview on the history of penetration testing, as well as collections of vulnerabilities.\n\nThe [OWASP Zed Attack Proxy Project](https://www.owasp.org/index.php/OWASP_Zed_Attack_Proxy_Project) (ZAP) is an open source Web site security scanner including several of the features discussed above, and many many more.",
"_____no_output_____"
],
[
"## Exercises",
"_____no_output_____"
],
[
"### Exercise 1: Fix the Server\n\nCreate a `BetterHTTPRequestHandler` class that fixes the several issues of `SimpleHTTPRequestHandler`:",
"_____no_output_____"
],
[
"#### Part 1: Silent Failures\n\nSet up the server such that it does not reveal internal information – in particular, tracebacks and HTTP status codes.",
"_____no_output_____"
],
[
"**Solution.** We define a better message that does not reveal tracebacks:",
"_____no_output_____"
]
],
[
[
"BETTER_HTML_INTERNAL_SERVER_ERROR = \\\n HTML_INTERNAL_SERVER_ERROR.replace(\"<pre>{error_message}</pre>\", \"\")",
"_____no_output_____"
],
[
"HTML(BETTER_HTML_INTERNAL_SERVER_ERROR)",
"_____no_output_____"
]
],
[
[
"We have the `internal_server_error()` message return `HTTPStatus.OK` to make it harder for machines to find out something went wrong:",
"_____no_output_____"
]
],
[
[
"class BetterHTTPRequestHandler(SimpleHTTPRequestHandler):\n def internal_server_error(self):\n # Note: No INTERNAL_SERVER_ERROR status\n self.send_response(HTTPStatus.OK, \"Internal Error\")\n\n self.send_header(\"Content-type\", \"text/html\")\n self.end_headers()\n\n exc = traceback.format_exc()\n self.log_message(\"%s\", exc.strip())\n\n # No traceback or other information\n message = BETTER_HTML_INTERNAL_SERVER_ERROR\n self.wfile.write(message.encode(\"utf8\"))",
"_____no_output_____"
]
],
[
[
"#### Part 2: Sanitized HTML\n\nSet up the server such that it is not vulnerable against HTML and JavaScript injection attacks, notably by using methods such as `html.escape()` to escape special characters when showing them.",
"_____no_output_____"
]
],
[
[
"import html",
"_____no_output_____"
]
],
[
[
"**Solution.** We pass all values read through `html.escape()` before showing them on the screen; this will properly encode `<`, `&`, and `>` characters.",
"_____no_output_____"
]
],
[
[
"class BetterHTTPRequestHandler(BetterHTTPRequestHandler):\n def send_order_received(self, values):\n sanitized_values = {}\n for field in values:\n sanitized_values[field] = html.escape(values[field])\n sanitized_values[\"item_name\"] = html.escape(\n FUZZINGBOOK_SWAG[values[\"item\"]])\n\n confirmation = HTML_ORDER_RECEIVED.format(\n **sanitized_values).encode(\"utf8\")\n\n self.send_response(HTTPStatus.OK, \"Order received\")\n self.send_header(\"Content-type\", \"text/html\")\n self.end_headers()\n self.wfile.write(confirmation)",
"_____no_output_____"
]
],
[
[
"#### Part 3: Sanitized SQL\n\nSet up the server such that it is not vulnerable against SQL injection attacks, notably by using _SQL parameter substitution._",
"_____no_output_____"
],
[
"**Solution.** We use SQL parameter substitution to avoid interpretation of inputs as SQL commands. Also, we use `execute()` rather than `executescript()` to avoid processing of multiple commands.",
"_____no_output_____"
]
],
[
[
"class BetterHTTPRequestHandler(BetterHTTPRequestHandler):\n def store_order(self, values):\n db = sqlite3.connect(ORDERS_DB)\n db.execute(\"INSERT INTO orders VALUES (?, ?, ?, ?, ?)\",\n (values['item'], values['name'], values['email'], values['city'], values['zip']))\n db.commit()",
"_____no_output_____"
]
],
[
[
"One could also argue not to save \"dangerous\" characters in the first place. But then, there might always be names or addresses with special characters which all need to be handled.",
"_____no_output_____"
],
[
"#### Part 4: A Robust Server\n\nSet up the server such that it does not crash with invalid or missing fields.",
"_____no_output_____"
],
[
"**Solution.** We set up a simple check at the beginning of `handle_order()` that checks whether all required fields are present. If not, we return to the order form.",
"_____no_output_____"
]
],
[
[
"class BetterHTTPRequestHandler(BetterHTTPRequestHandler):\n REQUIRED_FIELDS = ['item', 'name', 'email', 'city', 'zip']\n\n def handle_order(self):\n values = self.get_field_values()\n for required_field in self.REQUIRED_FIELDS:\n if required_field not in values:\n self.send_order_form()\n return\n\n self.store_order(values)\n self.send_order_received(values)",
"_____no_output_____"
]
],
[
[
"This could easily be extended to check for valid (at least non-empty) values. Also, the order form should be pre-filled with the originally submitted values, and come with a helpful error message.",
"_____no_output_____"
],
[
"#### Part 5: Test it!\n\nTest your improved server whether your measures have been successful.",
"_____no_output_____"
],
[
"**Solution.** Here we go:",
"_____no_output_____"
]
],
[
[
"httpd_process, httpd_url = start_httpd(BetterHTTPRequestHandler)",
"_____no_output_____"
],
[
"print_url(httpd_url)",
"_____no_output_____"
],
[
"print_httpd_messages()",
"_____no_output_____"
]
],
[
[
"We test standard behavior:",
"_____no_output_____"
]
],
[
[
"standard_order = \"/order?item=tshirt&name=Jane+Doe&email=doe%40example.com&city=Seattle&zip=98104\"\ncontents = webbrowser(httpd_url + standard_order)\nHTML(contents)",
"_____no_output_____"
],
[
"assert contents.find(\"Thank you\") > 0",
"_____no_output_____"
]
],
[
[
"We test for incomplete URLs:",
"_____no_output_____"
]
],
[
[
"bad_order = \"/order?item=\"\ncontents = webbrowser(httpd_url + bad_order)\nHTML(contents)",
"_____no_output_____"
],
[
"assert contents.find(\"Order Form\") > 0",
"_____no_output_____"
]
],
[
[
"We test for HTML (and JavaScript) injection:",
"_____no_output_____"
]
],
[
[
"injection_order = \"/order?item=tshirt&name=Jane+Doe\" + cgi_encode(\"<script></script>\") + \\\n \"&email=doe%40example.com&city=Seattle&zip=98104\"\ncontents = webbrowser(httpd_url + injection_order)\nHTML(contents)",
"_____no_output_____"
],
[
"assert contents.find(\"Thank you\") > 0\nassert contents.find(\"<script>\") < 0\nassert contents.find(\"<script>\") > 0",
"_____no_output_____"
]
],
[
[
"We test for SQL injection:",
"_____no_output_____"
]
],
[
[
"sql_order = \"/order?item=tshirt&name=\" + \\\n cgi_encode(\"Robert', 'x', 'x', 'x'); DELETE FROM orders; --\") + \\\n \"&email=doe%40example.com&city=Seattle&zip=98104\"\ncontents = webbrowser(httpd_url + sql_order)\nHTML(contents)",
"_____no_output_____"
]
],
[
[
"(Okay, so obviously we can now handle the weirdest of names; still, Robert should consider changing his name...)",
"_____no_output_____"
]
],
[
[
"assert contents.find(\"DELETE FROM\") > 0\nassert not orders_db_is_empty()",
"_____no_output_____"
]
],
[
[
"That's it – we're done!",
"_____no_output_____"
]
],
[
[
"httpd_process.terminate()",
"_____no_output_____"
],
[
"if os.path.exists(ORDERS_DB):\n os.remove(ORDERS_DB)",
"_____no_output_____"
]
],
[
[
"### Exercise 2: Protect the Server\n\nAssume that it is not possible for you to alter the server code. Create a _filter_ that is run on all URLs before they are passed to the server.",
"_____no_output_____"
],
[
"#### Part 1: A Blacklisting Filter\n\nSet up a filter function `blacklist(url)` that returns `False` for URLs that should not reach the server. Check the URL for whether it contains HTML, JavaScript, or SQL fragments.",
"_____no_output_____"
],
[
"#### Part 2: A Whitelisting Filter\n\nSet up a filter function `whitelist(url)` that returns `True` for URLs that are allowed to reach the server. Check the URL for whether it conforms to expectations; use a [parser](Parser.ipynb) and a dedicated grammar for this purpose.",
"_____no_output_____"
],
[
"**Solution.** Left to the reader.",
"_____no_output_____"
],
[
"### Exercise 3: Input Patterns\n\nTo fill out forms, fuzzers could be much smarter in how they generate input values. Starting with HTML 5, input fields can have a `pattern` attribute defining a _regular expression_ that an input value has to satisfy. A 5-digit ZIP code, for instance, could be defined by the pattern\n\n```html\n<input type=\"text\" pattern=\"[0-9][0-9][0-9][0-9][0-9]\">\n```\n\nExtract such patterns from the HTML page and convert them into equivalent grammar production rules, ensuring that only inputs satisfying the patterns are produced.",
"_____no_output_____"
],
[
"**Solution.** Left to the reader at this point.",
"_____no_output_____"
],
[
"### Exercise 4: Coverage-Driven Web Fuzzing\n\nCombine the above fuzzers with [coverage-driven](GrammarCoverageFuzzer.ipynb) and [search-based](SearchBasedFuzzer.ipynb) approaches to maximize feature and code coverage.",
"_____no_output_____"
],
[
"**Solution.** Left to the reader at this point.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
ecc2823b41c7386b81b030a4392d87dc5560fdf8 | 60,802 | ipynb | Jupyter Notebook | old_projects/quchem_ibm/IBM_workflow.ipynb | AlexisRalli/VQE-code | 4112d2bba4c327360e95dfd7cb6120b2ce67bf29 | [
"MIT"
] | 1 | 2021-04-01T14:01:46.000Z | 2021-04-01T14:01:46.000Z | old_projects/quchem_ibm/IBM_workflow.ipynb | AlexisRalli/VQE-code | 4112d2bba4c327360e95dfd7cb6120b2ce67bf29 | [
"MIT"
] | 5 | 2019-11-13T16:23:54.000Z | 2021-04-07T11:03:06.000Z | old_projects/quchem_ibm/IBM_workflow.ipynb | AlexisRalli/VQE-code | 4112d2bba4c327360e95dfd7cb6120b2ce67bf29 | [
"MIT"
] | null | null | null | 32.883721 | 231 | 0.494161 | [
[
[
"import numpy as np\n\nfrom qiskit.compiler import transpile, assemble\nfrom qiskit import Aer\nfrom qiskit.chemistry.drivers import PySCFDriver, UnitsType, HFMethodType\nfrom qiskit.chemistry import FermionicOperator\nfrom qiskit.aqua.algorithms import NumPyMinimumEigensolver\nfrom qiskit import QuantumCircuit, ClassicalRegister, QuantumRegister, execute\n\n\nfrom qiskit.chemistry.components.initial_states import HartreeFock",
"_____no_output_____"
]
],
[
[
"# Define Molecule",
"_____no_output_____"
]
],
[
[
"# PySCF calc\ndriver = PySCFDriver(\n atom='H .0 .0 .0; H .0 .0 0.74',\n# atom='Li .0 .0 .0; H .0 .0 1.44',\n unit=UnitsType.ANGSTROM,\n charge=0,\n spin=0,\n basis='sto3g',\n hf_method= HFMethodType.RHF,\n conv_tol=1e-9,\n max_cycle= 50)\nmolecule = driver.run()",
"_____no_output_____"
],
[
"# from qiskit.chemistry.core import Hamiltonian, TransformationType, QubitMappingType\n# #https://qiskit.org/documentation/_modules/qiskit/chemistry/core/hamiltonian.html\n\n\n# Chem_Ham = Hamiltonian(TransformationType.FULL,#TransformationType\n# QubitMappingType.BRAVYI_KITAEV,#QubitMappingType QubitMappingType.PARITY, QubitMappingType.JORDAN_WIGNER, QubitMappingType.BRAVYI_KITAEV\n# True, #two_qubit_reduction\n# False, #freeze_core\n# None, #orbital_reduction\n# 'auto') # z2symmetry_reduction\n\n# Chem_Ham.run(molecule)\n\n# # log_lines, results = Chem_Ham.process_algorithm_result()",
"_____no_output_____"
],
[
"h1 = molecule.one_body_integrals\nh2 = molecule.two_body_integrals\n\nnuclear_repulsion_energy = molecule.nuclear_repulsion_energy\n\nnum_particles = molecule.num_alpha + molecule.num_beta\nnum_spin_orbitals = molecule.num_orbitals * 2\nprint(\"HF energy: {}\".format(molecule.hf_energy - molecule.nuclear_repulsion_energy))\nprint(\"# of electrons: {}\".format(num_particles))\nprint(\"# of spin orbitals: {}\".format(num_spin_orbitals))",
"HF energy: -1.8318636464775067\n# of electrons: 2\n# of spin orbitals: 4\n"
]
],
[
[
"# Get Qubit Hamiltonian",
"_____no_output_____"
]
],
[
[
"ferOp = FermionicOperator(h1=h1, h2=h2)",
"_____no_output_____"
],
[
"# map_type = 'bravyi_kitaev'\nmap_type='jordan_wigner'\n# qubit_mapping='parity'\n\nqubitOp = ferOp.mapping(map_type=map_type, threshold=0.00000001)\n\nprint(len(qubitOp.to_dict()['paulis']))\nprint(qubitOp.num_qubits)\n\nexact_eigensolver = NumPyMinimumEigensolver(qubitOp)\nret = exact_eigensolver.run()\nprint('The total ground state energy is: {:.12f}'.format(ret.eigenvalue.real + nuclear_repulsion_energy))",
"15\n4\nThe total ground state energy is: -1.137283834489\n"
],
[
"# print(qubitOp.print_details())",
"_____no_output_____"
],
[
"from qiskit.quantum_info import Operator\nfrom scipy.sparse.linalg import eigs\n\nH_mat_sparse=qubitOp.to_opflow().to_spmatrix()\n\n\neig_values, eig_vectors = eigs(H_mat_sparse)\nFCI_Energy = min(eig_values)\nindex = np.where(eig_values==FCI_Energy)[0][0]\nground_state = eig_vectors[:, index]\n\n# H_mat = Operator(qubitOp.to_opflow().to_matrix())\n# # print(H_mat._data)\n\n# from scipy.linalg import eig\n# from openfermion import get_sparse_operator\n\n# eig_values, eig_vectors = eig(H_mat._data)\n# FCI_Energy = min(eig_values)\n# index = np.where(eig_values==FCI_Energy)[0][0]\nground_state = eig_vectors[:, index]\n\nprint('fci ground E =', FCI_Energy+ nuclear_repulsion_energy)\nprint('ground state = ', ground_state)",
"fci ground E = (-1.1372838344885001+3.3140182052923533e-17j)\nground state = [-2.18581528e-16-2.30138819e-16j -1.54890834e-16-6.83169323e-17j\n 5.97642671e-17+8.30731978e-17j -1.24274699e-16-1.03154909e-16j\n 2.73782248e-16-1.53785432e-16j 9.41870097e-01-3.16566888e-01j\n -4.32394593e-17+3.13075547e-17j -1.91799173e-16-7.32994847e-17j\n 2.01521344e-18+1.34946376e-16j 4.46065752e-17-2.29636609e-17j\n -1.06679483e-01+3.58554666e-02j -8.41178512e-17-3.86737554e-17j\n -8.60671455e-17+1.81991656e-16j 9.11396526e-17+1.08491034e-16j\n -6.35562357e-18+2.70764477e-17j 3.45758668e-16+5.67083911e-17j]\n"
]
],
[
[
"# TAPERING!",
"_____no_output_____"
]
],
[
[
"from qiskit.aqua.operators import Z2Symmetries\nprint(Z2Symmetries.find_Z2_symmetries(qubitOp))\n\n# Chemistry specific method: It can be used to taper two qubits in\n# --> parity\n# --> binary-tree == Bravyi-Kitaev (https://qiskit.org/documentation/apidoc/qiskit_chemistry.html)\n# mapped Fermionic Hamiltonians \n\n# NOTE when the spin orbitals are ordered in two spin sectors, (block spin order) \n# according to the number of particles in the system\n\nif (map_type == 'bravyi_kitaev') or (map_type == 'parity'):\n qubitOp = Z2Symmetries.two_qubit_reduction(qubitOp, num_particles)",
"Z2 symmetries:\nSymmetries:\nZIIZ\nZIZI\nZZII\nSingle-Qubit Pauli X:\nIIIX\nIIXI\nIXII\nCliffords:\nZIIZ\t(0.7071067811865475+0j)\nIIIX\t(0.7071067811865475+0j)\n\nZIZI\t(0.7071067811865475+0j)\nIIXI\t(0.7071067811865475+0j)\n\nZZII\t(0.7071067811865475+0j)\nIXII\t(0.7071067811865475+0j)\n\nQubit index:\n[0, 1, 2]\nTapering values:\n - Possible values: [1, 1, 1], [1, 1, -1], [1, -1, 1], [1, -1, -1], [-1, 1, 1], [-1, 1, -1], [-1, -1, 1], [-1, -1, -1]\n"
],
[
"print(len(qubitOp.to_dict()['paulis']))\nprint(qubitOp.num_qubits)\nprint(qubitOp.print_details())",
"15\n4\nIIII\t(-0.8121706072487107+0j)\nIIIZ\t(0.17141282644776898+0j)\nIIZI\t(-0.22343153690813541+0j)\nIZII\t(0.171412826447769+0j)\nZIII\t(-0.2234315369081354+0j)\nIIZZ\t(0.12062523483390412+0j)\nIZIZ\t(0.16868898170361207+0j)\nXXYY\t(0.04530261550379926+0j)\nYYYY\t(0.04530261550379926+0j)\nXXXX\t(0.04530261550379926+0j)\nYYXX\t(0.04530261550379926+0j)\nZIIZ\t(0.16592785033770338+0j)\nIZZI\t(0.16592785033770338+0j)\nZIZI\t(0.17441287612261575+0j)\nZZII\t(0.12062523483390412+0j)\n\n"
]
],
[
[
"#### re-check fci if two qubit reduction performed",
"_____no_output_____"
]
],
[
[
"if (map_type == 'bravyi_kitaev') or (map_type == 'parity'):\n H_mat_sparse=qubitOp.to_opflow().to_spmatrix()\n\n eig_values, eig_vectors = eigs(H_mat_sparse)\n FCI_Energy = min(eig_values)\n index = np.where(eig_values==FCI_Energy)[0][0]\n ground_state = eig_vectors[:, index]\n\n\n print('fci ground E =', FCI_Energy+ nuclear_repulsion_energy)\n print('ground state = ', ground_state)\n \n \n # Using exact eigensolver to get the smallest eigenvalue\n exact_eigensolver_new = NumPyMinimumEigensolver(qubitOp)\n ret_new = exact_eigensolver_new.run()\n print('The computed energy is: {:.12f}'.format(ret_new.eigenvalue.real))\n print('The total ground state energy is: {:.12f}'.format(ret_new.eigenvalue.real + nuclear_repulsion_energy))",
"_____no_output_____"
]
],
[
[
"### Get Hartree-Fock initial state",
"_____no_output_____"
]
],
[
[
"num_particles = molecule.num_alpha + molecule.num_beta\n# Args:\n# num_orbitals: number of spin orbitals, has a min. value of 1.\n# num_particles: number of particles, if it is a list, the first number\n# is alpha and the second number if beta.\n# qubit_mapping: mapping type for qubit operator\n# two_qubit_reduction: flag indicating whether or not two qubit is reduced\n# sq_list: position of the single-qubit operators that\n# anticommute with the cliffords\nHF_obj = HartreeFock(qubitOp.num_qubits, #molecule.num_orbitals,\n num_particles,\n qubit_mapping=map_type,\n two_qubit_reduction=False) # already done!\n\nq_reg = QuantumRegister(qubitOp.num_qubits)\n\nprint('HF state =', np.array(HF_obj.bitstr, dtype=int))\nHF_circuit = HF_obj.construct_circuit(mode='circuit', register=q_reg)\nHF_circuit.draw()",
"HF state = [0 1 0 1]\n"
],
[
"qubitOp.num_qubits",
"_____no_output_____"
],
[
"from qiskit.chemistry.components.variational_forms.uccsd import UCCSD\nnum_particles = molecule.num_alpha + molecule.num_beta\n\nUCCSD_ansatz= UCCSD(\n qubitOp.num_qubits, # number orbitals int,\n num_particles,\n reps=1, #number of repetitions of basic module\n active_occupied=None,\n active_unoccupied=None,\n initial_state=None,\n qubit_mapping=map_type,\n two_qubit_reduction=True,\n num_time_slices=1,\n shallow_circuit_concat=True,\n z2_symmetries=None,\n method_singles='both',\n method_doubles='ucc',\n excitation_type='sd',\n same_spin_doubles=True,\n skip_commute_test=False)",
"_____no_output_____"
],
[
"UCCSD_ansatz.num_parameters",
"_____no_output_____"
],
[
"singles, doubles = UCCSD_ansatz.compute_excitation_lists(\n num_particles,\n qubitOp.num_qubits,\n active_occ_list=None,\n active_unocc_list=None, \n same_spin_doubles=True,\n method_singles='both', \n method_doubles='ucc',\n excitation_type='sd')\nprint(singles)\nprint(doubles)",
"[[0, 1], [2, 3]]\n[[0, 1, 2, 3]]\n"
],
[
"test = UCCSD_ansatz.construct_circuit([np.pi, np.pi/2, np.pi/3])\ntest.decompose().draw()",
"_____no_output_____"
],
[
"from openfermion.ops import QubitOperator\n\nQubitHamiltonian = QubitOperator()\nfor P_term_dict in qubitOp.to_dict()['paulis']:\n \n # NOTE CHANGE ORDER for QubitOperator!\n Pauli = ' '.join(['{}{}'.format(P_str, index) for index, P_str in enumerate(P_term_dict['label'][::-1]) if P_str != 'I'])\n QubitHamiltonian+= QubitOperator(Pauli, P_term_dict['coeff']['real'])\n\nQubitHamiltonian",
"_____no_output_____"
]
],
[
[
"## check FCI",
"_____no_output_____"
]
],
[
[
"from scipy.linalg import eig\nfrom openfermion import get_sparse_operator\n\nH_mat=get_sparse_operator(QubitHamiltonian, n_qubits=qubitOp.num_qubits).todense()\neig_values, eig_vectors = eig(H_mat)\nFCI_Energy = min(eig_values)\nindex = np.where(eig_values==FCI_Energy)[0][0]\nground_state = eig_vectors[:, index]\n\nprint('fci ground E =', FCI_Energy+ nuclear_repulsion_energy)\nprint('ground state = ', ground_state)",
"_____no_output_____"
],
[
"## checking via lin alg\nE_elec=ground_state.reshape(ground_state.shape[0],1).conj().T.dot(H_mat.dot(ground_state.reshape(ground_state.shape[0],1)))\nE_elec+nuclear_repulsion_energy",
"_____no_output_____"
],
[
"# from scipy.sparse.linalg import eigs\n# from openfermion import get_sparse_operator\n\n# eig_values, eig_vectors = eigs(get_sparse_operator(QubitHamiltonian))#, n_qubits=qubitOp.num_qubits))\n# FCI_Energy = min(eig_values)\n# index = np.where(eig_values==FCI_Energy)[0][0]\n# ground_state = eig_vectors[:, index]\n# print('fci ground E =', FCI_Energy+ nuclear_repulsion_energy)\n# print('ground state = ', ground_state)",
"_____no_output_____"
]
],
[
[
"# Get anti-commuting sets",
"_____no_output_____"
]
],
[
[
"from quchem.Graph import *\n\nHamiltonian_graph_obj = Openfermion_Hamiltonian_Graph(QubitHamiltonian)\n\ncommutativity_flag = 'AC' ## <- defines relationship between sets!!!\nplot_graph = False\nGraph_colouring_strategy='largest_first'\n\nanti_commuting_sets = Hamiltonian_graph_obj.Get_Clique_Cover_as_QubitOp(commutativity_flag, Graph_colouring_strategy=Graph_colouring_strategy, plot_graph=plot_graph)\n\n\n",
"_____no_output_____"
],
[
"from qiskit.quantum_info import Pauli\n# PP = Pauli(z=[True, True, True, False, False, False, False, False, False, False], x=[False, True, True, False, False, False, False, False, False, False])\n# print(PP)",
"_____no_output_____"
],
[
"from qiskit.aqua.operators.primitive_ops import PauliOp\n# PPP = PauliOp(PP, coeff=0.5)\n# print(PPP)",
"_____no_output_____"
],
[
"# ## convert openfermion.QubitOperator to qiskit PauliOp\n# NN=5\n# Q_op = QubitOperator('X0 Y1 Z4')\n# P_strs, coeff = zip(list(*Q_op.terms.items()))\n\n# if P_strs[0]:\n# q_Nums, p_strs = zip(*P_strs[0])\n\n# # P_list = ['{}{}'.format(p_strs[q_Nums.index(qNo)], qNo) if qNo in q_Nums else '{}{}'.format('I', qNo) for qNo in range(N_qubits) ]\n# P_list = ['{}'.format(p_strs[q_Nums.index(qNo)]) if qNo in q_Nums else '{}'.format('I') for qNo in range(NN) ]\n# print(P_list)\n\n# z = np.zeros(len(P_list), dtype=np.bool)\n# x = np.zeros(len(P_list), dtype=np.bool)\n# for i, char in enumerate(P_list):\n# if char == 'X':\n# x[i] = True\n# elif char == 'Z':\n# z[i] = True\n# elif char == 'Y':\n# z[i] = True\n# x[i] = True\n# elif char != 'I':\n# raise QiskitError(\"Pauli string must be only consisted of 'I', 'X', \"\n# \"'Y' or 'Z' but you have {}.\".format(char))\n# Pauli_IBM = Pauli(z=z,x=x)\n# Pauli_Op_IBM = PauliOp(Pauli_IBM, coeff=coeff)\n# print(str(Pauli_Op_IBM.primitive))",
"_____no_output_____"
],
[
"## convert openfermion.QubitOperator to qiskit PauliOp\nN_qubits = qubitOp.num_qubits\n\nIBM_anti_commuting_sets={}\nfor key in anti_commuting_sets:\n OP_list=[]\n for Q_op in anti_commuting_sets[key]:\n P_strs, coeff = zip(list(*Q_op.terms.items()))\n \n if P_strs[0]:\n q_Nums, p_strs = zip(*P_strs[0])\n\n # P_list = ['{}{}'.format(p_strs[q_Nums.index(qNo)], qNo) if qNo in q_Nums else '{}{}'.format('I', qNo) for qNo in range(N_qubits) ]\n P_list = ['{}'.format(p_strs[q_Nums.index(qNo)]) if qNo in q_Nums else '{}'.format('I') for qNo in range(N_qubits) ]\n\n z = np.zeros(len(P_list), dtype=np.bool)\n x = np.zeros(len(P_list), dtype=np.bool)\n for i, char in enumerate(P_list):\n# if char == 'X':\n# x[-i - 1] = True\n# elif char == 'Z':\n# z[-i - 1] = True\n# elif char == 'Y':\n# z[-i - 1] = True\n# x[-i - 1] = True\n if char == 'X':\n x[i] = True\n elif char == 'Z':\n z[i] = True\n elif char == 'Y':\n z[i] = True\n x[i] = True\n elif char != 'I':\n raise QiskitError(\"Pauli string must be only consisted of 'I', 'X', \"\n \"'Y' or 'Z' but you have {}.\".format(char))\n Pauli_IBM = Pauli(z=z,x=x)\n Pauli_Op_IBM = PauliOp(Pauli_IBM, coeff=coeff)\n# print(Pauli_Op_IBM)\n OP_list.append(Pauli_Op_IBM)\n else:\n z = np.zeros(N_qubits, dtype=np.bool)\n x = np.zeros(N_qubits, dtype=np.bool)\n Pauli_IBM = Pauli(z=z,x=x)\n Pauli_Op_IBM = PauliOp(Pauli_IBM, coeff=coeff)\n# print(Pauli_Op_IBM)\n OP_list.append(Pauli_Op_IBM)\n \n IBM_anti_commuting_sets[key]=OP_list",
"_____no_output_____"
],
[
"print(anti_commuting_sets[1][0])\nstr(IBM_anti_commuting_sets[1][0].primitive)",
"_____no_output_____"
],
[
"print(anti_commuting_sets[7][3])\nstr(IBM_anti_commuting_sets[7][3].primitive)",
"_____no_output_____"
],
[
"#### compare dictionaries ",
"_____no_output_____"
],
[
"# anti_commuting_sets",
"_____no_output_____"
],
[
"# {key:[(str(op.primitive), op.coeff) for op in IBM_anti_commuting_sets[key]] for key in IBM_anti_commuting_sets}",
"_____no_output_____"
],
[
"#### compare dictionaries",
"_____no_output_____"
],
[
"set_key=3\nindex=0\nprint(IBM_anti_commuting_sets[set_key][index])\nprint(anti_commuting_sets[set_key][index])\n\nxx=IBM_anti_commuting_sets[set_key][index].to_circuit()\nprint(xx)",
"_____no_output_____"
],
[
"\nN_qubits = qubitOp.num_qubits\n# arb state initialization\n# https://github.com/Qiskit/qiskit-tutorials/blob/master/tutorials/circuits/3_summary_of_quantum_operations.ipynb\n\nq = QuantumRegister(N_qubits)\n\nqc = QuantumCircuit(q)\n\nqc.initialize(ground_state.tolist(), [q[i] for i in range(N_qubits)])\nqc.draw()\n",
"_____no_output_____"
],
[
"backend = Aer.get_backend('statevector_simulator')\njob = execute(qc, backend)\nqc_state = job.result().get_statevector(qc)\nqc_state",
"_____no_output_____"
],
[
"np.allclose(ground_state, qc_state)",
"_____no_output_____"
],
[
"qc.measure_all()\nbackend=Aer.get_backend('qasm_simulator')\njob = execute(qc, backend, shots=2000)\nresult = job.result()\nout = result.get_counts(qc)\nout",
"_____no_output_____"
],
[
"def change_basis_and_measure_IBM(PauliWord, q_register, q_circuit):\n\n # change basis\n \n # note change of order in enumerate\n for qNo, Pstr in enumerate(str(PauliWord.primitive)[::-1]):\n if Pstr == 'X':\n q_circuit.h(q_register[qNo])\n # q_circuit.measure(q_register[qNo], c_register[index])\n\n elif Pstr == 'Y':\n q_circuit.rx((+np.pi / 2), q_register[qNo])\n # q_circuit.measure(q_register[qNo], c_register[index])\n\n elif (Pstr == 'Z') or (Pstr == 'I'):\n continue\n # q_circuit.measure(q_register[qNo], c_register[index])\n\n else:\n raise ValueError('Not a PauliWord')\n\n q_circuit.measure_all()\n\n return q_circuit",
"_____no_output_____"
],
[
"q = QuantumRegister(N_qubits)\nqc = QuantumCircuit(q)\nqc.initialize(ground_state.tolist(), [q[i] for i in range(N_qubits)])\n\nz = np.array([1,0,0,0], dtype=np.bool)\nx = np.array([0,0,0,0], dtype=np.bool)\nPauli_test = Pauli(z=z,x=x)\nPaulitest_Op = PauliOp(Pauli_test, coeff=coeff)\nprint(str(Paulitest_Op.primitive))\n \ncir= change_basis_and_measure_IBM(Paulitest_Op, q, qc)\nprint(cir.draw())\n\nbackend=Aer.get_backend('qasm_simulator')\njob = execute(cir, backend, shots=2000)\nresult = job.result()\nout = result.get_counts(cir)\nprint(out)\n\ncalc_exp_pauliword(out, str(Paulitest_Op.primitive))",
"_____no_output_____"
],
[
"from qiskit.aqua.operators.primitive_ops import PauliOp\n# PPP = PauliOp(PP, coeff=0.5)\n# print(PPP)\nfrom qiskit.quantum_info import Pauli\nz=np.array([1,0,0], dtype=bool)\nx=np.array([1,1,0], dtype=bool)\nP = Pauli(z=z, x=x)\nPW = PauliOp(P, coeff=0.5)\nprint(str(PW.primitive))\n\nq = QuantumRegister(len(PW.primitive))\nqc = QuantumCircuit(q)\n\ncir= change_basis_and_measure_IBM(PW, q, qc)\ncir.draw()",
"_____no_output_____"
],
[
"N_qubits = qubitOp.num_qubits\n# arb state initialization\n# https://github.com/Qiskit/qiskit-tutorials/blob/master/tutorials/circuits/3_summary_of_quantum_operations.ipynb\n\n\nqc_list=[]\nPword_list=[]\n\narb_input_circuit=None\nfor set_key in IBM_anti_commuting_sets:\n for op in IBM_anti_commuting_sets[set_key]:\n \n IBM_q_circuit = op.to_circuit()\n \n if arb_input_circuit is None:\n q_reg = QuantumRegister(N_qubits)\n arb_input_circuit = QuantumCircuit(q_reg)\n\n arb_input_circuit.initialize(ground_state.tolist(), [q_reg[i] for i in range(N_qubits)])\n\n \n full_ibm_circuit=change_basis_and_measure_IBM(op, q_reg, arb_input_circuit.copy())\n qc_list.append(full_ibm_circuit)\n Pword_list.append((str(op.primitive), op.coeff[0]))\n ",
"_____no_output_____"
],
[
"qc_list[-1].draw()",
"_____no_output_____"
],
[
"circuit = qc_list[-1].copy()\ncircuit.remove_final_measurements()\nbackend = Aer.get_backend('statevector_simulator')\njob = execute(circuit, backend)\nqc_state = job.result().get_statevector(circuit)\nqc_state",
"_____no_output_____"
],
[
"print(qc_list[-1].draw())\n\nbackend=Aer.get_backend('qasm_simulator')\njob = execute(qc_list[-1], backend, shots=2000)\nresult = job.result()\nout = result.get_counts(qc_list[-1])\nout",
"_____no_output_____"
],
[
"circ = QuantumCircuit(3)\ncirc.x(0)\n\ncirc.measure_all()\n\nprint(circ.draw())\n\nbackend=Aer.get_backend('qasm_simulator')\njob = execute(circ, backend, shots=2000)\nresult = job.result()\nout = result.get_counts(circ)\nout",
"_____no_output_____"
],
[
"\nn_shots=2000\nbackend_simulator=Aer.get_backend('qasm_simulator')\n\ntranspiled_circs_sim = transpile(qc_list, backend=backend_simulator, optimization_level=0)\nqobjs_sim = assemble(transpiled_circs_sim, backend=backend_simulator, shots=n_shots)\n\nsim_job = backend_simulator.run(qobjs_sim)",
"_____no_output_____"
],
[
"raw_results = [sim_job.result().get_counts(transpiled_circs_sim[circ_index]) for circ_index in\n range(len(transpiled_circs_sim))]\n\nprint(Pword_list)\nraw_results",
"_____no_output_____"
],
[
"raw_res=[]\nbackend=Aer.get_backend('qasm_simulator')\nn_shots=2000\n\nfor circuit in transpiled_circs_sim:\n job = execute(circuit, backend, shots=n_shots)\n result = job.result()\n raw_res.append(result.get_counts(circuit))\n \nraw_res",
"_____no_output_____"
],
[
"print(qc_list[-1].draw())\n\nbackend=Aer.get_backend('qasm_simulator')\njob = execute(qc_list[-1], backend, shots=2000)\nresult = job.result()\nout = result.get_counts(qc_list[-1])\nout",
"_____no_output_____"
],
[
"def calc_exp_pauliword(count_dict, PauliWord_Str):\n # takes correct part of bitstring when all lines measured\n \n if np.alltrue(np.array(list(PauliWord_Str), dtype=str)=='I'):\n return 1\n else:\n Non_I_indices = np.where(np.array(list(PauliWord_Str), dtype=str) != 'I')\n n_zeros = 0\n n_ones = 0\n\n for bitstring in count_dict:\n # note reversed order!\n measure_term = np.take([int(bit) for bit in bitstring], Non_I_indices)[0]\n\n parity_m_term = sum(measure_term) % 2\n\n if parity_m_term == 0:\n n_zeros += count_dict[bitstring]\n elif parity_m_term == 1:\n n_ones += count_dict[bitstring]\n else:\n raise ValueError('state {} not allowed'.format(measure_term))\n\n expectation_value = (n_zeros - n_ones) / (n_zeros + n_ones)\n\n return expectation_value\n\ndef Calc_Energy(raw_results, PWord_list):\n E_list=[]\n for index, raw_result_dic in enumerate(raw_results):\n P_word=PWord_list[index][0]\n coeff=PWord_list[index][1]\n \n exp_val = calc_exp_pauliword(raw_result_dic, P_word)\n print(exp_val, coeff)\n E_list.append(exp_val*coeff)\n \n return sum(E_list)\n \n ",
"_____no_output_____"
],
[
"Pword_list",
"_____no_output_____"
],
[
"raw_results",
"_____no_output_____"
],
[
"raw_res",
"_____no_output_____"
],
[
"Calc_Energy(raw_results, Pword_list)+ nuclear_repulsion_energy",
"_____no_output_____"
],
[
"Calc_Energy(raw_res, Pword_list)+ nuclear_repulsion_energy",
"_____no_output_____"
],
[
"FCI_Energy + nuclear_repulsion_energy",
"_____no_output_____"
],
[
"import itertools\nlist_op=qubitOp.to_opflow().oplist\n\nindices = range(len(list_op))\n[(i, j) for i, j in itertools.combinations(indices, 2) if not list_op[i].commutes(list_op[j])]",
"_____no_output_____"
],
[
"import networkx as nx\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom tqdm import tqdm\n\n\ndef IBM_Build_Graph_Nodes(List_of_nodes, Graph, plot_graph=False):\n \"\"\"\n\n Function builds nodes of graph with attributes\n\n \"\"\"\n labels={}\n node_list=[]\n for node in List_of_nodes:\n Graph.add_node(node)\n\n if plot_graph is True:\n node_list.append(node)\n\n PauliWord = str(node.primitive)\n labels[node] = PauliWord\n\n\n if plot_graph is True:\n plt.figure()\n\n pos = nx.circular_layout(Graph)\n\n nx.draw_networkx_nodes(Graph, pos,\n nodelist=node_list,\n node_color='r',\n node_size=500,\n alpha=0.8)\n\n nx.draw_networkx_labels(Graph, pos, labels) # , font_size=8)\n plt.show()\n return Graph\n",
"_____no_output_____"
],
[
"G=nx.Graph()\nIBM_Build_Graph_Nodes(list_op, G, plot_graph=True)",
"_____no_output_____"
],
[
"def Openfermion_Build_Graph_Edges_COMMUTING_QWC_AntiCommuting(Graph, List_of_nodes, anti_comm_QWC, plot_graph = False):\n \"\"\"\n\n Function builds graph edges for commuting / anticommuting / QWC PauliWords\n\n Args:\n PauliWord_string_nodes_list (list): list of PauliWords (str)\n Graph: networkX graph with nodes already defined\n anti_comm_QWC (str): flags to find either:\n qubit wise commuting (QWC) terms -> flag = 'QWC',\n commuting terms -> flag = 'C',\n anti-commuting terms -> flag = 'AC'\n plot_graph (optional, bool): whether to plot graph\n\n Returns:\n Graph: Graph with nodes connected if they commute / QWC / anti-commute\n\n \"\"\"\n node_list=[]\n labels={}\n\n for index, selected_PauliWord in enumerate(tqdm(List_of_nodes, ascii=True, desc='Building Graph Edges')):\n\n for j in range(index + 1, len(List_of_nodes)):\n comparison_PauliWord = List_of_nodes[j]\n\n if OpenFermion_Commutativity(selected_PauliWord, comparison_PauliWord, anti_comm_QWC) is True:\n Graph.add_edge(selected_PauliWord, comparison_PauliWord)\n else:\n continue\n\n if plot_graph is True:\n node_list.append(selected_PauliWord)\n PauliStrs, _ = selected_PauliWord\n PauliStr_list = [''.join(map(str, [element for element in tupl[::-1]])) for tupl in PauliStrs]\n PauliWord = ' '.join(PauliStr_list)\n labels[selected_PauliWord] = PauliWord\n\n if plot_graph is True:\n plt.figure()\n\n pos = nx.circular_layout(Graph)\n\n nx.draw_networkx_nodes(Graph, pos,\n nodelist=node_list,\n node_color='r',\n node_size=500,\n alpha=0.8)\n\n nx.draw_networkx_labels(Graph, pos, labels) # , font_size=8)\n nx.draw_networkx_edges(Graph, pos, width=1.0, alpha=0.5)\n plt.show()\n\n return Graph",
"_____no_output_____"
],
[
"i=3\nj=-5\n\nprint(str(list_op[i].primitive))\nop1 = list_op[i]\n\nprint(str(list_op[j].primitive))\nop2 = list_op[j]",
"_____no_output_____"
],
[
"def IBM_Commutativity(Op1, Op2, Comm_flag):\n\n \n if Comm_flag=='C':\n # https://qiskit.org/documentation/_modules/qiskit/aqua/operators/primitive_ops/pauli_op.html#PauliOp\n return Op1.commutes(Op2)\n else:\n\n \n if Comm_flag=='QWC':\n Z_op1=Op1.primitive.z\n X_op1=Op1.primitive.x \n\n Z_op2=Op2.primitive.z\n X_op2=Op2.primitive.x \n \n Z_terms = np.array(Z_op1, dtype=int) + np.array(Z_op2, dtype=int)\n X_terms = np.array(X_op1, dtype=int)+ np.array(X_op2, dtype=int)\n \n print(Z_terms)\n print(X_terms)\n \n if (sum(Z_terms)<=len(Z_op2)) and (sum(X_terms)<=len(X_op2)) and ((Z_terms<=1).all()) and ((X_terms<=1).all()):\n return True\n elif Op1==Op2:\n return True\n else:\n return False\n if Op1.commutes(Op2) is False:\n return True\n else:\n return False\n\n \ni=5\nj=6\nprint(str(list_op[i].primitive))\nop1 = list_op[i]\nprint(str(list_op[j].primitive))\nop2 = list_op[j]\n\nIBM_Commutativity(op1, op2, 'QWC')",
"_____no_output_____"
],
[
"\n\ndef Openfermion_Build_Graph_Nodes(List_of_nodes, Graph, plot_graph=False):\n \"\"\"\n\n Function builds nodes of graph with attributes\n\n Args:\n List_of_nodes (list): A list of Pauliwords, where each entry is a tuple of (PauliWord, constant)\n Graph ():\n node_attributes_dict\n plot_graph (optional, bool): whether to plot graph\n\n Returns:\n\n\n\n .. code-block:: python\n\n from quchem.Graph import *\n\n node_attributes_dict = {'Cofactor': {'I0 I1 I2 I3': (-0.09706626861762624+0j),\n 'Z0 I1 I2 I3': (0.17141282639402405+0j),\n 'I0 Z1 I2 I3': (0.171412826394024+0j),\n 'I0 I1 Z2 I3': (-0.2234315367466397+0j),\n 'I0 I1 I2 Z3': (-0.2234315367466397+0j),\n 'Z0 Z1 I2 I3': (0.1686889816869329+0j),\n 'Y0 X1 X2 Y3': (0.04530261550868928+0j),\n 'Y0 Y1 X2 X3': (-0.04530261550868928+0j),\n 'X0 X1 Y2 Y3': (-0.04530261550868928+0j),\n 'X0 Y1 Y2 X3': (0.04530261550868928+0j),\n 'Z0 I1 Z2 I3': (0.12062523481381837+0j),\n 'Z0 I1 I2 Z3': (0.16592785032250768+0j),\n 'I0 Z1 Z2 I3': (0.16592785032250768+0j),\n 'I0 Z1 I2 Z3': (0.12062523481381837+0j),\n 'I0 I1 Z2 Z3': (0.174412876106516+0j)\n }\n }\n\n DO SOMETHING\n >> blah\n\n \"\"\"\n labels={}\n node_list=[]\n for node in List_of_nodes:\n Graph.add_node(node)\n\n if plot_graph is True:\n node_list.append(node)\n\n PauliStrs, _ = node\n PauliStr_list = [''.join(map(str,[element for element in tupl[::-1]])) for tupl in PauliStrs]\n PauliWord= ' '.join(PauliStr_list)\n labels[node] = PauliWord\n\n\n if plot_graph is True:\n plt.figure()\n\n pos = nx.circular_layout(Graph)\n\n nx.draw_networkx_nodes(Graph, pos,\n nodelist=node_list,\n node_color='r',\n node_size=500,\n alpha=0.8)\n\n nx.draw_networkx_labels(Graph, pos, labels) # , font_size=8)\n plt.show()\n return Graph\n\ndef Openfermion_Build_Graph_Edges_COMMUTING_QWC_AntiCommuting(Graph, List_of_nodes, anti_comm_QWC, plot_graph = False):\n \"\"\"\n\n Function builds graph edges for commuting / anticommuting / QWC PauliWords\n\n Args:\n PauliWord_string_nodes_list (list): list of PauliWords (str)\n Graph: networkX graph with nodes already defined\n anti_comm_QWC (str): flags to find either:\n qubit wise commuting (QWC) terms -> flag = 'QWC',\n commuting terms -> flag = 'C',\n anti-commuting terms -> flag = 'AC'\n plot_graph (optional, bool): whether to plot graph\n\n Returns:\n Graph: Graph with nodes connected if they commute / QWC / anti-commute\n\n \"\"\"\n node_list=[]\n labels={}\n\n for index, selected_PauliWord in enumerate(tqdm(List_of_nodes, ascii=True, desc='Building Graph Edges')):\n\n for j in range(index + 1, len(List_of_nodes)):\n comparison_PauliWord = List_of_nodes[j]\n\n if OpenFermion_Commutativity(selected_PauliWord, comparison_PauliWord, anti_comm_QWC) is True:\n Graph.add_edge(selected_PauliWord, comparison_PauliWord)\n else:\n continue\n\n if plot_graph is True:\n node_list.append(selected_PauliWord)\n PauliStrs, _ = selected_PauliWord\n PauliStr_list = [''.join(map(str, [element for element in tupl[::-1]])) for tupl in PauliStrs]\n PauliWord = ' '.join(PauliStr_list)\n labels[selected_PauliWord] = PauliWord\n\n if plot_graph is True:\n plt.figure()\n\n pos = nx.circular_layout(Graph)\n\n nx.draw_networkx_nodes(Graph, pos,\n nodelist=node_list,\n node_color='r',\n node_size=500,\n alpha=0.8)\n\n nx.draw_networkx_labels(Graph, pos, labels) # , font_size=8)\n nx.draw_networkx_edges(Graph, pos, width=1.0, alpha=0.5)\n plt.show()\n\n return Graph\n\ndef Openfermion_Get_Complemenary_Graph(Graph, plot_graph=False):\n\n Complement_Graph = nx.complement(Graph)\n\n node_list=[]\n labels={}\n if plot_graph is True:\n plt.figure()\n for node in Complement_Graph.nodes:\n node_list.append(node)\n PauliStrs, _ = node\n PauliStr_list = [''.join(map(str, [element for element in tupl[::-1]])) for tupl in PauliStrs]\n PauliWord = ' '.join(PauliStr_list)\n labels[node] = PauliWord\n\n pos = nx.circular_layout(Complement_Graph)\n\n nx.draw_networkx_nodes(Complement_Graph, pos,\n nodelist=node_list,\n node_color='r',\n node_size=500,\n alpha=0.8)\n\n nx.draw_networkx_labels(Complement_Graph, pos, labels) # , font_size=8)\n nx.draw_networkx_edges(Complement_Graph, pos, width=1.0, alpha=0.5)\n plt.show()\n return Complement_Graph\n\ndef Openfermion_Get_clique_cover(Graph, strategy='largest_first', plot_graph=False):\n \"\"\"\n https: // en.wikipedia.org / wiki / Clique_cover\n\n Function gets clique cover of a graph. Does this via a graph colouring approach - therefore\n strategy is important here!\n\n Args:\n Graph (networkx.classes.graph.Graph): networkx graph\n strategy (str): graph colouring method to find clique cover. (note is a heuristic alg)\n plot_graph (optional, bool): whether to plot graph\n node_attributes_dict (dict): Dictionary with nodes as keys and attributes as values\n\n Returns:\n colour_key_for_nodes (dict): A dictionary containing colours (sets) as keys and item as list of nodes\n that are completely connected by edges\n\n \"\"\"\n comp_GRAPH = Openfermion_Get_Complemenary_Graph(Graph, plot_graph=False)\n\n greedy_colouring_output_dic = nx.greedy_color(comp_GRAPH, strategy=strategy, interchange=False)\n unique_colours = set(greedy_colouring_output_dic.values())\n\n colour_key_for_nodes = {}\n for colour in unique_colours:\n colour_key_for_nodes[colour] = [k for k in greedy_colouring_output_dic.keys()\n if greedy_colouring_output_dic[k] == colour]\n\n if plot_graph is True:\n import matplotlib.cm as cm\n colour_list = cm.rainbow(np.linspace(0, 1, len(colour_key_for_nodes)))\n pos = nx.circular_layout(Graph)\n\n for colour in colour_key_for_nodes:\n nx.draw_networkx_nodes(Graph, pos,\n nodelist=[node for node in colour_key_for_nodes[colour]],\n node_color=colour_list[colour].reshape([1,4]),\n node_size=500,\n alpha=0.8)\n\n\n # labels = {node: node for node in list(Graph.nodes)}\n seperator = ' '\n labels = {node: seperator.join([tup[1] + str(tup[0]) for tup in node[0]]) for node in list(Graph.nodes)}\n\n nx.draw_networkx_labels(Graph, pos, labels) # , font_size=8)\n\n nx.draw_networkx_edges(Graph, pos, width=1.0, alpha=0.5)\n plt.show()\n\n return colour_key_for_nodes\n\ndef Convert_Clique_Cover_to_QubitOp(clique_cover_dict):\n from openfermion.ops import QubitOperator\n\n qubit_op_list_clique={}\n for key in clique_cover_dict:\n qubit_op_list=[]\n for PauliStr_const in clique_cover_dict[key]:\n PauliStrs, const = PauliStr_const\n Op = QubitOperator(PauliStrs, const)\n qubit_op_list.append(Op)\n qubit_op_list_clique[key] = qubit_op_list\n\n return qubit_op_list_clique\n\ndef Convert_Clique_Cover_to_str(clique_cover_dict):\n from openfermion.ops import QubitOperator\n\n qubit_op_list_clique={}\n for key in clique_cover_dict:\n qubit_op_list=[]\n for PauliStr_const in clique_cover_dict[key]:\n\n PauliStrs, const = PauliStr_const\n PauliStr_list = [''.join(map(str, [element for element in tupl[::-1]])) for tupl in PauliStrs]\n PauliWord = ' '.join(PauliStr_list)\n\n qubit_op_list.append((PauliWord, const))\n qubit_op_list_clique[key] = qubit_op_list\n\n return qubit_op_list_clique\n\nclass Openfermion_Hamiltonian_Graph():\n\n def __init__(self, QubitHamiltonian):\n\n self.QubitHamiltonian = QubitHamiltonian\n self.Graph = nx.Graph()\n\n def _Get_hashable_Hamiltonian(self):\n # networkX requires hashable object... therefore concert QubitHamiltonian to hashable form\n\n self.QubitHamiltonianFrozen = tuple(frozenset((PauliStr, const) for op in self.QubitHamiltonian \\\n for PauliStr, const in op.terms.items()))\n\n def _Build_Graph_nodes(self, plot_graph=False):\n\n self.Graph = Openfermion_Build_Graph_Nodes(self.QubitHamiltonianFrozen, self.Graph, plot_graph=plot_graph)\n\n def _Build_Graph_edges(self, commutativity_flag, plot_graph=False):\n\n self.Graph = Openfermion_Build_Graph_Edges_COMMUTING_QWC_AntiCommuting(self.Graph, self.QubitHamiltonianFrozen,\n commutativity_flag, plot_graph = plot_graph)\n\n def _Colour_Graph(self, Graph_colouring_strategy='largest_first', plot_graph=False):\n\n output_sets = Openfermion_Get_clique_cover(self.Graph, strategy=Graph_colouring_strategy, plot_graph=plot_graph)\n\n return output_sets\n\n def Get_Clique_Cover_as_QubitOp(self, commutativity_flag, Graph_colouring_strategy='largest_first', plot_graph=False):\n self.Graph.clear()\n self._Get_hashable_Hamiltonian()\n self._Build_Graph_nodes(plot_graph=plot_graph)\n self._Build_Graph_edges(commutativity_flag, plot_graph=plot_graph)\n output_sets = self._Colour_Graph(Graph_colouring_strategy=Graph_colouring_strategy, plot_graph=plot_graph)\n qubitOperator_list = Convert_Clique_Cover_to_QubitOp(output_sets)\n return qubitOperator_list\n\n def Get_Clique_Cover_as_Pauli_strings(self, commutativity_flag, Graph_colouring_strategy='largest_first', plot_graph=False):\n self.Graph.clear()\n self._Get_hashable_Hamiltonian()\n self._Build_Graph_nodes(plot_graph=plot_graph)\n self._Build_Graph_edges(commutativity_flag, plot_graph=plot_graph)\n output_sets = self._Colour_Graph(Graph_colouring_strategy=Graph_colouring_strategy, plot_graph=plot_graph)\n qubitOperator_list_str = Convert_Clique_Cover_to_str(output_sets)\n return qubitOperator_list_str",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecc2873edb2896cfbbeb10b8d13b886219bb6954 | 475,849 | ipynb | Jupyter Notebook | notebooks/15-GM-report_plots.ipynb | georgeamccarthy/acoustic-data-science | 62a974a8f52ffffa93c4468cc974916997cabff0 | [
"MIT"
] | 1 | 2021-12-05T22:58:36.000Z | 2021-12-05T22:58:36.000Z | notebooks/15-GM-report_plots.ipynb | georgeamccarthy/acoustic-data-science | 62a974a8f52ffffa93c4468cc974916997cabff0 | [
"MIT"
] | null | null | null | notebooks/15-GM-report_plots.ipynb | georgeamccarthy/acoustic-data-science | 62a974a8f52ffffa93c4468cc974916997cabff0 | [
"MIT"
] | null | null | null | 357.243994 | 192,718 | 0.910768 | [
[
[
"import pandas as pd\nimport datetime\nimport numpy as np\nimport os\nfrom acoustic_data_science import config, helpers\nimport matplotlib.pyplot as plt\nimport logging\n",
"_____no_output_____"
],
[
"df = pd.read_csv(\n config.processed_data_path\n + \"/cambridge_bay_sea_ice_properties_from_ice_charts.csv\"\n)\n\nice_properties = [\n \"total_concentration\",\n \"stage_of_development\",\n \"mean_temperature\",\n]",
"_____no_output_____"
],
[
"df = pd.read_csv(\n config.processed_data_path\n + \"/cambridge_bay_sea_ice_properties_from_ice_charts.csv\"\n)",
"_____no_output_____"
],
[
"plt.figure(figsize=(16, 10))\nfor i, ice_property in enumerate(ice_properties):\n mask = df[ice_property].notnull()\n x = df[\"timestamp\"][mask]\n y = df[ice_property][mask]\n # Min-max normalization\n # https://stackoverflow.com/questions/26414913/normalize-columns-of-pandas-data-frame\n if ice_property == \"mean_temperature\":\n y_norm = (y - y.min()) / (y.max() - y.min()) * 10\n ice_property = (\n f\"normalized_mean_temperature ({y.min():.0f} -\"\n f\" {y.max():.0f})->(0 - 10)\"\n )\n else:\n y_norm = y\n plt.plot(x, y_norm,)\n plt.scatter(x, y_norm, label=ice_property)\n\nplt.xlabel(\"Date (YYYY-MM)\")\nplt.ylabel(\"Noramalized quantity (0-1)\")\nplt.legend(loc=\"lower left\")\nfigure_path = helpers.get_figure_path(\n \"multiple_ice_coverage_properties_as_one_plot\", \"ice_coverage\"\n)\nplt.savefig(figure_path)",
"2021-12-17 23:06:46,831 - matplotlib.category - INFO - Using categorical units to plot a list of strings that are all parsable as floats or dates. If these strings should be plotted as numbers, cast to the appropriate data type before plotting.\n2021-12-17 23:06:46,834 - matplotlib.category - INFO - Using categorical units to plot a list of strings that are all parsable as floats or dates. If these strings should be plotted as numbers, cast to the appropriate data type before plotting.\n2021-12-17 23:06:46,836 - matplotlib.category - INFO - Using categorical units to plot a list of strings that are all parsable as floats or dates. If these strings should be plotted as numbers, cast to the appropriate data type before plotting.\n2021-12-17 23:06:46,839 - matplotlib.category - INFO - Using categorical units to plot a list of strings that are all parsable as floats or dates. If these strings should be plotted as numbers, cast to the appropriate data type before plotting.\n2021-12-17 23:06:46,841 - matplotlib.category - INFO - Using categorical units to plot a list of strings that are all parsable as floats or dates. If these strings should be plotted as numbers, cast to the appropriate data type before plotting.\n2021-12-17 23:06:46,843 - matplotlib.category - INFO - Using categorical units to plot a list of strings that are all parsable as floats or dates. If these strings should be plotted as numbers, cast to the appropriate data type before plotting.\n2021-12-17 23:06:46,848 - matplotlib.category - INFO - Using categorical units to plot a list of strings that are all parsable as floats or dates. If these strings should be plotted as numbers, cast to the appropriate data type before plotting.\n2021-12-17 23:06:46,850 - matplotlib.category - INFO - Using categorical units to plot a list of strings that are all parsable as floats or dates. If these strings should be plotted as numbers, cast to the appropriate data type before plotting.\n2021-12-17 23:06:46,852 - matplotlib.category - INFO - Using categorical units to plot a list of strings that are all parsable as floats or dates. If these strings should be plotted as numbers, cast to the appropriate data type before plotting.\n"
],
[
"pd.read_csv(config.external_data_path + '/cambridge_bay_sea_ice_properties_from_ice_charts.csv').head(3)",
"_____no_output_____"
],
[
"ice_maps_df = pd.read_csv(\n config.external_data_path\n + \"/cambridge_bay_sea_ice_properties_from_ice_charts.csv\", dtype={\"stage_of_development\":object})\n\nice_maps_df[\"total_concentration\"] = ice_maps_df[\"total_concentration\"].replace(\"<1\", 0.5).astype(\"float\")\nice_maps_df[\"timestamp\"] = pd.to_datetime(df[\"Date\"], format=\"%d/%m/%Y\")\nice_maps_df = ice_maps_df.sort_values(\"timestamp\", ignore_index=True)\nice_maps_df",
"_____no_output_____"
],
[
"spl_daily_df = pd.read_feather(config.processed_data_path + '/whole_year/whole_year.feather').groupby(pd.Grouper(key=\"timestamp\", freq='1D')).mean().reset_index()\nspl_daily_df",
"_____no_output_____"
],
[
"temperature_daily_df = pd.read_feather(config.processed_data_path + '/daily_temperature_cambay_shorestation.feather')\ntemperature_daily_df",
"_____no_output_____"
],
[
"daily_transients = pd.read_feather(config.processed_data_path + \"/transient_timestamps_and_durations/whole_year.feather\").groupby(pd.Grouper(key=\"timestamp\", freq='1D')).size()\ndaily_transients_df = pd.DataFrame({\"timestamp\":daily_transients.index, \"no_transients\":daily_transients.values})\ndaily_transients_df",
"_____no_output_____"
],
[
"from datetime import datetime\nonset_sod_1 = datetime.strptime('08/10/2018', '%d/%m/%Y')\nonset_sod_4 = datetime.strptime('22/10/2018', '%d/%m/%Y')\nonset_sod_7 = datetime.strptime('12/11/2018', '%d/%m/%Y')\nonset_sod_1dot = datetime.strptime('24/12/2018', '%d/%m/%Y')\nonset_sod_4dot = datetime.strptime('11/02/2019', '%d/%m/%Y')",
"_____no_output_____"
],
[
"plt.figure(figsize=(20,12))\nplt.plot(ice_maps_df[\"timestamp\"], ice_maps_df[\"total_concentration\"]*2)\nplt.plot(temperature_daily_df[\"timestamp\"], temperature_daily_df[\"mean_temperature\"])\nplt.plot(spl_daily_df[\"timestamp\"], spl_daily_df[\"broadband_spl\"]+50)\nplt.plot(daily_transients_df[\"timestamp\"], (daily_transients_df[\"no_transients\"]-200)/200)\nplt.axvline(onset_sod_1)\nplt.axvline(onset_sod_4)\nplt.axvline(onset_sod_7)\nplt.axvline(onset_sod_1dot)\nplt.axvline(onset_sod_4dot)",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(1,1,figsize=(20,12))\n\nax.plot(np.nan, np.nan)\nax.plot(spl_daily_df[\"timestamp\"], spl_daily_df[\"broadband_spl\"])\nax2 = ax.twinx()\nax2.plot(ice_maps_df[\"timestamp\"], ice_maps_df[\"total_concentration\"])\nax.axvline(onset_sod_1)\nax.axvline(onset_sod_4)\nax.axvline(onset_sod_7)\nax.axvline(onset_sod_1dot)\nax.axvline(onset_sod_4dot)",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(1,1,figsize=(8,6))\n\nax.plot(spl_daily_df[\"timestamp\"], spl_daily_df[\"broadband_spl\"])\nax2.set_ylabel(r\"Broadband SPL\")\n\nax2 = ax.twinx()\n#ax2.plot(temperature_daily_df[\"timestamp\"], temperature_daily_df[\"mean_temperature\"], label=r\"Daily mean temperature ($\\degree$C)\", c=\"tab:orange\")\nax2.set_ylabel(r\"Daily mean temperature ($\\degree$C)\")\nax2.plot(ice_maps_df[\"timestamp\"], ice_maps_df[\"total_concentration\"], label=\"Sea ice concentration (/10)\", color=\"tab:orange\")\nax2.set_ylabel(\"Sea ice concentration (/10)\")\n\nfig.legend()\n#fig.legend(loc=\"upper right\", bbox_to_anchor=(1,1), bbox_transform=ax.transAxes)\n\nimport matplotlib.dates as mdates\nax.xaxis.set_major_locator(mdates.MonthLocator(interval=1))\nax.xaxis.set_major_formatter(mdates.DateFormatter('%m/%Y'))\nplt.setp(ax.get_xticklabels(), rotation=30)\n\n'''\nax.axvline(onset_sod_1)\nax.axvline(onset_sod_4)\nax.axvline(onset_sod_7)\nax.axvline(onset_sod_1dot)\nax.axvline(onset_sod_4dot)\n'''\nfig.savefig('/Users/georgeamccarthy/Documents/workspace/mphys/acoustic-data-science/figures/concentration_thickness.jpg', dpi=300)\nplt.show()\n",
"_____no_output_____"
]
],
[
[
"1 - New ice, <10 cm\n4 - Grey ice, 10-15 cm\n7 - Thin first year ice, 30-70 cm\n1. - Medium first year ice, 70-120 cm\n4. - Thick first year ice, >120cm",
"_____no_output_____"
]
]
] | [
"code",
"markdown"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
ecc28d97b3a586690341de1a7cdfa2a5a1926648 | 21,190 | ipynb | Jupyter Notebook | Preprocessing Abalone.ipynb | adizz2407/Fuzzy-SVM | dde5fb0de3838f8c2679bc93fd74f6e97b46e9b1 | [
"MIT"
] | 7 | 2019-10-08T00:33:38.000Z | 2021-09-10T14:33:28.000Z | Preprocessing Abalone.ipynb | adityasahu-git/Fuzzy-SVM | dde5fb0de3838f8c2679bc93fd74f6e97b46e9b1 | [
"MIT"
] | 1 | 2021-04-05T18:20:12.000Z | 2021-04-05T18:20:12.000Z | Preprocessing Abalone.ipynb | adityasahu-git/Fuzzy-SVM | dde5fb0de3838f8c2679bc93fd74f6e97b46e9b1 | [
"MIT"
] | 3 | 2021-12-07T03:28:43.000Z | 2022-01-22T06:47:24.000Z | 32.650231 | 213 | 0.383058 | [
[
[
"# ADITYA SAHU",
"_____no_output_____"
],
[
"# Pre processing of Abalone dataset to make imbalance ratio of training and testing same",
"_____no_output_____"
]
],
[
[
"import numpy as np\nfrom numpy import linalg\nimport pandas as pd",
"_____no_output_____"
],
[
"train = pd.read_csv(\"Abalone.csv\")\ntrain.head()",
"_____no_output_____"
],
[
"train=train.replace(to_replace=['M', 'F', 'I'], value=[1, 2, 3])",
"_____no_output_____"
],
[
"train['rings'] = train['rings'].map({15: 1, 1:-1,2:-1,3:-1,4:-1,5:-1,6:-1,7:-1,8:-1,9:-1,10:-1,11:-1,12:-1,13:-1,14:-1,16:-1,17:-1,18:-1,19:-1,20:-1,21:-1,22:-1,23:-1,24:-1,25:-1,26:-1,27:-1,28:-1,29:-1})\nprint(train['rings'])",
"0 1\n1 -1\n2 -1\n3 -1\n4 -1\n5 -1\n6 -1\n7 -1\n8 -1\n9 -1\n10 -1\n11 -1\n12 -1\n13 -1\n14 -1\n15 -1\n16 -1\n17 -1\n18 -1\n19 -1\n20 -1\n21 -1\n22 -1\n23 -1\n24 -1\n25 -1\n26 -1\n27 -1\n28 1\n29 -1\n ..\n4147 -1\n4148 -1\n4149 -1\n4150 -1\n4151 -1\n4152 -1\n4153 -1\n4154 -1\n4155 -1\n4156 -1\n4157 -1\n4158 -1\n4159 -1\n4160 -1\n4161 -1\n4162 -1\n4163 -1\n4164 -1\n4165 -1\n4166 -1\n4167 -1\n4168 -1\n4169 -1\n4170 -1\n4171 -1\n4172 -1\n4173 -1\n4174 -1\n4175 -1\n4176 -1\nName: rings, Length: 4177, dtype: int64\n"
],
[
"train=np.asarray(train)",
"_____no_output_____"
],
[
"min_train=np.zeros((103,9))\nmax_train=np.zeros((4074,9))\nmin_train=np.asarray(min_train)\nmax_train=np.asarray(max_train)",
"_____no_output_____"
],
[
"k=0\nl=0\nfor i in range(0,4177):\n if(train[i][8]==1):\n for j in range(0,9):\n min_train[k][j]=train[i][j] \n k=k+1\n else :\n for j in range(0,9):\n max_train[l][j]=train[i][j]\n l=l+1",
"_____no_output_____"
],
[
"print(min_train)",
"[[1. 0.455 0.365 0.095 0.514 0.2245 0.101 0.15 1. ]\n [1. 0.605 0.475 0.18 0.9365 0.394 0.219 0.295 1. ]\n [2. 0.68 0.56 0.165 1.639 0.6055 0.2805 0.46 1. ]\n [2. 0.6 0.475 0.15 1.0075 0.4425 0.221 0.28 1. ]\n [1. 0.565 0.425 0.135 0.8115 0.341 0.1675 0.255 1. ]\n [1. 0.695 0.56 0.19 1.494 0.588 0.3425 0.485 1. ]\n [1. 0.55 0.435 0.145 0.843 0.328 0.1915 0.255 1. ]\n [1. 0.53 0.435 0.16 0.883 0.316 0.164 0.335 1. ]\n [1. 0.59 0.475 0.145 1.053 0.4415 0.262 0.325 1. ]\n [1. 0.56 0.45 0.16 0.922 0.432 0.178 0.26 1. ]\n [2. 0.53 0.415 0.16 0.783 0.2935 0.158 0.245 1. ]\n [2. 0.575 0.46 0.185 1.094 0.4485 0.217 0.345 1. ]\n [1. 0.6 0.495 0.165 1.2415 0.485 0.2775 0.34 1. ]\n [1. 0.56 0.45 0.175 1.011 0.3835 0.2065 0.37 1. ]\n [2. 0.635 0.505 0.17 1.415 0.605 0.297 0.365 1. ]\n [1. 0.63 0.505 0.225 1.525 0.56 0.3335 0.45 1. ]\n [2. 0.535 0.415 0.185 0.8415 0.314 0.1585 0.3 1. ]\n [1. 0.61 0.475 0.165 1.116 0.428 0.2205 0.315 1. ]\n [2. 0.565 0.45 0.195 1.0035 0.406 0.2505 0.285 1. ]\n [1. 0.565 0.465 0.175 0.995 0.3895 0.183 0.37 1. ]\n [1. 0.605 0.47 0.18 1.1405 0.3755 0.2805 0.385 1. ]\n [1. 0.59 0.5 0.165 1.1045 0.4565 0.2425 0.34 1. ]\n [2. 0.62 0.47 0.14 1.0325 0.3605 0.224 0.36 1. ]\n [2. 0.64 0.54 0.175 1.221 0.51 0.259 0.39 1. ]\n [1. 0.57 0.465 0.125 0.849 0.3785 0.1765 0.24 1. ]\n [2. 0.625 0.515 0.15 1.2415 0.5235 0.3065 0.36 1. ]\n [1. 0.655 0.53 0.175 1.2635 0.486 0.2635 0.415 1. ]\n [2. 0.625 0.5 0.15 0.953 0.3445 0.2235 0.305 1. ]\n [2. 0.62 0.47 0.225 1.115 0.378 0.2145 0.36 1. ]\n [1. 0.6 0.47 0.175 1.105 0.4865 0.247 0.315 1. ]\n [1. 0.585 0.455 0.225 1.055 0.3815 0.221 0.365 1. ]\n [2. 0.5 0.375 0.14 0.604 0.242 0.1415 0.179 1. ]\n [1. 0.42 0.325 0.115 0.2885 0.1 0.057 0.1135 1. ]\n [3. 0.45 0.35 0.145 0.525 0.2085 0.1 0.1655 1. ]\n [3. 0.465 0.36 0.105 0.498 0.214 0.116 0.14 1. ]\n [2. 0.485 0.38 0.15 0.605 0.2155 0.14 0.18 1. ]\n [1. 0.565 0.44 0.185 0.909 0.344 0.2325 0.255 1. ]\n [1. 0.555 0.44 0.15 1.092 0.416 0.212 0.4405 1. ]\n [1. 0.525 0.41 0.13 0.99 0.3865 0.243 0.295 1. ]\n [2. 0.52 0.4 0.12 0.6515 0.261 0.2015 0.165 1. ]\n [1. 0.52 0.4 0.12 0.823 0.298 0.1805 0.265 1. ]\n [1. 0.695 0.515 0.175 1.5165 0.578 0.4105 0.39 1. ]\n [2. 0.605 0.495 0.19 1.437 0.469 0.2655 0.41 1. ]\n [1. 0.57 0.43 0.12 1.0615 0.348 0.167 0.31 1. ]\n [1. 0.585 0.405 0.15 1.2565 0.435 0.202 0.325 1. ]\n [1. 0.505 0.385 0.145 0.6775 0.236 0.179 0.2 1. ]\n [1. 0.465 0.35 0.14 0.5755 0.2015 0.1505 0.19 1. ]\n [2. 0.47 0.36 0.145 0.537 0.1725 0.1375 0.195 1. ]\n [1. 0.55 0.415 0.175 1.042 0.3295 0.2325 0.2905 1. ]\n [1. 0.515 0.405 0.145 0.695 0.215 0.1635 0.234 1. ]\n [2. 0.48 0.4 0.125 0.759 0.2125 0.179 0.24 1. ]\n [1. 0.66 0.53 0.17 1.3905 0.5905 0.212 0.453 1. ]\n [1. 0.64 0.565 0.23 1.521 0.644 0.372 0.406 1. ]\n [2. 0.7 0.535 0.175 1.773 0.6805 0.48 0.512 1. ]\n [1. 0.62 0.495 0.195 1.5145 0.579 0.346 0.5195 1. ]\n [2. 0.675 0.55 0.18 1.6885 0.562 0.3705 0.6 1. ]\n [2. 0.595 0.48 0.2 0.975 0.358 0.2035 0.34 1. ]\n [1. 0.645 0.495 0.185 1.4935 0.5265 0.2785 0.455 1. ]\n [2. 0.56 0.435 0.185 1.106 0.422 0.2435 0.33 1. ]\n [2. 0.61 0.48 0.175 1.0675 0.391 0.216 0.42 1. ]\n [1. 0.635 0.51 0.21 1.598 0.6535 0.2835 0.58 1. ]\n [1. 0.695 0.57 0.2 2.033 0.751 0.4255 0.685 1. ]\n [2. 0.505 0.395 0.145 0.6515 0.2695 0.153 0.205 1. ]\n [2. 0.525 0.425 0.145 0.7995 0.3345 0.209 0.24 1. ]\n [3. 0.48 0.39 0.145 0.5825 0.2315 0.121 0.255 1. ]\n [1. 0.59 0.46 0.155 0.906 0.327 0.1485 0.335 1. ]\n [2. 0.6 0.47 0.2 1.031 0.392 0.2035 0.29 1. ]\n [1. 0.65 0.545 0.16 1.2425 0.487 0.296 0.48 1. ]\n [3. 0.555 0.455 0.17 0.8435 0.309 0.1905 0.3 1. ]\n [3. 0.655 0.515 0.145 1.25 0.5265 0.283 0.315 1. ]\n [3. 0.62 0.485 0.17 1.208 0.4805 0.3045 0.33 1. ]\n [3. 0.52 0.415 0.16 0.595 0.2105 0.142 0.26 1. ]\n [1. 0.49 0.39 0.135 0.592 0.242 0.096 0.1835 1. ]\n [2. 0.52 0.4 0.13 0.6245 0.215 0.2065 0.17 1. ]\n [1. 0.495 0.4 0.14 0.7775 0.2015 0.18 0.25 1. ]\n [1. 0.66 0.535 0.2 1.791 0.733 0.318 0.54 1. ]\n [1. 0.65 0.52 0.195 1.676 0.693 0.44 0.47 1. ]\n [1. 0.64 0.49 0.14 1.194 0.4445 0.238 0.375 1. ]\n [1. 0.605 0.49 0.155 1.153 0.503 0.2505 0.295 1. ]\n [1. 0.605 0.47 0.115 1.114 0.3925 0.291 0.31 1. ]\n [2. 0.505 0.41 0.135 0.657 0.291 0.133 0.195 1. ]\n [2. 0.665 0.53 0.185 1.3955 0.456 0.3205 0.49 1. ]\n [3. 0.48 0.38 0.125 0.523 0.2105 0.1045 0.175 1. ]\n [2. 0.69 0.54 0.185 1.5715 0.6935 0.318 0.47 1. ]\n [1. 0.555 0.435 0.135 0.858 0.377 0.1585 0.29 1. ]\n [1. 0.635 0.48 0.19 1.467 0.5825 0.303 0.42 1. ]\n [2. 0.61 0.495 0.19 1.213 0.464 0.306 0.365 1. ]\n [2. 0.465 0.39 0.14 0.5555 0.213 0.1075 0.215 1. ]\n [2. 0.605 0.475 0.145 1.0185 0.4695 0.225 0.27 1. ]\n [1. 0.535 0.42 0.16 0.72 0.275 0.164 0.225 1. ]\n [2. 0.71 0.575 0.175 1.555 0.6465 0.3705 0.52 1. ]\n [2. 0.48 0.37 0.13 0.5885 0.2475 0.1505 0.1595 1. ]\n [3. 0.66 0.525 0.18 1.6935 0.6025 0.4005 0.42 1. ]\n [2. 0.52 0.405 0.145 0.829 0.3535 0.1685 0.205 1. ]\n [1. 0.495 0.4 0.12 0.6605 0.2605 0.161 0.19 1. ]\n [2. 0.5 0.39 0.13 0.6355 0.2505 0.1635 0.195 1. ]\n [1. 0.545 0.44 0.165 0.744 0.2875 0.204 0.25 1. ]\n [2. 0.645 0.5 0.225 1.626 0.587 0.4055 0.41 1. ]\n [2. 0.61 0.49 0.17 1.1775 0.5655 0.2385 0.295 1. ]\n [2. 0.67 0.545 0.16 1.5415 0.5985 0.2565 0.495 1. ]\n [1. 0.445 0.345 0.14 0.476 0.2055 0.1015 0.1085 1. ]\n [3. 0.52 0.405 0.14 0.6765 0.2865 0.146 0.205 1. ]\n [2. 0.54 0.44 0.16 1.0905 0.391 0.2295 0.355 1. ]]\n"
],
[
"data1=np.zeros((834,9))\ndata2=np.zeros((835,9))\ndata3=np.zeros((836,9))\ndata4=np.zeros((836,9))\ndata5=np.zeros((836,9))",
"_____no_output_____"
],
[
"for i in range(0,103):\n for j in range(0,9):\n if(i<20):\n data1[i][j]=min_train[i][j]\n elif(19<i and i<40):\n data2[i-20][j]=min_train[i][j]\n elif(39<i and i<61):\n data3[i-40][j]=min_train[i][j]\n elif(60<i and i<82):\n data4[i-61][j]=min_train[i][j]\n elif(81<i and i<103):\n data5[i-82][j]=min_train[i][j]\n \n \nprint(data5[20])",
"[2. 0.54 0.44 0.16 1.0905 0.391 0.2295 0.355 1. ]\n"
],
[
"for i in range(0,4074):\n for j in range(0,9):\n if(i<814):\n data1[i+20][j]=max_train[i][j]\n elif(813<i and i<1629):\n data2[i-794][j]=max_train[i][j]\n elif(1628<i and i<2444):\n data3[i-1608][j]=max_train[i][j]\n elif(2443<i and i<3259):\n data4[i-2423][j]=max_train[i][j]\n elif(3258<i and i<4074):\n data5[i-3238][j]=max_train[i][j] \nprint(data5[0])",
"[3. 0.48 0.38 0.125 0.523 0.2105 0.1045 0.175 1. ]\n"
],
[
"print(data5.shape)\ndata5",
"(836, 9)\n"
],
[
"import csv\nwith open('newab.csv', 'w') as csvFile:\n writer = csv.writer(csvFile)\n writer.writerows(data1)\n\ncsvFile.close()",
"_____no_output_____"
],
[
"import csv\nwith open('newab.csv', 'a') as csvFile:\n writer = csv.writer(csvFile)\n writer.writerows(data2)\n\ncsvFile.close()",
"_____no_output_____"
],
[
"import csv\nwith open('newab.csv', 'a') as csvFile:\n writer = csv.writer(csvFile)\n writer.writerows(data3)\n\ncsvFile.close()",
"_____no_output_____"
],
[
"import csv\nwith open('newab.csv', 'a') as csvFile:\n writer = csv.writer(csvFile)\n writer.writerows(data4)\n\ncsvFile.close()",
"_____no_output_____"
],
[
"import csv\nwith open('newab.csv', 'a') as csvFile:\n writer = csv.writer(csvFile)\n writer.writerows(data5)\n\ncsvFile.close()",
"_____no_output_____"
],
[
"df = pd.read_csv(\"newab.csv\")\n#checking the number of empty rows in th csv file\nprint (df.isnull().sum())\n#Droping the empty rows\nmodifiedDF = df.dropna()\n#Saving it to the csv file \nmodifiedDF.to_csv('modifiedabalone.csv',index=False)",
"1.0 0\n0.455 0\n0.365 0\n0.095 0\n0.514 0\n0.2245 0\n0.10099999999999999 0\n0.15 0\n1.0.1 0\ndtype: int64\n"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecc298864db3877057c296c8a5a5f82e852b922b | 7,516 | ipynb | Jupyter Notebook | notebooks/04.Widget-libraries/04.05-ipyvolume.ipynb | jupytercon/2020-mwcraig | 0fd6cf2acc1498d148bcda1f274a0aa5cb0c9085 | [
"BSD-3-Clause"
] | 10 | 2020-09-03T15:34:22.000Z | 2021-12-18T21:06:50.000Z | notebooks/04.Widget-libraries/04.05-ipyvolume.ipynb | jupytercon/2020-mwcraig | 0fd6cf2acc1498d148bcda1f274a0aa5cb0c9085 | [
"BSD-3-Clause"
] | 8 | 2020-09-21T03:22:04.000Z | 2020-10-07T22:09:29.000Z | notebooks/04.Widget-libraries/04.05-ipyvolume.ipynb | jupytercon/2020-mwcraig | 0fd6cf2acc1498d148bcda1f274a0aa5cb0c9085 | [
"BSD-3-Clause"
] | 6 | 2020-08-31T16:22:00.000Z | 2020-10-12T01:16:43.000Z | 25.053333 | 285 | 0.530468 | [
[
[
"<!--NAVIGATION-->\n< [ipycanvas: Interactive Canvas](04.04-ipycanvas.ipynb) | [Contents](00.00-index.ipynb) |",
"_____no_output_____"
],
[
"# ipyvolume: 3D plotting in the notebook\n\n## https://github.com/maartenbreddels/ipyvolume\n\nIPyvolume is a Python library to visualize 3d volumes and glyphs (e.g. 3d scatter plots), in the Jupyter notebook, with minimal configuration and effort. It is currently pre-1.0, so use at own risk. IPyvolume’s volshow is to 3d arrays what matplotlib’s imshow is to 2d arrays.\n\n- MIT Licensed\n\nBy Maarten Breddels\n\n**Installation:**\n\n```bash\nconda install -c conda-forge ipyvolume\n```",
"_____no_output_____"
],
[
"# 3-D Scatter Plots",
"_____no_output_____"
]
],
[
[
"import ipyvolume as ipv\nimport numpy as np\nimport ipywidgets as widgets",
"_____no_output_____"
],
[
"x, y, z = np.random.random((3, 10000))\nipv.figure()\nscatter = ipv.scatter(x, y, z, size=1, marker=\"sphere\")\nipv.show()",
"_____no_output_____"
],
[
"x, y, z, u, v, w = np.random.random((6, 1000))*2-1\nselected = np.random.randint(0, 1000, 100)\nfig = ipv.figure()\nquiver = ipv.quiver(x, y, z, u, v, w, size=5, size_selected=8, selected=selected)\nipv.show()",
"_____no_output_____"
],
[
"size = widgets.FloatSlider(min=0, max=30, step=0.1)\nsize_selected = widgets.FloatSlider(min=0, max=30, step=0.1)\ncolor = widgets.ColorPicker()\ncolor_selected = widgets.ColorPicker()\nwidgets.jslink((quiver, 'size'), (size, 'value'))\nwidgets.jslink((quiver, 'size_selected'), (size_selected, 'value'))\nwidgets.jslink((quiver, 'color'), (color, 'value'))\nwidgets.jslink((quiver, 'color_selected'), (color_selected, 'value'))\nwidgets.VBox([size, size_selected, color, color_selected])",
"_____no_output_____"
]
],
[
[
"# Animations",
"_____no_output_____"
]
],
[
[
"# create 2d grids: x, y, and r\nu = np.linspace(-10, 10, 25)\nx, y = np.meshgrid(u, u)\nr = np.sqrt(x**2+y**2)\nprint(\"x,y and z are of shape\", x.shape)\n# and turn them into 1d\nx = x.flatten()\ny = y.flatten()\nr = r.flatten()\nprint(\"and flattened of shape\", x.shape)",
"x,y and z are of shape (25, 25)\nand flattened of shape (625,)\n"
],
[
"# create a sequence of 15 time elements\ntime = np.linspace(0, np.pi*2, 15)\nz = np.array([(np.cos(r + t) * np.exp(-r/5)) for t in time])\nprint(\"z is of shape\", z.shape)",
"z is of shape (15, 625)\n"
],
[
"# draw the scatter plot, and add controls with animate_glyphs\nipv.figure()\ns = ipv.scatter(x, z, y, marker=\"sphere\")\nipv.animation_control(s, interval=200)\nipv.ylim(-3,3)\nipv.show()",
"_____no_output_____"
],
[
"# Now also include, color, which containts rgb values\ncolor = np.array([[np.cos(r + t), 1-np.abs(z[i]), 0.1+z[i]*0] for i, t in enumerate(time)])\nsize = (z+1)\nprint(\"color is of shape\", color.shape)",
"color is of shape (15, 3, 625)\n"
],
[
"color = np.transpose(color, (0, 2, 1)) # flip the last axes",
"_____no_output_____"
],
[
"ipv.figure()\ns = ipv.scatter(x, z, y, color=color, size=size, marker=\"sphere\")\nipv.animation_control(s, interval=200)\nipv.ylim(-3, 3)\nipv.show()",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecc2a0b78d1c2d95cba8585792ba079915c023b6 | 124,962 | ipynb | Jupyter Notebook | Employee.ipynb | dheerajjoshim/machinelearningcourse | 61c798567ea5754c9e15153b60ce58beca21cac7 | [
"Unlicense"
] | null | null | null | Employee.ipynb | dheerajjoshim/machinelearningcourse | 61c798567ea5754c9e15153b60ce58beca21cac7 | [
"Unlicense"
] | null | null | null | Employee.ipynb | dheerajjoshim/machinelearningcourse | 61c798567ea5754c9e15153b60ce58beca21cac7 | [
"Unlicense"
] | null | null | null | 126.607903 | 21,806 | 0.813999 | [
[
[
"<a href=\"https://colab.research.google.com/github/dheerajjoshim/machinelearningcourse/blob/master/Employee.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"#Y=MX+C+Errors\n#Y- Dependent Variable\n#X= Independent Variable\n#m - slope\n#C- constant \n#Errors - Inevitable part of prediction :D \n\n",
"_____no_output_____"
],
[
"#The data is self created dataset from our ML team which consists of Employee name, ID & their Salary,\n #to be predicted in terms of 3 multivalued discrete and 5 continuous attributes.\nimport numpy as np #python library for numerical functions\nimport pandas as pd #for making dataframes\nimport scipy.stats as stats #library for statistics functions like probability etc\nimport statsmodels.api as sm #python library for stats models\nimport matplotlib.pyplot as plt # to plot charts\nimport sklearn #python library for linear models & others\nfrom sklearn.linear_model import LinearRegression ",
"/usr/local/lib/python3.6/dist-packages/statsmodels/tools/_testing.py:19: FutureWarning: pandas.util.testing is deprecated. Use the functions in the public API at pandas.testing instead.\n import pandas.util.testing as tm\n"
],
[
"from google.colab import files #loading data from google colab\nuploaded = files.upload()",
"_____no_output_____"
],
[
"#loading data from csv file in jupyter notebook\n#data = pd.read_csv('Employees_Details.csv') #It is used to read a csv(comma separated values) file and convert to pandas dataframe.\n#Pandas DataFrames is generally used for representing Excel Like Data In-Memory. \n#A Data frame is a two-dimensional data structure, i.e., data is aligned in a tabular fashion in rows and columns.\n#data.head()\nimport io\ndata = pd.read_csv(io.BytesIO(uploaded['Employees_Details.csv']))\n",
"_____no_output_____"
],
[
"data.head(5) #Read first 5 entries",
"_____no_output_____"
],
[
"data.shape #number of rows & columns ",
"_____no_output_____"
],
[
"data.describe() #gives the statistics of the data",
"_____no_output_____"
],
[
"#Plotting of graphs to see the relation between dependent & independent variable \nplt.scatter(data['Experience'], data['Salary'], color='red')\nplt.title('Experience Vs Salary', fontsize=14)\nplt.xlabel('Experience', fontsize=14)\nplt.ylabel('Salary',fontsize=14)\nplt.grid(True)\n#plt.show()",
"_____no_output_____"
],
[
"\n",
"_____no_output_____"
],
[
"data.corr()",
"_____no_output_____"
],
[
"#Pandas DataFrames is generally used for representing Excel Like Data In-Memory. \n#A Data frame is a two-dimensional data structure, i.e., data is aligned in a tabular fashion in rows and columns.\ndf = pd.DataFrame(data,columns=['Employee_Name','Employee_ID','Age','Department','Location','Experience','Role',\n 'ML','Python','Salary'])\n",
"_____no_output_____"
],
[
"\nX = df[['Experience']] #Independent Variable\nY = df['Salary'] #DEpendent Variable\n#print(X)\n#print(Y)\n\n",
"_____no_output_____"
],
[
"# with sklearn its just 4 lines of code\nregr = LinearRegression()\nregr.fit(X,Y)\n\nprint('Intercept: \\n', regr.intercept_)\nprint('Coefficients: \\n', regr.coef_)\n#print('Mean squared error: \\n',(np.mean((regr.predict(X)-Y) ** 2)))\n#print('variance score: \\n',regr.score(X,Y))\n#from sklearn import metrics \n#print('Mean Absolute Error:', metrics.mean_absolute_error(Y,(regr.predict(X))))\n\n#print('Mean Squared Error:', metrics.mean_squared_error(Y, (regr.predict(X))))\n#print('Root Mean Squared Error:', np.sqrt(metrics.mean_squared_error(Y,(regr.predict(X)))))\n\n#Y_pred= regr.predict(X),Y\n#The predict() function can evaluate response for a given input value (or list of values)\n#print(Y[0:10],Y_pred[0:10])\n#plt.scatter(regr.predict(X),Y)\n#plt.show()",
"Intercept: \n 15.182148853828256\nCoefficients: \n [2.97713281]\n"
],
[
"#This output includes the intercept and coefficients. \n#You can use this information to build the multiple linear regression equation as follows:\n#y=mx+c\n#Salary = (Experience coef)*X1 + (Intercept) \n\n#And once you plug the numbers:\n\n#Salary = (2.97713281)*X1 + 15.18214885382827\n\n# prediction with sklearn\nNew_Experience = 5\n\nprint ('Predicted Salary: \\n', regr.predict([[New_Experience]]))\n\n#Salary = (2.97713281)*X1 + 15.18214885382827\n#Salary = (2.97713281)* 5 + 15.18214885382827\n#Salary = 30.06781290382827",
"Predicted Salary: \n [30.06781293]\n"
],
[
"#Ordinary Least-Squares (OLS) Regression, is probably the most commonly used technique in Statistical Learning. \n#It is also the oldest, dating back to the eighteenth century and the work of Carl Friedrich Gauss and Adrien-Marie Legendre. \n#It is also one of the easier and more intuitive techniques to understand, and it provides a good basis for learning more advanced concepts and techniques. \n\n# with statsmodels\nX = sm.add_constant(X) # adding a constant\n #Example : Can you tell me why do we have this constant in the equation ? What significance it has? \n#Salary = (2.97713281)*X1 + 15.18214885382827\nmodel = sm.OLS(Y, X).fit()\npredictions = model.predict(X) \n \nprint(model.summary())\n",
" OLS Regression Results \n==============================================================================\nDep. Variable: Salary R-squared: 0.991\nModel: OLS Adj. R-squared: 0.991\nMethod: Least Squares F-statistic: 6.600e+04\nDate: Sun, 16 Aug 2020 Prob (F-statistic): 0.00\nTime: 06:18:51 Log-Likelihood: -1011.3\nNo. Observations: 580 AIC: 2027.\nDf Residuals: 578 BIC: 2035.\nDf Model: 1 \nCovariance Type: nonrobust \n==============================================================================\n coef std err t P>|t| [0.025 0.975]\n------------------------------------------------------------------------------\nconst 15.1821 0.125 121.378 0.000 14.936 15.428\nExperience 2.9771 0.012 256.910 0.000 2.954 3.000\n==============================================================================\nOmnibus: 22.817 Durbin-Watson: 0.421\nProb(Omnibus): 0.000 Jarque-Bera (JB): 14.273\nSkew: -0.242 Prob(JB): 0.000796\nKurtosis: 2.403 Cond. No. 23.6\n==============================================================================\n\nWarnings:\n[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.\n"
]
],
[
[
"#Residual plot",
"_____no_output_____"
]
],
[
[
"#Assignment is to plot all the model evaluation graphs like Residual Plots, PP-plots, Scatter Plots\n\nimport seaborn as sns\nsns.set(style=\"darkgrid\")\n\nsns.residplot('Experience', 'Salary', df, lowess=False, color=\"green\")",
"_____no_output_____"
]
],
[
[
"# Histogram",
"_____no_output_____"
]
],
[
[
"plt.hist(data['Experience'])",
"_____no_output_____"
]
],
[
[
"# Probability Plot",
"_____no_output_____"
]
],
[
[
"probplot = sm.ProbPlot(model.resid)\n\npp_y = sm.ProbPlot(data['Salary'], fit=False)\n#print(pp_y.sample_percentiles)\n#print('-----------------------')\n#print(pp_y.theoretical_percentiles)\n#pp_x = sm.ProbPlot(data['Experience'], fit=True)\nfig_y = pp_y.ppplot(line='45')\n#plt.rcParams[\"figure.figsize\"] = (5,5)\nplt.show()",
"_____no_output_____"
],
[
"pp_y = sm.ProbPlot(data['Salary'], fit=True)\n#print(pp_y.sample_percentiles)\n#print('-----------------------')\n#print(pp_y.theoretical_percentiles)\n#pp_x = sm.ProbPlot(data['Experience'], fit=True)\nfig_y = pp_y.qqplot(line='45')\nplt.show()",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
ecc2aafdcac6b23404c86f26778b6d91bbd26f8d | 11,029 | ipynb | Jupyter Notebook | notebooks/configuration.ipynb | z-tasker/comp-syn | 03333f84ebfea51b4cf55f7ab42ec0eb3f9a2fbb | [
"MIT"
] | 20 | 2020-04-18T12:49:33.000Z | 2022-01-27T13:36:35.000Z | notebooks/configuration.ipynb | z-tasker/comp-syn | 03333f84ebfea51b4cf55f7ab42ec0eb3f9a2fbb | [
"MIT"
] | 7 | 2020-04-27T01:53:58.000Z | 2021-12-16T03:27:07.000Z | notebooks/configuration.ipynb | z-tasker/comp-syn | 03333f84ebfea51b4cf55f7ab42ec0eb3f9a2fbb | [
"MIT"
] | 14 | 2020-04-18T12:49:35.000Z | 2022-01-27T13:36:41.000Z | 38.031034 | 412 | 0.566416 | [
[
[
"## The `CompsynConfig` class\n\n`compsyn.utils.CompsynConfig` provides a convenient way to setup your runtime configuration through code.\n\n```python\nclass CompsynConfig:\n def __init__(self, **kwargs: Dict[str, str]) -> None:\n self.config = dict()\n # fill argument values according to argparse config\n for key, val in self.args.items():\n set_env_var(key, val)\n self.config[key] = val\n # overwrite argparse values with those passed\n for key, val in kwargs.items():\n set_env_var(key, val) # sets passed config values in os.environ\n self.config[key] = val # store on self for convenience\n```\n\nIt is possible to configure compsyn entirely using environment variables, but this class provides a more code-centric way to set relevant environment variables. `CompsynConfig.args` are collected from the various `get_<component>_args` methods found throughout compsyn. `kwargs` passed to `CompsynConfig.__init__` will take precedence over those gathered from argparse. ",
"_____no_output_____"
]
],
[
[
"from compsyn.config import CompsynConfig\n\n# the host running this notebook has many compsyn environment variables set, so the CompsynConfig will see them.\nprint(CompsynConfig())",
"CompsynConfig\n\twork_dir = /media/tasker/WDBlue-B/comp-syn/data/local\n\tbrowser = Chrome\n\tjzazbz_array = /media/tasker/WDBlue-B/comp-syn/jzazbz_array.npy\n\tgoogle_application_credentials = None\n\ts3_bucket = comp-syn-shared\n\ts3_region_name = us-east-1\n\ts3_endpoint_url = None\n\ts3_access_key_id = AKIAYAYDTF7TCUF56JOT\n\ts3_secret_access_key = <redacted>\n\tlog_level = 20\n\tlog_file = None\n"
]
],
[
[
"The `CompsynConfig` class sets these values in `os.environ`, so that other parts of the code can access them. You may wish to set config values through code by passing arg values to the `CompsynConfig` instantiation.",
"_____no_output_____"
]
],
[
[
"from compsyn.trial import get_trial_from_env, Trial\n\nconfig = CompsynConfig(\n browser=\"Firefox\", \n driver_path=\"/usr/local/bin/geckodriver\", \n hostname=\"my-id\"\n)\n\nprint(config)",
"CompsynConfig\n\twork_dir = /media/tasker/WDBlue-B/comp-syn/data/local\n\tbrowser = Firefox\n\tjzazbz_array = /media/tasker/WDBlue-B/comp-syn/jzazbz_array.npy\n\tgoogle_application_credentials = None\n\ts3_bucket = comp-syn-shared\n\ts3_region_name = us-east-1\n\ts3_endpoint_url = None\n\ts3_access_key_id = AKIAYAYDTF7TCUF56JOT\n\ts3_secret_access_key = <redacted>\n\tlog_level = 20\n\tlog_file = None\n\tdriver_path = /usr/local/bin/geckodriver\n\thostname = my-id\n"
]
],
[
[
"## Purpose of `CompsynConfig`\n\nThe `CompsynConfig` class is a convenient mechanism for setting up the environment `compsyn` code uses to do it's multi-modal analyses. The values set through `CompsynConfig` are required for *the code to run successfully*.\n\nTo facilitate using compsyn as an experimental framework, further configuration may be achieved through the `Trial` class (See associated notebook trial_and_vector.ipynb). The values set in `Trial` should not be considered part of the `CompsynConfig`, as a given compsyn user may be analyzing data accross multiple trials. The values set through `Trial` are required to *implement experimental designs*.\n\n\n__Note__: The config values are likely to not change, so can be set in the environment. If you are using jupyter notebooks, this means the environment of the shell running the jupyter notebook server. \n\n__Note__: Usage is optional, or rather, defaults are provided for the core functionality of the `compsyn` package. Using more advanced features, like the shared s3 backend, will require configuration to be set. Here we will show those defaults by clearing the environment of this kernel:\n",
"_____no_output_____"
]
],
[
[
"import os\n\nfor key, val in os.environ.items():\n if key.startswith(\"COMPSYN_\"):\n del os.environ[key] # simulate an unset environment\n\n\ndefault_config = CompsynConfig()\ndefault_trial = get_trial_from_env()\n\nprint(\"default\", default_trial)\nprint()\nprint(\"default\", default_config)",
"[1639620741] (compsyn.CompsynConfig) WARNING: jzazbz_array.npy does not exist!\n[1639620741] (compsyn.Trial) INFO: experiment: default-experiment\n[1639620741] (compsyn.Trial) INFO: trial_id: default-trial\n[1639620741] (compsyn.Trial) INFO: hostname: default-hostname\ndefault Trial\n\texperiment_name = default-experiment\n\ttrial_id = default-trial\n\thostname = default-hostname\n\ttrial_timestamp = 2021-12-16\n\ndefault CompsynConfig\n\twork_dir = /home/tasker/comp-syn\n\tbrowser = Chrome\n\tjzazbz_array = jzazbz_array.npy\n\tgoogle_application_credentials = None\n\ts3_bucket = None\n\ts3_region_name = None\n\ts3_endpoint_url = None\n\ts3_access_key_id = None\n\ts3_secret_access_key = None\n\tlog_level = 20\n\tlog_file = None\n"
]
],
[
[
"*__Note__: the default work_dir will be the root of wherever you have the comp-syn repository cloned.*\n\n## Common Configuration patterns\n\nIt can get messy quickly to store data in the default work directory, which will be wherever the comp-syn repository is cloned. It is usually a good idea to use a `work_dir` that exists outside of the repo. For instance, if you are collecting a large amount of data, you may wish to use a `work_dir` located on an external harddrive, like:",
"_____no_output_____"
]
],
[
[
"config = CompsynConfig(\n work_dir=\"/media/tasker/WDBlue-B/comp-syn\",\n jzazbz_array=\"/media/tasker/WDBlue-B/comp-syn/jzazbz_array.npy\",\n)\n\nprint()\nprint(config)",
"\nCompsynConfig\n\twork_dir = /media/tasker/WDBlue-B/comp-syn\n\tbrowser = Chrome\n\tjzazbz_array = /media/tasker/WDBlue-B/comp-syn/jzazbz_array.npy\n\tgoogle_application_credentials = None\n\ts3_bucket = None\n\ts3_region_name = None\n\ts3_endpoint_url = None\n\ts3_access_key_id = None\n\ts3_secret_access_key = None\n\tlog_level = 20\n\tlog_file = None\n"
]
],
[
[
"### Use the environment for defaults\n\nA further improvement on this would be to set your desired `work_dir` in the environment running the jupyter notebook server. All of the `CompsynConfig` values can be set by environment variables named with a `COMPSYN_` prefix, for example `COMPSYN_WORK_DIR` and `COMPSYN_DRIVER_PATH`. \n\nUnlike the `CompsynConfig` values, there may be multiple sets of `Trial` values in a given jupyter notebook (or other workflow), so you should usually use the `Trial` class to set trial values directly in code:",
"_____no_output_____"
]
],
[
[
"# toy example trial for participating in some geolocation-sensitive experiment\ntrial = Trial(\n experiment_name=\"regional-differences\",\n trial_id=\"phase-0\",\n hostname=\"toronto\",\n)\n\nprint()\nprint(trial)",
"[1639620741] (compsyn.Trial) INFO: experiment: regional-differences\n[1639620741] (compsyn.Trial) INFO: trial_id: phase-0\n[1639620741] (compsyn.Trial) INFO: hostname: toronto\n\nTrial\n\texperiment_name = regional-differences\n\ttrial_id = phase-0\n\thostname = toronto\n\ttrial_timestamp = 2021-12-16\n"
]
],
[
[
"__Note__: Environment variables for the trial values are supported as well, to facilitate programmatic execution of compsyn experiments.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
ecc2bc05fb2e7efc2ec104fbec5690980272f8d2 | 2,278 | ipynb | Jupyter Notebook | convert_gcms_to_python_readable.ipynb | julianmwagner/sceptobius_behavior | c91561f7b442f2dffb12de3135150799d3434091 | [
"MIT"
] | null | null | null | convert_gcms_to_python_readable.ipynb | julianmwagner/sceptobius_behavior | c91561f7b442f2dffb12de3135150799d3434091 | [
"MIT"
] | null | null | null | convert_gcms_to_python_readable.ipynb | julianmwagner/sceptobius_behavior | c91561f7b442f2dffb12de3135150799d3434091 | [
"MIT"
] | null | null | null | 29.584416 | 538 | 0.625549 | [
[
[
"# How to convert a Shimadzu GCMS file types to MZXML (which can be read into python)",
"_____no_output_____"
],
[
"In order to convert GCMS files from a Shimadzu GCMS to a type readable into python, you must first have access to the proprietary Shimadzu [GCMSsolution](https://www.ssi.shimadzu.com/products/gas-chromatography-mass-spectrometry/gcmssolution-software.html) software, unfortunatly. However, this software is necessary to acquire data from the GCMS itself, so you will be able to perform these steps to convert your data into a python readable format before transferring it from your acquisition machine to a data storage location.\n\n**Open the data file in the GCMS Postrun Analyis. In the data explorer, open up the folder with your data files. Select the files that you wish to convert, `right click, mouse to File Convert, and select To mzXML`.**",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"**A box will pop up. You can then select all the files on the left part of the box that you wish to convert, and then click OK.**",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"**That's it! It may take a few minutes to convert depending on the number of files. By default, these will be put in the same folder as the original file, and have the `.mzXML` extension.**",
"_____no_output_____"
]
]
] | [
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
ecc2be1a77dae393b529cf430e1eb7680026c46d | 226,492 | ipynb | Jupyter Notebook | tutorials/textbook/Finding_paths_in_graphs.ipynb | AntonSimen06/qiskit-tutorials | f6d1f4acb0ce3e7a9329342b4e343baf83fa2d11 | [
"Apache-2.0"
] | null | null | null | tutorials/textbook/Finding_paths_in_graphs.ipynb | AntonSimen06/qiskit-tutorials | f6d1f4acb0ce3e7a9329342b4e343baf83fa2d11 | [
"Apache-2.0"
] | null | null | null | tutorials/textbook/Finding_paths_in_graphs.ipynb | AntonSimen06/qiskit-tutorials | f6d1f4acb0ce3e7a9329342b4e343baf83fa2d11 | [
"Apache-2.0"
] | null | null | null | 359.511111 | 90,692 | 0.931631 | [
[
[
"# **Finding Paths in Graphs Using Grover's Algorithm**\n\n",
"_____no_output_____"
],
[
"Grover's Algorithm is a quantum database search algorithm [1]. Finding one or more solutions to a problem can be solved in $O(\\sqrt{N}/t)$ steps, where $t$ is the number of solutions. In this tutorial, you will be shown how to find paths from one vertex to another in an undirected graph $G(V,E)$. If the state is prepared and measured $N$ times, the probability distribution shows all possible paths from one vertex to another. The solutions found are paths where none of the vertices is visited more than once.\n\n",
"_____no_output_____"
],
[
"##### **References:**\n\n[1]: GROVER, Lov. A fast quantum mechanical algorithm for database search. Título da Revista, Bell Labs, Murray Hill NJ, May, 1996. Available in: arXiv:quant-ph/9605043.\n\n",
"_____no_output_____"
],
[
"### **The Problem**",
"_____no_output_____"
],
[
"<img src=\"g2.jpeg\" width=\"250\" height=\"200\" />",
"_____no_output_____"
],
[
"Given a graph $G(v,e)$ with $v$ vertices and $e$ edges. The objective of this work is to use Grover's algorithm to search all paths between two vertices of $G(v,e)$ with time complexity $O(\\sqrt{v} /t)$. The encoding can be done so that the edges and vertices are represented as qubits in different registers. An untraveled edge remains in state $'0'$ while the traversed edge reverses its state to $'1'$. The vertices, on the other hand, invert their states if the edge connecting them has been traversed. Thus, if a path is traversed in the graph, the vertices in state $'1'$ will be just the starting and ending points of the path. The following image illustrates why the previous statement is valid.\n",
"_____no_output_____"
],
[
"<img src=\"g2.jpeg\" width=\"1000\" height=\"200\" />",
"_____no_output_____"
],
[
"The graph on the far right shows us the solution to the problem. The state of the edges $'0011011'$ shows us the Hamiltonian path, while the states of the vertices $'10100'$ show us what the final configuration of the vertices is for the path to be found. We see that, in a graph with $n$ vertices, the Hamiltonian path passes through $n−1$ edges.",
"_____no_output_____"
],
[
"### **Running the algorithm**",
"_____no_output_____"
],
[
"First, we need to specify how many vertices and edges the graph has. Two registers must be created so that: In the register where the measurements will be taken, each qubit represents an edge. In the other register, each qubit represents a vertex.",
"_____no_output_____"
]
],
[
[
"import qiskit\nfrom qiskit import *\nfrom qiskit.visualization import *\n\n# define the variables vertices (v) and edges (e)\nv, e = 5, 7 \n\nedge = QuantumRegister(e, 'edge')\nvertex = QuantumRegister(v, 'vertex')\nancilla = QuantumRegister(1, 'ancilla')\ncr = ClassicalRegister(e, 'cr')\nqc = QuantumCircuit(edge,vertex,ancilla,cr)",
"_____no_output_____"
],
[
"def initialize():\n init = QuantumCircuit(edge,vertex,ancilla)\n init.h(range(len(edge)))\n init.x(ancilla[0])\n init.h(ancilla[0])\n init.barrier()\n return init",
"_____no_output_____"
]
],
[
[
"We start by adding all the $2^m$ possible paths that exist in the graph. The way to do this is to apply the operation $H^{\\otimes m}$ on the qubits representing the edges\n\n\n$$|\\psi\\rangle = \\frac{1}{\\sqrt{2^m}} \\sum |x\\rangle \\otimes |0\\rangle^{\\otimes n}|-\\rangle$$",
"_____no_output_____"
]
],
[
[
"initialize().draw('mpl', scale=0.5)",
"_____no_output_____"
]
],
[
[
"We can code the graph as a quantum circuit, using CX operations, so that if the control is set to '1' (traveled path), the target reverses its state (vertices). In this way, we will have the following resulting state\n\n\\begin{equation}\n|\\psi\\rangle = \\frac{1}{\\sqrt{2^m}} \\sum |x\\rangle \\otimes |y\\rangle\n\\end{equation}\n\nwhere $y_i$ is the vertex configuration for a path $x_i$ traversed. Now, let's create the function that encodes the graph as a quantum circuit that works with the state changes at the vertices according to the edges traversed. The graph we'll use as an example in this tutorial is the one in the following image, where the index of each vertex and each edge corresponds to the qubits of the respective registers\n",
"_____no_output_____"
],
[
"<img src=\"g1.jpeg\" width=\"250\" height=\"100\" />",
"_____no_output_____"
]
],
[
[
"def graph_encoding():\n \n graph = QuantumCircuit(edge,vertex)\n \n graph.cx(edge[0],vertex[0])\n graph.cx(edge[0], vertex[1])\n \n graph.cx(edge[1],vertex[0])\n graph.cx(edge[1], vertex[3]) \n \n graph.cx(edge[2],vertex[1])\n graph.cx(edge[2], vertex[3])\n \n \n graph.cx(edge[3],vertex[1])\n graph.cx(edge[3], vertex[2])\n \n \n graph.cx(edge[4],vertex[2])\n graph.cx(edge[4], vertex[3])\n \n \n graph.cx(edge[5],vertex[3])\n graph.cx(edge[5], vertex[4])\n \n \n graph.cx(edge[6],vertex[0])\n graph.cx(edge[6], vertex[4])\n \n graph.barrier()\n \n return graph",
"_____no_output_____"
],
[
"graph_encoding().draw('mpl', scale=0.5, fold=-1)",
"_____no_output_____"
],
[
"qc = qc.compose(initialize())\nqc = qc.compose(graph_encoding())\nqc.draw('mpl', scale=0.5, fold=-1)",
"_____no_output_____"
],
[
"#flip phase of the solutions\ndef flip():\n fp = QuantumCircuit(edge, vertex, ancilla)\n fp.x([vertex[1],vertex[3],vertex[4]])\n #fp.x([vertex[0],vertex[1],vertex[2],vertex[3],vertex[4]])\n fp.mct([vertex[i] for i in range(len(vertex))], ancilla[0])\n #fp.x([vertex[0],vertex[1],vertex[2],vertex[3],vertex[4]])\n fp.x([vertex[1],vertex[3],vertex[4]])\n fp.barrier()\n return fp",
"_____no_output_____"
]
],
[
[
"The phase inversion operation is intended to invert the phase of the sought state HP. The HP is not known, but we know the final vertex state for a HP, as we saw in the example. In order to reverse the phase of the mapped edges state, we can apply the operation in the vertex register.\n\n\\begin{equation}\n |\\psi\\rangle = \\frac{1}{\\sqrt{2^b}} \\sum |path_x\\rangle \\otimes (-1)|10100\\rangle = \\frac{1}{\\sqrt{2^ b}} \\sum (-1)|path_x\\rangle \\otimes|10100\\rangle\n\\end{equation}\n",
"_____no_output_____"
]
],
[
[
"qc = qc.compose(flip())\nqc.draw('mpl',scale=0.5,fold=-1)",
"_____no_output_____"
],
[
"qc = qc.compose(graph_encoding())",
"_____no_output_____"
],
[
"#Diffuser operator to perform an inversion about the mean\ndef diffuser():\n dif = QuantumCircuit(edge)\n dif.h(range(len(edge)))\n dif.x(range(len(edge)))\n dif.h(edge[-1])\n dif.mct([edge[i] for i in range(len(edge)-1)], edge[-1])\n dif.h(edge[-1])\n dif.x(range(len(edge)))\n dif.h(range(len(edge)))\n dif.barrier()\n return dif",
"_____no_output_____"
],
[
"#Creating Grover iterations\nqc = qc.compose(diffuser())\n\nqc.barrier()\nqc = qc.compose(graph_encoding())\nqc = qc.compose(flip())\nqc = qc.compose(graph_encoding())\nqc = qc.compose(diffuser())\n\nqc = qc.compose(graph_encoding())\nqc = qc.compose(flip())\nqc = qc.compose(graph_encoding())\nqc = qc.compose(diffuser())",
"_____no_output_____"
],
[
"qc.draw('mpl', scale=0.5, fold=-1)",
"_____no_output_____"
],
[
"qc.measure(range(len(edge)), range(len(edge)))",
"_____no_output_____"
],
[
"simulator = Aer.get_backend('qasm_simulator')\ncounts = execute(qc, backend=simulator, shots=1024).result().get_counts(qc)\n",
"_____no_output_____"
],
[
"# removing paths with more than n-1 steps\noneslist = list()\nfor key, value in counts.items():\n if key.count('1') >= 5: oneslist.append(key)\n\nfor i in range(len(oneslist)): del counts[oneslist[i]]",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\nplot_histogram(counts, figsize=(16,8)) ",
"_____no_output_____"
]
],
[
[
"# Conclusion\n\nWe show that it is possible to find paths in graphs using Grover's algorithm. Paths that travel more than $n-1$ (where $n$ is the number of vertices in the graph) edges can be disregarded in the measurements, as they represent paths with repeated vertices. The implemented algorithm demonstrates quadratic speed up compared to a classic brute force algorithm.",
"_____no_output_____"
]
],
[
[
"import qiskit.tools.jupyter\n%qiskit_version_table\n%qiskit_copyright",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
ecc2c4076fcd77a75f40e60006763fe35cbb9a88 | 9,126 | ipynb | Jupyter Notebook | Utility Packages.ipynb | vravishankar/Jupyter-Books | 9d2d09ee6f38a5cfbc98a0bcc7e30cbbc796d526 | [
"MIT"
] | null | null | null | Utility Packages.ipynb | vravishankar/Jupyter-Books | 9d2d09ee6f38a5cfbc98a0bcc7e30cbbc796d526 | [
"MIT"
] | null | null | null | Utility Packages.ipynb | vravishankar/Jupyter-Books | 9d2d09ee6f38a5cfbc98a0bcc7e30cbbc796d526 | [
"MIT"
] | 1 | 2021-07-01T10:42:34.000Z | 2021-07-01T10:42:34.000Z | 20.325167 | 220 | 0.489371 | [
[
[
"# Timing it\n\nSometimes you may need to measure the performance of the code or at least want to know which piece of the code is slowing down. Python has a built-in timing module to do this.",
"_____no_output_____"
]
],
[
[
"import timeit",
"_____no_output_____"
]
],
[
[
"Lets use time it to time various methods of creating the string '0-1-2-3-.....-99'\n\nWe'll pass two arguments the actual line we want to test encapsulated as a string and the number of times we wish to run it. Here we'll choose 10,000 runs to get some high enough numbers to compare various methods.",
"_____no_output_____"
]
],
[
[
"# Using For Loop\ntimeit.timeit('\"-\".join(str(n) for n in range(100))', number=10000)",
"_____no_output_____"
],
[
"# Using List Comprehension\ntimeit.timeit('\"-\".join([str(n) for n in range(100)])', number=10000)",
"_____no_output_____"
],
[
"# Using Map Function\ntimeit.timeit('\"-\".join(map(str, range(100)))', number=10000)",
"_____no_output_____"
]
],
[
[
"It also has a Command-Line Interface",
"_____no_output_____"
]
],
[
[
"# $ python3 -m timeit '\"-\".join(str(n) for n in range(100))'\n# 10000 loops, best of 3: 30.2 usec per loop\n# $ python3 -m timeit '\"-\".join([str(n) for n in range(100)])'\n# 10000 loops, best of 3: 27.5 usec per loop\n# $ python3 -m timeit '\"-\".join(map(str, range(100)))'\n# 10000 loops, best of 3: 23.2 usec per loop",
"_____no_output_____"
]
],
[
[
"Now lets introduce iPython's magic function %timeit\n\niPython's %timeit will perform the code in the same line a certain number of times (loops) and will give you the fastest performance time (best of 3).\n\nLets repeat the above examinations using iPython magic!",
"_____no_output_____"
]
],
[
[
"%timeit \"-\".join(str(n) for n in range(100))",
"10000 loops, best of 3: 31.9 µs per loop\n"
],
[
"%timeit \"-\".join([str(n) for n in range(100)])",
"10000 loops, best of 3: 27.1 µs per loop\n"
],
[
"%timeit \"-\".join(map(str, range(100)))",
"10000 loops, best of 3: 21.5 µs per loop\n"
]
],
[
[
"# Date & Time\n\nThe datetime module supplies classes for manipulating dates and times in both simple and complex ways.",
"_____no_output_____"
],
[
"### date",
"_____no_output_____"
]
],
[
[
"from datetime import date\nnow = date.today()\nprint(now)",
"2017-10-29\n"
],
[
"now.strftime(\"%m-%d-%y. %d %b %Y is a %A on the %d day of %B.\")",
"_____no_output_____"
],
[
"print('ctime:', now.ctime())\nprint('tuple:', now.timetuple())\nprint('ordinal:', now.toordinal())\nprint('Year:', now.year)\nprint('Mon :', now.month)\nprint('Day :', now.day)",
"ctime: Sun Oct 29 00:00:00 2017\ntuple: time.struct_time(tm_year=2017, tm_mon=10, tm_mday=29, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=6, tm_yday=302, tm_isdst=-1)\nordinal: 736631\nYear: 2017\nMon : 10\nDay : 29\n"
],
[
"print('Earliest :', date.min)\nprint('Latest :', date.max)\nprint('Resolution:', date.resolution)",
"Earliest : 0001-01-01\nLatest : 9999-12-31\nResolution: 1 day, 0:00:00\n"
],
[
"d1 = date(2017, 3, 11)\nprint('d1:', d1)\n\nd2 = d1.replace(year=1997)\nprint('d2:', d2)",
"d1: 2017-03-11\nd2: 1997-03-11\n"
]
],
[
[
"### time",
"_____no_output_____"
]
],
[
[
"from datetime import time\nt = time(5,20,25,100)\nprint(t)",
"05:20:25.000100\n"
],
[
"print('hour :', t.hour)\nprint('minute:', t.minute)\nprint('second:', t.second)\nprint('microsecond:', t.microsecond)\nprint('tzinfo:', t.tzinfo)",
"hour : 5\nminute: 20\nsecond: 25\nmicrosecond: 100\ntzinfo: None\n"
],
[
"print('Earliest :', time.min)\nprint('Latest :', time.max)\nprint('Resolution:', time.resolution)",
"Earliest : 00:00:00\nLatest : 23:59:59.999999\nResolution: 0:00:00.000001\n"
]
],
[
[
"### arithmetic",
"_____no_output_____"
]
],
[
[
"birthday = date(1971,4,22)\nage = now - birthday\nage.days",
"_____no_output_____"
],
[
"d1 - d2",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
ecc2d5a26c1ba4eb456dc5b609d9041622336da6 | 48,119 | ipynb | Jupyter Notebook | kaggle/titanic.ipynb | jt120/start-ml | 46a9ba31e4e9ce0d82cef0d28a15bd999c7b4147 | [
"Apache-2.0"
] | null | null | null | kaggle/titanic.ipynb | jt120/start-ml | 46a9ba31e4e9ce0d82cef0d28a15bd999c7b4147 | [
"Apache-2.0"
] | null | null | null | kaggle/titanic.ipynb | jt120/start-ml | 46a9ba31e4e9ce0d82cef0d28a15bd999c7b4147 | [
"Apache-2.0"
] | null | null | null | 32.31632 | 136 | 0.452815 | [
[
[
"import pandas as pd\nimport numpy as np\nfrom sklearn import tree, model_selection, ensemble, linear_model, preprocessing\nimport xgboost as xgb\n\ndef clean_data(data):\n data[\"Fare\"] = data[\"Fare\"].fillna(data[\"Fare\"].dropna().median())\n data[\"Age\"] = data[\"Age\"].fillna(data[\"Age\"].dropna().median())\n\n data.loc[data[\"Sex\"] == \"male\", \"Sex\"] = 0\n data.loc[data[\"Sex\"] == \"female\", \"Sex\"] = 1\n\n data[\"Embarked\"] = data[\"Embarked\"].fillna(\"S\")\n data.loc[data[\"Embarked\"] == \"S\", \"Embarked\"] = 0\n data.loc[data[\"Embarked\"] == \"C\", \"Embarked\"] = 1\n data.loc[data[\"Embarked\"] == \"Q\", \"Embarked\"] = 2\n \ndef write_prediction(prediction, name):\n PassengerId = np.array(test[\"PassengerId\"]).astype(int)\n solution = pd.DataFrame(prediction, PassengerId, columns = [\"Survived\"])\n solution.to_csv(name, index_label = [\"PassengerId\"])\n\n# Definition of the CategoricalEncoder class, copied from PR #9151.\n# Just run this cell, or copy it to your code, no need to try to\n# understand every line.\n\nfrom sklearn.base import BaseEstimator, TransformerMixin\nfrom sklearn.utils import check_array\nfrom sklearn.preprocessing import LabelEncoder\nfrom scipy import sparse\n\nclass CategoricalEncoder(BaseEstimator, TransformerMixin):\n \"\"\"Encode categorical features as a numeric array.\n The input to this transformer should be a matrix of integers or strings,\n denoting the values taken on by categorical (discrete) features.\n The features can be encoded using a one-hot aka one-of-K scheme\n (``encoding='onehot'``, the default) or converted to ordinal integers\n (``encoding='ordinal'``).\n This encoding is needed for feeding categorical data to many scikit-learn\n estimators, notably linear models and SVMs with the standard kernels.\n Read more in the :ref:`User Guide <preprocessing_categorical_features>`.\n Parameters\n ----------\n encoding : str, 'onehot', 'onehot-dense' or 'ordinal'\n The type of encoding to use (default is 'onehot'):\n - 'onehot': encode the features using a one-hot aka one-of-K scheme\n (or also called 'dummy' encoding). This creates a binary column for\n each category and returns a sparse matrix.\n - 'onehot-dense': the same as 'onehot' but returns a dense array\n instead of a sparse matrix.\n - 'ordinal': encode the features as ordinal integers. This results in\n a single column of integers (0 to n_categories - 1) per feature.\n categories : 'auto' or a list of lists/arrays of values.\n Categories (unique values) per feature:\n - 'auto' : Determine categories automatically from the training data.\n - list : ``categories[i]`` holds the categories expected in the ith\n column. The passed categories are sorted before encoding the data\n (used categories can be found in the ``categories_`` attribute).\n dtype : number type, default np.float64\n Desired dtype of output.\n handle_unknown : 'error' (default) or 'ignore'\n Whether to raise an error or ignore if a unknown categorical feature is\n present during transform (default is to raise). When this is parameter\n is set to 'ignore' and an unknown category is encountered during\n transform, the resulting one-hot encoded columns for this feature\n will be all zeros.\n Ignoring unknown categories is not supported for\n ``encoding='ordinal'``.\n Attributes\n ----------\n categories_ : list of arrays\n The categories of each feature determined during fitting. When\n categories were specified manually, this holds the sorted categories\n (in order corresponding with output of `transform`).\n Examples\n --------\n Given a dataset with three features and two samples, we let the encoder\n find the maximum value per feature and transform the data to a binary\n one-hot encoding.\n >>> from sklearn.preprocessing import CategoricalEncoder\n >>> enc = CategoricalEncoder(handle_unknown='ignore')\n >>> enc.fit([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]])\n ... # doctest: +ELLIPSIS\n CategoricalEncoder(categories='auto', dtype=<... 'numpy.float64'>,\n encoding='onehot', handle_unknown='ignore')\n >>> enc.transform([[0, 1, 1], [1, 0, 4]]).toarray()\n array([[ 1., 0., 0., 1., 0., 0., 1., 0., 0.],\n [ 0., 1., 1., 0., 0., 0., 0., 0., 0.]])\n See also\n --------\n sklearn.preprocessing.OneHotEncoder : performs a one-hot encoding of\n integer ordinal features. The ``OneHotEncoder assumes`` that input\n features take on values in the range ``[0, max(feature)]`` instead of\n using the unique values.\n sklearn.feature_extraction.DictVectorizer : performs a one-hot encoding of\n dictionary items (also handles string-valued features).\n sklearn.feature_extraction.FeatureHasher : performs an approximate one-hot\n encoding of dictionary items or strings.\n \"\"\"\n\n def __init__(self, encoding='onehot', categories='auto', dtype=np.float64,\n handle_unknown='error'):\n self.encoding = encoding\n self.categories = categories\n self.dtype = dtype\n self.handle_unknown = handle_unknown\n\n def fit(self, X, y=None):\n \"\"\"Fit the CategoricalEncoder to X.\n Parameters\n ----------\n X : array-like, shape [n_samples, n_feature]\n The data to determine the categories of each feature.\n Returns\n -------\n self\n \"\"\"\n\n if self.encoding not in ['onehot', 'onehot-dense', 'ordinal']:\n template = (\"encoding should be either 'onehot', 'onehot-dense' \"\n \"or 'ordinal', got %s\")\n raise ValueError(template % self.handle_unknown)\n\n if self.handle_unknown not in ['error', 'ignore']:\n template = (\"handle_unknown should be either 'error' or \"\n \"'ignore', got %s\")\n raise ValueError(template % self.handle_unknown)\n\n if self.encoding == 'ordinal' and self.handle_unknown == 'ignore':\n raise ValueError(\"handle_unknown='ignore' is not supported for\"\n \" encoding='ordinal'\")\n\n X = check_array(X, dtype=np.object, accept_sparse='csc', copy=True)\n n_samples, n_features = X.shape\n\n self._label_encoders_ = [LabelEncoder() for _ in range(n_features)]\n\n for i in range(n_features):\n le = self._label_encoders_[i]\n Xi = X[:, i]\n if self.categories == 'auto':\n le.fit(Xi)\n else:\n valid_mask = np.in1d(Xi, self.categories[i])\n if not np.all(valid_mask):\n if self.handle_unknown == 'error':\n diff = np.unique(Xi[~valid_mask])\n msg = (\"Found unknown categories {0} in column {1}\"\n \" during fit\".format(diff, i))\n raise ValueError(msg)\n le.classes_ = np.array(np.sort(self.categories[i]))\n\n self.categories_ = [le.classes_ for le in self._label_encoders_]\n\n return self\n\n def transform(self, X):\n \"\"\"Transform X using one-hot encoding.\n Parameters\n ----------\n X : array-like, shape [n_samples, n_features]\n The data to encode.\n Returns\n -------\n X_out : sparse matrix or a 2-d array\n Transformed input.\n \"\"\"\n X = check_array(X, accept_sparse='csc', dtype=np.object, copy=True)\n n_samples, n_features = X.shape\n X_int = np.zeros_like(X, dtype=np.int)\n X_mask = np.ones_like(X, dtype=np.bool)\n\n for i in range(n_features):\n valid_mask = np.in1d(X[:, i], self.categories_[i])\n\n if not np.all(valid_mask):\n if self.handle_unknown == 'error':\n diff = np.unique(X[~valid_mask, i])\n msg = (\"Found unknown categories {0} in column {1}\"\n \" during transform\".format(diff, i))\n raise ValueError(msg)\n else:\n # Set the problematic rows to an acceptable value and\n # continue `The rows are marked `X_mask` and will be\n # removed later.\n X_mask[:, i] = valid_mask\n X[:, i][~valid_mask] = self.categories_[i][0]\n X_int[:, i] = self._label_encoders_[i].transform(X[:, i])\n\n if self.encoding == 'ordinal':\n return X_int.astype(self.dtype, copy=False)\n\n mask = X_mask.ravel()\n n_values = [cats.shape[0] for cats in self.categories_]\n n_values = np.array([0] + n_values)\n indices = np.cumsum(n_values)\n\n column_indices = (X_int + indices[:-1]).ravel()[mask]\n row_indices = np.repeat(np.arange(n_samples, dtype=np.int32),\n n_features)[mask]\n data = np.ones(n_samples * n_features)[mask]\n\n out = sparse.csc_matrix((data, (row_indices, column_indices)),\n shape=(n_samples, indices[-1]),\n dtype=self.dtype).tocsr()\n if self.encoding == 'onehot-dense':\n return out.toarray()\n else:\n return out\n \ndef transform_data(data):\n data[\"AgeBucket\"] = data[\"Age\"] // 15 * 15\n data[\"RelativesOnboard\"] = data[\"SibSp\"] + data[\"Parch\"]",
"_____no_output_____"
],
[
"data_path = 'd:/project/ml/data/titanic/'\ntrain = pd.read_csv(data_path+'train.csv')\ntest = pd.read_csv(data_path+'test.csv')\n\ntrain.head()",
"_____no_output_____"
],
[
"train.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 891 entries, 0 to 890\nData columns (total 12 columns):\nPassengerId 891 non-null int64\nSurvived 891 non-null int64\nPclass 891 non-null int64\nName 891 non-null object\nSex 891 non-null object\nAge 714 non-null float64\nSibSp 891 non-null int64\nParch 891 non-null int64\nTicket 891 non-null object\nFare 891 non-null float64\nCabin 204 non-null object\nEmbarked 889 non-null object\ndtypes: float64(2), int64(5), object(5)\nmemory usage: 83.6+ KB\n"
],
[
"train.describe()",
"_____no_output_____"
],
[
"clean_data(train)\nclean_data(test)",
"_____no_output_____"
],
[
"y_train = train[\"Survived\"].values\nX_train = train[[\"Pclass\", \"Sex\", \"Age\", \"Fare\"]].values",
"_____no_output_____"
],
[
"decision_tree = tree.DecisionTreeClassifier(random_state= 1)\ndecision_tree = decision_tree.fit(X_train, y_train)\n\nprint(decision_tree.feature_importances_)\n# print(decision_tree.score(X_train, y_train))\nscores = model_selection.cross_val_score(decision_tree, X_train, y_train, scoring='accuracy', cv=10)\nscores.mean()",
"[ 0.11682997 0.23486832 0.31088095 0.23230415 0.04892927 0.02973698\n 0.02645037]\n"
],
[
"X_train = train[[\"Pclass\", \"Age\", \"Sex\", \"Fare\", \"SibSp\", \"Parch\", \"Embarked\"]].values\ndecision_tree_two = tree.DecisionTreeClassifier(\n max_depth = 7,\n min_samples_split = 2,\n random_state = 1)\ndecision_tree_two = decision_tree_two.fit(X_train, target)\nscores = model_selection.cross_val_score(decision_tree_two, X_train, y_train, scoring='accuracy', cv=10)\nscores.mean()",
"_____no_output_____"
],
[
"logistic = linear_model.LogisticRegression()\nlogistic.fit(X_train, y_train)\nscores = model_selection.cross_val_score(logistic, X_train, y_train, scoring='accuracy', cv=10)\nscores",
"_____no_output_____"
],
[
"gbm = ensemble.GradientBoostingClassifier(\n learning_rate = 0.005,\n min_samples_split=40,\n min_samples_leaf=1,\n max_features=2,\n max_depth=12,\n n_estimators=1500,\n subsample=0.75,\n random_state=1)\ngbm = gbm.fit(X_train, y_train)\n\nprint(gbm.feature_importances_)\nprint(gbm.score(X_train, y_train))\n\nscores = model_selection.cross_val_score(gbm, X_train, y_train, scoring='accuracy', cv=20)\nscores.mean()",
"[ 0.05732547 0.32300303 0.11482147 0.36183847 0.05657822 0.04783569\n 0.03859766]\n0.94051627385\n"
],
[
"X_test = test[[\"Pclass\", \"Age\", \"Sex\", \"Fare\", \"SibSp\", \"Parch\", \"Embarked\"]].values\nprediction_forest = forest.predict(X_test)\nwrite_prediction(prediction_forest, \"results/random_forest.csv\")",
"_____no_output_____"
],
[
"params = {'max_depth':7,'eta':0.1,'subsample':0.7,'silent':1,'booster':'gbtree','objective':'multi:softmax', 'num_class':2}\n\nplst = list(params.items())\nnum_rounds = 100 # 迭代次数\n\n# random_state is of big influence for val-auc\n\n# xgb_val = xgb.DMatrix(val_X, label=val_y)\nxgb_train = xgb.DMatrix(X_train, label=y_train)\nxgb_test = xgb.DMatrix(X_test)\n\nwatchlist = [(xgb_train, 'train')]\n# providedpreds.size=524974, label.size=262487\n# training model\n# early_stopping_rounds 当设置的迭代次数较大时,early_stopping_rounds 可在一定的迭代次数内准确率没有提升就停止训练\nmodel = xgb.train(plst, xgb_train, num_rounds, watchlist, early_stopping_rounds=100)\n\nprint(\"best best_ntree_limit\", model.best_ntree_limit)\nprint('train bin', np.bincount(y_train))",
"[0]\ttrain-merror:0.136925\nWill train until train-merror hasn't improved in 100 rounds.\n[1]\ttrain-merror:0.124579\n[2]\ttrain-merror:0.127946\n[3]\ttrain-merror:0.114478\n[4]\ttrain-merror:0.114478\n[5]\ttrain-merror:0.114478\n[6]\ttrain-merror:0.118967\n[7]\ttrain-merror:0.114478\n[8]\ttrain-merror:0.114478\n[9]\ttrain-merror:0.112233\n[10]\ttrain-merror:0.114478\n[11]\ttrain-merror:0.109989\n[12]\ttrain-merror:0.109989\n[13]\ttrain-merror:0.109989\n[14]\ttrain-merror:0.107744\n[15]\ttrain-merror:0.107744\n[16]\ttrain-merror:0.107744\n[17]\ttrain-merror:0.107744\n[18]\ttrain-merror:0.108866\n[19]\ttrain-merror:0.105499\n[20]\ttrain-merror:0.104377\n[21]\ttrain-merror:0.103255\n[22]\ttrain-merror:0.102132\n[23]\ttrain-merror:0.102132\n[24]\ttrain-merror:0.102132\n[25]\ttrain-merror:0.103255\n[26]\ttrain-merror:0.102132\n[27]\ttrain-merror:0.099888\n[28]\ttrain-merror:0.10101\n[29]\ttrain-merror:0.10101\n[30]\ttrain-merror:0.10101\n[31]\ttrain-merror:0.099888\n[32]\ttrain-merror:0.10101\n[33]\ttrain-merror:0.097643\n[34]\ttrain-merror:0.098765\n[35]\ttrain-merror:0.095398\n[36]\ttrain-merror:0.095398\n[37]\ttrain-merror:0.095398\n[38]\ttrain-merror:0.093154\n[39]\ttrain-merror:0.093154\n[40]\ttrain-merror:0.089787\n[41]\ttrain-merror:0.088664\n[42]\ttrain-merror:0.087542\n[43]\ttrain-merror:0.088664\n[44]\ttrain-merror:0.08642\n[45]\ttrain-merror:0.08642\n[46]\ttrain-merror:0.08642\n[47]\ttrain-merror:0.08642\n[48]\ttrain-merror:0.08642\n[49]\ttrain-merror:0.08642\n[50]\ttrain-merror:0.085297\n[51]\ttrain-merror:0.085297\n[52]\ttrain-merror:0.084175\n[53]\ttrain-merror:0.085297\n[54]\ttrain-merror:0.085297\n[55]\ttrain-merror:0.084175\n[56]\ttrain-merror:0.083053\n[57]\ttrain-merror:0.083053\n[58]\ttrain-merror:0.083053\n[59]\ttrain-merror:0.08193\n[60]\ttrain-merror:0.080808\n[61]\ttrain-merror:0.079686\n[62]\ttrain-merror:0.078563\n[63]\ttrain-merror:0.078563\n[64]\ttrain-merror:0.078563\n[65]\ttrain-merror:0.080808\n[66]\ttrain-merror:0.080808\n[67]\ttrain-merror:0.08193\n[68]\ttrain-merror:0.080808\n[69]\ttrain-merror:0.080808\n[70]\ttrain-merror:0.079686\n[71]\ttrain-merror:0.079686\n[72]\ttrain-merror:0.078563\n[73]\ttrain-merror:0.076319\n[74]\ttrain-merror:0.078563\n[75]\ttrain-merror:0.078563\n[76]\ttrain-merror:0.078563\n[77]\ttrain-merror:0.076319\n[78]\ttrain-merror:0.076319\n[79]\ttrain-merror:0.076319\n[80]\ttrain-merror:0.075196\n[81]\ttrain-merror:0.075196\n[82]\ttrain-merror:0.075196\n[83]\ttrain-merror:0.075196\n[84]\ttrain-merror:0.075196\n[85]\ttrain-merror:0.075196\n[86]\ttrain-merror:0.074074\n[87]\ttrain-merror:0.075196\n[88]\ttrain-merror:0.075196\n[89]\ttrain-merror:0.075196\n[90]\ttrain-merror:0.075196\n[91]\ttrain-merror:0.075196\n[92]\ttrain-merror:0.075196\n[93]\ttrain-merror:0.075196\n[94]\ttrain-merror:0.075196\n[95]\ttrain-merror:0.075196\n[96]\ttrain-merror:0.075196\n[97]\ttrain-merror:0.074074\n[98]\ttrain-merror:0.074074\n[99]\ttrain-merror:0.074074\nbest best_ntree_limit 87\ntrain bin [549 342]\n"
],
[
"predict = model.predict(xgb_test)\npredict.astype(int)",
"_____no_output_____"
],
[
"model = xgb.XGBClassifier()\nscores = model_selection.cross_val_score(model, X_train, y_train, scoring='accuracy', cv=20)\nscores.mean()",
"_____no_output_____"
],
[
"from sklearn.base import BaseEstimator, TransformerMixin\n\n# A class to select numerical or categorical columns \n# since Scikit-Learn doesn't handle DataFrames yet\nclass DataFrameSelector(BaseEstimator, TransformerMixin):\n def __init__(self, attribute_names):\n self.attribute_names = attribute_names\n def fit(self, X, y=None):\n return self\n def transform(self, X):\n return X[self.attribute_names]",
"_____no_output_____"
],
[
"from sklearn.pipeline import Pipeline\nfrom sklearn.preprocessing import Imputer\n\nimputer = Imputer(strategy=\"median\")\n\nnum_pipeline = Pipeline([\n (\"select_numeric\", DataFrameSelector([\"Age\", \"AgeBucket\",\"SibSp\", \"Parch\", \"RelativesOnboard\", \"Fare\"])),\n (\"imputer\", Imputer(strategy=\"median\")),\n ])",
"_____no_output_____"
],
[
"num_pipeline.fit_transform(train)",
"_____no_output_____"
],
[
"# Inspired from stackoverflow.com/questions/25239958\nclass MostFrequentImputer(BaseEstimator, TransformerMixin):\n def fit(self, X, y=None):\n self.most_frequent = pd.Series([X[c].value_counts().index[0] for c in X],\n index=X.columns)\n return self\n def transform(self, X, y=None):\n return X.fillna(self.most_frequent)",
"_____no_output_____"
],
[
"cat_pipeline = Pipeline([\n (\"select_cat\", DataFrameSelector([\"Pclass\", \"Sex\", \"Embarked\"])),\n (\"imputer\", MostFrequentImputer()),\n (\"cat_encoder\", CategoricalEncoder(encoding='onehot-dense')),\n ])",
"_____no_output_____"
],
[
"cat_pipeline.fit_transform(train)",
"_____no_output_____"
],
[
"from sklearn.pipeline import FeatureUnion\npreprocess_pipeline = FeatureUnion(transformer_list=[\n (\"num_pipeline\", num_pipeline),\n (\"cat_pipeline\", cat_pipeline),\n ])",
"_____no_output_____"
],
[
"X_train = preprocess_pipeline.fit_transform(train)\nX_train",
"_____no_output_____"
],
[
"y_train = train[\"Survived\"]",
"_____no_output_____"
],
[
"from sklearn.ensemble import RandomForestClassifier\nfrom sklearn.model_selection import cross_val_score\n\nforest_clf = RandomForestClassifier(random_state=42)\nscores = cross_val_score(forest_clf, X_train, y_train, cv=10)\nscores.mean()",
"_____no_output_____"
],
[
"train[\"AgeBucket\"] = train[\"Age\"] // 15 * 15\ntrain[[\"AgeBucket\", \"Survived\"]].groupby(['AgeBucket']).mean()",
"_____no_output_____"
],
[
"train[\"RelativesOnboard\"] = train[\"SibSp\"] + train[\"Parch\"]\ntrain[[\"RelativesOnboard\", \"Survived\"]].groupby(['RelativesOnboard']).mean()",
"_____no_output_____"
],
[
"# gbm\ntrain = pd.read_csv(data_path+'train.csv')\ntest = pd.read_csv(data_path+'test.csv')\ntransform_data(train)\ntransform_data(test)\nX_train = preprocess_pipeline.fit_transform(train)\n\ngbm = ensemble.GradientBoostingClassifier(\n learning_rate = 0.005,\n min_samples_split=40,\n min_samples_leaf=1,\n max_features=2,\n max_depth=12,\n n_estimators=1500,\n subsample=0.75,\n random_state=1)\ngbm = gbm.fit(X_train, y_train)\n\nprint(gbm.feature_importances_)\nprint(gbm.score(X_train, y_train))\n\n# scores = model_selection.cross_val_score(gbm, X_train, y_train, scoring='accuracy', cv=20)\n# scores.mean()\n# 0.827",
"[ 0.1509222 0.12154798 0.45165627 0.0267628 0.01684683 0.03448312\n 0.06623131 0.07221939 0.02101543 0.01435315 0.02396153]\n0.910213243547\n"
],
[
"X_test = preprocess_pipeline.fit_transform(test)\npredict = gbm.predict(X_test)\nwrite_prediction(predict, 'results/result.csv')\n# gbm,并没有提高成绩,0.76076",
"_____no_output_____"
],
[
"# 随机森林\ntrain = pd.read_csv(data_path+'train.csv')\ntest = pd.read_csv(data_path+'test.csv')\ntransform_data(train)\ntransform_data(test)\nX_train = preprocess_pipeline.fit_transform(train)\n\nforest = ensemble.RandomForestClassifier(\n max_depth = 7,\n min_samples_split = 4,\n n_estimators = 1000,\n random_state = 1,\n n_jobs = -1\n)\n\nscores = model_selection.cross_val_score(forest, X_train, y_train, scoring='accuracy', cv=10)\nscores.mean()",
"_____no_output_____"
],
[
"forest = forest.fit(X_train, y_train)",
"_____no_output_____"
],
[
"X_test = preprocess_pipeline.fit_transform(test)\npredict = forest.predict(X_test)\nwrite_prediction(predict, 'results/result.csv')\n# 随机森林,成绩提高到了0.79",
"_____no_output_____"
],
[
"from sklearn.metrics import accuracy_score",
"_____no_output_____"
],
[
"cross_val_score?",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecc2dc85f74fd92d97b808d321bd987e0e609dc2 | 11,658 | ipynb | Jupyter Notebook | Spring2021-J/Problem-Sets/ProblemSet1/ProblemSet1_2021.ipynb | ds-modules/ENVECON-118 | 2a24f458a1bb17db3e3e0234fd22c743b82f7b63 | [
"BSD-3-Clause"
] | 2 | 2020-09-10T13:45:34.000Z | 2021-11-01T21:41:59.000Z | Spring2021-J/Problem-Sets/ProblemSet1/ProblemSet1_2021.ipynb | ds-modules/ENVECON-118 | 2a24f458a1bb17db3e3e0234fd22c743b82f7b63 | [
"BSD-3-Clause"
] | 1 | 2021-01-22T17:02:59.000Z | 2021-06-20T14:03:54.000Z | Spring2021-J/Problem-Sets/ProblemSet1/ProblemSet1_2021.ipynb | ds-modules/ENVECON-118 | 2a24f458a1bb17db3e3e0234fd22c743b82f7b63 | [
"BSD-3-Clause"
] | 7 | 2019-11-06T20:55:27.000Z | 2021-06-20T08:14:41.000Z | 35.327273 | 662 | 0.606365 | [
[
[
"# EEP/IAS 118 - Introductory Applied Econometrics\n## Problem Set 1, Spring 2021, Villas-Boas\n#### <span style=\"text-decoration: underline\">Due 9:30am on February 4, 2021</span> \n\n\nSubmit materials (all handwritten/typed answers, Excel workbooks, and R reports) as one combined pdf on [Gradescope](https://www.gradescope.com/courses/226571). All students currently on the EEP118 bCourses have been added using the bCourses email. If you do not have access to the Gradescope course, please reach out to the GSI's.\n\nFor help combining pdf's, see the recent announcement on bCourses.",
"_____no_output_____"
],
[
"## Exercise 1 (Excel)\n**Relationship between Gasoline Consumption Data and Price of Gasoline in 18 OECD countries.** \n\nWe will use data from Baltagi (2005) on gasoline consumption for 18 OECD countries. The original data span 19 years. In this first problem set we will only use the year 1960. \n\nThis exercise is to be completed using Excel. Looking at the first graph in the paper, there appears to be an association between Gasoline consumption per car and the price of gasoline. We will establish a simple linear relationship on a subset of 9 countries at a time.\n\n*Note: in economics, log always refers to the natural log, ln().*",
"_____no_output_____"
],
[
"\n<center><b> Table 1: Log of Gasoline Consumption Per Car and Log of Price of Gasoline, Sample 1</b></center>\n\n|CountryName\t|\tlog of Gasoline Consumption per Car\t|\tlog of Gasoline Price\t|\n|-----------|---------------|---------------|\n|sample 1\t|\tlog of Y\t|\tlog of X\t|\n|AUSTRIA| 4.173244195|-0.334547613|\n|BELGIUM|4.16401597|-0.165709611|\n|CANADA|4.855238441|-0.972106499|\n|DENMARK|4.50198595|-0.195702601|\n|FRANCE|3.907704233|-0.019598332|\n|GERMANY|3.916953172|-0.185910784|\n|GREECE|5.037405535|-0.083547398|\n|IRELAND|4.270420603|-0.076481181|\n|ITALY|4.050728238|0.165077076",
"_____no_output_____"
],
[
"(a) Use Excel to create a scatter plot of these observations. Don't forget to (1) label the axes and their units, and (2) title your graph. **You should use the tables provided here for these calculations, not the actual observations from the .csv data file.**",
"_____no_output_____"
],
[
"(b) This question has **two parts**. \n\nFirst: Estimate the linear relationship between the log of Gasoline\nconsumption per car (log(Y)) and the log of gasoline prices (log(X)) by OLS, showing all intermediate\ncalculations as we saw in the lecture 3 slides (use Excel to create the table and show all the steps).\n\nSecond: interpret the value of the estimated parameters $\\beta_0$ and $\\beta_1$.\n\n$$ \\widehat{log (Y_i)} = \\hat{\\beta_0} + \\hat{\\beta_1} log(X_i) \\ \\ \\ \\ \\ \\ \\text{i = \\{first 9 countries\\}}$$",
"_____no_output_____"
],
[
"➡️ Type your answer to _Exercise 1 (b) Second Part_ here (replacing this text)",
"_____no_output_____"
],
[
"(c) In your table, compute the fitted value and the residual for each observation, and verify that the residuals (approximately) sum to 0.",
"_____no_output_____"
],
[
"(d) According to the estimated relation, what is the predicted $\\hat{Y}$ (**level**, not log) for a country with a log price of -2? (Pay attention to units)",
"_____no_output_____"
],
[
"➡️ Type your answer to _Exercise 1 (d)_ here (replacing this text)",
"_____no_output_____"
],
[
"(e) How much of the variation in per capita log gasoline consumption in these 9 countries is explained by the log of price of gasoline in the countries?",
"_____no_output_____"
],
[
"➡️ Type your answer to _Exercise 1 (e)_ here (replacing this text)",
"_____no_output_____"
],
[
"<center><b> Table 2: Log of Gasoline Consumption Per Car and Log of Price of Gasoline, Sample 2</b></center>\n\n|CountryName\t|\tlog of Gasoline Consumption per Car\t|\tlog of Gasoline Price\t|\n|-----------|---------------|---------------|\n|sample 2\t|\tlog of Y\t|\tlog of X\t|\n|JAPAN|5.995286556|-0.14532271|\n|NETHERLANDS|4.646268005|-0.201484804|\n|NORWAY|4.43504067|-0.139689574|\n|SPAIN|4.749409172|1.125310702|\n|SWEDEN|4.063010036|-2.52041588|\n|SWITZERLAND|4.397621493|-0.82321833|\n|TURKEY|6.129552849|-0.253408214|\n|U.K.|4.100244284|-0.391085814|\n|U.S.A.|4.823964512|-1.121114893| \n\n",
"_____no_output_____"
],
[
"(f) Repeat exercise (b) for one additional set of 9 countries below. **You should use Table 2 provided\nabove for these calculations, not the actual observations from the .csv data file.**",
"_____no_output_____"
],
[
"➡️ Type your answer to _Exercise 1 (e) Second Part_ here (replacing this text)",
"_____no_output_____"
],
[
"(g) Do your estimates of $\\hat{\\beta_0}$ and $\\hat{\\beta_1}$ change between Tables 1, and 2? Why?\n",
"_____no_output_____"
],
[
"➡️ Type your answer to _Exercise 1 (g)_ here (replacing this text)",
"_____no_output_____"
],
[
"(h) Save a copy of your Excel workbook as a pdf (OLS tables and scatter plot) to combine with the later work.",
"_____no_output_____"
],
[
"## Exercise 2 (Functional Forms)",
"_____no_output_____"
],
[
"(a) Suppose you estimate alternative specifications as given below for the year of 1972 using all countries:\n\n$$ \\text{A linear relationship:} ~~~~\\hat{Y_i} = 121 + 2.23 X_i$$\n$$ \\text{A linear-log relationship:} ~~~~\\hat{Y_i} = 4.5 + 0.06 \\log(X)_i$$\n$$ \\text{A log-log relationship:} ~~~~\\widehat{\\log(Y)}_i = 4 + 0.09 \\log(X)_i$$\n\nNote that it is convention to always use the natural log.\n\n i. Interpret the parameter on gasoline price X (or log of gasoline price log(X)) in each of these equations.\n\n ii. What is the predicted per car gasoline consumption in dollars for a country with a gasoline price of 2 in each of these equations?\n",
"_____no_output_____"
],
[
"➡️ Type your answer to _Exercise 2 (a) i_ here (replacing this text)",
"_____no_output_____"
],
[
"➡️ Type your answer to _Exercise 2 (a) ii_ here (replacing this text)",
"_____no_output_____"
],
[
"## Exercise 3. Importing Data into R and Basic R First Commands \n\nFor the purposes of this class, we will be primarily Berkeley's _Datahub_ to conduct our analysis remotely using these notebooks.\n\nIf instead you already have an installation of R/RStudio on your personal computer and prefer to work offline, you can download the data for this assignment from bCourses (Make sure to install/update all packages mentioned in the problem sets in order to prevent issues regarding deprecated or outdated packages). The data files can be accessed directly through $Datahub$ and do not require you to install anything on your computer. This exercise is designed to get you familiar with accessing the service, loading data, and obtaining summary statistics. To start off, we're going to use Jupyter notebooks to help familiarize you with some R commands. \n\n*Note: [Coding Bootcamp Part 1](https://bcourses.berkeley.edu/courses/1502259/external_tools/70734) covers all necessary R methods.",
"_____no_output_____"
],
[
"(a) To access the Jupyter notebook for this problem set on Datahub, click the following link:\n\n*Skip! You are already here - nice work.*\n",
"_____no_output_____"
],
[
"(b) Load the data file *dataPset1_1960.csv* into R (since this is a \".csv\" file, you should use the `read.csv()` command).",
"_____no_output_____"
]
],
[
[
"# insert code here",
"_____no_output_____"
]
],
[
[
"(c) Provide basic summary statistics on the log of Gas Consumption per car (*LGASPCAR*) in the dataframe. Use the `summary()` command. This command is part of base R, so you do not need to load any packages before using it. What is the median value of log gasoline consumption per car?",
"_____no_output_____"
]
],
[
[
"# insert code here",
"_____no_output_____"
]
],
[
[
"(d) Next, generate custom summary statistics on the Log of Gasoline Price Variable(*LRPMG*) using the `summarise()` command provided by ***dplyr***. You will need to call the ***tidyverse*** package with the `library()` command to use it (***tidyverse*** is a collection of packages designed for data science. It includes ***dplyr*** and several other packages we'll use this term).",
"_____no_output_____"
]
],
[
[
"# insert code here",
"_____no_output_____"
]
],
[
[
"(e) Create a scatter plot of the *LGASPCAR* and *LRPMG* data. Use\n\n`figureAsked <- plot(my_data$LRPMG, my_data$LGASPCAR, \n main = \"Scatter of Log Y on Log X\",\n xlab = \"Log(X)=Log of Gas Price\", \n ylab = \"Log Y = Log of Gas Consumption per Car\")`\n\n*Note:* Make sure to run the code cell to print the scatterplot in the notebook.",
"_____no_output_____"
]
],
[
[
"# insert code here",
"_____no_output_____"
]
],
[
[
"(f) Save a pdf to your computer (note: this can be done by going to **File > Print Preview** in the menu and choosing to \"print\" the new tab as a pdf with Ctrl + P) and combine it with your excel workbook from Exercise 1 for submission on Gradescope.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
ecc2eeb8e8f2b941be4b9239d39533ddf28df03a | 218,704 | ipynb | Jupyter Notebook | 1 - Natural Language Processing with Classification and Vector Spaces/Week 2/C1W2_L1_Visualizing likelihoods and confidence ellipses.ipynb | nirav8403/coursera-natural-language-processing-specialization | a346be761597cc14226bfe21bbe1079c96c77376 | [
"MIT"
] | 116 | 2020-07-22T15:47:17.000Z | 2022-03-25T17:36:30.000Z | 1 - Natural Language Processing with Classification and Vector Spaces/Week 2/C1W2_L1_Visualizing likelihoods and confidence ellipses.ipynb | nirav8403/coursera-natural-language-processing-specialization | a346be761597cc14226bfe21bbe1079c96c77376 | [
"MIT"
] | null | null | null | 1 - Natural Language Processing with Classification and Vector Spaces/Week 2/C1W2_L1_Visualizing likelihoods and confidence ellipses.ipynb | nirav8403/coursera-natural-language-processing-specialization | a346be761597cc14226bfe21bbe1079c96c77376 | [
"MIT"
] | 183 | 2020-08-27T10:24:21.000Z | 2022-03-18T17:05:26.000Z | 602.490358 | 80,180 | 0.936371 | [
[
[
"# Visualizing Naive Bayes\n\nIn this lab, we will cover an essential part of data analysis that has not been included in the lecture videos. As we stated in the previous module, data visualization gives insight into the expected performance of any model. \n\nIn the following exercise, you are going to make a visual inspection of the tweets dataset using the Naïve Bayes features. We will see how we can understand the log-likelihood ratio explained in the videos as a pair of numerical features that can be fed in a machine learning algorithm. \n\nAt the end of this lab, we will introduce the concept of __confidence ellipse__ as a tool for representing the Naïve Bayes model visually.",
"_____no_output_____"
]
],
[
[
"import numpy as np # Library for linear algebra and math utils\nimport pandas as pd # Dataframe library\n\nimport matplotlib.pyplot as plt # Library for plots\nfrom utils import confidence_ellipse # Function to add confidence ellipses to charts",
"_____no_output_____"
]
],
[
[
" ## Calculate the likelihoods for each tweet\n\nFor each tweet, we have calculated the likelihood of the tweet to be positive and the likelihood to be negative. We have calculated in different columns the numerator and denominator of the likelihood ratio introduced previously. \n\n$$log \\frac{P(tweet|pos)}{P(tweet|neg)} = log(P(tweet|pos)) - log(P(tweet|neg)) $$\n$$positive = log(P(tweet|pos)) = \\sum_{i=0}^{n}{log P(W_i|pos)}$$\n$$negative = log(P(tweet|neg)) = \\sum_{i=0}^{n}{log P(W_i|neg)}$$\n\nWe did not include the code because this is part of this week's assignment. The __'bayes_features.csv'__ file contains the final result of this process. \n\nThe cell below loads the table in a dataframe. Dataframes are data structures that simplify the manipulation of data, allowing filtering, slicing, joining, and summarization.",
"_____no_output_____"
]
],
[
[
"data = pd.read_csv('bayes_features.csv'); # Load the data from the csv file\n\ndata.head(5) # Print the first 5 tweets features. Each row represents a tweet",
"_____no_output_____"
],
[
"# Plot the samples using columns 1 and 2 of the matrix\n\nfig, ax = plt.subplots(figsize = (8, 8)) #Create a new figure with a custom size\n\ncolors = ['red', 'green'] # Define a color palete\n\n# Color base on sentiment\nax.scatter(data.positive, data.negative, \n c=[colors[int(k)] for k in data.sentiment], s = 0.1, marker='*') # Plot a dot for each tweet\n\n# Custom limits for this chart\nplt.xlim(-250,0)\nplt.ylim(-250,0)\n\nplt.xlabel(\"Positive\") # x-axis label\nplt.ylabel(\"Negative\") # y-axis label",
"_____no_output_____"
]
],
[
[
"# Using Confidence Ellipses to interpret Naïve Bayes\n\nIn this section, we will use the [confidence ellipse]( https://matplotlib.org/3.1.1/gallery/statistics/confidence_ellipse.html#sphx-glr-gallery-statistics-confidence-ellipse-py) to give us an idea of what the Naïve Bayes model see.\n\nA confidence ellipse is a way to visualize a 2D random variable. It is a better way than plotting the points over a cartesian plane because, with big datasets, the points can overlap badly and hide the real distribution of the data. Confidence ellipses summarize the information of the dataset with only four parameters: \n\n* Center: It is the numerical mean of the attributes\n* Height and width: Related with the variance of each attribute. The user must specify the desired amount of standard deviations used to plot the ellipse. \n* Angle: Related with the covariance among attributes.\n\nThe parameter __n_std__ stands for the number of standard deviations bounded by the ellipse. Remember that for normal random distributions:\n\n* About 68% of the area under the curve falls within 1 standard deviation around the mean.\n* About 95% of the area under the curve falls within 2 standard deviations around the mean.\n* About 99.7% of the area under the curve falls within 3 standard deviations around the mean.\n\n<img src=std.jpg width=\"400\" >\n\n\nIn the next chart, we will plot the data and its corresponding confidence ellipses using 2 std and 3 std. ",
"_____no_output_____"
]
],
[
[
"# Plot the samples using columns 1 and 2 of the matrix\nfig, ax = plt.subplots(figsize = (8, 8))\n\ncolors = ['red', 'green'] # Define a color palete\n\n# Color base on sentiment\n\nax.scatter(data.positive, data.negative, c=[colors[int(k)] for k in data.sentiment], s = 0.1, marker='*') # Plot a dot for tweet\n\n# Custom limits for this chart\nplt.xlim(-200,40) \nplt.ylim(-200,40)\n\nplt.xlabel(\"Positive\") # x-axis label\nplt.ylabel(\"Negative\") # y-axis label\n\ndata_pos = data[data.sentiment == 1] # Filter only the positive samples\ndata_neg = data[data.sentiment == 0] # Filter only the negative samples\n\n# Print confidence ellipses of 2 std\nconfidence_ellipse(data_pos.positive, data_pos.negative, ax, n_std=2, edgecolor='black', label=r'$2\\sigma$' )\nconfidence_ellipse(data_neg.positive, data_neg.negative, ax, n_std=2, edgecolor='orange')\n\n# Print confidence ellipses of 3 std\nconfidence_ellipse(data_pos.positive, data_pos.negative, ax, n_std=3, edgecolor='black', linestyle=':', label=r'$3\\sigma$')\nconfidence_ellipse(data_neg.positive, data_neg.negative, ax, n_std=3, edgecolor='orange', linestyle=':')\nax.legend()\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"In the next cell, we will modify the features of the samples with positive sentiment (1), in a way that the two distributions overlap. In this case, the Naïve Bayes method will produce a lower accuracy than with the original data.",
"_____no_output_____"
]
],
[
[
"data2 = data.copy() # Copy the whole data frame\n\n# The following 2 lines only modify the entries in the data frame where sentiment == 1\ndata2.negative[data.sentiment == 1] = data2.negative * 1.5 + 50 # Modifiy the negative attribute\ndata2.positive[data.sentiment == 1] = data2.positive / 1.5 - 50 # Modifiy the positive attribute ",
"_____no_output_____"
]
],
[
[
"Now let us plot the two distributions and the confidence ellipses",
"_____no_output_____"
]
],
[
[
"# Plot the samples using columns 1 and 2 of the matrix\nfig, ax = plt.subplots(figsize = (8, 8))\n\ncolors = ['red', 'green'] # Define a color palete\n\n# Color base on sentiment\n\n#data.negative[data.sentiment == 1] = data.negative * 2\n\nax.scatter(data2.positive, data2.negative, c=[colors[int(k)] for k in data2.sentiment], s = 0.1, marker='*') # Plot a dot for tweet\n# Custom limits for this chart\nplt.xlim(-200,40) \nplt.ylim(-200,40)\n\nplt.xlabel(\"Positive\") # x-axis label\nplt.ylabel(\"Negative\") # y-axis label\n\ndata_pos = data2[data2.sentiment == 1] # Filter only the positive samples\ndata_neg = data[data2.sentiment == 0] # Filter only the negative samples\n\n# Print confidence ellipses of 2 std\nconfidence_ellipse(data_pos.positive, data_pos.negative, ax, n_std=2, edgecolor='black', label=r'$2\\sigma$' )\nconfidence_ellipse(data_neg.positive, data_neg.negative, ax, n_std=2, edgecolor='orange')\n\n# Print confidence ellipses of 3 std\nconfidence_ellipse(data_pos.positive, data_pos.negative, ax, n_std=3, edgecolor='black', linestyle=':', label=r'$3\\sigma$')\nconfidence_ellipse(data_neg.positive, data_neg.negative, ax, n_std=3, edgecolor='orange', linestyle=':')\nax.legend()\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"To give away: Understanding the data allows us to predict if the method will perform well or not. Alternatively, it will allow us to understand why it worked well or bad.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
ecc2fbd4b2c0b5ae61923793e04004900a3aa2c6 | 67,070 | ipynb | Jupyter Notebook | examples/2. REINFORCE TopK Off Policy Correction/1. Basic Reinforce with RecNN.ipynb | goutham8343/RecNN | 0bdb62f4c07fefbb95a99b4be71093cbfb93c745 | [
"Apache-2.0"
] | 1 | 2021-04-10T08:21:21.000Z | 2021-04-10T08:21:21.000Z | examples/2. REINFORCE TopK Off Policy Correction/1. Basic Reinforce with RecNN.ipynb | codeoverdoze/RecNN | 0bdb62f4c07fefbb95a99b4be71093cbfb93c745 | [
"Apache-2.0"
] | null | null | null | examples/2. REINFORCE TopK Off Policy Correction/1. Basic Reinforce with RecNN.ipynb | codeoverdoze/RecNN | 0bdb62f4c07fefbb95a99b4be71093cbfb93c745 | [
"Apache-2.0"
] | null | null | null | 263.019608 | 56,144 | 0.906784 | [
[
[
"# Reinforce with recnn\n\nThe following code contains an implementation of the REINFORCE algorithm, **without Off Policy Correction, LSTM state encoder, and Noise Contrastive Estimation**. Look for these in other notebooks.\n\nAlso, I am not google staff, and unlike the paper authors, I cannot have online feedback concerning the recommendations.\n\n**I use actor-critic for reward assigning.** In a real-world scenario that would be done through interactive user feedback, but here I use a neural network (critic) that aims to emulate it.\n\nnote: due to implementation details, this algorithm currently doesn't support testing",
"_____no_output_____"
]
],
[
[
"import torch\nimport torch.nn as nn\nfrom torch.utils.tensorboard import SummaryWriter\n\nimport numpy as np\nimport pandas as pd\nfrom tqdm.auto import tqdm\n\nfrom IPython.display import clear_output\nimport matplotlib.pyplot as plt\n%matplotlib inline\n\n\n# == recnn ==\nimport sys\nsys.path.append(\"../../\")\nimport recnn\n\ncuda = torch.device('cuda')\n\n# ---\nframe_size = 10\nbatch_size = 10\nn_epochs = 100\nplot_every = 30\nnum_items = 5000 # n items to recommend. Can be adjusted for your vram \n# --- \n\ntqdm.pandas()\n\n\nfrom jupyterthemes import jtplot\njtplot.style(theme='grade3')",
"/home/dev/.local/lib/python3.7/site-packages/tqdm/std.py:656: FutureWarning: The Panel class is removed from pandas. Accessing it from the top-level namespace will also be removed in the next version\n from pandas import Panel\n"
],
[
"def embed_batch(batch, item_embeddings_tensor, *args, **kwargs):\n return recnn.data.batch_contstate_discaction(batch, item_embeddings_tensor,\n frame_size=frame_size, num_items=num_items)\n\n \ndef prepare_dataset(**kwargs):\n recnn.data.build_data_pipeline([recnn.data.truncate_dataset,\n recnn.data.prepare_dataset], reduce_items_to=num_items, **kwargs)\n \n# embeddgings: https://drive.google.com/open?id=1EQ_zXBR3DKpmJR3jBgLvt-xoOvArGMsL\nenv = recnn.data.env.FrameEnv('../../data/embeddings/ml20_pca128.pkl',\n '../../data/ml-20m/ratings.csv', frame_size, batch_size,\n embed_batch=embed_batch, prepare_dataset=prepare_dataset,\n num_workers = 0)",
"action space is reduced to 26744 - 21744 = 5000\n"
],
[
"value_net = recnn.nn.Critic(1290, num_items, 2048, 54e-2).to(cuda)\npolicy_net = recnn.nn.DiscreteActor(1290, num_items, 2048).to(cuda)\n\nreinforce = recnn.nn.Reinforce(policy_net, value_net)\nreinforce = reinforce.to(cuda)\n\nreinforce.writer = SummaryWriter(log_dir='../../runs')\nplotter = recnn.utils.Plotter(reinforce.loss_layout, [['value', 'policy']],)",
"_____no_output_____"
],
[
"for epoch in range(n_epochs):\n for batch in tqdm(env.train_dataloader):\n loss = reinforce.update(batch)\n reinforce.step()\n if loss:\n plotter.log_losses(loss)\n if reinforce._step % plot_every == 0:\n clear_output(True)\n print('step', reinforce._step)\n plotter.plot_loss()\n if reinforce._step > 1000:\n pass\n # assert False\n ",
"step 1980\n"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
ecc300efcbca6aaa5159764a3f041e2c62aeff9a | 41,637 | ipynb | Jupyter Notebook | NearestNeighbors/.ipynb_checkpoints/NearestNeighborsWorkBook-checkpoint.ipynb | AstroLudwig/MachineLearningClass | 8a641878dfd1883c0208316845a13fc7f950775f | [
"MIT"
] | 1 | 2019-04-27T21:43:45.000Z | 2019-04-27T21:43:45.000Z | NearestNeighbors/.ipynb_checkpoints/NearestNeighborsWorkBook-checkpoint.ipynb | AstroLudwig/MachineLearningClass | 8a641878dfd1883c0208316845a13fc7f950775f | [
"MIT"
] | null | null | null | NearestNeighbors/.ipynb_checkpoints/NearestNeighborsWorkBook-checkpoint.ipynb | AstroLudwig/MachineLearningClass | 8a641878dfd1883c0208316845a13fc7f950775f | [
"MIT"
] | null | null | null | 146.609155 | 36,108 | 0.901002 | [
[
[
"!jt -l",
"Available Themes: \n chesterish\n grade3\n gruvboxd\n gruvboxl\n monokai\n oceans16\n onedork\n solarizedd\n solarizedl\n"
],
[
"!jt -t chesterish",
"_____no_output_____"
],
[
"%matplotlib inline",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt \nimport numpy as np \nimport pandas as pd \nimport seaborn as sns\nfrom sklearn.neighbors import KNeighborsClassifier\nfrom sklearn.model_selection import KFold",
"_____no_output_____"
],
[
"df = pd.read_csv(\"../DataSet/Merged_Reduced_SDSS_GZ_Catalog.csv\")\n# Drop unknowns\ndf = df.drop(df[df[\"P_DK\"]>0.5].index)\ndf = df.drop(df[np.isnan(df[\"dered_g\"])].index)\ndf.reset_index()\nconditions = [(df[\"P_EL\"] > df[\"P_CS\"]), (df[\"P_EL\"] < df[\"P_CS\"])]\ncases = [\"Elliptical\",\"Spiral\"]\ndf[\"Type\"] = np.select(conditions,cases,default=\"Unknown\")\ndf[\"dered_g-dered_r\"] = df[\"dered_g\"] - df[\"dered_r\"]",
"_____no_output_____"
],
[
"XX = np.zeros([len(df.dered_g),2]); XX[:,0] = df[\"dered_g-dered_r\"]\nXX[:,1] = np.array(df[\"dered_g\"]); yy = df.Type",
"_____no_output_____"
],
[
"sns.scatterplot(x=\"dered_g-dered_r\",y=\"dered_g\",data=df,hue=\"Type\",facecolor='w')\nplt.show()",
"_____no_output_____"
],
[
"neigh = KNeighborsClassifier(n_neighbors=5)",
"_____no_output_____"
],
[
"len(XX)",
"_____no_output_____"
],
[
"classifier = neigh.fit(XX,yy)",
"_____no_output_____"
],
[
"classifier.predict(XX)",
"_____no_output_____"
],
[
"x,y=np.meshgrid(np.arange(-3,13,0.1),np.arange(10,35))",
"_____no_output_____"
],
[
"np.shape(x)",
"_____no_output_____"
],
[
"test_x = np.zeros([len(x.flatten()),2]); test_x[:,0] = x.flatten(); test_x[:,1] = y.flatten()",
"_____no_output_____"
],
[
"test_x",
"_____no_output_____"
],
[
"len(y.flatten())",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecc3072bd1753b2d8e4e75574b351eafd3171bc6 | 40,999 | ipynb | Jupyter Notebook | Data Warehousing/Data Warehousing Exercises/OLAP Cubes /L1 E2 - 3 - Grouping Sets.ipynb | ivy-Ruxin-Tong/Udacity_DataEngineering | b39bdf2b8510ce4182b5a68878ad640c9c22e80b | [
"MIT"
] | null | null | null | Data Warehousing/Data Warehousing Exercises/OLAP Cubes /L1 E2 - 3 - Grouping Sets.ipynb | ivy-Ruxin-Tong/Udacity_DataEngineering | b39bdf2b8510ce4182b5a68878ad640c9c22e80b | [
"MIT"
] | null | null | null | Data Warehousing/Data Warehousing Exercises/OLAP Cubes /L1 E2 - 3 - Grouping Sets.ipynb | ivy-Ruxin-Tong/Udacity_DataEngineering | b39bdf2b8510ce4182b5a68878ad640c9c22e80b | [
"MIT"
] | null | null | null | 38.424555 | 263 | 0.537013 | [
[
[
"# Exercise 02 - OLAP Cubes - Grouping Sets",
"_____no_output_____"
],
[
"All the databases table in this demo are based on public database samples and transformations\n- `Sakila` is a sample database created by `MySql` [Link](https://dev.mysql.com/doc/sakila/en/sakila-structure.html)\n- The postgresql version of it is called `Pagila` [Link](https://github.com/devrimgunduz/pagila)\n- The facts and dimension tables design is based on O'Reilly's public dimensional modelling tutorial schema [Link](http://archive.oreilly.com/oreillyschool/courses/dba3/index.html)\n\nStart by connecting to the database by running the cells below. If you are coming back to this exercise, then uncomment and run the first cell to recreate the database. If you recently completed the slicing and dicing exercise, then skip to the second cell.",
"_____no_output_____"
]
],
[
[
"!PGPASSWORD=student createdb -h 127.0.0.1 -U student pagila_star\n!PGPASSWORD=student psql -q -h 127.0.0.1 -U student -d pagila_star -f Data/pagila-star.sql",
"createdb: database creation failed: ERROR: database \"pagila_star\" already exists\n set_config \n------------\n \n(1 row)\n\npsql:Data/pagila-star.sql:42: ERROR: type \"mpaa_rating\" already exists\npsql:Data/pagila-star.sql:52: ERROR: type \"year\" already exists\npsql:Data/pagila-star.sql:69: ERROR: function \"_group_concat\" already exists with same argument types\npsql:Data/pagila-star.sql:86: ERROR: function \"film_in_stock\" already exists with same argument types\npsql:Data/pagila-star.sql:103: ERROR: function \"film_not_in_stock\" already exists with same argument types\npsql:Data/pagila-star.sql:148: ERROR: function \"get_customer_balance\" already exists with same argument types\npsql:Data/pagila-star.sql:170: ERROR: function \"inventory_held_by_customer\" already exists with same argument types\npsql:Data/pagila-star.sql:207: ERROR: function \"inventory_in_stock\" already exists with same argument types\npsql:Data/pagila-star.sql:225: ERROR: function \"last_day\" already exists with same argument types\npsql:Data/pagila-star.sql:240: ERROR: function \"last_updated\" already exists with same argument types\npsql:Data/pagila-star.sql:264: ERROR: relation \"customer\" already exists\npsql:Data/pagila-star.sql:328: ERROR: function \"rewards_report\" already exists with same argument types\npsql:Data/pagila-star.sql:340: ERROR: function \"group_concat\" already exists with same argument types\npsql:Data/pagila-star.sql:354: ERROR: relation \"actor_actor_id_seq\" already exists\npsql:Data/pagila-star.sql:368: ERROR: relation \"actor\" already exists\npsql:Data/pagila-star.sql:382: ERROR: relation \"category_category_id_seq\" already exists\npsql:Data/pagila-star.sql:395: ERROR: relation \"category\" already exists\npsql:Data/pagila-star.sql:409: ERROR: relation \"film_film_id_seq\" already exists\npsql:Data/pagila-star.sql:433: ERROR: relation \"film\" already exists\npsql:Data/pagila-star.sql:446: ERROR: relation \"film_actor\" already exists\npsql:Data/pagila-star.sql:459: ERROR: relation \"film_category\" already exists\npsql:Data/pagila-star.sql:482: ERROR: relation \"actor_info\" already exists\npsql:Data/pagila-star.sql:496: ERROR: relation \"address_address_id_seq\" already exists\npsql:Data/pagila-star.sql:514: ERROR: relation \"address\" already exists\npsql:Data/pagila-star.sql:528: ERROR: relation \"city_city_id_seq\" already exists\npsql:Data/pagila-star.sql:542: ERROR: relation \"city\" already exists\npsql:Data/pagila-star.sql:556: ERROR: relation \"country_country_id_seq\" already exists\npsql:Data/pagila-star.sql:569: ERROR: relation \"country\" already exists\npsql:Data/pagila-star.sql:583: ERROR: relation \"customer_customer_id_seq\" already exists\npsql:Data/pagila-star.sql:597: ERROR: relation \"customer_customer_id_seq1\" already exists\npsql:Data/pagila-star.sql:629: ERROR: relation \"customer_list\" already exists\npsql:Data/pagila-star.sql:655: ERROR: relation \"dimcustomer\" already exists\npsql:Data/pagila-star.sql:669: ERROR: relation \"dimcustomer_customer_key_seq\" already exists\npsql:Data/pagila-star.sql:694: ERROR: relation \"dimdate\" already exists\npsql:Data/pagila-star.sql:715: ERROR: relation \"dimmovie\" already exists\npsql:Data/pagila-star.sql:729: ERROR: relation \"dimmovie_movie_key_seq\" already exists\npsql:Data/pagila-star.sql:758: ERROR: relation \"dimstore\" already exists\npsql:Data/pagila-star.sql:772: ERROR: relation \"dimstore_store_key_seq\" already exists\npsql:Data/pagila-star.sql:795: ERROR: relation \"factsales\" already exists\npsql:Data/pagila-star.sql:809: ERROR: relation \"factsales_sales_key_seq\" already exists\npsql:Data/pagila-star.sql:839: ERROR: relation \"film_list\" already exists\npsql:Data/pagila-star.sql:853: ERROR: relation \"inventory_inventory_id_seq\" already exists\npsql:Data/pagila-star.sql:867: ERROR: relation \"inventory\" already exists\npsql:Data/pagila-star.sql:881: ERROR: relation \"language_language_id_seq\" already exists\npsql:Data/pagila-star.sql:894: ERROR: relation \"language\" already exists\npsql:Data/pagila-star.sql:917: ERROR: relation \"nicer_but_slower_film_list\" already exists\npsql:Data/pagila-star.sql:931: ERROR: relation \"payment_payment_id_seq\" already exists\npsql:Data/pagila-star.sql:947: ERROR: relation \"payment\" already exists\npsql:Data/pagila-star.sql:961: ERROR: relation \"rental_rental_id_seq\" already exists\npsql:Data/pagila-star.sql:978: ERROR: relation \"rental\" already exists\npsql:Data/pagila-star.sql:997: ERROR: relation \"sales_by_film_category\" already exists\npsql:Data/pagila-star.sql:1011: ERROR: relation \"staff_staff_id_seq\" already exists\npsql:Data/pagila-star.sql:1032: ERROR: relation \"staff\" already exists\npsql:Data/pagila-star.sql:1046: ERROR: relation \"store_store_id_seq\" already exists\npsql:Data/pagila-star.sql:1060: ERROR: relation \"store\" already exists\npsql:Data/pagila-star.sql:1082: ERROR: relation \"sales_by_store\" already exists\npsql:Data/pagila-star.sql:1103: ERROR: relation \"staff_list\" already exists\npsql:Data/pagila-star.sql:1348: ERROR: duplicate key value violates unique constraint \"actor_pkey\"\nDETAIL: Key (actor_id)=(1) already exists.\nCONTEXT: COPY actor, line 1\n setval \n--------\n 200\n(1 row)\n\npsql:Data/pagila-star.sql:1966: ERROR: duplicate key value violates unique constraint \"address_pkey\"\nDETAIL: Key (address_id)=(1) already exists.\nCONTEXT: COPY address, line 1\n setval \n--------\n 605\n(1 row)\n\npsql:Data/pagila-star.sql:1997: ERROR: duplicate key value violates unique constraint \"category_pkey\"\nDETAIL: Key (category_id)=(1) already exists.\nCONTEXT: COPY category, line 1\n setval \n--------\n 16\n(1 row)\n\npsql:Data/pagila-star.sql:2612: ERROR: duplicate key value violates unique constraint \"city_pkey\"\nDETAIL: Key (city_id)=(1) already exists.\nCONTEXT: COPY city, line 1\n setval \n--------\n 600\n(1 row)\n\npsql:Data/pagila-star.sql:2736: ERROR: duplicate key value violates unique constraint \"country_pkey\"\nDETAIL: Key (country_id)=(1) already exists.\nCONTEXT: COPY country, line 1\n setval \n--------\n 109\n(1 row)\n\npsql:Data/pagila-star.sql:3350: ERROR: duplicate key value violates unique constraint \"customer_pkey\"\nDETAIL: Key (customer_id)=(1) already exists.\nCONTEXT: COPY customer, line 1\n setval \n--------\n 599\n(1 row)\n\n setval \n--------\n 1\n(1 row)\n\npsql:Data/pagila-star.sql:3971: ERROR: duplicate key value violates unique constraint \"dimcustomer_pkey\"\nDETAIL: Key (customer_key)=(1) already exists.\nCONTEXT: COPY dimcustomer, line 1\n setval \n--------\n 1\n(1 row)\n\npsql:Data/pagila-star.sql:4026: ERROR: duplicate key value violates unique constraint \"dimdate_pkey\"\nDETAIL: Key (date_key)=(20170216) already exists.\nCONTEXT: COPY dimdate, line 1\npsql:Data/pagila-star.sql:5034: ERROR: duplicate key value violates unique constraint \"dimmovie_pkey\"\nDETAIL: Key (movie_key)=(1) already exists.\nCONTEXT: COPY dimmovie, line 1\n setval \n--------\n 1\n(1 row)\n\npsql:Data/pagila-star.sql:5051: ERROR: duplicate key value violates unique constraint \"dimstore_pkey\"\nDETAIL: Key (store_key)=(1) already exists.\nCONTEXT: COPY dimstore, line 1\n setval \n--------\n 1\n(1 row)\n\npsql:Data/pagila-star.sql:21115: ERROR: duplicate key value violates unique constraint \"factsales_pkey\"\nDETAIL: Key (sales_key)=(1) already exists.\nCONTEXT: COPY factsales, line 1\n setval \n--------\n 16049\n(1 row)\n\npsql:Data/pagila-star.sql:22130: ERROR: duplicate key value violates unique constraint \"film_pkey\"\nDETAIL: Key (film_id)=(1) already exists.\nCONTEXT: COPY film, line 1: \"1\tACADEMY DINOSAUR\tA Epic Drama of a Feminist And a Mad Scientist who must Battle a Teacher in The C...\"\npsql:Data/pagila-star.sql:27600: ERROR: duplicate key value violates unique constraint \"film_actor_pkey\"\nDETAIL: Key (actor_id, film_id)=(1, 1) already exists.\nCONTEXT: COPY film_actor, line 1\npsql:Data/pagila-star.sql:28608: ERROR: duplicate key value violates unique constraint \"film_category_pkey\"\nDETAIL: Key (film_id, category_id)=(1, 6) already exists.\nCONTEXT: COPY film_category, line 1\n setval \n--------\n 1000\n(1 row)\n\npsql:Data/pagila-star.sql:33204: ERROR: duplicate key value violates unique constraint \"inventory_pkey\"\nDETAIL: Key (inventory_id)=(1) already exists.\nCONTEXT: COPY inventory, line 1\n setval \n--------\n 4581\n(1 row)\n\npsql:Data/pagila-star.sql:33225: ERROR: duplicate key value violates unique constraint \"language_pkey\"\nDETAIL: Key (language_id)=(1) already exists.\nCONTEXT: COPY language, line 1\n setval \n--------\n 6\n(1 row)\n\n"
]
],
[
[
"### Connect to the local database where Pagila is loaded",
"_____no_output_____"
]
],
[
[
"import sql\n%load_ext sql\n\nDB_ENDPOINT = \"127.0.0.1\"\nDB = 'pagila_star'\nDB_USER = 'student'\nDB_PASSWORD = 'student'\nDB_PORT = '5432'\n\n# postgresql://username:password@host:port/database\nconn_string = \"postgresql://{}:{}@{}:{}/{}\" \\\n .format(DB_USER, DB_PASSWORD, DB_ENDPOINT, DB_PORT, DB)\n\nprint(conn_string)\n%sql $conn_string",
"postgresql://student:[email protected]:5432/pagila_star\n"
]
],
[
[
"### Star Schema",
"_____no_output_____"
],
[
"<img src=\"pagila-star.png\" width=\"50%\"/>",
"_____no_output_____"
],
[
"# Grouping Sets\n- It happens often that for 3 dimensions, you want to aggregate a fact:\n - by nothing (total)\n - then by the 1st dimension\n - then by the 2nd \n - then by the 3rd \n - then by the 1st and 2nd\n - then by the 2nd and 3rd\n - then by the 1st and 3rd\n - then by the 1st and 2nd and 3rd\n \n- Since this is very common, and in all cases, we are iterating through all the fact table anyhow, there is a more clever way to do that using the SQL grouping statement \"GROUPING SETS\" ",
"_____no_output_____"
],
[
"## Total Revenue\n\nTODO: Write a query that calculates total revenue (sales_amount)",
"_____no_output_____"
]
],
[
[
"%%sql\nSELECT sum(sales_amount) as total_revenue\nFROM factSales;",
" * postgresql://student:***@127.0.0.1:5432/pagila_star\n1 rows affected.\n"
],
[
"# %%sql\n# SELECT ...\n# FROM ...",
"_____no_output_____"
]
],
[
[
"## Revenue by Country\nTODO: Write a query that calculates total revenue (sales_amount) by country",
"_____no_output_____"
]
],
[
[
"%%sql\nSELECT country, sum(sales_amount) as total_revenue\nFROM factSales f\njoin dimstore ds on f.store_key = ds.store_key\ngroup by 1\nlimit 5;",
" * postgresql://student:***@127.0.0.1:5432/pagila_star\n2 rows affected.\n"
],
[
"# %%sql\n# SELECT ...\n# FROM ...",
"_____no_output_____"
]
],
[
[
"## Revenue by Month\nTODO: Write a query that calculates total revenue (sales_amount) by month",
"_____no_output_____"
]
],
[
[
"%%sql\nSELECT month, sum(sales_amount) as total_revenue\nFROM factSales f\njoin dimdate dd on f.date_key = dd.date_key\ngroup by 1\nlimit 5;",
" * postgresql://student:***@127.0.0.1:5432/pagila_star\n5 rows affected.\n"
],
[
"# %%sql\n# SELECT ...\n# FROM ...",
"_____no_output_____"
]
],
[
[
"## Revenue by Month & Country\nTODO: Write a query that calculates total revenue (sales_amount) by month and country. Sort the data by month, country, and revenue in descending order. The first few rows of your output should match the table below.",
"_____no_output_____"
]
],
[
[
"%%sql\nSELECT month, country, sum(sales_amount) as total_revenue\nFROM factSales f\njoin dimdate dd on f.date_key = dd.date_key\njoin dimstore ds on f.store_key = ds.store_key\ngroup by 1,2\norder by 1,2,3 desc\nlimit 5;",
" * postgresql://student:***@127.0.0.1:5432/pagila_star\n5 rows affected.\n"
],
[
"# %%sql\n# SELECT ...\n# FROM ...",
"_____no_output_____"
]
],
[
[
"<div class=\"p-Widget jp-RenderedHTMLCommon jp-RenderedHTML jp-mod-trusted jp-OutputArea-output jp-OutputArea-executeResult\" data-mime-type=\"text/html\"><table>\n <tbody><tr>\n <th>month</th>\n <th>country</th>\n <th>revenue</th>\n </tr>\n <tr>\n <td>1</td>\n <td>Australia</td>\n <td>2364.19</td>\n </tr>\n <tr>\n <td>1</td>\n <td>Canada</td>\n <td>2460.24</td>\n </tr>\n <tr>\n <td>2</td>\n <td>Australia</td>\n <td>4895.10</td>\n </tr>\n <tr>\n <td>2</td>\n <td>Canada</td>\n <td>4736.78</td>\n </tr>\n <tr>\n <td>3</td>\n <td>Australia</td>\n <td>12060.33</td>\n </tr>\n</tbody></table></div>",
"_____no_output_____"
],
[
"## Revenue Total, by Month, by Country, by Month & Country All in one shot\n\nTODO: Write a query that calculates total revenue at the various grouping levels done above (total, by month, by country, by month & country) all at once using the grouping sets function. Your output should match the table below.",
"_____no_output_____"
]
],
[
[
"%%sql\nSELECT month, country, sum(sales_amount) as total_revenue\nFROM factSales f\njoin dimdate dd on f.date_key = dd.date_key\njoin dimstore ds on f.store_key = ds.store_key\ngroup by grouping sets ((), month,country, (month, country))",
" * postgresql://student:***@127.0.0.1:5432/pagila_star\n18 rows affected.\n"
],
[
"# %%sql\n# SELECT ...\n# FROM ...",
"_____no_output_____"
]
],
[
[
"<div class=\"p-Widget jp-RenderedHTMLCommon jp-RenderedHTML jp-mod-trusted jp-OutputArea-output jp-OutputArea-executeResult\" data-mime-type=\"text/html\"><table>\n <tbody><tr>\n <th>month</th>\n <th>country</th>\n <th>revenue</th>\n </tr>\n <tr>\n <td>1</td>\n <td>Australia</td>\n <td>2364.19</td>\n </tr>\n <tr>\n <td>1</td>\n <td>Canada</td>\n <td>2460.24</td>\n </tr>\n <tr>\n <td>1</td>\n <td>None</td>\n <td>4824.43</td>\n </tr>\n <tr>\n <td>2</td>\n <td>Australia</td>\n <td>4895.10</td>\n </tr>\n <tr>\n <td>2</td>\n <td>Canada</td>\n <td>4736.78</td>\n </tr>\n <tr>\n <td>2</td>\n <td>None</td>\n <td>9631.88</td>\n </tr>\n <tr>\n <td>3</td>\n <td>Australia</td>\n <td>12060.33</td>\n </tr>\n <tr>\n <td>3</td>\n <td>Canada</td>\n <td>11826.23</td>\n </tr>\n <tr>\n <td>3</td>\n <td>None</td>\n <td>23886.56</td>\n </tr>\n <tr>\n <td>4</td>\n <td>Australia</td>\n <td>14136.07</td>\n </tr>\n <tr>\n <td>4</td>\n <td>Canada</td>\n <td>14423.39</td>\n </tr>\n <tr>\n <td>4</td>\n <td>None</td>\n <td>28559.46</td>\n </tr>\n <tr>\n <td>5</td>\n <td>Australia</td>\n <td>271.08</td>\n </tr>\n <tr>\n <td>5</td>\n <td>Canada</td>\n <td>243.10</td>\n </tr>\n <tr>\n <td>5</td>\n <td>None</td>\n <td>514.18</td>\n </tr>\n <tr>\n <td>None</td>\n <td>None</td>\n <td>67416.51</td>\n </tr>\n <tr>\n <td>None</td>\n <td>Australia</td>\n <td>33726.77</td>\n </tr>\n <tr>\n <td>None</td>\n <td>Canada</td>\n <td>33689.74</td>\n </tr>\n</tbody></table></div>",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
ecc3135d9538f92e62af386a33b93ec427c1fae5 | 73,252 | ipynb | Jupyter Notebook | chatbot/src/notebooks/Data Exploration.ipynb | hpecl-sspku/hpecl-2017 | 895757eb7d5f984e0268ab99da95663172bc2f50 | [
"MIT"
] | null | null | null | chatbot/src/notebooks/Data Exploration.ipynb | hpecl-sspku/hpecl-2017 | 895757eb7d5f984e0268ab99da95663172bc2f50 | [
"MIT"
] | 8 | 2018-03-19T03:24:56.000Z | 2018-07-31T15:25:25.000Z | chatbot/src/notebooks/Data Exploration.ipynb | hpecl-sspku/hpecl-2017 | 895757eb7d5f984e0268ab99da95663172bc2f50 | [
"MIT"
] | 3 | 2018-11-13T06:46:51.000Z | 2020-07-20T05:53:56.000Z | 157.531183 | 18,981 | 0.831923 | [
[
[
"%matplotlib inline\n\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport matplotlib\nmatplotlib.style.use('ggplot')",
"_____no_output_____"
],
[
"# Load Data\ntrain_df = pd.read_csv(\"../data/train.csv\")\ntrain_df.Label = train_df.Label.astype('category')\n\ntest_df = pd.read_csv(\"../data/test.csv\")\nvalidation_df = pd.read_csv(\"../data/valid.csv\")",
"_____no_output_____"
],
[
"train_df.describe()",
"_____no_output_____"
],
[
"train_df.Label.hist()\nplt.title(\"Training Label Distribution\")",
"_____no_output_____"
],
[
"pd.options.display.max_colwidth = 500\ntrain_df.head()",
"_____no_output_____"
],
[
"plt.figure(1)\ntrain_df_context_len = train_df.Context.str.split(\" \").apply(len)\ntrain_df_context_len.hist(bins=40)\nplt.title(\"Training Context Length Statistics\")\nprint(train_df_context_len.describe())\n\nplt.figure(2)\ntrain_df_utterance_len = train_df.Utterance.str.split(\" \").apply(len)\ntrain_df_utterance_len.hist(bins=40)\nplt.title(\"Training Utterance Length Statistics\")\nprint(train_df_utterance_len.describe())",
"count 1000000.000000\nmean 86.339195\nstd 74.929713\nmin 5.000000\n25% 37.000000\n50% 63.000000\n75% 108.000000\nmax 1879.000000\nName: Context, dtype: float64\ncount 1000000.000000\nmean 17.246392\nstd 16.422901\nmin 1.000000\n25% 7.000000\n50% 13.000000\n75% 22.000000\nmax 653.000000\nName: Utterance, dtype: float64\n"
],
[
"pd.options.display.max_colwidth = 500\ntest_df.head()",
"_____no_output_____"
],
[
"test_df.describe()",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecc3152dc579c9fa3333cca46871932506a5fbfa | 24,996 | ipynb | Jupyter Notebook | lect01_git_basic_types/2021_DPO_1_4_Slices.ipynb | weqrwer/Python_DPO_2021_fall | 8558ed2c1a744638f693ad036cfafccd1a05f392 | [
"MIT"
] | null | null | null | lect01_git_basic_types/2021_DPO_1_4_Slices.ipynb | weqrwer/Python_DPO_2021_fall | 8558ed2c1a744638f693ad036cfafccd1a05f392 | [
"MIT"
] | null | null | null | lect01_git_basic_types/2021_DPO_1_4_Slices.ipynb | weqrwer/Python_DPO_2021_fall | 8558ed2c1a744638f693ad036cfafccd1a05f392 | [
"MIT"
] | null | null | null | 19.543393 | 365 | 0.484798 | [
[
[
"Центр непрерывного образования\n\n# Программа «Python для автоматизации и анализа данных»\n\nНеделя 2 - 1\n\n*Татьяна Рогович, НИУ ВШЭ* \n\n# Срезы. Метод строк find()",
"_____no_output_____"
]
],
[
[
"s = \"hello\"",
"_____no_output_____"
],
[
"s[0]",
"_____no_output_____"
],
[
"s[-5]",
"_____no_output_____"
],
[
"s[5]",
"_____no_output_____"
],
[
"s[-1]",
"_____no_output_____"
],
[
"s[4]",
"_____no_output_____"
],
[
"a = 1000",
"_____no_output_____"
],
[
"a[5]",
"_____no_output_____"
],
[
"str(a)[3]",
"_____no_output_____"
]
],
[
[
"Строки, кортежи и списки представляют собой последовательности, а это значит, что мы можем обратиться к любому их элементу по индексу.\n\nДля выполнения такой операции в питоне используются квадратные скобки [] после объекта. \nВ квадратных скобках указывается желаемый индекс. Индексирование начинается с 0.",
"_____no_output_____"
]
],
[
[
"s = 'Welcome to \"Brasil!\"' # заодно обратите внимание на кавычки внутри кавычек (используем разные типы)\nprint(s)\n\nprint(s[0]) # первый элемент\nprint(s[1]) # второй\nprint(s[2]) # третий\nprint(s[-1]) # последний\nprint(s[-2]) # второй с конца\n\n#Предыдущие действия никак не изменили строку\nprint(s)",
"Welcome to \"Brasil!\"\nW\ne\nl\n\"\n!\nWelcome to \"Brasil!\"\n"
]
],
[
[
"Кроме выбора одного элемента с помощью индексирования можно получить подстроку. \nДля этого надо указать индексы границ подстроки через двоеточие. \n\nПервое число - от какого индекса начинаем (если здесь ничего не написать, то начнем сначала). Второе число (после первого двоеточия) - каким индексом заканчивается срез (если ничего не написать, то питон возьмет последний символ). Третье число (необязательное, после второго двоеточия) - шаг, по умолчанию там стоит 1 (каждая буква).\n\nТаким образом, использовав одно число без двоеточий, мы получим один символ. Использовав два числа через двоеточие - срез строки, включая первый индекс и не включая второй (первое число обязательно меньше второго). Использовав три числа через два двоеточих - срез строки с определенным шагом, заданным третьим числом.",
"_____no_output_____"
]
],
[
[
"s2 = '0123456789'",
"_____no_output_____"
],
[
"s2[1:] # все элементы после индекса 1",
"_____no_output_____"
],
[
"s2[1:4]",
"_____no_output_____"
],
[
"s2[:5] # элемент с индексом 5 не войдет",
"_____no_output_____"
],
[
"s2[::2]",
"_____no_output_____"
],
[
"s2",
"_____no_output_____"
],
[
"s2[::3]",
"_____no_output_____"
],
[
"s2[::-1]",
"_____no_output_____"
],
[
"s2[::-2]",
"_____no_output_____"
],
[
"s2[::-3]",
"_____no_output_____"
],
[
"s2[1:7]",
"_____no_output_____"
],
[
"s2[1:7:2]",
"_____no_output_____"
],
[
"s2[1:7]",
"_____no_output_____"
],
[
"s2[1:7][::-1]",
"_____no_output_____"
],
[
"a = '1'",
"_____no_output_____"
],
[
"b = a",
"_____no_output_____"
],
[
"b += '2'",
"_____no_output_____"
],
[
"b",
"_____no_output_____"
],
[
"a",
"_____no_output_____"
],
[
"print(s[1:])\nprint(s[:4]) # четыре первых символа до порядкового номера 4\nprint(s[:]) # копия строки\nprint(s[:-1]) # вся строка кроме последнего символа\nprint(s[::2]) # также можно выбирать символы из строки с каким-то шагом\nprint(s[::-1]) # например, с помощью шага -1 можно получить строку наоборот",
"elcome to \"Brasil!\"\nWelc\nWelcome to \"Brasil!\"\nWelcome to \"Brasil!\nWloet Bai!\n\"!lisarB\" ot emocleW\n"
]
],
[
[
"По аналогии со строками, у списков и кортежей тоже можно брать срезы.",
"_____no_output_____"
]
],
[
[
"myList = [0, 1, 2, 3, 4, 5]\nmyTuple = (0, 1, 2, 3, 4, 5)",
"_____no_output_____"
],
[
"print(myList[1:]) # берем все, начиная с элемента с первым индексом\nprint(myTuple[2:])",
"[1, 2, 3, 4, 5]\n(2, 3, 4, 5)\n"
],
[
"print(myList[:3]) # берем все до элемента с третьим индексом (невключительно)\nprint(myTuple[:-1])",
"[0, 1, 2]\n(0, 1, 2, 3, 4)\n"
],
[
"print(myList[::2]) # берем все четные элементы\nprint(myTuple[1::2]) # берем все нечетные элементы",
"[0, 2, 4]\n(1, 3, 5)\n"
]
],
[
[
"#### Метод .find()\n\nКогда мы работаем со строками, у нас часто стоит задача брать срез не с конкретного индекса, а привязывать его к поиску определенного символа. У нас есть специальный метод строковых переменных .find().\n\nМетоды - это методы классы. Грубо говоря, это функции, которые будут работать только с определенным типом данных. Синтаксис метода следующий: `{название переменной или данные}.{название метода()}`.\n\nНапример, давайте проверим содержит ли строка упоминание университета.",
"_____no_output_____"
]
],
[
[
"'В ВШЭ стартовала новая программа по Data Science'.find('ВШЭ')",
"_____no_output_____"
],
[
"s4 = 'В ВШЭ стартовала новая программа по Data Science'",
"_____no_output_____"
],
[
"s4.find('м')",
"_____no_output_____"
],
[
"s4[29:35]",
"_____no_output_____"
],
[
"s4.rfind('м')",
"_____no_output_____"
],
[
"s4[30:35]",
"_____no_output_____"
],
[
"s4.find()",
"_____no_output_____"
]
],
[
[
"Метод .find() берет один аргумент - подстроку, которую ищет в строке. Возвращает метод индекс первого символа подстроки, если ее удалось найти.\n\nЕсли подстрока не была найдена, метод вернет -1 (на следующем занятии мы будем использовать это свойство, когда разберемся с условным оператором).",
"_____no_output_____"
]
],
[
[
"'В ВШЭ стартовала новая программа по Data Science'.find('вшэ') # обратите внимание, метод чувствителен к регистру",
"_____no_output_____"
]
],
[
[
".find() иногда используется в парсинге веб-страниц. Зная индекс первого элемента, мы можем достать интересующую нас информацию.\n\nНапример, мы скачали с сайта информацию о цене нового планшета и хотим достать оттуда собственно цену. Мы знаем, что цена идет после подстроки \"ЦЕНА:\" и что после самой цены идет постфикс \"руб.\". Давайте попробуем достать цену и посчитать, сколько стоит два таких планшета.",
"_____no_output_____"
]
],
[
[
"info = 'iPad 64 GB ЦЕНА: 39 990 руб. Скидка: 5%'\nprint(info.find('ЦЕНА:')) # нашли индекс Ц - начала подстроки \"ЦЕНА:\"\nprint(info.find('руб.')) # нашли индекс р\nprice = info[info.find('ЦЕНА:')+6:info.find('руб.')-1] # вывели срез от от начала до конца цены (с помощью\n # слогаемых 6 и -1 откорретировали индексы до начала и конца цены)\nprint(price)",
"11\n24\n39 990\n"
]
],
[
[
"Почти готово, но теперь мешается пробел. Кстати, это очень частая проблема, что числа в интернете оформлены с разделителями и перед конвертацией их приходится еще и приводить к стандартному виду, который можно скормить функции int(). Пока мы не знаем метода, который может заменять символы, поэтому давайте попробуем почистить цену с помощью .find() и срезов.",
"_____no_output_____"
]
],
[
[
"price",
"_____no_output_____"
],
[
"price.find(' ')",
"_____no_output_____"
],
[
"price[2]",
"_____no_output_____"
],
[
"price[price.find(' ')+1:]",
"_____no_output_____"
],
[
"price[:price.find(' ')]",
"_____no_output_____"
],
[
"price[:2]",
"_____no_output_____"
],
[
"price_clean = price[:price.find(' ')] + price[price.find(' ')+1:]\nprint(price_clean)",
"39990\n"
],
[
"price[:price.find(' ')]",
"_____no_output_____"
],
[
"price[price.find(' ')+1:]",
"_____no_output_____"
]
],
[
[
"Теперь с этим можно работать!",
"_____no_output_____"
]
],
[
[
"print(int(price_clean) * 2)",
"79980\n"
]
],
[
[
"Если подстрока входит в строку несколько раз, то find() вернет индекс только для первого вхождения.",
"_____no_output_____"
]
],
[
[
"price.find('9')",
"_____no_output_____"
]
],
[
[
"Есть модификация метода find(): rfind(substring) - возвращает позицию самого правого вхождения подстроки substring в строку string или -1, если подстрока не найдена. ",
"_____no_output_____"
]
],
[
[
"price.rfind('9')",
"_____no_output_____"
],
[
"len('123')",
"_____no_output_____"
],
[
"'123,2'.replace(',', '.')",
"_____no_output_____"
],
[
"'123,2'.replace('2', '!')",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
ecc31d7f93370c93d38536c8d027c0df93013b2b | 76,810 | ipynb | Jupyter Notebook | Project9- Password Strength Classifier.ipynb | Shruti0630/Shruti_PythonProject9 | 3fa05d79a3447618e2c17e79d0a1ef7b60558a83 | [
"Unlicense"
] | null | null | null | Project9- Password Strength Classifier.ipynb | Shruti0630/Shruti_PythonProject9 | 3fa05d79a3447618e2c17e79d0a1ef7b60558a83 | [
"Unlicense"
] | null | null | null | Project9- Password Strength Classifier.ipynb | Shruti0630/Shruti_PythonProject9 | 3fa05d79a3447618e2c17e79d0a1ef7b60558a83 | [
"Unlicense"
] | null | null | null | 32.313841 | 7,304 | 0.486525 | [
[
[
"# Importing Libraries & Dataset",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport seaborn as sns\nimport warnings\nwarnings.filterwarnings(\"ignore\")",
"_____no_output_____"
],
[
"data= pd.read_csv(r\"C:\\Users\\shruti\\Desktop\\data.csv\", error_bad_lines= False)",
"b'Skipping line 2810: expected 2 fields, saw 5\\nSkipping line 4641: expected 2 fields, saw 5\\nSkipping line 7171: expected 2 fields, saw 5\\nSkipping line 11220: expected 2 fields, saw 5\\nSkipping line 13809: expected 2 fields, saw 5\\nSkipping line 14132: expected 2 fields, saw 5\\nSkipping line 14293: expected 2 fields, saw 5\\nSkipping line 14865: expected 2 fields, saw 5\\nSkipping line 17419: expected 2 fields, saw 5\\nSkipping line 22801: expected 2 fields, saw 5\\nSkipping line 25001: expected 2 fields, saw 5\\nSkipping line 26603: expected 2 fields, saw 5\\nSkipping line 26742: expected 2 fields, saw 5\\nSkipping line 29702: expected 2 fields, saw 5\\nSkipping line 32767: expected 2 fields, saw 5\\nSkipping line 32878: expected 2 fields, saw 5\\nSkipping line 35643: expected 2 fields, saw 5\\nSkipping line 36550: expected 2 fields, saw 5\\nSkipping line 38732: expected 2 fields, saw 5\\nSkipping line 40567: expected 2 fields, saw 5\\nSkipping line 40576: expected 2 fields, saw 5\\nSkipping line 41864: expected 2 fields, saw 5\\nSkipping line 46861: expected 2 fields, saw 5\\nSkipping line 47939: expected 2 fields, saw 5\\nSkipping line 48628: expected 2 fields, saw 5\\nSkipping line 48908: expected 2 fields, saw 5\\nSkipping line 57582: expected 2 fields, saw 5\\nSkipping line 58782: expected 2 fields, saw 5\\nSkipping line 58984: expected 2 fields, saw 5\\nSkipping line 61518: expected 2 fields, saw 5\\nSkipping line 63451: expected 2 fields, saw 5\\nSkipping line 68141: expected 2 fields, saw 5\\nSkipping line 72083: expected 2 fields, saw 5\\nSkipping line 74027: expected 2 fields, saw 5\\nSkipping line 77811: expected 2 fields, saw 5\\nSkipping line 83958: expected 2 fields, saw 5\\nSkipping line 85295: expected 2 fields, saw 5\\nSkipping line 88665: expected 2 fields, saw 5\\nSkipping line 89198: expected 2 fields, saw 5\\nSkipping line 92499: expected 2 fields, saw 5\\nSkipping line 92751: expected 2 fields, saw 5\\nSkipping line 93689: expected 2 fields, saw 5\\nSkipping line 94776: expected 2 fields, saw 5\\nSkipping line 97334: expected 2 fields, saw 5\\nSkipping line 102316: expected 2 fields, saw 5\\nSkipping line 103421: expected 2 fields, saw 5\\nSkipping line 106872: expected 2 fields, saw 5\\nSkipping line 109363: expected 2 fields, saw 5\\nSkipping line 110117: expected 2 fields, saw 5\\nSkipping line 110465: expected 2 fields, saw 5\\nSkipping line 113843: expected 2 fields, saw 5\\nSkipping line 115634: expected 2 fields, saw 5\\nSkipping line 121518: expected 2 fields, saw 5\\nSkipping line 123692: expected 2 fields, saw 5\\nSkipping line 124708: expected 2 fields, saw 5\\nSkipping line 129608: expected 2 fields, saw 5\\nSkipping line 133176: expected 2 fields, saw 5\\nSkipping line 135532: expected 2 fields, saw 5\\nSkipping line 138042: expected 2 fields, saw 5\\nSkipping line 139485: expected 2 fields, saw 5\\nSkipping line 140401: expected 2 fields, saw 5\\nSkipping line 144093: expected 2 fields, saw 5\\nSkipping line 149850: expected 2 fields, saw 5\\nSkipping line 151831: expected 2 fields, saw 5\\nSkipping line 158014: expected 2 fields, saw 5\\nSkipping line 162047: expected 2 fields, saw 5\\nSkipping line 164515: expected 2 fields, saw 5\\nSkipping line 170313: expected 2 fields, saw 5\\nSkipping line 171325: expected 2 fields, saw 5\\nSkipping line 171424: expected 2 fields, saw 5\\nSkipping line 175920: expected 2 fields, saw 5\\nSkipping line 176210: expected 2 fields, saw 5\\nSkipping line 183603: expected 2 fields, saw 5\\nSkipping line 190264: expected 2 fields, saw 5\\nSkipping line 191683: expected 2 fields, saw 5\\nSkipping line 191988: expected 2 fields, saw 5\\nSkipping line 195450: expected 2 fields, saw 5\\nSkipping line 195754: expected 2 fields, saw 5\\nSkipping line 197124: expected 2 fields, saw 5\\nSkipping line 199263: expected 2 fields, saw 5\\nSkipping line 202603: expected 2 fields, saw 5\\nSkipping line 209960: expected 2 fields, saw 5\\nSkipping line 213218: expected 2 fields, saw 5\\nSkipping line 217060: expected 2 fields, saw 5\\nSkipping line 220121: expected 2 fields, saw 5\\nSkipping line 223518: expected 2 fields, saw 5\\nSkipping line 226293: expected 2 fields, saw 5\\nSkipping line 227035: expected 2 fields, saw 7\\nSkipping line 227341: expected 2 fields, saw 5\\nSkipping line 227808: expected 2 fields, saw 5\\nSkipping line 228516: expected 2 fields, saw 5\\nSkipping line 228733: expected 2 fields, saw 5\\nSkipping line 232043: expected 2 fields, saw 5\\nSkipping line 232426: expected 2 fields, saw 5\\nSkipping line 234490: expected 2 fields, saw 5\\nSkipping line 239626: expected 2 fields, saw 5\\nSkipping line 240461: expected 2 fields, saw 5\\nSkipping line 244518: expected 2 fields, saw 5\\nSkipping line 245395: expected 2 fields, saw 5\\nSkipping line 246168: expected 2 fields, saw 5\\nSkipping line 246655: expected 2 fields, saw 5\\nSkipping line 246752: expected 2 fields, saw 5\\nSkipping line 247189: expected 2 fields, saw 5\\nSkipping line 250276: expected 2 fields, saw 5\\nSkipping line 255327: expected 2 fields, saw 5\\nSkipping line 257094: expected 2 fields, saw 5\\n'\nb'Skipping line 264626: expected 2 fields, saw 5\\nSkipping line 265028: expected 2 fields, saw 5\\nSkipping line 269150: expected 2 fields, saw 5\\nSkipping line 271360: expected 2 fields, saw 5\\nSkipping line 273975: expected 2 fields, saw 5\\nSkipping line 274742: expected 2 fields, saw 5\\nSkipping line 276227: expected 2 fields, saw 5\\nSkipping line 279807: expected 2 fields, saw 5\\nSkipping line 283425: expected 2 fields, saw 5\\nSkipping line 287468: expected 2 fields, saw 5\\nSkipping line 292995: expected 2 fields, saw 5\\nSkipping line 293496: expected 2 fields, saw 5\\nSkipping line 293735: expected 2 fields, saw 5\\nSkipping line 295060: expected 2 fields, saw 5\\nSkipping line 296643: expected 2 fields, saw 5\\nSkipping line 296848: expected 2 fields, saw 5\\nSkipping line 308926: expected 2 fields, saw 5\\nSkipping line 310360: expected 2 fields, saw 5\\nSkipping line 317004: expected 2 fields, saw 5\\nSkipping line 318207: expected 2 fields, saw 5\\nSkipping line 331783: expected 2 fields, saw 5\\nSkipping line 333864: expected 2 fields, saw 5\\nSkipping line 335958: expected 2 fields, saw 5\\nSkipping line 336290: expected 2 fields, saw 5\\nSkipping line 343526: expected 2 fields, saw 5\\nSkipping line 343857: expected 2 fields, saw 5\\nSkipping line 344059: expected 2 fields, saw 5\\nSkipping line 348691: expected 2 fields, saw 5\\nSkipping line 353446: expected 2 fields, saw 5\\nSkipping line 357073: expected 2 fields, saw 5\\nSkipping line 359753: expected 2 fields, saw 5\\nSkipping line 359974: expected 2 fields, saw 5\\nSkipping line 366534: expected 2 fields, saw 5\\nSkipping line 369514: expected 2 fields, saw 5\\nSkipping line 377759: expected 2 fields, saw 5\\nSkipping line 379327: expected 2 fields, saw 5\\nSkipping line 380769: expected 2 fields, saw 5\\nSkipping line 381073: expected 2 fields, saw 5\\nSkipping line 381489: expected 2 fields, saw 5\\nSkipping line 386304: expected 2 fields, saw 5\\nSkipping line 387635: expected 2 fields, saw 5\\nSkipping line 389613: expected 2 fields, saw 5\\nSkipping line 392604: expected 2 fields, saw 5\\nSkipping line 393184: expected 2 fields, saw 5\\nSkipping line 395530: expected 2 fields, saw 5\\nSkipping line 396939: expected 2 fields, saw 5\\nSkipping line 397385: expected 2 fields, saw 5\\nSkipping line 397509: expected 2 fields, saw 5\\nSkipping line 402902: expected 2 fields, saw 5\\nSkipping line 405187: expected 2 fields, saw 5\\nSkipping line 408412: expected 2 fields, saw 5\\nSkipping line 419423: expected 2 fields, saw 5\\nSkipping line 420962: expected 2 fields, saw 5\\nSkipping line 425965: expected 2 fields, saw 5\\nSkipping line 427496: expected 2 fields, saw 5\\nSkipping line 438881: expected 2 fields, saw 5\\nSkipping line 439776: expected 2 fields, saw 5\\nSkipping line 440345: expected 2 fields, saw 5\\nSkipping line 445507: expected 2 fields, saw 5\\nSkipping line 445548: expected 2 fields, saw 5\\nSkipping line 447184: expected 2 fields, saw 5\\nSkipping line 448603: expected 2 fields, saw 5\\nSkipping line 451732: expected 2 fields, saw 5\\nSkipping line 458249: expected 2 fields, saw 5\\nSkipping line 460274: expected 2 fields, saw 5\\nSkipping line 467630: expected 2 fields, saw 5\\nSkipping line 473961: expected 2 fields, saw 5\\nSkipping line 476281: expected 2 fields, saw 5\\nSkipping line 478010: expected 2 fields, saw 5\\nSkipping line 478322: expected 2 fields, saw 5\\nSkipping line 479999: expected 2 fields, saw 5\\nSkipping line 480898: expected 2 fields, saw 5\\nSkipping line 481688: expected 2 fields, saw 5\\nSkipping line 485193: expected 2 fields, saw 5\\nSkipping line 485519: expected 2 fields, saw 5\\nSkipping line 486000: expected 2 fields, saw 5\\nSkipping line 489063: expected 2 fields, saw 5\\nSkipping line 494525: expected 2 fields, saw 5\\nSkipping line 495009: expected 2 fields, saw 5\\nSkipping line 501954: expected 2 fields, saw 5\\nSkipping line 508035: expected 2 fields, saw 5\\nSkipping line 508828: expected 2 fields, saw 5\\nSkipping line 509833: expected 2 fields, saw 5\\nSkipping line 510410: expected 2 fields, saw 5\\nSkipping line 518229: expected 2 fields, saw 5\\nSkipping line 520302: expected 2 fields, saw 5\\nSkipping line 520340: expected 2 fields, saw 5\\n'\nb'Skipping line 525174: expected 2 fields, saw 5\\nSkipping line 526251: expected 2 fields, saw 5\\nSkipping line 529611: expected 2 fields, saw 5\\nSkipping line 531398: expected 2 fields, saw 5\\nSkipping line 534146: expected 2 fields, saw 5\\nSkipping line 544954: expected 2 fields, saw 5\\nSkipping line 553002: expected 2 fields, saw 5\\nSkipping line 553883: expected 2 fields, saw 5\\nSkipping line 553887: expected 2 fields, saw 5\\nSkipping line 553915: expected 2 fields, saw 5\\nSkipping line 554172: expected 2 fields, saw 5\\nSkipping line 563534: expected 2 fields, saw 5\\nSkipping line 565191: expected 2 fields, saw 5\\nSkipping line 574108: expected 2 fields, saw 5\\nSkipping line 574412: expected 2 fields, saw 5\\nSkipping line 575985: expected 2 fields, saw 5\\nSkipping line 580091: expected 2 fields, saw 5\\nSkipping line 582682: expected 2 fields, saw 5\\nSkipping line 585885: expected 2 fields, saw 5\\nSkipping line 590171: expected 2 fields, saw 5\\nSkipping line 591924: expected 2 fields, saw 5\\nSkipping line 592515: expected 2 fields, saw 5\\nSkipping line 593888: expected 2 fields, saw 5\\nSkipping line 596245: expected 2 fields, saw 5\\nSkipping line 607344: expected 2 fields, saw 5\\nSkipping line 607633: expected 2 fields, saw 5\\nSkipping line 610939: expected 2 fields, saw 5\\nSkipping line 613638: expected 2 fields, saw 5\\nSkipping line 615643: expected 2 fields, saw 5\\nSkipping line 615901: expected 2 fields, saw 5\\nSkipping line 617389: expected 2 fields, saw 5\\nSkipping line 634641: expected 2 fields, saw 5\\nSkipping line 635755: expected 2 fields, saw 5\\nSkipping line 646243: expected 2 fields, saw 5\\nSkipping line 647165: expected 2 fields, saw 5\\nSkipping line 648610: expected 2 fields, saw 5\\nSkipping line 648772: expected 2 fields, saw 5\\nSkipping line 651833: expected 2 fields, saw 5\\nSkipping line 653663: expected 2 fields, saw 5\\nSkipping line 656233: expected 2 fields, saw 5\\nSkipping line 656694: expected 2 fields, saw 5\\nSkipping line 659783: expected 2 fields, saw 5\\nSkipping line 660478: expected 2 fields, saw 5\\nSkipping line 661133: expected 2 fields, saw 5\\nSkipping line 661736: expected 2 fields, saw 5\\nSkipping line 669827: expected 2 fields, saw 5\\n'\n"
],
[
"data.head()",
"_____no_output_____"
],
[
"data.tail()",
"_____no_output_____"
]
],
[
[
"# Exploratry Data Analysis",
"_____no_output_____"
]
],
[
[
"data.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 669640 entries, 0 to 669639\nData columns (total 2 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 password 669639 non-null object\n 1 strength 669640 non-null int64 \ndtypes: int64(1), object(1)\nmemory usage: 10.2+ MB\n"
],
[
"# Cheking for Null values\n\ndata.isnull().sum()",
"_____no_output_____"
],
[
"# Checking exact position of Null value\n\ndata[data[\"password\"].isnull()]",
"_____no_output_____"
],
[
"# Dropping Null value\n\ndata.dropna(inplace = True)",
"_____no_output_____"
],
[
"data.isnull().sum()",
"_____no_output_____"
],
[
"data.describe()",
"_____no_output_____"
]
],
[
[
"# Analyzing Data",
"_____no_output_____"
]
],
[
[
"data[\"strength\"].unique()",
"_____no_output_____"
],
[
"# Plotting against \"strength\"\n\nsns.countplot(data[\"strength\"])",
"_____no_output_____"
],
[
"password_data= np.array(data)",
"_____no_output_____"
],
[
"password_data",
"_____no_output_____"
],
[
"# Shuffling randomly for robustness\n\nimport random\nrandom.shuffle(password_data)",
"_____no_output_____"
],
[
"x= [labels[0] for labels in password_data]\ny= [labels[1] for labels in password_data]",
"_____no_output_____"
],
[
"x",
"_____no_output_____"
],
[
"# Creating a custom function to convert input into characters of list\n\ndef word_divide_character(inputs):\n character=[]\n for i in inputs:\n character.append(i)\n return character",
"_____no_output_____"
],
[
"word_divide_character(\"edcmki90\")",
"_____no_output_____"
]
],
[
[
"# Importing TF-IDF Vectorizer to convert String into numerical data",
"_____no_output_____"
]
],
[
[
"from sklearn.feature_extraction.text import TfidfVectorizer",
"_____no_output_____"
],
[
"vector= TfidfVectorizer(tokenizer=word_divide_character)",
"_____no_output_____"
],
[
"# Applying TD-IDF Vectorizer on data\n\nx= vector.fit_transform(x)",
"_____no_output_____"
],
[
"x.shape",
"_____no_output_____"
],
[
"vector.get_feature_names()",
"_____no_output_____"
],
[
"first_document_vector= x[0]\nfirst_document_vector",
"_____no_output_____"
],
[
"first_document_vector.T.todense()",
"_____no_output_____"
],
[
"df= pd.DataFrame(first_document_vector.T.todense(), index= vector.get_feature_names(), columns=[\"TF-IDF\"])\ndf.sort_values(by=[\"TF-IDF\"], ascending= False)",
"_____no_output_____"
]
],
[
[
"# Splitting data into Train & Test",
"_____no_output_____"
]
],
[
[
"# Train- To learn the realtionship within data\n# Test- To predict the data and this data will be unseen to model\n\nfrom sklearn.model_selection import train_test_split",
"_____no_output_____"
],
[
"x_train, x_test, y_train, y_test= train_test_split(x, y, test_size=0.2)",
"_____no_output_____"
],
[
"x_train.shape",
"_____no_output_____"
],
[
"from sklearn.linear_model import LogisticRegression",
"_____no_output_____"
],
[
"clf= LogisticRegression(random_state=0, multi_class=\"multinomial\")",
"_____no_output_____"
],
[
"clf.fit(x_train, y_train)",
"_____no_output_____"
],
[
"# Predicting special custom data\n\ndt= np.array([\"%@123abcd\"])\npred= vector.transform(dt)\nclf.predict(pred)",
"_____no_output_____"
],
[
"# Predicting x_test data\n\ny_pred= clf.predict(x_test)\ny_pred",
"_____no_output_____"
]
],
[
[
"# Checking Accuracy of Model using Accuracy_score & Confusion_matrix",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import accuracy_score, confusion_matrix",
"_____no_output_____"
],
[
"cm= confusion_matrix(y_test, y_pred)\nprint(cm)\nprint(accuracy_score(y_test, y_pred))",
"[[ 5330 12457 12]\n [ 3826 93357 2521]\n [ 29 5204 11192]]\n0.8204333671823666\n"
]
],
[
[
"# Creating report of Model",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import classification_report",
"_____no_output_____"
],
[
"print(classification_report(y_test, y_pred))",
" precision recall f1-score support\n\n 0 0.58 0.30 0.40 17799\n 1 0.84 0.94 0.89 99704\n 2 0.82 0.68 0.74 16425\n\n accuracy 0.82 133928\n macro avg 0.75 0.64 0.67 133928\nweighted avg 0.80 0.82 0.80 133928\n\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
ecc32e3e50967e8fcd77aaa983f20b56ee946b8d | 389,801 | ipynb | Jupyter Notebook | examples/bossqsos_example.ipynb | jtschindler/simqso | 4ab248afc244ccb937720574991cbe1e98e2d248 | [
"BSD-3-Clause"
] | 1 | 2021-03-24T03:30:19.000Z | 2021-03-24T03:30:19.000Z | examples/bossqsos_example.ipynb | jtschindler/simqso | 4ab248afc244ccb937720574991cbe1e98e2d248 | [
"BSD-3-Clause"
] | null | null | null | examples/bossqsos_example.ipynb | jtschindler/simqso | 4ab248afc244ccb937720574991cbe1e98e2d248 | [
"BSD-3-Clause"
] | null | null | null | 711.315693 | 122,946 | 0.935406 | [
[
[
"%pylab inline\nfrom astropy.io import fits\nfrom astropy.table import Table\nfrom simqso.sqrun import buildWaveGrid,load_sim_output\nfrom simqso import hiforest\nfrom simqso.sqmodels import WP11_model\nimport bossqsos",
"Populating the interactive namespace from numpy and matplotlib\n"
]
],
[
[
"### Input luminosity function",
"_____no_output_____"
]
],
[
[
"M1450 = linspace(-30,-22,20)\nzz = arange(0.7,3.5,0.5)\nple = bossqsos.BOSS_DR9_PLE()\nlede = bossqsos.BOSS_DR9_LEDE()\nfor z in zz:\n if z<2.2:\n qlf = ple if z<2.2 else lede\n plot(M1450,qlf(M1450,z),label='z=%.1f'%z)\nlegend(loc='lower left')\nxlim(-21.8,-30.2)\nxlabel(\"$M_{1450}$\")\nylabel(\"log Phi\")",
"_____no_output_____"
]
],
[
[
"### Run the simulation, save the spectra",
"_____no_output_____"
]
],
[
[
"_ = bossqsos.qsoSimulation(bossqsos.simParams,saveSpectra=True)",
"boss_dr9qlf_sim output not found\ngenerating QSO grid\nintegration returned 390 objects\n... building continuum grid\nWARNING: GaussianPLawDistribution continuum is deprecated\nsimulating 390 quasar spectra\nunits are flux\nmax number iterations: 5\nmapping photometry\n stage time elapsed frac\n Initialize Grid 2.744 2.744 0.032\n Generate Features 0.728 3.472 0.009\nBuild Quasar Spectra 82.069 85.541 0.959\n PhotoMap 0.016 85.557 0.000\n Finish 0.000 85.557 0.000\n\n"
]
],
[
[
"### Simulation outputs",
"_____no_output_____"
]
],
[
[
"wave,qsos = load_sim_output('boss_dr9qlf_sim','.')",
"WARNING: failed to restore BrokenPowerLawContinuumVar\nWARNING: failed to restore BossDr9EmissionLineTemplateVar\nWARNING: failed to restore HIAbsorptionVar\n"
]
],
[
[
"the table of simulated quasars, including redshift, luminosity, synthetic flux/mags in nine bands, and \"observed\" photometry with errors included.\n\nalso includes details of the model inputs for each quasar: `slopes` is the set of broken power law slopes defining the continuum, `emLines` is the set of Gaussian parameters for each emission line (wave, EW, sigma) measured in the rest frame.",
"_____no_output_____"
]
],
[
[
"qsos[::40]",
"_____no_output_____"
]
],
[
[
"the distribution in g-band magnitude:",
"_____no_output_____"
]
],
[
[
"_ = hist(qsos['obsMag'][:,1],linspace(17,22,20),log=True)",
"_____no_output_____"
]
],
[
[
"color-color diagram from __observed__ magnitudes, including errors:",
"_____no_output_____"
]
],
[
[
"scatter(qsos['obsMag'][:,0]-qsos['obsMag'][:,1],qsos['obsMag'][:,1]-qsos['obsMag'][:,2],\n c=qsos['z'],cmap=cm.autumn_r,alpha=0.7)\ncolorbar()\nxlabel('u-g')\nylabel('g-r')\nxlim(-0.75,3)\nylim(-0.5,1.5)",
"_____no_output_____"
]
],
[
[
"the list of emission lines in the model:",
"_____no_output_____"
]
],
[
[
"qsodatahdr = fits.getheader('boss_dr9qlf_sim.fits',1)\nfor i,n in enumerate(qsodatahdr['LINENAME'].split(',')):\n print('%d:%s, '% (i,n,),end=\" \")\nprint()",
"0:LyB, 1:ArI, 2:FeIII:UV1, 3:CIII*, 4:LyAn, 5:LyAb, 6:NV, 7:SiII, 8:OI, 9:CII, 10:SiIV+OIV], 11:L1480, 12:CIVn, 13:CIVb, 14:HeII, 15:OIII], 16:L1690, 17:NIII], 18:SiII_1818, 19:AlIII, 20:SiIII], 21:CIII]b, 22:CIII]n, 23:fe2120, 24:fe2220, 25:MgIIb, 26:MgIIn, 27:OIII_3133, 28:[NeV]3346, 29:[NeV]3426, 30:[OII]3728, 31:[NeIII]3869, 32:HeI3889, 33:[NeIII]3968, 34:Hd, 35:Hg, 36:[OIII]4364, 37:Hbeta, 38:[OIII]4960, 39:[OIII]5008, 40:HeI_5877, 41:[OI]6302, 42:[OI]6365, 43:[NII]6549, 44:[NII]6585, 45:HAb, 46:HAn, 47:[SII]6718, 48:[SII]6732, 49:HeI7067, 50:[OII]7321, 51:OI8446, 52:[SIII]9069, 53:FeII9202, 54:Pae, 55:Pad, 56:HeI10830, 57:Pag, 58:OI11287, 59:Pabeta, 60:Paalpha, 61:HeI20580, \n"
]
],
[
[
"broad CIV equivalent width, displaying the Baldwin Effect:",
"_____no_output_____"
]
],
[
[
"scatter(qsos['absMag'],qsos['emLines'][:,13,1],c=qsos['z'],cmap=cm.autumn_r)\ncolorbar()\nxlabel(\"$M_{1450}$\")\nylabel(\"CIV equivalent width $\\AA$\")",
"_____no_output_____"
]
],
[
[
"### Example spectra\n\nfor this example the wavelength cutoff is 30 micron, but the model doesn't include warm dust and thus is invalid beyond a few micron.",
"_____no_output_____"
]
],
[
[
"figure(figsize=(14,4))\nplot(wave/1e4,qsos['spec'][0])\nyscale('log')\nxlabel('wave [micron]')",
"_____no_output_____"
]
],
[
[
"zoom in on the lyman alpha - CIV region:",
"_____no_output_____"
]
],
[
[
"figure(figsize=(14,4))\nplot(wave,qsos['spec'][20])\nxlim(3500,7500)\ntitle('$z=%.3f$'%qsos['z'][20])",
"_____no_output_____"
]
],
[
[
"### IGM absorption model (`simqso.hiforest`)",
"_____no_output_____"
],
[
"an example of the forest transmission spectra at R=30,000 (the native resolution for the monte carlo forest spectra):",
"_____no_output_____"
]
],
[
[
"# XXX WARNING -- an ugly hack is needed here. Internally, a table of Voigt profiles is generated \n# at startup in order to speed the forest spectra generation. This table is defined in terms of\n# the wave dispersion the first time a simulation is run. Here we are changing the wavelength\n# model, and thus before executing the next cells you must restart the kernel and execute only\n# the first cell.\nnp.random.seed(12345)\nwave = buildWaveGrid(dict(waveRange=(3500,4800),SpecDispersion=30000))\nforest = hiforest.IGMTransmissionGrid(wave,WP11_model,1)\nT = forest.next_spec(0,2.9)",
"_____no_output_____"
],
[
"figure(figsize=(14,4))\nplot(wave,T)",
"_____no_output_____"
],
[
"figure(figsize=(14,4))\nplot(wave,T)\nxlim(4300,4800)",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
]
] |
ecc335b70adbf538e3bc6798e8df577e55c36329 | 28,839 | ipynb | Jupyter Notebook | Modulo2/Clase8_ModeloAhorro.ipynb | douglasparism/SimulacionM2018 | 85953efb86c7ebf2f398474608dfda18cb4cf5b8 | [
"MIT"
] | null | null | null | Modulo2/Clase8_ModeloAhorro.ipynb | douglasparism/SimulacionM2018 | 85953efb86c7ebf2f398474608dfda18cb4cf5b8 | [
"MIT"
] | null | null | null | Modulo2/Clase8_ModeloAhorro.ipynb | douglasparism/SimulacionM2018 | 85953efb86c7ebf2f398474608dfda18cb4cf5b8 | [
"MIT"
] | null | null | null | 35.341912 | 392 | 0.57502 | [
[
[
"<h3>Simulación matemática 2018 </h3>\n<div style=\"background-color:#0099cc;\"> \n <font color = white>\n<ul>\n <li>Lázaro Alonso </li>\n <li>Email: `[email protected], [email protected]`</li>\n</ul>\n </font>\n</div>",
"_____no_output_____"
],
[
"<!--NAVIGATION-->\n< [Clasificación Binaria](Clase7_ClasificacionBinaria.ipynb) | [Guía](Clase0_GuiaSimulacionM.ipynb) | [Mapa logístico](Clase9_MapaLogistico.ipynb) >\n___",
"_____no_output_____"
],
[
"# Introducción a ecuaciones diferenciales\n\n<img style=\"float: right; margin: 0px 0px 15px 15px;\" src=\"https://upload.wikimedia.org/wikipedia/commons/3/39/GodfreyKneller-IsaacNewton-1689.jpg\" width=\"100px\" height=\"100px\" />\n\n> Las primeras ecuaciones diferenciales se encuentran históricamente con la invención del cálculo por Newton y Leibniz. En el Capítulo 2 de su trabajo \"Methodus fluxionum et Serierum Infinitarum\", (Newton, 1671), Newton describe ecuaciones del tipo \n\n$$\\frac{dy(x)}{dx}=f(x,y(x)).$$\n\n**Referencia**\n- https://en.wikipedia.org/wiki/Differential_equation\n- https://www.mathsisfun.com/calculus/differential-equations.html\n- http://www.sympy.org\n- http://matplotlib.org\n- http://www.numpy.org\n- http://ipywidgets.readthedocs.io/en/latest/index.html",
"_____no_output_____"
],
[
"### Nociones básicas\n\n#### Definición\nUna ecuación diferencial es una ecuació que involucra una función y una o más de sus derivadas.\n\nPor ejemplo\n\n<img style=\"float: left; margin: 0px 0px 15px 15px;\" src=\"https://www.mathsisfun.com/calculus/images/diff-eq-1.svg\" width=\"200px\" height=\"100px\" />",
"_____no_output_____"
],
[
"una ecuación de la función $y(x)$ y su derivada $\\frac{dy(x)}{dx}$.",
"_____no_output_____"
],
[
"### Solución\n\nDecimos que hemos resuelto la ecuación diferencial si descubrimos la función $y(x)$ (o conjunto de funciones $y(x)$).\n\n**Ejemplo** Estudiar la ecuación diferencial:\n\n$$\\frac{dx}{dt}=a x(t).$$",
"_____no_output_____"
],
[
"___\n**Cuando una ecuación puede ser resuelta, hay varios trucos para intentar resolverla. En muchos casos, no es posible o es muy difícil encontrar la solución analítica. Por eso, en el curso examinaremos la forma de encontrar solución numérica.**",
"_____no_output_____"
],
[
"### ¿Porqué son útiles las ecuaciones diferenciales?\n\nAntes qué nada, conceptualmente, **¿qué significa la derivada $\\frac{dx}{dt}$?**",
"_____no_output_____"
],
[
"Nuestro mundo, y particularmente los fenómenos que estudiamos en ingeniería, es cambiante (evoluciona) en el tiempo. De modo que las descripciones (modelos) de como cambian las cosas en el tiempo terminan como una ecuación diferencial.",
"_____no_output_____"
],
[
"### Ejemplos",
"_____no_output_____"
],
[
"**1. Biología (crecimiento poblacional de conejos)**\n\nMientras más conejos tengamos, más bebés conejo obtendremos (los conejos tienen una grandiosa habilidad de reproducción). Luego, los bebés conejo crecen y tienen bebés a la vez. La población crece muy muy rápido.\n\nPartes importantes:\n\n- Población en el tiempo $t$: $N(t)$.\n- Tasa de crecimiento: $r$.\n- Tasa de cambio de la población: $\\frac{dN}{dt}$.\n\nImaginemos algunos valores:\n\n- La población actual (en el tiempo $t=0$) es $N(0)=1000$ conejos.\n- La tasa de crecimiento es de $0.01$ conejos por semana por cada conejo actualmente.\n\nEntonces la tasa de cambio de la población $\\left.\\frac{dN}{dt}\\right|_{t=0}=0.01\\times 1000$.\n\nSin embargo, esto sólo es cierto en el tiempo específico $t=0$, y esto no significa que la población crece de manera constante.\n\nRecordemos que: mientras más conejos, más conejos nuevos se obtienen.\n\nDe manera que es mejor decir que la tasa de cambio (en cualquier instante de tiempo $t$) es la tasa de crecimiento $r$ veces la población $N(t)$ en ese instante:\n\n$$\\frac{dN}{dt}=rN,$$\n\ny eso es una ecuación diferencial, porque es una ecuación de la función $N(t)$ y su derivada.\n\n**El poder de las matemáticas... con esa simple expresión decimos que \"la tasa de cambio de la población en el tiempo equivale a la tasa de crecimiento veces la población\".**",
"_____no_output_____"
],
[
"Las ecuaciones diferenciales pueden describir como cambia la población, como se dispersa el calor, como un material radioactivo se desintegra y mucho más. Son una forma natural de describir cambios o movimiento en el universo.\n\n### ¿Qué hacemos con la ecuación diferencial?\n\nEn principio, las ecuaciones diferenciales son magníficas para expresar (modelar) muchos fenómenos. Sin embargo, son difíciles de usar tal cual están.\n\nDe manera que intentamos **resolverlas** encontrando la(s) funciones que satisfagan la ecuación, es decir, quitando la derivada, de manera que podamos hacer cálculos, gráficas, predecir, y todo lo demás.",
"_____no_output_____"
],
[
"**2. Finanzas (interés continuamente compuesto)**\n\nEl valor del dinero cambia en el tiempo. Esto se expresa por medio de tasas de interés. Normalmente, el interés se puede calcular en tiempo fijados como años, meses, etcétera, y esto se añade al capital inicial y se reinvierte.\n\nEsto se llama interés compuesto.\n\nPero cuando se se compone continuamente (en todo tiempo), entonces a cada instante, el interés se añade al proporcionalmente a la inversión (o préstamo).\n\nMientras más inversión (o préstamo) más interés gana.\n\nUsando $t$ para el tiempo, $r$ para la tasa de interés y $V(t)$ para el valor en el instante $t$ de la inversión:\n\n$$\\frac{dV}{dt}=rV.$$\n\nNotar que es la misma ecuación que tenemos para los conejos, solo con diferentes letras. Entonces, las matemáticas muestran que esos dos fenómenos se comportan de la misma manera.\n\nYa dijimos que como ecuación, es difícil usar esta información. Pero tranquilos, se puede resolver (por separación de variables) y la solución es:\n\n$$V(t) = P e^{rt},$$\n\ndonde $P$ es el principal (capital inicial).\n\nDe forma que un préstamo continuamente compuesto de $1,000 por dos años y una tasa de interés del 10% se vuelve:\n\n$$V = 1000 × e^{2\\times0.1}$$\n$$V = 1000 × 1.22140...$$\n$$V = $1,221.40$$",
"_____no_output_____"
],
[
"**3. Mecánica Clásica**\n\nUn resorte tiene una masa amarrada:\n\n- la masa es jalada hacia abajo por la acción de gravedad,\n- cuando el resorte se estira, su tensión se incrementa,\n- la masa se detienne,\n- la tensión del resorte la jala de nuevo hacia arriba,\n- luego baja, luego sube, luego baja, etcétera...",
"_____no_output_____"
],
[
"# Modelo de ahorro",
"_____no_output_____"
],
[
"> **¿Tiene el dinero el mismo valor a lo largo del tiempo?** La respuesta es *no*. Todos lo hemos vivido. \n\n> Dos situaciones básicas:\n1. <font color=blue>Inflación</font>: ¿Cuánto dinero necesitabas para comprar unas papas y un refresco hace 10 años? ¿Cuánto necesitas hoy?\n2. <font color=blue>Interés</font>: no es lo mismo tener \\$10000 MXN disponibles hoy a recibir \\$10000 MXN en un año, pues los primeros pueden ser invertidos en un negocio o una cuenta bancaria para generar *interés*. Por lo tanto los \\$10000 MXN disponibles hoy valen más que los \\$10000 MXN que se recibirán en un año.\n\nReferencia:\n- Vidaurri Aguirre, Héctor Manuel. *Ingeniería económica básica*, ISBN: 978-607-519-017-4. (Disponible en biblioteca)",
"_____no_output_____"
],
[
"___\n## Interés\nNos centraremos en como cambia el valor del dinero en el tiempo debido al **interés**. Existen dos tipos:",
"_____no_output_____"
],
[
"### Capitalización por interés simple\nEste tipo de interés se calcula <font color=red>única y exclusivamente sobre la cantidad original que se invirtió</font>. Como consecuencia, el interés generado no forma parte del dinero que se invierte, es decir, los <font color=blue>intereses no ganan intereses</font>.\n\nSuponga que se tiene un capital inicial $C_0$ y se invierte a un plazo de $k$ periodos (pueden ser meses, trimestres, semestres, años...) a una tasa de **interés simple** por periodo $i$. Al final del primer periodo, el capital $C_1$ que se obtiene es:\n\n$$C_1=C_0+iC_0=C_0(1+i).$$\n\nDe la misma manera, como el interés solo se calcula sobre el capital inicial, al final del segundo periodo, el capital $C_2$ que se obtiene es:\n\n$$C_2=C_1+iC_0=C_0+iC_0+iC_0=C_0(1+2i).$$\n\nAsí, al final del $k-$ésimo periodo, el capital $C_k$ que se obtiene es:\n\n$$C_k=C_{k-1}+iC_0=C_0+kiC_0=C_0(1+ki).$$",
"_____no_output_____"
],
[
"> **Ejemplo.** Suponga que se tiene un capital de \\$10000 MXN, el cual se pone en un fondo de inversión que paga una tasa de interés simple del 0.8% mensual. \n\n> Si se tiene una meta de ahorro de \\$11000 MXN sin inversiones adicionales, ¿cuántos meses se debería dejar invertido el dinero?",
"_____no_output_____"
]
],
[
[
"import numpy as np",
"_____no_output_____"
],
[
"def Nper(c0, ck, interes):\n nper = (ck/c0 - 1 )/interes\n if (nper - int(nper)) == 0:\n return nper\n else:\n return int(nper) + 1",
"_____no_output_____"
],
[
"Nper(10000, 11000, .008 )",
"_____no_output_____"
]
],
[
[
"> <font color=blue>**Actividad.**</font>\n> - ¿Qué pasa si el interés no es del 0.8% mensual sino del 1% mensual?\n> - ¿Qué pasa si la meta no son \\$11000 MXN si no \\$12000 MXN?",
"_____no_output_____"
]
],
[
[
"# Solución\n\n",
"_____no_output_____"
]
],
[
[
"> **Una gráfica que nos permite ilustrar la situación anterior se puede realizar de la siguiente manera.**",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\n# Para que se muestren las gráficas en la misma ventana\n%matplotlib inline\n# Librería para widgets de jupyter\nfrom ipywidgets import *",
"_____no_output_____"
],
[
"def interes_simple(c0, meta, i):\n # Despejamos k\n k = Nper(c0, meta, i)\n # Vector de periodos\n kk = np.arange(0, k + 1, 1) \n # Vector de capitales por periodo\n cc = c0 * (1 + kk * i)\n # Gráfico\n plt.figure(num=1); plt.clf() # Figura 1, borrar lo que contenga\n plt.plot(kk, cc,'ro',linewidth=3.0) # Se grafica la evolución de los capitales\n plt.plot(kk, meta*np.ones(k+1),'--k') # Se grafica la meta\n plt.xlabel('k') # Etiqueta eje x\n plt.ylabel('C_k') # Etiqueta eje y\n plt.grid(False) # Malla en la gráfica\n plt.show() # Mostrar la figura",
"_____no_output_____"
],
[
"interact_manual(interes_simple, c0 = fixed(10000), meta = (10000,12000,100), i = fixed(0.008));",
"_____no_output_____"
]
],
[
[
"Como se esperaba, el capital en el $k-$ésimo periodo $C_k=C_0(1+ki)$ crece linealmente con $k$.",
"_____no_output_____"
],
[
"### Capitalización por interés compuesto\nEl capital que genera el interés simple permanece constante todo el tiempo de duración de la inversión. En cambio, el que produce el interés compuesto en un periodo se <font color=red>convierte en capital en el siguiente periodo</font>. Esto es, el interés generado al final de un periodo <font color=blue>se reinvierte para el siguiente periodo para también producir interés</font>.\n\nSuponga que se tiene un capital inicial $C_0$, y se va a ceder el uso de este capital por un periodo de tiempo determinado a una tasa de interés $i$. El capital que se obtiene al final del primer periodo $C_1$ se puede calcular por\n\n$$C_1=C_0(1+i).$$ \n\nSi la anterior suma se vuelve a ceder a la misma tasa de interés, al final del periodo dos el capital $C_2$ es \n\n$$C_2=C_1(1+i)=C_0(1+i)^2.$$\n\nSi se repite el anterior proceso $k$ veces, el capital al final del $k-$ésimo periodo $C_k$ es \n\n$$C_k=C_{k-1}(1+i)=C_0(1+i)^k.$$\n\n**Referencia**:\n- https://es.wikipedia.org/wiki/Inter%C3%A9s_compuesto.",
"_____no_output_____"
],
[
"> **Ejemplo.** Suponga que se tiene un capital de \\$10000 MXN, el cual se pone en un fondo de inversión que paga una tasa de interés del 0.8% mensual. \n\n> Si se tiene una meta de ahorro de \\$11000 MXN sin inversiones adicionales, ¿cuántos meses se debería dejar invertido el dinero?\n\n> Muestre una gráfica que ilustre la situación.",
"_____no_output_____"
]
],
[
[
"def NperComp(c0, ck, interes):\n nper = np.log(ck/c0)/np.log(1 + interes)\n if (nper - int(nper)) == 0:\n return nper\n else:\n return int(nper) + 1",
"_____no_output_____"
],
[
"def interes_compuesto(c0, meta, i):\n # Despejamos k\n k = NperComp(c0, meta, i)\n # Vector de periodos\n kk = np.arange(0, k + 1, 1) \n # Vector de capitales por periodo\n cc = c0 * (1 + i) ** kk\n # Gráfico\n plt.figure(num=1); plt.clf() # Figura 1, borrar lo que contenga\n plt.plot(kk, cc,'ro',linewidth=3.0) # Se grafica la evolución de los capitales\n plt.plot(kk, meta*np.ones(k + 1),'--k') # Se grafica la meta\n plt.xlabel('k') # Etiqueta eje x\n plt.ylabel('C_k') # Etiqueta eje y\n plt.grid(False) # Malla en la gráfica\n plt.show() # Mostrar la figura\n ",
"_____no_output_____"
],
[
"interact_manual(interes_compuesto, c0=fixed(10000), meta=(10000,12000,100), i=fixed(0.008));",
"_____no_output_____"
]
],
[
[
"El capital en el $k-$ésimo periodo $C_k=C_0(1+i)^k$ crece de manera exponencial con $k$.",
"_____no_output_____"
],
[
"> <font color=blue>**Actividad.**</font>\n> - Modificar el código anterior para dejar fija la meta de ahorro y variar la tasa de interés compuesta.",
"_____no_output_____"
]
],
[
[
"# Respuesta\n\n",
"_____no_output_____"
]
],
[
[
"### Capitalización continua de intereses\nLa capitalización continua se considera un tipo de capitalización compuesta, en la que a cada instante de tiempo $t$ se se capitalizan los intereses. Es decir, la frecuencia de capitalización es infinita (o, equivalentemente, el periodo de capitalización tiende a cero).\n\nSuponga que se tiene un capital inicial $C_0$, y que el capital acumulado en el tiempo $t$ es $C(t)$. Queremos saber cuanto será el capital pasado un periodo de tiempo $\\Delta t$, dado que la tasa de interés efectiva para este periodo de tiempo es $i$. De acuerdo a lo anterior tenemos\n\n$$C(t+\\Delta t)=C(t)(1+i)=C(t)(1+r\\Delta t),$$\n\ndonde $r=\\frac{i}{\\Delta t}$ es la tasa de interés instantánea. Manipulando la anterior expresión, obtenemos\n\n$$\\frac{C(t+\\Delta t)-C(t)}{\\Delta t}=r\\; C(t).$$\n\nHaciendo $\\Delta t\\to 0$, obtenemos la siguiente ecuación diferencial \n\n$$\\frac{d C(t)}{dt}=r\\; C(t),$$\n\nsujeta a la condición inicial (monto o capital inicial) $C(0)=C_0$.\n\nLa anterior, es una ecuación diferencial lineal de primer orden, para la cual se puede calcular la *solución analítica*.",
"_____no_output_____"
]
],
[
[
"# Librería de cálculo simbólico\nimport sympy as sym\n\n# Para imprimir en formato TeX\nfrom sympy import init_printing; init_printing(use_latex='mathjax')\n\n# Símbolos t(para el tiempo) y r(para el interés instantáneo)\n#t, r = sym.symbols('t r')\n# Otra forma de hacer lo anterior\nsym.var('t r')\n\nC = sym.Function('C')",
"_____no_output_____"
],
[
"eqn = sym.Eq(sym.Derivative(C(t),t) - r*C(t), 0) # Ecuación diferencial\neqn",
"_____no_output_____"
],
[
"sym.dsolve(eqn, C(t)) # Resolver",
"_____no_output_____"
]
],
[
[
"con $C_1=C_0$.",
"_____no_output_____"
],
[
"___\n¿Cómo podemos calcular la *solución numérica*?",
"_____no_output_____"
],
[
"> **Ejemplo.** Suponga que se tiene un capital de \\$10000 MXN, el cual se pone en un fondo de inversión que paga una tasa de interés del 0.8% mensual. \n\n> Si se tiene una meta de ahorro de \\$11000 MXN sin inversiones adicionales, ¿cuánto tiempo se debe dejar invertido el dinero?\n\n> Muestre una gráfica que ilustre la situación.",
"_____no_output_____"
]
],
[
[
"# Librerías para integración numérica\nfrom scipy.integrate import odeint\n\n# Modelo de capitalización continua\ndef cap_continua(C, t, r):\n return r * C",
"_____no_output_____"
],
[
"def interes_continuo(C_0, meta, r):\n # Despejamos t\n t = np.log(meta/C_0)/r\n # Vector de periodos\n tt = np.linspace(0,t,100)\n # Vector de capitales por periodo\n CC = odeint(cap_continua, C_0, tt, args = (r,))\n # Gráfico\n plt.figure(num=1); plt.clf() # Figura 1, borrar lo que contenga\n plt.plot(tt, CC,'-',linewidth=3.0) # Se grafica la evolución de los capitales\n plt.plot(tt,meta*np.ones(len(tt)),'--k') # Se grafica la meta\n plt.xlabel('t') # Etiqueta eje x\n plt.ylabel('C(t)') # Etiqueta eje y\n plt.grid(False) # Malla en la gráfica\n plt.show() # Mostrar la figura\n print(\"El tiempo que se debe dejar invertido el dinero para llegar a la meta de \", meta,\" es \", t, \" meses.\", sep=\"\")\n \ninteract_manual(interes_continuo, C_0=fixed(10000), meta=(10000,20000,100), r=fixed(np.log(1+.008)));",
"_____no_output_____"
]
],
[
[
"> <font color=blue>**Actividad.**</font>\n> - Averiguar tasas de interés reales en algún banco y proyectar un ahorro mensual para que al terminar su carrera tengan \\$50000 MXN en su cuenta.",
"_____no_output_____"
]
],
[
[
"# Respuesta\n\n",
"_____no_output_____"
]
],
[
[
"___\n<!--NAVIGATION-->\n< [Clasificación Binaria](Clase7_ClasificacionBinaria.ipynb) | [Guía](Clase0_GuiaSimulacionM.ipynb) | [Mapa logístico](Clase9_MapaLogistico.ipynb) >",
"_____no_output_____"
],
[
"<script>\n $(document).ready(function(){\n $('div.prompt').hide();\n $('div.back-to-top').hide();\n $('nav#menubar').hide();\n $('.breadcrumb').hide();\n $('.hidden-print').hide();\n });\n</script>\n\n<footer id=\"attribution\" style=\"float:right; color:#808080; background:#fff;\">\nCreated with Jupyter by Lázaro Alonso.\n <Strong> Copyright: </Strong> Public Domain como en [CC](https://creativecommons.org/licenses/by/2.0/) (Exepto donde se indique lo contrario)\n\n\n</footer>",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
ecc34383ddbe3f23e53dda1f3455e42441dcec77 | 36,569 | ipynb | Jupyter Notebook | site/ko/tutorials/generative/pix2pix.ipynb | phoenix-fork-tensorflow/docs-l10n | 2287738c22e3e67177555e8a41a0904edfcf1544 | [
"Apache-2.0"
] | 491 | 2020-01-27T19:05:32.000Z | 2022-03-31T08:50:44.000Z | site/ko/tutorials/generative/pix2pix.ipynb | phoenix-fork-tensorflow/docs-l10n | 2287738c22e3e67177555e8a41a0904edfcf1544 | [
"Apache-2.0"
] | 511 | 2020-01-27T22:40:05.000Z | 2022-03-21T08:40:55.000Z | site/ko/tutorials/generative/pix2pix.ipynb | phoenix-fork-tensorflow/docs-l10n | 2287738c22e3e67177555e8a41a0904edfcf1544 | [
"Apache-2.0"
] | 627 | 2020-01-27T21:49:52.000Z | 2022-03-28T18:11:50.000Z | 31.3897 | 339 | 0.487763 | [
[
[
"##### Copyright 2019 The TensorFlow Authors.\n\nLicensed under the Apache License, Version 2.0 (the \"License\");",
"_____no_output_____"
]
],
[
[
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
]
],
[
[
"# Pix2Pix",
"_____no_output_____"
],
[
"<table class=\"tfo-notebook-buttons\" align=\"left\">\n <td><a target=\"_blank\" href=\"https://www.tensorflow.org/tutorials/generative/pix2pix\"><img src=\"https://www.tensorflow.org/images/tf_logo_32px.png\">TensorFlow.org에서 보기</a></td>\n <td><a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/tutorials/generative/pix2pix.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\">Google Colab에서 실행하기</a></td>\n <td><a target=\"_blank\" href=\"https://github.com/tensorflow/docs/blob/master/site/en/tutorials/generative/pix2pix.ipynb\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\">GitHub에서소스 보기</a></td>\n <td><a href=\"https://storage.googleapis.com/tensorflow_docs/docs/site/en/tutorials/generative/pix2pix.ipynb\"><img src=\"https://www.tensorflow.org/images/download_logo_32px.png\">노트북 다운로드하기</a></td>\n</table>",
"_____no_output_____"
],
[
"이 노트북은 [Conditional Adversarial Networks를 사용한 이미지 간 변환](https://arxiv.org/abs/1611.07004)에서 설명한 대로 조건부 GAN을 사용한 이미지간 변환을 보여줍니다. 이 기법을 사용하여 흑백 사진을 채색하고, 구글 지도를 구글 어스로 변환하는 등의 작업을 수행할 수 있습니다. 여기서는 건물 정면을 실제 건물로 변환합니다.\n\n예제에서는 [프라하 체코 공과대학](http://cmp.felk.cvut.cz/~tylecr1/facade/)의 [기계 인식 센터](http://cmp.felk.cvut.cz/)에서 제공하는 [CMP Facade Database](https://www.cvut.cz/)를 사용할 것입니다. 예제를 간략하게 유지하기 위해 위의 [논문](https://people.eecs.berkeley.edu/~tinghuiz/projects/pix2pix/datasets/) 작성자가 만든 이 데이터세트의 전처리된 [사본](https://arxiv.org/abs/1611.07004)을 사용합니다.\n\n각 epoch는 단일 V100 GPU에서 약 15초가 걸립니다.\n\n다음은 200개 epoch 동안 모델을 훈련한 후에 생성된 출력입니다.\n\n",
"_____no_output_____"
],
[
"## TensorFlow 및 기타 라이브러리 가져오기",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\n\nimport os\nimport time\n\nfrom matplotlib import pyplot as plt\nfrom IPython import display",
"_____no_output_____"
],
[
"!pip install -U tensorboard",
"_____no_output_____"
]
],
[
[
"## 데이터세트 로드하기\n\n이 데이터세트 및 이와 유사한 데이터세트는 [여기](https://people.eecs.berkeley.edu/~tinghuiz/projects/pix2pix/datasets)에서 다운로드할 수 있습니다. [논문](https://arxiv.org/abs/1611.07004)에서 언급했듯이 훈련 데이터세트에 무작위 지터링 및 미러링을 적용합니다.\n\n- 무작위 지터링에서 이미지의 크기는 `286 x 286`로 조정되고 `256 x 256`로 무작위로 잘립니다.\n- 무작위 미러링에서는 이미지가 좌우로 무작위로 뒤집힙니다.",
"_____no_output_____"
]
],
[
[
"_URL = 'https://people.eecs.berkeley.edu/~tinghuiz/projects/pix2pix/datasets/facades.tar.gz'\n\npath_to_zip = tf.keras.utils.get_file('facades.tar.gz',\n origin=_URL,\n extract=True)\n\nPATH = os.path.join(os.path.dirname(path_to_zip), 'facades/')",
"_____no_output_____"
],
[
"BUFFER_SIZE = 400\nBATCH_SIZE = 1\nIMG_WIDTH = 256\nIMG_HEIGHT = 256",
"_____no_output_____"
],
[
"def load(image_file):\n image = tf.io.read_file(image_file)\n image = tf.image.decode_jpeg(image)\n\n w = tf.shape(image)[1]\n\n w = w // 2\n real_image = image[:, :w, :]\n input_image = image[:, w:, :]\n\n input_image = tf.cast(input_image, tf.float32)\n real_image = tf.cast(real_image, tf.float32)\n\n return input_image, real_image",
"_____no_output_____"
],
[
"inp, re = load(PATH+'train/100.jpg')\n# casting to int for matplotlib to show the image\nplt.figure()\nplt.imshow(inp/255.0)\nplt.figure()\nplt.imshow(re/255.0)",
"_____no_output_____"
],
[
"def resize(input_image, real_image, height, width):\n input_image = tf.image.resize(input_image, [height, width],\n method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)\n real_image = tf.image.resize(real_image, [height, width],\n method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)\n\n return input_image, real_image",
"_____no_output_____"
],
[
"def random_crop(input_image, real_image):\n stacked_image = tf.stack([input_image, real_image], axis=0)\n cropped_image = tf.image.random_crop(\n stacked_image, size=[2, IMG_HEIGHT, IMG_WIDTH, 3])\n\n return cropped_image[0], cropped_image[1]",
"_____no_output_____"
],
[
"# normalizing the images to [-1, 1]\n\ndef normalize(input_image, real_image):\n input_image = (input_image / 127.5) - 1\n real_image = (real_image / 127.5) - 1\n\n return input_image, real_image",
"_____no_output_____"
],
[
"@tf.function()\ndef random_jitter(input_image, real_image):\n # resizing to 286 x 286 x 3\n input_image, real_image = resize(input_image, real_image, 286, 286)\n\n # randomly cropping to 256 x 256 x 3\n input_image, real_image = random_crop(input_image, real_image)\n\n if tf.random.uniform(()) > 0.5:\n # random mirroring\n input_image = tf.image.flip_left_right(input_image)\n real_image = tf.image.flip_left_right(real_image)\n\n return input_image, real_image",
"_____no_output_____"
]
],
[
[
"무작위 지터링을 거치는 아래 이미지에서 볼 수 있듯이 논문의 설명에 따라 무작위 지터링은 다음 작업 수행을 의미합니다.\n\n1. 더 큰 높이와 너비로 이미지의 크기를 조정합니다.\n2. 대상 크기로 무작위 자릅니다.\n3. 이미지를 가로로 무작위 뒤집습니다.",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(6, 6))\nfor i in range(4):\n rj_inp, rj_re = random_jitter(inp, re)\n plt.subplot(2, 2, i+1)\n plt.imshow(rj_inp/255.0)\n plt.axis('off')\nplt.show()",
"_____no_output_____"
],
[
"def load_image_train(image_file):\n input_image, real_image = load(image_file)\n input_image, real_image = random_jitter(input_image, real_image)\n input_image, real_image = normalize(input_image, real_image)\n\n return input_image, real_image",
"_____no_output_____"
],
[
"def load_image_test(image_file):\n input_image, real_image = load(image_file)\n input_image, real_image = resize(input_image, real_image,\n IMG_HEIGHT, IMG_WIDTH)\n input_image, real_image = normalize(input_image, real_image)\n\n return input_image, real_image",
"_____no_output_____"
]
],
[
[
"## 입력 파이프라인",
"_____no_output_____"
]
],
[
[
"train_dataset = tf.data.Dataset.list_files(PATH+'train/*.jpg')\ntrain_dataset = train_dataset.map(load_image_train,\n num_parallel_calls=tf.data.experimental.AUTOTUNE)\ntrain_dataset = train_dataset.shuffle(BUFFER_SIZE)\ntrain_dataset = train_dataset.batch(BATCH_SIZE)",
"_____no_output_____"
],
[
"test_dataset = tf.data.Dataset.list_files(PATH+'test/*.jpg')\ntest_dataset = test_dataset.map(load_image_test)\ntest_dataset = test_dataset.batch(BATCH_SIZE)",
"_____no_output_____"
]
],
[
[
"## 생성기 빌드하기\n\n- 생성기 아키텍처는 수정된 U-Net입니다.\n- 인코더의 각 블록은 (Conv -> Batchnorm -> Leaky ReLU)입니다.\n- 디코더의 각 블록은 (Transposed Conv -> Batchnorm -> Dropout(처음 3개의 블록에 적용됨)-> ReLU)입니다.\n- 인코더와 디코더 사이에는 스킵(skip) 연결이 있습니다(U-Net에서와 같이).\n",
"_____no_output_____"
]
],
[
[
"OUTPUT_CHANNELS = 3",
"_____no_output_____"
],
[
"def downsample(filters, size, apply_batchnorm=True):\n initializer = tf.random_normal_initializer(0., 0.02)\n\n result = tf.keras.Sequential()\n result.add(\n tf.keras.layers.Conv2D(filters, size, strides=2, padding='same',\n kernel_initializer=initializer, use_bias=False))\n\n if apply_batchnorm:\n result.add(tf.keras.layers.BatchNormalization())\n\n result.add(tf.keras.layers.LeakyReLU())\n\n return result",
"_____no_output_____"
],
[
"down_model = downsample(3, 4)\ndown_result = down_model(tf.expand_dims(inp, 0))\nprint (down_result.shape)",
"_____no_output_____"
],
[
"def upsample(filters, size, apply_dropout=False):\n initializer = tf.random_normal_initializer(0., 0.02)\n\n result = tf.keras.Sequential()\n result.add(\n tf.keras.layers.Conv2DTranspose(filters, size, strides=2,\n padding='same',\n kernel_initializer=initializer,\n use_bias=False))\n\n result.add(tf.keras.layers.BatchNormalization())\n\n if apply_dropout:\n result.add(tf.keras.layers.Dropout(0.5))\n\n result.add(tf.keras.layers.ReLU())\n\n return result",
"_____no_output_____"
],
[
"up_model = upsample(3, 4)\nup_result = up_model(down_result)\nprint (up_result.shape)",
"_____no_output_____"
],
[
"def Generator():\n inputs = tf.keras.layers.Input(shape=[256,256,3])\n\n down_stack = [\n downsample(64, 4, apply_batchnorm=False), # (bs, 128, 128, 64)\n downsample(128, 4), # (bs, 64, 64, 128)\n downsample(256, 4), # (bs, 32, 32, 256)\n downsample(512, 4), # (bs, 16, 16, 512)\n downsample(512, 4), # (bs, 8, 8, 512)\n downsample(512, 4), # (bs, 4, 4, 512)\n downsample(512, 4), # (bs, 2, 2, 512)\n downsample(512, 4), # (bs, 1, 1, 512)\n ]\n\n up_stack = [\n upsample(512, 4, apply_dropout=True), # (bs, 2, 2, 1024)\n upsample(512, 4, apply_dropout=True), # (bs, 4, 4, 1024)\n upsample(512, 4, apply_dropout=True), # (bs, 8, 8, 1024)\n upsample(512, 4), # (bs, 16, 16, 1024)\n upsample(256, 4), # (bs, 32, 32, 512)\n upsample(128, 4), # (bs, 64, 64, 256)\n upsample(64, 4), # (bs, 128, 128, 128)\n ]\n\n initializer = tf.random_normal_initializer(0., 0.02)\n last = tf.keras.layers.Conv2DTranspose(OUTPUT_CHANNELS, 4,\n strides=2,\n padding='same',\n kernel_initializer=initializer,\n activation='tanh') # (bs, 256, 256, 3)\n\n x = inputs\n\n # Downsampling through the model\n skips = []\n for down in down_stack:\n x = down(x)\n skips.append(x)\n\n skips = reversed(skips[:-1])\n\n # Upsampling and establishing the skip connections\n for up, skip in zip(up_stack, skips):\n x = up(x)\n x = tf.keras.layers.Concatenate()([x, skip])\n\n x = last(x)\n\n return tf.keras.Model(inputs=inputs, outputs=x)",
"_____no_output_____"
],
[
"generator = Generator()\ntf.keras.utils.plot_model(generator, show_shapes=True, dpi=64)",
"_____no_output_____"
],
[
"gen_output = generator(inp[tf.newaxis,...], training=False)\nplt.imshow(gen_output[0,...])",
"_____no_output_____"
]
],
[
[
"- **생성기 손실**\n - 이것은 생성된 이미지 및 **1의 배열**의 시그모이드 교차 엔트로피 손실입니다.\n - [논문](https://arxiv.org/abs/1611.07004)에는 생성 이미지와 대상 이미지 사이의 MAE(평균 절대 오차)인 L1 손실도 포함됩니다.\n - 이를 통해 생성된 이미지가 대상 이미지와 구조적으로 유사해질 수 있습니다.\n - 총 생성기 손실을 계산하는 공식 = gan_loss + LAMBDA * l1_loss. 여기서 LAMBDA = 100. 이 값은 [논문](https://arxiv.org/abs/1611.07004) 작성자가 결정했습니다.",
"_____no_output_____"
],
[
"생성기의 훈련 절차는 다음과 같습니다.",
"_____no_output_____"
]
],
[
[
"LAMBDA = 100",
"_____no_output_____"
],
[
"def generator_loss(disc_generated_output, gen_output, target):\n gan_loss = loss_object(tf.ones_like(disc_generated_output), disc_generated_output)\n\n # mean absolute error\n l1_loss = tf.reduce_mean(tf.abs(target - gen_output))\n\n total_gen_loss = gan_loss + (LAMBDA * l1_loss)\n\n return total_gen_loss, gan_loss, l1_loss",
"_____no_output_____"
]
],
[
[
"\n",
"_____no_output_____"
],
[
"## 판별자 빌드하기\n\n- 판별자는 PatchGAN입니다.\n- 판별자의 각 블록은 (Conv -> BatchNorm -> Leaky ReLU)입니다.\n- 마지막 레이어 이후의 출력 형상은 (batch_size, 30, 30, 1)입니다.\n- 출력의 각 30x30 패치는 입력 이미지의 70x70 부분을 분류합니다(이러한 아키텍처를 PatchGAN이라고 함).\n- 판별자는 2개의 입력을 받습니다.\n - 진짜로 분류해야 하는 입력 이미지 및 대상 이미지\n - 가짜로 분류해야 하는 입력 이미지 및 생성된 이미지(생성기의 출력)\n - 코드에서 이 두 입력을 함께 연결합니다(`tf.concat([inp, tar], axis=-1)`).",
"_____no_output_____"
]
],
[
[
"def Discriminator():\n initializer = tf.random_normal_initializer(0., 0.02)\n\n inp = tf.keras.layers.Input(shape=[256, 256, 3], name='input_image')\n tar = tf.keras.layers.Input(shape=[256, 256, 3], name='target_image')\n\n x = tf.keras.layers.concatenate([inp, tar]) # (bs, 256, 256, channels*2)\n\n down1 = downsample(64, 4, False)(x) # (bs, 128, 128, 64)\n down2 = downsample(128, 4)(down1) # (bs, 64, 64, 128)\n down3 = downsample(256, 4)(down2) # (bs, 32, 32, 256)\n\n zero_pad1 = tf.keras.layers.ZeroPadding2D()(down3) # (bs, 34, 34, 256)\n conv = tf.keras.layers.Conv2D(512, 4, strides=1,\n kernel_initializer=initializer,\n use_bias=False)(zero_pad1) # (bs, 31, 31, 512)\n\n batchnorm1 = tf.keras.layers.BatchNormalization()(conv)\n\n leaky_relu = tf.keras.layers.LeakyReLU()(batchnorm1)\n\n zero_pad2 = tf.keras.layers.ZeroPadding2D()(leaky_relu) # (bs, 33, 33, 512)\n\n last = tf.keras.layers.Conv2D(1, 4, strides=1,\n kernel_initializer=initializer)(zero_pad2) # (bs, 30, 30, 1)\n\n return tf.keras.Model(inputs=[inp, tar], outputs=last)",
"_____no_output_____"
],
[
"discriminator = Discriminator()\ntf.keras.utils.plot_model(discriminator, show_shapes=True, dpi=64)",
"_____no_output_____"
],
[
"disc_out = discriminator([inp[tf.newaxis,...], gen_output], training=False)\nplt.imshow(disc_out[0,...,-1], vmin=-20, vmax=20, cmap='RdBu_r')\nplt.colorbar()",
"_____no_output_____"
]
],
[
[
"**판별자 손실**\n\n- 판별자 손실 함수는 **진짜 이미지, 생성된 이미지**의 두 입력을 받습니다.\n- real_loss는 **진짜 이미지** 및 **1의 배열(진짜 이미지이기 때문)**의 시그모이드 교차 엔트로피 손실입니다.\n- generated_loss는 **생성된 이미지** 및 **0의 배열(가짜 이미지이기 때문)**의 시그모이드 교차 엔트로피 손실입니다.\n- 그리고 total_loss는 real_loss와 generated_loss의 합계입니다.\n",
"_____no_output_____"
]
],
[
[
"loss_object = tf.keras.losses.BinaryCrossentropy(from_logits=True)",
"_____no_output_____"
],
[
"def discriminator_loss(disc_real_output, disc_generated_output):\n real_loss = loss_object(tf.ones_like(disc_real_output), disc_real_output)\n\n generated_loss = loss_object(tf.zeros_like(disc_generated_output), disc_generated_output)\n\n total_disc_loss = real_loss + generated_loss\n\n return total_disc_loss",
"_____no_output_____"
]
],
[
[
"판별자의 훈련 절차는 다음과 같습니다.\n\n아키텍처 및 하이퍼 매개변수에 대한 자세한 내용은 [논문](https://arxiv.org/abs/1611.07004)을 참조하세요.",
"_____no_output_____"
],
[
"\n",
"_____no_output_____"
],
[
"## 옵티마이저 및 체크포인트-세이버 정의하기\n",
"_____no_output_____"
]
],
[
[
"generator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)\ndiscriminator_optimizer = tf.keras.optimizers.Adam(2e-4, beta_1=0.5)",
"_____no_output_____"
],
[
"checkpoint_dir = './training_checkpoints'\ncheckpoint_prefix = os.path.join(checkpoint_dir, \"ckpt\")\ncheckpoint = tf.train.Checkpoint(generator_optimizer=generator_optimizer,\n discriminator_optimizer=discriminator_optimizer,\n generator=generator,\n discriminator=discriminator)",
"_____no_output_____"
]
],
[
[
"## 이미지 생성하기\n\n훈련 중에 일부 이미지를 플롯하는 함수를 작성합니다.\n\n- 테스트 데이터세트의 이미지를 생성기로 전달합니다.\n- 그러면 생성기가 입력 이미지를 출력으로 변환합니다.\n- 마지막 단계로 예상을 플롯합니다. **짜잔!**",
"_____no_output_____"
],
[
"참고: 여기서 `training=True`는 테스트 데이터세트에서 모델을 실행하는 동안 배치 통계를 얻으려고 하므로 의도적인 것입니다. training = False를 사용하면 훈련 데이터세트에서 학습한 누적 통계(이것을 원하지는 않음)를 얻게 됩니다.",
"_____no_output_____"
]
],
[
[
"def generate_images(model, test_input, tar):\n prediction = model(test_input, training=True)\n plt.figure(figsize=(15,15))\n\n display_list = [test_input[0], tar[0], prediction[0]]\n title = ['Input Image', 'Ground Truth', 'Predicted Image']\n\n for i in range(3):\n plt.subplot(1, 3, i+1)\n plt.title(title[i])\n # getting the pixel values between [0, 1] to plot it.\n plt.imshow(display_list[i] * 0.5 + 0.5)\n plt.axis('off')\n plt.show()",
"_____no_output_____"
],
[
"for example_input, example_target in test_dataset.take(1):\n generate_images(generator, example_input, example_target)",
"_____no_output_____"
]
],
[
[
"## 훈련하기\n\n- 각 예에서 입력은 출력을 생성합니다.\n- 판별자는 input_image 및 생성된 이미지를 첫 번째 입력으로 받습니다. 두 번째 입력은 input_image와 target_image입니다.\n- 다음으로 생성기와 판별자 손실을 계산합니다.\n- 그런 다음 생성기와 판별자 변수(입력) 모두에 대해 손실의 그래디언트를 계산하고 이를 옵티마이저에 적용합니다.\n- 그런 다음 손실을 TensorBoard에 기록합니다.",
"_____no_output_____"
]
],
[
[
"EPOCHS = 150",
"_____no_output_____"
],
[
"import datetime\nlog_dir=\"logs/\"\n\nsummary_writer = tf.summary.create_file_writer(\n log_dir + \"fit/\" + datetime.datetime.now().strftime(\"%Y%m%d-%H%M%S\"))",
"_____no_output_____"
],
[
"@tf.function\ndef train_step(input_image, target, epoch):\n with tf.GradientTape() as gen_tape, tf.GradientTape() as disc_tape:\n gen_output = generator(input_image, training=True)\n\n disc_real_output = discriminator([input_image, target], training=True)\n disc_generated_output = discriminator([input_image, gen_output], training=True)\n\n gen_total_loss, gen_gan_loss, gen_l1_loss = generator_loss(disc_generated_output, gen_output, target)\n disc_loss = discriminator_loss(disc_real_output, disc_generated_output)\n\n generator_gradients = gen_tape.gradient(gen_total_loss,\n generator.trainable_variables)\n discriminator_gradients = disc_tape.gradient(disc_loss,\n discriminator.trainable_variables)\n\n generator_optimizer.apply_gradients(zip(generator_gradients,\n generator.trainable_variables))\n discriminator_optimizer.apply_gradients(zip(discriminator_gradients,\n discriminator.trainable_variables))\n\n with summary_writer.as_default():\n tf.summary.scalar('gen_total_loss', gen_total_loss, step=epoch)\n tf.summary.scalar('gen_gan_loss', gen_gan_loss, step=epoch)\n tf.summary.scalar('gen_l1_loss', gen_l1_loss, step=epoch)\n tf.summary.scalar('disc_loss', disc_loss, step=epoch)",
"_____no_output_____"
]
],
[
[
"실제 훈련 루프:\n\n- epoch 수에 대해 반복합니다.\n- 각 epoch에서 표시 내용을 지우고 `generate_images`를 실행하여 진행 상황을 표시합니다.\n- 각 epoch마다 훈련 데이터세트에 대해 반복하여 각 예에 대해 '.'를 인쇄합니다.\n- 20개 epoch마다 체크포인트를 저장합니다.",
"_____no_output_____"
]
],
[
[
"def fit(train_ds, epochs, test_ds):\n for epoch in range(epochs):\n start = time.time()\n\n display.clear_output(wait=True)\n\n for example_input, example_target in test_ds.take(1):\n generate_images(generator, example_input, example_target)\n print(\"Epoch: \", epoch)\n\n # Train\n for n, (input_image, target) in train_ds.enumerate():\n print('.', end='')\n if (n+1) % 100 == 0:\n print()\n train_step(input_image, target, epoch)\n print()\n\n # saving (checkpoint) the model every 20 epochs\n if (epoch + 1) % 20 == 0:\n checkpoint.save(file_prefix = checkpoint_prefix)\n\n print ('Time taken for epoch {} is {} sec\\n'.format(epoch + 1,\n time.time()-start))\n checkpoint.save(file_prefix = checkpoint_prefix)",
"_____no_output_____"
]
],
[
[
"이 훈련 루프는 TensorBoard에서 쉽게 볼 수 있는 로그를 저장하여 훈련 진행 상황을 모니터링합니다. 로컬에서 작업하면 별도의 TensorBoard 프로세스가 시작됩니다. 노트북에서 TensorBoard로 모니터링하려는 경우 훈련을 시작하기 전에 뷰어를 시작하는 것이 편합니다.\n\n뷰어를 시작하려면 다음을 코드 셀에 붙여넣습니다.",
"_____no_output_____"
]
],
[
[
"#docs_infra: no_execute\n%load_ext tensorboard\n%tensorboard --logdir {log_dir}",
"_____no_output_____"
]
],
[
[
"이제 훈련 루프를 실행합니다.",
"_____no_output_____"
]
],
[
[
"fit(train_dataset, EPOCHS, test_dataset)",
"_____no_output_____"
]
],
[
[
"TensorBoard 결과를 *공개적으로* 공유하려면 다음을 코드 셀에 복사하여 [TensorBoard.dev](https://tensorboard.dev/)에 로그를 업로드할 수 있습니다.\n\n참고: 이를 위해 구글 계정이 필요합니다.\n\n```\n!tensorboard dev upload --logdir {log_dir}\n```",
"_____no_output_____"
],
[
"주의: 이 명령은 종료되지 않습니다. 장기 실행되는 실험 결과를 지속적으로 업로드하도록 설계되었습니다. 데이터가 업로드되면 노트북 도구에서 \"실행 중단\" 옵션을 사용하여 실행을 중단시켜야 합니다.",
"_____no_output_____"
],
[
"[TensorBoard.dev](https://tensorboard.dev/experiment/lZ0C6FONROaUMfjYkVyJqw)에서 이 노트북의 [이전 실행 결과](https://tensorboard.dev/)를 볼 수 있습니다.\n\nTensorBoard.dev는 ML 실험을 호스팅 및 추적하고 모든 사람과 공유하기 위한 관리 환경입니다.\n\n`<iframe>`을 사용하여 인라인으로 포함할 수도 있습니다.",
"_____no_output_____"
]
],
[
[
"display.IFrame(\n src=\"https://tensorboard.dev/experiment/lZ0C6FONROaUMfjYkVyJqw\",\n width=\"100%\",\n height=\"1000px\")",
"_____no_output_____"
]
],
[
[
"GAN의 로그 해석은 단순한 분류 또는 회귀 모델보다 까다롭습니다. 살펴 보아야 할 내용::\n\n- 어떤 모델에도 \"won\"이 없는 것을 확인합니다. `gen_gan_loss` 또는 `disc_loss`가 매우 낮아지면 이 모델이 다른 모델을 지배하고 있고 결합된 모델을 성공적으로 훈련하지 못하고 있음을 나타냅니다.\n- `log(2) = 0.69` 값은 판별자가 두 옵션에 대해 평균적으로 동일하게 확신하지 못함을 의미하는 2의 perplexity를 나타내기 때문에 이러한 손실에 대한 좋은 기준점입니다.\n- `disc_loss`의 경우 `0.69` 미만의 값은 진짜 + 생성된 이미지의 결합된 세트에서 판별자가 무작위보다 성능이 좋음을 나타냅니다.\n- `gen_gan_loss`의 경우 `0.69` 미만의 값은 생성기 i가 무작위보다 판별자를 더 잘 속인다는 것을 의미합니다.\n- 훈련이 진행됨에 따라 `gen_l1_loss`가 줄어듭니다.",
"_____no_output_____"
],
[
"## 최신 체크포인트를 복원하고 테스트",
"_____no_output_____"
]
],
[
[
"!ls {checkpoint_dir}",
"_____no_output_____"
],
[
"# restoring the latest checkpoint in checkpoint_dir\ncheckpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))",
"_____no_output_____"
]
],
[
[
"## 테스트 데이터세트를 사용하여 생성하기",
"_____no_output_____"
]
],
[
[
"# Run the trained model on a few examples from the test dataset\nfor inp, tar in test_dataset.take(5):\n generate_images(generator, inp, tar)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
ecc3458a4182bfc62167edfd770ef9709b8b1ee6 | 121,369 | ipynb | Jupyter Notebook | tour6_energy/7_2_Softening_law_with_embedded_fracture_energy.ipynb | bmcs-group/bmcs_tutorial | 4e008e72839fad8820a6b663a20d3f188610525d | [
"MIT"
] | null | null | null | tour6_energy/7_2_Softening_law_with_embedded_fracture_energy.ipynb | bmcs-group/bmcs_tutorial | 4e008e72839fad8820a6b663a20d3f188610525d | [
"MIT"
] | null | null | null | tour6_energy/7_2_Softening_law_with_embedded_fracture_energy.ipynb | bmcs-group/bmcs_tutorial | 4e008e72839fad8820a6b663a20d3f188610525d | [
"MIT"
] | null | null | null | 99.238757 | 19,292 | 0.815958 | [
[
[
"# 7.2 Softening function and damage function",
"_____no_output_____"
]
],
[
[
"%matplotlib widget\nimport sympy as sp\nimport numpy as np\nimport matplotlib.pylab as plt\nsp.init_printing()",
"_____no_output_____"
]
],
[
[
"Let us consider a softening function of the form\n\\begin{align}\nf(w) = c_1 exp( - c_2 w )\n\\end{align}\nThis is function should describe the decay of stress starting from the material tensile strength and continuously deminishing to zero.\nThe variable $w$ represents the crack opening and the parameters $c_1$ and $c_2$ are the material parameters.",
"_____no_output_____"
]
],
[
[
"c_1, c_2 = sp.symbols('c_1, c_2', positive=True)\nw = sp.symbols(r'w')",
"_____no_output_____"
],
[
"f = c_1 * sp.exp(-c_2*w)",
"_____no_output_____"
]
],
[
[
"Let us plot the function to verify its shape for the material parameters set to the value 1",
"_____no_output_____"
]
],
[
[
"f_w = f.subs({c_1:1, c_2:1})\nf_w",
"_____no_output_____"
],
[
"w_arr = np.linspace(0.01,10,100)\nfig.canvas.header_visible=False\nfig, ax = plt.subplots(1,1,figsize=(5,3), tight_layout=True)\nax.plot(w_arr, sp.lambdify(w, f_w)(w_arr));",
"_____no_output_____"
]
],
[
[
"The function can be already used in this form. The question is however, how to set the material parameters $c_1$ and $c_2$. They can be directly associated to a particular type of material parameters - namely, to the tensile strength $f_\\mathrm{t}$ and fracture energy $G_\\mathrm{f}$ ",
"_____no_output_____"
]
],
[
[
"f_t, G_f = sp.symbols('f_t, G_f', positive=True)",
"_____no_output_____"
]
],
[
[
"Softening starts at the level of the material strength so that we can set $f(w = 0) = f_\\mathrm{t}$ to obtain the equation",
"_____no_output_____"
]
],
[
[
"Eq1 = sp.Eq(f.subs({'w':0}), f_t)\nEq1",
"_____no_output_____"
]
],
[
[
"By solving for the $c_1$ we obtain the first substitution for our softening function.",
"_____no_output_____"
]
],
[
[
"c_1_subs = sp.solve({Eq1}, c_1)\nc_1_subs",
"_____no_output_____"
]
],
[
[
"Thus, if $w_0 = 0$, $c_1$ is equivalent to the tensile strength $f_\\mathrm{t}$\n\nThe second possible mechanical interpretation is provided by the statement that softening directly represents the energy dissipation of a unit crack area. Thus, for large $w \\rightarrow \\infty$ it is equivalent to the energy producing a stress-free crack. This is the meaning of fracture energy.\n\nWe can thus obtain the fracture energy represented by the softening function by evaluating its integral in the range $w \\in (0, \\infty)$. ",
"_____no_output_____"
]
],
[
[
"int_f_w = sp.integrate(f.subs(c_1_subs), w)\nint_f_w",
"_____no_output_____"
]
],
[
[
"As $c_2 > 0$, only the second term matters.\nThe determinate integral\n\\begin{align}\n\\left[ - \\frac{f_\\mathrm{t}}{c_2} \n\\exp(-c_2 w) \\right]_0^{\\infty}\n\\end{align}\nis zero for $w = \\infty$, so that the value in $w = 0$ delivers the result of the integral\n\\begin{align}\n\\frac{f_\\mathrm{t}}{c_2} \n\\end{align}\n\nThis integral is equal to the fracture energy $G_\\mathrm{f}$.",
"_____no_output_____"
]
],
[
[
"E_0 = sp.symbols('E_0', positive=True ) ",
"_____no_output_____"
],
[
"Eq2 = sp.Eq(-int_f_w.subs({'w':0}), G_f)\nEq2",
"_____no_output_____"
]
],
[
[
"and the value of $c_2$ delivers the second substitution for the softening function",
"_____no_output_____"
]
],
[
[
"c_2_subs = sp.solve({Eq2}, c_2)\nc_2_subs",
"_____no_output_____"
]
],
[
[
"The softening function with strength and fracture energy as a parameter now obtains the form",
"_____no_output_____"
]
],
[
[
"f_w = f.subs(c_1_subs).subs(c_2_subs)\nsp.simplify(f_w)",
"_____no_output_____"
]
],
[
[
"Verify that the fracture energy is recovered at $w$ in infinity",
"_____no_output_____"
]
],
[
[
"sp.integrate(f_w, (w,0,sp.oo))",
"_____no_output_____"
]
],
[
[
"## What if there is a finite elastic stiffness",
"_____no_output_____"
]
],
[
[
"E_0, w_0 = sp.symbols(r'E_b, w_0', positive=True)",
"_____no_output_____"
],
[
"f = c_1 * sp.exp(-c_2*w)",
"_____no_output_____"
],
[
"f_w_0 = sp.Piecewise(\n (1, w < w_0),\n (f.subs(w, w-w_0), True)\n)\nf_w_0",
"_____no_output_____"
],
[
"sig_w = E_0 * w * f_w_0\nsig_w",
"_____no_output_____"
],
[
"subs_c_1 = sp.solve( {sp.Eq( sig_w.subs(w, w_0), E_b * w_0 )}, {c_1} )\nsubs_c_1",
"_____no_output_____"
],
[
"G_f_ = sp.simplify( sp.integrate(sig_w.subs(subs_c_1), (w,0,sp.oo)) ).factor()\nG_f_",
"_____no_output_____"
],
[
"_, subs_c_2 = sp.solve( sp.Eq( G_f, G_f_ ), {c_2} )\nsp.simplify(subs_c_2)",
"_____no_output_____"
],
[
"g1_w_ = sp.simplify( f_w_0.subs(c_2, subs_c_2).subs(c_1,1) )\ng1_w_",
"_____no_output_____"
]
],
[
[
"\\begin{align}\ng(\\tilde{s}) = \\displaystyle{\\frac{w_0}{\\tilde{w}}}\n\\exp\\left(\\frac{2 E_\\mathrm{b} w_0 ( \\tilde{w} - w_0) }\n{E_\\mathrm{b} w^2_0 - 2 G_\\mathrm{f}} \n \\right)\n\\end{align}",
"_____no_output_____"
]
],
[
[
"g2_w_ = sp.Piecewise(\n (1, w < w_0),\n ( w_0 / w * sp.exp( \n (2*E_b*w_0*(w-w_0))/(E_b*w_0**2-2*G_f) \n ), True)\n)\ng2_w_",
"_____no_output_____"
],
[
"get_g1_w_ = sp.lambdify( (w, w_0, E_b, G_f), g1_w_ )\nget_g2_w_ = sp.lambdify( (w, w_0, E_b, G_f), g2_w_ )",
"_____no_output_____"
],
[
"get_g1_w_(0.1, 0.1, 10, 0.1)",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(1,1)\nax2 = ax.twinx()\nw_range = np.linspace(0.0001,1,100)\nax.plot(w_range, get_g1_w_(w_range, 0.1, 10, 0.1), color='red')\nax.plot(w_range, get_g2_w_(w_range, 0.1, 10, 0.1), color='blue')\nax2.plot()",
"_____no_output_____"
],
[
"#f_t = E_b * s_0\n#g30_s_ = f_t / E_b / s_equiv * sp.exp( - f_t / G_f_0 * (s_equiv - s_0) )\n#g3_s_ = sp.simplify(g30_s_.subs(G_f_0, G_f - E_b*s_0**2/2))",
"_____no_output_____"
]
],
[
[
"## How to apply the softening function to a zone of length $L_s$?\n\nIf we wish to embed the softening behavior into a finite element simulation we encounter the problem that the deformation is not described by the crack opening $w$. The finite element discretization assumes by definition a smooth stran field $verepilon$ and there is no notion of discontinuity. \n\nAs a consequence, we need to account for a length of the softening zone $L_s$ which is actually equivalent to the size of the finite element.",
"_____no_output_____"
]
],
[
[
"L_s, epsilon = sp.symbols('L_s, varepsilon')",
"_____no_output_____"
]
],
[
[
"The crack opening $w$ is simply substituted by\n\\begin{align}\n w = \\varepsilon L_\\mathrm{s}\n\\end{align}\nto obtain the softening function in terms of strains",
"_____no_output_____"
]
],
[
[
"f_epsilon = f_w.subs({'w' : epsilon * L_s})\nf_epsilon",
"_____no_output_____"
]
],
[
[
"Note the important fact that the integral of the softening function over the strains scales the dissipated energy by the term $1/L_\\mathrm{s}$. ",
"_____no_output_____"
]
],
[
[
"sp.integrate(f_epsilon.subs(L_s,1), (epsilon,0,sp.oo))",
"_____no_output_____"
]
],
[
[
"As a consequence, by changing the size of the softening zone we also change the total amount of the energy dissipated!!! This feature of the softening function will be exploited in the implementation of the finite elements.",
"_____no_output_____"
],
[
"## How to convert a softening function to damage function?\n\nThe shape of the softening function describes the process of deterioration - starting from an undamaged state and ending in a fully damage state. Let us establish an equivalence between softening and damage evolution by requiring that they describe the same kind of stress decay.\n\nConsidering the softening zone of the length $L_s$ let us describe the damage within this zone using the state variable $omega$ and the elastic modulus $E_c$",
"_____no_output_____"
]
],
[
[
"omega, E_c = sp.symbols('omega, E_c')",
"_____no_output_____"
]
],
[
[
"Then, the constitute law to be used in a finite element of the zone is given as",
"_____no_output_____"
]
],
[
[
"sigma = (1 - omega) * E_c * epsilon",
"_____no_output_____"
]
],
[
[
"The stress decay described by the damage law and by the softening law should be the same. Let them set equal and solve for the damage variable $omega$. Using the sympy solver we obtain the algebraic solution as",
"_____no_output_____"
]
],
[
[
"omega_Gf = sp.solve(sigma - f_epsilon, omega)[0]\nomega_Gf",
"_____no_output_____"
],
[
"sigma_v = (1- omega_Gf) * E_c * epsilon\nsigma_v",
"_____no_output_____"
]
],
[
[
"This new damage function is defined using material parameters with a clear mechanical interpretation. Such kind of material law is attractive because it makes it possible to design tests that focus on an isolated phenomenon, i.e. the determination of the material strength, E modulus or fracture energy. ",
"_____no_output_____"
],
[
"Let us now visually verify the shape of the damage function.\nThe set of parameters is assembled in a dictionary and then\nthey are all substituted into the damage function.",
"_____no_output_____"
]
],
[
[
"data_f = dict(E_c = 28000, f_t = 3, L_s = 1, G_f = 0.01)\nomega_Gf_epsilon = omega_Gf.subs(data_f)\nomega_Gf_epsilon",
"_____no_output_____"
]
],
[
[
"The damage function is only valid in an inelastic regime. Therefore, we have to quantify the onset of inelasticity first as\n\\begin{align}\n\\varepsilon_0 = \\frac{f_t}{E_c}\n\\end{align}",
"_____no_output_____"
]
],
[
[
"epsilon_0 = (f_t / E_c).subs(data_f)\nepsilon_0",
"_____no_output_____"
]
],
[
[
"Then the damage function can be plotted as",
"_____no_output_____"
]
],
[
[
"splot(omega_Gf_epsilon, (epsilon,epsilon_0,epsilon_0*100))",
"_____no_output_____"
]
],
[
[
"The corresponding stress strain curve has then the form",
"_____no_output_____"
]
],
[
[
"sigma = sp.Piecewise( (E_c * epsilon, epsilon < epsilon_0),\n (( 1 - omega_Gf ) * E_c * epsilon, epsilon >= epsilon_0))\nsigma",
"_____no_output_____"
],
[
"splot(sigma.subs(data_f), (epsilon,0,epsilon_0*100))",
"_____no_output_____"
]
],
[
[
"Note how the stress strain function scales with the change of the fracture energy and of the zone length.\n\nLarger fracture energy makes the stress-strain response more ductile, while smaller makes it brittle.\n\nOn the other hand, larger size of the softening zone makes the softening behavior more brittle and smaller size of the zone makes it more ductile. Why?",
"_____no_output_____"
]
],
[
[
"g_f = sp.integrate(sigma, epsilon)",
"_____no_output_____"
],
[
"g_f",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
ecc346733eea35cefdce544aee24532c9dd12e8f | 1,862 | ipynb | Jupyter Notebook | unix-training-notebooks/basic-answers.ipynb | sanger-pathogens/unix-training | c6ac5e1aada8a8278116a4af803535988add45e3 | [
"CC-BY-4.0"
] | null | null | null | unix-training-notebooks/basic-answers.ipynb | sanger-pathogens/unix-training | c6ac5e1aada8a8278116a4af803535988add45e3 | [
"CC-BY-4.0"
] | null | null | null | unix-training-notebooks/basic-answers.ipynb | sanger-pathogens/unix-training | c6ac5e1aada8a8278116a4af803535988add45e3 | [
"CC-BY-4.0"
] | null | null | null | 36.509804 | 307 | 0.58754 | [
[
[
"empty"
]
]
] | [
"empty"
] | [
[
"empty"
]
] |
ecc34ebcd6732f099c9ea94db647757e8d21338c | 29,956 | ipynb | Jupyter Notebook | WalmartSale/2.3.Import_Target_Related_ItemMeta_Dataset.ipynb | jihys/startup-forecast-workshop | 262b8cd159f6a69cf55a7fdd267f748132445aa9 | [
"MIT"
] | 2 | 2020-07-14T05:54:41.000Z | 2021-03-23T03:11:24.000Z | WalmartSale/2.3.Import_Target_Related_ItemMeta_Dataset.ipynb | jihys/startup-forecast-workshop | 262b8cd159f6a69cf55a7fdd267f748132445aa9 | [
"MIT"
] | null | null | null | WalmartSale/2.3.Import_Target_Related_ItemMeta_Dataset.ipynb | jihys/startup-forecast-workshop | 262b8cd159f6a69cf55a7fdd267f748132445aa9 | [
"MIT"
] | 3 | 2020-07-14T05:54:43.000Z | 2020-12-03T04:59:33.000Z | 31.665962 | 186 | 0.528876 | [
[
[
"# Import Target, Related and Item Meta Dataset\n* This notebook has the following processes:\n * Create IAM role\n * Create a dataset group\n * Create a schema for a dataset\n * Create the dataset\n * Attach the dataset to the dataset group\n * Create a dataset import job\n \n \n* **About 10 mins may be elapsed**\n",
"_____no_output_____"
]
],
[
[
"import boto3\nfrom time import sleep\nimport os\nimport pandas as pd\nimport json\nimport time\nimport pprint\nimport numpy as np",
"_____no_output_____"
]
],
[
[
"## Parameters",
"_____no_output_____"
]
],
[
[
"%store -r",
"_____no_output_____"
],
[
"DATASET_FREQUENCY = \"W\" \nTIMESTAMP_FORMAT = \"yyyy-MM-dd\"\n\nproject = 'WalmartKaggleWithThreeDatasets'\nsuffix = str(np.random.uniform())[4:9]\ntarget_suffix = '_target'\nrelated_suffix = '_related'\nitem_meta_suffix = '_ItemM'\n\ntarget_datasetName= project+'DS' + target_suffix + suffix\nitem_meta_dataset_name= project+'DS' + item_meta_suffix + suffix\nrelated_dataset_Name= project+'DS' + related_suffix + suffix\nitem_datasetGroupName= project +'DSG'+ item_meta_suffix + suffix",
"_____no_output_____"
],
[
"with open('/opt/ml/metadata/resource-metadata.json') as notebook_info:\n data = json.load(notebook_info)\n resource_arn = data['ResourceArn']\n region = resource_arn.split(':')[3]\nprint(region)",
"us-east-2\n"
],
[
"session = boto3.Session(region_name=region)\nforecast = session.client(service_name='forecast')\nforecast_query = session.client(service_name='forecastquery')",
"_____no_output_____"
]
],
[
[
"## Create role\n**Make sure that a role for SageMaker notebook instance has these policies attached such as AmazonSageMakerFullAccess, AmazonS3FullAccess, AmazonForecastFullAccess, IAMFullAccess**",
"_____no_output_____"
]
],
[
[
"iam = boto3.client(\"iam\")\n\n# Put the role name\nrole_name = \"ForecastRoleWalmart\" + suffix\nassume_role_policy_document = {\n \"Version\": \"2012-10-17\",\n \"Statement\": [\n {\n \"Effect\": \"Allow\",\n \"Principal\": {\n \"Service\": \"forecast.amazonaws.com\"\n },\n \"Action\": \"sts:AssumeRole\"\n }\n ]\n}\n\ncreate_role_response = iam.create_role(\n RoleName = role_name,\n AssumeRolePolicyDocument = json.dumps(assume_role_policy_document)\n)\n\n# AmazonPersonalizeFullAccess provides access to any S3 bucket with a name that includes \"personalize\" or \"Personalize\" \n# if you would like tåo use a bucket with a different name, please consider creating and attaching a new policy\n# that provides read access to your bucket or attaching the AmazonS3ReadOnlyAccess policy to the role\npolicy_arn = \"arn:aws:iam::aws:policy/AmazonForecastFullAccess\"\niam.attach_role_policy(\n RoleName = role_name,\n PolicyArn = policy_arn\n)\n\n# Now add S3 support\niam.attach_role_policy(\n PolicyArn='arn:aws:iam::aws:policy/AmazonS3FullAccess',\n RoleName=role_name\n)\ntime.sleep(60) # wait for a minute to allow IAM role policy attachment to propagate\n\nrole_arn = create_role_response[\"Role\"][\"Arn\"]\nprint(role_arn)",
"arn:aws:iam::057716757052:role/ForecastRoleWalmart35988\n"
]
],
[
[
"## Create DatasetGroup",
"_____no_output_____"
]
],
[
[
"# Create the DatasetGroup\ncreate_dataset_group_response = forecast.create_dataset_group(\n DatasetGroupName=item_datasetGroupName,\n Domain=\"CUSTOM\",\n )\nitem_meta_datasetGroupArn = create_dataset_group_response['DatasetGroupArn']",
"_____no_output_____"
],
[
"forecast.describe_dataset_group(DatasetGroupArn=item_meta_datasetGroupArn)",
"_____no_output_____"
]
],
[
[
"## Create schema for target data",
"_____no_output_____"
]
],
[
[
"# Specify the schema of your dataset here. Make sure the order of columns matches the raw data files.\ntarget_schema ={\n \"Attributes\":[\n {\n \"AttributeName\":\"timestamp\",\n \"AttributeType\":\"timestamp\"\n },\n {\n \"AttributeName\":\"target_value\",\n \"AttributeType\":\"float\"\n },\n {\n \"AttributeName\":\"item_id\",\n \"AttributeType\":\"string\"\n }\n ]\n}",
"_____no_output_____"
]
],
[
[
"## Create Target Time Sereis Dataset",
"_____no_output_____"
]
],
[
[
"response=forecast.create_dataset(\n Domain=\"CUSTOM\",\n DatasetType='TARGET_TIME_SERIES',\n DatasetName=target_datasetName,\n DataFrequency=DATASET_FREQUENCY, \n Schema = target_schema\n)",
"_____no_output_____"
],
[
"target_second_datasetArn = response['DatasetArn']\nforecast.describe_dataset(DatasetArn=target_second_datasetArn)",
"_____no_output_____"
]
],
[
[
"## Create schema for related data",
"_____no_output_____"
]
],
[
[
"# Specify the schema of your dataset here. Make sure the order of columns matches the raw data files.\nrelated_schema ={\n \"Attributes\":[\n {\n \"AttributeName\":\"timestamp\",\n \"AttributeType\":\"timestamp\"\n },\n {\n \"AttributeName\":\"Temperature\",\n \"AttributeType\":\"float\"\n },\n {\n \"AttributeName\":\"Fuel_Price\",\n \"AttributeType\":\"float\"\n },\n {\n \"AttributeName\":\"item_id\",\n \"AttributeType\":\"string\"\n } \n ]\n}",
"_____no_output_____"
]
],
[
[
"## Create Related Time Sereis Dataset",
"_____no_output_____"
]
],
[
[
"response=forecast.create_dataset(\n Domain=\"CUSTOM\",\n DatasetType='RELATED_TIME_SERIES',\n DatasetName=related_dataset_Name,\n DataFrequency=DATASET_FREQUENCY, \n Schema = related_schema\n)",
"_____no_output_____"
],
[
"related_datasetArn = response['DatasetArn']\nforecast.describe_dataset(DatasetArn=related_datasetArn)",
"_____no_output_____"
]
],
[
[
"## Create schema for Item Meta data",
"_____no_output_____"
]
],
[
[
"# Specify the schema of your dataset here. Make sure the order of columns matches the raw data files.\nitem_meta_schema ={\n \"Attributes\":[\n {\n \"AttributeName\":\"item_id\",\n \"AttributeType\":\"string\"\n }, \n {\n \"AttributeName\":\"StoreType\",\n \"AttributeType\":\"string\"\n } \n ]\n}",
"_____no_output_____"
]
],
[
[
"## Create Item-Meta Dataset",
"_____no_output_____"
]
],
[
[
"response=forecast.create_dataset(\n Domain=\"CUSTOM\",\n DatasetType='ITEM_METADATA',\n DatasetName=item_meta_dataset_name,\n DataFrequency=DATASET_FREQUENCY, \n Schema = item_meta_schema\n)",
"_____no_output_____"
],
[
"item_meta_datasetArn = response['DatasetArn']\nforecast.describe_dataset(DatasetArn=item_meta_datasetArn)",
"_____no_output_____"
]
],
[
[
"## Attach the target, related and item_meta dataset to the DatasetGroup",
"_____no_output_____"
]
],
[
[
"# Attach the target dataset and related data set to the Dataset Group:\nforecast.update_dataset_group(\n DatasetGroupArn=item_meta_datasetGroupArn, \n DatasetArns=[target_second_datasetArn,\n related_datasetArn,\n item_meta_datasetArn])",
"_____no_output_____"
]
],
[
[
"## Create a bucket",
"_____no_output_____"
]
],
[
[
"import boto3\nimport sagemaker\n\ns3_resource = boto3.resource('s3')\ns3 = boto3.client('s3')\n\n# if you want, replace with a name of your S3 bucket\nbucket_name = sagemaker.Session().default_bucket() \n\nif s3_resource.Bucket(bucket_name).creation_date is None:\n # bucket is not existing \n s3.create_bucket(Bucket=bucket_name, CreateBucketConfiguration={'LocationConstraint': region}) \nelse: \n # Bucket exists\n print(\"bucket name is \", bucket_name)\n ",
"bucket name is sagemaker-us-east-2-057716757052\n"
]
],
[
[
"### Upload three data to S3",
"_____no_output_____"
]
],
[
[
"# Upload Target File under a bucket folder\nbucket_folder = project\ns3_file_path = bucket_folder + \"/\" + target_time_series_filename\n\nboto3.Session().resource('s3').Bucket(bucket_name).Object(s3_file_path).upload_file(target_time_series_path)\ntarget_s3DataPath = \"s3://\"+bucket_name + \"/\" + s3_file_path",
"_____no_output_____"
],
[
"# Upload Related File under a bucket folder\nbucket_folder = project\ns3_file_path = bucket_folder + \"/\" + related_time_series_filename\n\nboto3.Session().resource('s3').Bucket(bucket_name).Object(s3_file_path).upload_file(related_time_series_path)\nrelated_s3DataPath = \"s3://\"+bucket_name + \"/\" + s3_file_path",
"_____no_output_____"
],
[
"# Upload Item Meta File under a bucket folder\nbucket_folder = project\ns3_file_path = bucket_folder + \"/\" + store_meta_filename\n\nboto3.Session().resource('s3').Bucket(bucket_name).Object(s3_file_path).upload_file(store_meta_path)\nitem_meta_s3DataPath = \"s3://\"+bucket_name + \"/\" + s3_file_path",
"_____no_output_____"
]
],
[
[
"## Create dataset_import_job used to download dataset from S3",
"_____no_output_____"
]
],
[
[
"# Target Import Job\ndatasetImportJobName = 'DSIMPORT_JOB_TARGET_WALMART' + suffix\nds_import_job_response=forecast.create_dataset_import_job(DatasetImportJobName=datasetImportJobName,\n DatasetArn=target_second_datasetArn,\n DataSource= {\n \"S3Config\" : {\n \"Path\":target_s3DataPath,\n \"RoleArn\": role_arn\n } \n },\n TimestampFormat=TIMESTAMP_FORMAT\n )",
"_____no_output_____"
],
[
"ds_target_second_import_job_arn=ds_import_job_response['DatasetImportJobArn']\nprint(ds_target_second_import_job_arn)",
"arn:aws:forecast:us-east-2:057716757052:dataset-import-job/WalmartKaggleWithThreeDatasetsDS_target35988/DSIMPORT_JOB_TARGET_WALMART35988\n"
],
[
"# Related Import Job\ndatasetImportJobName = 'DSIMPORT_JOB_RELATED_WALMART' + related_suffix + suffix\nds_import_job_response=forecast.create_dataset_import_job(DatasetImportJobName=datasetImportJobName,\n DatasetArn=related_datasetArn,\n DataSource= {\n \"S3Config\" : {\n \"Path\":related_s3DataPath,\n \"RoleArn\": role_arn\n } \n },\n TimestampFormat=TIMESTAMP_FORMAT\n )",
"_____no_output_____"
],
[
"ds_related_import_job_arn=ds_import_job_response['DatasetImportJobArn']\nprint(ds_related_import_job_arn)",
"arn:aws:forecast:us-east-2:057716757052:dataset-import-job/WalmartKaggleWithThreeDatasetsDS_related35988/DSIMPORT_JOB_RELATED_WALMART_related35988\n"
],
[
"# Finally we can call import the dataset\ndatasetImportJobName = 'DSIMPORT_JOB_RELATED_WALMART' + related_suffix + suffix\nds_import_job_response=forecast.create_dataset_import_job(DatasetImportJobName=datasetImportJobName,\n DatasetArn=item_meta_datasetArn,\n DataSource= {\n \"S3Config\" : {\n \"Path\":item_meta_s3DataPath,\n \"RoleArn\": role_arn\n } \n },\n TimestampFormat=TIMESTAMP_FORMAT\n )",
"_____no_output_____"
],
[
"ds_itme_meta_import_job_arn=ds_import_job_response['DatasetImportJobArn']\nprint(ds_itme_meta_import_job_arn)",
"arn:aws:forecast:us-east-2:057716757052:dataset-import-job/WalmartKaggleWithThreeDatasetsDS_ItemM35988/DSIMPORT_JOB_RELATED_WALMART_related35988\n"
],
[
"%%time\n\nwhile True:\n dataTargetImportStatus = forecast.describe_dataset_import_job(DatasetImportJobArn=ds_target_second_import_job_arn)['Status']\n print(\"Target: \", dataTargetImportStatus)\n dataRelatedImportStatus = forecast.describe_dataset_import_job(DatasetImportJobArn=ds_related_import_job_arn)['Status']\n print(\"Related: \", dataRelatedImportStatus)\n dataItemMetaImportStatus = forecast.describe_dataset_import_job(DatasetImportJobArn=ds_related_import_job_arn)['Status']\n print(\"Item Metadata: \", dataItemMetaImportStatus) \n if dataTargetImportStatus != 'ACTIVE' and dataTargetImportStatus != 'CREATE_FAILED':\n sleep(30)\n elif dataRelatedImportStatus != 'ACTIVE' and dataRelatedImportStatus != 'CREATE_FAILED':\n sleep(30)\n elif dataItemMetaImportStatus != 'ACTIVE' and dataItemMetaImportStatus != 'CREATE_FAILED':\n sleep(30) \n else:\n break",
"Target: CREATE_IN_PROGRESS\nRelated: CREATE_PENDING\nItem Metadata: CREATE_PENDING\nTarget: CREATE_IN_PROGRESS\nRelated: CREATE_IN_PROGRESS\nItem Metadata: CREATE_IN_PROGRESS\nTarget: CREATE_IN_PROGRESS\nRelated: CREATE_IN_PROGRESS\nItem Metadata: CREATE_IN_PROGRESS\nTarget: CREATE_IN_PROGRESS\nRelated: CREATE_IN_PROGRESS\nItem Metadata: CREATE_IN_PROGRESS\nTarget: ACTIVE\nRelated: CREATE_IN_PROGRESS\nItem Metadata: CREATE_IN_PROGRESS\nTarget: ACTIVE\nRelated: CREATE_IN_PROGRESS\nItem Metadata: CREATE_IN_PROGRESS\nTarget: ACTIVE\nRelated: CREATE_IN_PROGRESS\nItem Metadata: CREATE_IN_PROGRESS\nTarget: ACTIVE\nRelated: CREATE_IN_PROGRESS\nItem Metadata: CREATE_IN_PROGRESS\nTarget: ACTIVE\nRelated: CREATE_IN_PROGRESS\nItem Metadata: CREATE_IN_PROGRESS\nTarget: ACTIVE\nRelated: CREATE_IN_PROGRESS\nItem Metadata: CREATE_IN_PROGRESS\nTarget: ACTIVE\nRelated: CREATE_IN_PROGRESS\nItem Metadata: CREATE_IN_PROGRESS\nTarget: ACTIVE\nRelated: CREATE_IN_PROGRESS\nItem Metadata: CREATE_IN_PROGRESS\nTarget: ACTIVE\nRelated: ACTIVE\nItem Metadata: ACTIVE\nCPU times: user 110 ms, sys: 8.64 ms, total: 119 ms\nWall time: 6min 2s\n"
],
[
"%store project\n%store region\n%store bucket_name\n%store bucket_folder\n%store role_arn\n%store role_name\n%store suffix\n%store target_suffix\n%store item_meta_suffix\n%store related_suffix\n\n%store item_meta_datasetGroupArn\n%store target_second_datasetArn\n%store related_datasetArn\n%store item_meta_datasetArn\n%store ds_target_second_import_job_arn\n%store ds_related_import_job_arn\n%store ds_itme_meta_import_job_arn\n\n\n",
"Stored 'project' (str)\nStored 'region' (str)\nStored 'bucket_name' (str)\nStored 'bucket_folder' (str)\nStored 'role_arn' (str)\nStored 'role_name' (str)\nStored 'suffix' (str)\nStored 'target_suffix' (str)\nStored 'item_meta_suffix' (str)\nStored 'related_suffix' (str)\nStored 'item_meta_datasetGroupArn' (str)\nStored 'target_second_datasetArn' (str)\nStored 'related_datasetArn' (str)\nStored 'item_meta_datasetArn' (str)\nStored 'ds_target_second_import_job_arn' (str)\nStored 'ds_related_import_job_arn' (str)\nStored 'ds_itme_meta_import_job_arn' (str)\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
ecc35671b7838dd0175f69a4a8f1683ed3daae95 | 3,529 | ipynb | Jupyter Notebook | Laboratory Activity 1/LinAlg_58051_Hizon_Python_Programming.ipynb | TiffanyHizon/Linear_Algebra_58051 | f5ef3dfa094a4ea340d2af2f8ee4cf728c451ad2 | [
"Apache-2.0"
] | null | null | null | Laboratory Activity 1/LinAlg_58051_Hizon_Python_Programming.ipynb | TiffanyHizon/Linear_Algebra_58051 | f5ef3dfa094a4ea340d2af2f8ee4cf728c451ad2 | [
"Apache-2.0"
] | null | null | null | Laboratory Activity 1/LinAlg_58051_Hizon_Python_Programming.ipynb | TiffanyHizon/Linear_Algebra_58051 | f5ef3dfa094a4ea340d2af2f8ee4cf728c451ad2 | [
"Apache-2.0"
] | null | null | null | 34.262136 | 293 | 0.51261 | [
[
[
"<a href=\"https://colab.research.google.com/github/TiffanyHizon/Linear_Algebra_58051/blob/main/Laboratory%20Activity%201/LinAlg_58051_Hizon_Python_Programming.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
],
[
[
"**Python Exercise**\r\n",
"_____no_output_____"
],
[
"Instructions:\r\n Create a grade calculator that computes for the semestral grade of a course. Students could type their names, the name of the course, then their prelim, midterm, and final grade.\r\n The program should print the semestra grade in 2 decimal points and should display the following emojis depending on the situation:\r\n Happy - when grade is greater than 70.00\r\n laughing - when grade is exactly 70.00\r\n sad - when grade is below 70.00\r\n\r\n happy, lol, sad = \"\\U0001F600\",\"\\U0001F606\",\"\\U0001F62D\"\r\n",
"_____no_output_____"
]
],
[
[
"print(\"Hello Klasmeyt, Welcome to Grade Calculator!\")\r\n\r\ndef student_Grade():\r\n student_Name = input(\"Enter Name: \")\r\n student_Program = input(\"Enter Program: \")\r\n student_Course = input(\"Enter a Course: \")\r\n grades_Prelim = float(input(\"Enter Prelim Grades: \"))\r\n grades_Midterm = float(input(\"Enter Midterm Grades: \"))\r\n grades_Finals = float(input(\"Enter Final Grades: \"))\r\n sem_Grade = ((grades_Prelim*0.3) + (grades_Midterm*0.3) + (grades_Finals*0.4))\r\n sem_Grade = float(round(sem_Grade, 2))\r\n round(sem_Grade, 2)\r\n print(\"Hi Klasmeyt,\", student_Name,\", your semestral grade in \", student_Course , \"is: \", sem_Grade)\r\n\r\n if sem_Grade > 70.00:\r\n happy = \"\\U0001F600\"\r\n print(\"Mood: \", happy)\r\n # print(\"\\U0001F600\")\r\n elif sem_Grade == 70.00:\r\n laughing = \"\\U0001F606\"\r\n print(\"Mood: \", laughing)\r\n # print(\"\\U0001F606\")\r\n else:\r\n sad = \"\\U0001F62D\"\r\n print(\"Mood: \", sad)\r\n # print(\"\\U0001F62D\")\r\n\r\nstudent_Grade()",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
] |
ecc359434def7aacb4f1bb121fc9f6b6200d3004 | 16,084 | ipynb | Jupyter Notebook | Bert/ref/.ipynb_checkpoints/BERT_Embeddings_with_TensorFlow_2_0-checkpoint.ipynb | TeaKatz/Models_Corpus | 6d9e91eb97829e73d88ecfc4754492f6324ef383 | [
"MIT"
] | null | null | null | Bert/ref/.ipynb_checkpoints/BERT_Embeddings_with_TensorFlow_2_0-checkpoint.ipynb | TeaKatz/Models_Corpus | 6d9e91eb97829e73d88ecfc4754492f6324ef383 | [
"MIT"
] | null | null | null | Bert/ref/.ipynb_checkpoints/BERT_Embeddings_with_TensorFlow_2_0-checkpoint.ipynb | TeaKatz/Models_Corpus | 6d9e91eb97829e73d88ecfc4754492f6324ef383 | [
"MIT"
] | null | null | null | 28.366843 | 417 | 0.522009 | [
[
[
"# BERT Embeddings with TensorFlow 2.0\nWith the new release of TensorFlow, this Notebook aims to show a simple use of the BERT model.\n- See BERT on paper: https://arxiv.org/pdf/1810.04805.pdf\n- See BERT on GitHub: https://github.com/google-research/bert\n- See BERT on TensorHub: https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/1\n- See 'old' use of BERT for comparison: https://colab.research.google.com/github/google-research/bert/blob/master/predicting_movie_reviews_with_bert_on_tf_hub.ipynb",
"_____no_output_____"
],
[
"## Update TF\nWe need Tensorflow 2.0 and TensorHub 0.7 for this Colab",
"_____no_output_____"
]
],
[
[
"!pip install tensorflow\n!pip install tensorflow_hub\n!pip install bert-for-tf2\n!pip install sentencepiece",
"_____no_output_____"
],
[
"import tensorflow as tf\nimport tensorflow_hub as hub\nprint(\"TF version: \", tf.__version__)\nprint(\"Hub version: \", hub.__version__)",
"TF version: 2.0.0\nHub version: 0.7.0\n"
]
],
[
[
"If TensorFlow Hub is not 0.7 yet on release, use dev:\n\n",
"_____no_output_____"
]
],
[
[
"!pip install tf-hub-nightly",
"_____no_output_____"
],
[
"hub.__version__",
"_____no_output_____"
]
],
[
[
"## Import modules",
"_____no_output_____"
]
],
[
[
"import tensorflow_hub as hub\nimport tensorflow as tf\nimport bert\nFullTokenizer = bert.bert_tokenization.FullTokenizer\nfrom tensorflow.keras.models import Model # Keras is the new high level API for TensorFlow\nimport math",
"_____no_output_____"
]
],
[
[
"Building model using tf.keras and hub. from sentences to embeddings.\n\nInputs:\n - input token ids (tokenizer converts tokens using vocab file)\n - input masks (1 for useful tokens, 0 for padding)\n - segment ids (for 2 text training: 0 for the first one, 1 for the second one)\n\nOutputs:\n - pooled_output of shape `[batch_size, 768]` with representations for the entire input sequences\n - sequence_output of shape `[batch_size, max_seq_length, 768]` with representations for each input token (in context)",
"_____no_output_____"
]
],
[
[
"max_seq_length = 128 # Your choice here.\ninput_word_ids = tf.keras.layers.Input(shape=(max_seq_length,), dtype=tf.int32,\n name=\"input_word_ids\")\ninput_mask = tf.keras.layers.Input(shape=(max_seq_length,), dtype=tf.int32,\n name=\"input_mask\")\nsegment_ids = tf.keras.layers.Input(shape=(max_seq_length,), dtype=tf.int32,\n name=\"segment_ids\")\nbert_layer = hub.KerasLayer(\"https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/1\",\n trainable=True)\npooled_output, sequence_output = bert_layer([input_word_ids, input_mask, segment_ids])",
"_____no_output_____"
],
[
"model = Model(inputs=[input_word_ids, input_mask, segment_ids], outputs=[pooled_output, sequence_output])",
"_____no_output_____"
],
[
"model.summary()",
"Model: \"model\"\n__________________________________________________________________________________________________\nLayer (type) Output Shape Param # Connected to \n==================================================================================================\ninput_word_ids (InputLayer) [(None, 128)] 0 \n__________________________________________________________________________________________________\ninput_mask (InputLayer) [(None, 128)] 0 \n__________________________________________________________________________________________________\nsegment_ids (InputLayer) [(None, 128)] 0 \n__________________________________________________________________________________________________\nkeras_layer (KerasLayer) [(None, 768), (None, 109482241 input_word_ids[0][0] \n input_mask[0][0] \n segment_ids[0][0] \n==================================================================================================\nTotal params: 109,482,241\nTrainable params: 109,482,240\nNon-trainable params: 1\n__________________________________________________________________________________________________\n"
]
],
[
[
"Generating segments and masks based on the original BERT",
"_____no_output_____"
]
],
[
[
"# See BERT paper: https://arxiv.org/pdf/1810.04805.pdf\n# And BERT implementation convert_single_example() at https://github.com/google-research/bert/blob/master/run_classifier.py\n\ndef get_masks(tokens, max_seq_length):\n \"\"\"Mask for padding\"\"\"\n if len(tokens)>max_seq_length:\n raise IndexError(\"Token length more than max seq length!\")\n return [1]*len(tokens) + [0] * (max_seq_length - len(tokens))\n\n\ndef get_segments(tokens, max_seq_length):\n \"\"\"Segments: 0 for the first sequence, 1 for the second\"\"\"\n if len(tokens)>max_seq_length:\n raise IndexError(\"Token length more than max seq length!\")\n segments = []\n current_segment_id = 0\n for token in tokens:\n segments.append(current_segment_id)\n if token == \"[SEP]\":\n current_segment_id = 1\n return segments + [0] * (max_seq_length - len(tokens))\n\n\ndef get_ids(tokens, tokenizer, max_seq_length):\n \"\"\"Token ids from Tokenizer vocab\"\"\"\n token_ids = tokenizer.convert_tokens_to_ids(tokens)\n input_ids = token_ids + [0] * (max_seq_length-len(token_ids))\n return input_ids",
"_____no_output_____"
]
],
[
[
"Import tokenizer using the original vocab file",
"_____no_output_____"
]
],
[
[
"vocab_file = bert_layer.resolved_object.vocab_file.asset_path.numpy()\ndo_lower_case = bert_layer.resolved_object.do_lower_case.numpy()\ntokenizer = FullTokenizer(vocab_file, do_lower_case)",
"_____no_output_____"
]
],
[
[
"## Test BERT embedding generator model",
"_____no_output_____"
]
],
[
[
"s = \"This is a nice sentence.\"",
"_____no_output_____"
]
],
[
[
"Tokenizing the sentence",
"_____no_output_____"
]
],
[
[
"stokens = tokenizer.tokenize(s)",
"_____no_output_____"
]
],
[
[
"Adding separator tokens according to the paper",
"_____no_output_____"
]
],
[
[
"stokens = [\"[CLS]\"] + stokens + [\"[SEP]\"]",
"_____no_output_____"
]
],
[
[
"Get the model inputs from the tokens",
"_____no_output_____"
]
],
[
[
"input_ids = get_ids(stokens, tokenizer, max_seq_length)\ninput_masks = get_masks(stokens, max_seq_length)\ninput_segments = get_segments(stokens, max_seq_length)",
"_____no_output_____"
],
[
"print(stokens)\nprint(input_ids)\nprint(input_masks)\nprint(input_segments)",
"['[CLS]', 'this', 'is', 'a', 'nice', 'sentence', '.', '[SEP]']\n[101, 2023, 2003, 1037, 3835, 6251, 1012, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]\n[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]\n[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]\n"
]
],
[
[
"Generate Embeddings using the pretrained model",
"_____no_output_____"
]
],
[
[
"pool_embs, all_embs = model.predict([[input_ids],[input_masks],[input_segments]])",
"_____no_output_____"
],
[
"print(\"Model output for overall input sequence: {}\".format(pool_embs.shape))\nprint(\"Model output for each word in input sequence: {}\".format(all_embs.shape))",
"Model output for overall input sequence: (1, 768)\nModel output for each word in input sequence: (1, 128, 768)\n"
]
],
[
[
"## Pooled embedding vs [CLS] as sentence-level representation\n\nPreviously, the [CLS] token's embedding were used as sentence-level representation (see the original paper). However, here a pooled embedding were introduced. This part is a short comparison of the two embedding using cosine similarity",
"_____no_output_____"
]
],
[
[
"def square_rooted(x):\n return math.sqrt(sum([a*a for a in x]))\n\ndef cosine_similarity(x,y):\n numerator = sum(a*b for a,b in zip(x,y))\n denominator = square_rooted(x)*square_rooted(y)\n return numerator/float(denominator)",
"_____no_output_____"
],
[
"cosine_similarity(pool_embs[0], all_embs[0][0])",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
ecc36075f5cee4bfd19b47823a9e5dd33ca262ad | 50,257 | ipynb | Jupyter Notebook | python/d2l-en/tensorflow/chapter_appendix-mathematics-for-deep-learning/maximum-likelihood.ipynb | rtp-aws/devpost_aws_disaster_recovery | 2ccfff2d8b85614f3043f09d98c9981dedf43c05 | [
"MIT"
] | 1 | 2022-01-13T23:36:05.000Z | 2022-01-13T23:36:05.000Z | python/d2l-en/tensorflow/chapter_appendix-mathematics-for-deep-learning/maximum-likelihood.ipynb | rtp-aws/devpost_aws_disaster_recovery | 2ccfff2d8b85614f3043f09d98c9981dedf43c05 | [
"MIT"
] | 9 | 2022-01-13T19:34:34.000Z | 2022-01-14T19:41:18.000Z | python/d2l-en/tensorflow/chapter_appendix-mathematics-for-deep-learning/maximum-likelihood.ipynb | rtp-aws/devpost_aws_disaster_recovery | 2ccfff2d8b85614f3043f09d98c9981dedf43c05 | [
"MIT"
] | null | null | null | 47.322976 | 813 | 0.531608 | [
[
[
"# Maximum Likelihood\n:label:`sec_maximum_likelihood`\n\nOne of the most commonly encountered way of thinking in machine learning is the maximum likelihood point of view. This is the concept that when working with a probabilistic model with unknown parameters, the parameters which make the data have the highest probability are the most likely ones.\n\n## The Maximum Likelihood Principle\n\nThis has a Bayesian interpretation which can be helpful to think about. Suppose that we have a model with parameters $\\boldsymbol{\\theta}$ and a collection of data examples $X$. For concreteness, we can imagine that $\\boldsymbol{\\theta}$ is a single value representing the probability that a coin comes up heads when flipped, and $X$ is a sequence of independent coin flips. We will look at this example in depth later.\n\nIf we want to find the most likely value for the parameters of our model, that means we want to find\n\n$$\\mathop{\\mathrm{argmax}} P(\\boldsymbol{\\theta}\\mid X).$$\n:eqlabel:`eq_max_like`\n\nBy Bayes' rule, this is the same thing as\n\n$$\n\\mathop{\\mathrm{argmax}} \\frac{P(X \\mid \\boldsymbol{\\theta})P(\\boldsymbol{\\theta})}{P(X)}.\n$$\n\nThe expression $P(X)$, a parameter agnostic probability of generating the data, does not depend on $\\boldsymbol{\\theta}$ at all, and so can be dropped without changing the best choice of $\\boldsymbol{\\theta}$. Similarly, we may now posit that we have no prior assumption on which set of parameters are better than any others, so we may declare that $P(\\boldsymbol{\\theta})$ does not depend on theta either! This, for instance, makes sense in our coin flipping example where the probability it comes up heads could be any value in $[0,1]$ without any prior belief it is fair or not (often referred to as an *uninformative prior*). Thus we see that our application of Bayes' rule shows that our best choice of $\\boldsymbol{\\theta}$ is the maximum likelihood estimate for $\\boldsymbol{\\theta}$:\n\n$$\n\\hat{\\boldsymbol{\\theta}} = \\mathop{\\mathrm{argmax}} _ {\\boldsymbol{\\theta}} P(X \\mid \\boldsymbol{\\theta}).\n$$\n\nAs a matter of common terminology, the probability of the data given the parameters ($P(X \\mid \\boldsymbol{\\theta})$) is referred to as the *likelihood*.\n\n### A Concrete Example\n\nLet us see how this works in a concrete example. Suppose that we have a single parameter $\\theta$ representing the probability that a coin flip is heads. Then the probability of getting a tails is $1-\\theta$, and so if our observed data $X$ is a sequence with $n_H$ heads and $n_T$ tails, we can use the fact that independent probabilities multiply to see that \n\n$$\nP(X \\mid \\theta) = \\theta^{n_H}(1-\\theta)^{n_T}.\n$$\n\nIf we flip $13$ coins and get the sequence \"HHHTHTTHHHHHT\", which has $n_H = 9$ and $n_T = 4$, we see that this is\n\n$$\nP(X \\mid \\theta) = \\theta^9(1-\\theta)^4.\n$$\n\nOne nice thing about this example will be that we know the answer going in. Indeed, if we said verbally, \"I flipped 13 coins, and 9 came up heads, what is our best guess for the probability that the coin comes us heads?, \" everyone would correctly guess $9/13$. What this maximum likelihood method will give us is a way to get that number from first principals in a way that will generalize to vastly more complex situations.\n\nFor our example, the plot of $P(X \\mid \\theta)$ is as follows:\n",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport tensorflow as tf\nfrom d2l import tensorflow as d2l\n\ntheta = tf.range(0, 1, 0.001)\np = theta**9 * (1 - theta)**4.\n\nd2l.plot(theta, p, 'theta', 'likelihood')",
"_____no_output_____"
]
],
[
[
"This has its maximum value somewhere near our expected $9/13 \\approx 0.7\\ldots$. To see if it is exactly there, we can turn to calculus. Notice that at the maximum, the gradient of the function is flat. Thus, we could find the maximum likelihood estimate :eqref:`eq_max_like` by finding the values of $\\theta$ where the derivative is zero, and finding the one that gives the highest probability. We compute:\n\n$$\n\\begin{aligned}\n0 & = \\frac{d}{d\\theta} P(X \\mid \\theta) \\\\\n& = \\frac{d}{d\\theta} \\theta^9(1-\\theta)^4 \\\\\n& = 9\\theta^8(1-\\theta)^4 - 4\\theta^9(1-\\theta)^3 \\\\\n& = \\theta^8(1-\\theta)^3(9-13\\theta).\n\\end{aligned}\n$$\n\nThis has three solutions: $0$, $1$ and $9/13$. The first two are clearly minima, not maxima as they assign probability $0$ to our sequence. The final value does *not* assign zero probability to our sequence, and thus must be the maximum likelihood estimate $\\hat \\theta = 9/13$.\n\n## Numerical Optimization and the Negative Log-Likelihood\n\nThe previous example is nice, but what if we have billions of parameters and data examples?\n\nFirst, notice that if we make the assumption that all the data examples are independent, we can no longer practically consider the likelihood itself as it is a product of many probabilities. Indeed, each probability is in $[0,1]$, say typically of value about $1/2$, and the product of $(1/2)^{1000000000}$ is far below machine precision. We cannot work with that directly. \n\nHowever, recall that the logarithm turns products to sums, in which case \n\n$$\n\\log((1/2)^{1000000000}) = 1000000000\\cdot\\log(1/2) \\approx -301029995.6\\ldots\n$$\n\nThis number fits perfectly within even a single precision $32$-bit float. Thus, we should consider the *log-likelihood*, which is\n\n$$\n\\log(P(X \\mid \\boldsymbol{\\theta})).\n$$\n\nSince the function $x \\mapsto \\log(x)$ is increasing, maximizing the likelihood is the same thing as maximizing the log-likelihood. Indeed in :numref:`sec_naive_bayes` we will see this reasoning applied when working with the specific example of the naive Bayes classifier.\n\nWe often work with loss functions, where we wish to minimize the loss. We may turn maximum likelihood into the minimization of a loss by taking $-\\log(P(X \\mid \\boldsymbol{\\theta}))$, which is the *negative log-likelihood*.\n\nTo illustrate this, consider the coin flipping problem from before, and pretend that we do not know the closed form solution. We may compute that\n\n$$\n-\\log(P(X \\mid \\boldsymbol{\\theta})) = -\\log(\\theta^{n_H}(1-\\theta)^{n_T}) = -(n_H\\log(\\theta) + n_T\\log(1-\\theta)).\n$$\n\nThis can be written into code, and freely optimized even for billions of coin flips.\n",
"_____no_output_____"
]
],
[
[
"# Set up our data\nn_H = 8675309\nn_T = 25624\n\n# Initialize our paramteres\ntheta = tf.Variable(tf.constant(0.5))\n\n# Perform gradient descent\nlr = 0.00000000001\nfor iter in range(10):\n with tf.GradientTape() as t:\n loss = -(n_H * tf.math.log(theta) + n_T * tf.math.log(1 - theta))\n theta.assign_sub(lr * t.gradient(loss, theta))\n\n# Check output\ntheta, n_H / (n_H + n_T)",
"_____no_output_____"
]
],
[
[
"Numerical convenience is not the only reason why people like to use negative log-likelihoods. There are several other reasons why it is preferable.\n\n\n\nThe second reason we consider the log-likelihood is the simplified application of calculus rules. As discussed above, due to independence assumptions, most probabilities we encounter in machine learning are products of individual probabilities.\n\n$$\nP(X\\mid\\boldsymbol{\\theta}) = p(x_1\\mid\\boldsymbol{\\theta})\\cdot p(x_2\\mid\\boldsymbol{\\theta})\\cdots p(x_n\\mid\\boldsymbol{\\theta}).\n$$\n\nThis means that if we directly apply the product rule to compute a derivative we get\n\n$$\n\\begin{aligned}\n\\frac{\\partial}{\\partial \\boldsymbol{\\theta}} P(X\\mid\\boldsymbol{\\theta}) & = \\left(\\frac{\\partial}{\\partial \\boldsymbol{\\theta}}P(x_1\\mid\\boldsymbol{\\theta})\\right)\\cdot P(x_2\\mid\\boldsymbol{\\theta})\\cdots P(x_n\\mid\\boldsymbol{\\theta}) \\\\\n& \\quad + P(x_1\\mid\\boldsymbol{\\theta})\\cdot \\left(\\frac{\\partial}{\\partial \\boldsymbol{\\theta}}P(x_2\\mid\\boldsymbol{\\theta})\\right)\\cdots P(x_n\\mid\\boldsymbol{\\theta}) \\\\\n& \\quad \\quad \\quad \\quad \\quad \\quad \\quad \\quad \\quad \\quad \\vdots \\\\\n& \\quad + P(x_1\\mid\\boldsymbol{\\theta})\\cdot P(x_2\\mid\\boldsymbol{\\theta}) \\cdots \\left(\\frac{\\partial}{\\partial \\boldsymbol{\\theta}}P(x_n\\mid\\boldsymbol{\\theta})\\right).\n\\end{aligned}\n$$\n\nThis requires $n(n-1)$ multiplications, along with $(n-1)$ additions, so it is proportional to quadratic time in the inputs! Sufficient cleverness in grouping terms will reduce this to linear time, but it requires some thought. For the negative log-likelihood we have instead\n\n$$\n-\\log\\left(P(X\\mid\\boldsymbol{\\theta})\\right) = -\\log(P(x_1\\mid\\boldsymbol{\\theta})) - \\log(P(x_2\\mid\\boldsymbol{\\theta})) \\cdots - \\log(P(x_n\\mid\\boldsymbol{\\theta})),\n$$\n\nwhich then gives\n\n$$\n- \\frac{\\partial}{\\partial \\boldsymbol{\\theta}} \\log\\left(P(X\\mid\\boldsymbol{\\theta})\\right) = \\frac{1}{P(x_1\\mid\\boldsymbol{\\theta})}\\left(\\frac{\\partial}{\\partial \\boldsymbol{\\theta}}P(x_1\\mid\\boldsymbol{\\theta})\\right) + \\cdots + \\frac{1}{P(x_n\\mid\\boldsymbol{\\theta})}\\left(\\frac{\\partial}{\\partial \\boldsymbol{\\theta}}P(x_n\\mid\\boldsymbol{\\theta})\\right).\n$$\n\nThis requires only $n$ divides and $n-1$ sums, and thus is linear time in the inputs.\n\nThe third and final reason to consider the negative log-likelihood is the relationship to information theory, which we will discuss in detail in :numref:`sec_information_theory`. This is a rigorous mathematical theory which gives a way to measure the degree of information or randomness in a random variable. The key object of study in that field is the entropy which is \n\n$$\nH(p) = -\\sum_{i} p_i \\log_2(p_i),\n$$\n\nwhich measures the randomness of a source. Notice that this is nothing more than the average $-\\log$ probability, and thus if we take our negative log-likelihood and divide by the number of data examples, we get a relative of entropy known as cross-entropy. This theoretical interpretation alone would be sufficiently compelling to motivate reporting the average negative log-likelihood over the dataset as a way of measuring model performance.\n\n## Maximum Likelihood for Continuous Variables\n\nEverything that we have done so far assumes we are working with discrete random variables, but what if we want to work with continuous ones?\n\nThe short summary is that nothing at all changes, except we replace all the instances of the probability with the probability density. Recalling that we write densities with lower case $p$, this means that for example we now say\n\n$$\n-\\log\\left(p(X\\mid\\boldsymbol{\\theta})\\right) = -\\log(p(x_1\\mid\\boldsymbol{\\theta})) - \\log(p(x_2\\mid\\boldsymbol{\\theta})) \\cdots - \\log(p(x_n\\mid\\boldsymbol{\\theta})) = -\\sum_i \\log(p(x_i \\mid \\theta)).\n$$\n\nThe question becomes, \"Why is this OK?\" After all, the reason we introduced densities was because probabilities of getting specific outcomes themselves was zero, and thus is not the probability of generating our data for any set of parameters zero?\n\nIndeed, this is the case, and understanding why we can shift to densities is an exercise in tracing what happens to the epsilons.\n\nLet us first re-define our goal. Suppose that for continuous random variables we no longer want to compute the probability of getting exactly the right value, but instead matching to within some range $\\epsilon$. For simplicity, we assume our data is repeated observations $x_1, \\ldots, x_N$ of identically distributed random variables $X_1, \\ldots, X_N$. As we have seen previously, this can be written as\n\n$$\n\\begin{aligned}\n&P(X_1 \\in [x_1, x_1+\\epsilon], X_2 \\in [x_2, x_2+\\epsilon], \\ldots, X_N \\in [x_N, x_N+\\epsilon]\\mid\\boldsymbol{\\theta}) \\\\\n\\approx &\\epsilon^Np(x_1\\mid\\boldsymbol{\\theta})\\cdot p(x_2\\mid\\boldsymbol{\\theta}) \\cdots p(x_n\\mid\\boldsymbol{\\theta}).\n\\end{aligned}\n$$\n\nThus, if we take negative logarithms of this we obtain\n\n$$\n\\begin{aligned}\n&-\\log(P(X_1 \\in [x_1, x_1+\\epsilon], X_2 \\in [x_2, x_2+\\epsilon], \\ldots, X_N \\in [x_N, x_N+\\epsilon]\\mid\\boldsymbol{\\theta})) \\\\\n\\approx & -N\\log(\\epsilon) - \\sum_{i} \\log(p(x_i\\mid\\boldsymbol{\\theta})).\n\\end{aligned}\n$$\n\nIf we examine this expression, the only place that the $\\epsilon$ occurs is in the additive constant $-N\\log(\\epsilon)$. This does not depend on the parameters $\\boldsymbol{\\theta}$ at all, so the optimal choice of $\\boldsymbol{\\theta}$ does not depend on our choice of $\\epsilon$! If we demand four digits or four-hundred, the best choice of $\\boldsymbol{\\theta}$ remains the same, thus we may freely drop the epsilon to see that what we want to optimize is\n\n$$\n- \\sum_{i} \\log(p(x_i\\mid\\boldsymbol{\\theta})).\n$$\n\nThus, we see that the maximum likelihood point of view can operate with continuous random variables as easily as with discrete ones by replacing the probabilities with probability densities.\n\n## Summary\n* The maximum likelihood principle tells us that the best fit model for a given dataset is the one that generates the data with the highest probability.\n* Often people work with the negative log-likelihood instead for a variety of reasons: numerical stability, conversion of products to sums (and the resulting simplification of gradient computations), and theoretical ties to information theory.\n* While simplest to motivate in the discrete setting, it may be freely generalized to the continuous setting as well by maximizing the probability density assigned to the datapoints.\n\n## Exercises\n1. Suppose that you know that a random variable has density $\\frac{1}{\\alpha}e^{-\\alpha x}$ for some value $\\alpha$. You obtain a single observation from the random variable which is the number $3$. What is the maximum likelihood estimate for $\\alpha$?\n2. Suppose that you have a dataset of samples $\\{x_i\\}_{i=1}^N$ drawn from a Gaussian with unknown mean, but variance $1$. What is the maximum likelihood estimate for the mean?\n",
"_____no_output_____"
],
[
"[Discussions](https://discuss.d2l.ai/t/1097)\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
ecc3978c2decfa3e4f6bacc7fd0689e62ee0a52f | 59,779 | ipynb | Jupyter Notebook | SimpleLinearRegression_BostonHousing.ipynb | cc5824/CC | dc5e5f9ee90fb7c5f1aa84223f88ab2a0c97b97b | [
"MIT"
] | 1 | 2019-04-12T22:04:38.000Z | 2019-04-12T22:04:38.000Z | SimpleLinearRegression_BostonHousing.ipynb | cc5824/CC | dc5e5f9ee90fb7c5f1aa84223f88ab2a0c97b97b | [
"MIT"
] | null | null | null | SimpleLinearRegression_BostonHousing.ipynb | cc5824/CC | dc5e5f9ee90fb7c5f1aa84223f88ab2a0c97b97b | [
"MIT"
] | null | null | null | 95.341308 | 22,720 | 0.816039 | [
[
[
"# Simple Linear Regression on the Boston Housing Data\n\nTo do: \n* load data from a CSV file\n* plot data\n* perform simple mathematical manipulations, \n* fit a simple linear regression model. \n\nThis lab use the Boston housing data set, a widely-used machine learning data set for illustrating basic concepts. ",
"_____no_output_____"
],
[
"## Loading the data\n\nThe Boston housing data set was collected in the 1970s to study the relationship between house price and various factors such as the house size, crime rate, socio-economic status, etc. Since the variables are easy to understand, the data set is ideal for learning basic concepts in machine learning. The raw data and a complete description of the dataset can be found on the UCI website:\n\nhttps://archive.ics.uci.edu/ml/datasets/Housing \n\nFirst, use the `pd.read_csv` command to read the data from the file located at\n\nhttps://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data\n\nSet the options in the `read_csv` command to correctly delimit the data in the file and name the columns correctly.",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nnames =[\n 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', \n 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'PRICE'\n]\n\ndf = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/'+\n 'housing/housing.data', \n header=None,delim_whitespace=True,names=names)",
"_____no_output_____"
]
],
[
[
"Display the first six rows of the data frame",
"_____no_output_____"
]
],
[
[
"df.head(6)",
"_____no_output_____"
]
],
[
[
"## Basic Manipulations on the Data\n\nWhat is the shape of the data? How many attributes are there? How many samples?\nPrint a statement of the form:\n\n num samples=xxx, num attributes=yy",
"_____no_output_____"
]
],
[
[
"nsamp, natt = df.shape\nprint('num samples={0:d}, num attributes={1:d}'.format(nsamp,natt))",
"num samples=506, num attributes=14\n"
]
],
[
[
"Create a response vector `y` with the values in the column `PRICE`. The vector `y` should be a 1D `numpy.array` structure.",
"_____no_output_____"
]
],
[
[
"y = np.array(df['PRICE'])",
"_____no_output_____"
]
],
[
[
"Use the response vector `y` to find the mean house price in thousands and the fraction of homes that are above $40k. (You may realize this is very cheap. Prices have gone up a lot since the 1970s!). Create print statements of the form:\n\n The mean house price is xx.yy thousands of dollars.\n Only x.y percent are above $40k.",
"_____no_output_____"
]
],
[
[
"print('The mean house price is {0:5.2f} thousands of dollars'.format(np.mean(y)))\nprint('Only {0:.1f} percent are above $40k '.format(np.mean(y>40)*100))",
"The mean house price is 22.53 thousands of dollars\nOnly 6.1 percent are above $40k \n"
]
],
[
[
"## Visualizing the Data\n\nPython's `matplotlib` has very good routines for plotting and visualizing data that closely follows the format of MATLAB programs. You can load the `matplotlib` package with the following commands.",
"_____no_output_____"
]
],
[
[
"import matplotlib\nimport matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"Similar to the `y` vector, create a predictor vector `x` containing the values in the `RM` column, which represents the average number of rooms in each region.",
"_____no_output_____"
]
],
[
[
"x = np.array(df['RM'])",
"_____no_output_____"
]
],
[
[
"Create a scatter plot of the price vs. the `RM` attribute. Make sure your plot has grid lines and label the axes with reasonable labels so that someone else can understand the plot.",
"_____no_output_____"
]
],
[
[
"plt.plot(x,y,'o')\nplt.xlabel('Number of rooms')\nplt.ylabel('House price (thousands)')\nplt.grid(True)",
"_____no_output_____"
]
],
[
[
"## Fitting a Simple Linear Model\n\nWe will write a simple function to perform a linear fit. Use the formulae given in the class, to compute the parameters $\\beta_0,\\beta_1$ in the linear model $$y =\\beta_0 + \\beta_1 x + \\epsilon$$ as well as the coefficient of determination $R^2$.",
"_____no_output_____"
]
],
[
[
"def fit_linear(x,y):\n \"\"\"\n Given vectors of data points (x,y), performs a fit for the linear model:\n yhat = beta0 + beta1*x, \n The function returns beta0, beta1 and rsq, where rsq is the coefficient of determination.\n \"\"\"\n xm = np.mean(x)\n ym = np.mean(y)\n sxx = np.mean((x-xm)**2)\n sxy = np.mean((x-xm)*(y-ym))\n syy = np.mean((y-ym)**2)\n beta1 = sxy/sxx\n beta0 = ym - beta1*xm\n rsq = sxy**2/sxx/syy\n return beta0, beta1, rsq",
"_____no_output_____"
]
],
[
[
"Using the function `fit_linear` above, print the values `beta0`, `beta1` and `rsq` for the linear model of price vs. number of rooms.",
"_____no_output_____"
]
],
[
[
"beta0, beta1, rsq = fit_linear(x,y)\nprint(\"beta0={0:5.3f}, beta1={1:5.3f}, rsq={2:5.3f}\".format(beta0,beta1,rsq))",
"beta0=-34.671, beta1=9.102, rsq=0.484\n"
]
],
[
[
"Replot the scatter plot above, but now with the regression line. You can create the regression line by creating points `xp` from say 4 to 9, computing the linear predicted values `yp` on those points and plotting `yp` vs. `xp` on top of the above plot.",
"_____no_output_____"
]
],
[
[
"xp = np.linspace(4,9,100)\nyp = beta0 + beta1*xp",
"_____no_output_____"
],
[
"plt.plot(x,y,'o')\nplt.plot(xp,yp,'-')\nplt.xlabel('Number of rooms')\nplt.ylabel('House price (thousands)')\nplt.grid(True)",
"_____no_output_____"
]
],
[
[
"# Compute coefficients of determination\n\nWe next compute the $R^2$ values for all the predictors and output the values in a table. Your table should look like the following, where each the first column is the attribute name and the second column is the $R^2$ value.\n\n CRIM 0.151\n ZN 0.130\n INDUS 0.234\n ... ...\n\nTo index over the set of colunms in the dataframe `df`, you can either loop over the items in the `names` lists (skipping over the final name `PRICE`) or loop over integer indices and use the method, `df.iloc`.",
"_____no_output_____"
],
[
"I will first show the method looping directly over the names in `names`. Note that the for loop in python can directly loop over any set of elements in a container. ",
"_____no_output_____"
]
],
[
[
"# Loop over names. \nfor name in names:\n \n # Skip over the case where the attribute is the target variable.\n if name != 'PRICE':\n # compute the r^2 value for the predictor\n x = np.array(df[name])\n beta0,beta1,rsq = fit_linear(x,y)\n \n # print the value. note the syntax to format the string\n print('{0:10} {1:.3f}'.format(name, rsq)) ",
"CRIM 0.151\nZN 0.130\nINDUS 0.234\nCHAS 0.031\nNOX 0.183\nRM 0.484\nAGE 0.142\nDIS 0.062\nRAD 0.146\nTAX 0.220\nPTRATIO 0.258\nB 0.111\nLSTAT 0.544\n"
]
],
[
[
"Now, here is an implementation using a for-loop with an integer index. We can do either.",
"_____no_output_____"
]
],
[
[
"p = len(names)-1 # number of predictors\nfor ind in range(p):\n \n # compute the r^2 value for the predictor\n x = np.array(df.iloc[:,ind])\n beta0,beta1,rsq = fit_linear(x,y)\n \n \n # print the value. note the syntax to format the string\n print('{0:10} {1:.3f}'.format(names[ind], rsq)) \n ",
"CRIM 0.151\nZN 0.130\nINDUS 0.234\nCHAS 0.031\nNOX 0.183\nRM 0.484\nAGE 0.142\nDIS 0.062\nRAD 0.146\nTAX 0.220\nPTRATIO 0.258\nB 0.111\nLSTAT 0.544\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
ecc397d9d33c8c7a7bb82af63a91d897dfb21368 | 14,364 | ipynb | Jupyter Notebook | momentsintime/example_mit.ipynb | aitorarjona/applications | 0a942be5b8dc9e44d8a060ed7bfba1746c511a94 | [
"Apache-2.0"
] | 1 | 2021-09-18T01:20:28.000Z | 2021-09-18T01:20:28.000Z | momentsintime/example_mit.ipynb | webclinic017/applications | f9c9b2df7a22799f0ed3aac32b409a238f56c041 | [
"Apache-2.0"
] | null | null | null | momentsintime/example_mit.ipynb | webclinic017/applications | f9c9b2df7a22799f0ed3aac32b409a238f56c041 | [
"Apache-2.0"
] | null | null | null | 31.226087 | 136 | 0.553049 | [
[
[
"# Lithops Moments in Time dataset example\n## Video/image prediction\nIn this notebook we will process video clips from the MiT dataset at scale with Lithops\nby predicting the actions with a pretrained ResNet50 model and then counting how many\noccurrences of each category have been predicted.\n",
"_____no_output_____"
]
],
[
[
"import time\nimport builtins\nimport torch.optim\nimport torch.nn.parallel\nfrom torch import save, load\nfrom torch.nn import functional as F\n\nfrom utils import extract_frames\nfrom models import load_model, load_transform, load_categories\n\nfrom lithops.multiprocessing import Pool, Queue\nfrom lithops.multiprocessing.util import get_uuid",
"_____no_output_____"
]
],
[
[
"### Backends\nThe same program can be run in a local environtment with processes or executed by\nfunctions in the cloud. After we choose a backend, only a few file locations must\nbe changed. In this example we will be using the cloud functions backend.\n\nWe will be using a custom runtime for our functions which has torch, torchvision,\nffmpeg and opencv-python modules already installed.\nWe will store the pretrained weights in the cloud so that functions can access it.\nThen, after functions get the models weights they will start preprocessing input\nvideos and inferring them one by one.\n \nLater in this notebook, we will see a little improvement detail to this process. \n",
"_____no_output_____"
]
],
[
[
"LOCAL_EXEC = False",
"_____no_output_____"
],
[
"INPUT_DATA_DIR = 'momentsintime/input_data'\n\nif LOCAL_EXEC:\n import os\n from builtins import open\n pool_initargs = {\n 'compute_backend': 'localhost',\n 'storage_backend': 'localhost'\n }\n weights_location = '/dev/shm/model_weights'\n INPUT_DATA_DIR = os.path.abspath(INPUT_DATA_DIR)\n\nelse:\n from lithops.cloud_proxy import os, open\n pool_initargs = {\n 'compute_backend': 'ibm_cf',\n 'storage_backend': 'ibm_cos',\n 'runtime': 'dhak/pywren-runtime-pytorch:3.6',\n 'runtime_memory': 2048\n }\n weights_location = 'momentsintime/models/model_weights'\n ",
"_____no_output_____"
],
[
"video_locations = [os.path.join(INPUT_DATA_DIR, name) for name in os.listdir(INPUT_DATA_DIR)]",
"_____no_output_____"
]
],
[
[
"As you can see, we have masked the `open` function and `os` module with a proxy\nto manage files from the cloud transparently. \nWe will use `builtins.open` from now on to explicitly access a local file as some accesses have to occur in the very same machine.",
"_____no_output_____"
],
[
"### Download pretrained ResNet50 model weights and save them in a directory accessible by all functions (`weights_location`)",
"_____no_output_____"
]
],
[
[
"ROOT_URL = 'http://moments.csail.mit.edu/moments_models'\nWEIGHTS_FILE = 'moments_RGB_resnet50_imagenetpretrained.pth.tar'\n\nif not os.access(WEIGHTS_FILE, os.R_OK):\n os.system('wget ' + '/'.join([ROOT_URL, WEIGHTS_FILE]))\n\nwith builtins.open(WEIGHTS_FILE, 'rb') as f_in:\n weights = f_in.read()\nwith open(weights_location, 'wb') as f_out:\n f_out.write(weights)",
"_____no_output_____"
]
],
[
[
"### Video prediction and reduce function code\n",
"_____no_output_____"
]
],
[
[
"NUM_SEGMENTS = 16\n\n# Get dataset categories\ncategories = load_categories()\n\n# Load the video frame transform\ntransform = load_transform()\n\ndef predict_videos(queue, video_locations):\n with open(weights_location, 'rb') as f:\n model = load_model(f)\n model.eval()\n\n results = []\n local_video_loc = 'video_to_predict_{}.mp4'.format(get_uuid())\n\n for video_loc in video_locations:\n start = time.time()\n with open(video_loc, 'rb') as f_in:\n with builtins.open(local_video_loc, 'wb') as f_out:\n f_out.write(f_in.read())\n\n # Obtain video frames\n frames = extract_frames(local_video_loc, NUM_SEGMENTS)\n\n # Prepare input tensor [num_frames, 3, 224, 224]\n input_v = torch.stack([transform(frame) for frame in frames])\n\n # Make video prediction\n with torch.no_grad():\n logits = model(input_v)\n h_x = F.softmax(logits, 1).mean(dim=0)\n probs, idx = h_x.sort(0, True)\n\n # Output the prediction\n result = dict(key=video_loc)\n result['prediction'] = (idx[0], round(float(probs[0]), 5))\n result['iter_duration'] = time.time() - start\n results.append(result)\n queue.put(results)\n\n# Counts how many predictions of each category have been made\ndef reduce(queue, n):\n pred_x_categ = {}\n for categ in categories:\n pred_x_categ[categ] = 0\n\n checkpoint = 0.2\n res_count = 0\n\n for i in range(n):\n results = queue.get()\n res_count += len(results)\n for res in results:\n idx, prob = res['prediction']\n pred_x_categ[categories[idx]] += 1\n\n # print progress\n if i >= (N * checkpoint):\n print('Processed {} results.'.format(res_count))\n checkpoint += 0.2\n\n return pred_x_categ",
"_____no_output_____"
]
],
[
[
"### Map functions\nSimilar to the `multiprocessing` module API, we use a Pool to map the video keys\nacross n workers (concurrency). However, we do not have to instantiate a Pool of\nn workers *specificly*, it is the map function that will invoke as many workers according\nto the length of the list.",
"_____no_output_____"
]
],
[
[
"CONCURRENCY = 100",
"_____no_output_____"
],
[
"queue = Queue()\npool = Pool(initargs=pool_initargs)\n\n# Slice data keys\nN = min(CONCURRENCY, len(video_locations))\niterable = [(queue, video_locations[n::CONCURRENCY]) \n for n in range(N)]\n\n# Map and reduce on the go\nstart = time.time()\npool.map_async(func=predict_videos, iterable=iterable)\npred_x_categ = reduce(queue, N)\nend = time.time()\n \nprint('\\nDone.')\nprint('Videos processed:', len(video_locations))\nprint('Total duration:', round(end - start, 2), 'sec\\n')\n\nfor categ, count in pred_x_categ.items():\n if count != 0:\n print('{}: {}'.format(categ, count))",
"Lithops v2.2.0 init for IBM Cloud Functions - Namespace: pol23btr%40gmail.com_dev - Region: eu_gb\nExecutorID 6d3975/2 | JobID M000 - Selected Runtime: dhak/pywren-runtime-pytorch:3.6 - 2048MB \nExecutorID 6d3975/2 | JobID M000 - Uploading function and data - Total: 65.4KiB\nExecutorID 6d3975/2 | JobID M000 - Starting function invocation: predict_videos() - Total: 100 activations\nProcessed 21 results.\nProcessed 41 results.\nProcessed 64 results.\nProcessed 84 results.\n\nDone.\nVideos processed: 110\nTotal duration: 24.08 sec\n\nbicycling: 9\njuggling: 100\nmowing: 1\n"
]
],
[
[
"---------------\n\n## Performance improvement\nNow, since we know every function will have to pull the model weights from\nthe cloud storage, we can actually pack these weights with the runtime image\nand reduce the start-up cost substantially.",
"_____no_output_____"
]
],
[
[
"pool_initargs['runtime'] = 'dhak/pywren-runtime-resnet'\nweights_location = '/momentsintime/model_weights'",
"_____no_output_____"
],
[
"def predict_videos(queue, video_locations):\n # force local file access on new weights_location\n with builtins.open(weights_location, 'rb') as f:\n model = load_model(f)\n model.eval()\n\n results = []\n local_video_loc = 'video_to_predict_{}.mp4'.format(get_uuid())\n\n for video_loc in video_locations:\n start = time.time()\n with open(video_loc, 'rb') as f_in:\n with builtins.open(local_video_loc, 'wb') as f_out:\n f_out.write(f_in.read())\n\n # Obtain video frames\n frames = extract_frames(local_video_loc, NUM_SEGMENTS)\n\n # Prepare input tensor [num_frames, 3, 224, 224]\n input_v = torch.stack([transform(frame) for frame in frames])\n\n # Make video prediction\n with torch.no_grad():\n logits = model(input_v)\n h_x = F.softmax(logits, 1).mean(dim=0)\n probs, idx = h_x.sort(0, True)\n\n # Output the prediction\n result = dict(key=video_loc)\n result['prediction'] = (idx[0], round(float(probs[0]), 5))\n result['iter_duration'] = time.time() - start\n results.append(result)\n queue.put(results)",
"_____no_output_____"
],
[
"queue = Queue()\npool = Pool(initargs=pool_initargs)\n\n# Slice data keys\nN = min(CONCURRENCY, len(video_locations))\niterable = [(queue, video_locations[n::CONCURRENCY]) \n for n in range(N)]\n\n# Map and reduce on the go\nstart = time.time()\nr = pool.map_async(func=predict_videos, iterable=iterable)\npred_x_categ = reduce(queue, N)\nend = time.time()\n \nprint('\\nDone.')\nprint('Videos processed:', len(video_locations))\nprint('Total duration:', round(end - start, 2), 'sec\\n')\n\nfor categ, count in pred_x_categ.items():\n if count != 0:\n print('{}: {}'.format(categ, count))",
"Lithops v2.2.0 init for IBM Cloud Functions - Namespace: ibm_com_dev - Region: eu_gb\nExecutorID 6d3975/4 | JobID M000 - Selected Runtime: dhak/pywren-runtime-resnet - 2048MB \nExecutorID 6d3975/4 | JobID M000 - Uploading function and data - Total: 65.4KiB\nExecutorID 6d3975/4 | JobID M000 - Starting function invocation: predict_videos() - Total: 100 activations\nProcessed 21 results.\nProcessed 41 results.\nProcessed 66 results.\nProcessed 86 results.\n\nDone.\nVideos processed: 110\nTotal duration: 18.93 sec\n\nbicycling: 9\njuggling: 100\nmowing: 1\n"
]
],
[
[
"### Clean",
"_____no_output_____"
]
],
[
[
"try:\n os.remove(weights_location)\nexcept FileNotFoundError:\n pass\n\ntry:\n os.remove(WEIGHTS_FILE)\nexcept FileNotFoundError:\n pass",
"_____no_output_____"
]
],
[
[
"### Dockerfiles and build scripts for both runtimes can be found in the runtime/ folder.\n\n### Source code adapted from the demonstration in https://github.com/zhoubolei/moments_models\n\n### Moments in Time article: http://moments.csail.mit.edu/#paper\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
ecc3a838b84885ebfc76a9f6b8a9dbe527a8443c | 1,167 | ipynb | Jupyter Notebook | Learn Python the Hard Way/ex12.ipynb | avik-pal/ml_assignments | 874ef71225b8e79b1521179628b513a4cdb0f045 | [
"MIT"
] | 3 | 2021-05-18T12:33:03.000Z | 2022-02-07T05:10:42.000Z | Learn Python the Hard Way/ex12.ipynb | avik-pal/ml_assignments | 874ef71225b8e79b1521179628b513a4cdb0f045 | [
"MIT"
] | null | null | null | Learn Python the Hard Way/ex12.ipynb | avik-pal/ml_assignments | 874ef71225b8e79b1521179628b513a4cdb0f045 | [
"MIT"
] | 2 | 2020-09-24T17:29:21.000Z | 2022-02-07T05:10:49.000Z | 20.12069 | 81 | 0.503856 | [
[
[
"age = input(\"How old are you? \")\nheight = input(\"How tall are you? \")\nweight = input(\"How much do you weigh? \")\nprint(\"So, you're %s old, %s tall and %s heavy.\" % (age, height, weight))",
"How old are you? 18\nHow tall are you? 180\nHow much do you weigh? 95\nSo, you're 18 old, 180 tall and 95 heavy.\n"
]
]
] | [
"code"
] | [
[
"code"
]
] |
ecc3ac17a96fac4533aa89bd68379fffee01f169 | 154,070 | ipynb | Jupyter Notebook | runallbook/_build/.jupyter_cache/executed/31983d20ab9ac91fd3b1534f6a221f1e/base.ipynb | rsenft1/Another_test_jupyterbook | 29bef2c57bd6d37fadb1df21dfdb37719b43b46e | [
"MIT"
] | null | null | null | runallbook/_build/.jupyter_cache/executed/31983d20ab9ac91fd3b1534f6a221f1e/base.ipynb | rsenft1/Another_test_jupyterbook | 29bef2c57bd6d37fadb1df21dfdb37719b43b46e | [
"MIT"
] | null | null | null | runallbook/_build/.jupyter_cache/executed/31983d20ab9ac91fd3b1534f6a221f1e/base.ipynb | rsenft1/Another_test_jupyterbook | 29bef2c57bd6d37fadb1df21dfdb37719b43b46e | [
"MIT"
] | null | null | null | 1,525.445545 | 151,916 | 0.959668 | [
[
[
"from matplotlib import rcParams, cycler\nimport matplotlib.pyplot as plt\nimport numpy as np\nplt.ion()",
"_____no_output_____"
],
[
"var=1\nprint(var)",
"1\n"
],
[
"# Fixing random state for reproducibility\nnp.random.seed(19680801)\n\nN = 10\ndata = [np.logspace(0, 1, 100) + np.random.randn(100) + ii for ii in range(N)]\ndata = np.array(data).T\ncmap = plt.cm.coolwarm\nrcParams['axes.prop_cycle'] = cycler(color=cmap(np.linspace(0, 1, N)))\n\n\nfrom matplotlib.lines import Line2D\ncustom_lines = [Line2D([0], [0], color=cmap(0.), lw=4),\n Line2D([0], [0], color=cmap(.5), lw=4),\n Line2D([0], [0], color=cmap(1.), lw=4)]\n\nfig, ax = plt.subplots(figsize=(10, 5))\nlines = ax.plot(data)\nax.legend(custom_lines, ['Cold', 'Medium', 'Hot']);",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code"
]
] |
ecc3db2f4eae670bcce8c2f468c3885ffac47b91 | 916 | ipynb | Jupyter Notebook | PruebasGitkraken.ipynb | ic702103/hello-work-1 | 370eb8b7d654f2cccd20c0a33d4a9ecef08a686d | [
"MIT"
] | null | null | null | PruebasGitkraken.ipynb | ic702103/hello-work-1 | 370eb8b7d654f2cccd20c0a33d4a9ecef08a686d | [
"MIT"
] | null | null | null | PruebasGitkraken.ipynb | ic702103/hello-work-1 | 370eb8b7d654f2cccd20c0a33d4a9ecef08a686d | [
"MIT"
] | null | null | null | 19.083333 | 42 | 0.485808 | [
[
[
"from time import sleep\ndef print_words(sentence):\n for word in sentence.split():\n for l in word:\n sleep(.05)\n print(l, end = '')\n print(end = ' ')",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code"
]
] |
ecc3df87c45673b1210e15d3e69cff7a2e3d9c34 | 6,809 | ipynb | Jupyter Notebook | docs/source/examples/plotting/spider.ipynb | JustinGOSSES/pyrolite | 21eb5b28d9295625241b73b820fc8892b00fc6b0 | [
"BSD-3-Clause"
] | 1 | 2020-03-13T07:11:47.000Z | 2020-03-13T07:11:47.000Z | docs/source/examples/plotting/spider.ipynb | JustinGOSSES/pyrolite | 21eb5b28d9295625241b73b820fc8892b00fc6b0 | [
"BSD-3-Clause"
] | null | null | null | docs/source/examples/plotting/spider.ipynb | JustinGOSSES/pyrolite | 21eb5b28d9295625241b73b820fc8892b00fc6b0 | [
"BSD-3-Clause"
] | null | null | null | 34.388889 | 716 | 0.524747 | [
[
[
"%matplotlib inline",
"_____no_output_____"
]
],
[
[
"\nSpiderplots & Density Spiderplots\n==================================\n\n",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"Here we'll set up an example which uses EMORB as a starting point:\n\n\n",
"_____no_output_____"
]
],
[
[
"from pyrolite.geochem.norm import get_reference_composition\n\nref = get_reference_composition(\"EMORB_SM89\") # EMORB composition as a starting point\nref.set_units(\"ppm\")\ndf = ref.comp.pyrochem.compositional",
"_____no_output_____"
]
],
[
[
"Basic spider plots are straightforward to produce:\n\n",
"_____no_output_____"
]
],
[
[
"import pyrolite.plot\n\ndf.pyroplot.spider(color=\"k\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"Typically we'll normalise trace element compositions to a reference composition\nto be able to link the diagram to 'relative enrichement' occuring during geological\nprocesses:\n\n\n",
"_____no_output_____"
]
],
[
[
"normdf = df.pyrochem.normalize_to(\"PM_PON\", units=\"ppm\")\nnormdf.pyroplot.spider(color=\"k\", unity_line=True)\nplt.show()",
"_____no_output_____"
]
],
[
[
"The spiderplot can be extended to provide visualisations of ranges and density via the\nvarious modes. First let's take this composition and add some noise in log-space to\ngenerate multiple compositions about this mean (i.e. a compositional distribution):\n\n\n",
"_____no_output_____"
]
],
[
[
"start = normdf.applymap(np.log)\nnindex, nobs = normdf.columns.size, 120\n\nnoise_level = 0.5 # sigma for noise\nx = np.arange(nindex)\ny = np.tile(start.values, nobs).reshape(nobs, nindex)\ny += np.random.normal(0, noise_level / 2.0, size=(nobs, nindex)) # noise\ny += np.random.normal(0, noise_level, size=(1, nobs)).T # random pattern offset\n\ndistdf = pd.DataFrame(y, columns=normdf.columns)\ndistdf[\"Eu\"] += 1.0 # significant offset for Eu anomaly\ndistdf = distdf.applymap(np.exp)",
"_____no_output_____"
]
],
[
[
"We could now plot the range of compositions as a filled range:\n\n\n",
"_____no_output_____"
]
],
[
[
"distdf.pyroplot.spider(mode=\"fill\", color=\"green\", alpha=0.5, unity_line=True)\nplt.show()",
"_____no_output_____"
]
],
[
[
"Alternatively, we can plot a conditional density spider plot:\n\n\n",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots(2, 1, sharex=True, sharey=True, figsize=(10, 6))\n_ = distdf.pyroplot.spider(ax=ax[0], color=\"k\", alpha=0.05, unity_line=True)\n_ = distdf.pyroplot.spider(\n ax=ax[1],\n mode=\"binkde\",\n cmap=\"viridis\",\n vmin=0.05, # minimum percentile,\n resolution=10,\n unity_line=True\n)",
"_____no_output_____"
]
],
[
[
"We can now assemble a more complete comparison of some of the conditional density\nmodes for spider plots:\n\n\n",
"_____no_output_____"
]
],
[
[
"modes = [\n (\"plot\", \"plot\", [], dict(color=\"k\", alpha=0.01)),\n (\"fill\", \"fill\", [], dict(color=\"k\", alpha=0.5)),\n (\"binkde\", \"binkde\", [], dict(resolution=10)),\n (\n \"binkde\",\n \"binkde contours specified\",\n [],\n dict(contours=[0.95], resolution=10), # 95th percentile contour\n ),\n (\"histogram\", \"histogram\", [], dict(resolution=5, ybins=30)),\n]",
"_____no_output_____"
],
[
"down, across = len(modes), 1\nfig, ax = plt.subplots(\n down, across, sharey=True, sharex=True, figsize=(across * 8, 2 * down)\n)\n\nfor a, (m, name, args, kwargs) in zip(ax, modes):\n a.annotate( # label the axes rows\n \"Mode: {}\".format(name),\n xy=(0.1, 1.05),\n xycoords=a.transAxes,\n fontsize=8,\n ha=\"left\",\n va=\"bottom\",\n )\nax = ax.flat\nfor mix, (m, name, args, kwargs) in enumerate(modes):\n distdf.pyroplot.spider(\n mode=m,\n ax=ax[mix],\n cmap=\"viridis\",\n vmin=0.05, # minimum percentile\n fontsize=8,\n unity_line=True,\n *args,\n **kwargs\n )\n\nplt.tight_layout()",
"_____no_output_____"
]
],
[
[
".. seealso:: `Heatscatter Plots <heatscatter.html>`__,\n `Density Diagrams <density.html>`__\n\n",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
ecc3e582d83fdb783fc473d8e0061f9ab0a706f9 | 536,665 | ipynb | Jupyter Notebook | image_to_cartoon.ipynb | Eduar2TC/image_to_pencil_and_cartoon | a709b59ceb9cad47e9b1f922098ac53d5acf4d1f | [
"MIT"
] | null | null | null | image_to_cartoon.ipynb | Eduar2TC/image_to_pencil_and_cartoon | a709b59ceb9cad47e9b1f922098ac53d5acf4d1f | [
"MIT"
] | null | null | null | image_to_cartoon.ipynb | Eduar2TC/image_to_pencil_and_cartoon | a709b59ceb9cad47e9b1f922098ac53d5acf4d1f | [
"MIT"
] | null | null | null | 2,254.894958 | 405,996 | 0.962714 | [
[
[
"import numpy as np\nimport cv2\nimport matplotlib.pyplot as plt\nimport matplotlib.image as matim\nimport ipywidgets as widgets",
"_____no_output_____"
],
[
"img = matim.imread('./images/doge.jpg')",
"_____no_output_____"
],
[
"#Edge Mask\ndef edge_mask( img, ksize, block_size ):\n gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY )\n gray_median = cv2.medianBlur( gray, ksize )\n edges = cv2.adaptiveThreshold( gray_median, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, block_size, ksize )\n return edges",
"_____no_output_____"
],
[
"edge_img = edge_mask( img, 5, 3 )",
"_____no_output_____"
],
[
"plt.imshow( edge_img, cmap = 'gray')",
"_____no_output_____"
],
[
"def kmeans_cluster(img, k):\n #Transform image\n data = np.float32(img).reshape( (-1, 3) )\n\n criteria = ( cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 20, 0.001 )\n #k means\n ret, label, center = cv2.kmeans( data, k, None, criteria, 5, cv2.KMEANS_RANDOM_CENTERS )\n center = np.uint8( center )\n result = center[ label.flatten() ]\n result = result.reshape(img.shape)\n return result",
"_____no_output_____"
],
[
"cluster_img = kmeans_cluster( img, 6 )",
"_____no_output_____"
],
[
"plt.imshow( cluster_img )",
"_____no_output_____"
],
[
"#Apply bilateral filter\nd = 7\nsigmacolor = 200 #superior to 100\nsigmaspace = 300 #superior to 200\nbilateral = cv2.bilateralFilter( cluster_img, d = d, sigmaColor = sigmacolor, sigmaSpace = sigmaspace )\ncartoon = cv2.bitwise_and( bilateral, bilateral, mask = edge_img )",
"_____no_output_____"
],
[
"#display output\nplt.figure( figsize = ( 15, 8 ) )\nplt.subplot( 1, 2, 1 ) # original image\nplt.imshow(img)\nplt.yticks( [] ), plt.xticks( [] )\nplt.title( 'Original image' )\nplt.subplot( 1, 2, 2 ) #filtered image\nplt.imshow( cartoon )\nplt.title('Cartoon')\nplt.yticks( [] ),plt.xticks( [] )\nplt.show()",
"_____no_output_____"
],
[
"cv2.imwrite('./images/cartoon.png', cv2.cvtColor(cartoon, cv2.COLOR_RGB2BGR))",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.