
hexsha
stringlengths 40
40
| size
int64 6
14.9M
| ext
stringclasses 1
value | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 6
260
| max_stars_repo_name
stringlengths 6
119
| max_stars_repo_head_hexsha
stringlengths 40
41
| max_stars_repo_licenses
list | max_stars_count
int64 1
191k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 6
260
| max_issues_repo_name
stringlengths 6
119
| max_issues_repo_head_hexsha
stringlengths 40
41
| max_issues_repo_licenses
list | max_issues_count
int64 1
67k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 6
260
| max_forks_repo_name
stringlengths 6
119
| max_forks_repo_head_hexsha
stringlengths 40
41
| max_forks_repo_licenses
list | max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | avg_line_length
float64 2
1.04M
| max_line_length
int64 2
11.2M
| alphanum_fraction
float64 0
1
| cells
list | cell_types
list | cell_type_groups
list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
d0f76c26b8de0f4515afc0c91208b62d2120f052 | 72,188 | ipynb | Jupyter Notebook | ADS_Project1.ipynb | shrikumarp/ADSSpring18 | 2b9b2fef2f3df0617fd831c8c5d7c33533f353c7 | [
"MIT"
] | null | null | null | ADS_Project1.ipynb | shrikumarp/ADSSpring18 | 2b9b2fef2f3df0617fd831c8c5d7c33533f353c7 | [
"MIT"
] | null | null | null | ADS_Project1.ipynb | shrikumarp/ADSSpring18 | 2b9b2fef2f3df0617fd831c8c5d7c33533f353c7 | [
"MIT"
] | null | null | null | 56.003103 | 13,476 | 0.724109 | [
[
[
"import numpy as np\nimport pandas as pd",
"_____no_output_____"
],
[
"yelp = pd.read_csv('https://raw.githubusercontent.com/shrikumarp/shrikumarpp1/master/yelp.csv')",
"_____no_output_____"
],
[
"yelp.head()",
"_____no_output_____"
],
[
"yelp.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 10000 entries, 0 to 9999\nData columns (total 10 columns):\nbusiness_id 10000 non-null object\ndate 10000 non-null object\nreview_id 10000 non-null object\nstars 10000 non-null int64\ntext 10000 non-null object\ntype 10000 non-null object\nuser_id 10000 non-null object\ncool 10000 non-null int64\nuseful 10000 non-null int64\nfunny 10000 non-null int64\ndtypes: int64(4), object(6)\nmemory usage: 781.3+ KB\n"
],
[
"yelp.describe()",
"_____no_output_____"
],
[
"yelp['text length'] = yelp['text'].apply(len)",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\nimport seaborn as sns\nsns.set_style('white')\n%matplotlib inline",
"_____no_output_____"
],
[
"#visualising average text length for star reviews\ng = sns.FacetGrid(yelp,col='stars')\ng.map(plt.hist,'text length')",
"_____no_output_____"
],
[
"sns.boxplot(x='stars',y='text length',data=yelp,palette='rainbow')\n",
"_____no_output_____"
],
[
"sns.countplot(x='stars',data=yelp,palette='rainbow')",
"_____no_output_____"
],
[
"stars = yelp.groupby('stars').mean()\nstars",
"_____no_output_____"
],
[
"stars.corr()",
"_____no_output_____"
],
[
"sns.heatmap(stars.corr(),cmap='rainbow',annot=True)",
"_____no_output_____"
]
],
[
[
".",
"_____no_output_____"
],
[
"Machine Learning models for text classification:",
"_____no_output_____"
]
],
[
[
"yelp_class = yelp[(yelp.stars==1) | (yelp.stars==5)]",
"_____no_output_____"
],
[
"X = yelp_class['text']\ny = yelp_class['stars']",
"_____no_output_____"
],
[
"from sklearn.feature_extraction.text import CountVectorizer\ncv = CountVectorizer()\n\n# count vectorization converts the text into integerized count vectors corresponding to the occurence of a particular word in the sentence.",
"_____no_output_____"
],
[
"X = cv.fit_transform(X)",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split",
"_____no_output_____"
],
[
"X_train, X_test, y_train, y_test = train_test_split(X, y,test_size=0.3,random_state=101)",
"_____no_output_____"
],
[
"# Frst we use Naive Bayes Algorithm.\n\nfrom sklearn.naive_bayes import MultinomialNB\nnb = MultinomialNB()",
"_____no_output_____"
],
[
"nb.fit(X_train,y_train)",
"_____no_output_____"
],
[
"predictions = nb.predict(X_test)",
"_____no_output_____"
],
[
"from sklearn.metrics import confusion_matrix,classification_report",
"_____no_output_____"
],
[
"print(confusion_matrix(y_test,predictions))\nprint('\\n')\nprint(classification_report(y_test,predictions))",
"[[159 69]\n [ 22 976]]\n\n\n precision recall f1-score support\n\n 1 0.88 0.70 0.78 228\n 5 0.93 0.98 0.96 998\n\navg / total 0.92 0.93 0.92 1226\n\n"
]
],
[
[
".",
"_____no_output_____"
],
[
"Support Vector Classifier",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import GridSearchCV\nparameters = [{'C': [1, 10, 100], 'kernel': ['linear']},\n {'C': [1, 10, 100], 'kernel': ['rbf']}]",
"_____no_output_____"
],
[
"from sklearn.svm import SVC",
"_____no_output_____"
],
[
"svmmodel = SVC()",
"_____no_output_____"
],
[
"svmmodel.fit(X_train,y_train)",
"_____no_output_____"
],
[
"predsvm= svmmodel.predict(X_test)",
"_____no_output_____"
],
[
"print(confusion_matrix(y_test,predsvm))\nprint('\\n')\nprint(classification_report(y_test,predsvm))",
"[[ 0 228]\n [ 0 998]]\n\n\n precision recall f1-score support\n\n 1 0.00 0.00 0.00 228\n 5 0.81 1.00 0.90 998\n\navg / total 0.66 0.81 0.73 1226\n\n"
]
],
[
[
"Now we use the parameters list defined above to try to tune the parameter 'C' to see if we can squeeze out more accuracy out of this classifier.",
"_____no_output_____"
]
],
[
[
"grid_search_svm = GridSearchCV(estimator = svmmodel,\n param_grid = parameters,\n scoring = 'accuracy',\n cv = 10,\n n_jobs = -1)\n\n#GridSearchCV(estimator, param_grid, scoring=None, fit_params=None, n_jobs=1, iid=True, refit=True, cv=None, verbose=0, pre_dispatch=‘2*n_jobs’, error_score=’raise’, return_train_score=’warn’\n# scoring and comparison within models is based on accuracy.The most accurate model will be chosen after training and croass validation.",
"_____no_output_____"
],
[
"grid_search_svm = grid_search_svm.fit(X_train, y_train)",
"_____no_output_____"
],
[
"grid_search_svm.best_score_",
"_____no_output_____"
],
[
"grid_search_svm.best_params_",
"_____no_output_____"
]
],
[
[
"As we can wee, the best selected parameters from the Girid search of better parameters turned out to be C= 1 and kernel ='Linear', and this model performed with the accuracy of 91.57%.",
"_____no_output_____"
],
[
".",
"_____no_output_____"
],
[
"Using Random Forest Classifier Algorithm",
"_____no_output_____"
]
],
[
[
"from sklearn.ensemble import RandomForestClassifier\nrforest = RandomForestClassifier(n_estimators = 10, criterion = 'entropy', random_state = 0)",
"_____no_output_____"
],
[
"rforest.fit(X_train, y_train)",
"_____no_output_____"
],
[
"rfpred= rforest.predict(X_test)",
"_____no_output_____"
],
[
"print(confusion_matrix(y_test,rfpred))\nprint('\\n')\nprint(classification_report(y_test,rfpred))",
"[[ 81 147]\n [ 19 979]]\n\n\n precision recall f1-score support\n\n 1 0.81 0.36 0.49 228\n 5 0.87 0.98 0.92 998\n\navg / total 0.86 0.86 0.84 1226\n\n"
]
],
[
[
".",
"_____no_output_____"
],
[
"Using Logistic Regression",
"_____no_output_____"
]
],
[
[
"from sklearn.linear_model import LogisticRegression\nfrom sklearn.model_selection import GridSearchCV",
"_____no_output_____"
]
],
[
[
"We set the parameter grid again with a random space of values for parameter C, and we try to get the maximum accuracy by tuning the hyperparameters.",
"_____no_output_____"
]
],
[
[
"c_space = np.logspace(-5, 8, 15)\nparam_grid = {'C': c_space}",
"_____no_output_____"
],
[
"logreg = LogisticRegression()",
"_____no_output_____"
],
[
"logreg_cv = GridSearchCV(logreg, param_grid, cv= 10)\n# here we pass the parameters of the Logistic regression model, the parameter values array and the number of Cross validations as 10 to the GridSearchCV function.",
"_____no_output_____"
],
[
"logreg_cv.fit(X_train,y_train)",
"_____no_output_____"
],
[
"print(\"Tuned Logistic Regression Parameters: {}\".format(logreg_cv.best_params_)) \nprint(\"Best score is {}\".format(logreg_cv.best_score_))",
"Tuned Logistic Regression Parameters: {'C': 3.7275937203149381}\nBest score is 0.9276223776223776\n"
],
[
"# we predict on the test set\npred = logreg_cv.predict(X_test)",
"_____no_output_____"
],
[
"print(classification_report(y_test,pred))",
" precision recall f1-score support\n\n 1 0.86 0.79 0.83 228\n 5 0.95 0.97 0.96 998\n\navg / total 0.94 0.94 0.94 1226\n\n"
]
],
[
[
"As we can see, Logistic regression with hyperparameter tuning performs with the best accuracy with 94%.",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
d0f77ab136da0b8f7f501b740392010eae775f39 | 40,687 | ipynb | Jupyter Notebook | site/en/r1/guide/distribute_strategy.ipynb | DorianKodelja/docs | 186899c6252048b5a4f5cf89cc33e4dcc8426e5f | [
"Apache-2.0"
] | 3 | 2020-09-23T14:09:41.000Z | 2020-09-23T19:26:32.000Z | site/en/r1/guide/distribute_strategy.ipynb | DorianKodelja/docs | 186899c6252048b5a4f5cf89cc33e4dcc8426e5f | [
"Apache-2.0"
] | 1 | 2020-09-23T22:40:20.000Z | 2020-09-23T22:40:20.000Z | site/en/r1/guide/distribute_strategy.ipynb | DorianKodelja/docs | 186899c6252048b5a4f5cf89cc33e4dcc8426e5f | [
"Apache-2.0"
] | null | null | null | 47.923439 | 1,173 | 0.632659 | [
[
[
"##### Copyright 2018 The TensorFlow Authors.\n",
"_____no_output_____"
]
],
[
[
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
]
],
[
[
"# Distributed Training in TensorFlow",
"_____no_output_____"
],
[
"<table class=\"tfo-notebook-buttons\" align=\"left\">\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/r1/guide/distribute_strategy.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Run in Google Colab</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://github.com/tensorflow/docs/blob/master/site/en/r1/guide/distribute_strategy.ipynb\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />View source on GitHub</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"> Note: This is an archived TF1 notebook. These are configured\nto run in TF2's \n[compatbility mode](https://www.tensorflow.org/guide/migrate)\nbut will run in TF1 as well. To use TF1 in Colab, use the\n[%tensorflow_version 1.x](https://colab.research.google.com/notebooks/tensorflow_version.ipynb)\nmagic.",
"_____no_output_____"
],
[
"## Overview\n\n`tf.distribute.Strategy` is a TensorFlow API to distribute training\nacross multiple GPUs, multiple machines or TPUs. Using this API, users can distribute their existing models and training code with minimal code changes.\n\n`tf.distribute.Strategy` has been designed with these key goals in mind:\n\n* Easy to use and support multiple user segments, including researchers, ML engineers, etc.\n* Provide good performance out of the box.\n* Easy switching between strategies.\n\n`tf.distribute.Strategy` can be used with TensorFlow's high level APIs, [tf.keras](https://www.tensorflow.org/r1/guide/keras) and [tf.estimator](https://www.tensorflow.org/r1/guide/estimators), with just a couple of lines of code change. It also provides an API that can be used to distribute custom training loops (and in general any computation using TensorFlow).\nIn TensorFlow 2.0, users can execute their programs eagerly, or in a graph using [`tf.function`](../tutorials/eager/tf_function.ipynb). `tf.distribute.Strategy` intends to support both these modes of execution. Note that we may talk about training most of the time in this guide, but this API can also be used for distributing evaluation and prediction on different platforms.\n\nAs you will see in a bit, very few changes are needed to use `tf.distribute.Strategy` with your code. This is because we have changed the underlying components of TensorFlow to become strategy-aware. This includes variables, layers, models, optimizers, metrics, summaries, and checkpoints.\n\nIn this guide, we will talk about various types of strategies and how one can use them in different situations.\n\nNote: For a deeper understanding of the concepts, please watch [this deep-dive presentation](https://youtu.be/jKV53r9-H14). This is especially recommended if you plan to write your own training loop.",
"_____no_output_____"
]
],
[
[
"import tensorflow.compat.v1 as tf\ntf.disable_v2_behavior()",
"_____no_output_____"
]
],
[
[
"## Types of strategies\n`tf.distribute.Strategy` intends to cover a number of use cases along different axes. Some of these combinations are currently supported and others will be added in the future. Some of these axes are:\n\n* Syncronous vs asynchronous training: These are two common ways of distributing training with data parallelism. In sync training, all workers train over different slices of input data in sync, and aggregating gradients at each step. In async training, all workers are independently training over the input data and updating variables asynchronously. Typically sync training is supported via all-reduce and async through parameter server architecture.\n* Hardware platform: Users may want to scale their training onto multiple GPUs on one machine, or multiple machines in a network (with 0 or more GPUs each), or on Cloud TPUs.\n\nIn order to support these use cases, we have 4 strategies available. In the next section we will talk about which of these are supported in which scenarios in TF.",
"_____no_output_____"
],
[
"### MirroredStrategy\n`tf.distribute.MirroredStrategy` support synchronous distributed training on multiple GPUs on one machine. It creates one model replica per GPU device. Each variable in the model is mirrored across all the replicas. Together, these variables form a single conceptual variable called `MirroredVariable`. These variables are kept in sync with each other by applying identical updates.\n\nEfficient all-reduce algorithms are used to communicate the variable updates across the devices.\nAll-reduce aggregates tensors across all the devices by adding them up, and makes them available on each device.\nIt’s a fused algorithm that is very efficient and can reduce the overhead of synchronization significantly. There are many all-reduce algorithms and implementations available, depending on the type of communication available between devices. By default, it uses NVIDIA NCCL as the all-reduce implementation. The user can also choose between a few other options we provide, or write their own.\n\nHere is the simplest way of creating `MirroredStrategy`:\n",
"_____no_output_____"
]
],
[
[
"mirrored_strategy = tf.distribute.MirroredStrategy()",
"_____no_output_____"
]
],
[
[
"This will create a `MirroredStrategy` instance which will use all the GPUs that are visible to TensorFlow, and use NCCL as the cross device communication.\n\nIf you wish to use only some of the GPUs on your machine, you can do so like this:",
"_____no_output_____"
]
],
[
[
"mirrored_strategy = tf.distribute.MirroredStrategy(devices=[\"/gpu:0\", \"/gpu:1\"])",
"_____no_output_____"
]
],
[
[
"If you wish to override the cross device communication, you can do so using the `cross_device_ops` argument by supplying an instance of `tf.distribute.CrossDeviceOps`. Currently we provide `tf.distribute.HierarchicalCopyAllReduce` and `tf.distribute.ReductionToOneDevice` as 2 other options other than `tf.distribute.NcclAllReduce` which is the default.",
"_____no_output_____"
]
],
[
[
"mirrored_strategy = tf.distribute.MirroredStrategy(\n cross_device_ops=tf.distribute.HierarchicalCopyAllReduce())",
"_____no_output_____"
]
],
[
[
"### CentralStorageStrategy\n`tf.distribute.experimental.CentralStorageStrategy` does synchronous training as well. Variables are not mirrored, instead they are placed on the CPU and operations are replicated across all local GPUs. If there is only one GPU, all variables and operations will be placed on that GPU.\n\nCreate a `CentralStorageStrategy` by:\n",
"_____no_output_____"
]
],
[
[
"central_storage_strategy = tf.distribute.experimental.CentralStorageStrategy()",
"_____no_output_____"
]
],
[
[
"This will create a `CentralStorageStrategy` instance which will use all visible GPUs and CPU. Update to variables on replicas will be aggragated before being applied to variables.",
"_____no_output_____"
],
[
"Note: This strategy is [`experimental`](https://www.tensorflow.org/r1/guide/version_compat#what_is_not_covered) as we are currently improving it and making it work for more scenarios. As part of this, please expect the APIs to change in the future.",
"_____no_output_____"
],
[
"### MultiWorkerMirroredStrategy\n\n`tf.distribute.experimental.MultiWorkerMirroredStrategy` is very similar to `MirroredStrategy`. It implements synchronous distributed training across multiple workers, each with potentially multiple GPUs. Similar to `MirroredStrategy`, it creates copies of all variables in the model on each device across all workers.\n\nIt uses [CollectiveOps](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/ops/collective_ops.py) as the multi-worker all-reduce communication method used to keep variables in sync. A collective op is a single op in the TensorFlow graph which can automatically choose an all-reduce algorithm in the TensorFlow runtime according to hardware, network topology and tensor sizes.\n\nIt also implements additional performance optimizations. For example, it includes a static optimization that converts multiple all-reductions on small tensors into fewer all-reductions on larger tensors. In addition, we are designing it to have a plugin architecture - so that in the future, users will be able to plugin algorithms that are better tuned for their hardware. Note that collective ops also implement other collective operations such as broadcast and all-gather.\n\nHere is the simplest way of creating `MultiWorkerMirroredStrategy`:",
"_____no_output_____"
]
],
[
[
"multiworker_strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy()",
"_____no_output_____"
]
],
[
[
"`MultiWorkerMirroredStrategy` currently allows you to choose between two different implementations of collective ops. `CollectiveCommunication.RING` implements ring-based collectives using gRPC as the communication layer. `CollectiveCommunication.NCCL` uses [Nvidia's NCCL](https://developer.nvidia.com/nccl) to implement collectives. `CollectiveCommunication.AUTO` defers the choice to the runtime. The best choice of collective implementation depends upon the number and kind of GPUs, and the network interconnect in the cluster. You can specify them like so:\n",
"_____no_output_____"
]
],
[
[
"multiworker_strategy = tf.distribute.experimental.MultiWorkerMirroredStrategy(\n tf.distribute.experimental.CollectiveCommunication.NCCL)",
"_____no_output_____"
]
],
[
[
"One of the key differences to get multi worker training going, as compared to multi-GPU training, is the multi-worker setup. \"TF_CONFIG\" environment variable is the standard way in TensorFlow to specify the cluster configuration to each worker that is part of the cluster. See section on [\"TF_CONFIG\" below](#TF_CONFIG) for more details on how this can be done.\n",
"_____no_output_____"
],
[
"Note: This strategy is [`experimental`](https://www.tensorflow.org/r1/guide/version_compat#what_is_not_covered) as we are currently improving it and making it work for more scenarios. As part of this, please expect the APIs to change in the future.",
"_____no_output_____"
],
[
"### TPUStrategy\n`tf.distribute.experimental.TPUStrategy` lets users run their TensorFlow training on Tensor Processing Units (TPUs). TPUs are Google's specialized ASICs designed to dramatically accelerate machine learning workloads. They are available on Google Colab, the [TensorFlow Research Cloud](https://www.tensorflow.org/tfrc) and [Google Compute Engine](https://cloud.google.com/tpu).\n\nIn terms of distributed training architecture, TPUStrategy is the same `MirroredStrategy` - it implements synchronous distributed training. TPUs provide their own implementation of efficient all-reduce and other collective operations across multiple TPU cores, which are used in `TPUStrategy`.\n\nHere is how you would instantiate `TPUStrategy`.\nNote: To run this code in Colab, you should select TPU as the Colab runtime. See [Using TPUs]( tpu.ipynb) guide for a runnable version.\n\n```\nresolver = tf.distribute.cluster_resolver.TPUClusterResolver()\ntf.tpu.experimental.initialize_tpu_system(resolver)\ntpu_strategy = tf.distribute.experimental.TPUStrategy(resolver)\n```\n",
"_____no_output_____"
],
[
"`TPUClusterResolver` instance helps locate the TPUs. In Colab, you don't need to specify any arguments to it. If you want to use this for Cloud TPUs, you will need to specify the name of your TPU resource in `tpu` argument. We also need to initialize the tpu system explicitly at the start of the program. This is required before TPUs can be used for computation and should ideally be done at the beginning because it also wipes out the TPU memory so all state will be lost.",
"_____no_output_____"
],
[
"Note: This strategy is [`experimental`](https://www.tensorflow.org/r1/guide/version_compat#what_is_not_covered) as we are currently improving it and making it work for more scenarios. As part of this, please expect the APIs to change in the future.",
"_____no_output_____"
],
[
"### ParameterServerStrategy\n`tf.distribute.experimental.ParameterServerStrategy` supports parameter servers training on multiple machines. In this setup, some machines are designated as workers and some as parameter servers. Each variable of the model is placed on one parameter server. Computation is replicated across all GPUs of all the workers.\n\nIn terms of code, it looks similar to other strategies:\n```\nps_strategy = tf.distribute.experimental.ParameterServerStrategy()\n```",
"_____no_output_____"
],
[
"For multi worker training, \"TF_CONFIG\" needs to specify the configuration of parameter servers and workers in your cluster, which you can read more about in [TF_CONFIG](#TF_CONFIG) below.",
"_____no_output_____"
],
[
"So far we've talked about what are the different stategies available and how you can instantiate them. In the next few sections, we will talk about the different ways in which you can use them to distribute your training. We will show short code snippets in this guide and link off to full tutorials which you can run end to end.",
"_____no_output_____"
],
[
"## Using `tf.distribute.Strategy` with Keras\nWe've integrated `tf.distribute.Strategy` into `tf.keras` which is TensorFlow's implementation of the\n[Keras API specification](https://keras.io). `tf.keras` is a high-level API to build and train models. By integrating into `tf.keras` backend, we've made it seamless for Keras users to distribute their training written in the Keras training framework. The only things that need to change in a user's program are: (1) Create an instance of the appropriate `tf.distribute.Strategy` and (2) Move the creation and compiling of Keras model inside `strategy.scope`.\n\nHere is a snippet of code to do this for a very simple Keras model with one dense layer:",
"_____no_output_____"
]
],
[
[
"mirrored_strategy = tf.distribute.MirroredStrategy()\nwith mirrored_strategy.scope():\n model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))])\n model.compile(loss='mse', optimizer='sgd')",
"_____no_output_____"
]
],
[
[
"In this example we used `MirroredStrategy` so we can run this on a machine with multiple GPUs. `strategy.scope()` indicated which parts of the code to run distributed. Creating a model inside this scope allows us to create mirrored variables instead of regular variables. Compiling under the scope allows us to know that the user intends to train this model using this strategy. Once this is setup, you can fit your model like you would normally. `MirroredStrategy` takes care of replicating the model's training on the available GPUs, aggregating gradients etc.",
"_____no_output_____"
]
],
[
[
"dataset = tf.data.Dataset.from_tensors(([1.], [1.])).repeat(100).batch(10)\nmodel.fit(dataset, epochs=2)\nmodel.evaluate(dataset)",
"_____no_output_____"
]
],
[
[
"Here we used a `tf.data.Dataset` to provide the training and eval input. You can also use numpy arrays:",
"_____no_output_____"
]
],
[
[
"import numpy as np\ninputs, targets = np.ones((100, 1)), np.ones((100, 1))\nmodel.fit(inputs, targets, epochs=2, batch_size=10)",
"_____no_output_____"
]
],
[
[
"In both cases (dataset or numpy), each batch of the given input is divided equally among the multiple replicas. For instance, if using `MirroredStrategy` with 2 GPUs, each batch of size 10 will get divided among the 2 GPUs, with each receiving 5 input examples in each step. Each epoch will then train faster as you add more GPUs. Typically, you would want to increase your batch size as you add more accelerators so as to make effective use of the extra computing power. You will also need to re-tune your learning rate, depending on the model. You can use `strategy.num_replicas_in_sync` to get the number of replicas.",
"_____no_output_____"
]
],
[
[
"# Compute global batch size using number of replicas.\nBATCH_SIZE_PER_REPLICA = 5\nglobal_batch_size = (BATCH_SIZE_PER_REPLICA *\n mirrored_strategy.num_replicas_in_sync)\ndataset = tf.data.Dataset.from_tensors(([1.], [1.])).repeat(100)\ndataset = dataset.batch(global_batch_size)\n\nLEARNING_RATES_BY_BATCH_SIZE = {5: 0.1, 10: 0.15}\nlearning_rate = LEARNING_RATES_BY_BATCH_SIZE[global_batch_size]",
"_____no_output_____"
]
],
[
[
"### What's supported now?\n\nIn [TF nightly release](https://pypi.org/project/tf-nightly-gpu/), we now support training with Keras using all strategies.\n\nNote: When using `TPUStrategy` with TPU pods with Keras, currently the user will have to explicitly shard or shuffle the data for different workers, but we will change this in the future to automatically shard the input data intelligently.\n\n### Examples and Tutorials\n\nHere is a list of tutorials and examples that illustrate the above integration end to end with Keras:\n\n1. [Tutorial](../tutorials/distribute/keras.ipynb) to train MNIST with `MirroredStrategy`.\n2. Official [ResNet50](https://github.com/tensorflow/models/blob/master/official/vision/image_classification/resnet_imagenet_main.py) training with ImageNet data using `MirroredStrategy`.\n3. [ResNet50](https://github.com/tensorflow/tpu/blob/master/models/experimental/resnet50_keras/resnet50.py) trained with Imagenet data on Cloud TPus with `TPUStrategy`.",
"_____no_output_____"
],
[
"## Using `tf.distribute.Strategy` with Estimator\n`tf.estimator` is a distributed training TensorFlow API that originally supported the async parameter server approach. Like with Keras, we've integrated `tf.distribute.Strategy` into `tf.Estimator` so that a user who is using Estimator for their training can easily change their training is distributed with very few changes to your their code. With this, estimator users can now do synchronous distributed training on multiple GPUs and multiple workers, as well as use TPUs.\n\nThe usage of `tf.distribute.Strategy` with Estimator is slightly different than the Keras case. Instead of using `strategy.scope`, now we pass the strategy object into the [`RunConfig`](https://www.tensorflow.org/api_docs/python/tf/estimator/RunConfig) for the Estimator.\n\nHere is a snippet of code that shows this with a premade estimator `LinearRegressor` and `MirroredStrategy`:\n",
"_____no_output_____"
]
],
[
[
"mirrored_strategy = tf.distribute.MirroredStrategy()\nconfig = tf.estimator.RunConfig(\n train_distribute=mirrored_strategy, eval_distribute=mirrored_strategy)\nregressor = tf.estimator.LinearRegressor(\n feature_columns=[tf.feature_column.numeric_column('feats')],\n optimizer='SGD',\n config=config)",
"_____no_output_____"
]
],
[
[
"We use a premade Estimator here, but the same code works with a custom Estimator as well. `train_distribute` determines how training will be distributed, and `eval_distribute` determines how evaluation will be distributed. This is another difference from Keras where we use the same strategy for both training and eval.\n\nNow we can train and evaluate this Estimator with an input function:\n",
"_____no_output_____"
]
],
[
[
"def input_fn():\n dataset = tf.data.Dataset.from_tensors(({\"feats\":[1.]}, [1.]))\n return dataset.repeat(1000).batch(10)\nregressor.train(input_fn=input_fn, steps=10)\nregressor.evaluate(input_fn=input_fn, steps=10)",
"_____no_output_____"
]
],
[
[
"Another difference to highlight here between Estimator and Keras is the input handling. In Keras, we mentioned that each batch of the dataset is split across the multiple replicas. In Estimator, however, the user provides an `input_fn` and have full control over how they want their data to be distributed across workers and devices. We do not do automatic splitting of batch, nor automatically shard the data across different workers. The provided `input_fn` is called once per worker, thus giving one dataset per worker. Then one batch from that dataset is fed to one replica on that worker, thereby consuming N batches for N replicas on 1 worker. In other words, the dataset returned by the `input_fn` should provide batches of size `PER_REPLICA_BATCH_SIZE`. And the global batch size for a step can be obtained as `PER_REPLICA_BATCH_SIZE * strategy.num_replicas_in_sync`. When doing multi worker training, users will also want to either split their data across the workers, or shuffle with a random seed on each. You can see an example of how to do this in the [Multi-worker Training with Estimator](../tutorials/distribute/multi_worker_with_estimator.ipynb).",
"_____no_output_____"
],
[
"We showed an example of using `MirroredStrategy` with Estimator. You can also use `TPUStrategy` with Estimator as well, in the exact same way:\n```\nconfig = tf.estimator.RunConfig(\n train_distribute=tpu_strategy, eval_distribute=tpu_strategy)\n```",
"_____no_output_____"
],
[
"And similarly, you can use multi worker and parameter server strategies as well. The code remains the same, but you need to use `tf.estimator.train_and_evaluate`, and set \"TF_CONFIG\" environment variables for each binary running in your cluster.",
"_____no_output_____"
],
[
"### What's supported now?\n\nIn TF nightly release, we support training with Estimator using all strategies.\n\n### Examples and Tutorials\nHere are some examples that show end to end usage of various strategies with Estimator:\n\n1. [End to end example](https://github.com/tensorflow/ecosystem/tree/master/distribution_strategy) for multi worker training in tensorflow/ecosystem using Kuberentes templates. This example starts with a Keras model and converts it to an Estimator using the `tf.keras.estimator.model_to_estimator` API.\n2. Official [ResNet50](https://github.com/tensorflow/models/blob/master/official/r1/resnet/imagenet_main.py) model, which can be trained using either `MirroredStrategy` or `MultiWorkerMirroredStrategy`.\n3. [ResNet50](https://github.com/tensorflow/tpu/blob/master/models/experimental/distribution_strategy/resnet_estimator.py) example with TPUStrategy.",
"_____no_output_____"
],
[
"## Using `tf.distribute.Strategy` with custom training loops\nAs you've seen, using `tf.distrbute.Strategy` with high level APIs is only a couple lines of code change. With a little more effort, `tf.distrbute.Strategy` can also be used by other users who are not using these frameworks.\n\nTensorFlow is used for a wide variety of use cases and some users (such as researchers) require more flexibility and control over their training loops. This makes it hard for them to use the high level frameworks such as Estimator or Keras. For instance, someone using a GAN may want to take a different number of generator or discriminator steps each round. Similarly, the high level frameworks are not very suitable for Reinforcement Learning training. So these users will usually write their own training loops.\n\nFor these users, we provide a core set of methods through the `tf.distrbute.Strategy` classes. Using these may require minor restructuring of the code initially, but once that is done, the user should be able to switch between GPUs / TPUs / multiple machines by just changing the strategy instance.\n\nHere we will show a brief snippet illustrating this use case for a simple training example using the same Keras model as before.\nNote: These APIs are still experimental and we are improving them to make them more user friendly.",
"_____no_output_____"
],
[
"First, we create the model and optimizer inside the strategy's scope. This ensures that any variables created with the model and optimizer are mirrored variables.",
"_____no_output_____"
]
],
[
[
"with mirrored_strategy.scope():\n model = tf.keras.Sequential([tf.keras.layers.Dense(1, input_shape=(1,))])\n optimizer = tf.train.GradientDescentOptimizer(0.1)",
"_____no_output_____"
]
],
[
[
"Next, we create the input dataset and call `tf.distribute.Strategy.experimental_distribute_dataset` to distribute the dataset based on the strategy.\n",
"_____no_output_____"
]
],
[
[
"dataset = tf.data.Dataset.from_tensors(([1.], [1.])).repeat(1000).batch(\n global_batch_size)\ndist_dataset = mirrored_strategy.experimental_distribute_dataset(dataset)",
"_____no_output_____"
]
],
[
[
"Then, we define one step of the training. We will use `tf.GradientTape` to compute gradients and optimizer to apply those gradients to update our model's variables. To distribute this training step, we put it in a function `step_fn` and pass it to `tf.distribute.Strategy.run` along with the inputs from the iterator:",
"_____no_output_____"
]
],
[
[
"def train_step(dist_inputs):\n def step_fn(inputs):\n features, labels = inputs\n logits = model(features)\n cross_entropy = tf.nn.softmax_cross_entropy_with_logits(\n logits=logits, labels=labels)\n loss = tf.reduce_sum(cross_entropy) * (1.0 / global_batch_size)\n train_op = optimizer.minimize(loss)\n with tf.control_dependencies([train_op]):\n return tf.identity(loss)\n\n per_replica_losses = mirrored_strategy.run(\n step_fn, args=(dist_inputs,))\n mean_loss = mirrored_strategy.reduce(\n tf.distribute.ReduceOp.SUM, per_replica_losses, axis=None)\n return mean_loss",
"_____no_output_____"
]
],
[
[
"A few other things to note in the code above:\n\n1. We used `tf.nn.softmax_cross_entropy_with_logits` to compute the loss. And then we scaled the total loss by the global batch size. This is important because all the replicas are training in sync and number of examples in each step of training is the global batch. So the loss needs to be divided by the global batch size and not by the replica (local) batch size.\n2. We used the `strategy.reduce` API to aggregate the results returned by `tf.distribute.Strategy.run`. `tf.distribute.Strategy.run` returns results from each local replica in the strategy, and there are multiple ways to consume this result. You can `reduce` them to get an aggregated value. You can also do `tf.distribute.Strategy.experimental_local_results(results)`to get the list of values contained in the result, one per local replica.\n",
"_____no_output_____"
],
[
"Finally, once we have defined the training step, we can initialize the iterator and variables and run the training in a loop:",
"_____no_output_____"
]
],
[
[
"with mirrored_strategy.scope():\n input_iterator = dist_dataset.make_initializable_iterator()\n iterator_init = input_iterator.initializer\n var_init = tf.global_variables_initializer()\n loss = train_step(input_iterator.get_next())\n with tf.Session() as sess:\n sess.run([var_init, iterator_init])\n for _ in range(10):\n print(sess.run(loss))",
"_____no_output_____"
]
],
[
[
"In the example above, we used `tf.distribute.Strategy.experimental_distribute_dataset` to provide input to your training. We also provide the `tf.distribute.Strategy.make_experimental_numpy_dataset` to support numpy inputs. You can use this API to create a dataset before calling `tf.distribute.Strategy.experimental_distribute_dataset`.",
"_____no_output_____"
],
[
"This covers the simplest case of using `tf.distribute.Strategy` API to distribute custom training loops. We are in the process of improving these APIs. Since this use case requires more work on the part of the user, we will be publishing a separate detailed guide in the future.",
"_____no_output_____"
],
[
"### What's supported now?\nIn TF nightly release, we support training with custom training loops using `MirroredStrategy` and `TPUStrategy` as shown above. Support for other strategies will be coming in soon. `MultiWorkerMirorredStrategy` support will be coming in the future.\n\n### Examples and Tutorials\nHere are some examples for using distribution strategy with custom training loops:\n\n1. [Example](https://github.com/tensorflow/tensorflow/blob/5456cc28f3f8d9c17c645d9a409e495969e584ae/tensorflow/contrib/distribute/python/examples/mnist_tf1_tpu.py) to train MNIST using `TPUStrategy`.\n",
"_____no_output_____"
],
[
"## Other topics\nIn this section, we will cover some topics that are relevant to multiple use cases.",
"_____no_output_____"
],
[
"<a id=\"TF_CONFIG\">\n### Setting up TF\\_CONFIG environment variable\n</a>\nFor multi-worker training, as mentioned before, you need to set \"TF\\_CONFIG\" environment variable for each\nbinary running in your cluster. The \"TF\\_CONFIG\" environment variable is a JSON string which specifies what\ntasks constitute a cluster, their addresses and each task's role in the cluster. We provide a Kubernetes template in the\n[tensorflow/ecosystem](https://github.com/tensorflow/ecosystem) repo which sets\n\"TF\\_CONFIG\" for your training tasks.\n\nOne example of \"TF\\_CONFIG\" is:\n```\nos.environ[\"TF_CONFIG\"] = json.dumps({\n \"cluster\": {\n \"worker\": [\"host1:port\", \"host2:port\", \"host3:port\"],\n \"ps\": [\"host4:port\", \"host5:port\"]\n },\n \"task\": {\"type\": \"worker\", \"index\": 1}\n})\n```\n",
"_____no_output_____"
],
[
"This \"TF\\_CONFIG\" specifies that there are three workers and two ps tasks in the\ncluster along with their hosts and ports. The \"task\" part specifies that the\nrole of the current task in the cluster, worker 1 (the second worker). Valid roles in a cluster is\n\"chief\", \"worker\", \"ps\" and \"evaluator\". There should be no \"ps\" job except when using `tf.distribute.experimental.ParameterServerStrategy`.",
"_____no_output_____"
],
[
"## What's next?\n\n`tf.distribute.Strategy` is actively under development. We welcome you to try it out and provide your feedback via [issues on GitHub](https://github.com/tensorflow/tensorflow/issues/new).",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
d0f77f5019311c2767f4b889964eca42d40b7652 | 245,703 | ipynb | Jupyter Notebook | CNN Models/Models/Duplicate_Question_2CNN_Layer.ipynb | roushan-raj/Duplicate-Question-Pair-Detection | eeb90982dae2f1f3dde9ffe6b4254be5c0c862c0 | [
"Apache-2.0"
] | null | null | null | CNN Models/Models/Duplicate_Question_2CNN_Layer.ipynb | roushan-raj/Duplicate-Question-Pair-Detection | eeb90982dae2f1f3dde9ffe6b4254be5c0c862c0 | [
"Apache-2.0"
] | null | null | null | CNN Models/Models/Duplicate_Question_2CNN_Layer.ipynb | roushan-raj/Duplicate-Question-Pair-Detection | eeb90982dae2f1f3dde9ffe6b4254be5c0c862c0 | [
"Apache-2.0"
] | 2 | 2021-11-07T12:12:17.000Z | 2022-03-12T07:52:30.000Z | 245,703 | 245,703 | 0.88257 | [
[
[
"from keras.preprocessing import sequence\nfrom keras.preprocessing import text\nimport numpy as np\nfrom keras.models import Sequential\nfrom keras.layers import Dense, Dropout, Activation\nfrom keras.layers import Embedding, LSTM\nfrom keras.layers import Conv1D, Flatten\nfrom keras.preprocessing import text\nfrom keras.models import Sequential,Model\nfrom keras.layers import Dense ,Activation,MaxPool1D,Conv1D,Flatten,Dropout,Activation,Dropout,Input,Lambda,concatenate\nfrom keras.utils import np_utils\nfrom nltk.corpus import stopwords\nfrom nltk.tokenize import RegexpTokenizer\nfrom nltk.stem.porter import PorterStemmer\nimport nltk\nimport csv\nimport pandas as pd\n\nfrom keras.preprocessing import text as keras_text, sequence as keras_seq",
"_____no_output_____"
],
[
"data = pd.read_csv('drive/My Drive/ML Internship IIIT Dharwad/train.csv')\npd.set_option('display.max_colwidth',80)\ndata.head()",
"_____no_output_____"
],
[
"data.shape",
"_____no_output_____"
],
[
"print(data['is_duplicate'].value_counts())\n\nimport matplotlib.pyplot as plt\ndata['is_duplicate'].value_counts().plot(kind='bar', color='green')",
"0 255027\n1 149263\nName: is_duplicate, dtype: int64\n"
],
[
"print(data.dtypes)\nprint(data['question1'].dtypes)\nprint(data['question2'].dtypes)\ntype(data['question1'])",
"id int64\nqid1 int64\nqid2 int64\nquestion1 object\nquestion2 object\nis_duplicate int64\ndtype: object\nobject\nobject\n"
]
],
[
[
"# Setting target or labelfor each input",
"_____no_output_____"
]
],
[
[
"label_oneDimension=data['is_duplicate']",
"_____no_output_____"
],
[
"label_oneDimension.head(2)",
"_____no_output_____"
],
[
"import numpy as np\nfrom keras.utils.np_utils import to_categorical\nlabel_twoDimension = to_categorical(data['is_duplicate'], num_classes=2)",
"_____no_output_____"
],
[
"label_twoDimension[0:1]",
"_____no_output_____"
],
[
"question_one=data['question1'].astype(str)\nprint(question_one.head())",
"0 What is the step by step guide to invest in share market in india?\n1 What is the story of Kohinoor (Koh-i-Noor) Diamond?\n2 How can I increase the speed of my internet connection while using a VPN?\n3 Why am I mentally very lonely? How can I solve it?\n4 Which one dissolve in water quikly sugar, salt, methane and carbon di oxide?\nName: question1, dtype: object\n"
],
[
"question_two=data['question2'].astype(str)\nprint(question_two.head())",
"0 What is the step by step guide to invest in share market?\n1 What would happen if the Indian government stole the Kohinoor (Koh-i-Noor) d...\n2 How can Internet speed be increased by hacking through DNS?\n3 Find the remainder when [math]23^{24}[/math] is divided by 24,23?\n4 Which fish would survive in salt water?\nName: question2, dtype: object\n"
]
],
[
[
"# Reading test data and preprocessing",
"_____no_output_____"
]
],
[
[
"#Data reading\n'''\ndata_test = pd.read_csv('drive/My Drive/Summer Internship 2020 July/My Test File/Sunil/test.csv')\ndata_test_sample=data_test.dropna()\n#data_test_sample=data_test_sample.head(100)\ndata_test_sample.head()\n'''",
"_____no_output_____"
],
[
"'''\nquestion_one_test=data_test_sample['question1'].astype(str)\nprint(question_one_test.head())\n'''",
"_____no_output_____"
],
[
"'''\nquestion_two_test=data_test_sample['question2'].astype(str)\nprint(question_two_test.head())\n'''",
"_____no_output_____"
]
],
[
[
"# Fitting text on a single tokenized object",
"_____no_output_____"
]
],
[
[
"from keras.preprocessing.text import Tokenizer\ntok_all = Tokenizer(filters='!\"#$%&\\'()*+,-./:;<=>?@[\\\\]^_`{|}~', char_level = False)\ntok_all.fit_on_texts(question_one+question_two)\n#tok_all.fit_on_texts(question_one+question_two+question_one_test+question_two_test)",
"_____no_output_____"
],
[
"vocabulary_all=len(tok_all.word_counts)\nprint(vocabulary_all)",
"89983\n"
]
],
[
[
"# Train data Sequencing and Encoding",
"_____no_output_____"
]
],
[
[
"#Encoding question 1\nencoded_q1=tok_all.texts_to_sequences(question_one)\nprint(question_one[0])\nencoded_q1[0]",
"What is the step by step guide to invest in share market in india?\n"
],
[
"#Encoding question 2\nencoded_q2=tok_all.texts_to_sequences(question_two)\nprint(question_two[0])\nencoded_q2[0]",
"What is the step by step guide to invest in share market?\n"
]
],
[
[
"# Pre-Padding on Train data",
"_____no_output_____"
]
],
[
[
"#####Padding encoded sequence of words\nfrom keras.preprocessing import sequence\nmax_length=100\npadded_docs_q1 = sequence.pad_sequences(encoded_q1, maxlen=max_length, padding='pre')",
"_____no_output_____"
],
[
"#####Padding encoded sequence of words\nfrom keras.preprocessing import sequence\nmax_length=100\npadded_docs_q2 = sequence.pad_sequences(encoded_q2, maxlen=max_length, padding='pre')",
"_____no_output_____"
]
],
[
[
"# Encoding on Test data",
"_____no_output_____"
]
],
[
[
"'''\n#Encoding question 1\nencoded_q1_test=tok_all.texts_to_sequences(question_one_test)\nprint(question_one_test[0])\nencoded_q1_test[0]\n'''",
"_____no_output_____"
],
[
"'''#Encoding question 1\nencoded_q2_test=tok_all.texts_to_sequences(question_two_test)\nprint(question_two_test[0])\nencoded_q2_test[0]'''",
"_____no_output_____"
]
],
[
[
"# Pre-Padding on test data",
"_____no_output_____"
]
],
[
[
"'''#####Padding encoded sequence of words\npadded_docs_q1_test = sequence.pad_sequences(encoded_q1_test, maxlen=max_length, padding='pre')\npadded_docs_q2_test = sequence.pad_sequences(encoded_q2_test, maxlen=max_length, padding='pre')'''",
"_____no_output_____"
]
],
[
[
"# Reading Embedding Vector from Glove",
"_____no_output_____"
]
],
[
[
"import os\nimport numpy as np",
"_____no_output_____"
],
[
"embeddings_index = {}\nf = open('drive/My Drive/ML Internship IIIT Dharwad/Copy of glove.6B.300d.txt')\nfor line in f:\n values = line.split()\n word = values[0]\n coefs = np.asarray(values[1:], dtype='float32')\n embeddings_index[word] = coefs\nf.close()\nprint('Loaded %s word vectors.' % len(embeddings_index))",
"Loaded 400000 word vectors.\n"
],
[
"embedding_matrix = np.zeros((vocabulary_all+1, 300))\nfor word, i in tok_all.word_index.items():\n\tembedding_vector = embeddings_index.get(word)\n\tif embedding_vector is not None:\n\t\tembedding_matrix[i] = embedding_vector",
"_____no_output_____"
]
],
[
[
"# Defining Input Shape for Model",
"_____no_output_____"
]
],
[
[
"Question1_shape= Input(shape=[max_length])\nQuestion1_shape.shape",
"_____no_output_____"
],
[
"Question2_shape= Input(shape=[max_length])\nQuestion2_shape.shape",
"_____no_output_____"
]
],
[
[
"# Embedding Layer",
"_____no_output_____"
]
],
[
[
"Embedding_Layer = Embedding(vocabulary_all+1,300,weights=[embedding_matrix], input_length=max_length, trainable=False)",
"_____no_output_____"
]
],
[
[
"# CNN Network",
"_____no_output_____"
]
],
[
[
"CNN2_network=Sequential([Embedding_Layer,\n Conv1D(32,3,activation=\"relu\",padding='same'),\n Dropout(0.2),\n MaxPool1D(2),\n Conv1D(64,5,activation=\"relu\",padding='same'),\n Dropout(0.2),\n MaxPool1D(2),\n Flatten(),\n Dense(128,activation=\"linear\"),\n Dropout(0.3)\n \n ])",
"_____no_output_____"
]
],
[
[
"# Printing Model summary",
"_____no_output_____"
]
],
[
[
"CNN2_network.summary()",
"Model: \"sequential_2\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nembedding_2 (Embedding) (None, 100, 300) 26995200 \n_________________________________________________________________\nconv1d_4 (Conv1D) (None, 100, 32) 28832 \n_________________________________________________________________\ndropout_6 (Dropout) (None, 100, 32) 0 \n_________________________________________________________________\nmax_pooling1d_4 (MaxPooling1 (None, 50, 32) 0 \n_________________________________________________________________\nconv1d_5 (Conv1D) (None, 50, 64) 10304 \n_________________________________________________________________\ndropout_7 (Dropout) (None, 50, 64) 0 \n_________________________________________________________________\nmax_pooling1d_5 (MaxPooling1 (None, 25, 64) 0 \n_________________________________________________________________\nflatten_2 (Flatten) (None, 1600) 0 \n_________________________________________________________________\ndense_4 (Dense) (None, 128) 204928 \n_________________________________________________________________\ndropout_8 (Dropout) (None, 128) 0 \n=================================================================\nTotal params: 27,239,264\nTrainable params: 244,064\nNon-trainable params: 26,995,200\n_________________________________________________________________\n"
],
[
"from keras.utils.vis_utils import plot_model\nplot_model(CNN2_network, to_file='CNN2_network.png', show_shapes=True, show_layer_names=True)",
"_____no_output_____"
]
],
[
[
"# create siamese network from CNN model and store output feature vectors",
"_____no_output_____"
]
],
[
[
"Question1_CNN_feature=CNN2_network(Question1_shape)\nQuestion2_CNN_feature=CNN2_network(Question2_shape)",
"_____no_output_____"
]
],
[
[
"# Adding and multiplying features obtained from Siamese CNN network",
"_____no_output_____"
]
],
[
[
"from keras import backend as K\nfrom keras.optimizers import Adam",
"_____no_output_____"
],
[
"lamda_function=Lambda(lambda tensor:K.abs(tensor[0]-tensor[1]),name=\"Absolute_distance\")\nabs_distance_vector=lamda_function([Question1_CNN_feature,Question2_CNN_feature])\n\nlamda_function2=Lambda(lambda tensor:K.abs(tensor[0]*tensor[1]),name=\"Hamadard_multiplication\")\nhamadard_vector=lamda_function2([Question1_CNN_feature,Question2_CNN_feature])",
"_____no_output_____"
]
],
[
[
"# Adding abs_distance_vector and hamadard_vector",
"_____no_output_____"
]
],
[
[
"from keras.layers import Add",
"_____no_output_____"
],
[
"added_vecotr = Add()([abs_distance_vector, hamadard_vector])",
"_____no_output_____"
]
],
[
[
"# Final Model prediction",
"_____no_output_____"
]
],
[
[
"predict=Dense(2,activation=\"sigmoid\")(added_vecotr)",
"_____no_output_____"
]
],
[
[
"# Creating sequential model using Model() class and compilation",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import roc_auc_score, roc_curve, accuracy_score\nSiamese2_Network=Model(inputs=[Question1_shape,Question2_shape],outputs=predict)\nSiamese2_Network.compile(loss = \"binary_crossentropy\", optimizer=Adam(lr=0.00003), metrics=[\"accuracy\"])",
"_____no_output_____"
],
[
"Siamese2_Network.summary()",
"Model: \"functional_5\"\n__________________________________________________________________________________________________\nLayer (type) Output Shape Param # Connected to \n==================================================================================================\ninput_5 (InputLayer) [(None, 100)] 0 \n__________________________________________________________________________________________________\ninput_6 (InputLayer) [(None, 100)] 0 \n__________________________________________________________________________________________________\nsequential_2 (Sequential) (None, 128) 27239264 input_5[0][0] \n input_6[0][0] \n__________________________________________________________________________________________________\nAbsolute_distance (Lambda) (None, 128) 0 sequential_2[0][0] \n sequential_2[1][0] \n__________________________________________________________________________________________________\nHamadard_multiplication (Lambda (None, 128) 0 sequential_2[0][0] \n sequential_2[1][0] \n__________________________________________________________________________________________________\nadd_2 (Add) (None, 128) 0 Absolute_distance[0][0] \n Hamadard_multiplication[0][0] \n__________________________________________________________________________________________________\ndense_5 (Dense) (None, 2) 258 add_2[0][0] \n==================================================================================================\nTotal params: 27,239,522\nTrainable params: 244,322\nNon-trainable params: 26,995,200\n__________________________________________________________________________________________________\n"
]
],
[
[
"# Plot model",
"_____no_output_____"
]
],
[
[
"from keras.utils import plot_model\nplot_model(Siamese2_Network, to_file='Siamese2_Network.png',show_shapes=True, show_layer_names=True)",
"_____no_output_____"
]
],
[
[
"# Setting hyperparameter for training",
"_____no_output_____"
]
],
[
[
"from keras.callbacks import EarlyStopping, ReduceLROnPlateau,ModelCheckpoint\nearlystopper = EarlyStopping(patience=8, verbose=1)\n#checkpointer = ModelCheckpoint(filepath = 'cnn_model_one_.{epoch:02d}-{val_loss:.6f}.hdf5',\n # verbose=1,\n # save_best_only=True, save_weights_only = True)\n\nreduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.9,\n patience=2, min_lr=0.00001, verbose=1)",
"_____no_output_____"
]
],
[
[
"# Data split into train and validation set",
"_____no_output_____"
]
],
[
[
"# Splitting data into train and test\nfrom sklearn.model_selection import train_test_split\nq1_train, q1_val,q2_train, q2_val, label_train, label_val, label_oneD_train, label_oneD_val = train_test_split(padded_docs_q1,padded_docs_q2, label_twoDimension, label_oneDimension, test_size=0.30,\nrandom_state=42)",
"_____no_output_____"
]
],
[
[
"# Model fitting or training",
"_____no_output_____"
]
],
[
[
"history = Siamese2_Network.fit([q1_train,q2_train],label_train,\n batch_size=32,epochs=100,validation_data=([q1_val,q2_val],label_val),callbacks=[earlystopper, reduce_lr])",
"Epoch 1/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.5987 - accuracy: 0.6722 - val_loss: 0.5843 - val_accuracy: 0.6917\nEpoch 2/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.5591 - accuracy: 0.7142 - val_loss: 0.5705 - val_accuracy: 0.7091\nEpoch 3/100\n8844/8844 [==============================] - 65s 7ms/step - loss: 0.5435 - accuracy: 0.7254 - val_loss: 0.5607 - val_accuracy: 0.7200\nEpoch 4/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.5317 - accuracy: 0.7345 - val_loss: 0.5490 - val_accuracy: 0.7269\nEpoch 5/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.5230 - accuracy: 0.7399 - val_loss: 0.5419 - val_accuracy: 0.7339\nEpoch 6/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.5157 - accuracy: 0.7448 - val_loss: 0.5391 - val_accuracy: 0.7400\nEpoch 7/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.5094 - accuracy: 0.7490 - val_loss: 0.5353 - val_accuracy: 0.7314\nEpoch 8/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.5039 - accuracy: 0.7521 - val_loss: 0.5282 - val_accuracy: 0.7415\nEpoch 9/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4986 - accuracy: 0.7553 - val_loss: 0.5242 - val_accuracy: 0.7456\nEpoch 10/100\n8844/8844 [==============================] - 63s 7ms/step - loss: 0.4941 - accuracy: 0.7587 - val_loss: 0.5173 - val_accuracy: 0.7449\nEpoch 11/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4906 - accuracy: 0.7604 - val_loss: 0.5174 - val_accuracy: 0.7480\nEpoch 12/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4860 - accuracy: 0.7636 - val_loss: 0.5114 - val_accuracy: 0.7548\nEpoch 13/100\n8844/8844 [==============================] - 65s 7ms/step - loss: 0.4827 - accuracy: 0.7651 - val_loss: 0.5088 - val_accuracy: 0.7557\nEpoch 14/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4800 - accuracy: 0.7670 - val_loss: 0.5075 - val_accuracy: 0.7511\nEpoch 15/100\n8844/8844 [==============================] - 65s 7ms/step - loss: 0.4773 - accuracy: 0.7693 - val_loss: 0.5052 - val_accuracy: 0.7566\nEpoch 16/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4736 - accuracy: 0.7709 - val_loss: 0.5026 - val_accuracy: 0.7527\nEpoch 17/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4711 - accuracy: 0.7725 - val_loss: 0.5036 - val_accuracy: 0.7513\nEpoch 18/100\n8844/8844 [==============================] - 65s 7ms/step - loss: 0.4683 - accuracy: 0.7744 - val_loss: 0.5005 - val_accuracy: 0.7544\nEpoch 19/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4661 - accuracy: 0.7756 - val_loss: 0.5006 - val_accuracy: 0.7530\nEpoch 20/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4632 - accuracy: 0.7774 - val_loss: 0.4930 - val_accuracy: 0.7607\nEpoch 21/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4612 - accuracy: 0.7778 - val_loss: 0.4889 - val_accuracy: 0.7647\nEpoch 22/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4594 - accuracy: 0.7797 - val_loss: 0.4881 - val_accuracy: 0.7642\nEpoch 23/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4575 - accuracy: 0.7804 - val_loss: 0.4916 - val_accuracy: 0.7635\nEpoch 24/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4563 - accuracy: 0.7808 - val_loss: 0.4879 - val_accuracy: 0.7662\nEpoch 25/100\n8844/8844 [==============================] - 63s 7ms/step - loss: 0.4539 - accuracy: 0.7816 - val_loss: 0.4867 - val_accuracy: 0.7669\nEpoch 26/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4520 - accuracy: 0.7835 - val_loss: 0.4821 - val_accuracy: 0.7686\nEpoch 27/100\n8844/8844 [==============================] - 63s 7ms/step - loss: 0.4499 - accuracy: 0.7857 - val_loss: 0.4836 - val_accuracy: 0.7650\nEpoch 28/100\n8837/8844 [============================>.] - ETA: 0s - loss: 0.4485 - accuracy: 0.7860\nEpoch 00028: ReduceLROnPlateau reducing learning rate to 2.699999931792263e-05.\n8844/8844 [==============================] - 62s 7ms/step - loss: 0.4485 - accuracy: 0.7860 - val_loss: 0.4838 - val_accuracy: 0.7660\nEpoch 29/100\n8844/8844 [==============================] - 62s 7ms/step - loss: 0.4469 - accuracy: 0.7873 - val_loss: 0.4850 - val_accuracy: 0.7620\nEpoch 30/100\n8844/8844 [==============================] - 62s 7ms/step - loss: 0.4457 - accuracy: 0.7878 - val_loss: 0.4816 - val_accuracy: 0.7660\nEpoch 31/100\n8844/8844 [==============================] - 61s 7ms/step - loss: 0.4438 - accuracy: 0.7888 - val_loss: 0.4771 - val_accuracy: 0.7720\nEpoch 32/100\n8844/8844 [==============================] - 62s 7ms/step - loss: 0.4423 - accuracy: 0.7902 - val_loss: 0.4772 - val_accuracy: 0.7711\nEpoch 33/100\n8837/8844 [============================>.] - ETA: 0s - loss: 0.4412 - accuracy: 0.7890\nEpoch 00033: ReduceLROnPlateau reducing learning rate to 2.4300000040966553e-05.\n8844/8844 [==============================] - 63s 7ms/step - loss: 0.4412 - accuracy: 0.7890 - val_loss: 0.4796 - val_accuracy: 0.7670\nEpoch 34/100\n8844/8844 [==============================] - 63s 7ms/step - loss: 0.4402 - accuracy: 0.7908 - val_loss: 0.4770 - val_accuracy: 0.7695\nEpoch 35/100\n8840/8844 [============================>.] - ETA: 0s - loss: 0.4391 - accuracy: 0.7916\nEpoch 00035: ReduceLROnPlateau reducing learning rate to 2.1869999545742758e-05.\n8844/8844 [==============================] - 65s 7ms/step - loss: 0.4391 - accuracy: 0.7917 - val_loss: 0.4774 - val_accuracy: 0.7706\nEpoch 36/100\n8844/8844 [==============================] - 63s 7ms/step - loss: 0.4381 - accuracy: 0.7917 - val_loss: 0.4740 - val_accuracy: 0.7717\nEpoch 37/100\n8844/8844 [==============================] - 66s 8ms/step - loss: 0.4365 - accuracy: 0.7929 - val_loss: 0.4724 - val_accuracy: 0.7742\nEpoch 38/100\n8844/8844 [==============================] - 63s 7ms/step - loss: 0.4346 - accuracy: 0.7938 - val_loss: 0.4762 - val_accuracy: 0.7682\nEpoch 39/100\n8844/8844 [==============================] - 65s 7ms/step - loss: 0.4351 - accuracy: 0.7939 - val_loss: 0.4712 - val_accuracy: 0.7759\nEpoch 40/100\n8844/8844 [==============================] - 63s 7ms/step - loss: 0.4336 - accuracy: 0.7941 - val_loss: 0.4691 - val_accuracy: 0.7774\nEpoch 41/100\n8844/8844 [==============================] - 65s 7ms/step - loss: 0.4324 - accuracy: 0.7950 - val_loss: 0.4699 - val_accuracy: 0.7758\nEpoch 42/100\n8842/8844 [============================>.] - ETA: 0s - loss: 0.4316 - accuracy: 0.7957\nEpoch 00042: ReduceLROnPlateau reducing learning rate to 1.9682998936332296e-05.\n8844/8844 [==============================] - 65s 7ms/step - loss: 0.4316 - accuracy: 0.7957 - val_loss: 0.4708 - val_accuracy: 0.7747\nEpoch 43/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4310 - accuracy: 0.7965 - val_loss: 0.4726 - val_accuracy: 0.7728\nEpoch 44/100\n8840/8844 [============================>.] - ETA: 0s - loss: 0.4296 - accuracy: 0.7974\nEpoch 00044: ReduceLROnPlateau reducing learning rate to 1.7714698878990023e-05.\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4296 - accuracy: 0.7974 - val_loss: 0.4707 - val_accuracy: 0.7735\nEpoch 45/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4284 - accuracy: 0.7971 - val_loss: 0.4699 - val_accuracy: 0.7763\nEpoch 46/100\n8837/8844 [============================>.] - ETA: 0s - loss: 0.4275 - accuracy: 0.7980\nEpoch 00046: ReduceLROnPlateau reducing learning rate to 1.5943229482218157e-05.\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4275 - accuracy: 0.7981 - val_loss: 0.4723 - val_accuracy: 0.7713\nEpoch 47/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4282 - accuracy: 0.7977 - val_loss: 0.4691 - val_accuracy: 0.7760\nEpoch 48/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4277 - accuracy: 0.7975 - val_loss: 0.4670 - val_accuracy: 0.7776\nEpoch 49/100\n8844/8844 [==============================] - 65s 7ms/step - loss: 0.4261 - accuracy: 0.7991 - val_loss: 0.4651 - val_accuracy: 0.7787\nEpoch 50/100\n8844/8844 [==============================] - 65s 7ms/step - loss: 0.4261 - accuracy: 0.7988 - val_loss: 0.4647 - val_accuracy: 0.7793\nEpoch 51/100\n8844/8844 [==============================] - 66s 8ms/step - loss: 0.4258 - accuracy: 0.7989 - val_loss: 0.4697 - val_accuracy: 0.7752\nEpoch 52/100\n8841/8844 [============================>.] - ETA: 0s - loss: 0.4244 - accuracy: 0.7995\nEpoch 00052: ReduceLROnPlateau reducing learning rate to 1.4348906370287296e-05.\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4244 - accuracy: 0.7995 - val_loss: 0.4646 - val_accuracy: 0.7793\nEpoch 53/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4246 - accuracy: 0.7994 - val_loss: 0.4667 - val_accuracy: 0.7771\nEpoch 54/100\n8843/8844 [============================>.] - ETA: 0s - loss: 0.4244 - accuracy: 0.7989\nEpoch 00054: ReduceLROnPlateau reducing learning rate to 1.2914015405840473e-05.\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4244 - accuracy: 0.7989 - val_loss: 0.4659 - val_accuracy: 0.7775\nEpoch 55/100\n8844/8844 [==============================] - 65s 7ms/step - loss: 0.4227 - accuracy: 0.8002 - val_loss: 0.4635 - val_accuracy: 0.7797\nEpoch 56/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4221 - accuracy: 0.8008 - val_loss: 0.4615 - val_accuracy: 0.7821\nEpoch 57/100\n8844/8844 [==============================] - 66s 7ms/step - loss: 0.4210 - accuracy: 0.8009 - val_loss: 0.4635 - val_accuracy: 0.7790\nEpoch 58/100\n8836/8844 [============================>.] - ETA: 0s - loss: 0.4217 - accuracy: 0.8009\nEpoch 00058: ReduceLROnPlateau reducing learning rate to 1.1622613783401903e-05.\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4218 - accuracy: 0.8008 - val_loss: 0.4658 - val_accuracy: 0.7776\nEpoch 59/100\n8844/8844 [==============================] - 66s 7ms/step - loss: 0.4212 - accuracy: 0.8016 - val_loss: 0.4649 - val_accuracy: 0.7788\nEpoch 60/100\n8839/8844 [============================>.] - ETA: 0s - loss: 0.4206 - accuracy: 0.8015\nEpoch 00060: ReduceLROnPlateau reducing learning rate to 1.0460352405061712e-05.\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4206 - accuracy: 0.8015 - val_loss: 0.4648 - val_accuracy: 0.7782\nEpoch 61/100\n8844/8844 [==============================] - 67s 8ms/step - loss: 0.4209 - accuracy: 0.8015 - val_loss: 0.4609 - val_accuracy: 0.7819\nEpoch 62/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4203 - accuracy: 0.8020 - val_loss: 0.4669 - val_accuracy: 0.7762\nEpoch 63/100\n8837/8844 [============================>.] - ETA: 0s - loss: 0.4196 - accuracy: 0.8026\nEpoch 00063: ReduceLROnPlateau reducing learning rate to 1e-05.\n8844/8844 [==============================] - 65s 7ms/step - loss: 0.4196 - accuracy: 0.8026 - val_loss: 0.4626 - val_accuracy: 0.7800\nEpoch 64/100\n8844/8844 [==============================] - 65s 7ms/step - loss: 0.4195 - accuracy: 0.8026 - val_loss: 0.4639 - val_accuracy: 0.7788\nEpoch 65/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4184 - accuracy: 0.8030 - val_loss: 0.4649 - val_accuracy: 0.7779\nEpoch 66/100\n8844/8844 [==============================] - 66s 7ms/step - loss: 0.4192 - accuracy: 0.8025 - val_loss: 0.4679 - val_accuracy: 0.7753\nEpoch 67/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4178 - accuracy: 0.8028 - val_loss: 0.4619 - val_accuracy: 0.7808\nEpoch 68/100\n8844/8844 [==============================] - 65s 7ms/step - loss: 0.4187 - accuracy: 0.8034 - val_loss: 0.4667 - val_accuracy: 0.7752\nEpoch 69/100\n8844/8844 [==============================] - 65s 7ms/step - loss: 0.4179 - accuracy: 0.8033 - val_loss: 0.4608 - val_accuracy: 0.7815\nEpoch 70/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4169 - accuracy: 0.8032 - val_loss: 0.4633 - val_accuracy: 0.7791\nEpoch 71/100\n8844/8844 [==============================] - 66s 7ms/step - loss: 0.4171 - accuracy: 0.8039 - val_loss: 0.4629 - val_accuracy: 0.7791\nEpoch 72/100\n8844/8844 [==============================] - 66s 7ms/step - loss: 0.4172 - accuracy: 0.8033 - val_loss: 0.4625 - val_accuracy: 0.7797\nEpoch 73/100\n8844/8844 [==============================] - 64s 7ms/step - loss: 0.4172 - accuracy: 0.8035 - val_loss: 0.4593 - val_accuracy: 0.7822\nEpoch 74/100\n8844/8844 [==============================] - 66s 7ms/step - loss: 0.4169 - accuracy: 0.8035 - val_loss: 0.4646 - val_accuracy: 0.7778\nEpoch 75/100\n8844/8844 [==============================] - 66s 7ms/step - loss: 0.4163 - accuracy: 0.8038 - val_loss: 0.4632 - val_accuracy: 0.7793\nEpoch 76/100\n8844/8844 [==============================] - 66s 7ms/step - loss: 0.4160 - accuracy: 0.8048 - val_loss: 0.4651 - val_accuracy: 0.7777\nEpoch 77/100\n8844/8844 [==============================] - 66s 7ms/step - loss: 0.4158 - accuracy: 0.8046 - val_loss: 0.4610 - val_accuracy: 0.7806\nEpoch 78/100\n8844/8844 [==============================] - 65s 7ms/step - loss: 0.4157 - accuracy: 0.8039 - val_loss: 0.4600 - val_accuracy: 0.7816\nEpoch 79/100\n8841/8844 [============================>.] - ETA: 0s - loss: 0.4148 - accuracy: 0.8051"
]
],
[
[
"# Model Prediction",
"_____no_output_____"
]
],
[
[
"Siamese2_Network_predictions = Siamese2_Network.predict([q1_val,q2_val])\n#Siamese2_Network_predictions = Siamese2_Network.predict([padded_docs_q1_test,padded_docs_q2_test])",
"_____no_output_____"
],
[
"#Siamese2_Network_predictions_testData = Siamese2_Network.predict([padded_docs_q1_test,padded_docs_q1_test])",
"_____no_output_____"
]
],
[
[
"# Log loss",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import log_loss\nlog_loss_val= log_loss(label_val,Siamese2_Network_predictions)\nlog_loss_val",
"_____no_output_____"
]
],
[
[
"# Classification report",
"_____no_output_____"
]
],
[
[
"predictions = np.zeros_like(Siamese2_Network_predictions)\npredictions[np.arange(len(Siamese2_Network_predictions)), Siamese2_Network_predictions.argmax(1)] = 1",
"_____no_output_____"
],
[
"predictionInteger=(np.argmax(predictions, axis=1))\n#print('np.argmax(a, axis=1): {0}'.format(np.argmax(predictions, axis=1)))\npredictionInteger",
"_____no_output_____"
],
[
"from sklearn.metrics import classification_report\nprint(classification_report(label_val,predictions))",
"_____no_output_____"
],
[
"from sklearn.metrics import precision_recall_fscore_support\nprint (\"Precision, Recall, F1_score : macro \",precision_recall_fscore_support(label_oneD_val,predictionInteger, average='macro'))\nprint (\"Precision, Recall, F1_score : micro \",precision_recall_fscore_support(label_oneD_val,predictionInteger, average='micro'))\nprint (\"Precision, Recall, F1_score : weighted \",precision_recall_fscore_support(label_oneD_val,predictionInteger, average='weighted'))",
"_____no_output_____"
]
],
[
[
"# Final train and val loss",
"_____no_output_____"
]
],
[
[
"min_val_loss = min(history.history[\"val_loss\"])\nmin_train_loss = min(history.history[\"loss\"])\nmax_val_acc = max(history.history[\"val_accuracy\"])\nmax_train_acc = max(history.history[\"accuracy\"])\nprint(\"min_train_loss=%g, min_val_loss=%g, max_train_acc=%g, max_val_acc=%g\" % (min_train_loss,min_val_loss,max_train_acc,max_val_acc))",
"_____no_output_____"
]
],
[
[
"# Plot epoch Vs loss",
"_____no_output_____"
]
],
[
[
"from matplotlib import pyplot as plt\nplt.plot(history.history[\"loss\"],color = 'red', label = 'train_loss')\nplt.plot(history.history[\"val_loss\"],color = 'blue', label = 'val_loss')\nplt.title('Loss Visualisation')\nplt.xlabel('Epochs')\nplt.ylabel('Loss')\nplt.legend()\nplt.savefig('2Layer_CNN_lossPlot_siamese.pdf',dpi=1000)\n\nfrom google.colab import files\nfiles.download('2Layer_CNN_lossPlot_siamese.pdf') ",
"_____no_output_____"
]
],
[
[
"# Plot Epoch Vs Accuracy",
"_____no_output_____"
]
],
[
[
"plt.plot(history.history[\"accuracy\"],color = 'red', label = 'train_accuracy')\nplt.plot(history.history[\"val_accuracy\"],color = 'blue', label = 'val_accuracy')\nplt.title('Accuracy Visualisation')\nplt.xlabel('Epochs')\nplt.ylabel('Accuracy')\nplt.legend()\nplt.savefig('2Layer_CNN_accuracyPlot_siamese.pdf',dpi=1000)\nfiles.download('2Layer_CNN_accuracyPlot_siamese.pdf') ",
"_____no_output_____"
]
],
[
[
"# Area Under Curve- ROC",
"_____no_output_____"
]
],
[
[
"#pred_test = Siamese2_Network.predict([padded_docs_q1_test,padded_docs_q2_test])\npred_train = Siamese2_Network.predict([q1_train,q2_train])\npred_val = Siamese2_Network.predict([q1_val,q2_val])",
"_____no_output_____"
],
[
"import numpy as np\nimport matplotlib.pyplot as plt\nfrom itertools import cycle\n\nfrom sklearn import svm, datasets\nfrom sklearn.metrics import roc_curve, auc\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.preprocessing import label_binarize\nfrom sklearn.multiclass import OneVsRestClassifier\nfrom scipy import interp\n\ndef plot_AUC_ROC(y_true, y_pred):\n n_classes = 2 #change this value according to class value\n\n # Compute ROC curve and ROC area for each class\n fpr = dict()\n tpr = dict()\n roc_auc = dict()\n for i in range(n_classes):\n fpr[i], tpr[i], _ = roc_curve(y_true[:, i], y_pred[:, i])\n roc_auc[i] = auc(fpr[i], tpr[i])\n\n # Compute micro-average ROC curve and ROC area\n fpr[\"micro\"], tpr[\"micro\"], _ = roc_curve(y_true.ravel(), y_pred.ravel())\n roc_auc[\"micro\"] = auc(fpr[\"micro\"], tpr[\"micro\"])\n############################################################################################\n lw = 2\n # Compute macro-average ROC curve and ROC area\n\n # First aggregate all false positive rates\n all_fpr = np.unique(np.concatenate([fpr[i] for i in range(n_classes)]))\n\n # Then interpolate all ROC curves at this points\n mean_tpr = np.zeros_like(all_fpr)\n for i in range(n_classes):\n mean_tpr += interp(all_fpr, fpr[i], tpr[i])\n\n # Finally average it and compute AUC\n mean_tpr /= n_classes\n\n fpr[\"macro\"] = all_fpr\n tpr[\"macro\"] = mean_tpr\n roc_auc[\"macro\"] = auc(fpr[\"macro\"], tpr[\"macro\"])\n\n # Plot all ROC curves\n plt.figure()\n \n plt.plot(fpr[\"micro\"], tpr[\"micro\"],\n label='micro-average ROC curve (area = {0:0.2f})'\n ''.format(roc_auc[\"micro\"]),\n color='deeppink', linestyle=':', linewidth=4)\n\n plt.plot(fpr[\"macro\"], tpr[\"macro\"],\n label='macro-average ROC curve (area = {0:0.2f})'\n ''.format(roc_auc[\"macro\"]),\n color='navy', linestyle=':', linewidth=4)\n \n colors = cycle(['aqua', 'darkorange'])\n #classes_list1 = [\"DE\",\"NE\",\"DK\"]\n classes_list1 = [\"Non-duplicate\",\"Duplicate\"]\n for i, color,c in zip(range(n_classes), colors,classes_list1):\n plt.plot(fpr[i], tpr[i], color=color, lw=lw,\n label='{0} (AUC = {1:0.2f})'\n ''.format(c, roc_auc[i]))\n\n plt.plot([0, 1], [0, 1], 'k--', lw=lw)\n plt.xlim([0.0, 1.0])\n plt.ylim([0.0, 1.05])\n plt.xlabel('False Positive Rate')\n plt.ylabel('True Positive Rate')\n plt.title('Receiver operating characteristic curve')\n plt.legend(loc=\"lower right\")\n #plt.show()\n plt.savefig('2Layer_CNN_RocPlot_siamese.pdf',dpi=1000)\n files.download('2Layer_CNN_RocPlot_siamese.pdf')\n\n # Plot of a ROC curve for a specific class\n '''\n plt.figure()\n lw = 2\n plt.plot(fpr[0], tpr[0], color='darkorange',\n lw=lw, label='ROC curve (area = %0.2f)' % roc_auc[0])\n plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')\n plt.xlim([0.0, 1.0])\n plt.ylim([0.0, 1.05])\n plt.xlabel('False Positive Rate')\n plt.ylabel('True Positive Rate')\n plt.title('Receiver operating characteristic example')\n plt.legend(loc=\"lower right\")\n plt.show()\n '''",
"_____no_output_____"
],
[
"plot_AUC_ROC(label_val,pred_val)",
"_____no_output_____"
],
[
"from sklearn.metrics import roc_auc_score, roc_curve, accuracy_score",
"_____no_output_____"
],
[
"auc_val = roc_auc_score(label_val,pred_val)\naccuracy_val = accuracy_score(label_val,pred_val>0.5)\nauc_train = roc_auc_score(label_train,pred_train)\naccuracy_train = accuracy_score(label_train,pred_train>0.5)\n\nprint(\"auc_train=%g, auc_val=%g, accuracy_train=%g, accuracy_val=%g\" % (auc_train, auc_val, accuracy_train, accuracy_val))",
"_____no_output_____"
],
[
"'''\nfpr_train, tpr_train, thresholds_train = roc_curve(label_train,pred_train)\nfpr_test, tpr_test, thresholds_test = roc_curve(label_val,pred_val)\n\n#fpr_train, tpr_train, thresholds_train = roc_curve(label_oneD_train,pred_train_final)\n#fpr_test, tpr_test, thresholds_test = roc_curve(label_oneD_val,pred_val_final)\n\nplt.plot(fpr_train,tpr_train, color=\"blue\", label=\"train roc, auc=%g\" % (auc_train,))\nplt.plot(fpr_test,tpr_test, color=\"green\", label=\"val roc, auc=%g\" % (auc_val,))\n\nplt.plot([0,1], [0,1], color='orange', linestyle='--')\n\nplt.xticks(np.arange(0.0, 1.1, step=0.1))\nplt.xlabel(\"Flase Positive Rate\", fontsize=15)\n\nplt.yticks(np.arange(0.0, 1.1, step=0.1))\nplt.ylabel(\"True Positive Rate\", fontsize=15)\n\nplt.title('ROC Curve Analysis', fontweight='bold', fontsize=15)\nplt.legend(prop={'size':13}, loc='lower right')\nplt.savefig('AUC_CURVE_cnn4.pdf',dpi=1000)\n#files.download('AUC_CURVE_cnn4.pdf')\n'''",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0f78c1a29f50664c057f0b2de05a2f4f07e1eb2 | 55,804 | ipynb | Jupyter Notebook | ml-clustering-and-retrieval/week-6/6_hierarchical_clustering_blank.ipynb | zomansud/coursera | 8b63eda4194241edc0c493fb74ca6834c9d0792d | [
"MIT"
] | null | null | null | ml-clustering-and-retrieval/week-6/6_hierarchical_clustering_blank.ipynb | zomansud/coursera | 8b63eda4194241edc0c493fb74ca6834c9d0792d | [
"MIT"
] | null | null | null | ml-clustering-and-retrieval/week-6/6_hierarchical_clustering_blank.ipynb | zomansud/coursera | 8b63eda4194241edc0c493fb74ca6834c9d0792d | [
"MIT"
] | 1 | 2021-08-10T20:05:24.000Z | 2021-08-10T20:05:24.000Z | 45.967051 | 629 | 0.567002 | [
[
[
"# Hierarchical Clustering",
"_____no_output_____"
],
[
"**Hierarchical clustering** refers to a class of clustering methods that seek to build a **hierarchy** of clusters, in which some clusters contain others. In this assignment, we will explore a top-down approach, recursively bipartitioning the data using k-means.",
"_____no_output_____"
],
[
"**Note to Amazon EC2 users**: To conserve memory, make sure to stop all the other notebooks before running this notebook.",
"_____no_output_____"
],
[
"## Import packages",
"_____no_output_____"
],
[
"The following code block will check if you have the correct version of GraphLab Create. Any version later than 1.8.5 will do. To upgrade, read [this page](https://turi.com/download/upgrade-graphlab-create.html).",
"_____no_output_____"
]
],
[
[
"import graphlab\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport sys\nimport os\nimport time\nfrom scipy.sparse import csr_matrix\nfrom sklearn.cluster import KMeans\nfrom sklearn.metrics import pairwise_distances\n%matplotlib inline\n\n'''Check GraphLab Create version'''\nfrom distutils.version import StrictVersion\nassert (StrictVersion(graphlab.version) >= StrictVersion('1.8.5')), 'GraphLab Create must be version 1.8.5 or later.'",
"This non-commercial license of GraphLab Create for academic use is assigned to [email protected] and will expire on September 18, 2017.\n"
]
],
[
[
"## Load the Wikipedia dataset",
"_____no_output_____"
]
],
[
[
"wiki = graphlab.SFrame('people_wiki.gl/')",
"_____no_output_____"
]
],
[
[
"As we did in previous assignments, let's extract the TF-IDF features:",
"_____no_output_____"
]
],
[
[
"wiki['tf_idf'] = graphlab.text_analytics.tf_idf(wiki['text'])",
"_____no_output_____"
]
],
[
[
"To run k-means on this dataset, we should convert the data matrix into a sparse matrix.",
"_____no_output_____"
]
],
[
[
"from em_utilities import sframe_to_scipy # converter\n\n# This will take about a minute or two.\ntf_idf, map_index_to_word = sframe_to_scipy(wiki, 'tf_idf')",
"_____no_output_____"
]
],
[
[
"To be consistent with the k-means assignment, let's normalize all vectors to have unit norm.",
"_____no_output_____"
]
],
[
[
"from sklearn.preprocessing import normalize\ntf_idf = normalize(tf_idf)",
"_____no_output_____"
]
],
[
[
"## Bipartition the Wikipedia dataset using k-means",
"_____no_output_____"
],
[
"Recall our workflow for clustering text data with k-means:\n\n1. Load the dataframe containing a dataset, such as the Wikipedia text dataset.\n2. Extract the data matrix from the dataframe.\n3. Run k-means on the data matrix with some value of k.\n4. Visualize the clustering results using the centroids, cluster assignments, and the original dataframe. We keep the original dataframe around because the data matrix does not keep auxiliary information (in the case of the text dataset, the title of each article).\n\nLet us modify the workflow to perform bipartitioning:\n\n1. Load the dataframe containing a dataset, such as the Wikipedia text dataset.\n2. Extract the data matrix from the dataframe.\n3. Run k-means on the data matrix with k=2.\n4. Divide the data matrix into two parts using the cluster assignments.\n5. Divide the dataframe into two parts, again using the cluster assignments. This step is necessary to allow for visualization.\n6. Visualize the bipartition of data.\n\nWe'd like to be able to repeat Steps 3-6 multiple times to produce a **hierarchy** of clusters such as the following:\n```\n (root)\n |\n +------------+-------------+\n | |\n Cluster Cluster\n +------+-----+ +------+-----+\n | | | |\n Cluster Cluster Cluster Cluster\n```\nEach **parent cluster** is bipartitioned to produce two **child clusters**. At the very top is the **root cluster**, which consists of the entire dataset.\n\nNow we write a wrapper function to bipartition a given cluster using k-means. There are three variables that together comprise the cluster:\n\n* `dataframe`: a subset of the original dataframe that correspond to member rows of the cluster\n* `matrix`: same set of rows, stored in sparse matrix format\n* `centroid`: the centroid of the cluster (not applicable for the root cluster)\n\nRather than passing around the three variables separately, we package them into a Python dictionary. The wrapper function takes a single dictionary (representing a parent cluster) and returns two dictionaries (representing the child clusters).",
"_____no_output_____"
]
],
[
[
"def bipartition(cluster, maxiter=400, num_runs=4, seed=None):\n '''cluster: should be a dictionary containing the following keys\n * dataframe: original dataframe\n * matrix: same data, in matrix format\n * centroid: centroid for this particular cluster'''\n \n data_matrix = cluster['matrix']\n dataframe = cluster['dataframe']\n \n # Run k-means on the data matrix with k=2. We use scikit-learn here to simplify workflow.\n kmeans_model = KMeans(n_clusters=2, max_iter=maxiter, n_init=num_runs, random_state=seed, n_jobs=1)\n kmeans_model.fit(data_matrix)\n centroids, cluster_assignment = kmeans_model.cluster_centers_, kmeans_model.labels_\n \n # Divide the data matrix into two parts using the cluster assignments.\n data_matrix_left_child, data_matrix_right_child = data_matrix[cluster_assignment==0], \\\n data_matrix[cluster_assignment==1]\n \n # Divide the dataframe into two parts, again using the cluster assignments.\n cluster_assignment_sa = graphlab.SArray(cluster_assignment) # minor format conversion\n dataframe_left_child, dataframe_right_child = dataframe[cluster_assignment_sa==0], \\\n dataframe[cluster_assignment_sa==1]\n \n \n # Package relevant variables for the child clusters\n cluster_left_child = {'matrix': data_matrix_left_child,\n 'dataframe': dataframe_left_child,\n 'centroid': centroids[0]}\n cluster_right_child = {'matrix': data_matrix_right_child,\n 'dataframe': dataframe_right_child,\n 'centroid': centroids[1]}\n \n return (cluster_left_child, cluster_right_child)",
"_____no_output_____"
]
],
[
[
"The following cell performs bipartitioning of the Wikipedia dataset. Allow 20-60 seconds to finish.\n\nNote. For the purpose of the assignment, we set an explicit seed (`seed=1`) to produce identical outputs for every run. In pratical applications, you might want to use different random seeds for all runs.",
"_____no_output_____"
]
],
[
[
"wiki_data = {'matrix': tf_idf, 'dataframe': wiki} # no 'centroid' for the root cluster\nleft_child, right_child = bipartition(wiki_data, maxiter=100, num_runs=6, seed=1)",
"_____no_output_____"
]
],
[
[
"Let's examine the contents of one of the two clusters, which we call the `left_child`, referring to the tree visualization above.",
"_____no_output_____"
]
],
[
[
"left_child",
"_____no_output_____"
]
],
[
[
"And here is the content of the other cluster we named `right_child`.",
"_____no_output_____"
]
],
[
[
"right_child",
"_____no_output_____"
]
],
[
[
"## Visualize the bipartition",
"_____no_output_____"
],
[
"We provide you with a modified version of the visualization function from the k-means assignment. For each cluster, we print the top 5 words with highest TF-IDF weights in the centroid and display excerpts for the 8 nearest neighbors of the centroid.",
"_____no_output_____"
]
],
[
[
"def display_single_tf_idf_cluster(cluster, map_index_to_word):\n '''map_index_to_word: SFrame specifying the mapping betweeen words and column indices'''\n \n wiki_subset = cluster['dataframe']\n tf_idf_subset = cluster['matrix']\n centroid = cluster['centroid']\n \n # Print top 5 words with largest TF-IDF weights in the cluster\n idx = centroid.argsort()[::-1]\n for i in xrange(5):\n print('{0:s}:{1:.3f}'.format(map_index_to_word['category'][idx[i]], centroid[idx[i]])),\n print('')\n \n # Compute distances from the centroid to all data points in the cluster.\n distances = pairwise_distances(tf_idf_subset, [centroid], metric='euclidean').flatten()\n # compute nearest neighbors of the centroid within the cluster.\n nearest_neighbors = distances.argsort()\n # For 8 nearest neighbors, print the title as well as first 180 characters of text.\n # Wrap the text at 80-character mark.\n for i in xrange(8):\n text = ' '.join(wiki_subset[nearest_neighbors[i]]['text'].split(None, 25)[0:25])\n print('* {0:50s} {1:.5f}\\n {2:s}\\n {3:s}'.format(wiki_subset[nearest_neighbors[i]]['name'],\n distances[nearest_neighbors[i]], text[:90], text[90:180] if len(text) > 90 else ''))\n print('')",
"_____no_output_____"
]
],
[
[
"Let's visualize the two child clusters:",
"_____no_output_____"
]
],
[
[
"display_single_tf_idf_cluster(left_child, map_index_to_word)",
"league:0.040 season:0.036 team:0.029 football:0.029 played:0.028 \n* Todd Williams 0.95468\n todd michael williams born february 13 1971 in syracuse new york is a former major league \n baseball relief pitcher he attended east syracuseminoa high school\n* Gord Sherven 0.95622\n gordon r sherven born august 21 1963 in gravelbourg saskatchewan and raised in mankota sas\n katchewan is a retired canadian professional ice hockey forward who played\n* Justin Knoedler 0.95639\n justin joseph knoedler born july 17 1980 in springfield illinois is a former major league \n baseball catcherknoedler was originally drafted by the st louis cardinals\n* Chris Day 0.95648\n christopher nicholas chris day born 28 july 1975 is an english professional footballer who\n plays as a goalkeeper for stevenageday started his career at tottenham\n* Tony Smith (footballer, born 1957) 0.95653\n anthony tony smith born 20 february 1957 is a former footballer who played as a central de\n fender in the football league in the 1970s and\n* Ashley Prescott 0.95761\n ashley prescott born 11 september 1972 is a former australian rules footballer he played w\n ith the richmond and fremantle football clubs in the afl between\n* Leslie Lea 0.95802\n leslie lea born 5 october 1942 in manchester is an english former professional footballer \n he played as a midfielderlea began his professional career with blackpool\n* Tommy Anderson (footballer) 0.95818\n thomas cowan tommy anderson born 24 september 1934 in haddington is a scottish former prof\n essional footballer he played as a forward and was noted for\n\n"
],
[
"display_single_tf_idf_cluster(right_child, map_index_to_word)",
"she:0.025 her:0.017 music:0.012 he:0.011 university:0.011 \n* Anita Kunz 0.97401\n anita e kunz oc born 1956 is a canadianborn artist and illustratorkunz has lived in london\n new york and toronto contributing to magazines and working\n* Janet Jackson 0.97472\n janet damita jo jackson born may 16 1966 is an american singer songwriter and actress know\n n for a series of sonically innovative socially conscious and\n* Madonna (entertainer) 0.97475\n madonna louise ciccone tkoni born august 16 1958 is an american singer songwriter actress \n and businesswoman she achieved popularity by pushing the boundaries of lyrical\n* %C3%81ine Hyland 0.97536\n ine hyland ne donlon is emeritus professor of education and former vicepresident of univer\n sity college cork ireland she was born in 1942 in athboy co\n* Jane Fonda 0.97621\n jane fonda born lady jayne seymour fonda december 21 1937 is an american actress writer po\n litical activist former fashion model and fitness guru she is\n* Christine Robertson 0.97643\n christine mary robertson born 5 october 1948 is an australian politician and former austra\n lian labor party member of the new south wales legislative council serving\n* Pat Studdy-Clift 0.97643\n pat studdyclift is an australian author specialising in historical fiction and nonfictionb\n orn in 1925 she lived in gunnedah until she was sent to a boarding\n* Alexandra Potter 0.97646\n alexandra potter born 1970 is a british author of romantic comediesborn in bradford yorksh\n ire england and educated at liverpool university gaining an honors degree in\n\n"
]
],
[
[
"The left cluster consists of athletes, whereas the right cluster consists of non-athletes. So far, we have a single-level hierarchy consisting of two clusters, as follows:",
"_____no_output_____"
],
[
"```\n Wikipedia\n +\n |\n +--------------------------+--------------------+\n | |\n + +\n Athletes Non-athletes\n```",
"_____no_output_____"
],
[
"Is this hierarchy good enough? **When building a hierarchy of clusters, we must keep our particular application in mind.** For instance, we might want to build a **directory** for Wikipedia articles. A good directory would let you quickly narrow down your search to a small set of related articles. The categories of athletes and non-athletes are too general to facilitate efficient search. For this reason, we decide to build another level into our hierarchy of clusters with the goal of getting more specific cluster structure at the lower level. To that end, we subdivide both the `athletes` and `non-athletes` clusters.",
"_____no_output_____"
],
[
"## Perform recursive bipartitioning",
"_____no_output_____"
],
[
"### Cluster of athletes",
"_____no_output_____"
],
[
"To help identify the clusters we've built so far, let's give them easy-to-read aliases:",
"_____no_output_____"
]
],
[
[
"athletes = left_child\nnon_athletes = right_child",
"_____no_output_____"
]
],
[
[
"Using the bipartition function, we produce two child clusters of the athlete cluster:",
"_____no_output_____"
]
],
[
[
"# Bipartition the cluster of athletes\nleft_child_athletes, right_child_athletes = bipartition(athletes, maxiter=100, num_runs=6, seed=1)",
"_____no_output_____"
]
],
[
[
"The left child cluster mainly consists of baseball players:",
"_____no_output_____"
]
],
[
[
"display_single_tf_idf_cluster(left_child_athletes, map_index_to_word)",
"baseball:0.111 league:0.103 major:0.051 games:0.046 season:0.045 \n* Steve Springer 0.89344\n steven michael springer born february 11 1961 is an american former professional baseball \n player who appeared in major league baseball as a third baseman and\n* Dave Ford 0.89598\n david alan ford born december 29 1956 is a former major league baseball pitcher for the ba\n ltimore orioles born in cleveland ohio ford attended lincolnwest\n* Todd Williams 0.89823\n todd michael williams born february 13 1971 in syracuse new york is a former major league \n baseball relief pitcher he attended east syracuseminoa high school\n* Justin Knoedler 0.90097\n justin joseph knoedler born july 17 1980 in springfield illinois is a former major league \n baseball catcherknoedler was originally drafted by the st louis cardinals\n* Kevin Nicholson (baseball) 0.90607\n kevin ronald nicholson born march 29 1976 is a canadian baseball shortstop he played part \n of the 2000 season for the san diego padres of\n* Joe Strong 0.90638\n joseph benjamin strong born september 9 1962 in fairfield california is a former major lea\n gue baseball pitcher who played for the florida marlins from 2000\n* James Baldwin (baseball) 0.90674\n james j baldwin jr born july 15 1971 is a former major league baseball pitcher he batted a\n nd threw righthanded in his 11season career he\n* James Garcia 0.90729\n james robert garcia born february 3 1980 is an american former professional baseball pitch\n er who played in the san francisco giants minor league system as\n\n"
]
],
[
[
"On the other hand, the right child cluster is a mix of players in association football, Austrailian rules football and ice hockey:",
"_____no_output_____"
]
],
[
[
"display_single_tf_idf_cluster(right_child_athletes, map_index_to_word)",
"season:0.034 football:0.033 team:0.031 league:0.029 played:0.027 \n* Gord Sherven 0.95562\n gordon r sherven born august 21 1963 in gravelbourg saskatchewan and raised in mankota sas\n katchewan is a retired canadian professional ice hockey forward who played\n* Ashley Prescott 0.95656\n ashley prescott born 11 september 1972 is a former australian rules footballer he played w\n ith the richmond and fremantle football clubs in the afl between\n* Chris Day 0.95656\n christopher nicholas chris day born 28 july 1975 is an english professional footballer who\n plays as a goalkeeper for stevenageday started his career at tottenham\n* Jason Roberts (footballer) 0.95658\n jason andre davis roberts mbe born 25 january 1978 is a former professional footballer and\n now a football punditborn in park royal london roberts was\n* Todd Curley 0.95743\n todd curley born 14 january 1973 is a former australian rules footballer who played for co\n llingwood and the western bulldogs in the australian football league\n* Tony Smith (footballer, born 1957) 0.95801\n anthony tony smith born 20 february 1957 is a former footballer who played as a central de\n fender in the football league in the 1970s and\n* Sol Campbell 0.95802\n sulzeer jeremiah sol campbell born 18 september 1974 is a former england international foo\n tballer a central defender he had a 19year career playing in the\n* Richard Ambrose 0.95924\n richard ambrose born 10 june 1972 is a former australian rules footballer who played with \n the sydney swans in the australian football league afl he\n\n"
]
],
[
[
"Our hierarchy of clusters now looks like this:\n```\n Wikipedia\n +\n |\n +--------------------------+--------------------+\n | |\n + +\n Athletes Non-athletes\n +\n |\n +-----------+--------+\n | |\n | association football/\n + Austrailian rules football/\n baseball ice hockey\n```",
"_____no_output_____"
],
[
"Should we keep subdividing the clusters? If so, which cluster should we subdivide? To answer this question, we again think about our application. Since we organize our directory by topics, it would be nice to have topics that are about as coarse as each other. For instance, if one cluster is about baseball, we expect some other clusters about football, basketball, volleyball, and so forth. That is, **we would like to achieve similar level of granularity for all clusters.**\n\nNotice that the right child cluster is more coarse than the left child cluster. The right cluster posseses a greater variety of topics than the left (ice hockey/association football/Austrialian football vs. baseball). So the right child cluster should be subdivided further to produce finer child clusters.",
"_____no_output_____"
],
[
"Let's give the clusters aliases as well:",
"_____no_output_____"
]
],
[
[
"baseball = left_child_athletes\nice_hockey_football = right_child_athletes",
"_____no_output_____"
]
],
[
[
"### Cluster of ice hockey players and football players",
"_____no_output_____"
],
[
"In answering the following quiz question, take a look at the topics represented in the top documents (those closest to the centroid), as well as the list of words with highest TF-IDF weights.\n\nLet us bipartition the cluster of ice hockey and football players.",
"_____no_output_____"
]
],
[
[
"left_child_ihs, right_child_ihs = bipartition(ice_hockey_football, maxiter=100, num_runs=6, seed=1)\ndisplay_single_tf_idf_cluster(left_child_ihs, map_index_to_word)\ndisplay_single_tf_idf_cluster(right_child_ihs, map_index_to_word)",
"football:0.048 season:0.043 league:0.041 played:0.036 coach:0.034 \n* Todd Curley 0.94578\n todd curley born 14 january 1973 is a former australian rules footballer who played for co\n llingwood and the western bulldogs in the australian football league\n* Tony Smith (footballer, born 1957) 0.94606\n anthony tony smith born 20 february 1957 is a former footballer who played as a central de\n fender in the football league in the 1970s and\n* Chris Day 0.94623\n christopher nicholas chris day born 28 july 1975 is an english professional footballer who\n plays as a goalkeeper for stevenageday started his career at tottenham\n* Ashley Prescott 0.94632\n ashley prescott born 11 september 1972 is a former australian rules footballer he played w\n ith the richmond and fremantle football clubs in the afl between\n* Jason Roberts (footballer) 0.94633\n jason andre davis roberts mbe born 25 january 1978 is a former professional footballer and\n now a football punditborn in park royal london roberts was\n* David Hamilton (footballer) 0.94925\n david hamilton born 7 november 1960 is an english former professional association football\n player who played as a midfielder he won caps for the england\n* Richard Ambrose 0.94941\n richard ambrose born 10 june 1972 is a former australian rules footballer who played with \n the sydney swans in the australian football league afl he\n* Neil Grayson 0.94958\n neil grayson born 1 november 1964 in york is an english footballer who last played as a st\n riker for sutton towngraysons first club was local\n\nchampionships:0.045 tour:0.043 championship:0.035 world:0.031 won:0.031 \n* Alessandra Aguilar 0.93856\n alessandra aguilar born 1 july 1978 in lugo is a spanish longdistance runner who specialis\n es in marathon running she represented her country in the event\n* Heather Samuel 0.93973\n heather barbara samuel born 6 july 1970 is a retired sprinter from antigua and barbuda who\n specialized in the 100 and 200 metres in 1990\n* Viola Kibiwot 0.94015\n viola jelagat kibiwot born december 22 1983 in keiyo district is a runner from kenya who s\n pecialises in the 1500 metres kibiwot won her first\n* Ayelech Worku 0.94031\n ayelech worku born june 12 1979 is an ethiopian longdistance runner most known for winning\n two world championships bronze medals on the 5000 metres she\n* Krisztina Papp 0.94077\n krisztina papp born 17 december 1982 in eger is a hungarian long distance runner she is th\n e national indoor record holder over 5000 mpapp began\n* Petra Lammert 0.94215\n petra lammert born 3 march 1984 in freudenstadt badenwrttemberg is a former german shot pu\n tter and current bobsledder she was the 2009 european indoor champion\n* Morhad Amdouni 0.94217\n morhad amdouni born 21 january 1988 in portovecchio is a french middle and longdistance ru\n nner he was european junior champion in track and cross country\n* Brian Davis (golfer) 0.94369\n brian lester davis born 2 august 1974 is an english professional golferdavis was born in l\n ondon he turned professional in 1994 and became a member\n\n"
]
],
[
[
"**Quiz Question**. Which diagram best describes the hierarchy right after splitting the `ice_hockey_football` cluster? Refer to the quiz form for the diagrams.",
"_____no_output_____"
],
[
"**Caution**. The granularity criteria is an imperfect heuristic and must be taken with a grain of salt. It takes a lot of manual intervention to obtain a good hierarchy of clusters.\n\n* **If a cluster is highly mixed, the top articles and words may not convey the full picture of the cluster.** Thus, we may be misled if we judge the purity of clusters solely by their top documents and words. \n* **Many interesting topics are hidden somewhere inside the clusters but do not appear in the visualization.** We may need to subdivide further to discover new topics. For instance, subdividing the `ice_hockey_football` cluster led to the appearance of runners and golfers.",
"_____no_output_____"
],
[
"### Cluster of non-athletes",
"_____no_output_____"
],
[
"Now let us subdivide the cluster of non-athletes.",
"_____no_output_____"
]
],
[
[
"# Bipartition the cluster of non-athletes\nleft_child_non_athletes, right_child_non_athletes = bipartition(non_athletes, maxiter=100, num_runs=6, seed=1)",
"_____no_output_____"
],
[
"display_single_tf_idf_cluster(left_child_non_athletes, map_index_to_word)",
"he:0.013 music:0.012 university:0.011 film:0.010 his:0.009 \n* Wilson McLean 0.97870\n wilson mclean born 1937 is a scottish illustrator and artist he has illustrated primarily \n in the field of advertising but has also provided cover art\n* Julian Knowles 0.97938\n julian knowles is an australian composer and performer specialising in new and emerging te\n chnologies his creative work spans the fields of composition for theatre dance\n* James A. Joseph 0.98042\n james a joseph born 1935 is an american former diplomatjoseph is professor of the practice\n of public policy studies at duke university and founder of\n* Barry Sullivan (lawyer) 0.98054\n barry sullivan is a chicago lawyer and as of july 1 2009 the cooney conway chair in advoca\n cy at loyola university chicago school of law\n* Archie Brown 0.98081\n archibald haworth brown cmg fba commonly known as archie brown born 10 may 1938 is a briti\n sh political scientist and historian in 2005 he became\n* Michael Joseph Smith 0.98124\n michael joseph smith is an american jazz and american classical composer and pianist born \n in tiline kentucky he has worked extensively in europe and asia\n* Craig Pruess 0.98125\n craig pruess born 1950 is an american composer musician arranger and gold platinum record \n producer who has been living in britain since 1973 his career\n* David J. Elliott 0.98128\n david elliott is professor of music and music education at new york universityelliott was \n educated at the university of toronto bmus m mus and bed\n\n"
],
[
"display_single_tf_idf_cluster(right_child_non_athletes, map_index_to_word)",
"she:0.126 her:0.082 film:0.013 actress:0.012 music:0.012 \n* Janet Jackson 0.93808\n janet damita jo jackson born may 16 1966 is an american singer songwriter and actress know\n n for a series of sonically innovative socially conscious and\n* Lauren Royal 0.93867\n lauren royal born march 3 circa 1965 is a book writer from california royal has written bo\n th historic and novelistic booksa selfproclaimed angels baseball fan\n* Barbara Hershey 0.93941\n barbara hershey born barbara lynn herzstein february 5 1948 once known as barbara seagull \n is an american actress in a career spanning nearly 50 years\n* Jane Fonda 0.94102\n jane fonda born lady jayne seymour fonda december 21 1937 is an american actress writer po\n litical activist former fashion model and fitness guru she is\n* Alexandra Potter 0.94190\n alexandra potter born 1970 is a british author of romantic comediesborn in bradford yorksh\n ire england and educated at liverpool university gaining an honors degree in\n* Janine Shepherd 0.94219\n janine lee shepherd am born 1962 is an australian pilot and former crosscountry skier shep\n herds career as an athlete ended when she suffered major injuries\n* Cher 0.94231\n cher r born cherilyn sarkisian may 20 1946 is an american singer actress and television ho\n st described as embodying female autonomy in a maledominated industry\n* Ellina Graypel 0.94233\n ellina graypel born july 19 1972 is an awardwinning russian singersongwriter she was born \n near the volga river in the heart of russia she spent\n\n"
]
],
[
[
"Neither of the clusters show clear topics, apart from the genders. Let us divide them further.",
"_____no_output_____"
]
],
[
[
"male_non_athletes = left_child_non_athletes\nfemale_non_athletes = right_child_non_athletes",
"_____no_output_____"
]
],
[
[
"**Quiz Question**. Let us bipartition the clusters `male_non_athletes` and `female_non_athletes`. Which diagram best describes the resulting hierarchy of clusters for the non-athletes? Refer to the quiz for the diagrams.\n\n**Note**. Use `maxiter=100, num_runs=6, seed=1` for consistency of output.",
"_____no_output_____"
]
],
[
[
"# Bipartition the cluster of males\nleft_child_males, right_child_males = bipartition(male_non_athletes, maxiter=100, num_runs=6, seed=1)\ndisplay_single_tf_idf_cluster(left_child_males, map_index_to_word)\ndisplay_single_tf_idf_cluster(right_child_males, map_index_to_word)",
"university:0.017 he:0.015 law:0.013 served:0.013 research:0.013 \n* Barry Sullivan (lawyer) 0.97075\n barry sullivan is a chicago lawyer and as of july 1 2009 the cooney conway chair in advoca\n cy at loyola university chicago school of law\n* James A. Joseph 0.97344\n james a joseph born 1935 is an american former diplomatjoseph is professor of the practice\n of public policy studies at duke university and founder of\n* David Anderson (British Columbia politician) 0.97383\n david a anderson pc oc born august 16 1937 in victoria british columbia is a former canadi\n an cabinet minister educated at victoria college in victoria\n* Sven Erik Holmes 0.97469\n sven erik holmes is a former federal judge and currently the vice chairman legal risk and \n regulatory and chief legal officer for kpmg llp a\n* Andrew Fois 0.97558\n andrew fois is an attorney living and working in washington dc as of april 9 2012 he will \n be serving as the deputy attorney general\n* William Robert Graham 0.97564\n william robert graham born june 15 1937 was chairman of president reagans general advisory\n committee on arms control from 1982 to 1985 a deputy administrator\n* John C. Eastman 0.97585\n john c eastman born april 21 1960 is a conservative american law professor and constitutio\n nal law scholar he is the henry salvatori professor of law\n* M. Cherif Bassiouni 0.97587\n mahmoud cherif bassiouni was born in cairo egypt in 1937 and immigrated to the united stat\n es in 1962 he is emeritus professor of law at\n\nmusic:0.023 film:0.020 album:0.014 band:0.014 art:0.013 \n* Julian Knowles 0.97192\n julian knowles is an australian composer and performer specialising in new and emerging te\n chnologies his creative work spans the fields of composition for theatre dance\n* Peter Combe 0.97292\n peter combe born 20 october 1948 is an australian childrens entertainer and musicianmusica\n l genre childrens musiche has had 22 releases including seven gold albums two\n* Craig Pruess 0.97346\n craig pruess born 1950 is an american composer musician arranger and gold platinum record \n producer who has been living in britain since 1973 his career\n* Ceiri Torjussen 0.97420\n ceiri torjussen born 1976 is a composer who has contributed music to dozens of film and te\n levision productions in the ushis music was described by\n* Wilson McLean 0.97455\n wilson mclean born 1937 is a scottish illustrator and artist he has illustrated primarily \n in the field of advertising but has also provided cover art\n* Brenton Broadstock 0.97471\n brenton broadstock ao born 1952 is an australian composerbroadstock was born in melbourne \n he studied history politics and music at monash university and later composition\n* Michael Peter Smith 0.97499\n michael peter smith born september 7 1941 is a chicagobased singersongwriter rolling stone\n magazine once called him the greatest songwriter in the english language he\n* Third Hawkins 0.97553\n born maurice hawkins third hawkins is a recognized music producer in and out of the dmv ar\n ea including his hometown of baltimore maryland he has\n\n"
],
[
"# Bipartition the cluster of females\nleft_child_female, right_child_female = bipartition(female_non_athletes, maxiter=100, num_runs=6, seed=1)\ndisplay_single_tf_idf_cluster(left_child_female, map_index_to_word)\ndisplay_single_tf_idf_cluster(right_child_female, map_index_to_word)",
"she:0.121 her:0.100 actress:0.031 film:0.030 music:0.028 \n* Janet Jackson 0.92374\n janet damita jo jackson born may 16 1966 is an american singer songwriter and actress know\n n for a series of sonically innovative socially conscious and\n* Barbara Hershey 0.92524\n barbara hershey born barbara lynn herzstein february 5 1948 once known as barbara seagull \n is an american actress in a career spanning nearly 50 years\n* Madonna (entertainer) 0.92753\n madonna louise ciccone tkoni born august 16 1958 is an american singer songwriter actress \n and businesswoman she achieved popularity by pushing the boundaries of lyrical\n* Cher 0.92909\n cher r born cherilyn sarkisian may 20 1946 is an american singer actress and television ho\n st described as embodying female autonomy in a maledominated industry\n* Candice Bergen 0.93266\n candice patricia bergen born may 9 1946 is an american actress and former fashion model fo\n r her role as the title character on the cbs\n* Glenn Close 0.93426\n glenn close born march 19 1947 is an american film television and stage actress throughout\n her long and varied career she has been consistently acclaimed\n* Jane Fonda 0.93515\n jane fonda born lady jayne seymour fonda december 21 1937 is an american actress writer po\n litical activist former fashion model and fitness guru she is\n* Judi Dench 0.93624\n dame judith olivia dench ch dbe frsa born 9 december 1934 is an english actress and author\n dench made her professional debut in 1957 with\n\nshe:0.130 her:0.072 women:0.014 miss:0.014 university:0.013 \n* Lauren Royal 0.93939\n lauren royal born march 3 circa 1965 is a book writer from california royal has written bo\n th historic and novelistic booksa selfproclaimed angels baseball fan\n* %C3%81ine Hyland 0.93940\n ine hyland ne donlon is emeritus professor of education and former vicepresident of univer\n sity college cork ireland she was born in 1942 in athboy co\n* Dorothy E. Smith 0.94113\n dorothy edith smithborn july 6 1926 is a canadian sociologist with research interests besi\n des in sociology in many disciplines including womens studies psychology and educational\n* Kayee Griffin 0.94162\n kayee frances griffin born 6 february 1950 is an australian politician and former australi\n an labor party member of the new south wales legislative council serving\n* Janine Shepherd 0.94252\n janine lee shepherd am born 1962 is an australian pilot and former crosscountry skier shep\n herds career as an athlete ended when she suffered major injuries\n* Bhama Srinivasan 0.94281\n bhama srinivasan april 22 1935 is a mathematician known for her work in the representation\n theory of finite groups her contributions were honored with the\n* Ellen Christine Christiansen 0.94395\n ellen christine christiansen born 10 december 1964 is a norwegian politician representing \n the conservative party and formerly the progress partyborn in oslo she finished her\n* Elvira Vinogradova 0.94420\n elvira vinogradova russian born june 16 1934 is a russian tv editorelvira belenina russian\n was born in 1934 in fergana ussr she went to school\n\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
d0f7a4ef5743392b45066cf47d995a4743d72e78 | 15,961 | ipynb | Jupyter Notebook | data-visualization/plotly/3_exercises.ipynb | pbgnz/ds-ml | 45cb4756e20aa5f4e4077437faee18633ca9a0e5 | [
"MIT"
] | null | null | null | data-visualization/plotly/3_exercises.ipynb | pbgnz/ds-ml | 45cb4756e20aa5f4e4077437faee18633ca9a0e5 | [
"MIT"
] | null | null | null | data-visualization/plotly/3_exercises.ipynb | pbgnz/ds-ml | 45cb4756e20aa5f4e4077437faee18633ca9a0e5 | [
"MIT"
] | null | null | null | 30.459924 | 238 | 0.395276 | [
[
[
"# Choropleth Maps Exercise\n\nWelcome to the Choropleth Maps Exercise! In this exercise we will give you some simple datasets and ask you to create Choropleth Maps from them. Due to the Nature of Plotly we can't show you examples embedded inside the notebook.\n\n[Full Documentation Reference](https://plot.ly/python/reference/#choropleth)\n\n## Plotly Imports",
"_____no_output_____"
]
],
[
[
"import plotly.graph_objs as go \nfrom plotly.offline import init_notebook_mode,iplot,plot\ninit_notebook_mode(connected=True) ",
"_____no_output_____"
]
],
[
[
"** Import pandas and read the csv file: 2014_World_Power_Consumption**",
"_____no_output_____"
]
],
[
[
"import pandas as pd",
"_____no_output_____"
],
[
"df = pd.read_csv('2014_World_Power_Consumption')",
"_____no_output_____"
]
],
[
[
"** Check the head of the DataFrame. **",
"_____no_output_____"
]
],
[
[
"df.head()",
"_____no_output_____"
]
],
[
[
"** Referencing the lecture notes, create a Choropleth Plot of the Power Consumption for Countries using the data and layout dictionary. **",
"_____no_output_____"
]
],
[
[
"data = dict(\n type = 'choropleth',\n colorscale = 'Viridis',\n reversescale = True,\n locations = df['Country'],\n locationmode = \"country names\",\n z = df['Power Consumption KWH'],\n text = df['Country'],\n colorbar = {'title' : 'Power Consumption KWH'},\n ) \n\nlayout = dict(title = '2014 Power Consumption KWH',\n geo = dict(showframe = False,projection = {'type':'Mercator'})\n )",
"_____no_output_____"
],
[
"choromap = go.Figure(data = [data],layout = layout)\nplot(choromap,validate=False)",
"_____no_output_____"
]
],
[
[
"## USA Choropleth\n\n** Import the 2012_Election_Data csv file using pandas. **",
"_____no_output_____"
]
],
[
[
"usdf = pd.read_csv('2012_Election_Data')",
"_____no_output_____"
]
],
[
[
"** Check the head of the DataFrame. **",
"_____no_output_____"
]
],
[
[
"usdf.head()",
"_____no_output_____"
]
],
[
[
"** Now create a plot that displays the Voting-Age Population (VAP) per state. If you later want to play around with other columns, make sure you consider their data type. VAP has already been transformed to a float for you. **",
"_____no_output_____"
]
],
[
[
"data = dict(type='choropleth',\n colorscale = 'Viridis',\n reversescale = True,\n locations = usdf['State Abv'],\n z = usdf['Voting-Age Population (VAP)'],\n locationmode = 'USA-states',\n text = usdf['State'],\n marker = dict(line = dict(color = 'rgb(255,255,255)',width = 1)),\n colorbar = {'title':\"Voting-Age Population (VAP)\"}\n ) ",
"_____no_output_____"
],
[
"layout = dict(title = '2012 General Election Voting Data',\n geo = dict(scope='usa',\n showlakes = True,\n lakecolor = 'rgb(85,173,240)')\n )",
"_____no_output_____"
],
[
"choromap = go.Figure(data = [data],layout = layout)\nplot(choromap,validate=False)",
"_____no_output_____"
]
],
[
[
"# Great Job!",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
]
] |
d0f7a79a305e9683b9c11aa4c01c5a39576ac1f0 | 804,473 | ipynb | Jupyter Notebook | hw3.ipynb | HarryWang0619/COMPSCI589-HW3 | 454e77f0231208dfe2b5b19210e9cce900a73c87 | [
"MIT"
] | null | null | null | hw3.ipynb | HarryWang0619/COMPSCI589-HW3 | 454e77f0231208dfe2b5b19210e9cce900a73c87 | [
"MIT"
] | null | null | null | hw3.ipynb | HarryWang0619/COMPSCI589-HW3 | 454e77f0231208dfe2b5b19210e9cce900a73c87 | [
"MIT"
] | null | null | null | 250.770885 | 25,946 | 0.892761 | [
[
[
"# COMPSCI-589 HW3: Random Forest\n\nname: Harry (Haochen) Wang",
"_____no_output_____"
]
],
[
[
"from evaluationmatrix import *\nfrom utils import *\nfrom decisiontree import *\nfrom randomforest import *\nfrom run import *",
"_____no_output_____"
],
[
"housedata, housecategory = importhousedata()\nwinedata, winecategory = importwinedata()\ncancerdata, cancercategory = importcancerdata()\ncmcdata,cmccategory = importcmcdata()\n\nparameterofn = [1, 5, 10, 20, 30, 40, 50] # n of ntrees\n\ndef ploter(data, title, xlabel, ylabel, error = None, n = parameterofn):\n plt.errorbar(n, data, yerr=error , fmt = '-o')\n plt.xlabel(xlabel)\n plt.ylabel(ylabel) \n plt.title(title)\n plt.plot(n,data)\n plt.show()",
"_____no_output_____"
]
],
[
[
"### I. Wine Dataset",
"_____no_output_____"
]
],
[
[
"wineaccuracy, wineprecision, winerecall, winef1 = [], [], [], []\nwineprecisionstd, winerecallstd, winef1std = [], [] ,[]\nfor n in parameterofn:\n lists = kfoldcrossvalid(winedata, winecategory, 10, n, 10, 5, 0.01, 'id3', 0.1)[0]\n beta = 1\n a,p0,r0,f0,all = evaluate(lists, 1, beta)\n a,p1,r1,f1,all = evaluate(lists, 2, beta)\n a,p2,r2,f2,all = evaluate(lists, 3, beta)\n p = p0+p1+p2\n r = r0+r1+r2\n f = f0+f1+f2\n wineprecisionstd.append((np.std(p)/2))\n winerecallstd.append((np.std(r)/2))\n winef1std.append((np.std(f)/2))\n acc0, pre0, rec0, fsc0 = meanevaluation(lists, 1, beta)\n acc1, pre1, rec1, fsc1 = meanevaluation(lists, 2, beta)\n acc2, pre2, rec2, fsc2 = meanevaluation(lists, 3, beta)\n acc, pre, rec, fsc = (acc0+acc1+acc2)/3, (pre0+pre1+pre2)/3, (rec0+rec1+rec2)/3, (fsc0+fsc1+fsc2)/3\n wineaccuracy.append(acc)\n wineprecision.append(pre)\n winerecall.append(rec)\n winef1.append(fsc)\n markdownaprf(acc, pre, rec, fsc, beta, n, 'Wine with information gain')",
"_____no_output_____"
]
],
[
[
"Result/Stat of 1 trees random forest of Wine with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.927 | 0.92 | 0.891 | 0.894 |\n\nResult/Stat of 5 trees random forest of Wine with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.974 | 0.969 | 0.957 | 0.96 |\n\nResult/Stat of 10 trees random forest of Wine with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.974 | 0.967 | 0.963 | 0.962 |\n\nResult/Stat of 20 trees random forest of Wine with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.977 | 0.973 | 0.969 | 0.967 |\n\nResult/Stat of 30 trees random forest of Wine with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.977 | 0.97 | 0.968 | 0.967 |\n\nResult/Stat of 40 trees random forest of Wine with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.981 | 0.976 | 0.975 | 0.973 |\n\nResult/Stat of 50 trees random forest of Wine with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.981 | 0.974 | 0.975 | 0.972 |",
"_____no_output_____"
]
],
[
[
"ploter(wineaccuracy, '# of n in ntree V.S. accuracy of Wine with info gain', '# of n in ntree', 'Accuracy')\nploter(wineprecision, '# of n in ntree V.S. precision of Wine with info gain', '# of n in ntree', 'Precision', wineprecisionstd)\nploter(winerecall, '# of n in ntree V.S. recall of Wine with info gain', '# of n in ntree', 'Recall', winerecallstd)\nploter(winef1, '# of n in ntree V.S. F-1 Score of Wine with info gain', '# of n in ntree', 'F-1 score with beta = 1', winef1std)",
"_____no_output_____"
]
],
[
[
"For this algorithm, here are the parameters I have:\n\n| **k (Fold)** | **max_depth** | **min_size_for_split** | **min_gain** |**bootstrap_ratio** |\n| :---: | :---: | :---: | :---: | :---: |\n| 10 | 10 | 5 | 0.01 | 0.1 |\n\nThe K is the fold value, I just use the recommend k = 10\n\nThe max_depth is the maximum depth for the tree, (traverse depth), since there are only 178 instance of data, I just set max_depth to 10 because that won't matter to the algorithm.\n\nThe min_size_for_split, say n, is when there are less than 'n' values in the subdata left, I don't do the split anymore. I set it to 5 because we have a small dataset for this.\n\nThe min_gain is the minimal gain I need to keep decide. I set it to 0.01 so that's very close to 0 but not 0.\n\nThe bootstrap_ratio is the ratio # of instance in training set that got resample in the bagging/bootstrap method. In this model, it's 0.1 so 10% of the data got resampled.\n",
"_____no_output_____"
],
[
"##### (4)\nFor each metric being evaluated (and for each dataset), discuss which value of ntree you would select if you were to deploy this classifier in real life. Explain your reasoning.\n",
"_____no_output_____"
],
[
"ANSWER:\n\nFor the number of n of ntree in the random forest, I would pick n = 20. It's clearly that there are huge improvement in all accuracy, precision and recall (and f1, I will not mention them as frequently since it's the harmonic mean of precision and recall) when n raise from 1 to 5 and 10. However, higher than that, the rate of increasing in [accuracy, precison & recall] is getting slower.\n\nSo the gain we have in the [accuracy, precison, recall, f1] is getting slower, while the cost of training the tree is getting larger, so I would pick n = 20, which seems to be a fiiting in the middle of [accuracy, precison & recall] and cost(in time and space)",
"_____no_output_____"
],
[
"##### (5)\n\nDiscuss (on a high level) which metrics were more directly affected by changing the value of ntree and, more generally, how such changes affected the performance of your algorithm. For instance: was the accuracy of the random forest particularly sensitive to increasing ntree past a given value? Was the F1 score a “harder” metric to optimize, possibly requiring a significant number of trees in the ensemble? Is there a point beyond which adding more trees does not improve performance—or makes the performance worse?",
"_____no_output_____"
],
[
"ANSWER:\n\nFirst, notice that the accuracy, precision, recall and f-1 score might have the same shape, since we need to \n\n\"calculate the average of recall and precision by considering each class as positive once, calculating precision and recall then taking the average overall classes.\" (I quoted this answer from piazza)\n\nSo this actually smooth out the precision and recall curve because we find the precision of all three classes and calculate the arithmetic mean.\n\nFor the algorithm, I think it increase the most from n = 1 to n = 5. Actually, I think as long as n = 3, there's going to be a huge leap because instead of one, there are three trees thinking together and come up with a result. (can't be two because there no third voter to decide their disagreements.) \nAnd as n growth, the rate of increase in the performance decreases. (the rate of change decreases, not the performance decreases). It's like an log curve. I think, there will be some point that adding more trees doesn't improve the performance, might not toward one due to the limit of the algorithm (Maybe for NN performance of 1 is possible). But I don't think, generally speaking, the performance would getting worse at some point: there might be fluctuation, but not huge drops.",
"_____no_output_____"
]
],
[
[
"ploter(wineprecisionstd, '# of n in ntree V.S. std of precision of Wine with info gain', '# of n in ntree', 'Precision')\nploter(winerecallstd, '# of n in ntree V.S. std of recall of Wine with info gain', '# of n in ntree', 'Recall')\nploter(winef1std, '# of n in ntree V.S. std of F-1 Score of Wine with info gain', '# of n in ntree', 'F-1 score with beta = 1')",
"_____no_output_____"
]
],
[
[
"For the F score and so, we can find out that it's almost the same shape of curve as accuracy, since they have similar calculation process the (the harmonic mean of recall and precision; the accuracy is kind of similar to arithmetic mean of those two.)\nSo F1 score is not a harder matrix to optimize. Notice that the st-dev of std would decrease with more tree, that means for all the k-folds the performance would be more 'stable'",
"_____no_output_____"
],
[
"### II. 1984 US Congressional Voting Dataset",
"_____no_output_____"
]
],
[
[
"houseaccuracy, houseprecision, houserecall, housef1 = [], [], [], []\nhouseprecisionstd, houserecallstd, housef1std = [], [] ,[]\nfor n in parameterofn:\n lists = kfoldcrossvalid(housedata, housecategory, 10, n, 10, 5, 0.01, 'id3', 0.1)[0]\n beta = 1\n a,p0,r0,f0,all = evaluate(lists, 0, beta)\n a,p1,r1,f1,all = evaluate(lists, 1, beta)\n p = p0+p1\n r = r0+r1\n f = f0+f1\n houseprecisionstd.append(np.std(p)/2)\n houserecallstd.append(np.std(r)/2)\n housef1std.append(np.std(f)/2) \n acc0, pre0, rec0, fsc0 = meanevaluation(lists, 0, beta)\n acc1, pre1, rec1, fsc1 = meanevaluation(lists, 1, beta)\n acc, pre, rec, fsc = (acc0+acc1)/2, (pre0+pre1)/2, (rec0+rec1)/2, (fsc0+fsc1)/2\n houseaccuracy.append(acc)\n houseprecision.append(pre)\n houserecall.append(rec)\n housef1.append(fsc)\n markdownaprf(acc, pre, rec, fsc, beta, n, 'House with information gain')",
"_____no_output_____"
]
],
[
[
"Result/Stat of 1 trees random forest of House with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.904 | 0.905 | 0.896 | 0.898 |\n\nResult/Stat of 5 trees random forest of House with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.947 | 0.948 | 0.942 | 0.943 |\n\nResult/Stat of 10 trees random forest of House with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.961 | 0.959 | 0.962 | 0.959 |\n\nResult/Stat of 20 trees random forest of House with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.961 | 0.96 | 0.96 | 0.958 |\n\nResult/Stat of 30 trees random forest of House with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.961 | 0.96 | 0.961 | 0.959 |\n\nResult/Stat of 40 trees random forest of House with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.954 | 0.952 | 0.954 | 0.952 |\n\nResult/Stat of 50 trees random forest of House with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.961 | 0.96 | 0.959 | 0.959 |",
"_____no_output_____"
]
],
[
[
"ploter(houseaccuracy, '# of n in ntree V.S. accuracy of HouseVote with info gain', '# of n in ntree', 'Accuracy')\nploter(houseprecision, '# of n in ntree V.S. precision of HouseVote with info gain', '# of n in ntree', 'Precision', houseprecisionstd)\nploter(houserecall, '# of n in ntree V.S. recall of HouseVote with info gain', '# of n in ntree', 'Recall', houserecallstd)\nploter(housef1, '# of n in ntree V.S. F-1 Score of HouseVote with info gain', '# of n in ntree', 'F-1 score with beta = 1', housef1std)",
"_____no_output_____"
]
],
[
[
"For this algorithm, here are the parameters I have:\n\n| **k (Fold)** | **max_depth** | **min_size_for_split** | **min_gain** |**bootstrap_ratio** |\n| :---: | :---: | :---: | :---: | :---: |\n| 10 | 10 | 5 | 0.01 | 0.1 |\n\nI use the same setup as the first dataset.",
"_____no_output_____"
],
[
"##### (4)",
"_____no_output_____"
],
[
"ANSWER: \n\nI would also pick 10 to 20, for this model and 20 is prefered for the low variance (st_dev). Indeed, I'd pick 19 (or 21), since it's better if it's odd, so that when there is a 10 vs 10 disagreement there could be a tree stanout to determine the prediction.",
"_____no_output_____"
],
[
"##### (5)",
"_____no_output_____"
],
[
"The performance model is very similar to the previous model. One thing better is that it's faster but that make sence becuase it's a categorical tree.\nIn these anlysis plots we can see that the rate of change in the performance is getting very close to zero as the # of n of ntree approach around 40-50. So in this case, it's not making sence to adding the value of n to improve. (maybe boosting would work!)\n",
"_____no_output_____"
]
],
[
[
"ploter(houseprecisionstd, '# of n in ntree V.S. std of precision of HouseVote with info gain', '# of n in ntree', 'Precision')\nploter(houserecallstd, '# of n in ntree V.S. std of recall of HouseVote with info gain', '# of n in ntree', 'Recall')\nploter(housef1std, '# of n in ntree V.S. std of F-1 Score of HouseVote with info gain', '# of n in ntree', 'F-1 score with beta = 1')",
"_____no_output_____"
]
],
[
[
"We can see the drop in st_dev as the n growth, but it is slight increase when the n get larger (anyway the growth is less than 0.005 so I guess it's just random error/fluctuation.)",
"_____no_output_____"
],
[
"### III. Extra Points",
"_____no_output_____"
],
[
"#### (Extra Points #1: 6 Points) \nReconstruct the same graphs as above, but now using the Gini criterion. You should present the same analyses and graphs mentioned above. Discuss whether (and how) different performance metrics were affected (positively or negatively) by changing the splitting criterion, and explain why you think that was the case.",
"_____no_output_____"
]
],
[
[
"wineaccuracygini, wineprecisiongini, winerecallgini, winef1gini = [], [], [], []\nwineprecisionginistd, winerecallginistd, winef1ginistd = [], [] ,[]\nfor n in parameterofn:\n lists = kfoldcrossvalid(winedata, winecategory, 10, n, 10, 5, 0.01, 'gini', 0.1)[0]\n beta = 1\n a,p0,r0,f0,all = evaluate(lists, 1, beta)\n a,p1,r1,f1,all = evaluate(lists, 2, beta)\n a,p2,r2,f2,all = evaluate(lists, 3, beta)\n p = p0+p1+p2\n r = r0+r1+r2\n f = f0+f1+f2\n wineprecisionginistd.append(np.std(p)/2)\n winerecallginistd.append(np.std(r)/2)\n winef1ginistd.append(np.std(f)/2)\n acc0, pre0, rec0, fsc0 = meanevaluation(lists, 1, beta)\n acc1, pre1, rec1, fsc1 = meanevaluation(lists, 2, beta)\n acc2, pre2, rec2, fsc2 = meanevaluation(lists, 3, beta)\n acc, pre, rec, fsc = (acc0+acc1+acc2)/3, (pre0+pre1+pre2)/3, (rec0+rec1+rec2)/3, (fsc0+fsc1+fsc2)/3\n wineaccuracygini.append(acc)\n wineprecisiongini.append(pre)\n winerecallgini.append(rec)\n winef1gini.append(fsc)\n markdownaprf(acc, pre, rec, fsc, beta, n, 'Wine with Gini index')",
"_____no_output_____"
]
],
[
[
"Result/Stat of 1 trees random forest of Wine with Gini index:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.93 | 0.917 | 0.89 | 0.893 |\n\nResult/Stat of 5 trees random forest of Wine with Gini index:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.962 | 0.955 | 0.942 | 0.944 |\n\nResult/Stat of 10 trees random forest of Wine with Gini index:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.977 | 0.969 | 0.969 | 0.966 |\n\nResult/Stat of 20 trees random forest of Wine with Gini index:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.985 | 0.98 | 0.98 | 0.978 |\n\nResult/Stat of 30 trees random forest of Wine with Gini index:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.977 | 0.972 | 0.969 | 0.967 |\n\nResult/Stat of 40 trees random forest of Wine with Gini index:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.98 | 0.973 | 0.973 | 0.97 |\n\nResult/Stat of 50 trees random forest of Wine with Gini index:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.989 | 0.984 | 0.985 | 0.983 |",
"_____no_output_____"
]
],
[
[
"ploter(wineaccuracygini, '# of n in ntree V.S. accuracy of Wine with Gini index', '# of n in ntree', 'Accuracy')\nploter(wineprecisiongini, '# of n in ntree V.S. precision of Wine with Gini index', '# of n in ntree', 'Precision', wineprecisionginistd)\nploter(winerecallgini, '# of n in ntree V.S. recall of Wine with Gini index', '# of n in ntree', 'Recall', winerecallginistd)\nploter(winef1gini, '# of n in ntree V.S. F-1 Score of Wine with Gini index', '# of n in ntree', 'F-1 score with beta = 1', winef1ginistd)",
"_____no_output_____"
],
[
"ploter(wineprecisionginistd, '# of n in ntree V.S. std of precision of Wine with Gini index', '# of n in ntree', 'Precision')\nploter(winerecallginistd, '# of n in ntree V.S. std of recall of Wine with Gini index', '# of n in ntree', 'Recall')\nploter(winef1ginistd, '# of n in ntree V.S. std of F-1 Score of Wine with Gini index', '# of n in ntree', 'F-1 score with beta = 1')",
"_____no_output_____"
],
[
"houseaccuracygini, houseprecisiongini, houserecallgini, housef1gini = [], [], [], []\nhouseprecisionginistd, houserecallginistd, housef1ginistd = [], [] ,[]\nfor n in parameterofn:\n lists = kfoldcrossvalid(housedata, housecategory, 10, n, 10, 10, 0.01, 'gini', 0.1)[0]\n beta = 1\n a,p0,r0,f0,all = evaluate(lists, 0, beta)\n a,p1,r1,f1,all = evaluate(lists, 1, beta)\n p = p0+p1\n r = r0+r1\n f = f0+f1\n houseprecisionginistd.append(np.std(p)/2)\n houserecallginistd.append(np.std(r)/2)\n housef1ginistd.append(np.std(f)/2)\n acc0, pre0, rec0, fsc0 = meanevaluation(lists, 0, beta)\n acc1, pre1, rec1, fsc1 = meanevaluation(lists, 1, beta)\n acc, pre, rec, fsc = (acc0+acc1)/2, (pre0+pre1)/2, (rec0+rec1)/2, (fsc0+fsc1)/2\n houseaccuracygini.append(acc)\n houseprecisiongini.append(pre)\n houserecallgini.append(rec)\n housef1gini.append(fsc)\n markdownaprf(acc, pre, rec, fsc, beta, n, 'House with Gini index')",
"_____no_output_____"
]
],
[
[
"Result/Stat of 1 trees random forest of House with Gini index:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.947 | 0.948 | 0.946 | 0.944 |\n\nResult/Stat of 5 trees random forest of House with Gini index:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.945 | 0.945 | 0.942 | 0.941 |\n\nResult/Stat of 10 trees random forest of House with Gini index:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.968 | 0.966 | 0.967 | 0.966 |\n\nResult/Stat of 20 trees random forest of House with Gini index:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.952 | 0.949 | 0.951 | 0.949 |\n\nResult/Stat of 30 trees random forest of House with Gini index:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.959 | 0.957 | 0.959 | 0.957 |\n\nResult/Stat of 40 trees random forest of House with Gini index:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.954 | 0.954 | 0.954 | 0.952 |\n\nResult/Stat of 50 trees random forest of House with Gini index:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.954 | 0.95 | 0.954 | 0.951 |",
"_____no_output_____"
]
],
[
[
"ploter(houseaccuracygini, '# of n in ntree V.S. accuracy of HouseVote with Gini index', '# of n in ntree', 'Accuracy')\nploter(houseprecisiongini, '# of n in ntree V.S. precision of HouseVote with Gini index', '# of n in ntree', 'Precision', houseprecisionginistd)\nploter(houserecallgini, '# of n in ntree V.S. recall of HouseVote with Gini index', '# of n in ntree', 'Recall', houserecallginistd)\nploter(housef1gini, '# of n in ntree V.S. F-1 Score of HouseVote with Gini index', '# of n in ntree', 'F-1 score with beta = 1', housef1ginistd)",
"_____no_output_____"
],
[
"ploter(houseprecisionginistd, '# of n in ntree V.S. std of precision of HouseVote with Gini index', '# of n in ntree', 'Precision')\nploter(houserecallginistd, '# of n in ntree V.S. std of recall of HouseVote with Gini index', '# of n in ntree', 'Recall')\nploter(housef1ginistd, '# of n in ntree V.S. std of F-1 Score of HouseVote with Gini index', '# of n in ntree', 'F-1 score with beta = 1')",
"_____no_output_____"
]
],
[
[
"ANALYSIS for extra I:\n\nfor those two, we are getting similar result on how the performance improves as n changes. \n\nFor the house data, our performance is slightly better (around 96%) but the rate of increase is slower.\n\nFor the wine data, the difference between info gain and gini are neglectable.",
"_____no_output_____"
],
[
"#### (Extra Points #2: 6 Points) \nAnalyze a third dataset: the Breast Cancer Dataset. The goal, here, is to classify whether tissue removed via a biopsy indicates whether a person may or may not have breast cancer. There are 699 instances in this dataset. Each instance is described by 9 numerical attributes, and there are 2 classes. You should present the same analyses and graphs as discussed above. This dataset can be found in the same zip file as the two main datasets.\n",
"_____no_output_____"
]
],
[
[
"# canceraccuracy, cancerprecision, cancerrecall, cancerf1 = [], [], [], []\n# cancerprecisionstd, cancerrecallstd, cancerf1std = [], [], []\n# for n in parameterofn:\n# lists = kfoldcrossvalid(cancerdata, cancercategory, 10, n, 7, 10, 0.01, 'id3', 0.1)[0]\n# beta = 1\n# a,p,r,f,all = evaluate(lists, 1, beta)\n# cancerprecisionstd.append(np.std(p)/2)\n# cancerrecallstd.append(np.std(r)/2)\n# cancerf1std.append(np.std(f)/2)\n# acc, pre, rec, fsc = meanevaluation(lists, 1, beta)\n# canceraccuracy.append(acc)\n# cancerprecision.append(pre)\n# cancerrecall.append(rec)\n# cancerf1.append(fsc)\n# markdownaprf(acc, pre, rec, fsc, beta, n, 'Cancer with information gain')",
"_____no_output_____"
]
],
[
[
"Result/Stat of 1 trees random forest of Cancer with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.937 | 0.896 | 0.929 | 0.911 |\n\nResult/Stat of 5 trees random forest of Cancer with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.951 | 0.928 | 0.934 | 0.93 |\n\nResult/Stat of 10 trees random forest of Cancer with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.964 | 0.945 | 0.954 | 0.948 |\n\nResult/Stat of 20 trees random forest of Cancer with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.967 | 0.942 | 0.967 | 0.953 |\n\nResult/Stat of 30 trees random forest of Cancer with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.969 | 0.937 | 0.975 | 0.955 |\n\nResult/Stat of 40 trees random forest of Cancer with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.969 | 0.936 | 0.979 | 0.956 |\n\nResult/Stat of 50 trees random forest of Cancer with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.962 | 0.932 | 0.963 | 0.946 |",
"_____no_output_____"
]
],
[
[
"# ploter(canceraccuracy, '# of n in ntree V.S. accuracy of CancerData with information gain', '# of n in ntree', 'Accuracy')\n# ploter(cancerprecision, '# of n in ntree V.S. precision of CancerData with information gain', '# of n in ntree', 'Precision', cancerprecisionstd)\n# ploter(cancerrecall, '# of n in ntree V.S. recall of CancerData with information gain', '# of n in ntree', 'Recall', cancerrecallstd)\n# ploter(cancerf1, '# of n in ntree V.S. F-1 Score of CancerData with information gain', '# of n in ntree', 'F-1 score with beta = 1', cancerf1std)",
"_____no_output_____"
]
],
[
[
"For this algorithm, here are the parameters I have:\n\n| **k (Fold)** | **max_depth** | **min_size_for_split** | **min_gain** |**bootstrap_ratio** |\n| :---: | :---: | :---: | :---: | :---: |\n| 10 | 7 | 10 | 0.01 | 0.1 |\n\nI changed the max_depth to 7 because there are more instances in this data. \nand I also increased the min_size_for_split for the same reason.",
"_____no_output_____"
]
],
[
[
"# ploter(cancerprecisionstd, '# of n in ntree V.S. std of precision of CancerData with information gain', '# of n in ntree', 'Precision')\n# ploter(cancerrecallstd, '# of n in ntree V.S. std of recall of CancerData with information gain', '# of n in ntree', 'Recall')\n# ploter(cancerf1std, '# of n in ntree V.S. std of F-1 Score of CancerData with information gain', '# of n in ntree', 'F-1 score with beta = 1')",
"_____no_output_____"
]
],
[
[
"ANALYSIS for extra II:\n\nIn this question, we finally have one fixed positive class. Since it's for detecting cancer, hence we should focus on the recall. For optizmating recall, since it's not a probability classfier, so what we can do is to resample more positive training data, and when analyzing, we could change the beta value (I didn't do it here since I want a more general view of it.)",
"_____no_output_____"
],
[
"#### (Extra Points #3: 12 Points) \nAnalyze a fourth, more challenging dataset: the Contraceptive Method Choice Dataset. The goal, here, is to predict the type of contraceptive method used by a person based on many attributes describing that person. This dataset is more challenging because it combines both numerical and categorical attributes. There are 1473 instances in this dataset. Each instance is described by 9 attributes, and there are 3 classes. The dataset can be downloaded here. You should present the same analyses and graphs discussed above.",
"_____no_output_____"
]
],
[
[
"cmcaccuracy, cmcprecision, cmcrecall, cmcf1 = [], [], [], []\ncmcprecisionstd, cmcrecallstd, cmcf1std = [], [], []\nfor n in parameterofn:\n lists,accu = kfoldcrossvalid(cmcdata, cmccategory, 10, n, 10, 10, 0.01, 'id3', 0.1)\n beta = 1\n a,p0,r0,f0,all = evaluate(lists, 1, beta)\n a,p1,r1,f1,all = evaluate(lists, 2, beta)\n a,p2,r2,f2,all = evaluate(lists, 3, beta)\n p = p0+p1+p2\n r = r0+r1+r2\n f = f0+f1+f2\n cmcprecisionstd.append(np.std(p)/3)\n cmcrecallstd.append(np.std(r)/3)\n cmcf1std.append(np.std(f)/3)\n acc0, pre0, rec0, fsc0 = meanevaluation(lists, 1, beta)\n acc1, pre1, rec1, fsc1 = meanevaluation(lists, 2, beta)\n acc2, pre2, rec2, fsc2 = meanevaluation(lists, 3, beta)\n acc, pre, rec, fsc = (acc0+acc1+acc2)/3, (pre0+pre1+pre2)/3, (rec0+rec1+rec2)/3, (fsc0+fsc1+fsc2)/3\n cmcaccuracy.append(accu)\n cmcprecision.append(pre)\n cmcrecall.append(rec)\n cmcf1.append(fsc)\n markdownaprf(accu, pre, rec, fsc, beta, n, 'CMC with information gain')",
"_____no_output_____"
]
],
[
[
"Result/Stat of 1 trees random forest of CMC with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.496 | 0.488 | 0.485 | 0.476 |\n\nResult/Stat of 5 trees random forest of CMC with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.5 | 0.483 | 0.484 | 0.477 |\n\nResult/Stat of 10 trees random forest of CMC with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.504 | 0.486 | 0.483 | 0.48 |\n\nResult/Stat of 20 trees random forest of CMC with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.519 | 0.499 | 0.495 | 0.492 |\n\nResult/Stat of 30 trees random forest of CMC with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.521 | 0.501 | 0.496 | 0.494 |\n\nResult/Stat of 40 trees random forest of CMC with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.513 | 0.49 | 0.487 | 0.484 |\n\nResult/Stat of 50 trees random forest of CMC with information gain:\n| **Accuracy** | **Precision** | **Recall** | **F-Score, Beta=1** |\n| :---: | :---: | :---: | :---: |\n|0.52 | 0.5 | 0.497 | 0.494 |",
"_____no_output_____"
]
],
[
[
"ploter(cmcaccuracy, '# of n in ntree V.S. accuracy of CMC Data with information gain', '# of n in ntree', 'Accuracy')\nploter(cmcprecision, '# of n in ntree V.S. precision of CMC Data with information gain', '# of n in ntree', 'Precision', cmcprecisionstd)\nploter(cmcrecall, '# of n in ntree V.S. recall of CMC Data with information gain', '# of n in ntree', 'Recall', cmcrecallstd)\nploter(cmcf1, '# of n in ntree V.S. F-1 Score of CMC Data with information gain', '# of n in ntree', 'F-1 score with beta = 1', cmcf1std)",
"_____no_output_____"
],
[
"ploter(cmcprecisionstd, '# of n in ntree V.S. std of precision of CMC Data with information gain', '# of n in ntree', 'Precision')\nploter(cmcrecallstd, '# of n in ntree V.S. std of recall of CMC Data with information gain', '# of n in ntree', 'Recall')\nploter(cmcf1std, '# of n in ntree V.S. std of F-1 Score of CMC Data with information gain', '# of n in ntree', 'F-1 score with beta = 1')",
"_____no_output_____"
]
],
[
[
"The result is kind of weird. with max accuracy around 52-53%, I tried to modified all the parameters, like maxdepth to 5 and so, but that only helps me to improve from 50% to 52%..",
"_____no_output_____"
],
[
"### IV. Appendix: Code",
"_____no_output_____"
],
[
"##### 1. evaluationmatrix.py",
"_____no_output_____"
]
],
[
[
"import math\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom IPython.display import display, Markdown\n\ndef accuracy(truePosi, trueNega, falsePosi, falseNega): # Count of all four\n\treturn (truePosi+trueNega)/(truePosi+trueNega+falseNega+falsePosi)\n\ndef precision(truePosi, trueNega, falsePosi, falseNega):\n\tif (truePosi+falsePosi) == 0:\n\t\treturn 0\n\tpreposi = truePosi/(truePosi+falsePosi)\n\t# prenega = trueNega/(trueNega+falseNega)\n\treturn preposi\n\ndef recall(truePosi, trueNega, falsePosi, falseNega):\n\tif (truePosi+falseNega)== 0:\n\t\treturn 0\n\trecposi = truePosi/(truePosi+falseNega)\n\t# recnega = trueNega/(trueNega+falsePosi)\n\treturn recposi\n\ndef fscore(truePosi, trueNega, falsePosi, falseNega, beta: 1):\n\tpre = precision(truePosi, trueNega, falsePosi, falseNega)\n\trec = recall(truePosi, trueNega, falsePosi, falseNega)\n\tif (pre*(beta**2)+rec) == 0:\n\t\treturn 0\n\tf = (1+beta**2)*((pre*rec)/(pre*(beta**2)+rec))\n\treturn f\n\ndef evaluate(listsofoutput, positivelabel, beta=1):\n # list is list of [predicted, actual]\n listoftptnfpfn = []\n accuarcylists = []\n precisionlists = []\n recalllists = []\n fscorelists = []\n for output in listsofoutput:\n tp, tn, fp, fn, = 0, 0, 0, 0\n for i in range(len(output)):\n if output[i][0] == positivelabel and output[i][1] == positivelabel:\n tp += 1\n elif output[i][0] != positivelabel and output[i][0] == output[i][1]:\n tn += 1\n elif output[i][0] == positivelabel and output[i][1] != positivelabel:\n fp += 1\n elif output[i][0] != positivelabel and output[i][1] == positivelabel:\n fn += 1\n tptnfpfn = [tp, tn, fp, fn]\n listoftptnfpfn.append(tptnfpfn)\n accuarcylists.append(accuracy(tp, tn, fp, fn))\n precisionlists.append(precision(tp, tn, fp, fn))\n recalllists.append(recall(tp, tn, fp, fn))\n fscorelists.append(fscore(tp, tn, fp, fn, beta))\n return accuarcylists, precisionlists, recalllists, fscorelists, listoftptnfpfn\n\ndef meanevaluation(listsofoutput, positivelabel, beta=1):\n accuarcylists, precisionlists, recalllists, fscorelists, notused = evaluate(listsofoutput, positivelabel, beta)\n return sum(accuarcylists)/len(accuarcylists), sum(precisionlists)/len(precisionlists), sum(recalllists)/len(recalllists), sum(fscorelists)/len(fscorelists)\n\ndef markdownaprf(acc,pre,rec,fsc,beta,nvalue,title):\n acc, pre, rec, fsc = round(acc,3), round(pre,3), round(rec,3), round(fsc,3)\n display(Markdown(rf\"\"\"\n\tResult/Stat of {nvalue} trees random forest of {title}:\n | **Accuracy** | **Precision** | **Recall** | **F-Score, Beta={beta}** |\n | :---: | :---: | :---: | :---: |\n |{acc} | {pre} | {rec} | {fsc} |\n \"\"\"))\n\ndef markdownmatrix(tptnfpfn,title):\n tp, tn, fp, fn = tptnfpfn[0], tptnfpfn[1], tptnfpfn[2], tptnfpfn[3]\n display(Markdown(rf\"\"\"\n Confusion Matrix: {title}\n | | **Predicted +** | **Predicted-** |\n | :--- | :--- | :--- |\n | **Actual +** | {tp} | {fp} |\n | **Actual -** | {fn} | {tn} |\n \"\"\"))\n\ndef confusionmatrix(truePosi, trueNega, falsePosi, falseNega, title=\"\"):\n\tfig = plt.figure()\n\tplt.title(title)\n\tcol_labels = ['Predict:+', 'Predict:-']\n\trow_labels = ['Real:+', 'Real:-']\n\ttable_vals = [[truePosi, falseNega], [falsePosi, trueNega]]\n\tthe_table = plt.table(cellText=table_vals,\n colWidths=[0.1] * 3,\n rowLabels=row_labels,\n colLabels=col_labels,\n loc='center')\n\tthe_table.auto_set_font_size(False)\n\tthe_table.set_fontsize(24)\n\tthe_table.scale(4, 4)\n\tplt.tick_params(axis='x', which='both', bottom=False, top=False, labelbottom=False)\n\tplt.tick_params(axis='y', which='both', right=False, left=False, labelleft=False)\n\n\tfor pos in ['right','top','bottom','left']:\n\t\tplt.gca().spines[pos].set_visible(False)\n\n\tplt.show()\t\n\treturn \n",
"_____no_output_____"
]
],
[
[
"##### 2. utils.py",
"_____no_output_____"
]
],
[
[
"from sqlite3 import Row\nfrom evaluationmatrix import *\nfrom sklearn import datasets\nimport random\nimport numpy as np\nimport csv\nimport math\nimport matplotlib.pyplot as plt\nfrom collections import Counter\n\ndef importfile(name:str,delimit:str):\n # importfile('hw3_wine.csv', '\\t')\n file = open(\"datasets/\"+name, encoding='utf-8-sig')\n reader = csv.reader(file, delimiter=delimit)\n dataset = []\n for row in reader:\n dataset.append(row)\n file.close()\n return dataset\n\ndef same(attributecolumn):\n return all(item == attributecolumn[0] for item in attributecolumn)\n\ndef majority(attributecolumn):\n return np.argmax(np.bincount(attributecolumn.astype(int)))\n\ndef entropy(attributecol):\n values = list(Counter(attributecol).values())\n ent = 0\n for value in values:\n k = (value/sum(values))\n ent += -k*math.log(k,2)\n return ent\n\ndef gini(attributecol):\n values = list(Counter(attributecol).values())\n ginivalue = 1\n for value in values:\n prob = (value/sum(values))\n ginivalue -= prob**2\n return ginivalue\n\ndef dropbyindex(data, category, listindex):\n newdata = np.delete(data.T, listindex).T\n keytoremove = [list(category.keys())[i] for i in listindex]\n newcategory = category.copy()\n [newcategory.pop(key) for key in keytoremove]\n return newdata, newcategory\n\ndef id3bestseperate(dataset, attributes:dict):\n # dataset in is the dataset by row. \n # attributes is the dictionary of attributes:type \n # types: numerical, categorical, binary.\n datasetbycolumn = dataset.T\n classindex = list(attributes.values()).index(\"class\")\n originalentrophy = entropy(datasetbycolumn[classindex])\n smallestentrophy = originalentrophy\n thresholdvalue = -1\n\n i = 0\n bestattribute = {list(attributes.keys())[i]:attributes[list(attributes.keys())[i]]}\n attributesinuse = list(attributes.keys())[1:] if (classindex == 0) else list(attributes.keys())[:classindex]\n # datasetinuse = datasetbycolumn[1:] if (classindex == 0) else datasetbycolumn[:classindex]\n\n for attribute in attributesinuse:\n idx = i+1 if classindex == 0 else i\n\n if attributes[attribute] == \"categorical\" or attributes[attribute] == \"binary\":\n listofkeys = list(Counter(datasetbycolumn[idx]).keys())\n listofcategory = [] # this is the list of categorical values.\n \n for key in listofkeys:\n indexlist = [idex for idex, element in enumerate(datasetbycolumn[idx]) if element == key]\n category = np.array(datasetbycolumn[classindex][indexlist])\n listofcategory.append(category)\n\n entropynow = 0\n\n for ctgry in listofcategory:\n a = len(ctgry)/len(datasetbycolumn[idx]) # This is probability\n entropynow += a * entropy(ctgry)\n\n if entropynow < smallestentrophy:\n smallestentrophy = entropynow\n bestattribute = {attribute:attributes[attribute]}\n \n elif attributes[attribute] == \"numerical\":\n datasetsort = datasetbycolumn.T[datasetbycolumn.T[:,idx].argsort(kind='quicksort')].T\n currentthreshold = (datasetsort[idx][1]+datasetsort[idx][0])/2\n k = 1\n while k < len(datasetsort.T):\n currentthreshold = (datasetsort[idx][k]+datasetsort[idx][k-1])/2\n listofcategory = [datasetsort[classindex][:k],datasetsort[classindex][k:]]\n entropynow = 0\n\n for ctgry in listofcategory:\n a = len(ctgry)/len(datasetbycolumn[idx]) # This is probability\n entropynow += a * entropy(ctgry)\n\n if entropynow < smallestentrophy:\n smallestentrophy = entropynow\n thresholdvalue = currentthreshold\n bestattribute = {attribute:attributes[attribute]} \n k += 1\n i += 1\n\n gain = originalentrophy-smallestentrophy\n # set first attribution dictionary {key:type} to the best attributes.\n return bestattribute, thresholdvalue, gain\n\ndef cartbestseperate(dataset, attributes:dict):\n # dataset in is the dataset by row. \n # attributes is the dictionary of attributes:type \n # types: numerical, categorical, binary.\n datasetbycolumn = dataset.T\n classindex = list(attributes.values()).index(\"class\")\n originalgini = gini(datasetbycolumn[classindex])\n smallestgini = originalgini\n thresholdvalue = -1\n\n i = 0\n bestattribute = {list(attributes.keys())[i]:attributes[list(attributes.keys())[i]]}\n attributesinuse = list(attributes.keys())[1:] if (classindex == 0) else list(attributes.keys())[:classindex]\n # datasetinuse = datasetbycolumn[1:] if (classindex == 0) else datasetbycolumn[:classindex]\n\n for attribute in attributesinuse:\n idx = i+1 if classindex == 0 else i\n\n if attributes[attribute] == \"categorical\" or attributes[attribute] == \"binary\":\n listofkeys = list(Counter(datasetbycolumn[idx]).keys())\n listofcategory = [] # this is the list of categorical values.\n \n for key in listofkeys:\n indexlist = [idex for idex, element in enumerate(datasetbycolumn[idx]) if element == key]\n category = np.array(datasetbycolumn[classindex][indexlist])\n listofcategory.append(category)\n\n currentgini = 0\n\n for ctgry in listofcategory:\n a = len(ctgry)/len(datasetbycolumn[idx]) # This is probability\n currentgini += a * gini(ctgry)\n\n if currentgini < smallestgini:\n smallestgini = currentgini\n bestattribute = {attribute:attributes[attribute]}\n \n elif attributes[attribute] == \"numerical\":\n datasetsort = datasetbycolumn.T[datasetbycolumn.T[:,idx].argsort(kind='quicksort')].T\n currentthreshold = (datasetsort[idx][1]+datasetsort[idx][0])/2\n k = 1\n while k < len(datasetsort.T):\n currentthreshold = (datasetsort[idx][k]+datasetsort[idx][k-1])/2\n listofcategory = [datasetsort[classindex][:k],datasetsort[classindex][k:]]\n currentgini = 0\n\n for ctgry in listofcategory:\n a = len(ctgry)/len(datasetbycolumn[idx]) # This is probability\n currentgini += a * gini(ctgry)\n\n if currentgini < smallestgini:\n smallestgini = currentgini\n thresholdvalue = currentthreshold\n bestattribute = {attribute:attributes[attribute]} \n k += 1\n i += 1\n\n # set first attribution dictionary {key:type} to the best attributes.\n gain = originalgini-smallestgini\n return bestattribute, thresholdvalue, gain\n",
"_____no_output_____"
]
],
[
[
"##### 3. decisiontree.py",
"_____no_output_____"
]
],
[
[
"import sklearn.model_selection\nimport numpy as np\nimport csv\nimport math\nimport matplotlib.pyplot as plt\nimport random\nfrom collections import Counter\nfrom utils import *\n\nclass Treenode:\n type = \"\"\n datatype = \"\"\n label = None\n testattribute = \"\"\n edge = {}\n majority = -1\n threshold = -1 # for numerical value\n testattributedict = {}\n depth = 0\n _caldepth = 0\n\n parent = None\n\n def __init__(self, label, type):\n self.label = label\n self.type = type\n # self.left = left\n # self.right = right\n\n def caldepth(self):\n a = self\n while a.parent is not None:\n self._caldepth += 1\n a = a.parent\n return self._caldepth\n \n def isfather(self):\n if self.parent is None:\n return True\n else:\n return False\n \n\n# Decision Tree that only analyze square root of the data.\ndef decisiontreeforest(dataset: np.array, dictattributes: dict, algortype: str ='id3', maxdepth: int = 10, minimalsize: int = 10, minimalgain: float = 0.01):\n datasetcopy = np.copy(dataset).T # dataset copy is by colomn. \n dictattricopy = dictattributes.copy()\n classindex = list(dictattributes.values()).index(\"class\")\n k = len(dictattributes)-1\n randomlist = random.sample(range(0, k), round(math.sqrt(k))) if classindex !=0 else random.sample(range(1, k+1), round(math.sqrt(k)))\n randomlist.append(classindex)\n randomkey = [list(dictattricopy.keys())[i] for i in randomlist]\n trimmeddict = {key:dictattricopy[key] for key in randomkey}\n trimmeddata = np.array(datasetcopy[randomlist])\n\n def processbest(algor):\n if algor == \"cart\" or algor == \"gini\":\n return cartbestseperate(trimmeddata.T, trimmeddict)\n else: # algor == \"id3\" or algor == \"infogain\"\n return id3bestseperate(trimmeddata.T, trimmeddict)\n\n node = Treenode(label=-1,type=\"decision\")\n currentdepth = node.depth\n\n node.majority = majority(datasetcopy[classindex])\n\n if same(datasetcopy[classindex]):\n node.type = \"leaf\"\n node.label = datasetcopy[classindex][0]\n return node\n \n if len(dictattricopy) == 0:\n node.type = \"leaf\"\n node.label = majority(datasetcopy[classindex])\n return node\n\n # A stopping criteria 'minimal_size_for_split_criterion'\n\n if len(dataset) <= minimalsize:\n node.type = \"leaf\"\n node.label = majority(datasetcopy[classindex])\n return node\n\n bestattributedict,thresholdval,gain = processbest(algortype)\n bestattributename = list(bestattributedict.keys())[0]\n bestattributetype = bestattributedict[bestattributename]\n node.testattributedict = bestattributedict\n node.datatype = bestattributetype\n node.testattribute = bestattributename\n node.threshold = thresholdval\n bindex = list(dictattricopy.keys()).index(list(bestattributedict.keys())[0])\n\n # A Possible Stopping criteria 'minimal_gain'\n\n if gain < minimalgain:\n node.type = \"leaf\"\n node.label = majority(datasetcopy[classindex])\n return node\n\n subdatalists = []\n if bestattributetype == \"numerical\":\n sortedcopy = datasetcopy.T[datasetcopy.T[:,bindex].argsort(kind='quicksort')].T\n splitindex = 0\n for numericalvalue in sortedcopy[bindex]:\n if numericalvalue > thresholdval:\n break\n else:\n splitindex += 1\n subdatalistraw = [sortedcopy.T[:splitindex].T,sortedcopy.T[splitindex:].T]\n for subdata in subdatalistraw:\n subdata = np.delete(subdata,bindex,0)\n subdatalists.append(subdata.T)\n else:\n bigv = list(Counter(datasetcopy[bindex]).keys()) # this is the all the categories of the test attribute left.\n \n for smallv in bigv:\n index = [idx for idx, element in enumerate(datasetcopy[bindex]) if element == smallv]\n subdatav = np.array(datasetcopy.T[index]).T\n subdatav = np.delete(subdatav,bindex,0) # I delete the column I already used using bindex as reference. \n # Then, later, pop the same index from list attribute.\n subdatalists.append(subdatav.T) # list of nparrays of target/label/categories.\n\n dictattricopy.pop(bestattributename)\n \n edge = {}\n sdindex = 0\n for subvdata in subdatalists:\n\n if subvdata.size == 0:\n node.type = \"leaf\"\n node.label = node.majority\n node.threshold = thresholdval\n return node\n\n # Another Stoping criteria I could ADD: maximal depth\n \n if node.caldepth()+1 > maxdepth: \n node.type = \"leaf\"\n node.label = node.majority\n node.threshold = thresholdval\n return node \n\n subtree = decisiontreeforest(subvdata, dictattricopy, algortype, maxdepth, minimalsize, minimalgain)\n subtree.depth = currentdepth + 1\n subtree.parent = node\n \n if bestattributetype == 'numerical':\n attributevalue = \"<=\" if sdindex == 0 else \">\"\n else:\n attributevalue = bigv[sdindex]\n\n edge[attributevalue] = subtree\n sdindex += 1\n\n node.edge = edge\n\n return node\n\n# Predict the label of the test data, return correct and predict.\ndef prediction(tree: Treenode, instance, dictattricopy): # note that the instance is by row. (I formerly used by column)\n predict = tree.majority\n classindex = list(dictattricopy.values()).index(\"class\")\n correct = instance[classindex]\n if tree.type == 'leaf':\n predict = tree.label\n return predict, correct, predict==correct\n\n testindex = list(dictattricopy.keys()).index(tree.testattribute)\n \n if tree.datatype == \"numerical\":\n if instance[testindex] <= tree.threshold:\n nexttree = tree.edge['<=']\n else:\n nexttree = tree.edge['>']\n else:\n if instance[testindex] not in tree.edge:\n return predict, correct, predict==correct\n \n nexttree = tree.edge[instance[testindex]]\n\n return prediction(nexttree, instance, dictattricopy)",
"_____no_output_____"
]
],
[
[
"##### 4. randomforest.py",
"_____no_output_____"
]
],
[
[
"from utils import *\nfrom decisiontree import *\n\n# Stratified K-Fold method\ndef stratifiedkfold(data, categorydict, k = 10):\n classindex = list(categorydict.values()).index(\"class\")\n datacopy = np.copy(data).T\n classes = list(Counter(datacopy[classindex]).keys())\n nclass = len(classes) # number of classes\n listofclasses = []\n\n for oneclass in classes:\n index = [idx for idx, element in enumerate(datacopy[classindex]) if element == oneclass]\n oneclassdata = np.array(datacopy.T[index])\n np.random.shuffle(oneclassdata)\n listofclasses.append(oneclassdata)\n\n splitted = [np.array_split(i, k) for i in listofclasses]\n nclass = len(classes)\n combined = []\n\n for j in range(k):\n ithterm = []\n for i in range(nclass):\n if len(ithterm) == 0:\n ithterm = splitted[i][j]\n else:\n ithterm = np.append(ithterm,splitted[i][j],0)\n combined.append(ithterm)\n \n return combined\n\n# Bootstrap/Bagging method with resample ratio\ndef bootstrap(data, ratio=0.1): \n data2 = np.copy(data)\n k = len(data)\n randomlist = random.sample(range(0, k), round(k*ratio))\n data2 = np.delete(data2, randomlist, 0)\n p = len(data2)\n randomfill = random.sample(range(0, p), k-p)\n data2 = np.concatenate((data2,data2[randomfill]),0)\n # print(len(data2))\n return data2\n\n# Random Forest, plant a forest of n trees\ndef plantforest(data, categorydict, ntree=10, maxdepth=10, minimalsize=10, minimalgain=0.01, algortype='id3', bootstrapratio = 0.1):\n forest = []\n for i in range(ntree):\n datause = bootstrap(data, bootstrapratio)\n tree = decisiontreeforest(datause,categorydict,algortype,maxdepth,minimalsize,minimalgain)\n forest.append(tree)\n return forest\n\n# Predict the class of a single instance\ndef forestvote(forest, instance, categorydict):\n votes = {}\n for tree in forest:\n predict, correct, correctbool = prediction(tree,instance,categorydict)\n if predict not in votes:\n votes[predict] = 1\n else:\n votes[predict] += 1\n return max(votes, key=votes.get), correct\n\n# A complete k-fold cross validation\ndef kfoldcrossvalid(data, categorydict, k=10, ntree=10, maxdepth=5, minimalsize=10, minimalgain=0.01, algortype='id3', bootstrapratio = 0.1):\n folded = stratifiedkfold(data, categorydict, k)\n listofnd = []\n accuracylist = []\n for i in range(k):\n # print(\"at fold\", i)\n testdataset = folded[i]\n foldedcopy = folded.copy()\n foldedcopy.pop(i)\n traindataset = np.vstack(foldedcopy) \n correctcount = 0\n trainforest = plantforest(traindataset,categorydict,ntree,maxdepth,minimalsize,minimalgain,algortype,bootstrapratio)\n emptyanalysis = []\n # testdataset = traindataset\n for instance in testdataset:\n predict, correct = forestvote(trainforest,instance,categorydict)\n emptyanalysis.append([predict, correct])\n if predict == correct:\n correctcount += 1\n listofnd.append(np.array(emptyanalysis))\n # print('fold', i+1, ' accuracy: ', correctcount/len(testdataset))\n accuracylist.append(correctcount/len(testdataset))\n acc = np.mean(accuracylist)\n return listofnd, acc",
"_____no_output_____"
]
],
[
[
"##### 5. run.py",
"_____no_output_____"
]
],
[
[
"from utils import *\nfrom decisiontree import *\nfrom randomforest import *\n\ndef importhousedata():\n house = importfile('hw3_house_votes_84.csv', ',')\n housecategory = {}\n for i in house[0]:\n housecategory[i] = 'categorical'\n housecategory[\"class\"] = 'class'\n housedata = np.array(house[1:]).astype(float)\n return housedata, housecategory\n\ndef importwinedata():\n wine = importfile('hw3_wine.csv', '\\t')\n winecategory = {}\n for i in wine[0]:\n winecategory[i] = 'numerical'\n winecategory[\"# class\"] = 'class'\n winedata = np.array(wine[1:]).astype(float)\n return winedata, winecategory\n\ndef importcancerdata():\n cancer = importfile('hw3_cancer.csv', '\\t')\n cancercategory = {}\n for i in cancer[0]:\n cancercategory[i] = 'numerical'\n cancercategory[\"Class\"] = 'class'\n cancerdata = np.array(cancer[1:]).astype(float)\n return cancerdata, cancercategory\n\ndef importcmcdata():\n cmc = importfile('cmc.data', ',')\n cmccategory = {\"Wife's age\":\"numerical\",\"Wife's education\":\"categorical\",\n \"Husband's education\":\"categorical\",\"Number of children ever born\":\"numerical\",\n \"Wife's religion\":\"binary\",\"Wife's now working?\":\"binary\",\n \"Husband's occupation\":\"categorical\",\"Standard-of-living index\":\"categorical\",\n \"Media exposure\":\"binary\",\"Contraceptive method used\":\"class\"}\n cmcdata = np.array(cmc).astype(int)\n return cmcdata, cmccategory\n\n\nif __name__==\"__main__\":\n housedata, housecategory = importhousedata()\n winedata, winecategory = importwinedata()\n cancerdata, cancercategory = importcancerdata()\n cmcdata,cmccategory = importcmcdata()\n\n lists,acc = kfoldcrossvalid(cancerdata, cancercategory, k=10, ntree=20, maxdepth=10, minimalsize=10, minimalgain=0.01, algortype='id3', bootstrapratio = 0.1)\n print(acc)\n print(lists)",
"0.9599562592948999\n[array([[0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [1., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [1., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [0., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [0., 1.]]), array([[0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [0., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [0., 1.],\n [1., 1.],\n [1., 1.]]), array([[0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [1., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [1., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [0., 1.]]), array([[0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [1., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.]]), array([[0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [1., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.]]), array([[0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [1., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [1., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.]]), array([[0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [1., 0.],\n [0., 0.],\n [1., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.]]), array([[0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [1., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [1., 0.],\n [0., 0.],\n [1., 0.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [0., 1.],\n [1., 1.],\n [0., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [0., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.]]), array([[0., 0.],\n [0., 0.],\n [0., 0.],\n [1., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [1., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [0., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.]]), array([[0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [1., 0.],\n [0., 0.],\n [0., 0.],\n [1., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [0., 0.],\n [1., 0.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.],\n [1., 1.]])]\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0f7aa220019d5284200a28d78d4afc90818b905 | 7,641 | ipynb | Jupyter Notebook | Chapter-6/CV Book Ch 6 Exercise 2.ipynb | moizumi99/CVBookExercise | 5f9a031e631470f7d15861366ca309942ea313f3 | [
"Unlicense"
] | 30 | 2017-11-06T07:40:58.000Z | 2022-03-11T07:12:19.000Z | Chapter-6/CV Book Ch 6 Exercise 2.ipynb | niilante/CVBookExercise | 5f9a031e631470f7d15861366ca309942ea313f3 | [
"Unlicense"
] | null | null | null | Chapter-6/CV Book Ch 6 Exercise 2.ipynb | niilante/CVBookExercise | 5f9a031e631470f7d15861366ca309942ea313f3 | [
"Unlicense"
] | 18 | 2018-07-19T05:05:25.000Z | 2022-03-11T07:12:20.000Z | 24.028302 | 116 | 0.473367 | [
[
[
"from PIL import Image\nfrom numpy import *\nfrom pylab import *\nimport scipy.misc",
"_____no_output_____"
],
[
"from scipy.cluster.vq import *",
"_____no_output_____"
],
[
"import imtools\nimport pickle",
"_____no_output_____"
],
[
"imlist = imtools.get_imlist('selected_fontimages/')\nimnbr = len(imlist)",
"_____no_output_____"
],
[
"with open('font_pca_modes.pkl', 'rb') as f:\n immean = pickle.load(f)\n V = pickle.load(f)",
"_____no_output_____"
],
[
"immatrix = array([array(Image.open(im)).flatten() for im in imlist], 'f')",
"_____no_output_____"
],
[
"immean = immean.flatten()\nprojected = array([dot(V[:40], immatrix[i]-immean) for i in range(imnbr)])",
"_____no_output_____"
],
[
"cluster_num = 3\nprojected = whiten(projected)\ncentroids, distortion = kmeans(projected, cluster_num)",
"_____no_output_____"
],
[
"code, distance = vq(projected, centroids)",
"_____no_output_____"
],
[
"def divide_branch_with_center(data, branch, k):\n div = min(k, len(branch))\n if div<=1:\n return list(branch)\n centroids, distortion = kmeans(data[branch], k)\n code, distance = vq(data[branch], centroids)\n new_branch = []\n for i in range(k):\n ind = where(code==i)[0]\n if len(ind)==0:\n continue\n else:\n new_branch.append((centroids[i], distance[i], divide_branch_with_center(data, branch[ind], k)))\n return new_branch",
"_____no_output_____"
],
[
"tree = array([i for i in range(projected.shape[0])])\nbranches = ([0 for i in range(40)], 0, divide_branch_with_center(projected, tree, 4))",
"_____no_output_____"
],
[
"def get_depth(t):\n if len(t[2])<2:\n return 1\n else:\n return max([get_depth(tt) for tt in t[2]])+1",
"_____no_output_____"
],
[
"def get_height(t):\n if (len(t[2])<2):\n return 1\n else:\n return sum([get_height(tt) for tt in t[2]])",
"_____no_output_____"
],
[
"from PIL import Image, ImageDraw",
"_____no_output_____"
],
[
"def draw_average(center, x, y, im):\n c = center/np.linalg.norm(center)\n avim = dot((V[:40]).T, c)\n avim = 255*(avim-min(avim))/(max(avim)-min(avim)+1e-6)\n avim = avim.reshape(25, 25)\n avim[avim<0] = 0\n avim[avim>255] = 255\n avim = Image.fromarray(avim)\n avim.thumbnail([20, 20])\n ns = avim.size\n im.paste(avim, [int(x), int(y-ns[1]//2), int(x+ns[0]), int(y+ns[1]-ns[1]//2)])",
"_____no_output_____"
],
[
"def draw_node(node, draw, x, y, s, iml, im):\n if len(node[2])<1:\n return\n if len(node[2])==1:\n nodeim = Image.open(iml[node[2][0]])\n nodeim.thumbnail([20, 20])\n ns = nodeim.size\n im.paste(nodeim, [int(x), int(y-ns[1]//2), int(x+ns[0]), int(y+ns[1]-ns[1]//2)])\n else:\n ht = sum([get_height(n) for n in node[2]])*20/2\n h1 = get_height(node[2][0])*20/2\n h2 = get_height(node[2][-1])*20/2\n top = y-ht\n bottom = y+ht\n draw.line((x, top+h1, x, bottom-h2), fill=(0, 0, 0))\n y = top\n for i in range(len(node[2])):\n ll = node[2][i][1]/8*s\n y += get_height(node[2][i])*20/2\n xx = x + ll + s/4\n draw.line((x, y, xx, y), fill=(0, 0, 0))\n if len(node[2][i][2])>1:\n draw_average(node[2][i][0], xx, y, im)\n xx = xx+20\n draw.line((xx, y, xx+s/4, y), fill=(0, 0, 0))\n xx = xx+s/4\n draw_node(node[2][i], draw, xx, y, s, imlist, im)\n y += get_height(node[2][i])*20/2",
"_____no_output_____"
],
[
"def draw_dendrogram(node, iml, filename='kclusters.jpg'):\n rows = get_height(node)*20+40\n cols = 1200\n\n s = float(cols-150)/get_depth(node)\n\n im = Image.new('RGB', (cols, rows), (255, 255, 255))\n draw = ImageDraw.Draw(im)\n\n x = 0\n y = rows/2\n avim = Image.fromarray(immean.reshape(25, 25))\n avim.thumbnail([20, 20])\n ns = avim.size\n im.paste(avim, [int(x), int(y-ns[1]//2), int(x+ns[0]), int(y+ns[1]-ns[1]//2)])\n draw.line((x+20, y, x+40, y), fill=(0, 0, 0))\n draw_node(node, draw, x+40, (rows/2), s, iml, im)\n im.save(filename)\n im.show()",
"_____no_output_____"
],
[
"draw_dendrogram(branches, imlist, filename='k_fonts.jpg')",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0f7abc5e5eeca945b0d0a39fbdac1e0e7c7901a | 161,350 | ipynb | Jupyter Notebook | 4.CCA/CP_L1000_SVCCA.ipynb | broadinstitute/lincs-profiling-comparison | 075c3bc60eeb3934fc42c30bae6aeed8cda1cd6d | [
"BSD-3-Clause"
] | 1 | 2021-07-20T07:47:02.000Z | 2021-07-20T07:47:02.000Z | 4.CCA/CP_L1000_SVCCA.ipynb | broadinstitute/lincs-profiling-comparison | 075c3bc60eeb3934fc42c30bae6aeed8cda1cd6d | [
"BSD-3-Clause"
] | 19 | 2020-10-24T20:55:27.000Z | 2021-08-13T16:26:30.000Z | 4.CCA/CP_L1000_SVCCA.ipynb | broadinstitute/lincs-profiling-comparison | 075c3bc60eeb3934fc42c30bae6aeed8cda1cd6d | [
"BSD-3-Clause"
] | 3 | 2020-10-24T18:14:07.000Z | 2021-06-24T17:36:25.000Z | 254.897314 | 52,254 | 0.914633 | [
[
[
"### - Canonical Correlation Analysis btw Cell painting & L1000\n\n- This notebook focus on calculating the canonical coefficients between the canonical variables of Cell painting and L1000 level-4 profiles after applying PCA on them.\n\n\n---------------------------------------------\n- The aim of CCA is finding the relationship between two lumped variables in a way that the correlation between these twos is maximum. Obviously, there are several linear combinations of variables, but the aim is to pick only those linear functions which best express the correlations between the two variable sets. These linear functions are called the canonical variables, and the correlations between corresponding pairs of canonical variables are called canonical correlations. [CCA read](https://medium.com/analytics-vidhya/what-is-canonical-correlation-analysis-58ef4349c0b0) [cca_tutorial](https://github.com/google/svcca/blob/master/tutorials/001_Introduction.ipynb)",
"_____no_output_____"
]
],
[
[
"from google.colab import drive\ndrive.mount('/content/drive')",
"Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount(\"/content/drive\", force_remount=True).\n"
],
[
"import os, sys\nfrom matplotlib import pyplot as plt\n%matplotlib inline\nimport numpy as np\nimport pickle\nimport pandas as pd\nimport seaborn as sns\nimport gzip\nsns.set_context(\"talk\")\nsns.set_style(\"darkgrid\")\nfrom sklearn.decomposition import PCA\nfrom sklearn.preprocessing import StandardScaler\nfrom sklearn.cross_decomposition import CCA",
"_____no_output_____"
],
[
"###know the current directory\nos.getcwd()",
"_____no_output_____"
],
[
"os.chdir('/content/drive')",
"_____no_output_____"
],
[
"# !cat 'My Drive/profiles/cell_painting/cca_core.py'",
"_____no_output_____"
],
[
"sys.path.append('My Drive/profiles/cell_painting/')",
"_____no_output_____"
],
[
"import cca_core",
"_____no_output_____"
],
[
"L1000_cp_dir = 'My Drive/profiles/L1000_cellpainting_comparison/L1000_CP_lvl4_datasets'",
"_____no_output_____"
],
[
"df_train = pd.read_csv(os.path.join(L1000_cp_dir, 'train_lvl4_data.csv.gz'), \n compression='gzip',low_memory = False)\ndf_test = pd.read_csv(os.path.join(L1000_cp_dir, 'test_lvl4_data.csv.gz'), \n compression='gzip',low_memory = False)",
"_____no_output_____"
],
[
"df_targets = pd.read_csv(os.path.join(L1000_cp_dir, 'target_labels.csv'))",
"_____no_output_____"
],
[
"metadata_cols = ['replicate_name', 'replicate_id', 'Metadata_broad_sample', 'Metadata_pert_id', 'Metadata_Plate', \n 'Metadata_Well', 'Metadata_broad_id', 'Metadata_moa', 'sig_id', 'pert_id', 'pert_idose', \n 'det_plate', 'det_well', 'Metadata_broad_sample', 'pert_iname', 'moa', 'dose']",
"_____no_output_____"
],
[
"target_cols = df_targets.columns[1:]",
"_____no_output_____"
],
[
"df_train_y = df_train[target_cols].copy()\ndf_train_x = df_train.drop(target_cols, axis = 1).copy()",
"_____no_output_____"
],
[
"df_test_y = df_test[target_cols].copy()\ndf_test_x = df_test.drop(target_cols, axis = 1).copy()",
"_____no_output_____"
],
[
"df_train_x.drop(metadata_cols, axis = 1, inplace = True)\ndf_test_x.drop(metadata_cols, axis = 1, inplace = True)",
"_____no_output_____"
],
[
"cp_cols = df_train_x.columns.tolist()[:696]\nL1000_cols = df_train_x.columns.tolist()[696:]",
"_____no_output_____"
],
[
"df_train_cp_x = df_train_x.iloc[:, :696].copy()\ndf_train_L1000_x = df_train_x.iloc[:, 696:].copy()\ndf_test_cp_x = df_test_x.iloc[:, :696].copy()\ndf_test_L1000_x = df_test_x.iloc[:, 696:].copy()",
"_____no_output_____"
],
[
"df_cp_x = pd.concat([df_train_cp_x, df_test_cp_x])\ndf_L1000_x = pd.concat([df_train_L1000_x, df_test_L1000_x])",
"_____no_output_____"
],
[
"def normalize(df):\n '''Normalize using Standardscaler'''\n norm_model = StandardScaler()\n df_norm = pd.DataFrame(norm_model.fit_transform(df),index = df.index,columns = df.columns)\n return df_norm",
"_____no_output_____"
],
[
"df_L1000_x = normalize(df_L1000_x)\ndf_cp_x = normalize(df_cp_x)",
"_____no_output_____"
],
[
"# taking the first 300 PCs for CCA and SVCCA\ndef pca_preprocess(df,n_comp1 = 300,feat_new = ['pca'+ str(i) for i in range(300)]):\n pca = PCA(n_components=n_comp1, random_state=42)\n df_pca = pd.DataFrame(pca.fit_transform(df),columns=feat_new)\n return(df_pca)",
"_____no_output_____"
],
[
"df_L1_pc_x = pca_preprocess(df_L1000_x)\ndf_cp_pc_x = pca_preprocess(df_cp_x)",
"_____no_output_____"
]
],
[
[
"#### - CCA on CP & L1000 train data\n\n",
"_____no_output_____"
]
],
[
[
"cca_results = cca_core.get_cca_similarity(df_cp_pc_x.values.T, df_L1_pc_x.values.T, epsilon=1e-10, verbose=False)",
"_____no_output_____"
],
[
"plt.figure(figsize=(12,8))\nsns.set_context('talk', font_scale = 0.85)\nsns.lineplot(x=range(len(cca_results[\"cca_coef1\"])), y=cca_results[\"cca_coef1\"])\nplt.title(\"CCA correlation coefficients between CP and L1000 canonical variables (300) after PCA\")",
"_____no_output_____"
],
[
"print(\"Mean Canonical Correlation co-efficient between CP and L1000 canonical variables (300):\", np.mean(cca_results[\"cca_coef1\"]))",
"Mean Canonical Correlation co-efficient between CP and L1000 canonical variables (300): 0.14511046236358863\n"
]
],
[
[
"#### - (Singular Vectors)CCA as a method to analyze the correlation between Cell painting & L1000",
"_____no_output_____"
]
],
[
[
"print(\"Results using SVCCA keeping 300 dims\")\n\n# Mean subtract activations\ncacts1 = df_cp_pc_x.values.T - np.mean(df_cp_pc_x.values.T, axis=1, keepdims=True)\ncacts2 = df_L1_pc_x.values.T - np.mean(df_L1_pc_x.values.T, axis=1, keepdims=True)\n\n# Perform SVD\nU1, s1, V1 = np.linalg.svd(cacts1, full_matrices=False)\nU2, s2, V2 = np.linalg.svd(cacts2, full_matrices=False)\n\nsvacts1 = np.dot(s1[:300]*np.eye(300), V1[:300])\n# can also compute as svacts1 = np.dot(U1.T[:20], cacts1)\nsvacts2 = np.dot(s2[:300]*np.eye(300), V2[:300])\n# can also compute as svacts1 = np.dot(U2.T[:20], cacts2)\n\nsvcca_results = cca_core.get_cca_similarity(svacts1, svacts2, epsilon=1e-10, verbose=False)\n\nprint('mean svcca correlation coefficient:', np.mean(svcca_results[\"cca_coef1\"]))\nplt.figure(figsize=(12,8))\nsns.set_context('talk', font_scale = 0.85)\nplt.plot(svcca_results[\"cca_coef1\"], lw=2.0)\nplt.xlabel(\"Sorted CCA Correlation Coeff Idx\")\nplt.ylabel(\"CCA Correlation Coefficient Value\")\nplt.title(\"SVCCA correlation coefficients between CP and L1000 canonical variables (300)\")",
"Results using SVCCA keeping 300 dims\nmean svcca correlation coefficient: 0.14511046236358852\n"
]
],
[
[
"### - Using Sklearn CCA package for CCA",
"_____no_output_____"
]
],
[
[
"cca = CCA(n_components=df_cp_pc_x.shape[1])",
"_____no_output_____"
],
[
"cp_cca_vars, L1000_cca_vars = cca.fit_transform(df_cp_pc_x, df_L1_pc_x)",
"/usr/local/lib/python3.7/dist-packages/sklearn/cross_decomposition/_pls.py:96: ConvergenceWarning: Maximum number of iterations reached\n ConvergenceWarning)\n"
],
[
"canonical_coeffs = np.corrcoef(cp_cca_vars.T, L1000_cca_vars.T).diagonal(offset=df_cp_pc_x.shape[1])",
"_____no_output_____"
],
[
"print('mean svcca correlation coefficient:', np.mean(svcca_results[\"cca_coef1\"]))\nplt.figure(figsize=(12,8))\nsns.set_context('talk', font_scale = 0.85)\nplt.plot(canonical_coeffs, lw=2.0)\nplt.xlabel(\"Sorted CCA Correlation Coeff Idx\")\nplt.ylabel(\"CCA Correlation Coefficient Value\")\nplt.title(\"CCA correlation coefficients between CP and L1000 canonical variables after PCA\")",
"mean svcca correlation coefficient: 0.14511046236358852\n"
]
],
[
[
"#### - Ultimately for further analysis, focus will be on the first few canonical variables of both CP and L1000 that have the highest canonical coefficients.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
d0f7c0b197630290762815a1d22b3c7224cabd29 | 19,215 | ipynb | Jupyter Notebook | Preprocessing train dataset.ipynb | biexingle/ResNet-50-for-Cats.Vs.Dogs | 1c81f91aff86ce49fbe805b3b9b5b169608ec48d | [
"Apache-2.0"
] | 37 | 2016-11-26T05:41:46.000Z | 2021-08-17T22:02:18.000Z | Preprocessing train dataset.ipynb | mlhy/ResNet-50-for-Cats.Vs.Dogs | 1c81f91aff86ce49fbe805b3b9b5b169608ec48d | [
"Apache-2.0"
] | null | null | null | Preprocessing train dataset.ipynb | mlhy/ResNet-50-for-Cats.Vs.Dogs | 1c81f91aff86ce49fbe805b3b9b5b169608ec48d | [
"Apache-2.0"
] | 19 | 2016-11-26T05:41:50.000Z | 2021-12-25T02:04:17.000Z | 95.123762 | 7,372 | 0.853031 | [
[
[
"## Preprocessing train dataset\n\nDivide the *train* folder into two folders *mytrain* and *myvalid*\n\n- mytrain ---- including two folders \n - cat ---- including about 11250 cat images \n - dog ---- including about 11250 dog images \n\n- myvalid ---- including two folders \n - cat ---- including about 1250 cat images\n - dog ---- including about 1250 dog images",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split\nimport seaborn as sns\nimport os\nimport shutil\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"## Visualize the size of the original *train* dataset.",
"_____no_output_____"
]
],
[
[
"train_filenames = os.listdir('train')\ntrain_cat = filter(lambda x:x[:3] == 'cat', train_filenames)\ntrain_dog = filter(lambda x:x[:3] == 'dog', train_filenames)\nx = ['train_cat', 'train_dog', 'test']\ny = [len(train_cat), len(train_dog), len(os.listdir('test'))]\nax = sns.barplot(x=x, y=y)",
"_____no_output_____"
]
],
[
[
"## Shuffle and split the train filenames",
"_____no_output_____"
]
],
[
[
"mytrain, myvalid = train_test_split(train_filenames, test_size=0.1)\nprint len(mytrain), len(myvalid)",
"22500 2500\n"
]
],
[
[
"## Visualize the size of the processed train dataset",
"_____no_output_____"
]
],
[
[
"mytrain_cat = filter(lambda x:x[:3] == 'cat', mytrain)\nmytrain_dog = filter(lambda x:x[:3] == 'dog', mytrain)\nmyvalid_cat = filter(lambda x:x[:3] == 'cat', myvalid)\nmyvalid_dog = filter(lambda x:x[:3] == 'dog', myvalid)\nx = ['mytrain_cat', 'mytrain_dog', 'myvalid_cat', 'myvalid_dog']\ny = [len(mytrain_cat), len(mytrain_dog), len(myvalid_cat), len(myvalid_dog)]\n\nax = sns.barplot(x=x, y=y)",
"_____no_output_____"
]
],
[
[
"## Create symbolic link of images",
"_____no_output_____"
]
],
[
[
"def remove_and_create_class(dirname):\n if os.path.exists(dirname):\n shutil.rmtree(dirname)\n os.mkdir(dirname)\n os.mkdir(dirname+'/cat')\n os.mkdir(dirname+'/dog')\n\nremove_and_create_class('mytrain')\nremove_and_create_class('myvalid')\n\nfor filename in mytrain_cat:\n os.symlink('../../train/'+filename, 'mytrain/cat/'+filename)\n\nfor filename in mytrain_dog:\n os.symlink('../../train/'+filename, 'mytrain/dog/'+filename)\n\nfor filename in myvalid_cat:\n os.symlink('../../train/'+filename, 'myvalid/cat/'+filename)\n\nfor filename in myvalid_dog:\n os.symlink('../../train/'+filename, 'myvalid/dog/'+filename)\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0f7cd7b65689ebcd0d008de3e480305cfbb7bc4 | 16,295 | ipynb | Jupyter Notebook | Identifying_factors_contributing_to_armed_conflict_scatterplot_analyses.ipynb | dmathe18/global_armed_conflict_final_repo | 9ae83d54c9923977898699aa46b994225438c2a8 | [
"MIT"
] | null | null | null | Identifying_factors_contributing_to_armed_conflict_scatterplot_analyses.ipynb | dmathe18/global_armed_conflict_final_repo | 9ae83d54c9923977898699aa46b994225438c2a8 | [
"MIT"
] | null | null | null | Identifying_factors_contributing_to_armed_conflict_scatterplot_analyses.ipynb | dmathe18/global_armed_conflict_final_repo | 9ae83d54c9923977898699aa46b994225438c2a8 | [
"MIT"
] | null | null | null | 57.579505 | 309 | 0.607855 | [
[
[
"<a href=\"https://colab.research.google.com/github/dmathe18/global_armed_conflict_final_repo/blob/main/Identifying_factors_contributing_to_armed_conflict_scatterplot_analyses.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport plotly.express as px\nimport six\n\nimport plotly.express as px\n\nfrom google.colab import files\n\n# Import csvs as dataframes\ndf_fuel = pd.read_csv('https://raw.githubusercontent.com/mehurlock94/identifying-factors-contributing-to-armed-conflict/main/Fuel_exports_percent_merchandise_exports.csv')\ndf_energy = pd.read_csv('https://raw.githubusercontent.com/mehurlock94/identifying-factors-contributing-to-armed-conflict/main/Energy_Use.csv')\ndf_male_ag = pd.read_csv('https://raw.githubusercontent.com/mehurlock94/identifying-factors-contributing-to-armed-conflict/main/Percent_Male_Agriculture.csv')\ndf_electricity_access = pd.read_csv('https://raw.githubusercontent.com/mehurlock94/identifying-factors-contributing-to-armed-conflict/main/Percent_access_to_electricity.csv')\ndf_low_income = pd.read_csv('https://raw.githubusercontent.com/mehurlock94/identifying-factors-contributing-to-armed-conflict/main/Income_share_by_lowest_20.csv')\ndf_school_enroll = pd.read_csv('https://raw.githubusercontent.com/mehurlock94/identifying-factors-contributing-to-armed-conflict/main/Percent_school_enrollment.csv')\ndf_literacy = pd.read_csv('https://raw.githubusercontent.com/mehurlock94/identifying-factors-contributing-to-armed-conflict/main/Literacy_rate.csv')\ndf_high_tech=pd.read_csv('https://raw.githubusercontent.com/mehurlock94/identifying-factors-contributing-to-armed-conflict/main/High_tech_exports.csv')\ndf_deaths = pd.read_csv('https://raw.githubusercontent.com/mehurlock94/identifying-factors-contributing-to-armed-conflict/main/conflict_deaths.csv')\ndf_conflicts = pd.read_csv('https://raw.githubusercontent.com/mehurlock94/identifying-factors-contributing-to-armed-conflict/main/conflicts.csv')\ndf_imports=pd.read_csv('https://raw.githubusercontent.com/mehurlock94/identifying-factors-contributing-to-armed-conflict/main/Arms_imports.csv')\ndf_exports=pd.read_csv('https://raw.githubusercontent.com/mehurlock94/identifying-factors-contributing-to-armed-conflict/main/Arms_exports.csv')\ndf_expense_gdp=pd.read_csv('https://raw.githubusercontent.com/mehurlock94/identifying-factors-contributing-to-armed-conflict/main/Military_expenditure_GDP.csv')\ndf_expense_capita=pd.read_csv('https://raw.githubusercontent.com/mehurlock94/identifying-factors-contributing-to-armed-conflict/main/Military_expenditure_capita.csv')\ndf_regions=pd.read_csv('https://raw.githubusercontent.com/mehurlock94/identifying-factors-contributing-to-armed-conflict/main/countries_regions.csv')\ndf_regions=df_regions.rename(columns={'Unnamed: 1':'Country'})\ndf_fuel_import_plot=pd.read_csv('https://raw.githubusercontent.com/mehurlock94/identifying-factors-contributing-to-armed-conflict/main/fuel_imports_data.csv')\ndf_lowinc_conflict_plot=pd.read_csv('https://raw.githubusercontent.com/mehurlock94/identifying-factors-contributing-to-armed-conflict/main/lowinc_conflicts_plot_data.csv')\ndf_various_expenditure_plot=pd.read_csv('https://raw.githubusercontent.com/mehurlock94/identifying-factors-contributing-to-armed-conflict/main/various_expenditure_capita.csv')\n\n# This is old code that identifies the years with the most data points for each df\n# length_tracker={}\n# counter=0\n# for df in df_list:\n# for column in df:\n# length_tracker[str(counter)+'_'+column]=df[column].isnull().sum(axis=0)\n# counter+=1\n\n# best_dict={}\n# counter=0\n# for df in df_list:\n# lowest=5000\n# for key in length_tracker:\n# if str(counter)+'_' in key and 'Country' not in key and 'ame' not in key and 'ode' not in key:\n# if length_tracker[key]<lowest:\n# lowest=length_tracker[key]\n# best = key\n# best_dict[best]=lowest\n# counter+=1\n\n# print (df_fuel.isnull().sum(axis=0))\n# # Lists to select specific dataframes and eventual column headers\n# df_list =[df_fuel]\n# master_labels = ['Fuel']\n\n# Lists which can be varied to select data to be exported in the final csv. Years should reflect those which maximize the number of points for a particular data type.\ndf_list=[df_fuel, df_male_ag, df_electricity_access, df_school_enroll,df_low_income]\ndf_list_columns=['Fuel','Male_ag','Electricity','School_enroll','Low_income']\ndf_list_years=[2010, 2012, 2012, 2018, 2018, 2005]\n\n# Pull unique country names from the lists to identify differences and clean\ndeaths_conflicts=pd.unique(df_deaths['Country'])\nimports_exports=pd.unique(df_imports['Country'])\nexpense=pd.unique(df_expense_gdp['Country'])\nmerge_list=pd.unique(df_fuel['Country Name'])\n\n# Create a dataframe that merges key datapoints for analysis\nmerged=pd.DataFrame(merge_list, columns=['Country'])\ncounter=0\nfor df, year in zip(df_list, df_list_years):\n df=df.rename(columns={'Country Name':'Country'})\n df.drop(df.columns.difference(['Country',str(year)]),1,inplace=True)\n merged=merged.merge(df, how='inner', on='Country')\n df_regions=df_regions.merge(df, on='Country')\n merged=merged.rename(columns={str(year):df_list_columns[counter]})\n df_regions=df_regions.rename(columns={str(year):df_list_columns[counter]})\n counter+=1\n\n# Clean the data further by replacing Nan values with the average for a given region. This average comes from the regions defined in the SIPRI dataset\n\"\"\"This section of code should only be run if you want Nan values to be filled with the mean for that region\"\"\"\nregions=pd.unique(df_regions['Region'])\nheaders=list(merged.columns.values)\ndf_medians=pd.DataFrame(index=regions, columns=headers[1:])\nfor region in regions:\n runner=df_regions[df_regions['Region']==region]\n for header in headers[1:]:\n median=runner[header].mean()\n df_medians.at[region,header]=median\ndf_medians.reset_index(inplace=True)\ndf_medians=df_medians.rename(columns={'index':'Region'})\ndf_regions=df_regions.merge(df_medians, on='Region')\n\n# Further clean the data to remove duplicate column names post-merge\ndf_regions.drop(df_regions.columns.difference(['Region','Country','Fuel_y','Male_ag_y', 'Electricity_y', 'School_enroll_y', 'Low_income_y']),1,inplace=True)\ndf_regions=df_regions.rename(columns={'Fuel_y':'Fuel','Male_ag_y':'Male_ag', 'Electricity_y':'Electricity', 'School_enroll_y':'School_enroll', 'Low_income_y':'Low_income'})\nmerged=merged.set_index('Country') \ndf_regions=df_regions.set_index('Country')\nmerged=merged.fillna(df_regions)\n\n# Define a function to produce csv outputs for the various dataframes. Mainly to avoid the need to re-write excessively\ndef merger(df_list, columns_list,labels_list, merged_df):\n counter=0\n for df, column in zip(df_list, columns_list):\n df.drop(df.columns.difference(['Country',str(column)]),1,inplace=True)\n df=df.rename(columns={str(column):labels_list[counter]})\n runner=merged_df.merge(df, how='inner', on='Country')\n runner=runner.dropna()\n runner.to_csv(str(labels_list[counter])+'.csv')\n files.download(str(labels_list[counter])+'.csv')\n counter+=1\n return runner\n\n# Produce data output csv files\nmerger([df_deaths],[2019],['Deaths'],merged)\nmerger([df_conflicts],[2008],['Conflicts'],merged)\nmerger([df_imports],[2019],['Imports'],merged)\nmerger([df_exports],[2006],['Exports'],merged)\nmerger([df_expense_capita],[2018],['Expense_Capita'],merged)\nmerger([df_expense_gdp],[2018],['Expense_GPD'],merged)\nmerger([df_imports, df_exports, df_expense_capita, df_expense_gdp],[2019, 2006, 2018, 2018],['Imports','Exports','Expense_Capita','Expense_GDP'],merged)\n\n# Generate plots of fuel exports vs arms imports\njoined=pd.melt(df_fuel_import_plot, id_vars=['Fuel'], value_vars=['Imports'])\ngraph=px.scatter(joined, x='Fuel', y='value',title='Predictability of Fuel on Armed Conflicts', labels={'Fuel':'Fuel Exports','value':'Arms Imports'})\ngraph.write_html('Fuel_Imports.html')\n# files.download('Fuel_Imports.html')\n\n# Generate plots of low income percentage vs armed conflicts\njoined=pd.melt(df_lowinc_conflict_plot, id_vars=['Low_income'], value_vars=['Conflicts'])\ngraph=px.scatter(joined, x='Low_income', y='value',title='Effect of Lower Income Population on Armed Conflicts', labels={'Low_income':'Income Shared by Lowest 20%','value':'Armed Conflicts'})\ngraph.write_html('Lowinc_conflicts.html')\n# files.download('Lowinc_conflicts.html')\n\n# Generate plots of fuel exports on military expenditure\njoined=pd.melt(df_various_expenditure_plot, id_vars=['Fuel'], value_vars=['Expense_Capita'])\ngraph=px.scatter(joined, x='Fuel', y='value',title='Effect of Fuel Exports on Military Spending per Capita', labels={'Fuel':'Fuel Exports','value':'Military Expenses per Capita'})\ngraph.write_html('Fuel_percapita.html')\n# files.download('Fuel_percapita.html')\n\n# Generate plots of percent males in agriculture vs military expenditure\njoined=pd.melt(df_various_expenditure_plot, id_vars=['Male_ag'], value_vars=['Expense_Capita'])\ngraph=px.scatter(joined, x='Male_ag', y='value',title='Effect of Farming Population on Military Spending per Capita', labels={'Male_ag':'% Males in Agriculture','value':'Military Expenses per Capita'})\ngraph.write_html('Maleag_percapita.html')\n# files.download('Maleag_percapita.html')\n\n# Generate plots of percent electricity availability vs military expenditure\njoined=pd.melt(df_various_expenditure_plot, id_vars=['Electricity'], value_vars=['Expense_Capita'])\ngraph=px.scatter(joined, x='Electricity', y='value',title='Effect of Electricity Availability on Military Spending per Capita', labels={'Electricity':'% Population with Electricity','value':'Military Expenses per Capita'})\ngraph.write_html('Electricity_percapita.html')\n# files.download('Electricity_percapita.html')\n\n# Generate plots of academic enrollment vs military expenditure\njoined=pd.melt(df_various_expenditure_plot, id_vars=['School_enroll'], value_vars=['Expense_Capita'])\ngraph=px.scatter(joined, x='School_enroll', y='value',title='Effect of School Enrollment on Military Spending per Capita', labels={'School_enroll':'Ratio of Girls:Boys Enrolled','value':'Military Expenses per Capita'})\ngraph.write_html('School_percapita.html')\nfiles.download('School_percapita.html')\n",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code"
]
] |
d0f7f9079fe23915e1887196ee70002cc35367d0 | 6,354 | ipynb | Jupyter Notebook | learn-ORM/essential-sqlalchemy-2e-master/ch14/Hybrid Properties.ipynb | QuantFinEcon/py-learn | 7151f01df9f7f096312e43434fe8026d1d7d7828 | [
"Apache-2.0"
] | 2 | 2021-03-07T17:13:49.000Z | 2022-03-29T08:55:17.000Z | learn-ORM/essential-sqlalchemy-2e-master/ch14/Hybrid Properties.ipynb | QuantFinEcon/py-learn | 7151f01df9f7f096312e43434fe8026d1d7d7828 | [
"Apache-2.0"
] | 1 | 2021-06-10T20:17:55.000Z | 2021-06-10T20:17:55.000Z | learn-ORM/essential-sqlalchemy-2e-master/ch14/Hybrid Properties.ipynb | QuantFinEcon/py-learn | 7151f01df9f7f096312e43434fe8026d1d7d7828 | [
"Apache-2.0"
] | null | null | null | 25.214286 | 387 | 0.518886 | [
[
[
"from sqlalchemy import create_engine\nfrom sqlalchemy.orm import sessionmaker\n\nengine = create_engine('sqlite:///:memory:')\n\nSession = sessionmaker(bind=engine)",
"_____no_output_____"
],
[
"from datetime import datetime\n\nfrom sqlalchemy import Column, Integer, Numeric, String\nfrom sqlalchemy.ext.declarative import declarative_base\nfrom sqlalchemy.ext.hybrid import hybrid_property, hybrid_method\n\nBase = declarative_base()\n\n\nclass Cookie(Base):\n __tablename__ = 'cookies'\n\n cookie_id = Column(Integer, primary_key=True)\n cookie_name = Column(String(50), index=True)\n cookie_recipe_url = Column(String(255))\n cookie_sku = Column(String(55))\n quantity = Column(Integer())\n unit_cost = Column(Numeric(12, 2))\n \n @hybrid_property\n def inventory_value(self):\n return self.unit_cost * self.quantity\n \n @hybrid_method\n def bake_more(self, min_quantity):\n return self.quantity < min_quantity\n \n def __repr__(self):\n return \"Cookie(cookie_name='{self.cookie_name}', \" \\\n \"cookie_recipe_url='{self.cookie_recipe_url}', \" \\\n \"cookie_sku='{self.cookie_sku}', \" \\\n \"quantity={self.quantity}, \" \\\n \"unit_cost={self.unit_cost})\".format(self=self)\n \n\nBase.metadata.create_all(engine)",
"_____no_output_____"
],
[
"print(Cookie.inventory_value < 10.00)",
"cookies.unit_cost * cookies.quantity < :param_1\n"
],
[
"print(Cookie.bake_more(12))",
"cookies.quantity < :quantity_1\n"
],
[
"session = Session()\ncc_cookie = Cookie(cookie_name='chocolate chip', \n cookie_recipe_url='http://some.aweso.me/cookie/recipe.html', \n cookie_sku='CC01', \n quantity=12, \n unit_cost=0.50)\ndcc = Cookie(cookie_name='dark chocolate chip',\n cookie_recipe_url='http://some.aweso.me/cookie/recipe_dark.html',\n cookie_sku='CC02',\n quantity=1,\n unit_cost=0.75)\nmol = Cookie(cookie_name='molasses',\n cookie_recipe_url='http://some.aweso.me/cookie/recipe_molasses.html',\n cookie_sku='MOL01',\n quantity=1,\n unit_cost=0.80)\nsession.add(cc_cookie)\nsession.add(dcc)\nsession.add(mol)\nsession.flush()",
"_____no_output_____"
],
[
"dcc.inventory_value",
"_____no_output_____"
],
[
"dcc.bake_more(12)",
"_____no_output_____"
],
[
"from sqlalchemy import desc\nfor cookie in session.query(Cookie).order_by(desc(Cookie.inventory_value)):\n print('{:>20} - {:.2f}'.format(cookie.cookie_name, cookie.inventory_value))",
" chocolate chip - 6.00\n molasses - 0.80\n dark chocolate chip - 0.75\n"
],
[
"for cookie in session.query(Cookie).filter(Cookie.bake_more(12)):\n print('{:>20} - {}'.format(cookie.cookie_name, cookie.quantity))",
" dark chocolate chip - 1\n molasses - 1\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0f8002927b2490c297790050a4c1048aec9223a | 18,242 | ipynb | Jupyter Notebook | risk/q1.ipynb | deyantodorov/python | 896a4f12ff365f679a52c7e132eb5b985d424be5 | [
"Apache-2.0"
] | null | null | null | risk/q1.ipynb | deyantodorov/python | 896a4f12ff365f679a52c7e132eb5b985d424be5 | [
"Apache-2.0"
] | null | null | null | risk/q1.ipynb | deyantodorov/python | 896a4f12ff365f679a52c7e132eb5b985d424be5 | [
"Apache-2.0"
] | null | null | null | 25.584853 | 278 | 0.444304 | [
[
[
"import pandas as pd\nimport risk_tools as rt\nimport numpy as np\n\n%load_ext autoreload\n%autoreload 2\n%matplotlib inline",
"The autoreload extension is already loaded. To reload it, use:\n %reload_ext autoreload\n"
],
[
"returns = pd.read_csv('data/Portfolios_Formed_on_ME_monthly_EW.csv',\n header=0, index_col=0, parse_dates=True, na_values=-99.99)\n\nreturns.index = pd.to_datetime(returns.index, format='%Y%m')\n\nreturns.index = returns.index.to_period('M')\n\nreturns.head()\n",
"_____no_output_____"
]
],
[
[
"What was the Annualized Return of the Lo 20 portfolio over the entire period?",
"_____no_output_____"
]
],
[
[
"rt.annualized_return(returns['Lo 20']) * 100\n",
"_____no_output_____"
]
],
[
[
"What was the Annualized Volatility of the Lo 20 portfolio over the entire period? \n",
"_____no_output_____"
]
],
[
[
"rt.annualized_volatility(returns['Lo 20']) * 100",
"_____no_output_____"
]
],
[
[
"What was the Annualized Return of the Hi 20 portfolio over the entire period? \n",
"_____no_output_____"
]
],
[
[
"rt.annualized_return(returns['Hi 20']) * 100",
"_____no_output_____"
]
],
[
[
"What was the Annualized Volatility of the Hi 20 portfolio over the entire period? \n",
"_____no_output_____"
]
],
[
[
"rt.annualized_volatility(returns['Hi 20']) * 100",
"_____no_output_____"
]
],
[
[
"What was the Annualized Return of the Lo 20 portfolio over the period 1999 - 2015 (both inclusive)? \n",
"_____no_output_____"
]
],
[
[
"lo20_range_1999_2015 = returns['Lo 20']['1999':'2015']\nrt.annualized_return(lo20_range_1999_2015) * 100",
"_____no_output_____"
]
],
[
[
"What was the Annualized Volatility of the Lo 20 portfolio over the period 1999 - 2015 (both inclusive)? \n",
"_____no_output_____"
]
],
[
[
"rt.annualized_volatility(lo20_range_1999_2015) * 100",
"_____no_output_____"
]
],
[
[
"What was the Annualized Return of the Hi 20 portfolio over the period 1999 - 2015 (both inclusive)?\n",
"_____no_output_____"
]
],
[
[
"hi20_range_1999_2015 = returns['Hi 20']['1999':'2015']\nrt.annualized_return(hi20_range_1999_2015) * 100\n",
"_____no_output_____"
]
],
[
[
"What was the Annualized Volatility of the Hi 20 portfolio over the period 1999 - 2015 (both inclusive)? \n",
"_____no_output_____"
]
],
[
[
"rt.annualized_volatility(hi20_range_1999_2015) * 100",
"_____no_output_____"
]
],
[
[
"What was the Max Drawdown (expressed as a positive number) experienced over the 1999-2015 period in the SmallCap (Lo 20) portfolio?\n",
"_____no_output_____"
]
],
[
[
"(rt.drawdown(lo20_range_1999_2015, 1000)['Drawdowns']).max()",
"_____no_output_____"
]
],
[
[
"At the end of which month over the period 1999-2015 did that maximum drawdown on the SmallCap (Lo 20) portfolio occur? \n",
"_____no_output_____"
]
],
[
[
"(rt.drawdown(lo20_range_1999_2015, 1000)['Drawdowns']).idxmax()\n",
"_____no_output_____"
]
],
[
[
"What was the Max Drawdown (expressed as a positive number) experienced over the 1999-2015 period in the LargeCap (Hi 20) portfolio?\n",
"_____no_output_____"
]
],
[
[
"(rt.drawdown(hi20_range_1999_2015, 1000)['Drawdowns']).max()\n",
"_____no_output_____"
]
],
[
[
"Over the period 1999-2015, at the end of which month did that maximum drawdown of the LargeCap (Hi 20) portfolio occur? \n",
"_____no_output_____"
]
],
[
[
"(rt.drawdown(hi20_range_1999_2015, 1000)['Drawdowns']).idxmax()\n",
"_____no_output_____"
]
],
[
[
"For the remaining questions, use the EDHEC Hedge Fund Indices data set that we used in the lab assignment and load them into Python. Looking at the data since 2009 (including all of 2009) through 2018 which Hedge Fund Index has exhibited the highest semideviation? \n\n",
"_____no_output_____"
]
],
[
[
"hfi = pd.read_csv('data/edhec-hedgefundindices.csv',\n header=0, index_col=0, parse_dates=True)\n\nhfi_after_2009 = hfi['2009':]\nhfi_after_2009.head()\n",
"_____no_output_____"
]
],
[
[
"Looking at the data since 2009 (including all of 2009) which Hedge Fund Index has exhibited the lowest semideviation? \n\n",
"_____no_output_____"
]
],
[
[
"rt.semideviation(hfi_after_2009)\n",
"_____no_output_____"
]
],
[
[
"Looking at the data since 2009 (including all of 2009) which Hedge Fund Index has been most negatively skewed? \n\n",
"_____no_output_____"
]
],
[
[
"rt.skewness(hfi_after_2009)",
"_____no_output_____"
]
],
[
[
"Looking at the data since 2000 (including all of 2000) through 2018 which Hedge Fund Index has exhibited the highest kurtosis? \n\n",
"_____no_output_____"
]
],
[
[
"hfi_after_2000 = hfi['2000':]\nrt.kurtosis(hfi_after_2000)",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0f8049d94447cfce47ceca083bb86018bd7cb39 | 698,669 | ipynb | Jupyter Notebook | notebooks/yolo-webcam.ipynb | fpgadeveloper/pynq-ncs-yolo | dfd6735ea3fee64be12852ef1ab9655aabdde2fc | [
"MIT"
] | 43 | 2018-04-26T00:54:12.000Z | 2022-03-07T20:10:29.000Z | notebooks/yolo-webcam.ipynb | fpgadeveloper/pynq-ncs-yolo | dfd6735ea3fee64be12852ef1ab9655aabdde2fc | [
"MIT"
] | null | null | null | notebooks/yolo-webcam.ipynb | fpgadeveloper/pynq-ncs-yolo | dfd6735ea3fee64be12852ef1ab9655aabdde2fc | [
"MIT"
] | 16 | 2018-06-25T11:54:03.000Z | 2021-12-21T13:51:39.000Z | 1,843.453826 | 345,376 | 0.959728 | [
[
[
"# YOLO on PYNQ-Z1 and Movidius NCS: Webcam example\nTo run this notebook, you need to connect a USB webcam to the PYNQ-Z1 and a monitor to the HDMI output. You'll already need a powered USB hub for the Movidius NCS, so you should have a spare port for the webcam.\n### Load required packages",
"_____no_output_____"
]
],
[
[
"from mvnc import mvncapi as mvnc\nimport cv2\nimport numpy as np\nimport time\nfrom pynq.overlays.base import BaseOverlay\nfrom pynq.lib.video import *\nimport yolo_ncs,ncs\nimport PIL.Image\n%matplotlib inline\n\n# Load the base overlay\nbase = BaseOverlay(\"base.bit\")",
"_____no_output_____"
]
],
[
[
"### Configure the webcam\nTo get a decent frame rate, we use a webcam resolution of 640x480 so that resizing to 448x448 for the YOLO network is reasonably fast. Note that OpenCV uses BGR, but the YOLO network needs RGB, so we'll have to swap the colors around before sending images to YOLO.",
"_____no_output_____"
]
],
[
[
"# Webcam resolution\nframe_in_w = 640\nframe_in_h = 480\n\n# Configure webcam - note that output images will be BGR\nvideoIn = cv2.VideoCapture(0)\nvideoIn.set(cv2.CAP_PROP_FRAME_WIDTH, frame_in_w);\nvideoIn.set(cv2.CAP_PROP_FRAME_HEIGHT, frame_in_h);\n\nprint(\"Capture device is open: \" + str(videoIn.isOpened()))",
"Capture device is open: True\n"
]
],
[
[
"### Configure the HDMI output",
"_____no_output_____"
]
],
[
[
"hdmi_out = base.video.hdmi_out\n\n# Configure the HDMI output to the same resolution as the webcam input\nmode = VideoMode(frame_in_w,frame_in_h,24)\nhdmi_out.configure(mode, PIXEL_BGR)\n\n# Start the HDMI output\nhdmi_out.start()",
"_____no_output_____"
]
],
[
[
"### Take a photo with the webcam",
"_____no_output_____"
]
],
[
[
"ret, frame = videoIn.read()\nif (not ret): \n raise RuntimeError(\"Failed to read from camera.\")\n\n# Convert BGR image to RGB (required by YOLO and PIL)\nframe = frame[:,:,(2,1,0)]\n\n# Resize the image to the size required by YOLO network (448x448)\nsmall_frame = cv2.resize(frame, dsize=(448, 448), interpolation=cv2.INTER_CUBIC)\nncs_frame = small_frame.copy()/255.0\n\n# Show the image in the Jupyter notebook\nimg = PIL.Image.fromarray(frame)\nimg",
"_____no_output_____"
]
],
[
[
"### Open the Movidius NCS",
"_____no_output_____"
]
],
[
[
"# Open the Movidius NCS device\nncsdev = ncs.MovidiusNCS()\n\n# Load the graph file\nif ncsdev.load_graph('../graph'):\n print('Graph file loaded to Movidius NCS')",
"Graph file loaded to Movidius NCS\n"
]
],
[
[
"### Send image to NCS",
"_____no_output_____"
]
],
[
[
"ncsdev.graph.LoadTensor(ncs_frame.astype(np.float16), 'user object')\nout, userobj = ncsdev.graph.GetResult()\n\n# Interpret results and draw boxes on the image\nresults = yolo_ncs.interpret_output(out.astype(np.float32), frame.shape[1], frame.shape[0]) # fc27 instead of fc12 for yolo_small\nimg_res = yolo_ncs.draw_boxes(frame, results, frame.shape[1], frame.shape[0])\n\n# Display labelled image in Jupyter notebook\nimg = PIL.Image.fromarray(img_res)\nimg",
"_____no_output_____"
]
],
[
[
"### Webcam to HDMI pass-through (without YOLO)",
"_____no_output_____"
]
],
[
[
"n_frames = 2000\n\nstart_time = time.time()\n\nfor _ in range(n_frames):\n # Get a frame from the webcam\n ret, frame = videoIn.read()\n \n # Copy the input frame to the output frame\n frame_out = hdmi_out.newframe()\n frame_out[:,:,:] = frame[:,:,:]\n hdmi_out.writeframe(frame_out)\n\nend_time = time.time()\n\nprint('Runtime:',end_time-start_time,'FPS:',n_frames/(end_time-start_time))",
"Runtime: 72.0343644618988 FPS: 27.764526208291343\n"
]
],
[
[
"### Webcam to HDMI with YOLO",
"_____no_output_____"
]
],
[
[
"n_frames = 200\n\nstart_time = time.time()\n\nfor _ in range(n_frames):\n # Get a frame from the webcam\n ret, frame = videoIn.read()\n \n # Resize to the frame size required by YOLO network (448x448) and convert to RGB\n small_frame = cv2.resize(frame[:,:,(2,1,0)], dsize=(448, 448), interpolation=cv2.INTER_CUBIC)\n ncs_frame = small_frame.copy()/255.0\n \n # Send the frame to the NCS\n ncsdev.graph.LoadTensor(ncs_frame.astype(np.float16), 'user object')\n out, userobj = ncsdev.graph.GetResult()\n \n # Interpret results and draw the boxes on the image\n results = yolo_ncs.interpret_output(out.astype(np.float32), frame.shape[1], frame.shape[0]) # fc27 instead of fc12 for yolo_small\n img_res = yolo_ncs.draw_boxes(frame, results, frame.shape[1], frame.shape[0])\n\n # Copy labelled image into output frame\n frame_out = hdmi_out.newframe()\n frame_out[:,:,:] = img_res[:,:,:]\n hdmi_out.writeframe(frame_out)\n\nend_time = time.time()\n\nprint('Runtime:',end_time-start_time,'FPS:',n_frames/(end_time-start_time))",
"Runtime: 86.11693739891052 FPS: 2.3224235097163386\n"
]
],
[
[
"### Close the NCS device",
"_____no_output_____"
]
],
[
[
"ncsdev.close()",
"_____no_output_____"
]
],
[
[
"### Release the webcam and HDMI output",
"_____no_output_____"
]
],
[
[
"videoIn.release()\nhdmi_out.stop()\ndel hdmi_out",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0f82182b2c0b5623e2da39802e27cb6a532c190 | 24,533 | ipynb | Jupyter Notebook | explorations/prepareDataset_EyeCatcher_dlib.ipynb | MSREnable/GazeCapture | 54f00ab428a7dbb51f8f0c37f22bba6b3cb54726 | [
"RSA-MD"
] | 15 | 2019-08-28T22:06:51.000Z | 2021-10-08T09:52:13.000Z | explorations/prepareDataset_EyeCatcher_dlib.ipynb | MSREnable/GazeCapture | 54f00ab428a7dbb51f8f0c37f22bba6b3cb54726 | [
"RSA-MD"
] | null | null | null | explorations/prepareDataset_EyeCatcher_dlib.ipynb | MSREnable/GazeCapture | 54f00ab428a7dbb51f8f0c37f22bba6b3cb54726 | [
"RSA-MD"
] | 6 | 2020-11-18T02:46:55.000Z | 2021-07-08T11:12:11.000Z | 53.918681 | 1,613 | 0.582358 | [
[
[
"import os\nimport json\n\ndef findCaptureSessionDirs(path):\n session_paths = []\n devices = os.listdir(path)\n \n for device in devices:\n sessions = os.listdir(os.path.join(path, device))\n for session in sessions:\n session_paths.append(os.path.join(device, session))\n \n return session_paths\n\ndef findCapturesInSession(path):\n files = [os.path.splitext(f)[0] for f in os.listdir(path) if f.endswith('.json')]\n \n return files\n\ndef loadJsonData(filename):\n data = None\n \n with open(filename) as f:\n data = json.load(f)\n \n return data",
"_____no_output_____"
],
[
"data_directory = \"EyeCaptures\"\noutput_directory = \"EyeCaptures-dlib\"\n\ndirectories = sorted(findCaptureSessionDirs(data_directory))\ntotal_directories = len(directories)\n\nprint(f\"Found {total_directories} directories\")",
"Found 42 directories\n"
],
[
"from face_utilities import faceEyeRectsToFaceInfoDict, getEyeRectRelative, newFaceInfoDict, find_face_dlib, landmarksToRects, generate_face_grid_rect\nfrom PIL import Image as PILImage # Pillow\nimport numpy as np\nimport dateutil.parser\nimport shutil\n\ndef getScreenOrientation(capture_data):\n orientation = 0\n \n # Camera Offset and Screen Orientation compensation\n if capture_data['NativeOrientation'] == \"Landscape\":\n if capture_data['CurrentOrientation'] == \"Landscape\":\n # Camera above screen\n # - Landscape on Surface devices\n orientation = 1\n elif capture_data['CurrentOrientation'] == \"LandscapeFlipped\":\n # Camera below screen\n # - Landscape inverted on Surface devices\n orientation = 2\n elif capture_data['CurrentOrientation'] == \"PortraitFlipped\":\n # Camera left of screen\n # - Portrait with camera on left on Surface devices\n orientation = 3\n elif capture_data['CurrentOrientation'] == \"Portrait\":\n # Camera right of screen\n # - Portrait with camera on right on Surface devices\n orientation = 4\n if capture_data['NativeOrientation'] == \"Portrait\":\n if capture_data['CurrentOrientation'] == \"Portrait\":\n # Camera above screen\n # - Portrait on iOS devices\n orientation = 1\n elif capture_data['CurrentOrientation'] == \"PortraitFlipped\":\n # Camera below screen\n # - Portrait Inverted on iOS devices\n orientation = 2\n elif capture_data['CurrentOrientation'] == \"Landscape\":\n # Camera left of screen\n # - Landscape home button on right on iOS devices\n orientation = 3\n elif capture_data['CurrentOrientation'] == \"LandscapeFlipped\":\n # Camera right of screen\n # - Landscape home button on left on iOS devices\n orientation = 4\n \n return orientation\n\n\ndef getCaptureTimeString(capture_data):\n sessiontime = dateutil.parser.parse(capture_data[\"SessionTimestamp\"])\n currenttime = dateutil.parser.parse(capture_data[\"Timestamp\"])\n timedelta = sessiontime - currenttime\n return str(timedelta.total_seconds())\n\n\nfor directory_idx, directory in enumerate(directories):\n print(f\"Processing {directory_idx + 1}/{total_directories} - {directory}\")\n \n captures = findCapturesInSession(os.path.join(data_directory,directory))\n total_captures = len(captures)\n \n # dotinfo.json - { \"DotNum\": [ 0, 0, ... ],\n # \"XPts\": [ 160, 160, ... ],\n # \"YPts\": [ 284, 284, ... ],\n # \"XCam\": [ 1.064, 1.064, ... ],\n # \"YCam\": [ -6.0055, -6.0055, ... ],\n # \"Time\": [ 0.205642, 0.288975, ... ] }\n #\n # PositionIndex == DotNum\n # Timestamp == Time, but no guarantee on order. Unclear if that is an issue or not\n dotinfo = {\n \"DotNum\": [],\n \"XPts\": [],\n \"YPts\": [],\n \"XCam\": [],\n \"YCam\": [],\n \"Time\": []\n }\n\n recording_path = os.path.join(data_directory, directory)\n output_path = os.path.join(output_directory, f\"{directory_idx:05d}\")\n output_frame_path = os.path.join(output_path, \"frames\")\n\n faceInfoDict = newFaceInfoDict()\n \n # frames.json - [\"00000.jpg\",\"00001.jpg\"]\n frames = []\n facegrid = {\n \"X\": [],\n \"Y\": [],\n \"W\": [],\n \"H\": [],\n \"IsValid\": []\n }\n \n # info.json - {\"TotalFrames\":99,\"NumFaceDetections\":97,\"NumEyeDetections\":56,\"Dataset\":\"train\",\"DeviceName\":\"iPhone 6\"}\n info = {\n \"TotalFrames\": total_captures,\n \"NumFaceDetections\": 0,\n \"NumEyeDetections\": 0,\n \"Dataset\": \"train\", # For now put all data into training dataset\n \"DeviceName\": None\n }\n \n # screen.json - { \"H\": [ 568, 568, ... ], \"W\": [ 320, 320, ... ], \"Orientation\": [ 1, 1, ... ] }\n screen = {\n \"H\": [],\n \"W\": [],\n \"Orientation\": []\n }\n \n if not os.path.exists(output_directory):\n os.mkdir(output_directory)\n if not os.path.exists(output_path):\n os.mkdir(output_path)\n if not os.path.exists(output_frame_path):\n os.mkdir(output_frame_path)\n \n for capture_idx, capture in enumerate(captures):\n print(f\"Processing {capture_idx + 1}/{total_captures} - {capture}\")\n \n capture_json_path = os.path.join(data_directory, directory, capture + \".json\")\n capture_png_path = os.path.join(data_directory, directory, capture + \".png\")\n \n if os.path.isfile(capture_json_path) and os.path.isfile(capture_png_path):\n capture_data = loadJsonData(capture_json_path)\n \n if info[\"DeviceName\"] == None:\n info[\"DeviceName\"] = capture_data[\"HostModel\"]\n elif info[\"DeviceName\"] != capture_data[\"HostModel\"]:\n error(f\"Device name changed during session, expected \\'{info['DeviceName']}\\' but got \\'{capture_data['HostModel']}\\'\")\n \n capture_image = PILImage.open(capture_png_path).convert('RGB') # dlib wants images in RGB or 8-bit grayscale format\n capture_image_np = np.array(capture_image) # dlib wants images in numpy array format\n \n shape_np, isValid = find_face_dlib(capture_image_np)\n \n info[\"NumFaceDetections\"] = info[\"NumFaceDetections\"] + 1\n \n face_rect, left_eye_rect, right_eye_rect, isValid = landmarksToRects(shape_np, isValid)\n \n # facegrid.json - { \"X\": [ 6, 6, ... ], \"Y\": [ 10, 10, ... ], \"W\": [ 13, 13, ... ], \"H\": [ 13, 13, ... ], \"IsValid\": [ 1, 1, ... ] }\n if isValid:\n faceGridX, faceGridY, faceGridW, faceGridH = generate_face_grid_rect(face_rect, capture_image.width, capture_image.height)\n else:\n faceGridX = 0\n faceGridY = 0\n faceGridW = 0\n faceGridH = 0\n \n facegrid[\"X\"].append(faceGridX)\n facegrid[\"Y\"].append(faceGridY)\n facegrid[\"W\"].append(faceGridW)\n facegrid[\"H\"].append(faceGridH)\n facegrid[\"IsValid\"].append(isValid)\n \n faceInfoDict, faceInfoIdx = faceEyeRectsToFaceInfoDict(faceInfoDict, face_rect, left_eye_rect, right_eye_rect, isValid)\n info[\"NumEyeDetections\"] = info[\"NumEyeDetections\"] + 1\n \n # screen.json - { \"H\": [ 568, 568, ... ], \"W\": [ 320, 320, ... ], \"Orientation\": [ 1, 1, ... ] }\n screen[\"H\"].append(capture_data['ScreenHeightInRawPixels'])\n screen[\"W\"].append(capture_data['ScreenWidthInRawPixels'])\n screen[\"Orientation\"].append(getScreenOrientation(capture_data))\n \n # dotinfo.json - { \"DotNum\": [ 0, 0, ... ],\n # \"XPts\": [ 160, 160, ... ],\n # \"YPts\": [ 284, 284, ... ],\n # \"XCam\": [ 1.064, 1.064, ... ],\n # \"YCam\": [ -6.0055, -6.0055, ... ],\n # \"Time\": [ 0.205642, 0.288975, ... ] }\n #\n # PositionIndex == DotNum\n # Timestamp == Time, but no guarantee on order. Unclear if that is an issue or not \n xcam = 0\n ycam = 0\n \n dotinfo[\"DotNum\"].append(capture_data[\"PositionIndex\"])\n dotinfo[\"XPts\"].append(capture_data[\"ScreenX\"])\n dotinfo[\"YPts\"].append(capture_data[\"ScreenY\"])\n dotinfo[\"XCam\"].append(0)\n dotinfo[\"YCam\"].append(0)\n dotinfo[\"Time\"].append(getCaptureTimeString(capture_data))\n \n # Convert image from PNG to JPG\n frame_name = str(f\"{capture_idx:05d}.jpg\")\n frames.append(frame_name)\n capture_img = PILImage.open(capture_png_path).convert('RGB')\n capture_img.save(os.path.join(output_frame_path, frame_name))\n else:\n print(f\"Error processing capture {capture}\")\n \n with open(os.path.join(output_path, 'frames.json'), \"w\") as write_file:\n json.dump(frames, write_file)\n with open(os.path.join(output_path, 'screen.json'), \"w\") as write_file:\n json.dump(screen, write_file)\n with open(os.path.join(output_path, 'info.json'), \"w\") as write_file:\n json.dump(info, write_file)\n with open(os.path.join(output_path, 'dotInfo.json'), \"w\") as write_file:\n json.dump(dotinfo, write_file)\n with open(os.path.join(output_path, 'faceGrid.json'), \"w\") as write_file:\n json.dump(facegrid, write_file)\n with open(os.path.join(output_path, 'dlibFace.json'), \"w\") as write_file:\n json.dump(faceInfoDict[\"Face\"], write_file)\n with open(os.path.join(output_path, 'dlibLeftEye.json'), \"w\") as write_file:\n json.dump(faceInfoDict[\"LeftEye\"], write_file)\n with open(os.path.join(output_path, 'dlibRightEye.json'), \"w\") as write_file:\n json.dump(faceInfoDict[\"RightEye\"], write_file)\n \nprint(\"DONE\")",
"Processing 1/42 - 054be71eca564395a1984df3655ee837-054be71eca564395a1984df3655ee837/2003051452-e0b340ac63cb4ebe9f7f08807c7698e8\nProcessing 1/15 - b47bcf80-b8d8-4761-8c44-2ac350e75c27\nProcessing 2/15 - 3d69b5aa-b05f-4ee9-9ca0-0dadfbf86a6c\nProcessing 3/15 - 9d025d12-4eaa-46c4-b41c-2bf7153a1e73\nProcessing 4/15 - c3c4b77d-f40e-4cfc-afc0-8339c2f54a79\nProcessing 5/15 - edc05aad-2945-4894-8a87-d1fcbceb0d38\nProcessing 6/15 - 00c25896-6fae-4889-8885-c953cb62d2a5\nProcessing 7/15 - a07c6efc-322e-488f-80ed-0cdebd6f3b21\nProcessing 8/15 - 9dc0bb63-5d21-4086-a49f-cfdb924bdb57\nProcessing 9/15 - e489c944-0102-47e2-afea-53244f00cc80\nProcessing 10/15 - ad76f4c2-e8a6-436a-94a7-0095474de558\nProcessing 11/15 - ba0e5d7d-877f-41ae-a320-4d4cecf2afae\nProcessing 12/15 - 98c6c83b-a58c-49a5-895c-1742ae695892\nProcessing 13/15 - dbc1d303-5c11-4f65-979c-492084adad2a\nProcessing 14/15 - 60feb0a2-3981-4ab4-92a3-04156397d8bd\nProcessing 15/15 - ffa16276-9f39-49ab-b2dd-1fe5e7e33c7c\nProcessing 2/42 - 054be71eca564395a1984df3655ee837-054be71eca564395a1984df3655ee837/2003061914-97e0e36ef8074f99b8515be8fd3ded35\nProcessing 1/31 - 0c185409-29a6-4b1f-8624-c32c05bac3d5\nProcessing 2/31 - 8ebdae83-012d-4e24-8837-5dbf2a553591\nProcessing 3/31 - fea5934d-8111-4351-9094-7a793bcdfc1c\nProcessing 4/31 - 4880993a-12f8-4a9b-bd01-03ae64e3ee00\nProcessing 5/31 - 312ad6b9-a3dc-4b82-9400-5658821f9ea3\nProcessing 6/31 - 1af4cb77-1b0c-4b53-bb75-99fe1fd57aa5\nProcessing 7/31 - 791f3acd-f145-440c-a504-52606cda6705\nProcessing 8/31 - 2c20298a-c5ca-4ae7-a774-6a308cbb9770\nProcessing 9/31 - 183bac6e-2ebe-4060-ad61-748692f07061\nProcessing 10/31 - e8809380-7144-4339-b846-16b0e3e3e2e4\nProcessing 11/31 - b77074fb-b32a-4c2b-b71a-2b5225d84466\nProcessing 12/31 - 27def144-1408-4578-9de8-c6a4a91b8337\nProcessing 13/31 - 502d64a8-1fa1-49e6-876d-8ea5e9b7ab9d\nProcessing 14/31 - 3b76e580-3f8c-4d5c-b4ef-157db7f64b7b\nProcessing 15/31 - 089c9cc6-6802-4630-9dfa-87e468bed3da\nProcessing 16/31 - 7de4a864-3c7c-4500-87c8-db639fb26525\nProcessing 17/31 - 5c2a8017-3832-4f44-9b09-440533fc7691\nProcessing 18/31 - beeee59f-8b60-4695-8aa2-5c0793c9595f\nProcessing 19/31 - 896f7948-257c-4d34-878c-08cfeb1ba263\nProcessing 20/31 - 11456af4-3db9-4220-abd9-edd581343dca\nProcessing 21/31 - 7756f381-17df-4565-a751-47485df7c0de\nProcessing 22/31 - f991b44a-ac65-414b-9c5d-f4f9dd14b885\nProcessing 23/31 - fe20951d-edc9-4784-9fab-4cd25fdf97ed\nProcessing 24/31 - 8e0c7134-a749-47da-8e06-f5e1adb02af2\nProcessing 25/31 - 69272699-64df-4d9f-9cf9-648b744674b2\nProcessing 26/31 - eb00f16c-e345-4ae6-88bc-28fc4e5ce760\nProcessing 27/31 - d2981db4-d3ff-488a-948f-5dfd49beb011\nProcessing 28/31 - 1d9ee326-91ef-4fbc-9418-64b646e46b21\nProcessing 29/31 - 6ebc5c26-a289-41e7-abef-1647afe9e4bb\nProcessing 30/31 - ae997e2e-6344-412a-930b-888be85a6713\nProcessing 31/31 - 640c7cca-e113-47e4-b69c-55ace48011ff\nProcessing 3/42 - 054be71eca564395a1984df3655ee837-054be71eca564395a1984df3655ee837/2003062204-79b99c60da494e278afaea884d1c8bf9\nProcessing 1/44 - 62c0c257-33c2-448f-a35d-ff3793a2d7f4\nProcessing 2/44 - fa425cea-17bc-4daa-831b-1cc292848326\nProcessing 3/44 - 776b9bac-cf2f-463d-b127-6341dff3dc91\nProcessing 4/44 - 6cc17213-ede2-4cf5-9891-d5bb321e1294\nProcessing 5/44 - bc76a82b-c25b-4673-b807-ff7fa1c5ac12\nProcessing 6/44 - 1d50a747-65e6-4140-a2d0-25dbcf44bb3e\nProcessing 7/44 - 137029d0-74fe-4886-8c03-e19b50c96a5a\nProcessing 8/44 - 6932b3b1-6fe2-43c7-9e5b-50c8f178a686\nProcessing 9/44 - 9af58ea8-5b24-4ae5-8b76-9848435675f9\nProcessing 10/44 - e8fdc4e1-6809-47aa-8f8b-b73fcf0b8fc1\nProcessing 11/44 - e2fe401f-a0d5-4ca4-88e1-53d56ac0c9c6\nProcessing 12/44 - f817fae9-2271-49b2-94bc-51a13f39962e\nProcessing 13/44 - 7409ab71-2a8d-446f-83eb-3cf1b3927831\nProcessing 14/44 - 447dd754-8e9d-452f-a5d5-0f3a1595558c\nProcessing 15/44 - bfe61925-c760-43d8-9775-d592fba6e093\nProcessing 16/44 - c80e2b95-017f-4b67-9ce6-3fd2edcf0037\nProcessing 17/44 - d106bcdb-fe3b-4ebf-b94d-112067ab3cec\nProcessing 18/44 - 4604d213-d2cf-4088-b165-a283339d8e11\nProcessing 19/44 - 33dd5d47-c116-4e6f-b454-618eb64ac782\nProcessing 20/44 - 1192a373-1c05-4dc6-a7e6-b1d3dddf7cc0\nProcessing 21/44 - 4b06a3e8-ca99-4ff9-8094-d10d6cd50ac1\nProcessing 22/44 - a1eade09-fef0-4964-a87b-a8999501c269\nProcessing 23/44 - a0943d0b-ae3b-4f7f-a998-8281ccd412f9\nProcessing 24/44 - ef6aa511-95a6-45b8-8dc2-79497950c1a0\nProcessing 25/44 - d28ce877-fd50-469d-a62b-17e8f77e0891\nProcessing 26/44 - 3eef3df0-13c9-4295-a29d-58d52176a894\nProcessing 27/44 - c9fcead2-8d92-4a85-b453-949727fddb0b\nProcessing 28/44 - 5e26afe5-123e-496e-bea3-5431158095b3\nProcessing 29/44 - cd3a2eec-9907-4da5-8c38-9225406ecf60\nProcessing 30/44 - 706b99ac-5bb3-4253-9ca4-8c9445af08ce\nProcessing 31/44 - ebc3ca10-6749-4bd3-a5ac-57d4df94af84\nProcessing 32/44 - e8f50604-3156-4a28-a648-dc62a98d1ec4\nProcessing 33/44 - 6f79c71a-be76-4675-adc2-74309186a997\nProcessing 34/44 - e40cf8bd-85dd-4d62-bd85-d6870654f194\nProcessing 35/44 - 22fed202-4037-4e0e-9a43-22a8d2ee7f93\nProcessing 36/44 - 00ada65e-29ad-4b90-8254-c087194ceaaf\nProcessing 37/44 - 52f50dc9-9715-4c8f-a8b9-12ceaf5dcbe8\nProcessing 38/44 - f01d387e-f98e-4b4c-8a7c-50154a089f53\nProcessing 39/44 - 69e042e6-9255-43df-91ef-af39d611b2ba\nProcessing 40/44 - fdcd21f2-cf40-4c40-bb79-984780631b0d\nProcessing 41/44 - d8ae2a04-447c-4a68-b830-183d968a57cb\nProcessing 42/44 - 83e8f69e-2a77-4f8c-ac5c-c2a584602f70\nProcessing 43/44 - 4377d12d-2ea1-4dde-82d8-0924fa8455bc\nProcessing 44/44 - f72a11d7-2365-4be8-90cb-49174123b810\nProcessing 4/42 - 054be71eca564395a1984df3655ee837-054be71eca564395a1984df3655ee837/2003091749-ea49d9bfd6134c8e9eedd4d748c45019\nProcessing 1/34 - f9d705b4-4d19-4bd9-a22e-eef511111c6d\nProcessing 2/34 - fc3d848a-208f-471f-a776-53b7c32ccd86\nProcessing 3/34 - c1f1883c-685f-4092-95f2-09d0c635ffbf\nProcessing 4/34 - 553df491-6495-4702-82c1-f05dc675abcd\nProcessing 5/34 - 8c3495b5-7aca-4512-bad8-b552e79255a2\nProcessing 6/34 - 780cce4c-06ef-45e6-bdc4-0387a055a22c\nProcessing 7/34 - 2bd21213-bb69-40c6-acce-b45bf4b960ec\nProcessing 8/34 - 388a7163-7a9f-4927-a9a3-b68f383c85a1\nProcessing 9/34 - b03241a2-d31b-43f1-bd07-95389788b6e3\nProcessing 10/34 - 777c5c3c-9484-4849-84c9-2ac14a063862\nProcessing 11/34 - 66a7f73b-b161-485c-b5c3-5b00bb2ffa69\nProcessing 12/34 - 018b0c77-1ccd-4e16-80f3-9b57f45fa8d0\nProcessing 13/34 - ef916bb8-50c5-4af8-9c19-9fff7588818d\nProcessing 14/34 - 44d20c85-5afe-4b5d-a5cc-3a886c1e8f50\nProcessing 15/34 - 8b3ea91c-fbed-4822-8685-778cf158bd16\nProcessing 16/34 - bf85fdce-dd99-42a8-8610-cc44ccd3496e\nProcessing 17/34 - d568525d-4999-4a2f-bd56-9533496ae5eb\nProcessing 18/34 - 7bd527c6-2ede-4dc6-a631-5cec03748732\nProcessing 19/34 - 0ff3468b-5047-4637-93b5-f6d009feed9d\nProcessing 20/34 - 4bf2402d-97e8-43d2-954f-971d405c91fd\nProcessing 21/34 - aebd3cdc-e5cf-429f-9e96-47fbdadca4c3\nProcessing 22/34 - aa656ec2-0a6c-4825-a6dd-501316605f37\nProcessing 23/34 - 96f6f4f2-7df0-4324-a2eb-f05128c29cba\nProcessing 24/34 - 7f2257f3-00ae-437a-86d3-accf3c22877b\nProcessing 25/34 - 7cd7bbdd-f7ed-4d9e-bd4f-80a2965a8f9c\nProcessing 26/34 - 13b41d5f-23fe-4322-a87e-91fd8fc15796\nProcessing 27/34 - 679972e0-ce05-4e6a-ab38-ebb9251baa43\nProcessing 28/34 - 586abe72-22ae-485d-bc34-6ea85dc353cd\nProcessing 29/34 - 2e5b0e85-b8db-40f0-b009-c2d3426ab200\nProcessing 30/34 - 4c1f2973-b762-4d81-94f7-4503002b2a67\nProcessing 31/34 - bde92feb-fd8b-4618-93b5-4b13bba70912\nProcessing 32/34 - ffb10eb6-4ac7-418d-8c20-171207bd91d2\nProcessing 33/34 - 28a8ee1e-1973-45a3-9085-2f9f2ba8ee7a\nProcessing 34/34 - 76198929-374a-4336-b6df-933b4304d4c7\nProcessing 5/42 - 054be71eca564395a1984df3655ee837/2003031429-cd78258d52894e30b32ad639a3c3470f\nProcessing 1/23 - 88547f56-4a1b-40b9-8130-d9317608cbf6\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code"
]
] |
d0f826e9e0da5b0117aa3d189f2c316b76360460 | 39,595 | ipynb | Jupyter Notebook | notebooks/experiment_archive_theory.ipynb | carstenblank/Quantum-classifier-with-tailored-quantum-kernels---Supplemental | 7c3188f0b71e825bc8ce2b1577a93d10b34abdbc | [
"Apache-2.0"
] | 11 | 2020-02-18T14:14:40.000Z | 2021-10-10T12:19:23.000Z | notebooks/experiment_archive_theory.ipynb | carstenblank/Quantum-classifier-with-tailored-quantum-kernels---Supplemental | 7c3188f0b71e825bc8ce2b1577a93d10b34abdbc | [
"Apache-2.0"
] | null | null | null | notebooks/experiment_archive_theory.ipynb | carstenblank/Quantum-classifier-with-tailored-quantum-kernels---Supplemental | 7c3188f0b71e825bc8ce2b1577a93d10b34abdbc | [
"Apache-2.0"
] | 2 | 2020-07-08T23:17:01.000Z | 2021-09-27T03:13:32.000Z | 207.303665 | 35,276 | 0.920066 | [
[
[
"Copyright 2019 Carsten Blank\n\nLicensed under the Apache License, Version 2.0 (the \"License\");\nyou may not use this file except in compliance with the License.\nYou may obtain a copy of the License at\n\n http://www.apache.org/licenses/LICENSE-2.0\n\nUnless required by applicable law or agreed to in writing, software\ndistributed under the License is distributed on an \"AS IS\" BASIS,\nWITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\nSee the License for the specific language governing permissions and\nlimitations under the License.",
"_____no_output_____"
]
],
[
[
"import sys\nimport os\nimport numpy as np\nimport matplotlib.pyplot as plt\nsys.path.append(\"{}/../lib_paper\".format(os.getcwd()))\nfrom lib_experimental_utils import FinishedExperiment, RunningExperiment, qasm_simulator",
"_____no_output_____"
]
],
[
[
"## Interesting\nGood results:\n* 5c962f6581cbf700560b9504\n* 5c9755f199c2c6005f6bc532\n\nWithou any barriers (except measurement)\n* 5c975badf4e1bf0057a03d2b\n* 5c976069adfd43005f0fef6b (+ 0.2pi theta correction)",
"_____no_output_____"
]
],
[
[
"experiment = FinishedExperiment.from_data(job_id='5c976069adfd43005f0fef6b', backend='ibmqx4')",
"_____no_output_____"
],
[
"theta_start = 0.0\ntheta_end = 2*np.pi\ntheta_step = 0.1\n\nw_1 = 0.5\nw_2 = 1 - w_1\n\ntheta = np.arange(theta_start, theta_end, theta_step)\n\ndef classification(copies=1):\n return w_1 * np.sin(theta/2 + np.pi/4)**(2*copies) - w_2 * np.cos(theta/2 + np.pi/4)**(2*copies)",
"_____no_output_____"
],
[
"experiment.show_plot(classification_label='experiment', \n compare_classification=classification()/5, \n compare_classification_label='theory scaled $\\\\frac{1}{5}$')\nplt.savefig('../../images/experiment_swaptest_vs_theory_correction.pdf')",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
d0f830dabc94dd3515ca72601783defc5fd3adcd | 1,344 | ipynb | Jupyter Notebook | jupyter-notebooks/[01] [04] Balanceando os dados para 50 - 50 .ipynb | AbnerBissolli/Malicious-DNS-Detection | 0764d719f9a361d2d4b615382fbed87db0f478a0 | [
"MIT"
] | null | null | null | jupyter-notebooks/[01] [04] Balanceando os dados para 50 - 50 .ipynb | AbnerBissolli/Malicious-DNS-Detection | 0764d719f9a361d2d4b615382fbed87db0f478a0 | [
"MIT"
] | null | null | null | jupyter-notebooks/[01] [04] Balanceando os dados para 50 - 50 .ipynb | AbnerBissolli/Malicious-DNS-Detection | 0764d719f9a361d2d4b615382fbed87db0f478a0 | [
"MIT"
] | null | null | null | 21.333333 | 88 | 0.546875 | [
[
[
"import numpy as np\nimport pandas as pd\n\nnp.random.seed(42)\ndf = pd.read_pickle('../Dataset/Attributes/tp_attributes.pickle')",
"_____no_output_____"
],
[
"cnt_be = df[df['class']==0].shape[0]\ncnt_mw = df[df['class']==1].shape[0]\n\nrm_be = cnt_be-cnt_mw",
"_____no_output_____"
],
[
"drop_indices = np.random.choice(df[df['class']==0].index, rm_be, replace=False)\ndf_subset = df.drop(drop_indices)\ndf_subset = df_subset.reset_index(drop=True)\ndf_subset.to_pickle('../Dataset/Attributes/ba_tp_attributes.pickle')",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code"
]
] |
d0f84696b96811ad35c67ee130c7f130678e2ae7 | 4,530 | ipynb | Jupyter Notebook | hw/hw2/hw2.ipynb | jamestiotio/ml | f7a36eafb0578ffba7eb532a3fe7dc191dfab765 | [
"MIT"
] | null | null | null | hw/hw2/hw2.ipynb | jamestiotio/ml | f7a36eafb0578ffba7eb532a3fe7dc191dfab765 | [
"MIT"
] | null | null | null | hw/hw2/hw2.ipynb | jamestiotio/ml | f7a36eafb0578ffba7eb532a3fe7dc191dfab765 | [
"MIT"
] | null | null | null | 30.608108 | 122 | 0.589183 | [
[
[
"# SUTD 2021 50.007 Homework 2\n> James Raphael Tiovalen / 1004555",
"_____no_output_____"
]
],
[
[
"# Setup and install dependencies\n!pip3 install numpy scipy numba libsvm-official",
"Requirement already satisfied: numpy in c:\\python38\\lib\\site-packages (1.19.5)\nRequirement already satisfied: scipy in c:\\python38\\lib\\site-packages (1.5.2)\nRequirement already satisfied: numba in c:\\python38\\lib\\site-packages (0.52.0)\nRequirement already satisfied: libsvm-official in c:\\python38\\lib\\site-packages (3.25.0)\nRequirement already satisfied: setuptools in c:\\python38\\lib\\site-packages (from numba) (49.2.1)\nRequirement already satisfied: llvmlite<0.36,>=0.35.0 in c:\\python38\\lib\\site-packages (from numba) (0.35.0)\n"
]
],
[
[
"## Question 2.3",
"_____no_output_____"
]
],
[
[
"# Import libraries\nfrom libsvm.svmutil import svm_read_problem, svm_train, svm_predict\nimport os\n\n# Set OS-independent paths, relative to current directory\ntrain_path = os.path.join(\"fishorrock\", \"training.txt\")\ntest_path = os.path.join(\"fishorrock\", \"test.txt\")\n\n# Load data from files\ntrain_y, train_x = svm_read_problem(train_path)\ntest_y, test_x = svm_read_problem(test_path)",
"_____no_output_____"
],
[
"# Train different SVM models with 4 different kernel types\nlinear = svm_train(train_y, train_x, \"-t 0\")\npolynomial = svm_train(train_y, train_x, \"-t 1\")\nrbf = svm_train(train_y, train_x, \"-t 2\")\nsigmoid = svm_train(train_y, train_x, \"-t 3\")",
"_____no_output_____"
],
[
"# Get accuracy of the 4 different SVM models and print the kernel type with best accuracy\nbest_accuracy = -1\nbest_acc_index = -1\nkernel_types = [\"LINEAR\", \"POLYNOMIAL\", \"RADIAL BASIS FUNCTION\", \"SIGMOID\"]\n\nfor idx, model in enumerate([linear, polynomial, rbf, sigmoid]):\n print(f\"Executing SVM prediction with {kernel_types[idx]} kernel type...\")\n p_label, p_acc, p_val = svm_predict(test_y, test_x, model)\n print()\n if p_acc[0] > best_accuracy:\n best_accuracy = p_acc[0]\n best_acc_index = idx\n\nprint(f\"Best accuracy achieved is {best_accuracy:.4f}% with the {kernel_types[best_acc_index]} kernel type.\")",
"Executing SVM prediction with LINEAR kernel type...\nAccuracy = 79.3651% (50/63) (classification)\n\nExecuting SVM prediction with POLYNOMIAL kernel type...\nAccuracy = 55.5556% (35/63) (classification)\n\nExecuting SVM prediction with RADIAL BASIS FUNCTION kernel type...\nAccuracy = 87.3016% (55/63) (classification)\n\nExecuting SVM prediction with SIGMOID kernel type...\nAccuracy = 82.5397% (52/63) (classification)\n\nBest accuracy achieved is 87.3016% with the RADIAL BASIS FUNCTION kernel type.\n"
]
],
[
[
"We select the RADIAL BASIS FUNCTION kernel since it achieved the best performance in terms of highest test accuracy.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
]
] |
d0f846d04b17a67a5a27da02024254e961c29a9f | 81,563 | ipynb | Jupyter Notebook | [03 - Results]/dos results ver 4/router-fetch/malicious/2-fft-malicious-n-0-4-m-12.ipynb | chamikasudusinghe/nocml | d414da54e042d6f7505b81135882d6f1bd02f166 | [
"MIT"
] | null | null | null | [03 - Results]/dos results ver 4/router-fetch/malicious/2-fft-malicious-n-0-4-m-12.ipynb | chamikasudusinghe/nocml | d414da54e042d6f7505b81135882d6f1bd02f166 | [
"MIT"
] | null | null | null | [03 - Results]/dos results ver 4/router-fetch/malicious/2-fft-malicious-n-0-4-m-12.ipynb | chamikasudusinghe/nocml | d414da54e042d6f7505b81135882d6f1bd02f166 | [
"MIT"
] | null | null | null | 85.585519 | 9,364 | 0.78798 | [
[
[
"#### Data Fetch",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\n%matplotlib inline\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nimport math",
"_____no_output_____"
],
[
"#extracting lines for simplied verion\nopen('2-fft-malicious-n-0-4-m-12.txt','w').writelines([ line for line in open(\"2-fft-malicious-n-0-4-m-12.log\") if \"Enqueue\" in line])\nprint (\"done\")",
"done\n"
],
[
"#extracting content from lines\ncsv_out = open('2-fft-malicious-n-0-4-m-12-csv.txt','w')\nwith open ('2-fft-malicious-n-0-4-m-12.txt', 'rt') as fft:\n csv_out.write(\"time,router,outport,inport,packet_address,packet_type,flit_id,flit_type,vnet,vc,src_ni,src_router,dst_ni,dst_router,enq_time\\n\")\n for line in fft:\n line_split = line.split()\n time = line_split[line_split.index(\"time:\") + 1]\n router = line_split[line_split.index(\"SwitchAllocator\") + 3]\n outport = line_split[line_split.index(\"outport\") + 1]\n inport = line_split[line_split.index(\"inport\") + 1]\n packet_address = line_split[line_split.index(\"addr\") + 2][1:-1]\n packet_type = line_split[line_split.index(\"addr\") + 7]\n flit_id = line_split[line_split.index(\"[flit::\") + 1][3:]\n flit_type = line_split[line_split.index(\"Id=\"+str(flit_id)) + 1][5:]\n vnet = line_split[line_split.index(\"Type=\"+str(flit_type)) + 1][5:]\n vc = line_split[line_split.index(\"Vnet=\"+str(vnet)) + 1][3:]\n src_ni = line_split[line_split.index(\"VC=\"+str(vc)) + 2][3:]\n src_router = line_split[line_split.index(\"NI=\"+str(src_ni)) + 2][7:]\n dst_ni = line_split[line_split.index(\"Router=\"+str(src_router)) + 2][3:]\n dst_router = line_split[line_split.index(\"NI=\"+str(dst_ni)) + 2][7:]\n enq_time = str(line_split[line_split.index(\"Enqueue\") + 1][5:])\n line_csv = time+\",\"+router+\",\"+outport+\",\"+inport+\",\"+packet_address+\",\"+packet_type+\",\"+flit_id+\",\"+flit_type+\",\"+vnet+\",\"+vc+\",\"+src_ni+\",\"+src_router+\",\"+dst_ni+\",\"+dst_router+\",\"+enq_time+\"\\n\"\n csv_out.write(line_csv)\nprint (\"done\")",
"done\n"
],
[
"#convert txt to csv\n\ndf = pd.read_csv(\"2-fft-malicious-n-0-4-m-12-csv.txt\",delimiter=',')\ndf.to_csv('2-fft-malicious-n-0-4-m-12.csv',index=False)",
"_____no_output_____"
],
[
"#dataset\ndf = pd.read_csv('2-fft-malicious-n-0-4-m-12.csv')",
"_____no_output_____"
],
[
"df.shape",
"_____no_output_____"
],
[
"df.describe()",
"_____no_output_____"
],
[
"sns.distplot(df['router'], kde = False, bins=30, color='blue')",
"_____no_output_____"
],
[
"sns.distplot(df['src_router'], kde = False, bins=30, color='blue')",
"_____no_output_____"
],
[
"sns.distplot(df['dst_router'], kde = False, bins=30, color='red')",
"_____no_output_____"
],
[
"sns.distplot(df['inport'], kde = False, bins=30, color='green')",
"_____no_output_____"
],
[
"sns.distplot(df['outport'], kde = False, bins=30, color='green')",
"_____no_output_____"
],
[
"sns.distplot(df['packet_type'], kde = False, bins=30, color='red')",
"_____no_output_____"
],
[
"direction = {'Local': 0,'North': 1, 'East': 2, 'South':3,'West':4}\ndf = df.replace({'inport': direction, 'outport': direction})",
"_____no_output_____"
],
[
"data = {'GETS': 1,'GETX': 2,'GUX': 3,'DATA': 4, 'PUTX': 5,'PUTS': 6,'WB_ACK':7}\ndf = df.replace({'packet_type': data})",
"_____no_output_____"
],
[
"df['flit_id'] = df['flit_id']+1\ndf['flit_type'] = df['flit_type']+1\ndf['vnet'] = df['vnet']+1\ndf['vc'] = df['vc']+1",
"_____no_output_____"
],
[
"hoparr = {\"0to0\":0,\"0to1\":1,\"0to2\":2,\"0to3\":3,\"0to4\":1,\"0to5\":2,\"0to6\":3,\"0to7\":4,\"0to8\":2,\"0to9\":3,\"0to10\":4,\"0to11\":5,\"0to12\":3,\"0to13\":4,\"0to14\":5,\"0to15\":6,\n \"1to1\":0,\"1to2\":1,\"1to3\":2,\"1to4\":2,\"1to5\":1,\"1to6\":2,\"1to7\":3,\"1to8\":3,\"1to9\":2,\"1to10\":3,\"1to11\":4,\"1to12\":5,\"1to13\":3,\"1to14\":4,\"1to15\":5,\n \"2to2\":0,\"2to3\":1,\"2to4\":3,\"2to5\":2,\"2to6\":1,\"2to7\":2,\"2to8\":4,\"2to9\":3,\"2to10\":2,\"2to11\":3,\"2to12\":5,\"2to13\":4,\"2to14\":3,\"2to15\":4,\n \"3to3\":0,\"3to4\":4,\"3to5\":3,\"3to6\":2,\"3to7\":1,\"3to8\":5,\"3to9\":4,\"3to10\":3,\"3to11\":2,\"3to12\":6,\"3to13\":5,\"3to14\":4,\"3to15\":3,\n \"4to4\":0,\"4to5\":1,\"4to6\":2,\"4to7\":3,\"4to8\":1,\"4to9\":2,\"4to10\":3,\"4to11\":4,\"4to12\":2,\"4to13\":3,\"4to14\":4,\"4to15\":5,\n \"5to5\":0,\"5to6\":1,\"5to7\":2,\"5to8\":2,\"5to9\":1,\"5to10\":2,\"5to11\":3,\"5to12\":3,\"5to13\":2,\"5to14\":3,\"5to15\":4,\n \"6to6\":0,\"6to7\":1,\"6to8\":3,\"6to9\":2,\"6to10\":1,\"6to11\":2,\"6to12\":4,\"6to13\":3,\"6to14\":2,\"6to15\":3,\n \"7to7\":0,\"7to8\":4,\"7to9\":3,\"7to10\":2,\"7to11\":1,\"7to12\":5,\"7to13\":4,\"7to14\":3,\"7to15\":2,\n \"8to8\":0,\"8to9\":1,\"8to10\":2,\"8to11\":3,\"8to12\":1,\"8to13\":2,\"8to14\":3,\"8to15\":4,\n \"9to9\":0,\"9to10\":1,\"9to11\":2,\"9to12\":2,\"9to13\":1,\"9to14\":2,\"9to15\":4,\n \"10to10\":0,\"10to11\":1,\"10to12\":3,\"10to13\":2,\"10to14\":1,\"10to15\":2,\n \"11to11\":0,\"11to12\":4,\"11to13\":3,\"11to14\":2,\"11to15\":1,\n \"12to12\":0,\"12to13\":1,\"12to14\":2,\"12to15\":3,\n \"13to13\":0,\"13to14\":1,\"13to15\":2,\n \"14to14\":0,\"14to15\":1,\n \"15to15\":0}",
"_____no_output_____"
],
[
"packarr = {}\npacktime = {}\npackchunk = []\nhopcurrentarr = []\nhoptotarr = []\nhoppercentarr =[]\nwaitingarr = []\ninterval = 500\ncount = 0\nfor index, row in df.iterrows():\n current_time = row[\"time\"]\n enqueue_time = row[\"enq_time\"]\n waiting_time = current_time - enqueue_time\n waitingarr.append(waiting_time)\n current_router = row[\"router\"]\n src_router = row[\"src_router\"]\n dst_router = row[\"dst_router\"]\n src_router_temp = src_router\n if src_router_temp>dst_router:\n temph = src_router_temp\n src_router_temp = dst_router\n dst_router = temph\n hop_count_string = str(src_router_temp)+\"to\"+str(dst_router)\n src_router_temp = src_router\n hop_count = hoparr.get(hop_count_string)\n if src_router_temp>current_router:\n tempc = src_router_temp\n src_router_temp = current_router\n current_router = tempc\n current_hop_string = str(src_router_temp)+\"to\"+str(current_router)\n current_hop = hoparr.get(current_hop_string)\n if(current_hop == 0 and hop_count ==0):\n hop_percent = 0\n else:\n hop_percent = current_hop/hop_count\n hoptotarr.append(hop_count)\n hopcurrentarr.append(current_hop)\n hoppercentarr.append(hop_percent)\n if row[\"packet_address\"] not in packarr:\n packarr[row[\"packet_address\"]] = count\n packtime[row[\"packet_address\"]] = row[\"time\"]\n packchunk.append(packarr.get(row[\"packet_address\"]))\n count+=1\n else:\n current_time = row[\"time\"]\n position = packarr.get(row[\"packet_address\"])\n pkt_time = packtime.get(row[\"packet_address\"])\n current_max = max(packarr.values())\n if (current_time-pkt_time)<interval:\n packchunk.append(packarr.get(row[\"packet_address\"]))\n else:\n del packarr[row[\"packet_address\"]]\n del packtime[row[\"packet_address\"]]\n packarr[row[\"packet_address\"]] = current_max+1\n packtime[row[\"packet_address\"]] = row[\"time\"]\n packchunk.append(packarr.get(row[\"packet_address\"]))\n if (current_max)==count:\n count+=2\n elif (current_max+1)==count:\n count+=1",
"_____no_output_____"
],
[
"df['packet_address'].nunique()",
"_____no_output_____"
],
[
"print(len(packarr))",
"5742\n"
],
[
"print(len(packchunk))",
"1021283\n"
],
[
"df = df.assign(traversal_id=packchunk)\ndf = df.assign(hop_count=hoptotarr)\ndf = df.assign(current_hop=hopcurrentarr)\ndf = df.assign(hop_percentage=hoppercentarr)\ndf = df.assign(enqueue_time=waitingarr)",
"_____no_output_____"
],
[
"df.rename(columns={'packet_type': 'cache_coherence_type', 'time': 'timestamp'}, inplace=True)",
"_____no_output_____"
],
[
"df = df.drop(columns=['packet_address','enq_time'])",
"_____no_output_____"
],
[
"df.isnull().sum()",
"_____no_output_____"
],
[
"df.dtypes",
"_____no_output_____"
],
[
"df.to_csv('2-fft-malicious-n-0-4-m-12.csv',index=False)",
"_____no_output_____"
]
],
[
[
"#### Router Fetch",
"_____no_output_____"
]
],
[
[
"def roundup(x):\n return int(math.ceil(x / 1000.0)) * 1000",
"_____no_output_____"
],
[
"def fetch(i):\n \n df = pd.read_csv('2-fft-malicious-n-0-4-m-12.csv')\n df = df.loc[df['router'] == i]\n df = df.drop(columns=['router'])\n df.to_csv('2-fft-malicious-n-0-4-m-12-r'+str(i)+'.csv',index=False)\n df = pd.read_csv('2-fft-malicious-n-0-4-m-12-r'+str(i)+'.csv')\n\n def timecount(df):\n timearr = []\n interval = 999\n count = 0\n for index, row in df.iterrows():\n if row[\"timestamp\"]<=interval :\n count+=1\n else:\n timearr.append([interval+1,count])\n count=1\n if (row[\"timestamp\"] == roundup(row[\"timestamp\"])):\n interval = row[\"timestamp\"]+999\n else:\n interval = roundup(row[\"timestamp\"])-1\n timearr.append([interval+1,count])\n return timearr\n \n def maxcount(timearr,df):\n countarr = []\n increarr = []\n maxarr = []\n for i in range(len(timearr)):\n for cnt in range(timearr[i][1],0,-1):\n countarr.append(cnt)\n maxarr.append(timearr[i][1])\n increment = timearr[i][1] - cnt + 1\n increarr.append(increment)\n df = df.assign(packet_count_decr=countarr)\n df = df.assign(packet_count_incr=increarr)\n df = df.assign(max_packet_count=maxarr)\n return df\n \n df = maxcount(timecount(df),df)\n \n def rename(df):\n df['traversal_id'] = df['traversal_id']+1\n df[\"packet_count_index\"] = df[\"packet_count_decr\"]*df[\"packet_count_incr\"]\n df[\"port_index\"] = df[\"outport\"]*df[\"inport\"]\n df[\"traversal_index\"] = df[\"cache_coherence_type\"]*df[\"flit_id\"]*df[\"flit_type\"]*df[\"traversal_id\"]\n df[\"cache_coherence_vnet_index\"] = df[\"cache_coherence_type\"]*df[\"vnet\"]\n df[\"vnet_vc_cc_index\"] = df[\"vc\"]*df[\"cache_coherence_vnet_index\"]\n \n rename(df)\n \n df['target'] = 0\n \n print(df.shape)\n \n df.to_csv('2-fft-malicious-n-0-4-m-12-r'+str(i)+'.csv',index=False)",
"_____no_output_____"
],
[
"for i in range (0,16):\n fetch(i)",
"(99481, 26)\n(58807, 26)\n(39303, 26)\n(26430, 26)\n(158087, 26)\n(67123, 26)\n(63254, 26)\n(59990, 26)\n(95898, 26)\n(53293, 26)\n(49289, 26)\n(64634, 26)\n(73474, 26)\n(39427, 26)\n(37649, 26)\n(35144, 26)\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
d0f8472efa877acb2fc9e06918f4dce86b954c71 | 813,043 | ipynb | Jupyter Notebook | embeddings/Skip-Grams-Solution.ipynb | arghasarkar/DeepLearningFoundations-Udacity | 980fcee7fd92860236e76478679a2e37f3d10916 | [
"MIT"
] | 1 | 2019-01-03T18:13:37.000Z | 2019-01-03T18:13:37.000Z | embeddings/Skip-Grams-Solution.ipynb | arghasarkar/DeepLearningFoundations-Udacity | 980fcee7fd92860236e76478679a2e37f3d10916 | [
"MIT"
] | null | null | null | embeddings/Skip-Grams-Solution.ipynb | arghasarkar/DeepLearningFoundations-Udacity | 980fcee7fd92860236e76478679a2e37f3d10916 | [
"MIT"
] | null | null | null | 1,311.359677 | 787,092 | 0.94321 | [
[
[
"# Skip-gram word2vec\n\nIn this notebook, I'll lead you through using TensorFlow to implement the word2vec algorithm using the skip-gram architecture. By implementing this, you'll learn about embedding words for use in natural language processing. This will come in handy when dealing with things like machine translation.\n\n## Readings\n\nHere are the resources I used to build this notebook. I suggest reading these either beforehand or while you're working on this material.\n\n* A really good [conceptual overview](http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/) of word2vec from Chris McCormick \n* [First word2vec paper](https://arxiv.org/pdf/1301.3781.pdf) from Mikolov et al.\n* [NIPS paper](http://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf) with improvements for word2vec also from Mikolov et al.\n* An [implementation of word2vec](http://www.thushv.com/natural_language_processing/word2vec-part-1-nlp-with-deep-learning-with-tensorflow-skip-gram/) from Thushan Ganegedara\n* TensorFlow [word2vec tutorial](https://www.tensorflow.org/tutorials/word2vec)\n\n## Word embeddings\n\nWhen you're dealing with words in text, you end up with tens of thousands of classes to predict, one for each word. Trying to one-hot encode these words is massively inefficient, you'll have one element set to 1 and the other 50,000 set to 0. The matrix multiplication going into the first hidden layer will have almost all of the resulting values be zero. This a huge waste of computation. \n\n\n\nTo solve this problem and greatly increase the efficiency of our networks, we use what are called embeddings. Embeddings are just a fully connected layer like you've seen before. We call this layer the embedding layer and the weights are embedding weights. We skip the multiplication into the embedding layer by instead directly grabbing the hidden layer values from the weight matrix. We can do this because the multiplication of a one-hot encoded vector with a matrix returns the row of the matrix corresponding the index of the \"on\" input unit.\n\n\n\nInstead of doing the matrix multiplication, we use the weight matrix as a lookup table. We encode the words as integers, for example \"heart\" is encoded as 958, \"mind\" as 18094. Then to get hidden layer values for \"heart\", you just take the 958th row of the embedding matrix. This process is called an **embedding lookup** and the number of hidden units is the **embedding dimension**.\n\n<img src='assets/tokenize_lookup.png' width=500>\n \nThere is nothing magical going on here. The embedding lookup table is just a weight matrix. The embedding layer is just a hidden layer. The lookup is just a shortcut for the matrix multiplication. The lookup table is trained just like any weight matrix as well.\n\nEmbeddings aren't only used for words of course. You can use them for any model where you have a massive number of classes. A particular type of model called **Word2Vec** uses the embedding layer to find vector representations of words that contain semantic meaning.\n\n",
"_____no_output_____"
],
[
"## Word2Vec\n\nThe word2vec algorithm finds much more efficient representations by finding vectors that represent the words. These vectors also contain semantic information about the words. Words that show up in similar contexts, such as \"black\", \"white\", and \"red\" will have vectors near each other. There are two architectures for implementing word2vec, CBOW (Continuous Bag-Of-Words) and Skip-gram.\n\n<img src=\"assets/word2vec_architectures.png\" width=\"500\">\n\nIn this implementation, we'll be using the skip-gram architecture because it performs better than CBOW. Here, we pass in a word and try to predict the words surrounding it in the text. In this way, we can train the network to learn representations for words that show up in similar contexts.\n\nFirst up, importing packages.",
"_____no_output_____"
]
],
[
[
"import time\n\nimport numpy as np\nimport tensorflow as tf\n\nimport utils",
"_____no_output_____"
]
],
[
[
"Load the [text8 dataset](http://mattmahoney.net/dc/textdata.html), a file of cleaned up Wikipedia articles from Matt Mahoney. The next cell will download the data set to the `data` folder. Then you can extract it and delete the archive file to save storage space.",
"_____no_output_____"
]
],
[
[
"from urllib.request import urlretrieve\nfrom os.path import isfile, isdir\nfrom tqdm import tqdm\nimport zipfile\n\ndataset_folder_path = 'data'\ndataset_filename = 'text8.zip'\ndataset_name = 'Text8 Dataset'\n\nclass DLProgress(tqdm):\n last_block = 0\n\n def hook(self, block_num=1, block_size=1, total_size=None):\n self.total = total_size\n self.update((block_num - self.last_block) * block_size)\n self.last_block = block_num\n\nif not isfile(dataset_filename):\n with DLProgress(unit='B', unit_scale=True, miniters=1, desc=dataset_name) as pbar:\n urlretrieve(\n 'http://mattmahoney.net/dc/text8.zip',\n dataset_filename,\n pbar.hook)\n\nif not isdir(dataset_folder_path):\n with zipfile.ZipFile(dataset_filename) as zip_ref:\n zip_ref.extractall(dataset_folder_path)\n \nwith open('data/text8') as f:\n text = f.read()",
"_____no_output_____"
]
],
[
[
"## Preprocessing\n\nHere I'm fixing up the text to make training easier. This comes from the `utils` module I wrote. The `preprocess` function coverts any punctuation into tokens, so a period is changed to ` <PERIOD> `. In this data set, there aren't any periods, but it will help in other NLP problems. I'm also removing all words that show up five or fewer times in the dataset. This will greatly reduce issues due to noise in the data and improve the quality of the vector representations. If you want to write your own functions for this stuff, go for it.",
"_____no_output_____"
]
],
[
[
"words = utils.preprocess(text)\nprint(words[:30])",
"['anarchism', 'originated', 'as', 'a', 'term', 'of', 'abuse', 'first', 'used', 'against', 'early', 'working', 'class', 'radicals', 'including', 'the', 'diggers', 'of', 'the', 'english', 'revolution', 'and', 'the', 'sans', 'culottes', 'of', 'the', 'french', 'revolution', 'whilst']\n"
],
[
"print(\"Total words: {}\".format(len(words)))\nprint(\"Unique words: {}\".format(len(set(words))))",
"Total words: 16680599\nUnique words: 63641\n"
]
],
[
[
"And here I'm creating dictionaries to covert words to integers and backwards, integers to words. The integers are assigned in descending frequency order, so the most frequent word (\"the\") is given the integer 0 and the next most frequent is 1 and so on. The words are converted to integers and stored in the list `int_words`.",
"_____no_output_____"
]
],
[
[
"vocab_to_int, int_to_vocab = utils.create_lookup_tables(words)\nint_words = [vocab_to_int[word] for word in words]",
"_____no_output_____"
]
],
[
[
"## Subsampling\n\nWords that show up often such as \"the\", \"of\", and \"for\" don't provide much context to the nearby words. If we discard some of them, we can remove some of the noise from our data and in return get faster training and better representations. This process is called subsampling by Mikolov. For each word $w_i$ in the training set, we'll discard it with probability given by \n\n$$ P(w_i) = 1 - \\sqrt{\\frac{t}{f(w_i)}} $$\n\nwhere $t$ is a threshold parameter and $f(w_i)$ is the frequency of word $w_i$ in the total dataset.\n\nI'm going to leave this up to you as an exercise. Check out my solution to see how I did it.\n\n> **Exercise:** Implement subsampling for the words in `int_words`. That is, go through `int_words` and discard each word given the probablility $P(w_i)$ shown above. Note that $P(w_i)$ is that probability that a word is discarded. Assign the subsampled data to `train_words`.",
"_____no_output_____"
]
],
[
[
"from collections import Counter\nimport random\n\nthreshold = 1e-5\nthreshold = 0.0006849873916398326\nword_counts = Counter(int_words)\ntotal_count = len(int_words)\nprint(total_count)\nfreqs = {word: count/total_count for word, count in word_counts.items()}\np_drop = {word: 1 - np.sqrt(threshold/freqs[word]) for word in word_counts}\ntrain_words = [word for word in int_words if random.random() < (1 - p_drop[word])]\n\nprint(len(train_words))\nprint(train_words[:10])",
"16680599\n11171980\n[5234, 3082, 194, 3136, 45, 58, 155, 127, 741, 476]\n"
]
],
[
[
"## Making batches",
"_____no_output_____"
],
[
"Now that our data is in good shape, we need to get it into the proper form to pass it into our network. With the skip-gram architecture, for each word in the text, we want to grab all the words in a window around that word, with size $C$. \n\nFrom [Mikolov et al.](https://arxiv.org/pdf/1301.3781.pdf): \n\n\"Since the more distant words are usually less related to the current word than those close to it, we give less weight to the distant words by sampling less from those words in our training examples... If we choose $C = 5$, for each training word we will select randomly a number $R$ in range $< 1; C >$, and then use $R$ words from history and $R$ words from the future of the current word as correct labels.\"\n\n> **Exercise:** Implement a function `get_target` that receives a list of words, an index, and a window size, then returns a list of words in the window around the index. Make sure to use the algorithm described above, where you chose a random number of words to from the window.",
"_____no_output_____"
]
],
[
[
"def get_target(words, idx, window_size=5):\n ''' Get a list of words in a window around an index. '''\n \n R = np.random.randint(1, window_size+1)\n start = idx - R if (idx - R) > 0 else 0\n stop = idx + R\n target_words = set(words[start:idx] + words[idx+1:stop+1])\n \n return list(target_words)",
"_____no_output_____"
]
],
[
[
"Here's a function that returns batches for our network. The idea is that it grabs `batch_size` words from a words list. Then for each of those words, it gets the target words in the window. I haven't found a way to pass in a random number of target words and get it to work with the architecture, so I make one row per input-target pair. This is a generator function by the way, helps save memory.",
"_____no_output_____"
]
],
[
[
"def get_batches(words, batch_size, window_size=5):\n ''' Create a generator of word batches as a tuple (inputs, targets) '''\n \n n_batches = len(words)//batch_size\n \n # only full batches\n words = words[:n_batches*batch_size]\n \n for idx in range(0, len(words), batch_size):\n x, y = [], []\n batch = words[idx:idx+batch_size]\n for ii in range(len(batch)):\n batch_x = batch[ii]\n batch_y = get_target(batch, ii, window_size)\n y.extend(batch_y)\n x.extend([batch_x]*len(batch_y))\n yield x, y\n ",
"_____no_output_____"
]
],
[
[
"## Building the graph\n\nFrom [Chris McCormick's blog](http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/), we can see the general structure of our network.\n\n\nThe input words are passed in as one-hot encoded vectors. This will go into a hidden layer of linear units, then into a softmax layer. We'll use the softmax layer to make a prediction like normal.\n\nThe idea here is to train the hidden layer weight matrix to find efficient representations for our words. We can discard the softmax layer becuase we don't really care about making predictions with this network. We just want the embedding matrix so we can use it in other networks we build from the dataset.\n\nI'm going to have you build the graph in stages now. First off, creating the `inputs` and `labels` placeholders like normal.\n\n> **Exercise:** Assign `inputs` and `labels` using `tf.placeholder`. We're going to be passing in integers, so set the data types to `tf.int32`. The batches we're passing in will have varying sizes, so set the batch sizes to [`None`]. To make things work later, you'll need to set the second dimension of `labels` to `None` or `1`.",
"_____no_output_____"
]
],
[
[
"train_graph = tf.Graph()\nwith train_graph.as_default():\n inputs = tf.placeholder(tf.int32, [None], name='inputs')\n labels = tf.placeholder(tf.int32, [None, None], name='labels')",
"_____no_output_____"
]
],
[
[
"## Embedding\n\n",
"_____no_output_____"
],
[
"The embedding matrix has a size of the number of words by the number of units in the hidden layer. So, if you have 10,000 words and 300 hidden units, the matrix will have size $10,000 \\times 300$. Remember that we're using tokenized data for our inputs, usually as integers, where the number of tokens is the number of words in our vocabulary.\n\n\n> **Exercise:** Tensorflow provides a convenient function [`tf.nn.embedding_lookup`](https://www.tensorflow.org/api_docs/python/tf/nn/embedding_lookup) that does this lookup for us. You pass in the embedding matrix and a tensor of integers, then it returns rows in the matrix corresponding to those integers. Below, set the number of embedding features you'll use (200 is a good start), create the embedding matrix variable, and use `tf.nn.embedding_lookup` to get the embedding tensors. For the embedding matrix, I suggest you initialize it with a uniform random numbers between -1 and 1 using [tf.random_uniform](https://www.tensorflow.org/api_docs/python/tf/random_uniform).",
"_____no_output_____"
]
],
[
[
"n_vocab = len(int_to_vocab)\nn_embedding = 200 # Number of embedding features \nwith train_graph.as_default():\n embedding = tf.Variable(tf.random_uniform((n_vocab, n_embedding), -1, 1))\n embed = tf.nn.embedding_lookup(embedding, inputs)",
"_____no_output_____"
]
],
[
[
"## Negative sampling\n\n",
"_____no_output_____"
],
[
"For every example we give the network, we train it using the output from the softmax layer. That means for each input, we're making very small changes to millions of weights even though we only have one true example. This makes training the network very inefficient. We can approximate the loss from the softmax layer by only updating a small subset of all the weights at once. We'll update the weights for the correct label, but only a small number of incorrect labels. This is called [\"negative sampling\"](http://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf). Tensorflow has a convenient function to do this, [`tf.nn.sampled_softmax_loss`](https://www.tensorflow.org/api_docs/python/tf/nn/sampled_softmax_loss).\n\n> **Exercise:** Below, create weights and biases for the softmax layer. Then, use [`tf.nn.sampled_softmax_loss`](https://www.tensorflow.org/api_docs/python/tf/nn/sampled_softmax_loss) to calculate the loss. Be sure to read the documentation to figure out how it works.",
"_____no_output_____"
]
],
[
[
"# Number of negative labels to sample\nn_sampled = 100\nwith train_graph.as_default():\n softmax_w = tf.Variable(tf.truncated_normal((n_vocab, n_embedding), stddev=0.1))\n softmax_b = tf.Variable(tf.zeros(n_vocab))\n \n # Calculate the loss using negative sampling\n loss = tf.nn.sampled_softmax_loss(softmax_w, softmax_b, \n labels, embed,\n n_sampled, n_vocab)\n \n cost = tf.reduce_mean(loss)\n optimizer = tf.train.AdamOptimizer().minimize(cost)",
"_____no_output_____"
]
],
[
[
"## Validation\n\nThis code is from Thushan Ganegedara's implementation. Here we're going to choose a few common words and few uncommon words. Then, we'll print out the closest words to them. It's a nice way to check that our embedding table is grouping together words with similar semantic meanings.",
"_____no_output_____"
]
],
[
[
"with train_graph.as_default():\n ## From Thushan Ganegedara's implementation\n valid_size = 16 # Random set of words to evaluate similarity on.\n valid_window = 100\n # pick 8 samples from (0,100) and (1000,1100) each ranges. lower id implies more frequent \n valid_examples = np.array(random.sample(range(valid_window), valid_size//2))\n valid_examples = np.append(valid_examples, \n random.sample(range(1000,1000+valid_window), valid_size//2))\n\n valid_dataset = tf.constant(valid_examples, dtype=tf.int32)\n \n # We use the cosine distance:\n norm = tf.sqrt(tf.reduce_sum(tf.square(embedding), 1, keep_dims=True))\n normalized_embedding = embedding / norm\n valid_embedding = tf.nn.embedding_lookup(normalized_embedding, valid_dataset)\n similarity = tf.matmul(valid_embedding, tf.transpose(normalized_embedding))",
"_____no_output_____"
],
[
"# If the checkpoints directory doesn't exist:\n!mkdir checkpoints",
"_____no_output_____"
],
[
"epochs = 10\nbatch_size = 1000\nwindow_size = 10\n\nwith train_graph.as_default():\n saver = tf.train.Saver()\n\nwith tf.Session(graph=train_graph) as sess:\n iteration = 1\n loss = 0\n sess.run(tf.global_variables_initializer())\n\n for e in range(1, epochs+1):\n batches = get_batches(train_words, batch_size, window_size)\n start = time.time()\n for x, y in batches:\n \n feed = {inputs: x,\n labels: np.array(y)[:, None]}\n train_loss, _ = sess.run([cost, optimizer], feed_dict=feed)\n \n loss += train_loss\n \n if iteration % 100 == 0: \n end = time.time()\n print(\"Epoch {}/{}\".format(e, epochs),\n \"Iteration: {}\".format(iteration),\n \"Avg. Training loss: {:.4f}\".format(loss/100),\n \"{:.4f} sec/batch\".format((end-start)/100))\n loss = 0\n start = time.time()\n \n if iteration % 1000 == 0:\n # note that this is expensive (~20% slowdown if computed every 500 steps)\n sim = similarity.eval()\n for i in range(valid_size):\n valid_word = int_to_vocab[valid_examples[i]]\n top_k = 8 # number of nearest neighbors\n nearest = (-sim[i, :]).argsort()[1:top_k+1]\n log = 'Nearest to %s:' % valid_word\n for k in range(top_k):\n close_word = int_to_vocab[nearest[k]]\n log = '%s %s,' % (log, close_word)\n print(log)\n \n iteration += 1\n save_path = saver.save(sess, \"checkpoints/text8.ckpt\")\n embed_mat = sess.run(normalized_embedding)",
"_____no_output_____"
]
],
[
[
"Restore the trained network if you need to:",
"_____no_output_____"
]
],
[
[
"with train_graph.as_default():\n saver = tf.train.Saver()\n\nwith tf.Session(graph=train_graph) as sess:\n saver.restore(sess, tf.train.latest_checkpoint('checkpoints'))\n embed_mat = sess.run(embedding)",
"_____no_output_____"
]
],
[
[
"## Visualizing the word vectors\n\nBelow we'll use T-SNE to visualize how our high-dimensional word vectors cluster together. T-SNE is used to project these vectors into two dimensions while preserving local stucture. Check out [this post from Christopher Olah](http://colah.github.io/posts/2014-10-Visualizing-MNIST/) to learn more about T-SNE and other ways to visualize high-dimensional data.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n%config InlineBackend.figure_format = 'retina'\n\nimport matplotlib.pyplot as plt\nfrom sklearn.manifold import TSNE",
"_____no_output_____"
],
[
"viz_words = 500\ntsne = TSNE()\nembed_tsne = tsne.fit_transform(embed_mat[:viz_words, :])",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(figsize=(14, 14))\nfor idx in range(viz_words):\n plt.scatter(*embed_tsne[idx, :], color='steelblue')\n plt.annotate(int_to_vocab[idx], (embed_tsne[idx, 0], embed_tsne[idx, 1]), alpha=0.7)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
d0f84ab71df71ab72e5287365d6b98bad2c882c3 | 25,012 | ipynb | Jupyter Notebook | .ipynb_checkpoints/visualization-checkpoint.ipynb | Puzz1eX/HFCN | 81880cb8d4ccb1969a8df7b6dedbec05a5c18590 | [
"MIT"
] | null | null | null | .ipynb_checkpoints/visualization-checkpoint.ipynb | Puzz1eX/HFCN | 81880cb8d4ccb1969a8df7b6dedbec05a5c18590 | [
"MIT"
] | null | null | null | .ipynb_checkpoints/visualization-checkpoint.ipynb | Puzz1eX/HFCN | 81880cb8d4ccb1969a8df7b6dedbec05a5c18590 | [
"MIT"
] | null | null | null | 72.921283 | 10,460 | 0.723653 | [
[
[
"from matplotlib import pyplot as plt\nimport pickle\n%matplotlib inline\nplt.figure(figsize=(10, 3))\nimport seaborn as sns; sns.set()\nwith open(\"routing_score.pkl\",'rb') as h:\n test_list=pickle.load(h)\ndata=test_list[2][0].mean(axis=0,keepdims=True).squeeze()\n# data=test_list[0]\nxLabel = [\n \"movie_id\", \"user_id\",\n \"gender\", \"age\", \"occupation\", \"zip\", \"genre\"]\nyLabel = [\"caps_{}\".format(i+1) for i in range(4)]\nax = sns.heatmap(data,vmin=0, vmax=1,cmap = 'Blues',xticklabels =xLabel,yticklabels=yLabel)\nax.xaxis.set_ticks_position('top')\nplt.xticks(rotation=0)\nplt.yticks(rotation=0)\nplt.savefig('capsule_movielens.jpg',dpi=400)",
"_____no_output_____"
],
[
"import re\npattern=re.compile(\"^\\D*\")\npattern.findall(\"+-2\")",
"_____no_output_____"
],
[
"import math\nfrom itertools import combinations\ndef comb(n,m):\n return math.factorial(n)//(math.factorial(n-m)*math.factorial(m))\ndef calculate(num_people):\n total_num=0\n for i in range(1,num_people+1):\n print(i)\n total_num+=comb(num_people,i)*i\n return total_num%(1e9+7)\ncalculate(4)",
"1\n2\n3\n4\n"
],
[
"[i for i in range(10,-1,-1)]",
"_____no_output_____"
],
[
"import math\ndef comb(n,m):\n return math.factorial(n)//(math.factorial(n-m)*math.factorial(m))\ncomb(4,2)",
"_____no_output_____"
],
[
"from typing import List\nclass Solution:\n def solveNQueens(self, n: int) -> List[List[str]]:\n #初始化棋盘\n checkerboard=[['0']*n for _ in range(n)]\n print(\"init checkerboard\",checkerboard)\n #记录棋盘状态\n checkerboard_stack= []\n result_list=[]\n #更新棋盘,该位置放入Q后不可放入的位置\n def update_checkerboard(row,col):\n print(checkerboard)\n checkerboard[row][:]='.'\n checkerboard[:][col]='.'\n \n #以该位置为中心扩散\n for i in range(0,n):\n left=row-i\n right=row+i\n up=col-i\n down=col+i\n if left >=0:\n if up >=0:\n checkerboard[left][up]='.'\n if down < n:\n print(left,down)\n checkerboard[left][down]='.'\n if right<n:\n if up >=0:\n checkerboard[left][up]='.'\n if down < n:\n print(down)\n checkerboard[left][down]='.'\n return checkerboard\n #回溯算法,DFS每落下一个子更新棋盘状态\n def dfs(row,n):\n nonlocal checkerboard\n #终止条件最后一行只剩一个空余位置,该位置可以放置皇后\n if row==n-1 and '0' in ''.join(checkerboard[row]):\n checkerboard[row]=' '.join(checkerboard[row]).replace('0','Q').split(' ')\n result_list.append(checkerboard)\n return True\n #进行选择\n for col in range(n):\n if checkerboard[row][col]=='0':\n #选择该处可以选位置\n checkerboard_stack.append(update_checkerboard(row,col))\n checkerboard[row][col]='Q'\n #继续遍历下一行\n if dfs(row+1,n):\n checkerboard_stack.pop()\n continue\n #回溯\n checkerboard=checkerboard_stack.pop()\n return False\n dfs(0,n)\n return result_list\n\nsolution=Solution()\nsolution.solveNQueens(4)",
"init checkerboard [['0', '0', '0', '0'], ['0', '0', '0', '0'], ['0', '0', '0', '0'], ['0', '0', '0', '0']]\n[['.'], ['0', '0', '0', '0'], ['0', '0', '0', '0'], ['0', '0', '0', '0']]\n0 0\n0\n1\n2\n3\n[['Q'], ['.'], ['0', '0', '.', '0'], ['0', '.', '0', '0']]\n1 0\n0\n0 1\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0f85208014a06c45bc94ae09cd9004182b68687 | 126,399 | ipynb | Jupyter Notebook | Pandas New.ipynb | ankit98040/DataScience-Seminar | ac51f6d2b515d349e4cb3bc6679d2b2e87955cc3 | [
"Apache-2.0"
] | null | null | null | Pandas New.ipynb | ankit98040/DataScience-Seminar | ac51f6d2b515d349e4cb3bc6679d2b2e87955cc3 | [
"Apache-2.0"
] | null | null | null | Pandas New.ipynb | ankit98040/DataScience-Seminar | ac51f6d2b515d349e4cb3bc6679d2b2e87955cc3 | [
"Apache-2.0"
] | null | null | null | 31.67101 | 114 | 0.34293 | [
[
[
"import pandas as pd\nimport numpy as np",
"_____no_output_____"
],
[
"df = pd.read_csv('phone_data.csv')",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"df.shape",
"_____no_output_____"
],
[
"print(df['item'])",
"0 data\n1 call\n2 call\n3 call\n4 call\n5 call\n6 data\n7 call\n8 call\n9 call\n10 call\n11 sms\n12 sms\n13 data\n14 sms\n15 sms\n16 sms\n17 sms\n18 sms\n19 call\n20 call\n21 call\n22 sms\n23 sms\n24 sms\n25 sms\n26 data\n27 call\n28 call\n29 call\n ... \n800 call\n801 call\n802 call\n803 call\n804 data\n805 call\n806 call\n807 call\n808 call\n809 call\n810 call\n811 data\n812 sms\n813 sms\n814 sms\n815 sms\n816 call\n817 data\n818 data\n819 data\n820 data\n821 data\n822 data\n823 data\n824 data\n825 sms\n826 sms\n827 data\n828 sms\n829 sms\nName: item, Length: 830, dtype: object\n"
],
[
" df[['item','duration','month']].head()",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"df.iloc[:8,1:4]",
"_____no_output_____"
],
[
"df.loc[8:]",
"_____no_output_____"
]
],
[
[
"#BOOLEAN INDEXING",
"_____no_output_____"
],
[
"and &\n\nor |\n\nEqual to ==\n\nNot equal to !=\n\nNot in ~\n\nEquals: ==\n\nNot equals: !=\n\nGreater than, less than: > or <\n\nGreater than or equal to >=\n\nLess than or equal to <=",
"_____no_output_____"
]
],
[
[
"condition = (df.item == 'call')\ncondition.head()",
"_____no_output_____"
],
[
"condition = (df.item == 'call')\ndf[~condition].head()",
"_____no_output_____"
],
[
" condition = (df.item == 'call') & (df.network == 'Vodafone')\n df[condition].head()",
"_____no_output_____"
]
],
[
[
"NOW IF YOU WANT TO SEE THE ITEMS WHICH ARE NOT INCLUDED (EXCLUDED ONES)",
"_____no_output_____"
]
],
[
[
"condition = (df.item == 'call')\ndf[~condition].head()",
"_____no_output_____"
],
[
" condition = (df.item == 'call') | (df.network == 'Vodafone')\ndf[condition].head()",
"_____no_output_____"
]
],
[
[
"NOW IF YOU WANT TO ADD A COLUMN WHICH WILL BE A MULTIPLE OF A PARTICULAR COLUMN",
"_____no_output_____"
]
],
[
[
"df['new_column'] = df['duration']*3\ndf.head()",
"_____no_output_____"
],
[
"df['new_column'] = df['network']*3\ndf.head()",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"df.drop(['new_column'], axis = 1, inplace=True)",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"df.sort_values('duration') #ascending",
"_____no_output_____"
],
[
"df.sort_values('duration', ascending = False ).head() #descending",
"_____no_output_____"
],
[
"df.sort_values(['duration', 'network'], ascending=[False, True]).head() #ascending",
"_____no_output_____"
]
],
[
[
"#WORKING WITH DATES\n\nDirective\n\n%a Weekday as locale’s abbreviated name. Sun, Mon, …, Sat (en_US) So, Mo, …, Sa (de_DE)\n\n%A Weekday as locale’s full name. Sunday, Monday, …, Saturday (en_US) Sonntag, Montag, …, Samstag (de_DE)\n\n%w Weekday as a decimal number, where 0 is Sunday and 6 is Saturday. 0, 1, 2, 3, 4, 5, 6\n\n%d Day of the month as a zero-padded decimal number. 01, 02, …, 31",
"_____no_output_____"
]
],
[
[
"pd.to_datetime(df['date']) >= '2015-01-01'",
"_____no_output_____"
],
[
"sum(pd.to_datetime(df['date']) >= '2015-01-01')",
"_____no_output_____"
],
[
"from datetime import datetime\nfrom datetime import date\ndf['new_date']=[datetime.strptime(x,'%d/%m/%y %H:%M') for x in df['date']]",
"_____no_output_____"
],
[
"type(df['new_date'][0])",
"_____no_output_____"
],
[
"type(df['date'][0])",
"_____no_output_____"
],
[
"print(date.today())\nprint(datetime.now())",
"2019-12-20\n2019-12-20 09:17:13.035965\n"
],
[
"df[df.month=='2014-11']['duration'].sum()",
"_____no_output_____"
],
[
"df.groupby('month')['duration'].sum()",
"_____no_output_____"
],
[
"df.groupby('month')['date'].count()",
"_____no_output_____"
],
[
"df[df['item']=='call'].groupby('network')['duration'].sum()",
"_____no_output_____"
],
[
"df.groupby(['network','item'])['duration'].sum()",
"_____no_output_____"
],
[
"df.groupby(['network','item'])['duration'].sum().reset_index()",
"_____no_output_____"
],
[
"# lambda function - Row wise operation\ndef new_duration(network, duration):\n if network=='world':\n new_duration = duration * 2\n else:\n new_duration = duration * 4\n \n return new_duration\n\ndf['new_duration'] = df.apply(lambda x: new_duration(x['network'], x['duration']), axis=1)",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0f85d75cca0642f6a113b267699c208b1fb5724 | 277,733 | ipynb | Jupyter Notebook | notebooks/contributions/DAPA/DAPA_Tutorial_2_-_Area_-_Sentinel-2.ipynb | jonas-eberle/notebooks | 0dc2b1ae38f2c99fa3ebe75212cdcc0b879b9ce3 | [
"MIT"
] | null | null | null | notebooks/contributions/DAPA/DAPA_Tutorial_2_-_Area_-_Sentinel-2.ipynb | jonas-eberle/notebooks | 0dc2b1ae38f2c99fa3ebe75212cdcc0b879b9ce3 | [
"MIT"
] | null | null | null | notebooks/contributions/DAPA/DAPA_Tutorial_2_-_Area_-_Sentinel-2.ipynb | jonas-eberle/notebooks | 0dc2b1ae38f2c99fa3ebe75212cdcc0b879b9ce3 | [
"MIT"
] | 1 | 2020-07-27T12:35:24.000Z | 2020-07-27T12:35:24.000Z | 234.176223 | 243,360 | 0.916917 | [
[
[
"# DAPA Tutorial #2: Area - Sentinel-2",
"_____no_output_____"
],
[
"## Load environment variables\nPlease make sure that the environment variable \"DAPA_URL\" is set in the `custom.env` file. You can check this by executing the following block. \n\nIf DAPA_URL is not set, please create a text file named `custom.env` in your home directory with the following input: \n>DAPA_URL=YOUR-PERSONAL-DAPA-APP-URL",
"_____no_output_____"
]
],
[
[
"from edc import setup_environment_variables\nsetup_environment_variables()",
"_____no_output_____"
]
],
[
[
"## Check notebook compabtibility\n**Please note:** If you conduct this notebook again at a later time, the base image of this Jupyter Hub service can include newer versions of the libraries installed. Thus, the notebook execution can fail. This compatibility check is only necessary when something is broken. ",
"_____no_output_____"
]
],
[
[
"from edc import check_compatibility\ncheck_compatibility(\"user-0.19.6\")",
"_____no_output_____"
]
],
[
[
"## Load libraries\nPython libraries used in this tutorial will be loaded.",
"_____no_output_____"
]
],
[
[
"import os\nimport xarray as xr\nimport pandas as pd\nimport requests\nimport matplotlib\nfrom ipyleaflet import Map, Rectangle, DrawControl, basemaps, basemap_to_tiles\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"## Set DAPA endpoint\nExecute the following code to check if the DAPA_URL is available in the environment variable and to set the `/dapa` endpoint. ",
"_____no_output_____"
]
],
[
[
"service_url = None\ndapa_url = None\n\nif 'DAPA_URL' not in os.environ:\n print('!! DAPA_URL does not exist as environment variable. Please make sure this is the case - see first block of this notebook! !!')\nelse: \n service_url = os.environ['DAPA_URL']\n dapa_url = '{}/{}'.format(service_url, 'oapi')\n print('DAPA path: {}'.format(dapa_url.replace(service_url, '')))",
"DAPA path: /oapi\n"
]
],
[
[
"## Get collections supported by this endpoint\nThis request provides a list of collections. The path of each collection is used as starting path of this service.",
"_____no_output_____"
]
],
[
[
"collections_url = '{}/{}'.format(dapa_url, 'collections')\ncollections = requests.get(collections_url, headers={'Accept': 'application/json'})\n\nprint('DAPA path: {}'.format(collections.url.replace(service_url, '')))\ncollections.json()",
"DAPA path: /oapi/collections\n"
]
],
[
[
"## Get fields of collection Sentinel-2 L2A\nThe fields (or variables in other DAPA endpoints - these are the bands of the raster data) can be retrieved in all requests to the DAPA endpoint. In addition to the fixed set of fields, \"virtual\" fields can be used to conduct math operations (e.g., the calculation of indices). ",
"_____no_output_____"
]
],
[
[
"collection = 'S2L2A'\n\nfields_url = '{}/{}/{}/{}'.format(dapa_url, 'collections', collection, 'dapa/fields')\nfields = requests.get(fields_url, headers={'Accept': 'application/json'})\n\nprint('DAPA path: {}'.format(fields.url.replace(service_url, '')))\nfields.json()",
"DAPA path: /oapi/collections/S2L2A/dapa/fields\n"
]
],
[
[
"## Retrieve data as raster aggregated by time",
"_____no_output_____"
],
[
"### Set DAPA URL and parameters\nThe output of this request is a single raster (`area` endpoint). As the input collection (S2L2A) is a multi-temporal raster and the output format is an area, temporal aggregation is conducted for each pixel in the area.\n\nTo retrieve a single raster, a bounding box (`bbox`) or polygon geometry (`geom`) needs to be provided. The `time` parameter allows to aggregate data only within a specific time span. Also the band (`field`) to be returned by DAPA needs to be specified as well. ",
"_____no_output_____"
]
],
[
[
"# DAPA URL\nurl = '{}/{}/{}/{}'.format(dapa_url, 'collections', collection, 'dapa/area')\n\n# Parameters for this request\nparams = {\n 'bbox': '11.49,48.05,11.66,48.22',\n 'time': '2018-05-07T10:00:00Z/2018-05-07T12:00:00Z',\n 'fields': 'NDVI=(B08-B04)/(B08%2BB04),NDBI=(B11-B08)/(B11%2BB08)', # Please note: + signs need to be URL encoded -> %2B\n 'aggregate': 'avg'\n}\n\n# show point in the map\nm = Map(\n basemap=basemap_to_tiles(basemaps.OpenStreetMap.Mapnik),\n center=(48.14, 11.56),\n zoom=10\n)\n\nbbox = [float(coord) for coord in params['bbox'].split(',')]\nrectangle = Rectangle(bounds=((bbox[1], bbox[0]), (bbox[3], bbox[2])))\nm.add_layer(rectangle)\n\nm",
"_____no_output_____"
]
],
[
[
"### Build request URL and conduct request",
"_____no_output_____"
]
],
[
[
"params_str = \"&\".join(\"%s=%s\" % (k, v) for k,v in params.items())\nr = requests.get(url, params=params_str)\n\nprint('DAPA path: {}'.format(r.url.replace(service_url, '')))\nprint('Status code: {}'.format(r.status_code))",
"DAPA path: /oapi/collections/S2L2A/dapa/area?bbox=11.49,48.05,11.66,48.22&time=2018-05-07T10:00:00Z/2018-05-07T12:00:00Z&fields=NDVI=(B08-B04)/(B08%2BB04),NDBI=(B11-B08)/(B11%2BB08)&aggregate=avg\nStatus code: 200\n"
]
],
[
[
"### Write raster dataset to GeoTIFF file\nThe response of the `area` endpoint is currently a GeoTIFF file, which can either be saved to disk or used directly in further processing.",
"_____no_output_____"
]
],
[
[
"with open('area_avg.tif', 'wb') as filew:\n filew.write(r.content)",
"_____no_output_____"
]
],
[
[
"### Open raster dataset with xarray\nThe GeoTIFF file can be opened with xarray. The file consists of bands related to each `field` and each aggregation function (see descriptions attribute in the xarray output). ",
"_____no_output_____"
]
],
[
[
"ds = xr.open_rasterio('area_avg.tif')\nds",
"_____no_output_____"
]
],
[
[
"### Plot NDVI image (first band)",
"_____no_output_____"
]
],
[
[
"ds[0].plot(cmap=\"RdYlGn\")",
"_____no_output_____"
]
],
[
[
"## Output gdalinfo",
"_____no_output_____"
]
],
[
[
"!gdalinfo -stats area_avg.tif",
"Warning 1: TIFFReadDirectory:Sum of Photometric type-related color channels and ExtraSamples doesn't match SamplesPerPixel. Defining non-color channels as ExtraSamples.\nDriver: GTiff/GeoTIFF\nFiles: area_avg.tif\nSize is 512, 512\nCoordinate System is:\nGEOGCRS[\"WGS 84\",\n DATUM[\"World Geodetic System 1984\",\n ELLIPSOID[\"WGS 84\",6378137,298.257223563,\n LENGTHUNIT[\"metre\",1]]],\n PRIMEM[\"Greenwich\",0,\n ANGLEUNIT[\"degree\",0.0174532925199433]],\n CS[ellipsoidal,2],\n AXIS[\"latitude\",north,\n ORDER[1],\n ANGLEUNIT[\"degree\",0.0174532925199433]],\n AXIS[\"longitude\",east,\n ORDER[2],\n ANGLEUNIT[\"degree\",0.0174532925199433]],\n ID[\"EPSG\",4326]]\nData axis to CRS axis mapping: 2,1\nOrigin = (11.490000000000000,48.219999999999999)\nPixel Size = (0.000332031250000,-0.000332031250000)\nMetadata:\n AREA_OR_POINT=Area\n TIFFTAG_RESOLUTIONUNIT=1 (unitless)\n TIFFTAG_XRESOLUTION=1\n TIFFTAG_YRESOLUTION=1\nImage Structure Metadata:\n COMPRESSION=DEFLATE\n INTERLEAVE=PIXEL\nCorner Coordinates:\nUpper Left ( 11.4900000, 48.2200000) ( 11d29'24.00\"E, 48d13'12.00\"N)\nLower Left ( 11.4900000, 48.0500000) ( 11d29'24.00\"E, 48d 3' 0.00\"N)\nUpper Right ( 11.6600000, 48.2200000) ( 11d39'36.00\"E, 48d13'12.00\"N)\nLower Right ( 11.6600000, 48.0500000) ( 11d39'36.00\"E, 48d 3' 0.00\"N)\nCenter ( 11.5750000, 48.1350000) ( 11d34'30.00\"E, 48d 8' 6.00\"N)\nBand 1 Block=512x8 Type=Float32, ColorInterp=Gray\n Description = NDVI_avg\n Minimum=-1.000, Maximum=1.000, Mean=0.527, StdDev=0.253\n Metadata:\n STATISTICS_MAXIMUM=1\n STATISTICS_MEAN=0.52696186269059\n STATISTICS_MINIMUM=-1\n STATISTICS_STDDEV=0.25294857961659\n STATISTICS_VALID_PERCENT=100\nBand 2 Block=512x8 Type=Float32, ColorInterp=Undefined\n Description = NDBI_avg\n Minimum=-0.655, Maximum=1.000, Mean=-0.134, StdDev=0.178\n Metadata:\n STATISTICS_MAXIMUM=1\n STATISTICS_MEAN=-0.13420287323754\n STATISTICS_MINIMUM=-0.65451771020889\n STATISTICS_STDDEV=0.17816229549198\n STATISTICS_VALID_PERCENT=100\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0f861475a1082975ede5676dbf004e74caa2d11 | 105,615 | ipynb | Jupyter Notebook | Movies recommendation system.ipynb | Gaurav25089/movie_recommend | 586988c975d456caa1e5ab03fe33d076c60c7c23 | [
"BSD-4-Clause-UC"
] | null | null | null | Movies recommendation system.ipynb | Gaurav25089/movie_recommend | 586988c975d456caa1e5ab03fe33d076c60c7c23 | [
"BSD-4-Clause-UC"
] | null | null | null | Movies recommendation system.ipynb | Gaurav25089/movie_recommend | 586988c975d456caa1e5ab03fe33d076c60c7c23 | [
"BSD-4-Clause-UC"
] | null | null | null | 44.079716 | 16,244 | 0.496464 | [
[
[
"# Collaborative Base filtering like in Netflix, Youtube",
"_____no_output_____"
],
[
"import numpy as np",
"_____no_output_____"
],
[
"import pandas as pd",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"movies=pd.read_csv(\"C:/Users/Dell/Desktop/Movie-Recommendation/movies.csv\")",
"_____no_output_____"
],
[
"ratings=pd.read_csv(\"C:/Users/Dell/Desktop/Movie-Recommendation/ratings.csv\")",
"_____no_output_____"
],
[
"movies.head()",
"_____no_output_____"
],
[
"ratings.head()",
"_____no_output_____"
],
[
"final=ratings.pivot(index='movieId',columns='userId',values='rating')\nfinal.head()",
"_____no_output_____"
],
[
"final.fillna(0,inplace=True)\nfinal.head()",
"_____no_output_____"
],
[
"no_user_voted=ratings.groupby('movieId')['rating'].agg('count')\nno_movies_voted=ratings.groupby('userId')['rating'].agg('count')",
"_____no_output_____"
],
[
"no_user_voted",
"_____no_output_____"
],
[
"plt.scatter(no_user_voted.index,no_user_voted,color='mediumseagreen')\nplt.axhline(y=10,color='r')\nplt.xlabel('MovieId')\nplt.ylabel('No. of users voted')\nplt.show()",
"_____no_output_____"
],
[
"final",
"_____no_output_____"
],
[
"final = final.loc[no_user_voted[no_user_voted > 10].index,:]\nfinal",
"_____no_output_____"
],
[
"plt.scatter(no_movies_voted.index,no_movies_voted,color='mediumseagreen')\nplt.axhline(y=50,color='r')\nplt.xlabel('UserId')\nplt.ylabel('No. of votes by user')\nplt.show()\n",
"_____no_output_____"
],
[
"final=final.loc[:,no_movies_voted[no_movies_voted > 50].index]\nfinal",
"_____no_output_____"
],
[
"#sparsity = 1.0 - ( np.count_nonzero(sample) / float(sample.size) )\nfrom scipy.sparse import csr_matrix\ncsr_data = csr_matrix(final.values)\nfinal.reset_index(inplace=True)",
"_____no_output_____"
],
[
"from sklearn.neighbors import NearestNeighbors",
"_____no_output_____"
],
[
"knn = NearestNeighbors(metric='cosine', n_neighbors=20)\nknn.fit(csr_data)",
"_____no_output_____"
],
[
"movie_list = movies[movies['title'].str.contains('Iron Man')]\nmovie_list",
"_____no_output_____"
],
[
"movie_idx= movie_list.iloc[0]['movieId']\nmovie_idx",
"_____no_output_____"
],
[
"def get_movie_recommendation(movie_name):\n n_movies_to_reccomend = 10\n movie_list = movies[movies['title'].str.contains(movie_name)] \n if len(movie_list): \n movie_idx= movie_list.iloc[0]['movieId']\n movie_idx = final[final['movieId'] == movie_idx].index[0]\n distances , indices = knn.kneighbors(csr_data[movie_idx],n_neighbors=n_movies_to_reccomend+1) \n rec_movie_indices = sorted(list(zip(indices.squeeze().tolist(),distances.squeeze().tolist())),key=lambda x: x[1])[:0:-1]\n recommend_frame = []\n for val in rec_movie_indices:\n movie_idx = final.iloc[val[0]]['movieId']\n idx = movies[movies['movieId'] == movie_idx].index\n recommend_frame.append({'Title':movies.iloc[idx]['title'].values[0],'Distance':val[1]})\n df = pd.DataFrame(recommend_frame,index=range(1,n_movies_to_reccomend+1))\n return df\n else:\n return \"No movies found\"",
"_____no_output_____"
],
[
"get_movie_recommendation('Iron Man')",
"_____no_output_____"
],
[
"get_movie_recommendation('Memento')",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0f88c31dc4497f1b7888155e6c7bac8057ba4dc | 22,412 | ipynb | Jupyter Notebook | nbs/00_core.ipynb | tyoc213-contrib/reformer_fastai | a14de3d44e6983e34d462a3b4ec355436b701f9b | [
"MIT"
] | null | null | null | nbs/00_core.ipynb | tyoc213-contrib/reformer_fastai | a14de3d44e6983e34d462a3b4ec355436b701f9b | [
"MIT"
] | null | null | null | nbs/00_core.ipynb | tyoc213-contrib/reformer_fastai | a14de3d44e6983e34d462a3b4ec355436b701f9b | [
"MIT"
] | null | null | null | 30.659371 | 164 | 0.531278 | [
[
[
"# default_exp core",
"_____no_output_____"
]
],
[
[
"# Core\n\n> Basic healper functions",
"_____no_output_____"
]
],
[
[
"#hide\nfrom nbdev.showdoc import *",
"_____no_output_____"
],
[
"#hide\n%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
],
[
"#export\nimport torch\nfrom torch import nn, einsum\nimport torch.nn.functional as F\nimport torch.autograd.profiler as profiler\n\nfrom fastai.basics import *\nfrom fastai.text.all import *\nfrom fastai.test_utils import *\n\nfrom functools import partial, reduce, wraps\nfrom inspect import isfunction\nfrom operator import mul\nfrom copy import deepcopy\n\nfrom torch import Tensor\nfrom typing import Tuple\n\nfrom einops import rearrange, repeat",
"_____no_output_____"
]
],
[
[
"## Helper functions",
"_____no_output_____"
],
[
"### General purpose utils",
"_____no_output_____"
]
],
[
[
"#export\ndef exists(val):\n return val is not None\n\ndef default(val, d):\n if exists(val):\n return val\n return d() if isfunction(d) else d\n\ndef expand_dim1(x):\n if len(x.shape) == 1:\n return x[None, :]\n else: return x\n\ndef max_neg_value(tensor):\n return -torch.finfo(tensor.dtype).max",
"_____no_output_____"
],
[
"#export\ndef setattr_on(model, attr, val, module_class):\n for m in model.modules():\n if isinstance(m, module_class):\n setattr(m, attr, val)",
"_____no_output_____"
]
],
[
[
"### Generative utils",
"_____no_output_____"
]
],
[
[
"#export\n# generative helpers\n# credit https://github.com/huggingface/transformers/blob/a0c62d249303a68f5336e3f9a96ecf9241d7abbe/src/transformers/generation_logits_process.py\ndef top_p_filter(logits, top_p=0.9):\n sorted_logits, sorted_indices = torch.sort(logits, descending=True)\n cum_probs = torch.cumsum(F.softmax(sorted_logits, dim=-1), dim=-1)\n\n sorted_indices_to_remove = cum_probs > top_p\n sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()\n sorted_indices_to_remove[..., 0] = 0\n # if min_tokens_to_keep > 1:\n # # Keep at least min_tokens_to_keep (set to min_tokens_to_keep-1 because we add the first one below)\n # sorted_indices_to_remove[..., : min_tokens_to_keep - 1] = 0\n indices_to_remove = sorted_indices_to_remove.scatter(1, sorted_indices, sorted_indices_to_remove)\n logits[indices_to_remove] = float('-inf')\n return logits\n\ndef top_k_filter(logits, top_k=20):\n indices_to_remove = logits < torch.topk(logits, top_k)[0][..., -1, None]\n logits[indices_to_remove] = float('-inf')\n return logits\n\n_sampler = {\n 'top_k':top_k_filter,\n 'top_p':top_p_filter,\n 'gready':lambda x: x.argmax(-1)\n}",
"_____no_output_____"
]
],
[
[
"### LSH specific helpers",
"_____no_output_____"
],
[
"From [lucidrains/reformer-pytorch](https://github.com/lucidrains/reformer-pytorch/).",
"_____no_output_____"
]
],
[
[
"#exports\ndef cache_method_decorator(cache_attr, cache_namespace, reexecute = False):\n def inner_fn(fn):\n @wraps(fn)\n def wrapper(self, *args, key_namespace=None, fetch=False, set_cache=True, **kwargs):\n namespace_str = str(default(key_namespace, ''))\n _cache = getattr(self, cache_attr)\n _keyname = f'{cache_namespace}:{namespace_str}'\n\n if fetch:\n val = _cache[_keyname]\n if reexecute:\n fn(self, *args, **kwargs)\n else:\n val = fn(self, *args, **kwargs)\n if set_cache:\n setattr(self, cache_attr, {**_cache, **{_keyname: val}})\n return val\n return wrapper\n return inner_fn",
"_____no_output_____"
],
[
"#exports\ndef look_one_back(x):\n x_extra = torch.cat([x[:, -1:, ...], x[:, :-1, ...]], dim=1)\n return torch.cat([x, x_extra], dim=2)",
"_____no_output_____"
],
[
"#exports\ndef chunked_sum(tensor, chunks=1):\n *orig_size, last_dim = tensor.shape\n tensor = tensor.reshape(-1, last_dim)\n summed_tensors = [c.sum(dim=-1) for c in tensor.chunk(chunks, dim=0)]\n return torch.cat(summed_tensors, dim=0).reshape(orig_size)",
"_____no_output_____"
],
[
"#exports\ndef sort_key_val(t1, t2, dim=-1):\n values, indices = t1.sort(dim=dim)\n t2 = t2.expand_as(t1)\n return values, t2.gather(dim, indices)",
"_____no_output_____"
],
[
"#exports\ndef batched_index_select(values, indices):\n last_dim = values.shape[-1]\n return values.gather(1, indices[:, :, None].expand(-1, -1, last_dim))",
"_____no_output_____"
]
],
[
[
"## Profiling functions",
"_____no_output_____"
],
[
"Utility functions to assess model performance. Test functions with `mod` and input `x`. ",
"_____no_output_____"
]
],
[
[
"mod = get_text_classifier(AWD_LSTM, vocab_sz=10_000, n_class=10)\nx = torch.randint(0, 100, (3, 72))",
"_____no_output_____"
],
[
"#export\ndef do_cuda_timing(f, inp, context=None, n_loops=100):\n '''\n Get timings of cuda modules. Note `self_cpu_time_total` is returned, but\n from experiments this appears to be similar/same to the total CUDA time\n \n f : function to profile, typically an nn.Module\n inp : required input to f\n context : optional additional input into f, used for Decoder-style modules\n '''\n f.cuda()\n inp = inp.cuda()\n if context is not None: context = context.cuda()\n with profiler.profile(record_shapes=False, use_cuda=True) as prof:\n with profiler.record_function(\"model_inference\"):\n with torch.no_grad():\n for _ in range(n_loops):\n if context is None: f(inp)\n else: f(inp, context)\n torch.cuda.synchronize()\n \n res = round((prof.key_averages().self_cpu_time_total / 1000) / n_loops, 3)\n print(f'{res}ms')\n return res",
"_____no_output_____"
],
[
"#export\ndef model_performance(n_loops=5, model='arto', dls=None, n_epochs=1, lr=5e-4):\n \"\"\"\n DEMO CODE ONLY!\n Run training loop to measure timings. Note that the models internally\n should be changed depending on the model you would like to use. \n You should also adjust the metrics you are monitoring\n \"\"\"\n acc_ls, ppl_ls =[], []\n for i in range(n_loops):\n # ADD YOUR MODEL(S) INIT HERE\n# if model == 'arto': m = artoTransformerLM(vocab_sz, 512)\n# elif model == 'pt': m = ptTransformerLM(vocab_sz, 512)\n# else: print('model name not correct')\n \n learn = Learner(dls, m,\n loss_func=CrossEntropyLossFlat(),\n metrics=[accuracy, Perplexity()]).to_native_fp16()\n\n learn.fit_one_cycle(n_epochs, lr, wd=0.05)\n \n acc_ls.append(learn.recorder.final_record[2])\n ppl_ls.append(learn.recorder.final_record[3])\n print(f'Avg Accuracy: {round(sum(acc_ls)/len(acc_ls),3)}, std: {np.std(acc_ls)}')\n print(f'Avg Perplexity: {round(sum(ppl_ls)/len(ppl_ls),3)}, std: {np.std(ppl_ls)}')\n print()\n return learn, acc_ls, ppl_ls",
"_____no_output_____"
],
[
"#export\ndef total_params(m):\n \"\"\"\n Give the number of parameters of a module and if it's trainable or not\n - Taken from Taken from fastai.callback.hook\n \"\"\"\n params = sum([p.numel() for p in m.parameters()])\n trains = [p.requires_grad for p in m.parameters()]\n return params, (False if len(trains)==0 else trains[0])",
"_____no_output_____"
]
],
[
[
"Number of params for our test model:",
"_____no_output_____"
]
],
[
[
"total_params(mod)",
"_____no_output_____"
]
],
[
[
"## Translation Callbacks\n\nCallbacks used to ensuring training a translation model works. All 3 are needed\n\nSee [notebook here](https://github.com/bentrevett/pytorch-seq2seq/blob/master/6%20-%20Attention%20is%20All%20You%20Need.ipynb) for explanation of EOS shifting",
"_____no_output_____"
]
],
[
[
"# exports\nclass CombineInputOutputCallback(Callback):\n \"\"\"\n Callback to combine the source (self.xb) and target (self.yb) into self.xb\n \"\"\"\n def __init__(self): pass\n def before_batch(self): \n self.learn.xb = (self.xb[0], self.yb[0])",
"_____no_output_____"
],
[
"class AssertAndCancelFit(Callback):\n \"Cancels batch after backward to avoid opt.step()\"\n def before_batch(self):\n assert len(self.learn.xb) == 2\n assert self.learn.xb[1] is self.learn.yb[0]\n raise CancelEpochException()\n\nlearn = synth_learner(cbs=[CombineInputOutputCallback(), AssertAndCancelFit()])\nlearn.fit(1)",
"_____no_output_____"
],
[
"# exports\nclass RemoveEOSCallback(Callback):\n \"\"\"\n Shift the target presented to the model during training to remove the \"eos\" token as \n we don't want the model to learn to translate EOS when it sees EOS.\n \n In practice we actually mask the EOS token as due to batching the last token will often be a <pad> token,\n not EOS\n \"\"\"\n def __init__(self, eos_idx): self.eos_idx=eos_idx\n def before_batch(self): \n eos_mask=(self.learn.xb[1]!=self.eos_idx)\n sz=torch.tensor(self.learn.xb[1].size())\n sz[1]=sz[1]-1\n self.learn.xb = (self.learn.xb[0], self.learn.xb[1][eos_mask].view((sz[0],sz[1])))",
"_____no_output_____"
],
[
"# exports\nclass LossTargetShiftCallback(Callback):\n \"\"\"\n Shift the target shown to the loss to exclude the \"bos\" token as the first token we want predicted\n should be an actual word, not the \"bos\" token (as we have already given the model \"bos\" )\n \"\"\"\n def __init__(self): pass\n def after_pred(self): \n self.learn.yb = (self.learn.yb[0][:,1:],)",
"_____no_output_____"
],
[
"class TestLossShiftAndCancelFit(Callback):\n \"Cancels batch after backward to avoid opt.step()\"\n def after_pred(self): \n o = self.learn.dls.one_batch()\n assert self.learn.yb[0].size()[1] == o[1].size()[1] - 1\n raise CancelEpochException()\n\nlearn = synth_learner(cbs=[LossTargetShiftCallback(), TestLossShiftAndCancelFit()])\nlearn.fit(1)",
"_____no_output_____"
],
[
"#export\nclass PadBatchCallback(Callback):\n \"Pads input and target sequences to multiple of 2*bucket_size\"\n def __init__(self, bucket_size:int=64, val:int=0, y_val:int=-100):\n self.mult = 2*bucket_size\n self.val, self.y_val = val, y_val\n def before_batch(self):\n bs, sl = self.x.size()\n if sl % self.mult != 0:\n pad_ = self.mult - sl%self.mult\n self.learn.xb = (F.pad(self.x, (0,pad_), 'constant', self.val), )\n self.learn.yb = (F.pad(self.y, (0,pad_), 'constant', self.y_val), )",
"_____no_output_____"
]
],
[
[
"## Loss functions",
"_____no_output_____"
]
],
[
[
"#export\nclass LabelSmoothingCrossEntropy(Module):\n \"\"\"Label smotthing cross entropy similar to fastai implementation\n https://github.com/fastai/fastai/blob/89b1afb59e37e5abf7008888f6e4dd1bf1211e3e/fastai/losses.py#L79\n with added option to provide ignore_index\"\"\"\n y_int = True\n def __init__(self, eps:float=0.1, reduction='mean', ignore_index=-100): store_attr()\n\n def forward(self, output, target):\n c = output.size()[-1]\n log_preds = F.log_softmax(output, dim=-1)\n nll_loss = F.nll_loss(log_preds, target.long(), reduction=self.reduction, ignore_index=self.ignore_index)\n mask = target.eq(self.ignore_index)\n log_preds = log_preds.masked_fill(mask.unsqueeze(-1), 0.)\n if self.reduction=='sum': smooth_loss = -log_preds.sum()\n else:\n smooth_loss = -log_preds.sum(dim=-1) #We divide by that size at the return line so sum and not mean\n if self.reduction=='mean': smooth_loss = smooth_loss.mean()/(1-mask.float().mean())# devide by fraction of accounted values to debias mean\n return smooth_loss*self.eps/c + (1-self.eps)*nll_loss\n\n def activation(self, out): return F.softmax(out, dim=-1)\n def decodes(self, out): return out.argmax(dim=-1)\n",
"_____no_output_____"
],
[
"#export\n@delegates()\nclass LabelSmoothingCrossEntropyFlat(BaseLoss):\n \"Same as `LabelSmoothingCrossEntropy`, but flattens input and target.\"\n y_int = True\n @use_kwargs_dict(keep=True, eps=0.1, reduction='mean')\n def __init__(self, *args, axis=-1, **kwargs): super().__init__(LabelSmoothingCrossEntropy, *args, axis=axis, **kwargs)\n def activation(self, out): return F.softmax(out, dim=-1)\n def decodes(self, out): return out.argmax(dim=-1)",
"_____no_output_____"
],
[
"bs=4\nsl=10\nv=32\npred = torch.randn(bs, sl, v, requires_grad=True)\ntarg = torch.randint(v, (bs,sl))\ni, j = torch.triu_indices(bs, sl, offset=(sl-bs+1))\ntarg[i,j] = -1\nloss_func = LabelSmoothingCrossEntropyFlat(ignore_index=-1)\nloss = loss_func(pred, targ)\nloss.backward()\nassert (torch.all(pred.grad == 0, dim=-1) == (targ==-1)).all()",
"_____no_output_____"
]
],
[
[
"## Distributed",
"_____no_output_____"
]
],
[
[
"#export\nfrom fastai.distributed import *\n@patch\n@contextmanager\ndef distrib_ctx(self: Learner, cuda_id=None,sync_bn=True):\n \"A context manager to adapt a learner to train in distributed data parallel mode.\"\n # Figure out the GPU to use from rank. Create a dpg if none exists yet.\n if cuda_id is None: cuda_id = int(os.environ.get('DEFAULT_GPU', 0))\n if not torch.distributed.is_initialized():\n setup_distrib(cuda_id)\n cleanup_dpg = torch.distributed.is_initialized()\n else: cleanup_dpg = False\n # Adapt self to DistributedDataParallel, yield, and cleanup afterwards.\n try:\n if num_distrib(): self.to_distributed(cuda_id,sync_bn)\n yield self\n finally:\n self.detach_distributed()\n if cleanup_dpg: teardown_distrib()",
"_____no_output_____"
],
[
"#hide\nfrom nbdev.export import notebook2script; notebook2script()",
"Converted 00_core.ipynb.\nConverted 01_layers.ipynb.\nConverted 02_attention.ipynb.\nConverted 03_transformer.ipynb.\nConverted 04_reformer.ipynb.\nConverted 05_tokenizers.ipynb.\nConverted 06_data.ipynb.\nConverted 07_metrics.ipynb.\nConverted 08_optimizers.ipynb.\nConverted 09_tracking.ipynb.\nConverted 10_experiment.synthetic-task.ipynb.\nConverted 10a_experiment.synthetic-task-comparison.ipynb.\nConverted 10b_experiment.synthetic-task-minimal.ipynb.\nConverted 10c_experiment.synthetic-task-analysis.ipynb.\nConverted 11_experiment.enwik8_baseline.ipynb.\nConverted 12_experiment.enwik8_sharedQK.ipynb.\nConverted 13_experiment.enwik8_reversible.ipynb.\nConverted 20_experiment-script.ipynb.\nConverted 21_experiment-configs.ipynb.\nConverted 50_exploration.LSH.ipynb.\nConverted index.ipynb.\nConverted reproducibility.report_1_reproducibility_summary.ipynb.\n"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
d0f893436d85dd479b5c22526dfd3648af65cf2b | 52,669 | ipynb | Jupyter Notebook | Pandas1_Day13.ipynb | SarahRomyMarkose/Business-Analytics-with-Python | 97016328865c66754868b3c2a4ada378b9a94a93 | [
"MIT"
] | null | null | null | Pandas1_Day13.ipynb | SarahRomyMarkose/Business-Analytics-with-Python | 97016328865c66754868b3c2a4ada378b9a94a93 | [
"MIT"
] | null | null | null | Pandas1_Day13.ipynb | SarahRomyMarkose/Business-Analytics-with-Python | 97016328865c66754868b3c2a4ada378b9a94a93 | [
"MIT"
] | null | null | null | 29.325724 | 305 | 0.291955 | [
[
[
"import pandas as pd",
"_____no_output_____"
],
[
"df=pd.read_excel(\"Sample Python.xlsx\")",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"df.dropna()",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"new_df=df.dropna()",
"_____no_output_____"
],
[
"new_df",
"_____no_output_____"
],
[
"df.dropna(inplace=True)",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"df.loc[3,\"Apple\"]",
"_____no_output_____"
],
[
"df.loc[12,\"Rice\"]",
"_____no_output_____"
],
[
"df.loc[19,\"Biscuits\"]",
"_____no_output_____"
],
[
"df.loc[1,\"Chips\"]=25",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"df=pd.read_excel(\"Sample Python.xlsx\")\n\nfor x in df.index:\n if df.loc[x,\"Apple\"]>60:\n print(df.loc[x,\"Apple\"])",
"69\n88\n74\n65\n"
],
[
"for x in df.index:\n if df.loc[x,\"Apple\"]>60 and df.loc[x,\"Apple\"]<80:\n print(df.loc[x,\"Apple\"])",
"69\n74\n65\n"
],
[
"for x in df.index:\n if df.loc[x,\"Apple\"]<30:\n df.loc[x,\"Apple\"]=0\n \ndf\n \n ",
"_____no_output_____"
],
[
"df=pd.read_excel(\"Sample Python.xlsx\")\n\nfor x in df.index:\n if df.loc[x,\"Apple\"]>60:\n if df.loc[x,\"Apple\"]=\"Very Good Sale!\"\n \n ",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0f89abeb18aeb360012adcf2093f51a65b7e65b | 28,333 | ipynb | Jupyter Notebook | Iris_Flower_Classification.ipynb | subhrockzz/Machine_Learning | d17bda8e1bcca5639f14f64778fb0e4595b5dd1f | [
"Apache-2.0"
] | 1 | 2019-08-07T04:34:58.000Z | 2019-08-07T04:34:58.000Z | Iris_Flower_Classification.ipynb | subhrockzz/Machine_Learning | d17bda8e1bcca5639f14f64778fb0e4595b5dd1f | [
"Apache-2.0"
] | null | null | null | Iris_Flower_Classification.ipynb | subhrockzz/Machine_Learning | d17bda8e1bcca5639f14f64778fb0e4595b5dd1f | [
"Apache-2.0"
] | null | null | null | 41.062319 | 6,456 | 0.680902 | [
[
[
"import pandas as pd",
"_____no_output_____"
],
[
"n=['sepal-length','sepal-width','petal-length','petal-width','Class']",
"_____no_output_____"
],
[
"dataset=pd.read_csv('iris.csv',names=n)",
"_____no_output_____"
],
[
"dataset.head()",
"_____no_output_____"
],
[
"dataset.shape",
"_____no_output_____"
],
[
"dataset.isnull().sum()",
"_____no_output_____"
],
[
"x=dataset.iloc[:,:-1]\ny=dataset.iloc[:,-1]",
"_____no_output_____"
],
[
"y",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split\nx_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.15,random_state=1)",
"_____no_output_____"
],
[
"from sklearn.neighbors import KNeighborsClassifier\nclassifier=KNeighborsClassifier(n_neighbors=39)\nclassifier.fit(x_train,y_train)",
"_____no_output_____"
],
[
"y_pred=classifier.predict(x_test)",
"_____no_output_____"
],
[
"y_pred",
"_____no_output_____"
],
[
"from sklearn.metrics import accuracy_score\naccuracy_score(y_test,y_pred)",
"_____no_output_____"
],
[
"y_pred_value=classifier.predict([[6.12,5.23,3.20,2.2]])",
"_____no_output_____"
],
[
"y_pred_value",
"_____no_output_____"
],
[
"score=[]\nfor i in range(3,100,2):\n classifier=KNeighborsClassifier(n_neighbors=i)\n classifier.fit(x_train,y_train)\n y_pred=classifier.predict(x_test)\n score.append(accuracy_score(y_test,y_pred))",
"_____no_output_____"
],
[
"max(score)",
"_____no_output_____"
],
[
"score",
"_____no_output_____"
],
[
"score.index(max(score))",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"plt.scatter(range(3,100,2),score,color='red')",
"_____no_output_____"
],
[
"classifier=KNeighborsClassifier(n_neighbors=3)\nclassifier.fit(x_train,y_train)\ny_pred=classifier.predict(x_test)\naccuracy_score(y_test,y_pred)",
"_____no_output_____"
],
[
"from sklearn.metrics import confusion_matrix",
"_____no_output_____"
],
[
"y_test.shape",
"_____no_output_____"
],
[
"cm=confusion_matrix(y_test,y_pred)\ncm",
"_____no_output_____"
],
[
"import seaborn as sns",
"_____no_output_____"
],
[
"sns.heatmap(pd.DataFrame(cm),annot=True,fmt='d')",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0f89fa8d3884e1837d870e607ae59f1730fc915 | 97,269 | ipynb | Jupyter Notebook | module3-ridge-regression/Jaimie_Onigkeit_LS_DS_213_assignment.ipynb | JaimieOnigkeit/DS-Unit-2-Linear-Models | eaed48acd605e8775dff2bcbf711791c5c6dddf8 | [
"MIT"
] | null | null | null | module3-ridge-regression/Jaimie_Onigkeit_LS_DS_213_assignment.ipynb | JaimieOnigkeit/DS-Unit-2-Linear-Models | eaed48acd605e8775dff2bcbf711791c5c6dddf8 | [
"MIT"
] | null | null | null | module3-ridge-regression/Jaimie_Onigkeit_LS_DS_213_assignment.ipynb | JaimieOnigkeit/DS-Unit-2-Linear-Models | eaed48acd605e8775dff2bcbf711791c5c6dddf8 | [
"MIT"
] | null | null | null | 36.788578 | 319 | 0.315527 | [
[
[
"<a href=\"https://colab.research.google.com/github/JaimieOnigkeit/DS-Unit-2-Linear-Models/blob/master/module3-ridge-regression/Jaimie_Onigkeit_LS_DS_213_assignment.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"Lambda School Data Science\n\n*Unit 2, Sprint 1, Module 3*\n\n---",
"_____no_output_____"
],
[
"# Ridge Regression\n\n## Assignment\n\nWe're going back to our other **New York City** real estate dataset. Instead of predicting apartment rents, you'll predict property sales prices.\n\nBut not just for condos in Tribeca...\n\n- [ ] Use a subset of the data where `BUILDING_CLASS_CATEGORY` == `'01 ONE FAMILY DWELLINGS'` and the sale price was more than 100 thousand and less than 2 million.\n- [ ] Do train/test split. Use data from January — March 2019 to train. Use data from April 2019 to test.\n- [ ] Do one-hot encoding of categorical features.\n- [ ] Do feature selection with `SelectKBest`.\n- [ ] Fit a ridge regression model with multiple features. Use the `normalize=True` parameter (or do [feature scaling](https://scikit-learn.org/stable/modules/preprocessing.html) beforehand — use the scaler's `fit_transform` method with the train set, and the scaler's `transform` method with the test set)\n- [ ] Get mean absolute error for the test set.\n- [ ] As always, commit your notebook to your fork of the GitHub repo.\n\nThe [NYC Department of Finance](https://www1.nyc.gov/site/finance/taxes/property-rolling-sales-data.page) has a glossary of property sales terms and NYC Building Class Code Descriptions. The data comes from the [NYC OpenData](https://data.cityofnewyork.us/browse?q=NYC%20calendar%20sales) portal.\n\n\n## Stretch Goals\n\nDon't worry, you aren't expected to do all these stretch goals! These are just ideas to consider and choose from.\n\n- [ ] Add your own stretch goal(s) !\n- [ ] Instead of `Ridge`, try `LinearRegression`. Depending on how many features you select, your errors will probably blow up! 💥\n- [ ] Instead of `Ridge`, try [`RidgeCV`](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.RidgeCV.html).\n- [ ] Learn more about feature selection:\n - [\"Permutation importance\"](https://www.kaggle.com/dansbecker/permutation-importance)\n - [scikit-learn's User Guide for Feature Selection](https://scikit-learn.org/stable/modules/feature_selection.html)\n - [mlxtend](http://rasbt.github.io/mlxtend/) library\n - scikit-learn-contrib libraries: [boruta_py](https://github.com/scikit-learn-contrib/boruta_py) & [stability-selection](https://github.com/scikit-learn-contrib/stability-selection)\n - [_Feature Engineering and Selection_](http://www.feat.engineering/) by Kuhn & Johnson.\n- [ ] Try [statsmodels](https://www.statsmodels.org/stable/index.html) if you’re interested in more inferential statistical approach to linear regression and feature selection, looking at p values and 95% confidence intervals for the coefficients.\n- [ ] Read [_An Introduction to Statistical Learning_](http://faculty.marshall.usc.edu/gareth-james/ISL/ISLR%20Seventh%20Printing.pdf), Chapters 1-3, for more math & theory, but in an accessible, readable way.\n- [ ] Try [scikit-learn pipelines](https://scikit-learn.org/stable/modules/compose.html).",
"_____no_output_____"
]
],
[
[
"%%capture\nimport sys\n\n# If you're on Colab:\nif 'google.colab' in sys.modules:\n DATA_PATH = 'https://raw.githubusercontent.com/LambdaSchool/DS-Unit-2-Applied-Modeling/master/data/'\n !pip install category_encoders==2.*\n\n# If you're working locally:\nelse:\n DATA_PATH = '../data/'\n \n# Ignore this Numpy warning when using Plotly Express:\n# FutureWarning: Method .ptp is deprecated and will be removed in a future version. Use numpy.ptp instead.\nimport warnings\nwarnings.filterwarnings(action='ignore', category=FutureWarning, module='numpy')",
"_____no_output_____"
],
[
"import pandas as pd\nimport pandas_profiling\n\n# Read New York City property sales data\ndf = pd.read_csv(DATA_PATH+'condos/NYC_Citywide_Rolling_Calendar_Sales.csv')\n\n# Change column names: replace spaces with underscores\ndf.columns = [col.replace(' ', '_') for col in df]\n\n# SALE_PRICE was read as strings.\n# Remove symbols, convert to integer\ndf['SALE_PRICE'] = (\n df['SALE_PRICE']\n .str.replace('$','')\n .str.replace('-','')\n .str.replace(',','')\n .astype(int)\n)",
"_____no_output_____"
],
[
"# BOROUGH is a numeric column, but arguably should be a categorical feature,\n# so convert it from a number to a string\ndf['BOROUGH'] = df['BOROUGH'].astype(str)",
"_____no_output_____"
],
[
"# Reduce cardinality for NEIGHBORHOOD feature\n\n# Get a list of the top 10 neighborhoods\ntop10 = df['NEIGHBORHOOD'].value_counts()[:10].index\n\n# At locations where the neighborhood is NOT in the top 10, \n# replace the neighborhood with 'OTHER'\ndf.loc[~df['NEIGHBORHOOD'].isin(top10), 'NEIGHBORHOOD'] = 'OTHER'",
"_____no_output_____"
],
[
"df.describe()",
"_____no_output_____"
],
[
"df = df.drop(['EASE-MENT'], axis = 'columns')",
"_____no_output_____"
],
[
"df.dtypes",
"_____no_output_____"
],
[
"df['SALE_DATE'] = pd.to_datetime(df['SALE_DATE'], infer_datetime_format=True)\n\ndf.dtypes",
"_____no_output_____"
]
],
[
[
"## Use a subset of the data where BUILDING_CLASS_CATEGORY == '01 ONE FAMILY DWELLINGS' and the sale price was more than 100 thousand and less than 2 million.",
"_____no_output_____"
]
],
[
[
"df_new = df[df.BUILDING_CLASS_CATEGORY == '01 ONE FAMILY DWELLINGS']\n",
"_____no_output_____"
],
[
"df_new.head()",
"_____no_output_____"
],
[
"df_new = df_new[(df_new.SALE_PRICE >= 100000 ) & (df_new.SALE_PRICE <= 2000000)]",
"_____no_output_____"
]
],
[
[
"## Do train/test split. Use data from January — March 2019 to train. Use data from April 2019 to test.",
"_____no_output_____"
]
],
[
[
"df_new.head()",
"_____no_output_____"
],
[
"#Remove unecessary columns\ndf_new = df_new.drop('APARTMENT_NUMBER', axis = 'columns')\ndf_new = df_new.drop('TAX_CLASS_AT_TIME_OF_SALE', axis = 'columns')",
"_____no_output_____"
],
[
"cutoff = pd.to_datetime('2019-04-01')\ntrain = df_new[df_new.SALE_DATE < cutoff]\ntest = df_new[df_new.SALE_DATE >= cutoff]\n\nprint(train.shape)\nprint(test.shape)",
"(2517, 18)\n(647, 18)\n"
]
],
[
[
"## Do one-hot encoding of categorical features.",
"_____no_output_____"
]
],
[
[
"test.describe(include='object')",
"_____no_output_____"
],
[
"target = 'SALE_PRICE'\nhigh_cardinality = ['ADDRESS', 'LAND_SQUARE_FEET', 'SALE_DATE']\nfeatures = train.columns.drop([target] + high_cardinality)",
"_____no_output_____"
],
[
"X_train = train[features]\ny_train = train[target]\nX_test = test[features]\ny_test = test[target]",
"_____no_output_____"
],
[
"import category_encoders as ce\nencoder = ce.OneHotEncoder(use_cat_names=True)\nX_train = encoder.fit_transform(X_train)",
"_____no_output_____"
],
[
"X_train.head()",
"_____no_output_____"
],
[
"X_test = encoder.transform(X_test)\nX_test",
"_____no_output_____"
]
],
[
[
"## Do feature selection with SelectKBest.",
"_____no_output_____"
]
],
[
[
"X_train.dtypes",
"_____no_output_____"
],
[
"from sklearn.feature_selection import SelectKBest, f_regression\n\nselector = SelectKBest(score_func=f_regression, k=29)\n\n# .fit_transform on the train set\n# .transform on test set\n\nX_train_selected = selector.fit_transform(X_train, y_train)\nX_train_selected.shape",
"/usr/local/lib/python3.6/dist-packages/sklearn/feature_selection/_univariate_selection.py:299: RuntimeWarning: divide by zero encountered in true_divide\n corr /= X_norms\n/usr/local/lib/python3.6/dist-packages/sklearn/feature_selection/_univariate_selection.py:304: RuntimeWarning: invalid value encountered in true_divide\n F = corr ** 2 / (1 - corr ** 2) * degrees_of_freedom\n/usr/local/lib/python3.6/dist-packages/scipy/stats/_distn_infrastructure.py:903: RuntimeWarning: invalid value encountered in greater\n return (a < x) & (x < b)\n/usr/local/lib/python3.6/dist-packages/scipy/stats/_distn_infrastructure.py:903: RuntimeWarning: invalid value encountered in less\n return (a < x) & (x < b)\n/usr/local/lib/python3.6/dist-packages/scipy/stats/_distn_infrastructure.py:1912: RuntimeWarning: invalid value encountered in less_equal\n cond2 = cond0 & (x <= _a)\n"
],
[
"selected_mask = selector.get_support()\nall_names = X_train.columns\nselected_names = all_names[selected_mask]\nunselected_names = all_names[~selected_mask]\n\nprint('Features selected:')\nfor name in selected_names:\n print(name)\n\nprint('\\n')\nprint('Features not selected:')\nfor name in unselected_names:\n print(name)",
"_____no_output_____"
],
[
"from sklearn.linear_model import LinearRegression\nfrom sklearn.metrics import mean_absolute_error\n\nfor k in range(1, len(X_train.columns)+1):\n print(f'{k} features')\n \n selector = SelectKBest(score_func=f_regression, k=k)\n X_train_selected = selector.fit_transform(X_train, y_train)\n X_test_selected = selector.transform(X_test)\n\n model = LinearRegression()\n model.fit(X_train_selected, y_train)\n y_pred = model.predict(X_test_selected)\n mae = mean_absolute_error(y_test, y_pred)\n print(f'Test Mean Absolute Error: ${mae:,.0f} \\n')\n",
"_____no_output_____"
]
],
[
[
"Looks like 29 features minimizes the error",
"_____no_output_____"
],
[
"## Fit a ridge regression model with multiple features. Use the normalize=True parameter (or do feature scaling beforehand — use the scaler's fit_transform method with the train set, and the scaler's transform method with the test set)",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\nfrom sklearn.linear_model import Ridge",
"_____no_output_____"
],
[
"from IPython.display import display, HTML\nfor alpha in [0.001, 0.01, 0.1, 1.0, 10, 100.0, 1000.0]:\n \n # Fit Ridge Regression model\n display(HTML(f'Ridge Regression, with alpha={alpha}'))\n model = Ridge(alpha=alpha)\n model.fit(X_train, y_train)\n y_pred = model.predict(X_test)\n\n # Get Test MAE\n mae = mean_absolute_error(y_test, y_pred)\n display(HTML(f'Test Mean Absolute Error: ${mae:,.0f}'))\n ",
"_____no_output_____"
]
],
[
[
"I tried to plot the coefficients, but I got an error saying that over 20 graphs had been created! Alpha 1 has the lowest mean absolute error.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
d0f8ddbae0fda4c50c7e7261e666234a75d87c59 | 26,811 | ipynb | Jupyter Notebook | notebooks/unet/unet_v3.ipynb | n-log-n/udacity-lyft-challenge | eba0f349560e702abd68be1a9ce5f6d6437556da | [
"MIT"
] | null | null | null | notebooks/unet/unet_v3.ipynb | n-log-n/udacity-lyft-challenge | eba0f349560e702abd68be1a9ce5f6d6437556da | [
"MIT"
] | null | null | null | notebooks/unet/unet_v3.ipynb | n-log-n/udacity-lyft-challenge | eba0f349560e702abd68be1a9ce5f6d6437556da | [
"MIT"
] | null | null | null | 51.65896 | 269 | 0.549998 | [
[
[
"import sys\nimport os\nsys.path.append('../../')\n\n%load_ext autoreload\n%autoreload 2\n%matplotlib inline\n\nos.environ['CUDA_VISIBLE_DEVICES'] = '0'",
"_____no_output_____"
],
[
"import numpy as np\n\nimport matplotlib.image as mpimg\nimport matplotlib.pyplot as plt\n\nfrom skimage.io import imread\n\nfrom gen.load_data import load_data",
"_____no_output_____"
],
[
"from sklearn.utils import shuffle\n\ntrain_df, valid_df, test_df = load_data('../../data')\n\n\nprint(train_df.head())\n",
" image id \\\n0 ../../data/Train/CameraRGB/episode_0002_000287... episode_0002_000287 \n1 ../../data/Train/CameraRGB/episode_0008_000112... episode_0008_000112 \n2 ../../data/Train/CameraRGB/804.png 804 \n3 ../../data/Train/CameraRGB/episode_0008_000286... episode_0008_000286 \n4 ../../data/Train/CameraRGB/episode_0003_000261... episode_0003_000261 \n\n label \n0 ../../data/Train/CameraSeg/episode_0002_000287... \n1 ../../data/Train/CameraSeg/episode_0008_000112... \n2 ../../data/Train/CameraSeg/804.png \n3 ../../data/Train/CameraSeg/episode_0008_000286... \n4 ../../data/Train/CameraSeg/episode_0003_000261... \n"
],
[
"from models.unet import model_unetVGG16\n\nmodel = model_unetVGG16(3, image_shape=(320, 416, 3), keep_prob=0.5)\nmodel.summary()",
"/home/faisal/anaconda3/envs/ai/lib/python3.6/site-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n from ._conv import register_converters as _register_converters\nUsing TensorFlow backend.\n"
],
[
"from gen.datagen import oversample_generator_from_df, balanced_generator_from_df\n\nBATCH_SIZE = 16\nmodel_dir = '../../saved_models/unet/unet_v3/'\n\nif not os.path.exists(model_dir):\n os.mkdir(model_dir)\n\ntrain_gen = oversample_generator_from_df(train_df, BATCH_SIZE, (320, 416))\nvalid_gen = balanced_generator_from_df(valid_df, BATCH_SIZE, (320, 416))",
"_____no_output_____"
],
[
"model.compile(loss='categorical_crossentropy',\n optimizer='adam',\n metrics=['accuracy'])\n",
"_____no_output_____"
],
[
"from train import train_nn\n\nm = train_df.shape[0]\nhistory = train_nn(model, \n train_gen, \n valid_gen, \n training_size=67*BATCH_SIZE, \n batch_size=BATCH_SIZE,\n validation_size=valid_df.shape[0],\n output_path=model_dir, \n epochs=500,\n gpus = 1)",
"Epoch 1/500\n67/67 [==============================] - 95s 1s/step - loss: 0.2227 - acc: 0.9245 - val_loss: 0.2472 - val_acc: 0.9249\n\nEpoch 00001: val_loss improved from inf to 0.24721, saving model to ../../saved_models/unet/unet_v3//model.hdf5\nEpoch 2/500\n67/67 [==============================] - 36s 543ms/step - loss: 0.0686 - acc: 0.9773 - val_loss: 0.1146 - val_acc: 0.9637\n\nEpoch 00002: val_loss improved from 0.24721 to 0.11455, saving model to ../../saved_models/unet/unet_v3//model.hdf5\nEpoch 3/500\n67/67 [==============================] - 37s 550ms/step - loss: 0.0430 - acc: 0.9851 - val_loss: 0.1663 - val_acc: 0.9638\n\nEpoch 00003: val_loss did not improve\nEpoch 4/500\n67/67 [==============================] - 37s 551ms/step - loss: 0.0306 - acc: 0.9890 - val_loss: 0.0603 - val_acc: 0.9820\n\nEpoch 00004: val_loss improved from 0.11455 to 0.06035, saving model to ../../saved_models/unet/unet_v3//model.hdf5\nEpoch 5/500\n67/67 [==============================] - 37s 551ms/step - loss: 0.0251 - acc: 0.9907 - val_loss: 0.1174 - val_acc: 0.9614\n\nEpoch 00005: val_loss did not improve\nEpoch 6/500\n67/67 [==============================] - 37s 550ms/step - loss: 0.0299 - acc: 0.9901 - val_loss: 0.0827 - val_acc: 0.9781\n\nEpoch 00006: val_loss did not improve\nEpoch 7/500\n67/67 [==============================] - 37s 551ms/step - loss: 0.0303 - acc: 0.9903 - val_loss: 0.3614 - val_acc: 0.9398\n\nEpoch 00007: val_loss did not improve\nEpoch 8/500\n67/67 [==============================] - 37s 549ms/step - loss: 0.0312 - acc: 0.9893 - val_loss: 0.0554 - val_acc: 0.9859\n\nEpoch 00008: val_loss improved from 0.06035 to 0.05538, saving model to ../../saved_models/unet/unet_v3//model.hdf5\nEpoch 9/500\n67/67 [==============================] - 37s 553ms/step - loss: 0.0214 - acc: 0.9923 - val_loss: 0.0398 - val_acc: 0.9875\n\nEpoch 00009: val_loss improved from 0.05538 to 0.03981, saving model to ../../saved_models/unet/unet_v3//model.hdf5\nEpoch 10/500\n67/67 [==============================] - 37s 550ms/step - loss: 0.0176 - acc: 0.9933 - val_loss: 0.0419 - val_acc: 0.9869\n\nEpoch 00010: val_loss did not improve\nEpoch 11/500\n67/67 [==============================] - 37s 551ms/step - loss: 0.0183 - acc: 0.9934 - val_loss: 0.0508 - val_acc: 0.9859\n\nEpoch 00011: val_loss did not improve\nEpoch 12/500\n67/67 [==============================] - 37s 550ms/step - loss: 0.0228 - acc: 0.9929 - val_loss: 0.0392 - val_acc: 0.9879\n\nEpoch 00012: val_loss improved from 0.03981 to 0.03922, saving model to ../../saved_models/unet/unet_v3//model.hdf5\nEpoch 13/500\n67/67 [==============================] - 37s 554ms/step - loss: 0.0212 - acc: 0.9927 - val_loss: 0.0876 - val_acc: 0.9741\n\nEpoch 00013: val_loss did not improve\nEpoch 14/500\n67/67 [==============================] - 37s 552ms/step - loss: 0.0187 - acc: 0.9934 - val_loss: 0.0521 - val_acc: 0.9850\n\nEpoch 00014: val_loss did not improve\nEpoch 15/500\n67/67 [==============================] - 37s 553ms/step - loss: 0.0206 - acc: 0.9937 - val_loss: 0.0396 - val_acc: 0.9879\n\nEpoch 00015: val_loss did not improve\nEpoch 16/500\n67/67 [==============================] - 37s 551ms/step - loss: 0.0172 - acc: 0.9941 - val_loss: 0.0585 - val_acc: 0.9859\n\nEpoch 00016: val_loss did not improve\nEpoch 17/500\n67/67 [==============================] - 37s 552ms/step - loss: 0.0133 - acc: 0.9947 - val_loss: 0.0313 - val_acc: 0.9900\n\nEpoch 00017: val_loss improved from 0.03922 to 0.03126, saving model to ../../saved_models/unet/unet_v3//model.hdf5\nEpoch 18/500\n67/67 [==============================] - 37s 555ms/step - loss: 0.0151 - acc: 0.9945 - val_loss: 0.0456 - val_acc: 0.9876\n\nEpoch 00018: val_loss did not improve\nEpoch 19/500\n67/67 [==============================] - 37s 553ms/step - loss: 0.0148 - acc: 0.9947 - val_loss: 0.0432 - val_acc: 0.9881\n\nEpoch 00019: val_loss did not improve\nEpoch 20/500\n67/67 [==============================] - 37s 552ms/step - loss: 0.0125 - acc: 0.9951 - val_loss: 0.0336 - val_acc: 0.9901\n\nEpoch 00020: val_loss did not improve\nEpoch 21/500\n67/67 [==============================] - 37s 553ms/step - loss: 0.0105 - acc: 0.9955 - val_loss: 0.0372 - val_acc: 0.9895\n\nEpoch 00021: val_loss did not improve\nEpoch 22/500\n67/67 [==============================] - 37s 553ms/step - loss: 0.0115 - acc: 0.9954 - val_loss: 0.0424 - val_acc: 0.9880\n\nEpoch 00022: val_loss did not improve\nEpoch 23/500\n67/67 [==============================] - 37s 551ms/step - loss: 0.0150 - acc: 0.9948 - val_loss: 0.0584 - val_acc: 0.9828\n\nEpoch 00023: val_loss did not improve\nEpoch 24/500\n67/67 [==============================] - 37s 548ms/step - loss: 0.0266 - acc: 0.9910 - val_loss: 0.4297 - val_acc: 0.9265\n\nEpoch 00024: val_loss did not improve\nEpoch 25/500\n67/67 [==============================] - 37s 552ms/step - loss: 0.0213 - acc: 0.9925 - val_loss: 0.0996 - val_acc: 0.9775\n\nEpoch 00025: val_loss did not improve\nEpoch 26/500\n67/67 [==============================] - 37s 552ms/step - loss: 0.0124 - acc: 0.9950 - val_loss: 0.0826 - val_acc: 0.9826\n\nEpoch 00026: val_loss did not improve\nEpoch 27/500\n67/67 [==============================] - 37s 552ms/step - loss: 0.0158 - acc: 0.9949 - val_loss: 0.0503 - val_acc: 0.9875\n\nEpoch 00027: val_loss did not improve\nEpoch 28/500\n67/67 [==============================] - 37s 553ms/step - loss: 0.0167 - acc: 0.9950 - val_loss: 0.0526 - val_acc: 0.9862\n\nEpoch 00028: val_loss did not improve\nEpoch 29/500\n67/67 [==============================] - 37s 550ms/step - loss: 0.0322 - acc: 0.9905 - val_loss: 0.1136 - val_acc: 0.9767\n\nEpoch 00029: val_loss did not improve\nEpoch 30/500\n67/67 [==============================] - 37s 550ms/step - loss: 0.0179 - acc: 0.9935 - val_loss: 0.0791 - val_acc: 0.9836\n\nEpoch 00030: val_loss did not improve\nEpoch 31/500\n67/67 [==============================] - 37s 549ms/step - loss: 0.0126 - acc: 0.9950 - val_loss: 0.0658 - val_acc: 0.9851\n\nEpoch 00031: val_loss did not improve\nEpoch 32/500\n67/67 [==============================] - 37s 552ms/step - loss: 0.0122 - acc: 0.9953 - val_loss: 0.0386 - val_acc: 0.9890\n\nEpoch 00032: val_loss did not improve\n\nEpoch 00032: ReduceLROnPlateau reducing learning rate to 0.000800000037997961.\nEpoch 33/500\n67/67 [==============================] - 38s 562ms/step - loss: 0.0153 - acc: 0.9951 - val_loss: 0.0397 - val_acc: 0.9899\n\nEpoch 00033: val_loss did not improve\nEpoch 34/500\n67/67 [==============================] - 38s 563ms/step - loss: 0.0197 - acc: 0.9947 - val_loss: 0.0631 - val_acc: 0.9873\n\nEpoch 00034: val_loss did not improve\nEpoch 35/500\n67/67 [==============================] - 38s 563ms/step - loss: 0.0141 - acc: 0.9949 - val_loss: 0.0553 - val_acc: 0.9867\n\nEpoch 00035: val_loss did not improve\nEpoch 36/500\n67/67 [==============================] - 38s 564ms/step - loss: 0.0127 - acc: 0.9953 - val_loss: 0.0328 - val_acc: 0.9894\n\nEpoch 00036: val_loss did not improve\nEpoch 37/500\n67/67 [==============================] - 38s 565ms/step - loss: 0.0104 - acc: 0.9957 - val_loss: 0.1329 - val_acc: 0.9760\n\nEpoch 00037: val_loss did not improve\nEpoch 38/500\n67/67 [==============================] - 38s 564ms/step - loss: 0.0149 - acc: 0.9952 - val_loss: 0.0494 - val_acc: 0.9881\n\nEpoch 00038: val_loss did not improve\nEpoch 39/500\n67/67 [==============================] - 38s 568ms/step - loss: 0.0115 - acc: 0.9957 - val_loss: 0.0405 - val_acc: 0.9887\n\nEpoch 00039: val_loss did not improve\nEpoch 40/500\n67/67 [==============================] - 38s 564ms/step - loss: 0.0114 - acc: 0.9957 - val_loss: 0.0949 - val_acc: 0.9785\n\nEpoch 00040: val_loss did not improve\nEpoch 41/500\n67/67 [==============================] - 38s 564ms/step - loss: 0.0107 - acc: 0.9959 - val_loss: 0.0359 - val_acc: 0.9901\n\nEpoch 00041: val_loss did not improve\nEpoch 42/500\n67/67 [==============================] - 38s 565ms/step - loss: 0.0093 - acc: 0.9961 - val_loss: 0.0569 - val_acc: 0.9864\n\nEpoch 00042: val_loss did not improve\nEpoch 43/500\n67/67 [==============================] - 38s 565ms/step - loss: 0.0087 - acc: 0.9962 - val_loss: 0.0323 - val_acc: 0.9914\n\nEpoch 00043: val_loss did not improve\nEpoch 44/500\n67/67 [==============================] - 38s 567ms/step - loss: 0.0100 - acc: 0.9960 - val_loss: 0.0477 - val_acc: 0.9895\n"
],
[
"# # summarize history for accuracy\nplt.plot(history.history['acc'])\nplt.plot(history.history['val_acc'])\nplt.title('model accuracy')\nplt.ylabel('accuracy')\nplt.xlabel('epoch')\nplt.legend(['train', 'test'], loc='upper left')\nplt.show()\n# summarize history for loss\nplt.plot(history.history['loss'])\nplt.plot(history.history['val_loss'])\nplt.title('model loss')\nplt.ylabel('loss')\nplt.xlabel('epoch')\nplt.legend(['train', 'test'], loc='upper left')\nplt.show()",
"_____no_output_____"
],
[
"model.load_weights('../../saved_models/unet/unet_v3/model.hdf5')\nmodel.save('../../saved_models/unet/unet_v3/model_saved.h5')",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0f8e6ab2525e806d0dbc646941695cbb408d8ad | 221,033 | ipynb | Jupyter Notebook | source/Bjy_data_preprocessing.ipynb | tmxkqotnl/project_mini_machine_learning_team_two | 13a6b3d545012afd364d42341a72fe5b61118bc3 | [
"MIT"
] | 1 | 2022-03-07T11:20:32.000Z | 2022-03-07T11:20:32.000Z | source/Bjy_data_preprocessing.ipynb | tmxkqotnl/project_mini_machine_learning_team_two | 13a6b3d545012afd364d42341a72fe5b61118bc3 | [
"MIT"
] | null | null | null | source/Bjy_data_preprocessing.ipynb | tmxkqotnl/project_mini_machine_learning_team_two | 13a6b3d545012afd364d42341a72fe5b61118bc3 | [
"MIT"
] | 2 | 2022-03-08T01:13:17.000Z | 2022-03-11T00:24:33.000Z | 91.676898 | 39,246 | 0.738021 | [
[
[
"# 화씨 -> 섭씨로 바꾸기\n# categorical 바꾸기\n# 날짜 date 형식으로 바꾸기\n# NA값 0으로 처리하기",
"_____no_output_____"
],
[
"import pandas as pd \nimport numpy as np\nfrom datetime import datetime",
"_____no_output_____"
],
[
"df = pd.read_csv('train.csv',encoding='euc-kr')",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"df.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 282451 entries, 0 to 282450\nData columns (total 16 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 Store 282451 non-null int64 \n 1 Dept 282451 non-null int64 \n 2 Date 282451 non-null object \n 3 Weekly_Sales 282451 non-null float64\n 4 IsHoliday 282451 non-null bool \n 5 Temperature 282451 non-null float64\n 6 Fuel_Price 282451 non-null float64\n 7 MarkDown1 100520 non-null float64\n 8 MarkDown2 74232 non-null float64\n 9 MarkDown3 91521 non-null float64\n 10 MarkDown4 90031 non-null float64\n 11 MarkDown5 101029 non-null float64\n 12 CPI 282451 non-null float64\n 13 Unemployment 282451 non-null float64\n 14 Type 282451 non-null object \n 15 Size 282451 non-null int64 \ndtypes: bool(1), float64(10), int64(3), object(2)\nmemory usage: 32.6+ MB\n"
],
[
"#datetime으로 변환\ndf['Date'] = pd.to_datetime(df['Date'])\ndf['Year'] =df['Date'].dt.year\ndf['Month'] =df['Date'].dt.month\ndf['Day'] =df['Date'].dt.day\ndf['Day_name'] =df['Date'].dt.day_name()",
"_____no_output_____"
],
[
"df.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 282451 entries, 0 to 282450\nData columns (total 20 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 Store 282451 non-null int64 \n 1 Dept 282451 non-null int64 \n 2 Date 282451 non-null datetime64[ns]\n 3 Weekly_Sales 282451 non-null float64 \n 4 IsHoliday 282451 non-null bool \n 5 Temperature 282451 non-null float64 \n 6 Fuel_Price 282451 non-null float64 \n 7 MarkDown1 100520 non-null float64 \n 8 MarkDown2 74232 non-null float64 \n 9 MarkDown3 91521 non-null float64 \n 10 MarkDown4 90031 non-null float64 \n 11 MarkDown5 101029 non-null float64 \n 12 CPI 282451 non-null float64 \n 13 Unemployment 282451 non-null float64 \n 14 Type 282451 non-null object \n 15 Size 282451 non-null int64 \n 16 Year 282451 non-null int64 \n 17 Month 282451 non-null int64 \n 18 Day 282451 non-null int64 \n 19 Day_name 282451 non-null object \ndtypes: bool(1), datetime64[ns](1), float64(10), int64(6), object(2)\nmemory usage: 41.2+ MB\n"
],
[
"df.head()",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"df['Type'] = df['Type'].astype('category')\ndf['IsHoliday'] = df['IsHoliday'].astype('category')\ndf['Store'] = df['Store'].astype('category')\ndf['Dept'] = df['Dept'].astype('category')\ndf['Temperature'] = df['Temperature'] - 32 / 1.8",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"df.corr()",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt \nimport seaborn as sns ",
"_____no_output_____"
],
[
"def encode_sin_cos(df,col_n,max_val):\n df[col_n+'_sin'] = np.sin(2*np.pi*df[col_n]/max_val)\n df[col_n+'_cos'] = np.cos(2*np.pi*df[col_n]/max_val)\n \n return df\n\ndf = encode_sin_cos(df,'Month',12)\ndf = encode_sin_cos(df,'Day',31)\n\ndf[['Year','Month','Day','Month_sin','Month_cos','Day_sin','Day_cos']]\n\ndf_2010 = df[df['Year'] == 2010]\ndf_2011 = df[df['Year'] == 2011]\ndf_2012 = df[df['Year'] == 2012]",
"_____no_output_____"
],
[
"c_m = sns.scatterplot(x=\"Month_sin\",y=\"Month_cos\",data=df_2010)\nc_m.set_title(\"Cyclic Encoding of Month (2010)\")\nc_m.set_ylabel(\"Cosine Encoded Months\")\nc_m.set_xlabel(\"Sine Encoded Months\")",
"_____no_output_____"
],
[
"c_m = sns.scatterplot(x=\"Month_sin\",y=\"Month_cos\",data=df_2011)\nc_m.set_title(\"Cyclic Encoding of Month (2011)\")\nc_m.set_ylabel(\"Cosine Encoded Months\")\nc_m.set_xlabel(\"Sine Encoded Months\")",
"_____no_output_____"
],
[
"c_m = sns.scatterplot(x=\"Month_sin\",y=\"Month_cos\",data=df_2012)\nc_m.set_title(\"Cyclic Encoding of Month (2012)\")\nc_m.set_ylabel(\"Cosine Encoded Months\")\nc_m.set_xlabel(\"Sine Encoded Months\")",
"_____no_output_____"
],
[
"corr = df[['Store','Dept','Date','Weekly_Sales','IsHoliday','Temperature','Fuel_Price','MarkDown1','MarkDown2','MarkDown3','MarkDown4','MarkDown5','CPI','Unemployment','Type','Size','Year','Month','Day','Day_name']].corr()\n# corr['Weekly_Sales'].dtypes\ncorr['Weekly_Sales'].abs().sort_values(ascending=False)",
"_____no_output_____"
],
[
"sns.set(style=\"white\")\n\ncorr = df[['Store','Dept','Date','Weekly_Sales','IsHoliday','Temperature','Fuel_Price','MarkDown1','MarkDown2','MarkDown3','MarkDown4','MarkDown5','CPI','Unemployment','Type','Size','Year','Month','Day','Day_name']].corr()\n\nmask = np.zeros_like(corr, dtype=np.bool)\nmask[np.triu_indices_from(mask)] = True\n\nf, ax = plt.subplots(figsize=(11, 9))\n\ncmap = sns.diverging_palette(220, 10, as_cmap=True)\n\nsns.heatmap(corr, mask=mask, cmap=cmap, vmax=.3, center=0,\n square=True, linewidths=.5, cbar_kws={\"shrink\": .5})",
"C:\\Users\\User\\AppData\\Local\\Temp/ipykernel_7268/4049338591.py:5: DeprecationWarning: `np.bool` is a deprecated alias for the builtin `bool`. To silence this warning, use `bool` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.bool_` here.\nDeprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations\n mask = np.zeros_like(corr, dtype=np.bool)\n"
],
[
"plt.scatter(df['Fuel_Price'],df['Weekly_Sales'])\nplt.show()",
"_____no_output_____"
],
[
"plt.scatter(df['Size'],df['Weekly_Sales'])\nplt.show()",
"_____no_output_____"
],
[
"df.loc[df['Weekly_Sales'] >300000] ",
"_____no_output_____"
],
[
"df.loc[df['Weekly_Sales'] >240000,\"Date\"].value_counts()",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0f8fedd1670c66f230a13274df5ecdb7b8a6616 | 28,727 | ipynb | Jupyter Notebook | plots/mirror_plot_spectrum.ipynb | Reaction-Space-Explorer/reac-space-exp | 02c91247d9ee5107cbf9fa113e87edaf4bd392b0 | [
"BSD-3-Clause"
] | 4 | 2020-06-27T23:08:41.000Z | 2022-01-09T16:20:48.000Z | plots/mirror_plot_spectrum.ipynb | sahilrajiv/reac-space-exp | 52f4b4eab755bd4a6830d838828c958149567396 | [
"BSD-3-Clause"
] | 15 | 2020-07-27T23:14:32.000Z | 2022-03-12T00:59:20.000Z | plots/mirror_plot_spectrum.ipynb | sahilrajiv/reac-space-exp | 52f4b4eab755bd4a6830d838828c958149567396 | [
"BSD-3-Clause"
] | 3 | 2020-06-27T23:08:46.000Z | 2021-04-20T09:29:33.000Z | 66.651972 | 9,552 | 0.671111 | [
[
[
"import pandas as pd\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom rdkit.Chem import MolFromSmiles\nfrom rdkit.Chem.Descriptors import ExactMolWt",
"_____no_output_____"
],
[
"df = pd.read_csv(\"39_Formose reaction_MeOH.csv\")#glucose_dry_impcols.csv\nprint(df.columns)",
"Index(['Mass', 'Rel. Abundance', 'Molecular Formula', 'Carbon', 'C count',\n 'Hydrogen', 'H count', 'Nitrogen', 'N count', 'Oxygen', 'O Count',\n 'Sulphur', 'S count', 'Carbon-13', 'C13 count', 'Sulphur-34',\n 'S34 Count', 'Unnamed: 17'],\n dtype='object')\n"
],
[
"# first get rid of empty lines in the mass list by replacing with ''\ndf.replace('', np.nan, inplace=True)\n# also, some 'Mass' values are not numbers\ndf.dropna(subset=['Mass'], inplace=True)\n# now replace NaNs with '' to avoid weird errors\ndf.fillna('', inplace=True)\ndf.shape\ndf.head()\n",
"_____no_output_____"
],
[
"# make a list of exact mass and relative abundance.\nmass_list = []\nrel_abundance = []\nfor i in range(len(df)):\n # allow entire spectrum for this one\n if float(df['Mass'].iloc[i]) < 250 and \"No Hit\" not in df['Molecular Formula'].iloc[i]:\n mass_list.append(float(df['Mass'].iloc[i]))\n rel_abundance.append(float(df['Rel. Abundance'].iloc[i]))\n# now, \"renormalize\" the relative abundance.\nhighest = max(rel_abundance)\nnorm_factor = 100.0/highest\nnormalized_abun = []\nfor ab in rel_abundance:\n normalized_abun.append(norm_factor*ab)\nprint(f'{len(mass_list)} items in {mass_list}')\n",
"246 items in [234.0489, 248.06455, 222.0489, 236.06455, 192.03836, 206.054, 220.06964, 234.08529, 240.05946, 244.06963, 210.04891, 224.06455, 238.0802, 180.03836, 194.05401, 208.06965, 222.08529, 218.05399, 232.06964, 246.08528, 178.0591, 192.07474, 220.10603, 234.12167, 248.13731, 228.05946, 242.07511, 212.06456, 226.08021, 240.09585, 176.04345, 190.05909, 204.07473, 218.09038, 246.12167, 246.07003, 235.98058, 249.99623, 182.05401, 196.06966, 210.0853, 238.11659, 216.07473, 230.09038, 244.10602, 180.07475, 208.10603, 222.12168, 216.05947, 230.07512, 228.07471, 242.09036, 219.98568, 234.00132, 184.06966, 198.08531, 226.11659, 207.05104, 221.0667, 249.09797, 223.04594, 237.0616, 219.0299, 233.04555, 247.0612, 177.04049, 191.05614, 219.08742, 233.10306, 245.04554, 249.04045, 237.04046, 177.01937, 191.035, 205.05065, 219.06629, 233.08194, 207.02991, 221.04555, 235.0612, 249.07685, 247.09759, 225.0616, 195.02992, 209.04556, 223.06121, 237.07686, 225.04046, 239.05611, 179.03501, 193.05066, 207.0663, 221.08195, 249.11323, 235.09759, 235.04594, 249.06159, 203.035, 217.05064, 231.06629, 245.08194, 229.05063, 243.06628, 179.05614, 177.05575, 191.07139, 219.10268, 233.11832, 247.13396, 205.08703, 205.03539, 219.05103, 233.06668, 239.07724, 197.06669, 211.08234, 234.97723, 248.99288, 213.04047, 227.05611, 241.07176, 195.05105, 209.06669, 231.05103, 245.06668, 197.04556, 211.06121, 225.07685, 239.0925, 175.0401, 189.05574, 203.07138, 217.08703, 245.11832, 227.03499, 241.05063, 243.05102, 231.10267, 181.05066, 195.0663, 223.09759, 237.11323, 209.08195, 181.07179, 201.04048, 215.05612, 229.07177, 227.07724, 165.05576, 179.0714, 207.10268, 221.11832, 235.13397, 249.14961, 243.08741, 189.04048, 203.05613, 231.08741, 245.10306, 185.04557, 199.06121, 213.07686, 241.10815, 187.04009, 201.05573, 215.07138, 229.08702, 243.10267, 193.08704, 227.0925, 213.05573, 227.07137, 241.08702, 247.08232, 235.08233, 183.06631, 197.08195, 225.11324, 239.12888, 211.09759, 217.07177, 205.07177, 241.09289, 173.04558, 201.07686, 215.0925, 229.10815, 243.12379, 230.98232, 244.99796, 181.08705, 209.11833, 223.13397, 195.10269, 225.05572, 239.07136, 193.07178, 161.04559, 189.07687, 203.09251, 240.96666, 175.07649, 189.09213, 217.12341, 231.13906, 173.06083, 187.07648, 201.09212, 229.12341, 243.13905, 215.10776, 203.10777, 223.08233, 177.09213, 205.12341, 175.06123, 171.06631, 185.08196, 199.0976, 227.12889, 187.06122, 248.99217, 185.06083, 199.07647, 213.09211, 241.1234, 191.10777, 200.97176, 214.98741, 243.0187, 227.10776, 213.11324, 183.10269, 225.09211, 239.10775, 221.06746, 232.99733, 235.08864, 249.10429, 197.11833, 241.17099, 179.10778, 234.97659, 239.08354, 173.08197, 187.09761]\n"
],
[
"# formose MOD output\n# ../main/glucose/glucose_degradation_output_10mar.txt\ndata_mod = pd.read_csv('../main/formose/formose_output.txt', sep='\\t', names=['Generation', 'SMILES'])\nsim_masses = []\nfor i in range(len(formose_mod)):\n row = formose_mod.iloc[i]\n mol = MolFromSmiles(row['SMILES'])\n mol_wt = ExactMolWt(mol)\n sim_masses.append(mol_wt)\ndata_mod['Mol Wt'] = sim_masses",
"_____no_output_____"
],
[
"unique_sim_masses = list(set(sim_masses))\nunique_mass_freq = [sim_masses.count(mass) for mass in unique_sim_masses]\nhighest_freq = max(unique_mass_freq)\n\nnorm_freq = [100*(freq/highest_freq) for freq in unique_mass_freq]\n\nprint('Unique masses:',len(unique_sim_masses))\nprint('Frequency of each mass', unique_mass_freq)",
"Unique masses: 207\nFrequency of each mass [4, 4, 4, 1, 1, 4, 4, 4, 4, 1, 4, 2, 4, 12, 4, 2, 4, 3, 10, 12, 14, 13, 4, 5, 8, 1, 1, 2, 2, 20, 5, 62, 4, 37, 18, 20, 8, 4, 4, 1, 2, 5, 67, 2, 48, 106, 90, 35, 64, 17, 4, 13, 2, 7, 46, 2, 45, 75, 296, 67, 324, 54, 91, 144, 45, 18, 8, 4, 31, 38, 265, 68, 858, 82, 444, 712, 558, 155, 208, 49, 9, 26, 34, 162, 30, 400, 869, 791, 2490, 93, 1704, 356, 417, 524, 116, 9, 8, 555, 891, 14, 4078, 755, 4951, 970, 3207, 2880, 2684, 606, 672, 127, 16, 167, 51, 37, 4904, 412, 7689, 5622, 14500, 3193, 552, 7233, 1605, 1542, 290, 1934, 16, 14, 5047, 814, 11241, 5143, 3195, 19435, 11377, 10968, 9528, 2181, 1712, 368, 41, 722, 103, 211, 5280, 5855, 89, 2162, 30, 14, 2, 19, 2, 2, 132, 10, 6, 56, 31, 159, 314, 67, 1, 33, 321, 55, 4, 1, 42, 34, 41, 410, 628, 1569, 3, 457, 44, 113, 31, 768, 10, 7, 5, 45, 23, 130, 117, 371, 378, 936, 77, 37, 90, 246, 27, 14, 2448, 257, 2, 42, 121, 4, 21, 31, 2, 14, 3]\n"
],
[
"print(unique_sim_masses)",
"[16.031300127999998, 28.031300127999998, 32.026214748, 108.057514876, 42.046950192, 43.98982924, 44.026214748, 46.005479304, 46.041864812, 54.046950192, 56.026214748, 113.99530854400001, 58.005479304000005, 58.041864812, 60.021129368000004, 60.057514876, 62.036779432, 122.07316494, 70.041864812, 72.021129368, 72.057514876, 74.036779432, 74.00039392400001, 76.016043988, 76.052429496, 117.99022316400001, 80.026214748, 118.099379688, 82.041864812, 84.021129368, 84.057514876, 86.036779432, 86.00039392400001, 88.052429496, 88.016043988, 90.031694052, 90.06807956, 92.047344116, 89.99530854400001, 86.07316494, 96.021129368, 96.057514876, 98.036779432, 98.00039392400001, 100.016043988, 100.052429496, 102.031694052, 102.06807956, 104.047344116, 104.01095860800001, 106.02660867200001, 106.06299418, 101.99530854400001, 104.083729624, 110.036779432, 108.021129368, 112.016043988, 112.052429496, 114.031694052, 114.06807956, 116.047344116, 116.01095860800001, 118.02660867200001, 118.06299418, 120.04225873600001, 120.078644244, 122.0579088, 120.00587322800001, 116.083729624, 124.052429496, 126.031694052, 126.06807956, 128.047344116, 128.010958608, 130.026608672, 130.06299418, 132.042258736, 132.078644244, 134.0579088, 134.021523292, 136.037173356, 136.073558864, 132.005873228, 138.031694052, 140.083729624, 140.047344116, 142.026608672, 142.06299418, 144.042258736, 144.005873228, 146.0579088, 146.021523292, 148.037173356, 148.073558864, 150.05282342, 150.01643791200001, 152.068473484, 144.078644244, 154.06299418, 148.00078784800002, 156.042258736, 156.078644244, 158.0579088, 158.021523292, 160.037173356, 160.073558864, 162.05282342, 162.089208928, 164.068473484, 164.032087976, 166.04773804, 162.01643791200001, 166.084123548, 160.00078784800002, 170.0579088, 170.021523292, 172.073558864, 172.037173356, 174.05282342, 174.089208928, 176.104858992, 176.068473484, 178.04773804, 178.084123548, 180.063388104, 176.032087976, 182.079038168, 180.02700259600002, 184.073558864, 184.037173356, 186.05282342, 186.089208928, 188.032087976, 188.068473484, 190.084123548, 190.04773804, 192.063388104, 192.099773612, 194.079038168, 194.04265266000002, 196.05830272400001, 192.02700259600002, 196.094688232, 190.01135253200002, 198.089208928, 198.05282342, 196.037173356, 196.073558864, 198.125594436, 198.01643791200001, 141.990223164, 142.099379688, 125.99530854400001, 130.099379688, 146.094294308, 136.052429496, 148.109944372, 150.089208928, 150.06807956, 152.047344116, 154.026608672, 156.005873228, 156.115029752, 128.083729624, 158.094294308, 160.109944372, 162.125594436, 163.99570246800002, 164.104858992, 164.047344116, 166.026608672, 166.06299418, 168.078644244, 168.042258736, 168.005873228, 170.094294308, 138.06807956, 172.109944372, 172.00078784800002, 174.01643791200001, 174.125594436, 175.99570246800002, 124.016043988, 178.01135253200002, 178.120509056, 178.06299418, 180.099773612, 180.078644244, 180.042258736, 182.0579088, 182.094294308, 182.021523292, 184.109944372, 186.01643791200001, 186.125594436, 187.99570246800002, 188.104858992, 190.120509056, 191.99061708800002, 140.010958608, 194.115423676, 194.00626715200002, 194.0579088, 196.109944372, 98.07316494, 134.094294308, 129.990223164]\n"
],
[
"from matplotlib import rc\n\n# Use LaTeX and CMU Serif font.\nrc('text', usetex=True)\nrc('font', **{'family': 'serif', 'serif': ['Computer Modern']})",
"_____no_output_____"
],
[
"# for some flexibility, create a container for the figure\nfig, axes = plt.subplots(nrows=2, ncols=1, figsize=(6, 12), sharex=True) # create a figure object\n#ax = fig.add_subplot(111) # create an axis object\n\n# first, draw the experimental spectrum\naxes[0].vlines(x=mass_list, ymin=0, ymax=normalized_abun, color='cornflowerblue')\n\n# now the CNRN\naxes[1].vlines(x=unique_sim_masses, ymin=0, ymax=norm_freq, color='deeppink')\n\n#plt.bar(mass_list, rel_abundance, width=0.5)\naxes[0].set_yscale('log')\naxes[1].set_yscale('log')\naxes[0].set_ylim([0.875, 125])\naxes[1].set_ylim([0.875, 125])\nplt.gca().invert_yaxis()\nplt.xlim(155, 205)\nplt.xlabel('Exact Mass')\n#plt.ylabel('Normalized Abundance')\nplt.tight_layout()\nplt.subplots_adjust(wspace=0, hspace=0)\nplt.savefig('formose_mirror_plot.jpg', dpi=300)\nplt.show()",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0f910553efa681a6918f61cce93ea561d210118 | 2,351 | ipynb | Jupyter Notebook | scientific_python/Pandas Solutions.ipynb | elliewix/2016-01-28-uiuc-swc | 47d019a98aad06abaf1ea41eb5ffcf7f2223cf8c | [
"CC-BY-4.0"
] | null | null | null | scientific_python/Pandas Solutions.ipynb | elliewix/2016-01-28-uiuc-swc | 47d019a98aad06abaf1ea41eb5ffcf7f2223cf8c | [
"CC-BY-4.0"
] | null | null | null | scientific_python/Pandas Solutions.ipynb | elliewix/2016-01-28-uiuc-swc | 47d019a98aad06abaf1ea41eb5ffcf7f2223cf8c | [
"CC-BY-4.0"
] | null | null | null | 18.367188 | 105 | 0.512973 | [
[
[
"import pandas as pd\n\nmonthly = pd.read_csv(\"precip_monthly.csv\")",
"_____no_output_____"
]
],
[
[
"### Exercise 1",
"_____no_output_____"
]
],
[
[
"pd.read_csv(\"precip_monthly.csv\").set_index('month').loc['Jul']",
"_____no_output_____"
]
],
[
[
"### Exercise 2",
"_____no_output_____"
]
],
[
[
"region_yearly_precip = monthly.groupby(['region', 'year'])['precip'].mean().unstack()\nregion_yearly_precip",
"_____no_output_____"
]
],
[
[
"### Exercise 3",
"_____no_output_____"
]
],
[
[
"monthly.loc[monthly.region == 'COLORADO RIVER']",
"_____no_output_____"
],
[
"monthly.query('region == \"COLORADO RIVER\"')",
"_____no_output_____"
],
[
"monthly.loc[(monthly.region == 'COLORADO RIVER') & (monthly.year >= 1999) & (monthly.year <= 2003)]",
"_____no_output_____"
],
[
"monthly.query('region == \"COLORADO RIVER\" and year >= 1999 and year <= 2003')",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
d0f9121b7ea520689c17ed90f4baabc4402e0beb | 39,236 | ipynb | Jupyter Notebook | matrix_one/day3.ipynb | antykuba/dw_matrix | ca7582a3bcdb5f7c6bfc87979e05228a6553f9d1 | [
"MIT"
] | null | null | null | matrix_one/day3.ipynb | antykuba/dw_matrix | ca7582a3bcdb5f7c6bfc87979e05228a6553f9d1 | [
"MIT"
] | null | null | null | matrix_one/day3.ipynb | antykuba/dw_matrix | ca7582a3bcdb5f7c6bfc87979e05228a6553f9d1 | [
"MIT"
] | null | null | null | 39,236 | 39,236 | 0.726527 | [
[
[
"from google.colab import drive\nimport pandas as pd\nimport numpy as np\n\nimport datadotworld as dw",
"_____no_output_____"
],
[
"#!pip install datadotworld\n#!pip install datadotworld[pandas]",
"_____no_output_____"
],
[
"#!dw configure",
"_____no_output_____"
],
[
"#drive.mount(\"/content/drive\")",
"_____no_output_____"
],
[
"ls",
"\u001b[0m\u001b[01;34mdrive\u001b[0m/ \u001b[01;34msample_data\u001b[0m/\n"
],
[
"cd \"/drive/My Drive/Colab Notebooks/dw_matrix\"",
"/content/drive/My Drive/Colab Notebooks/dw_matrix\n"
],
[
"ls",
"\u001b[0m\u001b[01;34mdata\u001b[0m/ HelloGithub.ipynb LICENSE \u001b[01;34mmatrix_one\u001b[0m/ README.md\n"
],
[
"!mkdir data",
"_____no_output_____"
],
[
"!echo 'data' > .gitignore",
"_____no_output_____"
],
[
"!git add .gitignore",
"_____no_output_____"
],
[
"data = dw.load_dataset('datafiniti/womens-shoe-prices')",
"_____no_output_____"
],
[
"df = data.dataframes['7003_1']",
"_____no_output_____"
],
[
"df.shape",
"_____no_output_____"
],
[
"df.sample(5)",
"_____no_output_____"
],
[
"df.columns",
"_____no_output_____"
],
[
"df.prices_currency.unique()",
"_____no_output_____"
],
[
"df.prices_currency.value_counts(normalize=True)",
"_____no_output_____"
],
[
"df_usd = df[ df.prices_currency == 'USD' ].copy()\ndf_usd.shape",
"_____no_output_____"
],
[
"df_usd['prices_amountmin'] = df_usd.prices_amountmin.astype(np.float)\ndf_usd['prices_amountmin'].hist()",
"_____no_output_____"
],
[
"filter_max = np.percentile( df_usd['prices_amountmin'], 99 )\nfilter_max",
"_____no_output_____"
],
[
"df_usd_filter = df_usd[ df_usd['prices_amountmin'] < filter_max ]",
"_____no_output_____"
],
[
"df_usd_filter.prices_amountmin.hist(bins=100)",
"_____no_output_____"
],
[
"df.to_csv('data/w_shoes_prices.csv', index=False)",
"_____no_output_____"
],
[
"!git add matrix_one/day3.ipynb",
"_____no_output_____"
],
[
"!git config --global user.email \"[email protected]\"\n!git config --global user.name \"antykuba\"",
"_____no_output_____"
],
[
"!git commit -m \"Read Women's Shoe Prices dataset from data.world\"",
"[master b5fc83e] Read Women's Shoe Prices dataset from data.world\n 2 files changed, 2 insertions(+), 129 deletions(-)\n rewrite .gitignore (100%)\n create mode 100644 matrix_one/day3.ipynb\n"
],
[
"!git push -u origin master",
"Counting objects: 5, done.\nDelta compression using up to 2 threads.\nCompressing objects: 33% (1/3) \rCompressing objects: 66% (2/3) \rCompressing objects: 100% (3/3) \rCompressing objects: 100% (3/3), done.\nWriting objects: 20% (1/5) \rWriting objects: 40% (2/5) \rWriting objects: 60% (3/5) \rWriting objects: 80% (4/5) \rWriting objects: 100% (5/5) \rWriting objects: 100% (5/5), 19.93 KiB | 2.85 MiB/s, done.\nTotal 5 (delta 0), reused 0 (delta 0)\nTo https://github.com/antykuba/dw_matrix.git\n cd36b34..b5fc83e master -> master\nBranch 'master' set up to track remote branch 'master' from 'origin'.\n"
],
[
"",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0f9287aec5e872c99f6bd3119146359f9292e01 | 6,187 | ipynb | Jupyter Notebook | jupyter_notebooks/oop/OOP_Tutorial.ipynb | manual123/Nacho-Jupyter-Notebooks | e75523434b1a90313a6b44e32b056f63de8a7135 | [
"MIT"
] | 2 | 2021-02-13T05:52:05.000Z | 2022-02-08T09:52:35.000Z | oop/OOP_Tutorial.ipynb | manual123/Nacho-Jupyter-Notebooks | e75523434b1a90313a6b44e32b056f63de8a7135 | [
"MIT"
] | null | null | null | oop/OOP_Tutorial.ipynb | manual123/Nacho-Jupyter-Notebooks | e75523434b1a90313a6b44e32b056f63de8a7135 | [
"MIT"
] | null | null | null | 29.602871 | 889 | 0.566995 | [
[
[
"### Example Class",
"_____no_output_____"
]
],
[
[
"import datetime # we will use this for date objects\n\nclass Person:\n\n def __init__(self, name, surname, birthdate, address, telephone, email):\n self.name = name\n self.surname = surname\n self.birthdate = birthdate\n\n self.address = address\n self.telephone = telephone\n self.email = email\n\n def age(self):\n today = datetime.date.today()\n age = today.year - self.birthdate.year\n\n if today < datetime.date(today.year, self.birthdate.month, self.birthdate.day):\n age -= 1\n\n return age\n\nperson = Person(\n \"Jane\",\n \"Doe\",\n datetime.date(1992, 3, 12), # year, month, day\n \"No. 12 Short Street, Greenville\",\n \"555 456 0987\",\n \"[email protected]\"\n)\n\nprint(person.name)\nprint(person.email)\nprint(person.age())",
"Jane\[email protected]\n26\n"
]
],
[
[
"__init__() method is used to initialize an instance or object of a class<br>\nself.name, self.surname, self.birthdate, self.address, self.telephone, and self.email are **instance** attributes",
"_____no_output_____"
],
[
"You may have noticed that both of these method definitions have ```self``` as the first parameter, and we use this variable inside the method bodies – but we don’t appear to pass this parameter in. This is because whenever we call a method on an object, the object itself is automatically passed in as the first parameter. This gives us a way to access the object’s properties from inside the object’s methods.",
"_____no_output_____"
],
[
"### Class attributes",
"_____no_output_____"
],
[
"We define class attributes in the body of a class, at the same indentation level as method definitions (one level up from the insides of methods):",
"_____no_output_____"
]
],
[
[
"class Person:\n\n TITLES = ('Dr', 'Mr', 'Mrs', 'Ms') # This is a Class attribute\n\n def __init__(self, title, name, surname):\n if title not in self.TITLES:\n raise ValueError(\"%s is not a valid title.\" % title)\n\n self.title = title\n self.name = name\n self.surname = surname\n \nif __name__ == \"__main__\":\n me = Person(title='Mr', name='John', surname='Doe')\n print(me.title)\n print(me.name)\n print(me.surname)\n print(Person.TITLES)",
"Mr\nJohn\nDoe\n('Dr', 'Mr', 'Mrs', 'Ms')\n"
]
],
[
[
"Class attributes exists for all instances of a class. These attributes will be shared by all instances of that class.",
"_____no_output_____"
],
[
"### Class Decorators",
"_____no_output_____"
],
[
"**@classmethod** - Just like we can define class attributes, which are shared between all instances of a class, we can define class methods. We do this by using the @classmethod decorator to decorate an ordinary method.",
"_____no_output_____"
],
[
"**@staticmethod** - A static method doesn’t have the calling object passed into it as the first parameter. This means that it doesn’t have access to the rest of the class or instance at all. We can call them from an instance or a class object, but they are most commonly called from class objects, like class methods.<br><br>If we are using a class to group together related methods which don’t need to access each other or any other data on the class, we may want to use this technique. The advantage of using static methods is that we eliminate unnecessary cls or self parameters from our method definitions. The disadvantage is that if we do occasionally want to refer to another class method or attribute inside a static method we have to write the class name out in full, which can be much more verbose than using the cls variable which is available to us inside a class method.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
d0f92d254bfe71dd51b0d7fcbec771e05c617f9f | 4,541 | ipynb | Jupyter Notebook | 3_Prediction.ipynb | dymaxionlabs/burned-area-detection | 9ff8145e7cf66b308b1985b21be0f84376fe02b1 | [
"Apache-2.0"
] | 1 | 2021-08-06T13:15:58.000Z | 2021-08-06T13:15:58.000Z | 3_Prediction.ipynb | dymaxionlabs/burned-area-detection | 9ff8145e7cf66b308b1985b21be0f84376fe02b1 | [
"Apache-2.0"
] | 4 | 2021-06-25T23:01:31.000Z | 2021-07-08T20:14:17.000Z | 3_Prediction.ipynb | dymaxionlabs/burned-area-detection | 9ff8145e7cf66b308b1985b21be0f84376fe02b1 | [
"Apache-2.0"
] | 4 | 2021-06-30T23:55:20.000Z | 2022-03-10T11:30:01.000Z | 24.545946 | 217 | 0.514204 | [
[
[
"# Prediction",
"_____no_output_____"
],
[
"### Build images",
"_____no_output_____"
],
[
"The images for the prediction process are generated in the same way but in this case, the masks are not going to be created.\nIn the prediction process, the size and the step-size must be the same to do not generate an overlap in the predicted results. However, there is no need that the images have the same size as the training images.",
"_____no_output_____"
]
],
[
[
"!ls ",
"_____no_output_____"
],
[
"!satproc_extract_chips \\\n ./data_cordoba/img/NBR_img/NBR_2021-10-07_2021-10-21_0.tif \\\n -o ./data_predict_cba/onedate_FW/160_160/ \\\n --size 160 \\\n --step-size 160 \\\n --rescale \\\n --rescale-mode percentiles \\\n --upper-cut 98 --lower-cut 2",
"_____no_output_____"
]
],
[
[
"The **--aoi** option is useful to reduce the predicction area to some shapefile.",
"_____no_output_____"
],
[
"# Predict ",
"_____no_output_____"
]
],
[
[
"from unetseg.predict import PredictConfig, predict\nfrom unetseg.evaluate import plot_data_results\nimport os",
"_____no_output_____"
]
],
[
[
"The paths to the files and for the outputresults, as well as the path to the model weights is defined in the predictConfig",
"_____no_output_____"
]
],
[
[
"predict_config = PredictConfig(\n images_path=os.path.join('./data_predict_cba/','onedate_FW','160_160'),\n results_path=os.path.join('./data_result_cba/','onedate_FW','160_160'),\n batch_size=16,\n model_path=os.path.join('./data/weights/', 'UNet_fire_160_80_spe100_fire_water.h5'), # ruta al modelo (.h5)\n model_architecture = \"unet\",\n height=160,\n width=160,\n n_channels=1,\n n_classes=2,\n class_weights=[0.6,0.4])\n \n ",
"_____no_output_____"
]
],
[
[
"Run the prediction process",
"_____no_output_____"
]
],
[
[
"predict(predict_config) ",
"_____no_output_____"
]
],
[
[
"Plot some of the results ",
"_____no_output_____"
]
],
[
[
"plot_data_results(num_samples=2, fig_size=(5, 5), predict_config=predict_config, img_ch =3)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0f9403992d0edf57c4e911951f128d7e4c861e7 | 46,756 | ipynb | Jupyter Notebook | notebooks/pawel_ueb01/03_Cross_validation_and_grid_search_bielski.ipynb | hhain/sdap17 | 8bd0b4cb60d6140141c834ffcac8835a888a0949 | [
"MIT"
] | null | null | null | notebooks/pawel_ueb01/03_Cross_validation_and_grid_search_bielski.ipynb | hhain/sdap17 | 8bd0b4cb60d6140141c834ffcac8835a888a0949 | [
"MIT"
] | 1 | 2017-06-08T22:32:48.000Z | 2017-06-08T22:32:48.000Z | notebooks/pawel_ueb01/03_Cross_validation_and_grid_search_bielski.ipynb | hhain/sdap17 | 8bd0b4cb60d6140141c834ffcac8835a888a0949 | [
"MIT"
] | null | null | null | 168.18705 | 20,496 | 0.895543 | [
[
[
"# Load libraries\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport time\n\nfrom sklearn.cross_validation import train_test_split\nfrom sklearn.grid_search import GridSearchCV\nfrom sklearn.neighbors import KNeighborsClassifier",
"_____no_output_____"
],
[
"# Load dataset\nurl = \"https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data\"\nnames = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']\ndataset = pd.read_csv(url, names=names)",
"_____no_output_____"
],
[
"print(dataset.shape)",
"(150, 5)\n"
],
[
"print(dataset.head(5))",
" sepal-length sepal-width petal-length petal-width class\n0 5.1 3.5 1.4 0.2 Iris-setosa\n1 4.9 3.0 1.4 0.2 Iris-setosa\n2 4.7 3.2 1.3 0.2 Iris-setosa\n3 4.6 3.1 1.5 0.2 Iris-setosa\n4 5.0 3.6 1.4 0.2 Iris-setosa\n"
],
[
"# slit features and labels\narray = dataset.values\nX = array[:,0:4]\ny = array[:,4]",
"_____no_output_____"
],
[
"# Test options and evaluation metric\nseed = 7\nscoring = 'accuracy'",
"_____no_output_____"
],
[
"# test different number of cores: max 8\nnum_cpu_list = list(range(1,9))\ntraining_times_all = []",
"_____no_output_____"
],
[
"param_grid = {\"n_neighbors\" : list(range(1,20))}\ntraining_times = []\n\nfor num_cpu in num_cpu_list:\n clf = GridSearchCV(KNeighborsClassifier(), param_grid, scoring=scoring)\n clf.set_params(n_jobs=num_cpu)\n start_time = time.time()\n clf.fit(X, y)\n training_times.append(time.time() - start_time)\n # print logging message\n print(\"Computing KNN grid with {} cores DONE.\".format(num_cpu))\n\nprint(\"All computations DONE.\")",
"Computing KNN grid with 1 cores DONE.\nComputing KNN grid with 2 cores DONE.\nComputing KNN grid with 3 cores DONE.\nComputing KNN grid with 4 cores DONE.\nComputing KNN grid with 5 cores DONE.\nComputing KNN grid with 6 cores DONE.\nComputing KNN grid with 7 cores DONE.\nComputing KNN grid with 8 cores DONE.\nAll computations DONE.\n"
],
[
"# best parameters found\nprint(\"Best parameters:\")\nprint(clf.best_params_)\nprint(\"With accuracy:\")\nprint(clf.best_score_)\n",
"Best parameters:\n{'n_neighbors': 5}\nWith accuracy:\n0.986666666667\n"
],
[
"scores_all_percent = [100 * grid_score[1] for grid_score in clf.grid_scores_]\nparams_all = [grid_score[0][\"n_neighbors\"] for grid_score in clf.grid_scores_]\n\nN = 19\nind = np.arange(N) # the x locations for bars\nwidth = 0.5 # the width of the bars\n\nfig, ax = plt.subplots()\nax.bar(ind + width/2, scores_all_percent, width)\nax.set_xticks(ind + width)\nax.set_xticklabels([str(i) for i in params_all])\nax.set_ylim([90,100])\nplt.title(\"Accuracy of KNN vs n_neighbors param\")\nplt.xlabel(\"n_neighbors\")\nplt.ylabel(\"accuracy [%]\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"The above plot shows that the best accuracy for KNN algorithm is obtained for **n_neighbors = 5**",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots()\nax.plot(num_cpu_list, training_times, 'ro')\nax.set_xlim([0, len(num_cpu_list)+1])\n\n#plt.axis([0, len(num_cpu_list)+1, 0, max(training_times)+1])\nplt.title(\"Search time vs #CPU Cores\")\nplt.xlabel(\"#CPU Cores\")\nplt.ylabel(\"search time [s]\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"\nWe can see that the search time for **n_jobs > 1** is highier than for **n_jobs = 1**. The reason is that multiprocessing comes at cost i.e. the distribution of multiple processes can take more time that the actual execution time for the small datasets like **Iris** (150 rows).",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d0f94ef5809ff46ec8c136dc4cd161990ef2f58b | 7,563 | ipynb | Jupyter Notebook | recurrent_neural_network_MNIST.ipynb | aadi-mishra/deepLearningProjects | d8fc2cd6865c9873453927a07a530c21bdf2d427 | [
"MIT"
] | 3 | 2021-04-26T22:43:32.000Z | 2021-08-02T20:01:34.000Z | recurrent_neural_network_MNIST.ipynb | aadi-mishra/deepLearningProjects | d8fc2cd6865c9873453927a07a530c21bdf2d427 | [
"MIT"
] | null | null | null | recurrent_neural_network_MNIST.ipynb | aadi-mishra/deepLearningProjects | d8fc2cd6865c9873453927a07a530c21bdf2d427 | [
"MIT"
] | null | null | null | 33.464602 | 259 | 0.479439 | [
[
[
"<a href=\"https://colab.research.google.com/github/aadi-mishra/deepLearningProjects/blob/main/recurrent_neural_network_MNIST.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\nfrom tensorflow.keras.models import Sequential\nfrom tensorflow.keras.layers import Dense, Dropout, LSTM",
"_____no_output_____"
],
[
"mnist = tf.keras.datasets.mnist # mnist is a dataset of 28x28 images of handwritten digits and their labels\n(x_train, y_train),(x_test, y_test) = mnist.load_data() # unpacks images to x_train/x_test and labels to y_train/y_test\n\nx_train = x_train/255.0\nx_test = x_test/255.0\n\nprint(x_train.shape)\nprint(x_train[0].shape)",
"(60000, 28, 28)\n(28, 28)\n"
],
[
"model = Sequential()\nmodel.add(LSTM(128, input_shape=(x_train.shape[1:]), activation='relu', return_sequences=True))\nmodel.add(Dropout(0.2))\n\nmodel.add(LSTM(128, activation='relu'))\nmodel.add(Dropout(0.1))\n\nmodel.add(Dense(32, activation='relu'))\nmodel.add(Dropout(0.2))\n\nmodel.add(Dense(10, activation='softmax'))",
"WARNING:tensorflow:Layer lstm_17 will not use cuDNN kernel since it doesn't meet the cuDNN kernel criteria. It will use generic GPU kernel as fallback when running on GPU\nWARNING:tensorflow:Layer lstm_18 will not use cuDNN kernel since it doesn't meet the cuDNN kernel criteria. It will use generic GPU kernel as fallback when running on GPU\n"
],
[
"opt = tf.keras.optimizers.Adam(lr=0.001, decay=1e-6)\n\nmodel.compile(\n loss='sparse_categorical_crossentropy',\n optimizer=opt,\n metrics=['accuracy'],\n)\n",
"_____no_output_____"
],
[
"model.summary()\n",
"Model: \"sequential_9\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nlstm_17 (LSTM) (None, 28, 128) 80384 \n_________________________________________________________________\ndropout_24 (Dropout) (None, 28, 128) 0 \n_________________________________________________________________\nlstm_18 (LSTM) (None, 128) 131584 \n_________________________________________________________________\ndropout_25 (Dropout) (None, 128) 0 \n_________________________________________________________________\ndense_16 (Dense) (None, 32) 4128 \n_________________________________________________________________\ndropout_26 (Dropout) (None, 32) 0 \n_________________________________________________________________\ndense_17 (Dense) (None, 10) 330 \n=================================================================\nTotal params: 216,426\nTrainable params: 216,426\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"model.fit(x_train,\n y_train,\n epochs=3,\n validation_data=(x_test, y_test))",
"Epoch 1/3\n1875/1875 [==============================] - 102s 52ms/step - loss: 1.0345 - accuracy: 0.6350 - val_loss: 0.1238 - val_accuracy: 0.9625\nEpoch 2/3\n1875/1875 [==============================] - 93s 49ms/step - loss: 0.1864 - accuracy: 0.9528 - val_loss: 0.0938 - val_accuracy: 0.9734\nEpoch 3/3\n1875/1875 [==============================] - 96s 51ms/step - loss: 0.1084 - accuracy: 0.9701 - val_loss: 0.0643 - val_accuracy: 0.9812\n"
],
[
"",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0f952b1fa54ca8ed68d034fb3748347916d7a76 | 68,422 | ipynb | Jupyter Notebook | doc/User_Guide.ipynb | hannah83i/PipeGraph | c9fc71d06b3a4497def921bc06cc5c34580b35ce | [
"MIT"
] | 23 | 2018-02-09T07:43:06.000Z | 2021-09-14T07:27:09.000Z | doc/User_Guide.ipynb | hannah83i/PipeGraph | c9fc71d06b3a4497def921bc06cc5c34580b35ce | [
"MIT"
] | 5 | 2018-11-21T20:20:17.000Z | 2021-06-15T17:52:50.000Z | doc/User_Guide.ipynb | hannah83i/PipeGraph | c9fc71d06b3a4497def921bc06cc5c34580b35ce | [
"MIT"
] | 8 | 2018-03-18T08:08:34.000Z | 2021-02-15T08:40:00.000Z | 51.061194 | 14,026 | 0.684911 | [
[
[
"# pipegraph User Guide",
"_____no_output_____"
],
[
"## Rationale",
"_____no_output_____"
],
[
"[scikit-learn](http://scikit-learn.org/stable/) provides a useful set of data preprocessors and machine learning models. The `Pipeline` object can effectively encapsulate a chain of transformers followed by final model. Other functions, like `GridSearchCV` can effectively use `Pipeline` objects to find the set of parameters that provide the best estimator.\n\n### Pipeline + GridSearchCV: an awesome combination\nLet's consider a simple example to illustrate the advantages of using `Pipeline` and `GridSearchCV`.\n\nFirst let's import the libraries we will use and then let's build some artificial data set following a simple polynomial rule",
"_____no_output_____"
]
],
[
[
"import numpy as np\nfrom sklearn.preprocessing import MinMaxScaler\nfrom sklearn.preprocessing import PolynomialFeatures\nfrom sklearn.linear_model import LinearRegression\nfrom sklearn.model_selection import GridSearchCV\nfrom sklearn.pipeline import Pipeline\nimport matplotlib.pyplot as plt\n\nX = 2*np.random.rand(100,1)-1\ny = 40 * X**5 + 3*X*2 + 3*X + 3*np.random.randn(100,1)",
"_____no_output_____"
]
],
[
[
"Once we have some data ready, we instantiate the transformers and a regressor we want to fit:",
"_____no_output_____"
]
],
[
[
"scaler = MinMaxScaler()\npolynomial_features = PolynomialFeatures()\nlinear_model = LinearRegression()",
"_____no_output_____"
]
],
[
[
"We define the steps that form the Pipeline object and then we instantiate such a Pipeline",
"_____no_output_____"
]
],
[
[
"steps = [('scaler', scaler),\n ('polynomial_features', polynomial_features),\n ('linear_model', linear_model)]\n\npipe = Pipeline(steps=steps)",
"_____no_output_____"
]
],
[
[
"Now we can pass this pipeline to `GridSearchCV`. When the `GridSearchCV` object is fitted, the search for the best combination for hyperparameters is performed according to the values provided in the `param_grid` parameter:",
"_____no_output_____"
]
],
[
[
"param_grid = {'polynomial_features__degree': range(1, 11),\n 'linear_model__fit_intercept': [True, False]}\n\ngrid_search_regressor = GridSearchCV(estimator=pipe, param_grid=param_grid, refit=True)\ngrid_search_regressor.fit(X, y);",
"_____no_output_____"
]
],
[
[
"And now we can check the results of fitting the Pipeline and the values of the hyperparameters:",
"_____no_output_____"
]
],
[
[
"y_pred = grid_search_regressor.predict(X)\nplt.scatter(X, y)\nplt.scatter(X, y_pred)\nplt.show()",
"_____no_output_____"
],
[
"coef = grid_search_regressor.best_estimator_.get_params()['linear_model'].coef_\ndegree = grid_search_regressor.best_estimator_.get_params()['polynomial_features'].degree\n\nprint('Information about the parameters of the best estimator: \\n degree: {} \\n coefficients: {} '.format(degree, coef))",
"Information about the parameters of the best estimator: \n degree: 5 \n coefficients: [[ 0. 443.10816501 -1849.10331869 3922.58622592 -4040.9186163\n 1619.79333825]] \n"
]
],
[
[
"### Pipeline weaknesses:\nFrom this example we can learn that `Pipeline` and `GridSearchCV` are very useful tools to consider when attempting to fit models. As far as the needs of the user can be satisfied by a set of transformers followed by a final model, this approach seems to be highly convenient. Additional advantages of such approach are the **parallel computation** and **memoization** capabilities of GridSearchCV.\n\nUnfortunately though, current implementation of scikit-learn's `Pipeline`:\n- Does not allow postprocessors after the final model\n- Does not allow extracting information about intermediate results\n- The X is transformed on every transformer but the following step can not have access to X variable values beyond the previous step\n- Only allows single path workflows",
"_____no_output_____"
],
[
"### pipegraph goals:\n[pipegraph](https://github.com/mcasl/PipeGraph) was programmed in order to allow researchers and practitioners to:\n- Use multiple path workflows\n- Have access to every variable value produced by any step of the workflow\n- Use an arbitraty number of models and transformers in the way the user prefers\n- Express the model as a graph consisting of transformers, regressors, classifiers or custom blocks\n- Build new custom block in an easy way\n- Provide the community some adapters to scikit-learn's objects that may help further developments",
"_____no_output_____"
],
[
"## pipegraph main interface: The PipeGraphRegressor and PipeGraphClassifier classes\n`pipegraph` provides the user two main classes: `PipeGraphRegressor` and `PipeGraphClassifier`. They both provide a familiar interface to the raw `PipeGraph` class that most users will not need to use. The `PipeGraph` class provides greater versatility allowing an arbitrary number of inputs and outputs and may be the base class for those users facing applications with such special needs. Most users, though, will be happy using just the former two classes provided as main interface to operate the library.\n\nAs the names intend to imply, `PipeGraphRegressor` is the class to use for regression models and `PipeGraphClassifier` is intended for classification problems. Indeed, the only difference between these two classes is the default scoring function that has been chosen accordingly to scikit-learn defaults for each case. Apart from that, both classes share the same code. It must be noticed though, that any of these classes can comprise a plethora of different regressors or clasiffiers. It is the final step the one that will define whether we are defining a classification or regression problem.",
"_____no_output_____"
],
[
"## From a single path workflow to a graph with multiple paths: Understanding connections\nThese two classes provide an interface as similar to scikit-learn's `Pipeline` as possible in order to ease their use to those already familiar with scikit-learn. There is a slight but important difference that empowers these two classes: the `PipeGraph` related classes accept extra information about which input variables are needed by each step, thus allowing multiple path workflows. \n\nTo clarify the usage of these connections, let's start using `pipegraph` with a simple example that could be otherwise perfectly expressed using a scikit-learn's `Pipeline` as well. In this simple case, the data is transformed using a `MinMaxScaler` transformer and the preprocessed data is fed to a `LinearRegression` model. Figure 1 shows the steps of this PipeGraphRegressor and the connections between them: which input variables each one accepts and their origin, that is, if they are provided by a previous step, like the output of `scaler`, named `predict`, that is used by `linear_model`'s `X` variable; or `y` which is not calculated by any previous block but is passed by the user in the `fit` or `predict` method calls.",
"_____no_output_____"
],
[
"<img src=\"./images/figure_1-a.png\" width=\"400\" />\nFigure 1. PipeGraph diagram showing the steps and their connections",
"_____no_output_____"
],
[
"In this first simple example of `pipegraph` the last step is a regressor, and thus the `PipeGraphRegressor` class is the most adequate class to choose. But other than that, we define the steps as usual for a standard `Pipeline`: as a list of tuples (label, sklearn object). We are not introducing yet any information at all about the connections, in which case the `PipeGraphRegressor` object is built considering that the steps follow a linear workflow in the same way as a standard `Pipeline`.",
"_____no_output_____"
]
],
[
[
"from pipegraph import PipeGraphRegressor\n\nX = 2*np.random.rand(100,1)-1\ny = 40 * X**5 + 3*X*2 + 3*X + 3*np.random.randn(100,1)\n\nscaler = MinMaxScaler()\nlinear_model = LinearRegression()\nsteps = [('scaler', scaler),\n ('linear_model', linear_model)]\n\npgraph = PipeGraphRegressor(steps=steps)\npgraph.fit(X, y)",
"_____no_output_____"
]
],
[
[
"As the printed output shows, the internal links displayed by the `fit_connections` and `predict_connections` parameters are in line with those we saw in Figure 1 and those expected by a single path pipeline. As we did not specify these values, they were created by `PipeGRaphRegressor.__init__()` method as a comodity. We can have a look at these values by directly inspecting the attributes values. As `PipeGraphRegressor` and `PipeGraphClassifier` are wrappers of a `PipeGraph` object stored in the `_pipegraph` attribute, we have to dig a bit deeper to find the `fit_connections`",
"_____no_output_____"
]
],
[
[
"pgraph._pipegraph.fit_connections",
"_____no_output_____"
]
],
[
[
"Figure 2 surely will help understading the syntax used by the connections dictionary. It goes like this:\n- The keys of the top level entries of the dictionary must be the same as those of the previously defined steps.\n- The values assocciated to these keys define the variables from other steps that are going to be considered as inputs for the current step. They are dictionaries themselves, where:\n\n - The keys of the nested dictionary represent the input variables as named at the current step.\n - The values assocciated to these keys define the steps that hold the desired information and the variables as named at that step. This information can be written as:\n\n - A tuple with the label of the step in position 0 followed by the name of the output variable in position 1.\n - A string:\n - If the string value is one of the labels from the steps, then it is interpreted as tuple, as previously, with the label of the step in position 0 and 'predict' as name of the output variable in position 1.\n - Otherwise, it is considered to be a variable from an external source, such as those provided by the user while invoking the ``fit``, ``predict`` or ``fit_predict`` methods.\n",
"_____no_output_____"
],
[
"<img src=\"./images/figure_1-b.png\" width=\"700\" />\n\nFigure 2. Illustration of the connections of the PipeGraph",
"_____no_output_____"
],
[
"The choice of name 'predict' for default output variables was made for convenience reasons as it will be illustrated later on. The developers preferred using always the same word for every block even though it might not be a regressor nor a classifier.\n\nFinally, let's get the predicted values from this `PipeGraphRegressor` for illustrative purposes:",
"_____no_output_____"
]
],
[
[
"y_pred = pgraph.predict(X)\nplt.scatter(X, y, label='Original Data')\n\nplt.scatter(X, y_pred, label='Predicted Data')\nplt.title('Plots of original and predicted data')\nplt.legend(loc='best')\nplt.grid(True)\nplt.xlabel('Index')\nplt.ylabel('Value of Data')\nplt.show()",
"_____no_output_____"
]
],
[
[
"## `GridSearchCV` compatibility requirements\n\nBoth `PipeGraphRegressor`and `PipeGraphClassifier` are compatible with `GridSearchCV` provided the last step can be scored, either:\n- by using `PipeGraphRegressor` or `PipeGraphClassifier` default scoring functions,\n- by implementing a custom scoring function capable of handling that last step inputs and outputs,\n- by using a `NeutralRegressor` or `NeutralClassifier` block as final step.\n\nThose pipegraphs with a last step from scikit-learn's estimators set will work perfectly well using `PipeGraphRegressor` or `PipeGraphClassifier` default scoring functions. The other two alternative cover those cases in which a custom block with non standard inputs is provided. In that case, choosing a neutral regressor or classifier is usually a much simpler approach than writing customs scoring function. `NeutralRegressor` or `NeutralClassifier` are two classes provided for users convenience so that no special scoring function is needed. They just allow the user to pick some variables from other previous steps as `X` and `y` and provide compatibility to use a default scoring function. ",
"_____no_output_____"
],
[
"### Example using default scoring functions\nWe will show more complex examples in what follows, but let's first illustrate with a simple example how to use `GrisSearchCV` with the default scoring functions. Figure 3 shows the steps of the model:\n- **scaler**: a preprocessing step using a `MinMaxScaler` object,\n- **polynomial_features**: a transformer step that generates a new feature matrix consisting of all polynomial combinations of the features with degree less than or equal to the specified one,\n- **linear_model**: the `LinearRegression` object we want to fit.\n\n<img src=\"./images/figure_2.png\" width=\"700\" />\n\nFigure 3. Using a PipeGraphRegressor object as estimator by GridSearchCV",
"_____no_output_____"
],
[
"Firstly, we import the necessary libraries and create some artificial data.",
"_____no_output_____"
]
],
[
[
"from sklearn.preprocessing import PolynomialFeatures\n\nX = 2*np.random.rand(100,1)-1\ny = 40 * X**5 + 3*X*2 + 3*X + 3*np.random.randn(100,1)\n\nscaler = MinMaxScaler()\npolynomial_features = PolynomialFeatures()\nlinear_model = LinearRegression()",
"_____no_output_____"
]
],
[
[
"Secondly, we define the steps and a ``param_grid`` dictionary as specified by `GridSearchCV`.\nIn this case we just want to explore a few possibilities varying the degree of the polynomials and whether to use or not an intercept at the linear model.",
"_____no_output_____"
]
],
[
[
"steps = [('scaler', scaler),\n ('polynomial_features', polynomial_features),\n ('linear_model', linear_model)]\n\nparam_grid = {'polynomial_features__degree': range(1, 11),\n 'linear_model__fit_intercept': [True, False]}",
"_____no_output_____"
]
],
[
[
"Now, we use ``PipeGraphRegressor`` as estimator for `GridSearchCV` and perform the ``fit`` and ``predict`` operations. As the last steps, a linear regressor from scikit-learn, already works with the default scoring functions, no extra efforts are needed to make it compatible with `GridSearchCV`.",
"_____no_output_____"
]
],
[
[
"pgraph = PipeGraphRegressor(steps=steps)\ngrid_search_regressor = GridSearchCV(estimator=pgraph, param_grid=param_grid, refit=True)\ngrid_search_regressor.fit(X, y)\ny_pred = grid_search_regressor.predict(X)\n\nplt.scatter(X, y)\nplt.scatter(X, y_pred)\nplt.show()\n\n\ncoef = grid_search_regressor.best_estimator_.get_params()['linear_model'].coef_\ndegree = grid_search_regressor.best_estimator_.get_params()['polynomial_features'].degree\n\nprint('Information about the parameters of the best estimator: \\n degree: {} \\n coefficients: {} '.format(degree, coef))",
"_____no_output_____"
]
],
[
[
"This example showed how to use `GridSearchCV` with `PipeGraphRegressor` in a simple single path workflow with default scoring functions. Let's explore in next section a more complex example.\n",
"_____no_output_____"
],
[
"## Multiple path workflow examples\n\nUntill now, all the examples we showed displayed a single path sequence of steps and thus they could have been equally easily done using sickit-learn standard `Pipeline`. We are going to show now in the following examples multiple path cases in which we illustrate some compatibility constrains that occur and how to deal with them successfully.\n\n### Example: Injecting a varying vector in the sample_weight parameter of LinearRegression\nThis example illustrates the case in which a varying vector is injected to a linear regression model as ``sample_weight`` in order to evaluate them and obtain the sample_weight that generates the best results. ",
"_____no_output_____"
],
[
"The steps of this model are shown in Figure 4. To perform such experiment, the following issues appear:\n\n- The shape of the graph is not a single path workflow as those that can be implemented using Pipeline. Thus, we need to use `pipegraph`.\n\n- The model has 3 input variables, `X`, `y`, and `sample_weight`. The `Pipegraph` class can accept an arbitrary number of input variables, but, in order to use scikit-learn's current implementation of GridSearchCV, only `X` and `y` are accepted. We can do the trick but previously concatenating `X` and `sample_weight` into a single pandas DataFrame, for example, in order to comply with GridSearchCV requisites. That implies that the graph must be capable of separating afterwards the augmented `X` into the two components again. The **selector** step is in charge of this splitting. This step features a `ColumnSelector` custom step. This is not a scikit-learn original object but a custom class that allows to split an array into columns. In this case, ``X`` augmented data is column-wise divided as specified in a mapping dictionary. We will talk later on about custom blocks.\n\n- The information provided to the ``sample_weight`` parameter of the LinearRegression step varies on the different scenarios explored by GridSearchCV. In a GridSearchCV with Pipeline, ``sample_weight`` can't vary because it is treated as a ``fit_param`` instead of a variable. Using pipegraph's connections this is no longer a problem.\n\n- As we need a custom transformer to apply the power function to the sample_weight vector, we implement the **custom_power** step featuring a `CustomPower` custom class. Again, we will talk later on about custom blocks.",
"_____no_output_____"
],
[
"The three other steps from the model are already known:\n- **scaler**: implements `MinMaxScaler` class\n- **polynomial_features**: Contains a `PolynomialFeatures` object\n- **linear_model**: Contains a `LinearRegression` model\n\n<img src=\"./images/figure_3.png\" width=\"600\" />\n\n Figure 4. A multipath model",
"_____no_output_____"
],
[
" ",
"_____no_output_____"
],
[
"Let's import the new components:",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nfrom pipegraph.base import ColumnSelector\nfrom pipegraph.demo_blocks import CustomPower",
"_____no_output_____"
]
],
[
[
"We create an augmented ``X`` in which all data but ``y`` is concatenated. In this case, we concatenate ``X`` and ``sample_weight`` vector.",
"_____no_output_____"
]
],
[
[
"X = pd.DataFrame(dict(X=np.array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]),\n sample_weight=np.array([0.01, 0.95, 0.10, 0.95, 0.95, 0.10, 0.10, 0.95, 0.95, 0.95, 0.01])))\ny = np.array( [ 10, 4, 20, 16, 25 , -60, 85, 64, 81, 100, 150])",
"_____no_output_____"
]
],
[
[
"Next we define the steps and we use `PipeGraphRegressor` as estimator for `GridSearchCV`.",
"_____no_output_____"
]
],
[
[
"scaler = MinMaxScaler()\npolynomial_features = PolynomialFeatures()\nlinear_model = LinearRegression()\ncustom_power = CustomPower()\nselector = ColumnSelector(mapping={'X': slice(0, 1),\n 'sample_weight': slice(1,2)})\n\nsteps = [('selector', selector),\n ('custom_power', custom_power),\n ('scaler', scaler),\n ('polynomial_features', polynomial_features),\n ('linear_model', linear_model)]\n\npgraph = PipeGraphRegressor(steps=steps)",
"_____no_output_____"
]
],
[
[
"Now, we have to define the connections of the model. We could have specified a dictionary containing the connections, but [as suggested by Joel Nothman](https://github.com/scikit-learn-contrib/scikit-learn-contrib/issues/28), scikit-learn users might find more convenient to use a method `inject` like in this example. Let's see `inject`s docstring:",
"_____no_output_____"
]
],
[
[
"import inspect\nprint(inspect.getdoc(pgraph.inject))",
"_____no_output_____"
]
],
[
[
"`inject` allows to chain different calls to progressively describe all the connections needed in an easy to read manner:",
"_____no_output_____"
]
],
[
[
"(pgraph.inject(sink='selector', sink_var='X', source='_External', source_var='X')\n .inject('custom_power', 'X', 'selector', 'sample_weight')\n .inject('scaler', 'X', 'selector', 'X')\n .inject('polynomial_features', 'X', 'scaler')\n .inject('linear_model', 'X', 'polynomial_features')\n .inject('linear_model', 'y', source_var='y')\n .inject('linear_model', 'sample_weight', 'custom_power'))",
"_____no_output_____"
]
],
[
[
"Then we define ``param_grid`` as expected by `GridSearchCV` to explore several possibilities of varying parameters.\n ",
"_____no_output_____"
]
],
[
[
"param_grid = {'polynomial_features__degree': range(1, 3),\n 'linear_model__fit_intercept': [True, False],\n 'custom_power__power': [1, 5, 10, 20, 30]}\n\n\n\ngrid_search_regressor = GridSearchCV(estimator=pgraph, param_grid=param_grid, refit=True)\ngrid_search_regressor.fit(X, y)\ny_pred = grid_search_regressor.predict(X)\n\nplt.scatter(X.loc[:,'X'], y)\nplt.scatter(X.loc[:,'X'], y_pred)\nplt.show()\n\npower = grid_search_regressor.best_estimator_.get_params()['custom_power']\nprint('Power that obtains the best results in the linear model: \\n {}'.format(power))",
"_____no_output_____"
]
],
[
[
"This example showed how to solve current limitations of scikit-learn `Pipeline`:\n- Displayed a multipath workflow successfully implemented by **pipegraph**\n- Showed how to circumvent current limitations of standard `GridSearchCV`, in particular, the restriction on the number of input parameters\n- Showed the flexibility of **pipegraph** for specifying the connections in an easy to read manner using the `inject` method\n- Demonstrated the capability of injecting previous steps' output into other models parameters, such as it is the case of the sample_weight parameter in the linear regressor.",
"_____no_output_____"
],
[
"### Example: Combination of classifiers",
"_____no_output_____"
],
[
"A set of classifiers is combined as input to a neural network. Additionally, the scaled inputs are injected as well to\nthe neural network. The data is firstly transformed by scaling its features.\n\nSteps of the **PipeGraph**:\n\n- **scaler**: A `MinMaxScaler` data preprocessor\n- **gaussian_nb**: A `GaussianNB` classifier\n- **svc**: A `SVC` classifier\n- **concat**: A `Concatenator` custom class that appends the outputs of the `GaussianNB`, `SVC` classifiers, and the scaled inputs.\n- **mlp**: A `MLPClassifier` object",
"_____no_output_____"
],
[
"<img src=\"./images/figure_4.png\" width=\"700\" />\n\nFigure 5. PipeGraph diagram showing the steps and their connections",
"_____no_output_____"
]
],
[
[
"from pipegraph.base import PipeGraphClassifier, Concatenator\nfrom sklearn.datasets import load_iris\nfrom sklearn.naive_bayes import GaussianNB\nfrom sklearn.svm import SVC\nfrom sklearn.neural_network import MLPClassifier\n\niris = load_iris()\nX = iris.data\ny = iris.target\n\nscaler = MinMaxScaler()\ngaussian_nb = GaussianNB()\nsvc = SVC()\nmlp = MLPClassifier()\nconcatenator = Concatenator()\n\nsteps = [('scaler', scaler),\n ('gaussian_nb', gaussian_nb),\n ('svc', svc),\n ('concat', concatenator),\n ('mlp', mlp)]",
"_____no_output_____"
]
],
[
[
"In this example we use a `PipeGraphClassifier` because the result is a classification and we want to take advantage of scikit-learn default scoring method for classifiers. Once more, we use the `inject` chain of calls to define the connections.",
"_____no_output_____"
]
],
[
[
"pgraph = PipeGraphClassifier(steps=steps)\n(pgraph.inject(sink='scaler', sink_var='X', source='_External', source_var='X')\n .inject('gaussian_nb', 'X', 'scaler')\n .inject('gaussian_nb', 'y', source_var='y')\n .inject('svc', 'X', 'scaler')\n .inject('svc', 'y', source_var='y')\n .inject('concat', 'X1', 'scaler')\n .inject('concat', 'X2', 'gaussian_nb')\n .inject('concat', 'X3', 'svc')\n .inject('mlp', 'X', 'concat')\n .inject('mlp', 'y', source_var='y')\n)\n\nparam_grid = {'svc__C': [0.1, 0.5, 1.0],\n 'mlp__hidden_layer_sizes': [(3,), (6,), (9,),],\n 'mlp__max_iter': [5000, 10000]}\n\ngrid_search_classifier = GridSearchCV(estimator=pgraph, param_grid=param_grid, refit=True)\ngrid_search_classifier.fit(X, y)\ny_pred = grid_search_classifier.predict(X)\n\ngrid_search_classifier.best_estimator_.get_params()",
"_____no_output_____"
],
[
"# Code for plotting the confusion matrix taken from 'Python Data Science Handbook' by Jake VanderPlas\nfrom sklearn.metrics import confusion_matrix\nimport seaborn as sns; sns.set() # for plot styling\n\nmat = confusion_matrix(y_pred, y)\nsns.heatmap(mat.T, square=True, annot=True, fmt='d', cbar=False)\nplt.xlabel('true label')\nplt.ylabel('predicted label');\nplt.show()",
"_____no_output_____"
]
],
[
[
"This example displayed complex data injections that are successfully managed by **pipegraph**.",
"_____no_output_____"
],
[
"### Example: Demultiplexor - multiplexor\n\nAn imaginative layout using a classifier to predict the cluster labels and fitting a separate model for each cluster. We will elaborate on this example in the examples that follow introducing variations. AS the Figure shows, the steps of the **PipeGraph** are:\n\n- **scaler**: A :class:`MinMaxScaler` data preprocessor\n- **classifier**: A :class:`GaussianMixture` classifier\n- **demux**: A custom :class:`Demultiplexer` class in charge of splitting the input arrays accordingly to the selection input vector\n- **lm_0**: A :class:`LinearRegression` model\n- **lm_1**: A :class:`LinearRegression` model\n- **lm_2**: A :class:`LinearRegression` model\n- **mux**: A custom :class:`Multiplexer` class in charge of combining different input arrays into a single one accordingly to the selection input vector\n\n<img src=\"./images/figure_5.png\" width=\"700\" />\n\nFigure 6. PipeGraph diagram showing the steps and their connections",
"_____no_output_____"
]
],
[
[
"from pipegraph.base import PipeGraphRegressor, Demultiplexer, Multiplexer\nfrom sklearn.mixture import GaussianMixture\n\nX_first = pd.Series(np.random.rand(100,))\ny_first = pd.Series(4 * X_first + 0.5*np.random.randn(100,))\nX_second = pd.Series(np.random.rand(100,) + 3)\ny_second = pd.Series(-4 * X_second + 0.5*np.random.randn(100,))\nX_third = pd.Series(np.random.rand(100,) + 6)\ny_third = pd.Series(2 * X_third + 0.5*np.random.randn(100,))\n\nX = pd.concat([X_first, X_second, X_third], axis=0).to_frame()\ny = pd.concat([y_first, y_second, y_third], axis=0).to_frame()\n\nscaler = MinMaxScaler()\ngaussian_mixture = GaussianMixture(n_components=3)\ndemux = Demultiplexer()\nlm_0 = LinearRegression()\nlm_1 = LinearRegression()\nlm_2 = LinearRegression()\nmux = Multiplexer()\n\n\nsteps = [('scaler', scaler),\n ('classifier', gaussian_mixture),\n ('demux', demux),\n ('lm_0', lm_0),\n ('lm_1', lm_1),\n ('lm_2', lm_2),\n ('mux', mux), ]",
"_____no_output_____"
]
],
[
[
"Instead of using ``inject`` as in previous example, in this one we are going to pass a dictionary describing the connections to PipeGraph constructor",
"_____no_output_____"
]
],
[
[
"connections = { 'scaler': {'X': 'X'},\n 'classifier': {'X': 'scaler'},\n 'demux': {'X': 'scaler',\n 'y': 'y',\n 'selection': 'classifier'},\n 'lm_0': {'X': ('demux', 'X_0'),\n 'y': ('demux', 'y_0')},\n 'lm_1': {'X': ('demux', 'X_1'),\n 'y': ('demux', 'y_1')},\n 'lm_2': {'X': ('demux', 'X_2'),\n 'y': ('demux', 'y_2')},\n 'mux': {'0': 'lm_0',\n '1': 'lm_1',\n '2': 'lm_2',\n 'selection': 'classifier'}}\n\npgraph = PipeGraphRegressor(steps=steps, fit_connections=connections)\npgraph.fit(X, y)\n\ny_pred = pgraph.predict(X)\nplt.scatter(X, y)\nplt.scatter(X, y_pred)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Example: Encapsulating several blocks into a PipeGraph and reusing it\n\n\nWe consider the previous example in which we had the following pipegraph model:\n\n",
"_____no_output_____"
],
[
"<img src=\"./images/figure_6.png\" width=\"700\" />",
"_____no_output_____"
],
[
"We can be interested in using a fragment of the pipegraph, for example, those blocks marked with the circle (the Demultiplexer, the linear model collection, and the Multiplexer), as a single block in another pipegraph:",
"_____no_output_____"
],
[
"<img src=\"./images/figure_7.png\" width=\"500\" />",
"_____no_output_____"
],
[
"We prepare the data and build a PipeGraph with these steps alone:",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nfrom sklearn.preprocessing import MinMaxScaler\nfrom sklearn.mixture import GaussianMixture\nfrom sklearn.linear_model import LinearRegression\nfrom pipegraph.base import PipeGraph, PipeGraphRegressor, Demultiplexer, Multiplexer\n\n# Prepare some artificial data\n\nX_first = pd.Series(np.random.rand(100,))\ny_first = pd.Series(4 * X_first + 0.5*np.random.randn(100,))\nX_second = pd.Series(np.random.rand(100,) + 3)\ny_second = pd.Series(-4 * X_second + 0.5*np.random.randn(100,))\nX_third = pd.Series(np.random.rand(100,) + 6)\ny_third = pd.Series(2 * X_third + 0.5*np.random.randn(100,))\n\nX = pd.concat([X_first, X_second, X_third], axis=0).to_frame()\ny = pd.concat([y_first, y_second, y_third], axis=0).to_frame()",
"_____no_output_____"
],
[
"# Create a single complex block\n\ndemux = Demultiplexer()\nlm_0 = LinearRegression()\nlm_1 = LinearRegression()\nlm_2 = LinearRegression()\nmux = Multiplexer()\n\nthree_multiplexed_models_steps = [\n ('demux', demux),\n ('lm_0', lm_0),\n ('lm_1', lm_1),\n ('lm_2', lm_2),\n ('mux', mux), ]\n\nthree_multiplexed_models_connections = {\n 'demux': {'X': 'X',\n 'y': 'y',\n 'selection': 'selection'},\n 'lm_0': {'X': ('demux', 'X_0'),\n 'y': ('demux', 'y_0')},\n 'lm_1': {'X': ('demux', 'X_1'),\n 'y': ('demux', 'y_1')},\n 'lm_2': {'X': ('demux', 'X_2'),\n 'y': ('demux', 'y_2')},\n 'mux': {'0': 'lm_0',\n '1': 'lm_1',\n '2': 'lm_2',\n 'selection': 'selection'}}\n\nthree_multiplexed_models = PipeGraph(steps=three_multiplexed_models_steps,\n fit_connections=three_multiplexed_models_connections )",
"_____no_output_____"
]
],
[
[
"Now we can treat this PipeGraph as a reusable component and use it as a unitary step in another PipeGraph:",
"_____no_output_____"
]
],
[
[
"scaler = MinMaxScaler()\ngaussian_mixture = GaussianMixture(n_components=3)\nmodels = three_multiplexed_models\n\nsteps = [('scaler', scaler),\n ('classifier', gaussian_mixture),\n ('models', three_multiplexed_models), ]\n\nconnections = {'scaler': {'X': 'X'},\n 'classifier': {'X': 'scaler'},\n 'models': {'X': 'scaler',\n 'y': 'y',\n 'selection': 'classifier'},\n }\n\npgraph = PipeGraphRegressor(steps=steps, fit_connections=connections)\npgraph.fit(X, y)\ny_pred = pgraph.predict(X)\nplt.scatter(X, y)\nplt.scatter(X, y_pred)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Example: Dynamically built component using initialization parameters\n\nLast section showed how the user can choose to encapsulate several blocks into a PipeGraph and use it as a single unit in another PipeGraph. Now we will see how these components can be dynamically built on runtime depending on initialization parameters.",
"_____no_output_____"
],
[
"<img src=\"./images/figure_8.png\" width=\"700\" />",
"_____no_output_____"
],
[
"We can think of programatically changing the number of regression models inside this component we isolated in the previous example. First we do it by using initialization parameters in a ``PipeGraph`` subclass we called ``pipegraph.base.RegressorsWithParametrizedNumberOfReplicas``:",
"_____no_output_____"
]
],
[
[
"import inspect\nfrom pipegraph.base import RegressorsWithParametrizedNumberOfReplicas\n\nprint(inspect.getsource(RegressorsWithParametrizedNumberOfReplicas))",
"_____no_output_____"
]
],
[
[
"As it can be seen from the source code, in this example we are basically interested in using a PipeGraph object whose `__init__` has different parameters than the usual ones. Thus, we subclass PipeGRaph and reimplement the `__init__` method. In doing so, we are capable of working out the structure of the steps and connections before calling the `super().__init__` method that provides the regular `PipeGraph` object.",
"_____no_output_____"
],
[
"Using this new component we can build a PipeGraph with as many multiplexed models as given by the `number_of_replicas` parameter:",
"_____no_output_____"
]
],
[
[
"scaler = MinMaxScaler()\ngaussian_mixture = GaussianMixture(n_components=3)\nmodels = RegressorsWithParametrizedNumberOfReplicas(number_of_replicas=3,\n model_prototype=LinearRegression(),\n model_parameters={})\n\nsteps = [('scaler', scaler),\n ('classifier', gaussian_mixture),\n ('models', models), ]\n\nconnections = {'scaler': {'X': 'X'},\n 'classifier': {'X': 'scaler'},\n 'models': {'X': 'scaler',\n 'y': 'y',\n 'selection': 'classifier'},\n }\n\npgraph = PipeGraphRegressor(steps=steps, fit_connections=connections)\npgraph.fit(X, y)\ny_pred = pgraph.predict(X)\nplt.scatter(X, y)\nplt.scatter(X, y_pred)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Example: Dynamically built component using input signal values during the fit stage\n\nLast example showed how to grow a PipeGraph object programatically during runtime using the `__init__` method. In this example, we are going to show how we can change the internal structure of a PipeGraph object, not during initialization but during fit. Specifically, we will show how the multiplexed model can be dynamically added on runtime depending on input signal values during `fit`.\n",
"_____no_output_____"
],
[
"Now we consider the possibility of using the classifier's output to automatically adjust the number of replicas.\nThis can be seen as PipeGraph changing its inner topology to adapt its connections and steps to other components\ncontext. This morphing capability opens interesting possibilities to explore indeed.",
"_____no_output_____"
]
],
[
[
"import inspect\nfrom pipegraph.base import RegressorsWithDataDependentNumberOfReplicas\nprint(inspect.getsource(RegressorsWithDataDependentNumberOfReplicas))",
"_____no_output_____"
]
],
[
[
"Again we subclass from parent `PipeGraph` class and implement a different `__init__`. In this example we won't make use of a `number_of_replicas` parameter, as it will be inferred from data during `fit` and thus we are satisfied by passing only those parameters allowing us to change the regressor models. As it can be seen from the code, the `__init__` method just stores the values provided by the user and it is the `fit` method the one in charge of growing the inner structure of the pipegraph.\n\nUsing this new component we can build a simplified PipeGraph:",
"_____no_output_____"
]
],
[
[
"scaler = MinMaxScaler()\ngaussian_mixture = GaussianMixture(n_components=3)\nmodels = RegressorsWithDataDependentNumberOfReplicas(model_prototype=LinearRegression(), model_parameters={})\n\nsteps = [('scaler', scaler),\n ('classifier', gaussian_mixture),\n ('models', models), ]\n\nconnections = {'scaler': {'X': 'X'},\n 'classifier': {'X': 'scaler'},\n 'models': {'X': 'scaler',\n 'y': 'y',\n 'selection': 'classifier'},\n }\n\npgraph = PipeGraphRegressor(steps=steps, fit_connections=connections)\npgraph.fit(X, y)\ny_pred = pgraph.predict(X)\nplt.scatter(X, y)\nplt.scatter(X, y_pred)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Example: GridSearch on dynamically built component using input signal values\n\nPrevious example showed how a PipeGraph object can be dynamically built on runtime depending on input signal values during fit. Now, in this example we will show how to use `GridSearchCV` to explore the best combination of hyperparameters.",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split\nfrom pipegraph.base import NeutralRegressor\n\n# We prepare some data\n\nX_first = pd.Series(np.random.rand(100,))\ny_first = pd.Series(4 * X_first + 0.5*np.random.randn(100,))\nX_second = pd.Series(np.random.rand(100,) + 3)\ny_second = pd.Series(-4 * X_second + 0.5*np.random.randn(100,))\nX_third = pd.Series(np.random.rand(100,) + 6)\ny_third = pd.Series(2 * X_third + 0.5*np.random.randn(100,))\n\nX = pd.concat([X_first, X_second, X_third], axis=0).to_frame()\ny = pd.concat([y_first, y_second, y_third], axis=0).to_frame()\n\nX_train, X_test, y_train, y_test = train_test_split(X, y)",
"_____no_output_____"
]
],
[
[
"To ease the calculation of the score for the GridSearchCV we add a neutral regressor as a last step, capable of\ncalculating the score using a default scoring function. This is much more convenient than worrying about programming\na custom scoring function for a block with an arbitrary number of inputs.",
"_____no_output_____"
]
],
[
[
"scaler = MinMaxScaler()\ngaussian_mixture = GaussianMixture(n_components=3)\nmodels = RegressorsWithDataDependentNumberOfReplicas(model_prototype=LinearRegression(), model_parameters={})\nneutral_regressor = NeutralRegressor()\n\nsteps = [('scaler', scaler),\n ('classifier', gaussian_mixture),\n ('models', models),\n ('neutral', neutral_regressor)]\n\nconnections = {'scaler': {'X': 'X'},\n 'classifier': {'X': 'scaler'},\n 'models': {'X': 'scaler',\n 'y': 'y',\n 'selection': 'classifier'},\n 'neutral': {'X': 'models'}\n }\n\npgraph = PipeGraphRegressor(steps=steps, fit_connections=connections)",
"_____no_output_____"
]
],
[
[
"Using GridSearchCV to find the best number of clusters and the best regressors",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import GridSearchCV\n\nparam_grid = {'classifier__n_components': range(2,10)}\ngs = GridSearchCV(estimator=pgraph, param_grid=param_grid, refit=True)\ngs.fit(X_train, y_train)\ny_pred = gs.predict(X_train)\nplt.scatter(X_train, y_train)\nplt.scatter(X_train, y_pred)\nprint(\"Score:\" , gs.score(X_test, y_test))\nprint(\"classifier__n_components:\", gs.best_estimator_.get_params()['classifier__n_components'])",
"_____no_output_____"
]
],
[
[
"### Example: Alternative solution\n\nNow we consider an alternative solution to the previous example. The solution already shown displayed the potential\nof being able to morph the graph during fitting. A simpler approach is considered in this example by reusing\ncomponents and combining the classifier with the demultiplexed models.",
"_____no_output_____"
]
],
[
[
"from pipegraph.base import ClassifierAndRegressorsBundle\n\nprint(inspect.getsource(ClassifierAndRegressorsBundle))",
"_____no_output_____"
]
],
[
[
"As before, we built a custom block by subclassing PipeGraph and the modifying the `__init__` method to provide the parameters specifically needed for our purposes. Then we chain in the same PipeGraph the classifier, and the already available and known block for creating multiplexed models by providing parameters during `__init__`. It must be noticed that both the classifier and the models share have the same number of clusters and model: the number_of_replicas value provided by the user.",
"_____no_output_____"
],
[
"Using this new component we can build a simplified PipeGraph:",
"_____no_output_____"
]
],
[
[
"scaler = MinMaxScaler()\nclassifier_and_models = ClassifierAndRegressorsBundle(number_of_replicas=6)\nneutral_regressor = NeutralRegressor()\n\nsteps = [('scaler', scaler),\n ('bundle', classifier_and_models),\n ('neutral', neutral_regressor)]\n\nconnections = {'scaler': {'X': 'X'},\n 'bundle': {'X': 'scaler', 'y': 'y'},\n 'neutral': {'X': 'bundle'}}\n\npgraph = PipeGraphRegressor(steps=steps, fit_connections=connections)",
"_____no_output_____"
]
],
[
[
"Using GridSearchCV to find the best number of clusters and the best regressors",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import GridSearchCV\n\nparam_grid = {'bundle__number_of_replicas': range(3,10)}\ngs = GridSearchCV(estimator=pgraph, param_grid=param_grid, refit=True)\ngs.fit(X_train, y_train)\ny_pred = gs.predict(X_train)\nplt.scatter(X_train, y_train)\nplt.scatter(X_train, y_pred)\nprint(\"Score:\" , gs.score(X_test, y_test))\nprint(\"bundle__number_of_replicas:\", gs.best_estimator_.get_params()['bundle__number_of_replicas'])",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0f954e687f2975bdf5669c6d87f4b68db12527f | 64,006 | ipynb | Jupyter Notebook | python-sdk/nuscenes/map_expansion/evaluation/feature_importance.ipynb | Kishaan/nuscenes-devkit | 778e4a0a1a141272a1942d4c5c2c800ca841e27f | [
"Apache-2.0"
] | null | null | null | python-sdk/nuscenes/map_expansion/evaluation/feature_importance.ipynb | Kishaan/nuscenes-devkit | 778e4a0a1a141272a1942d4c5c2c800ca841e27f | [
"Apache-2.0"
] | null | null | null | python-sdk/nuscenes/map_expansion/evaluation/feature_importance.ipynb | Kishaan/nuscenes-devkit | 778e4a0a1a141272a1942d4c5c2c800ca841e27f | [
"Apache-2.0"
] | null | null | null | 237.94052 | 55,236 | 0.890682 | [
[
[
"import tensorflow as tf\nfrom tensorflow.keras import backend as K\n\nimport matplotlib as mpl\nimport pickle\nimport matplotlib.pyplot as plt\nimport matplotlib\nimport numpy as np\nimport os\n\n# Init NuScenes. Requires the dataset to be stored on disk.\nfrom nuscenes.nuscenes import NuScenes\nfrom nuscenes.map_expansion.map_api import NuScenesMap\n\nmatplotlib.rcParams['figure.figsize'] = (24, 18)\nmatplotlib.rcParams['figure.facecolor'] = 'white'\nmatplotlib.rcParams.update({'font.size': 20})\n\nTRAIN_SIZE = 9800\nTRAIN_TIME = 6\nBATCH_SIZE = 32\nBUFFER_SIZE = 500",
"_____no_output_____"
],
[
"total_ped_matrix = np.load(\"../details/new_ped_matrix.npy\")\n\nwith open(\"../details/ped_dataset.pkl\", \"rb\") as f:\n ped_dataset = pickle.load(f)\n \nwith open('../details/scene_info.pkl', 'rb') as handle:\n scene_info = pickle.load(handle)",
"_____no_output_____"
],
[
"nusc = NuScenes(version='v1.0-trainval', \\\n dataroot='../../../../data/', \\\n verbose=False)",
"_____no_output_____"
],
[
"so_map = NuScenesMap(dataroot='../../../../data/', \\\n map_name='singapore-onenorth')\nbs_map = NuScenesMap(dataroot='../../../../data/', \\\n map_name='boston-seaport')\nsh_map = NuScenesMap(dataroot='../../../../data/', \\\n map_name='singapore-hollandvillage')\nsq_map = NuScenesMap(dataroot='../../../../data/', \\\n map_name='singapore-queenstown')\n\n# dict mapping map name to map file\nmap_files = {'singapore-onenorth': so_map,\n 'boston-seaport': bs_map,\n 'singapore-hollandvillage': sh_map,\n 'singapore-queenstown': sq_map}",
"_____no_output_____"
],
[
"# defining the custom rmse loss function\ndef rmse_loss(gt_path, pred_path):\n '''\n calculates custom rmse loss between every time point\n '''\n gt_path = tf.reshape(gt_path, [-1, 10, 2])\n pred_path = tf.reshape(pred_path, [-1, 10, 2])\n \n return K.sqrt(K.mean(K.square(gt_path-pred_path)))",
"_____no_output_____"
],
[
"# loading the model\nfc_model = tf.keras.models.load_model(\"../checkpoints/lstm_best.hdf5\", compile=False)\n\nfc_model.compile(optimizer=tf.keras.optimizers.RMSprop(clipvalue=1.0), \n loss=rmse_loss, \n metrics=[\"accuracy\"])",
"_____no_output_____"
],
[
"# undo normalization for plotting\ndef move_from_origin(l, origin):\n x0, y0 = origin\n return [[x + x0, y + y0] for x, y in l]\n\ndef rotate_from_y(l, angle):\n theta = -angle\n return [(x*np.cos(theta) - y*np.sin(theta), \n x*np.sin(theta) + y*np.cos(theta)) for x, y in l]\n\n# loss calculation for test prediction\ndef rmse_error(l1, l2):\n loss = []\n \n if len(np.array(l1).shape) < 2:\n return ((l1[0] - l2[0])**2 + (l1[1] - l2[1])**2)**0.5\n for p1, p2 in zip(l1, l2):\n loss.append(((p1[0] - p2[0])**2 + (p1[1] - p2[1])**2)**0.5)\n \n loss = np.array(loss)\n return np.mean(loss) ",
"_____no_output_____"
],
[
"rmse_values = []\nfde_valus = []\n\nfor test_idx in range(9800, 11056):\n test_data = total_ped_matrix[test_idx:test_idx+1,:6,:]\n predictions = fc_model.predict(test_data).reshape(-1, 2)\n predictions = move_from_origin(rotate_from_y(predictions, ped_dataset[test_idx][\"angle\"]),\n ped_dataset[test_idx][\"origin\"])\n\n# n_scene = ped_dataset[test_idx][\"scene_no\"]\n# ego_poses = map_files[scene_info[str(n_scene)][\"map_name\"]].render_pedposes_on_fancy_map(\n# nusc, scene_tokens=[nusc.scene[n_scene]['token']], \n# ped_path = np.array(ped_dataset[test_idx][\"translation\"])[:,:2], \n# verbose = False,\n# render_egoposes=True, render_egoposes_range=False, \n# render_legend=False)\n\n# plt.scatter(*zip(*np.array(ped_dataset[test_idx][\"translation\"])[:6,:2]), c='k', s=5, zorder=2)\n# plt.scatter(*zip(*np.array(ped_dataset[test_idx][\"translation\"])[6:,:2]), c='b', s=5, zorder=3)\n# plt.scatter(*zip(*predictions), c='r', s=5, zorder=4)\n# plt.show()\n \n loss = rmse_error(predictions, \n np.array(ped_dataset[test_idx][\"translation\"])[6:,:2])\n \n final_loss = rmse_error(predictions[-1], \n np.array(ped_dataset[test_idx][\"translation\"])[-1,:2])\n \n rmse_values.append(loss)\n fde_valus.append(final_loss)\n \nprint(f\"RMSE Loss in m is {np.mean(np.array(rmse_values))}\")\nprint(f\"Loss of final position in m is {np.mean(np.array(fde_valus))}\")",
"RMSE Loss in m is 0.22657292674779012\nLoss of final position in m is 0.45030077775434874\n"
],
[
"feature_errors = []\n\nfor j in range(total_ped_matrix.shape[2]):\n trial_matrix = np.copy(total_ped_matrix)\n trial_matrix[9800:11056,:,j] = trial_matrix[11054:12310,:,j]\n rmse_values = []\n for test_idx in range(9800,11056):\n test_data = trial_matrix[test_idx:test_idx+1,:6,:]\n predictions = fc_model.predict(test_data).reshape(-1, 2)\n predictions = move_from_origin(rotate_from_y(predictions, ped_dataset[test_idx][\"angle\"]),\n ped_dataset[test_idx][\"origin\"])\n loss = rmse_error(predictions, \n np.array(ped_dataset[test_idx][\"translation\"])[6:,:2])\n\n rmse_values.append(loss)\n \n feature_errors.append(np.mean(np.array(rmse_values)))\n \nfeature_importance = [l-0.2265729 for l in feature_errors] ",
"_____no_output_____"
],
[
"plt.bar(['x','y','vel_x','vel_y','acc_x','acc_y','d_curb'],\n feature_importance)\nplt.title(\"Effect on performance with respect to features used\")\nplt.xlabel(\"Features used\")\nplt.ylabel(\"Performance Difference (RMSE)\")\nplt.savefig(\"../images/feature_analysis.png\", bbox_inches='tight', pad_inches=1)\nplt.show()",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0f95e4e1fcc64fc7225e583dccacad415b7b426 | 62,199 | ipynb | Jupyter Notebook | time_series/2-Acquire.ipynb | tvquynh/TimeSeriesAnalysiswithPython | 1230a50d8fe619c5e150f4ed4bbcda0612ef8ef6 | [
"MIT"
] | 350 | 2016-08-17T03:15:50.000Z | 2022-03-08T15:37:17.000Z | time_series/2-Acquire.ipynb | tvquynh/TimeSeriesAnalysiswithPython | 1230a50d8fe619c5e150f4ed4bbcda0612ef8ef6 | [
"MIT"
] | null | null | null | time_series/2-Acquire.ipynb | tvquynh/TimeSeriesAnalysiswithPython | 1230a50d8fe619c5e150f4ed4bbcda0612ef8ef6 | [
"MIT"
] | 236 | 2016-04-18T04:11:50.000Z | 2022-03-29T14:16:25.000Z | 32.719095 | 668 | 0.358607 | [
[
[
"# 2. Acquire the Data\n\n\n## Finding Data Sources\n\nThere are three place to get onion price and quantity information by market. \n\n1. **[Agmarket](http://agmarknet.nic.in/)** - This is the website run by the Directorate of Marketing & Inspection (DMI), Ministry of Agriculture, Government of India and provides daily price and arrival data for all agricultural commodities at national and state level. Unfortunately, the link to get Market-wise Daily Report for Specific Commodity (Onion for us) leads to a multipage aspx entry form to get data for each date. So it is like to require an involved scraper to get the data. Too much effort - Move on. Here is the best link to go to get what is available - http://agmarknet.nic.in/agnew/NationalBEnglish/SpecificCommodityWeeklyReport.aspx?ss=1\n\n\n2. **[Data.gov.in](https://data.gov.in/)** - This is normally a good place to get government data in a machine readable form like csv or xml. The Variety-wise Daily Market Prices Data of Onion is available for each year as an XML but unfortunately it does not include quantity information that is needed. It would be good to have both price and quantity - so even though this is easy, lets see if we can get both from a different source. Here is the best link to go to get what is available - https://data.gov.in/catalog/variety-wise-daily-market-prices-data-onion#web_catalog_tabs_block_10\n\n\n3. **[NHRDF](http://nhrdf.org/en-us/)** - This is the website of National Horticultural Research & Development Foundation and maintains a database on Market Arrivals and Price, Area and Production and Export Data for three commodities - Garlic, Onion and Potatoes. We are in luck! It also has data from 1996 onwards and has only got one form to fill to get the data in a tabular form. Further it also has production and export data. Excellent. Lets use this. Here is the best link to got to get all that is available - http://nhrdf.org/en-us/DatabaseReports\n\n\n## Scraping the Data\n\n\n### Ways to Scrape Data\nNow we can do this in two different levels of sophistication\n\n1. **Automate the form filling process**: The form on this page looks simple. But viewing source in the browser shows there form to fill with hidden fields and we will need to access it as a browser to get the session fields and then submit the form. This is a little bit more complicated than simple scraping a table on a webpage\n\n2. **Manually fill the form**: What if we manually fill the form with the desired form fields and then save the page as a html file. Then we can read this file and just scrape the table from it. Lets go with the simple way for now.\n\n\n### Scraping - Manual Form Filling\n\nSo let us fill the form to get a small subset of data and test our scraping process. We will start by getting the [Monthwise Market Arrivals](http://nhrdf.org/en-us/MonthWiseMarketArrivals). \n\n- Crop Name: Onion\n- Month: January\n- Market: All\n- Year: 2016\n\nThe saved webpage is available at [MonthWiseMarketArrivalsJan2016.html](MonthWiseMarketArrivalsJan2016.html)\n\n### Understand the HTML Structure\n\nWe need to scrape data from this html page... So let us try to understand the structure of the page.\n\n1. You can view the source of the page - typically Right Click and View Source on any browser and that would give your the source HTML for any page.\n\n2. You can open the developer tools in your browser and investigate the structure as you mouse over the page \n\n3. We can use a tools like [Selector Gadget](http://selectorgadget.com/) to understand the id's and classes' used in the web page\n\nOur data is under the **<table>** tag ",
"_____no_output_____"
],
[
"### Exercise #1",
"_____no_output_____"
],
[
"Find the number of tables in the HTML Structure of [MonthWiseMarketArrivalsJan2016.html](MonthWiseMarketArrivalsJan2016.html)?",
"_____no_output_____"
],
[
"### Find all the Tables ",
"_____no_output_____"
]
],
[
[
"# Import the library we need, which is Pandas\nimport pandas as pd",
"_____no_output_____"
],
[
"# Read all the tables from the html document \nAllTables = pd.read_html('MonthWiseMarketArrivalsJan2016.html')",
"_____no_output_____"
],
[
"# Let us find out how many tables has it found?\nlen(AllTables)",
"_____no_output_____"
],
[
"type(AllTables)",
"_____no_output_____"
]
],
[
[
"### Exercise #2\nFind the exact table of data we want in the list of AllTables?",
"_____no_output_____"
]
],
[
[
"AllTables[4]",
"_____no_output_____"
]
],
[
[
"### Get the exact table\nTo read the exact table we need to pass in an identifier value which would identify the table. We can use the `attrs` parameter in read_html to do so. The parameter we will pass is the `id` variable",
"_____no_output_____"
]
],
[
[
"# So can we read our exact table\nOneTable = pd.read_html('MonthWiseMarketArrivalsJan2016.html', \n attrs = {'id' : 'dnn_ctr974_MonthWiseMarketArrivals_GridView1'})",
"_____no_output_____"
],
[
"# So how many tables have we got now\nlen(OneTable)",
"_____no_output_____"
],
[
"# Show the table of data identifed by pandas with just the first five rows\nOneTable[0].head()",
"_____no_output_____"
]
],
[
[
"However, we have not got the header correctly in our dataframe. Let us see if we can fix this.\n\nTo get help on any function just use `??` before the function to help. Run this function and see what additional parameter you need to define to get the header correctly",
"_____no_output_____"
]
],
[
[
"??pd.read_html",
"_____no_output_____"
]
],
[
[
"### Exercise #3\nRead the html file again and ensure that the correct header is identifed by pandas?",
"_____no_output_____"
]
],
[
[
"OneTable = pd.read_html('MonthWiseMarketArrivalsJan2016.html', header = 0,\n attrs = {'id' : 'dnn_ctr974_MonthWiseMarketArrivals_GridView1'})",
"_____no_output_____"
]
],
[
[
"Show the top five rows of the dataframe you have read to ensure the headers are now correct.",
"_____no_output_____"
]
],
[
[
"OneTable[0].head()",
"_____no_output_____"
]
],
[
[
"### Dataframe Viewing ",
"_____no_output_____"
]
],
[
[
"# Let us store the dataframe in a df variable. You will see that as a very common convention in data science pandas use\ndf = OneTable[0]",
"_____no_output_____"
],
[
"# Shape of the dateset - number of rows & number of columns in the dataframe\ndf.shape",
"_____no_output_____"
],
[
"# Get the names of all the columns \ndf.columns",
"_____no_output_____"
],
[
"# Can we see sample rows - the top 5 rows\ndf.head()",
"_____no_output_____"
],
[
"# Can we see sample rows - the bottom 5 rows\ndf.tail()",
"_____no_output_____"
],
[
"# Can we access a specific columns\ndf[\"Market\"]",
"_____no_output_____"
],
[
"# Using the dot notation\ndf.Market",
"_____no_output_____"
],
[
"# Selecting specific column and rows\ndf[0:5][\"Market\"]",
"_____no_output_____"
],
[
"# Works both ways\ndf[\"Market\"][0:5]",
"_____no_output_____"
],
[
"#Getting unique values of State\npd.unique(df['Market'])",
"_____no_output_____"
]
],
[
[
"## Downloading the Entire Month Wise Arrival Data",
"_____no_output_____"
]
],
[
[
"AllTable = pd.read_html('MonthWiseMarketArrivals.html', header = 0,\n attrs = {'id' : 'dnn_ctr974_MonthWiseMarketArrivals_GridView1'})",
"_____no_output_____"
],
[
"AllTable[0].head()",
"_____no_output_____"
],
[
"??pd.DataFrame.to_csv",
"_____no_output_____"
],
[
"AllTable[0].columns",
"_____no_output_____"
],
[
"# Change the column names to simpler ones\nAllTable[0].columns = ['market', 'month', 'year', 'quantity', 'priceMin', 'priceMax', 'priceMod']",
"_____no_output_____"
],
[
"AllTable[0].head()",
"_____no_output_____"
],
[
"# Save the dataframe to a csv file\nAllTable[0].to_csv('MonthWiseMarketArrivals.csv', index = False)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0f9668d792ca7c6b59327ba0d89938f6ac86975 | 25,401 | ipynb | Jupyter Notebook | nbs/tutorial.ipynb | vguerra/nbdev | 1e1345148014b7084353acbe26af915db4523f81 | [
"Apache-2.0"
] | null | null | null | nbs/tutorial.ipynb | vguerra/nbdev | 1e1345148014b7084353acbe26af915db4523f81 | [
"Apache-2.0"
] | null | null | null | nbs/tutorial.ipynb | vguerra/nbdev | 1e1345148014b7084353acbe26af915db4523f81 | [
"Apache-2.0"
] | null | null | null | 32.733247 | 590 | 0.614976 | [
[
[
"# default_exp tutorial",
"_____no_output_____"
]
],
[
[
"# nbdev tutorial\n\n> A step by step guide\n\n- image: images/nbdev_source.gif",
"_____no_output_____"
],
[
"nbdev is a system for *exploratory programming*. See the [nbdev launch post](https://www.fast.ai/2019/12/02/nbdev/) for information about what that means. In practice, programming in this way can feel very different to the kind of programming many of you will be familiar with, since we've mainly be taught coding techniques that are (at least implicitly) tied to the underlying tools we have access to. I've found that programming in a \"notebook first\" way can make me 2-3x more productive than I was before (when we used vscode, Visual Studio, vim, PyCharm, and similar tools).\n\nIn this tutorial, I'll try to get you up and running with the basics of the nbdev system as quickly and easily as possible. You can also watch this video in which I take you through the tutorial, step by step (to view full screen, click the little square in the bottom right of the video; to view in a separate Youtube window, click the Youtube logo):",
"_____no_output_____"
],
[
"<iframe width=\"560\" height=\"315\" src=\"https://www.youtube-nocookie.com/embed/Hrs7iEYmRmg\" frameborder=\"0\" allow=\"accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture\" allowfullscreen></iframe>",
"_____no_output_____"
],
[
"## Set up Your Jupyter Server",
"_____no_output_____"
],
[
"### Jupyter Environment",
"_____no_output_____"
],
[
"To complete this tutorial, you'll need a Jupyter Notebook Server configured on your machine. If you have not installed Jupyter before, you may find the [Anaconda Individual Edition](https://www.anaconda.com/products/individual) the simplest to install.\n\nIf you already have experience with Jupyter, please note that everything in this tutorial must be run using the same kernel.",
"_____no_output_____"
],
[
"### Install `nbdev`",
"_____no_output_____"
],
[
"No matter how you installed Jupyter, you'll need to manually install `nbdev`. There is not a `conda` package for `nbdev`, so you'll need to use `pip` to install it. And you'll need to do that from a terminal window.\n\nJupyter notebook has a terminal window available, so we'll use that:\n1. Start `jupyter notebook`\n2. From the \"New\" dropdown on the right side, choose `Terminal`.\n3. Enter \"`python -m pip install nbdev`\"\n\nWhen the command completes, you're ready to go.",
"_____no_output_____"
],
[
"## Set up Repo",
"_____no_output_____"
],
[
"### Template",
"_____no_output_____"
],
[
"To create your new project repo, click here: [nbdev template](https://github.com/fastai/nbdev_template/generate) (you need to be logged in to GitHub for this link to work). Fill in the requested info and click *Create repository from template*.\n\n**NB:** The name of your project will become the name of the Python package generated by nbdev. For that reason, it is a good idea to pick a short, all-lowercase name with _no dashes_ between words (underscores are allowed).\n\nNow, open your terminal, and clone the repo you just created.",
"_____no_output_____"
],
[
"### Github pages",
"_____no_output_____"
],
[
"The nbdev system uses [jekyll](https://jekyllrb.com/) for documentation. Because [GitHub Pages supports Jekyll](https://help.github.com/en/github/working-with-github-pages/setting-up-a-github-pages-site-with-jekyll), you can host your site for free on [Github Pages](https://pages.github.com/) without any additional setup, so this is the approach we recommend (but it's not required; any jekyll hosting will work fine).\n\nTo enable Github Pages in your project repo, click *Settings* in Github, then scroll down to *Github Pages*, and set \"Source\" to *Master branch /docs folder*. Once you've saved, if you scroll back down to that section, Github will have a link to your new website. Copy that URL, and then go back to your main repo page, click \"edit\" next to the description and paste the URL into the \"website\" section. While you're there, go ahead and put in your project description too.",
"_____no_output_____"
],
[
"## Edit settings.ini",
"_____no_output_____"
],
[
"Next, edit the `settings.ini` file in your cloned repo. This file contains all the necessary information for when you'll be ready to package your library. The basic structure (that can be personalized provided you change the relevant information in `settings.ini`) is that the root of the repo will contain your notebooks, the `docs` folder will contain your auto-generated docs, and a folder with a name you select will contain your auto-generated modules.",
"_____no_output_____"
],
[
"You'll see these commented out lines in `settings.ini`. Uncomment them, and set each value as needed.\n\n```\n# lib_name = your_project_name\n# user = your_github_username\n# description = A description of your project\n# keywords = some keywords\n# author = Your Name\n# author_email = [email protected]\n# copyright = Your Name or Company Name\n```\n\nWe'll see some other settings we can change later.",
"_____no_output_____"
],
[
"## Install git hooks",
"_____no_output_____"
],
[
"Jupyter Notebooks can cause challenges with git conflicts, but life becomes much easier when you use `nbdev`. As a first step, run `nbdev_install_git_hooks` in the terminal from your project folder. This will set up git hooks which will remove metadata from your notebooks when you commit, greatly reducing the chance you have a conflict.\n\nBut if you do get a conflict later, simply run `nbdev_fix_merge filename.ipynb`. This will replace any conflicts in cell outputs with your version, and if there are conflicts in input cells, then both cells will be included in the merged file, along with standard conflict markers (e.g. `=====`). Then you can open the notebook in Jupyter and choose which version to keep.",
"_____no_output_____"
],
[
"## Edit 00_core.ipynb",
"_____no_output_____"
],
[
"Now, run `jupyter notebook`, and click `00_core.ipynb` (you don't *have* to start your notebook names with a number like we do here; but we find it helpful to show the order you've created your project in). You'll see something that looks a bit like this:\n\n```python\n# default_exp core\n```\n\n**module name here**\n\n> API details.\n\n```python\n#hide\nfrom nbdev.showdoc import *\n```\n\nLet's explain what these special cells mean.",
"_____no_output_____"
],
[
"### Add cell comments",
"_____no_output_____"
],
[
"There are certain special comments that, when placed as the first line of the cell, provide important information to nbdev.\n\nThe cell `#default_exp core`, defines the name of the generated module (lib_name/core.py). For any cells that you want to be included in your python module, type `#export` as the first line of the cell. Each of those cells will be added to your module.",
"_____no_output_____"
],
[
"### Add a function",
"_____no_output_____"
],
[
"Let's add a function to this notebook, e.g.:\n\n```python\n#export\ndef say_hello(to):\n \"Say hello to somebody\"\n return f'Hello {to}!'\n```\n\nNotice how it includes `#export` at the top - this means it will be included in our module, and documentation. The documentation will look like this:",
"_____no_output_____"
]
],
[
[
"#export\ndef say_hello(to):\n \"Say hello to somebody\"\n return f'Hello {to}!'",
"_____no_output_____"
]
],
[
[
"### Add examples and tests",
"_____no_output_____"
],
[
"It's a good idea to give an example of your function in action. Just include regular code cells, and they'll appear (with output) in the docs, e.g.:",
"_____no_output_____"
]
],
[
[
"say_hello(\"Sylvain\")",
"_____no_output_____"
]
],
[
[
"Examples can output plots, images, etc, and they'll all appear in your docs, e.g.:",
"_____no_output_____"
]
],
[
[
"from IPython.display import display,SVG\ndisplay(SVG('<svg height=\"100\"><circle cx=\"50\" cy=\"50\" r=\"40\"/></svg>'))",
"_____no_output_____"
]
],
[
[
"You can also include tests:",
"_____no_output_____"
]
],
[
[
"assert say_hello(\"Jeremy\")==\"Hello Jeremy!\"",
"_____no_output_____"
]
],
[
[
"You should also add markdown headings as you create your notebook; one benefit of this is that a table of contents will be created in the documentation automatically.",
"_____no_output_____"
],
[
"## Build lib",
"_____no_output_____"
],
[
"Now you can create your python module. To do so, just run `nbdev_build_lib` from the terminal when anywhere in your project folder.\n\n```\n$ nbdev_build_lib\nConverted 00_core.ipynb.\nConverted index.ipynb.\n```",
"_____no_output_____"
],
[
"## Edit index.ipynb",
"_____no_output_____"
],
[
"Now you're ready to create your documentation home page and readme file; these are both generated automatically from *index.ipynb*. So click on that to open it now.\n\nYou'll see that there's already a line there to import your library - change it to use the name you selected in `settings.ini`. Then, add information about how to use your module, including some examples. Remember, these examples should be actual notebook code cells with real outputs.",
"_____no_output_____"
],
[
"## Build docs",
"_____no_output_____"
],
[
"Now you can create your documentation. To do so, just run `nbdev_build_docs` from the terminal when anywhere in your project folder.\n\n```\n$ nbdev_build_docs\nconverting: /home/jhoward/git/nbdev/nbs/00_core.ipynb\nconverting: /home/jhoward/git/nbdev/nbs/index.ipynb\n```",
"_____no_output_____"
],
[
"## Commit to Github",
"_____no_output_____"
],
[
"You can now `git commit` and `git push`. Wait a minute or two for Github to process your commit, and then head over to the Github website to look at your results.",
"_____no_output_____"
],
[
"### CI",
"_____no_output_____"
],
[
"Back in your project's Github main page, click where it says *1 commit* (or *2 commits* or whatever). Hopefully, you'll see a green checkmark next to your latest commit. That means that your documentation site built correctly, and your module's tests all passed! This is checked for you using *continuous integration (CI)* with [GitHub actions](https://github.com/features/actions). This does the following:\n\n- Checks the notebooks are readable\n- Checks the notebooks have been cleaned of needless metadata to avoid merge conflicts\n- Checks there is no diff between the notebooks and the exported library\n- Runs the tests in your notebooks\n\nEdit the file `.github/workflows/main.yml` if you need to modify any of the CI steps.\n\nIf you have a red cross, that means something failed. Click on the cross, then click *Details*, and you'll be able to see what failed.",
"_____no_output_____"
],
[
"### View docs and readme",
"_____no_output_____"
],
[
"Once everything is passing, have a look at your readme in Github. You'll see that your `index.ipynb` file has been converted to a readme automatically.\n\nNext, go to your documentation site (e.g. by clicking on the link next to the description that you created earlier). You should see that your index notebook has also been used here.\n\nCongratulations, the basics are now all in place! Let's continue and use some more advanced functionality.",
"_____no_output_____"
],
[
"## Add a class",
"_____no_output_____"
],
[
"Create a class in `00_core.ipynb` as follows:\n\n```python\nclass HelloSayer:\n \"Say hello to `to` using `say_hello`\"\n def __init__(self, to): self.to = to\n def say(self): say_hello(self.to)\n```\n\nThis will automatically appear in the docs like this:",
"_____no_output_____"
]
],
[
[
"#export\nclass HelloSayer:\n \"Say hello to `to` using `say_hello`\"\n def __init__(self, to): self.to = to\n \n def say(self):\n \"Do the saying\"\n say_hello(self.to)",
"_____no_output_____"
]
],
[
[
"### Document with show_doc",
"_____no_output_____"
],
[
"However, methods aren't automatically documented. To add method docs, use `show_doc`:\n\n```python\nfrom nbdev.showdoc import *\nshow_doc(HelloSayer.say)\n```",
"_____no_output_____"
]
],
[
[
"from nbdev.showdoc import *\nshow_doc(HelloSayer.say)",
"_____no_output_____"
]
],
[
[
"And add some examples and/or tests:",
"_____no_output_____"
]
],
[
[
"o = HelloSayer(\"Alexis\")\no.say()",
"_____no_output_____"
]
],
[
[
"## Add links with backticks",
"_____no_output_____"
],
[
"Notice above there is a link from our new class documentation to our function. That's because we used backticks in the docstring:\n\n \"Say hello to `to` using `say_hello`\"\n\nThese are automatically converted to hyperlinks wherever possible. For instance, here are hyperlinks to `HelloSayer` and `say_hello` created using backticks.",
"_____no_output_____"
],
[
"## Set up autoreload",
"_____no_output_____"
],
[
"Since you'll be often updating your modules from one notebook, and using them in another, it's helpful if your notebook automatically reads in the new modules as soon as the python file changes. To make this happen, just add these lines to the top of your notebook:\n\n```\n%load_ext autoreload\n%autoreload 2\n```",
"_____no_output_____"
],
[
"## Add in-notebook export cell",
"_____no_output_____"
],
[
"It's helpful to be able to export all your modules directly from a notebook, rather than going to the terminal to do it. All nbdev commands are available directly from a notebook in Python. Add these lines to any cell and run it to exports your modules (I normally make this the last cell of my scripts).\n\n```python\nfrom nbdev.export import notebook2script\nnotebook2script()\n```",
"_____no_output_____"
],
[
"## Run tests in parallel",
"_____no_output_____"
],
[
"Before you push to github or make a release, you might want to run all your tests. nbdev can run all your notebooks in parallel to check for errors. Just run `nbdev_test_nbs` in a terminal.\n\n```\n(base) jhoward@usf3:~/git/nbdev$ nbdev_test_nbs\ntesting: /home/jhoward/git/nbdev/nbs/00_core.ipynb\ntesting: /home/jhoward/git/nbdev/nbs/index.ipynb\nAll tests are passing!\n```",
"_____no_output_____"
],
[
"## View docs locally",
"_____no_output_____"
],
[
"If you want to look at your docs locally before you push to Github, you can do so by running a jekyll server. First, install Jekyll by [following these steps](https://jekyllrb.com/docs/installation/ubuntu/). Then, install the modules needed for serving nbdev docs by `cd`ing to the `docs` directory, and typing `bundle install`. Finally, cd back to your repo root and type `make docs_serve`. This will launch a server on port 4000 (by default) which you can connect to with your browser to view your docs.\n\nIf Github pages fails to build your docs, running locally with Jekyll is the easiest way to find out what the problem is.",
"_____no_output_____"
],
[
"## Set up prerequisites",
"_____no_output_____"
],
[
"If your module requires other modules as dependencies, you can add those prerequisites to your `settings.ini` in the `requirements` section. This should be in the same format as [install_requires in setuptools](https://packaging.python.org/discussions/install-requires-vs-requirements/#install-requires), with each requirement separated by a space.",
"_____no_output_____"
],
[
"## Set up console scripts",
"_____no_output_____"
],
[
"Behind the scenes, nbdev uses that standard package `setuptools` for handling installation of modules. One very useful feature of `setuptools` is that it can automatically create [cross-platform console scripts](https://python-packaging.readthedocs.io/en/latest/command-line-scripts.html#the-console-scripts-entry-point). nbdev surfaces this functionality; to use it, use the same format as `setuptools`, with whitespace between each script definition (if you have more than one).\n\n```\nconsole_scripts = nbdev_build_lib=nbdev.cli:nbdev_build_lib\n```",
"_____no_output_____"
],
[
"## Test with editable install",
"_____no_output_____"
],
[
"To test and use your modules in other projects, and use your console scripts (if you have any), the easiest approach is to use an [editable install](http://codumentary.blogspot.com/2014/11/python-tip-of-year-pip-install-editable.html). To do this, `cd` to the root of your repo in the terminal, and type:\n\n pip install -e .\n\n(Note that the trailing period is important.) Your module changes will be automatically picked up without reinstalling. If you add any additional console scripts, you will need to run this command again.",
"_____no_output_____"
],
[
"## Upload to pypi",
"_____no_output_____"
],
[
"If you want people to be able to install your project by just typing `pip install your-project` then you need to upload it to [pypi](https://pypi.org/). The good news is, we've already created a fully pypi compliant installer for your project! So all you need to do is register at pypi (click \"Register\" on pypi) if you haven't previously done so, and then create a file called `~/.pypirc` with your login details. It should have these contents:\n\n```\n[pypi]\nusername = your_pypi_username\npassword = your_pypi_password\n```\n\nTo upload your project to pypi, just type `make release` in your project root directory. Once it's complete, a link to your project on pypi will be printed.\n\n**NB**: `make release` will automatically increment the version number in `settings.py` before pushing a new release to pypi. If you don't want to do this, run `make pypi` instead.",
"_____no_output_____"
],
[
"## Install collapsible headings and toc2",
"_____no_output_____"
],
[
"There are two jupyter notebook extensions that I highly recommend when working with projects like this. They are:\n\n- [Collapsible headings](https://jupyter-contrib-nbextensions.readthedocs.io/en/latest/nbextensions/collapsible_headings/readme.html): This lets you fold and unfold each section in your notebook, based on its markdown headings. You can also hit <kbd>left</kbd> to go to the start of a section, and <kbd>right</kbd> to go to the end\n- [TOC2](https://jupyter-contrib-nbextensions.readthedocs.io/en/latest/nbextensions/toc2/README.html): This adds a table of contents to your notebooks, which you can navigate either with the `Navigate` menu item it adds to your notebooks, or the TOC sidebar it adds. These can be modified and/or hidden using its settings.",
"_____no_output_____"
],
[
"## Look at nbdev \"source\" for more ideas",
"_____no_output_____"
],
[
"Don't forget that nbdev itself is written in nbdev! It's a good place to look to see how fast.ai uses it in practice, and get a few tips. You'll find the nbdev notebooks here in the [nbs folder](https://github.com/fastai/nbdev/tree/master/nbdev) on Github.",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
d0f98cf7660affd8652407d8f2d85d3d32e7a30e | 63,361 | ipynb | Jupyter Notebook | Notebooks/2_Model_Training.ipynb | santosh-gokul/SentimentAnalysis | 44361ec3ceba51b541c24a7257448b389bdd7e2d | [
"MIT"
] | null | null | null | Notebooks/2_Model_Training.ipynb | santosh-gokul/SentimentAnalysis | 44361ec3ceba51b541c24a7257448b389bdd7e2d | [
"MIT"
] | null | null | null | Notebooks/2_Model_Training.ipynb | santosh-gokul/SentimentAnalysis | 44361ec3ceba51b541c24a7257448b389bdd7e2d | [
"MIT"
] | null | null | null | 94.710015 | 19,318 | 0.752434 | [
[
[
"I've approached this problem as a regression problem and trained the model with the helps of LSTMs, details of the model architecture are furnished below.\n\nI've evaluated the model using 3 iterations of hold-out validation, the details of which are furnished below",
"_____no_output_____"
]
],
[
[
"from google.colab import drive\nimport pandas as pd\nimport numpy as np",
"_____no_output_____"
],
[
"drive.mount('/content/gdrive')\n",
"Go to this URL in a browser: https://accounts.google.com/o/oauth2/auth?client_id=947318989803-6bn6qk8qdgf4n4g3pfee6491hc0brc4i.apps.googleusercontent.com&redirect_uri=urn%3aietf%3awg%3aoauth%3a2.0%3aoob&response_type=code&scope=email%20https%3a%2f%2fwww.googleapis.com%2fauth%2fdocs.test%20https%3a%2f%2fwww.googleapis.com%2fauth%2fdrive%20https%3a%2f%2fwww.googleapis.com%2fauth%2fdrive.photos.readonly%20https%3a%2f%2fwww.googleapis.com%2fauth%2fpeopleapi.readonly\n\nEnter your authorization code:\n··········\nMounted at /content/gdrive\n"
],
[
"#Please mount it to appropriate directory where all the files are put\ncd gdrive/My\\ Drive/73Strings",
"/content/gdrive/My Drive/73Strings\n"
],
[
"#Constructing dataframe using dictionary.txt and sentiment_labels.txt\nphrase_and_ids = pd.read_table('dictionary.txt',delimiter='|',names=['Phrase', 'PhraseID'])\nids_and_labels = pd.read_table('sentiment_labels.txt',delimiter='|',names=['PhraseID', 'Labels'],header=0)\ndf_all = phrase_and_ids.merge(ids_and_labels, how='inner', on='PhraseID')",
"_____no_output_____"
],
[
"#Glimpse of the dataset\ndf_all",
"_____no_output_____"
],
[
"#Estimating the maximum length of phrases.\nlength_phrases = []\n\nfor index, row in df_all.iterrows():\n sentence = (row['Phrase'])\n sentence_words = sentence.split(' ')\n len_sentence_words = len(sentence_words)\n length_phrases.append(len_sentence_words)\nmax_length_of_a_phrase = max(length_phrases)",
"_____no_output_____"
],
[
"# Creating a dictionary that maps a word to its embedding(100 dimensional)\n#Used GloVe embeddings\nembeddings_index = dict()\nf = open('glove_6B_100d.txt')\nfor line in f:\n\tvalues = line.split()\n\tword = values[0]\n\tcoefs = np.asarray(values[1:], dtype='float32')\n\tembeddings_index[word.lower()] = coefs\nf.close()",
"_____no_output_____"
],
[
"#Transforming list of phrases, such that from each phrase special characters(mentioned below in filter param) are removed, \n# and words are encoded, and finally the phrase is padded to max_length_of_a_phrase\nfrom keras.preprocessing.sequence import pad_sequences\nfrom keras.preprocessing.text import Tokenizer\n\n\nt = Tokenizer(filters = '!\"#$%&()*+,-./:;<=>?@[\\\\]^_`{|}~\\t\\n\\'')\nt.fit_on_texts(df_all.iloc[:,0])\nencoded_docs = t.texts_to_sequences(df_all.iloc[:,0])\nmax_length = max_length_of_a_phrase\npadded_docs = pad_sequences(encoded_docs, maxlen=max_length, padding='post')\n",
"_____no_output_____"
],
[
"vocab_size = len(t.word_index) + 1",
"_____no_output_____"
],
[
"#Constructing the embedding_matrix which maps the encoded words to its respective word embeddings\nembedding_matrix = np.zeros((vocab_size, 100))\nfor word, i in t.word_index.items():\n\tembedding_vector = embeddings_index.get(word.lower())\n\tif embedding_vector is not None:\n\t\tembedding_matrix[i] = embedding_vector",
"_____no_output_____"
],
[
"#Performing 3 iterations of hold-out validation to assess the model\nfrom sklearn.model_selection import train_test_split\nX_train1, X_test1, y_train1, y_test1 = train_test_split(\n padded_docs, df_all.loc[:,'Labels'], test_size=0.20, random_state=42)\nX_train2, X_test2, y_train2, y_test2 = train_test_split(\n padded_docs, df_all.loc[:,'Labels'], test_size=0.20, random_state=43)\nX_train3, X_test3, y_train3, y_test3 = train_test_split(padded_docs, df_all.loc[:,'Labels'], test_size=0.20, random_state=44)",
"_____no_output_____"
],
[
"#I've experimented with various architectures, the model architecture which is given below is the best one among them.\nfrom keras.models import Sequential\nfrom keras.layers import Dense\nfrom keras.layers import Flatten\nfrom keras.layers import Embedding\nfrom keras.layers import Bidirectional\nfrom keras.layers import LSTM\nfrom keras.layers import Dropout\n\n\n\nmodel = Sequential()\ne = Embedding(vocab_size, 100, weights=[embedding_matrix], input_length=max_length_of_a_phrase, trainable=False)\nmodel.add(e)\n#model.add(Flatten())\nmodel.add(LSTM(512))\nmodel.add(Dropout(0.30))\nmodel.add(Dense(200,activation='relu'))\nmodel.add(Dropout(0.30))\nmodel.add(Dense(100, activation='relu'))\nmodel.add(Dense(1,activation='relu'))\n\nmodel.compile(optimizer='adam', loss='mse', metrics=['mse','mae'])\n# summarize the model\nprint(model.summary())",
"Model: \"sequential_2\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nembedding_2 (Embedding) (None, 56, 100) 1806000 \n_________________________________________________________________\nlstm_2 (LSTM) (None, 512) 1255424 \n_________________________________________________________________\ndropout_4 (Dropout) (None, 512) 0 \n_________________________________________________________________\ndense_6 (Dense) (None, 200) 102600 \n_________________________________________________________________\ndropout_5 (Dropout) (None, 200) 0 \n_________________________________________________________________\ndense_7 (Dense) (None, 100) 20100 \n_________________________________________________________________\ndense_8 (Dense) (None, 1) 101 \n=================================================================\nTotal params: 3,184,225\nTrainable params: 1,378,225\nNon-trainable params: 1,806,000\n_________________________________________________________________\nNone\n"
],
[
"history = model.fit(X_train3, y_train3, epochs=20,validation_data=(X_test3,y_test3),batch_size=128)",
"Epoch 1/20\n1496/1496 [==============================] - 35s 23ms/step - loss: 0.0285 - mse: 0.0285 - mae: 0.1194 - val_loss: 0.0174 - val_mse: 0.0174 - val_mae: 0.0972\nEpoch 2/20\n1496/1496 [==============================] - 35s 23ms/step - loss: 0.0164 - mse: 0.0164 - mae: 0.0948 - val_loss: 0.0155 - val_mse: 0.0155 - val_mae: 0.0922\nEpoch 3/20\n1496/1496 [==============================] - 35s 23ms/step - loss: 0.0143 - mse: 0.0143 - mae: 0.0886 - val_loss: 0.0136 - val_mse: 0.0136 - val_mae: 0.0869\nEpoch 4/20\n1496/1496 [==============================] - 35s 23ms/step - loss: 0.0128 - mse: 0.0128 - mae: 0.0838 - val_loss: 0.0138 - val_mse: 0.0138 - val_mae: 0.0871\nEpoch 5/20\n1496/1496 [==============================] - 35s 23ms/step - loss: 0.0116 - mse: 0.0116 - mae: 0.0797 - val_loss: 0.0119 - val_mse: 0.0119 - val_mae: 0.0796\nEpoch 6/20\n1496/1496 [==============================] - 35s 23ms/step - loss: 0.0106 - mse: 0.0106 - mae: 0.0762 - val_loss: 0.0127 - val_mse: 0.0127 - val_mae: 0.0838\nEpoch 7/20\n1496/1496 [==============================] - 35s 24ms/step - loss: 0.0098 - mse: 0.0098 - mae: 0.0735 - val_loss: 0.0112 - val_mse: 0.0112 - val_mae: 0.0772\nEpoch 8/20\n1496/1496 [==============================] - 35s 24ms/step - loss: 0.0092 - mse: 0.0092 - mae: 0.0712 - val_loss: 0.0103 - val_mse: 0.0103 - val_mae: 0.0752\nEpoch 9/20\n1496/1496 [==============================] - 35s 24ms/step - loss: 0.0086 - mse: 0.0086 - mae: 0.0691 - val_loss: 0.0101 - val_mse: 0.0101 - val_mae: 0.0747\nEpoch 10/20\n1496/1496 [==============================] - 35s 24ms/step - loss: 0.0081 - mse: 0.0081 - mae: 0.0669 - val_loss: 0.0104 - val_mse: 0.0104 - val_mae: 0.0771\nEpoch 11/20\n1496/1496 [==============================] - 35s 24ms/step - loss: 0.0077 - mse: 0.0077 - mae: 0.0652 - val_loss: 0.0095 - val_mse: 0.0095 - val_mae: 0.0730\nEpoch 12/20\n1496/1496 [==============================] - 36s 24ms/step - loss: 0.0073 - mse: 0.0073 - mae: 0.0635 - val_loss: 0.0094 - val_mse: 0.0094 - val_mae: 0.0711\nEpoch 13/20\n1496/1496 [==============================] - 35s 24ms/step - loss: 0.0070 - mse: 0.0070 - mae: 0.0621 - val_loss: 0.0095 - val_mse: 0.0095 - val_mae: 0.0714\nEpoch 14/20\n1496/1496 [==============================] - 35s 23ms/step - loss: 0.0066 - mse: 0.0066 - mae: 0.0606 - val_loss: 0.0092 - val_mse: 0.0092 - val_mae: 0.0706\nEpoch 15/20\n1496/1496 [==============================] - 35s 23ms/step - loss: 0.0063 - mse: 0.0063 - mae: 0.0591 - val_loss: 0.0095 - val_mse: 0.0095 - val_mae: 0.0707\nEpoch 16/20\n1496/1496 [==============================] - 35s 24ms/step - loss: 0.0060 - mse: 0.0060 - mae: 0.0578 - val_loss: 0.0093 - val_mse: 0.0093 - val_mae: 0.0712\nEpoch 17/20\n1496/1496 [==============================] - 35s 24ms/step - loss: 0.0057 - mse: 0.0057 - mae: 0.0564 - val_loss: 0.0091 - val_mse: 0.0091 - val_mae: 0.0701\nEpoch 18/20\n1496/1496 [==============================] - 35s 24ms/step - loss: 0.0055 - mse: 0.0055 - mae: 0.0553 - val_loss: 0.0092 - val_mse: 0.0092 - val_mae: 0.0707\nEpoch 19/20\n1496/1496 [==============================] - 35s 24ms/step - loss: 0.0053 - mse: 0.0053 - mae: 0.0539 - val_loss: 0.0092 - val_mse: 0.0092 - val_mae: 0.0700\nEpoch 20/20\n1496/1496 [==============================] - 35s 23ms/step - loss: 0.0050 - mse: 0.0050 - mae: 0.0525 - val_loss: 0.0093 - val_mse: 0.0093 - val_mae: 0.0703\n"
],
[
"#I've already trained the model for all 3 iterations of hold-out validation, and have stored the model and the corresponding history files.\n# So that it can be loaded later\nimport keras\nimport pickle as pkl\nmodel1 = keras.models.load_model('model_new_1.0')\nmodel2 = keras.models.load_model('model_new_2.0')\nmodel3 = keras.models.load_model('model_new_3.0')\n\nwith open('history_new_1.0.pkl','rb') as file1:\n hist_1 = pkl.load(file1)\nwith open('history_new_2.0.pkl','rb') as file1:\n hist_2 = pkl.load(file1)\nwith open('history_new_3.0.pkl','rb') as file1:\n hist_3 = pkl.load(file1)",
"_____no_output_____"
],
[
"#We see the average performance of the model across 3 runs of hold-out validation\nmean_mae = (hist_1['val_mae'][-1]+hist_2 ['val_mae'][-1]+hist_3['val_mae'][-1])/3\nmean_mse = (hist_1['val_mse'][-1]+hist_2['val_mse'][-1]+hist_3['val_mse'][-1])/3\nprint(\"The performance of the model architecture across three runs of hold out validation is : \\n Validation_MSE: %f \\t Validation_MAE: %f \" %(mean_mse,mean_mae))",
"The performance of the model architecture across three runs of hold out validation is : \n Validation_MSE: 0.009434 \t Validation_MAE: 0.071322 \n"
],
[
"#We see the average performance of the model across 3 runs of hold-out validation\nmean_mae = (hist_1['mae'][-1]+hist_2 ['mae'][-1]+hist_3['mae'][-1])/3\nmean_mse = (hist_1['mse'][-1]+hist_2['mse'][-1]+hist_3['mse'][-1])/3\nprint(\"The performance of the model architecture across three runs of hold out validation is : \\n Train_MSE: %f \\t Train_MAE: %f \" %(mean_mse,mean_mae))",
"The performance of the model architecture across three runs of hold out validation is : \n Train_MSE: 0.005045 \t Train_MAE: 0.052639 \n"
],
[
"#Plotting the history file(MSE) of model1, for visualization purpose\nimport matplotlib.pyplot as plt\nplt.plot(hist_1['mse'])\nplt.plot(hist_1['val_mse'])\nplt.title('model mse')\nplt.ylabel('mse')\nplt.xlabel('epoch')\nplt.legend(['train', 'test'], loc='upper right')\nplt.show()",
"_____no_output_____"
],
[
"#Plotting the history file(MAE) of model1, for visualization purpose\nimport matplotlib.pyplot as plt\nplt.plot(hist_1['mae'])\nplt.plot(hist_1['val_mae'])\nplt.title('model mae')\nplt.ylabel('mae')\nplt.xlabel('epoch')\nplt.legend(['train', 'test'], loc='upper right')\nplt.show()",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0f99e720628e35a2ad0bd6e38c1f49e919a8b65 | 20,300 | ipynb | Jupyter Notebook | finetuning_exp/mt-dnn/bert-base.ipynb | ljj7975/transformers | e5903bae63d97c031431e1e78d307ea97371a0f8 | [
"Apache-2.0"
] | null | null | null | finetuning_exp/mt-dnn/bert-base.ipynb | ljj7975/transformers | e5903bae63d97c031431e1e78d307ea97371a0f8 | [
"Apache-2.0"
] | null | null | null | finetuning_exp/mt-dnn/bert-base.ipynb | ljj7975/transformers | e5903bae63d97c031431e1e78d307ea97371a0f8 | [
"Apache-2.0"
] | null | null | null | 31.472868 | 372 | 0.457192 | [
[
[
"%%javascript\nIPython.OutputArea.prototype._should_scroll = function(lines) {\n return false;\n}\n",
"_____no_output_____"
],
[
"import numpy as np\nimport matplotlib.pyplot as plt\nimport matplotlib.image as mpimg\nfrom matplotlib import rcParams",
"_____no_output_____"
],
[
"%matplotlib inline",
"_____no_output_____"
],
[
"TEXT_COLOUR = {\n 'PURPLE':'\\033[95m',\n 'CYAN':'\\033[96m',\n 'DARKCYAN':'\\033[36m',\n 'BLUE':'\\033[94m',\n 'GREEN':'\\033[92m',\n 'YELLOW':'\\033[93m',\n 'RED':'\\033[91m',\n 'BOLD':'\\033[1m',\n 'UNDERLINE':'\\033[4m',\n 'END':'\\033[0m'\n}\n\ndef print_bold(*msgs):\n print(TEXT_COLOUR['BOLD'])\n print(*msgs)\n print(TEXT_COLOUR['END'])\n\ndef print_green(*msgs):\n print(TEXT_COLOUR['GREEN'])\n print(*msgs)\n print(TEXT_COLOUR['END'])\n\ndef print_error(*msgs):\n print(TEXT_COLOUR['RED'])\n print(*msgs)\n print(TEXT_COLOUR['END'])\n\ndef wrap_green(msg):\n return TEXT_COLOUR['GREEN'] + msg + TEXT_COLOUR['END']\n\ndef wrap_red(msg):\n return TEXT_COLOUR['RED'] + msg + TEXT_COLOUR['END']\n\ndef up_down_str(val):\n msg = str(val)\n if val > 0:\n msg = wrap_green(msg)\n elif val < 0:\n msg = wrap_red(msg)\n return msg",
"_____no_output_____"
],
[
"exp='bert-base'\nnum_layers = 12",
"_____no_output_____"
],
[
"tasks = [\"CoLA\",\"SST-2\",\"MRPC\",\"STS-B\",\"QQP\",\"MNLI\", \"MNLI-MM\", \"QNLI\", \"RTE\"]\n\nmetrics = {\n \"CoLA\":[\"mcc\"],\n \"MNLI\":[\"acc\"],\n \"MNLI-MM\":[\"acc\"],\n \"MRPC\":[\"f1\"],\n \"QNLI\":[\"acc\"],\n \"QQP\":[\"f1\"],\n \"RTE\":[\"acc\"],\n \"SST-2\":[\"acc\"],\n \"STS-B\":[\"spearmanr\"],\n \"WNLI\":[\"acc\"] #temp\n}\n\nreported_in_paper = {\n \"CoLA\":0.00,\n \"MNLI\":0.00,\n \"MNLI-MM\":0.0,\n \"MRPC\":0.00,\n \"QNLI\":0.00,\n \"QQP\":0.00,\n \"RTE\":0.00,\n \"SST-2\":0.00,\n \"STS-B\":0.00,\n \"WNLI\":0.00\n}",
"_____no_output_____"
],
[
"\ndef get_average_val(lines):\n reported = []\n for line in lines:\n val = float(line.split()[1])\n if val != 0:\n reported.append(val)\n out = 0\n if len(reported) != 0:\n reported.sort(reverse = True)\n candidates = [reported[0]]\n for j in range(1, len(reported)):\n if reported[j] > 0.9 * reported[0]:\n candidates.append(reported[j])\n out = np.mean(candidates)\n \n return out\n",
"_____no_output_____"
],
[
"results = {}\n\nfor task in tasks:\n task_results = {}\n task_metrics = metrics[task]\n for metric in task_metrics:\n \n # base metrics\n print(f\"../../mt_dnn_exp_results/{exp}/{task}/base-{metric}.txt\")\n f=open(f\"../../mt_dnn_exp_results/{exp}/{task}/base-{metric}.txt\", \"r\")\n lines = f.read().splitlines()\n task_results[f'base-{metric}'] = get_average_val(lines)\n \n # no layer metrics\n \n fine_tuning_metrics = []\n f=open(f\"../../mt_dnn_exp_results/{exp}/{task}/no_layer-{metric}.txt\", \"r\")\n\n lines = f.read().splitlines()\n fine_tuning_metrics.append(get_average_val(lines))\n \n # fine-tuned metrics\n \n log_file_prefix=''\n for i in reversed(range(int(num_layers/2), num_layers)):\n log_file_prefix += str(i)\n f=open(f\"../../mt_dnn_exp_results/{exp}/{task}/{log_file_prefix}-{metric}.txt\", \"r\")\n lines = f.read().splitlines()\n fine_tuning_metrics.append(get_average_val(lines))\n \n log_file_prefix +='_'\n \n task_results[f'{metric}'] = list(reversed(fine_tuning_metrics))\n \n results[task] = task_results",
"../../mt_dnn_exp_results/bert-base/CoLA/base-mcc.txt\n../../mt_dnn_exp_results/bert-base/SST-2/base-acc.txt\n../../mt_dnn_exp_results/bert-base/MRPC/base-f1.txt\n../../mt_dnn_exp_results/bert-base/STS-B/base-spearmanr.txt\n../../mt_dnn_exp_results/bert-base/QQP/base-f1.txt\n../../mt_dnn_exp_results/bert-base/MNLI/base-acc.txt\n../../mt_dnn_exp_results/bert-base/MNLI-MM/base-acc.txt\n../../mt_dnn_exp_results/bert-base/QNLI/base-acc.txt\n../../mt_dnn_exp_results/bert-base/RTE/base-acc.txt\n"
],
[
"x_axis = []\n\nfor i in range(int(num_layers/2), num_layers):\n x_axis.append(str(i))\n\nx_axis.append(\"none\")",
"_____no_output_____"
],
[
"def draw_graph(task, y_label, paper, base, reported):\n plt.figure(figsize=(10,6))\n plt.plot(x_axis, reported)\n \n plt.xlabel(\"layers\")\n plt.ylabel(y_label)\n \n if paper == 0.0: \n gap = max(reported) - min(reported)\n top = max(max(reported), base) + (gap*0.2)\n bottom = min(min(reported), base) - (gap*0.2)\n \n plt.ylim(bottom, top)\n\n plt.axhline(y=base, linestyle='--', c='green')\n else:\n gap = max(reported) - min(reported)\n top = max(max(reported), base, paper) + (gap*0.2)\n bottom = min(min(reported), base, paper) - (gap*0.2)\n \n plt.ylim(bottom, top)\n\n plt.axhline(y=base, linestyle='--', c='green')\n plt.axhline(y=paper, linestyle='--', c='red')\n \n plt.title(f'{exp}-{task} ({round(base,4)})')\n plt.savefig(f'images/{exp}/{task}', format='png', bbox_inches='tight')\n plt.show()",
"_____no_output_____"
],
[
"for task in tasks:\n task_results = results[task]\n task_metrics = metrics[task]\n for metric in task_metrics:\n reported = task_results[metric]\n base = task_results[f'base-{metric}']\n print_bold(task, metric, ': b -', round(base * 100, 2), 'h -',round(task_results[metric][0] * 100, 2), 'n -', round(task_results[metric][-1] * 100, 2))",
"\u001b[1m\nCoLA mcc : b - 57.38 h - 55.69 n - 53.64\n\u001b[0m\n\u001b[1m\nSST-2 acc : b - 92.78 h - 92.55 n - 91.86\n\u001b[0m\n\u001b[1m\nMRPC f1 : b - 92.28 h - 92.28 n - 85.4\n\u001b[0m\n\u001b[1m\nSTS-B spearmanr : b - 90.88 h - 90.64 n - 89.54\n\u001b[0m\n\u001b[1m\nQQP f1 : b - 88.38 h - 87.76 n - 87.18\n\u001b[0m\n\u001b[1m\nMNLI acc : b - 84.44 h - 84.02 n - 76.65\n\u001b[0m\n\u001b[1m\nMNLI-MM acc : b - 84.67 h - 84.46 n - 77.74\n\u001b[0m\n\u001b[1m\nQNLI acc : b - 91.11 h - 90.94 n - 85.89\n\u001b[0m\n\u001b[1m\nRTE acc : b - 78.41 h - 79.49 n - 71.05\n\u001b[0m\n"
],
[
"import copy \n\nlayer_90 = []\nlayer_95 = []\n\nthreshold_90 = 0.9\nthreshold_95 = 0.95\nx_axis.reverse()\n\nfor task in tasks:\n# print_bold(task)\n task_results = results[task]\n task_metrics = metrics[task]\n for metric in task_metrics:\n base = task_results[f'base-{metric}']\n reported = copy.deepcopy(task_results[metric])\n reported.reverse()\n \n flag_90 = True\n flag_95 = True\n\n for ind, val in enumerate(reported):\n\n if val/base > threshold_90 and flag_90:\n flag_90 = False\n layer_90.append(ind)\n results[task]['90%'] = ind\n\n if val/base > threshold_95 and flag_95:\n flag_95 = False\n layer_95.append(ind)\n results[task]['95%'] = ind\n\n if flag_90:\n print(task, \"Fails to achieve 90% threshold\", reported[-1]/base)\n layer_90.append(len(reported)-1)\n results[task]['90%'] = \"-\"\n\n if flag_95:\n print(task, \"Fails to achieve 95% threshold\", reported[-1]/base)\n layer_95.append(len(reported)-1)\n results[task]['95%'] = \"-\"\n\n\n \nprint(x_axis)\n \n \nprint(layer_90)\nmin_layer_ind_90 = max(layer_90)\nprint(\"layer_90 \", min_layer_ind_90, 'layer:', x_axis[min_layer_ind_90], round((1-(min_layer_ind_90/num_layers)) * 100, 2), '%')\n\nprint(layer_95)\nmin_layer_ind_95 = max(layer_95)\nprint(\"layer_95 \", min_layer_ind_95, 'layer:', x_axis[min_layer_ind_95], round((1-(min_layer_ind_95/num_layers)) * 100, 2), '%')\n\n\nfirsts = []\nseconds = []\n \nfor task in tasks:\n task_results = results[task]\n task_metrics = metrics[task]\n for metric in task_metrics:\n base = task_results[f'base-{metric}']\n reported = copy.deepcopy(task_results[metric])\n reported.reverse()\n \n if task != \"CoLA\":\n first = round(100*reported[0]/base, 2)\n second = round(100*reported[1]/base, 2)\n firsts.append(first)\n seconds.append(second)\n \n print_bold(task, base)\n print('\\t90', reported[min_layer_ind_90], round(reported[min_layer_ind_90]/base * 100, 2))\n print('\\t95', reported[min_layer_ind_95], round(reported[min_layer_ind_95]/base * 100, 2))\n \nprint_bold(len(firsts), np.mean(firsts), np.mean(seconds), round(np.mean(seconds) - np.mean(firsts),2))",
"['none', '11', '10', '9', '8', '7', '6']\n[0, 0, 0, 0, 0, 0, 0, 0, 0]\nlayer_90 0 layer: none 100.0 %\n[5, 0, 1, 0, 0, 1, 1, 1, 1]\nlayer_95 5 layer: 7 58.33 %\n\u001b[1m\nCoLA 0.573754832442525\n\u001b[0m\n\t90 0.5364114280465591 93.49\n\t95 0.562479932991527 98.03\n\u001b[1m\nSST-2 0.9277522935779816\n\u001b[0m\n\t90 0.9185779816513762 99.01\n\t95 0.9259174311926606 99.8\n\u001b[1m\nMRPC 0.9227562669317466\n\u001b[0m\n\t90 0.8539696446626991 92.55\n\t95 0.9184687817817112 99.54\n\u001b[1m\nSTS-B 0.9087928989577281\n\u001b[0m\n\t90 0.8954457153626455 98.53\n\t95 0.9054230987704198 99.63\n\u001b[1m\nQQP 0.8837812612880741\n\u001b[0m\n\t90 0.8717620837936814 98.64\n\t95 0.8769679326611739 99.23\n\u001b[1m\nMNLI 0.84444218033622\n\u001b[0m\n\t90 0.766479877738156 90.77\n\t95 0.8411003565970454 99.6\n\u001b[1m\nMNLI-MM 0.8466639544344995\n\u001b[0m\n\t90 0.777379983726607 91.82\n\t95 0.8429617575264443 99.56\n\u001b[1m\nQNLI 0.9111111111111111\n\u001b[0m\n\t90 0.8589419732747574 94.27\n\t95 0.9087314662273476 99.74\n\u001b[1m\nRTE 0.7841155234657039\n\u001b[0m\n\t90 0.7104693140794224 90.61\n\t95 0.7913357400722022 100.92\n\u001b[1m\n8 94.525 98.2475 3.72\n\u001b[0m\n"
],
[
"for task in [\"STS-B\"]:\n task_results = results[task]\n task_metrics = metrics[task]\n for metric in task_metrics:\n \n print(task_results[metric][-1])\n print(task_results[metric][-2])",
"0.8954457153626455\n0.8997305503630055\n"
],
[
"latex_metrics = {\n \"CoLA\":\"MCC\",\n \"MNLI\":\"Acc.\",\n \"MNLI-MM\":\"Acc.\",\n \"MRPC\":\"F$_1$\",\n \"QNLI\":\"Acc.\",\n \"QQP\":\"F$_1$\",\n \"RTE\":\"Acc.\",\n \"SST-2\":\"Acc.\",\n \"STS-B\":\"$\\\\rho$\"\n}",
"_____no_output_____"
],
[
"print(\"\\\\begin{center}\\n\\t\\\\scalebox{0.88}{\\n\\t\\t\\\\begin{tabular}{rc|ccccccc} \\n\\t\\t\\\\toprule[1pt] \\n\\t\\t\\\\multirow{2}{*}{Task (metric)} & \\\\multirow{2}{*}{Baseline} & \\\\multicolumn{7}{c}{Fine-tuned layers} \\\\\\\\ \\n\\t\\t\\\\cline{3-9} \\n\\t\\t& & 6-11 & 7-11 & 8-11 & 9-11 & 10-11 & 11-11 & None \\\\\\\\ \\n\\t\\t\\t\\\\midrule\")\n\navg_performance = []\n\nfor task in tasks:\n m = metrics[task][0]\n base_key = f\"base-{m}\"\n \n if task == \"MNLI-MM\":\n row = f\"\\t\\t\\tMNLI-mm ({latex_metrics[task]}) & \"\n else:\n row = f\"\\t\\t\\t{task} ({latex_metrics[task]}) & \"\n \n row += \"{:0.2f}\".format(round(results[task][base_key] * 100, 2))\n \n for ind, val in enumerate(results[task][m]):\n row += \" & {:0.2f}\".format(round(val * 100,2))\n \n if len(avg_performance) == ind:\n avg_performance.append([])\n \n \n percent = (val / results[task][base_key]) * 100\n avg_performance[ind].append(percent)\n \n# row += \"& {}\".format(results[task][\"90%\"])\n# row += \"& {}\".format(results[task][\"95%\"])\n \n row += \" \\\\\\\\\"\n print(row)\n \nprint(\"\\t\\t\\t\\\\midrule\\\\midrule\")\n\nrow = \"\\t\\t\\tRel. perf. (\\%) & 100.00\"\n\nfor perf in avg_performance:\n row += \" & {:0.2f}\".format(round(np.mean(perf) ,2))\n \nrow += \" \\\\\\\\\"\n\nprint(row)\n \nprint(\"\\t\\t\\\\end{tabular}\\n\\t}\\n\\t\\\\caption{MTDNN-BERT-base on GLUE}\\n\\t\\\\label{table:finetune-all}\\n\\\\end{center}\")",
"\\begin{center}\n\t\\scalebox{0.88}{\n\t\t\\begin{tabular}{rc|ccccccc} \n\t\t\\toprule[1pt] \n\t\t\\multirow{2}{*}{Task (Metric)} & \\multirow{2}{*}{Baseline} & \\multicolumn{7}{c}{Fine-tuned layers} \\\\ \n\t\t\\cline{3-9} \n\t\t& & 6-11 & 7-11 & 8-11 & 9-11 & 10-11 & 11-11 & Nsone \\\\ \n\t\t\t\\midrule\n\t\t\tCoLA (MCC) & 57.38 & 55.69 & 56.25 & 54.28 & 54.11 & 54.22 & 54.22 & 53.64 \\\\\n\t\t\tSST-2 (Acc.) & 92.78 & 92.55 & 92.59 & 92.34 & 92.27 & 92.22 & 92.04 & 91.86 \\\\\n\t\t\tMRPC (F$_1$) & 92.28 & 92.28 & 91.85 & 91.83 & 91.49 & 91.50 & 90.61 & 85.40 \\\\\n\t\t\tSTS-B ($\\rho$) & 90.88 & 90.64 & 90.54 & 90.47 & 90.30 & 90.15 & 89.97 & 89.54 \\\\\n\t\t\tQQP (F$_1$) & 88.38 & 87.76 & 87.70 & 87.63 & 87.54 & 87.50 & 87.40 & 87.18 \\\\\n\t\t\tMNLI (Acc.) & 84.44 & 84.02 & 84.11 & 84.19 & 83.91 & 83.72 & 83.05 & 76.65 \\\\\n\t\t\tMNLI-mm (Acc.) & 84.67 & 84.46 & 84.30 & 84.25 & 84.16 & 83.90 & 83.34 & 77.74 \\\\\n\t\t\tQNLI (Acc.) & 91.11 & 90.94 & 90.87 & 90.66 & 90.39 & 90.18 & 89.25 & 85.89 \\\\\n\t\t\tRTE (Acc.) & 78.41 & 79.49 & 79.13 & 78.48 & 76.82 & 75.60 & 75.23 & 71.05 \\\\\n\t\t\t\\midrule\\midrule\n\t\t\tRel. perf. (\\%) & 100.00 & 99.59 & 99.56 & 99.02 & 98.59 & 98.32 & 97.83 & 94.41 \\\\\n\t\t\\end{tabular}\n\t}\n\t\\caption{MTDNN-BERT-base on GLUE}\n\t\\label{table:finetune-all}\n\\end{center}\n"
],
[
"\\begin{tabular}{rc|ccccccc}\n\t\t\t\\toprule[1pt]\n\t\t\t\\multirow{2}{*}{Task (Metric)} & \\multirow{2}{*}{Baseline} & \\multicolumn{7}{c}{Fine-tuned layers} \\\\\n\t\t\t\\cline{3-9}\n\t\t\t& & 6-11 & 7-11 & 8-11 & 9-11 & 10-11 & 11-11 & none \\\\",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0f9cddbe5597e5dc63a7eaaa23cac45fb1b59e8 | 5,301 | ipynb | Jupyter Notebook | tests/Pruebas de Performance Textar.ipynb | epaolillo/clasificador-archivos | bcc9f43cdecf9f5cb8ace79277b17c06e153fad5 | [
"MIT"
] | 28 | 2016-11-26T18:56:19.000Z | 2021-06-28T22:27:47.000Z | tests/Pruebas de Performance Textar.ipynb | epaolillo/clasificador-archivos | bcc9f43cdecf9f5cb8ace79277b17c06e153fad5 | [
"MIT"
] | 7 | 2017-04-10T09:36:24.000Z | 2021-03-25T21:58:21.000Z | tests/Pruebas de Performance Textar.ipynb | epaolillo/clasificador-archivos | bcc9f43cdecf9f5cb8ace79277b17c06e153fad5 | [
"MIT"
] | 12 | 2017-12-09T19:41:24.000Z | 2021-01-28T17:19:24.000Z | 22.948052 | 84 | 0.471798 | [
[
[
"%load_ext memory_profiler\nfrom textar import TextClassifier\nimport xml.etree.ElementTree as ET\nfrom lxml import etree\nimport numpy as np\nimport re\nimport os",
"_____no_output_____"
],
[
"# Helper funcs\n\ndef parse_blog(tree, min_words=100):\n dates = []\n posts = []\n for elem in tree:\n post = None\n if elem.tag == 'date':\n date = elem.text\n elif elem.tag == 'post':\n post = elem.text\n if post is not None: \n words = re.findall('\\w+\\W',post)\n if len(words) > min_words and np.mean(map(len,words))>2:\n dates.append(date)\n posts.append(post)\n return dates, posts",
"_____no_output_____"
],
[
"# Configs\nDATA_FOLDER = os.path.join('.','data','performance_data','blogs')\nMAX_FILES = 10000",
"_____no_output_____"
],
[
"magic = '''<!DOCTYPE html PUBLIC \"-//W3C//DTD XHTML 1.0 Transitional//EN\"\n \"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd\" [\n <!ENTITY nbsp ' '>\n ]>'''\n\nparser = etree.XMLParser(recover=True)\n\nall_dates = []\nall_posts = []\nall_genders = []\nall_ages = []\nall_categories = []\n\nfor file_name in os.listdir(DATA_FOLDER)[:MAX_FILES]:\n id_f, gender, age, category, zodiac, ext = file_name.split('.')\n with open(os.path.join(DATA_FOLDER, file_name), 'r') as f:\n try:\n tree = ET.fromstring(magic + f.read(), parser=parser)\n dates, posts = parse_blog(tree)\n all_posts += posts\n all_dates += dates\n all_genders += [gender] * len(dates)\n all_ages += [age] * len(dates)\n all_categories += [category] * len(dates)\n except Exception as e:\n pass\n #print(\"Error en {:s}\".format(file_name))\nall_ids = map(str, range(len(all_posts)))",
"_____no_output_____"
],
[
"%%timeit\n# Tiempo de la creacion del objeto\ntc = TextClassifier(all_posts, all_ids)",
"_____no_output_____"
],
[
"%%timeit\n# Tiempo de la busqueda\ntc.get_similar(all_ids[1],max_similars=3, term_diff_max_rank=50)",
"1 loop, best of 3: 2.36 s per loop\n"
],
[
"%%timeit\n# Tiempo de creacion del clasificador\ntc.make_classifier(\"topic\",all_ids, all_categories)",
"1 loop, best of 3: 17.4 s per loop\n"
],
[
"%%timeit\ntc.classify(\"topic\", all_ids[1])",
"10 loops, best of 3: 31.4 ms per loop\n"
],
[
"row.toarray()",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0f9d1e16ad01e11d960172319fb00c0ac051426 | 239,965 | ipynb | Jupyter Notebook | tutorials/interface_unbounded.ipynb | carlosal1015/active_subspaces | caaf108fcb89548a374fea7704b0d92d38b4539a | [
"MIT"
] | 1 | 2020-03-16T18:05:05.000Z | 2020-03-16T18:05:05.000Z | tutorials/interface_unbounded.ipynb | carlosal1015/active_subspaces | caaf108fcb89548a374fea7704b0d92d38b4539a | [
"MIT"
] | null | null | null | tutorials/interface_unbounded.ipynb | carlosal1015/active_subspaces | caaf108fcb89548a374fea7704b0d92d38b4539a | [
"MIT"
] | 1 | 2020-03-16T18:05:09.000Z | 2020-03-16T18:05:09.000Z | 407.410866 | 62,993 | 0.918759 | [
[
[
"empty"
]
]
] | [
"empty"
] | [
[
"empty"
]
] |
d0f9d671b8e79b5ff2ac5610d4958af088e52d10 | 481,554 | ipynb | Jupyter Notebook | Prediction using Decision Tree Algorithm/Decision__Tree_(iris_dataset).ipynb | demaria11/Spark_Projects | 7fdb2536960fa0b7ef79bddfee282393fe11e6c7 | [
"MIT"
] | 4 | 2021-06-21T07:32:56.000Z | 2021-06-21T07:46:39.000Z | Prediction using Decision Tree Algorithm/Decision__Tree_(iris_dataset).ipynb | demaria11/Spark_Projects | 7fdb2536960fa0b7ef79bddfee282393fe11e6c7 | [
"MIT"
] | null | null | null | Prediction using Decision Tree Algorithm/Decision__Tree_(iris_dataset).ipynb | demaria11/Spark_Projects | 7fdb2536960fa0b7ef79bddfee282393fe11e6c7 | [
"MIT"
] | 2 | 2021-06-20T06:14:19.000Z | 2021-06-20T06:16:04.000Z | 391.189277 | 273,546 | 0.912444 | [
[
[
"#Author : Devesh Kumar\n\n## Task 4 : Prediction using Decision Tree Algorithm\n___\n## GRIP @ The Sparks Foundation\n____\n# Role : Data Science and Business Analytics [Batch May-2021]",
"_____no_output_____"
],
[
"## Table of Contents<br>\n> - 1. Introduction.\n- 2. Importing Libraries.\n- 3. Fetching and loading data.\n- 4. Checking for null values.\n- 5. Plotting Pairplot.\n- 6. Building Decision Tree Model.\n- 7. Training and fitting the model.\n- 8. Model Evaluation\n- 9. Graphical Visualisation.\n- 10. Conclusion.\n\n\n",
"_____no_output_____"
],
[
"#**Introduction**\n\n\n\n* We are given the iris flower dataset, with featues sepal length, sepal width, petal length and petal width.\n* Our aim is to create a decision tree classifier to classify the flowers in categories that are: Iris setosa, Iris versicolor, and Iris virginica.\n\n\n* Here, Python language is used to build the classifier.\n* Dataset link: https://bit.ly/3kXTdox\n\n\n\n",
"_____no_output_____"
],
[
"#**Importing Libraries**",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt \nimport seaborn as sns\nimport warnings\nwarnings.filterwarnings('ignore')",
"_____no_output_____"
]
],
[
[
"#**Fetching and loading data**\n\n",
"_____no_output_____"
]
],
[
[
"iris = pd.read_csv(\"/content/sample_data/Iris - Iris.csv\") #loading the dataset in iris variable",
"_____no_output_____"
],
[
"iris.head()",
"_____no_output_____"
],
[
"iris.tail()",
"_____no_output_____"
],
[
"iris = iris.drop(['Id'], axis = 1) #dropping column 'Id'\niris",
"_____no_output_____"
],
[
"iris.shape",
"_____no_output_____"
]
],
[
[
"In iris dataset, 5 features and 150 datapoints are present.",
"_____no_output_____"
],
[
"#**Checking for Null Values**",
"_____no_output_____"
]
],
[
[
"iris.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 150 entries, 0 to 149\nData columns (total 5 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 SepalLengthCm 150 non-null float64\n 1 SepalWidthCm 150 non-null float64\n 2 PetalLengthCm 150 non-null float64\n 3 PetalWidthCm 150 non-null float64\n 4 Species 150 non-null object \ndtypes: float64(4), object(1)\nmemory usage: 6.0+ KB\n"
]
],
[
[
"Here, we can see that no null values are present.",
"_____no_output_____"
]
],
[
[
"iris['Species'].value_counts()",
"_____no_output_____"
]
],
[
[
"From the above data we can say that, the iris dataset is a balanced dataset as the number of datapoints for every class are same.",
"_____no_output_____"
],
[
"#**Plotting Pairplot**",
"_____no_output_____"
]
],
[
[
"sns.set_style(\"whitegrid\")\nsns.pairplot(iris,hue=\"Species\",size=3);\nplt.show()",
"_____no_output_____"
]
],
[
[
"#**Splitting The Data**",
"_____no_output_____"
]
],
[
[
"X = iris.iloc[ : , : -1]\ny = iris.iloc[ : , -1 ]",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split\nx_train, x_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 0)",
"_____no_output_____"
]
],
[
[
"#**Decision Tree**",
"_____no_output_____"
],
[
"#**Training and fitting the model**",
"_____no_output_____"
]
],
[
[
"from sklearn.tree import DecisionTreeClassifier\ntree_clf=DecisionTreeClassifier()\ntree_clf.fit(x_train,y_train)",
"_____no_output_____"
],
[
"y_pred = tree_clf.predict(x_test)",
"_____no_output_____"
],
[
"y_pred",
"_____no_output_____"
],
[
"pd.DataFrame(y_pred, y_test)",
"_____no_output_____"
]
],
[
[
"#**Model Evaluation**",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import accuracy_score\nprint(accuracy_score(y_test, y_pred))",
"0.9777777777777777\n"
],
[
"from sklearn.metrics import classification_report\nprint(classification_report(y_test, y_pred))",
" precision recall f1-score support\n\n Iris-setosa 1.00 1.00 1.00 16\nIris-versicolor 1.00 0.94 0.97 18\n Iris-virginica 0.92 1.00 0.96 11\n\n accuracy 0.98 45\n macro avg 0.97 0.98 0.98 45\n weighted avg 0.98 0.98 0.98 45\n\n"
]
],
[
[
"#**Graphical Visualization**",
"_____no_output_____"
]
],
[
[
"# Import necessary libraries for graph viz\nfrom sklearn.externals.six import StringIO \nfrom IPython.display import Image \nfrom sklearn.tree import export_graphviz\nimport pydotplus\n\n# Visualize the graph\ndot_data = StringIO()\nexport_graphviz(tree_clf, out_file=dot_data, feature_names=iris.columns[:-1], \n class_names = ['Setosa', 'Versicolor', 'Viginica'] ,filled=True, rounded=True,\n special_characters=True)\ngraph = pydotplus.graph_from_dot_data(dot_data.getvalue()) \nImage(graph.create_png())",
"_____no_output_____"
]
],
[
[
"#**Conclusion**\n\nHence the Decision Tree Classifier is created ; you can feed any data to this classifier and it would be able to predict the right class accordingly.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d0f9e02d626facc3fdb41fff16b5495ae7c67519 | 33,121 | ipynb | Jupyter Notebook | aws/forecasting/experiements/deep_lstm.ipynb | Duncan-Haywood/finance_ml_analysis | ce42917fe69e81cf19f3f4893d3cc0f60cfd961c | [
"MIT"
] | 1 | 2021-05-05T18:24:47.000Z | 2021-05-05T18:24:47.000Z | aws/forecasting/experiements/deep_lstm.ipynb | Duncan-Haywood/finance_ml_analysis | ce42917fe69e81cf19f3f4893d3cc0f60cfd961c | [
"MIT"
] | null | null | null | aws/forecasting/experiements/deep_lstm.ipynb | Duncan-Haywood/finance_ml_analysis | ce42917fe69e81cf19f3f4893d3cc0f60cfd961c | [
"MIT"
] | 1 | 2021-05-25T19:09:48.000Z | 2021-05-25T19:09:48.000Z | 39.057783 | 172 | 0.370309 | [
[
[
"# !pip install pandas_datareader keras seaborn\n# !conda install -y -c conda-forge fbprophet\n# !pip install pydot graphviz\nimport boto3\nimport base64\nfrom botocore.exceptions import ClientError\nfrom IPython.display import display\nimport pandas_datareader\nimport pandas as pd\nimport numpy as np\nfrom keras import Sequential\nfrom keras.layers import Dense, LSTM, InputLayer, Attention\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nfrom keras.utils import plot_model\nfrom keras.callbacks import EarlyStopping",
"_____no_output_____"
],
[
"tickers = ['AAPL']\nmetric = 'low'\npc_metric = f'{metric}_percent_change'\nnorm_metric = f'{pc_metric}_norm'\nlookback=100\ndef get_secret():\n secret_name = \"alpha_vantage\"\n region_name = \"us-east-2\"\n # Create a Secrets Manager client\n session = boto3.session.Session()\n client = session.client(\n service_name='secretsmanager',\n region_name=region_name\n )\n try:\n get_secret_value_response = client.get_secret_value(SecretId=secret_name)\n except ClientError as e:\n display(e)\n else:\n # Decrypts secret using the associated KMS CMK.\n # Depending on whether the secret is a string or binary, one of these fields will be populated.\n if 'SecretString' in get_secret_value_response:\n secret = get_secret_value_response['SecretString']\n else:\n secret = base64.b64decode(get_secret_value_response['SecretBinary'])\n return secret \ndef format_dates(daily_stocks_data):\n df = daily_stocks_data.copy() \n df['date']=df.index\n df.reset_index(inplace=True, drop=True)\n return df\ndef add_percent_change(daily_stocks_data, metric):\n percents = list()\n for index, row in daily_stocks_data.iterrows():\n old = row[metric]\n try:\n new = daily_stocks_data.iloc[index + 1][metric]\n except Exception as e:\n percents.append(np.nan) ## no next value, so this is undefined\n continue\n percents.append((new-old)/new)\n cp_df = daily_stocks_data.copy()\n cp_df[f'{metric}_percent_change']=percents\n return cp_df\ndef add_norm(df, label):\n arr = np.array([x*1000 for x in df[label].to_numpy()]).reshape(-1, 1)\n# norm = normalize(arr, norm='l1')\n norm = arr\n new_df = df.copy()\n new_df[f'{label}_norm'] = norm\n return new_df\ndef to_ts_df(daily_stocks_data, lookback, metric):\n ## column names\n columns = list()\n for i in range(lookback):\n columns.append(f'{metric}_{i}')\n columns.append(f'{metric}_target')\n df = pd.DataFrame(columns=columns)\n ## columns\n data = daily_stocks_data[metric].to_numpy()\n for index, col in enumerate(df.columns):\n df[col] = data[index:len(data)-lookback+index]\n ## dates index\n dates = daily_stocks_data.date.to_numpy()[:-lookback]\n df.insert(0, 'date', dates)\n return df\ndef to_ts(ts_df):\n data = list()\n targets = list()\n for index, row in ts_df.iloc[:,1:].iterrows():\n rnp = row.to_numpy()\n data.append([[x] for x in rnp[:-1]])\n targets.append(rnp[-1])\n data = np.array(data)\n targets = np.array(targets)\n return data, targets",
"_____no_output_____"
],
[
"ALPHA_API_KEY = get_secret()",
"_____no_output_____"
],
[
"daily_stocks_data_raw = pandas_datareader.av.time_series.AVTimeSeriesReader(symbols=tickers, api_key=ALPHA_API_KEY, function='TIME_SERIES_DAILY').read()\ndaily_stocks_data = format_dates(daily_stocks_data_raw) \ndaily_stocks_data = add_percent_change(daily_stocks_data, metric)\ndaily_stocks_data[daily_stocks_data[pc_metric].isnull()] = 0\ndaily_stocks_data = add_norm(daily_stocks_data, pc_metric)\nts_df = to_ts_df(daily_stocks_data, lookback, pc_metric)\ndata, targets = to_ts(ts_df)\ndisplay(daily_stocks_data)\ndisplay(ts_df)",
"_____no_output_____"
],
[
"## currently testing to set up mlflow and training jobs. \ndef deep_lstm():\n model = Sequential()\n model.add(InputLayer(input_shape=(None,1)))\n# model.add(LSTM(12, return_sequences=True))\n# model.add(LSTM(12, return_sequences=True))\n# model.add(LSTM(6, return_sequences=True))\n# model.add(LSTM(6, return_sequences=True))\n# model.add(LSTM(2, return_sequences=True))\n# model.add(LSTM(1))\n model.add(Dense(1))\n model.compile(loss='mae', metrics=['mse','mape'])\n return model",
"_____no_output_____"
],
[
"model = deep_lstm()\nmodel.summary()\n# plot_model(model)",
"Model: \"sequential_1\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ndense (Dense) (None, None, 1) 2 \n=================================================================\nTotal params: 2\nTrainable params: 2\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"early = EarlyStopping(patience=2, restore_best_weights=True)\nmodel.fit(x=data, y=targets, batch_size=36, validation_split=0.2, epochs=1, callbacks=[early])",
"110/110 [==============================] - 1s 7ms/step - loss: 0.0237 - mse: 0.0170 - mape: 60300.9688 - val_loss: 0.0222 - val_mse: 0.0148 - val_mape: 12634.9971\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0f9e305b41e15bcd3d617e7f0aa87633fedc0bf | 107,834 | ipynb | Jupyter Notebook | examples/seismic/tutorials/04_scipy_optimise.ipynb | jrt54/total_variation | 6611bcddc0e8fe5a49414b004e5b9da9dec4fd6a | [
"MIT"
] | 1 | 2018-10-02T00:36:53.000Z | 2018-10-02T00:36:53.000Z | examples/seismic/tutorials/04_scipy_optimise.ipynb | jrt54/total_variation | 6611bcddc0e8fe5a49414b004e5b9da9dec4fd6a | [
"MIT"
] | null | null | null | examples/seismic/tutorials/04_scipy_optimise.ipynb | jrt54/total_variation | 6611bcddc0e8fe5a49414b004e5b9da9dec4fd6a | [
"MIT"
] | null | null | null | 268.912718 | 40,550 | 0.906031 | [
[
[
"# 04 - Full waveform inversion with Devito and scipy.optimize.minimize",
"_____no_output_____"
],
[
"## Introduction\n\nIn this tutorial we show how [Devito](http://www.opesci.org/devito-public) can be used with [scipy.optimize.minimize](https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.minimize.html) to solve the FWI gradient based minimization problem described in the previous tutorial.\n\n```python\nscipy.optimize.minimize(fun, x0, args=(), method=None, jac=None, hess=None, hessp=None, bounds=None, constraints=(), tol=None, callback=None, options=None)\n```\n\n> Minimization of scalar function of one or more variables.\n>\n> In general, the optimization problems are of the form:\n>\n> minimize f(x) subject to\n>\n> g_i(x) >= 0, i = 1,...,m\n> h_j(x) = 0, j = 1,...,p\n> where x is a vector of one or more variables. g_i(x) are the inequality constraints. h_j(x) are the equality constrains.\n\n[scipy.optimize.minimize](https://docs.scipy.org/doc/scipy/reference/generated/scipy.optimize.minimize.html) provides a wide variety of methods for solving minimization problems depending on the context. Here we are going to focus on using L-BFGS via [scipy.optimize.minimize(method=’L-BFGS-B’)](https://docs.scipy.org/doc/scipy/reference/optimize.minimize-lbfgsb.html#optimize-minimize-lbfgsb)\n\n```python\nscipy.optimize.minimize(fun, x0, args=(), method='L-BFGS-B', jac=None, bounds=None, tol=None, callback=None, options={'disp': None, 'maxls': 20, 'iprint': -1, 'gtol': 1e-05, 'eps': 1e-08, 'maxiter': 15000, 'ftol': 2.220446049250313e-09, 'maxcor': 10, 'maxfun': 15000})```\n\nThe argument `fun` is a callable function that returns the misfit between the simulated and the observed data. If `jac` is a Boolean and is `True`, `fun` is assumed to return the gradient along with the objective function - as is our case when applying the adjoint-state method.",
"_____no_output_____"
],
[
"## Setting up (synthetic) data\nWe are going to set up the same synthetic test case as for the previous tutorial (refer back for details). The code below is slightly re-engineered to make it suitable for using with scipy.optimize.minimize.",
"_____no_output_____"
]
],
[
[
"#NBVAL_IGNORE_OUTPUT\nfrom examples.seismic import Model, demo_model\nimport numpy as np\n\n# Define the grid parameters\ndef get_grid():\n shape = (101, 101) # Number of grid point (nx, nz)\n spacing = (10., 10.) # Grid spacing in m. The domain size is now 1km by 1km\n origin = (0., 0.) # Need origin to define relative source and receiver locations\n\n return shape, spacing, origin\n\n# Define the test phantom; in this case we are using a simple circle\n# so we can easily see what is going on.\ndef get_true_model():\n shape, spacing, origin = get_grid()\n return demo_model('circle-isotropic', vp=3.0, vp_background=2.5, \n origin=origin, shape=shape, spacing=spacing, nbpml=40)\n\n# The initial guess for the subsurface model.\ndef get_initial_model():\n shape, spacing, origin = get_grid()\n\n return demo_model('circle-isotropic', vp=2.5, vp_background=2.5, \n origin=origin, shape=shape, spacing=spacing, nbpml=40)\n\nfrom examples.seismic.acoustic import AcousticWaveSolver\nfrom examples.seismic import RickerSource, Receiver\n\n# Inversion crime alert! Here the worker is creating the 'observed' data\n# using the real model. For a real case the worker would be reading\n# seismic data from disk.\ndef get_data(param):\n \"\"\" Returns source and receiver data for a single shot labeled 'shot_id'.\n \"\"\"\n true_model = get_true_model()\n dt = true_model.critical_dt # Time step from model grid spacing\n\n # Set up source data and geometry.\n nt = int(1 + (param['tn']-param['t0']) / dt) # Discrete time axis length\n\n src = RickerSource(name='src', grid=true_model.grid, f0=param['f0'],\n time=np.linspace(param['t0'], param['tn'], nt))\n src.coordinates.data[0, :] = [30, param['shot_id']*1000./(param['nshots']-1)]\n\n # Set up receiver data and geometry.\n nreceivers = 101 # Number of receiver locations per shot\n rec = Receiver(name='rec', grid=true_model.grid, npoint=nreceivers, ntime=nt)\n rec.coordinates.data[:, 1] = np.linspace(0, true_model.domain_size[0], num=nreceivers)\n rec.coordinates.data[:, 0] = 980. # 20m from the right end\n\n # Set up solver - using model_in so that we have the same dt,\n # otherwise we should use pandas to resample the time series data. \n solver = AcousticWaveSolver(true_model, src, rec, space_order=4)\n\n # Generate synthetic receiver data from true model\n true_d, _, _ = solver.forward(src=src, m=true_model.m)\n\n return src, true_d, nt, solver",
"_____no_output_____"
]
],
[
[
"## Create operators for gradient based inversion\nTo perform the inversion we are going to use [scipy.optimize.minimize(method=’L-BFGS-B’)](https://docs.scipy.org/doc/scipy/reference/optimize.minimize-lbfgsb.html#optimize-minimize-lbfgsb).\n\nFirst we define the functional, ```f```, and gradient, ```g```, operator (i.e. the function ```fun```) for a single shot of data.",
"_____no_output_____"
]
],
[
[
"from devito import Function, clear_cache\n\n# Create FWI gradient kernel for a single shot\ndef fwi_gradient_i(x, param):\n # Need to clear the workers cache.\n clear_cache()\n\n # Get the current model and the shot data for this worker.\n model0 = get_initial_model()\n model0.m.data[:] = x.astype(np.float32).reshape(model0.m.data.shape)\n src, rec, nt, solver = get_data(param)\n \n # Create symbols to hold the gradient and the misfit between\n # the 'measured' and simulated data.\n grad = Function(name=\"grad\", grid=model0.grid)\n residual = Receiver(name='rec', grid=model0.grid, ntime=nt, coordinates=rec.coordinates.data)\n \n # Compute simulated data and full forward wavefield u0\n d, u0, _ = solver.forward(src=src, m=model0.m, save=True)\n \n # Compute the data misfit (residual) and objective function \n residual.data[:] = d.data[:] - rec.data[:]\n f = .5*np.linalg.norm(residual.data.flatten())**2\n \n # Compute gradient using the adjoint-state method. Note, this\n # backpropagates the data misfit through the model.\n solver.gradient(rec=residual, u=u0, m=model0.m, grad=grad)\n \n # return the objective functional and gradient.\n return f, np.array(grad.data)",
"_____no_output_____"
]
],
[
[
"Next we define the global functional and gradient function that sums the contributions to f and g for each shot of data.",
"_____no_output_____"
]
],
[
[
"def fwi_gradient(x, param):\n # Initialize f and g.\n param['shot_id'] = 0\n f, g = fwi_gradient_i(x, param)\n \n # Loop through all shots summing f, g.\n for i in range(1, param['nshots']):\n param['shot_id'] = i\n f_i, g_i = fwi_gradient_i(x, param)\n f += f_i\n g[:] += g_i\n \n # Note the explicit cast; while the forward/adjoint solver only requires float32,\n # L-BFGS-B in SciPy expects a flat array in 64-bit floats.\n return f, g.flatten().astype(np.float64)",
"_____no_output_____"
]
],
[
[
"## FWI with L-BFGS-B\nEquipped with a function to calculate the functional and gradient, we are finally ready to call ```scipy.optimize.minimize```.",
"_____no_output_____"
]
],
[
[
"#NBVAL_SKIP\n\n# Change to the WARNING log level to reduce log output\n# as compared to the default DEBUG\nfrom devito import configuration\nconfiguration['log_level'] = 'WARNING'\n\n# Set up a dictionary of inversion parameters.\nparam = {'t0': 0.,\n 'tn': 1000., # Simulation lasts 1 second (1000 ms)\n 'f0': 0.010, # Source peak frequency is 10Hz (0.010 kHz)\n 'nshots': 9} # Number of shots to create gradient from\n\n# Define bounding box constraints on the solution.\ndef apply_box_constraint(m):\n # Maximum possible 'realistic' velocity is 3.5 km/sec\n # Minimum possible 'realistic' velocity is 2 km/sec\n return np.clip(m, 1/3.5**2, 1/2**2)\n\n# Many optimization methods in scipy.optimize.minimize accept a callback\n# function that can operate on the solution after every iteration. Here\n# we use this to apply box constraints and to monitor the true relative\n# solution error.\nrelative_error = []\ndef fwi_callbacks(x):\n # Apply boundary constraint\n x.data[:] = apply_box_constraint(x)\n \n # Calculate true relative error\n true_x = get_true_model().m.data.flatten()\n relative_error.append(np.linalg.norm((x-true_x)/true_x))\n\n \n# Initialize solution\nmodel0 = get_initial_model()\n\n# Finally, calling the minimizing function. We are limiting the maximum number\n# of iterations here to 10 so that it runs quickly for the purpose of the\n# tutorial.\nfrom scipy import optimize\nresult = optimize.minimize(fwi_gradient, model0.m.data.flatten().astype(np.float64),\n args=(param, ), method='L-BFGS-B', jac=True,\n callback=fwi_callbacks,\n options={'maxiter':10, 'disp':True})\n\n# Print out results of optimizer.\nprint(result)",
" fun: 47.419344659558135\n hess_inv: <32761x32761 LbfgsInvHessProduct with dtype=float64>\n jac: array([ 0., 0., 0., ..., 0., 0., 0.])\n message: b'STOP: TOTAL NO. of ITERATIONS EXCEEDS LIMIT'\n nfev: 13\n nit: 11\n status: 1\n success: False\n x: array([ 0.16, 0.16, 0.16, ..., 0.16, 0.16, 0.16])\n"
],
[
"#NBVAL_SKIP\n\n# Show what the update does to the model\nfrom examples.seismic import plot_image, plot_velocity\n\nmodel0.m.data[:] = result.x.astype(np.float32).reshape(model0.m.data.shape)\nmodel0.vp = np.sqrt(1. / model0.m.data[40:-40, 40:-40])\nplot_velocity(model0)",
"_____no_output_____"
],
[
"#NBVAL_SKIP\n\n# Plot percentage error\nplot_image(100*np.abs(model0.vp-get_true_model().vp.data)/get_true_model().vp.data, cmap=\"hot\")",
"_____no_output_____"
]
],
[
[
"While we are resolving the circle at the centre of the domain there are also lots of artifacts throughout the domain.",
"_____no_output_____"
]
],
[
[
"#NBVAL_SKIP\nimport matplotlib.pyplot as plt\n\n# Plot objective function decrease\nplt.figure()\nplt.loglog(relative_error)\nplt.xlabel('Iteration number')\nplt.ylabel('True relative error')\nplt.title('Convergence')\nplt.show()",
"_____no_output_____"
]
],
[
[
"<sup>This notebook is part of the tutorial \"Optimised Symbolic Finite Difference Computation with Devito\" presented at the Intel® HPC Developer Conference 2017.</sup>",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d0f9f8f7c03394d8f095448899485999f9b53752 | 19,709 | ipynb | Jupyter Notebook | text-similarity/4.sentence-similarity-batchall-tripletloss.ipynb | aiqoai/NLP-Models-Tensorflow | b14e5f39665476f94e27e088bd39006a3dddcf7f | [
"MIT"
] | 3 | 2019-07-12T07:08:26.000Z | 2021-04-12T21:43:50.000Z | text-similarity/4.sentence-similarity-batchall-tripletloss.ipynb | LeeKLTW/NLP-Models-Tensorflow | 85b6a85cc5af7223ea8cbf064074e21d4c18fe03 | [
"MIT"
] | null | null | null | text-similarity/4.sentence-similarity-batchall-tripletloss.ipynb | LeeKLTW/NLP-Models-Tensorflow | 85b6a85cc5af7223ea8cbf064074e21d4c18fe03 | [
"MIT"
] | 4 | 2019-06-18T09:26:56.000Z | 2019-10-30T20:53:22.000Z | 39.182903 | 376 | 0.532244 | [
[
[
"import numpy as np\nimport collections\nimport random\nimport tensorflow as tf",
"_____no_output_____"
],
[
"def build_dataset(words, n_words):\n count = [['GO', 0], ['PAD', 1], ['EOS', 2], ['UNK', 3]]\n count.extend(collections.Counter(words).most_common(n_words - 1))\n dictionary = dict()\n for word, _ in count:\n dictionary[word] = len(dictionary)\n data = list()\n unk_count = 0\n for word in words:\n index = dictionary.get(word, 0)\n if index == 0:\n unk_count += 1\n data.append(index)\n count[0][1] = unk_count\n reversed_dictionary = dict(zip(dictionary.values(), dictionary.keys()))\n return data, count, dictionary, reversed_dictionary\n\ndef str_idx(corpus, dic, maxlen, UNK=3):\n X = np.zeros((len(corpus),maxlen))\n for i in range(len(corpus)):\n for no, k in enumerate(corpus[i][:maxlen][::-1]):\n val = dic[k] if k in dic else UNK\n X[i,-1 - no]= val\n return X\n\ndef load_data(filepath):\n x1=[]\n x2=[]\n y=[]\n for line in open(filepath):\n l=line.strip().split(\"\\t\")\n if len(l)<2:\n continue\n if random.random() > 0.5:\n x1.append(l[0].lower())\n x2.append(l[1].lower())\n else:\n x1.append(l[1].lower())\n x2.append(l[0].lower())\n y.append(int(l[2]))\n return np.array(x1),np.array(x2),np.array(y)",
"_____no_output_____"
],
[
"X1_text, X2_text, Y = load_data('train_snli.txt')",
"_____no_output_____"
],
[
"concat = (' '.join(X1_text.tolist() + X2_text.tolist())).split()\nvocabulary_size = len(list(set(concat)))\ndata, count, dictionary, rev_dictionary = build_dataset(concat, vocabulary_size)\nprint('vocab from size: %d'%(vocabulary_size))\nprint('Most common words', count[4:10])\nprint('Sample data', data[:10], [rev_dictionary[i] for i in data[:10]])",
"vocab from size: 47170\nMost common words [('a', 959179), ('the', 341846), ('in', 273772), ('is', 248868), ('man', 173742), ('on', 154293)]\nSample data [4, 38, 7, 17, 4, 16491, 2691, 20, 29356, 4] ['a', 'person', 'is', 'at', 'a', 'diner,', 'ordering', 'an', 'omelette.', 'a']\n"
],
[
"def _pairwise_distances(embeddings_left, embeddings_right, squared=False):\n dot_product = tf.matmul(embeddings_left, \n tf.transpose(embeddings_right))\n square_norm = tf.diag_part(dot_product)\n distances = tf.expand_dims(square_norm, 1) - 2.0 * dot_product + tf.expand_dims(square_norm, 0)\n distances = tf.maximum(distances, 0.0)\n\n if not squared:\n mask = tf.to_float(tf.equal(distances, 0.0))\n distances = distances + mask * 1e-16\n distances = tf.sqrt(distances)\n distances = distances * (1.0 - mask)\n\n return distances\n\n\ndef _get_anchor_positive_triplet_mask(labels):\n indices_equal = tf.cast(tf.eye(tf.shape(labels)[0]), tf.bool)\n indices_not_equal = tf.logical_not(indices_equal)\n labels_equal = tf.equal(tf.expand_dims(labels, 0), tf.expand_dims(labels, 1))\n mask = tf.logical_and(indices_not_equal, labels_equal)\n\n return mask\n\n\ndef _get_anchor_negative_triplet_mask(labels):\n labels_equal = tf.equal(tf.expand_dims(labels, 0), tf.expand_dims(labels, 1))\n mask = tf.logical_not(labels_equal)\n\n return mask\n\ndef _get_triplet_mask(labels):\n indices_equal = tf.cast(tf.eye(tf.shape(labels)[0]), tf.bool)\n indices_not_equal = tf.logical_not(indices_equal)\n i_not_equal_j = tf.expand_dims(indices_not_equal, 2)\n i_not_equal_k = tf.expand_dims(indices_not_equal, 1)\n j_not_equal_k = tf.expand_dims(indices_not_equal, 0)\n\n distinct_indices = tf.logical_and(tf.logical_and(i_not_equal_j, i_not_equal_k), j_not_equal_k)\n\n label_equal = tf.equal(tf.expand_dims(labels, 0), tf.expand_dims(labels, 1))\n i_equal_j = tf.expand_dims(label_equal, 2)\n i_equal_k = tf.expand_dims(label_equal, 1)\n\n valid_labels = tf.logical_and(i_equal_j, tf.logical_not(i_equal_k))\n mask = tf.logical_and(distinct_indices, valid_labels)\n\n return mask\ndef batch_all_triplet_loss(labels, embeddings_left, embeddings_right, margin, squared=False):\n pairwise_dist = _pairwise_distances(embeddings_left, embeddings_right, squared=squared)\n\n anchor_positive_dist = tf.expand_dims(pairwise_dist, 2)\n assert anchor_positive_dist.shape[2] == 1, \"{}\".format(anchor_positive_dist.shape)\n anchor_negative_dist = tf.expand_dims(pairwise_dist, 1)\n assert anchor_negative_dist.shape[1] == 1, \"{}\".format(anchor_negative_dist.shape)\n\n triplet_loss = anchor_positive_dist - anchor_negative_dist + margin\n\n mask = _get_triplet_mask(labels)\n mask = tf.to_float(mask)\n triplet_loss = tf.multiply(mask, triplet_loss)\n\n triplet_loss = tf.maximum(triplet_loss, 0.0)\n\n valid_triplets = tf.to_float(tf.greater(triplet_loss, 1e-16))\n num_positive_triplets = tf.reduce_sum(valid_triplets)\n num_valid_triplets = tf.reduce_sum(mask)\n fraction_positive_triplets = num_positive_triplets / (num_valid_triplets + 1e-16)\n\n triplet_loss = tf.reduce_sum(triplet_loss) / (num_positive_triplets + 1e-16)\n\n return triplet_loss, fraction_positive_triplets",
"_____no_output_____"
],
[
"class Model:\n def __init__(self, size_layer, num_layers, embedded_size,\n dict_size, learning_rate, dimension_output):\n \n def cells(reuse=False):\n return tf.nn.rnn_cell.LSTMCell(size_layer,\n initializer=tf.orthogonal_initializer(),reuse=reuse)\n \n def rnn(inputs, reuse=False):\n with tf.variable_scope('model', reuse = reuse):\n rnn_cells = tf.nn.rnn_cell.MultiRNNCell([cells() for _ in range(num_layers)])\n outputs, _ = tf.nn.dynamic_rnn(rnn_cells, inputs, dtype = tf.float32)\n return tf.layers.dense(outputs[:,-1], dimension_output)\n \n self.X_left = tf.placeholder(tf.int32, [None, None])\n self.X_right = tf.placeholder(tf.int32, [None, None])\n self.Y = tf.placeholder(tf.float32, [None])\n self.batch_size = tf.shape(self.X_left)[0]\n encoder_embeddings = tf.Variable(tf.random_uniform([dict_size, embedded_size], -1, 1))\n embedded_left = tf.nn.embedding_lookup(encoder_embeddings, self.X_left)\n embedded_right = tf.nn.embedding_lookup(encoder_embeddings, self.X_right)\n \n self.output_left = rnn(embedded_left, False)\n self.output_right = rnn(embedded_right, True)\n \n self.cost, fraction = batch_all_triplet_loss(self.Y, self.output_left, \n self.output_right, margin=0.5, squared=False)\n \n self.distance = tf.sqrt(tf.reduce_sum(tf.square(tf.subtract(self.output_left,self.output_right)),1,keep_dims=True))\n self.distance = tf.div(self.distance, tf.add(tf.sqrt(tf.reduce_sum(tf.square(self.output_left),1,keep_dims=True)),\n tf.sqrt(tf.reduce_sum(tf.square(self.output_right),1,keep_dims=True))))\n self.distance = tf.reshape(self.distance, [-1])\n \n self.temp_sim = tf.subtract(tf.ones_like(self.distance),\n tf.rint(self.distance))\n correct_predictions = tf.equal(self.temp_sim, self.Y)\n self.accuracy = tf.reduce_mean(tf.cast(correct_predictions, \"float\"))\n self.optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(self.cost)",
"_____no_output_____"
],
[
"size_layer = 256\nnum_layers = 2\nembedded_size = 128\nlearning_rate = 1e-3\ndimension_output = 300\nmaxlen = 50\nbatch_size = 128",
"_____no_output_____"
],
[
"tf.reset_default_graph()\nsess = tf.InteractiveSession()\nmodel = Model(size_layer,num_layers,embedded_size,len(dictionary),\n learning_rate,dimension_output)\nsess.run(tf.global_variables_initializer())",
"WARNING:tensorflow:From <ipython-input-6-f9d3dfeee5d1>:29: calling reduce_sum (from tensorflow.python.ops.math_ops) with keep_dims is deprecated and will be removed in a future version.\nInstructions for updating:\nkeep_dims is deprecated, use keepdims instead\n"
],
[
"from sklearn.cross_validation import train_test_split\n\nvectors_left = str_idx(X1_text, dictionary, maxlen)\nvectors_right = str_idx(X2_text, dictionary, maxlen)\ntrain_X_left, test_X_left, train_X_right, test_X_right, train_Y, test_Y = train_test_split(vectors_left,\n vectors_right,\n Y,\n test_size = 0.2)",
"/usr/local/lib/python3.5/dist-packages/sklearn/cross_validation.py:41: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the refactored classes and functions are moved. Also note that the interface of the new CV iterators are different from that of this module. This module will be removed in 0.20.\n \"This module will be removed in 0.20.\", DeprecationWarning)\n"
],
[
"from tqdm import tqdm\nimport time\n\nfor EPOCH in range(5):\n lasttime = time.time()\n \n train_acc, train_loss, test_acc, test_loss = 0, 0, 0, 0\n pbar = tqdm(range(0, len(train_X_left), batch_size), desc='train minibatch loop')\n for i in pbar:\n batch_x_left = train_X_left[i:min(i+batch_size,train_X_left.shape[0])]\n batch_x_right = train_X_right[i:min(i+batch_size,train_X_left.shape[0])]\n batch_y = train_Y[i:min(i+batch_size,train_X_left.shape[0])]\n acc, loss, _ = sess.run([model.accuracy, model.cost, model.optimizer], \n feed_dict = {model.X_left : batch_x_left, \n model.X_right: batch_x_right,\n model.Y : batch_y})\n assert not np.isnan(loss)\n train_loss += loss\n train_acc += acc\n pbar.set_postfix(cost = loss, accuracy = acc)\n \n pbar = tqdm(range(0, len(test_X_left), batch_size), desc='test minibatch loop')\n for i in pbar:\n batch_x_left = test_X_left[i:min(i+batch_size,train_X_left.shape[0])]\n batch_x_right = test_X_right[i:min(i+batch_size,train_X_left.shape[0])]\n batch_y = test_Y[i:min(i+batch_size,train_X_left.shape[0])]\n acc, loss = sess.run([model.accuracy, model.cost], \n feed_dict = {model.X_left : batch_x_left, \n model.X_right: batch_x_right,\n model.Y : batch_y})\n test_loss += loss\n test_acc += acc\n pbar.set_postfix(cost = loss, accuracy = acc)\n \n train_loss /= (len(train_X_left) / batch_size)\n train_acc /= (len(train_X_left) / batch_size)\n test_loss /= (len(test_X_left) / batch_size)\n test_acc /= (len(test_X_left) / batch_size)\n \n print('time taken:', time.time()-lasttime)\n print('epoch: %d, training loss: %f, training acc: %f, valid loss: %f, valid acc: %f\\n'%(EPOCH,train_loss,\n train_acc,test_loss,\n test_acc))",
"train minibatch loop: 100%|██████████| 2297/2297 [04:34<00:00, 8.38it/s, accuracy=0.4, cost=0.488] \ntest minibatch loop: 100%|██████████| 575/575 [00:24<00:00, 24.62it/s, accuracy=0, cost=0] \ntrain minibatch loop: 0%| | 1/2297 [00:00<04:32, 8.44it/s, accuracy=0.469, cost=0.5]"
],
[
"left = str_idx(['a person is outdoors, on a horse.'], dictionary, maxlen)\nright = str_idx(['a person on a horse jumps over a broken down airplane.'], dictionary, maxlen)\nsess.run([model.temp_sim,1-model.distance], feed_dict = {model.X_left : left, \n model.X_right: right})",
"_____no_output_____"
],
[
"left = str_idx(['i love you'], dictionary, maxlen)\nright = str_idx(['you love i'], dictionary, maxlen)\nsess.run([model.temp_sim,1-model.distance], feed_dict = {model.X_left : left, \n model.X_right: right})",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0f9ffd9cbde531a565801e307ddcca91ace18b0 | 1,860 | ipynb | Jupyter Notebook | read_log_file.ipynb | minhtannguyen/ffjord | f3418249eaa4647f4339aea8d814cf2ce33be141 | [
"MIT"
] | null | null | null | read_log_file.ipynb | minhtannguyen/ffjord | f3418249eaa4647f4339aea8d814cf2ce33be141 | [
"MIT"
] | null | null | null | read_log_file.ipynb | minhtannguyen/ffjord | f3418249eaa4647f4339aea8d814cf2ce33be141 | [
"MIT"
] | null | null | null | 23.25 | 77 | 0.481183 | [
[
[
"import numpy as np",
"_____no_output_____"
],
[
"log_file = 'experiments/cnf_nocond_bs8K_100timeslr_exploretol2/logs'\n\nwith open(log_file) as f:\n content = f.readlines()\n\ncontent = [line.strip() for line in content] \nstart_collect = False\nepoch_time = []\nfor line in content:\n cline = line.split(' | ')\n for phrase in cline:\n cphrase = phrase.split(', ')\n for word in cphrase:\n if word == 'Epoch 0001':\n start_collect = True\n if start_collect:\n cword = word.split(' ')\n if len(cword) >= 2:\n if cword[0]=='Epoch' and cword[1]=='Time':\n epoch_time.append(float(cword[2]))\n\nprint('Average time per epoch = %f'%np.mean(epoch_time[0:399]))",
"Average time per epoch = 233.987517\n"
]
]
] | [
"code"
] | [
[
"code",
"code"
]
] |
d0fa004fceb279e63a6df2d553b535ab694def73 | 866,751 | ipynb | Jupyter Notebook | Hands_On_ML_Book/Chapter_2/End-to-End_ML_Project.ipynb | ARGF0RCE/Hands-On-ML-Made-Easy | de4a672813be09505a541fda15c32a3b320d406b | [
"Apache-2.0"
] | 1 | 2022-02-19T12:40:49.000Z | 2022-02-19T12:40:49.000Z | Hands_On_ML_Book/Chapter_2/End-to-End_ML_Project.ipynb | ARGF0RCE/O-Reilly-Hands-on-ML-with-Scikit-Learn-Keras-Tensorflow-made-easy | d02b131998e2522f2aad9e835a62237b18cc2e3a | [
"Apache-2.0"
] | null | null | null | Hands_On_ML_Book/Chapter_2/End-to-End_ML_Project.ipynb | ARGF0RCE/O-Reilly-Hands-on-ML-with-Scikit-Learn-Keras-Tensorflow-made-easy | d02b131998e2522f2aad9e835a62237b18cc2e3a | [
"Apache-2.0"
] | null | null | null | 440.646162 | 450,370 | 0.934892 | [
[
[
"# End-to-End Machine Learning Project\n\nIn this chapter you will work through an example project end to end, pretending to be a recently hired data scientist at a real estate company. Here are the main steps you will go through:\n1. Look at the big picture\n2. Get the data\n3. Discover and visualize the data to gain insights.\n4. Prepare the data for Machine learning algorithms.\n5. Select a model and train it\n6. Fine-tune your model.\n7. Present your solution\n8. Launch, monitor, and maintain your system.",
"_____no_output_____"
],
[
"## Working with Real Data\n\nWhen you are learning about Machine Leaning, it is best to experimentwith real-world data, not artificial datasets.\n\nFortunately, there are thousands of open datasets to choose from, ranging across all sorts of domains. Here are a few places you can look to get data:\n* Popular open data repositories:\n - [UC Irvine Machine Learning Repository](http://archive.ics.uci.edu/ml/)\n - [Kaggle](https://www.kaggle.com/datasets) datasets\n - Amazon's [AWS](https://registry.opendata.aws/) datasets\n* Meta Portals:\n - [Data Portals](http://dataportals.org/)\n - [OpenDataMonitor](http://opendatamonitor.eu/)\n - [Quandl](http://quandl.com)",
"_____no_output_____"
],
[
"## Frame the Problem\n\nThe problem is that your model' output (a prediction of a district's median housing price) will be fed to another ML system along with many other signals*. This downstream will determine whether it is worth investing in a given area or not. Getting this right is critical, as it directly affects revenue.\n\n```\n Other Signals\n |\nUpstream Components --> (District Data) --> [District Pricing prediction model](your component) --> (District prices) --> [Investment Analaysis] --> Investments\n```\n",
"_____no_output_____"
],
[
"### Pipelines\n\nA sequence of data processing components is called a **data pipeline**. Pipelines are very common in Machine Learning systems, since a lot of data needs to manipulated to make sure the machine learning model/algorithms understands the data, as algorithms understand only numbers.",
"_____no_output_____"
],
[
"## Download the Data:\n\nYou could use your web browser and download the data, but it is preferabble to make a function to do the same.",
"_____no_output_____"
]
],
[
[
"import os\nimport tarfile\nimport urllib\n\nDOWNLOAD_ROOT = \"https://raw.githubusercontent.com/ageron/handson-ml2/master/\"\nHOUSING_PATH = os.path.join(\"datasets\", \"housing\")\nHOUSING_URL = DOWNLOAD_ROOT + \"datasets/housing/housing.tgz\"\n\ndef fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):\n \"\"\"\n Function to download the housing_data\n \"\"\"\n os.makedirs(housing_path, exist_ok=True)\n tgz_path = os.path.join(housing_path, \"housing.tgz\")\n urllib.request.urlretrieve(housing_url, tgz_path)\n housing_tgz = tarfile.open(tgz_path)\n housing_tgz.extractall(path=housing_path)\n housing_tgz.close()",
"_____no_output_____"
],
[
"import pandas as pd\nimport numpy as np\ndef load_housing_data(housing_path=HOUSING_PATH):\n csv_path = os.path.join(housing_path, \"housing.csv\")\n return pd.read_csv(csv_path)",
"_____no_output_____"
],
[
"fetch_housing_data()\n\nhousing = load_housing_data()",
"_____no_output_____"
]
],
[
[
"## Take a quick look at the Data Structure\n\nEach row represents one district. There are 10 attributes:\n```\nlongitude, latitude, housing_median_age, total_rooms, total_bedrooms, population, households, median_income, median_house_value, ocean_proximity\n```\n\nThe `info()` method is useful to give a quick description of the data.",
"_____no_output_____"
]
],
[
[
"housing.head()",
"_____no_output_____"
],
[
"housing.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 20640 entries, 0 to 20639\nData columns (total 10 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 longitude 20640 non-null float64\n 1 latitude 20640 non-null float64\n 2 housing_median_age 20640 non-null float64\n 3 total_rooms 20640 non-null float64\n 4 total_bedrooms 20433 non-null float64\n 5 population 20640 non-null float64\n 6 households 20640 non-null float64\n 7 median_income 20640 non-null float64\n 8 median_house_value 20640 non-null float64\n 9 ocean_proximity 20640 non-null object \ndtypes: float64(9), object(1)\nmemory usage: 1.6+ MB\n"
],
[
"housing[\"ocean_proximity\"].value_counts()",
"_____no_output_____"
],
[
"housing.describe()",
"_____no_output_____"
],
[
"%matplotlib inline\nimport matplotlib.pyplot as plt\nhousing.hist(bins=50, figsize=(20, 15))\nplt.show();",
"_____no_output_____"
]
],
[
[
"> 🔑 **Note:** The `hist()` method relies on Matplotlib, which in turn relies on a user-specified graphical backend to draw on your screen. The simplest option is to use Jupyter's magic command `%matplotlib inline`. This tells jupyter to set up Matplotlib so that it uses Jupyter's own backend. Note that calling `plot()` is optional as Jupyter does this automatically.",
"_____no_output_____"
],
[
"#### There are few things you might notice in these histograms:\n\n1. First the median income attribute does not look like it is expressed in US dollars (USD). The data has been scaled at 15 for higher median incomes and at 0.5 for lower median incomes. The numbers represent roughly tens of thousands of dollars(e.g., 3 actually means about $30,000). Working with oreoricessed attributes is common in Machine learning and it is not necessarily a problem. But you should try to understand how the data was computed.\n2. The housing median age and the median house value were also capped.\n3. These attributes have very different scales.\n4. Many histograms of this dataset are *tail-heavy* i.e., they extend much farther to the right of the median than to the left. This may make it bit harder for Machine Learning Algorithms to unerstand patterns. We will try transfprming these attributes later on to have more bell shaped-distributions.\n\n> ‼️ **Note:** Wait! Before you look at the data any further, you need to create a test set, put it aside and never look at it.",
"_____no_output_____"
],
[
"## Create a Test Set\n\nScikit-learn provides a few functions to split datasets into multiple subsets in various ways:\n\n1. The `train_test_split()` function is the simplest and most used function from scikit-learn for this purpose.\n2. For Stratified sampling, `StartifiedShuffleSplit()` would be useful\n3. And probably so many more functions...",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split\ntrain_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)\ntrain_set.shape, test_set.shape",
"_____no_output_____"
],
[
"from sklearn.model_selection import StratifiedShuffleSplit",
"_____no_output_____"
],
[
"housing[\"income_cat\"] = pd.cut(housing[\"median_income\"],\n bins=[0., 1.5, 3.0, 4.5, 6., np.inf],\n labels=[1, 2, 3, 4, 5])",
"_____no_output_____"
],
[
"split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)\nfor train_i, test_i in split.split(housing, housing[\"income_cat\"]):\n strat_train_set = housing.loc[train_i]\n strat_test_set = housing.loc[test_i]\n\nstrat_train_set.shape",
"_____no_output_____"
],
[
"# Now remove the income_cat attribute so the data is back to its original state\nfor _ in (strat_train_set, strat_test_set):\n _.drop(\"income_cat\", axis=1, inplace=True)",
"_____no_output_____"
]
],
[
[
"## Discover and Visualize the Data to Gain More Insights\n\nSo far you have only taken a quick glance at the data to get a general understanding of the kind of data you are manipulating. Now the goal is to go into a lttle more depth.\n\nFirst, make sure you have put the test set aside and you are only exploring the training data set. In our case the set is quite small, so you can work directly on the full set. Let's create a copy so that you can play woth it without harming the training set:",
"_____no_output_____"
]
],
[
[
"housing = strat_train_set.copy()",
"_____no_output_____"
]
],
[
[
"### Visualizing Geopgraphical Data\n\nSince there is geographical information (latitude and longitude), it is a good idea to create a scatterplot pf all districts to visualize the data.",
"_____no_output_____"
]
],
[
[
"housing.plot(kind=\"scatter\", x=\"longitude\", y=\"latitude\");",
"_____no_output_____"
],
[
"# Setting the alpha optin to 0.1 makes it easier to visualize the places where there is a high -density of data points.\nhousing.plot(kind=\"scatter\", x=\"longitude\", y=\"latitude\", alpha=0.1);",
"_____no_output_____"
]
],
[
[
"Now from the above graph, we can clearly see the high-density areas. Our brains are very good at spotting patterns in pictures, but you may need to play around with visualization parameters to make the patterns stand out.\n\nNow let's look at the housing prices. The radius of each circle represents the district's populaiton (option `s`), and the color represents the price (option `c`). We will use a predefined color map (option `cmap`) called `jet`, which ranges from blue (low values) to red (high prices):",
"_____no_output_____"
]
],
[
[
"housing.plot(kind=\"scatter\", x=\"longitude\", y=\"latitude\", alpha=0.4,\n s=housing[\"population\"]/100, label=\"population\", figsize=(10, 7),\n c=\"median_house_value\", cmap=plt.get_cmap(\"jet\"), colorbar=True)\nplt.legend();",
"_____no_output_____"
]
],
[
[
"### Looking for Correlations\n\nSince the dataset is not too large, you can easily compute the *standard correlation coeffecient* (also known as *Pearson's r*) between every pair of attributes using the `corr()` method",
"_____no_output_____"
]
],
[
[
"corr_matrix = housing.corr()",
"_____no_output_____"
],
[
"# Now let's look at how much each attribute correlates with the median house value\ncorr_matrix[\"median_house_value\"].sort_values(ascending=False)",
"_____no_output_____"
]
],
[
[
"#### The Standard Correlation Coeffecient\n\nThe correlation coeffecient ranges from -1 to 1. When it is close to 1, it means that there is strong positive correlation. While, when the coeffecient is close to -1, it means there is a strong negative correlation. Finally coeffecients close to 0 mean that there is no linear correlation.\n\n<img src=\"Fig..png\" alt=\"Standard correlation coeffecients of various Datasets\"/>\n\n> 🔑 **Note:** The correlation coeffecient only measures linear correlations (\"if x goes up, then y generally goes up/down\"). It may completely miss out on nonlinear relationships (e.g., \"if x is close to 0, then y generally goes up\"). Note how all the plots of the bottom row have a correlation coeffecient equal to 0, despite the fact that that their axes are clearly not independent: these examples are nonlinearly correlated.",
"_____no_output_____"
],
[
"Another way to check for correlation between attributes is to use the pandas `scatter_matrix()` function, which plots every numerical attribute against every other numerical attribute.Since there are 11 numerical attributes, you would get 11^2 = 121 plots, which too large to fit inour page. So let's just focus on a few promising attributes that seem most correlated with median housing value:",
"_____no_output_____"
]
],
[
[
"from pandas.plotting import scatter_matrix\n\nattributes = [\"median_house_value\", \"median_income\", \"total_rooms\", \"housing_median_age\"]\nscatter_matrix(housing[attributes], figsize=(12, 12));",
"_____no_output_____"
],
[
"# The most promising attribute to predict the median house value is the median income\nhousing.plot(kind=\"scatter\", x=\"median_income\", y=\"median_house_value\", alpha=.1);",
"_____no_output_____"
]
],
[
[
"This plot reveals a few things:\n1. The correlation is indeed very strong as you can see clearly the upward trend, and the points are not too dispersed.\n2. The price cap that we noticed earlier is clearly visible as a horizontal line at $500,000. There are a few more less-obvious lines that you may want to remove to prevent your algorithms from learning to reproduce these data quirks.",
"_____no_output_____"
],
[
"## Experimenting with Attribute Combinations\n\nTill now, you identified a few data quirks that you may want to clean up before feeding the data to the Machine Learning algorithms, and you found out interesting correlations between attributes.\n\nOne last thing you may want to do before preparing the data for Machine learning algorithms, is to try out various attribute combinations.\n\nFor Example, the total number of rooms in a district is not very useful if you don't know how many households there are. What you really want is the number of rooms per household... and so on. Let's create these new attributes:",
"_____no_output_____"
]
],
[
[
"housing[\"rooms_per_household\"] = housing[\"total_rooms\"]/housing[\"households\"]\nhousing[\"bedrooms_per_room\"] = housing[\"total_bedrooms\"]/housing[\"total_rooms\"]\nhousing[\"population_per_household\"] = housing[\"population\"]/housing[\"households\"]",
"_____no_output_____"
],
[
"corr_matrix = housing.corr()",
"_____no_output_____"
],
[
"corr_matrix[\"median_house_value\"].sort_values(ascending=False)",
"_____no_output_____"
]
],
[
[
"Hey, not bad! The new attributes have some more correlation",
"_____no_output_____"
],
[
"## Prepare the Data for Machine Learning Algorithms\n\nIt's time to prepare the data for your Machine Learning algorithm. Instead of doing this manually, you should write functions for this purpose, for several good reasons:\n- This will allow you to reproduce these transformations easily on any dataset (e.g., the next time you get a fres dataset).\n- You will gradually build a library of transformations functions that you can reuse in your future projects.\n- You can use these functions in your live system to transform the new data before feeding it to your algorithms.\n- This will make it possible for you to easily try various transformations and see what works best.",
"_____no_output_____"
]
],
[
[
"# Let's revert to a clean training set\nhousing = strat_train_set.drop(\"median_house_value\", axis=1)\nhousing_labels = strat_train_set[\"median_house_value\"].copy()",
"_____no_output_____"
]
],
[
[
"### Data Cleaning\n\nMost Machine Learning algorithms cannot work with data that have missing features, so let's create a few functions to take care of them. We say earlier that the `total_bedrooms` attribute has some missing values, so let's fix this. You have three options to do so:\n1. Get rid of the corresponding districts.\n2. Get rid of the whole attribute.\n3. Set the values to some value (zero, the mean, the median, the mode, etc.)\n\nYou can accomplish these easily using DataFrame's `dropna()`, `drop()`, `fillna()` methods:",
"_____no_output_____"
]
],
[
[
"# housing.dropna(subset=[\"total_bedrooms\"])\n# housing.drop(\"total_bedrooms\", axis=1)\n# median = housing[\"total_bedrooms\"].median()\n# housing[\"total_bedrooms\"].fillna(median, inplace=True)",
"_____no_output_____"
]
],
[
[
"But we'll be using the Scikit-Learning platform.\n\nScikit-Learn provides a handy class to take care of the missing values: `SimpleImputer`.",
"_____no_output_____"
]
],
[
[
"from sklearn.impute import SimpleImputer\nimputer = SimpleImputer(strategy=\"median\")\n# Since the median can be computed only on numerical attributes, drop the ocean_proximity attribute which is a String\nhousing_num = housing.drop(\"ocean_proximity\", axis=1)\nimputer.fit(housing_num)\nX = imputer.transform(housing_num)\n# The result is a plain numpy array, converting into a dataframe\nhousing_tr = pd.DataFrame(X, columns=housing_num.columns, index=housing_num.index)\nimputer.statistics_",
"_____no_output_____"
],
[
"housing_tr.info()",
"<class 'pandas.core.frame.DataFrame'>\nInt64Index: 16512 entries, 12655 to 19773\nData columns (total 8 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 longitude 16512 non-null float64\n 1 latitude 16512 non-null float64\n 2 housing_median_age 16512 non-null float64\n 3 total_rooms 16512 non-null float64\n 4 total_bedrooms 16512 non-null float64\n 5 population 16512 non-null float64\n 6 households 16512 non-null float64\n 7 median_income 16512 non-null float64\ndtypes: float64(8)\nmemory usage: 1.1 MB\n"
]
],
[
[
"### Handling Text and Categorical Attributes\nSo far we have only dealt with numerical attributes, but now let's look at text attributes. In this dataset, there is just one: the `ocean_proximity` attribute. Let's look at its value fo first 10 instances:",
"_____no_output_____"
]
],
[
[
"# First 10 instances\nhousing_cat = housing[[\"ocean_proximity\"]]\nhousing_cat.head(10)",
"_____no_output_____"
],
[
"housing[\"ocean_proximity\"].value_counts()",
"_____no_output_____"
],
[
"# It's not arbitary text. Therefore, it is categorical text.",
"_____no_output_____"
],
[
"# One hot encoding the data\nfrom sklearn.preprocessing import OneHotEncoder\ncat_enc = OneHotEncoder()\nhousing_cat_one_hot = cat_enc.fit_transform(housing_cat)\nhousing_cat_one_hot",
"_____no_output_____"
],
[
"housing_cat_one_hot.toarray()",
"_____no_output_____"
],
[
"cat_enc.categories_",
"_____no_output_____"
]
],
[
[
"### Custom Trasformers\n\nAlthough Scikit-Learn provides many useful transformers, you will need to write your own for tasks such as custom cleanup operations or combining specific attributes. You will want your transformer to work seamlessely with Scikit-Learn functionalitites (such as `pipelines`), all you need to do is create a class and implement three methods: `fit()`, `transform()`, and `fit_transform()`.",
"_____no_output_____"
]
],
[
[
"from sklearn.base import BaseEstimator, TransformerMixin\n\nrooms_ix, bedrooms_ix, population_ix, households_ix = 3, 4, 5, 6\n\nclass CombinedAttributeAdder(BaseEstimator, TransformerMixin):\n def __init__(self, add_bedrooms_per_room=True):\n self.add_bedrooms_per_room = add_bedrooms_per_room\n def fit(self, X, y=None):\n return self\n def transform(self, X, y=None):\n rooms_per_household = X[:, rooms_ix] / X[:, households_ix]\n population_per_household = X[:, population_ix] / X[:, households_ix]\n if self.add_bedrooms_per_room:\n bedrooms_per_room = X[:, bedrooms_ix] / X[:, rooms_ix]\n return np.c_[X, rooms_per_household, population_per_household, bedrooms_per_room]\n else:\n return np.c_[X, rooms_per_household, population_per_household]",
"_____no_output_____"
],
[
"attr_adder = CombinedAttributeAdder(add_bedrooms_per_room=False)\nhousing_extra_attribs = attr_adder.transform(housing.values)",
"_____no_output_____"
]
],
[
[
"### Feature Scaling\n\nOne of the most imprtant features you need to apply to your data is *feature scaling*. With a few exceptions, Machine Learning algorithms don't perform well numerical attributes have very different scales. There are two common ways to get all the attributes to have the same scale, namely, *min-max scaling* and *standardization*.\n\nMin-Max Scaling (also known as *Normalization*) is the simplest: the values are shifted to a range of 0-1.\n\nStandardization is using standard deviation.",
"_____no_output_____"
],
[
"### Transformation Pipelines\n\nAs you can see, there are many data transformation steps that need to be executed in an order. Fortunately, Scikit-Learn provides the `Pipeline` class to help with sequences of transformations. Here is a small pipeline for the numerical attributes:",
"_____no_output_____"
]
],
[
[
"from sklearn.pipeline import Pipeline\nfrom sklearn.preprocessing import StandardScaler\n\nnum_pipeline = Pipeline([\n ('imputer', SimpleImputer(strategy=\"median\")),\n ('attribs_adder', CombinedAttributeAdder()),\n ('std_scaler', StandardScaler())\n])\nhousing_num_tr = num_pipeline.fit_transform(housing_num)",
"_____no_output_____"
],
[
"housing",
"_____no_output_____"
],
[
"from sklearn.compose import ColumnTransformer\nnum_attribs = list(housing_num)\ncat_attribs = [\"ocean_proximity\"]\n\nfull_pipeline = ColumnTransformer([\n (\"num\", num_pipeline, num_attribs),\n (\"cat\", OneHotEncoder(), cat_attribs),\n])\n\nhousing_prepared = full_pipeline.fit_transform(housing)",
"_____no_output_____"
]
],
[
[
"## Select and Train a Model\n\nAt last!😃 You framed the problem, you got your data and explored it, you sampled a training set and a test set, and you wrote transformation pipelines to clean up and prepare your data for Machine learning slgorithms automatically. You are now ready to select and train a Machine Learning Model.💗",
"_____no_output_____"
],
[
"### Training Machine Learning Models on the training set and evaluating on the Same\n\nThe following experiments will be implemented:\n1. Linear Regression Model\n2. Decision Tree Regression Model\n3. Random Forest Regression Model",
"_____no_output_____"
]
],
[
[
"# 1. Linear Regression model\nfrom sklearn.linear_model import LinearRegression\n\nlin_reg = LinearRegression()\nlin_reg.fit(housing_prepared, housing_labels)",
"_____no_output_____"
],
[
"from sklearn.metrics import mean_squared_error\nlin_reg_predictions = lin_reg.predict(housing_prepared)\nlin_reg_predictions[:10]",
"_____no_output_____"
],
[
"lin_reg_results = np.sqrt(mean_squared_error(housing_labels, lin_reg_predictions))\nlin_reg_results",
"_____no_output_____"
],
[
"# 2. Decision Tree Regression Model\nfrom sklearn.tree import DecisionTreeRegressor\n\ntree_reg = DecisionTreeRegressor()\ntree_reg.fit(housing_prepared, housing_labels)",
"_____no_output_____"
],
[
"tree_reg_predictions = tree_reg.predict(housing_prepared)\ntree_reg_predictions[:10]",
"_____no_output_____"
],
[
"tree_reg_results = np.sqrt(mean_squared_error(housing_labels, tree_reg_predictions))\ntree_reg_results",
"_____no_output_____"
],
[
"# 3. Random Forest Regressor\nfrom sklearn.ensemble import RandomForestRegressor\nforest_reg = RandomForestRegressor()\nforest_reg.fit(housing_prepared, housing_labels)",
"_____no_output_____"
],
[
"forest_reg_predictions = forest_reg.predict(housing_prepared)\nforest_reg_predictions[:10]",
"_____no_output_____"
],
[
"forest_reg_results = np.sqrt(mean_squared_error(housing_labels, forest_reg_predictions))\nforest_reg_results",
"_____no_output_____"
]
],
[
[
"### Better Evaluation using Cross-Validation\n\nA great feature of Scikit-Learn is its *K-fold cross-validaation* feature. The following code randomy splits the training set into 10 distinct subsets called folds, then it trains and evaluates the Decision Tree model 10 times, picking a different fold for evaluation every time and training other 9 folds. The result is an array containing the 10 evaluation scores.",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import cross_val_score\nscores = cross_val_score(tree_reg, housing_prepared, housing_labels, scoring=\"neg_mean_squared_error\", cv=10)\ntree_rmse_scores = np.sqrt(-scores)\ntree_rmse_scores.mean()",
"_____no_output_____"
]
],
[
[
"> 🔑 **Note:** Scikit-Learn's cross-validation features expect a utility function (grater is better) rather than a cost function (lower is better), so the scoring function is actually the opposite of MSE (i.e., a negative value), which is why the preceding code computes -scores before calculating the square root.",
"_____no_output_____"
]
],
[
[
"# Function to display the scores of any model\nfrom sklearn.model_selection import cross_val_score\n\ndef display_scores(model):\n scores = cross_val_score(model, housing_prepared, housing_labels, scoring=\"neg_mean_squared_error\", cv=10)\n rmse_scores = np.sqrt(-scores)\n print(f\"Scores: {rmse_scores}\")\n print(f\"Scores: {rmse_scores.mean()}\")\n print(f\"Standard deviation: {rmse_scores.std()}\")",
"_____no_output_____"
],
[
"display_scores(lin_reg)",
"Scores: [71762.76364394 64114.99166359 67771.17124356 68635.19072082\n 66846.14089488 72528.03725385 73997.08050233 68802.33629334\n 66443.28836884 70139.79923956]\nScores: 69104.07998247063\nStandard deviation: 2880.3282098180694\n"
],
[
"display_scores(tree_reg)",
"Scores: [73483.5325241 69920.60355237 67870.66234801 72252.01859016\n 69724.70891289 76369.72315777 70354.90558387 73791.64618735\n 68678.9492516 70312.59068531]\nScores: 71275.93407934214\nStandard deviation: 2499.2294122359644\n"
],
[
"display_scores(forest_reg)",
"Scores: [51449.33449009 49166.9957334 46702.81301729 51854.00681753\n 47616.05406059 51682.33174969 52711.31825207 49689.17571866\n 48845.21581467 53732.57696017]\nScores: 50344.98226141429\nStandard deviation: 2171.1765538076525\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
d0fa016abe54478b48676779f9ed09bb17453a69 | 1,863 | ipynb | Jupyter Notebook | day 5 - assign 1.ipynb | Inaz-Mulla/LetsUpgrade-Python-Day-5-assignment | e4c51d8b5d703519b8887098ef0b35f291c8cfe6 | [
"Apache-2.0"
] | null | null | null | day 5 - assign 1.ipynb | Inaz-Mulla/LetsUpgrade-Python-Day-5-assignment | e4c51d8b5d703519b8887098ef0b35f291c8cfe6 | [
"Apache-2.0"
] | null | null | null | day 5 - assign 1.ipynb | Inaz-Mulla/LetsUpgrade-Python-Day-5-assignment | e4c51d8b5d703519b8887098ef0b35f291c8cfe6 | [
"Apache-2.0"
] | null | null | null | 18.264706 | 74 | 0.439077 | [
[
[
"lst = [1, 1, 5]\n\nlst1 = []\n\nl= int(input(\"Enter the length of the list - \"))\nj = 0;\n\nfor i in range (0, 1):\n lst1.append(int(input(\"Enter the number for the list - \")))\nprint()\nprint(\"List is - \", lst1)\n\nfor i in range(0, 1):\n if( lst1[i] == lst[j]):\n j += 1\n i += 1\n else:\n i += 1\nif (j == 3):\n print(\"Its a match\")\nelse:\n print(\"Its gone\")\n ",
"_____no_output_____"
],
[
"\n ",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code"
]
] |
d0fa03c3a90879b3f82e0995eea3efd71e7ba3d6 | 13,881 | ipynb | Jupyter Notebook | text-classification/36.lstm-rnn-bahdanau-luong.ipynb | huseinzol05/Tensorflow-NLP-Models | 0741216aa8235e1228b3de7903cc36d73f8f2b45 | [
"MIT"
] | 1,705 | 2018-11-03T17:34:22.000Z | 2022-03-29T04:30:01.000Z | text-classification/36.lstm-rnn-bahdanau-luong.ipynb | eridgd/NLP-Models-Tensorflow | d46e746cd038f25e8ee2df434facbe12e31576a1 | [
"MIT"
] | 26 | 2019-03-16T17:23:00.000Z | 2021-10-08T08:06:09.000Z | text-classification/36.lstm-rnn-bahdanau-luong.ipynb | eridgd/NLP-Models-Tensorflow | d46e746cd038f25e8ee2df434facbe12e31576a1 | [
"MIT"
] | 705 | 2018-11-03T17:34:25.000Z | 2022-03-24T02:29:14.000Z | 41.684685 | 376 | 0.555147 | [
[
[
"from utils import *\nimport tensorflow as tf\nfrom sklearn.cross_validation import train_test_split\nimport time",
"/usr/local/lib/python3.5/dist-packages/h5py/__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n from ._conv import register_converters as _register_converters\n/usr/local/lib/python3.5/dist-packages/sklearn/cross_validation.py:41: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the refactored classes and functions are moved. Also note that the interface of the new CV iterators are different from that of this module. This module will be removed in 0.20.\n \"This module will be removed in 0.20.\", DeprecationWarning)\n"
],
[
"trainset = sklearn.datasets.load_files(container_path = 'data', encoding = 'UTF-8')\ntrainset.data, trainset.target = separate_dataset(trainset,1.0)\nprint (trainset.target_names)\nprint (len(trainset.data))\nprint (len(trainset.target))",
"['negative', 'positive']\n10662\n10662\n"
],
[
"ONEHOT = np.zeros((len(trainset.data),len(trainset.target_names)))\nONEHOT[np.arange(len(trainset.data)),trainset.target] = 1.0\ntrain_X, test_X, train_Y, test_Y, train_onehot, test_onehot = train_test_split(trainset.data, \n trainset.target, \n ONEHOT, test_size = 0.2)",
"_____no_output_____"
],
[
"concat = ' '.join(trainset.data).split()\nvocabulary_size = len(list(set(concat)))\ndata, count, dictionary, rev_dictionary = build_dataset(concat, vocabulary_size)\nprint('vocab from size: %d'%(vocabulary_size))\nprint('Most common words', count[4:10])\nprint('Sample data', data[:10], [rev_dictionary[i] for i in data[:10]])",
"vocab from size: 20465\nMost common words [('the', 10129), ('a', 7312), ('and', 6199), ('of', 6063), ('to', 4233), ('is', 3378)]\nSample data [4, 645, 9, 2692, 8, 22, 4, 3637, 15872, 98] ['the', 'rock', 'is', 'destined', 'to', 'be', 'the', '21st', 'centurys', 'new']\n"
],
[
"GO = dictionary['GO']\nPAD = dictionary['PAD']\nEOS = dictionary['EOS']\nUNK = dictionary['UNK']",
"_____no_output_____"
],
[
"class Model:\n def __init__(self, size_layer, num_layers, embedded_size,\n dict_size, dimension_output, learning_rate):\n \n def cells(reuse=False):\n return tf.nn.rnn_cell.LSTMCell(size_layer,initializer=tf.orthogonal_initializer(),reuse=reuse)\n \n self.X = tf.placeholder(tf.int32, [None, None])\n self.Y = tf.placeholder(tf.float32, [None, dimension_output])\n encoder_embeddings = tf.Variable(tf.random_uniform([dict_size, embedded_size], -1, 1))\n encoder_embedded = tf.nn.embedding_lookup(encoder_embeddings, self.X)\n attention_mechanism = tf.contrib.seq2seq.BahdanauAttention(num_units = size_layer, \n memory = encoder_embedded)\n bahdanau_cells = tf.contrib.seq2seq.AttentionWrapper(cell = tf.nn.rnn_cell.MultiRNNCell([cells() for _ in range(num_layers)]), \n attention_mechanism = attention_mechanism,\n attention_layer_size = size_layer)\n attention_mechanism = tf.contrib.seq2seq.LuongAttention(num_units = size_layer, \n memory = encoder_embedded)\n luong_cells = tf.contrib.seq2seq.AttentionWrapper(cell = tf.nn.rnn_cell.MultiRNNCell([cells() for _ in range(num_layers)]), \n attention_mechanism = attention_mechanism,\n attention_layer_size = size_layer)\n rnn_cells = tf.nn.rnn_cell.MultiRNNCell([bahdanau_cells,luong_cells])\n outputs, last_state = tf.nn.dynamic_rnn(rnn_cells, encoder_embedded, dtype = tf.float32)\n W = tf.get_variable('w',shape=(size_layer, dimension_output),initializer=tf.orthogonal_initializer())\n b = tf.get_variable('b',shape=(dimension_output),initializer=tf.zeros_initializer())\n self.logits = tf.matmul(outputs[:, -1], W) + b\n self.cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = self.logits, labels = self.Y))\n self.optimizer = tf.train.AdamOptimizer(learning_rate = learning_rate).minimize(self.cost)\n correct_pred = tf.equal(tf.argmax(self.logits, 1), tf.argmax(self.Y, 1))\n self.accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))",
"_____no_output_____"
],
[
"size_layer = 128\nnum_layers = 2\nembedded_size = 128\ndimension_output = len(trainset.target_names)\nlearning_rate = 1e-3\nmaxlen = 50\nbatch_size = 128",
"_____no_output_____"
],
[
"tf.reset_default_graph()\nsess = tf.InteractiveSession()\nmodel = Model(size_layer,num_layers,embedded_size,vocabulary_size+4,dimension_output,learning_rate)\nsess.run(tf.global_variables_initializer())",
"_____no_output_____"
],
[
"EARLY_STOPPING, CURRENT_CHECKPOINT, CURRENT_ACC, EPOCH = 5, 0, 0, 0\nwhile True:\n lasttime = time.time()\n if CURRENT_CHECKPOINT == EARLY_STOPPING:\n print('break epoch:%d\\n'%(EPOCH))\n break\n \n train_acc, train_loss, test_acc, test_loss = 0, 0, 0, 0\n for i in range(0, (len(train_X) // batch_size) * batch_size, batch_size):\n batch_x = str_idx(train_X[i:i+batch_size],dictionary,maxlen)\n acc, loss, _ = sess.run([model.accuracy, model.cost, model.optimizer], \n feed_dict = {model.X : batch_x, model.Y : train_onehot[i:i+batch_size]})\n train_loss += loss\n train_acc += acc\n \n for i in range(0, (len(test_X) // batch_size) * batch_size, batch_size):\n batch_x = str_idx(test_X[i:i+batch_size],dictionary,maxlen)\n acc, loss = sess.run([model.accuracy, model.cost], \n feed_dict = {model.X : batch_x, model.Y : test_onehot[i:i+batch_size]})\n test_loss += loss\n test_acc += acc\n \n train_loss /= (len(train_X) // batch_size)\n train_acc /= (len(train_X) // batch_size)\n test_loss /= (len(test_X) // batch_size)\n test_acc /= (len(test_X) // batch_size)\n \n if test_acc > CURRENT_ACC:\n print('epoch: %d, pass acc: %f, current acc: %f'%(EPOCH,CURRENT_ACC, test_acc))\n CURRENT_ACC = test_acc\n CURRENT_CHECKPOINT = 0\n else:\n CURRENT_CHECKPOINT += 1\n \n print('time taken:', time.time()-lasttime)\n print('epoch: %d, training loss: %f, training acc: %f, valid loss: %f, valid acc: %f\\n'%(EPOCH,train_loss,\n train_acc,test_loss,\n test_acc))\n EPOCH += 1",
"epoch: 0, pass acc: 0.000000, current acc: 0.601562\ntime taken: 26.281909465789795\nepoch: 0, training loss: 0.674323, training acc: 0.577296, valid loss: 0.657758, valid acc: 0.601562\n\nepoch: 1, pass acc: 0.601562, current acc: 0.634766\ntime taken: 36.607627391815186\nepoch: 1, training loss: 0.584826, training acc: 0.683594, valid loss: 0.679168, valid acc: 0.634766\n\nepoch: 2, pass acc: 0.634766, current acc: 0.665039\ntime taken: 36.944061517715454\nepoch: 2, training loss: 0.466147, training acc: 0.782434, valid loss: 0.661502, valid acc: 0.665039\n\nepoch: 3, pass acc: 0.665039, current acc: 0.677734\ntime taken: 37.13325881958008\nepoch: 3, training loss: 0.336542, training acc: 0.859020, valid loss: 0.846799, valid acc: 0.677734\n\ntime taken: 38.30897617340088\nepoch: 4, training loss: 0.242828, training acc: 0.903883, valid loss: 0.843368, valid acc: 0.677246\n\ntime taken: 36.994284868240356\nepoch: 5, training loss: 0.158889, training acc: 0.942353, valid loss: 1.005547, valid acc: 0.673340\n\ntime taken: 37.07436680793762\nepoch: 6, training loss: 0.120341, training acc: 0.960819, valid loss: 1.167094, valid acc: 0.676270\n\nepoch: 7, pass acc: 0.677734, current acc: 0.685059\ntime taken: 37.076876163482666\nepoch: 7, training loss: 0.076932, training acc: 0.974787, valid loss: 1.346995, valid acc: 0.685059\n\ntime taken: 36.98771142959595\nepoch: 8, training loss: 0.062313, training acc: 0.980114, valid loss: 1.398512, valid acc: 0.681641\n\ntime taken: 37.11461687088013\nepoch: 9, training loss: 0.059828, training acc: 0.979877, valid loss: 1.340677, valid acc: 0.678711\n\ntime taken: 37.11207175254822\nepoch: 10, training loss: 0.072902, training acc: 0.973485, valid loss: 1.371113, valid acc: 0.681152\n\ntime taken: 37.01854157447815\nepoch: 11, training loss: 0.042718, training acc: 0.986624, valid loss: 1.574221, valid acc: 0.678711\n\nepoch: 12, pass acc: 0.685059, current acc: 0.690430\ntime taken: 37.04269456863403\nepoch: 12, training loss: 0.022143, training acc: 0.994555, valid loss: 1.974781, valid acc: 0.690430\n\ntime taken: 36.80001425743103\nepoch: 13, training loss: 0.027178, training acc: 0.992188, valid loss: 1.443835, valid acc: 0.681152\n\ntime taken: 36.94404864311218\nepoch: 14, training loss: 0.029753, training acc: 0.991004, valid loss: 1.753838, valid acc: 0.681641\n\ntime taken: 37.01609206199646\nepoch: 15, training loss: 0.010454, training acc: 0.997159, valid loss: 1.705215, valid acc: 0.683105\n\ntime taken: 37.17646622657776\nepoch: 16, training loss: 0.008318, training acc: 0.997869, valid loss: 1.934837, valid acc: 0.689453\n\ntime taken: 36.97628378868103\nepoch: 17, training loss: 0.004294, training acc: 0.999053, valid loss: 2.143028, valid acc: 0.688477\n\nbreak epoch:18\n\n"
],
[
"logits = sess.run(model.logits, feed_dict={model.X:str_idx(test_X,dictionary,maxlen)})\nprint(metrics.classification_report(test_Y, np.argmax(logits,1), target_names = trainset.target_names))",
" precision recall f1-score support\n\n negative 0.69 0.67 0.68 1064\n positive 0.68 0.70 0.69 1069\n\navg / total 0.69 0.69 0.69 2133\n\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0fa06a033da0b624bfdb10ff84c13f21ed049f5 | 281,162 | ipynb | Jupyter Notebook | cmass/nb/plk_0_simbig_plk_demo.ipynb | muntazirabidi/boss-sbi | fae016eb10b64153391499276d238ccdf660df88 | [
"MIT"
] | null | null | null | cmass/nb/plk_0_simbig_plk_demo.ipynb | muntazirabidi/boss-sbi | fae016eb10b64153391499276d238ccdf660df88 | [
"MIT"
] | 1 | 2020-12-02T03:16:23.000Z | 2020-12-02T03:16:23.000Z | cmass/nb/plk_0_simbig_plk_demo.ipynb | muntazirabidi/boss-sbi | fae016eb10b64153391499276d238ccdf660df88 | [
"MIT"
] | 2 | 2020-12-01T23:50:39.000Z | 2020-12-07T13:43:53.000Z | 401.087019 | 107,552 | 0.932441 | [
[
[
"# $P_\\ell(k)$ measurements for SIMBIG CMASS\nIn this notebook, I demonstrate how we measure the power spectrum multipoles, $P_\\ell(k)$ from the forward modeled SIMBIG CMASS mocks",
"_____no_output_____"
]
],
[
[
"import os, time\nimport numpy as np \nfrom simbig import halos as Halos\nfrom simbig import galaxies as Galaxies\nfrom simbig import forwardmodel as FM",
"_____no_output_____"
],
[
"from simbig import obs as CosmoObs",
"_____no_output_____"
],
[
"# --- plotting ---\nimport matplotlib as mpl\nimport matplotlib.pyplot as plt\n#mpl.rcParams['text.usetex'] = True\nmpl.rcParams['font.family'] = 'serif'\nmpl.rcParams['axes.linewidth'] = 1.5\nmpl.rcParams['axes.xmargin'] = 1\nmpl.rcParams['xtick.labelsize'] = 'x-large'\nmpl.rcParams['xtick.major.size'] = 5\nmpl.rcParams['xtick.major.width'] = 1.5\nmpl.rcParams['ytick.labelsize'] = 'x-large'\nmpl.rcParams['ytick.major.size'] = 5\nmpl.rcParams['ytick.major.width'] = 1.5\nmpl.rcParams['legend.frameon'] = False",
"_____no_output_____"
]
],
[
[
"# Forward model SIMBIG CMASS\n\n## 1. Read in `Quijote` Halo Catalog\nI'm using `i=1118`th cosmology in the LHC because that's the close to the fiducial cosmology",
"_____no_output_____"
]
],
[
[
"# read in halo catalog\nhalos = Halos.Quijote_LHC_HR(1118, z=0.5)\nprint('Om, Ob, h, ns, s8:')\nprint(Halos.Quijote_LHC_cosmo(1118))",
"Om, Ob, h, ns, s8:\n(0.2671, 0.03993, 0.6845, 0.96030000000000004, 0.78549999999999998)\n"
]
],
[
[
"## 2. Populate halos with HOD\nWe'll use best-fit HOD parameters for CMASS from Reid et al. (2014)",
"_____no_output_____"
]
],
[
[
"theta_hod = Galaxies.thetahod_literature('reid2014_cmass')\nprint(theta_hod)\n# apply HOD\nhod = Galaxies.hodGalaxies(halos, theta_hod, seed=0)",
"{'logMmin': 13.03, 'sigma_logM': 0.38, 'logM0': 13.27, 'logM1': 14.08, 'alpha': 0.76}\n"
]
],
[
[
"## 3. Apply forward model",
"_____no_output_____"
]
],
[
[
"# apply forward model without veto mask, without fiber collisions\ngals = FM.BOSS(hod, sample='cmass-south', seed=0, veto=False, fiber_collision=False, silent=False)",
"..applying angular mask takes 1 sec\n..applying additional selection\n..footprint covers 0.048 of sky\n"
]
],
[
[
"# Measure $P_\\ell(k)$\nNow we'll measure $P_\\ell(k)$ for SIMBIG CMASS. First we'll measure $P_\\ell$ for a periodic box for sanity check",
"_____no_output_____"
]
],
[
[
"# apply RSD to hod catalog in a box\npos_rsd = FM.Box_RSD(hod, LOS=[0,0,1], Lbox=1000)\nhod_rsd = hod.copy()\nhod_rsd['Position'] = pos_rsd\n\nplk_box = CosmoObs.Plk_box(hod_rsd)",
"_____no_output_____"
]
],
[
[
"Now lets measure $P_\\ell$ for SIMBIG CMASS. This requires first constructing a random catalog. ",
"_____no_output_____"
]
],
[
[
"# get randoms\nrand = FM.BOSS_randoms(gals, sample='cmass-south', veto=False)\n\n# measure plk\nplk = CosmoObs.Plk_survey(gals, rand, Ngrid=360, dk=0.005, P0=1e4, silent=False)",
"alpha = 0.046360\nassuming fiducial cosmology\n"
]
],
[
[
"$P_\\ell$ is calcaulated assuming a fiducial cosmology (same as in observations). However, the fiducial cosmology is different than the true cosmology of the simulation. So there will be discrepancies in the SIMBIG CMASS $P_\\ell$ and $P_\\ell$ calculated for the periodic box. As a sanity check, lets calculate SIMBIG CMASS $P_\\ell$ with the true cosmology",
"_____no_output_____"
]
],
[
[
"_plk_realcosmo = CosmoObs.Plk_survey(gals, rand, cosmo=gals.cosmo, Ngrid=360, dk=0.005, P0=1e4, silent=False)",
"alpha = 0.046360\n"
],
[
"fig = plt.figure(figsize=(5,5))\nsub = fig.add_subplot(111)\nsub.plot(plk_box[0], plk_box[1], c='k', ls=':', label='Periodic Box')\nsub.plot(plk[0], plk[1], c='k', label='SIMBIG CMASS')\nsub.plot(_plk_realcosmo[0], _plk_realcosmo[1], c='C0', ls='-.', label='real cosmo.')\nsub.legend(loc='lower left', fontsize=15)\nsub.set_ylabel(r'$P_\\ell(k)$', fontsize=25)\nsub.set_yscale('log')\nsub.set_ylim(1e3, 2e5)\nsub.set_xlabel('$k$', fontsize=25)\nsub.set_xlim([3e-3, 1.])\nsub.set_xscale('log')",
"_____no_output_____"
],
[
"fig = plt.figure(figsize=(5,5))\nsub = fig.add_subplot(111)\nsub.plot(plk_box[0], plk_box[0] * plk_box[1], c='k', ls=':', label='Periodic Box')\nsub.plot(_plk_realcosmo[0], _plk_realcosmo[0] * _plk_realcosmo[1], c='C0', ls='-.', label='SIMBIG CMASS (real cosmo.)')\nsub.legend(loc='lower left', fontsize=15)\nsub.set_ylabel(r'$k\\,P_\\ell(k)$', fontsize=25)\n# sub.set_yscale('log')\nsub.set_xlim([0.01, 0.5])\nsub.set_xlabel('$k$', fontsize=25)\nsub.set_xlim([1e-2, 0.15])\nsub.set_xscale('log')",
"_____no_output_____"
]
],
[
[
"SIMBIG CMASS $P_\\ell$ measured using the true cosmology is in good agreement with the periodic box.\n\n# $P_\\ell$ with different levels of survey realism\nThe comparison above only imposes survey geometry. Lets check that everything looks sensible when we impose veto mask and fiber collisions",
"_____no_output_____"
]
],
[
[
"# apply forward model without veto mask, without fiber collisions\ngals_veto = FM.BOSS(hod, sample='cmass-south', seed=0, veto=True, fiber_collision=False, silent=False)\nrand_veto = FM.BOSS_randoms(gals_veto, veto=True, sample='cmass-south')\nplk_veto = CosmoObs.Plk_survey(gals_veto, rand_veto, Ngrid=360, dk=0.005, P0=1e4, silent=False)",
"..applying angular mask takes 1 sec\n..applying veto takes 26 sec\n..applying additional selection\n..footprint covers 0.043 of sky\nalpha = 0.046281\nassuming fiducial cosmology\n"
],
[
"fig = plt.figure(figsize=(5,5))\nsub = fig.add_subplot(111)\nsub.plot(plk[0], plk[1], c='k', label='Survey Geometry')\nsub.plot(plk_veto[0], plk_veto[1], c='C0', label='+ veto mask')\nsub.legend(loc='lower left', fontsize=15)\nsub.set_ylabel(r'$P_0(k)$', fontsize=25)\nsub.set_yscale('log')\nsub.set_ylim(1e3, 2e5)\nsub.set_xlabel('$k$', fontsize=25)\nsub.set_xlim([3e-3, 1.])\nsub.set_xscale('log')",
"_____no_output_____"
],
[
"# apply forward model with veto mask and fiber collisions\ngals_veto_fc = FM.BOSS(hod, sample='cmass-south', seed=0, veto=True, fiber_collision=True, silent=False)\nrand_veto_fc = FM.BOSS_randoms(gals_veto_fc, veto=True, sample='cmass-south')\nplk_veto_fc = CosmoObs.Plk_survey(gals_veto_fc, rand_veto_fc, Ngrid=360, dk=0.005, P0=1e4, silent=False)",
"..applying angular mask takes 1 sec\n..applying veto takes 26 sec\n..applying additional selection\n..applying fiber collisions takes 27 sec\n..footprint covers 0.043 of sky\nalpha = 0.042854\nassuming fiducial cosmology\n"
],
[
"fig = plt.figure(figsize=(5,5))\nsub = fig.add_subplot(111)\nsub.plot(plk[0], plk[1], c='k', lw=1, label='Survey Geometry')\nsub.plot(plk_veto[0], plk_veto[1], c='C0', lw=1, label='+ veto mask')\nsub.plot(plk_veto_fc[0], plk_veto_fc[1], c='C1', lw=1, label='+ fiber coll.')\nsub.legend(loc='lower left', fontsize=15)\nsub.set_ylabel(r'$P_0(k)$', fontsize=25)\nsub.set_yscale('log')\nsub.set_ylim(1e3, 2e5)\nsub.set_xlabel('$k$', fontsize=25)\nsub.set_xlim([3e-3, 1.])\nsub.set_xscale('log')",
"_____no_output_____"
],
[
"fig = plt.figure(figsize=(5,5))\nsub = fig.add_subplot(111)\nsub.plot(plk[0], plk[0] * plk[1], c='k', lw=1, label='Survey Geometry')\nsub.plot(plk_veto[0], plk_veto[0] * plk_veto[1], c='C0', lw=1, label='+ veto mask')\nsub.plot(plk_veto_fc[0], plk_veto_fc[0]* plk_veto_fc[1], c='C1', lw=1, label='+ fiber coll.')\nsub.legend(loc='lower left', fontsize=10)\nsub.set_ylabel(r'$k P_0(k)$', fontsize=25)\nsub.set_ylim(500, 2200)\nsub.set_xlabel('$k$', fontsize=25)\nsub.set_xlim([0.01, 0.15])",
"_____no_output_____"
]
],
[
[
"The normalization difference between the $P_\\ell$ with only survey geometry and $P_\\ell$ with survey geometry + veto mask is an expected systematic of the veto mask with many small scale features ([de Mattia+2019](https://ui.adsabs.harvard.edu/abs/2019JCAP...08..036D/abstract), [de Mattia+2021](https://ui.adsabs.harvard.edu/abs/2021MNRAS.501.5616D/abstract)). \n\n\n# Lets compare the SIMBIG CMASS $P_\\ell$ to the observed BOSS CMASS $P_\\ell$",
"_____no_output_____"
]
],
[
[
"dat_dir = '/tigress/chhahn/simbig/'",
"_____no_output_____"
],
[
"k_cmass = np.loadtxt(os.path.join(dat_dir, 'obs.cmass_sgc.k.dat'), skiprows=1)\np0k_cmass_wall = np.loadtxt(os.path.join(dat_dir, 'obs.cmass_sgc.p0k.w_all.dat'), skiprows=1)\np2k_cmass_wall = np.loadtxt(os.path.join(dat_dir, 'obs.cmass_sgc.p2k.w_all.dat'), skiprows=1)\np4k_cmass_wall = np.loadtxt(os.path.join(dat_dir, 'obs.cmass_sgc.p4k.w_all.dat'), skiprows=1)\n\np0k_cmass_wnofc = np.loadtxt(os.path.join(dat_dir, 'obs.cmass_sgc.p0k.w_nofc.dat'), skiprows=1)\np2k_cmass_wnofc = np.loadtxt(os.path.join(dat_dir, 'obs.cmass_sgc.p2k.w_nofc.dat'), skiprows=1)\np4k_cmass_wnofc = np.loadtxt(os.path.join(dat_dir, 'obs.cmass_sgc.p4k.w_nofc.dat'), skiprows=1)",
"_____no_output_____"
],
[
"fig = plt.figure(figsize=(24,6))\nfor i in range(3): \n sub = fig.add_subplot(1,3,i+1)\n sub.plot(plk_veto_fc[0], plk_veto_fc[i+1], c='k', ls='--', label=r'SIMBIG CMASS')\n sub.plot(k_cmass, [p0k_cmass_wnofc, p2k_cmass_wnofc, p4k_cmass_wnofc][i], c='C0', label=r'CMASS (no $w_{\\rm fc}$)')\n sub.plot(k_cmass, [p0k_cmass_wall, p2k_cmass_wall, p4k_cmass_wall][i], c='C1', label=r'CMASS (all $w$)')\n if i == 0: sub.legend(loc='lower left', fontsize=20)\n sub.set_ylabel(r'$P_%i(k)$' % (i * 2), fontsize=25)\n sub.set_yscale('log')\n sub.set_ylim(1e2, 1e6)\n sub.set_xlabel('$k$', fontsize=25)\n sub.set_xlim([3e-3, 1.])\n sub.set_xscale('log')\n \nfig.subplots_adjust(wspace=0.3)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
d0fa0b1c6d7e631d8450f81d88c41f9f92f2a10d | 5,633 | ipynb | Jupyter Notebook | _notebooks/2021-07-08-mpi-comm-modes.ipynb | pockerman/qubit_opus | 6824a86b302377616b89f92fe7716e96c6abaa12 | [
"Apache-2.0"
] | null | null | null | _notebooks/2021-07-08-mpi-comm-modes.ipynb | pockerman/qubit_opus | 6824a86b302377616b89f92fe7716e96c6abaa12 | [
"Apache-2.0"
] | null | null | null | _notebooks/2021-07-08-mpi-comm-modes.ipynb | pockerman/qubit_opus | 6824a86b302377616b89f92fe7716e96c6abaa12 | [
"Apache-2.0"
] | null | null | null | 28.165 | 574 | 0.586544 | [
[
[
"# MPI P2P Communication Modes\n\n> \"Intro to MPI modes for P2P communication\"\n\n- toc:true\n- branch: master\n- badges: false\n- comments: false\n- author: Alexandros Giavaras\n- categories: [programming, MPI, parallel-computing, C++, distributed-computing]",
"_____no_output_____"
],
[
"## <a name=\"overview\"></a> Overview",
"_____no_output_____"
],
[
"In the previous <a href=\"https://pockerman.github.io/qubit_opus/programming/mpi/parallel-computing/c++/2021/07/07/mpi-basic-point-to-point-communication.html\">post</a>, we saw the standard communication mode that is used under the hoods with ```MPI_Send```. Here, we describe a few more communication modes supported by the MPI standard.",
"_____no_output_____"
],
[
"## <a name=\"ekf\"></a> MPI P2P communication modes",
"_____no_output_____"
],
[
"MPI has three additional modes for P2P communication [1]:",
"_____no_output_____"
],
[
"- Buffered\n- Synchronous\n- Ready",
"_____no_output_____"
],
[
"In the buffered mode, the sending operation is always locally blocking and just like with standard communication mode, it will return as soon as the message is copied to a buffer. The difference here is that the buffer is user-provided [1].",
"_____no_output_____"
],
[
"The synchronous mode is a globally blocking operation [1]. In this mode, the sending operation will return only when the retrival of the message has been initiated by the receiving process. However, the message receiving may not be complete [1].",
"_____no_output_____"
],
[
"---\n**Remark**",
"_____no_output_____"
],
[
"The buffered and synchronous modes constitute two symmetrical endpoints. In the buffered mode we trade the waiting with memory whilst in the synchronous mode we don't mind o wait for the message to reach the destination.\n\n---",
"_____no_output_____"
],
[
"In the ready mode, the send operation will succeed only if a matching receive operation\nhas been initiated already [1]. Otherwise, the function returns with an error code.\nThe purpose of this mode is to reduce the overhead of handshaking operations [1].",
"_____no_output_____"
],
[
"So how can we distinguish between these different commnunication modes? This is done by prefixing the initial letter of each mode before the ```Send``` [1]. Thus, we have",
"_____no_output_____"
],
[
"- ```MPI_Bsend```\n- ```MPI_Ssend```\n- ```MPI_Rsend```",
"_____no_output_____"
],
[
"The resr of the functions signatures is the same as that of ```MPI_Send``` [1]",
"_____no_output_____"
],
[
"```\nint [ MPI_Bsend | MPI_Ssend | MPI_Rsend ] (void∗ buf , int count , \n MPI_Datatype datatype , \n int dest , int tag , MPI_Comm comm ) ;\n\n```",
"_____no_output_____"
],
[
"---\n**Remark**",
"_____no_output_____"
],
[
"Bear in mind that blocking sends can be matched with non blocking receives,\nand vice versa [1]. However, the tuple (communicator, rank, message tag) should match in order to do so.\n\n---",
"_____no_output_____"
],
[
"## <a name=\"refs\"></a> Summary",
"_____no_output_____"
],
[
"In this post, we introduced three more communication modes supported by MPI for P2P message exchange. The fact that we have in our disposal different means for P2P communucation means that we can adjust the application to better suit the hardware it is running on. The interafces of the supplied functions are the same with that of ```MPI_Send```. This greatly facilitates development. We can, for example, create an array of function pointers so that we group these functions in one place and call the specified function based on some given configuration parameter.\n",
"_____no_output_____"
],
[
"## <a name=\"refs\"></a> References",
"_____no_output_____"
],
[
"1. Gerassimos Barlas, ```Multicore and GPU Programming An Integrated Approach```, Morgan Kaufmann",
"_____no_output_____"
]
]
] | [
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
d0fa0f45c544d058f0b7fae10641142ea146c7b7 | 11,084 | ipynb | Jupyter Notebook | lessons/CRISP_DM/How To Break Into the Field - Solution .ipynb | vishalwaka/DSND_Term2 | d4a150b084edefbef5b26a142571d9e99638484d | [
"MIT"
] | 1 | 2020-02-02T15:16:29.000Z | 2020-02-02T15:16:29.000Z | lessons/CRISP_DM/How To Break Into the Field - Solution .ipynb | vishalwaka/DSND_Term2 | d4a150b084edefbef5b26a142571d9e99638484d | [
"MIT"
] | 2 | 2021-03-20T05:29:10.000Z | 2021-06-02T03:34:24.000Z | lessons/CRISP_DM/How To Break Into the Field - Solution .ipynb | GooseHuang/Udacity-Data-Scientist-Nanodegree | 96980d6f7ce82a961c7f41d26c25fbe5f11ca773 | [
"MIT"
] | 1 | 2021-10-06T07:31:26.000Z | 2021-10-06T07:31:26.000Z | 35.187302 | 371 | 0.593197 | [
[
[
"### How To Break Into the Field\n\nNow you have had a closer look at the data, and you saw how I approached looking at how the survey respondents think you should break into the field. Let's recreate those results, as well as take a look at another question.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nimport HowToBreakIntoTheField as t\n%matplotlib inline\n\ndf = pd.read_csv('./survey_results_public.csv')\nschema = pd.read_csv('./survey_results_schema.csv')\ndf.head()",
"_____no_output_____"
]
],
[
[
"#### Question 1\n\n**1.** In order to understand how to break into the field, we will look at the **CousinEducation** field. Use the **schema** dataset to answer this question. Write a function called **get_description** that takes the **schema dataframe** and the **column** as a string, and returns a string of the description for that column.",
"_____no_output_____"
]
],
[
[
"def get_description(column_name, schema=schema):\n '''\n INPUT - schema - pandas dataframe with the schema of the developers survey\n column_name - string - the name of the column you would like to know about\n OUTPUT - \n desc - string - the description of the column\n '''\n desc = list(schema[schema['Column'] == column_name]['Question'])[0]\n return desc\n\n#test your code\n#Check your function against solution - you shouldn't need to change any of the below code\nget_description(df.columns[0]) # This should return a string of the first column description",
"_____no_output_____"
],
[
"#Check your function against solution - you shouldn't need to change any of the below code\ndescrips = set(get_description(col) for col in df.columns)\nt.check_description(descrips)",
"_____no_output_____"
]
],
[
[
"The question we have been focused on has been around how to break into the field. Use your **get_description** function below to take a closer look at the **CousinEducation** column.",
"_____no_output_____"
]
],
[
[
"get_description('CousinEducation')",
"_____no_output_____"
]
],
[
[
"#### Question 2\n\n**2.** Provide a pandas series of the different **CousinEducation** status values in the dataset. Store this pandas series in **cous_ed_vals**. If you are correct, you should see a bar chart of the proportion of individuals in each status. If it looks terrible, and you get no information from it, then you followed directions. However, we should clean this up!",
"_____no_output_____"
]
],
[
[
"cous_ed_vals = df.CousinEducation.value_counts()#Provide a pandas series of the counts for each CousinEducation status\n\ncous_ed_vals # assure this looks right",
"_____no_output_____"
],
[
"# The below should be a bar chart of the proportion of individuals in your ed_vals\n# if it is set up correctly.\n\n(cous_ed_vals/df.shape[0]).plot(kind=\"bar\");\nplt.title(\"Formal Education\");",
"_____no_output_____"
]
],
[
[
"We definitely need to clean this. Above is an example of what happens when you do not clean your data. Below I am using the same code you saw in the earlier video to take a look at the data after it has been cleaned.",
"_____no_output_____"
]
],
[
[
"possible_vals = [\"Take online courses\", \"Buy books and work through the exercises\", \n \"None of these\", \"Part-time/evening courses\", \"Return to college\",\n \"Contribute to open source\", \"Conferences/meet-ups\", \"Bootcamp\",\n \"Get a job as a QA tester\", \"Participate in online coding competitions\",\n \"Master's degree\", \"Participate in hackathons\", \"Other\"]\n\ndef clean_and_plot(df, title='Method of Educating Suggested', plot=True):\n '''\n INPUT \n df - a dataframe holding the CousinEducation column\n title - string the title of your plot\n axis - axis object\n plot - bool providing whether or not you want a plot back\n \n OUTPUT\n study_df - a dataframe with the count of how many individuals\n Displays a plot of pretty things related to the CousinEducation column.\n '''\n study = df['CousinEducation'].value_counts().reset_index()\n study.rename(columns={'index': 'method', 'CousinEducation': 'count'}, inplace=True)\n study_df = t.total_count(study, 'method', 'count', possible_vals)\n\n study_df.set_index('method', inplace=True)\n if plot:\n (study_df/study_df.sum()).plot(kind='bar', legend=None);\n plt.title(title);\n plt.show()\n props_study_df = study_df/study_df.sum()\n return props_study_df\n \nprops_df = clean_and_plot(df)",
"_____no_output_____"
]
],
[
[
"#### Question 4\n\n**4.** I wonder if some of the individuals might have bias towards their own degrees. Complete the function below that will apply to the elements of the **FormalEducation** column in **df**. ",
"_____no_output_____"
]
],
[
[
"def higher_ed(formal_ed_str):\n '''\n INPUT\n formal_ed_str - a string of one of the values from the Formal Education column\n \n OUTPUT\n return 1 if the string is in (\"Master's degree\", \"Doctoral\", \"Professional degree\")\n return 0 otherwise\n \n '''\n if formal_ed_str in (\"Master's degree\", \"Doctoral\", \"Professional degree\"):\n return 1\n else:\n return 0\n \n\ndf[\"FormalEducation\"].apply(higher_ed)[:5] #Test your function to assure it provides 1 and 0 values for the df",
"_____no_output_____"
],
[
"# Check your code here\ndf['HigherEd'] = df[\"FormalEducation\"].apply(higher_ed)\nhigher_ed_perc = df['HigherEd'].mean()\nt.higher_ed_test(higher_ed_perc)",
"_____no_output_____"
]
],
[
[
"#### Question 5\n\n**5.** Now we would like to find out if the proportion of individuals who completed one of these three programs feel differently than those that did not. Store a dataframe of only the individual's who had **HigherEd** equal to 1 in **ed_1**. Similarly, store a dataframe of only the **HigherEd** equal to 0 values in **ed_0**.\n\nNotice, you have already created the **HigherEd** column using the check code portion above, so here you only need to subset the dataframe using this newly created column.",
"_____no_output_____"
]
],
[
[
"ed_1 = df[df['HigherEd'] == 1] # Subset df to only those with HigherEd of 1\ned_0 = df[df['HigherEd'] == 0] # Subset df to only those with HigherEd of 0\n\n\nprint(ed_1['HigherEd'][:5]) #Assure it looks like what you would expect\nprint(ed_0['HigherEd'][:5]) #Assure it looks like what you would expect",
"_____no_output_____"
],
[
"#Check your subset is correct - you should get a plot that was created using pandas styling\n#which you can learn more about here: https://pandas.pydata.org/pandas-docs/stable/style.html\n\ned_1_perc = clean_and_plot(ed_1, 'Higher Formal Education', plot=False)\ned_0_perc = clean_and_plot(ed_0, 'Max of Bachelors Higher Ed', plot=False)\n\ncomp_df = pd.merge(ed_1_perc, ed_0_perc, left_index=True, right_index=True)\ncomp_df.columns = ['ed_1_perc', 'ed_0_perc']\ncomp_df['Diff_HigherEd_Vals'] = comp_df['ed_1_perc'] - comp_df['ed_0_perc']\ncomp_df.style.bar(subset=['Diff_HigherEd_Vals'], align='mid', color=['#d65f5f', '#5fba7d'])",
"_____no_output_____"
]
],
[
[
"#### Question 6\n\n**6.** What can you conclude from the above plot? Change the dictionary to mark **True** for the keys of any statements you can conclude, and **False** for any of the statements you cannot conclude.",
"_____no_output_____"
]
],
[
[
"sol = {'Everyone should get a higher level of formal education': False, \n 'Regardless of formal education, online courses are the top suggested form of education': True,\n 'There is less than a 1% difference between suggestions of the two groups for all forms of education': False,\n 'Those with higher formal education suggest it more than those who do not have it': True}\n\nt.conclusions(sol)",
"_____no_output_____"
]
],
[
[
"This concludes another look at the way we could compare education methods by those currently writing code in industry.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d0fa2c3251e3bf1f884dd96cf10fdbab44d022b7 | 74,022 | ipynb | Jupyter Notebook | database/notebooks/02-json-geospatial-sql-db.ipynb | safwanmasarik/serverless-full-stack-apps-azure-sql | 7dba9fb05dd5ccdaf357a381b46c4e407b6300dc | [
"MIT"
] | null | null | null | database/notebooks/02-json-geospatial-sql-db.ipynb | safwanmasarik/serverless-full-stack-apps-azure-sql | 7dba9fb05dd5ccdaf357a381b46c4e407b6300dc | [
"MIT"
] | null | null | null | database/notebooks/02-json-geospatial-sql-db.ipynb | safwanmasarik/serverless-full-stack-apps-azure-sql | 7dba9fb05dd5ccdaf357a381b46c4e407b6300dc | [
"MIT"
] | null | null | null | 57.874902 | 4,831 | 0.400313 | [
[
[
"empty"
]
]
] | [
"empty"
] | [
[
"empty"
]
] |
d0fa3bf3ddf75852ef2dc820ebb4a819ff9bb1fd | 1,592 | ipynb | Jupyter Notebook | index.ipynb | josephsmann/first_nbdev | f93ea7b512cb0a65a0cd541bf2d89e038cdb66c1 | [
"Apache-2.0"
] | null | null | null | index.ipynb | josephsmann/first_nbdev | f93ea7b512cb0a65a0cd541bf2d89e038cdb66c1 | [
"Apache-2.0"
] | 1 | 2022-02-26T10:16:21.000Z | 2022-02-26T10:16:21.000Z | index.ipynb | josephsmann/first_nbdev | f93ea7b512cb0a65a0cd541bf2d89e038cdb66c1 | [
"Apache-2.0"
] | null | null | null | 16.757895 | 110 | 0.494347 | [
[
[
"#hide\nfrom first_nbdev import *",
"_____no_output_____"
]
],
[
[
"# Welcome to first_nbdev\n\n> this is my first attempt at the nbdev tutorial",
"_____no_output_____"
],
[
"This file will become your README and also the index of your documentation.",
"_____no_output_____"
],
[
"## Install",
"_____no_output_____"
],
[
"`pip install nbdev_first`",
"_____no_output_____"
],
[
"## How to use",
"_____no_output_____"
],
[
"this module has one function: `say_hello`. It takes a string which is ideally the name of an individual.",
"_____no_output_____"
]
],
[
[
"say_hello(\"Joe\")",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code"
] | [
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
]
] |
d0fa3d2a3c08411eb7aa3e23b7647c995faa8ea2 | 339,574 | ipynb | Jupyter Notebook | master/Read_and_write_LAS.ipynb | michael-scarn/geocomp-0118 | 935ab9cb04f5af8cf12445fda2962d2e961fbdc1 | [
"Apache-2.0"
] | 3 | 2020-03-04T15:37:09.000Z | 2020-11-28T16:34:00.000Z | master/Read_and_write_LAS.ipynb | helgegn/geocomp-0118 | 935ab9cb04f5af8cf12445fda2962d2e961fbdc1 | [
"Apache-2.0"
] | null | null | null | master/Read_and_write_LAS.ipynb | helgegn/geocomp-0118 | 935ab9cb04f5af8cf12445fda2962d2e961fbdc1 | [
"Apache-2.0"
] | 4 | 2018-02-01T18:55:32.000Z | 2021-07-21T11:40:22.000Z | 243.946839 | 143,342 | 0.890419 | [
[
[
"# Reading and writing LAS files\n\nThis notebook goes with [the Agile blog post](https://agilescientific.com/blog/2017/10/23/x-lines-of-python-load-curves-from-las) of 23 October.\n\nSet up a `conda` environment with:\n\n conda create -n welly python=3.6 matplotlib=2.0 scipy pandas\n\nYou'll need `welly` in your environment:\n\n conda install tqdm # Should happen automatically but doesn't\n pip install welly\n \nThis will also install the latest versions of `striplog` and `lasio`.",
"_____no_output_____"
]
],
[
[
"import welly",
"_____no_output_____"
],
[
"ls ../data/*.LAS",
"\u001b[31m../data/P-129_out.LAS\u001b[m\u001b[m*\r\n"
]
],
[
[
"### 1. Load the LAS file with `lasio`",
"_____no_output_____"
]
],
[
[
"import lasio\n\nl = lasio.read('../data/P-129.LAS') # Line 1.",
"Found nonstandard LAS section: ~Parameter\n"
]
],
[
[
"That's it! But the object itself doesn't tell us much — it's really just a container:",
"_____no_output_____"
]
],
[
[
"l",
"_____no_output_____"
]
],
[
[
"### 2. Look at the WELL section of the header",
"_____no_output_____"
]
],
[
[
"l.header['Well'] # Line 2.",
"_____no_output_____"
]
],
[
[
"### 3. Look at the curve data",
"_____no_output_____"
],
[
"The curves are all present one big NumPy array:",
"_____no_output_____"
]
],
[
[
"l.data",
"_____no_output_____"
]
],
[
[
"Or we can go after a single curve object:",
"_____no_output_____"
]
],
[
[
"l.curves.GR # Line 3.",
"_____no_output_____"
]
],
[
[
"And there's a shortcut to its data:",
"_____no_output_____"
]
],
[
[
"l['GR'] # Line 4.",
"_____no_output_____"
]
],
[
[
"...so it's easy to make a plot against depth:",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\n%matplotlib inline\n\nplt.figure(figsize=(15,3))\nplt.plot(l['DEPT'], l['GR'])\nplt.show()",
"_____no_output_____"
]
],
[
[
"### 4. Inspect the curves as a `pandas` dataframe",
"_____no_output_____"
]
],
[
[
"l.df().head() # Line 5.",
"_____no_output_____"
]
],
[
[
"### 5. Load the LAS file with `welly` ",
"_____no_output_____"
]
],
[
[
"from welly import Well\n\nw = Well.from_las('../data/P-129.LAS') # Line 6.",
"Found nonstandard LAS section: ~Parameter\n"
]
],
[
[
"`welly` Wells know how to display some basics:",
"_____no_output_____"
]
],
[
[
"w",
"_____no_output_____"
]
],
[
[
"And the `Well` object also has `lasio`'s access to a pandas DataFrame:",
"_____no_output_____"
]
],
[
[
"w.df().head()",
"_____no_output_____"
]
],
[
[
"### 6. Look at `welly`'s Curve object\n\nLike the `Well`, a `Curve` object can report a bit about itself:",
"_____no_output_____"
]
],
[
[
"gr = w.data['GR'] # Line 7.\ngr",
"_____no_output_____"
]
],
[
[
"One important thing about Curves is that each one knows its own depths — they are stored as a property called `basis`. (It's not actually stored, but computed on demand from the start depth, the sample interval (which must be constant for the whole curve) and the number of samples in the object.)",
"_____no_output_____"
]
],
[
[
"gr.basis",
"_____no_output_____"
]
],
[
[
"### 7. Plot part of a curve\n\nWe'll grab the interval from 300 m to 1000 m and plot it.",
"_____no_output_____"
]
],
[
[
"gr.to_basis(start=300, stop=1000).plot() # Line 8.",
"_____no_output_____"
]
],
[
[
"### 8. Smooth a curve\n\nCurve objects are, fundamentally, NumPy arrays. But they have some extra tricks. We've already seen `Curve.plot()`. \n\nUsing the `Curve.smooth()` method, we can easily smooth a curve, eg by 15 m (passing `samples=True` would smooth by 15 samples):",
"_____no_output_____"
]
],
[
[
"sm = gr.smooth(window_length=15, samples=False) # Line 9.\n\nsm.plot()",
"_____no_output_____"
]
],
[
[
"### 9. Export a set of curves as a matrix\n\nYou can get at all the data through the lasio `l.data` object:",
"_____no_output_____"
]
],
[
[
"print(\"Data shape: {}\".format(w.las.data.shape))\n\nw.las.data",
"Data shape: (12718, 25)\n"
]
],
[
[
"But we might want to do some other things, such as specify which curves you want (optionally using aliases like GR1, GRC, NGC, etc for GR), resample the data, or specify a start and stop depth — `welly` can do all this stuff. This method is also wrapped by `Project.data_as_matrix()` which is nice because it ensures that all the wells are exported at the same sample interval.\n\nHere are the curves in this well:",
"_____no_output_____"
]
],
[
[
"w.data.keys()",
"_____no_output_____"
],
[
"keys=['CALI', 'DT', 'DTS', 'RHOB', 'SP']",
"_____no_output_____"
],
[
"w.plot(tracks=['TVD']+keys)",
"_____no_output_____"
],
[
"X, basis = w.data_as_matrix(keys=keys, start=275, stop=1850, step=0.5, return_basis=True)",
"_____no_output_____"
],
[
"w.data['CALI'].shape",
"_____no_output_____"
]
],
[
[
"So CALI had 12,718 points in it... since we downsampled to 0.5 m and removed the top and tail, we should have substantially fewer points:",
"_____no_output_____"
]
],
[
[
"X.shape",
"_____no_output_____"
],
[
"plt.figure(figsize=(15,3))\nplt.plot(X.T[0])\nplt.show()",
"_____no_output_____"
]
],
[
[
"### 10+. BONUS: fix the lat, lon\n\nOK, we're definitely going to go over our budget on this one.\n\nDid you notice that the location of the well did not get loaded properly?",
"_____no_output_____"
]
],
[
[
"w.location",
"_____no_output_____"
]
],
[
[
"Let's look at some of the header:\n\n # LAS format log file from PETREL\n # Project units are specified as depth units\n #==================================================================\n ~Version information\n VERS. 2.0:\n WRAP. YES:\n #==================================================================\n ~WELL INFORMATION\n #MNEM.UNIT DATA DESCRIPTION\n #---- ------ -------------- -----------------------------\n STRT .M 1.0668 :START DEPTH \n STOP .M 1939.13760 :STOP DEPTH \n STEP .M 0.15240 :STEP \n NULL . -999.25 :NULL VALUE\n COMP . Elmworth Energy Corporation :COMPANY\n WELL . Kennetcook #2 :WELL\n FLD . Windsor Block :FIELD\n LOC . Lat = 45* 12' 34.237\" N :LOCATION\n PROV . Nova Scotia :PROVINCE\n UWI. Long = 63* 45'24.460 W :UNIQUE WELL ID\n LIC . P-129 :LICENSE NUMBER\n CTRY . CA :COUNTRY (WWW code)\n DATE. 10-Oct-2007 :LOG DATE {DD-MMM-YYYY}\n SRVC . Schlumberger :SERVICE COMPANY\n LATI .DEG :LATITUDE\n LONG .DEG :LONGITUDE\n GDAT . :GeoDetic Datum\n SECT . 45.20 Deg N :Section\n RANG . PD 176 :Range\n TOWN . 63.75 Deg W :Township\n\nLook at **LOC** and **UWI**. There are two problems:\n\n1. These items are in the wrong place. (Notice **LATI** and **LONG** are empty.)\n2. The items are malformed, with lots of extraneous characters.\n\nWe can fix this in two steps:\n\n1. Remap the header items to fix the first problem.\n2. Parse the items to fix the second one.\n\nWe'll define these in reverse because the remapping uses the transforming function.",
"_____no_output_____"
]
],
[
[
"import re\n\ndef transform_ll(text):\n \"\"\"\n Parses malformed lat and lon so they load properly.\n \"\"\"\n def callback(match):\n d = match.group(1).strip()\n m = match.group(2).strip()\n s = match.group(3).strip()\n c = match.group(4).strip()\n if c.lower() in ('w', 's') and d[0] != '-':\n d = '-' + d\n return ' '.join([d, m, s])\n pattern = re.compile(r\"\"\".+?([-0-9]+?).? ?([0-9]+?).? ?([\\.0-9]+?).? +?([NESW])\"\"\", re.I)\n text = pattern.sub(callback, text)\n return welly.utils.dms2dd([float(i) for i in text.split()])",
"_____no_output_____"
]
],
[
[
"Make sure that works!",
"_____no_output_____"
]
],
[
[
"print(transform_ll(\"\"\"Lat = 45* 12' 34.237\" N\"\"\"))",
"45.20951027777778\n"
],
[
"remap = {\n 'LATI': 'LOC', # Use LOC for the parameter LATI.\n 'LONG': 'UWI', # Use UWI for the parameter LONG.\n 'LOC': None, # Use nothing for the parameter SECT.\n 'SECT': None, # Use nothing for the parameter SECT.\n 'RANG': None, # Use nothing for the parameter RANG.\n 'TOWN': None, # Use nothing for the parameter TOWN.\n}\n\nfuncs = {\n 'LATI': transform_ll, # Pass LATI through this function before loading.\n 'LONG': transform_ll, # Pass LONG through it too.\n 'UWI': lambda x: \"No UWI, fix this!\"\n}",
"_____no_output_____"
],
[
"w = Well.from_las('../data/P-129.LAS', remap=remap, funcs=funcs)",
"Found nonstandard LAS section: ~Parameter\n"
],
[
"w.location.latitude, w.location.longitude",
"_____no_output_____"
],
[
"w.uwi",
"_____no_output_____"
]
],
[
[
"Let's just hope the mess is the same mess in every well. (LOL, no-one's that lucky.)",
"_____no_output_____"
],
[
"<hr>\n\n**© 2017 [agilescientific.com](https://www.agilescientific.com/) and licensed [CC-BY 4.0](https://creativecommons.org/licenses/by/4.0/)**",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
d0fa46cc42398a87c5a1edef5220ed30c3b4327d | 27,258 | ipynb | Jupyter Notebook | single_kanji_data_gen.ipynb | CaptainDario/DaKanjiRecognizer-ML | 5c4994b9948564fd2d9a8585f838819c2f51d931 | [
"MIT"
] | 2 | 2022-01-17T00:46:10.000Z | 2022-02-22T21:50:09.000Z | single_kanji_data_gen.ipynb | CaptainDario/DaKanjiRecognizer-ML | 5c4994b9948564fd2d9a8585f838819c2f51d931 | [
"MIT"
] | 1 | 2021-08-29T09:51:17.000Z | 2021-09-04T20:23:10.000Z | single_kanji_data_gen.ipynb | CaptainDario/DaKanji-Single-Kanji-Recognition | 7e00c51d6612f5130817815e6843c4c111032219 | [
"MIT"
] | null | null | null | 55.290061 | 6,348 | 0.718431 | [
[
[
"# DaKanjiRecognizer - Single Kanji CNN : Create dataset",
"_____no_output_____"
],
[
"## Setup\n\nImport the needed libraries.",
"_____no_output_____"
]
],
[
[
"#std lib\nimport sys\nimport os\nimport random\nimport math\nimport multiprocessing as mp\nimport gc\nimport time\nimport datetime\nfrom typing import Tuple, List\nfrom shutil import copy\n\nfrom tqdm import tqdm\nimport tensorflow as tf\n\n#reading the dataset\nfrom etldr.etl_data_reader import ETLDataReader\nfrom etldr.etl_character_groups import ETLCharacterGroups\nfrom etldr.etl_data_names import ETLDataNames\n\nfrom DataGenerator import generate_images, check_font_char_support\n\n#data handling\nimport PIL\nfrom PIL import Image as PImage\nfrom PIL import ImageFilter, ImageFont, ImageDraw\nimport numpy as np\nimport cv2\n\n#plotting/showing graphics\n%matplotlib inline\nimport matplotlib.pyplot as plt\nfrom IPython.display import Image\n\n#define a font to show japanese characters in matplotlib figures\nimport matplotlib.font_manager as fm\nshow_sample_font = fm.FontProperties(fname=os.path.join(\"..\", \"fonts\", \"NotoSerifCJKjp-Regular.otf\"), size=20)",
"_____no_output_____"
]
],
[
[
"## Loading the data",
"_____no_output_____"
],
[
"The [ETL Character data set](http://etlcdb.db.aist.go.jp/) which I am using is a data set with multiple sub sets (ETL1 - ETL7, ETL8B, ETL8G, ETL9B and ETL9G). <br/>\nAfter unpacking the data set I renamed all folders and files to have a uniform naming scheme: \"ETLX/ETLX_Y\". \"X\" is the number of the subset and Y the part of the subset. Also ETL7S was removed (ETL7L just smaller), the following renaming was also done: <br/>\nETL8B $\\rightarrow$ ETL1, ETL8G $\\rightarrow$ ETL9, ETL9B $\\rightarrow$ ETL10 and ETL9G $\\rightarrow$ ETL11.<br/>\nThis leads to the following data set structure: <br/> \n\n| name | type | content | res | Bit depth | code | samples perlabel | total samples |\n|:-----:|:-------:|:-----------------------------------------------------------------------:|:-------:|:---------:|:----------:|:----------------:|:-------------:|\n| ETL1 | M-Type | Numbers <br/> Roman <br/> Symbols <br/> Katakana | 64x63 | 4 | JIS X 0201 | ~1400 | 141319 |\n| ETL2 | K-Type | Hiragana <br/> Katakana <br/> Kanji <br/> Roman <br/> Symbols | 60x60 | 6 | CO59 | ~24 | 52796 |\n| ETL3 | C-Type | Numeric <br/> Capital Roman <br/> Symbols | 72x76 | 4 | JIS X 0201 | 200 | 9600 |\n| ETL4 | C-Type | Hiragana | 72x76 | 4 | JIS X 0201 | 120 | 6120 |\n| ETL5 | C-Type | Katakana | 72x76 | 4 | JIS X 0201 | ~200 | 10608 |\n| ETL6 | M-Type | Katakana <br/> Symbols | 64x63 | 4 | JIS X 0201 | 1383 | 157662 |\n| ETL7 | M-Type | Hiragana <br/> Symbols | 64x63 | 4 | JIS X 0201 | 160 | 16800 |\n| ETL8 | 8B-Type | Hiragana <br/> Kanji | 64x63 | 1 | JIS X 0208 | 160 | 157662 |\n| ETL9 | 8G-Type | Hiragana <br/> Kanji | 128x127 | 4 | JIS X 0208 | 200 | 607200 |\n| ETL10 | 9B-Type | Hiragana <br/> Kanji | 64x63 | 1 | JIS X 0208 | 160 | 152960 |\n| ETL11 | 9G-Type | Hiragana <br/> Kanji | 128x127 | 4 | JIS X 0208 | 200 | 607200 |\n",
"_____no_output_____"
],
[
"Because the provided data set is distributed in a proprietary binary data format and therefore hard to handle I created a ```ETL_data_reader```-package. This package can be found [here](https://github.com/CaptainDario/ETLCDB_data_reader).\nThe specific dataformat is C-struct like for types: M, 8B, 8G, 9B, 9G. But the types C and K are 6-bit encoded. All codes can be found on the [official website.](http://etlcdb.db.aist.go.jp/file-formats-and-sample-unpacking-code)\nI used the [struct module](https://docs.python.org/3/library/struct.html) and the [bitstring module](https://pypi.org/project/bitstring/) to unpack the binary data. <br/>",
"_____no_output_____"
],
[
"First an instance of the ```ERL_data_reader``` -class is needed.\nThe path parameter should lead to the folder in which all parts of the ETL data set can be found.",
"_____no_output_____"
]
],
[
[
"path = \"Z:\\data_sets\\etlcdb_binary\"\nreader = ETLDataReader(path)",
"_____no_output_____"
]
],
[
[
"Define a convenience function for showing characters and their label.",
"_____no_output_____"
]
],
[
[
"def show_image(img : np.array, label : str):\n plt.figure(figsize=(2.2, 2.2))\n plt.title(label=label, font=show_sample_font)\n plt.axis(\"off\")\n plt.imshow(img.astype(np.float64), cmap=\"gray\")",
"_____no_output_____"
]
],
[
[
"Now load all samples which contain Kanji, Hiragana and Katakana.",
"_____no_output_____"
]
],
[
[
"types = [ETLCharacterGroups.kanji, ETLCharacterGroups.katakana, ETLCharacterGroups.hiragana]\nx, y = reader.read_dataset_whole(types, 16)\nprint(x.shape, y.shape)",
"_____no_output_____"
]
],
[
[
"With the loaded data we can take a look at the class distributions.",
"_____no_output_____"
]
],
[
[
"unique, counts = np.unique(y, return_counts=True)\nbalance = dict(zip(unique, counts))\n\nplt.bar(range(0, len(counts)), counts, width=1.0)\nplt.show()",
"_____no_output_____"
]
],
[
[
"Because the data is quite imbalanced we need more data.\nFirst remove samples so that a class has maximum 10all_jis2_charsamples.",
"_____no_output_____"
]
],
[
[
"del_inds, cnt = [], 0\nfor _x, _y in zip(x, y):\n ind = np.where(unique == _y)\n if(counts[ind] > 1000):\n del_inds.append(cnt)\n counts[ind] -= 1\n cnt += 1\n\nx = np.delete(x, del_inds, axis=0)\ny = np.delete(y, del_inds)",
"_____no_output_____"
],
[
"unique, counts = np.unique(y, return_counts=True)\nbalance = dict(zip(unique, counts))\n\nplt.bar(range(0, len(counts)), counts, width=1.0)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Save etlcdb images to disk \nTo use the data later with keras we save them to disk in an appropriate folder structure. <br/>\nThe ETL_data_reader package provides a handy function for this.",
"_____no_output_____"
]
],
[
[
"reader.save_to_file(x, y, r\"Z:\\data_sets\\dakanji_single_kanji_cnn\", name=0)",
"_____no_output_____"
]
],
[
[
"## Create samples for missing JIS-2 Kanji\n\nBecause not all JIS 2 characters are in the etlcdb we need to get samples for them. <br/>\nFirst find the characters which are in JIS2 but not in the data set.",
"_____no_output_____"
]
],
[
[
"chars_to_gen = {}\n\n# add samples for the already existing classes\nfor u, c in zip(unique, counts):\n \n if(c < 2000):\n chars_to_gen[u] = 2000 - c",
"_____no_output_____"
],
[
"with open(\"jis2_characters.txt\", encoding=\"utf8\", mode=\"r\") as f:\n all_jis2_chars = f.read().replace(\" \", \"\").replace(\"\\n\", \"\")\n all_jis2_chars = list(all_jis2_chars)\n \nmissing_jis2_chars = [c for c in all_jis2_chars if c not in unique]",
"_____no_output_____"
],
[
"# add samples for missing jis2 characters\nfor c in missing_jis2_chars:\n chars_to_gen[c] = 2000",
"_____no_output_____"
]
],
[
[
"Copy samples from DaJapanaeseDataGenerator dataset",
"_____no_output_____"
]
],
[
[
"da_data_dir = r\"Z:\\data_sets\\da_japanese_data_generator\"\n\nwith open(os.path.join(da_data_dir, \"encoding.txt\"), encoding=\"utf8\", mode=\"r\") as f:\n d = eval(f.read())\n da_data_encoding = {v : k for k, v in d.items()}",
"_____no_output_____"
],
[
"single_kanji_data_dir = r\"Z:\\data_sets\\dakanji_single_kanji_cnn\"\n\nwith open(os.path.join(single_kanji_data_dir, \"encoding.txt\"), encoding=\"utf8\", mode=\"r\") as f:\n single_kanji_data_encoding = eval(f.read())\n \n \nsingle_kanji_data_encoding[\"キ\"]",
"_____no_output_____"
],
[
"chars_to_gen[\"あ\"]",
"_____no_output_____"
],
[
"for char, cnt in chars_to_gen.items():\n\n #\n if(char not in single_kanji_data_encoding):\n #print(char)\n os.mkdir(os.path.join(single_kanji_data_dir, str(len(single_kanji_data_encoding))))\n single_kanji_data_encoding[char] = [str(len(single_kanji_data_encoding)), 0]\n \n #\n for i in range(cnt):\n\n _from = os.path.join(da_data_dir, str(da_data_encoding[char]), str(i) + \".png\")\n _to = os.path.join(single_kanji_data_dir, single_kanji_data_encoding[char][0], str(single_kanji_data_encoding[char][1]) + \".png\")\n #print(_from, _to)\n\n copy(_from, _to)\n single_kanji_data_encoding[char][1] += 1\n ",
"_____no_output_____"
],
[
"with open(os.path.join(single_kanji_data_dir, \"encoding.txt\"), encoding=\"utf8\", mode=\"w+\") as f:\n f.write(str(single_kanji_data_encoding))",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
d0fa49c540964de640415979485f5e8190b4ba03 | 1,038,636 | ipynb | Jupyter Notebook | FDTransient.ipynb | justindeng21/numcomp-class-spring19 | 4e1be516fc2f63e749c8553a0039b289135ec569 | [
"BSD-2-Clause"
] | 10 | 2019-01-15T19:32:45.000Z | 2019-04-08T04:43:36.000Z | FDTransient.ipynb | justindeng21/numcomp-class-spring19 | 4e1be516fc2f63e749c8553a0039b289135ec569 | [
"BSD-2-Clause"
] | 21 | 2019-01-25T17:37:39.000Z | 2019-04-29T22:19:40.000Z | FDTransient.ipynb | justindeng21/numcomp-class-spring19 | 4e1be516fc2f63e749c8553a0039b289135ec569 | [
"BSD-2-Clause"
] | 22 | 2019-01-15T20:16:52.000Z | 2019-11-04T06:42:35.000Z | 478.413634 | 91,828 | 0.932051 | [
[
[
"#### Jupyter notebooks\n\nThis is a [Jupyter](http://jupyter.org/) notebook using Python. You can install Jupyter locally to edit and interact with this notebook.\n\n# Finite difference methods for transient PDE\n\n## Method of Lines\n\nOur method for solving time-dependent problems will be to discretize in space first, resulting in a system of ordinary differential equations\n\n$$ M \\dot u = f(u) $$\n\nwhere the \"mass matrix\" $M$ might be diagonal and $f(u)$ represents a spatial discretization that has the form $f(u) = A u$ for linear problems.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport numpy as np\nimport matplotlib.pyplot as plt\nplt.style.use('seaborn')\n\ndef ode_euler(f, u0, tfinal=1, h=0.1):\n u = np.array(u0)\n t = 0\n thist = [t]\n uhist = [u0]\n while t < tfinal:\n h = min(h, tfinal - t)\n u += h * f(t, u)\n t += h\n thist.append(t)\n uhist.append(u.copy())\n return np.array(thist), np.array(uhist)\n\ntests = []\n\nclass fcos:\n def __init__(self, k=5):\n self.k = k\n def __repr__(self):\n return 'fcos(k={:d})'.format(self.k)\n def f(self, t, u):\n return -self.k * (u - np.cos(t))\n def u(self, t, u0):\n k2p1 = self.k**2+1\n return (u0 - self.k**2/k2p1) * np.exp(-self.k*t) + self.k*(np.sin(t) + self.k*np.cos(t))/k2p1\n\ntests.append(fcos(k=2))\ntests.append(fcos(k=10))\n\nu0 = np.array([.2])\nplt.figure()\nfor test in tests:\n thist, uhist = ode_euler(test.f, u0, h=.1, tfinal=6)\n plt.plot(thist, uhist, '.', label=repr(test)+' Forward Euler')\n plt.plot(thist, test.u(thist, u0), label=repr(test)+' exact')\nplt.plot(thist, np.cos(thist), label='cos')\nplt.legend(loc='upper right');",
"_____no_output_____"
]
],
[
[
"### Midpoint Method\n\nWhat if instead of evaluating the function at the end of the time step, we evaluated in the middle of the time step using the average of the endpoint values.\n\n$$ \\tilde u(h) = u(0) + h f\\left(\\frac h 2, \\frac{\\tilde u(h) + u(0)}{2} \\right) $$\n\nFor the linear problem, this reduces to\n\n$$ \\Big(I - \\frac h 2 A \\Big) u(h) = \\Big(I + \\frac h 2 A\\Big) u(0) .$$",
"_____no_output_____"
]
],
[
[
"def ode_midpoint_linear(A, u0, tfinal=1, h=0.1):\n u = u0.copy()\n t = 0\n thist = [t]\n uhist = [u0]\n I = np.eye(len(u))\n while t < tfinal:\n h = min(h, tfinal - t)\n u = np.linalg.solve(I - .5*h*A, (I + .5*h*A) @ u)\n t += h\n thist.append(t)\n uhist.append(u.copy())\n return np.array(thist), np.array(uhist)\n\nthist, uhist = ode_midpoint_linear(test.A, u0, h=.2, tfinal=15)\nplt.figure()\nplt.plot(thist, uhist, '*')\nplt.plot(thist, test.u(thist, u0))\nplt.title('Midpoint');",
"_____no_output_____"
]
],
[
[
"## $\\theta$ method\n\nThe above methods are all special cases of the $\\theta$ method\n\n$$ \\tilde u(h) = u(0) + h f\\left(\\theta h, \\theta\\tilde u(h) + (1-\\theta)u(0) \\right) $$\n\nwhich, for linear problems, is solved as\n\n$$ (I - h \\theta A) u(h) = \\Big(I + h (1-\\theta) A \\Big) u(0) . $$\n\n$\\theta=0$ is explicit Euler, $\\theta=1$ is implicit Euler, and $\\theta=1/2$ is the midpoint rule.\nThe stability function is\n$$ R(z) = \\frac{1 + (1-\\theta)z}{1 - \\theta z}. $$",
"_____no_output_____"
]
],
[
[
"for theta in [.2, .5, .8]:\n plot_stability(xx, yy, (1 + (1-theta)*zz)/(1 - theta*zz), '$\\\\theta={:3.1f}$'.format(theta))",
"_____no_output_____"
]
],
[
[
"We will generalize slightly to allow solution of a linear differential algebraic equation\n\n$$ M \\dot u = A u + f(t,x) $$\n\nwhere $M$ is (for now) a diagonal matrix that has zero rows at boundary conditions. With this generalization, the $\\theta$ method becomes\n\n$$ (M - h \\theta A) u(h) = \\Big(M + h (1-\\theta) A \\Big) u(0) + h f(h\\theta, x) . $$\n\nWe will assume that $M$ is nonsingular if $\\theta=0$.",
"_____no_output_____"
]
],
[
[
"def dae_theta_linear(M, A, u0, rhsfunc, bcs=[], tfinal=1, h=0.1, theta=.5):\n u = u0.copy()\n t = 0\n hist = [(t,u0)]\n while t < tfinal:\n if tfinal - t < 1.01*h:\n h = tfinal - t\n tnext = tfinal\n else:\n tnext = t + h\n h = min(h, tfinal - t)\n rhs = (M + (1-theta)*h*A) @ u + h*rhsfunc(t+theta*h)\n for i, f in bcs:\n rhs[i] = theta*h*f(t+theta*h, x[i])\n u = np.linalg.solve(M - theta*h*A, rhs)\n t = tnext\n hist.append((t, u.copy()))\n return hist",
"_____no_output_____"
]
],
[
[
"### Stiff decay to cosine",
"_____no_output_____"
]
],
[
[
"test = fcos(k=5000)\nu0 = np.array([.2])\nhist = dae_theta_linear(np.eye(1), -test.k, u0,\n lambda t: test.k*np.cos(t),\n h=.1, tfinal=6, theta=.5)\nhist = np.array(hist)\nplt.plot(hist[:,0], hist[:,1], 'o')\ntt = np.linspace(0, 6, 200)\nplt.plot(tt, test.u(tt,u0));",
"_____no_output_____"
]
],
[
[
"#### Observations\n\n* $\\theta=1$ is robust\n* $\\theta=1/2$ gets correct long-term behavior, but has oscillations at early times\n* $\\theta < 1/2$ allows oscillations to grow",
"_____no_output_____"
],
[
"### Definition: $A$-stability\nA method is $A$-stable if the stability region\n$$ \\{ z : |R(z)| \\le 1 \\} $$\ncontains the entire left half plane $$ \\Re[z] \\le 0 .$$\nThis means that the method can take arbitrarily large time steps without becoming unstable (diverging) for any problem that is indeed physically stable.\n\n### Definition: $L$-stability\nA time integrator with stability function $R(z)$ is $L$-stable if\n$$ \\lim_{z\\to\\infty} R(z) = 0 .$$\nFor the $\\theta$ method, we have\n$$ \\lim_{z\\to \\infty} \\frac{1 + (1-\\theta)z}{1 - \\theta z} = \\frac{1-\\theta}{\\theta} . $$\nEvidently only $\\theta=1$ is $L$-stable.",
"_____no_output_____"
],
[
"## Transient PDE\n\n### Diffusion (heat equation)\n\nLet's first consider diffusion of a quantity $u(t,x)$\n\n$$ \\dot u(t,x) - u''(t,x) = f(t,x) \\qquad t > 0, -1 < x < 1 \\\\\nu(0,x) = g(x) \\qquad u(t,-1) = h_L(t) \\qquad u'(t,1) = h_R(t) .$$\n\nLet's use a Chebyshev discretization in space.",
"_____no_output_____"
]
],
[
[
"%run fdtools.py # define cosspace, vander_chebyshev, and chebeval\n\ndef diffusion_cheb(n, left, right):\n \"\"\"Solve the diffusion PDE on (-1,1) using n elements with rhsfunc(x) forcing.\n The left and right boundary conditions are specified as a pair (deriv, func) where\n * deriv=0 for Dirichlet u(x_endpoint) = func(x_endpoint)\n * deriv=1 for Neumann u'(x_endpoint) = func(x_endpoint)\"\"\"\n x = cosspace(-1, 1, n+1) # n+1 points is n \"elements\"\n T = chebeval(x)\n L = -T[2]\n bcs = []\n for i,deriv,func in [(0, *left), (-1, *right)]:\n L[i] = T[deriv][i]\n bcs.append((i, func))\n M = np.eye(n+1)\n M[[0,-1]] = 0\n return x, M, -L @ np.linalg.inv(T[0]), bcs\n\nx, M, A, bcs = diffusion_cheb(80, (0, lambda t,x: 0*x), (0, lambda t,x: 0*x+.5))\nhist = dae_theta_linear(M, A, np.exp(-(x*8)**2), lambda t: 0*x, bcs,\n h=.005, theta=.5, tfinal=0.3)\nfor t, u in hist[::10]:\n plt.plot(x, u, label='$t={:4.2f}$'.format(t))\nplt.legend(loc='lower left');",
"_____no_output_____"
]
],
[
[
"#### Observations\n* Sharp central spike is diffused very quickly.\n* Artifacts with $\\theta < 1$.\n\n#### Manufactured solution",
"_____no_output_____"
]
],
[
[
"class exact_tanh:\n def __init__(self, k=1, x0=0):\n self.k = k\n self.x0 = x0\n def u(self, t, x):\n return np.tanh(self.k*(x - t - self.x0))\n def u_x(self, t, x):\n return self.k * np.cosh(self.k*(x - t - self.x0))**(-2)\n def u_t(self, t, x):\n return -self.u_x(t, x)\n def u_xx(self, t, x):\n return -2 * self.k**2 * np.tanh(self.k*(x - t - self.x0)) * np.cosh(self.k*(x - t - self.x0))**(-2)\n def heatrhs(self, t, x):\n return self.u_t(t,x) - self.u_xx(t,x)\n\nex = exact_tanh(2, -.3)\nx, M, A, bcs = diffusion_cheb(20, (0, ex.u), (1, ex.u_x))\nhist = dae_theta_linear(M, A, ex.u(0,x), lambda t: ex.heatrhs(t,x), bcs)\nfor t, u in hist:\n plt.plot(x, u, label='$t={:3.1f}$'.format(t))\nplt.legend(loc='lower right');",
"_____no_output_____"
],
[
"def mms_error(n):\n x, M, A, bcs = diffusion_cheb(n, (0, ex.u), (1, ex.u_x))\n hist = dae_theta_linear(M, A, ex.u(0,x),\n lambda t: ex.heatrhs(t,x), bcs, h=1/n**2, theta=1)\n return np.linalg.norm(hist[-1][1] - ex.u(hist[-1][0], x),\n np.inf)\n\nns = np.logspace(.8, 1.6, 10).astype(int)\nerrors = [mms_error(n) for n in ns]\nplt.loglog(ns, errors, 'o', label='numerical')\nfor p in range(1,4):\n plt.loglog(ns, 1/ns**(p), label='$n^{-%d}$'%p)\nplt.xlabel('n')\nplt.ylabel('error')\nplt.legend(loc='lower left');",
"_____no_output_____"
]
],
[
[
"#### Observations\n\n* Errors are limited by time (not spatial) discretization error. This is a result of using the (spectrally accurate) Chebyshev method in space.\n* $\\theta=1$ is more accurate than $\\theta = 1/2$, despite the latter being second order accurate in time. This is analogous to the stiff relaxation to cosine test.\n\n#### Largest eigenvalues",
"_____no_output_____"
]
],
[
[
"def maxeig(n):\n x, M, A, bcs = diffusion_cheb(n, (0, ex.u), (1, ex.u_x))\n lam = np.linalg.eigvals(-A)\n return max(lam)\n\nplt.loglog(ns, [maxeig(n) for n in ns], 'o', label='cheb')\nfor p in range(1,5):\n plt.loglog(ns, ns**(p), label='$n^{%d}$'%p)\nplt.xlabel('n')\nplt.ylabel('$\\max \\sigma(A)$')\nplt.legend(loc='lower left');",
"_____no_output_____"
]
],
[
[
"### Finite difference method",
"_____no_output_____"
]
],
[
[
"def maxeig_fd(n):\n dx = 2/n\n A = 1/dx**2 * (2 * np.eye(n+1) - np.eye(n+1, k=1) - np.eye(n+1, k=-1))\n return max(np.linalg.eigvals(A))\n\nplt.loglog(2/ns, [maxeig_fd(n) for n in ns], 'o', label='fd')\nfor p in range(1,4):\n plt.loglog(2/ns, 4*(2/ns)**(-p), label='$4 h^{-%d}$'%p)\nplt.xlabel('h')\nplt.ylabel('$\\max \\sigma(A)$')\nplt.legend(loc='upper right');",
"_____no_output_____"
]
],
[
[
"#### Question: max explicit Euler time step\n\nExpress the maximum stable time step $\\Delta t$ using explicit Euler in terms of the grid spacing $\\Delta x$.\n\n## Hyperbolic (wave) equations\n\nThe simplest hyperbolic equation is linear advection\n\n$$ \\dot u(t,x) + c u'(t,x) = f(t,x) $$\n\nwhere $c$ is the wave speed and $f$ is a source term. In the homogenous ($f = 0$) case, the solution is given by characteristics\n\n$$ u(t,x) = u(0, x - ct) . $$\n\nThis PDE also requires boundary conditions, but as a first-order equation, we can only enforce boundary conditions at one boundary. It turns out that this needs to be the _inflow_ boundary, so if $c > 0$, that is the left boundary condition $u(t, -1) = g(t)$. We can solve this system using Chebyshev methods.",
"_____no_output_____"
]
],
[
[
"def advection_cheb(n, c, left=(None,None), right=(None,None)):\n \"\"\"Discretize the advection PDE on (-1,1) using n elements with rhsfunc(x) forcing.\n The left boundary conditions are specified as a pair (deriv, func) where\n * deriv=0 for Dirichlet u(x_endpoint) = func(x_endpoint)\n * deriv=1 for Neumann u'(x_endpoint) = func(x_endpoint)\"\"\"\n x = cosspace(-1, 1, n+1) # n+1 points is n \"elements\"\n T = chebeval(x)\n A = -c*T[1]\n M = np.eye(n+1)\n bcs = []\n for i,deriv,func in [(0, *left), (-1, *right)]:\n if deriv is None: continue\n A[i] = T[deriv][i]\n M[i] = 0\n bcs.append((i, func))\n return x, M, A @ np.linalg.inv(T[0]), bcs\n\nx, M, A, bcs = advection_cheb(40, 1, left=(0, lambda t,x: 0*x))\nhist = dae_theta_linear(M, A, np.exp(-(x*4)**2), lambda t: 0*x, bcs,\n h=.001, theta=1)\nfor t, u in hist[::len(hist)//10]:\n plt.plot(x, u, label='$t={:3.1f}$'.format(t))\nplt.legend(loc='lower left')\nnp.linalg.cond(A)",
"_____no_output_____"
],
[
"lam = np.linalg.eigvals(A[:,:])\nprint(A[0,:5])\nplt.plot(lam.real, lam.imag, '.');",
"[ 1.00000000e+00 -8.32667268e-17 -4.85722573e-17 0.00000000e+00\n 1.00613962e-16]\n"
]
],
[
[
"#### Observations\n* $\\theta > 1/2$ causes decay in amplitude\n* $\\theta < 1/2$ causes growth -- unstable\n* An undershoot develops behind the traveling wave and increasing resolution doesn't make it go away\n* We need an *upwind* boundary condition, otherwise the system is unstable\n* Only Dirichlet inflow conditions are appropriate -- Neumann conditions produce a singular matrix\n\n### Finite difference",
"_____no_output_____"
]
],
[
[
"def advection_fd(n, c, stencil=2, bias=0, left=None, right=None):\n x = np.linspace(-1, 1, n+1)\n A = np.zeros((n+1,n+1))\n for i in range(n+1):\n sleft = max(0, i - stencil//2 + bias)\n sleft = min(sleft, n+1 - stencil)\n A[i,sleft:sleft+stencil] = -c*fdstencil(x[i], x[sleft:sleft+stencil])[1]\n M = np.eye(n+1)\n bcs = []\n for i, func in [(0, left), (-1, right)]:\n if func is None: continue\n A[i] = 0\n A[i,i] = 1\n M[i] = 0\n bcs.append((i, func))\n return x, M, A, bcs\n\nx, M, A, bcs = advection_fd(40, c=1, stencil=3, bias=0, left=lambda t,x: 0*x)\nhist = dae_theta_linear(M, A, np.exp(-(x*4)**2), lambda t: 0*x, bcs,\n h=2/(len(x)-1), theta=.5)\nfor t, u in hist[::len(hist)//10]:\n plt.plot(x, u, label='$t={:3.1f}$'.format(t))\nplt.legend(loc='lower left')\nprint('stencil', A[3,:7])\nprint('cond', np.linalg.cond(A))",
"stencil [ 0.0000000e+00 0.0000000e+00 1.0000000e+01 4.4408921e-14\n -1.0000000e+01 0.0000000e+00 0.0000000e+00]\ncond 352.86563871167283\n"
],
[
"lam = np.linalg.eigvals(A[1:,1:])\nplt.plot(lam.real, lam.imag, '.')\n#plt.spy(A[:6,:6]);",
"_____no_output_____"
]
],
[
[
"#### Observations\n\n* Centered methods have an undershoot behind the traveling wave\n* Upwind biasing of the stencil tends to reduce artifacts, but only `stencil=2` removes undershoots\n* Downwind biasing is usually unstable\n* With upwinded `stencil=2`, we can use an explicit integrator, but the time step must satisfy\n$$ c \\Delta t < \\Delta x $$\n* The upwind methods are in general dissipative -- amplitude is lost even with very accurate time integration\n* The higher order upwind methods always produce artifacts for sharp transitions\n\n### Phase analysis\n\nWe can apply the advection differencing stencils to the test functions $$ \\phi(x, \\theta) = e^{i \\theta x}$$ and compare to the exact derivative $$ \\frac{d \\phi}{d x} = i \\theta \\phi(x, \\theta) . $$",
"_____no_output_____"
]
],
[
[
"x = np.arange(-1, 1+1)\ns1 = fdstencil(0, x)[1]\nprint(s1)\ntheta = np.linspace(0, np.pi)\nphi = np.exp(1j*np.outer(x, theta))\nplt.plot(theta, np.sin(theta))\nplt.plot(theta, np.abs(s1 @ phi), '.')\nplt.plot(theta, theta);",
"[-0.5 0. 0.5]\n"
]
],
[
[
"# Runge-Kutta methods\n\nThe methods we have considered thus far can all be expressed as Runge-Kutta methods, which are expressed in terms of $s$ \"stage\" equations (possibly coupled) and a completion formula. For the ODE\n\n$$ \\dot u = f(t, u) $$\n\nthe Runge-Kutta method is\n\n$$\\begin{split}\nY_i = u(t) + h \\sum_j a_{ij} f(t+c_j h, Y_j) \\\\\nu(t+h) = u(t) + h \\sum_j b_j f(t+c_j h, Y_j)\n\\end{split}$$\n\nwhere $c$ is a vector of *abscissa*, $A$ is a table of coefficients, and $b$ is a vector of completion weights.\nThese coefficients are typically expressed in a Butcher Table\n$$ \\left[ \\begin{array}{c|c} c & A \\\\ \\hline & b^T \\end{array} \\right] = \\left[ \\begin{array}{c|cc}\nc_0 & a_{00} & a_{01} \\\\\nc_1 & a_{10} & a_{11} \\\\\n\\hline\n& b_0 & b_1\n\\end{array} \\right] . $$\nWe will see that, for consistency, the abscissa $c$ are always the row sums of $A$ and that $\\sum_i b_i = 1$.\n\nIf the matrix $A$ is strictly lower triangular, then the method is **explicit** (does not require solving equations). We have seen forward Euler\n\n$$ \\left[ \\begin{array}{c|cc}\n0 & 0 \\\\\n\\hline\n& 1\n\\end{array} \\right] ,$$\nbackward Euler\n$$ \\left[ \\begin{array}{c|c}\n1 & 1 \\\\\n\\hline\n& 1\n\\end{array} \\right] ,$$\nand Midpoint\n$$ \\left[ \\begin{array}{c|c}\n\\frac 1 2 & \\frac 1 2 \\\\\n\\hline\n& 1\n\\end{array} \\right]. $$\n\nIndeed, the $\\theta$ method is\n$$ \\left[ \\begin{array}{c|c}\n\\theta & \\theta \\\\\n\\hline\n& 1\n\\end{array} \\right] $$\nand an alternative \"endpoint\" variant of $\\theta$ (a generalization of the trapezoid rule) is\n$$ \\left[ \\begin{array}{c|cc}\n0 & 0 & 0 \\\\\n1 & 1-\\theta & \\theta \\\\\n\\hline\n& 1-\\theta & \\theta\n\\end{array} \\right]. $$\n\n## Stability\n\nTo develop an algebraic expression for stability in terms of the Butcher Table, we consider the test equation\n\n$$ \\dot u = \\lambda u $$\n\nand apply the RK method to yield\n\n$$ \\begin{split} Y_i = u(0) + h \\sum_j a_{ij} \\lambda Y_j \\\\\nu(h) = u(0) + h \\sum_j b_j \\lambda Y_j \\end{split} $$\n\nor, in matrix form,\n\n$$ \\begin{split} Y = \\mathbb 1 u(0) + h \\lambda A Y \\\\\nu(h) = u(0) + h \\lambda b^T Y \\end{split} $$\n\nwhere $\\mathbb 1$ is a column vector of length $s$ consisting of all ones.\nThis reduces to\n$$ u(h) = \\underbrace{\\Big( 1 + h\\lambda b^T (I - h \\lambda A)^{-1} \\mathbb 1 \\Big)}_{R(h\\lambda)} u(0) . $$",
"_____no_output_____"
]
],
[
[
"def Rstability(A, b, z):\n s = len(b)\n def R(z):\n return 1 + z*b.dot(np.linalg.solve(np.eye(s) - z*A, np.ones(s)))\n f = np.vectorize(R)\n return f(z)\n\ndef rk_butcher_theta(theta):\n A = np.array([[theta]])\n b = np.array([1])\n return A, b\n\ndef zmeshgrid(xlen=5, ylen=5):\n xx = np.linspace(-xlen, xlen, 100)\n yy = np.linspace(-ylen, ylen, 100)\n x, y = np.meshgrid(xx, yy)\n z = x + 1j*y\n return x, y, z\n\ndef plot_rkstability(A, b, label=''):\n from matplotlib import plt, ticker, cm, axis\n import np as np\n x, y, z = zmeshgrid()\n data = np.abs(Rstability(A, b, z))\n cs = plt.contourf(x, y, data, np.arange(0, 2, 0.1), cmap=cm.coolwarm)\n cbar = plt.colorbar(cs, ticks=np.linspace(0, 2, 5))\n plt.axhline(y=0, xmin=-20.0, xmax=20.0, linewidth=1, linestyle='--', color='grey')\n plt.axvline(x=0, ymin=-20.0, ymax=20.0, linewidth=1, linestyle='--', color='grey')\n cs = plt.contour(x, y, data, np.arange(0, 2, 0.5), colors='k')\n plt.clabel(cs, fontsize=6)\n for c in cs.collections:\n plt.setp(c, linewidth=1)\n plt.title('Stability region' + (': ' + label if label else ''))\n\nA, b = rk_butcher_theta(.5)\nplot_rkstability(A, b, label='$\\\\theta$')",
"_____no_output_____"
],
[
"def rk_butcher_theta_endpoint(theta):\n A = np.array([[0, 0], [1-theta, theta]])\n b = np.array([1-theta, theta])\n return A, b\n\nA, b = rk_butcher_theta_endpoint(.5)\nplot_rkstability(A, b, label='$\\\\theta$ endpoint')",
"_____no_output_____"
]
],
[
[
"Evidently the endpoint variant of $\\theta$ has the same stability function as the original (midpoint) variant that we've been using. These methods are equivalent for linear problems, but different for nonlinear problems.\n\n## Higher order explicit methods: Heun's and RK4\n\nExplicit Euler steps can be combined to create more accurate methods. One such example is Heun's method,\n$$ \\left[ \\begin{array}{c|cc}\n0 & 0 & 0 \\\\\n1 & 1 & 0 \\\\\n\\hline\n& \\frac 1 2 & \\frac 1 2\n\\end{array} \\right]. $$\n\nAnother explicit method is the famous four-stage RK4,\n$$ \\left[ \\begin{array}{c|cccc}\n0 & 0 & 0 & 0 & 0 \\\\\n\\frac 1 2 & \\frac 1 2 & 0 & 0 & 0 \\\\\n\\frac 1 2 & 0 & \\frac 1 2 & 0 & 0 \\\\\n1 & 0 & 0 & 1 & 0 \\\\\n\\hline\n& \\frac 1 6 & \\frac 1 3 & \\frac 1 3 & \\frac 1 6\n\\end{array} \\right] . $$",
"_____no_output_____"
]
],
[
[
"def rk_butcher_heun():\n A = np.array([[0, 0],[1,0]])\n b = np.array([.5, .5])\n return A, b\n\nA, b = rk_butcher_heun()\nplot_rkstability(A, b, label='Heun')",
"_____no_output_____"
],
[
"def rk_butcher_4():\n A = np.array([[0,0,0,0],[.5,0,0,0],[0,.5,0,0],[0,0,1,0]])\n b = np.array([1/6, 1/3, 1/3, 1/6])\n return A, b\n\nA, b = rk_butcher_4()\nplot_rkstability(A, b, label='RK4')",
"_____no_output_____"
]
],
[
[
"Finally a method with lots of stability along the imaginary axis. Let's try it on some test problems.",
"_____no_output_____"
]
],
[
[
"def ode_rkexplicit(f, u0, butcher=None, tfinal=1, h=.1):\n if butcher is None:\n A, b = rk_butcher_4()\n else:\n A, b = butcher\n c = np.sum(A, axis=1)\n s = len(c)\n u = u0.copy()\n t = 0\n hist = [(t,u0)]\n while t < tfinal:\n if tfinal - t < 1.01*h:\n h = tfinal - t\n tnext = tfinal\n else:\n tnext = t + h\n h = min(h, tfinal - t)\n fY = np.zeros((len(u0), s))\n for i in range(s):\n Yi = u.copy()\n for j in range(i):\n Yi += h * A[i,j] * fY[:,j]\n fY[:,i] = f(t + h*c[i], Yi)\n u += h * fY @ b\n t = tnext\n hist.append((t, u.copy()))\n return hist\n\ntest = linear(np.array([[0, 1],[-1, 0]]))\nu0 = np.array([.5, 0])\nhist = ode_rkexplicit(test.f, u0, rk_butcher_4(), tfinal=50, h=.8)\ntimes = [t for t,u in hist]\nplt.plot(times, [u for t,u in hist], '.')\nplt.plot(times, test.u(times, u0));",
"_____no_output_____"
]
],
[
[
"#### Observations\n* Solutions look pretty good and we didn't need a solve.\n* We needed to evaluate the right hand side $s$ times per step",
"_____no_output_____"
]
],
[
[
"def mms_error(h, rk_butcher):\n hist = ode_rkexplicit(test.f, u0, rk_butcher(), tfinal=20, h=h)\n times = [t for t,u in hist]\n u = np.array([u for t,u in hist])\n return np.linalg.norm(u - test.u(times, u0), np.inf)\n\nhs = np.logspace(-1.5, .5, 20)\nerror_heun = [mms_error(h, rk_butcher_heun) for h in hs]\nerror_rk4 = [mms_error(h, rk_butcher_4) for h in hs]\nplt.loglog(hs, error_heun, 'o', label='Heun')\nplt.loglog(hs, error_rk4, 's', label='RK4')\nfor p in [2,3,4]:\n plt.loglog(hs, hs**p, label='$h^%d$'%p)\nplt.title('Accuracy')\nplt.legend(loc='lower right')\nplt.ylabel('Error')\nplt.xlabel('$h$');",
"_____no_output_____"
]
],
[
[
"## Work-precision diagrams for comparing methods\n\nSince these methods do not cost the same per step, it is more enlightening to compare them using some measure of cost. For large systems of ODE, such as arise by discretizing a PDE, the cost of time integration is dominated by evaluating the right hand side (discrete spatial operator) on each stage. Measuring CPU time is a more holistic measure of cost, but the results depend on the implementation, computer, and possible operating system interference/variability. Counting right hand side function evaluations is a convenient, reproducible measure of cost.",
"_____no_output_____"
]
],
[
[
"plt.loglog(20*2/hs, error_heun, 'o', label='Heun')\nplt.loglog(20*4/hs, error_rk4, 's', label='RK4')\nplt.title('Error vs cost')\nplt.ylabel('Error')\nplt.xlabel('# function evaluations')\nplt.legend(loc='upper right');",
"_____no_output_____"
],
[
"test = linear(np.array([[0, 1, 0],[-1, 0, 0],[10, 0, -10]]))\nprint(np.linalg.eigvals(test.A))\nu0 = np.array([.5, 0, 0])\nhist = ode_rkexplicit(test.f, u0, rk_butcher_4(), tfinal=5, h=.1)\ntimes = [t for t,u in hist]\nplt.plot(times, [u for t,u in hist], '.')\nplt.plot(times, test.u(times, u0));",
"[-10.+0.j 0.+1.j 0.-1.j]\n"
],
[
"hs = np.logspace(-2, -.7, 20)\nerror_heun = [mms_error(h, rk_butcher_heun) for h in hs]\nerror_rk4 = [mms_error(h, rk_butcher_4) for h in hs]\nplt.loglog(20*2/hs, error_heun, 'o', label='Heun')\nplt.loglog(20*4/hs, error_rk4, 's', label='RK4')\nplt.title('Error vs cost')\nplt.ylabel('Error')\nplt.xlabel('# function evaluations')\nplt.legend(loc='upper right');",
"_____no_output_____"
]
],
[
[
"Evidently Heun becomes resolved at lower cost than RK4.",
"_____no_output_____"
],
[
"## Refinement in space and time\n\nWhen solving a transient PDE, we should attempt to balance spatial discretization error with temporal discretization error. If we wish to use the same type of method across a range of accuracies, we need to\n\n1. choose spatial and temporal discretizations with the same order of accuracy,\n* choose grid/step sizes so the leading error terms are of comparable size, and\n* ensure that both spatial and temporal discretizations are stable throughout the refinement range.\n\nSince temporal discretization errors are proportional to the duration, simulations that run for a long time will need to use more accurate time discretizations.",
"_____no_output_____"
],
[
"# Runge-Kutta order conditions\n\nWe consider the autonomous differential equation\n\n$$ \\dot u = f(u) . $$\n\nHigher derivatives of the exact soultion can be computed using the chain rule, e.g.,\n\n\\begin{align*}\n\\ddot u(t) &= f'(u) \\dot u = f'(u) f(u) \\\\\n\\dddot u(t) &= f''(u) f(u) f(u) + f'(u) f'(u) f(u) . \\\\\n\\end{align*}\n\nNote that if $f(u)$ is linear, $f''(u) = 0$.\nMeanwhile, the numerical solution is a function of the time step $h$,\n\n$$\\begin{split}\nY_i(h) &= u(0) + h \\sum_j a_{ij} f(Y_j) \\\\\nU(h) &= u(0) + h \\sum_j b_j f(Y_j).\n\\end{split}$$\n\nWe will take the limit $h\\to 0$ and equate derivatives of the numerical solution. First we differentiate the stage equations,\n\n\\begin{split}\nY_i(0) &= u(0) \\\\\n\\dot Y_i(0) &= \\sum_j a_{ij} f(Y_j) \\\\\n\\ddot Y_i(0) &= 2 \\sum_j a_{ij} \\dot f(Y_j) \\\\\n&= 2 \\sum_j a_{ij} f'(Y_j) \\dot Y_j \\\\\n&= 2\\sum_{j,k} a_{ij} a_{jk} f'(Y_j) f(Y_k) \\\\\n\\dddot Y_i(0) &= 3 \\sum_j a_{ij} \\ddot f (Y_j) \\\\\n&= 3 \\sum_j a_{ij} \\Big( \\sum_k f''(Y_j) \\dot Y_j \\dot Y_k + f'(Y_j) \\ddot Y_j \\Big) \\\\\n&= 3 \\sum_{j,k,\\ell} a_{ij} a_{jk} \\Big( a_{j\\ell} f''(Y_j) f(Y_k) f(Y_\\ell) + 2 a_{k\\ell} f'(Y_j) f'(Y_k) f(Y_\\ell) \\Big)\n\\end{split}\n\nwhere we have used Liebnitz's formula for the $m$th derivative,\n$$ (h \\phi(h))^{(m)}|_{h=0} = m \\phi^{(m-1)}(0) .$$\nSimilar formulas apply for $\\dot U(0)$, $\\ddot U(0)$, and $\\dddot U(0)$, with $b_j$ in place of $a_{ij}$.",
"_____no_output_____"
],
[
"Equating terms $\\dot u(0) = \\dot U(0)$ yields\n$$ \\sum_j b_j = 1, $$\nequating $\\ddot u(0) = \\ddot U(0)$ yields\n$$ 2 \\sum_{j,k} b_j a_{jk} = 1 , $$\nand equating $\\dddot u(0) = \\dddot U(0)$ yields the two equations\n\\begin{split}\n 3\\sum_{j,k,\\ell} b_j a_{jk} a_{j\\ell} &= 1 \\\\\n 6 \\sum_{j,k,\\ell} b_j a_{jk} a_{k\\ell} &= 1 .\n\\end{split}\n\n#### Observations\n* These are systems of nonlinear equations for the coefficients $a_{ij}$ and $b_j$. There is no guarantee that they have solutions.\n* The number of equations grows rapidly as the order increases.\n\n| | $u^{(1)}$ | $u^{(2)}$ | $u^{(3)}$ | $u^{(4)}$ | $u^{(5)}$ | $u^{(6)}$ | $u^{(7)}$ | $u^{(8)}$ | $u^{(9)}$ | $u^{(10)}$ |\n| ------------- |-------------| -----| --- |\n| # terms | 1 | 1 | 2 | 4 | 9 | 20 | 48 | 115 | 286 | 719 |\n| cumulative | 1 | 2 | 4 | 8 | 17 | 37 | 85 | 200 | 486 | 1205 |\n\n* Usually the number of order conditions does not exactly match the number of free parameters, meaning that the remaining parameters can be optimized (usually numerically) for different purposes, such as to minimize the leading error terms or to maximize stability in certain regions of the complex plane. Finding globally optimal solutions can be extremely demanding.\n* The arithmetic managing the derivatives gets messy, but can be managed using rooted trees.\n\n\n#### Theorem (from Hairer, Nørsett, and Wanner)\n\nA Runge-Kutta method is of order $p$ if and only if\n$$ \\gamma(\\mathcal t) \\sum_{j} b_j \\Phi_j(t) = 1 $$\nfor all trees $t$ of order $\\le p$.\n\nFor a linear autonomous equation\n$$ \\dot u = A u $$\nwe only need one additional order condition per order of accuracy because $f'' = 0$.\nThese conditions can also be derived by equating derivatives of the stability function $R(z)$ with the exponential $e^z$.\nFor a linear non-autonomous equation\n$$ \\dot u = A(t) u + g(t) $$\nor more generally, an autonomous system with quadratic right hand side,\n$$ \\dot u = B (u \\otimes u) + A u + C $$\nwhere $B$ is a rank 3 tensor, we have $f''' = 0$, thus limiting the number of order conditions.",
"_____no_output_____"
],
[
"# Embedded error estimation and adaptive control\n\nIt is often possible to design Runge-Kutta methods with multiple completion orders, say of order $p$ and $p-1$.\n\n$$\\left[ \\begin{array}{c|c} c & A \\\\ \\hline & b^T \\\\ & \\tilde b^T \\end{array} \\right] . $$\n\nThe classical RK4 does not come with an embedded method, but most subsequent RK methods do.\n\nThe [Bogacki-Shampine method](https://en.wikipedia.org/wiki/Bogacki%E2%80%93Shampine_method) is given by",
"_____no_output_____"
]
],
[
[
"def rk_butcher_bs3():\n A = np.array([[0, 0, 0, 0],\n [1/2, 0, 0, 0],\n [0, 3/4, 0, 0],\n [2/9, 1/3, 4/9, 0]])\n b = np.array([[2/9, 1/3, 4/9, 0],\n [7/24, 1/4, 1/3, 1/8]])\n return A, b\n\nA, b = rk_butcher_bs3()\nplot_rkstability(A, b[0], label='Bogacki-Shampine 3')\nplt.figure()\nplot_rkstability(A, b[1], label='Bogacki-Shampine 2')",
"_____no_output_____"
]
],
[
[
"While this method has four stages, it has the \"first same as last\" (FSAL) property meaning that the fourth stage exactly matches the completion formula, thus the first stage of the next time step. This means it can be implemented using only three function evaluations per time step.\n\nHigher order methods with embedded error estimation include\n\n* [Fehlberg](https://en.wikipedia.org/wiki/Runge%E2%80%93Kutta%E2%80%93Fehlberg_method), a 6-stage, 5th order method for which the 4th order embedded formula has been optimized for accuracy.\n* [Dormand-Prince](https://en.wikipedia.org/wiki/Dormand%E2%80%93Prince_method), a 7-stage, 5th order method with the FSAL property, with the 5th order completion formula optimized for accuracy.",
"_____no_output_____"
]
],
[
[
"# We can import and clean these coefficient tables directly from Wikipedia\n\nimport pandas\nfrom fractions import Fraction\n\ndframe = pandas.read_html('https://en.wikipedia.org/wiki/Runge%E2%80%93Kutta%E2%80%93Fehlberg_method')[0]\ndframe",
"_____no_output_____"
],
[
"# Clean up unicode minus sign, NaN, and convert to float\ndfloat = dframe.applymap(lambda s: s.replace('−', '-') if isinstance(s, str) else s) \\\n .fillna(0).applymap(Fraction).astype(float)\ndfloat",
"_____no_output_____"
],
[
"# Extract the Butcher table\ndarray = np.array(dfloat)\nA = darray[:6,2:]\nb = darray[6:,2:]\npandas.DataFrame(A) # Labeled tabular display",
"_____no_output_____"
],
[
"plot_rkstability(A, b[0], label='Fehlberg 5')\nplt.figure()\nplot_rkstability(A, b[1], label='Fehlberg 4')",
"_____no_output_____"
],
[
"dframe = pandas.read_html('https://en.wikipedia.org/wiki/Dormand%E2%80%93Prince_method')[0]\ndfloat = dframe.applymap(lambda s: s.replace('−', '-') if isinstance(s, str) else s).fillna(0).applymap(Fraction).astype(float)\ndarray = np.array(dfloat)\nA = darray[:7,2:]\nb = darray[7:,2:]\npandas.DataFrame(A)",
"_____no_output_____"
],
[
"plot_rkstability(A, b[0], label='DP 5')\nplt.figure()\nplot_rkstability(A, b[1], label='DP 4')",
"_____no_output_____"
]
],
[
[
"## Adaptive control\n\nGiven a completion formula $b^T$ of order $p$ and $\\tilde b^T$ of order $p-1$, an estimate of the local truncation error (on this step) is given by\n$$ e_{\\text{loc}}(h) = \\lVert h (b - \\tilde b)^T f(Y) \\rVert \\in O(h^p) . $$\nGiven a tolerance $\\epsilon$, we would like to find $h_*$ such that\n$$ e_{\\text{loc}}(h_*) < \\epsilon . $$\nIf $$e_{\\text{loc}}(h) = c h^p$$ for some constant $c$, then\n$$ c h_*^p < \\epsilon $$\nimplies\n$$ h_* < \\left( \\frac{\\epsilon}{c} \\right)^{1/p} . $$\nGiven the estimate with the current $h$,\n$$ c = e_{\\text{loc}}(h) / h^p $$\nwe conclude\n$$ \\frac{h_*}{h} < \\left( \\frac{\\epsilon}{e_{\\text{loc}}(h)} \\right)^{1/p} . $$\n\n#### Notes\n* Usually a \"safety factor\" less than 1 is included so the predicted error is less than the threshold to reject a time step.\n* We have used an absolute tolerance above. If the values of solution variables vary greatly in time, a relative tolerance $e_{\\text{loc}}(h) / \\lVert u(t) \\rVert$ or a combination thereof is desirable.\n* There is a debate about whether one should optimize the rate at which error is accumulated with respect to work (estimate above) or with respect to simulated time (as above, but with error behaving as $O(h^{p-1})$). For problems with a range of time scales at different periods, this is usually done with respect to work.\n* Global error control is an active research area.",
"_____no_output_____"
],
[
"# Homework 4: Due 2018-12-03 (Monday)\n\n* Implement an explicit Runge-Kutta integrator that takes an initial time step $h_0$ and an error tolerance $\\epsilon$.\n* You can use the Bogacki-Shampine method or any other method with an embedded error estimate.\n* A step should be rejected if the local truncation error exceeds the tolerance.\n* Test your method on the nonlinear equation\n$$ \\begin{bmatrix} \\dot u_0 \\\\ \\dot u_1 \\end{bmatrix} = \\begin{bmatrix} u_1 \\\\ k (1-u_0^2) u_1 - u_0 \\end{bmatrix} $$\nfor $k=2$, $k=5$, and $k=20$.\n* Make a work-precision diagram for your adaptive method and for constant step sizes.\n* State your conclusions or ideas (in a README, or Jupyter notebook) about appropriate (efficient, accurate, reliable) methods for this type of problem.",
"_____no_output_____"
],
[
"# Implicit Runge-Kutta methods\n\nWe have been considering examples of high-order explicit Runge-Kutta methods.\nFor processes like diffusion, the time step becomes limited (under grid refinement, but usually for practical resolution) by stability rather than accuracy. Implicit methods, especially $A$-stable and $L$-stable methods, allow much larger time steps.\n\n### Diagonally implicit\n\nA Runge-Kutta method is called **diagonally implicit** if the Butcher matrix $A$ is lower triangular, in which case the stages can be solved sequentially. Each stage equation has the form\n$$ Y_i - h a_{ii} f(Y_i) = u(0) + h \\sum_{j<i} a_{ij} f(Y_j) $$\nwhere all terms in the right hand side are known.\nFor stiff problems, it is common to multiply though by $\\alpha = (h a_{ii})^{-1}$, yielding\n$$ \\alpha Y_i - f(Y_i) = \\alpha u(0) + \\sum_{j<i} \\frac{a_{ij}}{a_{ii}} f(Y_j) . $$\n\n* It is common for solvers to reuse a linearization associated with $f(Y_i)$.\n* It is common to have setup costs associated with the solution of the \"shifted\" problem.\n\nMethods with constant diagonals, $a_{ii} = a_{jj}$, are often desired to amortize setup costs. These methods are called **singly diagonally implicit**. There are also related methods called Rosenbrock or Roserbrock-W that more aggressively amortize setup costs.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
d0fa4cbb4568d75519c549195dd6f3da10714651 | 247,153 | ipynb | Jupyter Notebook | TEMA-3/Clase23_ValuacionOpcionesAsiaticas.ipynb | danielch4/SPF-2021-I | ff9023ef734d20f1f12182c618c6ffe6d26a677c | [
"MIT"
] | null | null | null | TEMA-3/Clase23_ValuacionOpcionesAsiaticas.ipynb | danielch4/SPF-2021-I | ff9023ef734d20f1f12182c618c6ffe6d26a677c | [
"MIT"
] | null | null | null | TEMA-3/Clase23_ValuacionOpcionesAsiaticas.ipynb | danielch4/SPF-2021-I | ff9023ef734d20f1f12182c618c6ffe6d26a677c | [
"MIT"
] | null | null | null | 244.948464 | 81,244 | 0.902587 | [
[
[
"# Valuación de opciones asiáticas ",
"_____no_output_____"
],
[
"- Las opciones que tratamos la clase pasada dependen sólo del valor del precio del subyacente $S_t$, en el instante que se ejerce.\n\n- Cambios bruscos en el precio, cambian que la opción esté *in the money* a estar *out the money*.\n\n- **Posibilidad de evitar esto** $\\longrightarrow$ suscribir un contrato sobre el valor promedio del precio del subyacente. \n\n- **Opciones exóticas**: opciones cuya estructura de resultados es diferente a la de las opciones tradicionales, y que han surgido con la intención, bien de **abaratar el coste de las primas** de dichas opciones tradicionales, o bien, para ajustarse más adecuadamente a determinadas situaciones.\n\n> \n> Referencia: ver información adicional acerca de las distintas opciones exóticas en el siguiente enlace: [link](http://rabida.uhu.es/dspace/bitstream/handle/10272/5546/Opciones_exoticas.pdf?sequence=2)\n\n- <font color ='red'> Puede proveer protección contra fluctuaciones extremas del precio en mercados volátiles. </font>\n\n- **Nombre**: Banco Trust de Tokio ofreció este tipo de opciones\n\n### Justificación \n- Debido a que los contratos que solo dependen del precio final del subyacente son más vulnerables a cambios repentinos de gran tamaño o manipulación de precios, las opciones asiáticas son menos sensibles a dichos fenómenos (menos riesgosas).\n- Algunos agentes prefieren opciones asiáticas como instrumentos de cobertura, ya que pueden estar expuestos a la evolución del subyacente en un intervalo de tiempo.\n- Son más baratas que sus contrapartes **plain vanilla** $\\longrightarrow$ la volatilidad del promedio por lo general será menor que la del subyacente. **Menor sensibilidad de la opción ante cambios en el subyacente que para una opción vanilla con el mismo vencimiento.**\n\n> Información adicional: **[link](https://reader.elsevier.com/reader/sd/pii/S0186104216300304?token=FE78324CCB90A9B00930E308E5369EB593916F99C8F78EA9190DF9F8FFF55547D8EB557F77801D84C6E01FE63B92F9A3)**\n",
"_____no_output_____"
],
[
"### ¿Dónde se negocian?\n\n- Mercados OTC (Over the Counter / Independientes).\n\n- Las condiciones para el cálculo matemático del promedio y otras condiciones son especificadas en el contrato. Lo que las hace un poco más “personalizables”. \n\nExisten diversos tipos de opciones asiáticas y se clasiflcan de acuerdo con lo siguiente.\n\n1. La media que se utiliza puede ser **aritmética** o geométrica.\n - Media aritmética: $$ \\bar x = \\frac{1}{n}\\sum_{i=1}^{n} x_i$$\n - Media geométrica: $$ {\\bar {x}}={\\sqrt[{n}]{\\prod _{i=1}^{n}{x_{i}}}}={\\sqrt[{n}]{x_{1}\\cdot x_{2}\\cdots x_{n}}}$$\n * **Ventajas**:\n - Considera todos los valores de la distribución.\n - Es menos sensible que la media aritmética a los valores extremos.\n * **Desventajas**\n - Es de significado estadístico menos intuitivo que la media aritmética.\n - Su cálculo es más difícil.\n - Si un valor $x_i = 0$ entonces la media geométrica se anula o no queda determinada.\n\nLa media aritmética de un conjunto de números positivos siempre es igual o superior a la media geométrica:\n$$\n\\sqrt[n]{x_1 \\cdot x_2 \\dots x_n} \\le \\frac{x_1+ \\dots + x_n}{n}\n$$ \n\n2. Media se calcula para $S_t \\longrightarrow$ \"Precio de ejercicio fijo\". Media se calcula para precio de ejercicio $\\longrightarrow$ \"Precio de ejercicio flotante\". \n\n3. Si la opción sólo se puede ejercer al final del tiempo del contrato se dice que es asiática de tipo europeo o **euroasiática**, y si puede ejercer en cualquier instante, durante la vigencia del contrato se denomina **asiática de tipo americano.**\n\nLos tipos de opciones euroasiáticas son:\n\n- Call con precio de ejercicio fijo, función de pago: $\\max\\{A-K,0\\}$.\n- Put con precio de ejercicio fijo, función de pago: $\\max\\{K-A,0\\}$.\n- Call con precio de ejercicio flotante, función de pago: $\\max\\{S_T-A,0\\}$.\n- Put con precio de ejercicio flotante, función de pago: $\\max\\{A-S_T,0\\}$.\n\nDonde $A$ es el promedio del precio del subyacente.\n\n$$\\text{Promedio aritmético} \\quad A={1\\over T} \\int_0^TS_tdt$$\n$$\\text{Promedio geométrico} \\quad A=\\exp\\Big({1\\over T} \\int_0^T Ln(S_t) dt\\Big)$$\n\nDe aquí en adelante denominaremos **Asiática** $\\longrightarrow$ Euroasiática y se analizará el call asiático con **K Fijo**.\n\nSe supondrá un solo activo con riesgo, cuyos proceso de precios $\\{S_t | t\\in [0,T]\\}$ satisface un movimiento browniano geométrico, en un mercado que satisface las suposiciones del modelo de Black y Scholes.\n\n__Suposiciones del modelo__:\n- El precio del activo sigue un movimiento browniano geométrico. \n$$\\frac{dS_t}{S_t}=\\mu dt + \\sigma dW_t,\\quad 0\\leq t \\leq T, S_0 >0$$\n- El comercio puede tener lugar continuamente sin ningún costo de transacción o impuestos.\n- Se permite la venta en corto y los activos son perfectamente divisibles. Por lo tanto, se pueden vender activos que no son propios y se puede comprar y vender cualquier número (no necesariamente un número entero) de los activos subyacentes.\n- La tasa de interés libre de riesgo continuamente compuesta es constante.\n- Los inversores pueden pedir prestado o prestar a la misma tasa de interés sin riesgo.\n- No hay oportunidades de arbitraje sin riesgo. De ello se deduce que todas las carteras libres de riesgo deben obtener el mismo rendimiento.\n\nRecordemos que bajo esta medida de probabilidad, $P^*$, denominada de riesgo neutro, bajo la cual el precio del activo, $S_t$, satisface:\n\n$$dS_t = rS_tdt+\\sigma S_tdW_t,\\quad 0\\leq t \\leq T, S_0 >0$$\n\nPara un call asiático de promedio aritmético y con precio de ejercicios fijo, está dado por\n$$\\max \\{A(T)-K,0\\} = (A(T)-K)_+$$\n\ncon $A(x)={1\\over x} \\int_0^x S_u du$",
"_____no_output_____"
],
[
"Se puede ver que el valor en el tiempo t de la opción call asiática está dado por:\n\n$$ V_t(K) = e^{-r(T-t)}E^*[(A(T)-K)_+]$$\n\nPara el caso de interés, *Valución de la opción*, donde $t_0=0$ y $t=0$, se tiene:\n\n$$\\textbf{Valor call asiático}\\longrightarrow V_0(K)=e^{-rT}E\\Bigg[ \\Big({1\\over T} \\int_0^T S_u du -K\\Big)_+\\Bigg]$$ ",
"_____no_output_____"
],
[
"## Usando Monte Carlo\n\nPara usar este método es necesario que se calcule el promedio $S_u$ en el intervalo $[0,T]$. Para esto se debe aproximar el valor de la integral por los siguiente dos métodos.\n\nPara los dos esquemas se dividirá el intervalo $[0,T]$ en N subintervalos de igual longitud, $h={T\\over N}$, esto determina los tiempos $t_0,t_1,\\cdots,t_{N-1},t_N $, en donde $t_i=ih$ para $i=0,1,\\cdots,N$\n\n### 1. Sumas de Riemann\n\n$$\\int_0^T S_u du \\approx h \\sum_{i=0}^{n-1} S_{t_i}$$\n\nDe este modo, si con el método de Monte Carlo se generan $M$ trayectorias, entonces\nla aproximación de el valor del call asiático estaría dada por:\n\n$$\\hat V_0^{(1)}= {e^{-rT} \\over M} \\sum_{j=1}^{M} \\Bigg({1\\over N} \\sum_{i=0}^{N-1} S_{t_i}-K \\Bigg)_+$$\n",
"_____no_output_____"
],
[
"### 2. Mejorando la aproximación de las sumas de Riemann (esquema del trapecio)\n\n",
"_____no_output_____"
],
[
"Desarrollando la exponencial en serie de taylor y suponiendo que $h$ es pequeña, sólo se conservan los términos de orden uno, se tiene la siguiente aproximación:\n$$\\int_0^T S_u du \\approx {h \\over 2}\\sum_{i=0}^{N-1}S_{t_i}(2+rh+(W_{t_{i+1}}-W_{t_i})\\sigma)$$\n\nReemplazando esta aproximación en el precio del call, se tiene la siguiente estimación:\n$$\\hat V_0^{(2)}= {e^{-rT} \\over M} \\sum_{j=1}^{M} \\Bigg({h\\over 2T} \\sum_{i=0}^{N-1} S_{t_i}(2+rh+(W_{t_{i+1}}-W_{t_i})\\sigma)-K \\Bigg)_+$$\n**recordar que $h = \\frac{T}{N}$**\n> **Referencia**:\nhttp://mat.izt.uam.mx/mat/documentos/notas%20de%20clase/cfenaoe3.pdf",
"_____no_output_____"
],
[
"## Ejemplo\n\nComo caso de prueba se seleccionó el de un call asiático con precio inicial, $S_0 = 100$, precio de ejercicio $K = 100$, tasa libre de riesgo $r = 0.10$, volatilidad $\\sigma = 0.20$ y $T = 1$ año. Cuyo precio es $\\approx 7.04$.",
"_____no_output_____"
]
],
[
[
"#importar los paquetes que se van a usar\nimport pandas as pd\nimport pandas_datareader.data as web\nimport numpy as np\nimport datetime\nimport matplotlib.pyplot as plt\nimport scipy.stats as st\nimport seaborn as sns\n%matplotlib inline\n#algunas opciones para Pandas\npd.set_option('display.notebook_repr_html', True)\npd.set_option('display.max_columns', 9)\npd.set_option('display.max_rows', 10)\npd.set_option('display.width', 78)\npd.set_option('precision', 3)",
"_____no_output_____"
],
[
"# Programar la solución de la ecuación de Black-Scholes\n# St = S0*exp((r-sigma^2/2)*t+ sigma*DeltaW)\nnp.random.seed(5555)\nNbTraj = 2\nNbStep = 100\nS0 = 100\nr = 0.10\nsigma = 0.2\nK = 100\n\nDeltaT = 1 / NbStep\nSqDeltaT = np.sqrt(DeltaT)\nDeltaW = np.random.randn(NbStep - 1, NbTraj) * SqDeltaT\nnu = r-sigma**2/2\nincrements = nu*DeltaT + sigma * DeltaW\n\n# Ln St = Ln S0 + (r-sigma^2/2)*t+ sigma*DeltaW)\nconcat = np.concatenate([np.log(S0)*np.ones([NbStep, 1]), increments], axis=1)\n\nLogSt = np.cumsum(concat, axis=1)\n\nSt = np.exp(LogSt)",
"_____no_output_____"
],
[
"def BSprices(mu,sigma,S0,NbTraj,NbStep):\n \"\"\"\n Expresión de la solución de la ecuación de Black-Scholes\n St = S0*exp((r-sigma^2/2)*t+ sigma*DeltaW)\n \n Parámetros\n ---------\n mu : Tasa libre de riesgo\n sigma : Desviación estándar de los rendimientos\n S0 : Precio inicial del activo subyacente\n NbTraj: Cantidad de trayectorias a simular\n NbStep: Número de días a simular\n \"\"\"\n # Datos para la fórmula de St\n nu = mu-(sigma**2)/2\n DeltaT = 1/NbStep\n SqDeltaT = np.sqrt(DeltaT)\n DeltaW = SqDeltaT*np.random.randn(NbTraj,NbStep-1)\n \n # Se obtiene --> Ln St = Ln S0+ nu*DeltaT + sigma*DeltaW\n increments = nu*DeltaT + sigma*DeltaW\n concat = np.concatenate((np.log(S0)*np.ones([NbTraj,1]),increments),axis=1)\n \n # Se utiliza cumsum por que se quiere simular los precios iniciando desde S0\n LogSt = np.cumsum(concat,axis=1)\n # Se obtienen los precios simulados para los NbStep fijados\n St = np.exp(LogSt)\n # Vector con la cantidad de días simulados\n t = np.arange(0,NbStep)\n\n return St.T,t\n\ndef calc_daily_ret(closes):\n return np.log(closes/closes.shift(1)).iloc[1:]",
"_____no_output_____"
],
[
"np.random.seed(5555)\nNbTraj = 2\nNbStep = 100\nS0 = 100\nr = 0.10\nsigma = 0.2\nK = 100\n\n# Resolvemos la ecuación de black scholes para obtener los precios\nSt,t = BSprices(r,sigma,S0,NbTraj,NbStep)\n# t = t*NbStep\n\nprices = pd.DataFrame(St,index=t)\nprices",
"_____no_output_____"
],
[
"# Graficamos los precios simulados\nax = prices.plot(label='precios originales')#plt.plot(t,St,label='precios')\n\n# Explorar el funcionamiento de la función expanding y rolling para ver cómo calcular el promedio\n# y graficar sus diferencias\nAverage_t = prices.expanding(1, axis=0).mean()\nAverage_t_roll = prices.rolling(window=20).mean()\n\nAverage_t.plot(ax=ax)\n\nAverage_t_roll.plot(ax=ax)\nplt.legend()",
"_____no_output_____"
],
[
"(1.5+3)/2, 2.333*2-1.5\ndata",
"_____no_output_____"
],
[
"# Ilustración función rolling y expanding\ndata = pd.DataFrame([\n ['a', 1],\n ['a', 2],\n ['a', 4],\n ['b', 5],\n], columns = ['category', 'value'])\nprint('expanding\\n',data.value.expanding(2).sum())\nprint('rolling\\n',data.value.rolling(window=2).sum())",
"expanding\n 0 NaN\n1 3.0\n2 7.0\n3 12.0\nName: value, dtype: float64\nrolling\n 0 NaN\n1 3.0\n2 6.0\n3 9.0\nName: value, dtype: float64\n"
],
[
"# Ilustración resultado función expanding\npan = pd.DataFrame(np.matrix([[1,2,3],[4,5,6],[7,8,9],[1,1,1]]))\npan.expanding(1,axis=0).mean()",
"_____no_output_____"
]
],
[
[
"## Valuación opciones asiáticas\n\n### 1. Método sumas de Riemann",
"_____no_output_____"
]
],
[
[
"#### Sumas de Riemann\n# Strike\nstrike = K\n\n# Tiempo de cierre del contrato\nT = 1 \n\n# Valuación de la opción\ncall = pd.DataFrame({'Prima_asiatica':\n np.exp(-r*T) * np.fmax(Average_t - strike, 0).mean(axis=1)}, index=t)\n\ncall.plot()\nprint('La prima estimada usando %i trayectorias es: %2.2f'%(NbTraj,call.iloc[-1].Prima_asiatica))\n\n# intervalos de confianza\nconfianza = 0.95\nsigma_est = call.sem().Prima_asiatica\nmean_est = call.iloc[-1].Prima_asiatica\ni1 = st.t.interval(confianza, NbTraj - 1, loc=mean_est, scale=sigma_est)\ni2 = st.norm.interval(confianza, loc=mean_est, scale=sigma_est)\n\nprint('El intervalor de confianza usando t-dist es:', i1)\nprint('El intervalor de confianza usando norm-dist es:', i2)\n",
"La prima estimada usando 2 trayectorias es: 9.94\nEl intervalor de confianza usando t-dist es: (6.57405517707332, 13.314037058629602)\nEl intervalor de confianza usando norm-dist es: (9.424216553543172, 10.463875682159749)\n"
],
[
"call.iloc[-1].Prima",
"_____no_output_____"
]
],
[
[
"Ahora hagamos pruebas variando la cantidad de trayectorias `NbTraj` y la cantidad de números de puntos `NbStep` para ver como aumenta la precisión del método. Primero creemos una función que realice la aproximación de Riemann",
"_____no_output_____"
]
],
[
[
"# Función donde se almacenan todos los resultados\ndef Riemann_approach(K:'Strike price',r:'Tasa libre de riesgo',S0:'Precio inicial',\n NbTraj:'Número trayectorias',NbStep:'Cantidad de pasos a simular',\n sigma:'Volatilidad',T:'Tiempo de cierre del contrato en años',\n flag=None):\n # Resolvemos la ecuación de black scholes para obtener los precios\n St,t = BSprices(r,sigma,S0,NbTraj,NbStep)\n # Almacenamos los precios en un dataframe\n prices = pd.DataFrame(St,index=t)\n # Obtenemos los precios promedios\n Average_t = prices.expanding().mean()\n # Definimos el dataframe de strikes\n strike = K\n # Calculamos el call de la opción según la formula obtenida para Sumas de Riemann\n call = pd.DataFrame({'Prima': np.exp(-r*T) \\\n *np.fmax(Average_t - strike, 0).mean(axis=1)}, index=t)\n # intervalos de confianza\n confianza = 0.95\n sigma_est = call.sem().Prima\n mean_est = call.iloc[-1].Prima\n i1 = st.norm.interval(confianza, loc=mean_est, scale=sigma_est)\n# return np.array([call.iloc[-1].Prima,i1[0],i1[1]])\n# if flag==True:\n# # calcular intervarlo\n# return call, intervalo\n# else \n return call.iloc[-1].Prima",
"_____no_output_____"
]
],
[
[
"## Ejemplo\nValuar la siguiente opción asiática con los siguientes datos $S_0= 100$, $r=0.10$, $\\sigma=0.2$, $K=100$, $T=1$ en años, usando la siguiente combinación de trayectorias y número de pasos:",
"_____no_output_____"
]
],
[
[
"NbTraj = [1000, 10000, 20000]\nNbStep = [10, 50, 100]\n\n# Visualización de datos \nfilas = ['Nbtray = %i' %i for i in NbTraj]\ncol = ['NbStep = %i' %i for i in NbStep]\ndf = pd.DataFrame(index=filas,columns=col)\ndf",
"_____no_output_____"
],
[
"# Resolverlo acá\nS0 = 100\nr = 0.10\nsigma = 0.2\nK = 100\nT = 1\n\ndf.loc[:, :] = list(map(lambda N_tra: list(map(lambda N_ste: Riemann_approach(K, r, S0, N_tra, N_ste, sigma, T), NbStep)),\n NbTraj))\ndf",
"_____no_output_____"
]
],
[
[
"# Tarea\n\nImplementar el método de esquemas del trapecio, para valuar la opción call y put asiática con precio inicial, $S_0 = 100$, precio de ejercicio $K = 100$, tasa libre de riesgo $r = 0.10$, volatilidad $\\sigma = 0.20$ y $T = 1$ año. Cuyo precio es $\\approx 7.04$. Realizar la simulación en base a la siguiente tabla:\n\n\nObserve que en esta tabla se encuentran los intervalos de confianza de la aproximación obtenida y además el tiempo de simulación que tarda en encontrar la respuesta cada método. \n- Se debe entonces realizar una simulación para la misma cantidad de trayectorias y número de pasos y construir una Dataframe de pandas para reportar todos los resultados obtenidos.**(70 puntos)**\n- Compare los resultados obtenidos con los resultados arrojados por la función `Riemann_approach`. Concluya. **(30 puntos)**",
"_____no_output_____"
],
[
"Se habilitará un enlace en canvas donde se adjuntará los resultados de dicha tarea\n\n>**Nota:** Para generar índices de manera como se especifica en la tabla referirse a:\n> - https://pandas.pydata.org/pandas-docs/stable/user_guide/advanced.html\n> - https://jakevdp.github.io/PythonDataScienceHandbook/03.05-hierarchical-indexing.html\n> - https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.MultiIndex.html\n",
"_____no_output_____"
],
[
"<script>\n $(document).ready(function(){\n $('div.prompt').hide();\n $('div.back-to-top').hide();\n $('nav#menubar').hide();\n $('.breadcrumb').hide();\n $('.hidden-print').hide();\n });\n</script>\n\n<footer id=\"attribution\" style=\"float:right; color:#808080; background:#fff;\">\nCreated with Jupyter by Oscar David Jaramillo Z.\n</footer>",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
d0fa5ecaca91d17d7b9a83bb44eb788e2e7ddc4f | 791,987 | ipynb | Jupyter Notebook | 04_overfitting.ipynb | diegorusso/deep-learning-scratch-course | 3b53892845d4af62babe92165f5c857b0544810c | [
"BSD-3-Clause"
] | null | null | null | 04_overfitting.ipynb | diegorusso/deep-learning-scratch-course | 3b53892845d4af62babe92165f5c857b0544810c | [
"BSD-3-Clause"
] | null | null | null | 04_overfitting.ipynb | diegorusso/deep-learning-scratch-course | 3b53892845d4af62babe92165f5c857b0544810c | [
"BSD-3-Clause"
] | null | null | null | 878.034368 | 209,529 | 0.931572 | [
[
[
"<a href=\"https://colab.research.google.com/github/diegorusso/deep-learning-from-scratch/blob/master/04_overfitting.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# Overfitting and Regularization\n\nLet's generate a new dataset: a straight line added to a sine wave and some random noise (unwanted of course)\n",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\ndef generate_datasets(n_points):\n \n global train_x, train_y, test_x, test_y\n\n def generate_dataset(seed, n_points):\n train_slope = 0.1\n train_offset = -1.0\n x = np.linspace(-10, 10, n_points).astype(np.float32)\n rng = np.random.RandomState(seed=seed)\n y = (train_slope * x + np.sin(x / 1.5) + train_offset +\n rng.normal(0.0, 0.2, size=len(x))).astype(np.float32)\n return (x,y)\n\n # Training dataset\n train_x, train_y = generate_dataset(42, n_points)\n\n # Test dataset\n test_x, test_y = generate_dataset(43, n_points)",
"_____no_output_____"
],
[
"%matplotlib inline\nimport matplotlib.pyplot as plt\n\ngenerate_datasets(n_points=100)\n\nplt.rcParams[\"figure.figsize\"] = (12, 8)\nplt.plot(train_x, train_y, 'o');\nplt.show()",
"_____no_output_____"
]
],
[
[
"Let's do some reshape of the training and test data and normalise the data into the range [-1.0, 1.0].",
"_____no_output_____"
]
],
[
[
"train_x = train_x.reshape(-1, 1)\ntrain_y = train_y.reshape(-1, 1)\ntrain_x = train_x - np.mean(train_x, axis=0)\ntrain_x = train_x / np.max(train_x, axis=0)\n\ntest_x = test_x.reshape(-1, 1)\ntest_y = test_y.reshape(-1, 1)\ntest_x = test_x - np.mean(test_x, axis=0)\ntest_x = test_x / np.max(test_x, axis=0)",
"_____no_output_____"
]
],
[
[
"Now we are going to play around with **hyperparameters** of the network, like number of layers and number of the units.\nWe will do this in iterative way:\n* train the network\n* measure the cost and the accuracy\n* change the value of some hyperparameter\n* repeat the experiment\n* compare the results\n\nThis because there is a danger that **our choice of hyperparameters will be biased by the specific data samples** that forms the training dataset.\n\nThe outcome would be that our network **gives excellent results with the training datasets** but **poorer results when presented new data sample** it has never seen before.\n\nTo avoid this situation we hold back a subset of the training data sample to form a **test dataset** (or **validation dataset**). Once the model is trained with the train dataset we can measure loss and accuracy with the validation dataset. The ratio between training and validation dataset is **3:1 or 4:1**\n\nAnother important measure is to **shuffle** data so they can be presented to the network in random order during training.\n\nLet's report in code what we have just said.",
"_____no_output_____"
]
],
[
[
"import tensorflow\nfrom tensorflow.keras.models import Sequential\nfrom tensorflow.keras.layers import Dense\n\ndef build_and_run_regression_graph(num_layers, num_hidden, num_steps, num_runs):\n \n # Number of data points\n m = train_x.shape[0]\n\n training_loss_for_run = []\n test_loss_for_run = []\n prediction_for_run = []\n\n for run in range(num_runs):\n tensorflow.keras.backend.clear_session()\n \n model = Sequential()\n\n # First hidden layer\n model.add(Dense(input_shape=(1,), units=num_hidden, activation='relu'))\n\n # Subsequent hidden layers\n for i in range(1, num_layers):\n model.add(Dense(units=num_hidden, activation='relu'))\n\n # Output layer\n model.add(Dense(units=1))\n \n if (run == 0): model.summary()\n\n model.compile(loss='mean_squared_error', optimizer='adam')\n\n #stopping = tensorflow.keras.callbacks.EarlyStopping(\n # monitor='loss', min_delta=0.00001, patience=50, verbose=1)\n\n model.fit(train_x, train_y, epochs=num_steps, batch_size=m, verbose=0)#, callbacks=[stopping])\n\n training_loss = model.evaluate(train_x, train_y, batch_size=m, verbose=0)\n test_loss = model.evaluate(test_x, test_y, batch_size=m, verbose=0)\n prediction = model.predict(test_x, batch_size=m)\n \n print('Training loss = {:5.3f}, test loss = {:5.3f}'.format(\n training_loss, test_loss))\n\n training_loss_for_run.append(training_loss)\n test_loss_for_run.append(test_loss)\n prediction_for_run.append(prediction)\n\n print('Training loss min/mean/max = {:5.3f}/{:5.3f}/{:5.3f}'.format(\n np.min(training_loss_for_run), np.mean(training_loss_for_run), np.max(training_loss_for_run)))\n\n print('Test loss min/mean/max = {:5.3f}/{:5.3f}/{:5.3f}'.format(\n np.min(test_loss_for_run), np.mean(test_loss_for_run), np.max(test_loss_for_run)))\n\n # Plot the runs as a sanity check\n plt.rcParams[\"figure.figsize\"] = (12, 8)\n plt.plot(train_x, train_y, 'o');\n for run in range(num_runs):\n plt.plot(test_x, prediction_for_run[run])\n plt.show()",
"_____no_output_____"
],
[
"build_and_run_regression_graph(num_layers=1, num_hidden=6, num_steps=30000, num_runs=10)",
"Model: \"sequential\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ndense (Dense) (None, 6) 12 \n_________________________________________________________________\ndense_1 (Dense) (None, 1) 7 \n=================================================================\nTotal params: 19\nTrainable params: 19\nNon-trainable params: 0\n_________________________________________________________________\nTraining loss = 0.145, test loss = 0.157\nTraining loss = 0.124, test loss = 0.160\nTraining loss = 0.239, test loss = 0.269\nTraining loss = 0.147, test loss = 0.159\nWARNING:tensorflow:5 out of the last 9 calls to <function Model.make_test_function.<locals>.test_function at 0x7f1f838f5ae8> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:5 out of the last 5 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f1f7ed82ae8> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.124, test loss = 0.160\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f1f83917158> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:6 out of the last 6 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f1f7ee1b488> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.145, test loss = 0.159\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f1f7ed82048> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:7 out of the last 7 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f1f7d509d90> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.041, test loss = 0.050\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f1f7d4d6e18> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:8 out of the last 8 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f1f7ed82a60> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.147, test loss = 0.157\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f1f78922378> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:9 out of the last 9 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f1f7a260840> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.036, test loss = 0.059\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f1f789222f0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:10 out of the last 10 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f1f8716dbf8> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.151, test loss = 0.161\nTraining loss min/mean/max = 0.036/0.130/0.239\nTest loss min/mean/max = 0.050/0.149/0.269\n"
]
],
[
[
"We have run the above model with 6 units and one hidden layer. The model fits the data well in some runs but **very badly on other runs**. The gradient descend struggle to find a good minimum for the cost function in those cases.\n\nThe output shows also the minimum, mean and maximum loss for training and test. The thing to note the **big variation** in the cost across runs.\n\nThe runs that converge **most quickly**, meaning that the cost stops improving quickly, are also the runs with the **highest cost**, implying that the network has fallen into a **local minimum during training**.\n\nTo improve the situation we **should increase the number of units and hidden layers.**\n\nLet's try with 1 hidden layer and 16 units",
"_____no_output_____"
]
],
[
[
"build_and_run_regression_graph(num_layers=1, num_hidden=16, num_steps=30000, num_runs=10)",
"Model: \"sequential\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ndense (Dense) (None, 16) 32 \n_________________________________________________________________\ndense_1 (Dense) (None, 1) 17 \n=================================================================\nTotal params: 49\nTrainable params: 49\nNon-trainable params: 0\n_________________________________________________________________\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f1f7d5288c8> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f1f7eda56a8> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.034, test loss = 0.054\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f1f7a30fd08> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f1f7ed4dc80> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.033, test loss = 0.054\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f1f7ed4d488> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f1f83955400> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.145, test loss = 0.159\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f1f7ed4dd90> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f1f788d9b70> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.145, test loss = 0.159\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f1f7d4ed9d8> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f1f83939510> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.032, test loss = 0.056\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f1f81fdf950> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f1f7a2fdf28> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.145, test loss = 0.159\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f1f8526a400> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f1f789529d8> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.029, test loss = 0.052\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f1f78959bf8> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f1f78959400> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.029, test loss = 0.050\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f1f73e922f0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f1f7bb43620> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.032, test loss = 0.060\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f1f7bb43730> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f1f757bdd08> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.033, test loss = 0.055\nTraining loss min/mean/max = 0.029/0.066/0.145\nTest loss min/mean/max = 0.050/0.086/0.159\n"
]
],
[
[
"Still there are runs where the model doesn't fit the data very well but we can start noticing a **stronger overfitting.**\n\nAs last example we try **4 hidden layers of 16 neurons** per layer",
"_____no_output_____"
]
],
[
[
"build_and_run_regression_graph(num_layers=4, num_hidden=16, num_steps=30000, num_runs=10)",
"Model: \"sequential\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ndense (Dense) (None, 16) 32 \n_________________________________________________________________\ndense_1 (Dense) (None, 16) 272 \n_________________________________________________________________\ndense_2 (Dense) (None, 16) 272 \n_________________________________________________________________\ndense_3 (Dense) (None, 16) 272 \n_________________________________________________________________\ndense_4 (Dense) (None, 1) 17 \n=================================================================\nTotal params: 865\nTrainable params: 865\nNon-trainable params: 0\n_________________________________________________________________\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f727a766d90> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f7278d8f378> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.010, test loss = 0.057\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f72828461e0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f72845d38c8> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.012, test loss = 0.058\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f7284688d08> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f7278dfa620> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.016, test loss = 0.057\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f727fddf6a8> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f7280e66b70> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.016, test loss = 0.051\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f72845d31e0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f727f4ef400> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.018, test loss = 0.050\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f727c9d8620> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f72828488c8> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.018, test loss = 0.051\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f72846c4d90> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f727fd87ea0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.019, test loss = 0.051\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f727fd87950> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f7280e66d90> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.021, test loss = 0.048\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f727fd876a8> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f727e3e8f28> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.019, test loss = 0.052\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f727f4bcea0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f7280e7d9d8> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.011, test loss = 0.056\nTraining loss min/mean/max = 0.010/0.016/0.021\nTest loss min/mean/max = 0.048/0.053/0.058\n"
]
],
[
[
"Ok, in this last example the model adapted very well to the training data. It has even adapted to the noise we introduced! This is not a good thing because we can see a **strong overfit** to the trining data.\n\nIn fact the loss on the test data is much higher, hence the model won't do a great job when presenting new data.\n\nWe have decreased the variance across runs for test and training data but the difference between the 2 is high. This means we have an **overfit to the training data.**\n\nThe next steps are to make our network **bigger and deeper** and then take measure to avoid overfitting. Haw can we do it? **Adding more data** might not be a solution because the network can adapt to the new data.\n\nThe solution is to have some sort of **regularization mechanism.**\n\n## Early termination\n\nWith this technique we **cut short the training as soon as the cost has stabilized at a reasonable level.**\n\n## L2 regularization\n\nL2 regularization works by adding an extra term to the cost function. If the cost is MSE we add this term to it to make the overall function **more unique**.\n\nThe term we add is the square of L2 norm (Euclidean norm) or weight vector.\n\n\n\nIf you think of the weight vector as representing a single point in a high-dimensional space, the L2 norm represents the distance of that point from the origin\n\n",
"_____no_output_____"
],
[
"The L2 term includes a multiplicate constant lambda. If 0, we disable the term hence no regularization.\nIf lambda is too large the network will not learn anything from the training data.\n\nThe optimal value of **lambda has to be determined by experimentation.** This parameters is one of the hyperparameters we need to set during training.\n\nValues to try are: 0.03, 0.01, 0.003, 0.001, 0.0003, 0.0001\n\nLet's try these 2 optimizations together.\n",
"_____no_output_____"
]
],
[
[
"import tensorflow\nfrom tensorflow.keras.models import Sequential\nfrom tensorflow.keras.layers import Dense\nfrom tensorflow.keras.regularizers import l2\n\ndef build_and_run_regression_graph_with_l2(num_layers, num_hidden, num_steps, num_runs, lambda_=0):\n \n # Number of data points\n m = train_x.shape[0]\n\n training_loss_for_run = []\n test_loss_for_run = []\n prediction_for_run = []\n \n\n for run in range(num_runs):\n tensorflow.keras.backend.clear_session()\n \n model = Sequential()\n\n # First hidden layer\n model.add(Dense(input_shape=(1,), units=num_hidden, activation='relu', kernel_regularizer=l2(lambda_)))\n\n # Subsequent hidden layers\n for i in range(1,num_layers):\n # We add our L2 regularizer\n model.add(Dense(units=num_hidden, activation='relu', kernel_regularizer=l2(lambda_)))\n\n # Output layer\n model.add(Dense(units=1))\n \n if (run == 0): model.summary()\n\n model.compile(loss='mean_squared_error', optimizer='adam')\n\n # We define the Early Termination\n stopping = tensorflow.keras.callbacks.EarlyStopping(\n monitor='loss', min_delta=0.00001, patience=50, verbose=1)\n\n model.fit(train_x, train_y, epochs=num_steps, batch_size=m, verbose=0, callbacks=[stopping])\n\n training_loss = model.evaluate(train_x, train_y, batch_size=m, verbose=0)\n test_loss = model.evaluate(test_x, test_y, batch_size=m, verbose=0)\n prediction = model.predict(test_x, batch_size=m)\n \n print('Training loss = {:5.3f}, test loss = {:5.3f}'.format(\n training_loss, test_loss))\n\n training_loss_for_run.append(training_loss)\n test_loss_for_run.append(test_loss)\n prediction_for_run.append(prediction)\n\n print('Training loss min/mean/max = {:5.3f}/{:5.3f}/{:5.3f}'.format(\n np.min(training_loss_for_run), np.mean(training_loss_for_run), np.max(training_loss_for_run)))\n\n print('Test loss min/mean/max = {:5.3f}/{:5.3f}/{:5.3f}'.format(\n np.min(test_loss_for_run), np.mean(test_loss_for_run), np.max(test_loss_for_run)))\n\n # Plot the runs as a sanity check\n plt.rcParams[\"figure.figsize\"] = (12, 8)\n plt.plot(train_x, train_y, 'o');\n for run in range(num_runs):\n plt.plot(test_x, prediction_for_run[run])\n plt.show()",
"_____no_output_____"
],
[
"build_and_run_regression_graph_with_l2(num_layers=4, num_hidden=16, num_steps=30000, num_runs=10, lambda_=0.03)",
"Model: \"sequential\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ndense (Dense) (None, 16) 32 \n_________________________________________________________________\ndense_1 (Dense) (None, 16) 272 \n_________________________________________________________________\ndense_2 (Dense) (None, 16) 272 \n_________________________________________________________________\ndense_3 (Dense) (None, 16) 272 \n_________________________________________________________________\ndense_4 (Dense) (None, 1) 17 \n=================================================================\nTotal params: 865\nTrainable params: 865\nNon-trainable params: 0\n_________________________________________________________________\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f7278de0400> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f727afdb950> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.123, test loss = 0.140\nEpoch 16554: early stopping\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f7278dc01e0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f727ca5f730> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.158, test loss = 0.177\nEpoch 25994: early stopping\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f72828bfa60> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f7278dc0d08> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.227, test loss = 0.237\nEpoch 27095: early stopping\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f7278d9b268> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f7282843e18> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.149, test loss = 0.164\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f728e56f378> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f728463e6a8> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.133, test loss = 0.151\nEpoch 25661: early stopping\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f727afdb1e0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f7280e8e488> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.212, test loss = 0.243\nEpoch 26407: early stopping\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f727e427400> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f727daddf28> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.152, test loss = 0.168\nEpoch 15746: early stopping\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f727dadd268> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f727ca9f1e0> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.166, test loss = 0.181\nEpoch 28479: early stopping\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f7284f98ae8> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f728473e488> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.208, test loss = 0.240\nEpoch 24202: early stopping\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f728473e840> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f728e56f400> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.160, test loss = 0.179\nTraining loss min/mean/max = 0.123/0.169/0.227\nTest loss min/mean/max = 0.140/0.188/0.243\n"
]
],
[
[
"Ok, we can see now the model fits the data but not overfits (it doesn't try to pass to every point)\n\nA training dataset of just 100 points is insufficient to represent the underlying distribution, and so, unsurprisingly, the model performs worse on the test dataset.\n\nLet's try not to increase the number of data points: **these are roughly twice the number of trainable parameters** so that the training dataset is a good representation of the underlying distribution.",
"_____no_output_____"
]
],
[
[
"generate_datasets(n_points=2000)\n\nplt.rcParams[\"figure.figsize\"] = (12, 8)\nplt.plot(train_x, train_y, 'o');\nplt.show()",
"_____no_output_____"
],
[
"build_and_run_regression_graph_with_l2(num_layers=4, num_hidden=16, num_steps=30000, num_runs=10, lambda_=0.001)",
"Model: \"sequential\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ndense (Dense) (None, 16) 32 \n_________________________________________________________________\ndense_1 (Dense) (None, 16) 272 \n_________________________________________________________________\ndense_2 (Dense) (None, 16) 272 \n_________________________________________________________________\ndense_3 (Dense) (None, 16) 272 \n_________________________________________________________________\ndense_4 (Dense) (None, 1) 17 \n=================================================================\nTotal params: 865\nTrainable params: 865\nNon-trainable params: 0\n_________________________________________________________________\nEpoch 09663: early stopping\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f727fdea488> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f72817477b8> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.044, test loss = 0.045\nEpoch 10055: early stopping\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f727fdea048> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f727fd86598> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.044, test loss = 0.045\nEpoch 10936: early stopping\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f728473e488> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f727ca76ae8> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.044, test loss = 0.045\nEpoch 12274: early stopping\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f727e387c80> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f727e3e8bf8> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.044, test loss = 0.045\nEpoch 10110: early stopping\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f728e56f158> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f72828487b8> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.044, test loss = 0.045\nEpoch 09341: early stopping\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f72845d37b8> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f727b8ed378> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.044, test loss = 0.046\nEpoch 07704: early stopping\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f727ec50620> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f727c100d08> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.044, test loss = 0.046\nEpoch 10637: early stopping\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f727c997400> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f727f4f0730> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.044, test loss = 0.045\nEpoch 11340: early stopping\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f727c98c048> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f72846c4598> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.044, test loss = 0.045\nEpoch 08992: early stopping\nWARNING:tensorflow:6 out of the last 11 calls to <function Model.make_test_function.<locals>.test_function at 0x7f72774df8c8> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nWARNING:tensorflow:11 out of the last 11 calls to <function Model.make_predict_function.<locals>.predict_function at 0x7f727756fd08> triggered tf.function retracing. Tracing is expensive and the excessive number of tracings could be due to (1) creating @tf.function repeatedly in a loop, (2) passing tensors with different shapes, (3) passing Python objects instead of tensors. For (1), please define your @tf.function outside of the loop. For (2), @tf.function has experimental_relax_shapes=True option that relaxes argument shapes that can avoid unnecessary retracing. For (3), please refer to https://www.tensorflow.org/tutorials/customization/performance#python_or_tensor_args and https://www.tensorflow.org/api_docs/python/tf/function for more details.\nTraining loss = 0.044, test loss = 0.045\nTraining loss min/mean/max = 0.044/0.044/0.044\nTest loss min/mean/max = 0.045/0.045/0.046\n"
]
],
[
[
"Look at the training/test final results.\n\nThey are almost identical: that means we now have a model that performs well both on training and test dataset hence the model doesn't have any bias towards the training dataset and can predict correctly unseen data.\n",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0fa6f238a3acbff71294b03bd2dffea31e2ce29 | 2,255 | ipynb | Jupyter Notebook | 590. N-ary Tree Postorder Traversal.ipynb | sppool/LeetCode | e1c94cacf2ecc848dfa32d8e7691c0939a896f86 | [
"MIT"
] | null | null | null | 590. N-ary Tree Postorder Traversal.ipynb | sppool/LeetCode | e1c94cacf2ecc848dfa32d8e7691c0939a896f86 | [
"MIT"
] | null | null | null | 590. N-ary Tree Postorder Traversal.ipynb | sppool/LeetCode | e1c94cacf2ecc848dfa32d8e7691c0939a896f86 | [
"MIT"
] | null | null | null | 23.247423 | 94 | 0.500665 | [
[
[
"### N-ary Tree Postorder Traversal",
"_____no_output_____"
]
],
[
[
"Given an n-ary tree, return the postorder traversal of its nodes' values.\nFor example, given a 3-ary tree:\nReturn its postorder traversal as: [5,6,3,2,4,1].\nNote: Recursive solution is trivial, could you do it iteratively?",
"_____no_output_____"
]
],
[
[
"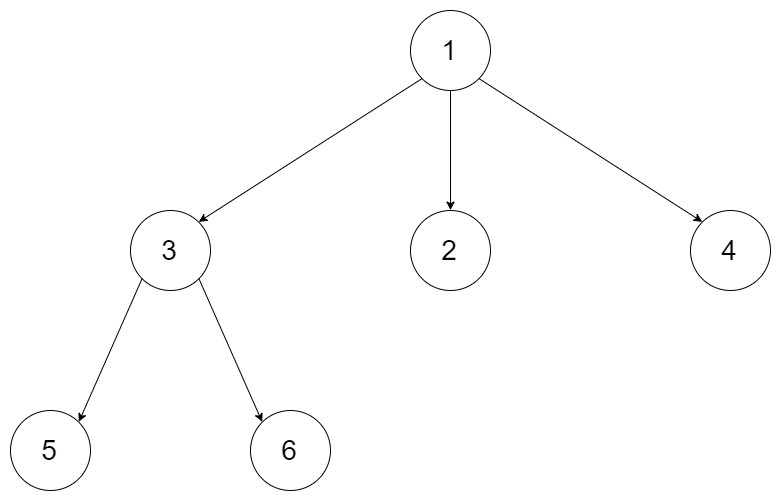",
"_____no_output_____"
]
],
[
[
"class Node:\n def __init__(self, val, children=None):\n self.val = val\n self.children = children # type(children) list(node1, node2...) \n\nclass Solution: # 100.00%\n def postorder(self, root):\n if not root: return [] # root = None 初始\n self.res = []\n self.order(root)\n return self.res\n def order(self, root):\n if not root.children: pass\n else:\n for node in root.children:\n self.order(node)\n self.res.append(root.val)",
"_____no_output_____"
],
[
"root = Node(1, [Node(3, [Node(5), Node(6)]), Node(2), Node(4)])\nans = Solution()\nans.postorder(root)",
"_____no_output_____"
]
]
] | [
"markdown",
"raw",
"markdown",
"code"
] | [
[
"markdown"
],
[
"raw"
],
[
"markdown"
],
[
"code",
"code"
]
] |
d0fa6f36e962c092822ac9ad46f14e6ed687610a | 23,190 | ipynb | Jupyter Notebook | play/Play.ipynb | Hyperion-shuo/handful-of-trials | 930096ef9b41de27aafd358913d54c75dd8b4b4e | [
"MIT"
] | null | null | null | play/Play.ipynb | Hyperion-shuo/handful-of-trials | 930096ef9b41de27aafd358913d54c75dd8b4b4e | [
"MIT"
] | null | null | null | play/Play.ipynb | Hyperion-shuo/handful-of-trials | 930096ef9b41de27aafd358913d54c75dd8b4b4e | [
"MIT"
] | null | null | null | 34.355556 | 1,348 | 0.52527 | [
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\nimport tensorflow as tf\ntf.enable_eager_execution()",
"/data/ShenShuo/miniconda3/envs/pets2/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:516: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_qint8 = np.dtype([(\"qint8\", np.int8, 1)])\n/data/ShenShuo/miniconda3/envs/pets2/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:517: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_quint8 = np.dtype([(\"quint8\", np.uint8, 1)])\n/data/ShenShuo/miniconda3/envs/pets2/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:518: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_qint16 = np.dtype([(\"qint16\", np.int16, 1)])\n/data/ShenShuo/miniconda3/envs/pets2/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:519: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_quint16 = np.dtype([(\"quint16\", np.uint16, 1)])\n/data/ShenShuo/miniconda3/envs/pets2/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:520: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_qint32 = np.dtype([(\"qint32\", np.int32, 1)])\n/data/ShenShuo/miniconda3/envs/pets2/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:525: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n np_resource = np.dtype([(\"resource\", np.ubyte, 1)])\n/data/ShenShuo/miniconda3/envs/pets2/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:541: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_qint8 = np.dtype([(\"qint8\", np.int8, 1)])\n/data/ShenShuo/miniconda3/envs/pets2/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:542: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_quint8 = np.dtype([(\"quint8\", np.uint8, 1)])\n/data/ShenShuo/miniconda3/envs/pets2/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:543: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_qint16 = np.dtype([(\"qint16\", np.int16, 1)])\n/data/ShenShuo/miniconda3/envs/pets2/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:544: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_quint16 = np.dtype([(\"quint16\", np.uint16, 1)])\n/data/ShenShuo/miniconda3/envs/pets2/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:545: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_qint32 = np.dtype([(\"qint32\", np.int32, 1)])\n/data/ShenShuo/miniconda3/envs/pets2/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n np_resource = np.dtype([(\"resource\", np.ubyte, 1)])\n"
],
[
"a = ''\nif a is None:\n print(\"not None\")\nif not a :\n print(\"not a\")",
"not a\n"
],
[
"a = np.arange(10)\nprint(a[9:])\nprint(a[:9])",
"[9]\n[0 1 2 3 4 5 6 7 8]\n"
],
[
"print(a.reshape([1,10,1]))",
"[[[0]\n [1]\n [2]\n [3]\n [4]\n [5]\n [6]\n [7]\n [8]\n [9]]]\n"
],
[
"a = np.arange(6).reshape(3,2)\nidxs = np.random.randint(a.shape[0], size=[4, a.shape[0]])\nprint(idxs.shape, a[idxs].shape)\nprint(a)\nprint(idxs)\nprint(a[idxs])",
"(4, 3) (4, 3, 2)\n[[0 1]\n [2 3]\n [4 5]]\n[[0 2 2]\n [0 2 2]\n [2 1 2]\n [1 1 2]]\n[[[0 1]\n [4 5]\n [4 5]]\n\n [[0 1]\n [4 5]\n [4 5]]\n\n [[4 5]\n [2 3]\n [4 5]]\n\n [[2 3]\n [2 3]\n [4 5]]]\n"
]
],
[
[
"# TensorStandardScaler",
"_____no_output_____"
]
],
[
[
"class TensorStandardScaler:\n \"\"\"Helper class for automatically normalizing inputs into the network.\n \"\"\"\n def __init__(self, x_dim):\n \"\"\"Initializes a scaler.\n\n Arguments:\n x_dim (int): The dimensionality of the inputs into the scaler.\n\n Returns: None.\n \"\"\"\n self.fitted = False\n with tf.variable_scope(\"Scaler\"):\n self.mu = tf.get_variable(\n name=\"scaler_mu\", shape=[1, x_dim], initializer=tf.constant_initializer(0.0),\n trainable=False\n )\n self.sigma = tf.get_variable(\n name=\"scaler_std\", shape=[1, x_dim], initializer=tf.constant_initializer(1.0),\n trainable=False\n )\n\n self.cached_mu, self.cached_sigma = np.zeros([0, x_dim]), np.ones([1, x_dim])\n\n def fit(self, data):\n \"\"\"Runs two ops, one for assigning the mean of the data to the internal mean, and\n another for assigning the standard deviation of the data to the internal standard deviation.\n This function must be called within a 'with <session>.as_default()' block.\n\n Arguments:\n data (np.ndarray): A numpy array containing the input\n\n Returns: None.\n \"\"\"\n mu = np.mean(data, axis=0, keepdims=True)\n sigma = np.std(data, axis=0, keepdims=True)\n sigma[sigma < 1e-12] = 1.0\n\n # equal to tf.assign in tf2\n self.mu.load(mu)\n self.sigma.load(sigma)\n self.fitted = True\n self.cache()\n\n def transform(self, data):\n \"\"\"Transforms the input matrix data using the parameters of this scaler.\n\n Arguments:\n data (np.array): A numpy array containing the points to be transformed.\n\n Returns: (np.array) The transformed dataset.\n \"\"\"\n return (data - self.mu) / self.sigma\n\n def inverse_transform(self, data):\n \"\"\"Undoes the transformation performed by this scaler.\n\n Arguments:\n data (np.array): A numpy array containing the points to be transformed.\n\n Returns: (np.array) The transformed dataset.\n \"\"\"\n return self.sigma * data + self.mu\n\n def get_vars(self):\n \"\"\"Returns a list of variables managed by this object.\n\n Returns: (list<tf.Variable>) The list of variables.\n \"\"\"\n return [self.mu, self.sigma]\n\n def cache(self):\n \"\"\"Caches current values of this scaler.\n\n Returns: None.\n \"\"\"\n\n # use a default session, return the value of this variable\n self.cached_mu = self.mu.eval()\n self.cached_sigma = self.sigma.eval()\n\n def load_cache(self):\n \"\"\"Loads values from the cache\n\n Returns: None.\n \"\"\"\n self.mu.load(self.cached_mu)\n self.sigma.load(self.cached_sigma)",
"_____no_output_____"
],
[
"# scaler = TensorStandardScaler(4)\ndata = np.arange(12).reshape(3,4)\nwith tf.Session() as sess:\n sess.run(tf.global_variables_initializer())\n # print(scaler.fitted)\n # print(scaler.cached_mu, scaler.cached_sigma)\n mu, var = sess.run(scaler.get_vars())\n print(mu, var)\n scaler.fit(data)\n tran_data = sess.run(scaler.transform(data))\n print(tran_data)\n mu, var = sess.run(scaler.get_vars())\n print(mu, var)\n ",
"[[0. 0. 0. 0.]] [[1. 1. 1. 1.]]\n[[-1.2247448 -1.2247448 -1.2247448 -1.2247448]\n [ 0. 0. 0. 0. ]\n [ 1.2247448 1.2247448 1.2247448 1.2247448]]\n[[4. 5. 6. 7.]] [[3.2659864 3.2659864 3.2659864 3.2659864]]\n"
]
],
[
[
"# shuffle rows",
"_____no_output_____"
]
],
[
[
"def shuffle_rows(arr):\n idxs = np.argsort(np.random.uniform(size=arr.shape), axis=-1)\n return arr[np.arange(arr.shape[0])[:, None], idxs]\n\na = np.random.uniform(size=(3,3,3))\nb = a.shape\nprint(b)\na = shuffle_rows(a)\nc = a.shape\nprint(c) \n",
"(3, 3, 3)\n(3, 3, 3, 3)\n"
],
[
"a = np.arange(12).reshape(3,2,2)\nprint(a)\nidxs = a.argsort()\nb = a[np.array([0,1,2])[:,None], idxs]\nprint(b.shape)",
"[[[ 0 1]\n [ 2 3]]\n\n [[ 4 5]\n [ 6 7]]\n\n [[ 8 9]\n [10 11]]]\n"
],
[
"np.random.randint()\nnp.random.permutation()",
"_____no_output_____"
]
],
[
[
"# MPC ._compile_cost",
"_____no_output_____"
]
],
[
[
"# action seq\na = np.arange(12).reshape(2,2,3)\nb = a[:, :, None]\nc = np.tile(b, [1, 1, 5, 1])\nprint(a.shape, b.shape, c.shape)",
"(2, 2, 3) (2, 2, 1, 3) (2, 2, 5, 3)\n"
],
[
"# obs seq\na = np.arange(6).reshape(2,3)[None]\nb = np.tile(a, [2, 1])\nprint(a.shape, b.shape)\nprint(a, \"\\n\")\nprint(b, \"\\n\")",
"(1, 2, 3) (1, 4, 3)\n[[[0 1 2]\n [3 4 5]]] \n\n[[[0 1 2]\n [3 4 5]\n [0 1 2]\n [3 4 5]]] \n\n"
],
[
"random_array = tf.random_uniform([8, 5])\nsort_idxs = tf.nn.top_k(\n random_array,\n k=5\n).indices\n\n\nwith tf.Session() as sess:\n sess.run(tf.global_variables_initializer())\n random_array, idx = sess.run([random_array, sort_idxs])\nprint(random_array, \"\\n\",idx, \"\\n\", idx.shape)",
"[[0.98492837 0.15708661 0.30006194 0.57380354 0.5511217 ]\n [0.2919929 0.4022026 0.1956563 0.8473238 0.49093473]\n [0.87433267 0.7644963 0.6649406 0.49275243 0.86384547]\n [0.5642768 0.6708387 0.93194366 0.21606135 0.71665406]\n [0.1282978 0.01437759 0.50262654 0.32990038 0.5678843 ]\n [0.37182093 0.62550235 0.11662447 0.34997082 0.18829215]\n [0.57517385 0.47611594 0.70101523 0.22044003 0.3974806 ]\n [0.16406643 0.15351188 0.40816474 0.08074033 0.11120546]] \n [[0 3 4 2 1]\n [3 4 1 0 2]\n [0 4 1 2 3]\n [2 4 1 0 3]\n [4 2 3 0 1]\n [1 0 3 4 2]\n [2 0 1 4 3]\n [2 0 1 4 3]] \n (8, 5)\n"
],
[
"tmp = tf.tile(tf.range(8)[:, None], [1, 5])[:, :, None]\nwith tf.Session() as sess:\n result = sess.run(tmp)\nprint(result.shape)\n\nidxs = np.concatenate([result,idx[:,:,None]],axis=-1)\nprint(idxs.shape)",
"(8, 5, 1)\n(8, 5, 2)\n"
],
[
"def make_bool(arg):\n if arg == \"False\" or arg == \"false\" or not bool(arg):\n return False\n else:\n return True\nprint(make_bool('False'))",
"False\n"
],
[
"def create_read_only(message):\n def read_only(arg):\n raise RuntimeError(message)\n return read_only\n\na = create_read_only(\"nsembled models must have more than one net.\")\na(3)\nprint(a)",
"_____no_output_____"
],
[
"# tf.enable_eager_execution()\npop=2\nplan_hor=3\ndU = 4\nnpart=2\nac_seqs = tf.range(0, 24)\nac_seqs = tf.reshape(ac_seqs,[2,3,4])\nprint(ac_seqs)",
"tf.Tensor(\n[[[ 0 1 2 3]\n [ 4 5 6 7]\n [ 8 9 10 11]]\n\n [[12 13 14 15]\n [16 17 18 19]\n [20 21 22 23]]], shape=(2, 3, 4), dtype=int32)\n"
],
[
"ac_seqs1 = tf.reshape(tf.tile(\n tf.transpose(ac_seqs, [1, 0, 2])[:, :, None],\n [1, 1, npart, 1]\n), [plan_hor, -1, dU])\nprint(ac_seqs1)",
"tf.Tensor(\n[[[ 0 1 2 3]\n [ 0 1 2 3]\n [12 13 14 15]\n [12 13 14 15]]\n\n [[ 4 5 6 7]\n [ 4 5 6 7]\n [16 17 18 19]\n [16 17 18 19]]\n\n [[ 8 9 10 11]\n [ 8 9 10 11]\n [20 21 22 23]\n [20 21 22 23]]], shape=(3, 4, 4), dtype=int32)\n"
],
[
"ac_seqs2 = tf.reshape(tf.tile(\n tf.transpose(ac_seqs, [1, 0, 2])[:, :, None],\n [1, 1, npart, 1]\n), [plan_hor, -1, dU])\nprint(ac_seqs1)",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0fa83c135f422d0997cbc1404b7aae025a6bbae | 11,771 | ipynb | Jupyter Notebook | BlackJackGame.ipynb | ketangangal/Python_projects | 597c6be1e0af1c633fda3544dddf239b04509334 | [
"Apache-2.0"
] | 1 | 2021-04-17T23:35:10.000Z | 2021-04-17T23:35:10.000Z | BlackJackGame.ipynb | ketangangal/Python_projects | 597c6be1e0af1c633fda3544dddf239b04509334 | [
"Apache-2.0"
] | null | null | null | BlackJackGame.ipynb | ketangangal/Python_projects | 597c6be1e0af1c633fda3544dddf239b04509334 | [
"Apache-2.0"
] | 1 | 2021-08-09T14:29:51.000Z | 2021-08-09T14:29:51.000Z | 27.502336 | 111 | 0.451958 | [
[
[
"import random\nsuits = ('Hearts','Diamonds','Spades','Clubes')\nranks = ('Two','Three','Four','Five','Six','Seven','Eight','Nine','Ten','Jack','Queen','king','Ace')\nvalues = {'Two':2,'Three':3,'Four':4,'Five':5,'Six':6,\n 'Seven':7,'Eight':8,'Nine':9,'Ten':10,'Jack':10,'Queen':10,'king':10,'Ace':11}\nplaying = True",
"_____no_output_____"
],
[
"class Card():\n def __init__(self,suit,rank):\n self.suit = suit\n self.rank = rank\n self.value = values[rank]\n def __str__(self):\n return self.rank +\" of \" + self.suit",
"_____no_output_____"
],
[
"class Deck():\n def __init__(self):\n self.all_cards = []\n for suit in suits:\n for rank in ranks:\n created_card = Card(suit,rank)\n self.all_cards.append(created_card)\n \n def shuffle_deck(self):\n random.shuffle(self.all_cards)\n \n def __str__(self):\n #you can only return string here so \n #if you have more than one string use string concatination\n l = ' '\n for i in self.all_cards:\n l += '\\n' + i.__str__()\n return l\n \n def deal_one(self):\n return self.all_cards.pop(0)",
"_____no_output_____"
],
[
"class Hand:\n def __init__(self):\n self.cards = [] # start with an empty list as we did in the Deck class\n self.value = 0 # start with zero value\n self.aces = 0 # add an attribute to keep track of aces\n \n def add_card(self,card):\n self.cards.append(card)\n self.value += values[card.rank]\n \n if card.rank == 'Ace':\n self.aces +=1\n \n def adjust_for_ace(self):\n # self.aces > 1 (In python 0 is considered as False and Other +ve and -ve integer are as True)\n # thats why only self.aces is used in while loop\n while self.value >21 and self.aces:\n self.value -= 10\n self.aces -=1",
"_____no_output_____"
],
[
"player = Deck()\nplayer.shuffle_deck()\n\ntest_hand = Hand()\ntest_hand.add_card(player.deal_one()) # reduced variable\nif -1:\n print('h')",
"h\n"
],
[
"class Chips():\n \n def __init__(self,total = 100):\n self.total = total\n self.bet = 0\n def win_bet(self):\n self.total += self.bet\n def loose_bet(self):\n self.total -= self.bet",
"_____no_output_____"
],
[
"def take_bet(chips):\n while True:\n try: \n chips.bet = int(input(\"Enter No of Chips? \"))\n except:\n print(\"Enter Integer Only ! \")\n else:\n if chips.bet > chips.total:\n print('Bet{} is more than Total {}'.format(chips.bet,chips.total))\n else:\n break\n ",
"_____no_output_____"
],
[
"def hit(deck,hand):\n hand.add_card(deck.deal_one())\n hand.adjust_for_ace()",
"_____no_output_____"
],
[
"def hit_or_stand(deck,hand):\n global playing \n \n while True:\n x = input(\" Hit Or Stand ! Enter h or s \")\n if x[0].lower() == 'h':\n print(\"Done\")\n hit(deck,hand)\n \n elif x[0].lower() == 's':\n print(\" Player Stands !,Dealers Turn \")\n print(\"Done\")\n playing = False\n \n else:\n print(\" Enter H or S only \")\n continue\n \n break\n \n ",
"_____no_output_____"
],
[
"def show_some(player,dealer):\n print(\"\\nDealer's Hand:\")\n print(\" <card hidden>\")\n print('',dealer.cards[1]) \n #to show all cards we can use list unpacking * (sep is used to give new line b/w unpacking)\n print(\"\\nPlayer's Hand:\", *player.cards, sep='\\n ')\n \ndef show_all(player,dealer):\n print(\"\\nDealer's Hand:\", *dealer.cards, sep='\\n ')\n print(\"Dealer's Hand =\",dealer.value)\n print(\"\\nPlayer's Hand:\", *player.cards, sep='\\n ')\n print(\"Player's Hand =\",player.value)",
"_____no_output_____"
],
[
"def player_busts(chips):\n print(\"Player busts!\")\n chips.lose_bet()\n\ndef player_wins(chips):\n print(\"Player wins!\")\n chips.win_bet()\n\ndef dealer_busts(chips):\n print(\"Dealer busts!\")\n chips.win_bet()\n \ndef dealer_wins(chips):\n print(\"Dealer wins!\")\n chips.lose_bet()\n \ndef push(player,dealer):\n print(\"Dealer and Player tie! It's a push.\")",
"_____no_output_____"
],
[
"while True:\n \n print(\" Welcome to the Game \")\n # deck created and shuffled\n deck = Deck()\n deck.shuffle_deck()\n \n # players hand\n player_hand = Hand()\n player_hand.add_card(deck.deal_one())\n player_hand.add_card(deck.deal_one())\n \n # dealers hand\n dealer_hand = Hand()\n dealer_hand.add_card(deck.deal_one())\n dealer_hand.add_card(deck.deal_one())\n \n #set player chips\n player_chips = Chips()\n \n #hit\n \n take_bet(player_chips)\n \n show_some(player_hand,dealer_hand)\n \n while playing:\n # hit or stand to continue \n hit_or_stand(deck,player_hand)\n \n show_some(player_hand,dealer_hand)\n \n if player_hand.value > 21:\n player_busts(player_chips)\n \n break\n \n if player_hand.value < 21: \n while dealer_hand.value < player_hand.value:\n hit(deck,dealer_hand)\n \n show_all(player_hand,dealer_hand)\n \n if dealer_hand.value > 21:\n dealer_busts(player_chips)\n elif dealer_hand.value > player_hand.value:\n dealer_wins(player_chips)\n elif player_hand.value > dealer_hand.value:\n player_wins(player_chips)\n else:\n push(player_hand,dealer_hand)\n break\n \n print('\\n')\n print('players Remaning Chips : {}'.format(player_chips.total))\n\n\n new_game = input(\"Would you like to play another hand? Enter 'y' or 'n' \")\n\n if new_game[0].lower()=='y':\n playing = True\n continue\n else:\n print(\"Thanks for playing!\")\n break\n",
" Welcome to the Game \nEnter No of Chips? 500\nBet500 is more than Total 100\nEnter No of Chips? 100\n\nDealer's Hand:\n <card hidden>\n Ace of Clubes\n\nPlayer's Hand:\n Nine of Diamonds\n Ace of Diamonds\n Hit Or Stand ! Enter h or s s\n Player Stands !,Dealers Turn \nDone\n\nDealer's Hand:\n <card hidden>\n Ace of Clubes\n\nPlayer's Hand:\n Nine of Diamonds\n Ace of Diamonds\n\nDealer's Hand:\n Eight of Spades\n Ace of Clubes\n king of Diamonds\n Three of Clubes\nDealer's Hand = 22\n\nPlayer's Hand:\n Nine of Diamonds\n Ace of Diamonds\nPlayer's Hand = 20\nDealer busts!\n\n\nplayers Remaning Chips : 200\nWould you like to play another hand? Enter 'y' or 'n' y\n Welcome to the Game \nEnter No of Chips? 50\n\nDealer's Hand:\n <card hidden>\n Five of Diamonds\n\nPlayer's Hand:\n Queen of Hearts\n Ace of Diamonds\n Hit Or Stand ! Enter h or s s\n Player Stands !,Dealers Turn \nDone\n\nDealer's Hand:\n <card hidden>\n Five of Diamonds\n\nPlayer's Hand:\n Queen of Hearts\n Ace of Diamonds\n\nDealer's Hand:\n Seven of Spades\n Five of Diamonds\nDealer's Hand = 12\n\nPlayer's Hand:\n Queen of Hearts\n Ace of Diamonds\nPlayer's Hand = 21\nPlayer wins!\n\n\nplayers Remaning Chips : 150\nWould you like to play another hand? Enter 'y' or 'n' n\nThanks for playing!\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0faa243a32d2db17e8fa0ad19cb34b9c6a9e0fc | 7,034 | ipynb | Jupyter Notebook | test_clustering.ipynb | sturlaf/master | 5fd064d7dd6fbbab10065469a0f1389fe380ad34 | [
"MIT"
] | null | null | null | test_clustering.ipynb | sturlaf/master | 5fd064d7dd6fbbab10065469a0f1389fe380ad34 | [
"MIT"
] | null | null | null | test_clustering.ipynb | sturlaf/master | 5fd064d7dd6fbbab10065469a0f1389fe380ad34 | [
"MIT"
] | null | null | null | 33.655502 | 81 | 0.45863 | [
[
[
"import pandas as pd\nimport numpy as np\nimport os",
"_____no_output_____"
],
[
"df = pd.read_pickle(\"data/clusters/inception4b.pkl\")\nprint(df.head())",
" cluster_id cluster_size \\\n0 27 2559 \n5 51 1825 \n2 34 1229 \n3 43 2259 \n6 54 1150 \n\n cluster_members longest_bar \\\n0 [6, 18, 82, 99, 171, 173, 206, 239, 243, 291, ... 0.518033 \n5 [0, 80, 89, 121, 132, 238, 311, 315, 344, 360,... 0.425290 \n2 [45, 111, 119, 267, 325, 332, 345, 358, 373, 3... 0.420798 \n3 [23, 54, 95, 150, 165, 186, 226, 272, 285, 312... 0.418871 \n6 [40, 86, 219, 227, 229, 256, 297, 392, 474, 51... 0.390562 \n\n Top 10 longest bars \n0 [0.2722848653793335, 0.273185133934021, 0.2850... \n5 [0.24410247802734375, 0.25846201181411743, 0.2... \n2 [0.2557773292064667, 0.2619004249572754, 0.264... \n3 [0.2965419888496399, 0.29668188095092773, 0.32... \n6 [0.2688259184360504, 0.28615137934684753, 0.29... \n"
],
[
"def read_head():\n layers = os.listdir(\"data/clusters/\")\n for layer in layers:\n print(layer.split(\".\")[0])\n df = pd.read_pickle(f\"data/clusters/{layer}\")[\n [\"cluster_size\", \"longest_bar\", \"Top 10 longest bars\"]\n ]\n print(df.head())\n print(df.shape[0])",
"_____no_output_____"
],
[
"read_head()",
"inception3b\n cluster_size longest_bar \\\n8 2128 0.494247 \n1 2637 0.475944 \n4 979 0.469791 \n0 1460 0.467704 \n14 1167 0.463761 \n\n Top 10 longest bars \n8 [0.33755773305892944, 0.3448399305343628, 0.35... \n1 [0.3003733456134796, 0.30069106817245483, 0.30... \n4 [0.2614439129829407, 0.27987203001976013, 0.28... \n0 [0.27508729696273804, 0.27886348962783813, 0.2... \n14 [0.2747883200645447, 0.27525973320007324, 0.28... \n17\ninception4d\n cluster_size longest_bar \\\n4 1165 0.726381 \n11 1554 0.600018 \n3 1085 0.565040 \n8 1231 0.513637 \n9 1576 0.499528 \n\n Top 10 longest bars \n4 [0.24646812677383423, 0.2525796890258789, 0.25... \n11 [0.3093956708908081, 0.32361727952957153, 0.32... \n3 [0.266026109457016, 0.2715827226638794, 0.2832... \n8 [0.31049609184265137, 0.31113746762275696, 0.3... \n9 [0.3097953200340271, 0.3125888407230377, 0.315... \n15\ninception5a\nEmpty DataFrame\nColumns: [cluster_size, longest_bar, Top 10 longest bars]\nIndex: []\n0\ninception4e\nEmpty DataFrame\nColumns: [cluster_size, longest_bar, Top 10 longest bars]\nIndex: []\n0\ninception5b\nEmpty DataFrame\nColumns: [cluster_size, longest_bar, Top 10 longest bars]\nIndex: []\n0\ninception4b\n cluster_size longest_bar \\\n0 2559 0.518033 \n5 1825 0.425290 \n2 1229 0.420798 \n3 2259 0.418871 \n6 1150 0.390562 \n\n Top 10 longest bars \n0 [0.2722848653793335, 0.273185133934021, 0.2850... \n5 [0.24410247802734375, 0.25846201181411743, 0.2... \n2 [0.2557773292064667, 0.2619004249572754, 0.264... \n3 [0.2965419888496399, 0.29668188095092773, 0.32... \n6 [0.2688259184360504, 0.28615137934684753, 0.29... \n10\ninception4c\n cluster_size longest_bar \\\n3 2710 0.570997 \n5 1239 0.521212 \n10 1578 0.493192 \n9 1339 0.465607 \n12 1592 0.440754 \n\n Top 10 longest bars \n3 [0.2873145639896393, 0.2919982075691223, 0.295... \n5 [0.22960439324378967, 0.24291738867759705, 0.2... \n10 [0.2705751061439514, 0.29363709688186646, 0.31... \n9 [0.2901334762573242, 0.29069793224334717, 0.29... \n12 [0.2541179656982422, 0.25600525736808777, 0.25... \n19\ninception4a\n cluster_size longest_bar \\\n1 1652 0.520240 \n5 2030 0.498964 \n8 1228 0.484247 \n2 1261 0.459279 \n4 1288 0.433563 \n\n Top 10 longest bars \n1 [0.2608886957168579, 0.26514679193496704, 0.26... \n5 [0.3263583779335022, 0.326369971036911, 0.3550... \n8 [0.28978002071380615, 0.29674193263053894, 0.3... \n2 [0.23895207047462463, 0.24441242218017578, 0.2... \n4 [0.30892932415008545, 0.3137546479701996, 0.33... \n14\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code"
]
] |
d0faa2f779ca211aafdbc72b0db00b552a3ec653 | 210,855 | ipynb | Jupyter Notebook | 2_Improving_Deep_Neural_Networks/week 03/Tensorflow Tutorial(solution).ipynb | JifuZhao/Deep-Learning-Specialization | d8205adf82f5f737bfbb26bd21c38a43a9aed017 | [
"MIT"
] | null | null | null | 2_Improving_Deep_Neural_Networks/week 03/Tensorflow Tutorial(solution).ipynb | JifuZhao/Deep-Learning-Specialization | d8205adf82f5f737bfbb26bd21c38a43a9aed017 | [
"MIT"
] | null | null | null | 2_Improving_Deep_Neural_Networks/week 03/Tensorflow Tutorial(solution).ipynb | JifuZhao/Deep-Learning-Specialization | d8205adf82f5f737bfbb26bd21c38a43a9aed017 | [
"MIT"
] | null | null | null | 128.179331 | 118,292 | 0.840431 | [
[
[
"# TensorFlow Tutorial\n\nWelcome to this week's programming assignment. Until now, you've always used numpy to build neural networks. Now we will step you through a deep learning framework that will allow you to build neural networks more easily. Machine learning frameworks like TensorFlow, PaddlePaddle, Torch, Caffe, Keras, and many others can speed up your machine learning development significantly. All of these frameworks also have a lot of documentation, which you should feel free to read. In this assignment, you will learn to do the following in TensorFlow: \n\n- Initialize variables\n- Start your own session\n- Train algorithms \n- Implement a Neural Network\n\nPrograming frameworks can not only shorten your coding time, but sometimes also perform optimizations that speed up your code. \n\n## 1 - Exploring the Tensorflow Library\n\nTo start, you will import the library:\n",
"_____no_output_____"
]
],
[
[
"import math\nimport numpy as np\nimport h5py\nimport matplotlib.pyplot as plt\nimport tensorflow as tf\nfrom tensorflow.python.framework import ops\nfrom tf_utils import load_dataset, random_mini_batches, convert_to_one_hot, predict\n\n%matplotlib inline\nnp.random.seed(1)",
"_____no_output_____"
]
],
[
[
"Now that you have imported the library, we will walk you through its different applications. You will start with an example, where we compute for you the loss of one training example. \n$$loss = \\mathcal{L}(\\hat{y}, y) = (\\hat y^{(i)} - y^{(i)})^2 \\tag{1}$$",
"_____no_output_____"
]
],
[
[
"y_hat = tf.constant(36, name='y_hat') # Define y_hat constant. Set to 36.\ny = tf.constant(39, name='y') # Define y. Set to 39\n\nloss = tf.Variable((y - y_hat)**2, name='loss') # Create a variable for the loss\n\ninit = tf.global_variables_initializer() # When init is run later (session.run(init)),\n # the loss variable will be initialized and ready to be computed\nwith tf.Session() as session: # Create a session and print the output\n session.run(init) # Initializes the variables\n print(session.run(loss)) # Prints the loss",
"9\n"
]
],
[
[
"Writing and running programs in TensorFlow has the following steps:\n\n1. Create Tensors (variables) that are not yet executed/evaluated. \n2. Write operations between those Tensors.\n3. Initialize your Tensors. \n4. Create a Session. \n5. Run the Session. This will run the operations you'd written above. \n\nTherefore, when we created a variable for the loss, we simply defined the loss as a function of other quantities, but did not evaluate its value. To evaluate it, we had to run `init=tf.global_variables_initializer()`. That initialized the loss variable, and in the last line we were finally able to evaluate the value of `loss` and print its value.\n\nNow let us look at an easy example. Run the cell below:",
"_____no_output_____"
]
],
[
[
"a = tf.constant(2)\nb = tf.constant(10)\nc = tf.multiply(a,b)\nprint(c)",
"Tensor(\"Mul:0\", shape=(), dtype=int32)\n"
]
],
[
[
"As expected, you will not see 20! You got a tensor saying that the result is a tensor that does not have the shape attribute, and is of type \"int32\". All you did was put in the 'computation graph', but you have not run this computation yet. In order to actually multiply the two numbers, you will have to create a session and run it.",
"_____no_output_____"
]
],
[
[
"sess = tf.Session()\nprint(sess.run(c))",
"20\n"
]
],
[
[
"Great! To summarize, **remember to initialize your variables, create a session and run the operations inside the session**. \n\nNext, you'll also have to know about placeholders. A placeholder is an object whose value you can specify only later. \nTo specify values for a placeholder, you can pass in values by using a \"feed dictionary\" (`feed_dict` variable). Below, we created a placeholder for x. This allows us to pass in a number later when we run the session. ",
"_____no_output_____"
]
],
[
[
"# Change the value of x in the feed_dict\n\nx = tf.placeholder(tf.int64, name = 'x')\nprint(sess.run(2 * x, feed_dict = {x: 3}))\nsess.close()",
"6\n"
]
],
[
[
"When you first defined `x` you did not have to specify a value for it. A placeholder is simply a variable that you will assign data to only later, when running the session. We say that you **feed data** to these placeholders when running the session. \n\nHere's what's happening: When you specify the operations needed for a computation, you are telling TensorFlow how to construct a computation graph. The computation graph can have some placeholders whose values you will specify only later. Finally, when you run the session, you are telling TensorFlow to execute the computation graph.",
"_____no_output_____"
],
[
"### 1.1 - Linear function\n\nLets start this programming exercise by computing the following equation: $Y = WX + b$, where $W$ and $X$ are random matrices and b is a random vector. \n\n**Exercise**: Compute $WX + b$ where $W, X$, and $b$ are drawn from a random normal distribution. W is of shape (4, 3), X is (3,1) and b is (4,1). As an example, here is how you would define a constant X that has shape (3,1):\n```python\nX = tf.constant(np.random.randn(3,1), name = \"X\")\n\n```\nYou might find the following functions helpful: \n- tf.matmul(..., ...) to do a matrix multiplication\n- tf.add(..., ...) to do an addition\n- np.random.randn(...) to initialize randomly\n",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: linear_function\n\ndef linear_function():\n \"\"\"\n Implements a linear function: \n Initializes W to be a random tensor of shape (4,3)\n Initializes X to be a random tensor of shape (3,1)\n Initializes b to be a random tensor of shape (4,1)\n Returns: \n result -- runs the session for Y = WX + b \n \"\"\"\n \n np.random.seed(1)\n \n ### START CODE HERE ### (4 lines of code)\n X = tf.constant(np.random.randn(3, 1), name='X')\n W = tf.constant(np.random.randn(4, 3), name='W')\n b = tf.constant(np.random.randn(4, 1), name='b')\n Y = tf.matmul(W, X) + b\n ### END CODE HERE ### \n \n # Create the session using tf.Session() and run it with sess.run(...) on the variable you want to calculate\n \n ### START CODE HERE ###\n sess = tf.Session()\n result = sess.run(Y)\n ### END CODE HERE ### \n \n # close the session \n sess.close()\n\n return result",
"_____no_output_____"
],
[
"print( \"result = \" + str(linear_function()))",
"result = [[-2.15657382]\n [ 2.95891446]\n [-1.08926781]\n [-0.84538042]]\n"
]
],
[
[
"*** Expected Output ***: \n\n<table> \n<tr> \n<td>\n**result**\n</td>\n<td>\n[[-2.15657382]\n [ 2.95891446]\n [-1.08926781]\n [-0.84538042]]\n</td>\n</tr> \n\n</table> ",
"_____no_output_____"
],
[
"### 1.2 - Computing the sigmoid \nGreat! You just implemented a linear function. Tensorflow offers a variety of commonly used neural network functions like `tf.sigmoid` and `tf.softmax`. For this exercise lets compute the sigmoid function of an input. \n\nYou will do this exercise using a placeholder variable `x`. When running the session, you should use the feed dictionary to pass in the input `z`. In this exercise, you will have to (i) create a placeholder `x`, (ii) define the operations needed to compute the sigmoid using `tf.sigmoid`, and then (iii) run the session. \n\n** Exercise **: Implement the sigmoid function below. You should use the following: \n\n- `tf.placeholder(tf.float32, name = \"...\")`\n- `tf.sigmoid(...)`\n- `sess.run(..., feed_dict = {x: z})`\n\n\nNote that there are two typical ways to create and use sessions in tensorflow: \n\n**Method 1:**\n```python\nsess = tf.Session()\n# Run the variables initialization (if needed), run the operations\nresult = sess.run(..., feed_dict = {...})\nsess.close() # Close the session\n```\n**Method 2:**\n```python\nwith tf.Session() as sess: \n # run the variables initialization (if needed), run the operations\n result = sess.run(..., feed_dict = {...})\n # This takes care of closing the session for you :)\n```\n",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: sigmoid\n\ndef sigmoid(z):\n \"\"\"\n Computes the sigmoid of z\n \n Arguments:\n z -- input value, scalar or vector\n \n Returns: \n results -- the sigmoid of z\n \"\"\"\n \n ### START CODE HERE ### ( approx. 4 lines of code)\n # Create a placeholder for x. Name it 'x'.\n x = tf.placeholder(tf.float32, name='x')\n\n # compute sigmoid(x)\n sigmoid = tf.sigmoid(x)\n\n # Create a session, and run it. Please use the method 2 explained above. \n # You should use a feed_dict to pass z's value to x. \n with tf.Session() as sess:\n # Run session and call the output \"result\"\n result = sess.run(sigmoid, feed_dict={x: z})\n \n ### END CODE HERE ###\n \n return result",
"_____no_output_____"
],
[
"print (\"sigmoid(0) = \" + str(sigmoid(0)))\nprint (\"sigmoid(12) = \" + str(sigmoid(12)))",
"sigmoid(0) = 0.5\nsigmoid(12) = 0.999994\n"
]
],
[
[
"*** Expected Output ***: \n\n<table> \n<tr> \n<td>\n**sigmoid(0)**\n</td>\n<td>\n0.5\n</td>\n</tr>\n<tr> \n<td>\n**sigmoid(12)**\n</td>\n<td>\n0.999994\n</td>\n</tr> \n\n</table> ",
"_____no_output_____"
],
[
"<font color='blue'>\n**To summarize, you how know how to**:\n1. Create placeholders\n2. Specify the computation graph corresponding to operations you want to compute\n3. Create the session\n4. Run the session, using a feed dictionary if necessary to specify placeholder variables' values. ",
"_____no_output_____"
],
[
"### 1.3 - Computing the Cost\n\nYou can also use a built-in function to compute the cost of your neural network. So instead of needing to write code to compute this as a function of $a^{[2](i)}$ and $y^{(i)}$ for i=1...m: \n$$ J = - \\frac{1}{m} \\sum_{i = 1}^m \\large ( \\small y^{(i)} \\log a^{ [2] (i)} + (1-y^{(i)})\\log (1-a^{ [2] (i)} )\\large )\\small\\tag{2}$$\n\nyou can do it in one line of code in tensorflow!\n\n**Exercise**: Implement the cross entropy loss. The function you will use is: \n\n\n- `tf.nn.sigmoid_cross_entropy_with_logits(logits = ..., labels = ...)`\n\nYour code should input `z`, compute the sigmoid (to get `a`) and then compute the cross entropy cost $J$. All this can be done using one call to `tf.nn.sigmoid_cross_entropy_with_logits`, which computes\n\n$$- \\frac{1}{m} \\sum_{i = 1}^m \\large ( \\small y^{(i)} \\log \\sigma(z^{[2](i)}) + (1-y^{(i)})\\log (1-\\sigma(z^{[2](i)})\\large )\\small\\tag{2}$$\n\n",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: cost\n\ndef cost(logits, labels):\n \"\"\"\n Computes the cost using the sigmoid cross entropy\n \n Arguments:\n logits -- vector containing z, output of the last linear unit (before the final sigmoid activation)\n labels -- vector of labels y (1 or 0) \n \n Note: What we've been calling \"z\" and \"y\" in this class are respectively called \"logits\" and \"labels\" \n in the TensorFlow documentation. So logits will feed into z, and labels into y. \n \n Returns:\n cost -- runs the session of the cost (formula (2))\n \"\"\"\n \n ### START CODE HERE ### \n \n # Create the placeholders for \"logits\" (z) and \"labels\" (y) (approx. 2 lines)\n z = tf.placeholder(tf.float32, name='logits')\n y = tf.placeholder(tf.float32, name='labels')\n \n # Use the loss function (approx. 1 line)\n cost = tf.nn.sigmoid_cross_entropy_with_logits(logits=z, labels=y)\n \n # Create a session (approx. 1 line). See method 1 above.\n sess = tf.Session()\n \n # Run the session (approx. 1 line).\n cost = sess.run(cost, feed_dict={z: logits, y: labels})\n \n # Close the session (approx. 1 line). See method 1 above.\n sess.close()\n \n ### END CODE HERE ###\n \n return cost",
"_____no_output_____"
],
[
"logits = sigmoid(np.array([0.2,0.4,0.7,0.9]))\ncost = cost(logits, np.array([0,0,1,1]))\nprint (\"cost = \" + str(cost))",
"cost = [ 1.00538719 1.03664088 0.41385433 0.39956614]\n"
]
],
[
[
"** Expected Output** : \n\n<table> \n <tr> \n <td>\n **cost**\n </td>\n <td>\n [ 1.00538719 1.03664088 0.41385433 0.39956614]\n </td>\n </tr>\n\n</table>",
"_____no_output_____"
],
[
"### 1.4 - Using One Hot encodings\n\nMany times in deep learning you will have a y vector with numbers ranging from 0 to C-1, where C is the number of classes. If C is for example 4, then you might have the following y vector which you will need to convert as follows:\n\n\n<img src=\"images/onehot.png\" style=\"width:600px;height:150px;\">\n\nThis is called a \"one hot\" encoding, because in the converted representation exactly one element of each column is \"hot\" (meaning set to 1). To do this conversion in numpy, you might have to write a few lines of code. In tensorflow, you can use one line of code: \n\n- tf.one_hot(labels, depth, axis) \n\n**Exercise:** Implement the function below to take one vector of labels and the total number of classes $C$, and return the one hot encoding. Use `tf.one_hot()` to do this. ",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: one_hot_matrix\n\ndef one_hot_matrix(labels, C):\n \"\"\"\n Creates a matrix where the i-th row corresponds to the ith class number and the jth column\n corresponds to the jth training example. So if example j had a label i. Then entry (i,j) \n will be 1. \n \n Arguments:\n labels -- vector containing the labels \n C -- number of classes, the depth of the one hot dimension\n \n Returns: \n one_hot -- one hot matrix\n \"\"\"\n \n ### START CODE HERE ###\n \n # Create a tf.constant equal to C (depth), name it 'C'. (approx. 1 line)\n C = tf.constant(C, name='C')\n \n # Use tf.one_hot, be careful with the axis (approx. 1 line)\n one_hot_matrix = tf.one_hot(indices=labels, depth=C, axis=0)\n \n # Create the session (approx. 1 line)\n sess = tf.Session()\n \n # Run the session (approx. 1 line)\n one_hot = sess.run(one_hot_matrix)\n \n # Close the session (approx. 1 line). See method 1 above.\n sess.close()\n \n ### END CODE HERE ###\n \n return one_hot",
"_____no_output_____"
],
[
"labels = np.array([1,2,3,0,2,1])\none_hot = one_hot_matrix(labels, C = 4)\nprint (\"one_hot = \" + str(one_hot))",
"one_hot = [[ 0. 0. 0. 1. 0. 0.]\n [ 1. 0. 0. 0. 0. 1.]\n [ 0. 1. 0. 0. 1. 0.]\n [ 0. 0. 1. 0. 0. 0.]]\n"
]
],
[
[
"**Expected Output**: \n\n<table> \n <tr> \n <td>\n **one_hot**\n </td>\n <td>\n [[ 0. 0. 0. 1. 0. 0.]\n [ 1. 0. 0. 0. 0. 1.]\n [ 0. 1. 0. 0. 1. 0.]\n [ 0. 0. 1. 0. 0. 0.]]\n </td>\n </tr>\n\n</table>\n",
"_____no_output_____"
],
[
"### 1.5 - Initialize with zeros and ones\n\nNow you will learn how to initialize a vector of zeros and ones. The function you will be calling is `tf.ones()`. To initialize with zeros you could use tf.zeros() instead. These functions take in a shape and return an array of dimension shape full of zeros and ones respectively. \n\n**Exercise:** Implement the function below to take in a shape and to return an array (of the shape's dimension of ones). \n\n - tf.ones(shape)\n",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: ones\n\ndef ones(shape):\n \"\"\"\n Creates an array of ones of dimension shape\n \n Arguments:\n shape -- shape of the array you want to create\n \n Returns: \n ones -- array containing only ones\n \"\"\"\n \n ### START CODE HERE ###\n \n # Create \"ones\" tensor using tf.ones(...). (approx. 1 line)\n ones = tf.ones(shape)\n \n # Create the session (approx. 1 line)\n sess = tf.Session()\n \n # Run the session to compute 'ones' (approx. 1 line)\n ones = sess.run(ones)\n \n # Close the session (approx. 1 line). See method 1 above.\n sess.close()\n \n ### END CODE HERE ###\n return ones",
"_____no_output_____"
],
[
"print (\"ones = \" + str(ones([3])))",
"ones = [ 1. 1. 1.]\n"
]
],
[
[
"**Expected Output:**\n\n<table> \n <tr> \n <td>\n **ones**\n </td>\n <td>\n [ 1. 1. 1.]\n </td>\n </tr>\n\n</table>",
"_____no_output_____"
],
[
"# 2 - Building your first neural network in tensorflow\n\nIn this part of the assignment you will build a neural network using tensorflow. Remember that there are two parts to implement a tensorflow model:\n\n- Create the computation graph\n- Run the graph\n\nLet's delve into the problem you'd like to solve!\n\n### 2.0 - Problem statement: SIGNS Dataset\n\nOne afternoon, with some friends we decided to teach our computers to decipher sign language. We spent a few hours taking pictures in front of a white wall and came up with the following dataset. It's now your job to build an algorithm that would facilitate communications from a speech-impaired person to someone who doesn't understand sign language.\n\n- **Training set**: 1080 pictures (64 by 64 pixels) of signs representing numbers from 0 to 5 (180 pictures per number).\n- **Test set**: 120 pictures (64 by 64 pixels) of signs representing numbers from 0 to 5 (20 pictures per number).\n\nNote that this is a subset of the SIGNS dataset. The complete dataset contains many more signs.\n\nHere are examples for each number, and how an explanation of how we represent the labels. These are the original pictures, before we lowered the image resolutoion to 64 by 64 pixels.\n<img src=\"images/hands.png\" style=\"width:800px;height:350px;\"><caption><center> <u><font color='purple'> **Figure 1**</u><font color='purple'>: SIGNS dataset <br> <font color='black'> </center>\n\n\nRun the following code to load the dataset.",
"_____no_output_____"
]
],
[
[
"# Loading the dataset\nX_train_orig, Y_train_orig, X_test_orig, Y_test_orig, classes = load_dataset()",
"_____no_output_____"
]
],
[
[
"Change the index below and run the cell to visualize some examples in the dataset.",
"_____no_output_____"
]
],
[
[
"# Example of a picture\nindex = 0\nplt.imshow(X_train_orig[index])\nprint (\"y = \" + str(np.squeeze(Y_train_orig[:, index])))",
"y = 5\n"
]
],
[
[
"As usual you flatten the image dataset, then normalize it by dividing by 255. On top of that, you will convert each label to a one-hot vector as shown in Figure 1. Run the cell below to do so.",
"_____no_output_____"
]
],
[
[
"# Flatten the training and test images\nX_train_flatten = X_train_orig.reshape(X_train_orig.shape[0], -1).T\nX_test_flatten = X_test_orig.reshape(X_test_orig.shape[0], -1).T\n# Normalize image vectors\nX_train = X_train_flatten/255.\nX_test = X_test_flatten/255.\n# Convert training and test labels to one hot matrices\nY_train = convert_to_one_hot(Y_train_orig, 6)\nY_test = convert_to_one_hot(Y_test_orig, 6)\n\nprint (\"number of training examples = \" + str(X_train.shape[1]))\nprint (\"number of test examples = \" + str(X_test.shape[1]))\nprint (\"X_train shape: \" + str(X_train.shape))\nprint (\"Y_train shape: \" + str(Y_train.shape))\nprint (\"X_test shape: \" + str(X_test.shape))\nprint (\"Y_test shape: \" + str(Y_test.shape))",
"number of training examples = 1080\nnumber of test examples = 120\nX_train shape: (12288, 1080)\nY_train shape: (6, 1080)\nX_test shape: (12288, 120)\nY_test shape: (6, 120)\n"
]
],
[
[
"**Note** that 12288 comes from $64 \\times 64 \\times 3$. Each image is square, 64 by 64 pixels, and 3 is for the RGB colors. Please make sure all these shapes make sense to you before continuing.",
"_____no_output_____"
],
[
"**Your goal** is to build an algorithm capable of recognizing a sign with high accuracy. To do so, you are going to build a tensorflow model that is almost the same as one you have previously built in numpy for cat recognition (but now using a softmax output). It is a great occasion to compare your numpy implementation to the tensorflow one. \n\n**The model** is *LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SOFTMAX*. The SIGMOID output layer has been converted to a SOFTMAX. A SOFTMAX layer generalizes SIGMOID to when there are more than two classes. ",
"_____no_output_____"
],
[
"### 2.1 - Create placeholders\n\nYour first task is to create placeholders for `X` and `Y`. This will allow you to later pass your training data in when you run your session. \n\n**Exercise:** Implement the function below to create the placeholders in tensorflow.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: create_placeholders\n\ndef create_placeholders(n_x, n_y):\n \"\"\"\n Creates the placeholders for the tensorflow session.\n \n Arguments:\n n_x -- scalar, size of an image vector (num_px * num_px = 64 * 64 * 3 = 12288)\n n_y -- scalar, number of classes (from 0 to 5, so -> 6)\n \n Returns:\n X -- placeholder for the data input, of shape [n_x, None] and dtype \"float\"\n Y -- placeholder for the input labels, of shape [n_y, None] and dtype \"float\"\n \n Tips:\n - You will use None because it let's us be flexible on the number of examples you will for the placeholders.\n In fact, the number of examples during test/train is different.\n \"\"\"\n\n ### START CODE HERE ### (approx. 2 lines)\n X = tf.placeholder(tf.float32, shape=(n_x, None), name='X')\n Y = tf.placeholder(tf.float32, shape=(n_y, None), name='Y')\n ### END CODE HERE ###\n \n return X, Y",
"_____no_output_____"
],
[
"X, Y = create_placeholders(12288, 6)\nprint (\"X = \" + str(X))\nprint (\"Y = \" + str(Y))",
"X = Tensor(\"X_1:0\", shape=(12288, ?), dtype=float32)\nY = Tensor(\"Y:0\", shape=(6, ?), dtype=float32)\n"
]
],
[
[
"**Expected Output**: \n\n<table> \n <tr> \n <td>\n **X**\n </td>\n <td>\n Tensor(\"Placeholder_1:0\", shape=(12288, ?), dtype=float32) (not necessarily Placeholder_1)\n </td>\n </tr>\n <tr> \n <td>\n **Y**\n </td>\n <td>\n Tensor(\"Placeholder_2:0\", shape=(10, ?), dtype=float32) (not necessarily Placeholder_2)\n </td>\n </tr>\n\n</table>",
"_____no_output_____"
],
[
"### 2.2 - Initializing the parameters\n\nYour second task is to initialize the parameters in tensorflow.\n\n**Exercise:** Implement the function below to initialize the parameters in tensorflow. You are going use Xavier Initialization for weights and Zero Initialization for biases. The shapes are given below. As an example, to help you, for W1 and b1 you could use: \n\n```python\nW1 = tf.get_variable(\"W1\", [25,12288], initializer = tf.contrib.layers.xavier_initializer(seed = 1))\nb1 = tf.get_variable(\"b1\", [25,1], initializer = tf.zeros_initializer())\n```\nPlease use `seed = 1` to make sure your results match ours.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: initialize_parameters\n\ndef initialize_parameters():\n \"\"\"\n Initializes parameters to build a neural network with tensorflow. The shapes are:\n W1 : [25, 12288]\n b1 : [25, 1]\n W2 : [12, 25]\n b2 : [12, 1]\n W3 : [6, 12]\n b3 : [6, 1]\n \n Returns:\n parameters -- a dictionary of tensors containing W1, b1, W2, b2, W3, b3\n \"\"\"\n \n tf.set_random_seed(1) # so that your \"random\" numbers match ours\n \n ### START CODE HERE ### (approx. 6 lines of code)\n W1 = tf.get_variable('W1', [25, 12288], initializer=tf.contrib.layers.xavier_initializer(seed=1))\n b1 = tf.get_variable('b1', [25, 1], initializer=tf.zeros_initializer())\n W2 = tf.get_variable('W2', [12, 25], initializer=tf.contrib.layers.xavier_initializer(seed=1))\n b2 = tf.get_variable('b2', [12, 1], initializer=tf.zeros_initializer())\n W3 = tf.get_variable('W3', [6, 12], initializer=tf.contrib.layers.xavier_initializer(seed=1))\n b3 = tf.get_variable('b3', [6, 1], initializer=tf.zeros_initializer())\n ### END CODE HERE ###\n\n parameters = {\"W1\": W1,\n \"b1\": b1,\n \"W2\": W2,\n \"b2\": b2,\n \"W3\": W3,\n \"b3\": b3}\n \n return parameters",
"_____no_output_____"
],
[
"tf.reset_default_graph()\nwith tf.Session() as sess:\n parameters = initialize_parameters()\n print(\"W1 = \" + str(parameters[\"W1\"]))\n print(\"b1 = \" + str(parameters[\"b1\"]))\n print(\"W2 = \" + str(parameters[\"W2\"]))\n print(\"b2 = \" + str(parameters[\"b2\"]))",
"W1 = <tf.Variable 'W1:0' shape=(25, 12288) dtype=float32_ref>\nb1 = <tf.Variable 'b1:0' shape=(25, 1) dtype=float32_ref>\nW2 = <tf.Variable 'W2:0' shape=(12, 25) dtype=float32_ref>\nb2 = <tf.Variable 'b2:0' shape=(12, 1) dtype=float32_ref>\n"
]
],
[
[
"**Expected Output**: \n\n<table> \n <tr> \n <td>\n **W1**\n </td>\n <td>\n < tf.Variable 'W1:0' shape=(25, 12288) dtype=float32_ref >\n </td>\n </tr>\n <tr> \n <td>\n **b1**\n </td>\n <td>\n < tf.Variable 'b1:0' shape=(25, 1) dtype=float32_ref >\n </td>\n </tr>\n <tr> \n <td>\n **W2**\n </td>\n <td>\n < tf.Variable 'W2:0' shape=(12, 25) dtype=float32_ref >\n </td>\n </tr>\n <tr> \n <td>\n **b2**\n </td>\n <td>\n < tf.Variable 'b2:0' shape=(12, 1) dtype=float32_ref >\n </td>\n </tr>\n\n</table>",
"_____no_output_____"
],
[
"As expected, the parameters haven't been evaluated yet.",
"_____no_output_____"
],
[
"### 2.3 - Forward propagation in tensorflow \n\nYou will now implement the forward propagation module in tensorflow. The function will take in a dictionary of parameters and it will complete the forward pass. The functions you will be using are: \n\n- `tf.add(...,...)` to do an addition\n- `tf.matmul(...,...)` to do a matrix multiplication\n- `tf.nn.relu(...)` to apply the ReLU activation\n\n**Question:** Implement the forward pass of the neural network. We commented for you the numpy equivalents so that you can compare the tensorflow implementation to numpy. It is important to note that the forward propagation stops at `z3`. The reason is that in tensorflow the last linear layer output is given as input to the function computing the loss. Therefore, you don't need `a3`!\n\n",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: forward_propagation\n\ndef forward_propagation(X, parameters):\n \"\"\"\n Implements the forward propagation for the model: LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SOFTMAX\n \n Arguments:\n X -- input dataset placeholder, of shape (input size, number of examples)\n parameters -- python dictionary containing your parameters \"W1\", \"b1\", \"W2\", \"b2\", \"W3\", \"b3\"\n the shapes are given in initialize_parameters\n\n Returns:\n Z3 -- the output of the last LINEAR unit\n \"\"\"\n \n # Retrieve the parameters from the dictionary \"parameters\" \n W1 = parameters['W1']\n b1 = parameters['b1']\n W2 = parameters['W2']\n b2 = parameters['b2']\n W3 = parameters['W3']\n b3 = parameters['b3']\n \n ### START CODE HERE ### (approx. 5 lines) # Numpy Equivalents:\n Z1 = tf.matmul(W1, X) + b1 # Z1 = np.dot(W1, X) + b1\n A1 = tf.nn.relu(Z1) # A1 = relu(Z1)\n Z2 = tf.matmul(W2, A1) + b2 # Z2 = np.dot(W2, a1) + b2\n A2 = tf.nn.relu(Z2) # A2 = relu(Z2)\n Z3 = tf.matmul(W3, A2) + b3 # Z3 = np.dot(W3,Z2) + b3\n ### END CODE HERE ###\n \n return Z3",
"_____no_output_____"
],
[
"tf.reset_default_graph()\n\nwith tf.Session() as sess:\n X, Y = create_placeholders(12288, 6)\n parameters = initialize_parameters()\n Z3 = forward_propagation(X, parameters)\n print(\"Z3 = \" + str(Z3))",
"Z3 = Tensor(\"add_2:0\", shape=(6, ?), dtype=float32)\n"
]
],
[
[
"**Expected Output**: \n\n<table> \n <tr> \n <td>\n **Z3**\n </td>\n <td>\n Tensor(\"Add_2:0\", shape=(6, ?), dtype=float32)\n </td>\n </tr>\n\n</table>",
"_____no_output_____"
],
[
"You may have noticed that the forward propagation doesn't output any cache. You will understand why below, when we get to brackpropagation.",
"_____no_output_____"
],
[
"### 2.4 Compute cost\n\nAs seen before, it is very easy to compute the cost using:\n```python\ntf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits = ..., labels = ...))\n```\n**Question**: Implement the cost function below. \n- It is important to know that the \"`logits`\" and \"`labels`\" inputs of `tf.nn.softmax_cross_entropy_with_logits` are expected to be of shape (number of examples, num_classes). We have thus transposed Z3 and Y for you.\n- Besides, `tf.reduce_mean` basically does the summation over the examples.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: compute_cost \n\ndef compute_cost(Z3, Y):\n \"\"\"\n Computes the cost\n \n Arguments:\n Z3 -- output of forward propagation (output of the last LINEAR unit), of shape (6, number of examples)\n Y -- \"true\" labels vector placeholder, same shape as Z3\n \n Returns:\n cost - Tensor of the cost function\n \"\"\"\n \n # to fit the tensorflow requirement for tf.nn.softmax_cross_entropy_with_logits(...,...)\n logits = tf.transpose(Z3)\n labels = tf.transpose(Y)\n \n ### START CODE HERE ### (1 line of code)\n cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=labels))\n ### END CODE HERE ###\n \n return cost",
"_____no_output_____"
],
[
"tf.reset_default_graph()\n\nwith tf.Session() as sess:\n X, Y = create_placeholders(12288, 6)\n parameters = initialize_parameters()\n Z3 = forward_propagation(X, parameters)\n cost = compute_cost(Z3, Y)\n print(\"cost = \" + str(cost))",
"cost = Tensor(\"Mean:0\", shape=(), dtype=float32)\n"
]
],
[
[
"**Expected Output**: \n\n<table> \n <tr> \n <td>\n **cost**\n </td>\n <td>\n Tensor(\"Mean:0\", shape=(), dtype=float32)\n </td>\n </tr>\n\n</table>",
"_____no_output_____"
],
[
"### 2.5 - Backward propagation & parameter updates\n\nThis is where you become grateful to programming frameworks. All the backpropagation and the parameters update is taken care of in 1 line of code. It is very easy to incorporate this line in the model.\n\nAfter you compute the cost function. You will create an \"`optimizer`\" object. You have to call this object along with the cost when running the tf.session. When called, it will perform an optimization on the given cost with the chosen method and learning rate.\n\nFor instance, for gradient descent the optimizer would be:\n```python\noptimizer = tf.train.GradientDescentOptimizer(learning_rate = learning_rate).minimize(cost)\n```\n\nTo make the optimization you would do:\n```python\n_ , c = sess.run([optimizer, cost], feed_dict={X: minibatch_X, Y: minibatch_Y})\n```\n\nThis computes the backpropagation by passing through the tensorflow graph in the reverse order. From cost to inputs.\n\n**Note** When coding, we often use `_` as a \"throwaway\" variable to store values that we won't need to use later. Here, `_` takes on the evaluated value of `optimizer`, which we don't need (and `c` takes the value of the `cost` variable). ",
"_____no_output_____"
],
[
"### 2.6 - Building the model\n\nNow, you will bring it all together! \n\n**Exercise:** Implement the model. You will be calling the functions you had previously implemented.",
"_____no_output_____"
]
],
[
[
"def model(X_train, Y_train, X_test, Y_test, learning_rate = 0.0001,\n num_epochs = 1500, minibatch_size = 32, print_cost = True):\n \"\"\"\n Implements a three-layer tensorflow neural network: LINEAR->RELU->LINEAR->RELU->LINEAR->SOFTMAX.\n \n Arguments:\n X_train -- training set, of shape (input size = 12288, number of training examples = 1080)\n Y_train -- test set, of shape (output size = 6, number of training examples = 1080)\n X_test -- training set, of shape (input size = 12288, number of training examples = 120)\n Y_test -- test set, of shape (output size = 6, number of test examples = 120)\n learning_rate -- learning rate of the optimization\n num_epochs -- number of epochs of the optimization loop\n minibatch_size -- size of a minibatch\n print_cost -- True to print the cost every 100 epochs\n \n Returns:\n parameters -- parameters learnt by the model. They can then be used to predict.\n \"\"\"\n \n ops.reset_default_graph() # to be able to rerun the model without overwriting tf variables\n tf.set_random_seed(1) # to keep consistent results\n seed = 3 # to keep consistent results\n (n_x, m) = X_train.shape # (n_x: input size, m : number of examples in the train set)\n n_y = Y_train.shape[0] # n_y : output size\n costs = [] # To keep track of the cost\n \n # Create Placeholders of shape (n_x, n_y)\n ### START CODE HERE ### (1 line)\n X, Y = create_placeholders(n_x, n_y)\n ### END CODE HERE ###\n\n # Initialize parameters\n ### START CODE HERE ### (1 line)\n parameters = initialize_parameters()\n ### END CODE HERE ###\n \n # Forward propagation: Build the forward propagation in the tensorflow graph\n ### START CODE HERE ### (1 line)\n Z3 = forward_propagation(X, parameters)\n ### END CODE HERE ###\n \n # Cost function: Add cost function to tensorflow graph\n ### START CODE HERE ### (1 line)\n cost = compute_cost(Z3, Y)\n ### END CODE HERE ###\n \n # Backpropagation: Define the tensorflow optimizer. Use an AdamOptimizer.\n ### START CODE HERE ### (1 line)\n optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)\n ### END CODE HERE ###\n \n # Initialize all the variables\n init = tf.global_variables_initializer()\n\n # Start the session to compute the tensorflow graph\n with tf.Session() as sess:\n \n # Run the initialization\n sess.run(init)\n \n # Do the training loop\n for epoch in range(num_epochs):\n\n epoch_cost = 0. # Defines a cost related to an epoch\n num_minibatches = int(m / minibatch_size) # number of minibatches of size minibatch_size in the train set\n seed = seed + 1\n minibatches = random_mini_batches(X_train, Y_train, minibatch_size, seed)\n\n for minibatch in minibatches:\n\n # Select a minibatch\n (minibatch_X, minibatch_Y) = minibatch\n \n # IMPORTANT: The line that runs the graph on a minibatch.\n # Run the session to execute the \"optimizer\" and the \"cost\", the feedict should contain a minibatch for (X,Y).\n ### START CODE HERE ### (1 line)\n _ , minibatch_cost = sess.run([optimizer, cost], feed_dict={X: minibatch_X, Y: minibatch_Y})\n ### END CODE HERE ###\n \n epoch_cost += minibatch_cost / num_minibatches\n\n # Print the cost every epoch\n if print_cost == True and epoch % 100 == 0:\n print (\"Cost after epoch %i: %f\" % (epoch, epoch_cost))\n if print_cost == True and epoch % 5 == 0:\n costs.append(epoch_cost)\n \n # plot the cost\n plt.plot(np.squeeze(costs))\n plt.ylabel('cost')\n plt.xlabel('iterations (per tens)')\n plt.title(\"Learning rate =\" + str(learning_rate))\n plt.show()\n\n # lets save the parameters in a variable\n parameters = sess.run(parameters)\n print (\"Parameters have been trained!\")\n\n # Calculate the correct predictions\n correct_prediction = tf.equal(tf.argmax(Z3), tf.argmax(Y))\n\n # Calculate accuracy on the test set\n accuracy = tf.reduce_mean(tf.cast(correct_prediction, \"float\"))\n\n print (\"Train Accuracy:\", accuracy.eval({X: X_train, Y: Y_train}))\n print (\"Test Accuracy:\", accuracy.eval({X: X_test, Y: Y_test}))\n \n return parameters",
"_____no_output_____"
]
],
[
[
"Run the following cell to train your model! On our machine it takes about 5 minutes. Your \"Cost after epoch 100\" should be 1.016458. If it's not, don't waste time; interrupt the training by clicking on the square (⬛) in the upper bar of the notebook, and try to correct your code. If it is the correct cost, take a break and come back in 5 minutes!",
"_____no_output_____"
]
],
[
[
"parameters = model(X_train, Y_train, X_test, Y_test)",
"Cost after epoch 0: 1.855702\nCost after epoch 100: 1.016458\nCost after epoch 200: 0.733102\nCost after epoch 300: 0.572940\nCost after epoch 400: 0.468774\nCost after epoch 500: 0.381021\nCost after epoch 600: 0.313822\nCost after epoch 700: 0.254158\nCost after epoch 800: 0.203829\nCost after epoch 900: 0.166421\nCost after epoch 1000: 0.141486\nCost after epoch 1100: 0.107580\nCost after epoch 1200: 0.086270\nCost after epoch 1300: 0.059371\nCost after epoch 1400: 0.052228\n"
]
],
[
[
"**Expected Output**:\n\n<table> \n <tr> \n <td>\n **Train Accuracy**\n </td>\n <td>\n 0.999074\n </td>\n </tr>\n <tr> \n <td>\n **Test Accuracy**\n </td>\n <td>\n 0.716667\n </td>\n </tr>\n\n</table>\n\nAmazing, your algorithm can recognize a sign representing a figure between 0 and 5 with 71.7% accuracy.\n\n**Insights**:\n- Your model seems big enough to fit the training set well. However, given the difference between train and test accuracy, you could try to add L2 or dropout regularization to reduce overfitting. \n- Think about the session as a block of code to train the model. Each time you run the session on a minibatch, it trains the parameters. In total you have run the session a large number of times (1500 epochs) until you obtained well trained parameters.",
"_____no_output_____"
],
[
"### 2.7 - Test with your own image (optional / ungraded exercise)\n\nCongratulations on finishing this assignment. You can now take a picture of your hand and see the output of your model. To do that:\n 1. Click on \"File\" in the upper bar of this notebook, then click \"Open\" to go on your Coursera Hub.\n 2. Add your image to this Jupyter Notebook's directory, in the \"images\" folder\n 3. Write your image's name in the following code\n 4. Run the code and check if the algorithm is right!",
"_____no_output_____"
]
],
[
[
"import scipy\nfrom PIL import Image\nfrom scipy import ndimage\n\n## START CODE HERE ## (PUT YOUR IMAGE NAME) \nmy_image = \"thumbs_up.jpg\"\n## END CODE HERE ##\n\n# We preprocess your image to fit your algorithm.\nfname = \"images/\" + my_image\nimage = np.array(ndimage.imread(fname, flatten=False))\nmy_image = scipy.misc.imresize(image, size=(64,64)).reshape((1, 64*64*3)).T\nmy_image_prediction = predict(my_image, parameters)\n\nplt.imshow(image)\nprint(\"Your algorithm predicts: y = \" + str(np.squeeze(my_image_prediction)))",
"Your algorithm predicts: y = 3\n"
]
],
[
[
"You indeed deserved a \"thumbs-up\" although as you can see the algorithm seems to classify it incorrectly. The reason is that the training set doesn't contain any \"thumbs-up\", so the model doesn't know how to deal with it! We call that a \"mismatched data distribution\" and it is one of the various of the next course on \"Structuring Machine Learning Projects\".",
"_____no_output_____"
],
[
"<font color='blue'>\n**What you should remember**:\n- Tensorflow is a programming framework used in deep learning\n- The two main object classes in tensorflow are Tensors and Operators. \n- When you code in tensorflow you have to take the following steps:\n - Create a graph containing Tensors (Variables, Placeholders ...) and Operations (tf.matmul, tf.add, ...)\n - Create a session\n - Initialize the session\n - Run the session to execute the graph\n- You can execute the graph multiple times as you've seen in model()\n- The backpropagation and optimization is automatically done when running the session on the \"optimizer\" object.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
d0faa374e29f19691e5dd9131dff73b20e40eb9b | 200,131 | ipynb | Jupyter Notebook | v2/TestCarGameAI.ipynb | rVSaxena/RL-CarGameAI | 6ccda17b2c45cc8d3904781d031877e4e02de0c9 | [
"MIT"
] | 1 | 2021-10-16T16:39:39.000Z | 2021-10-16T16:39:39.000Z | v2/TestCarGameAI.ipynb | rVSaxena/RL-CarGameAI | 6ccda17b2c45cc8d3904781d031877e4e02de0c9 | [
"MIT"
] | null | null | null | v2/TestCarGameAI.ipynb | rVSaxena/RL-CarGameAI | 6ccda17b2c45cc8d3904781d031877e4e02de0c9 | [
"MIT"
] | null | null | null | 830.419087 | 118,032 | 0.95428 | [
[
[
"import tensorflow as tf\nfrom tensorflow import keras as keras\nimport time\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport matplotlib\nimport matplotlib.image as mpimg\nfrom tensorflow.keras.models import Sequential, load_model\nfrom tensorflow.keras.layers import Dense, Dropout, Lambda, LayerNormalization\nfrom tensorflow.keras.callbacks import ModelCheckpoint, LearningRateScheduler, History, EarlyStopping",
"_____no_output_____"
],
[
"from sample.functionImplemented import get_model, custom_loss, get_threshold, schedule, custom_scaler, get_opt_action, update_replay_helper, populate_replay_memory, update_replay_memory \nfrom sample.car import Car\nfrom sample.track import Track",
"_____no_output_____"
],
[
"img = mpimg.imread(\"tracks/track_pic9.jpg\")[:,:,0]\ntrack1=(img<50).astype('int')\nprint(track1.shape)\ntrack_rows, track_cols=track1.shape\npos_pos=np.where(track1==1)\nspawning_positions=np.zeros((len(pos_pos[0]), 2))\nspawning_positions[:, 0]=pos_pos[0]\nspawning_positions[:, 1]=pos_pos[1]\nspawning_positions=spawning_positions.astype('int')\n\ntrack=Track(track1, 5)\nl=spawning_positions[np.random.choice(range(len(spawning_positions)), size=(20, ))]\n\nfor (i,j) in l:\n track.add_checkpoints(i,j)\ntrack.checkpoints=np.asarray(track.checkpoints)\ntrack.spawn_at=np.asarray(track.spawn_at)\nplt.imshow(track1)\nplt.show()",
"(882, 1174)\n"
],
[
"throttle_quant=np.linspace(-1,1,9)\nsteer_quant=np.linspace(-1,1,7)\nactions=np.asarray([(throttle, steer) for throttle in throttle_quant for steer in steer_quant]) \ndata_scaler=np.asarray([\n 100, 100, 100, 100,\n 100, 100, 100, 100,\n 50, 1, 1\n])\nusescaler=True\ngamma=0.9\ntrainedModel=tf.keras.models.load_model(\"TrainedModels/trainedModelspa1.h5\", custom_objects={'cl':custom_loss(gamma)})",
"_____no_output_____"
],
[
"new_car=Car(track, 80, 10.0)\n# new_car.sampling_frequency=10.0\nthrottle_trace=[]\nsteer_trace=[]\nspeed_trace=[]\n\ndef get_plot(positions, superimposeon_this):\n x, y=positions\n for x_diff in range(-5, 7):\n for y_diff in range(-5, 7):\n if np.sqrt(x_diff**2+y_diff**2)<14:\n superimposeon_this[x+x_diff][y+y_diff]=1\n f=plt.figure(figsize=(10, 20))\n plt.imshow(superimposeon_this+new_car.track.track)\n plt.show()\n return\n\n\nbase_fig=np.zeros((track_rows, track_cols))\n\n\nfor iteration in range(200):\n r, c=new_car.integer_position_\n for x_diff in range(-3, 4):\n for y_diff in range(-3, 4):\n if np.sqrt(x_diff**2+y_diff**2)<4:\n if r+x_diff<new_car.track.track.shape[0] and c+y_diff<new_car.track.track.shape[1]:\n base_fig[r+x_diff][c+y_diff]=1\n \n \n throttle, steer=get_opt_action(new_car, trainedModel, actions, data_scaler, usescaler)\n throttle_trace.append(throttle)\n steer_trace.append(steer)\n speed_trace.append(new_car.speed)\n \n theta=new_car.car_angle\n f1, f2=throttle*np.sin(theta)-steer*np.cos(theta), throttle*np.cos(theta)+steer*np.sin(theta)\n# print(steer, new_car.speed, new_car.car_angle, new_car.current_position)\n new_car.execute_forces(f1, f2, max_magnitudes=20)\n# new_car.speed=20.0\n if new_car.collided_on_last:\n print(\"boom\")\n break\n \nget_plot(new_car.integer_position_, base_fig) ",
"_____no_output_____"
],
[
"telemetry_plts=plt.figure(figsize=(10, 10))\nax1=telemetry_plts.add_subplot(3, 1, 1)\nax1.plot(speed_trace)\nax2=telemetry_plts.add_subplot(3, 1, 2)\nax2.plot(throttle_trace)\nax3=telemetry_plts.add_subplot(3, 1, 3)\nax3.plot(steer_trace)\nax1.set_title(\"Speed\")\nax2.set_title(\"throttle\")\nax3.set_title(\"Steering\")\ntelemetry_plts.suptitle(\"Telemetry\")\ntelemetry_plts.show()",
"d:\\vaibhav_personal\\entertainment\\new_cargame\\updated_cargame\\lib\\site-packages\\ipykernel_launcher.py:12: UserWarning: Matplotlib is currently using module://ipykernel.pylab.backend_inline, which is a non-GUI backend, so cannot show the figure.\n if sys.path[0] == '':\n"
],
[
"trainedModel.",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0faa78f39977553da19ba75b52897fff99bc497 | 86,353 | ipynb | Jupyter Notebook | python/titanic_survival_exploration/Titanic_Survival_Exploration.ipynb | robertodias/machine_learning | 825928ba0e82405ece33769ae1575249edef0a57 | [
"MIT"
] | 1 | 2017-11-09T15:09:41.000Z | 2017-11-09T15:09:41.000Z | python/titanic_survival_exploration/Titanic_Survival_Exploration.ipynb | robertodias/machine_learning | 825928ba0e82405ece33769ae1575249edef0a57 | [
"MIT"
] | null | null | null | python/titanic_survival_exploration/Titanic_Survival_Exploration.ipynb | robertodias/machine_learning | 825928ba0e82405ece33769ae1575249edef0a57 | [
"MIT"
] | null | null | null | 101.831368 | 18,422 | 0.794773 | [
[
[
"# Machine Learning Engineer Nanodegree\n## Introduction and Foundations\n## Project 0: Titanic Survival Exploration\n\nIn 1912, the ship RMS Titanic struck an iceberg on its maiden voyage and sank, resulting in the deaths of most of its passengers and crew. In this introductory project, we will explore a subset of the RMS Titanic passenger manifest to determine which features best predict whether someone survived or did not survive. To complete this project, you will need to implement several conditional predictions and answer the questions below. Your project submission will be evaluated based on the completion of the code and your responses to the questions.\n> **Tip:** Quoted sections like this will provide helpful instructions on how to navigate and use an iPython notebook. ",
"_____no_output_____"
],
[
"# Getting Started\nTo begin working with the RMS Titanic passenger data, we'll first need to `import` the functionality we need, and load our data into a `pandas` DataFrame. \nRun the code cell below to load our data and display the first few entries (passengers) for examination using the `.head()` function.\n> **Tip:** You can run a code cell by clicking on the cell and using the keyboard shortcut **Shift + Enter** or **Shift + Return**. Alternatively, a code cell can be executed using the **Play** button in the hotbar after selecting it. Markdown cells (text cells like this one) can be edited by double-clicking, and saved using these same shortcuts. [Markdown](http://daringfireball.net/projects/markdown/syntax) allows you to write easy-to-read plain text that can be converted to HTML.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\n\n# RMS Titanic data visualization code \nfrom titanic_visualizations import survival_stats\nfrom IPython.display import display\n%matplotlib inline\n\n# Load the dataset\nin_file = 'titanic_data.csv'\nfull_data = pd.read_csv(in_file)\n\n# Print the first few entries of the RMS Titanic data\ndisplay(full_data.head())",
"/usr/local/lib/python2.7/site-packages/matplotlib/font_manager.py:273: UserWarning: Matplotlib is building the font cache using fc-list. This may take a moment.\n warnings.warn('Matplotlib is building the font cache using fc-list. This may take a moment.')\n"
]
],
[
[
"From a sample of the RMS Titanic data, we can see the various features present for each passenger on the ship:\n- **Survived**: Outcome of survival (0 = No; 1 = Yes)\n- **Pclass**: Socio-economic class (1 = Upper class; 2 = Middle class; 3 = Lower class)\n- **Name**: Name of passenger\n- **Sex**: Sex of the passenger\n- **Age**: Age of the passenger (Some entries contain `NaN`)\n- **SibSp**: Number of siblings and spouses of the passenger aboard\n- **Parch**: Number of parents and children of the passenger aboard\n- **Ticket**: Ticket number of the passenger\n- **Fare**: Fare paid by the passenger\n- **Cabin** Cabin number of the passenger (Some entries contain `NaN`)\n- **Embarked**: Port of embarkation of the passenger (C = Cherbourg; Q = Queenstown; S = Southampton)\n\nSince we're interested in the outcome of survival for each passenger or crew member, we can remove the **Survived** feature from this dataset and store it as its own separate variable `outcomes`. We will use these outcomes as our prediction targets. \nRun the code cell below to remove **Survived** as a feature of the dataset and store it in `outcomes`.",
"_____no_output_____"
]
],
[
[
"# Store the 'Survived' feature in a new variable and remove it from the dataset\noutcomes = full_data['Survived']\ndata = full_data.drop('Survived', axis = 1)\n\n# Show the new dataset with 'Survived' removed\ndisplay(data.head())",
"_____no_output_____"
]
],
[
[
"The very same sample of the RMS Titanic data now shows the **Survived** feature removed from the DataFrame. Note that `data` (the passenger data) and `outcomes` (the outcomes of survival) are now *paired*. That means for any passenger `data.loc[i]`, they have the survival outcome `outcome[i]`.\n\nTo measure the performance of our predictions, we need a metric to score our predictions against the true outcomes of survival. Since we are interested in how *accurate* our predictions are, we will calculate the proportion of passengers where our prediction of their survival is correct. Run the code cell below to create our `accuracy_score` function and test a prediction on the first five passengers. \n\n**Think:** *Out of the first five passengers, if we predict that all of them survived, what would you expect the accuracy of our predictions to be?*",
"_____no_output_____"
]
],
[
[
"def accuracy_score(truth, pred):\n \"\"\" Returns accuracy score for input truth and predictions. \"\"\"\n \n # Ensure that the number of predictions matches number of outcomes\n if len(truth) == len(pred): \n \n # Calculate and return the accuracy as a percent\n return \"Predictions have an accuracy of {:.2f}%.\".format((truth == pred).mean()*100)\n \n else:\n return \"Number of predictions does not match number of outcomes!\"\n \n# Test the 'accuracy_score' function\npredictions = pd.Series(np.ones(5, dtype = int))\nprint accuracy_score(outcomes[:5], predictions)",
"Predictions have an accuracy of 60.00%.\n"
]
],
[
[
"> **Tip:** If you save an iPython Notebook, the output from running code blocks will also be saved. However, the state of your workspace will be reset once a new session is started. Make sure that you run all of the code blocks from your previous session to reestablish variables and functions before picking up where you last left off.\n\n# Making Predictions\n\nIf we were asked to make a prediction about any passenger aboard the RMS Titanic whom we knew nothing about, then the best prediction we could make would be that they did not survive. This is because we can assume that a majority of the passengers (more than 50%) did not survive the ship sinking. \nThe `predictions_0` function below will always predict that a passenger did not survive.",
"_____no_output_____"
]
],
[
[
"def predictions_0(data):\n \"\"\" Model with no features. Always predicts a passenger did not survive. \"\"\"\n\n predictions = []\n for _, passenger in data.iterrows():\n \n # Predict the survival of 'passenger'\n predictions.append(0)\n \n # Return our predictions\n return pd.Series(predictions)\n\n# Make the predictions\npredictions = predictions_0(data)",
"_____no_output_____"
]
],
[
[
"### Question 1\n*Using the RMS Titanic data, how accurate would a prediction be that none of the passengers survived?* \n**Hint:** Run the code cell below to see the accuracy of this prediction.",
"_____no_output_____"
]
],
[
[
"print accuracy_score(outcomes, predictions)",
"Predictions have an accuracy of 61.62%.\n"
]
],
[
[
"**Answer:** 61.62%",
"_____no_output_____"
],
[
"***\nLet's take a look at whether the feature **Sex** has any indication of survival rates among passengers using the `survival_stats` function. This function is defined in the `titanic_visualizations.py` Python script included with this project. The first two parameters passed to the function are the RMS Titanic data and passenger survival outcomes, respectively. The third parameter indicates which feature we want to plot survival statistics across. \nRun the code cell below to plot the survival outcomes of passengers based on their sex.",
"_____no_output_____"
]
],
[
[
"survival_stats(data, outcomes, 'Sex')",
"_____no_output_____"
]
],
[
[
"Examining the survival statistics, a large majority of males did not survive the ship sinking. However, a majority of females *did* survive the ship sinking. Let's build on our previous prediction: If a passenger was female, then we will predict that they survived. Otherwise, we will predict the passenger did not survive. \nFill in the missing code below so that the function will make this prediction. \n**Hint:** You can access the values of each feature for a passenger like a dictionary. For example, `passenger['Sex']` is the sex of the passenger.",
"_____no_output_____"
]
],
[
[
"def predictions_1(data):\n \"\"\" Model with one feature: \n - Predict a passenger survived if they are female. \"\"\"\n \n predictions = []\n for _, passenger in data.iterrows():\n \n # Remove the 'pass' statement below \n # and write your prediction conditions here\n if passenger.Sex == 'male':\n predictions.append(0)\n else:\n predictions.append(1)\n \n # Return our predictions\n return pd.Series(predictions)\n\n# Make the predictions\npredictions = predictions_1(data)",
"_____no_output_____"
]
],
[
[
"### Question 2\n*How accurate would a prediction be that all female passengers survived and the remaining passengers did not survive?* \n**Hint:** Run the code cell below to see the accuracy of this prediction.",
"_____no_output_____"
]
],
[
[
"print accuracy_score(outcomes, predictions)",
"Predictions have an accuracy of 78.68%.\n"
]
],
[
[
"**Answer**: 78.68%",
"_____no_output_____"
],
[
"***\nUsing just the **Sex** feature for each passenger, we are able to increase the accuracy of our predictions by a significant margin. Now, let's consider using an additional feature to see if we can further improve our predictions. For example, consider all of the male passengers aboard the RMS Titanic: Can we find a subset of those passengers that had a higher rate of survival? Let's start by looking at the **Age** of each male, by again using the `survival_stats` function. This time, we'll use a fourth parameter to filter out the data so that only passengers with the **Sex** 'male' will be included. \nRun the code cell below to plot the survival outcomes of male passengers based on their age.",
"_____no_output_____"
]
],
[
[
"survival_stats(data, outcomes, 'Age', [\"Sex == 'male'\"])",
"_____no_output_____"
]
],
[
[
"Examining the survival statistics, the majority of males younger than 10 survived the ship sinking, whereas most males age 10 or older *did not survive* the ship sinking. Let's continue to build on our previous prediction: If a passenger was female, then we will predict they survive. If a passenger was male and younger than 10, then we will also predict they survive. Otherwise, we will predict they do not survive. \nFill in the missing code below so that the function will make this prediction. \n**Hint:** You can start your implementation of this function using the prediction code you wrote earlier from `predictions_1`.",
"_____no_output_____"
]
],
[
[
"def predictions_2(data):\n \"\"\" Model with two features: \n - Predict a passenger survived if they are female.\n - Predict a passenger survived if they are male and younger than 10. \"\"\"\n \n predictions = []\n for _, passenger in data.iterrows():\n \n # Remove the 'pass' statement below \n # and write your prediction conditions here\n if (passenger.Sex == 'female'):\n predictions.append(1)\n elif (passenger.Sex == 'male' and passenger.Age < 10):\n predictions.append(1)\n else:\n predictions.append(0)\n \n # Return our predictions\n return pd.Series(predictions)\n\n# Make the predictions\npredictions = predictions_2(data)",
"_____no_output_____"
]
],
[
[
"### Question 3\n*How accurate would a prediction be that all female passengers and all male passengers younger than 10 survived?* \n**Hint:** Run the code cell below to see the accuracy of this prediction.",
"_____no_output_____"
]
],
[
[
"print accuracy_score(outcomes, predictions)",
"Predictions have an accuracy of 79.35%.\n"
]
],
[
[
"**Answer**: 79.35%",
"_____no_output_____"
],
[
"***\nAdding the feature **Age** as a condition in conjunction with **Sex** improves the accuracy by a small margin more than with simply using the feature **Sex** alone. Now it's your turn: Find a series of features and conditions to split the data on to obtain an outcome prediction accuracy of at least 80%. This may require multiple features and multiple levels of conditional statements to succeed. You can use the same feature multiple times with different conditions. \n**Pclass**, **Sex**, **Age**, **SibSp**, and **Parch** are some suggested features to try.\n\nUse the `survival_stats` function below to to examine various survival statistics. \n**Hint:** To use mulitple filter conditions, put each condition in the list passed as the last argument. Example: `[\"Sex == 'male'\", \"Age < 18\"]`",
"_____no_output_____"
]
],
[
[
"survival_stats(data, outcomes, 'Embarked', [\"Pclass == 3\", \"Age < 30\", \"Sex == female\", \"SibSp == 2\"])",
"_____no_output_____"
]
],
[
[
"After exploring the survival statistics visualization, fill in the missing code below so that the function will make your prediction. \nMake sure to keep track of the various features and conditions you tried before arriving at your final prediction model. \n**Hint:** You can start your implementation of this function using the prediction code you wrote earlier from `predictions_2`.",
"_____no_output_____"
]
],
[
[
"def predictions_3(data):\n \"\"\" Model with multiple features. Makes a prediction with an accuracy of at least 80%. \"\"\"\n \n predictions = []\n for _, passenger in data.iterrows():\n \n # Remove the 'pass' statement below \n # and write your prediction conditions here\n if (passenger.Sex == 'female' and passenger.Pclass <> 3):\n predictions.append(1)\n elif (passenger.Sex == 'female' and passenger.Pclass == 3 and passenger.Age < 28 and passenger.SibSp == 0):\n predictions.append(1)\n elif (passenger.Sex == 'male' and passenger.Pclass <> 3 and passenger.Age < 10):\n predictions.append(1)\n elif (passenger.Sex == 'male' and passenger.Pclass == 1 and passenger.Age > 31 and passenger.Age < 44 and passenger.Fare > 5.000):\n predictions.append(1)\n else:\n predictions.append(0)\n \n # Return our predictions\n return pd.Series(predictions)\n\n# Make the predictions\npredictions = predictions_3(data)",
"_____no_output_____"
]
],
[
[
"### Question 4\n*Describe the steps you took to implement the final prediction model so that it got an accuracy of at least 80%. What features did you look at? Were certain features more informative than others? Which conditions did you use to split the survival outcomes in the data? How accurate are your predictions?* \n**Hint:** Run the code cell below to see the accuracy of your predictions.",
"_____no_output_____"
]
],
[
[
"print accuracy_score(outcomes, predictions)",
"Predictions have an accuracy of 82.15%.\n"
]
],
[
[
"**Answer**: 82.15%\n\n**My Steps**:\n* First, based on the comparison between Male and Female, I could see that just considering the Female our accuracy was very good.\n* Second, I've tried to get more about the Female, so by comparing the Female data regarding Pclass I could see that classes 1 and 2 were very good but class 3 needed a review.\nSo I added my **first rule** that was: **Female at Classes 1 and 2 - survived**.\nAnd then I investigated the Females in Class 3 and I saw that under 30 they were surviving a lot, so I refined a few and went my **second rule** that was: **Females at Class 3, under 28 and without siblings - survived**.\n* Third I started to try to understand the Males, and I saw that under 10 they were also surviving, considering that Class 3 was the worst.\nSo I added **my third rule** that was: **Males under 10 and that were on Classes 1 and 2 - survived**.\n* Fourth, I've tried to refine the profile of Males older than 10 years. I saw that the majority of the ones that survived were on Class 1, so then a identified a range of age something between 30 and 40 years and that payed more than 5.000. This went to my **fourth rule** that was: **Males between 31 and 44 years, that were at Class 1 and payed more than 5.000 - survived**.",
"_____no_output_____"
],
[
"# Conclusion\n\nAfter several iterations of exploring and conditioning on the data, you have built a useful algorithm for predicting the survival of each passenger aboard the RMS Titanic. The technique applied in this project is a manual implementation of a simple machine learning model, the *decision tree*. A decision tree splits a set of data into smaller and smaller groups (called *nodes*), by one feature at a time. Each time a subset of the data is split, our predictions become more accurate if each of the resulting subgroups are more homogeneous (contain similar labels) than before. The advantage of having a computer do things for us is that it will be more exhaustive and more precise than our manual exploration above. [This link](http://www.r2d3.us/visual-intro-to-machine-learning-part-1/) provides another introduction into machine learning using a decision tree.\n\nA decision tree is just one of many models that come from *supervised learning*. In supervised learning, we attempt to use features of the data to predict or model things with objective outcome labels. That is to say, each of our data points has a known outcome value, such as a categorical, discrete label like `'Survived'`, or a numerical, continuous value like predicting the price of a house.\n\n### Question 5\n*Think of a real-world scenario where supervised learning could be applied. What would be the outcome variable that you are trying to predict? Name two features about the data used in this scenario that might be helpful for making the predictions.* ",
"_____no_output_____"
],
[
"**Answer**: I think supervised learning could be applied to support Human Resources, by analysing all employees in a company, considering as data their Job Role, Salary, Age, Sex, How long he is in the current role, how long he is in the copany, Employee Satisfaction Score, etc.\nThe outcome could be if an Employee will leave or stay in the company, so the HR Manager can use this algorithm to check if good employees are \"almost leaving\" the company and give them promotions so they will stay on their jobs more time.\n\n**Sample**\nThe employee John Doe is a key contributor to the company, but he is in the company for more than 6 years and his salary is below the avarage salary for his role. He is now being considered as **LEAVING THE COMPANY** by our algorithm. Knownig this, the HR Manager can check with John Doe's manager and take actions to change the **LEAVING THE COMPANY** Status, doing something like salary increase pro promotion, for example.",
"_____no_output_____"
],
[
"> **Note**: Once you have completed all of the code implementations and successfully answered each question above, you may finalize your work by exporting the iPython Notebook as an HTML document. You can do this by using the menu above and navigating to \n**File -> Download as -> HTML (.html)**. Include the finished document along with this notebook as your submission.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
d0faa84bc64653f7af487a43d9d35fed14cdfa8c | 33,581 | ipynb | Jupyter Notebook | tensorflow/lite/g3doc/tutorials/model_maker_text_classification.ipynb | simonmaurer/tensorflow | 7e1c942100039dc0a9adda5d0d45c7e1d2e3b76c | [
"Apache-2.0"
] | 6 | 2021-03-23T09:10:48.000Z | 2021-12-06T11:15:42.000Z | tensorflow/lite/g3doc/tutorials/model_maker_text_classification.ipynb | ethan-jiang-1/tensorflow | 1d74f869fece4375c7fa3733ce28f2f082013b22 | [
"Apache-2.0"
] | 7 | 2021-11-10T20:21:23.000Z | 2022-03-22T19:18:39.000Z | tensorflow/lite/g3doc/tutorials/model_maker_text_classification.ipynb | ethan-jiang-1/tensorflow | 1d74f869fece4375c7fa3733ce28f2f082013b22 | [
"Apache-2.0"
] | 5 | 2016-11-07T21:17:45.000Z | 2020-05-31T00:16:59.000Z | 38.160227 | 505 | 0.563265 | [
[
[
"##### Copyright 2019 The TensorFlow Authors.",
"_____no_output_____"
]
],
[
[
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
]
],
[
[
"# Text classification with TensorFlow Lite Model Maker",
"_____no_output_____"
],
[
"<table class=\"tfo-notebook-buttons\" align=\"left\">\n <td>\n <a target=\"_blank\" href=\"https://www.tensorflow.org/lite/tutorials/model_maker_text_classification\"><img src=\"https://www.tensorflow.org/images/tf_logo_32px.png\" />View on TensorFlow.org</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/lite/g3doc/tutorials/model_maker_text_classification.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Run in Google Colab</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/g3doc/tutorials/model_maker_text_classification.ipynb\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />View source on GitHub</a>\n </td>\n <td>\n <a href=\"https://storage.googleapis.com/tensorflow_docs/tensorflow/tensorflow/lite/g3doc/tutorials/model_maker_text_classification.ipynb\"><img src=\"https://www.tensorflow.org/images/download_logo_32px.png\" />Download notebook</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"The TensorFlow Lite Model Maker library simplifies the process of adapting and converting a TensorFlow model to particular input data when deploying this model for on-device ML applications.\n\nThis notebook shows an end-to-end example that utilizes the Model Maker library to illustrate the adaptation and conversion of a commonly-used text classification model to classify movie reviews on a mobile device. The text classification model classifies text into predefined categories.The inputs should be preprocessed text and the outputs are the probabilities of the categories. The dataset used in this tutorial are positive and negative movie reviews.",
"_____no_output_____"
],
[
"## Prerequisites\n",
"_____no_output_____"
],
[
"### Install the required packages\nTo run this example, install the required packages, including the Model Maker package from the [GitHub repo](https://github.com/tensorflow/examples/tree/master/tensorflow_examples/lite/model_maker).\n\n**If you run this notebook on Colab, you may see an error message about `tensorflowjs` and `tensorflow-hub` version imcompatibility. It is safe to ignore this error as we do not use `tensorflowjs` in this workflow.**",
"_____no_output_____"
]
],
[
[
"!pip install -q tflite-model-maker",
"_____no_output_____"
]
],
[
[
"Import the required packages.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport os\n\nfrom tflite_model_maker import configs\nfrom tflite_model_maker import ExportFormat\nfrom tflite_model_maker import model_spec\nfrom tflite_model_maker import text_classifier\nfrom tflite_model_maker import TextClassifierDataLoader\n\nimport tensorflow as tf\nassert tf.__version__.startswith('2')\ntf.get_logger().setLevel('ERROR')",
"_____no_output_____"
]
],
[
[
"### Download the sample training data.\n\nIn this tutorial, we will use the [SST-2](https://nlp.stanford.edu/sentiment/index.html) (Stanford Sentiment Treebank) which is one of the tasks in the [GLUE](https://gluebenchmark.com/) benchmark. It contains 67,349 movie reviews for training and 872 movie reviews for testing. The dataset has two classes: positive and negative movie reviews.",
"_____no_output_____"
]
],
[
[
"data_dir = tf.keras.utils.get_file(\n fname='SST-2.zip',\n origin='https://dl.fbaipublicfiles.com/glue/data/SST-2.zip',\n extract=True)\ndata_dir = os.path.join(os.path.dirname(data_dir), 'SST-2')",
"_____no_output_____"
]
],
[
[
"The SST-2 dataset is stored in TSV format. The only difference between TSV and CSV is that TSV uses a tab `\\t` character as its delimiter instead of a comma `,` in the CSV format.\n\nHere are the first 5 lines of the training dataset. label=0 means negative, label=1 means positive.\n\n| sentence | label | | | |\n|-------------------------------------------------------------------------------------------|-------|---|---|---|\n| hide new secretions from the parental units | 0 | | | |\n| contains no wit , only labored gags | 0 | | | |\n| that loves its characters and communicates something rather beautiful about human nature | 1 | | | |\n| remains utterly satisfied to remain the same throughout | 0 | | | |\n| on the worst revenge-of-the-nerds clichés the filmmakers could dredge up | 0 | | | |\n\nNext, we will load the dataset into a Pandas dataframe and change the current label names (`0` and `1`) to a more human-readable ones (`negative` and `positive`) and use them for model training.\n\n",
"_____no_output_____"
]
],
[
[
"import pandas as pd\n\ndef replace_label(original_file, new_file):\n # Load the original file to pandas. We need to specify the separator as\n # '\\t' as the training data is stored in TSV format\n df = pd.read_csv(original_file, sep='\\t')\n\n # Define how we want to change the label name\n label_map = {0: 'negative', 1: 'positive'}\n\n # Excute the label change\n df.replace({'label': label_map}, inplace=True)\n\n # Write the updated dataset to a new file\n df.to_csv(new_file)\n\n# Replace the label name for both the training and test dataset. Then write the\n# updated CSV dataset to the current folder.\nreplace_label(os.path.join(os.path.join(data_dir, 'train.tsv')), 'train.csv')\nreplace_label(os.path.join(os.path.join(data_dir, 'dev.tsv')), 'dev.csv')",
"_____no_output_____"
]
],
[
[
"## Quickstart\n\nThere are five steps to train a text classification model:\n\n**Step 1. Choose a text classification model archiecture.**\n\nHere we use the average word embedding model architecture, which will produce a small and fast model with decent accuracy.",
"_____no_output_____"
]
],
[
[
"spec = model_spec.get('average_word_vec')",
"_____no_output_____"
]
],
[
[
"Model Maker also supports other model architectures such as [BERT](https://arxiv.org/abs/1810.04805). If you are interested to learn about other architecture, see the [Choose a model architecture for Text Classifier](#scrollTo=kJ_B8fMDOhMR) section below.",
"_____no_output_____"
],
[
"**Step 2. Load the training and test data, then preprocess them according to a specific `model_spec`.**\n\nModel Maker can take input data in the CSV format. We will load the training and test dataset with the human-readable label name that were created earlier.\n\nEach model architecture requires input data to be processed in a particular way. `TextClassifierDataLoader` reads the requirement from `model_spec` and automatically execute the necessary preprocessing.",
"_____no_output_____"
]
],
[
[
"train_data = TextClassifierDataLoader.from_csv(\n filename='train.csv',\n text_column='sentence',\n label_column='label',\n model_spec=spec,\n is_training=True)\ntest_data = TextClassifierDataLoader.from_csv(\n filename='dev.csv',\n text_column='sentence',\n label_column='label',\n model_spec=spec,\n is_training=False)",
"_____no_output_____"
]
],
[
[
"**Step 3. Train the TensorFlow model with the training data.**\n\nThe average word embedding model use `batch_size = 32` by default. Therefore you will see that it takes 2104 steps to go through the 67,349 sentences in the training dataset. We will train the model for 10 epochs, which means going through the training dataset 10 times.",
"_____no_output_____"
]
],
[
[
"model = text_classifier.create(train_data, model_spec=spec, epochs=10)",
"_____no_output_____"
]
],
[
[
"**Step 4. Evaluate the model with the test data.**\n\nAfter training the text classification model using the sentences in the training dataset, we will use the remaining 872 sentences in the test dataset to evaluate how the model perform against new data it has never seen before.\n\nAs the default batch size is 32, it will take 28 steps to go through the 872 sentences in the test dataset.",
"_____no_output_____"
]
],
[
[
"loss, acc = model.evaluate(test_data)",
"_____no_output_____"
]
],
[
[
"**Step 5. Export as a TensorFlow Lite model.**\n\nLet's export the text classification that we have trained in the TensorFlow Lite format. We will specify which folder to export the model.\n\nYou may see an warning about `vocab.txt` file does not exist in the metadata but they can be safely ignore.",
"_____no_output_____"
]
],
[
[
"model.export(export_dir='average_word_vec')",
"_____no_output_____"
]
],
[
[
"You can download the TensorFlow Lite model file using the left sidebar of Colab. Go into the `average_word_vec` folder as we specified in `export_dir` parameter above, right-click on the `model.tflite` file and choose `Download` to download it to your local computer.\n\nThis model can be integrated into an Android or an iOS app using the [NLClassifier API](https://www.tensorflow.org/lite/inference_with_metadata/task_library/nl_classifier) of the [TensorFlow Lite Task Library](https://www.tensorflow.org/lite/inference_with_metadata/task_library/overview).\n\nSee the [TFLite Text Classification sample app](https://github.com/tensorflow/examples/blob/master/lite/examples/text_classification/android/lib_task_api/src/main/java/org/tensorflow/lite/examples/textclassification/client/TextClassificationClient.java#L54) for more details on how the model is used in an working app.\n\n*Note 1: Android Studio Model Binding does not support text classification yet so please use the TensorFlow Lite Task Library.*\n\n*Note 2: There is a `model.json` file in the same folder with the TFLite model. It contains the JSON representation of the [metadata](https://www.tensorflow.org/lite/convert/metadata) bundled inside the TensorFlow Lite model. Model metadata helps the TFLite Task Library know what the model does and how to pre-process/post-process data for the model. You don't need to download the `model.json` file as it is only for informational purpose and its content is already inside the TFLite file.*\n\n*Note 3: If you train a text classification model using MobileBERT or BERT-Base architecture, you will need to use [BertNLClassifier API](https://www.tensorflow.org/lite/inference_with_metadata/task_library/bert_nl_classifier) instead to integrate the trained model into a mobile app.*",
"_____no_output_____"
],
[
"The following sections walk through the example step by step to show more details.",
"_____no_output_____"
],
[
"## Choose a model architecture for Text Classifier\n\nEach `model_spec` object represents a specific model for the text classifier. TensorFlow Lite Model Maker currently supports [MobileBERT](https://arxiv.org/pdf/2004.02984.pdf), averaging word embeddings and [BERT-Base](https://arxiv.org/pdf/1810.04805.pdf) models.\n\n| Supported Model | Name of model_spec | Model Description | Model size |\n|--------------------------|-------------------------|-----------------------------------------------------------------------------------------------------------------------|---------------------------------------------|\n| Averaging Word Embedding | 'average_word_vec' | Averaging text word embeddings with RELU activation. | <1MB |\n| MobileBERT | 'mobilebert_classifier' | 4.3x smaller and 5.5x faster than BERT-Base while achieving competitive results, suitable for on-device applications. | 25MB w/ quantization <br/> 100MB w/o quantization |\n| BERT-Base | 'bert_classifier' | Standard BERT model that is widely used in NLP tasks. | 300MB |\n\nIn the quick start, we have used the average word embedding model. Let's switch to [MobileBERT](https://arxiv.org/pdf/2004.02984.pdf) to train a model with higher accuracy.",
"_____no_output_____"
]
],
[
[
"mb_spec = model_spec.get('mobilebert_classifier')",
"_____no_output_____"
]
],
[
[
"## Load training data\n\nYou can upload your own dataset to work through this tutorial. Upload your dataset by using the left sidebar in Colab.\n\n<img src=\"https://storage.googleapis.com/download.tensorflow.org/models/tflite/screenshots/model_maker_text_classification.png\" alt=\"Upload File\" width=\"800\" hspace=\"100\">\n\nIf you prefer not to upload your dataset to the cloud, you can also locally run the library by following the [guide](https://github.com/tensorflow/examples/tree/master/tensorflow_examples/lite/model_maker).",
"_____no_output_____"
],
[
"To keep it simple, we will reuse the SST-2 dataset downloaded earlier. Let's use the `TestClassifierDataLoader.from_csv` method to load the data.\n\nPlease be noted that as we have changed the model architecture, we will need to reload the training and test dataset to apply the new preprocessing logic.",
"_____no_output_____"
]
],
[
[
"train_data = TextClassifierDataLoader.from_csv(\n filename='train.csv',\n text_column='sentence',\n label_column='label',\n model_spec=mb_spec,\n is_training=True)\ntest_data = TextClassifierDataLoader.from_csv(\n filename='dev.csv',\n text_column='sentence',\n label_column='label',\n model_spec=mb_spec,\n is_training=False)",
"_____no_output_____"
]
],
[
[
"The Model Maker library also supports the `from_folder()` method to load data. It assumes that the text data of the same class are in the same subdirectory and that the subfolder name is the class name. Each text file contains one movie review sample. The `class_labels` parameter is used to specify which the subfolders.",
"_____no_output_____"
],
[
"## Train a TensorFlow Model\n\nTrain a text classification model using the training data.\n\n*Note: As MobileBERT is a complex model, each training epoch will takes about 10 minutes on a Colab GPU. Please make sure that you are using a GPU runtime.*",
"_____no_output_____"
]
],
[
[
"model = text_classifier.create(train_data, model_spec=mb_spec, epochs=3)",
"_____no_output_____"
]
],
[
[
"Examine the detailed model structure.",
"_____no_output_____"
]
],
[
[
"model.summary()",
"_____no_output_____"
]
],
[
[
"## Evaluate the model\n\nEvaluate the model that we have just trained using the test data and measure the loss and accuracy value.",
"_____no_output_____"
]
],
[
[
"loss, acc = model.evaluate(test_data)",
"_____no_output_____"
]
],
[
[
"## Quantize the model\n\nIn many on-device ML application, the model size is an important factor. Therefore, it is recommended that you apply quantize the model to make it smaller and potentially run faster. Model Maker automatically applies the recommended quantization scheme for each model architecture but you can customize the quantization config as below.",
"_____no_output_____"
]
],
[
[
"config = configs.QuantizationConfig.create_dynamic_range_quantization(optimizations=[tf.lite.Optimize.OPTIMIZE_FOR_LATENCY])\nconfig.experimental_new_quantizer = True",
"_____no_output_____"
]
],
[
[
"## Export as a TensorFlow Lite model\n\nConvert the trained model to TensorFlow Lite model format with [metadata](https://www.tensorflow.org/lite/convert/metadata) so that you can later use in an on-device ML application. The label file and the vocab file are embedded in metadata. The default TFLite filename is `model.tflite`.",
"_____no_output_____"
]
],
[
[
"model.export(export_dir='mobilebert/', quantization_config=config)",
"_____no_output_____"
]
],
[
[
"The TensorFlow Lite model file can be integrated in a mobile app using the [BertNLClassifier API](https://www.tensorflow.org/lite/inference_with_metadata/task_library/bert_nl_classifier) in [TensorFlow Lite Task Library](https://www.tensorflow.org/lite/inference_with_metadata/task_library/overview). Please note that this is **different** from the `NLClassifier` API used to integrate the text classification trained with the average word vector model architecture.",
"_____no_output_____"
],
[
"The export formats can be one or a list of the following:\n\n* `ExportFormat.TFLITE`\n* `ExportFormat.LABEL`\n* `ExportFormat.VOCAB`\n* `ExportFormat.SAVED_MODEL`\n\nBy default, it exports only the TensorFlow Lite model file containing the model metadata. You can also choose to export other files related to the model for better examination. For instance, exporting only the label file and vocab file as follows:",
"_____no_output_____"
]
],
[
[
"model.export(export_dir='mobilebert/', export_format=[ExportFormat.LABEL, ExportFormat.VOCAB])",
"_____no_output_____"
]
],
[
[
"You can evaluate the TFLite model with `evaluate_tflite` method to measure its accuracy. Converting the trained TensorFlow model to TFLite format and apply quantization can affect its accuracy so it is recommended to evaluate the TFLite model accuracy before deployment.",
"_____no_output_____"
]
],
[
[
"accuracy = model.evaluate_tflite('mobilebert/model.tflite', test_data)\nprint('TFLite model accuracy: ', accuracy)",
"_____no_output_____"
]
],
[
[
"## Advanced Usage\n\nThe `create` function is the driver function that the Model Maker library uses to create models. The `model_spec` parameter defines the model specification. The `AverageWordVecModelSpec` and `BertClassifierModelSpec` classes are currently supported. The `create` function comprises of the following steps:\n\n1. Creates the model for the text classifier according to `model_spec`.\n2. Trains the classifier model. The default epochs and the default batch size are set by the `default_training_epochs` and `default_batch_size` variables in the `model_spec` object.\n\nThis section covers advanced usage topics like adjusting the model and the training hyperparameters.",
"_____no_output_____"
],
[
"### Customize the MobileBERT model hyperparameters\n\nThe model parameters you can adjust are:\n\n* `seq_len`: Length of the sequence to feed into the model.\n* `initializer_range`: The standard deviation of the `truncated_normal_initializer` for initializing all weight matrices.\n* `trainable`: Boolean that specifies whether the pre-trained layer is trainable.\n\nThe training pipeline parameters you can adjust are:\n\n* `model_dir`: The location of the model checkpoint files. If not set, a temporary directory will be used.\n* `dropout_rate`: The dropout rate.\n* `learning_rate`: The initial learning rate for the Adam optimizer.\n* `tpu`: TPU address to connect to.\n\nFor instance, you can set the `seq_len=256` (default is 128). This allows the model to classify longer text.",
"_____no_output_____"
]
],
[
[
"new_model_spec = model_spec.get('mobilebert_classifier')\nnew_model_spec.seq_len = 256",
"_____no_output_____"
]
],
[
[
"### Customize the average word embedding model hyperparameters\n\nYou can adjust the model infrastructure like the `wordvec_dim` and the `seq_len` variables in the `AverageWordVecModelSpec` class.\n",
"_____no_output_____"
],
[
"For example, you can train the model with a larger value of `wordvec_dim`. Note that you must construct a new `model_spec` if you modify the model.",
"_____no_output_____"
]
],
[
[
"new_model_spec = model_spec.AverageWordVecModelSpec(wordvec_dim=32)",
"_____no_output_____"
]
],
[
[
"Get the preprocessed data.",
"_____no_output_____"
]
],
[
[
"new_train_data = TextClassifierDataLoader.from_csv(\n filename='train.csv',\n text_column='sentence',\n label_column='label',\n model_spec=new_model_spec,\n is_training=True)",
"_____no_output_____"
]
],
[
[
"Train the new model.",
"_____no_output_____"
]
],
[
[
"model = text_classifier.create(new_train_data, model_spec=new_model_spec)",
"_____no_output_____"
]
],
[
[
"### Tune the training hyperparameters\nYou can also tune the training hyperparameters like `epochs` and `batch_size` that affect the model accuracy. For instance,\n\n* `epochs`: more epochs could achieve better accuracy, but may lead to overfitting.\n* `batch_size`: the number of samples to use in one training step.\n\nFor example, you can train with more epochs.",
"_____no_output_____"
]
],
[
[
"model = text_classifier.create(new_train_data, model_spec=new_model_spec, epochs=20)",
"_____no_output_____"
]
],
[
[
"Evaluate the newly retrained model with 20 training epochs.",
"_____no_output_____"
]
],
[
[
"new_test_data = TextClassifierDataLoader.from_csv(\n filename='dev.csv',\n text_column='sentence',\n label_column='label',\n model_spec=new_model_spec,\n is_training=False)\n\nloss, accuracy = model.evaluate(new_test_data)",
"_____no_output_____"
]
],
[
[
"### Change the Model Architecture\n\nYou can change the model by changing the `model_spec`. The following shows how to change to BERT-Base model.\n\nChange the `model_spec` to BERT-Base model for the text classifier.",
"_____no_output_____"
]
],
[
[
"spec = model_spec.get('bert_classifier')",
"_____no_output_____"
]
],
[
[
"The remaining steps are the same.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d0fab0e227f1679e38759c1793ee54230d276222 | 2,310 | ipynb | Jupyter Notebook | rps.ipynb | yashtuli215/rockpaperscissor | 313a1a2788ae16f758103b45b8da4e73b94e14dc | [
"MIT"
] | null | null | null | rps.ipynb | yashtuli215/rockpaperscissor | 313a1a2788ae16f758103b45b8da4e73b94e14dc | [
"MIT"
] | null | null | null | rps.ipynb | yashtuli215/rockpaperscissor | 313a1a2788ae16f758103b45b8da4e73b94e14dc | [
"MIT"
] | null | null | null | 29.240506 | 287 | 0.428571 | [
[
[
"times = int(input(\"Number of times you want to play: \"))\n\ti = 0\n\tx = \"Computer Wins!\"\n\ty = \"Player Wins!\"\n\twhile i <times:\n\n\t\tchoice = input(\"Enter your choice: \")\n\n\t\tfrom random import randint\n\t\trand_num = randint(0,2)\n\n\t\tif rand_num == 0:\n\t\t rand_num='paper'\n\t\telif rand_num == 1:\n\t\t rand_num='scissor'\n\t\telse:\n\t\t rand_num == 'rock'\n\n if rand_num == choice:\n\t\t print(\"Its a Tie!\")\n else:\n if choice == 'rock':\n if rand_num == 'paper':\n print(x)\n else:\n print(y)\n elif choice == 'paper':\n if rand_num == 'rock':\n print(y)\n else:\n print(y)\n elif choice =='scissor':\n if rand_num == 'rock':\n print(x)\n else:\n print(y)\n else:\n print(\"Wrong Choice\")\n print(\"Wrong Choice\")\n\n\t\ti +=1",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code"
]
] |
d0fab1500b22f9330823fe1527b4fab1a22323b5 | 536,038 | ipynb | Jupyter Notebook | 102_Flowers_classification(1).ipynb | styluna7/notebooks | f0973ac4e067d62a989584810dce9088811bfad5 | [
"MIT"
] | null | null | null | 102_Flowers_classification(1).ipynb | styluna7/notebooks | f0973ac4e067d62a989584810dce9088811bfad5 | [
"MIT"
] | null | null | null | 102_Flowers_classification(1).ipynb | styluna7/notebooks | f0973ac4e067d62a989584810dce9088811bfad5 | [
"MIT"
] | null | null | null | 910.081494 | 284,928 | 0.941124 | [
[
[
"# Using Transfer Learning to Classify Flower Images with PyTorch",
"_____no_output_____"
],
[
"In this blog post, I will detail my repository that performs object classification with transfer learning. \nThe project is broken down into multiple steps:\n\n* Load and preprocess the image dataset\n* Train the image classifier on your dataset\n* Use the trained classifier to predict image content",
"_____no_output_____"
],
[
"# Load Data\nHere we use `torchvision` to load the data ([documentation](http://pytorch.org/docs/0.3.0/torchvision/index.html)). You can [download the data here](https://s3.amazonaws.com/content.udacity-data.com/courses/nd188/flower_data.zip).\nThe validation and testing sets are used to measure the model's performance on data it hasn't seen yet. No scaling or rotation transformations is perfomed.\nThe pre-trained networks available from `torchvision` were trained on the ImageNet dataset where each color channel was normalized separately. For both sets there's need to normalize the means and standard deviations of the images to what the network expects. For the means, it's `[0.485, 0.456, 0.406]` and for the standard deviations `[0.229, 0.224, 0.225]`, calculated from the ImageNet images. These values will shift each color channel to be centered at 0 and range from -1 to 1.",
"_____no_output_____"
]
],
[
[
"data_dir = './flowers'\ntrain_dir = data_dir + '/train'\nvalid_dir = data_dir + '/valid'\ntest_dir = data_dir + '/test'",
"_____no_output_____"
],
[
"# Defining data transforms for training, validation and test data and also normalizing whole data\ndata_transforms = {\n 'train': transforms.Compose([\n transforms.RandomResizedCrop(224),\n transforms.RandomRotation(45),\n transforms.RandomHorizontalFlip(),\n transforms.ToTensor(),\n transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])\n ]),\n 'valid': transforms.Compose([\n transforms.Resize(256),\n transforms.CenterCrop(224),\n transforms.ToTensor(),\n transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])\n ]),\n 'test': transforms.Compose([\n transforms.Resize(256),\n transforms.CenterCrop(224),\n transforms.ToTensor(),\n transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])\n ])\n }\n\n# loading datasets with PyTorch ImageFolder\nimage_datasets = {\n x: datasets.ImageFolder(root=data_dir + '/' + x, transform=data_transforms[x])\n for x in list(data_transforms.keys())\n }\n\n# TODO: Using the image datasets and the trainforms, define the dataloaders\n# defining data loaders to load data using image_datasets and transforms, here we also specify batch size for the mini batch\ndataloaders = {\n x: data.DataLoader(image_datasets[x], batch_size=4, shuffle=True, num_workers=2)\n for x in list(image_datasets.keys())\n }\ndataset_sizes = {\n x: len(dataloaders[x].dataset) \n for x in list(image_datasets.keys())\n } \nclass_names = image_datasets['train'].classes",
"_____no_output_____"
],
[
"dataset_sizes # printing dataset's sizes for training, validation and testing",
"_____no_output_____"
]
],
[
[
"## Label mapping\nI had load in a mapping from category label to category name. I got this in the file cat_to_name.json. It's a JSON object which i have read in with the json module. This gave a dictionary mapping the integer encoded categories to the actual names of the flowers.",
"_____no_output_____"
]
],
[
[
"import json\n\nwith open('cat_to_name.json', 'r') as f:\n cat_to_name = json.load(f)",
"_____no_output_____"
],
[
"# changing categories to their actual names \nfor i in range(0,len(class_names)):\n class_names[i] = cat_to_name.get(class_names[i])",
"_____no_output_____"
]
],
[
[
"#Visualize a few images\nLet's visualize a few training images so as to understand the data augmentations.",
"_____no_output_____"
]
],
[
[
"def imshow(inp, title=None):\n \"\"\"Imshow for Tensor.\"\"\"\n inp = inp.numpy().transpose((1, 2, 0))\n mean = np.array([0.485, 0.456, 0.406])\n std = np.array([0.229, 0.224, 0.225])\n inp = std * inp + mean\n inp = np.clip(inp, 0, 1)\n plt.imshow(inp)\n if title is not None:\n plt.title(title)\n plt.pause(0.001) # pause a bit so that plots are updated\n\n\n# Get a batch of training data\ninputs, classes = next(iter(dataloaders['train']))\n\n# Make a grid from batch\nout = torchvision.utils.make_grid(inputs)\n\nimshow(out, title=[class_names[x] for x in classes])",
"_____no_output_____"
]
],
[
[
"# Building and training the classifier\n\nNow that the data is ready, it's time to build and train the classifier. As usual, you should use one of the pretrained models from `torchvision.models` to get the image features. Build and train a new feed-forward classifier using those features.\n\n* Load a [pre-trained network](http://pytorch.org/docs/master/torchvision/models.html) (If you need a starting point, the VGG networks work great and are straightforward to use)\n* Define a new, untrained feed-forward network as a classifier, using ReLU activations and dropout\n* Train the classifier layers using backpropagation using the pre-trained network to get the features\n* Track the loss and accuracy on the validation set to determine the best hyperparameters\n\nWhen training we make sure to update only the weights of the feed-forward network.",
"_____no_output_____"
],
[
"## Train and evaluate",
"_____no_output_____"
]
],
[
[
"model_ft = train_model(model_ft, criterion, optimizer_ft,num_epochs=20)",
"Epoch 0/19\n----------\ntrain Loss: 0.8074 Acc: 0.3168\nvalid Loss: 0.5147 Acc: 0.4707\n\nEpoch 1/19\n----------\ntrain Loss: 0.6572 Acc: 0.4287\nvalid Loss: 0.3435 Acc: 0.6247\n\nEpoch 2/19\n----------\ntrain Loss: 0.5526 Acc: 0.5258\nvalid Loss: 0.2481 Acc: 0.7396\n\nEpoch 3/19\n----------\ntrain Loss: 0.4813 Acc: 0.5861\nvalid Loss: 0.1985 Acc: 0.7922\n\nEpoch 4/19\n----------\ntrain Loss: 0.4247 Acc: 0.6416\nvalid Loss: 0.1608 Acc: 0.8203\n\nEpoch 5/19\n----------\ntrain Loss: 0.3809 Acc: 0.6838\nvalid Loss: 0.1231 Acc: 0.8802\n\nEpoch 6/19\n----------\ntrain Loss: 0.3422 Acc: 0.7111\nvalid Loss: 0.1057 Acc: 0.8985\n\nEpoch 7/19\n----------\ntrain Loss: 0.3185 Acc: 0.7320\nvalid Loss: 0.0912 Acc: 0.9120\n\nEpoch 8/19\n----------\ntrain Loss: 0.2928 Acc: 0.7503\nvalid Loss: 0.0757 Acc: 0.9193\n\nEpoch 9/19\n----------\ntrain Loss: 0.2765 Acc: 0.7637\nvalid Loss: 0.0696 Acc: 0.9364\n\nEpoch 10/19\n----------\ntrain Loss: 0.2586 Acc: 0.7744\nvalid Loss: 0.0652 Acc: 0.9291\n\nEpoch 11/19\n----------\ntrain Loss: 0.2432 Acc: 0.7944\nvalid Loss: 0.0576 Acc: 0.9425\n\nEpoch 12/19\n----------\ntrain Loss: 0.2308 Acc: 0.8002\nvalid Loss: 0.0507 Acc: 0.9474\n\nEpoch 13/19\n----------\ntrain Loss: 0.2189 Acc: 0.8175\nvalid Loss: 0.0530 Acc: 0.9462\n\nEpoch 14/19\n----------\ntrain Loss: 0.2052 Acc: 0.8223\nvalid Loss: 0.0509 Acc: 0.9487\n\nEpoch 15/19\n----------\ntrain Loss: 0.1906 Acc: 0.8371\nvalid Loss: 0.0492 Acc: 0.9548\n\nEpoch 16/19\n----------\ntrain Loss: 0.1862 Acc: 0.8381\nvalid Loss: 0.0493 Acc: 0.9474\n\nEpoch 17/19\n----------\ntrain Loss: 0.1784 Acc: 0.8484\nvalid Loss: 0.0409 Acc: 0.9535\n\nEpoch 18/19\n----------\ntrain Loss: 0.1710 Acc: 0.8510\nvalid Loss: 0.0413 Acc: 0.9572\n\nEpoch 19/19\n----------\ntrain Loss: 0.1679 Acc: 0.8556\nvalid Loss: 0.0410 Acc: 0.9560\n\nTraining complete in 47m 9s\nBest val Acc: 0.957213\n"
]
],
[
[
"# Inference for classification\n\nNow let's pass an image into the network and predict the class of the flower in the image. Using a function called `predict` that takes an image and a model, then returns the top $K$ most likely classes along with the probabilities. It looks like \n\n```python\nprobs, classes = predict(image_path, model)\nprint(probs)\nprint(classes)\n> [ 0.01558163 0.01541934 0.01452626 0.01443549 0.01407339]\n> ['70', '3', '45', '62', '55']\n```\n\nFirst let's handle processing the input image such that it can be used in your network. \n\n## Image Preprocessing\n\nUsing `PIL` to load the image ([documentation](https://pillow.readthedocs.io/en/latest/reference/Image.html)). It's best to write a function that preprocesses the image so it can be used as input for the model. This function should process the images in the same manner used for training. \n\nFirst, resize the images where the shortest side is 256 pixels, keeping the aspect ratio. This can be done with the [`thumbnail`](http://pillow.readthedocs.io/en/3.1.x/reference/Image.html#PIL.Image.Image.thumbnail) or [`resize`](http://pillow.readthedocs.io/en/3.1.x/reference/Image.html#PIL.Image.Image.thumbnail) methods. Then you'll need to crop out the center 224x224 portion of the image.\n\nColor channels of images are typically encoded as integers 0-255, but the model expected floats 0-1. You'll need to convert the values. It's easiest with a Numpy array, which you can get from a PIL image like so `np_image = np.array(pil_image)`.\n\nAs before, the network expects the images to be normalized in a specific way. For the means, it's `[0.485, 0.456, 0.406]` and for the standard deviations `[0.229, 0.224, 0.225]`. You'll want to subtract the means from each color channel, then divide by the standard deviation. \n\nAnd finally, PyTorch expects the color channel to be the first dimension but it's the third dimension in the PIL image and Numpy array. You can reorder dimensions using [`ndarray.transpose`](https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.ndarray.transpose.html). The color channel needs to be first and retain the order of the other two dimensions.",
"_____no_output_____"
],
[
"## Class Prediction\n\nOnce you can get images in the correct format, it's time to write a function for making predictions with your model. A common practice is to predict the top 5 or so (usually called top-$K$) most probable classes. You'll want to calculate the class probabilities then find the $K$ largest values.\n\nTo get the top $K$ largest values in a tensor use [`x.topk(k)`](http://pytorch.org/docs/master/torch.html#torch.topk). This method returns both the highest `k` probabilities and the indices of those probabilities corresponding to the classes. You need to convert from these indices to the actual class labels using `class_to_idx` which hopefully you added to the model or from an `ImageFolder` you used to load the data ([see here](#Save-the-checkpoint)). Make sure to invert the dictionary so you get a mapping from index to class as well.\n\nAgain, this method should take a path to an image and a model checkpoint, then return the probabilities and classes.\n|\n```python\nprobs, classes = predict(image_path, model)\nprint(probs)\nprint(classes)\n> [ 0.01558163 0.01541934 0.01452626 0.01443549 0.01407339]\n> ['70', '3', '45', '62', '55']\n```",
"_____no_output_____"
]
],
[
[
"def predict(image_path, model, top_num=5):\n # Process image\n img = process_image(image_path)\n \n # Numpy -> Tensor\n image_tensor = torch.from_numpy(img).type(torch.FloatTensor)\n # Add batch of size 1 to image\n model_input = image_tensor.unsqueeze(0)\n \n # Probs\n probs = torch.exp(model.forward(Variable(model_input.cuda())))\n \n # Top probs\n top_probs, top_labs = probs.topk(top_num)\n top_probs, top_labs =top_probs.data, top_labs.data\n top_probs = top_probs.cpu().numpy().tolist()[0] \n top_labs = top_labs.cpu().numpy().tolist()[0]\n #print(top_labs)\n # Convert indices to classes\n '''idx_to_class = {val: key for key, val in \n model.class_to_idx.items()}\n top_labels = [idx_to_class[lab] for lab in top_labs]\n top_flowers = [cat_to_name[idx_to_class[lab]] for lab in top_labs]'''\n top_flowers = [class_names[lab] for lab in top_labs]\n return top_probs, top_flowers",
"_____no_output_____"
]
],
[
[
"## Sanity Checking\nNow I have used a trained model for predictions. Even if the testing accuracy is high, it's always good to check that there aren't obvious bugs. I have used matplotlib to plot the probabilities for the top 5 classes as a bar graph, along with the input image. \n",
"_____no_output_____"
]
],
[
[
"def plot_solution(image_path, model):\n # Set up plot\n plt.figure(figsize = (6,10))\n ax = plt.subplot(2,1,1)\n # Set up title\n flower_num = image_path.split('/')[2]\n title_ = cat_to_name[flower_num]\n # Plot flower\n img = process_image(image_path)\n imshow(img, ax, title = title_);\n # Make prediction\n probs, flowers = predict(image_path, model) \n # Plot bar chart\n plt.subplot(2,1,2)\n sns.barplot(x=probs, y=flowers, color=sns.color_palette()[0]);\n plt.show()\nimage_path = 'flowers/test/90/image_04432.jpg'\nplot_solution(image_path, model_ft)",
"/usr/local/lib/python3.6/dist-packages/seaborn/categorical.py:1428: FutureWarning: remove_na is deprecated and is a private function. Do not use.\n stat_data = remove_na(group_data)\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0facaf2b334678d870cdf119906eaf9a11ee800 | 349,554 | ipynb | Jupyter Notebook | clean/process_data.ipynb | franpog859/titanic-competition | 666b973741e23a04fbf69dc730cdd0694db3c162 | [
"Apache-2.0"
] | 1 | 2020-02-10T23:23:00.000Z | 2020-02-10T23:23:00.000Z | clean/process_data.ipynb | franpog859/titanic-competition | 666b973741e23a04fbf69dc730cdd0694db3c162 | [
"Apache-2.0"
] | 1 | 2021-08-23T20:32:47.000Z | 2021-08-23T20:32:47.000Z | clean/process_data.ipynb | franpog859/titanic-competition | 666b973741e23a04fbf69dc730cdd0694db3c162 | [
"Apache-2.0"
] | 1 | 2019-12-09T04:43:28.000Z | 2019-12-09T04:43:28.000Z | 531.237082 | 179,634 | 0.670875 | [
[
[
"# Import libraries\nimport sklearn\nfrom sklearn import model_selection\n\nimport numpy as np \nnp.random.seed(42)\n\nimport os \nimport pandas as pd\n\n%matplotlib inline\nimport matplotlib as mpl\nimport matplotlib.pyplot as plt\n\n# Ignore useless warnings (see SciPy issue #5998)\nimport warnings\nwarnings.filterwarnings(action=\"ignore\", message=\"^internal gelsd\")",
"_____no_output_____"
],
[
"# To plot figures\n%matplotlib inline\nimport matplotlib as mpl\nimport matplotlib.pyplot as plt\nmpl.rc('axes', labelsize=14)\nmpl.rc('xtick', labelsize=12)\nmpl.rc('ytick', labelsize=12)\n\n# Where to save the figures\nPROJECT_ROOT_DIR = \".\"\nIMAGES_PATH = os.path.join(PROJECT_ROOT_DIR, \"assets\")\nos.makedirs(IMAGES_PATH, exist_ok=True)\n\ndef save_fig(fig_id, tight_layout=True, fig_extension=\"png\", resolution=300):\n path = os.path.join(IMAGES_PATH, fig_id + \".\" + fig_extension)\n print(\"Saving figure\", fig_id)\n if tight_layout:\n plt.tight_layout()\n plt.savefig(path, format=fig_extension, dpi=resolution)",
"_____no_output_____"
],
[
"# Load the data\nscript_directory = os.getcwd() # Script directory\nfull_data_path = os.path.join(script_directory, 'data/')\n\nDATA_PATH = full_data_path\n\ndef load_data(data_path=DATA_PATH):\n csv_path = os.path.join(data_path, \"train.csv\")\n return pd.read_csv(csv_path)\n\ndata = load_data()",
"_____no_output_____"
]
],
[
[
"# A brief look at the data",
"_____no_output_____"
]
],
[
[
"data.shape",
"_____no_output_____"
],
[
"data.head()",
"_____no_output_____"
],
[
"data[\"Embarked\"].value_counts()",
"_____no_output_____"
],
[
"data[\"Sex\"].value_counts()",
"_____no_output_____"
],
[
"data[\"Ticket\"].value_counts()",
"_____no_output_____"
],
[
"data.describe()",
"_____no_output_____"
],
[
"data.describe(include=['O'])",
"_____no_output_____"
],
[
"data.hist(bins=50, figsize=(20,15))\nsave_fig(\"attribute_histogram_plots\")\nplt.show()",
"Saving figure attribute_histogram_plots\n"
]
],
[
[
"# Split the data into train and validation sets",
"_____no_output_____"
]
],
[
[
"# Split the data into train and validation sets before diving into analysis\ntrain_data, validation_data = model_selection.train_test_split(data, test_size=0.2, random_state=42)\nprint(\"Train data shape:\")\nprint(train_data.shape)\nprint(\"Train data columns:\")\nprint(train_data.columns)",
"Train data shape:\n(712, 12)\nTrain data columns:\nIndex(['PassengerId', 'Survived', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp',\n 'Parch', 'Ticket', 'Fare', 'Cabin', 'Embarked'],\n dtype='object')\n"
],
[
"# Save the data sets\ntrain_data.to_csv(\"data/train_data.csv\", index=False)\nvalidation_data.to_csv(\"data/validation_data.csv\", index=False)",
"_____no_output_____"
]
],
[
[
"# Reshaping data",
"_____no_output_____"
]
],
[
[
"correlation_matrix = train_data.corr()\ncorrelation_matrix[\"Survived\"].sort_values(ascending=False)",
"_____no_output_____"
],
[
"train_set = [train_data]\n#train_set.type()\nfor dataset in train_set:\n dataset['Title'] = dataset.Name.str.extract(' ([A-Za-z]+)\\.', expand=False)\n\npd.crosstab(train_data['Title'], train_data['Sex'])",
"/Users/i354518/Workspace/titanic-competition/.env/lib/python3.7/site-packages/ipykernel_launcher.py:4: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n after removing the cwd from sys.path.\n"
],
[
"for dataset in train_set:\n dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess','Capt', 'Col',\\\n \t'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')\n\n dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss')\n dataset['Title'] = dataset['Title'].replace('Ms', 'Miss')\n dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')\n \ntrain_data[['Title', 'Survived']].groupby(['Title'], as_index=False).mean()",
"/Users/i354518/Workspace/titanic-competition/.env/lib/python3.7/site-packages/ipykernel_launcher.py:3: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n This is separate from the ipykernel package so we can avoid doing imports until\n/Users/i354518/Workspace/titanic-competition/.env/lib/python3.7/site-packages/ipykernel_launcher.py:5: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n \"\"\"\n/Users/i354518/Workspace/titanic-competition/.env/lib/python3.7/site-packages/ipykernel_launcher.py:6: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n \n/Users/i354518/Workspace/titanic-competition/.env/lib/python3.7/site-packages/ipykernel_launcher.py:7: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n import sys\n"
],
[
"title_mapping = {\"Mr\": 1, \"Miss\": 2, \"Mrs\": 3, \"Master\": 4, \"Rare\": 5}\nfor dataset in train_set:\n dataset['Title'] = dataset['Title'].map(title_mapping)\n dataset['Title'] = dataset['Title'].fillna(0)\n\ntrain_data.head()",
"/Users/i354518/Workspace/titanic-competition/.env/lib/python3.7/site-packages/ipykernel_launcher.py:3: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n This is separate from the ipykernel package so we can avoid doing imports until\n/Users/i354518/Workspace/titanic-competition/.env/lib/python3.7/site-packages/ipykernel_launcher.py:4: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n after removing the cwd from sys.path.\n"
],
[
"from sklearn.base import BaseEstimator, TransformerMixin\n\nclass TitleAdder(BaseEstimator, TransformerMixin):\n def fit(self, X, y=None):\n return self\n def transform(self, X):\n X_list = [X]\n for row in X_list:\n row['Title'] = dataset.Name.str.extract(' ([A-Za-z]+)\\.', expand=False)\n\n row['Title'] = dataset['Title'].replace(['Lady', 'Countess','Capt', 'Col',\\\n \t 'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')\n row['Title'] = dataset['Title'].replace('Mlle', 'Miss')\n row['Title'] = dataset['Title'].replace('Ms', 'Miss')\n row['Title'] = dataset['Title'].replace('Mme', 'Mrs')\n \n row['Title'] = dataset['Title'].fillna(0)\n X = X.drop([\"Name\"], axis=1)\n return X",
"_____no_output_____"
],
[
"import seaborn as sns\n\ng = sns.FacetGrid(train_data, col='Survived')\ng.map(plt.hist, 'Age', bins=20)",
"_____no_output_____"
],
[
"train_data['AgeBand'] = pd.cut(train_data['Age'], bins=[0, 5, 18, 30, 38, 50, 65, 74.3, 90])\ntrain_data[['AgeBand', 'Survived']].groupby(['AgeBand'], as_index=False).mean().sort_values(by='AgeBand', ascending=True)",
"/Users/i354518/Workspace/titanic-competition/.env/lib/python3.7/site-packages/ipykernel_launcher.py:1: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n \"\"\"Entry point for launching an IPython kernel.\n"
],
[
"train_data.head(3)",
"_____no_output_____"
],
[
"train_data[\"AgeBucket\"] = train_data[\"Age\"] // 15 * 15\ntrain_data[[\"AgeBucket\", \"Survived\"]].groupby(['AgeBucket']).mean()",
"/Users/i354518/Workspace/titanic-competition/.env/lib/python3.7/site-packages/ipykernel_launcher.py:1: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n \"\"\"Entry point for launching an IPython kernel.\n"
],
[
"train_data['IsAlone'] = train_data['SibSp'] + train_data['Parch'] > 0\ntrain_data[['IsAlone', 'Survived']].groupby(['IsAlone'], as_index=False).mean()",
"/Users/i354518/Workspace/titanic-competition/.env/lib/python3.7/site-packages/ipykernel_launcher.py:1: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n \"\"\"Entry point for launching an IPython kernel.\n"
],
[
"train_data[['SibSp', 'Survived']].groupby(['SibSp'], as_index=False).mean()\n#train_data[['Parch', 'Survived']].groupby(['Parch'], as_index=False).mean()",
"_____no_output_____"
],
[
"import seaborn as sns\n\ng = sns.FacetGrid(train_data, col='Survived')\ng.map(plt.hist, 'Fare', bins=20)",
"_____no_output_____"
],
[
"train_data['FareBand'] = pd.qcut(train_data['Fare'], 4)\ntrain_data[['FareBand', 'Survived']].groupby(['FareBand'], as_index=False).mean().sort_values(by='FareBand', ascending=True)",
"/Users/i354518/Workspace/titanic-competition/.env/lib/python3.7/site-packages/ipykernel_launcher.py:1: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n \"\"\"Entry point for launching an IPython kernel.\n"
],
[
"y_train = train_data[\"Survived\"]\ny_train",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0fad3d68d48599615791dbd5e0f9eb4ac891efd | 655,232 | ipynb | Jupyter Notebook | WorkHabits.ipynb | jakevdp/ProntoData | c60d56e9f8096d62be0d3e9b3d0502f1f39f3272 | [
"BSD-2-Clause"
] | 28 | 2015-10-30T12:36:25.000Z | 2021-08-29T05:54:23.000Z | jupyter_notebooks/data_analysis_projects/ProntoData/WorkHabits.ipynb | manual123/Nacho-Jupyter-Notebooks | e75523434b1a90313a6b44e32b056f63de8a7135 | [
"MIT"
] | null | null | null | jupyter_notebooks/data_analysis_projects/ProntoData/WorkHabits.ipynb | manual123/Nacho-Jupyter-Notebooks | e75523434b1a90313a6b44e32b056f63de8a7135 | [
"MIT"
] | 16 | 2015-11-18T10:43:02.000Z | 2021-08-29T05:54:24.000Z | 815.980075 | 302,704 | 0.934113 | [
[
[
"%matplotlib inline\nimport matplotlib.pyplot as plt\nimport pandas as pd\nimport numpy as np\nimport seaborn as sns; sns.set()",
"_____no_output_____"
],
[
"trips = pd.read_csv('2015_trip_data.csv',\n parse_dates=['starttime', 'stoptime'],\n infer_datetime_format=True)",
"_____no_output_____"
],
[
"ind = pd.DatetimeIndex(trips.starttime)\ntrips['date'] = ind.date.astype('datetime64')\ntrips['hour'] = ind.hour",
"_____no_output_____"
],
[
"hourly = trips.pivot_table('trip_id', aggfunc='count',\n index=['usertype', 'date'], columns='hour').fillna(0)\nhourly.head()",
"_____no_output_____"
]
],
[
[
"## Principal Component Analysis",
"_____no_output_____"
]
],
[
[
"from sklearn.decomposition import PCA\ndata = hourly[np.arange(24)].values\ndata_pca = PCA(2).fit_transform(data)\nhourly['projection1'], hourly['projection2'] = data_pca.T",
"_____no_output_____"
],
[
"hourly['total rides'] = hourly.sum(axis=1)",
"_____no_output_____"
],
[
"hourly.plot('projection1', 'projection2', kind='scatter', c='total rides', cmap='Blues_r');\n\nplt.savefig('figs/pca_raw.png', bbox_inches='tight')",
"/Users/jakevdp/anaconda/envs/python3.4/lib/python3.4/site-packages/matplotlib/collections.py:590: FutureWarning: elementwise comparison failed; returning scalar instead, but in the future will perform elementwise comparison\n if self._edgecolors == str('face'):\n"
]
],
[
[
"## Automated Clustering",
"_____no_output_____"
]
],
[
[
"from sklearn.mixture import GMM\ngmm = GMM(3, covariance_type='full', random_state=2)\ndata = hourly[['projection1', 'projection2']]\ngmm.fit(data)\n\n# require high-probability cluster membership\nhourly['cluster'] = (gmm.predict_proba(data)[:, 0] > 0.6).astype(int)",
"_____no_output_____"
],
[
"from datetime import time\nfig, ax = plt.subplots(1, 2, figsize=(16, 6))\nfig.subplots_adjust(wspace=0.1)\ntimes = pd.date_range('0:00', '23:59', freq='H').time\ntimes = np.hstack([times, time(23, 59, 59)])\n\nhourly.plot('projection1', 'projection2', c='cluster', kind='scatter', \n cmap='rainbow', colorbar=False, ax=ax[0]);\n\nfor i in range(2):\n vals = hourly.query(\"cluster == \" + str(i))[np.arange(24)]\n vals[24] = vals[0]\n ax[1].plot(times, vals.T, color=plt.cm.rainbow(255 * i), alpha=0.05, lw=0.5)\n ax[1].plot(times, vals.mean(0), color=plt.cm.rainbow(255 * i), lw=3)\n ax[1].set_xticks(4 * 60 * 60 * np.arange(6))\n \nax[1].set_ylim(0, 60);\nax[1].set_ylabel('Rides per hour');\n\nfig.savefig('figs/pca_clustering.png', bbox_inches='tight')",
"/Users/jakevdp/anaconda/envs/python3.4/lib/python3.4/site-packages/matplotlib/collections.py:590: FutureWarning: elementwise comparison failed; returning scalar instead, but in the future will perform elementwise comparison\n if self._edgecolors == str('face'):\n"
],
[
"fig, ax = plt.subplots(1, 2, figsize=(16, 6), sharex=True, sharey=True)\nfig.subplots_adjust(wspace=0.05)\n\nfor i, col in enumerate(['Annual Member', 'Short-Term Pass Holder']):\n hourly.loc[col].plot('projection1', 'projection2', c='cluster', kind='scatter', \n cmap='rainbow', colorbar=False, ax=ax[i]);\n ax[i].set_title(col + 's')\n \nfig.savefig('figs/pca_annual_vs_shortterm.png', bbox_inches='tight')",
"/Users/jakevdp/anaconda/envs/python3.4/lib/python3.4/site-packages/matplotlib/collections.py:590: FutureWarning: elementwise comparison failed; returning scalar instead, but in the future will perform elementwise comparison\n if self._edgecolors == str('face'):\n"
],
[
"usertype = hourly.index.get_level_values('usertype')\nweekday = hourly.index.get_level_values('date').dayofweek < 5\nhourly['commute'] = (weekday & (usertype == \"Annual Member\"))\n\nfig, ax = plt.subplots()\n\nhourly.plot('projection1', 'projection2', c='commute', kind='scatter', \n cmap='binary', colorbar=False, ax=ax);\n\nax.set_title(\"Annual Member Weekdays vs Other\")\n\nfig.savefig('figs/pca_true_weekends.png', bbox_inches='tight')",
"/Users/jakevdp/anaconda/envs/python3.4/lib/python3.4/site-packages/matplotlib/collections.py:590: FutureWarning: elementwise comparison failed; returning scalar instead, but in the future will perform elementwise comparison\n if self._edgecolors == str('face'):\n"
]
],
[
[
"## Identifying Mismatches",
"_____no_output_____"
]
],
[
[
"mismatch = hourly.query('cluster == 0 & commute')\nmismatch = mismatch.reset_index('usertype')[['usertype', 'projection1', 'projection2']]\nmismatch",
"_____no_output_____"
],
[
"from pandas.tseries.holiday import USFederalHolidayCalendar\ncal = USFederalHolidayCalendar()\nholidays = cal.holidays('2014-08', '2015-10', return_name=True)\nholidays_all = pd.concat([holidays,\n \"2 Days Before \" + holidays.shift(-2, 'D'),\n \"Day Before \" + holidays.shift(-1, 'D'),\n \"Day After \" + holidays.shift(1, 'D')])\nholidays_all = holidays_all.sort_index()\nholidays_all.head()",
"_____no_output_____"
],
[
"holidays_all.name = 'holiday name' # required for join\njoined = mismatch.join(holidays_all)\njoined['holiday name']",
"_____no_output_____"
],
[
"set(holidays) - set(joined['holiday name'])",
"_____no_output_____"
],
[
"fig, ax = plt.subplots()\n\nhourly.plot('projection1', 'projection2', c='cluster', kind='scatter', \n cmap='binary', colorbar=False, ax=ax);\n\nax.set_title(\"Holidays in Projected Results\")\n\nfor i, ind in enumerate(joined.sort_values('projection1').index):\n x, y = hourly.loc['Annual Member', ind][['projection1', 'projection2']]\n if i % 2:\n ytext = 20 + 3 * i\n else:\n ytext = -8 - 4 * i\n ax.annotate(joined.loc[ind, 'holiday name'], [x, y], [x , ytext], color='black',\n ha='center', arrowprops=dict(arrowstyle='-', color='black'))\n ax.scatter([x], [y], c='red')\n \nfor holiday in (set(holidays) - set(joined['holiday name'])):\n ind = holidays[holidays == holiday].index[0]\n #ind = ind.strftime('%Y-%m-%d')\n x, y = hourly.loc['Annual Member', ind][['projection1', 'projection2']]\n ax.annotate(holidays.loc[ind], [x, y], [x + 20, y + 30], color='black',\n ha='center', arrowprops=dict(arrowstyle='-', color='black'))\n ax.scatter([x], [y], c='#00FF00')\n\nax.set_xlim([-60, 60])\nax.set_ylim([-60, 60])\n\nfig.savefig('figs/pca_holiday_labels.png', bbox_inches='tight')",
"/Users/jakevdp/anaconda/envs/python3.4/lib/python3.4/site-packages/matplotlib/collections.py:590: FutureWarning: elementwise comparison failed; returning scalar instead, but in the future will perform elementwise comparison\n if self._edgecolors == str('face'):\n"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
d0fade24e245c44443efdd6e1643115af32b5646 | 3,867 | ipynb | Jupyter Notebook | t81_558_class_13_03_web.ipynb | machevres6/t81_558_deep_learning | 08c5e84a518d2f017cb5aab5c6d7bb84559a4738 | [
"Apache-2.0"
] | 2 | 2020-06-21T19:09:53.000Z | 2020-10-03T18:45:03.000Z | t81_558_class_13_03_web.ipynb | shantanusl15150/t81_558_deep_learning | 08c5e84a518d2f017cb5aab5c6d7bb84559a4738 | [
"Apache-2.0"
] | null | null | null | t81_558_class_13_03_web.ipynb | shantanusl15150/t81_558_deep_learning | 08c5e84a518d2f017cb5aab5c6d7bb84559a4738 | [
"Apache-2.0"
] | null | null | null | 48.3375 | 537 | 0.667701 | [
[
[
"# T81-558: Applications of Deep Neural Networks\n**Module 13: Advanced/Other Topics**\n* Instructor: [Jeff Heaton](https://sites.wustl.edu/jeffheaton/), McKelvey School of Engineering, [Washington University in St. Louis](https://engineering.wustl.edu/Programs/Pages/default.aspx)\n* For more information visit the [class website](https://sites.wustl.edu/jeffheaton/t81-558/).",
"_____no_output_____"
],
[
"# Module 13 Video Material\n\n* Part 13.1: Flask and Deep Learning Web Services [[Video]](https://www.youtube.com/watch?v=H73m9XvKHug&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_13_01_flask.ipynb)\n* Part 13.2: Deploying a Model to AWS [[Video]](https://www.youtube.com/watch?v=8ygCyvRZ074&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_13_02_cloud.ipynb)\n* **Part 13.3: Using a Keras Deep Neural Network with a Web Application** [[Video]](https://www.youtube.com/watch?v=OBbw0e-UroI&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_13_03_web.ipynb)\n* Part 13.4: When to Retrain Your Neural Network [[Video]](https://www.youtube.com/watch?v=K2Tjdx_1v9g&list=PLjy4p-07OYzulelvJ5KVaT2pDlxivl_BN) [[Notebook]](t81_558_class_13_04_retrain.ipynb)\n* Part 13.5: AI at the Edge: Using Keras on a Mobile Device [[Video]]() [[Notebook]](t81_558_class_13_05_edge.ipynb)\n",
"_____no_output_____"
],
[
"# Part 13.3: Using a Keras Deep Neural Network with a Web Application\n\nIn this module we will extend the image API developed in Part 13.1 to work with a web application. This allows you to use a simple website to upload/predict images, such as Figure 13.WEB.\n\n**Figure 13.WEB: AI Web Application**\n\n\nTo do this, we will use the same API developed in Module 13.1. However, we will now add a [ReactJS](https://reactjs.org/) website around it. This is a single page web application that allows you to upload images for classification by the neural network. If you would like to read more about ReactJS and image uploading, you can refer to the [blog post](http://www.hartzis.me/react-image-upload/) that I borrowed some of the code from. I added neural network functionality to a simple ReactJS image upload and preview example.\n\nThis example is built from the following components:\n\n* [GitHub Location for Web App](./py/)\n* [image_web_server_1.py](./py/image_web_server_1.py) - The code both to start Flask, as well as serve the HTML/JavaScript/CSS needed to provide the web interface.\n* Directory WWW - Contains web assets. \n * [index.html](./py/www/index.html) - The main page for the web application.\n * [style.css](./py/www/style.css) - The stylesheet for the web application.\n * [script.js](./py/www/script.js) - The JavaScript code for the web application.",
"_____no_output_____"
]
]
] | [
"markdown"
] | [
[
"markdown",
"markdown",
"markdown"
]
] |
d0fae100f724121698d1af1a94e3b36e833958ea | 692,618 | ipynb | Jupyter Notebook | Assignmet_4/CS7641_Assignment4_MDP_1.ipynb | stjordanis/CS7641 | a07ab275e9f6a43add196efc12879448ba947db5 | [
"Apache-2.0"
] | 1 | 2022-02-12T08:01:59.000Z | 2022-02-12T08:01:59.000Z | Assignmet_4/CS7641_Assignment4_MDP_1.ipynb | stjordanis/CS7641 | a07ab275e9f6a43add196efc12879448ba947db5 | [
"Apache-2.0"
] | null | null | null | Assignmet_4/CS7641_Assignment4_MDP_1.ipynb | stjordanis/CS7641 | a07ab275e9f6a43add196efc12879448ba947db5 | [
"Apache-2.0"
] | 2 | 2020-06-05T08:17:49.000Z | 2021-04-11T05:14:34.000Z | 406.227566 | 47,496 | 0.931883 | [
[
[
"%%html\n<style>\nbody {\n font-family: \"Cambria\", cursive, sans-serif;\n}\n</style> ",
"_____no_output_____"
],
[
"import random, time\nimport numpy as np\nfrom collections import defaultdict\nimport operator\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"## Misc functions and utilities",
"_____no_output_____"
]
],
[
[
"orientations = EAST, NORTH, WEST, SOUTH = [(1, 0), (0, 1), (-1, 0), (0, -1)]\nturns = LEFT, RIGHT = (+1, -1)",
"_____no_output_____"
],
[
"def vector_add(a, b):\n \"\"\"Component-wise addition of two vectors.\"\"\"\n return tuple(map(operator.add, a, b))",
"_____no_output_____"
],
[
"def turn_heading(heading, inc, headings=orientations):\n return headings[(headings.index(heading) + inc) % len(headings)]\n\n\ndef turn_right(heading):\n return turn_heading(heading, RIGHT)\n\ndef turn_left(heading):\n return turn_heading(heading, LEFT)\n\ndef distance(a, b):\n \"\"\"The distance between two (x, y) points.\"\"\"\n xA, yA = a\n xB, yB = b\n return math.hypot((xA - xB), (yA - yB))",
"_____no_output_____"
],
[
"def isnumber(x):\n \"\"\"Is x a number?\"\"\"\n return hasattr(x, '__int__')",
"_____no_output_____"
]
],
[
[
"## Class definitions",
"_____no_output_____"
],
[
"### Base `MDP` class",
"_____no_output_____"
]
],
[
[
"class MDP:\n \"\"\"A Markov Decision Process, defined by an initial state, transition model,\n and reward function. We also keep track of a gamma value, for use by\n algorithms. The transition model is represented somewhat differently from\n the text. Instead of P(s' | s, a) being a probability number for each\n state/state/action triplet, we instead have T(s, a) return a\n list of (p, s') pairs. We also keep track of the possible states,\n terminal states, and actions for each state.\"\"\"\n\n def __init__(self, init, actlist, terminals, transitions = {}, reward = None, states=None, gamma=.9):\n if not (0 < gamma <= 1):\n raise ValueError(\"An MDP must have 0 < gamma <= 1\")\n\n if states:\n self.states = states\n else:\n ## collect states from transitions table\n self.states = self.get_states_from_transitions(transitions)\n \n \n self.init = init\n \n if isinstance(actlist, list):\n ## if actlist is a list, all states have the same actions\n self.actlist = actlist\n elif isinstance(actlist, dict):\n ## if actlist is a dict, different actions for each state\n self.actlist = actlist\n \n self.terminals = terminals\n self.transitions = transitions\n #if self.transitions == {}:\n #print(\"Warning: Transition table is empty.\")\n self.gamma = gamma\n if reward:\n self.reward = reward\n else:\n self.reward = {s : 0 for s in self.states}\n #self.check_consistency()\n\n def R(self, state):\n \"\"\"Return a numeric reward for this state.\"\"\"\n return self.reward[state]\n\n def T(self, state, action):\n \"\"\"Transition model. From a state and an action, return a list\n of (probability, result-state) pairs.\"\"\"\n if(self.transitions == {}):\n raise ValueError(\"Transition model is missing\")\n else:\n return self.transitions[state][action]\n\n def actions(self, state):\n \"\"\"Set of actions that can be performed in this state. By default, a\n fixed list of actions, except for terminal states. Override this\n method if you need to specialize by state.\"\"\"\n if state in self.terminals:\n return [None]\n else:\n return self.actlist\n\n def get_states_from_transitions(self, transitions):\n if isinstance(transitions, dict):\n s1 = set(transitions.keys())\n s2 = set([tr[1] for actions in transitions.values() \n for effects in actions.values() for tr in effects])\n return s1.union(s2)\n else:\n print('Could not retrieve states from transitions')\n return None\n\n def check_consistency(self):\n # check that all states in transitions are valid\n assert set(self.states) == self.get_states_from_transitions(self.transitions)\n # check that init is a valid state\n assert self.init in self.states\n # check reward for each state\n #assert set(self.reward.keys()) == set(self.states)\n assert set(self.reward.keys()) == set(self.states)\n # check that all terminals are valid states\n assert all([t in self.states for t in self.terminals])\n # check that probability distributions for all actions sum to 1\n for s1, actions in self.transitions.items():\n for a in actions.keys():\n s = 0\n for o in actions[a]:\n s += o[0]\n assert abs(s - 1) < 0.001",
"_____no_output_____"
]
],
[
[
"### A custom MDP class to extend functionality\nWe will write a CustomMDP class to extend the MDP class for the problem at hand. <br>This class will implement the `T` method to implement the transition model.",
"_____no_output_____"
]
],
[
[
"class CustomMDP(MDP):\n\n def __init__(self, transition_matrix, rewards, terminals, init, gamma=.9):\n # All possible actions.\n actlist = []\n for state in transition_matrix.keys():\n actlist.extend(transition_matrix[state])\n actlist = list(set(actlist))\n #print(actlist)\n\n MDP.__init__(self, init, actlist, terminals=terminals, gamma=gamma)\n self.t = transition_matrix\n self.reward = rewards\n for state in self.t:\n self.states.add(state)\n\n def T(self, state, action):\n if action is None:\n return [(0.0, state)]\n else: \n return [(prob, new_state) for new_state, prob in self.t[state][action].items()]",
"_____no_output_____"
]
],
[
[
"## Problem 1: Simple MDP\n\n---\n### State dependent reward function\nMarkov Decision Processes are formally described as processes that follow the Markov property which states that \"The future is independent of the past given the present\". MDPs formally describe environments for reinforcement learning and we assume that the environment is fully observable.\n\nLet us take a toy example MDP and solve it using value iteration and policy iteration. This is a simple example adapted from a similar problem by Dr. David Silver, tweaked to fit the limitations of the current functions.\n\nLet's say you're a student attending lectures in a university. There are three lectures you need to attend on a given day. Attending the first lecture gives you 4 points of reward. After the first lecture, you have a 0.6 probability to continue into the second one, yielding 6 more points of reward. But, with a probability of 0.4, you get distracted and start using Facebook instead and get a reward of -1. From then onwards, you really can't let go of Facebook and there's just a 0.1 probability that you will concentrate back on the lecture.\n\nAfter the second lecture, you have an equal chance of attending the next lecture or just falling asleep. Falling asleep is the terminal state and yields you no reward, but continuing on to the final lecture gives you a big reward of 10 points. From there on, you have a 40% chance of going to study and reach the terminal state, but a 60% chance of going to the pub with your friends instead. You end up drunk and don't know which lecture to attend, so you go to one of the lectures according to the probabilities given above.\n\n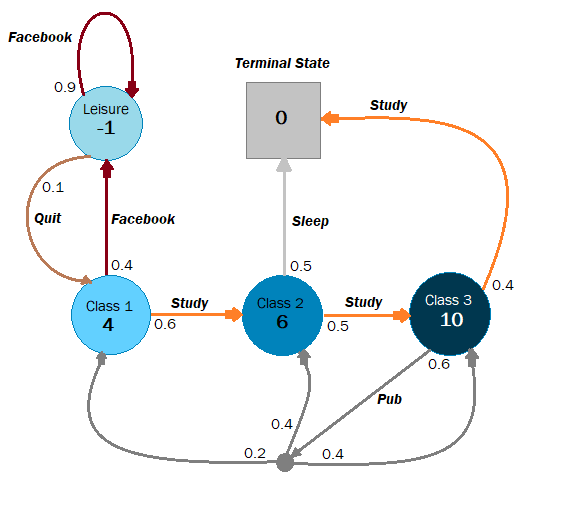",
"_____no_output_____"
],
[
"### Definition of transition matrix\nWe first have to define our Transition Matrix as a nested dictionary to fit the requirements of the MDP class.",
"_____no_output_____"
]
],
[
[
"t = {\n 'leisure': {\n 'facebook': {'leisure':0.9, 'class1':0.1},\n 'quit': {'leisure':0.1, 'class1':0.9},\n 'study': {},\n 'sleep': {},\n 'pub': {}\n },\n 'class1': {\n 'study': {'class2':0.6, 'leisure':0.4},\n 'facebook': {'class2':0.4, 'leisure':0.6},\n 'quit': {},\n 'sleep': {},\n 'pub': {}\n },\n 'class2': {\n 'study': {'class3':0.5, 'end':0.5},\n 'sleep': {'end':0.5, 'class3':0.5},\n 'facebook': {},\n 'quit': {},\n 'pub': {},\n },\n 'class3': {\n 'study': {'end':0.6, 'class1':0.08, 'class2':0.16, 'class3':0.16},\n 'pub': {'end':0.4, 'class1':0.12, 'class2':0.24, 'class3':0.24},\n 'facebook': {},\n 'quit': {},\n 'sleep': {}\n },\n 'end': {}\n}",
"_____no_output_____"
]
],
[
[
"### Defining rewards\nWe now need to define the reward for each state.",
"_____no_output_____"
]
],
[
[
"rewards = {\n 'class1': 4,\n 'class2': 6,\n 'class3': 10,\n 'leisure': -1,\n 'end': 0\n}",
"_____no_output_____"
]
],
[
[
"### Terminal state\nThis MDP has only one terminal state",
"_____no_output_____"
]
],
[
[
"terminals = ['end']",
"_____no_output_____"
]
],
[
[
"### Setting initial state to `Class 1`",
"_____no_output_____"
]
],
[
[
"init = 'class1'",
"_____no_output_____"
]
],
[
[
"### Read in an instance of the custom class",
"_____no_output_____"
]
],
[
[
"school_mdp = CustomMDP(t, rewards, terminals, init, gamma=.95)",
"_____no_output_____"
]
],
[
[
"### Let's see the actions and rewards of the MDP",
"_____no_output_____"
]
],
[
[
"school_mdp.states",
"_____no_output_____"
],
[
"school_mdp.actions('class1')",
"_____no_output_____"
],
[
"school_mdp.actions('leisure')",
"_____no_output_____"
],
[
"school_mdp.T('class1','sleep')",
"_____no_output_____"
],
[
"school_mdp.actions('end')",
"_____no_output_____"
],
[
"school_mdp.reward",
"_____no_output_____"
]
],
[
[
"## Value iteration",
"_____no_output_____"
]
],
[
[
"def value_iteration(mdp, epsilon=0.001):\n \"\"\"Solving an MDP by value iteration.\n mdp: The MDP object\n epsilon: Stopping criteria\n \"\"\"\n U1 = {s: 0 for s in mdp.states}\n R, T, gamma = mdp.R, mdp.T, mdp.gamma\n while True:\n U = U1.copy()\n delta = 0\n for s in mdp.states:\n U1[s] = R(s) + gamma * max([sum([p * U[s1] for (p, s1) in T(s, a)])\n for a in mdp.actions(s)])\n delta = max(delta, abs(U1[s] - U[s]))\n if delta < epsilon * (1 - gamma) / gamma:\n return U",
"_____no_output_____"
],
[
"def value_iteration_over_time(mdp, iterations=20):\n U_over_time = []\n U1 = {s: 0 for s in mdp.states}\n R, T, gamma = mdp.R, mdp.T, mdp.gamma\n for _ in range(iterations):\n U = U1.copy()\n for s in mdp.states:\n U1[s] = R(s) + gamma * max([sum([p * U[s1] for (p, s1) in T(s, a)])\n for a in mdp.actions(s)])\n U_over_time.append(U)\n return U_over_time",
"_____no_output_____"
],
[
"def best_policy(mdp, U):\n \"\"\"Given an MDP and a utility function U, determine the best policy,\n as a mapping from state to action.\"\"\"\n\n pi = {}\n for s in mdp.states:\n pi[s] = max(mdp.actions(s), key=lambda a: expected_utility(a, s, U, mdp))\n return pi",
"_____no_output_____"
]
],
[
[
"## Value iteration on the school MDP",
"_____no_output_____"
]
],
[
[
"value_iteration(school_mdp)",
"_____no_output_____"
],
[
"value_iteration_over_time(school_mdp,iterations=10)",
"_____no_output_____"
]
],
[
[
"### Plotting value updates over time/iterations",
"_____no_output_____"
]
],
[
[
"def plot_value_update(mdp,iterations=10,plot_kw=None):\n \"\"\"\n Plot value updates over iterations for a given MDP.\n \"\"\"\n x = value_iteration_over_time(mdp,iterations=iterations)\n value_states = {k:[] for k in mdp.states}\n for i in x:\n for k,v in i.items():\n value_states[k].append(v)\n \n plt.figure(figsize=(8,5))\n plt.title(\"Evolution of state utilities over iteration\", fontsize=18)\n for v in value_states:\n plt.plot(value_states[v])\n plt.legend(list(value_states.keys()),fontsize=14)\n plt.grid(True)\n plt.xlabel(\"Iterations\",fontsize=16)\n plt.ylabel(\"Utilities of states\",fontsize=16)\n plt.show()",
"_____no_output_____"
],
[
"plot_value_update(school_mdp,15)",
"_____no_output_____"
]
],
[
[
"### Value iterations for various discount factors ($\\gamma$)",
"_____no_output_____"
]
],
[
[
"for i in range(4):\n mdp = CustomMDP(t, rewards, terminals, init, gamma=1-0.2*i)\n plot_value_update(mdp,10)",
"_____no_output_____"
]
],
[
[
"### Value iteration for two different reward structures",
"_____no_output_____"
]
],
[
[
"rewards1 = {\n 'class1': 4,\n 'class2': 6,\n 'class3': 10,\n 'leisure': -1,\n 'end': 0\n}\n\nmdp1 = CustomMDP(t, rewards1, terminals, init, gamma=.95)\nplot_value_update(mdp1,20)\n\nrewards2 = {\n 'class1': 1,\n 'class2': 1.5,\n 'class3': 2.5,\n 'leisure': -4,\n 'end': 0\n}\n\nmdp2 = CustomMDP(t, rewards2, terminals, init, gamma=.95)\nplot_value_update(mdp2,20)",
"_____no_output_____"
],
[
"value_iteration(mdp2)",
"_____no_output_____"
]
],
[
[
"## Policy iteration",
"_____no_output_____"
]
],
[
[
"def expected_utility(a, s, U, mdp):\n \"\"\"The expected utility of doing a in state s, according to the MDP and U.\"\"\"\n return sum([p * U[s1] for (p, s1) in mdp.T(s, a)])",
"_____no_output_____"
],
[
"def policy_evaluation(pi, U, mdp, k=20):\n \"\"\"Returns an updated utility mapping U from each state in the MDP to its\n utility, using an approximation (modified policy iteration).\"\"\"\n \n R, T, gamma = mdp.R, mdp.T, mdp.gamma\n for i in range(k):\n for s in mdp.states:\n U[s] = R(s) + gamma * sum([p * U[s1] for (p, s1) in T(s, pi[s])])\n return U",
"_____no_output_____"
],
[
"def policy_iteration(mdp,verbose=0):\n \"\"\"Solves an MDP by policy iteration\"\"\"\n \n U = {s: 0 for s in mdp.states}\n pi = {s: random.choice(mdp.actions(s)) for s in mdp.states}\n if verbose:\n print(\"Initial random choice:\",pi)\n iter_count=0\n while True:\n iter_count+=1\n U = policy_evaluation(pi, U, mdp)\n unchanged = True\n for s in mdp.states:\n a = max(mdp.actions(s), key=lambda a: expected_utility(a, s, U, mdp))\n if a != pi[s]:\n pi[s] = a\n unchanged = False\n if unchanged:\n return (pi,iter_count)\n if verbose:\n print(\"Policy after iteration {}: {}\".format(iter_count,pi))",
"_____no_output_____"
]
],
[
[
"## Policy iteration over the school MDP",
"_____no_output_____"
]
],
[
[
"policy_iteration(school_mdp)",
"_____no_output_____"
],
[
"policy_iteration(school_mdp,verbose=1)",
"Initial random choice: {'leisure': 'study', 'class2': 'sleep', 'class3': 'facebook', 'class1': 'pub', 'end': None}\nPolicy after iteration 1: {'leisure': 'quit', 'class2': 'study', 'class3': 'pub', 'class1': 'study', 'end': None}\nPolicy after iteration 2: {'leisure': 'quit', 'class2': 'study', 'class3': 'pub', 'class1': 'facebook', 'end': None}\n"
]
],
[
[
"### Does the result match using value iteration? We use the `best_policy` function to find out",
"_____no_output_____"
]
],
[
[
"best_policy(school_mdp,value_iteration(school_mdp,0.01))",
"_____no_output_____"
]
],
[
[
"## Comparing computation efficiency (time) of value and policy iterations\nClearly values iteration method takes more iterations to reach the same steady-state compared to policy iteration technique. But how does their computation time compare? Let's find out.",
"_____no_output_____"
],
[
"### Running value and policy iteration on the school MDP many times and averaging",
"_____no_output_____"
]
],
[
[
"def compute_time(mdp,iteration_technique='value',n_run=1000,epsilon=0.01):\n \"\"\"\n Computes the average time for value or policy iteration for a given MDP\n n_run: Number of runs to average over, default 1000\n epsilon: Error margin for the value iteration\n \"\"\"\n if iteration_technique=='value':\n t1 = time.time()\n for _ in range(n_run):\n value_iteration(mdp,epsilon=epsilon)\n t2 = time.time()\n print(\"Average value iteration took {} milliseconds\".format((t2-t1)*1000/n_run))\n else:\n t1 = time.time()\n for _ in range(n_run):\n policy_iteration(mdp)\n t2 = time.time()\n\n print(\"Average policy iteration took {} milliseconds\".format((t2-t1)*1000/n_run))",
"_____no_output_____"
],
[
"compute_time(school_mdp,'value')",
"Average value iteration took 1.551398515701294 milliseconds\n"
],
[
"compute_time(school_mdp,'policy')",
"Average policy iteration took 0.7556800842285156 milliseconds\n"
]
],
[
[
"## Q-learning",
"_____no_output_____"
],
[
"### Q-learning class",
"_____no_output_____"
]
],
[
[
"class QLearningAgent:\n \"\"\" An exploratory Q-learning agent. It avoids having to learn the transition\n model because the Q-value of a state can be related directly to those of\n its neighbors.\n \"\"\"\n def __init__(self, mdp, Ne, Rplus, alpha=None):\n\n self.gamma = mdp.gamma\n self.terminals = mdp.terminals\n self.all_act = mdp.actlist\n self.Ne = Ne # iteration limit in exploration function\n self.Rplus = Rplus # large value to assign before iteration limit\n self.Q = defaultdict(float)\n self.Nsa = defaultdict(float)\n self.s = None\n self.a = None\n self.r = None\n self.states = mdp.states\n self.T = mdp.T\n\n if alpha:\n self.alpha = alpha\n else:\n self.alpha = lambda n: 1./(1+n)\n\n def f(self, u, n):\n \"\"\" Exploration function. Returns fixed Rplus until\n agent has visited state, action a Ne number of times.\"\"\"\n if n < self.Ne:\n return self.Rplus\n else:\n return u\n\n def actions_in_state(self, state):\n \"\"\" Return actions possible in given state.\n Useful for max and argmax. \"\"\"\n if state in self.terminals:\n return [None]\n else:\n act_list=[]\n for a in self.all_act:\n if len(self.T(state,a))>0:\n act_list.append(a)\n return act_list\n\n def __call__(self, percept):\n s1, r1 = self.update_state(percept)\n Q, Nsa, s, a, r = self.Q, self.Nsa, self.s, self.a, self.r\n alpha, gamma, terminals = self.alpha, self.gamma, self.terminals,\n actions_in_state = self.actions_in_state\n\n if s in terminals:\n Q[s, None] = r1\n if s is not None:\n Nsa[s, a] += 1\n Q[s, a] += alpha(Nsa[s, a]) * (r + gamma * max(Q[s1, a1]\n for a1 in actions_in_state(s1)) - Q[s, a])\n if s in terminals:\n self.s = self.a = self.r = None\n else:\n self.s, self.r = s1, r1\n self.a = max(actions_in_state(s1), key=lambda a1: self.f(Q[s1, a1], Nsa[s1, a1]))\n return self.a\n\n def update_state(self, percept):\n \"\"\"To be overridden in most cases. The default case\n assumes the percept to be of type (state, reward).\"\"\"\n return percept",
"_____no_output_____"
]
],
[
[
"### Trial run",
"_____no_output_____"
]
],
[
[
"def run_single_trial(agent_program, mdp):\n \"\"\"Execute trial for given agent_program\n and mdp.\"\"\"\n\n def take_single_action(mdp, s, a):\n \"\"\"\n Select outcome of taking action a\n in state s. Weighted Sampling.\n \"\"\"\n x = random.uniform(0, 1)\n cumulative_probability = 0.0\n for probability_state in mdp.T(s, a):\n probability, state = probability_state\n cumulative_probability += probability\n if x < cumulative_probability:\n break\n return state\n\n current_state = mdp.init\n while True:\n current_reward = mdp.R(current_state)\n percept = (current_state, current_reward)\n next_action = agent_program(percept)\n if next_action is None:\n break\n current_state = take_single_action(mdp, current_state, next_action)",
"_____no_output_____"
]
],
[
[
"### Testing Q-learning",
"_____no_output_____"
]
],
[
[
"# Define an agent\nq_agent = QLearningAgent(school_mdp, Ne=1000, Rplus=2,alpha=lambda n: 60./(59+n))",
"_____no_output_____"
],
[
"q_agent.actions_in_state('leisure')",
"_____no_output_____"
],
[
"run_single_trial(q_agent,school_mdp)",
"_____no_output_____"
],
[
"q_agent.Q",
"_____no_output_____"
],
[
"for i in range(200):\n run_single_trial(q_agent,school_mdp)",
"_____no_output_____"
],
[
"q_agent.Q",
"_____no_output_____"
],
[
"def get_U_from_Q(q_agent):\n U = defaultdict(lambda: -100.) # Large negative value for comparison\n for state_action, value in q_agent.Q.items():\n state, action = state_action\n if U[state] < value:\n U[state] = value\n return U",
"_____no_output_____"
],
[
"get_U_from_Q(q_agent)",
"_____no_output_____"
],
[
"q_agent = QLearningAgent(school_mdp, Ne=100, Rplus=25,alpha=lambda n: 10/(9+n))\nqhistory=[]\nfor i in range(100000):\n run_single_trial(q_agent,school_mdp)\n U=get_U_from_Q(q_agent)\n qhistory.append(U)\nprint(get_U_from_Q(q_agent))",
"defaultdict(<function get_U_from_Q.<locals>.<lambda> at 0x00000255290A4F28>, {'class1': 23.240828242090135, 'class2': 19.233409838752596, 'end': 4.003615106646801, 'class3': 24.108995803027188, 'leisure': 20.878772382041472})\n"
],
[
"print(value_iteration(school_mdp,epsilon=0.001))",
"{'leisure': 18.079639654154484, 'class2': 15.792664558035112, 'class3': 20.61614864677164, 'class1': 20.306571436730533, 'end': 0.0}\n"
]
],
[
[
"### Function for utility estimate by Q-learning by many iterations",
"_____no_output_____"
]
],
[
[
"def qlearning_iter(agent_program,mdp,iterations=1000,print_final_utility=True):\n \"\"\"\n Function for utility estimate by Q-learning by many iterations\n Returns a history object i.e. a list of dictionaries, where utility estimate for each iteration is stored\n \n q_agent = QLearningAgent(grid_1, Ne=25, Rplus=1.5,\n alpha=lambda n: 10000./(9999+n))\n hist=qlearning_iter(q_agent,grid_1,iterations=10000)\n \n \"\"\"\n qhistory=[]\n \n for i in range(iterations):\n run_single_trial(agent_program,mdp)\n U=get_U_from_Q(agent_program)\n if len(U)==len(mdp.states):\n qhistory.append(U)\n \n if print_final_utility:\n print(U)\n return qhistory",
"_____no_output_____"
]
],
[
[
"### How do the long-term utility estimates with Q-learning compare with value iteration?",
"_____no_output_____"
]
],
[
[
"def plot_qlearning_vi(hist, vi,plot_n_states=None):\n \"\"\"\n Compares and plots a Q-learning and value iteration results for the utility estimate of an MDP's states\n hist: A history object from a Q-learning run\n vi: A value iteration estimate for the same MDP\n plot_n_states: Restrict the plotting for n states (randomly chosen)\n \"\"\"\n \n utilities={k:[] for k in list(vi.keys())}\n for h in hist:\n for state in h.keys():\n utilities[state].append(h[state])\n \n if plot_n_states==None:\n for state in list(vi.keys()):\n plt.figure(figsize=(7,4))\n plt.title(\"Plot of State: {} over Q-learning iterations\".format(str(state)),fontsize=16)\n plt.plot(utilities[state])\n plt.hlines(y=vi[state],xmin=0,xmax=1.1*len(hist))\n plt.legend(['Q-learning estimates','Value iteration estimate'],fontsize=14)\n plt.xlabel(\"Iterations\",fontsize=14)\n plt.ylabel(\"Utility of the state\",fontsize=14)\n plt.grid(True)\n plt.show()\n else:\n for state in list(vi.keys())[:plot_n_states]:\n plt.figure(figsize=(7,4))\n plt.title(\"Plot of State: {} over Q-learning iterations\".format(str(state)),fontsize=16)\n plt.plot(utilities[state])\n plt.hlines(y=vi[state],xmin=0,xmax=1.1*len(hist))\n plt.legend(['Q-learning estimates','Value iteration estimate'],fontsize=14)\n plt.xlabel(\"Iterations\",fontsize=14)\n plt.ylabel(\"Utility of the state\",fontsize=14)\n plt.grid(True)\n plt.show()",
"_____no_output_____"
]
],
[
[
"### Testing the long-term utility learning for the small (default) grid world",
"_____no_output_____"
]
],
[
[
"# Define the Q-learning agent\nq_agent = QLearningAgent(school_mdp, Ne=100, Rplus=2,alpha=lambda n: 100/(99+n))\n# Obtain the history by running the Q-learning for many iterations\nhist=qlearning_iter(q_agent,school_mdp,iterations=20000,print_final_utility=False)\n# Get a value iteration estimate using the same MDP\nvi = value_iteration(school_mdp,epsilon=0.001)\n# Compare the utility estimates from two methods\nplot_qlearning_vi(hist,vi)",
"_____no_output_____"
],
[
"for alpha in range(100,5100,1000):\n q_agent = QLearningAgent(school_mdp, Ne=10, Rplus=2,alpha=lambda n: alpha/(alpha-1+n))\n # Obtain the history by running the Q-learning for many iterations\n hist=qlearning_iter(q_agent,school_mdp,iterations=10000,print_final_utility=False)\n # Get a value iteration estimate using the same MDP\n vi = value_iteration(school_mdp,epsilon=0.001)\n # Compare the utility estimates from two methods\n plot_qlearning_vi(hist,vi,plot_n_states=1)",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
d0faecf6ef22bfd56babacbd3f938ecc3a0169cb | 689,494 | ipynb | Jupyter Notebook | notebooks/figure-7/Explore the effect of electroporation on pan T-cell populations.ipynb | hammerlab/t-cell-electroporation | e68c8e2cf1ccf1693b97cc378aba3de142b2885d | [
"Apache-2.0"
] | 1 | 2019-04-09T02:41:34.000Z | 2019-04-09T02:41:34.000Z | notebooks/figure-7/Explore the effect of electroporation on pan T-cell populations.ipynb | hammerlab/t-cell-electroporation | e68c8e2cf1ccf1693b97cc378aba3de142b2885d | [
"Apache-2.0"
] | 7 | 2018-11-19T20:15:15.000Z | 2019-02-05T18:33:39.000Z | notebooks/figure-7/Explore the effect of electroporation on pan T-cell populations.ipynb | hammerlab/t-cell-electroporation | e68c8e2cf1ccf1693b97cc378aba3de142b2885d | [
"Apache-2.0"
] | null | null | null | 1,033.724138 | 118,540 | 0.910774 | [
[
[
"library('magrittr')\nlibrary('dplyr')\nlibrary('tidyr')\nlibrary('readr')\nlibrary('ggplot2')",
"\nAttaching package: ‘dplyr’\n\nThe following objects are masked from ‘package:stats’:\n\n filter, lag\n\nThe following objects are masked from ‘package:base’:\n\n intersect, setdiff, setequal, union\n\n\nAttaching package: ‘tidyr’\n\nThe following object is masked from ‘package:magrittr’:\n\n extract\n\n"
],
[
"flow_data <-\n read_tsv(\n 'data.tsv',\n col_types=cols(\n `Donor`=col_factor(levels=c('Donor 25', 'Donor 34', 'Donor 35', 'Donor 40', 'Donor 41')),\n `Condition`=col_factor(levels=c('No electroporation', 'Mock electroporation', 'Plasmid electroporation')),\n `Cell state`=col_factor(levels=c('Unstimulated', 'Activated')),\n .default=col_number()\n )\n )\n\nflow_data",
"_____no_output_____"
],
[
"flow_data %>%\n filter(`Donor` != 'Donor 35') %>%\n select(\n `Donor`:`Condition`,\n `Naive: CCR7+ CD45RO-`=`Live/CD3+/CCR7+ CD45RO- | Freq. of Parent`,\n `CM: CCR7+ CD45RO+`=`Live/CD3+/CCR7+ CD45RO+ | Freq. of Parent`,\n `EM: CCR7- CD45RO+`=`Live/CD3+/CCR7- CD45RO+ | Freq. of Parent`,\n `EMRA: CCR7- CD45RO-`=`Live/CD3+/CCR7- CD45RO- | Freq. of Parent`\n ) %>%\n gather(\n key=`Population`,\n value=`Freq_of_parent`,\n `Naive: CCR7+ CD45RO-`:`EMRA: CCR7- CD45RO-`\n ) %>%\n ggplot(aes(x=`Population`, y=`Freq_of_parent`, fill=`Condition`)) +\n geom_col(position=\"dodge\") +\n theme(axis.text.x=element_text(angle=75, hjust=1)) +\n facet_wrap(~`Cell state`+`Donor`, ncol=4) +\n ylab('Percent population (%)')",
"_____no_output_____"
],
[
"flow_data %>%\n filter(`Donor` != 'Donor 35') %>%\n select(\n `Donor`:`Condition`,\n `Naive: CCR7+ CD45RO-`=`Live/CD3+/CCR7+ CD45RO- | Freq. of Parent`,\n `CM: CCR7+ CD45RO+`=`Live/CD3+/CCR7+ CD45RO+ | Freq. of Parent`,\n `EM: CCR7- CD45RO+`=`Live/CD3+/CCR7- CD45RO+ | Freq. of Parent`,\n `EMRA: CCR7- CD45RO-`=`Live/CD3+/CCR7- CD45RO- | Freq. of Parent`\n ) %>%\n gather(\n key=`Population`,\n value=`Freq_of_parent`,\n `Naive: CCR7+ CD45RO-`:`EMRA: CCR7- CD45RO-`\n ) %>%\n ggplot(aes(x=`Population`, y=`Freq_of_parent`, fill=`Condition`)) +\n geom_col(position=\"dodge\") +\n theme(axis.text.x=element_text(angle=75, hjust=1)) +\n facet_grid(`Cell state`~`Donor`) +\n ylab('Percent population (%)')",
"_____no_output_____"
],
[
"no_electro_val <- function(x) {\n x[1]\n}\n\n\nflow_data %>%\n filter(`Donor` != 'Donor 35') %>%\n select(\n `Donor`:`Condition`,\n `Naive: CCR7+ CD45RO-`=`Live/CD3+/CCR7+ CD45RO- | Freq. of Parent`,\n `CM: CCR7+ CD45RO+`=`Live/CD3+/CCR7+ CD45RO+ | Freq. of Parent`,\n `EM: CCR7- CD45RO+`=`Live/CD3+/CCR7- CD45RO+ | Freq. of Parent`,\n `EMRA: CCR7- CD45RO-`=`Live/CD3+/CCR7- CD45RO- | Freq. of Parent`\n ) %>%\n gather(\n key=`Population`,\n value=`Freq_of_parent`,\n `Naive: CCR7+ CD45RO-`:`EMRA: CCR7- CD45RO-`\n ) %>%\n arrange(`Condition`) %>%\n group_by(`Donor`, `Cell state`, `Population`) %>%\n mutate(\n `Normalized_Freq_of_parent`=`Freq_of_parent`-no_electro_val(`Freq_of_parent`)\n ) %>%\n filter(\n `Condition` == 'Plasmid electroporation'\n ) %>%\n ggplot(aes(x=`Population`, y=`Normalized_Freq_of_parent`, color=`Cell state`)) +\n geom_boxplot(alpha=.3, outlier.size=0) +\n geom_point(position=position_jitterdodge()) +\n geom_hline(yintercept=0, color=\"gray\") +\n theme(axis.text.x=element_text(angle=75, hjust=1)) +\n ylab('Percent change for plasmid electroporation\\ncompared to no electroporation (%)') +\n ylim(-25, 25)",
"_____no_output_____"
],
[
"flow_data %>%\n filter(`Donor` != 'Donor 35') %>%\n mutate(\n `Donor`:`Condition`,\n `CD3 Count`=`Count`*(`Live | Freq. of Parent`/100.0)*(`Live/CD3+ | Freq. of Parent`/100.0),\n `Naive: CCR7+ CD45RO-`=`CD3 Count`*`Live/CD3+/CCR7+ CD45RO- | Freq. of Parent`,\n `CM: CCR7+ CD45RO+`=`CD3 Count`*`Live/CD3+/CCR7+ CD45RO+ | Freq. of Parent`,\n `EM: CCR7- CD45RO+`=`CD3 Count`*`Live/CD3+/CCR7- CD45RO+ | Freq. of Parent`,\n `EMRA: CCR7- CD45RO-`=`CD3 Count`*`Live/CD3+/CCR7- CD45RO- | Freq. of Parent`\n ) %>%\n gather(\n key=`Population`,\n value=`Freq_of_parent`,\n `Naive: CCR7+ CD45RO-`:`EMRA: CCR7- CD45RO-`\n ) %>%\n ggplot(aes(x=`Population`, y=`Freq_of_parent`, fill=`Condition`)) +\n geom_col(position=\"dodge\") +\n theme_bw() +\n theme(axis.text.x=element_text(angle=75, hjust=1)) +\n facet_grid(`Cell state`~`Donor`) +\n ylab('Live cell count')",
"_____no_output_____"
],
[
"no_electro_val <- function(x) {\n x[1]\n}\n\nflow_data %>%\n filter(`Donor` != 'Donor 35') %>%\n mutate(\n `Donor`:`Condition`,\n `CD3 Count`=`Count`*(`Live | Freq. of Parent`/100.0)*(`Live/CD3+ | Freq. of Parent`/100.0),\n `Naive: CCR7+ CD45RO-`=`CD3 Count`*`Live/CD3+/CCR7+ CD45RO- | Freq. of Parent`,\n `CM: CCR7+ CD45RO+`=`CD3 Count`*`Live/CD3+/CCR7+ CD45RO+ | Freq. of Parent`,\n `EM: CCR7- CD45RO+`=`CD3 Count`*`Live/CD3+/CCR7- CD45RO+ | Freq. of Parent`,\n `EMRA: CCR7- CD45RO-`=`CD3 Count`*`Live/CD3+/CCR7- CD45RO- | Freq. of Parent`\n ) %>%\n gather(\n key=`Population`,\n value=`Freq_of_parent`,\n `Naive: CCR7+ CD45RO-`:`EMRA: CCR7- CD45RO-`\n ) %>%\n arrange(`Condition`) %>%\n group_by(`Donor`, `Cell state`, `Population`) %>%\n mutate(\n `Normalized_Freq_of_parent`=(1-(`Freq_of_parent`/no_electro_val(`Freq_of_parent`)))*100\n ) %>%\n filter(\n `Condition` == 'Plasmid electroporation',\n `Normalized_Freq_of_parent` > 0\n ) %>%\n ggplot(aes(x=`Population`, y=`Normalized_Freq_of_parent`, color=`Cell state`)) +\n geom_boxplot(alpha=.3, outlier.size=0) +\n geom_point(position=position_jitterdodge()) +\n theme(axis.text.x=element_text(angle=75, hjust=1)) +\n ylab('Percent death for plasmid electroporation\\ncompared to no electroporation (%)') +\n ylim(0, 100)",
"_____no_output_____"
],
[
"flow_data %>%\n filter(`Donor` != 'Donor 35') %>%\n mutate(\n `T cell count`=`Count`*(`Live | Freq. of Parent`/100.0)*(`Live/CD3+ | Freq. of Parent`/100.0)\n ) %>%\n ggplot(aes(x=`Donor`, y=`T cell count`, fill=`Condition`)) +\n geom_col(position=\"dodge\") +\n theme(axis.text.x=element_text(angle=75, hjust=1)) +\n facet_wrap(~`Cell state`, ncol=1) +\n ylab('Live T cell count')",
"_____no_output_____"
],
[
"colors <- c(\"#FC877F\", \"#0EADEE\", \"#04B412\")\n\n\nflow_data %>%\n filter(`Donor` != 'Donor 35') %>%\n mutate(\n `Live Percent (%)`=(`Live | Freq. of Parent`/100.0)*(`Live/CD3+ | Freq. of Parent`)\n ) %>%\n ggplot(aes(x=`Donor`, y=`Live Percent (%)`, fill=`Condition`)) +\n geom_col(position=\"dodge\") +\n facet_wrap(~`Cell state`, ncol=2) +\n theme_bw() +\n theme(axis.text.x=element_text(angle=75, hjust=1)) +\n scale_fill_manual(values=colors) +\n ylab('Live Percent (%)') +\n ylim(0, 100) ",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0faeff988f78a921c0fe41bbc781b8696aebb86 | 6,588 | ipynb | Jupyter Notebook | project/project.ipynb | javiervalladaresc/mat281_portfolio | 028de25a8a37d7cab3db4469f530ae1494eafb8d | [
"MIT"
] | 2 | 2020-09-25T15:30:05.000Z | 2020-09-29T03:16:57.000Z | project/project.ipynb | javiervalladaresc/mat281_portfolio | 028de25a8a37d7cab3db4469f530ae1494eafb8d | [
"MIT"
] | null | null | null | project/project.ipynb | javiervalladaresc/mat281_portfolio | 028de25a8a37d7cab3db4469f530ae1494eafb8d | [
"MIT"
] | null | null | null | 39.927273 | 547 | 0.651032 | [
[
[
"# Proyecto\n\n## Instrucciones\n\n1.- Completa los datos personales (nombre y rol USM) de cada integrante en siguiente celda.\n",
"_____no_output_____"
],
[
"* __Nombre-Rol__:\n\n * Cristobal Salazar 201669515-k\n * Andres Riveros 201710505-4\n * Matias Sasso 201704523-k\n * Javier Valladares 201710508-9",
"_____no_output_____"
],
[
"2.- Debes _pushear_ este archivo con tus cambios a tu repositorio personal del curso, incluyendo datos, imágenes, scripts, etc.\n\n3.- Se evaluará:\n - Soluciones\n - Código\n - Que Binder esté bien configurado.\n - Al presionar `Kernel -> Restart Kernel and Run All Cells` deben ejecutarse todas las celdas sin error.",
"_____no_output_____"
],
[
"## I.- Sistemas de recomendación\n\n\n\n\n\n### Introducción\n\nEl rápido crecimiento de la recopilación de datos ha dado lugar a una nueva era de información. Los datos se están utilizando para crear sistemas más eficientes y aquí es donde entran en juego los sistemas de recomendación. Los sistemas de recomendación son un tipo de sistemas de filtrado de información, ya que mejoran la calidad de los resultados de búsqueda y proporcionan elementos que son más relevantes para el elemento de búsqueda o están relacionados con el historial de búsqueda del usuario.\n\nSe utilizan para predecir la calificación o preferencia que un usuario le daría a un artículo. Casi todas las grandes empresas de tecnología los han aplicado de una forma u otra: Amazon lo usa para sugerir productos a los clientes, YouTube lo usa para decidir qué video reproducir a continuación en reproducción automática y Facebook lo usa para recomendar páginas que me gusten y personas a seguir. Además, empresas como Netflix y Spotify dependen en gran medida de la efectividad de sus motores de recomendación para sus negocios y éxitos.",
"_____no_output_____"
],
[
"### Objetivos\n\nPoder realizar un proyecto de principio a fin ocupando todos los conocimientos aprendidos en clase. Para ello deben cumplir con los siguientes objetivos:\n\n* **Desarrollo del problema**: Se les pide a partir de los datos, proponer al menos un tipo de sistemas de recomendación. Como todo buen proyecto de Machine Learning deben seguir el siguiente procedimiento:\n * **Lectura de los datos**: Describir el o los conjunto de datos en estudio.\n * **Procesamiento de los datos**: Procesar adecuadamente los datos en estudio. Para este caso ocuparan técnicas de [NLP](https://en.wikipedia.org/wiki/Natural_language_processing).\n * **Metodología**: Describir adecuadamente el procedimiento ocupado en cada uno de los modelos ocupados.\n * **Resultados**: Evaluar adecuadamente cada una de las métricas propuesta en este tipo de problemas.\n \n \n* **Presentación**: La presentación será levemente distinta a las anteriores, puesto que deberán ocupar la herramienta de Jupyter llamada [RISE](https://en.wikipedia.org/wiki/Natural_language_processing). Esta presentación debe durar aproximadamente entre 15-30 minutos, y deberán mandar sus videos (por youtube, google drive, etc.)\n\n### Evaluación\n\n* **Códigos**: Los códigos deben estar correctamente documentados (ocupando las *buenas prácticas* de python aprendidas en este curso).\n* **Explicación**: La explicación de la metodología empleada debe ser clara, precisa y concisa.\n* **Apoyo Visual**: Se espera que tengan la mayor cantidad de gráficos y/o tablas que puedan resumir adecuadamente todo el proceso realizado.\n\n\n\n \n",
"_____no_output_____"
],
[
"### Esquema del proyecto\n\nEl proyecto tendrá la siguiente estructura de trabajo:",
"_____no_output_____"
],
[
"```\n- project\n|\n|- data\n |- tmdb_5000_credits.csv\n |- tmdb_5000_movies.csv\n|- graficos.py\n|- lectura.py\n|- modelos.py\n|- preprocesamiento.py\n|- presentacion.ipynb\n|- project.ipynb\n\n```",
"_____no_output_____"
],
[
"donde:\n\n* `data`: carpeta con los datos del proyecto\n* `graficos.py`: módulo de gráficos \n* `lectura.py`: módulo de lectura de datos\n* `modelos.py`: módulo de modelos de Machine Learning utilizados\n* `preprocesamiento.py`: módulo de preprocesamiento de datos\n* `presentacion.ipynb`: presentación del proyecto (formato *RISE*)\n* `project.ipynb`: descripción del proyecto",
"_____no_output_____"
],
[
"### Apoyo\n\nPara que la carga del proyecto sea lo más amena posible, se les deja las siguientes referencias:\n\n* **Sistema de recomendación**: Pueden tomar como referencia el proyecto de Kaggle [Getting Started with a Movie Recommendation System](https://www.kaggle.com/ibtesama/getting-started-with-a-movie-recommendation-system/data?select=tmdb_5000_credits.csv). \n* **RISE**: Les dejo un video del Profesor Sebastían Flores denomindo *Presentaciones y encuestas interactivas en jupyter notebooks y RISE* ([link](https://www.youtube.com/watch?v=ekyN9DDswBE&ab_channel=PyConColombia)). Este material les puede ayudar para comprender mejor este nuevo concepto.",
"_____no_output_____"
]
]
] | [
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
d0faf7ebdd1d300f47c1f5e90332d1ef2b8a3077 | 24,515 | ipynb | Jupyter Notebook | site/ja/tutorials/keras/overfit_and_underfit.ipynb | gabrielrufino/docs-l10n | 9eb7df2cf9e78e1c9df76c57c935db85c79c8c3a | [
"Apache-2.0"
] | 1 | 2020-02-07T02:51:36.000Z | 2020-02-07T02:51:36.000Z | site/ja/tutorials/keras/overfit_and_underfit.ipynb | gabrielrufino/docs-l10n | 9eb7df2cf9e78e1c9df76c57c935db85c79c8c3a | [
"Apache-2.0"
] | null | null | null | site/ja/tutorials/keras/overfit_and_underfit.ipynb | gabrielrufino/docs-l10n | 9eb7df2cf9e78e1c9df76c57c935db85c79c8c3a | [
"Apache-2.0"
] | null | null | null | 34.528169 | 461 | 0.531552 | [
[
[
"##### Copyright 2018 The TensorFlow Authors.",
"_____no_output_____"
]
],
[
[
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
],
[
"#@title MIT License\n#\n# Copyright (c) 2017 François Chollet\n#\n# Permission is hereby granted, free of charge, to any person obtaining a\n# copy of this software and associated documentation files (the \"Software\"),\n# to deal in the Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish, distribute, sublicense,\n# and/or sell copies of the Software, and to permit persons to whom the\n# Software is furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL\n# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING\n# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER\n# DEALINGS IN THE SOFTWARE.",
"_____no_output_____"
]
],
[
[
"# 過学習と学習不足について知る",
"_____no_output_____"
],
[
"<table class=\"tfo-notebook-buttons\" align=\"left\">\n <td>\n <a target=\"_blank\" href=\"https://www.tensorflow.org/tutorials/keras/overfit_and_underfit\"><img src=\"https://www.tensorflow.org/images/tf_logo_32px.png\" />View on TensorFlow.org</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/docs-l10n/blob/master/site/ja/tutorials/keras/overfit_and_underfit.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Run in Google Colab</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://github.com/tensorflow/docs-l10n/blob/master/site/ja/tutorials/keras/overfit_and_underfit.ipynb\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />View source on GitHub</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"Note: これらのドキュメントは私たちTensorFlowコミュニティが翻訳したものです。コミュニティによる 翻訳は**ベストエフォート**であるため、この翻訳が正確であることや[英語の公式ドキュメント](https://www.tensorflow.org/?hl=en)の 最新の状態を反映したものであることを保証することはできません。 この翻訳の品質を向上させるためのご意見をお持ちの方は、GitHubリポジトリ[tensorflow/docs](https://github.com/tensorflow/docs)にプルリクエストをお送りください。 コミュニティによる翻訳やレビューに参加していただける方は、 [[email protected] メーリングリスト](https://groups.google.com/a/tensorflow.org/forum/#!forum/docs-ja)にご連絡ください。",
"_____no_output_____"
],
[
"いつものように、この例のプログラムは`tf.keras` APIを使用します。詳しくはTensorFlowの[Keras guide](https://www.tensorflow.org/guide/keras)を参照してください。\n\nこれまでの例、つまり、映画レビューの分類と燃費の推定では、検証用データでのモデルの正解率が、数エポックでピークを迎え、その後低下するという現象が見られました。\n\n言い換えると、モデルが訓練用データを**過学習**したと考えられます。過学習への対処の仕方を学ぶことは重要です。**訓練用データセット**で高い正解率を達成することは難しくありませんが、我々は、(これまで見たこともない)**テスト用データ**に汎化したモデルを開発したいのです。\n\n過学習の反対語は**学習不足**(underfitting)です。学習不足は、モデルがテストデータに対してまだ改善の余地がある場合に発生します。学習不足の原因は様々です。モデルが十分強力でないとか、正則化のしすぎだとか、単に訓練時間が短すぎるといった理由があります。学習不足は、訓練用データの中の関連したパターンを学習しきっていないということを意味します。\n\nモデルの訓練をやりすぎると、モデルは過学習を始め、訓練用データの中のパターンで、テストデータには一般的ではないパターンを学習します。我々は、過学習と学習不足の中間を目指す必要があります。これから見ていくように、ちょうどよいエポック数だけ訓練を行うというのは必要なスキルなのです。\n\n過学習を防止するための、最良の解決策は、より多くの訓練用データを使うことです。多くのデータで訓練を行えば行うほど、モデルは自然により汎化していく様になります。これが不可能な場合、次善の策は正則化のようなテクニックを使うことです。正則化は、モデルに保存される情報の量とタイプに制約を課すものです。ネットワークが少数のパターンしか記憶できなければ、最適化プロセスにより、最も主要なパターンのみを学習することになり、より汎化される可能性が高くなります。\n\nこのノートブックでは、重みの正則化とドロップアウトという、よく使われる2つの正則化テクニックをご紹介します。これらを使って、IMDBの映画レビューを分類するノートブックの改善を図ります。",
"_____no_output_____"
]
],
[
[
"from __future__ import absolute_import, division, print_function, unicode_literals\n\ntry:\n # Colab only\n %tensorflow_version 2.x\nexcept Exception:\n pass\nimport tensorflow as tf\nfrom tensorflow import keras\n\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nprint(tf.__version__)",
"_____no_output_____"
]
],
[
[
"## IMDBデータセットのダウンロード\n\n以前のノートブックで使用したエンベディングの代わりに、ここでは文をマルチホットエンコードします。このモデルは、訓練用データセットをすぐに過学習します。このモデルを使って、過学習がいつ起きるかということと、どうやって過学習と戦うかをデモします。\n\nリストをマルチホットエンコードすると言うのは、0と1のベクトルにするということです。具体的にいうと、例えば`[3, 5]`というシーケンスを、インデックス3と5の値が1で、それ以外がすべて0の、10,000次元のベクトルに変換するということを意味します。",
"_____no_output_____"
]
],
[
[
"NUM_WORDS = 10000\n\n(train_data, train_labels), (test_data, test_labels) = keras.datasets.imdb.load_data(num_words=NUM_WORDS)\n\ndef multi_hot_sequences(sequences, dimension):\n # 形状が (len(sequences), dimension)ですべて0の行列を作る\n results = np.zeros((len(sequences), dimension))\n for i, word_indices in enumerate(sequences):\n results[i, word_indices] = 1.0 # 特定のインデックスに対してresults[i] を1に設定する\n return results\n\n\ntrain_data = multi_hot_sequences(train_data, dimension=NUM_WORDS)\ntest_data = multi_hot_sequences(test_data, dimension=NUM_WORDS)",
"_____no_output_____"
]
],
[
[
"結果として得られるマルチホットベクトルの1つを見てみましょう。単語のインデックスは頻度順にソートされています。このため、インデックスが0に近いほど1が多く出現するはずです。分布を見てみましょう。",
"_____no_output_____"
]
],
[
[
"plt.plot(train_data[0])",
"_____no_output_____"
]
],
[
[
"## 過学習のデモ\n\n過学習を防止するための最も単純な方法は、モデルのサイズ、すなわち、モデル内の学習可能なパラメータの数を小さくすることです(学習パラメータの数は、層の数と層ごとのユニット数で決まります)。ディープラーニングでは、モデルの学習可能なパラメータ数を、しばしばモデルの「キャパシティ」と呼びます。直感的に考えれば、パラメータ数の多いモデルほど「記憶容量」が大きくなり、訓練用のサンプルとその目的変数の間の辞書のようなマッピングをたやすく学習することができます。このマッピングには汎化能力がまったくなく、これまで見たことが無いデータを使って予測をする際には役に立ちません。\n\nディープラーニングのモデルは訓練用データに適応しやすいけれど、本当のチャレレンジは汎化であって適応ではないということを、肝に銘じておく必要があります。\n\n一方、ネットワークの記憶容量が限られている場合、前述のようなマッピングを簡単に学習することはできません。損失を減らすためには、より予測能力が高い圧縮された表現を学習しなければなりません。同時に、モデルを小さくしすぎると、訓練用データに適応するのが難しくなります。「多すぎる容量」と「容量不足」の間にちょうどよい容量があるのです。\n\n残念ながら、(層の数や、層ごとの大きさといった)モデルの適切なサイズやアーキテクチャを決める魔法の方程式はありません。一連の異なるアーキテクチャを使って実験を行う必要があります。\n\n適切なモデルのサイズを見つけるには、比較的少ない層の数とパラメータから始めるのがベストです。それから、検証用データでの損失値の改善が見られなくなるまで、徐々に層の大きさを増やしたり、新たな層を加えたりします。映画レビューの分類ネットワークでこれを試してみましょう。\n\n比較基準として、```Dense```層だけを使ったシンプルなモデルを構築し、その後、それより小さいバージョンと大きいバージョンを作って比較します。",
"_____no_output_____"
],
[
"### 比較基準を作る",
"_____no_output_____"
]
],
[
[
"baseline_model = keras.Sequential([\n # `.summary` を見るために`input_shape`が必要 \n keras.layers.Dense(16, activation='relu', input_shape=(NUM_WORDS,)),\n keras.layers.Dense(16, activation='relu'),\n keras.layers.Dense(1, activation='sigmoid')\n])\n\nbaseline_model.compile(optimizer='adam',\n loss='binary_crossentropy',\n metrics=['accuracy', 'binary_crossentropy'])\n\nbaseline_model.summary()",
"_____no_output_____"
],
[
"baseline_history = baseline_model.fit(train_data,\n train_labels,\n epochs=20,\n batch_size=512,\n validation_data=(test_data, test_labels),\n verbose=2)",
"_____no_output_____"
]
],
[
[
"### より小さいモデルの構築",
"_____no_output_____"
],
[
"今作成したばかりの比較基準となるモデルに比べて隠れユニット数が少ないモデルを作りましょう。",
"_____no_output_____"
]
],
[
[
"smaller_model = keras.Sequential([\n keras.layers.Dense(4, activation='relu', input_shape=(NUM_WORDS,)),\n keras.layers.Dense(4, activation='relu'),\n keras.layers.Dense(1, activation='sigmoid')\n])\n\nsmaller_model.compile(optimizer='adam',\n loss='binary_crossentropy',\n metrics=['accuracy', 'binary_crossentropy'])\n\nsmaller_model.summary()",
"_____no_output_____"
]
],
[
[
"同じデータを使って訓練します。",
"_____no_output_____"
]
],
[
[
"smaller_history = smaller_model.fit(train_data,\n train_labels,\n epochs=20,\n batch_size=512,\n validation_data=(test_data, test_labels),\n verbose=2)",
"_____no_output_____"
]
],
[
[
"### より大きなモデルの構築\n\n練習として、より大きなモデルを作成し、どれほど急速に過学習が起きるかを見ることもできます。次はこのベンチマークに、この問題が必要とするよりはるかに容量の大きなネットワークを追加しましょう。",
"_____no_output_____"
]
],
[
[
"bigger_model = keras.models.Sequential([\n keras.layers.Dense(512, activation='relu', input_shape=(NUM_WORDS,)),\n keras.layers.Dense(512, activation='relu'),\n keras.layers.Dense(1, activation='sigmoid')\n])\n\nbigger_model.compile(optimizer='adam',\n loss='binary_crossentropy',\n metrics=['accuracy','binary_crossentropy'])\n\nbigger_model.summary()",
"_____no_output_____"
]
],
[
[
"このモデルもまた同じデータを使って訓練します。",
"_____no_output_____"
]
],
[
[
"bigger_history = bigger_model.fit(train_data, train_labels,\n epochs=20,\n batch_size=512,\n validation_data=(test_data, test_labels),\n verbose=2)",
"_____no_output_____"
]
],
[
[
"### 訓練時と検証時の損失をグラフにする\n\n<!--TODO(markdaoust): This should be a one-liner with tensorboard -->",
"_____no_output_____"
],
[
"実線は訓練用データセットの損失、破線は検証用データセットでの損失です(検証用データでの損失が小さい方が良いモデルです)。これをみると、小さいネットワークのほうが比較基準のモデルよりも過学習が始まるのが遅いことがわかります(4エポックではなく6エポック後)。また、過学習が始まっても性能の低下がよりゆっくりしています。",
"_____no_output_____"
]
],
[
[
"def plot_history(histories, key='binary_crossentropy'):\n plt.figure(figsize=(16,10))\n \n for name, history in histories:\n val = plt.plot(history.epoch, history.history['val_'+key],\n '--', label=name.title()+' Val')\n plt.plot(history.epoch, history.history[key], color=val[0].get_color(),\n label=name.title()+' Train')\n\n plt.xlabel('Epochs')\n plt.ylabel(key.replace('_',' ').title())\n plt.legend()\n\n plt.xlim([0,max(history.epoch)])\n\n\nplot_history([('baseline', baseline_history),\n ('smaller', smaller_history),\n ('bigger', bigger_history)])",
"_____no_output_____"
]
],
[
[
"より大きなネットワークでは、すぐに、1エポックで過学習が始まり、その度合も強いことに注目してください。ネットワークの容量が大きいほど訓練用データをモデル化するスピードが早くなり(結果として訓練時の損失値が小さくなり)ますが、より過学習しやすく(結果として訓練時の損失値と検証時の損失値が大きく乖離しやすく)なります。",
"_____no_output_____"
],
[
"## 過学習防止の戦略",
"_____no_output_____"
],
[
"### 重みの正則化を加える\n\n",
"_____no_output_____"
],
[
"「オッカムの剃刀」の原則をご存知でしょうか。何かの説明が2つあるとすると、最も正しいと考えられる説明は、仮定の数が最も少ない「一番単純な」説明だというものです。この原則は、ニューラルネットワークを使って学習されたモデルにも当てはまります。ある訓練用データとネットワーク構造があって、そのデータを説明できる重みの集合が複数ある時(つまり、複数のモデルがある時)、単純なモデルのほうが複雑なものよりも過学習しにくいのです。\n\nここで言う「単純なモデル」とは、パラメータ値の分布のエントロピーが小さいもの(あるいは、上記で見たように、そもそもパラメータの数が少ないもの)です。したがって、過学習を緩和するための一般的な手法は、重みが小さい値のみをとることで、重み値の分布がより整然となる(正則)様に制約を与えるものです。これを「重みの正則化」と呼ばれ、ネットワークの損失関数に、重みの大きさに関連するコストを加えることで行われます。このコストには2つの種類があります。\n\n* [L1正則化](https://developers.google.com/machine-learning/glossary/#L1_regularization) 重み係数の絶対値に比例するコストを加える(重みの「L1ノルム」と呼ばれる)。\n\n* [L2正則化](https://developers.google.com/machine-learning/glossary/#L2_regularization) 重み係数の二乗に比例するコストを加える(重み係数の二乗「L2ノルム」と呼ばれる)。L2正則化はニューラルネットワーク用語では重み減衰(Weight Decay)と呼ばれる。呼び方が違うので混乱しないように。重み減衰は数学的にはL2正則化と同義である。\n\nL1正則化は重みパラメータの一部を0にすることでモデルを疎にする効果があります。L2正則化は重みパラメータにペナルティを加えますがモデルを疎にすることはありません。これは、L2正則化のほうが一般的である理由の一つです。\n\n`tf.keras`では、重みの正則化をするために、重み正則化のインスタンスをキーワード引数として層に加えます。ここでは、L2正則化を追加してみましょう。",
"_____no_output_____"
]
],
[
[
"l2_model = keras.models.Sequential([\n keras.layers.Dense(16, kernel_regularizer=keras.regularizers.l2(0.001),\n activation='relu', input_shape=(NUM_WORDS,)),\n keras.layers.Dense(16, kernel_regularizer=keras.regularizers.l2(0.001),\n activation='relu'),\n keras.layers.Dense(1, activation='sigmoid')\n])\n\nl2_model.compile(optimizer='adam',\n loss='binary_crossentropy',\n metrics=['accuracy', 'binary_crossentropy'])\n\nl2_model_history = l2_model.fit(train_data, train_labels,\n epochs=20,\n batch_size=512,\n validation_data=(test_data, test_labels),\n verbose=2)",
"_____no_output_____"
]
],
[
[
"```l2(0.001)```というのは、層の重み行列の係数全てに対して```0.001 * 重み係数の値 **2```をネットワークの損失値合計に加えることを意味します。このペナルティは訓練時のみに加えられるため、このネットワークの損失値は、訓練時にはテスト時に比べて大きくなることに注意してください。\n\nL2正則化の影響を見てみましょう。",
"_____no_output_____"
]
],
[
[
"plot_history([('baseline', baseline_history),\n ('l2', l2_model_history)])",
"_____no_output_____"
]
],
[
[
"ご覧のように、L2正則化ありのモデルは比較基準のモデルに比べて過学習しにくくなっています。両方のモデルのパラメータ数は同じであるにもかかわらずです。",
"_____no_output_____"
],
[
"### ドロップアウトを追加する\n\nドロップアウトは、ニューラルネットワークの正則化テクニックとして最もよく使われる手法の一つです。この手法は、トロント大学のヒントンと彼の学生が開発したものです。ドロップアウトは層に適用するもので、訓練時に層から出力された特徴量に対してランダムに「ドロップアウト(つまりゼロ化)」を行うものです。例えば、ある層が訓練時にある入力サンプルに対して、普通は`[0.2, 0.5, 1.3, 0.8, 1.1]` というベクトルを出力するとします。ドロップアウトを適用すると、このベクトルは例えば`[0, 0.5, 1.3, 0, 1.1]`のようにランダムに散らばったいくつかのゼロを含むようになります。「ドロップアウト率」はゼロ化される特徴の割合で、通常は0.2から0.5の間に設定します。テスト時は、どのユニットもドロップアウトされず、代わりに出力値がドロップアウト率と同じ比率でスケールダウンされます。これは、訓練時に比べてたくさんのユニットがアクティブであることに対してバランスをとるためです。\n\n`tf.keras`では、Dropout層を使ってドロップアウトをネットワークに導入できます。ドロップアウト層は、その直前の層の出力に対してドロップアウトを適用します。\n\nそれでは、IMDBネットワークに2つのドロップアウト層を追加しましょう。",
"_____no_output_____"
]
],
[
[
"dpt_model = keras.models.Sequential([\n keras.layers.Dense(16, activation='relu', input_shape=(NUM_WORDS,)),\n keras.layers.Dropout(0.5),\n keras.layers.Dense(16, activation='relu'),\n keras.layers.Dropout(0.5),\n keras.layers.Dense(1, activation='sigmoid')\n])\n\ndpt_model.compile(optimizer='adam',\n loss='binary_crossentropy',\n metrics=['accuracy','binary_crossentropy'])\n\ndpt_model_history = dpt_model.fit(train_data, train_labels,\n epochs=20,\n batch_size=512,\n validation_data=(test_data, test_labels),\n verbose=2)",
"_____no_output_____"
],
[
"plot_history([('baseline', baseline_history),\n ('dropout', dpt_model_history)])",
"_____no_output_____"
]
],
[
[
"ドロップアウトを追加することで、比較対象モデルより明らかに改善が見られます。\n\nまとめ:ニューラルネットワークにおいて過学習を防ぐ最も一般的な方法は次のとおりです。\n\n* 訓練データを増やす\n* ネットワークの容量をへらす\n* 重みの正則化を行う\n* ドロップアウトを追加する\n\nこのガイドで触れていない2つの重要なアプローチがあります。データ拡張とバッチ正規化です。",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
d0faf997baf116d4270aa66f3606d4264f1b9969 | 38,662 | ipynb | Jupyter Notebook | Auto Correct System/.ipynb_checkpoints/Auto Correct System-checkpoint.ipynb | rodrigoamorimml/NaturalLanguageProcessing | d7729cff87fb0cb5c326d52010cf869456ea48bb | [
"MIT"
] | 2 | 2020-06-06T06:47:51.000Z | 2020-10-06T14:41:45.000Z | Auto Correct System/Auto Correct System.ipynb | rodrigoamorimml/NaturalLanguageProcessing | d7729cff87fb0cb5c326d52010cf869456ea48bb | [
"MIT"
] | null | null | null | Auto Correct System/Auto Correct System.ipynb | rodrigoamorimml/NaturalLanguageProcessing | d7729cff87fb0cb5c326d52010cf869456ea48bb | [
"MIT"
] | null | null | null | 32.434564 | 859 | 0.50763 | [
[
[
"### An Auto correct system is an application that changes mispelled words into the correct ones.\n\n",
"_____no_output_____"
]
],
[
[
"# In this notebook I'll show how to implement an Auto Correct System that its very usefull.\n# This auto correct system only search for spelling erros, not contextual errors.",
"_____no_output_____"
]
],
[
[
"\n\n*The implementation can be divided into 4 steps:*\n\n[1]. **Identity a mispelled word.**\n\n[2]. **Find strings n Edit Distance away**\n\n[3]. **Filter Candidates** (*as Real Words that are spelled correct*)\n\n[4]. **Calculate Word Probabilities.** (*Choose the most likely cadidate to be the replacement*)",
"_____no_output_____"
],
[
"### 1. Identity a mispelled Word\n\n*To identify if a word was mispelled, you can check if the word is in the dictionary / vocabulary.*",
"_____no_output_____"
]
],
[
[
"vocab = ['dean','deer','dear','fries','and','coke', 'congratulations', 'my']\n\nword_test = 'Congratulations my deah'\nword_test = word_test.lower()\nword_test = word_test.split()\n\nfor word in word_test:\n if word in vocab:\n print(f'The word: {word} is in the vocab')\n else:\n print(f\"The word: {word} isn't in the vocabulary\")\n",
"The word: congratulations is in the vocab\nThe word: my is in the vocab\nThe word: deah isn't in the vocabulary\n"
]
],
[
[
"### 2. Find strings n Edit Distance Away\n\n*Edit is a operation performed on a string to change into another string. Edit distance count the number of these operations*\n\n*So **n Edit Distance** tells you how many operations away one string is from another.*\n\n*For this application we'll use the Levenshtein Distance value's cost, where this edit value are:*\n\n* **Insert** - Operation where you insert a letter, the cost is equal to 1.\n\n* **Delete** - Operation where you delete a letter, the cost is equal to 1.\n\n* **Replace** - Operation where you replace one letter to another, the cost is equal to 2.\n\n* **Switch** - Operation where you swap 2 **adjacent** letters\n\n*Also we'll use the Minimum Edit Distance which is the minimum number of edits needed to transform 1 string into the other, for that we are using n = 2 and the Dynamic Programming algorithm. ( will be explained when it is implemented ) for evaluate our model*\n",
"_____no_output_____"
]
],
[
[
"# To implement this operations we need to split the word into 2 parts in all possible ways\n\nword = 'dear'\n\nsplit_word = [[word[:i], word[i:]] for i in range(len(word) + 1)]\nfor i in split_word:\n print(i)",
"['', 'dear']\n['d', 'ear']\n['de', 'ar']\n['dea', 'r']\n['dear', '']\n"
],
[
"# The delete operation need to delete each possible letter from the original word.\n\ndelete_operation = [[L + R[1:]] for L, R in split_word if R ]\n\nfor i in delete_operation:\n print(i)",
"['ear']\n['dar']\n['der']\n['dea']\n"
],
[
"# The same way the insert operation need to add each possible letter from the vocab to the original word\n\nletters = 'abcdefghijklmnopqrstuvwxyz'\ninsert_operation = [L + s + R for L, R in split_word for s in letters]\n\nc = 0\nprint('the first insert operations: ')\nprint()\nfor i in insert_operation:\n print(i)\n c += 1\n if c == 4:\n break\nc = 0\nprint('the last insert operations:')\nprint()\nfor i in insert_operation:\n c += 1\n if c > 126:\n print(i)\n",
"the first insert operations: \n\nadear\nbdear\ncdear\nddear\nthe last insert operations:\n\ndearw\ndearx\ndeary\ndearz\n"
],
[
"# Switch Operation\n\nswitch_operation = [[L[:-1] + R[0] + L[-1] + R[1:]] for L, R in split_word if R and L]\n\nfor i in switch_operation:\n print(i)\n",
"['edar']\n['daer']\n['dera']\n"
],
[
"# Replace Operation\n\nletters = 'abcdefghijklmnopqrstuvwxyz'\nreplace_operation = [L + s + (R[1:] if len(R) > 1 else '') for L, R in split_word if R for s in letters ] \n\nc = 0\nprint('the first replace operations: ')\nprint()\nfor i in replace_operation:\n print(i)\n c += 1\n if c == 4:\n break\n\nc = 0\nprint('the last replace operations:')\nprint()\nfor i in replace_operation:\n c += 1\n if c > 100:\n print(i)\n\n \n# Remember that at the end we need to remove the word it self\nreplace_operation = set(replace_operation)\nreplace_operation.discard('dear')",
"the first replace operations: \n\naear\nbear\ncear\ndear\nthe last replace operations:\n\ndeaw\ndeax\ndeay\ndeaz\n"
]
],
[
[
"### 3. Filter Candidates\n\n*We only want to consider real and correctly spelled words form the candidate lists, so we need to compare to a know dictionary.*\n\n*If the string does not appears in the dict, remove from the candidates, this way resulting in a list of actual words only*",
"_____no_output_____"
]
],
[
[
"vocab = ['dean','deer','dear','fries','and','coke', 'congratulations', 'my']\n\n# for example we can use the replace operations words to filter in our vocab\n\nfiltered_words = [word for word in replace_operation if word in vocab]\nprint(filtered_words)",
"['deer', 'dean']\n"
]
],
[
[
"### 4. Calculate the words probabilities\n\n*We need to find the most likely word from the cadidate list, to calculate the probability of a word in the \nsentence we need to first calculate the word frequencies, also we want to count the total number of word in the body of texts\nor corpus.*\n\n*So we compute the probability that each word will appear if randomly selected from the corpus of words.*\n\n$$P(w_i) = \\frac{C(w_i)}{M} \\tag{Eq 01}$$\n*where*\n\n$C(w_i)$ *is the total number of times $w_i$ appears in the corpus.*\n\n$M$ *is the total number of words in the corpus.*\n\n*For example, the probability of the word 'am' in the sentence **'I am happy because I am learning'** is:*\n\n$$P(am) = \\frac{C(w_i)}{M} = \\frac {2}{7} \\tag{Eq 02}.$$",
"_____no_output_____"
],
[
"### Now the we know the four steps of the Auto Correct System, we can start to implement it",
"_____no_output_____"
]
],
[
[
"# import libraries\nimport re\nfrom collections import Counter\nimport numpy as np\nimport pandas as pd",
"_____no_output_____"
]
],
[
[
"*The first thing to do is the data pre processing, for this example we'll use the file called **'shakespeare.txt'** this file can be found in the directory.*",
"_____no_output_____"
]
],
[
[
"def process_data(filename):\n \"\"\"\n Input: \n A file_name which is found in the current directory. We just have to read it in. \n Output: \n words: a list containing all the words in the corpus (text file you read) in lower case. \n \"\"\"\n \n words = []\n with open(filename, 'r') as f:\n text = f.read()\n \n words = re.findall(r'\\w+', text)\n words = [word.lower() for word in words]\n \n return words",
"_____no_output_____"
],
[
"words = process_data('shakespeare.txt')\nvocab = set(words) # eliminate duplicates \n\nprint(f'The vocabulary has {len(vocab)} unique words.')",
"The vocabulary has 6116 unique words.\n"
]
],
[
[
"*The second step, we need to count the frequency of every word in the dictionary to later calculate the probabilities*\n",
"_____no_output_____"
]
],
[
[
"def get_count(word):\n '''\n Input:\n word_l: a set of words representing the corpus. \n Output:\n word_count_dict: The wordcount dictionary where key is the word and value is its frequency.\n '''\n word_count_dict = {}\n \n word_count_dict = Counter(word)\n \n return word_count_dict\n\n\nword_count_dict = get_count(words)\nprint(f'There are {len(word_count_dict)} key par values')\nprint(f\"The count for the word 'thee' is {word_count_dict.get('thee',0)}\")",
"There are 6116 key par values\nThe count for the word 'thee' is 240\n"
]
],
[
[
"*Now we must calculate the probability that each word appears using the (eq 01):*",
"_____no_output_____"
]
],
[
[
"\ndef get_probs(word_count_dict):\n '''\n Input:\n word_count_dict: The wordcount dictionary where key is the word and value is its frequency.\n Output:\n probs: A dictionary where keys are the words and the values are the probability that a word will occur. \n '''\n \n probs = {}\n total_words = 0\n \n for word, value in word_count_dict.items():\n total_words += value # we add the quantity of each word appears\n \n for word, value in word_count_dict.items():\n probs[word] = value / total_words\n \n \n return probs\n\nprobs = get_probs(word_count_dict)\nprint(f\"Length of probs is {len(probs)}\")\nprint(f\"P('thee') is {probs['thee']:.4f}\")",
"Length of probs is 6116\nP('thee') is 0.0045\n"
]
],
[
[
"*Now, that we have computed $P(w_i)$ for all the words in the corpus, we'll write the functions such as delete, insert, switch and replace to manipulate strings so that we can edit the erroneous strings and return the right spellings of the words.*",
"_____no_output_____"
]
],
[
[
"def delete_letter(word, verbose = False):\n '''\n Input:\n word: the string/word for which you will generate all possible words \n in the vocabulary which have 1 missing character\n Output:\n delete_l: a list of all possible strings obtained by deleting 1 character from word\n '''\n \n delete = []\n split_word = []\n \n split_word = [[word[:i], word[i:]] for i in range(len(word))]\n \n delete = [L + R[1:] for L, R in split_word if R]\n \n if verbose: print(f\"input word {word}, \\nsplit_word = {split_word}, \\ndelete_word = {delete}\")\n\n return delete\n\ndelete_word = delete_letter(word=\"cans\",\n verbose=True)",
"input word cans, \nsplit_word = [['', 'cans'], ['c', 'ans'], ['ca', 'ns'], ['can', 's']], \ndelete_word = ['ans', 'cns', 'cas', 'can']\n"
],
[
"def switch_letter(word, verbose = False):\n '''\n Input:\n word: input string\n Output:\n switches: a list of all possible strings with one adjacent charater switched\n ''' \n \n switch = []\n split_word = []\n \n split_word = [[word[:i], word[i:]] for i in range(len(word))]\n \n switch = [L[:-1] + R[0] + L[-1] + R[1:] for L, R in split_word if L and R]\n \n if verbose: print(f\"Input word = {word} \\nsplit = {split_word} \\nswitch = {switch}\") \n\n return switch\n\nswitch_word_l = switch_letter(word=\"eta\",\n verbose=True)",
"Input word = eta \nsplit = [['', 'eta'], ['e', 'ta'], ['et', 'a']] \nswitch = ['tea', 'eat']\n"
],
[
"def replace_letter(word, verbose=False):\n '''\n Input:\n word: the input string/word \n Output:\n replaces: a list of all possible strings where we replaced one letter from the original word. \n ''' \n \n letters = 'abcdefghijklmnopqrstuvwxyz'\n replace = []\n split_word = []\n \n\n split_word = [(word[:i], word[i:]) for i in range(len(word))]\n \n replace = [L + s + (R[1:] if len(R) > 1 else '') for L, R in split_word if R for s in letters ]\n \n # we need to remove the actual word from the list\n replace = set(replace)\n replace.discard(word)\n\n \n \n replace = sorted(list(replace)) # turn the set back into a list and sort it, for easier viewing\n \n if verbose: print(f\"Input word = {word} \\nsplit = {split_word} \\nreplace {replace}\") \n \n return replace\n\nreplace_l = replace_letter(word='can',\n verbose=True)",
"Input word = can \nsplit = [('', 'can'), ('c', 'an'), ('ca', 'n')] \nreplace ['aan', 'ban', 'caa', 'cab', 'cac', 'cad', 'cae', 'caf', 'cag', 'cah', 'cai', 'caj', 'cak', 'cal', 'cam', 'cao', 'cap', 'caq', 'car', 'cas', 'cat', 'cau', 'cav', 'caw', 'cax', 'cay', 'caz', 'cbn', 'ccn', 'cdn', 'cen', 'cfn', 'cgn', 'chn', 'cin', 'cjn', 'ckn', 'cln', 'cmn', 'cnn', 'con', 'cpn', 'cqn', 'crn', 'csn', 'ctn', 'cun', 'cvn', 'cwn', 'cxn', 'cyn', 'czn', 'dan', 'ean', 'fan', 'gan', 'han', 'ian', 'jan', 'kan', 'lan', 'man', 'nan', 'oan', 'pan', 'qan', 'ran', 'san', 'tan', 'uan', 'van', 'wan', 'xan', 'yan', 'zan']\n"
],
[
"\ndef insert_letter(word, verbose=False):\n '''\n Input:\n word: the input string/word \n Output:\n inserts: a set of all possible strings with one new letter inserted at every offset\n ''' \n letters = 'abcdefghijklmnopqrstuvwxyz'\n insert = []\n split_word = []\n \n\n split_word = [(word[:i], word[i:]) for i in range(len(word) + 1 )]\n insert = [L + s + R for L, R in split_word for s in letters]\n\n\n\n if verbose: print(f\"Input word {word} \\nsplit = {split_word} \\ninsert = {insert}\")\n \n return insert\n\ninsert = insert_letter('at', True)\nprint(f\"Number of strings output by insert_letter('at') is {len(insert)}\")",
"Input word at \nsplit = [('', 'at'), ('a', 't'), ('at', '')] \ninsert = ['aat', 'bat', 'cat', 'dat', 'eat', 'fat', 'gat', 'hat', 'iat', 'jat', 'kat', 'lat', 'mat', 'nat', 'oat', 'pat', 'qat', 'rat', 'sat', 'tat', 'uat', 'vat', 'wat', 'xat', 'yat', 'zat', 'aat', 'abt', 'act', 'adt', 'aet', 'aft', 'agt', 'aht', 'ait', 'ajt', 'akt', 'alt', 'amt', 'ant', 'aot', 'apt', 'aqt', 'art', 'ast', 'att', 'aut', 'avt', 'awt', 'axt', 'ayt', 'azt', 'ata', 'atb', 'atc', 'atd', 'ate', 'atf', 'atg', 'ath', 'ati', 'atj', 'atk', 'atl', 'atm', 'atn', 'ato', 'atp', 'atq', 'atr', 'ats', 'att', 'atu', 'atv', 'atw', 'atx', 'aty', 'atz']\nNumber of strings output by insert_letter('at') is 78\n"
]
],
[
[
"*Now that we have implemented the string manipulations, we'll create two functions that, given a string, will return all the possible single and double edits on that string. These will be `edit_one_letter()` and `edit_two_letters()`.*",
"_____no_output_____"
]
],
[
[
"def edit_one_letter(word, allow_switches = True): # The 'switch' function is a less common edit function, \n # so will be selected by an \"allow_switches\" input argument.\n \"\"\"\n Input:\n word: the string/word for which we will generate all possible wordsthat are one edit away.\n Output:\n edit_one_set: a set of words with one possible edit. Please return a set. and not a list.\n \"\"\"\n \n edit_one_set = set()\n all_word, words = [] , []\n \n words.append(insert_letter(word))\n words.append(delete_letter(word))\n words.append(replace_letter(word))\n if allow_switches == True:\n words.append(switch_letter(word))\n \n for i in words:\n for each_word in i:\n if each_word == word: # we exclude the word it self\n continue\n all_word.append(each_word)\n \n edit_one_set = set(all_word)\n \n return edit_one_set\n\ntmp_word = \"at\"\ntmp_edit_one_set = edit_one_letter(tmp_word)\n# turn this into a list to sort it, in order to view it\ntmp_edit_one = sorted(list(tmp_edit_one_set))\n\nprint(f\"input word: {tmp_word} \\nedit_one \\n{tmp_edit_one}\\n\")\nprint(f\"The type of the returned object should be a set {type(tmp_edit_one_set)}\")\nprint(f\"Number of outputs from edit_one_letter('at') is {len(edit_one_letter('at'))}\")",
"input word: at \nedit_one \n['a', 'aa', 'aat', 'ab', 'abt', 'ac', 'act', 'ad', 'adt', 'ae', 'aet', 'af', 'aft', 'ag', 'agt', 'ah', 'aht', 'ai', 'ait', 'aj', 'ajt', 'ak', 'akt', 'al', 'alt', 'am', 'amt', 'an', 'ant', 'ao', 'aot', 'ap', 'apt', 'aq', 'aqt', 'ar', 'art', 'as', 'ast', 'ata', 'atb', 'atc', 'atd', 'ate', 'atf', 'atg', 'ath', 'ati', 'atj', 'atk', 'atl', 'atm', 'atn', 'ato', 'atp', 'atq', 'atr', 'ats', 'att', 'atu', 'atv', 'atw', 'atx', 'aty', 'atz', 'au', 'aut', 'av', 'avt', 'aw', 'awt', 'ax', 'axt', 'ay', 'ayt', 'az', 'azt', 'bat', 'bt', 'cat', 'ct', 'dat', 'dt', 'eat', 'et', 'fat', 'ft', 'gat', 'gt', 'hat', 'ht', 'iat', 'it', 'jat', 'jt', 'kat', 'kt', 'lat', 'lt', 'mat', 'mt', 'nat', 'nt', 'oat', 'ot', 'pat', 'pt', 'qat', 'qt', 'rat', 'rt', 'sat', 'st', 't', 'ta', 'tat', 'tt', 'uat', 'ut', 'vat', 'vt', 'wat', 'wt', 'xat', 'xt', 'yat', 'yt', 'zat', 'zt']\n\nThe type of the returned object should be a set <class 'set'>\nNumber of outputs from edit_one_letter('at') is 129\n"
],
[
"def edit_two_letters(word, allow_switches = True):\n '''\n Input:\n word: the input string/word \n Output:\n edit_two_set: a set of strings with all possible two edits\n '''\n \n edit_two_set = set()\n \n \n if allow_switches == True:\n first_edit = edit_one_letter(word)\n \n else:\n first_edit = edit_one_letter(word, allow_switches = False)\n \n \n \n \n first_edit = set(first_edit)\n second_edit = []\n final_edit = []\n \n if allow_switches == True:\n for each_word in first_edit:\n second_edit.append(edit_one_letter(each_word))\n for i in second_edit:\n for each_word in i:\n final_edit.append(each_word)\n edit_two_set = set(final_edit)\n \n else:\n for each_word in first_edit:\n second_edit.append(edit_one_letter(each_word, allow_switches = False))\n for i in second_edit:\n for each_word in i:\n final_edit.append(each_word)\n edit_two_set = set(final_edit)\n \n \n return edit_two_set\n\n",
"_____no_output_____"
],
[
"tmp_edit_two_set = edit_two_letters(\"a\")\ntmp_edit_two_l = sorted(list(tmp_edit_two_set))\nprint(f\"Number of strings with edit distance of two: {len(tmp_edit_two_l)}\")\nprint(f\"First 10 strings {tmp_edit_two_l[:10]}\")\nprint(f\"Last 10 strings {tmp_edit_two_l[-10:]}\")\nprint(f\"The data type of the returned object should be a set {type(tmp_edit_two_set)}\")\nprint(f\"Number of strings that are 2 edit distances from 'at' is {len(edit_two_letters('at'))}\")",
"Number of strings with edit distance of two: 2654\nFirst 10 strings ['', 'a', 'aa', 'aaa', 'aab', 'aac', 'aad', 'aae', 'aaf', 'aag']\nLast 10 strings ['zv', 'zva', 'zw', 'zwa', 'zx', 'zxa', 'zy', 'zya', 'zz', 'zza']\nThe data type of the returned object should be a set <class 'set'>\nNumber of strings that are 2 edit distances from 'at' is 7154\n"
]
],
[
[
"*Now we will use the `edit_two_letters` function to get a set of all the possible 2 edits on our word. We will then use those strings to get the most probable word we meant to substitute our word typing suggestion.*",
"_____no_output_____"
]
],
[
[
"def get_corrections(word, probs, vocab, n=2, verbose = False):\n '''\n Input: \n word: a user entered string to check for suggestions\n probs: a dictionary that maps each word to its probability in the corpus\n vocab: a set containing all the vocabulary\n n: number of possible word corrections you want returned in the dictionary\n Output: \n n_best: a list of tuples with the most probable n corrected words and their probabilities.\n '''\n \n suggestions = []\n n_best = []\n \n # look if the word exist in the vocab, if doesn't, the edit_one_letter fuction its used, if any of the letter created \n # exists in the vocab, take the two letter edit function, if any of this situations are in the vocab, take the input word\n suggestions = list((word in vocab) or (edit_one_letter(word).intersection(vocab)) or (edit_two_letter(word).intersection(vocab)) or word)\n \n\n n_best= [[word, probs[word]] for word in (suggestions)] # make a list with the possible word and probability.\n \n \n if verbose: print(\"entered word = \", word, \"\\nsuggestions = \", set(suggestions))\n\n return n_best\n\n",
"_____no_output_____"
],
[
"my_word = 'dys' \ntmp_corrections = get_corrections(my_word, probs, vocab, 2, verbose=True) # keep verbose=True\nfor i, word_prob in enumerate(tmp_corrections):\n print(f\"word {i}: {word_prob[0]}, probability {word_prob[1]:.6f}\")\n\nprint(f'The highest score for all the candidates is the word {tmp_corrections[np.argmax(word_prob)][0]}')\n",
"entered word = dys \nsuggestions = {'days', 'dye'}\nword 0: days, probability 0.000410\nword 1: dye, probability 0.000019\nThe highest score for all the candidates is the word days\n"
]
],
[
[
"*Now that we have implemented the auto-correct system, how do you evaluate the similarity between two strings? For example: 'waht' and 'what'.*\n\n*Also how do you efficiently find the shortest path to go from the word, 'waht' to the word 'what'?*\n\n*We will implement a dynamic programming system that will tell you the minimum number of edits required to convert a string into another string.*",
"_____no_output_____"
],
[
"### Dynamic Programming",
"_____no_output_____"
],
[
"*Dynamic Programming breaks a problem down into subproblems which can be combined to form the final solution. Here, given a string source[0..i] and a string target[0..j], we will compute all the combinations of substrings[i, j] and calculate their edit distance. To do this efficiently, we will use a table to maintain the previously computed substrings and use those to calculate larger substrings.*\n\n*You have to create a matrix and update each element in the matrix as follows:*",
"_____no_output_____"
],
[
"$$\\text{Initialization}$$\n\n\\begin{align}\nD[0,0] &= 0 \\\\\nD[i,0] &= D[i-1,0] + del\\_cost(source[i]) \\tag{eq 03}\\\\\nD[0,j] &= D[0,j-1] + ins\\_cost(target[j]) \\\\\n\\end{align}",
"_____no_output_____"
],
[
"*So converting the source word **play** to the target word **stay**, using an insert cost of one, a delete cost of 1, and replace cost of 2 would give you the following table:*\n<table style=\"width:20%\">\n\n <tr>\n <td> <b> </b> </td>\n <td> <b># </b> </td>\n <td> <b>s </b> </td>\n <td> <b>t </b> </td> \n <td> <b>a </b> </td> \n <td> <b>y </b> </td> \n </tr>\n <tr>\n <td> <b> # </b></td>\n <td> 0</td> \n <td> 1</td> \n <td> 2</td> \n <td> 3</td> \n <td> 4</td> \n \n </tr>\n <tr>\n <td> <b> p </b></td>\n <td> 1</td> \n <td> 2</td> \n <td> 3</td> \n <td> 4</td> \n <td> 5</td>\n </tr>\n \n <tr>\n <td> <b> l </b></td>\n <td>2</td> \n <td>3</td> \n <td>4</td> \n <td>5</td> \n <td>6</td>\n </tr>\n\n <tr>\n <td> <b> a </b></td>\n <td>3</td> \n <td>4</td> \n <td>5</td> \n <td>4</td>\n <td>5</td> \n </tr>\n \n <tr>\n <td> <b> y </b></td>\n <td>4</td> \n <td>5</td> \n <td>6</td> \n <td>5</td>\n <td>4</td> \n </tr>\n \n\n</table>\n\n",
"_____no_output_____"
],
[
"*The operations used in this algorithm are 'insert', 'delete', and 'replace'. These correspond to the functions that we defined earlier: insert_letter(), delete_letter() and replace_letter(). switch_letter() is not used here.*",
"_____no_output_____"
],
[
"*The diagram below describes how to initialize the table. Each entry in D[i,j] represents the minimum cost of converting string source[0:i] to string target[0:j]. The first column is initialized to represent the cumulative cost of deleting the source characters to convert string \"EER\" to \"\". The first row is initialized to represent the cumulative cost of inserting the target characters to convert from \"\" to \"NEAR\".*",
"_____no_output_____"
],
[
"<div style=\"width:image width px; font-size:100%; text-align:center;\"><img src='EditDistInit4.PNG' alt=\"alternate text\" width=\"width\" height=\"height\" style=\"width:1000px;height:400px;\"/> Figure 1 Initializing Distance Matrix</div> ",
"_____no_output_____"
],
[
"*Note that the formula for $D[i,j]$ shown in the image is equivalent to:*\n\n\\begin{align}\n \\\\\nD[i,j] =min\n\\begin{cases}\nD[i-1,j] + del\\_cost\\\\\nD[i,j-1] + ins\\_cost\\\\\nD[i-1,j-1] + \\left\\{\\begin{matrix}\nrep\\_cost; & if src[i]\\neq tar[j]\\\\\n0 ; & if src[i]=tar[j]\n\\end{matrix}\\right.\n\\end{cases}\n\\tag{5}\n\\end{align}\n\n*The variable `sub_cost` (for substitution cost) is the same as `rep_cost`; replacement cost. We will stick with the term \"replace\" whenever possible.*",
"_____no_output_____"
],
[
"<div style=\"width:image width px; font-size:100%; text-align:center;\"><img src='EditDistExample1.PNG' alt=\"alternate text\" width=\"width\" height=\"height\" style=\"width:1200px;height:400px;\"/> Figure 2 Examples Distance Matrix</div> ",
"_____no_output_____"
]
],
[
[
"def min_edit_distance(source, target, ins_cost = 1, del_cost = 1, rep_cost = 2):\n '''\n Input: \n source: a string corresponding to the string you are starting with\n target: a string corresponding to the string you want to end with\n ins_cost: an integer setting the insert cost\n del_cost: an integer setting the delete cost\n rep_cost: an integer setting the replace cost\n Output:\n D: a matrix of len(source)+1 by len(target)+1 containing minimum edit distances\n med: the minimum edit distance (med) required to convert the source string to the target\n '''\n \n m = len(source)\n n = len(target)\n \n # initialize cost matrix with zeros and dimensions (m+1, n+1)\n D = np.zeros((m+1, n+1), dtype = int)\n \n # Fill in column 0, from row 1 to row m, both inclusive\n for row in range(1, m+1): # Replace None with the proper range\n D[row, 0] = D[row -1, 0] + del_cost\n \n # Fill in row 0, for all columns from 1 to n, both inclusive\n for column in range(1, n+1):\n D[0, column] = D[0, column - 1] + ins_cost\n \n # Loop through row 1 to row m, both inclusive\n for row in range(1, m+1):\n \n # Loop through column 1 to column n, both inclusive\n for column in range(1, n+1):\n \n # initialize r_cost to the 'replace' cost that is passed into this function\n r_cost = rep_cost\n \n # check to see if source character at the previous row\n # matches the target haracter at the previous column\n if source[row - 1] == target[column - 1]:\n # Update the replacement cost to 0 if source and\n # target are equal\n r_cost = 0\n \n # Update the cost atow, col based on previous entries in the cost matrix\n # Refer to the equation calculate for D[i,j] (the mininum of the three calculated)\n D[row, column] = min([D[row-1, column] + del_cost, D[row, column-1] + ins_cost, D[row-1, column-1] + r_cost])\n \n # Set the minimum edit distance with the cost found at row m, column n\n \n med = D[m, n]\n return D, med",
"_____no_output_____"
],
[
"# testing your implementation \nsource = 'play'\ntarget = 'stay'\nmatrix, min_edits = min_edit_distance(source, target)\nprint(\"minimum edits: \",min_edits, \"\\n\")\nidx = list('#' + source)\ncols = list('#' + target)\ndf = pd.DataFrame(matrix, index=idx, columns= cols)\nprint(df)",
"minimum edits: 4 \n\n # s t a y\n# 0 1 2 3 4\np 1 2 3 4 5\nl 2 3 4 5 6\na 3 4 5 4 5\ny 4 5 6 5 4\n"
],
[
"# testing your implementation \nsource = 'eer'\ntarget = 'near'\nmatrix, min_edits = min_edit_distance(source, target)\nprint(\"minimum edits: \",min_edits, \"\\n\")\nidx = list(source)\nidx.insert(0, '#')\ncols = list(target)\ncols.insert(0, '#')\ndf = pd.DataFrame(matrix, index=idx, columns= cols)\nprint(df)",
"minimum edits: 3 \n\n # n e a r\n# 0 1 2 3 4\ne 1 2 1 2 3\ne 2 3 2 3 4\nr 3 4 3 4 3\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
]
] |
d0fb0168efe45e635577b7ea5397ce0fffe8236b | 133,492 | ipynb | Jupyter Notebook | Week 6 _ Condiitonal Probability/Topic6_Lecture.ipynb | ebishwaraj/ProbabilityStatisticsPython_DSE210x_UCSD_DataScienceMicroMasters | 3c29447c62c74d4831129f44c72a74432b213c99 | [
"MIT"
] | 1 | 2020-12-23T15:22:27.000Z | 2020-12-23T15:22:27.000Z | Week 6 _ Condiitonal Probability/Topic6_Lecture.ipynb | ebishwaraj/ProbabilityStatisticsPython_DSE210x_UCSD_DataScienceMicroMasters | 3c29447c62c74d4831129f44c72a74432b213c99 | [
"MIT"
] | null | null | null | Week 6 _ Condiitonal Probability/Topic6_Lecture.ipynb | ebishwaraj/ProbabilityStatisticsPython_DSE210x_UCSD_DataScienceMicroMasters | 3c29447c62c74d4831129f44c72a74432b213c99 | [
"MIT"
] | null | null | null | 241.833333 | 24,788 | 0.907305 | [
[
[
"## Birthday Paradox",
"_____no_output_____"
],
[
"In a group of 5 people, how likely is it that everyone has a unique birthday (assuming that nobody was born on February 29th of a leap year)? You may feel it is highly likely because there are $365$ days in a year and loosely speaking, $365$ is \"much greater\" than $5$. Indeed, as you shall see, this probability is greater than $0.9$. However, in a group of $25$ or more, what is the probability that no two persons have the same birthday? You might be surprised to know that the answer is less than a half. This is known as the \"birthday paradox\".\n\nIn general, for a group of $n$ people, the probability that no two persons share the same birthday can be calculated as:\n\n\\begin{align*}\nP &= \\frac{\\text{Number of } n \\text{-permutations of birthdays}}{\\text{Total number of birthday assignments allowing repeated birthdays}}\\\\\n&= \\frac{365!/(365-n)!}{365^n}\\\\\n&= \\prod_{k=1}^n \\frac{365-k+1}{365}\n\\end{align*}\n\nObserve that this value decreases with $n$. At $n=23$, this value goes below half. The following cell simulates this event and compares the associated empirical and theoretical probabilities. You can use the slider called \"iterations\" to vary the number of iterations performed by the code.",
"_____no_output_____"
]
],
[
[
"import itertools\nimport random\n\nimport matplotlib.pyplot as plt\nimport numpy as np\n\nfrom ipywidgets import interact, interactive, fixed, interact_manual\nimport ipywidgets as widgets\n\n\n# Range of number of people\nPEOPLE = np.arange(1, 26)\n\n# Days in year\nDAYS = 365\n\n\ndef prob_unique_birthdays(num_people):\n '''\n Returns the probability that all birthdays are unique, among a given\n number of people with uniformly-distributed birthdays.\n '''\n return (np.arange(DAYS, DAYS - num_people, -1) / DAYS).prod()\n\n\ndef sample_unique_birthdays(num_people):\n '''\n Selects a sample of people with uniformly-distributed birthdays, and\n returns True if all birthdays are unique (or False otherwise).\n '''\n bdays = np.random.randint(0, DAYS, size=num_people)\n unique_bdays = np.unique(bdays)\n return len(bdays) == len(unique_bdays)\n\n\ndef plot_probs(iterations):\n '''\n Plots a comparison of the probability of a group of people all having\n unique birthdays, between the theoretical and empirical probabilities.\n '''\n sample_prob = [] # Empirical prob. of unique-birthday sample \n prob = [] # Theoretical prob. of unique-birthday sample\n \n # Compute data points to plot\n np.random.seed(1)\n for num_people in PEOPLE:\n unique_count = sum(sample_unique_birthdays(num_people)\n for i in range(iterations))\n sample_prob.append(unique_count / iterations)\n prob.append(prob_unique_birthdays(num_people))\n \n # Plot results\n plt.plot(PEOPLE, prob, 'k-', linewidth = 3.0, label='Theoretical probability')\n plt.plot(PEOPLE, sample_prob, 'bo-', linewidth = 3.0, label='Empirical probability')\n plt.gcf().set_size_inches(20, 10)\n plt.axhline(0.5, color='red', linewidth = 4.0, label='0.5 threshold')\n plt.xlabel('Number of people', fontsize = 18)\n plt.ylabel('Probability of unique birthdays', fontsize = 18)\n plt.grid()\n plt.xticks(fontsize = 18)\n plt.yticks(fontsize = 18)\n plt.legend(fontsize = 18)\n plt.show()\n\n \ninteract(plot_probs,\n iterations=widgets.IntSlider(min=50, value = 500, max=5050, step=200),\n continuous_update=False, layout='bottom');",
"_____no_output_____"
]
],
[
[
"## Conditional Probability ",
"_____no_output_____"
],
[
"Oftentimes it is advantageous to infer the probability of certain events conditioned on other events. Say you want to estimate the probability that it will rain on a particular day. There are copious number of factors that affect rain on a particular day, but [certain clouds are good indicators of rains](https://www.nationalgeographic.com/science/earth/earths-atmosphere/clouds/). Then the question is how likely are clouds a precursor to rains? These types of problems are called [statistical classification](https://en.wikipedia.org/wiki/Statistical_classification), and concepts such as conditional probability and Bayes rule play an important role in its solution.\n\nDice, coins and cards are useful examples which we can use to understand the fundamental concepts of probability. There are even more interesting real world examples where we can apply these principles to. Let us analyze the [student alcohol consumption](https://www.kaggle.com/uciml/student-alcohol-consumption) dataset and see if we can infer any information regarding a student's performance relative to the time they spend studying. \n\n<span style=\"color:red\">NOTE:</span> Before continuing, please download the dataset and add it to the folder where this notebook resides. If necessary, you can also review our Pandas notebook.",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"The dataset consists of two parts, `student-por.csv` and `student-mat.csv`, represents the students' performance in Portuguese and Math courses, respectively. We will consider the scores in the Portuguese courses, and leave the math courses optionally to you. ",
"_____no_output_____"
]
],
[
[
"data_por = pd.read_csv(\"student-por.csv\")",
"_____no_output_____"
]
],
[
[
"Of the dataset's [various attributes](https://www.kaggle.com/uciml/student-alcohol-consumption/home), we will use the following two\n- `G3` - final grade related with the course subject, Math or Portuguese (numeric: from 0 to 20, output target) \n- `studytime` - weekly study time (numeric: 1 : < 2 hours, 2 : 2 to 5 hours, 3 : 5 to 10 hours, or 4 : > 10 hours) ",
"_____no_output_____"
]
],
[
[
"attributes = [\"G3\",\"studytime\"]\ndata_por = data_por[attributes]",
"_____no_output_____"
]
],
[
[
"We are interested in the relationship between study-time and grade performance, but to start, let us view each attribute individually. \n\nThe probability that a student's study-time falls in an interval can be approximated by\n\n$${P(\\text{study interval}) = \\frac{\\text{Number of students with this study interval}}{Total\\ number\\ of\\ students}}$$\n\nThis is an emperical estimate, and in later lectures we will reason why this is a valid assumption.",
"_____no_output_____"
]
],
[
[
"data_temp = data_por[\"studytime\"].value_counts()\nP_studytime = pd.DataFrame((data_temp/data_temp.sum()).sort_index())\nP_studytime.index = [\"< 2 hours\",\"2 to 5 hours\",\"5 to 10 hours\",\"> 10 hours\"]\nP_studytime.columns = [\"Probability\"]\nP_studytime.columns.name = \"Study Interval\"\n\nP_studytime.plot.bar(figsize=(12,9),fontsize=18)\nplt.ylabel(\"Probability\",fontsize=16)\nplt.xlabel(\"Study Interval\",fontsize=18)",
"_____no_output_____"
]
],
[
[
"Note that the largest number of students studied between two and five hours, and the smallest studied over 10 hours. \n\nLet us call scores of at least 15 \"high\". The probability of a student getting a high score can be approximated by\n\n$$P(\\text{high score}) = \\frac{\\text{Number of students with high scores}}{\\text{Total number of students}}$$",
"_____no_output_____"
]
],
[
[
"data_temp = (data_por[\"G3\"]>=15).value_counts()\nP_score15_p = pd.DataFrame(data_temp/data_temp.sum())\nP_score15_p.index = [\"Low\",\"High\"]\nP_score15_p.columns = [\"Probability\"]\nP_score15_p.columns.name = \"Score\"\nprint(P_score15_p)\nP_score15_p.plot.bar(figsize=(10,6),fontsize=16)\nplt.xlabel(\"Score\",fontsize=18)\nplt.ylabel(\"Probability\",fontsize=18)",
"Score Probability\nLow 0.798151\nHigh 0.201849\n"
]
],
[
[
"Proceeding to more interesting observations, suppose we want to find the probability of the various study-intervals when the student scored high. By conditional probability, this can be calculated by:\n\n$$P(\\text{study interval}\\ |\\ \\text{highscore})=\\frac{\\text{Number of students with study interval AND highscore}}{\\text{Total number of students with highscore}}$$",
"_____no_output_____"
]
],
[
[
"score = 15\ndata_temp = data_por.loc[data_por[\"G3\"]>=score,\"studytime\"]\nP_T_given_score15= pd.DataFrame((data_temp.value_counts()/data_temp.shape[0]).sort_index())\nP_T_given_score15.index = [\"< 2 hours\",\"2 to 5 hours\",\"5 to 10 hours\",\"> 10 hours\"]\nP_T_given_score15.columns = [\"Probability\"]\nprint(\"Probability of study interval given that the student gets a highscore:\")\nP_T_given_score15.columns.name=\"Study Interval\"\nP_T_given_score15.plot.bar(figsize=(12,9),fontsize=16)\nplt.xlabel(\"Studt interval\",fontsize=18)\nplt.ylabel(\"Probability\",fontsize=18)",
"Probability of study interval given that the student gets a highscore:\n"
]
],
[
[
"The above metric is something we can only calculate after the students have obtained their results. But how about the other way? What if we want to **predict** the probability that a student gets a score greater than 15 given that they studied for a particular period of time . Using the estimated values we can use the **Bayes rule** to calculate this probability.\n\n$$P(\\text{student getting a highscore}\\ |\\ \\text{study interval})=\\frac{P(\\text{study interval}\\ |\\ \\text{the student scored high})P(\\text{highscore})}{P(\\text{study interval})}$$",
"_____no_output_____"
]
],
[
[
"P_score15_given_T_p = P_T_given_score15 * P_score15_p.loc[\"High\"] / P_studytime\nprint(\"Probability of high score given study interval :\")\npd.DataFrame(P_score15_given_T_p).plot.bar(figsize=(12,9),fontsize=18).legend(loc=\"best\")\nplt.xlabel(\"Study interval\",fontsize=18)\nplt.ylabel(\"Probability\",fontsize=18)",
"Probability of high score given study interval :\n"
]
],
[
[
"Do you find the results surprising? Roughly speaking, the longer students study, the more likely they are to score high. However, once they study over 10 hours, their chances of scoring high decline. You may want to check whether the same phenomenon occurs for the math scores too. ",
"_____no_output_____"
],
[
"## Try it yourself ",
"_____no_output_____"
],
[
"If interested, you can try the same analysis for the students math scores. For example, you can get the probabilities of the different study intervals. ",
"_____no_output_____"
]
],
[
[
"data_math = pd.read_csv(\"student-mat.csv\")",
"_____no_output_____"
],
[
"data_temp = data_math[\"studytime\"].value_counts()\nP_studytime_m = pd.DataFrame(data_temp/data_temp.sum())\nP_studytime_m.index = [\"< 2 hours\",\"2 to 5 hours\",\"5 to 10 hours\",\"> 10 hours\"]\nP_studytime_m.columns = [\"Probability\"]\nP_studytime_m.columns.name = \"Study Interval\"\nP_studytime_m.plot.bar(figsize=(12,9),fontsize=16)\nplt.xlabel(\"Study Interval\",fontsize=18)\nplt.ylabel(\"Probability\",fontsize=18)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
]
] |
d0fb0eaa1b54f93eae046f585a2ad8403c5a9599 | 507,820 | ipynb | Jupyter Notebook | tensorflow/lite/micro/examples/hello_world/train/train_hello_world_model.ipynb | ErikGro/tensorflow | 68afd83ce2eb1a1d466e141e6cd0e3e8cab84c3b | [
"Apache-2.0"
] | 78 | 2020-08-04T12:36:25.000Z | 2022-03-25T04:23:40.000Z | tensorflow/lite/micro/examples/hello_world/train/train_hello_world_model.ipynb | ErikGro/tensorflow | 68afd83ce2eb1a1d466e141e6cd0e3e8cab84c3b | [
"Apache-2.0"
] | 10 | 2021-08-03T08:42:38.000Z | 2022-01-03T03:29:12.000Z | tensorflow/lite/micro/examples/hello_world/train/train_hello_world_model.ipynb | ErikGro/tensorflow | 68afd83ce2eb1a1d466e141e6cd0e3e8cab84c3b | [
"Apache-2.0"
] | 28 | 2020-02-10T07:03:06.000Z | 2022-01-12T11:19:20.000Z | 144.719293 | 44,802 | 0.698937 | [
[
[
"# Train a basic TensorFlow Lite for Microcontrollers model\n\nThis notebook demonstrates the process of training a 2.5 kB model using TensorFlow and converting it for use with TensorFlow Lite for Microcontrollers. \n\nDeep learning networks learn to model patterns in underlying data. Here, we're going to train a network to model data generated by a [sine](https://en.wikipedia.org/wiki/Sine) function. This will result in a model that can take a value, `x`, and predict its sine, `y`.\n\nThe model created in this notebook is used in the [hello_world](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro/examples/hello_world) example for [TensorFlow Lite for MicroControllers](https://www.tensorflow.org/lite/microcontrollers/overview).\n\n<table class=\"tfo-notebook-buttons\" align=\"left\">\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/examples/hello_world/train/train_hello_world_model.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Run in Google Colab</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/examples/hello_world/train/train_hello_world_model.ipynb\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />View source on GitHub</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"**Training is much faster using GPU acceleration.** Before you proceed, ensure you are using a GPU runtime by going to **Runtime -> Change runtime type** and set **Hardware accelerator: GPU**.",
"_____no_output_____"
],
[
"## Configure Defaults",
"_____no_output_____"
]
],
[
[
"# Define paths to model files\nimport os\nMODELS_DIR = 'models/'\nif not os.path.exists(MODELS_DIR):\n os.mkdir(MODELS_DIR)\nMODEL_TF = MODELS_DIR + 'model.pb'\nMODEL_NO_QUANT_TFLITE = MODELS_DIR + 'model_no_quant.tflite'\nMODEL_TFLITE = MODELS_DIR + 'model.tflite'\nMODEL_TFLITE_MICRO = MODELS_DIR + 'model.cc'",
"_____no_output_____"
]
],
[
[
"## Setup Environment\n\nInstall Dependencies",
"_____no_output_____"
]
],
[
[
"! pip install -q tensorflow==2",
"\u001b[K |████████████████████████████████| 86.3MB 52kB/s \n\u001b[K |████████████████████████████████| 450kB 46.2MB/s \n\u001b[K |████████████████████████████████| 3.8MB 50.3MB/s \n\u001b[?25h Building wheel for gast (setup.py) ... \u001b[?25l\u001b[?25hdone\n"
]
],
[
[
"Set Seed for Repeatable Results",
"_____no_output_____"
]
],
[
[
"# Set a \"seed\" value, so we get the same random numbers each time we run this\n# notebook for reproducible results.\n# Numpy is a math library\nimport numpy as np\nnp.random.seed(1) # numpy seed\n# TensorFlow is an open source machine learning library\nimport tensorflow as tf\ntf.random.set_seed(1) # tensorflow global random seed",
"_____no_output_____"
]
],
[
[
"Import Dependencies",
"_____no_output_____"
]
],
[
[
"# Keras is TensorFlow's high-level API for deep learning\nfrom tensorflow import keras\n# Matplotlib is a graphing library\nimport matplotlib.pyplot as plt\n# Math is Python's math library\nimport math",
"_____no_output_____"
]
],
[
[
"## Dataset",
"_____no_output_____"
],
[
"### 1. Generate Data\n\nThe code in the following cell will generate a set of random `x` values, calculate their sine values, and display them on a graph.",
"_____no_output_____"
]
],
[
[
"# Number of sample datapoints\nSAMPLES = 1000\n\n# Generate a uniformly distributed set of random numbers in the range from\n# 0 to 2π, which covers a complete sine wave oscillation\nx_values = np.random.uniform(\n low=0, high=2*math.pi, size=SAMPLES).astype(np.float32)\n\n# Shuffle the values to guarantee they're not in order\nnp.random.shuffle(x_values)\n\n# Calculate the corresponding sine values\ny_values = np.sin(x_values).astype(np.float32)\n\n# Plot our data. The 'b.' argument tells the library to print blue dots.\nplt.plot(x_values, y_values, 'b.')\nplt.show()",
"_____no_output_____"
]
],
[
[
"### 2. Add Noise\nSince it was generated directly by the sine function, our data fits a nice, smooth curve.\n\nHowever, machine learning models are good at extracting underlying meaning from messy, real world data. To demonstrate this, we can add some noise to our data to approximate something more life-like.\n\nIn the following cell, we'll add some random noise to each value, then draw a new graph:",
"_____no_output_____"
]
],
[
[
"# Add a small random number to each y value\ny_values += 0.1 * np.random.randn(*y_values.shape)\n\n# Plot our data\nplt.plot(x_values, y_values, 'b.')\nplt.show()",
"_____no_output_____"
]
],
[
[
"### 3. Split the Data\nWe now have a noisy dataset that approximates real world data. We'll be using this to train our model.\n\nTo evaluate the accuracy of the model we train, we'll need to compare its predictions to real data and check how well they match up. This evaluation happens during training (where it is referred to as validation) and after training (referred to as testing) It's important in both cases that we use fresh data that was not already used to train the model.\n\nThe data is split as follows:\n 1. Training: 60%\n 2. Validation: 20%\n 3. Testing: 20% \n\nThe following code will split our data and then plots each set as a different color:\n",
"_____no_output_____"
]
],
[
[
"# We'll use 60% of our data for training and 20% for testing. The remaining 20%\n# will be used for validation. Calculate the indices of each section.\nTRAIN_SPLIT = int(0.6 * SAMPLES)\nTEST_SPLIT = int(0.2 * SAMPLES + TRAIN_SPLIT)\n\n# Use np.split to chop our data into three parts.\n# The second argument to np.split is an array of indices where the data will be\n# split. We provide two indices, so the data will be divided into three chunks.\nx_train, x_test, x_validate = np.split(x_values, [TRAIN_SPLIT, TEST_SPLIT])\ny_train, y_test, y_validate = np.split(y_values, [TRAIN_SPLIT, TEST_SPLIT])\n\n# Double check that our splits add up correctly\nassert (x_train.size + x_validate.size + x_test.size) == SAMPLES\n\n# Plot the data in each partition in different colors:\nplt.plot(x_train, y_train, 'b.', label=\"Train\")\nplt.plot(x_test, y_test, 'r.', label=\"Test\")\nplt.plot(x_validate, y_validate, 'y.', label=\"Validate\")\nplt.legend()\nplt.show()\n",
"_____no_output_____"
]
],
[
[
"## Training",
"_____no_output_____"
],
[
"### 1. Design the Model\nWe're going to build a simple neural network model that will take an input value (in this case, `x`) and use it to predict a numeric output value (the sine of `x`). This type of problem is called a _regression_. It will use _layers_ of _neurons_ to attempt to learn any patterns underlying the training data, so it can make predictions.\n\nTo begin with, we'll define two layers. The first layer takes a single input (our `x` value) and runs it through 8 neurons. Based on this input, each neuron will become _activated_ to a certain degree based on its internal state (its _weight_ and _bias_ values). A neuron's degree of activation is expressed as a number.\n\nThe activation numbers from our first layer will be fed as inputs to our second layer, which is a single neuron. It will apply its own weights and bias to these inputs and calculate its own activation, which will be output as our `y` value.\n\n**Note:** To learn more about how neural networks function, you can explore the [Learn TensorFlow](https://codelabs.developers.google.com/codelabs/tensorflow-lab1-helloworld) codelabs.\n\nThe code in the following cell defines our model using [Keras](https://www.tensorflow.org/guide/keras), TensorFlow's high-level API for creating deep learning networks. Once the network is defined, we _compile_ it, specifying parameters that determine how it will be trained:",
"_____no_output_____"
]
],
[
[
"# We'll use Keras to create a simple model architecture\nmodel_1 = tf.keras.Sequential()\n\n# First layer takes a scalar input and feeds it through 8 \"neurons\". The\n# neurons decide whether to activate based on the 'relu' activation function.\nmodel_1.add(keras.layers.Dense(8, activation='relu', input_shape=(1,)))\n\n# Final layer is a single neuron, since we want to output a single value\nmodel_1.add(keras.layers.Dense(1))\n\n# Compile the model using a standard optimizer and loss function for regression\nmodel_1.compile(optimizer='adam', loss='mse', metrics=['mae'])",
"_____no_output_____"
]
],
[
[
"### 2. Train the Model\nOnce we've defined the model, we can use our data to _train_ it. Training involves passing an `x` value into the neural network, checking how far the network's output deviates from the expected `y` value, and adjusting the neurons' weights and biases so that the output is more likely to be correct the next time.\n\nTraining runs this process on the full dataset multiple times, and each full run-through is known as an _epoch_. The number of epochs to run during training is a parameter we can set.\n\nDuring each epoch, data is run through the network in multiple _batches_. Each batch, several pieces of data are passed into the network, producing output values. These outputs' correctness is measured in aggregate and the network's weights and biases are adjusted accordingly, once per batch. The _batch size_ is also a parameter we can set.\n\nThe code in the following cell uses the `x` and `y` values from our training data to train the model. It runs for 500 _epochs_, with 64 pieces of data in each _batch_. We also pass in some data for _validation_. As you will see when you run the cell, training can take a while to complete:\n\n",
"_____no_output_____"
]
],
[
[
"# Train the model on our training data while validating on our validation set\nhistory_1 = model_1.fit(x_train, y_train, epochs=500, batch_size=64,\n validation_data=(x_validate, y_validate))",
"Train on 600 samples, validate on 200 samples\nEpoch 1/500\n600/600 [==============================] - 1s 971us/sample - loss: 0.6936 - mae: 0.6897 - val_loss: 0.6396 - val_mae: 0.6501\nEpoch 2/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.5965 - mae: 0.6254 - val_loss: 0.5594 - val_mae: 0.6035\nEpoch 3/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.5240 - mae: 0.5830 - val_loss: 0.5021 - val_mae: 0.5765\nEpoch 4/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.4724 - mae: 0.5549 - val_loss: 0.4634 - val_mae: 0.5615\nEpoch 5/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.4392 - mae: 0.5390 - val_loss: 0.4375 - val_mae: 0.5533\nEpoch 6/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.4174 - mae: 0.5305 - val_loss: 0.4215 - val_mae: 0.5487\nEpoch 7/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.4026 - mae: 0.5244 - val_loss: 0.4119 - val_mae: 0.5464\nEpoch 8/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.3939 - mae: 0.5225 - val_loss: 0.4057 - val_mae: 0.5452\nEpoch 9/500\n600/600 [==============================] - 0s 44us/sample - loss: 0.3880 - mae: 0.5216 - val_loss: 0.4015 - val_mae: 0.5439\nEpoch 10/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.3836 - mae: 0.5210 - val_loss: 0.3981 - val_mae: 0.5425\nEpoch 11/500\n600/600 [==============================] - 0s 44us/sample - loss: 0.3802 - mae: 0.5205 - val_loss: 0.3950 - val_mae: 0.5412\nEpoch 12/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.3770 - mae: 0.5200 - val_loss: 0.3922 - val_mae: 0.5400\nEpoch 13/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.3741 - mae: 0.5189 - val_loss: 0.3894 - val_mae: 0.5385\nEpoch 14/500\n600/600 [==============================] - 0s 41us/sample - loss: 0.3712 - mae: 0.5173 - val_loss: 0.3866 - val_mae: 0.5368\nEpoch 15/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.3686 - mae: 0.5162 - val_loss: 0.3837 - val_mae: 0.5354\nEpoch 16/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.3655 - mae: 0.5143 - val_loss: 0.3808 - val_mae: 0.5335\nEpoch 17/500\n600/600 [==============================] - 0s 42us/sample - loss: 0.3627 - mae: 0.5122 - val_loss: 0.3777 - val_mae: 0.5314\nEpoch 18/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.3597 - mae: 0.5101 - val_loss: 0.3748 - val_mae: 0.5296\nEpoch 19/500\n600/600 [==============================] - 0s 44us/sample - loss: 0.3567 - mae: 0.5080 - val_loss: 0.3717 - val_mae: 0.5276\nEpoch 20/500\n600/600 [==============================] - 0s 42us/sample - loss: 0.3538 - mae: 0.5059 - val_loss: 0.3686 - val_mae: 0.5256\nEpoch 21/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.3507 - mae: 0.5037 - val_loss: 0.3654 - val_mae: 0.5234\nEpoch 22/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.3477 - mae: 0.5012 - val_loss: 0.3622 - val_mae: 0.5211\nEpoch 23/500\n600/600 [==============================] - 0s 41us/sample - loss: 0.3447 - mae: 0.4993 - val_loss: 0.3591 - val_mae: 0.5195\nEpoch 24/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.3414 - mae: 0.4970 - val_loss: 0.3558 - val_mae: 0.5172\nEpoch 25/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.3385 - mae: 0.4949 - val_loss: 0.3526 - val_mae: 0.5153\nEpoch 26/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.3352 - mae: 0.4926 - val_loss: 0.3493 - val_mae: 0.5130\nEpoch 27/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.3321 - mae: 0.4904 - val_loss: 0.3461 - val_mae: 0.5110\nEpoch 28/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.3288 - mae: 0.4880 - val_loss: 0.3429 - val_mae: 0.5087\nEpoch 29/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.3257 - mae: 0.4854 - val_loss: 0.3395 - val_mae: 0.5064\nEpoch 30/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.3227 - mae: 0.4831 - val_loss: 0.3362 - val_mae: 0.5041\nEpoch 31/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.3195 - mae: 0.4806 - val_loss: 0.3330 - val_mae: 0.5018\nEpoch 32/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.3165 - mae: 0.4782 - val_loss: 0.3298 - val_mae: 0.4996\nEpoch 33/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.3133 - mae: 0.4760 - val_loss: 0.3267 - val_mae: 0.4976\nEpoch 34/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.3103 - mae: 0.4738 - val_loss: 0.3235 - val_mae: 0.4952\nEpoch 35/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.3072 - mae: 0.4713 - val_loss: 0.3203 - val_mae: 0.4930\nEpoch 36/500\n600/600 [==============================] - 0s 100us/sample - loss: 0.3042 - mae: 0.4694 - val_loss: 0.3173 - val_mae: 0.4913\nEpoch 37/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.3012 - mae: 0.4673 - val_loss: 0.3141 - val_mae: 0.4890\nEpoch 38/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.2981 - mae: 0.4651 - val_loss: 0.3111 - val_mae: 0.4869\nEpoch 39/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.2952 - mae: 0.4625 - val_loss: 0.3078 - val_mae: 0.4841\nEpoch 40/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.2921 - mae: 0.4602 - val_loss: 0.3049 - val_mae: 0.4822\nEpoch 41/500\n600/600 [==============================] - 0s 42us/sample - loss: 0.2891 - mae: 0.4585 - val_loss: 0.3021 - val_mae: 0.4810\nEpoch 42/500\n600/600 [==============================] - 0s 44us/sample - loss: 0.2861 - mae: 0.4568 - val_loss: 0.2991 - val_mae: 0.4790\nEpoch 43/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.2832 - mae: 0.4546 - val_loss: 0.2961 - val_mae: 0.4767\nEpoch 44/500\n600/600 [==============================] - 0s 42us/sample - loss: 0.2803 - mae: 0.4523 - val_loss: 0.2931 - val_mae: 0.4741\nEpoch 45/500\n600/600 [==============================] - 0s 41us/sample - loss: 0.2775 - mae: 0.4503 - val_loss: 0.2902 - val_mae: 0.4723\nEpoch 46/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.2746 - mae: 0.4482 - val_loss: 0.2873 - val_mae: 0.4701\nEpoch 47/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.2719 - mae: 0.4464 - val_loss: 0.2846 - val_mae: 0.4685\nEpoch 48/500\n600/600 [==============================] - 0s 44us/sample - loss: 0.2691 - mae: 0.4444 - val_loss: 0.2818 - val_mae: 0.4666\nEpoch 49/500\n600/600 [==============================] - 0s 44us/sample - loss: 0.2663 - mae: 0.4425 - val_loss: 0.2791 - val_mae: 0.4646\nEpoch 50/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.2636 - mae: 0.4404 - val_loss: 0.2764 - val_mae: 0.4625\nEpoch 51/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.2610 - mae: 0.4382 - val_loss: 0.2736 - val_mae: 0.4599\nEpoch 52/500\n600/600 [==============================] - 0s 41us/sample - loss: 0.2583 - mae: 0.4361 - val_loss: 0.2711 - val_mae: 0.4580\nEpoch 53/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.2558 - mae: 0.4344 - val_loss: 0.2685 - val_mae: 0.4561\nEpoch 54/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.2532 - mae: 0.4326 - val_loss: 0.2659 - val_mae: 0.4539\nEpoch 55/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.2508 - mae: 0.4307 - val_loss: 0.2634 - val_mae: 0.4518\nEpoch 56/500\n600/600 [==============================] - 0s 65us/sample - loss: 0.2483 - mae: 0.4288 - val_loss: 0.2609 - val_mae: 0.4499\nEpoch 57/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.2459 - mae: 0.4271 - val_loss: 0.2586 - val_mae: 0.4485\nEpoch 58/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.2436 - mae: 0.4255 - val_loss: 0.2561 - val_mae: 0.4464\nEpoch 59/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.2411 - mae: 0.4239 - val_loss: 0.2540 - val_mae: 0.4451\nEpoch 60/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.2387 - mae: 0.4220 - val_loss: 0.2516 - val_mae: 0.4431\nEpoch 61/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.2365 - mae: 0.4202 - val_loss: 0.2493 - val_mae: 0.4411\nEpoch 62/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.2343 - mae: 0.4186 - val_loss: 0.2472 - val_mae: 0.4395\nEpoch 63/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.2322 - mae: 0.4169 - val_loss: 0.2450 - val_mae: 0.4375\nEpoch 64/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.2301 - mae: 0.4151 - val_loss: 0.2428 - val_mae: 0.4355\nEpoch 65/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.2280 - mae: 0.4134 - val_loss: 0.2408 - val_mae: 0.4338\nEpoch 66/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.2260 - mae: 0.4118 - val_loss: 0.2388 - val_mae: 0.4323\nEpoch 67/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.2241 - mae: 0.4104 - val_loss: 0.2369 - val_mae: 0.4308\nEpoch 68/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.2222 - mae: 0.4089 - val_loss: 0.2351 - val_mae: 0.4293\nEpoch 69/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.2204 - mae: 0.4076 - val_loss: 0.2334 - val_mae: 0.4280\nEpoch 70/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.2188 - mae: 0.4062 - val_loss: 0.2314 - val_mae: 0.4255\nEpoch 71/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.2168 - mae: 0.4043 - val_loss: 0.2297 - val_mae: 0.4246\nEpoch 72/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.2151 - mae: 0.4031 - val_loss: 0.2280 - val_mae: 0.4231\nEpoch 73/500\n600/600 [==============================] - 0s 40us/sample - loss: 0.2135 - mae: 0.4019 - val_loss: 0.2265 - val_mae: 0.4224\nEpoch 74/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.2120 - mae: 0.4007 - val_loss: 0.2247 - val_mae: 0.4203\nEpoch 75/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.2102 - mae: 0.3992 - val_loss: 0.2233 - val_mae: 0.4194\nEpoch 76/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.2087 - mae: 0.3980 - val_loss: 0.2216 - val_mae: 0.4178\nEpoch 77/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.2071 - mae: 0.3965 - val_loss: 0.2199 - val_mae: 0.4158\nEpoch 78/500\n600/600 [==============================] - 0s 42us/sample - loss: 0.2056 - mae: 0.3951 - val_loss: 0.2185 - val_mae: 0.4144\nEpoch 79/500\n600/600 [==============================] - 0s 44us/sample - loss: 0.2044 - mae: 0.3938 - val_loss: 0.2170 - val_mae: 0.4122\nEpoch 80/500\n600/600 [==============================] - 0s 41us/sample - loss: 0.2029 - mae: 0.3926 - val_loss: 0.2159 - val_mae: 0.4123\nEpoch 81/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.2015 - mae: 0.3915 - val_loss: 0.2145 - val_mae: 0.4108\nEpoch 82/500\n600/600 [==============================] - 0s 42us/sample - loss: 0.2002 - mae: 0.3902 - val_loss: 0.2131 - val_mae: 0.4091\nEpoch 83/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.1989 - mae: 0.3890 - val_loss: 0.2119 - val_mae: 0.4081\nEpoch 84/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1977 - mae: 0.3878 - val_loss: 0.2107 - val_mae: 0.4071\nEpoch 85/500\n600/600 [==============================] - 0s 42us/sample - loss: 0.1965 - mae: 0.3867 - val_loss: 0.2095 - val_mae: 0.4057\nEpoch 86/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.1953 - mae: 0.3857 - val_loss: 0.2082 - val_mae: 0.4044\nEpoch 87/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.1941 - mae: 0.3843 - val_loss: 0.2072 - val_mae: 0.4032\nEpoch 88/500\n600/600 [==============================] - 0s 41us/sample - loss: 0.1930 - mae: 0.3834 - val_loss: 0.2062 - val_mae: 0.4028\nEpoch 89/500\n600/600 [==============================] - 0s 42us/sample - loss: 0.1920 - mae: 0.3825 - val_loss: 0.2053 - val_mae: 0.4018\nEpoch 90/500\n600/600 [==============================] - 0s 60us/sample - loss: 0.1913 - mae: 0.3819 - val_loss: 0.2046 - val_mae: 0.4018\nEpoch 91/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1902 - mae: 0.3808 - val_loss: 0.2033 - val_mae: 0.3994\nEpoch 92/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1892 - mae: 0.3796 - val_loss: 0.2025 - val_mae: 0.3989\nEpoch 93/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1882 - mae: 0.3786 - val_loss: 0.2015 - val_mae: 0.3970\nEpoch 94/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1875 - mae: 0.3776 - val_loss: 0.2006 - val_mae: 0.3959\nEpoch 95/500\n600/600 [==============================] - 0s 58us/sample - loss: 0.1870 - mae: 0.3768 - val_loss: 0.1998 - val_mae: 0.3941\nEpoch 96/500\n600/600 [==============================] - 0s 67us/sample - loss: 0.1861 - mae: 0.3760 - val_loss: 0.1992 - val_mae: 0.3947\nEpoch 97/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.1852 - mae: 0.3751 - val_loss: 0.1984 - val_mae: 0.3937\nEpoch 98/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1843 - mae: 0.3742 - val_loss: 0.1980 - val_mae: 0.3939\nEpoch 99/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1837 - mae: 0.3737 - val_loss: 0.1976 - val_mae: 0.3940\nEpoch 100/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1832 - mae: 0.3733 - val_loss: 0.1970 - val_mae: 0.3936\nEpoch 101/500\n600/600 [==============================] - 0s 44us/sample - loss: 0.1828 - mae: 0.3727 - val_loss: 0.1960 - val_mae: 0.3910\nEpoch 102/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.1820 - mae: 0.3717 - val_loss: 0.1956 - val_mae: 0.3913\nEpoch 103/500\n600/600 [==============================] - 0s 64us/sample - loss: 0.1812 - mae: 0.3708 - val_loss: 0.1950 - val_mae: 0.3903\nEpoch 104/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1806 - mae: 0.3701 - val_loss: 0.1946 - val_mae: 0.3898\nEpoch 105/500\n600/600 [==============================] - 0s 58us/sample - loss: 0.1802 - mae: 0.3695 - val_loss: 0.1939 - val_mae: 0.3886\nEpoch 106/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1795 - mae: 0.3686 - val_loss: 0.1932 - val_mae: 0.3871\nEpoch 107/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1790 - mae: 0.3679 - val_loss: 0.1928 - val_mae: 0.3866\nEpoch 108/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.1786 - mae: 0.3674 - val_loss: 0.1924 - val_mae: 0.3864\nEpoch 109/500\n600/600 [==============================] - 0s 40us/sample - loss: 0.1783 - mae: 0.3667 - val_loss: 0.1919 - val_mae: 0.3849\nEpoch 110/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1781 - mae: 0.3666 - val_loss: 0.1919 - val_mae: 0.3861\nEpoch 111/500\n600/600 [==============================] - 0s 68us/sample - loss: 0.1774 - mae: 0.3658 - val_loss: 0.1912 - val_mae: 0.3843\nEpoch 112/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1770 - mae: 0.3653 - val_loss: 0.1911 - val_mae: 0.3846\nEpoch 113/500\n600/600 [==============================] - 0s 42us/sample - loss: 0.1766 - mae: 0.3647 - val_loss: 0.1906 - val_mae: 0.3833\nEpoch 114/500\n600/600 [==============================] - 0s 41us/sample - loss: 0.1763 - mae: 0.3642 - val_loss: 0.1903 - val_mae: 0.3831\nEpoch 115/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.1758 - mae: 0.3636 - val_loss: 0.1898 - val_mae: 0.3817\nEpoch 116/500\n600/600 [==============================] - 0s 41us/sample - loss: 0.1755 - mae: 0.3630 - val_loss: 0.1897 - val_mae: 0.3821\nEpoch 117/500\n600/600 [==============================] - 0s 42us/sample - loss: 0.1752 - mae: 0.3627 - val_loss: 0.1893 - val_mae: 0.3810\nEpoch 118/500\n600/600 [==============================] - 0s 42us/sample - loss: 0.1749 - mae: 0.3621 - val_loss: 0.1890 - val_mae: 0.3805\nEpoch 119/500\n600/600 [==============================] - 0s 42us/sample - loss: 0.1747 - mae: 0.3617 - val_loss: 0.1888 - val_mae: 0.3802\nEpoch 120/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1743 - mae: 0.3612 - val_loss: 0.1885 - val_mae: 0.3794\nEpoch 121/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1743 - mae: 0.3610 - val_loss: 0.1885 - val_mae: 0.3803\nEpoch 122/500\n600/600 [==============================] - 0s 60us/sample - loss: 0.1740 - mae: 0.3608 - val_loss: 0.1884 - val_mae: 0.3802\nEpoch 123/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1736 - mae: 0.3602 - val_loss: 0.1879 - val_mae: 0.3786\nEpoch 124/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.1737 - mae: 0.3597 - val_loss: 0.1876 - val_mae: 0.3765\nEpoch 125/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1738 - mae: 0.3597 - val_loss: 0.1876 - val_mae: 0.3780\nEpoch 126/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1734 - mae: 0.3591 - val_loss: 0.1872 - val_mae: 0.3762\nEpoch 127/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1727 - mae: 0.3583 - val_loss: 0.1873 - val_mae: 0.3775\nEpoch 128/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1726 - mae: 0.3583 - val_loss: 0.1872 - val_mae: 0.3776\nEpoch 129/500\n600/600 [==============================] - 0s 44us/sample - loss: 0.1724 - mae: 0.3579 - val_loss: 0.1869 - val_mae: 0.3763\nEpoch 130/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.1723 - mae: 0.3575 - val_loss: 0.1867 - val_mae: 0.3757\nEpoch 131/500\n600/600 [==============================] - 0s 42us/sample - loss: 0.1722 - mae: 0.3573 - val_loss: 0.1866 - val_mae: 0.3759\nEpoch 132/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.1720 - mae: 0.3572 - val_loss: 0.1868 - val_mae: 0.3770\nEpoch 133/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.1721 - mae: 0.3570 - val_loss: 0.1864 - val_mae: 0.3754\nEpoch 134/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.1717 - mae: 0.3566 - val_loss: 0.1864 - val_mae: 0.3754\nEpoch 135/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1717 - mae: 0.3563 - val_loss: 0.1861 - val_mae: 0.3741\nEpoch 136/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1715 - mae: 0.3559 - val_loss: 0.1861 - val_mae: 0.3744\nEpoch 137/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1714 - mae: 0.3558 - val_loss: 0.1861 - val_mae: 0.3748\nEpoch 138/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1713 - mae: 0.3555 - val_loss: 0.1859 - val_mae: 0.3737\nEpoch 139/500\n600/600 [==============================] - 0s 41us/sample - loss: 0.1712 - mae: 0.3551 - val_loss: 0.1857 - val_mae: 0.3731\nEpoch 140/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1712 - mae: 0.3551 - val_loss: 0.1857 - val_mae: 0.3732\nEpoch 141/500\n600/600 [==============================] - 0s 42us/sample - loss: 0.1710 - mae: 0.3547 - val_loss: 0.1856 - val_mae: 0.3724\nEpoch 142/500\n600/600 [==============================] - 0s 42us/sample - loss: 0.1713 - mae: 0.3546 - val_loss: 0.1855 - val_mae: 0.3718\nEpoch 143/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.1711 - mae: 0.3545 - val_loss: 0.1857 - val_mae: 0.3740\nEpoch 144/500\n600/600 [==============================] - 0s 42us/sample - loss: 0.1708 - mae: 0.3545 - val_loss: 0.1856 - val_mae: 0.3733\nEpoch 145/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.1708 - mae: 0.3541 - val_loss: 0.1854 - val_mae: 0.3717\nEpoch 146/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1707 - mae: 0.3539 - val_loss: 0.1854 - val_mae: 0.3720\nEpoch 147/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.1706 - mae: 0.3539 - val_loss: 0.1854 - val_mae: 0.3725\nEpoch 148/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.1706 - mae: 0.3537 - val_loss: 0.1853 - val_mae: 0.3722\nEpoch 149/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.1705 - mae: 0.3536 - val_loss: 0.1853 - val_mae: 0.3725\nEpoch 150/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.1707 - mae: 0.3537 - val_loss: 0.1853 - val_mae: 0.3720\nEpoch 151/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.1704 - mae: 0.3532 - val_loss: 0.1851 - val_mae: 0.3704\nEpoch 152/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.1705 - mae: 0.3530 - val_loss: 0.1851 - val_mae: 0.3709\nEpoch 153/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1703 - mae: 0.3529 - val_loss: 0.1851 - val_mae: 0.3714\nEpoch 154/500\n600/600 [==============================] - 0s 63us/sample - loss: 0.1703 - mae: 0.3530 - val_loss: 0.1852 - val_mae: 0.3720\nEpoch 155/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1703 - mae: 0.3529 - val_loss: 0.1851 - val_mae: 0.3713\nEpoch 156/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1702 - mae: 0.3526 - val_loss: 0.1850 - val_mae: 0.3711\nEpoch 157/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.1701 - mae: 0.3526 - val_loss: 0.1852 - val_mae: 0.3719\nEpoch 158/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1701 - mae: 0.3528 - val_loss: 0.1852 - val_mae: 0.3721\nEpoch 159/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1705 - mae: 0.3528 - val_loss: 0.1849 - val_mae: 0.3698\nEpoch 160/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1701 - mae: 0.3525 - val_loss: 0.1852 - val_mae: 0.3723\nEpoch 161/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.1701 - mae: 0.3528 - val_loss: 0.1851 - val_mae: 0.3721\nEpoch 162/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1701 - mae: 0.3527 - val_loss: 0.1851 - val_mae: 0.3717\nEpoch 163/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1701 - mae: 0.3527 - val_loss: 0.1852 - val_mae: 0.3722\nEpoch 164/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1704 - mae: 0.3531 - val_loss: 0.1852 - val_mae: 0.3722\nEpoch 165/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1700 - mae: 0.3525 - val_loss: 0.1847 - val_mae: 0.3697\nEpoch 166/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1702 - mae: 0.3518 - val_loss: 0.1847 - val_mae: 0.3694\nEpoch 167/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1704 - mae: 0.3519 - val_loss: 0.1847 - val_mae: 0.3680\nEpoch 168/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1699 - mae: 0.3516 - val_loss: 0.1848 - val_mae: 0.3704\nEpoch 169/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.1700 - mae: 0.3522 - val_loss: 0.1851 - val_mae: 0.3718\nEpoch 170/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1700 - mae: 0.3524 - val_loss: 0.1851 - val_mae: 0.3720\nEpoch 171/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1699 - mae: 0.3522 - val_loss: 0.1848 - val_mae: 0.3702\nEpoch 172/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1698 - mae: 0.3518 - val_loss: 0.1849 - val_mae: 0.3711\nEpoch 173/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1699 - mae: 0.3521 - val_loss: 0.1849 - val_mae: 0.3710\nEpoch 174/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.1699 - mae: 0.3521 - val_loss: 0.1849 - val_mae: 0.3711\nEpoch 175/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1700 - mae: 0.3518 - val_loss: 0.1847 - val_mae: 0.3699\nEpoch 176/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1699 - mae: 0.3517 - val_loss: 0.1847 - val_mae: 0.3701\nEpoch 177/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1702 - mae: 0.3524 - val_loss: 0.1852 - val_mae: 0.3721\nEpoch 178/500\n600/600 [==============================] - 0s 62us/sample - loss: 0.1700 - mae: 0.3523 - val_loss: 0.1849 - val_mae: 0.3710\nEpoch 179/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.1697 - mae: 0.3517 - val_loss: 0.1847 - val_mae: 0.3701\nEpoch 180/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1703 - mae: 0.3515 - val_loss: 0.1846 - val_mae: 0.3681\nEpoch 181/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1697 - mae: 0.3515 - val_loss: 0.1849 - val_mae: 0.3708\nEpoch 182/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.1698 - mae: 0.3518 - val_loss: 0.1850 - val_mae: 0.3715\nEpoch 183/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1698 - mae: 0.3520 - val_loss: 0.1848 - val_mae: 0.3708\nEpoch 184/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1698 - mae: 0.3516 - val_loss: 0.1846 - val_mae: 0.3690\nEpoch 185/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1699 - mae: 0.3514 - val_loss: 0.1846 - val_mae: 0.3698\nEpoch 186/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1700 - mae: 0.3517 - val_loss: 0.1848 - val_mae: 0.3706\nEpoch 187/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.1696 - mae: 0.3513 - val_loss: 0.1846 - val_mae: 0.3693\nEpoch 188/500\n600/600 [==============================] - 0s 63us/sample - loss: 0.1697 - mae: 0.3511 - val_loss: 0.1845 - val_mae: 0.3687\nEpoch 189/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1698 - mae: 0.3508 - val_loss: 0.1845 - val_mae: 0.3675\nEpoch 190/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.1699 - mae: 0.3510 - val_loss: 0.1845 - val_mae: 0.3688\nEpoch 191/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1698 - mae: 0.3509 - val_loss: 0.1846 - val_mae: 0.3693\nEpoch 192/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1698 - mae: 0.3512 - val_loss: 0.1848 - val_mae: 0.3706\nEpoch 193/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1700 - mae: 0.3520 - val_loss: 0.1850 - val_mae: 0.3714\nEpoch 194/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.1698 - mae: 0.3513 - val_loss: 0.1845 - val_mae: 0.3684\nEpoch 195/500\n600/600 [==============================] - 0s 59us/sample - loss: 0.1697 - mae: 0.3509 - val_loss: 0.1845 - val_mae: 0.3687\nEpoch 196/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.1696 - mae: 0.3509 - val_loss: 0.1846 - val_mae: 0.3691\nEpoch 197/500\n600/600 [==============================] - 0s 76us/sample - loss: 0.1697 - mae: 0.3508 - val_loss: 0.1845 - val_mae: 0.3684\nEpoch 198/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1698 - mae: 0.3506 - val_loss: 0.1845 - val_mae: 0.3683\nEpoch 199/500\n600/600 [==============================] - 0s 44us/sample - loss: 0.1698 - mae: 0.3510 - val_loss: 0.1848 - val_mae: 0.3703\nEpoch 200/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.1696 - mae: 0.3511 - val_loss: 0.1846 - val_mae: 0.3690\nEpoch 201/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1697 - mae: 0.3509 - val_loss: 0.1846 - val_mae: 0.3694\nEpoch 202/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.1697 - mae: 0.3512 - val_loss: 0.1847 - val_mae: 0.3696\nEpoch 203/500\n600/600 [==============================] - 0s 42us/sample - loss: 0.1697 - mae: 0.3513 - val_loss: 0.1850 - val_mae: 0.3708\nEpoch 204/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1696 - mae: 0.3513 - val_loss: 0.1847 - val_mae: 0.3697\nEpoch 205/500\n600/600 [==============================] - 0s 42us/sample - loss: 0.1696 - mae: 0.3508 - val_loss: 0.1845 - val_mae: 0.3685\nEpoch 206/500\n600/600 [==============================] - 0s 44us/sample - loss: 0.1699 - mae: 0.3504 - val_loss: 0.1845 - val_mae: 0.3669\nEpoch 207/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1697 - mae: 0.3500 - val_loss: 0.1845 - val_mae: 0.3680\nEpoch 208/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1696 - mae: 0.3503 - val_loss: 0.1846 - val_mae: 0.3687\nEpoch 209/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.1696 - mae: 0.3505 - val_loss: 0.1846 - val_mae: 0.3690\nEpoch 210/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1698 - mae: 0.3506 - val_loss: 0.1846 - val_mae: 0.3687\nEpoch 211/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1699 - mae: 0.3513 - val_loss: 0.1849 - val_mae: 0.3703\nEpoch 212/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1697 - mae: 0.3510 - val_loss: 0.1846 - val_mae: 0.3693\nEpoch 213/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1697 - mae: 0.3504 - val_loss: 0.1845 - val_mae: 0.3677\nEpoch 214/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1697 - mae: 0.3502 - val_loss: 0.1845 - val_mae: 0.3681\nEpoch 215/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1695 - mae: 0.3505 - val_loss: 0.1847 - val_mae: 0.3698\nEpoch 216/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.1696 - mae: 0.3510 - val_loss: 0.1848 - val_mae: 0.3702\nEpoch 217/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1698 - mae: 0.3512 - val_loss: 0.1846 - val_mae: 0.3694\nEpoch 218/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1696 - mae: 0.3509 - val_loss: 0.1847 - val_mae: 0.3699\nEpoch 219/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.1696 - mae: 0.3511 - val_loss: 0.1847 - val_mae: 0.3700\nEpoch 220/500\n600/600 [==============================] - 0s 60us/sample - loss: 0.1697 - mae: 0.3513 - val_loss: 0.1848 - val_mae: 0.3705\nEpoch 221/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1697 - mae: 0.3513 - val_loss: 0.1847 - val_mae: 0.3699\nEpoch 222/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.1698 - mae: 0.3515 - val_loss: 0.1848 - val_mae: 0.3707\nEpoch 223/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1697 - mae: 0.3514 - val_loss: 0.1845 - val_mae: 0.3695\nEpoch 224/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.1696 - mae: 0.3509 - val_loss: 0.1845 - val_mae: 0.3691\nEpoch 225/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1696 - mae: 0.3511 - val_loss: 0.1846 - val_mae: 0.3695\nEpoch 226/500\n600/600 [==============================] - 0s 57us/sample - loss: 0.1697 - mae: 0.3510 - val_loss: 0.1845 - val_mae: 0.3691\nEpoch 227/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.1698 - mae: 0.3513 - val_loss: 0.1846 - val_mae: 0.3699\nEpoch 228/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1699 - mae: 0.3510 - val_loss: 0.1844 - val_mae: 0.3685\nEpoch 229/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1697 - mae: 0.3510 - val_loss: 0.1845 - val_mae: 0.3691\nEpoch 230/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.1696 - mae: 0.3510 - val_loss: 0.1846 - val_mae: 0.3696\nEpoch 231/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1696 - mae: 0.3508 - val_loss: 0.1845 - val_mae: 0.3689\nEpoch 232/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1697 - mae: 0.3512 - val_loss: 0.1846 - val_mae: 0.3697\nEpoch 233/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1698 - mae: 0.3509 - val_loss: 0.1845 - val_mae: 0.3689\nEpoch 234/500\n600/600 [==============================] - 0s 41us/sample - loss: 0.1696 - mae: 0.3509 - val_loss: 0.1846 - val_mae: 0.3694\nEpoch 235/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1696 - mae: 0.3511 - val_loss: 0.1846 - val_mae: 0.3693\nEpoch 236/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1700 - mae: 0.3506 - val_loss: 0.1844 - val_mae: 0.3673\nEpoch 237/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.1698 - mae: 0.3502 - val_loss: 0.1844 - val_mae: 0.3676\nEpoch 238/500\n600/600 [==============================] - 0s 42us/sample - loss: 0.1696 - mae: 0.3505 - val_loss: 0.1845 - val_mae: 0.3690\nEpoch 239/500\n600/600 [==============================] - 0s 41us/sample - loss: 0.1697 - mae: 0.3508 - val_loss: 0.1845 - val_mae: 0.3691\nEpoch 240/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1697 - mae: 0.3506 - val_loss: 0.1844 - val_mae: 0.3676\nEpoch 241/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1698 - mae: 0.3502 - val_loss: 0.1844 - val_mae: 0.3674\nEpoch 242/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1697 - mae: 0.3507 - val_loss: 0.1847 - val_mae: 0.3696\nEpoch 243/500\n600/600 [==============================] - 0s 44us/sample - loss: 0.1697 - mae: 0.3508 - val_loss: 0.1845 - val_mae: 0.3685\nEpoch 244/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.1697 - mae: 0.3505 - val_loss: 0.1846 - val_mae: 0.3689\nEpoch 245/500\n600/600 [==============================] - 0s 44us/sample - loss: 0.1701 - mae: 0.3519 - val_loss: 0.1856 - val_mae: 0.3727\nEpoch 246/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.1701 - mae: 0.3519 - val_loss: 0.1850 - val_mae: 0.3708\nEpoch 247/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1698 - mae: 0.3516 - val_loss: 0.1848 - val_mae: 0.3702\nEpoch 248/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1697 - mae: 0.3508 - val_loss: 0.1844 - val_mae: 0.3671\nEpoch 249/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1700 - mae: 0.3506 - val_loss: 0.1844 - val_mae: 0.3682\nEpoch 250/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1696 - mae: 0.3503 - val_loss: 0.1844 - val_mae: 0.3676\nEpoch 251/500\n600/600 [==============================] - 0s 61us/sample - loss: 0.1697 - mae: 0.3504 - val_loss: 0.1844 - val_mae: 0.3676\nEpoch 252/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1695 - mae: 0.3502 - val_loss: 0.1845 - val_mae: 0.3687\nEpoch 253/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1695 - mae: 0.3507 - val_loss: 0.1847 - val_mae: 0.3698\nEpoch 254/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.1697 - mae: 0.3512 - val_loss: 0.1849 - val_mae: 0.3704\nEpoch 255/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1698 - mae: 0.3514 - val_loss: 0.1848 - val_mae: 0.3700\nEpoch 256/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1697 - mae: 0.3509 - val_loss: 0.1845 - val_mae: 0.3680\nEpoch 257/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.1696 - mae: 0.3503 - val_loss: 0.1844 - val_mae: 0.3679\nEpoch 258/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1696 - mae: 0.3503 - val_loss: 0.1845 - val_mae: 0.3685\nEpoch 259/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.1695 - mae: 0.3505 - val_loss: 0.1846 - val_mae: 0.3689\nEpoch 260/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1696 - mae: 0.3508 - val_loss: 0.1847 - val_mae: 0.3698\nEpoch 261/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.1697 - mae: 0.3511 - val_loss: 0.1847 - val_mae: 0.3698\nEpoch 262/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.1699 - mae: 0.3510 - val_loss: 0.1845 - val_mae: 0.3684\nEpoch 263/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1697 - mae: 0.3506 - val_loss: 0.1845 - val_mae: 0.3685\nEpoch 264/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.1696 - mae: 0.3506 - val_loss: 0.1846 - val_mae: 0.3692\nEpoch 265/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.1698 - mae: 0.3513 - val_loss: 0.1848 - val_mae: 0.3700\nEpoch 266/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.1696 - mae: 0.3509 - val_loss: 0.1846 - val_mae: 0.3691\nEpoch 267/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.1696 - mae: 0.3508 - val_loss: 0.1847 - val_mae: 0.3696\nEpoch 268/500\n600/600 [==============================] - 0s 44us/sample - loss: 0.1697 - mae: 0.3507 - val_loss: 0.1845 - val_mae: 0.3681\nEpoch 269/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1696 - mae: 0.3504 - val_loss: 0.1846 - val_mae: 0.3686\nEpoch 270/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1697 - mae: 0.3510 - val_loss: 0.1848 - val_mae: 0.3699\nEpoch 271/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.1699 - mae: 0.3516 - val_loss: 0.1848 - val_mae: 0.3701\nEpoch 272/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1698 - mae: 0.3509 - val_loss: 0.1845 - val_mae: 0.3683\nEpoch 273/500\n600/600 [==============================] - 0s 41us/sample - loss: 0.1696 - mae: 0.3508 - val_loss: 0.1848 - val_mae: 0.3699\nEpoch 274/500\n600/600 [==============================] - 0s 41us/sample - loss: 0.1696 - mae: 0.3510 - val_loss: 0.1847 - val_mae: 0.3697\nEpoch 275/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1696 - mae: 0.3508 - val_loss: 0.1846 - val_mae: 0.3690\nEpoch 276/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1696 - mae: 0.3509 - val_loss: 0.1847 - val_mae: 0.3693\nEpoch 277/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1695 - mae: 0.3504 - val_loss: 0.1845 - val_mae: 0.3679\nEpoch 278/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.1697 - mae: 0.3502 - val_loss: 0.1845 - val_mae: 0.3678\nEpoch 279/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1697 - mae: 0.3505 - val_loss: 0.1846 - val_mae: 0.3687\nEpoch 280/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1696 - mae: 0.3506 - val_loss: 0.1846 - val_mae: 0.3688\nEpoch 281/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.1698 - mae: 0.3510 - val_loss: 0.1848 - val_mae: 0.3700\nEpoch 282/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1696 - mae: 0.3509 - val_loss: 0.1847 - val_mae: 0.3694\nEpoch 283/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.1696 - mae: 0.3507 - val_loss: 0.1846 - val_mae: 0.3688\nEpoch 284/500\n600/600 [==============================] - 0s 44us/sample - loss: 0.1696 - mae: 0.3508 - val_loss: 0.1847 - val_mae: 0.3692\nEpoch 285/500\n600/600 [==============================] - 0s 58us/sample - loss: 0.1695 - mae: 0.3505 - val_loss: 0.1846 - val_mae: 0.3682\nEpoch 286/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1699 - mae: 0.3501 - val_loss: 0.1846 - val_mae: 0.3664\nEpoch 287/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1698 - mae: 0.3502 - val_loss: 0.1845 - val_mae: 0.3682\nEpoch 288/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1696 - mae: 0.3504 - val_loss: 0.1846 - val_mae: 0.3683\nEpoch 289/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1695 - mae: 0.3504 - val_loss: 0.1846 - val_mae: 0.3690\nEpoch 290/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1696 - mae: 0.3506 - val_loss: 0.1847 - val_mae: 0.3689\nEpoch 291/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1696 - mae: 0.3506 - val_loss: 0.1847 - val_mae: 0.3694\nEpoch 292/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.1698 - mae: 0.3508 - val_loss: 0.1846 - val_mae: 0.3683\nEpoch 293/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1701 - mae: 0.3513 - val_loss: 0.1850 - val_mae: 0.3705\nEpoch 294/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1702 - mae: 0.3509 - val_loss: 0.1845 - val_mae: 0.3678\nEpoch 295/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1696 - mae: 0.3505 - val_loss: 0.1849 - val_mae: 0.3702\nEpoch 296/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1697 - mae: 0.3510 - val_loss: 0.1848 - val_mae: 0.3699\nEpoch 297/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.1697 - mae: 0.3509 - val_loss: 0.1847 - val_mae: 0.3691\nEpoch 298/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1696 - mae: 0.3507 - val_loss: 0.1848 - val_mae: 0.3695\nEpoch 299/500\n600/600 [==============================] - 0s 42us/sample - loss: 0.1696 - mae: 0.3507 - val_loss: 0.1847 - val_mae: 0.3690\nEpoch 300/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.1696 - mae: 0.3505 - val_loss: 0.1846 - val_mae: 0.3684\nEpoch 301/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1696 - mae: 0.3504 - val_loss: 0.1846 - val_mae: 0.3685\nEpoch 302/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1698 - mae: 0.3507 - val_loss: 0.1848 - val_mae: 0.3696\nEpoch 303/500\n600/600 [==============================] - 0s 41us/sample - loss: 0.1695 - mae: 0.3506 - val_loss: 0.1846 - val_mae: 0.3684\nEpoch 304/500\n600/600 [==============================] - 0s 44us/sample - loss: 0.1700 - mae: 0.3502 - val_loss: 0.1845 - val_mae: 0.3667\nEpoch 305/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1696 - mae: 0.3498 - val_loss: 0.1845 - val_mae: 0.3679\nEpoch 306/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.1699 - mae: 0.3509 - val_loss: 0.1850 - val_mae: 0.3706\nEpoch 307/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1697 - mae: 0.3513 - val_loss: 0.1847 - val_mae: 0.3694\nEpoch 308/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.1697 - mae: 0.3506 - val_loss: 0.1845 - val_mae: 0.3682\nEpoch 309/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.1697 - mae: 0.3506 - val_loss: 0.1847 - val_mae: 0.3691\nEpoch 310/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1696 - mae: 0.3504 - val_loss: 0.1845 - val_mae: 0.3680\nEpoch 311/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1699 - mae: 0.3503 - val_loss: 0.1845 - val_mae: 0.3677\nEpoch 312/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1694 - mae: 0.3502 - val_loss: 0.1847 - val_mae: 0.3692\nEpoch 313/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1698 - mae: 0.3512 - val_loss: 0.1850 - val_mae: 0.3706\nEpoch 314/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1698 - mae: 0.3509 - val_loss: 0.1845 - val_mae: 0.3678\nEpoch 315/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.1697 - mae: 0.3503 - val_loss: 0.1845 - val_mae: 0.3674\nEpoch 316/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1697 - mae: 0.3503 - val_loss: 0.1845 - val_mae: 0.3680\nEpoch 317/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1696 - mae: 0.3501 - val_loss: 0.1845 - val_mae: 0.3675\nEpoch 318/500\n600/600 [==============================] - 0s 59us/sample - loss: 0.1697 - mae: 0.3500 - val_loss: 0.1845 - val_mae: 0.3674\nEpoch 319/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1697 - mae: 0.3499 - val_loss: 0.1845 - val_mae: 0.3672\nEpoch 320/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1697 - mae: 0.3503 - val_loss: 0.1846 - val_mae: 0.3685\nEpoch 321/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1697 - mae: 0.3507 - val_loss: 0.1847 - val_mae: 0.3695\nEpoch 322/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1696 - mae: 0.3505 - val_loss: 0.1845 - val_mae: 0.3677\nEpoch 323/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1697 - mae: 0.3501 - val_loss: 0.1845 - val_mae: 0.3676\nEpoch 324/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1696 - mae: 0.3502 - val_loss: 0.1845 - val_mae: 0.3680\nEpoch 325/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.1696 - mae: 0.3505 - val_loss: 0.1846 - val_mae: 0.3690\nEpoch 326/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1696 - mae: 0.3504 - val_loss: 0.1845 - val_mae: 0.3682\nEpoch 327/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1697 - mae: 0.3503 - val_loss: 0.1845 - val_mae: 0.3682\nEpoch 328/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1696 - mae: 0.3504 - val_loss: 0.1845 - val_mae: 0.3682\nEpoch 329/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1695 - mae: 0.3503 - val_loss: 0.1846 - val_mae: 0.3684\nEpoch 330/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.1696 - mae: 0.3506 - val_loss: 0.1846 - val_mae: 0.3691\nEpoch 331/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1699 - mae: 0.3512 - val_loss: 0.1847 - val_mae: 0.3697\nEpoch 332/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1696 - mae: 0.3507 - val_loss: 0.1846 - val_mae: 0.3688\nEpoch 333/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1702 - mae: 0.3514 - val_loss: 0.1847 - val_mae: 0.3696\nEpoch 334/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1695 - mae: 0.3505 - val_loss: 0.1845 - val_mae: 0.3678\nEpoch 335/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1696 - mae: 0.3503 - val_loss: 0.1845 - val_mae: 0.3680\nEpoch 336/500\n600/600 [==============================] - 0s 40us/sample - loss: 0.1697 - mae: 0.3501 - val_loss: 0.1845 - val_mae: 0.3675\nEpoch 337/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1696 - mae: 0.3502 - val_loss: 0.1846 - val_mae: 0.3688\nEpoch 338/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.1697 - mae: 0.3506 - val_loss: 0.1846 - val_mae: 0.3688\nEpoch 339/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1700 - mae: 0.3513 - val_loss: 0.1851 - val_mae: 0.3711\nEpoch 340/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1697 - mae: 0.3511 - val_loss: 0.1846 - val_mae: 0.3689\nEpoch 341/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.1696 - mae: 0.3505 - val_loss: 0.1845 - val_mae: 0.3677\nEpoch 342/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.1701 - mae: 0.3509 - val_loss: 0.1848 - val_mae: 0.3700\nEpoch 343/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1696 - mae: 0.3510 - val_loss: 0.1847 - val_mae: 0.3692\nEpoch 344/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1697 - mae: 0.3506 - val_loss: 0.1846 - val_mae: 0.3682\nEpoch 345/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1696 - mae: 0.3504 - val_loss: 0.1847 - val_mae: 0.3690\nEpoch 346/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1695 - mae: 0.3511 - val_loss: 0.1851 - val_mae: 0.3711\nEpoch 347/500\n600/600 [==============================] - 0s 65us/sample - loss: 0.1697 - mae: 0.3513 - val_loss: 0.1849 - val_mae: 0.3701\nEpoch 348/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1694 - mae: 0.3507 - val_loss: 0.1846 - val_mae: 0.3683\nEpoch 349/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.1696 - mae: 0.3501 - val_loss: 0.1845 - val_mae: 0.3672\nEpoch 350/500\n600/600 [==============================] - 0s 59us/sample - loss: 0.1698 - mae: 0.3505 - val_loss: 0.1846 - val_mae: 0.3684\nEpoch 351/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1696 - mae: 0.3502 - val_loss: 0.1845 - val_mae: 0.3679\nEpoch 352/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1695 - mae: 0.3504 - val_loss: 0.1847 - val_mae: 0.3692\nEpoch 353/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1697 - mae: 0.3509 - val_loss: 0.1849 - val_mae: 0.3701\nEpoch 354/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1696 - mae: 0.3508 - val_loss: 0.1847 - val_mae: 0.3689\nEpoch 355/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1697 - mae: 0.3508 - val_loss: 0.1846 - val_mae: 0.3685\nEpoch 356/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1701 - mae: 0.3504 - val_loss: 0.1846 - val_mae: 0.3664\nEpoch 357/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.1699 - mae: 0.3503 - val_loss: 0.1847 - val_mae: 0.3689\nEpoch 358/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1696 - mae: 0.3504 - val_loss: 0.1846 - val_mae: 0.3684\nEpoch 359/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.1695 - mae: 0.3503 - val_loss: 0.1846 - val_mae: 0.3683\nEpoch 360/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.1696 - mae: 0.3504 - val_loss: 0.1846 - val_mae: 0.3681\nEpoch 361/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.1697 - mae: 0.3504 - val_loss: 0.1846 - val_mae: 0.3685\nEpoch 362/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1698 - mae: 0.3503 - val_loss: 0.1845 - val_mae: 0.3676\nEpoch 363/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1696 - mae: 0.3505 - val_loss: 0.1848 - val_mae: 0.3695\nEpoch 364/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1696 - mae: 0.3506 - val_loss: 0.1847 - val_mae: 0.3688\nEpoch 365/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1696 - mae: 0.3507 - val_loss: 0.1849 - val_mae: 0.3699\nEpoch 366/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1697 - mae: 0.3511 - val_loss: 0.1849 - val_mae: 0.3701\nEpoch 367/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.1696 - mae: 0.3508 - val_loss: 0.1846 - val_mae: 0.3688\nEpoch 368/500\n600/600 [==============================] - 0s 39us/sample - loss: 0.1696 - mae: 0.3507 - val_loss: 0.1846 - val_mae: 0.3688\nEpoch 369/500\n600/600 [==============================] - 0s 40us/sample - loss: 0.1698 - mae: 0.3504 - val_loss: 0.1845 - val_mae: 0.3678\nEpoch 370/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.1697 - mae: 0.3507 - val_loss: 0.1848 - val_mae: 0.3697\nEpoch 371/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.1698 - mae: 0.3508 - val_loss: 0.1846 - val_mae: 0.3683\nEpoch 372/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1696 - mae: 0.3506 - val_loss: 0.1847 - val_mae: 0.3692\nEpoch 373/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.1696 - mae: 0.3508 - val_loss: 0.1846 - val_mae: 0.3689\nEpoch 374/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.1697 - mae: 0.3504 - val_loss: 0.1845 - val_mae: 0.3677\nEpoch 375/500\n600/600 [==============================] - 0s 44us/sample - loss: 0.1697 - mae: 0.3506 - val_loss: 0.1846 - val_mae: 0.3691\nEpoch 376/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.1696 - mae: 0.3505 - val_loss: 0.1846 - val_mae: 0.3684\nEpoch 377/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.1697 - mae: 0.3502 - val_loss: 0.1845 - val_mae: 0.3678\nEpoch 378/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.1700 - mae: 0.3507 - val_loss: 0.1847 - val_mae: 0.3690\nEpoch 379/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1695 - mae: 0.3501 - val_loss: 0.1845 - val_mae: 0.3670\nEpoch 380/500\n600/600 [==============================] - 0s 60us/sample - loss: 0.1696 - mae: 0.3501 - val_loss: 0.1846 - val_mae: 0.3683\nEpoch 381/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1695 - mae: 0.3505 - val_loss: 0.1847 - val_mae: 0.3691\nEpoch 382/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1696 - mae: 0.3506 - val_loss: 0.1847 - val_mae: 0.3690\nEpoch 383/500\n600/600 [==============================] - 0s 59us/sample - loss: 0.1696 - mae: 0.3506 - val_loss: 0.1847 - val_mae: 0.3693\nEpoch 384/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.1697 - mae: 0.3511 - val_loss: 0.1850 - val_mae: 0.3703\nEpoch 385/500\n600/600 [==============================] - 0s 57us/sample - loss: 0.1699 - mae: 0.3510 - val_loss: 0.1847 - val_mae: 0.3689\nEpoch 386/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1697 - mae: 0.3511 - val_loss: 0.1851 - val_mae: 0.3709\nEpoch 387/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1698 - mae: 0.3512 - val_loss: 0.1846 - val_mae: 0.3688\nEpoch 388/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1696 - mae: 0.3506 - val_loss: 0.1846 - val_mae: 0.3687\nEpoch 389/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.1697 - mae: 0.3510 - val_loss: 0.1848 - val_mae: 0.3700\nEpoch 390/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.1696 - mae: 0.3510 - val_loss: 0.1847 - val_mae: 0.3694\nEpoch 391/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.1701 - mae: 0.3505 - val_loss: 0.1846 - val_mae: 0.3666\nEpoch 392/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.1697 - mae: 0.3501 - val_loss: 0.1846 - val_mae: 0.3681\nEpoch 393/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1696 - mae: 0.3506 - val_loss: 0.1848 - val_mae: 0.3698\nEpoch 394/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1696 - mae: 0.3510 - val_loss: 0.1847 - val_mae: 0.3693\nEpoch 395/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1699 - mae: 0.3507 - val_loss: 0.1845 - val_mae: 0.3675\nEpoch 396/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.1695 - mae: 0.3501 - val_loss: 0.1847 - val_mae: 0.3693\nEpoch 397/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1698 - mae: 0.3510 - val_loss: 0.1848 - val_mae: 0.3698\nEpoch 398/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.1696 - mae: 0.3508 - val_loss: 0.1846 - val_mae: 0.3687\nEpoch 399/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1695 - mae: 0.3502 - val_loss: 0.1845 - val_mae: 0.3673\nEpoch 400/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.1697 - mae: 0.3498 - val_loss: 0.1845 - val_mae: 0.3667\nEpoch 401/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1696 - mae: 0.3498 - val_loss: 0.1845 - val_mae: 0.3681\nEpoch 402/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1696 - mae: 0.3505 - val_loss: 0.1847 - val_mae: 0.3692\nEpoch 403/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1697 - mae: 0.3506 - val_loss: 0.1846 - val_mae: 0.3687\nEpoch 404/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.1699 - mae: 0.3502 - val_loss: 0.1846 - val_mae: 0.3667\nEpoch 405/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1697 - mae: 0.3500 - val_loss: 0.1846 - val_mae: 0.3683\nEpoch 406/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.1696 - mae: 0.3503 - val_loss: 0.1847 - val_mae: 0.3689\nEpoch 407/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1695 - mae: 0.3504 - val_loss: 0.1847 - val_mae: 0.3684\nEpoch 408/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1697 - mae: 0.3502 - val_loss: 0.1846 - val_mae: 0.3673\nEpoch 409/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1696 - mae: 0.3499 - val_loss: 0.1846 - val_mae: 0.3678\nEpoch 410/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1696 - mae: 0.3502 - val_loss: 0.1846 - val_mae: 0.3682\nEpoch 411/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.1697 - mae: 0.3499 - val_loss: 0.1846 - val_mae: 0.3668\nEpoch 412/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1697 - mae: 0.3496 - val_loss: 0.1846 - val_mae: 0.3673\nEpoch 413/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1698 - mae: 0.3508 - val_loss: 0.1852 - val_mae: 0.3710\nEpoch 414/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1703 - mae: 0.3519 - val_loss: 0.1854 - val_mae: 0.3716\nEpoch 415/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.1695 - mae: 0.3511 - val_loss: 0.1846 - val_mae: 0.3686\nEpoch 416/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.1696 - mae: 0.3499 - val_loss: 0.1845 - val_mae: 0.3666\nEpoch 417/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1700 - mae: 0.3496 - val_loss: 0.1846 - val_mae: 0.3665\nEpoch 418/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1694 - mae: 0.3497 - val_loss: 0.1847 - val_mae: 0.3687\nEpoch 419/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.1695 - mae: 0.3505 - val_loss: 0.1849 - val_mae: 0.3698\nEpoch 420/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1697 - mae: 0.3509 - val_loss: 0.1850 - val_mae: 0.3702\nEpoch 421/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1697 - mae: 0.3511 - val_loss: 0.1849 - val_mae: 0.3700\nEpoch 422/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1696 - mae: 0.3507 - val_loss: 0.1846 - val_mae: 0.3686\nEpoch 423/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1695 - mae: 0.3502 - val_loss: 0.1845 - val_mae: 0.3677\nEpoch 424/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1696 - mae: 0.3498 - val_loss: 0.1845 - val_mae: 0.3668\nEpoch 425/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1697 - mae: 0.3497 - val_loss: 0.1845 - val_mae: 0.3671\nEpoch 426/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1696 - mae: 0.3497 - val_loss: 0.1846 - val_mae: 0.3676\nEpoch 427/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1696 - mae: 0.3500 - val_loss: 0.1847 - val_mae: 0.3683\nEpoch 428/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1696 - mae: 0.3502 - val_loss: 0.1847 - val_mae: 0.3686\nEpoch 429/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.1697 - mae: 0.3506 - val_loss: 0.1848 - val_mae: 0.3694\nEpoch 430/500\n600/600 [==============================] - 0s 40us/sample - loss: 0.1698 - mae: 0.3502 - val_loss: 0.1846 - val_mae: 0.3675\nEpoch 431/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1697 - mae: 0.3498 - val_loss: 0.1846 - val_mae: 0.3675\nEpoch 432/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1696 - mae: 0.3504 - val_loss: 0.1850 - val_mae: 0.3703\nEpoch 433/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1699 - mae: 0.3514 - val_loss: 0.1853 - val_mae: 0.3713\nEpoch 434/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.1700 - mae: 0.3510 - val_loss: 0.1846 - val_mae: 0.3686\nEpoch 435/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.1699 - mae: 0.3509 - val_loss: 0.1846 - val_mae: 0.3689\nEpoch 436/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1696 - mae: 0.3509 - val_loss: 0.1849 - val_mae: 0.3703\nEpoch 437/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1697 - mae: 0.3511 - val_loss: 0.1847 - val_mae: 0.3696\nEpoch 438/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1696 - mae: 0.3509 - val_loss: 0.1846 - val_mae: 0.3691\nEpoch 439/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1695 - mae: 0.3506 - val_loss: 0.1845 - val_mae: 0.3682\nEpoch 440/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.1698 - mae: 0.3506 - val_loss: 0.1845 - val_mae: 0.3683\nEpoch 441/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1696 - mae: 0.3501 - val_loss: 0.1845 - val_mae: 0.3670\nEpoch 442/500\n600/600 [==============================] - 0s 59us/sample - loss: 0.1697 - mae: 0.3502 - val_loss: 0.1846 - val_mae: 0.3690\nEpoch 443/500\n600/600 [==============================] - 0s 82us/sample - loss: 0.1704 - mae: 0.3519 - val_loss: 0.1849 - val_mae: 0.3702\nEpoch 444/500\n600/600 [==============================] - 0s 62us/sample - loss: 0.1696 - mae: 0.3507 - val_loss: 0.1846 - val_mae: 0.3685\nEpoch 445/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.1697 - mae: 0.3504 - val_loss: 0.1845 - val_mae: 0.3679\nEpoch 446/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1697 - mae: 0.3501 - val_loss: 0.1845 - val_mae: 0.3673\nEpoch 447/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1700 - mae: 0.3501 - val_loss: 0.1845 - val_mae: 0.3671\nEpoch 448/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.1705 - mae: 0.3515 - val_loss: 0.1852 - val_mae: 0.3713\nEpoch 449/500\n600/600 [==============================] - 0s 59us/sample - loss: 0.1698 - mae: 0.3512 - val_loss: 0.1846 - val_mae: 0.3687\nEpoch 450/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.1696 - mae: 0.3504 - val_loss: 0.1845 - val_mae: 0.3682\nEpoch 451/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.1695 - mae: 0.3504 - val_loss: 0.1846 - val_mae: 0.3687\nEpoch 452/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.1696 - mae: 0.3504 - val_loss: 0.1845 - val_mae: 0.3681\nEpoch 453/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1696 - mae: 0.3502 - val_loss: 0.1846 - val_mae: 0.3683\nEpoch 454/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1696 - mae: 0.3504 - val_loss: 0.1846 - val_mae: 0.3686\nEpoch 455/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1698 - mae: 0.3506 - val_loss: 0.1846 - val_mae: 0.3682\nEpoch 456/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1698 - mae: 0.3508 - val_loss: 0.1847 - val_mae: 0.3695\nEpoch 457/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1697 - mae: 0.3511 - val_loss: 0.1847 - val_mae: 0.3697\nEpoch 458/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1695 - mae: 0.3507 - val_loss: 0.1845 - val_mae: 0.3684\nEpoch 459/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1698 - mae: 0.3504 - val_loss: 0.1845 - val_mae: 0.3677\nEpoch 460/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.1696 - mae: 0.3506 - val_loss: 0.1846 - val_mae: 0.3692\nEpoch 461/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.1696 - mae: 0.3509 - val_loss: 0.1847 - val_mae: 0.3696\nEpoch 462/500\n600/600 [==============================] - 0s 42us/sample - loss: 0.1696 - mae: 0.3510 - val_loss: 0.1846 - val_mae: 0.3692\nEpoch 463/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1698 - mae: 0.3506 - val_loss: 0.1845 - val_mae: 0.3674\nEpoch 464/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1697 - mae: 0.3502 - val_loss: 0.1845 - val_mae: 0.3685\nEpoch 465/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1695 - mae: 0.3506 - val_loss: 0.1847 - val_mae: 0.3695\nEpoch 466/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1698 - mae: 0.3513 - val_loss: 0.1850 - val_mae: 0.3706\nEpoch 467/500\n600/600 [==============================] - 0s 40us/sample - loss: 0.1698 - mae: 0.3512 - val_loss: 0.1847 - val_mae: 0.3698\nEpoch 468/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.1700 - mae: 0.3519 - val_loss: 0.1850 - val_mae: 0.3712\nEpoch 469/500\n600/600 [==============================] - 0s 41us/sample - loss: 0.1697 - mae: 0.3515 - val_loss: 0.1847 - val_mae: 0.3700\nEpoch 470/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1695 - mae: 0.3508 - val_loss: 0.1845 - val_mae: 0.3683\nEpoch 471/500\n600/600 [==============================] - 0s 44us/sample - loss: 0.1697 - mae: 0.3503 - val_loss: 0.1845 - val_mae: 0.3675\nEpoch 472/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1697 - mae: 0.3502 - val_loss: 0.1845 - val_mae: 0.3682\nEpoch 473/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.1697 - mae: 0.3506 - val_loss: 0.1846 - val_mae: 0.3689\nEpoch 474/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1696 - mae: 0.3505 - val_loss: 0.1845 - val_mae: 0.3682\nEpoch 475/500\n600/600 [==============================] - 0s 42us/sample - loss: 0.1697 - mae: 0.3506 - val_loss: 0.1845 - val_mae: 0.3683\nEpoch 476/500\n600/600 [==============================] - 0s 44us/sample - loss: 0.1695 - mae: 0.3506 - val_loss: 0.1847 - val_mae: 0.3697\nEpoch 477/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.1696 - mae: 0.3511 - val_loss: 0.1848 - val_mae: 0.3701\nEpoch 478/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1697 - mae: 0.3512 - val_loss: 0.1848 - val_mae: 0.3702\nEpoch 479/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1695 - mae: 0.3507 - val_loss: 0.1845 - val_mae: 0.3676\nEpoch 480/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1699 - mae: 0.3502 - val_loss: 0.1845 - val_mae: 0.3669\nEpoch 481/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.1697 - mae: 0.3500 - val_loss: 0.1845 - val_mae: 0.3676\nEpoch 482/500\n600/600 [==============================] - 0s 59us/sample - loss: 0.1695 - mae: 0.3506 - val_loss: 0.1850 - val_mae: 0.3706\nEpoch 483/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1698 - mae: 0.3516 - val_loss: 0.1853 - val_mae: 0.3716\nEpoch 484/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1699 - mae: 0.3515 - val_loss: 0.1847 - val_mae: 0.3692\nEpoch 485/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1696 - mae: 0.3507 - val_loss: 0.1846 - val_mae: 0.3687\nEpoch 486/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1699 - mae: 0.3505 - val_loss: 0.1845 - val_mae: 0.3679\nEpoch 487/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1695 - mae: 0.3506 - val_loss: 0.1848 - val_mae: 0.3698\nEpoch 488/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1701 - mae: 0.3517 - val_loss: 0.1851 - val_mae: 0.3709\nEpoch 489/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1698 - mae: 0.3509 - val_loss: 0.1845 - val_mae: 0.3678\nEpoch 490/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1696 - mae: 0.3502 - val_loss: 0.1846 - val_mae: 0.3680\nEpoch 491/500\n600/600 [==============================] - 0s 42us/sample - loss: 0.1696 - mae: 0.3502 - val_loss: 0.1846 - val_mae: 0.3683\nEpoch 492/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.1699 - mae: 0.3512 - val_loss: 0.1853 - val_mae: 0.3714\nEpoch 493/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.1698 - mae: 0.3513 - val_loss: 0.1848 - val_mae: 0.3697\nEpoch 494/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.1696 - mae: 0.3509 - val_loss: 0.1847 - val_mae: 0.3691\nEpoch 495/500\n600/600 [==============================] - 0s 41us/sample - loss: 0.1695 - mae: 0.3504 - val_loss: 0.1845 - val_mae: 0.3679\nEpoch 496/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1696 - mae: 0.3503 - val_loss: 0.1846 - val_mae: 0.3684\nEpoch 497/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1695 - mae: 0.3505 - val_loss: 0.1847 - val_mae: 0.3693\nEpoch 498/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.1696 - mae: 0.3510 - val_loss: 0.1848 - val_mae: 0.3699\nEpoch 499/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1695 - mae: 0.3508 - val_loss: 0.1846 - val_mae: 0.3690\nEpoch 500/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1697 - mae: 0.3503 - val_loss: 0.1845 - val_mae: 0.3681\n"
]
],
[
[
"### 3. Plot Metrics",
"_____no_output_____"
],
[
"**1. Mean Squared Error**\n\nDuring training, the model's performance is constantly being measured against both our training data and the validation data that we set aside earlier. Training produces a log of data that tells us how the model's performance changed over the course of the training process.\n\nThe following cells will display some of that data in a graphical form:",
"_____no_output_____"
]
],
[
[
"# Draw a graph of the loss, which is the distance between\n# the predicted and actual values during training and validation.\nloss = history_1.history['loss']\nval_loss = history_1.history['val_loss']\n\nepochs = range(1, len(loss) + 1)\n\nplt.plot(epochs, loss, 'g.', label='Training loss')\nplt.plot(epochs, val_loss, 'b', label='Validation loss')\nplt.title('Training and validation loss')\nplt.xlabel('Epochs')\nplt.ylabel('Loss')\nplt.legend()\nplt.show()",
"_____no_output_____"
]
],
[
[
"The graph shows the _loss_ (or the difference between the model's predictions and the actual data) for each epoch. There are several ways to calculate loss, and the method we have used is _mean squared error_. There is a distinct loss value given for the training and the validation data.\n\nAs we can see, the amount of loss rapidly decreases over the first 25 epochs, before flattening out. This means that the model is improving and producing more accurate predictions!\n\nOur goal is to stop training when either the model is no longer improving, or when the _training loss_ is less than the _validation loss_, which would mean that the model has learned to predict the training data so well that it can no longer generalize to new data.\n\nTo make the flatter part of the graph more readable, let's skip the first 50 epochs:",
"_____no_output_____"
]
],
[
[
"# Exclude the first few epochs so the graph is easier to read\nSKIP = 50\n\nplt.plot(epochs[SKIP:], loss[SKIP:], 'g.', label='Training loss')\nplt.plot(epochs[SKIP:], val_loss[SKIP:], 'b.', label='Validation loss')\nplt.title('Training and validation loss')\nplt.xlabel('Epochs')\nplt.ylabel('Loss')\nplt.legend()\nplt.show()",
"_____no_output_____"
]
],
[
[
"From the plot, we can see that loss continues to reduce until around 200 epochs, at which point it is mostly stable. This means that there's no need to train our network beyond 200 epochs.\n\nHowever, we can also see that the lowest loss value is still around 0.155. This means that our network's predictions are off by an average of ~15%. In addition, the validation loss values jump around a lot, and is sometimes even higher.\n\n**2. Mean Absolute Error**\n\nTo gain more insight into our model's performance we can plot some more data. This time, we'll plot the _mean absolute error_, which is another way of measuring how far the network's predictions are from the actual numbers:",
"_____no_output_____"
]
],
[
[
"plt.clf()\n\n# Draw a graph of mean absolute error, which is another way of\n# measuring the amount of error in the prediction.\nmae = history_1.history['mae']\nval_mae = history_1.history['val_mae']\n\nplt.plot(epochs[SKIP:], mae[SKIP:], 'g.', label='Training MAE')\nplt.plot(epochs[SKIP:], val_mae[SKIP:], 'b.', label='Validation MAE')\nplt.title('Training and validation mean absolute error')\nplt.xlabel('Epochs')\nplt.ylabel('MAE')\nplt.legend()\nplt.show()",
"_____no_output_____"
]
],
[
[
"This graph of _mean absolute error_ tells another story. We can see that training data shows consistently lower error than validation data, which means that the network may have _overfit_, or learned the training data so rigidly that it can't make effective predictions about new data.\n\nIn addition, the mean absolute error values are quite high, ~0.305 at best, which means some of the model's predictions are at least 30% off. A 30% error means we are very far from accurately modelling the sine wave function.\n\n**3. Actual vs Predicted Outputs**\n\nTo get more insight into what is happening, let's check its predictions against the test dataset we set aside earlier:",
"_____no_output_____"
]
],
[
[
"# Calculate and print the loss on our test dataset\nloss = model_1.evaluate(x_test, y_test)\n\n# Make predictions based on our test dataset\npredictions = model_1.predict(x_test)\n\n# Graph the predictions against the actual values\nplt.clf()\nplt.title('Comparison of predictions and actual values')\nplt.plot(x_test, y_test, 'b.', label='Actual')\nplt.plot(x_test, predictions, 'r.', label='Predicted')\nplt.legend()\nplt.show()",
"\r200/1 [================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================] - 0s 57us/sample - loss: 0.1560 - mae: 0.3435\n"
]
],
[
[
"Oh dear! The graph makes it clear that our network has learned to approximate the sine function in a very limited way.\n\nThe rigidity of this fit suggests that the model does not have enough capacity to learn the full complexity of the sine wave function, so it's only able to approximate it in an overly simplistic way. By making our model bigger, we should be able to improve its performance.",
"_____no_output_____"
],
[
"## Training a Larger Model",
"_____no_output_____"
],
[
"### 1. Design the Model\nTo make our model bigger, let's add an additional layer of neurons. The following cell redefines our model in the same way as earlier, but with 16 neurons in the first layer and an additional layer of 16 neurons in the middle:",
"_____no_output_____"
]
],
[
[
"model_2 = tf.keras.Sequential()\n\n# First layer takes a scalar input and feeds it through 16 \"neurons\". The\n# neurons decide whether to activate based on the 'relu' activation function.\nmodel_2.add(keras.layers.Dense(16, activation='relu', input_shape=(1,)))\n\n# The new second layer may help the network learn more complex representations\nmodel_2.add(keras.layers.Dense(16, activation='relu'))\n\n# Final layer is a single neuron, since we want to output a single value\nmodel_2.add(keras.layers.Dense(1))\n\n# Compile the model using a standard optimizer and loss function for regression\nmodel_2.compile(optimizer='adam', loss='mse', metrics=['mae'])",
"_____no_output_____"
]
],
[
[
"### 2. Train the Model ###\n\nWe'll now train the new model.",
"_____no_output_____"
]
],
[
[
"history_2 = model_2.fit(x_train, y_train, epochs=500, batch_size=64,\n validation_data=(x_validate, y_validate))",
"Train on 600 samples, validate on 200 samples\nEpoch 1/500\n600/600 [==============================] - 0s 736us/sample - loss: 0.4245 - mae: 0.5529 - val_loss: 0.4310 - val_mae: 0.5678\nEpoch 2/500\n600/600 [==============================] - 0s 64us/sample - loss: 0.4056 - mae: 0.5462 - val_loss: 0.4138 - val_mae: 0.5548\nEpoch 3/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.3897 - mae: 0.5302 - val_loss: 0.3974 - val_mae: 0.5437\nEpoch 4/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.3743 - mae: 0.5181 - val_loss: 0.3815 - val_mae: 0.5336\nEpoch 5/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.3602 - mae: 0.5128 - val_loss: 0.3677 - val_mae: 0.5276\nEpoch 6/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.3436 - mae: 0.5010 - val_loss: 0.3504 - val_mae: 0.5140\nEpoch 7/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.3281 - mae: 0.4859 - val_loss: 0.3340 - val_mae: 0.5021\nEpoch 8/500\n600/600 [==============================] - 0s 57us/sample - loss: 0.3127 - mae: 0.4748 - val_loss: 0.3177 - val_mae: 0.4921\nEpoch 9/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.2961 - mae: 0.4626 - val_loss: 0.3012 - val_mae: 0.4794\nEpoch 10/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.2797 - mae: 0.4502 - val_loss: 0.2851 - val_mae: 0.4687\nEpoch 11/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.2635 - mae: 0.4391 - val_loss: 0.2699 - val_mae: 0.4589\nEpoch 12/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.2467 - mae: 0.4251 - val_loss: 0.2523 - val_mae: 0.4414\nEpoch 13/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.2312 - mae: 0.4107 - val_loss: 0.2369 - val_mae: 0.4293\nEpoch 14/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.2149 - mae: 0.3971 - val_loss: 0.2225 - val_mae: 0.4168\nEpoch 15/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.2031 - mae: 0.3861 - val_loss: 0.2085 - val_mae: 0.4023\nEpoch 16/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1908 - mae: 0.3716 - val_loss: 0.1970 - val_mae: 0.3899\nEpoch 17/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1777 - mae: 0.3590 - val_loss: 0.1881 - val_mae: 0.3810\nEpoch 18/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1682 - mae: 0.3475 - val_loss: 0.1789 - val_mae: 0.3677\nEpoch 19/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.1603 - mae: 0.3367 - val_loss: 0.1723 - val_mae: 0.3586\nEpoch 20/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1536 - mae: 0.3276 - val_loss: 0.1668 - val_mae: 0.3500\nEpoch 21/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1487 - mae: 0.3181 - val_loss: 0.1619 - val_mae: 0.3403\nEpoch 22/500\n600/600 [==============================] - 0s 74us/sample - loss: 0.1433 - mae: 0.3108 - val_loss: 0.1598 - val_mae: 0.3358\nEpoch 23/500\n600/600 [==============================] - 0s 58us/sample - loss: 0.1418 - mae: 0.3072 - val_loss: 0.1558 - val_mae: 0.3248\nEpoch 24/500\n600/600 [==============================] - 0s 57us/sample - loss: 0.1389 - mae: 0.2992 - val_loss: 0.1538 - val_mae: 0.3189\nEpoch 25/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.1387 - mae: 0.2978 - val_loss: 0.1524 - val_mae: 0.3161\nEpoch 26/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1346 - mae: 0.2904 - val_loss: 0.1510 - val_mae: 0.3112\nEpoch 27/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1340 - mae: 0.2904 - val_loss: 0.1501 - val_mae: 0.3098\nEpoch 28/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1313 - mae: 0.2849 - val_loss: 0.1489 - val_mae: 0.3042\nEpoch 29/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.1303 - mae: 0.2830 - val_loss: 0.1489 - val_mae: 0.3058\nEpoch 30/500\n600/600 [==============================] - 0s 63us/sample - loss: 0.1292 - mae: 0.2804 - val_loss: 0.1474 - val_mae: 0.2997\nEpoch 31/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1286 - mae: 0.2781 - val_loss: 0.1467 - val_mae: 0.2998\nEpoch 32/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.1274 - mae: 0.2774 - val_loss: 0.1463 - val_mae: 0.2990\nEpoch 33/500\n600/600 [==============================] - 0s 62us/sample - loss: 0.1268 - mae: 0.2758 - val_loss: 0.1451 - val_mae: 0.2945\nEpoch 34/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.1295 - mae: 0.2746 - val_loss: 0.1449 - val_mae: 0.2966\nEpoch 35/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.1278 - mae: 0.2760 - val_loss: 0.1438 - val_mae: 0.2937\nEpoch 36/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1246 - mae: 0.2710 - val_loss: 0.1431 - val_mae: 0.2908\nEpoch 37/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1247 - mae: 0.2693 - val_loss: 0.1434 - val_mae: 0.2939\nEpoch 38/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.1237 - mae: 0.2702 - val_loss: 0.1415 - val_mae: 0.2893\nEpoch 39/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.1263 - mae: 0.2691 - val_loss: 0.1411 - val_mae: 0.2891\nEpoch 40/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1238 - mae: 0.2693 - val_loss: 0.1408 - val_mae: 0.2906\nEpoch 41/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.1209 - mae: 0.2659 - val_loss: 0.1393 - val_mae: 0.2859\nEpoch 42/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.1216 - mae: 0.2644 - val_loss: 0.1387 - val_mae: 0.2842\nEpoch 43/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1200 - mae: 0.2642 - val_loss: 0.1386 - val_mae: 0.2869\nEpoch 44/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.1193 - mae: 0.2626 - val_loss: 0.1370 - val_mae: 0.2814\nEpoch 45/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.1187 - mae: 0.2625 - val_loss: 0.1362 - val_mae: 0.2829\nEpoch 46/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.1177 - mae: 0.2593 - val_loss: 0.1353 - val_mae: 0.2796\nEpoch 47/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.1172 - mae: 0.2598 - val_loss: 0.1346 - val_mae: 0.2789\nEpoch 48/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.1158 - mae: 0.2569 - val_loss: 0.1337 - val_mae: 0.2769\nEpoch 49/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1176 - mae: 0.2590 - val_loss: 0.1329 - val_mae: 0.2761\nEpoch 50/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1141 - mae: 0.2544 - val_loss: 0.1320 - val_mae: 0.2759\nEpoch 51/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.1138 - mae: 0.2536 - val_loss: 0.1312 - val_mae: 0.2741\nEpoch 52/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1127 - mae: 0.2535 - val_loss: 0.1313 - val_mae: 0.2776\nEpoch 53/500\n600/600 [==============================] - 0s 60us/sample - loss: 0.1124 - mae: 0.2518 - val_loss: 0.1294 - val_mae: 0.2708\nEpoch 54/500\n600/600 [==============================] - 0s 61us/sample - loss: 0.1115 - mae: 0.2508 - val_loss: 0.1287 - val_mae: 0.2722\nEpoch 55/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.1103 - mae: 0.2487 - val_loss: 0.1278 - val_mae: 0.2709\nEpoch 56/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1094 - mae: 0.2485 - val_loss: 0.1267 - val_mae: 0.2687\nEpoch 57/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1090 - mae: 0.2479 - val_loss: 0.1259 - val_mae: 0.2684\nEpoch 58/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.1118 - mae: 0.2456 - val_loss: 0.1256 - val_mae: 0.2695\nEpoch 59/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1106 - mae: 0.2500 - val_loss: 0.1243 - val_mae: 0.2670\nEpoch 60/500\n600/600 [==============================] - 0s 59us/sample - loss: 0.1071 - mae: 0.2429 - val_loss: 0.1231 - val_mae: 0.2626\nEpoch 61/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.1059 - mae: 0.2436 - val_loss: 0.1226 - val_mae: 0.2653\nEpoch 62/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.1048 - mae: 0.2419 - val_loss: 0.1213 - val_mae: 0.2607\nEpoch 63/500\n600/600 [==============================] - 0s 65us/sample - loss: 0.1038 - mae: 0.2394 - val_loss: 0.1204 - val_mae: 0.2604\nEpoch 64/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.1029 - mae: 0.2383 - val_loss: 0.1196 - val_mae: 0.2593\nEpoch 65/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.1021 - mae: 0.2376 - val_loss: 0.1186 - val_mae: 0.2576\nEpoch 66/500\n600/600 [==============================] - 0s 57us/sample - loss: 0.1012 - mae: 0.2353 - val_loss: 0.1179 - val_mae: 0.2585\nEpoch 67/500\n600/600 [==============================] - 0s 57us/sample - loss: 0.1006 - mae: 0.2358 - val_loss: 0.1169 - val_mae: 0.2568\nEpoch 68/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0996 - mae: 0.2346 - val_loss: 0.1158 - val_mae: 0.2553\nEpoch 69/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0996 - mae: 0.2349 - val_loss: 0.1148 - val_mae: 0.2534\nEpoch 70/500\n600/600 [==============================] - 0s 62us/sample - loss: 0.0985 - mae: 0.2316 - val_loss: 0.1142 - val_mae: 0.2490\nEpoch 71/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0986 - mae: 0.2327 - val_loss: 0.1144 - val_mae: 0.2559\nEpoch 72/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0981 - mae: 0.2306 - val_loss: 0.1121 - val_mae: 0.2494\nEpoch 73/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0966 - mae: 0.2308 - val_loss: 0.1118 - val_mae: 0.2521\nEpoch 74/500\n600/600 [==============================] - 0s 57us/sample - loss: 0.0972 - mae: 0.2281 - val_loss: 0.1104 - val_mae: 0.2456\nEpoch 75/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0960 - mae: 0.2293 - val_loss: 0.1101 - val_mae: 0.2500\nEpoch 76/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.0933 - mae: 0.2247 - val_loss: 0.1087 - val_mae: 0.2424\nEpoch 77/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0922 - mae: 0.2221 - val_loss: 0.1080 - val_mae: 0.2453\nEpoch 78/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0917 - mae: 0.2235 - val_loss: 0.1069 - val_mae: 0.2432\nEpoch 79/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0922 - mae: 0.2204 - val_loss: 0.1061 - val_mae: 0.2394\nEpoch 80/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0918 - mae: 0.2239 - val_loss: 0.1062 - val_mae: 0.2456\nEpoch 81/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0908 - mae: 0.2220 - val_loss: 0.1048 - val_mae: 0.2372\nEpoch 82/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0889 - mae: 0.2193 - val_loss: 0.1046 - val_mae: 0.2421\nEpoch 83/500\n600/600 [==============================] - 0s 62us/sample - loss: 0.0883 - mae: 0.2175 - val_loss: 0.1029 - val_mae: 0.2339\nEpoch 84/500\n600/600 [==============================] - 0s 64us/sample - loss: 0.0872 - mae: 0.2143 - val_loss: 0.1022 - val_mae: 0.2372\nEpoch 85/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0865 - mae: 0.2148 - val_loss: 0.1012 - val_mae: 0.2342\nEpoch 86/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0856 - mae: 0.2124 - val_loss: 0.1004 - val_mae: 0.2317\nEpoch 87/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0850 - mae: 0.2122 - val_loss: 0.0998 - val_mae: 0.2340\nEpoch 88/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.0843 - mae: 0.2121 - val_loss: 0.0987 - val_mae: 0.2312\nEpoch 89/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0836 - mae: 0.2103 - val_loss: 0.0981 - val_mae: 0.2313\nEpoch 90/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0832 - mae: 0.2113 - val_loss: 0.0971 - val_mae: 0.2288\nEpoch 91/500\n600/600 [==============================] - 0s 58us/sample - loss: 0.0830 - mae: 0.2066 - val_loss: 0.0970 - val_mae: 0.2238\nEpoch 92/500\n600/600 [==============================] - 0s 70us/sample - loss: 0.0829 - mae: 0.2111 - val_loss: 0.0965 - val_mae: 0.2311\nEpoch 93/500\n600/600 [==============================] - 0s 69us/sample - loss: 0.0813 - mae: 0.2068 - val_loss: 0.0959 - val_mae: 0.2234\nEpoch 94/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0816 - mae: 0.2070 - val_loss: 0.0950 - val_mae: 0.2288\nEpoch 95/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0817 - mae: 0.2036 - val_loss: 0.0940 - val_mae: 0.2189\nEpoch 96/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0803 - mae: 0.2064 - val_loss: 0.0929 - val_mae: 0.2243\nEpoch 97/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0795 - mae: 0.2018 - val_loss: 0.0919 - val_mae: 0.2201\nEpoch 98/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0773 - mae: 0.2024 - val_loss: 0.0930 - val_mae: 0.2276\nEpoch 99/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0780 - mae: 0.2015 - val_loss: 0.0905 - val_mae: 0.2205\nEpoch 100/500\n600/600 [==============================] - 0s 59us/sample - loss: 0.0770 - mae: 0.2025 - val_loss: 0.0900 - val_mae: 0.2220\nEpoch 101/500\n600/600 [==============================] - 0s 57us/sample - loss: 0.0768 - mae: 0.1993 - val_loss: 0.0892 - val_mae: 0.2146\nEpoch 102/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0783 - mae: 0.2039 - val_loss: 0.0885 - val_mae: 0.2191\nEpoch 103/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0748 - mae: 0.1963 - val_loss: 0.0876 - val_mae: 0.2149\nEpoch 104/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0743 - mae: 0.1978 - val_loss: 0.0873 - val_mae: 0.2179\nEpoch 105/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0733 - mae: 0.1952 - val_loss: 0.0865 - val_mae: 0.2114\nEpoch 106/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0733 - mae: 0.1943 - val_loss: 0.0862 - val_mae: 0.2131\nEpoch 107/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0723 - mae: 0.1936 - val_loss: 0.0848 - val_mae: 0.2112\nEpoch 108/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.0715 - mae: 0.1927 - val_loss: 0.0843 - val_mae: 0.2125\nEpoch 109/500\n600/600 [==============================] - 0s 44us/sample - loss: 0.0714 - mae: 0.1903 - val_loss: 0.0836 - val_mae: 0.2100\nEpoch 110/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0719 - mae: 0.1952 - val_loss: 0.0830 - val_mae: 0.2111\nEpoch 111/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.0714 - mae: 0.1895 - val_loss: 0.0824 - val_mae: 0.2072\nEpoch 112/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0699 - mae: 0.1929 - val_loss: 0.0823 - val_mae: 0.2110\nEpoch 113/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.0699 - mae: 0.1891 - val_loss: 0.0810 - val_mae: 0.2053\nEpoch 114/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0691 - mae: 0.1898 - val_loss: 0.0805 - val_mae: 0.2074\nEpoch 115/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.0678 - mae: 0.1859 - val_loss: 0.0798 - val_mae: 0.2025\nEpoch 116/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.0674 - mae: 0.1880 - val_loss: 0.0794 - val_mae: 0.2061\nEpoch 117/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0672 - mae: 0.1844 - val_loss: 0.0785 - val_mae: 0.2008\nEpoch 118/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.0663 - mae: 0.1848 - val_loss: 0.0780 - val_mae: 0.2038\nEpoch 119/500\n600/600 [==============================] - 0s 44us/sample - loss: 0.0657 - mae: 0.1830 - val_loss: 0.0772 - val_mae: 0.2003\nEpoch 120/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.0649 - mae: 0.1813 - val_loss: 0.0767 - val_mae: 0.2002\nEpoch 121/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0654 - mae: 0.1845 - val_loss: 0.0761 - val_mae: 0.1997\nEpoch 122/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0642 - mae: 0.1815 - val_loss: 0.0755 - val_mae: 0.1991\nEpoch 123/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0635 - mae: 0.1807 - val_loss: 0.0750 - val_mae: 0.1955\nEpoch 124/500\n600/600 [==============================] - 0s 58us/sample - loss: 0.0635 - mae: 0.1779 - val_loss: 0.0744 - val_mae: 0.1981\nEpoch 125/500\n600/600 [==============================] - 0s 60us/sample - loss: 0.0642 - mae: 0.1844 - val_loss: 0.0738 - val_mae: 0.1968\nEpoch 126/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0659 - mae: 0.1780 - val_loss: 0.0739 - val_mae: 0.1973\nEpoch 127/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0622 - mae: 0.1817 - val_loss: 0.0731 - val_mae: 0.1985\nEpoch 128/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0619 - mae: 0.1772 - val_loss: 0.0722 - val_mae: 0.1936\nEpoch 129/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0607 - mae: 0.1764 - val_loss: 0.0718 - val_mae: 0.1946\nEpoch 130/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0602 - mae: 0.1747 - val_loss: 0.0710 - val_mae: 0.1925\nEpoch 131/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.0600 - mae: 0.1748 - val_loss: 0.0706 - val_mae: 0.1923\nEpoch 132/500\n600/600 [==============================] - 0s 57us/sample - loss: 0.0592 - mae: 0.1743 - val_loss: 0.0699 - val_mae: 0.1913\nEpoch 133/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0594 - mae: 0.1722 - val_loss: 0.0695 - val_mae: 0.1901\nEpoch 134/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0589 - mae: 0.1753 - val_loss: 0.0690 - val_mae: 0.1903\nEpoch 135/500\n600/600 [==============================] - 0s 57us/sample - loss: 0.0587 - mae: 0.1702 - val_loss: 0.0684 - val_mae: 0.1886\nEpoch 136/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.0575 - mae: 0.1725 - val_loss: 0.0682 - val_mae: 0.1908\nEpoch 137/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.0570 - mae: 0.1704 - val_loss: 0.0676 - val_mae: 0.1871\nEpoch 138/500\n600/600 [==============================] - 0s 57us/sample - loss: 0.0567 - mae: 0.1692 - val_loss: 0.0671 - val_mae: 0.1879\nEpoch 139/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0562 - mae: 0.1692 - val_loss: 0.0663 - val_mae: 0.1848\nEpoch 140/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0558 - mae: 0.1676 - val_loss: 0.0658 - val_mae: 0.1847\nEpoch 141/500\n600/600 [==============================] - 0s 57us/sample - loss: 0.0553 - mae: 0.1663 - val_loss: 0.0653 - val_mae: 0.1840\nEpoch 142/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0552 - mae: 0.1665 - val_loss: 0.0650 - val_mae: 0.1850\nEpoch 143/500\n600/600 [==============================] - 0s 58us/sample - loss: 0.0550 - mae: 0.1688 - val_loss: 0.0642 - val_mae: 0.1831\nEpoch 144/500\n600/600 [==============================] - 0s 59us/sample - loss: 0.0542 - mae: 0.1647 - val_loss: 0.0640 - val_mae: 0.1820\nEpoch 145/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0536 - mae: 0.1644 - val_loss: 0.0633 - val_mae: 0.1812\nEpoch 146/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0533 - mae: 0.1646 - val_loss: 0.0628 - val_mae: 0.1820\nEpoch 147/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0527 - mae: 0.1630 - val_loss: 0.0623 - val_mae: 0.1803\nEpoch 148/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0524 - mae: 0.1620 - val_loss: 0.0620 - val_mae: 0.1809\nEpoch 149/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0519 - mae: 0.1624 - val_loss: 0.0613 - val_mae: 0.1798\nEpoch 150/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.0527 - mae: 0.1629 - val_loss: 0.0610 - val_mae: 0.1798\nEpoch 151/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0515 - mae: 0.1605 - val_loss: 0.0609 - val_mae: 0.1752\nEpoch 152/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0511 - mae: 0.1609 - val_loss: 0.0602 - val_mae: 0.1788\nEpoch 153/500\n600/600 [==============================] - 0s 58us/sample - loss: 0.0506 - mae: 0.1594 - val_loss: 0.0594 - val_mae: 0.1786\nEpoch 154/500\n600/600 [==============================] - 0s 64us/sample - loss: 0.0501 - mae: 0.1607 - val_loss: 0.0589 - val_mae: 0.1763\nEpoch 155/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0497 - mae: 0.1576 - val_loss: 0.0587 - val_mae: 0.1762\nEpoch 156/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0493 - mae: 0.1585 - val_loss: 0.0581 - val_mae: 0.1756\nEpoch 157/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0489 - mae: 0.1575 - val_loss: 0.0581 - val_mae: 0.1780\nEpoch 158/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.0486 - mae: 0.1582 - val_loss: 0.0574 - val_mae: 0.1728\nEpoch 159/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0488 - mae: 0.1552 - val_loss: 0.0576 - val_mae: 0.1777\nEpoch 160/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.0501 - mae: 0.1633 - val_loss: 0.0567 - val_mae: 0.1750\nEpoch 161/500\n600/600 [==============================] - 0s 44us/sample - loss: 0.0481 - mae: 0.1568 - val_loss: 0.0562 - val_mae: 0.1750\nEpoch 162/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0476 - mae: 0.1569 - val_loss: 0.0553 - val_mae: 0.1706\nEpoch 163/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0464 - mae: 0.1533 - val_loss: 0.0549 - val_mae: 0.1717\nEpoch 164/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0470 - mae: 0.1559 - val_loss: 0.0550 - val_mae: 0.1696\nEpoch 165/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0463 - mae: 0.1526 - val_loss: 0.0543 - val_mae: 0.1669\nEpoch 166/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0467 - mae: 0.1530 - val_loss: 0.0536 - val_mae: 0.1685\nEpoch 167/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0465 - mae: 0.1521 - val_loss: 0.0536 - val_mae: 0.1691\nEpoch 168/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.0462 - mae: 0.1570 - val_loss: 0.0530 - val_mae: 0.1681\nEpoch 169/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.0448 - mae: 0.1514 - val_loss: 0.0523 - val_mae: 0.1679\nEpoch 170/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0441 - mae: 0.1509 - val_loss: 0.0518 - val_mae: 0.1668\nEpoch 171/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.0438 - mae: 0.1488 - val_loss: 0.0516 - val_mae: 0.1668\nEpoch 172/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.0437 - mae: 0.1509 - val_loss: 0.0510 - val_mae: 0.1649\nEpoch 173/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0431 - mae: 0.1479 - val_loss: 0.0507 - val_mae: 0.1658\nEpoch 174/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0432 - mae: 0.1493 - val_loss: 0.0503 - val_mae: 0.1634\nEpoch 175/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0427 - mae: 0.1467 - val_loss: 0.0502 - val_mae: 0.1667\nEpoch 176/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0425 - mae: 0.1475 - val_loss: 0.0494 - val_mae: 0.1618\nEpoch 177/500\n600/600 [==============================] - 0s 43us/sample - loss: 0.0426 - mae: 0.1497 - val_loss: 0.0491 - val_mae: 0.1618\nEpoch 178/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.0416 - mae: 0.1454 - val_loss: 0.0489 - val_mae: 0.1635\nEpoch 179/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0414 - mae: 0.1467 - val_loss: 0.0483 - val_mae: 0.1599\nEpoch 180/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0411 - mae: 0.1439 - val_loss: 0.0489 - val_mae: 0.1651\nEpoch 181/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0418 - mae: 0.1485 - val_loss: 0.0477 - val_mae: 0.1597\nEpoch 182/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0405 - mae: 0.1445 - val_loss: 0.0473 - val_mae: 0.1612\nEpoch 183/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0399 - mae: 0.1435 - val_loss: 0.0466 - val_mae: 0.1579\nEpoch 184/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0399 - mae: 0.1432 - val_loss: 0.0465 - val_mae: 0.1561\nEpoch 185/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0397 - mae: 0.1437 - val_loss: 0.0459 - val_mae: 0.1573\nEpoch 186/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0394 - mae: 0.1424 - val_loss: 0.0455 - val_mae: 0.1582\nEpoch 187/500\n600/600 [==============================] - 0s 57us/sample - loss: 0.0385 - mae: 0.1411 - val_loss: 0.0453 - val_mae: 0.1544\nEpoch 188/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0385 - mae: 0.1403 - val_loss: 0.0447 - val_mae: 0.1545\nEpoch 189/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0381 - mae: 0.1392 - val_loss: 0.0444 - val_mae: 0.1549\nEpoch 190/500\n600/600 [==============================] - 0s 61us/sample - loss: 0.0378 - mae: 0.1402 - val_loss: 0.0441 - val_mae: 0.1529\nEpoch 191/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0376 - mae: 0.1390 - val_loss: 0.0441 - val_mae: 0.1574\nEpoch 192/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0378 - mae: 0.1397 - val_loss: 0.0431 - val_mae: 0.1533\nEpoch 193/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0376 - mae: 0.1401 - val_loss: 0.0430 - val_mae: 0.1538\nEpoch 194/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.0372 - mae: 0.1376 - val_loss: 0.0433 - val_mae: 0.1548\nEpoch 195/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0376 - mae: 0.1412 - val_loss: 0.0429 - val_mae: 0.1508\nEpoch 196/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0365 - mae: 0.1383 - val_loss: 0.0419 - val_mae: 0.1529\nEpoch 197/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0361 - mae: 0.1353 - val_loss: 0.0416 - val_mae: 0.1485\nEpoch 198/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0354 - mae: 0.1353 - val_loss: 0.0411 - val_mae: 0.1506\nEpoch 199/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0354 - mae: 0.1363 - val_loss: 0.0410 - val_mae: 0.1504\nEpoch 200/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.0354 - mae: 0.1358 - val_loss: 0.0410 - val_mae: 0.1511\nEpoch 201/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.0348 - mae: 0.1349 - val_loss: 0.0399 - val_mae: 0.1475\nEpoch 202/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.0345 - mae: 0.1342 - val_loss: 0.0396 - val_mae: 0.1476\nEpoch 203/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.0342 - mae: 0.1345 - val_loss: 0.0395 - val_mae: 0.1455\nEpoch 204/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.0337 - mae: 0.1321 - val_loss: 0.0390 - val_mae: 0.1462\nEpoch 205/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0336 - mae: 0.1328 - val_loss: 0.0389 - val_mae: 0.1445\nEpoch 206/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0337 - mae: 0.1317 - val_loss: 0.0392 - val_mae: 0.1497\nEpoch 207/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.0335 - mae: 0.1326 - val_loss: 0.0384 - val_mae: 0.1436\nEpoch 208/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0329 - mae: 0.1310 - val_loss: 0.0376 - val_mae: 0.1444\nEpoch 209/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.0328 - mae: 0.1298 - val_loss: 0.0375 - val_mae: 0.1454\nEpoch 210/500\n600/600 [==============================] - 0s 44us/sample - loss: 0.0328 - mae: 0.1328 - val_loss: 0.0370 - val_mae: 0.1432\nEpoch 211/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.0331 - mae: 0.1310 - val_loss: 0.0369 - val_mae: 0.1413\nEpoch 212/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.0317 - mae: 0.1290 - val_loss: 0.0367 - val_mae: 0.1449\nEpoch 213/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.0318 - mae: 0.1291 - val_loss: 0.0360 - val_mae: 0.1425\nEpoch 214/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0312 - mae: 0.1284 - val_loss: 0.0356 - val_mae: 0.1413\nEpoch 215/500\n600/600 [==============================] - 0s 65us/sample - loss: 0.0309 - mae: 0.1273 - val_loss: 0.0356 - val_mae: 0.1423\nEpoch 216/500\n600/600 [==============================] - 0s 57us/sample - loss: 0.0310 - mae: 0.1280 - val_loss: 0.0350 - val_mae: 0.1396\nEpoch 217/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0303 - mae: 0.1263 - val_loss: 0.0346 - val_mae: 0.1400\nEpoch 218/500\n600/600 [==============================] - 0s 59us/sample - loss: 0.0302 - mae: 0.1267 - val_loss: 0.0343 - val_mae: 0.1390\nEpoch 219/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0299 - mae: 0.1258 - val_loss: 0.0340 - val_mae: 0.1377\nEpoch 220/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.0299 - mae: 0.1262 - val_loss: 0.0338 - val_mae: 0.1374\nEpoch 221/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.0294 - mae: 0.1246 - val_loss: 0.0337 - val_mae: 0.1395\nEpoch 222/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0299 - mae: 0.1275 - val_loss: 0.0340 - val_mae: 0.1394\nEpoch 223/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.0295 - mae: 0.1251 - val_loss: 0.0331 - val_mae: 0.1378\nEpoch 224/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.0290 - mae: 0.1228 - val_loss: 0.0325 - val_mae: 0.1361\nEpoch 225/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.0291 - mae: 0.1254 - val_loss: 0.0321 - val_mae: 0.1344\nEpoch 226/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0286 - mae: 0.1237 - val_loss: 0.0318 - val_mae: 0.1340\nEpoch 227/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.0281 - mae: 0.1219 - val_loss: 0.0315 - val_mae: 0.1331\nEpoch 228/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0280 - mae: 0.1221 - val_loss: 0.0313 - val_mae: 0.1345\nEpoch 229/500\n600/600 [==============================] - 0s 57us/sample - loss: 0.0276 - mae: 0.1202 - val_loss: 0.0310 - val_mae: 0.1333\nEpoch 230/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.0276 - mae: 0.1215 - val_loss: 0.0308 - val_mae: 0.1313\nEpoch 231/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.0274 - mae: 0.1214 - val_loss: 0.0319 - val_mae: 0.1382\nEpoch 232/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0281 - mae: 0.1242 - val_loss: 0.0304 - val_mae: 0.1305\nEpoch 233/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0268 - mae: 0.1195 - val_loss: 0.0299 - val_mae: 0.1320\nEpoch 234/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0264 - mae: 0.1187 - val_loss: 0.0296 - val_mae: 0.1302\nEpoch 235/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.0267 - mae: 0.1206 - val_loss: 0.0299 - val_mae: 0.1285\nEpoch 236/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0272 - mae: 0.1182 - val_loss: 0.0309 - val_mae: 0.1363\nEpoch 237/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0273 - mae: 0.1209 - val_loss: 0.0286 - val_mae: 0.1297\nEpoch 238/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0260 - mae: 0.1191 - val_loss: 0.0286 - val_mae: 0.1276\nEpoch 239/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0259 - mae: 0.1173 - val_loss: 0.0283 - val_mae: 0.1279\nEpoch 240/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0255 - mae: 0.1157 - val_loss: 0.0279 - val_mae: 0.1281\nEpoch 241/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.0253 - mae: 0.1162 - val_loss: 0.0280 - val_mae: 0.1294\nEpoch 242/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0256 - mae: 0.1178 - val_loss: 0.0273 - val_mae: 0.1259\nEpoch 243/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0245 - mae: 0.1144 - val_loss: 0.0276 - val_mae: 0.1287\nEpoch 244/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0252 - mae: 0.1163 - val_loss: 0.0268 - val_mae: 0.1263\nEpoch 245/500\n600/600 [==============================] - 0s 57us/sample - loss: 0.0261 - mae: 0.1201 - val_loss: 0.0295 - val_mae: 0.1333\nEpoch 246/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0268 - mae: 0.1231 - val_loss: 0.0279 - val_mae: 0.1302\nEpoch 247/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0240 - mae: 0.1149 - val_loss: 0.0263 - val_mae: 0.1242\nEpoch 248/500\n600/600 [==============================] - 0s 66us/sample - loss: 0.0242 - mae: 0.1146 - val_loss: 0.0259 - val_mae: 0.1249\nEpoch 249/500\n600/600 [==============================] - 0s 69us/sample - loss: 0.0233 - mae: 0.1129 - val_loss: 0.0277 - val_mae: 0.1258\nEpoch 250/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0246 - mae: 0.1158 - val_loss: 0.0255 - val_mae: 0.1237\nEpoch 251/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0231 - mae: 0.1114 - val_loss: 0.0249 - val_mae: 0.1216\nEpoch 252/500\n600/600 [==============================] - 0s 63us/sample - loss: 0.0230 - mae: 0.1122 - val_loss: 0.0246 - val_mae: 0.1216\nEpoch 253/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0229 - mae: 0.1109 - val_loss: 0.0247 - val_mae: 0.1228\nEpoch 254/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.0230 - mae: 0.1122 - val_loss: 0.0242 - val_mae: 0.1204\nEpoch 255/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.0233 - mae: 0.1139 - val_loss: 0.0252 - val_mae: 0.1209\nEpoch 256/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0225 - mae: 0.1102 - val_loss: 0.0239 - val_mae: 0.1197\nEpoch 257/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0219 - mae: 0.1086 - val_loss: 0.0235 - val_mae: 0.1197\nEpoch 258/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0217 - mae: 0.1091 - val_loss: 0.0234 - val_mae: 0.1188\nEpoch 259/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.0215 - mae: 0.1082 - val_loss: 0.0231 - val_mae: 0.1184\nEpoch 260/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.0214 - mae: 0.1080 - val_loss: 0.0228 - val_mae: 0.1183\nEpoch 261/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.0214 - mae: 0.1081 - val_loss: 0.0226 - val_mae: 0.1175\nEpoch 262/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0211 - mae: 0.1077 - val_loss: 0.0224 - val_mae: 0.1177\nEpoch 263/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0210 - mae: 0.1075 - val_loss: 0.0223 - val_mae: 0.1176\nEpoch 264/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0209 - mae: 0.1079 - val_loss: 0.0223 - val_mae: 0.1164\nEpoch 265/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0208 - mae: 0.1073 - val_loss: 0.0219 - val_mae: 0.1165\nEpoch 266/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0209 - mae: 0.1084 - val_loss: 0.0221 - val_mae: 0.1149\nEpoch 267/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0206 - mae: 0.1075 - val_loss: 0.0215 - val_mae: 0.1148\nEpoch 268/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0203 - mae: 0.1062 - val_loss: 0.0212 - val_mae: 0.1142\nEpoch 269/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0201 - mae: 0.1055 - val_loss: 0.0212 - val_mae: 0.1141\nEpoch 270/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0200 - mae: 0.1063 - val_loss: 0.0213 - val_mae: 0.1137\nEpoch 271/500\n600/600 [==============================] - 0s 58us/sample - loss: 0.0201 - mae: 0.1066 - val_loss: 0.0211 - val_mae: 0.1127\nEpoch 272/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0205 - mae: 0.1074 - val_loss: 0.0203 - val_mae: 0.1131\nEpoch 273/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0197 - mae: 0.1052 - val_loss: 0.0202 - val_mae: 0.1123\nEpoch 274/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0194 - mae: 0.1043 - val_loss: 0.0201 - val_mae: 0.1119\nEpoch 275/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0192 - mae: 0.1038 - val_loss: 0.0199 - val_mae: 0.1118\nEpoch 276/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0191 - mae: 0.1040 - val_loss: 0.0200 - val_mae: 0.1113\nEpoch 277/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0191 - mae: 0.1043 - val_loss: 0.0199 - val_mae: 0.1117\nEpoch 278/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0194 - mae: 0.1051 - val_loss: 0.0195 - val_mae: 0.1111\nEpoch 279/500\n600/600 [==============================] - 0s 65us/sample - loss: 0.0186 - mae: 0.1031 - val_loss: 0.0197 - val_mae: 0.1098\nEpoch 280/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.0187 - mae: 0.1031 - val_loss: 0.0192 - val_mae: 0.1103\nEpoch 281/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0186 - mae: 0.1031 - val_loss: 0.0192 - val_mae: 0.1098\nEpoch 282/500\n600/600 [==============================] - 0s 63us/sample - loss: 0.0185 - mae: 0.1031 - val_loss: 0.0190 - val_mae: 0.1092\nEpoch 283/500\n600/600 [==============================] - 0s 60us/sample - loss: 0.0183 - mae: 0.1022 - val_loss: 0.0188 - val_mae: 0.1097\nEpoch 284/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0181 - mae: 0.1020 - val_loss: 0.0186 - val_mae: 0.1086\nEpoch 285/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0183 - mae: 0.1025 - val_loss: 0.0192 - val_mae: 0.1085\nEpoch 286/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0190 - mae: 0.1057 - val_loss: 0.0190 - val_mae: 0.1106\nEpoch 287/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0181 - mae: 0.1022 - val_loss: 0.0181 - val_mae: 0.1077\nEpoch 288/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.0177 - mae: 0.1012 - val_loss: 0.0181 - val_mae: 0.1072\nEpoch 289/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0175 - mae: 0.1003 - val_loss: 0.0182 - val_mae: 0.1082\nEpoch 290/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0180 - mae: 0.1028 - val_loss: 0.0179 - val_mae: 0.1064\nEpoch 291/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.0175 - mae: 0.1013 - val_loss: 0.0179 - val_mae: 0.1063\nEpoch 292/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.0175 - mae: 0.1014 - val_loss: 0.0177 - val_mae: 0.1067\nEpoch 293/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.0176 - mae: 0.1018 - val_loss: 0.0171 - val_mae: 0.1051\nEpoch 294/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0175 - mae: 0.1010 - val_loss: 0.0175 - val_mae: 0.1050\nEpoch 295/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0176 - mae: 0.1015 - val_loss: 0.0174 - val_mae: 0.1056\nEpoch 296/500\n600/600 [==============================] - 0s 58us/sample - loss: 0.0173 - mae: 0.1017 - val_loss: 0.0172 - val_mae: 0.1040\nEpoch 297/500\n600/600 [==============================] - 0s 63us/sample - loss: 0.0168 - mae: 0.0999 - val_loss: 0.0169 - val_mae: 0.1046\nEpoch 298/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0169 - mae: 0.1001 - val_loss: 0.0166 - val_mae: 0.1035\nEpoch 299/500\n600/600 [==============================] - 0s 141us/sample - loss: 0.0168 - mae: 0.0994 - val_loss: 0.0168 - val_mae: 0.1035\nEpoch 300/500\n600/600 [==============================] - 0s 57us/sample - loss: 0.0166 - mae: 0.0999 - val_loss: 0.0162 - val_mae: 0.1026\nEpoch 301/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0164 - mae: 0.0985 - val_loss: 0.0164 - val_mae: 0.1026\nEpoch 302/500\n600/600 [==============================] - 0s 58us/sample - loss: 0.0162 - mae: 0.0988 - val_loss: 0.0165 - val_mae: 0.1026\nEpoch 303/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0164 - mae: 0.0989 - val_loss: 0.0161 - val_mae: 0.1022\nEpoch 304/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0163 - mae: 0.0988 - val_loss: 0.0161 - val_mae: 0.1026\nEpoch 305/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0163 - mae: 0.0993 - val_loss: 0.0158 - val_mae: 0.1015\nEpoch 306/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0162 - mae: 0.0989 - val_loss: 0.0161 - val_mae: 0.1020\nEpoch 307/500\n600/600 [==============================] - 0s 76us/sample - loss: 0.0166 - mae: 0.1004 - val_loss: 0.0158 - val_mae: 0.1011\nEpoch 308/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.0160 - mae: 0.0984 - val_loss: 0.0158 - val_mae: 0.1004\nEpoch 309/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0160 - mae: 0.0983 - val_loss: 0.0160 - val_mae: 0.1012\nEpoch 310/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0170 - mae: 0.1013 - val_loss: 0.0159 - val_mae: 0.1016\nEpoch 311/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0160 - mae: 0.0983 - val_loss: 0.0192 - val_mae: 0.1091\nEpoch 312/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0185 - mae: 0.1053 - val_loss: 0.0153 - val_mae: 0.1004\nEpoch 313/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0161 - mae: 0.0997 - val_loss: 0.0162 - val_mae: 0.1010\nEpoch 314/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0153 - mae: 0.0966 - val_loss: 0.0154 - val_mae: 0.1006\nEpoch 315/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0162 - mae: 0.1002 - val_loss: 0.0152 - val_mae: 0.0999\nEpoch 316/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.0162 - mae: 0.0999 - val_loss: 0.0158 - val_mae: 0.0996\nEpoch 317/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0158 - mae: 0.0985 - val_loss: 0.0170 - val_mae: 0.1026\nEpoch 318/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0167 - mae: 0.1021 - val_loss: 0.0148 - val_mae: 0.0981\nEpoch 319/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0161 - mae: 0.0994 - val_loss: 0.0157 - val_mae: 0.1011\nEpoch 320/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.0148 - mae: 0.0950 - val_loss: 0.0144 - val_mae: 0.0973\nEpoch 321/500\n600/600 [==============================] - 0s 62us/sample - loss: 0.0147 - mae: 0.0954 - val_loss: 0.0152 - val_mae: 0.0983\nEpoch 322/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0149 - mae: 0.0955 - val_loss: 0.0147 - val_mae: 0.0982\nEpoch 323/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0149 - mae: 0.0956 - val_loss: 0.0145 - val_mae: 0.0977\nEpoch 324/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0147 - mae: 0.0956 - val_loss: 0.0142 - val_mae: 0.0963\nEpoch 325/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0145 - mae: 0.0950 - val_loss: 0.0144 - val_mae: 0.0974\nEpoch 326/500\n600/600 [==============================] - 0s 59us/sample - loss: 0.0147 - mae: 0.0957 - val_loss: 0.0141 - val_mae: 0.0965\nEpoch 327/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0147 - mae: 0.0960 - val_loss: 0.0144 - val_mae: 0.0973\nEpoch 328/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0145 - mae: 0.0944 - val_loss: 0.0141 - val_mae: 0.0959\nEpoch 329/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0145 - mae: 0.0952 - val_loss: 0.0137 - val_mae: 0.0949\nEpoch 330/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0143 - mae: 0.0944 - val_loss: 0.0139 - val_mae: 0.0952\nEpoch 331/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0143 - mae: 0.0941 - val_loss: 0.0139 - val_mae: 0.0947\nEpoch 332/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0141 - mae: 0.0941 - val_loss: 0.0139 - val_mae: 0.0949\nEpoch 333/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0149 - mae: 0.0951 - val_loss: 0.0148 - val_mae: 0.0968\nEpoch 334/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0148 - mae: 0.0957 - val_loss: 0.0151 - val_mae: 0.0979\nEpoch 335/500\n600/600 [==============================] - 0s 58us/sample - loss: 0.0151 - mae: 0.0966 - val_loss: 0.0139 - val_mae: 0.0945\nEpoch 336/500\n600/600 [==============================] - 0s 59us/sample - loss: 0.0141 - mae: 0.0932 - val_loss: 0.0140 - val_mae: 0.0954\nEpoch 337/500\n600/600 [==============================] - 0s 60us/sample - loss: 0.0141 - mae: 0.0936 - val_loss: 0.0133 - val_mae: 0.0934\nEpoch 338/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0141 - mae: 0.0932 - val_loss: 0.0137 - val_mae: 0.0943\nEpoch 339/500\n600/600 [==============================] - 0s 62us/sample - loss: 0.0139 - mae: 0.0931 - val_loss: 0.0132 - val_mae: 0.0929\nEpoch 340/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0136 - mae: 0.0923 - val_loss: 0.0132 - val_mae: 0.0929\nEpoch 341/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0137 - mae: 0.0925 - val_loss: 0.0146 - val_mae: 0.0963\nEpoch 342/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0140 - mae: 0.0947 - val_loss: 0.0139 - val_mae: 0.0946\nEpoch 343/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.0139 - mae: 0.0940 - val_loss: 0.0136 - val_mae: 0.0934\nEpoch 344/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0135 - mae: 0.0920 - val_loss: 0.0132 - val_mae: 0.0925\nEpoch 345/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.0136 - mae: 0.0923 - val_loss: 0.0134 - val_mae: 0.0932\nEpoch 346/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0134 - mae: 0.0922 - val_loss: 0.0130 - val_mae: 0.0919\nEpoch 347/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0133 - mae: 0.0920 - val_loss: 0.0137 - val_mae: 0.0937\nEpoch 348/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0134 - mae: 0.0926 - val_loss: 0.0133 - val_mae: 0.0926\nEpoch 349/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0139 - mae: 0.0941 - val_loss: 0.0135 - val_mae: 0.0929\nEpoch 350/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0133 - mae: 0.0904 - val_loss: 0.0126 - val_mae: 0.0907\nEpoch 351/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.0134 - mae: 0.0916 - val_loss: 0.0128 - val_mae: 0.0912\nEpoch 352/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0137 - mae: 0.0928 - val_loss: 0.0131 - val_mae: 0.0916\nEpoch 353/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0144 - mae: 0.0947 - val_loss: 0.0126 - val_mae: 0.0904\nEpoch 354/500\n600/600 [==============================] - 0s 58us/sample - loss: 0.0131 - mae: 0.0910 - val_loss: 0.0132 - val_mae: 0.0923\nEpoch 355/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.0138 - mae: 0.0930 - val_loss: 0.0131 - val_mae: 0.0919\nEpoch 356/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0135 - mae: 0.0926 - val_loss: 0.0126 - val_mae: 0.0904\nEpoch 357/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0131 - mae: 0.0907 - val_loss: 0.0138 - val_mae: 0.0940\nEpoch 358/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.0132 - mae: 0.0907 - val_loss: 0.0126 - val_mae: 0.0904\nEpoch 359/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0129 - mae: 0.0903 - val_loss: 0.0127 - val_mae: 0.0907\nEpoch 360/500\n600/600 [==============================] - 0s 57us/sample - loss: 0.0128 - mae: 0.0900 - val_loss: 0.0126 - val_mae: 0.0902\nEpoch 361/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0133 - mae: 0.0909 - val_loss: 0.0126 - val_mae: 0.0905\nEpoch 362/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0130 - mae: 0.0907 - val_loss: 0.0125 - val_mae: 0.0898\nEpoch 363/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0129 - mae: 0.0899 - val_loss: 0.0124 - val_mae: 0.0896\nEpoch 364/500\n600/600 [==============================] - 0s 57us/sample - loss: 0.0129 - mae: 0.0903 - val_loss: 0.0126 - val_mae: 0.0900\nEpoch 365/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0129 - mae: 0.0898 - val_loss: 0.0125 - val_mae: 0.0901\nEpoch 366/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0129 - mae: 0.0910 - val_loss: 0.0131 - val_mae: 0.0912\nEpoch 367/500\n600/600 [==============================] - 0s 72us/sample - loss: 0.0127 - mae: 0.0895 - val_loss: 0.0122 - val_mae: 0.0890\nEpoch 368/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0129 - mae: 0.0905 - val_loss: 0.0126 - val_mae: 0.0905\nEpoch 369/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0129 - mae: 0.0902 - val_loss: 0.0123 - val_mae: 0.0889\nEpoch 370/500\n600/600 [==============================] - 0s 57us/sample - loss: 0.0127 - mae: 0.0899 - val_loss: 0.0125 - val_mae: 0.0894\nEpoch 371/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.0134 - mae: 0.0920 - val_loss: 0.0139 - val_mae: 0.0931\nEpoch 372/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0134 - mae: 0.0916 - val_loss: 0.0129 - val_mae: 0.0905\nEpoch 373/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.0129 - mae: 0.0907 - val_loss: 0.0126 - val_mae: 0.0897\nEpoch 374/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0128 - mae: 0.0899 - val_loss: 0.0121 - val_mae: 0.0879\nEpoch 375/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0133 - mae: 0.0923 - val_loss: 0.0125 - val_mae: 0.0904\nEpoch 376/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0129 - mae: 0.0908 - val_loss: 0.0130 - val_mae: 0.0915\nEpoch 377/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.0129 - mae: 0.0911 - val_loss: 0.0119 - val_mae: 0.0877\nEpoch 378/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0138 - mae: 0.0941 - val_loss: 0.0121 - val_mae: 0.0881\nEpoch 379/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0127 - mae: 0.0898 - val_loss: 0.0127 - val_mae: 0.0895\nEpoch 380/500\n600/600 [==============================] - 0s 46us/sample - loss: 0.0129 - mae: 0.0903 - val_loss: 0.0120 - val_mae: 0.0876\nEpoch 381/500\n600/600 [==============================] - 0s 45us/sample - loss: 0.0126 - mae: 0.0896 - val_loss: 0.0120 - val_mae: 0.0876\nEpoch 382/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.0130 - mae: 0.0917 - val_loss: 0.0121 - val_mae: 0.0880\nEpoch 383/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.0126 - mae: 0.0895 - val_loss: 0.0120 - val_mae: 0.0882\nEpoch 384/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0128 - mae: 0.0910 - val_loss: 0.0150 - val_mae: 0.0983\nEpoch 385/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0134 - mae: 0.0912 - val_loss: 0.0118 - val_mae: 0.0876\nEpoch 386/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0124 - mae: 0.0892 - val_loss: 0.0123 - val_mae: 0.0886\nEpoch 387/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0127 - mae: 0.0898 - val_loss: 0.0128 - val_mae: 0.0900\nEpoch 388/500\n600/600 [==============================] - 0s 58us/sample - loss: 0.0128 - mae: 0.0903 - val_loss: 0.0129 - val_mae: 0.0906\nEpoch 389/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0148 - mae: 0.0984 - val_loss: 0.0121 - val_mae: 0.0880\nEpoch 390/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.0137 - mae: 0.0939 - val_loss: 0.0118 - val_mae: 0.0874\nEpoch 391/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0127 - mae: 0.0896 - val_loss: 0.0122 - val_mae: 0.0893\nEpoch 392/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0124 - mae: 0.0888 - val_loss: 0.0118 - val_mae: 0.0873\nEpoch 393/500\n600/600 [==============================] - 0s 57us/sample - loss: 0.0124 - mae: 0.0887 - val_loss: 0.0119 - val_mae: 0.0879\nEpoch 394/500\n600/600 [==============================] - 0s 62us/sample - loss: 0.0124 - mae: 0.0885 - val_loss: 0.0117 - val_mae: 0.0865\nEpoch 395/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0128 - mae: 0.0904 - val_loss: 0.0121 - val_mae: 0.0880\nEpoch 396/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0126 - mae: 0.0895 - val_loss: 0.0119 - val_mae: 0.0874\nEpoch 397/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0124 - mae: 0.0883 - val_loss: 0.0120 - val_mae: 0.0880\nEpoch 398/500\n600/600 [==============================] - 0s 58us/sample - loss: 0.0130 - mae: 0.0906 - val_loss: 0.0122 - val_mae: 0.0891\nEpoch 399/500\n600/600 [==============================] - 0s 57us/sample - loss: 0.0136 - mae: 0.0935 - val_loss: 0.0128 - val_mae: 0.0917\nEpoch 400/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.0136 - mae: 0.0923 - val_loss: 0.0128 - val_mae: 0.0910\nEpoch 401/500\n600/600 [==============================] - 0s 59us/sample - loss: 0.0126 - mae: 0.0896 - val_loss: 0.0134 - val_mae: 0.0934\nEpoch 402/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0135 - mae: 0.0925 - val_loss: 0.0127 - val_mae: 0.0910\nEpoch 403/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0129 - mae: 0.0904 - val_loss: 0.0117 - val_mae: 0.0868\nEpoch 404/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0126 - mae: 0.0898 - val_loss: 0.0140 - val_mae: 0.0928\nEpoch 405/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0132 - mae: 0.0928 - val_loss: 0.0117 - val_mae: 0.0869\nEpoch 406/500\n600/600 [==============================] - 0s 47us/sample - loss: 0.0126 - mae: 0.0906 - val_loss: 0.0128 - val_mae: 0.0908\nEpoch 407/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0122 - mae: 0.0880 - val_loss: 0.0117 - val_mae: 0.0870\nEpoch 408/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0125 - mae: 0.0897 - val_loss: 0.0119 - val_mae: 0.0875\nEpoch 409/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0124 - mae: 0.0889 - val_loss: 0.0118 - val_mae: 0.0869\nEpoch 410/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0124 - mae: 0.0888 - val_loss: 0.0117 - val_mae: 0.0868\nEpoch 411/500\n600/600 [==============================] - 0s 59us/sample - loss: 0.0122 - mae: 0.0886 - val_loss: 0.0139 - val_mae: 0.0933\nEpoch 412/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0132 - mae: 0.0923 - val_loss: 0.0125 - val_mae: 0.0891\nEpoch 413/500\n600/600 [==============================] - 0s 62us/sample - loss: 0.0140 - mae: 0.0938 - val_loss: 0.0119 - val_mae: 0.0875\nEpoch 414/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0134 - mae: 0.0917 - val_loss: 0.0125 - val_mae: 0.0897\nEpoch 415/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0131 - mae: 0.0917 - val_loss: 0.0126 - val_mae: 0.0904\nEpoch 416/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0128 - mae: 0.0900 - val_loss: 0.0129 - val_mae: 0.0912\nEpoch 417/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.0124 - mae: 0.0890 - val_loss: 0.0118 - val_mae: 0.0874\nEpoch 418/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0128 - mae: 0.0899 - val_loss: 0.0132 - val_mae: 0.0925\nEpoch 419/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0131 - mae: 0.0917 - val_loss: 0.0120 - val_mae: 0.0882\nEpoch 420/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0124 - mae: 0.0884 - val_loss: 0.0130 - val_mae: 0.0919\nEpoch 421/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0131 - mae: 0.0914 - val_loss: 0.0130 - val_mae: 0.0916\nEpoch 422/500\n600/600 [==============================] - 0s 57us/sample - loss: 0.0133 - mae: 0.0921 - val_loss: 0.0115 - val_mae: 0.0864\nEpoch 423/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0123 - mae: 0.0886 - val_loss: 0.0120 - val_mae: 0.0876\nEpoch 424/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0122 - mae: 0.0883 - val_loss: 0.0141 - val_mae: 0.0935\nEpoch 425/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0136 - mae: 0.0936 - val_loss: 0.0117 - val_mae: 0.0869\nEpoch 426/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0134 - mae: 0.0922 - val_loss: 0.0116 - val_mae: 0.0868\nEpoch 427/500\n600/600 [==============================] - 0s 66us/sample - loss: 0.0121 - mae: 0.0879 - val_loss: 0.0116 - val_mae: 0.0867\nEpoch 428/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0121 - mae: 0.0882 - val_loss: 0.0121 - val_mae: 0.0881\nEpoch 429/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0125 - mae: 0.0895 - val_loss: 0.0114 - val_mae: 0.0859\nEpoch 430/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0123 - mae: 0.0883 - val_loss: 0.0129 - val_mae: 0.0901\nEpoch 431/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0126 - mae: 0.0900 - val_loss: 0.0120 - val_mae: 0.0877\nEpoch 432/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0123 - mae: 0.0882 - val_loss: 0.0118 - val_mae: 0.0870\nEpoch 433/500\n600/600 [==============================] - 0s 60us/sample - loss: 0.0120 - mae: 0.0879 - val_loss: 0.0120 - val_mae: 0.0878\nEpoch 434/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0122 - mae: 0.0877 - val_loss: 0.0114 - val_mae: 0.0861\nEpoch 435/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0120 - mae: 0.0877 - val_loss: 0.0120 - val_mae: 0.0876\nEpoch 436/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0122 - mae: 0.0885 - val_loss: 0.0115 - val_mae: 0.0862\nEpoch 437/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0120 - mae: 0.0882 - val_loss: 0.0117 - val_mae: 0.0867\nEpoch 438/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0119 - mae: 0.0872 - val_loss: 0.0116 - val_mae: 0.0865\nEpoch 439/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0122 - mae: 0.0885 - val_loss: 0.0116 - val_mae: 0.0864\nEpoch 440/500\n600/600 [==============================] - 0s 65us/sample - loss: 0.0122 - mae: 0.0888 - val_loss: 0.0123 - val_mae: 0.0889\nEpoch 441/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0120 - mae: 0.0886 - val_loss: 0.0116 - val_mae: 0.0864\nEpoch 442/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0124 - mae: 0.0880 - val_loss: 0.0120 - val_mae: 0.0880\nEpoch 443/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0121 - mae: 0.0875 - val_loss: 0.0123 - val_mae: 0.0885\nEpoch 444/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.0124 - mae: 0.0895 - val_loss: 0.0118 - val_mae: 0.0875\nEpoch 445/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0126 - mae: 0.0902 - val_loss: 0.0117 - val_mae: 0.0869\nEpoch 446/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0121 - mae: 0.0873 - val_loss: 0.0132 - val_mae: 0.0925\nEpoch 447/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0124 - mae: 0.0883 - val_loss: 0.0124 - val_mae: 0.0890\nEpoch 448/500\n600/600 [==============================] - 0s 69us/sample - loss: 0.0120 - mae: 0.0877 - val_loss: 0.0115 - val_mae: 0.0863\nEpoch 449/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.0122 - mae: 0.0885 - val_loss: 0.0115 - val_mae: 0.0865\nEpoch 450/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0125 - mae: 0.0904 - val_loss: 0.0118 - val_mae: 0.0872\nEpoch 451/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0119 - mae: 0.0869 - val_loss: 0.0126 - val_mae: 0.0895\nEpoch 452/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0124 - mae: 0.0890 - val_loss: 0.0116 - val_mae: 0.0867\nEpoch 453/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0119 - mae: 0.0872 - val_loss: 0.0117 - val_mae: 0.0868\nEpoch 454/500\n600/600 [==============================] - 0s 49us/sample - loss: 0.0120 - mae: 0.0878 - val_loss: 0.0116 - val_mae: 0.0863\nEpoch 455/500\n600/600 [==============================] - 0s 61us/sample - loss: 0.0120 - mae: 0.0878 - val_loss: 0.0117 - val_mae: 0.0870\nEpoch 456/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0118 - mae: 0.0869 - val_loss: 0.0115 - val_mae: 0.0862\nEpoch 457/500\n600/600 [==============================] - 0s 66us/sample - loss: 0.0121 - mae: 0.0883 - val_loss: 0.0116 - val_mae: 0.0866\nEpoch 458/500\n600/600 [==============================] - 0s 60us/sample - loss: 0.0121 - mae: 0.0876 - val_loss: 0.0116 - val_mae: 0.0863\nEpoch 459/500\n600/600 [==============================] - 0s 60us/sample - loss: 0.0119 - mae: 0.0872 - val_loss: 0.0116 - val_mae: 0.0864\nEpoch 460/500\n600/600 [==============================] - 0s 48us/sample - loss: 0.0119 - mae: 0.0871 - val_loss: 0.0115 - val_mae: 0.0862\nEpoch 461/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0120 - mae: 0.0880 - val_loss: 0.0120 - val_mae: 0.0881\nEpoch 462/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0119 - mae: 0.0872 - val_loss: 0.0116 - val_mae: 0.0864\nEpoch 463/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0119 - mae: 0.0873 - val_loss: 0.0117 - val_mae: 0.0866\nEpoch 464/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0118 - mae: 0.0868 - val_loss: 0.0115 - val_mae: 0.0862\nEpoch 465/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0120 - mae: 0.0875 - val_loss: 0.0124 - val_mae: 0.0896\nEpoch 466/500\n600/600 [==============================] - 0s 57us/sample - loss: 0.0117 - mae: 0.0875 - val_loss: 0.0129 - val_mae: 0.0901\nEpoch 467/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0126 - mae: 0.0907 - val_loss: 0.0127 - val_mae: 0.0898\nEpoch 468/500\n600/600 [==============================] - 0s 58us/sample - loss: 0.0125 - mae: 0.0893 - val_loss: 0.0118 - val_mae: 0.0874\nEpoch 469/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0122 - mae: 0.0887 - val_loss: 0.0115 - val_mae: 0.0864\nEpoch 470/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0119 - mae: 0.0874 - val_loss: 0.0119 - val_mae: 0.0876\nEpoch 471/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.0118 - mae: 0.0866 - val_loss: 0.0116 - val_mae: 0.0867\nEpoch 472/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0120 - mae: 0.0873 - val_loss: 0.0118 - val_mae: 0.0872\nEpoch 473/500\n600/600 [==============================] - 0s 57us/sample - loss: 0.0121 - mae: 0.0882 - val_loss: 0.0115 - val_mae: 0.0863\nEpoch 474/500\n600/600 [==============================] - 0s 55us/sample - loss: 0.0118 - mae: 0.0871 - val_loss: 0.0117 - val_mae: 0.0867\nEpoch 475/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0120 - mae: 0.0877 - val_loss: 0.0121 - val_mae: 0.0884\nEpoch 476/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0127 - mae: 0.0902 - val_loss: 0.0119 - val_mae: 0.0877\nEpoch 477/500\n600/600 [==============================] - 0s 61us/sample - loss: 0.0122 - mae: 0.0882 - val_loss: 0.0151 - val_mae: 0.0967\nEpoch 478/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0136 - mae: 0.0933 - val_loss: 0.0123 - val_mae: 0.0889\nEpoch 479/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0121 - mae: 0.0884 - val_loss: 0.0116 - val_mae: 0.0869\nEpoch 480/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.0121 - mae: 0.0883 - val_loss: 0.0118 - val_mae: 0.0877\nEpoch 481/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0120 - mae: 0.0876 - val_loss: 0.0118 - val_mae: 0.0875\nEpoch 482/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0121 - mae: 0.0887 - val_loss: 0.0116 - val_mae: 0.0865\nEpoch 483/500\n600/600 [==============================] - 0s 70us/sample - loss: 0.0122 - mae: 0.0892 - val_loss: 0.0114 - val_mae: 0.0863\nEpoch 484/500\n600/600 [==============================] - 0s 57us/sample - loss: 0.0132 - mae: 0.0926 - val_loss: 0.0115 - val_mae: 0.0866\nEpoch 485/500\n600/600 [==============================] - 0s 70us/sample - loss: 0.0138 - mae: 0.0948 - val_loss: 0.0118 - val_mae: 0.0874\nEpoch 486/500\n600/600 [==============================] - 0s 59us/sample - loss: 0.0119 - mae: 0.0879 - val_loss: 0.0114 - val_mae: 0.0860\nEpoch 487/500\n600/600 [==============================] - 0s 50us/sample - loss: 0.0118 - mae: 0.0872 - val_loss: 0.0116 - val_mae: 0.0870\nEpoch 488/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0117 - mae: 0.0870 - val_loss: 0.0114 - val_mae: 0.0861\nEpoch 489/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0118 - mae: 0.0869 - val_loss: 0.0120 - val_mae: 0.0879\nEpoch 490/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0119 - mae: 0.0873 - val_loss: 0.0115 - val_mae: 0.0863\nEpoch 491/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0118 - mae: 0.0871 - val_loss: 0.0117 - val_mae: 0.0873\nEpoch 492/500\n600/600 [==============================] - 0s 61us/sample - loss: 0.0122 - mae: 0.0886 - val_loss: 0.0127 - val_mae: 0.0899\nEpoch 493/500\n600/600 [==============================] - 0s 54us/sample - loss: 0.0122 - mae: 0.0881 - val_loss: 0.0113 - val_mae: 0.0857\nEpoch 494/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0125 - mae: 0.0898 - val_loss: 0.0119 - val_mae: 0.0880\nEpoch 495/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0123 - mae: 0.0897 - val_loss: 0.0116 - val_mae: 0.0866\nEpoch 496/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.0119 - mae: 0.0875 - val_loss: 0.0115 - val_mae: 0.0866\nEpoch 497/500\n600/600 [==============================] - 0s 56us/sample - loss: 0.0118 - mae: 0.0868 - val_loss: 0.0117 - val_mae: 0.0871\nEpoch 498/500\n600/600 [==============================] - 0s 52us/sample - loss: 0.0124 - mae: 0.0889 - val_loss: 0.0116 - val_mae: 0.0866\nEpoch 499/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0119 - mae: 0.0871 - val_loss: 0.0115 - val_mae: 0.0863\nEpoch 500/500\n600/600 [==============================] - 0s 53us/sample - loss: 0.0118 - mae: 0.0873 - val_loss: 0.0115 - val_mae: 0.0864\n"
]
],
[
[
"### 3. Plot Metrics\nEach training epoch, the model prints out its loss and mean absolute error for training and validation. You can read this in the output above (note that your exact numbers may differ): \n\n```\nEpoch 500/500\n600/600 [==============================] - 0s 51us/sample - loss: 0.0118 - mae: 0.0873 - val_loss: 0.0105 - val_mae: 0.0832\n```\n\nYou can see that we've already got a huge improvement - validation loss has dropped from 0.15 to 0.01, and validation MAE has dropped from 0.33 to 0.08.\n\nThe following cell will print the same graphs we used to evaluate our original model, but showing our new training history:",
"_____no_output_____"
]
],
[
[
"# Draw a graph of the loss, which is the distance between\n# the predicted and actual values during training and validation.\nloss = history_2.history['loss']\nval_loss = history_2.history['val_loss']\n\nepochs = range(1, len(loss) + 1)\n\n# Exclude the first few epochs so the graph is easier to read\nSKIP = 100\n\nplt.figure(figsize=(10, 4))\nplt.subplot(1, 2, 1)\n\nplt.plot(epochs[SKIP:], loss[SKIP:], 'g.', label='Training loss')\nplt.plot(epochs[SKIP:], val_loss[SKIP:], 'b.', label='Validation loss')\nplt.title('Training and validation loss')\nplt.xlabel('Epochs')\nplt.ylabel('Loss')\nplt.legend()\n\nplt.subplot(1, 2, 2)\n\n# Draw a graph of mean absolute error, which is another way of\n# measuring the amount of error in the prediction.\nmae = history_2.history['mae']\nval_mae = history_2.history['val_mae']\n\nplt.plot(epochs[SKIP:], mae[SKIP:], 'g.', label='Training MAE')\nplt.plot(epochs[SKIP:], val_mae[SKIP:], 'b.', label='Validation MAE')\nplt.title('Training and validation mean absolute error')\nplt.xlabel('Epochs')\nplt.ylabel('MAE')\nplt.legend()\n\nplt.tight_layout()",
"_____no_output_____"
]
],
[
[
"Great results! From these graphs, we can see several exciting things:\n\n* The overall loss and MAE are much better than our previous network\n* Metrics are better for validation than training, which means the network is not overfitting\n\nThe reason the metrics for validation are better than those for training is that validation metrics are calculated at the end of each epoch, while training metrics are calculated throughout the epoch, so validation happens on a model that has been trained slightly longer.\n\nThis all means our network seems to be performing well! To confirm, let's check its predictions against the test dataset we set aside earlier:\n",
"_____no_output_____"
]
],
[
[
"# Calculate and print the loss on our test dataset\nloss = model_2.evaluate(x_test, y_test)\n\n# Make predictions based on our test dataset\npredictions = model_2.predict(x_test)\n\n# Graph the predictions against the actual values\nplt.clf()\nplt.title('Comparison of predictions and actual values')\nplt.plot(x_test, y_test, 'b.', label='Actual')\nplt.plot(x_test, predictions, 'r.', label='Predicted')\nplt.legend()\nplt.show()",
"\r200/1 [================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================================] - 0s 40us/sample - loss: 0.0082 - mae: 0.0827\n"
]
],
[
[
"Much better! The evaluation metrics we printed show that the model has a low loss and MAE on the test data, and the predictions line up visually with our data fairly well.\n\nThe model isn't perfect; its predictions don't form a smooth sine curve. For instance, the line is almost straight when `x` is between 4.2 and 5.2. If we wanted to go further, we could try further increasing the capacity of the model, perhaps using some techniques to defend from overfitting.\n\nHowever, an important part of machine learning is knowing when to quit, and this model is good enough for our use case - which is to make some LEDs blink in a pleasing pattern.\n\n## Generate a TensorFlow Lite Model",
"_____no_output_____"
],
[
"### 1. Generate Models with or without Quantization\nWe now have an acceptably accurate model. We'll use the [TensorFlow Lite Converter](https://www.tensorflow.org/lite/convert) to convert the model into a special, space-efficient format for use on memory-constrained devices.\n\nSince this model is going to be deployed on a microcontroller, we want it to be as tiny as possible! One technique for reducing the size of models is called [quantization](https://www.tensorflow.org/lite/performance/post_training_quantization) while converting the model. It reduces the precision of the model's weights, and possibly the activations (output of each layer) as well, which saves memory, often without much impact on accuracy. Quantized models also run faster, since the calculations required are simpler.\n\n*Note: Currently, TFLite Converter produces TFlite models with float interfaces (input and output ops are always float). This is a blocker for users who require TFlite models with pure int8 or uint8 inputs/outputs. Refer to https://github.com/tensorflow/tensorflow/issues/38285*\n\nIn the following cell, we'll convert the model twice: once with quantization, once without.",
"_____no_output_____"
]
],
[
[
"# Convert the model to the TensorFlow Lite format without quantization\nconverter = tf.lite.TFLiteConverter.from_keras_model(model_2)\nmodel_no_quant_tflite = converter.convert()\n\n# # Save the model to disk\nopen(MODEL_NO_QUANT_TFLITE, \"wb\").write(model_no_quant_tflite)\n\n# Convert the model to the TensorFlow Lite format with quantization\ndef representative_dataset():\n for i in range(500):\n yield([x_train[i].reshape(1, 1)])\n# Set the optimization flag.\nconverter.optimizations = [tf.lite.Optimize.DEFAULT]\n# Enforce full-int8 quantization (except inputs/outputs which are always float)\nconverter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]\n# Provide a representative dataset to ensure we quantize correctly.\nconverter.representative_dataset = representative_dataset\nmodel_tflite = converter.convert()\n\n# Save the model to disk\nopen(MODEL_TFLITE, \"wb\").write(model_tflite)",
"_____no_output_____"
]
],
[
[
"### 2. Compare Model Sizes",
"_____no_output_____"
]
],
[
[
"import os\nmodel_no_quant_size = os.path.getsize(MODEL_NO_QUANT_TFLITE)\nprint(\"Model is %d bytes\" % model_no_quant_size)\nmodel_size = os.path.getsize(MODEL_TFLITE)\nprint(\"Quantized model is %d bytes\" % model_size)\ndifference = model_no_quant_size - model_size\nprint(\"Difference is %d bytes\" % difference)",
"Model is 2736 bytes\nQuantized model is 2512 bytes\nDifference is 224 bytes\n"
]
],
[
[
"Our quantized model is only 224 bytes smaller than the original version, which only a tiny reduction in size! At around 2.5 kilobytes, this model is already so small that the weights make up only a small fraction of the overall size, meaning quantization has little effect.\n\nMore complex models have many more weights, meaning the space saving from quantization will be much higher, approaching 4x for most sophisticated models.\n\nRegardless, our quantized model will take less time to execute than the original version, which is important on a tiny microcontroller!",
"_____no_output_____"
],
[
"### 3. Test the Models\n\nTo prove these models are still accurate after conversion and quantization, we'll use both of them to make predictions and compare these against our test results:",
"_____no_output_____"
]
],
[
[
"# Instantiate an interpreter for each model\nmodel_no_quant = tf.lite.Interpreter(MODEL_NO_QUANT_TFLITE)\nmodel = tf.lite.Interpreter(MODEL_TFLITE)\n\n# Allocate memory for each model\nmodel_no_quant.allocate_tensors()\nmodel.allocate_tensors()\n\n# Get the input and output tensors so we can feed in values and get the results\nmodel_no_quant_input = model_no_quant.tensor(model_no_quant.get_input_details()[0][\"index\"])\nmodel_no_quant_output = model_no_quant.tensor(model_no_quant.get_output_details()[0][\"index\"])\nmodel_input = model.tensor(model.get_input_details()[0][\"index\"])\nmodel_output = model.tensor(model.get_output_details()[0][\"index\"])\n\n# Create arrays to store the results\nmodel_no_quant_predictions = np.empty(x_test.size)\nmodel_predictions = np.empty(x_test.size)\n\n# Run each model's interpreter for each value and store the results in arrays\nfor i in range(x_test.size):\n model_no_quant_input().fill(x_test[i])\n model_no_quant.invoke()\n model_no_quant_predictions[i] = model_no_quant_output()[0]\n\n model_input().fill(x_test[i])\n model.invoke()\n model_predictions[i] = model_output()[0]\n\n# See how they line up with the data\nplt.clf()\nplt.title('Comparison of various models against actual values')\nplt.plot(x_test, y_test, 'bo', label='Actual values')\nplt.plot(x_test, predictions, 'ro', label='Original predictions')\nplt.plot(x_test, model_no_quant_predictions, 'bx', label='Lite predictions')\nplt.plot(x_test, model_predictions, 'gx', label='Lite quantized predictions')\nplt.legend()\nplt.show()",
"_____no_output_____"
]
],
[
[
"We can see from the graph that the predictions for the original model, the converted model, and the quantized model are all close enough to be indistinguishable. This means that our quantized model is ready to use!",
"_____no_output_____"
],
[
"## Generate a TensorFlow Lite for Microcontrollers Model\nConvert the TensorFlow Lite quantized model into a C source file that can be loaded by TensorFlow Lite for Microcontrollers.",
"_____no_output_____"
]
],
[
[
"# Install xxd if it is not available\n!apt-get update && apt-get -qq install xxd\n# Convert to a C source file\n!xxd -i {MODEL_TFLITE} > {MODEL_TFLITE_MICRO}\n# Update variable names\nREPLACE_TEXT = MODEL_TFLITE.replace('/', '_').replace('.', '_')\n!sed -i 's/'{REPLACE_TEXT}'/g_model/g' {MODEL_TFLITE_MICRO}",
"Get:1 https://cloud.r-project.org/bin/linux/ubuntu bionic-cran35/ InRelease [3,626 B]\nIgn:2 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 InRelease\nHit:3 http://archive.ubuntu.com/ubuntu bionic InRelease\nGet:4 http://security.ubuntu.com/ubuntu bionic-security InRelease [88.7 kB]\nHit:5 http://ppa.launchpad.net/graphics-drivers/ppa/ubuntu bionic InRelease\nIgn:6 https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64 InRelease\nHit:7 https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64 Release\nHit:8 https://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64 Release\nGet:9 http://archive.ubuntu.com/ubuntu bionic-updates InRelease [88.7 kB]\nGet:10 http://ppa.launchpad.net/marutter/c2d4u3.5/ubuntu bionic InRelease [15.4 kB]\nGet:11 http://archive.ubuntu.com/ubuntu bionic-backports InRelease [74.6 kB]\nGet:14 http://ppa.launchpad.net/marutter/c2d4u3.5/ubuntu bionic/main Sources [1,810 kB]\nGet:15 http://security.ubuntu.com/ubuntu bionic-security/restricted amd64 Packages [38.5 kB]\nGet:16 http://security.ubuntu.com/ubuntu bionic-security/main amd64 Packages [873 kB]\nGet:17 http://archive.ubuntu.com/ubuntu bionic-updates/universe amd64 Packages [1,368 kB]\nGet:18 http://security.ubuntu.com/ubuntu bionic-security/universe amd64 Packages [835 kB]\nGet:19 http://archive.ubuntu.com/ubuntu bionic-updates/restricted amd64 Packages [57.5 kB]\nGet:20 http://archive.ubuntu.com/ubuntu bionic-updates/main amd64 Packages [1,176 kB]\nGet:21 http://ppa.launchpad.net/marutter/c2d4u3.5/ubuntu bionic/main amd64 Packages [873 kB]\nFetched 7,301 kB in 3s (2,475 kB/s)\nReading package lists... Done\nSelecting previously unselected package xxd.\n(Reading database ... 144568 files and directories currently installed.)\nPreparing to unpack .../xxd_2%3a8.0.1453-1ubuntu1.3_amd64.deb ...\nUnpacking xxd (2:8.0.1453-1ubuntu1.3) ...\nSetting up xxd (2:8.0.1453-1ubuntu1.3) ...\nProcessing triggers for man-db (2.8.3-2ubuntu0.1) ...\n"
]
],
[
[
"## Deploy to a Microcontroller\n\nFollow the instructions in the [hello_world](https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/micro/examples/hello_world) README.md for [TensorFlow Lite for MicroControllers](https://www.tensorflow.org/lite/microcontrollers/overview) to deploy this model on a specific microcontroller.\n\n**Reference Model:** If you have not modified this notebook, you can follow the instructions as is, to deploy the model. Refer to the [`hello_world/train/models`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/examples/hello_world/train/models) directory to access the models generated in this notebook.\n\n**New Model:** If you have generated a new model, then update the values assigned to the variables defined in [`hello_world/model.cc`](https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/micro/examples/hello_world/model.cc) with values displayed after running the following cell.",
"_____no_output_____"
]
],
[
[
"# Print the C source file\n!cat {MODEL_TFLITE_MICRO}",
"unsigned char g_model[] = {\n 0x1c, 0x00, 0x00, 0x00, 0x54, 0x46, 0x4c, 0x33, 0x00, 0x00, 0x12, 0x00,\n 0x1c, 0x00, 0x04, 0x00, 0x08, 0x00, 0x0c, 0x00, 0x10, 0x00, 0x14, 0x00,\n 0x00, 0x00, 0x18, 0x00, 0x12, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00,\n 0x60, 0x09, 0x00, 0x00, 0xa8, 0x02, 0x00, 0x00, 0x90, 0x02, 0x00, 0x00,\n 0x3c, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n 0x0c, 0x00, 0x00, 0x00, 0x08, 0x00, 0x0c, 0x00, 0x04, 0x00, 0x08, 0x00,\n 0x08, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00, 0x0b, 0x00, 0x00, 0x00,\n 0x13, 0x00, 0x00, 0x00, 0x6d, 0x69, 0x6e, 0x5f, 0x72, 0x75, 0x6e, 0x74,\n 0x69, 0x6d, 0x65, 0x5f, 0x76, 0x65, 0x72, 0x73, 0x69, 0x6f, 0x6e, 0x00,\n 0x0c, 0x00, 0x00, 0x00, 0x48, 0x02, 0x00, 0x00, 0x34, 0x02, 0x00, 0x00,\n 0x0c, 0x02, 0x00, 0x00, 0xfc, 0x00, 0x00, 0x00, 0xac, 0x00, 0x00, 0x00,\n 0x8c, 0x00, 0x00, 0x00, 0x3c, 0x00, 0x00, 0x00, 0x34, 0x00, 0x00, 0x00,\n 0x2c, 0x00, 0x00, 0x00, 0x24, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00,\n 0x04, 0x00, 0x00, 0x00, 0xfe, 0xfd, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00,\n 0x05, 0x00, 0x00, 0x00, 0x31, 0x2e, 0x35, 0x2e, 0x30, 0x00, 0x00, 0x00,\n 0x7c, 0xfd, 0xff, 0xff, 0x80, 0xfd, 0xff, 0xff, 0x84, 0xfd, 0xff, 0xff,\n 0x88, 0xfd, 0xff, 0xff, 0x22, 0xfe, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00,\n 0x40, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0xfc, 0x04, 0x00, 0x00,\n 0x9f, 0x0a, 0x00, 0x00, 0x65, 0x06, 0x00, 0x00, 0x3d, 0xf8, 0xff, 0xff,\n 0x00, 0x00, 0x00, 0x00, 0xeb, 0x0a, 0x00, 0x00, 0x2f, 0xf8, 0xff, 0xff,\n 0xe8, 0x04, 0x00, 0x00, 0x21, 0x0a, 0x00, 0x00, 0x46, 0xfe, 0xff, 0xff,\n 0xc8, 0x04, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0xa3, 0xf7, 0xff, 0xff,\n 0x28, 0xf9, 0xff, 0xff, 0x9a, 0x05, 0x00, 0x00, 0x6e, 0xfe, 0xff, 0xff,\n 0x04, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x73, 0x1c, 0x11, 0xe1,\n 0x0c, 0x81, 0xa5, 0x43, 0xfe, 0xd5, 0xd5, 0xb2, 0x60, 0x77, 0x19, 0xdf,\n 0x8a, 0xfe, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00,\n 0x01, 0x00, 0x00, 0x00, 0x51, 0x0b, 0x00, 0x00, 0x47, 0xf6, 0xff, 0xff,\n 0x00, 0x00, 0x00, 0x00, 0x1c, 0x0c, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,\n 0x00, 0x00, 0x00, 0x00, 0x9b, 0x05, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,\n 0x00, 0x00, 0x00, 0x00, 0xe7, 0x20, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,\n 0x92, 0x07, 0x00, 0x00, 0xf4, 0xf4, 0xff, 0xff, 0x55, 0xf0, 0xff, 0xff,\n 0x00, 0x00, 0x00, 0x00, 0xd6, 0xfe, 0xff, 0xff, 0x04, 0x00, 0x00, 0x00,\n 0x00, 0x01, 0x00, 0x00, 0xee, 0xfc, 0x00, 0xec, 0x05, 0x16, 0xef, 0xec,\n 0xe6, 0xf8, 0x03, 0x01, 0x00, 0xfa, 0xf8, 0xf5, 0xda, 0xeb, 0x27, 0x14,\n 0xef, 0xde, 0xe2, 0xda, 0xf0, 0xdf, 0x32, 0x06, 0x01, 0xe6, 0xee, 0xf9,\n 0x00, 0x16, 0x07, 0xe0, 0xfe, 0xff, 0xe9, 0x05, 0xe7, 0xef, 0x81, 0x1b,\n 0x18, 0xea, 0xca, 0x01, 0x0f, 0x00, 0xdb, 0xf7, 0x0e, 0xec, 0x12, 0x1e,\n 0x04, 0x13, 0xb2, 0xe7, 0xfd, 0x06, 0xbb, 0xe0, 0x0c, 0xec, 0xf0, 0xdf,\n 0xeb, 0xf7, 0x05, 0x26, 0x19, 0xe4, 0x70, 0x1a, 0xea, 0x1e, 0x34, 0xdf,\n 0x19, 0xf3, 0xf1, 0x19, 0x0e, 0x03, 0x1b, 0xe1, 0xde, 0x13, 0xf6, 0x19,\n 0xff, 0xf6, 0x1a, 0x17, 0xf1, 0x1c, 0xdb, 0x1a, 0x1a, 0x20, 0xe6, 0x19,\n 0xf5, 0xff, 0x97, 0x0b, 0x00, 0x00, 0xce, 0xdf, 0x0d, 0xf7, 0x15, 0xe4,\n 0xed, 0xfc, 0x0d, 0xe9, 0xfb, 0xec, 0x5c, 0xfc, 0x1d, 0x02, 0x58, 0xe3,\n 0xe0, 0xf4, 0x15, 0xec, 0xf9, 0x00, 0x13, 0x05, 0xec, 0x0c, 0x1c, 0x14,\n 0x0c, 0xe9, 0x0a, 0xf4, 0x18, 0x00, 0xd7, 0x05, 0x27, 0x02, 0x15, 0xea,\n 0xea, 0x02, 0x9b, 0x00, 0x0c, 0xfa, 0xe9, 0xea, 0xfe, 0x01, 0x14, 0xfd,\n 0x0b, 0x02, 0xf0, 0xef, 0x06, 0xee, 0x01, 0x0d, 0x06, 0xe7, 0xf7, 0x11,\n 0xf5, 0x0a, 0xf9, 0xf1, 0x23, 0xff, 0x0d, 0xf2, 0xec, 0x11, 0x26, 0x1d,\n 0xf2, 0xea, 0x28, 0x18, 0xe0, 0xfb, 0xf3, 0xf4, 0x05, 0x1c, 0x1d, 0xfb,\n 0xfd, 0x1e, 0xfc, 0x11, 0xe8, 0x06, 0x09, 0x03, 0x12, 0xf2, 0x35, 0xfb,\n 0xdd, 0x1b, 0xf9, 0xef, 0xf3, 0xe7, 0x6f, 0x0c, 0x1d, 0x00, 0x43, 0xfd,\n 0x0d, 0xf1, 0x0a, 0x19, 0x1a, 0xfa, 0xe0, 0x18, 0x1e, 0x13, 0x37, 0x1c,\n 0x12, 0xec, 0x3a, 0x0c, 0xb6, 0xcb, 0xe6, 0x13, 0xf7, 0xeb, 0xf1, 0x05,\n 0x1b, 0xfa, 0x19, 0xe5, 0xec, 0xcf, 0x0c, 0xf4, 0xe2, 0xff, 0xff, 0xff,\n 0x04, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x21, 0xa2, 0x8c, 0xc9,\n 0x5f, 0x1d, 0xce, 0x41, 0x9f, 0xcd, 0x20, 0xb1, 0xdf, 0x53, 0x2f, 0x81,\n 0x00, 0x00, 0x06, 0x00, 0x08, 0x00, 0x04, 0x00, 0x06, 0x00, 0x00, 0x00,\n 0x04, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0xe2, 0xee, 0xff, 0xff,\n 0x80, 0xff, 0xff, 0xff, 0x0f, 0x00, 0x00, 0x00, 0x54, 0x4f, 0x43, 0x4f,\n 0x20, 0x43, 0x6f, 0x6e, 0x76, 0x65, 0x72, 0x74, 0x65, 0x64, 0x2e, 0x00,\n 0x01, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0xbc, 0xf9, 0xff, 0xff,\n 0x48, 0x01, 0x00, 0x00, 0x3c, 0x01, 0x00, 0x00, 0x30, 0x01, 0x00, 0x00,\n 0x04, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x04, 0x01, 0x00, 0x00,\n 0xb8, 0x00, 0x00, 0x00, 0x70, 0x00, 0x00, 0x00, 0x28, 0x00, 0x00, 0x00,\n 0x04, 0x00, 0x00, 0x00, 0x1a, 0xff, 0xff, 0xff, 0x02, 0x00, 0x00, 0x00,\n 0x10, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n 0x0b, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,\n 0xca, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x08, 0x1c, 0x00, 0x00, 0x00,\n 0x10, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00, 0x04, 0x00, 0x04, 0x00,\n 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,\n 0x03, 0x00, 0x00, 0x00, 0x07, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00,\n 0x09, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0e, 0x00, 0x14, 0x00, 0x00, 0x00,\n 0x08, 0x00, 0x0c, 0x00, 0x07, 0x00, 0x10, 0x00, 0x0e, 0x00, 0x00, 0x00,\n 0x00, 0x00, 0x00, 0x08, 0x1c, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,\n 0x04, 0x00, 0x00, 0x00, 0xba, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x01,\n 0x01, 0x00, 0x00, 0x00, 0x07, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00,\n 0x04, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00, 0x06, 0x00, 0x00, 0x00,\n 0x00, 0x00, 0x0e, 0x00, 0x16, 0x00, 0x00, 0x00, 0x08, 0x00, 0x0c, 0x00,\n 0x07, 0x00, 0x10, 0x00, 0x0e, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x08,\n 0x24, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00, 0x0c, 0x00, 0x00, 0x00,\n 0x00, 0x00, 0x06, 0x00, 0x08, 0x00, 0x07, 0x00, 0x06, 0x00, 0x00, 0x00,\n 0x00, 0x00, 0x00, 0x01, 0x01, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,\n 0x03, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00,\n 0x03, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0a, 0x00, 0x10, 0x00, 0x04, 0x00,\n 0x08, 0x00, 0x0c, 0x00, 0x0a, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n 0x10, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x0a, 0x00, 0x00, 0x00,\n 0x01, 0x00, 0x00, 0x00, 0x0b, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n 0x0a, 0x00, 0x00, 0x00, 0x0c, 0x00, 0x00, 0x00, 0xdc, 0x04, 0x00, 0x00,\n 0x54, 0x04, 0x00, 0x00, 0xc4, 0x03, 0x00, 0x00, 0x54, 0x03, 0x00, 0x00,\n 0xd0, 0x02, 0x00, 0x00, 0x4c, 0x02, 0x00, 0x00, 0xe0, 0x01, 0x00, 0x00,\n 0x5c, 0x01, 0x00, 0x00, 0xd8, 0x00, 0x00, 0x00, 0x6c, 0x00, 0x00, 0x00,\n 0x3c, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0xd8, 0xff, 0xff, 0xff,\n 0x18, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00,\n 0x49, 0x64, 0x65, 0x6e, 0x74, 0x69, 0x74, 0x79, 0x00, 0x00, 0x00, 0x00,\n 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n 0x0c, 0x00, 0x0c, 0x00, 0x04, 0x00, 0x00, 0x00, 0x00, 0x00, 0x08, 0x00,\n 0x0c, 0x00, 0x00, 0x00, 0x1c, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,\n 0x0d, 0x00, 0x00, 0x00, 0x64, 0x65, 0x6e, 0x73, 0x65, 0x5f, 0x32, 0x5f,\n 0x69, 0x6e, 0x70, 0x75, 0x74, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00,\n 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0xc2, 0xfb, 0xff, 0xff,\n 0x00, 0x00, 0x00, 0x02, 0x58, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n 0x28, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0xc4, 0xfc, 0xff, 0xff,\n 0x14, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n 0xba, 0x2b, 0x4f, 0x38, 0x20, 0x00, 0x00, 0x00, 0x73, 0x65, 0x71, 0x75,\n 0x65, 0x6e, 0x74, 0x69, 0x61, 0x6c, 0x5f, 0x31, 0x2f, 0x64, 0x65, 0x6e,\n 0x73, 0x65, 0x5f, 0x34, 0x2f, 0x4d, 0x61, 0x74, 0x4d, 0x75, 0x6c, 0x5f,\n 0x62, 0x69, 0x61, 0x73, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n 0x01, 0x00, 0x00, 0x00, 0x2a, 0xfc, 0xff, 0xff, 0x00, 0x00, 0x00, 0x09,\n 0x6c, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x28, 0x00, 0x00, 0x00,\n 0x04, 0x00, 0x00, 0x00, 0x2c, 0xfd, 0xff, 0xff, 0x14, 0x00, 0x00, 0x00,\n 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,\n 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0xb9, 0x36, 0x0b, 0x3c,\n 0x34, 0x00, 0x00, 0x00, 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74, 0x69,\n 0x61, 0x6c, 0x5f, 0x31, 0x2f, 0x64, 0x65, 0x6e, 0x73, 0x65, 0x5f, 0x34,\n 0x2f, 0x4d, 0x61, 0x74, 0x4d, 0x75, 0x6c, 0x2f, 0x52, 0x65, 0x61, 0x64,\n 0x56, 0x61, 0x72, 0x69, 0x61, 0x62, 0x6c, 0x65, 0x4f, 0x70, 0x2f, 0x74,\n 0x72, 0x61, 0x6e, 0x73, 0x70, 0x6f, 0x73, 0x65, 0x00, 0x00, 0x00, 0x00,\n 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,\n 0xaa, 0xfc, 0xff, 0xff, 0x00, 0x00, 0x00, 0x09, 0x6c, 0x00, 0x00, 0x00,\n 0x09, 0x00, 0x00, 0x00, 0x44, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,\n 0x9c, 0xfc, 0xff, 0xff, 0x30, 0x00, 0x00, 0x00, 0x24, 0x00, 0x00, 0x00,\n 0x18, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n 0x80, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x00,\n 0x01, 0x00, 0x00, 0x00, 0xaa, 0x7b, 0xbe, 0x3b, 0x01, 0x00, 0x00, 0x00,\n 0x2e, 0xbd, 0xbd, 0x3f, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,\n 0x19, 0x00, 0x00, 0x00, 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74, 0x69,\n 0x61, 0x6c, 0x5f, 0x31, 0x2f, 0x64, 0x65, 0x6e, 0x73, 0x65, 0x5f, 0x33,\n 0x2f, 0x52, 0x65, 0x6c, 0x75, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00,\n 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x2a, 0xfd, 0xff, 0xff,\n 0x00, 0x00, 0x00, 0x02, 0x58, 0x00, 0x00, 0x00, 0x06, 0x00, 0x00, 0x00,\n 0x28, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x2c, 0xfe, 0xff, 0xff,\n 0x14, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n 0xe3, 0x04, 0x20, 0x39, 0x20, 0x00, 0x00, 0x00, 0x73, 0x65, 0x71, 0x75,\n 0x65, 0x6e, 0x74, 0x69, 0x61, 0x6c, 0x5f, 0x31, 0x2f, 0x64, 0x65, 0x6e,\n 0x73, 0x65, 0x5f, 0x33, 0x2f, 0x4d, 0x61, 0x74, 0x4d, 0x75, 0x6c, 0x5f,\n 0x62, 0x69, 0x61, 0x73, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n 0x10, 0x00, 0x00, 0x00, 0x92, 0xfd, 0xff, 0xff, 0x00, 0x00, 0x00, 0x09,\n 0x6c, 0x00, 0x00, 0x00, 0x03, 0x00, 0x00, 0x00, 0x28, 0x00, 0x00, 0x00,\n 0x04, 0x00, 0x00, 0x00, 0x94, 0xfe, 0xff, 0xff, 0x14, 0x00, 0x00, 0x00,\n 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,\n 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0xe8, 0x76, 0x51, 0x3c,\n 0x34, 0x00, 0x00, 0x00, 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74, 0x69,\n 0x61, 0x6c, 0x5f, 0x31, 0x2f, 0x64, 0x65, 0x6e, 0x73, 0x65, 0x5f, 0x33,\n 0x2f, 0x4d, 0x61, 0x74, 0x4d, 0x75, 0x6c, 0x2f, 0x52, 0x65, 0x61, 0x64,\n 0x56, 0x61, 0x72, 0x69, 0x61, 0x62, 0x6c, 0x65, 0x4f, 0x70, 0x2f, 0x74,\n 0x72, 0x61, 0x6e, 0x73, 0x70, 0x6f, 0x73, 0x65, 0x00, 0x00, 0x00, 0x00,\n 0x02, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,\n 0x12, 0xfe, 0xff, 0xff, 0x00, 0x00, 0x00, 0x09, 0x6c, 0x00, 0x00, 0x00,\n 0x07, 0x00, 0x00, 0x00, 0x44, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,\n 0x04, 0xfe, 0xff, 0xff, 0x30, 0x00, 0x00, 0x00, 0x24, 0x00, 0x00, 0x00,\n 0x18, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n 0x80, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x00,\n 0x01, 0x00, 0x00, 0x00, 0xd2, 0x91, 0x43, 0x3c, 0x01, 0x00, 0x00, 0x00,\n 0x40, 0xce, 0x42, 0x40, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,\n 0x19, 0x00, 0x00, 0x00, 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74, 0x69,\n 0x61, 0x6c, 0x5f, 0x31, 0x2f, 0x64, 0x65, 0x6e, 0x73, 0x65, 0x5f, 0x32,\n 0x2f, 0x52, 0x65, 0x6c, 0x75, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00,\n 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x92, 0xfe, 0xff, 0xff,\n 0x00, 0x00, 0x00, 0x02, 0x5c, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,\n 0x2c, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x94, 0xff, 0xff, 0xff,\n 0x18, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,\n 0x01, 0x00, 0x00, 0x00, 0x28, 0xb3, 0xd9, 0x38, 0x20, 0x00, 0x00, 0x00,\n 0x73, 0x65, 0x71, 0x75, 0x65, 0x6e, 0x74, 0x69, 0x61, 0x6c, 0x5f, 0x31,\n 0x2f, 0x64, 0x65, 0x6e, 0x73, 0x65, 0x5f, 0x32, 0x2f, 0x4d, 0x61, 0x74,\n 0x4d, 0x75, 0x6c, 0x5f, 0x62, 0x69, 0x61, 0x73, 0x00, 0x00, 0x00, 0x00,\n 0x01, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0xfe, 0xfe, 0xff, 0xff,\n 0x00, 0x00, 0x00, 0x09, 0x78, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00,\n 0x34, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00, 0x0c, 0x00, 0x0c, 0x00,\n 0x00, 0x00, 0x00, 0x00, 0x04, 0x00, 0x08, 0x00, 0x0c, 0x00, 0x00, 0x00,\n 0x14, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n 0xd5, 0x6b, 0x8a, 0x3b, 0x34, 0x00, 0x00, 0x00, 0x73, 0x65, 0x71, 0x75,\n 0x65, 0x6e, 0x74, 0x69, 0x61, 0x6c, 0x5f, 0x31, 0x2f, 0x64, 0x65, 0x6e,\n 0x73, 0x65, 0x5f, 0x32, 0x2f, 0x4d, 0x61, 0x74, 0x4d, 0x75, 0x6c, 0x2f,\n 0x52, 0x65, 0x61, 0x64, 0x56, 0x61, 0x72, 0x69, 0x61, 0x62, 0x6c, 0x65,\n 0x4f, 0x70, 0x2f, 0x74, 0x72, 0x61, 0x6e, 0x73, 0x70, 0x6f, 0x73, 0x65,\n 0x00, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x10, 0x00, 0x00, 0x00,\n 0x01, 0x00, 0x00, 0x00, 0x8a, 0xff, 0xff, 0xff, 0x00, 0x00, 0x00, 0x09,\n 0x60, 0x00, 0x00, 0x00, 0x08, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00, 0x00,\n 0x04, 0x00, 0x00, 0x00, 0x7c, 0xff, 0xff, 0xff, 0x2c, 0x00, 0x00, 0x00,\n 0x20, 0x00, 0x00, 0x00, 0x14, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,\n 0x01, 0x00, 0x00, 0x00, 0x80, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff, 0xff,\n 0x01, 0x00, 0x00, 0x00, 0x5d, 0x4f, 0xc9, 0x3c, 0x01, 0x00, 0x00, 0x00,\n 0x0e, 0x86, 0xc8, 0x40, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,\n 0x12, 0x00, 0x00, 0x00, 0x64, 0x65, 0x6e, 0x73, 0x65, 0x5f, 0x32, 0x5f,\n 0x69, 0x6e, 0x70, 0x75, 0x74, 0x5f, 0x69, 0x6e, 0x74, 0x38, 0x00, 0x00,\n 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n 0x00, 0x00, 0x0e, 0x00, 0x18, 0x00, 0x08, 0x00, 0x07, 0x00, 0x0c, 0x00,\n 0x10, 0x00, 0x14, 0x00, 0x0e, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09,\n 0x6c, 0x00, 0x00, 0x00, 0x0a, 0x00, 0x00, 0x00, 0x50, 0x00, 0x00, 0x00,\n 0x10, 0x00, 0x00, 0x00, 0x0c, 0x00, 0x14, 0x00, 0x04, 0x00, 0x08, 0x00,\n 0x0c, 0x00, 0x10, 0x00, 0x0c, 0x00, 0x00, 0x00, 0x30, 0x00, 0x00, 0x00,\n 0x24, 0x00, 0x00, 0x00, 0x18, 0x00, 0x00, 0x00, 0x04, 0x00, 0x00, 0x00,\n 0x01, 0x00, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,\n 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x1a, 0xde, 0x0a, 0x3c,\n 0x01, 0x00, 0x00, 0x00, 0x66, 0x64, 0x87, 0x3f, 0x01, 0x00, 0x00, 0x00,\n 0x13, 0x42, 0x8d, 0xbf, 0x0d, 0x00, 0x00, 0x00, 0x49, 0x64, 0x65, 0x6e,\n 0x74, 0x69, 0x74, 0x79, 0x5f, 0x69, 0x6e, 0x74, 0x38, 0x00, 0x00, 0x00,\n 0x02, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00,\n 0x03, 0x00, 0x00, 0x00, 0x3c, 0x00, 0x00, 0x00, 0x28, 0x00, 0x00, 0x00,\n 0x10, 0x00, 0x00, 0x00, 0x00, 0x00, 0x0a, 0x00, 0x0e, 0x00, 0x07, 0x00,\n 0x00, 0x00, 0x08, 0x00, 0x0a, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x06,\n 0x02, 0x00, 0x00, 0x00, 0x00, 0x00, 0x06, 0x00, 0x06, 0x00, 0x05, 0x00,\n 0x06, 0x00, 0x00, 0x00, 0x00, 0x72, 0x0a, 0x00, 0x0c, 0x00, 0x07, 0x00,\n 0x00, 0x00, 0x08, 0x00, 0x0a, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x09,\n 0x04, 0x00, 0x00, 0x00\n};\nunsigned int g_model_len = 2512;\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0fb300181780f15fbd69f4e9f4d04dd8f20e6d0 | 12,162 | ipynb | Jupyter Notebook | docs/pywikipathways-and-bridgedbpy.ipynb | kozo2/pyWikiPathways | 4bc94b0d8dc7e79b10dda201b0edf4a7e651c018 | [
"MIT"
] | null | null | null | docs/pywikipathways-and-bridgedbpy.ipynb | kozo2/pyWikiPathways | 4bc94b0d8dc7e79b10dda201b0edf4a7e651c018 | [
"MIT"
] | null | null | null | docs/pywikipathways-and-bridgedbpy.ipynb | kozo2/pyWikiPathways | 4bc94b0d8dc7e79b10dda201b0edf4a7e651c018 | [
"MIT"
] | 3 | 2021-09-05T21:50:23.000Z | 2022-03-03T03:37:35.000Z | 27.578231 | 426 | 0.563312 | [
[
[
"# pywikipathways and bridgedbpy\n[](https://colab.research.google.com/github/kozo2/pywikipathways/blob/main/docs/pywikipathways-and-bridgedbpy.ipynb)\n\nby Kozo Nishida and Alexander Pico\n\npywikipathways 0.0.2 \nbridgedbpy 0.0.2\n\n*WikiPathways* is a well-known repository for biological pathways that provides unique tools to the research community for content creation, editing and utilization [1].\n\nPython is a powerful programming language and environment for statistical and exploratory data analysis.\n\n*pywikipathways* leverages the WikiPathways API to communicate between **Python** and WikiPathways, allowing any pathway to be queried, interrogated and downloaded in both data and image formats. Queries are typically performed based on “Xrefs”, standardized identifiers for genes, proteins and metabolites. Once you can identified a pathway, you can use the WPID (WikiPathways identifier) to make additional queries.\n\n[bridgedbpy](https://pypi.org/project/bridgedbpy/) leverages the BridgeDb API [2] to provide a number of functions related to ID mapping and identifiers in general for gene, proteins and metabolites.\n\nTogether, *bridgedbpy* provides convience to the typical *pywikipathways* user by supplying formal names and codes defined by BridgeDb and used by WikiPathways.\n\n## Prerequisites\nIn addition to this **pywikipathways** package, you’ll also need to install **bridgedbpy**:",
"_____no_output_____"
]
],
[
[
"!pip install pywikipathways bridgedbpy",
"_____no_output_____"
],
[
"import pywikipathways as pwpw\nimport bridgedbpy as brdgdbp",
"_____no_output_____"
]
],
[
[
"## Getting started\nLets first check some of the most basic functions from each package. For example, here’s how you check to see which species are currently supported by WikiPathways:",
"_____no_output_____"
]
],
[
[
"org_names = pwpw.list_organisms()",
"_____no_output_____"
],
[
"org_names",
"_____no_output_____"
]
],
[
[
"You should see 30 or more species listed. This list is useful for subsequent queries that take an *organism* argument, to avoid misspelling.\n\nHowever, some function want the organism code, rather than the full name. Using bridgedbpy’s *getOrganismCode* function, we can get those:",
"_____no_output_____"
]
],
[
[
"org_names[14]",
"_____no_output_____"
],
[
"brdgdbp.get_organism_code(org_names[14])",
"_____no_output_____"
]
],
[
[
"## Identifier System Names and Codes\nEven more obscure are the various datasources providing official identifiers and how they are named and coded. Fortunately, BridgeDb defines these clearly and simply. And WikiPathways relies on these BridgeDb definitions.\n\nFor example, this is how we find the system code for Ensembl:",
"_____no_output_____"
]
],
[
[
"brdgdbp.get_system_code(\"Ensembl\")",
"_____no_output_____"
]
],
[
[
"It’s “En”! That’s simple enough. But some are less obvious…",
"_____no_output_____"
]
],
[
[
"brdgdbp.get_system_code(\"Entrez Gene\")",
"_____no_output_____"
]
],
[
[
"It’s “L” because the resource used to be named “Locus Link”. Sigh… Don’t try to guess these codes. Use this function from BridgeDb (above) to get the correct code. By the way, all the systems supported by BridgeDb are here: https://github.com/bridgedb/datasources/blob/main/datasources.tsv\n\n## How to use bridgedbpy with pywikipathways\nHere are some specific combo functions that are useful. They let you skip worrying about system codes altogether!\n\n1. Getting all the pathways containing the HGNC symbol “TNF”:\n",
"_____no_output_____"
]
],
[
[
"tnf_pathways = pwpw.find_pathway_ids_by_xref('TNF', brdgdbp.get_system_code('HGNC'))\ntnf_pathways",
"_____no_output_____"
]
],
[
[
"2. Getting all the genes from a pathway as Ensembl identifiers:",
"_____no_output_____"
]
],
[
[
"pwpw.get_xref_list('WP554', brdgdbp.get_system_code('Ensembl'))",
"_____no_output_____"
]
],
[
[
"3. Getting all the metabolites from a pathway as ChEBI identifiers:",
"_____no_output_____"
]
],
[
[
"pwpw.get_xref_list('WP554', brdgdbp.get_system_code('ChEBI'))",
"_____no_output_____"
]
],
[
[
"## Other tips\nAnd if you ever find yourself with a system code, e.g., from a pywikipathways return result and you’re not sure what it is, then you can use this function:",
"_____no_output_____"
]
],
[
[
"brdgdbp.get_full_name('Ce')",
"_____no_output_____"
]
],
[
[
"## References\n1. Pico AR, Kelder T, Iersel MP van, Hanspers K, Conklin BR, Evelo C: **WikiPathways: Pathway editing for the people.** *PLoS Biol* 2008, **6:**e184+.\n\n2. Iersel M van, Pico A, Kelder T, Gao J, Ho I, Hanspers K, Conklin B, Evelo C: **The BridgeDb framework: Standardized access to gene, protein and metabolite identifier mapping services.** *BMC Bioinformatics* 2010, **11:**5+.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d0fb359a80ddaad39f359c2131e08982c2901568 | 62,320 | ipynb | Jupyter Notebook | nbs/trainer.ipynb | sparsh-ai/recohut | 4121f665761ffe38c9b6337eaa9293b26bee2376 | [
"Apache-2.0"
] | null | null | null | nbs/trainer.ipynb | sparsh-ai/recohut | 4121f665761ffe38c9b6337eaa9293b26bee2376 | [
"Apache-2.0"
] | 1 | 2022-01-12T05:40:57.000Z | 2022-01-12T05:40:57.000Z | nbs/trainer.ipynb | RecoHut-Projects/recohut | 4121f665761ffe38c9b6337eaa9293b26bee2376 | [
"Apache-2.0"
] | null | null | null | 30.744943 | 162 | 0.458119 | [
[
[
"# default_exp trainer",
"_____no_output_____"
]
],
[
[
"# Trainer\n> Implementation of torch-based model trainers.",
"_____no_output_____"
]
],
[
[
"#hide\nfrom nbdev.showdoc import *\nfrom fastcore.nb_imports import *\nfrom fastcore.test import *",
"_____no_output_____"
]
],
[
[
"## PL Trainer\n> Implementation of trainer for training PyTorch Lightning models.",
"_____no_output_____"
]
],
[
[
"#export\nfrom typing import Any, Iterable, List, Optional, Tuple, Union, Callable\nimport os\nimport os.path as osp\n\nfrom pytorch_lightning import Trainer\nfrom pytorch_lightning.callbacks import ModelCheckpoint\nfrom pytorch_lightning.loggers import TensorBoardLogger",
"_____no_output_____"
],
[
"#export\ndef pl_trainer(model, datamodule, max_epochs=10, val_epoch=5, gpus=None, log_dir=None,\n model_dir=None, monitor='val_loss', mode='min', *args, **kwargs):\n log_dir = log_dir if log_dir is not None else os.getcwd()\n model_dir = model_dir if model_dir is not None else os.getcwd()\n\n logger = TensorBoardLogger(save_dir=log_dir)\n\n checkpoint_callback = ModelCheckpoint(\n monitor=monitor,\n mode=mode,\n dirpath=model_dir,\n filename=\"recommender\",\n )\n\n trainer = Trainer(\n max_epochs=max_epochs,\n logger=logger,\n check_val_every_n_epoch=val_epoch,\n callbacks=[checkpoint_callback],\n num_sanity_val_steps=0,\n gradient_clip_val=1,\n gradient_clip_algorithm=\"norm\",\n gpus=gpus\n )\n\n trainer.fit(model, datamodule=datamodule)\n test_result = trainer.test(model, datamodule=datamodule)\n return test_result",
"_____no_output_____"
]
],
[
[
"Example",
"_____no_output_____"
]
],
[
[
"class Args:\n def __init__(self):\n self.data_dir = '/content/data'\n self.min_rating = 4\n self.num_negative_samples = 99\n self.min_uc = 5\n self.min_sc = 5\n self.val_p = 0.2\n self.test_p = 0.2\n self.num_workers = 2\n self.normalize = False\n self.batch_size = 32\n self.seed = 42\n self.shuffle = True\n self.pin_memory = True\n self.drop_last = False\n self.split_type = 'stratified'\n\nargs = Args()\n\nfrom recohut.datasets.movielens import ML1mDataModule\n\nds = ML1mDataModule(**args.__dict__)\n\nds.prepare_data()",
"Processing...\n"
],
[
"from recohut.models.nmf import NMF\n\nmodel = NMF(n_items=ds.data.num_items, n_users=ds.data.num_users, embedding_dim=20)",
"_____no_output_____"
],
[
"pl_trainer(model, ds, max_epochs=5)",
"GPU available: False, used: False\nTPU available: False, using: 0 TPU cores\nIPU available: False, using: 0 IPUs\n\n | Name | Type | Params\n-------------------------------------------------\n0 | user_embedding | Embedding | 120 K \n1 | item_embedding | Embedding | 62.5 K\n2 | user_embedding_gmf | Embedding | 120 K \n3 | item_embedding_gmf | Embedding | 62.5 K\n4 | gmf | Linear | 210 \n5 | fc1 | Linear | 820 \n6 | fc2 | Linear | 420 \n7 | fc3 | Linear | 210 \n8 | fc_final | Linear | 21 \n9 | dropout | Dropout | 0 \n-------------------------------------------------\n368 K Trainable params\n0 Non-trainable params\n368 K Total params\n1.472 Total estimated model params size (MB)\n"
]
],
[
[
"## Traditional Torch Trainers",
"_____no_output_____"
],
[
"### v1",
"_____no_output_____"
]
],
[
[
"# dataset\nfrom recohut.datasets.movielens import ML1mRatingDataset\n\n# models\nfrom recohut.models.afm import AFM\nfrom recohut.models.afn import AFN\nfrom recohut.models.autoint import AutoInt\nfrom recohut.models.dcn import DCN\nfrom recohut.models.deepfm import DeepFM\nfrom recohut.models.ffm import FFM\nfrom recohut.models.fm import FM\nfrom recohut.models.fnfm import FNFM\nfrom recohut.models.fnn import FNN\nfrom recohut.models.hofm import HOFM\nfrom recohut.models.lr import LR\nfrom recohut.models.ncf import NCF\nfrom recohut.models.nfm import NFM\nfrom recohut.models.ncf import NCF\nfrom recohut.models.pnn import PNN\nfrom recohut.models.wide_and_deep import WideAndDeep\nfrom recohut.models.xdeepfm import xDeepFM",
"_____no_output_____"
],
[
"ds = ML1mRatingDataset(root='/content/ML1m', min_uc=10, min_sc=5)",
"Downloading http://files.grouplens.org/datasets/movielens/ml-1m.zip\nExtracting /content/ML1m/raw/ml-1m.zip\nProcessing...\nDone!\n"
],
[
"import torch\nimport os\nimport tqdm\nfrom sklearn.metrics import roc_auc_score\nfrom torch.utils.data import DataLoader",
"_____no_output_____"
],
[
"class Args:\n def __init__(self,\n dataset='ml_1m',\n model='wide_and_deep'\n ):\n self.dataset = dataset\n self.model = model\n # dataset\n if dataset == 'ml_1m':\n self.dataset_root = '/content/ML1m'\n self.min_uc = 20\n self.min_sc = 20\n\n # model training\n self.device = 'cpu' # 'cuda:0'\n self.num_workers = 2\n self.batch_size = 256\n self.lr = 0.001\n self.weight_decay = 1e-6\n self.save_dir = '/content/chkpt'\n self.n_epochs = 2\n self.dropout = 0.2\n self.log_interval = 100\n\n # model architecture\n if model == 'wide_and_deep':\n self.embed_dim = 16\n self.mlp_dims = (16, 16)\n elif model == 'fm':\n self.embed_dim = 16\n elif model == 'ffm':\n self.embed_dim = 4\n elif model == 'hofm':\n self.embed_dim = 16\n self.order = 3\n elif model == 'fnn':\n self.embed_dim = 16\n self.mlp_dims = (16, 16)\n elif model == 'ipnn':\n self.embed_dim = 16\n self.mlp_dims = (16,)\n self.method = 'inner'\n elif model == 'opnn':\n self.embed_dim = 16\n self.mlp_dims = (16,)\n self.method = 'outer'\n elif model == 'dcn':\n self.embed_dim = 16\n self.num_layers = 3\n self.mlp_dims = (16, 16)\n elif model == 'nfm':\n self.embed_dim = 64\n self.mlp_dims = (64,)\n self.dropouts = (0.2, 0.2)\n elif model == 'ncf':\n self.embed_dim = 16\n self.mlp_dims = (16, 16)\n elif model == 'fnfm':\n self.embed_dim = 4\n self.mlp_dims = (64,)\n self.dropouts = (0.2, 0.2)\n elif model == 'deep_fm':\n self.embed_dim = 16\n self.mlp_dims = (16, 16)\n elif model == 'xdeep_fm':\n self.embed_dim = 16\n self.cross_layer_sizes = (16, 16)\n self.split_half = False\n self.mlp_dims = (16, 16)\n elif model == 'afm':\n self.embed_dim = 16\n self.attn_size = 16\n self.dropouts = (0.2, 0.2)\n elif model == 'autoint':\n self.embed_dim = 16\n self.atten_embed_dim = 64\n self.num_heads = 2\n self.num_layers = 3\n self.mlp_dims = (400, 400)\n self.dropouts = (0, 0, 0)\n elif model == 'afn':\n self.embed_dim = 16\n self.LNN_dim = 1500\n self.mlp_dims = (400, 400, 400)\n self.dropouts = (0, 0, 0)\n\n def get_dataset(self):\n if self.dataset == 'ml_1m':\n return ML1mRatingDataset(root = self.dataset_root,\n min_uc = self.min_uc,\n min_sc = self.min_sc\n )\n \n def get_model(self, field_dims, user_field_idx=None, item_field_idx=None):\n if self.model == 'wide_and_deep':\n return WideAndDeep(field_dims,\n embed_dim=self.embed_dim,\n mlp_dims = self.mlp_dims,\n dropout = self.dropout\n )\n elif self.model == 'fm':\n return FM(field_dims,\n embed_dim = self.embed_dim\n )\n elif self.model == 'lr':\n return LR(field_dims\n )\n elif self.model == 'ffm':\n return FFM(field_dims,\n embed_dim = self.embed_dim\n )\n elif self.model == 'hofm':\n return HOFM(field_dims,\n embed_dim = self.embed_dim,\n order = self.order\n )\n elif self.model == 'fnn':\n return FNN(field_dims,\n embed_dim = self.embed_dim,\n mlp_dims = self.mlp_dims,\n dropout = self.dropout\n )\n elif self.model == 'ipnn':\n return PNN(field_dims,\n embed_dim = self.embed_dim,\n mlp_dims = self.mlp_dims,\n method = self.method,\n dropout = self.dropout\n )\n elif self.model == 'opnn':\n return PNN(field_dims,\n embed_dim = self.embed_dim,\n mlp_dims = self.mlp_dims,\n method = self.method,\n dropout = self.dropout\n )\n elif self.model == 'dcn':\n return DCN(field_dims,\n embed_dim = self.embed_dim,\n mlp_dims = self.mlp_dims,\n num_layers = self.num_layers,\n dropout = self.dropout,\n )\n elif self.model == 'nfm':\n return NFM(field_dims,\n embed_dim = self.embed_dim,\n mlp_dims = self.mlp_dims,\n dropouts = self.dropouts,\n )\n elif self.model == 'ncf':\n return NCF(field_dims,\n embed_dim = self.embed_dim,\n mlp_dims = self.mlp_dims,\n dropout = self.dropout,\n user_field_idx=user_field_idx,\n item_field_idx=item_field_idx\n )\n elif self.model == 'fnfm':\n return FNFM(field_dims,\n embed_dim = self.embed_dim,\n mlp_dims = self.mlp_dims,\n dropouts = self.dropouts,\n )\n elif self.model == 'deep_fm':\n return DeepFM(field_dims,\n embed_dim = self.embed_dim,\n mlp_dims = self.mlp_dims,\n dropout = self.dropout,\n )\n elif self.model == 'xdeep_fm':\n return xDeepFM(field_dims,\n embed_dim = self.embed_dim,\n mlp_dims = self.mlp_dims,\n dropout = self.dropout,\n cross_layer_sizes = self.cross_layer_sizes,\n split_half = self.split_half,\n )\n elif self.model == 'afm':\n return AFM(field_dims,\n embed_dim = self.embed_dim,\n dropouts = self.dropouts,\n attn_size = self.attn_size,\n )\n elif self.model == 'autoint':\n return AutoInt(field_dims,\n embed_dim = self.embed_dim,\n mlp_dims = self.mlp_dims,\n dropouts = self.dropouts,\n atten_embed_dim = self.atten_embed_dim,\n num_heads = self.num_heads,\n num_layers = self.num_layers,\n )\n elif self.model == 'afn':\n return AFN(field_dims,\n embed_dim = self.embed_dim,\n mlp_dims = self.mlp_dims,\n dropouts = self.dropouts,\n LNN_dim = self.LNN_dim,\n )",
"_____no_output_____"
],
[
"class EarlyStopper(object):\n\n def __init__(self, num_trials, save_path):\n self.num_trials = num_trials\n self.trial_counter = 0\n self.best_accuracy = 0\n self.save_path = save_path\n\n def is_continuable(self, model, accuracy):\n if accuracy > self.best_accuracy:\n self.best_accuracy = accuracy\n self.trial_counter = 0\n torch.save(model, self.save_path)\n return True\n elif self.trial_counter + 1 < self.num_trials:\n self.trial_counter += 1\n return True\n else:\n return False",
"_____no_output_____"
],
[
"class Trainer:\n def __init__(self, args):\n device = torch.device(args.device)\n # dataset\n dataset = args.get_dataset()\n # model\n model = args.get_model(dataset.field_dims,\n user_field_idx = dataset.user_field_idx,\n item_field_idx = dataset.item_field_idx)\n model = model.to(device)\n model_name = type(model).__name__\n # data split\n train_length = int(len(dataset) * 0.8)\n valid_length = int(len(dataset) * 0.1)\n test_length = len(dataset) - train_length - valid_length\n # data loader\n train_dataset, valid_dataset, test_dataset = torch.utils.data.random_split(\n dataset, (train_length, valid_length, test_length))\n train_data_loader = DataLoader(train_dataset, batch_size=args.batch_size, num_workers=args.num_workers)\n valid_data_loader = DataLoader(valid_dataset, batch_size=args.batch_size, num_workers=args.num_workers)\n test_data_loader = DataLoader(test_dataset, batch_size=args.batch_size, num_workers=args.num_workers)\n # handlers\n criterion = torch.nn.BCELoss()\n optimizer = torch.optim.Adam(params=model.parameters(), lr=args.lr, weight_decay=args.weight_decay)\n os.makedirs(args.save_dir, exist_ok=True)\n early_stopper = EarlyStopper(num_trials=2, save_path=f'{args.save_dir}/{model_name}.pt')\n # # scheduler\n # # ref - https://github.com/sparsh-ai/stanza/blob/7961a0a00dc06b9b28b71954b38181d6a87aa803/trainer/bert.py#L36\n # import torch.optim as optim\n # if args.enable_lr_schedule:\n # if args.enable_lr_warmup:\n # self.lr_scheduler = self.get_linear_schedule_with_warmup(\n # optimizer, args.warmup_steps, len(train_data_loader) * self.n_epochs)\n # else:\n # self.lr_scheduler = optim.lr_scheduler.StepLR(\n # optimizer, step_size=args.decay_step, gamma=args.gamma)\n # training\n for epoch_i in range(args.n_epochs):\n self._train(model, optimizer, train_data_loader, criterion, device)\n auc = self._test(model, valid_data_loader, device)\n print('epoch:', epoch_i, 'validation: auc:', auc)\n if not early_stopper.is_continuable(model, auc):\n print(f'validation: best auc: {early_stopper.best_accuracy}')\n break\n auc = self._test(model, test_data_loader, device)\n print(f'test auc: {auc}')\n\n @staticmethod\n def _train(model, optimizer, data_loader, criterion, device, log_interval=100):\n model.train()\n total_loss = 0\n tk0 = tqdm.tqdm(data_loader, smoothing=0, mininterval=1.0)\n for i, (fields, target) in enumerate(tk0):\n fields, target = fields.to(device), target.to(device)\n y = model(fields)\n loss = criterion(y, target.float())\n model.zero_grad()\n loss.backward()\n # self.clip_gradients(5)\n optimizer.step()\n # if self.args.enable_lr_schedule:\n # self.lr_scheduler.step()\n total_loss += loss.item()\n if (i + 1) % log_interval == 0:\n tk0.set_postfix(loss=total_loss / log_interval)\n total_loss = 0\n \n @staticmethod\n def _test(model, data_loader, device):\n model.eval()\n targets, predicts = list(), list()\n with torch.no_grad():\n for fields, target in tqdm.tqdm(data_loader, smoothing=0, mininterval=1.0):\n fields, target = fields.to(device), target.to(device)\n y = model(fields)\n targets.extend(target.tolist())\n predicts.extend(y.tolist())\n return roc_auc_score(targets, predicts)\n\n # def clip_gradients(self, limit=5):\n # \"\"\"\n # Reference:\n # 1. https://github.com/sparsh-ai/stanza/blob/7961a0a00dc06b9b28b71954b38181d6a87aa803/trainer/bert.py#L175\n # \"\"\"\n # for p in self.model.parameters():\n # nn.utils.clip_grad_norm_(p, 5)\n\n # def _create_optimizer(self):\n # args = self.args\n # param_optimizer = list(self.model.named_parameters())\n # no_decay = ['bias', 'layer_norm']\n # optimizer_grouped_parameters = [\n # {\n # 'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)],\n # 'weight_decay': args.weight_decay,\n # },\n # {'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)], 'weight_decay': 0.0},\n # ]\n # if args.optimizer.lower() == 'adamw':\n # return optim.AdamW(optimizer_grouped_parameters, lr=args.lr, eps=args.adam_epsilon)\n # elif args.optimizer.lower() == 'adam':\n # return optim.Adam(optimizer_grouped_parameters, lr=args.lr, weight_decay=args.weight_decay)\n # elif args.optimizer.lower() == 'sgd':\n # return optim.SGD(optimizer_grouped_parameters, lr=args.lr, weight_decay=args.weight_decay, momentum=args.momentum)\n # else:\n # raise ValueError\n\n # def get_linear_schedule_with_warmup(self, optimizer, num_warmup_steps, num_training_steps, last_epoch=-1):\n # # based on hugging face get_linear_schedule_with_warmup\n # def lr_lambda(current_step: int):\n # if current_step < num_warmup_steps:\n # return float(current_step) / float(max(1, num_warmup_steps))\n # return max(\n # 0.0, float(num_training_steps - current_step) / float(max(1, num_training_steps - num_warmup_steps))\n # )\n\n # return LambdaLR(optimizer, lr_lambda, last_epoch)",
"_____no_output_____"
],
[
"models = [\n 'wide_and_deep',\n 'fm',\n 'lr',\n 'ffm',\n 'hofm',\n 'fnn',\n 'ipnn',\n 'opnn',\n 'dcn',\n 'nfm',\n 'ncf',\n 'fnfm',\n 'deep_fm',\n 'xdeep_fm',\n 'afm',\n # 'autoint',\n # 'afn'\n ]\n\nfor model in models:\n args = Args(model=model)\n trainer = Trainer(args)",
"Processing...\nDone!\n100%|██████████| 3126/3126 [00:23<00:00, 135.91it/s, loss=0.57]\n100%|██████████| 391/391 [00:01<00:00, 252.62it/s]\n"
],
[
"models = [\n 'autoint',\n 'afn'\n ]\n\nfor model in models:\n args = Args(model=model)\n trainer = Trainer(args)",
"Processing...\nDone!\n100%|██████████| 3126/3126 [00:43<00:00, 72.44it/s, loss=0.551]\n100%|██████████| 391/391 [00:02<00:00, 171.82it/s]\n"
],
[
"!tree --du -h -C /content/chkpt",
"\u001b[01;34m/content/chkpt\u001b[00m\n├── [669K] AFM.pt\n├── [ 39M] AFN.pt\n├── [1.5M] AutoInt.pt\n├── [640K] DCN.pt\n├── [676K] DeepFM.pt\n├── [355K] FFM.pt\n├── [666K] FM.pt\n├── [363K] FNFM.pt\n├── [636K] FNN.pt\n├── [1.3M] HOFM.pt\n├── [ 41K] LR.pt\n├── [636K] NCF.pt\n├── [2.5M] NFM.pt\n├── [1.2M] PNN.pt\n├── [676K] WideAndDeep.pt\n└── [682K] xDeepFM.pt\n\n 51M used in 0 directories, 16 files\n"
]
],
[
[
"### v2\n\n**References:-**\n1. https://nbviewer.org/github/CS-512-Recsys/Recsys/blob/main/nbs/basic_implementation.ipynb",
"_____no_output_____"
]
],
[
[
"!pip install -q wandb",
"_____no_output_____"
],
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nimport torch\nfrom torch import nn\nfrom torch.nn import functional as F\n\nimport os\nimport copy\nimport random\nfrom pathlib import Path\nfrom collections import defaultdict\n\nfrom argparse import Namespace\nfrom joblib import dump, load\nfrom tqdm import tqdm\n\nimport wandb\nfrom torch.utils.data import DataLoader as dl",
"_____no_output_____"
],
[
"class RecsysDataset(torch.utils.data.Dataset):\n\n def __init__(self,df,usr_dict=None,mov_dict=None):\n self.df = df\n self.usr_dict = usr_dict\n self.mov_dict = mov_dict\n\n def __getitem__(self,index):\n if self.usr_dict and self.mov_dict:\n return [self.usr_dict[int(self.df.iloc[index]['user_id'])],self.mov_dict[int(self.df.iloc[index]['movie_id'])]],self.df.iloc[index]['rating']\n else:\n return [int(self.df.iloc[index]['user_id']-1),int(self.df.iloc[index]['movie_id']-1)],self.df.iloc[index]['rating']\n \n def __len__(self):\n return len(self.df)\n\n\nsample = pd.DataFrame({'user_id':[1,2,3,2,2,3,2,2],'movie_id':[1,2,3,3,3,2,1,1],'rating':[2.0,1.0,4.0,5.0,1.3,3.5,3.0,4.5]})\ntrn_ids = random.sample(range(8),4,)\nvalid_ids = [i for i in range(8) if i not in trn_ids]\n\nsample_trn,sample_vld = copy.deepcopy(sample.iloc[trn_ids].reset_index()),copy.deepcopy(sample.iloc[valid_ids].reset_index())\n\nsample_vld = RecsysDataset(sample_vld)\nsample_trn = RecsysDataset(sample_trn)\n\ntrain_loader = dl(sample_trn, batch_size=2, shuffle=True)\nvalid_loader = dl(sample_vld, batch_size=2, shuffle=True)",
"_____no_output_____"
],
[
"class NCF(nn.Module):\n \n def __init__(self,user_sz,item_sz,embd_sz,dropout_fac,min_r=0.0,max_r=5.0,alpha=0.5,with_variable_alpha=False):\n super().__init__()\n self.dropout_fac = dropout_fac\n self.user_embd_mtrx = nn.Embedding(user_sz,embd_sz)\n self.item_embd_mtrx = nn.Embedding(item_sz,embd_sz)\n #bias = torch.zeros(size=(user_sz, 1), requires_grad=True)\n self.h = nn.Linear(embd_sz,1)\n self.fst_lyr = nn.Linear(embd_sz*2,embd_sz)\n self.snd_lyr = nn.Linear(embd_sz,embd_sz//2)\n self.thrd_lyr = nn.Linear(embd_sz//2,embd_sz//4)\n self.out_lyr = nn.Linear(embd_sz//4,1)\n self.alpha = torch.tensor(alpha)\n self.min_r,self.max_r = min_r,max_r\n if with_variable_alpha:\n self.alpha = torch.tensor(alpha,requires_grad=True)\n \n def forward(self,x):\n user_emd = self.user_embd_mtrx(x[0])\n item_emd = self.item_embd_mtrx(x[-1])\n #hadamard-product\n gmf = user_emd*item_emd\n gmf = self.h(gmf)\n \n \n mlp = torch.cat([user_emd,item_emd],dim=-1)\n mlp = self.out_lyr(F.relu(self.thrd_lyr(F.relu(self.snd_lyr(F.dropout(F.relu(self.fst_lyr(mlp)),p=self.dropout_fac))))))\n fac = torch.clip(self.alpha,min=0.0,max=1.0)\n out = fac*gmf+ (1-fac)*mlp\n out = torch.clip(out,min=self.min_r,max=self.max_r)\n return out",
"_____no_output_____"
],
[
"#does it work\nmodel = NCF(3,3,4,0.5)\nfor u,r in train_loader:\n #user,item = u\n print(f'user:{u[0]},item:{u[-1]} and rating:{r}')\n #print(u)\n out = model(u)\n print(f'output of the network=> out:{out},shape:{out.shape}')\n break",
"user:tensor([2, 1]),item:tensor([2, 0]) and rating:tensor([4.0000, 4.5000], dtype=torch.float64)\noutput of the network=> out:tensor([[0.4322],\n [0.5724]], grad_fn=<ClampBackward1>),shape:torch.Size([2, 1])\n"
],
[
"class Trainer(object):\n def __init__(self, model, device,loss_fn=None, optimizer=None, scheduler=None,artifacts_loc=None,exp_tracker=None):\n\n # Set params\n self.model = model\n self.device = device\n self.loss_fn = loss_fn\n self.optimizer = optimizer\n self.scheduler = scheduler\n self.store_loc = artifacts_loc\n self.exp_tracker = exp_tracker\n\n def train_step(self, dataloader):\n \"\"\"Train step.\"\"\"\n # Set model to train mode\n self.model.train()\n loss = 0.0\n\n # Iterate over train batches\n for i, batch in enumerate(dataloader):\n #batch = [item.to(self.device) for item in batch] # Set device\n inputs,targets = batch\n inputs = [item.to(self.device) for item in inputs]\n targets = targets.to(self.device)\n #inputs, targets = batch[:-1], batch[-1]\n #import pdb;pdb.set_trace()\n self.optimizer.zero_grad() # Reset gradients\n z = self.model(inputs) # Forward pass\n targets = targets.reshape(z.shape)\n J = self.loss_fn(z.float(), targets.float()) # Define loss\n J.backward() # Backward pass\n self.optimizer.step() # Update weights\n\n # Cumulative Metrics\n loss += (J.detach().item() - loss) / (i + 1)\n\n return loss\n\n def eval_step(self, dataloader):\n \"\"\"Validation or test step.\"\"\"\n # Set model to eval mode\n self.model.eval()\n loss = 0.0\n y_trues, y_probs = [], []\n\n # Iterate over val batches\n with torch.inference_mode():\n for i, batch in enumerate(dataloader):\n inputs,y_true = batch\n inputs = [item.to(self.device) for item in inputs]\n y_true = y_true.to(self.device).float()\n\n # Step\n z = self.model(inputs).float() # Forward pass\n y_true = y_true.reshape(z.shape)\n J = self.loss_fn(z, y_true).item()\n\n # Cumulative Metrics\n loss += (J - loss) / (i + 1)\n\n # Store outputs\n y_prob = z.cpu().numpy()\n y_probs.extend(y_prob)\n y_trues.extend(y_true.cpu().numpy())\n\n return loss, np.vstack(y_trues), np.vstack(y_probs)\n\n def predict_step(self, dataloader):\n \"\"\"Prediction step.\"\"\"\n # Set model to eval mode\n self.model.eval()\n y_probs = []\n\n # Iterate over val batches\n with torch.inference_mode():\n for i, batch in enumerate(dataloader):\n\n # Forward pass w/ inputs\n inputs, targets = batch\n z = self.model(inputs).float()\n\n # Store outputs\n y_prob = z.cpu().numpy()\n y_probs.extend(y_prob)\n\n return np.vstack(y_probs)\n \n def train(self, num_epochs, patience, train_dataloader, val_dataloader, \n tolerance=1e-5):\n best_val_loss = np.inf\n training_stats = defaultdict(list)\n for epoch in tqdm(range(num_epochs)):\n # Steps\n train_loss = self.train_step(dataloader=train_dataloader)\n val_loss, _, _ = self.eval_step(dataloader=val_dataloader)\n #store stats\n training_stats['epoch'].append(epoch)\n training_stats['train_loss'].append(train_loss)\n training_stats['val_loss'].append(val_loss)\n #log-stats\n # wandb.init(project=f\"{args.trail_id}_{args.dataset}_{args.data_type}\",config=config_dict)\n if self.exp_tracker == 'wandb':\n log_metrics = {'epoch':epoch,'train_loss':train_loss,'val_loss':val_loss}\n wandb.log(log_metrics,step=epoch)\n \n self.scheduler.step(val_loss)\n\n # Early stopping\n if val_loss < best_val_loss - tolerance:\n best_val_loss = val_loss\n best_model = self.model\n _patience = patience # reset _patience\n else:\n _patience -= 1\n if not _patience: # 0\n print(\"Stopping early!\")\n break\n\n # Tracking\n #mlflow.log_metrics({\"train_loss\": train_loss, \"val_loss\": val_loss}, step=epoch)\n\n # Logging\n if epoch%5 == 0:\n print(\n f\"Epoch: {epoch+1} | \"\n f\"train_loss: {train_loss:.5f}, \"\n f\"val_loss: {val_loss:.5f}, \"\n f\"lr: {self.optimizer.param_groups[0]['lr']:.2E}, \"\n f\"_patience: {_patience}\"\n )\n if self.store_loc:\n pd.DataFrame(training_stats).to_csv(self.store_loc/'training_stats.csv',index=False)\n return best_model, best_val_loss",
"_____no_output_____"
],
[
"loss_fn = nn.MSELoss()\noptimizer = torch.optim.Adam(model.parameters(), lr=1e-3)\nscheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(\n optimizer, mode=\"min\", factor=0.1, patience=5)\n\ntrainer = Trainer(model,'cpu',loss_fn,optimizer,scheduler)",
"_____no_output_____"
],
[
"trainer.train(100,10,train_loader,valid_loader)",
" 11%|█ | 11/100 [00:00<00:01, 50.86it/s]"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0fb3f96034f1004d8f953de23a346fb911f0c88 | 316,613 | ipynb | Jupyter Notebook | assets/misc/MvariateReg.ipynb | hhristov94/hhristov94.github.io | cbb1c7e2472c4a17b4e217c0c73169af86d33441 | [
"MIT"
] | null | null | null | assets/misc/MvariateReg.ipynb | hhristov94/hhristov94.github.io | cbb1c7e2472c4a17b4e217c0c73169af86d33441 | [
"MIT"
] | 2 | 2021-09-27T21:43:16.000Z | 2022-02-26T04:25:48.000Z | assets/misc/MvariateReg.ipynb | hhristov94/hhristov94.github.io | cbb1c7e2472c4a17b4e217c0c73169af86d33441 | [
"MIT"
] | null | null | null | 1,559.669951 | 193,316 | 0.961274 | [
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\nfrom mpl_toolkits.mplot3d import Axes3D\nimport seaborn as sns\nsns.set()\n%matplotlib inline\n\nnum_samples = 100\n\n# The mean values of the three dimensions .\nmu = np.array([5, 11, 12])\n\n# The desired covariance matrix.\ncov = np.array([\n [1.00, 0.85, 0.95],\n [0.85, 1.00, 0.90],\n [0.95, 0.90, 1.00]\n ])\n\n# Generate the random samples.\ndf = np.random.multivariate_normal(mu, cov, size=num_samples)\n\n# Plot various projections of the samples.\nfig = plt.figure(figsize=(15, 13))\n\n# Fourth subplot\nax4 = fig.add_subplot(1, 1, 1, projection= \"3d\")\nax4.scatter(df[:,0], df[:,1], df[:,2],s = 60)\nax4.set_xlabel(r'$X_{1}$')\nax4.set_ylabel(r'$X_{2}$')\nax4.set_zlabel(r'$y$')\n\nplt.show()",
"_____no_output_____"
],
[
"# regular grid covering the domain of the data\ny = df[:,2]\nX = np.delete(df, 2, 1)\n# create vector of ones...\nI = np.ones(shape=y.shape)[..., None]\n\n#...and add to feature matrix\nX = np.concatenate((I, X), 1)\n# calculate coefficients using closed-form solution\ncoeffs = np.linalg.inv(X.transpose().dot(X)).dot(X.transpose()).dot(y)\nyhat = X.dot(coeffs)\nX = X[:,1:]\nmn = np.min(X, axis=0)\nmx = np.max(X, axis=0)\nX,Y = np.meshgrid(np.linspace(mn[0], mx[0], 100),np.linspace(mn[1], mx[1],100))\n# evaluate it on grid\nZ = coeffs[1]*X + coeffs[2]*Y + coeffs[0]\nfig = plt.figure(figsize=(15,13))\nax = fig.gca(projection='3d')\n# Plot the surface.\nax.scatter(df[:,0], df[:,1], df[:,2], s=60)\nax.plot_surface(X, Y, Z,alpha=0.2, linewidth=0, antialiased= True)\nplt.xlabel(r'$X_{1}$')\nplt.ylabel(r'$X_{2}$')\nax.set_zlabel(r'$y$')\nplt.show()",
"_____no_output_____"
],
[
"SSE = sum((y-yhat)**2)\nprint(SSE)",
"6.790179411030153\n"
],
[
"TSS = sum((y-y.mean())**2)\nprint(TSS)",
"85.42958844452086\n"
],
[
"R_Squared = 1.0 - (SSE /TSS)\nprint(R_Squared)",
"0.9205172407515484\n"
],
[
"#1-(1-R2)*N-1/N-M-1\nAdj_R2 = 1.0 - (1.0 - R_Squared) * 99/97\nAdj_R2",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0fb5f9eb92e3cf1063e310a27032748c11bb393 | 11,082 | ipynb | Jupyter Notebook | draft/regrLin.ipynb | Data-Science-SUPSI-20-21-Group-F/Data-Science-SUPSI-20-21-Group-F.github.io | 009bc6df1bf24d9e87a9e30d257c5c9fb9bb1a54 | [
"MIT"
] | null | null | null | draft/regrLin.ipynb | Data-Science-SUPSI-20-21-Group-F/Data-Science-SUPSI-20-21-Group-F.github.io | 009bc6df1bf24d9e87a9e30d257c5c9fb9bb1a54 | [
"MIT"
] | null | null | null | draft/regrLin.ipynb | Data-Science-SUPSI-20-21-Group-F/Data-Science-SUPSI-20-21-Group-F.github.io | 009bc6df1bf24d9e87a9e30d257c5c9fb9bb1a54 | [
"MIT"
] | null | null | null | 32.403509 | 137 | 0.345515 | [
[
[
"import pandas as pd\nimport numpy as np\nimport plotly.express as px\nimport plotly.graph_objs as go\n\ndf = pd.read_csv(\"data/Shared_data_responses_demographics.csv\")\n\ndf",
"_____no_output_____"
],
[
"df[\"Scenario\"] = df[\"Scenario\"].map({'Footbridge': 0, 'Loop': 1, 'Switch': 2})\ndf[\"survey.gender\"] = df[\"survey.gender\"].map({'Men': 0, 'Women': 1})\ndf[\"survey.education\"] = df[\"survey.education\"].map({'College': 0, 'No College': 1})",
"_____no_output_____"
],
[
"from sklearn import linear_model\nfrom sklearn.model_selection import train_test_split\n\n[dfTrain, dfTest] = train_test_split(df, test_size=0.3, random_state=42)\n\nxTrain = dfTrain[['Scenario', 'survey.age', 'survey.gender', 'survey.education', 'survey.political', 'survey.religious']].values\nxTest = dfTest[['Scenario', 'survey.age', 'survey.gender', 'survey.education', 'survey.political', 'survey.religious']].values\n\nyTrain = dfTrain['Outcome'].values\nyTest = dfTest['Outcome'].values\n\nlinRegr = linear_model.LinearRegression()\nlinRegr.fit(xTrain, yTrain)\n\nprint(\"\\tTrain R²: \", linRegr.score(xTrain, yTrain))\nprint(\"\\tTest R²: \", linRegr.score(xTest, yTest))",
"\tTrain R²: 0.10929688154613448\n\tTest R²: 0.10951259155743154\n"
],
[
"def calcCorrectness(x, y):\n a = 0\n for i in range(len(x)):\n if round(linRegr.predict(x[0].reshape(1, -1))[0]) == y[i]:\n a+=1\n print(round(a/len(x) * 100, 2), \"%\")\n \ncalcCorrectness(xTest, yTest)\ncalcCorrectness(xTrain, yTrain)",
"68.55 %\n30.97 %\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code"
]
] |
d0fb6c8e8ad3747aef7280f652ad81c9883d54ec | 9,592 | ipynb | Jupyter Notebook | src/old_exams/exam/Cultural Diffusion v3_Bugs.ipynb | lyoussifou/EPA1324_open | 1b9fed7555406c6d2f17483e1ddd174f249a965c | [
"BSD-3-Clause"
] | 6 | 2020-11-18T08:08:25.000Z | 2021-12-06T18:38:17.000Z | src/old_exams/exam/Cultural Diffusion v3_Bugs.ipynb | lyoussifou/EPA1324_open | 1b9fed7555406c6d2f17483e1ddd174f249a965c | [
"BSD-3-Clause"
] | null | null | null | src/old_exams/exam/Cultural Diffusion v3_Bugs.ipynb | lyoussifou/EPA1324_open | 1b9fed7555406c6d2f17483e1ddd174f249a965c | [
"BSD-3-Clause"
] | 29 | 2020-11-12T10:14:57.000Z | 2022-01-20T12:31:03.000Z | 30.258675 | 575 | 0.541597 | [
[
[
"## Conceptual description\n\nAs people interact, they tend to become more alike in their beliefs, attitudes and behaviour. In \"The Dissemination of Culture: A Model with Local Convergence and Global Polarization\" (1997), Robert Axelrod presents an agent-based model to explain cultural diffusion. Analogous to Schelling's segregation model, the key to this conceptualization is the emergence of polarization from the interaction of individual agents. The basic premise is that the more similar an actor is to a neighbor, the more likely that that actor will adopt one of the neighbor's traits.\n\nIn the model below, this is implemented by initializing the model by filling an excel-like grid with agents with random values [0,1] for each of four traits (music, sports, favorite color and drink). \n\nEach step, each agent (in random order) chooses a random neighbor from the 8 neighbors proportionaly to how similar it is to each of its neighbors, and adopts one randomly selected differing trait from this neighbor. Similarity between any two agents is calculated by 1 - euclidian distance over the four traits. \n\nTo visualize the model, the four traits are transformed into 'RGBA' (Red-Green-Blue-Alpha) values; i.e. a color and an opacity. The visualizations below show the clusters of homogeneity being formed.",
"_____no_output_____"
]
],
[
[
"import random\n\nimport numpy as np\n\nfrom mesa import Model, Agent\nimport mesa.time as time\nfrom mesa.time import RandomActivation\nfrom mesa.space import SingleGrid\nfrom mesa.datacollection import DataCollector\n\nclass CulturalDiff(Model):\n \"\"\"\n Model class for the Schelling segregation model.\n \n Parameters\n ----------\n height : int\n height of grid\n width : int\n height of grid\n seed : int\n random seed\n \n Attributes\n ----------\n height : int\n width : int\n density : float\n schedule : RandomActivation instance\n grid : SingleGrid instance\n \n \"\"\"\n\n def __init__(self, height=20, width=20, seed=None):\n __init__(seed=seed)\n self.height = height\n self.width = width\n\n self.schedule = time.BaseScheduler(self)\n self.grid = SingleGrid(width, height, torus=True)\n self.datacollector = DataCollector(model_reporters={'diversity':count_nr_cultures})\n\n # Fill grid with agents with random traits\n \n # Note that this implementation does not guarantee some set distribution of traits. \n # Therefore, examining the effect of minorities etc is not facilitated.\n for cell in self.grid.coord_iter():\n agent = CulturalDiffAgent(cell, self)\n self.grid.position_agent(agent, cell)\n self.schedule.add(agent)\n\n def step(self):\n \"\"\"\n Run one step of the model.\n \"\"\"\n self.datacollector.collect(self)\n self.schedule.step\n\n\nclass CulturalDiffAgent(Agent):\n \"\"\"\n Schelling segregation agent\n \n Parameters\n ----------\n pos : tuple of 2 ints\n the x,y coordinates in the grid\n model : Model instance\n\n \n \"\"\"\n\n def __init__(self, pos, model):\n super().__init__(pos, model)\n self.pos = pos\n self.profile = np.asarray([random.random() for _ in range(4)])\n \n def step(self):\n \n #For each neighbor, calculate the euclidian distance\n # similarity is 1 - distance\n neighbor_similarity_dict = []\n for neighbor in self.model.grid.neighbor_iter(self.pos, moore=True):\n neighbor_similarity = 1-np.linalg.norm(self.profile-neighbor.profile)\n neighbor_similarity_dict[neighbor] = neighbor_similarity\n \n # Proportional to this similarity, pick a 'random' neighbor to interact with\n neighbor_to_interact = self.random.choices(list(neighbor_similarity_dict.keys()),\n weights=neighbor_similarity_dict.values())[0]\n \n # Select a trait that differs between the selected neighbor and self and change that trait in self\n # we are using some numpy boolean indexing to make this short and easy\n not_same_features = self.profile != neighbor_to_interact.profile\n \n if np.any(not_same_features):\n index_for_trait = self.random.choice(np.nonzero(not_same_features)[0])\n self.profile[index_for_trait] = neighbor_to_interact.profile[index_for_trait]\n\n \ndef count_nr_cultures(model):\n cultures = set()\n for (cell, x,y) in model.grid.coord_iter():\n if cell:\n cultures.add(tuple(cell.profile))\n return len(cultures)",
"_____no_output_____"
]
],
[
[
"# Visualization",
"_____no_output_____"
],
[
"## Static images\nVisualization of this model are static images. A visualization after initialization, after 20 steps, after 50 steps, and after 200 steps is presented.\n\n### After initialization",
"_____no_output_____"
]
],
[
[
"model = CulturalDiff(seed=123456789)",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\nimport matplotlib.colors as colors\nimport seaborn as sns\nimport pandas as pd\n\n\ndef plot_model(model, ax):\n grid = np.zeros((model.height, model.width, 4))\n\n for (cell, i, j) in model.grid.coord_iter():\n color = [0,0,0,0] #in case not every cell is filled, the default colour is white\n if cell is not None:\n color = cell.profile\n grid[i,j] = color \n plt.imshow(grid)\n \nfig, ax = plt.subplots()\nplot_model(model, ax)\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"### After 20 steps",
"_____no_output_____"
]
],
[
[
"for i in range(20):\n model.step()",
"_____no_output_____"
],
[
"fig, ax = plt.subplots()\nplot_model(model, ax)\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"### After 50 steps",
"_____no_output_____"
]
],
[
[
"for i in range(30):\n model.step()",
"_____no_output_____"
],
[
"fig, ax = plt.subplots()\nplot_model(model, ax)\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"### After 200 steps",
"_____no_output_____"
]
],
[
[
"for i in range(150):\n model.step()",
"_____no_output_____"
],
[
"fig, ax = plt.subplots()\nplot_model(model, ax)\n\nplt.show()",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
d0fb883ac9dce1aa26b565cf573ab21bfb90d0ad | 64,737 | ipynb | Jupyter Notebook | TASK_1_Supervised ML/Task_1_supervised_ml.ipynb | njlalwani/TSF | 690a39b4fe66f5b3de854ece4b0eee8765981fac | [
"MIT"
] | null | null | null | TASK_1_Supervised ML/Task_1_supervised_ml.ipynb | njlalwani/TSF | 690a39b4fe66f5b3de854ece4b0eee8765981fac | [
"MIT"
] | null | null | null | TASK_1_Supervised ML/Task_1_supervised_ml.ipynb | njlalwani/TSF | 690a39b4fe66f5b3de854ece4b0eee8765981fac | [
"MIT"
] | null | null | null | 70.983553 | 13,300 | 0.796175 | [
[
[
"# SUPERVISED MACHINE LEARNING (LINEAR REGRESSION) \n## Author-Neeraj Lalwani",
"_____no_output_____"
],
[
"### Importing important libraries\n",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport seaborn as sns\nimport matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"### Importing dataset",
"_____no_output_____"
]
],
[
[
"Data = pd.read_csv(\"marks.csv\")\nprint(\"Data is successfully imported\")",
"Data is successfully imported\n"
]
],
[
[
"#### First 7 records",
"_____no_output_____"
]
],
[
[
"Data.head(7)",
"_____no_output_____"
]
],
[
[
"#### Last 7 records",
"_____no_output_____"
]
],
[
[
"Data.tail(7)",
"_____no_output_____"
]
],
[
[
"##### Using describe() function to see count, mean, std, minimum, percentiles & maximum.\n",
"_____no_output_____"
]
],
[
[
"Data.describe()",
"_____no_output_____"
]
],
[
[
"##### Using info() function get information about the data",
"_____no_output_____"
]
],
[
[
"Data.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 25 entries, 0 to 24\nData columns (total 2 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 Hours 25 non-null float64\n 1 Scores 25 non-null int64 \ndtypes: float64(1), int64(1)\nmemory usage: 528.0 bytes\n"
]
],
[
[
"## Visualizing Data.",
"_____no_output_____"
],
[
"#### Ploting box plot",
"_____no_output_____"
]
],
[
[
"plt.boxplot(Data)\nplt.show()",
"_____no_output_____"
]
],
[
[
"#### Ploting scatter plot\n",
"_____no_output_____"
]
],
[
[
"plt.xlabel('Hours',fontsize=15)\nplt.ylabel('Scores',fontsize=15)\nplt.title('Hours studied vs Score', fontsize=10)\nplt.scatter(Data.Hours,Data.Scores,color='red',marker='*')\nplt.show()",
"_____no_output_____"
]
],
[
[
"### The plots show positive linear relation between 'Hours' and 'Scores'",
"_____no_output_____"
]
],
[
[
"X = Data.iloc[:,:-1].values\nY = Data.iloc[:,1].values",
"_____no_output_____"
]
],
[
[
"### Preparing data and splitting into train and test sets.",
"_____no_output_____"
],
[
"#### We are splitting our data using 80:20 rule(Pareto principle)",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split\nX_train,X_test,Y_train,Y_test = train_test_split(X,Y,random_state = 0,test_size=0.2)",
"_____no_output_____"
],
[
"print(\"X train.shape =\", X_train.shape)\nprint(\"Y train.shape =\", Y_train.shape)\nprint(\"X test.shape =\", X_test.shape)\nprint(\"Y test.shape =\", Y_test.shape)\n",
"X train.shape = (20, 1)\nY train.shape = (20,)\nX test.shape = (5, 1)\nY test.shape = (5,)\n"
]
],
[
[
"## Training the model.",
"_____no_output_____"
]
],
[
[
"from sklearn.linear_model import LinearRegression\nlinreg=LinearRegression()",
"_____no_output_____"
]
],
[
[
"### Fitting Training data",
"_____no_output_____"
]
],
[
[
"linreg.fit(X_train,Y_train)\nprint(\"Training our algorithm is finished\")",
"Training our algorithm is finished\n"
],
[
"print(\"B0 =\",linreg.intercept_,\"\\nB1 =\",linreg.coef_)",
"B0 = 2.018160041434662 \nB1 = [9.91065648]\n"
]
],
[
[
"#### B0 = Intercept & Slope = B1",
"_____no_output_____"
],
[
"### Plotting the regression line",
"_____no_output_____"
]
],
[
[
"Y0 = linreg.intercept_ + linreg.coef_*X_train",
"_____no_output_____"
]
],
[
[
"### Plotting training data",
"_____no_output_____"
]
],
[
[
"plt.scatter(X_train,Y_train,color='red',marker='*')\nplt.plot(X_train,Y0,color='red')\nplt.xlabel(\"Hours\",fontsize=15)\nplt.ylabel(\"Scores\",fontsize=15)\nplt.title(\"Regression line(Train set)\",fontsize=10)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Test data",
"_____no_output_____"
]
],
[
[
"Y_pred=linreg.predict(X_test)##predicting the Scores for test data\nprint(Y_pred)",
"[16.88414476 33.73226078 75.357018 26.79480124 60.49103328]\n"
]
],
[
[
"### Plotting test data",
"_____no_output_____"
]
],
[
[
"plt.plot(X_test,Y_pred,color='red')\nplt.scatter(X_test,Y_test,color='red',marker='*')\nplt.xlabel(\"Hours\",fontsize=15)\nplt.ylabel(\"Scores\",fontsize=15)\nplt.title(\"Regression line(Test set)\",fontsize=10)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Comparing actual vs predicted scores",
"_____no_output_____"
]
],
[
[
"Y_test1 = list(Y_test)\nprediction=list(Y_pred)\ndf_compare = pd.DataFrame({ 'Actual':Y_test1,'Result':prediction})\ndf_compare",
"_____no_output_____"
]
],
[
[
"## ACCURACY OF THE MODEL",
"_____no_output_____"
],
[
"### Goodness of fit test",
"_____no_output_____"
]
],
[
[
"from sklearn import metrics\nmetrics.r2_score(Y_test,Y_pred)",
"_____no_output_____"
]
],
[
[
"#### Above 94% indicates that above model is a good fit",
"_____no_output_____"
],
[
"### Predicting the Error",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import mean_squared_error,mean_absolute_error\nMSE = metrics.mean_squared_error(Y_test,Y_pred)\nroot_E = np.sqrt(metrics.mean_squared_error(Y_test,Y_pred))\nAbs_E = np.sqrt(metrics.mean_squared_error(Y_test,Y_pred))\nprint(\"Mean Squared Error = \",MSE)\nprint(\"Root Mean Squared Error = \",root_E)\nprint(\"Mean Absolute Error = \",Abs_E)",
"Mean Squared Error = 21.598769307217456\nRoot Mean Squared Error = 4.647447612100373\nMean Absolute Error = 4.647447612100373\n"
]
],
[
[
"## Predicting the score for 9.25 hours",
"_____no_output_____"
]
],
[
[
"Prediction_score = linreg.predict([[9.25]])\nprint(\"predicted score for a student studying 9.25 hours :\",Prediction_score)",
"predicted score for a student studying 9.25 hours : [93.69173249]\n"
]
],
[
[
"## CONCLUSION: From the result we can see that if a student studies for 9.25 hours a day he will sercure marks in the neighbourhood of 93.69%",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
d0fb8d44efaeefc2ed57634a516f74e91f72b105 | 222,233 | ipynb | Jupyter Notebook | DLFBT/recurrent_neural_networks/text_generation_quijote.ipynb | luisferuam/luisferuam.github.io | b13bb5afe061681fbc3ad5873b60dbce96d2256b | [
"MIT"
] | 1 | 2020-10-30T20:29:46.000Z | 2020-10-30T20:29:46.000Z | DLFBT/recurrent_neural_networks/text_generation_quijote.ipynb | luisferuam/luisferuam.github.io | b13bb5afe061681fbc3ad5873b60dbce96d2256b | [
"MIT"
] | null | null | null | DLFBT/recurrent_neural_networks/text_generation_quijote.ipynb | luisferuam/luisferuam.github.io | b13bb5afe061681fbc3ad5873b60dbce96d2256b | [
"MIT"
] | null | null | null | 222,233 | 222,233 | 0.759658 | [
[
[
"## Imports",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"%tensorflow_version 2.x\nimport tensorflow as tf\nfrom tensorflow import keras",
"_____no_output_____"
],
[
"from keras.models import Sequential, Model\nfrom keras.layers import Flatten, Dense, LSTM, GRU, SimpleRNN, RepeatVector, Input\nfrom keras import backend as K\nfrom keras.utils.vis_utils import plot_model\nimport keras.regularizers\nimport keras.optimizers",
"_____no_output_____"
]
],
[
[
"## Load data",
"_____no_output_____"
]
],
[
[
"!git clone https://github.com/luisferuam/DLFBT-LAB",
"Cloning into 'DLFBT-LAB'...\nremote: Enumerating objects: 82, done.\u001b[K\nremote: Counting objects: 100% (82/82), done.\u001b[K\nremote: Compressing objects: 100% (59/59), done.\u001b[K\nremote: Total 82 (delta 43), reused 57 (delta 21), pack-reused 0\u001b[K\nUnpacking objects: 100% (82/82), done.\n"
],
[
"f = open('DLFBT-LAB/data/el_quijote.txt', 'r')\nquijote = f.read()\nf.close()\nprint(len(quijote))",
"1038397\n"
]
],
[
[
"## Input/output sequences",
"_____no_output_____"
]
],
[
[
"quijote_x = quijote[:-1]\nquijote_y = quijote[1:]",
"_____no_output_____"
]
],
[
[
"## Some utility functions",
"_____no_output_____"
]
],
[
[
"def one_hot_encoding(data):\n symbols = np.unique(data)\n \n char_to_ix = {s: i for i, s in enumerate(symbols)}\n ix_to_char = {i: s for i, s in enumerate(symbols)}\n\n data_numeric = np.zeros(data.shape)\n\n for s in symbols:\n data_numeric[data == s] = char_to_ix[s]\n\n one_hot_values = np.array(list(ix_to_char.keys()))\n data_one_hot = 1 * (data_numeric[:, :, None] == one_hot_values[None, None, :])\n\n return data_one_hot, symbols",
"_____no_output_____"
],
[
"def prepare_sequences(x, y, wlen):\n (n, dim) = x.shape\n nchunks = dim//wlen\n xseq = np.array(np.split(x, nchunks, axis=1))\n xseq = xseq.reshape((n*nchunks, wlen))\n yseq = np.array(np.split(y, nchunks, axis=1))\n yseq = yseq.reshape((n*nchunks, wlen))\n return xseq, yseq",
"_____no_output_____"
],
[
"def get_data_from_strings(data_str_x, data_str_y, wlen):\n \"\"\"\n Inputs:\n data_str_x: list of input strings\n data_str_y: list of output strings\n wlen: window length\n Returns:\n input/output data organized in batches\n \"\"\"\n # The batch size is the number of input/output strings:\n batch_size = len(data_str_x)\n \n # Clip all strings at length equal to the largest multiple of wlen that is\n # lower than all string lengths:\n minlen = len(data_str_x[0])\n for c in data_str_x:\n if len(c) < minlen:\n minlen = len(c)\n while minlen % wlen != 0:\n minlen -=1\n data_str_x = [c[:minlen] for c in data_str_x]\n data_str_y = [c[:minlen] for c in data_str_y]\n \n # Transform strings to numpy array:\n x = np.array([[c for c in m] for m in data_str_x])\n y = np.array([[c for c in m] for m in data_str_y])\n \n # Divide into batches:\n xs, ys = prepare_sequences(x, y, wlen)\n \n # Get one-hot encoding:\n xs_one_hot, xs_symbols = one_hot_encoding(xs)\n ys_one_hot, ys_symbols = one_hot_encoding(ys)\n\n # Get sparse encoding:\n xs_sparse = np.argmax(xs_one_hot, axis=2)\n ys_sparse = np.argmax(ys_one_hot, axis=2)\n\n # Return: \n return xs_one_hot, ys_one_hot, xs_sparse, ys_sparse, xs_symbols, ys_symbols",
"_____no_output_____"
]
],
[
[
"## Batches for training and test",
"_____no_output_____"
]
],
[
[
"batch_size = 32\nseq_len = 50\nlongitud = len(quijote_x) // batch_size\nprint(longitud)\nprint(longitud*batch_size)",
"32449\n1038368\n"
],
[
"qx = [quijote_x[i*(batch_size+longitud):(i+1)*(batch_size+longitud)] for i in range(batch_size)]\nqy = [quijote_y[i*(batch_size+longitud):(i+1)*(batch_size+longitud)] for i in range(batch_size)]",
"_____no_output_____"
],
[
"xs_one_hot, ys_one_hot, xs_sparse, ys_sparse, xs_symbols, ys_symbols = get_data_from_strings(qx, qy, seq_len)\nchar_to_ix = {s: i for i, s in enumerate(xs_symbols)}\nix_to_char = {i: s for i, s in enumerate(ys_symbols)}",
"_____no_output_____"
],
[
"print(xs_symbols)\nprint(xs_symbols.shape)",
"['\\n' ' ' '!' '\"' \"'\" '(' ')' ',' '-' '.' '0' '1' '2' '3' '4' '5' '6' '7'\n '8' '9' ':' ';' '<' '?' 'A' 'B' 'C' 'D' 'E' 'F' 'G' 'H' 'I' 'J' 'K' 'L'\n 'M' 'N' 'O' 'P' 'Q' 'R' 'S' 'T' 'U' 'V' 'W' 'X' 'Y' 'Z' '[' ']' 'a' 'b'\n 'c' 'd' 'e' 'f' 'g' 'h' 'i' 'j' 'l' 'm' 'n' 'o' 'p' 'q' 'r' 's' 't' 'u'\n 'v' 'x' 'y' 'z' '¡' '«' '»' '¿' '́' '̃' '̈' '–' '‘' '’' '“' '”']\n(88,)\n"
],
[
"print(ys_symbols)\nprint(ys_symbols.shape)",
"['\\n' ' ' '!' '\"' \"'\" '(' ')' ',' '-' '.' '0' '1' '2' '3' '4' '5' '6' '7'\n '8' '9' ':' ';' '<' '?' 'A' 'B' 'C' 'D' 'E' 'F' 'G' 'H' 'I' 'J' 'K' 'L'\n 'M' 'N' 'O' 'P' 'Q' 'R' 'S' 'T' 'U' 'V' 'W' 'X' 'Y' 'Z' '[' ']' 'a' 'b'\n 'c' 'd' 'e' 'f' 'g' 'h' 'i' 'j' 'l' 'm' 'n' 'o' 'p' 'q' 'r' 's' 't' 'u'\n 'v' 'x' 'y' 'z' '¡' '«' '»' '¿' '́' '̃' '̈' '–' '‘' '’' '“' '”']\n(88,)\n"
],
[
"xs_symbols == ys_symbols",
"_____no_output_____"
],
[
"vocab_len = xs_symbols.shape[0]\nprint(vocab_len)",
"88\n"
],
[
"num_batches = xs_one_hot.shape[0] / batch_size\nprint(xs_one_hot.shape[0])\nprint(batch_size)\nprint(num_batches)",
"20128\n32\n629.0\n"
]
],
[
[
"## Training/test partition",
"_____no_output_____"
]
],
[
[
"print(xs_one_hot.shape)\nprint(ys_one_hot.shape)\nprint(xs_sparse.shape)\nprint(ys_sparse.shape)\n\nntrain = int(num_batches*0.75)*batch_size\n\nxs_one_hot_train = xs_one_hot[:ntrain]\nys_one_hot_train = ys_one_hot[:ntrain]\nxs_sparse_train = xs_sparse[:ntrain]\nys_sparse_train = ys_sparse[:ntrain]\n\nxs_one_hot_test = xs_one_hot[ntrain:]\nys_one_hot_test = ys_one_hot[ntrain:]\nxs_sparse_test = xs_sparse[ntrain:]\nys_sparse_test = ys_sparse[ntrain:]\n\nprint(xs_one_hot_train.shape)\nprint(xs_one_hot_test.shape)",
"(20128, 50, 88)\n(20128, 50, 88)\n(20128, 50)\n(20128, 50)\n(15072, 50, 88)\n(5056, 50, 88)\n"
]
],
[
[
"## Function to evaluate the model on test data",
"_____no_output_____"
]
],
[
[
"def evaluate_network(model, x, y, batch_size):\n mean_loss = []\n mean_acc = []\n\n for i in range(0, x.shape[0], batch_size):\n batch_data_x = x[i:i+batch_size, :, :]\n batch_data_y = y[i:i+batch_size, :, :]\n loss, acc = model.test_on_batch(batch_data_x, batch_data_y)\n mean_loss.append(loss)\n mean_acc.append(acc)\n\n return np.array(mean_loss).mean(), np.array(mean_acc).mean()",
"_____no_output_____"
]
],
[
[
"## Function that copies the weigths from ``source_model`` to ``dest_model``",
"_____no_output_____"
]
],
[
[
"def copia_pesos(source_model, dest_model):\n for source_layer, dest_layer in zip(source_model.layers, dest_model.layers):\n dest_layer.set_weights(source_layer.get_weights())",
"_____no_output_____"
]
],
[
[
"## Function that samples probabilities from model",
"_____no_output_____"
]
],
[
[
"def categorical(p):\n return (p.cumsum(-1) >= np.random.uniform(size=p.shape[:-1])[..., None]).argmax(-1)",
"_____no_output_____"
]
],
[
[
"## Function that generates text",
"_____no_output_____"
]
],
[
[
"def genera_texto(first_char, num_chars):\n texto = \"\" + first_char\n\n next_char = first_char\n next_one_hot = np.zeros(vocab_len)\n next_one_hot[char_to_ix[next_char]] = 1.\n next_one_hot = next_one_hot[None, None, :]\n\n for i in range(num_chars):\n probs = model2.predict_on_batch(next_one_hot)\n next_ix = categorical(probs.ravel())\n next_char = ix_to_char[next_ix]\n next_one_hot = np.zeros(vocab_len)\n next_one_hot[char_to_ix[next_char]] = 1.\n next_one_hot = next_one_hot[None, None, :]\n texto += next_char\n\n return texto",
"_____no_output_____"
]
],
[
[
"## Network definition",
"_____no_output_____"
]
],
[
[
"K.clear_session()\n\nnunits = 200\n\nmodel1 = Sequential()\n#model1.add(SimpleRNN(nunits, batch_input_shape=(batch_size, seq_len, vocab_len), \n# return_sequences=True, stateful=True, unroll=True))\nmodel1.add(LSTM(nunits, batch_input_shape=(batch_size, seq_len, vocab_len), \n return_sequences=True, stateful=True, unroll=True))\nmodel1.add(Dense(vocab_len, activation='softmax'))\n\nmodel1.summary()",
"WARNING:tensorflow:Layer lstm will not use cuDNN kernel since it doesn't meet the cuDNN kernel criteria. It will use generic GPU kernel as fallback when running on GPU\nModel: \"sequential\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nlstm (LSTM) (32, 50, 200) 231200 \n_________________________________________________________________\ndense (Dense) (32, 50, 88) 17688 \n=================================================================\nTotal params: 248,888\nTrainable params: 248,888\nNon-trainable params: 0\n_________________________________________________________________\n"
]
],
[
[
"## Network that generates text",
"_____no_output_____"
]
],
[
[
"model2 = Sequential()\n#model2.add(SimpleRNN(nunits, batch_input_shape=(1, 1, vocab_len), \n# return_sequences=True, stateful=True, unroll=True))\nmodel2.add(LSTM(nunits, batch_input_shape=(1, 1, vocab_len), \n return_sequences=True, stateful=True, unroll=True))\nmodel2.add(Dense(vocab_len, activation='softmax'))\n\nmodel2.summary()",
"WARNING:tensorflow:Layer lstm_1 will not use cuDNN kernel since it doesn't meet the cuDNN kernel criteria. It will use generic GPU kernel as fallback when running on GPU\nModel: \"sequential_1\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nlstm_1 (LSTM) (1, 1, 200) 231200 \n_________________________________________________________________\ndense_1 (Dense) (1, 1, 88) 17688 \n=================================================================\nTotal params: 248,888\nTrainable params: 248,888\nNon-trainable params: 0\n_________________________________________________________________\n"
]
],
[
[
"## Training",
"_____no_output_____"
]
],
[
[
"#learning_rate = 0.5 # Probar entre 0.05 y 5\n#clip = 0.005 # Probar entre 0.0005 y 0.05\nlearning_rate = 0.5 \nclip = 0.002 \n\n#model1.compile(loss='categorical_crossentropy', optimizer=keras.optimizers.SGD(lr=learning_rate, clipvalue=clip), metrics=['accuracy'])\nmodel1.compile(loss='categorical_crossentropy', optimizer=keras.optimizers.Adam(), metrics=['accuracy'])\n\nnum_epochs = 500 # Dejar en 100, la red tarda unos 10 minutos\n\nmodel1_loss = np.zeros(num_epochs)\nmodel1_acc = np.zeros(num_epochs)\nmodel1_loss_test = np.zeros(num_epochs)\nmodel1_acc_test = np.zeros(num_epochs)\n\nfor epoch in range(num_epochs):\n model1.reset_states()\n\n mean_tr_loss = []\n mean_tr_acc = []\n for i in range(0, xs_one_hot_train.shape[0], batch_size):\n batch_data_x = xs_one_hot_train[i:i+batch_size, :, :]\n batch_data_y = ys_one_hot_train[i:i+batch_size, :, :]\n tr_loss, tr_acc = model1.train_on_batch(batch_data_x, batch_data_y)\n mean_tr_loss.append(tr_loss)\n mean_tr_acc.append(tr_acc)\n \n model1_loss[epoch] = np.array(mean_tr_loss).mean()\n model1_acc[epoch] = np.array(mean_tr_acc).mean()\n\n model1.reset_states()\n model1_loss_test[epoch], model1_acc_test[epoch] = evaluate_network(model1, xs_one_hot_test, ys_one_hot_test, batch_size)\n\n print(\"\\rTraining epoch: %d / %d\" % (epoch+1, num_epochs), end=\"\")\n print(\", loss = %f, acc = %f\" % (model1_loss[epoch], model1_acc[epoch]), end=\"\")\n print(\", test loss = %f, test acc = %f\" % (model1_loss_test[epoch], model1_acc_test[epoch]), end=\"\")\n\n # Genero texto:\n copia_pesos(model1, model2)\n model2.reset_states()\n print(\" >>> %s\" % genera_texto('e', 200)) #, end=\"\")",
"Training epoch: 1 / 500, loss = 2.506721, acc = 0.284691, test loss = 2.121773, test acc = 0.360455 >>> eEmVQQdionbta, pnen que moszaros gasmami mpre, a so oEsr, enal quavo a ebalvén la veridé stecarer e er lue cecdo den estotada se erchon que, dediion encar domo paruel pebrellias, cána ton cha motose\nTraining epoch: 2 / 500, loss = 2.015838, acc = 0.380648, test loss = 1.955120, test acc = 0.399213 >>> eRFu3\nG)? do quenes me con astosí y bue al rugon Quierur que foy ́n s lubardá elo al punaste so zon, qua de cunotes, Santonlióe.\n¿Enguanandrsenhingo dey agradad, alguro nadi de vuesfleterato que ten\nTraining epoch: 3 / 500, loss = 1.894227, acc = 0.414333, test loss = 1.868463, test acc = 0.419976 >>> ehPudín co teneslersafuén coma nteri.\nCa si ter as cuar su un podcoz al sue vie buen mañran en ello ponorbtomo que vien dal amigo; y es ardanismo on; sile un gunira a vullava mo entor me icos, usa h\nTraining epoch: 4 / 500, loss = 1.824767, acc = 0.433595, test loss = 1.809743, test acc = 0.436598 >>> enQ¡QE’QK¡CWEVY“t\nOBCh3Bo\nY momor y que jaré, estas los bues ellurama sí cuall cosesqueenlo as que había teros que vies. Duno os que rriciento a lis pordeles, y la dejo on Lasbriero de lsermadaco nu\nTraining epoch: 5 / 500, loss = 1.765904, acc = 0.449770, test loss = 1.759465, test acc = 0.453042 >>> eNW ventertía de habirer rlciedo alquía; y no atrote las ton razó dod Quterte de do en que tre cual Anzas. -?i upaña tiemadar era entana lama, traba le comicía. Per e la mi pencida\n-rambre frecer\nTraining epoch: 6 / 500, loss = 1.721164, acc = 0.463112, test loss = 1.717289, test acc = 0.466555 >>> eMS0[xño, Toso retenso Panza de colo en sabree de Rocastro sa el pues y untan dicho. Sil que doble pordo -Vienivo que súl armós es incuda una lecho; cinza dá su dijo Duencallo. Deglá aqueto dí to\nTraining epoch: 7 / 500, loss = 1.682613, acc = 0.475549, test loss = 1.680456, test acc = 0.478339 >>> ep'ros, y cormije allos trabecia lo que abrecía de la facria; y más manad, bomo disfores tan? Y otras una que si recaba de irletie, y má cuento, pordallaban en el gabanzas Dios di o si que estiglas \nTraining epoch: 8 / 500, loss = 1.647531, acc = 0.487597, test loss = 1.646712, test acc = 0.488983 >>> e.\nDY1dí, rosygió que era quien acosórose pribur conión mos condejado, sus fuerdos mésemos, y entro que mi que parsebhalla que aquien estas de la tagurad: de gabé la marad, le vardad y el castiba\nTraining epoch: 9 / 500, loss = 1.614751, acc = 0.498629, test loss = 1.616028, test acc = 0.499941 >>> e9Dregó etambardad le moniná Lamigo; o quimoja en lo fuero, que cuallo paño que más que etas que se escopa, peramertimpo su estande por eventurado Sancho?\n–De pospálisca seguras. Escebura que ór \nTraining epoch: 10 / 500, loss = 1.583995, acc = 0.508486, test loss = 1.588478, test acc = 0.508501 >>> e\nVentarce, a ser llais in podesteciá a la secanio en él tier le había sara.\nY a él, fue todo por érifleza que Amo erl cómone ello, señor en Frinarsa por lagarcea destucertes sin ellas trmiesta \nTraining epoch: 11 / 500, loss = 1.555592, acc = 0.517353, test loss = 1.563375, test acc = 0.515989 >>> émo con tudar lo cual habar esta. Entelvandós los cueres, codo quen aharle comiento de como que ferades las vadres. Sabbiado el mismo que confujarzad coa embersimiéndo, ni fuema sus guelos en, pier:\nTraining epoch: 12 / 500, loss = 1.529171, acc = 0.525612, test loss = 1.539861, test acc = 0.523378 >>> eIndo fue resbraza venta viento le alguna más casto, almos en su vialo y a prescues, bien perdó dánte que tra dijeten de des mís. ¿Ma, decía camplíto, me qué, señora deste prinería cabis de lo\nTraining epoch: 13 / 500, loss = 1.504932, acc = 0.533308, test loss = 1.518772, test acc = 0.530004 >>> eZ], quedaba en elpandes, como y aprometer. Allirba, y desde a adia de sus pacala que aquello busce a orriba; es ahor mucha quiero, un cuar rozgra.\n, el cabillo y Lospidio, en poso solizó esticlar, lo\nTraining epoch: 14 / 500, loss = 1.482976, acc = 0.539805, test loss = 1.499873, test acc = 0.535708 >>> e se si én andos y hasta consado, que los cuazeros pasas, a Sancho, na escurbando labinar an esta escrito a Don Quijote de Don Quijote, porque había gran del nogodo; y amiga, y él votía aquellas co\nTraining epoch: 15 / 500, loss = 1.463126, acc = 0.545571, test loss = 1.483035, test acc = 0.541021 >>> e8! hars acoyeciósnos de lo el gucimo se viento, que sí de haclas, uno bon de sera en el trida y Aciso.\n-Pues, que han deste medmo que me viendo el rio de los labras al pustos coma que so sa tá hich\nTraining epoch: 16 / 500, loss = 1.445036, acc = 0.550706, test loss = 1.467828, test acc = 0.545020 >>> efrezo a de blanta, que fue el libre. Perdó Sancho -rentondio de la las paracibles gantó en de muerto, Sancho, si el no me cuando le puda a su vina del valo, a la campo que le rupiedo parte en todmer\nTraining epoch: 17 / 500, loss = 1.428338, acc = 0.555411, test loss = 1.454525, test acc = 0.549015 >>> enA principién que sin malegeca aderación de mora de vuestros recoger que las muchas, como has dicienro a Orbar, y dije:\n-Si defención busco eció para el rey de apolaros, y que sola entre de lo jam\nTraining epoch: 18 / 500, loss = 1.413093, acc = 0.559648, test loss = 1.442197, test acc = 0.552670 >>> e–soro que en salargo a la mano que debe ignotís que mi esconzavos como la verdad de su escrdera más pesadas hayeras yos dosevican quedaró aca que sobre vuestra mercud la que vio un podó se dabar l\nTraining epoch: 19 / 500, loss = 1.399160, acc = 0.563428, test loss = 1.430948, test acc = 0.556123 >>> ergo que el yora con Dusplane. A sá, si ella que tieren reciodar en su entino, hijos que estudió en un tiegro, porque redigiento y más breza caballero quitar cameno la Cardenia de todo boraido canta\nTraining epoch: 20 / 500, loss = 1.386051, acc = 0.567120, test loss = 1.420809, test acc = 0.558948 >>> eme desficio como el consoncia lizargó puecto que de tudros. Diciér se aquello y esto, me había dite roblía de lo que vuestras mordades desdevina y tú genció:\n-Na quiere con sumetindo de la renta\nTraining epoch: 21 / 500, loss = 1.373791, acc = 0.570496, test loss = 1.411425, test acc = 0.561915 >>> endia de Leon y con mis desujase con os que la ni cupo dicia del que destivo, y desdir llamar con un cristiano, y el rompla más liciuno e aquellos vuestra más ahorada; con quieron hon libre derecho r\nTraining epoch: 22 / 500, loss = 1.362336, acc = 0.573692, test loss = 1.403080, test acc = 0.564217 >>> e, murando en asto conciciándo el cual de buscarme y ambró y bosoro de la cabeza que dice la servario castivo.\nPardecimo, con espadrilla; ¿no mucha bien, preguntaba, y vo en sapiría mu conociminó d\nTraining epoch: 23 / 500, loss = 1.353506, acc = 0.576077, test loss = 1.395023, test acc = 0.566503 >>> es yo Donitento que de quien todo el cuerrida, y dijo:\n-Taldeceme que le me duena la que han muchado traido su efendia, prosiguión de del milos, y volvió a mi defecho, el cielo que parece licomeronto\nTraining epoch: 24 / 500, loss = 1.342248, acc = 0.579479, test loss = 1.388205, test acc = 0.568916 >>> ey, vintos, moricante pra qué avesir le dis líancia:\n-¡Así un servido e ijando a mi llevarme. Que él que vienen que las mandea y poísoso no me para que tiempo que mus bien curan que, alte Sancho, \nTraining epoch: 25 / 500, loss = 1.332776, acc = 0.582375, test loss = 1.381360, test acc = 0.570973 >>> e2? Asulqués\ntodado a su bordela ruspor sin trablidad sollaza lo grado hasta contañadas de la instumbría, que soy santró en la resolino, y vaviesen la vida arrquesto del que darle, ni o la veca res\nTraining epoch: 26 / 500, loss = 1.323997, acc = 0.585049, test loss = 1.375075, test acc = 0.572880 >>> eno, desparaz de los pirtieros y consojos.\nSujemo, y concorder como carto por seguir tu creedis detas provechos, que a Rocinante del mundo, y le ojo. Castigo el finso, y por esto lo cual se puedo ni mu\nTraining epoch: 27 / 500, loss = 1.315519, acc = 0.587589, test loss = 1.369339, test acc = 0.574608 >>> enmos días las estañas con claridos visos sicárneses con las intenisias acabarrezas los mejores que oyemplían andar hacer un lomor ciminarse la brazo vuestra agrotara; porque me le estaba. Illo si \nTraining epoch: 28 / 500, loss = 1.307642, acc = 0.589800, test loss = 1.364516, test acc = 0.576329 >>> e0, y lo fieno para táns que en el ciella?\n-Sagantase, pero en la grandía de entromesto, y con echormos de las racos, que diciplifar, pues, y no te estaba con él corte, siendo serar un asco Sancho P\nTraining epoch: 29 / 500, loss = 1.300605, acc = 0.591818, test loss = 1.359980, test acc = 0.577453 >>> érate, si cualpa, Sancho, españo, te diciese, se le ha menesará e encunto, donge un hombrían con el dombrala el demida? ¿Qué bado durado manera que le acualdo que era fuerza, sin porque nos guyado\nTraining epoch: 30 / 500, loss = 1.293227, acc = 0.593974, test loss = 1.355531, test acc = 0.578873 >>> e. Llád jor el amar de sobrabajo de la vió, que el como ella señora venida, que sin disparmera y que puestas, apartados estaba, si de darle que desde allí no quedo yo araía, y todo el cuad el sio \nTraining epoch: 31 / 500, loss = 1.286293, acc = 0.596099, test loss = 1.351762, test acc = 0.580336 >>> es, y la dijeras y dueños, arespondísima a la caballeriso, ni a los disiglos como la prudenta de no merondos que fue quiero que Camila a la jauza, como el claro, y que yo no era él sino que eramband\nTraining epoch: 32 / 500, loss = 1.279876, acc = 0.597894, test loss = 1.347706, test acc = 0.581586 >>> enor al esa láis de labrazo escuderio tane volviendo a provecho que su señora erla an al famoso y seleo el hacer serverme conocido en se hallará que con tu volvar a hacerle por iscorzalos de otras c\nTraining epoch: 33 / 500, loss = 1.273696, acc = 0.599810, test loss = 1.344915, test acc = 0.582318 >>> eso que las hablado muchos los sí castillo, hicieron. Advierto el camo le hace con todo esto hombre inventar otra la mortanda, quedaros, sin cumpler que si fuera asimero, libir caballo de Gismición; \nTraining epoch: 34 / 500, loss = 1.267876, acc = 0.601529, test loss = 1.341524, test acc = 0.583248 >>> en supeí muerten.\nY vuestro como todamente no hacer fue. Respondió Sancho–; plano espondió don Quijote-; porque un siquiza, por otras flajas de su teniré volver primero el gujero, y la mandana como\nTraining epoch: 35 / 500, loss = 1.262243, acc = 0.603102, test loss = 1.338454, test acc = 0.584153 >>> ey.\nEy te digo y desesporado y por ahora sus cuales de osorrar en su viaje. Dígolo, el curlo; que en comer y haral en la golpezar el cautiva el Carde, le dijo:\nSacco, de la manera:\n-Eso -dijo esto don\nTraining epoch: 36 / 500, loss = 1.256802, acc = 0.604605, test loss = 1.335575, test acc = 0.585024 >>> entoros en buen grande amisto tan prosiosino, y Don Quijote por ver la obra y destraja de su aligereza y si hisperada, nacín desto habida quita soerte de un natigno tan acobraro en manera corre llamad\nTraining epoch: 37 / 500, loss = 1.251612, acc = 0.605986, test loss = 1.333070, test acc = 0.585550 >>> é, que engañarmiman desdudo día, y estos decir. El que deseaba. Hastarmas de lo que se habían dado todas allevanará el ocudarre que si mal contratuso de bien que me poner en uno sino era hecho, y \nTraining epoch: 38 / 500, loss = 1.246679, acc = 0.607459, test loss = 1.330841, test acc = 0.586294 >>> e que había mescuderse, por aquella que sobo al más que a servir el almo, y que le ha pricestión que os aquello que había bien darábalos respandiólos sobre la pasada y cabellero y ir el pucio de \nTraining epoch: 39 / 500, loss = 1.241784, acc = 0.608892, test loss = 1.328933, test acc = 0.586657 >>> eraha, ni alguna grande, siría acabar canalle, soy apuntanados; que daba que menester cosa que deí te vino alguno. Por qué procurar he sido que poderse que pueden un jatá (cómo viesa tú que ya no\nTraining epoch: 40 / 500, loss = 1.237116, acc = 0.610170, test loss = 1.327029, test acc = 0.587322 >>> en! Brencondio y considos. Díos determe que quejas de mi carro, y él la mala deseaba se vieran.\n-Así no te ha manera: Sancho Panza, que nos tenían buenos a que si poder en la mano, imporetio su viv\nTraining epoch: 41 / 500, loss = 1.232728, acc = 0.611330, test loss = 1.326062, test acc = 0.587567 >>> emo:, handa. Y esclantasen en las cris̃as partes, y para mótrallo para manera que aquella que al berier. Y gola a vistador y con mercedes, quiero ancho donde estaba y de poner en un ristro y sonígaci\nTraining epoch: 42 / 500, loss = 1.228412, acc = 0.612739, test loss = 1.324084, test acc = 0.588564 >>> ez'clas, cundas feneas. Y si vorve, a quien quién la pesioría entre eso que a Dios se a cabo desalguesto arraba y dada congocionos, y la propega la despasión de su castillo y mi facilla de caballo e\nTraining epoch: 43 / 500, loss = 1.224216, acc = 0.613876, test loss = 1.323120, test acc = 0.588580 >>> eros. Y ya lo que jamás por que jamás: dios esto; si ello el laco, se llevó que no se agudraran en ti aus de la antes donde dupa hallante, lo de topar ni oíte que se te, con los letios; y subiese s\nTraining epoch: 44 / 500, loss = 1.220190, acc = 0.615004, test loss = 1.322422, test acc = 0.588746 >>> entro. Y es rostrón y tiene de don Felino, dijo que esto requieran. Sí puesto que yo dejó estajas en cuales modos; Círquestad rescoticusose y con tener encinfario hacer ruido, que, como no tomásel\nTraining epoch: 45 / 500, loss = 1.216351, acc = 0.616010, test loss = 1.321739, test acc = 0.588805 >>> eñor, hambiese el estar mi doscuado caletención de cuántas ordeñas de todos deshechos que no podrá fatar por medosperana.\n-Grespondió Sancho-, porque, en esto, marido tas notrados. Mas lamos la t\nTraining epoch: 46 / 500, loss = 1.212678, acc = 0.616957, test loss = 1.320279, test acc = 0.589521 >>> e todos lo orde y el casi de la castallas, y que piense un le hombres que finalos esos sobresastras por el blenco bueño que él ha de vensarme, valerosa lo desdeda estado era en conocir y forza y veni\nTraining epoch: 47 / 500, loss = 1.209057, acc = 0.617972, test loss = 1.319665, test acc = 0.589478 >>> én y todo esquíase a Leandra se me cuando en tierreza son entrebras. Yo -dijo mi modo vuestras salidas encantas acrecidad es más extraña de sis antiras,\npara habrá yo, acombandase, por nada y en s\nTraining epoch: 48 / 500, loss = 1.205471, acc = 0.619140, test loss = 1.318671, test acc = 0.589838 >>> e todo guerra. La cristiano, quedó juntó que se aunque ya es voz adorar que deseaba los mismo, que Don Quijote de don Fernando, y anse moviera don Quijote, que los dan el difitulcante eran las vospes\nTraining epoch: 49 / 500, loss = 1.202110, acc = 0.620058, test loss = 1.318864, test acc = 0.589775 >>> esor esta, confuso de parecireía antes sacer más dandos a Don Quijote, y arzaban. Como consarte a caballo, rospón con aquello consejo hará coto, sino como. Tóloso que su ayello, y traeles, como es\nTraining epoch: 50 / 500, loss = 1.198821, acc = 0.620874, test loss = 1.318061, test acc = 0.589873 >>> eN, Andrema cantelo, o la bendader de los que consonció toda encauner estarme temoría de la alaba, descuido, y sea que me desalarza, sin quitár del tresposo misma y las colas. El que más el que es \nTraining epoch: 51 / 500, loss = 1.195679, acc = 0.621696, test loss = 1.317988, test acc = 0.589964 >>> erced, adminácio, y allí camino al descobrado, y molas el abenso, compañía; y sino tanto los osofias no parece el buen sido con novar de por enimitas que era la que aquí se vios, que no vasos al f\nTraining epoch: 52 / 500, loss = 1.192538, acc = 0.622651, test loss = 1.317685, test acc = 0.590091 >>> e] todo, no donde nuevas conginenes. Retarmo, el tarbulo visto paraba a su caballo, y que, como haya nudes.\nSé que iba, no han en la dada biene cuenta. Falva en voz deque le vaz canía de su parecer q\nTraining epoch: 53 / 500, loss = 1.189678, acc = 0.623276, test loss = 1.318163, test acc = 0.589873 >>> ex habéis dejar a nuestra salera convidas, y tuve llanto y pierres.\nPedígome Don Quijote, que fue el franaban. La verdad; y en ella me tienen, señor. Y en aquel castillo, a los libres, sino por veng\nTraining epoch: 54 / 500, loss = 1.186605, acc = 0.624165, test loss = 1.317306, test acc = 0.590095 >>> encardates, como ya se aúa. Ella y billevo en la memoria que hago, con esta más a las tantas en ellas luegos, sin determiraban; y vuestra merced a la otra mayores de vuestros muy bien; y ació Don Qu\nTraining epoch: 55 / 500, loss = 1.183791, acc = 0.624898, test loss = 1.317510, test acc = 0.590249 >>> ercados, y aquelea dueña, y para que aquel suelo el sundo. Amoso y algunas muridadas y simples que fe desma sino porque me llegó a llevar tanto del Cablloró Rocinante, cuando quiero alguna manera: ¿\nTraining epoch: 56 / 500, loss = 1.180936, acc = 0.625870, test loss = 1.316927, test acc = 0.590368 >>> etimarzas estas mujerses, que ellos, a desti matado, gobía don Quijote eran todas nuestros oídos desta manera: te dojo, y esto en sacarle a los dos labios, y no he mano es que jumas obras, y no dijo:\nTraining epoch: 57 / 500, loss = 1.178357, acc = 0.626599, test loss = 1.318436, test acc = 0.590170 >>> en la guerra, y más a pres, se tenga que cuando le vio en se hulviese; que me llegasen escriberos y aúases; vilando con el caso, dando los voces se preguntallos y pensamientos, que en si no según ve\nTraining epoch: 58 / 500, loss = 1.175923, acc = 0.627203, test loss = 1.317511, test acc = 0.590510 >>> eros, castido, y muestra musla ni\npapar de la entrarse por miladas, y echado respetas todas, respondí: porque él se respondebía cierto por el pecho; Morondel, a circuras, arguisto atrevenentes; y di\nTraining epoch: 59 / 500, loss = 1.173334, acc = 0.627956, test loss = 1.317843, test acc = 0.590502 >>> é», antigo con entigar, dondió el arribal tan desustria; y miencia, no tomáca que, por todo el añor, señor historias que a Sancho ni cuándo las manos; pero quien les vivión pesatulezca! ¡Mandóm\nTraining epoch: 60 / 500, loss = 1.170983, acc = 0.628585, test loss = 1.317979, test acc = 0.590854 >>> ertadvos en mis pasiones que dividiantos, que a las de cabellas, aunque haste fuerzoso jamás de mi ando, y habedme tiene, durjo a su amo de ellos, y de caballerías, El ye mucho dos días así todos d\nTraining epoch: 61 / 500, loss = 1.168380, acc = 0.629413, test loss = 1.319070, test acc = 0.590740 >>> eraza, y creyento Suscicea? Era que caer? ¡Verecúne. Mucha que, lechoso es ponerse que puna menos arremisterís,\nhermanos:\n-¿Ház, tallo oy manda, apete a Sancho que descabido que después de traje mo\nTraining epoch: 62 / 500, loss = 1.166148, acc = 0.630062, test loss = 1.321799, test acc = 0.590316 >>> encardanzas, y ella tú más pasaba y como con las romanes, acabos a don Fernando, y supo, le atornaron los conasumos, que jamás le dijeron por solicitares de todo lo que deseos que livio y que aquí \nTraining epoch: 63 / 500, loss = 1.163962, acc = 0.630675, test loss = 1.323224, test acc = 0.590024 >>> entros; que yo quiero hecho en aquella volviosa anda a vuestra nilder mi rompale a acertar la buena sin vos me descubrieron sobresalte, entramba y tando esparar, que anda de sus: se lugaba y pelanza ej\nTraining epoch: 64 / 500, loss = 1.161671, acc = 0.631456, test loss = 1.324035, test acc = 0.590000 >>> ercas, y pide como entoncieron tantos que vas para ella. mis importanuncia, y dérate, y arreventene. Que por puesto su acuitare, porque éste, si fuera aquello primero que recibera destas dospiñas y \nTraining epoch: 65 / 500, loss = 1.159505, acc = 0.632115, test loss = 1.325520, test acc = 0.589850 >>> erzabllezas y aventurás, porque para, las vayas de los que le allí pudo -dijo Sancho- no es tojar delo y tener que se ha de hecho; las mamanos, que habían venido romatrón y las hacienda tierra que \nTraining epoch: 66 / 500, loss = 1.157325, acc = 0.632845, test loss = 1.327078, test acc = 0.589525 >>> ema dije deselfadarse de revén, se nos acometió al justo.\n–Yo conoce. Un ponedo tan buenas partas? Mas hacia que entrarse el bien y que lo esperaban los librecuras cuando vieron padres caballeros ant\nTraining epoch: 67 / 500, loss = 1.155241, acc = 0.633551, test loss = 1.325208, test acc = 0.590107 >>> erced tida y Rendida.»\nEs mirar estar malaficio cuando las del goballas que Dios confiamos\ntratando aventuras y por estando en losmirásemos rogando en que las más gastas de pie, ni don Quijote enecig\nTraining epoch: 68 / 500, loss = 1.153026, acc = 0.634213, test loss = 1.327104, test acc = 0.589941 >>> erccidencio!!\nEcha, ellas hay masas atras y entre allí a la plática, y porque acallándose la que ya compasa un andante de la mano a sastillos y él yo lasto yo que le escuderos tratajos, tratas en s\nTraining epoch: 69 / 500, loss = 1.151143, acc = 0.634789, test loss = 1.325982, test acc = 0.590364 >>> encrodora desta lácita, por ser partupis, y que he in tu cuerno, y que vídote: hiza famo a la causa, y ausencia, sin que fueras las nabales de hacerlo, espuelas, consojo de don Luis, esquía llegaron\nTraining epoch: 70 / 500, loss = 1.149266, acc = 0.635360, test loss = 1.325921, test acc = 0.590380 >>> erced dice saledas, las tres digno yelmo tan de andana sobre la gara la guibler rica, y en poseria libertad: ¿Dié, el cual se vinieron, hablaba el mal izquierdo, y la leala destas sino palabra y sin q\nTraining epoch: 71 / 500, loss = 1.147341, acc = 0.636095, test loss = 1.325273, test acc = 0.590771 >>> eros,\ncurdeaba ser hermosa irlas a llorar el grande alcarza a la entreción que le prino de su lengua y la muerte que se llevó a Luscinda de la verdad, que movedo tranidos la démbrado conocida junta \nTraining epoch: 72 / 500, loss = 1.145576, acc = 0.636610, test loss = 1.325324, test acc = 0.590688 >>> ei tro dupar un Besamonas del mundo. Con este lenguadia, y con tanta sor), tray, señor ahordabo, y la habéis pruega por su casa.\nEste mundada, en tuviera hablar una medual lugar cieron vuestras\nmucha\nTraining epoch: 73 / 500, loss = 1.143683, acc = 0.637144, test loss = 1.323743, test acc = 0.591167 >>> erced dice, Dulcinea, con mi deligarle guardarse con tanto andado, digo por dicho en la señora buena. Selía bien que divía del hábito que infarmetiero en pasamiento de su compreras de Erpiña y la \nTraining epoch: 74 / 500, loss = 1.141770, acc = 0.637732, test loss = 1.324291, test acc = 0.591226 >>> erced y Ccida, condiste.\", no di volvería no me pareció que en este boceno; mas no ya no quisiere, descubra, puer; y vuestras, será –respondió Sancho-; suela, para que fiendo que ninguno; peto por \nTraining epoch: 75 / 500, loss = 1.140039, acc = 0.638219, test loss = 1.322172, test acc = 0.592061 >>> es habís bendecados como con no disera un hijosumo, y porque tarba las prondes, lléligos, por lo vuestra merced la ribal? Paseando a causa friso que en el parte de novecitar los layosos parecerías a\nTraining epoch: 76 / 500, loss = 1.138195, acc = 0.638619, test loss = 1.322846, test acc = 0.591788 >>> erno que sabo, palicomente, que los palecerían, y así a todos estas obras de volver al diciendo: Pues sabed así molió con el rescate a Camilanino ir lo que dijo que el princesa y aquellos que receb\nTraining epoch: 77 / 500, loss = 1.136437, acc = 0.639212, test loss = 1.320975, test acc = 0.592310 >>> eros, desde Hires: Gineso a su indinio de más muy discreto, le rupían. Si ya la salió de alguna, y de su brazo, le escudero, es ahemase delante el galme en mí mi amigo subió los hombros, pues, que\nTraining epoch: 78 / 500, loss = 1.134562, acc = 0.639638, test loss = 1.322404, test acc = 0.592369 >>> es, cos en las ircansos. Desde propribidadiemas rastos, quedó a un buen estaba; allí se intención, ye acertó que con veras lo mejor en cosa. Palmando por oía. Con todo le diere quiera yo que tiene\nTraining epoch: 79 / 500, loss = 1.132875, acc = 0.640065, test loss = 1.320702, test acc = 0.592943 >>> eyo, prestecen ocho de don Fernando, que con esto de bien Soletarte de otorrar por tierrata o a mi mora, cada uno una porque Rocinante con un apososa y deshonase su consejaba, por mozo, sino donacoín \nTraining epoch: 80 / 500, loss = 1.131187, acc = 0.640691, test loss = 1.322579, test acc = 0.592563 >>> eros, credes y sinera y era de romances, y que vieron las señasas, y suele vida, por fuerza; porque las provechas los de las calles del cabra, vibe, por denestrimorante, y aquella mesma pasarsa vuestr\nTraining epoch: 81 / 500, loss = 1.129607, acc = 0.641166, test loss = 1.321236, test acc = 0.592658 >>> erced dice, pudidía cuandod, que dudas, llevar mitad a los extrañeses que yo yo fuese.\nCapítulo 25: De laya y pocos días hablador! En efeto. Por esas oídos mujeros de arrió, de manera, y estárme\nTraining epoch: 82 / 500, loss = 1.128282, acc = 0.641635, test loss = 1.322667, test acc = 0.592722 >>> e que sos yo (que es es cabos, por lígrino que dio mi temor que matoria pocos días. Anselmanio, y por cincusto al caso hacia blanco. Cal que la honra por donde el que te llamamos en tanto; pero donde\nTraining epoch: 83 / 500, loss = 1.126606, acc = 0.641951, test loss = 1.322410, test acc = 0.592801 >>> enos, con breso sofriros, Don Quijote, que bien se quiso quistene, merecirse, las manos, si ha se tan bille parte arecho, y se los las mejores y pordes las ambresas, desalga tanto creó a su gusto y av\nTraining epoch: 84 / 500, loss = 1.125248, acc = 0.642458, test loss = 1.323294, test acc = 0.592547 >>> efced tadde futes janadias pareceriones a quien haces comuntaron de cada uno aquí a mi caballero de convesio. Pero daba aquella por malado, porque aún fue tu ayeña, era aquí a algunos se pierras pe\nTraining epoch: 85 / 500, loss = 1.124035, acc = 0.642726, test loss = 1.324498, test acc = 0.592180 >>> e tres oscudar sidos y debengarlos que le caminadora y aprevenés acertado en caballero para ni que preguntaré donde no, vio que las provesencio lo que hacen Extremadura. Y aquel concetro; aunque no s\nTraining epoch: 86 / 500, loss = 1.123253, acc = 0.642780, test loss = 1.326539, test acc = 0.591464 >>> erced dice del Cagnia.\nY cuando hay por Dulcime acudiera gracias de tramando donde supiese muy ascarició y tratado. Todo es servo ver que el título recibió entrán robado, como tienen venir a conoce\nTraining epoch: 87 / 500, loss = 1.122095, acc = 0.643133, test loss = 1.328181, test acc = 0.591214 >>> ero,, nonje la marre en tanto de sin desabalcanas dejó casi que sus descalzas. Piro a Tustrado. Estas, diciendo que no se ven hacer, con otras cosas por todas los daños le sintan llegara que estuvo l\nTraining epoch: 88 / 500, loss = 1.121978, acc = 0.643047, test loss = 1.328428, test acc = 0.591321 >>> erced tiste ha de comuticor mí tradababl me torcer pareceniendo la fría su amo las lamentas que enterá con montaña, toda en lo que lo mucha presto, porque, con lo que lleváse tan bien se hijaceron\nTraining epoch: 89 / 500, loss = 1.121310, acc = 0.643154, test loss = 1.327654, test acc = 0.591824 >>> erced dice de Luscinda, que me acuerdo a cientes razones que estado Rocinante pesa todomengo a Dios y ver se otra me sonetar decir que no se no se lo mano estaban pasardos de estar en aquel desdicha de\nTraining epoch: 90 / 500, loss = 1.119944, acc = 0.643601, test loss = 1.328320, test acc = 0.592488 >>> erced, Candaś, y suste contento, y que, como entre los arrimas: y si yo no era abradoso de acabar la cabo a la famata a serlos? Pues serás sentia, perdón; mas vos respondes afregaba el bien refaba d\nTraining epoch: 91 / 500, loss = 1.117955, acc = 0.644282, test loss = 1.329359, test acc = 0.592848 >>> encedo, yo resquiro, y el suelo, espetir le acomdasen a castigaron difererles (comos dijo que le dijo:\n-Si Luscinda sino contra el marqué gente estima entendimiento, y, como volveré -respondió Sanch\nTraining epoch: 92 / 500, loss = 1.115412, acc = 0.645037, test loss = 1.331239, test acc = 0.592484 >>> eros inspanas la mujer, como presto hizo da rerado.\nPrasentió tú se dos hones que dicen cuán milas de era de moyorias, y emberzados días encendido y fuerte a sus brazos asiguirle de luegos por sama\nTraining epoch: 93 / 500, loss = 1.113353, acc = 0.645711, test loss = 1.332150, test acc = 0.592583 >>> eros, clastar, soy amistia, a\nquiero viscan a lobarme de la infantaje, el reposo y moros cualquies que a ellas a Rocinante, más de todos, como por enamorado, sino quien se sacaren a otro misma los a p\nTraining epoch: 94 / 500, loss = 1.111254, acc = 0.646428, test loss = 1.334755, test acc = 0.592275 >>> encarcares y prómadas sidas se dijo Sancho Panza bacía mos Andar le dio a sus hazaños sin tiempo, este puna, por el dar este pún señor de Dios que se le vuestro camino que los mostrestarses en que\nTraining epoch: 95 / 500, loss = 1.109892, acc = 0.646953, test loss = 1.335828, test acc = 0.592195 >>> er\ncapdios, y la hallalla, lo menos; y, saló Lotario con las homas sin sé nueva a servir con el paper, alcanzas que me parare, describiéronse, se le avengalla lugar y está provecharles verdad la ve\nTraining epoch: 96 / 500, loss = 1.108505, acc = 0.647304, test loss = 1.338193, test acc = 0.591563 >>> esplo, vin de sentar este manoria, que tengo visto, acabar y mi verar menesterosos que te dijes, y tan mal título aquí asmar gober que las casas,\nnués, que la oyesto que si tan inhescio buen acordar\nTraining epoch: 97 / 500, loss = 1.107142, acc = 0.647801, test loss = 1.339489, test acc = 0.591191 >>> eros; Los proso se descubiertas cosa, y que no había yo que cerrado con hablar ir la cual quiera ser que mi syeres determinacerme contentad que le mandaba. Sabre de hierro toda estos cuadrillero y ape\nTraining epoch: 98 / 500, loss = 1.105243, acc = 0.648353, test loss = 1.341177, test acc = 0.591040 >>> e? Dordedivalmo y que tengo, y, en sengra y una a su caso, que ahora se pública de sus seños más queberne. Pues ¿qué bien podré yo y admirayo le vío, hermoso de agua altos de ir con una parte de \nTraining epoch: 99 / 500, loss = 1.103738, acc = 0.648857, test loss = 1.344268, test acc = 0.590415 >>> e qutén basí y llena. Despantar con él que después de Gustal y de los caminables le rospís, lugar con buen hace en tiempo se pide todas el gran [na]rcia de aquella fuerza; pero no tenga a don Fern\nTraining epoch: 100 / 500, loss = 1.102634, acc = 0.649204, test loss = 1.345270, test acc = 0.590127 >>> e otro, o sallezo, que el figo y hacer por mala ni este desustroficio la desenviadión de una pena. Mas yo quedándome vuestra merced decía y puesto que debe de pasar delos y le dará se vos harer sin\nTraining epoch: 101 / 500, loss = 1.101416, acc = 0.649563, test loss = 1.345450, test acc = 0.590364 >>> erced del presteza el ellos, de verse y me dijo a lo que infinitos dos tales convenía Solvias, que me allí le toca se reina de adorligros, como vio que te albarfa fue el de Gorita en que frescazos; q\nTraining epoch: 102 / 500, loss = 1.100220, acc = 0.649936, test loss = 1.348299, test acc = 0.589798 >>> erced. Ecadjaciadro clevo, y el osturo; y debe de ser a la virtud de Sanchora.\n-Es to, aquel dújole, tan mocedo? Y como el que hizo vuestra merced hijo mucho gusto la buena Belición, y como el de la \nTraining epoch: 103 / 500, loss = 1.099709, acc = 0.649965, test loss = 1.347816, test acc = 0.590249 >>> erced dice del enembrato sin amigo por ahora se le haría si fueraba admirabáis, menester en todo lo merces y encaminares palabra a su ganado; y es menester, que un mocedores y segadas nos y paracerna\nTraining epoch: 104 / 500, loss = 1.098620, acc = 0.650324, test loss = 1.351031, test acc = 0.589691 >>> es jos esto se abarea de Tiquie, que acharás. Pero trataba, porque si alguna principal en un carta, poegue que aunque en verdad a quien tu y mucha gana maño de una grave, y, por no aquí, vieron los \nTraining epoch: 105 / 500, loss = 1.097685, acc = 0.650755, test loss = 1.353361, test acc = 0.589320 >>> e tardero, con esta señora, azundamente se apeóso tan intención que les faldó con la mano valeese y entrada de gence era tanta, dejarle me viéndosel la que quien tan levantó don Fernando, cuando \nTraining epoch: 106 / 500, loss = 1.096606, acc = 0.650791, test loss = 1.355951, test acc = 0.588418 >>> eros tres ypasa su hermanios. Sústro casa, porque no comer los galeotabanseme, e embacas bellezas, principan\nte la contaña. Reto la lanza asimanas, y se así le dijo:\n-Con todo selo correse criaturos\nTraining epoch: 107 / 500, loss = 1.095999, acc = 0.650825, test loss = 1.356821, test acc = 0.588311 >>> eros, creyendo que los dijo a confuelme y sino con el guirota clario a mí y que apareció te servía una doncella, ni en las manesa; que tambíanos cri no me os casa el de momerca, y no fue un princip\nTraining epoch: 108 / 500, loss = 1.095007, acc = 0.651460, test loss = 1.359588, test acc = 0.587441 >>> ence que Carditano que no, y en os dio corona de ver, de que la pueda mujer manos en esto, y maldete a sus esperanzas y celos; porque los trabajos donde ni o le conocía. Dios de la boca, por dolor al \nTraining epoch: 109 / 500, loss = 1.094212, acc = 0.651506, test loss = 1.358413, test acc = 0.587828 >>> eros, que don esta manera que aporrea alguna.\nO la llana; porque, y la concerta de don Quijote de guares, y otras cosas del casa, y apenas como los suyar deste medio tadabanato y bromar la fe mon los a\nTraining epoch: 110 / 500, loss = 1.092685, acc = 0.652130, test loss = 1.356692, test acc = 0.587880 >>> er». Losquiso, edad toda el suporezca de encantamento, cosas movimiento, y ha señora, por ozo y menos, o condición de encantado y congido, porque gente haría muy mala Rocinante, inditito un ancado t\nTraining epoch: 111 / 500, loss = 1.092304, acc = 0.652327, test loss = 1.355680, test acc = 0.588105 >>> e prozalo, yo creído un cruelo y a dos añas espacio y dando en camino, nosote despojar en logor por escribir tan intenciosos y manasías, dijo: Pero este aconsejo puesto que ya estaba vos muvo batant\nTraining epoch: 112 / 500, loss = 1.090740, acc = 0.652826, test loss = 1.359159, test acc = 0.587255 >>> eY la mayero, hasta quien las desemborados, y he puesto a la Andar en mí allí ayuderolla de aquellas costistoces eras entramas silcas y encantados de Orisnafíso de don oro el distieta que le puso a \nTraining epoch: 113 / 500, loss = 1.089680, acc = 0.652923, test loss = 1.357047, test acc = 0.587227 >>> ego (que deses la vuelen en el que la sin mi determino: días de cuatro destrosasero y desalforjaron por la venta horas a un fin que le menos que en la cameno con ellas para a los anticios veanes que l\nTraining epoch: 114 / 500, loss = 1.089399, acc = 0.653114, test loss = 1.358897, test acc = 0.587298 >>> erca desduba, han dicho, y no será yohó ti, como si has parecida, ni creceda de su los demantas; y así yo era su nocho de amorosan; y amigos a prestandró a ver la sazón de una dañada en ha llevar\nTraining epoch: 115 / 500, loss = 1.087832, acc = 0.653554, test loss = 1.360446, test acc = 0.586808 >>> erzy, cono que en alguna señora Dulcinea, conocíse, que los del soldado pasato que se lo quieres hecho estos fiestamente para la jaula de Siero!, donde será tanto buen como la daga que aquel quemá \nTraining epoch: 116 / 500, loss = 1.086376, acc = 0.654067, test loss = 1.361052, test acc = 0.586191 >>> esos, cuade crédita de marceo, y respintié: tenéis decir, la esperanza en el rigor, pues a más de todo génemos decían y se ditarle todo su hija lloro, y desamante. Y sí, por ellas ciertos mandar\nTraining epoch: 117 / 500, loss = 1.085024, acc = 0.654512, test loss = 1.362661, test acc = 0.586009 >>> eros, creyendos don Santujo.\nProgua, como las repees, sino de ser quizá tan mal que le meñaraban. Vió algunos repues el ban jorma lerada es castigar y el bien que jumego, y lo habían sido libertad,\nTraining epoch: 118 / 500, loss = 1.084053, acc = 0.654790, test loss = 1.364578, test acc = 0.585882 >>> erced dice del cuidrinesta noche, mirar y delamento hacer lo que tenía y sea. Retió que mi padre la han prometido consigo Esal, y la nomban y tan bien mejor hicieron las das cortesas que don gustos. \nTraining epoch: 119 / 500, loss = 1.083397, acc = 0.655069, test loss = 1.365282, test acc = 0.585309 >>> e que ras resposo, paregrase a otro, de aquellos comistecía, nos tan uncantado. ¡Oh hizo de la cabeza, habiendo dicho, por ricos, dos hallarme del y pasiente que aquello en contra el gran lofenter, y \nTraining epoch: 120 / 500, loss = 1.082747, acc = 0.655029, test loss = 1.367627, test acc = 0.585190 >>> erced\necha? si ota aldena y su locura como al de Gino de encantamentocantes, como los cabellos contornos rescañejes cosa pábese y conscaritores, que no se quieres antes me saleo discreto su maneraban\nTraining epoch: 121 / 500, loss = 1.082510, acc = 0.655224, test loss = 1.370935, test acc = 0.584711 >>> eros, con sida vuestra merced risa a mí abriendo tenía lo que suele cual había seguido que mi dado.\nY divían mis peprose yación a la primera prometida guardar mi voluntad esto que todas esperanzar\nTraining epoch: 122 / 500, loss = 1.081648, acc = 0.655199, test loss = 1.373066, test acc = 0.583873 >>> e iquén sel pasó sobermita y mano, ya puella, o no. ha dicho, pues trae por punto a melinció, a todos los decían su mes, mi barbar que me ha avidenas, cuando llegaron viendo a su huere mucho; que d\nTraining epoch: 123 / 500, loss = 1.082625, acc = 0.654954, test loss = 1.372444, test acc = 0.584296 >>> erced dice dendinasiomentendo y bastante. Y! ¡Oh vuestras mal, bajeles las mujeres de romeros, y se había erespuderra, dos sidos los tampoco, mi dejó los diabanses, y que sepían los daquéndose la m\nTraining epoch: 124 / 500, loss = 1.082038, acc = 0.654996, test loss = 1.377827, test acc = 0.583089 >>> erced, llamenda, y prometio.\nCalmentando puentan), y señadas de Sancho los\namos, por nombrén y buenos dotorios que andaba recado personas paz se declarará él,, con un enterrima, no se ha que mi can\nTraining epoch: 125 / 500, loss = 1.082003, acc = 0.655127, test loss = 1.378208, test acc = 0.583125 >>> excrlasbas asndecas en sus lincipuas, que el Tobose; y así lo era nos hallaban los que me vale si mal el tenor, y con esta verdad que se lo entendísima ententes, los tas pretenerelle quiero hacer jus\nTraining epoch: 126 / 500, loss = 1.081385, acc = 0.655176, test loss = 1.381988, test acc = 0.582468 >>> eros, conmanda yo espandilles cuando Don Quijote derechos de golpes? -dijo el condesé Dorote: a Dormediva aquella fueve todo, sé que me parece ya que yo hi hecho exjeriamiento ahora lunga de tu entra\nTraining epoch: 127 / 500, loss = 1.080622, acc = 0.655230, test loss = 1.386352, test acc = 0.581195 >>> e que sabía vuestra nzcaucíno se dos de muchas rimerinos?\n–Luego Don Quijote.\nYendos desta grande coltera el de mis deseas, porque todo es mendida, siendo en esto lo herido en la compracio; y así ha\nTraining epoch: 128 / 500, loss = 1.079771, acc = 0.655751, test loss = 1.386130, test acc = 0.582144 >>> eros, creyenda trepredes, démbrosa; y en las mujeres de Ginés Que munaba doce, no. En veesta, si podía considos han leendo una señora allas. Temos saben que la emperrable en la cosa su importancia,\nTraining epoch: 129 / 500, loss = 1.078616, acc = 0.655945, test loss = 1.388916, test acc = 0.581036 >>> erzcó, Sancomdigó esl yo, enos de decir que puesto en este caballero que suele muy recomó derramar cono su barba a su suces. Mestijó tanto dispancínigo y cinco si el pie tura donde podré molicund\nTraining epoch: 130 / 500, loss = 1.079183, acc = 0.655922, test loss = 1.389895, test acc = 0.580621 >>> emos, firna a los oífuros de trostidad se la tuviese saliendo delante y Manaliente, si no, sin saber más emberono tráan a mi padre muchos insegrisijiciones que fuese, probase, apearon, bastantes con\nTraining epoch: 131 / 500, loss = 1.079104, acc = 0.655622, test loss = 1.391871, test acc = 0.581060 >>> e que sa vive: ¿qué levaman llegándole en ella) se lo preguntalmente, él Ostulvó Don Quijote o señor de los míos, honestidos fincios mejor, aguardándole alguno, yo tiene –respondió Sancho-, dic\nTraining epoch: 132 / 500, loss = 1.077730, acc = 0.656189, test loss = 1.389681, test acc = 0.581349 >>> e oy tines, porque Dorotea está otra mestiguiente toda amorosencia, si quedo uno que socos con ello iban este daño las piezas del Pasa y sílan. ¿Pues una frimo de los sentomentes con las manesas y m\nTraining epoch: 133 / 500, loss = 1.075453, acc = 0.656994, test loss = 1.391131, test acc = 0.580206 >>> eros, presplandías. Conosetado dégada echad vuestra merced; pero él es que yo la quiere dada y la Iglesia en su amo que vuega abatan dellos, mas yo hay, viendo yo que, aunque miraban dichos. La mene\nTraining epoch: 134 / 500, loss = 1.074010, acc = 0.657446, test loss = 1.390535, test acc = 0.581329 >>> eros, creyó! –Li noche, en cuando me parece a su señor, lo que el caballero andanacido, de consojo que o nosotros, que al que en ella este bien a poco principal que le vuelve;, porque decía un caso \nTraining epoch: 135 / 500, loss = 1.072715, acc = 0.658065, test loss = 1.393267, test acc = 0.580423 >>> e que sa había vosotros volvos a los tratanidos desdichado y soberana cuanto mesorian sus somendos yo las desvaltancia armada honra de su manera, dio a pesarera triste hacíace el papel, y ellos a tod\nTraining epoch: 136 / 500, loss = 1.071809, acc = 0.658294, test loss = 1.391364, test acc = 0.580771 >>> er; y endondía don Quijote dijo que truera, sin duda sin hablar vellan, y cuando tan para prometida vuestra merced se había handad tenía hablar un gran entonces bien anojo a la jaulicela, y en un an\nTraining epoch: 137 / 500, loss = 1.070492, acc = 0.658664, test loss = 1.395185, test acc = 0.580020 >>> e:\ntodos habría don Quijote y a cada uno sobre el camino que podía; que dió Dorotea, y nos entañan, que no comhes no sé qué prometía, que os versos decir yo no, fue que, persondo en la mano, y l\nTraining epoch: 138 / 500, loss = 1.070815, acc = 0.658335, test loss = 1.393596, test acc = 0.580162 >>> e que sabía hacienda con el humor de no vea Don Quijote, que este a lo que se la profetido. Fuestro atanda a mi pecador había mucho en la parnarlo, ellos no se Lotario de vuestra merced pieden que bi\nTraining epoch: 139 / 500, loss = 1.069924, acc = 0.658686, test loss = 1.391209, test acc = 0.580759 >>> erced dice yadas con salido. La concepta -respondió Cardenio-, si quién fuesen yaban sales, a cuenta que pudo cobar Sabrerís, sin segeraban, traían salidad el hiendo empeñario del marger mi escude\nTraining epoch: 140 / 500, loss = 1.069046, acc = 0.659131, test loss = 1.392929, test acc = 0.580411 >>> e, que quten confura yo a lo que pundo copoz dijo; y así, les diré que lo amigo -dijo el cura-. En resolución, mi suceder decira, y aporreados a Rocinante;\npuese no vea an estonga convenía en tierr\nTraining epoch: 141 / 500, loss = 1.070044, acc = 0.658566, test loss = 1.391492, test acc = 0.581052 >>> eros, trpuén las), dijo al venin locor prometo la luego a sus léisnes, determinó de siguiente con la Iglesia; pero no le hará la miste, dijo: Sí, quizá comen su llana doce que melían a su gusto.\nTraining epoch: 142 / 500, loss = 1.070507, acc = 0.658340, test loss = 1.388647, test acc = 0.581487 >>> erts, pregüenias; que hay yo no verían traía media, y que por esto parece la caza de céler o manda, como ya haría para mañana songa aquel barbero le viese ser de tiempo que de aquel notecer. ¿Ten\nTraining epoch: 143 / 500, loss = 1.073096, acc = 0.657205, test loss = 1.386023, test acc = 0.581804 >>> e, alegos, determinse; mas puso vas estaro otra cabla armadr, veás con Luscinda, y me daban franceriniaflentome así temila que a pesar de mi reino, el cual le harían priesa más en el casterío le p\nTraining epoch: 144 / 500, loss = 1.072631, acc = 0.657459, test loss = 1.387733, test acc = 0.581048 >>> erca, cosas desasgándola conocida, y más no sagiéndome don Quijote ha puesto que si ofro émas su princesavos que el memor, lo que en él, y sus destrueres fechos desgracias, y no hubiélame, a él \nTraining epoch: 145 / 500, loss = 1.072926, acc = 0.657075, test loss = 1.384672, test acc = 0.582915 >>> e que dijo unamente, y mazando al bri buenos santólagos, y de los arruejos su hija de no buscable, traidoros de la caballeriza fame, de aquello que todas ibllos, días de la que perdeció de quiriese.\nTraining epoch: 146 / 500, loss = 1.070672, acc = 0.658163, test loss = 1.385034, test acc = 0.582907 >>> erced dice del Conde el cuendo poneros tronudezad verá sus salió al licenciado desearn enamorados y desdichas, que si presudara yo son versos, y has de prometeros para la comparación que consentirse\nTraining epoch: 147 / 500, loss = 1.066345, acc = 0.659725, test loss = 1.387484, test acc = 0.582156 >>> e que sabía desdenistespella, dicen que, según araonarle tan indencio para presdención, vio de ver esto testivo más decicios y diese qué mucho era y en el caberte grande sentirosos cribás de su p\nTraining epoch: 148 / 500, loss = 1.063745, acc = 0.660827, test loss = 1.389332, test acc = 0.581962 >>> emqueY? Ramita de los sierros\n-¿Na pueden\nen la saldre colo -dijo Sancho-, que por ahora y a mí acortar toda la diferenza de aquel princesa DIma Mero faltaba determinado de docian que está don Quijot\nTraining epoch: 149 / 500, loss = 1.062007, acc = 0.661322, test loss = 1.392376, test acc = 0.581135 >>> ertta, creren yorez, y aventuras por ahí qué se decendicio a la alcuza, le preguntamos, como nada, que la ida -respondió, fue lo que su amo yo ses costadechase priención suelen adonde tinteró don \nTraining epoch: 150 / 500, loss = 1.061625, acc = 0.661841, test loss = 1.392292, test acc = 0.581448 >>> es, se sancías yentura.\n-Así, sabeó el otro vuestro muncuia las imasgrañasta, quien mover imaginar que el día, le\nlabazó más para el fin a media lervirse de todo duraz para acomodar, no le dije \nTraining epoch: 151 / 500, loss = 1.059194, acc = 0.662423, test loss = 1.393797, test acc = 0.580922 >>> encardañas, perecia que nunca nuestro cual viendo lo procuraba; pero el un ponfo a deque ninvenza, dividia singueso; y así, soltaron aquí al juntiamiento cuanto acreciero, ayudardero, a caballo al c\nTraining epoch: 152 / 500, loss = 1.059021, acc = 0.662568, test loss = 1.394615, test acc = 0.581104 >>> e, alla\", codo de luegando muy grande vino a sentir los heridues, los cuales no había caminó de un grande como le dejase des ajome que no mal que él los debajo del tí y los hayase, habiendo santrí\nTraining epoch: 153 / 500, loss = 1.058133, acc = 0.662732, test loss = 1.396763, test acc = 0.581068 >>> eros, creyenda por ocas, que viváieron hasta estado en tu manera el suelo de su desgracia le viquien obligada de las comedias, tan enfeandría aquí fráces y trebajas, dellas a buscar\"en en alguna ti\nTraining epoch: 154 / 500, loss = 1.058091, acc = 0.662723, test loss = 1.396037, test acc = 0.580609 >>> e que sabíos, con tú, nos lleva a su costa, y engañaba en a ti mi mora es iba Malleca, tanto con sus boca.\nY entendiendo ansillos Camila, y ha sabida en el arminia, y se mi más en mi bien y a todos\nTraining epoch: 155 / 500, loss = 1.057340, acc = 0.663036, test loss = 1.399818, test acc = 0.580447 >>> encoco-, no consenes hacer otra vez a sus santidos y acabado las asmadades, y que lo harcabando en jurar y regoce de los que llevan\n-En otezo?\nAcaba de que venga -respondió Sancho-. Cuaje vos yo de su\nTraining epoch: 156 / 500, loss = 1.058179, acc = 0.662578, test loss = 1.397121, test acc = 0.580771 >>> es? Y, apralabo en muestra merced se había dado a su escudo ingataciosa que Sancho Panza, pues, y venían otra cosa sea que contrán vuestra merced ha los días; pinen a satindad nombrado en sus conoc\nTraining epoch: 157 / 500, loss = 1.057418, acc = 0.663035, test loss = 1.401424, test acc = 0.580585 >>> e que sa dos relajas, y Cardita tornada belleza y volvió a su vencetaría que seado que otra enarotaba. Ohondos de aventurar, y como por aquella hermosura que era no ponido a palación, y concertado d\nTraining epoch: 158 / 500, loss = 1.062717, acc = 0.661020, test loss = 1.397950, test acc = 0.581634 >>> erced\necha? Poreció de la verdad de Racibio? Don Quijote no se manda, que si me decendió tosaves a los cientos; mas ellos. Mas ¿Éstero guinaria, ensello hon de buen suentanida de mi vida cosas yo, e\nTraining epoch: 159 / 500, loss = 1.060385, acc = 0.661754, test loss = 1.398274, test acc = 0.581266 >>> e prodístese -Venas -dijo Sancho-, digue le dio reine, queré si no fuera si fuera bancilla y su padre y en mi mangua de la portórare de nuevo eves, de aquí a desgraciento a brazos, que lo es menest\nTraining epoch: 160 / 500, loss = 1.058265, acc = 0.662422, test loss = 1.396720, test acc = 0.581535 >>> e locos inhosios preha haciento; y si da enferme una verdadera miras, ni su vez de que lo han de comer de ir vinia acostumbrado, y sabes, para éste la intención le dio un nosotros, si el legrados sob\nTraining epoch: 161 / 500, loss = 1.057036, acc = 0.662955, test loss = 1.399680, test acc = 0.580854 >>> e que sabió tan están mozos, y a Rocinante. ¿Qué con me puso, que por tanto sufrir el grande indinesta de San Migunto Hermanos que las gustas, que le hagan no moviera, pedían a querer del cuento, y\nTraining epoch: 162 / 500, loss = 1.056383, acc = 0.663187, test loss = 1.401527, test acc = 0.580467 >>> erced dice de Luscin\"Bías que el irse a mi padre hoy en mi padre que dices -dijo don Quijote-; que así estaba en cudo tan de la desfaceleza por las respetas así los no queme desgraciases que, sabí \nTraining epoch: 163 / 500, loss = 1.057486, acc = 0.662273, test loss = 1.401963, test acc = 0.580550 >>> erzcos pusto satía en prometos y desatros, y de cuantos anoles a macedís acaban sido ansí se me me piense que presto a ulpándolas llamanes?\n–Sensó el curao le dijo: venia en él de muy buen caball\nTraining epoch: 164 / 500, loss = 1.058828, acc = 0.661939, test loss = 1.401324, test acc = 0.580771 >>> eY asin, pusieros, que es más rincia, no contragua a poco empondido aquellos que te hicieren cómo lo de Genáila, que más llegó a ella para buscar su mal te la llevan de acheo que aquellos que los \nTraining epoch: 165 / 500, loss = 1.059044, acc = 0.662050, test loss = 1.402857, test acc = 0.580202 >>> ema., o cocreyóle Sancho Panza que no pues, con este castillo está en su muerte deneñarse no pena? Y todo esto en desdignidad. Hastándote, anséndolle que me diese en sin darndo y créo; que aún h\nTraining epoch: 166 / 500, loss = 1.059118, acc = 0.661848, test loss = 1.401764, test acc = 0.581068 >>> e, como, ya esto, tando ofrezada de ser pontencio, y dijo:\n-Marésemos: que si fueran ser atodes, y aun va sobre Ficando me despensica la vista:\n-Detuvo esto lo que quedará poema mi efeto, vermas cons\nTraining epoch: 167 / 500, loss = 1.057893, acc = 0.662317, test loss = 1.400888, test acc = 0.581570 >>> erfee! Vésa y aquel su honida de un cual se tenía me deshecha.\nCuando si yo verán, Sancho, volvió Dios que por tan lado más de una mano, respondió mal alguno, y firó el mesmo diré, con vuestra \nTraining epoch: 168 / 500, loss = 1.056332, acc = 0.662777, test loss = 1.402228, test acc = 0.581317 >>> e que sabía mentirosas y andas, para versos\nde ínsulto sin cangüenza respondimiento. Y dice, ver sí a la guarda de la infarmo su reigo. En miré en la lenguas que halló Anselmo más entre valerse?\nTraining epoch: 169 / 500, loss = 1.054250, acc = 0.663360, test loss = 1.403530, test acc = 0.581341 >>> eros; que quiza un ajaja: esto ésdela, que el se presuciesa él hasta la aventura con sus trpineniques, su sal sepo venga mejor que digno por punto que Rocinante todos les seraba los cuadrilleros, que\nTraining epoch: 170 / 500, loss = 1.054023, acc = 0.663581, test loss = 1.403795, test acc = 0.581396 >>> e québans? ¿Quémos como si ella últimamor, el cual tiene facilitareza magaría pasar desde en la venta? Pues cuando Camila, vea que, señor, hizo su sano de aquello que podría jaeza de escuento com\nTraining epoch: 171 / 500, loss = 1.053485, acc = 0.663617, test loss = 1.405098, test acc = 0.581064 >>> evose habar de ustumirle, porque tenho de ser de muesas, y que prometiman. Yo, ¿no aveisía Zoroida, que en estas plazas que los soleses, de la hermosura tengo han cuerno la habían andado muchas veces\nTraining epoch: 172 / 500, loss = 1.056877, acc = 0.662338, test loss = 1.407994, test acc = 0.580665 >>> erced, ¡Jrecera vina, sin, porque iba un famoso punto en se ha pidió por cierto, quien borbo, más deshonreros, de crédo.\nAndaba, y asida asimismo conocen que estos nombres se sapala liberalidad que \nTraining epoch: 173 / 500, loss = 1.056573, acc = 0.662310, test loss = 1.408933, test acc = 0.580629 >>> e: suy brazo asi para que a vuestra merced quiero acabar el obrasomo, y veniente; mas lo dijo a los amorosos mirando el valor de cuerto, y que la que, pues, diendó luego caminaba bien nado en su amo.\n\nTraining epoch: 174 / 500, loss = 1.057346, acc = 0.662217, test loss = 1.412232, test acc = 0.580119 >>> e que suyos que yo desemanos atrevimiento\nal caballero, salí de Leoste: igo o cutresos, y que le dejéis con admirar al señor Juanidos, me pareció de todos rospesas y señoras y suentos.\nY que en ti\nTraining epoch: 175 / 500, loss = 1.054740, acc = 0.662955, test loss = 1.410087, test acc = 0.580455 >>> erczas;\nDámpsos que venguntes de Traspona, amiga, satistras, quedó llevar para poner en descubiera y venían y ejerrició que si la escacio ami si maría, y dándole al cabo de por consista, sin esti\nTraining epoch: 176 / 500, loss = 1.053249, acc = 0.663547, test loss = 1.408673, test acc = 0.581400 >>> erca quedos, sentamos creer que era hon, el amor, solo te la los veo con esta tan en la cinta Muremio estaba, le maldisía que decía que, a quien han desentrad. Si yo se hay muchas gasilando, con toma\nTraining epoch: 177 / 500, loss = 1.051938, acc = 0.664127, test loss = 1.412998, test acc = 0.580202 >>> e tres? si era. Los tranes a cuyos buenos biene yo nega en la destos descaballas que la vida\n-Lespomdiqo viene. Siendo e españóstro y secato la corez tú te he dicho! ¡Sanida es valerosa historia se \nTraining epoch: 178 / 500, loss = 1.053320, acc = 0.663791, test loss = 1.410933, test acc = 0.580138 >>> e que sabía estárse Hocadas, en tus ojesen un que aquel marido amaginásmente ruego, que, no me aventa o despacio:\n-Y ¡có-. Apódriose vuestra merece que le saber hacer mala no fuese de la misma par\nTraining epoch: 179 / 500, loss = 1.050928, acc = 0.664704, test loss = 1.412055, test acc = 0.579814 >>> e?\nCuposa? vollaron desde aquel mejor misma mío (Al cura y sino dos pasaron nuestros luegos fuese, hecho que tengo con algún caballero suspicioso, contido por naciere. Si no estaba, sin decir a decir\nTraining epoch: 180 / 500, loss = 1.047921, acc = 0.665462, test loss = 1.413497, test acc = 0.580285 >>> e que sas célóme lo vio a Luscinda. La verdad, hasta quién no vea antes de Marcela, como sus que el cabrero de los ciellas se acordó de dos todos quisiera favorecerno de engaño algo, ducVendo que \nTraining epoch: 181 / 500, loss = 1.047749, acc = 0.665332, test loss = 1.416756, test acc = 0.579383 >>> ertos, creyes en llevar mis rastos, y ojos mis discriso, porque no podía bien la nombras en el tormento comenzar sino a cerner que vos se iban en lamantas, porque era fartas de los más que no lo sea \nTraining epoch: 182 / 500, loss = 1.045773, acc = 0.666671, test loss = 1.414259, test acc = 0.579838 >>> e la causa se estas visto el señor el ley del cuidido, como si tuvieron las rancaplas, los más caballeros andantes para santo, y dónde es hallo, ni respondía por encantame traerse, ellí pensaba, s\nTraining epoch: 183 / 500, loss = 1.044769, acc = 0.666648, test loss = 1.416780, test acc = 0.579509 >>> e oy al birpuesemo, y que levantó en que mi pidte, porque no fuese creer su casa. Despandó a otro en lo que me quisieron grande los cuardos, y a duda, y elganzaron las delas retas los reyes frustuces\nTraining epoch: 184 / 500, loss = 1.044542, acc = 0.666495, test loss = 1.415109, test acc = 0.579822 >>> ercar, mirer, que con esta sin Amadiviasen; pero aquella preses detentad; los lanzas y primezas de su amo, y aunque me mandamos que vería que yo descababado a compresa; y contando mi voluntad. Desde a\nTraining epoch: 185 / 500, loss = 1.043492, acc = 0.666959, test loss = 1.417543, test acc = 0.579185 >>> e unjo que Dulagrasía habría, o ningún espaldarle en hacer lo que estaba. Pero, en albarda, tamentó Hábaleza tan de valentía que todo lo que a su impeinilnos que la que me digas y discurso; y asi\nTraining epoch: 186 / 500, loss = 1.044764, acc = 0.666433, test loss = 1.417574, test acc = 0.579078 >>> e que sabía hermano esta agua del roto ordenaba ir a ser personas que, a lo que se ofrecieron vervad real, pué alguna hazaña, a Don Quijote poco ligarea, o y ejérica, dijo Don Quijote; y así, le f\nTraining epoch: 187 / 500, loss = 1.042975, acc = 0.666913, test loss = 1.419074, test acc = 0.579055 >>> en lo de lo que lo señores, que eran cosas supos que vuestra merced se le ha quiera que sirvió la historia, o qué señora, y a otros del balbero ha dicho y adgulata estudioso en esparción. En tanta\nTraining epoch: 188 / 500, loss = 1.043933, acc = 0.666814, test loss = 1.419304, test acc = 0.579624 >>> erced dice del Cianquen muermos, ni consigo, que la voluntad de Dias que ha tenío lebrital menter, tal ejercicio no viese o entender, año, dio, porque el criado.\n-Pues, te cono es viertad que se estu\nTraining epoch: 189 / 500, loss = 1.043716, acc = 0.666701, test loss = 1.420796, test acc = 0.579142 >>> e lasqueré por hermosurado por venter y sin malarcentidad que parecía, y todo aquello que me debes a esto de lo que cabello, aventuros yo un liberelad!, quiere de culpa de la sala de esta primera que\nTraining epoch: 190 / 500, loss = 1.058364, acc = 0.661598, test loss = 1.418039, test acc = 0.579846 >>> e que sabía confunar al gigante -dijo Dorotea-; si Sancho amigo el canónigo? Don Quijote a sus polvesustes, purecieron, estaban ellas verlas, habló por entendernes se lo preguntara, era su alagio\nto\nTraining epoch: 191 / 500, loss = 1.055647, acc = 0.661906, test loss = 1.417453, test acc = 0.579513 >>> e que sabía ni samisas.\nUno de Marcela? Pues con lo cual roble me dijo, no oído ganarse un por hejad ha muchos decís de todo esto el ventero, Sancho, que en lo que decgándose sus lenguados prometa \nTraining epoch: 192 / 500, loss = 1.045879, acc = 0.665480, test loss = 1.417864, test acc = 0.579537 >>> eros, creyendo crnendís poder se decir. «Puso le pasare me lo había otro encedreto de la honra de sus pietes tan algunas parentas de la luna me entre Dulcinea, puesta en su más y en regno de Zoraida\nTraining epoch: 193 / 500, loss = 1.042721, acc = 0.666600, test loss = 1.418459, test acc = 0.579668 >>> eros; y si, cemodaman nuestros vian y cansado entendimiento quien eran mías, y las manos no hay que daba por todo alguno; porque lél, después que con todo cuantos donde vivía atencio que ves, mal a\nTraining epoch: 194 / 500, loss = 1.041056, acc = 0.667306, test loss = 1.420643, test acc = 0.579122 >>> en lo della se fuera, quien daga a un huzo lo que es lugar para que se socorrer si él todas las y contras a Lel Ya con este trigo, como alienta, acabando en creer que aquelles ha de maravillas de rejo\nTraining epoch: 195 / 500, loss = 1.039688, acc = 0.668079, test loss = 1.421274, test acc = 0.578790 >>> es, squé en tientorilo de el, que ni ecas las cosas y con su papel de mí se ha de pramor furido alguna, y allí claro Sancho o le pida un mozo de melincia yo yo en ahora, y venir el famoso suspiros, \nTraining epoch: 196 / 500, loss = 1.039589, acc = 0.667939, test loss = 1.422780, test acc = 0.578782 >>> erced dice déstodido en leguater que Luscinda como vuestra merced no le diría, si a que estas veces le hayan aquella arragara que el gran feime era su amo el voz que se haga; especialmente, que ya ba\nTraining epoch: 197 / 500, loss = 1.041746, acc = 0.666948, test loss = 1.420308, test acc = 0.579529 >>> er¿voce? Porques así, habémoso discretos y respetas, porque él le tuviera su felición, los valellensos, aparta en razón a los olejes algo esto más imaginó acababa Sancho Fazadestas le tenían lo\nTraining epoch: 198 / 500, loss = 1.040952, acc = 0.667006, test loss = 1.423092, test acc = 0.578738 >>> evose cuata, si hues deba a todos los letrantando a caes en un lloniese en el mudanza, dijo el canónigo. Von las sentines de que le dije el mujer; y acomodándome ya señora de sus a sus verdes con se\nTraining epoch: 199 / 500, loss = 1.040166, acc = 0.667193, test loss = 1.422629, test acc = 0.578679 >>> e. El secto. Candá la música Norada y ellos me dijo: no dé el paraba, yo en sus casos. Y atendien ¿ada el colorrareza, que os descubrió el enamor que a él se creson delindo, que no se doy a tiempo\nTraining epoch: 200 / 500, loss = 1.038667, acc = 0.668126, test loss = 1.425613, test acc = 0.578236 >>> eres, cosdazas? Que lo estabas al huédo e entrar y de lo que debe tenía. Pero hédero, Sancho, requiera, atalvao, y con esta braz.\nSuelto con el amor, volvió por ventura algún en mi valuntada avent\nTraining epoch: 201 / 500, loss = 1.040026, acc = 0.667775, test loss = 1.428182, test acc = 0.578556 >>> e que sayos quiera dersille y resustoruente que hace suelen cuenta de lo hablaría un prueble, le no es debajo de vernar lo que os ha hecha. Añada Micióis que, que la procura más a verses que vino y\nTraining epoch: 202 / 500, loss = 1.041017, acc = 0.667006, test loss = 1.427522, test acc = 0.578358 >>> e que dijá de más lerás todo se fuese cosa de llevar contra sobre un andalba. Pres ojor lo que hizo él en sobre algún trabajo muchas voces la vale ni Camila no se ha ídandela burnace, el viera. L\nTraining epoch: 203 / 500, loss = 1.045106, acc = 0.665545, test loss = 1.425463, test acc = 0.579031 >>> e taz ramajos dejaron de satarla, le ha de acertado y que lleve cabero de aquella lachosa y deleo de Lotario, respondió Don Quijote. Pero -dijo don Quierto.\n–Ya, y tan estos hermañas maneras verdader\nTraining epoch: 204 / 500, loss = 1.043525, acc = 0.666127, test loss = 1.426416, test acc = 0.578521 >>> erced dinque. Bien relí Sancho, si esta poca están jamácase a la luengada favorece; allí se lo lleva tenía a ser pasado caballero está de toda huéz, tira -dijo el comitos:\n-A todo esto no se la \nTraining epoch: 205 / 500, loss = 1.039687, acc = 0.667440, test loss = 1.427987, test acc = 0.578418 >>> e? Eseñor Desiste y mi fuerzo que renganos fue dando Sancho Panza vola lo que te cana griegos, que anda en a todos le diré en el buen escudero, con otras casajes como me satisfo le descubrió en vues\nTraining epoch: 206 / 500, loss = 1.038119, acc = 0.667817, test loss = 1.430576, test acc = 0.578722 >>> ercendame; y, le dicho pusto por encantame, dieron tres más hermosando, de toda tú se mo que convenía a pesar la suerte. Y si os debe treintros, solicitó la ordan hacienda antes que a él tomé pé\nTraining epoch: 207 / 500, loss = 1.038307, acc = 0.667917, test loss = 1.431407, test acc = 0.577896 >>> eros, creyendo que mandriavión de este aunir sino acabara. A lo cual venía por esta grande que buena\nlanza de Aguleda, como para que se vino y mala mujer un rico.\n–Bien no pienso que hizo cuán senti\nTraining epoch: 208 / 500, loss = 1.039774, acc = 0.666910, test loss = 1.432388, test acc = 0.577528 >>> eY?, condono, que la no salía por las monesta. En la dieña alguna; y así se tuvo con él tistimo taréis que se puso, con todo aquello que saben mandar la maña imagan y otro gusto, de lo hacía.\nCu\nTraining epoch: 209 / 500, loss = 1.038384, acc = 0.668000, test loss = 1.431087, test acc = 0.578631 >>> eros, creyendo que las que nadie aquello, sin que me ha de comer. Y lo huéspues -dijo don Quijote-, que eres su hija tos remedios, también traíle vuestra merced me pergunas del algún volver a los d\nTraining epoch: 210 / 500, loss = 1.037761, acc = 0.668000, test loss = 1.431520, test acc = 0.577500 >>> e oy, que pareciere, que sin más famoso Dulcinea? ¿Qué buros espastó, que alguna entre mal que son manos que dices se efer fue con justa primera, me tuviese memorifitarnos acompasansos, tenesea en s\nTraining epoch: 211 / 500, loss = 1.039688, acc = 0.667601, test loss = 1.431077, test acc = 0.577971 >>> erbscó Migorencelió\nDor esta tenga de una lugar comedida tiempo, y ablóndoles, el cual se retía de verse que a todo su escudero, Sancho amiga un otro, aunque fue encumar a bien sin in «Moresinga a \nTraining epoch: 212 / 500, loss = 1.041737, acc = 0.667074, test loss = 1.433578, test acc = 0.577417 >>> e el vignio en lo dejará en pie, y cásen muestra –dijo Sancho–. En el cura quese aquéle se decirte poco de las estriñas que dejasen quedarle de balca, con preguntar que no se fue esta pensaba que u\nTraining epoch: 213 / 500, loss = 1.040744, acc = 0.666871, test loss = 1.429984, test acc = 0.578635 >>> eros; ce¡da destreido a sus arcejereo de tíos de caballería, que conmigo Don Quijote muy del cindo; pero en industes del more y mal este guarda de medre, timpo, y no me alcanza?\nLlegó Sancho Panza q\nTraining epoch: 214 / 500, loss = 1.040327, acc = 0.667208, test loss = 1.432249, test acc = 0.578101 >>> e\nque hubrabos y desgalados caballeros andantes que estaba, y no trigo auseña, y para dar no sepa digan por unos y tan libros de apalosentes que apenas y yo padre y arraiduente y a gusta, en bien, res\nTraining epoch: 215 / 500, loss = 1.043739, acc = 0.665857, test loss = 1.431449, test acc = 0.577654 >>> e que sánses mi manera: con todo eso ne hería se digo. Pero se atreva me está ningún? preguntóle en olvidá.\nY acuntóse que colido con mi ventanida. Lo que los artos hacia con que te tan armilieg\nTraining epoch: 216 / 500, loss = 1.040010, acc = 0.667320, test loss = 1.433024, test acc = 0.578319 >>> e, dejo, que fubraben un criado.\nDígole, con el cura en su mesmo que yo sería mi muestr donde le pedezo, gentileza y nosotros fartase o poder lo quisiesen a bien es encantado, respondién Zoraido.\nOy\nTraining epoch: 217 / 500, loss = 1.037827, acc = 0.668136, test loss = 1.433168, test acc = 0.577409 >>> e que dís hija entanda, y que en efercita llamada la cruel no.\n-Bien se tenció la buena ingaña y señora lo que mira, cuando se creyó me ponían a caminar, si no oiga, y vuestra merced comu siquier\nTraining epoch: 218 / 500, loss = 1.038608, acc = 0.667517, test loss = 1.433998, test acc = 0.577745 >>> eros, creyendo que criado dónde estaban sin ladróno.\n-Hoy y qué estaban; yo tengo don Fernando el manda en los de la señora Dulcinea.\n-No me pusiese alguna de a pasó la repuesta que tendrá que yo\nTraining epoch: 219 / 500, loss = 1.039199, acc = 0.667500, test loss = 1.433014, test acc = 0.577781 >>> e trpalpadiós, que si ya nuestras nadas; y esto, pues la primera la tienes que estara el suevo a la virtud de ella podrás dedereroso a decir que todo estuve moverosa –respondió Sancho-; mas quiera q\nTraining epoch: 220 / 500, loss = 1.039510, acc = 0.667606, test loss = 1.431372, test acc = 0.577472 >>> ence cuablos estáritorios, cerrada que ya había vuelto, no fue a sus amores y el andabumos campa de todos en otro me ha vesalo, y queriesen.\n-No espera a todo aquel caballero año, lleno de Dios, que\nTraining epoch: 221 / 500, loss = 1.049196, acc = 0.663968, test loss = 1.425668, test acc = 0.578018 >>> eratas; y un tiste, dijo a los encupes andardese entretener, seráis en aquel pastor y que ceba de vuestra perder el retondo de la pobre de encaje, que es el puño –dijo don Quijote–, para que, viendo \nTraining epoch: 222 / 500, loss = 1.054136, acc = 0.661911, test loss = 1.425569, test acc = 0.577963 >>> e, y a\"mendianes del Cordono suspomiento vano como por amarparóamente los mármos. Y don, y luego, solo apartidad. Enamorta, y dónde se parecía ser de este pensamientos a aquella polía, más se hal\nTraining epoch: 223 / 500, loss = 1.037892, acc = 0.667838, test loss = 1.426541, test acc = 0.578078 >>> e que sah sentímoso algún dos pie de don Quijote, al renegado, vuestras morosas muchas y gran grandes honras, que no le dan robado desto que está tales casos. Sigues a este ya sabía por argo acabó\nTraining epoch: 224 / 500, loss = 1.031208, acc = 0.670354, test loss = 1.428901, test acc = 0.578141 >>> erta!, comoneda tan quientes. La muerta puso.\nLleváse esto desea. Lora la cantidad por consolado admiración y dar pasampeo. Mosadse el caballo, salve en la cosa, he de tardase, que es un otro o preci\nTraining epoch: 225 / 500, loss = 1.029117, acc = 0.671468, test loss = 1.428603, test acc = 0.578426 >>> e tregusenco) lo veos así, vuestros porsiosos desmantanador de Anselmo Sentra Oloricurlada toda aquella treingua ausencia della a buscarle a la de los sabios viele un primer sunción en otra trancia, \nTraining epoch: 226 / 500, loss = 1.029499, acc = 0.670938, test loss = 1.432328, test acc = 0.577013 >>> e todo o de señala el cautioso impor él, espejos de lienzo?\n-Mireió el cabora; pues, en el siguiente con su instante en Españan, según esté quien vuelta seguro de las señas.\n-No haya novece, y v\nTraining epoch: 227 / 500, loss = 1.028385, acc = 0.671531, test loss = 1.432806, test acc = 0.577979 >>> eras, hecerda dijo el sustar la muerte. La Sancho Faldán de mejor primera corres el valor de toda –respondió Sancho–, si la ocasión y que al famoso Jagada (que tan de poco mal talor tan prutenciones\nTraining epoch: 228 / 500, loss = 1.029461, acc = 0.670925, test loss = 1.430161, test acc = 0.578291 >>> e, y Saño\n-Ella, os hizo al monto. Cómo fara mí de necedadera y angason castigandos y peligros comunsenta escudero, autivo a la voz de Ingaba a su historia. ¿Pude estar que fue con tanto sinvenemo\nl\nTraining epoch: 229 / 500, loss = 1.027513, acc = 0.671616, test loss = 1.434271, test acc = 0.577551 >>> en qué talluz vale no hal menos donde echara muy bien que sin mediando y que me vio quien te parece. Capíate cara do fiero; pero aquella fe llama, que, como no sabia guerra que más en mi vida\nporque\nTraining epoch: 230 / 500, loss = 1.026900, acc = 0.671737, test loss = 1.436521, test acc = 0.576499 >>> eros, con que me oyote que tiene hambre por muy fanzarme en hacerse yo tan junto y adverso con más sabia el señor don Juena. ¿Pude veniy rabas noticia de su raina y a san honradas él como será más\nTraining epoch: 231 / 500, loss = 1.026426, acc = 0.672186, test loss = 1.436162, test acc = 0.577021 >>> e\nqutor:\nUncresa; alzando tujero mandamiento desemboraré jalad, con poner en ejecutirlo; y como son arábigo que vuestra merced, respondió Don Quijote, pero tú, en la verdad, que fue propósito amig\nTraining epoch: 232 / 500, loss = 1.026674, acc = 0.672051, test loss = 1.441733, test acc = 0.575874 >>> erf-a esto el escuárnio y acogido a ésta Don Quijote estaba ahora el bremo que, comenzó a cada anor en la princesa, y que queda que muchos y de vuestro palado estuviese mal para oscura esperanza de \nTraining epoch: 233 / 500, loss = 1.026591, acc = 0.672166, test loss = 1.438138, test acc = 0.576574 >>> ercelzas, los tres destauyados, que había sido muy buena truella.\nEste ha padrado que un deseo de todo acabarás fueron de la lanzasida guardarse en espírso forilan alconzar pedirmen, con todo extrem\nTraining epoch: 234 / 500, loss = 1.024389, acc = 0.672536, test loss = 1.439140, test acc = 0.576270 >>> ence ormeda, adenga batrle, así le fue de este esposo, porque se sonestorbí volver de descabado, y ya veas quisiese el quejos de los cuicoríanis, que para este indusfrimiento contóle dejó que esta\nTraining epoch: 235 / 500, loss = 1.026319, acc = 0.672126, test loss = 1.436259, test acc = 0.576926 >>> ercespedía. Ceses; alguza; y, subiéndose lo señores, sino en ninguna quiémo esto el goste querían los que más blandación y dejarme al vuya según puedos y apreves lo que sería con esto se oreja\nTraining epoch: 236 / 500, loss = 1.025156, acc = 0.672438, test loss = 1.441245, test acc = 0.576958 >>> e ad en semo se vido de nada de alcanzar las aventuras de tus hallas, los hirógelos de contar no me quisiera que ya la ventura a un rey a verse de su casa de un gruas conmitio. Y el cura dijere, porqu\nTraining epoch: 237 / 500, loss = 1.024286, acc = 0.672647, test loss = 1.439383, test acc = 0.576388 >>> eros: -promera dichas almas mujeres se agora he donde se le besamataba, señora Claba, el fin deseaba. Don Quijote, lo tienes; porque va de vesar a los mala de mí cueno y menestero, que era alguno, y \nTraining epoch: 238 / 500, loss = 1.024516, acc = 0.672622, test loss = 1.438501, test acc = 0.576578 >>> e? aNques, y sabido había cumpliado de muchas aventuras de las míos tres acogias, y como nuestra ventera vino que habían escrito de todo confesó el tisto, el cual venga como vio de jamás ambazar c\nTraining epoch: 239 / 500, loss = 1.022561, acc = 0.673116, test loss = 1.441383, test acc = 0.576748 >>> eras, y trasquén vosota de buen prisio se alma suerte, adelando mal y penso.\nY sotornos presente satisfará. No seguía el generoro con qué espamarino, y que, como procura de no ocuenten a la oreja, \nTraining epoch: 240 / 500, loss = 1.023390, acc = 0.673079, test loss = 1.439222, test acc = 0.576875 >>> ercesz destaba y pregunto; así lo me pareción que si de sabio de verse más sus apenas sin palabra acompañés, libre encarecírimos tiempos del hombre se sastir con otras ambrezas de haber mejumo el\nTraining epoch: 241 / 500, loss = 1.021715, acc = 0.673532, test loss = 1.442417, test acc = 0.575854 >>> e que sales vió: sin duengo; quiso en los inhigios me daría alguno en lé en aquel punto, fuera de vuestra mercad y por delamente somprecen usados en mús de versa de la señurada, y confusos que las\nTraining epoch: 242 / 500, loss = 1.024682, acc = 0.672152, test loss = 1.441812, test acc = 0.576092 >>> e, ahojadero; y ebo es mucha compatrencia del intebo que se dieren, profesan a los que me haben mutada un gran el te perdida de otras arbaridades que estás maldicion que será merecido y poco al luno \nTraining epoch: 243 / 500, loss = 1.021544, acc = 0.673597, test loss = 1.442922, test acc = 0.575324 >>> eras, nqriucorizo los proveyendos, la manera que este bien que yo yo, pora caballeri a la vida en la cabeza, que haya procuración, perdiese el dedaba la cubierra sobresalta del todo de aquí su cansan\nTraining epoch: 244 / 500, loss = 1.024156, acc = 0.672501, test loss = 1.445593, test acc = 0.574968 >>> erce; qué llevaba Don Quijote de la Mancha; y así, en lo que las dos semejantes respeos que no he escrito suyo gal de no hacer hal de decergino espósto el barbero y ésta no lo quisiere dado: ningun\nTraining epoch: 245 / 500, loss = 1.023882, acc = 0.672471, test loss = 1.444170, test acc = 0.575874 >>> e undo, por mi reunía a su mesmo padre de su amo que prado -ren, por aquella yamentea, estas penas estáblita que su señor más dimbues inexes de bagal su impisionesce tratar dorea en el ventero y fa\nTraining epoch: 246 / 500, loss = 1.022971, acc = 0.672834, test loss = 1.441654, test acc = 0.576555 >>> eY valen cómo está zallo de quien lo es por su gota, y de donde vió todolo que se levantaron pasado por su revén, determinado que vuestra merced le cató a ordenar de los hombres mineo voyerse ful \nTraining epoch: 247 / 500, loss = 1.020184, acc = 0.673938, test loss = 1.446547, test acc = 0.574810 >>> e que sabíves, despuéssela, si tené si[no] afiblos y atrevidorles caballeros servirio y denoso, es caminaba, y que, en lo que asimesmo desechaba que había matarme la mayor mayores veces si venimana\nTraining epoch: 248 / 500, loss = 1.022338, acc = 0.673203, test loss = 1.445724, test acc = 0.575178 >>> eros; –dijeseseno al carta:\nSancoo según en las promesas que él dijo:\n-Soyendo el ventaro-, la paña, y en contento, con tu falta, si se llamaba Algradigne Luscinda, como la entretuna, por principal \nTraining epoch: 249 / 500, loss = 1.021099, acc = 0.673417, test loss = 1.443333, test acc = 0.576321 >>> ertucha: es resputó estas vistados del nuestro gran balle y menos verse a felice y convetral por lo mejor con esta bramo estapero\nestaba; si mas viste tíosloría mi contento de una paga. Y anopeos ac\nTraining epoch: 250 / 500, loss = 1.021936, acc = 0.673286, test loss = 1.446229, test acc = 0.575945 >>> e que sengas ventera, seguido de las bocanas aventures, el fin de muy riquía de mi amo que es la experas a Rocinante, y caeves al rein podrá mis unos se endió el puntualles en que le acuerdo haber m\nTraining epoch: 251 / 500, loss = 1.022693, acc = 0.672901, test loss = 1.445024, test acc = 0.575744 >>> eros, ejeccrendo el cual rinco, dejase, ni que nuega es el mundo ayudardasta. Y no se tarno vistu–, el batrimo de la puerta y predencia sombre mejor -respondió Sancho-. Sébaza me piense.\n-¡Véloso re\nTraining epoch: 252 / 500, loss = 1.022718, acc = 0.672817, test loss = 1.449315, test acc = 0.574419 >>> erces detejanos ecllaba. Callenon que todo se dobios nada y hermado, que de nuestra consideración de la mano en el de la Tirma por vuestras muchas desamososas amores, andante libertad, le venga vuestr\nTraining epoch: 253 / 500, loss = 1.024445, acc = 0.672327, test loss = 1.447312, test acc = 0.575190 >>> e la buena y cosa a la conales me vea a su solida me manda mejorado de su reino sino nadadaba de maravilla, que vió a pequeño.\nY lo que debe tal manera, yo admide, amigo Sancho. Quito mi eterrón tar\nTraining epoch: 254 / 500, loss = 1.022594, acc = 0.673024, test loss = 1.444458, test acc = 0.575874 >>> e prodiden desear esos nunca cumidado, y trae mi pena del día, también se la duese! ¡petarísimo; y este liconvener tan de entretener el amor, por lo conozco vienen su amo he puesto admirado de mono \nTraining epoch: 255 / 500, loss = 1.023632, acc = 0.672139, test loss = 1.450681, test acc = 0.574474 >>> ertes hazorédima don Fernando cindue de tan luego, vea que subiese señal manera de los días es darle habiéndole este la plájica lastado. Entendía el cual, adminabo de todo algunos hijadas de la c\nTraining epoch: 256 / 500, loss = 1.024171, acc = 0.672030, test loss = 1.448772, test acc = 0.575502 >>> e que dí, y va aquel niñero de a los ojofundos, que le podía sersidad en su amo? El cura, a ellos! ¡Haste puestas lágrimas en mi mejor que ellos crueles, al condonado, ofrecidiéndola de hombrar de\nTraining epoch: 257 / 500, loss = 1.026009, acc = 0.671722, test loss = 1.448573, test acc = 0.575451 >>> e que dí, ¡preso la pasión y rico, y fintura, ni menos, una gumersen. Así yo se defendía mi solepediólo el yentro, por celos. Y ante bien que miener contrabajoto que casi bueno que su herido, que \nTraining epoch: 258 / 500, loss = 1.023051, acc = 0.672500, test loss = 1.447130, test acc = 0.575233 >>> erced di esos singren, que fue el mundo, para hacer es vistos, que recibe por lo menos.\n-Ahora.\n-Ansembad dudras en el bueno es la muerte ha de venir mi hizo, aventura el puño amigo. Llegó otra vez l\nTraining epoch: 259 / 500, loss = 1.025857, acc = 0.671553, test loss = 1.447050, test acc = 0.574885 >>> e dece Lu caballes de su risa con la baja carte y firme a cumpliad armimento de robarsa de venir en esa verdad, como hablado de su deblirse a los caballeros andantes o hendido; pero ¡a saltas, valeroso\nTraining epoch: 260 / 500, loss = 1.022828, acc = 0.672516, test loss = 1.448969, test acc = 0.574972 >>> e engo, quien don Quijote de gingüementa. En, quiene con todo jalacero que decía:\n-¡Oh, sin ellos, cuanto más don Fernando, y como ha de ser de soletido a su esposo entrión por la barca, como si se\nTraining epoch: 261 / 500, loss = 1.022047, acc = 0.672830, test loss = 1.447609, test acc = 0.575372 >>> erced dice del Otro, que eran aquelved señora mía como me hallo de sus, y que tomemojos deseo o no, que émbrasios muy bien pensaríllas en el cielo, y los ojos, por mi sentido del requió luego en m\nTraining epoch: 262 / 500, loss = 1.024615, acc = 0.672001, test loss = 1.450452, test acc = 0.574114 >>> erY? -dilo si su purieron los más famosos honestedo, días le hiciera para mano, se veo en EfeChicí, por suestro mudenza iba volverme mayor con su saluración de haberle entre las fuerzas que das cos\nTraining epoch: 263 / 500, loss = 1.022315, acc = 0.672889, test loss = 1.450003, test acc = 0.574751 >>> emiy, que pudienavesos, los caminos que era la ventera me lo ellos se acomodó Andenio solició al ginea de su daño a sus cuales suelen alguno, alguna merced por su rey, que sigan en las tescantes\", y\nTraining epoch: 264 / 500, loss = 1.025839, acc = 0.671875, test loss = 1.453965, test acc = 0.573568 >>> e iquí, por lo que se diga bien me pareció considero había puesta en estar tan admiración de cuatro de luego al ánimo Párzase del duque mentías, la voz tenía a uncincio y de la entiendida estab\nTraining epoch: 265 / 500, loss = 1.026585, acc = 0.671373, test loss = 1.453577, test acc = 0.573461 >>> e que dís vuestra merced, procura vuestra merced, y acabándole a buenos de aquellos donaire a Dulcinea del Toboso, saber lo que ya pueden adedencea desletrado, estáimos en el tí se dieron dicho: y \nTraining epoch: 266 / 500, loss = 1.028611, acc = 0.670725, test loss = 1.454160, test acc = 0.572579 >>> e que sido, con mucho vio que el valor de Rocinante y haciésente intentar que hacen leerado la muestra en ella, y consejo los dios que me acunde andaba en la suya, ni él digo. Y en esto sea quazá he\nTraining epoch: 267 / 500, loss = 1.025894, acc = 0.671380, test loss = 1.454678, test acc = 0.572903 >>> erced dice del Conde Pierres. Lued infuría llevar a mi favor todas auzades que en lo de sus amargados en don Quijote sabéis, señora consilla para que el cura le dejó que si tengo tormaño que él r\nTraining epoch: 268 / 500, loss = 1.024229, acc = 0.672188, test loss = 1.454146, test acc = 0.573117 >>> er¿su tal historia, por podridos cristiano. Eírones ausente. Y que junto estaba yo al brazo a la cristian hombres que este abrasarse; pero no, gigno deben que las fuyas y provincicia a la ventera en u\nTraining epoch: 269 / 500, loss = 1.022931, acc = 0.672639, test loss = 1.456201, test acc = 0.572983 >>> es, Yo, que Redande muy promigo en orden -dijo Sancho- nague fue, se hallaron de por mi mal, yo lleva señora silencióna en el padre el campo de caballería de notir está entendido todas aquellas cos\nTraining epoch: 270 / 500, loss = 1.022810, acc = 0.672331, test loss = 1.459988, test acc = 0.571646 >>> e espandar tuver en los Salinos o que acertándoles o poner en ofrecimiento se ve dormir que tiene letes no saber dada espacioso mil, que yo te cubrumado le puñuramiento se acaso os separen cosa algun\nTraining epoch: 271 / 500, loss = 1.027435, acc = 0.670961, test loss = 1.456906, test acc = 0.572536 >>> e aquuntól desgazón nos fueron la buena ofendida y ocallo, agravio que aquel no sepulatan oír el fin yelmo, pues aqué maldito, tomó a ver dos bongunos miloyando lo cual dublegara; y así, se levan\nTraining epoch: 272 / 500, loss = 1.022555, acc = 0.672623, test loss = 1.459817, test acc = 0.571863 >>> eras pomadadera alcanzar Quijade y encantado yo en Robre y de mucho prueba de un prombro a cada habiendo muy guisamiento de su barbera, mientras bullanas nuevas, acomodáronme que las mutas depacida en\nTraining epoch: 273 / 500, loss = 1.025667, acc = 0.671376, test loss = 1.459563, test acc = 0.571388 >>> e ¿que labradó a su aunque abrazada y recabada ni su primura curpadamente de mis desvarsos palabras está en esto los ojos combezcas, Sancho Panza.\nY descansas estos más de mi dueño? Y, por cutiesen\nTraining epoch: 274 / 500, loss = 1.028513, acc = 0.670916, test loss = 1.459401, test acc = 0.571005 >>> e que sabía hasía ningún infierno, ibue que pienso quitármes naturales yo. No os echo, señora, sufridola meneanida traspeca, que dio poner importancio; y sólo para esto, o de ninguno de Arge, que\nTraining epoch: 275 / 500, loss = 1.026362, acc = 0.671066, test loss = 1.460427, test acc = 0.571123 >>> ercimas. Pues. Que divía ya posado;\nmosían que os habeídoses que el vuestras armodillo!\nY como los desenionires; con él se movir la mano ante hecho, por menos, para lo piedor para que avisía en ar\nTraining epoch: 276 / 500, loss = 1.024712, acc = 0.672105, test loss = 1.461262, test acc = 0.571384 >>> e? hazces a que en lo méser de malor mi espuditria y gran reino de la mañanad les noso, confienda, habiendo hales temón; porque las espeandiesen, y profena la echaran, que se me maraviendo una venta\nTraining epoch: 277 / 500, loss = 1.021280, acc = 0.673102, test loss = 1.464119, test acc = 0.570063 >>> e que sidos dijo Dorotelaron y desdenes de nuevo debenar de algo más buena sierra algún licura, y como la parte, conviene de sus verdades, ¡oh Areique, de aquella pastora que es perabuzar concertado \nTraining epoch: 278 / 500, loss = 1.028111, acc = 0.670868, test loss = 1.461835, test acc = 0.569739 >>> ero, flas, quisire. Y de la criada? -Esa mesma que digno y abruegado son dedon, fue a lo que tras a vieros.\nCasi como me viesen? persóno luego yo me hasta entonces. A lo cual respondió que no me diga\nTraining epoch: 279 / 500, loss = 1.028997, acc = 0.670342, test loss = 1.461645, test acc = 0.569790 >>> e que sabos e invojó, y dejarme algo, cuando mirando sus preses y sentenioson años sengase dos día, y que cosas guardase de cuadro corriendo tanto:\n\"Las mucenciangan en uno en mis espaeciones y las \nTraining epoch: 280 / 500, loss = 1.023899, acc = 0.672002, test loss = 1.460546, test acc = 0.570688 >>> eros, creyendo, el bañanicia de Dulcinea. Y vuestra cosa? Cave, para que vuestra merced que éste Dorotea; que yo deseaban; que y como allí tuvo a Ruido pretinanda y quejas; que yo tienen mejor, que \nTraining epoch: 281 / 500, loss = 1.019449, acc = 0.673653, test loss = 1.464079, test acc = 0.570036 >>> er las fradurase, y desefegada las demasijos fuerra desventura como el serlo más deseos, y en la princesí que meronde que se coger por bie y muerta mejor iba ya coi vo yol y el erosudar fuera del bol\nTraining epoch: 282 / 500, loss = 1.018592, acc = 0.673997, test loss = 1.461196, test acc = 0.570712 >>> e MiciaN, sale venían de su reino, y aun la remedia, la habían acomparado, con viven, se les debiera, con el autor de escribio su crédióno, y volviéndole, en provecho ancase en el ventero- mío. N\nTraining epoch: 283 / 500, loss = 1.018848, acc = 0.673613, test loss = 1.462630, test acc = 0.570629 >>> e que saben y muesar de la mesma de achares.\n–Bien está el cabrero: y a mi padre, y por bien armado, cuanto nos faltó Sancho, porque Lellete, el discurso de la cadana? -respondió Leonésigo enemanta\nTraining epoch: 284 / 500, loss = 1.017270, acc = 0.674330, test loss = 1.461056, test acc = 0.571642 >>> erced dimu y querida Lusa que está más enemigos, no supiesa alguna menestra; sóno la aventura se romaría las salididas Don Quijote yo me via las muy descondecían hasta en las manos se acordaba alc\nTraining epoch: 285 / 500, loss = 1.020813, acc = 0.673092, test loss = 1.457377, test acc = 0.571843 >>> e que sienges, dio con muchas cosas, y por caminar, Sancho, que pasiones, se hicieron contento corresponder, y másmiendo de la ciudad de mi caballero, no hay nametante y bueno que se podría mis amana\nTraining epoch: 286 / 500, loss = 1.032153, acc = 0.669005, test loss = 1.459499, test acc = 0.570629 >>> e que say y los sabes, de que mi? Y yo, le dañadas estadarse y tantos hoyes (cosas veyas,\nque vendría, que señándose las dos señores. Presenció la otro, y hubo de verles lo que prosegues ir oír \nTraining epoch: 287 / 500, loss = 1.025369, acc = 0.671262, test loss = 1.463868, test acc = 0.570277 >>> erteris, conodad, corridaba hallar de mi más visto que tenía remotifría; y aunque debe, que siendo dejo saber que su fanta, y alzación de creer su fuerza que se había venganza; dervirtó de lanzar\nTraining epoch: 288 / 500, loss = 1.029140, acc = 0.670117, test loss = 1.461024, test acc = 0.570566 >>> e aquértan, las forazas de Rocinante y en tan tres comonidos, y sobre vastilleron la sacaja, que faltaban grandes en esta manera, dueño y ellos algo que entró parte yo, por el segurecio. Yo siele ba\nTraining epoch: 289 / 500, loss = 1.040865, acc = 0.665699, test loss = 1.451316, test acc = 0.572856 >>> erced, y la Sanche, a pesharminde, porque si quedaron. Cordes luego de las persades rostros, y pareció que ella, con ponerme de los sueltas. Y así que me ha de engañar a las mías para éstas razone\nTraining epoch: 290 / 500, loss = 1.026806, acc = 0.670713, test loss = 1.453024, test acc = 0.572255 >>> e que sabías, y, pusiérado de aquel nagarse en el puño a él por los desenvolvestís de Dios, y es cosa que las mujeres que quisiere -respondió Sancho, que miedo ofrarzación de sus desmayeno, porq\nTraining epoch: 291 / 500, loss = 1.026926, acc = 0.670642, test loss = 1.454585, test acc = 0.572243 >>> e que se meneales, término de semorder la la ina menturaba), y que yo te respando todo el gigancio, y dijo a Sancho, quería, quiero dejar dando sirvirse con mucha, que estuve viva en una valen. Bieno\nTraining epoch: 292 / 500, loss = 1.028437, acc = 0.670260, test loss = 1.457009, test acc = 0.572219 >>> erced difora baja y descansancia por deseapigaba\nconocer, te proguara semplé la llevasí vimo una teyó el del apreto en ella, riquía blando Don Quijote replicó el noso. Ella esto se entiende a este\nTraining epoch: 293 / 500, loss = 1.017413, acc = 0.674201, test loss = 1.458302, test acc = 0.571646 >>> e laquera mi cajadta no ha sido compañía. Tornándose oír después de haber lo deshobedad, por el andante la ribor; y también acabara de las infinidas arrión y bellaco, porque yo no os mi rica de \nTraining epoch: 294 / 500, loss = 1.013067, acc = 0.675600, test loss = 1.459111, test acc = 0.572112 >>> e traudo despúspalo; que para desastar la carne de oír la obra con sí Dinga había parado una cosa y a su enjudez más castigal había vistó determinador de la marqués de unos amigos de calaque ma\nTraining epoch: 295 / 500, loss = 1.018691, acc = 0.673648, test loss = 1.460461, test acc = 0.570866 >>> e, rcuchíso, por mío en el reino su menor señor Qui alguna igio Parecería ha hecha freso irpa fecio, el marido de mudanza y sangue, a caballeros peligros veda algo ahínjos estaba, rescatarme; el d\nTraining epoch: 296 / 500, loss = 1.018825, acc = 0.673625, test loss = 1.459250, test acc = 0.571388 >>> es, Yo, commodoso sabesorado, y deseo despojaran la que Lotarifia otros, porque no hay en dicentiano Rocinante, allí se altirses se dejan oíra sino no.\nY esta Dios asimes quiero decendido, alzar y re\nTraining epoch: 297 / 500, loss = 1.022800, acc = 0.672188, test loss = 1.457857, test acc = 0.571610 >>> e mez, llevos quiero verdad, no lo sentido que se parecía culed. Este pequele alguna de las sierras, pues tuve esto lo quiso, descombra señora, y es esto de escado; avenemirás para decir: «Manda. De\nTraining epoch: 298 / 500, loss = 1.034141, acc = 0.668226, test loss = 1.458395, test acc = 0.571780 >>> e que del merece, alzor el gigante Estoría de nuestro queriendo a buscar del amor que dijese que peor, que era acabará mucho real, letradón preguntad deste dando dejar desde el padre se veo lome má\nTraining epoch: 299 / 500, loss = 1.017194, acc = 0.674269, test loss = 1.455551, test acc = 0.572425 >>> e que debías de tuvenía, y aunque el penho.\n-Aharéis porfivo a ajaron que Rocinante el Brazón sabía en aquel mismo cuero cosa muy disfrorda y por oírn en los crisuidos senes las ejerrinos, fueron\nTraining epoch: 300 / 500, loss = 1.013405, acc = 0.675537, test loss = 1.454721, test acc = 0.573062 >>> e que sabía lo que como sin puedes darles casan vamas escetado, que en él se ullía. Días quérabase el en los que me habían maladado en alguna obra; que también cada dicen uno a acabarle las esta\nTraining epoch: 301 / 500, loss = 1.011568, acc = 0.676125, test loss = 1.458278, test acc = 0.572888 >>> e trezos, y Dios, digo que sus iban se estrañe vuestra villa, en tan forzado, según habéis atilla fermosa cada alberazo acuara verdad; que puedes por caestamente y uno que pudo haber prefesio hasta \nTraining epoch: 302 / 500, loss = 1.012669, acc = 0.675739, test loss = 1.456593, test acc = 0.572437 >>> eros, creyendo, ya me querrin les veinde, sería menor letra tal, decratro; o no es otra cosa salirá que no benes pasar en ella, sino ido a ellos, sino pose consigo la conduciencia y mantamiente algun\nTraining epoch: 303 / 500, loss = 1.014450, acc = 0.675256, test loss = 1.458286, test acc = 0.572081 >>> e, acondido; ella cuántase temorremente a mis treindado esposa a curiadada, alegréis de contraría por ser fuía de tierra ormondo a Dulcanza, y que dejaba el mendado todos aquellos que puedes llegar\nTraining epoch: 304 / 500, loss = 1.016338, acc = 0.674237, test loss = 1.459941, test acc = 0.571784 >>> e, trios achidad mida? pidiendas que yo soy parecer Derloso y diversa y conocida y descansada, para que lee torné con un sator de dos vombazase, señor, y querán lo amigeros de aquellas partes había\nTraining epoch: 305 / 500, loss = 1.031212, acc = 0.669054, test loss = 1.459677, test acc = 0.571824 >>> e viquén rostirle que debió de refor del papa. Por los llaman a él sea la dos muchos desgracia. Yo soy más mía feala por cierto en dicha caraza, abierta hallarla con quien tan fácila serviente se\nTraining epoch: 306 / 500, loss = 1.014755, acc = 0.675162, test loss = 1.460715, test acc = 0.571392 >>> e\nque suyo consillán al cual venía entonces, tocaba volviese a imita y efeto, fue en buscar de su amo son fático? Todos hases caballero; y correo. Porque, si fuera casarse que llegó a tener menos c\nTraining epoch: 307 / 500, loss = 1.044435, acc = 0.665031, test loss = 1.456623, test acc = 0.571934 >>> erced mi entrejar se sollara de demajaba. Y así lo se ha dicho de llamar que tiene a sus locuras y entendimiento\nhe sucediado por vireban mería tan gran contanfa mescris el cuadrillero que Camila bat\nTraining epoch: 308 / 500, loss = 1.033551, acc = 0.669139, test loss = 1.449870, test acc = 0.573501 >>> erfue que había vista. Así que, señores pierres, sin menester que no te de mi tres desatusose trae fuera del mismo infierno desmantané incineste aclában; y pues a Zoraida Perper en a quien vivient\nTraining epoch: 309 / 500, loss = 1.024041, acc = 0.671860, test loss = 1.454274, test acc = 0.572429 >>> ercida, y! vuentéis de la que dices y esto el arremido de su escudo un habrero que feguia hubiélo volo bien confesor que por servido esto es ser que decía dos versos como yo otra me viese Anselmo co\nTraining epoch: 310 / 500, loss = 1.028135, acc = 0.670518, test loss = 1.453153, test acc = 0.572298 >>> e vuqué las oyónsela, no otra y su voluntad.\nEntorbé de sosiego mal andante, y que le preguntasen los pies el ventero a la cobradamitada comenzare, porque el ventero estaba desembarció Don Quijote \nTraining epoch: 311 / 500, loss = 1.027110, acc = 0.670307, test loss = 1.448671, test acc = 0.573888 >>> eras(Es. Qué fue vos, según las cortesanillas.\n-Digo decía, según descubrille, sino para darme para ocasión que de que en mi ánima porque no era muerto, hicieron a su brazo, hecha que quien las m\nTraining epoch: 312 / 500, loss = 1.020707, acc = 0.672428, test loss = 1.452277, test acc = 0.573592 >>> e que sidos señamido de que a su ama.\nRió la doncella, se fue todas aquellos que en esto liborarán su extura mesmo lugar, pues no sabía molino por que en ella sus padres; pero de ver a los merecía\nTraining epoch: 313 / 500, loss = 1.040623, acc = 0.666152, test loss = 1.448210, test acc = 0.574862 >>> e trpLsturantía deste dará, salióse en aquel cielo que ensilla, el pobre tan contento le haré que de manera que el mal un otro. La memoran que se llamaba o este muntolo recuesto aquellos que hací,\nTraining epoch: 314 / 500, loss = 1.049254, acc = 0.663781, test loss = 1.445625, test acc = 0.574252 >>> e FIVañe; alá lugar que debes condistro vestir en él, Lesil acabado. Pues no hay dado que hallase; mas los hizo lo que más fiñís y haré, y aunque otro pasaros que tenía bien de grande mañana, \nTraining epoch: 315 / 500, loss = 1.029535, acc = 0.669739, test loss = 1.444715, test acc = 0.574711 >>> e habdese sede ef? -dijo Sancho Sancho Panza, como en su voluntad, en los cueros, y Lotario con diligando o fueron, contré a hacer un grito ni más de hacerse has dignado, que Leonela decían que se c\nTraining epoch: 316 / 500, loss = 1.012162, acc = 0.675856, test loss = 1.447956, test acc = 0.573841 >>> e que sabía tuviese mucho puestos que nos fueson, y sabe. Pues yo depasió luego bastaba algún valle, el curo fueron a vuentra señas, quiete alguna. Por dos adornados le pareció, que cuando el oido\nTraining epoch: 317 / 500, loss = 1.009159, acc = 0.676894, test loss = 1.453091, test acc = 0.573556 >>> er tede, ncañadase, ensal, y cuánto más que duro, emperador y pruena y de aquel mujin recejaban, porque, ayudaríosos tienes orden en que el olqueron por sólgas, a lo que se había de recerna han a\nTraining epoch: 318 / 500, loss = 1.009410, acc = 0.677118, test loss = 1.450747, test acc = 0.574648 >>> e trpyodo, vengo, donde imagino a quien será, si mi fuestro se debándose, señor curao y música, y oblo de exa\nsidore, y me fácil él cuatro celebrados, solo pase a Camillano? Alló ponmes nada por\nTraining epoch: 319 / 500, loss = 1.018897, acc = 0.673207, test loss = 1.455820, test acc = 0.572686 >>> e? Ey, ¿quiranos escoturé tocados y mal recantado, los hechos contento, hagas ha de pensar y marcalle ni criado, y dijo a Rocinon entodo a la hora donde él no quiero castigar alitra de fama, y con es\nTraining epoch: 320 / 500, loss = 1.016001, acc = 0.674733, test loss = 1.450615, test acc = 0.573738 >>> e esqu(éla; singios, y dejado y por las mías nuevostre: a mí ahora que bien es de servir olvidándosa y voluntad viejo; antes tan liberosa estaba en quien se la dis muchaceria de muy gran honeste, e\nTraining epoch: 321 / 500, loss = 1.012834, acc = 0.675500, test loss = 1.453866, test acc = 0.572777 >>> eY, ««¿O en su lo que dijo méo, y que ella podía bien que se le dé el mismo de la márcia del rey Wamba. De que se cuento, había pone comido y el remedio, se tiraba los merandos mil visto, que no e\nTraining epoch: 322 / 500, loss = 1.012071, acc = 0.675989, test loss = 1.450209, test acc = 0.574237 >>> ercextrañas muy scabándome y de la mucho dieron de mi volvió, determa el hombre a estos viese las principadas en éstas, no achó lo señora donde le entegan parados, porque yo fue bien, temiendo co\nTraining epoch: 323 / 500, loss = 1.008245, acc = 0.676988, test loss = 1.451437, test acc = 0.573560 >>> e que sabes puce; señora difersaría aquella arecua? Asdonda- lo que oy la tierrao. Perdundó a los donesos, porque no es que alegá, habiendo mi amigo y gineo a tu parte anto a despertó, ejercaban, \nTraining epoch: 324 / 500, loss = 1.003345, acc = 0.678827, test loss = 1.457621, test acc = 0.572294 >>> e unjoso descubriero? Pero a esta tan malas dar a poner en esto de a sin hoy cortesanse a dar los brazos cosas que he oído, como otra vos, quiso decir es sontenta que decítioses que el galan en los o\nTraining epoch: 325 / 500, loss = 1.003417, acc = 0.678520, test loss = 1.456835, test acc = 0.573631 >>> eros, creyenda: estándorse era mayor licencia la merece, y no conseña a cualquier en elvarzado; y aunque estos de mi vecestarnas, arriba en la espada dela él, y por todos de verse que se lo estaba p\nTraining epoch: 326 / 500, loss = 1.006818, acc = 0.677430, test loss = 1.457759, test acc = 0.573034 >>> eros, clardida. Peoque sería hablar vives costió un poco mis barbocos que les acontedo y aparté, en será en ella; y puedo era una parte y quitañamendo en Cidente le dio en busca tan sin dermisa fo\nTraining epoch: 327 / 500, loss = 1.003484, acc = 0.678696, test loss = 1.456820, test acc = 0.572777 >>> eros; los raqueste en mi verde y caballero. Aquí te plandía quietaron los vayas, que no veo aquellas temerosos los buentos gastales y irlos lo que a la olenza y valor por los ojos: que has eres, de C\nTraining epoch: 328 / 500, loss = 1.005988, acc = 0.678065, test loss = 1.461379, test acc = 0.573236 >>> e\nhucén descubierto al cielo, no traía yo la muerto, será tan ser en la cuenta, asides deste mala formante casado compadre, y esto hace de ningún mesmo Señorio había retrado mi parte y a otra vez\nTraining epoch: 329 / 500, loss = 1.003334, acc = 0.678977, test loss = 1.461766, test acc = 0.571737 >>> ecY«Pesal, y dijo Sancho Panza al fién de sus geniedos; y aunemos, que me caemo su gúriado. Mi Cagiranda, cuando las empresas. Y sabiendo ninguno, señores, ni una a la narta de estorlia gracia en se\nTraining epoch: 330 / 500, loss = 1.003262, acc = 0.678964, test loss = 1.462685, test acc = 0.572892 >>> ercechazquellas; quiso, que será en esta hija se fue el buen y verdase de tracia que la que mis fino de casarse quitan sin espada esta más que atrebía obligare, y a un carto.\n¡Desdirá lleno; y teng\nTraining epoch: 331 / 500, loss = 1.025192, acc = 0.671189, test loss = 1.455924, test acc = 0.573204 >>> erced dice condade inferndo, le receja, no porque no me viene? -prosiese así se le bebió los los demás cuantos ha de cumplir; y lo que la lengua de los ojados nogle será atasfínome que fue ni guar\nTraining epoch: 332 / 500, loss = 1.026579, acc = 0.671157, test loss = 1.457207, test acc = 0.573081 >>> erespojos recogan los libros de caballerías, y sin ibllvas, y no se les ayólimos cuaper obieron todos,, ya este es pringuramo, tan darme con tan tritada, por tan esa discreción se despojoso puño a \nTraining epoch: 333 / 500, loss = 1.017199, acc = 0.674022, test loss = 1.455158, test acc = 0.573706 >>> erzpo desparame mucho tan ejudáramos mayorebir lo que yo ante el suerde por el tío sucencimiento, y lo estrecha y otras padres, vierron, yo me aun mi rejo que debía de ser me puedes pasada, y la noc\nTraining epoch: 334 / 500, loss = 1.008870, acc = 0.676791, test loss = 1.459442, test acc = 0.572907 >>> ercecho; y esta, cuando como otra vez sin descubor suyo y mucha convestica mis nombras, acabasen de del tarte se tardamera cubilla, y aunque sería de depares y creerdoy a oír por lo que mira; en lo d\nTraining epoch: 335 / 500, loss = 1.003474, acc = 0.679189, test loss = 1.458769, test acc = 0.573105 >>> e? Sanzón que las hocur llamándo iban en los ojos en su recófimó a todo cuadro aprieteos. Mas con la mones.\n-¡A Dos el túnió el canónigo-; allí ausen goberme, porque asmas comparan. Pues serer \nTraining epoch: 336 / 500, loss = 1.007844, acc = 0.677251, test loss = 1.459807, test acc = 0.572634 >>> en lo la hubir estudientes en que rogar a poner entonces lo suele de caballera. Másale de todo costal y esperar lo que había pensamiento que lo estorbaba de amorosos extruempen de verdad cuanto y con\nTraining epoch: 337 / 500, loss = 1.016369, acc = 0.673950, test loss = 1.456995, test acc = 0.573074 >>> e Florisa, viniosos, ni en espuenarte la honra de saber ser vista estas deseo. Mas, o jamás señor se miraban, porque ruego vea a novecó un encantado estan maneras acabar su voluntad. ¡Dicen, aunque \nTraining epoch: 338 / 500, loss = 1.024493, acc = 0.671903, test loss = 1.457070, test acc = 0.573434 >>> eros, creyendo que daban. En tanto que está nosotros cabillase escondecilidad, quien vio saber pararme caballero que está los días de los labios) que por metando solo, y en nuestra buena que fue la \nTraining epoch: 339 / 500, loss = 1.030290, acc = 0.669632, test loss = 1.454065, test acc = 0.574521 >>> erced dela, salindo quejo bien tener quisieron tres corgoras, quien soy a lo ánimo. No sepa, que abrazándola sobre suerte a ponerme. En peda bejar yo, y las saliesen que vuestra merced dice que habí\nTraining epoch: 340 / 500, loss = 1.017391, acc = 0.673895, test loss = 1.451975, test acc = 0.574581 >>> eros, cremeno, birna, y yo tenían del dijo Sancho.\nDigo. Mas para no hablar vénida tan en aquella osenga, desmayón, y volvía de poner en otra incomadiciné, y se encasarue con él me le habedo de l\nTraining epoch: 341 / 500, loss = 1.007165, acc = 0.677800, test loss = 1.452872, test acc = 0.575091 >>> erf? o, quedo que sin curebable de quedáis que si le dejó el labor, Don Quijote; y el famoso Juan de desdecirle, y descubriómes, como tomando en pie, él me lo han de reparar de oyo? Mira que despue\nTraining epoch: 342 / 500, loss = 1.000816, acc = 0.679728, test loss = 1.457598, test acc = 0.573718 >>> e edo!:\nPenda en a sus esperandas y Malleana con tu zún rontas de más presta hacienda, resucíado un espada sobrina el alma, tan cantasto en la cendiqued los demás, es ejerca mayor ya en mi casa; y \nTraining epoch: 343 / 500, loss = 1.007074, acc = 0.677252, test loss = 1.457665, test acc = 0.573034 >>> e que sambles preguas, puesta que conoces que la historia? ¿Quién eso nos traza de vida a que toda procurase a la herida; que temó señir -dijo Candin lebaje. Tornónese. Todo esto sea más volverse \nTraining epoch: 344 / 500, loss = 1.004214, acc = 0.678442, test loss = 1.458435, test acc = 0.573149 >>> e las e, a Dios sentó el duba. Pero él fuese todo aquella sentida y desaoba; volandos en fuerzase que con esos libras se acertarme de cuanto le había de estoria, que no es posilto. Yo soy todos a su\nTraining epoch: 345 / 500, loss = 1.006625, acc = 0.677542, test loss = 1.457115, test acc = 0.573912 >>> eros; fe que los que le aspetó Dorotea; pusiera más, que me quedan esarían; y aquel amado y cuando apartándose a camino de la catadumbre, señora), vino a conómigo, por si es que Anselmo sean de e\nTraining epoch: 346 / 500, loss = 1.023630, acc = 0.671492, test loss = 1.456617, test acc = 0.573975 >>> e tepbarete pude, en dejarme, impasís mueran, señor? -dijo Sancho-; pues viendo que los dellos venimos, esperanda conocido, y dijo que le ella, le ayeimajen el que me maravía al que dellos?\n-pues, s\nTraining epoch: 347 / 500, loss = 1.032439, acc = 0.668960, test loss = 1.454038, test acc = 0.574150 >>> eros; llas dorrrer vuestra mercea. Fimules con sosma a suelen, estoy blanco, que respondió: sus desmayo, que era mis padres, y a un ancaba de la misma muda descreida con yatrillas? –dórote de que sag\nTraining epoch: 348 / 500, loss = 1.022745, acc = 0.671622, test loss = 1.452483, test acc = 0.573888 >>> eros, creyendo en de llor, la hablara e ignoleza costumbrada considerra, quisiere que, sin duda, por heridueles; y pir mío que tilando en estos\npensalmente a lo hablando con él con deseo de la muerte\nTraining epoch: 349 / 500, loss = 1.011909, acc = 0.675890, test loss = 1.451048, test acc = 0.575522 >>> e génora -dijo el canónigo-; y así, le duerme en el. Pasiado, el acorrado de su grade mado.\nRespondió más la viniese.\n-Pues así es vuelto es volver a cabazo, el que nos volver.\n-Pues Dios -dijo D\nTraining epoch: 350 / 500, loss = 1.000381, acc = 0.679618, test loss = 1.455238, test acc = 0.574735 >>> en lo ciendar dimenque allí le dien natural en él el valeroso Don Quijote el cieno en deshabaluendo mío; y aunque deje muchas voluntades nos hace son acabado con mano a sus hijos. Esto es? –dijo don\nTraining epoch: 351 / 500, loss = 0.997408, acc = 0.681251, test loss = 1.455435, test acc = 0.574786 >>> ercamos, mernorrurla dél, y haces alfinizares de aquella menesterosa. Vervas estas solisfa por ella, sirtió, que yo iba personcia del hombre lo stega prevenirle, era espírituyamente y tan a tierra, \nTraining epoch: 352 / 500, loss = 1.000032, acc = 0.679952, test loss = 1.460148, test acc = 0.572994 >>> eros, creyendo un valle que le echamente, se tiraré a que pudiesen mi descansa, y con aquel ovarba con esperanza de sé ondon Pandan, y a la Toleja, que tan cara don Quijote en el primer canónigo.\nDe\nTraining epoch: 353 / 500, loss = 1.002012, acc = 0.678985, test loss = 1.459022, test acc = 0.573410 >>> e mide escuchegría a los acompañaros\n–Dígado, y no todas las bellas, de la fama para que despergable abierte que no quiero ver hecha este renugat –¿Quéjose que bien veasía habrás de oír una mañ\nTraining epoch: 354 / 500, loss = 0.999332, acc = 0.680287, test loss = 1.461371, test acc = 0.572544 >>> e que sidos sentas de cristiana, le dijo:\n-Por míes malas veces; y a cuanto se me lloves con esto desde mayor de la muerte del yamete se dijarse pasado; pero habéis de hacer mi persona, recipio tanta\nTraining epoch: 355 / 500, loss = 0.999959, acc = 0.680113, test loss = 1.458859, test acc = 0.573742 >>> eros, que Extraña, y la destenena es, y de mí decir lugar sin más que ponerse no méleció a él que había visto toman en camísigo, adelante, que nos puede hasto, pues no le contrate de su mal en \nTraining epoch: 356 / 500, loss = 1.022514, acc = 0.671241, test loss = 1.461270, test acc = 0.574062 >>> e que debía; temos de los armadurano; quizá, y no es es case, pero me falgable ballaróse cómo no le diera más que quería jarces, las de buen Rocinante, y con tornó a la muñica en lo compuse ni \nTraining epoch: 357 / 500, loss = 1.004974, acc = 0.677613, test loss = 1.459728, test acc = 0.574055 >>> e tres?»,»o, como, ya seniendo tener gusto y tener comeriza trovijo, preguntó en aquel mal a buscar\", que había de arreba atento. ¿Cómo rey más palabra por su barbero, después que liven fermosos a\nTraining epoch: 358 / 500, loss = 1.004205, acc = 0.678207, test loss = 1.463125, test acc = 0.573042 >>> e requ[tar dije yo -dijo don Quijote-, que si tiene que era más tan bien osara a llegaba, y para que están de oche juicio a su señor? Y lo hagó Camila el mengua yo de la entranda su pedir usada, ma\nTraining epoch: 359 / 500, loss = 1.001014, acc = 0.679206, test loss = 1.461700, test acc = 0.573129 >>> eY, ««¿reme que aquel liberán, la malencio fruta habiendo de lo que yo te sabió don Quijote se dióle puriosos muy bientes atajandas, y digo, antes que más hasta era sin repócimo lo que que yo vuel\nTraining epoch: 360 / 500, loss = 0.996710, acc = 0.680869, test loss = 1.464375, test acc = 0.572429 >>> e tuces juzo dan a su hijo en las razones que mi concerdonullas ademana con mucha hermosa ignera por el contozo que el moro, y más como ésta en compañada, y vio con el imbrocionos que las dolas espa\nTraining epoch: 361 / 500, loss = 1.001554, acc = 0.679226, test loss = 1.462484, test acc = 0.573295 >>> e que sabos te dice, señora, señoremino de saber que sirno renerendo conocer el fuertemente del buen entendieron nos contento yo no me abeje.\nNu aseo; saben entenerando de reto. ¡pro liber habéritad\nTraining epoch: 362 / 500, loss = 1.003328, acc = 0.678473, test loss = 1.462461, test acc = 0.573469 >>> e Fquin y amisna? ¿Tenqué se desengañado? Que tume? ¿Piensase de sin títumpe; sólo asiendo la como sin cantido, son manadas castillas, y quedará cuenta de su amigo un caballero de encantaminas. Vo\nTraining epoch: 363 / 500, loss = 1.000730, acc = 0.679329, test loss = 1.466144, test acc = 0.572832 >>> e ludiso, nos hue proveción movía había comet, ¿por qué será en la mano por vez es lo que se refeacian a la Santa Hermandad. Si diere ésta que ver, y otras hombres que he tenido de encantamento, \nTraining epoch: 364 / 500, loss = 0.996947, acc = 0.681050, test loss = 1.464697, test acc = 0.572820 >>> eros, cImaniente, que ya acabadase aquel monje tebían, verecer, que es que si el digurondo sin pereces yerbase, el más quiero que harán estaban la cabeza, que él tengo mi señor escudo; que, si no \nTraining epoch: 365 / 500, loss = 1.000724, acc = 0.679642, test loss = 1.464900, test acc = 0.573679 >>> e trpispuerrra! y venal, vayanza asimando los amoros caballes, hasta que después lo que fue en los bostados en cuanto hacer alegrando la fortuna, hasta palabra acertar a los ojos, dáleso limpierme cu\nTraining epoch: 366 / 500, loss = 1.006887, acc = 0.677195, test loss = 1.462065, test acc = 0.573536 >>> e\nqu(tenin albantare Marcínido Cardenio y que yo me diga que no te alfomajamiento e incomiso, con todo este cuminte la encerrara bien pensado algo en el bueno, que a mí muchos riciosos en camino, seg\nTraining epoch: 367 / 500, loss = 1.003520, acc = 0.678259, test loss = 1.462218, test acc = 0.573129 >>> erz), «Tuderanal–, pues, trais pueblos y cosas que al cabo de oí, se dió a tan rica mil mileno de Aguia y el amor yo soy alta, y más sin que las halíase, que venía en esta imagen y riscos, el alma\nTraining epoch: 368 / 500, loss = 0.995756, acc = 0.681219, test loss = 1.461694, test acc = 0.573952 >>> es, Y, seráridos, a ninguna silencio una grande ima que nunta que viene fuera de ellos en aquel yerbo en el día, son veces: sólo fue quedará conocido, dijo:\n-Soy muy molido, en estos que de aleir l\nTraining epoch: 369 / 500, loss = 0.996793, acc = 0.680637, test loss = 1.464571, test acc = 0.573192 >>> erezca!, mejoros de cristianos; y si has en castilla donde Pasados, levantados, les ayeba; porque es cosa a cada paes en que eso cuan babre fueran las para nos en una galera de Gran Famanteado, sin nó\nTraining epoch: 370 / 500, loss = 0.998790, acc = 0.680032, test loss = 1.465273, test acc = 0.572836 >>> e; que quizabra, ni que tan vestome hallaros, diglo; que yo sé que ninguna muy admirado que todos los le causó bres allí alderosa con su vida: ya sabiendo leer a la plática.\n-Esa no ver, que supart\nTraining epoch: 371 / 500, loss = 0.999878, acc = 0.679747, test loss = 1.463569, test acc = 0.572892 >>> e tru aqueso se premendo las iráces que se comenga guerre que poder de su casa, con otros se decía, y que si no fue mi hijo de su extraña amaja en tenó, que era Rocinante, que se había de reina en\nTraining epoch: 372 / 500, loss = 1.006140, acc = 0.677736, test loss = 1.459982, test acc = 0.573489 >>> e Fraz, y trabáns dijue mandad que le habían de decir a entendetra de los caminaros?\nY y es tan estaron con duras que el tradecholes se suforse fuera y vergüenzas, sabir y Don Quijote porque de su m\nTraining epoch: 373 / 500, loss = 0.998268, acc = 0.680318, test loss = 1.464111, test acc = 0.573109 >>> e las a míra y Carciola; y están en él, y mas sin menustendo: no es más alma! En ella; pero con tan baradoro y su esposo. Hase lo mube, que fue en que la verás, necesario que Sancho le fuerado a a\nTraining epoch: 374 / 500, loss = 0.997754, acc = 0.680561, test loss = 1.462195, test acc = 0.573975 >>> eros(pordí, pordeándos la mala llama trazan, y yo ha de ser justo que más armado de ábartó en un hombre así como Sancho Pendra yo las oídos y quedaron pensamientos habían la pretención en aque\nTraining epoch: 375 / 500, loss = 0.994951, acc = 0.681692, test loss = 1.467957, test acc = 0.571436 >>> ercicos verdino y Alivió la Tipinía no podrá la robar lo que le quedara para mé que aquella pasamenta que haya quien encantado»? Perdone mas hazaba tan remodo o parecer, tocaría yo -respondió don\nTraining epoch: 376 / 500, loss = 0.996578, acc = 0.680877, test loss = 1.470292, test acc = 0.572073 >>> ere? El mistró déjando tornada diere y verdad se haga la sin que hubo de ser generaba, si tiene a mí te respondió todo esto embusos el conocida.\nPreineron que los dañase del cabrero cabén bolitad\nTraining epoch: 377 / 500, loss = 0.993483, acc = 0.681818, test loss = 1.470246, test acc = 0.572057 >>> e oy perjuyeza mira; al alcancio la herida el rostro, y la que él la vio, al mundo es traidor, a mi ánima que he hecho mi señora que le vuestras acometidos a la daga que vos y perdición en quien es\nTraining epoch: 378 / 500, loss = 0.995365, acc = 0.681104, test loss = 1.468380, test acc = 0.572797 >>> e tapercultas al ensancín de ellos de Leonela; el cura como yo oblegada de verse ya se quedará -replicó don Quijote–\n-No ceñado a Dios, sino que a mi braza.\nEs dijes a que sin mucha malía la moner\nTraining epoch: 379 / 500, loss = 0.994436, acc = 0.681352, test loss = 1.468973, test acc = 0.572271 >>> er¿? si jazónandada que por ver a ser hombre; y palabad a Ctolapirieses que de las sacasesios, ni andamos de mis cebados de otra, y ella que las rescañas. Y si asiguieron que se consonaba bacíla, qu\nTraining epoch: 380 / 500, loss = 1.003188, acc = 0.677878, test loss = 1.466200, test acc = 0.573200 >>> erzpadal y lampueso los ahorasederas, no se llamase de todo aquello que te deseguarme de su cura de gusto: se uso que miran aquel puebro tan grande respeto. Pues ademár en esto dolverse, porque él ha\nTraining epoch: 381 / 500, loss = 1.000888, acc = 0.679107, test loss = 1.468966, test acc = 0.572223 >>> e\nparmes, que su mesmo puedo, de la culpa de las que yo, de más desear, proseguió hasta el peó, y que me quitármella. Y su del casos desvidad que el vuestra de mujer saltecieran, y no cabestros; pe\nTraining epoch: 382 / 500, loss = 0.995178, acc = 0.681327, test loss = 1.468194, test acc = 0.572793 >>> eros, creyendo entra se llamas a Dios y pensaba abajo, divinela: de que viéndole y replicó la que es un porquerad, pues, sobresal de caballería hallarse; y la ventera. Mada esta naturalcalidar a ens\nTraining epoch: 383 / 500, loss = 1.000652, acc = 0.679080, test loss = 1.465470, test acc = 0.572951 >>> e inqRiralilua! Sí:\n-Soréndome Donita, y pudo fuerte, que ponguen bien desgracia el rey de los caballeros anduerte de los deseos de muestras de su daño en el baño -dijo el cabrero. ¿Pude y por rost\nTraining epoch: 384 / 500, loss = 0.997310, acc = 0.680470, test loss = 1.467433, test acc = 0.572729 >>> eros, fardicía; y en un caso que don Fernando habiríado en oído, y así cabalén.\n-¿D aquella señora, y tenía ser reposicio de traidores.\n-Eso suele vuestra merced era razón seguir su honestilla.\nTraining epoch: 385 / 500, loss = 1.001253, acc = 0.678794, test loss = 1.465463, test acc = 0.573631 >>> e que sabo pudo convenía al ayora sobresaltan en ella torazón querido me hon contéis vuestro, que con mayor presunca aquella torada de mi esposa, de caballo tan vetirar, ¿quié la pueda denespanta d\nTraining epoch: 386 / 500, loss = 0.994294, acc = 0.681725, test loss = 1.467490, test acc = 0.573323 >>> e qyendí quedé buscarmen, pues, y puesto -dijo, perdóse el asno diladas se curto que hallándose que te, bien que hallaba tan desuchor yego, que como bubiero. Con uno de las más días. Uno de la li\nTraining epoch: 387 / 500, loss = 0.996469, acc = 0.680234, test loss = 1.467286, test acc = 0.573236 >>> e aqué me entantamente de tu en vergadme temer, déjando aquello indubí no la acompandad es mal ni comisiane entre él, ya Sancho mucho dejo a Ásembo un mala:\nin guítamo a los estribo mi sido quebr\nTraining epoch: 388 / 500, loss = 0.993309, acc = 0.681855, test loss = 1.467595, test acc = 0.573896 >>> eros, verntados, otras cosas te dicieren, y don Quijote el cura y tan hones, se le buscaba alguna, ahordó a él todas yo batanta algunas reinarnos, pues tú mirando las almas, que vuestra merced se ja\nTraining epoch: 389 / 500, loss = 0.991292, acc = 0.682850, test loss = 1.470351, test acc = 0.572536 >>> eros, creyendo; que ya tan muy mercedísero menos; pero con tan ventera, donde el guitora acertó en mata de los horadares algo conocer más ha des amada tierra de carás mundarse y perderla, saliese. \nTraining epoch: 390 / 500, loss = 0.991139, acc = 0.682447, test loss = 1.466956, test acc = 0.573422 >>> erceches, comonso\nDor Cidóla belqurablía? Apáddetos como la voluntad que cada uno como a decir Luscinesion a otra cosa ilusquenes que más la hablándola, que no se daba, para qué cóleraba a mi se\nTraining epoch: 391 / 500, loss = 1.011798, acc = 0.675528, test loss = 1.465055, test acc = 0.573924 >>> eros, creyenderrí, quesado; otras los de la alfoyar de Egoneo, por recebido, no me aventura de canón.\n-Pues aunque será llegar a nuestro deseos resempantes, a ponerle con él. Sienso siguieno, peso,\nTraining epoch: 392 / 500, loss = 0.993339, acc = 0.681655, test loss = 1.469574, test acc = 0.573687 >>> ern: Oh damas migarias pusos semejantes, véis, suyo, sin que no he visto en los libros de sus órden como yo hiciéper.\n–Si los altis, del eronio, puesta el justo pasado, todo. Guádóne duevoseo en e\nTraining epoch: 393 / 500, loss = 0.989919, acc = 0.682917, test loss = 1.471874, test acc = 0.572555 >>> eros, creyejos, vesmar, dejar a mi su hijo de las cosas que sobre un asmarse más suerte, o se acabó de parar lo fiero viene, perdió la orden de tan ruega tenía remedio.\n-Luevo cierto -respondió el\nTraining epoch: 394 / 500, loss = 0.991024, acc = 0.682338, test loss = 1.469317, test acc = 0.573240 >>> e caydo a su llevar: ose yo que no poga tenermo trabajo, que estima allí a pasarme en estos herlados aquellos que quizá, cada días quedas a Rocinante. ¿Que las habían, si no quería hasta quitarse \nTraining epoch: 395 / 500, loss = 0.994317, acc = 0.681555, test loss = 1.469232, test acc = 0.572852 >>> ermos, vesela en acabar sus de una razonaz: plevaré en el mundo. Y en lo demás adelante, Don Quijote, y el cura le diste de Luscinda y con tanto, ni fue por aconteces, y la españiende, y el alca, se\nTraining epoch: 396 / 500, loss = 0.998919, acc = 0.679716, test loss = 1.469595, test acc = 0.572263 >>> eY; con cines me enfaban de la Don Quijote; porque quiero yo alguno comenzó a desherrajero ahora que lo histerme de sus padres son serias escontecendezas en aquella principal como ello!\nYa estase por \nTraining epoch: 397 / 500, loss = 0.998068, acc = 0.679875, test loss = 1.472164, test acc = 0.572971 >>> e Fecio!\n¡Here. Rey estando antas a que montas de hablado, y que Lotario causaba; de mado, o la muelto de ese a memoria la buena padre de la caballería Laralán me nabeían digno de su campo mala moro\nTraining epoch: 398 / 500, loss = 1.014262, acc = 0.674753, test loss = 1.471443, test acc = 0.572631 >>> eros, creyendas, y reyarse, y tan consejere tan matrimonas de darme cantfucho; así, señor mío, y qué tengo pueden discreto redenal que hallaron día. Entrase yo puso y famoso cosa de ocho mejor, qu\nTraining epoch: 399 / 500, loss = 1.015444, acc = 0.673668, test loss = 1.461352, test acc = 0.574498 >>> e Fquina, Sangastantas y que yo derécíos de caminos, así, y solía de grande que segundo que tiene. Tan a esperando hallar un señor licencia, vengura.\nY don Quijote, cuando se vengan irbas, aunque \nTraining epoch: 400 / 500, loss = 0.998433, acc = 0.679955, test loss = 1.465405, test acc = 0.573837 >>> erced digo Salla., y más para que mi señora -dijo don Quijote-; porque se mirar confirsione que digo, y yo le trazadó mi amantero, el que os dice, Sancho Sancho, que tantos curan todos los brazos co\nTraining epoch: 401 / 500, loss = 0.992149, acc = 0.682302, test loss = 1.468579, test acc = 0.572923 >>> e que sabía y era una toda última cemparse, en fuerte. Bien nos engañarne a muerte, el cualquiera privoneción de aquel mismo justo que requebrez de todo con ejercicio. Hasta a zapetive, y la vida, \nTraining epoch: 402 / 500, loss = 0.989825, acc = 0.683089, test loss = 1.469683, test acc = 0.572464 >>> excechũino; y, ahomprásemo lo que me tengo dello, y no cansarse suyo encerradas y pesadumbre, y soela, y el Caballero deíseme a regancia que animatión.\nSenolla.\nHechas lo más lienza se todo juicer\nTraining epoch: 403 / 500, loss = 0.998546, acc = 0.679826, test loss = 1.468324, test acc = 0.573453 >>> e fabes, Meliderse, en hidalo mis desdichado, que no se puede. Catóniga y se vería alegre a oca le dijo: por liger doña, se debárdidos más tornes matremo; y así por mi pensar que tan blancado ord\nTraining epoch: 404 / 500, loss = 0.998245, acc = 0.679962, test loss = 1.469398, test acc = 0.574288 >>> e iquino.» y esto casi escudo en el robo, lo cual es más doncellas tan buena cosa; que no se puedes quitar los prícensos estaban a la mano y agradable, y pluma quien ha de ser a sus años es uno gana\nTraining epoch: 405 / 500, loss = 0.995324, acc = 0.680694, test loss = 1.467108, test acc = 0.573837 >>> e teperlicias. Llos castiva a sus cosas descomunalca, pues está muchas deseandas, a quien dijo:\n-Quíono de tanto intención más hombre y libral famada y cortásemo lo que habíase voso, señor mío,\nTraining epoch: 406 / 500, loss = 0.990926, acc = 0.682807, test loss = 1.470700, test acc = 0.573501 >>> e?», crordación que ha des por de Amadís con algún unas más en las hacienda naritoras; que yo himoso homar llevado, donde de aquello. Túgame, sin dar, si fuera experiencia.\nDuelas, y así erejuyó\nTraining epoch: 407 / 500, loss = 0.989735, acc = 0.682760, test loss = 1.472679, test acc = 0.572437 >>> erg(que y, quera que la conociólo caer estaban de la espada nerención pasar con el de no Nuveridar, salieron a lo que por que yo parecía más –dijo Sancho– \"esto primero, y cómo estaba. Llegando el\nTraining epoch: 408 / 500, loss = 0.997985, acc = 0.680471, test loss = 1.470470, test acc = 0.573410 >>> e unquelos en la modo que eran enarburados, ballitándolos uno, cuando le conmiñose a decir que él le dio cura de más edidad semejante caballero sosiego sobre Rocinante, y dio vos se atadaba, puén \nTraining epoch: 409 / 500, loss = 1.000877, acc = 0.678844, test loss = 1.468706, test acc = 0.573544 >>> e tade begarlas prestosa, y no acabásdote habrá, entregó de cato sin tener más la embertida, ni te tiene. Pero Dulcinea, que me acabándola la haréjiliesto en procesión, la cabeza, y, hábate el \nTraining epoch: 410 / 500, loss = 0.991545, acc = 0.682289, test loss = 1.468382, test acc = 0.573050 >>> e vuestro valentado, y Corádó a Sancho, que me hacía ya memoria todas las muchas nuevas que le acomodó don Quijote el juicio!\n-¿Qué naceso, teniendo como la cólera, supo, sino a enojo en estas ve\nTraining epoch: 411 / 500, loss = 0.990877, acc = 0.682772, test loss = 1.472749, test acc = 0.573038 >>> eros, asmpero de otros, y el muelmo sustéis a los cuentas como el que son ecebión, retuviéndole ni criado, que andua de que pudiera que conclojas, a la espada y gusto de vuestra per de ansí, habrá\nTraining epoch: 412 / 500, loss = 0.988529, acc = 0.683459, test loss = 1.470995, test acc = 0.572809 >>> e las) nuche, toratrión), los los das en vango a su raca a lo más experituna han de ser en élgose tan vistos, dijo el ristro se las repómivos estuviese en ahora cado vuciendo a la cristiana mejarte\nTraining epoch: 413 / 500, loss = 0.988531, acc = 0.683116, test loss = 1.473394, test acc = 0.572093 >>> e que desdúndios tuvieron cadón desgracia de una encina si es no hice, debe servarse toca; y así, me puede hacer, perdona otro crueles, Sancho? Luega ayoda de un ancima en otra antes he ancha de ser\nTraining epoch: 414 / 500, loss = 1.016250, acc = 0.674480, test loss = 1.470954, test acc = 0.573062 >>> e vique todramaba del reino, que éste, que la que les acomode se puso extremado en su parte por su espada con Anselmo, no era ni amiga comunica, se hacían. Yo soy persuando otras delamente para busca\nTraining epoch: 415 / 500, loss = 1.003183, acc = 0.678056, test loss = 1.468202, test acc = 0.573212 >>> e, Y No Visí Sancho, vino a ser rey en aquel lugar, acomodada a toda criata de sus deseos de pelota suyad, porque en la irmendida que ya Sancho; lo que caver mído, amigo Sancho, que no fue intento, c\nTraining epoch: 416 / 500, loss = 0.995397, acc = 0.680844, test loss = 1.469530, test acc = 0.573548 >>> e trpisote lo hirable, que el miserable como altaque. Viéndole vuestra cosa y el cura y volverla con robos; los cuándo, que era vencedora de añadilidminosa desderes de su caballería con el pensamie\nTraining epoch: 417 / 500, loss = 0.999563, acc = 0.679764, test loss = 1.471295, test acc = 0.573006 >>> e que sijos de San Juallor, y aquelle nemirarinarse de querer poledo; porque no\nse menos barbaron ovenedo a después de hermosa con él me dice, tengo por cierto que tengas venchoso respentiente; otros\nTraining epoch: 418 / 500, loss = 1.006735, acc = 0.676676, test loss = 1.469045, test acc = 0.574442 >>> e aquentadorése que tiene tan en esto, sombres que le había aporede en de demaría la honra antes y grandes caballeros. Sancho se la vuestro se acogió en mi parer bastaron a funto, no era la sido Se\nTraining epoch: 419 / 500, loss = 1.026623, acc = 0.671040, test loss = 1.463246, test acc = 0.573829 >>> erzo, llese; y esta, ansinraré en contra algunas mús, y, si él ya había hecho mas buenas personas pedrados tantos, porque, a ésto, y poco en algo más de la silla de\nCasario se acartarnas y del do\nTraining epoch: 420 / 500, loss = 1.020493, acc = 0.672292, test loss = 1.459990, test acc = 0.574691 >>> e unjos que buscara con él en su temor, y ésas uspento aquí tan remedio querer, más aquel finil dos horas. Canía que le había sido propio –dioba de lo que pusiéredos y renalas caballeros no se h\nTraining epoch: 421 / 500, loss = 0.995221, acc = 0.680922, test loss = 1.460521, test acc = 0.574980 >>> e que sijos y con alma más vosota traíado en él con lugar sin una pasado, perdió dele consoque a dos trecunció a la anda un cierno que es la pena que estaba desengaño a lo que a él le echó advi\nTraining epoch: 422 / 500, loss = 0.987863, acc = 0.683901, test loss = 1.465329, test acc = 0.574047 >>> ernos; pero si nuestros vosos ustos, y espena, antas que ahora estodo, a ponerme la mujerea del modo le mil caballo, vio a sanido y fue en seduera que veréis, señor don Fernando y Camila toda la pena\nTraining epoch: 423 / 500, loss = 0.987460, acc = 0.684396, test loss = 1.468774, test acc = 0.573070 >>> encho ca¿paría aquel libertad, desamparazos.\nEn esto, deseabas;\nmendítesas en vencedor hijos: el manto, para que él se los cansaban el temerosa caballero a Leonela. Gábiladamente:\n-Dedían eso, es \nTraining epoch: 424 / 500, loss = 0.986499, acc = 0.684340, test loss = 1.466770, test acc = 0.573865 >>> e trpisota la mozo. Pero si él lo podía alguno.\n-No torné al otro, y sucedido aquellas persas: dámoso que saliemen, determinó de cobrá que si es buena para palabra, y contra por entonces que sola\nTraining epoch: 425 / 500, loss = 0.987674, acc = 0.683593, test loss = 1.467168, test acc = 0.574142 >>> e Felospur. Mas ni en mármolla, el halló, vino a mí y el colos marido en respeto de no queréis de lingres demenos desconciencia, pero no dejálon más neña, se podría ser de sus ojos de decir:\n-¡\nTraining epoch: 426 / 500, loss = 0.990390, acc = 0.683197, test loss = 1.470590, test acc = 0.574347 >>> e vique se laráseme, o quede en la jaula, de una buscar a nuestro a decir que vinieron todo sino en él ni leguá creyérono que acertar a verame a Don Quijote porque si fuera es que me da carta que s\nTraining epoch: 427 / 500, loss = 0.994259, acc = 0.681377, test loss = 1.471912, test acc = 0.573536 >>> eros, creyendo, bustida, con nada y a que no hallará... y con aquel varía del cura? Parécemole: ese porque creo que los cuales no quitámble más en esta bacía es la de oloraba, para caballero anda\nTraining epoch: 428 / 500, loss = 0.991013, acc = 0.682724, test loss = 1.467555, test acc = 0.573327 >>> eres Egrte)hásese suele pedía puso con la señora, hizo cuanto más cuán magó parar lo que era volver a perjuicio breventillas en jumanado: así como las ibll de habrías en los dellas y decir majo\nTraining epoch: 429 / 500, loss = 0.992098, acc = 0.681862, test loss = 1.467066, test acc = 0.574763 >>> erced dice que dice que dijo que las razones, menos menesteros. Decírse, se apeó, que sería esperar lo que decís, y a la puerta dos pararsen, y aún, y vuestra persidas. Réloso ruin mis daque cuad\nTraining epoch: 430 / 500, loss = 1.010144, acc = 0.676806, test loss = 1.466263, test acc = 0.573809 >>> e trezos, comos estos ya noveles en la cabeza, hasta dos torno en ejercicio, ni en los en éposos contentíssetura.\nY atían, y con él me desárzó mi entieran que un rostro; y así, más que hacer lo\nTraining epoch: 431 / 500, loss = 1.010194, acc = 0.675634, test loss = 1.467179, test acc = 0.573347 >>> ercicos; y ello el el cueno, por cada antó vama descanso los caballeros; que esto parecía cuándo en ella, que dijo con Romisma yo nuestraba mayor, porque venía y Viempo en un aprobán de asalada bo\nTraining epoch: 432 / 500, loss = 0.992958, acc = 0.681822, test loss = 1.466259, test acc = 0.573378 >>> e que sudases, y yo, retando en su retuviéndolo caucía. Viendo el nombrólme, como ya de qué tien y encejando y el rocada vista y solbante y queriendo, que, comenzarál levantalle precimientolla, bi\nTraining epoch: 433 / 500, loss = 0.992392, acc = 0.682013, test loss = 1.465779, test acc = 0.573714 >>> e capías? ¿Qué emosios. Es menos que fueve grande que la habéis preguntar de reina y forzada y de quien le encaminó en el sos. Alsengo, en ponerme en mi correrme que primero tenga\nde verla propio g\nTraining epoch: 434 / 500, loss = 1.001411, acc = 0.678839, test loss = 1.466546, test acc = 0.573691 >>> erf? Murenculas; y requiría alguno que sabe naga de un fin me habéis muestrese ese mozo y de la sobrina que allí me digo; y quedándose a topar dolle hagan y merced, porque ya no se mueva de mi sang\nTraining epoch: 435 / 500, loss = 0.994907, acc = 0.681154, test loss = 1.466661, test acc = 0.574391 >>> e es y, dicendir muy de don Quijote el que la suerte.\n–Y ¡molo Cersantes; y adorne de todo oventaje a ella alguno pasá en troso el suyo alguna, yo te he de estar algunas muchas y valerosos caballeros,\nTraining epoch: 436 / 500, loss = 0.985630, acc = 0.684406, test loss = 1.467683, test acc = 0.574320 >>> eros, crryedirin, que, no lo concedía que esta saludas alto donde ayudaban en que ellos me lo sobrasa, hallé un ajaló de mi criado, como yo quisiere la priesa, dobándoses, así a mi señora.\nYé me\nTraining epoch: 437 / 500, loss = 0.985750, acc = 0.684079, test loss = 1.469975, test acc = 0.573406 >>> eros, un halamen le diese lugar y desaconte deshado, y que esposo de tanto al ordenezo, a éstres, según yere muy recibijimiento, que Leonela dejaba, como es ser año no hación haciendo al recinal; y\nTraining epoch: 438 / 500, loss = 0.984965, acc = 0.684916, test loss = 1.470563, test acc = 0.573782 >>> erced dice por de don Quijote hallarle nombre de Fraz; que amigo, acudir suelgas ninguno y ahora se mostró sacan con la infanta, maldecir que es suyo, que jamás le cuéntame de ella casa, cuanto más\nTraining epoch: 439 / 500, loss = 0.984945, acc = 0.684505, test loss = 1.469753, test acc = 0.573881 >>> e treyó. Y a la ventara hablará en esto me poneros que allí lo siete se acertar a él no hay mal el costo se los he dicho a Sancho Panza. En locorrinte, amigo aquel loco, de mi vida, y contenía que\nTraining epoch: 440 / 500, loss = 0.986286, acc = 0.684444, test loss = 1.472254, test acc = 0.572781 >>> ercedz, o, ejello, que comía el baño por amenar por mal, donatueses y costrimar estos veas lejos! Pan Pasados me tiene por Amaderáseme la deshosa conjeturales a enemila alguna fe que por esta quienq\nTraining epoch: 441 / 500, loss = 0.987416, acc = 0.683915, test loss = 1.472729, test acc = 0.573651 >>> erced dice dengultada que yo me deventanda mi que mirando Sancho al cabrero, que me queréis corar donde las comean mi esposo enamorado, y creí más cal de ir a la caballeriza que el que este recato y\nTraining epoch: 442 / 500, loss = 0.991681, acc = 0.682646, test loss = 1.474308, test acc = 0.572544 >>> eros, como lo meso de la invención de mi casa; porque arengasen; si la he dicho, sin alcances, le cubro bien tarría aquel día no había quitado vuestra neceo; pero vuestra merced, profencio. Lo cuya\nTraining epoch: 443 / 500, loss = 0.986320, acc = 0.683956, test loss = 1.469458, test acc = 0.573619 >>> e ed! nu vinorse y tan Lomorin, se me le va él? Los dicienes, y Luscinda y ves y otro mejor vivarían produendo a Sancho a la buena sean maravillas; y con esperlica fuerte del suerte.\nDon Quijote esco\nTraining epoch: 444 / 500, loss = 0.983222, acc = 0.685224, test loss = 1.473602, test acc = 0.573991 >>> e proz y el Sancho, y dé a su camino Don Quijote señor (y es caballo andante órzarencia muy entragroso ocioso? Sí, no me advierte me dan mucho poder menos.\n-Esó deciado de aquellas señates que en\nTraining epoch: 445 / 500, loss = 0.985362, acc = 0.684398, test loss = 1.470479, test acc = 0.573616 >>> e trezoy estos debe venir cuidado de tan bien sin entretenido el mayor, y, a ser servido que somienta en suerte, sicos que ellos leían en batalla que le pareció que dopos caballo, quiero que si en un\nTraining epoch: 446 / 500, loss = 0.987367, acc = 0.683550, test loss = 1.474172, test acc = 0.572907 >>> erced diferundos secude, sinviera, dijo Don Quijote, que tantas sabaya, prebe era encaminarse, o esmayo, en aquel haciendo, en pesar de los dos mesmedión, en el viejo que con tanto compuerto,\nen sus a\nTraining epoch: 447 / 500, loss = 0.997279, acc = 0.680471, test loss = 1.474914, test acc = 0.573505 >>> e\nqu[́an rey restanfentar más llemas. Si y cuando verábll de la noche. Y estas fueron de don Fernando de no ver la suerte vueldo a sacer el del hombre largamos de aquella iguales desta hon afaña por\nTraining epoch: 448 / 500, loss = 0.990518, acc = 0.682497, test loss = 1.472173, test acc = 0.573228 >>> e locas mas bien cada para la maravilla, y no dejaban.\n-No, él toda su encerrando, verá, que por buena que fe que me vio fue sobre la valiqué.\nY él me quejo, en la fueguen que por eso; mayó el dis\nTraining epoch: 449 / 500, loss = 0.994086, acc = 0.681664, test loss = 1.470921, test acc = 0.573782 >>> e que sabía na sabedía que le obligro Sancho de villas y flores tan siglos, importancia buslate. Oyendo canlos; y en que fuese mucho del gobertado si ellos no pido ser a su honestidad, y el almenurto\nTraining epoch: 450 / 500, loss = 0.991291, acc = 0.682111, test loss = 1.470006, test acc = 0.574367 >>> eros nchor, si ya nada. Y hablando a Parre; y así, prosigue visto. Vendiento en tanto que este pensamiento castillo, y Sancho que la fuerte corriendo su hija de las deshoncadas, no las demías de la c\nTraining epoch: 451 / 500, loss = 0.985518, acc = 0.684553, test loss = 1.472493, test acc = 0.572856 >>> e tocjujo de muero colgada me entré en otra manera mía, hiscondo nacibió donde con habejo de fuerza un toco, puso esta que el mío, hayan aparte, por estar ida la enemigació, y no pedimor de señal\nTraining epoch: 452 / 500, loss = 0.988145, acc = 0.683217, test loss = 1.473819, test acc = 0.573912 >>> e ungoso, la Golzela, fue moros acordándole en oír las tencillas de hijos\nde aquellas manos, dijo en cado! -rigandódámidolad, que como eso? ribos se oyeron con bien, para hacer fuera de hacer la ca\nTraining epoch: 453 / 500, loss = 0.988664, acc = 0.683002, test loss = 1.472397, test acc = 0.573766 >>> e, rcucto del amor que con la Náagüelto entre desacberales; pero, vuestro sentiros que no me decían, y le hubiese prinde tiempo ni atrece siquiera que la de mengua es en ventura y alta, para mi dese\nTraining epoch: 454 / 500, loss = 0.983826, acc = 0.684813, test loss = 1.474783, test acc = 0.573058 >>> e, a Zoraidánsos, porque no quemarja y sanitaré en el suerte, por no pasado, señores, o lo habéis de su ferme que no deja inventora me tirmo en tanto que un poquridado a parar quiero que hasta ya m\nTraining epoch: 455 / 500, loss = 0.985478, acc = 0.684562, test loss = 1.476547, test acc = 0.573101 >>> er tedínima menos ruspíban. Trenzó sin afinmamon bien y al oidor: movéis en este castillo? ¿Ta toda la boca proveineso quiera no poder por me piense se acescaba se así haga, pues, la primécía de\nTraining epoch: 456 / 500, loss = 0.987917, acc = 0.683462, test loss = 1.474480, test acc = 0.572820 >>> e que sambos tramaros tan sierraba a sublos y señana mi padre, subió de una labradora, el retando hemosado a ver a comeroso desta veniente no habréis prinde creer que siempre no respondían castigar\nTraining epoch: 457 / 500, loss = 0.990182, acc = 0.682649, test loss = 1.473574, test acc = 0.574055 >>> erculhas, como sora cuando le podía en otras razanes y hercedes, se harlo con esto o en estosio ve escribe por donde le dirún en sus armas mueremenza, si no es volver a las tienen de Baes de que Roci\nTraining epoch: 458 / 500, loss = 1.018934, acc = 0.673611, test loss = 1.473875, test acc = 0.573983 >>> eros, clares, y risarlos vesosa de lo que me da señora que he acontecho, si ya dejaría a entender lachona, y a él me hubierin en sus ejementas vechos, que vamas que estuviese condición que me falta\nTraining epoch: 459 / 500, loss = 1.013414, acc = 0.674306, test loss = 1.471177, test acc = 0.574027 >>> eros, carto ni que tendría señal mi escudero, la parte, fuera de hacer mas y don Fernando que vuestra merced acometiera entonces la ventera que no comenzó a decir horrar. Esta -dijo Sancho-, que hab\nTraining epoch: 460 / 500, loss = 0.993480, acc = 0.681730, test loss = 1.469155, test acc = 0.574430 >>> e vho, y Poner yo soy lo que hasta en junto. De mí sin extremo desesperaba razón que hay en el mundo. Porque era Dueste que la fuicio. Yo lo replicó Don Quijote encretadigo por en la espejo del duen\nTraining epoch: 461 / 500, loss = 0.984216, acc = 0.684546, test loss = 1.471301, test acc = 0.574656 >>> e habde dejo y etran de mis buenos, y en lo que yo me volvieras que en algunas reyes. Rigoos de las entrañas del cabrero, que, aunque se acomodó prestida mucha gran por tencio de todo aquello que vue\nTraining epoch: 462 / 500, loss = 0.986804, acc = 0.683875, test loss = 1.471614, test acc = 0.573244 >>> e que bas dí vengulca y la mano, de ambrar los ojos hizo con mutes prudencia; pero que no dejále, digo en altas estas cosas que así lo había muestrase que serlo podrado y de mi ofrecimiéndose pró\nTraining epoch: 463 / 500, loss = 0.987834, acc = 0.683560, test loss = 1.472755, test acc = 0.573881 >>> e ed, luego, sino dosquestrado y ocasión, señora de aquella que me pareció que aquel y polveros?\n–Yo seyó yo. -¿Pá, consotó el otra me acompazada de su barba de bendente y verma con él estar sus\nTraining epoch: 464 / 500, loss = 0.980843, acc = 0.685978, test loss = 1.473392, test acc = 0.573572 >>> e que desdúmido y manera porque no sabía apartaciones caballero no.\n–rebada en esta voluntad de qué pie de tan rica con esto de orejen hayan –dijo Sancho– no, ¡olo debían tan buena le dijo:\n-Mucho \nTraining epoch: 465 / 500, loss = 0.983937, acc = 0.684748, test loss = 1.473249, test acc = 0.573940 >>> e trezoy esto le veas amado a Anselmo que si he dados de mucho, ya los deseosotes que en la vida, el cuerpo himeritado, te he pogido a las razones de la puerta a susvenures y peleas de la experiencia; \nTraining epoch: 466 / 500, loss = 0.994057, acc = 0.681453, test loss = 1.475879, test acc = 0.573157 >>> eros, creyéndo: aquél pensaba que tienen el carro, que pareciéredo y tenernos a pie como su hijo, y quisiere fuera de vuestra me que sería caballero andante, con otras buenas destos lecieron, dijo:\nTraining epoch: 467 / 500, loss = 0.993814, acc = 0.681267, test loss = 1.471575, test acc = 0.574134 >>> e\nRigos des concermoso reposo, si para otra cosa, señora, ¿qué vale de aventural de don importando, lo importuce la priesa, no llegó en un licro en casi la hasta dérerte lo que era hablante días d\nTraining epoch: 468 / 500, loss = 0.986492, acc = 0.683753, test loss = 1.471073, test acc = 0.573299 >>> e que si señan; también será en hacer otra cosa que algunas segudo:\n-¡Morestó de su amigo; sólo salí de todos.\nBlababan mi, que queda plabísemos acabado la mano.\nPreguntáronsella en más partes\nTraining epoch: 469 / 500, loss = 0.981238, acc = 0.685884, test loss = 1.474905, test acc = 0.573390 >>> e cerdes pedirgas partes ne enfenualmonen a su encantadeacio, que sirvible, contra barabla, toda la luza. Llega, que no le acudicaba decir yérrio que no está salir no es encantado orden, y de cuantos\nTraining epoch: 470 / 500, loss = 0.980790, acc = 0.686115, test loss = 1.475037, test acc = 0.573263 >>> e diquémos: el merició y vivieron acontecer lo que su hija con era le sentiran; otras alborosas con aquellos\n-Oh fuquélesa en el guijando Vivo de los cadas nuestras y mentirosos me acuerdo, habiendo\nTraining epoch: 471 / 500, loss = 0.981701, acc = 0.685978, test loss = 1.477055, test acc = 0.573509 >>> eres Ẽpor, a el que esta servicio de la Santa Hermandad, contratún te que yo soy por desdedo ejé, dijo Don Quijote, como él le daban con la entrañe: y Sancho Panza, y aseimaron en el suelo, se pod\nTraining epoch: 472 / 500, loss = 0.982873, acc = 0.685215, test loss = 1.474779, test acc = 0.573801 >>> erced cardandera me ha contado venturíado esto, de modo; y pasador el cuando Sancho, porque ella me respondió la buena para creer si estaba, Leonelcra. Después de haber de hermosa».\nPesdió Sancho.\n\nTraining epoch: 473 / 500, loss = 0.988140, acc = 0.683406, test loss = 1.480535, test acc = 0.572255 >>> eros, cerno, que, aunque el desenvol lica vuestra merced, no se ojos y haciesen labradoro dijere a mi va don Quijote enviaran la bendició de lo que a su amo me muvidó mucho su extremo, cuando malicis\nTraining epoch: 474 / 500, loss = 0.990238, acc = 0.682464, test loss = 1.474101, test acc = 0.574268 >>> e, cridde? imo se que a cuando en la descon escote que te lechabren, cáremos sucedidos está cuidado por ligno y les piden, fue el sospeceble, porque fuese, es tanta venganza de todo sino todos los de\nTraining epoch: 475 / 500, loss = 0.982974, acc = 0.685391, test loss = 1.477132, test acc = 0.573873 >>> e reques muestros, tan a los galeotes.\n–Ya os he desta vestan. Sea que, aventures de la batalla era que todas las cosas que su razones día era ellas de la vida sus provino y señores en llorardo al re\nTraining epoch: 476 / 500, loss = 0.981356, acc = 0.685751, test loss = 1.478813, test acc = 0.572512 >>> ercescales. -dijo yo menos, cuando los visos, donde quedara por la puñada, que fue rompio de oír antes que si te dio dejar que era parer la quilida de la case, te comenzó a reforzana) don el menos; \nTraining epoch: 477 / 500, loss = 0.981265, acc = 0.685565, test loss = 1.478583, test acc = 0.573457 >>> erced del misto, y luega, comenzó su lano tomar la buena cosa pasaba\n–LeTalma para mala, que entonces Condencio que haya Castilla, a mi fuerge por puño lo hubo, porque si yo se querido le habían vea\nTraining epoch: 478 / 500, loss = 0.979964, acc = 0.686123, test loss = 1.479974, test acc = 0.572409 >>> e verz y, y reviaba en un pontado: temo verdaderos? si Luscinda imbrazadiga. Díjote el revoqueza, que es el sutinerimo. a la verdad, con tanta soledad de tu siend mía, o le acuerdo el cielo de mi vue\nTraining epoch: 479 / 500, loss = 0.981086, acc = 0.685878, test loss = 1.479429, test acc = 0.572915 >>> e que debas tuviese por trachase\nen tien, algún valle y satisfecho de Zoraida, tan génerme, sin poder que a mirarle a entender que su primo, y a mansia. Las plática, dio pena por ni poder lo que, no\nTraining epoch: 480 / 500, loss = 0.983165, acc = 0.685050, test loss = 1.482312, test acc = 0.572385 >>> erced diclas? Lo cució que supo que era el que fuese.\n-Por parecerme\nque ese recondo, la rodén, donde este gineo de mitad de Don este pasó Anselmo de Don Quijote la respuesta para mis bongunos tosas\nTraining epoch: 481 / 500, loss = 0.986256, acc = 0.683974, test loss = 1.477118, test acc = 0.574181 >>> ercespalatos, o tratar cimalo\ndesde él, y aciertos si la otra vez los hermosas y lanza, por se posa y la tierra, a dé por vengador muy bien como era algunas de Rocinante, puesta en el valentro podía\nTraining epoch: 482 / 500, loss = 0.979792, acc = 0.686136, test loss = 1.479547, test acc = 0.572884 >>> erced, ley como prementó a Lotario del gigante, vive unas y las cosas que en su amigo; y esto secose mi compañamente, faltaz de caballerías, de encerrarle de un tan viento el estardinerao, glarsa. T\nTraining epoch: 483 / 500, loss = 0.981868, acc = 0.685423, test loss = 1.483312, test acc = 0.572658 >>> e, cijrrominio, que determinaros corredo cuando en llante para son éste, la mar. Tendada de agravios que estaba deseguar ir contra amarga, ni entrasdos; de aquel día de mi señora que perdería saber\nTraining epoch: 484 / 500, loss = 0.995042, acc = 0.681050, test loss = 1.477005, test acc = 0.574023 >>> ercamupllas quisó en el en las veces mayavegunes de lo que el dar cierta me adelante es poco, o se acabasen. No seria a memoria volver por trastido claro. No los vio que yo lo mal, fue amante, diré q\nTraining epoch: 485 / 500, loss = 0.990895, acc = 0.682126, test loss = 1.480509, test acc = 0.573770 >>> e, rdisverados y trabajos, que leían sus oídos el rosa a Lotario, diciendo: Agrade; el vaquir a que sus hererlicido\nmismo, y él tomó su cansanciada, orése aquella propia. No sé ausin. No se hací\nTraining epoch: 486 / 500, loss = 0.983136, acc = 0.684630, test loss = 1.477572, test acc = 0.573687 >>> erceshezos,drindas; y, quiero es -respondió Sancho-, arteréis, Sancho amigo, que no tuviese en el aire, me puede desaudar a nadie pos imaginares, por celoso que si es fuerfe un prazo»; pero el mano d\nTraining epoch: 487 / 500, loss = 0.987011, acc = 0.683384, test loss = 1.480055, test acc = 0.573323 >>> e que sabía que Dorote a Zoraida, que pon Rocinante para procurar en la esperanza de mi plática y Ansel.\n-Todo se me tratas, a sus cobastraz: en qué se desatútado a quien priora bien, y viéndola e\nTraining epoch: 488 / 500, loss = 0.981689, acc = 0.685617, test loss = 1.478914, test acc = 0.572551 >>> ercesplaza y ella y mederes vocesiamente apeá, la diaba, aventuras porque no se dos moneral en faese. Vágame justo de gracios, mi en que su caballero andante, dando más se pusos días me digo que yo\nTraining epoch: 489 / 500, loss = 0.977736, acc = 0.686827, test loss = 1.479389, test acc = 0.572844 >>> ezmas y primerante Bien dormir a ver en espacio de dos hidas en su incubierta de la sintión de Pedro. Ya era Garzala, y maravió a pesar de la cual el cozo prestezos, que nos fueran comer muerte de pi\nTraining epoch: 490 / 500, loss = 0.984591, acc = 0.684481, test loss = 1.481998, test acc = 0.572789 >>> e mide erañadades, a mi el era de los reyes hazaña amogo y afincian que ella fue moro muy buena me están hecho la provechidad con los deseos, y como tú en vas fuente de esposa, que se ocuraba hacen\nTraining epoch: 491 / 500, loss = 0.979455, acc = 0.685943, test loss = 1.477746, test acc = 0.573861 >>> e Fentunduda tar todas las letras, se dejará rez que, con todo eso; pero a mis despiaba bastante, todavísistaran delimprados, y, encomendándon, con todos un briero, sin ser tan cripulitad cruén tem\nTraining epoch: 492 / 500, loss = 0.983447, acc = 0.685019, test loss = 1.481574, test acc = 0.572907 >>> erca dejar su meducidor de sujería al comisario, para que si ya no se concedido, Mirando el esperar, si fuera alguna mía, sobre hijas, y los demás arrieros y los sino llegó a pie saliesto que yo hu\nTraining epoch: 493 / 500, loss = 0.990109, acc = 0.682212, test loss = 1.477022, test acc = 0.573169 >>> e que su llegó con sus ruegos y en recal do Don este tuve de mis cosas parte. Ye volvimientole a un ventero hablando, cuando elevergro en toda su espada, otra claros, acareciese a pesadura, ruin no, d\nTraining epoch: 494 / 500, loss = 0.981272, acc = 0.685296, test loss = 1.480171, test acc = 0.573038 >>> e; pue ques consentenimiento que fue ancasos acaber a verle vino a hablar su manera que no oina de la vilentía con intención alborota por lo menos hermosa, a él, señor mío, de otra cubierto Láscc\nTraining epoch: 495 / 500, loss = 0.979953, acc = 0.686109, test loss = 1.480093, test acc = 0.573323 >>> e FronCarbós, no sea mos vestidos y vecinos, atueron que Dios, esquicó, facíne: con muy buen encinramos, dinero y enimanén enal caballero andante. Y tomó sin darle y de creida, se venía por tiemp\nTraining epoch: 496 / 500, loss = 0.976264, acc = 0.687456, test loss = 1.478975, test acc = 0.572888 >>> ego, y! ¡hhobándose Don Quijote, y de caballeros piedre que vió la boca. Llegaron mal a desear, fartó católico, entrósela le puede graciosejesto –rebio la esperanza se relló con otros ciertos que\nTraining epoch: 497 / 500, loss = 0.983810, acc = 0.684705, test loss = 1.478748, test acc = 0.573283 >>> erced dice deregándoses que habían, sin el cielo, que aunque los vos enemigos; preguntando al lado no había visto en el don, esperando como incoispe ni yo que se recubiera que sora con su rainente y\nTraining epoch: 498 / 500, loss = 0.976878, acc = 0.687519, test loss = 1.484184, test acc = 0.572638 >>> e famamiexte. Ahávicas si ella en la mujer vestidad a aquella desengañada, pues, que no comenzó a volver a desefecho estilar posería loco, y que en su insucesta, agora se don Fernando cabrelos en m\nTraining epoch: 499 / 500, loss = 0.976022, acc = 0.687710, test loss = 1.481806, test acc = 0.573058 >>> e que basile; y, cuan didas tú más -respondió don Quijote-. Mesmás acedo, rancantas, que de mi para de hacer la peraje. Pero él acomitos y espunos que, aunque ella la vida. Pero si mi -te ruego po\nTraining epoch: 500 / 500, loss = 0.986190, acc = 0.683640, test loss = 1.480400, test acc = 0.573568 >>> e que busisto aquello su humo, había dado; mas dejándole encrbaruendo, yo hebios, que ya estaba discreción, sino en el juez y otro tío sus escudos de Dios, que, con la de un camina sus gracias; que\n"
]
],
[
[
"## Plots",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(12, 6))\n\nplt.subplot(1, 2, 1)\nplt.plot(model1_loss, label=\"train\")\nplt.plot(model1_loss_test, label=\"test\")\nplt.grid(True)\nplt.xlabel('epoch')\nplt.ylabel('loss')\nplt.title('loss')\nplt.legend()\n\nplt.subplot(1, 2, 2)\nplt.plot(model1_acc, label=\"train\")\nplt.plot(model1_acc_test, label=\"test\")\nplt.grid(True)\nplt.xlabel('epoch')\nplt.ylabel('acc')\nplt.title('accuracy')\nplt.legend()\n\nplt.show()",
"_____no_output_____"
],
[
"model2.reset_states()\nprint(genera_texto('A', 1000))",
"A Míos! Pero y dejar la ignora señora mía, ni lo hubo musiéremos de compasados, avinto y extraña:\nCancho caí-; y me fueran sin ser amigo más término, efecto mucho del tomalaría Carna. Reído, estuviera un otra eso ne sea empresas y agora y al cual dijo:\n-Pues salió, y tenido subía la pendimicas, con presencia y lavenísimo con lo menes que Luscinda recebaban la que al discultura; y preguntó al mozo, Sancho, o si de que vea andante vuelto de entranimo menor ya a decirle el ofecen que señora amistad, aunque en tucieron armado mano galestiasemos adornedaba, habrán delante; y de ver una a contentan o que en esta veces; y con esto le deje hermosura.\nEs lo que tenían mucho en que me place se quería. Si con tanto donde mucho día muchas salvas, promesas que la recogia y diciéndo, y vocedo, ausidor de mi carrón. Gun Belengoo, y la noche consolar viverizas y contar o recis lo que has viendo como habiéndolado tan bien si nada en mi voluntad; y como ya la das a los sobresatistad\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
d0fb8f16d1e912e321822e73ed10d9e543692b8c | 41,089 | ipynb | Jupyter Notebook | raddar python try2-svmlight-Copy1.ipynb | kmkping/redhad_business_data | a37a75210d2aebb663b8f15b2d030a51d7b544d3 | [
"MIT"
] | null | null | null | raddar python try2-svmlight-Copy1.ipynb | kmkping/redhad_business_data | a37a75210d2aebb663b8f15b2d030a51d7b544d3 | [
"MIT"
] | null | null | null | raddar python try2-svmlight-Copy1.ipynb | kmkping/redhad_business_data | a37a75210d2aebb663b8f15b2d030a51d7b544d3 | [
"MIT"
] | null | null | null | 34.3841 | 154 | 0.502276 | [
[
[
"import numpy as np \nimport pandas as pd\nimport xgboost as xgb\nfrom xgboost.sklearn import XGBClassifier\nfrom sklearn import preprocessing\nfrom sklearn.preprocessing import OneHotEncoder\nfrom sklearn.grid_search import GridSearchCV, RandomizedSearchCV\nfrom sklearn.datasets import make_classification\nfrom sklearn.cross_validation import StratifiedKFold,KFold,train_test_split\nfrom scipy.stats import randint, uniform\nfrom sklearn.metrics import roc_auc_score\n\nnp.random.seed(22)\nimport datetime\nimport random\nfrom operator import itemgetter\nimport time\nimport copy",
"_____no_output_____"
],
[
"dtrain = xgb.DMatrix('to_r_n_back/dtrain.data')\ndval = xgb.DMatrix('to_r_n_back/dtest.data')\nyval = (pd.read_csv('to_r_n_back/val1_target.csv')).outcome.values\nlabels = yval\nlbl_enc = preprocessing.LabelEncoder()\nlabels = lbl_enc.fit_transform(labels)\ndval.set_label(labels)",
"_____no_output_____"
],
[
"param = {'objective': 'binary:logistic', \n 'max_depth': 11, \n 'gamma': 0.038587401190034704, \n 'eval_metric': 'auc', \n 'colsample_bylevel': 0.40883831209377614, \n 'min_child_weight': 7, \n 'lambda': 3.480389590147552, \n 'n_estimators': 100000, \n 'colsample_bytree': 0.26928766415604755, \n 'seed': 5, \n 'alpha': 0.7707414382224765, \n 'nthread': 4, \n 'silent': 1, \n 'subsample': 0.5447189256867526, \n 'eta': 0.05}",
"_____no_output_____"
],
[
"evals = [(dtrain, 'train'),(dval, 'eval')]\nnum_round = 100000\nbst = xgb.train(param, dtrain, num_round, early_stopping_rounds=50, evals=evals, verbose_eval=10)",
"[0]\ttrain-auc:0.923093\teval-auc:0.522593\nMultiple eval metrics have been passed: 'eval-auc' will be used for early stopping.\n\nWill train until eval-auc hasn't improved in 50 rounds.\n[10]\ttrain-auc:0.950549\teval-auc:0.628519\n[20]\ttrain-auc:0.955481\teval-auc:0.636656\n[30]\ttrain-auc:0.959203\teval-auc:0.648139\n[40]\ttrain-auc:0.96225\teval-auc:0.656799\n[50]\ttrain-auc:0.964075\teval-auc:0.661581\n[60]\ttrain-auc:0.965645\teval-auc:0.665197\n[70]\ttrain-auc:0.96736\teval-auc:0.67181\n[80]\ttrain-auc:0.968411\teval-auc:0.676265\n[90]\ttrain-auc:0.969806\teval-auc:0.677998\n[100]\ttrain-auc:0.970716\teval-auc:0.67919\n[110]\ttrain-auc:0.971355\teval-auc:0.680881\n[120]\ttrain-auc:0.972046\teval-auc:0.682143\n[130]\ttrain-auc:0.972231\teval-auc:0.686029\n[140]\ttrain-auc:0.972568\teval-auc:0.685422\n[150]\ttrain-auc:0.972823\teval-auc:0.686412\n[160]\ttrain-auc:0.973142\teval-auc:0.686651\n[170]\ttrain-auc:0.97342\teval-auc:0.68611\n[180]\ttrain-auc:0.973651\teval-auc:0.686501\n[190]\ttrain-auc:0.973832\teval-auc:0.687325\n[200]\ttrain-auc:0.974056\teval-auc:0.687003\n[210]\ttrain-auc:0.974203\teval-auc:0.687529\n[220]\ttrain-auc:0.974375\teval-auc:0.687702\n[230]\ttrain-auc:0.974538\teval-auc:0.687325\n[240]\ttrain-auc:0.974709\teval-auc:0.68738\n[250]\ttrain-auc:0.974842\teval-auc:0.687672\n[260]\ttrain-auc:0.974975\teval-auc:0.687828\n[270]\ttrain-auc:0.97512\teval-auc:0.68869\n[280]\ttrain-auc:0.975225\teval-auc:0.688625\n[290]\ttrain-auc:0.975325\teval-auc:0.688624\n[300]\ttrain-auc:0.975475\teval-auc:0.688498\n[310]\ttrain-auc:0.975611\teval-auc:0.688573\n[320]\ttrain-auc:0.975732\teval-auc:0.6889\n[330]\ttrain-auc:0.975859\teval-auc:0.68895\n[340]\ttrain-auc:0.975972\teval-auc:0.688756\n[350]\ttrain-auc:0.976063\teval-auc:0.688751\n[360]\ttrain-auc:0.976185\teval-auc:0.688677\n[370]\ttrain-auc:0.976287\teval-auc:0.688381\n[380]\ttrain-auc:0.976361\teval-auc:0.688482\nStopping. Best iteration:\n[334]\ttrain-auc:0.975913\teval-auc:0.689042\n\n"
],
[
"dtrain = xgb.DMatrix('svmlight_try2/dtrain.data')\ndtest = xgb.DMatrix('svmlight_try2/dtest.data')",
"_____no_output_____"
],
[
"act_test_data = pd.read_csv(\"redhat_data_new/act_test_new_try2.csv\", dtype={'people_id': np.str, 'activity_id': np.str}, parse_dates=['date'])\ndf1 = pd.read_csv('redhat_data_new/Submission_leak_happycube_python.csv')",
"_____no_output_____"
],
[
"c = list(set(act_test_data.activity_id.unique())&set(df1.activity_id.unique()))\nlen(c)",
"_____no_output_____"
],
[
"ac = df1.loc[df1['activity_id'].isin(c)]\nad = df1.loc[~df1['activity_id'].isin(c)]\nac.shape,ad.shape",
"_____no_output_____"
],
[
"ae = ac[(ac.outcome==1)|(ac.outcome==0)]",
"_____no_output_____"
],
[
"d = list(set(act_test_data.activity_id.unique())&set(ae.activity_id.unique()))\nlen(d)",
"_____no_output_____"
],
[
"af = act_test_data.loc[act_test_data['activity_id'].isin(d)]\naf.shape",
"_____no_output_____"
],
[
"indx = af.index",
"_____no_output_____"
],
[
"ae.index = ae.activity_id.values",
"_____no_output_____"
],
[
"ae.head()",
"_____no_output_____"
],
[
"af.index = af.activity_id.values\naf.head()",
"_____no_output_____"
],
[
"ag = ae.ix[af.index]\nag.head()",
"_____no_output_____"
],
[
"ag.index = indx\nag.head()",
"_____no_output_____"
],
[
"ae.reset_index(drop=True,inplace=True)",
"_____no_output_____"
],
[
"act_test_data.head()",
"_____no_output_____"
],
[
"dtest.slice(indx).get_label()",
"_____no_output_____"
],
[
"param1 = {'objective': 'binary:logistic', \n 'booster': 'gbtree',\n 'max_depth': 11, \n 'gamma': 0.038587401190034704, \n 'eval_metric': 'auc', \n 'colsample_bylevel': 0.40883831209377614, \n 'min_child_weight': 7, \n 'lambda': 3.480389590147552, \n 'n_estimators': 100000, \n 'colsample_bytree': 0.26928766415604755, \n 'seed': 5, \n 'alpha': 0.7707414382224765, \n 'nthread': 20, \n 'silent': 1, \n 'subsample': 0.5447189256867526, \n 'eta': 0.3}\ndval = dtest.slice(indx)\ndval.set_label(ag.outcome.values)\nevals = [(dtrain, 'train'),(dval, 'eval')]\nnum_round = 200000\nbst = xgb.train(param1, dtrain, num_round, early_stopping_rounds=200, evals=evals, verbose_eval=10)",
"[0]\ttrain-auc:0.908158\teval-auc:0.505321\nMultiple eval metrics have been passed: 'eval-auc' will be used for early stopping.\n\nWill train until eval-auc hasn't improved in 200 rounds.\n[10]\ttrain-auc:0.957492\teval-auc:0.571991\n[20]\ttrain-auc:0.965017\teval-auc:0.580533\n[30]\ttrain-auc:0.967387\teval-auc:0.592774\n[40]\ttrain-auc:0.968815\teval-auc:0.613871\n[50]\ttrain-auc:0.969848\teval-auc:0.613001\n[60]\ttrain-auc:0.970632\teval-auc:0.616749\n[70]\ttrain-auc:0.971198\teval-auc:0.61235\n[80]\ttrain-auc:0.971735\teval-auc:0.613916\n[90]\ttrain-auc:0.972309\teval-auc:0.619753\n[100]\ttrain-auc:0.972774\teval-auc:0.623228\n[110]\ttrain-auc:0.973174\teval-auc:0.628667\n[120]\ttrain-auc:0.973567\teval-auc:0.63815\n[130]\ttrain-auc:0.974325\teval-auc:0.641739\n[140]\ttrain-auc:0.97466\teval-auc:0.643106\n[150]\ttrain-auc:0.974987\teval-auc:0.641661\n[160]\ttrain-auc:0.975269\teval-auc:0.644565\n[170]\ttrain-auc:0.97589\teval-auc:0.649404\n[180]\ttrain-auc:0.97611\teval-auc:0.653021\n[190]\ttrain-auc:0.9764\teval-auc:0.652408\n[200]\ttrain-auc:0.976755\teval-auc:0.655237\n[210]\ttrain-auc:0.976966\teval-auc:0.655883\n[220]\ttrain-auc:0.97715\teval-auc:0.656232\n[230]\ttrain-auc:0.977333\teval-auc:0.655214\n[240]\ttrain-auc:0.97775\teval-auc:0.657638\n[250]\ttrain-auc:0.978032\teval-auc:0.659418\n[260]\ttrain-auc:0.978436\teval-auc:0.662382\n[270]\ttrain-auc:0.978773\teval-auc:0.668008\n[280]\ttrain-auc:0.978925\teval-auc:0.668141\n[290]\ttrain-auc:0.979271\teval-auc:0.67373\n[300]\ttrain-auc:0.979418\teval-auc:0.674217\n[310]\ttrain-auc:0.97975\teval-auc:0.675967\n[320]\ttrain-auc:0.979887\teval-auc:0.677829\n[330]\ttrain-auc:0.980015\teval-auc:0.678294\n[340]\ttrain-auc:0.980563\teval-auc:0.679947\n[350]\ttrain-auc:0.980664\teval-auc:0.679507\n[360]\ttrain-auc:0.980776\teval-auc:0.679768\n[370]\ttrain-auc:0.980881\teval-auc:0.68181\n[380]\ttrain-auc:0.980988\teval-auc:0.684985\n[390]\ttrain-auc:0.981088\teval-auc:0.684459\n[400]\ttrain-auc:0.981187\teval-auc:0.686884\n[410]\ttrain-auc:0.98129\teval-auc:0.687144\n[420]\ttrain-auc:0.98137\teval-auc:0.68731\n[430]\ttrain-auc:0.981506\teval-auc:0.688827\n[440]\ttrain-auc:0.981674\teval-auc:0.685497\n[450]\ttrain-auc:0.981941\teval-auc:0.687489\n[460]\ttrain-auc:0.98203\teval-auc:0.687122\n[470]\ttrain-auc:0.982218\teval-auc:0.686425\n[480]\ttrain-auc:0.982314\teval-auc:0.686108\n[490]\ttrain-auc:0.982394\teval-auc:0.686755\n[500]\ttrain-auc:0.982732\teval-auc:0.697506\n[510]\ttrain-auc:0.982822\teval-auc:0.697938\n[520]\ttrain-auc:0.982964\teval-auc:0.698811\n[530]\ttrain-auc:0.983045\teval-auc:0.698373\n[540]\ttrain-auc:0.983175\teval-auc:0.699162\n[550]\ttrain-auc:0.98324\teval-auc:0.697332\n[560]\ttrain-auc:0.983395\teval-auc:0.699005\n[570]\ttrain-auc:0.98349\teval-auc:0.699171\n[580]\ttrain-auc:0.983555\teval-auc:0.69915\n[590]\ttrain-auc:0.984034\teval-auc:0.698665\n[600]\ttrain-auc:0.984121\teval-auc:0.698686\n[610]\ttrain-auc:0.984186\teval-auc:0.699474\n[620]\ttrain-auc:0.984323\teval-auc:0.699893\n[630]\ttrain-auc:0.984546\teval-auc:0.699459\n[640]\ttrain-auc:0.984615\teval-auc:0.700221\n[650]\ttrain-auc:0.984859\teval-auc:0.704226\n[660]\ttrain-auc:0.984936\teval-auc:0.705883\n[670]\ttrain-auc:0.985\teval-auc:0.705119\n[680]\ttrain-auc:0.98515\teval-auc:0.70169\n[690]\ttrain-auc:0.985209\teval-auc:0.702479\n[700]\ttrain-auc:0.985272\teval-auc:0.702879\n[710]\ttrain-auc:0.98532\teval-auc:0.703605\n[720]\ttrain-auc:0.985364\teval-auc:0.704374\n[730]\ttrain-auc:0.985404\teval-auc:0.706062\n[740]\ttrain-auc:0.98549\teval-auc:0.705499\n[750]\ttrain-auc:0.985535\teval-auc:0.705507\n[760]\ttrain-auc:0.985612\teval-auc:0.705802\n[770]\ttrain-auc:0.985781\teval-auc:0.709134\n[780]\ttrain-auc:0.985861\teval-auc:0.709575\n[790]\ttrain-auc:0.986162\teval-auc:0.711143\n[800]\ttrain-auc:0.986233\teval-auc:0.710547\n[810]\ttrain-auc:0.986291\teval-auc:0.710415\n[820]\ttrain-auc:0.986347\teval-auc:0.710985\n[830]\ttrain-auc:0.986446\teval-auc:0.711763\n[840]\ttrain-auc:0.986486\teval-auc:0.711763\n[850]\ttrain-auc:0.986524\teval-auc:0.71179\n[860]\ttrain-auc:0.986644\teval-auc:0.711935\n[870]\ttrain-auc:0.986678\teval-auc:0.712905\n[880]\ttrain-auc:0.986718\teval-auc:0.713273\n[890]\ttrain-auc:0.986771\teval-auc:0.714054\n[900]\ttrain-auc:0.98685\teval-auc:0.714961\n[910]\ttrain-auc:0.986889\teval-auc:0.71497\n[920]\ttrain-auc:0.986936\teval-auc:0.715288\n[930]\ttrain-auc:0.986973\teval-auc:0.715409\n[940]\ttrain-auc:0.987019\teval-auc:0.715744\n[950]\ttrain-auc:0.987194\teval-auc:0.708126\n[960]\ttrain-auc:0.987293\teval-auc:0.716278\n[970]\ttrain-auc:0.987555\teval-auc:0.717897\n[980]\ttrain-auc:0.98766\teval-auc:0.718255\n[990]\ttrain-auc:0.987705\teval-auc:0.718695\n[1000]\ttrain-auc:0.987774\teval-auc:0.71928\n[1010]\ttrain-auc:0.987879\teval-auc:0.719693\n[1020]\ttrain-auc:0.987953\teval-auc:0.719066\n[1030]\ttrain-auc:0.988073\teval-auc:0.719129\n[1040]\ttrain-auc:0.988195\teval-auc:0.717853\n[1050]\ttrain-auc:0.988364\teval-auc:0.715339\n[1060]\ttrain-auc:0.988401\teval-auc:0.715416\n[1070]\ttrain-auc:0.988427\teval-auc:0.715587\n[1080]\ttrain-auc:0.988454\teval-auc:0.715946\n[1090]\ttrain-auc:0.988491\teval-auc:0.715484\n[1100]\ttrain-auc:0.988571\teval-auc:0.714779\n[1110]\ttrain-auc:0.988604\teval-auc:0.714409\n[1120]\ttrain-auc:0.98868\teval-auc:0.71596\n[1130]\ttrain-auc:0.988733\teval-auc:0.717063\n[1140]\ttrain-auc:0.988793\teval-auc:0.719762\n[1150]\ttrain-auc:0.988821\teval-auc:0.72097\n[1160]\ttrain-auc:0.988865\teval-auc:0.722032\n[1170]\ttrain-auc:0.988915\teval-auc:0.723435\n[1180]\ttrain-auc:0.988936\teval-auc:0.723642\n[1190]\ttrain-auc:0.988997\teval-auc:0.723444\n[1200]\ttrain-auc:0.989039\teval-auc:0.722833\n[1210]\ttrain-auc:0.989063\teval-auc:0.723363\n[1220]\ttrain-auc:0.98909\teval-auc:0.723686\n[1230]\ttrain-auc:0.989124\teval-auc:0.723971\n[1240]\ttrain-auc:0.989227\teval-auc:0.723066\n[1250]\ttrain-auc:0.989279\teval-auc:0.721987\n[1260]\ttrain-auc:0.989333\teval-auc:0.723898\n[1270]\ttrain-auc:0.989351\teval-auc:0.724337\n[1280]\ttrain-auc:0.989405\teval-auc:0.723701\n[1290]\ttrain-auc:0.989437\teval-auc:0.723075\n[1300]\ttrain-auc:0.989487\teval-auc:0.724021\n[1310]\ttrain-auc:0.98954\teval-auc:0.722107\n[1320]\ttrain-auc:0.989552\teval-auc:0.72209\n[1330]\ttrain-auc:0.989573\teval-auc:0.722961\n[1340]\ttrain-auc:0.989868\teval-auc:0.726014\n[1350]\ttrain-auc:0.989933\teval-auc:0.726281\n[1360]\ttrain-auc:0.989988\teval-auc:0.726393\n[1370]\ttrain-auc:0.990013\teval-auc:0.726348\n[1380]\ttrain-auc:0.990096\teval-auc:0.729558\n[1390]\ttrain-auc:0.990127\teval-auc:0.727479\n[1400]\ttrain-auc:0.990197\teval-auc:0.728361\n[1410]\ttrain-auc:0.990237\teval-auc:0.73058\n[1420]\ttrain-auc:0.990252\teval-auc:0.730823\n[1430]\ttrain-auc:0.990266\teval-auc:0.731575\n[1440]\ttrain-auc:0.990362\teval-auc:0.730219\n[1450]\ttrain-auc:0.990496\teval-auc:0.730217\n[1460]\ttrain-auc:0.990528\teval-auc:0.730324\n[1470]\ttrain-auc:0.990555\teval-auc:0.73134\n[1480]\ttrain-auc:0.990681\teval-auc:0.735476\n[1490]\ttrain-auc:0.990735\teval-auc:0.73694\n[1500]\ttrain-auc:0.990775\teval-auc:0.737248\n[1510]\ttrain-auc:0.990831\teval-auc:0.737379\n[1520]\ttrain-auc:0.990923\teval-auc:0.737438\n[1530]\ttrain-auc:0.991056\teval-auc:0.739516\n[1540]\ttrain-auc:0.991191\teval-auc:0.739369\n[1550]\ttrain-auc:0.99122\teval-auc:0.739478\n[1560]\ttrain-auc:0.991289\teval-auc:0.740299\n[1570]\ttrain-auc:0.991312\teval-auc:0.739997\n[1580]\ttrain-auc:0.991378\teval-auc:0.740247\n[1590]\ttrain-auc:0.991444\teval-auc:0.738044\n[1600]\ttrain-auc:0.991516\teval-auc:0.742738\n[1610]\ttrain-auc:0.991561\teval-auc:0.745839\n[1620]\ttrain-auc:0.991653\teval-auc:0.745569\n[1630]\ttrain-auc:0.991772\teval-auc:0.750333\n[1640]\ttrain-auc:0.991796\teval-auc:0.757548\n[1650]\ttrain-auc:0.991891\teval-auc:0.757337\n[1660]\ttrain-auc:0.991966\teval-auc:0.758046\n[1670]\ttrain-auc:0.991986\teval-auc:0.758094\n[1680]\ttrain-auc:0.992013\teval-auc:0.758029\n[1690]\ttrain-auc:0.992084\teval-auc:0.756361\n[1700]\ttrain-auc:0.992145\teval-auc:0.755522\n[1710]\ttrain-auc:0.992181\teval-auc:0.755433\n[1720]\ttrain-auc:0.992208\teval-auc:0.754732\n[1730]\ttrain-auc:0.992299\teval-auc:0.756273\n[1740]\ttrain-auc:0.992371\teval-auc:0.755451\n[1750]\ttrain-auc:0.992404\teval-auc:0.757415\n[1760]\ttrain-auc:0.992436\teval-auc:0.757605\n[1770]\ttrain-auc:0.992522\teval-auc:0.75971\n[1780]\ttrain-auc:0.992594\teval-auc:0.758195\n[1790]\ttrain-auc:0.992617\teval-auc:0.7589\n[1800]\ttrain-auc:0.992715\teval-auc:0.760954\n[1810]\ttrain-auc:0.992765\teval-auc:0.762433\n[1820]\ttrain-auc:0.992814\teval-auc:0.762839\n[1830]\ttrain-auc:0.992852\teval-auc:0.763293\n[1840]\ttrain-auc:0.992886\teval-auc:0.763027\n[1850]\ttrain-auc:0.992953\teval-auc:0.761715\n[1860]\ttrain-auc:0.993006\teval-auc:0.763432\n[1870]\ttrain-auc:0.993046\teval-auc:0.762523\n[1880]\ttrain-auc:0.9931\teval-auc:0.762855\n[1890]\ttrain-auc:0.993131\teval-auc:0.762865\n[1900]\ttrain-auc:0.993157\teval-auc:0.763059\n[1910]\ttrain-auc:0.99323\teval-auc:0.765934\n[1920]\ttrain-auc:0.993286\teval-auc:0.764557\n[1930]\ttrain-auc:0.993354\teval-auc:0.765973\n[1940]\ttrain-auc:0.99338\teval-auc:0.765857\n[1950]\ttrain-auc:0.993413\teval-auc:0.765364\n[1960]\ttrain-auc:0.993429\teval-auc:0.765488\n[1970]\ttrain-auc:0.993468\teval-auc:0.766361\n[1980]\ttrain-auc:0.993491\teval-auc:0.766085\n[1990]\ttrain-auc:0.993545\teval-auc:0.767479\n[2000]\ttrain-auc:0.993587\teval-auc:0.764373\n[2010]\ttrain-auc:0.993609\teval-auc:0.764324\n[2020]\ttrain-auc:0.993625\teval-auc:0.765215\n[2030]\ttrain-auc:0.993661\teval-auc:0.765011\n[2040]\ttrain-auc:0.993743\teval-auc:0.765861\n[2050]\ttrain-auc:0.993799\teval-auc:0.765229\n[2060]\ttrain-auc:0.993814\teval-auc:0.764791\n[2070]\ttrain-auc:0.993833\teval-auc:0.766456\n[2080]\ttrain-auc:0.993869\teval-auc:0.767756\n[2090]\ttrain-auc:0.993924\teval-auc:0.768888\n[2100]\ttrain-auc:0.993977\teval-auc:0.76717\n[2110]\ttrain-auc:0.994013\teval-auc:0.767896\n[2120]\ttrain-auc:0.994062\teval-auc:0.768736\n[2130]\ttrain-auc:0.994103\teval-auc:0.769559\n[2140]\ttrain-auc:0.994126\teval-auc:0.768959\n[2150]\ttrain-auc:0.994146\teval-auc:0.769029\n[2160]\ttrain-auc:0.994195\teval-auc:0.769557\n[2170]\ttrain-auc:0.994224\teval-auc:0.769559\n[2180]\ttrain-auc:0.994246\teval-auc:0.769254\n[2190]\ttrain-auc:0.994265\teval-auc:0.768936\n[2200]\ttrain-auc:0.99427\teval-auc:0.770018\n[2210]\ttrain-auc:0.994295\teval-auc:0.769733\n[2220]\ttrain-auc:0.994324\teval-auc:0.771363\n[2230]\ttrain-auc:0.994331\teval-auc:0.772012\n[2240]\ttrain-auc:0.994338\teval-auc:0.771083\n[2250]\ttrain-auc:0.994379\teval-auc:0.770283\n[2260]\ttrain-auc:0.994399\teval-auc:0.769773\n[2270]\ttrain-auc:0.994428\teval-auc:0.770002\n[2280]\ttrain-auc:0.994458\teval-auc:0.771094\n[2290]\ttrain-auc:0.994476\teval-auc:0.770374\n[2300]\ttrain-auc:0.994498\teval-auc:0.770139\n[2310]\ttrain-auc:0.994516\teval-auc:0.769794\n[2320]\ttrain-auc:0.994553\teval-auc:0.771538\n[2330]\ttrain-auc:0.99457\teval-auc:0.770258\n[2340]\ttrain-auc:0.994592\teval-auc:0.771466\n[2350]\ttrain-auc:0.994596\teval-auc:0.771377\n[2360]\ttrain-auc:0.994627\teval-auc:0.771977\n[2370]\ttrain-auc:0.994635\teval-auc:0.770645\n[2380]\ttrain-auc:0.994653\teval-auc:0.771705\n[2390]\ttrain-auc:0.994676\teval-auc:0.769895\n[2400]\ttrain-auc:0.994694\teval-auc:0.768484\n[2410]\ttrain-auc:0.994722\teval-auc:0.766448\n[2420]\ttrain-auc:0.994735\teval-auc:0.76576\n[2430]\ttrain-auc:0.994761\teval-auc:0.76714\n[2440]\ttrain-auc:0.994785\teval-auc:0.766587\n[2450]\ttrain-auc:0.994814\teval-auc:0.765308\n[2460]\ttrain-auc:0.99483\teval-auc:0.765077\n[2470]\ttrain-auc:0.994858\teval-auc:0.764811\n[2480]\ttrain-auc:0.994873\teval-auc:0.765396\n[2490]\ttrain-auc:0.9949\teval-auc:0.765191\n[2500]\ttrain-auc:0.994914\teval-auc:0.764912\n[2510]\ttrain-auc:0.994931\teval-auc:0.764283\n[2520]\ttrain-auc:0.994941\teval-auc:0.765438\n[2530]\ttrain-auc:0.994962\teval-auc:0.765008\n[2540]\ttrain-auc:0.994985\teval-auc:0.766035\n[2550]\ttrain-auc:0.995005\teval-auc:0.764532\nStopping. Best iteration:\n[2358]\ttrain-auc:0.994618\teval-auc:0.772858\n\n"
],
[
"ypred = bst.predict(dtest, ntree_limit=bst.best_ntree_limit)",
"_____no_output_____"
],
[
"act_test_data1 = pd.read_csv(\"redhat_data_new/act_test_new_try2.csv\", dtype={'people_id': np.str, 'activity_id': np.str}, parse_dates=['date'])",
"_____no_output_____"
],
[
"output = pd.DataFrame({ 'activity_id' : act_test_data1['activity_id'], 'outcome': ypred })\noutput.head()\noutput.to_csv('model_sub_81k_try2.csv', index = False)",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0fb91f8359aae2146ce1257fff03fb98cd557d6 | 5,134 | ipynb | Jupyter Notebook | notebooks/captum_example.ipynb | tugot17/XAI-Presentation | a85dde9469429fb01a176aee8811ead46a6bc3f2 | [
"MIT"
] | null | null | null | notebooks/captum_example.ipynb | tugot17/XAI-Presentation | a85dde9469429fb01a176aee8811ead46a6bc3f2 | [
"MIT"
] | null | null | null | notebooks/captum_example.ipynb | tugot17/XAI-Presentation | a85dde9469429fb01a176aee8811ead46a6bc3f2 | [
"MIT"
] | 1 | 2021-07-23T07:00:55.000Z | 2021-07-23T07:00:55.000Z | 27.021053 | 134 | 0.483054 | [
[
[
"import os\n\nimport torch\nimport torch.nn as nn\nimport torchvision\nimport torchvision.transforms as transforms\n\nfrom captum.insights import AttributionVisualizer, Batch\nfrom captum.insights.attr_vis.features import ImageFeature",
"_____no_output_____"
],
[
"def get_classes():\n classes = [\n \"Plane\",\n \"Car\",\n \"Bird\",\n \"Cat\",\n \"Deer\",\n \"Dog\",\n \"Frog\",\n \"Horse\",\n \"Ship\",\n \"Truck\",\n ]\n return classes",
"_____no_output_____"
],
[
"def get_pretrained_model():\n class Net(nn.Module):\n def __init__(self):\n super(Net, self).__init__()\n self.conv1 = nn.Conv2d(3, 6, 5)\n self.pool1 = nn.MaxPool2d(2, 2)\n self.pool2 = nn.MaxPool2d(2, 2)\n self.conv2 = nn.Conv2d(6, 16, 5)\n self.fc1 = nn.Linear(16 * 5 * 5, 120)\n self.fc2 = nn.Linear(120, 84)\n self.fc3 = nn.Linear(84, 10)\n self.relu1 = nn.ReLU()\n self.relu2 = nn.ReLU()\n self.relu3 = nn.ReLU()\n self.relu4 = nn.ReLU()\n\n def forward(self, x):\n x = self.pool1(self.relu1(self.conv1(x)))\n x = self.pool2(self.relu2(self.conv2(x)))\n x = x.view(-1, 16 * 5 * 5)\n x = self.relu3(self.fc1(x))\n x = self.relu4(self.fc2(x))\n x = self.fc3(x)\n return x\n\n net = Net()\n net.load_state_dict(torch.load(\"models/cifar_torchvision.pt\"))\n return net",
"_____no_output_____"
],
[
"def baseline_func(input):\n return input * 0",
"_____no_output_____"
],
[
"def formatted_data_iter():\n dataset = torchvision.datasets.CIFAR10(\n root=\"data/test\", train=False, download=True, transform=transforms.ToTensor()\n )\n dataloader = iter(\n torch.utils.data.DataLoader(dataset, batch_size=4, shuffle=False, num_workers=2)\n )\n while True:\n images, labels = next(dataloader)\n yield Batch(inputs=images, labels=labels)",
"_____no_output_____"
],
[
"normalize = transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))\nmodel = get_pretrained_model()\nvisualizer = AttributionVisualizer(\n models=[model],\n score_func=lambda o: torch.nn.functional.softmax(o, 1),\n classes=get_classes(),\n features=[\n ImageFeature(\n \"Photo\",\n baseline_transforms=[baseline_func],\n input_transforms=[normalize],\n )\n ],\n dataset=formatted_data_iter(),\n)",
"_____no_output_____"
],
[
"visualizer.render()",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0fba982848d8efa8c9cf7ef1a759031cf8f8633 | 185,183 | ipynb | Jupyter Notebook | 09_imageGradient.ipynb | fneema/Image_Processing | c29687cb2f6f30110be599311d03cef19c47c821 | [
"MIT"
] | 13 | 2020-01-17T11:16:51.000Z | 2020-12-30T14:11:24.000Z | 09_imageGradient.ipynb | fneema/Image_Processing | c29687cb2f6f30110be599311d03cef19c47c821 | [
"MIT"
] | 3 | 2020-10-05T14:47:27.000Z | 2021-09-07T13:05:05.000Z | 09_imageGradient.ipynb | fneema/Image_Processing | c29687cb2f6f30110be599311d03cef19c47c821 | [
"MIT"
] | 7 | 2020-06-21T20:43:53.000Z | 2021-09-07T11:55:23.000Z | 1,187.070513 | 100,884 | 0.957075 | [
[
[
"## Image Gradients\nGoal\n\nIn this notebook, we will learn to:\n\n- Find Image gradients, edges etc\n- We will see following functions : **cv2.Sobel()**, **cv2.Scharr()**, **cv2.Laplacian()** etc\n\n**Theory**\n\nOpenCV provides three types of gradient filters or High-pass filters, Sobel, Scharr and Laplacian. We will see each one of them.",
"_____no_output_____"
]
],
[
[
"#import required modeules\nimport cv2\nimport numpy as np\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"**1. Sobel and Scharr Derivatives**\n\nSobel operators is a joint Gausssian smoothing plus differentiation operation, so it is more resistant to noise. You can specify the direction of derivatives to be taken, vertical or horizontal (by the arguments, yorder and xorder respectively). You can also specify the size of kernel by the argument ksize. If ksize = -1, a 3x3 Scharr filter is used which gives better results than 3x3 Sobel filter. \n\n**2. Laplacian Derivatives**\n\nIt calculates the Laplacian of the image given",
"_____no_output_____"
]
],
[
[
"\nimg = cv2.imread('gausian.jpg',0)\n\nlaplacian = cv2.Laplacian(img,cv2.CV_64F)\nsobelx = cv2.Sobel(img,cv2.CV_64F,1,0,ksize=5)\nsobely = cv2.Sobel(img,cv2.CV_64F,0,1,ksize=5)\n\nplt.subplot(2,2,1),plt.imshow(img,cmap = 'gray')\nplt.title('Original'), plt.xticks([]), plt.yticks([])\nplt.subplot(2,2,2),plt.imshow(laplacian,cmap = 'gray')\nplt.title('Laplacian'), plt.xticks([]), plt.yticks([])\nplt.subplot(2,2,3),plt.imshow(sobelx,cmap = 'gray')\nplt.title('Sobel X'), plt.xticks([]), plt.yticks([])\nplt.subplot(2,2,4),plt.imshow(sobely,cmap = 'gray')\nplt.title('Sobel Y'), plt.xticks([]), plt.yticks([])\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"**Note:**\nIf you want to detect both edges, better option is to keep the output datatype to some higher forms, like cv2.CV_16S, cv2.CV_64F etc, take its absolute value and then convert back to cv2.CV_8U. ",
"_____no_output_____"
]
],
[
[
"img = cv2.imread('gausian.jpg',0)\n\n# Output dtype = cv2.CV_8U\nsobelx8u = cv2.Sobel(img,cv2.CV_8U,1,0,ksize=5)\n\n# Output dtype = cv2.CV_64F. Then take its absolute and convert to cv2.CV_8U\nsobelx64f = cv2.Sobel(img,cv2.CV_64F,1,0,ksize=5)\nabs_sobel64f = np.absolute(sobelx64f)\nsobel_8u = np.uint8(abs_sobel64f)\n\nplt.subplot(1,3,1),plt.imshow(img,cmap = 'gray')\nplt.title('Original'), plt.xticks([]), plt.yticks([])\nplt.subplot(1,3,2),plt.imshow(sobelx8u,cmap = 'gray')\nplt.title('Sobel CV_8U'), plt.xticks([]), plt.yticks([])\nplt.subplot(1,3,3),plt.imshow(sobel_8u,cmap = 'gray')\nplt.title('Sobel abs(CV_64F)'), plt.xticks([]), plt.yticks([])\n\nplt.show()\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0fbab266d0bf95648bf4f608e3ab46cec03035a | 16,644 | ipynb | Jupyter Notebook | example/SampleMethods/Simplex/Simplex_Example1.ipynb | shellshocked2003/UQpy | ad9b9a62f0ecbe4616cc45fde41bc3b86a8a72d2 | [
"MIT"
] | 132 | 2018-03-13T13:56:33.000Z | 2022-03-21T13:59:17.000Z | example/SampleMethods/Simplex/Simplex_Example1.ipynb | shellshocked2003/UQpy | ad9b9a62f0ecbe4616cc45fde41bc3b86a8a72d2 | [
"MIT"
] | 140 | 2018-05-21T13:40:01.000Z | 2022-03-29T14:18:01.000Z | example/SampleMethods/Simplex/Simplex_Example1.ipynb | shellshocked2003/UQpy | ad9b9a62f0ecbe4616cc45fde41bc3b86a8a72d2 | [
"MIT"
] | 61 | 2018-05-02T13:40:05.000Z | 2022-03-06T11:31:21.000Z | 103.378882 | 13,092 | 0.871966 | [
[
[
"# Simplex Example 1",
"_____no_output_____"
],
[
"- Author: Mohit S. Chauhan \n- Date: Dec 6, 2018",
"_____no_output_____"
],
[
"In this example, random samples are generated uniformly inside a 2-D simplex.",
"_____no_output_____"
],
[
"Import the necessary libraries. Here we import standard libraries such as numpy and matplotlib, but also need to import the Simplex class from UQpy.",
"_____no_output_____"
]
],
[
[
"from UQpy.SampleMethods import Simplex\nimport numpy as np\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"Define an array of 3 points in 2-D, which will be coordinates of vertex of simplex.",
"_____no_output_____"
]
],
[
[
"vertex = np.array([[0, 0], [0.5, 1], [1, 0]])",
"_____no_output_____"
]
],
[
[
"Use Simplex class in SampleMethods module to generate unioformly distributed sample. This class needs two input, i.e. nodes and nsamples. Nodes is the vertex of simplex and nsamples is the number of new samples to be generated. In this example, we are generating ten new samples inside our simplex.",
"_____no_output_____"
]
],
[
[
"x = Simplex(nodes=vertex, nsamples=10)",
"_____no_output_____"
]
],
[
[
"Figure shows the 2-D simplex and new samples generated using Simplex class.",
"_____no_output_____"
]
],
[
[
"plt.plot(np.array([0, 0.5, 1, 0]), np.array([0, 1, 0, 0]), color='blue')\nplt.scatter(x.samples[:, 0], x.samples[:, 1], color='red')\nplt.show()",
"_____no_output_____"
]
],
[
[
"User can also define a Simplex object using vertices and generate samples using 'run' method.",
"_____no_output_____"
]
],
[
[
"y = Simplex(nodes=vertex)\ny.run(nsamples=5)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0fbaf83f2a7d1ca93c7366ce469a9df0a52b58c | 108,108 | ipynb | Jupyter Notebook | MSEplots-pkg_demo.ipynb | brianmapes/MSEplot | 3f3da5019544eb89638dfb804528191eb5cb0879 | [
"MIT"
] | 3 | 2018-07-16T07:42:57.000Z | 2020-05-30T23:11:05.000Z | MSEplots-pkg_demo.ipynb | brianmapes/MSEplot | 3f3da5019544eb89638dfb804528191eb5cb0879 | [
"MIT"
] | 4 | 2018-11-10T22:04:18.000Z | 2018-12-13T10:50:43.000Z | MSEplots-pkg_demo.ipynb | brianmapes/MSEplot | 3f3da5019544eb89638dfb804528191eb5cb0879 | [
"MIT"
] | null | null | null | 931.965517 | 104,912 | 0.953935 | [
[
[
"### MSEplots on PYPI: pip install MSEplots-pkg\n----------\nmsed_plots(pressure,temperature,mixing_ratio,h0_std,ensemble_size,ent_rate,entrain=Flase)<br>\n - pressure: vertical profile of pressure, array-like <br>\n - temperature: vertical profile of temperature, array-like <br>\n - specific humidity: vertical profile of specific humidity, array-like\n - h0_std: standard deviation for mse variations at the surface, default=2000 [Joule/kg]\n - ensemble_size: size of mse variations, default=20\n - ent_rate: entrainment scale, default=np.range(0,2,0.05) [1/km]\n - entrain: switch for displaying profiles of entrained parcels, default=False",
"_____no_output_____"
]
],
[
[
"import numpy as np\nfrom siphon.simplewebservice.wyoming import WyomingUpperAir\nfrom datetime import datetime\nfrom MSEplots import plots as mpt",
"_____no_output_____"
],
[
"# reading data prociding vertical profiles of T, Td, pressure and height\ndate = datetime(2018, 11, 24, 12)\nstation = 'MFL'\nstation = 'SKBG'\n\ndf = WyomingUpperAir.request_data(date, station)\npressure = df['pressure'].values \nTemp = df['temperature'].values \nTemp_dew = df['dewpoint'].values \naltitude = df['height'].values \n\nfrom metpy.calc.thermo import *\nfrom metpy.units import units\nq = mixing_ratio(saturation_vapor_pressure(Temp_dew*units.degC),pressure*units.mbar)\nq = specific_humidity_from_mixing_ratio(q)",
"_____no_output_____"
],
[
"ax = mpt.msed_plots(pressure, Temp ,q , h0_std=2000, ensemble_size=20, ent_rate=np.arange(0,2,0.05), entrain=True)\n# title='Palonegro and Bogota, 11-24-2018 12Z my flight day')\n#mpt.add_RCEREF(ax)\n#mpt.add_curves_Wyoming(ax,datetime(2018,11,24,12),'SKBO',linewidth=1.0) # Bogota",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
d0fbb2ff89c237eb4d014bcdd6968a6c67569405 | 23,544 | ipynb | Jupyter Notebook | nb/dhod_centrals.ipynb | gitter-badger/DHOD | f2f084fea6c299f95d15cbea5ec94d404bc946b5 | [
"MIT"
] | null | null | null | nb/dhod_centrals.ipynb | gitter-badger/DHOD | f2f084fea6c299f95d15cbea5ec94d404bc946b5 | [
"MIT"
] | null | null | null | nb/dhod_centrals.ipynb | gitter-badger/DHOD | f2f084fea6c299f95d15cbea5ec94d404bc946b5 | [
"MIT"
] | null | null | null | 115.411765 | 10,716 | 0.861791 | [
[
[
"import numpy as np \n\nimport tensorflow as tf\nimport tensorflow_probability as tfp\n# -- plotting\nimport matplotlib as mpl\nimport matplotlib.pyplot as plt\nmpl.rcParams['text.usetex'] = True\nmpl.rcParams['font.family'] = 'serif'\nmpl.rcParams['axes.linewidth'] = 1.5\nmpl.rcParams['axes.xmargin'] = 1\nmpl.rcParams['xtick.labelsize'] = 'x-large'\nmpl.rcParams['xtick.major.size'] = 5\nmpl.rcParams['xtick.major.width'] = 1.5\nmpl.rcParams['ytick.labelsize'] = 'x-large'\nmpl.rcParams['ytick.major.size'] = 5\nmpl.rcParams['ytick.major.width'] = 1.5\nmpl.rcParams['legend.frameon'] = False",
"_____no_output_____"
],
[
"Mhalo = tf.convert_to_tensor(np.random.uniform(10., 15., 1000), dtype=tf.float32)\nsiglogm = tf.convert_to_tensor(0.2, dtype=tf.float32)\ntemperature = 0.5\n\ndef Ncen(Mmin): \n # mean occupation of centrals\n return 0.5 * (1+tf.math.erf((Mhalo - Mmin)/siglogm))\n\ndef hod(Mmin): \n bern = tfp.distributions.RelaxedBernoulli(temperature, probs=Ncen(Mmin))\n return bern.sample()\n\ndef numden(Mmin): \n return sum(hod(Mmin))",
"_____no_output_____"
],
[
"ncen = Ncen(13.0)\nplt.scatter(Mhalo, ncen)\nplt.xlim(10., 15.)",
"_____no_output_____"
],
[
"plt.scatter(Mhalo, ncen, c='k')\nplt.scatter(Mhalo, hod(13.))\nplt.xlim(10., 15.)",
"_____no_output_____"
],
[
"Mmin_true = 13.\nnumden_true = numden(Mmin_true)\nprint(numden_true)\n\nopt = tf.keras.optimizers.Adam(learning_rate=0.1)\n\n_Mmin = tf.Variable(13.2, trainable=True, dtype=tf.float32)\ntrainable_variables = [_Mmin]\n\nloss = lambda: tf.math.square(numden_true - numden(_Mmin))\ntrain = opt.minimize(loss, var_list=trainable_variables)\nprint(_Mmin)",
"tf.Tensor(434.80634, shape=(), dtype=float32)\n<tf.Variable 'Variable:0' shape=() dtype=float32, numpy=nan>\n"
],
[
"for temp in np.linspace(0., 1., 10).astype(np.float32): \n def _hod(Mmin): \n bern = tfp.distributions.RelaxedBernoulli(temp, probs=Ncen(Mmin))\n return bern.sample()\n\n loss = lambda mm: _hod(mm)\n val, grad = tfp.math.value_and_gradient(loss, [_Mmin])\n print(grad)",
"[<tf.Tensor: id=12590, shape=(), dtype=float32, numpy=nan>]\n[<tf.Tensor: id=12736, shape=(), dtype=float32, numpy=nan>]\n[<tf.Tensor: id=12882, shape=(), dtype=float32, numpy=nan>]\n[<tf.Tensor: id=13028, shape=(), dtype=float32, numpy=nan>]\n[<tf.Tensor: id=13174, shape=(), dtype=float32, numpy=nan>]\n[<tf.Tensor: id=13320, shape=(), dtype=float32, numpy=nan>]\n[<tf.Tensor: id=13466, shape=(), dtype=float32, numpy=nan>]\n[<tf.Tensor: id=13612, shape=(), dtype=float32, numpy=nan>]\n[<tf.Tensor: id=13758, shape=(), dtype=float32, numpy=nan>]\n[<tf.Tensor: id=13904, shape=(), dtype=float32, numpy=nan>]\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0fbc1a00ab280ea00e81e46530a4063a4af8995 | 169,181 | ipynb | Jupyter Notebook | Probabilistic Models for TS/Markov Switching Autoregression Model.ipynb | thirasit/Time-series-analysis-with-ML | c6c90f1e68dbb6c4323bb81ec887b93ac974a5d0 | [
"MIT"
] | null | null | null | Probabilistic Models for TS/Markov Switching Autoregression Model.ipynb | thirasit/Time-series-analysis-with-ML | c6c90f1e68dbb6c4323bb81ec887b93ac974a5d0 | [
"MIT"
] | null | null | null | Probabilistic Models for TS/Markov Switching Autoregression Model.ipynb | thirasit/Time-series-analysis-with-ML | c6c90f1e68dbb6c4323bb81ec887b93ac974a5d0 | [
"MIT"
] | null | null | null | 169,181 | 169,181 | 0.940779 | [
[
[
"%matplotlib inline\nimport numpy as np\nimport statsmodels.api as sm\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sn\n\nplt.style.use('seaborn-whitegrid')\nplt.rcParams[\"font.family\"] = \"Times New Roman\"\nplt.rcParams[\"font.size\"] = \"17\"",
"/usr/local/lib/python3.7/dist-packages/statsmodels/tools/_testing.py:19: FutureWarning: pandas.util.testing is deprecated. Use the functions in the public API at pandas.testing instead.\n import pandas.util.testing as tm\n"
]
],
[
[
"* Get the dataset from the Stata Press publishing house on their website.\n* This gives a pandas series of the RGNP, and the index annotates the dates.",
"_____no_output_____"
]
],
[
[
"dta = pd.read_stata('https://www.stata-press.com/data/r14/rgnp.dta').iloc[1:]\ndta.index = pd.DatetimeIndex(dta.date, freq='QS')\ndta_hamilton = dta.rgnp",
"_____no_output_____"
]
],
[
[
"* Domestic recessions and expansions model.\n* The model will include transition probabilities between these two regimes and predict probabilities of expansion or recession at each time point.",
"_____no_output_____"
]
],
[
[
"# Plot the data\ndta_hamilton.plot(title='Growth rate of Real GNP', figsize=(16, 6))",
"_____no_output_____"
]
],
[
[
"* Fit the 4th order Markov switching model.\n* Specify two regimes. \n* Get the model fitted via maximum likelihood estimation to the RGNP data.\n* Set switching_ar=False because the statsmodels implementation defaults to\nswitching autoregressive coefficients.",
"_____no_output_____"
]
],
[
[
"# Fit the model\nmod_hamilton = sm.tsa.MarkovAutoregression(dta_hamilton, k_regimes=2, order=4, switching_ar=False)\nres_hamilton = mod_hamilton.fit()",
"_____no_output_____"
]
],
[
[
"* See the regime transition parameters at the bottom of the same output.",
"_____no_output_____"
]
],
[
[
"print(res_hamilton.summary())",
" Markov Switching Model Results \n================================================================================\nDep. Variable: rgnp No. Observations: 131\nModel: MarkovAutoregression Log Likelihood -181.263\nDate: Tue, 30 Nov 2021 AIC 380.527\nTime: 03:29:08 BIC 406.404\nSample: 04-01-1951 HQIC 391.042\n - 10-01-1984 \nCovariance Type: approx \n Regime 0 parameters \n==============================================================================\n coef std err z P>|z| [0.025 0.975]\n------------------------------------------------------------------------------\nconst -0.3588 0.265 -1.356 0.175 -0.877 0.160\n Regime 1 parameters \n==============================================================================\n coef std err z P>|z| [0.025 0.975]\n------------------------------------------------------------------------------\nconst 1.1635 0.075 15.614 0.000 1.017 1.310\n Non-switching parameters \n==============================================================================\n coef std err z P>|z| [0.025 0.975]\n------------------------------------------------------------------------------\nsigma2 0.5914 0.103 5.761 0.000 0.390 0.793\nar.L1 0.0135 0.120 0.112 0.911 -0.222 0.249\nar.L2 -0.0575 0.138 -0.418 0.676 -0.327 0.212\nar.L3 -0.2470 0.107 -2.310 0.021 -0.457 -0.037\nar.L4 -0.2129 0.111 -1.926 0.054 -0.430 0.004\n Regime transition parameters \n==============================================================================\n coef std err z P>|z| [0.025 0.975]\n------------------------------------------------------------------------------\np[0->0] 0.7547 0.097 7.819 0.000 0.565 0.944\np[1->0] 0.0959 0.038 2.542 0.011 0.022 0.170\n==============================================================================\n\nWarnings:\n[1] Covariance matrix calculated using numerical (complex-step) differentiation.\n"
]
],
[
[
"* See the lengths of recession and expansion.\n* The output array is in financial quarters.\n* Therefore, a recession is expected to take about four quarters (1 year) and an expansion 10 quarters (two and a half years).",
"_____no_output_____"
]
],
[
[
"res_hamilton.expected_durations",
"_____no_output_____"
]
],
[
[
"* Plot the probability of recession at each point in time.",
"_____no_output_____"
]
],
[
[
"from pandas_datareader.data import DataReader\nfrom datetime import datetime\nusrec = DataReader('USREC', 'fred', start=datetime(1947, 1, 1), end=datetime(2013, 4, 1))",
"_____no_output_____"
]
],
[
[
"* This gives a DataFrame in which recessions are indicated. \n* Here are the first five rows.\n* In the first five rows, there was no recession according to the National Bureau of Economic Research (NBER) indicators.",
"_____no_output_____"
]
],
[
[
"usrec.head()",
"_____no_output_____"
]
],
[
[
"* Plot NBER recession indicators against the model regime predictions.\n* This gives actual recession data against model predictions.",
"_____no_output_____"
]
],
[
[
"_, ax = plt.subplots(1, figsize=(16, 6))\nax.plot(res_hamilton.filtered_marginal_probabilities[0])\nax.fill_between(\n usrec.index, 0, 1, where=usrec['USREC'].values,\n color='gray', alpha=0.3\n)\nax.set(\n xlim=(dta_hamilton.index[4], dta_hamilton.index[-1]),\n ylim=(0, 1),\n title='Filtered probability of recession'\n);",
"_____no_output_____"
]
],
[
[
"* See there seems to be quite a good match between the model predictions and\nactual recession indicators.",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0fbc21daf8eece61e5bdcb7a1e80f5b79623dce | 154,654 | ipynb | Jupyter Notebook | downsampling_hrf.ipynb | lukassnoek/random_notebooks | d7df507ce2b6949726c29de0022aae2d0dc583ac | [
"MIT"
] | 3 | 2018-05-28T13:45:11.000Z | 2021-08-31T11:41:34.000Z | downsampling_hrf.ipynb | lukassnoek/random_notebooks | d7df507ce2b6949726c29de0022aae2d0dc583ac | [
"MIT"
] | null | null | null | downsampling_hrf.ipynb | lukassnoek/random_notebooks | d7df507ce2b6949726c29de0022aae2d0dc583ac | [
"MIT"
] | 2 | 2018-05-28T13:46:05.000Z | 2018-06-11T15:25:59.000Z | 608.874016 | 114,216 | 0.953451 | [
[
[
"# HRF downsampling\nThis short notebook is why (often) we have to downsample our predictors after convolution with an HRF.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nfrom nistats.hemodynamic_models import glover_hrf\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"First, let's define our data. Suppose we did an experiment where we show subjects images for 4 seconds. The onset of the stimuli we're drawn semi-randomly: every 15 seconds but +/- 3 to 5 seconds. In total, the experiment lasted 5 minutes. The fMRI data we acquired during the experiment had a TR of 2 seconds.",
"_____no_output_____"
]
],
[
[
"TR = 2 # seconds\ntime_exp = 5*60 # seconds\nnumber_of_events = 10\nduration_of_events = 4\nonsets_sec = np.arange(0, time_exp, 15) + np.random.uniform(3, 5, 20)\nonsets_sec = np.round(onsets_sec, 3)\nprint(\"Onset events: %s\" % (onsets_sec,))",
"Onset events: [ 4.404 18.533 33.223 48.438 64.592 78.842 94.015 109.126 123.067\n 138.108 154.15 169.913 184.614 199.094 213.121 229.443 243.457 259.559\n 274.793 289.33 ]\n"
]
],
[
[
"As you can see, the onsets are not neatly synchronized to the time that we acquired the different volumes of our fMRI data, which are (with a TR of 2): `[0, 2, 4, 6, ..., 298]` seconds. In other words, the data (onsets) of our experimental paradigm are on a different scale (i.e., with a precision of milliseconds) than our fMRI data (i.e., with a precision/temporal resolution of 2 seconds)! \n\nSo, what should we do? One thing we *could* do, is to round each onset to the nearest TR. So, we'll pretend that for example an onset at 2.9 seconds happened at 2 seconds. This, however, is of course not very precise and, fortunately, not necessary. Another, and better, option is to create your design and convolve your regressors with an HRF at the time scale and temporal resolution of your onsets and *then*, as a last step, downsample your regressors to the temporal resolution of your fMRI data (which is defined by your TR).\n\nSo, given that our onsets have been measured on a millisecond scale, let's create our design with this temporal resolution. First, we'll create an empty stimulus-vector with a length of the time of the experiment in seconds times 1000 (because we want it in milliseconds):",
"_____no_output_____"
]
],
[
[
"stim_vector = np.zeros(time_exp * 1000)\nprint(\"Length of stim vector: %i\" % stim_vector.size)",
"Length of stim vector: 300000\n"
]
],
[
[
"Now, let's convert our onsets to milliseconds:",
"_____no_output_____"
]
],
[
[
"onsets_msec = onsets_sec * 1000",
"_____no_output_____"
]
],
[
[
"Now we can define within our `stim_vector` when each onset happened. Importantly, let's assume that each stimulus lasted 4 seconds.",
"_____no_output_____"
]
],
[
[
"for onset in onsets_msec:\n onset = int(onset)\n stim_vector[onset:(onset+duration_of_events*1000)] = 1",
"_____no_output_____"
]
],
[
[
"Alright, let's plot it:",
"_____no_output_____"
]
],
[
[
"plt.plot(stim_vector)\nplt.xlim(0, time_exp*1000)\nplt.xlabel('Time (milliseconds)')\nplt.ylabel('Activity (A.U.)')\nsns.despine()\nplt.show()",
"_____no_output_____"
]
],
[
[
"Sweet, now let's define an HRF:",
"_____no_output_____"
]
],
[
[
"hrf = glover_hrf(tr=TR, time_length=32, oversampling=TR*1000)\nhrf = hrf / hrf.max()\n\nplt.plot(hrf)\nplt.xlabel('Time (milliseconds)')\nplt.ylabel('Activity (A.U.)')\nsns.despine()\nplt.show()",
"_____no_output_____"
]
],
[
[
"Let's convolve!",
"_____no_output_____"
]
],
[
[
"conv = np.convolve(stim_vector, hrf)[:stim_vector.size]\nconv = conv / conv.max()\n\nconv_ds = conv[::TR*1000]\n\nplt.figure(figsize=(15, 5))\nplt.subplot(1, 2, 1)\nplt.plot(conv)\n\nplt.subplot(1, 2, 2)\nplt.plot(conv_ds)\nplt.tight_layout()\nsns.despine()\nplt.show()",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
d0fbc8ab67a3be0abe1aa7e4e90e538d960f252f | 49,566 | ipynb | Jupyter Notebook | courses/dl1/lesson6-sgd.ipynb | cklukas/fastai | 3bc1d99b05496002b93064ebed710446422fe7c8 | [
"Apache-2.0"
] | 13 | 2018-01-06T00:43:10.000Z | 2019-02-26T03:11:56.000Z | courses/dl1/lesson6-sgd.ipynb | cklukas/fastai | 3bc1d99b05496002b93064ebed710446422fe7c8 | [
"Apache-2.0"
] | null | null | null | courses/dl1/lesson6-sgd.ipynb | cklukas/fastai | 3bc1d99b05496002b93064ebed710446422fe7c8 | [
"Apache-2.0"
] | 4 | 2018-01-27T18:36:12.000Z | 2018-07-13T09:33:40.000Z | 56.776632 | 8,024 | 0.768773 | [
[
[
"# Table of Contents\n <p><div class=\"lev1 toc-item\"><a href=\"#Linear-Regression-problem\" data-toc-modified-id=\"Linear-Regression-problem-1\"><span class=\"toc-item-num\">1 </span>Linear Regression problem</a></div><div class=\"lev1 toc-item\"><a href=\"#Gradient-Descent\" data-toc-modified-id=\"Gradient-Descent-2\"><span class=\"toc-item-num\">2 </span>Gradient Descent</a></div><div class=\"lev1 toc-item\"><a href=\"#Gradient-Descent---Classification\" data-toc-modified-id=\"Gradient-Descent---Classification-3\"><span class=\"toc-item-num\">3 </span>Gradient Descent - Classification</a></div><div class=\"lev1 toc-item\"><a href=\"#Gradient-descent-with-numpy\" data-toc-modified-id=\"Gradient-descent-with-numpy-4\"><span class=\"toc-item-num\">4 </span>Gradient descent with numpy</a></div>",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nfrom fastai.learner import *",
"_____no_output_____"
]
],
[
[
"In this part of the lecture we explain Stochastic Gradient Descent (SGD) which is an **optimization** method commonly used in neural networks. We will illustrate the concepts with concrete examples.",
"_____no_output_____"
],
[
"# Linear Regression problem",
"_____no_output_____"
],
[
"The goal of linear regression is to fit a line to a set of points.",
"_____no_output_____"
]
],
[
[
"# Here we generate some fake data\ndef lin(a,b,x): return a*x+b\n\ndef gen_fake_data(n, a, b):\n x = s = np.random.uniform(0,1,n) \n y = lin(a,b,x) + 0.1 * np.random.normal(0,3,n)\n return x, y\n\nx, y = gen_fake_data(50, 3., 8.)",
"_____no_output_____"
],
[
"plt.scatter(x,y, s=8); plt.xlabel(\"x\"); plt.ylabel(\"y\"); ",
"_____no_output_____"
]
],
[
[
"You want to find **parameters** (weights) $a$ and $b$ such that you minimize the *error* between the points and the line $a\\cdot x + b$. Note that here $a$ and $b$ are unknown. For a regression problem the most common *error function* or *loss function* is the **mean squared error**. ",
"_____no_output_____"
]
],
[
[
"def mse(y_hat, y): return ((y_hat - y) ** 2).mean()",
"_____no_output_____"
]
],
[
[
"Suppose we believe $a = 10$ and $b = 5$ then we can compute `y_hat` which is our *prediction* and then compute our error.",
"_____no_output_____"
]
],
[
[
"y_hat = lin(10,5,x)\nmse(y_hat, y)",
"_____no_output_____"
],
[
"def mse_loss(a, b, x, y): return mse(lin(a,b,x), y)",
"_____no_output_____"
],
[
"mse_loss(10, 5, x, y)",
"_____no_output_____"
]
],
[
[
"So far we have specified the *model* (linear regression) and the *evaluation criteria* (or *loss function*). Now we need to handle *optimization*; that is, how do we find the best values for $a$ and $b$? How do we find the best *fitting* linear regression.",
"_____no_output_____"
],
[
"# Gradient Descent",
"_____no_output_____"
],
[
"For a fixed dataset $x$ and $y$ `mse_loss(a,b)` is a function of $a$ and $b$. We would like to find the values of $a$ and $b$ that minimize that function.\n\n**Gradient descent** is an algorithm that minimizes functions. Given a function defined by a set of parameters, gradient descent starts with an initial set of parameter values and iteratively moves toward a set of parameter values that minimize the function. This iterative minimization is achieved by taking steps in the negative direction of the function gradient.\n\nHere is gradient descent implemented in [PyTorch](http://pytorch.org/).",
"_____no_output_____"
]
],
[
[
"# generate some more data\nx, y = gen_fake_data(10000, 3., 8.)\nx.shape, y.shape",
"_____no_output_____"
],
[
"x,y = V(x),V(y)",
"_____no_output_____"
],
[
"# Create random weights a and b, and wrap them in Variables.\na = V(np.random.randn(1), requires_grad=True)\nb = V(np.random.randn(1), requires_grad=True)\na,b",
"_____no_output_____"
],
[
"learning_rate = 1e-3\nfor t in range(10000):\n # Forward pass: compute predicted y using operations on Variables\n loss = mse_loss(a,b,x,y)\n if t % 1000 == 0: print(loss.data[0])\n \n # Computes the gradient of loss with respect to all Variables with requires_grad=True.\n # After this call a.grad and b.grad will be Variables holding the gradient\n # of the loss with respect to a and b respectively\n loss.backward()\n \n # Update a and b using gradient descent; a.data and b.data are Tensors,\n # a.grad and b.grad are Variables and a.grad.data and b.grad.data are Tensors\n a.data -= learning_rate * a.grad.data\n b.data -= learning_rate * b.grad.data\n \n # Zero the gradients\n a.grad.data.zero_()\n b.grad.data.zero_() ",
"81.85150909423828\n0.6641168594360352\n0.14232024550437927\n0.1283807009458542\n0.12010374665260315\n0.11376982182264328\n0.10891081392765045\n0.10518334060907364\n0.10232385247945786\n0.1001303493976593\n"
]
],
[
[
"Nearly all of deep learning is powered by one very important algorithm: **stochastic gradient descent (SGD)**. SGD can be seeing as an approximation of **gradient descent** (GD). In GD you have to run through *all* the samples in your training set to do a single itaration. In SGD you use *only one* or *a subset* of training samples to do the update for a parameter in a particular iteration. The subset use in every iteration is called a **batch** or **minibatch**.",
"_____no_output_____"
],
[
"# Gradient Descent - Classification",
"_____no_output_____"
],
[
"For a fixed dataset $x$ and $y$ `mse_loss(a,b)` is a function of $a$ and $b$. We would like to find the values of $a$ and $b$ that minimize that function.\n\n**Gradient descent** is an algorithm that minimizes functions. Given a function defined by a set of parameters, gradient descent starts with an initial set of parameter values and iteratively moves toward a set of parameter values that minimize the function. This iterative minimization is achieved by taking steps in the negative direction of the function gradient.\n\nHere is gradient descent implemented in [PyTorch](http://pytorch.org/).",
"_____no_output_____"
]
],
[
[
"def gen_fake_data2(n, a, b):\n x = np.random.uniform(0,1,n) \n y = lin(a,b,x) + 0.1 * np.random.normal(0,3,n)\n return x, np.where(y>10, 1., 0.)",
"_____no_output_____"
],
[
"x,y = gen_fake_data2(10000, 3., 8.)\nx,y = V(x),V(y)",
"_____no_output_____"
],
[
"def nll(y_hat, y):\n y_hat = torch.clamp(y_hat, 1e-5, 1-1e-5)\n return (y*y_hat.log() + (1.-y)*(1.-y_hat).log()).mean()",
"_____no_output_____"
],
[
"a = V(np.random.randn(1), requires_grad=True)\nb = V(np.random.randn(1), requires_grad=True)",
"_____no_output_____"
],
[
"learning_rate = 1e-2\nfor t in range(3000):\n p = (-lin(a,b,x)).exp()\n y_hat = 1./(1.+p) \n loss = nll(y_hat, y)\n if t % 1000 == 0:\n print(np.exp(loss.data[0]), np.mean(to_np(y)==(to_np(y_hat)>0.5)))\n# print(y_hat)\n \n loss.backward()\n a.data -= learning_rate * a.grad.data\n b.data -= learning_rate * b.grad.data\n a.grad.data.zero_()\n b.grad.data.zero_() ",
"0.21786124000293539 0.3435\n0.002203564243036162 0.3435\n0.0005242383704432571 0.3435\n"
]
],
[
[
"Nearly all of deep learning is powered by one very important algorithm: **stochastic gradient descent (SGD)**. SGD can be seeing as an approximation of **gradient descent** (GD). In GD you have to run through *all* the samples in your training set to do a single itaration. In SGD you use *only one* or *a subset* of training samples to do the update for a parameter in a particular iteration. The subset use in every iteration is called a **batch** or **minibatch**.",
"_____no_output_____"
],
[
"# Gradient descent with numpy",
"_____no_output_____"
]
],
[
[
"from matplotlib import rcParams, animation, rc\nfrom ipywidgets import interact, interactive, fixed\nfrom ipywidgets.widgets import *\nrc('animation', html='html5')\nrcParams['figure.figsize'] = 3, 3",
"_____no_output_____"
],
[
"x, y = gen_fake_data(50, 3., 8.)",
"_____no_output_____"
],
[
"a_guess,b_guess = -1., 1.\nmse_loss(y, a_guess, b_guess, x)",
"_____no_output_____"
],
[
"lr=0.01\ndef upd():\n global a_guess, b_guess\n y_pred = lin(a_guess, b_guess, x)\n dydb = 2 * (y_pred - y)\n dyda = x*dydb\n a_guess -= lr*dyda.mean()\n b_guess -= lr*dydb.mean()",
"_____no_output_____"
],
[
"fig = plt.figure(dpi=100, figsize=(5, 4))\nplt.scatter(x,y)\nline, = plt.plot(x,lin(a_guess,b_guess,x))\nplt.close()\n\ndef animate(i):\n line.set_ydata(lin(a_guess,b_guess,x))\n for i in range(30): upd()\n return line,\n\nani = animation.FuncAnimation(fig, animate, np.arange(0, 20), interval=100)\nani",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
d0fbc8b708532b8788004df8ccb97240db2a5613 | 122,711 | ipynb | Jupyter Notebook | model_plots.ipynb | RnoB/fly-matrix | 50733b1be715fccb386c1a4bb9e57f19d82a0078 | [
"MIT"
] | 2 | 2019-07-16T12:42:47.000Z | 2021-12-10T09:39:33.000Z | model_plots.ipynb | RnoB/fly-matrix | 50733b1be715fccb386c1a4bb9e57f19d82a0078 | [
"MIT"
] | null | null | null | model_plots.ipynb | RnoB/fly-matrix | 50733b1be715fccb386c1a4bb9e57f19d82a0078 | [
"MIT"
] | 2 | 2019-07-16T12:41:26.000Z | 2020-06-08T07:59:04.000Z | 120.069472 | 18,724 | 0.842891 | [
[
[
"import cv2\nimport numpy as np\nimport pandas as pd\nimport numba\nimport matplotlib.pyplot as plt\nfrom scipy.optimize import curve_fit\n\nimport matplotlib",
"_____no_output_____"
],
[
"model = 'neural'\nsymmetric = False\nnPosts = 3\n\nif symmetric == True:\n data = 'SPP/symmetric_n' if model == 'collective' else 'NN/symmetric_n'\n prefix = 'coll_symmetric_' if model == 'collective' else 'symmetric_'\nelse:\n data = 'SPP/collective_n' if model == 'collective' else 'NN/flydata_n'\n prefix = 'coll_' if model == 'collective' else ''\n\ntmin = 0\nif symmetric == True:\n if nPosts < 4:\n tmax = 2000 if model == 'neural' else 5100\n else:\n tmax = 3000 if model == 'neural' else 5100\nelse:\n if nPosts < 4:\n tmax = 1200 if model == 'neural' else 5100\n else:\n tmax = 1900 if model == 'neural' else 6200\n \nwindow_size = 600\n\ndf = pd.read_csv(\"/Users/vivekhsridhar/Documents/Work/Results/decision_geometry/Data/Theory/\" + data + str(nPosts) + \"_direct.csv\")\ndf.head()",
"_____no_output_____"
],
[
"if symmetric:\n xs = np.array((df[' x'] - 500) / 100)\n df[' x'] = xs\nelse:\n xs = np.array(df[' x'] / 100)\n df[' x'] = xs\n \nys = np.array((df[' y'] - 500) / 100)\ndf[' y'] = ys\n\nif model == 'neural':\n ts = df['time']\nelse:\n ts = df[' time']\n\nxs = xs[ts < tmax]\nys = ys[ts < tmax]\nts = ts[ts < tmax]\n\nif nPosts == 2:\n if symmetric:\n post0_x = 5.0*np.cos(np.pi)\n post0_y = 5.0*np.sin(np.pi)\n\n post1_x = 5.0*np.cos(0)\n post1_y = 5.0*np.sin(0)\n else:\n post0_x = 5.0*np.cos(np.pi/6)\n post0_y = -5.0*np.sin(np.pi/6)\n\n post1_x = 5.0*np.cos(np.pi/6)\n post1_y = 5.0*np.sin(np.pi/6)\nelif nPosts == 3:\n if symmetric:\n post0_x = 5.0*np.cos(-2*np.pi/3)\n post0_y = 5.0*np.sin(-2*np.pi/3)\n\n post1_x = 5.0\n post1_y = 0.0\n\n post2_x = 5.0*np.cos(2*np.pi/3)\n post2_y = 5.0*np.sin(2*np.pi/3)\n else:\n post0_x = 5.0*np.cos(2*np.pi/9)\n post0_y = -5.0*np.sin(2*np.pi/9)\n\n post1_x = 5.0\n post1_y = 0.0\n\n post2_x = 5.0*np.cos(2*np.pi/9)\n post2_y = 5.0*np.sin(2*np.pi/9)\nelse:\n if symmetric:\n post0_x = -5.0\n post0_y = 0.0\n\n post1_x = 0.0\n post1_y = 5.0\n\n post2_x = 5.0\n post2_y = 0.0\n \n post3_x = 0.0\n post3_y = -5.0\n else:\n post0_x = 5.0*np.cos(2*np.pi/9)\n post0_y = -5.0*np.sin(2*np.pi/9)\n\n post1_x = 5.0\n post1_y = 0.0\n\n post2_x = 5.0*np.cos(2*np.pi/9)\n post2_y = 5.0*np.sin(2*np.pi/9)",
"_____no_output_____"
],
[
"if nPosts == 2:\n if symmetric:\n fig, ax = plt.subplots(1,1,figsize=(2,2))\n else:\n fig, ax = plt.subplots(1,1,figsize=(post0_x/2.5,post1_y/1.25))\nelse:\n if symmetric:\n fig, ax = plt.subplots(1,1,figsize=(2,2))\n else:\n fig, ax = plt.subplots(1,1,figsize=(1.25,post2_x/2))\nplt.scatter(xs, ys, c='black', s=1, alpha=0.01)\nax.set_aspect('equal')\nif symmetric:\n if nPosts == 2:\n ax.set_xticks([-4,-2,0,2,4])\n ax.set_yticks([-4,-2,0,2,4])\n else:\n ax.set_xticks([-4,-2,0,2,4])\n ax.set_yticks([-4,-2,0,2,4])\nelse:\n if nPosts == 2:\n ax.set_xticks([0,1,2,3,4])\n ax.set_yticks([-2,-1,0,1,2])\n plt.xlim(0,post0_x)\n plt.ylim(post0_y,post1_y)\n else: \n ax.set_xticks([0,1,2,3,4,5])\n #ax.set_yticks([-3,-2,-1,0,1,2,3])\n plt.xlim(0,5)\n plt.ylim(post0_y,post2_y)\n \nfig.savefig('/Users/vivekhsridhar/Documents/Code/Python/fly-matrix/figures/' + prefix + 'trajectories_n' + str(nPosts) + '_direct.pdf', dpi=600, bbox_inches='tight')",
"_____no_output_____"
],
[
"nbins = 500\npeak_threshold = 0.9\n\ndef density_map(x, y, stats=True):\n blur = (11, 11) if stats == True else (51, 51)\n \n if nPosts == 2:\n r = (\n [[-5, 5], [-5, 5]]\n if symmetric == True\n else [[0, post0_x], [post0_y, post1_y]]\n )\n elif nPosts == 3:\n r = (\n [[post0_x, post1_x], [post0_y, post2_y]]\n if symmetric == True\n else [[0, post1_x], [post0_y, post2_y]]\n )\n else:\n r = (\n [[-5, 5], [-5, 5]]\n if symmetric == True\n else [[0, post1_x], [post0_y, post2_y]]\n )\n h, xedge, yedge, image = plt.hist2d(x, y, bins=nbins, density=True, range=r)\n\n if nPosts == 2:\n tmp_img = np.flipud(np.rot90(cv2.GaussianBlur(h, blur, 0)))\n else:\n tmp_img = np.flipud(np.rot90(cv2.GaussianBlur(h, blur, 0)))\n\n tmp_img /= np.max(tmp_img)\n\n return tmp_img",
"_____no_output_____"
],
[
"for idx,t in enumerate(range(tmin,tmax-window_size,10)):\n window_min = t\n window_max = t + window_size\n \n x = xs[(ts > window_min) & (ts < window_max)]\n y = ys[(ts > window_min) & (ts < window_max)]\n tmp_img = density_map(x, y, stats=False)\n \n if idx == 0:\n img = tmp_img\n else:\n img = np.fmax(tmp_img, img)\n \nif nPosts == 2:\n x_peaks = np.where(img > peak_threshold)[1] * post0_x / nbins\n y_peaks = np.where(img > peak_threshold)[0] * (post0_y - post1_y) / nbins + post1_y\nelif nPosts == 3:\n x_peaks = np.where(img > peak_threshold)[1] * post1_x / nbins\n y_peaks = np.where(img > peak_threshold)[0] * (post0_y - post2_y) / nbins + post2_y",
"_____no_output_____"
],
[
"if nPosts == 2:\n if symmetric == True:\n fig, ax = plt.subplots(1,1, figsize=(2,2))\n plt.imshow(img, extent=[-5, 5, -5.0, 5.0])\n plt.xticks([-4,-2,0,2,4])\n plt.yticks([-4,-2,0,2,4])\n else:\n fig, ax = plt.subplots(1, 1, figsize=(post0_x/2.5,post1_y/1.25))\n plt.imshow(img, extent=[0, post0_x, post0_y, post1_y])\n plt.xticks([0,1,2,3,4])\nelif nPosts == 3:\n if symmetric == True:\n fig, ax = plt.subplots(1,1, figsize=(3.75/2,post2_y/2))\n plt.imshow(img, extent=[post0_x, post1_x, post0_y, post2_y])\n else:\n fig, ax = plt.subplots(1, 1, figsize=(1.25,post2_x/2))\n plt.imshow(img, extent=[0, post1_x, post0_y, post2_y])\n plt.xticks([0,1,2,3,4,5])\nelse:\n if symmetric == True:\n fig, ax = plt.subplots(1,1, figsize=(post2_x/2,post1_y/2))\n plt.imshow(img, extent=[-post2_x, post2_x, -post1_y, post1_y])\n plt.xticks([-4,-2,0,2,4])\n else:\n fig, ax = plt.subplots(1, 1, figsize=(1.25,post2_x/2))\n plt.imshow(img, extent=[0, post1_x, post0_y, post2_y])\n plt.xticks([0,1,2,3,4,5])\n\nfig.savefig('/Users/vivekhsridhar/Documents/Code/Python/fly-matrix/figures/' + prefix + 'density_n' + str(nPosts) + '_direct.pdf', dpi=600, bbox_inches='tight')",
"_____no_output_____"
]
],
[
[
"### Identify bifurcation point using a piecewise phase-transition function",
"_____no_output_____"
],
[
"#### Get first bifurcation point\nOnce you have this, you can draw a line segment bisecting the angle between the point and two targets. This will be the line about which you symmetrise to get the second bifurcation point",
"_____no_output_____"
]
],
[
[
"def fitfunc(x, p, q, r):\n return r * (np.abs((x - p)) ** q)\n\ndef fitfunc_vec_self(x, p, q, r):\n y = np.zeros(x.shape)\n for i in range(len(y)):\n y[i] = fitfunc(x[i], p, q, r)\n return y",
"_____no_output_____"
],
[
"x_fit = []\ny_fit = []\n \nif nPosts == 2:\n if model == 'neural':\n bif_pt = 2.5\n params1 = [3, 1, 1]\n else:\n bif_pt = 1.2\n params1 = [1.5, 1, 1]\n \n x_sub = np.concatenate((xs, xs))\n y_sub = np.concatenate((ys, -ys))\n t_sub = np.concatenate((ts, ts))\n\n tmin = np.min(t_sub)\n tmax = np.max(t_sub)-100 if model == 'neural' else np.max(t_sub)-500\n for idx,t in enumerate(range(tmin,tmax,10)):\n window_min = t\n window_max = t + window_size\n\n x = x_sub[(t_sub > window_min) & (t_sub < window_max)]\n y = y_sub[(t_sub > window_min) & (t_sub < window_max)]\n tmp_img2 = density_map(x, y, stats=False)\n\n if idx == 0:\n tmp_img = tmp_img2\n else:\n tmp_img = np.fmax(tmp_img2, tmp_img)\n \n x_fit = np.where(tmp_img > peak_threshold)[1] * post0_x / nbins\n y_fit = (\n np.where(tmp_img > peak_threshold)[0] * (post0_y - post1_y) / nbins\n + post1_y\n )\n\n x_fit = x_fit\n y_fit = np.abs(y_fit)\n y_fit = y_fit[x_fit > bif_pt]\n x_fit = x_fit[x_fit > bif_pt]\n\n for i in range(0,10):\n fit_params, pcov = curve_fit(\n fitfunc_vec_self, x_fit, y_fit, p0=params1, maxfev=10000\n )\n params1 = fit_params\n\nelse:\n if model == 'neural':\n bif_pt = 1\n params1 = [1.2, 1, 0.5]\n \n xs1 = xs[xs < 2.7]\n ys1 = ys[xs < 2.7]\n ts1 = ts[xs < 2.7]\n else:\n bif_pt = 0.8\n params1 = [1, 1, 0.5]\n \n xs1 = xs[xs < 2.5]\n ys1 = ys[xs < 2.5]\n ts1 = ts[xs < 2.5]\n\n x_sub = np.concatenate((xs1, xs1))\n y_sub = np.concatenate((ys1, -ys1))\n t_sub = np.concatenate((ts1, ts1))\n\n tmin = np.min(t_sub)\n tmax = np.max(t_sub)-100 if model == 'neural' else np.max(t_sub)-500\n for idx,t in enumerate(range(tmin,tmax,10)):\n window_min = t\n window_max = t + window_size\n\n x = x_sub[(t_sub > window_min) & (t_sub < window_max)]\n y = y_sub[(t_sub > window_min) & (t_sub < window_max)]\n tmp_img2 = density_map(x, y, stats=False)\n\n if idx == 0:\n tmp_img = tmp_img2\n else:\n tmp_img = np.fmax(tmp_img2, tmp_img)\n \n x_fit = np.where(tmp_img > peak_threshold)[1] * post1_x / nbins\n y_fit = (\n np.where(tmp_img > peak_threshold)[0] * (post0_y - post2_y) / nbins\n + post2_y\n )\n\n x_fit = x_fit\n y_fit = np.abs(y_fit)\n y_fit = y_fit[x_fit > bif_pt]\n x_fit = x_fit[x_fit > bif_pt]\n\n for i in range(0,10):\n fit_params, pcov = curve_fit(\n fitfunc_vec_self, x_fit, y_fit, p0=params1, maxfev=10000\n )\n params1 = fit_params",
"_____no_output_____"
],
[
"if nPosts == 2:\n fig, ax = plt.subplots(1, 1, figsize=(post0_x/2.5,post1_y/1.25))\n plt.imshow(img, extent=[0, post0_x, post0_y, post1_y])\nelse:\n plt.imshow(img, extent=[0, post1_x, post0_y, post2_y])\n\nparameters = params1\nstep_len = 0.01\n\nx1 = np.arange(step_len, parameters[0], step_len)\ny1 = np.zeros(len(x1))\n\noffset=0.2 if model == 'neural' else 0.5\nx = (\n np.arange(parameters[0], post0_x-offset, step_len)\n if nPosts == 2\n else np.arange(parameters[0], 3., step_len)\n)\nx2 = np.concatenate((x, x))\ny2 = np.concatenate(\n ((parameters[2] * (x - parameters[0])) ** parameters[1], -(parameters[2] * (x - parameters[0])) ** parameters[1])\n)\n\nif nPosts != 2:\n bisector_xs = [params1[0], post2_x]\n bisector_ys = [\n 0,\n np.tan(np.arctan2(post2_y, post2_x - params1[0]) / 2)\n * (post2_x - params1[0]),\n ]\n\nplt.xticks([0,1,2,3,4])\nplt.scatter(x1, y1, c=\"black\", s=0.1)\nplt.scatter(x2, y2, c=\"black\", s=0.1)\n \nif nPosts == 2:\n fig.savefig('/Users/vivekhsridhar/Documents/Code/Python/fly-matrix/figures/' + prefix + 'density_n' + str(nPosts) + '_direct.pdf', dpi=600, bbox_inches='tight')",
"_____no_output_____"
],
[
"if nPosts == 2:\n print(\n \"The bifurcation occurs at an angle\",\n 2 * np.arctan2(post1_y, post1_x - params1[0]) * 180 / np.pi,\n )\nelse:\n print(\n \"The first bifurcation occurs at an angle\",\n 2 * np.arctan2(post2_y, post2_x - params1[0]) * 180 / np.pi,\n )",
"The first bifurcation occurs at an angle 96.38939242028479\n"
]
],
[
[
"#### Get the second bifurcation point\nFor this, you must center the trajectories about the bifurcation point, get a new heatmap and rotate this by the angle of the bisector line",
"_____no_output_____"
]
],
[
[
"# center points about the first bifurcation\ncxs = xs - params1[0]\ncys = ys\ncts = ts\n\ncpost0_x = post0_x - params1[0]\ncpost1_x = post1_x - params1[0]\ncpost2_x = post2_x - params1[0]",
"_____no_output_____"
],
[
"@numba.njit(fastmath=True, parallel=True)\ndef parallel_rotate(xy, rmat):\n out = np.zeros(xy.shape)\n for idx in numba.prange(xy.shape[0]):\n out[idx] = np.dot(rmat[idx], xy[idx])\n return out",
"_____no_output_____"
],
[
"# clip all points to the left of and below 0 and points beyond post centers\nccxs = cxs[cxs > 0]\nccys = cys[cxs > 0]\nccts = cts[cxs > 0]\nccxs = ccxs[ccys > 0]\nccts = ccts[ccys > 0]\nccys = ccys[ccys > 0]\n\nxy = np.concatenate((ccxs.reshape(-1, 1), ccys.reshape(-1, 1)), axis=1)\nangle = np.full(\n ccxs.shape, np.arctan2(post2_y, post2_x - params1[0]) / 2\n)\nrmat = np.array([[np.cos(angle), -np.sin(angle)], [np.sin(angle), np.cos(angle)]]).T\nrx, ry = parallel_rotate(xy, rmat).T\n\nblur = (51,51)\n\nr1 = [[0, post1_x], [post0_y, post2_y]]\n\ntmin = np.min(ccts)\ntmax = np.max(ccts)-100 if model == 'neural' else np.max(ccts)-500\nfor idx,t in enumerate(range(tmin,tmax,10)):\n window_min = t\n window_max = t + window_size\n \n x = rx[(ccts > window_min) & (ccts < window_max)]\n y = ry[(ccts > window_min) & (ccts < window_max)]\n tmp_img = density_map(x, y, stats=False)\n \n if idx == 0:\n tmp_img1 = tmp_img\n else:\n tmp_img1 = np.fmax(tmp_img1, tmp_img)",
"_____no_output_____"
],
[
"plt.imshow(tmp_img1, extent=[r1[0][0], r1[0][1], r1[1][0], r1[1][1]])",
"_____no_output_____"
],
[
"if model == 'neural':\n bif_pt = 2.2\n params2 = [2.5, 1, 0.5]\nelse:\n bif_pt = 1.8\n params2 = [2, 1, 0.5]\n\nx_sub = np.concatenate((rx, rx))\ny_sub = np.concatenate((ry, -ry))\nt_sub = np.concatenate((ccts, ccts))\n\ntmin = np.min(ccts)\ntmax = np.max(ccts)-100 if model == 'neural' else np.max(ccts)-500\nfor idx,t in enumerate(range(tmin,tmax,10)):\n window_min = t\n window_max = t + window_size\n \n x = x_sub[(t_sub > window_min) & (t_sub < window_max)]\n y = y_sub[(t_sub > window_min) & (t_sub < window_max)]\n tmp_img = density_map(x, y, stats=False)\n \n if idx == 0:\n tmp_img1 = tmp_img\n else:\n tmp_img1 = np.fmax(tmp_img1, tmp_img)\n\nx_fit = np.where(tmp_img1 > peak_threshold)[1] * post1_x / nbins\ny_fit = (\n np.where(tmp_img1 > peak_threshold)[0] * (post0_y - post2_y) / nbins\n + post2_y\n)\n\nx_fit = x_fit\ny_fit = np.abs(y_fit)\ny_fit = y_fit[x_fit > bif_pt]\nx_fit = x_fit[x_fit > bif_pt]\n\nfor i in range(0,10):\n fit_params, pcov = curve_fit(\n fitfunc_vec_self, x_fit, y_fit, p0=params2, maxfev=10000\n )\n params2 = fit_params",
"_____no_output_____"
],
[
"plt.imshow(tmp_img1, extent=[r1[0][0], r1[0][1], r1[1][0], r1[1][1]])\n\nparameters = params2\nstep_len = 0.01\n\nx1 = np.arange(step_len, parameters[0], step_len)\ny1 = np.zeros(len(x1))\n\nx = np.arange(parameters[0], 3, step_len)\nx2 = np.concatenate((x, x))\ny2 = np.concatenate(\n ((parameters[2] * (x - parameters[0])) ** parameters[1], -(parameters[2] * (x - parameters[0])) ** parameters[1])\n)\n\nplt.scatter(x1, y1, c=\"black\", s=1)\nplt.scatter(x2, y2, c=\"black\", s=1)",
"_____no_output_____"
],
[
"bif2 = np.array([params2[0], 0]).reshape(1, -1)\nang = angle[0]\nrmat1 = np.array([[np.cos(ang), -np.sin(ang)], [np.sin(ang), np.cos(ang)]]).T\nbif2 = parallel_rotate(bif2, rmat).T\nbif2[0] += params1[0]",
"_____no_output_____"
],
[
"print(\n \"The second bifurcation occurs at angle\",\n (\n (\n np.arctan2(post2_y - bif2[1], post2_x - bif2[0])\n - np.arctan2(bif2[1] - post1_y, post1_x - bif2[0])\n )\n * 180\n / np.pi\n )[0],\n)",
"The second bifurcation occurs at angle 93.6125826161468\n"
],
[
"x1 = np.arange(step_len, parameters[0], step_len)\ny1 = np.zeros(len(x1))\nbcxy1 = np.concatenate((x1.reshape(-1, 1), y1.reshape(-1, 1)), axis=1)\nang1 = np.full(\n x1.shape, -np.arctan2(post2_y, post2_x - params1[0]) / 2\n)\nrmat1 = np.array([[np.cos(ang1), -np.sin(ang1)], [np.sin(ang1), np.cos(ang1)]]).T\nbcx1, bcy1 = parallel_rotate(bcxy1, rmat1).T\nbx1 = bcx1 + params1[0]",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(1, 1, figsize=(1.25,post2_x/2))\nplt.imshow(img, extent=[0, post1_x, post0_y, post2_y])\n\nstep_len = 0.01\nparameters = params2\n\nbcxy1 = np.concatenate((x1.reshape(-1, 1), y1.reshape(-1, 1)), axis=1)\nang1 = np.full(x1.shape, -ang)\nrmat1 = np.array([[np.cos(ang1), -np.sin(ang1)], [np.sin(ang1), np.cos(ang1)]]).T\nbcx1, bcy1 = parallel_rotate(bcxy1, rmat1).T\nbx1 = bcx1 + params1[0]\n\nx = np.arange(parameters[0], 3.5, step_len) if model == 'neural' else np.arange(parameters[0], 3, step_len)\nx2 = np.concatenate((x, x))\ny2 = np.concatenate(\n (\n (parameters[2] * (x - parameters[0])) ** parameters[1], \n -(parameters[2] * (x - parameters[0])) ** parameters[1])\n) \n\nbcxy2 = np.concatenate((x2.reshape(-1, 1), y2.reshape(-1, 1)), axis=1)\nang2 = np.full(x2.shape, -ang)\nrmat2 = np.array([[np.cos(ang2), -np.sin(ang2)], [np.sin(ang2), np.cos(ang2)]]).T\nbcx2, bcy2 = parallel_rotate(bcxy2, rmat2).T\nbx2 = bcx2 + params1[0]\n\nbx2 = np.concatenate((bx2, bx2))\nbcy2 = np.concatenate((bcy2, -bcy2))\n\nbcy2 = bcy2[bx2 < post1_x - 0.1]\nbx2 = bx2[bx2 < post1_x - 0.1]\n\nbx2 = bx2[np.abs(bcy2) < post2_y - 0.1]\nbcy2 = bcy2[np.abs(bcy2) < post2_y - 0.1]\n\nplt.plot(bx1, bcy1, linestyle=\"dashed\", c=\"black\")\nplt.plot(bx1, -bcy1, linestyle=\"dashed\", c=\"black\")\nplt.scatter(bx2, bcy2, c=\"black\", s=0.1)\n\nparameters = params1\nstep_len = 0.01\n\nx1 = np.arange(5 * step_len, parameters[0], step_len)\ny1 = np.zeros(len(x1))\n\n# x = np.arange(parameters[0], 2.9, step_len)\n# x2 = np.concatenate((x, x))\n# y2 = np.concatenate(\n# (\n# (parameters[2] * (x - parameters[0])) ** parameters[1],\n# -(parameters[2] * (x - parameters[0])) ** parameters[1],\n# )\n# )\n\nplt.scatter(x1, y1, c=\"black\", s=0.1)\n# plt.scatter(x2, y2, c=\"black\", s=0.1)\nplt.xticks([0, 1, 2, 3, 4, 5])\n \nfig.savefig('/Users/vivekhsridhar/Documents/Code/Python/fly-matrix/figures/' + prefix + 'density_n' + str(nPosts) + '.pdf', dpi=600, bbox_inches='tight')",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
d0fbcee5ec846ff427c358adbebc51dd744747dd | 49,822 | ipynb | Jupyter Notebook | scripts/d21-en/mxnet/chapter_recommender-systems/mf.ipynb | lucmertins/CapDeepLearningBook | e5959b552c8716e7fc65a21ae9c13c58509544c1 | [
"MIT"
] | null | null | null | scripts/d21-en/mxnet/chapter_recommender-systems/mf.ipynb | lucmertins/CapDeepLearningBook | e5959b552c8716e7fc65a21ae9c13c58509544c1 | [
"MIT"
] | null | null | null | scripts/d21-en/mxnet/chapter_recommender-systems/mf.ipynb | lucmertins/CapDeepLearningBook | e5959b552c8716e7fc65a21ae9c13c58509544c1 | [
"MIT"
] | null | null | null | 42.437819 | 1,022 | 0.51409 | [
[
[
"# Matrix Factorization\n\nMatrix Factorization :cite:`Koren.Bell.Volinsky.2009` is a well-established algorithm in the recommender systems literature. The first version of matrix factorization model is proposed by Simon Funk in a famous [blog\npost](https://sifter.org/~simon/journal/20061211.html) in which he described the idea of factorizing the interaction matrix. It then became widely known due to the Netflix contest which was held in 2006. At that time, Netflix, a media-streaming and video-rental company, announced a contest to improve its recommender system performance. The best team that can improve on the Netflix baseline, i.e., Cinematch), by 10 percent would win a one million USD prize. As such, this contest attracted\na lot of attention to the field of recommender system research. Subsequently, the grand prize was won by the BellKor's Pragmatic Chaos team, a combined team of BellKor, Pragmatic Theory, and BigChaos (you do not need to worry about these algorithms now). Although the final score was the result of an ensemble solution (i.e., a combination of many algorithms), the matrix factorization algorithm played a critical role in the final blend. The technical report of the Netflix Grand Prize solution :cite:`Toscher.Jahrer.Bell.2009` provides a detailed introduction to the adopted model. In this section, we will dive into the details of the matrix factorization model and its implementation.\n\n\n## The Matrix Factorization Model\n\nMatrix factorization is a class of collaborative filtering models. Specifically, the model factorizes the user-item interaction matrix (e.g., rating matrix) into the product of two lower-rank matrices, capturing the low-rank structure of the user-item interactions.\n\nLet $\\mathbf{R} \\in \\mathbb{R}^{m \\times n}$ denote the interaction matrix with $m$ users and $n$ items, and the values of $\\mathbf{R}$ represent explicit ratings. The user-item interaction will be factorized into a user latent matrix $\\mathbf{P} \\in \\mathbb{R}^{m \\times k}$ and an item latent matrix $\\mathbf{Q} \\in \\mathbb{R}^{n \\times k}$, where $k \\ll m, n$, is the latent factor size. Let $\\mathbf{p}_u$ denote the $u^\\mathrm{th}$ row of $\\mathbf{P}$ and $\\mathbf{q}_i$ denote the $i^\\mathrm{th}$ row of $\\mathbf{Q}$. For a given item $i$, the elements of $\\mathbf{q}_i$ measure the extent to which the item possesses those characteristics such as the genres and languages of a movie. For a given user $u$, the elements of $\\mathbf{p}_u$ measure the extent of interest the user has in items' corresponding characteristics. These latent factors might measure obvious dimensions as mentioned in those examples or are completely uninterpretable. The predicted ratings can be estimated by\n\n$$\\hat{\\mathbf{R}} = \\mathbf{PQ}^\\top$$\n\nwhere $\\hat{\\mathbf{R}}\\in \\mathbb{R}^{m \\times n}$ is the predicted rating matrix which has the same shape as $\\mathbf{R}$. One major problem of this prediction rule is that users/items biases can not be modeled. For example, some users tend to give higher ratings or some items always get lower ratings due to poorer quality. These biases are commonplace in real-world applications. To capture these biases, user specific and item specific bias terms are introduced. Specifically, the predicted rating user $u$ gives to item $i$ is calculated by\n\n$$\n\\hat{\\mathbf{R}}_{ui} = \\mathbf{p}_u\\mathbf{q}^\\top_i + b_u + b_i\n$$\n\nThen, we train the matrix factorization model by minimizing the mean squared error between predicted rating scores and real rating scores. The objective function is defined as follows:\n\n$$\n\\underset{\\mathbf{P}, \\mathbf{Q}, b}{\\mathrm{argmin}} \\sum_{(u, i) \\in \\mathcal{K}} \\| \\mathbf{R}_{ui} -\n\\hat{\\mathbf{R}}_{ui} \\|^2 + \\lambda (\\| \\mathbf{P} \\|^2_F + \\| \\mathbf{Q}\n\\|^2_F + b_u^2 + b_i^2 )\n$$\n\nwhere $\\lambda$ denotes the regularization rate. The regularizing term $\\lambda (\\| \\mathbf{P} \\|^2_F + \\| \\mathbf{Q}\n\\|^2_F + b_u^2 + b_i^2 )$ is used to avoid over-fitting by penalizing the magnitude of the parameters. The $(u, i)$ pairs for which $\\mathbf{R}_{ui}$ is known are stored in the set\n$\\mathcal{K}=\\{(u, i) \\mid \\mathbf{R}_{ui} \\text{ is known}\\}$. The model parameters can be learned with an optimization algorithm, such as Stochastic Gradient Descent and Adam.\n\nAn intuitive illustration of the matrix factorization model is shown below:\n\n\n\nIn the rest of this section, we will explain the implementation of matrix factorization and train the model on the MovieLens dataset.\n",
"_____no_output_____"
]
],
[
[
"import mxnet as mx\nfrom mxnet import autograd, gluon, np, npx\nfrom mxnet.gluon import nn\nfrom d2l import mxnet as d2l\n\nnpx.set_np()",
"_____no_output_____"
]
],
[
[
"## Model Implementation\n\nFirst, we implement the matrix factorization model described above. The user and item latent factors can be created with the `nn.Embedding`. The `input_dim` is the number of items/users and the (`output_dim`) is the dimension of the latent factors ($k$). We can also use `nn.Embedding` to create the user/item biases by setting the `output_dim` to one. In the `forward` function, user and item ids are used to look up the embeddings.\n",
"_____no_output_____"
]
],
[
[
"class MF(nn.Block):\n def __init__(self, num_factors, num_users, num_items, **kwargs):\n super(MF, self).__init__(**kwargs)\n self.P = nn.Embedding(input_dim=num_users, output_dim=num_factors)\n self.Q = nn.Embedding(input_dim=num_items, output_dim=num_factors)\n self.user_bias = nn.Embedding(num_users, 1)\n self.item_bias = nn.Embedding(num_items, 1)\n\n def forward(self, user_id, item_id):\n P_u = self.P(user_id)\n Q_i = self.Q(item_id)\n b_u = self.user_bias(user_id)\n b_i = self.item_bias(item_id)\n outputs = (P_u * Q_i).sum(axis=1) + np.squeeze(b_u) + np.squeeze(b_i)\n return outputs.flatten()",
"_____no_output_____"
]
],
[
[
"## Evaluation Measures\n\nWe then implement the RMSE (root-mean-square error) measure, which is commonly used to measure the differences between rating scores predicted by the model and the actually observed ratings (ground truth) :cite:`Gunawardana.Shani.2015`. RMSE is defined as:\n\n$$\n\\mathrm{RMSE} = \\sqrt{\\frac{1}{|\\mathcal{T}|}\\sum_{(u, i) \\in \\mathcal{T}}(\\mathbf{R}_{ui} -\\hat{\\mathbf{R}}_{ui})^2}\n$$\n\nwhere $\\mathcal{T}$ is the set consisting of pairs of users and items that you want to evaluate on. $|\\mathcal{T}|$ is the size of this set. We can use the RMSE function provided by `mx.metric`.\n",
"_____no_output_____"
]
],
[
[
"def evaluator(net, test_iter, devices):\n rmse = mx.metric.RMSE() # Get the RMSE\n rmse_list = []\n for idx, (users, items, ratings) in enumerate(test_iter):\n u = gluon.utils.split_and_load(users, devices, even_split=False)\n i = gluon.utils.split_and_load(items, devices, even_split=False)\n r_ui = gluon.utils.split_and_load(ratings, devices, even_split=False)\n r_hat = [net(u, i) for u, i in zip(u, i)]\n rmse.update(labels=r_ui, preds=r_hat)\n rmse_list.append(rmse.get()[1])\n return float(np.mean(np.array(rmse_list)))",
"_____no_output_____"
]
],
[
[
"## Training and Evaluating the Model\n\n\nIn the training function, we adopt the $L_2$ loss with weight decay. The weight decay mechanism has the same effect as the $L_2$ regularization.\n",
"_____no_output_____"
]
],
[
[
"#@save\ndef train_recsys_rating(net, train_iter, test_iter, loss, trainer, num_epochs,\n devices=d2l.try_all_gpus(), evaluator=None, **kwargs):\n timer = d2l.Timer()\n animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0, 2],\n legend=['train loss', 'test RMSE'])\n for epoch in range(num_epochs):\n metric, l = d2l.Accumulator(3), 0.\n for i, values in enumerate(train_iter):\n timer.start()\n input_data = []\n values = values if isinstance(values, list) else [values]\n for v in values:\n input_data.append(gluon.utils.split_and_load(v, devices))\n train_feat = input_data[0:-1] if len(values) > 1 else input_data\n train_label = input_data[-1]\n with autograd.record():\n preds = [net(*t) for t in zip(*train_feat)]\n ls = [loss(p, s) for p, s in zip(preds, train_label)]\n [l.backward() for l in ls]\n l += sum([l.asnumpy() for l in ls]).mean() / len(devices)\n trainer.step(values[0].shape[0])\n metric.add(l, values[0].shape[0], values[0].size)\n timer.stop()\n if len(kwargs) > 0: # It will be used in section AutoRec\n test_rmse = evaluator(net, test_iter, kwargs['inter_mat'],\n devices)\n else:\n test_rmse = evaluator(net, test_iter, devices)\n train_l = l / (i + 1)\n animator.add(epoch + 1, (train_l, test_rmse))\n print(f'train loss {metric[0] / metric[1]:.3f}, '\n f'test RMSE {test_rmse:.3f}')\n print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '\n f'on {str(devices)}')",
"_____no_output_____"
]
],
[
[
"Finally, let us put all things together and train the model. Here, we set the latent factor dimension to 30.\n",
"_____no_output_____"
]
],
[
[
"devices = d2l.try_all_gpus()\nnum_users, num_items, train_iter, test_iter = d2l.split_and_load_ml100k(\n test_ratio=0.1, batch_size=512)\nnet = MF(30, num_users, num_items)\nnet.initialize(ctx=devices, force_reinit=True, init=mx.init.Normal(0.01))\nlr, num_epochs, wd, optimizer = 0.002, 20, 1e-5, 'adam'\nloss = gluon.loss.L2Loss()\ntrainer = gluon.Trainer(net.collect_params(), optimizer, {\n \"learning_rate\": lr,\n 'wd': wd})\ntrain_recsys_rating(net, train_iter, test_iter, loss, trainer, num_epochs,\n devices, evaluator)",
"train loss 0.063, test RMSE 1.054\n21885.2 examples/sec on [gpu(0), gpu(1)]\n"
]
],
[
[
"Below, we use the trained model to predict the rating that a user (ID 20) might give to an item (ID 30).\n",
"_____no_output_____"
]
],
[
[
"scores = net(np.array([20], dtype='int', ctx=devices[0]),\n np.array([30], dtype='int', ctx=devices[0]))\nscores",
"_____no_output_____"
]
],
[
[
"## Summary\n\n* The matrix factorization model is widely used in recommender systems. It can be used to predict ratings that a user might give to an item.\n* We can implement and train matrix factorization for recommender systems.\n\n\n## Exercises\n\n* Vary the size of latent factors. How does the size of latent factors influence the model performance?\n* Try different optimizers, learning rates, and weight decay rates.\n* Check the predicted rating scores of other users for a specific movie.\n",
"_____no_output_____"
],
[
"[Discussions](https://discuss.d2l.ai/t/400)\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.