
hexsha
stringlengths 40
40
| size
int64 6
14.9M
| ext
stringclasses 1
value | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 6
260
| max_stars_repo_name
stringlengths 6
119
| max_stars_repo_head_hexsha
stringlengths 40
41
| max_stars_repo_licenses
list | max_stars_count
int64 1
191k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 6
260
| max_issues_repo_name
stringlengths 6
119
| max_issues_repo_head_hexsha
stringlengths 40
41
| max_issues_repo_licenses
list | max_issues_count
int64 1
67k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 6
260
| max_forks_repo_name
stringlengths 6
119
| max_forks_repo_head_hexsha
stringlengths 40
41
| max_forks_repo_licenses
list | max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | avg_line_length
float64 2
1.04M
| max_line_length
int64 2
11.2M
| alphanum_fraction
float64 0
1
| cells
list | cell_types
list | cell_type_groups
list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
cb310fa6d34dcfa621403e5baa46e245c85e432b | 39,620 | ipynb | Jupyter Notebook | notebooks/3_WordNet.ipynb | ilaiadaya/AUC_TMCI_2021 | 1da449b70e66d73f604e78b2e1621dff87382291 | [
"CC-BY-4.0"
] | null | null | null | notebooks/3_WordNet.ipynb | ilaiadaya/AUC_TMCI_2021 | 1da449b70e66d73f604e78b2e1621dff87382291 | [
"CC-BY-4.0"
] | null | null | null | notebooks/3_WordNet.ipynb | ilaiadaya/AUC_TMCI_2021 | 1da449b70e66d73f604e78b2e1621dff87382291 | [
"CC-BY-4.0"
] | 13 | 2021-01-28T22:53:52.000Z | 2022-02-10T08:27:32.000Z | 22.473057 | 354 | 0.517163 | [
[
[
"# Accessing WordNet through the NLTK interface",
"_____no_output_____"
],
[
">- [Accessing WordNet](#Accessing-WordNet)\n>\n>\n>- [WN-based Semantic Similarity](#WN-based-Semantic-Similarity)",
"_____no_output_____"
],
[
"---",
"_____no_output_____"
],
[
"## Accessing WordNet\n\nWordNet 3.0 can be accessed from NLTK by calling the appropriate NLTK corpus reader",
"_____no_output_____"
]
],
[
[
"from nltk.corpus import wordnet as wn",
"_____no_output_____"
]
],
[
[
"### Retrieving Synsets",
"_____no_output_____"
],
[
"The easiest way to retrieve synsets is by submitting the relevant lemma to the `synsets()` method, that returns the list of all the synsets containing it:",
"_____no_output_____"
]
],
[
[
"print(wn.synsets('dog'))",
"[Synset('dog.n.01'), Synset('frump.n.01'), Synset('dog.n.03'), Synset('cad.n.01'), Synset('frank.n.02'), Synset('pawl.n.01'), Synset('andiron.n.01'), Synset('chase.v.01')]\n"
]
],
[
[
"The optional paramater `pos` allows you to constrain the search to a given part of speech \n\n- available options: `wn.NOUN`, `wn.VERB`, `wn.ADJ`, `wn.ADV`",
"_____no_output_____"
]
],
[
[
"# let's ignore the verbal synsets from our previous results\nprint(wn.synsets('dog', pos = wn.NOUN))",
"[Synset('dog.n.01'), Synset('frump.n.01'), Synset('dog.n.03'), Synset('cad.n.01'), Synset('frank.n.02'), Synset('pawl.n.01'), Synset('andiron.n.01')]\n"
]
],
[
[
"You can use the `synset()` method together with the notation `lemma.pos.number` (e.g. `dog.n.01`) to access a given synset",
"_____no_output_____"
]
],
[
[
"# retrive the gloss of a given synset\nwn.synset('dog.n.01').definition()",
"_____no_output_____"
],
[
"# let's see some examples\nwn.synset('dog.n.01').examples()",
"_____no_output_____"
]
],
[
[
"Did anyone notice something weird in these results? Why did I get `frank.n.02`?",
"_____no_output_____"
]
],
[
[
"# let's retrieve the lemmas associated with a given synset\nwn.synset('frank.n.02').lemmas()",
"_____no_output_____"
]
],
[
[
"What's the definition?",
"_____no_output_____"
]
],
[
[
"wn.synset('frank.n.02').definition()",
"_____no_output_____"
]
],
[
[
"The notation `lemmas.pos.number` is used to identify the **name** of the synset, that is the unique id that is used to store it in the semantic resources \n\n- note that it is different from the notation used to refer to synset lemmas, e.g. `frank.n.02.frank`",
"_____no_output_____"
]
],
[
[
"wn.synset('frank.n.02').name()",
"_____no_output_____"
]
],
[
[
"Applied to our original query...",
"_____no_output_____"
]
],
[
[
"# synsets for a given word\nwn.synsets('dog', pos = wn.NOUN)",
"_____no_output_____"
],
[
"# synonyms for a particular meaning of a word\nwn.synset('dog.n.01').lemmas()",
"_____no_output_____"
],
[
"wn.synset('dog.n.01').definition()",
"_____no_output_____"
],
[
"wn.synset('dog.n.03').lemmas()",
"_____no_output_____"
],
[
"wn.synset('dog.n.03').definition()",
"_____no_output_____"
]
],
[
[
"**Q. How are the senses in WordNet ordered?**\n\nA. *WordNet senses are ordered using sparse data from semantically tagged text. The order of the senses is given simply so that some of the most common uses are listed above others (and those for which there is no data are randomly ordered). The sense numbers and ordering of senses in WordNet should be considered random for research purposes.*\n\n(source: the [FAQ section](https://wordnet.princeton.edu/frequently-asked-questions) of the official WordNet web page)",
"_____no_output_____"
],
[
"Finally, the method `all_synsets()` allows you to retrieve all the synsets in the resource:",
"_____no_output_____"
]
],
[
[
"for synset in list(wn.all_synsets())[:10]:\n print(synset)",
"Synset('able.a.01')\nSynset('unable.a.01')\nSynset('abaxial.a.01')\nSynset('adaxial.a.01')\nSynset('acroscopic.a.01')\nSynset('basiscopic.a.01')\nSynset('abducent.a.01')\nSynset('adducent.a.01')\nSynset('nascent.a.01')\nSynset('emergent.s.02')\n"
]
],
[
[
"... again, you can use the optional `pos` paramter to constrain your search:",
"_____no_output_____"
]
],
[
[
"for synset in list(wn.all_synsets(wn.ADV))[:10]:\n print(synset)",
"Synset('a_cappella.r.01')\nSynset('ad.r.01')\nSynset('ce.r.01')\nSynset('bc.r.01')\nSynset('bce.r.01')\nSynset('horseback.r.01')\nSynset('barely.r.01')\nSynset('just.r.06')\nSynset('hardly.r.02')\nSynset('anisotropically.r.01')\n"
]
],
[
[
"### Retrieving Semantic and Lexical Relations",
"_____no_output_____"
],
[
"#### the Nouns sub-net\n\nNLTK makes it easy to explore the WordNet hierarchy. The `hyponyms()` method allows you to retrieve all the immediate hyponyms of our target synset ",
"_____no_output_____"
]
],
[
[
"wn.synset('dog.n.01').hyponyms()",
"_____no_output_____"
]
],
[
[
"to move in the opposite direction (i.e. towards more general synsets) we can use:\n\n- either the `hypernyms()` method to retrieve the immediate hypernym (or hypernyms in the following case)",
"_____no_output_____"
]
],
[
[
"wn.synset('dog.n.01').hypernyms()",
"_____no_output_____"
]
],
[
[
"- or the `hypernym_paths()` method to retrieve all the hyperonymyc chain **up to the root node**",
"_____no_output_____"
]
],
[
[
"wn.synset('dog.n.01').hypernym_paths()",
"_____no_output_____"
]
],
[
[
"Another important semantic relation for the nouns sub-net is **meronymy**, that links an object (holonym) with its parts (meronym). There are three semantic relations of this kind in WordNet:\n\n\n- **Part meronymy**: the relation between an object and its separable components:",
"_____no_output_____"
]
],
[
[
"wn.synset('tree.n.01').part_meronyms()",
"_____no_output_____"
]
],
[
[
"- **Substance meronymy**: the relation between an object and the substance it is made of",
"_____no_output_____"
]
],
[
[
"wn.synset('tree.n.01').substance_meronyms()",
"_____no_output_____"
]
],
[
[
"- **Member meronymy**: the relation between a group and its members ",
"_____no_output_____"
]
],
[
[
"wn.synset('tree.n.01').member_holonyms()",
"_____no_output_____"
]
],
[
[
"**Instances** do not have hypernyms, but **instance_hypernyms**:",
"_____no_output_____"
]
],
[
[
"# amsterdam is a national capital vs *Amsterdam is a kind of a national capital\nwn.synset('amsterdam.n.01').instance_hypernyms()",
"_____no_output_____"
],
[
"wn.synset('amsterdam.n.01').hypernyms()",
"_____no_output_____"
]
],
[
[
"#### the Verbs sub-net\n\nMoving in the Verbs sub-net, the **troponymy** relation can be navigated by using the same methods used to navigate the nominal hyperonymyc relations",
"_____no_output_____"
]
],
[
[
"wn.synset('sleep.v.01').hypernyms()",
"_____no_output_____"
],
[
"wn.synset('sleep.v.01').hypernym_paths()",
"_____no_output_____"
]
],
[
[
"The other central relation in the organization of the verbs is the **entailment** one:",
"_____no_output_____"
]
],
[
[
"wn.synset('eat.v.01').entailments()",
"_____no_output_____"
]
],
[
[
"#### Adjective clusters\n\nAdjectives are organized in clusters of **satellites** adjectives (labeled as `lemma.s.number`) connected to a central adjective (labeled as `lemma.a.number`) by means of the **similar_to** relation",
"_____no_output_____"
]
],
[
[
"# a satellite adjective is linked just to one central adjective\nwn.synset('quick.s.01').similar_tos()",
"_____no_output_____"
],
[
"# a central adjective is linked to many satellite adjectives\nwn.synset('fast.a.01').similar_tos()",
"_____no_output_____"
]
],
[
[
"The **lemmas** of the central adjective of each cluster, moreover, are connected to their **antonyms**, that is to lemmas that have the opposite meaning",
"_____no_output_____"
]
],
[
[
"wn.lemma('fast.a.01.fast').antonyms()",
"_____no_output_____"
]
],
[
[
"But take note:",
"_____no_output_____"
]
],
[
[
"try:\n wn.synset('fast.a.01').antonyms()\nexcept AttributeError:\n print(\"antonymy is a LEXICAL relation, it cannot involve synsets\")",
"antonymy is a LEXICAL relation, it cannot involve synsets\n"
]
],
[
[
"## WN-based Semantic Similarity",
"_____no_output_____"
],
[
"Simulating the human ability to estimate semantic distances between concepts is crucial for:\n\n\n- Psycholinguistics: for long time the study of human semantic memory has been tied to the study of concepts similarity\n\n\n- Natural Language Processing: for any task that requires some sort of semantic comprehensions",
"_____no_output_____"
],
[
"### Classes of Semantic Distance Measures",
"_____no_output_____"
],
[
"#### Relatedness\n\n- two concepts are related if **a relation of any sort** holds between them\n\n\n- information can be extracted from:\n\n - semantic networks\n \n - dictionaries\n \n - corpora",
"_____no_output_____"
],
[
"#### Similarity\n\n\n- it is a special case of relatedness\n\n\n- the relation holding between two concepts **by virtue of their ontological status**, i.e. by virtue of their taxonomic positions (Resnik, 1995)\n\n - car - bicycle\n - \\*car - fuel\n\n\n- information can be extracted from\n\n - hierarchical networks\n \n - taxnomies",
"_____no_output_____"
],
[
"### WordNet-based Similarity Measures",
"_____no_output_____"
]
],
[
[
"dog = wn.synset('dog.n.01')\ncat = wn.synset('cat.n.01')\nhit = wn.synset('hit.v.01')\nslap = wn.synset('slap.v.01')\nfish = wn.synset('fish.n.01')\nbird = wn.synset('bird.n.01')",
"_____no_output_____"
]
],
[
[
"#### Path Length-based measures\n\n\nThese measures are based on $pathlen(c_1, c_2)$: \n\n- i.e. the number of arc in the shorted path connecting two nodes $c_1$ and $c_2$",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"you can use the `shortest_path_distance()` method to count the number of arcs",
"_____no_output_____"
]
],
[
[
"fish.shortest_path_distance(bird)",
"_____no_output_____"
],
[
"dog.shortest_path_distance(cat)",
"_____no_output_____"
]
],
[
[
"When two notes belongs to different sub-nets, it does not return any values...",
"_____no_output_____"
]
],
[
[
"print(dog.shortest_path_distance(hit))",
"None\n"
]
],
[
[
"... unless you simulate the existance of a **dummy root** by setting the `simulate_root` option to `True`",
"_____no_output_____"
]
],
[
[
"print(dog.shortest_path_distance(hit, simulate_root = True))",
"12\n"
]
],
[
[
"This is quite handy expecially when working on the **verb sub-net** that **do not have a unique root node** (differently to what happens in the nouns sub-net)",
"_____no_output_____"
]
],
[
[
"print(hit.shortest_path_distance(slap))",
"None\n"
],
[
"print(hit.shortest_path_distance(slap, simulate_root = True))",
"6\n"
]
],
[
[
"**Simple Path Length**:\n\n$$sim_{simple}(c_1,c_2) = \\frac{1}{pathlen(c_1,c_2) + 1}$$",
"_____no_output_____"
],
[
"use the `path_similarity()` method to calculate this measure",
"_____no_output_____"
]
],
[
[
"dog.path_similarity(cat)",
"_____no_output_____"
]
],
[
[
"**Leacock & Chodorow (1998)**\n\n$$sim_{L\\&C}(c_1,c_2) = -log \\left(\\frac{pathlen(c_1,c_2)}{2 \\times D}\\right)$$",
"_____no_output_____"
],
[
"where $D$ is the maximum depth of the taxonomy\n\n- as a consequence, $2 \\times D$ is the maximum possible pathlen",
"_____no_output_____"
]
],
[
[
"dog.lch_similarity(cat)",
"_____no_output_____"
]
],
[
[
"you cannot compare synset belonging to different pos",
"_____no_output_____"
]
],
[
[
"try:\n dog.lch_similarity(hit)\nexcept Exception as e:\n print(e)",
"Computing the lch similarity requires Synset('dog.n.01') and Synset('hit.v.01') to have the same part of speech.\n"
]
],
[
[
"#### Wu & Palmer (1994)\n\nThis measure is based on the notion of **Least Common Subsumer**\n\n- i.e. the lowest node that dominates both synsets, e.g. `LCS({fish}, {bird}) = {vertebrate, craniate}`",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"NLTK allows you to use the `lowest_common_hypernyms()` method to identify the Least Common Subsumer of two nodes",
"_____no_output_____"
]
],
[
[
"dog.lowest_common_hypernyms(cat)",
"_____no_output_____"
]
],
[
[
"If necessary, use option `simulate_root` to simulate the existance onf a dummy root: ",
"_____no_output_____"
]
],
[
[
"print(hit.lowest_common_hypernyms(slap, simulate_root = True))",
"[Synset('*ROOT*')]\n"
]
],
[
[
"Wu & Palmer (1998) proposed to measure the semantic simliiarity between concepts by contrasting the depth of the LCS with the depths of the nodes:",
"_____no_output_____"
],
[
"$$sim_{W\\&P(c_1, c_2)} = \\frac{2 \\times depth(LCS(c_1, c_2))}{depth(c_1) + depth(c_2)}$$",
"_____no_output_____"
],
[
"where $depth(s)$ is the number of arcs between the root node and the node $s$",
"_____no_output_____"
],
[
"the minimum and the maximum depths of each node can be calculated with the `min_depth()` and `max_depth()` modules",
"_____no_output_____"
]
],
[
[
"print(dog.min_depth(), dog.max_depth())",
"8 13\n"
]
],
[
[
"...and the `wup_similarity()` (authors' names) method to calculate this measure (option `simulate_root` available)",
"_____no_output_____"
]
],
[
[
"print(dog.wup_similarity(cat))",
"0.8571428571428571\n"
]
],
[
[
"#### Information Content-based measures\n\n- the **Information Content** of a concept $C$ is the probability of a randomly selected word to be an instance of the concept $C$ (i.e. the synset $c$ or one of its hyponyms)",
"_____no_output_____"
],
[
"$$IC(C) = -log(P(C))$$",
"_____no_output_____"
],
[
"- Following Resnik (1995), corpus frequencies can be used to estimate this probability",
"_____no_output_____"
],
[
"$$P(C) = \\frac{freq(C)}{N} = \\frac{\\sum_{w \\in words(c)}count(w)}{N}$$",
"_____no_output_____"
],
[
"- $words(c)$ = set of words that are hierarchically included by $C$ (i.e. its hyponyms)\n\n\n- N = number of corpus tokens for which there is a representation in WordNet",
"_____no_output_____"
],
[
"A fragment of the WN nominal hierarchy, in which each node has been labeled with its $P(C)$ (from Lin, 1998)",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"**Resnik (1995)**",
"_____no_output_____"
],
[
"$$sim_{resnik}(c_1,c_2) = IC(LCS(c_1,c_2)) = -log(P(LCS(c_1,c_2)))$$",
"_____no_output_____"
],
[
"Several Information Content dictionaries are available in NLTK...",
"_____no_output_____"
]
],
[
[
"from nltk.corpus import wordnet_ic",
"_____no_output_____"
],
[
"# the IC estimated from the brown corpus\nbrown_ic = wordnet_ic.ic('ic-brown.dat')",
"_____no_output_____"
],
[
"# the IC estimated from the semcor\nsemcor_ic = wordnet_ic.ic('ic-semcor.dat')",
"_____no_output_____"
]
],
[
[
"... or it can be estimated form an available corpus",
"_____no_output_____"
]
],
[
[
"from nltk.corpus import genesis\ngenesis_ic = wn.ic(genesis, False, 0.0)",
"_____no_output_____"
]
],
[
[
"Note that these calculation of the resnick measure depends on the corpus used to generate the information content ",
"_____no_output_____"
]
],
[
[
"print(dog.res_similarity(cat, ic = brown_ic))\nprint(dog.res_similarity(cat, ic = semcor_ic))\nprint(dog.res_similarity(cat, ic = genesis_ic))",
"7.911666509036577\n7.2549003421277245\n7.204023991374837\n"
]
],
[
[
"**Lin (1998)**",
"_____no_output_____"
],
[
"$$sim_{lin}(c_1,c_2) = \\frac{log(P(common(c_1,c_2)))}{log(P(description(c_1,c_2)))} = \\frac{2 \\times IC(LCS(c_1,c_2))}{IC(c_1) + IC(c_2)}$$",
"_____no_output_____"
],
[
"- $common(c_1,c_2)$ = the information that is common between $c_1$ and $c_2$\n\n\n- $description(c_1,c_2)$ = the information that is needed to describe $c_1$ and $c_2$",
"_____no_output_____"
]
],
[
[
"print(dog.lin_similarity(cat, ic = brown_ic))\nprint(dog.lin_similarity(cat, ic = semcor_ic))\nprint(dog.lin_similarity(cat, ic = genesis_ic))",
"0.8768009843733973\n0.8863288628086228\n0.8043806652422293\n"
]
],
[
[
"**Jiang & Conrath (1997)**",
"_____no_output_____"
],
[
"$$sim_{J\\&C}(c_1,c_2) = \\frac{1}{dist(c_1,c_2)} = \\frac{1}{IC(c_1) + IC(c_2) - 2 \\times IC(LCS(c_1, c_2))}$$",
"_____no_output_____"
]
],
[
[
"print(dog.jcn_similarity(cat, ic = brown_ic))\nprint(dog.jcn_similarity(cat, ic = semcor_ic))\nprint(dog.jcn_similarity(cat, ic = genesis_ic))",
"0.4497755285516739\n0.537382154955756\n0.28539390848096946\n"
]
],
[
[
"### WordNet-based Relatedness Measures",
"_____no_output_____"
],
[
"#### The Lesk algorithm (1986)\n\n\n- *“how to tell a pine cone from an ice cream cone”*\n\n\n- Lesk's intuition: let's have a look at the dictionary glosses",
"_____no_output_____"
],
[
"pine [1]: *kind of **evergreen tree** with needle-shaped leaves*\n\npine [2]: *waste away through sorrow or illness*",
"_____no_output_____"
],
[
"cone [1]: *solid body which narrows to a point*\n\ncone [2]: *something of this shape wheter solid or hollow*\n\ncone [3]: *fruit of certain **evergreen tree**.*",
"_____no_output_____"
],
[
"#### Extended Lesk (Banerjee and Pedersen, 2003)\n\nGlosses overlap score = sum of $n^2$, where $n$ is the length in words of each locution shared by two glosses ",
"_____no_output_____"
],
[
"- in what follows the gloss overlap score is $1^2 + 3^2$\n\n`{chest of drawers, chest, bureau, dresser}` : *a **piece of furniture** with drawers for keeping **clothes**.*\n\n`{wardrobe, closet, press}` : *a tall **piece of furniture** that provides storage space for **clothes**.*",
"_____no_output_____"
],
[
"This measure takes into consideration also che glosses of the synsets that are related to the target synsets by one of an apriori specified set of relations RELS:",
"_____no_output_____"
],
[
"$$sim_{eLesk}(c_1, c_2) = \\sum_{r,q \\in RELS}overlap\\ (gloss(r(c_1)),\\ gloss(q(c_2)))$$",
"_____no_output_____"
],
[
"---",
"_____no_output_____"
],
[
"#### Now, here's a challenge for you...\n\nLet's suppose you have a list of word pair and that you want to measure their similarity by using WordNet. Your immediate problem is polisemy: a single word may refer to multiple concepts, so that a lemma may appear in more WordNet synsets. \n\n**Can you think of a way to deal with this issue** other that relying on some existing WSD tool? (TIP: *can you think of a way of filtering out some senses and/or combining multiple similarity scores in order to derive an unique word pair similarity score?*)",
"_____no_output_____"
],
[
"---",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
cb3122bb34eb4508add9679aaf900c030d57c264 | 337,288 | ipynb | Jupyter Notebook | Steane_code_FTb_encoding.ipynb | goldsmdn/SteaneCode | dc9a2a2f54b93d44d1249c7ff1acbb0188e46c2e | [
"Apache-2.0"
] | 1 | 2021-12-21T14:52:12.000Z | 2021-12-21T14:52:12.000Z | Steane_code_FTb_encoding.ipynb | goldsmdn/SteaneCode | dc9a2a2f54b93d44d1249c7ff1acbb0188e46c2e | [
"Apache-2.0"
] | 62 | 2021-04-02T15:33:02.000Z | 2021-09-01T08:47:29.000Z | Steane_code_FTb_encoding.ipynb | goldsmdn/SteaneCode | dc9a2a2f54b93d44d1249c7ff1acbb0188e46c2e | [
"Apache-2.0"
] | 1 | 2022-02-11T15:32:55.000Z | 2022-02-11T15:32:55.000Z | 1,322.698039 | 328,732 | 0.955872 | [
[
[
"Steane code fault tolerance encoding scheme b\n======================================= \n\n1. Set up two logical zero for Steane code based on the parity matrix in the book by Nielsen MA, Chuang IL. Quantum Computation and Quantum Information, 10th Anniversary Edition. Cambridge University Press; 2016. p. 474\n\n2. Set up fault tolerance as per scheme (b) from Goto H. Minimizing resource overheads for fault-tolerant preparation of encoded states of the Steane code. Sci Rep. 2016 Jan 27;6:19578. \n\n3. Find out if this scheme has a tolerance.",
"_____no_output_____"
],
[
"Import the necessary function modules, including the SteaneCodeLogicalQubit class. The methods of this class are called in this notebook.",
"_____no_output_____"
]
],
[
[
"from qiskit import(\n QuantumCircuit,\n QuantumRegister,\n ClassicalRegister,\n execute,\n Aer\n )\n\nfrom qiskit.providers.aer.noise import NoiseModel\nfrom qiskit.providers.aer.noise.errors import pauli_error, depolarizing_error\n\nfrom circuits import SteaneCodeLogicalQubit\n\nfrom helper_functions import (\n get_noise, \n count_valid_output_strings,\n string_reverse,\n process_FT_results, \n mean_of_list,\n calculate_standard_error,\n get_parity_check_matrix,\n get_codewords\n )",
"_____no_output_____"
]
],
[
[
"Define constants so the process flow can be controlled from one place:",
"_____no_output_____"
]
],
[
[
"SINGLE_GATE_ERRORS = ['x', 'y', 'z', 'h', 's', 'sdg']\nTWO_GATE_ERRORS = ['cx', 'cz']\n\nNOISE = True #Test with noise\nSHOTS = 250000 #Number of shots to run \nMEASURE_NOISE = 0.0046 #Measurement noise not relevant\nSINGLE_GATE_DEPOLARISING = 0.000366 #Single gate noise \nTWO_GATE_DEPOLARISING = 0.022\nITERATIONS = 1\nPOST_SELECTION = True\n\nSIMULATOR = Aer.get_backend('qasm_simulator')",
"_____no_output_____"
]
],
[
[
"We specify the parity check matrix, since this defines the Steane code. It is validated before the logical qubit is initiated to check that it is orthogonal to the valid codewords.",
"_____no_output_____"
]
],
[
[
"parity_check_matrix = get_parity_check_matrix()\nprint(parity_check_matrix)",
"['0001111', '0110011', '1010101']\n"
],
[
"codewords = get_codewords()\nprint(codewords)",
"['0000000', '1010101', '0110011', '1100110', '0001111', '1011010', '0111100', '1101001']\n"
],
[
"if NOISE:\n noise_model = get_noise(MEASURE_NOISE, SINGLE_GATE_DEPOLARISING, \n TWO_GATE_DEPOLARISING, SINGLE_GATE_ERRORS, TWO_GATE_ERRORS )",
"_____no_output_____"
],
[
"rejected_accum = 0\naccepted_accum = 0\nvalid_accum = 0\ninvalid_accum = 0\nresults = []\nfor iteration in range(ITERATIONS):\n qubit = SteaneCodeLogicalQubit(2, parity_check_matrix, codewords, \n ancilla = False, fault_tolerant_b = True, \n data_rounds = 3\n )\n qubit.set_up_logical_zero(0)\n for i in range(3):\n qubit.barrier()\n qubit.set_up_logical_zero(1)\n qubit.barrier()\n qubit.logical_gate_CX(0, 1)\n qubit.barrier()\n qubit.logical_measure_data_FT(logical_qubit = 1, measure_round = i + 1)\n qubit.barrier() \n qubit.logical_measure_data(0)\n if NOISE:\n result = execute(qubit, SIMULATOR, noise_model = noise_model, shots = SHOTS).result()\n else:\n result = execute(qubit, SIMULATOR, shots = SHOTS).result()\n counts = result.get_counts(qubit)\n error_rate, rejected, accepted, valid, invalid = process_FT_results(counts, codewords, verbose = True,\n data_start = 3, data_meas_qubits = 1,\n data_meas_repeats = 3, data_meas_strings = codewords,\n post_selection = POST_SELECTION\n )\n rejected_accum = rejected + rejected_accum\n accepted_accum = accepted_accum + accepted\n valid_accum = valid_accum + valid\n invalid_accum = invalid_accum + invalid \n results.append(error_rate)\nmean_error_rate = mean_of_list(results)\noutside_accum = accepted_accum - valid_accum - invalid_accum\nstandard_deviation, standard_error = calculate_standard_error(results)\nprint(f'There are {rejected_accum} strings rejected and {accepted_accum} strings submitted for validation')\nprint(f'Of these {accepted_accum} strings processed there are {valid_accum} valid strings and {invalid_accum} invalid_strings')\nif POST_SELECTION:\n print(f'There are {outside_accum} strings outside the codeword')\nprint(f'The error rate is {mean_error_rate:.6f} and the standard error is {standard_error:.6f} ')",
"At the data validation stage\nThere are 177305 strings rejected and 72695 strings submitted for processing\nMaking 250000 in total submitted for data processing\n\nAt the ancilla validation stage\nThere are 0 strings rejected and 72695 strings submitted for validation\nMaking 72695 in total submitted to check against ancilla\n\nOf these 72695 strings validated there are 64944 valid strings and 2 invalid_strings\nThere were 7749 strings that were neither logical one or logical zero\nThe error rate is 0.0000\nUnable to carry out standard error calcuation with one point. \nStandard error of 0 used.\nThere are 177305 strings rejected and 72695 strings submitted for validation\nOf these 72695 strings processed there are 64944 valid strings and 2 invalid_strings\nThere are 7749 strings outside the codeword\nThe error rate is 0.000028 and the standard error is 0.000000 \n"
],
[
"qubit.draw(output='mpl', filename = './circuits/Steane_code_circuit_encoding_FTb.jpg', fold = 43)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
cb3123fc9b95580a3c33b317fb4b81f9ac62a897 | 405,173 | ipynb | Jupyter Notebook | examples/interpol_tests.ipynb | MiguelMque/interpolML | 980d55583285ba1d289de69b5c05c65fc34097f5 | [
"MIT"
] | null | null | null | examples/interpol_tests.ipynb | MiguelMque/interpolML | 980d55583285ba1d289de69b5c05c65fc34097f5 | [
"MIT"
] | null | null | null | examples/interpol_tests.ipynb | MiguelMque/interpolML | 980d55583285ba1d289de69b5c05c65fc34097f5 | [
"MIT"
] | null | null | null | 172.560903 | 99,172 | 0.872995 | [
[
[
"import pandas as pd\nimport numpy as np\n\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nsns.set_style('whitegrid')\nplt.style.use(\"fivethirtyeight\")\n%matplotlib inline\n\n# For reading stock data from yahoo\nfrom pandas_datareader.data import DataReader\n\n# For time stamps\nfrom datetime import datetime",
"_____no_output_____"
],
[
"tech_list = ['AAPL', 'GOOG', 'MSFT', 'AMZN']\n\n# Set up End and Start times for data grab\nend = datetime.now()\nstart = datetime(end.year - 1, end.month, end.day)\n\n\n#For loop for grabing yahoo finance data and setting as a dataframe\nfor stock in tech_list: \n # Set DataFrame as the Stock Ticker\n globals()[stock] = DataReader(stock, 'yahoo', start, end)",
"_____no_output_____"
],
[
"company_list = [AAPL, GOOG, MSFT, AMZN]\ncompany_name = [\"APPLE\", \"GOOGLE\", \"MICROSOFT\", \"AMAZON\"]\n\nfor company, com_name in zip(company_list, company_name):\n company[\"company_name\"] = com_name\n \ndf = pd.concat(company_list, axis=0)\ndf.tail(10)",
"_____no_output_____"
],
[
"plt.figure(figsize=(15, 6))\nplt.subplots_adjust(top=1.25, bottom=1.2)\n\nfor i, company in enumerate(company_list, 1):\n plt.subplot(2, 2, i)\n company['Adj Close'].plot()\n plt.ylabel('Adj Close')\n plt.xlabel(None)\n plt.title(f\"Closing Price of {tech_list[i - 1]}\")\n \nplt.tight_layout()",
"_____no_output_____"
],
[
"end_date = datetime(2021,1,1)\ncut_date = datetime(2020,1,1)\nfrac_missing = 0.3\ndf = DataReader('AAPL', data_source='yahoo', start='2012-01-01', end=end_date)\ndf",
"_____no_output_____"
],
[
"def delete_10(col):\n \n return col\n\ndf_missing = df.copy().apply(delete_10, axis=0)",
"_____no_output_____"
],
[
"df.isnull().sum()",
"_____no_output_____"
],
[
"plt.figure(figsize=(16,6))\nplt.title('Close Price History')\nplt.plot(df['Close'], 'o', markersize = 0.5)\nplt.xlabel('Date', fontsize=18)\nplt.ylabel('Close Price USD ($)', fontsize=18)\nplt.show()",
"_____no_output_____"
],
[
"plt.figure(figsize=(16,6))\nplt.title('Close Price History')\nplt.plot(df_missing['Close'], 'o', markersize = 0.5)\nplt.xlabel('Date', fontsize=18)\nplt.ylabel('Close Price USD ($)', fontsize=18)\nplt.show()",
"_____no_output_____"
],
[
"# Select the variable of interest\ndf_closed = df['Close']\n\n# Define the X and Y vectors\nx = np.arange(0,df_closed.shape[0],1)\ny = df_closed.tolist()\n\n# Plot\nplt.figure(figsize = (16,6))\nplt.plot(x,y, 'ok', markersize = 0.5)",
"_____no_output_____"
],
[
"def stock(variable):\n\n index = np.floor(variable)\n difference = int((round(variable - index,1)*100))\n\n values = np.linspace(y[index],y[index+1],100)\n\n value = values[difference]\n\n return value",
"_____no_output_____"
],
[
"x_normalized = np.linspace(-1,1, len(x))\nx_normalized",
"_____no_output_____"
],
[
"df_missing['Close']",
"_____no_output_____"
],
[
"tointclose=df_missing['Close']\ntointclose\n",
"_____no_output_____"
],
[
"import pandas as pd\nimport sympy as sym\nimport numpy\nimport matplotlib.pyplot as plt\nfrom pylab import mpl\nimport numpy as np\nimport pandas as pd\nimport math\n\nclass Interpolation:\n\n def __init__(self, data : pd.DataFrame):\n\n self.data = data\n self.x = np.arange(0,self.data.shape[0],1)\n self.y = self.data.tolist()\n self.xx=x.tolist()\n\n k=len(y)\n i=0\n self.lista_x=[]\n self.lista_y=[]\n while (i<k):\n if pd.isna(self.y[i]):\n self.lista_y.append(self.y.pop(i))\n self.lista_x.append(self.xx.pop(i))\n k=len(self.y)\n i=0\n else:\n i+=1\n \n def newton_interpolation(self,X,Y,x):\n sum=Y[0]\n temp=np.zeros((len(X),len(X)))\n # Asignar la primera línea\n for i in range(0,len(X)):\n temp[i,0]=Y[i]\n temp_sum=1.0\n for i in range(1,len(X)):\n #x polinomio\n temp_sum=temp_sum*(x-X[i-1])\n # Calcular diferencia de medias\n for j in range(i,len(X)):\n temp[j,i]=(temp[j,i-1]-temp[j-1,i-1])/(X[j]-X[j-i])\n sum+=temp_sum*temp[i,i] \n return sum\n\n def lagrange_interpolation(self,xi,fi):\n n = len(xi)\n x = sym.Symbol('x')\n polinomio = 0\n divisorL = np.zeros(n, dtype = float)\n for i in range(0,n,1):\n \n # Termino de Lagrange\n numerador = 1\n denominador = 1\n for j in range(0,n,1):\n if (j!=i):\n numerador = numerador*(x-xi[j])\n denominador = denominador*(xi[i]-xi[j])\n terminoLi = numerador/denominador\n\n polinomio = polinomio + terminoLi*fi[i]\n divisorL[i] = denominador\n\n # simplifica el polinomio\n polisimple = polinomio.expand()\n\n # para evaluación numérica\n px = sym.lambdify(x,polisimple)\n\n # Puntos para la gráfica\n muestras = 101\n a = np.min(xi)\n b = np.max(xi)\n pxi = np.linspace(a,b,muestras)\n pfi = px(pxi)\n\n return polisimple",
"_____no_output_____"
],
[
"obj_interpolar=Interpolation(tointclose)",
"_____no_output_____"
],
[
"funcion=obj_interpolar.lagrange_interpolation(obj_interpolar.xx[1:5],obj_interpolar.y[1:5])",
"_____no_output_____"
],
[
"min_pol = 3\nmax_pol = 6\n\ninterval = []\n\nintervals = []\n\ndef cut_interval(interval):\n\n first_interval = interval[:min_pol+1]\n second_interval = []\n\n done = False\n for x in interval[min_pol+1:]:\n if x != first_interval[-1] + 1 and not done:\n first_interval.append(x)\n else:\n second_interval.append(x)\n done = True\n\n return first_interval, second_interval\n\n\nfor i, x in enumerate(obj_interpolar.xx):\n\n # Llenar la lista hasta su maximo\n if len(interval) == max_pol:\n intervals.append(interval)\n interval = []\n\n # Si el intervalo esta vacio\n elif interval == []:\n\n # Verificar si lista de intervalos esta vacia\n if intervals != []:\n\n\n if x != intervals[-1][-1] + 1:\n first_interval, second_interval = cut_interval(intervals[-1])\n intervals[-1] = first_interval\n interval = second_interval\n\n if len(interval) < max_pol:\n interval.append(x)\n else:\n intervals.append(interval)\n interval = [x]\n\n # Se puede agregar con tranquilidad, no hay discontinuidades\n else:\n interval.append(x)\n # Si esta vacia simplemente adicione elementos al intervalo actual\n # ya que esta construyendo el primer interbalo\n else:\n interval.append(x)\n \n # Si no esta vacio y no ha alzanzado el maximo adicionar hasta llegar a su \n # maximo\n else:\n interval.append(x)\n\nprint(intervals)\n\ninterval_tuples = [(interval[0], interval[-1]) for interval in intervals]\ninterval_tuples\n\ncont = 0\nlast = -1\nmalos = 0\nalgo_pasa = []\nfor i, inter in enumerate(interval_tuples):\n print(inter)\n if obj_interpolar.xx.index(inter[1])-obj_interpolar.xx.index(inter[0]) > max_pol:\n cont += 1\n\n if last != inter[0]-1:\n print('ALGO PASA')\n algo_pasa.append(i)\n malos +=1\n\n last = inter[1]\n\nprint(cont)\nprint(malos)\nprint(algo_pasa)\n\n# replacements = []\n\n# for i in algo_pasa:\n# first_interval = intervals[i-1]\n# second_interval = intervals[i]\n\n# joint = first_interval + second_interval\n\n# new_intervals = []\n# new_interval = []\n# for i, x in enumerate(joint):\n# if len(new_interval) >= min_pol:\n# if new_intervals == []:\n# if x == new_interval[-1] + 1:\n# new_intervals.append(new_interval)\n# new_interval = []\n# else:\n# new_interval.append(x)\n# else:\n# if x == new_interval[-1]+1:\n# new_intervals.append(new_interval)\n# new_interval = []\n# else:\n# new_interval.append(x)\n# else:\n# new_interval.append(x)\n\n# if i == len(joint)-1:\n# new_intervals.append(new_interval)\n\n# replacements.extend(new_intervals)\n\n# replacements",
"[[0, 1, 2, 3], [4, 5, 7, 8], [9, 10, 12, 13], [14, 15, 17, 18], [19, 20, 22, 23], [24, 25, 27, 28], [29, 30, 32, 33], [34, 35, 37, 38], [39, 40, 42, 43], [44, 45, 47, 48], [49, 50, 52, 53], [54, 55, 57, 58], [59, 60, 62, 63], [64, 65, 67, 68], [69, 70, 72, 73], [74, 75, 77, 78], [79, 80, 82, 83], [84, 85, 87, 88], [89, 90, 92, 93], [94, 95, 97, 98], [99, 100, 102, 103], [104, 105, 107, 108], [109, 110, 112, 113], [114, 115, 117, 118], [119, 120, 122, 123], [124, 125, 127, 128], [129, 130, 132, 133], [134, 135, 137, 138], [139, 140, 142, 143], [144, 145, 147, 148], [149, 150, 152, 153], [154, 155, 157, 158], [159, 160, 162, 163], [164, 165, 167, 168], [169, 170, 172, 173], [174, 175, 177, 178], [179, 180, 182, 183], [184, 185, 187, 188], [189, 190, 192, 193], [194, 195, 197, 198], [199, 200, 202, 203], [204, 205, 207, 208], [209, 210, 212, 213], [214, 215, 217, 218], [219, 220, 222, 223], [224, 225, 227, 228], [229, 230, 232, 233], [234, 235, 237, 238], [239, 240, 242, 243], [244, 245, 247, 248], [249, 250, 252, 253], [254, 255, 257, 258], [259, 260, 262, 263], [264, 265, 267, 268], [269, 270, 272, 273], [274, 275, 277, 278], [279, 280, 282, 283], [284, 285, 287, 288], [289, 290, 292, 293], [294, 295, 297, 298], [299, 300, 302, 303], [304, 305, 307, 308], [309, 310, 312, 313], [314, 315, 317, 318], [319, 320, 322, 323], [324, 325, 327, 328], [329, 330, 332, 333], [334, 335, 337, 338], [339, 340, 342, 343], [344, 345, 347, 348], [349, 350, 352, 353], [354, 355, 357, 358], [359, 360, 362, 363], [364, 365, 367, 368], [369, 370, 372, 373], [374, 375, 377, 378], [379, 380, 382, 383], [384, 385, 387, 388], [389, 390, 392, 393], [394, 395, 397, 398], [399, 400, 402, 403], [404, 405, 407, 408], [409, 410, 412, 413], [414, 415, 417, 418], [419, 420, 422, 423], [424, 425, 427, 428], [429, 430, 432, 433], [434, 435, 437, 438], [439, 440, 442, 443], [444, 445, 447, 448], [449, 450, 452, 453], [454, 455, 457, 458], [459, 460, 462, 463], [464, 465, 467, 468], [469, 470, 472, 473], [474, 475, 477, 478], [479, 480, 482, 483], [484, 485, 487, 488], [489, 490, 492, 493], [494, 495, 497, 498], [499, 500, 502, 503], [504, 505, 507, 508], [509, 510, 512, 513], [514, 515, 517, 518], [519, 520, 522, 523], [524, 525, 527, 528], [529, 530, 532, 533], [534, 535, 537, 538], [539, 540, 542, 543], [544, 545, 547, 548], [549, 550, 552, 553], [554, 555, 557, 558], [559, 560, 562, 563], [564, 565, 567, 568], [569, 570, 572, 573], [574, 575, 577, 578], [579, 580, 582, 583], [584, 585, 587, 588], [589, 590, 592, 593], [594, 595, 597, 598], [599, 600, 602, 603], [604, 605, 607, 608], [609, 610, 612, 613], [614, 615, 617, 618], [619, 620, 622, 623], [624, 625, 627, 628], [629, 630, 632, 633], [634, 635, 637, 638], [639, 640, 642, 643], [644, 645, 647, 648], [649, 650, 652, 653], [654, 655, 657, 658], [659, 660, 662, 663], [664, 665, 667, 668], [669, 670, 672, 673], [674, 675, 677, 678], [679, 680, 682, 683], [684, 685, 687, 688], [689, 690, 692, 693], [694, 695, 697, 698], [699, 700, 702, 703], [704, 705, 707, 708], [709, 710, 712, 713], [714, 715, 717, 718], [719, 720, 722, 723], [724, 725, 727, 728], [729, 730, 732, 733], [734, 735, 737, 738], [739, 740, 742, 743], [744, 745, 747, 748], [749, 750, 752, 753], [754, 755, 757, 758], [759, 760, 762, 763], [764, 765, 767, 768], [769, 770, 772, 773], [774, 775, 777, 778], [779, 780, 782, 783], [784, 785, 787, 788], [789, 790, 792, 793], [794, 795, 797, 798], [799, 800, 802, 803], [804, 805, 807, 808], [809, 810, 812, 813], [814, 815, 817, 818], [819, 820, 822, 823], [824, 825, 827, 828], [829, 830, 832, 833], [834, 835, 837, 838], [839, 840, 842, 843], [844, 845, 847, 848], [849, 850, 852, 853], [854, 855, 857, 858], [859, 860, 862, 863], [864, 865, 867, 868], [869, 870, 872, 873], [874, 875, 877, 878], [879, 880, 882, 883], [884, 885, 887, 888], [889, 890, 892, 893], [894, 895, 897, 898], [899, 900, 902, 903], [904, 905, 907, 908], [909, 910, 912, 913], [914, 915, 917, 918], [919, 920, 922, 923], [924, 925, 927, 928], [929, 930, 932, 933], [934, 935, 937, 938], [939, 940, 942, 943], [944, 945, 947, 948], [949, 950, 952, 953], [954, 955, 957, 958], [959, 960, 962, 963], [964, 965, 967, 968], [969, 970, 972, 973], [974, 975, 977, 978], [979, 980, 982, 983], [984, 985, 987, 988], [989, 990, 992, 993], [994, 995, 997, 998], [999, 1000, 1002, 1003], [1004, 1005, 1007, 1008], [1009, 1010, 1012, 1013], [1014, 1015, 1017, 1018], [1019, 1020, 1022, 1023], [1024, 1025, 1027, 1028], [1029, 1030, 1032, 1033], [1034, 1035, 1037, 1038], [1039, 1040, 1042, 1043], [1044, 1045, 1047, 1048], [1049, 1050, 1052, 1053], [1054, 1055, 1057, 1058], [1059, 1060, 1062, 1063], [1064, 1065, 1067, 1068], [1069, 1070, 1072, 1073], [1074, 1075, 1077, 1078], [1079, 1080, 1082, 1083], [1084, 1085, 1087, 1088], [1089, 1090, 1092, 1093], [1094, 1095, 1097, 1098], [1099, 1100, 1102, 1103], [1104, 1105, 1107, 1108], [1109, 1110, 1112, 1113], [1114, 1115, 1117, 1118], [1119, 1120, 1122, 1123], [1124, 1125, 1127, 1128], [1129, 1130, 1132, 1133], [1134, 1135, 1137, 1138], [1139, 1140, 1142, 1143], [1144, 1145, 1147, 1148], [1149, 1150, 1152, 1153], [1154, 1155, 1157, 1158], [1159, 1160, 1162, 1163], [1164, 1165, 1167, 1168], [1169, 1170, 1172, 1173], [1174, 1175, 1177, 1178], [1179, 1180, 1182, 1183], [1184, 1185, 1187, 1188], [1189, 1190, 1192, 1193], [1194, 1195, 1197, 1198], [1199, 1200, 1202, 1203], [1204, 1205, 1207, 1208], [1209, 1210, 1212, 1213], [1214, 1215, 1217, 1218], [1219, 1220, 1222, 1223], [1224, 1225, 1227, 1228], [1229, 1230, 1232, 1233], [1234, 1235, 1237, 1238], [1239, 1240, 1242, 1243], [1244, 1245, 1247, 1248], [1249, 1250, 1252, 1253], [1254, 1255, 1257, 1258], [1259, 1260, 1262, 1263], [1264, 1265, 1267, 1268], [1269, 1270, 1272, 1273], [1274, 1275, 1277, 1278], [1279, 1280, 1282, 1283], [1284, 1285, 1287, 1288], [1289, 1290, 1292, 1293], [1294, 1295, 1297, 1298], [1299, 1300, 1302, 1303], [1304, 1305, 1307, 1308], [1309, 1310, 1312, 1313], [1314, 1315, 1317, 1318], [1319, 1320, 1322, 1323], [1324, 1325, 1327, 1328], [1329, 1330, 1332, 1333], [1334, 1335, 1337, 1338], [1339, 1340, 1342, 1343], [1344, 1345, 1347, 1348], [1349, 1350, 1352, 1353], [1354, 1355, 1357, 1358], [1359, 1360, 1362, 1363], [1364, 1365, 1367, 1368], [1369, 1370, 1372, 1373], [1374, 1375, 1377, 1378], [1379, 1380, 1382, 1383], [1384, 1385, 1387, 1388], [1389, 1390, 1392, 1393], [1394, 1395, 1397, 1398], [1399, 1400, 1402, 1403], [1404, 1405, 1407, 1408], [1409, 1410, 1412, 1413], [1414, 1415, 1417, 1418], [1419, 1420, 1422, 1423], [1424, 1425, 1427, 1428], [1429, 1430, 1432, 1433], [1434, 1435, 1437, 1438], [1439, 1440, 1442, 1443], [1444, 1445, 1447, 1448], [1449, 1450, 1452, 1453], [1454, 1455, 1457, 1458], [1459, 1460, 1462, 1463], [1464, 1465, 1467, 1468], [1469, 1470, 1472, 1473], [1474, 1475, 1477, 1478], [1479, 1480, 1482, 1483], [1484, 1485, 1487, 1488], [1489, 1490, 1492, 1493], [1494, 1495, 1497, 1498], [1499, 1500, 1502, 1503], [1504, 1505, 1507, 1508], [1509, 1510, 1512, 1513], [1514, 1515, 1517, 1518], [1519, 1520, 1522, 1523], [1524, 1525, 1527, 1528], [1529, 1530, 1532, 1533], [1534, 1535, 1537, 1538], [1539, 1540, 1542, 1543], [1544, 1545, 1547, 1548], [1549, 1550, 1552, 1553], [1554, 1555, 1557, 1558], [1559, 1560, 1562, 1563], [1564, 1565, 1567, 1568], [1569, 1570, 1572, 1573], [1574, 1575, 1577, 1578], [1579, 1580, 1582, 1583], [1584, 1585, 1587, 1588], [1589, 1590, 1592, 1593], [1594, 1595, 1597, 1598], [1599, 1600, 1602, 1603], [1604, 1605, 1607, 1608], [1609, 1610, 1612, 1613], [1614, 1615, 1617, 1618], [1619, 1620, 1622, 1623], [1624, 1625, 1627, 1628], [1629, 1630, 1632, 1633], [1634, 1635, 1637, 1638], [1639, 1640, 1642, 1643], [1644, 1645, 1647, 1648], [1649, 1650, 1652, 1653], [1654, 1655, 1657, 1658], [1659, 1660, 1662, 1663], [1664, 1665, 1667, 1668], [1669, 1670, 1672, 1673], [1674, 1675, 1677, 1678], [1679, 1680, 1682, 1683], [1684, 1685, 1687, 1688], [1689, 1690, 1692, 1693], [1694, 1695, 1697, 1698], [1699, 1700, 1702, 1703], [1704, 1705, 1707, 1708], [1709, 1710, 1712, 1713], [1714, 1715, 1717, 1718], [1719, 1720, 1722, 1723], [1724, 1725, 1727, 1728], [1729, 1730, 1732, 1733], [1734, 1735, 1737, 1738], [1739, 1740, 1742, 1743], [1744, 1745, 1747, 1748], [1749, 1750, 1752, 1753], [1754, 1755, 1757, 1758], [1759, 1760, 1762, 1763], [1764, 1765, 1767, 1768], [1769, 1770, 1772, 1773], [1774, 1775, 1777, 1778], [1779, 1780, 1782, 1783], [1784, 1785, 1787, 1788], [1789, 1790, 1792, 1793], [1794, 1795, 1797, 1798], [1799, 1800, 1802, 1803], [1804, 1805, 1807, 1808], [1809, 1810, 1812, 1813], [1814, 1815, 1817, 1818], [1819, 1820, 1822, 1823], [1824, 1825, 1827, 1828], [1829, 1830, 1832, 1833], [1834, 1835, 1837, 1838], [1839, 1840, 1842, 1843], [1844, 1845, 1847, 1848], [1849, 1850, 1852, 1853], [1854, 1855, 1857, 1858], [1859, 1860, 1862, 1863], [1864, 1865, 1867, 1868], [1869, 1870, 1872, 1873], [1874, 1875, 1877, 1878], [1879, 1880, 1882, 1883], [1884, 1885, 1887, 1888], [1889, 1890, 1892, 1893], [1894, 1895, 1897, 1898], [1899, 1900, 1902, 1903], [1904, 1905, 1907, 1908], [1909, 1910, 1912, 1913], [1914, 1915, 1917, 1918], [1919, 1920, 1922, 1923], [1924, 1925, 1927, 1928], [1929, 1930, 1932, 1933], [1934, 1935, 1937, 1938], [1939, 1940, 1942, 1943], [1944, 1945, 1947, 1948], [1949, 1950, 1952, 1953], [1954, 1955, 1957, 1958], [1959, 1960, 1962, 1963], [1964, 1965, 1967, 1968], [1969, 1970, 1972, 1973], [1974, 1975, 1977, 1978], [1979, 1980, 1982, 1983], [1984, 1985, 1987, 1988], [1989, 1990, 1992, 1993], [1994, 1995, 1997, 1998], [1999, 2000, 2002, 2003], [2004, 2005, 2007, 2008], [2009, 2010, 2012, 2013], [2014, 2015, 2017, 2018], [2019, 2020, 2022, 2023], [2024, 2025, 2027, 2028], [2029, 2030, 2032, 2033], [2034, 2035, 2037, 2038], [2039, 2040, 2042, 2043], [2044, 2045, 2047, 2048], [2049, 2050, 2052, 2053], [2054, 2055, 2057, 2058], [2059, 2060, 2062, 2063], [2064, 2065, 2067, 2068], [2069, 2070, 2072, 2073], [2074, 2075, 2077, 2078], [2079, 2080, 2082, 2083], [2084, 2085, 2087, 2088], [2089, 2090, 2092, 2093], [2094, 2095, 2097, 2098], [2099, 2100, 2102, 2103], [2104, 2105, 2107, 2108], [2109, 2110, 2112, 2113], [2114, 2115, 2117, 2118], [2119, 2120, 2122, 2123], [2124, 2125, 2127, 2128], [2129, 2130, 2132, 2133], [2134, 2135, 2137, 2138], [2139, 2140, 2142, 2143], [2144, 2145, 2147, 2148], [2149, 2150, 2152, 2153], [2154, 2155, 2157, 2158], [2159, 2160, 2162, 2163], [2164, 2165, 2167, 2168], [2169, 2170, 2172, 2173], [2174, 2175, 2177, 2178], [2179, 2180, 2182, 2183], [2184, 2185, 2187, 2188], [2189, 2190, 2192, 2193], [2194, 2195, 2197, 2198], [2199, 2200, 2202, 2203], [2204, 2205, 2207, 2208], [2209, 2210, 2212, 2213], [2214, 2215, 2217, 2218], [2219, 2220, 2222, 2223], [2224, 2225, 2227, 2228], [2229, 2230, 2232, 2233], [2234, 2235, 2237, 2238], [2239, 2240, 2242, 2243], [2244, 2245, 2247, 2248], [2249, 2250, 2252, 2253], [2254, 2255, 2257, 2258]]\n(0, 3)\n(4, 8)\n(9, 13)\n(14, 18)\n(19, 23)\n(24, 28)\n(29, 33)\n(34, 38)\n(39, 43)\n(44, 48)\n(49, 53)\n(54, 58)\n(59, 63)\n(64, 68)\n(69, 73)\n(74, 78)\n(79, 83)\n(84, 88)\n(89, 93)\n(94, 98)\n(99, 103)\n(104, 108)\n(109, 113)\n(114, 118)\n(119, 123)\n(124, 128)\n(129, 133)\n(134, 138)\n(139, 143)\n(144, 148)\n(149, 153)\n(154, 158)\n(159, 163)\n(164, 168)\n(169, 173)\n(174, 178)\n(179, 183)\n(184, 188)\n(189, 193)\n(194, 198)\n(199, 203)\n(204, 208)\n(209, 213)\n(214, 218)\n(219, 223)\n(224, 228)\n(229, 233)\n(234, 238)\n(239, 243)\n(244, 248)\n(249, 253)\n(254, 258)\n(259, 263)\n(264, 268)\n(269, 273)\n(274, 278)\n(279, 283)\n(284, 288)\n(289, 293)\n(294, 298)\n(299, 303)\n(304, 308)\n(309, 313)\n(314, 318)\n(319, 323)\n(324, 328)\n(329, 333)\n(334, 338)\n(339, 343)\n(344, 348)\n(349, 353)\n(354, 358)\n(359, 363)\n(364, 368)\n(369, 373)\n(374, 378)\n(379, 383)\n(384, 388)\n(389, 393)\n(394, 398)\n(399, 403)\n(404, 408)\n(409, 413)\n(414, 418)\n(419, 423)\n(424, 428)\n(429, 433)\n(434, 438)\n(439, 443)\n(444, 448)\n(449, 453)\n(454, 458)\n(459, 463)\n(464, 468)\n(469, 473)\n(474, 478)\n(479, 483)\n(484, 488)\n(489, 493)\n(494, 498)\n(499, 503)\n(504, 508)\n(509, 513)\n(514, 518)\n(519, 523)\n(524, 528)\n(529, 533)\n(534, 538)\n(539, 543)\n(544, 548)\n(549, 553)\n(554, 558)\n(559, 563)\n(564, 568)\n(569, 573)\n(574, 578)\n(579, 583)\n(584, 588)\n(589, 593)\n(594, 598)\n(599, 603)\n(604, 608)\n(609, 613)\n(614, 618)\n(619, 623)\n(624, 628)\n(629, 633)\n(634, 638)\n(639, 643)\n(644, 648)\n(649, 653)\n(654, 658)\n(659, 663)\n(664, 668)\n(669, 673)\n(674, 678)\n(679, 683)\n(684, 688)\n(689, 693)\n(694, 698)\n(699, 703)\n(704, 708)\n(709, 713)\n(714, 718)\n(719, 723)\n(724, 728)\n(729, 733)\n(734, 738)\n(739, 743)\n(744, 748)\n(749, 753)\n(754, 758)\n(759, 763)\n(764, 768)\n(769, 773)\n(774, 778)\n(779, 783)\n(784, 788)\n(789, 793)\n(794, 798)\n(799, 803)\n(804, 808)\n(809, 813)\n(814, 818)\n(819, 823)\n(824, 828)\n(829, 833)\n(834, 838)\n(839, 843)\n(844, 848)\n(849, 853)\n(854, 858)\n(859, 863)\n(864, 868)\n(869, 873)\n(874, 878)\n(879, 883)\n(884, 888)\n(889, 893)\n(894, 898)\n(899, 903)\n(904, 908)\n(909, 913)\n(914, 918)\n(919, 923)\n(924, 928)\n(929, 933)\n(934, 938)\n(939, 943)\n(944, 948)\n(949, 953)\n(954, 958)\n(959, 963)\n(964, 968)\n(969, 973)\n(974, 978)\n(979, 983)\n(984, 988)\n(989, 993)\n(994, 998)\n(999, 1003)\n(1004, 1008)\n(1009, 1013)\n(1014, 1018)\n(1019, 1023)\n(1024, 1028)\n(1029, 1033)\n(1034, 1038)\n(1039, 1043)\n(1044, 1048)\n(1049, 1053)\n(1054, 1058)\n(1059, 1063)\n(1064, 1068)\n(1069, 1073)\n(1074, 1078)\n(1079, 1083)\n(1084, 1088)\n(1089, 1093)\n(1094, 1098)\n(1099, 1103)\n(1104, 1108)\n(1109, 1113)\n(1114, 1118)\n(1119, 1123)\n(1124, 1128)\n(1129, 1133)\n(1134, 1138)\n(1139, 1143)\n(1144, 1148)\n(1149, 1153)\n(1154, 1158)\n(1159, 1163)\n(1164, 1168)\n(1169, 1173)\n(1174, 1178)\n(1179, 1183)\n(1184, 1188)\n(1189, 1193)\n(1194, 1198)\n(1199, 1203)\n(1204, 1208)\n(1209, 1213)\n(1214, 1218)\n(1219, 1223)\n(1224, 1228)\n(1229, 1233)\n(1234, 1238)\n(1239, 1243)\n(1244, 1248)\n(1249, 1253)\n(1254, 1258)\n(1259, 1263)\n(1264, 1268)\n(1269, 1273)\n(1274, 1278)\n(1279, 1283)\n(1284, 1288)\n(1289, 1293)\n(1294, 1298)\n(1299, 1303)\n(1304, 1308)\n(1309, 1313)\n(1314, 1318)\n(1319, 1323)\n(1324, 1328)\n(1329, 1333)\n(1334, 1338)\n(1339, 1343)\n(1344, 1348)\n(1349, 1353)\n(1354, 1358)\n(1359, 1363)\n(1364, 1368)\n(1369, 1373)\n(1374, 1378)\n(1379, 1383)\n(1384, 1388)\n(1389, 1393)\n(1394, 1398)\n(1399, 1403)\n(1404, 1408)\n(1409, 1413)\n(1414, 1418)\n(1419, 1423)\n(1424, 1428)\n(1429, 1433)\n(1434, 1438)\n(1439, 1443)\n(1444, 1448)\n(1449, 1453)\n(1454, 1458)\n(1459, 1463)\n(1464, 1468)\n(1469, 1473)\n(1474, 1478)\n(1479, 1483)\n(1484, 1488)\n(1489, 1493)\n(1494, 1498)\n(1499, 1503)\n(1504, 1508)\n(1509, 1513)\n(1514, 1518)\n(1519, 1523)\n(1524, 1528)\n(1529, 1533)\n(1534, 1538)\n(1539, 1543)\n(1544, 1548)\n(1549, 1553)\n(1554, 1558)\n(1559, 1563)\n(1564, 1568)\n(1569, 1573)\n(1574, 1578)\n(1579, 1583)\n(1584, 1588)\n(1589, 1593)\n(1594, 1598)\n(1599, 1603)\n(1604, 1608)\n(1609, 1613)\n(1614, 1618)\n(1619, 1623)\n(1624, 1628)\n(1629, 1633)\n(1634, 1638)\n(1639, 1643)\n(1644, 1648)\n(1649, 1653)\n(1654, 1658)\n(1659, 1663)\n(1664, 1668)\n(1669, 1673)\n(1674, 1678)\n(1679, 1683)\n(1684, 1688)\n(1689, 1693)\n(1694, 1698)\n(1699, 1703)\n(1704, 1708)\n(1709, 1713)\n(1714, 1718)\n(1719, 1723)\n(1724, 1728)\n(1729, 1733)\n(1734, 1738)\n(1739, 1743)\n(1744, 1748)\n(1749, 1753)\n(1754, 1758)\n(1759, 1763)\n(1764, 1768)\n(1769, 1773)\n(1774, 1778)\n(1779, 1783)\n(1784, 1788)\n(1789, 1793)\n(1794, 1798)\n(1799, 1803)\n(1804, 1808)\n(1809, 1813)\n(1814, 1818)\n(1819, 1823)\n(1824, 1828)\n(1829, 1833)\n(1834, 1838)\n(1839, 1843)\n(1844, 1848)\n(1849, 1853)\n(1854, 1858)\n(1859, 1863)\n(1864, 1868)\n(1869, 1873)\n(1874, 1878)\n(1879, 1883)\n(1884, 1888)\n(1889, 1893)\n(1894, 1898)\n(1899, 1903)\n(1904, 1908)\n(1909, 1913)\n(1914, 1918)\n(1919, 1923)\n(1924, 1928)\n(1929, 1933)\n(1934, 1938)\n(1939, 1943)\n(1944, 1948)\n(1949, 1953)\n(1954, 1958)\n(1959, 1963)\n(1964, 1968)\n(1969, 1973)\n(1974, 1978)\n(1979, 1983)\n(1984, 1988)\n(1989, 1993)\n(1994, 1998)\n(1999, 2003)\n(2004, 2008)\n(2009, 2013)\n(2014, 2018)\n(2019, 2023)\n(2024, 2028)\n(2029, 2033)\n(2034, 2038)\n(2039, 2043)\n(2044, 2048)\n(2049, 2053)\n(2054, 2058)\n(2059, 2063)\n(2064, 2068)\n(2069, 2073)\n(2074, 2078)\n(2079, 2083)\n(2084, 2088)\n(2089, 2093)\n(2094, 2098)\n(2099, 2103)\n(2104, 2108)\n(2109, 2113)\n(2114, 2118)\n(2119, 2123)\n(2124, 2128)\n(2129, 2133)\n(2134, 2138)\n(2139, 2143)\n(2144, 2148)\n(2149, 2153)\n(2154, 2158)\n(2159, 2163)\n(2164, 2168)\n(2169, 2173)\n(2174, 2178)\n(2179, 2183)\n(2184, 2188)\n(2189, 2193)\n(2194, 2198)\n(2199, 2203)\n(2204, 2208)\n(2209, 2213)\n(2214, 2218)\n(2219, 2223)\n(2224, 2228)\n(2229, 2233)\n(2234, 2238)\n(2239, 2243)\n(2244, 2248)\n(2249, 2253)\n(2254, 2258)\n0\n0\n[]\n"
],
[
"x_interpolate = []\ny_interpolate = []\n\nintervals = interval_tuples\n\nl=sym.Symbol('x')\ncont = 0\nfor inter in intervals:\n print(inter)\n beg = obj_interpolar.xx.index(inter[0])\n end = obj_interpolar.xx.index(inter[1])\n\n datos_interpolar_x = obj_interpolar.xx[beg:end+1]\n datos_interpolar_y = obj_interpolar.y[beg:end+1]\n funcion = obj_interpolar.lagrange_interpolation(datos_interpolar_x,datos_interpolar_y)\n\n for x in np.arange(datos_interpolar_x[0],datos_interpolar_x[-1]+1, 0.5):\n # print(x)\n cont += 1\n x_interpolate.append(x)\n y = funcion.subs(l,x)\n y_interpolate.append(y)\n\nprint(cont)",
"(0, 3)\n(4, 8)\n(9, 13)\n(14, 18)\n(19, 23)\n(24, 28)\n(29, 33)\n(34, 38)\n(39, 43)\n(44, 48)\n(49, 53)\n(54, 58)\n(59, 63)\n(64, 68)\n(69, 73)\n(74, 78)\n(79, 83)\n(84, 88)\n(89, 93)\n(94, 98)\n(99, 103)\n(104, 108)\n(109, 113)\n(114, 118)\n(119, 123)\n(124, 128)\n(129, 133)\n(134, 138)\n(139, 143)\n(144, 148)\n(149, 153)\n(154, 158)\n(159, 163)\n(164, 168)\n(169, 173)\n(174, 178)\n(179, 183)\n(184, 188)\n(189, 193)\n(194, 198)\n(199, 203)\n(204, 208)\n(209, 213)\n(214, 218)\n(219, 223)\n(224, 228)\n(229, 233)\n(234, 238)\n(239, 243)\n(244, 248)\n(249, 253)\n(254, 258)\n(259, 263)\n(264, 268)\n(269, 273)\n(274, 278)\n(279, 283)\n(284, 288)\n(289, 293)\n(294, 298)\n(299, 303)\n(304, 308)\n(309, 313)\n(314, 318)\n(319, 323)\n(324, 328)\n(329, 333)\n(334, 338)\n(339, 343)\n(344, 348)\n(349, 353)\n(354, 358)\n(359, 363)\n(364, 368)\n(369, 373)\n(374, 378)\n(379, 383)\n(384, 388)\n(389, 393)\n(394, 398)\n(399, 403)\n(404, 408)\n(409, 413)\n(414, 418)\n(419, 423)\n(424, 428)\n(429, 433)\n(434, 438)\n(439, 443)\n(444, 448)\n(449, 453)\n(454, 458)\n(459, 463)\n(464, 468)\n(469, 473)\n(474, 478)\n(479, 483)\n(484, 488)\n(489, 493)\n(494, 498)\n(499, 503)\n(504, 508)\n(509, 513)\n(514, 518)\n(519, 523)\n(524, 528)\n(529, 533)\n(534, 538)\n(539, 543)\n(544, 548)\n(549, 553)\n(554, 558)\n(559, 563)\n(564, 568)\n(569, 573)\n(574, 578)\n(579, 583)\n(584, 588)\n(589, 593)\n(594, 598)\n(599, 603)\n(604, 608)\n(609, 613)\n(614, 618)\n(619, 623)\n(624, 628)\n(629, 633)\n(634, 638)\n(639, 643)\n(644, 648)\n(649, 653)\n(654, 658)\n(659, 663)\n(664, 668)\n(669, 673)\n(674, 678)\n(679, 683)\n(684, 688)\n(689, 693)\n(694, 698)\n(699, 703)\n(704, 708)\n(709, 713)\n(714, 718)\n(719, 723)\n(724, 728)\n(729, 733)\n(734, 738)\n(739, 743)\n(744, 748)\n(749, 753)\n(754, 758)\n(759, 763)\n(764, 768)\n(769, 773)\n(774, 778)\n(779, 783)\n(784, 788)\n(789, 793)\n(794, 798)\n(799, 803)\n(804, 808)\n(809, 813)\n(814, 818)\n(819, 823)\n(824, 828)\n(829, 833)\n(834, 838)\n(839, 843)\n(844, 848)\n(849, 853)\n(854, 858)\n(859, 863)\n(864, 868)\n(869, 873)\n(874, 878)\n(879, 883)\n(884, 888)\n(889, 893)\n(894, 898)\n(899, 903)\n(904, 908)\n(909, 913)\n(914, 918)\n(919, 923)\n(924, 928)\n(929, 933)\n(934, 938)\n(939, 943)\n(944, 948)\n(949, 953)\n(954, 958)\n(959, 963)\n(964, 968)\n(969, 973)\n(974, 978)\n(979, 983)\n(984, 988)\n(989, 993)\n(994, 998)\n(999, 1003)\n(1004, 1008)\n(1009, 1013)\n(1014, 1018)\n(1019, 1023)\n(1024, 1028)\n(1029, 1033)\n(1034, 1038)\n(1039, 1043)\n(1044, 1048)\n(1049, 1053)\n(1054, 1058)\n(1059, 1063)\n(1064, 1068)\n(1069, 1073)\n(1074, 1078)\n(1079, 1083)\n(1084, 1088)\n(1089, 1093)\n(1094, 1098)\n(1099, 1103)\n(1104, 1108)\n(1109, 1113)\n(1114, 1118)\n(1119, 1123)\n(1124, 1128)\n(1129, 1133)\n(1134, 1138)\n(1139, 1143)\n(1144, 1148)\n(1149, 1153)\n(1154, 1158)\n(1159, 1163)\n(1164, 1168)\n(1169, 1173)\n(1174, 1178)\n(1179, 1183)\n(1184, 1188)\n(1189, 1193)\n(1194, 1198)\n(1199, 1203)\n(1204, 1208)\n(1209, 1213)\n(1214, 1218)\n(1219, 1223)\n(1224, 1228)\n(1229, 1233)\n(1234, 1238)\n(1239, 1243)\n(1244, 1248)\n(1249, 1253)\n(1254, 1258)\n(1259, 1263)\n(1264, 1268)\n(1269, 1273)\n(1274, 1278)\n(1279, 1283)\n(1284, 1288)\n(1289, 1293)\n(1294, 1298)\n(1299, 1303)\n(1304, 1308)\n(1309, 1313)\n(1314, 1318)\n(1319, 1323)\n(1324, 1328)\n(1329, 1333)\n(1334, 1338)\n(1339, 1343)\n(1344, 1348)\n(1349, 1353)\n(1354, 1358)\n(1359, 1363)\n(1364, 1368)\n(1369, 1373)\n(1374, 1378)\n(1379, 1383)\n(1384, 1388)\n(1389, 1393)\n(1394, 1398)\n(1399, 1403)\n(1404, 1408)\n(1409, 1413)\n(1414, 1418)\n(1419, 1423)\n(1424, 1428)\n(1429, 1433)\n(1434, 1438)\n(1439, 1443)\n(1444, 1448)\n(1449, 1453)\n(1454, 1458)\n(1459, 1463)\n(1464, 1468)\n(1469, 1473)\n(1474, 1478)\n(1479, 1483)\n(1484, 1488)\n(1489, 1493)\n(1494, 1498)\n(1499, 1503)\n(1504, 1508)\n(1509, 1513)\n(1514, 1518)\n(1519, 1523)\n(1524, 1528)\n(1529, 1533)\n(1534, 1538)\n(1539, 1543)\n(1544, 1548)\n(1549, 1553)\n(1554, 1558)\n(1559, 1563)\n(1564, 1568)\n(1569, 1573)\n(1574, 1578)\n(1579, 1583)\n(1584, 1588)\n(1589, 1593)\n(1594, 1598)\n(1599, 1603)\n(1604, 1608)\n(1609, 1613)\n(1614, 1618)\n(1619, 1623)\n(1624, 1628)\n(1629, 1633)\n(1634, 1638)\n(1639, 1643)\n(1644, 1648)\n(1649, 1653)\n(1654, 1658)\n(1659, 1663)\n(1664, 1668)\n(1669, 1673)\n(1674, 1678)\n(1679, 1683)\n(1684, 1688)\n(1689, 1693)\n(1694, 1698)\n(1699, 1703)\n(1704, 1708)\n(1709, 1713)\n(1714, 1718)\n(1719, 1723)\n(1724, 1728)\n(1729, 1733)\n(1734, 1738)\n(1739, 1743)\n(1744, 1748)\n(1749, 1753)\n(1754, 1758)\n(1759, 1763)\n(1764, 1768)\n(1769, 1773)\n(1774, 1778)\n(1779, 1783)\n(1784, 1788)\n(1789, 1793)\n(1794, 1798)\n(1799, 1803)\n(1804, 1808)\n(1809, 1813)\n(1814, 1818)\n(1819, 1823)\n(1824, 1828)\n(1829, 1833)\n(1834, 1838)\n(1839, 1843)\n(1844, 1848)\n(1849, 1853)\n(1854, 1858)\n(1859, 1863)\n(1864, 1868)\n(1869, 1873)\n(1874, 1878)\n(1879, 1883)\n(1884, 1888)\n(1889, 1893)\n(1894, 1898)\n(1899, 1903)\n(1904, 1908)\n(1909, 1913)\n(1914, 1918)\n(1919, 1923)\n(1924, 1928)\n(1929, 1933)\n(1934, 1938)\n(1939, 1943)\n(1944, 1948)\n(1949, 1953)\n(1954, 1958)\n(1959, 1963)\n(1964, 1968)\n(1969, 1973)\n(1974, 1978)\n(1979, 1983)\n(1984, 1988)\n(1989, 1993)\n(1994, 1998)\n(1999, 2003)\n(2004, 2008)\n(2009, 2013)\n(2014, 2018)\n(2019, 2023)\n(2024, 2028)\n(2029, 2033)\n(2034, 2038)\n(2039, 2043)\n(2044, 2048)\n(2049, 2053)\n(2054, 2058)\n(2059, 2063)\n(2064, 2068)\n(2069, 2073)\n(2074, 2078)\n(2079, 2083)\n(2084, 2088)\n(2089, 2093)\n(2094, 2098)\n(2099, 2103)\n(2104, 2108)\n(2109, 2113)\n(2114, 2118)\n(2119, 2123)\n(2124, 2128)\n(2129, 2133)\n(2134, 2138)\n(2139, 2143)\n(2144, 2148)\n(2149, 2153)\n(2154, 2158)\n(2159, 2163)\n(2164, 2168)\n(2169, 2173)\n(2174, 2178)\n(2179, 2183)\n(2184, 2188)\n(2189, 2193)\n(2194, 2198)\n(2199, 2203)\n(2204, 2208)\n(2209, 2213)\n(2214, 2218)\n(2219, 2223)\n(2224, 2228)\n(2229, 2233)\n(2234, 2238)\n(2239, 2243)\n(2244, 2248)\n(2249, 2253)\n(2254, 2258)\n4518\n"
],
[
"plt.figure(figsize = (10,10))\nplt.plot(x_interpolate[:2000],y_interpolate[:2000], 'k-', markersize = 0.5, label = 'Interpolacion')\nplt.plot(range(0,2000),df_closed.iloc[:2000], 'r-', markersize = 0.5, label = 'Real')\nplt.legend(loc = 'best')\nplt.show()",
"_____no_output_____"
],
[
"plt.figure(figsize = (10,10))\nplt.plot(x_interpolate,y_interpolate, 'k-', markersize = 0.5, label = 'Interpolacion')\nplt.plot(range(0,len(df_closed)),df_closed, 'r-', markersize = 0.5, label = 'Real')\nplt.legend(loc = 'best')\nplt.show()",
"_____no_output_____"
],
[
"len(x_interpolate)",
"_____no_output_____"
],
[
"tointclose.tail()",
"_____no_output_____"
],
[
"len(x_interpolate)",
"_____no_output_____"
],
[
"len(y_interpolate)",
"_____no_output_____"
],
[
"dato_original",
"_____no_output_____"
],
[
"dato_interpolado",
"_____no_output_____"
],
[
"obj_interpolar.newton_interpolation(obj_interpolar.xx[1:5],obj_interpolar.y[1:5],obj_interpolar.lista_x[0])",
"_____no_output_____"
],
[
"#1. Randomly construct data\nimport numpy as np\nx=range (10)\ny=np.random.randint (10, size=10)\n#2. Draw the original image\nimport matplotlib as mpl\nimport matplotlib.pyplot as plt\n%matplotlib inline \n#jupyter notebook\nimport scipy\nfrom scipy.interpolate import splrep #with scipy library\nplt.plot (x, y)\nplt.show ()\n#3. Draw a smooth curve\nfrom scipy.interpolate import splrep\n #Interpolation method, 50 represents the number of interpolation,Number>= number of actual data,Generally speaking, the greater the number of differences,The smoother the curve\nx_new=np.linspace (min (x), max (x), 50)\ny_smooth=splrep (x, y, x_new)\nplt.plot (x_new, y_smooth)\nplt.show ()",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb31454a8e843bf90a90ff3570b781226956570e | 20,882 | ipynb | Jupyter Notebook | scripts/visualize_benchmark.ipynb | CeadeS/PyTorchH5Dataset | 9ee6e49f2a780345abd708abf2e0c47bb5475e0a | [
"BSD-3-Clause"
] | null | null | null | scripts/visualize_benchmark.ipynb | CeadeS/PyTorchH5Dataset | 9ee6e49f2a780345abd708abf2e0c47bb5475e0a | [
"BSD-3-Clause"
] | null | null | null | scripts/visualize_benchmark.ipynb | CeadeS/PyTorchH5Dataset | 9ee6e49f2a780345abd708abf2e0c47bb5475e0a | [
"BSD-3-Clause"
] | null | null | null | 103.376238 | 1,510 | 0.652763 | [
[
[
"from pytorch_h5dataset.benchmark import Benchmarker, BenchmarkDataset\nfrom pytorch_h5dataset import H5DataLoader\n\nfrom torch.utils.data import DataLoader\nfrom torch import nn, float32, as_tensor\nfrom torch.nn import MSELoss\nfrom time import time\nfrom numpy import prod\nimport seaborn as sns\nfrom matplotlib import pyplot as plt\nimport psutil\nimport platform\ncpu_count = 0 if platform.system() == 'Windows' else psutil.cpu_count()\n\n\n\nbenchmarkdataset = BenchmarkDataset(dataset_root=\"H:/Datasets/coco2017\")\n\nbatch_size = 100\nepochs = 100\ndevice = 'cuda:0'\n\nbenchmarker1 = Benchmarker()\ndataLoader1 = benchmarker1.decorate_iterator_class(H5DataLoader)(dataset=benchmarkdataset.h5dataset,\n device=device, batch_size=batch_size,\n return_meta_indices=True,\n pin_memory=True,\n num_workers=cpu_count)\n\nbenchmarker2 = Benchmarker()\ndataloader2 = benchmarker2.decorate_iterator_class(DataLoader)(benchmarkdataset.imageFolderDataset,\n batch_size=batch_size,\n num_workers=cpu_count,\n pin_memory=True)\n\ncriterion = MSELoss()\n\n\nfor benchmarker, dataloader in ((benchmarker1, dataLoader1) , (benchmarker2,dataloader2)):\n benchmarker.reset_benchmarker()\n model = nn.Linear(3 * 244 * 244, 1000).to(device)\n sum_loss = 0\n num_out = 0\n t0 = time()\n for e in range(epochs):\n print('\\r',e, end='')\n for sample, label in dataloader:\n if isinstance(label, tuple):\n label = label[0]\n x = sample.to(device).view(sample.size(0),-1)\n y = as_tensor(label.view(-1), dtype=float32,device=device).requires_grad_(True)\n y_out = model(x).argmax(1).float()\n num_out += prod(y_out.shape)\n loss = criterion(y, y_out)\n loss = loss.sum()\n sum_loss += loss.item()\n loss.backward()\n\n print(f\"Time for {epochs} epochs was {time() - t0}\")\n print(x.min(),x.max())\n print(loss, num_out)\n #del dataloader, x,y, model, loss, sum_loss",
" 99Time for 100 epochs was 1079.5236911773682\ntensor(-1., device='cuda:0') tensor(1., device='cuda:0')\ntensor(295457.2812, device='cuda:0', grad_fn=<SumBackward0>) 500000\n 1"
],
[
"\ndf = benchmarker1.get_stats_df()\nsns.set()\nlegend = ['proc_cpu_util','proc_disk_io_bytes_read','proc_disk_io_count_read','proc_cpu_time_user', 'proc_mem_bytes_vms', 'sys_net_io_bytes_recv']\nplt.rcParams[\"figure.figsize\"] = (15,5)\nfor col in legend:\n plt.plot(df[col]/ max(abs(df[col])))\nplt.legend(legend)\nplt.show()\nlegend = ['proc_cpu_util','proc_disk_io_bytes_read_acc','proc_disk_io_count_read_acc','proc_cpu_time_user_acc', 'proc_mem_bytes_vms_acc', 'sys_net_io_bytes_recv_acc']\nplt.rcParams[\"figure.figsize\"] = (15,5)\nfor col in legend:\n plt.plot(df[col])\nplt.legend(legend)\nplt.show()",
"_____no_output_____"
],
[
"df = benchmarker2.get_stats_df()\nsns.set()\nlegend = ['proc_cpu_util','proc_disk_io_bytes_read','proc_disk_io_count_read','proc_cpu_time_user', 'proc_mem_bytes_vms', 'sys_net_io_bytes_recv']\nplt.rcParams[\"figure.figsize\"] = (15,5)\nfor col in legend:\n plt.plot(df[col]/ max(abs(df[col])))\nplt.legend(legend)\nplt.show()\nlegend = ['proc_cpu_util','proc_disk_io_bytes_read_acc','proc_disk_io_count_read_acc','proc_cpu_time_user_acc', 'proc_mem_bytes_vms_acc', 'sys_net_io_bytes_recv_acc']\nplt.rcParams[\"figure.figsize\"] = (15,5)\nfor col in legend:\n plt.plot(df[col])\nplt.legend(legend)\nplt.show()\n\n\n",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code"
]
] |
cb3155cea46ada1800aeb54504aef7f39d054242 | 714,496 | ipynb | Jupyter Notebook | titanic-survival-predictions.ipynb | DavidMorgan1999/psychic-invention | 59c51fc8308d19d26db1be6f05e1ce35498693b2 | [
"MIT"
] | null | null | null | titanic-survival-predictions.ipynb | DavidMorgan1999/psychic-invention | 59c51fc8308d19d26db1be6f05e1ce35498693b2 | [
"MIT"
] | null | null | null | titanic-survival-predictions.ipynb | DavidMorgan1999/psychic-invention | 59c51fc8308d19d26db1be6f05e1ce35498693b2 | [
"MIT"
] | null | null | null | 714,496 | 714,496 | 0.937328 | [
[
[
"# This Python 3 environment comes with many helpful analytics libraries installed\n# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python\n# For example, here's several helpful packages to load\n\nimport numpy as np # linear algebra\nimport pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)\nimport random as rnd\nfrom random import seed\nfrom random import gauss\n\nimport seaborn as sns#Understanding my variables\nimport matplotlib.pyplot as plt\n%matplotlib inline\n\n# machine learning\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.svm import SVC, LinearSVC\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn.tree import DecisionTreeClassifier\n\n\n# Input data files are available in the read-only \"../input/\" directory\n# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory\n\nimport os\nfor dirname, _, filenames in os.walk('/kaggle/input'):\n for filename in filenames:\n print(os.path.join(dirname, filename))\n\n# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using \"Save & Run All\" \n# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session",
"/kaggle/input/titanic/train.csv\n/kaggle/input/titanic/test.csv\n/kaggle/input/titanic/gender_submission.csv\n"
],
[
"test_data = pd.read_csv(\"/kaggle/input/titanic/test.csv\")\ntrain_data = pd.read_csv(\"/kaggle/input/titanic/train.csv\")",
"_____no_output_____"
],
[
"train_data.shape",
"_____no_output_____"
],
[
"test_data.shape",
"_____no_output_____"
],
[
"train_data.columns",
"_____no_output_____"
],
[
"test_data.columns",
"_____no_output_____"
],
[
"train_data.head()",
"_____no_output_____"
],
[
"test_data.head()",
"_____no_output_____"
],
[
"graphshow_traindata = train_data.drop(['PassengerId'], axis=1)\nplt.figure(figsize=(10,10))\nsns.lineplot(data=graphshow_traindata)",
"_____no_output_____"
],
[
"test_data.isnull().values.sum()",
"_____no_output_____"
],
[
"train_data.isnull().values.sum()",
"_____no_output_____"
],
[
" test_data.columns[test_data.isna().any()].tolist()",
"_____no_output_____"
],
[
" train_data.columns[train_data.isna().any()].tolist()",
"_____no_output_____"
],
[
"test_data.nunique(axis=0)",
"_____no_output_____"
],
[
"train_data.nunique(axis=0)",
"_____no_output_____"
],
[
"sns.countplot('Survived',data=train_data)\nplt.show()",
"/opt/conda/lib/python3.7/site-packages/seaborn/_decorators.py:43: FutureWarning: Pass the following variable as a keyword arg: x. From version 0.12, the only valid positional argument will be `data`, and passing other arguments without an explicit keyword will result in an error or misinterpretation.\n FutureWarning\n"
],
[
"train_data.describe().apply(lambda s: s.apply(lambda x: format(x, 'f')))",
"_____no_output_____"
],
[
"train_data.describe(include=['O'])",
"_____no_output_____"
],
[
"test_data.describe().apply(lambda s: s.apply(lambda x: format(x, 'f')))",
"_____no_output_____"
],
[
"test_data.describe(include=['O'])",
"_____no_output_____"
],
[
"corr = train_data.corr()# plot the heatmap\nsns.heatmap(corr, xticklabels=corr.columns, yticklabels=corr.columns, annot=True, cmap=sns.diverging_palette(220, 20, as_cmap=True))",
"_____no_output_____"
],
[
"sns.pairplot(train_data)",
"_____no_output_____"
],
[
"train_data['Age'].plot(kind='hist', bins=20, figsize=(12,6), facecolor='grey',edgecolor='black')",
"_____no_output_____"
],
[
"train_data['Pclass'].plot(kind='hist', bins=5, figsize=(2,2), facecolor='grey',edgecolor='black') ",
"_____no_output_____"
],
[
"train_data['Fare'].plot(kind='hist', bins=20, figsize=(10,5), facecolor='grey',edgecolor='black')",
"_____no_output_____"
],
[
"firstclass = train_data.loc[train_data.Pclass == 1][\"Survived\"]\nrate_firstclass = sum(firstclass)/len(firstclass)\n\n\n\nsecondclass = train_data.loc[train_data.Pclass == 2][\"Survived\"]\nrate_secondclass = sum(secondclass)/len(secondclass)\n\n\n\nthirdclass = train_data.loc[train_data.Pclass == 3][\"Survived\"]\nrate_thirdclass = sum(thirdclass)/len(thirdclass)\n\nprint(\"% of First class who survived:\", rate_firstclass)\nprint(\"% of Second class who survived:\", rate_secondclass)\nprint(\"% of First class who survived:\", rate_thirdclass)",
"% of First class who survived: 0.6296296296296297\n% of Second class who survived: 0.47282608695652173\n% of First class who survived: 0.24236252545824846\n"
],
[
"pd.crosstab([train_data.Pclass],train_data.Survived,margins=True).style.background_gradient('Greens')",
"_____no_output_____"
],
[
"embarkedq = train_data.loc[train_data.Embarked == \"Q\"][\"Survived\"]\nrate_embarkedq = sum(embarkedq)/len(embarkedq)\n\nembarkeds = train_data.loc[train_data.Embarked == \"S\"][\"Survived\"]\nrate_embarkeds = sum(embarkeds)/len(embarkeds)\n\nembarkedc = train_data.loc[train_data.Embarked == \"C\"][\"Survived\"]\nrate_embarkedc = sum(embarkedc)/len(embarkedc)\n\nprint(\"% of Queenstown passengers who survived:\", rate_embarkedq)\nprint(\"% of Cherbourg passengers who survived:\", rate_embarkeds)\nprint(\"% of Southampton passengers who survived:\", rate_embarkedc)",
"% of Queenstown passengers who survived: 0.38961038961038963\n% of Cherbourg passengers who survived: 0.33695652173913043\n% of Southampton passengers who survived: 0.5535714285714286\n"
],
[
"pd.crosstab([train_data.Embarked],train_data.Survived,margins=True).style.background_gradient('Greens')",
"_____no_output_____"
],
[
"women = train_data.loc[train_data.Sex == 'female'][\"Survived\"]\nrate_women = sum(women)/len(women)\n\n\nmen = train_data.loc[train_data.Sex == 'male'][\"Survived\"]\nrate_men = sum(men)/len(men)\n\nprint(\"% of women who survived:\", rate_women)\n\nprint(\"% of men who survived:\", rate_men)",
"% of women who survived: 0.7420382165605095\n% of men who survived: 0.18890814558058924\n"
],
[
"pd.crosstab([train_data.Sex,train_data.Survived],train_data.Pclass,margins=True).style.background_gradient(cmap='Greens')",
"_____no_output_____"
],
[
" train_data.columns[train_data.isna().any()].tolist()",
"_____no_output_____"
],
[
"g = sns.FacetGrid(train_data, col='Survived')\ng.map(plt.hist, 'Age', bins=20)",
"_____no_output_____"
],
[
"sns.violinplot(\"Sex\",\"Age\", hue=\"Survived\", data=train_data,split=True)",
"/opt/conda/lib/python3.7/site-packages/seaborn/_decorators.py:43: FutureWarning: Pass the following variables as keyword args: x, y. From version 0.12, the only valid positional argument will be `data`, and passing other arguments without an explicit keyword will result in an error or misinterpretation.\n FutureWarning\n"
],
[
"sns.violinplot(\"Pclass\",\"Age\", hue=\"Survived\", data=train_data,split=True)",
"/opt/conda/lib/python3.7/site-packages/seaborn/_decorators.py:43: FutureWarning: Pass the following variables as keyword args: x, y. From version 0.12, the only valid positional argument will be `data`, and passing other arguments without an explicit keyword will result in an error or misinterpretation.\n FutureWarning\n"
],
[
"grid = sns.FacetGrid(train_data, row='Embarked', height=2.2, aspect=1.6)\ngrid.map(sns.pointplot, 'Pclass', 'Survived', 'Sex')\ngrid.add_legend()",
"/opt/conda/lib/python3.7/site-packages/seaborn/axisgrid.py:643: UserWarning: Using the pointplot function without specifying `order` is likely to produce an incorrect plot.\n warnings.warn(warning)\n/opt/conda/lib/python3.7/site-packages/seaborn/axisgrid.py:648: UserWarning: Using the pointplot function without specifying `hue_order` is likely to produce an incorrect plot.\n warnings.warn(warning)\n"
],
[
"age_guess = train_data[\"Age\"].mean()\ntrain_data[\"Age\"].fillna(age_guess, inplace = True)\ntest_data[\"Age\"].fillna(age_guess, inplace = True)\ntrain_data.Age.unique()",
"_____no_output_____"
],
[
"mostCommonPort = train_data.Embarked.dropna().mode()[0]\ntrain_data[\"Embarked\"].fillna(mostCommonPort, inplace = True)\ntest_data[\"Embarked\"].fillna(mostCommonPort, inplace = True)",
"_____no_output_____"
],
[
"train_data = train_data.drop(['Ticket', 'Cabin'], axis=1)\ntest_data = test_data.drop(['Ticket', 'Cabin'], axis=1)",
"_____no_output_____"
],
[
"y = train_data[\"Survived\"]\n\nfeatures = [\"Pclass\", \"Sex\", \"Embarked\", \"Age\"]\nX = pd.get_dummies(train_data[features])\nX_test = pd.get_dummies(test_data[features])\n\nX.shape, y.shape, X_test.shape",
"_____no_output_____"
],
[
"rdm_Forest = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)\nrdm_Forest.fit(X, y)\npredictionsForest = rdm_Forest.predict(X_test)",
"_____no_output_____"
],
[
"decision_tree = DecisionTreeClassifier()\ndecision_tree.fit(X, y)\npredictionsDecisionTree = decision_tree.predict(X_test)",
"_____no_output_____"
],
[
"output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictionsDecisionTree})\noutput.to_csv('my_submission_DecisionTree.csv', index=False)\n\noutput = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictionsForest})\noutput.to_csv('my_submission_Forest.csv', index=False)\nprint(\"Your submission was successfully saved!\")",
"Your submission was successfully saved!\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3157982eebdfbb6fbc2a67ec1d55dab92b4186 | 120,956 | ipynb | Jupyter Notebook | Workshop_Keras_PyTorch .ipynb | Ravitha/Ravitha.github.io | 15e46cf491300cf1b4e13b76156c4180ebe9b1dc | [
"MIT"
] | null | null | null | Workshop_Keras_PyTorch .ipynb | Ravitha/Ravitha.github.io | 15e46cf491300cf1b4e13b76156c4180ebe9b1dc | [
"MIT"
] | null | null | null | Workshop_Keras_PyTorch .ipynb | Ravitha/Ravitha.github.io | 15e46cf491300cf1b4e13b76156c4180ebe9b1dc | [
"MIT"
] | null | null | null | 56.468721 | 14,990 | 0.617712 | [
[
[
"#Design a Deep Neural Network using Keras and pyTorch",
"_____no_output_____"
]
],
[
[
"import keras\nprint(keras.__version__)\n\nimport torch\nprint(torch.__version__)",
"2.4.3\n1.8.1+cu101\n"
]
],
[
[
"##Tensors and Attributes",
"_____no_output_____"
]
],
[
[
"data = torch.tensor([[1,2,3],[4,5,6]])\nprint(data.shape)\nprint(data.dtype) #dimesnion along each axis\nprint(data.ndim) #number of axes\nprint(data.device)",
"torch.Size([2, 3])\ntorch.int64\n2\ncpu\n"
],
[
"import numpy as np\ndata_np = np.array([[1,2,3],[4,5,6]])\nprint(data_np.shape)\nprint(data_np.dtype)\nprint(data_np.ndim)",
"(2, 3)\nint64\n2\n"
]
],
[
[
"##Special Tensors",
"_____no_output_____"
]
],
[
[
"np_zeros = np.zeros((3,4),dtype='uint8')\nnp_ones = np.ones((3,4))\nnp_rand = np.random.rand(3,4) # 3,4 indicates the shape of the resulting array\nnp_arr = np.array([[1,2],[3,4],[5,6]])\nprint(np_zeros.shape)\nprint(np_zeros.dtype)\nprint(np_ones.shape)\nprint(np_arr.shape)\nprint(np_arr.ndim)\nprint(np_arr.dtype)\n",
"(3, 4)\nuint8\n(3, 4)\n(3, 2)\n2\nint64\n"
],
[
"shape = (2,3)\nrand_tensor = torch.rand(shape)\nones_tensor = torch.ones(shape)\nzeros_tensor = torch.zeros(shape)\n\nprint(rand_tensor.shape)\nprint(rand_tensor.ndim)\nprint(rand_tensor.dtype)\n",
"torch.Size([2, 3])\n2\ntorch.float32\n"
]
],
[
[
"##Indexing and Slicing",
"_____no_output_____"
]
],
[
[
"tensor = torch.ones((5, 4))\ntensor[:,1] = 0\nprint(tensor)",
"tensor([[1., 0., 1., 1.],\n [1., 0., 1., 1.],\n [1., 0., 1., 1.],\n [1., 0., 1., 1.],\n [1., 0., 1., 1.]])\n"
],
[
"np_ones = np.ones((5,4))\nnp_ones[:,1] = 0\nprint(np_ones)\nprint(np_ones.shape)",
"[[1. 0. 1. 1.]\n [1. 0. 1. 1.]\n [1. 0. 1. 1.]\n [1. 0. 1. 1.]\n [1. 0. 1. 1.]]\n(5, 4)\n"
],
[
"torch.mean(tensor,dim=0)",
"_____no_output_____"
],
[
"np.mean(np_ones,axis=0)",
"_____no_output_____"
],
[
"tensor = tensor +5 \nprint(tensor)",
"tensor([[6., 5., 6., 6.],\n [6., 5., 6., 6.],\n [6., 5., 6., 6.],\n [6., 5., 6., 6.],\n [6., 5., 6., 6.]])\n"
],
[
"tensor = tensor * 5\nprint(tensor)",
"tensor([[30., 25., 30., 30.],\n [30., 25., 30., 30.],\n [30., 25., 30., 30.],\n [30., 25., 30., 30.],\n [30., 25., 30., 30.]])\n"
],
[
"W = torch.ones([1,4])\ny = torch.matmul(W , torch.transpose(tensor,0,1))\nprint(y)",
"tensor([[115., 115., 115., 115., 115.]])\n"
],
[
"np_ones = np_ones * 5\nW_np = np.ones((1,4))\ny_np = np.dot(W,np.transpose(np_ones))\nprint(y_np)",
"[[15. 15. 15. 15. 15.]]\n"
]
],
[
[
"#Designing a Feed Forward Neural Network",
"_____no_output_____"
],
[
"## Checking for arbitrary values of w\nSimple Function y = w * x \nx single dimensional Tensor\ny single scalar value for wach sample",
"_____no_output_____"
]
],
[
[
"import numpy as np\nfrom matplotlib import pyplot as plt\n\nx_data =[1.0,2.0,3.0]\ny_data =[2.0,3.0,4.0]\nw = 1.0\n\ndef forward(x):\n\treturn w*x\n\ndef loss(x,y):\n\ty_pred = forward(x)\n\treturn (y_pred-y) * (y_pred - y)\n\nmse_list = []\nw_list = []\nfor w in np.arange(0.0,4.1,0.1):\n\tl=0;\n\tfor x,y in zip(x_data,y_data):\n\t\tl = l+loss(x,y)\n\tmse_list.append(l/3)\n\tw_list.append(w)\n\n#print(mse_list)\n#print(w_list)\n\nplt.plot(w_list,mse_list)\nplt.xlabel('Parameter(w)')\nplt.ylabel('Loss (mse)')\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Gradient Descent Computation",
"_____no_output_____"
]
],
[
[
"import numpy as np\nfrom matplotlib import pyplot as plt\n\nx_data =[1.0,2.0,3.0]\ny_data =[2.0,3.0,4.0]\nw = 1.0\n\ndef forward(x):\n\treturn w*x\n\ndef loss(x,y):\n\ty_pred = forward(x)\n\treturn (y_pred-y) * (y_pred - y)\n\ndef gradient(x,y,w):\n\treturn 2*x*(w*x-y)\n\nepochs=[]\nloss_epoch=[]\nfor epoch in range(100):\n\tfor(x,y) in zip(x_data,y_data):\n\t\tgrad = gradient(x,y,w)\n\t\tw = w - grad*0.01\n\t\tl = loss(x,y)\n\t#print(str(epoch)+\":\"+str(l))\n\tepochs.append(epoch)\n\tloss_epoch.append(l)\n\n\n\nplt.plot(epochs,loss_epoch)\nplt.xlabel('Epochs')\nplt.ylabel('Loss Value')\nplt.show()\nprint(w)",
"_____no_output_____"
]
],
[
[
"# Keras Workflow",
"_____no_output_____"
]
],
[
[
"import numpy as np\nfrom keras import models\nfrom keras import layers\n\n# Define Data\nx_data =np.array([1.0,2.0,3.0])\ny_data =np.array([2.0,3.0,4.0])\n\n#Define layers in the model\nmodel = models.Sequential()\nmodel.add(layers.Dense(1, use_bias=False, input_shape=(1,)))\n\nprint(model.summary())",
"Model: \"sequential_7\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ndense_9 (Dense) (None, 1) 1 \n=================================================================\nTotal params: 1\nTrainable params: 1\nNon-trainable params: 0\n_________________________________________________________________\nNone\n"
],
[
"#Configure the learning process\nfrom keras import optimizers\nimport keras\nmodel.compile(optimizer='sgd', loss='mse', metrics=keras.metrics.MeanSquaredError())\n\n#Iterate the training data using fit\nhist = model.fit(x_data.reshape(3,1),y_data.reshape(3,1),batch_size=1,epochs=100)",
"Epoch 1/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1077 - mean_squared_error: 0.1077 \nEpoch 2/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1666 - mean_squared_error: 0.1666\nEpoch 3/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1350 - mean_squared_error: 0.1350\nEpoch 4/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1013 - mean_squared_error: 0.1013\nEpoch 5/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.0982 - mean_squared_error: 0.0982\nEpoch 6/100\n3/3 [==============================] - 0s 2ms/step - loss: 0.2168 - mean_squared_error: 0.2168\nEpoch 7/100\n3/3 [==============================] - 0s 2ms/step - loss: 0.0957 - mean_squared_error: 0.0957\nEpoch 8/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2141 - mean_squared_error: 0.2141\nEpoch 9/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1278 - mean_squared_error: 0.1278\nEpoch 10/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1430 - mean_squared_error: 0.1430\nEpoch 11/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2125 - mean_squared_error: 0.2125\nEpoch 12/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1053 - mean_squared_error: 0.1053\nEpoch 13/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2016 - mean_squared_error: 0.2016\nEpoch 14/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2030 - mean_squared_error: 0.2030\nEpoch 15/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1446 - mean_squared_error: 0.1446\nEpoch 16/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.0946 - mean_squared_error: 0.0946\nEpoch 17/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.0946 - mean_squared_error: 0.0946\nEpoch 18/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1467 - mean_squared_error: 0.1467\nEpoch 19/100\n3/3 [==============================] - 0s 4ms/step - loss: 0.1241 - mean_squared_error: 0.1241\nEpoch 20/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1250 - mean_squared_error: 0.1250\nEpoch 21/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1256 - mean_squared_error: 0.1256\nEpoch 22/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1261 - mean_squared_error: 0.1261\nEpoch 23/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2042 - mean_squared_error: 0.2042\nEpoch 24/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2049 - mean_squared_error: 0.2049\nEpoch 25/100\n3/3 [==============================] - 0s 6ms/step - loss: 0.0949 - mean_squared_error: 0.0949\nEpoch 26/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1443 - mean_squared_error: 0.1443\nEpoch 27/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2120 - mean_squared_error: 0.2120\nEpoch 28/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1253 - mean_squared_error: 0.1253\nEpoch 29/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1452 - mean_squared_error: 0.1452\nEpoch 30/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2020 - mean_squared_error: 0.2020\nEpoch 31/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1055 - mean_squared_error: 0.1055\nEpoch 32/100\n3/3 [==============================] - 0s 4ms/step - loss: 0.1074 - mean_squared_error: 0.1074\nEpoch 33/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.0946 - mean_squared_error: 0.0946\nEpoch 34/100\n3/3 [==============================] - 0s 4ms/step - loss: 0.1087 - mean_squared_error: 0.1087\nEpoch 35/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1996 - mean_squared_error: 0.1996\nEpoch 36/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.0946 - mean_squared_error: 0.0946\nEpoch 37/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2013 - mean_squared_error: 0.2013\nEpoch 38/100\n3/3 [==============================] - 0s 4ms/step - loss: 0.2027 - mean_squared_error: 0.2027\nEpoch 39/100\n3/3 [==============================] - 0s 4ms/step - loss: 0.1448 - mean_squared_error: 0.1448\nEpoch 40/100\n3/3 [==============================] - 0s 4ms/step - loss: 0.0946 - mean_squared_error: 0.0946\nEpoch 41/100\n3/3 [==============================] - 0s 4ms/step - loss: 0.1069 - mean_squared_error: 0.1069\nEpoch 42/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2006 - mean_squared_error: 0.2006\nEpoch 43/100\n3/3 [==============================] - 0s 4ms/step - loss: 0.1463 - mean_squared_error: 0.1463\nEpoch 44/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.0946 - mean_squared_error: 0.0946\nEpoch 45/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2012 - mean_squared_error: 0.2012\nEpoch 46/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2120 - mean_squared_error: 0.2120\nEpoch 47/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1253 - mean_squared_error: 0.1253\nEpoch 48/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.0946 - mean_squared_error: 0.0946\nEpoch 49/100\n3/3 [==============================] - 0s 4ms/step - loss: 0.2121 - mean_squared_error: 0.2121\nEpoch 50/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2026 - mean_squared_error: 0.2026\nEpoch 51/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1050 - mean_squared_error: 0.1050\nEpoch 52/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1467 - mean_squared_error: 0.1467\nEpoch 53/100\n3/3 [==============================] - 0s 5ms/step - loss: 0.0946 - mean_squared_error: 0.0946\nEpoch 54/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2010 - mean_squared_error: 0.2010\nEpoch 55/100\n3/3 [==============================] - 0s 5ms/step - loss: 0.2119 - mean_squared_error: 0.2119\nEpoch 56/100\n3/3 [==============================] - 0s 4ms/step - loss: 0.1064 - mean_squared_error: 0.1064\nEpoch 57/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1477 - mean_squared_error: 0.1477\nEpoch 58/100\n3/3 [==============================] - 0s 4ms/step - loss: 0.1237 - mean_squared_error: 0.1237\nEpoch 59/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2016 - mean_squared_error: 0.2016\nEpoch 60/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1256 - mean_squared_error: 0.1256\nEpoch 61/100\n3/3 [==============================] - 0s 4ms/step - loss: 0.2124 - mean_squared_error: 0.2124\nEpoch 62/100\n3/3 [==============================] - 0s 5ms/step - loss: 0.1258 - mean_squared_error: 0.1258\nEpoch 63/100\n3/3 [==============================] - 0s 4ms/step - loss: 0.2039 - mean_squared_error: 0.2039\nEpoch 64/100\n3/3 [==============================] - 0s 4ms/step - loss: 0.0948 - mean_squared_error: 0.0948\nEpoch 65/100\n3/3 [==============================] - 0s 4ms/step - loss: 0.1448 - mean_squared_error: 0.1448\nEpoch 66/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1066 - mean_squared_error: 0.1066\nEpoch 67/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2008 - mean_squared_error: 0.2008\nEpoch 68/100\n3/3 [==============================] - 0s 5ms/step - loss: 0.1252 - mean_squared_error: 0.1252\nEpoch 69/100\n3/3 [==============================] - 0s 5ms/step - loss: 0.1055 - mean_squared_error: 0.1055\nEpoch 70/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.0946 - mean_squared_error: 0.0946\nEpoch 71/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2115 - mean_squared_error: 0.2115\nEpoch 72/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2016 - mean_squared_error: 0.2016\nEpoch 73/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.0946 - mean_squared_error: 0.0946\nEpoch 74/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2025 - mean_squared_error: 0.2025\nEpoch 75/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.0947 - mean_squared_error: 0.0947\nEpoch 76/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1456 - mean_squared_error: 0.1456\nEpoch 77/100\n3/3 [==============================] - 0s 5ms/step - loss: 0.1469 - mean_squared_error: 0.1469\nEpoch 78/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1479 - mean_squared_error: 0.1479\nEpoch 79/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2111 - mean_squared_error: 0.2111\nEpoch 80/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1480 - mean_squared_error: 0.1480\nEpoch 81/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2111 - mean_squared_error: 0.2111\nEpoch 82/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1085 - mean_squared_error: 0.1085\nEpoch 83/100\n3/3 [==============================] - 0s 4ms/step - loss: 0.2109 - mean_squared_error: 0.2109\nEpoch 84/100\n3/3 [==============================] - 0s 4ms/step - loss: 0.0946 - mean_squared_error: 0.0946\nEpoch 85/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1482 - mean_squared_error: 0.1482\nEpoch 86/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1094 - mean_squared_error: 0.1094\nEpoch 87/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2107 - mean_squared_error: 0.2107\nEpoch 88/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2000 - mean_squared_error: 0.2000\nEpoch 89/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2116 - mean_squared_error: 0.2116\nEpoch 90/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1467 - mean_squared_error: 0.1467\nEpoch 91/100\n3/3 [==============================] - 0s 4ms/step - loss: 0.2009 - mean_squared_error: 0.2009\nEpoch 92/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2024 - mean_squared_error: 0.2024\nEpoch 93/100\n3/3 [==============================] - 0s 4ms/step - loss: 0.0947 - mean_squared_error: 0.0947\nEpoch 94/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2029 - mean_squared_error: 0.2029\nEpoch 95/100\n3/3 [==============================] - 0s 4ms/step - loss: 0.1263 - mean_squared_error: 0.1263\nEpoch 96/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1267 - mean_squared_error: 0.1267\nEpoch 97/100\n3/3 [==============================] - 0s 5ms/step - loss: 0.1040 - mean_squared_error: 0.1040\nEpoch 98/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.1460 - mean_squared_error: 0.1460\nEpoch 99/100\n3/3 [==============================] - 0s 4ms/step - loss: 0.2115 - mean_squared_error: 0.2115\nEpoch 100/100\n3/3 [==============================] - 0s 3ms/step - loss: 0.2017 - mean_squared_error: 0.2017\n"
],
[
"for layer in model.layers: \n print(layer.get_weights())",
"[array([[1.4246372]], dtype=float32)]\n"
],
[
"for key,value in hist.history.items():\n print(key)\n\nhist.history['loss']\nplt.plot(hist.history['loss'])\nplt.plot(hist.history['mean_squared_error'],'g*')\nplt.show()",
"loss\nmean_squared_error\n"
],
[
"model.predict([[8.1]])",
"_____no_output_____"
],
[
"for layer in model.layers:\n print(layer.get_weights())",
"[array([[1.4216367]], dtype=float32)]\n"
]
],
[
[
"# PyTorch Workflow\n\n```\n# This is formatted as code\n```\n\n",
"_____no_output_____"
],
[
"Autograd and NN in pyTorch",
"_____no_output_____"
]
],
[
[
"import torch\n\na = torch.tensor([2.,3.], requires_grad=True) #requires_grad is not set, gradient will noot be computed for that tensor\nb = torch.tensor([6.,3.], requires_grad=True)\nQ = 3*a**3 - b**2\n\n\n#Explixitly mention the gradient computation\nexternal_grad = torch.tensor([1.,1.]) # Number of input values for which gradient to be computed\nQ.backward(gradient=external_grad) # Computes gradients and store the information in the tensors grad attribute\n\n\nprint(9*a**2 == a.grad)\nprint(-2*b == b.grad)\n",
"tensor([True, True])\ntensor([True, True])\n"
],
[
"import torch\n# Define Data\nx_data =np.array([1.0,2.0,3.0])\ny_data =np.array([2.0,3.0,4.0])\nx_data = x_data.reshape((3,1))\ny_data = y_data.reshape((3,1))\n\nx_tensor = torch.from_numpy(x_data)\ny_tensor = torch.from_numpy(y_data)",
"_____no_output_____"
],
[
"#nn depends on autograd to define models and differentiate them. An nn.Module contains layers, and a method forward(input) that returns the output.\n#Define architecture\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\n\n\nclass Net(nn.Module):\n\n def __init__(self):\n super(Net, self).__init__()\n \n # an affine operation: y = Wx + b\n self.fc1 = nn.Linear(1, 1,bias=False) # 13 feature dimension\n \n def forward(self, x):\n x = self.fc1(x)\n return x",
"_____no_output_____"
],
[
"model = Net()\nprint(model)",
"Net(\n (fc1): Linear(in_features=1, out_features=1, bias=False)\n)\n"
],
[
"params = list(model.parameters()) # Each layer contains Weight and Biases\nprint(len(params))\nprint(params[0].shape) \n",
"1\ntorch.Size([1, 1])\n"
],
[
"print(params[0].requires_grad)\nprint(params[0].dtype)\nprint(type(params[0]))",
"True\ntorch.float32\n<class 'torch.nn.parameter.Parameter'>\n"
],
[
"# Configure the training process\nCriterion = torch.nn.MSELoss()\noptimizer = torch.optim.SGD(model.parameters(),lr=0.01)\n\n\n#Train_Model\nepoch_list=[]\nloss_list=[]\nfor epoch in range(100):\n \n out = model(x_tensor.float())\n loss = Criterion(out, y_tensor.float() )\n \n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n\n epoch_list.append(epoch)\n loss_list.append(loss)\n",
"_____no_output_____"
],
[
"from matplotlib import pyplot as plt\nplt.plot(epoch_list,loss_list)\nplt.xlabel('Epochs')\nplt.ylabel('Loss')\nplt.show()",
"_____no_output_____"
],
[
"print(params[0])",
"Parameter containing:\ntensor([[1.4285]], requires_grad=True)\n"
]
],
[
[
"# Regression Example\n\n> Predict Median Price of home based on certain statistics about the area\n\n",
"_____no_output_____"
],
[
"## Keras Model\n\nIt takes as an input a two dimensional array with 404 samples and 13 features \nPredicts a single sclar value for y",
"_____no_output_____"
]
],
[
[
"from keras.datasets import boston_housing\n\n(train_data,train_targets) , (test_data,test_targets) = boston_housing.load_data()\nprint(train_data.shape)\nprint(test_data.shape)",
"(404, 13)\n(102, 13)\n"
],
[
"train_data.mean(axis=0)",
"_____no_output_____"
],
[
"#Preparing Data\nmean = train_data.mean(axis=0)\ntrain_data -=mean\nstd = train_data.std(axis=0)\ntrain_data /=std\n\ntest_data -=mean\ntest_data /=std",
"_____no_output_____"
],
[
"print(test_targets)",
"[ 7.2 18.8 19. 27. 22.2 24.5 31.2 22.9 20.5 23.2 18.6 14.5 17.8 50.\n 20.8 24.3 24.2 19.8 19.1 22.7 12. 10.2 20. 18.5 20.9 23. 27.5 30.1\n 9.5 22. 21.2 14.1 33.1 23.4 20.1 7.4 15.4 23.8 20.1 24.5 33. 28.4\n 14.1 46.7 32.5 29.6 28.4 19.8 20.2 25. 35.4 20.3 9.7 14.5 34.9 26.6\n 7.2 50. 32.4 21.6 29.8 13.1 27.5 21.2 23.1 21.9 13. 23.2 8.1 5.6\n 21.7 29.6 19.6 7. 26.4 18.9 20.9 28.1 35.4 10.2 24.3 43.1 17.6 15.4\n 16.2 27.1 21.4 21.5 22.4 25. 16.6 18.6 22. 42.8 35.1 21.5 36. 21.9\n 24.1 50. 26.7 25. ]\n"
],
[
"def build_model():\n model = models.Sequential()\n model.add(layers.Dense(64, activation='relu', input_shape=(train_data.shape[1],)))\n model.add(layers.Dense(64, activation='relu'))\n model.add(layers.Dense(1))\n model.compile(optimizer='rmsprop',loss='mse',metrics=['mse'])\n return model",
"_____no_output_____"
],
[
"model = build_model()\nhistory = model.fit(train_data, train_targets, epochs=100, batch_size=4)",
"Epoch 1/100\n101/101 [==============================] - 1s 2ms/step - loss: 256.9818 - mse: 256.9818\nEpoch 2/100\n101/101 [==============================] - 0s 2ms/step - loss: 155.9660 - mse: 155.9660\nEpoch 3/100\n101/101 [==============================] - 0s 2ms/step - loss: 116.8007 - mse: 116.8007\nEpoch 4/100\n101/101 [==============================] - 0s 2ms/step - loss: 85.8233 - mse: 85.8233\nEpoch 5/100\n101/101 [==============================] - 0s 2ms/step - loss: 95.6000 - mse: 95.6000\nEpoch 6/100\n101/101 [==============================] - 0s 2ms/step - loss: 77.5281 - mse: 77.5281\nEpoch 7/100\n101/101 [==============================] - 0s 2ms/step - loss: 78.5830 - mse: 78.5830\nEpoch 8/100\n101/101 [==============================] - 0s 2ms/step - loss: 64.5642 - mse: 64.5642\nEpoch 9/100\n101/101 [==============================] - 0s 2ms/step - loss: 66.0230 - mse: 66.0230\nEpoch 10/100\n101/101 [==============================] - 0s 2ms/step - loss: 78.5776 - mse: 78.5776\nEpoch 11/100\n101/101 [==============================] - 0s 2ms/step - loss: 76.5208 - mse: 76.5208\nEpoch 12/100\n101/101 [==============================] - 0s 2ms/step - loss: 79.1671 - mse: 79.1671\nEpoch 13/100\n101/101 [==============================] - 0s 2ms/step - loss: 57.6798 - mse: 57.6798\nEpoch 14/100\n101/101 [==============================] - 0s 2ms/step - loss: 53.1696 - mse: 53.1696\nEpoch 15/100\n101/101 [==============================] - 0s 2ms/step - loss: 43.5919 - mse: 43.5919\nEpoch 16/100\n101/101 [==============================] - 0s 2ms/step - loss: 38.8624 - mse: 38.8624\nEpoch 17/100\n101/101 [==============================] - 0s 2ms/step - loss: 48.2223 - mse: 48.2223\nEpoch 18/100\n101/101 [==============================] - 0s 2ms/step - loss: 53.6075 - mse: 53.6075\nEpoch 19/100\n101/101 [==============================] - 0s 2ms/step - loss: 43.6979 - mse: 43.6979\nEpoch 20/100\n101/101 [==============================] - 0s 2ms/step - loss: 46.2283 - mse: 46.2283\nEpoch 21/100\n101/101 [==============================] - 0s 2ms/step - loss: 46.7705 - mse: 46.7705\nEpoch 22/100\n101/101 [==============================] - 0s 2ms/step - loss: 38.2396 - mse: 38.2396\nEpoch 23/100\n101/101 [==============================] - 0s 2ms/step - loss: 33.6050 - mse: 33.6050\nEpoch 24/100\n101/101 [==============================] - 0s 2ms/step - loss: 37.4467 - mse: 37.4467\nEpoch 25/100\n101/101 [==============================] - 0s 2ms/step - loss: 42.9243 - mse: 42.9243\nEpoch 26/100\n101/101 [==============================] - 0s 2ms/step - loss: 36.2702 - mse: 36.2702\nEpoch 27/100\n101/101 [==============================] - 0s 2ms/step - loss: 27.4176 - mse: 27.4176\nEpoch 28/100\n101/101 [==============================] - 0s 2ms/step - loss: 31.3881 - mse: 31.3881\nEpoch 29/100\n101/101 [==============================] - 0s 2ms/step - loss: 38.3801 - mse: 38.3801\nEpoch 30/100\n101/101 [==============================] - 0s 2ms/step - loss: 28.0544 - mse: 28.0544\nEpoch 31/100\n101/101 [==============================] - 0s 2ms/step - loss: 30.1889 - mse: 30.1889\nEpoch 32/100\n101/101 [==============================] - 0s 2ms/step - loss: 31.0841 - mse: 31.0841\nEpoch 33/100\n101/101 [==============================] - 0s 2ms/step - loss: 30.0545 - mse: 30.0545\nEpoch 34/100\n101/101 [==============================] - 0s 2ms/step - loss: 28.1166 - mse: 28.1166\nEpoch 35/100\n101/101 [==============================] - 0s 2ms/step - loss: 30.6828 - mse: 30.6828\nEpoch 36/100\n101/101 [==============================] - 0s 2ms/step - loss: 27.1427 - mse: 27.1427\nEpoch 37/100\n101/101 [==============================] - 0s 2ms/step - loss: 22.6478 - mse: 22.6478\nEpoch 38/100\n101/101 [==============================] - 0s 2ms/step - loss: 27.1610 - mse: 27.1610\nEpoch 39/100\n101/101 [==============================] - 0s 2ms/step - loss: 26.0829 - mse: 26.0829\nEpoch 40/100\n101/101 [==============================] - 0s 2ms/step - loss: 25.7093 - mse: 25.7093\nEpoch 41/100\n101/101 [==============================] - 0s 2ms/step - loss: 20.8223 - mse: 20.8223\nEpoch 42/100\n101/101 [==============================] - 0s 2ms/step - loss: 23.2895 - mse: 23.2895\nEpoch 43/100\n101/101 [==============================] - 0s 2ms/step - loss: 28.3386 - mse: 28.3386\nEpoch 44/100\n101/101 [==============================] - 0s 2ms/step - loss: 21.3986 - mse: 21.3986\nEpoch 45/100\n101/101 [==============================] - 0s 2ms/step - loss: 19.8351 - mse: 19.8351\nEpoch 46/100\n101/101 [==============================] - 0s 2ms/step - loss: 22.3030 - mse: 22.3030\nEpoch 47/100\n101/101 [==============================] - 0s 2ms/step - loss: 21.8073 - mse: 21.8073\nEpoch 48/100\n101/101 [==============================] - 0s 2ms/step - loss: 18.1339 - mse: 18.1339\nEpoch 49/100\n101/101 [==============================] - 0s 2ms/step - loss: 18.5989 - mse: 18.5989\nEpoch 50/100\n101/101 [==============================] - 0s 2ms/step - loss: 17.7148 - mse: 17.7148\nEpoch 51/100\n101/101 [==============================] - 0s 2ms/step - loss: 19.8738 - mse: 19.8738\nEpoch 52/100\n101/101 [==============================] - 0s 2ms/step - loss: 24.6428 - mse: 24.6428\nEpoch 53/100\n101/101 [==============================] - 0s 2ms/step - loss: 18.1539 - mse: 18.1539\nEpoch 54/100\n101/101 [==============================] - 0s 2ms/step - loss: 22.0123 - mse: 22.0123\nEpoch 55/100\n101/101 [==============================] - 0s 2ms/step - loss: 21.3022 - mse: 21.3022\nEpoch 56/100\n101/101 [==============================] - 0s 2ms/step - loss: 18.0283 - mse: 18.0283\nEpoch 57/100\n101/101 [==============================] - 0s 2ms/step - loss: 17.9284 - mse: 17.9284\nEpoch 58/100\n101/101 [==============================] - 0s 2ms/step - loss: 24.2995 - mse: 24.2995\nEpoch 59/100\n101/101 [==============================] - 0s 2ms/step - loss: 21.1715 - mse: 21.1715\nEpoch 60/100\n101/101 [==============================] - 0s 2ms/step - loss: 16.5494 - mse: 16.5494\nEpoch 61/100\n101/101 [==============================] - 0s 2ms/step - loss: 18.5524 - mse: 18.5524\nEpoch 62/100\n101/101 [==============================] - 0s 2ms/step - loss: 17.9266 - mse: 17.9266\nEpoch 63/100\n101/101 [==============================] - 0s 2ms/step - loss: 16.7725 - mse: 16.7725\nEpoch 64/100\n101/101 [==============================] - 0s 2ms/step - loss: 18.7857 - mse: 18.7857\nEpoch 65/100\n101/101 [==============================] - 0s 2ms/step - loss: 21.9618 - mse: 21.9618\nEpoch 66/100\n101/101 [==============================] - 0s 2ms/step - loss: 20.9204 - mse: 20.9204\nEpoch 67/100\n101/101 [==============================] - 0s 2ms/step - loss: 15.4806 - mse: 15.4806\nEpoch 68/100\n101/101 [==============================] - 0s 2ms/step - loss: 17.5782 - mse: 17.5782\nEpoch 69/100\n101/101 [==============================] - 0s 2ms/step - loss: 15.0908 - mse: 15.0908\nEpoch 70/100\n101/101 [==============================] - 0s 2ms/step - loss: 15.3186 - mse: 15.3186\nEpoch 71/100\n101/101 [==============================] - 0s 2ms/step - loss: 17.0259 - mse: 17.0259\nEpoch 72/100\n101/101 [==============================] - 0s 2ms/step - loss: 16.2496 - mse: 16.2496\nEpoch 73/100\n101/101 [==============================] - 0s 2ms/step - loss: 18.6967 - mse: 18.6967\nEpoch 74/100\n101/101 [==============================] - 0s 2ms/step - loss: 15.3571 - mse: 15.3571\nEpoch 75/100\n101/101 [==============================] - 0s 2ms/step - loss: 15.3060 - mse: 15.3060\nEpoch 76/100\n101/101 [==============================] - 0s 2ms/step - loss: 16.2395 - mse: 16.2395\nEpoch 77/100\n101/101 [==============================] - 0s 2ms/step - loss: 15.4414 - mse: 15.4414\nEpoch 78/100\n101/101 [==============================] - 0s 2ms/step - loss: 17.4121 - mse: 17.4121\nEpoch 79/100\n101/101 [==============================] - 0s 2ms/step - loss: 23.2003 - mse: 23.2003\nEpoch 80/100\n101/101 [==============================] - 0s 2ms/step - loss: 14.5453 - mse: 14.5453\nEpoch 81/100\n101/101 [==============================] - 0s 2ms/step - loss: 13.8119 - mse: 13.8119\nEpoch 82/100\n101/101 [==============================] - 0s 2ms/step - loss: 19.6077 - mse: 19.6077\nEpoch 83/100\n101/101 [==============================] - 0s 2ms/step - loss: 17.6259 - mse: 17.6259\nEpoch 84/100\n101/101 [==============================] - 0s 2ms/step - loss: 16.6938 - mse: 16.6938\nEpoch 85/100\n101/101 [==============================] - 0s 2ms/step - loss: 16.0966 - mse: 16.0966\nEpoch 86/100\n101/101 [==============================] - 0s 2ms/step - loss: 13.4812 - mse: 13.4812\nEpoch 87/100\n101/101 [==============================] - 0s 2ms/step - loss: 14.9930 - mse: 14.9930\nEpoch 88/100\n101/101 [==============================] - 0s 2ms/step - loss: 17.0514 - mse: 17.0514\nEpoch 89/100\n101/101 [==============================] - 0s 2ms/step - loss: 14.3263 - mse: 14.3263\nEpoch 90/100\n101/101 [==============================] - 0s 2ms/step - loss: 17.3450 - mse: 17.3450\nEpoch 91/100\n101/101 [==============================] - 0s 2ms/step - loss: 20.3455 - mse: 20.3455\nEpoch 92/100\n101/101 [==============================] - 0s 2ms/step - loss: 15.3584 - mse: 15.3584\nEpoch 93/100\n101/101 [==============================] - 0s 2ms/step - loss: 13.0929 - mse: 13.0929\nEpoch 94/100\n101/101 [==============================] - 0s 2ms/step - loss: 15.4380 - mse: 15.4380\nEpoch 95/100\n101/101 [==============================] - 0s 2ms/step - loss: 15.5867 - mse: 15.5867\nEpoch 96/100\n101/101 [==============================] - 0s 2ms/step - loss: 20.8437 - mse: 20.8437\nEpoch 97/100\n101/101 [==============================] - 0s 2ms/step - loss: 13.8532 - mse: 13.8532\nEpoch 98/100\n101/101 [==============================] - 0s 2ms/step - loss: 23.3444 - mse: 23.3444\nEpoch 99/100\n101/101 [==============================] - 0s 2ms/step - loss: 19.7357 - mse: 19.7357\nEpoch 100/100\n101/101 [==============================] - 0s 2ms/step - loss: 17.0952 - mse: 17.0952\n"
],
[
"model.evaluate(test_data,test_targets)",
"4/4 [==============================] - 0s 3ms/step - loss: 12.6808 - mse: 12.6808\n"
],
[
"model.predict(test_data[5:7])",
"_____no_output_____"
],
[
"test_targets[6]",
"_____no_output_____"
]
],
[
[
"## pyTorch Model",
"_____no_output_____"
]
],
[
[
"#nn depends on autograd to define models and differentiate them. An nn.Module contains layers, and a method forward(input) that returns the output.\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\n\n\nclass Net(nn.Module):\n\n def __init__(self):\n super(Net, self).__init__()\n \n # an affine operation: y = Wx + b\n self.fc1 = nn.Linear(13, 64) # 13 feature dimension\n self.fc2 = nn.Linear(64, 64)\n self.fc3 = nn.Linear(64,1)\n \n def forward(self, x):\n x = F.relu(self.fc1(x))\n x = F.relu(self.fc2(x))\n x = self.fc3(x)\n return x",
"_____no_output_____"
],
[
"model = Net()\nprint(model)",
"Net(\n (fc1): Linear(in_features=13, out_features=64, bias=True)\n (fc2): Linear(in_features=64, out_features=64, bias=True)\n (fc3): Linear(in_features=64, out_features=1, bias=True)\n)\n"
],
[
"params = list(model.parameters()) # Each layer contains Weight and Biases\nprint(len(params))\nprint(params[0].shape) \n",
"6\ntorch.Size([64, 13])\n"
],
[
"print(params[0].requires_grad)\nprint(params[0].dtype)\nprint(type(params[0]))",
"True\ntorch.float32\n<class 'torch.nn.parameter.Parameter'>\n"
],
[
"tensor_train_data = torch.from_numpy(train_data)\ntensor_train_targets = torch.from_numpy(train_targets)\n",
"_____no_output_____"
],
[
"tensor_train_targets= tensor_train_targets.view((404,1))",
"_____no_output_____"
],
[
"out = model(tensor_train_data.float())\nprint(out.shape)",
"torch.Size([404, 1])\n"
],
[
"Criterion = torch.nn.MSELoss()\noptimizer = torch.optim.RMSprop(model.parameters())\n",
"_____no_output_____"
],
[
"loss = Criterion(out, tensor_train_targets.float() )",
"_____no_output_____"
],
[
"dataset = torch.utils.data.TensorDataset(tensor_train_data, tensor_train_targets)\n",
"_____no_output_____"
],
[
"trainloader = torch.utils.data.DataLoader(dataset, batch_size=4,shuffle=True)",
"_____no_output_____"
],
[
"for epoch in range(100): # loop over the dataset multiple times\n\n running_loss = 0.0\n for i, data in enumerate(trainloader, 0):\n # get the inputs; data is a list of [inputs, labels]\n inputs, labels = data\n\n # zero the parameter gradients\n optimizer.zero_grad()\n\n # forward + backward + optimize\n outputs =model(inputs.float())\n loss = Criterion(outputs, labels.float())\n loss.backward()\n optimizer.step()\n\n # print statistics\n running_loss += loss.item()\n if i % 101 == 100: # print every 2000 mini-batches\n print('[%d, %5d] loss: %.3f' %\n (epoch + 1, i + 1, running_loss / 101))\n running_loss = 0.0\n \n\nprint('Finished Training')\n",
"[1, 101] loss: 78.432\n[2, 101] loss: 18.495\n[3, 101] loss: 17.509\n[4, 101] loss: 17.206\n[5, 101] loss: 16.337\n[6, 101] loss: 15.303\n[7, 101] loss: 16.745\n[8, 101] loss: 14.691\n[9, 101] loss: 14.048\n[10, 101] loss: 14.847\n[11, 101] loss: 12.403\n[12, 101] loss: 10.982\n[13, 101] loss: 14.589\n[14, 101] loss: 9.358\n[15, 101] loss: 14.457\n[16, 101] loss: 10.647\n[17, 101] loss: 11.410\n[18, 101] loss: 11.863\n[19, 101] loss: 10.675\n[20, 101] loss: 9.730\n[21, 101] loss: 10.887\n[22, 101] loss: 10.237\n[23, 101] loss: 10.924\n[24, 101] loss: 10.314\n[25, 101] loss: 9.279\n[26, 101] loss: 8.366\n[27, 101] loss: 7.586\n[28, 101] loss: 10.110\n[29, 101] loss: 8.661\n[30, 101] loss: 8.857\n[31, 101] loss: 8.073\n[32, 101] loss: 7.731\n[33, 101] loss: 9.442\n[34, 101] loss: 8.106\n[35, 101] loss: 8.097\n[36, 101] loss: 7.034\n[37, 101] loss: 10.409\n[38, 101] loss: 6.828\n[39, 101] loss: 7.440\n[40, 101] loss: 6.462\n[41, 101] loss: 7.952\n[42, 101] loss: 5.986\n[43, 101] loss: 7.007\n[44, 101] loss: 6.687\n[45, 101] loss: 6.117\n[46, 101] loss: 6.524\n[47, 101] loss: 5.462\n[48, 101] loss: 5.098\n[49, 101] loss: 7.244\n[50, 101] loss: 6.453\n[51, 101] loss: 6.757\n[52, 101] loss: 5.272\n[53, 101] loss: 6.156\n[54, 101] loss: 5.405\n[55, 101] loss: 6.499\n[56, 101] loss: 5.829\n[57, 101] loss: 6.284\n[58, 101] loss: 5.053\n[59, 101] loss: 5.918\n[60, 101] loss: 5.431\n[61, 101] loss: 4.752\n[62, 101] loss: 4.956\n[63, 101] loss: 4.885\n[64, 101] loss: 4.530\n[65, 101] loss: 4.693\n[66, 101] loss: 6.390\n[67, 101] loss: 4.642\n[68, 101] loss: 4.467\n[69, 101] loss: 4.716\n[70, 101] loss: 5.041\n[71, 101] loss: 4.647\n[72, 101] loss: 4.631\n[73, 101] loss: 4.056\n[74, 101] loss: 5.425\n[75, 101] loss: 4.622\n[76, 101] loss: 4.344\n[77, 101] loss: 4.349\n[78, 101] loss: 4.324\n[79, 101] loss: 4.721\n[80, 101] loss: 3.869\n[81, 101] loss: 5.234\n[82, 101] loss: 3.449\n[83, 101] loss: 3.727\n[84, 101] loss: 4.139\n[85, 101] loss: 4.095\n[86, 101] loss: 3.700\n[87, 101] loss: 6.283\n[88, 101] loss: 5.010\n[89, 101] loss: 3.906\n[90, 101] loss: 3.490\n[91, 101] loss: 3.181\n[92, 101] loss: 4.134\n[93, 101] loss: 4.145\n[94, 101] loss: 3.869\n[95, 101] loss: 4.223\n[96, 101] loss: 3.374\n[97, 101] loss: 3.556\n[98, 101] loss: 4.308\n[99, 101] loss: 3.650\n[100, 101] loss: 3.653\nFinished Training\n"
],
[
"tensor_test_data = torch.from_numpy(test_data)\ntensor_test_data = tensor_test_data.float()\nprint(model(tensor_test_data[5]))",
"tensor([22.9501], grad_fn=<AddBackward0>)\n"
],
[
"print(test_targets[5])",
"24.5\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb315bdd5ac32dadc57ad345f766232caa9e9ae3 | 41,066 | ipynb | Jupyter Notebook | notebooks/initial_exploration/public_transport_routing.ipynb | CorrelAid/gender-equality-and-mobility | 2f86b6fac3d8e70bbd0f753679780e3d700fbeba | [
"MIT"
] | 2 | 2020-08-03T17:37:15.000Z | 2021-01-18T11:27:51.000Z | notebooks/initial_exploration/public_transport_routing.ipynb | CorrelAid/gender-equality-and-mobility | 2f86b6fac3d8e70bbd0f753679780e3d700fbeba | [
"MIT"
] | null | null | null | notebooks/initial_exploration/public_transport_routing.ipynb | CorrelAid/gender-equality-and-mobility | 2f86b6fac3d8e70bbd0f753679780e3d700fbeba | [
"MIT"
] | null | null | null | 32.905449 | 331 | 0.427775 | [
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\n%matplotlib inline\nfrom datetime import time\nimport geopandas as gpd\n\nfrom shapely.geometry import Point, LineString, shape",
"_____no_output_____"
]
],
[
[
"## Load Data",
"_____no_output_____"
]
],
[
[
"df = pd.read_csv(r'..\\data\\processed\\trips_custom_variables.csv', dtype = {'VORIHORAINI':str, 'VDESHORAFIN':str}, parse_dates = ['start_time','end_time'])\netap = pd.read_excel (r'..\\data\\raw\\EDM2018XETAPAS.xlsx')",
"_____no_output_____"
],
[
"df.set_index([\"ID_HOGAR\", \"ID_IND\", \"ID_VIAJE\"], inplace =True)\netap.set_index([\"ID_HOGAR\", \"ID_IND\", \"ID_VIAJE\"], inplace =True)\nlegs = df.join(etap, rsuffix = \"_etap\")",
"_____no_output_____"
],
[
"# select only public transport trips\nlegs = legs[legs.mode_simple == \"public transport\"]",
"_____no_output_____"
],
[
"codes = pd.read_csv(r'..\\data\\processed\\codes_translated.csv', dtype = {'CODE': float})",
"_____no_output_____"
],
[
"stops = gpd.read_file(r'..\\data\\raw\\public_transport_madrid\\madrid_crtm_stops.shp')",
"_____no_output_____"
],
[
"legs_start_end = legs.sort_values(\"ID_ETAPA\").groupby([\"ID_HOGAR\", \"ID_IND\", \"ID_VIAJE\"]).agg(\n {\"C2SEXO\": \"first\",\"ESUBIDA\": \"first\", \"ESUBIDA_cod\": \"first\", \"EBAJADA\": \"last\", \"EBAJADA_cod\": \"last\", \"N_ETAPAS_POR_VIAJE\": \"first\", \"VORIHORAINI\": \"first\", \"duration\":\"first\", \"DANNO\": \"first\", \"DMES\": \"first\", \"DDIA\":\"first\"})",
"_____no_output_____"
],
[
"legs_start_end= legs_start_end[legs_start_end.ESUBIDA_cod.notna()]\nlegs_start_end= legs_start_end[legs_start_end.EBAJADA_cod.notna()]",
"_____no_output_____"
]
],
[
[
"### Preprocessing",
"_____no_output_____"
]
],
[
[
"# stops[\"id_custom\"] = stops.stop_id.str.split(\"_\").apply(lambda x: x[len(x)-1])\n# s = stops.reset_index().set_index([\"id_custom\", \"stop_name\"])[[\"geometry\"]]\n\n# Problem: match not working properly: id_custom multiple times within df_stations. For names not a match for every start / end\nstops_unique_name = stops.drop_duplicates(\"stop_name\").set_index(\"stop_name\")\n\ndf_stations = legs_start_end.join(stops_unique_name, on ='ESUBIDA', how= \"inner\")\ndf_stations = df_stations.join(stops_unique_name, how= \"inner\", on ='EBAJADA', lsuffix = \"_dep\", rsuffix = \"_arrival\")\n\n#df_stations[\"line\"] = df_stations.apply(lambda x: LineString([x.geometry_dep, x.geometry_arrival]), axis = 1)\n#df_stations = gpd.GeoDataFrame(df_stations, geometry = df_stations.line)",
"_____no_output_____"
],
[
"# df_stations[[\"VORIHORAINI\", \"VDESHORAFIN\", \"start_time\", \"end_time\", \"duration\", \"DANNO\", \"DMES\", \"DDIA\", \"activity_simple\", \"motive_simple\", \"daytime\", \"speed\", \"C2SEXO\", \"EDAD_FIN\", \"ESUBIDA\", \"ESUBIDA_cod\", \"EBAJADA\", \"EBAJADA_cod\", \"geometry_dep\", \"geometry_arrival\"]].to_csv(\n# r'..\\data\\processed\\public_transport_georeferenced.csv')",
"_____no_output_____"
],
[
"#df_stations[[\"activity_simple\", \"motive_simple\", \"daytime\", \"speed\", \"C2SEXO\", \"EDAD_FIN\", \"ESUBIDA\", \"ESUBIDA_cod\", \"EBAJADA\", \"EBAJADA_cod\", \"geometry\"]].to_file(\n# r'..\\data\\processed\\public_transport_georeferenced.geojson', driver = \"GeoJSON\")",
"_____no_output_____"
]
],
[
[
"### (use preprocessed data)",
"_____no_output_____"
]
],
[
[
"# df_stations = pd.read_csv(r'..\\data\\processed\\public_transport_georeferenced.csv', dtype = {'VORIHORAINI':str, 'VDESHORAFIN':str, 'geometry_dep':'geometry'})",
"_____no_output_____"
]
],
[
[
"### counts for Flowmap",
"_____no_output_____"
]
],
[
[
"# todo: add linestring again for flowmap\ncounts = df_stations.groupby([\"ESUBIDA\", \"EBAJADA\", \"activity_simple\", \"C2SEXO\"]).agg({\"ID_ETAPA\": \"count\", \"ELE_G_POND_ESC2\" : \"sum\", \"geometry\": \"first\"})",
"_____no_output_____"
],
[
"counts.rename({\"ELE_G_POND_ESC2\": \"weighted_count\"}, axis = 1, inplace = True)",
"_____no_output_____"
],
[
"df_counts = gpd.GeoDataFrame(counts, geometry = \"geometry\")",
"_____no_output_____"
],
[
"df_counts.to_file(\n r'..\\data\\processed\\trip_counts_georef.geojson', driver = \"GeoJSON\")",
"_____no_output_____"
],
[
"counts.shape",
"_____no_output_____"
],
[
"counts_gender = df_stations.groupby([\"ESUBIDA\", \"EBAJADA\", \"C2SEXO\"]).agg({\"ID_ETAPA\": \"count\", \"ELE_G_POND_ESC2\" : \"sum\", \"geometry\": \"first\"})\n\ncounts_gender.rename({\"ELE_G_POND_ESC2\": \"weighted_count\"}, axis = 1, inplace = True)\n\ndf_counts_gender = gpd.GeoDataFrame(counts_gender, geometry = \"geometry\")\n\ndf_counts_gender.to_file(\n r'..\\data\\processed\\trip_counts_gender_georef.geojson', driver = \"GeoJSON\")",
"_____no_output_____"
],
[
"counts_activity = df_stations.groupby([\"ESUBIDA\", \"EBAJADA\", \"activity_simple\"]).agg({\"ID_ETAPA\": \"count\", \"ELE_G_POND_ESC2\" : \"sum\", \"geometry\": \"first\"})\n\ncounts_activity.rename({\"ELE_G_POND_ESC2\": \"weighted_count\"}, axis = 1, inplace = True)\n\ndf_counts_activity = gpd.GeoDataFrame(counts_activity, geometry = \"geometry\")\n\ndf_counts_activity.to_file(\n r'..\\data\\processed\\trip_counts_activity_georef.geojson', driver = \"GeoJSON\")",
"_____no_output_____"
],
[
"counts_motive = df_stations.groupby([\"ESUBIDA\", \"EBAJADA\", \"motive_simple\"]).agg({\"ID_ETAPA\": \"count\", \"ELE_G_POND_ESC2\" : \"sum\", \"geometry\": \"first\"})\n\ncounts_motive.rename({\"ELE_G_POND_ESC2\": \"weighted_count\"}, axis = 1, inplace = True)\n\ndf_counts_motive = gpd.GeoDataFrame(counts_motive, geometry = \"geometry\")\n\ndf_counts_motive.to_file(\n r'..\\data\\processed\\trip_counts_motive_georef.geojson', driver = \"GeoJSON\")",
"_____no_output_____"
]
],
[
[
"### comparison to car",
"_____no_output_____"
]
],
[
[
"import herepy",
"_____no_output_____"
],
[
"routingApi = herepy.RoutingApi('i5L1qsCmPo7AkwqhCWGA9J2QKnuC-TSI9KNWBqEkdIk')",
"_____no_output_____"
],
[
"# time and speed \ndf_stations['start_time'] = pd.to_datetime(df_stations.VORIHORAINI, format = '%H%M')\n# df_stations['end_time'] = pd.to_datetime(df_stations.VDESHORAFIN, format = '%H%M', errors = 'coerce')\n# df_stations['duration'] = df_stations.end_time - df_stations.start_time",
"_____no_output_____"
],
[
"df_stations[\"formatted_time\"] = df_stations.DANNO.astype(str) + '-' + df_stations.DMES.astype(str).str.zfill(2) + '-' + df_stations.DDIA.astype(str).str.zfill(2) + 'T'+ df_stations.VORIHORAINI.str.slice(0,2) + \":\" + df_stations.VORIHORAINI.str.slice(2,4) + ':00'",
"_____no_output_____"
],
[
"df_stations[\"car_traveltime\"] = None\ndf_stations[\"pt_traveltime\"] = None",
"_____no_output_____"
],
[
"df_unique_routes = df_stations.drop_duplicates([\"ESUBIDA\", \"EBAJADA\", \"geometry_dep\", \"geometry_arrival\"]).copy()",
"_____no_output_____"
],
[
"df_unique_routes.reset_index(drop = True, inplace = True)",
"_____no_output_____"
],
[
"for i in range (len(df_unique_routes)):\n if(df_unique_routes.car_traveltime.notna()[i]):\n continue\n if i % 1000 == 0:\n print(i)\n try:\n resp_car = routingApi.car_route([df_unique_routes.iloc[i, ].geometry_dep.y, df_unique_routes.iloc[i, ].geometry_dep.x],\n [df_unique_routes.iloc[i, ].geometry_arrival.y, df_unique_routes.iloc[i, ].geometry_arrival.x],\n [herepy.RouteMode.car, herepy.RouteMode.fastest],\n departure = df_unique_routes.loc[i, \"formatted_time\"])\n \n df_unique_routes.loc[i, \"car_traveltime\"] = resp_car.response[\"route\"][0][\"summary\"][\"travelTime\"]\n\n except:\n print('car no route found, id:', i)\n df_unique_routes.loc[i, \"car_traveltime\"] = None \n \n \n try:\n resp_pt = routingApi.public_transport([df_unique_routes.iloc[i, ].geometry_dep.y, df_unique_routes.iloc[i, ].geometry_dep.x],\n [df_unique_routes.iloc[i, ].geometry_arrival.y, df_unique_routes.iloc[i, ].geometry_arrival.x],\n True,\n modes = [herepy.RouteMode.publicTransport, herepy.RouteMode.fastest],\n departure = df_unique_routes.loc[i, \"formatted_time\"])\n df_unique_routes.loc[i, \"pt_traveltime\"] = resp_pt.response[\"route\"][0][\"summary\"][\"travelTime\"]\n\n except:\n print('pt no route found, id:', i)\n df_unique_routes.loc[i, \"pt_traveltime\"] = None \n ",
"0\npt no route found, id: 215\n1000\n2000\npt no route found, id: 2098\npt no route found, id: 2100\npt no route found, id: 2101\n3000\npt no route found, id: 3092\npt no route found, id: 3991\n4000\npt no route found, id: 4398\npt no route found, id: 4509\npt no route found, id: 4876\npt no route found, id: 4957\n5000\npt no route found, id: 5205\npt no route found, id: 5206\npt no route found, id: 5365\ncar no route found, id: 5746\npt no route found, id: 5782\n6000\npt no route found, id: 6265\npt no route found, id: 6769\n7000\npt no route found, id: 7877\npt no route found, id: 7886\npt no route found, id: 7934\npt no route found, id: 7960\n8000\npt no route found, id: 8125\npt no route found, id: 8139\npt no route found, id: 8697\npt no route found, id: 8736\npt no route found, id: 8757\n9000\npt no route found, id: 9132\npt no route found, id: 9202\n10000\npt no route found, id: 10930\n11000\npt no route found, id: 11464\npt no route found, id: 11507\n12000\npt no route found, id: 12752\n13000\npt no route found, id: 13072\npt no route found, id: 13073\npt no route found, id: 13074\npt no route found, id: 13465\npt no route found, id: 13724\npt no route found, id: 13732\n14000\npt no route found, id: 14029\npt no route found, id: 14113\npt no route found, id: 14127\npt no route found, id: 14422\npt no route found, id: 14524\npt no route found, id: 14750\npt no route found, id: 14852\npt no route found, id: 14920\npt no route found, id: 14970\npt no route found, id: 14988\n15000\npt no route found, id: 15009\npt no route found, id: 15167\npt no route found, id: 15345\npt no route found, id: 15624\npt no route found, id: 15643\npt no route found, id: 15661\npt no route found, id: 15662\npt no route found, id: 15686\npt no route found, id: 15917\n16000\npt no route found, id: 16691\npt no route found, id: 16692\npt no route found, id: 16700\npt no route found, id: 16792\npt no route found, id: 16795\npt no route found, id: 16916\npt no route found, id: 16917\npt no route found, id: 16918\npt no route found, id: 16919\npt no route found, id: 16953\npt no route found, id: 16954\npt no route found, id: 16955\n17000\n"
],
[
"df_unique_routes[df_unique_routes.pt_traveltime.isna()].shape",
"_____no_output_____"
],
[
"df_unique_routes[df_unique_routes.car_traveltime.isna()].shape",
"_____no_output_____"
],
[
"df_unique_routes.to_csv(r'..\\data\\processed\\unique_routings_run2_2.csv')",
"_____no_output_____"
],
[
"df_unique_routes[\"car_traveltime_min\"] = df_unique_routes.car_traveltime / 60\ndf_unique_routes[\"pt_traveltime_min\"] = df_unique_routes.pt_traveltime / 60",
"_____no_output_____"
],
[
"df_stations = df_stations.join(df_unique_routes.set_index([\"ESUBIDA\", \"EBAJADA\"])[[\"car_traveltime_min\", \"pt_traveltime_min\"]], on = [\"ESUBIDA\", \"EBAJADA\"])",
"_____no_output_____"
],
[
"df_stations = df_stations.join(legs[\"C2SEXO\"],how = \"left\")",
"_____no_output_____"
],
[
"df_stations = df_stations.join(legs[\"age_group\"],how = \"left\")",
"_____no_output_____"
],
[
"#days, seconds = df_stations.duration.dt.days, df_stations.duration.dt.seconds\n#df_stations[\"minutes\"] = seconds % 3600",
"_____no_output_____"
],
[
"df_stations.drop_duplicates(inplace = True)",
"_____no_output_____"
],
[
"df_stations[\"tt_ratio\"] = None",
"_____no_output_____"
],
[
"df_stations.loc[df_stations.pt_traveltime_min != 0, \"tt_ratio\"] = df_stations[df_stations.pt_traveltime_min != 0].pt_traveltime_min / df_stations[df_stations.pt_traveltime_min != 0].car_traveltime_min",
"_____no_output_____"
],
[
"df_stations.loc[df_stations.car_traveltime_min != 0, \"tt_ratio_duration\"] = df_stations[df_stations.car_traveltime_min != 0].duration / df_stations[df_stations.car_traveltime_min != 0].car_traveltime_min",
"_____no_output_____"
],
[
"df_stations[[\"start_time\", \"duration\", \"car_traveltime_min\", \"pt_traveltime_min\", \"tt_ratio\", \"tt_ratio_duration\", \"age_group\"]]",
"_____no_output_____"
],
[
"df_stations.tt_ratio = df_stations.tt_ratio.astype(float)",
"_____no_output_____"
],
[
"df_stations.tt_ratio_duration = df_stations.tt_ratio_duration.astype(float)",
"_____no_output_____"
],
[
"df_stations.groupby([\"age_group\", \"C2SEXO\"]).tt_ratio_duration.describe()",
"_____no_output_____"
],
[
"df_stations.groupby([\"age_group\", \"C2SEXO\"]).tt_ratio.describe()",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb317b0a200f9e25cae45c247de015543f18845b | 161,209 | ipynb | Jupyter Notebook | RY/RY_VQE_LiH.ipynb | Phystro/VQEProject | 3cbb7edc193e9ee3f32354214a16683007e8a78c | [
"MIT"
] | null | null | null | RY/RY_VQE_LiH.ipynb | Phystro/VQEProject | 3cbb7edc193e9ee3f32354214a16683007e8a78c | [
"MIT"
] | null | null | null | RY/RY_VQE_LiH.ipynb | Phystro/VQEProject | 3cbb7edc193e9ee3f32354214a16683007e8a78c | [
"MIT"
] | null | null | null | 203.290038 | 50,672 | 0.887308 | [
[
[
"# Variational Quantum Eigensolver - Ground State Energy for $LiH$ Molecule using the RY ansatz",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\n# Importing standard Qiskit libraries\nfrom qiskit import QuantumCircuit, transpile, IBMQ\n\nfrom qiskit.tools.jupyter import *\n\nfrom qiskit.visualization import *\n\nfrom ibm_quantum_widgets import *\n\nfrom qiskit.providers.aer import QasmSimulator, StatevectorSimulator\n\n# Loading your IBM Quantum account(s)\nprovider = IBMQ.load_account()",
"<frozen importlib._bootstrap>:219: RuntimeWarning: scipy._lib.messagestream.MessageStream size changed, may indicate binary incompatibility. Expected 56 from C header, got 64 from PyObject\n"
],
[
"# Chemistry Drivers\nfrom qiskit_nature.drivers.second_quantization.pyscfd import PySCFDriver\n\nfrom qiskit_nature.transformers.second_quantization.electronic import FreezeCoreTransformer\n\nfrom qiskit.opflow.primitive_ops import Z2Symmetries\n\n# Electroinic structure problem\nfrom qiskit_nature.problems.second_quantization.electronic import ElectronicStructureProblem\n\n# Qubit converter\nfrom qiskit_nature.converters.second_quantization.qubit_converter import QubitConverter\n\n# Mappers\nfrom qiskit_nature.mappers.second_quantization import ParityMapper, BravyiKitaevMapper, JordanWignerMapper\n\n# Initial state\nfrom qiskit_nature.circuit.library import HartreeFock\n\n# Variational form - circuit\nfrom qiskit.circuit.library import TwoLocal\n\n# Optimizer\nfrom qiskit.algorithms.optimizers import COBYLA, SLSQP, SPSA\n\n# Eigen Solvers\n# NumPy Minimum Eigen Solver\nfrom qiskit_nature.algorithms.ground_state_solvers.minimum_eigensolver_factories import NumPyMinimumEigensolverFactory\n# ground state\nfrom qiskit_nature.algorithms.ground_state_solvers import GroundStateEigensolver\n# VQE Solver\nfrom qiskit.algorithms import VQE",
"_____no_output_____"
]
],
[
[
"Backend",
"_____no_output_____"
]
],
[
[
"qasm_sim = QasmSimulator()\nstate_sim = StatevectorSimulator()",
"_____no_output_____"
]
],
[
[
"Drivers\n\nBelow we set up a PySCF driver for LIH molecule at equilibrium bond length 1.5474 Angstrom",
"_____no_output_____"
]
],
[
[
"def exact_diagonalizer(es_problem, qubit_converter):\n solver = NumPyMinimumEigensolverFactory()\n calc = GroundStateEigensolver(qubit_converter, solver)\n result = calc.solve(es_problem)\n return result",
"_____no_output_____"
],
[
"def get_mapper(mapper_str: str):\n if mapper_str == \"jw\":\n mapper = JordanWignerMapper()\n elif mapper_str == \"pa\":\n mapper = ParityMapper()\n elif mapper_str == \"bk\":\n mapper = BravyiKitaevMapper()\n \n return mapper",
"_____no_output_____"
],
[
"def initial_state_preparation(mapper_str: str = \"jw\"):\n \n molecule = \"Li 0.0 0.0 0.0; H 0.0 0.0 1.5474\"\n driver = PySCFDriver(atom=molecule)\n qmolecule = driver.run()\n \n transformer = FreezeCoreTransformer()\n qmolecule = transformer.transform(qmolecule)\n es_problem = ElectronicStructureProblem(driver)\n \n # generating second_quzntized operators\n second_q_ops = es_problem.second_q_ops()\n \n # Hamiltonian\n main_op = second_q_ops[0]\n \n # return tuple of number of particles if available\n num_particles = es_problem.num_particles\n # return the number of spin orbitals\n num_spin_orbitals = es_problem.num_spin_orbitals\n \n mapper = get_mapper(mapper_str)\n \n qubit_converter = QubitConverter(mapper=mapper, two_qubit_reduction=True, z2symmetry_reduction=[1, 1])\n \n # Qubit Hamiltonian\n qubit_op = qubit_converter.convert(main_op, num_particles=num_particles)\n \n return (qubit_op, num_particles, num_spin_orbitals, qubit_converter, es_problem)",
"_____no_output_____"
],
[
"qubit_op, num_particles, num_spin_orbitals, qubit_converter, es_problem = initial_state_preparation(\"pa\")",
"_____no_output_____"
],
[
"init_state = HartreeFock(num_spin_orbitals, num_particles, qubit_converter)\n\ninit_state.barrier()\n\ninit_state.draw(\"mpl\", initial_state=True).savefig(\"ry_vqe_lih_init_state.png\", dpi=300)\ninit_state.draw(\"mpl\", initial_state=True)",
"_____no_output_____"
],
[
"# Setting up TwoLocal for our ansatz\nansatz_type = \"RY\"\n\n# Single qubit rotations that are placed on all qubits with independent parameters\nrotation_blocks = [\"ry\"]\n# Entangling gates\nentanglement_blocks = \"cx\"\n# How the qubits are entangled?\nentanglement = 'linear'\n# Repetitions of rotation_blocks + entanglement_blocks with independent parameters\nrepetitions = 1\n# Skipoing the final rotation_blocks layer\nskip_final_rotation_layer = False\n\nansatz = TwoLocal(\n qubit_op.num_qubits,\n rotation_blocks,\n entanglement_blocks,\n reps=repetitions,\n entanglement=entanglement,\n skip_final_rotation_layer=skip_final_rotation_layer,\n # insert_barriers=True\n)\n\n# Add the initial state\nansatz.compose(init_state, front=True, inplace=True) ",
"_____no_output_____"
],
[
"ansatz.draw(output=\"mpl\", initial_state=True).savefig(\"ry_vqe_lih_ansatz.png\", dpi=300)\n\nansatz.draw(output=\"mpl\", initial_state=True)",
"_____no_output_____"
],
[
"ansatz.decompose().draw(output=\"mpl\", initial_state=True).savefig(\"ry_vqe_lih_ansatz_decomposed.png\", dpi=300)\n\nansatz.decompose().draw(output=\"mpl\", initial_state=True)",
"_____no_output_____"
],
[
"optimizer = COBYLA(maxiter=10000)",
"_____no_output_____"
]
],
[
[
"## Solver\n\n### Exact Eigensolver using NumPyMinimumEigensolver",
"_____no_output_____"
]
],
[
[
"result_exact = exact_diagonalizer(es_problem, qubit_converter)\nexact_energy = np.real(result_exact.eigenenergies[0])\n\nprint(\"Exact Electronic Energy: {:.4f} Eh\\n\\n\".format(exact_energy))\n\nprint(\"Results:\\n\\n\", result_exact)",
"Exact Electronic Energy: -8.9087 Eh\n\n\nResults:\n\n === GROUND STATE ENERGY ===\n \n* Electronic ground state energy (Hartree): -8.908697116424\n - computed part: -8.908697116424\n~ Nuclear repulsion energy (Hartree): 1.025934879643\n> Total ground state energy (Hartree): -7.882762236781\n \n=== MEASURED OBSERVABLES ===\n \n 0: # Particles: 4.000 S: 0.000 S^2: 0.000 M: 0.000\n \n=== DIPOLE MOMENTS ===\n \n~ Nuclear dipole moment (a.u.): [0.0 0.0 2.92416221]\n \n"
]
],
[
[
"### VQE Solver",
"_____no_output_____"
]
],
[
[
"\nfrom IPython.display import display, clear_output\n\ndef callback(eval_count, parameters, mean, std):\n # overwrites same line when printing\n display(\"Evaluation: {},\\tEnergy: {},\\tStd: {}\".format(eval_count, mean, std))\n clear_output(wait=True)\n counts.append(eval_count)\n values.append(mean)\n params.append(parameters)\n deviation.append(std)\n \ncounts = []\nvalues = []\nparams = []\ndeviation = []\n\n# Set initial parameters of the ansatz\n# we choose a fixed small displacement\n\ntry:\n initial_point = [0.01] * len(ansatz.ordered_parameters)\nexcept:\n initial_point = [0.01] * ansatz.num_parameters\n \nalgorithm = VQE(\n ansatz,\n optimizer=optimizer,\n quantum_instance=state_sim,\n callback=callback,\n initial_point=initial_point\n)\n\nresult = algorithm.compute_minimum_eigenvalue(qubit_op)\n\nprint(result)",
"{ 'aux_operator_eigenvalues': None,\n 'cost_function_evals': 2288,\n 'eigenstate': array([ 4.17541727e-08-1.47826751e-21j, -6.08978182e-05+3.04430835e-22j,\n -2.06912153e-09+8.47454827e-22j, 3.50174240e-05-1.74522798e-22j,\n 3.76085218e-08-6.90758373e-21j, -2.85325448e-04+1.42253109e-21j,\n -2.66845151e-07-3.23121507e-21j, -1.34850125e-04+6.65428616e-22j,\n -9.06850237e-05+1.50590930e-17j, 6.21990402e-01-3.10123318e-18j,\n 5.67545519e-04+6.64729135e-18j, 2.77505431e-01-1.36892710e-18j,\n -7.16666942e-05+8.52060183e-21j, 4.17620536e-06-1.75471213e-21j,\n -1.16618395e-04-3.26609779e-18j, -1.35562439e-01+6.72612279e-19j,\n 1.27662106e-08-3.16630074e-21j, -1.30809302e-04+6.52060317e-22j,\n -1.29620131e-07-1.68534725e-21j, -7.02891187e-05+3.47076336e-22j,\n 9.20450969e-09+1.32293082e-21j, 5.47248034e-05-2.72441173e-22j,\n 7.78969117e-08+1.36796965e-21j, 5.69199328e-05-2.81716362e-22j,\n 1.73933883e-05-2.88833540e-18j, -1.19297816e-01+5.94816807e-19j,\n -1.08855295e-04-1.27495143e-18j, -5.32255812e-02+2.62560414e-19j,\n 1.37456715e-05-1.63266997e-21j, -7.35632468e-07+3.36228104e-22j,\n 2.23674825e-05+6.26438667e-19j, 2.60009222e-02-1.29007264e-19j,\n -5.45188483e-12+7.73838983e-25j, 3.19582671e-08-1.59362529e-25j,\n 2.78713329e-11+3.05427547e-25j, 1.27594390e-08-6.28990104e-26j,\n -4.41966670e-12+1.66918432e-25j, 6.87770372e-09-3.43747783e-26j,\n 7.15337748e-13-8.22209139e-26j, -3.39492670e-09+1.69323762e-26j,\n 2.18589929e-09-3.62988673e-22j, -1.49926341e-05+7.47530093e-23j,\n -1.36802765e-08-1.60228133e-22j, -6.68906702e-06+3.29969943e-23j,\n 1.72747594e-09-2.05721591e-25j, -1.14651268e-10+4.23658068e-26j,\n 2.81098941e-09+7.87267787e-23j, 3.26762845e-06-1.62128024e-23j,\n -3.82578643e-11+7.58911513e-24j, 3.13491727e-07-1.56288402e-24j,\n 2.98171921e-10+3.68979388e-24j, 1.53956475e-07-7.59867228e-25j,\n -2.91897649e-11-1.56058037e-24j, -6.46445115e-08+3.21382148e-25j,\n -1.21823839e-10-2.45071303e-24j, -1.01885783e-07+5.04693915e-25j,\n -2.05464259e-08+3.41192829e-21j, 1.40923936e-04-7.02644261e-22j,\n 1.28588425e-07+1.50607300e-21j, 6.28742466e-05-3.10157031e-22j,\n -1.62374574e-08+1.92687257e-24j, 7.96062799e-10-3.96815476e-25j,\n -2.64222956e-08-7.39999390e-22j, -3.07143663e-05+1.52393685e-22j,\n -3.42333447e-13+1.22336588e-26j, 5.03986031e-10-2.51937010e-27j,\n 2.23656458e-14-6.86667495e-27j, -2.83708601e-10+1.41410643e-27j,\n -3.08248081e-13+5.64899507e-26j, 2.33337707e-09-1.16334038e-26j,\n 2.18112737e-12+2.63933810e-26j, 1.10149702e-09-5.43538905e-27j,\n 7.41617523e-10-1.23152498e-22j, -5.08660595e-06+2.53617276e-23j,\n -4.64135846e-09-5.43612114e-23j, -2.26942533e-06+1.11950164e-23j,\n 5.86086590e-10-6.96811158e-26j, -3.41555327e-11+1.43499605e-26j,\n 9.53699313e-10+2.67099820e-23j, 1.10862275e-06-5.50058909e-24j,\n -1.11828014e-13+2.73640507e-26j, 1.13048305e-09-5.63528643e-27j,\n 1.11776570e-12+1.44968026e-26j, 6.04617551e-10-2.98543647e-27j,\n -8.09428386e-14-1.11180160e-26j, -4.59929028e-10+2.28961732e-27j,\n -6.60509666e-13-1.16603219e-26j, -4.85158201e-10+2.40129850e-27j,\n -1.46181001e-10+2.42747277e-23j, 1.00262663e-06-4.99907872e-24j,\n 9.14863503e-10+1.07152026e-23j, 4.47329108e-07-2.20666291e-24j,\n -1.15524128e-10+1.37212670e-26j, 6.16827920e-12-2.82572453e-27j,\n -1.87985297e-10-5.26484167e-24j, -2.18522173e-07+1.08422876e-24j,\n -3.61069448e-11+5.99551383e-24j, 2.47634562e-07-1.23470162e-24j,\n 2.25954554e-10+2.64639783e-24j, 1.10479577e-07-5.44992768e-25j,\n -2.85349714e-11+3.87431873e-27j, 2.15742207e-11-7.97867830e-28j,\n -4.64101484e-11-1.30009170e-24j, -5.39614692e-08+2.67737741e-25j,\n 6.51452659e-12-1.07962589e-24j, -4.45920606e-08+2.22335545e-25j,\n -4.06674707e-11-4.75964579e-25j, -1.98703058e-08+9.80189943e-26j,\n 5.15014543e-12-3.36061734e-27j, -1.13894610e-10+6.92077406e-28j,\n 8.24988320e-12+2.32741047e-25j, 9.65984172e-09-4.79301283e-26j,\n -3.08216328e-10+6.10160382e-23j, 2.52045197e-06-1.25654953e-23j,\n 2.39626354e-09+2.96371724e-23j, 1.23661587e-06-6.10340761e-24j,\n -2.35265967e-10-1.24155012e-23j, -5.14306773e-07+2.55681829e-24j,\n -9.74159053e-10-1.96359776e-23j, -8.16335443e-07+4.04378575e-24j,\n -1.63465824e-07+2.71450460e-20j, 1.12118028e-03-5.59018511e-21j,\n 1.02303988e-06+1.19822041e-20j, 5.00222800e-04-2.46758612e-21j,\n -1.29183993e-07+1.53297614e-23j, 6.32133525e-09-3.15697398e-24j,\n -2.10213817e-07-5.88737987e-21j, -2.44361204e-04+1.21243277e-21j,\n 3.99002838e-13-1.41257734e-26j, -5.81916782e-10+2.90902762e-27j,\n -1.97463954e-14+8.09867162e-27j, 3.34642887e-10-1.66782085e-27j,\n 3.59387469e-13-6.60095611e-26j, -2.72659854e-09+1.35938494e-26j,\n -2.55000438e-12-3.08779661e-26j, -1.28864758e-09+6.35893367e-27j,\n -8.66595163e-10+1.43906200e-22j, 5.94380254e-06-2.96356947e-23j,\n 5.42352179e-09+6.35221815e-23j, 2.65186967e-06-1.30816044e-23j,\n -6.84854103e-10+8.14237236e-26j, 3.99082232e-11-1.67682047e-26j,\n -1.11441705e-09-3.12111574e-23j, -1.29544824e-06+6.42755026e-24j,\n 1.21959261e-13-3.02503748e-26j, -1.24973300e-09+6.22968902e-27j,\n -1.23838363e-12-1.61018925e-26j, -6.71545713e-10+3.31598479e-27j,\n 8.79317938e-14+1.26406121e-26j, 5.22895751e-10-2.60317709e-27j,\n 7.44277137e-13+1.30701661e-26j, 5.43837423e-10-2.69163840e-27j,\n 1.66193906e-10-2.75980582e-23j, -1.13989118e-06+5.68347735e-24j,\n -1.04011285e-09-1.21821668e-23j, -5.08570676e-07+2.50876598e-24j,\n 1.31339955e-10-1.56001708e-26j, -7.02904068e-12+3.21266144e-27j,\n 2.13721399e-10+5.98562437e-24j, 2.48438932e-07-1.23266501e-24j,\n -1.74718210e-13+2.90104829e-26j, 1.19822891e-09-5.97434868e-27j,\n 1.09331353e-12+1.28047740e-26j, 5.34562952e-10-2.63698419e-27j,\n -1.38079188e-13+2.03435539e-29j, 1.70360537e-13-4.18950229e-30j,\n -2.24500365e-13-6.28993037e-27j, -2.61069017e-10+1.29533305e-27j,\n 5.24889085e-14-8.70576299e-27j, -3.59576531e-10+1.79284378e-27j,\n -3.27998546e-13-3.83995432e-27j, -1.60307823e-10+7.90790906e-28j,\n 4.14898945e-14-1.82308860e-29j, -5.52060756e-13+3.75442456e-30j,\n 6.68817790e-14+1.88131092e-27j, 7.80841499e-11-3.87432620e-28j,\n -1.49135122e-12+2.95235457e-25j, 1.21955933e-08-6.08000760e-26j,\n 1.15946898e-11+1.43404037e-25j, 5.98355690e-09-2.95322806e-26j,\n -1.13836976e-12-6.00744633e-26j, -2.48855867e-09+1.23715897e-26j,\n -4.71362428e-12-9.50117695e-26j, -3.94996758e-09+1.95664940e-26j,\n -7.90956517e-10+1.31345809e-22j, 5.42501684e-06-2.70490383e-23j,\n 4.95014822e-09+5.79778827e-23j, 2.42041103e-06-1.19398249e-23j,\n -6.25078188e-10+7.41755946e-26j, 3.05868441e-11-1.52755426e-26j,\n -1.01715444e-09-2.84870645e-23j, -1.18238224e-06+5.86655716e-24j,\n 8.60928037e-12-2.40598602e-25j, -9.90274911e-09+4.95482941e-26j,\n 2.62445266e-12+2.20730780e-25j, 9.13611052e-09-4.54567629e-26j,\n 7.80875665e-12-1.50552220e-24j, -6.21891575e-08+3.10043600e-25j,\n -5.87931735e-11-7.21970068e-25j, -3.01263562e-08+1.48680770e-25j,\n -1.97655926e-08+3.28226080e-21j, 1.35568239e-04-6.75940851e-22j,\n 1.23701502e-07+1.44883520e-21j, 6.04847321e-05-2.98369617e-22j,\n -1.56203816e-08+1.85710214e-24j, 9.08694294e-10-3.82447124e-25j,\n -2.54179989e-08-7.11874551e-22j, -2.95470182e-05+1.46601723e-22j,\n -1.41257247e-12+1.40355306e-25j, 5.79438386e-09-2.89044322e-26j,\n 4.36326279e-12+3.60498715e-26j, 1.51122052e-09-7.42402335e-27j,\n -1.19596197e-12+1.19359856e-25j, 4.92764014e-09-2.45806800e-26j,\n 3.71923705e-12+3.08995500e-26j, 1.29521730e-09-6.36337860e-27j,\n 1.56614594e-09-2.60073081e-22j, -1.07418794e-05+5.35588212e-23j,\n -9.80160664e-09-1.14799834e-22j, -4.79256522e-06+2.36416001e-23j,\n 1.23769616e-09-1.47204898e-25j, -7.42993730e-11+3.03150206e-26j,\n 2.01401727e-09+5.64060338e-23j, 2.34118511e-06-1.16161222e-23j,\n -2.03958574e-08+3.38670643e-21j, 1.39882183e-04-6.97450132e-22j,\n 1.27635717e-07+1.49487963e-21j, 6.24069699e-05-3.07851896e-22j,\n -1.61186506e-08+2.18930474e-24j, 1.22199611e-08-4.50860123e-25j,\n -2.62158270e-08-7.34386840e-22j, -3.04813827e-05+1.51237850e-22j,\n 3.69045308e-09-6.11607244e-22j, -2.52613685e-05+1.25952917e-22j,\n -2.30381259e-08-2.69634542e-22j, -1.12565534e-05+5.55278855e-23j,\n 2.91753367e-09-1.89931650e-24j, -6.43365219e-08+3.91140646e-25j,\n 4.67373268e-09+1.31849925e-22j, 5.47238887e-06-2.71528546e-23j,\n -1.74103206e-07+3.44663371e-20j, 1.42373628e-03-7.09791411e-21j,\n 1.35358554e-06+1.67412504e-20j, 6.98531413e-04-3.44765263e-21j,\n -1.32895487e-07-7.01318649e-21j, -2.90518220e-04+1.44427866e-21j,\n -5.50276542e-07-1.10918415e-20j, -4.61126181e-04+2.28422702e-21j,\n -9.23374974e-05+1.53335146e-17j, 6.33324927e-01-3.15774692e-18j,\n 5.77888024e-04+6.76842845e-18j, 2.82562558e-01-1.39387379e-18j,\n -7.29726026e-05+8.65937457e-21j, 3.57075420e-06-1.78329066e-21j,\n -1.18744195e-04-3.32562434e-18j, -1.38033146e-01+6.84871033e-19j]),\n 'eigenvalue': (-8.674434163824406+0j),\n 'optimal_parameters': { ParameterVectorElement(θ[5]): -0.1895386305139751,\n ParameterVectorElement(θ[6]): 0.00043592026003921576,\n ParameterVectorElement(θ[7]): 0.0017798624402431862,\n ParameterVectorElement(θ[8]): -0.40619639883144604,\n ParameterVectorElement(θ[9]): 2.4363237710280887,\n ParameterVectorElement(θ[10]): 1.404916916703023,\n ParameterVectorElement(θ[11]): 1.5684502286705253,\n ParameterVectorElement(θ[12]): -0.18945941935936594,\n ParameterVectorElement(θ[15]): -0.0017607539731759152,\n ParameterVectorElement(θ[14]): -1.7127607893169742e-05,\n ParameterVectorElement(θ[0]): 0.40571468943456257,\n ParameterVectorElement(θ[1]): 1.5749289046127293,\n ParameterVectorElement(θ[2]): -1.928035701851615,\n ParameterVectorElement(θ[4]): 1.573141882842339,\n ParameterVectorElement(θ[3]): -1.569866095374729,\n ParameterVectorElement(θ[13]): -4.819086720561373e-05},\n 'optimal_point': array([ 4.05714689e-01, 1.57492890e+00, -1.92803570e+00, -1.56986610e+00,\n 1.57314188e+00, -1.89538631e-01, 4.35920260e-04, 1.77986244e-03,\n -4.06196399e-01, 2.43632377e+00, 1.40491692e+00, 1.56845023e+00,\n -1.89459419e-01, -4.81908672e-05, -1.71276079e-05, -1.76075397e-03]),\n 'optimal_value': -8.674434163824406,\n 'optimizer_evals': None,\n 'optimizer_time': 31.37525963783264}\n"
],
[
"# Storing results in a dictionary\nfrom qiskit.transpiler import PassManager\nfrom qiskit.transpiler.passes import Unroller\n# Unroller transpile our circuit into CNOTs and U gates\npass_ = Unroller(['u', 'cx'])\npm = PassManager(pass_)\nansatz_tp = pm.run(ansatz)\ncnots = ansatz_tp.count_ops()['cx']\nscore = cnots\naccuracy_threshold = 4.0 # in mHa\nenergy = result.optimal_value\n\n# if ansatz_type == \"TwoLocal\":\nresult_dict = {\n 'optimizer': optimizer.__class__.__name__,\n 'mapping': qubit_converter.mapper.__class__.__name__,\n 'ansatz': ansatz.__class__.__name__,\n 'rotation blocks': rotation_blocks,\n 'entanglement_blocks': entanglement_blocks,\n 'entanglement': entanglement,\n 'repetitions': repetitions,\n 'skip_final_rotation_layer': skip_final_rotation_layer,\n 'energy (Ha)': energy,\n 'error (mHa)': (energy-exact_energy)*1000,\n 'pass': (energy-exact_energy)*1000 <= accuracy_threshold,\n '# of parameters': len(result.optimal_point),\n 'final parameters': result.optimal_point,\n '# of evaluations': result.optimizer_evals,\n 'optimizer time': result.optimizer_time,\n '# of qubits': int(qubit_op.num_qubits),\n '# of CNOTs': cnots,\n 'score': score}",
"_____no_output_____"
],
[
"# Plotting the results\n\nimport matplotlib.pyplot as plt\n\nfig, ax = plt.subplots(1, 1, figsize=(19.20, 10.80))\n\nplt.rc('font', size=14)\nplt.rc('axes', labelsize=14)\nplt.rc('xtick', labelsize=14) \nplt.rc('ytick', labelsize=14)\nplt.rc('legend', fontsize=14)\n\n# ax.set_facecolor(\"#293952\")\nax.set_xlabel('Iterations')\nax.set_ylabel('Energy (Eh)')\nax.grid()\n\nfig.text(0.7, 0.75, f'VQE Energy: {result.optimal_value:.4f} Eh\\nExact Energy: {exact_energy:.4f} Eh\\nScore: {score:.0f}')\n\nplt.title(f\"Ground State Energy of LiH using RY VQE Ansatz\\nOptimizer: {result_dict['optimizer']} \\n Mapper: {result_dict['mapping']}\\nVariational Form: {result_dict['ansatz']} - RY\")\n\nax.plot(counts, values)\nax.axhline(exact_energy, linestyle='--')\n\n# fig_title = f\"\\\n# {result_dict['optimizer']}-\\\n# {result_dict['mapping']}-\\\n# {result_dict['ansatz']}-\\\n# Energy({result_dict['energy (Ha)']:.3f})-\\\n# Score({result_dict['score']:.0f})\\\n# .png\"\n\nfig.savefig(\"ry_vqe_lih_fig\", dpi=300)\n\n\n# Displaying and saving the data\n\nimport pandas as pd\n\nresult_df = pd.DataFrame.from_dict([result_dict])\nresult_df[['optimizer','ansatz', '# of qubits', 'error (mHa)', 'pass', 'score','# of parameters','rotation blocks', 'entanglement_blocks',\n\n 'entanglement', 'repetitions']]\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
cb318173c38edbfc5435a4ee76c63b6357399eac | 63,410 | ipynb | Jupyter Notebook | ai-platform-unified/notebooks/unofficial/gapic/automl/showcase_automl_text_sentiment_analysis_online.ipynb | yinghsienwu/ai-platform-samples | 8bdca3099138dfbcf83d8ac6e0bf5f0c9ac7349b | [
"Apache-2.0"
] | null | null | null | ai-platform-unified/notebooks/unofficial/gapic/automl/showcase_automl_text_sentiment_analysis_online.ipynb | yinghsienwu/ai-platform-samples | 8bdca3099138dfbcf83d8ac6e0bf5f0c9ac7349b | [
"Apache-2.0"
] | null | null | null | ai-platform-unified/notebooks/unofficial/gapic/automl/showcase_automl_text_sentiment_analysis_online.ipynb | yinghsienwu/ai-platform-samples | 8bdca3099138dfbcf83d8ac6e0bf5f0c9ac7349b | [
"Apache-2.0"
] | null | null | null | 40.673509 | 503 | 0.560101 | [
[
[
"# Copyright 2020 Google LLC\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
]
],
[
[
"# AI Platform (Unified) client library: AutoML text sentiment analysis model for online prediction\n\n<table align=\"left\">\n <td>\n <a href=\"https://colab.research.google.com/github/GoogleCloudPlatform/ai-platform-samples/blob/master/ai-platform-unified/showcase_automl_text_sentiment_analysis_online.ipynb\">\n <img src=\"https://cloud.google.com/ml-engine/images/colab-logo-32px.png\" alt=\"Colab logo\"> Run in Colab\n </a>\n </td>\n <td>\n <a href=\"https://github.com/GoogleCloudPlatform/ai-platform-samples/blob/master/ai-platform-unified/showcase_automl_text_sentiment_analysis_online.ipynb\">\n <img src=\"https://cloud.google.com/ml-engine/images/github-logo-32px.png\" alt=\"GitHub logo\">\n View on GitHub\n </a>\n </td>\n</table>\n<br/><br/><br/>",
"_____no_output_____"
],
[
"## Overview\n\n\nThis tutorial demonstrates how to use the AI Platform (Unified) Python client library to create text sentiment analysis models and do online prediction using Google Cloud's [AutoML](https://cloud.google.com/ai-platform-unified/docs/start/automl-users).",
"_____no_output_____"
],
[
"### Dataset\n\nThe dataset used for this tutorial is the [Crowdflower Claritin-Twitter dataset](https://data.world/crowdflower/claritin-twitter) from [data.world Datasets](https://data.world). The version of the dataset you will use in this tutorial is stored in a public Cloud Storage bucket.",
"_____no_output_____"
],
[
"### Objective\n\nIn this tutorial, you create an AutoML text sentiment analysis model and deploy for online prediction from a Python script using the AI Platform (Unified) client library. You can alternatively create and deploy models using the `gcloud` command-line tool or online using the Google Cloud Console.\n\nThe steps performed include:\n\n- Create a AI Platform (Unified) `Dataset` resource.\n- Train the model.\n- View the model evaluation.\n- Deploy the `Model` resource to a serving `Endpoint` resource.\n- Make a prediction.\n- Undeploy the `Model`.",
"_____no_output_____"
],
[
"### Costs\n\nThis tutorial uses billable components of Google Cloud (GCP):\n\n* AI Platform (Unified)\n* Cloud Storage\n\nLearn about [AI Platform (Unified)\npricing](https://cloud.google.com/ai-platform-unified/pricing) and [Cloud Storage\npricing](https://cloud.google.com/storage/pricing), and use the [Pricing\nCalculator](https://cloud.google.com/products/calculator/)\nto generate a cost estimate based on your projected usage.",
"_____no_output_____"
],
[
"## Installation\n\nInstall the latest version of AI Platform (Unified) client library.",
"_____no_output_____"
]
],
[
[
"import sys\n\nif \"google.colab\" in sys.modules:\n USER_FLAG = \"\"\nelse:\n USER_FLAG = \"--user\"\n\n! pip3 install -U google-cloud-aiplatform $USER_FLAG",
"_____no_output_____"
]
],
[
[
"Install the latest GA version of *google-cloud-storage* library as well.",
"_____no_output_____"
]
],
[
[
"! pip3 install -U google-cloud-storage $USER_FLAG",
"_____no_output_____"
]
],
[
[
"### Restart the kernel\n\nOnce you've installed the AI Platform (Unified) client library and Google *cloud-storage*, you need to restart the notebook kernel so it can find the packages.",
"_____no_output_____"
]
],
[
[
"import os\n\nif not os.getenv(\"IS_TESTING\"):\n # Automatically restart kernel after installs\n import IPython\n\n app = IPython.Application.instance()\n app.kernel.do_shutdown(True)",
"_____no_output_____"
]
],
[
[
"## Before you begin\n\n### GPU runtime\n\n*Make sure you're running this notebook in a GPU runtime if you have that option. In Colab, select* **Runtime > Change Runtime Type > GPU**\n\n### Set up your Google Cloud project\n\n**The following steps are required, regardless of your notebook environment.**\n\n1. [Select or create a Google Cloud project](https://console.cloud.google.com/cloud-resource-manager). When you first create an account, you get a $300 free credit towards your compute/storage costs.\n\n2. [Make sure that billing is enabled for your project.](https://cloud.google.com/billing/docs/how-to/modify-project)\n\n3. [Enable the AI Platform (Unified) APIs and Compute Engine APIs.](https://console.cloud.google.com/flows/enableapi?apiid=ml.googleapis.com,compute_component)\n\n4. [The Google Cloud SDK](https://cloud.google.com/sdk) is already installed in AI Platform (Unified) Notebooks.\n\n5. Enter your project ID in the cell below. Then run the cell to make sure the\nCloud SDK uses the right project for all the commands in this notebook.\n\n**Note**: Jupyter runs lines prefixed with `!` as shell commands, and it interpolates Python variables prefixed with `$` into these commands.",
"_____no_output_____"
]
],
[
[
"PROJECT_ID = \"[your-project-id]\" # @param {type:\"string\"}",
"_____no_output_____"
],
[
"if PROJECT_ID == \"\" or PROJECT_ID is None or PROJECT_ID == \"[your-project-id]\":\n # Get your GCP project id from gcloud\n shell_output = !gcloud config list --format 'value(core.project)' 2>/dev/null\n PROJECT_ID = shell_output[0]\n print(\"Project ID:\", PROJECT_ID)",
"_____no_output_____"
],
[
"! gcloud config set project $PROJECT_ID",
"_____no_output_____"
]
],
[
[
"#### Region\n\nYou can also change the `REGION` variable, which is used for operations\nthroughout the rest of this notebook. Below are regions supported for AI Platform (Unified). We recommend that you choose the region closest to you.\n\n- Americas: `us-central1`\n- Europe: `europe-west4`\n- Asia Pacific: `asia-east1`\n\nYou may not use a multi-regional bucket for training with AI Platform (Unified). Not all regions provide support for all AI Platform (Unified) services. For the latest support per region, see the [AI Platform (Unified) locations documentation](https://cloud.google.com/ai-platform-unified/docs/general/locations)",
"_____no_output_____"
]
],
[
[
"REGION = \"us-central1\" # @param {type: \"string\"}",
"_____no_output_____"
]
],
[
[
"#### Timestamp\n\nIf you are in a live tutorial session, you might be using a shared test account or project. To avoid name collisions between users on resources created, you create a timestamp for each instance session, and append onto the name of resources which will be created in this tutorial.",
"_____no_output_____"
]
],
[
[
"from datetime import datetime\n\nTIMESTAMP = datetime.now().strftime(\"%Y%m%d%H%M%S\")",
"_____no_output_____"
]
],
[
[
"### Authenticate your Google Cloud account\n\n**If you are using AI Platform (Unified) Notebooks**, your environment is already authenticated. Skip this step.\n\n**If you are using Colab**, run the cell below and follow the instructions when prompted to authenticate your account via oAuth.\n\n**Otherwise**, follow these steps:\n\nIn the Cloud Console, go to the [Create service account key](https://console.cloud.google.com/apis/credentials/serviceaccountkey) page.\n\n**Click Create service account**.\n\nIn the **Service account name** field, enter a name, and click **Create**.\n\nIn the **Grant this service account access to project** section, click the Role drop-down list. Type \"AI Platform (Unified)\" into the filter box, and select **AI Platform (Unified) Administrator**. Type \"Storage Object Admin\" into the filter box, and select **Storage Object Admin**.\n\nClick Create. A JSON file that contains your key downloads to your local environment.\n\nEnter the path to your service account key as the GOOGLE_APPLICATION_CREDENTIALS variable in the cell below and run the cell.",
"_____no_output_____"
]
],
[
[
"import os\nimport sys\n\n# If you are running this notebook in Colab, run this cell and follow the\n# instructions to authenticate your GCP account. This provides access to your\n# Cloud Storage bucket and lets you submit training jobs and prediction\n# requests.\n\n# If on AI Platform, then don't execute this code\nif not os.path.exists(\"/opt/deeplearning/metadata/env_version\"):\n if \"google.colab\" in sys.modules:\n from google.colab import auth as google_auth\n\n google_auth.authenticate_user()\n\n # If you are running this notebook locally, replace the string below with the\n # path to your service account key and run this cell to authenticate your GCP\n # account.\n elif not os.getenv(\"IS_TESTING\"):\n %env GOOGLE_APPLICATION_CREDENTIALS ''",
"_____no_output_____"
]
],
[
[
"### Set up variables\n\nNext, set up some variables used throughout the tutorial.\n### Import libraries and define constants",
"_____no_output_____"
],
[
"#### Import AI Platform (Unified) client library\n\nImport the AI Platform (Unified) client library into our Python environment.",
"_____no_output_____"
]
],
[
[
"import os\nimport sys\nimport time\n\nimport google.cloud.aiplatform_v1 as aip\nfrom google.protobuf import json_format\nfrom google.protobuf.json_format import MessageToJson, ParseDict\nfrom google.protobuf.struct_pb2 import Struct, Value",
"_____no_output_____"
]
],
[
[
"#### AI Platform (Unified) constants\n\nSetup up the following constants for AI Platform (Unified):\n\n- `API_ENDPOINT`: The AI Platform (Unified) API service endpoint for dataset, model, job, pipeline and endpoint services.\n- `PARENT`: The AI Platform (Unified) location root path for dataset, model, job, pipeline and endpoint resources.",
"_____no_output_____"
]
],
[
[
"# API service endpoint\nAPI_ENDPOINT = \"{}-aiplatform.googleapis.com\".format(REGION)\n\n# AI Platform (Unified) location root path for your dataset, model and endpoint resources\nPARENT = \"projects/\" + PROJECT_ID + \"/locations/\" + REGION",
"_____no_output_____"
]
],
[
[
"#### AutoML constants\n\nSet constants unique to AutoML datasets and training:\n\n- Dataset Schemas: Tells the `Dataset` resource service which type of dataset it is.\n- Data Labeling (Annotations) Schemas: Tells the `Dataset` resource service how the data is labeled (annotated).\n- Dataset Training Schemas: Tells the `Pipeline` resource service the task (e.g., classification) to train the model for.",
"_____no_output_____"
]
],
[
[
"# Text Dataset type\nDATA_SCHEMA = \"gs://google-cloud-aiplatform/schema/dataset/metadata/text_1.0.0.yaml\"\n# Text Labeling type\nLABEL_SCHEMA = \"gs://google-cloud-aiplatform/schema/dataset/ioformat/text_sentiment_io_format_1.0.0.yaml\"\n# Text Training task\nTRAINING_SCHEMA = \"gs://google-cloud-aiplatform/schema/trainingjob/definition/automl_text_sentiment_1.0.0.yaml\"",
"_____no_output_____"
]
],
[
[
"# Tutorial\n\nNow you are ready to start creating your own AutoML text sentiment analysis model.",
"_____no_output_____"
],
[
"## Set up clients\n\nThe AI Platform (Unified) client library works as a client/server model. On your side (the Python script) you will create a client that sends requests and receives responses from the AI Platform (Unified) server.\n\nYou will use different clients in this tutorial for different steps in the workflow. So set them all up upfront.\n\n- Dataset Service for `Dataset` resources.\n- Model Service for `Model` resources.\n- Pipeline Service for training.\n- Endpoint Service for deployment.\n- Prediction Service for serving.",
"_____no_output_____"
]
],
[
[
"# client options same for all services\nclient_options = {\"api_endpoint\": API_ENDPOINT}\n\n\ndef create_dataset_client():\n client = aip.DatasetServiceClient(client_options=client_options)\n return client\n\n\ndef create_model_client():\n client = aip.ModelServiceClient(client_options=client_options)\n return client\n\n\ndef create_pipeline_client():\n client = aip.PipelineServiceClient(client_options=client_options)\n return client\n\n\ndef create_endpoint_client():\n client = aip.EndpointServiceClient(client_options=client_options)\n return client\n\n\ndef create_prediction_client():\n client = aip.PredictionServiceClient(client_options=client_options)\n return client\n\n\nclients = {}\nclients[\"dataset\"] = create_dataset_client()\nclients[\"model\"] = create_model_client()\nclients[\"pipeline\"] = create_pipeline_client()\nclients[\"endpoint\"] = create_endpoint_client()\nclients[\"prediction\"] = create_prediction_client()\n\nfor client in clients.items():\n print(client)",
"_____no_output_____"
]
],
[
[
"## Dataset\n\nNow that your clients are ready, your first step in training a model is to create a managed dataset instance, and then upload your labeled data to it.\n\n### Create `Dataset` resource instance\n\nUse the helper function `create_dataset` to create the instance of a `Dataset` resource. This function does the following:\n\n1. Uses the dataset client service.\n2. Creates an AI Platform (Unified) `Dataset` resource (`aip.Dataset`), with the following parameters:\n - `display_name`: The human-readable name you choose to give it.\n - `metadata_schema_uri`: The schema for the dataset type.\n3. Calls the client dataset service method `create_dataset`, with the following parameters:\n - `parent`: The AI Platform (Unified) location root path for your `Database`, `Model` and `Endpoint` resources.\n - `dataset`: The AI Platform (Unified) dataset object instance you created.\n4. The method returns an `operation` object.\n\nAn `operation` object is how AI Platform (Unified) handles asynchronous calls for long running operations. While this step usually goes fast, when you first use it in your project, there is a longer delay due to provisioning.\n\nYou can use the `operation` object to get status on the operation (e.g., create `Dataset` resource) or to cancel the operation, by invoking an operation method:\n\n| Method | Description |\n| ----------- | ----------- |\n| result() | Waits for the operation to complete and returns a result object in JSON format. |\n| running() | Returns True/False on whether the operation is still running. |\n| done() | Returns True/False on whether the operation is completed. |\n| canceled() | Returns True/False on whether the operation was canceled. |\n| cancel() | Cancels the operation (this may take up to 30 seconds). |",
"_____no_output_____"
]
],
[
[
"TIMEOUT = 90\n\n\ndef create_dataset(name, schema, labels=None, timeout=TIMEOUT):\n start_time = time.time()\n try:\n dataset = aip.Dataset(\n display_name=name, metadata_schema_uri=schema, labels=labels\n )\n\n operation = clients[\"dataset\"].create_dataset(parent=PARENT, dataset=dataset)\n print(\"Long running operation:\", operation.operation.name)\n result = operation.result(timeout=TIMEOUT)\n print(\"time:\", time.time() - start_time)\n print(\"response\")\n print(\" name:\", result.name)\n print(\" display_name:\", result.display_name)\n print(\" metadata_schema_uri:\", result.metadata_schema_uri)\n print(\" metadata:\", dict(result.metadata))\n print(\" create_time:\", result.create_time)\n print(\" update_time:\", result.update_time)\n print(\" etag:\", result.etag)\n print(\" labels:\", dict(result.labels))\n return result\n except Exception as e:\n print(\"exception:\", e)\n return None\n\n\nresult = create_dataset(\"claritin-\" + TIMESTAMP, DATA_SCHEMA)",
"_____no_output_____"
]
],
[
[
"Now save the unique dataset identifier for the `Dataset` resource instance you created.",
"_____no_output_____"
]
],
[
[
"# The full unique ID for the dataset\ndataset_id = result.name\n# The short numeric ID for the dataset\ndataset_short_id = dataset_id.split(\"/\")[-1]\n\nprint(dataset_id)",
"_____no_output_____"
]
],
[
[
"### Data preparation\n\nThe AI Platform (Unified) `Dataset` resource for text has a couple of requirements for your text data.\n\n- Text examples must be stored in a CSV or JSONL file.",
"_____no_output_____"
],
[
"#### CSV\n\nFor text sentiment analysis, the CSV file has a few requirements:\n\n- No heading.\n- First column is the text example or Cloud Storage path to text file.\n- Second column the label (i.e., sentiment).\n- Third column is the maximum sentiment value. For example, if the range is 0 to 3, then the maximum value is 3.",
"_____no_output_____"
],
[
"#### Location of Cloud Storage training data.\n\nNow set the variable `IMPORT_FILE` to the location of the CSV index file in Cloud Storage.",
"_____no_output_____"
]
],
[
[
"IMPORT_FILE = \"gs://cloud-samples-data/language/claritin.csv\"\nSENTIMENT_MAX = 4",
"_____no_output_____"
]
],
[
[
"#### Quick peek at your data\n\nYou will use a version of the Crowdflower Claritin-Twitter dataset that is stored in a public Cloud Storage bucket, using a CSV index file.\n\nStart by doing a quick peek at the data. You count the number of examples by counting the number of rows in the CSV index file (`wc -l`) and then peek at the first few rows.",
"_____no_output_____"
]
],
[
[
"if \"IMPORT_FILES\" in globals():\n FILE = IMPORT_FILES[0]\nelse:\n FILE = IMPORT_FILE\n\ncount = ! gsutil cat $FILE | wc -l\nprint(\"Number of Examples\", int(count[0]))\n\nprint(\"First 10 rows\")\n! gsutil cat $FILE | head",
"_____no_output_____"
]
],
[
[
"### Import data\n\nNow, import the data into your AI Platform (Unified) Dataset resource. Use this helper function `import_data` to import the data. The function does the following:\n\n- Uses the `Dataset` client.\n- Calls the client method `import_data`, with the following parameters:\n - `name`: The human readable name you give to the `Dataset` resource (e.g., claritin).\n - `import_configs`: The import configuration.\n\n- `import_configs`: A Python list containing a dictionary, with the key/value entries:\n - `gcs_sources`: A list of URIs to the paths of the one or more index files.\n - `import_schema_uri`: The schema identifying the labeling type.\n\nThe `import_data()` method returns a long running `operation` object. This will take a few minutes to complete. If you are in a live tutorial, this would be a good time to ask questions, or take a personal break.",
"_____no_output_____"
]
],
[
[
"def import_data(dataset, gcs_sources, schema):\n config = [{\"gcs_source\": {\"uris\": gcs_sources}, \"import_schema_uri\": schema}]\n print(\"dataset:\", dataset_id)\n start_time = time.time()\n try:\n operation = clients[\"dataset\"].import_data(\n name=dataset_id, import_configs=config\n )\n print(\"Long running operation:\", operation.operation.name)\n\n result = operation.result()\n print(\"result:\", result)\n print(\"time:\", int(time.time() - start_time), \"secs\")\n print(\"error:\", operation.exception())\n print(\"meta :\", operation.metadata)\n print(\n \"after: running:\",\n operation.running(),\n \"done:\",\n operation.done(),\n \"cancelled:\",\n operation.cancelled(),\n )\n\n return operation\n except Exception as e:\n print(\"exception:\", e)\n return None\n\n\nimport_data(dataset_id, [IMPORT_FILE], LABEL_SCHEMA)",
"_____no_output_____"
]
],
[
[
"## Train the model\n\nNow train an AutoML text sentiment analysis model using your AI Platform (Unified) `Dataset` resource. To train the model, do the following steps:\n\n1. Create an AI Platform (Unified) training pipeline for the `Dataset` resource.\n2. Execute the pipeline to start the training.",
"_____no_output_____"
],
[
"### Create a training pipeline\n\nYou may ask, what do we use a pipeline for? You typically use pipelines when the job (such as training) has multiple steps, generally in sequential order: do step A, do step B, etc. By putting the steps into a pipeline, we gain the benefits of:\n\n1. Being reusable for subsequent training jobs.\n2. Can be containerized and ran as a batch job.\n3. Can be distributed.\n4. All the steps are associated with the same pipeline job for tracking progress.\n\nUse this helper function `create_pipeline`, which takes the following parameters:\n\n- `pipeline_name`: A human readable name for the pipeline job.\n- `model_name`: A human readable name for the model.\n- `dataset`: The AI Platform (Unified) fully qualified dataset identifier.\n- `schema`: The dataset labeling (annotation) training schema.\n- `task`: A dictionary describing the requirements for the training job.\n\nThe helper function calls the `Pipeline` client service'smethod `create_pipeline`, which takes the following parameters:\n\n- `parent`: The AI Platform (Unified) location root path for your `Dataset`, `Model` and `Endpoint` resources.\n- `training_pipeline`: the full specification for the pipeline training job.\n\nLet's look now deeper into the *minimal* requirements for constructing a `training_pipeline` specification:\n\n- `display_name`: A human readable name for the pipeline job.\n- `training_task_definition`: The dataset labeling (annotation) training schema.\n- `training_task_inputs`: A dictionary describing the requirements for the training job.\n- `model_to_upload`: A human readable name for the model.\n- `input_data_config`: The dataset specification.\n - `dataset_id`: The AI Platform (Unified) dataset identifier only (non-fully qualified) -- this is the last part of the fully-qualified identifier.\n - `fraction_split`: If specified, the percentages of the dataset to use for training, test and validation. Otherwise, the percentages are automatically selected by AutoML.",
"_____no_output_____"
]
],
[
[
"def create_pipeline(pipeline_name, model_name, dataset, schema, task):\n\n dataset_id = dataset.split(\"/\")[-1]\n\n input_config = {\n \"dataset_id\": dataset_id,\n \"fraction_split\": {\n \"training_fraction\": 0.8,\n \"validation_fraction\": 0.1,\n \"test_fraction\": 0.1,\n },\n }\n\n training_pipeline = {\n \"display_name\": pipeline_name,\n \"training_task_definition\": schema,\n \"training_task_inputs\": task,\n \"input_data_config\": input_config,\n \"model_to_upload\": {\"display_name\": model_name},\n }\n\n try:\n pipeline = clients[\"pipeline\"].create_training_pipeline(\n parent=PARENT, training_pipeline=training_pipeline\n )\n print(pipeline)\n except Exception as e:\n print(\"exception:\", e)\n return None\n return pipeline",
"_____no_output_____"
]
],
[
[
"### Construct the task requirements\n\nNext, construct the task requirements. Unlike other parameters which take a Python (JSON-like) dictionary, the `task` field takes a Google protobuf Struct, which is very similar to a Python dictionary. Use the `json_format.ParseDict` method for the conversion.\n\nThe minimal fields we need to specify are:\n\n- `sentiment_max`: The maximum value for the sentiment (e.g., 4).\n\nFinally, create the pipeline by calling the helper function `create_pipeline`, which returns an instance of a training pipeline object.",
"_____no_output_____"
]
],
[
[
"PIPE_NAME = \"claritin_pipe-\" + TIMESTAMP\nMODEL_NAME = \"claritin_model-\" + TIMESTAMP\n\ntask = json_format.ParseDict(\n {\n \"sentiment_max\": SENTIMENT_MAX,\n },\n Value(),\n)\n\nresponse = create_pipeline(PIPE_NAME, MODEL_NAME, dataset_id, TRAINING_SCHEMA, task)",
"_____no_output_____"
]
],
[
[
"Now save the unique identifier of the training pipeline you created.",
"_____no_output_____"
]
],
[
[
"# The full unique ID for the pipeline\npipeline_id = response.name\n# The short numeric ID for the pipeline\npipeline_short_id = pipeline_id.split(\"/\")[-1]\n\nprint(pipeline_id)",
"_____no_output_____"
]
],
[
[
"### Get information on a training pipeline\n\nNow get pipeline information for just this training pipeline instance. The helper function gets the job information for just this job by calling the the job client service's `get_training_pipeline` method, with the following parameter:\n\n- `name`: The AI Platform (Unified) fully qualified pipeline identifier.\n\nWhen the model is done training, the pipeline state will be `PIPELINE_STATE_SUCCEEDED`.",
"_____no_output_____"
]
],
[
[
"def get_training_pipeline(name, silent=False):\n response = clients[\"pipeline\"].get_training_pipeline(name=name)\n if silent:\n return response\n\n print(\"pipeline\")\n print(\" name:\", response.name)\n print(\" display_name:\", response.display_name)\n print(\" state:\", response.state)\n print(\" training_task_definition:\", response.training_task_definition)\n print(\" training_task_inputs:\", dict(response.training_task_inputs))\n print(\" create_time:\", response.create_time)\n print(\" start_time:\", response.start_time)\n print(\" end_time:\", response.end_time)\n print(\" update_time:\", response.update_time)\n print(\" labels:\", dict(response.labels))\n return response\n\n\nresponse = get_training_pipeline(pipeline_id)",
"_____no_output_____"
]
],
[
[
"# Deployment\n\nTraining the above model may take upwards of 180 minutes time.\n\nOnce your model is done training, you can calculate the actual time it took to train the model by subtracting `end_time` from `start_time`. For your model, you will need to know the fully qualified AI Platform (Unified) Model resource identifier, which the pipeline service assigned to it. You can get this from the returned pipeline instance as the field `model_to_deploy.name`.",
"_____no_output_____"
]
],
[
[
"while True:\n response = get_training_pipeline(pipeline_id, True)\n if response.state != aip.PipelineState.PIPELINE_STATE_SUCCEEDED:\n print(\"Training job has not completed:\", response.state)\n model_to_deploy_id = None\n if response.state == aip.PipelineState.PIPELINE_STATE_FAILED:\n raise Exception(\"Training Job Failed\")\n else:\n model_to_deploy = response.model_to_upload\n model_to_deploy_id = model_to_deploy.name\n print(\"Training Time:\", response.end_time - response.start_time)\n break\n time.sleep(60)\n\nprint(\"model to deploy:\", model_to_deploy_id)",
"_____no_output_____"
]
],
[
[
"## Model information\n\nNow that your model is trained, you can get some information on your model.",
"_____no_output_____"
],
[
"## Evaluate the Model resource\n\nNow find out how good the model service believes your model is. As part of training, some portion of the dataset was set aside as the test (holdout) data, which is used by the pipeline service to evaluate the model.",
"_____no_output_____"
],
[
"### List evaluations for all slices\n\nUse this helper function `list_model_evaluations`, which takes the following parameter:\n\n- `name`: The AI Platform (Unified) fully qualified model identifier for the `Model` resource.\n\nThis helper function uses the model client service's `list_model_evaluations` method, which takes the same parameter. The response object from the call is a list, where each element is an evaluation metric.\n\nFor each evaluation -- you probably only have one, we then print all the key names for each metric in the evaluation, and for a small set (`meanAbsoluteError` and `precision`) you will print the result.",
"_____no_output_____"
]
],
[
[
"def list_model_evaluations(name):\n response = clients[\"model\"].list_model_evaluations(parent=name)\n for evaluation in response:\n print(\"model_evaluation\")\n print(\" name:\", evaluation.name)\n print(\" metrics_schema_uri:\", evaluation.metrics_schema_uri)\n metrics = json_format.MessageToDict(evaluation._pb.metrics)\n for metric in metrics.keys():\n print(metric)\n print(\"meanAbsoluteError\", metrics[\"meanAbsoluteError\"])\n print(\"precision\", metrics[\"precision\"])\n\n return evaluation.name\n\n\nlast_evaluation = list_model_evaluations(model_to_deploy_id)",
"_____no_output_____"
]
],
[
[
"## Deploy the `Model` resource\n\nNow deploy the trained AI Platform (Unified) `Model` resource you created with AutoML. This requires two steps:\n\n1. Create an `Endpoint` resource for deploying the `Model` resource to.\n\n2. Deploy the `Model` resource to the `Endpoint` resource.",
"_____no_output_____"
],
[
"### Create an `Endpoint` resource\n\nUse this helper function `create_endpoint` to create an endpoint to deploy the model to for serving predictions, with the following parameter:\n\n- `display_name`: A human readable name for the `Endpoint` resource.\n\nThe helper function uses the endpoint client service's `create_endpoint` method, which takes the following parameter:\n\n- `display_name`: A human readable name for the `Endpoint` resource.\n\nCreating an `Endpoint` resource returns a long running operation, since it may take a few moments to provision the `Endpoint` resource for serving. You call `response.result()`, which is a synchronous call and will return when the Endpoint resource is ready. The helper function returns the AI Platform (Unified) fully qualified identifier for the `Endpoint` resource: `response.name`.",
"_____no_output_____"
]
],
[
[
"ENDPOINT_NAME = \"claritin_endpoint-\" + TIMESTAMP\n\n\ndef create_endpoint(display_name):\n endpoint = {\"display_name\": display_name}\n response = clients[\"endpoint\"].create_endpoint(parent=PARENT, endpoint=endpoint)\n print(\"Long running operation:\", response.operation.name)\n\n result = response.result(timeout=300)\n print(\"result\")\n print(\" name:\", result.name)\n print(\" display_name:\", result.display_name)\n print(\" description:\", result.description)\n print(\" labels:\", result.labels)\n print(\" create_time:\", result.create_time)\n print(\" update_time:\", result.update_time)\n return result\n\n\nresult = create_endpoint(ENDPOINT_NAME)",
"_____no_output_____"
]
],
[
[
"Now get the unique identifier for the `Endpoint` resource you created.",
"_____no_output_____"
]
],
[
[
"# The full unique ID for the endpoint\nendpoint_id = result.name\n# The short numeric ID for the endpoint\nendpoint_short_id = endpoint_id.split(\"/\")[-1]\n\nprint(endpoint_id)",
"_____no_output_____"
]
],
[
[
"### Compute instance scaling\n\nYou have several choices on scaling the compute instances for handling your online prediction requests:\n\n- Single Instance: The online prediction requests are processed on a single compute instance.\n - Set the minimum (`MIN_NODES`) and maximum (`MAX_NODES`) number of compute instances to one.\n\n- Manual Scaling: The online prediction requests are split across a fixed number of compute instances that you manually specified.\n - Set the minimum (`MIN_NODES`) and maximum (`MAX_NODES`) number of compute instances to the same number of nodes. When a model is first deployed to the instance, the fixed number of compute instances are provisioned and online prediction requests are evenly distributed across them.\n\n- Auto Scaling: The online prediction requests are split across a scaleable number of compute instances.\n - Set the minimum (`MIN_NODES`) number of compute instances to provision when a model is first deployed and to de-provision, and set the maximum (`MAX_NODES) number of compute instances to provision, depending on load conditions.\n\nThe minimum number of compute instances corresponds to the field `min_replica_count` and the maximum number of compute instances corresponds to the field `max_replica_count`, in your subsequent deployment request.",
"_____no_output_____"
]
],
[
[
"MIN_NODES = 1\nMAX_NODES = 1",
"_____no_output_____"
]
],
[
[
"### Deploy `Model` resource to the `Endpoint` resource\n\nUse this helper function `deploy_model` to deploy the `Model` resource to the `Endpoint` resource you created for serving predictions, with the following parameters:\n\n- `model`: The AI Platform (Unified) fully qualified model identifier of the model to upload (deploy) from the training pipeline.\n- `deploy_model_display_name`: A human readable name for the deployed model.\n- `endpoint`: The AI Platform (Unified) fully qualified endpoint identifier to deploy the model to.\n\nThe helper function calls the `Endpoint` client service's method `deploy_model`, which takes the following parameters:\n\n- `endpoint`: The AI Platform (Unified) fully qualified `Endpoint` resource identifier to deploy the `Model` resource to.\n- `deployed_model`: The requirements specification for deploying the model.\n- `traffic_split`: Percent of traffic at the endpoint that goes to this model, which is specified as a dictionary of one or more key/value pairs.\n - If only one model, then specify as **{ \"0\": 100 }**, where \"0\" refers to this model being uploaded and 100 means 100% of the traffic.\n - If there are existing models on the endpoint, for which the traffic will be split, then use `model_id` to specify as **{ \"0\": percent, model_id: percent, ... }**, where `model_id` is the model id of an existing model to the deployed endpoint. The percents must add up to 100.\n\nLet's now dive deeper into the `deployed_model` parameter. This parameter is specified as a Python dictionary with the minimum required fields:\n\n- `model`: The AI Platform (Unified) fully qualified model identifier of the (upload) model to deploy.\n- `display_name`: A human readable name for the deployed model.\n- `disable_container_logging`: This disables logging of container events, such as execution failures (default is container logging is enabled). Container logging is typically enabled when debugging the deployment and then disabled when deployed for production.\n- `automatic_resources`: This refers to how many redundant compute instances (replicas). For this example, we set it to one (no replication).\n\n#### Traffic Split\n\nLet's now dive deeper into the `traffic_split` parameter. This parameter is specified as a Python dictionary. This might at first be a tad bit confusing. Let me explain, you can deploy more than one instance of your model to an endpoint, and then set how much (percent) goes to each instance.\n\nWhy would you do that? Perhaps you already have a previous version deployed in production -- let's call that v1. You got better model evaluation on v2, but you don't know for certain that it is really better until you deploy to production. So in the case of traffic split, you might want to deploy v2 to the same endpoint as v1, but it only get's say 10% of the traffic. That way, you can monitor how well it does without disrupting the majority of users -- until you make a final decision.\n\n#### Response\n\nThe method returns a long running operation `response`. We will wait sychronously for the operation to complete by calling the `response.result()`, which will block until the model is deployed. If this is the first time a model is deployed to the endpoint, it may take a few additional minutes to complete provisioning of resources.",
"_____no_output_____"
]
],
[
[
"DEPLOYED_NAME = \"claritin_deployed-\" + TIMESTAMP\n\n\ndef deploy_model(\n model, deployed_model_display_name, endpoint, traffic_split={\"0\": 100}\n):\n\n deployed_model = {\n \"model\": model,\n \"display_name\": deployed_model_display_name,\n \"automatic_resources\": {\n \"min_replica_count\": MIN_NODES,\n \"max_replica_count\": MAX_NODES,\n },\n }\n\n response = clients[\"endpoint\"].deploy_model(\n endpoint=endpoint, deployed_model=deployed_model, traffic_split=traffic_split\n )\n\n print(\"Long running operation:\", response.operation.name)\n result = response.result()\n print(\"result\")\n deployed_model = result.deployed_model\n print(\" deployed_model\")\n print(\" id:\", deployed_model.id)\n print(\" model:\", deployed_model.model)\n print(\" display_name:\", deployed_model.display_name)\n print(\" create_time:\", deployed_model.create_time)\n\n return deployed_model.id\n\n\ndeployed_model_id = deploy_model(model_to_deploy_id, DEPLOYED_NAME, endpoint_id)",
"_____no_output_____"
]
],
[
[
"## Make a online prediction request\n\nNow do a online prediction to your deployed model.",
"_____no_output_____"
],
[
"### Get test item\n\nYou will use an arbitrary example out of the dataset as a test item. Don't be concerned that the example was likely used in training the model -- we just want to demonstrate how to make a prediction.",
"_____no_output_____"
]
],
[
[
"test_item = ! gsutil cat $IMPORT_FILE | head -n1\nif len(test_item[0]) == 3:\n _, test_item, test_label, max = str(test_item[0]).split(\",\")\nelse:\n test_item, test_label, max = str(test_item[0]).split(\",\")\n\nprint(test_item, test_label)",
"_____no_output_____"
]
],
[
[
"### Make a prediction\n\nNow you have a test item. Use this helper function `predict_item`, which takes the following parameters:\n\n- `filename`: The Cloud Storage path to the test item.\n- `endpoint`: The AI Platform (Unified) fully qualified identifier for the `Endpoint` resource where the `Model` resource was deployed.\n- `parameters_dict`: Additional filtering parameters for serving prediction results.\n\nThis function calls the prediction client service's `predict` method with the following parameters:\n\n- `endpoint`: The AI Platform (Unified) fully qualified identifier for the `Endpoint` resource where the `Model` resource was deployed.\n- `instances`: A list of instances (text files) to predict.\n- `parameters`: Additional filtering parameters for serving prediction results. *Note*, text models do not support additional parameters.\n\n#### Request\n\nThe format of each instance is:\n\n { 'content': text_item }\n\nSince the `predict()` method can take multiple items (instances), you send your single test item as a list of one test item. As a final step, you package the instances list into Google's protobuf format -- which is what you pass to the `predict()` method.\n\n#### Response\n\nThe `response` object returns a list, where each element in the list corresponds to the corresponding text in the request. You will see in the output for each prediction -- in our case there is just one:\n\n- The sentiment rating",
"_____no_output_____"
]
],
[
[
"def predict_item(data, endpoint, parameters_dict):\n\n parameters = json_format.ParseDict(parameters_dict, Value())\n\n # The format of each instance should conform to the deployed model's prediction input schema.\n instances_list = [{\"content\": data}]\n instances = [json_format.ParseDict(s, Value()) for s in instances_list]\n\n response = clients[\"prediction\"].predict(\n endpoint=endpoint, instances=instances, parameters=parameters\n )\n print(\"response\")\n print(\" deployed_model_id:\", response.deployed_model_id)\n predictions = response.predictions\n print(\"predictions\")\n for prediction in predictions:\n print(\" prediction:\", dict(prediction))\n return response\n\n\nresponse = predict_item(test_item, endpoint_id, None)",
"_____no_output_____"
]
],
[
[
"## Undeploy the `Model` resource\n\nNow undeploy your `Model` resource from the serving `Endpoint` resoure. Use this helper function `undeploy_model`, which takes the following parameters:\n\n- `deployed_model_id`: The model deployment identifier returned by the endpoint service when the `Model` resource was deployed to.\n- `endpoint`: The AI Platform (Unified) fully qualified identifier for the `Endpoint` resource where the `Model` is deployed to.\n\nThis function calls the endpoint client service's method `undeploy_model`, with the following parameters:\n\n- `deployed_model_id`: The model deployment identifier returned by the endpoint service when the `Model` resource was deployed.\n- `endpoint`: The AI Platform (Unified) fully qualified identifier for the `Endpoint` resource where the `Model` resource is deployed.\n- `traffic_split`: How to split traffic among the remaining deployed models on the `Endpoint` resource.\n\nSince this is the only deployed model on the `Endpoint` resource, you simply can leave `traffic_split` empty by setting it to {}.",
"_____no_output_____"
]
],
[
[
"def undeploy_model(deployed_model_id, endpoint):\n response = clients[\"endpoint\"].undeploy_model(\n endpoint=endpoint, deployed_model_id=deployed_model_id, traffic_split={}\n )\n print(response)\n\n\nundeploy_model(deployed_model_id, endpoint_id)",
"_____no_output_____"
]
],
[
[
"# Cleaning up\n\nTo clean up all GCP resources used in this project, you can [delete the GCP\nproject](https://cloud.google.com/resource-manager/docs/creating-managing-projects#shutting_down_projects) you used for the tutorial.\n\nOtherwise, you can delete the individual resources you created in this tutorial:\n\n- Dataset\n- Pipeline\n- Model\n- Endpoint\n- Batch Job\n- Custom Job\n- Hyperparameter Tuning Job\n- Cloud Storage Bucket",
"_____no_output_____"
]
],
[
[
"delete_dataset = True\ndelete_pipeline = True\ndelete_model = True\ndelete_endpoint = True\ndelete_batchjob = True\ndelete_customjob = True\ndelete_hptjob = True\ndelete_bucket = True\n\n# Delete the dataset using the AI Platform (Unified) fully qualified identifier for the dataset\ntry:\n if delete_dataset and \"dataset_id\" in globals():\n clients[\"dataset\"].delete_dataset(name=dataset_id)\nexcept Exception as e:\n print(e)\n\n# Delete the training pipeline using the AI Platform (Unified) fully qualified identifier for the pipeline\ntry:\n if delete_pipeline and \"pipeline_id\" in globals():\n clients[\"pipeline\"].delete_training_pipeline(name=pipeline_id)\nexcept Exception as e:\n print(e)\n\n# Delete the model using the AI Platform (Unified) fully qualified identifier for the model\ntry:\n if delete_model and \"model_to_deploy_id\" in globals():\n clients[\"model\"].delete_model(name=model_to_deploy_id)\nexcept Exception as e:\n print(e)\n\n# Delete the endpoint using the AI Platform (Unified) fully qualified identifier for the endpoint\ntry:\n if delete_endpoint and \"endpoint_id\" in globals():\n clients[\"endpoint\"].delete_endpoint(name=endpoint_id)\nexcept Exception as e:\n print(e)\n\n# Delete the batch job using the AI Platform (Unified) fully qualified identifier for the batch job\ntry:\n if delete_batchjob and \"batch_job_id\" in globals():\n clients[\"job\"].delete_batch_prediction_job(name=batch_job_id)\nexcept Exception as e:\n print(e)\n\n# Delete the custom job using the AI Platform (Unified) fully qualified identifier for the custom job\ntry:\n if delete_customjob and \"job_id\" in globals():\n clients[\"job\"].delete_custom_job(name=job_id)\nexcept Exception as e:\n print(e)\n\n# Delete the hyperparameter tuning job using the AI Platform (Unified) fully qualified identifier for the hyperparameter tuning job\ntry:\n if delete_hptjob and \"hpt_job_id\" in globals():\n clients[\"job\"].delete_hyperparameter_tuning_job(name=hpt_job_id)\nexcept Exception as e:\n print(e)\n\nif delete_bucket and \"BUCKET_NAME\" in globals():\n ! gsutil rm -r $BUCKET_NAME",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
cb318fb41e7ebdc9f047d66ffd5d08955f276a4a | 56,898 | ipynb | Jupyter Notebook | jupyter-book/training_models.ipynb | codingalzi/handson-ml3 | adbaef504bf94d55558c9ffb8249e5b4690b6c7b | [
"MIT"
] | null | null | null | jupyter-book/training_models.ipynb | codingalzi/handson-ml3 | adbaef504bf94d55558c9ffb8249e5b4690b6c7b | [
"MIT"
] | null | null | null | jupyter-book/training_models.ipynb | codingalzi/handson-ml3 | adbaef504bf94d55558c9ffb8249e5b4690b6c7b | [
"MIT"
] | null | null | null | 23.540753 | 210 | 0.480193 | [
[
[
"(ch:trainingModels)=\n# 모델 훈련",
"_____no_output_____"
],
[
"**감사의 글**\n\n자료를 공개한 저자 오렐리앙 제롱과 강의자료를 지원한 한빛아카데미에게 진심어린 감사를 전합니다.",
"_____no_output_____"
],
[
"**소스코드**\n\n본문 내용의 일부를 파이썬으로 구현한 내용은 \n[(구글코랩) 모델 훈련](https://colab.research.google.com/github/codingalzi/handson-ml3/blob/master/notebooks/code_training_models.ipynb)에서 \n확인할 수 있다.",
"_____no_output_____"
],
[
"**주요 내용**\n\n* 선형 회귀 모델 구현\n * 선형대수 활용\n * 경사하강법 활용\n* 경사하강법 종류\n * 배치 경사하강법\n * 미니배치 경사하강법\n * 확률적 경사하강법(SGD)\n* 다항 회귀: 비선형 회귀 모델\n* 학습 곡선: 과소, 과대 적합 감지\n* 모델 규제: 과대 적합 방지\n* 로지스틱 회귀와 소프트맥스 회귀: 분류 모델",
"_____no_output_____"
],
[
"**목표**\n\n모델 훈련의 기본 작동 과정과 원리를 살펴보며,\n이를 통해 다음 사항들에 대한 이해를 넓힌다.\n\n- 적정 모델 선택\n- 적정 훈련 알고리즘 선택\n- 적정 하이퍼파라미터 선택\n- 디버깅과 오차 분석\n- 신경망 구현 및 훈련 과정 이해",
"_____no_output_____"
],
[
"## 선형 회귀",
"_____no_output_____"
],
[
"**선형 회귀 예제: 1인당 GDP와 삶의 만족도**",
"_____no_output_____"
],
[
"{numref}`%s 절 <sec:model_based_learning>`에서 1인당 GDP와 삶의 만족도 사이의 \n관계를 다음 1차 함수로 표현할 수 있었다.\n\n$$(\\text{삶의만족도}) = \\theta_0 + \\theta_1\\cdot (\\text{1인당GDP})$$\n\n즉, 1인당 GDP가 주어지면 위 함수를 이용하여 삶의 만족도를 예측하였다.\n주어진 1인당 GDP를 **입력 특성**<font size=\"2\">input feature</font> $x$, \n예측된 삶의 만족도를 **예측값** $\\hat y$ 라 하면 다음 식으로 변환된다.\n\n$$\\hat y = \\theta_0 + \\theta_1\\cdot x_1$$\n\n절편 $\\theta_0$ 와 기울기 $\\theta_1$ 은 (선형) 모델의 **파라미터**<font size=\"2\">weight parameter</font>이다.\n머신러닝에서는 절편은 **편향**<font size=\"2\">bias</font>, \n기울기는 **가중치**<font size=\"2\">weight</font> 라 부른다.\n\n따라서 1인당 GDP와 삶의 만족도 사이의 선형 관계를 모델로 구현하려면\n적절한 하나의 편향과 하나의 가중치, 즉 총 2개의 파라미터를 결정해야 한다.",
"_____no_output_____"
],
[
"**선형 회귀 예제: 캘리포니아 주택 가격 예측**",
"_____no_output_____"
],
[
"반면에 {numref}`%s 장 <ch:end2end>`의 캘리포니아 주택 가격 예측 선형 회귀 모델은\n24개의 입력 특성을 사용하는 다음 함수를 이용한다.\n\n$$\\hat y = \\theta_0 + \\theta_1\\cdot x_1 + \\cdots + \\theta_{24}\\cdot x_{24}$$\n\n* $\\hat y$: 예측값\n* $x_i$: 구역의 $i$ 번째 특성값(위도, 경도, 중간소득, 가구당 인원 등등등)\n* $\\theta_0$: 편향\n* $\\theta_i$: $i$ 번째 특성에 대한 (가중치) 파라미터, 단 $i > 0$.\n\n따라서 캘리포니아의 구역별 중간 주택 가격을 예측하는 선형 회귀 모델을 구하려면 \n적절한 하나의 편향과 24개의 가중치,\n즉 총 25개의 파라미터를 결정해야 한다.",
"_____no_output_____"
],
[
"**선형 회귀 함수**",
"_____no_output_____"
],
[
"이를 일반화하면 다음과 같다.\n\n$$\\hat y = \\theta_0 + \\theta_1\\cdot x_1 + \\cdots + \\theta_{n}\\cdot x_{n}$$\n\n* $\\hat y$: 예측값\n* $n$: 특성 수\n* $x_i$: 구역의 $i$ 번째 특성값\n* $\\theta_0$: 편향\n* $\\theta_j$: $j$ 번째 특성에 대한 (가중치) 파라미터(단, $1 \\le j \\le n$)\n\n일반적으로 선형 회귀 모델을 구현하려면\n한 개의 편향과 $n$ 개의 가중치, 즉 총 $(1+n)$ 개의 파라미터를 결정해야 한다.",
"_____no_output_____"
],
[
"**벡터 표기법**\n\n예측값을 벡터의 **내적**<font size=\"2\">inner product</font>으로 표현할 수 있다.\n\n$$\n\\hat y\n= h_\\theta (\\mathbf{x})\n= \\mathbf{\\theta} \\cdot \\mathbf{x}\n$$\n\n* $h_\\theta(\\cdot)$: 예측 함수, 즉 모델의 `predict()` 메서드.\n* $\\mathbf{x} = (1, x_1, \\dots, x_n)$\n* $\\mathbf{\\theta} = (\\theta_0, \\theta_1, \\dots, \\theta_n)$",
"_____no_output_____"
],
[
"**2D 어레이 표기법**\n\n머신러닝에서는 훈련 샘플을 나타내는 입력 벡터와 파라미터 벡터를 일반적으로 아래 모양의 행렬로 나타낸다.\n\n$$\n\\mathbf{x}=\n\\begin{bmatrix}\n1 \\\\\nx_1 \\\\\n\\vdots \\\\\nx_n\n\\end{bmatrix},\n\\qquad\n\\mathbf{\\theta}=\n\\begin{bmatrix}\n\\theta_0\\\\\n\\theta_1 \\\\\n\\vdots \\\\\n\\theta_n\n\\end{bmatrix}\n$$\n\n따라서 예측값은 다음과 같이 행렬 연산으로 표기된다.\n단, $A^T$ 는 행렬 $A$의 전치행렬을 가리킨다.\n\n$$\n\\hat y\n= h_\\theta (\\mathbf{x})\n= \\mathbf{\\theta}^{T} \\mathbf{x}\n$$",
"_____no_output_____"
],
[
"**선형 회귀 모델의 행렬 연산 표기법**",
"_____no_output_____"
],
[
"$\\mathbf{X}$가 전체 입력 데이터셋, 즉 전체 훈련셋을 가리키는 (m, 1+n) 모양의 2D 어레이, 즉 행렬이라 하자.\n- $m$: 훈련셋의 크기.\n- $n$: 특성 수\n\n그러면 $\\mathbf{X}$ 는 다음과 같이 표현된다.\n단, $\\mathbf{x}_j^{(i)}$ 는 $i$-번째 입력 샘플의 $j$-번째 특성값을 가리킨다.\n\n$$\n\\mathbf{X}= \n\\begin{bmatrix} \n[1, \\mathbf{x}_1^{(1)}, \\dots, \\mathbf{x}_n^{(1)}] \\\\\n\\vdots \\\\\n[1, \\mathbf{x}_1^{(m)}, \\dots, \\mathbf{x}_n^{(m)}] \\\\\n\\end{bmatrix}\n$$",
"_____no_output_____"
],
[
"결론적으로 모든 입력값에 대한 예측값을 하나의 행렬식으로 표현하면 다음과 같다.",
"_____no_output_____"
],
[
"$$\n\\begin{bmatrix}\n\\hat y_1 \\\\\n\\vdots \\\\\n\\hat y_m\n\\end{bmatrix}\n= \n\\begin{bmatrix} \n[1, \\mathbf{x}_1^{(1)}, \\dots, \\mathbf{x}_n^{(1)}] \\\\\n\\vdots \\\\\n[1, \\mathbf{x}_1^{(m)}, \\dots, \\mathbf{x}_n^{(m)}] \\\\\n\\end{bmatrix}\n\\,\\, \n\\begin{bmatrix}\n\\theta_0\\\\\n\\theta_1 \\\\\n\\vdots \\\\\n\\theta_n\n\\end{bmatrix}\n$$",
"_____no_output_____"
],
[
"간략하게 줄이면 다음과 같다.",
"_____no_output_____"
],
[
"$$\n\\hat{\\mathbf y} = \\mathbf{X}\\, \\mathbf{\\theta}\n$$",
"_____no_output_____"
],
[
"위 식에 사용된 기호들의 의미와 어레이 모양은 다음과 같다.\n\n| 데이터 | 어레이 기호 | 어레이 모양(shape) | \n|:-------------:|:-------------:|:---------------:|\n| 예측값 | $\\hat{\\mathbf y}$ | $(m, 1)$ |\n| 훈련셋 | $\\mathbf X$ | $(m, 1+n)$ |\n| 파라미터 | $\\mathbf{\\theta}$ | $(1+n, 1)$ |",
"_____no_output_____"
],
[
"**비용함수: 평균 제곱 오차(MSE)**",
"_____no_output_____"
],
[
"회귀 모델은 훈련 중에 **평균 제곱 오차**<font size=\"2\">mean squared error</font>(MSE)를 이용하여\n성능을 평가한다.",
"_____no_output_____"
],
[
"$$\n\\mathrm{MSE}(\\mathbf{\\theta}) := \\mathrm{MSE}(\\mathbf X, h_{\\mathbf{\\theta}}) = \n\\frac 1 m \\sum_{i=1}^{m} \\big(\\mathbf{\\theta}^{T}\\, \\mathbf{x}^{(i)} - y^{(i)}\\big)^2\n$$",
"_____no_output_____"
],
[
"최종 목표는 훈련셋이 주어졌을 때 $\\mathrm{MSE}(\\mathbf{\\theta})$가 최소가 되도록 하는 \n$\\mathbf{\\theta}$를 찾는 것이다.\n\n* 방식 1: 정규방정식 또는 특이값 분해(SVD) 활용\n * 드물지만 수학적으로 비용함수를 최소화하는 $\\mathbf{\\theta}$ 값을 직접 계산할 수 있는 경우 활용\n * 계산복잡도가 $O(n^2)$ 이상인 행렬 연산을 수행해야 함. \n * 따라서 특성 수($n$)이 큰 경우 메모리 관리 및 시간복잡도 문제때문에 비효율적임.\n\n* 방식 2: 경사하강법\n * 특성 수가 매우 크거나 훈련 샘플이 너무 많아 메모리에 한꺼번에 담을 수 없을 때 적합\n * 일반적으로 선형 회귀 모델 훈련에 적용되는 기법",
"_____no_output_____"
],
[
"### 정규 방정식",
"_____no_output_____"
],
[
"비용함수를 최소화 하는 $\\theta$를 \n정규 방정식<font size=\"2\">normal equation</font>을 이용하여 \n아래와 같이 바로 계산할 수 있다.\n단, $\\mathbf{X}^T\\, \\mathbf{X}$ 의 역행렬이 존재해야 한다.\n\n$$\n\\hat{\\mathbf{\\theta}} = \n(\\mathbf{X}^T\\, \\mathbf{X})^{-1}\\, \\mathbf{X}^T\\, \\mathbf{y}\n$$",
"_____no_output_____"
],
[
"### `LinearRegression` 클래스",
"_____no_output_____"
],
[
"**SVD(특잇값 분해) 활용**\n\n그런데 행렬 연산과 역행렬 계산은 계산 복잡도가 $O(n^{2.4})$ 이상이며\n항상 역행렬 계산이 가능한 것도 아니다.\n반면에, **특잇값 분해**를 활용하여 얻어지는 \n**무어-펜로즈(Moore-Penrose) 유사 역행렬** $\\mathbf{X}^+$은 항상 존재하며\n계산 복잡도가 $O(n^2)$ 로 보다 빠른 계산을 지원한다.\n또한 다음이 성립한다.\n\n$$\n\\hat{\\mathbf{\\theta}} = \n\\mathbf{X}^+\\, \\mathbf{y}\n$$",
"_____no_output_____"
],
[
"**`LinearRegression` 모델**",
"_____no_output_____"
],
[
"사이킷런의 `LinearRegression` 모델은 특잇값 분해와 무어-펜로즈 유사 역행렬을 이용하여 \n최적의 $\\hat \\theta$ 를 계산한다.",
"_____no_output_____"
],
[
"(sec:gradient-descent)=\n## 경사하강법",
"_____no_output_____"
],
[
"훈련 세트를 이용한 훈련 과정 중에 가중치 파라미터를 조금씩 반복적으로 조정한다. \n이때 비용 함수의 크기를 줄이는 방향으로 조정한다.",
"_____no_output_____"
],
[
"**경사하강법**<font size=\"2\">gradient descent</font>(GD) 이해를 위해 다음 개념들을 충분히 이해하고 있어야 한다.",
"_____no_output_____"
],
[
"**최적 학습 모델**\n\n비용 함수를 최소화하는 또는 효용 함수를 최대화하는 파라미터를 사용하는 모델이며,\n최종적으로 훈련시킬 대상이다.",
"_____no_output_____"
],
[
"**파라미터<font size=\"2\">parameter</font>**\n\n선형 회귀 모델에 사용되는 편향과 가중치 파라미터처럼 모델 훈련중에 학습되는 파라미터를 가리킨다.",
"_____no_output_____"
],
[
"**비용 함수<font size=\"2\">cost function</font>**\n\n평균 제곱 오차(MSE)처럼 모델이 얼마나 나쁜가를 측정하는 함수다.",
"_____no_output_____"
],
[
"**전역 최솟값<font size=\"2\">global minimum</font>**\n\n비용 함수의 전역 최솟값이다. ",
"_____no_output_____"
],
[
"**비용 함수의 그레이디언트 벡터**\n\nMSE를 비용함수로 사용하는 경우 $\\textrm{MSE}(\\mathbf{\\theta})$ 함수의 $\\mathbf{\\mathbf{\\theta}}$ 에 \n대한 그레이디언트<font size=\"2\">gradient</font> 벡터를 사용한다.\n\n$$\n\\nabla_\\mathbf{\\theta} \\textrm{MSE}(\\mathbf{\\theta}) =\n\\begin{bmatrix}\n \\frac{\\partial}{\\partial \\mathbf{\\theta}_0} \\textrm{MSE}(\\mathbf{\\theta}) \\\\\n \\frac{\\partial}{\\partial \\mathbf{\\theta}_1} \\textrm{MSE}(\\mathbf{\\theta}) \\\\\n \\vdots \\\\\n \\frac{\\partial}{\\partial \\mathbf{\\theta}_n} \\textrm{MSE}(\\mathbf{\\theta})\n\\end{bmatrix}\n$$",
"_____no_output_____"
],
[
"**학습률($\\eta$)**\n\n훈련 과정에서의 비용함수의 파라미터($\\mathbf{\\theta}$)를 조정할 때 사용하는 조정 비율이다.",
"_____no_output_____"
],
[
"**에포크<font size=\"2\">epoch</font>**\n\n훈련셋에 포함된 모든 데이터를 대상으로 예측값을 계산하는 과정을 가리킨다.",
"_____no_output_____"
],
[
"**허용오차<font size=\"2\">tolerance</font>**\n\n비용함수의 값이 허용오차보다 작아지면 훈련을 종료시킨다.",
"_____no_output_____"
],
[
"**배치 크기<font size=\"2\">batch size</font>**\n\n파라미터를 업데이트하기 위해, 즉 그레이디언트 벡터를 계산하기 위해 사용되는 훈련 데이터의 개수이다.",
"_____no_output_____"
],
[
"**하이퍼파라미터<font size=\"2\">hyperparameter</font>**\n\n학습률, 에포크, 허용오차, 배치 크기 처럼 모델을 지정할 때 사용되는 값을 나타낸다.",
"_____no_output_____"
],
[
"### 선형 회귀 모델과 경사하강법",
"_____no_output_____"
],
[
"선형회귀 모델 파라미터를 조정하는 과정을 이용하여 경사하강법의 기본 아이디어를 설명한다.\n\n먼저 $\\mathrm{MSE}(\\mathbf{\\theta})$ 는 $\\mathbf{\\theta}$ 에 대한 2차 함수임에 주의한다.\n여기서는 $\\mathbf{\\theta}$ 가 하나의 파라미터로 구성되었다고 가정한다.\n따라서 $\\mathrm{MSE}(\\mathbf{\\theta})$의 그래프는 포물선이 된다.\n\n$$\n\\mathrm{MSE}(\\mathbf{\\theta}) =\n\\frac 1 m \\sum_{i=1}^{m} \\big(\\mathbf{\\theta}^{T}\\, \\mathbf{x}^{(i)} - y^{(i)}\\big)^2\n$$\n\n$\\mathrm{MSE}(\\mathbf{\\theta})$의 그레이디언트 벡터는 다음과 같다.\n\n$$\n\\nabla_\\theta \\textrm{MSE}(\\theta) = \\frac{2}{m}\\, \\mathbf{X}^T\\, (\\mathbf{X}\\, \\theta^T - \\mathbf y)\n$$",
"_____no_output_____"
],
[
"경사하강법은 다음 과정으로 이루어진다. \n\n1. $\\mathbf{\\theta}$를 임의의 값으로 지정한 후 훈련을 시작한다.\n\n1. 아래 단계를 $\\textrm{MSE}(\\theta)$ 가 허용오차보다 적게 작아지는 단계까지 반복한다.\n * 지정된 수의 훈련 샘플을 이용한 학습.\n * $\\mathrm{MSE}(\\mathbf{\\theta})$ 계산.\n * 이전 $\\mathbf{\\theta}$에서 $\\nabla_\\mathbf{\\theta} \\textrm{MSE}(\\mathbf{\\theta})$ 와\n 학습률 $\\eta$를 곱한 값 빼기.<br><br>\n\n $$\n \\theta^{(\\text{new})} = \\theta^{(\\text{old})}\\, -\\, \\eta\\cdot \\nabla_\\theta \\textrm{MSE}(\\theta^{(\\text{old})})\n $$",
"_____no_output_____"
],
[
"위 수식은 산에서 가장 경사가 급한 길을 따를 때 가장 빠르게 하산하는 원리와 동일하다.\n이유는 해당 지점에서 그레이디언트 벡터를 계산하면 정상으로 가는 가장 빠른 길을 안내할 것이기에\n그 반대방향으로 움직여야 하기 때문이다.",
"_____no_output_____"
],
[
":::{admonition} 벡터의 방향과 크기\n:class: info\n\n모든 벡터는 방향과 크기를 갖는다. \n\n<div align=\"center\"><img src=\"https://raw.githubusercontent.com/codingalzi/handson-ml3/master/jupyter-book/imgs/ch04/vector01.png\" width=\"200\"/></div>\n\n그레이디언트 벡터 또한 방향과 크기에 대한 정보를 제공하며, \n그레이디언트가 가리키는 방향의 __반대 방향__으로 움직이면 빠르게 전역 최솟값에 접근한다.\n\n이는 아래 그림이 표현하듯이 산에서 가장 경사가 급한 길을 따를 때 가장 빠르게 하산하는 원리와 동일하다.\n이유는 해당 지점에서 그레이디언트 벡터를 계산하면 정상으로 가는 가장 빠른 길을 안내할 것이기에\n그 반대방향으로 움직여야 하기 때문이다.\n\n아래 그림은 경사하강법을 담당하는 여러 알고리즘을 비교해서 보여준다.\n\n<table>\n <tr>\n <td style=\"padding:1px\">\n <figure>\n <img src=\"https://ruder.io/content/images/2016/09/contours_evaluation_optimizers.gif\" style=\"width:90%\" title=\"SGD without momentum\">\n <figcaption>SGD optimization on loss surface contours</figcaption>\n </figure>\n </td>\n <td style=\"padding:1px\">\n <figure>\n <img src=\"https://ruder.io/content/images/2016/09/saddle_point_evaluation_optimizers.gif\" style=\"width:90%\" title=\"SGD without momentum\">\n <figcaption>SGD optimization on saddle point</figcaption>\n </figure>\n </td> \n </tr>\n</table>\n\n**그림 출처:** [An overview of gradient descent optimization algorithms](https://ruder.io/optimizing-gradient-descent/index.html)\n:::",
"_____no_output_____"
],
[
"**학습률의 중요성**\n\n선형 회귀 모델은 적절할 학습률로 훈련될 경우 빠른 시간에 비용 함수의 최솟값에 도달한다.",
"_____no_output_____"
],
[
"<div align=\"center\"><img src=\"https://raw.githubusercontent.com/codingalzi/handson-ml3/master/jupyter-book/imgs/ch04/homl04-01.png\" width=\"500\"/></div>",
"_____no_output_____"
],
[
"반면에 학습률이 너무 작거나 크면 비용 함수의 전역 최솟값에 수렴하지 않을 수 있다.\n\n- 학습률이 너무 작은 경우: 비용 함수가 전역 최소값에 너무 느리게 수렴.",
"_____no_output_____"
],
[
"<div align=\"center\"><img src=\"https://raw.githubusercontent.com/codingalzi/handson-ml3/master/jupyter-book/imgs/ch04/homl04-02.png\" width=\"500\"/></div>",
"_____no_output_____"
],
[
"* 학습률이 너무 큰 경우: 비용 함수가 수렴하지 않음.",
"_____no_output_____"
],
[
"<div align=\"center\"><img src=\"https://raw.githubusercontent.com/codingalzi/handson-ml3/master/jupyter-book/imgs/ch04/homl04-03.png\" width=\"500\"/></div>",
"_____no_output_____"
],
[
"선형 회귀가 아닌 경우에는 시작점에 따라 지역 최솟값에 수렴하거나 정체될 수 있음을\n아래 그림이 잘 보여준다.",
"_____no_output_____"
],
[
"<div align=\"center\"><img src=\"https://raw.githubusercontent.com/codingalzi/handson-ml3/master/jupyter-book/imgs/ch04/homl04-04.png\" width=\"500\"/></div>",
"_____no_output_____"
],
[
"**특성 스케일링의 중요성**\n\n특성들의 스켈일을 통일시키면 보다 빠른 학습이 이루어지는 이유를 \n아래 그림이 설명한다.\n\n* 왼편 그림: 두 특성의 스케일이 동일하게 조정된 경우 비용 함수의 최솟값으로 최단거리로 수렴한다.\n* 오른편 그림: 두 특성의 스케일이 다른 경우 비용 함수의 최솟값으로 보다 먼 거리를 지나간다.",
"_____no_output_____"
],
[
"<div align=\"center\"><img src=\"https://raw.githubusercontent.com/codingalzi/handson-ml3/master/jupyter-book/imgs/ch04/homl04-04a.png\" width=\"500\"/></div>",
"_____no_output_____"
],
[
"### 경사하강법 종류",
"_____no_output_____"
],
[
"모델을 지정할 때 지정하는 배치 크기에 따라 세 종류로 나뉜다.",
"_____no_output_____"
],
[
"**참고:** 지정된 배치 크기의 샘플에 대해 예측을 한 후에 경사하강법을 이용하여 파라미터를 조정하는 단계를\n스텝<font size=\"2\">step</font>이라 하며, 다음이 성립힌다.\n\n 스텝 크기 = (훈련 샘플 수) / (배치 크기)\n\n예를 들어, 훈련 세트의 크기가 1,000이고 배치 크기가 10이면, 에포크 당 100번의 스텝이 실행된다.",
"_____no_output_____"
],
[
"#### 배치 경사하강법",
"_____no_output_____"
],
[
"에포크마다 그레이디언트를 계산하여 파라미터를 조정한다.\n즉, 배치의 크기가 전체 훈련셋의 크기와 같고 따라서 스텝의 크기는 1이다.\n\n단점으로 훈련 세트가 크면 그레이디언트를 계산하는 데에 많은 시간과 메모리가 필요해지는 문제가 있다. \n이와 같은 이유로 인해 사이킷런은 배치 경사하강법을 지원하지 않는다.",
"_____no_output_____"
],
[
"**학습율과 경사하강법의 관계**\n\n학습률에 따라 파라미터($\\theta$)의 수렴 여부와 속도가 달라진다.\n최적의 학습률은 그리드 탐색 등을 이용하여 찾아볼 수 있다.",
"_____no_output_____"
],
[
"<div align=\"center\"><img src=\"https://raw.githubusercontent.com/codingalzi/handson-ml3/master/jupyter-book/imgs/ch04/homl04-04b.png\" width=\"700\"/></div>",
"_____no_output_____"
],
[
"**에포크 수와 허용오차**\n\n에포크 수는 크게 설정한 후 허용오차를 지정하여 학습 시간을 제한할 필요가 있다.\n이유는 포물선의 최솟점에 가까워질 수록 그레이디언트 벡터의 크기가 0에 수렴하기 때문이다.\n\n허용오차와 에포크 수는 서로 반비례의 관계이다. \n예를 들어, 허용오차를 1/10로 줄이려면 에포크 수를 10배 늘려야한다.",
"_____no_output_____"
],
[
"#### 확률적 경사하강법(SGD)",
"_____no_output_____"
],
[
"배치 크기가 1이다.\n즉, 하나의 스텝에 하나의 훈련 셈플에 대한 예측값을 실행한 후에 \n그 결과를 이용하여 그레이디언트를 계산하고 파라미터를 조정한다.\n\n샘플은 무작위로 선택된다.\n따라서 경우에 따라 하나의 에포크에서 여러 번 선택되거나 전혀 선택되지 않는 샘플이\n존재할 수도 있지만, 이는 별 문제가 되지 않는다.\n\n확률적 경사하강법<font size=\"2\">stochastic graidient descent</font>(SGD)을 이용하면 \n계산량이 상대적으로 적어 아주 큰 훈련 세트를 다룰 수 있으며,\n따라서 외부 메모리(out-of-core) 학습에 활용될 수 있다.\n또한 파라미터 조정이 불안정하게 이뤄질 수 있기 때문에 지역 최솟값에 상대적으로 덜 민감하다.\n반면에 동일한 이유로 경우에 따라 전역 최솟값에 수렴하지 못하고 주변을 맴돌 수도 있다.",
"_____no_output_____"
],
[
"<div align=\"center\"><img src=\"https://raw.githubusercontent.com/codingalzi/handson-ml3/master/jupyter-book/imgs/ch04/homl04-04c.png\" width=\"300\"/></div>",
"_____no_output_____"
],
[
"아래 그림은 처음 20 단계 동안의 SGD 학습 과정을 보여주는데, 모델이 수렴하지 못함을 확인할 수 있다.",
"_____no_output_____"
],
[
"<div align=\"center\"><img src=\"https://raw.githubusercontent.com/codingalzi/handson-ml3/master/jupyter-book/imgs/ch04/homl04-04d.png\" width=\"500\"/></div>",
"_____no_output_____"
],
[
"**독립 항등 분포**\n\n확률적 경사하강법을 적용하려면 훈련셋이 \n독립 항등 분포<font size=\"2\">independently and identically distributed</font>(iid)를 따르도록 해야 한다.\n이를 위해 매 에포크마다 훈련 셋을 무작위로 섞는 방법이 일반적으로 사용된다.",
"_____no_output_____"
],
[
"**학습 스케줄<font size=\"2\">learning schedule</font>**\n\n요동치는 파라미터를 제어하기 위해 학습률을 학습 과정 동안 천천히 줄어들게 만드는 기법을 의미한다.\n일반적으로 훈련이 지속될 수록 학습률을 조금씩 줄이며,\n에포크 수, 훈련 샘플 수, 학습되는 샘플의 인덱스를 이용하여 지정한다. ",
"_____no_output_____"
],
[
"**사이킷런의 `SGDRegressor` 클래스**\n\n확률적 경사하강법을 기본적으로 지원한다.\n\n```python\nSGDRegressor(max_iter=1000, tol=1e-5, penalty=None, eta0=0.01,\n n_iter_no_change=100, random_state=42)\n```\n\n* `max_iter=1000`: 최대 에포크 수\n* `tol=1e-3`: 허용오차\n* `eta0=0.1`: 학습 스케줄 함수에 사용되는 매개 변수. 일종의 학습률.\n* `penalty=None`: 규제 사용 여부 결정(추후 설명). 여기서는 사용하지 않음.",
"_____no_output_____"
],
[
"#### 미니 배치 경사하강법",
"_____no_output_____"
],
[
"배치 크기가 2에서 수백 사이로 정해지며, 최적의 배치 크기는 경우에 따라 다르다.\n배치 크기를 어느 정도 크게 하면 확률적 경사하강법(SGD) 보다 파라미터의 움직임이 덜 불규칙적이 되며,\n배치 경사하강법보다 빠르게 학습한다.\n반면에 SGD에 비해 지역 최솟값에 수렴할 위험도가 보다 커진다.",
"_____no_output_____"
],
[
"**경사하강법 비교**\n\n배치 GD, 미니 배치 GD, SGD의 순서대로 최적의 파라미터 값에 \n수렴할 확률이 높다.\n훈련 시간 또한 동일한 순서대로 오래 걸린다. ",
"_____no_output_____"
],
[
"<div align=\"center\"><img src=\"https://raw.githubusercontent.com/codingalzi/handson-ml3/master/jupyter-book/imgs/ch04/homl04-05.png\" width=\"500\"/></div>",
"_____no_output_____"
],
[
"**선형 회귀 알고리즘 비교**\n\n| 알고리즘 | 많은 샘플 수 | 외부 메모리 학습 | 많은 특성 수 | 하이퍼 파라미터 수 | 스케일 조정 | 사이킷런 지원 |\n|:--------:|:---------:|:---------:|:---------:|:---------:|:---------:|:---------:|\n| 정규방정식 | 빠름 | 지원 안됨 | 느림 | 0 | 불필요 | 지원 없음 |\n| SVD | 빠름 | 지원 안됨 | 느림 | 0 | 불필요 | LinearRegression |\n| 배치 GD | 느림 | 지원 안됨 | 빠름 | 2 | 필요 | (?) |\n| SGD | 빠름 | 지원 | 빠름 | >= 2 | 필요 | SGDRegressor |\n| 미니배치 GD | 빠름 | 지원 | 빠름 | >=2 | 필요 | 지원 없음 |",
"_____no_output_____"
],
[
"**참고:** 심층 신경망을 지원하는 텐서플로우<font size=\"2\">Tensorflow</font>는 \n기본적으로 미니 배치 경사하강법을 지원한다.",
"_____no_output_____"
],
[
"(sec:poly_reg)=\n## 다항 회귀",
"_____no_output_____"
],
[
"비선형 데이터를 선형 회귀를 이용하여 학습하는 기법을\n**다항 회귀**<font size=\"2\">polynomial regression</font>라 한다.\n이때 다항식을 이용하여 새로운 특성을 생성하는 아이디어를 사용한다.",
"_____no_output_____"
],
[
"**2차 함수 모델를 따르는 데이터셋에 선형 회귀 모델 적용 결과**\n\n아래 그림은 2차 함수의 그래프 형식으로 분포된 데이터셋을 선형 회귀 모델로 학습시킨 결과를 보여준다.\n\n$$\\hat y = \\theta_0 + \\theta_1\\, x_1$$",
"_____no_output_____"
],
[
"<div align=\"center\"><img src=\"https://raw.githubusercontent.com/codingalzi/handson-ml3/master/jupyter-book/imgs/ch04/homl04-06.png\" width=\"500\"/></div>",
"_____no_output_____"
],
[
"**2차 함수 모델를 따르는 데이터셋에 2차 다항식 모델 적용 결과**\n\n반면에 아래 그림은 $x_1^2$ 에 해당하는 특성 $x_2$ 를 새로이 추가한 후에\n선형 회귀 모델을 학습시킨 결과를 보여준다.\n\n$$\\hat y = \\theta_0 + \\theta_1\\, x_1 + \\theta_2\\, x_{2}$$",
"_____no_output_____"
],
[
"<div align=\"center\"><img src=\"https://raw.githubusercontent.com/codingalzi/handson-ml3/master/jupyter-book/imgs/ch04/homl04-07.png\" width=\"500\"/></div>",
"_____no_output_____"
],
[
"**사이킷런의 `PolynomialFeatures` 변환기**\n\n활용하고자 하는 다항식에 포함되어야 하는 항목에 해당하는 특성들을 생성하는 변환기이다.\n\n```python\nPolynomialFeatures(degree=d, include_bias=False)\n```\n`degree=d`는 몇 차 다항식을 활용할지 지정하는 하이퍼파라미터이다. ",
"_____no_output_____"
],
[
":::{prf:example} 3차 다항 회귀\n:label: exp:3rd_poly_reg\n\n기존에 두 개의 $x_1, x_2$ 두 개의 특성을 갖는 데이터셋에 대해\n3차 다항식 모델을 훈련시키고자 하면 $d=3$으로 설정한다.\n그러면 $x_1, x_2$ 을 이용한 2차, 3차 다항식에 포함될 항목을 새로운 특성으로 추가해야 한다.\n이는 $(x_1+x_2)^2$과 $(x_1+x_2)^3$의 항목에 해당하는 다음 7개의 특성을 추가해야 함을 의미한다.\n\n$$x_1^2,\\,\\, x_1 x_2,\\,\\, x_2^2,\\,\\, x_1^3,\\,\\, x_1^2 x_2,\\,\\, x_1 x_2^2,\\,\\, x_2^3$$\n:::",
"_____no_output_____"
],
[
"## 학습 곡선",
"_____no_output_____"
],
[
"다항 회귀 모델의 차수에 따라 훈련된 모델이 훈련 세트에 과소 또는 과대 적합할 수 있다.\n아래 그림이 보여주듯이 선형 모델은 과소 적합되어 있는 반면에 \n300차 다항 회귀 모델 과대 적합 되어 있다. \n그리고 2차 다항 회귀 모델의 일반화 성능이 가장 좋다.",
"_____no_output_____"
],
[
"<div align=\"center\"><img src=\"https://raw.githubusercontent.com/codingalzi/handson-ml3/master/jupyter-book/imgs/ch04/homl04-08.png\" width=\"500\"/></div>",
"_____no_output_____"
],
[
"**교차 검증 vs. 학습 곡선**\n\n하지만 일반적으로 몇 차 다항 회귀가 가장 좋은지 미리 알 수 없다. \n따라서 다양한 모델을 대상으로 교차 검증을 진행하여 과소 또는 과대 적합 모델을 구별해야 한다.\n\n* 과소 적합: 훈련 세트와 교차 검증 점수 모두 낮은 경우\n* 과대 적합: 훈련 세트에 대한 검증은 우수하지만 교차 검증 점수가 낮은 경우\n\n다른 검증 방법은 **학습 곡선**<font size='2'>learning curve</font>을 잘 살펴보는 것이다.\n학습 곡선은 훈련 세트와 검증 세트에 대한 모델 성능을 비교하는 그래프이며,\n학습 곡선의 모양에 따라 과소 적합 또는 과대 적합 여부를 판정할 수 있다.\n\n사이킷런의 `learning_curve()` 함수를 이용하여 학습 곡선을 그릴 수 있다.\n\n* x 축: 훈련셋 크기. 전체 훈련셋의 10%에서 출발하여 훈련셋 전체를 대상으로 할 때까지 \n 훈련셋의 크기를 키워가며 교차 검증 진행.\n* y 축: 교차 검증을 통해 확인된 훈련셋 및 검증셋 대상 RMSE(평균 제곱근 오차).",
"_____no_output_____"
],
[
"**과소 적합 모델의 학습 곡선 특징**\n\n* 훈련셋(빨강)에 대한 성능: 훈련 세트가 커지면서 RMSE 증가하지만 \n 훈련 세트가 어느 정도 커지면 거의 불변.\n\n* 검증셋(파랑)에 대한 성능: 검증 세트에 대한 성능이 훈련 세트에 대한 성능과 거의 비슷해짐.",
"_____no_output_____"
],
[
"<div align=\"center\"><img src=\"https://raw.githubusercontent.com/codingalzi/handson-ml3/master/jupyter-book/imgs/ch04/homl04-09.png\" width=\"500\"/></div>",
"_____no_output_____"
],
[
"**과대 적합 모델의 학습 곡선 특징**\n\n* 훈련셋(빨강)에 대한 성능: 훈련 데이터에 대한 평균 제곱근 오차가 매우 낮음.\n* 검증셋(파랑)에 대한 성능: 훈련 데이터에 대한 성능과 차이가 어느 정도 이상 벌어짐.\n* 과대 적합 모델 개선법: 두 그래프가 맞닿을 때까지 훈련 데이터 추가. \n 하지만 일반적으로 더 많은 훈련 데이터를 구하는 일이 매우 어렵거나 불가능할 수 있음.\n 아니면 모델에 규제를 가할 수 있음.",
"_____no_output_____"
],
[
"<div align=\"center\"><img src=\"https://raw.githubusercontent.com/codingalzi/handson-ml3/master/jupyter-book/imgs/ch04/homl04-10.png\" width=\"500\"/></div>",
"_____no_output_____"
],
[
"**모델 일반화 오차의 종류**\n\n훈련 후에 새로운 데이터 대한 예측에서 발생하는 오차를 가리키며 세 종류의 오차가 있다.\n\n- 편향: 실제로는 2차원 모델인데 1차원 모델을 사용하는 경우처럼 잘못된 가정으로 인해 발생한다.\n 과소 적합이 발생할 가능성이 매우 높다.\n\n- 분산: 모델이 훈련 데이터에 민감하게 반응하는 정도를 가리킨다.\n 고차 다항 회귀 모델일 수록 분산이 높아질 수 있다.\n 일반적으로 **자유도**<font size='2'>degree of freedom</font>가 높은 모델일 수록 분산이 커지며,\n 과대 적합이 발생할 가능성도 매우 높다.\n- 축소 불가능 오차: 잡음(noise) 등 데이터 자체의 한계로 인해 발생한다.\n 잡음 등을 제거해야 오차를 줄일 수 있다.",
"_____no_output_____"
],
[
":::{prf:example} 편향-분산 트레이드오프\n:label: exp:bias_variance\n\n복잡한 모델일 수록 편향을 줄어들지만 분산을 커진다.\n :::",
"_____no_output_____"
],
[
"## 규제 사용 선형 모델",
"_____no_output_____"
],
[
"훈련 중에 과소 적합이 발생하면 보다 복잡한 모델을 선택해야 한다.\n반면에 과대 적합이 발생할 경우 먼저 모델에 규제를 가해 과대 적합을 방지하거나\n아니면 최소한 과대 적합이 최대한 늦게 발생하도록 유도해야 한다. ",
"_____no_output_____"
],
[
"모델 규제는 보통 모델의 자유도를 제한하는 방식으로 이루어진다. \n**자유도**<font size=\"2\">degree of freedom</font>는 모델 결정에 영향을 주는 요소들의 개수이다.\n예를 들어 선형 회귀의 경우에는 특성 수가 자유도를 결정하며,\n다항 회귀의 경우엔 차수도 자유도에 기여한다.\n\n선형 회귀 모델에 대한 **규제**<font size='2'>regularization</font>는 가중치를 제한하는 방식으로 이루어지며,\n방식에 따라 다음 세 가지 선형 회귀 모델이 지정된다.\n\n* 릿지 회귀\n* 라쏘 회귀\n* 엘라스틱 넷",
"_____no_output_____"
],
[
":::{admonition} 주의\n:class: warning\n\n규제는 훈련 과정에만 사용된다. 테스트 과정에는 다른 기준으로 성능을 평가한다.\n\n* 훈련 과정: 비용 최소화 목표\n* 테스트 과정: 최종 목표에 따른 성능 평가. \n 예를 들어, 분류기의 경우 재현율/정밀도 기준으로 모델의 성능을 평가한다.\n:::",
"_____no_output_____"
],
[
"### 릿지 회귀<font size='2'>Ridge Regression</font>",
"_____no_output_____"
],
[
"다음 비용 함수를 사용하며,\n특성 스케일링을 해야 규제의 성능이 좋아진다.\n\n$$J(\\theta) = \\textrm{MSE}(\\theta) + \\alpha \\sum_{i=1}^{n}\\theta_i^2$$\n\n* $\\alpha$(알파)는 규제의 강도를 지정한다. \n $\\alpha=0$ 이면 규제가 전혀 없는 기본 선형 회귀이다.\n\n* $\\alpha$ 가 커질 수록 가중치의 역할이 줄어든다.\n 왜냐하면 비용을 줄이기 위해 보다 작은 가중치를 선호하는 방향으로 훈련되기 때문이다.\n\n* $\\theta_0$ 는 규제하지 않는다.",
"_____no_output_____"
],
[
"아래 그림은 릿지 규제를 적용한 적용한 6 개의 경우를 보여준다.\n\n- 왼편: 선형 회귀 모델에 세 개의 $\\alpha$ 값 적용.\n- 오른편: 10차 다항 회귀 모델에 세 개의 $\\alpha$ 값 적용.",
"_____no_output_____"
],
[
"<div align=\"center\"><img src=\"https://raw.githubusercontent.com/codingalzi/handson-ml3/master/jupyter-book/imgs/ch04/ridge01.png\" width=\"600\"/></div>",
"_____no_output_____"
],
[
":::{admonition} 릿지 회귀의 정규 방정식\n:class: info\n\n$A$ 가 `(n+1)x(n+1)` 모양의 단위 행렬<font size='2'>identity matrix</font>일 때 다음이 성립한다.\n\n$$\n\\hat{\\mathbf{\\theta}} = \n(\\mathbf{X}^T\\, \\mathbf{X} + \\alpha A)^{-1}\\, \\mathbf{X}^T\\, \\mathbf{y}\n$$\n:::",
"_____no_output_____"
],
[
"### 라쏘 회귀<font size='2'>Lasso Regression</font>",
"_____no_output_____"
],
[
"다음 비용 함수를 사용한다.\n\n$$J(\\theta) = \\textrm{MSE}(\\theta) + \\alpha \\, \\sum_{i=1}^{n}\\mid \\theta_i\\mid$$\n\n* 별로 중요하지 않은 특성에 대해 $\\theta_i$가 0에 빠르게 수렴하도록 훈련 중에 유도된다.\n 이유는 $\\mid \\theta_i \\mid$ 의 미분값이 1또는 -1 이기에 상대적으로 큰 값이기에\n 파라미터 업데이크 과정에서 보다 작은 $\\mid \\theta_i \\mid$ 가 보다 빠르게 0에 수렴하기 때문이다.\n \n* $\\alpha$ 와 $\\theta_0$ 에 대한 설명은 릿지 회귀의 경우와 동일하다.",
"_____no_output_____"
],
[
"아래 그림은 라쏘 규제를 적용한 적용한 6 개의 경우를 보여준다.\n\n- 왼편: 선형 회귀 모델에 세 개의 $\\alpha$ 값 적용.\n- 오른편: 10차 다항 회귀 모델에 세 개의 $\\alpha$ 값 적용.",
"_____no_output_____"
],
[
"<div align=\"center\"><img src=\"https://raw.githubusercontent.com/codingalzi/handson-ml3/master/jupyter-book/imgs/ch04/lasso01.png\" width=\"600\"/></div>",
"_____no_output_____"
],
[
":::{admonition} 주의 사항\n:class: warning\n\n라쏘 회귀는 정규 방정식을 지원하지 않는다.\n:::",
"_____no_output_____"
],
[
"### 엘라스틱 넷<font size='2'>Elastic Net</font>",
"_____no_output_____"
],
[
"릿지 회귀와 라쏘 회귀를 절충한 모델이며 다음 비용 함수를 사용한다.\n$r$ 은 릿지 규제와 라쏘 규제의 사용 비율이다. \n단, 규제 강도를 의미하는 `\\alpha` 가 각 규제에 가해지는 정도가 다름에 주의한다.\n\n$$\nJ(\\theta) = \n\\textrm{MSE}(\\theta) + \nr\\cdot \\bigg (2 \\alpha \\, \\sum_{i=1}^{n}\\mid\\theta_i\\mid \\bigg) + \n(1-r)\\cdot \\bigg (\\frac{\\alpha}{m}\\, \\sum_{i=1}^{n}\\theta_i^2 \\bigg )\n$$",
"_____no_output_____"
],
[
":::{admonition} 규제 선택\n:class: info\n\n약간이라도 규제를 사용해야 하며, 일반적으로 릿지 회귀가 추천된다.\n반면에 유용한 속성이 그렇게 많지 않다고 판단되는 경우엔 라쏘 회귀 또는 엘라스틱 넷이 추천된다.\n\n하지만 특성 수가 훈련 샘플 수보다 크거나 특성 몇 개가 강하게 연관되어 있는 경우엔 엘라스틱 넷을\n사용해야 한다.\n:::",
"_____no_output_____"
],
[
"(sec:early-stopping)=\n### 조기 종료",
"_____no_output_____"
],
[
"**조기 종료**<font size='2'>Early Stopping</font>는 \n모델이 훈련셋에 과대 적합하는 것을 방지하기 위해 훈련을 적절한 시기에 중단시키는 기법이며,\n검증 데이터에 대한 손실이 줄어들다가 다시 커지는 순간 훈련을 종료한다. \n\n확률적 경사하강법, 미니 배치 경사하강법에서는 손실 곡선이 보다 많이 진동하기에\n검증 손실이 언제 최소가 되었는지 알기 어렵다.\n따라서 한동안 최솟값보다 높게 유지될 때 훈련을 멈추고 기억해둔 최적의 모델로\n되돌린다.",
"_____no_output_____"
],
[
"<div align=\"center\"><img src=\"https://raw.githubusercontent.com/codingalzi/handson-ml3/master/jupyter-book/imgs/ch04/homl04-11.png\" width=\"500\"/></div>",
"_____no_output_____"
],
[
"## 로지스틱 회귀",
"_____no_output_____"
],
[
"회귀 모델을 분류 모델로 활용할 수 있다. \n\n* 이진 분류: 로지스틱 회귀\n* 다중 클래스 분류: 소프트맥스 회귀",
"_____no_output_____"
],
[
"### 확률 추정",
"_____no_output_____"
],
[
"선형 회귀 모델이 예측한 값에 **시그모이드**<font size='2'>sigmoid</font> 함수를\n적용하여 0과 1 사이의 값, 즉 양성일 **확률** $\\hat p$ 로 지정한다.\n\n$$\n\\hat p = h_\\theta(\\mathbf{x}) = \\sigma(\\mathbf{\\theta}^T \\, \\mathbf{x})\n= \\sigma(\\theta_0 + \\theta_1\\, x_1 + \\cdots + \\theta_n\\, x_n)\n$$",
"_____no_output_____"
],
[
"**시그모이드 함수**\n\n$$\\sigma(t) = \\frac{1}{1 + \\exp(-t)}$$",
"_____no_output_____"
],
[
"<div align=\"center\"><img src=\"https://raw.githubusercontent.com/codingalzi/handson-ml3/master/jupyter-book/imgs/ch04/homl04-12.png\" width=\"500\"/></div>",
"_____no_output_____"
],
[
"로지스틱 회귀 모델의 **예측값**은 다음과 같다.\n\n$$\n\\hat y = \n\\begin{cases}\n0 & \\text{if}\\,\\, \\hat p < 0.5 \\\\[1ex]\n1 & \\text{if}\\,\\, \\hat p \\ge 0.5\n\\end{cases}\n$$",
"_____no_output_____"
],
[
"즉, 다음이 성립한다.\n\n* 양성: $\\theta_0 + \\theta_1\\, x_1 + \\cdots + \\theta_n\\, x_n \\ge 0$\n\n* 음성: $\\theta_0 + \\theta_1\\, x_1 + \\cdots + \\theta_n\\, x_n < 0$",
"_____no_output_____"
],
[
"### 훈련과 비용함수",
"_____no_output_____"
],
[
"로지스틱 회귀 모델은 양성 샘플에 대해서는 1에 가까운 확률값을,\n음성 샘플에 대해서는 0에 가까운 확률값을 내도록 훈련한다.\n각 샘플에 대한 비용은 다음과 같다.\n\n$$\nc(\\theta) = \n\\begin{cases}\n-\\log(\\,\\hat p\\,) & \\text{$y=1$ 인 경우}\\\\\n-\\log(\\,1 - \\hat p\\,) & \\text{$y=0$ 인 경우}\n\\end{cases}\n$$\n\n양성 샘플에 대해 0에 가까운 값을 예측하거나,\n음성 샘플에 대해 1에 가까운 값을 예측하면 \n위 비용 함수의 값이 무한히 커진다.\n\n모델 훈련은 따라서 전체 훈련셋에 대한 다음 \n**로그 손실**<font size='2'>log loss</font> 함수는 다음과 같다.\n\n$$\nJ(\\theta) = \n- \\frac{1}{m}\\, \\sum_{i=1}^{m}\\, [y^{(i)}\\, \\log(\\,\\hat p^{(i)}\\,) + (1-y^{(i)})\\, \\log(\\,1 - \\hat p^{(i)}\\,)]\n$$",
"_____no_output_____"
],
[
":::{admonition} 로그 손실 함수 이해\n:class: info\n\n$c(\\theta)$ 는 틀린 예측을 하면 손실값이 매우 커진다.\n\n<div align=\"center\"><img src=\"https://raw.githubusercontent.com/codingalzi/handson-ml3/master/jupyter-book/imgs/ch04/homl04-12-10a.png\" width=\"500\"/></div>\n\n훈련셋이 가우시안 분포를 따른다는 전제하에 로그 손실 함수를 최소화하면 \n**최대 우도**<font size='2'>maximal likelihood</font>를 갖는 최적의 모델을 얻을 수 있다는 사실은\n수학적으로 증명되었다.\n상세 내용은 [앤드류 응(Andrew Ng) 교수의 Stanford CS229](https://www.youtube.com/watch?v=jGwO_UgTS7I&list=PLoROMvodv4rMiGQp3WXShtMGgzqpfVfbU) 강의에서 들을 수 있다.\n:::",
"_____no_output_____"
],
[
"최적의 $\\theta$ 를 계산하는 정규 방정식은 하지 않는다.\n하지만 다행히도 경사하강법은 적용할 수 있으며,\n선형 회귀의 경우처럼 적절한 학습률을 사용하면 언제나 최소 비용에 수렴하도록\n파라미터가 훈련된다.\n\n참고로 로그 손실 함수의 그레이디이언트 벡터는 선형 회귀의 그것과 매우 유사하며,\n다음 편도 함수들로 이루어진다.\n\n$$\n\\dfrac{\\partial}{\\partial \\theta_j} J(\\boldsymbol{\\theta}) = \\dfrac{1}{m}\\sum\\limits_{i=1}^{m}\\left(\\mathbf{\\sigma(\\boldsymbol{\\theta}}^T \\mathbf{x}^{(i)}) - y^{(i)}\\right)\\, x_j^{(i)}\n$$",
"_____no_output_____"
],
[
"### 결정 경계",
"_____no_output_____"
],
[
"붓꽃 데이터셋을 이용하여 로지스틱 회귀의 사용법을 살펴 본다. \n하나의 붓꽃 샘플은 꽃받침<font size='2'>sepal</font>의 길이와 너비, \n꽃입<font size='2'>petal</font>의 길이와 너비 등 총 4개의 특성으로 \n이루어진다. \n\n타깃값은 0, 1, 2 중에 하나이며 각 숫자는 다음 세 개의 품종을 가리킨다. \n\n* 0: Iris-Setosa(세토사)\n* 1: Iris-Versicolor(버시컬러)\n* 2: Iris-Virginica(버지니카)",
"_____no_output_____"
],
[
"<div align=\"center\"><img src=\"https://raw.githubusercontent.com/codingalzi/handson-ml3/master/jupyter-book/imgs/ch04/iris01.png\" width=\"600\"/></div>",
"_____no_output_____"
],
[
"**버지니카 품종 감지기**\n\n로지스틱 회귀 모델을 이용하여 아이리스 데이터셋을 대상으로 버지니카 품종을 감지하는\n이진 분류기를 다음과 같이 훈련시킨다.\n단, 문제를 간단하기 만들기 위해 꽃잎의 너비 속성 하나만 이용한다. \n\n```python\nX = iris.data[[\"petal width (cm)\"]].values\ny = iris.target_names[iris.target] == 'virginica'\nX_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)\n\nlog_reg = LogisticRegression(random_state=42)\nlog_reg.fit(X_train, y_train)\n```\n\n훈련 결과 꽃잎의 넙가 약 1.65cm 보다 큰 경우 버지니카 품종일 가능성이 높아짐이 확인된다.\n즉, 버지니카 품좀 감지기의 \n**결정 경계**<font size='2'>decision boundary</font>는 꽃잎 넙 기준으로 약 1.65cm 이다.",
"_____no_output_____"
],
[
"<div align=\"center\"><img src=\"https://raw.githubusercontent.com/codingalzi/handson-ml3/master/jupyter-book/imgs/ch04/iris02.png\" width=\"700\"/></div>",
"_____no_output_____"
],
[
"아래 그림은 꽃잎의 너비와 길이 두 속성을 이용한 버지니카 품종 감지기가 찾은 \n결정 경계(검정 파선)를 보여준다. \n반면에 다양한 색상의 직선은 버지니카 품종일 가능성을 보여주는 영역을 표시한다. ",
"_____no_output_____"
],
[
"<div align=\"center\"><img src=\"https://raw.githubusercontent.com/codingalzi/handson-ml3/master/jupyter-book/imgs/ch04/homl04-15.png\" width=\"700\"/></div>",
"_____no_output_____"
],
[
"**로지스틱 회귀 규제**\n\n`LogisticRegression` 모델의 하이퍼파라미터 `penalty` 와 `C` 를 이용하여 규제와 규제의 강도를 지정한다. \n\n* `penalty`: `l1`(라쏘 규제), `l2`(릿지 규제), `elasticnet`(엘라스틱 넷) 방식 중 하나 선택하며,\n 기본값은 `l2`, 즉, 릿지 규제를 기본으로 적용한다.\n\n* `C`: 릿지 또는 라쏘 규제 정도를 지정하는 $\\alpha$의 역수에 해당한다. \n 따라서 0에 가까울 수록 강한 규제를 의미한다.",
"_____no_output_____"
],
[
"### 소프트맥스 회귀",
"_____no_output_____"
],
[
"로지스틱 회귀 모델을 일반화하여 다중 클래스 분류를 지원하도록 만든 모델이\n**소프트맥스 회귀**<font size='2'>Softmax Regression</font>이며, \n**다항 로지스틱 회귀** 라고도 불린다.",
"_____no_output_____"
],
[
"**클래스별 확률 예측**\n\n샘플 $\\mathbf x$가 주어졌을 때 각각의 분류 클래스 $k$ 에 대한 점수 $s_k(\\mathbf x)$를\n선형 회귀 방식으로 계산한다.\n\n$$\ns_k(\\mathbf{x}) = \\theta_0^{(k)} + \\theta_1^{(k)} x_1 + \\cdots + \\theta_n^{(k)} x_n\n$$ \n\n이는 $k\\, (n+1)$ 개의 파라미터를 학습시켜야 함을 의미한다.\n위 식에서 $\\theta_i^{(k)}$ 는 분류 클래스 $k$에 대해 필요한 $i$ 번째 속성을 \n대상으로 파라미터를 가리킨다.\n\n예를 들어, 붓꽃 데이터를 대상으로 하는 경우 최대 15개의 파라미터를 훈련시켜야 한다.\n\n$$\n\\Theta = \n\\begin{bmatrix}\n\\theta_0^{(0)} & \\theta_1^{(0)} & \\theta_2^{(0)} & \\theta_3^{(0)} & \\theta_4^{(0)}\\\\\n\\theta_0^{(1)} & \\theta_1^{(1)} & \\theta_2^{(1)} & \\theta_3^{(1)} & \\theta_4^{(1)}\\\\\n\\theta_0^{(2)} & \\theta_1^{(2)} & \\theta_2^{(2)} & \\theta_3^{(2)} & \\theta_4^{(2)}\n\\end{bmatrix}\n$$\n\n이제 다음 **소프트맥스** 함수를 이용하여 클래스 $k$에 속할 확률 $\\hat p_k$ 를 계산한다.\n단, $K$ 는 클래스의 개수를 나타낸다.\n\n$$\n\\hat p_k = \n\\frac{\\exp(s_k(\\mathbf x))}{\\sum_{j=1}^{K}\\exp(s_j(\\mathbf x))}\n$$\n\n소프트맥스 회귀 모델은 각 샘플에 대해 추정 확률이 가장 높은 클래스를 선택한다. \n\n$$\n\\hat y = \n\\mathrm{argmax}_k s_k(\\mathbf x)\n$$",
"_____no_output_____"
],
[
":::{admonition} 소프트맥스 회귀와 다중 출력 분류\n:class: tip\n\n소프트맥스 회귀는 다중 출력<font size='2'>multioutput</font> 분류를 지원하지 않는다.\n예를 들어, 하나의 사진에서 여러 사람의 얼굴을 인식하는 데에 사용할 수 없다.\n:::",
"_____no_output_____"
],
[
"**소프트맥스 회귀의 비용 함수**\n\n각 분류 클래스 $k$에 대한 적절한 가중치 벡터 $\\theta_k$를 \n경사하강법을 이용하여 업데이트 한다.\n이를 위해 **크로스 엔트로피**<font size='2'>cross entropy</font>를 비용 함수로 사용한다.\n\n$$\nJ(\\Theta) = \n- \\frac{1}{m}\\, \\sum_{i=1}^{m}\\sum_{k=1}^{K} y^{(i)}_k\\, \\log\\big( \\hat{p}_k^{(i)}\\big)\n$$\n\n위 식에서 $y^{(i)}_k$ 는 타깃 확률값을 가리키며, 0 또는 1 중에 하나의 값을 갖는다. \n$K=2$이면 로지스틱 회귀의 로그 손실 함수와 정확하게 일치한다.\n\n크로스 엔트로피는 주어진 샘플의 타깃 클래스를 제대로 예측하지 못하는 경우 높은 값을 갖는다.\n크로스 엔트로피 개념은 정보 이론에서 유래하며, 여기서는 더 이상 설명하지 않는다.",
"_____no_output_____"
],
[
"**붓꽃 데이터 다중 클래스 분류**\n\n사이킷런의 `LogisticRegression` 예측기를 활용한다.\n기본값 `solver=lbfgs` 사용하면 모델이 알아서 다중 클래스 분류를 훈련한다.\n아래 코드는 꽃잎의 길이와 너비 두 특성을 이용하여 \n세토사, 버시컬러, 버지니카 클래스를 선택하는 모델을 훈련시킨다.\n\n```python\nX = iris.data[[\"petal length (cm)\", \"petal width (cm)\"]].values\ny = iris[\"target\"]\nX_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)\n\nsoftmax_reg = LogisticRegression(C=30, random_state=42)\nsoftmax_reg.fit(X_train, y_train)\n```\n\n아래 그림은 붓꽃 꽃잎의 너비와 길이를 기준으로 세 개의 품종을 색까로 구분하는 결정 경계를 보여준다. \n다양한 색상의 곡선은 버시컬러 품종에 속할 확률의 영력을 보여준다.",
"_____no_output_____"
],
[
"<div align=\"center\"><img src=\"https://raw.githubusercontent.com/codingalzi/handson-ml3/master/jupyter-book/imgs/ch04/homl04-16.png\" width=\"700\"/></div>",
"_____no_output_____"
],
[
"## 연습문제",
"_____no_output_____"
],
[
"참고: [(실습) 모델 훈련](https://colab.research.google.com/github/codingalzi/handson-ml3/blob/master/practices/practice_training_models.ipynb)",
"_____no_output_____"
]
]
] | [
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
cb3191d579d48ae8fccc88227c475aabe5b618c5 | 61,099 | ipynb | Jupyter Notebook | notebooks/04-tidy.ipynb | chendaniely/2019-07-29-python | dab95fd49fa6259422c46235ec43c1344562403b | [
"MIT"
] | 4 | 2019-07-29T14:07:48.000Z | 2019-07-31T16:59:34.000Z | notebooks/04-tidy.ipynb | chendaniely/2019-07-29-python | dab95fd49fa6259422c46235ec43c1344562403b | [
"MIT"
] | null | null | null | notebooks/04-tidy.ipynb | chendaniely/2019-07-29-python | dab95fd49fa6259422c46235ec43c1344562403b | [
"MIT"
] | 8 | 2019-07-29T14:06:41.000Z | 2019-11-18T15:48:59.000Z | 29.067079 | 104 | 0.337485 | [
[
[
"import pandas as pd\nfrom pyprojroot import here",
"_____no_output_____"
],
[
"pew = pd.read_csv(here(\"./data/pew.csv\"))",
"_____no_output_____"
],
[
"pew.head()",
"_____no_output_____"
],
[
"# pew_long = pd.melt()\npew_long = pew.melt(id_vars=['religion'], var_name='income', value_name='count')",
"_____no_output_____"
],
[
"pew_long.sample(10)",
"_____no_output_____"
],
[
"billboard = pd.read_csv(here(\"./data/billboard.csv\"))",
"_____no_output_____"
],
[
"billboard.sample(5)",
"_____no_output_____"
],
[
"billboard_long = billboard.melt(\n id_vars=['year', 'artist', 'track', 'time', 'date.entered'],\n var_name='week',\n value_name='rating'\n)",
"_____no_output_____"
],
[
"billboard_long.sample(4)",
"_____no_output_____"
],
[
"billboard.shape",
"_____no_output_____"
],
[
"billboard_long.shape",
"_____no_output_____"
],
[
"ebola = pd.read_csv(here(\"./data/country_timeseries.csv\"))",
"_____no_output_____"
],
[
"ebola.sample(4)",
"_____no_output_____"
],
[
"ebola_long = ebola.melt(id_vars=['Date', 'Day'])\nebola_long.sample(5)",
"_____no_output_____"
],
[
"'Deaths_UnitedStates'.split('_')",
"_____no_output_____"
],
[
"'Deaths_UnitedStates'.split('_')[0]",
"_____no_output_____"
],
[
"'Deaths_UnitedStates'.split('_')[1]",
"_____no_output_____"
],
[
"ebola_long[['case_death', 'country']] = ebola_long['variable'].str.split('_', expand=True)",
"_____no_output_____"
],
[
"ebola_long.sample(5)",
"_____no_output_____"
],
[
"weather = pd.read_csv(here(\"./data/weather.csv\"))",
"_____no_output_____"
],
[
"weather.sample(5)",
"_____no_output_____"
],
[
"weather.columns",
"_____no_output_____"
],
[
"weather_melt = weather.melt(\n id_vars=['id', 'year', 'month', 'element'],\n var_name='day',\n value_name='temp'\n)",
"_____no_output_____"
],
[
"weather_melt.head()",
"_____no_output_____"
],
[
"weather_tidy = weather_melt.pivot_table(\n index=['id', 'year', 'month', 'day'],\n columns='element',\n values='temp'\n)",
"_____no_output_____"
],
[
"weather_melt = (\n weather_melt\n .pivot_table(\n index=['id', 'year', 'month', 'day'],\n columns='element',\n values='temp')\n .reset_index()\n)",
"_____no_output_____"
],
[
"weather_melt.head()",
"_____no_output_____"
]
],
[
[
"# exercise\n\nTaken from the r4ds \"Tidy Data\" Chapter: https://r4ds.had.co.nz/exploratory-data-analysis.html\n",
"_____no_output_____"
]
],
[
[
"import pandas as pd\ntbl1 = pd.read_csv('../data/table1.csv')\ntbl2 = pd.read_csv('../data/table2.csv')\ntbl3 = pd.read_csv('../data/table3.csv')\n",
"_____no_output_____"
],
[
"# Tidy the tbl2 dataset",
"_____no_output_____"
],
[
"tbl2",
"_____no_output_____"
],
[
"(tbl2.pivot_table(index=['country', 'year'],\n columns='type',\n values='count')\n .reset_index()\n)",
"_____no_output_____"
],
[
"# Tidy the tbl3 dataset\n# just give me the population",
"_____no_output_____"
],
[
"tbl3",
"_____no_output_____"
],
[
"tbl3['population'] = tbl3['rate'].str.split('/').str.get(1)",
"_____no_output_____"
],
[
"tbl3",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb31a16fed31cad79252438aafa833bd84ff3cd7 | 88,697 | ipynb | Jupyter Notebook | notebooks/demonstration-pymatgen-for-optimade-queries.ipynb | ctoher/optimade-tutorial-exercises | 3fda71bb46e5c5c3557fd8d8a88f68eda1b515d5 | [
"MIT"
] | null | null | null | notebooks/demonstration-pymatgen-for-optimade-queries.ipynb | ctoher/optimade-tutorial-exercises | 3fda71bb46e5c5c3557fd8d8a88f68eda1b515d5 | [
"MIT"
] | null | null | null | notebooks/demonstration-pymatgen-for-optimade-queries.ipynb | ctoher/optimade-tutorial-exercises | 3fda71bb46e5c5c3557fd8d8a88f68eda1b515d5 | [
"MIT"
] | null | null | null | 62.727723 | 21,861 | 0.490163 | [
[
[
"# OPTIMADE and *pymatgen*",
"_____no_output_____"
],
[
"# What is *pymatgen*?\n\n[*pymatgen*](https://pymatgen.org) is a materials science analysis code written in the Python programming language. It helps power the [Materials Project](https://materialsproject.org)'s high-throughput DFT workflows. It supports integration with a wide variety of simulation codes and can perform many analysis tasks such as the generation of phase diagrams or diffraction patterns.\n\n# The motivation behind this tutorial\n\n**This tutorial is aimed either at:**\n\n* People who are already familiar with using *pymatgen* or the Materials Project\n * In particular, anyone already using the Materials Project API through the `MPRester`, and who would like to start using the OPTIMADE API in a similar way\n\n* People who like using Python and think they might appreciate an interface like the one provided by *pymatgen*.\n * *pymatgen* provides a lot of input/output routines (such as conversion to CIF, POSCAR, etc.) and analysis tools (such as determination of symmetry, analysis of possible bonds, etc.) that can be performed directly on structures retrieved from OPTIMADE providers.\n\n**What this tutorial is not:**\n\n* This is not necessarily the way everyone should be accessing OPTIMADE providers!\n * This tool may be useful to you, or it may not be. There are a lot of good tools available in our community. You are encouraged to try out different tools and find the one that's most useful for your own work.\n\n* It is not currently the best way to access OPTIMADE APIs for advanced users.\n * It is still under development.\n * It is unit tested against several OPTIMADE providers but **some do not work yet**.\n * It only currently supports information retrieval from `/v1/structures/` routes.\n\n# Pre-requisites\n\nThis tutorial is aimed at people who already have a basic understanding of Python, including how to import modules, the use of basic data structures like dictionaries and lists, and how to intantiate and use objects.\n\nIf you do not have this understanding of Python, this tutorial may help you become familiar, but you are highly encouraged to follow a dedicated Python course such as those provided by [Software Carpentry](https://software-carpentry.org).",
"_____no_output_____"
],
[
"# Install pymatgen",
"_____no_output_____"
],
[
"This tutorial uses the Python programming language. It can be run on any computer with Python installed. For convenience, here we are running in Google's \"Colaboratory\" notebook environment.\n\nBefore we begin, we must install the `pymatgen` package:",
"_____no_output_____"
]
],
[
[
"!pip install pymatgen pybtex retrying",
"Requirement already satisfied: pymatgen in /usr/local/lib/python3.7/dist-packages (2022.0.14)\nRequirement already satisfied: pybtex in /usr/local/lib/python3.7/dist-packages (0.24.0)\nRequirement already satisfied: typing-extensions>=3.7.4.3 in /usr/local/lib/python3.7/dist-packages (from pymatgen) (3.7.4.3)\nRequirement already satisfied: matplotlib>=1.5 in /usr/local/lib/python3.7/dist-packages (from pymatgen) (3.2.2)\nRequirement already satisfied: requests in /usr/local/lib/python3.7/dist-packages (from pymatgen) (2.23.0)\nRequirement already satisfied: plotly>=4.5.0 in /usr/local/lib/python3.7/dist-packages (from pymatgen) (5.3.1)\nRequirement already satisfied: tabulate in /usr/local/lib/python3.7/dist-packages (from pymatgen) (0.8.9)\nRequirement already satisfied: sympy in /usr/local/lib/python3.7/dist-packages (from pymatgen) (1.7.1)\nRequirement already satisfied: spglib>=1.9.9.44 in /usr/local/lib/python3.7/dist-packages (from pymatgen) (1.16.2)\nRequirement already satisfied: pandas in /usr/local/lib/python3.7/dist-packages (from pymatgen) (1.1.5)\nRequirement already satisfied: uncertainties>=3.1.4 in /usr/local/lib/python3.7/dist-packages (from pymatgen) (3.1.6)\nRequirement already satisfied: networkx>=2.2 in /usr/local/lib/python3.7/dist-packages (from pymatgen) (2.6.2)\nRequirement already satisfied: monty>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from pymatgen) (2021.8.17)\nRequirement already satisfied: scipy>=1.5.0 in /usr/local/lib/python3.7/dist-packages (from pymatgen) (1.7.1)\nRequirement already satisfied: numpy>=1.20.1 in /usr/local/lib/python3.7/dist-packages (from pymatgen) (1.21.2)\nRequirement already satisfied: ruamel.yaml>=0.15.6 in /usr/local/lib/python3.7/dist-packages (from pymatgen) (0.17.16)\nRequirement already satisfied: palettable>=3.1.1 in /usr/local/lib/python3.7/dist-packages (from pymatgen) (3.3.0)\nRequirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.7/dist-packages (from matplotlib>=1.5->pymatgen) (0.10.0)\nRequirement already satisfied: python-dateutil>=2.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib>=1.5->pymatgen) (2.8.2)\nRequirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib>=1.5->pymatgen) (2.4.7)\nRequirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.7/dist-packages (from matplotlib>=1.5->pymatgen) (1.3.1)\nRequirement already satisfied: six in /usr/local/lib/python3.7/dist-packages (from cycler>=0.10->matplotlib>=1.5->pymatgen) (1.15.0)\nRequirement already satisfied: tenacity>=6.2.0 in /usr/local/lib/python3.7/dist-packages (from plotly>=4.5.0->pymatgen) (8.0.1)\nRequirement already satisfied: ruamel.yaml.clib>=0.1.2 in /usr/local/lib/python3.7/dist-packages (from ruamel.yaml>=0.15.6->pymatgen) (0.2.6)\nRequirement already satisfied: future in /usr/local/lib/python3.7/dist-packages (from uncertainties>=3.1.4->pymatgen) (0.16.0)\nRequirement already satisfied: latexcodec>=1.0.4 in /usr/local/lib/python3.7/dist-packages (from pybtex) (2.0.1)\nRequirement already satisfied: PyYAML>=3.01 in /usr/local/lib/python3.7/dist-packages (from pybtex) (3.13)\nRequirement already satisfied: pytz>=2017.2 in /usr/local/lib/python3.7/dist-packages (from pandas->pymatgen) (2018.9)\nRequirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests->pymatgen) (2021.5.30)\nRequirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests->pymatgen) (1.24.3)\nRequirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests->pymatgen) (3.0.4)\nRequirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests->pymatgen) (2.10)\nRequirement already satisfied: mpmath>=0.19 in /usr/local/lib/python3.7/dist-packages (from sympy->pymatgen) (1.2.1)\n"
]
],
[
[
"Next, let us **verify the correct version of *pymatgen* is installed**. This is good practice to do before starting out! For this tutorial we need version 2022.0.14 or above. We also need the `pybtex` package installed.",
"_____no_output_____"
]
],
[
[
"from importlib_metadata import version",
"_____no_output_____"
],
[
"version(\"pymatgen\")",
"_____no_output_____"
]
],
[
[
"# Import and learn about the `OptimadeRester`",
"_____no_output_____"
],
[
"The `OptimadeRester` is a class that is designed to retrieve data from an OPTIMADE provider and automatically convert the data into *pymatgen* `Structure` objects. These `Structure` objects are designed as a good intermediate format for crystallographic structure analysis, transformation and input/output.\n\nYou can read documentation on the `OptimadeRester` here: https://pymatgen.org/pymatgen.ext.optimade.html",
"_____no_output_____"
]
],
[
[
"from pymatgen.ext.optimade import OptimadeRester",
"_____no_output_____"
]
],
[
[
"The first step is to inspect the **documentation** for the `OptimadeRester`. We can run:",
"_____no_output_____"
]
],
[
[
"OptimadeRester?",
"_____no_output_____"
]
],
[
[
"# Understanding \"aliases\" as shortcuts for accessing given providers",
"_____no_output_____"
]
],
[
[
"OptimadeRester.aliases",
"_____no_output_____"
]
],
[
[
"These aliases are useful since they can provide a quick shorthand for a given database without having to remember a full URL.\n\nThis list of aliases is updated periodically. However, new OPTIMADE providers can be made available and will be listed at https://providers.optimade.org. The `OptimadeRester` can query the OPTIMADE providers list to refresh the available aliases.\n\nYou can do this as follows, but be aware this might take a few moments:",
"_____no_output_____"
]
],
[
[
"opt = OptimadeRester()\nopt.refresh_aliases()",
"Connecting to all known OPTIMADE providers, this will be slow. Please connect to only the OPTIMADE providers you want to query. Choose from: aflow, cod, mcloud.2dstructures, mcloud.2dtopo, mcloud.curated-cofs, mcloud.li-ion-conductors, mcloud.optimade-sample, mcloud.pyrene-mofs, mcloud.scdm, mcloud.sssp, mcloud.stoceriaitf, mcloud.tc-applicability, mcloud.threedd, mp, odbx, omdb.omdb_production, oqmd, tcod\n"
]
],
[
[
"# Connecting to one or more OPTIMADE providers\n\nLet's begin by connecting to the Materials Project (`mp`) and Materials Cloud \"3DD\" (`mcloud.threedd`) databases.",
"_____no_output_____"
]
],
[
[
"opt = OptimadeRester([\"mp\", \"mcloud.threedd\"])",
"_____no_output_____"
]
],
[
[
"We can find more information about the OPTIMADE providers we are connected to using the `describe()` method.",
"_____no_output_____"
]
],
[
[
"print(opt.describe())",
"OptimadeRester connected to:\nProvider(name='The Materials Project', base_url='https://optimade.materialsproject.org', description='The Materials Project OPTIMADE endpoint', homepage='https://materialsproject.org', prefix='mp')\nProvider(name='Materials Cloud', base_url='https://aiida.materialscloud.org/3dd/optimade', description='A platform for Open Science built for seamless sharing of resources in computational materials science', homepage='https://materialscloud.org', prefix='mcloud')\n"
]
],
[
[
"# Query for materials: binary nitrides case study\n\n`OptimadeRester` provides an `get_structures` method. **It does not support all features of OPTIMADE filters** but is a good place to get started.\n\nFor this case study, we will search for materials containing nitrogen and that have two elements.",
"_____no_output_____"
]
],
[
[
"results = opt.get_structures(elements=[\"N\"], nelements=2)",
"\n\n\nmp: 2%|▏ | 20/892 [00:00<?, ?it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 4%|▍ | 40/892 [00:00<00:10, 80.59it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 7%|▋ | 60/892 [00:00<00:16, 50.73it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 9%|▉ | 80/892 [00:01<00:15, 52.98it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 11%|█ | 100/892 [00:01<00:13, 57.95it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 13%|█▎ | 120/892 [00:01<00:15, 50.05it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 16%|█▌ | 140/892 [00:02<00:13, 54.44it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 18%|█▊ | 160/892 [00:02<00:13, 54.04it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 20%|██ | 180/892 [00:03<00:14, 47.85it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 22%|██▏ | 200/892 [00:03<00:14, 46.13it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 25%|██▍ | 220/892 [00:04<00:15, 44.63it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 27%|██▋ | 240/892 [00:04<00:14, 43.67it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 29%|██▉ | 260/892 [00:04<00:13, 46.71it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 31%|███▏ | 280/892 [00:05<00:12, 49.17it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 34%|███▎ | 300/892 [00:05<00:12, 46.48it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 36%|███▌ | 320/892 [00:06<00:10, 52.24it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 38%|███▊ | 340/892 [00:06<00:09, 56.87it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 40%|████ | 360/892 [00:06<00:08, 59.89it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 43%|████▎ | 380/892 [00:07<00:09, 52.13it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 45%|████▍ | 400/892 [00:07<00:08, 55.45it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 47%|████▋ | 420/892 [00:07<00:07, 59.55it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 100%|██████████| 892/892 [07:30<00:00, 1.94it/s]\nmcloud.threedd: 100%|██████████| 87/87 [07:13<00:00, 6.02s/it]\nodbx: 100%|██████████| 54/54 [00:30<00:00, 1.11it/s]\n\n\n\nmp: 52%|█████▏ | 460/892 [00:08<00:08, 50.54it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 54%|█████▍ | 480/892 [00:08<00:08, 48.59it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 56%|█████▌ | 500/892 [00:09<00:07, 52.73it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 58%|█████▊ | 520/892 [00:09<00:07, 52.49it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 61%|██████ | 540/892 [00:09<00:06, 56.16it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 63%|██████▎ | 560/892 [00:10<00:06, 55.00it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 65%|██████▌ | 580/892 [00:10<00:05, 58.61it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 67%|██████▋ | 600/892 [00:11<00:05, 57.08it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 70%|██████▉ | 620/892 [00:11<00:04, 56.17it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 72%|███████▏ | 640/892 [00:11<00:04, 58.87it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 74%|███████▍ | 660/892 [00:12<00:04, 56.31it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 76%|███████▌ | 680/892 [00:12<00:03, 58.23it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 78%|███████▊ | 700/892 [00:12<00:03, 60.50it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 81%|████████ | 720/892 [00:12<00:02, 62.29it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 83%|████████▎ | 740/892 [00:13<00:02, 59.05it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 85%|████████▌ | 760/892 [00:13<00:02, 55.66it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 87%|████████▋ | 780/892 [00:14<00:01, 59.02it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 90%|████████▉ | 800/892 [00:14<00:01, 61.37it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 92%|█████████▏| 820/892 [00:14<00:01, 53.02it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 94%|█████████▍| 840/892 [00:15<00:00, 59.87it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 96%|█████████▋| 860/892 [00:15<00:00, 61.36it/s]\u001b[A\u001b[A\u001b[A\n\n\nmp: 99%|█████████▊| 880/892 [00:15<00:00, 62.68it/s]\u001b[A\u001b[A\u001b[A\n\n\nmcloud.threedd: 100%|██████████| 87/87 [00:02<00:00, 32.31it/s]"
]
],
[
[
"We see that the `OptimadeRester` does some of the hard work for us: it automatically retrieves multiple pages of results when many results are available, and also gives us a progress bar.\n\nLet us inspect the `results`:",
"_____no_output_____"
]
],
[
[
"type(results) # this method returns a dictionary, so let's examine the keys of this dictionary...",
"_____no_output_____"
],
[
"results.keys() # we see that the results dictionary is keyed by provider/alias",
"_____no_output_____"
],
[
"results['mp'].keys() # and these are then keyed by that database's unique identifier",
"_____no_output_____"
]
],
[
[
"So let us inspect one structure as an example:",
"_____no_output_____"
]
],
[
[
"example_structure = results['mp']['mp-804']\nprint(example_structure)",
"Full Formula (Ga2 N2)\nReduced Formula: GaN\nabc : 3.216290 3.216290 5.239962\nangles: 90.000000 90.000000 120.000003\nSites (4)\n # SP a b c\n--- ---- -------- -------- -------\n 0 Ga 0.666667 0.333333 0.49912\n 1 Ga 0.333333 0.666667 0.99912\n 2 N 0.666667 0.333333 0.87588\n 3 N 0.333333 0.666667 0.37588\n"
]
],
[
[
"We can then use *pymatgen* to further manipulate these `Structure` objects, for example to calculate the spacegroup or to convert to a CIF:",
"_____no_output_____"
]
],
[
[
"example_structure.get_space_group_info()",
"_____no_output_____"
],
[
"print(example_structure.to(fmt=\"cif\", symprec=0.01))",
"# generated using pymatgen\ndata_GaN\n_symmetry_space_group_name_H-M P6_3mc\n_cell_length_a 3.21629007\n_cell_length_b 3.21629007\n_cell_length_c 5.23996200\n_cell_angle_alpha 90.00000000\n_cell_angle_beta 90.00000000\n_cell_angle_gamma 120.00000000\n_symmetry_Int_Tables_number 186\n_chemical_formula_structural GaN\n_chemical_formula_sum 'Ga2 N2'\n_cell_volume 46.94282137\n_cell_formula_units_Z 2\nloop_\n _symmetry_equiv_pos_site_id\n _symmetry_equiv_pos_as_xyz\n 1 'x, y, z'\n 2 'x-y, x, z+1/2'\n 3 '-y, x-y, z'\n 4 '-x, -y, z+1/2'\n 5 '-x+y, -x, z'\n 6 'y, -x+y, z+1/2'\n 7 'y, x, z+1/2'\n 8 'x, x-y, z'\n 9 'x-y, -y, z+1/2'\n 10 '-y, -x, z'\n 11 '-x, -x+y, z+1/2'\n 12 '-x+y, y, z'\nloop_\n _atom_site_type_symbol\n _atom_site_label\n _atom_site_symmetry_multiplicity\n _atom_site_fract_x\n _atom_site_fract_y\n _atom_site_fract_z\n _atom_site_occupancy\n Ga Ga0 2 0.33333333 0.66666667 0.99912000 1\n N N1 2 0.33333333 0.66666667 0.37588000 1\n\n"
]
],
[
[
"# Data analysis",
"_____no_output_____"
],
[
"This section I will use some code I prepared earlier to summarize the `results` into a tabular format (`DataFrame`).",
"_____no_output_____"
]
],
[
[
"import pandas as pd",
"_____no_output_____"
],
[
"records = []\nfor provider, structures in results.items():\n for identifier, structure in structures.items():\n records.append({\n \"provider\": provider,\n \"identifier\": identifier,\n \"formula\": structure.composition.reduced_formula,\n \"spacegroup\": structure.get_space_group_info()[0],\n \"a_lattice_param\": structure.lattice.a,\n \"volume\": structure.volume,\n })\ndf = pd.DataFrame(records)",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
]
],
[
[
"To pick one specific formula as an example, we can use tools from `pandas` to show the spacegroups present for that formula:",
"_____no_output_____"
]
],
[
[
"df[df[\"formula\"] == \"GaN\"].spacegroup",
"_____no_output_____"
]
],
[
[
"Here, we see that there are a few common high-symmetry spacegroups (such as $P6_3mc$) there are also many low-symmetry structures ($P1$).\n\nI know that in this instance, this is because the $P1$ structures are actually amorphous and not crystalline. This highlights the importance of doing appropraiate **data cleaning** on retrieved data.",
"_____no_output_____"
],
[
"### Plotting data\n\nAs a quick example, we can also plot information in our table:",
"_____no_output_____"
]
],
[
[
"import plotly.express as px",
"_____no_output_____"
],
[
"px.bar(df, x=\"spacegroup\", facet_row=\"provider\")",
"_____no_output_____"
]
],
[
[
"**Remember, there is no single \"best database\" to use. Every database might be constructed for a specific purpose, subject to different biases, with different data qualities and sources.**\n\nThe ideal database for one scientist with one application in mind may be different to the ideal database for another scientist with a different application.\n\n**The power of OPTIMADE is that you can query across multiple databases!**",
"_____no_output_____"
],
[
"# Advanced usage: querying using the OPTIMADE filter grammar",
"_____no_output_____"
],
[
"You can also query using an OPTIMADE filter as defined in the OPTIMADE specification and publication.\n\n**This is recommended** for advanced queries to use the full power of OPTIMADE.\n\nFor example, the above query could have equally been performed as:",
"_____no_output_____"
]
],
[
[
"results = opt.get_structures_with_filter('(elements HAS ALL \"N\") AND (nelements=2)')",
"\nmp: 2%|▏ | 20/892 [00:00<?, ?it/s]\u001b[A\nmp: 4%|▍ | 40/892 [00:00<00:11, 72.90it/s]\u001b[A\nmp: 7%|▋ | 60/892 [00:00<00:11, 72.88it/s]\u001b[A\nmp: 9%|▉ | 80/892 [00:00<00:11, 72.95it/s]\u001b[A\nmp: 11%|█ | 100/892 [00:01<00:12, 65.69it/s]\u001b[A\nmp: 13%|█▎ | 120/892 [00:01<00:14, 54.45it/s]\u001b[A\n\n\nmp: 100%|██████████| 892/892 [00:27<00:00, 47.21it/s]\u001b[A\u001b[A\u001b[A\nmp: 16%|█▌ | 140/892 [00:02<00:13, 54.42it/s]\u001b[A\nmp: 18%|█▊ | 160/892 [00:02<00:13, 54.52it/s]\u001b[A\nmp: 20%|██ | 180/892 [00:02<00:12, 57.95it/s]\u001b[A\nmp: 22%|██▏ | 200/892 [00:02<00:11, 61.80it/s]\u001b[A\nmp: 25%|██▍ | 220/892 [00:03<00:10, 63.65it/s]\u001b[A\nmp: 100%|██████████| 892/892 [00:29<00:00, 29.79it/s]\nmcloud.threedd: 100%|██████████| 87/87 [00:12<00:00, 5.91it/s]\n\nmp: 29%|██▉ | 260/892 [00:03<00:10, 57.87it/s]\u001b[A\nmp: 31%|███▏ | 280/892 [00:04<00:10, 57.30it/s]\u001b[A\nmp: 34%|███▎ | 300/892 [00:04<00:09, 60.09it/s]\u001b[A\nmp: 36%|███▌ | 320/892 [00:04<00:09, 62.86it/s]\u001b[A\nmp: 38%|███▊ | 340/892 [00:05<00:08, 64.44it/s]\u001b[A\nmp: 40%|████ | 360/892 [00:05<00:08, 64.95it/s]\u001b[A\nmp: 43%|████▎ | 380/892 [00:05<00:07, 70.98it/s]\u001b[A\nmp: 45%|████▍ | 400/892 [00:06<00:06, 70.61it/s]\u001b[A\nmp: 47%|████▋ | 420/892 [00:06<00:06, 70.85it/s]\u001b[A\nmp: 49%|████▉ | 440/892 [00:06<00:06, 68.00it/s]\u001b[A\nmp: 52%|█████▏ | 460/892 [00:06<00:06, 69.75it/s]\u001b[A\nmp: 54%|█████▍ | 480/892 [00:07<00:06, 63.08it/s]\u001b[A\nmp: 56%|█████▌ | 500/892 [00:07<00:06, 64.69it/s]\u001b[A\nmp: 58%|█████▊ | 520/892 [00:07<00:05, 65.02it/s]\u001b[A\nmp: 61%|██████ | 540/892 [00:08<00:05, 67.29it/s]\u001b[A\nmp: 63%|██████▎ | 560/892 [00:08<00:05, 62.68it/s]\u001b[A\nmp: 65%|██████▌ | 580/892 [00:08<00:04, 62.63it/s]\u001b[A\nmp: 67%|██████▋ | 600/892 [00:09<00:04, 58.89it/s]\u001b[A\nmp: 70%|██████▉ | 620/892 [00:09<00:04, 57.19it/s]\u001b[A\nmp: 72%|███████▏ | 640/892 [00:09<00:04, 58.50it/s]\u001b[A\nmp: 74%|███████▍ | 660/892 [00:10<00:03, 62.53it/s]\u001b[A\nmp: 76%|███████▌ | 680/892 [00:10<00:03, 54.97it/s]\u001b[A\nmp: 78%|███████▊ | 700/892 [00:10<00:03, 58.01it/s]\u001b[A\nmp: 81%|████████ | 720/892 [00:11<00:02, 60.39it/s]\u001b[A\nmp: 83%|████████▎ | 740/892 [00:11<00:03, 49.75it/s]\u001b[A\nmp: 85%|████████▌ | 760/892 [00:12<00:02, 51.13it/s]\u001b[A\nmp: 87%|████████▋ | 780/892 [00:12<00:02, 55.38it/s]\u001b[A\nmp: 90%|████████▉ | 800/892 [00:12<00:01, 58.72it/s]\u001b[A\nmp: 92%|█████████▏| 820/892 [00:13<00:01, 53.50it/s]\u001b[A\nmp: 94%|█████████▍| 840/892 [00:13<00:00, 56.96it/s]\u001b[A\nmp: 96%|█████████▋| 860/892 [00:13<00:00, 63.27it/s]\u001b[A\nmp: 99%|█████████▊| 880/892 [00:14<00:00, 64.92it/s]\u001b[A\nmcloud.threedd: 100%|██████████| 87/87 [00:02<00:00, 31.86it/s]"
]
],
[
[
"# Advanced usage: retrieving provider-specific property information\n\nThe OPTIMADE specification allows for providers to include database-specific information in the returned data, prefixed by namespace.\n\nTo access this information with *pymatgen* we have to request \"snls\" (`StructureNL`) instead of \"structures\". A `StructureNL` is a `Structure` with additional metadata included, such as the URL it was downloaded from and any of this additional database-specific information.",
"_____no_output_____"
]
],
[
[
"results_snls = OptimadeRester(\"odbx\").get_snls(nelements=2)",
"\n\nodbx: 37%|███▋ | 20/54 [00:00<?, ?it/s]\u001b[A\u001b[A\n\nodbx: 74%|███████▍ | 40/54 [00:00<00:00, 31.84it/s]\u001b[A\u001b[A\n\nodbx: 100%|██████████| 54/54 [00:01<00:00, 27.29it/s]\u001b[A\u001b[A"
],
[
"example_snl = results_snls['odbx']['odbx/2']",
"_____no_output_____"
],
[
"example_snl.data['_optimade']['_odbx_thermodynamics']",
"_____no_output_____"
]
],
[
[
"This extra data provided differs from every database, and sometimes from material to material, so some exploration is required!",
"_____no_output_____"
],
[
"# When Things Go Wrong and How to Get Help\n\nBugs may be present! The `OptimadeRester` is still fairly new.\n\nIf it does not work it is likely because of either:\n\n* A bug in the *pymatgen* code. This may be reported directly to Matthew Horton at [email protected] or an issue can be opened in the *pymatgen* code repository. Matt apologises in advance if this is the case! \n\n* An issue with a provider. This may be because the provider does not yet fully follow the OPTIMADE specification, because the provider is suffering an outage, or because the filters are not yet optimized with that provider.\n\n * If this happens, you may try to first increase the `timeout` value to something larger. The default is too low for some providers.\n\n * Otherwise, you may want to contact the provider directly, or create a post at the OPTIMADE discussion forum: https://matsci.org/optimade\n\n# How to Get Involved\n\nNew developers are very welcome to add code to *pymatgen*! If you want to get involved, help fix bugs or add new features, your help would be very much appreciated. *pymatgen* can only exist and be what it is today thanks to the many efforts of its [development team](https://pymatgen.org/team.html).",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
cb31a3dd7e020ed604e3e6548ea509fe17b20901 | 3,066 | ipynb | Jupyter Notebook | complete_solutions/2019-08-27_sof_57684391.ipynb | Queen9516/stack_overflow | 8862dd7ce172c1fceec8a01d2c55668a03d323df | [
"MIT"
] | 1 | 2021-06-08T01:51:28.000Z | 2021-06-08T01:51:28.000Z | complete_solutions/2019-08-27_sof_57684391.ipynb | Queen9516/stack_overflow | 8862dd7ce172c1fceec8a01d2c55668a03d323df | [
"MIT"
] | null | null | null | complete_solutions/2019-08-27_sof_57684391.ipynb | Queen9516/stack_overflow | 8862dd7ce172c1fceec8a01d2c55668a03d323df | [
"MIT"
] | 2 | 2020-09-14T16:41:06.000Z | 2021-07-06T12:46:54.000Z | 21 | 200 | 0.518265 | [
[
[
"## How to read a variable width white space string table into a panda dataframe?\n\n* [stack overflow link](https://stackoverflow.com/questions/57684391/how-to-read-a-variable-width-white-space-string-table-into-a-panda-dataframe/57684983?noredirect=1#comment101815965_57684983)",
"_____no_output_____"
]
],
[
[
"import requests\nimport pandas as pd\nfrom pathlib import Path\nimport json",
"_____no_output_____"
],
[
"response = requests.get('https://api.weather.gov/products/16a535da-eb2c-4580-9725-b536890e923d')",
"_____no_output_____"
],
[
"fj = Path.cwd() / 'data' / 'weather_57684391.json'\n\nwith fj.open('w') as outfile:\n json.dump(response.json(), outfile)",
"_____no_output_____"
],
[
"data = response.json()['productText']",
"_____no_output_____"
],
[
"data_list = data.split('\\n')",
"_____no_output_____"
],
[
"data_clean = list(filter(lambda x: x != '', data_list))",
"_____no_output_____"
],
[
"f = Path.cwd() / 'data' / 'weather_57684391.csv'",
"_____no_output_____"
],
[
"with f.open(mode='w') as wf:\n count = 0\n for line in data_clean:\n if line.startswith('==='):\n count += 1\n if (count == 2 and not line.startswith('===')) or (line.startswith('DY MAX')):\n wf.write(f'{line}\\n')",
"_____no_output_____"
],
[
"df = pd.read_csv('weather.csv', sep='\\\\s+')",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"data_clean",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb31a6c75e599b90d78a3a1e3f2fcbc8ce55fb71 | 577,097 | ipynb | Jupyter Notebook | Notebooks/CBP-Apprehensions.ipynb | emersoncollective/data-repo-mvp | aebd8b6cb82855d1338e45cc2d32903c1237f489 | [
"MIT"
] | 3 | 2022-03-01T23:08:04.000Z | 2022-03-17T18:59:04.000Z | Notebooks/CBP-Apprehensions.ipynb | emersoncollective/data-repo-mvp | aebd8b6cb82855d1338e45cc2d32903c1237f489 | [
"MIT"
] | 4 | 2022-03-16T15:53:01.000Z | 2022-03-21T17:17:15.000Z | Notebooks/CBP-Apprehensions.ipynb | emersoncollective/data-repo-mvp | aebd8b6cb82855d1338e45cc2d32903c1237f489 | [
"MIT"
] | null | null | null | 245.468737 | 340,240 | 0.901599 | [
[
[
"# U.S. Border Patrol Nationwide Apprehensions by Citizenship and Sector\n**Data Source:** [CBP Apprehensions](https://www.cbp.gov/sites/default/files/assets/documents/2021-Aug/USBORD~3.PDF) <br>\n**Download the Output:** [here](../data/extracted_data/)\n\n\n## Overview\n\nThe source PDF is a large and complex PDF with varying formats across pages. This notebook demonstrates how to extract all data from this PDF into a single structured table. \n\nThough not explored in this notebook there are many other PDFs which could be extracted, including many more that CBP posts on their website. This code can be use to extract data from PDFs, and convert them into a more usable format (either within Python, or a csv).\n\n**See**: dataset source: https://www.cbp.gov/newsroom/media-resources/stats <br>\n\n## Technical Approach\nWe download our PDF of interest and then use [tabula](https://github.com/chezou/tabula-py) and a good deal of custom Python code to process all pages of the PDF into a single structured table that can be used for further analysis. \n\n## Skills Learned\n1. How to download a PDF\n2. How to use tabula to extract data from a complex pdf\n3. How to deal with errors generated in the extraction process\n4. How to clean up and format final output table \n\n\n\n\n## The Code",
"_____no_output_____"
],
[
"**PLEASE NOTE**: We have made this notebook READ only to ensure you receive all updates we make to it. Do not edit this notebook directly, create a copy instead.\n\nTo customize and experiment with this notebook:\n1. Create a copy: `Select File -> Make a Copy` at the top-left of the notebook\n2. Unlock cells in your copy: Press `CMD + A` on your keyboard to select all cells, then click the small unlocked padlock button near the mid-top right of the notebook.\n",
"_____no_output_____"
]
],
[
[
"import logging\nimport logging.config\nfrom pathlib import Path\nimport pandas as pd\nimport requests\nimport tabula\n\nfrom tabula.io import read_pdf\nfrom PyPDF2 import PdfFileReader\n\npd.set_option(\"max_rows\", 400)\n# Below just limits warnings that can be ignored\nlogging.config.dictConfig(\n {\n \"version\": 1,\n \"disable_existing_loggers\": True,\n }\n)",
"_____no_output_____"
]
],
[
[
"---------",
"_____no_output_____"
],
[
"# 1. Download PDF",
"_____no_output_____"
],
[
"Let's first download the [PDF](https://www.cbp.gov/sites/default/files/assets/documents/2021-Aug/USBORD~3.PDF) we want to extract data from. \n\n**Below we pass the:**\n* Path to the pdf file on the internet\n* What we want to call it \n* And the folder we want to save the file to",
"_____no_output_____"
]
],
[
[
"def download_pdf(url, name, output_folder):\n \"\"\"\n Function to download a single pdf file from a provided link.\n\n Parameters:\n url: Url of the file you want to download\n name: name label you want to apply to the file\n output_folder: Folder path to savae file\n\n Returns:\n Saves the file to the output directory, function itself returns nothing.\n\n Example:\n download_pdf(\n 'https://travel.state.gov/content/travel/en/legal/visa-law0/visa-statistics/immigrant-visa-statistics/monthly-immigrant-visa-issuances.html',\n 'July 2020 - IV Issuances by Post and Visa Class',\n 'visa_test/'\n )\n \"\"\"\n output_folder = Path(output_folder)\n response = requests.get(url)\n if response.status_code == 200:\n # Write content in pdf file\n outpath = output_folder / f\"{name}.pdf\"\n pdf = open(str(outpath), \"wb\")\n pdf.write(response.content)\n pdf.close()\n print(\"File \", f\"{name}.pdf\", \" downloaded\")\n else:\n print(\"File \", f\"{name}.pdf\", \" not found.\")",
"_____no_output_____"
]
],
[
[
"Now call our function",
"_____no_output_____"
]
],
[
[
"download_pdf(\n \"https://www.cbp.gov/sites/default/files/assets/documents/2021-Aug/USBORD~3.PDF\", # <- the url\n \"US Border Patrol Nationwide Apps by Citizenship & Sector\", # <- our name for it\n \"../data/raw_source_files/\", # <- Output directory\n)",
"File US Border Patrol Nationwide Apps by Citizenship & Sector.pdf downloaded\n"
]
],
[
[
"**We have now downloaded the file locally**\n\n\nWe will create variable to store path to local PDF file path",
"_____no_output_____"
]
],
[
[
"pdf_path = \"../data/raw_source_files/US Border Patrol Nationwide Apps by Citizenship & Sector.pdf\"",
"_____no_output_____"
]
],
[
[
"## 2. Reviewing the PDF and Preparing to Extract Data\n\n\nThis file is somewhat hard to extract data from. The columns merged fields and sub headings etc. Also if you scroll through the whole file you will see that the table format changes somewhat. Therefore we are going to hardcode the actual columnns we are interested in. Below we see an image of the first table in the pdf. ",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"Since it is hard to capture the correct column names, below we create a variable called `cols` where we save the columns names we will use in our table. These columns refer to citizenship of the person, where they were encountered and different aggregations based on border location (SW, North, Coast). ",
"_____no_output_____"
]
],
[
[
"cols = [\n \"citizenship\",\n \"bbt\",\n \"drt\",\n \"elc\",\n \"ept\",\n \"lrt\",\n \"rgv\",\n \"sdc\",\n \"tca\",\n \"yum\",\n \"sbo_total\", # SBO\n \"blw\",\n \"bun\",\n \"dtm\",\n \"gfn\",\n \"hlt\",\n \"hvm\",\n \"spw\",\n \"swb\",\n \"nbo_total\",\n \"mip\",\n \"nll\",\n \"rmy\",\n \"cbo_total\",\n \"total\",\n]",
"_____no_output_____"
]
],
[
[
"-------",
"_____no_output_____"
],
[
"## 3. Extracting the Data ",
"_____no_output_____"
],
[
"Below we have a bunch of code that will iterate through the PDF pages and extract data. We know this is a lot but suggest reviewing the comments in the code (anything starting with a #) to get a sense of what is going on. ",
"_____no_output_____"
],
[
"**Now run the process**",
"_____no_output_____"
]
],
[
[
"print(\"*Starting Process\")\n\n\ndef fix_header_pages(df):\n df.columns = cols\n df = df.drop([0, 1], axis=0)\n return df\n\n\n# List to store the tables we encounter\ntables = []\n# Dataframe to store table segments\ntable_segments = pd.DataFrame()\n\n# Start on page 1 (PDF is not zero indexed like python but regular indexed .. starts with 1 not 0)\nstart = 1\n# Read the pdf with PdfFileReader to get the number of pages\nstop = PdfFileReader(pdf_path).getNumPages() + 1\n\n# Something to count the number of table swe encounter\ntable_num = -1\nfor page_num in range(start, stop):\n print(f\" **Processing Page: {page_num} of {stop}\")\n new_table = False # New tables are where a new year starts (2007, 2008, etc)\n\n # Extract data using tabula\n df = read_pdf(\n pdf_path, pages=f\"{page_num}\", lattice=True, pandas_options={\"header\": None}\n )[0]\n\n # If it is AFGHANISTAN we have a new table\n if \"AFGHANISTAN\" in df.loc[2][0]:\n new_table = True\n table_num += 1\n\n # If CITIZENSHIP is in the first row - its a header not data so we want to remove\n if \"CITIZENSHIP\" in df.loc[0][0]:\n df = fix_header_pages(df) # Mixed formats in this pdf\n else:\n df.columns = cols\n\n # Check for errors\n check_for_error = df[df.citizenship.str.isdigit()]\n if len(check_for_error) > 0:\n # If there was an error we try to fix it with some special tabula arguments\n fixed = False\n missing_country_df = read_pdf(\n pdf_path,\n pages=f\"{page_num}\",\n stream=True,\n area=(500, 5.65, 570, 5.65 + 800),\n pandas_options={\"header\": None},\n )[0]\n missing_country = missing_country_df.tail(1)[0].squeeze()\n print(\n f\" *** --> ERROR!! pg:{page_num}, country={missing_country}, review table_num={table_num} in tables (list object) - if not fixed automatically\"\n )\n\n if missing_country_df.shape[1] == df.shape[1]:\n fixed = True\n print(\" *** --> --> !! Success - Likely Fixed Automatically\")\n missing_country_df.columns = cols\n df.loc[check_for_error.index[0]] = missing_country_df.iloc[-1]\n if not fixed:\n df.loc[\n check_for_error.index[0], \"citizenship\"\n ] = f\" *** -->ERROR - {missing_country}\"\n\n # Check if new table\n if page_num != start and new_table:\n tables.append(table_segments)\n table_segments = df\n\n else:\n table_segments = table_segments.append(df)\ntables.append(table_segments)\ntables = [table.reset_index(drop=True) for table in tables if len(table) > 0]\n\nprint(\"*Process Complete\")",
"*Starting Process\n **Processing Page: 1 of 43\n **Processing Page: 2 of 43\n **Processing Page: 3 of 43\n **Processing Page: 4 of 43\n **Processing Page: 5 of 43\n **Processing Page: 6 of 43\n **Processing Page: 7 of 43\n **Processing Page: 8 of 43\n **Processing Page: 9 of 43\n **Processing Page: 10 of 43\n **Processing Page: 11 of 43\n **Processing Page: 12 of 43\n **Processing Page: 13 of 43\n **Processing Page: 14 of 43\n **Processing Page: 15 of 43\n **Processing Page: 16 of 43\n **Processing Page: 17 of 43\n **Processing Page: 18 of 43\n **Processing Page: 19 of 43\n **Processing Page: 20 of 43\n **Processing Page: 21 of 43\n **Processing Page: 22 of 43\n **Processing Page: 23 of 43\n **Processing Page: 24 of 43\n **Processing Page: 25 of 43\n **Processing Page: 26 of 43\n **Processing Page: 27 of 43\n **Processing Page: 28 of 43\n **Processing Page: 29 of 43\n **Processing Page: 30 of 43\n **Processing Page: 31 of 43\n **Processing Page: 32 of 43\n **Processing Page: 33 of 43\n **Processing Page: 34 of 43\n **Processing Page: 35 of 43\n *** --> ERROR!! pg:35, country=SYRIA, review table_num=11 in tables (list object) - if not fixed automatically\n **Processing Page: 36 of 43\n **Processing Page: 37 of 43\n *** --> ERROR!! pg:37, country=IRELAND, review table_num=12 in tables (list object) - if not fixed automatically\n *** --> --> !! Success - Likely Fixed Automatically\n **Processing Page: 38 of 43\n *** --> ERROR!! pg:38, country=UNKNOWN, review table_num=12 in tables (list object) - if not fixed automatically\n **Processing Page: 39 of 43\n **Processing Page: 40 of 43\n **Processing Page: 41 of 43\n **Processing Page: 42 of 43\n*Process Complete\n"
]
],
[
[
"### Manual Fixes\nAbove, we see that there were 3 errors. \n\n1. pg: 35, Syria\n2. pg: 37, Ireland\n3. pg: 38, Unknown\n\nWe were able to fix `#2` automatically but `#1` and `#3` need manual correction. \n\nIf you are wondering why these were not collected correctly it is because on pg 35, 37 and 38 the table is missing a strong black line at the bottom of the table. \n\nTabula uses strong lines to differentiate data from other parts of the pdf. Below we see the pg 35, Syria example.\n\nIreland was fixed automatically by using some different arguments for the python tabula package. In that instance it worked and allowed for automatically correcting the data, for Syria and Unknown though it was not successful. ",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"We can examine the actual data by reviweing the table in the `tables` list. ",
"_____no_output_____"
]
],
[
[
"example = tables[12].reset_index()\nexample.iloc[117:120]",
"_____no_output_____"
]
],
[
[
"Above we look at table `#12` which referes to FY2018, and specifically the end of page 35 and the beginning of page 36. We see that SYRIA has no information. But if we look at the pdf (see image above) it does have information. \n\nTherefore we will have to correct this manually.\n",
"_____no_output_____"
],
[
"**Below is just a list of values that provides the information that was not collected for Syria on pg 35**",
"_____no_output_____"
]
],
[
[
"syria_correct = [\n \"SYRIA\",\n 0,\n 0,\n 0,\n 1,\n 2,\n 0,\n 0,\n 0,\n 0,\n 3,\n 0,\n 0,\n 0,\n 0,\n 0,\n 0,\n 0,\n 0,\n 0,\n 0,\n 0,\n 0,\n 0,\n 3,\n]\nlen(syria_correct)",
"_____no_output_____"
]
],
[
[
"**And then the Unknown countries for page 38**",
"_____no_output_____"
]
],
[
[
"unknown_correct = [\n \"UNNKOWN\",\n 0,\n 1,\n 0,\n 0,\n 0,\n 0,\n 0,\n 0,\n 0,\n 1,\n 0,\n 0,\n 0,\n 0,\n 0,\n 0,\n 0,\n 0,\n 0,\n 0,\n 0,\n 0,\n 0,\n 1,\n]\nlen(unknown_correct)",
"_____no_output_____"
]
],
[
[
"**We grab the table and then assign the correct data to that row**",
"_____no_output_____"
],
[
"Fix Syria",
"_____no_output_____"
]
],
[
[
"# the value assigned to tbl_index corresponds to the table_num value shown in our error message for each country\ntbl_index = 11\ntables[tbl_index].loc[\n tables[tbl_index][tables[tbl_index].citizenship.str.contains(\"SYRIA\")].index[0]\n] = syria_correct",
"_____no_output_____"
]
],
[
[
"Fix Unkown",
"_____no_output_____"
]
],
[
[
"tbl_index = 12\ntables[tbl_index].loc[\n tables[tbl_index][tables[tbl_index].citizenship.str.contains(\"UNKNOWN\")].index[0]\n] = unknown_correct",
"_____no_output_____"
]
],
[
[
"-----------",
"_____no_output_____"
],
[
"## 4. Clean Up Tables",
"_____no_output_____"
],
[
"We need to remove commas from numbers and convert string numbers to actual integer values. Below we can see that there are many cell values with `,` present. ",
"_____no_output_____"
]
],
[
[
"tables[0][tables[0].total.str.contains(\",\")]",
"_____no_output_____"
]
],
[
[
" We will also create a dictionary with the cleaned tables and better labels",
"_____no_output_____"
]
],
[
[
"# Get just the specific station/crossing columns (not totals)\nstation_cols = [\n i\n for i in cols\n if i not in [\"citizenship\", \"sbo_total\", \"nbo_total\", \"cbo_total\", \"total\"]\n]\n\ntotal_cols = [\"sbo_total\", \"nbo_total\", \"cbo_total\", \"total\"]\n\n\ndef clean_tables(df):\n df = df.fillna(0).reset_index(drop=True)\n df[\"total\"] = [\n int(i.replace(\",\", \"\")) if isinstance(i, str) else i for i in df[\"total\"]\n ]\n for c in station_cols + total_cols:\n df.loc[:, c] = [\n int(i.replace(\",\", \"\")) if isinstance(i, str) else i for i in df[c]\n ]\n\n return df",
"_____no_output_____"
],
[
"data = {\n f\"total_apprehensions_FY{idx+7:02}\": clean_tables(df)\n for idx, df in enumerate(tables)\n}",
"_____no_output_____"
]
],
[
[
"**Here are the keys in the dictionary - they relate to the specific `FY-Year` of the data**",
"_____no_output_____"
]
],
[
[
"data.keys()",
"_____no_output_____"
]
],
[
[
"**Sanity Check**",
"_____no_output_____"
],
[
"We can compare the `TOTAL` column to the actual summed row totals to see if the data was extracted correctly",
"_____no_output_____"
]
],
[
[
"table_name = \"total_apprehensions_FY19\"\ntotals = data[table_name].query('citizenship == \"TOTAL\"')\npd.concat(\n [data[table_name].query('citizenship != \"TOTAL\"').sum(axis=0), totals.T], axis=1\n)",
"_____no_output_____"
]
],
[
[
"Looks pretty good! ",
"_____no_output_____"
],
[
"## Combine the data into a single dataframe",
"_____no_output_____"
],
[
"We will create a single dataframe but will add two columns, one (`label`) that will store the file key, and two (`year`) the fiscal year. ",
"_____no_output_____"
]
],
[
[
"combined = pd.DataFrame()\nfor k in data:\n tmp = data[k]\n tmp[\"label\"] = k\n combined = combined.append(tmp)",
"_____no_output_____"
],
[
"combined[\"year\"] = combined.label.apply(lambda x: int(f\"20{x[-2:]}\"))",
"_____no_output_____"
],
[
"combined",
"_____no_output_____"
],
[
"combined.citizenship = [str(i) for i in combined.citizenship]",
"_____no_output_____"
]
],
[
[
"**Export file to csv**",
"_____no_output_____"
]
],
[
[
"combined.to_csv(\"../data/extracted_data/cbp-apprehensions-nov2021.csv\")",
"_____no_output_____"
]
],
[
[
"-----------",
"_____no_output_____"
],
[
"# Appendix ",
"_____no_output_____"
],
[
"## Visualizations",
"_____no_output_____"
],
[
"### Sample Visualization ",
"_____no_output_____"
],
[
"Now that we have the data in a usable format, we can also visualize the data. One visualization we can make is a graph of apprehensions by citizenship.",
"_____no_output_____"
]
],
[
[
"pd.pivot(\n index=\"year\",\n columns=\"citizenship\",\n values=\"total\",\n data=combined[\n combined.citizenship.isin(\n combined.groupby(\"citizenship\")\n .sum()\n .sort_values(\"total\", ascending=False)\n .head(6)\n .index.tolist()\n )\n ],\n).plot(\n figsize=(15, 8),\n marker=\"o\",\n color=[\"yellow\", \"red\", \"blue\", \"black\", \"gray\", \"orange\"],\n title=\"FY07-19 Total Apprehensions by Citizenship at US Borders\",\n)",
"_____no_output_____"
]
],
[
[
"# End",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
cb31b7faafd6c7ffdeca6878705c302954626fe9 | 14,272 | ipynb | Jupyter Notebook | Lecture06_ProbGenModels/Lecture 06 - Probabilistic Generative Models.ipynb | jbocinsky/LectureNotes | 762b1ec87fa4e951af0628a3749063f09647fa12 | [
"MIT"
] | 1 | 2021-09-30T04:58:59.000Z | 2021-09-30T04:58:59.000Z | Lecture06_ProbGenModels/Lecture 06 - Probabilistic Generative Models.ipynb | jbocinsky/LectureNotes | 762b1ec87fa4e951af0628a3749063f09647fa12 | [
"MIT"
] | 1 | 2018-10-16T22:02:31.000Z | 2018-10-16T22:02:31.000Z | Lecture06_ProbGenModels/Lecture 06 - Probabilistic Generative Models.ipynb | jbocinsky/LectureNotes | 762b1ec87fa4e951af0628a3749063f09647fa12 | [
"MIT"
] | 1 | 2021-09-30T04:59:06.000Z | 2021-09-30T04:59:06.000Z | 46.187702 | 1,255 | 0.624369 | [
[
[
"# FAQs for Regression, MAP and MLE",
"_____no_output_____"
],
[
"* So far we have focused on regression. We began with the polynomial regression example where we have training data $\\mathbf{X}$ and associated training labels $\\mathbf{t}$ and we use these to estimate weights, $\\mathbf{w}$ to fit a polynomial curve through the data: \n\\begin{equation}\ny(x, \\mathbf{w}) = \\sum_{j=0}^M w_j x^j\n\\end{equation}\n\n* We derived how to estimate the weights using both maximum likelihood estimation (MLE) and maximum a-posteriori estimation (MAP). \n\n* Then, last class we said that we can generalize this further using basis functions (instead of only raising x to the jth power): \n\\begin{equation}\ny(x, \\mathbf{w}) = \\sum_{j=0}^M w_j \\phi_j(x)\n\\end{equation}\nwhere $\\phi_j(\\cdot)$ is any basis function you choose to use on the data. \n\n\n* *Why is regression useful?* \n * Regression is a common type of machine learning problem where we want to map inputs to a value (instead of a class label). For example, the example we used in our first class was mapping silhouttes of individuals to their age. So regression is an important technique whenever you want to map from a data set to another value of interest. *Can you think of other examples of regression problems?*\n \n \n* *Why would I want to use other basis functions?*\n * So, we began with the polynomial curve fitting example just so we can have a concrete example to work through but polynomial curve fitting is not the best approach for every problem. You can think of the basis functions as methods to extract useful features from your data. For example, if it is more useful to compute distances between data points (instead of raising each data point to various powers), then you should do that instead! \n \n \n* *Why did we go through all the math derivations? You could've just provided the MLE and MAP solution to us since that is all we need in practice to code this up.* \n * In practice, you may have unique requirements for a particular problem and will need to decide upon and set up a different data likelihood and prior for a problem. For example, we assumed Gaussian noise for our regression example with a Gaussian zero-mean prior on the weights. You may have an application in which you know the noise is Gamma disributed and have other requirements for the weights that you want to incorporate into the prior. Knowing the process used to derive the estimate for weights in this case is a helpful guide for deriving your solution. (Also, on a practical note for the course, stepping through the math served as a quick review of various linear algebra, calculus and statistics topics that will be useful throughout the course.) \n \n \n* *What is overfitting and why is it bad?* \n * The goal of a supervised machine learning algorithm is to be able to learn a mapping from inputs to desired outputs from training data. When you overfit, you memorize your training data such that you can recreate the samples perfectly. This often comes about when you have a model that is more complex than your underlying true model and/or you do not have the data to support such a complex model. However, you do this at the cost of generalization. When you overfit, you do very well on training data but poorly on test (or unseen) data. So, to have useful trained machine learning model, you need to avoid overfitting. You can avoid overfitting through a number of ways. The methods we discussed in class are using *enough* data and regularization. Overfitting is related to the \"bias-variance trade-off\" (discussed in section 3.2 of the reading). There is a trade-off between bias and variance. Complex models have low bias and high variance (which is another way of saying, they fit the training data very well but may oscillate widely between training data points) where as rigid (not-complex-enough) models have high bias and low variance (they do not oscillate widely but may not fit the training data very well either). \n \n \n* *What is the goal of MLE and MAP?*\n * MLE and MAP are general approaches for estimating parameter values. For example, you may have data from some unknown distribution that you would like to model as best you can with a Gaussian distribution. You can use MLE or MAP to estimate the Gaussian parameters to fit the data and determine your estimate at what the true (but unknown) distribution is. \n \n \n* *Why would you use MAP over MLE (or vice versa)?* \n * As we saw in class, MAP is a method to add in other terms to trade off against the data likelihood during optimization. It is a mechanism to incorporate our \"prior belief\" about the parameters. In our example in class, we used the MAP solution for the weights in regression to help prevent overfitting by imposing the assumptions that the weights should be small in magnitude. When you have enough data, the MAP and the MLE solution converge to the same solution. The amount of data you need for this to occur varies based on how strongly you impose the prior (which is done using the variance of the prior distribution). ",
"_____no_output_____"
],
[
"# Probabilistic Generative Models\n\n* So far we have focused on regression. Today we will begin to discuss classification. \n* Suppose we have training data from two classes, $C_1$ and $C_2$, and we would like to train a classifier to assign a label to incoming test points whether they belong to class 1 or 2. \n* There are *many* classifiers in the machine learning literature. We will cover a few in this class. Today we will focus on probabilistic generative approaches for classification. \n* A *generative* approach for classification is one in which we estimate the parameters for distributions that generate the data for each class. Then, when we have a test point, we can compute the posterior probability of that point belonging to each class and assign the point to the class with the highest posterior probability. ",
"_____no_output_____"
]
],
[
[
"import numpy as np \nimport matplotlib.pyplot as plt\nfrom scipy.stats import multivariate_normal\n%matplotlib inline \n\nmean1 = [-1.5, -1]\nmean2 = [1, 1]\ncov1 = [[1,0], [0,2]]\ncov2 = [[2,.1],[.1,.2]]\nN1 = 250\nN2 = 100\n\ndef generateData(mean1, mean2, cov1, cov2, N1=100, N2=100):\n # We are generating data from two Gaussians to represent two classes. \n # In practice, we would not do this - we would just have data from the problem we are trying to solve. \n class1X = np.random.multivariate_normal(mean1, cov1, N1)\n class2X = np.random.multivariate_normal(mean2, cov2, N2)\n \n fig = plt.figure()\n ax = fig.add_subplot(*[1,1,1])\n ax.scatter(class1X[:,0], class1X[:,1], c='r') \n ax.scatter(class2X[:,0], class2X[:,1]) \n plt.show()\n return class1X, class2X\n \nclass1X, class2X = generateData(mean1, mean2,cov1,cov2, N1,N2)",
"_____no_output_____"
]
],
[
[
"In the data we generated above, we have a \"red\" class and a \"blue\" class. When we are given a test sample, we will want to assign the label of either red or blue. \n\nWe can compute the posterior probability for class $C_1$ as follows:\n\n\\begin{eqnarray}\np(C_1 | x) &=& \\frac{p(x|C_1)p(C_1)}{p(x)}\\\\\n &=& \\frac{p(x|C_1)p(C_1)}{p(x|C_1)p(C_1) + p(x|C_2)p(C_2)}\\\\\n\\end{eqnarray}\n\nWe can similarly compute the posterior probability for class $C_2$: \n\n\\begin{eqnarray}\np(C_2 | x) &=& \\frac{p(x|C_2)p(C_2)}{p(x|C_1)p(C_1) + p(x|C_2)p(C_2)}\\\\\n\\end{eqnarray}\n\nNote that $p(C_1|x) + p(C_2|x) = 1$. \n\nSo, to train the classifier, what we need is to determine the parametric forms and estimate the parameters for $p(x|C_1)$, $p(x|C_2)$, $p(C_1)$ and $p(C_2)$. \n\nFor example, we can assume that the data from both $C_1$ and $C_2$ are distributed according to Gaussian distributions. In this case,\n\\begin{eqnarray}\np(\\mathbf{x}|C_k) = \\frac{1}{(2\\pi)^{1/2}}\\frac{1}{|\\Sigma|^{1/2}}\\exp\\left\\{ - \\frac{1}{2} (\\mathbf{x}-\\mu_k)^T\\Sigma_k^{-1}(\\mathbf{x}-\\mu_k)\\right\\}\n\\end{eqnarray}\n\nGiven the assumption of the Gaussian form, how would you estimate the parameter for $p(x|C_1)$ and $p(x|C_2)$? *You can use maximum likelihood estimate for the mean and covariance!* \n\nThe MLE estimate for the mean of class $C_k$ is: \n\\begin{eqnarray}\n\\mu_{k,MLE} = \\frac{1}{N_k} \\sum_{n \\in C_k} \\mathbf{x}_n\n\\end{eqnarray}\nwhere $N_k$ is the number of training data points that belong to class $C_k$\n\nThe MLE estimate for the covariance of class $C_k$ is: \n\\begin{eqnarray}\n\\Sigma_k = \\frac{1}{N_k} \\sum_{n \\in C_k} (\\mathbf{x}_n - \\mu_{k,MLE})(\\mathbf{x}_n - \\mu_{k,MLE})^T\n\\end{eqnarray}\n\nWe can determine the values for $p(C_1)$ and $p(C_2)$ from the number of data points in each class:\n\\begin{eqnarray}\np(C_k) = \\frac{N_k}{N}\n\\end{eqnarray}\nwhere $N$ is the total number of data points. \n\n",
"_____no_output_____"
]
],
[
[
"#Estimate the mean and covariance for each class from the training data\nmu1 = np.mean(class1X, axis=0)\nprint(mu1)\n\ncov1 = np.cov(class1X.T)\nprint(cov1)\n\nmu2 = np.mean(class2X, axis=0)\nprint(mu2)\n\ncov2 = np.cov(class2X.T)\nprint(cov2)\n\n# Estimate the prior for each class\npC1 = class1X.shape[0]/(class1X.shape[0] + class2X.shape[0])\nprint(pC1)\n\npC2 = class2X.shape[0]/(class1X.shape[0] + class2X.shape[0])\nprint(pC2)",
"[-1.4463101 -1.05228092]\n[[ 1.02951348 0.03276955]\n [ 0.03276955 2.03127459]]\n[ 1.06117615 0.94563646]\n[[ 2.38426029 0.09798675]\n [ 0.09798675 0.15495013]]\n0.7142857142857143\n0.2857142857142857\n"
],
[
"#We now have all parameters needed and can compute values for test samples\nfrom scipy.stats import multivariate_normal\n\nx = np.linspace(-5, 4, 100)\ny = np.linspace(-6, 6, 100)\nxm,ym = np.meshgrid(x, y)\nX = np.dstack([xm,ym])\n\n#look at the pdf for class 1\ny1 = multivariate_normal.pdf(X, mean=mu1, cov=cov1)\nplt.imshow(y1)\n",
"_____no_output_____"
],
[
"#look at the pdf for class 2\ny2 = multivariate_normal.pdf(X, mean=mu2, cov=cov2);\nplt.imshow(y2)",
"_____no_output_____"
],
[
"#Look at the posterior for class 1\npos1 = (y1*pC1)/(y1*pC1 + y2*pC2 );\nplt.imshow(pos1)",
"_____no_output_____"
],
[
"#Look at the posterior for class 2\npos2 = (y2*pC2)/(y1*pC1 + y2*pC2 );\nplt.imshow(pos2)",
"_____no_output_____"
],
[
"#Look at the decision boundary\nplt.imshow(pos1>pos2)",
"_____no_output_____"
]
],
[
[
"*How did we come up with using the MLE solution for the mean and variance? How did we determine how to compute $p(C_1)$ and $p(C_2)$?\n\n* We can define a likelihood for this problem and maximize it!\n\n\\begin{eqnarray}\np(\\mathbf{t}, \\mathbf{X}|\\pi, \\mu_1, \\mu_2, \\Sigma_1, \\Sigma_2) = \\prod_{n=1}^N \\left[\\pi N(x_n|\\mu_1, \\Sigma_1)\\right]^{t_n}\\left[(1-\\pi)N(x_n|\\mu_2, \\Sigma_2) \\right]^{1-t_n}\n\\end{eqnarray}\n\n* *How would we maximize this?* As usual, we would use our \"trick\" and take the log of the likelihood function. Then, we would take the derivative with respect to each parameter we are interested in, set the derivative to zero, and solve for the parameter of interest. ",
"_____no_output_____"
],
[
"## Reading Assignment: Read Section 4.2 and Section 2.5.2",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
cb31ced0853322eff96bd66864081d1f019a03a5 | 180,812 | ipynb | Jupyter Notebook | docs/deep_learning/boosting_models_pytorch/(inc)_overfitting.ipynb | sofiendhouib/deep-learning-wizard | 7857e8363ffc3241f984860265feabce8a87ddc4 | [
"MIT"
] | 506 | 2018-07-06T07:50:00.000Z | 2022-03-30T05:53:55.000Z | docs/deep_learning/boosting_models_pytorch/(inc)_overfitting.ipynb | sofiendhouib/deep-learning-wizard | 7857e8363ffc3241f984860265feabce8a87ddc4 | [
"MIT"
] | 5 | 2021-01-13T02:44:44.000Z | 2022-02-06T10:07:46.000Z | docs/deep_learning/boosting_models_pytorch/(inc)_overfitting.ipynb | sofiendhouib/deep-learning-wizard | 7857e8363ffc3241f984860265feabce8a87ddc4 | [
"MIT"
] | 191 | 2018-11-09T07:52:06.000Z | 2022-03-28T05:15:25.000Z | 118.100588 | 8,172 | 0.839358 | [
[
[
"# 7. Overfitting Prevention",
"_____no_output_____"
],
[
"## Why do we need to solve overfitting? \n- To increase the generalization ability of our deep learning algorithms\n- Able to make predictions well for out-of-sample data ",
"_____no_output_____"
],
[
"## Overfitting and Underfitting: Examples",
"_____no_output_____"
],
[
"\n- **_This is an example from scikit-learn's website where you can easily (but shouldn't waste time) recreate via matplotlib :)_**\n\n#### Degree 1: underfitting\n- Insufficiently fits data\n - High training loss\n- Unable to represent the true function\n - Bad generalization ability\n - Low testing accuracy\n \n#### Degree 4: \"goodfitting\"\n- Sufficiently fits data\n - Low training loss\n- Able to represent the true function\n - Good generalization ability\n - High testing accuracy\n \n#### Degree 15: overfitting\n- Overfits data\n - Very low to zero training loss\n- Unable to represent the true function\n - Bad generalization ability\n - Low testing accuracy",
"_____no_output_____"
],
[
"## Overfitting and Underfitting: Learning Curves\n- Separate training/testing datasets\n- Understand generalization ability through the learning curve\n",
"_____no_output_____"
],
[
"#### Underfitting: High Bias\n- Training/testing errors converged at a high level\n - More data does not help\n - Model has insufficient representational capacity $\\rightarrow$ unable to represent underlying function\n - Poor data fit (high training error)\n - Poor generalization (high testing error)\n- Solution\n - Increase model's complexity/capacity\n - More layers\n - Larger hidden states\n \n#### Overfitting: High Variance\n- Training/testing errors converged with a large gap between\n - Excessive data fit (almost 0 training error)\n - Poor generalization (high testing error)\n- Solutions\n - Decrease model complexity\n - More data\n \n#### Goodfitting\n- Training/testing errors converged with very small gap at a low error level\n - Good data fit (low training error; not excessively low)\n - Good generalization (low testing error)",
"_____no_output_____"
],
[
"## Solving Overfitting\n- Data augmentation (more data) \n- Early stopping\n- Regularization: any changes to the learning algorithm to reduce testing error, not training error\n - Weight decay (L2 regularization)\n - Dropout \n - Batch Normalization",
"_____no_output_____"
],
[
"## Overfitting Solution 1: Data Augmentation\n- Expanding the existing dataset, MNIST (28x28 images)\n- Works for most if not all image datasets (CIFAR-10, CIFAR-100, SVHN, etc.)",
"_____no_output_____"
],
[
"### Centre Crop: 28 pixels",
"_____no_output_____"
]
],
[
[
"import torch\nimport torch.nn as nn\nimport torchvision.transforms as transforms\nimport torchvision.datasets as dsets\nfrom torch.autograd import Variable\n\n# Set seed\ntorch.manual_seed(0)\n\n\n'''\nSTEP 0: CREATE TRANSFORMATIONS\n'''\n\ntransform = transforms.Compose([\n transforms.CenterCrop(28),\n transforms.ToTensor(),\n ])\n\n\n'''\nSTEP 1: LOADING DATASET\n'''\n\ntrain_dataset = dsets.MNIST(root='./data', \n train=True, \n #transform=transforms.ToTensor(),\n transform=transform,\n download=True)\n\ntrain_dataset_orig = dsets.MNIST(root='./data', \n train=True, \n transform=transforms.ToTensor(),\n download=True)\n\n'''\nSTEP 2: MAKING DATASET ITERABLE\n'''\n\nbatch_size = 100\nn_iters = 3000\nnum_epochs = n_iters / (len(train_dataset) / batch_size)\nnum_epochs = int(num_epochs)\n\ntrain_loader = torch.utils.data.DataLoader(dataset=train_dataset, \n batch_size=batch_size, \n shuffle=True)\n\n\ntrain_loader_orig = torch.utils.data.DataLoader(dataset=train_dataset_orig, \n batch_size=batch_size, \n shuffle=True)",
"Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz\nDownloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz\nDownloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz\nDownloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz\nProcessing...\nDone!\n"
],
[
"import matplotlib.pyplot as plt\n%matplotlib inline\n\nfor i, (images, labels) in enumerate(train_loader):\n torch.manual_seed(0)\n # Transformed image\n plt.imshow(images.numpy()[i][0], cmap='gray')\n plt.title('Transformed image')\n plt.show()\n \n if i == 1:\n break\n \nfor i, (images, labels) in enumerate(train_loader_orig):\n torch.manual_seed(0)\n # Transformed image\n plt.imshow(images.numpy()[i][0], cmap='gray')\n plt.title('Original image')\n plt.show()\n \n if i == 1:\n break",
"_____no_output_____"
]
],
[
[
"### Centre Crop: 22 pixels",
"_____no_output_____"
]
],
[
[
"import torch\nimport torch.nn as nn\nimport torchvision.transforms as transforms\nimport torchvision.datasets as dsets\n\n# Set seed\ntorch.manual_seed(0)\n\n\n'''\nSTEP 0: CREATE TRANSFORMATIONS\n'''\n\ntransform = transforms.Compose([\n transforms.CenterCrop(22),\n transforms.ToTensor(),\n ])\n\n\n'''\nSTEP 1: LOADING DATASET\n'''\n\ntrain_dataset = dsets.MNIST(root='./data', \n train=True, \n #transform=transforms.ToTensor(),\n transform=transform,\n download=True)\n\ntrain_dataset_orig = dsets.MNIST(root='./data', \n train=True, \n transform=transforms.ToTensor(),\n download=True)\n\n'''\nSTEP 2: MAKING DATASET ITERABLE\n'''\n\nbatch_size = 100\nn_iters = 3000\nnum_epochs = n_iters / (len(train_dataset) / batch_size)\nnum_epochs = int(num_epochs)\n\ntrain_loader = torch.utils.data.DataLoader(dataset=train_dataset, \n batch_size=batch_size, \n shuffle=True)\n\n\ntrain_loader_orig = torch.utils.data.DataLoader(dataset=train_dataset_orig, \n batch_size=batch_size, \n shuffle=True)",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\n%matplotlib inline\n\nfor i, (images, labels) in enumerate(train_loader):\n torch.manual_seed(0)\n # Transformed image\n plt.imshow(images.numpy()[i][0], cmap='gray')\n plt.title('Transformed image')\n plt.show()\n \n if i == 1:\n break\n \nfor i, (images, labels) in enumerate(train_loader_orig):\n torch.manual_seed(0)\n # Transformed image\n plt.imshow(images.numpy()[i][0], cmap='gray')\n plt.title('Original image')\n plt.show()\n \n if i == 1:\n break",
"_____no_output_____"
]
],
[
[
"### Random Crop: 22 pixels",
"_____no_output_____"
]
],
[
[
"import torch\nimport torch.nn as nn\nimport torchvision.transforms as transforms\nimport torchvision.datasets as dsets\n\n# Set seed\ntorch.manual_seed(0)\n\n\n'''\nSTEP 0: CREATE TRANSFORMATIONS\n'''\n\ntransform = transforms.Compose([\n transforms.RandomCrop(22),\n transforms.ToTensor(),\n ])\n\n\n'''\nSTEP 1: LOADING DATASET\n'''\n\ntrain_dataset = dsets.MNIST(root='./data', \n train=True, \n #transform=transforms.ToTensor(),\n transform=transform,\n download=True)\n\ntrain_dataset_orig = dsets.MNIST(root='./data', \n train=True, \n transform=transforms.ToTensor(),\n download=True)\n\n'''\nSTEP 2: MAKING DATASET ITERABLE\n'''\n\nbatch_size = 100\nn_iters = 3000\nnum_epochs = n_iters / (len(train_dataset) / batch_size)\nnum_epochs = int(num_epochs)\n\ntrain_loader = torch.utils.data.DataLoader(dataset=train_dataset, \n batch_size=batch_size, \n shuffle=True)\n\n\ntrain_loader_orig = torch.utils.data.DataLoader(dataset=train_dataset_orig, \n batch_size=batch_size, \n shuffle=True)",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\n%matplotlib inline\n\nfor i, (images, labels) in enumerate(train_loader):\n torch.manual_seed(0)\n # Transformed image\n plt.imshow(images.numpy()[i][0], cmap='gray')\n plt.title('Transformed image')\n plt.show()\n \n if i == 1:\n break\n \nfor i, (images, labels) in enumerate(train_loader_orig):\n torch.manual_seed(0)\n # Transformed image\n plt.imshow(images.numpy()[i][0], cmap='gray')\n plt.title('Original image')\n plt.show()\n \n if i == 1:\n break",
"_____no_output_____"
]
],
[
[
"### Random Horizontal Flip: p=0.5",
"_____no_output_____"
]
],
[
[
"import torch\nimport torch.nn as nn\nimport torchvision.transforms as transforms\nimport torchvision.datasets as dsets\n\n# Set seed\ntorch.manual_seed(0)\n\n\n'''\nSTEP 0: CREATE TRANSFORMATIONS\n'''\n\ntransform = transforms.Compose([\n transforms.RandomHorizontalFlip(),\n transforms.ToTensor(),\n ])\n\n\n'''\nSTEP 1: LOADING DATASET\n'''\n\ntrain_dataset = dsets.MNIST(root='./data', \n train=True, \n #transform=transforms.ToTensor(),\n transform=transform,\n download=True)\n\ntrain_dataset_orig = dsets.MNIST(root='./data', \n train=True, \n transform=transforms.ToTensor(),\n download=True)\n\n'''\nSTEP 2: MAKING DATASET ITERABLE\n'''\n\nbatch_size = 100\nn_iters = 3000\nnum_epochs = n_iters / (len(train_dataset) / batch_size)\nnum_epochs = int(num_epochs)\n\ntrain_loader = torch.utils.data.DataLoader(dataset=train_dataset, \n batch_size=batch_size, \n shuffle=True)\n\n\ntrain_loader_orig = torch.utils.data.DataLoader(dataset=train_dataset_orig, \n batch_size=batch_size, \n shuffle=True)",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\n%matplotlib inline\n\nfor i, (images, labels) in enumerate(train_loader):\n torch.manual_seed(0)\n # Transformed image\n plt.imshow(images.numpy()[i][0], cmap='gray')\n plt.title('Transformed image')\n plt.show()\n \n if i == 3:\n break\n \nfor i, (images, labels) in enumerate(train_loader_orig):\n torch.manual_seed(0)\n # Transformed image\n plt.imshow(images.numpy()[i][0], cmap='gray')\n plt.title('Original image')\n plt.show()\n \n if i == 3:\n break",
"_____no_output_____"
]
],
[
[
"### Normalization\n- Not augmentation, but required for our initializations to have constant variance (Xavier/He)\n - We assumed inputs/weights drawn i.i.d. with Gaussian distribution of mean=0\n- We can normalize by calculating the mean and standard deviation of each channel\n - MNIST only 1 channel, black\n - 1 mean, 1 standard deviation\n- Once we've the mean/std $\\rightarrow$ normalize our images to have zero mean\n - $X = \\frac{X - mean}{std}$\n - X: 28 by 28 pixels (1 channel, grayscale)",
"_____no_output_____"
]
],
[
[
"import torch\nimport torch.nn as nn\nimport torchvision.transforms as transforms\nimport torchvision.datasets as dsets\n\n# Set seed\ntorch.manual_seed(0)\n\n\n'''\nSTEP 0: CREATE TRANSFORMATIONS\n'''\n\ntransform = transforms.Compose([\n transforms.ToTensor(),\n # Normalization always after ToTensor and all transformations\n transforms.Normalize((0.1307,), (0.3081,)),\n ])\n\n\n'''\nSTEP 1: LOADING DATASET\n'''\n\ntrain_dataset = dsets.MNIST(root='./data', \n train=True, \n #transform=transforms.ToTensor(),\n transform=transform,\n download=True)\n\n'''\nSTEP 2: MAKING DATASET ITERABLE\n'''\n\nbatch_size = 100\nn_iters = 3000\nnum_epochs = n_iters / (len(train_dataset) / batch_size)\nnum_epochs = int(num_epochs)\n\ntrain_loader = torch.utils.data.DataLoader(dataset=train_dataset, \n batch_size=batch_size, \n shuffle=True)\n",
"_____no_output_____"
]
],
[
[
"#### How did we get the mean/std?\n- mean=0.1307\n- std=0.3081",
"_____no_output_____"
]
],
[
[
"print(list(train_dataset.train_data.size()))",
"[60000, 28, 28]\n"
],
[
"print(train_dataset.train_data.float().mean()/255)",
"tensor(0.1307)\n"
],
[
"print(train_dataset.train_data.float().std()/255)",
"tensor(0.3081)\n"
]
],
[
[
"#### Why divide by 255?\n- 784 inputs: each pixel 28x28\n- Each pixel value: 0-255 (single grayscale)\n- Divide by 255 to have any single pixel value to be within [0,1] $\\rightarrow$simple rescaling",
"_____no_output_____"
],
[
"### Putting everything together",
"_____no_output_____"
]
],
[
[
"import torch\nimport torch.nn as nn\nimport torchvision.transforms as transforms\nimport torchvision.datasets as dsets\nfrom torch.autograd import Variable\n\n# Set seed\ntorch.manual_seed(0)\n\n# Scheduler import\nfrom torch.optim.lr_scheduler import StepLR\n\n'''\nSTEP 0: CREATE TRANSFORMATIONS\n'''\ntrain_dataset = dsets.MNIST(root='./data', \n train=True, \n transform=transforms.ToTensor(),\n download=True)\n\nmean_mnist = train_dataset.train_data.float().mean()/255\nstd_mnist = train_dataset.train_data.float().std()/255\n\ntransform = transforms.Compose([\n transforms.RandomHorizontalFlip(),\n transforms.ToTensor(),\n transforms.Normalize((mean_mnist,), (std_mnist,)),\n ])\n\n\n'''\nSTEP 1: LOADING DATASET\n'''\n\ntrain_dataset = dsets.MNIST(root='./data', \n train=True, \n #transform=transforms.ToTensor(),\n transform=transform,\n download=True)\n\ntest_dataset = dsets.MNIST(root='./data', \n train=False, \n #transform=transforms.ToTensor(),\n transform=transform)\n\n'''\nSTEP 2: MAKING DATASET ITERABLE\n'''\n\nbatch_size = 128\nn_iters = 10000\nnum_epochs = n_iters / (len(train_dataset) / batch_size)\nnum_epochs = int(num_epochs)\n\ntrain_loader = torch.utils.data.DataLoader(dataset=train_dataset, \n batch_size=batch_size, \n shuffle=True)\n\ntest_loader = torch.utils.data.DataLoader(dataset=test_dataset, \n batch_size=batch_size, \n shuffle=False)\n\n'''\nSTEP 3: CREATE MODEL CLASS\n'''\nclass FeedforwardNeuralNetModel(nn.Module):\n def __init__(self, input_dim, hidden_dim, output_dim):\n super(FeedforwardNeuralNetModel, self).__init__()\n # Linear function\n self.fc1 = nn.Linear(input_dim, hidden_dim) \n # Linear weight, W, Y = WX + B\n nn.init.kaiming_normal_(self.fc1.weight)\n # Non-linearity\n self.relu = nn.ReLU()\n # Linear function (readout)\n self.fc2 = nn.Linear(hidden_dim, output_dim) \n nn.init.kaiming_normal_(self.fc2.weight)\n \n def forward(self, x):\n # Linear function\n out = self.fc1(x)\n # Non-linearity\n out = self.relu(out)\n # Linear function (readout)\n out = self.fc2(out)\n return out\n \n'''\nSTEP 4: INSTANTIATE MODEL CLASS\n'''\ninput_dim = 28*28\nhidden_dim = 100\noutput_dim = 10\n\nmodel = FeedforwardNeuralNetModel(input_dim, hidden_dim, output_dim)\n\n#######################\n# USE GPU FOR MODEL #\n#######################\n\ndevice = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")\nmodel.to(device)\n\n'''\nSTEP 5: INSTANTIATE LOSS CLASS\n'''\ncriterion = nn.CrossEntropyLoss()\n\n\n'''\nSTEP 6: INSTANTIATE OPTIMIZER CLASS\n'''\nlearning_rate = 0.1\n\noptimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9, nesterov=True)\n\n'''\nSTEP 7: INSTANTIATE STEP LEARNING SCHEDULER CLASS\n'''\n# step_size: at how many multiples of epoch you decay\n# step_size = 1, after every 2 epoch, new_lr = lr*gamma \n# step_size = 2, after every 2 epoch, new_lr = lr*gamma \n\n# gamma = decaying factor\nscheduler = StepLR(optimizer, step_size=1, gamma=0.96)\n\n'''\nSTEP 8: TRAIN THE MODEL\n'''\niter = 0\nfor epoch in range(num_epochs):\n # Decay Learning Rate\n scheduler.step()\n # Print Learning Rate\n print('Epoch:', epoch,'LR:', scheduler.get_lr())\n for i, (images, labels) in enumerate(train_loader):\n # Load images as tensors with gradient accumulation abilities\n images = images.view(-1, 28*28).requires_grad_().to(device)\n labels = labels.to(device)\n \n # Clear gradients w.r.t. parameters\n optimizer.zero_grad()\n \n # Forward pass to get output/logits\n outputs = model(images)\n \n # Calculate Loss: softmax --> cross entropy loss\n loss = criterion(outputs, labels)\n \n # Getting gradients w.r.t. parameters\n loss.backward()\n \n # Updating parameters\n optimizer.step()\n \n iter += 1\n \n if iter % 500 == 0:\n # Calculate Accuracy \n correct = 0\n total = 0\n # Iterate through test dataset\n for images, labels in test_loader:\n # Load images and resize\n images = images.view(-1, 28*28).to(device)\n \n # Forward pass only to get logits/output\n outputs = model(images)\n \n # Get predictions from the maximum value\n _, predicted = torch.max(outputs.data, 1)\n \n # Total number of labels\n total += labels.size(0)\n \n # Total correct predictions \n correct += (predicted.type(torch.FloatTensor).cpu() == labels.type(torch.FloatTensor)).sum()\n\n accuracy = 100. * correct.item() / total\n\n # Print Loss\n print('Iteration: {}. Loss: {}. Accuracy: {}'.format(iter, loss.item(), accuracy))",
"Epoch: 0 LR: [0.1]\nEpoch: 1 LR: [0.096]\nIteration: 500. Loss: 0.25855910778045654. Accuracy: 93.0\nEpoch: 2 LR: [0.09216]\nIteration: 1000. Loss: 0.13369649648666382. Accuracy: 94.57\nEpoch: 3 LR: [0.08847359999999999]\nIteration: 1500. Loss: 0.12088318914175034. Accuracy: 94.26\nEpoch: 4 LR: [0.084934656]\nIteration: 2000. Loss: 0.27535250782966614. Accuracy: 95.21\nEpoch: 5 LR: [0.08153726975999999]\nIteration: 2500. Loss: 0.12434098869562149. Accuracy: 95.38\nEpoch: 6 LR: [0.07827577896959999]\nIteration: 3000. Loss: 0.13227976858615875. Accuracy: 95.68\nEpoch: 7 LR: [0.07514474781081598]\nIteration: 3500. Loss: 0.03038594126701355. Accuracy: 95.71\nEpoch: 8 LR: [0.07213895789838334]\nIteration: 4000. Loss: 0.10637575387954712. Accuracy: 95.58\nEpoch: 9 LR: [0.06925339958244801]\nIteration: 4500. Loss: 0.07112938165664673. Accuracy: 95.43\nEpoch: 10 LR: [0.06648326359915008]\nIteration: 5000. Loss: 0.0519864596426487. Accuracy: 95.67\nEpoch: 11 LR: [0.06382393305518408]\nIteration: 5500. Loss: 0.0947360098361969. Accuracy: 95.8\nEpoch: 12 LR: [0.06127097573297671]\nIteration: 6000. Loss: 0.05479373782873154. Accuracy: 95.78\nEpoch: 13 LR: [0.05882013670365765]\nIteration: 6500. Loss: 0.14708858728408813. Accuracy: 96.07\nEpoch: 14 LR: [0.056467331235511335]\nIteration: 7000. Loss: 0.0989505797624588. Accuracy: 95.98\nEpoch: 15 LR: [0.05420863798609088]\nIteration: 7500. Loss: 0.02780088409781456. Accuracy: 95.85\nEpoch: 16 LR: [0.052040292466647244]\nEpoch: 17 LR: [0.04995868076798135]\nIteration: 8000. Loss: 0.017397794872522354. Accuracy: 96.31\nEpoch: 18 LR: [0.04796033353726209]\nIteration: 8500. Loss: 0.01682233437895775. Accuracy: 96.42\nEpoch: 19 LR: [0.04604192019577161]\nIteration: 9000. Loss: 0.006680376827716827. Accuracy: 96.31\nEpoch: 20 LR: [0.04420024338794074]\nIteration: 9500. Loss: 0.0933283120393753. Accuracy: 96.38\n"
]
],
[
[
"## Overfitting Solution 2: Early Stopping\n",
"_____no_output_____"
],
[
"### How do we do this via PyTorch? 3 Steps.\n1. Track validation accuracy\n2. Whenever validation accuracy is better, we save the model's parameters\n3. Load the model's best parameters to test",
"_____no_output_____"
]
],
[
[
"import torch\nimport torch.nn as nn\nimport torchvision.transforms as transforms\nimport torchvision.datasets as dsets\nfrom torch.autograd import Variable\n# New import for creating directories in your folder\nimport os\n\n# Set seed\ntorch.manual_seed(0)\n\n# Scheduler import\nfrom torch.optim.lr_scheduler import StepLR\n\n'''\nCHECK LOG OR MAKE LOG DIRECTORY\n'''\n# This will create a directory if there isn't one to store models\nif not os.path.isdir('logs'):\n os.mkdir('logs')\n \n'''\nSTEP 0: CREATE TRANSFORMATIONS\n'''\ntrain_dataset = dsets.MNIST(root='./data', \n train=True, \n transform=transforms.ToTensor(),\n download=True)\n\nmean_mnist = train_dataset.train_data.float().mean()/255\nstd_mnist = train_dataset.train_data.float().std()/255\n\ntransform = transforms.Compose([\n transforms.RandomHorizontalFlip(),\n transforms.ToTensor(),\n transforms.Normalize((mean_mnist,), (std_mnist,)),\n ])\n\n\n'''\nSTEP 1: LOADING DATASET\n'''\n\ntrain_dataset = dsets.MNIST(root='./data', \n train=True, \n #transform=transforms.ToTensor(),\n transform=transform,\n download=True)\n\ntest_dataset = dsets.MNIST(root='./data', \n train=False, \n #transform=transforms.ToTensor(),\n transform=transform)\n\n'''\nSTEP 2: MAKING DATASET ITERABLE\n'''\n\nbatch_size = 128\nn_iters = 10000\nnum_epochs = n_iters / (len(train_dataset) / batch_size)\nnum_epochs = int(num_epochs)\n\ntrain_loader = torch.utils.data.DataLoader(dataset=train_dataset, \n batch_size=batch_size, \n shuffle=True)\n\ntest_loader = torch.utils.data.DataLoader(dataset=test_dataset, \n batch_size=batch_size, \n shuffle=False)\n\n'''\nSTEP 3: CREATE MODEL CLASS\n'''\nclass FeedforwardNeuralNetModel(nn.Module):\n def __init__(self, input_dim, hidden_dim, output_dim):\n super(FeedforwardNeuralNetModel, self).__init__()\n # Linear function\n self.fc1 = nn.Linear(input_dim, hidden_dim) \n # Linear weight, W, Y = WX + B\n nn.init.kaiming_normal_(self.fc1.weight)\n # Non-linearity\n self.relu = nn.ReLU()\n # Linear function (readout)\n self.fc2 = nn.Linear(hidden_dim, output_dim) \n nn.init.kaiming_normal_(self.fc2.weight)\n \n def forward(self, x):\n # Linear function\n out = self.fc1(x)\n # Non-linearity\n out = self.relu(out)\n # Linear function (readout)\n out = self.fc2(out)\n return out\n \n'''\nSTEP 4: INSTANTIATE MODEL CLASS\n'''\ninput_dim = 28*28\nhidden_dim = 100\noutput_dim = 10\n\nmodel = FeedforwardNeuralNetModel(input_dim, hidden_dim, output_dim)\n\n#######################\n# USE GPU FOR MODEL #\n#######################\n\ndevice = torch.device(\"cuda:0\" if torch.cuda.is_available() else \"cpu\")\nmodel.to(device)\n'''\nSTEP 5: INSTANTIATE LOSS CLASS\n'''\ncriterion = nn.CrossEntropyLoss()\n\n\n'''\nSTEP 6: INSTANTIATE OPTIMIZER CLASS\n'''\nlearning_rate = 0.1\n\noptimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9, nesterov=True)\n\n'''\nSTEP 7: INSTANTIATE STEP LEARNING SCHEDULER CLASS\n'''\n# step_size: at how many multiples of epoch you decay\n# step_size = 1, after every 2 epoch, new_lr = lr*gamma \n# step_size = 2, after every 2 epoch, new_lr = lr*gamma \n\n# gamma = decaying factor\nscheduler = StepLR(optimizer, step_size=1, gamma=0.96)\n\n'''\nSTEP 8: TRAIN THE MODEL\n'''\niter = 0\n\n# Validation accuracy tracker\nval_acc = 0\n\nfor epoch in range(num_epochs):\n # Decay Learning Rate\n scheduler.step()\n # Print Learning Rate\n print('Epoch:', epoch,'LR:', scheduler.get_lr())\n for i, (images, labels) in enumerate(train_loader):\n # Load images\n images = images.view(-1, 28*28).requires_grad_().to(device)\n labels = labels.to(device)\n \n # Clear gradients w.r.t. parameters\n optimizer.zero_grad()\n \n # Forward pass to get output/logits\n outputs = model(images)\n \n # Calculate Loss: softmax --> cross entropy loss\n loss = criterion(outputs, labels)\n \n # Getting gradients w.r.t. parameters\n loss.backward()\n \n # Updating parameters\n optimizer.step()\n \n iter += 1\n \n # Calculate Accuracy at every epoch \n correct = 0\n total = 0\n # Iterate through test dataset\n for images, labels in test_loader:\n # Load images\n images = images.view(-1, 28*28).to(device)\n\n # Forward pass only to get logits/output\n outputs = model(images)\n\n # Get predictions from the maximum value\n _, predicted = torch.max(outputs.data, 1)\n\n # Total number of labels\n total += labels.size(0)\n\n # Total correct predictions \n correct += (predicted.type(torch.FloatTensor).cpu() == labels.type(torch.FloatTensor)).sum()\n\n accuracy = 100. * correct.item() / total\n \n # if epoch 0, best accuracy is this\n\n if epoch == 0:\n val_acc = accuracy\n elif accuracy > val_acc:\n val_acc = accuracy\n # Save your model\n torch.save(model.state_dict(), './logs/best_model.pt')\n # Print Loss\n print('Iteration: {}. Loss: {}. Accuracy: {}. Best Accuracy: {}'.format(iter, loss.item(), accuracy, val_acc))",
"Epoch: 0 LR: [0.1]\nIteration: 469. Loss: 0.2285567671060562. Accuracy: 92.38. Best Accuracy: 92.38\nEpoch: 1 LR: [0.096]\nIteration: 938. Loss: 0.3470817506313324. Accuracy: 93.65. Best Accuracy: 93.65\nEpoch: 2 LR: [0.09216]\nIteration: 1407. Loss: 0.32325246930122375. Accuracy: 94.52. Best Accuracy: 94.52\nEpoch: 3 LR: [0.08847359999999999]\nIteration: 1876. Loss: 0.1460786610841751. Accuracy: 94.62. Best Accuracy: 94.62\nEpoch: 4 LR: [0.084934656]\nIteration: 2345. Loss: 0.102019764482975. Accuracy: 94.47. Best Accuracy: 94.62\nEpoch: 5 LR: [0.08153726975999999]\nIteration: 2814. Loss: 0.06490271538496017. Accuracy: 95.53. Best Accuracy: 95.53\nEpoch: 6 LR: [0.07827577896959999]\nIteration: 3283. Loss: 0.13248136639595032. Accuracy: 94.82. Best Accuracy: 95.53\nEpoch: 7 LR: [0.07514474781081598]\nIteration: 3752. Loss: 0.09072074294090271. Accuracy: 95.4. Best Accuracy: 95.53\nEpoch: 8 LR: [0.07213895789838334]\nIteration: 4221. Loss: 0.09402436017990112. Accuracy: 95.62. Best Accuracy: 95.62\nEpoch: 9 LR: [0.06925339958244801]\nIteration: 4690. Loss: 0.1331033855676651. Accuracy: 95.83. Best Accuracy: 95.83\nEpoch: 10 LR: [0.06648326359915008]\nIteration: 5159. Loss: 0.04624582454562187. Accuracy: 95.45. Best Accuracy: 95.83\nEpoch: 11 LR: [0.06382393305518408]\nIteration: 5628. Loss: 0.03372932970523834. Accuracy: 95.94. Best Accuracy: 95.94\nEpoch: 12 LR: [0.06127097573297671]\nIteration: 6097. Loss: 0.042957354336977005. Accuracy: 95.91. Best Accuracy: 95.94\nEpoch: 13 LR: [0.05882013670365765]\nIteration: 6566. Loss: 0.10592807084321976. Accuracy: 96.1. Best Accuracy: 96.1\nEpoch: 14 LR: [0.056467331235511335]\nIteration: 7035. Loss: 0.0715859904885292. Accuracy: 95.96. Best Accuracy: 96.1\nEpoch: 15 LR: [0.05420863798609088]\nIteration: 7504. Loss: 0.08129043877124786. Accuracy: 96.29. Best Accuracy: 96.29\nEpoch: 16 LR: [0.052040292466647244]\nIteration: 7973. Loss: 0.08950412273406982. Accuracy: 96.37. Best Accuracy: 96.37\nEpoch: 17 LR: [0.04995868076798135]\nIteration: 8442. Loss: 0.1426319032907486. Accuracy: 96.05. Best Accuracy: 96.37\nEpoch: 18 LR: [0.04796033353726209]\nIteration: 8911. Loss: 0.113959401845932. Accuracy: 96.25. Best Accuracy: 96.37\nEpoch: 19 LR: [0.04604192019577161]\nIteration: 9380. Loss: 0.0410139262676239. Accuracy: 96.4. Best Accuracy: 96.4\nEpoch: 20 LR: [0.04420024338794074]\nIteration: 9849. Loss: 0.05333830788731575. Accuracy: 96.48. Best Accuracy: 96.48\n"
],
[
"'''\nSTEP 9: TEST THE MODEL\nThis model should produce the exact same best test accuracy!\n96.48%\n'''\n\n# Load the model\nmodel.load_state_dict(torch.load('./logs/best_model.pt'))\n\n# Evaluate model\nmodel.eval()\n\n# Calculate Accuracy at every epoch \ncorrect = 0\ntotal = 0\n\n# Iterate through test dataset\nfor images, labels in test_loader:\n # Load images\n images = images.view(-1, 28*28).to(device)\n\n # Forward pass only to get logits/output\n outputs = model(images)\n\n # Get predictions from the maximum value\n _, predicted = torch.max(outputs.data, 1)\n\n # Total number of labels\n total += labels.size(0)\n\n # Total correct predictions \n correct += (predicted.type(torch.FloatTensor).cpu() == labels.type(torch.FloatTensor)).sum()\n\naccuracy = 100. * correct.item() / total\n\n# Print Loss\nprint('Iteration: {}. Loss: {}. Accuracy: {}'.format(iter, loss.item(), accuracy))",
"Iteration: 9849. Loss: 0.05333830788731575. Accuracy: 96.35\n"
]
],
[
[
"## Overfitting Solution 3: Regularization",
"_____no_output_____"
],
[
"## Overfitting Solution 3a: Weight Decay (L2 Regularization)",
"_____no_output_____"
],
[
"## Overfitting Solution 3b: Dropout",
"_____no_output_____"
],
[
"## Overfitting Solution 4: Batch Normalization",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
cb31d0e3dd96ef0e4733a655e5a5f16dbc56248c | 4,961 | ipynb | Jupyter Notebook | Wiskunde/FunctiesPythagoras/0201_ExtraOefeningenFuncties.ipynb | dwengovzw/PythonNotebooks | 633bea4b07efbd920349d6f1dc346522ce118b70 | [
"CC0-1.0"
] | null | null | null | Wiskunde/FunctiesPythagoras/0201_ExtraOefeningenFuncties.ipynb | dwengovzw/PythonNotebooks | 633bea4b07efbd920349d6f1dc346522ce118b70 | [
"CC0-1.0"
] | 3 | 2021-09-30T11:38:24.000Z | 2021-10-04T09:25:39.000Z | Wiskunde/FunctiesPythagoras/0201_ExtraOefeningenFuncties.ipynb | dwengovzw/PythonNotebooks | 633bea4b07efbd920349d6f1dc346522ce118b70 | [
"CC0-1.0"
] | null | null | null | 23.400943 | 392 | 0.489216 | [
[
[
"<img src=\"images/bannerugentdwengo.png\" alt=\"Banner\" width=\"250\"/>",
"_____no_output_____"
],
[
"<div>\n <font color=#690027 markdown=\"1\"> \n <h1>EXTRA OEFENINGEN FUNCTIES</h1> \n </font>\n</div>",
"_____no_output_____"
],
[
"<div>\n <font color=#690027 markdown=\"1\"> \n <h2>Oefening 1</h2> \n </font>\n</div>",
"_____no_output_____"
],
[
"- Voer de volgende code-cel nog niet uit, maar kijk alvast of je de code begrijpt. Wat is de output van dit script? ",
"_____no_output_____"
],
[
"Antwoord:",
"_____no_output_____"
],
[
"- Vul de docstring aan.\n- Voer het script uit. Had je de output correct voorspeld? Indien niet, omschrijf waarom je fout zat. ",
"_____no_output_____"
]
],
[
[
"def bewerking(a, b):\n \"\"\"................................................\"\"\"\n ks = (a + b)**2\n return ks\n\ngetal1 = bewerking(2, 5)\ngetal2 = bewerking(1, -1)\ngetal3 = bewerking(7, -2)\n\nprint(getal1, getal2, getal3)",
"_____no_output_____"
]
],
[
[
"Antwoord:",
"_____no_output_____"
],
[
"<div>\n <font color=#690027 markdown=\"1\"> \n <h2>Oefening 2</h2> \n </font>\n</div>",
"_____no_output_____"
],
[
"- Vul het script aan en voer het uit. ",
"_____no_output_____"
]
],
[
[
"# inhouden berekenen\n\nimport ...\n\ndef inhoud_bol(r):\n \"\"\"Inhoud van bol met straal r.\"\"\"\n i = 4 / 3 * math.pi * r**3\n return i\n\ndef inhoud_kubus(...):\n \"\"\"Inhoud van kubus met zijde z.\"\"\"\n ...\n return i\n\ndef ...:\n \"\"\"Inhoud van cilinder met straal r en hoogte h.\"\"\"\n ... \n ...\n \n# oefeningen\n# inhoud van cilinder C met straal 4 m en hoogte 10 m\n...\nprint(\"De inhoud van C is\", inhoud_C, \"m³.\")\n\n# inhoud van kubus K met zijde 2 cm\n...\n...\n\n# inhoud van bol B met straal 15 mm\n...\n...",
"_____no_output_____"
]
],
[
[
"<div>\n <font color=#690027 markdown=\"1\"> \n <h2>Oefening 3</h2> \n </font>\n</div>",
"_____no_output_____"
],
[
"Een winkel die uitverkoop houdt, geeft op alle kledij een korting van 35 %. <br><br>\nSchrijf een script dat:\n- de (oude) prijs (een kommagetal) van een kledingstuk vraagt aan de gebruiker;\n- de nieuwe prijs van het kledingstuk berekent, gebruikmakend van een functie;\n- een zin die de nieuwe prijs vermeldt, teruggeeft.\n\nVoer het script uit.",
"_____no_output_____"
],
[
"<img src=\"images/cclic.png\" alt=\"Banner\" align=\"left\" width=\"100\"/><br><br>\nNotebook Python in wiskunde, zie Computationeel denken - Programmeren in Python van <a href=\"http://www.aiopschool.be\">AI Op School</a>, van F. wyffels, C. Boitsios, E. Staelens & N. Gesquière is in licentie gegeven volgens een <a href=\"http://creativecommons.org/licenses/by-nc-sa/4.0/\">Creative Commons Naamsvermelding-NietCommercieel-GelijkDelen 4.0 Internationaal-licentie</a>. ",
"_____no_output_____"
],
[
"### Met steun van",
"_____no_output_____"
],
[
"<img src=\"images/logobavo.jpg\" alt=\"Banner\" width=\"150\"/>",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
cb31dffa1e70ca67b3c731664377e2a73bc551f9 | 24,572 | ipynb | Jupyter Notebook | _archived/sstats/sstats-v1.2.ipynb | Gilbertly/notebooks | 4741cf600c8a78e429418b6493fa22dbe06a1e3e | [
"MIT"
] | 1 | 2022-03-04T07:05:00.000Z | 2022-03-04T07:05:00.000Z | _archived/sstats/sstats-v1.2.ipynb | Gilbertly/notebooks | 4741cf600c8a78e429418b6493fa22dbe06a1e3e | [
"MIT"
] | null | null | null | _archived/sstats/sstats-v1.2.ipynb | Gilbertly/notebooks | 4741cf600c8a78e429418b6493fa22dbe06a1e3e | [
"MIT"
] | null | null | null | 34.657264 | 151 | 0.552539 | [
[
[
"# Soccerstats Predictions v1.2",
"_____no_output_____"
],
[
"The changelog from v1.1:\n* Train on `train` data, and validate using `test` data.",
"_____no_output_____"
],
[
"## A. Data Cleaning & Preparation",
"_____no_output_____"
],
[
"### 1. Read csv file",
"_____no_output_____"
]
],
[
[
"# load and cache data\nstat_df = sqlContext.read\\\n .format(\"com.databricks.spark.csv\")\\\n .options(header = True)\\\n .load(\"data/teamFixtures.csv\")\\\n .cache()",
"_____no_output_____"
],
[
"# from pyspark.sql.functions import isnan, when, count, col\n# count hyphen nulls (\"-\") per column\n# stat_df.select([count(when(stat_df[c] == \"-\", c)).alias(c) for c in stat_df.columns]).show()",
"_____no_output_____"
]
],
[
[
"### 2. Filter-out \"gameFtScore\" column values",
"_____no_output_____"
]
],
[
[
"from pyspark.sql.functions import udf\nfrom pyspark.sql.types import StringType\n\n# replace non-\"-\" values with null: gameFtScore\nnullify_ft_scores = udf(\n lambda row_value: None if row_value != \"-\" else row_value, \n StringType()\n)\n\n# replace \"-\" values with null: HTS_teamAvgOpponentPPG, ATS_teamAvgOpponentPPG\nnullify_hyphen_cols = udf(\n lambda row_value: None if row_value == \"-\" else row_value, \n StringType()\n)\n\nstat_df = (stat_df.withColumn(\"gameFtScore\", nullify_ft_scores(stat_df.gameFtScore)))\nstat_df = (stat_df.withColumn(\"HTS_teamAvgOpponentPPG\", nullify_hyphen_cols(stat_df.HTS_teamAvgOpponentPPG))\n .withColumn(\"ATS_teamAvgOpponentPPG\", nullify_hyphen_cols(stat_df.ATS_teamAvgOpponentPPG))\n )\n\n# drop Null values\nstat_df = stat_df.dropna()\nstat_df.select(\"gameFtScore\", \"HTS_teamAvgOpponentPPG\", \"ATS_teamAvgOpponentPPG\").show(5)\nprint(\"Total rows: {}\".format(stat_df.count()))",
"+-----------+----------------------+----------------------+\n|gameFtScore|HTS_teamAvgOpponentPPG|ATS_teamAvgOpponentPPG|\n+-----------+----------------------+----------------------+\n| -| 1.67| 1.45|\n| -| 1.36| 1.47|\n| -| 1.13| 1.50|\n| -| 1.33| 1.60|\n| -| 1.43| 1.57|\n+-----------+----------------------+----------------------+\nonly showing top 5 rows\n\nTotal rows: 5843\n"
]
],
[
[
"### 3. Write-out new dataframe to Json",
"_____no_output_____"
]
],
[
[
"# optional: save to file\n# stat_df.coalesce(1).write.format('json').save('sstats_fixtures.json')",
"_____no_output_____"
]
],
[
[
"### 4. Read fixtures Json to dataframe",
"_____no_output_____"
]
],
[
[
"fx_df = spark.read.json('data/fixtures1.json')\nfx_df.printSchema()",
"root\n |-- fixture_id: string (nullable = true)\n |-- ft_score: string (nullable = true)\n\n"
]
],
[
[
"### 5. Encode \"fixture_id\" on stat_df dataframe",
"_____no_output_____"
]
],
[
[
"import hashlib\nfrom pyspark.sql.functions import array\n\ndef encode_string(value):\n return hashlib.sha1(\n value.encode(\"utf-8\")\n ).hexdigest()\n\n# add an encoded col to \"stat_df\"; fixture_id\nfxcol_df = udf(\n lambda row_value: encode_string(u\"\".join([x for x in row_value])), \n StringType()\n)\nstat_df = (stat_df.withColumn(\"fixture_id\", fxcol_df(array(\n \"leagueName\",\n \"leagueDivisionName\",\n \"gamePlayDate\",\n \"gameHomeTeamName\",\n \"gameAwayTeamName\"\n))))",
"_____no_output_____"
],
[
"# display some encoded fixtures\nstat_df.select(\"fixture_id\").show(5, False)",
"+----------------------------------------+\n|fixture_id |\n+----------------------------------------+\n|3b79d8a00bc8cbeca1420dbb6a9aa32445fda126|\n|150b869d4f65dcf116029730b4125423f426e897|\n|060b2cf9f890f91dc19144c7fda4b524c11d306b|\n|ce4ef98077387fc029126dad72dd9fede782a504|\n|b001915d73f8c501b61a9db0ce13c966a71fa10b|\n+----------------------------------------+\nonly showing top 5 rows\n\n"
]
],
[
[
"### 6. Concat the two dataframes: \"stat_df\" and \"fx_df\"",
"_____no_output_____"
]
],
[
[
"from pyspark.sql.functions import col\n\n# use \"left-outer-join\" to concat\nfull_df = stat_df.alias(\"a\")\\\n .join(fx_df, stat_df.fixture_id == fx_df.fixture_id, \"left_outer\")\\\n .select(*[col(\"a.\"+c) for c in stat_df.columns] + [fx_df.ft_score])\n\nfull_df.select(\"leagueName\", \"leagueDivisionName\", \"gamePlayDate\", \"gameHomeTeamName\", \"gameAwayTeamName\", \"ft_score\").show(5, False)",
"+----------+---------------------+------------+----------------+----------------+--------+\n|leagueName|leagueDivisionName |gamePlayDate|gameHomeTeamName|gameAwayTeamName|ft_score|\n+----------+---------------------+------------+----------------+----------------+--------+\n|England |League Two |2018-04-17 |Lincoln |Wycombe |0-0 |\n|England |Northern league |2018-04-17 |Buxton |Altrincham |0-0 |\n|England |National League South|2018-04-17 |Concord Rangers |Bognor Regis |2-1 |\n|England |League One |2018-04-17 |Doncaster |Bury |3-3 |\n|Argentina |Primera B Metro. |2018-04-17 |Tristan Suarez |Defensores Bel. |2-0 |\n+----------+---------------------+------------+----------------+----------------+--------+\nonly showing top 5 rows\n\n"
]
],
[
[
"### 7. Assess damage on \"ft_score \" nulls",
"_____no_output_____"
]
],
[
[
"# count nulls per column\ndef count_null(df, col):\n return df.where(df[col].isNull()).count()\n\nprint(\"Total rows: {}\".format(full_df.count()))\nprint(\"Ft_score nulls: {}\".format(count_null(full_df, \"ft_score\")))",
"Total rows: 5843\nFt_score nulls: 624\n"
],
[
"# drop null values in ft_Score\nfull_df = full_df.dropna()\n\nprint(\"Total rows: {}\".format(full_df.count()))\nprint(\"Ft_score nulls: {}\".format(count_null(full_df, \"ft_score\")))",
"Total rows: 5219\nFt_score nulls: 0\n"
]
],
[
[
"## B. Deep Learning",
"_____no_output_____"
],
[
"### 1. Clean data",
"_____no_output_____"
]
],
[
[
"# drop unnecessary columns\nml_df = full_df.drop(\n \"gameID\", \"gamePlayDate\", \"gamePlayTime\", \"gameHomeTeamName\",\n \"gameAwayTeamName\", \"gameHomeTeamID\",\"gameAwayTeamID\", \"leagueName\", \n \"leagueDivisionName\", \"gameFtScore\", \"fixture_id\"\n)",
"_____no_output_____"
],
[
"# separate col types: double & string\n# double type features\ndtype_features = [\n \"leagueCompletion\", \"HTS_teamPosition\", \"HTS_teamGamesPlayed\", \"HTS_teamGamesWon\", \n \"HTS_teamGamesDraw\", \"HTS_teamGamesLost\", \"HTS_teamGoalsScored\", \"HTS_teamGoalsConceded\",\n \"HTS_teamPoints\", \"HTS_teamPointsPerGame\", \"HTS_teamPPGlast8\", \"HTS_homeGamesWon\",\n \"HTS_homeGamesDraw\", \"HTS_homeGamesLost\", \"HTS_homeGamesPlayed\", \"HTS_awayGamesWon\", \n \"HTS_awayGamesDraw\", \"HTS_awayGamesLost\", \"HTS_awayGamesPlayed\", \"HTS_teamPPGHome\",\n \"HTS_teamPPGAway\", \"HTS_teamAvgOpponentPPG\", \"HTS_homeGoalMargin_by1_wins\",\n \"HTS_homeGoalMargin_by1_losses\", \"HTS_homeGoalMargin_by2_wins\", \"HTS_homeGoalMargin_by2_losses\", \n \"HTS_homeGoalMargin_by3_wins\", \"HTS_homeGoalMargin_by3_losses\", \"HTS_homeGoalMargin_by4p_wins\", \n \"HTS_homeGoalMargin_by4p_losses\", \"HTS_awayGoalMargin_by1_wins\", \"HTS_awayGoalMargin_by1_losses\", \n \"HTS_awayGoalMargin_by2_wins\", \"HTS_awayGoalMargin_by2_losses\", \"HTS_awayGoalMargin_by3_wins\", \n \"HTS_awayGoalMargin_by3_losses\", \"HTS_awayGoalMargin_by4p_wins\", \"HTS_awayGoalMargin_by4p_losses\", \n \"HTS_totalGoalMargin_by1_wins\", \"HTS_totalGoalMargin_by1_losses\", \"HTS_totalGoalMargin_by2_wins\", \n \"HTS_totalGoalMargin_by2_losses\", \"HTS_totalGoalMargin_by3_wins\", \"HTS_totalGoalMargin_by3_losses\", \n \"HTS_totalGoalMargin_by4p_wins\", \"HTS_totalGoalMargin_by4p_losses\", \"HTS_homeGoalsScored\", \n \"HTS_homeGoalsConceded\", \"HTS_homeGoalsScoredPerMatch\", \"HTS_homeGoalsConcededPerMatch\", \n \"HTS_homeScored_ConcededPerMatch\", \"HTS_awayGoalsScored\", \"HTS_awayGoalsConceded\", \n \"HTS_awayGoalsScoredPerMatch\", \"HTS_awayGoalsConcededPerMatch\", \"HTS_awayScored_ConcededPerMatch\", \n \"ATS_teamPosition\", \"ATS_teamGamesPlayed\", \"ATS_teamGamesWon\", \"ATS_teamGamesDraw\", \"ATS_teamGamesLost\", \n \"ATS_teamGoalsScored\", \"ATS_teamGoalsConceded\", \"ATS_teamPoints\", \"ATS_teamPointsPerGame\", \n \"ATS_teamPPGlast8\", \"ATS_homeGamesWon\", \"ATS_homeGamesDraw\", \"ATS_homeGamesLost\", \n \"ATS_homeGamesPlayed\", \"ATS_awayGamesWon\", \"ATS_awayGamesDraw\", \"ATS_awayGamesLost\", \n \"ATS_awayGamesPlayed\", \"ATS_teamPPGHome\", \"ATS_teamPPGAway\", \"ATS_teamAvgOpponentPPG\", \n \"ATS_homeGoalMargin_by1_wins\", \"ATS_homeGoalMargin_by1_losses\", \"ATS_homeGoalMargin_by2_wins\", \n \"ATS_homeGoalMargin_by2_losses\", \"ATS_homeGoalMargin_by3_wins\", \"ATS_homeGoalMargin_by3_losses\", \n \"ATS_homeGoalMargin_by4p_wins\", \"ATS_homeGoalMargin_by4p_losses\", \"ATS_awayGoalMargin_by1_wins\",\n \"ATS_awayGoalMargin_by1_losses\", \"ATS_awayGoalMargin_by2_wins\", \"ATS_awayGoalMargin_by2_losses\", \n \"ATS_awayGoalMargin_by3_wins\", \"ATS_awayGoalMargin_by3_losses\", \"ATS_awayGoalMargin_by4p_wins\", \n \"ATS_awayGoalMargin_by4p_losses\", \"ATS_totalGoalMargin_by1_wins\", \"ATS_totalGoalMargin_by1_losses\", \n \"ATS_totalGoalMargin_by2_wins\", \"ATS_totalGoalMargin_by2_losses\", \"ATS_totalGoalMargin_by3_wins\", \n \"ATS_totalGoalMargin_by3_losses\", \"ATS_totalGoalMargin_by4p_wins\", \"ATS_totalGoalMargin_by4p_losses\", \n \"ATS_homeGoalsScored\", \"ATS_homeGoalsConceded\", \"ATS_homeGoalsScoredPerMatch\", \"ATS_homeGoalsConcededPerMatch\", \n \"ATS_homeScored_ConcededPerMatch\", \"ATS_awayGoalsScored\", \"ATS_awayGoalsConceded\", \"ATS_awayGoalsScoredPerMatch\", \n \"ATS_awayGoalsConcededPerMatch\", \"ATS_awayScored_ConcededPerMatch\"\n]\n# string type features\nstype_features = [\n \"HTS_teamGoalsDifference\", \"HTS_teamCleanSheetPercent\", \"HTS_homeOver1_5GoalsPercent\",\n \"HTS_homeOver2_5GoalsPercent\", \"HTS_homeOver3_5GoalsPercent\", \"HTS_homeOver4_5GoalsPercent\", \n \"HTS_awayOver1_5GoalsPercent\", \"HTS_awayOver2_5GoalsPercent\", \"HTS_awayOver3_5GoalsPercent\", \n \"HTS_awayOver4_5GoalsPercent\", \"HTS_homeCleanSheets\", \"HTS_homeWonToNil\", \"HTS_homeBothTeamsScored\", \n \"HTS_homeFailedToScore\", \"HTS_homeLostToNil\", \"HTS_awayCleanSheets\", \"HTS_awayWonToNil\", \n \"HTS_awayBothTeamsScored\", \"HTS_awayFailedToScore\", \"HTS_awayLostToNil\", \"HTS_homeScored_ConcededBy_0\",\n \"HTS_homeScored_ConcededBy_1\", \"HTS_homeScored_ConcededBy_2\", \"HTS_homeScored_ConcededBy_3\", \n \"HTS_homeScored_ConcededBy_4\", \"HTS_homeScored_ConcededBy_5p\", \"HTS_homeScored_ConcededBy_0_or_1\", \n \"HTS_homeScored_ConcededBy_2_or_3\", \"HTS_homeScored_ConcededBy_4p\", \"HTS_awayScored_ConcededBy_0\",\n \"HTS_awayScored_ConcededBy_1\", \"HTS_awayScored_ConcededBy_2\", \"HTS_awayScored_ConcededBy_3\", \n \"HTS_awayScored_ConcededBy_4\", \"HTS_awayScored_ConcededBy_5p\", \"HTS_awayScored_ConcededBy_0_or_1\", \n \"HTS_awayScored_ConcededBy_2_or_3\", \"HTS_awayScored_ConcededBy_4p\", \"ATS_teamGoalsDifference\",\n \"ATS_teamCleanSheetPercent\", \"ATS_homeOver1_5GoalsPercent\", \"ATS_homeOver2_5GoalsPercent\", \n \"ATS_homeOver3_5GoalsPercent\", \"ATS_homeOver4_5GoalsPercent\", \"ATS_awayOver1_5GoalsPercent\",\n \"ATS_awayOver2_5GoalsPercent\", \"ATS_awayOver3_5GoalsPercent\", \"ATS_awayOver4_5GoalsPercent\", \n \"ATS_homeCleanSheets\", \"ATS_homeWonToNil\", \"ATS_homeBothTeamsScored\", \"ATS_homeFailedToScore\", \n \"ATS_homeLostToNil\", \"ATS_awayCleanSheets\", \"ATS_awayWonToNil\", \"ATS_awayBothTeamsScored\", \n \"ATS_awayFailedToScore\", \"ATS_awayLostToNil\", \"ATS_homeScored_ConcededBy_0\", \"ATS_homeScored_ConcededBy_1\", \n \"ATS_homeScored_ConcededBy_2\", \"ATS_homeScored_ConcededBy_3\", \"ATS_homeScored_ConcededBy_4\", \n \"ATS_homeScored_ConcededBy_5p\", \"ATS_homeScored_ConcededBy_0_or_1\", \"ATS_homeScored_ConcededBy_2_or_3\", \n \"ATS_homeScored_ConcededBy_4p\", \"ATS_awayScored_ConcededBy_0\", \"ATS_awayScored_ConcededBy_1\", \n \"ATS_awayScored_ConcededBy_2\", \"ATS_awayScored_ConcededBy_3\", \"ATS_awayScored_ConcededBy_4\", \n \"ATS_awayScored_ConcededBy_5p\", \"ATS_awayScored_ConcededBy_0_or_1\", \"ATS_awayScored_ConcededBy_2_or_3\", \n \"ATS_awayScored_ConcededBy_4p\" \n]",
"_____no_output_____"
],
[
"# cast types to columns: doubles\nml_df = ml_df.select(*[col(c).cast(\"double\").alias(c) for c in dtype_features] + stype_features + [ml_df.ft_score])",
"_____no_output_____"
],
[
"# add extra column; over/under\nover_under_udf = udf(\n lambda r: \"over\" if (int(r.split(\"-\")[0]) + int(r.split(\"-\")[1])) > 2 else \"under\", \n StringType()\n)\nml_df = (ml_df.withColumn(\"over_under\", over_under_udf(ml_df.ft_score)))\nml_df.select(\"ft_score\", \"over_under\").show(5)\n# drop \"ft_score\"\nml_df = ml_df.drop(\"ft_score\")",
"+--------+----------+\n|ft_score|over_under|\n+--------+----------+\n| 0-0| under|\n| 0-0| under|\n| 2-1| over|\n| 3-3| over|\n| 2-0| under|\n+--------+----------+\nonly showing top 5 rows\n\n"
],
[
"from pyspark.sql.types import DoubleType\n\n# convert percent cols to float\npercent_udf = udf(\n lambda r: float(r.split(\"%\")[0])/100, \n DoubleType()\n)\nml_df = ml_df.select(*[percent_udf(col(col_name)).name(col_name) for col_name in stype_features] + dtype_features + [ml_df.over_under])",
"_____no_output_____"
]
],
[
[
"### 2. Some featurization",
"_____no_output_____"
]
],
[
[
"from pyspark.ml.feature import StringIndexer, OneHotEncoder, VectorIndexer, VectorAssembler\nfrom pyspark.sql import Row\nfrom pyspark.ml import Pipeline\n\n# index the label; \"over_under\"\nsi = StringIndexer(inputCol = \"over_under\", outputCol = \"over_under_indx\")\ndf_indexed = si\\\n .fit(ml_df)\\\n .transform(ml_df)\\\n .drop(\"over_under\")\\\n .withColumnRenamed(\"over_under_indx\", \"over_under\")",
"_____no_output_____"
],
[
"from pyspark.ml.feature import Normalizer\nfrom pyspark.sql.functions import mean, stddev\n\n# normalize feature columns; [(x - mean)/std_dev]\ndef normalize_col(df, cols):\n # find mean & std for each column\n aggExpr = []\n aggStd = []\n for col in cols:\n aggExpr.append(mean(df[col]).alias(col))\n aggStd.append(stddev(df[col]).alias(col + \"_stddev\"))\n \n averages = df.agg(*aggExpr).collect()[0]\n std_devs = df.agg(*aggStd).collect()[0]\n # standardize dataframe\n for col in cols:\n df = df.withColumn(col + \"_norm\", ((df[col] - averages[col]) / std_devs[col + \"_stddev\"]))\n \n return df, averages, std_devs\n\n# normalize dataframe\nfeature_cols = dtype_features + stype_features\ndf_indexed, averages, std_devs = normalize_col(df_indexed, feature_cols)",
"_____no_output_____"
],
[
"# # display some normalized column\n# df_indexed.select(\"HTS_teamPosition\", \"HTS_teamPosition_norm\").show(5)",
"_____no_output_____"
],
[
"from pyspark.ml.linalg import Vectors\nfrom pyspark.sql import Row\n\nfeature_cols = [col+\"_norm\" for col in feature_cols]\ndf_indexed = df_indexed[feature_cols + [\"over_under\"]]\n\n# # vectorize labels and features\n# row = Row(\"label\", \"features\")\n# label_fts = df_indexed.rdd.map(\n# lambda r: (row(r[-1], Vectors.dense(r[:-1])))\n# ).toDF()\n# label_fts.show(5)",
"_____no_output_____"
],
[
"# label_fts.select(\"features\").take(1)",
"_____no_output_____"
],
[
"# split train/test values\ntrain, test = df_indexed.randomSplit([0.8, 0.2])\n# split train/validate values\ntrain, validate = train.randomSplit([0.9, 0.1])\n\nprint(\"Train shape: '{}, {}'\".format(train.count(), len(train.columns)))\nprint(\"Test shape: '{}, {}'\".format(test.count(), len(test.columns)))\nprint(\"Validate shape: '{}, {}'\".format(validate.count(), len(validate.columns)))",
"Train shape: '3789, 188'\nTest shape: '1045, 188'\nValidate shape: '385, 188'\n"
]
],
[
[
"### 3. Compose Neural-network",
"_____no_output_____"
]
],
[
[
"import numpy as np\nX = np.array(train.select(feature_cols).collect())\ny = np.array(train.select(\"over_under\").collect())\nprint(\"train features shape: '{}'\".format(X.shape))\nprint(\"train labels shape: '{}'\".format(y.shape))\n\nX_test = np.array(test.select(feature_cols).collect())\ny_test = np.array(test.select(\"over_under\").collect())\nprint(\"test features shape: '{}'\".format(X_test.shape))\nprint(\"test labels shape: '{}'\".format(y_test.shape))",
"train features shape: '(3789, 187)'\ntrain labels shape: '(3789, 1)'\ntest features shape: '(1045, 187)'\ntest labels shape: '(1045, 1)'\n"
],
[
"# get some Keras essentials\nfrom keras.models import Sequential\nfrom keras.layers import Dense, Dropout\n# build model\nmodel = Sequential()\nmodel.add(Dense(60, activation=\"relu\", input_dim = 187))\nmodel.add(Dropout(0.4))\nmodel.add(Dense(50, activation=\"relu\"))\n# output layer\nmodel.add(Dense(1, activation=\"sigmoid\"))",
"_____no_output_____"
],
[
"# compile & evaluate training\nmodel.compile(loss=\"binary_crossentropy\", optimizer=\"adam\", metrics=[\"accuracy\"])\nmodel.fit(X, y, epochs=1000, batch_size=60)",
"_____no_output_____"
],
[
"# evaluate the model\nscores = model.evaluate(X_test, y_test)\nprint(\"{}: {}%\".format(model.metrics_names[1], scores[1]*100))\nprint(\"Loss: {}\".format(scores[0]))",
"1045/1045 [==============================] - 0s 103us/step\nacc: 51.29186608%\nLoss: 2.14083539607\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
cb31f6f3414d0ef58523bc675d6a655049186f21 | 30,840 | ipynb | Jupyter Notebook | notebooks/EDA_trashcan_trashicra_uavvaste_drinkwaste_mjuwaste_wasteai.ipynb | ver0z/detect-waste | 7dbe029022d71e3f3643fc76d302fef684390d37 | [
"MIT"
] | 69 | 2020-11-22T21:21:23.000Z | 2022-03-31T20:50:34.000Z | notebooks/EDA_trashcan_trashicra_uavvaste_drinkwaste_mjuwaste_wasteai.ipynb | ver0z/detect-waste | 7dbe029022d71e3f3643fc76d302fef684390d37 | [
"MIT"
] | 13 | 2020-12-09T10:03:02.000Z | 2022-03-22T11:22:47.000Z | notebooks/EDA_trashcan_trashicra_uavvaste_drinkwaste_mjuwaste_wasteai.ipynb | ver0z/detect-waste | 7dbe029022d71e3f3643fc76d302fef684390d37 | [
"MIT"
] | 25 | 2020-11-23T11:23:20.000Z | 2022-03-25T14:04:46.000Z | 29.455587 | 140 | 0.545979 | [
[
[
"# Credits\n\nUpdated to detectwaste by:\n* Sylwia Majchrowska",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport sys\nfrom pycocotools.coco import COCO\nimport json\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns; sns.set()\nimport os\nimport skimage\nimport skimage.io as io\nimport copy",
"_____no_output_____"
],
[
"def show_values_on_bars(axs, h_v=\"v\", space=0.4):\n def _show_on_single_plot(ax):\n if h_v == \"v\":\n for p in ax.patches:\n _x = p.get_x() + p.get_width() / 2\n _y = p.get_y() + p.get_height()\n value = int(p.get_height())\n ax.text(_x, _y, value, ha=\"center\") \n elif h_v == \"h\":\n for p in ax.patches:\n _x = p.get_x() + p.get_width() + float(space)\n _y = p.get_y() + p.get_height()\n value = int(p.get_width())\n ax.text(_x, _y, value, ha=\"left\")\n\n if isinstance(axs, np.ndarray):\n for idx, ax in np.ndenumerate(axs):\n _show_on_single_plot(ax)\n else:\n _show_on_single_plot(axs)",
"_____no_output_____"
]
],
[
[
"## TrashCan 1.0\n- background: under watter\n- classes: 8\n- comment: captured frames of 3 videos (very similiar photos of the same objects)\n- annotation: inastance masks",
"_____no_output_____"
]
],
[
[
"dataDir='/dih4/dih4_2/wimlds/data/TrashCan_v1/material_version'\ndataType='all'\nannFile='{}/instances_{}_trashcan.json'.format(dataDir,dataType)\n\n# initialize COCO api for instance annotations\ncoco=COCO(annFile)",
"_____no_output_____"
],
[
"# display COCO categories and supercategories\ncats = coco.loadCats(coco.getCatIds())\nnms=[cat['name'] for cat in cats]\nprint('COCO categories: \\n{}\\n'.format(', '.join(nms)))\n\nnms = set([cat['supercategory'] for cat in cats])\nprint('COCO supercategories: \\n{}'.format(', '.join(nms)))",
"_____no_output_____"
],
[
"# load and display image\ncatIds = coco.getCatIds(catNms=['trash_wood']);\nimgIds = coco.getImgIds(catIds=catIds);\nimg_id = imgIds[np.random.randint(0,len(imgIds))]\nprint('Image n°{}'.format(img_id))\n\nimg = coco.loadImgs(img_id)[0]\n\nimg_name = '%s/%s/%s'%(dataDir, dataType, img['file_name'])\n#img_name = '%s/%s'%(dataDir, img['file_name'])\nprint('Image name: {}'.format(img_name))\n\nI = io.imread(img_name)\nplt.figure()\nplt.imshow(I)\nplt.axis('off')",
"_____no_output_____"
],
[
"# load and display instance annotations\nplt.imshow(I); plt.axis('off')\nannIds = coco.getAnnIds(imgIds=img['id'], catIds=catIds)\nanns = coco.loadAnns(annIds)\ncoco.showAnns(anns, draw_bbox=True)",
"_____no_output_____"
],
[
"with open(annFile, 'r') as f:\n dataset = json.loads(f.read())\n\n# select only trash\n#trash_categories = [item for item in dataset['categories'] if item['name'].startswith('trash')]\ncat_names = [item['name'] for item in dataset['categories'] if item['name'].startswith('trash')]\n#trash_categories\n\n# define variables\ncategories = dataset['categories']\nanns = dataset['annotations']\nimgs = dataset['images']\nnr_cats = len(categories)\nnr_annotations = len(anns)\nnr_images = len(imgs)",
"_____no_output_____"
],
[
"# Count annotations\ncat_histogram = np.zeros(len(dataset['categories']),dtype=int)\nfor ann in dataset['annotations']:\n cat_histogram[ann['category_id'] - 1] += 1\n\n# Initialize the matplotlib figure\nf, ax = plt.subplots(figsize=(5,15))\n\n# Convert to DataFrame\ndf = pd.DataFrame({'Categories': cat_names, 'Number of annotations': cat_histogram})\ndf = df.sort_values('Number of annotations', 0, False)\n\n# Plot the histogram\nsns.set_color_codes(\"pastel\")\nsns.set(style=\"whitegrid\")\nplot_1 = sns.barplot(x=\"Number of annotations\", y=\"Categories\", data=df,\n label=\"Total\", color=\"b\")\nshow_values_on_bars(plot_1, \"h\", 0.3)",
"_____no_output_____"
],
[
"print(len(dataset['images']), len([ann for ann in dataset['annotations'] if ann['image_id'] in [i['id'] for i in dataset['images']]]))",
"_____no_output_____"
],
[
"def trashcan_to_detectwaste(label):\n metals_and_plastics = ['trash_plastic', 'trash_metal']\n \n non_recyclable = ['trash_fabric', 'trash_rubber', 'trash_paper']\n \n other = ['trash_fishing_gear']\n bio = ['trash_wood']\n unknown = ['trash_etc']\n\n if (label in metals_and_plastics):\n label=\"metals_and_plastics\"\n elif(label in non_recyclable):\n label=\"non-recyclable\"\n elif(label in other):\n label=\"other\"\n elif(label in bio):\n label=\"bio\"\n elif(label in unknown):\n label=\"unknown\"\n else:\n print(label, \"is non-trashcan label\")\n label = \"unknown\"\n return label",
"_____no_output_____"
]
],
[
[
"## Trash-ICRA19\n- background: under watter\n- classes: 7\n- comment: captured frames of 3 videos (very similiar photos of the same objects)\n- annotation: bboxes",
"_____no_output_____"
]
],
[
[
"dataDir='/dih4/dih4_2/wimlds/data/trash_icra19/'\ndataType='all'\nannFile='{}/{}_icra_coco.json'.format(dataDir,dataType)\n\n# initialize COCO api for instance annotations\ncoco=COCO(annFile)",
"_____no_output_____"
],
[
"# display COCO categories and supercategories\ncats = coco.loadCats(coco.getCatIds())\nnms=[cat['name'] for cat in cats]\nprint('COCO categories: \\n{}\\n'.format(', '.join(nms)))\n\nnms = set([cat['supercategory'] for cat in cats])\nprint('COCO supercategories: \\n{}'.format(', '.join(nms)))",
"_____no_output_____"
],
[
"# load and display image\ncatIds = coco.getCatIds(catNms=['rubber']);\nimgIds = coco.getImgIds(catIds=catIds);\nimg_id = imgIds[np.random.randint(0,len(imgIds))]\nprint('Image n°{}'.format(img_id))\n\nimg = coco.loadImgs(img_id)[0]\n\nimg_name = '%s/%s/%s'%(dataDir, dataType, img['file_name'])\n#img_name = '%s/%s'%(dataDir, img['file_name'])\nprint('Image name: {}'.format(img_name))\n\nI = io.imread(img_name)\nplt.figure()\nplt.imshow(I)\nplt.axis('off')",
"_____no_output_____"
],
[
"# load and display instance annotations\nplt.imshow(I); plt.axis('off')\nannIds = coco.getAnnIds(imgIds=img['id'], catIds=catIds)\nanns = coco.loadAnns(annIds)\ncoco.showAnns(anns, draw_bbox=True)",
"_____no_output_____"
],
[
"with open(annFile, 'r') as f:\n dataset = json.loads(f.read())\n\n# select only trash\nallowed_items = ['plastic', 'unknown', 'cloth', 'rubber', 'metal', 'wood', 'platstic', 'paper', 'papper']\ncat_names = [item['name'] for item in dataset['categories'] if item['name'] in allowed_items]\ntrash_categories = [item for item in dataset['categories'] if item['name'] in allowed_items]\n\nprint(trash_categories)\n\n# define variables\ncategories = dataset['categories']\nanns = dataset['annotations']\nimgs = dataset['images']\nnr_cats = len(categories)\nnr_annotations = len(anns)\nnr_images = len(imgs)",
"_____no_output_____"
],
[
"# Count annotations\ncat_histogram = np.zeros(len(trash_categories),dtype=int)\nfor ann in dataset['annotations']:\n cat_histogram[ann['category_id'] - 1] += 1\n\n# Initialize the matplotlib figure\nf, ax = plt.subplots(figsize=(5,15))\n\n# Convert to DataFrame\ndf = pd.DataFrame({'Categories': cat_names, 'Number of annotations': cat_histogram})\ndf = df.sort_values('Number of annotations', 0, False)\n\n# Plot the histogram\nsns.set_color_codes(\"pastel\")\nsns.set(style=\"whitegrid\")\nplot_1 = sns.barplot(x=\"Number of annotations\", y=\"Categories\", data=df,\n label=\"Total\", color=\"b\")\nshow_values_on_bars(plot_1, \"h\", 0.3)",
"_____no_output_____"
],
[
"print(len(dataset['images']), len([ann for ann in dataset['annotations'] if ann['image_id'] in [i['id'] for i in dataset['images']]]))",
"_____no_output_____"
],
[
"def trashicra_to_detectwaste(label):\n metals_and_plastics = ['plastic', 'metal', 'rubber']\n non_recyclable = ['cloth', 'paper']\n bio = ['wood']\n unknown = ['unknown']\n\n if (label in metals_and_plastics):\n label=\"metals_and_plastics\"\n elif(label in non_recyclable):\n label=\"non-recyclable\"\n elif(label in bio):\n label=\"bio\"\n elif(label in unknown):\n label=\"unknown\"\n else:\n print(label, \"is non-trashicra label\")\n label = \"unknown\"\n return label",
"_____no_output_____"
]
],
[
[
"## UAVVaste\n- background: outside\n- classes: 1\n- comment: very distance trash (from dron)\n- annotation: instance masks",
"_____no_output_____"
]
],
[
[
"dataDir='/dih4/dih4_2/wimlds/data/uavvaste'\ndataType='images'\nannFile='{}/annotations.json'.format(dataDir,dataType)\n\n# initialize COCO api for instance annotations\ncoco=COCO(annFile)",
"_____no_output_____"
],
[
"# display COCO categories and supercategories\ncats = coco.loadCats(coco.getCatIds())\nnms=[cat['name'] for cat in cats]\nprint('COCO categories: \\n{}\\n'.format(', '.join(nms)))\n\nnms = set([cat['supercategory'] for cat in cats])\nprint('COCO supercategories: \\n{}'.format(', '.join(nms)))",
"_____no_output_____"
],
[
"# load and display image\ncatIds = coco.getCatIds(catNms=['rubber']);\nimgIds = coco.getImgIds(catIds=catIds);\nimg_id = imgIds[np.random.randint(0,len(imgIds))]\nprint('Image n°{}'.format(img_id))\n\nimg = coco.loadImgs(img_id)[0]\n\nimg_name = '%s/%s/%s'%(dataDir, dataType, img['file_name'])\n#img_name = '%s/%s'%(dataDir, img['file_name'])\nprint('Image name: {}'.format(img_name))\n\nI = io.imread(img_name)\nplt.figure()\nplt.imshow(I)\nplt.axis('off')",
"_____no_output_____"
],
[
"# load and display instance annotations\nplt.imshow(I); plt.axis('off')\nannIds = coco.getAnnIds(imgIds=img['id'], catIds=catIds)\nanns = coco.loadAnns(annIds)\ncoco.showAnns(anns, draw_bbox=True)",
"_____no_output_____"
],
[
"with open(annFile, 'r') as f:\n dataset = json.loads(f.read())\n\ncat_names = [item['name'] for item in dataset['categories'] if item['name']]\ntrash_categories = dataset['categories']\n \n# define variables\ncategories = dataset['categories']\nanns = dataset['annotations']\nimgs = dataset['images']\nnr_cats = len(categories)\nnr_annotations = len(anns)\nnr_images = len(imgs)",
"_____no_output_____"
],
[
"# Count annotations\ncat_histogram = np.zeros(len(trash_categories),dtype=int)\nfor ann in dataset['annotations']:\n cat_histogram[ann['category_id'] - 1] += 1\n\n# Initialize the matplotlib figure\nf, ax = plt.subplots(figsize=(5,15))\n\n# Convert to DataFrame\ndf = pd.DataFrame({'Categories': cat_names, 'Number of annotations': cat_histogram})\ndf = df.sort_values('Number of annotations', 0, False)\n\n# Plot the histogram\nsns.set_color_codes(\"pastel\")\nsns.set(style=\"whitegrid\")\nplot_1 = sns.barplot(x=\"Number of annotations\", y=\"Categories\", data=df,\n label=\"Total\", color=\"b\")\nshow_values_on_bars(plot_1, \"h\", 0.3)",
"_____no_output_____"
]
],
[
[
"## Drink waste\n- background: indoor\n- classes: 4\n- comment: very similiar photos of the same objects\n- annotation: bboxes",
"_____no_output_____"
]
],
[
[
"dataDir='/dih4/dih4_2/wimlds/data/'\ndataType='drinking-waste/YOLO_imgs'\nannFile='{}/drinkwaste_coco.json'.format(dataDir)\n\n# initialize COCO api for instance annotations\ncoco=COCO(annFile)",
"_____no_output_____"
],
[
"# display COCO categories and supercategories\ncats = coco.loadCats(coco.getCatIds())\nnms=[cat['name'] for cat in cats]\nprint('COCO categories: \\n{}\\n'.format(', '.join(nms)))\n\nnms = set([cat['supercategory'] for cat in cats])\nprint('COCO supercategories: \\n{}'.format(', '.join(nms)))",
"_____no_output_____"
],
[
"# load and display image\ncatIds = coco.getCatIds(catNms=['Glass']);\nimgIds = coco.getImgIds(catIds=catIds);\nimg_id = imgIds[np.random.randint(0,len(imgIds))]\nprint('Image n°{}'.format(img_id))\n\nimg = coco.loadImgs(img_id)[0]\n\nimg_name = '%s/%s/%s'%(dataDir, dataType, img['file_name'])\n#img_name = '%s/%s'%(dataDir, img['file_name'])\nprint('Image name: {}'.format(img_name))\n\nI = io.imread(img_name)\nplt.figure()\nplt.imshow(I)\nplt.axis('off')",
"_____no_output_____"
],
[
"# load and display instance annotations\nplt.imshow(I); plt.axis('off')\nannIds = coco.getAnnIds(imgIds=img['id'], catIds=catIds)\nanns = coco.loadAnns(annIds)\ncoco.showAnns(anns, draw_bbox=True)",
"_____no_output_____"
],
[
"with open(annFile, 'r') as f:\n dataset = json.loads(f.read())\n\ncat_names = [item['name'] for item in dataset['categories'] if item['name']]\ntrash_categories = dataset['categories']\n \n# define variables\ncategories = dataset['categories']\nanns = dataset['annotations']\nimgs = dataset['images']\nnr_cats = len(categories)\nnr_annotations = len(anns)\nnr_images = len(imgs)",
"_____no_output_____"
],
[
"# Count annotations\ncat_histogram = np.zeros(len(trash_categories),dtype=int)\nfor ann in dataset['annotations']:\n cat_histogram[ann['category_id'] - 1] += 1\n\n# Initialize the matplotlib figure\nf, ax = plt.subplots(figsize=(5,15))\n\n# Convert to DataFrame\ndf = pd.DataFrame({'Categories': cat_names, 'Number of annotations': cat_histogram})\ndf = df.sort_values('Number of annotations', 0, False)\n\n# Plot the histogram\nsns.set_color_codes(\"pastel\")\nsns.set(style=\"whitegrid\")\nplot_1 = sns.barplot(x=\"Number of annotations\", y=\"Categories\", data=df,\n label=\"Total\", color=\"b\")\nshow_values_on_bars(plot_1, \"h\", 0.3)",
"_____no_output_____"
],
[
"def drinkingwaste_to_detectwaste(label):\n metals_and_plastics = ['PET', 'HDPEM', 'AluCan']\n glass = ['Glass']\n\n if (label in metals_and_plastics):\n label=\"metals_and_plastics\"\n elif(label in glass):\n label=\"glass\"\n else:\n print(label, \"is non-drinkingwaste label\")\n label = \"unknown\"\n return label",
"_____no_output_____"
]
],
[
[
"## MJU-Waste v1.0\n- background: indoor, in hand\n- classes: 1\n- comment: such simply background, labolatroy\n- annotation: instance masks (and depth - RGBD images)",
"_____no_output_____"
]
],
[
[
"dataDir='/dih4/dih4_2/wimlds/data/mju-waste-v1'\ndataType='JPEGImages'\ntype_ann='all'\nannFile='{}/mju-waste/{}.json'.format(dataDir, type_ann)\n\n# initialize COCO api for instance annotations\ncoco=COCO(annFile)",
"_____no_output_____"
],
[
"# display COCO categories and supercategories\ncats = coco.loadCats(coco.getCatIds())\nnms=[cat['name'] for cat in cats]\nprint('COCO categories: \\n{}\\n'.format(', '.join(nms)))\n\nnms = set([cat['supercategory'] for cat in cats])\nprint('COCO supercategories: \\n{}'.format(', '.join(nms)))",
"_____no_output_____"
],
[
"# load and display image\ncatIds = coco.getCatIds(catNms=['Rubbish']);\nimgIds = coco.getImgIds(catIds=catIds);\nimg_id = imgIds[np.random.randint(0,len(imgIds))]\nprint('Image n°{}'.format(img_id))\n\nimg = coco.loadImgs(img_id)[0]\n\nimg_name = '%s/%s/%s'%(dataDir, dataType, img['file_name'])\n#img_name = '%s/%s'%(dataDir, img['file_name'])\nprint('Image name: {}'.format(img_name))\n\nI = io.imread(img_name)\nplt.figure()\nplt.imshow(I)\nplt.axis('off')",
"_____no_output_____"
],
[
"# load and display instance annotations\nplt.imshow(I); plt.axis('off')\nannIds = coco.getAnnIds(imgIds=img['id'], catIds=catIds)\nanns = coco.loadAnns(annIds)\ncoco.showAnns(anns, draw_bbox=True)",
"_____no_output_____"
],
[
"with open(annFile, 'r') as f:\n dataset = json.loads(f.read())\n\ncat_names = [item['name'] for item in dataset['categories'] if item['name']]\ntrash_categories = dataset['categories']\n \n# define variables\ncategories = dataset['categories']\nanns = dataset['annotations']\nimgs = dataset['images']\nnr_cats = len(categories)\nnr_annotations = len(anns)\nnr_images = len(imgs)",
"_____no_output_____"
],
[
"# Count annotations\ncat_histogram = np.zeros(len(trash_categories),dtype=int)\nfor ann in dataset['annotations']:\n cat_histogram[ann['category_id'] - 1] += 1\n\n# Initialize the matplotlib figure\nf, ax = plt.subplots(figsize=(5,15))\n\n# Convert to DataFrame\ndf = pd.DataFrame({'Categories': cat_names, 'Number of annotations': cat_histogram})\ndf = df.sort_values('Number of annotations', 0, False)\n\n# Plot the histogram\nsns.set_color_codes(\"pastel\")\nsns.set(style=\"whitegrid\")\nplot_1 = sns.barplot(x=\"Number of annotations\", y=\"Categories\", data=df,\n label=\"Total\", color=\"b\")\nshow_values_on_bars(plot_1, \"h\", 0.3)",
"_____no_output_____"
]
],
[
[
"## wade-ai\n- background: outside, google maps\n- classes: 1\n- comment: roads and pavements\n- annotation: instance masks",
"_____no_output_____"
]
],
[
[
"dataDir='/dih4/dih4_2/wimlds/data/wade-ai'\ndataType='wade-ai_images'\ntype_ann='all'\nannFile='{}/{}_wade_ai.json'.format(dataDir, type_ann)\n\n# initialize COCO api for instance annotations\ncoco=COCO(annFile)",
"_____no_output_____"
],
[
"# display COCO categories and supercategories\ncats = coco.loadCats(coco.getCatIds())\nnms=[cat['name'] for cat in cats]\nprint('COCO categories: \\n{}\\n'.format(', '.join(nms)))\n\nnms = set([cat['supercategory'] for cat in cats])\nprint('COCO supercategories: \\n{}'.format(', '.join(nms)))",
"_____no_output_____"
],
[
"# load and display image\ncatIds = coco.getCatIds(catNms=['Rubbish']);\nimgIds = coco.getImgIds(catIds=catIds);\nimg_id = imgIds[np.random.randint(0,len(imgIds))]\nprint('Image n°{}'.format(img_id))\n\nimg = coco.loadImgs(img_id)[0]\n\nimg_name = '%s/%s/%s'%(dataDir, dataType, img['file_name'])\n#img_name = '%s/%s'%(dataDir, img['file_name'])\nprint('Image name: {}'.format(img_name))\n\nI = io.imread(img_name)\nplt.figure()\nplt.imshow(I)\nplt.axis('off')",
"_____no_output_____"
],
[
"# load and display instance annotations\nplt.imshow(I); plt.axis('off')\nannIds = coco.getAnnIds(imgIds=img['id'], catIds=catIds)\nanns = coco.loadAnns(annIds)\ncoco.showAnns(anns)#, draw_bbox=True)",
"_____no_output_____"
],
[
"with open(annFile, 'r') as f:\n dataset = json.loads(f.read())\n\ncat_names = [item['name'] for item in dataset['categories'] if item['name']]\ntrash_categories = dataset['categories']\n \n# define variables\ncategories = dataset['categories']\nanns = dataset['annotations']\nimgs = dataset['images']\nnr_cats = len(categories)\nnr_annotations = len(anns)\nnr_images = len(imgs)",
"_____no_output_____"
],
[
"# Count annotations\ncat_histogram = np.zeros(len(trash_categories),dtype=int)\nfor ann in dataset['annotations']:\n ann['category_id'] = 1\n cat_histogram[ann['category_id'] - 1] += 1\n\n# Initialize the matplotlib figure\nf, ax = plt.subplots(figsize=(5,15))\n\n# Convert to DataFrame\ndf = pd.DataFrame({'Categories': cat_names, 'Number of annotations': cat_histogram})\ndf = df.sort_values('Number of annotations', 0, False)\n\n# Plot the histogram\nsns.set_color_codes(\"pastel\")\nsns.set(style=\"whitegrid\")\nplot_1 = sns.barplot(x=\"Number of annotations\", y=\"Categories\", data=df,\n label=\"Total\", color=\"b\")\nshow_values_on_bars(plot_1, \"h\", 0.3)",
"_____no_output_____"
],
[
"with open('/dih4/dih4_home/smajchrowska/detect-waste/annotations/annotations_binary_train.json', 'r') as f:\n dataset = json.loads(f.read())\ncat_names = [item['name'] for item in dataset['categories'] if item['name']]\ntrash_categories = dataset['categories']\n \n# define variables\ncategories = dataset['categories']\nanns = dataset['annotations']\nimgs = dataset['images']\nnr_cats = len(categories)\nnr_annotations = len(anns)\nnr_images = len(imgs)",
"_____no_output_____"
],
[
"# Count annotations\ncat_histogram = np.zeros(len(trash_categories),dtype=int)\nfor ann in dataset['annotations']:\n cat_histogram[ann['category_id']-1] += 1\n\n# Initialize the matplotlib figure\nf, ax = plt.subplots(figsize=(5,15))\n\n# Convert to DataFrame\ndf = pd.DataFrame({'Categories': cat_names, 'Number of annotations': cat_histogram})\ndf = df.sort_values('Number of annotations', 0, False)\n\n# Plot the histogram\nsns.set_color_codes(\"pastel\")\nsns.set(style=\"whitegrid\")\nplot_1 = sns.barplot(x=\"Number of annotations\", y=\"Categories\", data=df,\n label=\"Total\", color=\"b\")\nshow_values_on_bars(plot_1, \"h\", 0.3)",
"_____no_output_____"
],
[
"len(imgs)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb31fa7e6e5bd67f8bc487dcc872f819fa4c2cd8 | 83,988 | ipynb | Jupyter Notebook | Obesity_In_the_US/.ipynb_checkpoints/Obesity-checkpoint.ipynb | joeyzhouchosen/Work_Demo | 50e5af5337c7f2e71e7914796725190468963f9e | [
"MIT"
] | null | null | null | Obesity_In_the_US/.ipynb_checkpoints/Obesity-checkpoint.ipynb | joeyzhouchosen/Work_Demo | 50e5af5337c7f2e71e7914796725190468963f9e | [
"MIT"
] | null | null | null | Obesity_In_the_US/.ipynb_checkpoints/Obesity-checkpoint.ipynb | joeyzhouchosen/Work_Demo | 50e5af5337c7f2e71e7914796725190468963f9e | [
"MIT"
] | null | null | null | 100.584431 | 1,430 | 0.299567 | [
[
[
"library(dplyr)\nlibrary(ggplot2)\nlibrary(reshape2)",
"_____no_output_____"
],
[
"raw <- read.csv(\"Nutrition_Physical_Activity_and_Obesity_Behavioral_Risk_Factor_Surveillance_System.csv\")\n\nprint(nrow(raw))\nprint(ncol(raw))\nhead(raw)",
"[1] 53392\n[1] 33\n"
],
[
"clean <- subset(raw, select = c(YearStart, LocationDesc, Topic, Question, Data_Value, StratificationCategory1, Stratification1))\nclean = rename(clean, Year = YearStart, State = LocationDesc, Obesity = Data_Value, Category = StratificationCategory1, Group = Stratification1)\n\nhead(clean)",
"_____no_output_____"
],
[
"obesity <- filter(clean, Question == \"Percent of adults aged 18 years and older who have obesity\")\nobesity <- filter(obesity, State != \"National\" & State != \"Guam\" & State != \"Puerto Rico\")\n\nnrow(obesity)\nhead(obesity)",
"_____no_output_____"
]
],
[
[
"## Map By States",
"_____no_output_____"
]
],
[
[
"state <- filter(obesity, Category == \"Total\")\nhead(state, 10)",
"_____no_output_____"
]
],
[
[
"## Gender",
"_____no_output_____"
]
],
[
[
"gender <- filter(obesity, Category == \"Gender\") %>% group_by(Year, Group) %>%\n summarize(Obesity_Percantage = mean(Obesity))\nhead(gender, 8)",
"_____no_output_____"
],
[
"ggplot(gender, aes(x=Year, Y=Obesity, group=1)) + \n labs(x=\"Year\", y=\"Obesity Rate\") + facet_wrap(~Group)",
"_____no_output_____"
]
],
[
[
"## Age Group ",
"_____no_output_____"
]
],
[
[
"age <- filter(obesity, Category == \"Age (years)\") %>% \n group_by(Year, Group) %>% summarize(Obesity_Percentage = mean(Obesity))\n\nhead(age)",
"_____no_output_____"
],
[
"#year <- melt(age_trend, id = \"Year\")\n\nggplot(age_trend, aes(x=Year, colour=Group)) + \n geom_point(aes(y=Obesity))\n geom_line()",
"_____no_output_____"
]
],
[
[
"## Level of Education ",
"_____no_output_____"
]
],
[
[
"edu <- filter(obesity, Category == \"Education\") %>% \n group_by(Year, Group) %>% summarize(Obesity_Percentage = mean(Obesity))\n\nhead(edu)",
"_____no_output_____"
]
],
[
[
"## Level of Income",
"_____no_output_____"
]
],
[
[
"income <- filter(obesity, Category == \"Income\") %>% \n group_by(Year, Group) %>% summarize(Obesity_Percentage = mean(Obesity))\n\nhead(income)",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
cb322565beb9dd158d37490ebe6243e72d4e94f1 | 200,230 | ipynb | Jupyter Notebook | Titanic_survival_main.ipynb | Vedant1202/ML_Titanic_Survivors_Prediction | dcb2eda56cde716d0191e50b7c5a5f31e458bac0 | [
"MIT"
] | null | null | null | Titanic_survival_main.ipynb | Vedant1202/ML_Titanic_Survivors_Prediction | dcb2eda56cde716d0191e50b7c5a5f31e458bac0 | [
"MIT"
] | null | null | null | Titanic_survival_main.ipynb | Vedant1202/ML_Titanic_Survivors_Prediction | dcb2eda56cde716d0191e50b7c5a5f31e458bac0 | [
"MIT"
] | null | null | null | 60.952816 | 15,420 | 0.585856 | [
[
[
"import pandas as pd\nimport numpy as np\nimport seaborn as sns\nimport matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
],
[
"train = pd.read_csv('titanic_train.csv')\ntest = pd.read_csv('titanic_test.csv')",
"_____no_output_____"
],
[
"train.head()",
"_____no_output_____"
],
[
"sns.heatmap(train.isnull(), yticklabels=False, cbar=False, cmap='viridis')",
"_____no_output_____"
],
[
"##There is maximum number of data points missing in 'Cabin'",
"_____no_output_____"
],
[
"sns.set_style('whitegrid')",
"_____no_output_____"
],
[
"sns.countplot(x='Survived', hue='Pclass', data=train)",
"_____no_output_____"
],
[
"## Max survivors from class '1', and least from class '2'\n## Max deaths from class '3', and least from class '1'",
"_____no_output_____"
],
[
"sns.countplot(x='Survived', hue='Sex', data=train)",
"_____no_output_____"
],
[
"## Max survivors were women\n## Max deaths were of men",
"_____no_output_____"
],
[
"sns.distplot(train['Age'].dropna(), kde=False, bins=30)",
"C:\\Users\\VEDANT NANDOSKAR\\Anaconda3\\lib\\site-packages\\matplotlib\\axes\\_axes.py:6462: UserWarning: The 'normed' kwarg is deprecated, and has been replaced by the 'density' kwarg.\n warnings.warn(\"The 'normed' kwarg is deprecated, and has been \"\n"
],
[
"## Average age of passengers was between 20-30 years with elder people the least on board.",
"_____no_output_____"
],
[
"train.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 891 entries, 0 to 890\nData columns (total 12 columns):\nPassengerId 891 non-null int64\nSurvived 891 non-null int64\nPclass 891 non-null int64\nName 891 non-null object\nSex 891 non-null object\nAge 714 non-null float64\nSibSp 891 non-null int64\nParch 891 non-null int64\nTicket 891 non-null object\nFare 891 non-null float64\nCabin 204 non-null object\nEmbarked 889 non-null object\ndtypes: float64(2), int64(5), object(5)\nmemory usage: 83.6+ KB\n"
],
[
"sns.countplot(x='SibSp', data=train)",
"_____no_output_____"
],
[
"## Most people were alone on board without any siblings or spouses",
"_____no_output_____"
],
[
"train['Fare'].hist(bins=40, figsize=(10,4))",
"_____no_output_____"
],
[
"## Most passengers are in the cheaper tickets sections wich is in agreement\n## with the max-deaths plot with respect to 'Pclass'",
"_____no_output_____"
],
[
"plt.figure(figsize=(20,10))\nsns.boxplot(x='Pclass', y='Age', data=train)",
"_____no_output_____"
],
[
"def impute_age(cols):\n Age = cols[0]\n Pclass = cols[1]\n \n if pd.isnull(Age):\n \n if Pclass == 1:\n return 37\n elif Pclass == 2:\n return 29\n else:\n return 24\n else: \n return Age",
"_____no_output_____"
],
[
"train['Age'] = train[['Age', 'Pclass']].apply(impute_age, axis=1)\ntest['Age'] = test[['Age', 'Pclass']].apply(impute_age, axis=1)",
"_____no_output_____"
],
[
"sns.heatmap(train.isnull(), yticklabels=False, cbar=False)",
"_____no_output_____"
],
[
"## Solved the missing data in Age \n## However Cabin needs to be dropped",
"_____no_output_____"
],
[
"train.drop('Cabin', axis=1, inplace=True)\ntest.drop('Cabin', axis=1, inplace=True)",
"_____no_output_____"
],
[
"## Drop the missing row in 'Embarked'\ntrain.dropna(inplace=True)\ntest.dropna(inplace=True)",
"_____no_output_____"
],
[
"sns.heatmap(train.isnull(), yticklabels=False, cbar=False)",
"_____no_output_____"
],
[
"## Data is cleaned!",
"_____no_output_____"
],
[
"sex = pd.get_dummies(train['Sex'], drop_first=True)\nsex_test = pd.get_dummies(test['Sex'], drop_first=True)",
"_____no_output_____"
],
[
"embark = pd.get_dummies(train['Embarked'], drop_first=True)\nembark_test = pd.get_dummies(test['Embarked'], drop_first=True)",
"_____no_output_____"
],
[
"train = pd.concat([train, sex, embark], axis=1)\ntest = pd.concat([test, sex_test, embark_test], axis=1)",
"_____no_output_____"
],
[
"train.head()",
"_____no_output_____"
],
[
"test.head()",
"_____no_output_____"
],
[
"names = test['Name']\nnames",
"_____no_output_____"
],
[
"train.drop(['Sex', 'Embarked', 'Name', 'Ticket'], axis=1, inplace=True)\ntest.drop(['Sex', 'Embarked', 'Name', 'Ticket'], axis=1, inplace=True)",
"_____no_output_____"
],
[
"train.head()",
"_____no_output_____"
],
[
"test.head()",
"_____no_output_____"
],
[
"train.drop('PassengerId', axis=1, inplace=True)\n##index_test = test.drop('PassengerId', axis=1, inplace=False)\nindex_test = test['PassengerId']\nindex_test\n##test.drop('PassengerId', axis=1, inplace=True)",
"_____no_output_____"
],
[
"test.drop('PassengerId', axis=1, inplace=True)\ntest",
"_____no_output_____"
],
[
"## Data filtered for machine learning algorithms",
"_____no_output_____"
],
[
"x = train.drop('Survived', axis=1)\ny = train['Survived']",
"_____no_output_____"
],
[
"from sklearn.cross_validation import train_test_split",
"C:\\Users\\VEDANT NANDOSKAR\\Anaconda3\\lib\\site-packages\\sklearn\\cross_validation.py:41: DeprecationWarning: This module was deprecated in version 0.18 in favor of the model_selection module into which all the refactored classes and functions are moved. Also note that the interface of the new CV iterators are different from that of this module. This module will be removed in 0.20.\n \"This module will be removed in 0.20.\", DeprecationWarning)\n"
],
[
"x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=1, random_state=300)",
"_____no_output_____"
],
[
"from sklearn.linear_model import LogisticRegression",
"_____no_output_____"
],
[
"logmodel = LogisticRegression()",
"_____no_output_____"
],
[
"logmodel.fit(x_train, y_train)",
"_____no_output_____"
],
[
"predictions = logmodel.predict(test)",
"_____no_output_____"
],
[
"from sklearn.metrics import classification_report",
"_____no_output_____"
],
[
"print(classification_report(index_test,predictions))",
" precision recall f1-score support\n\n 0 0.00 0.00 0.00 0\n 1 0.00 0.00 0.00 0\n 892 0.00 0.00 0.00 1\n 893 0.00 0.00 0.00 1\n 894 0.00 0.00 0.00 1\n 895 0.00 0.00 0.00 1\n 896 0.00 0.00 0.00 1\n 897 0.00 0.00 0.00 1\n 898 0.00 0.00 0.00 1\n 899 0.00 0.00 0.00 1\n 900 0.00 0.00 0.00 1\n 901 0.00 0.00 0.00 1\n 902 0.00 0.00 0.00 1\n 903 0.00 0.00 0.00 1\n 904 0.00 0.00 0.00 1\n 905 0.00 0.00 0.00 1\n 906 0.00 0.00 0.00 1\n 907 0.00 0.00 0.00 1\n 908 0.00 0.00 0.00 1\n 909 0.00 0.00 0.00 1\n 910 0.00 0.00 0.00 1\n 911 0.00 0.00 0.00 1\n 912 0.00 0.00 0.00 1\n 913 0.00 0.00 0.00 1\n 914 0.00 0.00 0.00 1\n 915 0.00 0.00 0.00 1\n 916 0.00 0.00 0.00 1\n 917 0.00 0.00 0.00 1\n 918 0.00 0.00 0.00 1\n 919 0.00 0.00 0.00 1\n 920 0.00 0.00 0.00 1\n 921 0.00 0.00 0.00 1\n 922 0.00 0.00 0.00 1\n 923 0.00 0.00 0.00 1\n 924 0.00 0.00 0.00 1\n 925 0.00 0.00 0.00 1\n 926 0.00 0.00 0.00 1\n 927 0.00 0.00 0.00 1\n 928 0.00 0.00 0.00 1\n 929 0.00 0.00 0.00 1\n 930 0.00 0.00 0.00 1\n 931 0.00 0.00 0.00 1\n 932 0.00 0.00 0.00 1\n 933 0.00 0.00 0.00 1\n 934 0.00 0.00 0.00 1\n 935 0.00 0.00 0.00 1\n 936 0.00 0.00 0.00 1\n 937 0.00 0.00 0.00 1\n 938 0.00 0.00 0.00 1\n 939 0.00 0.00 0.00 1\n 940 0.00 0.00 0.00 1\n 941 0.00 0.00 0.00 1\n 942 0.00 0.00 0.00 1\n 943 0.00 0.00 0.00 1\n 944 0.00 0.00 0.00 1\n 945 0.00 0.00 0.00 1\n 946 0.00 0.00 0.00 1\n 947 0.00 0.00 0.00 1\n 948 0.00 0.00 0.00 1\n 949 0.00 0.00 0.00 1\n 950 0.00 0.00 0.00 1\n 951 0.00 0.00 0.00 1\n 952 0.00 0.00 0.00 1\n 953 0.00 0.00 0.00 1\n 954 0.00 0.00 0.00 1\n 955 0.00 0.00 0.00 1\n 956 0.00 0.00 0.00 1\n 957 0.00 0.00 0.00 1\n 958 0.00 0.00 0.00 1\n 959 0.00 0.00 0.00 1\n 960 0.00 0.00 0.00 1\n 961 0.00 0.00 0.00 1\n 962 0.00 0.00 0.00 1\n 963 0.00 0.00 0.00 1\n 964 0.00 0.00 0.00 1\n 965 0.00 0.00 0.00 1\n 966 0.00 0.00 0.00 1\n 967 0.00 0.00 0.00 1\n 968 0.00 0.00 0.00 1\n 969 0.00 0.00 0.00 1\n 970 0.00 0.00 0.00 1\n 971 0.00 0.00 0.00 1\n 972 0.00 0.00 0.00 1\n 973 0.00 0.00 0.00 1\n 974 0.00 0.00 0.00 1\n 975 0.00 0.00 0.00 1\n 976 0.00 0.00 0.00 1\n 977 0.00 0.00 0.00 1\n 978 0.00 0.00 0.00 1\n 979 0.00 0.00 0.00 1\n 980 0.00 0.00 0.00 1\n 981 0.00 0.00 0.00 1\n 982 0.00 0.00 0.00 1\n 983 0.00 0.00 0.00 1\n 984 0.00 0.00 0.00 1\n 985 0.00 0.00 0.00 1\n 986 0.00 0.00 0.00 1\n 987 0.00 0.00 0.00 1\n 988 0.00 0.00 0.00 1\n 989 0.00 0.00 0.00 1\n 990 0.00 0.00 0.00 1\n 991 0.00 0.00 0.00 1\n 992 0.00 0.00 0.00 1\n 993 0.00 0.00 0.00 1\n 994 0.00 0.00 0.00 1\n 995 0.00 0.00 0.00 1\n 996 0.00 0.00 0.00 1\n 997 0.00 0.00 0.00 1\n 998 0.00 0.00 0.00 1\n 999 0.00 0.00 0.00 1\n 1000 0.00 0.00 0.00 1\n 1001 0.00 0.00 0.00 1\n 1002 0.00 0.00 0.00 1\n 1003 0.00 0.00 0.00 1\n 1004 0.00 0.00 0.00 1\n 1005 0.00 0.00 0.00 1\n 1006 0.00 0.00 0.00 1\n 1007 0.00 0.00 0.00 1\n 1008 0.00 0.00 0.00 1\n 1009 0.00 0.00 0.00 1\n 1010 0.00 0.00 0.00 1\n 1011 0.00 0.00 0.00 1\n 1012 0.00 0.00 0.00 1\n 1013 0.00 0.00 0.00 1\n 1014 0.00 0.00 0.00 1\n 1015 0.00 0.00 0.00 1\n 1016 0.00 0.00 0.00 1\n 1017 0.00 0.00 0.00 1\n 1018 0.00 0.00 0.00 1\n 1019 0.00 0.00 0.00 1\n 1020 0.00 0.00 0.00 1\n 1021 0.00 0.00 0.00 1\n 1022 0.00 0.00 0.00 1\n 1023 0.00 0.00 0.00 1\n 1024 0.00 0.00 0.00 1\n 1025 0.00 0.00 0.00 1\n 1026 0.00 0.00 0.00 1\n 1027 0.00 0.00 0.00 1\n 1028 0.00 0.00 0.00 1\n 1029 0.00 0.00 0.00 1\n 1030 0.00 0.00 0.00 1\n 1031 0.00 0.00 0.00 1\n 1032 0.00 0.00 0.00 1\n 1033 0.00 0.00 0.00 1\n 1034 0.00 0.00 0.00 1\n 1035 0.00 0.00 0.00 1\n 1036 0.00 0.00 0.00 1\n 1037 0.00 0.00 0.00 1\n 1038 0.00 0.00 0.00 1\n 1039 0.00 0.00 0.00 1\n 1040 0.00 0.00 0.00 1\n 1041 0.00 0.00 0.00 1\n 1042 0.00 0.00 0.00 1\n 1043 0.00 0.00 0.00 1\n 1045 0.00 0.00 0.00 1\n 1046 0.00 0.00 0.00 1\n 1047 0.00 0.00 0.00 1\n 1048 0.00 0.00 0.00 1\n 1049 0.00 0.00 0.00 1\n 1050 0.00 0.00 0.00 1\n 1051 0.00 0.00 0.00 1\n 1052 0.00 0.00 0.00 1\n 1053 0.00 0.00 0.00 1\n 1054 0.00 0.00 0.00 1\n 1055 0.00 0.00 0.00 1\n 1056 0.00 0.00 0.00 1\n 1057 0.00 0.00 0.00 1\n 1058 0.00 0.00 0.00 1\n 1059 0.00 0.00 0.00 1\n 1060 0.00 0.00 0.00 1\n 1061 0.00 0.00 0.00 1\n 1062 0.00 0.00 0.00 1\n 1063 0.00 0.00 0.00 1\n 1064 0.00 0.00 0.00 1\n 1065 0.00 0.00 0.00 1\n 1066 0.00 0.00 0.00 1\n 1067 0.00 0.00 0.00 1\n 1068 0.00 0.00 0.00 1\n 1069 0.00 0.00 0.00 1\n 1070 0.00 0.00 0.00 1\n 1071 0.00 0.00 0.00 1\n 1072 0.00 0.00 0.00 1\n 1073 0.00 0.00 0.00 1\n 1074 0.00 0.00 0.00 1\n 1075 0.00 0.00 0.00 1\n 1076 0.00 0.00 0.00 1\n 1077 0.00 0.00 0.00 1\n 1078 0.00 0.00 0.00 1\n 1079 0.00 0.00 0.00 1\n 1080 0.00 0.00 0.00 1\n 1081 0.00 0.00 0.00 1\n 1082 0.00 0.00 0.00 1\n 1083 0.00 0.00 0.00 1\n 1084 0.00 0.00 0.00 1\n 1085 0.00 0.00 0.00 1\n 1086 0.00 0.00 0.00 1\n 1087 0.00 0.00 0.00 1\n 1088 0.00 0.00 0.00 1\n 1089 0.00 0.00 0.00 1\n 1090 0.00 0.00 0.00 1\n 1091 0.00 0.00 0.00 1\n 1092 0.00 0.00 0.00 1\n 1093 0.00 0.00 0.00 1\n 1094 0.00 0.00 0.00 1\n 1095 0.00 0.00 0.00 1\n 1096 0.00 0.00 0.00 1\n 1097 0.00 0.00 0.00 1\n 1098 0.00 0.00 0.00 1\n 1099 0.00 0.00 0.00 1\n 1100 0.00 0.00 0.00 1\n 1101 0.00 0.00 0.00 1\n 1102 0.00 0.00 0.00 1\n 1103 0.00 0.00 0.00 1\n 1104 0.00 0.00 0.00 1\n 1105 0.00 0.00 0.00 1\n 1106 0.00 0.00 0.00 1\n 1107 0.00 0.00 0.00 1\n 1108 0.00 0.00 0.00 1\n 1109 0.00 0.00 0.00 1\n 1110 0.00 0.00 0.00 1\n 1111 0.00 0.00 0.00 1\n 1112 0.00 0.00 0.00 1\n 1113 0.00 0.00 0.00 1\n 1114 0.00 0.00 0.00 1\n 1115 0.00 0.00 0.00 1\n 1116 0.00 0.00 0.00 1\n 1117 0.00 0.00 0.00 1\n 1118 0.00 0.00 0.00 1\n 1119 0.00 0.00 0.00 1\n 1120 0.00 0.00 0.00 1\n 1121 0.00 0.00 0.00 1\n 1122 0.00 0.00 0.00 1\n 1123 0.00 0.00 0.00 1\n 1124 0.00 0.00 0.00 1\n 1125 0.00 0.00 0.00 1\n 1126 0.00 0.00 0.00 1\n 1127 0.00 0.00 0.00 1\n 1128 0.00 0.00 0.00 1\n 1129 0.00 0.00 0.00 1\n 1130 0.00 0.00 0.00 1\n 1131 0.00 0.00 0.00 1\n 1132 0.00 0.00 0.00 1\n 1133 0.00 0.00 0.00 1\n 1134 0.00 0.00 0.00 1\n 1135 0.00 0.00 0.00 1\n 1136 0.00 0.00 0.00 1\n 1137 0.00 0.00 0.00 1\n 1138 0.00 0.00 0.00 1\n 1139 0.00 0.00 0.00 1\n 1140 0.00 0.00 0.00 1\n 1141 0.00 0.00 0.00 1\n 1142 0.00 0.00 0.00 1\n 1143 0.00 0.00 0.00 1\n 1144 0.00 0.00 0.00 1\n 1145 0.00 0.00 0.00 1\n 1146 0.00 0.00 0.00 1\n 1147 0.00 0.00 0.00 1\n 1148 0.00 0.00 0.00 1\n 1149 0.00 0.00 0.00 1\n 1150 0.00 0.00 0.00 1\n 1151 0.00 0.00 0.00 1\n 1152 0.00 0.00 0.00 1\n 1153 0.00 0.00 0.00 1\n 1154 0.00 0.00 0.00 1\n 1155 0.00 0.00 0.00 1\n 1156 0.00 0.00 0.00 1\n 1157 0.00 0.00 0.00 1\n 1158 0.00 0.00 0.00 1\n 1159 0.00 0.00 0.00 1\n 1160 0.00 0.00 0.00 1\n 1161 0.00 0.00 0.00 1\n 1162 0.00 0.00 0.00 1\n 1163 0.00 0.00 0.00 1\n 1164 0.00 0.00 0.00 1\n 1165 0.00 0.00 0.00 1\n 1166 0.00 0.00 0.00 1\n 1167 0.00 0.00 0.00 1\n 1168 0.00 0.00 0.00 1\n 1169 0.00 0.00 0.00 1\n 1170 0.00 0.00 0.00 1\n 1171 0.00 0.00 0.00 1\n 1172 0.00 0.00 0.00 1\n 1173 0.00 0.00 0.00 1\n 1174 0.00 0.00 0.00 1\n 1175 0.00 0.00 0.00 1\n 1176 0.00 0.00 0.00 1\n 1177 0.00 0.00 0.00 1\n 1178 0.00 0.00 0.00 1\n 1179 0.00 0.00 0.00 1\n 1180 0.00 0.00 0.00 1\n 1181 0.00 0.00 0.00 1\n 1182 0.00 0.00 0.00 1\n 1183 0.00 0.00 0.00 1\n 1184 0.00 0.00 0.00 1\n 1185 0.00 0.00 0.00 1\n 1186 0.00 0.00 0.00 1\n 1187 0.00 0.00 0.00 1\n 1188 0.00 0.00 0.00 1\n 1189 0.00 0.00 0.00 1\n 1190 0.00 0.00 0.00 1\n 1191 0.00 0.00 0.00 1\n 1192 0.00 0.00 0.00 1\n 1193 0.00 0.00 0.00 1\n 1194 0.00 0.00 0.00 1\n 1195 0.00 0.00 0.00 1\n 1196 0.00 0.00 0.00 1\n 1197 0.00 0.00 0.00 1\n 1198 0.00 0.00 0.00 1\n 1199 0.00 0.00 0.00 1\n 1200 0.00 0.00 0.00 1\n 1201 0.00 0.00 0.00 1\n 1202 0.00 0.00 0.00 1\n 1203 0.00 0.00 0.00 1\n 1204 0.00 0.00 0.00 1\n 1205 0.00 0.00 0.00 1\n 1206 0.00 0.00 0.00 1\n 1207 0.00 0.00 0.00 1\n 1208 0.00 0.00 0.00 1\n 1209 0.00 0.00 0.00 1\n 1210 0.00 0.00 0.00 1\n 1211 0.00 0.00 0.00 1\n 1212 0.00 0.00 0.00 1\n 1213 0.00 0.00 0.00 1\n 1214 0.00 0.00 0.00 1\n 1215 0.00 0.00 0.00 1\n 1216 0.00 0.00 0.00 1\n 1217 0.00 0.00 0.00 1\n 1218 0.00 0.00 0.00 1\n 1219 0.00 0.00 0.00 1\n 1220 0.00 0.00 0.00 1\n 1221 0.00 0.00 0.00 1\n 1222 0.00 0.00 0.00 1\n 1223 0.00 0.00 0.00 1\n 1224 0.00 0.00 0.00 1\n 1225 0.00 0.00 0.00 1\n 1226 0.00 0.00 0.00 1\n 1227 0.00 0.00 0.00 1\n 1228 0.00 0.00 0.00 1\n 1229 0.00 0.00 0.00 1\n 1230 0.00 0.00 0.00 1\n 1231 0.00 0.00 0.00 1\n 1232 0.00 0.00 0.00 1\n 1233 0.00 0.00 0.00 1\n 1234 0.00 0.00 0.00 1\n 1235 0.00 0.00 0.00 1\n 1236 0.00 0.00 0.00 1\n 1237 0.00 0.00 0.00 1\n 1238 0.00 0.00 0.00 1\n 1239 0.00 0.00 0.00 1\n 1240 0.00 0.00 0.00 1\n 1241 0.00 0.00 0.00 1\n 1242 0.00 0.00 0.00 1\n 1243 0.00 0.00 0.00 1\n 1244 0.00 0.00 0.00 1\n 1245 0.00 0.00 0.00 1\n 1246 0.00 0.00 0.00 1\n 1247 0.00 0.00 0.00 1\n 1248 0.00 0.00 0.00 1\n 1249 0.00 0.00 0.00 1\n 1250 0.00 0.00 0.00 1\n 1251 0.00 0.00 0.00 1\n 1252 0.00 0.00 0.00 1\n 1253 0.00 0.00 0.00 1\n 1254 0.00 0.00 0.00 1\n 1255 0.00 0.00 0.00 1\n 1256 0.00 0.00 0.00 1\n 1257 0.00 0.00 0.00 1\n 1258 0.00 0.00 0.00 1\n 1259 0.00 0.00 0.00 1\n 1260 0.00 0.00 0.00 1\n 1261 0.00 0.00 0.00 1\n 1262 0.00 0.00 0.00 1\n 1263 0.00 0.00 0.00 1\n 1264 0.00 0.00 0.00 1\n 1265 0.00 0.00 0.00 1\n 1266 0.00 0.00 0.00 1\n 1267 0.00 0.00 0.00 1\n 1268 0.00 0.00 0.00 1\n 1269 0.00 0.00 0.00 1\n 1270 0.00 0.00 0.00 1\n 1271 0.00 0.00 0.00 1\n 1272 0.00 0.00 0.00 1\n 1273 0.00 0.00 0.00 1\n 1274 0.00 0.00 0.00 1\n 1275 0.00 0.00 0.00 1\n 1276 0.00 0.00 0.00 1\n 1277 0.00 0.00 0.00 1\n 1278 0.00 0.00 0.00 1\n 1279 0.00 0.00 0.00 1\n 1280 0.00 0.00 0.00 1\n 1281 0.00 0.00 0.00 1\n 1282 0.00 0.00 0.00 1\n 1283 0.00 0.00 0.00 1\n 1284 0.00 0.00 0.00 1\n 1285 0.00 0.00 0.00 1\n 1286 0.00 0.00 0.00 1\n 1287 0.00 0.00 0.00 1\n 1288 0.00 0.00 0.00 1\n 1289 0.00 0.00 0.00 1\n 1290 0.00 0.00 0.00 1\n 1291 0.00 0.00 0.00 1\n 1292 0.00 0.00 0.00 1\n 1293 0.00 0.00 0.00 1\n 1294 0.00 0.00 0.00 1\n 1295 0.00 0.00 0.00 1\n 1296 0.00 0.00 0.00 1\n 1297 0.00 0.00 0.00 1\n 1298 0.00 0.00 0.00 1\n 1299 0.00 0.00 0.00 1\n 1300 0.00 0.00 0.00 1\n 1301 0.00 0.00 0.00 1\n 1302 0.00 0.00 0.00 1\n 1303 0.00 0.00 0.00 1\n 1304 0.00 0.00 0.00 1\n 1305 0.00 0.00 0.00 1\n 1306 0.00 0.00 0.00 1\n 1307 0.00 0.00 0.00 1\n 1308 0.00 0.00 0.00 1\n 1309 0.00 0.00 0.00 1\n\navg / total 0.00 0.00 0.00 417\n\n"
],
[
"from sklearn.metrics import confusion_matrix",
"_____no_output_____"
],
[
"confusion_matrix(index_test, predictions)",
"_____no_output_____"
],
[
"predictions\n",
"_____no_output_____"
],
[
"predictionsDataFrame = pd.DataFrame(\n data={'Name':names, 'Survived':predictions})",
"_____no_output_____"
],
[
"predictionsDataFrame",
"_____no_output_____"
],
[
"predictionsDataFrame.to_csv('predictions_TitanicSurvival.csv', header=True, index_label='Index')",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3228e7e3ed00e4d2b69846cb1986d8f77125d4 | 36,595 | ipynb | Jupyter Notebook | docs/examples/jupyter-notebooks/scatter_plot.ipynb | ASmirnov-HORIS/lets-plot-kotlin | 9d0a73399684fa17f3b0d9fb4cf9c2dc8372cdce | [
"MIT"
] | null | null | null | docs/examples/jupyter-notebooks/scatter_plot.ipynb | ASmirnov-HORIS/lets-plot-kotlin | 9d0a73399684fa17f3b0d9fb4cf9c2dc8372cdce | [
"MIT"
] | null | null | null | docs/examples/jupyter-notebooks/scatter_plot.ipynb | ASmirnov-HORIS/lets-plot-kotlin | 9d0a73399684fa17f3b0d9fb4cf9c2dc8372cdce | [
"MIT"
] | null | null | null | 57.358934 | 2,994 | 0.612024 | [
[
[
"%useLatestDescriptors\n%use lets-plot\nimport java.util.Random",
"_____no_output_____"
],
[
"// This example was found at: \n// www.cookbook-r.com/Graphs/Scatterplots_(ggplot2)\n\nval rand = java.util.Random(123)\nval n = 20\nval data = mapOf<String, List<*>>(\n \"cond\" to List(n / 2) { \"A\" } + List(n / 2) { \"B\" },\n \"xvar\" to List(n) { i:Int-> i }, \n \"yvar\" to List(n) { i:Int-> i + rand.nextGaussian() * 3 }\n)",
"_____no_output_____"
]
],
[
[
"#### Basic scatter plot",
"_____no_output_____"
]
],
[
[
"val p = letsPlot(data) { x = \"xvar\"; y = \"yvar\" } + ggsize(300, 250)\np + geomPoint(shape = 1)",
"_____no_output_____"
]
],
[
[
"#### Add regression line",
"_____no_output_____"
]
],
[
[
"p + geomPoint(shape = 1) +\n geomSmooth()",
"_____no_output_____"
],
[
"// Without standard error band.\np + geomPoint(shape = 1) +\n geomSmooth(se = false)",
"_____no_output_____"
]
],
[
[
"#### Split dataset by the `cond` variable",
"_____no_output_____"
]
],
[
[
"val p1 = letsPlot(data) { x = \"xvar\"; y = \"yvar\"; color = \"cond\" } + ggsize(500, 250)\np1 + geomPoint(shape = 1) +\n geomSmooth(se = false)",
"_____no_output_____"
],
[
"// Map `shape` to the `cond` variable.\np1 + geomPoint(size = 5) { shape = \"cond\" }",
"_____no_output_____"
],
[
"// Choose different shapes using `scale_shape_manual`:\n// 1 - hollow circle \n// 2 - hollow triangle\np1 + geomPoint(size = 5) { shape = \"cond\" } + \n scaleShapeManual(values = listOf(1,2))",
"_____no_output_____"
]
],
[
[
"#### Handling overplotting",
"_____no_output_____"
]
],
[
[
"// Create data with overlapping points.\nval data1 = mapOf(\n \"xvar\" to (data[\"xvar\"] as List<Double>).map { (it / 5).toInt() * 5 },\n \"yvar\" to (data[\"yvar\"] as List<Double>).map { (it / 5).toInt() * 5 },\n )",
"_____no_output_____"
],
[
"val p2 = letsPlot(data1) { x = \"xvar\"; y = \"yvar\"} + ggsize(500, 250) +\n scaleXContinuous(breaks = listOf(0, 5, 10, 15))\n// Use `alpha` to show overplotting.\np2 + geomPoint(alpha = .3, size = 7)",
"_____no_output_____"
],
[
"// `jitter` points to show overplotting in another way.\np2 + geomPoint(shape = 1, position = positionJitter(width=.1, height=.1))",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
cb32338b6d9e7a3e1eecc25e4dc5116ff3e075c2 | 189,462 | ipynb | Jupyter Notebook | .ipynb_checkpoints/LSTM-Google-checkpoint.ipynb | Vishal7017/DataScienceBlogPost | 3012bd4ebff216a519a91221da6d561b8dc953d8 | [
"BSD-2-Clause"
] | 1 | 2021-06-28T17:43:34.000Z | 2021-06-28T17:43:34.000Z | LSTM-Google.ipynb | Vishal7017/DataScienceBlogPost | 3012bd4ebff216a519a91221da6d561b8dc953d8 | [
"BSD-2-Clause"
] | null | null | null | LSTM-Google.ipynb | Vishal7017/DataScienceBlogPost | 3012bd4ebff216a519a91221da6d561b8dc953d8 | [
"BSD-2-Clause"
] | null | null | null | 147.441245 | 77,988 | 0.869562 | [
[
[
"## In this notebook we are going to Predict the Growth of Google Stock using LSTM Model and CRISP-DM.",
"_____no_output_____"
]
],
[
[
"#importing the libraries\nimport math\nimport numpy as np\nimport pandas as pd\nfrom sklearn.preprocessing import MinMaxScaler\nfrom keras.models import Sequential\nfrom keras.layers import Dense, LSTM\nimport matplotlib.pyplot as plt\nplt.style.use('fivethirtyeight')\n\"\"\"For LSTM model please use Numpy --version = 1.19 or lower Cause latest Tensorflow array don't accept np tensors\n\"\"\"",
"_____no_output_____"
]
],
[
[
"# Data Understanding",
"_____no_output_____"
],
[
"The data is already processed to price-split values so it is easy to analysis but we are creating new tables to optimize our model",
"_____no_output_____"
]
],
[
[
"#importing Price Split Data\ndata = pd.read_csv('prices-split-adjusted.csv')\ndata",
"_____no_output_____"
],
[
"#checking data for null values\ndata.isnull().sum()",
"_____no_output_____"
]
],
[
[
"# Data Preprocessing",
"_____no_output_____"
],
[
"Creating Table for a specific Stock",
"_____no_output_____"
]
],
[
[
"#Initializing the Dataset for the Stock to be Analysized\ndata = data.loc[(data['symbol'] == 'GOOG')]\ndata = data.drop(columns=['symbol'])\ndata = data[['date','open','close','low','volume','high']]\ndata",
"_____no_output_____"
],
[
"#Number of rows and columns we are working with\ndata.shape",
"_____no_output_____"
]
],
[
[
"Ploting the closing price of the Stock",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(16,8))\nplt.title('Closing Price of the Stock Historically')\nplt.plot(data['close'])\nplt.xlabel('Year', fontsize=20)\nplt.ylabel('Closing Price Historically ($)', fontsize=20)\nplt.show()",
"_____no_output_____"
]
],
[
[
"#### Here we can see that there is Long-Term growth in this stock.",
"_____no_output_____"
],
[
"# Preparing Data for LSTM",
"_____no_output_____"
],
[
"Here we are going to use LSTM to more accurate prediction of the stock value change. We are checking for accuracy on a particular Stock.\nFirst we create a seperate dataframe only with \"Close\" cloumn",
"_____no_output_____"
]
],
[
[
"#Getting the rows and columns we need\ndata = data.filter(['close'])\ndataset = data.values\n\n#Find out the number of rows that are present in this dataset in order to train our model.\ntraining_data_len = math.ceil(len(dataset)* .8)\ntraining_data_len",
"_____no_output_____"
]
],
[
[
"Scaling the Data to make better Predictions",
"_____no_output_____"
]
],
[
[
"scaler = MinMaxScaler(feature_range=(0,1))\nscaled_data = scaler.fit_transform(dataset)\nscaled_data",
"_____no_output_____"
],
[
"#Creating a train test datasets\ntrain_data = scaled_data[0:training_data_len , :]\nx_train = []\ny_train = []\n\nfor j in range(60, len(train_data)):\n x_train.append(train_data[j-60:j,0])\n y_train.append(train_data[j,0])\n if j<=60:\n print(x_train)\n print(y_train)\n print()",
"[array([0.15939908, 0.15709185, 0.14394234, 0.13210528, 0.13872603,\n 0.1379653 , 0.12907917, 0.12624527, 0.12855249, 0.12031836,\n 0.12668832, 0.12066114, 0.1228095 , 0.09524822, 0.08688037,\n 0.08890336, 0.08863587, 0.08210705, 0.07847068, 0.0810454 ,\n 0.07945711, 0.08756581, 0.07582908, 0.07959922, 0.08142161,\n 0.0839044 , 0.08224082, 0.08387095, 0.08112903, 0.08796707,\n 0.08538401, 0.08957211, 0.08751567, 0.08922104, 0.08275911,\n 0.07974969, 0.0755365 , 0.07584583, 0.08076956, 0.08776647,\n 0.09132761, 0.0990769 , 0.10711872, 0.10567255, 0.10375818,\n 0.11735074, 0.12127135, 0.11993385, 0.10625771, 0.10794633,\n 0.10824726, 0.10894945, 0.10359937, 0.10150949, 0.09440391,\n 0.10136737, 0.10600692, 0.10584811, 0.10564745, 0.10920859])]\n[0.10955136446292446]\n\n"
],
[
"\nx_train, y_train = np.array(x_train), np.array(y_train)\n\n",
"_____no_output_____"
],
[
"x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1))\nx_train.shape",
"_____no_output_____"
]
],
[
[
"# Building LSTM Model",
"_____no_output_____"
]
],
[
[
"model = Sequential()\nmodel.add(LSTM(50, return_sequences=True, input_shape = (x_train.shape[1], 1)))\nmodel.add(LSTM(50, return_sequences=False))\nmodel.add(Dense(25))\nmodel.add(Dense(1))",
"_____no_output_____"
],
[
"model.compile(optimizer='adam', loss='mean_squared_error')\n\n",
"_____no_output_____"
]
],
[
[
"##### Training the Model",
"_____no_output_____"
]
],
[
[
"model.fit(x_train, y_train, batch_size=1, epochs=1)",
"1350/1350 [==============================] - 36s 25ms/step - loss: 0.0025\n"
],
[
"test_data = scaled_data[training_data_len - 60: , :]\nx_test = []\ny_test = dataset[training_data_len:, :]\n\nfor j in range(60, len(test_data)):\n x_test.append(test_data[j-60:j, 0])\n ",
"_____no_output_____"
],
[
"x_test = np.array(x_test)",
"_____no_output_____"
],
[
"x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1], 1))",
"_____no_output_____"
],
[
"predictions = model.predict(x_test)\npredictions = scaler.inverse_transform(predictions)\n\n",
"_____no_output_____"
],
[
"#Finding the Root Mean Squared Error for the Stock\nrmse = np.sqrt( np.mean( predictions - y_test)**2)\nrmse",
"_____no_output_____"
]
],
[
[
"# Visualization",
"_____no_output_____"
],
[
"### Plotting Acutal Close values vs Predicted Values in LR Model",
"_____no_output_____"
]
],
[
[
"#builing close value and prediction value table for comparison\ntrain = data[:training_data_len]\nval = data[training_data_len:]\nval['Predictions'] = predictions\n\nplt.figure(figsize=(16,8))\nplt.title('LSTM Model Data')\nplt.xlabel('Date', fontsize=16)\nplt.ylabel('Close Price', fontsize=16)\nplt.plot(train['close'])\nplt.plot(val[['close', 'Predictions']])\nplt.legend(['Trained Dataset', 'Actual Value', 'Predictions'])\nplt.show()",
"<ipython-input-22-ae9cabdc9c7d>:4: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n val['Predictions'] = predictions\n"
]
],
[
[
"# Evaluation of the model",
"_____no_output_____"
],
[
"Making table for Actual price and Predicted Price",
"_____no_output_____"
]
],
[
[
"#actual close values against predictions\nval",
"_____no_output_____"
],
[
"new_data = pd.read_csv('prices-split-adjusted.csv')\nnew_data = data.filter(['close'])\nlast_60_days = new_data[-60:].values\nlast_60_scaled = scaler.transform(last_60_days)\nX_test = []\nX_test.append(last_60_scaled)\nX_test = np.array(X_test)\nX_test = np.reshape(X_test, (X_test.shape[0], X_test.shape[1], 1))\npredicted_price = model.predict(X_test)\npredicted_price = scaler.inverse_transform(predicted_price)\nprint('The predicted price of the final value of the dataset', predicted_price)",
"The predicted price of the final value of the dataset [[787.44696]]\n"
],
[
"new_data.tail(1)",
"_____no_output_____"
]
],
[
[
"#### The predicted price is USD 122.0, whereas the actual observed value is USD 115.82",
"_____no_output_____"
]
],
[
[
"#check predicted values\npredictions = model.predict(x_test) \n#Undo scaling\npredictions = scaler.inverse_transform(predictions)\n\n#Calculate RMSE score\nrmse=np.sqrt(np.mean(((predictions- y_test)**2)))\nrmse",
"_____no_output_____"
],
[
"neww_data = pd.read_csv('prices-split-adjusted.csv')",
"_____no_output_____"
],
[
"val.describe()",
"_____no_output_____"
],
[
"x = val.close.mean()\ny = val.Predictions.mean()\nAccuracy = x/y*100\nprint(\"The accuracy of the model is \" , Accuracy)",
"The accuracy of the model is 99.39638872040469\n"
]
],
[
[
"The LSTM model Accuracy is 99.39%\nAs we can see the predictions made by LSTM model show a greater accuracy than LR model. So we can finally conclude that the stock is going to grow for long-term.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
cb3236d5fa1f899ade147b44784d4142f240f529 | 1,022,839 | ipynb | Jupyter Notebook | test_notebooks/test_PlateTree.ipynb | siwill22/GPlatesClassStruggle | 713a87ff4f054d3a493ec09e5f310aa3036d3bc5 | [
"MIT"
] | 7 | 2020-05-04T03:05:09.000Z | 2022-01-28T13:52:53.000Z | test_notebooks/test_PlateTree.ipynb | siwill22/GPlatesClassStruggle | 713a87ff4f054d3a493ec09e5f310aa3036d3bc5 | [
"MIT"
] | null | null | null | test_notebooks/test_PlateTree.ipynb | siwill22/GPlatesClassStruggle | 713a87ff4f054d3a493ec09e5f310aa3036d3bc5 | [
"MIT"
] | 3 | 2021-05-23T01:53:52.000Z | 2021-09-14T12:21:53.000Z | 6,598.96129 | 484,840 | 0.964398 | [
[
[
"## PlateTree class usage examples",
"_____no_output_____"
]
],
[
[
"%load_ext autoreload\n%autoreload 2\n\nfrom gprm import PlateTree\nfrom gprm.datasets import Reconstructions",
"_____no_output_____"
],
[
"M2019 = Reconstructions.fetch_Muller2019()\n",
"_____no_output_____"
],
[
"tree_object = PlateTree(M2019)\n\ntree_object.plot_snapshot(200.)\n",
"_____no_output_____"
],
[
"tree_object.plot_snapshot(50., figsize=(20,10))\n",
"_____no_output_____"
],
[
"import pygmt\n\nreconstruction_time = 250.\n\nregion = 'd'\nprojection=\"N6i\"\n\nfig = pygmt.Figure()\nfig.basemap(region=region, projection=projection, frame='afg')\n\nM2019.polygon_snapshot('continents', reconstruction_time).plot(fig, transparency=30)\n\ntree_object.plot_gmt(fig, reconstruction_time)\n\nfig.savefig('../plots/platetree.png')\nfig.show(width=800)\n",
"working on time 250.00 Ma\n"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
cb3237fd5ea7410ea846c38bd4d62a05e7bbd829 | 172,613 | ipynb | Jupyter Notebook | computer-vision-pytorch/3-train-dense-neural-networks.ipynb | leestott/pytorchfundamentals | db4d7fcd8a489514dced676dda9cc617603a9221 | [
"CC-BY-4.0",
"MIT"
] | 7 | 2021-05-12T10:53:09.000Z | 2022-03-24T10:48:21.000Z | computer-vision-pytorch/3-train-dense-neural-networks.ipynb | leestott/pytorchfundamentals | db4d7fcd8a489514dced676dda9cc617603a9221 | [
"CC-BY-4.0",
"MIT"
] | 10 | 2021-07-15T07:22:25.000Z | 2022-01-20T12:10:00.000Z | computer-vision-pytorch/3-train-dense-neural-networks.ipynb | leestott/pytorchfundamentals | db4d7fcd8a489514dced676dda9cc617603a9221 | [
"CC-BY-4.0",
"MIT"
] | 10 | 2021-05-25T17:10:37.000Z | 2022-02-26T03:53:31.000Z | 436.994937 | 119,012 | 0.935121 | [
[
[
"# Training a dense neural network\n\nThe handwritten digit recognition is a classification problem. We will start with the simplest possible approach for image classification - a fully-connected neural network (which is also called a *perceptron*). We use `pytorchcv` helper to load all data we have talked about in the previous unit.",
"_____no_output_____"
]
],
[
[
"!wget https://raw.githubusercontent.com/MicrosoftDocs/pytorchfundamentals/main/computer-vision-pytorch/pytorchcv.py",
"_____no_output_____"
],
[
"import torch\nimport torch.nn as nn\nimport torchvision\nimport matplotlib.pyplot as plt\n\nimport pytorchcv\npytorchcv.load_mnist()",
"_____no_output_____"
]
],
[
[
"## Fully-connected dense neural networks\r\n\r\nA basic **neural network** in PyTorch consists of a number of **layers**. The simplest network would include just one fully-connected layer, which is called **Linear** layer, with 784 inputs (one input for each pixel of the input image) and 10 outputs (one output for each class).\r\n\r\n\r\n\r\nAs we discussed above, the dimension of our digit images is $1\\times28\\times28$. Because the input dimension of a fully-connected layer is 784, we need to insert another layer into the network, called **Flatten**, to change tensor shape from $1\\times28\\times28$ to $784$.\r\n\r\nWe want $n$-th output of the network to return the probability of the input digit being equal to $n$. Because the output of a fully-connected layer is not normalized to be between 0 and 1, it cannot be thought of as probability. To turn it into a probability we need to apply another layer called **Softmax**.\r\n\r\nIn PyTorch, it is easier to use **LogSoftmax** function, which will also compute logarithms of output probabilities. To turn the output vector into the actual probabilities, we need to take **torch.exp** of the output. \r\n\r\nThus, the architecture of our network can be represented by the following sequence of layers:\r\n\r\n\r\n\r\nIt can be defined in PyTorch in the following way, using `Sequential` syntax:",
"_____no_output_____"
]
],
[
[
"net = nn.Sequential(\n nn.Flatten(), \n nn.Linear(784,10), # 784 inputs, 10 outputs\n nn.LogSoftmax())",
"_____no_output_____"
]
],
[
[
"## Training the network\r\n\r\nA network defined this way can take any digit as input and produce a vector of probabilities as an output. Let's see how this network performs by giving it a digit from our dataset:",
"_____no_output_____"
]
],
[
[
"print('Digit to be predicted: ',data_train[0][1])\ntorch.exp(net(data_train[0][0]))",
"_____no_output_____"
]
],
[
[
"As you can see the network predicts similar probabilities for each digit. This is because it has not been trained on how to recognize the digits. We need to give it our training data to train it on our dataset.\r\n\r\nTo train the model we will need to create **batches** of our datasets of a certain size, let's say 64. PyTorch has an object called **DataLoader** that can create batches of our data for us automatically:",
"_____no_output_____"
]
],
[
[
"train_loader = torch.utils.data.DataLoader(data_train,batch_size=64)\ntest_loader = torch.utils.data.DataLoader(data_test,batch_size=64) # we can use larger batch size for testing",
"_____no_output_____"
]
],
[
[
"The training process steps are as follows:\r\n\r\n1. We take a minibatch from the input dataset, which consists of input data (features) and expected result (label).\r\n2. We calculate the predicted result for this minibatch. \r\n3. The difference between this result and expected result is calculated using a special function called the **loss function**\r\n4. We calculate the gradients of this loss function with respect to model weights (parameters), which are then used to adjust the weights to optimize the performance of the network. The amount of adjustment is controlled by a parameter called **learning rate**, and the details of optimization algorithm are defined in the **optimizer** object.\r\n5. We repeat those steps until the whole dataset is processed. One complete pass through the dataset is called **an epoch**. \r\n\r\nHere is a function that performs one epoch training: ",
"_____no_output_____"
]
],
[
[
"def train_epoch(net,dataloader,lr=0.01,optimizer=None,loss_fn = nn.NLLLoss()):\n optimizer = optimizer or torch.optim.Adam(net.parameters(),lr=lr)\n net.train()\n total_loss,acc,count = 0,0,0\n for features,labels in dataloader:\n optimizer.zero_grad()\n out = net(features)\n loss = loss_fn(out,labels) #cross_entropy(out,labels)\n loss.backward()\n optimizer.step()\n total_loss+=loss\n _,predicted = torch.max(out,1)\n acc+=(predicted==labels).sum()\n count+=len(labels)\n return total_loss.item()/count, acc.item()/count\n\ntrain_epoch(net,train_loader)",
"_____no_output_____"
]
],
[
[
"Since this function is pretty generic we will be able to use it later in our other examples. The function takes the following parameters:\r\n* **Neural network**\r\n* **DataLoader**, which defines the data to train on\r\n* **Loss Function**, which is a function that measures the difference between the expected result and the one produced by the network. In most of the classification tasks `NLLLoss` is used, so we will make it a default.\r\n* **Optimizer**, which defined an *optimization algorithm*. The most traditional algorithm is *stochastic gradient descent*, but we will use a more advanced version called **Adam** by default.\r\n* **Learning rate** defines the speed at which the network learns. During learning, we show the same data multiple times, and each time weights are adjusted. If the learning rate is too high, new values will overwrite the knowledge from the old ones, and the network would perform badly. If the learning rate is too small it results in a very slow learning process. \r\n\r\nHere is what we do when training:\r\n* Switch the network to training mode (`net.train()`)\r\n* Go over all batches in the dataset, and for each batch do the following:\r\n - compute predictions made by the network on this batch (`out`)\r\n - compute `loss`, which is the discrepancy between predicted and expected values\r\n - try to minimize the loss by adjusting weights of the network (`optimizer.step()`)\r\n - compute the number of correctly predicted cases (**accuracy**)\r\n\r\nThe function calculates and returns the average loss per data item, and training accuracy (percentage of cases guessed correctly). By observing this loss during training we can see whether the network is improving and learning from the data provided.\r\n\r\nIt is also important to control the accuracy on the test dataset (also called **validation accuracy**). A good neural network with a lot of parameters can predict with decent accuracy on any training dataset, but it may poorly generalize to other data. That's why in most cases we set aside part of our data, and then periodically check how well the model performs on them. Here is the function to evaluate the network on test dataset:\r\n",
"_____no_output_____"
]
],
[
[
"def validate(net, dataloader,loss_fn=nn.NLLLoss()):\n net.eval()\n count,acc,loss = 0,0,0\n with torch.no_grad():\n for features,labels in dataloader:\n out = net(features)\n loss += loss_fn(out,labels) \n pred = torch.max(out,1)[1]\n acc += (pred==labels).sum()\n count += len(labels)\n return loss.item()/count, acc.item()/count\n\nvalidate(net,test_loader)",
"_____no_output_____"
]
],
[
[
"We train the model for several epochs observing training and validation accuracy. If training accuracy increases while validation accuracy decreases that would be an indication of **overfitting**. Meaning it will do well on your dataset but not on new data.\r\n\r\nBelow is the training function that can be used to perform both training and validation. It prints the training and validation accuracy for each epoch, and also returns the history that can be used to plot the loss and accuracy on the graph.",
"_____no_output_____"
]
],
[
[
"def train(net,train_loader,test_loader,optimizer=None,lr=0.01,epochs=10,loss_fn=nn.NLLLoss()):\n optimizer = optimizer or torch.optim.Adam(net.parameters(),lr=lr)\n res = { 'train_loss' : [], 'train_acc': [], 'val_loss': [], 'val_acc': []}\n for ep in range(epochs):\n tl,ta = train_epoch(net,train_loader,optimizer=optimizer,lr=lr,loss_fn=loss_fn)\n vl,va = validate(net,test_loader,loss_fn=loss_fn)\n print(f\"Epoch {ep:2}, Train acc={ta:.3f}, Val acc={va:.3f}, Train loss={tl:.3f}, Val loss={vl:.3f}\")\n res['train_loss'].append(tl)\n res['train_acc'].append(ta)\n res['val_loss'].append(vl)\n res['val_acc'].append(va)\n return res\n\n# Re-initialize the network to start from scratch\nnet = nn.Sequential(\n nn.Flatten(), \n nn.Linear(784,10), # 784 inputs, 10 outputs\n nn.LogSoftmax())\n\nhist = train(net,train_loader,test_loader,epochs=5)",
"Epoch 0, Train acc=0.893, Val acc=0.893, Train loss=0.006, Val loss=0.006\nEpoch 1, Train acc=0.910, Val acc=0.899, Train loss=0.005, Val loss=0.006\nEpoch 2, Train acc=0.913, Val acc=0.899, Train loss=0.005, Val loss=0.006\nEpoch 3, Train acc=0.915, Val acc=0.897, Train loss=0.005, Val loss=0.006\nEpoch 4, Train acc=0.916, Val acc=0.896, Train loss=0.005, Val loss=0.006\n"
]
],
[
[
"This function logs messages with the accuracy on training and validation data from each epoch. It also returns this data as a dictionary (called **history**). We can then visualize this data to better understand our model training.",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(15,5))\nplt.subplot(121)\nplt.plot(hist['train_acc'], label='Training acc')\nplt.plot(hist['val_acc'], label='Validation acc')\nplt.legend()\nplt.subplot(122)\nplt.plot(hist['train_loss'], label='Training loss')\nplt.plot(hist['val_loss'], label='Validation loss')\nplt.legend()\n",
"_____no_output_____"
]
],
[
[
"The diagram on the left shows the `training accuracy` increasing (which corresponds to the network learning to classify our training data better and better), while `validation accuracy` starts to fall. The diagram on the right show the `training loss` and `validation loss`, you can see the `training loss` decreasing (meaning its performing better) and the `validation loss` increasing (meaning its performing worse). These graphs would indicate the model is **overfitted**. ",
"_____no_output_____"
],
[
"## Visualizing network weights\n\nNow lets visualize our weights of our neural network and see what they look like. When the network is more complex than just one layer it can be a difficult to visulize the results like this. However, in our case (classification of a digit) it happens by multiplying the initial image by a weight matrix allowing us to visualize the network weights with a bit of added logic.\n\nLet's create a `weight_tensor` which will have a dimension of 784x10. This tensor can be obtained by calling the `net.parameters()` method. In this example, if we want to see if our number is 0 or not, we will multiply input digit by `weight_tensor[0]` and pass the result through a softmax normalization to get the answer. This results in the weight tensor elements somewhat resembling the average shape of the digit it classifies:",
"_____no_output_____"
]
],
[
[
"weight_tensor = next(net.parameters())\nfig,ax = plt.subplots(1,10,figsize=(15,4))\nfor i,x in enumerate(weight_tensor):\n ax[i].imshow(x.view(28,28).detach())",
"_____no_output_____"
]
],
[
[
"## Takeaway \r\n\r\nTraining a neural network in PyTorch can be programmed with a training loop. It may seem like a complicated process, but in real life we need to write it once, and we can then re-use this training code later without changing it.\r\n\r\nWe can see that a single-layer dense neural network shows relatively good performance, but we definitely want to get higher than 91% on accuracy! In the next unit, we will try to use multi-level perceptrons.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
cb32384fd8e11643b0d518ca81a750ccebba68f3 | 3,854 | ipynb | Jupyter Notebook | lecture/CH01_01_Python.ipynb | kkkjerry/python_camp | e438f7c4982442c1845bc2091407a16757445e14 | [
"CC0-1.0"
] | null | null | null | lecture/CH01_01_Python.ipynb | kkkjerry/python_camp | e438f7c4982442c1845bc2091407a16757445e14 | [
"CC0-1.0"
] | null | null | null | lecture/CH01_01_Python.ipynb | kkkjerry/python_camp | e438f7c4982442c1845bc2091407a16757445e14 | [
"CC0-1.0"
] | null | null | null | 28.338235 | 194 | 0.461079 | [
[
[
"# About Python\n---\n## Contents\n\n- [Python?](#python)\n- [Why we use Python?](#why-we-use-python)\n- [Who uses Python?](#who-uses-python)\n- [What can we do?](#what-can-i-do)\n- [The Downside?](#the-downside)\n---\n### Python?\n\n**인터프리터** 언어 중 하나. [나무위키](https://namu.wiki/w/%EC%9D%B8%ED%84%B0%ED%94%84%EB%A6%AC%ED%84%B0) , [Wikipedia](https://ko.wikipedia.org/wiki/%EC%9D%B8%ED%84%B0%ED%94%84%EB%A6%AC%ED%84%B0) \n귀도 반 로섬(Guido van Rossum)이 1989년에 크리스마스 주에 연구실에서 **심심해서** 만들었다고 함..\n> 인터프리터 언어?\n> - 컴파일러와 대조적으로 line 단위로 실행되는 언어.\n> - 스크립트(script) 언어라고도 불림. \n\n\n\n[Python의 철학](https://www.python.org/dev/peps/pep-0020/)\n - Beautiful is better than ugly.\n - Explicit is better than implicit.\n - Simple is better than complex.\n - Complex is better than complicated.\n - Readability counts.\n - ....\n\n### Why we use Python?\n- **인터프리터 언어**\n - line 단위 실행 -> 결과 -> 수정의 절차를 가짐.\n \n- **Cross-flatform**\n - 윈도우, 리눅스, 맥OS 등 다양한 운영체제에서 실행이 가능.\n \n- **동적 타이핑**\n - C, C++ 에서 처럼 타입이나 크기에 대한 선언을 요구하지 않음.\n\n ``` c\n // Using C\n int *array = new int[3];\n array[0] = 1;\n array[1] = 3;\n array[2] = 5;\n ```\n\n ``` python\n # Using Python\n array = [1,3,5]\n ```\n \n \n- **단순한 문법**\n - \"Hello, World\" 출력 예시.\n ``` c\n // Using C\n #include <stdio.h>\n int main(){\n printf(\"Hello, World!\");\n return 0;\n }\n ```\n\n ``` python\n # Using Python\n print(\"Hello, World!\")\n ```\n \n\n- **많은 자료**\n - `Python` 사용자가 증가하면서 참고할 자료도 매우 많아짐.\n - 다양한 라이브러리가 있고 설치도 쉬움.\n - `numpy`, `matplotlib`, `pandas`, `Pillow`, `scikit-image`, ...\n\n\n- **확장성**\n - C, C++등 다른 언어로 만든 프로그램을 쉽게 접근해서 파이썬에서 사용이 가능.\n \n \n- **개발 기간 단축**\n - 물론 사람마다의 개인차는 있지만 다른 언어에 비해 처음부터 배우고 개발하는데 시간이 적게 드는 편. \n\n\n### Who uses Python?\n[파이썬 사용현황](https://ko.wikipedia.org/wiki/%ED%8C%8C%EC%9D%B4%EC%8D%AC#%EC%82%AC%EC%9A%A9_%ED%98%84%ED%99%A9)\n- Google\n- Yahoo\n- NASA\n- 카카오\n- Dropbox\n- ...\n\n### What can we do?\n[List of Python software](https://en.wikipedia.org/wiki/List_of_Python_software)\n- Systems Programming\n- GUI\n- [Game](https://www.youtube.com/watch?v=zPlJ-ma32T0)\n- [Image Processing](https://opencv-python-tutroals.readthedocs.io/en/latest/_images/face.jpg)\n- [Robot control](https://pythonprogramming.net/robotics-raspberry-pi-tutorial-gopigo-introduction/)\n- ...\n\n### The Downside?\n- **느.리.다.**\n - C 또는 C++ 같은 완전한 컴파일 및 저수준 언어만큼 항상 빠르게 실행되지는 않는다.",
"_____no_output_____"
]
]
] | [
"markdown"
] | [
[
"markdown"
]
] |
cb323ab0265462a561cfbf6325698a830c957552 | 42,807 | ipynb | Jupyter Notebook | code/03-gather-html-from-newsrooms.ipynb | danielmberry/fortune-100-company-press-release-language-analysis | 9b74a557a15d4f60af8efaaf5e470ce483be0839 | [
"CC0-1.0"
] | null | null | null | code/03-gather-html-from-newsrooms.ipynb | danielmberry/fortune-100-company-press-release-language-analysis | 9b74a557a15d4f60af8efaaf5e470ce483be0839 | [
"CC0-1.0"
] | null | null | null | code/03-gather-html-from-newsrooms.ipynb | danielmberry/fortune-100-company-press-release-language-analysis | 9b74a557a15d4f60af8efaaf5e470ce483be0839 | [
"CC0-1.0"
] | null | null | null | 38.016874 | 353 | 0.47609 | [
[
[
"# Gather HTML from Newsrooms\n\nAfter confirming all of the newsroom links, the next step is to figure out how to best iterate through the pages/tabs of these links, and collect all of the HTML from each page/tab of the company's newsroom. This HTML will contain the links to the press releases, which can then be used to gather the press release text and then begin to model.\n\nIn this notebook, I limit the number of companies I am working with to just the top five Fortune 100 companies. However, I have included several different code blocks that future iterations of this project can use and expand upon to more easily include more companies.",
"_____no_output_____"
],
[
"## Imports",
"_____no_output_____"
]
],
[
[
"import pandas as pd\n\nfrom tqdm import tqdm\nimport time\n\nfrom selenium import webdriver\nfrom selenium.webdriver.common.by import By\n\nimport warnings\nwarnings.filterwarnings('ignore')",
"_____no_output_____"
]
],
[
[
"## Read in the data",
"_____no_output_____"
]
],
[
[
"# read in the data\ncos = pd.read_csv('../data/fortune_100_data_w_links.csv')",
"_____no_output_____"
]
],
[
[
"Because this project is a proof of concept, I am limiting the DataFrame to just the top five Fortune 100 companies. ",
"_____no_output_____"
]
],
[
[
"cos = cos[cos['rank'] <=5]\ncos",
"_____no_output_____"
]
],
[
[
"## Adding the `loop_url`, `type` and `page_type` columns ",
"_____no_output_____"
],
[
"Part of the overall process not seen in these notebooks is determining how each company website works. For instance, Walmart's newsroom has pages that can be iterated through, while Amazon's press releases are organized in a long list by year, which each year getting its own tab on its newsroom. \n\nFor some of the companies not included in the reduced list, the structure of their page urls don't follow the same pattern.\n\nAfter examining the newsrooms for the top five Fortune 100 companies, I've saved the additional information needed to get us one step closer to our end goal in `company_loop_info.csv`.\n\nBelow are the descriptions for what each column contains:\n\n* **company**: The name of the company.\n* **loop_url**: This column is the base of the url that the code can use to iterate through.\n* **type**: The category of iteration used - for the top five companies, the types are `pages` and `years`\n* **page_type**: This is used in a function created below to return the right ending as the code loops through the values.",
"_____no_output_____"
]
],
[
[
"loops = pd.read_csv('../data/company_loop_info.csv')\nloops",
"_____no_output_____"
],
[
"cos = cos.merge(loops, on='company')\ncos",
"_____no_output_____"
]
],
[
[
"## Get html for companies with `type` == `pages`",
"_____no_output_____"
],
[
"I decided to split up this part of the data collection by `type` in order to keep the code blocks shorter and more manageable, rather than try to cram all of the code into one long block. Additionally, I believe this will make the code and these notebooks more adaptable for future iterations of this project that include more companies. ",
"_____no_output_____"
]
],
[
[
"pages = cos[cos['type'] == 'pages'].reset_index(drop= True)\npages",
"_____no_output_____"
]
],
[
[
"Another way I've made this code more flexible is by creating functions that can be used to get the end of the url for the iteration process. Other `page_type`s aren't necessarily as straightforward as adding on page number as a string at the end of a url.",
"_____no_output_____"
]
],
[
[
"# create a function that will return the appropriate page ending \n\ndef get_page_ending(i, page_type):\n\n if page_type == 'page':\n return str(i)",
"_____no_output_____"
],
[
"# set up the webdriver\noptions = webdriver.ChromeOptions()\noptions.page_load_strategy = 'normal'\noptions.add_argument('headless')\noptions.add_experimental_option(\"excludeSwitches\", [\"enable-automation\"])\noptions.add_experimental_option('useAutomationExtension', False)\nbrowser = webdriver.Chrome(options=options)\nbrowser.execute_cdp_cmd(\n 'Network.setUserAgentOverride', {\n \"userAgent\":\n 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) \\\n Chrome/83.0.4103.53 Safari/537.36'\n })\n\n# loop through each row in the `pages` dataframe\nfor row in range(len(pages)):\n\n # create a list that can be appended to\n htmls = []\n \n # get the page type as a variable\n page_type = pages.loc[row, 'page_type']\n \n # get the url\n url = pages.loc[row, 'loop_url']\n\n for i in tqdm(range(50)):\n \n try:\n # create a dictionary that we can add to\n page_html = {}\n \n # create a variable for the end of the page url, \n # calling on the previously created function\n ending = get_page_ending(i, page_type)\n \n # add the page number to the end of the url\n page_url = url + ending\n\n # open the browser\n browser.get(page_url)\n time.sleep(5)\n \n browser.execute_script(\"window.scrollTo(0, document.body.scrollHeight/2);\")\n \n # add information for each row in case needed later\n page_html['company'] = pages.loc[row, 'company']\n page_html['base_url'] = pages.loc[row, 'final']\n page_html['url'] = page_url\n page_html['page_num'] = i\n\n # add the html to the dictionary\n page_html['html'] = browser.page_source\n\n # append the dictionary for this page to the list\n htmls.append(page_html)\n time.sleep(3)\n \n except:\n print()\n print(f\"Company: {pages.loc[row, 'company']} | Web page: {i} | Page type: {pages.loc[row,'page_type']} | Status: Error\" )\n \n #create a dataframe and save locally\n html_df = pd.DataFrame(htmls)\n html_df.to_csv(f'../data/html/{pages.loc[row,\"company\"].replace(\" \",\"_\").lower()}_html.csv',index=False)\n",
"100%|██████████| 50/50 [07:25<00:00, 8.90s/it]\n100%|██████████| 50/50 [07:16<00:00, 8.73s/it]\n100%|██████████| 50/50 [07:45<00:00, 9.31s/it]\n100%|██████████| 50/50 [08:41<00:00, 10.42s/it]\n"
]
],
[
[
"## Getting html for companies with `type` == `years`",
"_____no_output_____"
]
],
[
[
"years = cos[cos['type'] == 'years'].reset_index(drop= True)\nyears",
"_____no_output_____"
]
],
[
[
"Similar to the function I created above (i.e., `get_page_ending()`), some of the year endings are formatted differently than just the year as a string. Creating the function now makes this code more adaptable for future iterations.",
"_____no_output_____"
]
],
[
[
"def get_year_ending(i, page_type):\n\n if page_type == 'year':\n return str(i)",
"_____no_output_____"
],
[
"# set up the webdriver\noptions = webdriver.ChromeOptions()\noptions.page_load_strategy = 'normal'\noptions.add_argument('headless')\noptions.add_experimental_option(\"excludeSwitches\", [\"enable-automation\"])\noptions.add_experimental_option('useAutomationExtension', False)\nbrowser = webdriver.Chrome(options=options)\nbrowser.execute_cdp_cmd(\n 'Network.setUserAgentOverride', {\n \"userAgent\":\n 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) \\\n Chrome/83.0.4103.53 Safari/537.36'\n })\n\n# loop through each row in the `pages` dataframe\nfor row in range(len(years)):\n\n # create a list that can be appended to\n htmls = []\n \n # get the page type as a variable\n page_type = years.loc[row, 'page_type']\n \n # get the url\n url = years.loc[row, 'loop_url']\n \n for i in tqdm(range(2019,2022)):\n \n try:\n # create a dictionary that we can add to\n page_html = {}\n \n # create a variable for the end of the page url, \n # calling on the previously created function\n ending = get_year_ending(i, page_type)\n \n # add the page number to the end of the url\n page_url = url + ending\n\n # open the browser\n browser.get(page_url)\n time.sleep(5)\n \n browser.execute_script(\"window.scrollTo(0, document.body.scrollHeight/2);\")\n \n # add information for each row in case needed later\n page_html['company'] = years.loc[row, 'company']\n page_html['base_url'] = years.loc[row, 'final']\n page_html['url'] = page_url\n page_html['page_num'] = i\n\n # add the html to the dictionary\n page_html['html'] = browser.page_source\n\n # append the dictionary for this page to the list\n htmls.append(page_html)\n time.sleep(3)\n \n except:\n print()\n print(f\"Company: {years.loc[row, 'company']} | Web page: {i} | Page type: {years.loc[row,'page_type']} | Status: Error\" )\n \n #create a dataframe and save locally\n html_df = pd.DataFrame(htmls)\n html_df.to_csv(f'../data/html/{years.loc[row,\"company\"].replace(\" \",\"_\").lower()}_html.csv',index=False)\n",
"100%|██████████| 3/3 [00:32<00:00, 10.94s/it]\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
cb325addcb25ed2e5e86d884381628a27cf16ac8 | 238,992 | ipynb | Jupyter Notebook | 02-AI-stack/pandas.ipynb | afo/dataXhmrc | e614e033d768bb0d45cfcb4e86a40a7e44e6e53d | [
"Apache-2.0"
] | 3 | 2021-06-30T07:42:43.000Z | 2022-01-12T23:10:04.000Z | 02-AI-stack/pandas.ipynb | afo/data-x_prague19 | 49963c9efe1d0a15f1d949755d9065537460d387 | [
"Apache-2.0"
] | null | null | null | 02-AI-stack/pandas.ipynb | afo/data-x_prague19 | 49963c9efe1d0a15f1d949755d9065537460d387 | [
"Apache-2.0"
] | 2 | 2020-10-14T10:36:22.000Z | 2022-01-11T23:11:04.000Z | 40.658727 | 28,644 | 0.527972 | [
[
[
"\n\n---\n# Pandas Introduction \n### with Stock Data and Correlation Examples\n\n\n**Author list:** Alexander Fred-Ojala & Ikhlaq Sidhu\n\n**References / Sources:** \nIncludes examples from Wes McKinney and the 10min intro to Pandas\n\n\n**License Agreement:** Feel free to do whatever you want with this code\n\n___",
"_____no_output_____"
],
[
"## What Does Pandas Do?\n<img src=\"https://github.com/ikhlaqsidhu/data-x/raw/master/imgsource/pandas-p1.jpg\">",
"_____no_output_____"
],
[
"## What is a Pandas Table Object?\n<img src=\"https://github.com/ikhlaqsidhu/data-x/raw/master/imgsource/pandas-p2.jpg\">\n",
"_____no_output_____"
],
[
"# Import packages",
"_____no_output_____"
]
],
[
[
"# import packages\n\nimport pandas as pd\n\n# Extra packages\nimport numpy as np\nimport matplotlib.pyplot as plt # for plotting\nimport seaborn as sns # for plotting and styling\n\n# jupyter notebook magic to display plots in output\n%matplotlib inline\n\nplt.rcParams['figure.figsize'] = (10,6) # make the plots bigger",
"_____no_output_____"
]
],
[
[
"# Part 1\n### Simple creation and manipulation of Pandas objects\n**Key Points:** Pandas has two / three main data types:\n* Series (similar to numpy arrays, but with index)\n* DataFrames (table or spreadsheet with Series in the columns)\n* Panels (3D version of DataFrame, not as common)",
"_____no_output_____"
],
[
"### It is easy to create a DataFrame\n\n### We use `pd.DataFrame(**inputs**)` and can insert almost any data type as an argument\n\n**Function:** `pd.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)`\n\nInput data can be a numpy ndarray (structured or homogeneous), dict, or DataFrame. \nDict can contain Series, arrays, constants, or list-like objects as the values.",
"_____no_output_____"
]
],
[
[
"# Try it with an array\nnp.random.seed(0) # set seed for reproducibility\n\na1 = np.array(np.random.randn(3))\na2 = np.array(np.random.randn(3))\na3 = np.array(np.random.randn(3))\n\nprint (a1)\nprint (a2)\nprint (a3)",
"[1.76405235 0.40015721 0.97873798]\n[ 2.2408932 1.86755799 -0.97727788]\n[ 0.95008842 -0.15135721 -0.10321885]\n"
],
[
"# Create our first DataFrame w/ an np.array - it becomes a column\ndf0 = pd.DataFrame(a1)\nprint(type(df0))\ndf0",
"<class 'pandas.core.frame.DataFrame'>\n"
],
[
"# DataFrame from list of np.arrays\n\ndf0 = pd.DataFrame([a1, a2, a3])\ndf0\n\n# notice that there is no column label, only integer values,\n# and the index is set automatically",
"_____no_output_____"
],
[
"# DataFrame from 2D np.array\n\nax = np.random.randn(9).reshape(3,3)\nax",
"_____no_output_____"
],
[
"df0 = pd.DataFrame(ax,columns=['rand_normal_1','Random Again','Third'],\n index=[100,200,99]) # we can also assign columns and indices, sizes have to match\ndf0",
"_____no_output_____"
],
[
"# DataFrame from a Dictionary\n\ndict1 = {'A':a1, 'B':a2}\ndf1 = pd.DataFrame(dict1) \ndf1\n# note that we now have columns without assignment",
"_____no_output_____"
],
[
"# We can easily add another column (just as you add values to a dictionary)\ndf1['C']=a3\ndf1",
"_____no_output_____"
],
[
"# We can add a list with strings and ints as a column \ndf1['L'] = [\"Something\", 3, \"words\"]\ndf1",
"_____no_output_____"
]
],
[
[
"# Pandas Series object\n### Like an np.array, but we can combine data types and it has its own index\nNote: Every column in a DataFrame is a Series",
"_____no_output_____"
]
],
[
[
"print(df1[['L','A']])",
" L A\n0 Something 1.764052\n1 3 0.400157\n2 words 0.978738\n"
],
[
"print(type(df1['L']))",
"<class 'pandas.core.series.Series'>\n"
],
[
"df1",
"_____no_output_____"
],
[
"# We can also rename columns\ndf1 = df1.rename(columns = {'L':'Renamed'})\ndf1",
"_____no_output_____"
],
[
"# We can delete columns\ndel df1['C']\ndf1",
"_____no_output_____"
],
[
"# or drop columns\ndf1.drop('A',axis=1,inplace=True) # does not change df1 if we don't set inplace=True",
"_____no_output_____"
],
[
"df1",
"_____no_output_____"
],
[
"df1",
"_____no_output_____"
],
[
"# or drop rows\ndf1.drop(0)",
"_____no_output_____"
],
[
"# Example: view only one column\ndf1['B']",
"_____no_output_____"
],
[
"# Or view several column\ndf1[['B','Renamed']]",
"_____no_output_____"
]
],
[
[
"# Other ways of slicing\nIn the 10 min Pandas Guide, you will see many ways to view, slice a dataframe\n\n* view/slice by rows, eg `df[1:3]`, etc.\n\n* view by index location, see `df.iloc` (iloc)\n\n* view by ranges of labels, ie index label 2 to 5, or dates feb 3 to feb 25, see `df.loc` (loc)\n \n* view a single row by the index `df.xs` (xs) or `df.ix` (ix)\n\n* filtering rows that have certain conditions\n* add column\n* add row\n\n* How to change the index\n\nand more...",
"_____no_output_____"
]
],
[
[
"print (df1[0:2]) # ok",
" B Renamed\n0 2.240893 Something\n1 1.867558 3\n"
],
[
"df1",
"_____no_output_____"
],
[
"df1.iloc[1,1]",
"_____no_output_____"
],
[
"df1",
"_____no_output_____"
]
],
[
[
"# Part 2\n## Finance example: Large Data Frames\n\n### Now, lets get some data in CSV format.\n\nSee https://www.quantshare.com/sa-43-10-ways-to-download-historical-stock-quotes-data-for-free\n",
"_____no_output_____"
]
],
[
[
"!ls data/",
"apple.csv boeing.csv googl.csv microsoft.csv nike.csv\r\n"
],
[
"# We can download data from the web by using pd.read_csv\n# A CSV file is a comma seperated file\n# We can use this 'pd.read_csv' method with urls that host csv files\n\nbase_url = 'https://google.com/finance?output=csv&q='\n\ndfg = pd.read_csv('data/googl.csv').drop('Unnamed: 0',axis=1) # Google stock data\ndfa = pd.read_csv('data/apple.csv').drop('Unnamed: 0',axis=1)",
"_____no_output_____"
],
[
"dfg",
"_____no_output_____"
],
[
"dfg.head() # show first five values",
"_____no_output_____"
],
[
"dfg.tail(3) # last three",
"_____no_output_____"
],
[
"dfg.columns # returns columns, can be used to loop over",
"_____no_output_____"
],
[
"dfg.index # return",
"_____no_output_____"
]
],
[
[
"# Convert the index to pandas datetime object",
"_____no_output_____"
]
],
[
[
"dfg['Date'][0]",
"_____no_output_____"
],
[
"type(dfg['Date'][0])",
"_____no_output_____"
],
[
"dfg.index = pd.to_datetime(dfg['Date']) # set index",
"_____no_output_____"
],
[
"dfg.drop(['Date'],axis=1,inplace=True)",
"_____no_output_____"
],
[
"dfg.head()",
"_____no_output_____"
],
[
"print(type(dfg.index[0]))\ndfg.index[0]",
"<class 'pandas._libs.tslibs.timestamps.Timestamp'>\n"
],
[
"dfg.index",
"_____no_output_____"
],
[
"dfg['2017-08':'2017-06']",
"_____no_output_____"
]
],
[
[
"# Attributes & general statitics of a Pandas DataFrame",
"_____no_output_____"
]
],
[
[
"dfg.shape # 251 business days last year",
"_____no_output_____"
],
[
"dfg.columns",
"_____no_output_____"
],
[
"dfg.size",
"_____no_output_____"
],
[
"# Some general statistics\n\ndfg.describe()",
"_____no_output_____"
],
[
"# Boolean indexing\ndfg['Open'][dfg['Open']>1130] # check what dates the opening",
"_____no_output_____"
],
[
"# Check where Open, High, Low and Close where greater than 1130\ndfg[dfg>1000].drop('Volume',axis=1)",
"_____no_output_____"
],
[
"# If you want the values in an np array\ndfg.values",
"_____no_output_____"
]
],
[
[
"## .loc()",
"_____no_output_____"
]
],
[
[
"# Getting a cross section with .loc - BY VALUES of the index and columns\n# df.loc[a:b, x:y], by rows and column location\n\n# Note: You have to know indices and columns\n\ndfg.loc['2017-08-31':'2017-08-21','Open':'Low']",
"_____no_output_____"
]
],
[
[
"## .iloc()",
"_____no_output_____"
]
],
[
[
"# .iloc slicing at specific location - BY POSITION in the table\n# Recall:\n# dfg[a:b] by rows\n# dfg[[col]] or df[[col1, col2]] by columns\n# df.loc[a:b, x:y], by index and column values + location\n# df.iloc[3:5,0:2], numeric position in table\n\ndfg.iloc[1:4,3:5] # 2nd to 4th row, 4th to 5th column",
"_____no_output_____"
]
],
[
[
"### More Basic Statistics",
"_____no_output_____"
]
],
[
[
"# We can change the index sorting\ndfg.sort_index(axis=0, ascending=True).head() # starts a year ago",
"_____no_output_____"
],
[
"# sort by value\ndfg.sort_values(by='Open')[0:10]",
"_____no_output_____"
]
],
[
[
"# Boolean",
"_____no_output_____"
]
],
[
[
"dfg[dfg>1115].head(10)",
"_____no_output_____"
],
[
"# we can also drop all NaN values\ndfg[dfg>1115].head(10).dropna()",
"_____no_output_____"
],
[
"dfg2 = dfg # make a copy and not a view\ndfg2 is dfg",
"_____no_output_____"
]
],
[
[
"### Setting Values\n",
"_____no_output_____"
]
],
[
[
"# Recall\ndfg.head(4)",
"_____no_output_____"
],
[
"# All the ways to view\n# can also be used to set values\n# good for data normalization\n\ndfg['Volume'] = dfg['Volume']/100000.0\ndfg.head(4)",
"_____no_output_____"
]
],
[
[
"### More Statistics and Operations",
"_____no_output_____"
]
],
[
[
"# mean by column, also try var() for variance\ndfg.mean() ",
"_____no_output_____"
],
[
"dfg[0:5].mean(axis = 1) # row means of first five rows",
"_____no_output_____"
]
],
[
[
"# PlotCorrelation\n### Load several stocks",
"_____no_output_____"
]
],
[
[
"# Reload\ndfg = pd.read_csv('data/googl.csv').drop('Unnamed: 0',axis=1) # Google stock data\ndfa = pd.read_csv('data/apple.csv').drop('Unnamed: 0',axis=1) # Apple stock data\ndfm = pd.read_csv('data/microsoft.csv').drop('Unnamed: 0',axis=1) # Google stock data\ndfn = pd.read_csv('data/nike.csv').drop('Unnamed: 0',axis=1) # Apple stock data\ndfb = pd.read_csv('data/boeing.csv').drop('Unnamed: 0',axis=1) # Apple stock data",
"_____no_output_____"
],
[
"dfb.head()",
"_____no_output_____"
],
[
"# Rename columns\ndfg = dfg.rename(columns = {'Close':'GOOG'})\n#print (dfg.head())\n\ndfa = dfa.rename(columns = {'Close':'AAPL'})\n#print (dfa.head())\n\ndfm = dfm.rename(columns = {'Close':'MSFT'})\n#print (dfm.head())\n\ndfn = dfn.rename(columns = {'Close':'NKE'})\n#print (dfn.head())\n\ndfb = dfb.rename(columns = {'Close':'BA'})",
"_____no_output_____"
],
[
"dfb.head(2)",
"_____no_output_____"
],
[
"# Lets merge some tables\n# They will all merge on the common column Date\n\ndf = dfg[['Date','GOOG']].merge(dfa[['Date','AAPL']])\ndf = df.merge(dfm[['Date','MSFT']])\ndf = df.merge(dfn[['Date','NKE']])\ndf = df.merge(dfb[['Date','BA']])\n\ndf.head()",
"_____no_output_____"
],
[
"df['Date'] = pd.to_datetime(df['Date'])\ndf = df.set_index('Date')\ndf.head()",
"_____no_output_____"
],
[
"df.plot()",
"_____no_output_____"
],
[
"df['2017'][['NKE','BA']].plot()",
"_____no_output_____"
],
[
"# show a correlation matrix (pearson)\ncrl = df.corr()\ncrl",
"_____no_output_____"
],
[
"crl.sort_values(by='GOOG',ascending=False)",
"_____no_output_____"
],
[
"s = crl.unstack()\nso = s.sort_values(ascending=False)\nso[so<1]",
"_____no_output_____"
],
[
"df.mean()",
"_____no_output_____"
],
[
"sim=df-df.mean()\nsim.tail()",
"_____no_output_____"
],
[
"sim[['MSFT','BA']].plot()",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb326764436b2b7cbf240481190637d314529d02 | 57,746 | ipynb | Jupyter Notebook | EE393_Semester_Project_Map_SimpleGUI_CompanyObject_Version2.ipynb | iscanegemen/Data-Science-with-Foursquare-API- | 8523509275a1abd6a2598746f86b2dfb33750b5a | [
"MIT"
] | 1 | 2020-11-26T17:33:28.000Z | 2020-11-26T17:33:28.000Z | EE393_Semester_Project_Map_SimpleGUI_CompanyObject_Version2.ipynb | iscanegemen/Data-Science-with-Foursquare-API | 8523509275a1abd6a2598746f86b2dfb33750b5a | [
"MIT"
] | null | null | null | EE393_Semester_Project_Map_SimpleGUI_CompanyObject_Version2.ipynb | iscanegemen/Data-Science-with-Foursquare-API | 8523509275a1abd6a2598746f86b2dfb33750b5a | [
"MIT"
] | null | null | null | 74.033333 | 21,480 | 0.746303 | [
[
[
"| Name | Surname | Student No | Department |\n|---|---|---|---|\n| Emin | Kartci | S014877 | EE Engineering |",
"_____no_output_____"
],
[
"## Emin Kartci\n#### Student ID: S014877\n#### Department : Electrical & Electronics Engineering\n---\n### Semester Project - Foursquare & Restaurant Report\n---\n#### This module is prepared for GUI\n---\n\n",
"_____no_output_____"
]
],
[
[
"# To interact with user use ipywidgets library - Generate a simple GUI\nfrom __future__ import print_function\nfrom ipywidgets import interact, interactive, fixed, interact_manual\nimport ipywidgets as widgets\nimport matplotlib.pyplot as plt\nimport numpy as np",
"_____no_output_____"
],
[
"################################-- Function Description --#################################\n\n# Purpose:\n# This class represents a company. For other modules we will need its values.\n# Moreover, creating a class makes simple our code.\n\n# PROPERTIES:\n# \n# From constructor:\n# name -> Name of the company (String)\n# longitude -> To represent at the map (String)\n# latitude -> To represent at the map (String)\n# servicesList -> To compare with others (List)\n# averagePrice -> For income statement - Simulation (Float)\n# averageUnitCost -> For incoma statement - Simulation (Float)\n# salesVolume -> For incoma statement - Simulation (Float)\n# fixedCost -> For incoma statement - Simulation (Float)\n# taxRate -> For incoma statement - Simulation (Float)\n#\n# Calculate:\n#\n# contributionMargin -> For incoma statement - Simulation (Float)\n# revenue -> For incoma statement - Simulation (Float)\n# costOfGoodSold -> For incoma statement - Simulation (Float)\n# grossMargin -> For incoma statement - Simulation (Float)\n# taxes -> For incoma statement - Simulation (Float)\n# netIncome -> For incoma statement - Simulation (Float)\n#\n\n\n# BEHAVIOUR:\n# \n# print_company_description -> prints the company inputs to the console\n# print_income_statement -> prints the income statemnt to the console\n\n#################################-- END Function Description --##############################\n\n\n# Create a Company class\nclass Company():\n \n # Constuctor\n def __init__(self, name,longitude,latitude,servicesList,averagePrice,averageUnitCost,salesVolume,fixedCost,taxRate):\n \n \n \n self.name = name\n self.longitude = longitude\n self.latitude = latitude\n self.servicesList = servicesList\n \n self.averagePrice = averagePrice\n self.averageUnitCost = averageUnitCost\n self.salesVolume = salesVolume\n self.fixedCost = fixedCost\n self.taxRate = taxRate/100\n \n # calculate remain properties\n self.contributionMargin = self.calculate_contribution_margin()\n self.revenue = self.calculate_revenue()\n self.costOfGoodSold = self.calculate_COGS()\n self.totalCost = self.calculate_total_cost()\n self.grossMargin = self.calculate_gross_margin()\n self.taxes = self.calculate_taxes()\n self.netIncome = self.calculate_net_income()\n \n \n \n def calculate_contribution_margin(self):\n \n return self.averagePrice - self.averageUnitCost\n \n def calculate_revenue(self):\n \n return self.averagePrice * self.salesVolume\n \n def calculate_COGS(self):\n \n return self.salesVolume * self.averageUnitCost\n \n def calculate_gross_margin(self):\n \n return self.revenue - self.costOfGoodSold\n \n def calculate_taxes(self):\n \n return self.grossMargin * self.taxRate\n \n def calculate_net_income(self):\n \n return self.grossMargin - self.taxes\n \n def calculate_total_cost(self):\n \n return self.costOfGoodSold + self.fixedCost\n \n \n ########################################################################\n \n def print_company_description(self):\n \n companyDescription = \"\"\"\n \n Company Name: {}\n \n Location:\n - Longitude : {}° N\n - Latitude : {}° E\n \n Services:\n {}\n Average Price : {}\n Average Unit Cost : {}\n \n Sales Volume : {}\n \n Fixed Cost : {}\n \n Tax Rate : {}\n \n \n \"\"\".format(self.name,self.longitude,self.latitude,self.set_services_string(),self.averagePrice,self.averageUnitCost,self.salesVolume,self.fixedCost,self.taxRate)\n \n print(companyDescription)\n \n def set_services_string(self):\n \n \n serviesString = \"\"\n \n for index in range(1,len(self.servicesList)+1):\n \n serviesString += \"{} - {}\\n\\t\\t\".format(index,self.servicesList[index-1])\n \n \n return serviesString\n \n def print_income_statement(self):\n \n incomeStatementStr = \"\"\"\n \n ========== {}'s MONTHLY INCOME STATEMENT ==========\n +------------------------------------------------------\n | Unit Price : {}\n | Unit Cost : {}\n +------------------\n | Contribution Margin : {}\n | Sales Volume : {}\n | Revenue : {} (Monthly)\n +------------------\n | Cost of Goods Sold : {} (Monthly)\n | Total Fixed Cost : {} (Monthly)\n | Total Cost : {}\n +------------------\n | Gross Margin : {}\n | Taxes : {}\n +------------------\n | NET INCOME : {}\n +------------------------------------------------------\n \n \n \"\"\".format(self.name,self.averagePrice,self.averageUnitCost,self.contributionMargin,self.salesVolume,self.revenue\n ,self.costOfGoodSold,self.fixedCost,self.totalCost,self.grossMargin,self.taxes,self.netIncome)\n \n print(incomeStatementStr)\n \n \n ",
"_____no_output_____"
],
[
"programLabel = widgets.Label('--------------------------> RESTAURANT SIMULATOR PROGRAM <--------------------------', layout=widgets.Layout(width='100%'))\n\ncompanyName = widgets.Text(description=\"Comp. Name\",value=\"Example LTD\",layout=widgets.Layout(width=\"50%\"))\nlongitude = widgets.Text(description=\"Longitude\",value=\"48.8566\",layout=widgets.Layout(width=\"30%\"))\nlatitude = widgets.Text(description=\"Latitude\",value=\"2.3522\",layout=widgets.Layout(width=\"30%\"))\n\nbr1Label = widgets.Label('-----------------------------------------------------------------------------------------------------', layout=widgets.Layout(width='100%'))\n\nservicesLabel = widgets.Label('Select Services:', layout=widgets.Layout(width='100%'))\nDessertbox = widgets.Checkbox(False, description='Dessert')\nSaladbox = widgets.Checkbox(False, description='Salad')\nDrinkbox = widgets.Checkbox(False, description='Drink')\n\nbr2Label = widgets.Label('-----------------------------------------------------------------------------------------------------', layout=widgets.Layout(width='100%'))\n\nexpectedPriceLabel = widgets.Label('Expected Average Price:', layout=widgets.Layout(width='100%'))\nexpectedAveragePrice = widgets.IntSlider(min=0, max=100, step=1, description='(Euro): ',value=0)\n\nexpectedUnitCostLabel = widgets.Label('Expected Average Unit Cost:', layout=widgets.Layout(width='100%'))\nexpectedUnitCost = widgets.IntSlider(min=0, max=100, step=1, description='(Euro): ',value=0)\n\nexpectedSalesLabel = widgets.Label('Expected Sales Monthly:', layout=widgets.Layout(width='100%'))\nexpectedSales = widgets.IntSlider(min=0, max=10000, step=1, description='(Euro): ',value=0)\n\nfixedCostLabel = widgets.Label('Fixed Costs:', layout=widgets.Layout(width='100%'))\nfixedCost = widgets.FloatText(value=10000, description='(Euro): ',color = 'blue')\n\ntaxRateLabel = widgets.Label('Tax Rate:', layout=widgets.Layout(width='100%'))\ntaxRate = widgets.FloatSlider(min=0, max=100, step=1, description='%: ',value=0)\n\nbr3Label = widgets.Label('-----------------------------------------------------------------------------------------------------', layout=widgets.Layout(width='100%'))",
"_____no_output_____"
],
[
"# create a string list bu considering checkbox widgets\ndef set_service_list():\n \n # create an empty list\n serviceList = []\n \n # if it is checked\n if Dessertbox.value:\n # add to the list\n serviceList.append('Dessert')\n # if it is checked\n if Saladbox.value:\n # add to the list\n serviceList.append('Salad')\n # if it is checked\n if Drinkbox.value:\n # add to the list\n serviceList.append('Drink')\n \n # return the list\n return serviceList",
"_____no_output_____"
],
[
"# display the widgets \ndisplay(programLabel)\n\ndisplay(companyName)\ndisplay(longitude)\ndisplay(latitude)\n\ndisplay(br1Label)\n\ndisplay(servicesLabel)\ndisplay(Dessertbox)\ndisplay(Saladbox)\ndisplay(Drinkbox)\n\ndisplay(br2Label)\n\ndisplay(expectedPriceLabel)\ndisplay(expectedAveragePrice)\n\ndisplay(expectedUnitCostLabel)\ndisplay(expectedUnitCost)\n\ndisplay(expectedSalesLabel)\ndisplay(expectedSales)\n\ndisplay(fixedCostLabel)\ndisplay(fixedCost)\n\ndisplay(taxRateLabel)\ndisplay(taxRate)\n\ndisplay(br3Label)\n",
"_____no_output_____"
],
[
"# create a company object\ncompany = Company(companyName.value,longitude.value,latitude.value,set_service_list(),expectedAveragePrice.value,expectedUnitCost.value,expectedSales.value,fixedCost.value,taxRate.value)\n# print income statement\ncompany.print_income_statement()\n\ncompany.plotting_price_cost()\n\n\n\n\n",
"\n \n ========== Example LTD's MONTHLY INCOME STATEMENT ==========\n +------------------------------------------------------\n | Unit Price : 24\n | Unit Cost : 12\n +------------------\n | Contribution Margin : 12\n | Sales Volume : 4306\n | Revenue : 103344 (Monthly)\n +------------------\n | Cost of Goods Sold : 51672 (Monthly)\n | Total Fixed Cost : 10000.0 (Monthly)\n | Total Cost : 61672.0\n +------------------\n | Gross Margin : 51672\n | Taxes : 8267.52\n +------------------\n | NET INCOME : 43404.479999999996\n +------------------------------------------------------\n \n \n \n"
],
[
"plt.plot(self.priceList, \"g--\")\nplt.plot(self.costList, \"o--\")\nplt.axhline(y=0, color='r', \n linewidth=0.5, linestyle='-')\nplt.axvline(x=0, color='r', \n linewidth=0.5, linestyle='-')\nplt.xlabel(\"Price\"); plt.ylabel(\"Cost\")\nplt.legend([\"Corresponding Cost\",\"Price\"])\nplt.title(\"Price vs. Cost\")\nplt.grid()\nplt.show()",
"_____no_output_____"
],
[
"x_labels = [\"PROFIT\", \"Avg Price\", \"Avg Cost\", \"Contribution Margin\", \"Sales Vol\"]\nplt.bar(x_labels, [96, 21.31, 10.53, 10.78, 899], color = \"g\")\nplt.legend([\"Profit is shown as %, e.g, 96%\"])\nplt.show()",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb326d2450067282f9d62eb1232422c90818d225 | 2,447 | ipynb | Jupyter Notebook | code/iUma22_EscherMapping.ipynb | iAMB-RWTH-Aachen/Ustilago_maydis-GEM | 97e05f9a143e4a84b2bf3e5502ef588b91c4eda8 | [
"CC-BY-4.0"
] | null | null | null | code/iUma22_EscherMapping.ipynb | iAMB-RWTH-Aachen/Ustilago_maydis-GEM | 97e05f9a143e4a84b2bf3e5502ef588b91c4eda8 | [
"CC-BY-4.0"
] | 1 | 2022-03-03T15:24:59.000Z | 2022-03-03T15:24:59.000Z | code/iUma22_EscherMapping.ipynb | iAMB-RWTH-Aachen/Ustilago_maydis-GEM | 97e05f9a143e4a84b2bf3e5502ef588b91c4eda8 | [
"CC-BY-4.0"
] | null | null | null | 23.084906 | 70 | 0.557417 | [
[
[
"# Metabolic pathway visualization of Ustilago maydis with Escher",
"_____no_output_____"
],
[
"## Conversion of the model iCL1079 from sbml to json",
"_____no_output_____"
]
],
[
[
"# import cobra.test\nfrom os.path import join\nfrom cobra.io import read_sbml_model\n# import escher\nfrom escher import Builder\n# import cobra\n# from time import sleep\n# data_dir = cobra.test.data_dir\n\n# pip install pytest-astropy",
"_____no_output_____"
],
[
"ModelFile = join('..','model','iUma22.xml')\nmodel=read_sbml_model(ModelFile)\n# cobra.io.save_json_model(model, \"iCL1079.json\")\nmedium = model.medium\nmedium['EX_glc__D_e'] = 1\nmedium['EX_co2_e'] = 0\nmodel.medium = medium\nmodel.summary()\n# model.reactions.get_by_id('EX_co2_e').lb = 0\n# model.summary()",
"_____no_output_____"
]
],
[
[
"## Export of central carbon pathway map",
"_____no_output_____"
]
],
[
[
"builder=Builder()\n\nEscher_Central = join('Maps','iUma22_MetMap_TCA.json')\nEscher_Glycine = join('Maps','iUma22_MetMap_glycine.json')\nbuilder = Builder(\n map_json=Escher_Central,\n model = model, # 'iCL1079.json',\n)\n# Run FBA with the model and add the flux data to the map\nsolution = builder.model.optimize()\nbuilder.reaction_data = solution.fluxes\n\nbuilder.save_html('../code/example_map.html')",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
cb3270d7e87d7ef514d5b89bec8ffda9be8a0a70 | 105,521 | ipynb | Jupyter Notebook | 1_5_CNN_Layers/5_2. Visualize Your Net.ipynb | sids07/CVND_Exercise | eb4812af3bc715e512d7d67fbb87a864583b4663 | [
"MIT"
] | null | null | null | 1_5_CNN_Layers/5_2. Visualize Your Net.ipynb | sids07/CVND_Exercise | eb4812af3bc715e512d7d67fbb87a864583b4663 | [
"MIT"
] | null | null | null | 1_5_CNN_Layers/5_2. Visualize Your Net.ipynb | sids07/CVND_Exercise | eb4812af3bc715e512d7d67fbb87a864583b4663 | [
"MIT"
] | null | null | null | 290.69146 | 45,280 | 0.915306 | [
[
[
"# CNN for Classification\n---\nIn this notebook, we define **and train** an CNN to classify images from the [Fashion-MNIST database](https://github.com/zalandoresearch/fashion-mnist).",
"_____no_output_____"
],
[
"### Load the [data](http://pytorch.org/docs/master/torchvision/datasets.html)\n\nIn this cell, we load in both **training and test** datasets from the FashionMNIST class.",
"_____no_output_____"
]
],
[
[
"# our basic libraries\nimport torch\nimport torchvision\n\n# data loading and transforming\nfrom torchvision.datasets import FashionMNIST\nfrom torch.utils.data import DataLoader\nfrom torchvision import transforms\n\n# The output of torchvision datasets are PILImage images of range [0, 1]. \n# We transform them to Tensors for input into a CNN\n\n## Define a transform to read the data in as a tensor\ndata_transform = transforms.ToTensor()\n\n# choose the training and test datasets\ntrain_data = FashionMNIST(root='./data', train=True,\n download=True, transform=data_transform)\n\ntest_data = FashionMNIST(root='./data', train=False,\n download=True, transform=data_transform)\n\n\n# Print out some stats about the training and test data\nprint('Train data, number of images: ', len(train_data))\nprint('Test data, number of images: ', len(test_data))",
"Train data, number of images: 60000\nTest data, number of images: 10000\n"
],
[
"# prepare data loaders, set the batch_size\n## TODO: you can try changing the batch_size to be larger or smaller\n## when you get to training your network, see how batch_size affects the loss\nbatch_size = 20\n\ntrain_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)\ntest_loader = DataLoader(test_data, batch_size=batch_size, shuffle=True)\n\n# specify the image classes\nclasses = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', \n 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']",
"_____no_output_____"
]
],
[
[
"### Visualize some training data\n\nThis cell iterates over the training dataset, loading a random batch of image/label data, using `dataiter.next()`. It then plots the batch of images and labels in a `2 x batch_size/2` grid.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\n\n%matplotlib inline\n \n# obtain one batch of training images\ndataiter = iter(train_loader)\nimages, labels = dataiter.next()\nimages = images.numpy()\nprint(images.shape)\n# plot the images in the batch, along with the corresponding labels\nfig = plt.figure(figsize=(25, 4))\nfor idx in np.arange(batch_size):\n ax = fig.add_subplot(2, batch_size/2, idx+1, xticks=[], yticks=[])\n ax.imshow(np.squeeze(images[idx]), cmap='gray')\n ax.set_title(classes[labels[idx]])",
"(20, 1, 28, 28)\n"
]
],
[
[
"### Define the network architecture\n\nThe various layers that make up any neural network are documented, [here](http://pytorch.org/docs/master/nn.html). For a convolutional neural network, we'll use a simple series of layers:\n* Convolutional layers\n* Maxpooling layers\n* Fully-connected (linear) layers\n\nYou are also encouraged to look at adding [dropout layers](http://pytorch.org/docs/stable/nn.html#dropout) to avoid overfitting this data.\n\n---\n\n### TODO: Define the Net\n\nDefine the layers of your **best, saved model from the classification exercise** in the function `__init__` and define the feedforward behavior of that Net in the function `forward`. Defining the architecture here, will allow you to instantiate and load your best Net.",
"_____no_output_____"
]
],
[
[
"import torch.nn as nn\nimport torch.nn.functional as F\n\nclass Net(nn.Module):\n\n def __init__(self):\n super(Net, self).__init__()\n \n # 1 input image channel (grayscale), 10 output channels/feature maps\n # 3x3 square convolution kernel\n self.conv1 = nn.Conv2d(1, 10, 3)\n self.pool = nn.MaxPool2d(2,2)\n \n self.conv2 = nn.Conv2d(10,20,3)\n \n self.fc1 = nn.Linear(20*5*5,30)\n self.fc1_dropout= nn.Dropout(p=0.4)\n \n self.fc2 = nn.Linear(30,10)\n ## TODO: Define the rest of the layers:\n # include another conv layer, maxpooling layers, and linear layers\n # also consider adding a dropout layer to avoid overfitting\n \n\n ## TODO: define the feedforward behavior\n def forward(self, x):\n # one activated conv layer\n x = F.relu(self.conv1(x))\n x = self.pool(x)\n x = F.relu(self.conv2(x))\n x = self.pool(x)\n \n x = x.view(x.size[0],-1)\n \n x = self.fc1_dropout(self.fc1(x))\n x = self.fc2(x)\n # final output\n return x\n",
"_____no_output_____"
]
],
[
[
"### Load a Trained, Saved Model\n\nTo instantiate a trained model, you'll first instantiate a new `Net()` and then initialize it with a saved dictionary of parameters. This notebook needs to know the network architecture, as defined above, and once it knows what the \"Net\" class looks like, we can instantiate a model and load in an already trained network.\n\nYou should have a trained net in `saved_models/`.\n",
"_____no_output_____"
]
],
[
[
"# instantiate your Net\nnet = Net()\n\n# load the net parameters by name, uncomment the line below to load your model\n# net.load_state_dict(torch.load('saved_models/model_1.pt'))\n\nprint(net)",
"Net(\n (conv1): Conv2d(1, 10, kernel_size=(3, 3), stride=(1, 1))\n (pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)\n (conv2): Conv2d(10, 20, kernel_size=(3, 3), stride=(1, 1))\n (fc1): Linear(in_features=500, out_features=30, bias=True)\n (fc1_dropout): Dropout(p=0.4, inplace=False)\n (fc2): Linear(in_features=30, out_features=10, bias=True)\n)\n"
]
],
[
[
"## Feature Visualization\n\nTo see what your network has learned, make a plot of the learned image filter weights and the activation maps (for a given image) at each convolutional layer.\n\n### TODO: Visualize the learned filter weights and activation maps of the convolutional layers in your trained Net\n\nChoose a sample input image and apply the filters in every convolutional layer to that image to see the activation map.",
"_____no_output_____"
]
],
[
[
"# As a reminder, here is how we got the weights in the first conv layer (conv1), before\nweights = net.conv1.weight.data\nw = weights.numpy()",
"_____no_output_____"
]
],
[
[
"### Question: Choose a filter from one of your trained convolutional layers; looking at these activations, what purpose do you think it plays? What kind of feature do you think it detects?\n",
"_____no_output_____"
]
],
[
[
"import cv2\ndataiter = iter(test_loader)\nimage,label = dataiter.next()\nimage = image.numpy()\nidx = 11\n\nimg = np.squeeze(image[idx])\n\nplt.imshow(img,cmap=\"gray\")\n\nrow = 2\ncolumn = 5*2\n\nfig = plt.figure(figsize=(30,10))\n\nfor i in range(0,column*row):\n fig.add_subplot(row,column,i+1)\n if(i%2)==0:\n plt.imshow(w[int(i/2)][0],cmap=\"gray\")\n else:\n c = cv2.filter2D(img,-1,w[int((i-1)/2)][0])\n plt.imshow(c,cmap=\"gray\")\nplt.show()",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
cb3284d93c7ac121aa997636e8d5a8c33cc73f2c | 12,388 | ipynb | Jupyter Notebook | downloaded_kernels/loan_data/kernel_171.ipynb | josepablocam/common-code-extraction | a6978fae73eee8ece6f1db09f2f38cf92f03b3ad | [
"MIT"
] | null | null | null | downloaded_kernels/loan_data/kernel_171.ipynb | josepablocam/common-code-extraction | a6978fae73eee8ece6f1db09f2f38cf92f03b3ad | [
"MIT"
] | null | null | null | downloaded_kernels/loan_data/kernel_171.ipynb | josepablocam/common-code-extraction | a6978fae73eee8ece6f1db09f2f38cf92f03b3ad | [
"MIT"
] | 2 | 2021-07-12T00:48:08.000Z | 2021-08-11T12:53:05.000Z | 32.344648 | 125 | 0.515095 | [
[
[
"# This Python 3 environment comes with many helpful analytics libraries installed\n# It is defined by the kaggle/python docker image: https://github.com/kaggle/docker-python\n# For example, here's several helpful packages to load in \n\nimport numpy as np # linear algebra\nimport pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)\n\n# Input data files are available in the \"../input/\" directory.\n# For example, running this (by clicking run or pressing Shift+Enter) will list the files in the input directory\n\nfrom subprocess import check_output\nprint(check_output([\"ls\", \"../input\"]).decode(\"utf8\"))\n\n# Any results you write to the current directory are saved as output.\n\nimport tensorflow as tf\n\n## Load Data\n\ndata = pd.read_csv(\"../input/loan.csv\", low_memory=False)\n\n#data.info()\n#data.shape\n\n## Clean data.\n\nclean_data = data.dropna(thresh=len(data),axis=1)\n#clean_data.shape\nlist(clean_data)",
"_____no_output_____"
],
[
"#clean_data.loan_status.str.contains(\"Fully Paid\").astype(int)\n\n#clean_data.loan_status[clean_data.loan_status.str.contains(\"Fully Paid\") == True] = 1\n#clean_data.loan_status[clean_data.loan_status.str.contains(\"Fully Paid\") == False] = 0",
"_____no_output_____"
],
[
"## Remove data that does not meet the credit policy.\nclean_data = clean_data[clean_data.loan_status.str.contains(\"Does not meet the credit policy\") == False]\n\n#clean_data.loan_status[clean_data.loan_status.str.contains(\"Fully Paid\")].astype(int)\nclean_data.loan_status[clean_data.loan_status.str.contains(\"Fully Paid\") == True] = 1\nclean_data.loan_status[clean_data.loan_status.str.contains(\"Fully Paid\") == False] = 0",
"_____no_output_____"
],
[
"clean_data.loan_status.unique()\n\nclean_data.shape\n\nclean_data_orig = clean_data.copy()\n\nlist(clean_data)",
"_____no_output_____"
],
[
"## Split Data\nratio = 0.7\nmsk = np.random.rand(len(clean_data)) < ratio\ntrain_data = clean_data[msk]\ntest_data = clean_data[~msk]\n\n## Use loan status as label for loan defaulters\ny_label['loan_status'] = clean_data['loan_status'][msk]\ny_test_label['loan_status'] = clean_data['loan_status'][~msk]\n\ntrain_data = train_data.select_dtypes(exclude=[np.object])\ntest_data = test_data.select_dtypes(exclude=[np.object])\n\n\nlen(train_data)\nlen(test_data)\n\n#train_data['loan_amnt'].hist()",
"_____no_output_____"
],
[
"##Vizualization\n\nimport matplotlib.pyplot as plt\n\n#train_data.plot()\n\n#plt.figure(); train_data.plot(); plt.legend(loc='best')",
"_____no_output_____"
],
[
"#y_label[y_label.str.contains(\"Does not\") == True].size",
"_____no_output_____"
],
[
"list(train_data)\n\n#train_data.drop('id', axis=1, inplace=True)\n#train_data.drop('member_id', axis=1, inplace=True)\ntrain_data.drop('funded_amnt_inv', axis=1, inplace=True)\n#train_data.drop('url', axis=1, inplace=True)\n#train_data.drop('loan_status', axis=1, inplace=True)\n#train_data.drop('application_type', axis=1, inplace=True)\n\n\n#test_data.drop('id', axis=1, inplace=True)\n#test_data.drop('member_id', axis=1, inplace=True)\ntest_data.drop('funded_amnt_inv', axis=1, inplace=True)\n#test_data.drop('url', axis=1, inplace=True)\n#test_data.drop('loan_status', axis=1, inplace=True)\n#test_data.drop('application_type', axis=1, inplace=True)\n",
"_____no_output_____"
],
[
"train_data.shape",
"_____no_output_____"
],
[
"# machine learning\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.svm import SVC, LinearSVC\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn.neighbors import KNeighborsClassifier\nfrom sklearn.naive_bayes import GaussianNB\nfrom sklearn.linear_model import Perceptron\nfrom sklearn.linear_model import SGDClassifier\nfrom sklearn.tree import DecisionTreeClassifier",
"_____no_output_____"
],
[
"unique, counts = np.unique(msk, return_counts=True)\ncounts",
"_____no_output_____"
],
[
"y_label.shape",
"_____no_output_____"
],
[
"# Logistic Regression\n\nlogreg = LogisticRegression()\nlogreg.fit(train_data, y_label)\nY_pred = logreg.predict(test_data)\nacc_log = round(logreg.score(train_data, y_label) * 100, 2)\nacc_log\n",
"_____no_output_____"
],
[
"train_data.info()",
"_____no_output_____"
],
[
"import numpy as np\ndef get_series_ids(x):\n '''Function returns a pandas series consisting of ids, \n corresponding to objects in input pandas series x\n Example: \n get_series_ids(pd.Series(['a','a','b','b','c'])) \n returns Series([0,0,1,1,2], dtype=int)'''\n\n values = np.unique(x)\n values2nums = dict(zip(values,range(len(values))))\n return x.replace(values2nums)",
"_____no_output_____"
],
[
"x = tf.placeholder(tf.float32, shape=[len(train_data), None])\ny = tf.placeholder(tf.float32, shape=[None, 2])\n\nW = tf.Variable(tf.zeros([len(train_data),2]))\nb = tf.Variable(tf.zeros([2]))\n",
"_____no_output_____"
],
[
"learning_rate = 0.01\ntraining_epochs = 25\nbatch_size = 100\ndisplay_step = 1\n\npred = tf.nn.softmax(tf.matmul(x, W) + b) # Softmax\n\n# Minimize error using cross entropy\ncost = tf.reduce_mean(-tf.reduce_sum(y*tf.log(pred), reduction_indices=1))\n# Gradient Descent\noptimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)\n\n# Initializing the variables\ninit = tf.global_variables_initializer()\n\n# Launch the graph\nwith tf.Session() as sess:\n sess.run(init)\n\n # Training cycle\n for epoch in range(training_epochs):\n avg_cost = 0.\n total_batch = len(train_data)\n # Loop over all batches\n for i in range(total_batch):\n batch_xs = train_data\n batch_ys = y_label\n # Run optimization op (backprop) and cost op (to get loss value)\n _, c = sess.run([optimizer, cost], feed_dict={x: batch_xs,\n y: batch_ys})\n # Compute average loss\n avg_cost += c / total_batch\n # Display logs per epoch step\n if (epoch+1) % display_step == 0:\n print(\"Epoch:\", '%04d' % (epoch+1), \"cost=\", \"{:.9f}\".format(avg_cost))\n\n print(\"Optimization Finished!\")\n\n # Test model\n correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))\n # Calculate accuracy\n accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))\nprint(\"Accuracy:\", accuracy.eval({x: test_data, y: y_test_labels}))",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb32948bb59d3bb835baa65fbee58cd1f92f0c3f | 647,702 | ipynb | Jupyter Notebook | Topic modeling with gensim.ipynb | Akashhhhh/topic-modeling-LDA | e5597074317609fc9694679560cec38cc1d0433f | [
"MIT"
] | null | null | null | Topic modeling with gensim.ipynb | Akashhhhh/topic-modeling-LDA | e5597074317609fc9694679560cec38cc1d0433f | [
"MIT"
] | null | null | null | Topic modeling with gensim.ipynb | Akashhhhh/topic-modeling-LDA | e5597074317609fc9694679560cec38cc1d0433f | [
"MIT"
] | null | null | null | 426.400263 | 322,072 | 0.859491 | [
[
[
"### Run in python console\nimport nltk; nltk.download('stopwords')\n\n### Run in terminal or command prompt\npython3 -m spacy download en\n\n### Import Packages\n\nThe core packages used in this tutorial are re, gensim, spacy and pyLDAvis. Besides this we will also using matplotlib, numpy and pandas for data handling and visualization. Let’s import them.",
"_____no_output_____"
]
],
[
[
"import re\nimport numpy as np\nimport pandas as pd\nfrom pprint import pprint",
"_____no_output_____"
],
[
"# Gensim\nimport gensim\nimport gensim.corpora as corpora\nfrom gensim.utils import simple_preprocess\nfrom gensim.models import CoherenceModel # https://radimrehurek.com/gensim/models/coherencemodel.html",
"_____no_output_____"
],
[
"# Spacy for lemmatization\nimport spacy\n\n#Plotting tools # conda install -c memex pyldavis\nimport pyLDAvis\nimport pyLDAvis.gensim # don't skip this\nimport matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"#### import data",
"_____no_output_____"
]
],
[
[
"dataframe = pd.read_csv('voted-kaggle-dataset.csv')\n#dataframe['Description']\ndataframe.head()",
"_____no_output_____"
],
[
"# !pip install seaborn\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nfrom nltk import FreqDist\ndef freq_words(text_data, terms):\n all_words = ' '.join([str(text) for text in text_data])\n all_words = all_words.split()\n \n fdist = FreqDist(all_words)\n words_df = pd.DataFrame({'word':list(fdist.keys()), 'count':list(fdist.values())})\n \n #selecting top 20 most frequent words\n most_frequent_word = words_df.nlargest(columns='count', n=terms)\n plt.figure(figsize=(20,5))\n ax = sns.barplot(data=most_frequent_word, x='word', y='count')\n ax.set(ylabel='Count')\n plt.show()",
"_____no_output_____"
],
[
"freq_words(dataframe['Description'], terms=30)",
"_____no_output_____"
],
[
"from nltk.corpus import stopwords\nstop_words = stopwords.words('english')\nprint(stop_words)\nstop_words.extend(['from', 'subject', 're', 'edu', 'use'])",
"['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', \"you're\", \"you've\", \"you'll\", \"you'd\", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', \"she's\", 'her', 'hers', 'herself', 'it', \"it's\", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', \"that'll\", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', \"don't\", 'should', \"should've\", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', \"aren't\", 'couldn', \"couldn't\", 'didn', \"didn't\", 'doesn', \"doesn't\", 'hadn', \"hadn't\", 'hasn', \"hasn't\", 'haven', \"haven't\", 'isn', \"isn't\", 'ma', 'mightn', \"mightn't\", 'mustn', \"mustn't\", 'needn', \"needn't\", 'shan', \"shan't\", 'shouldn', \"shouldn't\", 'wasn', \"wasn't\", 'weren', \"weren't\", 'won', \"won't\", 'wouldn', \"wouldn't\"]\n"
],
[
"# Convert to list\ndata = dataframe['Description'].tolist()\n\n# Remove Emails\ndata = [re.sub('\\S*@\\S*\\s?', '', str(sent)) for sent in data]\n\n# Remove new line characters\ndata = [re.sub('\\s+', ' ', sent) for sent in data]\n\n# Remove distracting single quotes\ndata = [re.sub(\"\\'\", \"\", sent) for sent in data]\n\npprint(data[:1])",
"<>:5: DeprecationWarning: invalid escape sequence \\S\n<>:8: DeprecationWarning: invalid escape sequence \\s\n<>:5: DeprecationWarning: invalid escape sequence \\S\n<>:8: DeprecationWarning: invalid escape sequence \\s\n<>:5: DeprecationWarning: invalid escape sequence \\S\n<>:8: DeprecationWarning: invalid escape sequence \\s\n<ipython-input-8-f8b73b705db2>:5: DeprecationWarning: invalid escape sequence \\S\n data = [re.sub('\\S*@\\S*\\s?', '', str(sent)) for sent in data]\n<ipython-input-8-f8b73b705db2>:8: DeprecationWarning: invalid escape sequence \\s\n data = [re.sub('\\s+', ' ', sent) for sent in data]\n"
],
[
"freq_words(data, terms=30)",
"_____no_output_____"
],
[
"def sent_to_words(sentences):\n for sentence in sentences:\n yield(gensim.utils.simple_preprocess(str(sentence), deacc=True)) # deacc=True removes punctuations\n\ndata_words = list(sent_to_words(data))\n\nprint(data_words[:1])",
"[['the', 'datasets', 'contains', 'transactions', 'made', 'by', 'credit', 'cards', 'in', 'september', 'by', 'european', 'cardholders', 'this', 'dataset', 'presents', 'transactions', 'that', 'occurred', 'in', 'two', 'days', 'where', 'we', 'have', 'frauds', 'out', 'of', 'transactions', 'the', 'dataset', 'is', 'highly', 'unbalanced', 'the', 'positive', 'class', 'frauds', 'account', 'for', 'of', 'all', 'transactions', 'it', 'contains', 'only', 'numerical', 'input', 'variables', 'which', 'are', 'the', 'result', 'of', 'pca', 'transformation', 'unfortunately', 'due', 'to', 'confidentiality', 'issues', 'we', 'cannot', 'provide', 'the', 'original', 'features', 'and', 'more', 'background', 'information', 'about', 'the', 'data', 'features', 'are', 'the', 'principal', 'components', 'obtained', 'with', 'pca', 'the', 'only', 'features', 'which', 'have', 'not', 'been', 'transformed', 'with', 'pca', 'are', 'time', 'and', 'amount', 'feature', 'time', 'contains', 'the', 'seconds', 'elapsed', 'between', 'each', 'transaction', 'and', 'the', 'first', 'transaction', 'in', 'the', 'dataset', 'the', 'feature', 'amount', 'is', 'the', 'transaction', 'amount', 'this', 'feature', 'can', 'be', 'used', 'for', 'example', 'dependant', 'cost', 'senstive', 'learning', 'feature', 'class', 'is', 'the', 'response', 'variable', 'and', 'it', 'takes', 'value', 'in', 'case', 'of', 'fraud', 'and', 'otherwise', 'given', 'the', 'class', 'imbalance', 'ratio', 'we', 'recommend', 'measuring', 'the', 'accuracy', 'using', 'the', 'area', 'under', 'the', 'precision', 'recall', 'curve', 'auprc', 'confusion', 'matrix', 'accuracy', 'is', 'not', 'meaningful', 'for', 'unbalanced', 'classification', 'the', 'dataset', 'has', 'been', 'collected', 'and', 'analysed', 'during', 'research', 'collaboration', 'of', 'worldline', 'and', 'the', 'machine', 'learning', 'group', 'http', 'mlg', 'ulb', 'ac', 'be', 'of', 'ulb', 'universite', 'libre', 'de', 'bruxelles', 'on', 'big', 'data', 'mining', 'and', 'fraud', 'detection', 'more', 'details', 'on', 'current', 'and', 'past', 'projects', 'on', 'related', 'topics', 'are', 'available', 'on', 'http', 'mlg', 'ulb', 'ac', 'be', 'brufence', 'and', 'http', 'mlg', 'ulb', 'ac', 'be', 'artml', 'please', 'cite', 'andrea', 'dal', 'pozzolo', 'olivier', 'caelen', 'reid', 'johnson', 'and', 'gianluca', 'bontempi', 'calibrating', 'probability', 'with', 'undersampling', 'for', 'unbalanced', 'classification', 'in', 'symposium', 'on', 'computational', 'intelligence', 'and', 'data', 'mining', 'cidm', 'ieee']]\n"
],
[
"# Build the bigram and trigram models\nbigram = gensim.models.Phrases(data_words, min_count=5, threshold=100) # higher threshold fewer phrases.\ntrigram = gensim.models.Phrases(bigram[data_words], threshold=100) \n\n# Faster way to get a sentence clubbed as a trigram/bigram\nbigram_mod = gensim.models.phrases.Phraser(bigram)\ntrigram_mod = gensim.models.phrases.Phraser(trigram)\n\n# See trigram example\nprint(trigram_mod[bigram_mod[data_words[0]]])",
"/home/akash/anaconda3/envs/ml/lib/python3.6/site-packages/gensim/models/phrases.py:494: UserWarning: For a faster implementation, use the gensim.models.phrases.Phraser class\n warnings.warn(\"For a faster implementation, use the gensim.models.phrases.Phraser class\")\n"
]
],
[
[
"### remove the stopwords",
"_____no_output_____"
]
],
[
[
"def remove_stop_words(texts):\n nostop_data_words = list()\n for doc in texts:\n data = list()\n for word in simple_preprocess(str(doc)):\n if word not in stop_words:\n data.append(word)\n nostop_data_words.append(data)\n \n return nostop_data_words\n ",
"_____no_output_____"
]
],
[
[
"#### make bigram, trigram",
"_____no_output_____"
]
],
[
[
"def make_bigrams(texts):\n return [bigram_mod[doc] for doc in texts]\n\n\ndef make_trigram(texts):\n return [trigram_mod[bigram_mod[doc]] for doc in texts]\n ",
"_____no_output_____"
]
],
[
[
"### lemmatization",
"_____no_output_____"
]
],
[
[
"def lemmatization(texts, allowed_postags):\n texts_output = []\n nlp = spacy.load('en', disable=['parser', 'ner'])\n for sent in texts:\n doc = nlp(\" \".join(sent))\n texts_output.append([token.lemma_ for token in doc if token.pos_ in allowed_postags])\n \n return texts_output\n\n",
"_____no_output_____"
],
[
"nostop_data_words = remove_stop_words(data_words)\nprint(nostop_data_words[:1])\ndata_words_bigram = make_bigrams(nostop_data_words)\n\ndata_lemma = lemmatization(texts = data_words_bigram, allowed_postags=['NOUN','ADJ','VERB','ADV'])",
"[['datasets', 'contains', 'transactions', 'made', 'credit', 'cards', 'september', 'european', 'cardholders', 'dataset', 'presents', 'transactions', 'occurred', 'two', 'days', 'frauds', 'transactions', 'dataset', 'highly', 'unbalanced', 'positive', 'class', 'frauds', 'account', 'transactions', 'contains', 'numerical', 'input', 'variables', 'result', 'pca', 'transformation', 'unfortunately', 'due', 'confidentiality', 'issues', 'cannot', 'provide', 'original', 'features', 'background', 'information', 'data', 'features', 'principal', 'components', 'obtained', 'pca', 'features', 'transformed', 'pca', 'time', 'amount', 'feature', 'time', 'contains', 'seconds', 'elapsed', 'transaction', 'first', 'transaction', 'dataset', 'feature', 'amount', 'transaction', 'amount', 'feature', 'used', 'example', 'dependant', 'cost', 'senstive', 'learning', 'feature', 'class', 'response', 'variable', 'takes', 'value', 'case', 'fraud', 'otherwise', 'given', 'class', 'imbalance', 'ratio', 'recommend', 'measuring', 'accuracy', 'using', 'area', 'precision', 'recall', 'curve', 'auprc', 'confusion', 'matrix', 'accuracy', 'meaningful', 'unbalanced', 'classification', 'dataset', 'collected', 'analysed', 'research', 'collaboration', 'worldline', 'machine', 'learning', 'group', 'http', 'mlg', 'ulb', 'ac', 'ulb', 'universite', 'libre', 'de', 'bruxelles', 'big', 'data', 'mining', 'fraud', 'detection', 'details', 'current', 'past', 'projects', 'related', 'topics', 'available', 'http', 'mlg', 'ulb', 'ac', 'brufence', 'http', 'mlg', 'ulb', 'ac', 'artml', 'please', 'cite', 'andrea', 'dal', 'pozzolo', 'olivier', 'caelen', 'reid', 'johnson', 'gianluca', 'bontempi', 'calibrating', 'probability', 'undersampling', 'unbalanced', 'classification', 'symposium', 'computational', 'intelligence', 'data', 'mining', 'cidm', 'ieee']]\n"
],
[
"print(data_lemma[:1])",
"[['dataset', 'contain', 'transaction', 'make', 'credit', 'card', 'september', 'european', 'cardholder', 'dataset', 'present', 'transaction', 'occur', 'day', 'fraud', 'transaction', 'dataset', 'highly', 'unbalanced', 'positive', 'class', 'fraud', 'account', 'transaction', 'contain', 'numerical', 'input', 'variable', 'result', 'transformation', 'unfortunately', 'due', 'confidentiality', 'issue', 'can', 'not', 'provide', 'original', 'feature', 'background', 'information', 'datum', 'feature', 'principal', 'component', 'obtain', 'pca', 'feature', 'transform', 'pca', 'time', 'amount', 'feature', 'time', 'contain', 'second', 'elapse', 'transaction', 'first', 'transaction', 'dataset', 'feature', 'amount', 'transaction', 'amount', 'feature', 'use', 'example', 'dependant', 'cost', 'senstive', 'learn', 'feature', 'class', 'response', 'variable', 'take', 'value', 'case', 'fraud', 'otherwise', 'give', 'class', 'imbalance', 'ratio', 'recommend', 'measure', 'accuracy', 'use', 'area', 'precision', 'recall', 'curve', 'auprc', 'confusion', 'matrix', 'accuracy', 'meaningful', 'unbalanced', 'classification', 'dataset', 'collect', 'analyse', 'research', 'collaboration', 'worldline', 'machine_learn', 'group', 'http', 'mlg', 'ulb', 'ulb', 'universite', 'libre', 'bruxell', 'big', 'datum', 'mining', 'fraud_detection', 'detail', 'current', 'past', 'project', 'relate', 'topic', 'available', 'http', 'mlg', 'ulb', 'brufence', 'http', 'mlg', 'ulb', 'artml', 'please_cite', 'andrea', 'dal', 'pozzolo', 'olivier', 'caelen', 'reid', 'johnson', 'gianluca', 'bontempi', 'calibrate', 'probability', 'undersampl', 'unbalanced', 'classification', 'symposium', 'computational', 'intelligence', 'datum', 'mining', 'cidm', 'ieee']]\n"
],
[
"freq_words(data_lemma, terms=30)",
"_____no_output_____"
]
],
[
[
"#### Gensim creates a unique id for each word in the document. The produced corpus shown above is a mapping of (word_id, word_frequency).",
"_____no_output_____"
]
],
[
[
"# Create dictionary\n# This is used as the input by the LDA model.\nid2word = corpora.Dictionary(data_lemma)\ntexts = data_lemma\ncorpus = [id2word.doc2bow(text) for text in texts]\nprint(corpus[:1])",
"[[(0, 1), (1, 2), (2, 3), (3, 1), (4, 1), (5, 1), (6, 1), (7, 1), (8, 1), (9, 1), (10, 1), (11, 1), (12, 1), (13, 1), (14, 1), (15, 1), (16, 1), (17, 1), (18, 1), (19, 1), (20, 1), (21, 3), (22, 2), (23, 1), (24, 1), (25, 1), (26, 1), (27, 1), (28, 1), (29, 3), (30, 1), (31, 1), (32, 1), (33, 1), (34, 1), (35, 5), (36, 3), (37, 1), (38, 1), (39, 1), (40, 1), (41, 1), (42, 1), (43, 1), (44, 7), (45, 1), (46, 3), (47, 1), (48, 1), (49, 1), (50, 1), (51, 1), (52, 3), (53, 1), (54, 1), (55, 1), (56, 1), (57, 1), (58, 1), (59, 1), (60, 1), (61, 1), (62, 1), (63, 1), (64, 1), (65, 1), (66, 1), (67, 2), (68, 3), (69, 1), (70, 1), (71, 1), (72, 1), (73, 1), (74, 1), (75, 1), (76, 1), (77, 2), (78, 1), (79, 1), (80, 1), (81, 1), (82, 1), (83, 1), (84, 1), (85, 1), (86, 1), (87, 1), (88, 1), (89, 1), (90, 1), (91, 1), (92, 1), (93, 1), (94, 1), (95, 1), (96, 1), (97, 1), (98, 1), (99, 1), (100, 2), (101, 1), (102, 7), (103, 1), (104, 1), (105, 4), (106, 3), (107, 1), (108, 1), (109, 1), (110, 2), (111, 1), (112, 2), (113, 1)]]\n"
]
],
[
[
"#### # Human readable format of corpus (term-frequency)",
"_____no_output_____"
]
],
[
[
"[[(id2word[id], freq) for id, freq in corpora] for corpora in corpus[:1]]",
"_____no_output_____"
],
[
"# Build LDA model\nLDA = gensim.models.ldamodel.LdaModel\n# lda_model = LDA(corpus=corpus,\n# id2word=id2word,\n# num_topics=20, \n# random_state=100,\n# update_every=1,\n# chunksize=100,\n# passes=10,\n# alpha='auto',\n# per_word_topics=True)",
"_____no_output_____"
],
[
"from gensim.test.utils import datapath\nmodel_name = '/home/akash/Dev/Topic modeling/LDA_model'\ntemp_file = datapath(model_name)\n\n# # Save model to disk.\n# lda_model.save(temp_file)",
"_____no_output_____"
],
[
"# Load a potentially pretrained model from disk.\nlda_model = LDA.load(temp_file)",
"/home/akash/anaconda3/envs/ml/lib/python3.6/site-packages/smart_open/smart_open_lib.py:398: UserWarning: This function is deprecated, use smart_open.open instead. See the migration notes for details: https://github.com/RaRe-Technologies/smart_open/blob/master/README.rst#migrating-to-the-new-open-function\n 'See the migration notes for details: %s' % _MIGRATION_NOTES_URL\n"
],
[
"# https://rare-technologies.com/what-is-topic-coherence/\n\n# Compute Coherence Score\n# coherence_model_lda = CoherenceModel(model=lda_model, texts=data_lemma, dictionary=id2word, coherence='c_v')\n# coherence_lda = coherence_model_lda.get_coherence()\n# print('\\nCoherence Score: ', coherence_lda)\n\n# a measure of how good the model is. lower the better.\n# Compute Perplexity\n#print('\\nPerplexity: ', lda_model.log_perplexity(corpus)) ",
"_____no_output_____"
],
[
"# Visualize the topics\npyLDAvis.enable_notebook()\nvis = pyLDAvis.gensim.prepare(lda_model, corpus, id2word)\nvis",
"/home/akash/anaconda3/envs/ml/lib/python3.6/site-packages/pyLDAvis/_prepare.py:257: FutureWarning: Sorting because non-concatenation axis is not aligned. A future version\nof pandas will change to not sort by default.\n\nTo accept the future behavior, pass 'sort=False'.\n\nTo retain the current behavior and silence the warning, pass 'sort=True'.\n\n return pd.concat([default_term_info] + list(topic_dfs))\n"
]
],
[
[
"In LDA models, each document is composed of multiple topics. But, typically only one of the topics is dominant. The below code extracts this dominant topic for each sentence and shows the weight of the topic and the keywords in a nicely formatted output.\n\nThis way, you will know which document belongs predominantly to which topic.\n\n",
"_____no_output_____"
]
],
[
[
"def format_topics_sentences(ldamodel, corpus, texts):\n # Init output\n sent_topics_df = pd.DataFrame()\n\n # Get main topic in each document\n for i, row_list in enumerate(ldamodel[corpus]):\n row = row_list[0] if ldamodel.per_word_topics else row_list \n #print(row)\n row = sorted(row, key=lambda x: (x[1]), reverse=True)\n # Get the Dominant topic, Perc Contribution and Keywords for each document\n for j, (topic_num, prop_topic) in enumerate(row):\n if j == 0: # => dominant topic\n wp = ldamodel.show_topic(topic_num)\n topic_keywords = \", \".join([word for word, prop in wp])\n sent_topics_df = sent_topics_df.append(pd.Series([int(topic_num), round(prop_topic,4), topic_keywords]), ignore_index=True)\n else:\n break\n sent_topics_df.columns = ['Dominant_Topic', 'Perc_Contribution', 'Topic_Keywords']\n # Add original text to the end of the output\n contents = pd.Series(texts)\n sent_topics_df = pd.concat([sent_topics_df, contents], axis=1)\n return(sent_topics_df) \n \ndf_topic_sents_keywords=format_topics_sentences(ldamodel=lda_model, corpus=corpus, texts=data_lemma)\n\n# Format\ndf_dominant_topic = df_topic_sents_keywords.reset_index()\ndf_dominant_topic.columns = ['Document_No', 'Dominant_Topic', 'Topic_Perc_Contrib', 'Keywords', 'Text']\ndf_dominant_topic.head(10)",
"_____no_output_____"
]
],
[
[
"#### Frequency Distribution of Word Counts in Documents",
"_____no_output_____"
]
],
[
[
"doc_lens = [len(d) for d in df_dominant_topic.Text]\n\n# Plot\nplt.figure(figsize=(16,7), dpi=120)\nplt.hist(doc_lens, bins = 1000, color='green')\nplt.text(750, 450, \"Mean : \" + str(round(np.mean(doc_lens))))\nplt.text(750, 400, \"Median : \" + str(round(np.median(doc_lens))))\nplt.text(750, 350, \"Stdev : \" + str(round(np.std(doc_lens))))\nplt.text(750, 300, \"1%ile : \" + str(round(np.quantile(doc_lens, q=0.01))))\nplt.text(750, 250, \"99%ile : \" + str(round(np.quantile(doc_lens, q=0.99))))\n\nplt.gca().set(xlim=(0, 1100), ylabel='Number of Documents', xlabel='Document Word Count')\nplt.tick_params(size=16)\nplt.xticks(np.linspace(0,1100,9))\nplt.title('Distribution of Document Word Counts', fontdict=dict(size=22))\nplt.show()",
"_____no_output_____"
],
[
"import seaborn as sns\nimport matplotlib.colors as mcolors\ncols = [color for name, color in mcolors.TABLEAU_COLORS.items()] # more colors: 'mcolors.XKCD_COLORS'\n\nfig, axes = plt.subplots(2,2,figsize=(16,14), dpi=160, sharex=True, sharey=True)\n\nfor i, ax in enumerate(axes.flatten()): \n df_dominant_topic_sub = df_dominant_topic.loc[df_dominant_topic.Dominant_Topic == i, :]\n doc_lens = [len(d) for d in df_dominant_topic_sub.Text]\n ax.hist(doc_lens, bins = 1000, color=cols[i])\n ax.tick_params(axis='y', labelcolor=cols[i], color=cols[i])\n sns.kdeplot(doc_lens, color=\"black\", shade=False, ax=ax.twinx())\n ax.set(xlim=(0, 1000), xlabel='Document Word Count')\n ax.set_ylabel('Number of Documents', color=cols[i])\n ax.set_title('Topic: '+str(i), fontdict=dict(size=16, color=cols[i]))\n\nfig.tight_layout()\nfig.subplots_adjust(top=0.90)\nplt.xticks(np.linspace(0,1000,9))\nfig.suptitle('Distribution of Document Word Counts by Dominant Topic', fontsize=22)\nplt.show()",
"/home/akash/anaconda3/envs/ml/lib/python3.6/site-packages/scipy/stats/stats.py:1713: FutureWarning: Using a non-tuple sequence for multidimensional indexing is deprecated; use `arr[tuple(seq)]` instead of `arr[seq]`. In the future this will be interpreted as an array index, `arr[np.array(seq)]`, which will result either in an error or a different result.\n return np.add.reduce(sorted[indexer] * weights, axis=axis) / sumval\n"
]
],
[
[
"#### t-SNE Clustering Chart",
"_____no_output_____"
]
],
[
[
"# pip install bokeh\n\n# Get topic weights and dominant topics ------------\n# from sklearn.manifold import TSNE\n# from bokeh.plotting import figure, output_file, show\n# from bokeh.models import Label\n# from bokeh.io import output_notebook\n\n# # Get topic weights\n# topic_weights = []\n# for i, row_list in enumerate(lda_model[corpus]):\n# topic_weights.append([w for i, w in row_list[0]])\n\n# # Array of topic weights \n# arr = pd.DataFrame(topic_weights).fillna(0).values\n\n# # Keep the well separated points (optional)\n# arr = arr[np.amax(arr, axis=1) > 0.35]\n\n# # Dominant topic number in each doc\n# topic_num = np.argmax(arr, axis=1)\n\n# # tSNE Dimension Reduction\n# tsne_model = TSNE(n_components=2, verbose=1, random_state=0, angle=.99, init='pca')\n# tsne_lda = tsne_model.fit_transform(arr)\n\n# # Plot the Topic Clusters using Bokeh\n# output_notebook()\n# n_topics = 4\n# mycolors = np.array([color for name, color in mcolors.TABLEAU_COLORS.items()])\n# plot = figure(title=\"t-SNE Clustering of {} LDA Topics\".format(n_topics), \n# plot_width=900, plot_height=700)\n# plot.scatter(x=tsne_lda[:,0], y=tsne_lda[:,1], color=mycolors[topic_num])\n# # show(plot)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
cb3299d06fa876e1771650d9caf2dd14882ee3f6 | 75,749 | ipynb | Jupyter Notebook | Laboratorios/m04_c02_lab_masnu_simon/m04_c02_lab_masnu_simon.ipynb | simonmasnu/mat281_portfolio | 9c7c0b5747c8db33a75d700fbfdb3ad61017e65c | [
"MIT",
"BSD-3-Clause"
] | null | null | null | Laboratorios/m04_c02_lab_masnu_simon/m04_c02_lab_masnu_simon.ipynb | simonmasnu/mat281_portfolio | 9c7c0b5747c8db33a75d700fbfdb3ad61017e65c | [
"MIT",
"BSD-3-Clause"
] | null | null | null | Laboratorios/m04_c02_lab_masnu_simon/m04_c02_lab_masnu_simon.ipynb | simonmasnu/mat281_portfolio | 9c7c0b5747c8db33a75d700fbfdb3ad61017e65c | [
"MIT",
"BSD-3-Clause"
] | null | null | null | 97.740645 | 53,520 | 0.835417 | [
[
[
"<img src=\"https://upload.wikimedia.org/wikipedia/commons/4/47/Logo_UTFSM.png\" width=\"200\" alt=\"utfsm-logo\" align=\"left\"/>\n\n# MAT281\n### Aplicaciones de la Matemática en la Ingeniería",
"_____no_output_____"
],
[
"## Módulo 04\n## Laboratorio Clase 02: Regresión Lineal",
"_____no_output_____"
],
[
"### Instrucciones\n\n\n* Completa tus datos personales (nombre y rol USM) en siguiente celda.\n* La escala es de 0 a 4 considerando solo valores enteros.\n* Debes _pushear_ tus cambios a tu repositorio personal del curso.\n* Como respaldo, debes enviar un archivo .zip con el siguiente formato `mXX_cYY_lab_apellido_nombre.zip` a [email protected], debe contener todo lo necesario para que se ejecute correctamente cada celda, ya sea datos, imágenes, scripts, etc.\n* Se evaluará:\n - Soluciones\n - Código\n - Que Binder esté bien configurado.\n - Al presionar `Kernel -> Restart Kernel and Run All Cells` deben ejecutarse todas las celdas sin error.",
"_____no_output_____"
],
[
"__Nombre__: Simón Masnú\n\n__Rol__: 201503026-K",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport altair as alt\n\nfrom sklearn import datasets, linear_model\nfrom sklearn.metrics import mean_squared_error, r2_score\n\nalt.themes.enable('opaque')\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"## Ejercicio 1: Diabetes",
"_____no_output_____"
],
[
"Realizar análisis de regresión a los datos de diabetes disponibles en scikit-learn",
"_____no_output_____"
]
],
[
[
"diabetes = datasets.load_diabetes()\nprint(dir(diabetes)) ## Atributos",
"['DESCR', 'data', 'data_filename', 'feature_names', 'target', 'target_filename']\n"
],
[
"print(diabetes.DESCR)",
".. _diabetes_dataset:\n\nDiabetes dataset\n----------------\n\nTen baseline variables, age, sex, body mass index, average blood\npressure, and six blood serum measurements were obtained for each of n =\n442 diabetes patients, as well as the response of interest, a\nquantitative measure of disease progression one year after baseline.\n\n**Data Set Characteristics:**\n\n :Number of Instances: 442\n\n :Number of Attributes: First 10 columns are numeric predictive values\n\n :Target: Column 11 is a quantitative measure of disease progression one year after baseline\n\n :Attribute Information:\n - Age\n - Sex\n - Body mass index\n - Average blood pressure\n - S1\n - S2\n - S3\n - S4\n - S5\n - S6\n\nNote: Each of these 10 feature variables have been mean centered and scaled by the standard deviation times `n_samples` (i.e. the sum of squares of each column totals 1).\n\nSource URL:\nhttps://www4.stat.ncsu.edu/~boos/var.select/diabetes.html\n\nFor more information see:\nBradley Efron, Trevor Hastie, Iain Johnstone and Robert Tibshirani (2004) \"Least Angle Regression,\" Annals of Statistics (with discussion), 407-499.\n(https://web.stanford.edu/~hastie/Papers/LARS/LeastAngle_2002.pdf)\n"
],
[
"diabetes_df = (\n pd.DataFrame(\n diabetes.data,\n columns=diabetes.feature_names\n )\n .assign(prog=diabetes.target)\n)\n\ndiabetes_df.head()",
"_____no_output_____"
]
],
[
[
"#### Pregunta 1 (1 pto):\n\n* ¿Por qué la columna de sexo tiene esos valores?\n* ¿Cuál es la columna a predecir?",
"_____no_output_____"
],
[
"Respuesta:\n\n* La columna sexo tiene esos datos pues seguramente se le asignó un valor cuantitativo a cada sexo y luego, como se menciona en la descripición del dataset, se normalizaron los datos de esa columna de modo que la suma de los cuadrados de la columna sea 1.\n\n* La columna a predecir es \"prog\", una medida cuantitativa de la progresión de la enfermedad a lo largo de un año.",
"_____no_output_____"
],
[
"#### Pregunta 2 (1 pto)\n\nRealiza una regresión lineal con todas las _features_ incluyendo intercepto.",
"_____no_output_____"
]
],
[
[
"X = diabetes_df.drop(\"prog\",axis=1).values\ny = diabetes_df[\"prog\"].values\n\nprint(X)",
"[[ 0.03807591 0.05068012 0.06169621 ... -0.00259226 0.01990842\n -0.01764613]\n [-0.00188202 -0.04464164 -0.05147406 ... -0.03949338 -0.06832974\n -0.09220405]\n [ 0.08529891 0.05068012 0.04445121 ... -0.00259226 0.00286377\n -0.02593034]\n ...\n [ 0.04170844 0.05068012 -0.01590626 ... -0.01107952 -0.04687948\n 0.01549073]\n [-0.04547248 -0.04464164 0.03906215 ... 0.02655962 0.04452837\n -0.02593034]\n [-0.04547248 -0.04464164 -0.0730303 ... -0.03949338 -0.00421986\n 0.00306441]]\n"
]
],
[
[
"Ajusta el modelo",
"_____no_output_____"
]
],
[
[
"from sklearn.linear_model import LinearRegression\nregr = LinearRegression(fit_intercept=True)\nregr.fit(X,y)\n\nregr.coef_",
"_____no_output_____"
]
],
[
[
"Imprime el intercepto y los coeficientes luego de ajustar el modelo.",
"_____no_output_____"
]
],
[
[
"print(f\"Intercept: \\n{ regr.intercept_ }\\n\")\nprint(f\"Coefficients: \\n{regr.coef_}\\n\")",
"Intercept: \n152.1334841628965\n\nCoefficients: \n[ -10.01219782 -239.81908937 519.83978679 324.39042769 -792.18416163\n 476.74583782 101.04457032 177.06417623 751.27932109 67.62538639]\n\n"
]
],
[
[
"Haz una predicción del modelo con los datos `X`.",
"_____no_output_____"
]
],
[
[
"y_pred=regr.predict(X)\n\n\n",
"_____no_output_____"
]
],
[
[
"Calcula e imprime el error cuadrático medio y el coeficiente de determinación de este modelo ajustado.",
"_____no_output_____"
]
],
[
[
"# Error cuadrático medio\nprint(f\"Mean squared error: {mean_squared_error(y, y_pred):.2f}\\n\")\n\n# Coeficiente de determinación\nprint(f\"Coefficient of determination: {r2_score(y,y_pred):.2f}\")",
"Mean squared error: 2859.69\n\nCoefficient of determination: 0.52\n"
]
],
[
[
"**Pregunta: ¿Qué tan bueno fue el ajuste del modelo?**",
"_____no_output_____"
],
[
"Basandonos en el coeficiente de determinación, podemos decir que el 52% de la variabilidad de los datos es explicada por el modelo, lo es bastante pobre.\n\nPor regla general, un modelo se puede considerar bueno con un $r^{2}$ en torno al 0.9 o mayor.",
"_____no_output_____"
],
[
"### Pregunta 3 (2 ptos).\n\nRealizar multiples regresiones lineales utilizando una sola _feature_ a la vez. \n\nEn cada iteración:\n\n- Crea un arreglo `X`con solo una feature filtrando `X`.\n- Crea un modelo de regresión lineal con intercepto.\n- Ajusta el modelo anterior.\n- Genera una predicción con el modelo.\n- Calcula e imprime las métricas de la pregunta anterior.",
"_____no_output_____"
]
],
[
[
"for i in range(X.shape[1]):\n X_i = X[:, np.newaxis, i] # Protip! Trata de entender este paso por tu cuenta, es muy clever\n regr_i = LinearRegression(fit_intercept=True)\n regr_i.fit(X_i,y)\n y_pred_i = regr_i.predict(X_i)\n print(f\"{diabetes_df.columns[i]}:\")\n print(f\"\\tCoefficients: {regr.coef_}\")\n print(f\"\\tIntercept: {regr.intercept_}\")\n print(f\"\\tMean squared error: {mean_squared_error(y,y_pred_i):.2f}\")\n print(f\"\\tCoefficient of determination: {r2_score(y,y_pred_i):.2f}\\n\")",
"age:\n\tCoefficients: [ -10.01219782 -239.81908937 519.83978679 324.39042769 -792.18416163\n 476.74583782 101.04457032 177.06417623 751.27932109 67.62538639]\n\tIntercept: 152.1334841628965\n\tMean squared error: 5720.55\n\tCoefficient of determination: 0.04\n\nsex:\n\tCoefficients: [ -10.01219782 -239.81908937 519.83978679 324.39042769 -792.18416163\n 476.74583782 101.04457032 177.06417623 751.27932109 67.62538639]\n\tIntercept: 152.1334841628965\n\tMean squared error: 5918.89\n\tCoefficient of determination: 0.00\n\nbmi:\n\tCoefficients: [ -10.01219782 -239.81908937 519.83978679 324.39042769 -792.18416163\n 476.74583782 101.04457032 177.06417623 751.27932109 67.62538639]\n\tIntercept: 152.1334841628965\n\tMean squared error: 3890.46\n\tCoefficient of determination: 0.34\n\nbp:\n\tCoefficients: [ -10.01219782 -239.81908937 519.83978679 324.39042769 -792.18416163\n 476.74583782 101.04457032 177.06417623 751.27932109 67.62538639]\n\tIntercept: 152.1334841628965\n\tMean squared error: 4774.10\n\tCoefficient of determination: 0.19\n\ns1:\n\tCoefficients: [ -10.01219782 -239.81908937 519.83978679 324.39042769 -792.18416163\n 476.74583782 101.04457032 177.06417623 751.27932109 67.62538639]\n\tIntercept: 152.1334841628965\n\tMean squared error: 5663.32\n\tCoefficient of determination: 0.04\n\ns2:\n\tCoefficients: [ -10.01219782 -239.81908937 519.83978679 324.39042769 -792.18416163\n 476.74583782 101.04457032 177.06417623 751.27932109 67.62538639]\n\tIntercept: 152.1334841628965\n\tMean squared error: 5750.24\n\tCoefficient of determination: 0.03\n\ns3:\n\tCoefficients: [ -10.01219782 -239.81908937 519.83978679 324.39042769 -792.18416163\n 476.74583782 101.04457032 177.06417623 751.27932109 67.62538639]\n\tIntercept: 152.1334841628965\n\tMean squared error: 5005.66\n\tCoefficient of determination: 0.16\n\ns4:\n\tCoefficients: [ -10.01219782 -239.81908937 519.83978679 324.39042769 -792.18416163\n 476.74583782 101.04457032 177.06417623 751.27932109 67.62538639]\n\tIntercept: 152.1334841628965\n\tMean squared error: 4831.14\n\tCoefficient of determination: 0.19\n\ns5:\n\tCoefficients: [ -10.01219782 -239.81908937 519.83978679 324.39042769 -792.18416163\n 476.74583782 101.04457032 177.06417623 751.27932109 67.62538639]\n\tIntercept: 152.1334841628965\n\tMean squared error: 4030.99\n\tCoefficient of determination: 0.32\n\ns6:\n\tCoefficients: [ -10.01219782 -239.81908937 519.83978679 324.39042769 -792.18416163\n 476.74583782 101.04457032 177.06417623 751.27932109 67.62538639]\n\tIntercept: 152.1334841628965\n\tMean squared error: 5062.38\n\tCoefficient of determination: 0.15\n\n"
]
],
[
[
"**Si tuvieras que escoger una sola _feauture_, ¿Cuál sería? ¿Por qué?**",
"_____no_output_____"
],
[
"Escogería el bmi pues es el que presenta menor error medio cuadrático y mayor coeficiente de determinación",
"_____no_output_____"
],
[
"Con la feature escogida haz el siguiente gráfico:\n\n- Scatter Plot\n- Eje X: Valores de la feature escogida.\n- Eje Y: Valores de la columna a predecir (target).\n- En color rojo dibuja la recta correspondiente a la regresión lineal (utilizando `intercept_`y `coefs_`).\n- Coloca un título adecuado, nombre de los ejes, etc.\n\nPuedes utilizar `matplotlib` o `altair`, el que prefiera.",
"_____no_output_____"
]
],
[
[
"def ajuste(x):\n return x*regr.coef_ + regr.intercept_\n\nx = diabetes_df[\"bmi\"].values[:, np.newaxis]\n\nregr=LinearRegression(fit_intercept=True)\nregr.fit(x,y)\n\nfig=plt.figure(figsize=(20, 12))\n\naj=plt.plot(x,ajuste(x),'r')\nsc=plt.scatter(x,y)\n\nplt.title('Ajuste lineal de la Progresión de la enfermedad en función del BMI')\nplt.ylabel('Progesión')\nplt.xlabel('BMI')\n\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
]
] |
cb32b4226bfe33c6551ef4d26a8465d0b12fe4a3 | 7,318 | ipynb | Jupyter Notebook | 1_generate_hangul_images.ipynb | hephaex/tensorflow-hangul-recognition | 8dd2bf6f0f1cacd44310b6515e24b54d136b805d | [
"Apache-2.0"
] | 3 | 2020-01-16T04:39:54.000Z | 2020-07-22T07:28:01.000Z | 1_generate_hangul_images.ipynb | hephaex/tensorflow-hangul-recognition | 8dd2bf6f0f1cacd44310b6515e24b54d136b805d | [
"Apache-2.0"
] | null | null | null | 1_generate_hangul_images.ipynb | hephaex/tensorflow-hangul-recognition | 8dd2bf6f0f1cacd44310b6515e24b54d136b805d | [
"Apache-2.0"
] | 2 | 2020-01-14T06:00:00.000Z | 2020-01-15T13:33:30.000Z | 33.263636 | 88 | 0.527193 | [
[
[
"import argparse\nimport glob\nimport io\nimport os\nimport random\n\nimport numpy\nfrom PIL import Image, ImageFont, ImageDraw\nfrom scipy.ndimage.interpolation import map_coordinates\nfrom scipy.ndimage.filters import gaussian_filter\n\nSCRIPT_PATH = os.path.dirname(os.path.abspath('./hangul-WR'))",
"_____no_output_____"
],
[
"# Default data paths.\nDEFAULT_LABEL_FILE = os.path.join(SCRIPT_PATH,\n './labels/2350-common-hangul.txt')\nDEFAULT_FONTS_DIR = os.path.join(SCRIPT_PATH, './fonts')\nDEFAULT_OUTPUT_DIR = os.path.join(SCRIPT_PATH, './image-data')\n\n# Number of random distortion images to generate per font and character.\nDISTORTION_COUNT = 3\n\n# Width and height of the resulting image.\nIMAGE_WIDTH = 64\nIMAGE_HEIGHT = 64",
"_____no_output_____"
],
[
"def generate_hangul_images(label_file, fonts_dir, output_dir):\n \"\"\"Generate Hangul image files.\n\n This will take in the passed in labels file and will generate several\n images using the font files provided in the font directory. The font\n directory is expected to be populated with *.ttf (True Type Font) files.\n The generated images will be stored in the given output directory. Image\n paths will have their corresponding labels listed in a CSV file.\n \"\"\"\n with io.open(label_file, 'r', encoding='utf-8') as f:\n labels = f.read().splitlines()\n\n image_dir = os.path.join(output_dir, 'hangul-images')\n if not os.path.exists(image_dir):\n os.makedirs(os.path.join(image_dir))\n\n # Get a list of the fonts.\n fonts = glob.glob(os.path.join(fonts_dir, '*.ttf'))\n\n labels_csv = io.open(os.path.join(output_dir, 'labels-map.csv'), 'w',\n encoding='utf-8')\n\n total_count = 0\n prev_count = 0\n for character in labels:\n # Print image count roughly every 5000 images.\n if total_count - prev_count > 5000:\n prev_count = total_count\n print('{} images generated...'.format(total_count))\n\n for font in fonts:\n total_count += 1\n image = Image.new('L', (IMAGE_WIDTH, IMAGE_HEIGHT), color=0)\n font = ImageFont.truetype(font, 48)\n drawing = ImageDraw.Draw(image)\n w, h = drawing.textsize(character, font=font)\n drawing.text(\n ((IMAGE_WIDTH-w)/2, (IMAGE_HEIGHT-h)/2),\n character,\n fill=(255),\n font=font\n )\n file_string = 'hangul_{}.jpeg'.format(total_count)\n file_path = os.path.join(image_dir, file_string)\n image.save(file_path, 'JPEG')\n labels_csv.write(u'{},{}\\n'.format(file_path, character))\n\n for i in range(DISTORTION_COUNT):\n total_count += 1\n file_string = 'hangul_{}.jpeg'.format(total_count)\n file_path = os.path.join(image_dir, file_string)\n arr = numpy.array(image)\n\n distorted_array = elastic_distort(\n arr, alpha=random.randint(30, 36),\n sigma=random.randint(5, 6)\n )\n distorted_image = Image.fromarray(distorted_array)\n distorted_image.save(file_path, 'JPEG')\n labels_csv.write(u'{},{}\\n'.format(file_path, character))\n\n print('Finished generating {} images.'.format(total_count))\n labels_csv.close()",
"_____no_output_____"
],
[
"def elastic_distort(image, alpha, sigma):\n \"\"\"Perform elastic distortion on an image.\n\n Here, alpha refers to the scaling factor that controls the intensity of the\n deformation. The sigma variable refers to the Gaussian filter standard\n deviation.\n \"\"\"\n random_state = numpy.random.RandomState(None)\n shape = image.shape\n\n dx = gaussian_filter(\n (random_state.rand(*shape) * 2 - 1),\n sigma, mode=\"constant\"\n ) * alpha\n dy = gaussian_filter(\n (random_state.rand(*shape) * 2 - 1),\n sigma, mode=\"constant\"\n ) * alpha\n\n x, y = numpy.meshgrid(numpy.arange(shape[0]), numpy.arange(shape[1]))\n indices = numpy.reshape(y+dy, (-1, 1)), numpy.reshape(x+dx, (-1, 1))\n return map_coordinates(image, indices, order=1).reshape(shape)",
"_____no_output_____"
],
[
"# label_file = './labels/2350-common-hangul.txt'\nlabel_file = DEFAULT_LABEL_FILE\n\n# fonts_dir = './fonts'\nfonts_dir = DEFAULT_FONTS_DIR\n\n# output_dir = './image-data'\noutput_dir = DEFAULT_OUTPUT_DIR",
"_____no_output_____"
],
[
"generate_hangul_images(label_file, fonts_dir, output_dir)",
"5012 images generated...\n10024 images generated...\n15036 images generated...\n20048 images generated...\n25060 images generated...\n30072 images generated...\n35084 images generated...\n40096 images generated...\n45108 images generated...\n50120 images generated...\n55132 images generated...\n60144 images generated...\n65156 images generated...\nFinished generating 65800 images.\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb32b72485d2ede4388506750f65788790894028 | 107,046 | ipynb | Jupyter Notebook | PosTagging and NER.ipynb | laraolmos/tfm-nlp-qa | a88f88b1477c6e2347dfc1050fc82d7fdb73131c | [
"MIT"
] | null | null | null | PosTagging and NER.ipynb | laraolmos/tfm-nlp-qa | a88f88b1477c6e2347dfc1050fc82d7fdb73131c | [
"MIT"
] | null | null | null | PosTagging and NER.ipynb | laraolmos/tfm-nlp-qa | a88f88b1477c6e2347dfc1050fc82d7fdb73131c | [
"MIT"
] | null | null | null | 49.44388 | 1,092 | 0.531669 | [
[
[
"# PosTagging and Named Entity Recognition (NER)",
"_____no_output_____"
],
[
"We consider some texts from QA SQuAD collection to annotate for its characterization with PosTagging and Named Entity Reconigtion (NER) open source frameworks: treetagger, Stanford CoreNLP, spacy, stanza",
"_____no_output_____"
],
[
"### Example texts",
"_____no_output_____"
]
],
[
[
"question_example = 'When was the Tower Theatre built?'\nresponse_example = '1939'\ncontext_example = 'The popular neighborhood known as the Tower District is centered around the historic Tower Theatre, which is included on the National List of Historic Places. The theater was built in 1939 and is at Olive and Wishon Avenues in the heart of the Tower District. (The name of the theater refers to a well-known landmark water tower, which is actually in another nearby area). The Tower District neighborhood is just north of downtown Fresno proper, and one-half mile south of Fresno City College. Although the neighborhood was known as a residential area prior, the early commercial establishments of the Tower District began with small shops and services that flocked to the area shortly after World War II. The character of small local businesses largely remains today. To some extent, the businesses of the Tower District were developed due to the proximity of the original Fresno Normal School, (later renamed California State University at Fresno). In 1916 the college moved to what is now the site of Fresno City College one-half mile north of the Tower District.'",
"_____no_output_____"
],
[
"amazon_context_example= \"The Amazon rainforest (Portuguese: Floresta Amazônica or Amazônia; Spanish: Selva Amazónica, Amazonía or usually Amazonia; French: Forêt amazonienne; Dutch: Amazoneregenwoud), also known in English as Amazonia or the Amazon Jungle, is a moist broadleaf forest that covers most of the Amazon basin of South America. This basin encompasses 7,000,000 square kilometres (2,700,000 sq mi), of which 5,500,000 square kilometres (2,100,000 sq mi) are covered by the rainforest. This region includes territory belonging to nine nations. The majority of the forest is contained within Brazil, with 60% of the rainforest, followed by Peru with 13%, Colombia with 10%, and with minor amounts in Venezuela, Ecuador, Bolivia, Guyana, Suriname and French Guiana. States or departments in four nations contain 'Amazonas' in their names. The Amazon represents over half of the planet's remaining rainforests, and comprises the largest and most biodiverse tract of tropical rainforest in the world, with an estimated 390 billion individual trees divided into 16,000 species.\"",
"_____no_output_____"
],
[
"beyonce_context= 'In August, the couple attended the 2011 MTV Video Music Awards, at which Beyoncé performed \"Love on Top\" and started the performance saying \"Tonight I want you to stand up on your feet, I want you to feel the love that\\'s growing inside of me\". At the end of the performance, she dropped her microphone, unbuttoned her blazer and rubbed her stomach, confirming her pregnancy she had alluded to earlier in the evening. Her appearance helped that year\\'s MTV Video Music Awards become the most-watched broadcast in MTV history, pulling in 12.4 million viewers; the announcement was listed in Guinness World Records for \"most tweets per second recorded for a single event\" on Twitter, receiving 8,868 tweets per second and \"Beyonce pregnant\" was the most Googled term the week of August 29, 2011.'",
"_____no_output_____"
]
],
[
[
"### PosTagging",
"_____no_output_____"
],
[
"#### TreeTagger",
"_____no_output_____"
]
],
[
[
"# https://www.cis.uni-muenchen.de/~schmid/tools/TreeTagger/\nimport treetaggerwrapper",
"c:\\users\\larao_000\\appdata\\local\\programs\\python\\python37\\lib\\site-packages\\treetaggerwrapper.py:740: FutureWarning: Possible nested set at position 8\n re.IGNORECASE | re.VERBOSE)\nc:\\users\\larao_000\\appdata\\local\\programs\\python\\python37\\lib\\site-packages\\treetaggerwrapper.py:2044: FutureWarning: Possible nested set at position 152\n re.VERBOSE | re.IGNORECASE)\nc:\\users\\larao_000\\appdata\\local\\programs\\python\\python37\\lib\\site-packages\\treetaggerwrapper.py:2067: FutureWarning: Possible nested set at position 409\n UrlMatch_re = re.compile(UrlMatch_expression, re.VERBOSE | re.IGNORECASE)\nc:\\users\\larao_000\\appdata\\local\\programs\\python\\python37\\lib\\site-packages\\treetaggerwrapper.py:2079: FutureWarning: Possible nested set at position 192\n EmailMatch_re = re.compile(EmailMatch_expression, re.VERBOSE | re.IGNORECASE)\n"
],
[
"tagger = treetaggerwrapper.TreeTagger(TAGLANG='en', TAGDIR='C:\\\\Users\\\\larao_000\\\\Documents\\\\nlp\\\\tree-tagger-windows-3.2.3\\\\TreeTagger\\\\')",
"_____no_output_____"
],
[
"def pos_tagging(text, max_length=1000):\n results = []\n for i in range(0, len(text), max_length):\n partial_text = text[i:i+max_length]\n tags = tagger.tag_text(partial_text)\n results += treetaggerwrapper.make_tags(tags)\n return results",
"_____no_output_____"
],
[
"%%time\npos_tagging(question_example)",
"Wall time: 575 ms\n"
],
[
"%%time\npos_tagging(response_example)",
"Wall time: 2 ms\n"
],
[
"print(pos_tagging('Which name is also used to describe the Amazon rainforest in English?'))\nprint(pos_tagging('also known in English as Amazonia or the Amazon Jungle,'))",
"[Tag(word='Which', pos='WDT', lemma='which'), Tag(word='name', pos='NN', lemma='name'), Tag(word='is', pos='VBZ', lemma='be'), Tag(word='also', pos='RB', lemma='also'), Tag(word='used', pos='VVN', lemma='use'), Tag(word='to', pos='TO', lemma='to'), Tag(word='describe', pos='VV', lemma='describe'), Tag(word='the', pos='DT', lemma='the'), Tag(word='Amazon', pos='NP', lemma='Amazon'), Tag(word='rainforest', pos='NN', lemma='rainforest'), Tag(word='in', pos='IN', lemma='in'), Tag(word='English', pos='NP', lemma='English'), Tag(word='?', pos='SENT', lemma='?')]\n[Tag(word='also', pos='RB', lemma='also'), Tag(word='known', pos='VVN', lemma='know'), Tag(word='in', pos='IN', lemma='in'), Tag(word='English', pos='NP', lemma='English'), Tag(word='as', pos='IN', lemma='as'), Tag(word='Amazonia', pos='NP', lemma='Amazonia'), Tag(word='or', pos='CC', lemma='or'), Tag(word='the', pos='DT', lemma='the'), Tag(word='Amazon', pos='NP', lemma='Amazon'), Tag(word='Jungle', pos='NN', lemma='jungle'), Tag(word=',', pos=',', lemma=',')]\n"
],
[
"print(pos_tagging('Jay Z and Beyonce attended which event together in August of 2011?'))\nprint(pos_tagging('MTV Video Music Awards'))",
"[Tag(word='Jay', pos='NP', lemma='Jay'), Tag(word='Z', pos='NP', lemma='Z'), Tag(word='and', pos='CC', lemma='and'), Tag(word='Beyonce', pos='NP', lemma='Beyonce'), Tag(word='attended', pos='VVN', lemma='attend'), Tag(word='which', pos='WDT', lemma='which'), Tag(word='event', pos='NN', lemma='event'), Tag(word='together', pos='RB', lemma='together'), Tag(word='in', pos='IN', lemma='in'), Tag(word='August', pos='NP', lemma='August'), Tag(word='of', pos='IN', lemma='of'), Tag(word='2011', pos='CD', lemma='@card@'), Tag(word='?', pos='SENT', lemma='?')]\n[Tag(word='MTV', pos='NP', lemma='MTV'), Tag(word='Video', pos='NP', lemma='Video'), Tag(word='Music', pos='NP', lemma='Music'), Tag(word='Awards', pos='VVZ', lemma='award')]\n"
],
[
"%%time\npos_tagging(context_example)",
"Wall time: 17 ms\n"
]
],
[
[
"#### Spacy",
"_____no_output_____"
]
],
[
[
"import spacy\nnlp_spacy = spacy.load(\"en_core_web_sm\")",
"_____no_output_____"
],
[
"def pos_tagging_spacy(nlp, text):\n postags = []\n doc = nlp(text)\n for token in doc:\n postags.append((token.text, token.lemma_, token.pos_, token.tag_, token.dep_,\n token.shape_, token.is_alpha, token.is_stop))\n return postags",
"_____no_output_____"
],
[
"%%time\npos_tagging_spacy(nlp_spacy, question_example)",
"Wall time: 31.3 ms\n"
],
[
"%%time\npos_tagging_spacy(nlp_spacy, response_example)",
"Wall time: 8.01 ms\n"
],
[
"%%time\npos_tagging_spacy(nlp_spacy, context_example)",
"Wall time: 88.3 ms\n"
]
],
[
[
"#### Stanza",
"_____no_output_____"
]
],
[
[
"#!pip install stanza\nimport stanza\n#stanza.download('en')",
"_____no_output_____"
],
[
"nlp = stanza.Pipeline('en')",
"2021-06-20 15:57:26 INFO: Loading these models for language: en (English):\n=========================\n| Processor | Package |\n-------------------------\n| tokenize | combined |\n| pos | combined |\n| lemma | combined |\n| depparse | combined |\n| sentiment | sstplus |\n| ner | ontonotes |\n=========================\n\n2021-06-20 15:57:26 INFO: Use device: cpu\n2021-06-20 15:57:26 INFO: Loading: tokenize\n2021-06-20 15:57:26 INFO: Loading: pos\n2021-06-20 15:57:27 INFO: Loading: lemma\n2021-06-20 15:57:27 INFO: Loading: depparse\n2021-06-20 15:57:27 INFO: Loading: sentiment\n2021-06-20 15:57:28 INFO: Loading: ner\n2021-06-20 15:57:29 INFO: Done loading processors!\n"
],
[
"def pos_tagging_stanza(nlp, text):\n postags = []\n doc = nlp(text)\n for sent in doc.sentences:\n for token in sent.words:\n postags.append((token.text, token.upos, token.xpos, token.feats))\n return postags",
"_____no_output_____"
],
[
"%%time\npos_tagging_stanza(nlp, question_example)",
"Wall time: 245 ms\n"
],
[
"%%time\npos_tagging_stanza(nlp, response_example)",
"Wall time: 84.1 ms\n"
],
[
"%%time\npos_tagging_stanza(nlp, context_example)",
"Wall time: 3.05 s\n"
],
[
"def ner_stanza(nlp, text):\n nertags = []\n doc = nlp(text)\n for token in doc.ents:\n nertags.append((token.text, token.type))\n return nertags",
"_____no_output_____"
],
[
"print(ner_stanza(nlp, 'Which name is also used to describe the Amazon rainforest in English?'))\nprint(ner_stanza(nlp, 'also known in English as Amazonia or the Amazon Jungle,'))",
"[('Amazon', 'LOC'), ('English', 'LANGUAGE')]\n[('English', 'LANGUAGE'), ('Amazonia', 'LOC'), ('the Amazon Jungle', 'LOC')]\n"
],
[
"print(ner_stanza(nlp, 'Jay Z and Beyonce attended which event together in August of 2011?'))\nprint(ner_stanza(nlp, 'MTV Video Music Awards'))",
"[('Jay Z', 'PERSON'), ('Beyonce', 'PERSON'), ('August of 2011', 'DATE')]\n[('MTV Video Music Awards', 'ORG')]\n"
],
[
"print(ner_stanza(nlp, question_example))\nprint(ner_stanza(nlp, response_example))",
"[('the Tower Theatre', 'FAC')]\n[('1939', 'DATE')]\n"
],
[
"print(ner_stanza(nlp, context_example))",
"[('the Tower District', 'LOC'), ('Tower Theatre', 'FAC'), ('the National List of Historic Places', 'ORG'), ('1939', 'DATE'), ('Olive and Wishon Avenues', 'FAC'), ('the Tower District', 'LOC'), ('Tower District', 'LOC'), ('Fresno', 'GPE'), ('one-half mile', 'QUANTITY'), ('Fresno City College', 'FAC'), ('the Tower District', 'LOC'), ('World War II', 'EVENT'), ('today', 'DATE'), ('the Tower District', 'LOC'), ('Fresno Normal School', 'ORG'), ('California State University', 'ORG'), ('Fresno', 'GPE'), ('1916', 'DATE'), ('Fresno City College', 'ORG'), ('one-half mile', 'QUANTITY'), ('the Tower District', 'LOC')]\n"
],
[
"print(ner_stanza(nlp, amazon_context_example))",
"[('Amazon', 'LOC'), ('Portuguese', 'NORP'), ('Amazônia', 'GPE'), ('Selva Amazónica', 'LOC'), ('Amazonía', 'LOC'), ('Amazonia', 'LOC'), ('French', 'NORP'), ('Dutch', 'NORP'), ('English', 'LANGUAGE'), ('Amazonia', 'LOC'), ('the Amazon Jungle', 'LOC'), ('Amazon', 'LOC'), ('South America', 'LOC'), ('7,000,000 square kilometres', 'QUANTITY'), ('2,700,000 sq mi', 'QUANTITY'), ('5,500,000 square kilometres', 'QUANTITY'), ('2,100,000 sq mi', 'QUANTITY'), ('nine', 'CARDINAL'), ('Brazil', 'GPE'), ('60%', 'PERCENT'), ('Peru', 'GPE'), ('13%', 'PERCENT'), ('Colombia', 'GPE'), ('10%', 'PERCENT'), ('Venezuela', 'GPE'), ('Ecuador', 'GPE'), ('Bolivia', 'GPE'), ('Guyana', 'GPE'), ('Suriname', 'GPE'), ('French Guiana', 'GPE'), ('four', 'CARDINAL'), ('Amazonas', 'ORG'), ('Amazon', 'ORG'), ('over half', 'CARDINAL'), ('390 billion', 'CARDINAL'), ('16,000', 'CARDINAL')]\n"
],
[
"print(ner_stanza(nlp, beyonce_context))",
"[('August', 'DATE'), ('2011', 'DATE'), ('MTV Video Music Awards', 'EVENT'), ('Beyoncé', 'PERSON'), ('\"Love on Top\"', 'WORK_OF_ART'), ('Tonight', 'TIME'), ('earlier in the evening', 'TIME'), ('year', 'DATE'), ('MTV Video Music Awards', 'WORK_OF_ART'), ('MTV', 'ORG'), ('12.4 million', 'CARDINAL'), ('Guinness World Records', 'WORK_OF_ART'), ('second', 'ORDINAL'), ('Twitter', 'ORG'), ('8,868', 'CARDINAL'), ('\"Beyonce pregnant\"', 'WORK_OF_ART'), ('the week of August 29, 2011', 'DATE')]\n"
],
[
"print(ner_stanza(nlp, 'This poster of Madrid costs 3 euros during 3 hours with 5% of discount to first buyers'))",
"[('Madrid', 'GPE'), ('3 euros', 'MONEY'), ('3 hours', 'TIME'), ('5%', 'PERCENT'), ('first', 'ORDINAL')]\n"
]
],
[
[
"### Stanford Core NLP NER",
"_____no_output_____"
]
],
[
[
"#from stanfordnlp.server import CoreNLPClient\nfrom stanfordcorenlp import StanfordCoreNLP",
"_____no_output_____"
],
[
"import re\ndef preprocess_text(text_str):\n regular_expr = re.compile('\\n|\\r|\\t|\\(|\\)|\\[|\\]|:|\\,|\\;|\"|\\?|\\-|\\%')\n text_str = re.sub(regular_expr, ' ', text_str)\n token_list = text_str.split(' ')\n token_list = [element for element in token_list if element]\n return ' '.join(token_list)",
"_____no_output_____"
],
[
"def filter_ner_relevant(tuple_list):\n ner_dictionary = {}\n previous_ner = 'O'\n for element in tuple_list:\n if element[1] != 'O':\n if element[1] == previous_ner:\n ner_dictionary[element[1]][-1] += ' ' + element[0]\n elif element[1] in ner_dictionary.keys():\n ner_dictionary[element[1]].append(element[0])\n else:\n ner_dictionary[element[1]] = [element[0]] \n previous_ner = element[1]\n return ner_dictionary",
"_____no_output_____"
]
],
[
[
"Start server with command: java -mx4g -cp \"*\" edu.stanford.nlp.pipeline.StanfordCoreNLPServer -annotators \"tokenize,ssplit\n,pos,lemma,parse,ner,sentiment\" -port 9000 -timeout 30000",
"_____no_output_____"
]
],
[
[
"# https://www.khalidalnajjar.com/setup-use-stanford-corenlp-server-python/\n# https://stanfordnlp.github.io/CoreNLP/index.html#download\n# https://stanfordnlp.github.io/stanfordnlp/corenlp_client.html\nnlp = StanfordCoreNLP('http://localhost', port=9000, timeout=30000)",
"_____no_output_____"
],
[
"#filter_ner_relevant(nlp.ner(preprocess_text(question_example)))\nnlp.ner(preprocess_text(question_example))",
"_____no_output_____"
],
[
"filter_ner_relevant(nlp.ner(preprocess_text(response_example)))",
"_____no_output_____"
],
[
"#filter_ner_relevant(nlp.ner(preprocess_text(context_example)))",
"_____no_output_____"
],
[
"print(filter_ner_relevant(nlp.ner(preprocess_text('Which name is also used to describe the Amazon rainforest in English?'))))\nprint(filter_ner_relevant(nlp.ner(preprocess_text('also known in English as Amazonia or the Amazon Jungle,'))))",
"{'LOCATION': ['Amazon'], 'NATIONALITY': ['English']}\n{'NATIONALITY': ['English'], 'LOCATION': ['Amazonia', 'Amazon Jungle']}\n"
],
[
"filter_ner_relevant(nlp.ner(preprocess_text(amazon_context_example)))",
"_____no_output_____"
],
[
"print(filter_ner_relevant(nlp.ner(preprocess_text('Jay Z and Beyonce attended which event together in August of 2011?'))))\nprint(filter_ner_relevant(nlp.ner(preprocess_text('MTV Video Music Awards'))))",
"{'PERSON': ['Jay Z', 'Beyonce'], 'DATE': ['August of 2011']}\n{'ORGANIZATION': ['MTV']}\n"
],
[
"filter_ner_relevant(nlp.ner(preprocess_text(beyonce_context)))",
"_____no_output_____"
],
[
"#example_tosend = preprocess_text(example)\n#result = nlp.ner(example_tosend)",
"_____no_output_____"
],
[
"#print(result)",
"_____no_output_____"
],
[
"#filter_ner_relevant(result)",
"_____no_output_____"
]
],
[
[
"## Spacy NER",
"_____no_output_____"
]
],
[
[
"import spacy\nnlp_spacy = spacy.load(\"en_core_web_sm\")",
"_____no_output_____"
],
[
"spacy.explain('FAC')",
"_____no_output_____"
],
[
"spacy.displacy.render(nlp_spacy(context_example), style='ent', jupyter=True)",
"_____no_output_____"
],
[
"spacy.displacy.render(nlp_spacy(amazon_context_example), style='ent', jupyter=True)",
"_____no_output_____"
],
[
"spacy.displacy.render(nlp_spacy(beyonce_context), style='ent', jupyter=True)",
"_____no_output_____"
],
[
"# https://spacy.io/api/annotation#named-entities\n# https://spacy.io/usage/linguistic-features#named-entities\n# 'PERSON', 'NORP', 'FAC', 'ORG', 'GPE', 'LOC', 'PRODUCT', 'EVENT', 'WORK_OF_ART', \n# 'LAW', 'LANGUAGE', 'DATE', 'TIME', 'PERCENT', 'MONEY', 'QUANTITY', 'ORDINAL', 'CARDINAL'\ndef detect_entities(nlp, text, ner_tag):\n entities = []\n doc = nlp(text)\n for ent in doc.ents:\n if ent.label_ in ner_tag:\n entities.append(ent.text)\n return entities",
"_____no_output_____"
],
[
"result = detect_entities(nlp_spacy, context_example, ['PERSON', 'NORP', 'FAC', 'ORG', 'GPE', 'LOC', 'PRODUCT', 'EVENT', 'WORK_OF_ART', 'LAW', 'LANGUAGE', 'DATE', 'TIME', 'PERCENT', 'MONEY', 'QUANTITY', 'ORDINAL', 'CARDINAL'])\nprint(context_example)\nprint(result)",
"The popular neighborhood known as the Tower District is centered around the historic Tower Theatre, which is included on the National List of Historic Places. The theater was built in 1939 and is at Olive and Wishon Avenues in the heart of the Tower District. (The name of the theater refers to a well-known landmark water tower, which is actually in another nearby area). The Tower District neighborhood is just north of downtown Fresno proper, and one-half mile south of Fresno City College. Although the neighborhood was known as a residential area prior, the early commercial establishments of the Tower District began with small shops and services that flocked to the area shortly after World War II. The character of small local businesses largely remains today. To some extent, the businesses of the Tower District were developed due to the proximity of the original Fresno Normal School, (later renamed California State University at Fresno). In 1916 the college moved to what is now the site of Fresno City College one-half mile north of the Tower District.\n['the Tower District', 'Tower Theatre', 'the National List of Historic Places', '1939', 'the Tower District', 'The Tower District', 'Fresno', 'one-half mile', 'Fresno City College', 'the Tower District', 'World War II', 'today', 'the Tower District', 'Fresno Normal School', 'California State University at Fresno', '1916', 'Fresno City College', 'one-half mile', 'the Tower District']\n"
],
[
"people_entities = detect_entities(nlp_spacy, context_example, 'PERSON')\nprint('PERSON: ' + str(people_entities))\nnorp_entities = detect_entities(nlp_spacy, context_example, 'NORP')\nprint('NORP: ' + str(norp_entities))\nfac_entities = detect_entities(nlp_spacy, context_example, 'FAC')\nprint('FAC: ' + str(fac_entities))\norg_entities = detect_entities(nlp_spacy, context_example, 'ORG')\nprint('ORG: ' + str(org_entities))\ngpe_entities = detect_entities(nlp_spacy, context_example, 'GPE')\nprint('GPE: ' + str(gpe_entities))\nloc_entities = detect_entities(nlp_spacy, context_example, 'LOC')\nprint('LOC: ' + str(loc_entities))\nproduct_entities = detect_entities(nlp_spacy, context_example, 'PRODUCT')\nprint('PRODUCT: ' + str(product_entities))\nevent_entities = detect_entities(nlp_spacy, context_example, 'EVENT')\nprint('EVENT: ' + str(event_entities))\nworkofart_entities = detect_entities(nlp_spacy, context_example, 'WORK_OF_ART')\nprint('WORK_OF_ART: ' + str(workofart_entities))\nlang_entities = detect_entities(nlp_spacy, context_example, 'LANGUAGE')\nprint('LANGUAGE: ' + str(lang_entities))\ndate_entities = detect_entities(nlp_spacy, context_example, 'DATE')\nprint('DATE: ' + str(date_entities))\ntime_entities = detect_entities(nlp_spacy, context_example, 'TIME')\nprint('TIME: ' + str(time_entities))\npercent_entities = detect_entities(nlp_spacy, context_example, 'PERCENT')\nprint('PERCENT: ' + str(percent_entities))\nmoney_entities = detect_entities(nlp_spacy, context_example, 'MONEY')\nprint('MONEY: ' + str(money_entities))\nquantity_entities = detect_entities(nlp_spacy, context_example, 'QUANTITY')\nprint('QUANTITY: ' + str(quantity_entities))\ncardinal_entities = detect_entities(nlp_spacy, context_example, 'CARDINAL')\nprint('CARDINAL: ' + str(cardinal_entities))\nordinal_entities = detect_entities(nlp_spacy, context_example, 'ORDINAL')\nprint('ORDINAL: ' + str(ordinal_entities))",
"PERSON: []\nNORP: []\nFAC: ['Tower Theatre', 'the Tower District', 'The Tower District']\nORG: ['the National List of Historic Places', 'Fresno City College', 'Fresno Normal School', 'California State University at Fresno', 'Fresno City College']\nGPE: []\nLOC: ['the Tower District', 'the Tower District', 'the Tower District', 'the Tower District']\nPRODUCT: []\nEVENT: ['Fresno', 'World War II']\nWORK_OF_ART: []\nLANGUAGE: []\nDATE: ['1939', 'today', '1916']\nTIME: []\nPERCENT: []\nMONEY: []\nQUANTITY: ['one-half mile', 'one-half mile']\nCARDINAL: []\nORDINAL: []\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb32bc3adcbd8f2224af82f19f3a7cfe064cdf0f | 56,778 | ipynb | Jupyter Notebook | parser.ipynb | gaabgonca/pseudocode_parser | b8c75856ca6fe2d213a681c966ba2f7a1f9f8524 | [
"Apache-2.0"
] | null | null | null | parser.ipynb | gaabgonca/pseudocode_parser | b8c75856ca6fe2d213a681c966ba2f7a1f9f8524 | [
"Apache-2.0"
] | null | null | null | parser.ipynb | gaabgonca/pseudocode_parser | b8c75856ca6fe2d213a681c966ba2f7a1f9f8524 | [
"Apache-2.0"
] | null | null | null | 62.877076 | 5,969 | 0.375339 | [
[
[
"import sympy as sp\nfrom sympy.parsing.sympy_parser import parse_expr\nimport pandas as pd",
"_____no_output_____"
],
[
"def get_lines(filename):\n file = open(filename, 'r+')\n lines = file.readlines()\n #\n lines = map(lambda line : line[:-1],lines)\n file.close()\n return lines",
"_____no_output_____"
],
[
"lines = get_lines('./tests/ejercicio1.txt')",
"_____no_output_____"
],
[
"syntax = pd.DataFrame(data=lines, columns=['line'])\nsyntax.head()",
"_____no_output_____"
],
[
"syntax[\"length\"] = syntax[\"line\"].map(lambda line: len(line))\nsyntax.head()",
"_____no_output_____"
],
[
"def get_type(line):\n #If not line.lower().find('x') returns true if x starts at line[0] \n if not line.lower().find('inicio'):\n return \"inicio\"\n if not line.lower().find('pare'):\n return \"pare\"\n if not line.lower().find('para'):\n return \"para\"\n if not line.lower().find('lea'):\n return \"lea\"\n if not line.lower().find('esc'):\n return \"esc\"\n if not line.lower().find('fpara'):\n return \"fpara\"\n if not line.lower().find('sino'):\n return \"sino\"\n if not line.lower().find('si'):\n return \"si\"\n if not line.lower().find('fsi'):\n return \"fsi\"\n if line.lower().find('='):\n return \"assignment\"\n return \"Indefinite so far\"\n\nsyntax[\"type\"] = syntax[\"line\"].map(get_type)\nsyntax.head(len(syntax))",
"_____no_output_____"
],
[
"def process_for(line):\n raw_data = line[line.index('=')+1:]\n split_data = raw_data.split(',')\n print(split_data)\n lower_bound = parse_expr(split_data[0])\n upper_bound = parse_expr(split_data[1])\n increment = parse_expr(split_data[2])\n return {\n 'lower_b' : lower_bound,\n 'upper_b' : upper_bound,\n 'inc' : increment\n }",
"_____no_output_____"
],
[
"test_for_line = 'Para i=100,a+b,-10'\nprocess_for(test_for_line)",
"['100', 'a+b', '-10']\n"
],
[
"def process_if(line):\n comparisons = [pos for pos, char in enumerate(line) if char == '(']\n return {\n 'comparisons' : len(comparisons)\n }",
"_____no_output_____"
],
[
"\ndef new_get_statement_runtime(syntax):\n lines_dict_list = lines = syntax.to_dict('records')\n order = 0\n for index in range(len(lines_dict_list)):\n line = lines[index]\n # print(line['type'])\n line_type = line['type']\n if line_type in ('inicio','pare','sino'):\n #order does not change\n line['runtime'] = 0\n # line['data'] = 'Control statement'\n line['order'] = order\n elif line_type in (\"assignment\",'lea','esc'):\n line['runtime'] = 1\n # line['data'] = 'Assignment i/o'\n line['order'] = order\n elif line_type in ('fsi','fpara'):\n order -= 1\n line['runtime'] = 0\n # line['data'] = 'End of block'\n line['order'] = order\n \n elif line_type is 'para':\n line['runtime'] = 'Nan'\n line['data'] = process_for(line['line'])\n line['order'] = order\n order += 1\n elif line_type is 'si':\n line['runtime'] = 'Nan' #Number of comparisons + instructions inside\n line['data'] = process_if(line['line'])\n line['order'] = order\n order +=1\n # print(f'Line : {line}')\n\n \n return pd.DataFrame.from_dict(lines)\n \n\n \n\n\n\n",
"_____no_output_____"
],
[
"new_syntax = new_get_statement_runtime(syntax)\nnew_syntax.head(len(new_syntax))",
"['1', 'n', '+1']\n['1', 'n', '+1']\n['1', 'n', '+1']\n['1', 'n', '+1']\n['1', 'n', '+1']\n['1', 'n', '+1']\n['1', 'n', '+1']\n"
],
[
"new_line = 'Si (i==j) y (j==1)'\nprocess_if(new_line)",
"_____no_output_____"
],
[
"def get_if_block_runtime(block_lines):\n runtime = 0\n for line in block_lines:\n runtime += line['runtime']\n return runtime",
"_____no_output_____"
],
[
"def get_if_blocks_runtime(syntax):\n lines_dict_list = lines = syntax.to_dict('records')\n if_indices = [pos for pos, line in enumerate(lines) if line['type'] is 'si']\n else_indices = [pos for pos, line in enumerate(lines) if line['type'] is 'sino']\n end_if_indices = [pos for pos, line in enumerate(lines) if line['type'] is 'fsi']\n # done = False\n\n #Let's begin by processing the ifs statements\n if_statements = []\n for x, if_index in enumerate(if_indices):\n #Find closing endif\n end_if_index = end_if_indices[x]\n #Is there an else?\n else_index = False\n for line_index in range(if_index,end_if_index):\n if line_index in else_indices:\n else_index = line_index\n break\n # print((if_index,else_index,end_if_index))\n comparisons = lines[if_index]['data']['comparisons']\n if_runtime = comparisons\n if else_index:\n block_a = lines[if_index+1:else_index]\n block_b = lines[else_index+1: end_if_index]\n bloc_a_runtime = get_if_block_runtime(block_a)\n bloc_b_runtime = get_if_block_runtime(block_b)\n if_runtime += max(bloc_a_runtime,bloc_b_runtime)\n else:\n block = lines[if_index+1:end_if_index]\n bloc_runtime = get_if_block_runtime(block)\n if_runtime += bloc_runtime\n print((if_index,else_index,end_if_index,if_runtime))\n lines[if_index]['runtime'] = if_runtime\n return pd.DataFrame.from_dict(lines)\n\n\n \n\n # print('para',for_indices)\n # print('fpara',end_for_indices)\n # print('si',if_indices)\n # print('sino',else_indices)\n # print('fsi',end_if_indices)\n\n",
"_____no_output_____"
],
[
"syntax_with_ifs = get_if_blocks_runtime(new_syntax)\nsyntax_with_ifs.head(len(syntax_with_ifs))",
"(19, False, 21, 2)\n(24, 27, 29, 3)\n"
],
[
"# orders = []\n# for line in lines:\n# orders.append(line['order'])\n# max_order = max(orders)\n# if max_order is 3:\n#There exists at least a combination of two nested loops with an if\n# for_indices = [pos for pos, line in enumerate(lines) if line['type'] is 'para']\n# end_for_indices = [pos for pos, line in enumerate(lines) if line['type'] is 'fpara']",
"_____no_output_____"
],
[
"def for_runtime_formula(for_data,content_runtime):\n lower_bound = for_data['lower_b']\n upper_bound = for_data['upper_b']\n try:\n lower_bound = int(lower_bound)\n except TypeError:\n lower_bound = lower_bound\n try: \n upper_bound = int(upper_bound)\n except TypeError:\n upper_bound = upper_bound\n\n increment = parse_expr(str(for_data['inc']))\n ceil = sp.Function('ceil')\n iterations = (ceil((upper_bound-lower_bound+1)/increment)*(content_runtime +2)) + 2\n return iterations ",
"_____no_output_____"
],
[
"int(parse_expr('8'))",
"_____no_output_____"
],
[
"lower_bound = parse_expr('n-1')\nupper_bound = parse_expr('8')\ntry:\n lb = int(lower_bound)\nexcept TypeError:\n lb = lower_bound\nlb + 2\n\n",
"_____no_output_____"
],
[
"def get_for_blocks_runtime(syntax):\n lines_dict_list = lines = syntax.to_dict('records')\n for_indices = [pos for pos, line in enumerate(lines) if line['type'] is 'para']\n print('for_indices',for_indices)\n endfor_indices = [pos for pos,line in enumerate(lines) if line['type'] is 'fpara']\n print('endfor_indices',endfor_indices)\n #get for blocks and their orders\n block_orders = []\n for x ,for_index in enumerate(for_indices):\n if x < len(for_indices) -1 :\n next_end_for = endfor_indices[x]\n next_for = for_indices[x+1]\n if next_for < next_end_for:\n block_orders.append((for_index,0))\n else:\n block_orders.append((for_index,1))\n else:\n block_orders.append((for_index,1))\n # print(block_orders)\n\n #get inner for runtime\n for for_index in [bloc_order[0] for bloc_order in block_orders if bloc_order[1] is 1]:\n # print(for_index)\n for end_for in endfor_indices:\n if end_for > for_index:\n break\n for_order = lines[for_index]['order']\n instruction_order = for_order + 1\n inner_instructions = lines[for_index+1:end_for]\n content_runtime = 0 #placeholder\n for line in inner_instructions:\n if(line['order'] is instruction_order):\n content_runtime+= line['runtime']\n for_runtime = for_runtime_formula(lines[for_index]['data'],content_runtime)\n lines[for_index]['runtime'] = for_runtime\n \n\n #get outer for runtimes\n for for_index in [bloc_order[0] for bloc_order in block_orders if bloc_order[1] is 0]:\n for x, end_for in enumerate(endfor_indices):\n if lines[end_for]['order'] == lines[for_index]['order'] and end_for >for_index:\n break\n for_order = lines[for_index]['order']\n instruction_order = for_order + 1\n inner_instructions = lines[for_index+1:end_for]\n content_runtime = \"\" #placeholder\n for line in inner_instructions:\n if(line['order'] is instruction_order):\n content_runtime += '+'+str(line['runtime'])\n for_runtime =for_runtime_formula(lines[for_index]['data'],parse_expr(str(content_runtime)))\n lines[for_index]['runtime'] = for_runtime \n return pd.DataFrame.from_dict(lines)\n \n\n\n ",
"_____no_output_____"
],
[
"syntax_complete = get_for_blocks_runtime(syntax_with_ifs)\nsyntax_complete.head(len(syntax_complete))",
"for_indices [2, 3, 7, 8, 13, 17, 18]\nendfor_indices [5, 6, 10, 11, 15, 22, 23]\n"
],
[
"test_for_data = {'lower_b': parse_expr('1'), 'upper_b': parse_expr('n'), 'inc': parse_expr(str(1))}\nfor_runtime_formula(test_for_data,2)",
"_____no_output_____"
],
[
"ceil = sp.Function('ceil')\nupper_bound = parse_expr('n')\nlower_bound = parse_expr('3')\nincrement = parse_expr('2')\niterations = ceil((upper_bound-lower_bound)/increment)\niterations",
"_____no_output_____"
],
[
"def get_runtime(syntax_complete):\n lines = syntax_complete.to_dict('records')\n runtime = parse_expr('0')\n for line in lines:\n if line['order'] is 0:\n runtime += line['runtime']\n return runtime",
"_____no_output_____"
],
[
"str(sp.simplify(get_runtime(syntax_complete)))",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb32d0572d94c381dbf6e5ac28594209bdbe95bb | 631,525 | ipynb | Jupyter Notebook | utils/speedup_model/archive/r_speedup_adam_batch_norm_True_MAPE_nlayers_4_log_False-27_03_2019_19_26.ipynb | nassimTchoulak/tiramisu | fe7da4ad4cc4efd20339b7a1abf693a9a264e58f | [
"MIT"
] | 1 | 2019-11-19T21:17:46.000Z | 2019-11-19T21:17:46.000Z | utils/speedup_model/archive/r_speedup_adam_batch_norm_True_MAPE_nlayers_4_log_False-27_03_2019_19_26.ipynb | houssam2293/tiramisu | cbe81184cb91fb0144ce22d874dbe6a44b129e69 | [
"MIT"
] | null | null | null | utils/speedup_model/archive/r_speedup_adam_batch_norm_True_MAPE_nlayers_4_log_False-27_03_2019_19_26.ipynb | houssam2293/tiramisu | cbe81184cb91fb0144ce22d874dbe6a44b129e69 | [
"MIT"
] | 1 | 2020-04-22T23:25:20.000Z | 2020-04-22T23:25:20.000Z | 306.565534 | 249,920 | 0.904404 | [
[
[
"from os import environ\n\nenviron['optimizer'] = 'Adam'\nenviron['num_workers']= '2'\nenviron['batch_size']= str(2048)\nenviron['n_epochs']= '1000'\nenviron['batch_norm']= 'True'\nenviron['loss_func']='MAPE'\nenviron['layers'] = '600 350 200 180'\nenviron['dropouts'] = '0.1 '* 4\nenviron['log'] = 'False'\nenviron['weight_decay'] = '0.01'\nenviron['cuda_device'] ='cuda:3'\nenviron['dataset'] = 'data/speedup_dataset2.pkl'\n\n%run utils.ipynb",
"_____no_output_____"
],
[
"train_dl, val_dl, test_dl = train_dev_split(dataset, batch_size, num_workers, log=log)\n\ndb = fai.basic_data.DataBunch(train_dl, val_dl, test_dl, device=device)",
"_____no_output_____"
],
[
"input_size = train_dl.dataset.X.shape[1]\noutput_size = train_dl.dataset.Y.shape[1]\n\n\nmodel = None \n\nif batch_norm:\n model = Model_BN(input_size, output_size, hidden_sizes=layers_sizes, drops=drops)\nelse:\n model = Model(input_size, output_size)\n \nif loss_func == 'MSE':\n criterion = nn.MSELoss()\nelse:\n criterion = smape_criterion\n# criterion = mape_criterion\n\nl = fai.Learner(db, model, loss_func=criterion, metrics=[mape_criterion, rmse_criterion])\n\nif optimizer == 'SGD':\n l.opt_func = optim.SGD",
"_____no_output_____"
],
[
"l = l.load(f\"r_speedup_{optimizer}_batch_norm_{batch_norm}_{loss_func}_nlayers_{len(layers_sizes)}_log_{log}\")",
"_____no_output_____"
],
[
"l.lr_find()",
"_____no_output_____"
],
[
"l.recorder.plot()",
"_____no_output_____"
],
[
"lr = 1e-03",
"_____no_output_____"
],
[
"l.fit_one_cycle(450, lr)",
"_____no_output_____"
],
[
"l.recorder.plot_losses()",
"_____no_output_____"
],
[
"l.save(f\"r_speedup_{optimizer}_batch_norm_{batch_norm}_{loss_func}_nlayers_{len(layers_sizes)}_log_{log}\")",
"_____no_output_____"
],
[
"!ls models",
"old_models\r\nold_repr\r\nr_speedup_Adam_batch_norm_True_MAPE_nlayers_5_log_False.pth\r\nspeedup_Adam_batch_norm_True_MAPE_nlayers_5_log_False2.pth\r\nspeedup_Adam_batch_norm_True_MAPE_nlayers_5_log_False.pth\r\nspeedup_Adam_batch_norm_True_MSE_nlayers_5_log_False.pth\r\nspeedup_Adam_batch_norm_True_MSE_nlayers_5_log_True.pth\r\ntmp.pth\r\n"
],
[
"val_df = get_results_df(val_dl, l.model)\ntrain_df = get_results_df(train_dl, l.model)",
"_____no_output_____"
],
[
"df = val_df\n",
"_____no_output_____"
],
[
"df[:][['prediction','target', 'abs_diff','APE']].describe()",
"_____no_output_____"
],
[
"df = train_df",
"_____no_output_____"
],
[
"df[:][['prediction','target', 'abs_diff','APE']].describe()",
"_____no_output_____"
],
[
"df[:][['prediction','target', 'abs_diff','APE']].describe()",
"_____no_output_____"
],
[
"df[(df.interchange==0) & (df.unroll == 0) & (df.tile == 0)][['prediction','target', 'abs_diff','APE']].describe()",
"_____no_output_____"
],
[
"df[(df.interchange==0) & (df.unroll == 0) & (df.tile == 1)][['prediction','target', 'abs_diff','APE']].describe()",
"_____no_output_____"
],
[
"df[(df.interchange==0) & (df.unroll == 1) & (df.tile == 0)][['prediction','target', 'abs_diff','APE']].describe()",
"_____no_output_____"
],
[
"df[(df.interchange==1) & (df.unroll == 0) & (df.tile == 0)][['prediction','target', 'abs_diff','APE']].describe()",
"_____no_output_____"
],
[
"df[(df.interchange==0) & (df.unroll == 1) & (df.tile == 1)][['prediction','target', 'abs_diff','APE']].describe()",
"_____no_output_____"
],
[
"df[(df.interchange==1) & (df.unroll == 1) & (df.tile == 0)][['prediction','target', 'abs_diff','APE']].describe()",
"_____no_output_____"
],
[
"df[(df.interchange==1) & (df.unroll == 0) & (df.tile == 1)][['prediction','target', 'abs_diff','APE']].describe()",
"_____no_output_____"
],
[
"df[(df.interchange==1) & (df.unroll == 1) & (df.tile == 1)][['prediction','target', 'abs_diff','APE']].describe()",
"_____no_output_____"
],
[
"df[(df.interchange + df.tile + df.unroll != 0)][['prediction','target', 'abs_diff','APE']].describe()",
"_____no_output_____"
],
[
"df1 = df[(df.interchange==0) & (df.unroll == 0) & (df.tile == 0)]\njoint_plot(df1, f\"Validation dataset, {loss_func} loss\")\ndf1 = df[(df.interchange==0) & (df.unroll == 0) & (df.tile == 1)]\njoint_plot(df1, f\"Validation dataset, {loss_func} loss\")\ndf1 = df[(df.interchange==0) & (df.unroll == 1) & (df.tile == 0)]\njoint_plot(df1, f\"Validation dataset, {loss_func} loss\")\ndf1 = df[(df.interchange==1) & (df.unroll == 0) & (df.tile == 0)]\njoint_plot(df1, f\"Validation dataset, {loss_func} loss\")\ndf1 = df[(df.interchange==0) & (df.unroll == 1) & (df.tile == 1)]\njoint_plot(df1, f\"Validation dataset, {loss_func} loss\")\ndf1 = df[(df.interchange==1) & (df.unroll == 1) & (df.tile == 0)]\njoint_plot(df1, f\"Validation dataset, {loss_func} loss\")\ndf1 = df[(df.interchange==1) & (df.unroll == 0) & (df.tile == 1)]\njoint_plot(df1, f\"Validation dataset, {loss_func} loss\")\ndf1 = df[(df.interchange==0) & (df.unroll == 1) & (df.tile == 1)]\njoint_plot(df1, f\"Validation dataset, {loss_func} loss\")\ndf1 = df[(df.interchange==1) & (df.unroll == 1) & (df.tile == 1)]\njoint_plot(df1, f\"Validation dataset, {loss_func} loss\")\ndf1 = df[(df.interchange + df.tile + df.unroll != 0)]\njoint_plot(df1, f\"Validation dataset, {loss_func} loss\")\ndf2 = df\njoint_plot(df2, f\"Validation dataset, {loss_func} loss\")",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb32e9d2318abfc53022691a3c2f3a87335bf5cd | 354,390 | ipynb | Jupyter Notebook | _notebooks/_2021-04-19-intro.ipynb | RJuro/am-notebooks | 74a7ec183fbe0f4a5ad9e333d6f5923a4ebd0c05 | [
"Apache-2.0"
] | null | null | null | _notebooks/_2021-04-19-intro.ipynb | RJuro/am-notebooks | 74a7ec183fbe0f4a5ad9e333d6f5923a4ebd0c05 | [
"Apache-2.0"
] | null | null | null | _notebooks/_2021-04-19-intro.ipynb | RJuro/am-notebooks | 74a7ec183fbe0f4a5ad9e333d6f5923a4ebd0c05 | [
"Apache-2.0"
] | null | null | null | 129.05681 | 172,120 | 0.864054 | [
[
[
"# \"Intro til Anvendt Matematik og Python opfriskning\"\n> \"19 April 2021 - HA-AAUBS\"\n\n- toc: true\n- branch: master\n- badges: true\n- comments: true\n- author: Roman Jurowetzki\n- categories: [intro, forelæsning]",
"_____no_output_____"
],
[
"# Intro til Anvendt Matematik og Python opfriskning\n\n\n- Matematik bruges i finance, økonomistyring, data science, tech og meget andet - men også helt sikkert senere hvis I skal videre med en kandidat.\n- Analytiske skills er meget [eftertragtede på arbejdsmarkedet](https://youtu.be/u2oupkbxddc \n) \n> [Ny DI-analyse viser](https://www.danskindustri.dk/tech-der-taller/analysearkiv/analyser/2020/10/kompetencer-til-et-digitalt-arbejdsliv/), at den digitale omstilling i virksomheder ikke kan drives af it-specialisterne alene. Der er i stærkt stigende omfang behov for, at samfundsvidenskabelige profiler også har gode digitale kompetencer.\n",
"_____no_output_____"
],
[
"### Hvad sker her fra idag til 21 Juni?\n\n- overblik over linkeær algebra og calculus (ikke meget mere end B niveau)\n- Brug gerne fx https://www.webmatematik.dk/ \n- $\\LaTeX$ [cheat-sheet](http://tug.ctan.org/info/undergradmath/undergradmath.pdf)\n- [Markdown cheatsheet](https://www.markdownguide.org/cheat-sheet/)\n- Lære at **bruge** matematik - ikke være matematiker¨\n- lære fra et data/computer science perspektiv, hvor det handler mest at kunne implementere matematik direkte og bruge til fx at bygge en søgemaskine, recommender system, visualisere eller automatisere BI \n- \"computational tilgang\" - Python som tool\n- Danglish",
"_____no_output_____"
],
[
"### Pingvin Motivation og Intuition - Fra Data og Statistik til Liniær Algebra",
"_____no_output_____"
],
[
"Pingvin data: https://github.com/allisonhorst/palmerpenguins\n\n\nVi bygger en søgemaskine til pingviner 🤔\n\nAntagelse:\n- Pingviner kan bedst lide at være sammen med dem, der ligner dem mest\n",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\n\nnp.set_printoptions(suppress=True)\n\nimport seaborn as sns\nsns.set(color_codes=True, rc={'figure.figsize':(10,8)})",
"_____no_output_____"
],
[
"pinguins = pd.read_csv(\"https://github.com/allisonhorst/palmerpenguins/raw/5b5891f01b52ae26ad8cb9755ec93672f49328a8/data/penguins_size.csv\")",
"_____no_output_____"
],
[
"pinguins.head()",
"_____no_output_____"
],
[
"pinguins = pinguins.dropna()\npinguins.species_short.value_counts()",
"_____no_output_____"
],
[
"pinguins.index = range(len(pinguins))",
"_____no_output_____"
],
[
"# Hvordan ser vores data ud?\n\nsns.pairplot(pinguins, hue='species_short', kind=\"reg\", corner=True, markers=[\"o\", \"s\", \"D\"], plot_kws={'line_kws':{'color':'white'}})",
"_____no_output_____"
]
],
[
[
"Vi danner alle variable om til Z-scores (så de er på samme skala)\n\n$Z = \\frac{x-\\mu}{\\sigma} $\n\nx = værdi, \n$\\mu$ = gennemsnit, $\\sigma$ = stadnardafvigelse\n",
"_____no_output_____"
]
],
[
[
"# scaling - vi tager kun de 4 nummeriske variable\n\nfrom sklearn.preprocessing import StandardScaler\nscaled_pinguins = StandardScaler().fit_transform(pinguins.loc[:,'culmen_length_mm':'body_mass_g'])",
"_____no_output_____"
],
[
"# plot af alle skalerede variable, som nu har gennemsnit ~ 0 og std ~ 1\n\nfor i in range(4):\n sns.kdeplot(scaled_pinguins[:,i])",
"_____no_output_____"
],
[
"print(scaled_pinguins.shape)\nscaled_pinguins",
"(334, 4)\n"
],
[
"# pinguin 1 kan representeres som en 4D række-vektor\n\nscaled_pinguins[0,:]",
"_____no_output_____"
]
],
[
[
"Nu bruger vi noget, som vi måske kommer til at se på helt til sidst i Liniær Algebra, næmlig Principal Component Analysis eller PCA.\n- læs mere om PCA og hvordan man [bygger det fra bunden](https://towardsdatascience.com/principal-component-analysis-pca-from-scratch-in-python-7f3e2a540c51))\n- Hvis du er meget interesseret - [læs her](https://jakevdp.github.io/PythonDataScienceHandbook/05.09-principal-component-analysis.html)\n\nVi bruger 2 components (dvs. vores 4D vektorer bliver skrumpet til 2D hvor PCA forsøger at beholde så meget information som muligt\n\n",
"_____no_output_____"
]
],
[
[
"# import PCA\nfrom sklearn.decomposition import PCA\npca = PCA(n_components=2)",
"_____no_output_____"
],
[
"# Transform penguin matrix med PCA\n\npca_pinguins = pca.fit_transform(scaled_pinguins)",
"_____no_output_____"
],
[
"print(pca_pinguins.shape)\npca_pinguins",
"(334, 2)\n"
]
],
[
[
"Nu bruger vi denne 2D matrix og plotter, hvor 1.kollonne = x; 2. kolonne = y; vi bruger farver fra pingvin-arter i vores start-data",
"_____no_output_____"
]
],
[
[
"sns.scatterplot(x = pca_pinguins[:,0], y = pca_pinguins[:,1], hue = pinguins['species_short'] )",
"_____no_output_____"
]
],
[
[
"Hvordan finder vi så en buddy for en given pingvin?\n\n- det er den, der er tættest på 🤖\n\n**Eucledian Distance**\n\n\n\n**Vi kan også gå fra 2D til n-D**\n\n$d(\\vec{u}, \\vec{v}) = \\| \\vec{u} - \\vec{v} \\| = \\sqrt{(u_1 - v_1)^2 + (u_2 - v_2)^2 ... (u_n - v_n)^2}$\n\nfx\n\nVi kan regne ED mellem\n$\\vec{u} = (2, 3, 4, 2)$ \n\nog \n\n$\\vec{v} = (1, -2, 1, 3)$\n\n$\\begin{align} d(\\vec{u}, \\vec{v}) = \\| \\vec{u} - \\vec{v} \\| = \\sqrt{(2-1)^2 + (3+2)^2 + (4-1)^2 + (2-3)^2} \\\\ d(\\vec{u}, \\vec{v}) = \\| \\vec{u} - \\vec{v} \\| = \\sqrt{1 + 25 + 9 + 1} \\\\ d(\\vec{u}, \\vec{v}) = \\| \\vec{u} - \\vec{v} \\| = \\sqrt{36} \\\\ d(\\vec{u}, \\vec{v}) = \\| \\vec{u} - \\vec{v} \\| = 6 \\end{align}$",
"_____no_output_____"
]
],
[
[
"# hvor tæt er de første 2\nprint(scaled_pinguins[0,:])\nprint(scaled_pinguins[1,:])",
"[-0.89765322 0.78348666 -1.42952144 -0.57122888]\n[-0.82429023 0.12189602 -1.07240838 -0.50901123]\n"
],
[
"# kvardarod er ikke standard og skal importeres\nfrom math import sqrt",
"_____no_output_____"
],
[
"# manuelt\nsqrt((-0.89765322--0.82429023)**2 + (0.78348666-0.12189602)**2 + (-1.42952144--1.07240838)**2 + (-0.57122888--0.50901123)**2)",
"_____no_output_____"
],
[
"# med numpy\nnp.linalg.norm(scaled_pinguins[0,:] - scaled_pinguins[1,:])",
"_____no_output_____"
],
[
"np.linalg.norm(scaled_pinguins[0,:] - scaled_pinguins[2,:])",
"_____no_output_____"
],
[
"pinguins.iloc[:5,:]",
"_____no_output_____"
],
[
"pinguins.iloc[-5:,:]",
"_____no_output_____"
],
[
"np.linalg.norm(scaled_pinguins[0,:] - scaled_pinguins[333,:])",
"_____no_output_____"
],
[
"np.linalg.norm(scaled_pinguins[0,:] - scaled_pinguins[331,:])",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"# This code draws the x and y axis as lines.\n\npoints = [0,1,2,333,331]\n\n\nfig, ax = plt.subplots()\n\nax.scatter(pca_pinguins[[points],0], pca_pinguins[[points],1])\n\nplt.axhline(0, c='black', lw=0.5)\nplt.axvline(0, c='black', lw=0.5)\nplt.xlim(-2,3)\nplt.ylim(-1,1)\n\nplt.quiver(0, 0, pca_pinguins[0,0], pca_pinguins[0,1], angles='xy', scale_units='xy', scale=1, color='blue')\nplt.quiver(0, 0, pca_pinguins[1,0], pca_pinguins[1,1], angles='xy', scale_units='xy', scale=1, color='green')\nplt.quiver(0, 0, pca_pinguins[2,0], pca_pinguins[2,1], angles='xy', scale_units='xy', scale=1, color='yellow')\nplt.quiver(0, 0, pca_pinguins[333,0], pca_pinguins[333,1], angles='xy', scale_units='xy', scale=1, color='violet')\nplt.quiver(0, 0, pca_pinguins[331,0], pca_pinguins[331,1], angles='xy', scale_units='xy', scale=1, color='black')\n\nfor i in points:\n ax.annotate(str(i), (pca_pinguins[i,0], pca_pinguins[i,1]))",
"_____no_output_____"
]
],
[
[
"Man kunne nu enten skrive noget, som gentager denne beregning for alle kombinationer...eller",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics.pairwise import euclidean_distances",
"_____no_output_____"
],
[
"euclidean_matrix = euclidean_distances(scaled_pinguins)",
"_____no_output_____"
],
[
"print(euclidean_matrix.shape)\neuclidean_matrix",
"(334, 334)\n"
],
[
"np.argmin(euclidean_matrix[0,:])",
"_____no_output_____"
],
[
"np.argsort(euclidean_matrix[0,:])[:3]",
"_____no_output_____"
],
[
"scaled_pinguins[[0,139,16],:]",
"_____no_output_____"
],
[
"euclidean_distances(scaled_pinguins[[0,139,16],:])",
"_____no_output_____"
]
],
[
[
"### Python fresh-up\n\n- Simple datatyper\n- Grundlæggende matematiske operationer\n- Lister\n- Funktioner\n- Control Flow\n",
"_____no_output_____"
],
[
"#### Simple datatyper\n- Integers - hele tal **6**\n- Floating-Point Numbers - decimaltal **3.2**\n- Boolean - digital data type / bit **True / False**\n- String - text **Roman*",
"_____no_output_____"
]
],
[
[
"i = 6\nprint(i, type(i))",
"6 <class 'int'>\n"
],
[
"x = 3.2\nprint(x, type(x))",
"3.2 <class 'float'>\n"
],
[
"t = i == 6\nprint(t, type(t))",
"True <class 'bool'>\n"
],
[
"s = 'Hello'\nprint(s, type(s))",
"Hello <class 'str'>\n"
]
],
[
[
"#### Grundlæggende matematiske operationer",
"_____no_output_____"
]
],
[
[
"a = 2.0\nb = 3.0\nprint(a+b, a*b, a-b, a/b, a**2, a+b**2, (a+b)**2)",
"5.0 6.0 -1.0 0.6666666666666666 4.0 11.0 25.0\n"
],
[
"c = a + b\nprint(c)",
"5.0\n"
],
[
"a + b == c",
"_____no_output_____"
],
[
"a + b < c",
"_____no_output_____"
]
],
[
[
"#### Lister\n\nman kan pakke alt i en liste :-)",
"_____no_output_____"
]
],
[
[
"l = ['Eskil', 1.0, sqrt]\ntype(l)",
"_____no_output_____"
],
[
"l[2]",
"_____no_output_____"
],
[
"l[0]",
"_____no_output_____"
],
[
"l.append('Roman')",
"_____no_output_____"
],
[
"l",
"_____no_output_____"
],
[
"l.extend(['Marie',37])",
"_____no_output_____"
],
[
"l",
"_____no_output_____"
],
[
"l.pop(2)",
"_____no_output_____"
],
[
"l",
"_____no_output_____"
]
],
[
[
"#### Funktioner\n\nFunktioner har (normalt) in og outputs. $a$ og $b$ er vores input her og funktionen producerer $\\sqrt{a^2 + b^2}$ som output.\n\nVi prøver lige ...\n\n$\\begin{align} a^2 + b^2 = c^2 \\rightarrow c = \\sqrt{a^2 + b^2} \\end{align}$ ",
"_____no_output_____"
]
],
[
[
"def pythagoras(a, b):\n return sqrt(a**2 + b**2)",
"_____no_output_____"
],
[
"pythagoras(1,2)",
"_____no_output_____"
],
[
"# Hvis man gør det rigtigt, så er det en god ide at kommentere hvad der sker. \n# Her er det en no-brainer men funktioner kan blive indviklede og\n# det er good-practice at skrive \"docstrings\" til en anden eller en selv (i)\n\ndef pythagoras(a, b):\n \"\"\"\n Computes the length of the hypotenuse of a right triangle\n \n Arguments\n a, b: the two lengths of the right triangle\n \"\"\"\n \n return sqrt(a**2 + b**2)",
"_____no_output_____"
]
],
[
[
"##### Mini-assignment\n* Lav en funktion, som tager to punkter $(x_1, y_1), (x_2, y_2)$ på en linje og beregner hældning $a$\n\n$$ y = ax + b$$\n\n$$ a = \\frac{y_2- y_1}{x_2 - x_1}$$",
"_____no_output_____"
]
],
[
[
"plt.plot((1,2), (2,3), 'ro-')\nplt.plot((1,2), (2,2), 'bo-')\nplt.plot((2,2), (2,3), 'bo-')",
"_____no_output_____"
],
[
"# slope(1,2,2,3)",
"_____no_output_____"
]
],
[
[
"#### Control flow",
"_____no_output_____"
]
],
[
[
"def isNegative(n):\n if n < 0:\n return True\n else:\n return False",
"_____no_output_____"
]
],
[
[
"##### Mini-assignment\n* Lav en funktion `KtoC` som regner Kelvin om til Celcius\n$$ C = K - 273.15 \\quad \\text{ved} \\quad C\\geq - 273.15$$\nFunktionen udgiver `None` hvis $C < -273.15$",
"_____no_output_____"
]
],
[
[
"list(range(10))",
"_____no_output_____"
],
[
"# for-loop\n\neven = [] # tom liste\nfor i in range(10):\n even.append(i*2)\n\n\nprint(even)",
"[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]\n"
],
[
"# list-comprehension \n\neven = [2*i for i in range(10)]\n\nprint(even)",
"[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]\n"
]
],
[
[
"##### Mini-assignment\n1. Beregn summen af integers 1 ... 100 ved at bruge `sum`, list-comprehension, for-loop\n2. Beregn summen af integers 1 ... 100 ved at bruge partial-sum formula\n$$ \\sum_{k=1}^n k = 1 + 2 + \\cdots + (n-1) + n = \\frac{n(n+1)}{2}$$",
"_____no_output_____"
],
[
"### Matematik fresh-up\nalle øvelser taget fra https://tutorial.math.lamar.edu/Problems/Alg/Preliminaries.aspx\n\nErfaringen viser, at det er en god idé at få sig en god routine med at løse matematiske problemer.\n\n- Integer Exponents\n- Rational Exponents\n- Radicals\n- Polynomials\n\nVi arbejder old-school med papir men bruger også `SymPy` for at tjekke vores løsninger",
"_____no_output_____"
],
[
"#### Integer Exponents\n\n$- {6^2} + 4 \\cdot {3^2}$\n\n${\\left( {2{w^4}{v^{ - 5}}} \\right)^{ - 2}}$ (løsning med kun positive eksponenter!)",
"_____no_output_____"
]
],
[
[
"from sympy import *",
"_____no_output_____"
],
[
"simplify(-6**2+4*3**2)",
"_____no_output_____"
],
[
"w, v = symbols('w v')\nsimplify((2*w**4*v**-5)**-2)",
"_____no_output_____"
]
],
[
[
"#### Rational Exponents\n${\\left( { - 125} \\right)^{\\frac{1}{3}}}$\n\n${\\left( {{a^3}\\,{b^{ - \\,\\,\\frac{1}{4}}}} \\right)^{\\frac{2}{3}}}$",
"_____no_output_____"
]
],
[
[
"simplify(-125**(1/3), rational=True)",
"_____no_output_____"
],
[
"a, b = symbols('a b')\nsimplify((a**3*b**(-1/4))**(2/3), rational=True)",
"_____no_output_____"
]
],
[
[
"#### Radicals\n$$\\begin{array}{c} \\sqrt[7]{y}\\\\ \\sqrt[3]{{{x^2}}} \\\\ \\sqrt[3]{{ - 512}} \\\\ \\sqrt x \\left( {4 - 3\\sqrt x } \\right)\\end{array}$$",
"_____no_output_____"
]
],
[
[
"x, y, z = symbols('x, y , z')",
"_____no_output_____"
],
[
"simplify((x**2)**(1/3), rational=True)",
"_____no_output_____"
],
[
"simplify(-512**(1/3), rational=True)",
"_____no_output_____"
],
[
"simplify(sqrt(x)*(4 - 3*sqrt(x)), rational = True)",
"_____no_output_____"
]
],
[
[
"#### Polynomials\n\n$$(4{x^3} - 2{x^2} + 1) + (7{x^2} + 12x)$$\n",
"_____no_output_____"
]
],
[
[
"simplify((4*x**3-2*x**2+1)+(7*x**2+12*x))",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
cb32ea00947ecdc7dfc4f0aa7219575627a1f53f | 72,240 | ipynb | Jupyter Notebook | HPO_Regression.ipynb | baalasangar/Hyperparameter-Optimization-of-Machine-Learning-Algorithms | 8b3e0f385ce76110a619bffa84b58fa888b09c57 | [
"MIT"
] | 947 | 2020-08-04T05:15:43.000Z | 2022-03-30T03:57:33.000Z | HPO_Regression.ipynb | SuperMan0010/Hyperparameter-Optimization-of-Machine-Learning-Algorithms | 9c0a1d11f4551183d1e52f6ed9485af30b8ff3f5 | [
"MIT"
] | 2 | 2020-08-10T00:25:54.000Z | 2022-03-24T01:50:51.000Z | HPO_Regression.ipynb | SuperMan0010/Hyperparameter-Optimization-of-Machine-Learning-Algorithms | 9c0a1d11f4551183d1e52f6ed9485af30b8ff3f5 | [
"MIT"
] | 199 | 2020-08-06T22:58:52.000Z | 2022-03-26T08:43:11.000Z | 37.103236 | 2,468 | 0.532254 | [
[
[
"# Hyperparameter Optimization (HPO) of Machine Learning Models\nL. Yang and A. Shami, “On hyperparameter optimization of machine learning algorithms: Theory and practice,” Neurocomputing, vol. 415, pp. 295–316, 2020, doi: https://doi.org/10.1016/j.neucom.2020.07.061.\n\n### **Sample code for regression problems** \n**Dataset used:** \n Boson Housing dataset from sklearn\n\n**Machine learning algorithms used:** \n Random forest (RF), support vector machine (SVM), k-nearest neighbor (KNN), artificial neural network (ANN)\n\n**HPO algorithms used:** \n Grid search, random search, hyperband, Bayesian Optimization with Gaussian Processes (BO-GP), Bayesian Optimization with Tree-structured Parzen Estimator (BO-TPE), particle swarm optimization (PSO), genetic algorithm (GA).\n\n**Performance metric:** \n Mean square error (MSE)",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nfrom sklearn.model_selection import train_test_split,cross_val_score\nfrom sklearn.ensemble import RandomForestClassifier,RandomForestRegressor\nfrom sklearn.metrics import classification_report,confusion_matrix,accuracy_score\nfrom sklearn.neighbors import KNeighborsClassifier,KNeighborsRegressor\nfrom sklearn.svm import SVC,SVR\nfrom sklearn import datasets\nimport scipy.stats as stats",
"_____no_output_____"
]
],
[
[
"## Load Boston Housing dataset\nWe will take the Housing dataset which contains information about different houses in Boston. There are 506 samples and 13 feature variables in this Boston dataset. The main goal is to predict the value of prices of the house using the given features.\n\nYou can read more about the data and the variables [[1]](https://www.cs.toronto.edu/~delve/data/boston/bostonDetail.html) [[2]](https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_boston.html).",
"_____no_output_____"
]
],
[
[
"X, y = datasets.load_boston(return_X_y=True)",
"_____no_output_____"
],
[
"datasets.load_boston()",
"_____no_output_____"
]
],
[
[
"## Baseline Machine Learning models: Regressors with Default Hyperparameters",
"_____no_output_____"
]
],
[
[
"#Random Forest\nclf = RandomForestRegressor()\nscores = cross_val_score(clf, X, y, cv=3,scoring='neg_mean_squared_error') # 3-fold cross-validation\nprint(\"MSE:\"+ str(-scores.mean()))",
"MSE:32.42882531816474\n"
],
[
"#SVM\nclf = SVR(gamma='scale')\nscores = cross_val_score(clf, X, y, cv=3,scoring='neg_mean_squared_error')\nprint(\"MSE:\"+ str(-scores.mean()))",
"MSE:77.42951812579331\n"
],
[
"#KNN\nclf = KNeighborsRegressor()\nscores = cross_val_score(clf, X, y, cv=3,scoring='neg_mean_squared_error')\nprint(\"MSE:\"+ str(-scores.mean()))",
"MSE:81.48773186343571\n"
],
[
"#ANN\nfrom keras.models import Sequential, Model\nfrom keras.layers import Dense, Input\nfrom sklearn.model_selection import GridSearchCV\nfrom keras.wrappers.scikit_learn import KerasRegressor\nfrom keras.callbacks import EarlyStopping\ndef ANN(optimizer = 'adam',neurons=32,batch_size=32,epochs=50,activation='relu',patience=5,loss='mse'):\n model = Sequential()\n model.add(Dense(neurons, input_shape=(X.shape[1],), activation=activation))\n model.add(Dense(neurons, activation=activation))\n model.add(Dense(1))\n model.compile(optimizer = optimizer, loss=loss)\n early_stopping = EarlyStopping(monitor=\"loss\", patience = patience)# early stop patience\n history = model.fit(X, y,\n batch_size=batch_size,\n epochs=epochs,\n callbacks = [early_stopping],\n verbose=0) #verbose set to 1 will show the training process\n return model",
"Using TensorFlow backend.\n"
],
[
"clf = KerasRegressor(build_fn=ANN, verbose=0)\nscores = cross_val_score(clf, X, y, cv=3,scoring='neg_mean_squared_error')\nprint(\"MSE:\"+ str(-scores.mean()))",
"MSE:43.28833796634842\n"
]
],
[
[
"## HPO Algorithm 1: Grid Search\nSearch all the given hyper-parameter configurations\n\n**Advantages:**\n* Simple implementation. \n\n**Disadvantages:** \n* Time-consuming,\n* Only efficient with categorical HPs.",
"_____no_output_____"
]
],
[
[
"#Random Forest\nfrom sklearn.model_selection import GridSearchCV\n# Define the hyperparameter configuration space\nrf_params = {\n 'n_estimators': [10, 20, 30],\n #'max_features': ['sqrt',0.5],\n 'max_depth': [15,20,30,50],\n #'min_samples_leaf': [1,2,4,8],\n #\"bootstrap\":[True,False],\n #\"criterion\":['mse','mae']\n}\nclf = RandomForestRegressor(random_state=0)\ngrid = GridSearchCV(clf, rf_params, cv=3, scoring='neg_mean_squared_error')\ngrid.fit(X, y)\nprint(grid.best_params_)\nprint(\"MSE:\"+ str(-grid.best_score_))",
"{'n_estimators': 20, 'max_depth': 15}\nMSE:29.03074736502433\n"
],
[
"#SVM\nfrom sklearn.model_selection import GridSearchCV\nrf_params = {\n 'C': [1,10, 100],\n \"kernel\":['poly','rbf','sigmoid'],\n \"epsilon\":[0.01,0.1,1]\n}\nclf = SVR(gamma='scale')\ngrid = GridSearchCV(clf, rf_params, cv=3, scoring='neg_mean_squared_error')\ngrid.fit(X, y)\nprint(grid.best_params_)\nprint(\"MSE:\"+ str(-grid.best_score_))",
"{'kernel': 'poly', 'epsilon': 0.01, 'C': 100}\nMSE:67.07483887754718\n"
],
[
"#KNN\nfrom sklearn.model_selection import GridSearchCV\nrf_params = {\n 'n_neighbors': [2, 3, 5,7,10]\n}\nclf = KNeighborsRegressor()\ngrid = GridSearchCV(clf, rf_params, cv=3, scoring='neg_mean_squared_error')\ngrid.fit(X, y)\nprint(grid.best_params_)\nprint(\"MSE:\"+ str(-grid.best_score_))",
"{'n_neighbors': 5}\nMSE:81.52933517786562\n"
],
[
"#ANN\nfrom sklearn.model_selection import GridSearchCV\nrf_params = {\n 'optimizer': ['adam','rmsprop'],\n 'activation': ['relu','tanh'],\n 'loss': ['mse','mae'],\n 'batch_size': [16,32],\n 'neurons':[16,32],\n 'epochs':[20,50],\n 'patience':[2,5]\n}\nclf = KerasRegressor(build_fn=ANN, verbose=0)\ngrid = GridSearchCV(clf, rf_params, cv=3,scoring='neg_mean_squared_error')\ngrid.fit(X, y)\nprint(grid.best_params_)\nprint(\"MSE:\"+ str(-grid.best_score_))",
"{'patience': 5, 'optimizer': 'adam', 'batch_size': 16, 'loss': 'mse', 'activation': 'relu', 'neurons': 32, 'epochs': 50}\nMSE:52.18262109619083\n"
]
],
[
[
"## HPO Algorithm 2: Random Search\nRandomly search hyper-parameter combinations in the search space\n\n**Advantages:**\n* More efficient than GS.\n* Enable parallelization. \n\n**Disadvantages:** \n* Not consider previous results.\n* Not efficient with conditional HPs.",
"_____no_output_____"
]
],
[
[
"#Random Forest\nfrom scipy.stats import randint as sp_randint\nfrom sklearn.model_selection import RandomizedSearchCV\n# Define the hyperparameter configuration space\nrf_params = {\n 'n_estimators': sp_randint(10,100),\n \"max_features\":sp_randint(1,13),\n 'max_depth': sp_randint(5,50),\n \"min_samples_split\":sp_randint(2,11),\n \"min_samples_leaf\":sp_randint(1,11),\n \"criterion\":['mse','mae']\n}\nn_iter_search=20 #number of iterations is set to 20, you can increase this number if time permits\nclf = RandomForestRegressor(random_state=0)\nRandom = RandomizedSearchCV(clf, param_distributions=rf_params,n_iter=n_iter_search,cv=3,scoring='neg_mean_squared_error')\nRandom.fit(X, y)\nprint(Random.best_params_)\nprint(\"MSE:\"+ str(-Random.best_score_))",
"{'criterion': 'mse', 'min_samples_leaf': 1, 'min_samples_split': 7, 'n_estimators': 98, 'max_depth': 14, 'max_features': 5}\nMSE:26.377428606830506\n"
],
[
"#SVM\nfrom scipy.stats import randint as sp_randint\nfrom sklearn.model_selection import RandomizedSearchCV\nrf_params = {\n 'C': stats.uniform(0,50),\n \"kernel\":['poly','rbf','sigmoid'],\n \"epsilon\":stats.uniform(0,1)\n}\nn_iter_search=20\nclf = SVR(gamma='scale')\nRandom = RandomizedSearchCV(clf, param_distributions=rf_params,n_iter=n_iter_search,cv=3,scoring='neg_mean_squared_error')\nRandom.fit(X, y)\nprint(Random.best_params_)\nprint(\"MSE:\"+ str(-Random.best_score_))",
"{'kernel': 'poly', 'epsilon': 0.49678099309788193, 'C': 27.417074148575495}\nMSE:60.03157881614154\n"
],
[
"#KNN\nfrom scipy.stats import randint as sp_randint\nfrom sklearn.model_selection import RandomizedSearchCV\nrf_params = {\n 'n_neighbors': sp_randint(1,20),\n}\nn_iter_search=10\nclf = KNeighborsRegressor()\nRandom = RandomizedSearchCV(clf, param_distributions=rf_params,n_iter=n_iter_search,cv=3,scoring='neg_mean_squared_error')\nRandom.fit(X, y)\nprint(Random.best_params_)\nprint(\"MSE:\"+ str(-Random.best_score_))",
"{'n_neighbors': 13}\nMSE:80.7723025469514\n"
],
[
"#ANN\nfrom scipy.stats import randint as sp_randint\nfrom random import randrange as sp_randrange\nfrom sklearn.model_selection import RandomizedSearchCV\nrf_params = {\n 'optimizer': ['adam','rmsprop'],\n 'activation': ['relu','tanh'],\n 'loss': ['mse','mae'],\n 'batch_size': [16,32,64],\n 'neurons':sp_randint(10,100),\n 'epochs':[20,50],\n #'epochs':[20,50,100,200],\n 'patience':sp_randint(3,20)\n}\nn_iter_search=10\nclf = KerasRegressor(build_fn=ANN, verbose=0)\nRandom = RandomizedSearchCV(clf, param_distributions=rf_params,n_iter=n_iter_search,cv=3,scoring='neg_mean_squared_error')\nRandom.fit(X, y)\nprint(Random.best_params_)\nprint(\"MSE:\"+ str(-Random.best_score_))",
"{'activation': 'relu', 'optimizer': 'adam', 'batch_size': 64, 'neurons': 72, 'epochs': 50, 'patience': 9, 'loss': 'mse'}\nMSE:53.522195500716826\n"
]
],
[
[
"## HPO Algorithm 3: Hyperband\nGenerate small-sized subsets and allocate budgets to each hyper-parameter combination based on its performance\n\n**Advantages:**\n* Enable parallelization. \n\n**Disadvantages:** \n* Not efficient with conditional HPs.\n* Require subsets with small budgets to be representative.",
"_____no_output_____"
]
],
[
[
"#Random Forest\nfrom hyperband import HyperbandSearchCV\nfrom scipy.stats import randint as sp_randint\n# Define the hyperparameter configuration space\nrf_params = {\n 'n_estimators': sp_randint(10,100),\n \"max_features\":sp_randint(1,13),\n 'max_depth': sp_randint(5,50),\n \"min_samples_split\":sp_randint(2,11),\n \"min_samples_leaf\":sp_randint(1,11),\n \"criterion\":['mse','mae']\n}\nclf = RandomForestRegressor(random_state=0)\nhyper = HyperbandSearchCV(clf, param_distributions =rf_params,cv=3,min_iter=10,max_iter=100,scoring='neg_mean_squared_error')\nhyper.fit(X, y)\nprint(hyper.best_params_)\nprint(\"MSE:\"+ str(-hyper.best_score_))",
"{'criterion': 'mae', 'min_samples_leaf': 3, 'min_samples_split': 6, 'max_features': 6, 'n_estimators': 11, 'max_depth': 21}\nMSE:26.44144227942378\n"
],
[
"#SVM\nfrom hyperband import HyperbandSearchCV\nfrom scipy.stats import randint as sp_randint\nrf_params = {\n 'C': stats.uniform(0,50),\n \"kernel\":['poly','rbf','sigmoid'],\n \"epsilon\":stats.uniform(0,1)\n}\nclf = SVR(gamma='scale')\nhyper = HyperbandSearchCV(clf, param_distributions =rf_params,cv=3,min_iter=1,max_iter=10,scoring='neg_mean_squared_error',resource_param='C')\nhyper.fit(X, y)\nprint(hyper.best_params_)\nprint(\"MSE:\"+ str(-hyper.best_score_))",
"{'kernel': 'poly', 'epsilon': 0.4490042156616516, 'C': 10}\nMSE:70.78132735518886\n"
],
[
"#KNN\nfrom hyperband import HyperbandSearchCV\nfrom scipy.stats import randint as sp_randint\nrf_params = {\n 'n_neighbors': range(1,20),\n}\nclf = KNeighborsRegressor()\nhyper = HyperbandSearchCV(clf, param_distributions =rf_params,cv=3,min_iter=1,max_iter=20,scoring='neg_mean_squared_error',resource_param='n_neighbors')\nhyper.fit(X, y)\nprint(hyper.best_params_)\nprint(\"MSE:\"+ str(-hyper.best_score_))",
"{'n_neighbors': 6}\nMSE:80.87024044795783\n"
],
[
"#ANN\nfrom hyperband import HyperbandSearchCV\nfrom scipy.stats import randint as sp_randint\nrf_params = {\n 'optimizer': ['adam','rmsprop'],\n 'activation': ['relu','tanh'],\n 'loss': ['mse','mae'],\n 'batch_size': [16,32,64],\n 'neurons':sp_randint(10,100),\n 'epochs':[20,50],\n #'epochs':[20,50,100,200],\n 'patience':sp_randint(3,20)\n}\nclf = KerasRegressor(build_fn=ANN, epochs=20, verbose=0)\nhyper = HyperbandSearchCV(clf, param_distributions =rf_params,cv=3,min_iter=1,max_iter=10,scoring='neg_mean_squared_error',resource_param='epochs')\nhyper.fit(X, y)\nprint(hyper.best_params_)\nprint(\"MSE:\"+ str(-hyper.best_score_))",
"{'patience': 3, 'batch_size': 16, 'loss': 'mse', 'activation': 'relu', 'optimizer': 'adam', 'neurons': 48, 'epochs': 10}\nMSE:56.59321886927081\n"
]
],
[
[
"## HPO Algorithm 4: BO-GP\nBayesian Optimization with Gaussian Process (BO-GP)\n\n**Advantages:**\n* Fast convergence speed for continuous HPs. \n\n**Disadvantages:** \n* Poor capacity for parallelization.\n* Not efficient with conditional HPs.",
"_____no_output_____"
],
[
"### Using skopt.BayesSearchCV",
"_____no_output_____"
]
],
[
[
"#Random Forest\nfrom skopt import Optimizer\nfrom skopt import BayesSearchCV \nfrom skopt.space import Real, Categorical, Integer\n# Define the hyperparameter configuration space\nrf_params = {\n 'n_estimators': Integer(10,100),\n \"max_features\":Integer(1,13),\n 'max_depth': Integer(5,50),\n \"min_samples_split\":Integer(2,11),\n \"min_samples_leaf\":Integer(1,11),\n \"criterion\":['mse','mae']\n}\nclf = RandomForestRegressor(random_state=0)\nBayes = BayesSearchCV(clf, rf_params,cv=3,n_iter=20, scoring='neg_mean_squared_error') \n#number of iterations is set to 20, you can increase this number if time permits\nBayes.fit(X, y)\nprint(Bayes.best_params_)\nbclf = Bayes.best_estimator_\nprint(\"MSE:\"+ str(-Bayes.best_score_))",
"{'criterion': 'mse', 'min_samples_leaf': 1, 'min_samples_split': 11, 'max_depth': 38, 'n_estimators': 86, 'max_features': 8}\nMSE:26.138895388690205\n"
],
[
"#SVM\nfrom skopt import Optimizer\nfrom skopt import BayesSearchCV \nfrom skopt.space import Real, Categorical, Integer\nrf_params = {\n 'C': Real(0,50),\n \"kernel\":['poly','rbf','sigmoid'],\n 'epsilon': Real(0,1)\n}\nclf = SVR(gamma='scale')\nBayes = BayesSearchCV(clf, rf_params,cv=3,n_iter=20, scoring='neg_mean_squared_error')\nBayes.fit(X, y)\nprint(Bayes.best_params_)\nprint(\"MSE:\"+ str(-Bayes.best_score_))",
"{'kernel': 'poly', 'epsilon': 0.16781739810509447, 'C': 43.14510166511289}\nMSE:59.52440851660976\n"
],
[
"#KNN\nfrom skopt import Optimizer\nfrom skopt import BayesSearchCV \nfrom skopt.space import Real, Categorical, Integer\nrf_params = {\n 'n_neighbors': Integer(1,20),\n}\nclf = KNeighborsRegressor()\nBayes = BayesSearchCV(clf, rf_params,cv=3,n_iter=10, scoring='neg_mean_squared_error')\nBayes.fit(X, y)\nprint(Bayes.best_params_)\nprint(\"MSE:\"+ str(-Bayes.best_score_))",
"{'n_neighbors': 13}\nMSE:80.7723025469514\n"
],
[
"#ANN\nfrom skopt import Optimizer\nfrom skopt import BayesSearchCV \nfrom skopt.space import Real, Categorical, Integer\nrf_params = {\n 'optimizer': ['adam','rmsprop'],\n 'activation': ['relu','tanh'],\n 'loss': ['mse','mae'],\n 'batch_size': [16,32,64],\n 'neurons':Integer(10,100),\n 'epochs':[20,50],\n #'epochs':[20,50,100,200],\n 'patience':Integer(3,20)\n}\nclf = KerasRegressor(build_fn=ANN, verbose=0)\nBayes = BayesSearchCV(clf, rf_params,cv=3,n_iter=10, scoring='neg_mean_squared_error')\nBayes.fit(X, y)\nprint(Bayes.best_params_)\nprint(\"MSE:\"+ str(-Bayes.best_score_))",
"{'patience': 15, 'optimizer': 'rmsprop', 'batch_size': 32, 'loss': 'mae', 'activation': 'relu', 'neurons': 43, 'epochs': 38}\nMSE:63.93545981123919\n"
]
],
[
[
"### Using skopt.gp_minimize",
"_____no_output_____"
]
],
[
[
"#Random Forest\nfrom skopt.space import Real, Integer\nfrom skopt.utils import use_named_args\n\nreg = RandomForestRegressor()\n# Define the hyperparameter configuration space\nspace = [Integer(10, 100, name='n_estimators'),\n Integer(5, 50, name='max_depth'),\n Integer(1, 13, name='max_features'),\n Integer(2, 11, name='min_samples_split'),\n Integer(1, 11, name='min_samples_leaf'),\n Categorical(['mse', 'mae'], name='criterion')\n ]\n# Define the objective function\n@use_named_args(space)\ndef objective(**params):\n reg.set_params(**params)\n\n return -np.mean(cross_val_score(reg, X, y, cv=3, n_jobs=-1,\n scoring=\"neg_mean_squared_error\"))\nfrom skopt import gp_minimize\nres_gp = gp_minimize(objective, space, n_calls=20, random_state=0)\n#number of iterations is set to 20, you can increase this number if time permits\nprint(\"MSE:%.4f\" % res_gp.fun)\nprint(res_gp.x)",
"MSE:26.4279\n[100, 50, 8, 11, 1, 'mse']\n"
],
[
"#SVM\nfrom skopt.space import Real, Integer\nfrom skopt.utils import use_named_args\n\nreg = SVR(gamma='scale')\nspace = [Real(0, 50, name='C'),\n Categorical(['poly','rbf','sigmoid'], name='kernel'),\n Real(0, 1, name='epsilon'),\n ]\n\n@use_named_args(space)\ndef objective(**params):\n reg.set_params(**params)\n\n return -np.mean(cross_val_score(reg, X, y, cv=3, n_jobs=-1,\n scoring=\"neg_mean_squared_error\"))\nfrom skopt import gp_minimize\nres_gp = gp_minimize(objective, space, n_calls=20, random_state=0)\nprint(\"MSE:%.4f\" % res_gp.fun)\nprint(res_gp.x)",
"MSE:61.2510\n[37.93078121611787, 'poly', 0.47360041934665753]\n"
],
[
"#KNN\nfrom skopt.space import Real, Integer\nfrom skopt.utils import use_named_args\n\nreg = KNeighborsRegressor()\nspace = [Integer(1, 20, name='n_neighbors')]\n\n@use_named_args(space)\ndef objective(**params):\n reg.set_params(**params)\n\n return -np.mean(cross_val_score(reg, X, y, cv=3, n_jobs=-1,\n scoring=\"neg_mean_squared_error\"))\nfrom skopt import gp_minimize\nres_gp = gp_minimize(objective, space, n_calls=10, random_state=0)\nprint(\"MSE:%.4f\" % res_gp.fun)\nprint(res_gp.x)",
"MSE:80.7412\n[13]\n"
]
],
[
[
"## HPO Algorithm 5: BO-TPE\nBayesian Optimization with Tree-structured Parzen Estimator (TPE)\n\n**Advantages:**\n* Efficient with all types of HPs.\n* Keep conditional dependencies.\n\n**Disadvantages:** \n* Poor capacity for parallelization.",
"_____no_output_____"
]
],
[
[
"#Random Forest\nfrom hyperopt import hp, fmin, tpe, STATUS_OK, Trials\nfrom sklearn.model_selection import cross_val_score, StratifiedKFold\n# Define the objective function\ndef objective(params):\n params = {\n 'n_estimators': int(params['n_estimators']), \n 'max_depth': int(params['max_depth']),\n 'max_features': int(params['max_features']),\n \"min_samples_split\":int(params['min_samples_split']),\n \"min_samples_leaf\":int(params['min_samples_leaf']),\n \"criterion\":str(params['criterion'])\n }\n clf = RandomForestRegressor( **params)\n score = -np.mean(cross_val_score(clf, X, y, cv=3, n_jobs=-1,\n scoring=\"neg_mean_squared_error\"))\n\n return {'loss':score, 'status': STATUS_OK }\n# Define the hyperparameter configuration space\nspace = {\n 'n_estimators': hp.quniform('n_estimators', 10, 100, 1),\n 'max_depth': hp.quniform('max_depth', 5, 50, 1),\n \"max_features\":hp.quniform('max_features', 1, 13, 1),\n \"min_samples_split\":hp.quniform('min_samples_split',2,11,1),\n \"min_samples_leaf\":hp.quniform('min_samples_leaf',1,11,1),\n \"criterion\":hp.choice('criterion',['mse','mae'])\n}\n\nbest = fmin(fn=objective,\n space=space,\n algo=tpe.suggest,\n max_evals=20)\nprint(\"Random Forest: Hyperopt estimated optimum {}\".format(best))",
"100%|████████████████████████████████████████████████████| 20/20 [00:05<00:00, 3.38it/s, best loss: 26.87220311513259]\nRandom Forest: Hyperopt estimated optimum {'criterion': 0, 'min_samples_leaf': 3.0, 'min_samples_split': 5.0, 'max_depth': 50.0, 'n_estimators': 46.0, 'max_features': 8.0}\n"
],
[
"#SVM\nfrom hyperopt import hp, fmin, tpe, STATUS_OK, Trials\nfrom sklearn.model_selection import cross_val_score, StratifiedKFold\ndef objective(params):\n params = {\n 'C': abs(float(params['C'])), \n \"kernel\":str(params['kernel']),\n 'epsilon': abs(float(params['epsilon'])),\n }\n clf = SVR(gamma='scale', **params)\n score = -np.mean(cross_val_score(clf, X, y, cv=3, n_jobs=-1,\n scoring=\"neg_mean_squared_error\"))\n \n return {'loss':score, 'status': STATUS_OK }\n\nspace = {\n 'C': hp.normal('C', 0, 50),\n \"kernel\":hp.choice('kernel',['poly','rbf','sigmoid']),\n 'epsilon': hp.normal('epsilon', 0, 1),\n}\n\nbest = fmin(fn=objective,\n space=space,\n algo=tpe.suggest,\n max_evals=20)\nprint(\"SVM: Hyperopt estimated optimum {}\".format(best))",
"100%|████████████████████████████████████████████████████| 20/20 [00:03<00:00, 5.10it/s, best loss: 63.07694330646493]\nSVM: Hyperopt estimated optimum {'kernel': 0, 'epsilon': 0.6784908715313539, 'C': 50.9909224663369}\n"
],
[
"#KNN\nfrom hyperopt import hp, fmin, tpe, STATUS_OK, Trials\nfrom sklearn.model_selection import cross_val_score, StratifiedKFold\ndef objective(params):\n params = {\n 'n_neighbors': abs(int(params['n_neighbors']))\n }\n clf = KNeighborsRegressor( **params)\n score = -np.mean(cross_val_score(clf, X, y, cv=3, n_jobs=-1,\n scoring=\"neg_mean_squared_error\"))\n\n return {'loss':score, 'status': STATUS_OK }\n\nspace = {\n 'n_neighbors': hp.quniform('n_neighbors', 1, 20, 1),\n}\n\nbest = fmin(fn=objective,\n space=space,\n algo=tpe.suggest,\n max_evals=10)\nprint(\"KNN: Hyperopt estimated optimum {}\".format(best))",
"100%|███████████████████████████████████████████████████| 10/10 [00:00<00:00, 125.34it/s, best loss: 81.26511555604914]\nKNN: Hyperopt estimated optimum {'n_neighbors': 14.0}\n"
],
[
"#ANN\nfrom hyperopt import hp, fmin, tpe, STATUS_OK, Trials\nfrom sklearn.model_selection import cross_val_score, StratifiedKFold\ndef objective(params):\n params = {\n \"optimizer\":str(params['optimizer']),\n \"activation\":str(params['activation']),\n \"loss\":str(params['loss']),\n 'batch_size': abs(int(params['batch_size'])),\n 'neurons': abs(int(params['neurons'])),\n 'epochs': abs(int(params['epochs'])),\n 'patience': abs(int(params['patience']))\n }\n clf = KerasRegressor(build_fn=ANN,**params, verbose=0)\n score = -np.mean(cross_val_score(clf, X, y, cv=3, \n scoring=\"neg_mean_squared_error\"))\n\n return {'loss':score, 'status': STATUS_OK }\n\nspace = {\n \"optimizer\":hp.choice('optimizer',['adam','rmsprop']),\n \"activation\":hp.choice('activation',['relu','tanh']),\n \"loss\":hp.choice('loss',['mse','mae']),\n 'batch_size': hp.quniform('batch_size', 16, 64, 16),\n 'neurons': hp.quniform('neurons', 10, 100, 10),\n 'epochs': hp.quniform('epochs', 20, 50, 10),\n 'patience': hp.quniform('patience', 3, 20, 3),\n}\n\nbest = fmin(fn=objective,\n space=space,\n algo=tpe.suggest,\n max_evals=10)\nprint(\"ANN: Hyperopt estimated optimum {}\".format(best))",
"100%|████████████████████████████████████████████████████| 10/10 [04:50<00:00, 29.06s/it, best loss: 58.39425089889795]\nANN: Hyperopt estimated optimum {'activation': 1, 'patience': 18.0, 'neurons': 80.0, 'batch_size': 32.0, 'loss': 0, 'epochs': 50.0, 'optimizer': 1}\n"
]
],
[
[
"## HPO Algorithm 6: PSO\nPartical swarm optimization (PSO): Each particle in a swarm communicates with other particles to detect and update the current global optimum in each iteration until the final optimum is detected.\n\n**Advantages:**\n* Efficient with all types of HPs.\n* Enable parallelization. \n\n**Disadvantages:** \n* Require proper initialization.",
"_____no_output_____"
]
],
[
[
"#Random Forest\nimport optunity\nimport optunity.metrics\n# Define the hyperparameter configuration space\nsearch = {\n 'n_estimators': [10, 100],\n 'max_features': [1, 13],\n 'max_depth': [5,50],\n \"min_samples_split\":[2,11],\n \"min_samples_leaf\":[1,11],\n }\n# Define the objective function\[email protected]_validated(x=X, y=y, num_folds=3)\ndef performance(x_train, y_train, x_test, y_test,n_estimators=None, max_features=None,max_depth=None,min_samples_split=None,min_samples_leaf=None):\n # fit the model\n model = RandomForestRegressor(n_estimators=int(n_estimators),\n max_features=int(max_features),\n max_depth=int(max_depth),\n min_samples_split=int(min_samples_split),\n min_samples_leaf=int(min_samples_leaf),\n )\n scores=-np.mean(cross_val_score(model, X, y, cv=3, n_jobs=-1,\n scoring=\"neg_mean_squared_error\"))\n return scores\n\noptimal_configuration, info, _ = optunity.minimize(performance,\n solver_name='particle swarm',\n num_evals=20,\n **search\n )\nprint(optimal_configuration)\nprint(\"MSE:\"+ str(info.optimum))",
"{'max_depth': 37.745028056718674, 'min_samples_leaf': 1.2694935979785371, 'min_samples_split': 6.3674769629093, 'n_estimators': 97.73792799268917, 'max_features': 6.383593749999999}\nMSE:26.072547695737644\n"
],
[
"#SVM\nimport optunity\nimport optunity.metrics\nsearch = {\n 'C': (0,50),\n 'kernel':[0,3],\n 'epsilon': (0, 1)\n }\[email protected]_validated(x=X, y=y, num_folds=3)\ndef performance(x_train, y_train, x_test, y_test,C=None,kernel=None,epsilon=None):\n # fit the model\n if kernel<1:\n ke='poly'\n elif kernel<2:\n ke='rbf'\n else:\n ke='sigmoid'\n model = SVR(C=float(C),\n kernel=ke,\n gamma='scale',\n epsilon=float(epsilon)\n )\n\n scores=-np.mean(cross_val_score(model, X, y, cv=3, n_jobs=-1,\n scoring=\"neg_mean_squared_error\"))\n\n return scores\n\noptimal_configuration, info, _ = optunity.minimize(performance,\n solver_name='particle swarm',\n num_evals=20,\n **search\n )\nprint(optimal_configuration)\nprint(\"MSE:\"+ str(info.optimum))",
"{'kernel': 0.4658203125, 'epsilon': 0.4736328125, 'C': 25.341796875}\nMSE:60.25879498950017\n"
],
[
"#KNN\nimport optunity\nimport optunity.metrics\nsearch = {\n 'n_neighbors': [1, 20],\n }\[email protected]_validated(x=X, y=y, num_folds=3)\ndef performance(x_train, y_train, x_test, y_test,n_neighbors=None):\n # fit the model\n model = KNeighborsRegressor(n_neighbors=int(n_neighbors),\n )\n\n scores=-np.mean(cross_val_score(model, X, y, cv=3, n_jobs=-1,\n scoring=\"neg_mean_squared_error\"))\n\n return scores\n\noptimal_configuration, info, _ = optunity.minimize(performance,\n solver_name='particle swarm',\n num_evals=10,\n **search\n )\nprint(optimal_configuration)\nprint(\"MSE:\"+ str(info.optimum))",
"{'n_neighbors': 13.84912109375}\nMSE:80.74121499347262\n"
],
[
"#ANN\nimport optunity\nimport optunity.metrics\nsearch = {\n 'optimizer':[0,2],\n 'activation':[0,2],\n 'loss':[0,2],\n 'batch_size': [0, 2],\n 'neurons': [10, 100],\n 'epochs': [20, 50],\n 'patience': [3, 20],\n }\[email protected]_validated(x=X, y=y, num_folds=3)\ndef performance(x_train, y_train, x_test, y_test,optimizer=None,activation=None,loss=None,batch_size=None,neurons=None,epochs=None,patience=None):\n # fit the model\n if optimizer<1:\n op='adam'\n else:\n op='rmsprop'\n if activation<1:\n ac='relu'\n else:\n ac='tanh'\n if loss<1:\n lo='mse'\n else:\n lo='mae'\n if batch_size<1:\n ba=16\n else:\n ba=32\n model = ANN(optimizer=op,\n activation=ac,\n loss=lo,\n batch_size=ba,\n neurons=int(neurons),\n epochs=int(epochs),\n patience=int(patience)\n )\n clf = KerasRegressor(build_fn=ANN, verbose=0)\n scores=-np.mean(cross_val_score(clf, X, y, cv=3, \n scoring=\"neg_mean_squared_error\"))\n\n return scores\n\noptimal_configuration, info, _ = optunity.minimize(performance,\n solver_name='particle swarm',\n num_evals=20,\n **search\n )\nprint(optimal_configuration)\nprint(\"MSE:\"+ str(info.optimum))",
"{'activation': 0.28555402710064154, 'neurons': 90.55370287990607, 'loss': 1.3789121219831286, 'batch_size': 0.6972214016007146, 'patience': 14.611429743835629, 'epochs': 35.81883196486749, 'optimizer': 1.1613324876783653}\nMSE:39.0195776769448\n"
]
],
[
[
"## HPO Algorithm 7: Genetic Algorithm\nGenetic algorithms detect well-performing hyper-parameter combinations in each generation, and pass them to the next generation until the best-performing combination is identified.\n\n**Advantages:**\n* Efficient with all types of HPs.\n* Not require good initialization.\n \n\n**Disadvantages:** \n* Poor capacity for parallelization.",
"_____no_output_____"
],
[
"### Using DEAP",
"_____no_output_____"
]
],
[
[
"#Random Forest\nfrom evolutionary_search import EvolutionaryAlgorithmSearchCV\nfrom scipy.stats import randint as sp_randint\n# Define the hyperparameter configuration space\nrf_params = {\n 'n_estimators': range(10,100),\n \"max_features\":range(1,13),\n 'max_depth': range(5,50),\n \"min_samples_split\":range(2,11),\n \"min_samples_leaf\":range(1,11),\n \"criterion\":['mse','mae']\n}\nclf = RandomForestRegressor(random_state=0)\n# Set the hyperparameters of GA \nga1 = EvolutionaryAlgorithmSearchCV(estimator=clf,\n params=rf_params,\n scoring=\"neg_mean_squared_error\",\n cv=3,\n verbose=1,\n population_size=10,\n gene_mutation_prob=0.10,\n gene_crossover_prob=0.5,\n tournament_size=3,\n generations_number=5,\n n_jobs=1)\nga1.fit(X, y)\nprint(ga1.best_params_)\nprint(\"MSE:\"+ str(-ga1.best_score_))",
"Types [1, 1, 1, 1, 1, 1] and maxint [1, 89, 44, 8, 11, 9] detected\n--- Evolve in 8748000 possible combinations ---\ngen\tnevals\tavg \tmin \tmax \tstd \n0 \t10 \t-32.0014\t-54.374\t-27.5166\t7.55455\n1 \t6 \t-28.6069\t-31.6563\t-26.2084\t1.44316\n2 \t4 \t-27.7354\t-29.2441\t-26.2084\t1.11775\n3 \t1 \t-26.4502\t-27.5166\t-26.2084\t0.392132\n4 \t2 \t-26.2462\t-26.5859\t-26.2084\t0.113246\n5 \t9 \t-26.4494\t-27.7558\t-26.0528\t0.488179\nBest individual is: {'criterion': 'mse', 'n_estimators': 97, 'max_depth': 29, 'min_samples_split': 7, 'max_features': 8, 'min_samples_leaf': 3}\nwith fitness: -26.052847277193734\n{'criterion': 'mse', 'n_estimators': 97, 'max_depth': 29, 'min_samples_split': 7, 'max_features': 8, 'min_samples_leaf': 3}\nMSE:26.052847277193734\n"
],
[
"#SVM\nfrom evolutionary_search import EvolutionaryAlgorithmSearchCV\nrf_params = {\n 'C': np.random.uniform(0,50,1000),\n \"kernel\":['poly','rbf','sigmoid'],\n 'epsilon': np.random.uniform(0,1,100),\n}\nclf = SVR(gamma='scale')\nga1 = EvolutionaryAlgorithmSearchCV(estimator=clf,\n params=rf_params,\n scoring=\"neg_mean_squared_error\",\n cv=3,\n verbose=1,\n population_size=10,\n gene_mutation_prob=0.10,\n gene_crossover_prob=0.5,\n tournament_size=3,\n generations_number=5,\n n_jobs=1)\nga1.fit(X, y)\nprint(ga1.best_params_)\nprint(\"MSE:\"+ str(-ga1.best_score_))",
"Types [2, 2, 1] and maxint [999, 99, 2] detected\n--- Evolve in 300000 possible combinations ---\ngen\tnevals\tavg \tmin \tmax \tstd \n0 \t10 \t-1622.54\t-7880.66\t-61.3248\t2655.55\n1 \t8 \t-68.6978\t-81.931 \t-61.0316\t8.46914\n2 \t5 \t-64.2231\t-78.2337\t-60.2699\t5.09324\n3 \t2 \t-61.5322\t-65.247 \t-60.2699\t1.32565\n4 \t10 \t-60.9099\t-62.4522\t-59.4154\t0.848694\n5 \t6 \t-60.1359\t-61.5717\t-59.4154\t0.689567\nBest individual is: {'C': 36.961021855583446, 'epsilon': 0.1079957723914794, 'kernel': 'poly'}\nwith fitness: -59.41536985706522\n{'C': 36.961021855583446, 'epsilon': 0.1079957723914794, 'kernel': 'poly'}\nMSE:59.41536985706522\n"
],
[
"#KNN\nfrom evolutionary_search import EvolutionaryAlgorithmSearchCV\nrf_params = {\n 'n_neighbors': range(1,20),\n}\nclf = KNeighborsRegressor()\nga1 = EvolutionaryAlgorithmSearchCV(estimator=clf,\n params=rf_params,\n scoring=\"neg_mean_squared_error\",\n cv=3,\n verbose=1,\n population_size=10,\n gene_mutation_prob=0.10,\n gene_crossover_prob=0.5,\n tournament_size=3,\n generations_number=5,\n n_jobs=1)\nga1.fit(X, y)\nprint(ga1.best_params_)\nprint(\"MSE:\"+ str(-ga1.best_score_))",
"Types [1] and maxint [18] detected\n--- Evolve in 19 possible combinations ---\ngen\tnevals\tavg \tmin \tmax \tstd \n0 \t10 \t-82.2005\t-82.7914\t-80.8702\t0.621814\n1 \t7 \t-81.5525\t-82.7021\t-80.8702\t0.599417\n2 \t8 \t-80.8702\t-80.8702\t-80.8702\t0 \n3 \t8 \t-80.8702\t-80.8702\t-80.8702\t0 \n4 \t10 \t-80.9662\t-81.8295\t-80.8702\t0.287764\n5 \t8 \t-80.8604\t-80.8702\t-80.7723\t0.0293814\nBest individual is: {'n_neighbors': 13}\nwith fitness: -80.7723025469514\n{'n_neighbors': 13}\nMSE:80.7723025469514\n"
],
[
"#ANN\nfrom evolutionary_search import EvolutionaryAlgorithmSearchCV\n# Define the hyperparameter configuration space\nrf_params = {\n 'optimizer': ['adam','rmsprop'],\n 'activation': ['relu','tanh'],\n 'loss': ['mse','mae'],\n 'batch_size': [16,32,64],\n 'neurons':range(10,100),\n 'epochs':[20,50],\n #'epochs':[20,50,100,200],\n 'patience':range(3,20)\n}\nclf = KerasRegressor(build_fn=ANN, verbose=0)\n# Set the hyperparameters of GA \nga1 = EvolutionaryAlgorithmSearchCV(estimator=clf,\n params=rf_params,\n scoring=\"neg_mean_squared_error\",\n cv=3,\n verbose=1,\n population_size=10,\n gene_mutation_prob=0.10,\n gene_crossover_prob=0.5,\n tournament_size=3,\n generations_number=5,\n n_jobs=1)\nga1.fit(X, y)\nprint(ga1.best_params_)\nprint(\"MSE:\"+ str(-ga1.best_score_))",
"Types [1, 1, 1, 1, 1, 1, 1] and maxint [1, 16, 2, 1, 1, 89, 1] detected\n--- Evolve in 73440 possible combinations ---\ngen\tnevals\tavg \tmin \tmax \tstd \n0 \t10 \t-88.4899\t-157.552\t-50.727\t37.5649\n1 \t2 \t-60.9958\t-99.4323\t-50.727\t13.8181\n2 \t8 \t-74.4071\t-174.246\t-50.727\t42.0684\n3 \t7 \t-59.5146\t-138.603\t-50.727\t26.3628\n4 \t3 \t-54.6543\t-90.0003\t-50.727\t11.782 \n5 \t3 \t-50.727 \t-50.727 \t-50.727\t7.10543e-15\nBest individual is: {'patience': 5, 'batch_size': 32, 'loss': 'mse', 'activation': 'relu', 'optimizer': 'rmsprop', 'neurons': 30, 'epochs': 50}\nwith fitness: -50.72700946933739\n{'patience': 5, 'batch_size': 32, 'loss': 'mse', 'activation': 'relu', 'optimizer': 'rmsprop', 'neurons': 30, 'epochs': 50}\nMSE:50.72700946933739\n"
]
],
[
[
"### Using TPOT",
"_____no_output_____"
]
],
[
[
"#Random Forest\nfrom tpot import TPOTRegressor\n# Define the hyperparameter configuration space\nparameters = {\n 'n_estimators': range(20,200),\n \"max_features\":range(1,13),\n 'max_depth': range(10,100),\n \"min_samples_split\":range(2,11),\n \"min_samples_leaf\":range(1,11),\n #\"criterion\":['mse','mae']\n }\n# Set the hyperparameters of GA \nga2 = TPOTRegressor(generations= 3, population_size= 10, offspring_size= 5,\n verbosity= 3, early_stop= 5,\n config_dict=\n {'sklearn.ensemble.RandomForestRegressor': parameters}, \n cv = 3, scoring = 'neg_mean_squared_error')\nga2.fit(X, y)",
"1 operators have been imported by TPOT.\nGeneration 1 - Current Pareto front scores:\n-1\t-27.250793005044518\tRandomForestRegressor(input_matrix, RandomForestRegressor__max_depth=78, RandomForestRegressor__max_features=5, RandomForestRegressor__min_samples_leaf=2, RandomForestRegressor__min_samples_split=9, RandomForestRegressor__n_estimators=168)\n-2\t-25.332016721242965\tRandomForestRegressor(RandomForestRegressor(input_matrix, RandomForestRegressor__max_depth=62, RandomForestRegressor__max_features=4, RandomForestRegressor__min_samples_leaf=5, RandomForestRegressor__min_samples_split=6, RandomForestRegressor__n_estimators=34), RandomForestRegressor__max_depth=78, RandomForestRegressor__max_features=5, RandomForestRegressor__min_samples_leaf=2, RandomForestRegressor__min_samples_split=9, RandomForestRegressor__n_estimators=168)\n\nGeneration 2 - Current Pareto front scores:\n-1\t-27.250793005044518\tRandomForestRegressor(input_matrix, RandomForestRegressor__max_depth=78, RandomForestRegressor__max_features=5, RandomForestRegressor__min_samples_leaf=2, RandomForestRegressor__min_samples_split=9, RandomForestRegressor__n_estimators=168)\n-2\t-25.332016721242965\tRandomForestRegressor(RandomForestRegressor(input_matrix, RandomForestRegressor__max_depth=62, RandomForestRegressor__max_features=4, RandomForestRegressor__min_samples_leaf=5, RandomForestRegressor__min_samples_split=6, RandomForestRegressor__n_estimators=34), RandomForestRegressor__max_depth=78, RandomForestRegressor__max_features=5, RandomForestRegressor__min_samples_leaf=2, RandomForestRegressor__min_samples_split=9, RandomForestRegressor__n_estimators=168)\n\nGeneration 3 - Current Pareto front scores:\n-1\t-27.250793005044518\tRandomForestRegressor(input_matrix, RandomForestRegressor__max_depth=78, RandomForestRegressor__max_features=5, RandomForestRegressor__min_samples_leaf=2, RandomForestRegressor__min_samples_split=9, RandomForestRegressor__n_estimators=168)\n-2\t-24.584400304272155\tRandomForestRegressor(RandomForestRegressor(input_matrix, RandomForestRegressor__max_depth=38, RandomForestRegressor__max_features=5, RandomForestRegressor__min_samples_leaf=7, RandomForestRegressor__min_samples_split=2, RandomForestRegressor__n_estimators=45), RandomForestRegressor__max_depth=81, RandomForestRegressor__max_features=5, RandomForestRegressor__min_samples_leaf=1, RandomForestRegressor__min_samples_split=7, RandomForestRegressor__n_estimators=103)\n\n"
],
[
"#SVM\nfrom tpot import TPOTRegressor\n\nparameters = {\n 'C': np.random.uniform(0,50,1000),\n \"kernel\":['poly','rbf','sigmoid'],\n 'epsilon': np.random.uniform(0,1,100),\n 'gamma': ['scale']\n }\n \nga2 = TPOTRegressor(generations= 3, population_size= 10, offspring_size= 5,\n verbosity= 3, early_stop= 5,\n config_dict=\n {'sklearn.svm.SVR': parameters}, \n cv = 3, scoring = 'neg_mean_squared_error')\nga2.fit(X, y)",
"1 operators have been imported by TPOT.\nGeneration 1 - Current Pareto front scores:\n-1\t-76.22342756605103\tSVR(CombineDFs(input_matrix, input_matrix), SVR__C=9.66289149097888, SVR__epsilon=0.6491076078954555, SVR__gamma=scale, SVR__kernel=rbf)\n-2\t-61.22653072468754\tSVR(SVR(CombineDFs(input_matrix, input_matrix), SVR__C=2.988848947755768, SVR__epsilon=0.31470079088508107, SVR__gamma=scale, SVR__kernel=poly), SVR__C=49.38466344757709, SVR__epsilon=0.9554593389709706, SVR__gamma=scale, SVR__kernel=poly)\n\nGeneration 2 - Current Pareto front scores:\n-1\t-73.46312983258913\tSVR(input_matrix, SVR__C=9.66289149097888, SVR__epsilon=0.6491076078954555, SVR__gamma=scale, SVR__kernel=poly)\n-2\t-61.22653072468754\tSVR(SVR(CombineDFs(input_matrix, input_matrix), SVR__C=2.988848947755768, SVR__epsilon=0.31470079088508107, SVR__gamma=scale, SVR__kernel=poly), SVR__C=49.38466344757709, SVR__epsilon=0.9554593389709706, SVR__gamma=scale, SVR__kernel=poly)\n\nGeneration 3 - Current Pareto front scores:\n-1\t-59.46539136594907\tSVR(input_matrix, SVR__C=40.42400106501475, SVR__epsilon=0.09227083238549583, SVR__gamma=scale, SVR__kernel=poly)\n\n"
],
[
"#KNN\nfrom tpot import TPOTRegressor\n\nparameters = {\n 'n_neighbors': range(1,20),\n }\n \nga2 = TPOTRegressor(generations= 3, population_size= 10, offspring_size= 5,\n verbosity= 3, early_stop= 5,\n config_dict=\n {'sklearn.neighbors.KNeighborsRegressor': parameters}, \n cv = 3, scoring = 'neg_mean_squared_error')\nga2.fit(X, y)",
"1 operators have been imported by TPOT.\nGeneration 1 - Current Pareto front scores:\n-1\t-80.83005201647829\tKNeighborsRegressor(input_matrix, KNeighborsRegressor__n_neighbors=6)\n\nPipeline encountered that has previously been evaluated during the optimization process. Using the score from the previous evaluation.\nGeneration 2 - Current Pareto front scores:\n-1\t-80.83005201647829\tKNeighborsRegressor(input_matrix, KNeighborsRegressor__n_neighbors=6)\n\nPipeline encountered that has previously been evaluated during the optimization process. Using the score from the previous evaluation.\nGeneration 3 - Current Pareto front scores:\n-1\t-80.83005201647829\tKNeighborsRegressor(input_matrix, KNeighborsRegressor__n_neighbors=6)\n\n\nThe optimized pipeline was not improved after evaluating 5 more generations. Will end the optimization process.\n\nTPOT closed prematurely. Will use the current best pipeline.\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
cb32fe56d617f1822a1d3d8812151fdc8a07d4de | 81,596 | ipynb | Jupyter Notebook | HW_4_pixelcnn.ipynb | rtkn07/dl_hse_intensive | 83815c492c7c423035598519ec9e2ab8908fb652 | [
"Unlicense"
] | null | null | null | HW_4_pixelcnn.ipynb | rtkn07/dl_hse_intensive | 83815c492c7c423035598519ec9e2ab8908fb652 | [
"Unlicense"
] | null | null | null | HW_4_pixelcnn.ipynb | rtkn07/dl_hse_intensive | 83815c492c7c423035598519ec9e2ab8908fb652 | [
"Unlicense"
] | null | null | null | 107.363158 | 17,584 | 0.813986 | [
[
[
"# Нейросети и вероятностные модели\n\n**Разработчик: Алексей Умнов**",
"_____no_output_____"
],
[
"# Авторегрессионные модели\n\nМы поработаем с авторегрессионными моделями на примере архитектуры PixelCNN. Мы обучим модель для задачи генерации изображений и для задачи дорисовывания недостающих частей изображения.",
"_____no_output_____"
],
[
"### LCD digits dataset\n\nВ качестве примера мы возьмем датасет из простых LCD-цифр. Ниже приведен код, который его загружает и рисует примеры сэмплов.\n\nИсточник датасета: https://gist.github.com/benjaminwilson/b25a321f292f98d74269b83d4ed2b9a8#file-lcd-digits-dataset-nmf-ipynb",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport pickle\nimport numpy as np\nfrom matplotlib import pyplot as plt\nimport torch\nfrom torch.utils.data import DataLoader\nimport torch.nn as nn\nfrom torchvision import datasets, utils",
"_____no_output_____"
],
[
"from utils import LcdDigits, IMAGE_WIDTH, IMAGE_HEIGHT\n\nBATCH_SIZE = 100\n\ntrain_dataset = LcdDigits(BATCH_SIZE * 50)\ntrain_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE)\n\n\ndef show_as_image(image, figsize=(10, 5)):\n plt.figure(figsize=figsize)\n plt.imshow(image, cmap='gray')\n plt.xticks([]); plt.yticks([])\n \ndef batch_images_to_one(batches_images):\n n_square_elements = int(np.sqrt(batches_images.shape[0]))\n rows_images = np.split(np.squeeze(batches_images), n_square_elements)\n return np.vstack([np.hstack(row_images) for row_images in rows_images])\n\nfor batch, _ in train_loader:\n show_as_image(batch_images_to_one(batch[:25]), figsize=(10, 10))\n break",
"_____no_output_____"
]
],
[
[
"Здесь специально выбран простой датасет, так как вероятностные модели обычно требуют больших ресурсов. Также обратите внимание, что хотя данные очень простые (фактически всего 10 разных сэмплов), они находятся в пространстве значительно большей размерности ($2^{8 \\times 13}$). Мы будем подавать модели сырые пиксели на вход, и будем хотеть, чтобы она нашла в них правильные зависимости и научилась строить только валидные изображения.",
"_____no_output_____"
],
[
"### PixelCNN\n\nКоротко вспомним, что такое PixelCNN. Авторегрессионные модели в общем виде моделируют распределения на векторах $x = (x_1, \\ldots, x_N)$ в виде:\n\n$$\n p(x) = \\prod_{i=1}^{N} p(x_i \\mid x_1, \\ldots, x_{i-1}).\n$$\n\nРаспределения $p(x_i \\mid x_1, \\ldots, x_{i-1})$ можно моделировать при помощи нейронных сетей, которые получают на вход значения $x_1, \\ldots, x_{i-1}$ и выдают распределение вероятностей для значений $x_i$. Так как входов здесь переменное число, можно использовать рекуррентные сети (например, PixelRNN), но неплохо работает и более простая модель — PixelCNN, — которая подает на вход не все значения $x_1, \\ldots, x_{i-1}$, а только соседние на некотором расстоянии с помощью сверточных слоев.\n\n",
"_____no_output_____"
],
[
"\n\nДля того, чтобы для данного пикселя подавать на вход только значения идущие ранее, вместо обычных сверток нужно использовать маскированные свертки. Напишите недостающий код, чтобы создать соответствующие маски и потом сделайте из них слой для pytorch. Такие слои можно добавлять последовательно, сохраняя корректные зависимости, при этом во всех слоях кроме первого можно использовать центральный пиксель. У вас должны получаться вот такие маски (с `include_center=False` и с `include_center=True` соответственно):\n\n\n\n\nHint: можно умножить на маску не входы, а веса.",
"_____no_output_____"
]
],
[
[
"def causal_mask(width, height, starting_point):\n \n mask = torch.cat((\n torch.ones(starting_point[0], height),\n torch.cat((\n torch.ones(1, starting_point[1] + 1),\n torch.zeros(1, height - starting_point[1] - 1)\n ), 1),\n torch.zeros(width - starting_point[0] - 1, height)\n ), 0)\n return mask.numpy()\n\ndef conv_mask(height, width, include_center=False):\n cm = causal_mask(\n width, height, \n starting_point=(height//2, width//2 + include_center - 1))\n return 1.0 * torch.Tensor(cm)",
"_____no_output_____"
],
[
"conv_mask(5, 5, True)",
"_____no_output_____"
],
[
"class MaskedConv2d(nn.Conv2d):\n def __init__(self, include_center, *args, **kwargs):\n super(MaskedConv2d, self).__init__(*args, **kwargs)\n self.include_center = include_center\n cm = conv_mask(\n *self.weight.data.shape[2:], include_center\n )\n self.weight.data = torch.matmul(cm, self.weight)\n \n # YOUR CODE\n ",
"_____no_output_____"
]
],
[
[
"\n\nТеперь соберите сеть с несколькими слоями маскированных сверток и обучите ее.\n\nHint 1: в задаче хорошо помогает сверточный слой 1x1 в конце.\n\nHint 2: если ошибиться и нарушить казуальность (т.е. сделать зависимости вперед), то обучаться будет хорошо, а генерировать плохо.",
"_____no_output_____"
]
],
[
[
"class PixelCNN(nn.Module):\n N_PIXELS_OUT = 2 # binary 0/1 pixels\n \n def __init__(self, n_channels, kernel_size, padding):\n super(PixelCNN, self).__init__()\n self.layers = nn.Sequential(\n MaskedConv2d(\n False,\n in_channels=1,\n out_channels=n_channels,\n kernel_size=kernel_size,\n padding=padding\n ),\n nn.BatchNorm2d(n_channels),\n nn.ReLU(),\n MaskedConv2d(\n True,\n in_channels=n_channels,\n out_channels=n_channels,\n kernel_size=kernel_size,\n padding=padding\n ),\n nn.BatchNorm2d(n_channels),\n nn.ReLU(),\n MaskedConv2d(\n True,\n in_channels=n_channels,\n out_channels=n_channels,\n kernel_size=kernel_size,\n padding=padding\n ),\n nn.BatchNorm2d(n_channels),\n nn.ReLU(),\n MaskedConv2d(\n True,\n in_channels=n_channels,\n out_channels=n_channels,\n kernel_size=kernel_size,\n padding=padding\n ),\n nn.BatchNorm2d(n_channels),\n nn.ReLU(),\n MaskedConv2d(\n True,\n in_channels=n_channels,\n out_channels=n_channels,\n kernel_size=kernel_size,\n padding=padding\n ),\n nn.BatchNorm2d(n_channels),\n nn.ReLU(),\n MaskedConv2d(\n True,\n in_channels=n_channels,\n out_channels=n_channels,\n kernel_size=kernel_size,\n padding=padding\n ),\n nn.BatchNorm2d(n_channels),\n nn.ReLU(),\n MaskedConv2d(\n True,\n in_channels=n_channels,\n out_channels=n_channels,\n kernel_size=kernel_size,\n padding=padding\n ),\n nn.BatchNorm2d(n_channels),\n nn.ReLU(),\n MaskedConv2d(\n True,\n in_channels=n_channels,\n out_channels=n_channels,\n kernel_size=kernel_size,\n padding=padding\n ),\n nn.BatchNorm2d(n_channels),\n nn.ReLU(),\n MaskedConv2d(\n True,\n in_channels=n_channels,\n out_channels=n_channels,\n kernel_size=kernel_size,\n padding=padding\n ),\n nn.BatchNorm2d(n_channels),\n nn.ReLU(),\n MaskedConv2d(\n True,\n in_channels=n_channels,\n out_channels=n_channels,\n kernel_size=kernel_size,\n padding=padding\n ),\n nn.BatchNorm2d(n_channels),\n nn.ReLU(),\n MaskedConv2d(\n True,\n in_channels=n_channels,\n out_channels=n_channels,\n kernel_size=kernel_size,\n padding=padding\n ),\n nn.BatchNorm2d(n_channels),\n nn.ReLU(),\n MaskedConv2d(\n True,\n in_channels=n_channels,\n out_channels=n_channels,\n kernel_size=kernel_size,\n padding=padding\n ),\n nn.BatchNorm2d(n_channels),\n nn.ReLU(),\n MaskedConv2d(\n True,\n in_channels=n_channels,\n out_channels=n_channels,\n kernel_size=kernel_size,\n padding=padding\n ),\n nn.BatchNorm2d(n_channels),\n nn.ReLU(),\n MaskedConv2d(\n True,\n in_channels=n_channels,\n out_channels=n_channels,\n kernel_size=kernel_size,\n padding=padding\n ),\n nn.BatchNorm2d(n_channels),\n nn.ReLU(),\n nn.Conv2d(\n in_channels=n_channels,\n out_channels=self.N_PIXELS_OUT,\n kernel_size=(1, 1)\n )\n )\n \n # YOUR CODE\n \n def forward(self, x):\n pixel_logits = self.layers(x)\n return pixel_logits",
"_____no_output_____"
],
[
"N_EPOCHS = 25\nLR = 0.005\n\ncnn = PixelCNN(n_channels=4, kernel_size=7, padding=3)\noptimizer = torch.optim.Adam(cnn.parameters(), lr=LR)",
"_____no_output_____"
]
],
[
[
"Обратите внимание, что полученной сети достаточно подать на вход изображение, и на выходе получится распределение для значений каждого пикселя. Осталось только минимизировать кросс-энтропию этих значений и пикселей примеров в выборке. В случае успеха итоговая кросс-энтропия будет около 0.02.",
"_____no_output_____"
]
],
[
[
"import torch.nn.functional as F\n\n\nfor epoch in range(N_EPOCHS):\n for i, (images, _) in enumerate(train_loader):\n optimizer.zero_grad()\n \n # TRAIN\n output = cnn(images)\n target = images[:,0].long()\n loss = F.cross_entropy(output, target)\n pickle.dump(output, open(\"./output.pkl\", \"wb\"))\n \n \n # YOUR CODE\n \n loss.backward()\n optimizer.step()\n \n if i % 100 == 0:\n print ('Epoch [%d/%d], Loss: %.4f' \n %(epoch+1, N_EPOCHS, loss.data.item()))",
"Epoch [1/25], Loss: 0.6623\nEpoch [2/25], Loss: 0.2767\nEpoch [3/25], Loss: 0.1260\nEpoch [4/25], Loss: 0.0274\nEpoch [5/25], Loss: 0.0081\nEpoch [6/25], Loss: 0.0041\nEpoch [7/25], Loss: 0.0028\nEpoch [8/25], Loss: 0.0020\nEpoch [9/25], Loss: 0.0015\nEpoch [10/25], Loss: 0.0012\nEpoch [11/25], Loss: 0.0010\nEpoch [12/25], Loss: 0.0008\nEpoch [13/25], Loss: 0.0007\nEpoch [14/25], Loss: 0.0006\nEpoch [15/25], Loss: 0.0005\nEpoch [16/25], Loss: 0.0005\nEpoch [17/25], Loss: 0.0004\nEpoch [18/25], Loss: 0.0004\nEpoch [19/25], Loss: 0.0003\nEpoch [20/25], Loss: 0.0003\nEpoch [21/25], Loss: 0.0003\nEpoch [22/25], Loss: 0.0002\nEpoch [23/25], Loss: 0.0002\nEpoch [24/25], Loss: 0.0002\nEpoch [25/25], Loss: 0.0002\n"
]
],
[
[
"\n\nПри генерации изображений можно начинать с пустого изображения, а можно подавать какие-то начальные пиксели. Допишите функцию генерации и проверьте ее для задачи генерации (на вход пустое изображения) и для задачи дорисовывания (на вход - верхняя часть изображения).\n\nУ вас должны получиться разумные изображения цифр, допускается небольшая доля \"плохих\" изображений.\n\n*Упражнение:* почему при одинаковых пустых входных изображениях получаются разные изображения на выходе?",
"_____no_output_____"
]
],
[
[
"data = pickle.load(open(\"./out.pkl\", \"rb\"))\ndata_1 = data[:, 0, :, :].view(-1, 1, 13, 8)\ndata_2 = data[:, 1, :, :].view(-1, 1, 13, 8)\n\nprint(f\"\"\"\ndata1: {data_1.shape}\ndata2: {data_2.shape}\n\"\"\")\n\nshow_as_image(batch_images_to_one(data_1.detach().numpy()), figsize=(10, 20))\nshow_as_image(batch_images_to_one(data_2.detach().numpy()), figsize=(10, 20))",
"\ndata1: torch.Size([100, 1, 13, 8])\ndata2: torch.Size([100, 1, 13, 8])\n\n"
],
[
"# def generate_samples(n_samples, starting_point=(0, 0), starting_image=None):\n\n# samples = torch.from_numpy(\n# starting_image if starting_image is not None else \n# np.zeros((n_samples * n_samples, 1, IMAGE_HEIGHT, IMAGE_WIDTH))).float()\n\n# cnn.train(False)\n# optimizer.zero_grad()\n# out = cnn(samples)\n \n# sm_layer = nn.Softmax()\n# samples = sm_layer(out)\n# dist = torch.distributions.Multinomial(1000, samples)\n# samples = dist.sample().detach()\n# samples = samples[:,0].view(-1, 1, 13, 8)\n# return samples.detach().numpy()\n\n\n# def generate_samples(n_samples, starting_point=(0, 0), starting_image=None):\n\n# samples = torch.from_numpy(\n# starting_image if starting_image is not None else \n# np.zeros((n_samples * n_samples, 1, IMAGE_HEIGHT, IMAGE_WIDTH))).float()\n\n# cnn.train(False)\n# optimizer.zero_grad()\n# out = cnn(samples)\n# samples = F.softmax(out)\n# samples = -1 * (samples - 1)\n# samples = torch.bernoulli(samples)\n# samples = samples.detach()[:,0].view(-1, 1, 13, 8)\n# return samples.numpy()\n\n\n\ndef generate_samples(n_samples, starting_point=(0, 0), starting_image=None):\n\n samples = torch.from_numpy(\n starting_image if starting_image is not None else \n np.zeros((n_samples * n_samples, 1, IMAGE_HEIGHT, IMAGE_WIDTH))).float()\n\n cnn.train(False)\n optimizer.zero_grad()\n out = cnn(samples)\n _, samples = torch.max(out, 1)\n# samples = samples[0].view(-1, 1, 13, 8)\n return samples.numpy()\n\n\n# def binarize(images):\n# return (np.random.uniform(size=images.shape) < images).astype('float32')\n\n\n# def generate_samples(n_samples, starting_point=(0, 0), starting_image=None):\n\n# samples = torch.from_numpy(\n# starting_image if starting_image is not None else \n# np.zeros((n_samples * n_samples, 1, IMAGE_HEIGHT, IMAGE_WIDTH))).float()\n\n# cnn.train(False)\n# optimizer.zero_grad()\n# out = cnn(samples)\n \n# pickle.dump(out, open(\"./out.pkl\", \"wb\"))\n \n# prob = F.softmax(out, dim=1)\n\n# samples = torch.zeros((100, 1, 13, 8))\n\n\n# for k in range(100):\n# for i in range(13):\n# for j in range(8):\n# n_samples = torch.multinomial(prob[:, :, i, j].view(-1), 1)\n# samples[k, 0, i, j] = n_samples\n# return samples.detach().numpy()\n\n\n# def generate_samples(n_samples, starting_point=(0, 0), starting_image=None):\n\n# samples = torch.from_numpy(\n# starting_image if starting_image is not None else \n# np.zeros((n_samples * n_samples, 1, IMAGE_HEIGHT, IMAGE_WIDTH))).float()\n\n# cnn.train(False)\n# optimizer.zero_grad()\n# out = cnn(samples)\n# samples_tensors = []\n# for k in range(out.shape[0]):\n# t_pair = out[k].view(2, 13, 8)\n# prob = F.softm(t_pair)\n# sample = torch.multinomial(prob.view(13*8, 2), 1)\n# samples_tensors.append(sample)\n \n# samples = torch.cat(samples_tensors).view(-1, 1, 13, 8)\n# samples = samples.detach()\n# return samples\n\n\nshow_as_image(batch_images_to_one(generate_samples(n_samples=10)), figsize=(10, 20))",
"_____no_output_____"
],
[
"from utils import random_digits\n\nn_images = 10\nstarting_point = (4, 3)\n\nmask = causal_mask(IMAGE_HEIGHT, IMAGE_WIDTH, starting_point)\n\nstarting_images = digits_list = [random_digits(fixed_label=d)[0] for d in range(10)]\nbatch_starting_images = np.expand_dims(np.stack([i * mask for i in starting_images] * n_images), axis=1)\n\nsamples = generate_samples(n_images, starting_image=batch_starting_images, starting_point=starting_point)\n\nshow_as_image(np.hstack([(1 + mask) * i for i in starting_images]), figsize=(10, 10))\n\nshow_as_image(\n batch_images_to_one((samples * (1 + mask))),\n figsize=(10, 20))",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
cb33222971acc87e3e192eadcd8badf4dd63416c | 413,531 | ipynb | Jupyter Notebook | 1.1.MachineLearning/Chapter3/Task3.ipynb | mihaighidoveanu/machine-learning-examples | e5a7ab71e52ae2809115eb7d7c943b46ebf394f3 | [
"MIT"
] | null | null | null | 1.1.MachineLearning/Chapter3/Task3.ipynb | mihaighidoveanu/machine-learning-examples | e5a7ab71e52ae2809115eb7d7c943b46ebf394f3 | [
"MIT"
] | null | null | null | 1.1.MachineLearning/Chapter3/Task3.ipynb | mihaighidoveanu/machine-learning-examples | e5a7ab71e52ae2809115eb7d7c943b46ebf394f3 | [
"MIT"
] | 1 | 2021-05-02T13:12:21.000Z | 2021-05-02T13:12:21.000Z | 116.750706 | 83,658 | 0.793791 | [
[
[
"%reload_ext autoreload\n%autoreload 2\n%matplotlib inline\n\n# enable outputs \nfrom IPython.core.interactiveshell import InteractiveShell\nInteractiveShell.ast_node_interactivity = \"all\"\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport tensorflow as tf\nfrom tensorflow import keras",
"_____no_output_____"
],
[
"from google.colab import files\n# upload data_generator file\nfiles.upload()\n",
"_____no_output_____"
]
],
[
[
"# Number classification\n\nFor our first task, we will build a **CNN** that will learn to identify which number appears in a image\n\n## Data at hand\nOur dataset was created by applying random transformations to digit images in MNIST database , concatenating them and afterwards padding the final image. \nThe results consist of images of maximum three digit numbers, ranging from **0 to 255**. Each image is **28x84** and has 1 channel of colour, grayscale.\n\nOur dataset is created on demand as explained above by two generator functions, *training_generator* and *test_generator*. These generator functions return a pair of images as described above, a pair of labels with the numbers in the images, and a label with the sum of these numbers.\n\n## Input preprocessing\n\nWe create a wrapper for the given generator and unfold the pair of images and the pair of corresponding labels into an array of images and an array of labels. We will also normalize pixels by *dividing each of the pixel value by 255*.\n\n## To generate or not to generate\n\nGenerators enable us to **train** and **evaluate** our model by not loading all data into memory. But this will increase fitting and testing times. \n\nThis notebook ran in a *Google Colab* environment, that managed our workload well. **60000 training samples** and **6000 testing samples** were used.",
"_____no_output_____"
]
],
[
[
"# define generator wrapper and function to generate data based on a generator\nfrom data_generator import training_generator, test_generator\n\n# unpack array of pairs of images into an array\ndef seq_gen(generator, batch_size = 32):\n # a sample in generator will create pairs of two numbers.\n # So we halve the test size\n for batch in generator(batch_size // 2):\n x_new_batch = []\n y_new_batch = []\n x_batch , y_batch, sum_batch = batch\n for x_sample in x_batch:\n x_new_batch.append(x_sample[0])\n x_new_batch.append(x_sample[1])\n for y_sample in y_batch:\n y_new_batch.append(y_sample[0])\n y_new_batch.append(y_sample[1])\n yield (np.array(x_new_batch), np.array(y_new_batch), sum_batch)\n \n#function to extract a batch from generator\ndef generate_data(generator):\n x_samples = []\n y_samples = []\n x_samples, y_samples, sum_samples = next(generator)\n x_samples = x_samples / 255.0\n x_samples = np.expand_dims(x_samples, -1)\n return x_samples, y_samples, sum_samples\n\n ",
"_____no_output_____"
],
[
"%%time\ntrain_size = 60000\ntest_size = 6000\nseq_train_gen = seq_gen(training_generator, train_size)\nX_train, Y_train, _ = generate_data(seq_train_gen)\nseq_test_gen = seq_gen(test_generator, test_size)\nX_test, Y_test, _ = generate_data(seq_train_gen)\n",
"CPU times: user 4min 30s, sys: 528 ms, total: 4min 31s\nWall time: 4min 31s\n"
]
],
[
[
"## Data Exploration\nTake a look at how some of the images look like.",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(10,10))\nfor i in range(25):\n plt.subplot(5,5,i+1)\n plt.xticks([])\n plt.yticks([])\n plt.grid(False)\n plt.imshow(X_train.squeeze()[i], cmap=plt.cm.binary)\n plt.xlabel(Y_train[i])",
"_____no_output_____"
]
],
[
[
"For our model to work at its best, data should be **balanced**. So we check if all present labels have, with some approximation, the same number of occurences in our data.\n\n",
"_____no_output_____"
]
],
[
[
"labels, counts = np.unique(Y_train, return_counts=True)\nfig, ax = plt.subplots()\nfig.suptitle('Count distribution of samples by classes', fontsize=16);\nprint('Media aparitiilor : %.2f' % (counts.mean()))\nprint('Cea mai rar intalnita clasa apare de %d ori' % (counts.min()))\nprint('Cea mai des intalnita clasa apare de %d ori.' % (counts.max()))\n# ax.bar(labels, counts )\ncounts_p = counts / sum(counts)\nax.set_xlabel('Number of occurences');\nax.set_ylabel('Number of classes');\nax.hist(counts);",
"Media aparitiilor : 235.29\nCea mai rar intalnita clasa apare de 189 ori\nCea mai des intalnita clasa apare de 293 ori.\n"
]
],
[
[
"## Model Arhitecture\n\nWe use **3 Convolutional layers** , followed by **MaxPooling** to train filters to extract relevant information from the image. \nNumber of filters in the first layer is usually chosen smaller than at following layers because simpler features are usually extracted in the first layer : things like digit contours and shapes. \n\nWe follow each of these with a **Dropout** layer of *0.4* dropout rate. We tried values ranging from 0.2 to 0.5 and model scores didn't vary much. \n\nWe then **flatten** the output and add an additional **Dense** layer of *128* neurons.\n\nFinally, we get the network result by adding a **Dense** layer with **softmax**. The rest of the layers are activated using **relu**.\n\nWe tried **sgd**, **adam** and **rmsprop** as the optimizers of the problem. Even though *rmsprop* is usually used at rnn networks, it worked best here. The *sgd* trained slower than the others and *adam* gave comparable but smaller results than *rmsprop*.",
"_____no_output_____"
]
],
[
[
"model = tf.keras.models.Sequential()\nmodel.add(tf.keras.layers.Conv2D(32, (3, 3), activation = 'relu', input_shape = (28, 84, 1)))\nmodel.add(tf.keras.layers.MaxPooling2D(2, 2))\nmodel.add(tf.keras.layers.Dropout(0.5))\nmodel.add(tf.keras.layers.Conv2D(64, (3, 3), activation = 'relu'))\nmodel.add(tf.keras.layers.MaxPooling2D(2, 2))\nmodel.add(tf.keras.layers.Dropout(0.5))\nmodel.add(tf.keras.layers.Conv2D(64, (3, 3), activation = 'relu'))\nmodel.add(tf.keras.layers.Flatten())\nmodel.add(tf.keras.layers.Dense(128, activation = 'relu'))\n# model.add(tf.keras.layers.Dropout(0.5))\nmodel.add(tf.keras.layers.Dense(256, activation = 'softmax'))\n\nmodel.summary()\n# rmsprop pare cel mai bun, dar e recomandat pentru rnn-uri. \n# Mai încearca si cu adam si cu asta\n# pentru input = 10000 (.3 split), cu 25 de epoci se ajunge la 75-80%\n# pentru input = 60000 (.3 split), cu 5-10 epoci se ajunge la 70-80%\n#rmsprop - 25 (27 val)\n#sgd - 0.7\n#adam - 26\nmodel.compile(optimizer = 'rmsprop', loss = 'categorical_crossentropy', metrics = ['accuracy'])\n",
"_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nconv2d_33 (Conv2D) (None, 26, 82, 32) 320 \n_________________________________________________________________\nmax_pooling2d_22 (MaxPooling (None, 13, 41, 32) 0 \n_________________________________________________________________\ndropout_26 (Dropout) (None, 13, 41, 32) 0 \n_________________________________________________________________\nconv2d_34 (Conv2D) (None, 11, 39, 64) 18496 \n_________________________________________________________________\nmax_pooling2d_23 (MaxPooling (None, 5, 19, 64) 0 \n_________________________________________________________________\ndropout_27 (Dropout) (None, 5, 19, 64) 0 \n_________________________________________________________________\nconv2d_35 (Conv2D) (None, 3, 17, 64) 36928 \n_________________________________________________________________\nflatten_12 (Flatten) (None, 3264) 0 \n_________________________________________________________________\ndense_21 (Dense) (None, 128) 417920 \n_________________________________________________________________\ndense_22 (Dense) (None, 256) 33024 \n=================================================================\nTotal params: 506,688\nTrainable params: 506,688\nNon-trainable params: 0\n_________________________________________________________________\n"
]
],
[
[
"## Data preprocessing\nOur labels are numbers ranging from 0 to 255. We will **one-hot encode** these labels to be compliant with the network arhitecture.",
"_____no_output_____"
]
],
[
[
"from keras.utils import to_categorical\nY_train_OH = to_categorical(Y_train, num_classes=256)\nY_test_OH = to_categorical(Y_test, num_classes = 256)",
"_____no_output_____"
]
],
[
[
"For proper evaluation of the model and to avoid overfitting, we split train data into training and validation samples. We will fit our model on the train samples, but evaluate its performance after an epoch of training on the validation samples.",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split\nx_train, x_val, y_train, y_val = train_test_split(X_train, Y_train_OH, test_size = 0.3, random_state = 48)\nx_test = X_test\ny_test = Y_test_OH\n",
"_____no_output_____"
]
],
[
[
"## Fitting\nWe save the weights of the model with the best results on the validation set.",
"_____no_output_____"
]
],
[
[
"no_epochs = 30\n# save best model in hdf5 file\ncheckpointer = keras.callbacks.ModelCheckpoint(filepath=\"numbers_2.hdf5\", verbose=1, save_best_only=True)\nhistory = model.fit(x_train, y_train, epochs=no_epochs, validation_data= (x_val, y_val) , callbacks=[checkpointer])",
"Train on 42000 samples, validate on 18000 samples\nEpoch 1/30\n41920/42000 [============================>.] - ETA: 0s - loss: 3.5271 - acc: 0.2211\nEpoch 00001: val_loss improved from inf to 1.71302, saving model to numbers_2.hdf5\n42000/42000 [==============================] - 30s 720us/step - loss: 3.5247 - acc: 0.2215 - val_loss: 1.7130 - val_acc: 0.5633\nEpoch 2/30\n41984/42000 [============================>.] - ETA: 0s - loss: 1.3470 - acc: 0.6588\nEpoch 00002: val_loss improved from 1.71302 to 0.90095, saving model to numbers_2.hdf5\n42000/42000 [==============================] - 15s 353us/step - loss: 1.3468 - acc: 0.6588 - val_loss: 0.9009 - val_acc: 0.7926\nEpoch 3/30\n41920/42000 [============================>.] - ETA: 0s - loss: 0.8941 - acc: 0.7839\nEpoch 00003: val_loss improved from 0.90095 to 0.70320, saving model to numbers_2.hdf5\n42000/42000 [==============================] - 15s 348us/step - loss: 0.8940 - acc: 0.7839 - val_loss: 0.7032 - val_acc: 0.8426\nEpoch 4/30\n41920/42000 [============================>.] - ETA: 0s - loss: 0.7318 - acc: 0.8280\nEpoch 00004: val_loss improved from 0.70320 to 0.62536, saving model to numbers_2.hdf5\n42000/42000 [==============================] - 15s 347us/step - loss: 0.7318 - acc: 0.8280 - val_loss: 0.6254 - val_acc: 0.8599\nEpoch 5/30\n41888/42000 [============================>.] - ETA: 0s - loss: 0.6534 - acc: 0.8472\nEpoch 00005: val_loss improved from 0.62536 to 0.59966, saving model to numbers_2.hdf5\n42000/42000 [==============================] - 15s 347us/step - loss: 0.6536 - acc: 0.8471 - val_loss: 0.5997 - val_acc: 0.8699\nEpoch 6/30\n41824/42000 [============================>.] - ETA: 0s - loss: 0.6100 - acc: 0.8566\nEpoch 00006: val_loss improved from 0.59966 to 0.56293, saving model to numbers_2.hdf5\n42000/42000 [==============================] - 15s 347us/step - loss: 0.6104 - acc: 0.8566 - val_loss: 0.5629 - val_acc: 0.8776\nEpoch 7/30\n41984/42000 [============================>.] - ETA: 0s - loss: 0.5876 - acc: 0.8680\nEpoch 00007: val_loss did not improve from 0.56293\n42000/42000 [==============================] - 15s 347us/step - loss: 0.5879 - acc: 0.8680 - val_loss: 0.5854 - val_acc: 0.8769\nEpoch 8/30\n41888/42000 [============================>.] - ETA: 0s - loss: 0.5750 - acc: 0.8691\nEpoch 00008: val_loss improved from 0.56293 to 0.54879, saving model to numbers_2.hdf5\n42000/42000 [==============================] - 15s 349us/step - loss: 0.5751 - acc: 0.8691 - val_loss: 0.5488 - val_acc: 0.8808\nEpoch 9/30\n41888/42000 [============================>.] - ETA: 0s - loss: 0.5611 - acc: 0.8731\nEpoch 00009: val_loss improved from 0.54879 to 0.54343, saving model to numbers_2.hdf5\n42000/42000 [==============================] - 15s 348us/step - loss: 0.5616 - acc: 0.8730 - val_loss: 0.5434 - val_acc: 0.8812\nEpoch 10/30\n41856/42000 [============================>.] - ETA: 0s - loss: 0.5505 - acc: 0.8749\nEpoch 00010: val_loss improved from 0.54343 to 0.54205, saving model to numbers_2.hdf5\n42000/42000 [==============================] - 15s 347us/step - loss: 0.5499 - acc: 0.8750 - val_loss: 0.5421 - val_acc: 0.8853\nEpoch 11/30\n41984/42000 [============================>.] - ETA: 0s - loss: 0.5475 - acc: 0.8760\nEpoch 00011: val_loss did not improve from 0.54205\n42000/42000 [==============================] - 15s 351us/step - loss: 0.5477 - acc: 0.8760 - val_loss: 0.6390 - val_acc: 0.8802\nEpoch 12/30\n41984/42000 [============================>.] - ETA: 0s - loss: 0.5339 - acc: 0.8791\nEpoch 00012: val_loss improved from 0.54205 to 0.53427, saving model to numbers_2.hdf5\n42000/42000 [==============================] - 15s 348us/step - loss: 0.5337 - acc: 0.8792 - val_loss: 0.5343 - val_acc: 0.8863\nEpoch 13/30\n41824/42000 [============================>.] - ETA: 0s - loss: 0.5321 - acc: 0.8810\nEpoch 00013: val_loss did not improve from 0.53427\n42000/42000 [==============================] - 15s 350us/step - loss: 0.5321 - acc: 0.8811 - val_loss: 0.6433 - val_acc: 0.8599\nEpoch 14/30\n41952/42000 [============================>.] - ETA: 0s - loss: 0.5408 - acc: 0.8775\nEpoch 00014: val_loss did not improve from 0.53427\n42000/42000 [==============================] - 15s 351us/step - loss: 0.5408 - acc: 0.8775 - val_loss: 0.6060 - val_acc: 0.8778\nEpoch 15/30\n41856/42000 [============================>.] - ETA: 0s - loss: 0.5350 - acc: 0.8790\nEpoch 00015: val_loss did not improve from 0.53427\n42000/42000 [==============================] - 15s 348us/step - loss: 0.5356 - acc: 0.8789 - val_loss: 0.5958 - val_acc: 0.8843\nEpoch 16/30\n41952/42000 [============================>.] - ETA: 0s - loss: 0.5334 - acc: 0.8802\nEpoch 00016: val_loss did not improve from 0.53427\n42000/42000 [==============================] - 15s 347us/step - loss: 0.5331 - acc: 0.8802 - val_loss: 0.5581 - val_acc: 0.8848\nEpoch 17/30\n41920/42000 [============================>.] - ETA: 0s - loss: 0.5259 - acc: 0.8797\nEpoch 00017: val_loss did not improve from 0.53427\n42000/42000 [==============================] - 15s 347us/step - loss: 0.5260 - acc: 0.8797 - val_loss: 0.6092 - val_acc: 0.8725\nEpoch 18/30\n41984/42000 [============================>.] - ETA: 0s - loss: 0.5281 - acc: 0.8813\nEpoch 00018: val_loss did not improve from 0.53427\n42000/42000 [==============================] - 15s 347us/step - loss: 0.5280 - acc: 0.8813 - val_loss: 0.5484 - val_acc: 0.8843\nEpoch 19/30\n41920/42000 [============================>.] - ETA: 0s - loss: 0.5258 - acc: 0.8812\nEpoch 00019: val_loss did not improve from 0.53427\n42000/42000 [==============================] - 15s 348us/step - loss: 0.5257 - acc: 0.8811 - val_loss: 0.5880 - val_acc: 0.8754\nEpoch 20/30\n41824/42000 [============================>.] - ETA: 0s - loss: 0.5278 - acc: 0.8820\nEpoch 00020: val_loss did not improve from 0.53427\n42000/42000 [==============================] - 15s 348us/step - loss: 0.5275 - acc: 0.8820 - val_loss: 0.5537 - val_acc: 0.8830\nEpoch 21/30\n41824/42000 [============================>.] - ETA: 0s - loss: 0.5307 - acc: 0.8811\nEpoch 00021: val_loss did not improve from 0.53427\n42000/42000 [==============================] - 15s 347us/step - loss: 0.5309 - acc: 0.8811 - val_loss: 0.5678 - val_acc: 0.8822\nEpoch 22/30\n41824/42000 [============================>.] - ETA: 0s - loss: 0.5321 - acc: 0.8801\nEpoch 00022: val_loss did not improve from 0.53427\n42000/42000 [==============================] - 15s 347us/step - loss: 0.5316 - acc: 0.8802 - val_loss: 0.5835 - val_acc: 0.8804\nEpoch 23/30\n41920/42000 [============================>.] - ETA: 0s - loss: 0.5319 - acc: 0.8796\nEpoch 00023: val_loss did not improve from 0.53427\n42000/42000 [==============================] - 15s 347us/step - loss: 0.5321 - acc: 0.8796 - val_loss: 0.6401 - val_acc: 0.8655\nEpoch 24/30\n41824/42000 [============================>.] - ETA: 0s - loss: 0.5347 - acc: 0.8781\nEpoch 00024: val_loss did not improve from 0.53427\n42000/42000 [==============================] - 15s 347us/step - loss: 0.5351 - acc: 0.8781 - val_loss: 0.6063 - val_acc: 0.8681\nEpoch 25/30\n41952/42000 [============================>.] - ETA: 0s - loss: 0.5360 - acc: 0.8777\nEpoch 00025: val_loss did not improve from 0.53427\n42000/42000 [==============================] - 15s 348us/step - loss: 0.5357 - acc: 0.8778 - val_loss: 0.5540 - val_acc: 0.8802\nEpoch 26/30\n41856/42000 [============================>.] - ETA: 0s - loss: 0.5348 - acc: 0.8792\nEpoch 00026: val_loss did not improve from 0.53427\n42000/42000 [==============================] - 15s 349us/step - loss: 0.5355 - acc: 0.8791 - val_loss: 0.6297 - val_acc: 0.8588\nEpoch 27/30\n41952/42000 [============================>.] - ETA: 0s - loss: 0.5410 - acc: 0.8768\nEpoch 00027: val_loss did not improve from 0.53427\n42000/42000 [==============================] - 15s 347us/step - loss: 0.5406 - acc: 0.8769 - val_loss: 0.6068 - val_acc: 0.8693\nEpoch 28/30\n41952/42000 [============================>.] - ETA: 0s - loss: 0.5415 - acc: 0.8774\nEpoch 00028: val_loss did not improve from 0.53427\n42000/42000 [==============================] - 15s 347us/step - loss: 0.5412 - acc: 0.8775 - val_loss: 0.5927 - val_acc: 0.8740\nEpoch 29/30\n41888/42000 [============================>.] - ETA: 0s - loss: 0.5443 - acc: 0.8776\nEpoch 00029: val_loss did not improve from 0.53427\n42000/42000 [==============================] - 15s 346us/step - loss: 0.5441 - acc: 0.8775 - val_loss: 0.5935 - val_acc: 0.8713\nEpoch 30/30\n41920/42000 [============================>.] - ETA: 0s - loss: 0.5460 - acc: 0.8777\nEpoch 00030: val_loss did not improve from 0.53427\n42000/42000 [==============================] - 15s 347us/step - loss: 0.5456 - acc: 0.8779 - val_loss: 0.6453 - val_acc: 0.8684\n"
]
],
[
[
"### Plotting results\n\nDefine functions to plot training loss and validation loss of the training process. Do the same for training accuracy and validation accuracy.",
"_____no_output_____"
]
],
[
[
"def get_loss(history = history):\n loss = history.history['loss']\n val_loss = history.history['val_loss'] \n return loss, val_loss\n\ndef get_acc(history = history):\n acc = history.history['acc']\n val_acc = history.history['val_acc']\n return acc, val_acc\n\ndef get_epochs(no_epochs = no_epochs):\n epochs = range(1, no_epochs + 1)\n return epochs\n\n\ndef plot_loss(history = history, no_epochs = no_epochs):\n epochs = get_epochs(no_epochs)\n loss, val_loss = get_loss(history)\n plt.plot(epochs, loss, 'ko', label = 'Training Loss')\n plt.plot(epochs, val_loss, 'k', label = 'Validation Loss')\n plt.xlabel('Epochs')\n plt.ylabel('Loss')\n plt.title('Training and Validation Loss')\n plt.legend()\n \ndef plot_acc(history = history, no_epochs = no_epochs):\n epochs = get_epochs(no_epochs)\n acc, val_acc = get_acc(history)\n plt.plot(epochs, acc, 'bo', label = 'Training Accuracy')\n plt.plot(epochs, val_acc, 'b', label = 'Validation Accuracy')\n plt.xlabel('Epochs')\n plt.ylabel('Accuracy')\n plt.title('Training and Validation Accuracy')\n plt.legend()",
"_____no_output_____"
],
[
"plot_loss()",
"_____no_output_____"
],
[
"plot_acc()",
"_____no_output_____"
]
],
[
[
"### Score on test data",
"_____no_output_____"
]
],
[
[
"model = keras.models.load_model(\"numbers_2.hdf5\")\nmodel.evaluate(x_test,y_test)",
"60000/60000 [==============================] - 13s 208us/step\n"
]
],
[
[
"### Plotting activations \n\nWe plot activation of the some filters of some layers of the CNN.",
"_____no_output_____"
]
],
[
[
"from tensorflow.keras.models import Model\n\ndef get_activations(model, sample):\n layer_outputs = [layer.output for layer in model.layers]\n activation_model = Model(inputs=model.input, outputs=layer_outputs)\n activations = activation_model.predict(sample) #change the index for x_train[index] to use another image\n return activations\n \n\n#when you call the function, col_size*row_size must be equal to the number of filters in that conv layer\ndef display_activation(activations, col_size, row_size, act_index): \n activation = activations[act_index] #act_index is the index of the layer eg. 0 is the first layer\n activation_index=0\n fig, ax = plt.subplots(row_size, col_size, figsize=(row_size*5,col_size*5))\n for row in range(0,row_size):\n for col in range(0,col_size):\n ax[row][col].imshow(activation[0, :, :, activation_index], cmap='gray')\n activation_index += 1",
"_____no_output_____"
],
[
"layer_to_inspect = 1\nx = x_train[48].reshape(1,28, 84, 1)\nactivations = get_activations(model, x)\ndisplay_activation(activations, 4, 8, layer_to_inspect)",
"_____no_output_____"
]
],
[
[
"# Addition \n\nGiven a pair of numbers, we will create an **RNN** that learns to output their sum. \nWe will use the original generator function to generate data for this problem, but will also *normalize* the pixels. \n\nWe will use **30 000 training samples** and **3 000 test samples**.\n",
"_____no_output_____"
]
],
[
[
"%%time\ntrain_size = 30000\ntest_size = 3000\n_, X_train, Y_train = generate_data(training_generator(train_size))\n_, X_test, Y_test = generate_data(test_generator(test_size))",
"CPU times: user 2min 29s, sys: 2.13 s, total: 2min 31s\nWall time: 2min 31s\n"
]
],
[
[
"Obviously, we can define a simple MLP that does addition of two numbers. With a *Dense* layer of a **single neuron** with **weights set to 1** and **bias set to 0**, the network will perform addition of two input numbers.\n\nBut the problem at hand will be solved with an RNN, to illustrate training of reccurent neural networks.",
"_____no_output_____"
]
],
[
[
"\n# ADDITION MLP\nadder = keras.models.Sequential()\nadder.add(keras.layers.Flatten( input_shape = (2,)))\nadder.add(keras.layers.Dense(1, weights = [np.array([[1], [1]]), np.array([0])]))\nadder.compile(loss='mean_squared_error', optimizer='adam', metrics = ['accuracy'])\n\npredictions = adder.predict(X_test)\ncorrect_labels = np.sum(predictions == Y_test)\nprint('Accuracy of simple MLP : {}'.format( correct_labels / len(predictions) ))\n",
"Accuracy of simple MLP : 1.0\n"
]
],
[
[
"## Input / Output Preprocessing\n\nTo treat the problem as a **sequence-to-sequence** one, we will encode input and output as follow :\n\nEach of the numbers will be converted to a padded string of three characters and the numbers will be concatenated afterwards. \nOutput will be a three character string representing the addition of the numbers.\n\n```\nInput : (23, 101) -> '023101' \nOutput : '124' \n```\nTo feed this data into our model, we will **one-hot encode** each of the digits of the sequence and thus will obtain following input and output sizes : \n\n```\ninput.shape == (6,10)\noutput.shape == (3,10)\n",
"_____no_output_____"
]
],
[
[
"from keras.utils import to_categorical\n\ndef stringify_X(X):\n X_S = [''.join([str(number).zfill(3) for number in pair]) for pair in X.squeeze()]\n return X_S\n\ndef stringify_Y(Y):\n Y_S = [str(number).zfill(3) for number in Y.squeeze()]\n return Y_S\n \ndef onehot(arr):\n arr_split = np.array( [list(string) for string in arr])\n arr_OH = to_categorical(arr_split, num_classes = 10)\n return arr_OH\n\ndef encode_X(X):\n X_S = stringify_X(X)\n X_OH = onehot(X_S)\n return X_OH\n\ndef encode_Y(Y):\n Y_S = stringify_Y(Y)\n Y_OH = onehot(Y_S)\n return Y_OH",
"Using TensorFlow backend.\n"
],
[
"X_train_OH, Y_train_OH = encode_X(X_train), encode_Y(Y_train)\nx_test, y_test = encode_X(X_test), encode_Y(Y_test)",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split\nx_train, x_val, y_train, y_val = train_test_split(X_train_OH, Y_train_OH, test_size = 0.3, random_state = 48)",
"_____no_output_____"
]
],
[
[
"## Model arhitecture\n\nWe will use a **encoder-decoder** arhitecture for the task at hand. \n\nFirst, we **encode** the input sequence using a **LSTM** of *128* units and will get an output of *128*.\n\nThe **decoder** will be another **LSTM** layer of *128* units. Output of the encoder will be repeatedly served to the decoder **3 times** using a **Repeat Vector** layer, because the maximum length of our addition output is 3 digits :\n```\n255 + 255 = 510\n```\nWe then apply a **Dense** layer of *10 neurons* to every temporal slice of the input. This layer will decide which digit we keep for each of the step of the output sequence. \n\nTo apply the above layer to every temporal slice, we wrap it in a **TimeDimensional** layer. Because it expects the first dimension of the input to be the timesteps, we must set **return_sequences** to *True* on the decoder layer. This makes the decoder output the whole output steps so far in the following form : \n\n```\noutput_so_far.shape == (num_samples, timesteps, output_dim)\n```\n\nWe choose **rmsprop** as the optimizer of this problem because of its inclined advantage in *rnn arhitectures*.\n\n\n\n",
"_____no_output_____"
]
],
[
[
"model = keras.models.Sequential()\nmodel.add(keras.layers.LSTM(128, input_shape=(6, 10)))\nmodel.add(keras.layers.RepeatVector(3))\nmodel.add(keras.layers.LSTM(128, return_sequences=True))\nmodel.add(keras.layers.TimeDistributed(keras.layers.Dense(10, activation='softmax')))\n\nmodel.compile(loss='categorical_crossentropy',\n optimizer='rmsprop',\n metrics=['accuracy'])\n\nmodel.summary()\n",
"_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nlstm (LSTM) (None, 128) 71168 \n_________________________________________________________________\nrepeat_vector (RepeatVector) (None, 3, 128) 0 \n_________________________________________________________________\nlstm_1 (LSTM) (None, 3, 128) 131584 \n_________________________________________________________________\ntime_distributed (TimeDistri (None, 3, 10) 1290 \n=================================================================\nTotal params: 204,042\nTrainable params: 204,042\nNon-trainable params: 0\n_________________________________________________________________\n"
]
],
[
[
"## Fitting",
"_____no_output_____"
]
],
[
[
"no_epochs = 30\ncheckpointer = keras.callbacks.ModelCheckpoint(filepath=\"add.hdf5\", verbose=1, save_best_only=True)\nhistory = model.fit(x_train, y_train, epochs = no_epochs, \n validation_data=(x_val, y_val), callbacks=[checkpointer])\nmodel.evaluate(x_test, y_test)",
"Train on 21000 samples, validate on 9000 samples\nEpoch 1/30\n20960/21000 [============================>.] - ETA: 0s - loss: 1.9083 - acc: 0.2445\nEpoch 00001: val_loss improved from inf to 1.89729, saving model to add.hdf5\n21000/21000 [==============================] - 23s 1ms/step - loss: 1.9081 - acc: 0.2446 - val_loss: 1.8973 - val_acc: 0.2492\nEpoch 2/30\n20960/21000 [============================>.] - ETA: 0s - loss: 1.7519 - acc: 0.3138\nEpoch 00002: val_loss improved from 1.89729 to 1.67201, saving model to add.hdf5\n21000/21000 [==============================] - 22s 1ms/step - loss: 1.7517 - acc: 0.3139 - val_loss: 1.6720 - val_acc: 0.3483\nEpoch 3/30\n20960/21000 [============================>.] - ETA: 0s - loss: 1.5454 - acc: 0.4064\nEpoch 00003: val_loss improved from 1.67201 to 1.55726, saving model to add.hdf5\n21000/21000 [==============================] - 22s 1ms/step - loss: 1.5453 - acc: 0.4066 - val_loss: 1.5573 - val_acc: 0.3933\nEpoch 4/30\n20960/21000 [============================>.] - ETA: 0s - loss: 1.3499 - acc: 0.4733\nEpoch 00004: val_loss improved from 1.55726 to 1.32386, saving model to add.hdf5\n21000/21000 [==============================] - 22s 1ms/step - loss: 1.3500 - acc: 0.4732 - val_loss: 1.3239 - val_acc: 0.4653\nEpoch 5/30\n20960/21000 [============================>.] - ETA: 0s - loss: 1.1661 - acc: 0.5433\nEpoch 00005: val_loss improved from 1.32386 to 1.03665, saving model to add.hdf5\n21000/21000 [==============================] - 22s 1ms/step - loss: 1.1658 - acc: 0.5436 - val_loss: 1.0367 - val_acc: 0.6116\nEpoch 6/30\n20960/21000 [============================>.] - ETA: 0s - loss: 0.8889 - acc: 0.6562\nEpoch 00006: val_loss improved from 1.03665 to 0.73807, saving model to add.hdf5\n21000/21000 [==============================] - 22s 1ms/step - loss: 0.8887 - acc: 0.6562 - val_loss: 0.7381 - val_acc: 0.7115\nEpoch 7/30\n20960/21000 [============================>.] - ETA: 0s - loss: 0.5644 - acc: 0.8011\nEpoch 00007: val_loss improved from 0.73807 to 0.50102, saving model to add.hdf5\n21000/21000 [==============================] - 23s 1ms/step - loss: 0.5642 - acc: 0.8011 - val_loss: 0.5010 - val_acc: 0.8164\nEpoch 8/30\n20960/21000 [============================>.] - ETA: 0s - loss: 0.3744 - acc: 0.8836\nEpoch 00008: val_loss improved from 0.50102 to 0.43187, saving model to add.hdf5\n21000/21000 [==============================] - 22s 1ms/step - loss: 0.3743 - acc: 0.8837 - val_loss: 0.4319 - val_acc: 0.8547\nEpoch 9/30\n20960/21000 [============================>.] - ETA: 0s - loss: 0.2631 - acc: 0.9232\nEpoch 00009: val_loss improved from 0.43187 to 0.17872, saving model to add.hdf5\n21000/21000 [==============================] - 22s 1ms/step - loss: 0.2629 - acc: 0.9233 - val_loss: 0.1787 - val_acc: 0.9631\nEpoch 10/30\n20960/21000 [============================>.] - ETA: 0s - loss: 0.1883 - acc: 0.9471\nEpoch 00010: val_loss improved from 0.17872 to 0.14819, saving model to add.hdf5\n21000/21000 [==============================] - 22s 1ms/step - loss: 0.1882 - acc: 0.9472 - val_loss: 0.1482 - val_acc: 0.9629\nEpoch 11/30\n20960/21000 [============================>.] - ETA: 0s - loss: 0.1395 - acc: 0.9611\nEpoch 00011: val_loss improved from 0.14819 to 0.12928, saving model to add.hdf5\n21000/21000 [==============================] - 22s 1ms/step - loss: 0.1394 - acc: 0.9611 - val_loss: 0.1293 - val_acc: 0.9622\nEpoch 12/30\n20960/21000 [============================>.] - ETA: 0s - loss: 0.1085 - acc: 0.9702\nEpoch 00012: val_loss improved from 0.12928 to 0.09210, saving model to add.hdf5\n21000/21000 [==============================] - 22s 1ms/step - loss: 0.1084 - acc: 0.9703 - val_loss: 0.0921 - val_acc: 0.9714\nEpoch 13/30\n20960/21000 [============================>.] - ETA: 0s - loss: 0.0865 - acc: 0.9760\nEpoch 00013: val_loss did not improve from 0.09210\n21000/21000 [==============================] - 22s 1ms/step - loss: 0.0868 - acc: 0.9759 - val_loss: 0.1666 - val_acc: 0.9406\nEpoch 14/30\n20960/21000 [============================>.] - ETA: 0s - loss: 0.0687 - acc: 0.9810\nEpoch 00014: val_loss improved from 0.09210 to 0.03776, saving model to add.hdf5\n21000/21000 [==============================] - 22s 1ms/step - loss: 0.0686 - acc: 0.9810 - val_loss: 0.0378 - val_acc: 0.9927\nEpoch 15/30\n20960/21000 [============================>.] - ETA: 0s - loss: 0.0564 - acc: 0.9845\nEpoch 00015: val_loss did not improve from 0.03776\n21000/21000 [==============================] - 22s 1ms/step - loss: 0.0564 - acc: 0.9846 - val_loss: 0.0577 - val_acc: 0.9864\nEpoch 16/30\n20960/21000 [============================>.] - ETA: 0s - loss: 0.0493 - acc: 0.9865\nEpoch 00016: val_loss improved from 0.03776 to 0.02144, saving model to add.hdf5\n21000/21000 [==============================] - 22s 1ms/step - loss: 0.0493 - acc: 0.9865 - val_loss: 0.0214 - val_acc: 0.9965\nEpoch 17/30\n20960/21000 [============================>.] - ETA: 0s - loss: 0.0399 - acc: 0.9889\nEpoch 00017: val_loss did not improve from 0.02144\n21000/21000 [==============================] - 22s 1ms/step - loss: 0.0399 - acc: 0.9889 - val_loss: 0.0276 - val_acc: 0.9940\nEpoch 18/30\n20960/21000 [============================>.] - ETA: 0s - loss: 0.0361 - acc: 0.9902\nEpoch 00018: val_loss did not improve from 0.02144\n21000/21000 [==============================] - 22s 1ms/step - loss: 0.0367 - acc: 0.9900 - val_loss: 0.0690 - val_acc: 0.9760\nEpoch 19/30\n20960/21000 [============================>.] - ETA: 0s - loss: 0.0320 - acc: 0.9909\nEpoch 00019: val_loss improved from 0.02144 to 0.01172, saving model to add.hdf5\n21000/21000 [==============================] - 22s 1ms/step - loss: 0.0319 - acc: 0.9909 - val_loss: 0.0117 - val_acc: 0.9979\nEpoch 20/30\n20960/21000 [============================>.] - ETA: 0s - loss: 0.0278 - acc: 0.9922\nEpoch 00020: val_loss did not improve from 0.01172\n21000/21000 [==============================] - 22s 1ms/step - loss: 0.0278 - acc: 0.9921 - val_loss: 0.1973 - val_acc: 0.9435\nEpoch 21/30\n20960/21000 [============================>.] - ETA: 0s - loss: 0.0242 - acc: 0.9929\nEpoch 00021: val_loss did not improve from 0.01172\n21000/21000 [==============================] - 22s 1ms/step - loss: 0.0242 - acc: 0.9929 - val_loss: 0.0255 - val_acc: 0.9925\nEpoch 22/30\n20960/21000 [============================>.] - ETA: 0s - loss: 0.0238 - acc: 0.9934\nEpoch 00022: val_loss did not improve from 0.01172\n21000/21000 [==============================] - 22s 1ms/step - loss: 0.0238 - acc: 0.9934 - val_loss: 0.0212 - val_acc: 0.9931\nEpoch 23/30\n20960/21000 [============================>.] - ETA: 0s - loss: 0.0219 - acc: 0.9934\nEpoch 00023: val_loss improved from 0.01172 to 0.00852, saving model to add.hdf5\n21000/21000 [==============================] - 22s 1ms/step - loss: 0.0218 - acc: 0.9934 - val_loss: 0.0085 - val_acc: 0.9979\nEpoch 24/30\n20960/21000 [============================>.] - ETA: 0s - loss: 0.0196 - acc: 0.9941\nEpoch 00024: val_loss improved from 0.00852 to 0.00760, saving model to add.hdf5\n21000/21000 [==============================] - 22s 1ms/step - loss: 0.0195 - acc: 0.9941 - val_loss: 0.0076 - val_acc: 0.9983\nEpoch 25/30\n20960/21000 [============================>.] - ETA: 0s - loss: 0.0187 - acc: 0.9944\nEpoch 00025: val_loss did not improve from 0.00760\n21000/21000 [==============================] - 22s 1ms/step - loss: 0.0187 - acc: 0.9944 - val_loss: 0.0210 - val_acc: 0.9931\nEpoch 26/30\n20960/21000 [============================>.] - ETA: 0s - loss: 0.0164 - acc: 0.9952\nEpoch 00026: val_loss did not improve from 0.00760\n21000/21000 [==============================] - 22s 1ms/step - loss: 0.0163 - acc: 0.9952 - val_loss: 0.0104 - val_acc: 0.9974\nEpoch 27/30\n20960/21000 [============================>.] - ETA: 0s - loss: 0.0174 - acc: 0.9951\nEpoch 00027: val_loss did not improve from 0.00760\n21000/21000 [==============================] - 22s 1ms/step - loss: 0.0175 - acc: 0.9951 - val_loss: 0.0455 - val_acc: 0.9838\nEpoch 28/30\n20960/21000 [============================>.] - ETA: 0s - loss: 0.0131 - acc: 0.9963\nEpoch 00028: val_loss did not improve from 0.00760\n21000/21000 [==============================] - 22s 1ms/step - loss: 0.0132 - acc: 0.9963 - val_loss: 0.0126 - val_acc: 0.9957\nEpoch 29/30\n20960/21000 [============================>.] - ETA: 0s - loss: 0.0143 - acc: 0.9959\nEpoch 00029: val_loss did not improve from 0.00760\n21000/21000 [==============================] - 22s 1ms/step - loss: 0.0143 - acc: 0.9959 - val_loss: 0.0102 - val_acc: 0.9966\nEpoch 30/30\n20960/21000 [============================>.] - ETA: 0s - loss: 0.0139 - acc: 0.9959\nEpoch 00030: val_loss improved from 0.00760 to 0.00737, saving model to add.hdf5\n21000/21000 [==============================] - 22s 1ms/step - loss: 0.0140 - acc: 0.9959 - val_loss: 0.0074 - val_acc: 0.9978\n3000/3000 [==============================] - 1s 347us/step\n"
],
[
"files.download(\"add.hdf5\")",
"_____no_output_____"
]
],
[
[
"## Plotting\nPlot accuracy and loss throughout training process, both on training and validation data",
"_____no_output_____"
]
],
[
[
"plot_loss()",
"_____no_output_____"
],
[
"plot_acc()",
"_____no_output_____"
]
],
[
[
"## Evaluate the model\n\nBecause of the way our **LSTM** arhitecture works, it counts as its output each of the digits of the sequence. \n```\ninput = '023101'\noutput = '128'\nreal_output = '124'\naccuracy = 2 / 3 (66%)\nreal_accuracy = 0 \n```\nThus, if it correctly predicts two of three digits of a number, as above, it has *66%* accuracy, but its true accuracy on our problem is *0*, because it gave the wrong number. It esentially counts how many digits it got correctly, but we actually care how many numbers it got correctly.\n\nTo measure this, we will make predictions with our network and compare the predictions with the test data.\n",
"_____no_output_____"
]
],
[
[
"model = tf.keras.models.load_model(\"add.hdf5\")\nmodel.evaluate(x_test, y_test)",
"3000/3000 [==============================] - 4s 1ms/step\n"
],
[
"def true_accuracy(model, x_test, y_test):\n predicted = model.predict(x_test)\n predicted_OH = to_categorical(np.argmax(predicted, axis = 2), num_classes = 10)\n\n bool_test = np.all(predicted_OH == y_test, axis = (1,2))\n true_acc = np.sum(bool_test) / len(y_test)\n return true_acc\n",
"_____no_output_____"
],
[
"model = keras.models.load_model(\"add.hdf5\")\n\ntrue_acc = true_accuracy(model, x_test, y_test)\nprint('True accuracy : {}'.format(true_acc))",
"True accuracy : 0.9936666666666667\n"
]
],
[
[
"# End-to-End network\n\nWe train a network that receives a pair of images with numbers and outputs their sum.\nWe attempt to concatenate the above networks (referred below as **CNN** and **RNN**) in the following way :\n1. Concatenate two images and add them as input to the *CNN*. \n```\ninput.shape == (28,168,1)\n```\n2. Remove the layer with **softmax** from cnn and replace it with a **reshape** layer. We reshape the output of the cnn and halve it to obtain pairs of parameters representing each image. \n```\ncnn_output.shape == (128)\nreshaped_output.shape == (2,64)\n```\n3. Run the obtained output through the **RNN**. ",
"_____no_output_____"
]
],
[
[
"%%time\ntrain_size = 30000\ntest_size = 3000\ntrain_gen = training_generator(train_size)\ntest_gen = test_generator(test_size)\nX_train, _ , Y_train = generate_data(train_gen)\nX_test, _ , Y_test = generate_data(test_gen)",
"CPU times: user 2min 37s, sys: 1.99 s, total: 2min 39s\nWall time: 2min 39s\n"
],
[
"#concatenate images\nX_train_CAT = np.array([np.hstack( (pair[0], pair[1])) for pair in X_train])\nx_test = np.array([np.hstack( (pair[0], pair[1])) for pair in X_test])\nY_train_OH = encode_Y(Y_train)\n# Y_train_OH = to_categorical(Y_train, num_classes=510)\ny_test = encode_Y(Y_test)\n# y_test = to_categorical(Y_test, num_classes=510)",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split\nx_train, x_val, y_train, y_val = train_test_split(X_train_CAT, Y_train_OH, test_size = 0.3, random_state = 48)",
"_____no_output_____"
],
[
"cnn = keras.models.Sequential()\ncnn.add(tf.keras.layers.Conv2D(32, (3, 3), activation = 'relu', input_shape = (28, 168, 1)))\ncnn.add(tf.keras.layers.MaxPooling2D(2, 2))\ncnn.add(tf.keras.layers.Dropout(0.6))\ncnn.add(tf.keras.layers.Conv2D(64, (3, 3), activation = 'relu'))\ncnn.add(tf.keras.layers.MaxPooling2D(2, 2))\ncnn.add(tf.keras.layers.Dropout(0.6))\ncnn.add(tf.keras.layers.Conv2D(64, (3, 3), activation = 'relu'))\ncnn.add(tf.keras.layers.Flatten())\ncnn.add(tf.keras.layers.Dense(128, activation = 'relu'))\n# cnn.add(tf.keras.layers.Dropout(0.5))\n\ncnn.compile(optimizer = 'rmsprop',\n loss='sparse_categorical_crossentropy',\n metrics=['accuracy'])\n\ncnn.summary()\n\n\nmodel = keras.models.Sequential()\nmodel.add(cnn)\n\n# lstm\nmodel.add(tf.keras.layers.Reshape((2, 64)))\nmodel.add(tf.keras.layers.LSTM(128, kernel_initializer = 'random_normal', recurrent_initializer = 'random_normal'))\nmodel.add(tf.keras.layers.RepeatVector(3))\nmodel.add(tf.keras.layers.LSTM(128, return_sequences=True))\nmodel.add(tf.keras.layers.TimeDistributed(keras.layers.Dense(10, activation='softmax')))\n\n#convlstm\n# model = keras.models.Sequential()\n# model.add(tf.keras.layers.ConvLSTM2D(filters = 32, kernel_size = (3,3), activation = 'relu', \n# padding = 'same', dropout = .2, input_shape = (28,168,1)))\n# model.add(tf.keras.layers.RepeatVector(3))\n# model.add(tf.keras.layers.ConvLSTM2D(filters = 32, kernel_size = (3,3), activation = 'relu', \n# padding = 'same', dropout = .2 ))\n# model.add(tf.keras.layers.TimeDistributed(keras.layers.Dense(10, activation='softmax')))\n\n\n\nmodel.compile(optimizer='rmsprop',\n loss='categorical_crossentropy',\n metrics=['accuracy'])\n\nmodel.summary()\n",
"_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nconv2d_9 (Conv2D) (None, 26, 166, 32) 320 \n_________________________________________________________________\nmax_pooling2d_6 (MaxPooling2 (None, 13, 83, 32) 0 \n_________________________________________________________________\ndropout_6 (Dropout) (None, 13, 83, 32) 0 \n_________________________________________________________________\nconv2d_10 (Conv2D) (None, 11, 81, 64) 18496 \n_________________________________________________________________\nmax_pooling2d_7 (MaxPooling2 (None, 5, 40, 64) 0 \n_________________________________________________________________\ndropout_7 (Dropout) (None, 5, 40, 64) 0 \n_________________________________________________________________\nconv2d_11 (Conv2D) (None, 3, 38, 64) 36928 \n_________________________________________________________________\nflatten_3 (Flatten) (None, 7296) 0 \n_________________________________________________________________\ndense_6 (Dense) (None, 128) 934016 \n=================================================================\nTotal params: 989,760\nTrainable params: 989,760\nNon-trainable params: 0\n_________________________________________________________________\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nsequential_6 (Sequential) (None, 128) 989760 \n_________________________________________________________________\nreshape_3 (Reshape) (None, 2, 64) 0 \n_________________________________________________________________\nlstm_6 (LSTM) (None, 128) 98816 \n_________________________________________________________________\nrepeat_vector_3 (RepeatVecto (None, 3, 128) 0 \n_________________________________________________________________\nlstm_7 (LSTM) (None, 3, 128) 131584 \n_________________________________________________________________\ntime_distributed_3 (TimeDist (None, 3, 10) 1290 \n=================================================================\nTotal params: 1,221,450\nTrainable params: 1,221,450\nNon-trainable params: 0\n_________________________________________________________________\n"
]
],
[
[
"## Fitting",
"_____no_output_____"
]
],
[
[
"no_epochs = 30\ncheckpointer = keras.callbacks.ModelCheckpoint(filepath=\"end_to_end_2.hdf5\", verbose=1, save_best_only=True)\nhistory = model.fit(x_train, y_train, epochs = no_epochs, validation_data= (x_val, y_val), callbacks=[checkpointer])",
"Train on 21000 samples, validate on 9000 samples\nEpoch 1/30\n20960/21000 [============================>.] - ETA: 0s - loss: 1.9442 - acc: 0.2261\nEpoch 00001: val_loss improved from inf to 1.90013, saving model to end_to_end_2.hdf5\n21000/21000 [==============================] - 34s 2ms/step - loss: 1.9440 - acc: 0.2262 - val_loss: 1.9001 - val_acc: 0.2493\nEpoch 2/30\n20960/21000 [============================>.] - ETA: 0s - loss: 1.8657 - acc: 0.2561\nEpoch 00002: val_loss improved from 1.90013 to 1.84230, saving model to end_to_end_2.hdf5\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.8657 - acc: 0.2561 - val_loss: 1.8423 - val_acc: 0.2686\nEpoch 3/30\n20960/21000 [============================>.] - ETA: 0s - loss: 1.8288 - acc: 0.2717\nEpoch 00003: val_loss improved from 1.84230 to 1.81671, saving model to end_to_end_2.hdf5\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.8288 - acc: 0.2718 - val_loss: 1.8167 - val_acc: 0.2818\nEpoch 4/30\n20960/21000 [============================>.] - ETA: 0s - loss: 1.7999 - acc: 0.2920\nEpoch 00004: val_loss improved from 1.81671 to 1.78647, saving model to end_to_end_2.hdf5\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.7999 - acc: 0.2919 - val_loss: 1.7865 - val_acc: 0.2964\nEpoch 5/30\n20960/21000 [============================>.] - ETA: 0s - loss: 1.7736 - acc: 0.3058\nEpoch 00005: val_loss improved from 1.78647 to 1.77948, saving model to end_to_end_2.hdf5\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.7735 - acc: 0.3058 - val_loss: 1.7795 - val_acc: 0.3033\nEpoch 6/30\n20992/21000 [============================>.] - ETA: 0s - loss: 1.7488 - acc: 0.3209\nEpoch 00006: val_loss improved from 1.77948 to 1.75229, saving model to end_to_end_2.hdf5\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.7488 - acc: 0.3209 - val_loss: 1.7523 - val_acc: 0.3164\nEpoch 7/30\n20992/21000 [============================>.] - ETA: 0s - loss: 1.7206 - acc: 0.3353\nEpoch 00007: val_loss improved from 1.75229 to 1.72843, saving model to end_to_end_2.hdf5\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.7205 - acc: 0.3353 - val_loss: 1.7284 - val_acc: 0.3303\nEpoch 8/30\n20992/21000 [============================>.] - ETA: 0s - loss: 1.6920 - acc: 0.3492\nEpoch 00008: val_loss improved from 1.72843 to 1.71950, saving model to end_to_end_2.hdf5\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.6920 - acc: 0.3492 - val_loss: 1.7195 - val_acc: 0.3297\nEpoch 9/30\n20960/21000 [============================>.] - ETA: 0s - loss: 1.6649 - acc: 0.3621\nEpoch 00009: val_loss did not improve from 1.71950\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.6650 - acc: 0.3620 - val_loss: 1.7327 - val_acc: 0.3335\nEpoch 10/30\n20960/21000 [============================>.] - ETA: 0s - loss: 1.6368 - acc: 0.3737\nEpoch 00010: val_loss did not improve from 1.71950\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.6372 - acc: 0.3735 - val_loss: 1.7390 - val_acc: 0.3343\nEpoch 11/30\n20960/21000 [============================>.] - ETA: 0s - loss: 1.6105 - acc: 0.3860\nEpoch 00011: val_loss improved from 1.71950 to 1.68527, saving model to end_to_end_2.hdf5\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.6105 - acc: 0.3860 - val_loss: 1.6853 - val_acc: 0.3505\nEpoch 12/30\n20960/21000 [============================>.] - ETA: 0s - loss: 1.5835 - acc: 0.3941\nEpoch 00012: val_loss improved from 1.68527 to 1.68150, saving model to end_to_end_2.hdf5\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.5836 - acc: 0.3942 - val_loss: 1.6815 - val_acc: 0.3538\nEpoch 13/30\n20960/21000 [============================>.] - ETA: 0s - loss: 1.5531 - acc: 0.4085\nEpoch 00013: val_loss improved from 1.68150 to 1.67250, saving model to end_to_end_2.hdf5\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.5530 - acc: 0.4084 - val_loss: 1.6725 - val_acc: 0.3603\nEpoch 14/30\n20960/21000 [============================>.] - ETA: 0s - loss: 1.5281 - acc: 0.4201\nEpoch 00014: val_loss did not improve from 1.67250\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.5282 - acc: 0.4200 - val_loss: 1.6749 - val_acc: 0.3601\nEpoch 15/30\n20960/21000 [============================>.] - ETA: 0s - loss: 1.5026 - acc: 0.4281\nEpoch 00015: val_loss did not improve from 1.67250\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.5025 - acc: 0.4282 - val_loss: 1.6992 - val_acc: 0.3526\nEpoch 16/30\n20992/21000 [============================>.] - ETA: 0s - loss: 1.4792 - acc: 0.4387\nEpoch 00016: val_loss did not improve from 1.67250\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.4792 - acc: 0.4387 - val_loss: 1.6858 - val_acc: 0.3605\nEpoch 17/30\n20960/21000 [============================>.] - ETA: 0s - loss: 1.4570 - acc: 0.4459\nEpoch 00017: val_loss did not improve from 1.67250\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.4570 - acc: 0.4459 - val_loss: 1.6889 - val_acc: 0.3586\nEpoch 18/30\n20960/21000 [============================>.] - ETA: 0s - loss: 1.4309 - acc: 0.4580\nEpoch 00018: val_loss did not improve from 1.67250\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.4311 - acc: 0.4580 - val_loss: 1.7069 - val_acc: 0.3613\nEpoch 19/30\n20992/21000 [============================>.] - ETA: 0s - loss: 1.4063 - acc: 0.4703\nEpoch 00019: val_loss did not improve from 1.67250\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.4062 - acc: 0.4703 - val_loss: 1.7159 - val_acc: 0.3611\nEpoch 20/30\n20992/21000 [============================>.] - ETA: 0s - loss: 1.3859 - acc: 0.4783\nEpoch 00020: val_loss did not improve from 1.67250\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.3860 - acc: 0.4782 - val_loss: 1.7312 - val_acc: 0.3618\nEpoch 21/30\n20960/21000 [============================>.] - ETA: 0s - loss: 1.3648 - acc: 0.4850\nEpoch 00021: val_loss did not improve from 1.67250\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.3649 - acc: 0.4850 - val_loss: 1.7242 - val_acc: 0.3623\nEpoch 22/30\n20992/21000 [============================>.] - ETA: 0s - loss: 1.3419 - acc: 0.4958\nEpoch 00022: val_loss did not improve from 1.67250\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.3419 - acc: 0.4958 - val_loss: 1.7288 - val_acc: 0.3664\nEpoch 23/30\n20992/21000 [============================>.] - ETA: 0s - loss: 1.3160 - acc: 0.5050\nEpoch 00023: val_loss did not improve from 1.67250\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.3160 - acc: 0.5050 - val_loss: 1.7596 - val_acc: 0.3645\nEpoch 24/30\n20992/21000 [============================>.] - ETA: 0s - loss: 1.2969 - acc: 0.5138\nEpoch 00024: val_loss did not improve from 1.67250\n21000/21000 [==============================] - 29s 1ms/step - loss: 1.2970 - acc: 0.5138 - val_loss: 1.7526 - val_acc: 0.3636\nEpoch 25/30\n20992/21000 [============================>.] - ETA: 0s - loss: 1.2760 - acc: 0.5212\nEpoch 00025: val_loss did not improve from 1.67250\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.2761 - acc: 0.5212 - val_loss: 1.7739 - val_acc: 0.3684\nEpoch 26/30\n20960/21000 [============================>.] - ETA: 0s - loss: 1.2570 - acc: 0.5318\nEpoch 00026: val_loss did not improve from 1.67250\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.2572 - acc: 0.5317 - val_loss: 1.8189 - val_acc: 0.3678\nEpoch 27/30\n20960/21000 [============================>.] - ETA: 0s - loss: 1.2356 - acc: 0.5402\nEpoch 00027: val_loss did not improve from 1.67250\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.2357 - acc: 0.5401 - val_loss: 1.8140 - val_acc: 0.3653\nEpoch 28/30\n20960/21000 [============================>.] - ETA: 0s - loss: 1.2246 - acc: 0.5457\nEpoch 00028: val_loss did not improve from 1.67250\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.2244 - acc: 0.5457 - val_loss: 1.8365 - val_acc: 0.3677\nEpoch 29/30\n20960/21000 [============================>.] - ETA: 0s - loss: 1.1933 - acc: 0.5605\nEpoch 00029: val_loss did not improve from 1.67250\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.1933 - acc: 0.5606 - val_loss: 1.8794 - val_acc: 0.3660\nEpoch 30/30\n20960/21000 [============================>.] - ETA: 0s - loss: 1.1778 - acc: 0.5641\nEpoch 00030: val_loss did not improve from 1.67250\n21000/21000 [==============================] - 28s 1ms/step - loss: 1.1777 - acc: 0.5641 - val_loss: 1.8844 - val_acc: 0.3640\n"
]
],
[
[
"## Plotting\nWe plot the loss and accuracy during training.\nWe observed that our validation set is actually helping us. \n\nThe accuracy on training grows quickly, but the one on validation stays the same. It means that we are **overfitting**.",
"_____no_output_____"
]
],
[
[
"plot_loss()",
"_____no_output_____"
],
[
"plot_acc()",
"_____no_output_____"
]
],
[
[
"## Evaluate the model\n\nWe evaluate the model below, both with the network accuracy and the true accuracy.",
"_____no_output_____"
]
],
[
[
"model = keras.models.load_model(\"end_to_end_2.hdf5\")\nmodel.evaluate(x_test, y_test)",
"3000/3000 [==============================] - 2s 828us/step\n"
],
[
"model = keras.models.load_model(\"end_to_end_2.hdf5\")\ntrue_acc =true_accuracy(model,x_test,y_test)\nprint(\"True accuracy : {}\".format(true_acc))",
"True accuracy : 0.018666666666666668\n"
]
],
[
[
"## Further improvements\n\nWe can add more dropout to prevent overfitting. Overfitting may also be caused by our model being too complex.\nAlso tried using **Convolutional LSTM** layers to apply the *RNN* directly on the image, but was stopped by some keras error. ",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
cb33225323f84630672f852da11f2ad3816af34f | 197,180 | ipynb | Jupyter Notebook | Analise_Exploratoria_DIO.ipynb | geansm2/PI2B | a0d162ddf17d3bd403311a19b1a855ae92357e39 | [
"MIT"
] | null | null | null | Analise_Exploratoria_DIO.ipynb | geansm2/PI2B | a0d162ddf17d3bd403311a19b1a855ae92357e39 | [
"MIT"
] | null | null | null | Analise_Exploratoria_DIO.ipynb | geansm2/PI2B | a0d162ddf17d3bd403311a19b1a855ae92357e39 | [
"MIT"
] | null | null | null | 104.107709 | 47,678 | 0.777675 | [
[
[
"<a href=\"https://colab.research.google.com/github/geansm2/PI2B/blob/master/Analise_Exploratoria_DIO.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"#Importando as bibliotecas\nimport pandas as pd\nimport matplotlib.pyplot as plt\nplt.style.use(\"seaborn\")",
"_____no_output_____"
],
[
"#Upload do arquivo\nfrom google.colab import files\narq = files.upload()",
"_____no_output_____"
],
[
"#Criando nosso DataFrame\ndf = pd.read_excel(\"AdventureWorks.xlsx\")",
"_____no_output_____"
],
[
"#Visualizando as 5 primeiras linhas\ndf.head()",
"_____no_output_____"
],
[
"#Quantidade de linhas e colunas\ndf.shape",
"_____no_output_____"
],
[
"#Verificando os tipos de dados\ndf.dtypes",
"_____no_output_____"
],
[
"#Qual a Receita total?\ndf[\"Valor Venda\"].sum()",
"_____no_output_____"
],
[
"#Qual o custo Total?\ndf[\"custo\"] = df[\"Custo Unitário\"].mul(df[\"Quantidade\"]) #Criando a coluna de custo",
"_____no_output_____"
],
[
"df.head(1)",
"_____no_output_____"
],
[
"#Qual o custo Total?\nround(df[\"custo\"].sum(), 2)",
"_____no_output_____"
],
[
"#Agora que temos a receita e custo e o total, podemos achar o Lucro total\n#Vamos criar uma coluna de Lucro que será Receita - Custo\ndf[\"lucro\"] = df[\"Valor Venda\"] - df[\"custo\"] ",
"_____no_output_____"
],
[
"df.head(1)",
"_____no_output_____"
],
[
"#Total Lucro\nround(df[\"lucro\"].sum(),2)",
"_____no_output_____"
],
[
"#Criando uma coluna com total de dias para enviar o produto\ndf[\"Tempo_envio\"] = df[\"Data Envio\"] - df[\"Data Venda\"]",
"_____no_output_____"
],
[
"df.head(1)",
"_____no_output_____"
]
],
[
[
"**Agora, queremos saber a média do tempo de envio para cada Marca, e para isso precisamos transformar a coluna Tempo_envio em númerica**",
"_____no_output_____"
]
],
[
[
"#Extraindo apenas os dias\ndf[\"Tempo_envio\"] = (df[\"Data Envio\"] - df[\"Data Venda\"]).dt.days",
"_____no_output_____"
],
[
"df.head(1)",
"_____no_output_____"
],
[
"#Verificando o tipo da coluna Tempo_envio\ndf[\"Tempo_envio\"].dtype",
"_____no_output_____"
],
[
"#Média do tempo de envio por Marca\ndf.groupby(\"Marca\")[\"Tempo_envio\"].mean()",
"_____no_output_____"
]
],
[
[
" **Missing Values**",
"_____no_output_____"
]
],
[
[
"#Verificando se temos dados faltantes\ndf.isnull().sum()",
"_____no_output_____"
]
],
[
[
"**E, se a gente quiser saber o Lucro por Ano e Por Marca?**",
"_____no_output_____"
]
],
[
[
"#Vamos Agrupar por ano e marca\ndf.groupby([df[\"Data Venda\"].dt.year, \"Marca\"])[\"lucro\"].sum()",
"_____no_output_____"
],
[
" pd.options.display.float_format = '{:20,.2f}'.format",
"_____no_output_____"
],
[
"#Resetando o index\nlucro_ano = df.groupby([df[\"Data Venda\"].dt.year, \"Marca\"])[\"lucro\"].sum().reset_index()\nlucro_ano",
"_____no_output_____"
],
[
"#Qual o total de produtos vendidos?\ndf.groupby(\"Produto\")[\"Quantidade\"].sum().sort_values(ascending=False)",
"_____no_output_____"
],
[
"#Gráfico Total de produtos vendidos\ndf.groupby(\"Produto\")[\"Quantidade\"].sum().sort_values(ascending=True).plot.barh(title=\"Total Produtos Vendidos\")\nplt.xlabel(\"Total\")\nplt.ylabel(\"Produto\");",
"_____no_output_____"
],
[
"df.groupby(df[\"Data Venda\"].dt.year)[\"lucro\"].sum().plot.bar(title=\"Lucro x Ano\")\nplt.xlabel(\"Ano\")\nplt.ylabel(\"Receita\");",
"_____no_output_____"
],
[
"df.groupby(df[\"Data Venda\"].dt.year)[\"lucro\"].sum()",
"_____no_output_____"
],
[
"#Selecionando apenas as vendas de 2009\ndf_2009 = df[df[\"Data Venda\"].dt.year == 2009]",
"_____no_output_____"
],
[
"df_2009.head()",
"_____no_output_____"
],
[
"df_2009.groupby(df_2009[\"Data Venda\"].dt.month)[\"lucro\"].sum().plot(title=\"Lucro x Mês\")\nplt.xlabel(\"Mês\")\nplt.ylabel(\"Lucro\");",
"_____no_output_____"
],
[
"df_2009.groupby(\"Marca\")[\"lucro\"].sum().plot.bar(title=\"Lucro x Marca\")\nplt.xlabel(\"Marca\")\nplt.ylabel(\"Lucro\")\nplt.xticks(rotation='horizontal');",
"_____no_output_____"
],
[
"df_2009.groupby(\"Classe\")[\"lucro\"].sum().plot.bar(title=\"Lucro x Classe\")\nplt.xlabel(\"Classe\")\nplt.ylabel(\"Lucro\")\nplt.xticks(rotation='horizontal');",
"_____no_output_____"
],
[
"df[\"Tempo_envio\"].describe()",
"_____no_output_____"
],
[
"#Gráfico de Boxplot\nplt.boxplot(df[\"Tempo_envio\"]);",
"_____no_output_____"
],
[
"#Histograma\nplt.hist(df[\"Tempo_envio\"]);",
"_____no_output_____"
],
[
"#Tempo mínimo de envio\ndf[\"Tempo_envio\"].min()",
"_____no_output_____"
],
[
"#Tempo máximo de envio\ndf['Tempo_envio'].max()",
"_____no_output_____"
],
[
"#Identificando o Outlier\ndf[df[\"Tempo_envio\"] == 20]",
"_____no_output_____"
],
[
"df.to_csv(\"df_vendas_novo.csv\", index=False)",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb332eb5e6025c19da35dc2f600aea078ddf2df8 | 21,091 | ipynb | Jupyter Notebook | data_prep/decals_c_ilifu.ipynb | Virodroid/GalaxyClassification | a4aa1ab235e09c7f13bd31b522051e4caf1e9f23 | [
"MIT"
] | 1 | 2021-11-15T14:08:39.000Z | 2021-11-15T14:08:39.000Z | data_prep/decals_c_ilifu.ipynb | Virodroid/GalaxyClassification | a4aa1ab235e09c7f13bd31b522051e4caf1e9f23 | [
"MIT"
] | null | null | null | data_prep/decals_c_ilifu.ipynb | Virodroid/GalaxyClassification | a4aa1ab235e09c7f13bd31b522051e4caf1e9f23 | [
"MIT"
] | null | null | null | 36.238832 | 155 | 0.340572 | [
[
[
"import pandas as pd\nfrom sklearn.model_selection import train_test_split\nimport os.path",
"_____no_output_____"
],
[
"decals_c = pd.read_csv('../GZD_data/gz_decals_volunteers_c.csv')",
"_____no_output_____"
],
[
"decals_c",
"_____no_output_____"
],
[
"decals_c_edit = decals_c.replace({'/dr5/':'/idia/projects/hippo/gzd/dr5/'}, regex=True)",
"_____no_output_____"
],
[
"#decals_c_edit = decals_c_edit[[os.path.isfile(i) for i in decals_c_edit['png_loc']]]",
"_____no_output_____"
],
[
"decals_c_edit = decals_c_edit.rename(columns={'png_loc':'file_loc'})\ndecals_c_edit = decals_c_edit.rename(columns={'iauname':'id_str'})",
"_____no_output_____"
],
[
"decals_subset = decals_c_edit.query('`smooth-or-featured_total-votes`>2 | `smooth-or-featured_featured-or-disk`>2 | `smooth-or-featured_artifact`>2')",
"_____no_output_____"
],
[
"test = decals_subset[decals_subset[\"id_str\"]==\"J104325.29+190335.0\"]",
"_____no_output_____"
],
[
"test.to_csv(\"../Ilifu_data/decals_ilifu_dummytrain.csv\", index=False)",
"_____no_output_____"
],
[
"train, test = train_test_split(decals_subset, test_size=0.2)",
"_____no_output_____"
],
[
"train.to_csv(\"decals_ilifu_train.csv\", index=False)\ntest.to_csv(\"decals_ilifu_test.csv\", index=False)",
"_____no_output_____"
],
[
"decals_c_edit.to_csv(\"decals_ilifu_c.csv\", index=False)",
"_____no_output_____"
],
[
"decals_subset.to_csv(\"decals_ilifu_subset.csv\", index=False)",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb334c23fcba046300065f3ee0d58fd830ed0d7e | 770 | ipynb | Jupyter Notebook | 2021-12-2-Advent-of-Code-day-2.ipynb | cmondorf/blog | 615dc05d5420d20715ed04775fbca1e6ccb0eba4 | [
"Apache-2.0"
] | null | null | null | 2021-12-2-Advent-of-Code-day-2.ipynb | cmondorf/blog | 615dc05d5420d20715ed04775fbca1e6ccb0eba4 | [
"Apache-2.0"
] | null | null | null | 2021-12-2-Advent-of-Code-day-2.ipynb | cmondorf/blog | 615dc05d5420d20715ed04775fbca1e6ccb0eba4 | [
"Apache-2.0"
] | null | null | null | 20.810811 | 53 | 0.437662 | [
[
[
"# Advent of Code 2021, day 2\n> Onwards to day 2 of Advent of Code.\n\n- toc: true \n- badges: true\n- comments: true\n- sticky_rank: 1\n- author: Christian Mondorf\n- image: \n- categories: [advent of code]",
"_____no_output_____"
]
]
] | [
"markdown"
] | [
[
"markdown"
]
] |
cb335e95e75e610693094cdfc20ad57f5dcf7646 | 328,665 | ipynb | Jupyter Notebook | A Network Analysis of Game of Thrones/notebook.ipynb | tawabshakeel/DataCamp-Projects | a6082d43cb1c1e886d311457719b60b7a5bf8eef | [
"MIT"
] | 5 | 2019-06-14T19:45:59.000Z | 2021-05-25T20:30:49.000Z | A Network Analysis of Game of Thrones/notebook.ipynb | tawabshakeel/DataCamp-Projects | a6082d43cb1c1e886d311457719b60b7a5bf8eef | [
"MIT"
] | null | null | null | A Network Analysis of Game of Thrones/notebook.ipynb | tawabshakeel/DataCamp-Projects | a6082d43cb1c1e886d311457719b60b7a5bf8eef | [
"MIT"
] | 9 | 2019-06-15T00:48:29.000Z | 2021-11-09T09:49:05.000Z | 328,665 | 328,665 | 0.817145 | [
[
[
"## 1. Winter is Coming. Let's load the dataset ASAP!\n<p>If you haven't heard of <em>Game of Thrones</em>, then you must be really good at hiding. Game of Thrones is the hugely popular television series by HBO based on the (also) hugely popular book series <em>A Song of Ice and Fire</em> by George R.R. Martin. In this notebook, we will analyze the co-occurrence network of the characters in the Game of Thrones books. Here, two characters are considered to co-occur if their names appear in the vicinity of 15 words from one another in the books. </p>\n<p><img src=\"https://assets.datacamp.com/production/project_76/img/got_network.jpeg\" style=\"width: 550px\"></p>\n<p>This dataset constitutes a network and is given as a text file describing the <em>edges</em> between characters, with some attributes attached to each edge. Let's start by loading in the data for the first book <em>A Game of Thrones</em> and inspect it.</p>",
"_____no_output_____"
]
],
[
[
"# Importing modules\n# ... YOUR CODE FOR TASK 1 ...\nimport pandas as pd\n\n# Reading in datasets/book1.csv\nbook1 = pd.read_csv('datasets/book1.csv')\n\nbook1.head()\n# Printing out the head of the dataset\n# ... YOUR CODE FOR TASK 1 ...",
"_____no_output_____"
]
],
[
[
"## 2. Time for some Network of Thrones\n<p>The resulting DataFrame <code>book1</code> has 5 columns: <code>Source</code>, <code>Target</code>, <code>Type</code>, <code>weight</code>, and <code>book</code>. Source and target are the two nodes that are linked by an edge. A network can have directed or undirected edges and in this network all the edges are undirected. The weight attribute of every edge tells us the number of interactions that the characters have had over the book, and the book column tells us the book number.</p>\n<p>Once we have the data loaded as a pandas DataFrame, it's time to create a network. We will use <code>networkx</code>, a network analysis library, and create a graph object for the first book.</p>",
"_____no_output_____"
]
],
[
[
"# Importing modules\n# ... YOUR CODE FOR TASK 2 ...\nimport networkx as nx\n# Creating an empty graph object\nG_book1 = nx.Graph()",
"_____no_output_____"
]
],
[
[
"## 3. Populate the network with the DataFrame\n<p>Currently, the graph object <code>G_book1</code> is empty. Let's now populate it with the edges from <code>book1</code>. And while we're at it, let's load in the rest of the books too!</p>",
"_____no_output_____"
]
],
[
[
"# Iterating through the DataFrame to add edges\n# ... YOUR CODE FOR TASK 3 ...\nfor _, edge in book1.iterrows():\n G_book1.add_edge(edge['Source'], edge['Target'], weight=edge['weight'])\n\n# Creating a list of networks for all the books\nbooks = [G_book1]\nbook_fnames = ['datasets/book2.csv', 'datasets/book3.csv', 'datasets/book4.csv', 'datasets/book5.csv']\nfor book_fname in book_fnames:\n book = pd.read_csv(book_fname)\n G_book = nx.Graph()\n for _, edge in book.iterrows():\n G_book.add_edge(edge['Source'], edge['Target'], weight=edge['weight'])\n books.append(G_book)",
"_____no_output_____"
]
],
[
[
"## 4. The most important character in Game of Thrones\n<p>Is it Jon Snow, Tyrion, Daenerys, or someone else? Let's see! Network science offers us many different metrics to measure the importance of a node in a network. Note that there is no \"correct\" way of calculating the most important node in a network, every metric has a different meaning.</p>\n<p>First, let's measure the importance of a node in a network by looking at the number of neighbors it has, that is, the number of nodes it is connected to. For example, an influential account on Twitter, where the follower-followee relationship forms the network, is an account which has a high number of followers. This measure of importance is called <em>degree centrality</em>.</p>\n<p>Using this measure, let's extract the top ten important characters from the first book (<code>book[0]</code>) and the fifth book (<code>book[4]</code>).</p>",
"_____no_output_____"
]
],
[
[
"# Calculating the degree centrality of book 1\ndeg_cen_book1 = nx.degree_centrality(books[0])\n\n# Calculating the degree centrality of book 5\ndeg_cen_book5 = nx.degree_centrality(books[4])\n\n\n# Sorting the dictionaries according to their degree centrality and storing the top 10\nsorted_deg_cen_book1 = sorted(deg_cen_book1.items(), key=lambda x: x[1], reverse=True)[0:10]\n\n# Sorting the dictionaries according to their degree centrality and storing the top 10\nsorted_deg_cen_book5 = sorted(deg_cen_book5.items(), key=lambda x: x[1], reverse=True)[0:10]\n\nprint(sorted_deg_cen_book1)\nprint(sorted_deg_cen_book5)\n# Printing out the top 10 of book1 and book5\n# ... YOUR CODE FOR TASK 4 ...",
"[('Eddard-Stark', 0.3548387096774194), ('Robert-Baratheon', 0.2688172043010753), ('Tyrion-Lannister', 0.24731182795698928), ('Catelyn-Stark', 0.23118279569892475), ('Jon-Snow', 0.19892473118279572), ('Sansa-Stark', 0.18817204301075272), ('Robb-Stark', 0.18817204301075272), ('Bran-Stark', 0.17204301075268819), ('Joffrey-Baratheon', 0.16129032258064518), ('Cersei-Lannister', 0.16129032258064518)]\n[('Jon-Snow', 0.1962025316455696), ('Daenerys-Targaryen', 0.18354430379746836), ('Stannis-Baratheon', 0.14873417721518986), ('Theon-Greyjoy', 0.10443037974683544), ('Tyrion-Lannister', 0.10443037974683544), ('Cersei-Lannister', 0.08860759493670886), ('Barristan-Selmy', 0.07911392405063292), ('Hizdahr-zo-Loraq', 0.06962025316455696), ('Asha-Greyjoy', 0.056962025316455694), ('Melisandre', 0.05379746835443038)]\n"
]
],
[
[
"## 5. The evolution of character importance\n<p>According to degree centrality, the most important character in the first book is Eddard Stark but he is not even in the top 10 of the fifth book. The importance of characters changes over the course of five books because, you know, stuff happens... ;)</p>\n<p>Let's look at the evolution of degree centrality of a couple of characters like Eddard Stark, Jon Snow, and Tyrion, which showed up in the top 10 of degree centrality in the first book.</p>",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n\n# Creating a list of degree centrality of all the books\nevol = [nx.degree_centrality(book) for book in books]\n \n# Creating a DataFrame from the list of degree centralities in all the books\ndegree_evol_df = pd.DataFrame.from_records(evol)\n\ndegree_evol_df[['Eddard-Stark','Tyrion-Lannister','Jon-Snow']].plot()\n# Plotting the degree centrality evolution of Eddard-Stark, Tyrion-Lannister and Jon-Snow\n# ... YOUR CODE FOR TASK 5 ...",
"_____no_output_____"
]
],
[
[
"## 6. What's up with Stannis Baratheon?\n<p>We can see that the importance of Eddard Stark dies off as the book series progresses. With Jon Snow, there is a drop in the fourth book but a sudden rise in the fifth book.</p>\n<p>Now let's look at various other measures like <em>betweenness centrality</em> and <em>PageRank</em> to find important characters in our Game of Thrones character co-occurrence network and see if we can uncover some more interesting facts about this network. Let's plot the evolution of betweenness centrality of this network over the five books. We will take the evolution of the top four characters of every book and plot it.</p>",
"_____no_output_____"
]
],
[
[
"# Creating a list of betweenness centrality of all the books just like we did for degree centrality\nevol = [nx.betweenness_centrality(book,weight='weight') for book in books]\n\n# Making a DataFrame from the list\nbetweenness_evol_df = pd.DataFrame.from_records(evol)\n\n# Finding the top 4 characters in every book\nset_of_char = set()\nfor i in range(5):\n set_of_char |= set(list(betweenness_evol_df.T[i].sort_values(ascending=False)[0:4].index))\nlist_of_char = list(set_of_char)\nbetweenness_evol_df[list_of_char].plot()\n# Plotting the evolution of the top characters\n# ... YOUR CODE FOR TASK 6 ...",
"_____no_output_____"
]
],
[
[
"## 7. What does Google PageRank tell us about GoT?\n<p>We see a peculiar rise in the importance of Stannis Baratheon over the books. In the fifth book, he is significantly more important than other characters in the network, even though he is the third most important character according to degree centrality.</p>\n<p>PageRank was the initial way Google ranked web pages. It evaluates the inlinks and outlinks of webpages in the world wide web, which is, essentially, a directed network. Let's look at the importance of characters in the Game of Thrones network according to PageRank. </p>",
"_____no_output_____"
]
],
[
[
"# Creating a list of pagerank of all the characters in all the books\nevol = [nx.pagerank(book) for book in books]\n\n# Making a DataFrame from the list\npagerank_evol_df = pd.DataFrame.from_records(evol)\n\n# Finding the top 4 characters in every book\nset_of_char = set()\nfor i in range(5):\n set_of_char |= set(list(pagerank_evol_df.T[i].sort_values(ascending=False)[0:4].index))\nlist_of_char = list(set_of_char)\npagerank_evol_df[list_of_char].plot(figsize=(13, 7))\n# Plotting the top characters\n# ... YOUR CODE FOR TASK 7 ...",
"_____no_output_____"
]
],
[
[
"## 8. Correlation between different measures\n<p>Stannis, Jon Snow, and Daenerys are the most important characters in the fifth book according to PageRank. Eddard Stark follows a similar curve but for degree centrality and betweenness centrality: He is important in the first book but dies into oblivion over the book series.</p>\n<p>We have seen three different measures to calculate the importance of a node in a network, and all of them tells us something about the characters and their importance in the co-occurrence network. We see some names pop up in all three measures so maybe there is a strong correlation between them?</p>\n<p>Let's look at the correlation between PageRank, betweenness centrality and degree centrality for the fifth book using Pearson correlation.</p>",
"_____no_output_____"
]
],
[
[
"# Creating a list of pagerank, betweenness centrality, degree centrality\n# of all the characters in the fifth book.\nmeasures = [nx.pagerank(books[4]), \n nx.betweenness_centrality(books[4], weight='weight'), \n nx.degree_centrality(books[4])]\n\n# Creating the correlation DataFrame\ncor = pd.DataFrame.from_records(measures)\ncor.corr()\n# Calculating the correlation\n# ... YOUR CODE FOR TASK 8 ...",
"_____no_output_____"
]
],
[
[
"## 9. Conclusion\n<p>We see a high correlation between these three measures for our character co-occurrence network.</p>\n<p>So we've been looking at different ways to find the important characters in the Game of Thrones co-occurrence network. According to degree centrality, Eddard Stark is the most important character initially in the books. But who is/are the most important character(s) in the fifth book according to these three measures? </p>",
"_____no_output_____"
]
],
[
[
"# Finding the most important character in the fifth book, \n# according to degree centrality, betweenness centrality and pagerank.\np_rank, b_cent, d_cent = cor.idxmax(axis=1)\n\n\n# Printing out the top character accoding to the three measures\n# ... YOUR CODE FOR TASK 9 ...",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
cb33684c6abdcfe867b5c2a5da02a10a8d1d56dd | 10,547 | ipynb | Jupyter Notebook | versions/2020/cnn/code/cnn-mnist.ipynb | shin-mashita/Deep-Learning-Experiments | c5f75c012d9eba2fa34e38b4122b2eceb498c8bf | [
"MIT"
] | 994 | 2017-01-17T11:56:51.000Z | 2022-03-22T11:51:40.000Z | versions/2020/cnn/code/cnn-mnist.ipynb | shin-mashita/Deep-Learning-Experiments | c5f75c012d9eba2fa34e38b4122b2eceb498c8bf | [
"MIT"
] | 20 | 2017-06-01T01:30:16.000Z | 2021-06-11T17:27:51.000Z | versions/2020/cnn/code/cnn-mnist.ipynb | shin-mashita/Deep-Learning-Experiments | c5f75c012d9eba2fa34e38b4122b2eceb498c8bf | [
"MIT"
] | 789 | 2017-02-16T08:53:14.000Z | 2022-03-27T14:33:39.000Z | 39.8 | 450 | 0.532284 | [
[
[
"## CNN on MNIST digits classification\n\nThis example is the same as the MLP for MNIST classification. The difference is we are going to use `Conv2D` layers instead of `Dense` layers.\n\nThe model that will be costructed below is made of:\n\n- First 2 layers - `Conv2D-ReLU-MaxPool`\n- 3rd layer - `Conv2D-ReLU`\n- 4th layer - `Dense(10)`\n- Output Activation - `softmax`\n- Optimizer - `SGD`\n\nLet us first load the packages and perform the initial pre-processing such as loading the dataset, performing normalization and conversion of labels to one-hot.\n\nRecall that in our `3-Dense` MLP example, we achieved ~95.3% accuracy at 269k parameters. Here, we can achieve ~98.5% using 105k parameters. CNN is more parameter efficient.",
"_____no_output_____"
]
],
[
[
"from __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport numpy as np\nfrom tensorflow.keras.models import Sequential\nfrom tensorflow.keras.layers import Activation, Dense, Dropout\nfrom tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten\nfrom tensorflow.keras.utils import to_categorical, plot_model\nfrom tensorflow.keras.datasets import mnist\n\n# load mnist dataset\n(x_train, y_train), (x_test, y_test) = mnist.load_data()\n\n# compute the number of labels\nnum_labels = len(np.unique(y_train))\n\n# convert to one-hot vector\ny_train = to_categorical(y_train)\ny_test = to_categorical(y_test)\n\n# input image dimensions\nimage_size = x_train.shape[1]\n# resize and normalize\nx_train = np.reshape(x_train,[-1, image_size, image_size, 1])\nx_test = np.reshape(x_test,[-1, image_size, image_size, 1])\nx_train = x_train.astype('float32') / 255\nx_test = x_test.astype('float32') / 255",
"_____no_output_____"
]
],
[
[
"### Hyper-parameters\n\nThis hyper-parameters are similar to our MLP example. The differences are `kernel_size = 3` which is a typical kernel size in most CNNs and `filters = 64`. ",
"_____no_output_____"
]
],
[
[
"# network parameters\n# image is processed as is (square grayscale)\ninput_shape = (image_size, image_size, 1)\nbatch_size = 128\nkernel_size = 3\nfilters = 64",
"_____no_output_____"
]
],
[
[
"### Sequential Model Building\n\nThe model is similar to our previous example in MLP. The difference is we use `Conv2D` instead of `Dense`. Note that due to mismatch in dimensions, the output of the last `Conv2D` is flattened via `Flatten()` layer to suit the input vector dimensions of the `Dense`. Note that though we use `Activation(softmax)` as the last layer, this can also be integrated within the `Dense` layer in the parameter `activation='softmax'`. Both are the same.",
"_____no_output_____"
]
],
[
[
"# model is a stack of CNN-ReLU-MaxPooling\nmodel = Sequential()\nmodel.add(Conv2D(filters=filters,\n kernel_size=kernel_size,\n activation='relu',\n padding='same',\n input_shape=input_shape))\nmodel.add(MaxPooling2D())\nmodel.add(Conv2D(filters=filters,\n kernel_size=kernel_size,\n padding='same',\n activation='relu'))\nmodel.add(MaxPooling2D())\nmodel.add(Conv2D(filters=filters,\n kernel_size=kernel_size,\n padding='same',\n activation='relu'))\nmodel.add(Flatten())\n# dropout added as regularizer\n# model.add(Dropout(dropout))\n# output layer is 10-dim one-hot vector\nmodel.add(Dense(num_labels))\nmodel.add(Activation('softmax'))\nmodel.summary()",
"Model: \"sequential_4\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nconv2d_12 (Conv2D) (None, 28, 28, 64) 640 \n_________________________________________________________________\nmax_pooling2d_8 (MaxPooling2 (None, 14, 14, 64) 0 \n_________________________________________________________________\nconv2d_13 (Conv2D) (None, 14, 14, 64) 36928 \n_________________________________________________________________\nmax_pooling2d_9 (MaxPooling2 (None, 7, 7, 64) 0 \n_________________________________________________________________\nconv2d_14 (Conv2D) (None, 7, 7, 64) 36928 \n_________________________________________________________________\nflatten_4 (Flatten) (None, 3136) 0 \n_________________________________________________________________\ndense_4 (Dense) (None, 10) 31370 \n_________________________________________________________________\nactivation_4 (Activation) (None, 10) 0 \n=================================================================\nTotal params: 105,866\nTrainable params: 105,866\nNon-trainable params: 0\n_________________________________________________________________\n"
]
],
[
[
"## Model Training and Evaluation\n\nAfter building the model, it is time to train and evaluate. This part is similar to MLP training and evaluation.",
"_____no_output_____"
]
],
[
[
"#plot_model(model, to_file='cnn-mnist.png', show_shapes=True)\n\n# loss function for one-hot vector\n# use of adam optimizer\n# accuracy is good metric for classification tasks\nmodel.compile(loss='categorical_crossentropy',\n optimizer='sgd',\n metrics=['accuracy'])\n# train the network\nmodel.fit(x_train, y_train, epochs=20, batch_size=batch_size)\n\nloss, acc = model.evaluate(x_test, y_test, batch_size=batch_size)\nprint(\"\\nTest accuracy: %.1f%%\" % (100.0 * acc))\n",
"Epoch 1/20\n469/469 [==============================] - 44s 93ms/step - loss: 1.2029 - accuracy: 0.6349\nEpoch 2/20\n469/469 [==============================] - 44s 94ms/step - loss: 0.3460 - accuracy: 0.8959\nEpoch 3/20\n469/469 [==============================] - 44s 94ms/step - loss: 0.2564 - accuracy: 0.9221\nEpoch 4/20\n469/469 [==============================] - 44s 93ms/step - loss: 0.2008 - accuracy: 0.9401\nEpoch 5/20\n469/469 [==============================] - 44s 95ms/step - loss: 0.1630 - accuracy: 0.9521\nEpoch 6/20\n469/469 [==============================] - 45s 95ms/step - loss: 0.1369 - accuracy: 0.9588\nEpoch 7/20\n469/469 [==============================] - 44s 95ms/step - loss: 0.1176 - accuracy: 0.9652\nEpoch 8/20\n469/469 [==============================] - 44s 94ms/step - loss: 0.1046 - accuracy: 0.9686\nEpoch 9/20\n469/469 [==============================] - 45s 96ms/step - loss: 0.0940 - accuracy: 0.9717\nEpoch 10/20\n469/469 [==============================] - 45s 95ms/step - loss: 0.0862 - accuracy: 0.9741\nEpoch 11/20\n469/469 [==============================] - 45s 95ms/step - loss: 0.0798 - accuracy: 0.9757\nEpoch 12/20\n469/469 [==============================] - 44s 95ms/step - loss: 0.0748 - accuracy: 0.9776\nEpoch 13/20\n469/469 [==============================] - 44s 95ms/step - loss: 0.0700 - accuracy: 0.9793\nEpoch 14/20\n469/469 [==============================] - 45s 95ms/step - loss: 0.0664 - accuracy: 0.9801\nEpoch 15/20\n469/469 [==============================] - 44s 94ms/step - loss: 0.0636 - accuracy: 0.9808\nEpoch 16/20\n469/469 [==============================] - 45s 96ms/step - loss: 0.0604 - accuracy: 0.9815\nEpoch 17/20\n469/469 [==============================] - 45s 96ms/step - loss: 0.0577 - accuracy: 0.9822\nEpoch 18/20\n469/469 [==============================] - 46s 99ms/step - loss: 0.0560 - accuracy: 0.9825\nEpoch 19/20\n469/469 [==============================] - 46s 98ms/step - loss: 0.0533 - accuracy: 0.9841\nEpoch 20/20\n469/469 [==============================] - 51s 108ms/step - loss: 0.0516 - accuracy: 0.9843\n79/79 [==============================] - 2s 23ms/step - loss: 0.0455 - accuracy: 0.9848\n\nTest accuracy: 98.5%\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
cb337782fb39426ea1acbadb41290ed1206bf7f1 | 206,741 | ipynb | Jupyter Notebook | notebooks/shortest_path.ipynb | BNN-UPC/ignnition | 905e4aa756ad6dd92d620f5f8b37d8190bb5273a | [
"BSD-3-Clause"
] | 18 | 2021-06-09T15:52:55.000Z | 2022-03-28T05:54:14.000Z | notebooks/shortest_path.ipynb | BNN-UPC/ignnition | 905e4aa756ad6dd92d620f5f8b37d8190bb5273a | [
"BSD-3-Clause"
] | 11 | 2021-06-03T07:55:04.000Z | 2022-03-11T16:54:15.000Z | notebooks/shortest_path.ipynb | knowledgedefinednetworking/ignnition | 905e4aa756ad6dd92d620f5f8b37d8190bb5273a | [
"BSD-3-Clause"
] | 12 | 2020-07-07T16:45:09.000Z | 2021-04-05T15:55:30.000Z | 290.366573 | 167,690 | 0.881562 | [
[
[
"<a href=\"https://colab.research.google.com/github/BNN-UPC/ignnition/blob/ignnition-nightly/notebooks/shortest_path.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# IGNNITION: Quick start tutorial\n\n### **Problem**: Find the shortest path in graphs with a Graph Neural Network\n\nFind more details on this quick-start tutorial at:\nhttps://ignnition.net/doc/quick_tutorial/\n",
"_____no_output_____"
],
[
"---\n# Prepare the environment\n\n#### **Note**: Follow the instructions below to finish the installation",
"_____no_output_____"
]
],
[
[
"#@title Installing libraries and load resources\n#@markdown ####Hit **\"enter\"** to complete the installation of libraries\n!add-apt-repository ppa:deadsnakes/ppa\n!apt-get update\n!apt-get install python3.7\n!python -m pip install --upgrade pip\n!pip install jupyter-client==6.1.5\n!pip install ignnition==1.2.2\n!pip install ipython-autotime\n\n",
"_____no_output_____"
],
[
"#@title Import libraries { form-width: \"30%\" }\nimport networkx as nx\nimport random\nimport json\nfrom networkx.readwrite import json_graph\nimport os\nimport ignnition\n%load_ext tensorboard\n%load_ext autotime",
"time: 104 µs (started: 2021-09-29 16:40:02 +00:00)\n"
],
[
"#@markdown #### Download three YAML files we will need after (train_options.yaml, model_description.yaml, global_variables.yaml)\n# Download YAML files for this tutorial\n!curl -O https://raw.githubusercontent.com/BNN-UPC/ignnition/ignnition-nightly/examples/Shortest_Path/train_options.yaml\n!curl -O https://raw.githubusercontent.com/BNN-UPC/ignnition/ignnition-nightly/examples/Shortest_Path/global_variables.yaml\n!curl -O https://raw.githubusercontent.com/BNN-UPC/ignnition/ignnition-nightly/examples/Shortest_Path/model_description.yaml\n\n\n",
"_____no_output_____"
],
[
"#@title Generate the datasets (training and validation)\nimport os\n\ndef generate_random_graph(min_nodes, max_nodes, min_edge_weight, max_edge_weight, p):\n while True:\n # Create a random Erdos Renyi graph\n G = nx.erdos_renyi_graph(random.randint(min_nodes, max_nodes), p)\n complement = list(nx.k_edge_augmentation(G, k=1, partial=True))\n G.add_edges_from(complement)\n nx.set_node_attributes(G, 0, 'src-tgt')\n nx.set_node_attributes(G, 0, 'sp')\n nx.set_node_attributes(G, 'node', 'entity')\n\n # Assign randomly weights to graph edges\n for (u, v, w) in G.edges(data=True):\n w['weight'] = random.randint(min_edge_weight, max_edge_weight)\n\n # Select a source and target nodes to compute the shortest path\n src, tgt = random.sample(list(G.nodes), 2)\n\n G.nodes[src]['src-tgt'] = 1\n G.nodes[tgt]['src-tgt'] = 1\n\n # Compute all the shortest paths between source and target nodes\n try:\n shortest_paths = list(nx.all_shortest_paths(G, source=src, target=tgt,weight='weight'))\n except:\n shortest_paths = []\n # Check if there exists only one shortest path\n if len(shortest_paths) == 1:\n for node in shortest_paths[0]:\n G.nodes[node]['sp'] = 1\n return nx.DiGraph(G)\n\ndef generate_dataset(file_name, num_samples, min_nodes=5, max_nodes=15, min_edge_weight=1, max_edge_weight=10, p=0.3):\n samples = []\n for _ in range(num_samples):\n G = generate_random_graph(min_nodes, max_nodes, min_edge_weight, max_edge_weight, p)\n G.remove_nodes_from([node for node, degree in dict(G.degree()).items() if degree == 0])\n samples.append(json_graph.node_link_data(G))\n\n with open(file_name, \"w\") as f:\n json.dump(samples, f)\n\nroot_dir=\"./data\"\nif not os.path.exists(root_dir):\n os.makedirs(root_dir)\nif not os.path.exists(root_dir+\"/train\"):\n os.makedirs(root_dir+\"/train\")\nif not os.path.exists(root_dir + \"/validation\"):\n os.makedirs(root_dir + \"/validation\")\ngenerate_dataset(\"./data/train/data.json\", 20000)\ngenerate_dataset(\"./data/validation/data.json\", 1000)",
"_____no_output_____"
]
],
[
[
"---\n# GNN model training",
"_____no_output_____"
]
],
[
[
"#@title Remove all the models previously trained (CheckPoints)\n#@markdown (It is not needed to execute this the first time)\n! rm -r ./CheckPoint\n! rm -r ./computational_graphs",
"_____no_output_____"
],
[
"#@title Load TensorBoard to visualize the evolution of learning metrics along training\n#@markdown **IMPORTANT NOTE**: Click on \"settings\" in the TensorBoard GUI and check the option \"Reload data\" to see the evolution in real time. Note you can set the reload time interval (in seconds).\nfrom tensorboard import notebook\nnotebook.list() # View open TensorBoard instances\n\ndir=\"./CheckPoint\"\nif not os.path.exists(dir):\n os.makedirs(dir)\n%tensorboard --logdir $dir\n\n# Para finalizar instancias anteriores de TensorBoard\n# !kill 2953\n# !ps aux",
"_____no_output_____"
],
[
"#@title Run the training of your GNN model\n#@markdown </u>**Note**</u>: You can stop the training whenever you want to continue making predictions below\n\nimport ignnition\n\nmodel = ignnition.create_model(model_dir= './')\nmodel.computational_graph()\nmodel.train_and_validate()\n\n",
"\u001b[1m\nProcessing the described model...\n---------------------------------------------------------------------------\n\u001b[0m\n\u001b[1mCreating the GNN model...\n---------------------------------------------------------------------------\n\u001b[0m\n\n\u001b[1mGenerating the computational graph... \n---------------------------------------------------------------------------\n\u001b[0m\n/content/computational_graphs/experiment_2021_09_29_16_40_27\n\n\u001b[1mStarting the training and validation process...\n---------------------------------------------------------------------------\n\u001b[0m\nNumber of devices: 1\nEpoch 1/60\n200/200 [==============================] - 18s 67ms/step - loss: 0.6197 - binary_accuracy: 0.6652 - precision: 0.3234 - recall: 0.0227 - val_loss: 0.4774 - val_binary_accuracy: 0.8521 - val_precision: 1.0000 - val_recall: 0.5970\nEpoch 2/60\n200/200 [==============================] - 11s 55ms/step - loss: 0.3923 - binary_accuracy: 0.8768 - precision: 0.9704 - recall: 0.6312 - val_loss: 0.2899 - val_binary_accuracy: 0.8872 - val_precision: 0.9361 - val_recall: 0.7433\nEpoch 3/60\n200/200 [==============================] - 11s 54ms/step - loss: 0.2391 - binary_accuracy: 0.9063 - precision: 0.8890 - recall: 0.7791 - val_loss: 0.2616 - val_binary_accuracy: 0.8828 - val_precision: 0.9750 - val_recall: 0.6985\nEpoch 4/60\n200/200 [==============================] - 11s 54ms/step - loss: 0.1912 - binary_accuracy: 0.9248 - precision: 0.9164 - recall: 0.8188 - val_loss: 0.2198 - val_binary_accuracy: 0.9124 - val_precision: 0.9100 - val_recall: 0.8448\nEpoch 5/60\n200/200 [==============================] - 11s 55ms/step - loss: 0.2172 - binary_accuracy: 0.9123 - precision: 0.9089 - recall: 0.8077 - val_loss: 0.2137 - val_binary_accuracy: 0.9179 - val_precision: 0.8939 - val_recall: 0.8806\nEpoch 6/60\n200/200 [==============================] - 10s 52ms/step - loss: 0.2128 - binary_accuracy: 0.9126 - precision: 0.8738 - recall: 0.8528 - val_loss: 0.2421 - val_binary_accuracy: 0.9025 - val_precision: 0.9805 - val_recall: 0.7493\nEpoch 7/60\n200/200 [==============================] - 10s 50ms/step - loss: 0.2011 - binary_accuracy: 0.9218 - precision: 0.9008 - recall: 0.8374 - val_loss: 0.2122 - val_binary_accuracy: 0.9124 - val_precision: 0.9022 - val_recall: 0.8537\nEpoch 8/60\n200/200 [==============================] - 10s 50ms/step - loss: 0.1970 - binary_accuracy: 0.9247 - precision: 0.8937 - recall: 0.8652 - val_loss: 0.2120 - val_binary_accuracy: 0.9157 - val_precision: 0.9082 - val_recall: 0.8567\nEpoch 9/60\n200/200 [==============================] - 9s 47ms/step - loss: 0.2141 - binary_accuracy: 0.9207 - precision: 0.9093 - recall: 0.8443 - val_loss: 0.2435 - val_binary_accuracy: 0.8861 - val_precision: 0.9833 - val_recall: 0.7015\nEpoch 10/60\n200/200 [==============================] - 10s 48ms/step - loss: 0.1778 - binary_accuracy: 0.9284 - precision: 0.9137 - recall: 0.8500 - val_loss: 0.2191 - val_binary_accuracy: 0.9014 - val_precision: 0.9487 - val_recall: 0.7731\nEpoch 11/60\n200/200 [==============================] - 9s 47ms/step - loss: 0.2096 - binary_accuracy: 0.9123 - precision: 0.8852 - recall: 0.8259 - val_loss: 0.2142 - val_binary_accuracy: 0.9146 - val_precision: 0.8579 - val_recall: 0.9194\nEpoch 12/60\n200/200 [==============================] - 9s 46ms/step - loss: 0.1921 - binary_accuracy: 0.9241 - precision: 0.8921 - recall: 0.8598 - val_loss: 0.2036 - val_binary_accuracy: 0.9189 - val_precision: 0.8991 - val_recall: 0.8776\nEpoch 13/60\n200/200 [==============================] - 9s 46ms/step - loss: 0.2240 - binary_accuracy: 0.9159 - precision: 0.8857 - recall: 0.8777 - val_loss: 0.2261 - val_binary_accuracy: 0.9113 - val_precision: 0.8629 - val_recall: 0.9015\nEpoch 14/60\n200/200 [==============================] - 9s 46ms/step - loss: 0.1691 - binary_accuracy: 0.9361 - precision: 0.9005 - recall: 0.8913 - val_loss: 0.2137 - val_binary_accuracy: 0.9113 - val_precision: 0.8872 - val_recall: 0.8687\nEpoch 15/60\n200/200 [==============================] - 9s 45ms/step - loss: 0.1764 - binary_accuracy: 0.9354 - precision: 0.9324 - recall: 0.8460 - val_loss: 0.1971 - val_binary_accuracy: 0.9233 - val_precision: 0.8841 - val_recall: 0.9104\nEpoch 16/60\n200/200 [==============================] - 9s 44ms/step - loss: 0.1600 - binary_accuracy: 0.9353 - precision: 0.9130 - recall: 0.8834 - val_loss: 0.2726 - val_binary_accuracy: 0.8894 - val_precision: 0.9795 - val_recall: 0.7134\nEpoch 17/60\n200/200 [==============================] - 9s 44ms/step - loss: 0.1968 - binary_accuracy: 0.9193 - precision: 0.9030 - recall: 0.8508 - val_loss: 0.1916 - val_binary_accuracy: 0.9146 - val_precision: 0.9028 - val_recall: 0.8597\nEpoch 18/60\n200/200 [==============================] - 9s 43ms/step - loss: 0.1860 - binary_accuracy: 0.9270 - precision: 0.9096 - recall: 0.8524 - val_loss: 0.1771 - val_binary_accuracy: 0.9310 - val_precision: 0.9024 - val_recall: 0.9104\nEpoch 19/60\n200/200 [==============================] - 8s 42ms/step - loss: 0.1921 - binary_accuracy: 0.9195 - precision: 0.8666 - recall: 0.8841 - val_loss: 0.1797 - val_binary_accuracy: 0.9222 - val_precision: 0.9258 - val_recall: 0.8567\nEpoch 20/60\n200/200 [==============================] - 8s 42ms/step - loss: 0.1585 - binary_accuracy: 0.9305 - precision: 0.9076 - recall: 0.8667 - val_loss: 0.1755 - val_binary_accuracy: 0.9299 - val_precision: 0.9094 - val_recall: 0.8985\nEpoch 21/60\n200/200 [==============================] - 8s 42ms/step - loss: 0.1698 - binary_accuracy: 0.9282 - precision: 0.9061 - recall: 0.8690 - val_loss: 0.2084 - val_binary_accuracy: 0.8905 - val_precision: 0.9719 - val_recall: 0.7224\nEpoch 22/60\n200/200 [==============================] - 8s 41ms/step - loss: 0.1597 - binary_accuracy: 0.9287 - precision: 0.9185 - recall: 0.8516 - val_loss: 0.1838 - val_binary_accuracy: 0.9266 - val_precision: 0.9497 - val_recall: 0.8448\nEpoch 23/60\n200/200 [==============================] - 8s 40ms/step - loss: 0.1858 - binary_accuracy: 0.9298 - precision: 0.9234 - recall: 0.8585 - val_loss: 0.1794 - val_binary_accuracy: 0.9321 - val_precision: 0.9124 - val_recall: 0.9015\nEpoch 24/60\n200/200 [==============================] - 8s 39ms/step - loss: 0.1377 - binary_accuracy: 0.9436 - precision: 0.9161 - recall: 0.8988 - val_loss: 0.2079 - val_binary_accuracy: 0.8981 - val_precision: 0.9802 - val_recall: 0.7373\nEpoch 25/60\n200/200 [==============================] - 8s 39ms/step - loss: 0.1571 - binary_accuracy: 0.9269 - precision: 0.9103 - recall: 0.8534 - val_loss: 0.1836 - val_binary_accuracy: 0.9321 - val_precision: 0.8845 - val_recall: 0.9373\nEpoch 26/60\n200/200 [==============================] - 8s 39ms/step - loss: 0.2113 - binary_accuracy: 0.9023 - precision: 0.8615 - recall: 0.8521 - val_loss: 0.1766 - val_binary_accuracy: 0.9255 - val_precision: 0.8658 - val_recall: 0.9433\nEpoch 27/60\n200/200 [==============================] - 8s 38ms/step - loss: 0.1590 - binary_accuracy: 0.9388 - precision: 0.9027 - recall: 0.8995 - val_loss: 0.1941 - val_binary_accuracy: 0.9124 - val_precision: 0.9412 - val_recall: 0.8119\nEpoch 28/60\n200/200 [==============================] - 8s 38ms/step - loss: 0.1843 - binary_accuracy: 0.9162 - precision: 0.8804 - recall: 0.8817 - val_loss: 0.1932 - val_binary_accuracy: 0.9124 - val_precision: 0.9073 - val_recall: 0.8478\nEpoch 29/60\n200/200 [==============================] - 7s 37ms/step - loss: 0.1696 - binary_accuracy: 0.9321 - precision: 0.9152 - recall: 0.8792 - val_loss: 0.1682 - val_binary_accuracy: 0.9299 - val_precision: 0.8839 - val_recall: 0.9313\nEpoch 30/60\n200/200 [==============================] - 7s 37ms/step - loss: 0.1491 - binary_accuracy: 0.9361 - precision: 0.8985 - recall: 0.8842 - val_loss: 0.1664 - val_binary_accuracy: 0.9321 - val_precision: 0.9361 - val_recall: 0.8746\nEpoch 31/60\n200/200 [==============================] - 7s 37ms/step - loss: 0.1512 - binary_accuracy: 0.9334 - precision: 0.9060 - recall: 0.8990 - val_loss: 0.1663 - val_binary_accuracy: 0.9222 - val_precision: 0.9000 - val_recall: 0.8866\nEpoch 32/60\n200/200 [==============================] - 7s 36ms/step - loss: 0.1951 - binary_accuracy: 0.9063 - precision: 0.8837 - recall: 0.8457 - val_loss: 0.1550 - val_binary_accuracy: 0.9376 - val_precision: 0.9162 - val_recall: 0.9134\nEpoch 33/60\n200/200 [==============================] - 7s 35ms/step - loss: 0.1204 - binary_accuracy: 0.9512 - precision: 0.9299 - recall: 0.9131 - val_loss: 0.1749 - val_binary_accuracy: 0.9299 - val_precision: 0.8883 - val_recall: 0.9254\nEpoch 34/60\n200/200 [==============================] - 7s 36ms/step - loss: 0.1350 - binary_accuracy: 0.9415 - precision: 0.9126 - recall: 0.8984 - val_loss: 0.1734 - val_binary_accuracy: 0.9310 - val_precision: 0.8636 - val_recall: 0.9642\nEpoch 35/60\n200/200 [==============================] - 7s 34ms/step - loss: 0.1680 - binary_accuracy: 0.9222 - precision: 0.8814 - recall: 0.8858 - val_loss: 0.1533 - val_binary_accuracy: 0.9409 - val_precision: 0.9297 - val_recall: 0.9075\nEpoch 36/60\n200/200 [==============================] - 7s 34ms/step - loss: 0.1573 - binary_accuracy: 0.9404 - precision: 0.9212 - recall: 0.8934 - val_loss: 0.1729 - val_binary_accuracy: 0.9244 - val_precision: 0.9156 - val_recall: 0.8746\nEpoch 37/60\n200/200 [==============================] - 7s 34ms/step - loss: 0.1486 - binary_accuracy: 0.9414 - precision: 0.9281 - recall: 0.8785 - val_loss: 0.1551 - val_binary_accuracy: 0.9398 - val_precision: 0.9545 - val_recall: 0.8776\nEpoch 38/60\n200/200 [==============================] - 7s 33ms/step - loss: 0.1593 - binary_accuracy: 0.9318 - precision: 0.9026 - recall: 0.8882 - val_loss: 0.1602 - val_binary_accuracy: 0.9266 - val_precision: 0.9161 - val_recall: 0.8806\nEpoch 39/60\n200/200 [==============================] - 7s 33ms/step - loss: 0.1580 - binary_accuracy: 0.9311 - precision: 0.8971 - recall: 0.8814 - val_loss: 0.1723 - val_binary_accuracy: 0.9277 - val_precision: 0.8944 - val_recall: 0.9104\nEpoch 40/60\n200/200 [==============================] - 7s 33ms/step - loss: 0.1659 - binary_accuracy: 0.9246 - precision: 0.8869 - recall: 0.8723 - val_loss: 0.1575 - val_binary_accuracy: 0.9354 - val_precision: 0.9132 - val_recall: 0.9104\nEpoch 41/60\n200/200 [==============================] - 6s 32ms/step - loss: 0.1279 - binary_accuracy: 0.9481 - precision: 0.9209 - recall: 0.9061 - val_loss: 0.1663 - val_binary_accuracy: 0.9321 - val_precision: 0.8740 - val_recall: 0.9522\nEpoch 42/60\n200/200 [==============================] - 6s 33ms/step - loss: 0.1592 - binary_accuracy: 0.9309 - precision: 0.8941 - recall: 0.8978 - val_loss: 0.1517 - val_binary_accuracy: 0.9376 - val_precision: 0.9427 - val_recall: 0.8836\nEpoch 43/60\n200/200 [==============================] - 6s 31ms/step - loss: 0.1339 - binary_accuracy: 0.9417 - precision: 0.9319 - recall: 0.8788 - val_loss: 0.1530 - val_binary_accuracy: 0.9321 - val_precision: 0.9252 - val_recall: 0.8866\nEpoch 44/60\n200/200 [==============================] - 6s 31ms/step - loss: 0.1570 - binary_accuracy: 0.9273 - precision: 0.9032 - recall: 0.8829 - val_loss: 0.1509 - val_binary_accuracy: 0.9299 - val_precision: 0.9094 - val_recall: 0.8985\nEpoch 45/60\n200/200 [==============================] - 6s 30ms/step - loss: 0.1390 - binary_accuracy: 0.9383 - precision: 0.9174 - recall: 0.8959 - val_loss: 0.1645 - val_binary_accuracy: 0.9266 - val_precision: 0.9408 - val_recall: 0.8537\nEpoch 46/60\n200/200 [==============================] - 6s 29ms/step - loss: 0.1411 - binary_accuracy: 0.9381 - precision: 0.9060 - recall: 0.8998 - val_loss: 0.1443 - val_binary_accuracy: 0.9441 - val_precision: 0.9128 - val_recall: 0.9373\nEpoch 47/60\n200/200 [==============================] - 6s 29ms/step - loss: 0.1311 - binary_accuracy: 0.9404 - precision: 0.9189 - recall: 0.8901 - val_loss: 0.1481 - val_binary_accuracy: 0.9419 - val_precision: 0.9147 - val_recall: 0.9284\nEpoch 48/60\n200/200 [==============================] - 6s 29ms/step - loss: 0.1400 - binary_accuracy: 0.9479 - precision: 0.9310 - recall: 0.8964 - val_loss: 0.1565 - val_binary_accuracy: 0.9332 - val_precision: 0.8892 - val_recall: 0.9343\nEpoch 49/60\n200/200 [==============================] - 6s 29ms/step - loss: 0.1343 - binary_accuracy: 0.9472 - precision: 0.9306 - recall: 0.9133 - val_loss: 0.1498 - val_binary_accuracy: 0.9376 - val_precision: 0.9264 - val_recall: 0.9015\nEpoch 50/60\n200/200 [==============================] - 6s 28ms/step - loss: 0.1013 - binary_accuracy: 0.9508 - precision: 0.9264 - recall: 0.9210 - val_loss: 0.1648 - val_binary_accuracy: 0.9310 - val_precision: 0.8636 - val_recall: 0.9642\nEpoch 51/60\n200/200 [==============================] - 6s 29ms/step - loss: 0.1530 - binary_accuracy: 0.9347 - precision: 0.8985 - recall: 0.8947 - val_loss: 0.1391 - val_binary_accuracy: 0.9463 - val_precision: 0.9133 - val_recall: 0.9433\nEpoch 52/60\n200/200 [==============================] - 5s 27ms/step - loss: 0.1455 - binary_accuracy: 0.9370 - precision: 0.8958 - recall: 0.9030 - val_loss: 0.1367 - val_binary_accuracy: 0.9485 - val_precision: 0.9337 - val_recall: 0.9254\nEpoch 53/60\n200/200 [==============================] - 5s 27ms/step - loss: 0.1180 - binary_accuracy: 0.9522 - precision: 0.9459 - recall: 0.9015 - val_loss: 0.1437 - val_binary_accuracy: 0.9387 - val_precision: 0.9189 - val_recall: 0.9134\nEpoch 54/60\n200/200 [==============================] - 5s 26ms/step - loss: 0.1351 - binary_accuracy: 0.9449 - precision: 0.9308 - recall: 0.9038 - val_loss: 0.1396 - val_binary_accuracy: 0.9430 - val_precision: 0.9492 - val_recall: 0.8925\nEpoch 55/60\n200/200 [==============================] - 5s 26ms/step - loss: 0.1435 - binary_accuracy: 0.9435 - precision: 0.9358 - recall: 0.8927 - val_loss: 0.1452 - val_binary_accuracy: 0.9430 - val_precision: 0.9436 - val_recall: 0.8985\nEpoch 56/60\n200/200 [==============================] - 5s 25ms/step - loss: 0.1497 - binary_accuracy: 0.9365 - precision: 0.9118 - recall: 0.8964 - val_loss: 0.1453 - val_binary_accuracy: 0.9452 - val_precision: 0.9495 - val_recall: 0.8985\nEpoch 57/60\n200/200 [==============================] - 5s 25ms/step - loss: 0.1148 - binary_accuracy: 0.9584 - precision: 0.9459 - recall: 0.9180 - val_loss: 0.1642 - val_binary_accuracy: 0.9288 - val_precision: 0.8709 - val_recall: 0.9463\nEpoch 58/60\n200/200 [==============================] - 5s 24ms/step - loss: 0.1478 - binary_accuracy: 0.9390 - precision: 0.9116 - recall: 0.8919 - val_loss: 0.1445 - val_binary_accuracy: 0.9419 - val_precision: 0.9247 - val_recall: 0.9164\nEpoch 59/60\n200/200 [==============================] - 5s 24ms/step - loss: 0.1533 - binary_accuracy: 0.9276 - precision: 0.8988 - recall: 0.8732 - val_loss: 0.1431 - val_binary_accuracy: 0.9409 - val_precision: 0.9489 - val_recall: 0.8866\nEpoch 60/60\n200/200 [==============================] - 5s 24ms/step - loss: 0.1056 - binary_accuracy: 0.9616 - precision: 0.9548 - recall: 0.9215 - val_loss: 0.1407 - val_binary_accuracy: 0.9376 - val_precision: 0.9513 - val_recall: 0.8746\ntime: 7min 56s (started: 2021-09-29 16:40:27 +00:00)\n"
]
],
[
[
"---\n# Make predictions\n## (This can be only excuted once the training is finished or stopped)",
"_____no_output_____"
]
],
[
[
"#@title Load functions to generate random graphs and print them\nimport os\nimport networkx as nx\nimport matplotlib.pyplot as plt\nimport json\nfrom networkx.readwrite import json_graph\nimport ignnition\nimport numpy as np\nimport random\n%load_ext autotime\n\ndef generate_random_graph(min_nodes, max_nodes, min_edge_weight, max_edge_weight, p):\n while True:\n # Create a random Erdos Renyi graph\n G = nx.erdos_renyi_graph(random.randint(min_nodes, max_nodes), p)\n complement = list(nx.k_edge_augmentation(G, k=1, partial=True))\n G.add_edges_from(complement)\n nx.set_node_attributes(G, 0, 'src-tgt')\n nx.set_node_attributes(G, 0, 'sp')\n nx.set_node_attributes(G, 'node', 'entity')\n\n # Assign randomly weights to graph edges\n for (u, v, w) in G.edges(data=True):\n w['weight'] = random.randint(min_edge_weight, max_edge_weight)\n\n # Select the source and target nodes to compute the shortest path\n src, tgt = random.sample(list(G.nodes), 2)\n\n G.nodes[src]['src-tgt'] = 1\n G.nodes[tgt]['src-tgt'] = 1\n\n # Compute all the shortest paths between source and target nodes\n try:\n shortest_paths = list(nx.all_shortest_paths(G, source=src, target=tgt,weight='weight'))\n except:\n shortest_paths = []\n # Check if there exists only one shortest path\n if len(shortest_paths) == 1:\n if len(shortest_paths[0])>=3 and len(shortest_paths[0])<=5:\n for node in shortest_paths[0]:\n G.nodes[node]['sp'] = 1\n return shortest_paths[0], nx.DiGraph(G)\n\ndef print_graph_predictions(G, path, predictions,ax):\n predictions = np.array(predictions)\n node_border_colors = []\n links = []\n for i in range(len(path)-1):\n links.append([path[i], path[i+1]])\n links.append([path[i+1], path[i]])\n\n # Add colors to node borders for source and target nodes\n for node in G.nodes(data=True):\n if node[1]['src-tgt'] == 1:\n node_border_colors.append('red')\n else:\n node_border_colors.append('white')\n # Add colors for predictions [0,1]\n node_colors = predictions\n\n # Add colors for edges\n edge_colors = []\n for edge in G.edges(data=True):\n e=[edge[0],edge[1]]\n if e in links:\n edge_colors.append('red')\n else:\n edge_colors.append('black')\n pos= nx.shell_layout(G)\n vmin = node_colors.min()\n vmax = node_colors.max()\n vmin = 0\n vmax = 1\n cmap = plt.cm.coolwarm\n nx.draw_networkx_nodes(G, pos=pos, node_color=node_colors, cmap=cmap, vmin=vmin, vmax=vmax,\n edgecolors=node_border_colors, linewidths=4, ax=ax)\n nx.draw_networkx_edges(G, pos=pos, edge_color=edge_colors, arrows=False, ax=ax, width=2)\n nx.draw_networkx_edge_labels(G, pos=pos, label_pos=0.5, edge_labels=nx.get_edge_attributes(G, 'weight'), ax=ax)\n sm = plt.cm.ScalarMappable(cmap=cmap, norm=plt.Normalize(vmin=vmin, vmax=vmax))\n sm.set_array([])\n plt.colorbar(sm, ax=ax)\n\ndef print_graph_solution(G, path, predictions,ax, pred_th):\n predictions = np.array(predictions)\n node_colors = []\n node_border_colors = []\n links = []\n for i in range(len(path)-1):\n links.append([path[i], path[i+1]])\n links.append([path[i+1], path[i]])\n\n # Add colors on node borders for source and target nodes\n for node in G.nodes(data=True):\n if node[1]['src-tgt'] == 1:\n node_border_colors.append('red')\n else:\n node_border_colors.append('white')\n\n # Add colors for predictions Blue or Red\n cmap = plt.cm.get_cmap('coolwarm')\n dark_red = cmap(1.0)\n for p in predictions:\n if p >= pred_th:\n node_colors.append(dark_red)\n else:\n node_colors.append('blue')\n\n # Add colors for edges\n edge_colors = []\n for edge in G.edges(data=True):\n e=[edge[0],edge[1]]\n if e in links:\n edge_colors.append('red')\n else:\n edge_colors.append('black')\n pos= nx.shell_layout(G)\n nx.draw_networkx_nodes(G, pos=pos, node_color=node_colors, edgecolors=node_border_colors, linewidths=4, ax=ax)\n nx.draw_networkx_edges(G, pos=pos, edge_color=edge_colors, arrows=False, ax=ax, width=2)\n nx.draw_networkx_edge_labels(G, pos=pos, label_pos=0.5, edge_labels=nx.get_edge_attributes(G, 'weight'), ax=ax)\n\ndef print_input_graph(G, ax):\n node_colors = []\n node_border_colors = []\n\n # Add colors to node borders for source and target nodes\n for node in G.nodes(data=True):\n if node[1]['src-tgt'] == 1:\n node_border_colors.append('red')\n else:\n node_border_colors.append('white')\n\n pos= nx.shell_layout(G)\n nx.draw_networkx_nodes(G, pos=pos, edgecolors=node_border_colors, linewidths=4, ax=ax)\n nx.draw_networkx_edges(G, pos=pos, arrows=False, ax=ax, width=2)\n nx.draw_networkx_edge_labels(G, pos=pos, label_pos=0.5, edge_labels=nx.get_edge_attributes(G, 'weight'), ax=ax)",
"_____no_output_____"
],
[
"#@title Make predictions on random graphs\n#@markdown **NOTE**: IGNNITION will automatically load the latest trained model (CheckPoint) to make the predictions\n\ndataset_samples = []\nsh_path, G = generate_random_graph(min_nodes=8, max_nodes=12, min_edge_weight=1, max_edge_weight=10, p=0.3)\ngraph = G.to_undirected()\ndataset_samples.append(json_graph.node_link_data(G))\n\n# write prediction dataset\nroot_dir=\"./data\"\nif not os.path.exists(root_dir):\n os.makedirs(root_dir)\nif not os.path.exists(root_dir+\"/test\"):\n os.makedirs(root_dir+\"/test\")\nwith open(root_dir+\"/test/data.json\", \"w\") as f:\n json.dump(dataset_samples, f)\n\n# Make predictions\npredictions = model.predict()\n\n# Print the results\nfig, axes = plt.subplots(nrows=1, ncols=3)\nax = axes.flatten()\n\n# Print input graph\nax1 = ax[0]\nax1.set_title(\"Input graph\")\nprint_input_graph(graph, ax1)\n\n# Print graph with predictions (soft values)\nax1 = ax[1]\nax1.set_title(\"GNN predictions (soft values)\")\nprint_graph_predictions(graph, sh_path, predictions[0], ax1)\n\n# Print solution of the GNN\npred_th = 0.5\nax1 = ax[2]\nax1.set_title(\"GNN solution (p >= \"+str(pred_th)+\")\")\nprint_graph_solution(graph, sh_path, predictions[0], ax1, pred_th)\n\n# Show plot in full screen\nplt.rcParams['figure.figsize'] = [10, 4]\nplt.rcParams['figure.dpi'] = 100\nplt.tight_layout()\nplt.show()\n",
"\n\u001b[1mStarting to make the predictions...\n---------------------------------------------------------\n\u001b[0m\n"
]
],
[
[
"---\n# Try to improve your GNN model",
"_____no_output_____"
],
[
"**Optional exercise**:\n\nThe previous training was executed with some parameters set by default, so the accuracy of the GNN model is far from optimal.\n\nHere, we propose an alternative configuration that defines better training parameters for the GNN model.\n\nFor this, you can check and modify the following YAML files to configure your GNN model:\n* /content/model_description.yaml -> GNN model description\n* /content/train_options.yaml -> Configuration of training parameters\n\nTry to define an optimizer with learning rate decay and set the number of samples and epochs adding the following lines in the train_options.yaml file:\n```\noptimizer:\n type: Adam\n learning_rate: # define a schedule\n type: ExponentialDecay\n initial_learning_rate: 0.001\n decay_steps: 10000\n decay_rate: 0.5\n...\nbatch_size: 1\nepochs: 150\nepoch_size: 200\n```\nThen, you can train a new model from scratch by executing al the code snippets from section \"GNN model training\"\n\nPlease note that the training process may take quite a long time depending on the machine where it is executed.\n\nIn this example, there are a total of 30,000 training samples:\n\n1 sample/step * 200 steps/epoch * 150 epochs = 30.000 samples",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
cb338dbf9e95b51d10eb917a92ede5bcd6714b8f | 12,033 | ipynb | Jupyter Notebook | AdvancedPython/PythonForDataScience/Sklearn introduction II.ipynb | laklaja/ScriptingLanguagesCourseMaterials | 86dd683bf59e4fcb74709aee3aa274dc63def561 | [
"CC-BY-4.0"
] | 44 | 2016-11-09T22:33:27.000Z | 2021-01-23T03:23:19.000Z | AdvancedPython/PythonForDataScience/Sklearn introduction II.ipynb | laklaja/ScriptingLanguagesCourseMaterials | 86dd683bf59e4fcb74709aee3aa274dc63def561 | [
"CC-BY-4.0"
] | 1 | 2020-04-30T07:20:32.000Z | 2020-04-30T07:20:32.000Z | AdvancedPython/PythonForDataScience/Sklearn introduction II.ipynb | laklaja/ScriptingLanguagesCourseMaterials | 86dd683bf59e4fcb74709aee3aa274dc63def561 | [
"CC-BY-4.0"
] | 12 | 2016-11-10T08:30:22.000Z | 2021-01-23T03:22:27.000Z | 39.844371 | 216 | 0.592537 | [
[
[
"## Building a pipeline",
"_____no_output_____"
]
],
[
[
"%pylab inline",
"Populating the interactive namespace from numpy and matplotlib\n"
],
[
"import sklearn\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.datasets import load_digits\nfrom sklearn.pipeline import Pipeline\nfrom sklearn.decomposition import PCA",
"_____no_output_____"
],
[
"digits = load_digits()\nX_digits = digits.data\ny_digits = digits.target",
"_____no_output_____"
],
[
"logistic = LogisticRegression()\npca = PCA()\npipe = Pipeline(steps=[('pca', pca), ('logistic', logistic)])",
"_____no_output_____"
],
[
"pipe.fit(X_digits, y_digits)",
"_____no_output_____"
],
[
"pipe.predict(X_digits[:1])",
"_____no_output_____"
]
],
[
[
"## Finding the best model",
"_____no_output_____"
]
],
[
[
"from sklearn.grid_search import GridSearchCV",
"_____no_output_____"
],
[
"n_components = [20, 40, 64] # number of compomentens in PCA \nCs = np.logspace(-4, 0, 3, 4) # Inverse of regularization strength\npenalty = [\"l1\", \"l2\"] # Norm used by the Logistic regression penalization\nclass_weight = [None, \"balanced\"] # Weights associatied with clases\n\nestimator = GridSearchCV(pipe,\n {\"pca__n_components\": n_components,\n \"logistic__C\": Cs,\n \"logistic__class_weight\": class_weight,\n \"logistic__penalty\": penalty\n }, n_jobs=8, cv=5)\nestimator.fit(X_digits, y_digits)",
"_____no_output_____"
],
[
"estimator.grid_scores_",
"_____no_output_____"
],
[
"print(estimator.best_score_)\nprint(estimator.best_params_)",
"0.922092376183\n{'logistic__class_weight': None, 'pca__n_components': 40, 'logistic__penalty': 'l1', 'logistic__C': 1.0}\n"
]
],
[
[
"## Exercise",
"_____no_output_____"
],
[
"Find the best model for the diabetes dataset\n\nhttp://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_diabetes.html#sklearn.datasets.load_diabetes",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
cb33a023b1130b62b7bb250237e77f2e6535e683 | 144,659 | ipynb | Jupyter Notebook | .ipynb_checkpoints/Extra_Credit-checkpoint.ipynb | lai1737/IPA-Taste-Analysis | fdf44d7f290a03ca3bf38fdeee3d0557690d8b9d | [
"MIT"
] | null | null | null | .ipynb_checkpoints/Extra_Credit-checkpoint.ipynb | lai1737/IPA-Taste-Analysis | fdf44d7f290a03ca3bf38fdeee3d0557690d8b9d | [
"MIT"
] | null | null | null | .ipynb_checkpoints/Extra_Credit-checkpoint.ipynb | lai1737/IPA-Taste-Analysis | fdf44d7f290a03ca3bf38fdeee3d0557690d8b9d | [
"MIT"
] | null | null | null | 75.343229 | 39,644 | 0.703226 | [
[
[
"# Do IPAs Really Taste Better??",
"_____no_output_____"
],
[
"## Introduction:\nThe craft beer industry in the US has grown tremendously over the past decade. Of the types of beer that are new to the market, India Pale Ales (IPAs) seem to be the most popular. IPAs are known for their bold, bitter and hoppy taste, and while many fanatics can't get enough of this unique taste, the IPA critics are driven away by those exact features. This project aims to analyze the popularity of IPA's taste using a beer review dataset.",
"_____no_output_____"
],
[
"### Dataset:\nThe dataset utilized for this analysis is the \"Beer Profile and Ratings Data Set\" (beer_profile_and_ratings.csv). \nThe following information is posted on the Kaggle page where the dataset is located. (The link to full description and information: https://www.kaggle.com/ruthgn/beer-profile-and-ratings-data-set)\n\nBelow is an overview/summary description of the dataset.\n\nThis data set contains tasting profiles and consumer reviews for 3197 unique beers from 934 different breweries. It was created by integrating information from two existing data sets on Kaggle: \n**Beer Tasting Profiles Dataset** \n**1.5 Million Beer Reviews**",
"_____no_output_____"
]
],
[
[
"# Load necessary packages\nimport pandas as pd\nimport matplotlib.pyplot as plt\n%matplotlib inline\nplt.style.use('ggplot')",
"_____no_output_____"
]
],
[
[
"Read dataset and inspect first few rows:",
"_____no_output_____"
]
],
[
[
"data = pd.read_csv('beer_profile_and_ratings.csv')",
"_____no_output_____"
],
[
"data.head()",
"_____no_output_____"
]
],
[
[
"Look at the columns/features of this dataset:",
"_____no_output_____"
]
],
[
[
"data.describe()",
"_____no_output_____"
],
[
"print(data.columns)",
"Index(['Name', 'Style', 'Brewery', 'Beer Name (Full)', 'Description', 'ABV',\n 'Min IBU', 'Max IBU', 'Astringency', 'Body', 'Alcohol', 'Bitter',\n 'Sweet', 'Sour', 'Salty', 'Fruits', 'Hoppy', 'Spices', 'Malty',\n 'review_aroma', 'review_appearance', 'review_palate', 'review_taste',\n 'review_overall', 'number_of_reviews'],\n dtype='object')\n"
]
],
[
[
"Verify that there are 3197 beer profiles in this dataset as stated in the description from the source.",
"_____no_output_____"
]
],
[
[
"print(data.shape)",
"(3197, 25)\n"
]
],
[
[
"### Drilling down",
"_____no_output_____"
],
[
"Since we want to analyze the taste of IPA compared to other styles of beer, we first need to see all varieties of beer styles included in this dataset.",
"_____no_output_____"
]
],
[
[
"data['Style'].unique()",
"_____no_output_____"
]
],
[
[
"As we can see above, the styles of beer are listed with their broad category, followed by a sub-style. \nFor the purpose of this analysis, we are considering IPA at its broad category level. All sub-styles of IPA (American, English, Imperial) are considered IPAs.",
"_____no_output_____"
],
[
"Here we extract the broad category by getting the first element (before '-').",
"_____no_output_____"
]
],
[
[
"data['Style Category'] = data['Style'].str.rsplit(pat=' - ', expand=True)[0]",
"_____no_output_____"
]
],
[
[
"Then we look again at all values of broad category.",
"_____no_output_____"
]
],
[
[
"data['Style Category'].unique()",
"_____no_output_____"
]
],
[
[
"Check if there are any NaN values in the review_taste column, as we will focus on the analysis of this value.",
"_____no_output_____"
]
],
[
[
"data['review_taste'].isnull().values.any()",
"_____no_output_____"
]
],
[
[
"No NaN values in the review_taste column.",
"_____no_output_____"
],
[
"Since we are particularly interested in IPAs, we can look at a distribution of taste reviews for all IPAs.",
"_____no_output_____"
]
],
[
[
"data[data['Style Category'] == 'IPA']['review_taste'].hist()",
"_____no_output_____"
]
],
[
[
"Most taste reviews for IPAs are at around 4, with some low tail between 2.5 and 3.5.",
"_____no_output_____"
],
[
"Find average taste review of each style category.",
"_____no_output_____"
]
],
[
[
"style_taste_review_avg = data.groupby(by='Style Category')['review_taste'].mean() \\\n .rename('review_taste_avg') \\\n .reset_index() \\\n .sort_values(by='review_taste_avg', ascending=False) \\\n .reset_index(drop = True)",
"_____no_output_____"
]
],
[
[
"Display the average taste review by style category in descending order",
"_____no_output_____"
]
],
[
[
"style_taste_review_avg",
"_____no_output_____"
]
],
[
[
"From the above list, we can see the rank of **average taste review of IPA is 8th with an average taste review of 3.98**, after many other style categories. Wile Ale appears to be \"the tastiest\" style category with an average taste review of 4.30.",
"_____no_output_____"
],
[
"Get top 10 best tasting beer style category",
"_____no_output_____"
]
],
[
[
"top10_style = style_taste_review_avg.iloc[:10]\ntop10_style",
"_____no_output_____"
]
],
[
[
"Next, we can create a visualizatoin of the above information and **highlight IPA's spot (in orange)** in the top 10 beer style categories.",
"_____no_output_____"
]
],
[
[
"x = top10_style['Style Category']\nreview_taste_avg = top10_style['review_taste_avg']\n\nx_pos = [i for i, _ in enumerate(x)]\n\ncolor_list = ['royalblue']*7 + ['orange'] + ['royalblue']*3\nplt.bar(x_pos, review_taste_avg, color=color_list)\nplt.xlabel(\"Beer Style Category\")\nplt.ylabel(\"Average Taste Review\")\nplt.title(\"Average Taste Review of Top 10 Beer Style Categories\")\n\nplt.xticks(x_pos, x, rotation = 90)\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"IPA certainly ranks high (at 8th place) among all beer styles in terms of taste. However, it appears that IPA's taste still doesn't beat that of some of the more traditional beer styles.",
"_____no_output_____"
],
[
"Interestingly, the beers that rank higher in terms of taste than IPA **seem to (by definition) have higher alcohol content**. To see if this is true, we can see if the average alcohol by volume (ABV) of these style categories are higher than IPA.",
"_____no_output_____"
]
],
[
[
"style_abv_avg = data.groupby(by='Style Category')['ABV'].mean() \\\n .rename('abv_avg') \\\n .reset_index() \\\n .sort_values(by='abv_avg', ascending=False) \\\n .reset_index(drop = True)\nstyle_abv_avg",
"_____no_output_____"
]
],
[
[
"In this list, we see many overlapping style categories in the top ranking spots with the taste ranking. \nSpecifically, **Barleywine, Quadrupel, Bière de Champagne / Bière Brut, Old Ale, Wild Ale** all have higher contents than IPA. These also ranked higher in taste than IPA.",
"_____no_output_____"
]
],
[
[
"abv_ipa_comp = style_abv_avg[:13]\nabv_ipa_comp",
"_____no_output_____"
],
[
"x = abv_ipa_comp['Style Category']\nabv_avg = abv_ipa_comp['abv_avg']\n\nx_pos = [i for i, _ in enumerate(x)]\n\ncolor_list = ['red']*4 + ['cyan'] + ['royalblue'] + ['red'] + ['royalblue']+['cyan']+['royalblue']*3 + ['orange']\nplt.bar(x_pos, abv_avg, color=color_list)\nplt.xlabel(\"Beer Style Category\")\nplt.ylabel(\"Average Alcohol By Volume (ABV)\")\nplt.title(\"Average Alcohol By Volume (ABV) by Beer Style Categories\")\n\nplt.xticks(x_pos, x, rotation = 90)\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"As we can see above, 5 beer style categories (red) that ranked higher in taste than IPA (Barleywine, Quadrupel, Bière de Champagne / Bière Brut, Old Ale, and Wild Ale) also have higher averge ABV than IPA. \nOn the other hand, there are 2 beer styles (cyan) with higher average ABV that ranked lower in taste than IPA (Tripel, Scotch Ale / Wee Heavy).",
"_____no_output_____"
],
[
"The fact that there are 8 out of the top 10 beer categories in terms of taste among the highest ABV beer categories suggests that taste could be correlated with ABV. \nPerhaps beer drinkers collectively tend to prefer the taste of strong (high ABV) beers. ",
"_____no_output_____"
],
[
"## Conclusion:\n**IPA seems to be a very popular beer category lately, and analysis looked into the tastiness of IPA compared to other beer categories. In doing so, a potential feature that seems to be associated with tastiness was identifies: alcohol content.** \n\nMore analysis is needed to identify if there are other features/metrics associated with a beer being rated highly in tastiness. \n\nSome possible future analysis includes correlation analysis between each feature of all beer categories.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
cb33a18f9cb1cf330aab1d8623af38e976675de4 | 1,346 | ipynb | Jupyter Notebook | assignments/array/Rectangle Overlap problem.ipynb | Anjani100/logicmojo | 25763e401f5cc7e874d28866c06cf39ad42b3a8d | [
"MIT"
] | null | null | null | assignments/array/Rectangle Overlap problem.ipynb | Anjani100/logicmojo | 25763e401f5cc7e874d28866c06cf39ad42b3a8d | [
"MIT"
] | null | null | null | assignments/array/Rectangle Overlap problem.ipynb | Anjani100/logicmojo | 25763e401f5cc7e874d28866c06cf39ad42b3a8d | [
"MIT"
] | 2 | 2021-09-15T19:16:18.000Z | 2022-03-31T11:14:26.000Z | 21.03125 | 57 | 0.456909 | [
[
[
"def rectangle_overlap(rec1, rec2):\n if rec1[0] >= rec2[2] or rec2[0] >= rec1[2]:\n return False\n if rec1[1] <= rec2[3] or rec2[1] <= rec1[3]:\n return False\n return True\n\nif __name__=='__main__':\n test_cases = [[[0,0,2,2], [1,1,3,3]],\n [[0,0,1,1], [1,0,2,1]],\n [[1,4,3,2], [2,3,4,1]]]\n for rec1, rec2 in test_cases:\n print(rectangle_overlap(rec1, rec2))",
"False\nFalse\nTrue\n"
]
]
] | [
"code"
] | [
[
"code"
]
] |
cb33a363e2fd349397633a970ab7be7e4a0f20eb | 735,511 | ipynb | Jupyter Notebook | web/03/Optimize_print_and_plot.ipynb | mariusgruenewald/lectures-2019 | 36812db370dfe7229be2df88b5020940394e54c0 | [
"MIT"
] | 14 | 2019-01-11T09:47:18.000Z | 2019-08-25T05:45:18.000Z | web/03/Optimize_print_and_plot.ipynb | mariusgruenewald/lectures-2019 | 36812db370dfe7229be2df88b5020940394e54c0 | [
"MIT"
] | 10 | 2019-01-09T19:32:09.000Z | 2020-03-02T15:51:44.000Z | web/03/Optimize_print_and_plot.ipynb | mariusgruenewald/lectures-2019 | 36812db370dfe7229be2df88b5020940394e54c0 | [
"MIT"
] | 31 | 2019-02-11T09:23:44.000Z | 2020-01-13T10:54:42.000Z | 307.745188 | 146,072 | 0.929939 | [
[
[
"# Lecture 3: Optimize, print and plot",
"_____no_output_____"
],
[
"[Download on GitHub](https://github.com/NumEconCopenhagen/lectures-2019)\n\n[<img src=\"https://mybinder.org/badge_logo.svg\">](https://mybinder.org/v2/gh/NumEconCopenhagen/lectures-2019/master?urlpath=lab/tree/03/Optimize_print_and_plot.ipynb)",
"_____no_output_____"
],
[
"1. [The consumer problem](#The-consumer-problem)\n2. [Numerical python (numpy)](#Numerical-python-(numpy))\n3. [Utility function](#Utility-function)\n4. [Algorithm 1: Simple loops](#Algorithm-1:-Simple-loops)\n5. [Algorithm 2: Use monotonicity](#Algorithm-2:-Use-monotonicity)\n6. [Algorithm 3: Call a solver](#Algorithm-3:-Call-a-solver)\n7. [Indifference curves](#Indifference-curves)\n8. [A classy solution](#A-classy-solution)\n9. [Summary](#Summary)\n",
"_____no_output_____"
],
[
"You will learn how to work with numerical data (**numpy**) and solve simple numerical optimization problems (**scipy.optimize**) and report the results both in text (**print**) and in figures (**matplotlib**).",
"_____no_output_____"
],
[
"**Links:**:\n\n- **print**: [examples](https://www.python-course.eu/python3_formatted_output.php) (very detailed)\n- **numpy**: [detailed tutorial](https://www.python-course.eu/numpy.php)\n- **matplotlib**: [examples](https://matplotlib.org/tutorials/introductory/sample_plots.html#sphx-glr-tutorials-introductory-sample-plots-py), [documentation](https://matplotlib.org/users/index.html), [styles](https://matplotlib.org/3.1.0/gallery/style_sheets/style_sheets_reference.html)\n- **scipy-optimize**: [documentation](https://docs.scipy.org/doc/scipy/reference/optimize.html)",
"_____no_output_____"
],
[
"<a id=\"The-consumer-problem\"></a>\n\n# 1. The consumer problem",
"_____no_output_____"
],
[
"Consider the following 2-good consumer problem with \n\n* utility function $u(x_1,x_2):\\mathbb{R}^2_{+}\\rightarrow\\mathbb{R}$,\n* exogenous income $I$, and \n* price-vector $(p_1,p_2)$,",
"_____no_output_____"
],
[
"given by\n\n$$\n\\begin{aligned}\nV(p_{1},p_{2},I) & = \\max_{x_{1},x_{2}}u(x_{1},x_{2})\\\\\n \\text{s.t.}\\\\\np_{1}x_{1}+p_{2}x_{2} & \\leq I,\\,\\,\\,p_{1},p_{2},I>0\\\\\nx_{1},x_{2} & \\geq 0\n\\end{aligned}\n$$",
"_____no_output_____"
],
[
"**Specific example:** Let the utility function be Cobb-Douglas,\n\n$$\nu(x_1,x_2) = x_1^{\\alpha}x_2^{1-\\alpha}\n$$\n\nWe then know the solution is given by\n\n$$\n\\begin{aligned}\nx_1^{\\ast} &= \\alpha \\frac{I}{p_1} \\\\\nx_2^{\\ast} &= (1-\\alpha) \\frac{I}{p_2}\n\\end{aligned}\n$$\n\nwhich implies that $\\alpha$ is the budget share of the first good and $1-\\alpha$ is the budget share of the second good.",
"_____no_output_____"
],
[
"<a id=\"Numerical-python-(numpy)\"></a>\n\n# 2. Numerical python (numpy)",
"_____no_output_____"
]
],
[
[
"import numpy as np # import the numpy module",
"_____no_output_____"
]
],
[
[
"A **numpy array** is like a list, but with two important differences:\n\n1. Elements must be of **one homogenous type**\n2. A **slice returns a view** rather than extract content",
"_____no_output_____"
],
[
"## 2.1 Basics",
"_____no_output_____"
],
[
"Numpy arrays can be **created from lists** and can be **multi-dimensional**:",
"_____no_output_____"
]
],
[
[
"A = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) # one dimension\nB = np.array([[3.4, 8.7, 9.9], \n [1.1, -7.8, -0.7],\n [4.1, 12.3, 4.8]]) # two dimensions\n\nprint(type(A),type(B)) # type\nprint(A.dtype,B.dtype) # data type\nprint(A.ndim,B.ndim) # dimensions\nprint(A.shape,B.shape) # shape (1d: (columns,), 2d: (row,columns))\nprint(A.size,B.size) # size",
"<class 'numpy.ndarray'> <class 'numpy.ndarray'>\nint32 float64\n1 2\n(10,) (3, 3)\n10 9\n"
]
],
[
[
"**Slicing** a numpy array returns a **view**:",
"_____no_output_____"
]
],
[
[
"A = np.array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])\nB = A.copy() # a copy of A\nC = A[2:6] # a view into A\nC[0] = 0\nC[1] = 0\nprint(A) # changed\nprint(B) # not changed",
"[0 1 0 0 4 5 6 7 8 9]\n[0 1 2 3 4 5 6 7 8 9]\n"
]
],
[
[
"Numpy array can also be created using numpy functions:",
"_____no_output_____"
]
],
[
[
"print(np.ones((2,3)))\nprint(np.zeros((4,2)))\nprint(np.linspace(0,1,6)) # linear spacing",
"[[1. 1. 1.]\n [1. 1. 1.]]\n[[0. 0.]\n [0. 0.]\n [0. 0.]\n [0. 0.]]\n[0. 0.2 0.4 0.6 0.8 1. ]\n"
]
],
[
[
"**Tip 1:** Try pressing <kbd>Shift</kbd>+<kbd>Tab</kbd> inside a function.<br>\n\n**Tip 2:** Try to write `?np.linspace` in a cell",
"_____no_output_____"
]
],
[
[
"?np.linspace",
"_____no_output_____"
]
],
[
[
"## 2.2 Math",
"_____no_output_____"
],
[
"Standard **mathematical operations** can be applied:",
"_____no_output_____"
]
],
[
[
"A = np.array([[1,0],[0,1]])\nB = np.array([[2,2],[2,2]])\nprint(A+B)\nprint(A-B)\nprint(A*B) # element-by-element product\nprint(A/B) # element-by-element division\nprint(A@B) # matrix product",
"[[3 2]\n [2 3]]\n[[-1 -2]\n [-2 -1]]\n[[2 0]\n [0 2]]\n[[0.5 0. ]\n [0. 0.5]]\n[[2 2]\n [2 2]]\n"
]
],
[
[
"If arrays does not fit together **broadcasting** is applied. Here is an example with multiplication:",
"_____no_output_____"
]
],
[
[
"A = np.array([ [10, 20, 30], [40, 50, 60] ]) # shape = (2,3) \nB = np.array([1, 2, 3]) # shape = (3,) = (1,3)\nC = np.array([[1],[2]]) # shape = (2,1)\n\nprint(A)\nprint(A*B) # every row is multiplied by B\nprint(A*C) # every column is multiplied by C",
"[[10 20 30]\n [40 50 60]]\n[[ 10 40 90]\n [ 40 100 180]]\n[[ 10 20 30]\n [ 80 100 120]]\n"
]
],
[
[
"**General rule:** Numpy arrays can be added/substracted/multiplied/divided if they in all dimensions have the same size or one of them has a size of one. If the numpy arrays differ in number of dimensions, this only has to be true for the (inner) dimensions they share. ",
"_____no_output_____"
],
[
"**More on broadcasting:** [Documentation](https://docs.scipy.org/doc/numpy-1.13.0/user/basics.broadcasting.html).",
"_____no_output_____"
],
[
"A lot of **mathematical procedures** can easily be performed on numpy arrays.",
"_____no_output_____"
]
],
[
[
"A = np.array([3.1, 2.3, 9.1, -2.5, 12.1])\nprint(np.min(A)) # find minimum\nprint(np.argmin(A)) # find index for minimum\nprint(np.mean(A)) # calculate mean\nprint(np.sort(A)) # sort (ascending)",
"-2.5\n3\n4.82\n[-2.5 2.3 3.1 9.1 12.1]\n"
]
],
[
[
"**Note:** Sometimes a method can be used instead of a function, e.g. ``A.mean()``. Personally, I typically stick to functions because that always works. ",
"_____no_output_____"
],
[
"## 2.3 Indexing",
"_____no_output_____"
],
[
"**Multi-dimensional** indexing is done as:",
"_____no_output_____"
]
],
[
[
"X = np.array([ [11, 12, 13], [21, 22, 23] ])\nprint(X)\nprint(X[0,0]) # first row, first column\nprint(X[0,1]) # first row, second column\nprint(X[1,2]) # second row, third column",
"[[11 12 13]\n [21 22 23]]\n11\n12\n23\n"
],
[
"X[0]",
"_____no_output_____"
]
],
[
[
"Indexes can be **logical**. Logical 'and' is `&` and logical 'or' is `|`.",
"_____no_output_____"
]
],
[
[
"A = np.array([1,2,3,4,1,2,3,4])\nB = np.array([3,3,3,3,2,2,2,2])\nI = (A < 3) & (B == 3) # note & instead of 'and'\nprint(type(I),I.dtype)\nprint(I)\nprint(A[I])",
"<class 'numpy.ndarray'> bool\n[ True True False False False False False False]\n[1 2]\n"
],
[
"I = (A < 3) | (B == 3) # note | instead of 'or'\nprint(A[I])",
"[1 2 3 4 1 2]\n"
]
],
[
[
"## 2.4 List of good things to know",
"_____no_output_____"
],
[
"**Attributes and methods** to know:\n\n- size / ndim / shape\n- ravel / reshape / sort\n- copy",
"_____no_output_____"
],
[
"**Functions** to know:\n\n- array / empty / zeros / ones / linspace\n- mean / median / std / var / sum / percentile\n- min/max, argmin/argmax / fmin / fmax / sort / clip\n- meshgrid / hstack / vstack / concatenate / tile / insert\n- allclose / isnan / isinf / isfinite / any / all",
"_____no_output_____"
],
[
"**Concepts** to know:\n\n- view vs. copy\n- broadcasting\n- logical indexing",
"_____no_output_____"
],
[
"**Question:** Consider the following code:",
"_____no_output_____"
]
],
[
[
"A = np.array([1,2,3,4,5])\nB = A[3:]\nB[:] = 0",
"_____no_output_____"
]
],
[
[
"What is `np.sum(A)` equal to?\n- **A:** 15\n- **B:** 10\n- **C:** 6\n- **D:** 0\n- **E:** Don't know",
"_____no_output_____"
],
[
"## 2.5 Extra: Memory",
"_____no_output_____"
],
[
"Memory is structured in **rows**:",
"_____no_output_____"
]
],
[
[
"A = np.array([[3.1,4.2],[5.7,9.3]])\nB = A.ravel() # one-dimensional view of A\nprint(A.shape,A[0,:])\nprint(B.shape,B)",
"(2, 2) [3.1 4.2]\n(4,) [3.1 4.2 5.7 9.3]\n"
]
],
[
[
"<a id=\"Utility-function\"></a>\n\n# 3. Utility function",
"_____no_output_____"
],
[
"Define the utility function:",
"_____no_output_____"
]
],
[
[
"def u_func(x1,x2,alpha=0.50):\n return x1**alpha*x2**(1-alpha)\n\n# x1,x2 are positional arguments\n# alpha is a keyword argument with default value 0.50",
"_____no_output_____"
]
],
[
[
"## 3.1 Print to screen",
"_____no_output_____"
],
[
"Print a **single evaluation** of the utility function.",
"_____no_output_____"
]
],
[
[
"x1 = 1\nx2 = 3\nu = u_func(x1,x2)\n\n# f'text' is called a \"formatted string\"\n# {x1:.3f} prints variable x1 as floating point number with 3 decimals\n\nprint(f'x1 = {x1:.3f}, x2 = {x2:.3f} -> u = {u:.3f}') ",
"x1 = 1.000, x2 = 3.000 -> u = 1.732\n"
],
[
"print(u)",
"1.7320508075688772\n"
]
],
[
[
"Print **multiple evaluations** of the utility function.",
"_____no_output_____"
]
],
[
[
"x1_list = [2,4,6,8,10,12]\nx2 = 3\n\nfor x1 in x1_list: # loop through each element in x1_list\n u = u_func(x1,x2,alpha=0.25)\n print(f'x1 = {x1:.3f}, x2 = {x2:.3f} -> u = {u:.3f}')",
"x1 = 2.000, x2 = 3.000 -> u = 2.711\nx1 = 4.000, x2 = 3.000 -> u = 3.224\nx1 = 6.000, x2 = 3.000 -> u = 3.568\nx1 = 8.000, x2 = 3.000 -> u = 3.834\nx1 = 10.000, x2 = 3.000 -> u = 4.054\nx1 = 12.000, x2 = 3.000 -> u = 4.243\n"
]
],
[
[
"And a little nicer...",
"_____no_output_____"
]
],
[
[
"for i,x1 in enumerate(x1_list): # i is a counter\n u = u_func(x1,x2,alpha=0.25)\n print(f'{i:2d}: x1 = {x1:<6.3f} x2 = {x2:<6.3f} -> u = {u:<6.3f}')\n \n# {i:2d}: integer a width of 2 (right-aligned)\n# {x1:<6.3f}: float width of 6 and 3 decimals (<, left-aligned)",
" 0: x1 = 2.000 x2 = 3.000 -> u = 2.711 \n 1: x1 = 4.000 x2 = 3.000 -> u = 3.224 \n 2: x1 = 6.000 x2 = 3.000 -> u = 3.568 \n 3: x1 = 8.000 x2 = 3.000 -> u = 3.834 \n 4: x1 = 10.000 x2 = 3.000 -> u = 4.054 \n 5: x1 = 12.000 x2 = 3.000 -> u = 4.243 \n"
]
],
[
[
"**Task**: Write a loop printing the results shown in the answer below.",
"_____no_output_____"
]
],
[
[
"# write your code here",
"_____no_output_____"
]
],
[
[
"**Answer:**",
"_____no_output_____"
]
],
[
[
"for i,x1 in enumerate(x1_list): # i is a counter\n u = u_func(x1,x2,alpha=0.25)\n print(f'{i:2d}: u({x1:.2f},{x1:.2f}) = {u:.4f}')",
" 0: u(2.00,2.00) = 2.7108\n 1: u(4.00,4.00) = 3.2237\n 2: u(6.00,6.00) = 3.5676\n 3: u(8.00,8.00) = 3.8337\n 4: u(10.00,10.00) = 4.0536\n 5: u(12.00,12.00) = 4.2426\n"
]
],
[
[
"**More formatting options?** See these [examples](https://www.python-course.eu/python3_formatted_output.php).",
"_____no_output_____"
],
[
"## 3.2 Print to file",
"_____no_output_____"
],
[
"Open a text-file and write lines in it:",
"_____no_output_____"
]
],
[
[
"with open('somefile.txt', 'w') as the_file: # 'w' is for 'write'\n \n for i, x1 in enumerate(x1_list):\n u = u_func(x1,x2,alpha=0.25)\n text = f'{i+10:2d}: x1 = {x1:<6.3f} x2 = {x2:<6.3f} -> u = {u:<6.3f}'\n the_file.write(text + '\\n') # \\n gives a lineshift\n\n# note: the with clause ensures that the file is properly closed afterwards",
"_____no_output_____"
]
],
[
[
"Open a text-file and read the lines in it and then print them:",
"_____no_output_____"
]
],
[
[
"with open('somefile.txt', 'r') as the_file: # 'r' is for 'read'\n \n lines = the_file.readlines()\n for line in lines:\n print(line,end='') # end='' removes the extra lineshift print creates",
"10: x1 = 2.000 x2 = 3.000 -> u = 2.711 \n11: x1 = 4.000 x2 = 3.000 -> u = 3.224 \n12: x1 = 6.000 x2 = 3.000 -> u = 3.568 \n13: x1 = 8.000 x2 = 3.000 -> u = 3.834 \n14: x1 = 10.000 x2 = 3.000 -> u = 4.054 \n15: x1 = 12.000 x2 = 3.000 -> u = 4.243 \n"
]
],
[
[
"> **Note:** You could also write tables in LaTeX format and the import them in your LaTeX document.",
"_____no_output_____"
],
[
"## 3.3 Calculate the utility function on a grid",
"_____no_output_____"
],
[
"**Calculate the utility function** on a 2-dimensional grid with $N$ elements in each dimension:",
"_____no_output_____"
]
],
[
[
"# a. settings\nN = 100 # number of elements\nx_max = 10 # maximum value\n\n# b. allocate numpy arrays\nshape_tuple = (N,N)\nx1_values = np.empty(shape_tuple) # allocate 2d numpy array with shape=(N,N)\nx2_values = np.empty(shape_tuple)\nu_values = np.empty(shape_tuple)\n\n# c. fill numpy arrays\nfor i in range(N): # 0,1,...,N-1\n for j in range(N): # 0,1,...,N-1\n x1_values[i,j] = (i/(N-1))*x_max # in [0,x_max]\n x2_values[i,j] = (j/(N-1))*x_max # in [0,x_max]\n u_values[i,j] = u_func(x1_values[i,j],x2_values[i,j],alpha=0.25)",
"_____no_output_____"
]
],
[
[
"**Alternatively:** Use internal numpy functions:",
"_____no_output_____"
]
],
[
[
"x_vec = np.linspace(0,x_max,N)\nx1_values_alt,x2_values_alt = np.meshgrid(x_vec,x_vec,indexing='ij')\nu_values_alt = u_func(x1_values_alt,x2_values_alt,alpha=0.25)",
"_____no_output_____"
]
],
[
[
"Test whether the results are the same:",
"_____no_output_____"
]
],
[
[
"# a. maximum absolute difference\nmax_abs_diff = np.max(np.abs(u_values-u_values_alt))\nprint(max_abs_diff) # very close to zero \n\n# b. test if all values are \"close\"\nprint(np.allclose(u_values,u_values_alt))",
"2.6645352591003757e-15\nTrue\n"
]
],
[
[
"**Note:** The results are not exactly the same due to floating point arithmetics.",
"_____no_output_____"
],
[
"## 3.4 Plot the utility function",
"_____no_output_____"
],
[
"Import modules and state that the figures should be inlined:",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport matplotlib.pyplot as plt # baseline modul\nfrom mpl_toolkits.mplot3d import Axes3D # for 3d figures\nplt.style.use('seaborn-whitegrid') # whitegrid nice with 3d",
"_____no_output_____"
]
],
[
[
"Construct the actual plot:",
"_____no_output_____"
]
],
[
[
"fig = plt.figure() # create the figure\nax = fig.add_subplot(1,1,1,projection='3d') # create a 3d axis in the figure \nax.plot_surface(x1_values,x2_values,u_values); # create surface plot in the axis\n\n# note: fig.add_subplot(a,b,c) creates the c'th subplot in a grid of a times b plots",
"_____no_output_____"
]
],
[
[
"Make the figure **zoomable** and **panable** using a widget:",
"_____no_output_____"
]
],
[
[
"%matplotlib widget\nfig = plt.figure() # create the figure\nax = fig.add_subplot(1,1,1,projection='3d') # create a 3d axis in the figure \nax.plot_surface(x1_values,x2_values,u_values); # create surface plot in the axis",
"_____no_output_____"
]
],
[
[
"Turn back to normal inlining:",
"_____no_output_____"
]
],
[
[
"%matplotlib inline",
"_____no_output_____"
]
],
[
[
"**Extensions**: Use a colormap, make it pretier, and save to disc.",
"_____no_output_____"
]
],
[
[
"from matplotlib import cm # for colormaps\n\n# a. actual plot\nfig = plt.figure()\nax = fig.add_subplot(1,1,1,projection='3d')\nax.plot_surface(x1_values,x2_values,u_values,cmap=cm.jet)\n\n# b. add labels\nax.set_xlabel('$x_1$')\nax.set_ylabel('$x_2$')\nax.set_zlabel('$u$')\n\n# c. invert xaxis\nax.invert_xaxis()\n\n# d. save\nfig.tight_layout()\nfig.savefig('someplot.pdf') # or e.g. .png ",
"_____no_output_____"
]
],
[
[
"**More formatting options?** See these [examples](https://matplotlib.org/tutorials/introductory/sample_plots.html#sphx-glr-tutorials-introductory-sample-plots-py).",
"_____no_output_____"
],
[
"**Task**: Construct the following plot:",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"**Answer:**",
"_____no_output_____"
]
],
[
[
"# write your code here",
"_____no_output_____"
],
[
"# a. actual plot\nfig = plt.figure()\nax = fig.add_subplot(1,1,1,projection='3d')\nax.plot_wireframe(x1_values,x2_values,u_values,edgecolor='black')\n\n# b. add labels\nax.set_xlabel('$x_1$')\nax.set_ylabel('$x_2$')\nax.set_zlabel('$u$')\n\n# c. invert xaxis\nax.invert_xaxis()\n\n# e. save\nfig.tight_layout()\nfig.savefig('someplot_wireframe.png')\nfig.savefig('someplot_wireframe.pdf')",
"_____no_output_____"
]
],
[
[
"## 3.5 Summary",
"_____no_output_____"
],
[
"We have talked about:\n\n1. Print (to screen and file)\n2. Figures (matplotlib)",
"_____no_output_____"
],
[
"**Other plotting libraries:** [seaborn](https://seaborn.pydata.org/) and [bokeh](https://bokeh.pydata.org/en/latest/).",
"_____no_output_____"
],
[
"<a id=\"Algorithm-1:-Simple-loops\"></a>\n\n# 4. Algorithm 1: Simple loops",
"_____no_output_____"
],
[
"Remember the problem we wanted to solve:",
"_____no_output_____"
],
[
"$$\n\\begin{aligned}\nV(p_{1},p_{2},I) & = \\max_{x_{1},x_{2}}u(x_{1},x_{2})\\\\\n & \\text{s.t.}\\\\\np_{1}x_{1}+p_{2}x_{2} & \\leq I,\\,\\,\\,p_{1},p_{2},I>0\\\\\nx_{1},x_{2} & \\geq 0\n\\end{aligned}\n$$",
"_____no_output_____"
],
[
"**Idea:** Loop through a grid of $N_1 \\times N_2$ possible solutions. This is the same as solving:\n\n$$\n\\begin{aligned}\nV(p_{1},p_{2},I) & = \\max_{x_{1}\\in X_1,x_{2} \\in X_2} x_1^{\\alpha}x_2^{1-\\alpha}\\\\\n & \\text{s.t.}\\\\\n X_1 & = \\left\\{0,\\frac{1}{N_1-1}\\frac{I}{p_1},\\frac{2}{N_1-1}\\frac{I}{p_1},\\dots,\\frac{I}{p_1}\\right\\} \\\\\n X_2 & = \\left\\{0,\\frac{1}{N_2-1}\\frac{I}{p_2},\\frac{2}{N_2-1}\\frac{ I}{p_2},\\dots,\\frac{ I}{p_2}\\right\\} \\\\\np_{1}x_{1}+p_{2}x_{2} & \\leq I\\\\\n\\end{aligned}\n$$",
"_____no_output_____"
],
[
"Function doing just this:",
"_____no_output_____"
]
],
[
[
"def find_best_choice(alpha,I,p1,p2,N1,N2,do_print=True):\n \n # a. allocate numpy arrays\n shape_tuple = (N1,N2)\n x1_values = np.empty(shape_tuple)\n x2_values = np.empty(shape_tuple)\n u_values = np.empty(shape_tuple)\n \n # b. start from guess of x1=x2=0\n x1_best = 0\n x2_best = 0\n u_best = u_func(0,0,alpha=alpha)\n \n # c. loop through all possibilities\n for i in range(N1):\n for j in range(N2):\n \n # i. x1 and x2 (chained assignment)\n x1_values[i,j] = x1 = (i/(N1-1))*I/p1\n x2_values[i,j] = x2 = (j/(N2-1))*I/p2\n \n # ii. utility\n if p1*x1+p2*x2 <= I: # u(x1,x2) if expenditures <= income \n u_values[i,j] = u_func(x1,x2,alpha=alpha)\n else: # u(0,0) if expenditures > income\n u_values[i,j] = u_func(0,0,alpha=alpha)\n \n # iii. check if best sofar\n if u_values[i,j] > u_best:\n x1_best = x1_values[i,j]\n x2_best = x2_values[i,j] \n u_best = u_values[i,j]\n \n # d. print\n if do_print:\n print_solution(x1_best,x2_best,u_best,I,p1,p2)\n\n return x1_best,x2_best,u_best,x1_values,x2_values,u_values\n\n# function for printing the solution\ndef print_solution(x1,x2,u,I,p1,p2):\n print(f'x1 = {x1:.8f}')\n print(f'x2 = {x2:.8f}')\n print(f'u = {u:.8f}')\n print(f'I-p1*x1-p2*x2 = {I-p1*x1-p2*x2:.8f}') ",
"_____no_output_____"
]
],
[
[
"Call the function:",
"_____no_output_____"
]
],
[
[
"sol = find_best_choice(alpha=0.25,I=20,p1=1,p2=2,N1=500,N2=400)",
"x1 = 5.01002004\nx2 = 7.49373434\nu = 6.77615896\nI-p1*x1-p2*x2 = 0.00251129\n"
]
],
[
[
"Plot the solution:",
"_____no_output_____"
]
],
[
[
"%matplotlib widget\n\n# a. unpack solution\nx1_best,x2_best,u_best,x1_values,x2_values,u_values = sol\n\n# b. setup figure\nfig = plt.figure(dpi=100,num='')\nax = fig.add_subplot(1,1,1,projection='3d')\n\n# c. plot 3d surface of utility values for different choices\nax.plot_surface(x1_values,x2_values,u_values,cmap=cm.jet)\nax.invert_xaxis()\n\n# d. plot optimal choice\nax.scatter(x1_best,x2_best,u_best,s=50,color='black');",
"_____no_output_____"
],
[
"%matplotlib inline",
"_____no_output_____"
]
],
[
[
"**Task**: Can you find a better solution with higher utility and lower left-over income, $I-p_1 x_1-p_2 x_2$?",
"_____no_output_____"
]
],
[
[
"# write your code here\n# sol = find_best_choice()",
"_____no_output_____"
]
],
[
[
"**Answer:**",
"_____no_output_____"
]
],
[
[
"sol = find_best_choice(alpha=0.25,I=10,p1=1,p2=2,N1=1000,N2=1000)",
"x1 = 2.50250250\nx2 = 3.74874875\nu = 3.38850695\nI-p1*x1-p2*x2 = 0.00000000\n"
]
],
[
[
"<a id=\"Algorithm-2:-Use-monotonicity\"></a>\n\n# 5. Algorithm 2: Use monotonicity",
"_____no_output_____"
],
[
"**Idea:** Loop through a grid of $N$ possible solutions for $x_1$ and assume the remainder is spent on $x_2$. This is the same as solving:\n\n$$\n\\begin{aligned}\nV(p_{1},p_{2},I) & = \\max_{x_{1}\\in X_1} x_1^{\\alpha}x_2^{1-\\alpha}\\\\\n \\text{s.t.}\\\\\n X_1 & = \\left\\{0,\\frac{1}{N-1}\\frac{}{p_1},\\frac{2}{N-1}\\frac{I}{p_1},\\dots,\\frac{I}{p_1}\\right\\} \\\\\nx_{2} & = \\frac{I-p_{1}x_{1}}{p_2}\\\\\n\\end{aligned}\n$$",
"_____no_output_____"
],
[
"Function doing just this:",
"_____no_output_____"
]
],
[
[
"def find_best_choice_monotone(alpha,I,p1,p2,N,do_print=True):\n \n # a. allocate numpy arrays\n shape_tuple = (N)\n x1_values = np.empty(shape_tuple)\n x2_values = np.empty(shape_tuple)\n u_values = np.empty(shape_tuple)\n \n # b. start from guess of x1=x2=0\n x1_best = 0\n x2_best = 0\n u_best = u_func(0,0,alpha)\n \n # c. loop through all possibilities\n for i in range(N):\n \n # i. x1\n x1_values[i] = x1 = i/(N-1)*I/p1\n \n # ii. implied x2\n x2_values[i] = x2 = (I-p1*x1)/p2\n \n # iii. utility \n u_values[i] = u_func(x1,x2,alpha)\n \n if u_values[i] >= u_best: \n x1_best = x1_values[i]\n x2_best = x2_values[i] \n u_best = u_values[i]\n \n # d. print\n if do_print:\n print_solution(x1_best,x2_best,u_best,I,p1,p2) \n\n return x1_best,x2_best,u_best,x1_values,x2_values,u_values",
"_____no_output_____"
],
[
"sol_monotone = find_best_choice_monotone(alpha=0.25,I=10,p1=1,p2=2,N=1000) ",
"x1 = 2.50250250\nx2 = 3.74874875\nu = 3.38850695\nI-p1*x1-p2*x2 = 0.00000000\n"
]
],
[
[
"Plot the solution:",
"_____no_output_____"
]
],
[
[
"plt.style.use(\"seaborn\")\n\n# a. create the figure\nfig = plt.figure(figsize=(10,4))# figsize is in inches...\n\n# b. unpack solution\nx1_best,x2_best,u_best,x1_values,x2_values,u_values = sol_monotone\n\n# c. left plot\nax_left = fig.add_subplot(1,2,1)\n\nax_left.plot(x1_values,u_values)\nax_left.scatter(x1_best,u_best)\n\nax_left.set_title('value of choice, $u(x_1,x_2)$')\nax_left.set_xlabel('$x_1$')\nax_left.set_ylabel('$u(x_1,(I-p_1 x_1)/p_2)$')\nax_left.grid(True)\n\n# c. right plot\nax_right = fig.add_subplot(1,2,2)\n\nax_right.plot(x1_values,x2_values)\nax_right.scatter(x1_best,x2_best)\n\nax_right.set_title('implied $x_2$')\nax_right.set_xlabel('$x_1$')\nax_right.set_ylabel('$x_2$')\nax_right.grid(True)",
"_____no_output_____"
]
],
[
[
"<a id=\"Algorithm-3:-Call-a-solver\"></a>\n\n# 6. Algorithm 3: Call a solver\n",
"_____no_output_____"
]
],
[
[
"from scipy import optimize",
"_____no_output_____"
]
],
[
[
"Choose paramters:",
"_____no_output_____"
]
],
[
[
"alpha = 0.25 # preference parameter\nI = 10 # income\np1 = 1 # price 1\np2 = 2 # price 2",
"_____no_output_____"
]
],
[
[
"**Case 1**: Scalar solver using monotonicity.",
"_____no_output_____"
]
],
[
[
"# a. objective funciton (to minimize)\ndef value_of_choice(x1,alpha,I,p1,p2):\n x2 = (I-p1*x1)/p2\n return -u_func(x1,x2,alpha)\n\n# b. call solver\nsol_case1 = optimize.minimize_scalar(\n value_of_choice,method='bounded',\n bounds=(0,I/p1),args=(alpha,I,p1,p2))\n\n# c. unpack solution\nx1 = sol_case1.x\nx2 = (I-p1*x1)/p2\nu = u_func(x1,x2,alpha)\nprint_solution(x1,x2,u,I,p1,p2)",
"x1 = 2.50000006\nx2 = 3.74999997\nu = 3.38850751\nI-p1*x1-p2*x2 = 0.00000000\n"
]
],
[
[
"**Case 2**: Multi-dimensional constrained solver.",
"_____no_output_____"
]
],
[
[
"# a. objective function (to minimize)\ndef value_of_choice(x,alpha,I,p1,p2):\n # note: x is a vector\n x1 = x[0]\n x2 = x[1]\n return -u_func(x1,x2,alpha)\n\n# b. constraints (violated if negative) and bounds\nconstraints = ({'type': 'ineq', 'fun': lambda x: I-p1*x[0]-p2*x[1]})\nbounds = ((0,I/p1),(0,I/p2))\n\n# c. call solver\ninitial_guess = [I/p1/2,I/p2/2]\nsol_case2 = optimize.minimize(\n value_of_choice,initial_guess,args=(alpha,I,p1,p2),\n method='SLSQP',bounds=bounds,constraints=constraints)\n\n# d. unpack solution\nx1 = sol_case2.x[0]\nx2 = sol_case2.x[1]\nu = u_func(x1,x2,alpha)\nprint_solution(x1,x2,u,I,p1,p2)",
"x1 = 2.49937952\nx2 = 3.75031024\nu = 3.38850748\nI-p1*x1-p2*x2 = 0.00000000\n"
]
],
[
[
"**Case 3**: Multi-dimensional unconstrained solver with constrains implemented via penalties.",
"_____no_output_____"
]
],
[
[
"# a. objective function (to minimize)\ndef value_of_choice(x,alpha,I,p1,p2):\n \n # i. unpack\n x1 = x[0]\n x2 = x[1]\n \n # ii. penalty\n penalty = 0\n E = p1*x1+p2*x2 # total expenses\n if E > I: # expenses > income -> not allowed\n fac = I/E\n penalty += 1000*(E-I) # calculate penalty \n x1 *= fac # force E = I\n x2 *= fac # force E = I\n \n return -u_func(x1,x2,alpha)\n\n# b. call solver\ninitial_guess = [I/p1/2,I/p2/2]\nsol_case3 = optimize.minimize(\n value_of_choice,initial_guess,method='Nelder-Mead',\n args=(alpha,I,p1,p2))\n\n# c. unpack solution\nx1 = sol_case3.x[0]\nx2 = sol_case3.x[1]\nu = u_func(x1,x2,alpha)\nprint_solution(x1,x2,u,I,p1,p2)",
"x1 = 2.58573053\nx2 = 3.87859581\nu = 3.50470694\nI-p1*x1-p2*x2 = -0.34292214\n"
]
],
[
[
"**Task:** Find the error in the code in the previous cell.",
"_____no_output_____"
]
],
[
[
"# write your code here",
"_____no_output_____"
]
],
[
[
"**Answer:**",
"_____no_output_____"
]
],
[
[
"# a. objective function (to minimize)\ndef value_of_choice(x,alpha,I,p1,p2):\n \n # i. unpack\n x1 = x[0]\n x2 = x[1]\n \n # ii. penalty\n penalty = 0\n E = p1*x1+p2*x2 # total expenses\n if E > I: # expenses > income -> not allowed\n fac = I/E\n penalty += 1000*(E-I) # calculate penalty \n x1 *= fac # force E = I\n x2 *= fac # force E = I\n \n return -u_func(x1,x2,alpha) + penalty # the error\n\n# b. call solver\ninitial_guess = [I/p1/2,I/p2/2]\nsol_case3 = optimize.minimize(\n value_of_choice,initial_guess,method='Nelder-Mead',\n args=(alpha,I,p1,p2))\n\n# c. unpack solution\nx1 = sol_case3.x[0]\nx2 = sol_case3.x[1]\nu = u_func(x1,x2,alpha)\nprint_solution(x1,x2,u,I,p1,p2)",
"x1 = 2.49995337\nx2 = 3.75002332\nu = 3.38850751\nI-p1*x1-p2*x2 = 0.00000000\n"
]
],
[
[
"<a id=\"Indifference-curves\"></a>\n\n# 7. Indifference curves",
"_____no_output_____"
],
[
"Remember that the indifference curve through the point $(y_1,y_2)$ is given by\n\n$$\n\\big\\{(x_1,x_2) \\in \\mathbb{R}^2_+ \\,|\\, u(x_1,x_2) = u(y_1,y_2)\\big\\}\n$$\n\nTo find the indifference curve, we can fix a grid for $x_2$, and then find the corresponding $x_1$ which solves $u(x_1,x_2) = u(y_1,y_2)$ for each value of $x_2$.",
"_____no_output_____"
]
],
[
[
"def objective(x1,x2,alpha,u):\n return u_func(x1,x2,alpha)-u \n # = 0 then on indifference curve with utility = u\n\ndef find_indifference_curve(y1,y2,alpha,N,x2_max):\n \n # a. utiltty in (y1,y2)\n u_y1y2 = u_func(y1,y2,alpha)\n \n # b. allocate numpy arrays\n x1_vec = np.empty(N)\n x2_vec = np.linspace(1e-8,x2_max,N)\n \n # c. loop through x2\n for i,x2 in enumerate(x2_vec):\n\n x1_guess = 0 # initial guess\n sol = optimize.root(objective, x1_guess, args=(x2,alpha,u_y1y2)) \n # optimize.root -> solve objective = 0 starting from x1 = x1_guess\n \n x1_vec[i] = sol.x[0]\n \n return x1_vec,x2_vec",
"_____no_output_____"
]
],
[
[
"Find and plot an inddifference curve:",
"_____no_output_____"
]
],
[
[
"# a. find indifference curve through (2,2) for x2 in [0,10]\nx2_max = 10\nx1_vec,x2_vec = find_indifference_curve(y1=2,y2=2,alpha=0.25,N=100,x2_max=x2_max) \n\n# b. plot inddifference curve\nfig = plt.figure(figsize=(6,6))\nax = fig.add_subplot(1,1,1)\n\nax.plot(x1_vec,x2_vec)\n\nax.set_xlabel('$x_1$')\nax.set_ylabel('$x_2$')\nax.set_xlim([0,x2_max])\nax.set_ylim([0,x2_max])\nax.grid(True)",
"_____no_output_____"
]
],
[
[
"**Task:** Find the indifference curve through $x_1 = 15$ and $x_2 = 3$ with $\\alpha = 0.5$.",
"_____no_output_____"
]
],
[
[
"# write your code here",
"_____no_output_____"
],
[
"x2_max = 20\nx1_vec,x2_vec = find_indifference_curve(y1=15,y2=3,alpha=0.5,N=100,x2_max=x2_max) \n\nfig = plt.figure(figsize=(6,6))\nax = fig.add_subplot(1,1,1)\nax.plot(x1_vec,x2_vec)\n\nax.set_xlabel('$x_1$')\nax.set_ylabel('$x_2$')\nax.set_xlim([0,x2_max])\nax.set_ylim([0,x2_max])\nax.grid(True)",
"_____no_output_____"
]
],
[
[
"<a id=\"A-classy-solution\"></a>\n\n# 8. A classy solution",
"_____no_output_____"
],
[
"> **Note:** This section is advanced due to the use of a module with a class. It is, however, a good example of how to structure code for solving and illustrating a model.",
"_____no_output_____"
],
[
"**Load module** I have written (consumer_module.py in the same folder as this notebook).",
"_____no_output_____"
]
],
[
[
"from consumer_module import consumer",
"_____no_output_____"
]
],
[
[
"## 8.1 Jeppe",
"_____no_output_____"
],
[
"Give birth to a consumer called **jeppe**:",
"_____no_output_____"
]
],
[
[
"jeppe = consumer() # create an instance of the consumer class called jeppe\nprint(jeppe)",
"alpha = 0.500\nprice vector = (p1,p2) = (1.000,2.000)\nincome = I = 10.000\n\n"
]
],
[
[
"Solve **jeppe**'s problem.",
"_____no_output_____"
]
],
[
[
"jeppe.solve()\nprint(jeppe)",
"alpha = 0.500\nprice vector = (p1,p2) = (1.000,2.000)\nincome = I = 10.000\nsolution:\n x1 = 5.00\n x2 = 2.50\n\n"
]
],
[
[
"## 8.2 Mette",
"_____no_output_____"
],
[
"Create a new consumer, called Mette, and solve her problem.",
"_____no_output_____"
]
],
[
[
"mette = consumer(alpha=0.25)\nmette.solve()\nmette.find_indifference_curves()\nprint(mette)",
"alpha = 0.250\nprice vector = (p1,p2) = (1.000,2.000)\nincome = I = 10.000\nsolution:\n x1 = 2.50\n x2 = 3.75\n\n"
]
],
[
[
"Make an illustration of Mette's problem and it's solution:",
"_____no_output_____"
]
],
[
[
"fig = plt.figure(figsize=(6,6))\nax = fig.add_subplot(1,1,1)\n\nmette.plot_indifference_curves(ax)\nmette.plot_budgetset(ax)\nmette.plot_solution(ax)\nmette.plot_details(ax)",
"_____no_output_____"
]
],
[
[
"<a id=\"Summary\"></a>\n\n# 9. Summary",
"_____no_output_____"
],
[
"**This lecture:** We have talked about:\n\n1. Numpy (view vs. copy, indexing, broadcasting, functions, methods)\n2. Print (to screen and file)\n3. Figures (matplotlib)\n4. Optimization (using loops or scipy.optimize)\n5. Advanced: Consumer class",
"_____no_output_____"
],
[
"Most economic models contain optimizing agents solving a constrained optimization problem. The tools applied in this lecture is not specific to the consumer problem in anyway.",
"_____no_output_____"
],
[
"**Your work:** Before solving Problem Set 1 read through this notebook and play around with the code. To solve the problem set, you only need to modify the code used here slightly.",
"_____no_output_____"
],
[
"**Next lecture:** Random numbers and simulation.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
cb33aa5f135fd0e9d9a15cf7ad6257908f574ea1 | 22,157 | ipynb | Jupyter Notebook | Codes/Creating Eblow Method/Prepare Elbow Method Graph.ipynb | nibukdk/Thesis | dad2a6198cc0ef39f07b8de383024dfa82183c20 | [
"MIT"
] | null | null | null | Codes/Creating Eblow Method/Prepare Elbow Method Graph.ipynb | nibukdk/Thesis | dad2a6198cc0ef39f07b8de383024dfa82183c20 | [
"MIT"
] | null | null | null | Codes/Creating Eblow Method/Prepare Elbow Method Graph.ipynb | nibukdk/Thesis | dad2a6198cc0ef39f07b8de383024dfa82183c20 | [
"MIT"
] | null | null | null | 321.115942 | 20,644 | 0.94029 | [
[
[
"#Import Libraries\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nimport numpy as np\nimport pandas as pd\n\n%matplotlib inline # Display in Browser",
"_____no_output_____"
],
[
"sns.set_style('darkgrid') # sets background to beautiful dark color\nplt.figure(figsize=(10,5))\nerror_list = [0.9,0.7,0.55,0.45,0.35,0.3,0.3,0.3,0.3,0.3]\nk_list = [1,2,3,4,5,6,7,8,9,10]\nplt.plot(k_list, error_list, marker='o',markerfacecolor='yellow', markersize=8)\nplt.title('Elbow Method')\nplt.ylabel('Error Rates')\nplt.xlabel('K Values')\nplt.savefig('Elbow Method In Theory.png')",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code"
]
] |
cb33b0ec575dad0e4f7e8ba4fce1e2da62a17a69 | 488,776 | ipynb | Jupyter Notebook | ch00python/010exemplar.ipynb | nasseralidoust/rsd-engineeringcourse | 6d86c0563afae2f7dff8190a65c90988529f6a0f | [
"CC-BY-3.0"
] | null | null | null | ch00python/010exemplar.ipynb | nasseralidoust/rsd-engineeringcourse | 6d86c0563afae2f7dff8190a65c90988529f6a0f | [
"CC-BY-3.0"
] | null | null | null | ch00python/010exemplar.ipynb | nasseralidoust/rsd-engineeringcourse | 6d86c0563afae2f7dff8190a65c90988529f6a0f | [
"CC-BY-3.0"
] | 1 | 2022-02-20T07:59:49.000Z | 2022-02-20T07:59:49.000Z | 497.228891 | 69,165 | 0.952299 | [
[
[
"## An example Python data analysis notebook",
"_____no_output_____"
],
[
"This page illustrates how to use Python to perform a simple but complete analysis: retrieve data, do some computations based on it, and visualise the results.\n\n**Don't worry if you don't understand everything on this page!** Its purpose is to give you an example of things you can do and how to go about doing them - you are not expected to be able to reproduce an analysis like this in Python at this stage! We will be looking at the concepts and practices introduced on this page as we go along the course.\n\nAs we show the code for different parts of the work, we will be touching on various aspects you may want to keep in mind, either related to Python specifically, or to research programming more generally.",
"_____no_output_____"
],
[
"### Why write software to manage your data and plots? ",
"_____no_output_____"
],
[
"We can use programs for our entire research pipeline. Not just big scientific simulation codes, but also the small scripts which we use to tidy up data and produce plots. This should be code, so that the whole research pipeline\nis recorded for reproducibility. Data manipulation in spreadsheets is much harder to share or \ncheck. ",
"_____no_output_____"
],
[
"You can see another similar demonstration on the [software carpentry site](https://swcarpentry.github.io/python-novice-inflammation/01-numpy/index.html). \nWe'll try to give links to other sources of Python training along the way.\nPart of our approach is that we assume you know how to use the internet! If you\nfind something confusing out there, please bring it along to the next session. In this course, we'll always try to draw your attention to other sources of information about what we're learning. Paying attention to as many of these as you need to, is just as important as these core notes.",
"_____no_output_____"
],
[
"### Importing Libraries",
"_____no_output_____"
],
[
"Research programming is all about using libraries: tools other people have provided programs that do many cool things.\nBy combining them we can feel really powerful but doing minimum work ourselves. The python syntax to import someone else's library is \"import\".",
"_____no_output_____"
]
],
[
[
"import geopy # A python library for investigating geographic information.\n# https://pypi.org/project/geopy/",
"_____no_output_____"
]
],
[
[
"Now, if you try to follow along on this example in an Jupyter notebook, you'll probably find that \nyou just got an error message.\n\nYou'll need to wait until we've covered installation of additional python libraries later in the course, then come\nback to this and try again. For now, just follow along and try get the feel for how programming for data-focused\nresearch works.",
"_____no_output_____"
]
],
[
[
"geocoder = geopy.geocoders.Nominatim(user_agent=\"my-application\")\ngeocoder.geocode('Cambridge', exactly_one=False)",
"_____no_output_____"
]
],
[
[
"The results come out as a **list** inside a list: `[Name, [Latitude, Longitude]]`. \nPrograms represent data in a variety of different containers like this.",
"_____no_output_____"
],
[
"### Comments",
"_____no_output_____"
],
[
"Code after a `#` symbol doesn't get run.",
"_____no_output_____"
]
],
[
[
"print(\"This runs\") # print \"This doesn't\"\n# print This doesn't either",
"This runs\n"
]
],
[
[
"### Functions",
"_____no_output_____"
],
[
"We can wrap code up in a **function**, so that we can repeatedly get just the information we want.\n",
"_____no_output_____"
]
],
[
[
"def geolocate(place):\n return geocoder.geocode(place, exactly_one = False)[0][1]",
"_____no_output_____"
]
],
[
[
"Defining **functions** which put together code to make a more complex task seem simple from the outside is the most important thing in programming. The output of the function is stated by \"return\"; the input comes in in brackets after the function name:\n",
"_____no_output_____"
]
],
[
[
"geolocate('Cambridge')",
"_____no_output_____"
]
],
[
[
"### Variables",
"_____no_output_____"
],
[
"We can store a result in a variable:",
"_____no_output_____"
]
],
[
[
"london_location = geolocate(\"London\")\nprint(london_location)",
"(51.5073219, -0.1276474)\n"
]
],
[
[
"### More complex functions",
"_____no_output_____"
],
[
"The Yandex API allows us to fetch a map of a place, given a longitude and latitude.\nThe URLs look like: https://static-maps.yandex.ru/1.x/?size=400,400&ll=-0.1275,51.51&z=10&l=sat&lang=en_US \nWe'll probably end up working out these URLs quite a bit. So we'll make ourselves another function to build up a URL given our parameters.",
"_____no_output_____"
]
],
[
[
"import requests\ndef request_map_at(lat, long, satellite=True,\n zoom=12, size=(400, 400)):\n base = \"https://static-maps.yandex.ru/1.x/?\"\n \n params = dict(\n z = zoom,\n size = str(size[0]) + \",\" + str(size[1]),\n ll = str(long) + \",\" + str(lat),\n l = \"sat\" if satellite else \"map\",\n lang = \"en_US\"\n )\n\n return requests.get(base,params=params)",
"_____no_output_____"
],
[
"map_response = request_map_at(51.5072, -0.1275)",
"_____no_output_____"
]
],
[
[
"### Checking our work",
"_____no_output_____"
],
[
"Let's see what URL we ended up with:",
"_____no_output_____"
]
],
[
[
"url = map_response.url\nprint(url[0:50])\nprint(url[50:100])\nprint(url[100:])",
"https://static-maps.yandex.ru/1.x/?z=12&size=400%2\nC400&ll=-0.1275%2C51.5072&l=sat&lang=en_US\n\n"
]
],
[
[
"We can write **automated tests** so that if we change our code later, we can check the results are still valid.",
"_____no_output_____"
]
],
[
[
"from nose.tools import assert_in\n\nassert_in(\"https://static-maps.yandex.ru/1.x/?\", url)\nassert_in(\"ll=-0.1275%2C51.5072\", url)\nassert_in(\"z=12\", url)\nassert_in(\"size=400%2C400\", url)",
"_____no_output_____"
]
],
[
[
"Our previous function comes back with an Object representing the web request. In object oriented programming, we use the .\noperator to get access to a particular **property** of the object, in this case, the actual image at that URL is in the `content` property. It's a big file, so I'll just get the first few chars:",
"_____no_output_____"
]
],
[
[
"map_response.content[0:20]",
"_____no_output_____"
]
],
[
[
"### Displaying results",
"_____no_output_____"
],
[
"I'll need to do this a lot, so I'll wrap up our previous function in another function, to save on typing.",
"_____no_output_____"
]
],
[
[
"def map_at(*args, **kwargs):\n return request_map_at(*args, **kwargs).content",
"_____no_output_____"
]
],
[
[
"I can use a library that comes with Jupyter notebook to display the image. Being able to work with variables which contain images, or documents, or any other weird kind of data, just as easily as we can with numbers or letters, is one of the really powerful things about modern programming languages like Python. ",
"_____no_output_____"
]
],
[
[
"import IPython\nmap_png = map_at(*london_location)",
"_____no_output_____"
],
[
"print(\"The type of our map result is actually a: \", type(map_png))",
"The type of our map result is actually a: <class 'bytes'>\n"
],
[
"IPython.core.display.Image(map_png)",
"_____no_output_____"
],
[
"IPython.core.display.Image(map_at(*geolocate(\"New Delhi\")))",
"_____no_output_____"
]
],
[
[
"### Manipulating Numbers",
"_____no_output_____"
],
[
"Now we get to our research project: we want to find out how urbanised the world is, based on satellite imagery, along a line\n between two cites. We expect the satellite image to be greener in the countryside.",
"_____no_output_____"
],
[
"We'll use lots more libraries to count how much green there is in an image.",
"_____no_output_____"
]
],
[
[
"from io import BytesIO # A library to convert between files and strings\nimport numpy as np # A library to deal with matrices\nimport imageio # A library to deal with images",
"_____no_output_____"
]
],
[
[
"Let's define what we count as green:",
"_____no_output_____"
]
],
[
[
"def is_green(pixels):\n threshold = 1.1\n greener_than_red = pixels[:,:,1] > threshold * pixels[:,:,0]\n greener_than_blue = pixels[:,:,1] > threshold * pixels[:,:,2]\n green = np.logical_and(greener_than_red, greener_than_blue) \n return green",
"_____no_output_____"
]
],
[
[
"This code has assumed we have our pixel data for the image as a $400 \\times 400 \\times 3$ 3-d matrix,\nwith each of the three layers being red, green, and blue pixels.\n\nWe find out which pixels are green by comparing, element-by-element, the middle (green, number 1) layer to the top (red, zero) and bottom (blue, 2)",
"_____no_output_____"
],
[
"Now we just need to parse in our data, which is a PNG image, and turn it into our matrix format:",
"_____no_output_____"
]
],
[
[
"def count_green_in_png(data):\n f = BytesIO(data)\n pixels = imageio.imread(f) # Get our PNG image as a numpy array\n return np.sum(is_green(pixels))",
"_____no_output_____"
],
[
"print(count_green_in_png( map_at(*london_location) ))",
"8605\n"
]
],
[
[
"We'll also need a function to get an evenly spaced set of places between two endpoints:",
"_____no_output_____"
]
],
[
[
"def location_sequence(start, end, steps):\n lats = np.linspace(start[0], end[0], steps) # \"Linearly spaced\" data\n longs = np.linspace(start[1], end[1], steps)\n return np.vstack([lats, longs]).transpose()",
"_____no_output_____"
],
[
"location_sequence(geolocate(\"London\"), geolocate(\"Cambridge\"), 5)",
"_____no_output_____"
]
],
[
[
"### Creating Images",
"_____no_output_____"
],
[
"We should display the green content to check our work:",
"_____no_output_____"
]
],
[
[
"def show_green_in_png(data):\n pixels = imageio.imread(BytesIO(data)) # Get our PNG image as rows of pixels\n green = is_green(pixels)\n\n out = green[:, :, np.newaxis] * np.array([0, 1, 0])[np.newaxis, np.newaxis, :]\n \n\n buffer = BytesIO()\n result = imageio.imwrite(buffer, out, format='png')\n return buffer.getvalue()",
"_____no_output_____"
],
[
"IPython.core.display.Image(\n map_at(*london_location, satellite=True)\n)",
"_____no_output_____"
],
[
"IPython.core.display.Image(\n show_green_in_png(\n map_at(\n *london_location,\n satellite=True)))",
"Lossy conversion from int64 to uint8. Range [0, 1]. Convert image to uint8 prior to saving to suppress this warning.\n"
]
],
[
[
"### Looping",
"_____no_output_____"
],
[
"We can loop over each element in out list of coordinates, and get a map for that place:",
"_____no_output_____"
]
],
[
[
"for location in location_sequence(geolocate(\"London\"), \n geolocate(\"Birmingham\"),\n 4):\n IPython.core.display.display( \n IPython.core.display.Image(map_at(*location)))",
"_____no_output_____"
]
],
[
[
"So now we can count the green from London to Birmingham!",
"_____no_output_____"
]
],
[
[
"[count_green_in_png(map_at(*location))\n for location in \n location_sequence(geolocate(\"London\"),\n geolocate(\"Birmingham\"),\n 10)]",
"_____no_output_____"
]
],
[
[
"### Plotting graphs",
"_____no_output_____"
],
[
"Let's plot a graph.",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
],
[
"plt.plot([count_green_in_png(map_at(*location))\n for location in \n location_sequence(geolocate(\"London\"), \n geolocate(\"Birmingham\"), \n 10)])",
"_____no_output_____"
]
],
[
[
"From a research perspective, of course, this code needs a lot of work. But I hope the power of using programming is clear.\n",
"_____no_output_____"
],
[
"### Composing Program Elements",
"_____no_output_____"
],
[
"We built little pieces of useful code, to:\n\n* Find latitude and longitude of a place\n* Get a map at a given latitude and longitude\n* Decide whether a (red,green,blue) triple is mainly green\n* Decide whether each pixel is mainly green\n* Plot a new image showing the green places\n* Find evenly spaced points between two places",
"_____no_output_____"
],
[
"By putting these together, we can make a function which can plot this graph automatically for any two places:",
"_____no_output_____"
]
],
[
[
"def green_between(start, end,steps):\n return [count_green_in_png( map_at(*location) )\n for location in location_sequence(\n geolocate(start),\n geolocate(end),\n steps)]",
"_____no_output_____"
],
[
"plt.plot(green_between('New York', 'Chicago', 20))",
"_____no_output_____"
]
],
[
[
"And that's it! We've covered, very very quickly, the majority of the python language, and much of the theory of software engineering.",
"_____no_output_____"
],
[
"Now we'll go back, carefully, through all the concepts we touched on, and learn how to use them properly ourselves.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
cb33c9a1570b24a126a1122edf29ea9682973170 | 588,375 | ipynb | Jupyter Notebook | notebooks/introduction_to_tensorflow/labs/adv_logistic_reg_TF2.0.ipynb | ctivanovich/asl-ml-immersion | a2251b0368e5a5575ccdfbefd51ac1688bc7f110 | [
"Apache-2.0"
] | null | null | null | notebooks/introduction_to_tensorflow/labs/adv_logistic_reg_TF2.0.ipynb | ctivanovich/asl-ml-immersion | a2251b0368e5a5575ccdfbefd51ac1688bc7f110 | [
"Apache-2.0"
] | null | null | null | notebooks/introduction_to_tensorflow/labs/adv_logistic_reg_TF2.0.ipynb | ctivanovich/asl-ml-immersion | a2251b0368e5a5575ccdfbefd51ac1688bc7f110 | [
"Apache-2.0"
] | null | null | null | 214.344262 | 59,836 | 0.890495 | [
[
[
"# Advanced Logistic Regression in TensorFlow 2.0 \n\n\n\n## Learning Objectives\n\n1. Load a CSV file using Pandas\n2. Create train, validation, and test sets\n3. Define and train a model using Keras (including setting class weights)\n4. Evaluate the model using various metrics (including precision and recall)\n5. Try common techniques for dealing with imbalanced data like:\n Class weighting and\n Oversampling\n\n\n\n## Introduction \nThis lab how to classify a highly imbalanced dataset in which the number of examples in one class greatly outnumbers the examples in another. You will work with the [Credit Card Fraud Detection](https://www.kaggle.com/mlg-ulb/creditcardfraud) dataset hosted on Kaggle. The aim is to detect a mere 492 fraudulent transactions from 284,807 transactions in total. You will use [Keras](../../guide/keras/overview.ipynb) to define the model and [class weights](https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/Model) to help the model learn from the imbalanced data. \n\nPENDING LINK UPDATE: Each learning objective will correspond to a __#TODO__ in the [student lab notebook](https://training-data-analyst/courses/machine_learning/deepdive2/image_classification/labs/5_fashion_mnist_class.ipynb) -- try to complete that notebook first before reviewing this solution notebook.",
"_____no_output_____"
],
[
"Start by importing the necessary libraries for this lab.",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\nfrom tensorflow import keras\n\nimport os\nimport tempfile\n\nimport matplotlib as mpl\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd\nimport seaborn as sns\n\nimport sklearn\nfrom sklearn.metrics import confusion_matrix\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.preprocessing import StandardScaler\n\nprint(\"TensorFlow version: \",tf.version.VERSION)",
"TensorFlow version: 2.1.0\n"
]
],
[
[
"In the next cell, we're going to customize our Matplot lib visualization figure size and colors. Note that each time Matplotlib loads, it defines a runtime configuration (rc) containing the default styles for every plot element we create. This configuration can be adjusted at any time using the plt.rc convenience routine. ",
"_____no_output_____"
]
],
[
[
"mpl.rcParams['figure.figsize'] = (12, 10)\ncolors = plt.rcParams['axes.prop_cycle'].by_key()['color']",
"_____no_output_____"
]
],
[
[
"## Data processing and exploration",
"_____no_output_____"
],
[
"### Download the Kaggle Credit Card Fraud data set\n\nPandas is a Python library with many helpful utilities for loading and working with structured data and can be used to download CSVs into a dataframe.\n\nNote: This dataset has been collected and analysed during a research collaboration of Worldline and the [Machine Learning Group](http://mlg.ulb.ac.be) of ULB (Université Libre de Bruxelles) on big data mining and fraud detection. More details on current and past projects on related topics are available [here](https://www.researchgate.net/project/Fraud-detection-5) and the page of the [DefeatFraud](https://mlg.ulb.ac.be/wordpress/portfolio_page/defeatfraud-assessment-and-validation-of-deep-feature-engineering-and-learning-solutions-for-fraud-detection/) project",
"_____no_output_____"
]
],
[
[
"file = tf.keras.utils\nraw_df = pd.read_csv('https://storage.googleapis.com/download.tensorflow.org/data/creditcard.csv')\nraw_df.head()",
"_____no_output_____"
]
],
[
[
"Now, let's view the statistics of the raw dataframe.",
"_____no_output_____"
]
],
[
[
"raw_df[['Time', 'V1', 'V2', 'V3', 'V4', 'V5', 'V26', 'V27', 'V28', 'Amount', 'Class']].describe()",
"_____no_output_____"
]
],
[
[
"### Examine the class label imbalance\n\nLet's look at the dataset imbalance:",
"_____no_output_____"
]
],
[
[
"neg, pos = np.bincount(raw_df['Class'])\ntotal = neg + pos\nprint('Examples:\\n Total: {}\\n Positive: {} ({:.2f}% of total)\\n'.format(\n total, pos, 100 * pos / total))",
"Examples:\n Total: 284807\n Positive: 492 (0.17% of total)\n\n"
]
],
[
[
"This shows the small fraction of positive samples.",
"_____no_output_____"
],
[
"### Clean, split and normalize the data\n\nThe raw data has a few issues. First the `Time` and `Amount` columns are too variable to use directly. Drop the `Time` column (since it's not clear what it means) and take the log of the `Amount` column to reduce its range.",
"_____no_output_____"
]
],
[
[
"cleaned_df = raw_df.copy()\n\n# You don't want the `Time` column.\ncleaned_df.pop('Time')\n\n# The `Amount` column covers a huge range. Convert to log-space.\neps=0.001 # 0 => 0.1¢\ncleaned_df['Log Ammount'] = np.log(cleaned_df.pop('Amount')+eps)",
"_____no_output_____"
]
],
[
[
"Split the dataset into train, validation, and test sets. The validation set is used during the model fitting to evaluate the loss and any metrics, however the model is not fit with this data. The test set is completely unused during the training phase and is only used at the end to evaluate how well the model generalizes to new data. This is especially important with imbalanced datasets where [overfitting](https://developers.google.com/machine-learning/crash-course/generalization/peril-of-overfitting) is a significant concern from the lack of training data.",
"_____no_output_____"
]
],
[
[
"# TODO 1\n# Use a utility from sklearn to split and shuffle our dataset.\ntrain_df, test_df = #TODO: Your code goes here.\ntrain_df, val_df = #TODO: Your code goes here.\n\n# Form np arrays of labels and features.\ntrain_labels = #TODO: Your code goes here.\nbool_train_labels = #TODO: Your code goes here.\nval_labels = #TODO: Your code goes here.\ntest_labels = #TODO: Your code goes here.\n\ntrain_features = np.array(train_df)\nval_features = np.array(val_df)\ntest_features = np.array(test_df)",
"_____no_output_____"
]
],
[
[
"Normalize the input features using the sklearn StandardScaler.\nThis will set the mean to 0 and standard deviation to 1.\n\nNote: The `StandardScaler` is only fit using the `train_features` to be sure the model is not peeking at the validation or test sets. ",
"_____no_output_____"
]
],
[
[
"scaler = StandardScaler()\ntrain_features = scaler.fit_transform(train_features)\n\nval_features = scaler.transform(val_features)\ntest_features = scaler.transform(test_features)\n\ntrain_features = np.clip(train_features, -5, 5)\nval_features = np.clip(val_features, -5, 5)\ntest_features = np.clip(test_features, -5, 5)\n\n\nprint('Training labels shape:', train_labels.shape)\nprint('Validation labels shape:', val_labels.shape)\nprint('Test labels shape:', test_labels.shape)\n\nprint('Training features shape:', train_features.shape)\nprint('Validation features shape:', val_features.shape)\nprint('Test features shape:', test_features.shape)\n",
"Training labels shape: (182276,)\nValidation labels shape: (45569,)\nTest labels shape: (56962,)\nTraining features shape: (182276, 29)\nValidation features shape: (45569, 29)\nTest features shape: (56962, 29)\n"
]
],
[
[
"Caution: If you want to deploy a model, it's critical that you preserve the preprocessing calculations. The easiest way to implement them as layers, and attach them to your model before export.\n",
"_____no_output_____"
],
[
"### Look at the data distribution\n\nNext compare the distributions of the positive and negative examples over a few features. Good questions to ask yourself at this point are:\n\n* Do these distributions make sense? \n * Yes. You've normalized the input and these are mostly concentrated in the `+/- 2` range.\n* Can you see the difference between the ditributions?\n * Yes the positive examples contain a much higher rate of extreme values.",
"_____no_output_____"
]
],
[
[
"pos_df = pd.DataFrame(train_features[ bool_train_labels], columns = train_df.columns)\nneg_df = pd.DataFrame(train_features[~bool_train_labels], columns = train_df.columns)\n\nsns.jointplot(pos_df['V5'], pos_df['V6'],\n kind='hex', xlim = (-5,5), ylim = (-5,5))\nplt.suptitle(\"Positive distribution\")\n\nsns.jointplot(neg_df['V5'], neg_df['V6'],\n kind='hex', xlim = (-5,5), ylim = (-5,5))\n_ = plt.suptitle(\"Negative distribution\")",
"_____no_output_____"
]
],
[
[
"## Define the model and metrics\n\nDefine a function that creates a simple neural network with a densly connected hidden layer, a [dropout](https://developers.google.com/machine-learning/glossary/#dropout_regularization) layer to reduce overfitting, and an output sigmoid layer that returns the probability of a transaction being fraudulent: ",
"_____no_output_____"
]
],
[
[
"METRICS = [\n keras.metrics.TruePositives(name='tp'),\n keras.metrics.FalsePositives(name='fp'),\n keras.metrics.TrueNegatives(name='tn'),\n keras.metrics.FalseNegatives(name='fn'), \n keras.metrics.BinaryAccuracy(name='accuracy'),\n keras.metrics.Precision(name='precision'),\n keras.metrics.Recall(name='recall'),\n keras.metrics.AUC(name='auc'),\n]\n\ndef make_model(metrics = METRICS, output_bias=None):\n if output_bias is not None:\n output_bias = tf.keras.initializers.Constant(output_bias)\n # TODO 1\n model = keras.Sequential(\n #TODO: Your code goes here.\n #TODO: Your code goes here.\n #TODO: Your code goes here.\n #TODO: Your code goes here.\n)\n\n model.compile(\n optimizer=keras.optimizers.Adam(lr=1e-3),\n loss=keras.losses.BinaryCrossentropy(),\n metrics=metrics)\n\n return model",
"_____no_output_____"
]
],
[
[
"### Understanding useful metrics\n\nNotice that there are a few metrics defined above that can be computed by the model that will be helpful when evaluating the performance.\n\n\n\n* **False** negatives and **false** positives are samples that were **incorrectly** classified\n* **True** negatives and **true** positives are samples that were **correctly** classified\n* **Accuracy** is the percentage of examples correctly classified\n> $\\frac{\\text{true samples}}{\\text{total samples}}$\n* **Precision** is the percentage of **predicted** positives that were correctly classified\n> $\\frac{\\text{true positives}}{\\text{true positives + false positives}}$\n* **Recall** is the percentage of **actual** positives that were correctly classified\n> $\\frac{\\text{true positives}}{\\text{true positives + false negatives}}$\n* **AUC** refers to the Area Under the Curve of a Receiver Operating Characteristic curve (ROC-AUC). This metric is equal to the probability that a classifier will rank a random positive sample higher than than a random negative sample.\n\nNote: Accuracy is not a helpful metric for this task. You can 99.8%+ accuracy on this task by predicting False all the time. \n\nRead more:\n* [True vs. False and Positive vs. Negative](https://developers.google.com/machine-learning/crash-course/classification/true-false-positive-negative)\n* [Accuracy](https://developers.google.com/machine-learning/crash-course/classification/accuracy)\n* [Precision and Recall](https://developers.google.com/machine-learning/crash-course/classification/precision-and-recall)\n* [ROC-AUC](https://developers.google.com/machine-learning/crash-course/classification/roc-and-auc)",
"_____no_output_____"
],
[
"## Baseline model",
"_____no_output_____"
],
[
"### Build the model\n\nNow create and train your model using the function that was defined earlier. Notice that the model is fit using a larger than default batch size of 2048, this is important to ensure that each batch has a decent chance of containing a few positive samples. If the batch size was too small, they would likely have no fraudulent transactions to learn from.\n\n\nNote: this model will not handle the class imbalance well. You will improve it later in this tutorial.",
"_____no_output_____"
]
],
[
[
"EPOCHS = 100\nBATCH_SIZE = 2048\n\nearly_stopping = tf.keras.callbacks.EarlyStopping(\n monitor='val_auc', \n verbose=1,\n patience=10,\n mode='max',\n restore_best_weights=True)",
"_____no_output_____"
],
[
"model = make_model()\nmodel.summary()",
"Model: \"sequential_8\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ndense_16 (Dense) (None, 16) 480 \n_________________________________________________________________\ndropout_8 (Dropout) (None, 16) 0 \n_________________________________________________________________\ndense_17 (Dense) (None, 1) 17 \n=================================================================\nTotal params: 497\nTrainable params: 497\nNon-trainable params: 0\n_________________________________________________________________\n"
]
],
[
[
"Test run the model:",
"_____no_output_____"
]
],
[
[
"model.predict(train_features[:10])",
"_____no_output_____"
]
],
[
[
"### Optional: Set the correct initial bias.",
"_____no_output_____"
],
[
"These are initial guesses are not great. You know the dataset is imbalanced. Set the output layer's bias to reflect that (See: [A Recipe for Training Neural Networks: \"init well\"](http://karpathy.github.io/2019/04/25/recipe/#2-set-up-the-end-to-end-trainingevaluation-skeleton--get-dumb-baselines)). This can help with initial convergence.",
"_____no_output_____"
],
[
"With the default bias initialization the loss should be about `math.log(2) = 0.69314` ",
"_____no_output_____"
]
],
[
[
"results = model.evaluate(train_features, train_labels, batch_size=BATCH_SIZE, verbose=0)\nprint(\"Loss: {:0.4f}\".format(results[0]))",
"Loss: 1.7441\n"
]
],
[
[
"The correct bias to set can be derived from:\n\n$$ p_0 = pos/(pos + neg) = 1/(1+e^{-b_0}) $$\n$$ b_0 = -log_e(1/p_0 - 1) $$\n$$ b_0 = log_e(pos/neg)$$",
"_____no_output_____"
]
],
[
[
"initial_bias = np.log([pos/neg])\ninitial_bias",
"_____no_output_____"
]
],
[
[
"Set that as the initial bias, and the model will give much more reasonable initial guesses. \n\nIt should be near: `pos/total = 0.0018`",
"_____no_output_____"
]
],
[
[
"model = make_model(output_bias = initial_bias)\nmodel.predict(train_features[:10])",
"_____no_output_____"
]
],
[
[
"With this initialization the initial loss should be approximately:\n\n$$-p_0log(p_0)-(1-p_0)log(1-p_0) = 0.01317$$",
"_____no_output_____"
]
],
[
[
"results = model.evaluate(train_features, train_labels, batch_size=BATCH_SIZE, verbose=0)\nprint(\"Loss: {:0.4f}\".format(results[0]))",
"Loss: 0.0275\n"
]
],
[
[
"This initial loss is about 50 times less than if would have been with naive initilization.\n\nThis way the model doesn't need to spend the first few epochs just learning that positive examples are unlikely. This also makes it easier to read plots of the loss during training.",
"_____no_output_____"
],
[
"### Checkpoint the initial weights\n\nTo make the various training runs more comparable, keep this initial model's weights in a checkpoint file, and load them into each model before training.",
"_____no_output_____"
]
],
[
[
"initial_weights = os.path.join(tempfile.mkdtemp(),'initial_weights')\nmodel.save_weights(initial_weights)",
"_____no_output_____"
]
],
[
[
"### Confirm that the bias fix helps\n\nBefore moving on, confirm quick that the careful bias initialization actually helped.\n\nTrain the model for 20 epochs, with and without this careful initialization, and compare the losses: ",
"_____no_output_____"
]
],
[
[
"model = make_model()\nmodel.load_weights(initial_weights)\nmodel.layers[-1].bias.assign([0.0])\nzero_bias_history = model.fit(\n train_features,\n train_labels,\n batch_size=BATCH_SIZE,\n epochs=20,\n validation_data=(val_features, val_labels), \n verbose=0)",
"_____no_output_____"
],
[
"model = make_model()\nmodel.load_weights(initial_weights)\ncareful_bias_history = model.fit(\n train_features,\n train_labels,\n batch_size=BATCH_SIZE,\n epochs=20,\n validation_data=(val_features, val_labels), \n verbose=0)",
"_____no_output_____"
],
[
"def plot_loss(history, label, n):\n # Use a log scale to show the wide range of values.\n plt.semilogy(history.epoch, history.history['loss'],\n color=colors[n], label='Train '+label)\n plt.semilogy(history.epoch, history.history['val_loss'],\n color=colors[n], label='Val '+label,\n linestyle=\"--\")\n plt.xlabel('Epoch')\n plt.ylabel('Loss')\n \n plt.legend()",
"_____no_output_____"
],
[
"plot_loss(zero_bias_history, \"Zero Bias\", 0)\nplot_loss(careful_bias_history, \"Careful Bias\", 1)",
"_____no_output_____"
]
],
[
[
"The above figure makes it clear: In terms of validation loss, on this problem, this careful initialization gives a clear advantage. ",
"_____no_output_____"
],
[
"### Train the model",
"_____no_output_____"
]
],
[
[
"model = make_model()\nmodel.load_weights(initial_weights)\nbaseline_history = model.fit(\n train_features,\n train_labels,\n batch_size=BATCH_SIZE,\n epochs=EPOCHS,\n callbacks = [early_stopping],\n validation_data=(val_features, val_labels))",
"Train on 182276 samples, validate on 45569 samples\nEpoch 1/100\n182276/182276 [==============================] - 3s 16us/sample - loss: 0.0256 - tp: 64.0000 - fp: 745.0000 - tn: 181227.0000 - fn: 240.0000 - accuracy: 0.9946 - precision: 0.0791 - recall: 0.2105 - auc: 0.8031 - val_loss: 0.0079 - val_tp: 17.0000 - val_fp: 7.0000 - val_tn: 45479.0000 - val_fn: 66.0000 - val_accuracy: 0.9984 - val_precision: 0.7083 - val_recall: 0.2048 - val_auc: 0.9377\nEpoch 2/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.0100 - tp: 111.0000 - fp: 131.0000 - tn: 181841.0000 - fn: 193.0000 - accuracy: 0.9982 - precision: 0.4587 - recall: 0.3651 - auc: 0.8758 - val_loss: 0.0056 - val_tp: 40.0000 - val_fp: 7.0000 - val_tn: 45479.0000 - val_fn: 43.0000 - val_accuracy: 0.9989 - val_precision: 0.8511 - val_recall: 0.4819 - val_auc: 0.9422\nEpoch 3/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.0075 - tp: 148.0000 - fp: 57.0000 - tn: 181915.0000 - fn: 156.0000 - accuracy: 0.9988 - precision: 0.7220 - recall: 0.4868 - auc: 0.9206 - val_loss: 0.0048 - val_tp: 52.0000 - val_fp: 7.0000 - val_tn: 45479.0000 - val_fn: 31.0000 - val_accuracy: 0.9992 - val_precision: 0.8814 - val_recall: 0.6265 - val_auc: 0.9382\nEpoch 4/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.0065 - tp: 157.0000 - fp: 48.0000 - tn: 181924.0000 - fn: 147.0000 - accuracy: 0.9989 - precision: 0.7659 - recall: 0.5164 - auc: 0.9210 - val_loss: 0.0045 - val_tp: 52.0000 - val_fp: 7.0000 - val_tn: 45479.0000 - val_fn: 31.0000 - val_accuracy: 0.9992 - val_precision: 0.8814 - val_recall: 0.6265 - val_auc: 0.9387\nEpoch 5/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.0058 - tp: 172.0000 - fp: 43.0000 - tn: 181929.0000 - fn: 132.0000 - accuracy: 0.9990 - precision: 0.8000 - recall: 0.5658 - auc: 0.9246 - val_loss: 0.0042 - val_tp: 51.0000 - val_fp: 7.0000 - val_tn: 45479.0000 - val_fn: 32.0000 - val_accuracy: 0.9991 - val_precision: 0.8793 - val_recall: 0.6145 - val_auc: 0.9390\nEpoch 6/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.0054 - tp: 169.0000 - fp: 28.0000 - tn: 181944.0000 - fn: 135.0000 - accuracy: 0.9991 - precision: 0.8579 - recall: 0.5559 - auc: 0.9210 - val_loss: 0.0039 - val_tp: 56.0000 - val_fp: 7.0000 - val_tn: 45479.0000 - val_fn: 27.0000 - val_accuracy: 0.9993 - val_precision: 0.8889 - val_recall: 0.6747 - val_auc: 0.9391\nEpoch 7/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.0054 - tp: 167.0000 - fp: 33.0000 - tn: 181939.0000 - fn: 137.0000 - accuracy: 0.9991 - precision: 0.8350 - recall: 0.5493 - auc: 0.9224 - val_loss: 0.0038 - val_tp: 60.0000 - val_fp: 7.0000 - val_tn: 45479.0000 - val_fn: 23.0000 - val_accuracy: 0.9993 - val_precision: 0.8955 - val_recall: 0.7229 - val_auc: 0.9392\nEpoch 8/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.0050 - tp: 182.0000 - fp: 28.0000 - tn: 181944.0000 - fn: 122.0000 - accuracy: 0.9992 - precision: 0.8667 - recall: 0.5987 - auc: 0.9215 - val_loss: 0.0038 - val_tp: 62.0000 - val_fp: 7.0000 - val_tn: 45479.0000 - val_fn: 21.0000 - val_accuracy: 0.9994 - val_precision: 0.8986 - val_recall: 0.7470 - val_auc: 0.9332\nEpoch 9/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.0047 - tp: 186.0000 - fp: 36.0000 - tn: 181936.0000 - fn: 118.0000 - accuracy: 0.9992 - precision: 0.8378 - recall: 0.6118 - auc: 0.9238 - val_loss: 0.0036 - val_tp: 63.0000 - val_fp: 7.0000 - val_tn: 45479.0000 - val_fn: 20.0000 - val_accuracy: 0.9994 - val_precision: 0.9000 - val_recall: 0.7590 - val_auc: 0.9332\nEpoch 10/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.0048 - tp: 176.0000 - fp: 33.0000 - tn: 181939.0000 - fn: 128.0000 - accuracy: 0.9991 - precision: 0.8421 - recall: 0.5789 - auc: 0.9208 - val_loss: 0.0036 - val_tp: 63.0000 - val_fp: 7.0000 - val_tn: 45479.0000 - val_fn: 20.0000 - val_accuracy: 0.9994 - val_precision: 0.9000 - val_recall: 0.7590 - val_auc: 0.9332\nEpoch 11/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.0045 - tp: 180.0000 - fp: 32.0000 - tn: 181940.0000 - fn: 124.0000 - accuracy: 0.9991 - precision: 0.8491 - recall: 0.5921 - auc: 0.9341 - val_loss: 0.0035 - val_tp: 64.0000 - val_fp: 7.0000 - val_tn: 45479.0000 - val_fn: 19.0000 - val_accuracy: 0.9994 - val_precision: 0.9014 - val_recall: 0.7711 - val_auc: 0.9331\nEpoch 12/100\n169984/182276 [==========================>...] - ETA: 0s - loss: 0.0045 - tp: 175.0000 - fp: 30.0000 - tn: 169674.0000 - fn: 105.0000 - accuracy: 0.9992 - precision: 0.8537 - recall: 0.6250 - auc: 0.9306Restoring model weights from the end of the best epoch.\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.0045 - tp: 188.0000 - fp: 31.0000 - tn: 181941.0000 - fn: 116.0000 - accuracy: 0.9992 - precision: 0.8584 - recall: 0.6184 - auc: 0.9326 - val_loss: 0.0034 - val_tp: 63.0000 - val_fp: 6.0000 - val_tn: 45480.0000 - val_fn: 20.0000 - val_accuracy: 0.9994 - val_precision: 0.9130 - val_recall: 0.7590 - val_auc: 0.9332\nEpoch 00012: early stopping\n"
]
],
[
[
"### Check training history\nIn this section, you will produce plots of your model's accuracy and loss on the training and validation set. These are useful to check for overfitting, which you can learn more about in this [tutorial](https://www.tensorflow.org/tutorials/keras/overfit_and_underfit).\n\nAdditionally, you can produce these plots for any of the metrics you created above. False negatives are included as an example.",
"_____no_output_____"
]
],
[
[
"def plot_metrics(history):\n metrics = ['loss', 'auc', 'precision', 'recall']\n for n, metric in enumerate(metrics):\n name = metric.replace(\"_\",\" \").capitalize()\n plt.subplot(2,2,n+1)\n plt.plot(history.epoch, history.history[metric], color=colors[0], label='Train')\n plt.plot(history.epoch, history.history['val_'+metric],\n color=colors[0], linestyle=\"--\", label='Val')\n plt.xlabel('Epoch')\n plt.ylabel(name)\n if metric == 'loss':\n plt.ylim([0, plt.ylim()[1]])\n elif metric == 'auc':\n plt.ylim([0.8,1])\n else:\n plt.ylim([0,1])\n\n plt.legend()\n",
"_____no_output_____"
],
[
"plot_metrics(baseline_history)",
"_____no_output_____"
]
],
[
[
"Note: That the validation curve generally performs better than the training curve. This is mainly caused by the fact that the dropout layer is not active when evaluating the model.",
"_____no_output_____"
],
[
"### Evaluate metrics\n\nYou can use a [confusion matrix](https://developers.google.com/machine-learning/glossary/#confusion_matrix) to summarize the actual vs. predicted labels where the X axis is the predicted label and the Y axis is the actual label.",
"_____no_output_____"
]
],
[
[
"# TODO 1\ntrain_predictions_baseline = #TODO: Your code goes here.\ntest_predictions_baseline = #TODO: Your code goes here.",
"_____no_output_____"
],
[
"def plot_cm(labels, predictions, p=0.5):\n cm = confusion_matrix(labels, predictions > p)\n plt.figure(figsize=(5,5))\n sns.heatmap(cm, annot=True, fmt=\"d\")\n plt.title('Confusion matrix @{:.2f}'.format(p))\n plt.ylabel('Actual label')\n plt.xlabel('Predicted label')\n\n print('Legitimate Transactions Detected (True Negatives): ', cm[0][0])\n print('Legitimate Transactions Incorrectly Detected (False Positives): ', cm[0][1])\n print('Fraudulent Transactions Missed (False Negatives): ', cm[1][0])\n print('Fraudulent Transactions Detected (True Positives): ', cm[1][1])\n print('Total Fraudulent Transactions: ', np.sum(cm[1]))",
"_____no_output_____"
]
],
[
[
"Evaluate your model on the test dataset and display the results for the metrics you created above.",
"_____no_output_____"
]
],
[
[
"baseline_results = model.evaluate(test_features, test_labels,\n batch_size=BATCH_SIZE, verbose=0)\nfor name, value in zip(model.metrics_names, baseline_results):\n print(name, ': ', value)\nprint()\n\nplot_cm(test_labels, test_predictions_baseline)",
"loss : 0.005941324691873794\ntp : 55.0\nfp : 12.0\ntn : 56845.0\nfn : 50.0\naccuracy : 0.99891156\nprecision : 0.8208955\nrecall : 0.52380955\nauc : 0.9390888\n\nLegitimate Transactions Detected (True Negatives): 56845\nLegitimate Transactions Incorrectly Detected (False Positives): 12\nFraudulent Transactions Missed (False Negatives): 50\nFraudulent Transactions Detected (True Positives): 55\nTotal Fraudulent Transactions: 105\n"
]
],
[
[
"If the model had predicted everything perfectly, this would be a [diagonal matrix](https://en.wikipedia.org/wiki/Diagonal_matrix) where values off the main diagonal, indicating incorrect predictions, would be zero. In this case the matrix shows that you have relatively few false positives, meaning that there were relatively few legitimate transactions that were incorrectly flagged. However, you would likely want to have even fewer false negatives despite the cost of increasing the number of false positives. This trade off may be preferable because false negatives would allow fraudulent transactions to go through, whereas false positives may cause an email to be sent to a customer to ask them to verify their card activity.",
"_____no_output_____"
],
[
"### Plot the ROC\n\nNow plot the [ROC](https://developers.google.com/machine-learning/glossary#ROC). This plot is useful because it shows, at a glance, the range of performance the model can reach just by tuning the output threshold.",
"_____no_output_____"
]
],
[
[
"def plot_roc(name, labels, predictions, **kwargs):\n fp, tp, _ = sklearn.metrics.roc_curve(labels, predictions)\n\n plt.plot(100*fp, 100*tp, label=name, linewidth=2, **kwargs)\n plt.xlabel('False positives [%]')\n plt.ylabel('True positives [%]')\n plt.xlim([-0.5,20])\n plt.ylim([80,100.5])\n plt.grid(True)\n ax = plt.gca()\n ax.set_aspect('equal')",
"_____no_output_____"
],
[
"plot_roc(\"Train Baseline\", train_labels, train_predictions_baseline, color=colors[0])\nplot_roc(\"Test Baseline\", test_labels, test_predictions_baseline, color=colors[0], linestyle='--')\nplt.legend(loc='lower right')",
"_____no_output_____"
]
],
[
[
"It looks like the precision is relatively high, but the recall and the area under the ROC curve (AUC) aren't as high as you might like. Classifiers often face challenges when trying to maximize both precision and recall, which is especially true when working with imbalanced datasets. It is important to consider the costs of different types of errors in the context of the problem you care about. In this example, a false negative (a fraudulent transaction is missed) may have a financial cost, while a false positive (a transaction is incorrectly flagged as fraudulent) may decrease user happiness.",
"_____no_output_____"
],
[
"## Class weights",
"_____no_output_____"
],
[
"### Calculate class weights\n\nThe goal is to identify fradulent transactions, but you don't have very many of those positive samples to work with, so you would want to have the classifier heavily weight the few examples that are available. You can do this by passing Keras weights for each class through a parameter. These will cause the model to \"pay more attention\" to examples from an under-represented class.",
"_____no_output_____"
]
],
[
[
"# Scaling by total/2 helps keep the loss to a similar magnitude.\n# The sum of the weights of all examples stays the same.\n# TODO 1\nweight_for_0 = #TODO: Your code goes here.\nweight_for_1 = #TODO: Your code goes here.\n\nclass_weight = #TODO: Your code goes here.\n\nprint('Weight for class 0: {:.2f}'.format(weight_for_0))\nprint('Weight for class 1: {:.2f}'.format(weight_for_1))",
"Weight for class 0: 0.50\nWeight for class 1: 289.44\n"
]
],
[
[
"### Train a model with class weights\n\nNow try re-training and evaluating the model with class weights to see how that affects the predictions.\n\nNote: Using `class_weights` changes the range of the loss. This may affect the stability of the training depending on the optimizer. Optimizers whose step size is dependent on the magnitude of the gradient, like `optimizers.SGD`, may fail. The optimizer used here, `optimizers.Adam`, is unaffected by the scaling change. Also note that because of the weighting, the total losses are not comparable between the two models.",
"_____no_output_____"
]
],
[
[
"weighted_model = make_model()\nweighted_model.load_weights(initial_weights)\n\nweighted_history = weighted_model.fit(\n train_features,\n train_labels,\n batch_size=BATCH_SIZE,\n epochs=EPOCHS,\n callbacks = [early_stopping],\n validation_data=(val_features, val_labels),\n # The class weights go here\n class_weight=class_weight) ",
"WARNING:tensorflow:sample_weight modes were coerced from\n ...\n to \n ['...']\nWARNING:tensorflow:sample_weight modes were coerced from\n ...\n to \n ['...']\nTrain on 182276 samples, validate on 45569 samples\nEpoch 1/100\n182276/182276 [==============================] - 3s 19us/sample - loss: 1.0524 - tp: 138.0000 - fp: 2726.0000 - tn: 179246.0000 - fn: 166.0000 - accuracy: 0.9841 - precision: 0.0482 - recall: 0.4539 - auc: 0.8321 - val_loss: 0.4515 - val_tp: 59.0000 - val_fp: 432.0000 - val_tn: 45054.0000 - val_fn: 24.0000 - val_accuracy: 0.9900 - val_precision: 0.1202 - val_recall: 0.7108 - val_auc: 0.9492\nEpoch 2/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.5537 - tp: 216.0000 - fp: 3783.0000 - tn: 178189.0000 - fn: 88.0000 - accuracy: 0.9788 - precision: 0.0540 - recall: 0.7105 - auc: 0.9033 - val_loss: 0.3285 - val_tp: 69.0000 - val_fp: 514.0000 - val_tn: 44972.0000 - val_fn: 14.0000 - val_accuracy: 0.9884 - val_precision: 0.1184 - val_recall: 0.8313 - val_auc: 0.9605\nEpoch 3/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.4178 - tp: 238.0000 - fp: 4540.0000 - tn: 177432.0000 - fn: 66.0000 - accuracy: 0.9747 - precision: 0.0498 - recall: 0.7829 - auc: 0.9237 - val_loss: 0.2840 - val_tp: 69.0000 - val_fp: 570.0000 - val_tn: 44916.0000 - val_fn: 14.0000 - val_accuracy: 0.9872 - val_precision: 0.1080 - val_recall: 0.8313 - val_auc: 0.9669\nEpoch 4/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.3848 - tp: 247.0000 - fp: 5309.0000 - tn: 176663.0000 - fn: 57.0000 - accuracy: 0.9706 - precision: 0.0445 - recall: 0.8125 - auc: 0.9292 - val_loss: 0.2539 - val_tp: 71.0000 - val_fp: 622.0000 - val_tn: 44864.0000 - val_fn: 12.0000 - val_accuracy: 0.9861 - val_precision: 0.1025 - val_recall: 0.8554 - val_auc: 0.9709\nEpoch 5/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.3596 - tp: 254.0000 - fp: 6018.0000 - tn: 175954.0000 - fn: 50.0000 - accuracy: 0.9667 - precision: 0.0405 - recall: 0.8355 - auc: 0.9323 - val_loss: 0.2363 - val_tp: 72.0000 - val_fp: 713.0000 - val_tn: 44773.0000 - val_fn: 11.0000 - val_accuracy: 0.9841 - val_precision: 0.0917 - val_recall: 0.8675 - val_auc: 0.9725\nEpoch 6/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.3115 - tp: 255.0000 - fp: 6366.0000 - tn: 175606.0000 - fn: 49.0000 - accuracy: 0.9648 - precision: 0.0385 - recall: 0.8388 - auc: 0.9477 - val_loss: 0.2243 - val_tp: 72.0000 - val_fp: 768.0000 - val_tn: 44718.0000 - val_fn: 11.0000 - val_accuracy: 0.9829 - val_precision: 0.0857 - val_recall: 0.8675 - val_auc: 0.9728\nEpoch 7/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.3179 - tp: 258.0000 - fp: 6804.0000 - tn: 175168.0000 - fn: 46.0000 - accuracy: 0.9624 - precision: 0.0365 - recall: 0.8487 - auc: 0.9435 - val_loss: 0.2165 - val_tp: 72.0000 - val_fp: 812.0000 - val_tn: 44674.0000 - val_fn: 11.0000 - val_accuracy: 0.9819 - val_precision: 0.0814 - val_recall: 0.8675 - val_auc: 0.9739\nEpoch 8/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.2880 - tp: 260.0000 - fp: 6669.0000 - tn: 175303.0000 - fn: 44.0000 - accuracy: 0.9632 - precision: 0.0375 - recall: 0.8553 - auc: 0.9530 - val_loss: 0.2122 - val_tp: 72.0000 - val_fp: 783.0000 - val_tn: 44703.0000 - val_fn: 11.0000 - val_accuracy: 0.9826 - val_precision: 0.0842 - val_recall: 0.8675 - val_auc: 0.9769\nEpoch 9/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.2676 - tp: 262.0000 - fp: 6904.0000 - tn: 175068.0000 - fn: 42.0000 - accuracy: 0.9619 - precision: 0.0366 - recall: 0.8618 - auc: 0.9594 - val_loss: 0.2056 - val_tp: 72.0000 - val_fp: 855.0000 - val_tn: 44631.0000 - val_fn: 11.0000 - val_accuracy: 0.9810 - val_precision: 0.0777 - val_recall: 0.8675 - val_auc: 0.9750\nEpoch 10/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.2498 - tp: 266.0000 - fp: 6833.0000 - tn: 175139.0000 - fn: 38.0000 - accuracy: 0.9623 - precision: 0.0375 - recall: 0.8750 - auc: 0.9593 - val_loss: 0.2001 - val_tp: 73.0000 - val_fp: 840.0000 - val_tn: 44646.0000 - val_fn: 10.0000 - val_accuracy: 0.9813 - val_precision: 0.0800 - val_recall: 0.8795 - val_auc: 0.9761\nEpoch 11/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.2681 - tp: 262.0000 - fp: 6845.0000 - tn: 175127.0000 - fn: 42.0000 - accuracy: 0.9622 - precision: 0.0369 - recall: 0.8618 - auc: 0.9559 - val_loss: 0.1964 - val_tp: 73.0000 - val_fp: 865.0000 - val_tn: 44621.0000 - val_fn: 10.0000 - val_accuracy: 0.9808 - val_precision: 0.0778 - val_recall: 0.8795 - val_auc: 0.9768\nEpoch 12/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.2406 - tp: 268.0000 - fp: 7070.0000 - tn: 174902.0000 - fn: 36.0000 - accuracy: 0.9610 - precision: 0.0365 - recall: 0.8816 - auc: 0.9646 - val_loss: 0.1940 - val_tp: 73.0000 - val_fp: 848.0000 - val_tn: 44638.0000 - val_fn: 10.0000 - val_accuracy: 0.9812 - val_precision: 0.0793 - val_recall: 0.8795 - val_auc: 0.9771\nEpoch 13/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.2285 - tp: 269.0000 - fp: 6976.0000 - tn: 174996.0000 - fn: 35.0000 - accuracy: 0.9615 - precision: 0.0371 - recall: 0.8849 - auc: 0.9680 - val_loss: 0.1930 - val_tp: 73.0000 - val_fp: 857.0000 - val_tn: 44629.0000 - val_fn: 10.0000 - val_accuracy: 0.9810 - val_precision: 0.0785 - val_recall: 0.8795 - val_auc: 0.9772\nEpoch 14/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.2322 - tp: 268.0000 - fp: 6718.0000 - tn: 175254.0000 - fn: 36.0000 - accuracy: 0.9629 - precision: 0.0384 - recall: 0.8816 - auc: 0.9644 - val_loss: 0.1915 - val_tp: 73.0000 - val_fp: 808.0000 - val_tn: 44678.0000 - val_fn: 10.0000 - val_accuracy: 0.9820 - val_precision: 0.0829 - val_recall: 0.8795 - val_auc: 0.9781\nEpoch 15/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.2631 - tp: 267.0000 - fp: 6578.0000 - tn: 175394.0000 - fn: 37.0000 - accuracy: 0.9637 - precision: 0.0390 - recall: 0.8783 - auc: 0.9551 - val_loss: 0.1900 - val_tp: 73.0000 - val_fp: 803.0000 - val_tn: 44683.0000 - val_fn: 10.0000 - val_accuracy: 0.9822 - val_precision: 0.0833 - val_recall: 0.8795 - val_auc: 0.9781\nEpoch 16/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.2314 - tp: 266.0000 - fp: 6644.0000 - tn: 175328.0000 - fn: 38.0000 - accuracy: 0.9633 - precision: 0.0385 - recall: 0.8750 - auc: 0.9672 - val_loss: 0.1882 - val_tp: 73.0000 - val_fp: 806.0000 - val_tn: 44680.0000 - val_fn: 10.0000 - val_accuracy: 0.9821 - val_precision: 0.0830 - val_recall: 0.8795 - val_auc: 0.9784\nEpoch 17/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.2152 - tp: 271.0000 - fp: 6663.0000 - tn: 175309.0000 - fn: 33.0000 - accuracy: 0.9633 - precision: 0.0391 - recall: 0.8914 - auc: 0.9687 - val_loss: 0.1895 - val_tp: 73.0000 - val_fp: 754.0000 - val_tn: 44732.0000 - val_fn: 10.0000 - val_accuracy: 0.9832 - val_precision: 0.0883 - val_recall: 0.8795 - val_auc: 0.9785\nEpoch 18/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.2420 - tp: 264.0000 - fp: 6535.0000 - tn: 175437.0000 - fn: 40.0000 - accuracy: 0.9639 - precision: 0.0388 - recall: 0.8684 - auc: 0.9610 - val_loss: 0.1895 - val_tp: 73.0000 - val_fp: 749.0000 - val_tn: 44737.0000 - val_fn: 10.0000 - val_accuracy: 0.9833 - val_precision: 0.0888 - val_recall: 0.8795 - val_auc: 0.9786\nEpoch 19/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.2279 - tp: 268.0000 - fp: 6443.0000 - tn: 175529.0000 - fn: 36.0000 - accuracy: 0.9645 - precision: 0.0399 - recall: 0.8816 - auc: 0.9672 - val_loss: 0.1895 - val_tp: 73.0000 - val_fp: 763.0000 - val_tn: 44723.0000 - val_fn: 10.0000 - val_accuracy: 0.9830 - val_precision: 0.0873 - val_recall: 0.8795 - val_auc: 0.9788\nEpoch 20/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.2247 - tp: 267.0000 - fp: 6596.0000 - tn: 175376.0000 - fn: 37.0000 - accuracy: 0.9636 - precision: 0.0389 - recall: 0.8783 - auc: 0.9684 - val_loss: 0.1896 - val_tp: 73.0000 - val_fp: 760.0000 - val_tn: 44726.0000 - val_fn: 10.0000 - val_accuracy: 0.9831 - val_precision: 0.0876 - val_recall: 0.8795 - val_auc: 0.9797\nEpoch 21/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.2296 - tp: 269.0000 - fp: 6562.0000 - tn: 175410.0000 - fn: 35.0000 - accuracy: 0.9638 - precision: 0.0394 - recall: 0.8849 - auc: 0.9656 - val_loss: 0.1889 - val_tp: 73.0000 - val_fp: 750.0000 - val_tn: 44736.0000 - val_fn: 10.0000 - val_accuracy: 0.9833 - val_precision: 0.0887 - val_recall: 0.8795 - val_auc: 0.9797\nEpoch 22/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.1982 - tp: 271.0000 - fp: 6583.0000 - tn: 175389.0000 - fn: 33.0000 - accuracy: 0.9637 - precision: 0.0395 - recall: 0.8914 - auc: 0.9756 - val_loss: 0.1879 - val_tp: 73.0000 - val_fp: 764.0000 - val_tn: 44722.0000 - val_fn: 10.0000 - val_accuracy: 0.9830 - val_precision: 0.0872 - val_recall: 0.8795 - val_auc: 0.9777\nEpoch 23/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.2154 - tp: 273.0000 - fp: 6552.0000 - tn: 175420.0000 - fn: 31.0000 - accuracy: 0.9639 - precision: 0.0400 - recall: 0.8980 - auc: 0.9682 - val_loss: 0.1882 - val_tp: 73.0000 - val_fp: 762.0000 - val_tn: 44724.0000 - val_fn: 10.0000 - val_accuracy: 0.9831 - val_precision: 0.0874 - val_recall: 0.8795 - val_auc: 0.9779\nEpoch 24/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.1861 - tp: 272.0000 - fp: 6248.0000 - tn: 175724.0000 - fn: 32.0000 - accuracy: 0.9655 - precision: 0.0417 - recall: 0.8947 - auc: 0.9779 - val_loss: 0.1885 - val_tp: 73.0000 - val_fp: 772.0000 - val_tn: 44714.0000 - val_fn: 10.0000 - val_accuracy: 0.9828 - val_precision: 0.0864 - val_recall: 0.8795 - val_auc: 0.9785\nEpoch 25/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.1953 - tp: 270.0000 - fp: 6501.0000 - tn: 175471.0000 - fn: 34.0000 - accuracy: 0.9641 - precision: 0.0399 - recall: 0.8882 - auc: 0.9751 - val_loss: 0.1877 - val_tp: 73.0000 - val_fp: 768.0000 - val_tn: 44718.0000 - val_fn: 10.0000 - val_accuracy: 0.9829 - val_precision: 0.0868 - val_recall: 0.8795 - val_auc: 0.9786\nEpoch 26/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.1704 - tp: 277.0000 - fp: 6215.0000 - tn: 175757.0000 - fn: 27.0000 - accuracy: 0.9658 - precision: 0.0427 - recall: 0.9112 - auc: 0.9808 - val_loss: 0.1903 - val_tp: 73.0000 - val_fp: 698.0000 - val_tn: 44788.0000 - val_fn: 10.0000 - val_accuracy: 0.9845 - val_precision: 0.0947 - val_recall: 0.8795 - val_auc: 0.9788\nEpoch 27/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.1946 - tp: 271.0000 - fp: 6036.0000 - tn: 175936.0000 - fn: 33.0000 - accuracy: 0.9667 - precision: 0.0430 - recall: 0.8914 - auc: 0.9748 - val_loss: 0.1908 - val_tp: 73.0000 - val_fp: 692.0000 - val_tn: 44794.0000 - val_fn: 10.0000 - val_accuracy: 0.9846 - val_precision: 0.0954 - val_recall: 0.8795 - val_auc: 0.9786\nEpoch 28/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.2115 - tp: 271.0000 - fp: 5873.0000 - tn: 176099.0000 - fn: 33.0000 - accuracy: 0.9676 - precision: 0.0441 - recall: 0.8914 - auc: 0.9688 - val_loss: 0.1914 - val_tp: 73.0000 - val_fp: 691.0000 - val_tn: 44795.0000 - val_fn: 10.0000 - val_accuracy: 0.9846 - val_precision: 0.0955 - val_recall: 0.8795 - val_auc: 0.9785\nEpoch 29/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.2237 - tp: 266.0000 - fp: 6047.0000 - tn: 175925.0000 - fn: 38.0000 - accuracy: 0.9666 - precision: 0.0421 - recall: 0.8750 - auc: 0.9672 - val_loss: 0.1909 - val_tp: 73.0000 - val_fp: 698.0000 - val_tn: 44788.0000 - val_fn: 10.0000 - val_accuracy: 0.9845 - val_precision: 0.0947 - val_recall: 0.8795 - val_auc: 0.9784\nEpoch 30/100\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.2232 - tp: 272.0000 - fp: 5990.0000 - tn: 175982.0000 - fn: 32.0000 - accuracy: 0.9670 - precision: 0.0434 - recall: 0.8947 - auc: 0.9668 - val_loss: 0.1919 - val_tp: 73.0000 - val_fp: 642.0000 - val_tn: 44844.0000 - val_fn: 10.0000 - val_accuracy: 0.9857 - val_precision: 0.1021 - val_recall: 0.8795 - val_auc: 0.9785\nEpoch 31/100\n178176/182276 [============================>.] - ETA: 0s - loss: 0.2022 - tp: 273.0000 - fp: 5659.0000 - tn: 172216.0000 - fn: 28.0000 - accuracy: 0.9681 - precision: 0.0460 - recall: 0.9070 - auc: 0.9705Restoring model weights from the end of the best epoch.\n182276/182276 [==============================] - 1s 4us/sample - loss: 0.1989 - tp: 276.0000 - fp: 5796.0000 - tn: 176176.0000 - fn: 28.0000 - accuracy: 0.9680 - precision: 0.0455 - recall: 0.9079 - auc: 0.9708 - val_loss: 0.1920 - val_tp: 73.0000 - val_fp: 626.0000 - val_tn: 44860.0000 - val_fn: 10.0000 - val_accuracy: 0.9860 - val_precision: 0.1044 - val_recall: 0.8795 - val_auc: 0.9788\nEpoch 00031: early stopping\n"
]
],
[
[
"### Check training history",
"_____no_output_____"
]
],
[
[
"plot_metrics(weighted_history)",
"_____no_output_____"
]
],
[
[
"### Evaluate metrics",
"_____no_output_____"
]
],
[
[
"# TODO 1\ntrain_predictions_weighted = #TODO: Your code goes here.\ntest_predictions_weighted = #TODO: Your code goes here.",
"_____no_output_____"
],
[
"weighted_results = weighted_model.evaluate(test_features, test_labels,\n batch_size=BATCH_SIZE, verbose=0)\nfor name, value in zip(weighted_model.metrics_names, weighted_results):\n print(name, ': ', value)\nprint()\n\nplot_cm(test_labels, test_predictions_weighted)",
"loss : 0.06950428275801711\ntp : 94.0\nfp : 905.0\ntn : 55952.0\nfn : 11.0\naccuracy : 0.9839191\nprecision : 0.0940941\nrecall : 0.8952381\nauc : 0.9844724\n\nLegitimate Transactions Detected (True Negatives): 55952\nLegitimate Transactions Incorrectly Detected (False Positives): 905\nFraudulent Transactions Missed (False Negatives): 11\nFraudulent Transactions Detected (True Positives): 94\nTotal Fraudulent Transactions: 105\n"
]
],
[
[
"Here you can see that with class weights the accuracy and precision are lower because there are more false positives, but conversely the recall and AUC are higher because the model also found more true positives. Despite having lower accuracy, this model has higher recall (and identifies more fraudulent transactions). Of course, there is a cost to both types of error (you wouldn't want to bug users by flagging too many legitimate transactions as fraudulent, either). Carefully consider the trade offs between these different types of errors for your application.",
"_____no_output_____"
],
[
"### Plot the ROC",
"_____no_output_____"
]
],
[
[
"plot_roc(\"Train Baseline\", train_labels, train_predictions_baseline, color=colors[0])\nplot_roc(\"Test Baseline\", test_labels, test_predictions_baseline, color=colors[0], linestyle='--')\n\nplot_roc(\"Train Weighted\", train_labels, train_predictions_weighted, color=colors[1])\nplot_roc(\"Test Weighted\", test_labels, test_predictions_weighted, color=colors[1], linestyle='--')\n\n\nplt.legend(loc='lower right')",
"_____no_output_____"
]
],
[
[
"## Oversampling",
"_____no_output_____"
],
[
"### Oversample the minority class\n\nA related approach would be to resample the dataset by oversampling the minority class.",
"_____no_output_____"
]
],
[
[
"# TODO 1\npos_features = #TODO: Your code goes here.\nneg_features = train_features[~bool_train_labels]\n\npos_labels = #TODO: Your code goes here.\nneg_labels = #TODO: Your code goes here.",
"_____no_output_____"
]
],
[
[
"#### Using NumPy\n\nYou can balance the dataset manually by choosing the right number of random \nindices from the positive examples:",
"_____no_output_____"
]
],
[
[
"ids = np.arange(len(pos_features))\nchoices = np.random.choice(ids, len(neg_features))\n\nres_pos_features = pos_features[choices]\nres_pos_labels = pos_labels[choices]\n\nres_pos_features.shape",
"_____no_output_____"
],
[
"resampled_features = np.concatenate([res_pos_features, neg_features], axis=0)\nresampled_labels = np.concatenate([res_pos_labels, neg_labels], axis=0)\n\norder = np.arange(len(resampled_labels))\nnp.random.shuffle(order)\nresampled_features = resampled_features[order]\nresampled_labels = resampled_labels[order]\n\nresampled_features.shape",
"_____no_output_____"
]
],
[
[
"#### Using `tf.data`",
"_____no_output_____"
],
[
"If you're using `tf.data` the easiest way to produce balanced examples is to start with a `positive` and a `negative` dataset, and merge them. See [the tf.data guide](../../guide/data.ipynb) for more examples.",
"_____no_output_____"
]
],
[
[
"BUFFER_SIZE = 100000\n\ndef make_ds(features, labels):\n ds = tf.data.Dataset.from_tensor_slices((features, labels))#.cache()\n ds = ds.shuffle(BUFFER_SIZE).repeat()\n return ds\n\npos_ds = make_ds(pos_features, pos_labels)\nneg_ds = make_ds(neg_features, neg_labels)",
"_____no_output_____"
]
],
[
[
"Each dataset provides `(feature, label)` pairs:",
"_____no_output_____"
]
],
[
[
"for features, label in pos_ds.take(1):\n print(\"Features:\\n\", features.numpy())\n print()\n print(\"Label: \", label.numpy())",
"Features:\n [-2.46955933 3.42534191 -4.42937043 3.70651659 -3.17895499 -1.30458304\n -5. 2.86676917 -4.9308611 -5. 3.58555137 -5.\n 1.51535494 -5. 0.01049775 -5. -5. -5.\n 2.02380731 0.36595419 1.61836304 -1.16743779 0.31324117 -0.35515978\n -0.62579636 -0.55952005 0.51255883 1.15454727 0.87478003]\n\nLabel: 1\n"
]
],
[
[
"Merge the two together using `experimental.sample_from_datasets`:",
"_____no_output_____"
]
],
[
[
"resampled_ds = tf.data.experimental.sample_from_datasets([pos_ds, neg_ds], weights=[0.5, 0.5])\nresampled_ds = resampled_ds.batch(BATCH_SIZE).prefetch(2)",
"_____no_output_____"
],
[
"for features, label in resampled_ds.take(1):\n print(label.numpy().mean())",
"0.48974609375\n"
]
],
[
[
"To use this dataset, you'll need the number of steps per epoch.\n\nThe definition of \"epoch\" in this case is less clear. Say it's the number of batches required to see each negative example once:",
"_____no_output_____"
]
],
[
[
"resampled_steps_per_epoch = np.ceil(2.0*neg/BATCH_SIZE)\nresampled_steps_per_epoch",
"_____no_output_____"
]
],
[
[
"### Train on the oversampled data\n\nNow try training the model with the resampled data set instead of using class weights to see how these methods compare.\n\nNote: Because the data was balanced by replicating the positive examples, the total dataset size is larger, and each epoch runs for more training steps. ",
"_____no_output_____"
]
],
[
[
"resampled_model = make_model()\nresampled_model.load_weights(initial_weights)\n\n# Reset the bias to zero, since this dataset is balanced.\noutput_layer = resampled_model.layers[-1] \noutput_layer.bias.assign([0])\n\nval_ds = tf.data.Dataset.from_tensor_slices((val_features, val_labels)).cache()\nval_ds = val_ds.batch(BATCH_SIZE).prefetch(2) \n\nresampled_history = resampled_model.fit(\n resampled_ds,\n epochs=EPOCHS,\n steps_per_epoch=resampled_steps_per_epoch,\n callbacks = [early_stopping],\n validation_data=val_ds)",
"Train for 278.0 steps, validate for 23 steps\nEpoch 1/100\n278/278 [==============================] - 13s 48ms/step - loss: 0.4624 - tp: 267186.0000 - fp: 124224.0000 - tn: 160439.0000 - fn: 17495.0000 - accuracy: 0.7511 - precision: 0.6826 - recall: 0.9385 - auc: 0.9268 - val_loss: 0.3299 - val_tp: 79.0000 - val_fp: 2825.0000 - val_tn: 42661.0000 - val_fn: 4.0000 - val_accuracy: 0.9379 - val_precision: 0.0272 - val_recall: 0.9518 - val_auc: 0.9799\nEpoch 2/100\n278/278 [==============================] - 11s 39ms/step - loss: 0.2362 - tp: 264077.0000 - fp: 26654.0000 - tn: 257570.0000 - fn: 21043.0000 - accuracy: 0.9162 - precision: 0.9083 - recall: 0.9262 - auc: 0.9708 - val_loss: 0.1926 - val_tp: 75.0000 - val_fp: 1187.0000 - val_tn: 44299.0000 - val_fn: 8.0000 - val_accuracy: 0.9738 - val_precision: 0.0594 - val_recall: 0.9036 - val_auc: 0.9779\nEpoch 3/100\n278/278 [==============================] - 11s 40ms/step - loss: 0.1887 - tp: 263490.0000 - fp: 12935.0000 - tn: 271381.0000 - fn: 21538.0000 - accuracy: 0.9395 - precision: 0.9532 - recall: 0.9244 - auc: 0.9804 - val_loss: 0.1373 - val_tp: 75.0000 - val_fp: 1064.0000 - val_tn: 44422.0000 - val_fn: 8.0000 - val_accuracy: 0.9765 - val_precision: 0.0658 - val_recall: 0.9036 - val_auc: 0.9778\nEpoch 4/100\n278/278 [==============================] - 11s 41ms/step - loss: 0.1605 - tp: 263933.0000 - fp: 10513.0000 - tn: 274505.0000 - fn: 20393.0000 - accuracy: 0.9457 - precision: 0.9617 - recall: 0.9283 - auc: 0.9866 - val_loss: 0.1078 - val_tp: 75.0000 - val_fp: 1070.0000 - val_tn: 44416.0000 - val_fn: 8.0000 - val_accuracy: 0.9763 - val_precision: 0.0655 - val_recall: 0.9036 - val_auc: 0.9783\nEpoch 5/100\n278/278 [==============================] - 11s 39ms/step - loss: 0.1423 - tp: 265715.0000 - fp: 9592.0000 - tn: 275145.0000 - fn: 18892.0000 - accuracy: 0.9500 - precision: 0.9652 - recall: 0.9336 - auc: 0.9901 - val_loss: 0.0928 - val_tp: 75.0000 - val_fp: 1051.0000 - val_tn: 44435.0000 - val_fn: 8.0000 - val_accuracy: 0.9768 - val_precision: 0.0666 - val_recall: 0.9036 - val_auc: 0.9762\nEpoch 6/100\n278/278 [==============================] - 11s 40ms/step - loss: 0.1297 - tp: 267181.0000 - fp: 8944.0000 - tn: 275445.0000 - fn: 17774.0000 - accuracy: 0.9531 - precision: 0.9676 - recall: 0.9376 - auc: 0.9920 - val_loss: 0.0847 - val_tp: 75.0000 - val_fp: 1077.0000 - val_tn: 44409.0000 - val_fn: 8.0000 - val_accuracy: 0.9762 - val_precision: 0.0651 - val_recall: 0.9036 - val_auc: 0.9748\nEpoch 7/100\n278/278 [==============================] - 11s 39ms/step - loss: 0.1203 - tp: 267440.0000 - fp: 8606.0000 - tn: 276459.0000 - fn: 16839.0000 - accuracy: 0.9553 - precision: 0.9688 - recall: 0.9408 - auc: 0.9933 - val_loss: 0.0775 - val_tp: 75.0000 - val_fp: 1003.0000 - val_tn: 44483.0000 - val_fn: 8.0000 - val_accuracy: 0.9778 - val_precision: 0.0696 - val_recall: 0.9036 - val_auc: 0.9742\nEpoch 8/100\n278/278 [==============================] - 11s 40ms/step - loss: 0.1132 - tp: 268799.0000 - fp: 8165.0000 - tn: 276260.0000 - fn: 16120.0000 - accuracy: 0.9573 - precision: 0.9705 - recall: 0.9434 - auc: 0.9941 - val_loss: 0.0716 - val_tp: 75.0000 - val_fp: 927.0000 - val_tn: 44559.0000 - val_fn: 8.0000 - val_accuracy: 0.9795 - val_precision: 0.0749 - val_recall: 0.9036 - val_auc: 0.9713\nEpoch 9/100\n278/278 [==============================] - 11s 40ms/step - loss: 0.1074 - tp: 269627.0000 - fp: 7971.0000 - tn: 276559.0000 - fn: 15187.0000 - accuracy: 0.9593 - precision: 0.9713 - recall: 0.9467 - auc: 0.9947 - val_loss: 0.0670 - val_tp: 75.0000 - val_fp: 880.0000 - val_tn: 44606.0000 - val_fn: 8.0000 - val_accuracy: 0.9805 - val_precision: 0.0785 - val_recall: 0.9036 - val_auc: 0.9713\nEpoch 10/100\n278/278 [==============================] - 11s 39ms/step - loss: 0.1017 - tp: 270359.0000 - fp: 7590.0000 - tn: 277311.0000 - fn: 14084.0000 - accuracy: 0.9619 - precision: 0.9727 - recall: 0.9505 - auc: 0.9952 - val_loss: 0.0629 - val_tp: 75.0000 - val_fp: 848.0000 - val_tn: 44638.0000 - val_fn: 8.0000 - val_accuracy: 0.9812 - val_precision: 0.0813 - val_recall: 0.9036 - val_auc: 0.9717\nEpoch 11/100\n276/278 [============================>.] - ETA: 0s - loss: 0.0977 - tp: 269672.0000 - fp: 7408.0000 - tn: 274621.0000 - fn: 13547.0000 - accuracy: 0.9629 - precision: 0.9733 - recall: 0.9522 - auc: 0.9955Restoring model weights from the end of the best epoch.\n278/278 [==============================] - 11s 39ms/step - loss: 0.0978 - tp: 271609.0000 - fp: 7474.0000 - tn: 276625.0000 - fn: 13636.0000 - accuracy: 0.9629 - precision: 0.9732 - recall: 0.9522 - auc: 0.9955 - val_loss: 0.0615 - val_tp: 75.0000 - val_fp: 841.0000 - val_tn: 44645.0000 - val_fn: 8.0000 - val_accuracy: 0.9814 - val_precision: 0.0819 - val_recall: 0.9036 - val_auc: 0.9637\nEpoch 00011: early stopping\n"
]
],
[
[
"If the training process were considering the whole dataset on each gradient update, this oversampling would be basically identical to the class weighting.\n\nBut when training the model batch-wise, as you did here, the oversampled data provides a smoother gradient signal: Instead of each positive example being shown in one batch with a large weight, they're shown in many different batches each time with a small weight. \n\nThis smoother gradient signal makes it easier to train the model.",
"_____no_output_____"
],
[
"### Check training history\n\nNote that the distributions of metrics will be different here, because the training data has a totally different distribution from the validation and test data. ",
"_____no_output_____"
]
],
[
[
"plot_metrics(resampled_history )",
"_____no_output_____"
]
],
[
[
"### Re-train\n",
"_____no_output_____"
],
[
"Because training is easier on the balanced data, the above training procedure may overfit quickly. \n\nSo break up the epochs to give the `callbacks.EarlyStopping` finer control over when to stop training.",
"_____no_output_____"
]
],
[
[
"resampled_model = make_model()\nresampled_model.load_weights(initial_weights)\n\n# Reset the bias to zero, since this dataset is balanced.\noutput_layer = resampled_model.layers[-1] \noutput_layer.bias.assign([0])\n\nresampled_history = resampled_model.fit(\n resampled_ds,\n # These are not real epochs\n steps_per_epoch = 20,\n epochs=10*EPOCHS,\n callbacks = [early_stopping],\n validation_data=(val_ds))",
"Train for 20 steps, validate for 23 steps\nEpoch 1/1000\n20/20 [==============================] - 4s 181ms/step - loss: 0.8800 - tp: 18783.0000 - fp: 16378.0000 - tn: 4036.0000 - fn: 1763.0000 - accuracy: 0.5571 - precision: 0.5342 - recall: 0.9142 - auc: 0.7752 - val_loss: 1.3661 - val_tp: 83.0000 - val_fp: 40065.0000 - val_tn: 5421.0000 - val_fn: 0.0000e+00 - val_accuracy: 0.1208 - val_precision: 0.0021 - val_recall: 1.0000 - val_auc: 0.9425\nEpoch 2/1000\n20/20 [==============================] - 1s 35ms/step - loss: 0.7378 - tp: 19613.0000 - fp: 15282.0000 - tn: 5187.0000 - fn: 878.0000 - accuracy: 0.6055 - precision: 0.5621 - recall: 0.9572 - auc: 0.8680 - val_loss: 1.1629 - val_tp: 83.0000 - val_fp: 36851.0000 - val_tn: 8635.0000 - val_fn: 0.0000e+00 - val_accuracy: 0.1913 - val_precision: 0.0022 - val_recall: 1.0000 - val_auc: 0.9580\nEpoch 3/1000\n20/20 [==============================] - 1s 39ms/step - loss: 0.6431 - tp: 19522.0000 - fp: 13990.0000 - tn: 6558.0000 - fn: 890.0000 - accuracy: 0.6367 - precision: 0.5825 - recall: 0.9564 - auc: 0.8950 - val_loss: 0.9853 - val_tp: 82.0000 - val_fp: 32268.0000 - val_tn: 13218.0000 - val_fn: 1.0000 - val_accuracy: 0.2919 - val_precision: 0.0025 - val_recall: 0.9880 - val_auc: 0.9660\nEpoch 4/1000\n20/20 [==============================] - 1s 39ms/step - loss: 0.5563 - tp: 19488.0000 - fp: 12475.0000 - tn: 8032.0000 - fn: 965.0000 - accuracy: 0.6719 - precision: 0.6097 - recall: 0.9528 - auc: 0.9135 - val_loss: 0.8430 - val_tp: 82.0000 - val_fp: 26633.0000 - val_tn: 18853.0000 - val_fn: 1.0000 - val_accuracy: 0.4155 - val_precision: 0.0031 - val_recall: 0.9880 - val_auc: 0.9713\nEpoch 5/1000\n20/20 [==============================] - 1s 37ms/step - loss: 0.4984 - tp: 19489.0000 - fp: 11049.0000 - tn: 9377.0000 - fn: 1045.0000 - accuracy: 0.7047 - precision: 0.6382 - recall: 0.9491 - auc: 0.9242 - val_loss: 0.7307 - val_tp: 82.0000 - val_fp: 20850.0000 - val_tn: 24636.0000 - val_fn: 1.0000 - val_accuracy: 0.5424 - val_precision: 0.0039 - val_recall: 0.9880 - val_auc: 0.9753\nEpoch 6/1000\n20/20 [==============================] - 1s 39ms/step - loss: 0.4463 - tp: 19305.0000 - fp: 9622.0000 - tn: 10895.0000 - fn: 1138.0000 - accuracy: 0.7373 - precision: 0.6674 - recall: 0.9443 - auc: 0.9336 - val_loss: 0.6405 - val_tp: 82.0000 - val_fp: 15843.0000 - val_tn: 29643.0000 - val_fn: 1.0000 - val_accuracy: 0.6523 - val_precision: 0.0051 - val_recall: 0.9880 - val_auc: 0.9773\nEpoch 7/1000\n20/20 [==============================] - 1s 40ms/step - loss: 0.4121 - tp: 19365.0000 - fp: 8524.0000 - tn: 11931.0000 - fn: 1140.0000 - accuracy: 0.7641 - precision: 0.6944 - recall: 0.9444 - auc: 0.9411 - val_loss: 0.5691 - val_tp: 82.0000 - val_fp: 11981.0000 - val_tn: 33505.0000 - val_fn: 1.0000 - val_accuracy: 0.7371 - val_precision: 0.0068 - val_recall: 0.9880 - val_auc: 0.9787\nEpoch 8/1000\n20/20 [==============================] - 1s 39ms/step - loss: 0.3784 - tp: 19242.0000 - fp: 7375.0000 - tn: 13072.0000 - fn: 1271.0000 - accuracy: 0.7889 - precision: 0.7229 - recall: 0.9380 - auc: 0.9461 - val_loss: 0.5120 - val_tp: 80.0000 - val_fp: 9309.0000 - val_tn: 36177.0000 - val_fn: 3.0000 - val_accuracy: 0.7957 - val_precision: 0.0085 - val_recall: 0.9639 - val_auc: 0.9794\nEpoch 9/1000\n20/20 [==============================] - 1s 45ms/step - loss: 0.3551 - tp: 19106.0000 - fp: 6529.0000 - tn: 13989.0000 - fn: 1336.0000 - accuracy: 0.8080 - precision: 0.7453 - recall: 0.9346 - auc: 0.9495 - val_loss: 0.4657 - val_tp: 80.0000 - val_fp: 7354.0000 - val_tn: 38132.0000 - val_fn: 3.0000 - val_accuracy: 0.8386 - val_precision: 0.0108 - val_recall: 0.9639 - val_auc: 0.9799\nEpoch 10/1000\n20/20 [==============================] - 1s 38ms/step - loss: 0.3350 - tp: 19149.0000 - fp: 5794.0000 - tn: 14698.0000 - fn: 1319.0000 - accuracy: 0.8263 - precision: 0.7677 - recall: 0.9356 - auc: 0.9535 - val_loss: 0.4275 - val_tp: 80.0000 - val_fp: 5832.0000 - val_tn: 39654.0000 - val_fn: 3.0000 - val_accuracy: 0.8720 - val_precision: 0.0135 - val_recall: 0.9639 - val_auc: 0.9802\nEpoch 11/1000\n20/20 [==============================] - 1s 40ms/step - loss: 0.3168 - tp: 19224.0000 - fp: 5013.0000 - tn: 15322.0000 - fn: 1401.0000 - accuracy: 0.8434 - precision: 0.7932 - recall: 0.9321 - auc: 0.9552 - val_loss: 0.3969 - val_tp: 80.0000 - val_fp: 4730.0000 - val_tn: 40756.0000 - val_fn: 3.0000 - val_accuracy: 0.8961 - val_precision: 0.0166 - val_recall: 0.9639 - val_auc: 0.9805\nEpoch 12/1000\n20/20 [==============================] - 1s 40ms/step - loss: 0.3077 - tp: 19028.0000 - fp: 4564.0000 - tn: 16058.0000 - fn: 1310.0000 - accuracy: 0.8566 - precision: 0.8065 - recall: 0.9356 - auc: 0.9593 - val_loss: 0.3695 - val_tp: 80.0000 - val_fp: 3819.0000 - val_tn: 41667.0000 - val_fn: 3.0000 - val_accuracy: 0.9161 - val_precision: 0.0205 - val_recall: 0.9639 - val_auc: 0.9804\nEpoch 13/1000\n20/20 [==============================] - 1s 40ms/step - loss: 0.2936 - tp: 19047.0000 - fp: 4028.0000 - tn: 16444.0000 - fn: 1441.0000 - accuracy: 0.8665 - precision: 0.8254 - recall: 0.9297 - auc: 0.9597 - val_loss: 0.3461 - val_tp: 79.0000 - val_fp: 3149.0000 - val_tn: 42337.0000 - val_fn: 4.0000 - val_accuracy: 0.9308 - val_precision: 0.0245 - val_recall: 0.9518 - val_auc: 0.9802\nEpoch 14/1000\n20/20 [==============================] - 1s 38ms/step - loss: 0.2829 - tp: 19087.0000 - fp: 3596.0000 - tn: 16855.0000 - fn: 1422.0000 - accuracy: 0.8775 - precision: 0.8415 - recall: 0.9307 - auc: 0.9619 - val_loss: 0.3266 - val_tp: 79.0000 - val_fp: 2691.0000 - val_tn: 42795.0000 - val_fn: 4.0000 - val_accuracy: 0.9409 - val_precision: 0.0285 - val_recall: 0.9518 - val_auc: 0.9803\nEpoch 15/1000\n20/20 [==============================] - 1s 39ms/step - loss: 0.2748 - tp: 19020.0000 - fp: 3174.0000 - tn: 17283.0000 - fn: 1483.0000 - accuracy: 0.8863 - precision: 0.8570 - recall: 0.9277 - auc: 0.9627 - val_loss: 0.3095 - val_tp: 79.0000 - val_fp: 2360.0000 - val_tn: 43126.0000 - val_fn: 4.0000 - val_accuracy: 0.9481 - val_precision: 0.0324 - val_recall: 0.9518 - val_auc: 0.9797\nEpoch 16/1000\n20/20 [==============================] - 1s 40ms/step - loss: 0.2666 - tp: 18890.0000 - fp: 2889.0000 - tn: 17757.0000 - fn: 1424.0000 - accuracy: 0.8947 - precision: 0.8673 - recall: 0.9299 - auc: 0.9653 - val_loss: 0.2945 - val_tp: 78.0000 - val_fp: 2101.0000 - val_tn: 43385.0000 - val_fn: 5.0000 - val_accuracy: 0.9538 - val_precision: 0.0358 - val_recall: 0.9398 - val_auc: 0.9796\nEpoch 17/1000\n20/20 [==============================] - 1s 38ms/step - loss: 0.2583 - tp: 18959.0000 - fp: 2517.0000 - tn: 17973.0000 - fn: 1511.0000 - accuracy: 0.9017 - precision: 0.8828 - recall: 0.9262 - auc: 0.9657 - val_loss: 0.2817 - val_tp: 78.0000 - val_fp: 1929.0000 - val_tn: 43557.0000 - val_fn: 5.0000 - val_accuracy: 0.9576 - val_precision: 0.0389 - val_recall: 0.9398 - val_auc: 0.9794\nEpoch 18/1000\n20/20 [==============================] - 1s 46ms/step - loss: 0.2511 - tp: 19104.0000 - fp: 2344.0000 - tn: 18043.0000 - fn: 1469.0000 - accuracy: 0.9069 - precision: 0.8907 - recall: 0.9286 - auc: 0.9678 - val_loss: 0.2704 - val_tp: 78.0000 - val_fp: 1787.0000 - val_tn: 43699.0000 - val_fn: 5.0000 - val_accuracy: 0.9607 - val_precision: 0.0418 - val_recall: 0.9398 - val_auc: 0.9793\nEpoch 19/1000\n20/20 [==============================] - 1s 40ms/step - loss: 0.2445 - tp: 19183.0000 - fp: 2087.0000 - tn: 18215.0000 - fn: 1475.0000 - accuracy: 0.9130 - precision: 0.9019 - recall: 0.9286 - auc: 0.9693 - val_loss: 0.2598 - val_tp: 78.0000 - val_fp: 1665.0000 - val_tn: 43821.0000 - val_fn: 5.0000 - val_accuracy: 0.9634 - val_precision: 0.0448 - val_recall: 0.9398 - val_auc: 0.9791\nEpoch 20/1000\n20/20 [==============================] - 1s 39ms/step - loss: 0.2373 - tp: 18995.0000 - fp: 1906.0000 - tn: 18602.0000 - fn: 1457.0000 - accuracy: 0.9179 - precision: 0.9088 - recall: 0.9288 - auc: 0.9712 - val_loss: 0.2500 - val_tp: 78.0000 - val_fp: 1587.0000 - val_tn: 43899.0000 - val_fn: 5.0000 - val_accuracy: 0.9651 - val_precision: 0.0468 - val_recall: 0.9398 - val_auc: 0.9788\nEpoch 21/1000\n19/20 [===========================>..] - ETA: 0s - loss: 0.2378 - tp: 18121.0000 - fp: 1821.0000 - tn: 17599.0000 - fn: 1371.0000 - accuracy: 0.9180 - precision: 0.9087 - recall: 0.9297 - auc: 0.9714Restoring model weights from the end of the best epoch.\n20/20 [==============================] - 1s 40ms/step - loss: 0.2376 - tp: 19083.0000 - fp: 1918.0000 - tn: 18513.0000 - fn: 1446.0000 - accuracy: 0.9179 - precision: 0.9087 - recall: 0.9296 - auc: 0.9714 - val_loss: 0.2401 - val_tp: 78.0000 - val_fp: 1485.0000 - val_tn: 44001.0000 - val_fn: 5.0000 - val_accuracy: 0.9673 - val_precision: 0.0499 - val_recall: 0.9398 - val_auc: 0.9785\nEpoch 00021: early stopping\n"
]
],
[
[
"### Re-check training history",
"_____no_output_____"
]
],
[
[
"plot_metrics(resampled_history)",
"_____no_output_____"
]
],
[
[
"### Evaluate metrics",
"_____no_output_____"
]
],
[
[
"# TODO 1\ntrain_predictions_resampled = #TODO: Your code goes here.\ntest_predictions_resampled = #TODO: Your code goes here.",
"_____no_output_____"
],
[
"resampled_results = resampled_model.evaluate(test_features, test_labels,\n batch_size=BATCH_SIZE, verbose=0)\nfor name, value in zip(resampled_model.metrics_names, resampled_results):\n print(name, ': ', value)\nprint()\n\nplot_cm(test_labels, test_predictions_resampled)",
"loss : 0.3960801533448772\ntp : 99.0\nfp : 5892.0\ntn : 50965.0\nfn : 6.0\naccuracy : 0.8964573\nprecision : 0.016524788\nrecall : 0.94285715\nauc : 0.9804354\n\nLegitimate Transactions Detected (True Negatives): 50965\nLegitimate Transactions Incorrectly Detected (False Positives): 5892\nFraudulent Transactions Missed (False Negatives): 6\nFraudulent Transactions Detected (True Positives): 99\nTotal Fraudulent Transactions: 105\n"
]
],
[
[
"### Plot the ROC",
"_____no_output_____"
]
],
[
[
"plot_roc(\"Train Baseline\", train_labels, train_predictions_baseline, color=colors[0])\nplot_roc(\"Test Baseline\", test_labels, test_predictions_baseline, color=colors[0], linestyle='--')\n\nplot_roc(\"Train Weighted\", train_labels, train_predictions_weighted, color=colors[1])\nplot_roc(\"Test Weighted\", test_labels, test_predictions_weighted, color=colors[1], linestyle='--')\n\nplot_roc(\"Train Resampled\", train_labels, train_predictions_resampled, color=colors[2])\nplot_roc(\"Test Resampled\", test_labels, test_predictions_resampled, color=colors[2], linestyle='--')\nplt.legend(loc='lower right')",
"_____no_output_____"
]
],
[
[
"## Applying this tutorial to your problem\n\nImbalanced data classification is an inherantly difficult task since there are so few samples to learn from. You should always start with the data first and do your best to collect as many samples as possible and give substantial thought to what features may be relevant so the model can get the most out of your minority class. At some point your model may struggle to improve and yield the results you want, so it is important to keep in mind the context of your problem and the trade offs between different types of errors.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
cb33ca2425f3eee2712833443ae8390fd34fe55e | 22,320 | ipynb | Jupyter Notebook | .ipynb_checkpoints/W207_Final_Project_Baseline_v1-checkpoint.ipynb | maynard242/Classification-Pizza | 4622688b027978c9edf97b7e18c4935e04ec7e28 | [
"MIT"
] | null | null | null | .ipynb_checkpoints/W207_Final_Project_Baseline_v1-checkpoint.ipynb | maynard242/Classification-Pizza | 4622688b027978c9edf97b7e18c4935e04ec7e28 | [
"MIT"
] | null | null | null | .ipynb_checkpoints/W207_Final_Project_Baseline_v1-checkpoint.ipynb | maynard242/Classification-Pizza | 4622688b027978c9edf97b7e18c4935e04ec7e28 | [
"MIT"
] | null | null | null | 38.615917 | 2,799 | 0.622267 | [
[
[
"# W207 Final Project\nErika, Jen Jen, Geoff, Leslie\n\n(In Python 3)",
"_____no_output_____"
],
[
"As of 3/35\n\nOutline:\n\n* Data Pre-Processing \n* Simple Feature Selection\n* Basline Models\n* Possible Approaches\n ",
"_____no_output_____"
],
[
"# Section 1 Loading and Processing Data",
"_____no_output_____"
]
],
[
[
"## Import Libraries ##\nimport json\nfrom pprint import pprint\nfrom pandas import *\nfrom pandas.io.json import json_normalize\n\n\n# General libraries.\nimport re\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n# SK-learn libraries for learning.\nfrom sklearn.pipeline import Pipeline\nfrom sklearn.neighbors import KNeighborsClassifier\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.naive_bayes import BernoulliNB\nfrom sklearn.naive_bayes import MultinomialNB\nfrom sklearn.grid_search import GridSearchCV\nfrom sklearn.metrics import recall_score\n\n# SK-learn libraries for evaluation.\nfrom sklearn.metrics import confusion_matrix\nfrom sklearn import metrics\nfrom sklearn.metrics import classification_report\n\n# SK-learn library for importing the newsgroup data.\nfrom sklearn.datasets import fetch_20newsgroups\n\n# SK-learn libraries for feature extraction from text.\nfrom sklearn.feature_extraction.text import *",
"_____no_output_____"
],
[
"## Get Data ##\n\n#reference on data: https://www.kaggle.com/c/random-acts-of-pizza/data\n# pull in the training and test data\nwith open('/Users/erikaananda/Documents/MIDS/W207/Final Project/data/train.json', encoding='utf-8') as data_file:\n#with open('/home/levi/Documents/W207_Proj/data/train.json', encoding='utf-8') as data_file:\n trainData = json.loads(data_file.read()) \nwith open('/Users/erikaananda/Documents/MIDS/W207/Final Project/data/test.json', encoding='utf-8') as data_file:\n#with open('/home/levi/Documents/W207_Proj/data/train.json', encoding='utf-8') as data_file:\n testData = json.loads(data_file.read()) \n\n# create a dev data set \ndevData = trainData[0:1000]\ntrainData = trainData[1000:]\n\n# show how the data looks in its original format\n#pprint(\"data in json format:\")\n#pprint(trainData[1])\n\n# create a normalized view\nallTData = json_normalize(trainData)\nprint(\"\\nSize of the normalized Data:\", allTData.shape)\nprint(\"\\nnormalized data columns:\", list(allTData))\n\nallDData = json_normalize(devData)\n",
"\nSize of the normalized Data: (3040, 32)\n\nnormalized data columns: ['giver_username_if_known', 'number_of_downvotes_of_request_at_retrieval', 'number_of_upvotes_of_request_at_retrieval', 'post_was_edited', 'request_id', 'request_number_of_comments_at_retrieval', 'request_text', 'request_text_edit_aware', 'request_title', 'requester_account_age_in_days_at_request', 'requester_account_age_in_days_at_retrieval', 'requester_days_since_first_post_on_raop_at_request', 'requester_days_since_first_post_on_raop_at_retrieval', 'requester_number_of_comments_at_request', 'requester_number_of_comments_at_retrieval', 'requester_number_of_comments_in_raop_at_request', 'requester_number_of_comments_in_raop_at_retrieval', 'requester_number_of_posts_at_request', 'requester_number_of_posts_at_retrieval', 'requester_number_of_posts_on_raop_at_request', 'requester_number_of_posts_on_raop_at_retrieval', 'requester_number_of_subreddits_at_request', 'requester_received_pizza', 'requester_subreddits_at_request', 'requester_upvotes_minus_downvotes_at_request', 'requester_upvotes_minus_downvotes_at_retrieval', 'requester_upvotes_plus_downvotes_at_request', 'requester_upvotes_plus_downvotes_at_retrieval', 'requester_user_flair', 'requester_username', 'unix_timestamp_of_request', 'unix_timestamp_of_request_utc']\n"
],
[
"## Create subsets of data for analysis ###\n\n# create a flat dataset without the subreddits list\nflatData = allTData.drop('requester_subreddits_at_request', 1)\n# create a separate dataset with just subreddits, indexed on request id\n# we can creata a count vector on the words, run Naive Bayes against it, \n# and add the probabilities to our flat dataset\nsubredTData = allTData[['request_id','requester_subreddits_at_request']]\nsubredTData.set_index('request_id', inplace=True)\n\nsubredDData= allDData[['request_id','requester_subreddits_at_request']]\nsubredDData.set_index('request_id', inplace=True)\n\n# our training labels\ntrainLabel = allTData['requester_received_pizza']\n\ndevLabel = allDData['requester_received_pizza']\n\n# what do these look like?\n#print(list(flatData))\nprint(subredTData.shape)\n#print(subredTData['requester_subreddits_at_request'][1])\n\n# create a corpus of subreddits to vectorize\ntrainCorpus = []\nfor index in range(len(subredTData)):\n trainCorpus.append(' '.join(subredTData['requester_subreddits_at_request'][index]))\n\ndevCorpus = []\nfor index in range(len(subredDData)):\n devCorpus.append(' '.join(subredDData['requester_subreddits_at_request'][index]))\n \n",
"(3040, 1)\n"
],
[
"# combine all text sources into a single corpus\nfldTText = allTData[['request_id','request_text', 'request_text_edit_aware', 'request_title']]\nfldDText = allDData[['request_id','request_text', 'request_text_edit_aware', 'request_title']]\n\ntrainCorpus = []\nfor index in range(len(subredTData)):\n a = ' '.join(subredTData['requester_subreddits_at_request'][index])\n b = (a, fldTText['request_text'][index], fldTText['request_text_edit_aware'][index],\n fldTText['request_title'][index])\n trainCorpus.append(' '.join(b))\n\ndevCorpus = []\nfor index in range(len(subredDData)):\n a = ' '.join(subredDData['requester_subreddits_at_request'][index])\n b = (a, fldDText['request_text'][index], fldDText['request_text_edit_aware'][index],\n fldDText['request_title'][index])\n devCorpus.append(' '.join(b))\n\n# Print 3 examples \nprint (trainCorpus[:3])\nlabels = trainLabel.astype(int)\nlabels = list(labels)\nprint(labels[:3])\nprint('-'*75)\n\nprint ('\\n' , devCorpus[:3])\nlabels_dev = devLabel.astype(int)\nlabels_dev = list(labels_dev)\nprint(labels_dev[:3])",
"[\"FoodstuffsAllAround IAmA RandomActsOfCookies RandomActsofCards RandomKindness Random_Acts_Of_Pizza comiccon cosplay cosplayers So it's been a while since it's happened, but yeah. Just got dumped by a girl I like... My brother has used up pretty much everything in the freezer. I would really appreciate a pizza right now... So it's been a while since it's happened, but yeah. Just got dumped by a girl I like... My brother has used up pretty much everything in the freezer. I would really appreciate a pizza right now... [Request] Just got dumped, no food in the freezer. Pizza?\", \"AskReddit Guitar Jazz Music NSFW_GIF Psychonaut RoomPorn StAugustine TwoXChromosomes WTF YouShouldKnow atheism aww bakedart catpictures cats crochet dubstep ents entwives food funny gonewild hiphopheads listentothis meetup offbeat pics realpics self sex tattoos treecomics treemusic trees videos vinyl zombies My boyfriend and I live in Saint Augustine, Florida and have been having a rough time financially the past few months. In and out of various jobs, we've had to survive off of coscto sized ramen packs, and pasta and olive oil. I applied for food stamps a couple days ago, and am waiting to hear back from them. It's getting a little trite, and we're quite hungry tonight, a hot pizza would be a delight. We'll happily pay it forward in the future. Much love. My boyfriend and I live in Saint Augustine, Florida and have been having a rough time financially the past few months. In and out of various jobs, we've had to survive off of coscto sized ramen packs, and pasta and olive oil. I applied for food stamps a couple days ago, and am waiting to hear back from them. It's getting a little trite, and we're quite hungry tonight, a hot pizza would be a delight. We'll happily pay it forward in the future. Much love. [Request] Saint Augustine, US. Boyfriend and I have no money till next week, and are awaiting food stamps approval.\", \"Albany AskReddit Brooklyn Favors ImGoingToHellForThis Random_Acts_Of_Amazon Random_Acts_Of_Pizza YouShouldKnow cars cigars gaming pics shutupandtakemymoney ualbany upstate_new_york videos I seriously love buffalo chicken pizza. Like, straight up addicted. There's a local pizzeria that delivers and they make the best buffalo chicken pizza I've ever had; however if you dont feel safe with that or have a Giftcard to a chain I could care less, I just want a buffalo chicken pizza soooo bad! I seriously love buffalo chicken pizza. Like, straight up addicted. There's a local pizzeria that delivers and they make the best buffalo chicken pizza I've ever had; however if you dont feel safe with that or have a Giftcard to a chain I could care less, I just want a buffalo chicken pizza soooo bad! [Request] I'd love a Buffalo Chicken Puzza!\"]\n[0, 0, 1]\n---------------------------------------------------------------------------\n\n [' Hi I am in need of food for my 4 children we are a military family that has really hit hard times and we have exahusted all means of help just to be able to feed my family and make it through another night is all i ask i know our blessing is coming so whatever u can find in your heart to give is greatly appreciated Hi I am in need of food for my 4 children we are a military family that has really hit hard times and we have exahusted all means of help just to be able to feed my family and make it through another night is all i ask i know our blessing is coming so whatever u can find in your heart to give is greatly appreciated Request Colorado Springs Help Us Please', 'AskReddit Eve IAmA MontereyBay RandomKindness RedditBiography dubstep gamecollecting gaming halo i18n techsupport I spent the last money I had on gas today. Im broke until next Thursday :( I spent the last money I had on gas today. Im broke until next Thursday :( [Request] California, No cash and I could use some dinner', \" My girlfriend decided it would be a good idea to get off at Perth bus station when she was coming to visit me and has since had to spend all her money on a taxi to get to me here in Dundee. Any chance some kind soul would get us some pizza since we don't have any cash anymore? My girlfriend decided it would be a good idea to get off at Perth bus station when she was coming to visit me and has since had to spend all her money on a taxi to get to me here in Dundee. Any chance some kind soul would get us some pizza since we don't have any cash anymore? [Request] Hungry couple in Dundee, Scotland would love some pizza!\"]\n[0, 0, 0]\n"
]
],
[
[
"# Section 2. Simple Feature Selection and Pre-Processing",
"_____no_output_____"
]
],
[
[
"# Simple Pre-Processing\n\ndef data_preprocessor(s):\n \"\"\"\n Note: this function pre-processors data:\n (1) removes non-alpha characters\n (2) converts digits to 'number'\n (3) regularizes spaces (although CountVectorizer ignores this unless they are part of words)\n (4) reduces word size to n\n \"\"\"\n\n s = [re.sub(r'[?|$|.|!|@|\\n|(|)|<|>|_|-|,|\\']',r' ',s) for s in s] # strip out non-alpha numeric char, replace with space\n s = [re.sub(r'\\d+',r'number ',s) for s in s] # convert digits to number\n s = [re.sub(r' +',r' ',s) for s in s] # convert multiple spaces to single space\n \n # This sets word size to n=5\n num = 5\n def set_word(s):\n temp = []\n for s in s:\n x = s.split()\n z = [elem[:num] for elem in x]\n z = ' '.join(z)\n temp.append(z) \n return temp\n \n s = set_word(s)\n \n return s\n\n",
"_____no_output_____"
],
[
"# Set up the data with CountVectorizer\n\n#vectorizer = CountVectorizer(lowercase=True, strip_accents='unicode',stop_words='english')\n\nvectorizer = CountVectorizer(min_df=1,lowercase=True)\ntVector = vectorizer.fit_transform(trainCorpus)\ndVector = vectorizer.transform(devCorpus)\n\nprint ('\\nRaw data:')\nprint (\"The size of the vocabulary for the training text data is\", tVector.shape[1])\nprint (\"First 5 feature Names:\", vectorizer.get_feature_names()[1:6], \"\\n\")\n\ntVector_p = vectorizer.fit_transform(data_preprocessor(trainCorpus))\ndVector_p = vectorizer.transform(data_preprocessor(devCorpus))\n\nprint ('\\nPre-Processed data:')\nprint (\"The size of the vocabulary for the training text data is\", tVector_p.shape[1])\nprint (\"First 5 feature Names:\", vectorizer.get_feature_names()[1:6], \"\\n\")",
"\nRaw data:\nThe size of the vocabulary for the training text data is 17213\nFirst 5 feature Names: ['000', '0000', '0011011001111000', '00243364', '00pm'] \n\n\nPre-Processed data:\nThe size of the vocabulary for the training text data is 10491\nFirst 5 feature Names: ['aaaaa', 'aan', 'ab', 'aback', 'aband'] \n\n"
]
],
[
[
"# Section 3. Baseline Models",
"_____no_output_____"
],
[
"## Logistic Regression",
"_____no_output_____"
]
],
[
[
"# Logistic Regression\n\nC = 0.01 #(For now)\n\nmodelLogit = LogisticRegression(penalty='l2', C=C)\nmodelLogit.fit(tVector,trainLabel)\nlogitScore = round(modelLogit.score(dVector, devLabel), 4)\nprint(\"For C = \", C, \"Logistic regression accuracy:\", logitScore)\n\nmodelLogit.fit(tVector_p,trainLabel)\nlogitScore = round(modelLogit.score(dVector_p, devLabel), 4)\nprint(\"For C = \", C, \"Logistic regression (processed data) accuracy:\", logitScore)\n",
"For C = 0.01 Logistic regression accuracy: 0.736\nFor C = 0.01 Logistic regression (processed data) accuracy: 0.73\n"
]
],
[
[
"## Naive Bayes",
"_____no_output_____"
]
],
[
[
"# Multinomial NB\n\nalpha = 0.01\n\nclf = BernoulliNB(alpha=alpha)\nclf.fit(tVector, trainLabel)\ntest_predicted_labels = clf.predict(dVector) \nprint ('Bernoulli NB using raw data with alpha = %1.3f:' %alpha, metrics.accuracy_score(devLabel,test_predicted_labels) )\n\nclf.fit(tVector_p, trainLabel)\ntest_predicted_labels = clf.predict(dVector_p) \nprint ('Bernoulli NB using processed data with alpha = %1.3f:' %alpha, metrics.accuracy_score(devLabel,test_predicted_labels) )\n",
"Bernoulli NB using raw data with alpha = 0.010: 0.719\nBernoulli NB using processed data with alpha = 0.010: 0.708\n"
]
],
[
[
"## Logistic Regression More Feature Selection",
"_____no_output_____"
]
],
[
[
"# get the best regularization\nregStrength = [0.0001, 0.001, 0.01, 0.1, 0.5, 1.0, 2.0, 6.0, 10.0]\n\n\nfor c in regStrength:\n modelLogit = LogisticRegression(penalty='l1', C=c)\n modelLogit.fit(tVector_p, trainLabel)\n logitScore = round(modelLogit.score(dVector_p, devLabel), 4)\n print(\"For C = \", c, \"Logistic regression accuracy:\", logitScore)\n\n# although the best score comes from c=.001, the bet F1-score \n# comes from c=.5, and this gives better weight options\nmodelLogit = LogisticRegression(penalty='l1', C=.5, tol = .1)\nmodelLogit.fit(tVector_p, trainLabel)\n\nprint(max(modelLogit.coef_[0]))\nnumWeights = 5\n\nsortIndex = np.argsort(modelLogit.coef_)\niLen = len(sortIndex[0])\nprint(\"\\nTop\", numWeights, \"Weighted Features:\")\n\nfor index in range((iLen - numWeights) , iLen):\n lookup = sortIndex[0][index]\n print(lookup)\n weight = modelLogit.coef_[0][lookup]\n print(vectorizer.get_feature_names()[sortIndex[0][index]], weight)",
"For C = 0.0001 Logistic regression accuracy: 0.74\nFor C = 0.001 Logistic regression accuracy: 0.74\nFor C = 0.01 Logistic regression accuracy: 0.74\nFor C = 0.1 Logistic regression accuracy: 0.734\nFor C = 0.5 Logistic regression accuracy: 0.673\nFor C = 1.0 Logistic regression accuracy: 0.654\nFor C = 2.0 Logistic regression accuracy: 0.652\nFor C = 6.0 Logistic regression accuracy: 0.644\nFor C = 10.0 Logistic regression accuracy: 0.646\n1.01512990172\n\nTop 5 Weighted Features:\n6651\npacka 0.779252474921\n4411\nimpre 0.824352416127\n10070\nweds 0.856426903328\n4292\nhurti 0.964784420232\n10175\nwiiu 1.01512990172\n"
]
],
[
[
"# Future Steps",
"_____no_output_____"
],
[
"* More data pre-processing (looking for newer features too)\n* Explore PCA/LSA\n* Ideas on features\n - Combination of words\n - Pruning\n - Timing (of requests)\n - Location\n ",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
cb33ce3e4c30b82a04f25b762845d93baf4b9a1d | 32,815 | ipynb | Jupyter Notebook | notebooks/20200608 - Cataine dev.ipynb | TheoLvs/westworld | 7fb435f3a028ff3d3156bf2a023b44ee06aa9f8b | [
"MIT"
] | null | null | null | notebooks/20200608 - Cataine dev.ipynb | TheoLvs/westworld | 7fb435f3a028ff3d3156bf2a023b44ee06aa9f8b | [
"MIT"
] | 3 | 2021-09-06T23:12:23.000Z | 2021-09-17T01:04:34.000Z | notebooks/20200608 - Cataine dev.ipynb | TheoLvs/westworld | 7fb435f3a028ff3d3156bf2a023b44ee06aa9f8b | [
"MIT"
] | null | null | null | 48.399705 | 6,948 | 0.658053 | [
[
[
"# Base Data Science snippet\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport os\nimport time\nfrom tqdm import tqdm_notebook\n\n%matplotlib inline\n%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
],
[
"import sys\nsys.path.append(\"../\")\n\nimport westworld\nfrom westworld.assets import *\nfrom westworld.colors import *\nfrom westworld.objects import *\nfrom westworld.agents import *\nfrom westworld.environment import *\nfrom westworld.simulation import *\nfrom westworld.logger import Logger",
"pygame 1.9.6\nHello from the pygame community. https://www.pygame.org/contribute.html\n"
]
],
[
[
"# Playground",
"_____no_output_____"
],
[
"## Beta law for fight evaluations",
"_____no_output_____"
],
[
"- https://fr.wikipedia.org/wiki/Loi_b%C3%AAta\n- https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.beta.html",
"_____no_output_____"
]
],
[
[
"from scipy.stats import beta",
"_____no_output_____"
],
[
"r = beta.rvs(10, 1, size=1000)",
"_____no_output_____"
],
[
"from ipywidgets import interact,IntSlider\n\n@interact(a = IntSlider(min = 1,max = 10,value = 1,step = 1),b = IntSlider(min = 1,max = 10,value = 1,step = 1))\ndef explore(a,b):\n x = np.linspace(0,1,100)\n rv = beta(a, b)\n plt.plot(x, rv.pdf(x), 'k-', lw=2, label='frozen pdf')\n plt.show()",
"_____no_output_____"
],
[
"def win(a,b):\n return beta.rvs(a, b) > 0.5",
"_____no_output_____"
]
],
[
[
"## Env development",
"_____no_output_____"
],
[
"### Dev decorators",
"_____no_output_____"
]
],
[
[
"env.data",
"_____no_output_____"
],
[
"import functools\n\n\n\nclass Test:\n\n @staticmethod\n def decorator(func):\n @functools.wraps(func)\n def wrapper_decorator(*args, **kwargs):\n print(\"Something is happening before the function is called.\")\n # Do something before\n value = func(*args, **kwargs)\n print(\"Something is happening after the function is called.\")\n # Do something after\n return value\n return wrapper_decorator\n \n @self.decorator\n def __init__(self):\n pass\n \n @self.decorator\n def render(self):\n pass\n \n \nclass CTest(Test):\n pass\n \n \n ",
"_____no_output_____"
],
[
"import functools\n\n\ndef decorator(func):\n @functools.wraps(func)\n def wrapper_decorator(self,*args, **kwargs):\n print(\"Something is happening before the function is called.\")\n # Do something before\n print(func)\n value = func(self,*args, **kwargs)\n self.post_init()\n print(\"Something is happening after the function is called.\")\n # Do something after\n return value\n return wrapper_decorator\n\nclass Test:\n \n @decorator\n def __init__(self):\n pass\n \n @decorator\n def render(self):\n pass\n \n def post_init(self):\n print(\"postinit1\")\n \n \nclass CTest(Test):\n \n @decorator\n def __init__(self):\n \n super().__init__()\n \n \n def post_init(self):\n print(\"postinit2\")\n \n \n ",
"_____no_output_____"
],
[
"env.quit()",
"_____no_output_____"
],
[
"t = CTest()",
"Something is happening before the function is called.\nSomething is happening before the function is called.\npostinit2\nSomething is happening after the function is called.\npostinit2\nSomething is happening after the function is called.\n"
]
],
[
[
"### Dev env",
"_____no_output_____"
]
],
[
[
"class Player(BaseAgent):\n \n attrs = [\"color\",\"stacked\"]\n \n def post_bind(self):\n self.stacked = 1\n self.other_color = RED if self.color == BLUE else BLUE\n \n @property\n def blocking(self):\n return False\n \n def step(self):\n self.wander()\n \n def render(self,screen):\n super().render(screen = screen)\n self.render_text(self.stacked,size = 25)\n \n \n# def prerender(self):\n\n# player1 = self.env.make_group({\"color\":RED})\n# player2 = self.env.make_group({\"color\":BLUE})\n \n# collision1 = self.collides_group(player1,method = \"rect\")\n# collision2 = self.collides_group(player2,method = \"rect\")\n \n# self.pop = 1 + (len(collision1) if self.color == RED else len(collision2))\n\n \nclass Environment(GridEnvironment):\n \n def count_stacked(self):\n \n count = self.data.groupby([\"color\",\"pos\"])[\"stacked\"].transform(lambda x : len(x))\n for obj,stacked in count.to_dict().items():\n self[obj].stacked = stacked\n \n def prerender(self):\n self.count_stacked()\n \n \n\nspawner1 = lambda x,y : Player(x,y,color = RED)\nspawner2 = lambda x,y : Player(x,y,color = BLUE)\n\nenv = Environment(width = 20,height = 10,cell_size=30,show_grid = True)\nenv.spawn(spawner1,20)\nenv.spawn(spawner2,20)\n\nenv.render()\nenv.get_img()",
"_____no_output_____"
],
[
"sim = Simulation(env,fps = 10)\nsim.run_episode(n_steps = 20,replay = True,save = True)",
"_____no_output_____"
],
[
"class Player(BaseAgent):\n \n def step(self):\n self.wander()\n \n\nspawner1 = lambda x,y : Player(x,y,color = BLUE,img_asset = \"blob\")\n\nenv = GridEnvironment(width = 20,height = 10,cell_size=30,show_grid = True)\nenv.spawn(spawner1,50)\n\nenv.render()\nenv.get_img()",
"_____no_output_____"
],
[
"sim = Simulation(env,fps = 3)\nsim.run_episode(n_steps = 500,replay = True,save = False)",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
cb33f895b2e67bbc15ebe38afc35e31522b429bb | 9,231 | ipynb | Jupyter Notebook | 2_Strategies/Strategy_Breakout.ipynb | imyoungyang/algotrading-workshop | 9d494be73e46867111217a63f4da4f89f996c389 | [
"Unlicense",
"MIT"
] | 3 | 2020-02-26T07:30:15.000Z | 2020-04-09T09:29:54.000Z | 2_Strategies/Strategy_Breakout.ipynb | imyoungyang/algotrading-workshop | 9d494be73e46867111217a63f4da4f89f996c389 | [
"Unlicense",
"MIT"
] | null | null | null | 2_Strategies/Strategy_Breakout.ipynb | imyoungyang/algotrading-workshop | 9d494be73e46867111217a63f4da4f89f996c389 | [
"Unlicense",
"MIT"
] | 1 | 2020-01-23T04:44:00.000Z | 2020-01-23T04:44:00.000Z | 29.492013 | 230 | 0.565703 | [
[
[
"# Step 1) Data Preparation",
"_____no_output_____"
]
],
[
[
"%run data_prep.py INTC\n\nimport pandas as pd\n\ndf = pd.read_csv(\"../1_Data/INTC.csv\",infer_datetime_format=True, parse_dates=['dt'], index_col=['dt'])\n\ntrainCount=int(len(df)*0.4)\ndfTrain = df.iloc[:trainCount]\n\ndfTest = df.iloc[trainCount:]\ndfTest.to_csv('local_test/test_dir/input/data/training/data.csv')\ndfTest.head()",
"_____no_output_____"
],
[
"%matplotlib notebook\ndfTest[\"close\"].plot()",
"_____no_output_____"
]
],
[
[
"# Step 2) Modify Strategy Configuration \n\nIn the following cell, you can adjust the parameters for the strategy.\n\n* `user` = Name for Leaderboard (optional)\n* `go_long` = Go Long for Breakout (true or false)\n* `go_short` = Go Short for Breakout (true or false)\n* `period` = Length of window for previous high and low\n* `size` = The number of shares for a transaction\n\n`Tip`: A good starting point for improving the strategy is to lengthen the period of the previous high and low. Equity Markets tend to have a long bias and if you only consider long trades this might improve the performance.",
"_____no_output_____"
]
],
[
[
"%%writefile model/algo_config\n{ \"user\" : \"user\",\n \"go_long\" : true,\n \"go_short\" : true,\n \"period\" : 9,\n \"size\" : 1000\n}",
"_____no_output_____"
],
[
"%run update_config.py daily_breakout",
"_____no_output_____"
]
],
[
[
"# Step 3) Modify Strategy Code\n\n`Tip`: A good starting point for improving the strategy is to add additional indicators like ATR (Average True Range) before placing a trade. You want to avoid false signals if there is not enough volatility.\n\nHere are some helpful links:\n* Backtrader Documentation: https://www.backtrader.com/docu/strategy/\n* TA-Lib Indicator Reference: https://www.backtrader.com/docu/talibindautoref/\n* Backtrader Indicator Reference: https://www.backtrader.com/docu/indautoref/",
"_____no_output_____"
]
],
[
[
"%%writefile model/algo_daily_breakout.py\nimport backtrader as bt\nfrom algo_base import *\nimport pytz\nfrom pytz import timezone\n\nclass MyStrategy(StrategyTemplate):\n\n def __init__(self): # Initiation\n super(MyStrategy, self).__init__()\n self.highest = bt.ind.Highest(period=self.config[\"period\"])\n self.lowest = bt.ind.Lowest(period=self.config[\"period\"])\n self.size = self.config[\"size\"]\n\n def next(self): # Processing\n super(MyStrategy, self).next()\n dt=self.datas[0].datetime.datetime(0)\n if not self.position:\n if self.config[\"go_long\"] and self.datas[0] > self.highest[-1]:\n self.buy(size=self.size) # Go long\n elif self.config[\"go_short\"] and self.datas[0] < self.lowest[-1]:\n self.sell(size=self.size) # Go short\n elif self.position.size>0 and self.datas[0] < self.highest[-1]:\n self.close()\n elif self.position.size<0 and self.datas[0] > self.lowest[-1]: \n self.close()",
"_____no_output_____"
]
],
[
[
"# Step 4) Backtest Locally (historical data)\n\n**Please note that the initial docker image build may take up to 5 min. Subsequent runs are fast.**",
"_____no_output_____"
]
],
[
[
"#Build Local Algo Image\n!docker build -t algo_$(cat model/algo_name) .\n!docker run -v $(pwd)/local_test/test_dir:/opt/ml --rm algo_$(cat model/algo_name) train",
"_____no_output_____"
],
[
"from IPython.display import Image\nImage(filename='local_test/test_dir/model/chart.png')",
"_____no_output_____"
]
],
[
[
"## Refine your trading strategy (step 2 to 4). Once you are ready to test the performance of your strategy in a forwardtest, move on to the next step.",
"_____no_output_____"
],
[
"# Step 5) Forwardtest on SageMaker (simulated data) and submit performance\n\n**Please note that the forwardtest in SageMaker runs each time with a new simulated dataset to validate the performance of the strategy. Feel free to run it multiple times to compare performance.**",
"_____no_output_____"
]
],
[
[
"#Deploy Algo Image to ECS\n!./build_and_push.sh",
"_____no_output_____"
],
[
"#Run Remote Forwardtest via SageMaker\nimport sagemaker as sage\nfrom sagemaker import get_execution_role\nfrom sagemaker.estimator import Estimator \n\nrole = get_execution_role()\nsess = sage.Session()\n\nWORK_DIRECTORY = 'local_test/test_dir/input/data/training'\ndata_location = sess.upload_data(WORK_DIRECTORY, key_prefix='data')\nprint(data_location)\n\nwith open('model/algo_config', 'r') as f:\n config = json.load(f)\nalgo_name=config['algo_name']\n\nconfig['sim_data']=True\n\nprefix='algo_'+algo_name\njob_name=prefix.replace('_','-')\n\naccount = sess.boto_session.client('sts').get_caller_identity()['Account']\nregion = sess.boto_session.region_name\nimage = f'{account}.dkr.ecr.{region}.amazonaws.com/{prefix}:latest'\n\nalgo = sage.estimator.Estimator(\n image_name=image,\n role=role,\n train_instance_count=1,\n train_instance_type='ml.m4.xlarge',\n output_path=\"s3://{}/output\".format(sess.default_bucket()),\n sagemaker_session=sess,\n base_job_name=job_name,\n hyperparameters=config,\n metric_definitions=[\n {\n \"Name\": \"algo:pnl\",\n \"Regex\": \"Total PnL:(.*?)]\"\n },\n {\n \"Name\": \"algo:sharpe_ratio\",\n \"Regex\": \"Sharpe Ratio:(.*?),\"\n }\n ])\nalgo.fit(data_location)",
"_____no_output_____"
],
[
"#Get Algo Metrics\nfrom sagemaker.analytics import TrainingJobAnalytics\n\nlatest_job_name = algo.latest_training_job.job_name\nmetrics_dataframe = TrainingJobAnalytics(training_job_name=latest_job_name).dataframe()\nmetrics_dataframe",
"_____no_output_____"
],
[
"#Get Algo Chart from S3\nmodel_name=algo.model_data.replace('s3://'+sess.default_bucket()+'/','')\nimport boto3\ns3 = boto3.resource('s3')\nmy_bucket = s3.Bucket(sess.default_bucket())\nmy_bucket.download_file(model_name,'model.tar.gz')\n!tar -xzf model.tar.gz\n!rm model.tar.gz\nfrom IPython.display import Image\nImage(filename='chart.png') ",
"_____no_output_____"
]
],
[
[
"### Congratulations! You've completed this strategy. Verify your submission on the leaderboard.",
"_____no_output_____"
]
],
[
[
"%run leaderboard.py",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
cb3400676c4c30a40ef16c7a98cf53a9974ebba0 | 6,854 | ipynb | Jupyter Notebook | doc/installation.ipynb | margitaii/nbsphinx | af1d2fc91dba35bd61b83f9e4ae0a4ffcb3ce474 | [
"MIT"
] | 1 | 2020-08-11T07:07:04.000Z | 2020-08-11T07:07:04.000Z | doc/installation.ipynb | margitaii/nbsphinx | af1d2fc91dba35bd61b83f9e4ae0a4ffcb3ce474 | [
"MIT"
] | null | null | null | doc/installation.ipynb | margitaii/nbsphinx | af1d2fc91dba35bd61b83f9e4ae0a4ffcb3ce474 | [
"MIT"
] | 1 | 2020-08-11T07:07:12.000Z | 2020-08-11T07:07:12.000Z | 41.792683 | 336 | 0.631748 | [
[
[
"This notebook is part of the `nbsphinx` documentation: https://nbsphinx.readthedocs.io/.",
"_____no_output_____"
],
[
"# Installation\n\nNote that some packages may be out of date.\nYou can always get the newest `nbsphinx` release from [PyPI](https://pypi.org/project/nbsphinx) (using `pip`).\nIf you want to try the latest development version, have a look at the file [CONTRIBUTING.rst](https://github.com/spatialaudio/nbsphinx/blob/master/CONTRIBUTING.rst).\n\n## nbsphinx Packages\n\n[](https://anaconda.org/conda-forge/nbsphinx)\n\nIf you are using the `conda` package manager (e.g. with [Anaconda](https://www.anaconda.com/distribution/) for Linux/macOS/Windows), you can install `nbsphinx` from the [conda-forge](https://conda-forge.org/) channel:\n\n conda install -c conda-forge nbsphinx\n\nIf you are using Linux, there are packages available for many distributions.\n\n[](https://repology.org/project/python:nbsphinx/versions)\n\n[](https://pypi.org/project/nbsphinx)\n\nOn any platform, you can also install `nbsphinx` with `pip`, Python's own package manager:\n\n python3 -m pip install nbsphinx --user\n\nIf you want to install it system-wide for all users (assuming you have the necessary rights), just drop the `--user` flag.\n\nTo upgrade an existing `nbsphinx` installation to the newest release, use the `--upgrade` flag:\n\n python3 -m pip install nbsphinx --upgrade --user\n\nIf you suddenly change your mind, you can un-install it with:\n\n python3 -m pip uninstall nbsphinx\n\nDepending on your Python installation, you may have to use `python` instead of `python3`.",
"_____no_output_____"
],
[
"## nbsphinx Prerequisites\n\nSome of the aforementioned packages will install some of these prerequisites automatically, some of the things may be already installed on your computer anyway.\n\n### Python\n\nOf course you'll need Python, because both Sphinx and `nbsphinx` are implemented in Python.\nThere are many ways to get Python.\nIf you don't know which one is best for you, you can try [Anaconda](https://www.anaconda.com/distribution/).\n\n### Sphinx\n\nYou'll need [Sphinx](https://www.sphinx-doc.org/) as well, because `nbsphinx` is just a Sphinx extension and doesn't do anything on its own.\n\nIf you use `conda`, you can get [Sphinx from the conda-forge channel](https://anaconda.org/conda-forge/sphinx):\n\n conda install -c conda-forge sphinx\n\nAlternatively, you can install it with `pip` (see below):\n\n python3 -m pip install Sphinx --user\n\n### pip\n\nRecent versions of Python already come with `pip` pre-installed.\nIf you don't have it, you can [install it manually](https://pip.pypa.io/en/latest/installing/).\n\n### pandoc\n\nThe stand-alone program [pandoc](https://pandoc.org/) is used to convert Markdown content to something Sphinx can understand. You have to install this program separately, ideally with your package manager. If you are using `conda`, you can install [pandoc from the conda-forge channel](https://anaconda.org/conda-forge/pandoc):\n\n conda install -c conda-forge pandoc\n\nIf that doesn't work out for you, have a look at `pandoc`'s [installation instructions](https://pandoc.org/installing.html).\n\n<div class=\"alert alert-info\">\n\n**Note:**\n\nThe use of `pandoc` in `nbsphinx` is temporary, but will likely stay that way for a long time, see [issue #36](https://github.com/spatialaudio/nbsphinx/issues/36).\n\n</div>\n\n### Pygments Lexer for Syntax Highlighting\n\nTo get proper syntax highlighting in code cells, you'll need an appropriate *Pygments lexer*.\nThis of course depends on the programming language of your Jupyter notebooks (more specifically, the `pygments_lexer` metadata of your notebooks).\n\nFor example, if you use Python in your notebooks, you'll have to have the `IPython` package installed, e.g. with\n\n conda install -c conda-forge ipython\n\nor\n\n python3 -m pip install IPython --user\n\n<div class=\"alert alert-info\">\n\n**Note:**\n\nIf you are using Anaconda with the default channel and syntax highlighting in code cells doesn't seem to work,\nyou can try to install IPython from the `conda-forge` channel or directly with `pip`, or as a work-around,\nadd `'IPython.sphinxext.ipython_console_highlighting'` to `extensions` in your `conf.py`.\n\nFor details, see [Anaconda issue #1430](https://github.com/ContinuumIO/anaconda-issues/issues/1430) and\n[nbsphinx issue #24](https://github.com/spatialaudio/nbsphinx/issues/24).\n\n</div>\n\n### Jupyter Kernel\n\nIf you want to execute your notebooks during the Sphinx build process (see [Controlling Notebook Execution](executing-notebooks.ipynb)), you need an appropriate [Jupyter kernel](https://jupyter.readthedocs.io/en/latest/projects/kernels.html) installed.\n\nFor example, if you use Python, you should install the `ipykernel` package, e.g. with\n\n conda install -c conda-forge ipykernel\n\nor\n\n python3 -m pip install ipykernel --user\n\nIf you created your notebooks yourself with Jupyter, it's very likely that you have the right kernel installed already.",
"_____no_output_____"
]
]
] | [
"markdown"
] | [
[
"markdown",
"markdown",
"markdown"
]
] |
cb34020fa3153632edb1f70963d04e2b1330aa36 | 58,979 | ipynb | Jupyter Notebook | notebooks/analysis/forks/overall_pattern_adoption_over_forks.ipynb | joaorafaelsantos/msc-thesis | 5f35fa3264535288a6849ec23bf9e5d5f2855485 | [
"MIT"
] | 1 | 2021-02-05T16:34:53.000Z | 2021-02-05T16:34:53.000Z | notebooks/analysis/forks/overall_pattern_adoption_over_forks.ipynb | joaorafaelsantos/msc-thesis | 5f35fa3264535288a6849ec23bf9e5d5f2855485 | [
"MIT"
] | null | null | null | notebooks/analysis/forks/overall_pattern_adoption_over_forks.ipynb | joaorafaelsantos/msc-thesis | 5f35fa3264535288a6849ec23bf9e5d5f2855485 | [
"MIT"
] | null | null | null | 487.429752 | 55,572 | 0.941691 | [
[
[
"import seaborn as sns\nimport matplotlib.pyplot as plt\nimport pandas as pd\nimport json",
"_____no_output_____"
],
[
"# x axis\ninitial = 0\nend = 182717\n\ncurrent = initial\nx_axis = []\nwhile current < end:\n x_axis.append(current)\n current += 1000\n\n# y axis\nforks = []\nwith open(\"../../../data/analysis/patterns_last_data_point.json\") as patterns_file:\n patterns = json.load(patterns_file)\n patterns = sorted(patterns, key=lambda k: k['name'])\n \n for fork in x_axis: \n for pattern in patterns:\n count = 0\n \n for project in pattern[\"projects\"]:\n if fork >= project[\"forks\"] and project[\"forks\"] != -1:\n count += 1\n forks.append({\"fork\": fork, \"pattern\": pattern[\"name\"], \"count\": count})",
"_____no_output_____"
],
[
"sns.set(context=\"paper\", palette=\"muted\", style=\"whitegrid\", font='sans-serif', font_scale=1.2)\ndf = pd.DataFrame(data={'count': [record[\"count\"] for record in forks], 'pattern': [record[\"pattern\"] for record in forks], 'fork': [record[\"fork\"] for record in forks]})\n\ng = sns.FacetGrid(df, col=\"pattern\", hue=\"pattern\", col_wrap=4, height=2, aspect=1.2)\n\ng.map(sns.lineplot, \"fork\", \"count\", linewidth=2)\n\nfor i in range(0, 10):\n g.axes[i].xaxis.labelpad = 10\n g.axes[i].yaxis.labelpad = 10\n g.axes[i].set(xticks=[0, 50000, 100000, 185000], yticks=[0, 1, 2, 3, 4, 5], xlabel=\"Number of Forks\")\n\nfor ax in g.axes.flatten():\n ax.tick_params(labelbottom=True)\n\ng.set_titles(col_template=\"{col_name}\", pad=10)\n\ng.set(ylabel=\"Number of Adoptions\")\n\ng.fig.tight_layout()\ng.savefig(f'../../../figures/pattern_adoption/overall_pattern_adoption_over_forks.pdf', format='pdf', bbox_inches=\"tight\")",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code"
]
] |
cb340ff80b45a7daa4bc0e483fbc651828acc743 | 59,271 | ipynb | Jupyter Notebook | Week 4 PA 1/Building+your+Deep+Neural+Network+-+Step+by+Step+v5.ipynb | Arvind19999/Coursera-Ng-Neural-Networks-and-Deep-Learning | 7eae1f12672e7f0635dc20069566128cb272f905 | [
"MIT"
] | 52 | 2018-05-16T07:40:17.000Z | 2022-02-11T09:53:04.000Z | Week 4 PA 1/Building+your+Deep+Neural+Network+-+Step+by+Step+v5.ipynb | Arvind19999/Coursera-Ng-Neural-Networks-and-Deep-Learning | 7eae1f12672e7f0635dc20069566128cb272f905 | [
"MIT"
] | null | null | null | Week 4 PA 1/Building+your+Deep+Neural+Network+-+Step+by+Step+v5.ipynb | Arvind19999/Coursera-Ng-Neural-Networks-and-Deep-Learning | 7eae1f12672e7f0635dc20069566128cb272f905 | [
"MIT"
] | 37 | 2018-05-15T20:01:26.000Z | 2022-02-06T00:12:13.000Z | 35.598198 | 562 | 0.515412 | [
[
[
"# Building your Deep Neural Network: Step by Step\n\nWelcome to your week 4 assignment (part 1 of 2)! You have previously trained a 2-layer Neural Network (with a single hidden layer). This week, you will build a deep neural network, with as many layers as you want!\n\n- In this notebook, you will implement all the functions required to build a deep neural network.\n- In the next assignment, you will use these functions to build a deep neural network for image classification.\n\n**After this assignment you will be able to:**\n- Use non-linear units like ReLU to improve your model\n- Build a deeper neural network (with more than 1 hidden layer)\n- Implement an easy-to-use neural network class\n\n**Notation**:\n- Superscript $[l]$ denotes a quantity associated with the $l^{th}$ layer. \n - Example: $a^{[L]}$ is the $L^{th}$ layer activation. $W^{[L]}$ and $b^{[L]}$ are the $L^{th}$ layer parameters.\n- Superscript $(i)$ denotes a quantity associated with the $i^{th}$ example. \n - Example: $x^{(i)}$ is the $i^{th}$ training example.\n- Lowerscript $i$ denotes the $i^{th}$ entry of a vector.\n - Example: $a^{[l]}_i$ denotes the $i^{th}$ entry of the $l^{th}$ layer's activations).\n\nLet's get started!",
"_____no_output_____"
],
[
"## 1 - Packages\n\nLet's first import all the packages that you will need during this assignment. \n- [numpy](www.numpy.org) is the main package for scientific computing with Python.\n- [matplotlib](http://matplotlib.org) is a library to plot graphs in Python.\n- dnn_utils provides some necessary functions for this notebook.\n- testCases provides some test cases to assess the correctness of your functions\n- np.random.seed(1) is used to keep all the random function calls consistent. It will help us grade your work. Please don't change the seed. ",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport h5py\nimport matplotlib.pyplot as plt\nfrom testCases_v3 import *\nfrom dnn_utils_v2 import sigmoid, sigmoid_backward, relu, relu_backward\n\n%matplotlib inline\nplt.rcParams['figure.figsize'] = (5.0, 4.0) # set default size of plots\nplt.rcParams['image.interpolation'] = 'nearest'\nplt.rcParams['image.cmap'] = 'gray'\n\n%load_ext autoreload\n%autoreload 2\n\nnp.random.seed(1)",
"/opt/conda/lib/python3.5/site-packages/matplotlib/font_manager.py:273: UserWarning: Matplotlib is building the font cache using fc-list. This may take a moment.\n warnings.warn('Matplotlib is building the font cache using fc-list. This may take a moment.')\n/opt/conda/lib/python3.5/site-packages/matplotlib/font_manager.py:273: UserWarning: Matplotlib is building the font cache using fc-list. This may take a moment.\n warnings.warn('Matplotlib is building the font cache using fc-list. This may take a moment.')\n"
]
],
[
[
"## 2 - Outline of the Assignment\n\nTo build your neural network, you will be implementing several \"helper functions\". These helper functions will be used in the next assignment to build a two-layer neural network and an L-layer neural network. Each small helper function you will implement will have detailed instructions that will walk you through the necessary steps. Here is an outline of this assignment, you will:\n\n- Initialize the parameters for a two-layer network and for an $L$-layer neural network.\n- Implement the forward propagation module (shown in purple in the figure below).\n - Complete the LINEAR part of a layer's forward propagation step (resulting in $Z^{[l]}$).\n - We give you the ACTIVATION function (relu/sigmoid).\n - Combine the previous two steps into a new [LINEAR->ACTIVATION] forward function.\n - Stack the [LINEAR->RELU] forward function L-1 time (for layers 1 through L-1) and add a [LINEAR->SIGMOID] at the end (for the final layer $L$). This gives you a new L_model_forward function.\n- Compute the loss.\n- Implement the backward propagation module (denoted in red in the figure below).\n - Complete the LINEAR part of a layer's backward propagation step.\n - We give you the gradient of the ACTIVATE function (relu_backward/sigmoid_backward) \n - Combine the previous two steps into a new [LINEAR->ACTIVATION] backward function.\n - Stack [LINEAR->RELU] backward L-1 times and add [LINEAR->SIGMOID] backward in a new L_model_backward function\n- Finally update the parameters.\n\n<img src=\"images/final outline.png\" style=\"width:800px;height:500px;\">\n<caption><center> **Figure 1**</center></caption><br>\n\n\n**Note** that for every forward function, there is a corresponding backward function. That is why at every step of your forward module you will be storing some values in a cache. The cached values are useful for computing gradients. In the backpropagation module you will then use the cache to calculate the gradients. This assignment will show you exactly how to carry out each of these steps. ",
"_____no_output_____"
],
[
"## 3 - Initialization\n\nYou will write two helper functions that will initialize the parameters for your model. The first function will be used to initialize parameters for a two layer model. The second one will generalize this initialization process to $L$ layers.\n\n### 3.1 - 2-layer Neural Network\n\n**Exercise**: Create and initialize the parameters of the 2-layer neural network.\n\n**Instructions**:\n- The model's structure is: *LINEAR -> RELU -> LINEAR -> SIGMOID*. \n- Use random initialization for the weight matrices. Use `np.random.randn(shape)*0.01` with the correct shape.\n- Use zero initialization for the biases. Use `np.zeros(shape)`.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: initialize_parameters\n\ndef initialize_parameters(n_x, n_h, n_y):\n \"\"\"\n Argument:\n n_x -- size of the input layer\n n_h -- size of the hidden layer\n n_y -- size of the output layer\n \n Returns:\n parameters -- python dictionary containing your parameters:\n W1 -- weight matrix of shape (n_h, n_x)\n b1 -- bias vector of shape (n_h, 1)\n W2 -- weight matrix of shape (n_y, n_h)\n b2 -- bias vector of shape (n_y, 1)\n \"\"\"\n \n np.random.seed(1)\n \n ### START CODE HERE ### (≈ 4 lines of code)\n W1 = np.random.randn(n_h,n_x) * 0.01\n b1 = np.zeros((n_h,1))\n W2 = np.random.randn(n_y,n_h) * 0.01\n b2 = np.zeros((n_y,1))\n ### END CODE HERE ###\n \n assert(W1.shape == (n_h, n_x))\n assert(b1.shape == (n_h, 1))\n assert(W2.shape == (n_y, n_h))\n assert(b2.shape == (n_y, 1))\n \n parameters = {\"W1\": W1,\n \"b1\": b1,\n \"W2\": W2,\n \"b2\": b2}\n \n return parameters ",
"_____no_output_____"
],
[
"parameters = initialize_parameters(3,2,1)\nprint(\"W1 = \" + str(parameters[\"W1\"]))\nprint(\"b1 = \" + str(parameters[\"b1\"]))\nprint(\"W2 = \" + str(parameters[\"W2\"]))\nprint(\"b2 = \" + str(parameters[\"b2\"]))",
"W1 = [[ 0.01624345 -0.00611756 -0.00528172]\n [-0.01072969 0.00865408 -0.02301539]]\nb1 = [[ 0.]\n [ 0.]]\nW2 = [[ 0.01744812 -0.00761207]]\nb2 = [[ 0.]]\n"
]
],
[
[
"**Expected output**:\n \n<table style=\"width:80%\">\n <tr>\n <td> **W1** </td>\n <td> [[ 0.01624345 -0.00611756 -0.00528172]\n [-0.01072969 0.00865408 -0.02301539]] </td> \n </tr>\n\n <tr>\n <td> **b1**</td>\n <td>[[ 0.]\n [ 0.]]</td> \n </tr>\n \n <tr>\n <td>**W2**</td>\n <td> [[ 0.01744812 -0.00761207]]</td>\n </tr>\n \n <tr>\n <td> **b2** </td>\n <td> [[ 0.]] </td> \n </tr>\n \n</table>",
"_____no_output_____"
],
[
"### 3.2 - L-layer Neural Network\n\nThe initialization for a deeper L-layer neural network is more complicated because there are many more weight matrices and bias vectors. When completing the `initialize_parameters_deep`, you should make sure that your dimensions match between each layer. Recall that $n^{[l]}$ is the number of units in layer $l$. Thus for example if the size of our input $X$ is $(12288, 209)$ (with $m=209$ examples) then:\n\n<table style=\"width:100%\">\n\n\n <tr>\n <td> </td> \n <td> **Shape of W** </td> \n <td> **Shape of b** </td> \n <td> **Activation** </td>\n <td> **Shape of Activation** </td> \n <tr>\n \n <tr>\n <td> **Layer 1** </td> \n <td> $(n^{[1]},12288)$ </td> \n <td> $(n^{[1]},1)$ </td> \n <td> $Z^{[1]} = W^{[1]} X + b^{[1]} $ </td> \n \n <td> $(n^{[1]},209)$ </td> \n <tr>\n \n <tr>\n <td> **Layer 2** </td> \n <td> $(n^{[2]}, n^{[1]})$ </td> \n <td> $(n^{[2]},1)$ </td> \n <td>$Z^{[2]} = W^{[2]} A^{[1]} + b^{[2]}$ </td> \n <td> $(n^{[2]}, 209)$ </td> \n <tr>\n \n <tr>\n <td> $\\vdots$ </td> \n <td> $\\vdots$ </td> \n <td> $\\vdots$ </td> \n <td> $\\vdots$</td> \n <td> $\\vdots$ </td> \n <tr>\n \n <tr>\n <td> **Layer L-1** </td> \n <td> $(n^{[L-1]}, n^{[L-2]})$ </td> \n <td> $(n^{[L-1]}, 1)$ </td> \n <td>$Z^{[L-1]} = W^{[L-1]} A^{[L-2]} + b^{[L-1]}$ </td> \n <td> $(n^{[L-1]}, 209)$ </td> \n <tr>\n \n \n <tr>\n <td> **Layer L** </td> \n <td> $(n^{[L]}, n^{[L-1]})$ </td> \n <td> $(n^{[L]}, 1)$ </td>\n <td> $Z^{[L]} = W^{[L]} A^{[L-1]} + b^{[L]}$</td>\n <td> $(n^{[L]}, 209)$ </td> \n <tr>\n\n</table>\n\nRemember that when we compute $W X + b$ in python, it carries out broadcasting. For example, if: \n\n$$ W = \\begin{bmatrix}\n j & k & l\\\\\n m & n & o \\\\\n p & q & r \n\\end{bmatrix}\\;\\;\\; X = \\begin{bmatrix}\n a & b & c\\\\\n d & e & f \\\\\n g & h & i \n\\end{bmatrix} \\;\\;\\; b =\\begin{bmatrix}\n s \\\\\n t \\\\\n u\n\\end{bmatrix}\\tag{2}$$\n\nThen $WX + b$ will be:\n\n$$ WX + b = \\begin{bmatrix}\n (ja + kd + lg) + s & (jb + ke + lh) + s & (jc + kf + li)+ s\\\\\n (ma + nd + og) + t & (mb + ne + oh) + t & (mc + nf + oi) + t\\\\\n (pa + qd + rg) + u & (pb + qe + rh) + u & (pc + qf + ri)+ u\n\\end{bmatrix}\\tag{3} $$",
"_____no_output_____"
],
[
"**Exercise**: Implement initialization for an L-layer Neural Network. \n\n**Instructions**:\n- The model's structure is *[LINEAR -> RELU] $ \\times$ (L-1) -> LINEAR -> SIGMOID*. I.e., it has $L-1$ layers using a ReLU activation function followed by an output layer with a sigmoid activation function.\n- Use random initialization for the weight matrices. Use `np.random.rand(shape) * 0.01`.\n- Use zeros initialization for the biases. Use `np.zeros(shape)`.\n- We will store $n^{[l]}$, the number of units in different layers, in a variable `layer_dims`. For example, the `layer_dims` for the \"Planar Data classification model\" from last week would have been [2,4,1]: There were two inputs, one hidden layer with 4 hidden units, and an output layer with 1 output unit. Thus means `W1`'s shape was (4,2), `b1` was (4,1), `W2` was (1,4) and `b2` was (1,1). Now you will generalize this to $L$ layers! \n- Here is the implementation for $L=1$ (one layer neural network). It should inspire you to implement the general case (L-layer neural network).\n```python\n if L == 1:\n parameters[\"W\" + str(L)] = np.random.randn(layer_dims[1], layer_dims[0]) * 0.01\n parameters[\"b\" + str(L)] = np.zeros((layer_dims[1], 1))\n```",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: initialize_parameters_deep\n\ndef initialize_parameters_deep(layer_dims):\n \"\"\"\n Arguments:\n layer_dims -- python array (list) containing the dimensions of each layer in our network\n \n Returns:\n parameters -- python dictionary containing your parameters \"W1\", \"b1\", ..., \"WL\", \"bL\":\n Wl -- weight matrix of shape (layer_dims[l], layer_dims[l-1])\n bl -- bias vector of shape (layer_dims[l], 1)\n \"\"\"\n \n np.random.seed(3)\n parameters = {}\n L = len(layer_dims) # number of layers in the network\n\n for l in range(1, L):\n ### START CODE HERE ### (≈ 2 lines of code)\n parameters['W' + str(l)] = np.random.randn(layer_dims[l], layer_dims[l-1]) * 0.01\n parameters['b' + str(l)] = np.zeros((layer_dims[l], 1))\n ### END CODE HERE ###\n \n assert(parameters['W' + str(l)].shape == (layer_dims[l], layer_dims[l-1]))\n assert(parameters['b' + str(l)].shape == (layer_dims[l], 1))\n\n \n return parameters",
"_____no_output_____"
],
[
"parameters = initialize_parameters_deep([5,4,3])\nprint(\"W1 = \" + str(parameters[\"W1\"]))\nprint(\"b1 = \" + str(parameters[\"b1\"]))\nprint(\"W2 = \" + str(parameters[\"W2\"]))\nprint(\"b2 = \" + str(parameters[\"b2\"]))",
"W1 = [[ 0.01788628 0.0043651 0.00096497 -0.01863493 -0.00277388]\n [-0.00354759 -0.00082741 -0.00627001 -0.00043818 -0.00477218]\n [-0.01313865 0.00884622 0.00881318 0.01709573 0.00050034]\n [-0.00404677 -0.0054536 -0.01546477 0.00982367 -0.01101068]]\nb1 = [[ 0.]\n [ 0.]\n [ 0.]\n [ 0.]]\nW2 = [[-0.01185047 -0.0020565 0.01486148 0.00236716]\n [-0.01023785 -0.00712993 0.00625245 -0.00160513]\n [-0.00768836 -0.00230031 0.00745056 0.01976111]]\nb2 = [[ 0.]\n [ 0.]\n [ 0.]]\n"
]
],
[
[
"**Expected output**:\n \n<table style=\"width:80%\">\n <tr>\n <td> **W1** </td>\n <td>[[ 0.01788628 0.0043651 0.00096497 -0.01863493 -0.00277388]\n [-0.00354759 -0.00082741 -0.00627001 -0.00043818 -0.00477218]\n [-0.01313865 0.00884622 0.00881318 0.01709573 0.00050034]\n [-0.00404677 -0.0054536 -0.01546477 0.00982367 -0.01101068]]</td> \n </tr>\n \n <tr>\n <td>**b1** </td>\n <td>[[ 0.]\n [ 0.]\n [ 0.]\n [ 0.]]</td> \n </tr>\n \n <tr>\n <td>**W2** </td>\n <td>[[-0.01185047 -0.0020565 0.01486148 0.00236716]\n [-0.01023785 -0.00712993 0.00625245 -0.00160513]\n [-0.00768836 -0.00230031 0.00745056 0.01976111]]</td> \n </tr>\n \n <tr>\n <td>**b2** </td>\n <td>[[ 0.]\n [ 0.]\n [ 0.]]</td> \n </tr>\n \n</table>",
"_____no_output_____"
],
[
"## 4 - Forward propagation module\n\n### 4.1 - Linear Forward \nNow that you have initialized your parameters, you will do the forward propagation module. You will start by implementing some basic functions that you will use later when implementing the model. You will complete three functions in this order:\n\n- LINEAR\n- LINEAR -> ACTIVATION where ACTIVATION will be either ReLU or Sigmoid. \n- [LINEAR -> RELU] $\\times$ (L-1) -> LINEAR -> SIGMOID (whole model)\n\nThe linear forward module (vectorized over all the examples) computes the following equations:\n\n$$Z^{[l]} = W^{[l]}A^{[l-1]} +b^{[l]}\\tag{4}$$\n\nwhere $A^{[0]} = X$. \n\n**Exercise**: Build the linear part of forward propagation.\n\n**Reminder**:\nThe mathematical representation of this unit is $Z^{[l]} = W^{[l]}A^{[l-1]} +b^{[l]}$. You may also find `np.dot()` useful. If your dimensions don't match, printing `W.shape` may help.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: linear_forward\n\ndef linear_forward(A, W, b):\n \"\"\"\n Implement the linear part of a layer's forward propagation.\n\n Arguments:\n A -- activations from previous layer (or input data): (size of previous layer, number of examples)\n W -- weights matrix: numpy array of shape (size of current layer, size of previous layer)\n b -- bias vector, numpy array of shape (size of the current layer, 1)\n\n Returns:\n Z -- the input of the activation function, also called pre-activation parameter \n cache -- a python dictionary containing \"A\", \"W\" and \"b\" ; stored for computing the backward pass efficiently\n \"\"\"\n \n ### START CODE HERE ### (≈ 1 line of code)\n Z = np.dot(W,A) + b\n ### END CODE HERE ###\n \n assert(Z.shape == (W.shape[0], A.shape[1]))\n cache = (A, W, b)\n \n return Z, cache",
"_____no_output_____"
],
[
"A, W, b = linear_forward_test_case()\n\nZ, linear_cache = linear_forward(A, W, b)\nprint(\"Z = \" + str(Z))",
"Z = [[ 3.26295337 -1.23429987]]\n"
]
],
[
[
"**Expected output**:\n\n<table style=\"width:35%\">\n \n <tr>\n <td> **Z** </td>\n <td> [[ 3.26295337 -1.23429987]] </td> \n </tr>\n \n</table>",
"_____no_output_____"
],
[
"### 4.2 - Linear-Activation Forward\n\nIn this notebook, you will use two activation functions:\n\n- **Sigmoid**: $\\sigma(Z) = \\sigma(W A + b) = \\frac{1}{ 1 + e^{-(W A + b)}}$. We have provided you with the `sigmoid` function. This function returns **two** items: the activation value \"`a`\" and a \"`cache`\" that contains \"`Z`\" (it's what we will feed in to the corresponding backward function). To use it you could just call: \n``` python\nA, activation_cache = sigmoid(Z)\n```\n\n- **ReLU**: The mathematical formula for ReLu is $A = RELU(Z) = max(0, Z)$. We have provided you with the `relu` function. This function returns **two** items: the activation value \"`A`\" and a \"`cache`\" that contains \"`Z`\" (it's what we will feed in to the corresponding backward function). To use it you could just call:\n``` python\nA, activation_cache = relu(Z)\n```",
"_____no_output_____"
],
[
"For more convenience, you are going to group two functions (Linear and Activation) into one function (LINEAR->ACTIVATION). Hence, you will implement a function that does the LINEAR forward step followed by an ACTIVATION forward step.\n\n**Exercise**: Implement the forward propagation of the *LINEAR->ACTIVATION* layer. Mathematical relation is: $A^{[l]} = g(Z^{[l]}) = g(W^{[l]}A^{[l-1]} +b^{[l]})$ where the activation \"g\" can be sigmoid() or relu(). Use linear_forward() and the correct activation function.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: linear_activation_forward\n\ndef linear_activation_forward(A_prev, W, b, activation):\n \"\"\"\n Implement the forward propagation for the LINEAR->ACTIVATION layer\n\n Arguments:\n A_prev -- activations from previous layer (or input data): (size of previous layer, number of examples)\n W -- weights matrix: numpy array of shape (size of current layer, size of previous layer)\n b -- bias vector, numpy array of shape (size of the current layer, 1)\n activation -- the activation to be used in this layer, stored as a text string: \"sigmoid\" or \"relu\"\n\n Returns:\n A -- the output of the activation function, also called the post-activation value \n cache -- a python dictionary containing \"linear_cache\" and \"activation_cache\";\n stored for computing the backward pass efficiently\n \"\"\"\n \n if activation == \"sigmoid\":\n # Inputs: \"A_prev, W, b\". Outputs: \"A, activation_cache\".\n ### START CODE HERE ### (≈ 2 lines of code)\n Z, linear_cache = linear_forward(A_prev, W, b)\n A, activation_cache = sigmoid(Z)\n ### END CODE HERE ###\n \n elif activation == \"relu\":\n # Inputs: \"A_prev, W, b\". Outputs: \"A, activation_cache\".\n ### START CODE HERE ### (≈ 2 lines of code)\n Z, linear_cache = linear_forward(A_prev, W, b)\n A, activation_cache = relu(Z)\n ### END CODE HERE ###\n \n assert (A.shape == (W.shape[0], A_prev.shape[1]))\n cache = (linear_cache, activation_cache)\n\n return A, cache",
"_____no_output_____"
],
[
"A_prev, W, b = linear_activation_forward_test_case()\n\nA, linear_activation_cache = linear_activation_forward(A_prev, W, b, activation = \"sigmoid\")\nprint(\"With sigmoid: A = \" + str(A))\n\nA, linear_activation_cache = linear_activation_forward(A_prev, W, b, activation = \"relu\")\nprint(\"With ReLU: A = \" + str(A))",
"With sigmoid: A = [[ 0.96890023 0.11013289]]\nWith ReLU: A = [[ 3.43896131 0. ]]\n"
]
],
[
[
"**Expected output**:\n \n<table style=\"width:35%\">\n <tr>\n <td> **With sigmoid: A ** </td>\n <td > [[ 0.96890023 0.11013289]]</td> \n </tr>\n <tr>\n <td> **With ReLU: A ** </td>\n <td > [[ 3.43896131 0. ]]</td> \n </tr>\n</table>\n",
"_____no_output_____"
],
[
"**Note**: In deep learning, the \"[LINEAR->ACTIVATION]\" computation is counted as a single layer in the neural network, not two layers. ",
"_____no_output_____"
],
[
"### d) L-Layer Model \n\nFor even more convenience when implementing the $L$-layer Neural Net, you will need a function that replicates the previous one (`linear_activation_forward` with RELU) $L-1$ times, then follows that with one `linear_activation_forward` with SIGMOID.\n\n<img src=\"images/model_architecture_kiank.png\" style=\"width:600px;height:300px;\">\n<caption><center> **Figure 2** : *[LINEAR -> RELU] $\\times$ (L-1) -> LINEAR -> SIGMOID* model</center></caption><br>\n\n**Exercise**: Implement the forward propagation of the above model.\n\n**Instruction**: In the code below, the variable `AL` will denote $A^{[L]} = \\sigma(Z^{[L]}) = \\sigma(W^{[L]} A^{[L-1]} + b^{[L]})$. (This is sometimes also called `Yhat`, i.e., this is $\\hat{Y}$.) \n\n**Tips**:\n- Use the functions you had previously written \n- Use a for loop to replicate [LINEAR->RELU] (L-1) times\n- Don't forget to keep track of the caches in the \"caches\" list. To add a new value `c` to a `list`, you can use `list.append(c)`.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: L_model_forward\n\ndef L_model_forward(X, parameters):\n \"\"\"\n Implement forward propagation for the [LINEAR->RELU]*(L-1)->LINEAR->SIGMOID computation\n \n Arguments:\n X -- data, numpy array of shape (input size, number of examples)\n parameters -- output of initialize_parameters_deep()\n \n Returns:\n AL -- last post-activation value\n caches -- list of caches containing:\n every cache of linear_relu_forward() (there are L-1 of them, indexed from 0 to L-2)\n the cache of linear_sigmoid_forward() (there is one, indexed L-1)\n \"\"\"\n\n caches = []\n A = X\n L = len(parameters) // 2 # number of layers in the neural network\n \n # Implement [LINEAR -> RELU]*(L-1). Add \"cache\" to the \"caches\" list.\n for l in range(1, L):\n A_prev = A \n ### START CODE HERE ### (≈ 2 lines of code)\n A, cache = linear_activation_forward(A_prev, parameters['W' + str(l)], parameters['b' + str(l)], activation = \"relu\")\n caches.append(cache)\n ### END CODE HERE ###\n \n # Implement LINEAR -> SIGMOID. Add \"cache\" to the \"caches\" list.\n ### START CODE HERE ### (≈ 2 lines of code)\n AL, cache = linear_activation_forward(A, parameters['W' + str(L)], parameters['b' + str(L)], activation = \"sigmoid\")\n caches.append(cache)\n ### END CODE HERE ###\n \n assert(AL.shape == (1,X.shape[1]))\n \n return AL, caches",
"_____no_output_____"
],
[
"X, parameters = L_model_forward_test_case_2hidden()\nAL, caches = L_model_forward(X, parameters)\nprint(\"AL = \" + str(AL))\nprint(\"Length of caches list = \" + str(len(caches)))",
"AL = [[ 0.03921668 0.70498921 0.19734387 0.04728177]]\nLength of caches list = 3\n"
]
],
[
[
"<table style=\"width:50%\">\n <tr>\n <td> **AL** </td>\n <td > [[ 0.03921668 0.70498921 0.19734387 0.04728177]]</td> \n </tr>\n <tr>\n <td> **Length of caches list ** </td>\n <td > 3 </td> \n </tr>\n</table>",
"_____no_output_____"
],
[
"Great! Now you have a full forward propagation that takes the input X and outputs a row vector $A^{[L]}$ containing your predictions. It also records all intermediate values in \"caches\". Using $A^{[L]}$, you can compute the cost of your predictions.",
"_____no_output_____"
],
[
"## 5 - Cost function\n\nNow you will implement forward and backward propagation. You need to compute the cost, because you want to check if your model is actually learning.\n\n**Exercise**: Compute the cross-entropy cost $J$, using the following formula: $$-\\frac{1}{m} \\sum\\limits_{i = 1}^{m} (y^{(i)}\\log\\left(a^{[L] (i)}\\right) + (1-y^{(i)})\\log\\left(1- a^{[L](i)}\\right)) \\tag{7}$$\n",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: compute_cost\n\ndef compute_cost(AL, Y):\n \"\"\"\n Implement the cost function defined by equation (7).\n\n Arguments:\n AL -- probability vector corresponding to your label predictions, shape (1, number of examples)\n Y -- true \"label\" vector (for example: containing 0 if non-cat, 1 if cat), shape (1, number of examples)\n\n Returns:\n cost -- cross-entropy cost\n \"\"\"\n \n m = Y.shape[1]\n\n # Compute loss from aL and y.\n ### START CODE HERE ### (≈ 1 lines of code)\n logprobs = np.multiply(np.log(AL),Y) + np.multiply(np.log(1-AL),1-Y)\n cost = - np.sum(logprobs) / m \n ### END CODE HERE ###\n \n cost = np.squeeze(cost) # To make sure your cost's shape is what we expect (e.g. this turns [[17]] into 17).\n assert(cost.shape == ())\n \n return cost",
"_____no_output_____"
],
[
"Y, AL = compute_cost_test_case()\n\nprint(\"cost = \" + str(compute_cost(AL, Y)))",
"cost = 0.414931599615\n"
]
],
[
[
"**Expected Output**:\n\n<table>\n\n <tr>\n <td>**cost** </td>\n <td> 0.41493159961539694</td> \n </tr>\n</table>",
"_____no_output_____"
],
[
"## 6 - Backward propagation module\n\nJust like with forward propagation, you will implement helper functions for backpropagation. Remember that back propagation is used to calculate the gradient of the loss function with respect to the parameters. \n\n**Reminder**: \n<img src=\"images/backprop_kiank.png\" style=\"width:650px;height:250px;\">\n<caption><center> **Figure 3** : Forward and Backward propagation for *LINEAR->RELU->LINEAR->SIGMOID* <br> *The purple blocks represent the forward propagation, and the red blocks represent the backward propagation.* </center></caption>\n\n<!-- \nFor those of you who are expert in calculus (you don't need to be to do this assignment), the chain rule of calculus can be used to derive the derivative of the loss $\\mathcal{L}$ with respect to $z^{[1]}$ in a 2-layer network as follows:\n\n$$\\frac{d \\mathcal{L}(a^{[2]},y)}{{dz^{[1]}}} = \\frac{d\\mathcal{L}(a^{[2]},y)}{{da^{[2]}}}\\frac{{da^{[2]}}}{{dz^{[2]}}}\\frac{{dz^{[2]}}}{{da^{[1]}}}\\frac{{da^{[1]}}}{{dz^{[1]}}} \\tag{8} $$\n\nIn order to calculate the gradient $dW^{[1]} = \\frac{\\partial L}{\\partial W^{[1]}}$, you use the previous chain rule and you do $dW^{[1]} = dz^{[1]} \\times \\frac{\\partial z^{[1]} }{\\partial W^{[1]}}$. During the backpropagation, at each step you multiply your current gradient by the gradient corresponding to the specific layer to get the gradient you wanted.\n\nEquivalently, in order to calculate the gradient $db^{[1]} = \\frac{\\partial L}{\\partial b^{[1]}}$, you use the previous chain rule and you do $db^{[1]} = dz^{[1]} \\times \\frac{\\partial z^{[1]} }{\\partial b^{[1]}}$.\n\nThis is why we talk about **backpropagation**.\n!-->\n\nNow, similar to forward propagation, you are going to build the backward propagation in three steps:\n- LINEAR backward\n- LINEAR -> ACTIVATION backward where ACTIVATION computes the derivative of either the ReLU or sigmoid activation\n- [LINEAR -> RELU] $\\times$ (L-1) -> LINEAR -> SIGMOID backward (whole model)",
"_____no_output_____"
],
[
"### 6.1 - Linear backward\n\nFor layer $l$, the linear part is: $Z^{[l]} = W^{[l]} A^{[l-1]} + b^{[l]}$ (followed by an activation).\n\nSuppose you have already calculated the derivative $dZ^{[l]} = \\frac{\\partial \\mathcal{L} }{\\partial Z^{[l]}}$. You want to get $(dW^{[l]}, db^{[l]} dA^{[l-1]})$.\n\n<img src=\"images/linearback_kiank.png\" style=\"width:250px;height:300px;\">\n<caption><center> **Figure 4** </center></caption>\n\nThe three outputs $(dW^{[l]}, db^{[l]}, dA^{[l]})$ are computed using the input $dZ^{[l]}$.Here are the formulas you need:\n$$ dW^{[l]} = \\frac{\\partial \\mathcal{L} }{\\partial W^{[l]}} = \\frac{1}{m} dZ^{[l]} A^{[l-1] T} \\tag{8}$$\n$$ db^{[l]} = \\frac{\\partial \\mathcal{L} }{\\partial b^{[l]}} = \\frac{1}{m} \\sum_{i = 1}^{m} dZ^{[l](i)}\\tag{9}$$\n$$ dA^{[l-1]} = \\frac{\\partial \\mathcal{L} }{\\partial A^{[l-1]}} = W^{[l] T} dZ^{[l]} \\tag{10}$$\n",
"_____no_output_____"
],
[
"**Exercise**: Use the 3 formulas above to implement linear_backward().",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: linear_backward\n\ndef linear_backward(dZ, cache):\n \"\"\"\n Implement the linear portion of backward propagation for a single layer (layer l)\n\n Arguments:\n dZ -- Gradient of the cost with respect to the linear output (of current layer l)\n cache -- tuple of values (A_prev, W, b) coming from the forward propagation in the current layer\n\n Returns:\n dA_prev -- Gradient of the cost with respect to the activation (of the previous layer l-1), same shape as A_prev\n dW -- Gradient of the cost with respect to W (current layer l), same shape as W\n db -- Gradient of the cost with respect to b (current layer l), same shape as b\n \"\"\"\n A_prev, W, b = cache\n m = A_prev.shape[1]\n\n ### START CODE HERE ### (≈ 3 lines of code)\n dW = np.dot(dZ, A_prev.T) * 1. / m\n db = 1. / m * np.sum(dZ, axis=1, keepdims=True)\n dA_prev = np.dot(W.T, dZ)\n ### END CODE HERE ###\n \n assert (dA_prev.shape == A_prev.shape)\n assert (dW.shape == W.shape)\n assert (db.shape == b.shape)\n \n return dA_prev, dW, db",
"_____no_output_____"
],
[
"# Set up some test inputs\ndZ, linear_cache = linear_backward_test_case()\n\ndA_prev, dW, db = linear_backward(dZ, linear_cache)\nprint (\"dA_prev = \"+ str(dA_prev))\nprint (\"dW = \" + str(dW))\nprint (\"db = \" + str(db))",
"dA_prev = [[ 0.51822968 -0.19517421]\n [-0.40506361 0.15255393]\n [ 2.37496825 -0.89445391]]\ndW = [[-0.10076895 1.40685096 1.64992505]]\ndb = [[ 0.50629448]]\n"
]
],
[
[
"**Expected Output**: \n\n<table style=\"width:90%\">\n <tr>\n <td> **dA_prev** </td>\n <td > [[ 0.51822968 -0.19517421]\n [-0.40506361 0.15255393]\n [ 2.37496825 -0.89445391]] </td> \n </tr> \n \n <tr>\n <td> **dW** </td>\n <td > [[-0.10076895 1.40685096 1.64992505]] </td> \n </tr> \n \n <tr>\n <td> **db** </td>\n <td> [[ 0.50629448]] </td> \n </tr> \n \n</table>\n\n",
"_____no_output_____"
],
[
"### 6.2 - Linear-Activation backward\n\nNext, you will create a function that merges the two helper functions: **`linear_backward`** and the backward step for the activation **`linear_activation_backward`**. \n\nTo help you implement `linear_activation_backward`, we provided two backward functions:\n- **`sigmoid_backward`**: Implements the backward propagation for SIGMOID unit. You can call it as follows:\n\n```python\ndZ = sigmoid_backward(dA, activation_cache)\n```\n\n- **`relu_backward`**: Implements the backward propagation for RELU unit. You can call it as follows:\n\n```python\ndZ = relu_backward(dA, activation_cache)\n```\n\nIf $g(.)$ is the activation function, \n`sigmoid_backward` and `relu_backward` compute $$dZ^{[l]} = dA^{[l]} * g'(Z^{[l]}) \\tag{11}$$. \n\n**Exercise**: Implement the backpropagation for the *LINEAR->ACTIVATION* layer.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: linear_activation_backward\n\ndef linear_activation_backward(dA, cache, activation):\n \"\"\"\n Implement the backward propagation for the LINEAR->ACTIVATION layer.\n \n Arguments:\n dA -- post-activation gradient for current layer l \n cache -- tuple of values (linear_cache, activation_cache) we store for computing backward propagation efficiently\n activation -- the activation to be used in this layer, stored as a text string: \"sigmoid\" or \"relu\"\n \n Returns:\n dA_prev -- Gradient of the cost with respect to the activation (of the previous layer l-1), same shape as A_prev\n dW -- Gradient of the cost with respect to W (current layer l), same shape as W\n db -- Gradient of the cost with respect to b (current layer l), same shape as b\n \"\"\"\n linear_cache, activation_cache = cache\n \n if activation == \"relu\":\n ### START CODE HERE ### (≈ 2 lines of code)\n dZ = relu_backward(dA, activation_cache)\n dA_prev, dW, db = linear_backward(dZ, linear_cache)\n ### END CODE HERE ###\n \n elif activation == \"sigmoid\":\n ### START CODE HERE ### (≈ 2 lines of code)\n dZ = sigmoid_backward(dA, activation_cache)\n dA_prev, dW, db = linear_backward(dZ, linear_cache)\n ### END CODE HERE ###\n \n return dA_prev, dW, db",
"_____no_output_____"
],
[
"AL, linear_activation_cache = linear_activation_backward_test_case()\n\ndA_prev, dW, db = linear_activation_backward(AL, linear_activation_cache, activation = \"sigmoid\")\nprint (\"sigmoid:\")\nprint (\"dA_prev = \"+ str(dA_prev))\nprint (\"dW = \" + str(dW))\nprint (\"db = \" + str(db) + \"\\n\")\n\ndA_prev, dW, db = linear_activation_backward(AL, linear_activation_cache, activation = \"relu\")\nprint (\"relu:\")\nprint (\"dA_prev = \"+ str(dA_prev))\nprint (\"dW = \" + str(dW))\nprint (\"db = \" + str(db))",
"sigmoid:\ndA_prev = [[ 0.11017994 0.01105339]\n [ 0.09466817 0.00949723]\n [-0.05743092 -0.00576154]]\ndW = [[ 0.10266786 0.09778551 -0.01968084]]\ndb = [[-0.05729622]]\n\nrelu:\ndA_prev = [[ 0.44090989 0. ]\n [ 0.37883606 0. ]\n [-0.2298228 0. ]]\ndW = [[ 0.44513824 0.37371418 -0.10478989]]\ndb = [[-0.20837892]]\n"
]
],
[
[
"**Expected output with sigmoid:**\n\n<table style=\"width:100%\">\n <tr>\n <td > dA_prev </td> \n <td >[[ 0.11017994 0.01105339]\n [ 0.09466817 0.00949723]\n [-0.05743092 -0.00576154]] </td> \n\n </tr> \n \n <tr>\n <td > dW </td> \n <td > [[ 0.10266786 0.09778551 -0.01968084]] </td> \n </tr> \n \n <tr>\n <td > db </td> \n <td > [[-0.05729622]] </td> \n </tr> \n</table>\n\n",
"_____no_output_____"
],
[
"**Expected output with relu:**\n\n<table style=\"width:100%\">\n <tr>\n <td > dA_prev </td> \n <td > [[ 0.44090989 0. ]\n [ 0.37883606 0. ]\n [-0.2298228 0. ]] </td> \n\n </tr> \n \n <tr>\n <td > dW </td> \n <td > [[ 0.44513824 0.37371418 -0.10478989]] </td> \n </tr> \n \n <tr>\n <td > db </td> \n <td > [[-0.20837892]] </td> \n </tr> \n</table>\n\n",
"_____no_output_____"
],
[
"### 6.3 - L-Model Backward \n\nNow you will implement the backward function for the whole network. Recall that when you implemented the `L_model_forward` function, at each iteration, you stored a cache which contains (X,W,b, and z). In the back propagation module, you will use those variables to compute the gradients. Therefore, in the `L_model_backward` function, you will iterate through all the hidden layers backward, starting from layer $L$. On each step, you will use the cached values for layer $l$ to backpropagate through layer $l$. Figure 5 below shows the backward pass. \n\n\n<img src=\"images/mn_backward.png\" style=\"width:450px;height:300px;\">\n<caption><center> **Figure 5** : Backward pass </center></caption>\n\n** Initializing backpropagation**:\nTo backpropagate through this network, we know that the output is, \n$A^{[L]} = \\sigma(Z^{[L]})$. Your code thus needs to compute `dAL` $= \\frac{\\partial \\mathcal{L}}{\\partial A^{[L]}}$.\nTo do so, use this formula (derived using calculus which you don't need in-depth knowledge of):\n```python\ndAL = - (np.divide(Y, AL) - np.divide(1 - Y, 1 - AL)) # derivative of cost with respect to AL\n```\n\nYou can then use this post-activation gradient `dAL` to keep going backward. As seen in Figure 5, you can now feed in `dAL` into the LINEAR->SIGMOID backward function you implemented (which will use the cached values stored by the L_model_forward function). After that, you will have to use a `for` loop to iterate through all the other layers using the LINEAR->RELU backward function. You should store each dA, dW, and db in the grads dictionary. To do so, use this formula : \n\n$$grads[\"dW\" + str(l)] = dW^{[l]}\\tag{15} $$\n\nFor example, for $l=3$ this would store $dW^{[l]}$ in `grads[\"dW3\"]`.\n\n**Exercise**: Implement backpropagation for the *[LINEAR->RELU] $\\times$ (L-1) -> LINEAR -> SIGMOID* model.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: L_model_backward\n\ndef L_model_backward(AL, Y, caches):\n \"\"\"\n Implement the backward propagation for the [LINEAR->RELU] * (L-1) -> LINEAR -> SIGMOID group\n \n Arguments:\n AL -- probability vector, output of the forward propagation (L_model_forward())\n Y -- true \"label\" vector (containing 0 if non-cat, 1 if cat)\n caches -- list of caches containing:\n every cache of linear_activation_forward() with \"relu\" (it's caches[l], for l in range(L-1) i.e l = 0...L-2)\n the cache of linear_activation_forward() with \"sigmoid\" (it's caches[L-1])\n \n Returns:\n grads -- A dictionary with the gradients\n grads[\"dA\" + str(l)] = ... \n grads[\"dW\" + str(l)] = ...\n grads[\"db\" + str(l)] = ... \n \"\"\"\n grads = {}\n L = len(caches) # the number of layers\n m = AL.shape[1]\n Y = Y.reshape(AL.shape) # after this line, Y is the same shape as AL\n \n # Initializing the backpropagation\n ### START CODE HERE ### (1 line of code)\n dAL = - (np.divide(Y, AL) - np.divide(1 - Y, 1 - AL)) # derivative of cost with respect to AL\n ### END CODE HERE ###\n \n # Lth layer (SIGMOID -> LINEAR) gradients. Inputs: \"AL, Y, caches\". Outputs: \"grads[\"dAL\"], grads[\"dWL\"], grads[\"dbL\"]\n ### START CODE HERE ### (approx. 2 lines)\n current_cache = caches[-1]\n grads[\"dA\" + str(L)], grads[\"dW\" + str(L)], grads[\"db\" + str(L)] = linear_activation_backward(dAL, current_cache, activation = \"sigmoid\")\n ### END CODE HERE ###\n \n for l in reversed(range(L-1)):\n # lth layer: (RELU -> LINEAR) gradients.\n # Inputs: \"grads[\"dA\" + str(l + 2)], caches\". Outputs: \"grads[\"dA\" + str(l + 1)] , grads[\"dW\" + str(l + 1)] , grads[\"db\" + str(l + 1)] \n ### START CODE HERE ### (approx. 5 lines)\n current_cache = caches[l]\n dA_prev_temp, dW_temp, db_temp = linear_activation_backward(grads[\"dA\" + str(l + 2)], current_cache, activation = \"relu\")\n grads[\"dA\" + str(l + 1)] = dA_prev_temp\n grads[\"dW\" + str(l + 1)] = dW_temp\n grads[\"db\" + str(l + 1)] = db_temp\n ### END CODE HERE ###\n\n return grads",
"_____no_output_____"
],
[
"AL, Y_assess, caches = L_model_backward_test_case()\ngrads = L_model_backward(AL, Y_assess, caches)\nprint_grads(grads)",
"dW1 = [[ 0.41010002 0.07807203 0.13798444 0.10502167]\n [ 0. 0. 0. 0. ]\n [ 0.05283652 0.01005865 0.01777766 0.0135308 ]]\ndb1 = [[-0.22007063]\n [ 0. ]\n [-0.02835349]]\ndA1 = [[ 0.12913162 -0.44014127]\n [-0.14175655 0.48317296]\n [ 0.01663708 -0.05670698]]\n"
]
],
[
[
"**Expected Output**\n\n<table style=\"width:60%\">\n \n <tr>\n <td > dW1 </td> \n <td > [[ 0.41010002 0.07807203 0.13798444 0.10502167]\n [ 0. 0. 0. 0. ]\n [ 0.05283652 0.01005865 0.01777766 0.0135308 ]] </td> \n </tr> \n \n <tr>\n <td > db1 </td> \n <td > [[-0.22007063]\n [ 0. ]\n [-0.02835349]] </td> \n </tr> \n \n <tr>\n <td > dA1 </td> \n <td > [[ 0.12913162 -0.44014127]\n [-0.14175655 0.48317296]\n [ 0.01663708 -0.05670698]] </td> \n\n </tr> \n</table>\n\n",
"_____no_output_____"
],
[
"### 6.4 - Update Parameters\n\nIn this section you will update the parameters of the model, using gradient descent: \n\n$$ W^{[l]} = W^{[l]} - \\alpha \\text{ } dW^{[l]} \\tag{16}$$\n$$ b^{[l]} = b^{[l]} - \\alpha \\text{ } db^{[l]} \\tag{17}$$\n\nwhere $\\alpha$ is the learning rate. After computing the updated parameters, store them in the parameters dictionary. ",
"_____no_output_____"
],
[
"**Exercise**: Implement `update_parameters()` to update your parameters using gradient descent.\n\n**Instructions**:\nUpdate parameters using gradient descent on every $W^{[l]}$ and $b^{[l]}$ for $l = 1, 2, ..., L$. \n",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: update_parameters\n\ndef update_parameters(parameters, grads, learning_rate):\n \"\"\"\n Update parameters using gradient descent\n \n Arguments:\n parameters -- python dictionary containing your parameters \n grads -- python dictionary containing your gradients, output of L_model_backward\n \n Returns:\n parameters -- python dictionary containing your updated parameters \n parameters[\"W\" + str(l)] = ... \n parameters[\"b\" + str(l)] = ...\n \"\"\"\n \n L = len(parameters) // 2 # number of layers in the neural network\n\n # Update rule for each parameter. Use a for loop.\n ### START CODE HERE ### (≈ 3 lines of code)\n for l in range(1,L+1):\n parameters[\"W\" + str(l)] -= learning_rate * grads[\"dW\" + str(l)] \n parameters[\"b\" + str(l)] -= learning_rate * grads[\"db\" + str(l)] \n ### END CODE HERE ###\n return parameters",
"_____no_output_____"
],
[
"parameters, grads = update_parameters_test_case()\nparameters = update_parameters(parameters, grads, 0.1)\n\nprint (\"W1 = \"+ str(parameters[\"W1\"]))\nprint (\"b1 = \"+ str(parameters[\"b1\"]))\nprint (\"W2 = \"+ str(parameters[\"W2\"]))\nprint (\"b2 = \"+ str(parameters[\"b2\"]))",
"W1 = [[-0.59562069 -0.09991781 -2.14584584 1.82662008]\n [-1.76569676 -0.80627147 0.51115557 -1.18258802]\n [-1.0535704 -0.86128581 0.68284052 2.20374577]]\nb1 = [[-0.04659241]\n [-1.28888275]\n [ 0.53405496]]\nW2 = [[-0.55569196 0.0354055 1.32964895]]\nb2 = [[-0.84610769]]\n"
]
],
[
[
"**Expected Output**:\n\n<table style=\"width:100%\"> \n <tr>\n <td > W1 </td> \n <td > [[-0.59562069 -0.09991781 -2.14584584 1.82662008]\n [-1.76569676 -0.80627147 0.51115557 -1.18258802]\n [-1.0535704 -0.86128581 0.68284052 2.20374577]] </td> \n </tr> \n \n <tr>\n <td > b1 </td> \n <td > [[-0.04659241]\n [-1.28888275]\n [ 0.53405496]] </td> \n </tr> \n <tr>\n <td > W2 </td> \n <td > [[-0.55569196 0.0354055 1.32964895]]</td> \n </tr> \n \n <tr>\n <td > b2 </td> \n <td > [[-0.84610769]] </td> \n </tr> \n</table>\n",
"_____no_output_____"
],
[
"\n## 7 - Conclusion\n\nCongrats on implementing all the functions required for building a deep neural network! \n\nWe know it was a long assignment but going forward it will only get better. The next part of the assignment is easier. \n\nIn the next assignment you will put all these together to build two models:\n- A two-layer neural network\n- An L-layer neural network\n\nYou will in fact use these models to classify cat vs non-cat images!",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
cb341d4dce6d3bb796ee078de45321986bf5d44d | 474,719 | ipynb | Jupyter Notebook | simplemods/VegDepAngle.ipynb | tuguldurs/lacuna | 6e81bbd898f852f9af696b3c44e10a97f84d2736 | [
"MIT"
] | null | null | null | simplemods/VegDepAngle.ipynb | tuguldurs/lacuna | 6e81bbd898f852f9af696b3c44e10a97f84d2736 | [
"MIT"
] | null | null | null | simplemods/VegDepAngle.ipynb | tuguldurs/lacuna | 6e81bbd898f852f9af696b3c44e10a97f84d2736 | [
"MIT"
] | null | null | null | 460.445199 | 164,492 | 0.937755 | [
[
[
"## Some exploratory data analysis and the development of vegetation dependent angle model\n\nauthors: Tuguldur Sukhbold",
"_____no_output_____"
]
],
[
[
"datapath = '../d/'\n\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\n\nfrom itertools import product as iterp\nfrom math import sin, cos, radians, pi\nfrom sklearn.metrics import mean_absolute_error\nfrom skimage.transform import warp_polar\nfrom skimage.io import imread as rdtif\n\nnp.random.seed(123)\n\ntrain = pd.read_csv(f'{datapath}train-unique.csv')\netrain = pd.read_csv(f'{datapath}extra_train.csv')\n#train = pd.concat([train, etrain], ignore_index=True)",
"_____no_output_____"
],
[
"psz = train.PlotSize_acres\n\nx, y = train.x, train.y\nd = np.sqrt(x*x + y*y)\n\nplt.hist(d, density=True, color='steelblue', alpha=0.5, bins=30)\nplt.xlabel('distance [km]')\nplt.ylabel('PDF')",
"_____no_output_____"
],
[
"adeg = np.rad2deg(np.arctan2(y, x))\narad = np.arctan2(y, x)\n\nplt.figure(figsize=(10,8))\nplt.scatter(adeg, d, c=psz, s=psz*150, cmap='Set3', alpha=0.75)\nplt.xlabel('angle [deg]')\nplt.ylabel('distance [km]')\nplt.ylim(0,1.79)\nplt.xlim(-180, 180)\nplt.colorbar(label='Area [acres]')",
"_____no_output_____"
],
[
"fig = plt.figure(figsize=(12,10))\nax = fig.add_subplot(projection='polar')\nc = ax.scatter(arad, d, c=psz, s=psz*150, cmap='Set3', alpha=0.75)",
"_____no_output_____"
],
[
"def mkFreqHist(ax, df, rng):\n x, y = df.x, df.y\n d = np.sqrt(x*x + y*y)\n w = np.ones_like(d) / len(d)\n ax.hist(d, weights=w, color='gray', alpha=0.75, bins=10)\n ax.set_xlabel('distance [km]')\n ax.set_ylabel('Frequency')\n ax.set_title(f'{rng[0]} < Size [acres] <= {rng[1]} (tot={len(d)})')\n\n \n\nrngs = [(0, 0.2), (0.2, 0.5), (0.5, 1), (1, 100)]\nfig, axes = plt.subplots(ncols=2, nrows=2, figsize=(10,8), tight_layout=True)\nk = 0\nfor i,j in iterp(range(2), range(2)):\n subdf = train.loc[(train.PlotSize_acres > rngs[k][0]) & (train.PlotSize_acres <= rngs[k][1])]\n mkFreqHist(axes[i,j], subdf, rngs[k])\n k += 1",
"_____no_output_____"
]
],
[
[
"## 2. Models checked on train set",
"_____no_output_____"
]
],
[
[
"def getSentinelTimeData(path2tif, filterCloudy=True):\n \"\"\"\n process input Sentinel TIFF file to map its contents into a dictionary\n with filter keys and monthly images as values\n \n note: it won't process images with number of channels other than 192\n \n when filterCloudy flag is True:\n - excludes cloudy images based on cloud-mask (filter#16)\n - final dictionary contains 13 real filter data\n \"\"\"\n \n # filter and month IDs\n filters = np.arange(16, dtype=int) + 1\n months = np.arange(12) + 1\n\n # read TIFF file into 3D array\n img = rdtif(path2tif)\n \n # stop if its a funky image, proceed only if there are usual 192 channels:\n if img.shape[-1] != 192: exit(f' cannot process this funky image with {img.shape[-1]} channels')\n \n # initialize the dict with empty list for each filter\n d = {}\n for f in filters: d[f] = []\n \n # populate with 2D images\n for i, j in iterp(months, filters):\n\n channel = (i - 1) * len(filters) + j - 1\n \n # append normalized image\n maxFrame = np.amax(img[:, :, channel])\n if maxFrame == 0.:\n d[j].append(img[:, :, channel])\n else:\n d[j].append(img[:, :, channel] / maxFrame)\n \n # exclude cloudy images\n if filterCloudy:\n \n for f in filters:\n for month in months:\n \n # max value of cloud mask image\n maxCloudMask = np.amax(d[16][month-1])\n \n # its cloudy if max is not 0\n if maxCloudMask != 0: d[f][month-1] = None\n \n # we don't need the last 3 elements\n del d[16] # cloudmask itself\n del d[15] # QA20\n del d[14] # QA10\n\n return d\n\n\ndef getIndex(d, ID):\n l = []\n for m in range(len(d[1])):\n if d[1][m] is None:\n indx = None\n else:\n if ID == 'NDVI': indx = (d[7][m] - d[4][m]) / (d[7][m] + d[4][m])\n if ID == 'TBWI': indx = (d[10][m] - d[12][m]) / d[11][m]\n \n l.append(indx) \n\n return l\n\n\ndef getVegFreq(img):\n radius = int(len(img) / 2)\n polar = warp_polar(img, radius=radius).T\n freq = np.array([sum(polar[:, i]) for i in range(max(polar.shape))])\n return freq / np.sum(freq)\n\n\ndef getSampleF4(dS):\n NDVI= getIndex(dS, ID = 'NDVI')\n if dS[4][6] is not None:\n sample = dS[4][6]\n k = 6\n elif dS[4][5] is not None:\n sample = dS[4][5]\n k=5\n else:\n for i in range(3,12):\n print(i, type(dS[4][i]))\n if dS[4][i] is not None:\n sample = dS[4][i]\n k=i\n break\n return sample, NDVI[k]\n\n\ndef getPszRange(szval, qual, realTest=False):\n if not realTest:\n rng = (0, 0.2)\n if qual == 3:\n if szval > 0.2 and szval <= 0.5: rng = (0.25, 0.5)\n if szval > 0.5 and szval <= 1.0: rng = (0.5, 1)\n if szval > 1: rng = (1, 100)\n \n else: # assume always bad quality in realTest\n rng = (0, 0.2)\n \n return rng\n\n\ndef getPszRange_Test(): \n return (0, 0.2)\n\n\ndef getDistance(rng):\n sdf = train.loc[(train.PlotSize_acres > rng[0]) & (train.PlotSize_acres <= rng[1])]\n x, y = sdf.x, sdf.y\n d = np.sqrt(x*x + y*y)\n w = np.ones_like(d) / len(d)\n return np.random.choice(d, p=w)\n\n\ndef getXY(d, adeg):\n \"\"\"\n (x,y) displacements in [km] based on distance (d[km]) and angle (adeg[degrees])\n \"\"\"\n arad = pi / 2 - radians(adeg)\n return d * cos(arad)/2, d * sin(arad)/2\n\n\ndef getScore(x,y, M_x, M_y):\n \"\"\"\n MAE score based on test (x,y) and predicted (M_x, M_y)\n \"\"\"\n tst = np.vstack((x, y))\n pred = np.vstack((M_x, M_y))\n return mean_absolute_error(tst, pred)",
"_____no_output_____"
]
],
[
[
"### 2.1 Zeros and Means\n\nHere all (x,y) predictions are set to all zeros or all mean values; these scores will be used as our benchmark:",
"_____no_output_____"
]
],
[
[
"M_x, M_y = np.zeros(len(x)), np.zeros(len(y))\nzeros_score = getScore(x, y, M_x, M_y)\n\nM_x = np.zeros(len(x)) + np.mean(x)\nM_y = np.zeros(len(y)) + np.mean(y)\nmeans_score = getScore(x, y, M_x, M_y)\n\nprint(f' zeros: {zeros_score:.4f} means: {means_score:.4f}')",
" zeros: 0.2022 means: 0.2049\n"
]
],
[
[
"### 2.2 Uniform Angle and Exact Distances\n\nHere the angles are drawn randomly from uniform, and distances from the exact training distribution:",
"_____no_output_____"
]
],
[
[
"M_adeg = np.random.uniform(low=-180, high=180, size=(len(train), ))\n\nM_d = np.zeros(len(train))\nfor i in range(len(train)):\n rng = getPszRange(train.PlotSize_acres[i], train.Quality[i])\n M_d[i] = getDistance(rng)\n\nM_x, M_y = np.zeros(len(M_d)), np.zeros(len(M_d))\nfor i in range(len(M_adeg)): M_x[i], M_y[i] = getXY(M_d[i], M_adeg[i])",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(ncols=3, figsize=(15,5), tight_layout=True)\nax[0].hist(M_d, bins=30)\nax[0].set(ylabel='frequency', xlabel='distance [km]')\nax[1].scatter(d, M_d)\nax[1].plot(d,d, color='black')\nax[1].set(ylabel='model distance [km]', xlabel='test distance [km]')\nax[2].scatter(y, M_y)\nax[2].plot(y,y, color='black')\nax[2].set(ylabel='model y-component [km]', xlabel='test y-component [km]')",
"_____no_output_____"
],
[
"getScore(x,y, M_x, M_y)",
"_____no_output_____"
]
],
[
[
"### 2.3 Uniform Angle and Uniform Limited Distances\n\nHere the angles are still drawn randomly from uniform, but the distances are now draw from a limited uniform in the range [0, 0.25] km:",
"_____no_output_____"
]
],
[
[
"M_adeg = np.random.uniform(low=-180, high=180, size=(len(train), ))\nM_d = np.random.uniform(low=0, high=0.25, size=(len(train), ))\n\nM_x, M_y = np.zeros(len(M_d)), np.zeros(len(M_d))\nfor i in range(len(M_adeg)): M_x[i], M_y[i] = getXY(M_d[i], M_adeg[i])",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(ncols=3, figsize=(15,5), tight_layout=True)\nax[0].hist(M_d, bins=30)\nax[0].set(ylabel='frequency', xlabel='distance [km]')\nax[1].scatter(d, M_d)\nax[1].plot(d,d, color='black')\nax[1].set(ylabel='model distance [km]', xlabel='test distance [km]', xlim=[0,1])\nax[2].scatter(y, M_y)\nax[2].plot(y,y, color='black')\nax[2].set(ylabel='model y-component [km]', xlabel='test y-component [km]')",
"_____no_output_____"
],
[
"getScore(x,y, M_x, M_y)",
"_____no_output_____"
]
],
[
[
"### 2.4 Vegetation Dependent Angle and Uniform Limited Distances\n\nNow the angles are drawn from a distribution based on the vegetation map of Sentinel-2 images. The distances are still draw from a limited uniform in the range [0, 0.25] km:",
"_____no_output_____"
]
],
[
[
"fieldID = 'a5e136b4'\nimg = rdtif(f'{datapath}sentinel/{fieldID}.tif')\ndS = getSentinelTimeData(f'{datapath}sentinel/{fieldID}.tif')\ndS[4][6] is None",
"_____no_output_____"
],
[
"M_adeg = np.array([])\nM_d = np.array([])\nM_x = np.array([])\nM_y = np.array([])\nx,y = np.array([]), np.array([])\n\nfor i in range(len(train)):\n fieldID = train.ID[i].split('_')[-1] \n img = rdtif(f'{datapath}sentinel/{fieldID}.tif')\n \n if img.shape[-1] == 192:\n dS = getSentinelTimeData(f'{datapath}sentinel/{fieldID}.tif')\n \n # normalized mask\n sampleF4, NDVI = getSampleF4(dS)\n img = sampleF4 * NDVI - NDVI\n img = img + abs(np.amin(img))\n img = img / np.amax(img)\n img[img > 0.5] = 0\n img[img > 0] = 1\n \n # draw angle based on vegetation probability\n probV = getVegFreq(img) \n adeg = np.random.choice(np.arange(360)-180, p=probV)\n M_adeg = np.append(M_adeg, adeg)\n \n # random distance\n dval = np.random.uniform(low=0, high=0.25)\n M_d = np.append(M_d, dval)\n \n # model x,y\n xval, yval = getXY(dval, adeg)\n M_x = np.append(M_x, xval)\n M_y = np.append(M_y, yval)\n \n # corresponding test x,y\n x = np.append(x, train.x[i])\n y = np.append(y, train.y[i])",
"_____no_output_____"
],
[
"getScore(x,y, M_x, M_y)",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(tight_layout=True)\nax.scatter(y, M_y)\nax.plot(y,y, color='black')\nax.set(ylabel='model y-component [km]', xlabel='test y-component [km]')",
"_____no_output_____"
]
],
[
[
"## Test and Submission",
"_____no_output_____"
]
],
[
[
"test = pd.read_csv(f'{datapath}test.csv')\n\nnp.random.seed(0)\n\nM_x = np.array([])\nM_y = np.array([])\n\nfor i in range(len(test)):\n fieldID = test.ID[i].split('_')[-1] \n img = rdtif(f'{datapath}sentinel/{fieldID}.tif')\n \n if img.shape[-1] == 192:\n dS = getSentinelTimeData(f'{datapath}sentinel/{fieldID}.tif')\n \n # normalized mask\n sampleF4, NDVI = getSampleF4(dS)\n img = sampleF4 * NDVI - NDVI\n img = img + abs(np.amin(img))\n img = img / np.amax(img)\n img[img > 0.5] = 0\n img[img > 0] = 1\n \n # draw angle based on vegetation probability\n probV = getVegFreq(img) \n adeg = np.random.choice(np.arange(360)-180, p=probV)\n \n # random distance\n dval = np.random.uniform(low=0.1, high=0.25)\n \n # model x,y\n xval, yval = getXY(dval, adeg)\n M_x = np.append(M_x, xval)\n M_y = np.append(M_y, yval)\n \n else:\n M_x = np.append(M_x, 0.0)\n M_y = np.append(M_y, 0.0)\n \n",
"3 <class 'numpy.ndarray'>\n3 <class 'numpy.ndarray'>\n3 <class 'numpy.ndarray'>\n3 <class 'numpy.ndarray'>\n3 <class 'NoneType'>\n4 <class 'numpy.ndarray'>\n3 <class 'numpy.ndarray'>\n3 <class 'numpy.ndarray'>\n"
],
[
"submit = pd.read_csv(f'{datapath}sample_submission.csv')\n\nsubmit.x = M_x\nsubmit.y = M_y\n\nsubmit.head()",
"_____no_output_____"
],
[
"submit.to_csv('limRange_SentinelDepAngle_submission.csv', index=False)",
"_____no_output_____"
],
[
"plt.scatter(M_x, M_y)",
"_____no_output_____"
]
],
[
[
"### Zeros and Means",
"_____no_output_____"
]
],
[
[
"train = pd.read_csv(f'{datapath}train-unique.csv')\n \nsubmit = pd.read_csv(f'{datapath}sample_submission.csv')\n\nsubmit.x = 0\nsubmit.y = 0\n\nsubmit.to_csv('zeros_submission.csv', index=False)\n\nsubmit.x = np.mean(train.x)\nsubmit.y = np.mean(train.y)\n\nsubmit.to_csv('means_submission.csv', index=False)\n\nsubmit.head()",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
cb342af7f9dc79b267280af16982a6f0f7d44af8 | 277,947 | ipynb | Jupyter Notebook | ipynb/.ipynb_checkpoints/large-exp-unigram-analysis-checkpoint.ipynb | kemskems/otdet | a5e52e2d5ab1aea2f1b63676c87a051f187567da | [
"MIT"
] | 1 | 2015-10-03T18:20:25.000Z | 2015-10-03T18:20:25.000Z | ipynb/old/large-exp-unigram-analysis.ipynb | kemskems/otdet | a5e52e2d5ab1aea2f1b63676c87a051f187567da | [
"MIT"
] | null | null | null | ipynb/old/large-exp-unigram-analysis.ipynb | kemskems/otdet | a5e52e2d5ab1aea2f1b63676c87a051f187567da | [
"MIT"
] | null | null | null | 129.097538 | 13,561 | 0.760274 | [
[
[
"empty"
]
]
] | [
"empty"
] | [
[
"empty"
]
] |
cb343518da8f34929b299fb9a5f3b8ef3de66534 | 4,306 | ipynb | Jupyter Notebook | final.ipynb | melekayas/hu-bby162-2021 | b5efa68851a9142b6d6b1bf4edf916e0ff1d33c6 | [
"MIT"
] | null | null | null | final.ipynb | melekayas/hu-bby162-2021 | b5efa68851a9142b6d6b1bf4edf916e0ff1d33c6 | [
"MIT"
] | null | null | null | final.ipynb | melekayas/hu-bby162-2021 | b5efa68851a9142b6d6b1bf4edf916e0ff1d33c6 | [
"MIT"
] | null | null | null | 33.640625 | 226 | 0.467719 | [
[
[
"<a href=\"https://colab.research.google.com/github/melekayas/hu-bby162-2021/blob/main/final.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"\ndosya = \"/content/drive/MyDrive/Colab Notebooks/final.txt\"\ndef eserListesi():\n dosya = \"/content/drive/MyDrive/Colab Notebooks/final.txt\"\n f = open(dosya, \"r\") \n\n for line in f.readlines():\n print(line)\n\n f.close()\n\n\n\ndef eserKaydet():\n ad = input(\" Eser adı giriniz: \")\n yazar = input(\" Yazar adı giriniz: \")\n yayın = input(\" Yayınevi giriniz: \")\n basım = input(\" Basım tarihi giriniz: \")\n Isbn = input(\" ISBN numarası giriniz: \")\n\n with open(\"/content/drive/MyDrive/Colab Notebooks/final.txt\", \"a\", encoding=\"utf-8\") as file:\n file.write(ad+ \",\"+yazar+ \".\"+yayın+ \",\"+basım+ \",\"+Isbn+\"\\n\")\n\ndef menu():\n print(\" *** Kütüphane Bilgi Sistemi ***\")\n while True:\n islem = input(\"1- Eserleri görüntüle\\n2- Eserleri kaydet\\n3- Çıkış yap.\")\n \n if islem == \"1\":\n eserListesi()\n elif islem == \"2\":\n eserKaydet()\n elif islem == \"3\":\n print(\"Çıkış yapılıyor.\")\n break\nmenu()\n",
" *** Kütüphane Bilgi Sistemi ***\n1- Eserleri görüntüle\n2- Eserleri kaydet\n3- Çıkış yap.1\nBir Idam Mahkumunun Son Gunu, Victor Hugo, Turkiye İş Bankası, 2013, 9786053609902\n\n\n\nDönüşüm, Franz Kafka, Türkiye İş Bankası, 2020, 9786053609322\n\n\n\nBin Dokuz Yüz Seksen Dört, George Orwell, Can Yayınları, 2011, 9789750718533\n\n\n\nBaskerville'lerin Köpeği, Sherlock Holmes; Maviçatı Yayınları, 2018, 9789752401259\n\n\n\nSuç Ve Ceza, Fyodor Mihaylovic Dostoyevski, Türkiye İş Bankası, 2020, 9789754589023\n\nTtutunamayanlar,Oğuz Atay.Türkiye İş Bankası,2020,9789757894356\n\nBilinmeyen Bir Kadının Mektubu,Stefan Zweig.Türkiye İş Bankası,2020,9786053606604\n\n1- Eserleri görüntüle\n2- Eserleri kaydet\n3- Çıkış yap.2\n Eser adı giriniz: Kızıl\n Yazar adı giriniz: Stefan Zweig\n Yayınevi giriniz: Türkiye İş Bankası\n Basım tarihi giriniz: 2020\n ISBN numarası giriniz: 9786052954539\n1- Eserleri görüntüle\n2- Eserleri kaydet\n3- Çıkış yap.3\nÇıkış yapılıyor.\n"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
]
] |
cb3440346c9f8fc8f9867473fc16a352cf211b01 | 15,644 | ipynb | Jupyter Notebook | table2sql.ipynb | LotuSrc/SQL2NL | e34838214f7911210c7229000aa7b1d6368f7602 | [
"Apache-2.0"
] | 1 | 2021-03-11T15:40:03.000Z | 2021-03-11T15:40:03.000Z | table2sql.ipynb | LotuSrc/SQL2NL | e34838214f7911210c7229000aa7b1d6368f7602 | [
"Apache-2.0"
] | null | null | null | table2sql.ipynb | LotuSrc/SQL2NL | e34838214f7911210c7229000aa7b1d6368f7602 | [
"Apache-2.0"
] | null | null | null | 40.528497 | 193 | 0.440552 | [
[
[
"import time\nimport numpy as np\nimport random\n\ndef write_table2sql(table, engine, sql=None):\n\n def select_col_agg(mask):\n \"\"\"\n select col agg pair\n :return:\n \"\"\"\n col_num = len(table['header'])\n sel_idx = np.argmax(np.random.rand(col_num) * mask)\n sel_type = table['types'][sel_idx]\n if sel_type == 'text':\n sel_agg = random.sample([0, 3], 1)\n else:\n sel_agg = random.sample([0,1,2,3,4,5], 1)\n sel_agg = sel_agg[0]\n return sel_idx, sel_agg\n\n def select_cond_op(type):\n if type == 'text':\n return 0\n else:\n flag = random.randint(0, 2)\n return flag\n\n datas = []\n\n for j in range(1):\n data = {}\n sql = {}\n agg = None\n sel = None\n conds = []\n data['table_id'] = table['id']\n mask = np.asarray([1] * len(table['header']))\n ret = None\n # make sure at least one condition\n cnt = 0\n while(1):\n cnt += 1\n col_num = len(table['header'])\n sel_idx = np.argmax(np.random.rand(col_num))\n sel_type = table['types'][sel_idx]\n cond_op = select_cond_op(sel_type)\n rows = table['rows']\n if len(rows) == 0:\n return []\n row_num = len(rows)\n select_row = random.randint(0, row_num-1)\n cond_value = rows[select_row][sel_idx]\n if len(str(cond_value).split()) > 20 or str(cond_value) == '':\n continue\n conds.append([sel_idx, cond_op, cond_value])\n \n start = time.time()\n ret = engine.execute(table['id'], 0, 0, conds, ret_rows=True)\n \n if time.time() - start > 1:\n mask[sel_idx] = -1\n break\n \n if len(ret) != 0:\n mask[sel_idx] = -1\n break\n\n conds.pop()\n\n if len(ret) != 0:\n \n for i in range(min(3, len(ret[0])-1)):\n col_num = len(table['header'])\n sel_idx = np.argmax(np.random.rand(col_num) * mask)\n sel_type = table['types'][sel_idx]\n cond_op = select_cond_op(sel_type)\n rows = ret\n row_num = len(rows)\n select_row = random.randint(0, row_num-1)\n\n cond_value = list(rows[select_row])[sel_idx]\n conds.append([sel_idx, cond_op, cond_value])\n ret = engine.execute(table['id'], 0, 0, conds, ret_rows=True)\n # result doesn't change\n if len(ret) == row_num:\n conds.pop()\n break\n\n if len(str(cond_value).split()) > 20 or str(cond_value) == '':\n conds.pop()\n break\n mask[sel_idx] = -1\n if len(ret) == 0:\n break\n\n sel_idx, sel_agg = select_col_agg(mask)\n sel = sel_idx\n agg = sel_agg\n sql['agg'] = agg\n sql['sel'] = sel\n sql['conds'] = conds\n data['sql'] = sql\n\n question = sql2qst(sql, table)\n data['question'] = question\n datas.append(data)\n\n return datas",
"_____no_output_____"
],
[
"op_sql_dict = {0: \"=\", 1: \">\", 2: \"<\", 3: \"OP\"}\nagg_sql_dict = {0: \"\", 1: \"MAX\", 2: \"MIN\", 3: \"COUNT\", 4: \"SUM\", 5: \"AVG\"}\n\nagg_str_dict = {0: \"What is \", 1: \"What is the maximum of \", 2: \"What is the minimum \", 3: \"What is the number of \", 4: \"What is the sum of \", 5: \"What is the average of \"}\nop_str_dict = {0: \"is\", 1: \"is more than\", 2: \"is less than\", 3: \"\"}\n\ndef sql2qst(sql, table):\n select_index = sql['sel']\n aggregation_index = sql['agg']\n conditions = sql['conds']\n\n # select part\n select_part = \"\"\n select_str = table['header'][select_index]\n agg_str = agg_str_dict[aggregation_index]\n select_part += '{}{}'.format(agg_str, select_str)\n\n # where part\n where_part = []\n for col_index, op, val in conditions:\n cond_col = table['header'][col_index]\n where_part.append('{} {} {}'.format(cond_col, op_str_dict[op], val))\n # print('where part:', where_part)\n final_question = \"{} that {}\".format(select_part, ' and '.join(where_part))\n # print('final question:', final_question)\n return final_question",
"_____no_output_____"
],
[
"import records\nfrom sqlalchemy import *\nimport re, time\nfrom babel.numbers import parse_decimal, NumberFormatError\n\n\nschema_re = re.compile(r'\\((.+)\\)') # group (.......) dfdf (.... )group\nnum_re = re.compile(r'[-+]?\\d*\\.\\d+|\\d+') # ? zero or one time appear of preceding character, * zero or several time appear of preceding character.\n# Catch something like -34.34, .4543,\n# | is 'or'\n\nagg_ops = ['', 'MAX', 'MIN', 'COUNT', 'SUM', 'AVG']\ncond_ops = ['=', '>', '<', 'OP']\n\nclass DBEngine:\n\n def __init__(self, fdb):\n self.db = create_engine('sqlite:///{}'.format(fdb))\n self.conn = self.db.connect()\n self.table_id = ''\n self.schema_str = ''\n\n def execute_query(self, table_id, query, *args, **kwargs):\n return self.execute(table_id, query.sel_index, query.agg_index, query.conditions, *args, **kwargs)\n\n def execute(self, table_id, select_index, aggregation_index, conditions, lower=True, ret_rows=False):\n if not table_id.startswith('table'):\n table_id = 'table_{}'.format(table_id.replace('-', '_'))\n\n start = time.time()\n if table_id != self.table_id:\n self.table_id = table_id\n table_info = self.conn.execute('SELECT sql from sqlite_master WHERE tbl_name = :name', name=table_id).fetchall()[0].sql.replace('\\n','')\n self.schema_str = schema_re.findall(table_info)[0]\n\n schema = {}\n for tup in self.schema_str.split(', '):\n c, t = tup.split()\n schema[c] = t\n select = 'col{}'.format(select_index)\n agg = agg_ops[aggregation_index]\n if agg:\n select = '{}({})'.format(agg, select)\n if ret_rows is True:\n select = '*'\n where_clause = []\n where_map = {}\n for col_index, op, val in conditions:\n if lower and (isinstance(val, str) or isinstance(val, str)):\n val = val.lower()\n if schema['col{}'.format(col_index)] == 'real' and not isinstance(val, (int, float)):\n try:\n # print('!!!!!!value of val is: ', val, 'type is: ', type(val))\n # val = float(parse_decimal(val)) # somehow it generates error.\n val = float(parse_decimal(val, locale='en_US'))\n # print('!!!!!!After: val', val)\n\n except NumberFormatError as e:\n try:\n val = float(num_re.findall(val)[0]) # need to understand and debug this part.\n except:\n # Although column is of number, selected one is not number. Do nothing in this case.\n pass\n where_clause.append('col{} {} :col{}'.format(col_index, cond_ops[op], col_index))\n where_map['col{}'.format(col_index)] = val\n where_str = ''\n if where_clause:\n where_str = 'WHERE ' + ' AND '.join(where_clause)\n query = 'SELECT {} FROM {} {}'.format(select, table_id, where_str)\n\n out = self.conn.execute(query, **where_map)\n\n if ret_rows is False:\n return [o[0] for o in out]\n return [o for o in out]\n def execute_return_query(self, table_id, select_index, aggregation_index, conditions, lower=True):\n if not table_id.startswith('table'):\n table_id = 'table_{}'.format(table_id.replace('-', '_'))\n table_info = self.db.query('SELECT sql from sqlite_master WHERE tbl_name = :name', name=table_id).all()[0].sql.replace('\\n','')\n schema_str = schema_re.findall(table_info)[0]\n schema = {}\n for tup in schema_str.split(', '):\n c, t = tup.split()\n schema[c] = t\n select = 'col{}'.format(select_index)\n agg = agg_ops[aggregation_index]\n if agg:\n select = '{}({})'.format(agg, select)\n where_clause = []\n where_map = {}\n for col_index, op, val in conditions:\n if lower and (isinstance(val, str) or isinstance(val, str)):\n val = val.lower()\n if schema['col{}'.format(col_index)] == 'real' and not isinstance(val, (int, float)):\n try:\n # print('!!!!!!value of val is: ', val, 'type is: ', type(val))\n # val = float(parse_decimal(val)) # somehow it generates error.\n val = float(parse_decimal(val, locale='en_US'))\n # print('!!!!!!After: val', val)\n\n except NumberFormatError as e:\n val = float(num_re.findall(val)[0])\n where_clause.append('col{} {} :col{}'.format(col_index, cond_ops[op], col_index))\n where_map['col{}'.format(col_index)] = val\n where_str = ''\n if where_clause:\n where_str = 'WHERE ' + ' AND '.join(where_clause)\n query = 'SELECT {} AS result FROM {} {}'.format(select, table_id, where_str)\n #print query\n out = self.db.query(query, **where_map)\n\n\n# return [o.result for o in out], query\n return [o[0] for o in out], query\n def show_table(self, table_id):\n if not table_id.startswith('table'):\n table_id = 'table_{}'.format(table_id.replace('-', '_'))\n rows = self.db.query('select * from ' +table_id)\n print(rows.dataset)",
"_____no_output_____"
],
[
"import json\n\nclass NpEncoder(json.JSONEncoder):\n def default(self, obj):\n if isinstance(obj, np.integer):\n return int(obj)\n elif isinstance(obj, np.floating):\n return float(obj)\n elif isinstance(obj, np.ndarray):\n return obj.tolist()\n else:\n return super(NpEncoder, self).default(obj)\n\nimport numpy as np\nwith open('train.tables.jsonl', 'r') as fr:\n tables = []\n for table in fr:\n table = json.loads(table)\n if '' in table['header']:\n continue\n tables.append(table)\n \nengine = DBEngine('train.db')\nwith open(\"train_augment.jsonl\",\"w\") as f:\n for i in range(1000):\n probs = np.random.rand(len(tables))\n table_i = tables[np.argmax(probs)]\n data = write_table2sql(table_i, engine)\n if len(data) == 0:\n print('couldnt find a valid sql!')\n for js in data:\n js[\"phase\"] = js[\"table_id\"][0]\n agg_str = ['', 'max ', 'min ', 'count ', 'sum ', 'avg ']\n op_str = ['=', '>', '<']\n\n js1 = {}\n sql_str = ''\n sql_str += 'select '\n sql_str += agg_str[js['sql']['agg']]\n sql_str += table_i['header'][js['sql']['sel']].lower() + ' '\n sql_str += 'where '\n for j in range(len(js['sql']['conds'])):\n sql_str += table_i['header'][js['sql']['conds'][j][0]].lower() + ' '\n sql_str += op_str[js['sql']['conds'][j][1]] + ' '\n sql_str += str(js['sql']['conds'][j][2]).lower()\n if len(js['sql']['conds']) > 1 and j != len(js['sql']['conds']) - 1:\n sql_str += ' and '\n src = sql_str.split(' ')\n trg = js['question'].lower().split(' ')\n while (trg[-1] == ''):\n trg = trg[:-1]\n if trg[-1][-1] == '?':\n trg[-1] = trg[-1][:-1]\n trg += ['?']\n js['src'] = src\n js['trg'] = trg\n f.write(json.dumps(js, cls=NpEncoder) + '\\n')\n\n print('finished!')",
"finished!\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code"
]
] |
cb3445aad8db8deb439836a868cb6742b08e9424 | 12,423 | ipynb | Jupyter Notebook | previsao_de_probabilidade_em_machine_learning.ipynb | sales-victor/probabilidades_e_redes_bayesianas | 1c6c68cdbeeb70b10553bcc006626dec477a00ed | [
"CC0-1.0"
] | null | null | null | previsao_de_probabilidade_em_machine_learning.ipynb | sales-victor/probabilidades_e_redes_bayesianas | 1c6c68cdbeeb70b10553bcc006626dec477a00ed | [
"CC0-1.0"
] | null | null | null | previsao_de_probabilidade_em_machine_learning.ipynb | sales-victor/probabilidades_e_redes_bayesianas | 1c6c68cdbeeb70b10553bcc006626dec477a00ed | [
"CC0-1.0"
] | null | null | null | 29.720096 | 288 | 0.418337 | [
[
[
"<a href=\"https://colab.research.google.com/github/sales-victor/probabilidades_e_redes_bayesianas/blob/main/previsao_de_probabilidade_em_machine_learning.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"###Importações",
"_____no_output_____"
]
],
[
[
"import pandas as pd \nfrom scipy import stats \nimport math \nimport numpy as np \nfrom sklearn.naive_bayes import GaussianNB",
"_____no_output_____"
],
[
"#Importando a base de dados em csv \ndataset = pd.read_csv('credit_data.csv') #Atribuindo os dados à variável \ndataset.dropna(inplace=True) #Removendo os dados nulos ou faltantes da base de dados \ndataset.head() #Imprimindo os 5 primeiros dados (cabeçalho)",
"_____no_output_____"
],
[
"X = dataset.iloc[:, 1:4].values #Atribuindo à variável X apenas as colunas \"income\", \"age\" e \"loan\" (.values atribui as apenas os valores na forma do numpy array)\nX #imprimindo os valores em array",
"_____no_output_____"
],
[
"y = dataset.iloc[:,4].values #Atribuindo à variável y as respostas para as previsões(0 = usuário pagou o empréstimo, 1 = o usuário não pagou)\ny #imprimindo os valores ",
"_____no_output_____"
],
[
"naive_bayes = GaussianNB() #Atribuindo a função GaussianNB à variável naive_bayes\nnaive_bayes.fit(X, y) #Realizando o treinamendo da base de dados",
"_____no_output_____"
],
[
"X[0], X[0].shape #Verificando os atributos do primeiro registro da base de dados",
"_____no_output_____"
],
[
"novo = X[0].reshape(1, -1) #Transformando os dados em forma de matriz para que seja utilizado no algoritmo previsão\nnovo.shape",
"_____no_output_____"
],
[
"novo #confirmando a alteração para matriz (os dados possuem dois cochetes)",
"_____no_output_____"
],
[
"naive_bayes.predict(novo) #fazendo a previsão de acordo com os dados do usuário escolhido, a previsão indica que o perfil do usuário é \"confiavél\"",
"_____no_output_____"
],
[
"previsao = naive_bayes.predict_proba(novo) #Utilizando a previsão por probabilidade (predict_proba), os valores retornados são as probabilidades do usuário pertencer a Classe 0 e a Classe 1\nprevisao",
"_____no_output_____"
],
[
"np.argmax(previsao) #Retorna a classe que possui o maior valor na variável. ",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3448d410839139690980c2784f852304c60f8c | 25,777 | ipynb | Jupyter Notebook | 03_Lorenz_equations/03_LorenzEquations_fdsolve.ipynb | daniel-koehn/Differential-equations-earth-system | 3916cbc968da43d0971b7139476350c1dd798746 | [
"MIT"
] | 30 | 2019-10-16T19:07:36.000Z | 2022-02-10T03:48:44.000Z | 03_Lorenz_equations/03_LorenzEquations_fdsolve.ipynb | daniel-koehn/Differential-equations-earth-system | 3916cbc968da43d0971b7139476350c1dd798746 | [
"MIT"
] | null | null | null | 03_Lorenz_equations/03_LorenzEquations_fdsolve.ipynb | daniel-koehn/Differential-equations-earth-system | 3916cbc968da43d0971b7139476350c1dd798746 | [
"MIT"
] | 9 | 2020-11-19T08:21:55.000Z | 2021-08-10T09:33:37.000Z | 35.456671 | 656 | 0.53571 | [
[
[
"###### Text provided under a Creative Commons Attribution license, CC-BY. All code is made available under the FSF-approved MIT license. (c) Daniel Koehn based on Jupyter notebooks by Marc Spiegelman [Dynamical Systems APMA 4101](https://github.com/mspieg/dynamical-systems) and Kyle Mandli from his course [Introduction to numerical methods](https://github.com/mandli/intro-numerical-methods), notebook style sheet by L.A. Barba, N.C. Clementi [Engineering Computations](https://github.com/engineersCode)",
"_____no_output_____"
]
],
[
[
"# Execute this cell to load the notebook's style sheet, then ignore it\nfrom IPython.core.display import HTML\ncss_file = '../style/custom.css'\nHTML(open(css_file, \"r\").read())",
"_____no_output_____"
]
],
[
[
"# Exploring the Lorenz Equations\n\nThe Lorenz Equations are a 3-D dynamical system that is a simplified model of Rayleigh-Benard thermal convection. They are derived and described in detail in Edward Lorenz' 1963 paper [Deterministic Nonperiodic Flow](http://journals.ametsoc.org/doi/pdf/10.1175/1520-0469%281963%29020%3C0130%3ADNF%3E2.0.CO%3B2) in the Journal of Atmospheric Science. In their classical form they can be written\n\n\\begin{equation}\n\\begin{split}\n\\frac{\\partial X}{\\partial t} &= \\sigma( Y - X)\\\\\n\\frac{\\partial Y}{\\partial t} &= rX - Y - XZ \\\\\n\\frac{\\partial Z}{\\partial t} &= XY -b Z\n\\end{split}\n\\tag{1}\n\\end{equation}\n\nwhere $\\sigma$ is the \"Prandtl number\", $r = \\mathrm{Ra}/\\mathrm{Ra}_c$ is a scaled \"Rayleigh number\" and $b$ is a parameter that is related to the the aspect ratio of a convecting cell in the original derivation.\n\nHere, $X(t)$, $Y(t)$ and $Z(t)$ are the time dependent amplitudes of the streamfunction and temperature fields, expanded in a highly truncated Fourier Series where the streamfunction contains one cellular mode\n\n$$\n \\psi(x,z,t) = X(t)\\sin(a\\pi x)\\sin(\\pi z)\n$$\n\nand temperature has two modes\n\n$$\n \\theta(x,z,t) = Y(t)\\cos(a\\pi x)\\sin(\\pi z) - Z(t)\\sin(2\\pi z)\n$$\n\nThis Jupyter notebook, will provide some simple python routines for numerical integration and visualization of the Lorenz Equations.",
"_____no_output_____"
],
[
"## Numerical solution of the Lorenz Equations\n\nWe have to solve the uncoupled ordinary differential equations (1) using the finite difference method introduced in [this lecture](https://nbviewer.jupyter.org/github/daniel-koehn/Differential-equations-earth-system/blob/master/02_finite_difference_intro/1_fd_intro.ipynb).\n\nThe approach is similar to the one used in [Exercise: How to sail without wind](https://nbviewer.jupyter.org/github/daniel-koehn/Differential-equations-earth-system/blob/master/02_finite_difference_intro/3_fd_ODE_example_sailing_wo_wind.ipynb), except that eqs.(1) are coupled ordinary differential equations, we have an additional differential equation and the RHS are more complex. \n\nApproximating the temporal derivatives in eqs. (1) using the **backward FD operator** \n\n\\begin{equation}\n\\frac{df}{dt} = \\frac{f(t)-f(t-dt)}{dt} \\notag\n\\end{equation}\n\nwith the time sample interval $dt$ leads to \n\n\\begin{equation}\n\\begin{split}\n\\frac{X(t)-X(t-dt)}{dt} &= \\sigma(Y - X)\\\\\n\\frac{Y(t)-Y(t-dt)}{dt} &= rX - Y - XZ\\\\\n\\frac{Y(t)-Y(t-dt)}{dt} &= XY -b Z\\\\\n\\end{split}\n\\notag\n\\end{equation}\n\nAfter solving for $X(t), Y(t), Z(t)$, we get the **explicit time integration scheme** for the Lorenz equations:\n\n\\begin{equation}\n\\begin{split}\nX(t) &= X(t-dt) + dt\\; \\sigma(Y - X)\\\\\nY(t) &= Y(t-dt) + dt\\; (rX - Y - XZ)\\\\\nZ(t) &= Z(t-dt) + dt\\; (XY -b Z)\\\\\n\\end{split}\n\\notag\n\\end{equation}\n\nand by introducing a temporal dicretization $t^n = n * dt$ with $n \\in [0,1,...,nt]$, where $nt$ denotes the maximum time steps, the final FD code becomes:\n\n\\begin{equation}\n\\begin{split}\nX^{n} &= X^{n-1} + dt\\; \\sigma(Y^{n-1} - X^{n-1})\\\\\nY^{n} &= Y^{n-1} + dt\\; (rX^{n-1} - Y^{n-1} - X^{n-1}Z^{n-1})\\\\\nZ^{n} &= Z^{n-1} + dt\\; (X^{n-1}Y^{n-1} - b Z^{n-1})\\\\\n\\end{split}\n\\tag{2}\n\\end{equation}\n\nThe Python implementation is quite straightforward, because we can reuse some old codes ...\n\n##### Exercise 1\n\nFinish the function `Lorenz`, which computes and returns the RHS of eqs. (1) for a given $X$, $Y$, $Z$.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom mpl_toolkits.mplot3d import Axes3D",
"_____no_output_____"
],
[
"def Lorenz(X,Y,Z,sigma,r,b):\n \n '''\n Returns the RHS of the Lorenz equations\n '''\n\n # ADD RHS OF LORENZ EQUATIONS (1) HERE!\n X_dot_rhs =\n Y_dot_rhs =\n Z_dot_rhs =\n\n # return the state derivatives\n return X_dot_rhs, Y_dot_rhs, Z_dot_rhs",
"_____no_output_____"
]
],
[
[
"Next, we write the function to solve the Lorenz equation `SolveLorenz` based on the `sailing_boring` code from the [Exercise: How to sail without wind](https://nbviewer.jupyter.org/github/daniel-koehn/Differential-equations-earth-system/blob/master/02_finite_difference_intro/3_fd_ODE_example_sailing_wo_wind.ipynb)\n\n##### Exercise 2\n\nFinish the FD-code implementation `SolveLorenz`",
"_____no_output_____"
]
],
[
[
"def SolveLorenz(tmax, dt, X0, Y0, Z0, sigma=10.,r=28.,b=8./3.0):\n \n '''\n Integrate the Lorenz equations from initial condition (X0,Y0,Z0)^T at t=0 \n for parameters sigma, r, b\n \n Returns: X, Y, Z, time\n '''\n \n # Compute number of time steps based on tmax and dt\n nt = (int)(tmax/dt)\n \n # vectors for storage of X, Y, Z positions and time t\n X = np.zeros(nt + 1)\n Y = np.zeros(nt + 1)\n Z = np.zeros(nt + 1)\n t = np.zeros(nt + 1)\n \n # define initial position and time\n X[0] = X0\n Y[0] = Y0\n Z[0] = Z0\n \n # start time stepping over time samples n\n for n in range(1,nt + 1):\n \n # compute RHS of Lorenz eqs. (1) at current position (X,Y,Z)^T\n X_dot_rhs, Y_dot_rhs, Z_dot_rhs = Lorenz(X[n-1],Y[n-1],Z[n-1],sigma,r,b)\n \n # compute new position using FD approximation of time derivative\n # ADD FD SCHEME OF THE LORENZ EQS. HERE!\n X[n] = \n Y[n] = \n Z[n] =\n t[n] = n * dt\n\n return X, Y, Z, t",
"_____no_output_____"
]
],
[
[
"Finally, we create a function to plot the solution (X,Y,Z)^T of the Lorenz eqs. ...",
"_____no_output_____"
]
],
[
[
"def PlotLorenzXvT(X,Y,Z,t,sigma,r,b):\n \n '''\n Create time series plots of solutions of the Lorenz equations X(t),Y(t),Z(t)\n '''\n\n plt.figure()\n ax = plt.subplot(111)\n ax.plot(t,X,'r',label='X')\n ax.plot(t,Y,'g',label='Y')\n ax.plot(t,Z,'b',label='Z')\n ax.set_xlabel('time t')\n plt.title('Lorenz Equations: $\\sigma=${}, $r=${}, $b=${}'.format(sigma,r,b))\n # Shrink current axis's height by 10% on the bottom\n box = ax.get_position()\n ax.set_position([box.x0, box.y0 + box.height * 0.1,\n box.width, box.height * 0.9])\n\n # Put a legend below current axis\n ax.legend(loc='upper center', bbox_to_anchor=(0.5, -0.05),ncol=3)\n plt.show()",
"_____no_output_____"
]
],
[
[
"... and a function to plot the trajectory in the **phase space portrait**:",
"_____no_output_____"
]
],
[
[
"def PlotLorenz3D(X,Y,Z,sigma,r,b):\n '''\n Show 3-D Phase portrait using mplot3D\n '''\n # do some fancy 3D plotting\n fig = plt.figure()\n ax = fig.gca(projection='3d')\n ax.plot(X,Y,Z)\n ax.set_xlabel('X')\n ax.set_ylabel('Y')\n ax.set_zlabel('Z')\n plt.title('Lorenz Equations: $\\sigma=${}, $r=${}, $b=${}'.format(sigma,r,b))\n plt.show()",
"_____no_output_____"
]
],
[
[
"##### Exercise 3\n\nSolve the Lorenz equations for a Prandtl number $\\sigma=10$, $b=8/3$ and a scaled Rayleigh number $r=0.5$, starting from the initial condition ${\\bf{X_0}}=(X_0,Y_0,Z_0)^T=(2,3,4)^T$. Plot the temporal evolution and 3D phase potrait of the solution $(X(t),Y(t),Z(t))^T$. Mark the fix points, you derived in [Stationary Solutions of Time-Dependent Problems](http://nbviewer.ipython.org/urls/github.com/daniel-koehn/Differential-equations-earth-system/tree/master/03_Lorenz_equations/02_Stationary_solutions_of_DE.ipynb) in the 3D phase portrait. Describe and interpret the results.",
"_____no_output_____"
]
],
[
[
"# SET THE PARAMETERS HERE!\nsigma= \nb = \n\n# SET THE INITIAL CONDITIONS HERE!\nX0 = \nY0 = \nZ0 =\n\n# Set maximum integration time and sample interval dt\ntmax = 30\ndt = 0.01\n\n# SET THE RAYLEIGH NUMBER HERE!\nr =\n\n# Solve the Equations\nX, Y, Z, t = SolveLorenz(tmax, dt, X0, Y0, Z0, sigma,r,b)\n\n# and Visualize as a time series\nPlotLorenzXvT(X,Y,Z,t,sigma,r,b)\n\n# and as a 3-D phase portrait\nPlotLorenz3D(X,Y,Z,sigma,r,b)",
"_____no_output_____"
]
],
[
[
"##### Exercise 4\n\nSolve the Lorenz equations for a Prandtl number $\\sigma=10$, $b=8/3$ and a scaled Rayleigh number $r=10$, starting from the initial condition ${\\bf{X_0}}=(X_0,Y_0,Z_0)^T=(2,3,4)^T$. Plot the temporal evolution and 3D phase potrait of the solution $(X(t),Y(t),Z(t))^T$. Mark the fix points, you derived in [Stationary Solutions of Time-Dependent Problems](http://nbviewer.ipython.org/urls/github.com/daniel-koehn/Differential-equations-earth-system/tree/master/03_Lorenz_equations/02_Stationary_solutions_of_DE.ipynb) in the 3D phase portrait. Describe and interpret the results.",
"_____no_output_____"
]
],
[
[
"# SET THE PARAMETERS HERE!\nsigma= \nb = \n\n# SET THE INITIAL CONDITIONS HERE!\nX0 = \nY0 = \nZ0 =\n\n# Set maximum integration time and sample interval dt\ntmax = 30\ndt = 0.01\n\n# SET THE RAYLEIGH NUMBER HERE!\nr =\n\n# Solve the Equations\nX, Y, Z, t = SolveLorenz(tmax, dt, X0, Y0, Z0, sigma,r,b)\n\n# and Visualize as a time series\nPlotLorenzXvT(X,Y,Z,t,sigma,r,b)\n\n# and as a 3-D phase portrait\nPlotLorenz3D(X,Y,Z,sigma,r,b)",
"_____no_output_____"
]
],
[
[
"##### Exercise 5\n\nSolve the Lorenz equations again for a Prandtl number $\\sigma=10$, $b=8/3$ and a scaled Rayleigh number $r=10$. However, starting from the initial condition ${\\bf{X_0}}=(X_0,Y_0,Z_0)^T=(-2,-3,4)^T$. Plot the temporal evolution and 3D phase potrait of the solution $(X(t),Y(t),Z(t))^T$. Mark the fix points, you derived in [Stationary Solutions of Time-Dependent Problems](http://nbviewer.ipython.org/urls/github.com/daniel-koehn/Differential-equations-earth-system/tree/master/03_Lorenz_equations/02_Stationary_solutions_of_DE.ipynb) in the 3D phase portrait. Describe and interpret the results. How does the solution change compared to exercise 4?",
"_____no_output_____"
]
],
[
[
"# SET THE PARAMETERS HERE!\nsigma= \nb = \n\n# SET THE INITIAL CONDITIONS HERE!\nX0 = \nY0 = \nZ0 =\n\n# Set maximum integration time and sample interval dt\ntmax = 30\ndt = 0.01\n\n# SET THE RAYLEIGH NUMBER HERE!\nr =\n\n# Solve the Equations\nX, Y, Z, t = SolveLorenz(tmax, dt, X0, Y0, Z0, sigma,r,b)\n\n# and Visualize as a time series\nPlotLorenzXvT(X,Y,Z,t,sigma,r,b)\n\n# and as a 3-D phase portrait\nPlotLorenz3D(X,Y,Z,sigma,r,b)",
"_____no_output_____"
]
],
[
[
"##### Exercise 6\n\nSolve the Lorenz equations for a Prandtl number $\\sigma=10$, $b=8/3$ and a scaled Rayleigh number $r=28$, starting from the initial condition ${\\bf{X_0}}=(X_0,Y_0,Z_0)^T=(2,3,4)^T$. Plot the temporal evolution and 3D phase potrait of the solution $(X(t),Y(t),Z(t))^T$. Mark the fix points, you derived in [Stationary Solutions of Time-Dependent Problems](http://nbviewer.ipython.org/urls/github.com/daniel-koehn/Differential-equations-earth-system/tree/master/03_Lorenz_equations/02_Stationary_solutions_of_DE.ipynb) in the 3D phase portrait. Describe and interpret the results. Compare with the previous results.",
"_____no_output_____"
]
],
[
[
"# SET THE PARAMETERS HERE!\nsigma= \nb = \n\n# SET THE INITIAL CONDITIONS HERE!\nX0 = \nY0 = \nZ0 =\n\n# Set maximum integration time and sample interval dt\ntmax = 30\ndt = 5e-4\n\n# SET THE RAYLEIGH NUMBER HERE!\nr =\n\n# Solve the Equations\nX, Y, Z, t = SolveLorenz(tmax, dt, X0, Y0, Z0, sigma,r,b)\n\n# and Visualize as a time series\nPlotLorenzXvT(X,Y,Z,t,sigma,r,b)\n\n# and as a 3-D phase portrait\nPlotLorenz3D(X,Y,Z,sigma,r,b)",
"_____no_output_____"
]
],
[
[
"##### Exercise 7\n\nIn his 1963 paper Lorenz also investigated the influence of small changes of the initial conditions on the long-term evolution of the thermal convection problem for large Rayleigh numbers. \n\nSolve the Lorenz equations for a Prandtl number $\\sigma=10$, $b=8/3$ and a scaled Rayleigh number $r=28$, however starting from the initial condition ${\\bf{X_0}}=(X_0,Y_0,Z_0)^T=(2,3.001,4)^T$. Plot the temporal evolution and compare with the solution of exercise 6. Describe and interpret the results.\n\nExplain why Lorenz introduced the term **Butterfly effect** based on your results.",
"_____no_output_____"
]
],
[
[
"# SET THE PARAMETERS HERE!\nsigma= \nb = \n\n# SET THE INITIAL CONDITIONS HERE!\nX0 = \nY0 = \nZ0 =\n\n# Set maximum integration time and sample interval dt\ntmax = 30\ndt = 5e-4\n\n# SET THE RAYLEIGH NUMBER HERE!\nr =\n\n# Solve the Equations\nX1, Y1, Z1, t = SolveLorenz(tmax, dt, X0, Y0, Z0, sigma,r,b)\n\n# and Visualize differences as a time series\nPlotLorenzXvT(X-X1,Y-Y1,Z-Z1,t,sigma,r,b)\n\n# and Visualize as a time series\nPlotLorenzXvT(X1,Y1,Z1,t,sigma,r,b)\n\n# and Visualize as a time series\nPlotLorenzXvT(X,Y,Z,t,sigma,r,b)",
"_____no_output_____"
]
],
[
[
"##### Exercise 8\n\nSolve the Lorenz equations for a Prandtl number $\\sigma=10$, $b=8/3$ and a scaled Rayleigh number $r=350$, starting from the initial condition ${\\bf{X_0}}=(X_0,Y_0,Z_0)^T=(2,3,4)^T$. Plot the temporal evolution and 3D phase potrait of the solution $(X(t),Y(t),Z(t))^T$. Mark the fix points, you derived in [Stationary Solutions of Time-Dependent Problems](http://nbviewer.ipython.org/urls/github.com/daniel-koehn/Differential-equations-earth-system/tree/master/03_Lorenz_equations/02_Stationary_solutions_of_DE.ipynb) in the 3D phase portrait. Describe and interpret the results. Compare with the previous result from exercise 8.",
"_____no_output_____"
]
],
[
[
"# SET THE PARAMETERS HERE!\nsigma= \nb = \n\n# SET THE INITIAL CONDITIONS HERE!\nX0 = \nY0 = \nZ0 =\n\n# Set maximum integration time and sample interval dt\ntmax = 8.\ndt = 5e-4\n\n# SET THE RAYLEIGH NUMBER HERE!\nr =\n\n# Solve the Equations\nX, Y, Z, t = SolveLorenz(tmax, dt, X0, Y0, Z0, sigma,r,b)\n\n# and Visualize as a time series\nPlotLorenzXvT(X,Y,Z,t,sigma,r,b)\n\n# and as a 3-D phase portrait\nPlotLorenz3D(X,Y,Z,sigma,r,b)",
"_____no_output_____"
]
],
[
[
"## What we learned:\n\n- How to solve the Lorenz equations using a simple finite-difference scheme. \n\n- How to visualize the solution of ordinary differential equations using the temporal evolution and phase portrait.\n\n- Exporing the dynamic of non-linear differential equations and the sensitivity of small changes of the initial conditions to the long term evolution of the system.\n\n- Why physicists can only predict the time evolution of complex dynamical systems to some extent.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
cb3459a20065453e71b5ee2e44924719bd1c1811 | 55,232 | ipynb | Jupyter Notebook | notebooks/02_model/vowpal_wabbit_deep_dive.ipynb | Tian-Su/Recommenders | 995b0789d449c6d485e76fe01e387e4148b281e4 | [
"MIT"
] | 3 | 2020-07-26T16:23:23.000Z | 2021-04-08T13:24:48.000Z | notebooks/02_model/vowpal_wabbit_deep_dive.ipynb | amydaali/Recommenders | 995b0789d449c6d485e76fe01e387e4148b281e4 | [
"MIT"
] | null | null | null | notebooks/02_model/vowpal_wabbit_deep_dive.ipynb | amydaali/Recommenders | 995b0789d449c6d485e76fe01e387e4148b281e4 | [
"MIT"
] | 1 | 2019-06-09T23:45:04.000Z | 2019-06-09T23:45:04.000Z | 39.994207 | 981 | 0.528172 | [
[
[
"<i>Copyright (c) Microsoft Corporation. All rights reserved.</i>\n\n<i>Licensed under the MIT License.</i>",
"_____no_output_____"
],
[
"# Vowpal Wabbit Deep Dive",
"_____no_output_____"
],
[
"<center>\n<img src=\"https://github.com/VowpalWabbit/vowpal_wabbit/blob/master/logo_assets/vowpal-wabbits-github-logo.png?raw=true\" height=\"30%\" width=\"30%\" alt=\"Vowpal Wabbit\">\n</center>\n\n[Vowpal Wabbit](https://github.com/VowpalWabbit/vowpal_wabbit) is a fast online machine learning library that implements several algorithms relevant to the recommendation use case.\n\nThe main advantage of Vowpal Wabbit (VW) is that training is done in an online fashion typically using Stochastic Gradient Descent or similar variants, which allows it to scale well to very large datasets. Additionally, it is optimized to run very quickly and can support distributed training scenarios for extremely large datasets. \n\nVW is best applied to problems where the dataset is too large to fit into memory but can be stored on disk in a single node. Though distributed training is possible with additional setup and configuration of the nodes. The kinds of problems that VW handles well mostly fall into the supervised classification domain of machine learning (Linear Regression, Logistic Regression, Multiclass Classification, Support Vector Machines, Simple Neural Nets). It also supports Matrix Factorization approaches and Latent Dirichlet Allocation, as well as a few other algorithms (see the [wiki](https://github.com/VowpalWabbit/vowpal_wabbit/wiki) for more information).\n\nA good example of a typical deployment use case is a Real Time Bidding scenario, where an auction to place an ad for a user is being decided in a matter of milliseconds. Feature information about the user and items must be extracted and passed into a model to predict likelihood of click (or other interaction) in short order. And if the user and context features are constantly changing (e.g. user browser and local time of day) it may be infeasible to score every possible input combination before hand. This is where VW provides value, as a platform to explore various algorithms offline to train a highly accurate model on a large set of historical data then deploy the model into production so it can generate rapid predictions in real time. Of course this isn't the only manner VW can be deployed, it is also possible to use it entirely online where the model is constantly updating, or use active learning approaches, or work completely offline in a pre-scoring mode. ",
"_____no_output_____"
],
[
"<h3>Vowpal Wabbit for Recommendations</h3>\n\nIn this notebook we demonstrate how to use the VW library to generate recommendations on the [Movielens](https://grouplens.org/datasets/movielens/) dataset.\n\nSeveral things are worth noting in how VW is being used in this notebook:\n\nBy leveraging an Azure Data Science Virtual Machine ([DSVM](https://azure.microsoft.com/en-us/services/virtual-machines/data-science-virtual-machines/)), VW comes pre-installed and can be used directly from the command line. If you are not using a DSVM you must install vw yourself. \n\nThere are also python bindings to allow VW use within a python environment and even a wrapper conforming to the SciKit-Learn Estimator API. However, the python bindings must be installed as an additional python package with Boost dependencies, so for simplicity's sake execution of VW is done via a subprocess call mimicking what would happen from the command line execution of the model.\n\nVW expects a specific [input format](https://github.com/VowpalWabbit/vowpal_wabbit/wiki/Input-format), in this notebook to_vw() is a convenience function that converts the standard movielens dataset into the required data format. Datafiles are then written to disk and passed to VW for training.\n\nThe examples shown are to demonstrate functional capabilities of VW not to indicate performance advantages of different approaches. There are several hyper-parameters (e.g. learning rate and regularization terms) that can greatly impact performance of VW models which can be adjusted using [command line options](https://github.com/VowpalWabbit/vowpal_wabbit/wiki/Command-Line-Arguments). To properly compare approaches it is helpful to learn about and tune these parameters on the relevant dataset.",
"_____no_output_____"
],
[
"# 0. Global Setup",
"_____no_output_____"
]
],
[
[
"import sys\nsys.path.append('../..')\n\nimport os\nfrom subprocess import run\nfrom tempfile import TemporaryDirectory\nfrom time import process_time\n\nimport pandas as pd\nimport papermill as pm\n\nfrom reco_utils.common.notebook_utils import is_jupyter\nfrom reco_utils.dataset.movielens import load_pandas_df\nfrom reco_utils.dataset.python_splitters import python_random_split\nfrom reco_utils.evaluation.python_evaluation import (rmse, mae, exp_var, rsquared, get_top_k_items,\n map_at_k, ndcg_at_k, precision_at_k, recall_at_k)\n\nprint(\"System version: {}\".format(sys.version))\nprint(\"Pandas version: {}\".format(pd.__version__))",
"System version: 3.6.0 | packaged by conda-forge | (default, Feb 9 2017, 14:36:55) \n[GCC 4.8.2 20140120 (Red Hat 4.8.2-15)]\nPandas version: 0.23.4\n"
],
[
"def to_vw(df, output, logistic=False):\n \"\"\"Convert Pandas DataFrame to vw input format\n Args:\n df (pd.DataFrame): input DataFrame\n output (str): path to output file\n logistic (bool): flag to convert label to logistic value\n \"\"\"\n with open(output, 'w') as f:\n tmp = df.reset_index()\n\n # we need to reset the rating type to an integer to simplify the vw formatting\n tmp['rating'] = tmp['rating'].astype('int64')\n \n # convert rating to binary value\n if logistic:\n tmp['rating'] = tmp['rating'].apply(lambda x: 1 if x >= 3 else -1)\n \n # convert each row to VW input format (https://github.com/VowpalWabbit/vowpal_wabbit/wiki/Input-format)\n # [label] [tag]|[user namespace] [user id feature] |[item namespace] [movie id feature]\n # label is the true rating, tag is a unique id for the example just used to link predictions to truth\n # user and item namespaces separate the features to support interaction features through command line options\n for _, row in tmp.iterrows():\n f.write('{rating} {index}|user {userID} |item {itemID}\\n'.format_map(row))",
"_____no_output_____"
],
[
"def run_vw(train_params, test_params, test_data, prediction_path, logistic=False):\n \"\"\"Convenience function to train, test, and show metrics of interest\n Args:\n train_params (str): vw training parameters\n test_params (str): vw testing parameters\n test_data (pd.dataFrame): test data\n prediction_path (str): path to vw prediction output\n logistic (bool): flag to convert label to logistic value\n Returns:\n (dict): metrics and timing information\n \"\"\"\n\n # train model\n train_start = process_time()\n run(train_params.split(' '), check=True)\n train_stop = process_time()\n \n # test model\n test_start = process_time()\n run(test_params.split(' '), check=True)\n test_stop = process_time()\n \n # read in predictions\n pred_df = pd.read_csv(prediction_path, delim_whitespace=True, names=['prediction'], index_col=1).join(test_data)\n \n test_df = test_data.copy()\n if logistic:\n # make the true label binary so that the metrics are captured correctly\n test_df['rating'] = test['rating'].apply(lambda x: 1 if x >= 3 else -1)\n else:\n # ensure results are integers in correct range\n pred_df['prediction'] = pred_df['prediction'].apply(lambda x: int(max(1, min(5, round(x)))))\n\n # calculate metrics\n result = dict()\n result['RMSE'] = rmse(test_df, pred_df)\n result['MAE'] = mae(test_df, pred_df)\n result['R2'] = rsquared(test_df, pred_df)\n result['Explained Variance'] = exp_var(test_df, pred_df)\n result['Train Time (ms)'] = (train_stop - train_start) * 1000\n result['Test Time (ms)'] = (test_stop - test_start) * 1000\n \n return result",
"_____no_output_____"
],
[
"# create temp directory to maintain data files\ntmpdir = TemporaryDirectory()\n\nmodel_path = os.path.join(tmpdir.name, 'vw.model')\nsaved_model_path = os.path.join(tmpdir.name, 'vw_saved.model')\ntrain_path = os.path.join(tmpdir.name, 'train.dat')\ntest_path = os.path.join(tmpdir.name, 'test.dat')\ntrain_logistic_path = os.path.join(tmpdir.name, 'train_logistic.dat')\ntest_logistic_path = os.path.join(tmpdir.name, 'test_logistic.dat')\nprediction_path = os.path.join(tmpdir.name, 'prediction.dat')\nall_test_path = os.path.join(tmpdir.name, 'new_test.dat')\nall_prediction_path = os.path.join(tmpdir.name, 'new_prediction.dat')",
"_____no_output_____"
]
],
[
[
"# 1. Load & Transform Data",
"_____no_output_____"
]
],
[
[
"# Select Movielens data size: 100k, 1m, 10m, or 20m\nMOVIELENS_DATA_SIZE = '100k'\nTOP_K = 10",
"_____no_output_____"
],
[
"# load movielens data (use the 1M dataset)\ndf = load_pandas_df(MOVIELENS_DATA_SIZE)\n\n# split data to train and test sets, default values take 75% of each users ratings as train, and 25% as test\ntrain, test = python_random_split(df, 0.75)\n\n# save train and test data in vw format\nto_vw(df=train, output=train_path)\nto_vw(df=test, output=test_path)\n\n# save data for logistic regression (requires adjusting the label)\nto_vw(df=train, output=train_logistic_path, logistic=True)\nto_vw(df=test, output=test_logistic_path, logistic=True)",
"_____no_output_____"
]
],
[
[
"# 2. Regression Based Recommendations\n\nWhen considering different approaches for solving a problem with machine learning it is helpful to generate a baseline approach to understand how more complex solutions perform across dimensions of performance, time, and resource (memory or cpu) usage.\n\nRegression based approaches are some of the simplest and fastest baselines to consider for many ML problems.",
"_____no_output_____"
],
[
"## 2.1 Linear Regression\n\nAs the data provides a numerical rating between 1-5, fitting those values with a linear regression model is easy approach. This model is trained on examples of ratings as the target variable and corresponding user ids and movie ids as independent features.\n\nBy passing each user-item rating in as an example the model will begin to learn weights based on average ratings for each user as well as average ratings per item.\n\nThis however can generate predicted ratings which are no longer integers, so some additional adjustments should be made at prediction time to convert them back to the integer scale of 1 through 5 if necessary. Here, this is done in the evaluate function.",
"_____no_output_____"
]
],
[
[
"\"\"\"\nQuick description of command line parameters used\n Other optional parameters can be found here: https://github.com/VowpalWabbit/vowpal_wabbit/wiki/Command-Line-Arguments\n VW uses linear regression by default, so no extra command line options\n -f <model_path>: indicates where the final model file will reside after training\n -d <data_path>: indicates which data file to use for training or testing\n --quiet: this runs vw in quiet mode silencing stdout (for debugging it's helpful to not use quiet mode)\n -i <model_path>: indicates where to load the previously model file created during training\n -t: this executes inference only (no learned updates to the model)\n -p <prediction_path>: indicates where to store prediction output\n\"\"\"\ntrain_params = 'vw -f {model} -d {data} --quiet'.format(model=model_path, data=train_path)\n# save these results for later use during top-k analysis\ntest_params = 'vw -i {model} -d {data} -t -p {pred} --quiet'.format(model=model_path, data=test_path, pred=prediction_path)\n\nresult = run_vw(train_params=train_params, \n test_params=test_params, \n test_data=test, \n prediction_path=prediction_path)\n\ncomparison = pd.DataFrame(result, index=['Linear Regression'])\ncomparison",
"_____no_output_____"
]
],
[
[
"## 2.2 Linear Regression with Interaction Features\n\nPreviously we treated the user features and item features independently, but taking into account interactions between features can provide a mechanism to learn more fine grained preferences of the users.\n\nTo generate interaction features use the quadratic command line argument and specify the namespaces that should be combined: '-q ui' combines the user and item namespaces based on the first letter of each.\n\nCurrently the userIDs and itemIDs used are integers which means the feature ID is used directly, for instance when user ID 123 rates movie 456, the training example puts a 1 in the values for features 123 and 456. However when interaction is specified (or if a feature is a string) the resulting interaction feature is hashed into the available feature space. Feature hashing is a way to take a very sparse high dimensional feature space and reduce it into a lower dimensional space. This allows for reduced memory while retaining fast computation of feature and model weights.\n\nThe caveat with feature hashing, is that it can lead to hash collisions, where separate features are mapped to the same location. In this case it can be beneficial to increase the size of the space to support interactions between features of high cardinality. The available feature space is dictated by the --bit_precision (-b) <N> argument. Where the total available space for all features in the model is 2<sup>N</sup>. \n\nSee [Feature Hashing and Extraction](https://github.com/VowpalWabbit/vowpal_wabbit/wiki/Feature-Hashing-and-Extraction) for more details.",
"_____no_output_____"
]
],
[
[
"\"\"\"\nQuick description of command line parameters used\n -b <N>: sets the memory size to 2<sup>N</sup> entries\n -q <ab>: create quadratic feature interactions between features in namespaces starting with 'a' and 'b' \n\"\"\"\ntrain_params = 'vw -b 26 -q ui -f {model} -d {data} --quiet'.format(model=saved_model_path, data=train_path)\ntest_params = 'vw -i {model} -d {data} -t -p {pred} --quiet'.format(model=saved_model_path, data=test_path, pred=prediction_path)\n\nresult = run_vw(train_params=train_params,\n test_params=test_params,\n test_data=test,\n prediction_path=prediction_path)\nsaved_result = result\n\ncomparison = comparison.append(pd.DataFrame(result, index=['Linear Regression w/ Interaction']))\ncomparison",
"_____no_output_____"
]
],
[
[
"## 2.3 Multinomial Logistic Regression\n\nAn alternative to linear regression is to leverage multinomial logistic regression, or multiclass classification, which treats each rating value as a distinct class. \n\nThis avoids any non integer results, but also reduces the training data for each class which could lead to poorer performance if the counts of different rating levels are skewed.\n\nBasic multiclass logistic regression can be accomplished using the One Against All approach specified by the '--oaa N' option, where N is the number of classes and proving the logistic option for the loss function to be used.",
"_____no_output_____"
]
],
[
[
"\"\"\"\nQuick description of command line parameters used\n --loss_function logistic: sets the model loss function for logistic regression\n --oaa <N>: trains N separate models using One-Against-All approach (all models are captured in the single model file)\n This expects the labels to be contiguous integers starting at 1\n --link logistic: converts the predicted output from logit to probability\nThe predicted output is the model (label) with the largest likelihood\n\"\"\"\ntrain_params = 'vw --loss_function logistic --oaa 5 -f {model} -d {data} --quiet'.format(model=model_path, data=train_path)\ntest_params = 'vw --link logistic -i {model} -d {data} -t -p {pred} --quiet'.format(model=model_path, data=test_path, pred=prediction_path)\n\nresult = run_vw(train_params=train_params,\n test_params=test_params,\n test_data=test,\n prediction_path=prediction_path)\n\ncomparison = comparison.append(pd.DataFrame(result, index=['Multinomial Regression']))\ncomparison",
"_____no_output_____"
]
],
[
[
"## 2.4 Logistic Regression\n\nAdditionally, one might simply be interested in whether the user likes or dislikes an item and we can adjust the input data to represent a binary outcome, where ratings in (1,3] are dislikes (negative results) and (3,5] are likes (positive results).\n\nThis framing allows for a simple logistic regression model to be applied. To perform logistic regression the loss_function parameter is changed to 'logistic' and the target label is switched to [0, 1]. Also, be sure to set '--link logistic' during prediction to convert the logit output back to a probability value.",
"_____no_output_____"
]
],
[
[
"train_params = 'vw --loss_function logistic -f {model} -d {data} --quiet'.format(model=model_path, data=train_logistic_path)\ntest_params = 'vw --link logistic -i {model} -d {data} -t -p {pred} --quiet'.format(model=model_path, data=test_logistic_path, pred=prediction_path)\n\nresult = run_vw(train_params=train_params,\n test_params=test_params,\n test_data=test,\n prediction_path=prediction_path,\n logistic=True)\n\ncomparison = comparison.append(pd.DataFrame(result, index=['Logistic Regression']))\ncomparison",
"_____no_output_____"
]
],
[
[
"# 3. Matrix Factorization Based Recommendations\n\nAll of the above approaches train a regression model, but VW also supports matrix factorization with two different approaches.\n\nAs opposed to learning direct weights for specific users, items and interactions when training a regression model, matrix factorization attempts to learn latent factors that determine how a user rates an item. An example of how this might work is if you could represent user preference and item categorization by genre. Given a smaller set of genres we can associate how much each item belongs to each genre class, and we can set weights for a user's preference for each genre. Both sets of weights could be represented as a vectors where the inner product would be the user-item rating. Matrix factorization approaches learn low rank matrices for latent features of users and items such that those matrices can be combined to approximate the original user item matrix.\n\n## 3.1. Singular Value Decomposition Based Matrix Factorization\n\nThe first approach performs matrix factorization based on Singular Value Decomposition (SVD) to learn a low rank approximation for the user-item rating matix. It is is called using the '--rank' command line argument.\n\nSee the [Matrix Factorization Example](https://github.com/VowpalWabbit/vowpal_wabbit/wiki/Matrix-factorization-example) for more detail.",
"_____no_output_____"
]
],
[
[
"\"\"\"\nQuick description of command line parameters used\n --rank <N>: sets the number of latent factors in the reduced matrix\n\"\"\"\ntrain_params = 'vw --rank 5 -q ui -f {model} -d {data} --quiet'.format(model=model_path, data=train_path)\ntest_params = 'vw -i {model} -d {data} -t -p {pred} --quiet'.format(model=model_path, data=test_path, pred=prediction_path)\n\nresult = run_vw(train_params=train_params,\n test_params=test_params,\n test_data=test,\n prediction_path=prediction_path)\n\ncomparison = comparison.append(pd.DataFrame(result, index=['Matrix Factorization (Rank)']))\ncomparison",
"_____no_output_____"
]
],
[
[
"## 3.2. Factorization Machine Based Matrix Factorization\n\nAn alternative approach based on [Rendel's factorization machines](https://cseweb.ucsd.edu/classes/fa17/cse291-b/reading/Rendle2010FM.pdf) is called using '--lrq' (low rank quadratic). More LRQ details in this [demo](https://github.com/VowpalWabbit/vowpal_wabbit/tree/master/demo/movielens).\n\nThis learns two lower rank matrices which are multiplied to generate an approximation of the user-item rating matrix. Compressing the matrix in this way leads to learning generalizable factors which avoids some of the limitations of using regression models with extremely sparse interaction features. This can lead to better convergence and smaller on-disk models.\n\nAn additional term to improve performance is --lrqdropout which will dropout columns during training. This however tends to increase the optimal rank size. Other parameters such as L2 regularization can help avoid overfitting.",
"_____no_output_____"
]
],
[
[
"\"\"\"\nQuick description of command line parameters used\n --lrq <abN>: learns approximations of rank N for the quadratic interaction between namespaces starting with 'a' and 'b'\n --lrqdroupout: performs dropout during training to improve generalization\n\"\"\"\ntrain_params = 'vw --lrq ui7 -f {model} -d {data} --quiet'.format(model=model_path, data=train_path)\ntest_params = 'vw -i {model} -d {data} -t -p {pred} --quiet'.format(model=model_path, data=test_path, pred=prediction_path)\n\nresult = run_vw(train_params=train_params,\n test_params=test_params,\n test_data=test,\n prediction_path=prediction_path)\n\ncomparison = comparison.append(pd.DataFrame(result, index=['Matrix Factorization (LRQ)']))\ncomparison",
"_____no_output_____"
]
],
[
[
"# 4. Conclusion\n\nThe table above shows a few of the approaches in the VW library that can be used for recommendation prediction. The relative performance can change when applied to different datasets and properly tuned, but it is useful to note the rapid speed at which all approaches are able to train (75,000 examples) and test (25,000 examples).",
"_____no_output_____"
],
[
"# 5. Scoring",
"_____no_output_____"
],
[
"After training a model with any of the above approaches, the model can be used to score potential user-pairs in offline batch mode, or in a real-time scoring mode. The example below shows how to leverage the utilities in the reco_utils directory to generate Top-K recommendations from offline scored output.",
"_____no_output_____"
]
],
[
[
"# First construct a test set of all items (except those seen during training) for each user\nusers = df[['userID']].drop_duplicates()\nusers['key'] = 1\n\nitems = df[['itemID']].drop_duplicates()\nitems['key'] = 1\n\nall_pairs = pd.merge(users, items, on='key').drop(columns=['key'])\n\n# now combine with training data and filter only those entries that don't match\nmerged = pd.merge(train, all_pairs, on=[\"userID\", \"itemID\"], how=\"outer\")\nall_user_items = merged[merged['rating'].isnull()].copy()\nall_user_items['rating'] = 0\n\n# save in vw format (this can take a while)\nto_vw(df=all_user_items, output=all_test_path)",
"_____no_output_____"
],
[
"# run the saved model (linear regression with interactions) on the new dataset\ntest_start = process_time()\ntest_params = 'vw -i {model} -d {data} -t -p {pred} --quiet'.format(model=saved_model_path, data=all_test_path, pred=prediction_path)\nrun(test_params.split(' '), check=True)\ntest_stop = process_time()\ntest_time = test_stop - test_start\n\n# load predictions and get top-k from previous saved results\npred_data = pd.read_csv(prediction_path, delim_whitespace=True, names=['prediction'], index_col=1).join(test)\npred_data['prediction'] = pred_data['prediction'].apply(lambda x: int(max(1, min(5, round(x)))))\n\ntop_k = get_top_k_items(pred_data, col_rating='prediction', k=TOP_K)[['prediction', 'userID', 'itemID', 'rating']]\n\n# convert dtypes of userID and itemID columns.\nfor col in ['userID', 'itemID']:\n top_k[col] = top_k[col].astype(int)\n \ntop_k.head()",
"_____no_output_____"
],
[
"# get ranking metrics\nargs = [test, top_k]\nkwargs = dict(col_user='userID', col_item='itemID', col_rating='rating', col_prediction='prediction',\n relevancy_method='top_k', k=TOP_K)\n\nrank_metrics = {'MAP': map_at_k(*args, **kwargs), \n 'NDCG': ndcg_at_k(*args, **kwargs),\n 'Precision': precision_at_k(*args, **kwargs),\n 'Recall': recall_at_k(*args, **kwargs)}",
"_____no_output_____"
],
[
"# final results\nall_results = ['{k}: {v}'.format(k=k, v=v) for k, v in saved_result.items()]\nall_results += ['{k}: {v}'.format(k=k, v=v) for k, v in rank_metrics.items()]\nprint('\\n'.join(all_results))",
"RMSE: 0.9957509728842849\nMAE: 0.72024\nR2: 0.22961479092361414\nExplained Variance: 0.22967066343101572\nTrain Time (ms): 7.741038000002476\nTest Time (ms): 4.576859000000155\nMAP: 0.2568488766282023\nNDCG: 0.6533904587110557\nPrecision: 0.5147381242387332\nRecall: 0.2568488766282023\n"
]
],
[
[
"# 6. Cleanup",
"_____no_output_____"
]
],
[
[
"# record results for testing\nif is_jupyter():\n pm.record('rmse', saved_result['RMSE'])\n pm.record('mae', saved_result['MAE'])\n pm.record('rsquared', saved_result['R2'])\n pm.record('exp_var', saved_result['Explained Variance'])\n pm.record(\"train_time\", saved_result['Train Time (ms)'])\n pm.record(\"test_time\", test_time)\n pm.record('map', rank_metrics['MAP'])\n pm.record('ndcg', rank_metrics['NDCG'])\n pm.record('precision', rank_metrics['Precision'])\n pm.record('recall', rank_metrics['Recall'])",
"_____no_output_____"
],
[
"tmpdir.cleanup()",
"_____no_output_____"
]
],
[
[
"## References\n\n1. John Langford, et. al. Vowpal Wabbit Wiki. URL: https://github.com/VowpalWabbit/vowpal_wabbit/wiki\n2. Steffen Rendel. Factorization Machines. 2010 IEEE International Conference on Data Mining.\n3. Jake Hoffman. Matrix Factorization Example. URL: https://github.com/VowpalWabbit/vowpal_wabbit/wiki/Matrix-factorization-example\n4. Paul Minero. Low Rank Quadratic Example. URL: https://github.com/VowpalWabbit/vowpal_wabbit/tree/master/demo/movielens",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
cb3466f521d7d240092d79202415eb83424fa205 | 83,205 | ipynb | Jupyter Notebook | 3_Neural_Network/Tutorials/1_Neural_Network.ipynb | dadatu/tensorflow_basics | 3efca05ce136ade6447b701cba2f3cab14feceeb | [
"MIT"
] | null | null | null | 3_Neural_Network/Tutorials/1_Neural_Network.ipynb | dadatu/tensorflow_basics | 3efca05ce136ade6447b701cba2f3cab14feceeb | [
"MIT"
] | null | null | null | 3_Neural_Network/Tutorials/1_Neural_Network.ipynb | dadatu/tensorflow_basics | 3efca05ce136ade6447b701cba2f3cab14feceeb | [
"MIT"
] | null | null | null | 96.637631 | 24,045 | 0.788859 | [
[
[
"# Neural Network\n\nIn this tutorial, we'll create a simple neural network classifier in TensorFlow. The key advantage of this model over the [Linear Classifier](https://github.com/easy-tensorflow/easy-tensorflow/blob/master/3_Neural_Network/Tutorials/1_Neural_Network.ipynb) trained in the previous tutorial is that it can separate data which is __NOT__ linearly separable. We will implement this model for classifying images of hand-written digits from the so-called MNIST data-set.\n\nWe assume that you have the basic knowledge over the concept and you are just interested in the __Tensorflow__ implementation of the Neural Nets. If you want to know more about the Neural Nets we suggest you to take [this](https://www.coursera.org/learn/machine-learning) amazing course on machine learning or check out the following tutorials:\n\n [Neural Networks Part 1: Setting up the Architecture](https://cs231n.github.io/neural-networks-1/)\n \n [Neural Networks Part 2: Setting up the Data and the Loss](https://cs231n.github.io/neural-networks-2/)\n \n [Neural Networks Part 3: Learning and Evaluation](https://cs231n.github.io/neural-networks-3/)\n\nThe structure of the neural network that we're going to implement is as follows. Like before, we're using images of handw-ritten digits of the MNIST data which has 10 classes (i.e. digits from 0 to 9). The implemented network has 2 hidden layers: the first one with 200 hidden units (neurons) and the second one (also known as classifier layer) with 10 (number of classes) neurons.\n\n<img src=\"files/files/nn.png\">\n\n___Fig. 1-___ Sample Neural Network architecture with two layers implemented for classifying MNIST digits\n\n\n\n\n## 0. Import the required libraries:\nWe will start with importing the required Python libraries.",
"_____no_output_____"
]
],
[
[
"# imports\nimport tensorflow as tf\nimport numpy as np\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"## 1. Load the MNIST data\n\nFor this tutorial we use the MNIST dataset. MNIST is a dataset of handwritten digits. If you are into machine learning, you might have heard of this dataset by now. MNIST is kind of benchmark of datasets for deep learning and is easily accesible through Tensorflow\n\nThe dataset contains $55,000$ examples for training, $5,000$ examples for validation and $10,000$ examples for testing. The digits have been size-normalized and centered in a fixed-size image ($28\\times28$ pixels) with values from $0$ to $1$. For simplicity, each image has been flattened and converted to a 1-D numpy array of $784$ features ($28\\times28$).\n\n<img src=\"files/files/mnist.png\">\n\n\nIf you want to know more about the MNIST dataset you can check __Yann Lecun__'s [website](http://yann.lecun.com/exdb/mnist/).\n\n### 1.1. Data dimension\nHere, we specify the dimensions of the images which will be used in several places in the code below. Defining these variables makes it easier (compared with using hard-coded number all throughout the code) to modify them later. Ideally these would be inferred from the data that has been read, but here we will just write the numbers.\n\nIt's important to note that in a linear model, we have to flatten the input images into a vector. Here, each of the $28\\times28$ images are flattened into a $1\\times784$ vector. ",
"_____no_output_____"
]
],
[
[
"img_h = img_w = 28 # MNIST images are 28x28\nimg_size_flat = img_h * img_w # 28x28=784, the total number of pixels\nn_classes = 10 # Number of classes, one class per digit",
"_____no_output_____"
]
],
[
[
"### 1.2. Helper functions to load the MNIST data\n\nIn this section, we'll write the function which automatically loads the MNIST data and returns it in our desired shape and format. If you wanna learn more about loading your data, you may read our __How to Load Your Data in TensorFlow __ tutorial which explains all the available methods to load your own data; no matter how big it is. \n\nHere, we'll simply write a function (__`load_data`__) which has two modes: train (which loads the training and validation images and their corresponding labels) and test (which loads the test images and their corresponding labels). You can replace this function to use your own dataset. \n\nOther than a function for loading the images and corresponding labels, we define two more functions:\n\n1. __randomize__: which randomizes the order of images and their labels. This is important to make sure that the input images are sorted in a completely random order. Moreover, at the beginning of each __epoch__, we will re-randomize the order of data samples to make sure that the trained model is not sensitive to the order of data.\n\n2. __get_next_batch__: which only selects a few number of images determined by the batch_size variable (if you don't know why, read about Stochastic Gradient Method)\n",
"_____no_output_____"
]
],
[
[
"def load_data(mode='train'):\n \"\"\"\n Function to (download and) load the MNIST data\n :param mode: train or test\n :return: images and the corresponding labels\n \"\"\"\n from tensorflow.examples.tutorials.mnist import input_data\n mnist = input_data.read_data_sets(\"MNIST_data/\", one_hot=True)\n if mode == 'train':\n x_train, y_train, x_valid, y_valid = mnist.train.images, mnist.train.labels, \\\n mnist.validation.images, mnist.validation.labels\n return x_train, y_train, x_valid, y_valid\n elif mode == 'test':\n x_test, y_test = mnist.test.images, mnist.test.labels\n return x_test, y_test\n\n\ndef randomize(x, y):\n \"\"\" Randomizes the order of data samples and their corresponding labels\"\"\"\n permutation = np.random.permutation(y.shape[0])\n shuffled_x = x[permutation, :]\n shuffled_y = y[permutation]\n return shuffled_x, shuffled_y\n\n\ndef get_next_batch(x, y, start, end):\n x_batch = x[start:end]\n y_batch = y[start:end]\n return x_batch, y_batch",
"_____no_output_____"
]
],
[
[
"### 1.3. Load the data and display the sizes\nNow we can use the defined helper function in __train__ mode which loads the train and validation images and their corresponding labels. We'll also display their sizes:",
"_____no_output_____"
]
],
[
[
"# Load MNIST data\nx_train, y_train, x_valid, y_valid = load_data(mode='train')\nprint(\"Size of:\")\nprint(\"- Training-set:\\t\\t{}\".format(len(y_train)))\nprint(\"- Validation-set:\\t{}\".format(len(y_valid)))",
"Successfully downloaded train-images-idx3-ubyte.gz 9912422 bytes.\nExtracting MNIST_data/train-images-idx3-ubyte.gz\nSuccessfully downloaded train-labels-idx1-ubyte.gz 28881 bytes.\nExtracting MNIST_data/train-labels-idx1-ubyte.gz\nSuccessfully downloaded t10k-images-idx3-ubyte.gz 1648877 bytes.\nExtracting MNIST_data/t10k-images-idx3-ubyte.gz\nSuccessfully downloaded t10k-labels-idx1-ubyte.gz 4542 bytes.\nExtracting MNIST_data/t10k-labels-idx1-ubyte.gz\nSize of:\n- Training-set:\t\t55000\n- Validation-set:\t5000\n"
]
],
[
[
"To get a better sense of the data, let's checkout the shapes of the loaded arrays.",
"_____no_output_____"
]
],
[
[
"print('x_train:\\t{}'.format(x_train.shape))\nprint('y_train:\\t{}'.format(y_train.shape))\nprint('x_train:\\t{}'.format(x_valid.shape))\nprint('y_valid:\\t{}'.format(y_valid.shape))",
"x_train:\t(55000, 784)\ny_train:\t(55000, 10)\nx_train:\t(5000, 784)\ny_valid:\t(5000, 10)\n"
]
],
[
[
"As you can see, __`x_train`__ and __`x_valid`__ arrays contain $55000$ and $5000$ flattened images ( of size $28\\times28=784$ values). __`y_train`__ and __`y_valid`__ contain the corresponding labels of the images in the training and validation set respectively. \n\nBased on the dimesnion of the arrays, for each image, we have 10 values as its label. Why? This technique is called __One-Hot Encoding__. This means the labels have been converted from a single number to a vector whose length equals the number of possible classes. All elements of the vector are zero except for the $i^{th}$ element which is one and means the class is $i$. For example, the One-Hot encoded labels for the first 5 images in the validation set are:",
"_____no_output_____"
]
],
[
[
"y_valid[:5, :]",
"_____no_output_____"
]
],
[
[
"where the $10$ values in each row represents the label assigned to that partiular image. ",
"_____no_output_____"
],
[
"## 2. Hyperparameters\n\nHere, we have about $55,000$ images in our training set. It takes a long time to calculate the gradient of the model using all these images. We therefore use __Stochastic Gradient Descent__ which only uses a small batch of images in each iteration of the optimizer. Let's define some of the terms usually used in this context:\n\n- __epoch__: one forward pass and one backward pass of __all__ the training examples.\n- __batch size__: the number of training examples in one forward/backward pass. The higher the batch size, the more memory space you'll need.\n- __iteration__: one forward pass and one backward pass of __one batch of images__ the training examples.",
"_____no_output_____"
]
],
[
[
"# Hyper-parameters\nepochs = 10 # Total number of training epochs\nbatch_size = 100 # Training batch size\ndisplay_freq = 100 # Frequency of displaying the training results\nlearning_rate = 0.001 # The optimization initial learning rate\n\nh1 = 200 # number of nodes in the 1st hidden layer",
"_____no_output_____"
]
],
[
[
"Given the above definitions, each epoch consists of $55,000/100=550$ iterations.",
"_____no_output_____"
],
[
"## 3. Helper functions for creating the network\n\n### 3.1. Helper functions for creating new variables\n\nAs explained (and also illustrated in Fig. 1), we need to define two variables $\\mathbf{W}$ and $\\mathbf{b}$ to construt our linear model. These are generally called model parameters and as explained in our [Tensor Types](https://github.com/easy-tensorflow/easy-tensorflow/blob/master/1_TensorFlow_Basics/Tutorials/2_Tensor_Types.ipynb) tutorial, we use __Tensorflow Variables__ of proper size and initialization to define them.The following functions are written to be later used for generating the weight and bias variables of the desired shape:",
"_____no_output_____"
]
],
[
[
"# weight and bais wrappers\ndef weight_variable(name, shape):\n \"\"\"\n Create a weight variable with appropriate initialization\n :param name: weight name\n :param shape: weight shape\n :return: initialized weight variable\n \"\"\"\n initer = tf.truncated_normal_initializer(stddev=0.01)\n return tf.get_variable('W_' + name,\n dtype=tf.float32,\n shape=shape,\n initializer=initer)\n\n\ndef bias_variable(name, shape):\n \"\"\"\n Create a bias variable with appropriate initialization\n :param name: bias variable name\n :param shape: bias variable shape\n :return: initialized bias variable\n \"\"\"\n initial = tf.constant(0., shape=shape, dtype=tf.float32)\n return tf.get_variable('b_' + name,\n dtype=tf.float32,\n initializer=initial)",
"_____no_output_____"
]
],
[
[
"### 3.2. Helper-function for creating a fully-connected layer\n\nNeural network consists of stacks of fully-connected (dense) layers. Having the weight ($\\mathbf{W}$) and bias ($\\mathbf{b}$) variables, a fully-connected layer is defined as $activation(\\mathbf{W}\\times \\mathbf{x} + \\mathbf{b})$. We define __`fc_layer`__ function as follows:",
"_____no_output_____"
]
],
[
[
"def fc_layer(x, num_units, name, use_relu=True):\n \"\"\"\n Create a fully-connected layer\n :param x: input from previous layer\n :param num_units: number of hidden units in the fully-connected layer\n :param name: layer name\n :param use_relu: boolean to add ReLU non-linearity (or not)\n :return: The output array\n \"\"\"\n in_dim = x.get_shape()[1]\n W = weight_variable(name, shape=[in_dim, num_units])\n b = bias_variable(name, [num_units])\n layer = tf.matmul(x, W)\n layer += b\n if use_relu:\n layer = tf.nn.relu(layer)\n return layer",
"_____no_output_____"
]
],
[
[
"## 4. Create the network graph\n\nNow that we have defined all the helped functions to create our model, we can create our network.\n\n### 4.1. Placeholders for the inputs (x) and corresponding labels (y)\n\nFirst we need to define the proper tensors to feed in the input values to our model. As explained in the [Tensor Types](https://github.com/easy-tensorflow/easy-tensorflow/blob/master/1_TensorFlow_Basics/Tutorials/2_Tensor_Types.ipynb) tutorial, placeholder variable is the suitable choice for the input images and corresponding labels. This allows us to change the inputs (images and labels) to the TensorFlow graph.",
"_____no_output_____"
]
],
[
[
"# Create the graph for the linear model\n# Placeholders for inputs (x) and outputs(y)\nx = tf.placeholder(tf.float32, shape=[None, img_size_flat], name='X')\ny = tf.placeholder(tf.float32, shape=[None, n_classes], name='Y')",
"_____no_output_____"
]
],
[
[
"Placeholder __`x`__ is defined for the images; its data-type is set to __`float32`__ and the shape is set to __[None, img_size_flat]__, where __`None`__ means that the tensor may hold an arbitrary number of images with each image being a vector of length __`img_size_flat`__.\n\n\nNext we have __`y`__ which is the placeholder variable for the true labels associated with the images that were input in the placeholder variable __`x`__. The shape of this placeholder variable is __[None, num_classes]__ which means it may hold an arbitrary number of labels and each label is a vector of length __`num_classes`__ which is $10$ in this case.",
"_____no_output_____"
],
[
"### 4.2. Create the network layers\n\n\nAfter creating the proper input, we have to pass it to our model. Since we have a neural network, we can stack multiple fully-connected layers using __`fc_layer`__ method. Note that we will not use any activation function (`use_relu=False`) in the last layer. The reason is that we can use `tf.nn.softmax_cross_entropy_with_logits` to calculate the `loss`.",
"_____no_output_____"
]
],
[
[
"# Create a fully-connected layer with h1 nodes as hidden layer\nfc1 = fc_layer(x, h1, 'FC1', use_relu=True)\n# Create a fully-connected layer with n_classes nodes as output layer\noutput_logits = fc_layer(fc1, n_classes, 'OUT', use_relu=False)",
"_____no_output_____"
]
],
[
[
"### 4.3. Define the loss function, optimizer, accuracy, and predicted class\n\nAfter creating the network, we have to calculate the loss and optimize it. Also, to evaluate our model, we have to calculate the `correct_prediction` and `accuracy`. We will also define `cls_prediction` to visualize our results.",
"_____no_output_____"
]
],
[
[
"# Define the loss function, optimizer, and accuracy\nloss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=output_logits), name='loss')\noptimizer = tf.train.AdamOptimizer(learning_rate=learning_rate, name='Adam-op').minimize(loss)\ncorrect_prediction = tf.equal(tf.argmax(output_logits, 1), tf.argmax(y, 1), name='correct_pred')\naccuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32), name='accuracy')\n\n# Network predictions\ncls_prediction = tf.argmax(output_logits, axis=1, name='predictions')",
"WARNING:tensorflow:From <ipython-input-12-61597c158d19>:2: softmax_cross_entropy_with_logits (from tensorflow.python.ops.nn_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\n\nFuture major versions of TensorFlow will allow gradients to flow\ninto the labels input on backprop by default.\n\nSee tf.nn.softmax_cross_entropy_with_logits_v2.\n\n"
]
],
[
[
"### 4.4. Initialize all variables\n\nAs explained in the [Tensor Types](https://github.com/easy-tensorflow/easy-tensorflow/blob/master/1_TensorFlow_Basics/Tutorials/2_Tensor_Types.ipynb) tutorial, we have to invoke a variable initializer operation to initialize all variables.",
"_____no_output_____"
]
],
[
[
"# Create the op for initializing all variables\ninit = tf.global_variables_initializer()",
"_____no_output_____"
]
],
[
[
"## 5. Train\n\nAfter creating the graph, it is time to train our model. To train the model, As explained in the [Graph_and_Session](https://github.com/easy-tensorflow/easy-tensorflow/blob/master/1_TensorFlow_Basics/Tutorials/1_Graph_and_Session.ipynb) tutorial, we have to create a session and run the graph in our session.",
"_____no_output_____"
]
],
[
[
"# Create an interactive session (to keep the session in the other cells)\nsess = tf.InteractiveSession()\n# Initialize all variables\nsess.run(init)\n# Number of training iterations in each epoch\nnum_tr_iter = int(len(y_train) / batch_size)\nfor epoch in range(epochs):\n print('Training epoch: {}'.format(epoch + 1))\n # Randomly shuffle the training data at the beginning of each epoch \n x_train, y_train = randomize(x_train, y_train)\n for iteration in range(num_tr_iter):\n start = iteration * batch_size\n end = (iteration + 1) * batch_size\n x_batch, y_batch = get_next_batch(x_train, y_train, start, end)\n\n # Run optimization op (backprop)\n feed_dict_batch = {x: x_batch, y: y_batch}\n sess.run(optimizer, feed_dict=feed_dict_batch)\n\n if iteration % display_freq == 0:\n # Calculate and display the batch loss and accuracy\n loss_batch, acc_batch = sess.run([loss, accuracy],\n feed_dict=feed_dict_batch)\n\n print(\"iter {0:3d}:\\t Loss={1:.2f},\\tTraining Accuracy={2:.01%}\".\n format(iteration, loss_batch, acc_batch))\n\n # Run validation after every epoch\n feed_dict_valid = {x: x_valid[:1000], y: y_valid[:1000]}\n loss_valid, acc_valid = sess.run([loss, accuracy], feed_dict=feed_dict_valid)\n print('---------------------------------------------------------')\n print(\"Epoch: {0}, validation loss: {1:.2f}, validation accuracy: {2:.01%}\".\n format(epoch + 1, loss_valid, acc_valid))\n print('---------------------------------------------------------')",
"Training epoch: 1\niter 0:\t Loss=2.28,\tTraining Accuracy=58.0%\niter 100:\t Loss=0.56,\tTraining Accuracy=84.0%\niter 200:\t Loss=0.15,\tTraining Accuracy=95.0%\niter 300:\t Loss=0.31,\tTraining Accuracy=92.0%\niter 400:\t Loss=0.37,\tTraining Accuracy=91.0%\niter 500:\t Loss=0.15,\tTraining Accuracy=96.0%\n---------------------------------------------------------\nEpoch: 1, validation loss: 0.24, validation accuracy: 93.4%\n---------------------------------------------------------\nTraining epoch: 2\niter 0:\t Loss=0.18,\tTraining Accuracy=95.0%\niter 100:\t Loss=0.16,\tTraining Accuracy=94.0%\niter 200:\t Loss=0.11,\tTraining Accuracy=97.0%\niter 300:\t Loss=0.14,\tTraining Accuracy=95.0%\niter 400:\t Loss=0.14,\tTraining Accuracy=96.0%\niter 500:\t Loss=0.15,\tTraining Accuracy=95.0%\n---------------------------------------------------------\nEpoch: 2, validation loss: 0.16, validation accuracy: 95.6%\n---------------------------------------------------------\nTraining epoch: 3\niter 0:\t Loss=0.15,\tTraining Accuracy=95.0%\niter 100:\t Loss=0.12,\tTraining Accuracy=97.0%\niter 200:\t Loss=0.12,\tTraining Accuracy=96.0%\niter 300:\t Loss=0.06,\tTraining Accuracy=99.0%\niter 400:\t Loss=0.06,\tTraining Accuracy=99.0%\niter 500:\t Loss=0.15,\tTraining Accuracy=98.0%\n---------------------------------------------------------\nEpoch: 3, validation loss: 0.13, validation accuracy: 95.8%\n---------------------------------------------------------\nTraining epoch: 4\niter 0:\t Loss=0.10,\tTraining Accuracy=97.0%\niter 100:\t Loss=0.05,\tTraining Accuracy=100.0%\niter 200:\t Loss=0.10,\tTraining Accuracy=97.0%\niter 300:\t Loss=0.04,\tTraining Accuracy=100.0%\niter 400:\t Loss=0.08,\tTraining Accuracy=97.0%\niter 500:\t Loss=0.18,\tTraining Accuracy=96.0%\n---------------------------------------------------------\nEpoch: 4, validation loss: 0.11, validation accuracy: 96.3%\n---------------------------------------------------------\nTraining epoch: 5\niter 0:\t Loss=0.15,\tTraining Accuracy=96.0%\niter 100:\t Loss=0.11,\tTraining Accuracy=95.0%\niter 200:\t Loss=0.15,\tTraining Accuracy=99.0%\niter 300:\t Loss=0.06,\tTraining Accuracy=99.0%\niter 400:\t Loss=0.04,\tTraining Accuracy=99.0%\niter 500:\t Loss=0.02,\tTraining Accuracy=100.0%\n---------------------------------------------------------\nEpoch: 5, validation loss: 0.10, validation accuracy: 97.1%\n---------------------------------------------------------\nTraining epoch: 6\niter 0:\t Loss=0.06,\tTraining Accuracy=99.0%\niter 100:\t Loss=0.07,\tTraining Accuracy=98.0%\niter 200:\t Loss=0.04,\tTraining Accuracy=100.0%\niter 300:\t Loss=0.04,\tTraining Accuracy=98.0%\niter 400:\t Loss=0.04,\tTraining Accuracy=100.0%\niter 500:\t Loss=0.11,\tTraining Accuracy=97.0%\n---------------------------------------------------------\nEpoch: 6, validation loss: 0.09, validation accuracy: 96.9%\n---------------------------------------------------------\nTraining epoch: 7\niter 0:\t Loss=0.04,\tTraining Accuracy=99.0%\niter 100:\t Loss=0.05,\tTraining Accuracy=98.0%\niter 200:\t Loss=0.04,\tTraining Accuracy=99.0%\niter 300:\t Loss=0.06,\tTraining Accuracy=98.0%\niter 400:\t Loss=0.03,\tTraining Accuracy=99.0%\niter 500:\t Loss=0.03,\tTraining Accuracy=100.0%\n---------------------------------------------------------\nEpoch: 7, validation loss: 0.09, validation accuracy: 97.2%\n---------------------------------------------------------\nTraining epoch: 8\niter 0:\t Loss=0.01,\tTraining Accuracy=100.0%\niter 100:\t Loss=0.12,\tTraining Accuracy=99.0%\niter 200:\t Loss=0.01,\tTraining Accuracy=100.0%\niter 300:\t Loss=0.02,\tTraining Accuracy=100.0%\niter 400:\t Loss=0.05,\tTraining Accuracy=98.0%\niter 500:\t Loss=0.07,\tTraining Accuracy=98.0%\n---------------------------------------------------------\nEpoch: 8, validation loss: 0.09, validation accuracy: 97.6%\n---------------------------------------------------------\nTraining epoch: 9\niter 0:\t Loss=0.07,\tTraining Accuracy=98.0%\niter 100:\t Loss=0.04,\tTraining Accuracy=98.0%\niter 200:\t Loss=0.05,\tTraining Accuracy=98.0%\niter 300:\t Loss=0.03,\tTraining Accuracy=99.0%\niter 400:\t Loss=0.03,\tTraining Accuracy=100.0%\niter 500:\t Loss=0.01,\tTraining Accuracy=100.0%\n---------------------------------------------------------\nEpoch: 9, validation loss: 0.08, validation accuracy: 97.4%\n---------------------------------------------------------\nTraining epoch: 10\niter 0:\t Loss=0.02,\tTraining Accuracy=99.0%\niter 100:\t Loss=0.01,\tTraining Accuracy=100.0%\niter 200:\t Loss=0.03,\tTraining Accuracy=98.0%\niter 300:\t Loss=0.03,\tTraining Accuracy=98.0%\niter 400:\t Loss=0.02,\tTraining Accuracy=99.0%\niter 500:\t Loss=0.04,\tTraining Accuracy=99.0%\n---------------------------------------------------------\nEpoch: 10, validation loss: 0.08, validation accuracy: 97.5%\n---------------------------------------------------------\n"
]
],
[
[
"## 6. Test\n\nAfter the training is done, we have to test our model to see how good it performs on a new dataset. There are multiple approaches to for this purpose. We will use two different methods.\n\n## 6.1. Accuracy\nOne way that we can evaluate our model is reporting the accuracy on the test set.",
"_____no_output_____"
]
],
[
[
"# Test the network after training\n# Accuracy\nx_test, y_test = load_data(mode='test')\nfeed_dict_test = {x: x_test[:1000], y: y_test[:1000]}\nloss_test, acc_test = sess.run([loss, accuracy], feed_dict=feed_dict_test)\nprint('---------------------------------------------------------')\nprint(\"Test loss: {0:.2f}, test accuracy: {1:.01%}\".format(loss_test, acc_test))\nprint('---------------------------------------------------------')",
"Extracting MNIST_data/train-images-idx3-ubyte.gz\nExtracting MNIST_data/train-labels-idx1-ubyte.gz\nExtracting MNIST_data/t10k-images-idx3-ubyte.gz\nExtracting MNIST_data/t10k-labels-idx1-ubyte.gz\n---------------------------------------------------------\nTest loss: 0.06, test accuracy: 97.4%\n---------------------------------------------------------\n"
]
],
[
[
"## 6.2. plot some results\nAnother way to evaluate the model is to visualize the input and the model results and compare them with the true label of the input. This is advantages in numerous ways. For example, even if you get a decent accuracy, when you plot the results, you might see all the samples have been classified in one class. Another example is when you plot, you can have a rough idea on which examples your model failed. Let's define the helper functions to plot some correct and missclassified examples.\n\n### 6.2.1 Helper functions for plotting the results",
"_____no_output_____"
]
],
[
[
"def plot_images(images, cls_true, cls_pred=None, title=None):\n \"\"\"\n Create figure with 3x3 sub-plots.\n :param images: array of images to be plotted, (9, img_h*img_w)\n :param cls_true: corresponding true labels (9,)\n :param cls_pred: corresponding true labels (9,)\n \"\"\"\n fig, axes = plt.subplots(3, 3, figsize=(9, 9))\n fig.subplots_adjust(hspace=0.3, wspace=0.3)\n for i, ax in enumerate(axes.flat):\n # Plot image.\n ax.imshow(images[i].reshape(28, 28), cmap='binary')\n\n # Show true and predicted classes.\n if cls_pred is None:\n ax_title = \"True: {0}\".format(cls_true[i])\n else:\n ax_title = \"True: {0}, Pred: {1}\".format(cls_true[i], cls_pred[i])\n\n ax.set_title(ax_title)\n\n # Remove ticks from the plot.\n ax.set_xticks([])\n ax.set_yticks([])\n\n if title:\n plt.suptitle(title, size=20)\n plt.show(block=False)\n\n\ndef plot_example_errors(images, cls_true, cls_pred, title=None):\n \"\"\"\n Function for plotting examples of images that have been mis-classified\n :param images: array of all images, (#imgs, img_h*img_w)\n :param cls_true: corresponding true labels, (#imgs,)\n :param cls_pred: corresponding predicted labels, (#imgs,)\n \"\"\"\n # Negate the boolean array.\n incorrect = np.logical_not(np.equal(cls_pred, cls_true))\n\n # Get the images from the test-set that have been\n # incorrectly classified.\n incorrect_images = images[incorrect]\n\n # Get the true and predicted classes for those images.\n cls_pred = cls_pred[incorrect]\n cls_true = cls_true[incorrect]\n\n # Plot the first 9 images.\n plot_images(images=incorrect_images[0:9],\n cls_true=cls_true[0:9],\n cls_pred=cls_pred[0:9],\n title=title)",
"_____no_output_____"
]
],
[
[
"### 6.2.2 Visualize correct and missclassified examples",
"_____no_output_____"
]
],
[
[
"# Plot some of the correct and misclassified examples\ncls_pred = sess.run(cls_prediction, feed_dict=feed_dict_test)\ncls_true = np.argmax(y_test[:1000], axis=1)\nplot_images(x_test, cls_true, cls_pred, title='Correct Examples')\nplot_example_errors(x_test[:1000], cls_true, cls_pred, title='Misclassified Examples')\nplt.show()",
"_____no_output_____"
]
],
[
[
"After we finished, we have to close the __`session`__ to free the memory. We could have also used:\n```python\nwith tf.Session as sess:\n ...\n```\n\nPlease check our [Graph_and_Session](https://github.com/easy-tensorflow/easy-tensorflow/blob/master/1_TensorFlow_Basics/Tutorials/1_Graph_and_Session.ipynb) tutorial if you do not know the differences between these two implementations.\n ",
"_____no_output_____"
]
],
[
[
"sess.close()",
"_____no_output_____"
]
],
[
[
"Thanks for reading! If you have any question or doubt, feel free to leave a comment in our [website](http://easy-tensorflow.com/).",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
cb346da927fa4b18ee2dfc67c2714ac2e93e628b | 15,710 | ipynb | Jupyter Notebook | Field_extraction.ipynb | hungrayho/ocr | 9c9834454af719cba60edcc2f7311a17f04ac95c | [
"MIT"
] | 1 | 2019-02-04T10:43:16.000Z | 2019-02-04T10:43:16.000Z | Field_extraction.ipynb | hungrayho/ocr | 9c9834454af719cba60edcc2f7311a17f04ac95c | [
"MIT"
] | null | null | null | Field_extraction.ipynb | hungrayho/ocr | 9c9834454af719cba60edcc2f7311a17f04ac95c | [
"MIT"
] | null | null | null | 50.841424 | 6,576 | 0.649077 | [
[
[
"import cv2\nimport numpy as np\nimport pandas as pd\nfrom matplotlib import pyplot as plt\nimport time",
"_____no_output_____"
],
[
"img1 = cv2.imread(\"test.png\", cv2.IMREAD_GRAYSCALE)\nimg2 = cv2.imread(\"test2.png\", cv2.IMREAD_GRAYSCALE)\nwith open(\"data/fieldmap_1040_1988_1\") as f:\n bbox_map_1 = f.read().splitlines()\nwith open(\"data/fieldmap_1040_1988_2\") as f:\n bbox_map_2 = f.read().splitlines() ",
"_____no_output_____"
],
[
"bbox_map_split_1 = []\nfor i in bbox_map_1:\n bbox_map_split_1.append(i.split())\n \nbbox_map_split_2 = []\nfor i in bbox_map_2:\n bbox_map_split_2.append(i.split())",
"_____no_output_____"
],
[
"df_1 = pd.DataFrame(bbox_map_split_1, columns=['ENTRY_FIELD', 'TYPE', 'CONTEXT', 'FIELD_DESC', 'XMIN', 'YMIN', 'XMAX', 'YMAX'])\ndf_1['PAGE'] = 1\ndf_2 = pd.DataFrame(bbox_map_split_2, columns=['ENTRY_FIELD', 'TYPE', 'CONTEXT', 'FIELD_DESC', 'XMIN', 'YMIN', 'XMAX', 'YMAX'])\ndf_2['PAGE'] = 2",
"_____no_output_____"
],
[
"df = df_1.append(df_2)\ndf = df.reset_index()\ndf['ENTRY'] = np.empty((len(df), 0)).tolist()",
"_____no_output_____"
],
[
"def field_extract(df):\n for i in range (0, len(df)):\n if df[\"PAGE\"][i] == 1:\n df[\"ENTRY\"][i] = img1[int(df[\"YMIN\"][i]):int(df[\"YMAX\"][i]), int(df[\"XMIN\"][i]):int(df[\"XMAX\"][i])]\n if df[\"PAGE\"][i] == 2:\n df[\"ENTRY\"][i] = img2[int(df[\"YMIN\"][i]):int(df[\"YMAX\"][i]), int(df[\"XMIN\"][i]):int(df[\"XMAX\"][i])]",
"_____no_output_____"
],
[
"field_extract(df)",
"C:\\Users\\Chris\\Anaconda3\\envs\\py36\\lib\\site-packages\\ipykernel_launcher.py:4: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n after removing the cwd from sys.path.\nC:\\Users\\Chris\\Anaconda3\\envs\\py36\\lib\\site-packages\\ipykernel_launcher.py:6: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n \n"
],
[
"df.head()",
"_____no_output_____"
],
[
"plt.imshow(df[\"ENTRY\"][3], cmap='gray')",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb347695c907065b1769a06c3493cd910720f321 | 15,149 | ipynb | Jupyter Notebook | notebooks/.ipynb_checkpoints/RAC_bashop-checkpoint.ipynb | tsommerfeld/L2-methods_for_resonances | acba48bfede415afd99c89ff2859346e1eb4f96c | [
"MIT"
] | null | null | null | notebooks/.ipynb_checkpoints/RAC_bashop-checkpoint.ipynb | tsommerfeld/L2-methods_for_resonances | acba48bfede415afd99c89ff2859346e1eb4f96c | [
"MIT"
] | null | null | null | notebooks/.ipynb_checkpoints/RAC_bashop-checkpoint.ipynb | tsommerfeld/L2-methods_for_resonances | acba48bfede415afd99c89ff2859346e1eb4f96c | [
"MIT"
] | null | null | null | 27.593807 | 126 | 0.438115 | [
[
[
"import numpy as np\nfrom scipy.optimize import least_squares\nfrom scipy.optimize import basinhopping\nfrom pandas import Series, DataFrame\nimport pandas as pd\nimport matplotlib\nimport matplotlib.pyplot as plt\nmatplotlib.use('Qt5Agg')\n%matplotlib qt5\n#\n# if pade.py is not in the current directory, set this path:\n#\n#import sys\nfrom rac_aux import *",
"_____no_output_____"
],
[
"Angs2Bohr=1.8897259886\nau2eV=27.211386027\nau2cm=219474.63068\n#\n# files in the current directory do not need the path name\n#\n#df = pd.read_csv(\"/home/thomas/Python/StabPlots/Stab_data/1D_a0.2_b0_c0.14/crossing_1.dat\", delim_whitespace=True)\ndf = pd.read_csv(\"sb_rac.csv\")\n#df = pd.read_csv(\"crossing_1.dat\", delim_whitespace=True)\nplt.cla()\nplt.plot(df.l.values, df.E1.values, 'o-')\nplt.plot(df.l.values, df.E2.values, 'o-')\nplt.plot(df.l.values, df.E3.values, 'o-')\nplt.show()\ndf[:5]",
"_____no_output_____"
],
[
"i_neg = np.argmin(abs(df.E1.values))\nif df.E1[i_neg] > 0:\n i_neg += 1\nls = df.l.values[i_neg:]\nprint('N=',len(ls))\nEs = df.E1.values[i_neg:]\nplt.cla()\nplt.plot(df.l.values, df.E1.values, 'b-')\nplt.plot(df.l.values, df.E2.values, 'b-')\nplt.plot(df.l.values, df.E3.values, 'b-')\nplt.plot(ls, Es, 'o', color=\"orange\")\nplt.plot([df.l[0],df.l.values[-1]],[0,0],'-', color='black')\nplt.show()",
"N= 89\n"
],
[
"#\n# kappas, kappa**2, and sigmas (weights = sigma**2)\n# least_squares() passes parg to each pade_nm function\n#\nk2s = -Es\nks = np.sqrt(k2s)\nsigmas = weights(len(Es), 'ones')\n#sigmas = weights(len(Es), 'energy', E0=Es[11], Es=Es)\nparg=(ks,k2s,ls,sigmas)",
"_____no_output_____"
],
[
"#\n# So far, nm can be in [21, 31, 32, 42, 53]\n#\nnm=53\n\npade_fns = {\"21\":(pade_21_lsq, pade_21j_lsq), \n \"31\":(pade_31_lsq, pade_31j_lsq), \n \"32\":(pade_32_lsq, pade_32j_lsq),\n \"42\":(pade_42_lsq, pade_42j_lsq),\n \"53\":(pade_53_lsq, pade_53j_lsq)}\n\nfun=pade_fns[str(nm)][0]\njac=pade_fns[str(nm)][1]",
"_____no_output_____"
],
[
"# start params depend on nm\n# basin_hopping should be less sensitive to good p0s\np31_opt = [2.4022, 0.2713, 1.2813, 0.4543]\np42_opt = [2.3919, 0.2964, 1.3187, 1.3736, 0.29655, 0.5078]\n\nE0 = linear_extra(ls,Es)\nG0 = 0.2*E0\nif nm == 21:\n p0s=[ls[0]] + guess(E0, G0)\nelif nm == 31:\n p0s=[ls[0]] + guess(E0, G0) + [10]\nelif nm == 32:\n p0s=[ls[0]] + guess(E0, G0) + [10, 1]\n #p0s=p31_opt + [0.2]\nelif nm == 42:\n p0s=[ls[0]] + guess(E0, G0) + guess(5*E0,10*G0) + [10]\nelif nm == 53:\n p0s = p42_opt[0:5] + p31_opt[3:] + p42_opt[5:] + [1]\nelse:\n print(\"Warning\", nm, \"not implemented\")\nprint(p0s)\nprint(chi2_gen(p0s, ks, k2s, ls, sigmas, fun))",
"[2.3919, 0.2964, 1.3187, 1.3736, 0.29655, 0.4543, 0.5078, 1]\n33.16551690973274\n"
],
[
"#\n# Because basin_hopping calls a minimize()-like function, \n# calling instead least_squares() requires jumping through some hoops\n#\n# We minimize chi2 = 1/M sum_i (rac(k_i) - lambda_i)**2\n#\n# basin_hopping needs bh_chi2() as parameter and will call this function directly \n# (not just the local minimizer)\n#\n# \n# To call least_squares() a wrapper-function knowing how to call f_lsq(k)=rac(k)-lambda and \n# a function returning the gradient matrix of f_lsq(k_i) with respect to the parameter p_j \n#\narg_nm = (ks, k2s, ls, sigmas, fun, jac)\n\ndef bh_chi2(params, args=()):\n \"\"\"\n at the moment 'args':(ks, k2s, ls, f_lsq, j_lsq)\n \"\"\"\n (ks, k2s, ls, sigmas, f_lsq, j_lsq) = args\n diffs = f_lsq(params, ks, k2s, ls, sigmas)\n return np.sum(np.square(diffs))\n\ndef lsq_wrapper(fun, x0, args=(), method=None, jac=None, hess=None,\n hessp=None, bounds=None, constraints=(), tol=None,\n callback=None, options=None):\n (ks, k2s, ls, sigmas, f_lsq, j_lsq) = args\n res = least_squares(f_lsq, x0, method='trf', jac=j_lsq, \n args=(ks, k2s, ls, sigmas))\n res.fun = res.cost*2\n #print(res.fun, res.x)\n #print('wrapper:', res.fun)\n #delattr(res, 'njev')\n return res\n\ndef bh_call_back(x, f, accepted):\n global jbh, chi2s, alphas, betas\n #nonlocal jbh, chi2s, alphas, betas\n chi2s[jbh] = f\n alphas[jbh], betas[jbh] = x[1], x[2]\n jbh += 1",
"_____no_output_____"
],
[
"# check lsq_wrapper and bh_chi\nres = lsq_wrapper(bh_chi2, p0s, args=arg_nm)\nprint(res.fun)\nprint(bh_chi2(res.x, args=arg_nm))",
"4.929080018263523e-10\n4.929080018263522e-10\n"
],
[
"#\n# for least_squares:\n#\nmin_kwargs = {'method':lsq_wrapper, 'args':arg_nm, 'jac':True}\n\njbh=0\nn_bh = 1000\nchi2s = np.zeros(n_bh)\nalphas = np.zeros(n_bh)\nbetas = np.zeros(n_bh)\nres = basinhopping(bh_chi2, p0s, minimizer_kwargs=min_kwargs, niter=n_bh, \n T=1e-2, seed=1, callback=bh_call_back)\nprint(res.fun)\nprint(res.x)\nprint(res_ene(res.x[1],res.x[2]))",
"2.338187743918324e-11\n[ 2.39268253 0.24355147 1.32306903 0.48814693 -1.67346061 -0.31170181\n 2.20312499 0.83989187]\n(1.746993122077947, 0.3139236176592722)\n"
],
[
"Ers, Gms = res_ene(alphas, betas)\nlogs = np.log10(chi2s)\nsrt=np.sort(logs)\nprint(srt[0:3], srt[-3:])",
"[-10.63112062 -10.63112062 -10.63112062] [3.97233924 4.37782949 4.5341454 ]\n"
],
[
"dic = {'logs':logs, 'Er':Ers, 'G':Gms}\nrf = DataFrame(dic)\n#print(rf[:5])\nrf = rf.sort_values('logs')\nrf[:5]",
"_____no_output_____"
],
[
"plt.cla()\npop, edges, patches = plt.hist(logs, bins=50)\npop",
"_____no_output_____"
],
[
"if 'cb' in vars():\n cb.remove()\n del cb\nplt.cla()\nN=100 # needed for [5,3]\n# 'viridis', 'plasma'\nplt.scatter(rf.Er.values[:N], rf.G.values[:N], c=rf.logs[:N], s=20, cmap='viridis')\n#plt.xlim(0,3)\n#plt.ylim(0,1)\ncb = plt.colorbar()\nplt.tick_params(labelsize=12)\nplt.xlabel('$E_r$ [eV]', fontsize=10)\nplt.ylabel('$\\Gamma$ [eV]', fontsize=10)\nplt.show()",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb347e49fe4d24d29348d5ca7e39697a84c5c788 | 120,073 | ipynb | Jupyter Notebook | examples/peak_detection.ipynb | pnnl/deimos | 3f5e8d67a698818679bea91b7605c6418ef02265 | [
"BSD-3-Clause"
] | 5 | 2021-12-09T15:13:37.000Z | 2022-02-17T12:38:33.000Z | examples/peak_detection.ipynb | pnnl/deimos | 3f5e8d67a698818679bea91b7605c6418ef02265 | [
"BSD-3-Clause"
] | 1 | 2022-03-15T15:07:46.000Z | 2022-03-18T12:49:43.000Z | examples/peak_detection.ipynb | pnnl/deimos | 3f5e8d67a698818679bea91b7605c6418ef02265 | [
"BSD-3-Clause"
] | 3 | 2022-02-05T11:54:18.000Z | 2022-02-17T12:58:05.000Z | 289.33253 | 71,040 | 0.92368 | [
[
[
"# Peak Detection",
"_____no_output_____"
],
[
"Feature detection, also referred to as peak detection, is the process by which local maxima that fulfill certain criteria (such as sufficient signal-to-noise ratio) are located in the signal acquired by a given analytical instrument. \nThis process results in “features” associated with the analysis of molecular analytes from the sample under study or from chemical, instrument, or random noise.\nTypically, feature detection involves a mass dimension (*m/z*) as well as one or more separation dimensions (e.g. drift and/or retention time), the latter offering distinction among isobaric/isotopic features.",
"_____no_output_____"
],
[
"DEIMoS implements an N-dimensional maximum filter from [scipy.ndimage](https://docs.scipy.org/doc/scipy/reference/ndimage.html) that convolves the instrument signal with a structuring element, also known as a kernel, and compares the result against the input array to identify local maxima as candidate features or peaks.\nTo demonstrate, we will operate on a subset of 2D data to minimize memory usage and computation time.",
"_____no_output_____"
]
],
[
[
"import deimos\nimport numpy as np\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"# load data, excluding scanid column\nms1 = deimos.load('example_data.h5', key='ms1', columns=['mz', 'drift_time', 'retention_time', 'intensity'])\n\n# sum over retention time\nms1_2d = deimos.collapse(ms1, keep=['mz', 'drift_time'])\n\n# take a subset in m/z\nms1_2d = deimos.slice(ms1_2d, by='mz', low=200, high=400)",
"_____no_output_____"
],
[
"%%time\n# perform peak detection\nms1_peaks = deimos.peakpick.local_maxima(ms1_2d, dims=['mz', 'drift_time'], bins=[9.5, 4.25])",
"CPU times: user 2.02 s, sys: 204 ms, total: 2.22 s\nWall time: 2.23 s\n"
]
],
[
[
"## Selecting Kernel Size",
"_____no_output_____"
],
[
"Key to this process is the selection of kernel size, which can vary by instrument, dataset, and even compound.\nFor example, in LC-IMS-MS/MS data, peak width increases with increasing *m/z* and drift time, and also varies in retention time. \nIdeally, the kernel would be the same size as the N-dimensional peak (i.e. wavelets), though computational efficiency considerations for high-dimensional data currently limit the ability to dynamically adjust kernel size.\nThus, the selected kernel size should be representative of likely features of interest.",
"_____no_output_____"
],
[
"This process is exploratory, and selections can be further refined pending an initial processing of the data.\nTo start, we will get a sense of our data by visualizing a high-intensity feature.",
"_____no_output_____"
]
],
[
[
"# get maximal data point\nmz_i, dt_i, rt_i, intensity_i = ms1.loc[ms1['intensity'] == ms1['intensity'].max(), :].values[0]\n\n# subset the raw data\nfeature = deimos.slice(ms1,\n by=['mz', 'drift_time', 'retention_time'],\n low=[mz_i - 0.1, dt_i - 1, rt_i - 1],\n high=[mz_i + 0.2, dt_i + 1, rt_i + 2])\n\n# visualize\ndeimos.plot.multipanel(feature, dpi=150)\nplt.tight_layout()\nplt.show()",
"_____no_output_____"
],
[
"print('{}:\\t\\t{}'.format('mz', len(feature['mz'].unique())))\nprint('{}:\\t{}'.format('drift_time', len(feature['drift_time'].unique())))\nprint('{}:\\t{}'.format('retention_time', len(feature['retention_time'].unique())))",
"mz:\t\t38\ndrift_time:\t17\nretention_time:\t74\n"
]
],
[
[
"The number of sampled data points in each dimension informs selection of suitable peak detection parameters, in this case 38 values in *m/z*, 17 values in drift time, and 74 values in retention time. \nFor the kernel to be centered on each \"voxel\", however, selections must be odd. \nDue to the multidimensional nature of the data, kernel size need not be exact: two features need only be separated in one dimension, not all dimensions simultaneously.",
"_____no_output_____"
],
[
"## Partitioning",
"_____no_output_____"
],
[
"This dataset is comprised of almost 200,000 unique *m/z* values, 416 unique drift times, and 568 unique retention times.\nIn order to process the data by N-dimensional filter convolution, the data frame-based coordinate format must be converted into a dense array. \nIn this case, a dense array would comprise 4.7E9 cells and, for 32-bit intensities, requiring approximately 174 GB of memory. ",
"_____no_output_____"
]
],
[
[
"print('{}:\\t\\t{}'.format('mz', len(ms1['mz'].unique())))\nprint('{}:\\t{}'.format('drift_time', len(ms1['drift_time'].unique())))\nprint('{}:\\t{}'.format('retention_time', len(ms1['retention_time'].unique())))",
"mz:\t\t197408\ndrift_time:\t416\nretention_time:\t568\n"
]
],
[
[
"This is of course not tenable for many workstations, necessitating a partitioning utility by which the input may be split along a given dimension, each partition processed separately. \nHere, we create a `Partitions` object to divide the *m/z* dimension into chunks of 1000 unique values, with a partition overlap of 0.2 Da to ameliorate artifacts arising from artificial partition \"edges\".\nNext, its `map` method is invoked to apply peak detection to each partition.",
"_____no_output_____"
],
[
"The `processes` flag may also be specified to spread the computational load over multiple cores.\nMemory footprint scales linearly with number of processes.",
"_____no_output_____"
]
],
[
[
"%%time\n# partition the data\npartitions = deimos.partition(ms1_2d, split_on='mz', size=500, overlap=0.2)\n\n# map peak detection over partitions\nms1_peaks_partitioned = partitions.map(deimos.peakpick.local_maxima,\n dims=['mz', 'drift_time'],\n bins=[9.5, 4.25],\n processes=4)",
"CPU times: user 4.21 s, sys: 403 ms, total: 4.62 s\nWall time: 5.03 s\n"
]
],
[
[
"With `overlap` selected appropriately, the partitioned result should be identical to the previous result.",
"_____no_output_____"
]
],
[
[
"all(ms1_peaks_partitioned == ms1_peaks)",
"_____no_output_____"
]
],
[
[
"## Kernel Scaling",
"_____no_output_____"
],
[
"Peak width in *m/z* and drift time increase with *m/z*. \nIn the example data used here, the sample inverval in *m/z* also increases with increasing *m/z*.\nThis means that our kernel effectively \"grows\" as *m/z* increases, as kernel is selected by number of such intervals rather than an *m/z* range.",
"_____no_output_____"
]
],
[
[
"# unique m/z values\nmz_unq = np.unique(ms1_2d['mz'])\n\n# m/z sample intervals\nmz_diff = np.diff(mz_unq)\n\n# visualize\nplt.figure(dpi=150)\nplt.plot(mz_unq[1:], mz_diff)\nplt.xlabel('m/z', fontweight='bold')\nplt.ylabel('Interval', fontweight='bold')\nplt.show()",
"_____no_output_____"
]
],
[
[
"However, the drift time sample interval is constant throughout the acquisition. \nTo accommodate increasing peak width in drift time, we can scale the kernel in that dimension by the *m/z* per partition, scaled by a reference resolution (i.e. the minimum interval in the above).\nThus, the drift time kernel size of the first partition will be scaled by a factor of 1 (no change), the last by a factor of ~1.4.\nThis represents an advanced usage scenario and should only be considered with sufficient justification. \nThat is, knowledge of sample intervals in each dimension, peak widths as a function of these sample intervals, and whether the relationship(s) scale linearly.",
"_____no_output_____"
]
],
[
[
"%%time\n# partition the data\npartitions = deimos.partition(ms1_2d, split_on='mz', size=500, overlap=0.2)\n\n# map peak detection over partitions\nms1_peaks_partitioned = partitions.map(deimos.peakpick.local_maxima,\n dims=['mz', 'drift_time'],\n bins=[9.5, 4.25],\n scale_by='mz',\n ref_res=mz_diff.min(),\n scale=['drift_time'],\n processes=4)",
"CPU times: user 4.29 s, sys: 247 ms, total: 4.54 s\nWall time: 4.79 s\n"
]
],
[
[
"Note that, though we have ignored retention time, its sample interval in these data is also constant.\nHowever, there is no discernable relationship with *m/z*, thus barring use of this scaling functionality.\nIn such cases, simply determining an average, representative kernel size is typically sufficient.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
cb348c1d320b6fd4a922bbf8fa6121a788127529 | 60,909 | ipynb | Jupyter Notebook | HW0_solutions.ipynb | aliciagrande/content | 479ff136c0f5d2fe001d021c4dca47c40bbe32e5 | [
"MIT"
] | null | null | null | HW0_solutions.ipynb | aliciagrande/content | 479ff136c0f5d2fe001d021c4dca47c40bbe32e5 | [
"MIT"
] | null | null | null | HW0_solutions.ipynb | aliciagrande/content | 479ff136c0f5d2fe001d021c4dca47c40bbe32e5 | [
"MIT"
] | null | null | null | 80.46103 | 27,306 | 0.799373 | [
[
[
"# Homework 0\n\n### Due Tuesday, September 10 (but no submission is required)\n\n---\n\nWelcome to CS109 / STAT121 / AC209 / E-109 (http://cs109.org/). In this class, we will be using a variety of tools that will require some initial configuration. To ensure everything goes smoothly moving forward, we will setup the majority of those tools in this homework. While some of this will likely be dull, doing it now will enable us to do more exciting work in the weeks that follow without getting bogged down in further software configuration. This homework will not be graded, however it is essential that you complete it timely since it will enable us to set up your accounts. You do not have to hand anything in, with the exception of filling out the online survey. \n\n## Class Survey, Piazza, and Introduction\n\n**Class Survey**\n\nPlease complete the mandatory course survey located [here](https://docs.google.com/spreadsheet/viewform?formkey=dFg1ZFJwLWJ6ZWhWR1JJb0tES3lGMEE6MA#gid=0). It should only take a few moments of your time. Once you fill in the survey we will sign you up to the course forum on Piazza and the dropbox system that you will use to hand in the homework. It is imperative that you fill out the survey on time as we use the provided information to sign you up for these services. \n\n**Piazza**\n\nGo to [Piazza](https://piazza.com/harvard/fall2013/cs109/home) and sign up for the class using your Harvard e-mail address. \n\nYou will use Piazza as a forum for discussion, to find team members, to arrange appointments, and to ask questions. Piazza should be your primary form of communication with the staff. Use the staff e-mail ([email protected]) only for individual requests, e.g., to excuse yourself from a mandatory guest lecture. All readings, homeworks, and project descriptions will be announced on Piazza first. \n\n**Introduction**\n\nOnce you are signed up to the Piazza course forum, introduce yourself to your classmates and course staff with a follow-up post in the introduction thread. Include your name/nickname, your affiliation, why you are taking this course, and tell us something interesting about yourself (e.g., an industry job, an unusual hobby, past travels, or a cool project you did, etc.). Also tell us whether you have experience with data science. \n\n## Programming expectations\n\nAll the assignments and labs for this class will use Python and, for the most part, the browser-based IPython notebook format you are currently viewing. Knowledge of Python is not a prerequisite for this course, **provided you are comfortable learning on your own as needed**. While we have strived to make the programming component of this course straightforward, we will not devote much time to teaching prorgramming or Python syntax. Basically, you should feel comfortable with:\n\n* How to look up Python syntax on Google and StackOverflow.\n* Basic programming concepts like functions, loops, arrays, dictionaries, strings, and if statements.\n* How to learn new libraries by reading documentation.\n* Asking questions on StackOverflow or Piazza.\n\nThere are many online tutorials to introduce you to scientific python programming. [Here is one](https://github.com/jrjohansson/scientific-python-lectures) that is very nice. Lectures 1-4 are most relevant to this class.\n\n## Getting Python\n\nYou will be using Python throughout the course, including many popular 3rd party Python libraries for scientific computing. [Anaconda](http://continuum.io/downloads) is an easy-to-install bundle of Python and most of these libraries. We recommend that you use Anaconda for this course.\n\nPlease visit [this page](https://github.com/cs109/content/wiki/Installing-Python) and follow the instructions to set up Python\n\n<hline>\n\n## Hello, Python\n\nThe IPython notebook is an application to build interactive computational notebooks. You'll be using them to complete labs and homework. Once you've set up Python, please <a href=https://raw.github.com/cs109/content/master/HW0.ipynb download=\"HW0.ipynb\">download this page</a>, and open it with IPython by typing\n\n```\nipython notebook <name_of_downloaded_file>\n```\n\nFor the rest of the assignment, use your local copy of this page, running on IPython.\n\nNotebooks are composed of many \"cells\", which can contain text (like this one), or code (like the one below). Double click on the cell below, and evaluate it by clicking the \"play\" button above, for by hitting shift + enter",
"_____no_output_____"
]
],
[
[
"x = [10, 20, 30, 40, 50]\nfor item in x:\n print \"Item is \", item",
"Item is 10\nItem is 20\nItem is 30\nItem is 40\nItem is 50\n"
]
],
[
[
"## Python Libraries\n\nWe will be using a several different libraries throughout this course. If you've successfully completed the [installation instructions](https://github.com/cs109/content/wiki/Installing-Python), all of the following statements should run.",
"_____no_output_____"
]
],
[
[
"#IPython is what you are using now to run the notebook\nimport IPython\nprint \"IPython version: %6.6s (need at least 1.0)\" % IPython.__version__\n\n# Numpy is a library for working with Arrays\nimport numpy as np\nprint \"Numpy version: %6.6s (need at least 1.7.1)\" % np.__version__\n\n# SciPy implements many different numerical algorithms\nimport scipy as sp\nprint \"SciPy version: %6.6s (need at least 0.12.0)\" % sp.__version__\n\n# Pandas makes working with data tables easier\nimport pandas as pd\nprint \"Pandas version: %6.6s (need at least 0.11.0)\" % pd.__version__\n\n# Module for plotting\nimport matplotlib\nprint \"Mapltolib version: %6.6s (need at least 1.2.1)\" % matplotlib.__version__\n\n# SciKit Learn implements several Machine Learning algorithms\nimport sklearn\nprint \"Scikit-Learn version: %6.6s (need at least 0.13.1)\" % sklearn.__version__\n\n# Requests is a library for getting data from the Web\nimport requests\nprint \"requests version: %6.6s (need at least 1.2.3)\" % requests.__version__\n\n# Networkx is a library for working with networks\nimport networkx as nx\nprint \"NetworkX version: %6.6s (need at least 1.7)\" % nx.__version__\n\n#BeautifulSoup is a library to parse HTML and XML documents\nimport BeautifulSoup\nprint \"BeautifulSoup version:%6.6s (need at least 3.2)\" % BeautifulSoup.__version__\n\n#MrJob is a library to run map reduce jobs on Amazon's computers\nimport mrjob\nprint \"Mr Job version: %6.6s (need at least 0.4)\" % mrjob.__version__\n\n#Pattern has lots of tools for working with data from the internet\nimport pattern\nprint \"Pattern version: %6.6s (need at least 2.6)\" % pattern.__version__",
"IPython version: 1.0.0 (need at least 1.0)\nNumpy version: 1.7.1 (need at least 1.7.1)\nSciPy version: 0.12.0 (need at least 0.12.0)\nPandas version: 0.11.0 (need at least 0.11.0)\nMapltolib version: 1.4.x (need at least 1.2.1)\nScikit-Learn version: 0.14.1 (need at least 0.13.1)\nrequests version: 1.2.3 (need at least 1.2.3)\nNetworkX version: 1.7 (need at least 1.7)\nBeautifulSoup version: 3.2.1 (need at least 3.2)\nMr Job version: 0.4 (need at least 0.4)\nPattern version: 2.6 (need at least 2.6)\n"
]
],
[
[
"If any of these libraries are missing or out of date, you will need to [install them](https://github.com/cs109/content/wiki/Installing-Python#installing-additional-libraries) and restart IPython",
"_____no_output_____"
],
[
"## Hello matplotlib",
"_____no_output_____"
],
[
"The notebook integrates nicely with Matplotlib, the primary plotting package for python. This should embed a figure of a sine wave:",
"_____no_output_____"
]
],
[
[
"#this line prepares IPython for working with matplotlib\n%matplotlib inline \n\n# this actually imports matplotlib\nimport matplotlib.pyplot as plt \n\nx = np.linspace(0, 10, 30) #array of 30 points from 0 to 10\ny = np.sin(x)\nz = y + np.random.normal(size=30) * .2\nplt.plot(x, y, 'ro-', label='A sine wave')\nplt.plot(x, z, 'b-', label='Noisy sine')\nplt.legend(loc = 'lower right')\nplt.xlabel(\"X axis\")\nplt.ylabel(\"Y axis\") ",
"_____no_output_____"
]
],
[
[
"If that last cell complained about the `%matplotlib` line, you need to update IPython to v1.0, and restart the notebook. See the [installation page](https://github.com/cs109/content/wiki/Installing-Python)",
"_____no_output_____"
],
[
"## Hello Numpy\n\nThe Numpy array processing library is the basis of nearly all numerical computing in Python. Here's a 30 second crash course. For more details, consult Chapter 4 of Python for Data Analysis, or the [Numpy User's Guide](http://docs.scipy.org/doc/numpy-dev/user/index.html)",
"_____no_output_____"
]
],
[
[
"print \"Make a 3 row x 4 column array of random numbers\"\nx = np.random.random((3, 4))\nprint x\nprint\n\nprint \"Add 1 to every element\"\nx = x + 1\nprint x\nprint\n\nprint \"Get the element at row 1, column 2\"\nprint x[1, 2]\nprint\n\n# The colon syntax is called \"slicing\" the array. \nprint \"Get the first row\"\nprint x[0, :]\nprint\n\nprint \"Get every 2nd column of the first row\"\nprint x[0, ::2]\nprint",
"Make a 3 row x 4 column array of random numbers\n[[ 0.57900652 0.03366009 0.16879928 0.75102823]\n [ 0.1953485 0.84906771 0.23505389 0.23498041]\n [ 0.54731531 0.79778484 0.55777833 0.0765986 ]]\n\nAdd 1 to every element\n[[ 1.57900652 1.03366009 1.16879928 1.75102823]\n [ 1.1953485 1.84906771 1.23505389 1.23498041]\n [ 1.54731531 1.79778484 1.55777833 1.0765986 ]]\n\nGet the element at row 1, column 2\n1.23505388985\n\nGet the first row\n[ 1.57900652 1.03366009 1.16879928 1.75102823]\n\nGet every 2nd column of the first row\n[ 1.57900652 1.16879928]\n\n"
]
],
[
[
"Print the maximum, minimum, and mean of the array. This does **not** require writing a loop. In the code cell below, type `x.m<TAB>`, to find built-in operations for common array statistics like this",
"_____no_output_____"
]
],
[
[
"#your code here\nprint \"Max is \", x.max()\nprint \"Min is \", x.min()\nprint \"Mean is \", x.mean()",
"Max is 1.84906771031\nMin is 1.03366009099\nMean is 1.41886847666\n"
]
],
[
[
"Call the `x.max` function again, but use the `axis` keyword to print the maximum of each row in x.",
"_____no_output_____"
]
],
[
[
"#your code here\nprint x.max(axis=1)",
"[ 1.75102823 1.84906771 1.79778484]\n"
]
],
[
[
"Here's a way to quickly simulate 500 coin \"fair\" coin tosses (where the probabily of getting Heads is 50%, or 0.5)",
"_____no_output_____"
]
],
[
[
"x = np.random.binomial(500, .5)\nprint \"number of heads:\", x",
"number of heads: 258\n"
]
],
[
[
"Repeat this simulation 500 times, and use the [plt.hist() function](http://matplotlib.org/api/pyplot_api.html#matplotlib.pyplot.hist) to plot a histogram of the number of Heads (1s) in each simulation",
"_____no_output_____"
]
],
[
[
"#your code here\n\n# 3 ways to run the simulations\n\n# loop\nheads = []\nfor i in range(500):\n heads.append(np.random.binomial(500, .5))\n\n# \"list comprehension\"\nheads = [np.random.binomial(500, .5) for i in range(500)]\n\n# pure numpy\nheads = np.random.binomial(500, .5, size=500)\n\nhistogram = plt.hist(heads, bins=10)",
"_____no_output_____"
],
[
"heads.shape",
"_____no_output_____"
]
],
[
[
"## The Monty Hall Problem\n\n\nHere's a fun and perhaps surprising statistical riddle, and a good way to get some practice writing python functions\n\nIn a gameshow, contestants try to guess which of 3 closed doors contain a cash prize (goats are behind the other two doors). Of course, the odds of choosing the correct door are 1 in 3. As a twist, the host of the show occasionally opens a door after a contestant makes his or her choice. This door is always one of the two the contestant did not pick, and is also always one of the goat doors (note that it is always possible to do this, since there are two goat doors). At this point, the contestant has the option of keeping his or her original choice, or swtiching to the other unopened door. The question is: is there any benefit to switching doors? The answer surprises many people who haven't heard the question before.\n\nWe can answer the problem by running simulations in Python. We'll do it in several parts.\n\nFirst, write a function called `simulate_prizedoor`. This function will simulate the location of the prize in many games -- see the detailed specification below:",
"_____no_output_____"
]
],
[
[
"\"\"\"\nFunction\n--------\nsimulate_prizedoor\n\nGenerate a random array of 0s, 1s, and 2s, representing\nhiding a prize between door 0, door 1, and door 2\n\nParameters\n----------\nnsim : int\n The number of simulations to run\n\nReturns\n-------\nsims : array\n Random array of 0s, 1s, and 2s\n\nExample\n-------\n>>> print simulate_prizedoor(3)\narray([0, 0, 2])\n\"\"\"\ndef simulate_prizedoor(nsim):\n #compute here\n return answer\n#your code here\n\ndef simulate_prizedoor(nsim):\n return np.random.randint(0, 3, (nsim))",
"_____no_output_____"
]
],
[
[
"Next, write a function that simulates the contestant's guesses for `nsim` simulations. Call this function `simulate_guess`. The specs:",
"_____no_output_____"
]
],
[
[
"\"\"\"\nFunction\n--------\nsimulate_guess\n\nReturn any strategy for guessing which door a prize is behind. This\ncould be a random strategy, one that always guesses 2, whatever.\n\nParameters\n----------\nnsim : int\n The number of simulations to generate guesses for\n\nReturns\n-------\nguesses : array\n An array of guesses. Each guess is a 0, 1, or 2\n\nExample\n-------\n>>> print simulate_guess(5)\narray([0, 0, 0, 0, 0])\n\"\"\"\n#your code here\n\ndef simulate_guess(nsim):\n return np.zeros(nsim, dtype=np.int)",
"_____no_output_____"
]
],
[
[
"Next, write a function, `goat_door`, to simulate randomly revealing one of the goat doors that a contestant didn't pick.",
"_____no_output_____"
]
],
[
[
"\"\"\"\nFunction\n--------\ngoat_door\n\nSimulate the opening of a \"goat door\" that doesn't contain the prize,\nand is different from the contestants guess\n\nParameters\n----------\nprizedoors : array\n The door that the prize is behind in each simulation\nguesses : array\n THe door that the contestant guessed in each simulation\n\nReturns\n-------\ngoats : array\n The goat door that is opened for each simulation. Each item is 0, 1, or 2, and is different\n from both prizedoors and guesses\n\nExamples\n--------\n>>> print goat_door(np.array([0, 1, 2]), np.array([1, 1, 1]))\n>>> array([2, 2, 0])\n\"\"\"\n#your code here\n\ndef goat_door(prizedoors, guesses):\n \n #strategy: generate random answers, and\n #keep updating until they satisfy the rule\n #that they aren't a prizedoor or a guess\n result = np.random.randint(0, 3, prizedoors.size)\n while True:\n bad = (result == prizedoors) | (result == guesses)\n if not bad.any():\n return result\n result[bad] = np.random.randint(0, 3, bad.sum())",
"_____no_output_____"
]
],
[
[
"Write a function, `switch_guess`, that represents the strategy of always switching a guess after the goat door is opened.",
"_____no_output_____"
]
],
[
[
"\"\"\"\nFunction\n--------\nswitch_guess\n\nThe strategy that always switches a guess after the goat door is opened\n\nParameters\n----------\nguesses : array\n Array of original guesses, for each simulation\ngoatdoors : array\n Array of revealed goat doors for each simulation\n\nReturns\n-------\nThe new door after switching. Should be different from both guesses and goatdoors\n\nExamples\n--------\n>>> print switch_guess(np.array([0, 1, 2]), np.array([1, 2, 1]))\n>>> array([2, 0, 0])\n\"\"\"\n#your code here\n\ndef switch_guess(guesses, goatdoors):\n result = np.zeros(guesses.size)\n switch = {(0, 1): 2, (0, 2): 1, (1, 0): 2, (1, 2): 1, (2, 0): 1, (2, 1): 0}\n for i in [0, 1, 2]:\n for j in [0, 1, 2]:\n mask = (guesses == i) & (goatdoors == j)\n if not mask.any():\n continue\n result = np.where(mask, np.ones_like(result) * switch[(i, j)], result)\n return result",
"_____no_output_____"
]
],
[
[
"Last function: write a `win_percentage` function that takes an array of `guesses` and `prizedoors`, and returns the percent of correct guesses",
"_____no_output_____"
]
],
[
[
"\"\"\"\nFunction\n--------\nwin_percentage\n\nCalculate the percent of times that a simulation of guesses is correct\n\nParameters\n-----------\nguesses : array\n Guesses for each simulation\nprizedoors : array\n Location of prize for each simulation\n\nReturns\n--------\npercentage : number between 0 and 100\n The win percentage\n\nExamples\n---------\n>>> print win_percentage(np.array([0, 1, 2]), np.array([0, 0, 0]))\n33.333\n\"\"\"\n#your code here\n\ndef win_percentage(guesses, prizedoors):\n return 100 * (guesses == prizedoors).mean()",
"_____no_output_____"
]
],
[
[
"Now, put it together. Simulate 10000 games where contestant keeps his original guess, and 10000 games where the contestant switches his door after a goat door is revealed. Compute the percentage of time the contestant wins under either strategy. Is one strategy better than the other?",
"_____no_output_____"
]
],
[
[
"#your code here\n\nnsim = 10000\n\n#keep guesses\nprint \"Win percentage when keeping original door\"\nprint win_percentage(simulate_prizedoor(nsim), simulate_guess(nsim))\n\n#switch\npd = simulate_prizedoor(nsim)\nguess = simulate_guess(nsim)\ngoats = goat_door(pd, guess)\nguess = switch_guess(guess, goats)\nprint \"Win percentage when switching doors\"\nprint win_percentage(pd, guess).mean()",
"Win percentage when keeping original door\n32.35\nWin percentage when switching doors\n67.14\n"
]
],
[
[
"Many people find this answer counter-intuitive (famously, PhD mathematicians have incorrectly claimed the result must be wrong. Clearly, none of them knew Python). \n\nOne of the best ways to build intuition about why opening a Goat door affects the odds is to re-run the experiment with 100 doors and one prize. If the game show host opens 98 goat doors after you make your initial selection, would you want to keep your first pick or switch? Can you generalize your simulation code to handle the case of `n` doors?",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
cb349b25267313f20b06b28a68e2d57406b60ebe | 3,536 | ipynb | Jupyter Notebook | notebooks/analysis/EDA/EDA-autoEDA_libraries/notebook-auto_eda-PandasGUI.ipynb | jmquintana79/DStools | 582c76aff1002d662d19dfba073de29c7054b15d | [
"MIT"
] | null | null | null | notebooks/analysis/EDA/EDA-autoEDA_libraries/notebook-auto_eda-PandasGUI.ipynb | jmquintana79/DStools | 582c76aff1002d662d19dfba073de29c7054b15d | [
"MIT"
] | null | null | null | notebooks/analysis/EDA/EDA-autoEDA_libraries/notebook-auto_eda-PandasGUI.ipynb | jmquintana79/DStools | 582c76aff1002d662d19dfba073de29c7054b15d | [
"MIT"
] | null | null | null | 24.386207 | 157 | 0.536765 | [
[
[
"# AutoEDA: PandasGUI\n\n> Anaconda env: *eda3*",
"_____no_output_____"
]
],
[
[
"!pip install -U scikit-learn",
"Collecting sklearn\n Using cached sklearn-0.0-py2.py3-none-any.whl\nCollecting scikit-learn\n Downloading scikit_learn-1.0-cp37-cp37m-macosx_10_13_x86_64.whl (7.9 MB)\n\u001b[K |████████████████████████████████| 7.9 MB 4.0 MB/s eta 0:00:01\n\u001b[?25hCollecting threadpoolctl>=2.0.0\n Downloading threadpoolctl-3.0.0-py3-none-any.whl (14 kB)\nCollecting joblib>=0.11\n Downloading joblib-1.1.0-py2.py3-none-any.whl (306 kB)\n\u001b[K |████████████████████████████████| 306 kB 35.5 MB/s eta 0:00:01\n\u001b[?25hCollecting scipy>=1.1.0\n Using cached scipy-1.7.1-cp37-cp37m-macosx_10_9_x86_64.whl (32.6 MB)\nRequirement already satisfied: numpy>=1.14.6 in /Users/juan/miniconda3/envs/eda3/lib/python3.7/site-packages (from scikit-learn->sklearn) (1.21.2)\nInstalling collected packages: threadpoolctl, scipy, joblib, scikit-learn, sklearn\nSuccessfully installed joblib-1.1.0 scikit-learn-1.0 scipy-1.7.1 sklearn-0.0 threadpoolctl-3.0.0\n"
],
[
"%matplotlib inline\nimport warnings\nwarnings.filterwarnings('ignore')\nfrom sklearn.datasets import load_iris\nimport pandas as pd",
"_____no_output_____"
]
],
[
[
"## load data",
"_____no_output_____"
]
],
[
[
"# load dataset\ndataset = load_iris()\ndataset.keys()\n# dataset to df\ndata = pd.DataFrame(dataset.data, columns = dataset.feature_names)\ndata['class'] = dataset.target\ndclass = dict()\nfor i, ic in enumerate(dataset.target_names):\n dclass[i] = ic\ndata['class'] = data['class'].map(dclass)",
"_____no_output_____"
]
],
[
[
"## AutoEDA",
"_____no_output_____"
]
],
[
[
"from pandasgui import show\n#Deploy the GUI of the mpg dataset\ngui = show(data)",
"PandasGUI INFO — pandasgui.gui — Opening PandasGUI\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
cb34a185d2baddb71961af525ce96d0ad9c917f3 | 447,602 | ipynb | Jupyter Notebook | old/create_artistic_data_in_advance.ipynb | konatasick/face-of-art | e796747d0ef2df2df863adf53e217ff5c86c816b | [
"MIT"
] | 220 | 2019-09-01T01:52:04.000Z | 2022-03-28T12:52:07.000Z | old/create_artistic_data_in_advance.ipynb | TrueMatthewKirkham/face-of-art | ffa62a579cc8bc389e2088923736c4947a1fad70 | [
"MIT"
] | 16 | 2019-10-24T07:55:11.000Z | 2022-02-10T01:28:13.000Z | old/create_artistic_data_in_advance.ipynb | TrueMatthewKirkham/face-of-art | ffa62a579cc8bc389e2088923736c4947a1fad70 | [
"MIT"
] | 33 | 2019-09-23T15:08:50.000Z | 2022-02-08T07:54:52.000Z | 827.360444 | 425,210 | 0.938427 | [
[
[
"import os\nimport numpy as np\nfrom glob import glob\nfrom deformation_functions import *\nfrom menpo_functions import *\nfrom logging_functions import *\nfrom data_loading_functions import *\nfrom time import time\nfrom scipy.misc import imsave\n\n%matplotlib inline\n",
"_____no_output_____"
],
[
"dataset='training'\nimg_dir='/Users/arik/Dropbox/a_mac_thesis/face_heatmap_networks/conventional_landmark_detection_dataset/'\ntrain_crop_dir = 'crop_gt_margin_0.25'\nimg_dir_ns=os.path.join(img_dir,train_crop_dir+'_ns')\nbb_dir = os.path.join(img_dir, 'Bounding_Boxes')\nbb_type='gt'\ngt = bb_type=='gt'\nmargin = 0.25\nimage_size = 256\nmode='TRAIN'\naugment_basic=True\naugment_texture=True\naugment_geom=True\nbb_dictionary = load_bb_dictionary(bb_dir, mode=mode, test_data=dataset)",
"_____no_output_____"
],
[
"def augment_menpo_img_ns(img, img_dir_ns, p_ns=0, ns_ind=None):\n \"\"\"texture style image augmentation using stylized copies in *img_dir_ns*\"\"\"\n\n img = img.copy()\n if p_ns > 0.5:\n ns_augs = glob(os.path.join(img_dir_ns, img.path.name.split('.')[0] + '*'))\n num_augs = len(ns_augs)\n if num_augs > 0:\n if ns_ind is None or ns_ind >= num_augs:\n ns_ind = np.random.randint(0, num_augs)\n ns_aug = mio.import_image(ns_augs[ns_ind])\n ns_pixels = ns_aug.pixels\n img.pixels = ns_pixels\n return img\n\ndef augment_menpo_img_ns_dont_apply(img, img_dir_ns, p_ns=0, ns_ind=None):\n \"\"\"texture style image augmentation using stylized copies in *img_dir_ns*\"\"\"\n\n img = img.copy()\n if p_ns > 0.5:\n ns_augs = glob(os.path.join(img_dir_ns, img.path.name.split('.')[0] + '*'))\n num_augs = len(ns_augs)\n if num_augs > 0:\n if ns_ind is None or ns_ind >= num_augs:\n ns_ind = np.random.randint(0, num_augs)\n ns_aug = mio.import_image(ns_augs[ns_ind])\n ns_pixels = ns_aug.pixels\n return img\n\ndef augment_menpo_img_geom_dont_apply(img, p_geom=0):\n \"\"\"geometric style image augmentation using random face deformations\"\"\"\n\n img = img.copy()\n if p_geom > 0.5:\n lms_geom_warp = deform_face_geometric_style(img.landmarks['PTS'].points.copy(), p_scale=p_geom, p_shift=p_geom)\n return img\n\ndef load_menpo_image_list(\n img_dir, train_crop_dir, img_dir_ns, mode, bb_dictionary=None, image_size=256, margin=0.25,\n bb_type='gt', test_data='full', augment_basic=True, augment_texture=False, p_texture=0,\n augment_geom=False, p_geom=0, verbose=False,ns_ind=None):\n\n def crop_to_face_image_gt(img):\n return crop_to_face_image(img, bb_dictionary, gt=True, margin=margin, image_size=image_size)\n\n def crop_to_face_image_init(img):\n return crop_to_face_image(img, bb_dictionary, gt=False, margin=margin, image_size=image_size)\n\n def augment_menpo_img_ns_rand(img):\n return augment_menpo_img_ns(img, img_dir_ns, p_ns=1. * (np.random.rand() < p_texture),ns_ind=ns_ind)\n\n def augment_menpo_img_geom_rand(img):\n return augment_menpo_img_geom(img, p_geom=1. * (np.random.rand() < p_geom))\n\n if mode is 'TRAIN':\n if train_crop_dir is None:\n img_set_dir = os.path.join(img_dir, 'training_set')\n out_image_list = mio.import_images(img_set_dir, verbose=verbose, normalize=False)\n if bb_type is 'gt':\n out_image_list = out_image_list.map(crop_to_face_image_gt)\n elif bb_type is 'init':\n out_image_list = out_image_list.map(crop_to_face_image_init)\n else:\n img_set_dir = os.path.join(img_dir, train_crop_dir)\n out_image_list = mio.import_images(img_set_dir, verbose=verbose)\n\n if augment_texture:\n out_image_list = out_image_list.map(augment_menpo_img_ns_rand)\n if augment_geom:\n out_image_list = out_image_list.map(augment_menpo_img_geom_rand)\n if augment_basic:\n out_image_list = out_image_list.map(augment_face_image)\n\n else:\n img_set_dir = os.path.join(img_dir, test_data + '_set')\n if test_data in ['full', 'challenging', 'common', 'training', 'test']:\n out_image_list = mio.import_images(img_set_dir, verbose=verbose, normalize=False)\n if bb_type is 'gt':\n out_image_list = out_image_list.map(crop_to_face_image_gt)\n elif bb_type is 'init':\n out_image_list = out_image_list.map(crop_to_face_image_init)\n else:\n out_image_list = mio.import_images(img_set_dir, verbose=verbose)\n\n return out_image_list\n\n\ndef load_menpo_image_list_no_geom(\n img_dir, train_crop_dir, img_dir_ns, mode, bb_dictionary=None, image_size=256, margin=0.25,\n bb_type='gt', test_data='full', augment_basic=True, augment_texture=False, p_texture=0,\n augment_geom=False, p_geom=0, verbose=False,ns_ind=None):\n\n def crop_to_face_image_gt(img):\n return crop_to_face_image(img, bb_dictionary, gt=True, margin=margin, image_size=image_size)\n\n def crop_to_face_image_init(img):\n return crop_to_face_image(img, bb_dictionary, gt=False, margin=margin, image_size=image_size)\n\n def augment_menpo_img_ns_rand(img):\n return augment_menpo_img_ns(img, img_dir_ns, p_ns=1. * (np.random.rand() < p_texture),ns_ind=ns_ind)\n\n def augment_menpo_img_geom_rand(img):\n return augment_menpo_img_geom_dont_apply(img, p_geom=1. * (np.random.rand() < p_geom))\n\n if mode is 'TRAIN':\n if train_crop_dir is None:\n img_set_dir = os.path.join(img_dir, 'training_set')\n out_image_list = mio.import_images(img_set_dir, verbose=verbose, normalize=False)\n if bb_type is 'gt':\n out_image_list = out_image_list.map(crop_to_face_image_gt)\n elif bb_type is 'init':\n out_image_list = out_image_list.map(crop_to_face_image_init)\n else:\n img_set_dir = os.path.join(img_dir, train_crop_dir)\n out_image_list = mio.import_images(img_set_dir, verbose=verbose)\n\n if augment_texture:\n out_image_list = out_image_list.map(augment_menpo_img_ns_rand)\n if augment_geom:\n out_image_list = out_image_list.map(augment_menpo_img_geom_rand)\n if augment_basic:\n out_image_list = out_image_list.map(augment_face_image)\n\n else:\n img_set_dir = os.path.join(img_dir, test_data + '_set')\n if test_data in ['full', 'challenging', 'common', 'training', 'test']:\n out_image_list = mio.import_images(img_set_dir, verbose=verbose, normalize=False)\n if bb_type is 'gt':\n out_image_list = out_image_list.map(crop_to_face_image_gt)\n elif bb_type is 'init':\n out_image_list = out_image_list.map(crop_to_face_image_init)\n else:\n out_image_list = mio.import_images(img_set_dir, verbose=verbose)\n\n return out_image_list\n\n\ndef load_menpo_image_list_no_texture(\n img_dir, train_crop_dir, img_dir_ns, mode, bb_dictionary=None, image_size=256, margin=0.25,\n bb_type='gt', test_data='full', augment_basic=True, augment_texture=False, p_texture=0,\n augment_geom=False, p_geom=0, verbose=False,ns_ind=None):\n\n def crop_to_face_image_gt(img):\n return crop_to_face_image(img, bb_dictionary, gt=True, margin=margin, image_size=image_size)\n\n def crop_to_face_image_init(img):\n return crop_to_face_image(img, bb_dictionary, gt=False, margin=margin, image_size=image_size)\n\n def augment_menpo_img_ns_rand(img):\n return augment_menpo_img_ns_dont_apply(img, img_dir_ns, p_ns=1. * (np.random.rand() < p_texture),ns_ind=ns_ind)\n\n def augment_menpo_img_geom_rand(img):\n return augment_menpo_img_geom(img, p_geom=1. * (np.random.rand() < p_geom))\n\n if mode is 'TRAIN':\n if train_crop_dir is None:\n img_set_dir = os.path.join(img_dir, 'training_set')\n out_image_list = mio.import_images(img_set_dir, verbose=verbose, normalize=False)\n if bb_type is 'gt':\n out_image_list = out_image_list.map(crop_to_face_image_gt)\n elif bb_type is 'init':\n out_image_list = out_image_list.map(crop_to_face_image_init)\n else:\n img_set_dir = os.path.join(img_dir, train_crop_dir)\n out_image_list = mio.import_images(img_set_dir, verbose=verbose)\n\n if augment_texture:\n out_image_list = out_image_list.map(augment_menpo_img_ns_rand)\n if augment_geom:\n out_image_list = out_image_list.map(augment_menpo_img_geom_rand)\n if augment_basic:\n out_image_list = out_image_list.map(augment_face_image)\n\n else:\n img_set_dir = os.path.join(img_dir, test_data + '_set')\n if test_data in ['full', 'challenging', 'common', 'training', 'test']:\n out_image_list = mio.import_images(img_set_dir, verbose=verbose, normalize=False)\n if bb_type is 'gt':\n out_image_list = out_image_list.map(crop_to_face_image_gt)\n elif bb_type is 'init':\n out_image_list = out_image_list.map(crop_to_face_image_init)\n else:\n out_image_list = mio.import_images(img_set_dir, verbose=verbose)\n\n return out_image_list\n\n\ndef load_menpo_image_list_no_artistic(\n img_dir, train_crop_dir, img_dir_ns, mode, bb_dictionary=None, image_size=256, margin=0.25,\n bb_type='gt', test_data='full', augment_basic=True, augment_texture=False, p_texture=0,\n augment_geom=False, p_geom=0, verbose=False,ns_ind=None):\n\n def crop_to_face_image_gt(img):\n return crop_to_face_image(img, bb_dictionary, gt=True, margin=margin, image_size=image_size)\n\n def crop_to_face_image_init(img):\n return crop_to_face_image(img, bb_dictionary, gt=False, margin=margin, image_size=image_size)\n\n def augment_menpo_img_ns_rand(img):\n return augment_menpo_img_ns_dont_apply(img, img_dir_ns, p_ns=1. * (np.random.rand() < p_texture),ns_ind=ns_ind)\n\n def augment_menpo_img_geom_rand(img):\n return augment_menpo_img_geom_dont_apply(img, p_geom=1. * (np.random.rand() < p_geom))\n\n if mode is 'TRAIN':\n if train_crop_dir is None:\n img_set_dir = os.path.join(img_dir, 'training_set')\n out_image_list = mio.import_images(img_set_dir, verbose=verbose, normalize=False)\n if bb_type is 'gt':\n out_image_list = out_image_list.map(crop_to_face_image_gt)\n elif bb_type is 'init':\n out_image_list = out_image_list.map(crop_to_face_image_init)\n else:\n img_set_dir = os.path.join(img_dir, train_crop_dir)\n out_image_list = mio.import_images(img_set_dir, verbose=verbose)\n\n if augment_texture:\n out_image_list = out_image_list.map(augment_menpo_img_ns_rand)\n if augment_geom:\n out_image_list = out_image_list.map(augment_menpo_img_geom_rand)\n if augment_basic:\n out_image_list = out_image_list.map(augment_face_image)\n\n else:\n img_set_dir = os.path.join(img_dir, test_data + '_set')\n if test_data in ['full', 'challenging', 'common', 'training', 'test']:\n out_image_list = mio.import_images(img_set_dir, verbose=verbose, normalize=False)\n if bb_type is 'gt':\n out_image_list = out_image_list.map(crop_to_face_image_gt)\n elif bb_type is 'init':\n out_image_list = out_image_list.map(crop_to_face_image_init)\n else:\n out_image_list = mio.import_images(img_set_dir, verbose=verbose)\n\n return out_image_list",
"_____no_output_____"
],
[
"plt.figure(figsize=[10,10])\nnum_augs=9\nns_inds = np.arange(num_augs)\n\nfor i in range(16):\n if i % num_augs == 0:\n np.random.shuffle(ns_inds)\n print ns_inds\n img_list = load_menpo_image_list(\n img_dir=img_dir, train_crop_dir=train_crop_dir, img_dir_ns=img_dir_ns, mode=mode, bb_dictionary=bb_dictionary,\n image_size=image_size, margin=margin, bb_type=bb_type, augment_basic=augment_basic, augment_texture=augment_texture, p_texture=1.,\n augment_geom=augment_geom, p_geom=1.,ns_ind=ns_inds[i % num_augs])\n\n plt.subplot(4,4,i +1)\n img_list[0].view()\n# plt.savefig('g.png',bbox='tight')",
"[2 3 1 7 5 0 6 8 4]\n[6 8 1 7 4 5 3 2 0]\n"
],
[
"outdir = os.path.join('/Users/arik/Desktop/test_art_data3')\nif not os.path.exists(outdir):\n os.mkdir(outdir)\n \naug_geom_dir = os.path.join(outdir,'aug_geom')\naug_texture_dir = os.path.join(outdir,'aug_texture')\naug_geom_texture_dir = os.path.join(outdir,'aug_geom_texture')\naug_basic_dir = os.path.join(outdir,'aug_basic')\n\n\nif not os.path.exists(aug_texture_dir):\n os.mkdir(aug_texture_dir)\nif not os.path.exists(aug_geom_dir):\n os.mkdir(aug_geom_dir)\nif not os.path.exists(aug_geom_texture_dir):\n os.mkdir(aug_geom_texture_dir)\nif not os.path.exists(aug_basic_dir):\n os.mkdir(aug_basic_dir)",
"_____no_output_____"
],
[
"num_train_images = 3148.\ntrain_iter=100000\nbatch_size = 6\nnum_epochs = int(np.ceil((1. * train_iter) / (1. * num_train_images / batch_size)))+1\n\nnum_augs=9\nnum_epochs = 10\ndebug_data_size =5\ndebug=True\n\naug_geom = True\naug_texture = True",
"_____no_output_____"
],
[
"np.random.seed(1234)\nns_inds = np.arange(num_augs)\nif not aug_geom and aug_texture:\n save_aug_path = aug_texture_dir\nelif aug_geom and not aug_texture:\n save_aug_path = aug_geom_dir\nelif aug_geom and aug_texture:\n save_aug_path = aug_geom_texture_dir\nelse:\n save_aug_path = aug_basic_dir\nprint ('saving augmented images: aug_geom='+str(aug_geom)+' aug_texture='+str(aug_texture)+' : '+str(save_aug_path))\n\nfor i in range(num_epochs):\n print ('saving augmented images of epoch %d/%d'%(i+1,num_epochs))\n if not os.path.exists(os.path.join(save_aug_path,str(i))):\n os.mkdir(os.path.join(save_aug_path,str(i)))\n \n if i % num_augs == 0:\n np.random.shuffle(ns_inds) \n \n if not aug_geom and aug_texture: \n img_list = load_menpo_image_list_no_geom(\n img_dir=img_dir, train_crop_dir=train_crop_dir, img_dir_ns=img_dir_ns, mode=mode, bb_dictionary=bb_dictionary,\n image_size=image_size, margin=margin, bb_type=bb_type, augment_basic=augment_basic, augment_texture=augment_texture, p_texture=1.,\n augment_geom=augment_geom, p_geom=1.,ns_ind=ns_inds[i % num_augs])\n elif aug_geom and not aug_texture: \n img_list = load_menpo_image_list_no_texture(\n img_dir=img_dir, train_crop_dir=train_crop_dir, img_dir_ns=img_dir_ns, mode=mode, bb_dictionary=bb_dictionary,\n image_size=image_size, margin=margin, bb_type=bb_type, augment_basic=augment_basic, augment_texture=augment_texture, p_texture=1.,\n augment_geom=augment_geom, p_geom=1.,ns_ind=ns_inds[i % num_augs])\n elif aug_geom and aug_texture: \n img_list = load_menpo_image_list(\n img_dir=img_dir, train_crop_dir=train_crop_dir, img_dir_ns=img_dir_ns, mode=mode, bb_dictionary=bb_dictionary,\n image_size=image_size, margin=margin, bb_type=bb_type, augment_basic=augment_basic, augment_texture=augment_texture, p_texture=1.,\n augment_geom=augment_geom, p_geom=1.,ns_ind=ns_inds[i % num_augs])\n else: \n img_list = load_menpo_image_list_no_artistic(\n img_dir=img_dir, train_crop_dir=train_crop_dir, img_dir_ns=img_dir_ns, mode=mode, bb_dictionary=bb_dictionary,\n image_size=image_size, margin=margin, bb_type=bb_type, augment_basic=augment_basic, augment_texture=augment_texture, p_texture=1.,\n augment_geom=augment_geom, p_geom=1.,ns_ind=ns_inds[i % num_augs])\n \n if debug:\n img_list=img_list[:debug_data_size]\n \n for im in img_list:\n if im.pixels.shape[0] == 1:\n im_pixels = gray2rgb(np.squeeze(im.pixels))\n else:\n im_pixels = np.rollaxis(im.pixels,0,3)\n imsave( os.path.join(os.path.join(save_aug_path,str(i)),im.path.name.split('.')[0]+'.png'),im_pixels)\n mio.export_landmark_file(im.landmarks['PTS'],os.path.join(os.path.join(save_aug_path,str(i)),im.path.name.split('.')[0]+'.pts'),overwrite=True)\n ",
"saving augmented images: aug_geom=True aug_texture=True : /Users/arik/Desktop/test_art_data3/aug_geom_texture\nsaving augmented images of epoch 1/10\nsaving augmented images of epoch 2/10\nsaving augmented images of epoch 3/10\nsaving augmented images of epoch 4/10\nsaving augmented images of epoch 5/10\nsaving augmented images of epoch 6/10\nsaving augmented images of epoch 7/10\nsaving augmented images of epoch 8/10\nsaving augmented images of epoch 9/10\nsaving augmented images of epoch 10/10\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb34c6271f5a83dcbad8e013273eef4cf46872cc | 151,231 | ipynb | Jupyter Notebook | notebooks/optional/S15C_Native_Code_Compilation.ipynb | abbarcenasj/bios-823-2019 | 399299a120b6bf717106440916c7f5d6b7612421 | [
"BSD-3-Clause"
] | 5 | 2019-08-29T17:50:24.000Z | 2020-03-06T04:10:01.000Z | notebooks/optional/S15C_Native_Code_Compilation.ipynb | abbarcenasj/bios-823-2019 | 399299a120b6bf717106440916c7f5d6b7612421 | [
"BSD-3-Clause"
] | null | null | null | notebooks/optional/S15C_Native_Code_Compilation.ipynb | abbarcenasj/bios-823-2019 | 399299a120b6bf717106440916c7f5d6b7612421 | [
"BSD-3-Clause"
] | 12 | 2019-08-29T02:00:15.000Z | 2020-07-30T17:31:27.000Z | 50.765693 | 713 | 0.571331 | [
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\nimport cython\nimport timeit\nimport math",
"_____no_output_____"
],
[
"%load_ext cython",
"_____no_output_____"
]
],
[
[
"# Native code compilation\n\nWe will see how to convert Python code to native compiled code. We will use the example of calculating the pairwise distance between a set of vectors, a $O(n^2)$ operation. \n\nFor native code compilation, it is usually preferable to use explicit for loops and minimize the use of `numpy` vectorization and broadcasting because\n\n- It makes it easier for the `numba` JIT to optimize\n- It is easier to \"cythonize\"\n- It is easier to port to C++\n\nHowever, use of vectors and matrices is fine especially if you will be porting to use a C++ library such as Eigen.",
"_____no_output_____"
],
[
"## Timing code",
"_____no_output_____"
],
[
"### Manual",
"_____no_output_____"
]
],
[
[
"import time\n\ndef f(n=1):\n start = time.time()\n time.sleep(n)\n elapsed = time.time() - start\n return elapsed",
"_____no_output_____"
],
[
"f(1)",
"_____no_output_____"
]
],
[
[
"### Clock time",
"_____no_output_____"
]
],
[
[
"%%time\n\ntime.sleep(1)",
"CPU times: user 634 µs, sys: 1.11 ms, total: 1.74 ms\nWall time: 1 s\n"
]
],
[
[
"### Using `timeit`\n\nThe `-r` argument says how many runs to average over, and `-n` says how many times to run the function in a loop per run.",
"_____no_output_____"
]
],
[
[
"%timeit time.sleep(0.01)",
"11.3 ms ± 117 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)\n"
],
[
"%timeit -r3 time.sleep(0.01)",
"11.1 ms ± 124 µs per loop (mean ± std. dev. of 3 runs, 100 loops each)\n"
],
[
"%timeit -n10 time.sleep(0.01)",
"11.2 ms ± 215 µs per loop (mean ± std. dev. of 7 runs, 10 loops each)\n"
],
[
"%timeit -r3 -n10 time.sleep(0.01)",
"11 ms ± 99.5 µs per loop (mean ± std. dev. of 3 runs, 10 loops each)\n"
]
],
[
[
"### Time unit conversions\n\n```\n1 s = 1,000 ms\n1 ms = 1,000 µs\n1 µs = 1,000 ns\n```",
"_____no_output_____"
],
[
"## Profiling\n\nIf you want to identify bottlenecks in a Python script, do the following:\n \n- First make sure that the script is modular - i.e. it consists mainly of function calls\n- Each function should be fairly small and only do one thing\n- Then run a profiler to identify the bottleneck function(s) and optimize them\n\nSee the Python docs on [profiling Python code](https://docs.python.org/3/library/profile.html)",
"_____no_output_____"
],
[
"Profiling can be done in a notebook with %prun, with the following readouts as column headers:\n\n- ncalls\n - for the number of calls,\n- tottime\n - for the total time spent in the given function (and excluding time made in calls to sub-functions),\n- percall\n - is the quotient of tottime divided by ncalls\n- cumtime\n - is the total time spent in this and all subfunctions (from invocation till exit). This figure is accurate even for recursive functions.\n- percall\n - is the quotient of cumtime divided by primitive calls\n- filename:lineno(function)\n - provides the respective data of each function ",
"_____no_output_____"
]
],
[
[
"def foo1(n):\n return np.sum(np.square(np.arange(n)))\n\ndef foo2(n):\n return sum(i*i for i in range(n))\n\ndef foo3(n):\n [foo1(n) for i in range(10)]\n foo2(n)\n\ndef foo4(n):\n return [foo2(n) for i in range(100)]\n \ndef work(n):\n foo1(n)\n foo2(n)\n foo3(n)\n foo4(n)",
"_____no_output_____"
],
[
"%%time\n\nwork(int(1e5))",
"CPU times: user 1.33 s, sys: 4.25 ms, total: 1.33 s\nWall time: 1.34 s\n"
],
[
"%prun -q -D work.prof work(int(1e5))",
" \n*** Profile stats marshalled to file 'work.prof'. \n"
],
[
"import pstats\np = pstats.Stats('work.prof')\np.print_stats()\npass",
"Fri Mar 30 15:17:26 2018 work.prof\n\n 10200380 function calls in 2.535 seconds\n\n Random listing order was used\n\n ncalls tottime percall cumtime percall filename:lineno(function)\n 1 0.000 0.000 2.535 2.535 {built-in method builtins.exec}\n 11 0.000 0.000 0.000 0.000 {built-in method builtins.isinstance}\n 102 1.088 0.011 2.531 0.025 {built-in method builtins.sum}\n 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}\n 1 0.000 0.000 0.003 0.003 <ipython-input-10-32cd1fde8562>:8(<listcomp>)\n 11 0.001 0.000 0.001 0.000 {built-in method numpy.core.multiarray.arange}\n 11 0.001 0.000 0.001 0.000 {method 'reduce' of 'numpy.ufunc' objects}\n 11 0.000 0.000 0.001 0.000 /usr/local/lib/python3.6/site-packages/numpy/core/fromnumeric.py:1778(sum)\n 11 0.000 0.000 0.001 0.000 /usr/local/lib/python3.6/site-packages/numpy/core/_methods.py:31(_sum)\n 102 0.000 0.000 2.531 0.025 <ipython-input-10-32cd1fde8562>:4(foo2)\n 1 0.000 0.000 2.480 2.480 <ipython-input-10-32cd1fde8562>:12(<listcomp>)\n 1 0.000 0.000 0.028 0.028 <ipython-input-10-32cd1fde8562>:7(foo3)\n 11 0.002 0.000 0.003 0.000 <ipython-input-10-32cd1fde8562>:1(foo1)\n 10200102 1.443 0.000 1.443 0.000 <ipython-input-10-32cd1fde8562>:5(<genexpr>)\n 1 0.000 0.000 2.535 2.535 <ipython-input-10-32cd1fde8562>:14(work)\n 1 0.000 0.000 2.480 2.480 <ipython-input-10-32cd1fde8562>:11(foo4)\n 1 0.000 0.000 2.535 2.535 <string>:1(<module>)\n\n\n"
],
[
"p.sort_stats('time', 'cumulative').print_stats('foo')\npass",
"Fri Mar 30 15:17:26 2018 work.prof\n\n 10200380 function calls in 2.535 seconds\n\n Ordered by: internal time, cumulative time\n List reduced from 17 to 4 due to restriction <'foo'>\n\n ncalls tottime percall cumtime percall filename:lineno(function)\n 11 0.002 0.000 0.003 0.000 <ipython-input-10-32cd1fde8562>:1(foo1)\n 102 0.000 0.000 2.531 0.025 <ipython-input-10-32cd1fde8562>:4(foo2)\n 1 0.000 0.000 0.028 0.028 <ipython-input-10-32cd1fde8562>:7(foo3)\n 1 0.000 0.000 2.480 2.480 <ipython-input-10-32cd1fde8562>:11(foo4)\n\n\n"
],
[
"p.sort_stats('ncalls').print_stats(5)\npass",
"Fri Mar 30 15:17:26 2018 work.prof\n\n 10200380 function calls in 2.535 seconds\n\n Ordered by: call count\n List reduced from 17 to 5 due to restriction <5>\n\n ncalls tottime percall cumtime percall filename:lineno(function)\n 10200102 1.443 0.000 1.443 0.000 <ipython-input-10-32cd1fde8562>:5(<genexpr>)\n 102 1.088 0.011 2.531 0.025 {built-in method builtins.sum}\n 102 0.000 0.000 2.531 0.025 <ipython-input-10-32cd1fde8562>:4(foo2)\n 11 0.000 0.000 0.000 0.000 {built-in method builtins.isinstance}\n 11 0.001 0.000 0.001 0.000 {built-in method numpy.core.multiarray.arange}\n\n\n"
]
],
[
[
"## Optimizing a function\n\nOur example will be to optimize a function that calculates the pairwise distance between a set of vectors.\n\nWe first use a built-in function from`scipy` to check that our answers are right and also to benchmark how our code compares in speed to an optimized compiled routine.",
"_____no_output_____"
]
],
[
[
"from scipy.spatial.distance import squareform, pdist",
"_____no_output_____"
],
[
"n = 100\np = 100\nxs = np.random.random((n, p))",
"_____no_output_____"
],
[
"sol = squareform(pdist(xs))",
"_____no_output_____"
],
[
"%timeit -r3 -n10 squareform(pdist(xs))",
"492 µs ± 14.1 µs per loop (mean ± std. dev. of 3 runs, 10 loops each)\n"
]
],
[
[
"## Python",
"_____no_output_____"
],
[
"### Simple version",
"_____no_output_____"
]
],
[
[
"def pdist_py(xs):\n \"\"\"Unvectorized Python.\"\"\"\n n, p = xs.shape\n A = np.zeros((n, n))\n for i in range(n):\n for j in range(n):\n for k in range(p):\n A[i,j] += (xs[i, k] - xs[j, k])**2\n A[i,j] = np.sqrt(A[i,j])\n return A",
"_____no_output_____"
]
],
[
[
"Note that we \n\n- first check that the output is **right**\n- then check how fast the code is",
"_____no_output_____"
]
],
[
[
"func = pdist_py\nprint(np.allclose(func(xs), sol))\n%timeit -r3 -n10 func(xs)",
"True\n1.17 s ± 2.98 ms per loop (mean ± std. dev. of 3 runs, 10 loops each)\n"
]
],
[
[
"### Exploiting symmetry",
"_____no_output_____"
]
],
[
[
"def pdist_sym(xs):\n \"\"\"Unvectorized Python.\"\"\"\n n, p = xs.shape\n A = np.zeros((n, n))\n for i in range(n):\n for j in range(i+1, n):\n for k in range(p):\n A[i,j] += (xs[i, k] - xs[j, k])**2\n A[i,j] = np.sqrt(A[i,j])\n A += A.T\n return A",
"_____no_output_____"
],
[
"func = pdist_sym\nprint(np.allclose(func(xs), sol))\n%timeit -r3 -n10 func(xs)",
"True\n573 ms ± 2.35 ms per loop (mean ± std. dev. of 3 runs, 10 loops each)\n"
]
],
[
[
"### Vectorizing inner loop",
"_____no_output_____"
]
],
[
[
"def pdist_vec(xs): \n \"\"\"Vectorize inner loop.\"\"\"\n n, p = xs.shape\n A = np.zeros((n, n))\n for i in range(n):\n for j in range(i+1, n):\n A[i,j] = np.sqrt(np.sum((xs[i] - xs[j])**2))\n A += A.T\n return A",
"_____no_output_____"
],
[
"func = pdist_vec\nprint(np.allclose(func(xs), sol))\n%timeit -r3 -n10 func(xs)",
"True\n70.8 ms ± 275 µs per loop (mean ± std. dev. of 3 runs, 10 loops each)\n"
]
],
[
[
"### Broadcasting and vectorizing\n\nNote that the broadcast version does twice as much work as it does not exploit symmetry.",
"_____no_output_____"
]
],
[
[
"def pdist_numpy(xs):\n \"\"\"Fully vectroized version.\"\"\"\n return np.sqrt(np.square(xs[:, None] - xs[None, :]).sum(axis=-1))",
"_____no_output_____"
],
[
"func = pdist_numpy\nprint(np.allclose(func(xs), sol))\n%timeit -r3 -n10 squareform(func(xs))",
"True\n4.23 ms ± 165 µs per loop (mean ± std. dev. of 3 runs, 10 loops each)\n"
]
],
[
[
"## JIT with `numba`",
"_____no_output_____"
],
[
"We use the `numba.jit` decorator which will trigger generation and execution of compiled code when the function is first called.",
"_____no_output_____"
]
],
[
[
"from numba import jit",
"_____no_output_____"
]
],
[
[
"### Using `jit` as a function",
"_____no_output_____"
]
],
[
[
"pdist_numba_py = jit(pdist_py, nopython=True, cache=True)",
"_____no_output_____"
],
[
"func = pdist_numba_py\nprint(np.allclose(func(xs), sol))\n%timeit -r3 -n10 func(xs)",
"True\n1.8 ms ± 25 µs per loop (mean ± std. dev. of 3 runs, 10 loops each)\n"
]
],
[
[
"### Using `jit` as a decorator",
"_____no_output_____"
]
],
[
[
"@jit(nopython=True, cache=True)\ndef pdist_numba_py_1(xs):\n \"\"\"Unvectorized Python.\"\"\"\n n, p = xs.shape\n A = np.zeros((n, n))\n for i in range(n):\n for j in range(n):\n for k in range(p):\n A[i,j] += (xs[i, k] - xs[j, k])**2\n A[i,j] = np.sqrt(A[i,j])\n return A",
"_____no_output_____"
],
[
"func = pdist_numba_py_1\nprint(np.allclose(func(xs), sol))\n%timeit -r3 -n10 func(xs)",
"True\n1.75 ms ± 34.8 µs per loop (mean ± std. dev. of 3 runs, 10 loops each)\n"
]
],
[
[
"### Can we make the code faster?\n\nNote that in the inner loop, we are updating a matrix when we only need to update a scalar. Let's fix this.",
"_____no_output_____"
]
],
[
[
"@jit(nopython=True, cache=True)\ndef pdist_numba_py_2(xs):\n \"\"\"Unvectorized Python.\"\"\"\n n, p = xs.shape\n A = np.zeros((n, n))\n for i in range(n):\n for j in range(n):\n d = 0.0\n for k in range(p):\n d += (xs[i, k] - xs[j, k])**2\n A[i,j] = np.sqrt(d)\n return A",
"_____no_output_____"
],
[
"func = pdist_numba_py_2\nprint(np.allclose(func(xs), sol))\n%timeit -r3 -n10 func(xs)",
"True\n954 µs ± 25.2 µs per loop (mean ± std. dev. of 3 runs, 10 loops each)\n"
]
],
[
[
"### Can we make the code even faster?\n\nWe can also try to exploit symmetry.",
"_____no_output_____"
]
],
[
[
"@jit(nopython=True, cache=True)\ndef pdist_numba_py_sym(xs):\n \"\"\"Unvectorized Python.\"\"\"\n n, p = xs.shape\n A = np.zeros((n, n))\n for i in range(n):\n for j in range(i+1, n):\n d = 0.0\n for k in range(p):\n d += (xs[i, k] - xs[j, k])**2\n A[i,j] = np.sqrt(d)\n A += A.T\n return A",
"_____no_output_____"
],
[
"func = pdist_numba_py_sym\nprint(np.allclose(func(xs), sol))\n%timeit -r3 -n10 func(xs)",
"True\n521 µs ± 7.12 µs per loop (mean ± std. dev. of 3 runs, 10 loops each)\n"
]
],
[
[
"### Does `jit` work with vectorized code?",
"_____no_output_____"
]
],
[
[
"pdist_numba_vec = jit(pdist_vec, nopython=True, cache=True)",
"_____no_output_____"
],
[
"%timeit -r3 -n10 pdist_vec(xs)",
"70.1 ms ± 454 µs per loop (mean ± std. dev. of 3 runs, 10 loops each)\n"
],
[
"func = pdist_numba_vec\nprint(np.allclose(func(xs), sol))\n%timeit -r3 -n10 func(xs)",
"True\n1.58 ms ± 17.8 µs per loop (mean ± std. dev. of 3 runs, 10 loops each)\n"
]
],
[
[
"### Does `jit` work with broadcasting?",
"_____no_output_____"
]
],
[
[
"pdist_numba_numpy = jit(pdist_numpy, nopython=True, cache=True)",
"_____no_output_____"
],
[
"%timeit -r3 -n10 pdist_numpy(xs)",
"4.01 ms ± 159 µs per loop (mean ± std. dev. of 3 runs, 10 loops each)\n"
],
[
"func = pdist_numba_numpy\ntry:\n print(np.allclose(func(xs), sol))\n %timeit -r3 -n10 func(xs)\nexcept Exception as e:\n print(e)",
"Failed at nopython (nopython frontend)\nInternal error at <numba.typeinfer.StaticGetItemConstraint object at 0x11310b9e8>:\n--%<-----------------------------------------------------------------\nTraceback (most recent call last):\n File \"/usr/local/lib/python3.6/site-packages/numba/errors.py\", line 259, in new_error_context\n yield\n File \"/usr/local/lib/python3.6/site-packages/numba/typeinfer.py\", line 503, in __call__\n self.resolve(typeinfer, typeinfer.typevars, fnty=self.func)\n File \"/usr/local/lib/python3.6/site-packages/numba/typeinfer.py\", line 441, in resolve\n sig = typeinfer.resolve_call(fnty, pos_args, kw_args, literals=literals)\n File \"/usr/local/lib/python3.6/site-packages/numba/typeinfer.py\", line 1115, in resolve_call\n literals=literals)\n File \"/usr/local/lib/python3.6/site-packages/numba/typing/context.py\", line 191, in resolve_function_type\n res = defn.apply(args, kws)\n File \"/usr/local/lib/python3.6/site-packages/numba/typing/templates.py\", line 207, in apply\n sig = generic(args, kws)\n File \"/usr/local/lib/python3.6/site-packages/numba/typing/arraydecl.py\", line 165, in generic\n out = get_array_index_type(ary, idx)\n File \"/usr/local/lib/python3.6/site-packages/numba/typing/arraydecl.py\", line 71, in get_array_index_type\n % (ty, idx))\nTypeError: unsupported array index type none in (slice<a:b>, none)\n\nDuring handling of the above exception, another exception occurred:\n\nTraceback (most recent call last):\n File \"/usr/local/lib/python3.6/site-packages/numba/typeinfer.py\", line 137, in propagate\n constraint(typeinfer)\n File \"/usr/local/lib/python3.6/site-packages/numba/typeinfer.py\", line 341, in __call__\n self.fallback(typeinfer)\n File \"/usr/local/lib/python3.6/site-packages/numba/typeinfer.py\", line 503, in __call__\n self.resolve(typeinfer, typeinfer.typevars, fnty=self.func)\n File \"/usr/local/Cellar/python/3.6.4_4/Frameworks/Python.framework/Versions/3.6/lib/python3.6/contextlib.py\", line 99, in __exit__\n self.gen.throw(type, value, traceback)\n File \"/usr/local/lib/python3.6/site-packages/numba/errors.py\", line 265, in new_error_context\n six.reraise(type(newerr), newerr, sys.exc_info()[2])\n File \"/usr/local/lib/python3.6/site-packages/numba/six.py\", line 658, in reraise\n raise value.with_traceback(tb)\n File \"/usr/local/lib/python3.6/site-packages/numba/errors.py\", line 259, in new_error_context\n yield\n File \"/usr/local/lib/python3.6/site-packages/numba/typeinfer.py\", line 503, in __call__\n self.resolve(typeinfer, typeinfer.typevars, fnty=self.func)\n File \"/usr/local/lib/python3.6/site-packages/numba/typeinfer.py\", line 441, in resolve\n sig = typeinfer.resolve_call(fnty, pos_args, kw_args, literals=literals)\n File \"/usr/local/lib/python3.6/site-packages/numba/typeinfer.py\", line 1115, in resolve_call\n literals=literals)\n File \"/usr/local/lib/python3.6/site-packages/numba/typing/context.py\", line 191, in resolve_function_type\n res = defn.apply(args, kws)\n File \"/usr/local/lib/python3.6/site-packages/numba/typing/templates.py\", line 207, in apply\n sig = generic(args, kws)\n File \"/usr/local/lib/python3.6/site-packages/numba/typing/arraydecl.py\", line 165, in generic\n out = get_array_index_type(ary, idx)\n File \"/usr/local/lib/python3.6/site-packages/numba/typing/arraydecl.py\", line 71, in get_array_index_type\n % (ty, idx))\nnumba.errors.InternalError: unsupported array index type none in (slice<a:b>, none)\n[1] During: typing of intrinsic-call at <ipython-input-26-f5984e680640> (3)\n[2] During: typing of static-get-item at <ipython-input-26-f5984e680640> (3)\n--%<-----------------------------------------------------------------\n\nFile \"<ipython-input-26-f5984e680640>\", line 3\n"
]
],
[
[
"#### We need to use `reshape` to broadcast",
"_____no_output_____"
]
],
[
[
"def pdist_numpy_(xs):\n \"\"\"Fully vectroized version.\"\"\"\n return np.sqrt(np.square(xs.reshape(n,1,p) - xs.reshape(1,n,p)).sum(axis=-1))",
"_____no_output_____"
],
[
"pdist_numba_numpy_ = jit(pdist_numpy_, nopython=True, cache=True)",
"_____no_output_____"
],
[
"%timeit -r3 -n10 pdist_numpy_(xs)",
"4.17 ms ± 310 µs per loop (mean ± std. dev. of 3 runs, 10 loops each)\n"
],
[
"func = pdist_numba_numpy_\nprint(np.allclose(func(xs), sol))\n%timeit -r3 -n10 func(xs)",
"True\n6.02 ms ± 65.9 µs per loop (mean ± std. dev. of 3 runs, 10 loops each)\n"
]
],
[
[
"### Summary\n\n- `numba` appears to work best with converting fairly explicit Python code\n- This might change in the future as the `numba` JIT compiler becomes more sophisticated\n- Always check optimized code for correctness\n- We can use `timeit` magic as a simple way to benchmark functions",
"_____no_output_____"
],
[
"## Cython\n\nCython is an Ahead Of Time (AOT) compiler. It compiles the code and replaces the function invoked with the compiled version.\n\nIn the notebook, calling `%cython -a` magic shows code colored by how many Python C API calls are being made. You want to reduce the yellow as much as possible.",
"_____no_output_____"
]
],
[
[
"%%cython -a \n\nimport numpy as np\n\ndef pdist_cython_1(xs): \n n, p = xs.shape\n A = np.zeros((n, n))\n for i in range(n):\n for j in range(i+1, n):\n d = 0.0\n for k in range(p):\n d += (xs[i,k] - xs[j,k])**2\n A[i,j] = np.sqrt(d)\n A += A.T\n return A",
"_____no_output_____"
],
[
"def pdist_base(xs): \n n, p = xs.shape\n A = np.zeros((n, n))\n for i in range(n):\n for j in range(i+1, n):\n d = 0.0\n for k in range(p):\n d += (xs[i,k] - xs[j,k])**2\n A[i,j] = np.sqrt(d)\n A += A.T\n return A",
"_____no_output_____"
],
[
"%timeit -r3 -n1 pdist_base(xs)",
"424 ms ± 1.52 ms per loop (mean ± std. dev. of 3 runs, 1 loop each)\n"
],
[
"func = pdist_cython_1\nprint(np.allclose(func(xs), sol))\n%timeit -r3 -n1 func(xs)",
"True\n399 ms ± 7.19 ms per loop (mean ± std. dev. of 3 runs, 1 loop each)\n"
]
],
[
[
"## Cython with static types\n\n- We provide types for all variables so that Cython can optimize their compilation to C code.\n- Note `numpy` functions are optimized for working with `ndarrays` and have unnecessary overhead for scalars. We therefor replace them with math functions from the C `math` library.",
"_____no_output_____"
]
],
[
[
"%%cython -a \n\nimport cython\nimport numpy as np\ncimport numpy as np\nfrom libc.math cimport sqrt, pow\n\[email protected](False)\[email protected](False)\ndef pdist_cython_2(double[:, :] xs):\n cdef int n, p\n cdef int i, j, k\n cdef double[:, :] A\n cdef double d\n \n n = xs.shape[0]\n p = xs.shape[1]\n A = np.zeros((n, n))\n for i in range(n):\n for j in range(i+1, n):\n d = 0.0\n for k in range(p):\n d += pow(xs[i,k] - xs[j,k],2)\n A[i,j] = sqrt(d)\n for i in range(1, n):\n for j in range(i):\n A[i, j] = A[j, i] \n return A",
"_____no_output_____"
],
[
"func = pdist_cython_2\nprint(np.allclose(func(xs), sol))\n%timeit -r3 -n1 func(xs)",
"True\n693 µs ± 342 µs per loop (mean ± std. dev. of 3 runs, 1 loop each)\n"
]
],
[
[
"## Wrapping C++ cdoe",
"_____no_output_____"
],
[
"### Function to port",
"_____no_output_____"
],
[
"```python\ndef pdist_base(xs): \n n, p = xs.shape\n A = np.zeros((n, n))\n for i in range(n):\n for j in range(i+1, n):\n d = 0.0\n for k in range(p):\n d += (xs[i,k] - xs[j,k])**2\n A[i,j] = np.sqrt(d)\n A += A.T\n return A\n```",
"_____no_output_____"
],
[
"### First check that the function works as expected",
"_____no_output_____"
]
],
[
[
"%%file main.cpp\n#include <iostream>\n#include <Eigen/Dense>\n#include <cmath>\n\nusing std::cout;\n\n// takes numpy array as input and returns another numpy array\nEigen::MatrixXd pdist(Eigen::MatrixXd xs) {\n int n = xs.rows() ;\n int p = xs.cols();\n \n Eigen::MatrixXd A = Eigen::MatrixXd::Zero(n, n);\n for (int i=0; i<n; i++) {\n for (int j=i+1; j<n; j++) {\n double d = 0;\n for (int k=0; k<p; k++) {\n d += std::pow(xs(i,k) - xs(j,k), 2);\n }\n A(i, j) = std::sqrt(d);\n }\n }\n A += A.transpose().eval();\n \n return A;\n}\n\nint main() {\n using namespace Eigen;\n \n MatrixXd A(3,2);\n A << 0, 0, \n 3, 4,\n 5, 12;\n std::cout << pdist(A) << \"\\n\"; \n}",
"Overwriting main.cpp\n"
],
[
"%%bash\n\ng++ -o main.exe main.cpp -I./eigen3",
"_____no_output_____"
],
[
"%%bash\n\n./main.exe",
" 0 5 13\n 5 0 8.24621\n 13 8.24621 0\n"
],
[
"A = np.array([\n [0, 0], \n [3, 4],\n [5, 12]\n])",
"_____no_output_____"
],
[
"squareform(pdist(A))",
"_____no_output_____"
]
],
[
[
"### Now use the boiler plate for wrapping",
"_____no_output_____"
]
],
[
[
"%%file wrap.cpp\n<%\ncfg['compiler_args'] = ['-std=c++11']\ncfg['include_dirs'] = ['./eigen3']\nsetup_pybind11(cfg)\n%>\n\n#include <pybind11/pybind11.h>\n#include <pybind11/eigen.h>\n\n// takes numpy array as input and returns another numpy array\nEigen::MatrixXd pdist(Eigen::MatrixXd xs) {\n int n = xs.rows() ;\n int p = xs.cols();\n \n Eigen::MatrixXd A = Eigen::MatrixXd::Zero(n, n);\n for (int i=0; i<n; i++) {\n for (int j=i+1; j<n; j++) {\n double d = 0;\n for (int k=0; k<p; k++) {\n d += std::pow(xs(i,k) - xs(j,k), 2);\n }\n A(i, j) = std::sqrt(d);\n }\n }\n A += A.transpose().eval();\n \n return A;\n}\n\nPYBIND11_PLUGIN(wrap) {\n pybind11::module m(\"wrap\", \"auto-compiled c++ extension\");\n m.def(\"pdist\", &pdist);\n return m.ptr();\n}",
"Overwriting wrap.cpp\n"
],
[
"import cppimport\nimport numpy as np\n\ncode = cppimport.imp(\"wrap\")\nprint(code.pdist(A))",
"[[ 0. 5. 13. ]\n [ 5. 0. 8.24621125]\n [13. 8.24621125 0. ]]\n"
],
[
"func = code.pdist\nprint(np.allclose(func(xs), sol))\n%timeit -r3 -n1 func(xs)",
"True\n614 µs ± 144 µs per loop (mean ± std. dev. of 3 runs, 1 loop each)\n"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
cb34d28cf313ddeb436c95f5b393674ca25a8980 | 324,682 | ipynb | Jupyter Notebook | MSOA Mapping - England.ipynb | Sahanxa/loneliness | 489825897f8aaaca655b0518e9d7ee44d96d0ac3 | [
"MIT"
] | 6 | 2020-03-20T11:42:54.000Z | 2021-03-18T13:54:38.000Z | MSOA Mapping - England.ipynb | Sahanxa/loneliness | 489825897f8aaaca655b0518e9d7ee44d96d0ac3 | [
"MIT"
] | null | null | null | MSOA Mapping - England.ipynb | Sahanxa/loneliness | 489825897f8aaaca655b0518e9d7ee44d96d0ac3 | [
"MIT"
] | 9 | 2020-03-13T18:01:06.000Z | 2020-08-26T16:31:05.000Z | 436.987887 | 117,636 | 0.931213 | [
[
[
"# MSOA Mapping - England",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport geopandas as gpd\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom shapely.geometry import Point\nfrom sklearn.neighbors import KNeighborsRegressor\nimport rasterio as rst\nfrom rasterstats import zonal_stats\n\n%matplotlib inline",
"_____no_output_____"
],
[
"path = r\"[CHANGE THIS PATH]\\England\\\\\"",
"_____no_output_____"
],
[
"data = pd.read_csv(path + \"final_data.csv\", index_col = 0)",
"_____no_output_____"
]
],
[
[
"# Convert to GeoDataFrame",
"_____no_output_____"
]
],
[
[
"geo_data = gpd.GeoDataFrame(data = data, \n crs = {'init':'epsg:27700'}, \n geometry = data.apply(lambda geom: Point(geom['oseast1m'],geom['osnrth1m']),axis=1))\ngeo_data.head()",
"_____no_output_____"
],
[
"f, (ax1, ax2, ax3) = plt.subplots(1,3, figsize = (16,6), sharex = True, sharey = True)\n\ngeo_data[geo_data['Year'] == 2016].plot(column = 'loneills', scheme = 'quantiles', cmap = 'Reds', marker = '.', ax = ax1);\ngeo_data[geo_data['Year'] == 2017].plot(column = 'loneills', scheme = 'quantiles', cmap = 'Reds', marker = '.', ax = ax2);\ngeo_data[geo_data['Year'] == 2018].plot(column = 'loneills', scheme = 'quantiles', cmap = 'Reds', marker = '.', ax = ax3);",
"C:\\Users\\...\\AppData\\Local\\Continuum\\anaconda3\\lib\\site-packages\\geopandas\\plotting.py:405: UserWarning: The GeoDataFrame you are attempting to plot is empty. Nothing has been displayed.\n \"empty. Nothing has been displayed.\", UserWarning)\n"
]
],
[
[
"## k-nearest neighbour interpolation\n\nNon-parametric interpolation of loneliness based on local set of _k_ nearest neighbours for each cell in our evaluation grid.\n\nEffectively becomes an inverse distance weighted (idw) interpolation when weights are set to be distance based.",
"_____no_output_____"
]
],
[
[
"def idw_model(k, p):\n def _inv_distance_index(weights, index=p):\n return (test==0).astype(int) if np.any(weights == 0) else 1. / weights**index\n return KNeighborsRegressor(k, weights=_inv_distance_index)\n\ndef grid(xmin, xmax, ymin, ymax, cellsize):\n # Set x and y ranges to accommodate cellsize\n xmin = (xmin // cellsize) * cellsize\n xmax = -(-xmax // cellsize) * cellsize # ceiling division\n ymin = (ymin // cellsize) * cellsize\n ymax = -(-ymax // cellsize) * cellsize\n # Make meshgrid\n x = np.linspace(xmin,xmax,(xmax-xmin)/cellsize)\n y = np.linspace(ymin,ymax,(ymax-ymin)/cellsize)\n return np.meshgrid(x,y)\n\ndef reshape_grid(xx,yy):\n return np.append(xx.ravel()[:,np.newaxis],yy.ravel()[:,np.newaxis],1)\n\ndef reshape_image(z, xx):\n return np.flip(z.reshape(np.shape(xx)),0)\n\ndef idw_surface(locations, values, xmin, xmax, ymin, ymax, cellsize, k=5, p=2):\n # Make and fit the idw model\n idw = idw_model(k,p).fit(locations, values)\n # Make the grid to estimate over\n xx, yy = grid(xmin, xmax, ymin, ymax, cellsize)\n # reshape the grid for estimation\n xy = reshape_grid(xx,yy)\n # Predict the grid values\n z = idw.predict(xy)\n # reshape to image array\n z = reshape_image(z, xx)\n return z",
"_____no_output_____"
]
],
[
[
"## 2016 data",
"_____no_output_____"
]
],
[
[
"# Get point locations and values from data\npoints = geo_data[geo_data['Year'] == 2016][['oseast1m','osnrth1m']].values\nvals = geo_data[geo_data['Year'] == 2016]['loneills'].values\n\nsurface2016 = idw_surface(points, vals, 90000,656000,10000,654000,250,7,2)",
"_____no_output_____"
],
[
"# Look at surface\nf, ax = plt.subplots(figsize = (8,10))\nax.imshow(surface2016, cmap='Reds')\nax.set_aspect('equal')",
"_____no_output_____"
]
],
[
[
"## 2017 Data",
"_____no_output_____"
]
],
[
[
"# Get point locations and values from data\npoints = geo_data[geo_data['Year'] == 2017][['oseast1m','osnrth1m']].values\nvals = geo_data[geo_data['Year'] == 2017]['loneills'].values\n\nsurface2017 = idw_surface(points, vals, 90000,656000,10000,654000,250,7,2)",
"_____no_output_____"
],
[
"# Look at surface\nf, ax = plt.subplots(figsize = (8,10))\nax.imshow(surface2017, cmap='Reds')\nax.set_aspect('equal')",
"_____no_output_____"
]
],
[
[
"## 2018 Data",
"_____no_output_____"
],
[
"Get minimum and maximum bounds from the data. Round these down (in case of the 'min's) and up (in case of the 'max's) to get the values for `idw_surface()`",
"_____no_output_____"
]
],
[
[
"print(\"xmin = \", geo_data['oseast1m'].min(), \"\\n\\r\",\n \"xmax = \", geo_data['oseast1m'].max(), \"\\n\\r\",\n \"ymin = \", geo_data['osnrth1m'].min(), \"\\n\\r\",\n \"ymax = \", geo_data['osnrth1m'].max())",
"xmin = 90770.0 \n\r xmax = 655131.0 \n\r ymin = 10283.0 \n\r ymax = 653236.0\n"
],
[
"xmin = 90000\nxmax = 656000\nymin = 10000\nymax = 654000",
"_____no_output_____"
],
[
"# Get point locations and values from data\npoints = geo_data[geo_data['Year'] == 2018][['oseast1m','osnrth1m']].values\nvals = geo_data[geo_data['Year'] == 2018]['loneills'].values\n\nsurface2018 = idw_surface(points, vals, xmin,xmax,ymin,ymax,250,7,2)",
"C:\\Users\\...\\AppData\\Local\\Continuum\\anaconda3\\lib\\site-packages\\ipykernel_launcher.py:13: DeprecationWarning: object of type <class 'float'> cannot be safely interpreted as an integer.\n del sys.path[0]\nC:\\Users\\...\\AppData\\Local\\Continuum\\anaconda3\\lib\\site-packages\\ipykernel_launcher.py:14: DeprecationWarning: object of type <class 'float'> cannot be safely interpreted as an integer.\n \n"
],
[
"# Look at surface\nf, ax = plt.subplots(figsize = (8,10))\nax.imshow(surface2018, cmap='Reds')\nax.set_aspect('equal')",
"_____no_output_____"
]
],
[
[
"# Extract Values to MSOAs\n\nGet 2011 MSOAs from the Open Geography Portal: http://geoportal.statistics.gov.uk/",
"_____no_output_____"
]
],
[
[
"# Get MSOAs which we use to aggregate the loneills variable.\n#filestring = './Data/MSOAs/Middle_Layer_Super_Output_Areas_December_2011_Full_Clipped_Boundaries_in_England_and_Wales.shp'\nfilestring = r'[CHANGE THIS PATH]\\Data\\Boundaries\\England and Wales\\Middle_Layer_Super_Output_Areas_December_2011_Super_Generalised_Clipped_Boundaries_in_England_and_Wales.shp'\n\nmsoas = gpd.read_file(filestring)\nmsoas.to_crs({'init':'epsg:27700'})\n# drop the Wales MSOAs\nmsoas = msoas[msoas['msoa11cd'].str[:1] == 'E'].copy()",
"_____no_output_____"
],
[
"# Get GB countries data to use for representation\n#gb = gpd.read_file('./Data/GB/Countries_December_2017_Generalised_Clipped_Boundaries_in_UK_WGS84.shp')\n#gb = gb.to_crs({'init':'epsg:27700'})\n# get England\n#eng = gb[gb['ctry17nm'] == 'England'].copy()",
"_____no_output_____"
],
[
"# Make affine transform for raster\ntrans = rst.Affine.from_gdal(xmin-125,250,0,ymax+125,0,-250)",
"_____no_output_____"
],
[
"# NB This process is slooow - write bespoke method?\n# 2016\n#msoa_zones = zonal_stats(msoas['geometry'], surface2016, affine = trans, stats = 'mean', nodata = np.nan)\n#msoas['loneills_2016'] = list(map(lambda x: x['mean'] , msoa_zones))\n# 2017\n#msoa_zones = zonal_stats(msoas['geometry'], surface2017, affine = trans, stats = 'mean', nodata = np.nan)\n#msoas['loneills_2017'] = list(map(lambda x: x['mean'] , msoa_zones))\n# 2018\nmsoa_zones = zonal_stats(msoas['geometry'], surface2018, affine = trans, stats = 'mean', nodata = np.nan)\nmsoas['loneills_2018'] = list(map(lambda x: x['mean'] , msoa_zones))",
"_____no_output_____"
],
[
"# Check out the distributions of loneills by MSOA\nf, [ax1, ax2, ax3] = plt.subplots(1,3, figsize=(14,5), sharex = True, sharey=True)\n\n#ax1.hist(msoas['loneills_2016'], bins = 30)\n#ax2.hist(msoas['loneills_2017'], bins = 30)\nax3.hist(msoas['loneills_2018'], bins = 30)\n\nax1.set_title(\"2016\")\nax2.set_title(\"2017\")\nax3.set_title(\"2018\");",
"_____no_output_____"
],
[
"bins = [-10, -5, -3, -2, -1, 1, 2, 3, 5, 10, 22]\nlabels = ['#01665e','#35978f', '#80cdc1','#c7eae5','#f5f5f5','#f6e8c3','#dfc27d','#bf812d','#8c510a','#543005']\n\n#msoas['loneills_2016_class'] = pd.cut(msoas['loneills_2016'], bins, labels = labels)\n#msoas['loneills_2017_class'] = pd.cut(msoas['loneills_2017'], bins, labels = labels)\nmsoas['loneills_2018_class'] = pd.cut(msoas['loneills_2018'], bins, labels = labels)\n\nmsoas['loneills_2018_class'] = msoas.loneills_2018_class.astype(str) # convert categorical to string",
"_____no_output_____"
],
[
"f, (ax1, ax2, ax3) = plt.subplots(1,3,figsize = (16,10))\n\n#msoas.plot(color = msoas['loneills_2016_class'], ax=ax1)\n#msoas.plot(color = msoas['loneills_2017_class'], ax=ax2)\nmsoas.plot(color = msoas['loneills_2018_class'], ax=ax3)\n\n#gb.plot(edgecolor = 'k', linewidth = 0.5, facecolor='none', ax=ax1)\n#gb.plot(edgecolor = 'k', linewidth = 0.5, facecolor='none', ax=ax2)\n#gb.plot(edgecolor = 'k', linewidth = 0.5, facecolor='none', ax=ax3)\n\n# restrict to England\n#ax1.set_xlim([82672,656000])\n#ax1.set_ylim([5342,658000])\n#ax2.set_xlim([82672,656000])\n#ax2.set_ylim([5342,658000])\n#ax3.set_xlim([82672,656000])\n#ax3.set_ylim([5342,658000])\n\n# Make a legend\n# make bespoke legend\nfrom matplotlib.patches import Patch\nhandles = []\nranges = [\"-10, -5\",\"-5, -3\",\"-3, -2\",\"-2, -1\",\"-1, 1\",\"1, 2\",\"3, 3\",\"3, 5\",\"5, 10\",\"10, 22\"]\nfor color, label in zip(labels,ranges):\n handles.append(Patch(facecolor = color, label = label))\n\nax1.legend(handles = handles, loc = 2);",
"_____no_output_____"
],
[
"# Save out msoa data as shapefile and geojson\nmsoas.to_file(path + \"msoa_loneliness.shp\", driver = 'ESRI Shapefile')\n#msoas.to_file(path + \"msoa_loneliness.geojson\", driver = 'GeoJSON')",
"_____no_output_____"
],
[
"# save out msoa data as csv\nmsoas.to_csv(path + \"msoa_loneliness.csv\")",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb34d588cd49a4ddd21a33ad144030f1b620830c | 10,535 | ipynb | Jupyter Notebook | research/object_detection/inference_from_saved_model_tf2_colab.ipynb | Apidwalin/models-tensorflow | b7000f7b156a30421d0e86b0bd0a7294f533280f | [
"Apache-2.0",
"CNRI-Python-GPL-Compatible"
] | null | null | null | research/object_detection/inference_from_saved_model_tf2_colab.ipynb | Apidwalin/models-tensorflow | b7000f7b156a30421d0e86b0bd0a7294f533280f | [
"Apache-2.0",
"CNRI-Python-GPL-Compatible"
] | 2 | 2021-07-17T18:02:27.000Z | 2021-07-22T13:26:17.000Z | research/object_detection/inference_from_saved_model_tf2_colab.ipynb | Apidwalin/models-tensorflow | b7000f7b156a30421d0e86b0bd0a7294f533280f | [
"Apache-2.0",
"CNRI-Python-GPL-Compatible"
] | null | null | null | 32.217125 | 186 | 0.494447 | [
[
[
"# Intro to Object Detection Colab\n\nWelcome to the object detection colab! This demo will take you through the steps of running an \"out-of-the-box\" detection model in SavedModel format on a collection of images.\n\n",
"_____no_output_____"
],
[
"Imports",
"_____no_output_____"
]
],
[
[
"!pip install -U --pre tensorflow==\"2.2.0\"",
"_____no_output_____"
],
[
"import os\nimport pathlib\n\n# Clone the tensorflow models repository if it doesn't already exist\nif \"models\" in pathlib.Path.cwd().parts:\n while \"models\" in pathlib.Path.cwd().parts:\n os.chdir('..')\nelif not pathlib.Path('models').exists():\n !git clone --depth 1 https://github.com/tensorflow/models",
"_____no_output_____"
],
[
"# Install the Object Detection API\n%%bash\ncd models/research/\nprotoc object_detection/protos/*.proto --python_out=.\ncp object_detection/packages/tf2/setup.py .\npython -m pip install .",
"_____no_output_____"
],
[
"import io\nimport os\nimport scipy.misc\nimport numpy as np\nimport six\nimport time\n\nfrom six import BytesIO\n\nimport matplotlib\nimport matplotlib.pyplot as plt\nfrom PIL import Image, ImageDraw, ImageFont\n\nimport tensorflow as tf\nfrom object_detection.utils import visualization_utils as viz_utils\n\n%matplotlib inline",
"_____no_output_____"
],
[
"def load_image_into_numpy_array(path):\n \"\"\"Load an image from file into a numpy array.\n\n Puts image into numpy array to feed into tensorflow graph.\n Note that by convention we put it into a numpy array with shape\n (height, width, channels), where channels=3 for RGB.\n\n Args:\n path: a file path (this can be local or on colossus)\n\n Returns:\n uint8 numpy array with shape (img_height, img_width, 3)\n \"\"\"\n img_data = tf.io.gfile.GFile(path, 'rb').read()\n image = Image.open(BytesIO(img_data))\n (im_width, im_height) = image.size\n return np.array(image.getdata()).reshape(\n (im_height, im_width, 3)).astype(np.uint8)\n\n# Load the COCO Label Map\ncategory_index = {\n 1: {'id': 1, 'name': 'person'},\n 2: {'id': 2, 'name': 'bicycle'},\n 3: {'id': 3, 'name': 'car'},\n 4: {'id': 4, 'name': 'motorcycle'},\n 5: {'id': 5, 'name': 'airplane'},\n 6: {'id': 6, 'name': 'bus'},\n 7: {'id': 7, 'name': 'train'},\n 8: {'id': 8, 'name': 'truck'},\n 9: {'id': 9, 'name': 'boat'},\n 10: {'id': 10, 'name': 'traffic light'},\n 11: {'id': 11, 'name': 'fire hydrant'},\n 13: {'id': 13, 'name': 'stop sign'},\n 14: {'id': 14, 'name': 'parking meter'},\n 15: {'id': 15, 'name': 'bench'},\n 16: {'id': 16, 'name': 'bird'},\n 17: {'id': 17, 'name': 'cat'},\n 18: {'id': 18, 'name': 'dog'},\n 19: {'id': 19, 'name': 'horse'},\n 20: {'id': 20, 'name': 'sheep'},\n 21: {'id': 21, 'name': 'cow'},\n 22: {'id': 22, 'name': 'elephant'},\n 23: {'id': 23, 'name': 'bear'},\n 24: {'id': 24, 'name': 'zebra'},\n 25: {'id': 25, 'name': 'giraffe'},\n 27: {'id': 27, 'name': 'backpack'},\n 28: {'id': 28, 'name': 'umbrella'},\n 31: {'id': 31, 'name': 'handbag'},\n 32: {'id': 32, 'name': 'tie'},\n 33: {'id': 33, 'name': 'suitcase'},\n 34: {'id': 34, 'name': 'frisbee'},\n 35: {'id': 35, 'name': 'skis'},\n 36: {'id': 36, 'name': 'snowboard'},\n 37: {'id': 37, 'name': 'sports ball'},\n 38: {'id': 38, 'name': 'kite'},\n 39: {'id': 39, 'name': 'baseball bat'},\n 40: {'id': 40, 'name': 'baseball glove'},\n 41: {'id': 41, 'name': 'skateboard'},\n 42: {'id': 42, 'name': 'surfboard'},\n 43: {'id': 43, 'name': 'tennis racket'},\n 44: {'id': 44, 'name': 'bottle'},\n 46: {'id': 46, 'name': 'wine glass'},\n 47: {'id': 47, 'name': 'cup'},\n 48: {'id': 48, 'name': 'fork'},\n 49: {'id': 49, 'name': 'knife'},\n 50: {'id': 50, 'name': 'spoon'},\n 51: {'id': 51, 'name': 'bowl'},\n 52: {'id': 52, 'name': 'banana'},\n 53: {'id': 53, 'name': 'apple'},\n 54: {'id': 54, 'name': 'sandwich'},\n 55: {'id': 55, 'name': 'orange'},\n 56: {'id': 56, 'name': 'broccoli'},\n 57: {'id': 57, 'name': 'carrot'},\n 58: {'id': 58, 'name': 'hot dog'},\n 59: {'id': 59, 'name': 'pizza'},\n 60: {'id': 60, 'name': 'donut'},\n 61: {'id': 61, 'name': 'cake'},\n 62: {'id': 62, 'name': 'chair'},\n 63: {'id': 63, 'name': 'couch'},\n 64: {'id': 64, 'name': 'potted plant'},\n 65: {'id': 65, 'name': 'bed'},\n 67: {'id': 67, 'name': 'dining table'},\n 70: {'id': 70, 'name': 'toilet'},\n 72: {'id': 72, 'name': 'tv'},\n 73: {'id': 73, 'name': 'laptop'},\n 74: {'id': 74, 'name': 'mouse'},\n 75: {'id': 75, 'name': 'remote'},\n 76: {'id': 76, 'name': 'keyboard'},\n 77: {'id': 77, 'name': 'cell phone'},\n 78: {'id': 78, 'name': 'microwave'},\n 79: {'id': 79, 'name': 'oven'},\n 80: {'id': 80, 'name': 'toaster'},\n 81: {'id': 81, 'name': 'sink'},\n 82: {'id': 82, 'name': 'refrigerator'},\n 84: {'id': 84, 'name': 'book'},\n 85: {'id': 85, 'name': 'clock'},\n 86: {'id': 86, 'name': 'vase'},\n 87: {'id': 87, 'name': 'scissors'},\n 88: {'id': 88, 'name': 'teddy bear'},\n 89: {'id': 89, 'name': 'hair drier'},\n 90: {'id': 90, 'name': 'toothbrush'},\n}",
"_____no_output_____"
],
[
"# Download the saved model and put it into models/research/object_detection/test_data/\n!wget http://download.tensorflow.org/models/object_detection/tf2/20200711/efficientdet_d5_coco17_tpu-32.tar.gz\n!tar -xf efficientdet_d5_coco17_tpu-32.tar.gz\n!mv efficientdet_d5_coco17_tpu-32/ models/research/object_detection/test_data/",
"_____no_output_____"
],
[
"start_time = time.time()\ntf.keras.backend.clear_session()\ndetect_fn = tf.saved_model.load('models/research/object_detection/test_data/efficientdet_d5_coco17_tpu-32/saved_model/')\nend_time = time.time()\nelapsed_time = end_time - start_time\nprint('Elapsed time: ' + str(elapsed_time) + 's')",
"_____no_output_____"
],
[
"import time\n\nimage_dir = 'models/research/object_detection/test_images'\n\nelapsed = []\nfor i in range(2):\n image_path = os.path.join(image_dir, 'image' + str(i + 1) + '.jpg')\n image_np = load_image_into_numpy_array(image_path)\n input_tensor = np.expand_dims(image_np, 0)\n start_time = time.time()\n detections = detect_fn(input_tensor)\n end_time = time.time()\n elapsed.append(end_time - start_time)\n\n plt.rcParams['figure.figsize'] = [42, 21]\n label_id_offset = 1\n image_np_with_detections = image_np.copy()\n viz_utils.visualize_boxes_and_labels_on_image_array(\n image_np_with_detections,\n detections['detection_boxes'][0].numpy(),\n detections['detection_classes'][0].numpy().astype(np.int32),\n detections['detection_scores'][0].numpy(),\n category_index,\n use_normalized_coordinates=True,\n max_boxes_to_draw=200,\n min_score_thresh=.40,\n agnostic_mode=False)\n plt.subplot(2, 1, i+1)\n plt.imshow(image_np_with_detections)\n\nmean_elapsed = sum(elapsed) / float(len(elapsed))\nprint('Elapsed time: ' + str(mean_elapsed) + ' second per image')",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb34e9993090eda29efd8604e81ad0c9023733ab | 10,855 | ipynb | Jupyter Notebook | Multi Agent env/Multi-Agent RL.ipynb | abhishekdabas31/Reinforcement-Learning-World | 92bb96e4e8f40df39b25d29b8b09ea3b6b0742f0 | [
"MIT"
] | null | null | null | Multi Agent env/Multi-Agent RL.ipynb | abhishekdabas31/Reinforcement-Learning-World | 92bb96e4e8f40df39b25d29b8b09ea3b6b0742f0 | [
"MIT"
] | null | null | null | Multi Agent env/Multi-Agent RL.ipynb | abhishekdabas31/Reinforcement-Learning-World | 92bb96e4e8f40df39b25d29b8b09ea3b6b0742f0 | [
"MIT"
] | 1 | 2020-12-26T05:10:08.000Z | 2020-12-26T05:10:08.000Z | 36.304348 | 1,104 | 0.642377 | [
[
[
"# Multi-Agent Reinforcement Learning",
"_____no_output_____"
],
[
"### Where do we see it?\n\nMulti agent reinforcement learning is a type of Reinforcement Learning which involves more than one agent interacting with an environment.\nThere are many examples of Multi Agent systems around us",
"_____no_output_____"
],
[
"Be it early morning with all the cars going to work\n<img src=\"image/cars_on_the_street.png\" alt=\"Cars on the Street\" align=\"left\"/>",
"_____no_output_____"
],
[
"Or your soccer players on the field\n<img src=\"image/soccer.png\" alt=\"Soccer Players\" align=\"left\"/>",
"_____no_output_____"
],
[
"Or Bees working inside a honeycomb\n<img src=\"image/bees.png\" alt=\"Honeybees in a honeycomb\" align=\"left\" />",
"_____no_output_____"
],
[
"Let's consider a case where an autonomous car is driving you to office. And its goal is to safely take you to the office in time\n<img src=\"image/autonomous_car.png\" alt=\"Autonomous Cars\" align=\"left\" />",
"_____no_output_____"
],
[
"Anytime it has to accelerate, break or change lanes....\n<img src=\"image/car_learning.png\" alt=\"car_learning\" align=\"left\"/>",
"_____no_output_____"
],
[
"It does so by considering the other cars in it vicinity\n<img src=\"image/car_overtaking.png\" alt=\"Car Overtaking\" align=\"left\"/>",
"_____no_output_____"
],
[
"Other cars are trying to do the same as they get more and more driving experience\nIf you contrast this to a scenario where the car is alone on the street and driving around, it can go as fast as possible so the task of driving becomes relatively simpler and so the agent does not ever learn the complications that come with driving.",
"_____no_output_____"
],
[
"This is nothing but a Multi Agent system where multiple agents interact with one another. In a multi-agent system each agent may or may not know about the other agents that are present in the system",
"_____no_output_____"
],
[
"## Markov Game Framework",
"_____no_output_____"
],
[
"Consider a single RL Drone Agent and its task is to pickup a package\n<img src=\"image/drone1.png\" align=\"left\"/>",
"_____no_output_____"
],
[
"It has a set of possible actions that it can take.\n\nIt can go Right\n<img src=\"image/drone2.png\" align=\"left\"/>",
"_____no_output_____"
],
[
"Left\n<img src=\"image/drone3.png\"/>",
"_____no_output_____"
],
[
"Up\n<img src=\"image/drone4.png\"/>",
"_____no_output_____"
],
[
"Down\n<img src=\"image/drone5.png\"/>",
"_____no_output_____"
],
[
"And Grasping\n<img src=\"image/drone6.png\"/>",
"_____no_output_____"
],
[
"And we decide that we give it a reward of +50 if it picks up the package\n<img src=\"image/drone7.png\"/>",
"_____no_output_____"
],
[
"And -1 if it drops the package\n<img src=\"image/drone8.png\"/>",
"_____no_output_____"
],
[
"Now the difference in Multi Agent RL is that we have another agent, in this case another drone in our environment.\nAnd now both the drones will collectively try to grasp the package.\nThey're both trying to observe the package from their own perspective.\n<img src=\"image/drone9.png\"/>",
"_____no_output_____"
],
[
"They both have their own policies that returned an action for their observations\n<img src=\"image/drone10.png\"/>",
"_____no_output_____"
],
[
"Both also have their own set of actions\n<img src=\"image/drone12.png\" />",
"_____no_output_____"
],
[
"The main thing about Multi-Agent RL is that they have a joint set of actions that they can take to interact in their environment. Both the left drone and the right drone must begin the action.\n<img src=\"image/drone13.png\"/>",
"_____no_output_____"
],
[
"For example, the pair DL is when the left drone moves down and the right drone moves to the left\n<img src=\"image/drone15.png\"/>",
"_____no_output_____"
],
[
"This example illustrates the Markov Game Framework\n\nA Markov Game is a tuple written as this\n<img src=\"image/drone16.png\"/>",
"_____no_output_____"
],
[
"n: Number of Agents\n\nS: Set of states in the environment\n\nAi: A is the set of actions in the environment by agent i\n\nOi: O is the set of observations in the environment by agent i\n\nRi: R is the set of rewards for the actions taken in the environment by agent i\n\n$\\pi$i: $\\pi$ is the set of policy of agent i\n\nT: T is Transition Function, given the current state and joint action it gives a probability distribution over the set of possible states\n\n<img src=\"image/markov_eqn.png\"/>",
"_____no_output_____"
],
[
"Even here, the State transitions are Markovian, that is the MDP only depends upon the current state and the action take in this state.\nHowever, when it comes to the Transition function, it depends upon the Joint action taken in the current state",
"_____no_output_____"
],
[
"## Multi Agent Environment Types:\n\n* **Cooperative Environments**: \n\nAn environment where multiple agents have to accomplish a goal by working together is called a cooperative environment. In this kind of environment, when both agents are able to successfully complete a task together, they are rewarded and so both of them learn to cooperate in the environment. A good example for this kind of environment is the example we covered above where two drones have to work together to pick a package and deliver it.\n\n* **Competitive Environments**: \n\nAn environment where multiple agents have to compete with each other to reach their goal is called a Competitive Environment. In this kind of environment, each agent is tasked with a similar goal which can only be achieved by one of them and the agent that is able to achieve the goal is rewarded. This reinforces the idea of competing with the other agent in the environment. A good example for this kind of environment is one you will see an implementation of very soon, which is the Tennis Environment in which we work with two agents present on opposite sides of the net and both are tasked with not letting the ball drop on their side. And if the ball drops on the opponent's side then they are rewarded.\n\n* **Mixed Environments**: \n\nAn environment where multiple agents have to both cooperate and compete with each other by interacting with their environment is called a Mixed Environment. In this kind of environment, each agent is tasked with achieving a goal for which they not only have to cooperate with other agents in the environment but also compete with them. Here depending upon which has more preference, you will assign higher rewards for the kind of action you prefer your agent to fulfill. Say, giving higher positive reward to cooperation and lower positive reward to competition. In this kind of setting the agents would cooperate more and compete less, but they will do both the actions. A good example for Mixed Environment is a Traffic Control setting, where each agent is tasked with reaching their goal as fast as possible. For a Traffic Control environment, each agent has to adhere to the traffic rules and make sure that it does not crash into other agents while driving, but at the same time they have to overtake the other agents in order to reach their goal faster while driving within the speed limits.",
"_____no_output_____"
],
[
"#### Copyright 2020 Sonali Vinodkumar Singh\n\n\nPermission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the \"Software\"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:\n\nThe above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.\n\nTHE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.",
"_____no_output_____"
]
]
] | [
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
cb34fff91e3aafb55bc989976a23ba777df407fc | 393,833 | ipynb | Jupyter Notebook | Sequelize/Sequelize/climate_analysis.ipynb | long2691/activities | f78041b4e0c02f1c6fea598d9dfc67796bc99009 | [
"MIT"
] | null | null | null | Sequelize/Sequelize/climate_analysis.ipynb | long2691/activities | f78041b4e0c02f1c6fea598d9dfc67796bc99009 | [
"MIT"
] | null | null | null | Sequelize/Sequelize/climate_analysis.ipynb | long2691/activities | f78041b4e0c02f1c6fea598d9dfc67796bc99009 | [
"MIT"
] | null | null | null | 101.503351 | 82,471 | 0.769925 | [
[
[
"%matplotlib notebook\nfrom matplotlib import style\nstyle.use('fivethirtyeight')\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"import numpy as np\nimport pandas as pd",
"_____no_output_____"
],
[
"import datetime as dt",
"_____no_output_____"
]
],
[
[
"# Reflect Tables into SQLAlchemy ORM",
"_____no_output_____"
]
],
[
[
"# Python SQL toolkit and Object Relational Mapper\nimport sqlalchemy\nfrom sqlalchemy.ext.automap import automap_base\nfrom sqlalchemy.orm import Session\nfrom sqlalchemy import create_engine, func",
"_____no_output_____"
],
[
"engine = create_engine(\"sqlite:///hawaii.sqlite\")",
"_____no_output_____"
],
[
"# reflect an existing database into a new model\nBase = automap_base()\n# reflect the tables\nBase.prepare(engine, reflect=True)",
"_____no_output_____"
],
[
"# We can view all of the classes that automap found\nBase.classes.keys()",
"_____no_output_____"
],
[
"# Save references to each table\nMeasurement = Base.classes.measurement\nStation = Base.classes.station",
"_____no_output_____"
],
[
"# Create our session (link) from Python to the DB\nsession = Session(engine)",
"_____no_output_____"
]
],
[
[
"# Exploratory Climate Analysis",
"_____no_output_____"
]
],
[
[
"# Design a query to retrieve the last 12 months of precipitation data and plot the results\n\n# Calculate the date 1 year ago from today\nprev_year = dt.date.today() - dt.timedelta(days=365)\n\n# Perform a query to retrieve the data and precipitation scores\nresults = session.query(Measurement.date, Measurement.prcp).filter(Measurement.date >= prev_year).all()\n\n# Save the query results as a Pandas DataFrame and set the index to the date column\ndf = pd.DataFrame(results, columns=['date', 'precipitation'])\ndf.set_index(df['date'], inplace=True)\n\n# Sort the dataframe by date\ndf.sort_values(\"date\")\n\n# Use Pandas Plotting with Matplotlib to plot the data\ndf.plot(x_compat=True)\n\n# Rotate the xticks for the dates\nplt.xticks(rotation='45')\nplt.tight_layout()",
"_____no_output_____"
],
[
"# Use Pandas to calcualte the summary statistics for the precipitation data\ndf.describe()",
"_____no_output_____"
],
[
"# How many stations are available in this dataset?\nsession.query(func.count(Station.station)).all()",
"_____no_output_____"
],
[
"# What are the most active stations?\n# List the stations and the counts in descending order.\nsession.query(Measurement.station, func.count(Measurement.station)).\\\n group_by(Measurement.station).order_by(func.count(Measurement.station).desc()).all()",
"_____no_output_____"
],
[
"# Using the station id from the previous query, calculate the lowest temperature recorded, \n# highest temperature recorded, and average temperature most active station?\nsession.query(func.min(Measurement.tobs), func.max(Measurement.tobs), func.avg(Measurement.tobs)).\\\n filter(Measurement.station == 'USC00519281').all()",
"_____no_output_____"
],
[
"# Choose the station with the highest number of temperature observations.\n# Query the last 12 months of temperature observation data for this station and plot the results as a histogram\nimport datetime as dt\nfrom pandas.plotting import table\nprev_year = dt.date.today() - dt.timedelta(days=365)\n\nresults = session.query(Measurement.tobs).\\\n filter(Measurement.station == 'USC00519281').\\\n filter(Measurement.date >= prev_year).all()\ndf = pd.DataFrame(results, columns=['tobs'])\ndf.plot.hist(bins=12)\nplt.tight_layout()",
"_____no_output_____"
],
[
"# Write a function called `calc_temps` that will accept start date and end date in the format '%Y-%m-%d' \n# and return the minimum, average, and maximum temperatures for that range of dates\ndef calc_temps(start_date, end_date):\n \"\"\"TMIN, TAVG, and TMAX for a list of dates.\n \n Args:\n start_date (string): A date string in the format %Y-%m-%d\n end_date (string): A date string in the format %Y-%m-%d\n \n Returns:\n TMIN, TAVE, and TMAX\n \"\"\"\n \n return session.query(func.min(Measurement.tobs), func.avg(Measurement.tobs), func.max(Measurement.tobs)).\\\n filter(Measurement.date >= start_date).filter(Measurement.date <= end_date).all()\nprint(calc_temps('2012-02-28', '2012-03-05'))",
"[(62.0, 69.57142857142857, 74.0)]\n"
],
[
"# Use your previous function `calc_temps` to calculate the tmin, tavg, and tmax \n# for your trip using the previous year's data for those same dates.\nimport datetime as dt\n\nprev_year_start = dt.date(2018, 1, 1) - dt.timedelta(days=365)\nprev_year_end = dt.date(2018, 1, 7) - dt.timedelta(days=365)\n\ntmin, tavg, tmax = calc_temps(prev_year_start.strftime(\"%Y-%m-%d\"), prev_year_end.strftime(\"%Y-%m-%d\"))[0]\nprint(tmin, tavg, tmax)",
"62.0 68.36585365853658 74.0\n"
],
[
"# Plot the results from your previous query as a bar chart. \n# Use \"Trip Avg Temp\" as your Title\n# Use the average temperature for the y value\n# Use the peak-to-peak (tmax-tmin) value as the y error bar (yerr)\nfig, ax = plt.subplots(figsize=plt.figaspect(2.))\nxpos = 1\nyerr = tmax-tmin\n\nbar = ax.bar(xpos, tmax, yerr=yerr, alpha=0.5, color='coral', align=\"center\")\nax.set(xticks=range(xpos), xticklabels=\"a\", title=\"Trip Avg Temp\", ylabel=\"Temp (F)\")\nax.margins(.2, .2)\n# fig.autofmt_xdate()\nfig.tight_layout()\nfig.show()",
"_____no_output_____"
],
[
"# Calculate the rainfall per weather station for your trip dates using the previous year's matching dates.\n# Sort this in descending order by precipitation amount and list the station, name, latitude, longitude, and elevation\n\nstart_date = '2012-01-01'\nend_date = '2012-01-07'\n\nsel = [Station.station, Station.name, Station.latitude, \n Station.longitude, Station.elevation, func.sum(Measurement.prcp)]\n\nresults = session.query(*sel).\\\n filter(Measurement.station == Station.station).\\\n filter(Measurement.date >= start_date).\\\n filter(Measurement.date <= end_date).\\\n group_by(Station.name).order_by(func.sum(Measurement.prcp).desc()).all()\nprint(results)",
"[('USC00516128', 'MANOA LYON ARBO 785.2, HI US', 21.3331, -157.8025, 152.4, 0.31), ('USC00519281', 'WAIHEE 837.5, HI US', 21.45167, -157.84888999999998, 32.9, 0.25), ('USC00518838', 'UPPER WAHIAWA 874.3, HI US', 21.4992, -158.0111, 306.6, 0.1), ('USC00513117', 'KANEOHE 838.1, HI US', 21.4234, -157.8015, 14.6, 0.060000000000000005), ('USC00511918', 'HONOLULU OBSERVATORY 702.2, HI US', 21.3152, -157.9992, 0.9, 0.0), ('USC00514830', 'KUALOA RANCH HEADQUARTERS 886.9, HI US', 21.5213, -157.8374, 7.0, 0.0), ('USC00517948', 'PEARL CITY, HI US', 21.3934, -157.9751, 11.9, 0.0), ('USC00519397', 'WAIKIKI 717.2, HI US', 21.2716, -157.8168, 3.0, 0.0), ('USC00519523', 'WAIMANALO EXPERIMENTAL FARM, HI US', 21.33556, -157.71139, 19.5, 0.0)]\n"
]
],
[
[
"## Optional Challenge Assignment",
"_____no_output_____"
]
],
[
[
"# Create a query that will calculate the daily normals \n# (i.e. the averages for tmin, tmax, and tavg for all historic data matching a specific month and day)\n\ndef daily_normals(date):\n \"\"\"Daily Normals.\n \n Args:\n date (str): A date string in the format '%m-%d'\n \n Returns:\n A list of tuples containing the daily normals, tmin, tavg, and tmax\n \n \"\"\"\n \n sel = [func.min(Measurement.tobs), func.avg(Measurement.tobs), func.max(Measurement.tobs)]\n return session.query(*sel).filter(func.strftime(\"%m-%d\", Measurement.date) == date).all()\n \ndaily_normals(\"01-01\")",
"_____no_output_____"
],
[
"# calculate the daily normals for your trip\n# push each tuple of calculations into a list called `normals`\n\n# Set the start and end date of the trip\ntrip_start = '2018-01-01'\ntrip_end = '2018-01-07'\n\n# Use the start and end date to create a range of dates\ntrip_dates = pd.date_range(trip_start, trip_end, freq='D')\n\n# Stip off the year and save a list of %m-%d strings\ntrip_month_day = trip_dates.strftime('%m-%d')\n\n# Loop through the list of %m-%d strings and calculate the normals for each date\nnormals = []\nfor date in trip_month_day:\n normals.append(*daily_normals(date))\n \nnormals",
"_____no_output_____"
],
[
"# Load the previous query results into a Pandas DataFrame and add the `trip_dates` range as the `date` index\ndf = pd.DataFrame(normals, columns=['tmin', 'tavg', 'tmax'])\ndf['date'] = trip_dates\ndf.set_index(['date'],inplace=True)\ndf.head()",
"_____no_output_____"
],
[
"# Plot the daily normals as an area plot with `stacked=False`\ndf.plot(kind='area', stacked=False, x_compat=True, alpha=.2)\nplt.tight_layout()",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
cb35029ec64776481a8426beccfd9cc4e4acdc86 | 366,846 | ipynb | Jupyter Notebook | Spectroscopy/CH4_09-Analyse_Core_Loss.ipynb | ahoust17/MSE672-Introduction-to-TEM | 6b412a3ad07ee273428a95a7158aa09058d7e2ee | [
"MIT"
] | 5 | 2021-01-22T18:09:53.000Z | 2021-07-26T20:17:34.000Z | Spectroscopy/CH4_09-Analyse_Core_Loss.ipynb | ahoust17/MSE672-Introduction-to-TEM | 6b412a3ad07ee273428a95a7158aa09058d7e2ee | [
"MIT"
] | null | null | null | Spectroscopy/CH4_09-Analyse_Core_Loss.ipynb | ahoust17/MSE672-Introduction-to-TEM | 6b412a3ad07ee273428a95a7158aa09058d7e2ee | [
"MIT"
] | 9 | 2021-01-26T16:10:11.000Z | 2022-03-03T14:53:16.000Z | 103.017692 | 78,971 | 0.759286 | [
[
[
"\n\n<font size = \"5\"> **Chapter 4: [Spectroscopy](CH4-Spectroscopy.ipynb)** </font>\n\n<hr style=\"height:1px;border-top:4px solid #FF8200\" />\n\n\n\n# Analysis of Core-Loss Spectra\n\n<font size = \"5\"> **This notebook does not work in Google Colab** </font>\n\n\n[Download](https://raw.githubusercontent.com/gduscher/MSE672-Introduction-to-TEM/main/Spectroscopy/CH4_09-Analyse_Core_Loss.ipynb)\n \n\n\npart of \n\n<font size = \"5\"> **[MSE672: Introduction to Transmission Electron Microscopy](../_MSE672_Intro_TEM.ipynb)**</font>\n\nby Gerd Duscher, Spring 2021\n\nMicroscopy Facilities<br>\nJoint Institute of Advanced Materials<br>\nMaterials Science & Engineering<br>\nThe University of Tennessee, Knoxville\n\nBackground and methods to analysis and quantification of data acquired with transmission electron microscopes.\n",
"_____no_output_____"
],
[
"## Content\n\nQuantitative determination of chemical composition from a core-loss EELS spectrum\n\nPlease cite:\n\n[M. Tian et al. *Measuring the areal density of nanomaterials by electron energy-loss spectroscopy*\nUltramicroscopy Volume 196, 2019, pages 154-160](https://doi.org/10.1016/j.ultramic.2018.10.009)\n\nas a reference of this quantification method.\n\n## Load important packages\n\n### Check Installed Packages",
"_____no_output_____"
]
],
[
[
"import sys\nfrom pkg_resources import get_distribution, DistributionNotFound\n\ndef test_package(package_name):\n \"\"\"Test if package exists and returns version or -1\"\"\"\n try:\n version = (get_distribution(package_name).version)\n except (DistributionNotFound, ImportError) as err:\n version = '-1'\n return version\n\n\n# pyTEMlib setup ------------------\nif test_package('sidpy') < '0.0.5':\n print('installing sidpy')\n !{sys.executable} -m pip install --upgrade sidpy -q \nif test_package('pyTEMlib') < '0.2021.4.20':\n print('installing pyTEMlib')\n !{sys.executable} -m pip install --upgrade pyTEMlib -q\n# ------------------------------\nprint('done')",
"done\n"
]
],
[
[
"### Import all relevant libraries\n\nPlease note that the EELS_tools package from pyTEMlib is essential.",
"_____no_output_____"
]
],
[
[
"%pylab --no-import-all notebook\n%gui qt\n\n# Import libraries from pyTEMlib\nimport pyTEMlib\nimport pyTEMlib.file_tools as ft # File input/ output library\nimport pyTEMlib.image_tools as it\nimport pyTEMlib.eels_tools as eels # EELS methods \nimport pyTEMlib.interactive_eels as ieels # Dialogs for EELS input and quantification\n\n# For archiving reasons it is a good idea to print the version numbers out at this point\nprint('pyTEM version: ',pyTEMlib.__version__)\n\n__notebook__ = 'analyse_core_loss'\n__notebook_version__ = '2021_04_22'",
"Populating the interactive namespace from numpy and matplotlib\n"
]
],
[
[
"## Load and plot a spectrum\n\nAs an example we load the spectrum **1EELS Acquire (high-loss).dm3** from the *example data* folder.\n\nPlease see [Loading an EELS Spectrum](LoadEELS.ipynb) for details on storage and plotting.\n\nFirst a dialog to select a file will apear.\n\nThen the spectrum plot and ``Spectrum Info`` dialog will appear, in which we set the experimental parameters.\n\nPlease use the ``Set Energy Scale`` button to change the energy scale. When pressed a new dialog and a cursor will appear in which one is able to set the energy scale based on known features in the spectrum.\n",
"_____no_output_____"
]
],
[
[
"# -----Input -------#\nload_example = True\n\ntry:\n main_dataset.h5_dataset.file.close()\nexcept:\n pass\n\nif load_example:\n main_dataset = ft.open_file('../example_data/EELS_STO.dm3')\nelse:\n main_dataset = ft.open_file()\n\ncurrent_channel = main_dataset.h5_dataset.parent\n\nif 'experiment' not in main_dataset.metadata:\n main_dataset.metadata['experiment']= eels.read_dm3_eels_info(main_dataset.original_metadata)\n\neels.set_previous_quantification(main_dataset)\n\n# US 200 does not set acceleration voltage correctly.\n# comment out next line for other microscopes\n# current_dataset.metadata['experiment']['acceleration_voltage'] = 200000\n\ninfo = ieels.InfoDialog(main_dataset)",
"C:\\Users\\gduscher\\Anaconda3\\lib\\site-packages\\pyNSID\\io\\hdf_utils.py:351: FutureWarning: validate_h5_dimension may be removed in a future version\n warn('validate_h5_dimension may be removed in a future version',\n"
]
],
[
[
"## Chemical Composition \nThe fit of the cross-section and background to the spectrum results in the chemical composition. If the calibration is correct this composition is given as areal density in atoms/nm$^2$\n\n\n### Fit of Data\nA dialog window will open, enter the elements first (0 will open a periodic table) and press \n``Fit Composition`` button (bottom right). Adjust parameters as needed and check fit by pressing the ``Fit Composition`` button again.\n\nSelect the ``Region`` checkbox to see which parts of the spectrum you choose to fit.\n\nChanging the multiplier value will make a simulation of your spectrum.\n\nThe ``InfoDialog``, if open, still works to change experimental parameters and the energy scale.",
"_____no_output_____"
]
],
[
[
"# current_dataset.metadata['edges'] = {'0': {}, 'model': {}}\ncomposition = ieels.CompositionDialog(main_dataset)",
"_____no_output_____"
]
],
[
[
"### Output of Results",
"_____no_output_____"
]
],
[
[
"edges = main_dataset.metadata['edges']\nelement = []\nareal_density = []\nfor key, edge in edges.items():\n if key.isdigit():\n element.append(edge['element'])\n areal_density.append(edge['areal_density'])\n \nprint('Relative chemical composition of ', main_dataset.title)\nfor i in range(len(element)):\n print(f'{element[i]}: {areal_density[i]/np.sum(areal_density)*100:.1f} %')\n \nsaved_edges_metadata = edges\n",
"Relative chemical composition of EELS_STO\nTi: 21.3 %\nO: 78.7 %\n"
]
],
[
[
"### Log Data\nWe write all the data to the hdf5 file associated with our dataset.\n\nIn our case that is only the ``metadata``, in which we stored the ``experimental parameters`` and the ``fitting parameters and result``.",
"_____no_output_____"
]
],
[
[
"current_group = main_dataset.h5_dataset.parent.parent\nif 'Log_000' in current_group:\n del current_group['Log_000']\n\nlog_group = current_group.create_group('Log_000')\nlog_group['analysis'] = 'EELS_quantification'\nlog_group['EELS_quantification'] = ''\nflat_dict = ft.flatten_dict(main_dataset.metadata)\nif 'peak_fit-peak_out_list' in flat_dict: \n del flat_dict['peak_fit-peak_out_list']\nfor key, item in flat_dict.items():\n if not key == 'peak_fit-peak_out_list':\n log_group.attrs[key]= item\ncurrent_group.file.flush()\nft.h5_tree(main_dataset.h5_dataset.file)",
"/\n├ Measurement_000\n ---------------\n ├ Channel_000\n -----------\n ├ EELS_STO\n --------\n ├ EELS_STO\n ├ __dict__\n --------\n ├ _axes\n -----\n ├ _original_metadata\n ------------------\n ├ energy_loss\n ├ original_metadata\n -----------------\n ├ Log_000\n -------\n ├ EELS_quantification\n ├ analysis\n"
]
],
[
[
"## ELNES\nThe electron energy-loss near edge structure is determined by fititng the spectrum after quantification model subtraction. \n\nFirst smooth the spectrum (2 iterations are ususally sufficient) and then \nfind the number of peaks you want (Can be repeated as oftern as one wants).\n",
"_____no_output_____"
]
],
[
[
"peak_dialog = ieels.PeakFitDialog(main_dataset)",
"_____no_output_____"
]
],
[
[
"### Output",
"_____no_output_____"
]
],
[
[
"areas = []\nfor p, peak in peak_dialog.peaks['peaks'].items():\n area = np.sqrt(2* np.pi)* peak['amplitude'] * np.abs(peak['width'] / np.sqrt(2 *np.log(2))) \n areas.append(area)\n if 'associated_edge' not in peak:\n peak['associated_edge']= ''\n print(f\"peak {p}: position: {peak['position']:7.1f}, area: {area:12.3f} associated edge: {peak['associated_edge']}\")\n#print(f'\\n M4/M5 peak 2 to peak 1 ratio: {(areas[1])/areas[0]:.2f}')",
"peak 0: position: 506.5, area: -6722143.802 associated edge: Ti-L2\npeak 1: position: 933.7, area: -4819176.064 associated edge: \npeak 2: position: 515.9, area: 3289440.959 associated edge: \npeak 3: position: 493.8, area: 2197645.853 associated edge: Ti-L2\npeak 4: position: 905.3, area: 1857244.132 associated edge: \npeak 5: position: 1157.2, area: 1694326.260 associated edge: \npeak 6: position: 461.9, area: 1039384.757 associated edge: Ti-L2\npeak 7: position: 853.9, area: 476364.383 associated edge: \npeak 8: position: 457.1, area: 348689.573 associated edge: Ti-L3\n"
]
],
[
[
"### Log Data",
"_____no_output_____"
]
],
[
[
"current_group = main_dataset.h5_dataset.parent.parent\nif 'Log_001' in current_group:\n del current_group['Log_001']\n \nlog_group = current_group.create_group('Log_001')\nlog_group['analysis'] = 'ELNES_fit'\nlog_group['ELNES_fit'] = ''\nmetadata = ft.flatten_dict(main_dataset.metadata)\n\nif 'peak_fit-peak_out_list' in flat_dict: \n del flat_dict['peak_fit-peak_out_list']\nfor key, item in metadata.items():\n if not key == 'peak_fit-peak_out_list':\n log_group.attrs[key]= item\ncurrent_group.file.flush()\n\nprint('Logged Data of ', main_dataset.title)\nfor key in current_group:\n if 'Log_' in key:\n if 'analysis' in current_group[key]:\n print(f\" {key}: {current_group[key]['analysis'][()]}\")",
"Logged Data of 1EELS Acquire (high_loss)\n Log_000: b'EELS_quantification'\n Log_001: b'ELNES_fit'\n"
]
],
[
[
"## Close File\nFile needs to be closed to be used with other notebooks",
"_____no_output_____"
]
],
[
[
"main_dataset.h5_dataset.file.close()",
"_____no_output_____"
]
],
[
[
"## Navigation\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
cb350f7a5928684a394d152c376d8ebb75af5789 | 1,282 | ipynb | Jupyter Notebook | notebooks/session_01-intro/Notebook1_Datasets.ipynb | Coleridge-Initiative/ada-2017-justice | 112a486e638974e8632ed29b81f3e8b041d58bde | [
"CC0-1.0"
] | null | null | null | notebooks/session_01-intro/Notebook1_Datasets.ipynb | Coleridge-Initiative/ada-2017-justice | 112a486e638974e8632ed29b81f3e8b041d58bde | [
"CC0-1.0"
] | 1 | 2020-11-18T21:19:56.000Z | 2020-11-18T21:19:56.000Z | notebooks/session_01-intro/Notebook1_Datasets.ipynb | Coleridge-Initiative/ada-2017-justice | 112a486e638974e8632ed29b81f3e8b041d58bde | [
"CC0-1.0"
] | 3 | 2019-02-12T15:58:02.000Z | 2021-04-14T13:42:40.000Z | 23.740741 | 224 | 0.580343 | [
[
[
"## Introduction to datasets\n1. IL Department of Corrections\n * admissions\n * exits\n2. IL parole data\n3. Wage record data\n4. HUD data",
"_____no_output_____"
],
[
"### IL Department of Corrections\n**Admissions** data - has a record for when each person was incarcerated and many other data points (~200 columns, described in excel book `PRSN_COLUMN_MAP.xlsx` on tab `admit`), admission dates range from 1946 to 2015",
"_____no_output_____"
],
[
"**Exits** data - has a record for when each person exited a prison, detailed description also in excel book `PRSN_COLUMN_MAP.xlsx` on tab `exit`",
"_____no_output_____"
]
]
] | [
"markdown"
] | [
[
"markdown",
"markdown",
"markdown"
]
] |
cb351758a428748772db25948310af6007246717 | 128,857 | ipynb | Jupyter Notebook | Perturbaciones/Chema/Teoria_de_perturbaciones.ipynb | lazarusA/Density-functional-theory | c74fd44a66f857de570dc50471b24391e3fa901f | [
"MIT"
] | null | null | null | Perturbaciones/Chema/Teoria_de_perturbaciones.ipynb | lazarusA/Density-functional-theory | c74fd44a66f857de570dc50471b24391e3fa901f | [
"MIT"
] | null | null | null | Perturbaciones/Chema/Teoria_de_perturbaciones.ipynb | lazarusA/Density-functional-theory | c74fd44a66f857de570dc50471b24391e3fa901f | [
"MIT"
] | null | null | null | 86.539288 | 21,978 | 0.759532 | [
[
[
"# Método para resolver las energías y eigenfunciones de un sistema cuántico numéricamente por Teoría de Pertubaciones\n# Modelado Molecular 2\n# By: José Manuel Casillas Martín 22-oct-2017\nimport numpy as np\nfrom sympy import *\nfrom sympy.physics.qho_1d import E_n, psi_n\nfrom sympy.physics.hydrogen import E_nl, R_nl\nfrom sympy import init_printing; init_printing(use_latex = 'mathjax')\nfrom scipy import integrate\nfrom scipy.constants import hbar, m_e, m_p, e\nfrom mpmath import spherharm\nfrom numpy import inf, array\nimport numpy as np\nimport matplotlib.pyplot as plt \nimport traitlets\nfrom IPython.display import display\nfrom ipywidgets import Layout, Box, Text, Dropdown, Label, IntRangeSlider, IntSlider, RadioButtons",
"_____no_output_____"
]
],
[
[
"<h1><center>Teoría de Perturbaciones</center></h1>",
"_____no_output_____"
],
[
"Consiste en resolver un sistema perturbado(se conoce la solución al no perturbado), y donde el interés es conocer la contribución de la parte perturbada $H'$ al nuevo sistema total. ",
"_____no_output_____"
],
[
"$$ H = H^{0}+H'$$",
"_____no_output_____"
],
[
"La resolución adecuada del problema, depende en gran parte, de una correcta elección de $H'$.",
"_____no_output_____"
]
],
[
[
"form_item_layout = Layout(display='flex',flex_flow='row',justify_content='space-between')\n\nPType=Dropdown(options=['Particle in a one-dimensional box', 'Harmonic oscilator', 'Hydrogen atom (Helium correction)'])\nPert=Text()\nRang=IntRangeSlider(min=0, max=20, step=1, disabled=False, continuous_update=False, orientation='horizontal',\\\n readout=True, readout_format='d')\nM=Text()\nCorrec=Dropdown(options=['1', '2'])\nhbarra=Dropdown(options=[1, 1.0545718e-34])\n\nform_items = [\n Box([Label(value='Problem'),PType], layout=form_item_layout),\n Box([Label(value='Perturbation'),Pert], layout=form_item_layout),\n Box([Label(value='Correction order'),Correc], layout=form_item_layout),\n Box([Label(value='n Range'),Rang], layout=form_item_layout),\n Box([Label(value='Mass'),M], layout=form_item_layout),\n Box([Label(value='Hbar'),hbarra], layout=form_item_layout),]\n\nform = Box(form_items, layout=Layout(display='flex',flex_flow='column',border='solid 2px',align_items='stretch',width='40%'))\nform",
"_____no_output_____"
]
],
[
[
"En esta caja interactiva llena los datos del problema que deseas resolver.",
"_____no_output_____"
],
[
"# Nota 1:\nEs recomendable usar unidades atómicas de Hartree para eficientar los cálculos. 1 u.a. (energía)= 27.211eV.",
"_____no_output_____"
],
[
"# Nota 2:\nPara la partícula en una caja unidimensional es recomendable que n sea mayor o igual a 1.",
"_____no_output_____"
],
[
"## Nota 3:\nPara la correción a la energía del átomo de Helio sólo es necesario seleccionar el problema, automáticamente se calcula la correción a primer orden y no se corrigen las funciones de onda.",
"_____no_output_____"
]
],
[
[
"Problem=PType.value\nform_item_layout = Layout(display='flex',flex_flow='row',justify_content='space-between')\n\nL=Text()\nW=Text()\natomic_number=RadioButtons(options=['1 (Show Hydrogen energies)','2 (Correct Helium first energy)'],disabled=False)\n\nif Problem=='Particle in a one-dimensional box':\n form_items = [Box([Label(value='Large of box'),L], layout=form_item_layout)]\n\nif Problem=='Harmonic oscilator':\n form_items = [Box([Label(value='Angular Fr'),W], layout=form_item_layout)]\n\nif Problem=='Hydrogen atom (Helium correction)':\n form_items = [Box([Label(value='Atomic number'),atomic_number], layout=form_item_layout)]\n\nform = Box(form_items, layout=Layout(display='flex',flex_flow='column',border='solid 2px',align_items='stretch',width='40%'))\nform",
"_____no_output_____"
],
[
"# Variables que se utilizarán\n# x=variable de integracion, l=largo del pozo, m=masa del electrón, w=frecuencia angular\n# n=número cuántico principal, Z=Número atómico, q=número cuántico angular(l)\nvar('x theta phi')\nvar('r1 r2', real=True)\nvar('l m hbar w n Z', positive=True, real=True)\n\n# Perturbación\nif Pert.value!='':\n H_p=sympify(Pert.value)\n h_p=eval(Pert.value)\nelse:\n H_p=0\n h_p=0\n\n# Constantes\nh=hbarra.value\na0=5.2917721067e-11\nif M.value!='':\n mass=float(eval(M.value))\nelse:\n mass=1\n\n# Energías y funciones que se desea corregir\nn_inf=min(Rang.value)\nn_sup=max(Rang.value)\n \nif Problem=='Particle in a one-dimensional box':\n if L.value=='':\n large=1\n else:\n large=float(eval(L.value))\n omega=0\n # Energías del pozo de potencial infinito\n k=n*pi/l\n En=hbar**2*k**2/(2*m)\n \n # Funciones de onda del pozo de potencial infinito\n Psin=sqrt(2/l)*sin(n*pi*x/l)\n \n # Límites del pozo definido de 0 a l para sympy\n li_sympy=0\n ls_sympy=l\n # Mismo limites para scipy\n li_scipy=0\n ls_scipy=large\n\nif Problem=='Harmonic oscilator':\n large=0\n if W.value=='':\n omega=1\n else:\n omega=float(eval(W.value))\n # Energías del oscilador armónico cuántico\n En=E_n(n,w)\n \n # Funciones de onda del oscilador armónico cuántico\n Psin=psi_n(n,x,m,w)\n\n # Límites del pozo definido de -oo a oo para sympy\n li_sympy=-oo\n ls_sympy=oo\n # Límites del pozo definido de -oo a oo para scipy\n li_scipy=-inf\n ls_scipy=inf\n \nif Problem=='Hydrogen atom (Helium correction)':\n if atomic_number.value=='1 (Show Hydrogen energies)':\n z=1\n if atomic_number.value=='2 (Correct Helium first energy)':\n z=2\n large=0\n omega=0\n \n # Energías del átomo hidrogenoide\n En=z*E_nl(n,z)\n \n # Funciones de onda del átomo de hidrógeno\n # Número cuántico l=0\n q=0 # La variable l ya esta siendo utilizada para el largo de la caja por ello se sustituyo por q\n Psin=(R_nl(n,q,r1,z)*R_nl(n,q,r2,z))\n \n # Límites del átomo de hidrógeno de 0 a oo para sympy\n li_sympy=0\n ls_sympy=oo\n # Límites del átomo de hidrógeno de 0 a oo para scipy\n li_scipy=0\n ls_scipy=inf",
"_____no_output_____"
]
],
[
[
"Para sistemas no degenerados, la corrección a la energía a primer orden se calcula como \n\n$$ E_{n}^{(1)} = \\int\\psi_{n}^{(0)*} H' \\psi_{n}^{(0)}d\\tau$$",
"_____no_output_____"
],
[
"** Tarea 1 : Programar esta ecuación si conoces $H^{0}$ y sus soluciones. **",
"_____no_output_____"
]
],
[
[
"def correcion_1st_order_Energy(E_n,Psi_n,H_p,li,ls):\n E1_n=Integral(Psi_n*(H_p)*Psi_n,(x,li,ls)).doit()\n return(E_n+E1_n)",
"_____no_output_____"
],
[
"# Correción de la energía a primer orden\nE=[]\nEev=[]\nEc1=[]\nif Problem=='Particle in a one-dimensional box' or Problem=='Harmonic oscilator':\n for i in range(n_inf,n_sup+1):\n E.append(En.subs({n:i}))\n Eev.append(E[i-n_inf].subs({m:mass, l:large, hbar:h}).evalf())\n Ec1.append(correcion_1st_order_Energy(En.subs({n:i}),Psin.subs({n:i}),H_p,li_sympy,ls_sympy))\nif Problem=='Hydrogen atom (Helium correction)':\n for i in range(n_inf,n_sup+1):\n E.append(En.subs({n:i}))\n Eev.append(E[i-n_inf])\n if z==2:\n integral_1=Integral(Integral((16*z**6*r1*r2**2*exp(-2*z*(r1+r2))),(r2,0,r1)),(r1,0,oo)).doit()\n integral_2=Integral(Integral((16*z**6*r1**2*r2*exp(-2*z*(r1+r2))),(r2,r1,oo)),(r1,0,oo)).doit()\n integral_total=(integral_1+integral_2)\n Ec1.append(E[0]+integral_total)",
"_____no_output_____"
]
],
[
[
"Y la corrección a la función de onda, también a primer orden, se obtiene como:\n\n $$ \\psi_{n}^{(1)} = \\sum_{m\\neq n} \\frac{\\langle\\psi_{m}^{(0)} | H' | \\psi_{n}^{(0)} \\rangle}{E_{n}^{(0)} - E_{m}^{(0)}} \\psi_{m}^{(0)}$$",
"_____no_output_____"
],
[
"**Tarea 2: Programar esta ecuación si conoces $H^{0}$ y sus soluciones. **",
"_____no_output_____"
]
],
[
[
"# Correción de las funciones a primer orden\nif Pert.value!='':\n if Problem=='Particle in a one-dimensional box' or Problem=='Harmonic oscilator':\n Psi_c=[]\n integrals=np.zeros((n_sup+1,n_sup+1))\n for i in range(n_inf,n_sup+1):\n a=0\n for j in range(n_inf,n_sup+1):\n if i!=j:\n integ= lambda x: eval(str(Psin.subs({n:j})*(h_p)*Psin.subs({n:i}))).subs({m:mass,l:large,w:omega,hbar:h})\n integrals[i,j]=integrate.quad(integ,li_scipy,ls_scipy)[0]\n cte=integrals[i,j]/(En.subs({n:i,m:mass,l:large})-En.subs({n:j,m:mass,l:large})).evalf()\n a=a+cte*Psin.subs({n:j})\n Psi_c.append(Psin.subs({n:i})+a) ",
"_____no_output_____"
]
],
[
[
"**Tarea 3: Investigue las soluciones a segundo orden y también programe las soluciones. **",
"_____no_output_____"
],
[
"Y la corrección a la energía a segundo orden, se obtiene como:\n\n $$ E_{n}^{(2)} = \\sum_{m\\neq n} \\frac{|\\langle\\psi_{m}^{(0)} | H' | \\psi_{n}^{(0)} \\rangle|^{2}}{E_{n}^{(0)} - E_{m}^{(0)}} $$",
"_____no_output_____"
]
],
[
[
"# Correción a la energía a segundo orden\nif Pert.value!='':\n if Problem=='Particle in a one-dimensional box' or Problem=='Harmonic oscilator':\n if Correc.value=='2':\n Ec2=[]\n for i in range(n_inf,n_sup+1):\n a=0\n for j in range(n_inf,n_sup+1):\n if i!=j:\n cte=((integrals[i,j])**2)/(En.subs({n:i,m:mass,l:large,hbar:h})-En.subs({n:j,m:mass,l:large,hbar:h})).evalf()\n a=a+cte\n Ec2.append(Ec1[i-n_inf]+a) ",
"_____no_output_____"
]
],
[
[
"**A continuación se muestran algunos de los resultados al problema resuelto**",
"_____no_output_____"
],
[
"Las energías sin perturbación son:",
"_____no_output_____"
]
],
[
[
"E",
"_____no_output_____"
]
],
[
[
"La correción a primer orden de las energías son:",
"_____no_output_____"
]
],
[
[
"Ec1",
"_____no_output_____"
]
],
[
[
"Si seleccionaste en los parámetros iniciales una correción a segundo orden entonces...",
"_____no_output_____"
],
[
"Las correciones a la energía a segundo orden son:",
"_____no_output_____"
]
],
[
[
"Ec2",
"_____no_output_____"
]
],
[
[
"Ahora vamos con la función de onda $(\\psi)$",
"_____no_output_____"
]
],
[
[
"form_item_layout = Layout(\n display='flex',\n flex_flow='row',\n justify_content='space-between')\n\nGraph=IntSlider(min=n_inf, max=n_sup, step=1, disabled=False, continuous_update=False, orientation='horizontal',\\\n readout=True, readout_format='d')\n\nform_items = [\n Box([Label(value='What function do you want to see?'),\n Graph], layout=form_item_layout)]\n\nform = Box(form_items, layout=Layout(\n display='flex',\n flex_flow='column',\n border='solid 2px',\n align_items='stretch',\n width='40%'))\nform",
"_____no_output_____"
]
],
[
[
"La función de onda original es:",
"_____no_output_____"
]
],
[
[
"Psin.subs({n:Graph.value})",
"_____no_output_____"
]
],
[
[
"La correción a primer orden a la función de onda (utilizando todas las funciones en el rango seleccionado) es:",
"_____no_output_____"
]
],
[
[
"Psi_c[Graph.value-n_inf]",
"_____no_output_____"
]
],
[
[
"Vamos a graficarlas para verlas mejor...",
"_____no_output_____"
],
[
"La función de onda original es:",
"_____no_output_____"
]
],
[
[
"if Problem=='Particle in a one-dimensional box':\n plot(eval(str(Psin)).subs({n:Graph.value,m:mass,l:large,w:omega,hbar:h}),xlim=(li_scipy,ls_scipy),\\\n title='$\\psi_{%d}$'%Graph.value)\nif Problem=='Harmonic oscilator':\n plot(eval(str(Psin)).subs({n:Graph.value,m:mass,l:large,w:omega,hbar:h}),xlim=(-10*h/(mass*omega),10*h/(mass*omega)),\\\n title='$\\psi_{%d}$'%Graph.value)\nif Problem=='Hydrogen atom (Helium correction)':\n print('Densidad de probabilidad para un electrón')\n plot(eval(str((4*pi*x**2*R_nl(Graph.value,q,x,z)**2))),xlim=(0,10),ylim=(0,20/Graph.value), title='$\\psi_{%ds}$'%Graph.value)\n print('Tome en cuenta que debido a la dificultad para seleccionar los límites de la gráfica se muestran bien los primeros\\n\\\n3 estados. A partir de ahí visualizar la gráfica se complica.')",
"_____no_output_____"
]
],
[
[
"La corrección a la función de onda es:",
"_____no_output_____"
]
],
[
[
"if Problem=='Particle in a one-dimensional box':\n if Pert.value!='':\n plot(eval(str(Psi_c[Graph.value-n_inf])).subs({n:Graph.value,m:mass,l:large,w:omega,hbar:h}),\\\n xlim=(li_scipy,ls_scipy),title='$\\psi_{%d}$'%Graph.value)\n if Pert.value=='':\n print('No se ingreso ninguna perturbación')\nif Problem=='Harmonic oscilator':\n if Pert.value!='':\n plot(eval(str(Psi_c[Graph.value-n_inf])).subs({n:Graph.value,m:mass,l:large,w:omega,hbar:h}),\\\n xlim=(-10*h/(mass*omega),10*h/(mass*omega)),title='$\\psi_{%d}$' %Graph.value)\n if Pert.value=='':\n print('No se ingreso ninguna perturbación')\nif Problem=='Hydrogen atom (Helium correction)':\n print('Este programa no corrige las fucniones de un átomo hidrogenoide')",
"_____no_output_____"
]
],
[
[
"**Tarea 4. Resolver el átomo de helio aplicando los programas anteriores.** ",
"_____no_output_____"
],
[
"Para el cálculo a las correciones del átomo de Helio se tomó en cuenta lo siguiente...",
"_____no_output_____"
],
[
"La función de onda del átomo de Helio puede ser representada como:\n\n$$ \\psi_{nlm} = \\psi(r1)_{nlm} \\psi(r2)_{nlm}$$",
"_____no_output_____"
],
[
"Donde, para el estado fundamental:\n\n$$ \\psi(r_{1}.r_{2})_{100} = \\frac{Z^{3}}{\\pi a_{0}^{3}} e^{\\frac{-Z}{a_{0}}(r_{1}+r_{2})}$$",
"_____no_output_____"
],
[
"Y la perturbación sería el término de repulsión entre los dos electrones, es decir:\n\n$$ H'= \\frac{e^{2}}{r_{12}}=\\frac{e^{2}}{|r_{1}-r_{2}|}$$",
"_____no_output_____"
],
[
"Finalmente la correción a primer orden de la energía sería:\n \n$$ E^{(1)}= \\langle\\psi_{n}^{(0)} | H' | \\psi_{n}^{(0)} \\rangle =\\frac{Z^{6}e^{2}}{\\pi^{2} a_{0}^{6}} \\int_{0}^{2\\pi}\\int_{0}^{2\\pi}\\int_{0}^{\\pi}\\int_{0}^{\\pi}\\int_{0}^{\\infty}\\int_{0}^{\\infty} \\frac{e^{\\frac{-2Z}{a_{0}}(r_{1}+r_{2})}}{r_{12}} r_{1}^{2}r_{2}^{2}sen{\\theta_{1}}sen{\\theta_{2}} dr_{2} dr_{1} d\\theta_{2} d\\theta_{1} d\\phi_{2} d\\phi_{1}$$",
"_____no_output_____"
],
[
"Se utiliza una expansión del termino de repulsión con los armónicos esféricos y se integra la parte angular. Una vez hecho eso, la integral queda expresada de la siguiente manera:",
"_____no_output_____"
],
[
"$$ E^{(1)}= \\frac{16Z^{6}e^{2}}{a_{0}^{6}} \\left[\\int_{0}^{\\infty} r_{1}^{2} e^{\\frac{-2Z}{a_{0}}r_{1}} \\left(\\int_{0}^{r_{1}} \\frac{r_{2}^{2}}{r_{1}} e^{\\frac{-2Z}{a_{0}}r_{2}} dr_{2}+\\int_{r_{1}}^{\\infty}r_{2} e^{\\frac{-2Z}{a_{0}}r_{2}}dr_{2}\\right) dr_{1} \\right]$$",
"_____no_output_____"
],
[
"Esta fue la integral que se programó para hacer la correción a la energía del Helio",
"_____no_output_____"
],
[
"**Tarea 5: Método variacional-perturbativo. **",
"_____no_output_____"
],
[
"Este método nos permite estimar de forma precisa $E^{(2)}$ y correcciones perturbativas de la energía de órdenes más elevados para el estado fundamental del sistema, sin evaluar sumas infinitas. Ver ecuación 9.38 del libro. ",
"_____no_output_____"
],
[
"$$ \\langle u | H^{0} - E_{g}^{(0)} | u \\rangle + \\langle u | H' - E_{g}^{(1)} | \\psi_{g}^{(0)} \\rangle +\\langle\\psi_{g}^{(0)} | H' - E_{g}^{(1)} | u \\rangle \\geq E_{g}^{(2)} $$",
"_____no_output_____"
],
[
"Donde:",
"_____no_output_____"
],
[
"u, es cualquier función que se comporte bien y satisfaga condiciones de frontera.",
"_____no_output_____"
],
[
"Por lo general, u tiene un parámetro variacional que permite minimizar el lado izquierdo de la ecuación para estimar $E_{g}^{(2)} $. La función u resulta ser una aproximación a $\\psi_{g}^{(1)}$, por lo que se puede utilizar está misma función para estimar $E_{g}^{(3)}$ y seguir haciendo iteraciones para hacer correciones de orden superior tanto a la energía como a la función de onda.",
"_____no_output_____"
],
[
"Es necesario meter parámetros de optimización a las funciones de prueba para que tenga sentido intentar programar esto. Esto nos limita a usar Sympy para resolver la integral simbólicamente. Entonces, estamos limitados a las capacidades de esta librería para resolver las integrales y a la capacidad de nuestro procesador.",
"_____no_output_____"
],
[
"A continuación se muestra un código que, aprovechando los datos introducidos anteriormente, encuentra por medio del método variacional-perturbativo la correción a segundo orden de la energía y a primer orden de la función de onda.",
"_____no_output_____"
]
],
[
[
"form_item_layout = Layout(display='flex',flex_flow='row',justify_content='space-between')\n\nF_prueba=Text()\nRan_n=IntSlider(min=n_inf, max=n_sup, step=1, disabled=False, continuous_update=False, orientation='horizontal',\\\n readout=True, readout_format='d')\nCorrecc=RadioButtons(options=[2],disabled=False)\n\nform_items = [\n Box([Label(value='Test function'),F_prueba], layout=form_item_layout),\n Box([Label(value='Correction order'),Correcc], layout=form_item_layout),\n Box([Label(value='Function to correct'),Ran_n], layout=form_item_layout),]\n\nform = Box(form_items, layout=Layout(display='flex',flex_flow='column',border='solid 2px',align_items='stretch',width='40%'))\nform",
"_____no_output_____"
]
],
[
[
"Para la función de prueba se espera que el usuario introduzca una función que sea cuadrado-integrable y que sea compatible en las fronteras con el tipo de problema que se esta solucionando. Además, puede intruducir una constante de optimización (utilice \"c\")",
"_____no_output_____"
]
],
[
[
"# Variables que se utilizarán\n# c y d=constantes de optimización\nvar('c')#, real=True)\n\nu=eval(F_prueba.value)\norder=Correcc.value\nn_n=Ran_n.value\n\nif Problem=='Particle in a one-dimensional box':\n V=0\n \nif Problem=='Harmonic oscilator':\n V=(m/2)*w**2*x**2\n \nif Problem=='Particle in a one-dimensional box' or Problem=='Harmonic oscilator':\n integrando_a=(u)*((-hbar**2)/(2*m)*diff(u,x,2))+(u)*V*(u)-(u)*En.subs({n:n_n})*(u)\n integrando_b=(u)*h_p*(Psin.subs({n:n_n}))-(u)*(Ec1[n_n-n_inf]-En.subs({n:n_n}))*(Psin.subs({n:n_n}))\n integral_a=Integral(eval(str(integrando_a)),(x,li_sympy,ls_sympy)).doit()\n integral_b=Integral(eval(str(integrando_b)),(x,li_sympy,ls_sympy)).doit()\n integral_T=integral_a+2*integral_b\n f_opt=diff(integral_T,c,1)\n c2=solve(f_opt,c)\n E_c2=Ec1[n_n-n_inf]+integral_T.subs({c:c2[0]})\n Psi_c1=(Psin.subs({n:n_n})+u.subs({c:c2[0]}))",
"_____no_output_____"
]
],
[
[
"Se considero que para fines de esta tarea que:",
"_____no_output_____"
],
[
" $$\\langle u | H' - E_{g}^{(1)} | \\psi_{g}^{(0)} \\rangle =\\langle\\psi_{g}^{(0)} | H' - E_{g}^{(1)} | u \\rangle$$",
"_____no_output_____"
],
[
"Lo cual se cumple cuando $H'$ es una función sin operadores diferenciales, y además, u y $\\psi_{g}^{(0)}$ son funciones reales.",
"_____no_output_____"
],
[
"Las correciones a la energía son:",
"_____no_output_____"
]
],
[
[
"E[n_n-n_inf]",
"_____no_output_____"
],
[
"Ec1[n_n-n_inf]",
"_____no_output_____"
],
[
"E_c2",
"_____no_output_____"
]
],
[
[
"Las correción a la función de onda:",
"_____no_output_____"
]
],
[
[
"Psin.subs({n:n_n})",
"_____no_output_____"
],
[
"Psi_c1",
"_____no_output_____"
]
],
[
[
"Veamos ahora las gráficas de estas funciones...",
"_____no_output_____"
],
[
"La función de onda original es:",
"_____no_output_____"
]
],
[
[
"if Problem=='Particle in a one-dimensional box':\n plot(eval(str(Psin)).subs({n:n_n,m:mass,l:large,w:omega,hbar:h}),xlim=(li_scipy,ls_scipy),\\\n title='$\\psi_{%d}$'%n_n)\nif Problem=='Harmonic oscilator':\n plot(eval(str(Psin)).subs({n:n_n,m:mass,l:large,w:omega,hbar:h}),xlim=(-10*h/(mass*omega),10*h/(mass*omega)),\\\n title='$\\psi_{%d}$'%n_n)",
"_____no_output_____"
]
],
[
[
"Su correción por medio del método variacional-perturbativo es:",
"_____no_output_____"
]
],
[
[
"if Problem=='Particle in a one-dimensional box':\n if Pert.value!='':\n plot(Psi_c1.subs({m:mass,l:large,w:omega,hbar:h}),\\\n xlim=(li_scipy,ls_scipy),ylim=(-1.5,1.5),title='$\\psi_{%d}$'%n_n)\n if Pert.value=='':\n print('No se ingreso ninguna perturbación')\nif Problem=='Harmonic oscilator':\n if Pert.value!='':\n plot(Psi_c1.subs({m:mass,l:large,w:omega,hbar:h}),\\\n xlim=(-10*h/(mass*omega),10*h/(mass*omega)),title='$\\psi_{%d}$' %n_n)",
"_____no_output_____"
]
],
[
[
"**Tarea 6. Revisar sección 9.7. **\n\nInicialmente a mano, y en segunda instancia favor de intentar programar sección del problema, i.e. integral de Coulomb e integral de intercambio.",
"_____no_output_____"
],
[
"Para comenzar a solucionar este problema, es necesario ser capaz de escribir el termino de repulsión que aparece en la fuerza coulombiana ($\\frac {1} {r_{12} }$) en términos de los armónicos esféricos de la siguiente manera:",
"_____no_output_____"
],
[
"$$ \\frac {1} {r_{12} } = \\sum_{l=0}^{\\infty} \\sum_{m=-l}^{l} \\frac{4\\pi}{2l+1} \\frac{r_{<}^{l}}{r_{>}^{l+1}} \\left[Y_{l}^{m}(\\theta_{1},\\phi_{1}) \\right]^{*} Y_{l}^{m}(\\theta_{2},\\phi_{2}) $$",
"_____no_output_____"
],
[
"Se tiene el problema de que para programar esta ecuación los armónicos esféricos no están programados de forma simbólica, así como tampoco estan programados los polinomios asociados de Legendre.",
"_____no_output_____"
],
[
"Se podría intentar programar las integral de intercambio y de Coulomb de forma numérica o intentar aprovechar la ortogonalidad de los armónicos esféricos, que al integrar aparecen los términos $\\delta_{l,l'}$ y $\\delta_{m,m'}$, por lo que la mayoría de las integrales se hacen $0$.",
"_____no_output_____"
],
[
"Aún cuando se lograra programar todo esto, hace falta verificar que se seleccionaron correctamente los límites de integración radiales para que el término $\\frac{r_{<}^{l}}{r_{>}^{l+1}}$ tenga sentido.",
"_____no_output_____"
]
],
[
[
"form_item_layout = Layout(display='flex',flex_flow='row',justify_content='space-between')\n\nT1=RadioButtons(options=['1s','2s','2p','3s'],disabled=False)\nT2=RadioButtons(options=['1s','2s','2p','3s'],disabled=False)\n\nform_items = [\n Box([Label(value='Type electron 1'),T1], layout=form_item_layout),\n Box([Label(value='Type electron 2'),T2], layout=form_item_layout)]\n\nform = Box(form_items, layout=Layout(display='flex',flex_flow='column',border='solid 2px',align_items='stretch',width='40%'))\nform",
"_____no_output_____"
],
[
"# Se puede intentar programar aprovechando la ortogonalidad de los armónicos esféricos para evitar las 4 integrales angulares\n# y solo integrar sobre las coordenadas radiales\nvar('rmenor rmayor')\nvar('lq',integrer=True, positive=True)\nType1=T1.value\nType2=T2.value\nn_a=2\n\nif Type1=='1s':\n n1=1\n l1=0\nif Type1=='2s':\n n1=2 \n l1=0\nif Type1=='2p':\n n1=2\n l1=1\nif Type1=='3s':\n n1=3\n l1=0\n \nif Type2=='1s':\n n2=1\n l2=0\nif Type2=='2s':\n n2=2\n l2=0\nif Type2=='2p':\n n2=2\n l2=1\nif Type2=='3s':\n n2=3\n l2=0\n \nr12_inv=1/(2*lq+1)*rmenor**lq/rmayor**(lq+1)\n\nif n1>n2:\n n_m=n1\nelse:\n n_m=n2\n\n\nfor n in range(1,n_m+1):\n a=[]\n for nn in range(1,n_m+1):\n b=[]\n for o in range(n_m):\n c=[]\n if o<nn:\n for m in range(-o,o+1):\n c.append(r12_inv.subs({lq:o}))\n b.append(c)\n a.append(b)\n# Después de esto tengo una lista que para utilizarla debo usar a[n-1][l][m+l]\n\n\nPsi1=R_nl(n1,l1,r1,n_a)\nPsi2=R_nl(n2,l2,r2,n_a)\nPsi_t=Psi1*Psi2\n\nIntegral_Coulumb1=0\nIntegral_Coulumb2=0\nIntegral_Intercambio1=0\nIntegral_Intercambio2=0\n\nif l1==l2:\n for m in range(-l1,l1+1):\n Integral_Coulumb1=Integral_Coulumb1+Integral(Integral(r1**2*r2**2*Psi1**2*Psi2**2*\\\n a[n1-1][l1][l1].subs({rmayor:r1,rmenor:r2,lq:0}),(r2,0,r1)),(r1,0,oo)).doit()\n Integral_Coulumb2=Integral_Coulumb2+Integral(Integral(r1**2*r2**2*Psi1**2*Psi2**2*\\\n a[n1-1][l1][l1].subs({rmayor:r2,rmenor:r1,lq:0}),(r2,r1,oo)),(r1,0,oo)).doit()\n Integral_CoulumbT=Integral_Coulumb1+Integral_Coulumb2\nelse:\n Integral_CoulumbT=0\n \nif l1!=l2:\n Integral_Intercambio1=Integral(Integral(r1**2*r2**2*Psi1*Psi2*Psi1.subs({r1:r2})*Psi2.subs({r2:r1})*\\\n a[n1-1][l1][l1].subs({rmayor:r1,rmenor:r2,lq:0}),(r2,0,r1)),(r1,0,oo)).doit()\n Integral_Intercambio2=Integral(Integral(r1**2*r2**2*Psi1*Psi2*Psi1.subs({r1:r2})*Psi2.subs({r2:r1})*\\\n a[n1-1][l1][l1].subs({rmayor:r2,rmenor:r1,lq:0}),(r2,r1,oo)),(r1,0,oo)).doit()\n Integral_IntercambioT=Integral_Intercambio1+Integral_Intercambio2 \nelse:\n Integral_IntercambioT=0",
"_____no_output_____"
],
[
"# Programa funciona para 1s\n\n# Encontrar la manera de hacer matrices nxlxm que puedan ser llenadas con variables para posteriormente revisar\n# como encontrar las integrales aprovechando ortogonalidad de los armónicos esféricos.\n\n# Una opción para la matriz puedes hacer una lista y hacer reshape cada ciertas iteraciones en el ciclo for",
"_____no_output_____"
]
],
[
[
"Falta verificar la ortogonalidad de los armónicos esféricos y como aprovecharla para hacer únicamente las integrales radiales pero aún no esta listo.\n",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
]
] |
cb35270d01d46ee36eee2d484706dc87216e637e | 28,503 | ipynb | Jupyter Notebook | site/tr/r1/tutorials/keras/basic_text_classification.ipynb | sriyogesh94/docs | b2e7670f95d360c64493d1b3a9ff84c96d285ca4 | [
"Apache-2.0"
] | 2 | 2019-09-11T03:14:24.000Z | 2019-09-11T03:14:28.000Z | site/tr/r1/tutorials/keras/basic_text_classification.ipynb | sriyogesh94/docs | b2e7670f95d360c64493d1b3a9ff84c96d285ca4 | [
"Apache-2.0"
] | null | null | null | site/tr/r1/tutorials/keras/basic_text_classification.ipynb | sriyogesh94/docs | b2e7670f95d360c64493d1b3a9ff84c96d285ca4 | [
"Apache-2.0"
] | 1 | 2019-09-15T17:30:32.000Z | 2019-09-15T17:30:32.000Z | 38.413747 | 575 | 0.577413 | [
[
[
"##### Copyright 2018 The TensorFlow Authors.",
"_____no_output_____"
]
],
[
[
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
],
[
"#@title MIT License\n#\n# Copyright (c) 2017 François Chollet\n#\n# Permission is hereby granted, free of charge, to any person obtaining a\n# copy of this software and associated documentation files (the \"Software\"),\n# to deal in the Software without restriction, including without limitation\n# the rights to use, copy, modify, merge, publish, distribute, sublicense,\n# and/or sell copies of the Software, and to permit persons to whom the\n# Software is furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL\n# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING\n# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER\n# DEALINGS IN THE SOFTWARE.",
"_____no_output_____"
]
],
[
[
"# Film yorumları ile metin sınıflandırma",
"_____no_output_____"
],
[
"<table class=\"tfo-notebook-buttons\" align=\"left\">\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/docs/blob/master/site/tr/r1/tutorials/keras/basic_text_classification.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />Google Colab’da Çalıştır</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://github.com/tensorflow/docs/blob/master/site/tr/r1/tutorials/keras/basic_text_classification.ipynb\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />GitHub'da Kaynağı Görüntüle</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"Note: Bu dökümanlar TensorFlow gönüllü kullanıcıları tarafından çevirilmiştir.\nTopluluk tarafından sağlananan çeviriler gönüllülerin ellerinden geldiğince\ngüncellendiği için [Resmi İngilizce dökümanlar](https://www.tensorflow.org/?hl=en)\nile bire bir aynı olmasını garantileyemeyiz. Eğer bu tercümeleri iyileştirmek\niçin önerileriniz var ise lütfen [tensorflow/docs](https://github.com/tensorflow/docs)\nhavuzuna pull request gönderin. Gönüllü olarak çevirilere katkıda bulunmak için\n[[email protected]](https://groups.google.com/a/tensorflow.org/forum/#!forum/docs-tr)\nlistesi ile iletişime geçebilirsiniz.",
"_____no_output_____"
],
[
"\nBu yardımcı döküman, yorum metinlerini kullanarak film yorumlarını *olumlu* veya *olumsuz* olarak sınıflandırmaktadır. Bu örnek, yoğun olarak kullanılan ve önemli bir makina öğrenmesi uygulaması olan *ikili* veya *iki kategorili sınıflandırma*' yı kapsamaktadır. \n\nBu örnekte, [Internet Film Veritabanı](https://www.imdb.com/) sitesinde yer alan 50,000 film değerlendirme metnini içeren [IMDB veri seti](https://www.tensorflow.org/api_docs/python/tf/keras/datasets/imdb) 'ni kullancağız. Bu veri seti içerisindeki 25,000 yorum modelin eğitimi için, 25,000 yorum ise modelin testi için ayrılmıştır. Eğitim ve test veri setleri eşit miktarda olumlu ve olumsuz yorum içerecek şekilde dengelenmiştir. \n\nBu yardımcı döküman, Tensorflow'da modellerin oluşturulması ve eğitilmesinde kullanına yüksek-seviye API [tf.keras](https://www.tensorflow.org/r1/guide/keras) 'ı kullanır. `tf.keras` ile ileri seviye metin sınıflandımayı öğrenmek için [MLCC Metin Sınıflandırma ](https://developers.google.com/machine-learning/guides/text-classification/)'a göz atabilirsiniz.",
"_____no_output_____"
]
],
[
[
"# keras.datasets.imdb is broken in 1.13 and 1.14, by np 1.16.3\n!pip install tf_nightly",
"_____no_output_____"
],
[
"from __future__ import absolute_import, division, print_function, unicode_literals\n\nimport tensorflow as tf\nfrom tensorflow import keras\n\nimport numpy as np\n\nprint(tf.__version__)",
"_____no_output_____"
]
],
[
[
"## IMDB veri setini indirelim\n\nIMDB veri seti TensorFlow ile birlikte bütünleşik olarak gelmektedir. Yorumların kelime diziliş sıraları, her bir sayının bir kelimeyi temsil ettiği sıralı bir tam sayı dizisine çevrilerek veri seti ön işlemden geçirilmiştir. \n\nAşağıdaki kodlar, IMDB veri setini bilgisayarınıza indirir (eğer daha önceden indirme yapmışsanız, önbellekteki veri kullanılır) :",
"_____no_output_____"
]
],
[
[
"imdb = keras.datasets.imdb\n\n(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)",
"_____no_output_____"
]
],
[
[
"`num_words=10000` değişkeni eğitim veri setinde en sık kullanılan 10,000 kelimeyi tutar, az kullanılan kelimeleri veri boyutunun yönetilebilir olması için ihmal eder.",
"_____no_output_____"
],
[
"## Veriyi inceleyelim \n\nVeri formatını aşağıdaki kodlar yardımı ile birlikte inceleyelim. Veri seti, ön işlem uygulanmış şekilde gelmektedir: tüm film yorum örnekleri, her bir sayının yorumundaki bir kelimeye denk geldiği tam sayı dizisi olarak gelmektedir. Tüm etiketler 0 veya 1 değerine sahiptir (0 olumsuz değerlendirme, 1 olumlu değerlendirme).",
"_____no_output_____"
]
],
[
[
"print(\"Training entries: {}, labels: {}\".format(len(train_data), len(train_labels)))",
"_____no_output_____"
]
],
[
[
"Yorum metinleri, her bir sayının sözlükte yer alan bir kelimeye denk geldiği sayı dizisine çevrilmiştir. İlk yorum metni, aşağıdaki gibidir:",
"_____no_output_____"
]
],
[
[
"print(train_data[0])",
"_____no_output_____"
]
],
[
[
"Farklı film yorumlarının uzunlukları farklı olabilir. Aşağıdaki kod, ilk ve ikinci yorumda yer alan kelime sayılarını göstermektedir. Sinir ağlarında girdi boyutlarının aynı olması gerekmektedir, bu problemi daha sonra çözeceğiz. ",
"_____no_output_____"
]
],
[
[
"len(train_data[0]), len(train_data[1])",
"_____no_output_____"
]
],
[
[
"### Tam sayıları kelimelere geri çevirelerim\n\nTam sayıları metin'e çevirme işlemini bilmemiz, bazı durumlarda işimize yarayabilir. Bunun için bir yardımcı fonksiyon oluşturacağız. Bu fonksiyon, tam sayı-karakter eşleştirmesi içeren bir sözlük nesnesini sorguyabilmemizi sağlayacak:",
"_____no_output_____"
]
],
[
[
"# A dictionary mapping words to an integer index\nword_index = imdb.get_word_index()\n\n# İlk indisler rezervedir\nword_index = {k:(v+3) for k,v in word_index.items()} \nword_index[\"<PAD>\"] = 0\nword_index[\"<START>\"] = 1\nword_index[\"<UNK>\"] = 2 # unknown\nword_index[\"<UNUSED>\"] = 3\n\nreverse_word_index = dict([(value, key) for (key, value) in word_index.items()])\n\ndef decode_review(text):\n return ' '.join([reverse_word_index.get(i, '?') for i in text])",
"_____no_output_____"
]
],
[
[
"'decode_review' fonksiyonunu kullanarak ilk yorum metnini şimdi ekranda gösterebiliriz:",
"_____no_output_____"
]
],
[
[
"decode_review(train_data[0])",
"_____no_output_____"
]
],
[
[
"## Veriyi hazırlayalım\n\nYorumlar -tam sayı dizileri- sinir ağına beslenmeden önce ilk olarak tensor yapısına çevrilmelidir. Bu çevirme işlemi birkaç farklı şekilde yapabilir: \n\n* Bu ilk yöntemde, one-hot encoding işlemine benzer şekilde, tam sayı dizileri kelimelerin mevcut olup olmamasına göre 0 ve 1 ler içeren, vektörlere çevrilir. Örnek olarak, [3, 5] dizisini vektör'e dönüştürdüğümüzde, bu dizi 3üncü ve 5inci indeksleri dışında tüm değerleri 0 olan 10,000 boyutlu bir vektor'e dönüşür. Sonrasında, ağımızın ilk katmanını floating point vektor verisini işleyebilen yoğun katman (dense layer) olarak oluşturabiliriz. Bu yöntem, 'num_words * num_reviews' boyutlu bir matris oluşturduğumuz için, yoğun hafıza kullanımına ihtiyaç duyar.\n\n* Alternatif olarak, tüm dizileri aynı boyutta olacak şekilde doldurabiliriz. Sonrasında 'max_length * max_review' boyutlu bir tam sayı vektorü oluşturabiliriz. Son olarak, bu boyuttaki vektörleri işleyebilen gömülü katmanı, ağımızın ilk katmanı olarak oluşturabiliriz.\n\nBu örnekte ikinci yöntem ile ilerleyeceğiz. \n\nFilm yorumlarımızın aynı boyutta olması gerektiği için, yorum boyutlarını standart uzunluğa dönüştüren [pad_sequences](https://www.tensorflow.org/api_docs/python/tf/keras/preprocessing/sequence/pad_sequences) fonksiyonunu kullanacağız:",
"_____no_output_____"
]
],
[
[
"train_data = keras.preprocessing.sequence.pad_sequences(train_data,\n value=word_index[\"<PAD>\"],\n padding='post',\n maxlen=256)\n\ntest_data = keras.preprocessing.sequence.pad_sequences(test_data,\n value=word_index[\"<PAD>\"],\n padding='post',\n maxlen=256)",
"_____no_output_____"
]
],
[
[
"Şimdi, ilk yorum örneklerinin uzunluklarına birlikte bakalım:",
"_____no_output_____"
]
],
[
[
"len(train_data[0]), len(train_data[1])",
"_____no_output_____"
]
],
[
[
"Ve ilk yorumu (doldurulmuş şekliyle) inceleyelim:",
"_____no_output_____"
]
],
[
[
"print(train_data[0])",
"_____no_output_____"
]
],
[
[
"## Modeli oluşturalım\n\nSinir ağları, katmanların birleştirilmesiyle oluşturulur. Bu noktada, modelin yapısıyla ilgili iki temel karar vermemiz gerekmektedir:\n\n* Modeli oluşturuken kaç adet katman kullanacağız?\n* Her bir katmanda kaç adet *gizli birim* (hidden units) kullanacağız?\n\nBu örnekte modelimizin girdi verisi, kelime indekslerini kapsayan bir tam sayı dizisidir. Tahmin edilecek etiket değerleri 0 ve 1'dir. Problemimiz için modelimizi oluşturalım:",
"_____no_output_____"
]
],
[
[
"# Girdiler film yorumları için kullanılan kelime sayısıdır (10,000 kelime)\nvocab_size = 10000\n\nmodel = keras.Sequential()\nmodel.add(keras.layers.Embedding(vocab_size, 16))\nmodel.add(keras.layers.GlobalAveragePooling1D())\nmodel.add(keras.layers.Dense(16, activation=tf.nn.relu))\nmodel.add(keras.layers.Dense(1, activation=tf.nn.sigmoid))\n\nmodel.summary()",
"_____no_output_____"
]
],
[
[
"Sınıflandırıcı modelimizi oluşturmak için katmanlar sıralı bir şekilde birleştirilmiştir:\n\n1. İlk katmanımız 'gömülü-embedding' katmandır. Bu katman tam sayı olarak şifrelenmiş sözcük grubu içerisinden kelime değerlerini alıp, her bir kelime indeksi için bu değeri gömülü vektör içerisinde arar. Bu vektörler modelin eğitimi sırasında öğrenilirler ve çıktı dizisine bir boyut eklerler. Sonuç olarak boyutlar '(batch, sequence, embedding)' şeklinde oluşur:\n2. Sonrasında, `GlobalAveragePooling1D` katmanı, her bir yorum örneği için, ardaşık boyutların ortalamasını alarak sabit uzunlukta bir çıktı vektörü oluştur. Bu işlem, en basit şekliyle, modelimizin faklı boyutlardaki girdileri işleyebilmesini sağlar.\n3. Bu sabit boyutlu çıktı vektörü, 16 gizli birim (hidden units) içeren tam-bağlı (fully-connected) yoğun katman'a beslenir.\n4. Son katman, tek bir çıktı düğümü içeren yoğun bağlı bir katmandır. 'sigmoid' aktivasyon fonksiyonunu kullanarak, bu düğümün çıktısı 0 ile 1 arasında, olasılık veya güven değerini temsil eden bir değer alır.",
"_____no_output_____"
],
[
"### Gizli birimler (Hidden units)\n\nYukarıdaki model, girdi ve çıktı arasında iki adet ara veya \"gizli\" katman içerir. Çıktıların sayısı (birimler, düğümler veya neronlar), mevcut katman içerisinde yapılan çıkarımların boyutudur. Başka bir ifade ile, ağın öğrenirken yapabileceği ara çıkarım miktarını, katmanın çıktı boyutu belirler.\n\nEğer model fazla gizli birim (daha fazla boyutta çıkarım alanı) veya fazla katmana sahipse, model daha kompleks çıkarımlar yapabilir. Bu durumda daha yoğun hesaplama gücüne ihtiyaç duyulur. Bununla birlikte, modelimiz problemin çözümü için gerekli olmayacak derecede çıkarımlar yaparak eğitim verisi ile çok iyi sonuçlar verse de, test verisinde aynı oranda başarılı olmayabilir. Buna *aşırı uyum - overfitting* denir, bu kavramı daha sonra tekrar inceleyeceğiz.",
"_____no_output_____"
],
[
"### Kayıp fonksiyonu ve optimize edici\n\nModelimizin eğitilmesi için bir kayıp fonksiyonuna ve optimize ediciye ihitiyacımız vardır. Problemimiz, film yorumlarını olumlu ve olumsuz olarak sınıflandırmak (yani ikili siniflandirma problemi) olduğu için, 'binary_crossentropy' kayıp fonksiyonunu kullanacağız. \n\nBu kayıp fonksiyonu tek seçeneğimiz olmasa da, örneğin 'mean_squared_error' kayıp fonksiyonunu da kullanabilirdik, 'binary_crossentropy' kayıp fonksiyonu, olasılık dağılımları (kesin referans ile tahmin edilen olaralık dağılımı) arasındaki farkı ölçerek, olasılık hesaplamaları için daha iyi sonuç verir.\n\nDaha sonra, regrasyon problemlerini incelediğimizde (yani bir evin fiyatını tahmin etmek için), 'mean squared error' gibi diğer kayıp fonksiyonlarını nasıl kullanabileceğimizi göreceğiz.\n\nŞimdi, kayıp fonksiyonu ve optimize ediciyi kullanarak modelimizi yapılandıralım:",
"_____no_output_____"
]
],
[
[
"model.compile(optimizer='adam',\n loss='binary_crossentropy',\n metrics=['acc'])",
"_____no_output_____"
]
],
[
[
"## Doğrulama veri setini oluşturalım\n\nEğitim sürecinde, daha önce görmediği veriler ile modelin doğrulunu kontrol etmek isteriz. *Doğrulama veri seti* oluşturmak için eğitim veri seti içerisinden 10,000 yorum ayıralım. (Doğrulama için neden test veri setini şimdi kullanmıyoruz? Bunun nedeni modeli oluşturulması ve düzenlenmesi için sadece eğitim veri setini kullanmak istememizdir. Modelimiz oluşup, eğitildikten sonra, test verisini modelimizin doğruluğunu değerlendirmek için kullanacağız).",
"_____no_output_____"
]
],
[
[
"x_val = train_data[:10000]\npartial_x_train = train_data[10000:]\n\ny_val = train_labels[:10000]\npartial_y_train = train_labels[10000:]",
"_____no_output_____"
]
],
[
[
"## Modelin eğitilmesi\n\nModeli, her bir mini-batch te 512 yorum örneği olacak şekilde 40 epoch döngüsü ile eğitelim. 'x_train' ve 'y_train' tensorlarını kullanarak tüm yorumları bu 40 iterasyon ile kapsıyoruz. Eğitim süresince, doğrulama veri setini kullanarak modelin kayıp fonksiyon değerini ve doğruluğunu gözlemleyelim:",
"_____no_output_____"
]
],
[
[
"history = model.fit(partial_x_train,\n partial_y_train,\n epochs=40,\n batch_size=512,\n validation_data=(x_val, y_val),\n verbose=1)",
"_____no_output_____"
]
],
[
[
"## Modeli değerlendirelim\n\nVe modelin nasıl performans gösterdiğini görelim. Bunun için iki değer kullanacağız. Kayıp (hatayı temsil eden sayı, düşük değerler daha iyi anlamına gelmektedir) ve doğruluk değeri.",
"_____no_output_____"
]
],
[
[
"results = model.evaluate(test_data, test_labels)\n\nprint(results)",
"_____no_output_____"
]
],
[
[
"Bu oldukça basit yöntem ile %87 gibi bir doğruluk değeri elde ediyoruz. Daha ileri yöntemler ile modelimiz %95'e kadar çıkan doğruluk sonuçları verebilir.",
"_____no_output_____"
],
[
"## Doğruluk ve kayıp değerlerinin zamana göre değişimini veren bir grafik oluşturalım\n\n`model.fit()` methodu eğitim sürecinde olan biten herşeyi görebileceğimiz 'History' sözlük nesnesi oluşturur:",
"_____no_output_____"
]
],
[
[
"history_dict = history.history\nhistory_dict.keys()",
"_____no_output_____"
]
],
[
[
"Grafiğimiz için 4 adet girdimiz mevcut: eğitim ve doğrulama olmak üzere, gözlemlenen metrikler (kayıp ve doğruluk değeri) için birer değer mevcuttur. Bu değerleri, eğitim ve doğrulama kayıplarını, aynı şekilde doğruluk değerlerini karşılaştırmak için grafik üzerine çizdireceğiz:",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\n\nacc = history_dict['acc']\nval_acc = history_dict['val_acc']\nloss = history_dict['loss']\nval_loss = history_dict['val_loss']\n\nepochs = range(1, len(acc) + 1)\n\n# \"bo\", \"mavi nokta\"'nın kısaltmasıdır\nplt.plot(epochs, loss, 'bo', label='Training loss')\n# b, \"düz mavi çizgi\"'nin kısaltmasıdır\nplt.plot(epochs, val_loss, 'b', label='Validation loss')\nplt.title('Training and validation loss')\nplt.xlabel('Epochs')\nplt.ylabel('Loss')\nplt.legend()\n\nplt.show()",
"_____no_output_____"
],
[
"plt.clf() # grafiğin görüntüsünü temizleyelim\n\nplt.plot(epochs, acc, 'bo', label='Training acc')\nplt.plot(epochs, val_acc, 'b', label='Validation acc')\nplt.title('Training and validation accuracy')\nplt.xlabel('Epochs')\nplt.ylabel('Accuracy')\nplt.legend()\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"\nGrafikte noktalı çizgiler eğitim kayıp ve doğruluk değerlerini temsil etmektedir. Aynı şekilde, düz çizgiler doğrulama kayıp ve doğruluk değerlerini temsil etmektedir.\n\nEğitim kayıp değerleri her bir epoch iterasyonuyla *düşerken*, eğitim doğruluk değerlerinin *arttığını* görebilirsiniz. Gradient descent optimizasyonu, her bir iterasyonda belirli bir oranda değerleri minimize ettiği için, bu beklenen bir durumdur.\n\nAynı durum doğrulama kayıp ve doğruluk değerleri için geçerli değildir. Görüldüğü gibi doğrulama değerleri, 20nci epoch iterasyonunda en iyi değerlere ulaşmaktadır. Bu durum aşırı uyuma bir örnektir: modelin eğitim veri kümesiyle, daha önceden hiç görmediği verilere göre daha iyi sonuç vermesi durumu. Bu noktadan sonra model gereğinden fazla optimize edilir ve eğitim veri setine özgü, test verisine genellenemeyen çıkarımları öğrenir.\n\nÖrneğimizdeki bu özel durum nedeniyle, gözlemlemiş olduğumuz fazla uyumu giderebilmek için, eğitim işlemini 20nci epoch iterasyonu sonrası durdurabiliriz. Bunu otomatik olarak nasıl yapabileceğimizi daha sonra göreceğiz.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
cb352883e0fe44c06f03dac5dafdfd2916a85030 | 32,402 | ipynb | Jupyter Notebook | src/notebook/Sample.ipynb | aaneloy/data-scaler | 532bc5bfa5e8d63517d1de7d0aaecd25b9f0a4a4 | [
"MIT"
] | null | null | null | src/notebook/Sample.ipynb | aaneloy/data-scaler | 532bc5bfa5e8d63517d1de7d0aaecd25b9f0a4a4 | [
"MIT"
] | 5 | 2021-12-28T22:37:59.000Z | 2021-12-30T18:27:23.000Z | src/notebook/Sample.ipynb | aaneloy/scaler_selector | 532bc5bfa5e8d63517d1de7d0aaecd25b9f0a4a4 | [
"MIT"
] | null | null | null | 33.857889 | 134 | 0.329671 | [
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
],
[
"house_data=pd.read_csv('house_data.csv')\nhouse_data",
"_____no_output_____"
],
[
"house_data.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 21613 entries, 0 to 21612\nData columns (total 21 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 id 21613 non-null int64 \n 1 date 21613 non-null object \n 2 price 21613 non-null float64\n 3 bedrooms 21613 non-null int64 \n 4 bathrooms 21613 non-null float64\n 5 sqft_living 21613 non-null int64 \n 6 sqft_lot 21613 non-null int64 \n 7 floors 21613 non-null float64\n 8 waterfront 21613 non-null int64 \n 9 view 21613 non-null int64 \n 10 condition 21613 non-null int64 \n 11 grade 21613 non-null int64 \n 12 sqft_above 21613 non-null int64 \n 13 sqft_basement 21613 non-null int64 \n 14 yr_built 21613 non-null int64 \n 15 yr_renovated 21613 non-null int64 \n 16 zipcode 21613 non-null int64 \n 17 lat 21613 non-null float64\n 18 long 21613 non-null float64\n 19 sqft_living15 21613 non-null int64 \n 20 sqft_lot15 21613 non-null int64 \ndtypes: float64(5), int64(15), object(1)\nmemory usage: 3.5+ MB\n"
],
[
"house_data=house_data.drop(['id','date','waterfront','view'],axis=1)\nhouse_data",
"_____no_output_____"
],
[
"house_data.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 21613 entries, 0 to 21612\nData columns (total 17 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 price 21613 non-null float64\n 1 bedrooms 21613 non-null int64 \n 2 bathrooms 21613 non-null float64\n 3 sqft_living 21613 non-null int64 \n 4 sqft_lot 21613 non-null int64 \n 5 floors 21613 non-null float64\n 6 condition 21613 non-null int64 \n 7 grade 21613 non-null int64 \n 8 sqft_above 21613 non-null int64 \n 9 sqft_basement 21613 non-null int64 \n 10 yr_built 21613 non-null int64 \n 11 yr_renovated 21613 non-null int64 \n 12 zipcode 21613 non-null int64 \n 13 lat 21613 non-null float64\n 14 long 21613 non-null float64\n 15 sqft_living15 21613 non-null int64 \n 16 sqft_lot15 21613 non-null int64 \ndtypes: float64(5), int64(12)\nmemory usage: 2.8 MB\n"
],
[
"X=house_data[['bedrooms', 'bathrooms', 'sqft_living',\n 'sqft_lot', 'floors', 'condition', 'grade', 'sqft_above',\n 'sqft_basement', 'yr_built','yr_renovated', 'zipcode', 'lat', 'long',\n 'sqft_living15', 'sqft_lot15']]\ny=house_data['price']\n",
"_____no_output_____"
],
[
"#pip install -i https://test.pypi.org/simple/ DataScalerSelector==1.0.7\n!pip install DataScalerSelector==1.0.8",
"Requirement already satisfied: DataScalerSelector==1.0.7 in c:\\users\\neloy\\onedrive\\github\\scaler_selector\\src (1.0.7)\n"
],
[
"from DataScalerSelector import *",
"_____no_output_____"
],
[
"scalerselector_regression",
"_____no_output_____"
],
[
"scalerselector_regression(X,y)",
"Train Data Size (14480, 16) (14480,)\nTest Data Size (7133, 16) (7133,)\n\n\n\nLinear Regression Results\n RMSE R2\nOriginal 228214.751158 0.653639\nNormalized 228242.510585 0.653555\nStandardized 228168.824025 0.653779\nRobustScaler 228214.751158 0.653639\n\n\n\nRandom Forest Results\n RMSE R2\nOriginal 158720.116567 0.832465\nNormalized 158362.588192 0.833219\nStandardized 158575.777146 0.832770\nRobustScaler 159277.175079 0.831287\n\n\n\nSVR Results\n\n RMSE R2\nOriginal 398844.567635 -0.057910\nNormalized 398488.841372 -0.056024\nStandardized 398416.057301 -0.055638\nRobustScaler 398845.967290 -0.057917\n\n\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb35311de5af08929171c2676ac957ce176647e9 | 1,423 | ipynb | Jupyter Notebook | algorithms/190-Reverse-Bits.ipynb | DjangoPeng/leetcode-solutions | 9aa2b911b0278e743448f04241828d33182c9d76 | [
"Apache-2.0"
] | 10 | 2019-03-23T15:15:55.000Z | 2020-07-12T02:37:31.000Z | algorithms/190-Reverse-Bits.ipynb | DjangoPeng/leetcode-solutions | 9aa2b911b0278e743448f04241828d33182c9d76 | [
"Apache-2.0"
] | null | null | null | algorithms/190-Reverse-Bits.ipynb | DjangoPeng/leetcode-solutions | 9aa2b911b0278e743448f04241828d33182c9d76 | [
"Apache-2.0"
] | 3 | 2019-06-21T12:13:23.000Z | 2020-12-08T07:49:33.000Z | 18.012658 | 42 | 0.45889 | [
[
[
"class Solution:\n # @param n, an integer\n # @return an integer\n def reverseBits(self, n):\n num = 0\n for i in range(32):\n num = num * 2 + n % 2\n n = n // 2\n return num",
"_____no_output_____"
],
[
"s = Solution()",
"_____no_output_____"
],
[
"s.reverseBits(4294967293)",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code"
]
] |
cb35315828b8bd1494d54329507c5d521fb65d43 | 40,411 | ipynb | Jupyter Notebook | chapter 7 Modern Convolutional Networks/DenseNet.ipynb | TLDX-XIONG/d2l-notebook | 682cf03f9e609752d93f4f07eb16a7ddd834bf7b | [
"Apache-2.0"
] | 2 | 2021-12-20T13:48:39.000Z | 2022-01-02T13:08:01.000Z | chapter 7 Modern Convolutional Networks/DenseNet.ipynb | TLDX-XIONG/d2l-notebook | 682cf03f9e609752d93f4f07eb16a7ddd834bf7b | [
"Apache-2.0"
] | null | null | null | chapter 7 Modern Convolutional Networks/DenseNet.ipynb | TLDX-XIONG/d2l-notebook | 682cf03f9e609752d93f4f07eb16a7ddd834bf7b | [
"Apache-2.0"
] | null | null | null | 145.363309 | 29,871 | 0.601346 | [
[
[
"import torch\nfrom torch import nn\nimport d2l.torch as d2l",
"_____no_output_____"
],
[
"def conv_block(in_channels, out_channels):\n return nn.Sequential(\n nn.BatchNorm2d(in_channels), nn.ReLU(),\n nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),\n )",
"_____no_output_____"
],
[
"class DenseBlock(nn.Module):\n def __init__(self, num_convs, in_channels, grow_rate):\n super(DenseBlock, self).__init__()\n layers = []\n for i in range(num_convs):\n layers.append(conv_block(in_channels + grow_rate * i, grow_rate))\n self.net = nn.Sequential(*layers)\n def forward(self, X):\n for blk in self.net:\n Y = blk(X)\n X = torch.cat((X, Y), dim=1)\n return X\ndef transition_block(in_channels, out_channels):\n return nn.Sequential(\n nn.BatchNorm2d(in_channels),\n nn.Conv2d(in_channels, out_channels, kernel_size=1),\n nn.AvgPool2d(kernel_size=2, stride=2)\n )",
"_____no_output_____"
],
[
"b1 = nn.Sequential(\n nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),\n nn.BatchNorm2d(64),nn.ReLU(),\n nn.MaxPool2d(kernel_size=3, stride=2, padding=1)\n)\nin_channels, grow_rate = 64, 32\nnum_convs_in_denese_blk = [4, 4, 4, 4]\nblks = []\nfor i, num_convs in enumerate(num_convs_in_denese_blk):\n blks.append(DenseBlock(num_convs, in_channels, grow_rate))\n in_channels += num_convs * grow_rate\n\n if i != len(num_convs_in_denese_blk) - 1:\n blks.append(transition_block(in_channels, in_channels // 2))\n in_channels = in_channels // 2\n\nnet = nn.Sequential(\n b1, *blks,\n nn.BatchNorm2d(in_channels), nn.ReLU(),\n nn.AdaptiveAvgPool2d((1,1)),\n nn.Flatten(),\n nn.Linear(in_channels, 10)\n)\nnet",
"_____no_output_____"
],
[
"lr, num_epochs, batch_size = 0.1, 10, 256\ntrain_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)\nd2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())",
"loss 0.160, train acc 0.941, test acc 0.901\n1766.3 examples/sec on cuda:0\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code"
]
] |
cb35386cb9e8a75d37e5b0f7e53a4724833a733b | 4,499 | ipynb | Jupyter Notebook | searching/fibonacci_search.ipynb | codacy-badger/algorithms-1 | bad63e6ec73c7196c3378d26ef3dbb9e172940e8 | [
"MIT"
] | 8 | 2019-08-19T21:43:44.000Z | 2021-01-24T20:45:49.000Z | searching/fibonacci_search.ipynb | codacy-badger/algorithms-1 | bad63e6ec73c7196c3378d26ef3dbb9e172940e8 | [
"MIT"
] | 74 | 2019-10-23T21:13:54.000Z | 2021-01-26T22:24:13.000Z | searching/fibonacci_search.ipynb | codacy-badger/algorithms-1 | bad63e6ec73c7196c3378d26ef3dbb9e172940e8 | [
"MIT"
] | 1 | 2022-01-21T12:02:33.000Z | 2022-01-21T12:02:33.000Z | 29.405229 | 231 | 0.522561 | [
[
[
"## Problem\n\nGiven a sorted list of integers of length N, determine if an element x is in the list without performing any multiplication, division, or bit-shift operations.\n\nDo this in `O(log N)` time.",
"_____no_output_____"
],
[
"## Solution\nWe can't use binary search to locate the element because involves dividing by two to get the middle element. \n\nWe can use Fibonacci search to get around this limitation. The idea is that fibonacci numbers are used to locate indices to check in the array, and by cleverly updating these indices, we can efficiently locate our element.\n\nLet `p` and `q` be consequtive Fibonacci numbers. `q` is the smallest Fibonacci number that is **greater than or equal to** the size of the array. We compare `x` with `array[p]` and perform the following logic:\n\n1. If `x == array[p]`, we have found the element. Return true.\n2. If `x < array[p]` move p and q down two indices each, cutting down the largest two elements from the search.\n3. If `x > array[p]` move p and q down index each, and add an offset of p to the next search value.\n\nIf we have exhausted our list of Fibonacci numbers, we can be assured that the element is not in our array.\n\n\nLet's go through an example.\n\nFirst, we need a helper function to generate the Fibonacci numbers, given the length of the array => N.",
"_____no_output_____"
]
],
[
[
"def get_fib_sequence(n):\n a, b = 0, 1\n \n sequence = [a]\n while a < n:\n a, b = b, a + b\n sequence.append(a)\n return sequence",
"_____no_output_____"
]
],
[
[
"Suppose we have array \n```\n[2, 4, 10, 16, 25, 45, 55, 65, 80, 100]\n```\n\nSince there are 10 elements in the array, the generated sequence of Fibonacci numbers will be \n```\n[0, 1, 1, 2, 3, 5, 8, 13]\n```\n\nSo the values of p and q are: `p == 6, q == 7` (The second last and last indices in the sequence) \n\nNow suppose we are searching for `45`, we'll carry out the following steps:\n\n- Compare 45 with `array[fib[p]] => array[8]`. Since 45 < 80, we move p and q down two indices. p = 4, q = 5.\n- Next, compare 45 with `array[fib[p]] => array[3]`. Since 45 > 16, we set p = 3 and create an offset of 2. So p = 5, q = 4. \n- Finally, we compare 45 with `array[fib[p]]`. Since array[5] == 45, we have found x.\n",
"_____no_output_____"
]
],
[
[
"def fibo_search(array, x):\n n = len(array)\n fibs = get_fib_sequence(n)\n \n p, q = len(fibs) - 2, len(fibs) - 1\n offset = 0\n \n while q > 0:\n index = min(offset + fibs[p], n - 1)\n if x == array[index]:\n return True\n elif x < array[index]:\n p -= 2\n q -= 2\n else:\n p -= 1\n q -= 1\n offset = index\n return False",
"_____no_output_____"
],
[
"fibo_search([2, 4, 10, 16, 25, 45, 55, 65, 80, 100], 45)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
cb354b229714df0d8a28434535268d353b2dbe92 | 24,749 | ipynb | Jupyter Notebook | lab_classes/machine_learning/week10.ipynb | mikecroucher/notebook | 5b62f2c0d51d7af7ffbcddcd4f714030d742479e | [
"BSD-3-Clause"
] | 1 | 2015-12-25T18:02:38.000Z | 2015-12-25T18:02:38.000Z | lab_classes/machine_learning/week10.ipynb | mikecroucher/notebook | 5b62f2c0d51d7af7ffbcddcd4f714030d742479e | [
"BSD-3-Clause"
] | null | null | null | lab_classes/machine_learning/week10.ipynb | mikecroucher/notebook | 5b62f2c0d51d7af7ffbcddcd4f714030d742479e | [
"BSD-3-Clause"
] | null | null | null | 36.994021 | 786 | 0.574205 | [
[
[
"empty"
]
]
] | [
"empty"
] | [
[
"empty"
]
] |
cb355012a64969cd739d77ed26500b080439bb96 | 4,192 | ipynb | Jupyter Notebook | examples/notebook/contrib/lectures.ipynb | jspricke/or-tools | 45770b833997f827d322e929b1ed4781c4e60d44 | [
"Apache-2.0"
] | 1 | 2020-07-18T16:24:09.000Z | 2020-07-18T16:24:09.000Z | examples/notebook/contrib/lectures.ipynb | jspricke/or-tools | 45770b833997f827d322e929b1ed4781c4e60d44 | [
"Apache-2.0"
] | 1 | 2021-02-23T10:22:55.000Z | 2021-02-23T13:57:14.000Z | examples/notebook/contrib/lectures.ipynb | jspricke/or-tools | 45770b833997f827d322e929b1ed4781c4e60d44 | [
"Apache-2.0"
] | 1 | 2021-03-16T14:30:59.000Z | 2021-03-16T14:30:59.000Z | 31.051852 | 85 | 0.529819 | [
[
[
"empty"
]
]
] | [
"empty"
] | [
[
"empty"
]
] |
cb3564bcf72d1e8b4dc490222ed21c91d606a4f1 | 35,648 | ipynb | Jupyter Notebook | advanced_functionality/inference_pipeline_sparkml_blazingtext_dbpedia/inference_pipeline_sparkml_blazingtext_dbpedia.ipynb | phiamazon/amazon-sagemaker-examples | abf3d06d3ea21c5ec425344d517700338a620f8c | [
"Apache-2.0"
] | 5 | 2019-01-19T23:53:35.000Z | 2022-01-29T14:04:31.000Z | advanced_functionality/inference_pipeline_sparkml_blazingtext_dbpedia/inference_pipeline_sparkml_blazingtext_dbpedia.ipynb | phiamazon/amazon-sagemaker-examples | abf3d06d3ea21c5ec425344d517700338a620f8c | [
"Apache-2.0"
] | 6 | 2020-01-28T23:08:49.000Z | 2022-02-10T00:27:19.000Z | advanced_functionality/inference_pipeline_sparkml_blazingtext_dbpedia/inference_pipeline_sparkml_blazingtext_dbpedia.ipynb | phiamazon/amazon-sagemaker-examples | abf3d06d3ea21c5ec425344d517700338a620f8c | [
"Apache-2.0"
] | 8 | 2020-12-14T15:49:24.000Z | 2022-03-23T18:38:36.000Z | 44.393524 | 617 | 0.638241 | [
[
[
"# Feature processing with Spark, training with BlazingText and deploying as Inference Pipeline\n\nTypically a Machine Learning (ML) process consists of few steps: gathering data with various ETL jobs, pre-processing the data, featurizing the dataset by incorporating standard techniques or prior knowledge, and finally training an ML model using an algorithm.\n\nIn many cases, when the trained model is used for processing real time or batch prediction requests, the model receives data in a format which needs to pre-processed (e.g. featurized) before it can be passed to the algorithm. In the following notebook, we will demonstrate how you can build your ML Pipeline leveraging Spark Feature Transformers and SageMaker BlazingText algorithm & after the model is trained, deploy the Pipeline (Feature Transformer and BlazingText) as an Inference Pipeline behind a single Endpoint for real-time inference and for batch inferences using Amazon SageMaker Batch Transform.\n\nIn this notebook, we use Amazon Glue to run serverless Spark. Though the notebook demonstrates the end-to-end flow on a small dataset, the setup can be seamlessly used to scale to larger datasets.",
"_____no_output_____"
],
[
"## Objective: Text Classification on DBPedia dataset",
"_____no_output_____"
],
[
"In this example, we will train the text classification model using SageMaker `BlazingText` algorithm on the [DBPedia Ontology Dataset](https://wiki.dbpedia.org/services-resources/dbpedia-data-set-2014#2) as done by [Zhang et al](https://arxiv.org/pdf/1509.01626.pdf). \n\nThe DBpedia ontology dataset is constructed by picking 14 nonoverlapping classes from DBpedia 2014. It has 560,000 training samples and 70,000 testing samples. The fields we used for this dataset contain title and abstract of each Wikipedia article.\n\n\nBefore passing the input data to `BlazingText`, we need to process this dataset into white-space separated tokens, have the label field in every line prefixed with `__label__` and all input data should be in a single file.",
"_____no_output_____"
],
[
"## Methodologies\nThe Notebook consists of a few high-level steps:\n\n* Using AWS Glue for executing the SparkML feature processing job.\n* Using SageMaker BlazingText to train on the processed dataset produced by SparkML job.\n* Building an Inference Pipeline consisting of SparkML & BlazingText models for a realtime inference endpoint.\n* Building an Inference Pipeline consisting of SparkML & BlazingText models for a single Batch Transform job.",
"_____no_output_____"
],
[
"## Using AWS Glue for executing Spark jobs",
"_____no_output_____"
],
[
"We'll be running the SparkML job using [AWS Glue](https://aws.amazon.com/glue). AWS Glue is a serverless ETL service which can be used to execute standard Spark/PySpark jobs. Glue currently only supports `Python 2.7`, hence we'll write the script in `Python 2.7`.",
"_____no_output_____"
],
[
"## Permission setup for invoking AWS Glue from this Notebook\nIn order to enable this Notebook to run AWS Glue jobs, we need to add one additional permission to the default execution role of this notebook. We will be using SageMaker Python SDK to retrieve the default execution role and then you have to go to [IAM Dashboard](https://console.aws.amazon.com/iam/home) to edit the Role to add AWS Glue specific permission.",
"_____no_output_____"
],
[
"### Finding out the current execution role of the Notebook\nWe are using SageMaker Python SDK to retrieve the current role for this Notebook which needs to be enhanced.",
"_____no_output_____"
]
],
[
[
"# Import SageMaker Python SDK to get the Session and execution_role\nimport sagemaker\nfrom sagemaker import get_execution_role\nsess = sagemaker.Session()\nrole = get_execution_role()\nprint(role[role.rfind('/') + 1:])",
"_____no_output_____"
]
],
[
[
"### Adding AWS Glue as an additional trusted entity to this role\nThis step is needed if you want to pass the execution role of this Notebook while calling Glue APIs as well without creating an additional **Role**. If you have not used AWS Glue before, then this step is mandatory. \n\nIf you have used AWS Glue previously, then you should have an already existing role that can be used to invoke Glue APIs. In that case, you can pass that role while calling Glue (later in this notebook) and skip this next step.",
"_____no_output_____"
],
[
"On the IAM dashboard, please click on **Roles** on the left sidenav and search for this Role. Once the Role appears, click on the Role to go to its **Summary** page. Click on the **Trust relationships** tab on the **Summary** page to add AWS Glue as an additional trusted entity. \n\nClick on **Edit trust relationship** and replace the JSON with this JSON.\n```\n{\n \"Version\": \"2012-10-17\",\n \"Statement\": [\n {\n \"Effect\": \"Allow\",\n \"Principal\": {\n \"Service\": [\n \"sagemaker.amazonaws.com\",\n \"glue.amazonaws.com\"\n ]\n },\n \"Action\": \"sts:AssumeRole\"\n }\n ]\n}\n```\nOnce this is complete, click on **Update Trust Policy** and you are done.",
"_____no_output_____"
],
[
"## Downloading dataset and uploading to S3\nSageMaker team has downloaded the dataset and uploaded to one of the S3 buckets in our account. In this notebook, we will download from that bucket and upload to your bucket so that AWS Glue can access the data. The default AWS Glue permissions we just added expects the data to be present in a bucket with the string `aws-glue`. Hence, after we download the dataset, we will create an S3 bucket in your account with a valid name and then upload the data to S3. ",
"_____no_output_____"
]
],
[
[
"!wget https://s3-us-west-2.amazonaws.com/sparkml-mleap/data/dbpedia/train.csv\n!wget https://s3-us-west-2.amazonaws.com/sparkml-mleap/data/dbpedia/test.csv",
"_____no_output_____"
]
],
[
[
"### Creating an S3 bucket and uploading this dataset\nNext we will create an S3 bucket with the `aws-glue` string in the name and upload this data to the S3 bucket. In case you want to use some existing bucket to run your Spark job via AWS Glue, you can use that bucket to upload your data provided the `Role` has access permission to upload and download from that bucket.\n\nOnce the bucket is created, the following cell would also update the `train.csv` and `test.csv` files downloaded locally to this bucket under the `input/dbpedia` prefix.",
"_____no_output_____"
]
],
[
[
"import boto3\nimport botocore\nfrom botocore.exceptions import ClientError\n\nboto_session = sess.boto_session\ns3 = boto_session.resource('s3')\naccount = boto_session.client('sts').get_caller_identity()['Account']\nregion = boto_session.region_name\ndefault_bucket = 'aws-glue-{}-{}'.format(account, region)\n\ntry:\n if region == 'us-east-1':\n s3.create_bucket(Bucket=default_bucket)\n else:\n s3.create_bucket(Bucket=default_bucket, CreateBucketConfiguration={'LocationConstraint': region})\nexcept ClientError as e:\n error_code = e.response['Error']['Code']\n message = e.response['Error']['Message']\n if error_code == 'BucketAlreadyOwnedByYou':\n print ('A bucket with the same name already exists in your account - using the same bucket.')\n pass \n\n# Uploading the training data to S3\nsess.upload_data(path='train.csv', bucket=default_bucket, key_prefix='input/dbpedia') \nsess.upload_data(path='test.csv', bucket=default_bucket, key_prefix='input/dbpedia')",
"_____no_output_____"
]
],
[
[
"## Writing the feature processing script using SparkML\n\nThe code for feature transformation using SparkML can be found in `dbpedia_processing.py` file written in the same directory. You can go through the code itself to see how it is using standard SparkML feature transformers to define the Pipeline for featurizing and processing the data.\n\nOnce the Spark ML Pipeline `fit` and `transform` is done, we are tranforming the `train` and `test` file and writing it in the format `BlazingText` expects before uploading to S3.",
"_____no_output_____"
],
[
"### Serializing the trained Spark ML Model with [MLeap](https://github.com/combust/mleap)\nApache Spark is best suited batch processing workloads. In order to use the Spark ML model we trained for low latency inference, we need to use the MLeap library to serialize it to an MLeap bundle and later use the [SageMaker SparkML Serving](https://github.com/aws/sagemaker-sparkml-serving-container) to perform realtime and batch inference. \n\nBy using the `SerializeToBundle()` method from MLeap in the script, we are serializing the ML Pipeline into an MLeap bundle and uploading to S3 in `tar.gz` format as SageMaker expects.",
"_____no_output_____"
],
[
"## Uploading the code and other dependencies to S3 for AWS Glue\nUnlike SageMaker, in order to run your code in AWS Glue, we do not need to prepare a Docker image. We can upload your code and dependencies directly to S3 and pass those locations while invoking the Glue job.",
"_____no_output_____"
],
[
"### Upload the featurizer script to S3\nWe will be uploading the `dbpedia_processing.py` script to S3 now so that Glue can use it to run the PySpark job. You can replace it with your own script if needed. If your code has multiple files, you need to zip those files and upload to S3 instead of uploading a single file like it's being done here.",
"_____no_output_____"
]
],
[
[
"script_location = sess.upload_data(path='dbpedia_processing.py', bucket=default_bucket, key_prefix='codes')",
"_____no_output_____"
]
],
[
[
"### Upload MLeap dependencies to S3",
"_____no_output_____"
],
[
"For our job, we will also have to pass MLeap dependencies to Glue.MLeap is an additional library we are using which does not come bundled with default Spark.\nSimilar to most of the packages in the Spark ecosystem, MLeap is also implemented as a Scala package with a front-end wrapper written in Python so that it can be used from PySpark. We need to make sure that the MLeap Python library as well as the JAR is available within the Glue job environment. In the following cell, we will download the MLeap Python dependency & JAR from a SageMaker hosted bucket and upload to the S3 bucket we created above in your account. \nIf you are using some other Python libraries like `nltk` in your code, you need to download the wheel file from PyPI and upload to S3 in the same way. At this point, Glue only supports passing pure Python libraries in this way (e.g. you can not pass `Pandas` or `OpenCV`). However you can use `NumPy` & `SciPy` without having to pass these as packages because these are pre-installed in the Glue environment. ",
"_____no_output_____"
]
],
[
[
"!wget https://s3-us-west-2.amazonaws.com/sparkml-mleap/0.9.6/python/python.zip\n!wget https://s3-us-west-2.amazonaws.com/sparkml-mleap/0.9.6/jar/mleap_spark_assembly.jar ",
"_____no_output_____"
],
[
"python_dep_location = sess.upload_data(path='python.zip', bucket=default_bucket, key_prefix='dependencies/python')\njar_dep_location = sess.upload_data(path='mleap_spark_assembly.jar', bucket=default_bucket, key_prefix='dependencies/jar')",
"_____no_output_____"
]
],
[
[
"## Defining output locations for the data and model\nNext we define the output location where the transformed dataset should be uploaded. We are also specifying a model location where the MLeap serialized model would be updated. This locations should be consumed as part of the Spark script using `getResolvedOptions` method of AWS Glue library (see `dbpedia_processing.py` for details).\nBy designing our code in this way, we can re-use these variables as part of the SageMaker training job (details below).",
"_____no_output_____"
]
],
[
[
"from time import gmtime, strftime\nimport time\n\ntimestamp_prefix = strftime(\"%Y-%m-%d-%H-%M-%S\", gmtime())\n\n# Input location of the data, We uploaded our train.csv file to input key previously\ns3_input_bucket = default_bucket\ns3_input_key_prefix = 'input/dbpedia'\n\n# Output location of the data. The input data will be split, transformed, and \n# uploaded to output/train and output/validation\ns3_output_bucket = default_bucket\ns3_output_key_prefix = timestamp_prefix + '/dbpedia'\n\n# the MLeap serialized SparkML model will be uploaded to output/mleap\ns3_model_bucket = default_bucket\ns3_model_key_prefix = s3_output_key_prefix + '/mleap'",
"_____no_output_____"
]
],
[
[
"### Calling Glue APIs",
"_____no_output_____"
],
[
"Next we'll be creating Glue client via Boto so that we can invoke the `create_job` API of Glue. `create_job` API will create a job definition which can be used to execute your jobs in Glue. The job definition created here is mutable. While creating the job, we are also passing the code location as well as the dependencies location to Glue.\n\n`AllocatedCapacity` parameter controls the hardware resources that Glue will use to execute this job. It is measures in units of `DPU`. For more information on `DPU`, please see [here](https://docs.aws.amazon.com/glue/latest/dg/add-job.html).",
"_____no_output_____"
]
],
[
[
"glue_client = boto_session.client('glue')\njob_name = 'sparkml-dbpedia-' + timestamp_prefix\nresponse = glue_client.create_job(\n Name=job_name,\n Description='PySpark job to featurize the DBPedia dataset',\n Role=role, # you can pass your existing AWS Glue role here if you have used Glue before\n ExecutionProperty={\n 'MaxConcurrentRuns': 1\n },\n Command={\n 'Name': 'glueetl',\n 'ScriptLocation': script_location\n },\n DefaultArguments={\n '--job-language': 'python',\n '--extra-jars' : jar_dep_location,\n '--extra-py-files': python_dep_location\n },\n AllocatedCapacity=10,\n Timeout=60,\n)\nglue_job_name = response['Name']\nprint(glue_job_name)",
"_____no_output_____"
]
],
[
[
"The aforementioned job will be executed now by calling `start_job_run` API. This API creates an immutable run/execution corresponding to the job definition created above. We will require the `job_run_id` for the particular job execution to check for status. We'll pass the data and model locations as part of the job execution parameters.",
"_____no_output_____"
]
],
[
[
"job_run_id = glue_client.start_job_run(JobName=job_name,\n Arguments = {\n '--S3_INPUT_BUCKET': s3_input_bucket,\n '--S3_INPUT_KEY_PREFIX': s3_input_key_prefix,\n '--S3_OUTPUT_BUCKET': s3_output_bucket,\n '--S3_OUTPUT_KEY_PREFIX': s3_output_key_prefix,\n '--S3_MODEL_BUCKET': s3_model_bucket,\n '--S3_MODEL_KEY_PREFIX': s3_model_key_prefix\n })['JobRunId']\nprint(job_run_id)",
"_____no_output_____"
]
],
[
[
"### Checking Glue job status",
"_____no_output_____"
],
[
"Now we will check for the job status to see if it has `succeeded`, `failed` or `stopped`. Once the job is succeeded, we have the transformed data into S3 in CSV format which we can use with `BlazingText` for training. If the job fails, you can go to [AWS Glue console](https://us-west-2.console.aws.amazon.com/glue/home), click on **Jobs** tab on the left, and from the page, click on this particular job and you will be able to find the CloudWatch logs (the link under **Logs**) link for these jobs which can help you to see what exactly went wrong in the `spark-submit` call.",
"_____no_output_____"
]
],
[
[
"job_run_status = glue_client.get_job_run(JobName=job_name,RunId=job_run_id)['JobRun']['JobRunState']\nwhile job_run_status not in ('FAILED', 'SUCCEEDED', 'STOPPED'):\n job_run_status = glue_client.get_job_run(JobName=job_name,RunId=job_run_id)['JobRun']['JobRunState']\n print (job_run_status)\n time.sleep(30)",
"_____no_output_____"
]
],
[
[
"## Using SageMaker BlazingText to train on the processed dataset produced by SparkML job",
"_____no_output_____"
],
[
"Now we will use SageMaker `BlazingText` algorithm to train a text classification model this dataset. We already know the S3 location where the preprocessed training data was uploaded as part of the Glue job.",
"_____no_output_____"
],
[
"### We need to retrieve the BlazingText algorithm image",
"_____no_output_____"
]
],
[
[
"from sagemaker.amazon.amazon_estimator import get_image_uri\n\ntraining_image = get_image_uri(sess.boto_region_name, 'blazingtext', repo_version=\"latest\")\nprint (training_image)",
"_____no_output_____"
]
],
[
[
"### Next BlazingText model parameters and dataset details will be set properly\nWe have parameterized the notebook so that the same data location which was used in the PySpark script can now be passed to `BlazingText` Estimator as well.",
"_____no_output_____"
]
],
[
[
"s3_train_data = 's3://{}/{}/{}'.format(s3_output_bucket, s3_output_key_prefix, 'train')\ns3_validation_data = 's3://{}/{}/{}'.format(s3_output_bucket, s3_output_key_prefix, 'validation')\ns3_output_location = 's3://{}/{}/{}'.format(s3_output_bucket, s3_output_key_prefix, 'bt_model')\n\nbt_model = sagemaker.estimator.Estimator(training_image,\n role, \n train_instance_count=1, \n train_instance_type='ml.c4.xlarge',\n train_volume_size = 20,\n train_max_run = 3600,\n input_mode= 'File',\n output_path=s3_output_location,\n sagemaker_session=sess)\n\nbt_model.set_hyperparameters(mode=\"supervised\",\n epochs=10,\n min_count=2,\n learning_rate=0.05,\n vector_dim=10,\n early_stopping=True,\n patience=4,\n min_epochs=5,\n word_ngrams=2)\n\ntrain_data = sagemaker.session.s3_input(s3_train_data, distribution='FullyReplicated', \n content_type='text/plain', s3_data_type='S3Prefix')\nvalidation_data = sagemaker.session.s3_input(s3_validation_data, distribution='FullyReplicated', \n content_type='text/plain', s3_data_type='S3Prefix')\n\ndata_channels = {'train': train_data, 'validation': validation_data}",
"_____no_output_____"
]
],
[
[
"### Finally BlazingText training will be performed",
"_____no_output_____"
]
],
[
[
"bt_model.fit(inputs=data_channels, logs=True)",
"_____no_output_____"
]
],
[
[
"# Building an Inference Pipeline consisting of SparkML & BlazingText models for a realtime inference endpoint",
"_____no_output_____"
],
[
"Next we will proceed with deploying the models in SageMaker to create an Inference Pipeline. You can create an Inference Pipeline with upto five containers.\n\nDeploying a model in SageMaker requires two components:\n\n* Docker image residing in ECR.\n* Model artifacts residing in S3.\n\n**SparkML**\n\nFor SparkML, Docker image for MLeap based SparkML serving is provided by SageMaker team. For more information on this, please see [SageMaker SparkML Serving](https://github.com/aws/sagemaker-sparkml-serving-container). MLeap serialized SparkML model was uploaded to S3 as part of the SparkML job we executed in AWS Glue.\n\n**BlazingText**\n\nFor BlazingText, we will use the same Docker image we used for training. The model artifacts for BlazingText was uploaded as part of the training job we just ran.",
"_____no_output_____"
],
[
"### Creating the Endpoint with both containers\nNext we'll create a SageMaker inference endpoint with both the `sagemaker-sparkml-serving` & `BlazingText` containers. For this, we will first create a `PipelineModel` which will consist of both the `SparkML` model as well as `BlazingText` model in the right sequence.",
"_____no_output_____"
],
[
"### Passing the schema of the payload via environment variable\nSparkML serving container needs to know the schema of the request that'll be passed to it while calling the `predict` method. In order to alleviate the pain of not having to pass the schema with every request, `sagemaker-sparkml-serving` allows you to pass it via an environment variable while creating the model definitions. This schema definition will be required in our next step for creating a model.\n\nWe will see later that you can overwrite this schema on a per request basis by passing it as part of the individual request payload as well.",
"_____no_output_____"
]
],
[
[
"import json\nschema = {\n \"input\": [\n {\n \"name\": \"abstract\",\n \"type\": \"string\"\n }\n ],\n \"output\": \n {\n \"name\": \"tokenized_abstract\",\n \"type\": \"string\",\n \"struct\": \"array\"\n }\n}\nschema_json = json.dumps(schema)\nprint(schema_json)",
"_____no_output_____"
]
],
[
[
"### Creating a `PipelineModel` which comprises of the SparkML and BlazingText model in the right order\n\nNext we'll create a SageMaker `PipelineModel` with SparkML and BlazingText.The `PipelineModel` will ensure that both the containers get deployed behind a single API endpoint in the correct order. The same model would later be used for Batch Transform as well to ensure that a single job is sufficient to do prediction against the Pipeline. \n\nHere, during the `Model` creation for SparkML, we will pass the schema definition that we built in the previous cell.",
"_____no_output_____"
],
[
"### Controlling the output format from `sagemaker-sparkml-serving` to the next container\n\nBy default, `sagemaker-sparkml-serving` returns an output in `CSV` format. However, BlazingText does not understand CSV format and it supports a different format. \n\nIn order for the `sagemaker-sparkml-serving` to emit the output with the right format, we need to pass a second environment variable `SAGEMAKER_DEFAULT_INVOCATIONS_ACCEPT` with the value `application/jsonlines;data=text` to ensure that `sagemaker-sparkml-serving` container emits response in the proper format which BlazingText can parse.\n\nFor more information on different output formats `sagemaker-sparkml-serving` supports, please check the documentation pointed above. ",
"_____no_output_____"
]
],
[
[
"from sagemaker.model import Model\nfrom sagemaker.pipeline import PipelineModel\nfrom sagemaker.sparkml.model import SparkMLModel\n\nsparkml_data = 's3://{}/{}/{}'.format(s3_model_bucket, s3_model_key_prefix, 'model.tar.gz')\n# passing the schema defined above by using an environment variable that sagemaker-sparkml-serving understands\nsparkml_model = SparkMLModel(model_data=sparkml_data,\n env={'SAGEMAKER_SPARKML_SCHEMA' : schema_json, \n 'SAGEMAKER_DEFAULT_INVOCATIONS_ACCEPT': \"application/jsonlines;data=text\"})\nbt_model = Model(model_data=bt_model.model_data, image=training_image)\n\nmodel_name = 'inference-pipeline-' + timestamp_prefix\nsm_model = PipelineModel(name=model_name, role=role, models=[sparkml_model, bt_model])",
"_____no_output_____"
]
],
[
[
"### Deploying the `PipelineModel` to an endpoint for realtime inference\nNext we will deploy the model we just created with the `deploy()` method to start an inference endpoint and we will send some requests to the endpoint to verify that it works as expected.",
"_____no_output_____"
]
],
[
[
"endpoint_name = 'inference-pipeline-ep-' + timestamp_prefix\nsm_model.deploy(initial_instance_count=1, instance_type='ml.c4.xlarge', endpoint_name=endpoint_name)",
"_____no_output_____"
]
],
[
[
"### Invoking the newly created inference endpoint with a payload to transform the data\nNow we will invoke the endpoint with a valid payload that `sagemaker-sparkml-serving` can recognize. There are three ways in which input payload can be passed to the request:\n\n* Pass it as a valid CSV string. In this case, the schema passed via the environment variable will be used to determine the schema. For CSV format, every column in the input has to be a basic datatype (e.g. int, double, string) and it can not be a Spark `Array` or `Vector`.\n\n* Pass it as a valid JSON string. In this case as well, the schema passed via the environment variable will be used to infer the schema. With JSON format, every column in the input can be a basic datatype or a Spark `Vector` or `Array` provided that the corresponding entry in the schema mentions the correct value.\n\n* Pass the request in JSON format along with the schema and the data. In this case, the schema passed in the payload will take precedence over the one passed via the environment variable (if any).",
"_____no_output_____"
],
[
"#### Passing the payload in CSV format\nWe will first see how the payload can be passed to the endpoint in CSV format.",
"_____no_output_____"
]
],
[
[
"from sagemaker.predictor import json_serializer, csv_serializer, json_deserializer, RealTimePredictor\nfrom sagemaker.content_types import CONTENT_TYPE_CSV, CONTENT_TYPE_JSON\npayload = \"Convair was an american aircraft manufacturing company which later expanded into rockets and spacecraft.\"\npredictor = RealTimePredictor(endpoint=endpoint_name, sagemaker_session=sess, serializer=csv_serializer,\n content_type=CONTENT_TYPE_CSV, accept='application/jsonlines')\nprint(predictor.predict(payload))",
"_____no_output_____"
]
],
[
[
"#### Passing the payload in JSON format\nWe will now pass a different payload in JSON format.",
"_____no_output_____"
]
],
[
[
"payload = {\"data\": [\"Berwick secondary college is situated in the outer melbourne metropolitan suburb of berwick .\"]}\npredictor = RealTimePredictor(endpoint=endpoint_name, sagemaker_session=sess, serializer=json_serializer,\n content_type=CONTENT_TYPE_JSON)\n\nprint(predictor.predict(payload))",
"_____no_output_____"
]
],
[
[
"### [Optional] Deleting the Endpoint\nIf you do not plan to use this endpoint, then it is a good practice to delete the endpoint so that you do not incur the cost of running it.",
"_____no_output_____"
]
],
[
[
"sm_client = boto_session.client('sagemaker')\nsm_client.delete_endpoint(EndpointName=endpoint_name)",
"_____no_output_____"
]
],
[
[
"# Building an Inference Pipeline consisting of SparkML & BlazingText models for a single Batch Transform job\nSageMaker Batch Transform also supports chaining multiple containers together when deploying an Inference Pipeline and performing a single Batch Transform job to transform your data for a batch use-case similar to the real-time use-case we have seen above.",
"_____no_output_____"
],
[
"### Preparing data for Batch Transform\nBatch Transform requires data in the same format described above, with one CSV or JSON being per line. For this notebook, SageMaker team has created a sample input in CSV format which Batch Transform can process. The input is a simple CSV file with one input string per line.\n\nNext we will download a sample of this data from one of the SageMaker buckets (named `batch_input_dbpedia.csv`) and upload to your S3 bucket. We will also inspect first five rows of the data post downloading.",
"_____no_output_____"
]
],
[
[
"!wget https://s3-us-west-2.amazonaws.com/sparkml-mleap/data/batch_input_dbpedia.csv\n!printf \"\\n\\nShowing first two lines\\n\\n\" \n!head -n 3 batch_input_dbpedia.csv\n!printf \"\\n\\nAs we can see, it is just one input string per line.\\n\\n\" ",
"_____no_output_____"
],
[
"batch_input_loc = sess.upload_data(path='batch_input_dbpedia.csv', bucket=default_bucket, key_prefix='batch')",
"_____no_output_____"
]
],
[
[
"### Invoking the Transform API to create a Batch Transform job\nNext we will create a Batch Transform job using the `Transformer` class from Python SDK to create a Batch Transform job.",
"_____no_output_____"
]
],
[
[
"input_data_path = 's3://{}/{}/{}'.format(default_bucket, 'batch', 'batch_input_dbpedia.csv')\noutput_data_path = 's3://{}/{}/{}'.format(default_bucket, 'batch_output/dbpedia', timestamp_prefix)\ntransformer = sagemaker.transformer.Transformer(\n model_name = model_name,\n instance_count = 1,\n instance_type = 'ml.m4.xlarge',\n strategy = 'SingleRecord',\n assemble_with = 'Line',\n output_path = output_data_path,\n base_transform_job_name='serial-inference-batch',\n sagemaker_session=sess,\n accept = CONTENT_TYPE_CSV\n)\ntransformer.transform(data = input_data_path, \n content_type = CONTENT_TYPE_CSV, \n split_type = 'Line')\ntransformer.wait()",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
cb356eddde20de17f863f1b88f0943eb173a57dd | 498,610 | ipynb | Jupyter Notebook | lectures/Apr-20-nonlinear_regression/polynomial_regression.ipynb | nishadalal120/NEU-365P-385L-Spring-2021 | eff075482913a6c72737c578f1c5fc42527c12bb | [
"Unlicense"
] | 12 | 2021-01-05T18:26:42.000Z | 2021-03-11T19:26:07.000Z | lectures/Apr-20-nonlinear_regression/polynomial_regression.ipynb | nishadalal120/NEU-365P-385L-Spring-2021 | eff075482913a6c72737c578f1c5fc42527c12bb | [
"Unlicense"
] | 1 | 2021-04-21T00:57:10.000Z | 2021-04-21T00:57:10.000Z | lectures/Apr-20-nonlinear_regression/polynomial_regression.ipynb | nishadalal120/NEU-365P-385L-Spring-2021 | eff075482913a6c72737c578f1c5fc42527c12bb | [
"Unlicense"
] | 22 | 2021-01-21T18:52:41.000Z | 2021-04-15T20:22:20.000Z | 496.623506 | 80,968 | 0.944091 | [
[
[
"# Polynomial Regression",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\nplt.rcParams['axes.labelsize'] = 14\nplt.rcParams['axes.titlesize'] = 14\nplt.rcParams['legend.fontsize'] = 12\nplt.rcParams['figure.figsize'] = (8, 5)\n%config InlineBackend.figure_format = 'retina'",
"_____no_output_____"
]
],
[
[
"### Linear models\n\n$y = \\beta_0 + \\beta_1 x_1 + \\beta_2 x_2 + \\dots + \\beta_n x_n + \\epsilon$",
"_____no_output_____"
],
[
"$\\begin{bmatrix} \\vdots \\\\ y \\\\ \\vdots \\end{bmatrix} = \\beta_0\n+ \\beta_1 \\begin{bmatrix} \\vdots \\\\ x_1 \\\\ \\vdots \\end{bmatrix}\n+ \\beta_2 \\begin{bmatrix} \\vdots \\\\ x_2 \\\\ \\vdots \\end{bmatrix}\n+ \\dots\n+ \\beta_n \\begin{bmatrix} \\vdots \\\\ x_n \\\\ \\vdots \\end{bmatrix}\n+ \\begin{bmatrix} \\vdots \\\\ \\epsilon \\\\ \\vdots \\end{bmatrix}$",
"_____no_output_____"
],
[
"$X = \n\\begin{bmatrix} \n\\vdots & \\vdots & & \\vdots \\\\ \nx_1 & x_2 & \\dots & x_n \\\\ \n\\vdots & \\vdots & & \\vdots \n\\end{bmatrix}$",
"_____no_output_____"
],
[
"### A simple linear model\n\n$y = \\beta_1 x_1 + \\beta_2 x_2 + \\epsilon$",
"_____no_output_____"
],
[
"### Extending this to a $2^{nd}$ degree polynomial model\n\n$y = \\beta_1 x_1 + \\beta_2 x_2 + \\beta_3 x_1^2 + \\beta_4 x_1 x_2 + \\beta_5 x_2^2 + \\epsilon$",
"_____no_output_____"
],
[
"$x_1 x_2$ is an interaction term between $x_1$ and $x_2$",
"_____no_output_____"
],
[
"### Reparameterize the model\n\n$y = \\beta_1 x_1 + \\beta_2 x_2 + \\beta_3 x_1^2 + \\beta_4 x_1 x_2 + \\beta_5 x_2^2 + \\epsilon$\n\n$\\begin{matrix}\nx_3 & \\rightarrow & x_1^2 \\\\\nx_4 & \\rightarrow & x_1 x_2 \\\\\nx_5 & \\rightarrow & x_2^2\n\\end{matrix}$",
"_____no_output_____"
],
[
"$y = \\beta_1 x_1 + \\beta_2 x_2 + \\beta_3 x_3 + \\beta_4 x_4 + \\beta_5 x_5 + \\epsilon$",
"_____no_output_____"
],
[
"### !!! But that's just a linear model",
"_____no_output_____"
],
[
"### Given the matrix of measured features $X$:\n\n$X = \n\\begin{bmatrix} \n\\vdots & \\vdots \\\\ \nx_1 & x_2 \\\\ \n\\vdots & \\vdots\n\\end{bmatrix}$",
"_____no_output_____"
],
[
"### All we need to do is fit a linear model using the following feature matrix $X_{poly}$:\n\n$X_{poly} = \n\\begin{bmatrix} \n\\vdots & \\vdots & \\vdots & \\vdots & \\vdots \\\\ \nx_1 & x_2 & x_1^2 & x_1 x_2 & x_2^2 \\\\ \n\\vdots & \\vdots & \\vdots & \\vdots & \\vdots \n\\end{bmatrix}$",
"_____no_output_____"
],
[
"## Some experimental data: Temperature vs. Yield",
"_____no_output_____"
]
],
[
[
"temperature = np.array([50, 50, 50, 70, 70, 70, 80, 80, 80, 90, 90, 90, 100, 100, 100])\nexperimental_yield = np.array([3.3, 2.8, 2.9, 2.3, 2.6, 2.1, 2.5, 2.9, 2.4, 3, 3.1, 2.8, 3.3, 3.5, 3])\n\nplt.plot(temperature, experimental_yield, 'o')\nplt.xlabel('Temperature')\nplt.ylabel('Experimental Yield');",
"_____no_output_____"
]
],
[
[
"### Rearranging the data for use with sklearn",
"_____no_output_____"
]
],
[
[
"X = temperature.reshape([-1,1])\ny = experimental_yield\nX",
"_____no_output_____"
]
],
[
[
"# Fit yield vs. temperature data with a linear model",
"_____no_output_____"
]
],
[
[
"from sklearn.linear_model import LinearRegression\n\nols_model = LinearRegression()\nols_model.fit(X, y)\n\nplt.plot(temperature, experimental_yield, 'o')\nplt.plot(temperature, ols_model.predict(X), '-', label='OLS')\nplt.xlabel('Temperature')\nplt.ylabel('Experimental Yield')\nplt.legend();",
"_____no_output_____"
]
],
[
[
"# Fit yield vs. temperature data with a $2^{nd}$ degree polynomial model",
"_____no_output_____"
]
],
[
[
"from sklearn.preprocessing import PolynomialFeatures\n\npoly2 = PolynomialFeatures(degree=2)\nX_poly2 = poly2.fit_transform(X)\n\nX.shape, X_poly2.shape",
"_____no_output_____"
],
[
"poly2_model = LinearRegression()\npoly2_model.fit(X_poly2, y)",
"_____no_output_____"
],
[
"plt.plot(temperature, experimental_yield, 'o')\nplt.plot(temperature, ols_model.predict(X), '-', label='OLS')\nplt.plot(temperature, poly2_model.predict(X_poly2), '-', label='Poly2')\nplt.xlabel('Temperature')\nplt.ylabel('Experimental Yield')\nplt.legend();",
"_____no_output_____"
]
],
[
[
"Note that you could very well use a regularization model such as Ridge or Lasso instead of the simple ordinary least squares LinearRegression model. In this case, it doesn't matter too much becuase we have only one feature (Temperature).",
"_____no_output_____"
],
[
"# Smoothing the plot of the model fit",
"_____no_output_____"
]
],
[
[
"X_fit = np.arange(50, 101).reshape([-1, 1])\nX_fit_poly2 = poly2.fit_transform(X_fit)\n\nplt.plot(temperature, experimental_yield, 'o')\nplt.plot(X_fit, ols_model.predict(X_fit), '-', label='OLS')\nplt.plot(X_fit, poly2_model.predict(X_fit_poly2), '-', label='Poly2')\nplt.xlabel('Temperature')\nplt.ylabel('Experimental Yield')\nplt.legend();",
"_____no_output_____"
]
],
[
[
"# Fit yield vs. temperature data with a $3^{rd}$ degree polynomial model",
"_____no_output_____"
]
],
[
[
"poly3 = PolynomialFeatures(degree=3)\nX_poly3 = poly.fit_transform(X)\n\nX.shape, X_poly3.shape",
"_____no_output_____"
],
[
"poly3_model = LinearRegression()\npoly3_model.fit(X_poly3, y)",
"_____no_output_____"
],
[
"X_fit_poly3 = poly3.fit_transform(X_fit)\nplt.plot(temperature, experimental_yield, 'o')\nplt.plot(X_fit, ols_model.predict(X_fit), '-', label='OLS')\nplt.plot(X_fit, poly2_model.predict(X_fit_poly2), '-', label='Poly2')\nplt.plot(X_fit, poly3_model.predict(X_fit_poly3), '-', label='Poly3')\nplt.xlabel('Temperature')\nplt.ylabel('Experimental Yield')\nplt.legend();",
"_____no_output_____"
]
],
[
[
"### Polynomial fit is clearly better than a linear fit, but which degree polynomial should we use?",
"_____no_output_____"
],
[
"### Why not try a range of polynomiall degrees, and see which one is best?",
"_____no_output_____"
],
[
"### But how do we determine which degree is best?",
"_____no_output_____"
],
[
"### We could use cross validation to determine the degree of polynomial that is most likely to best explain new data.",
"_____no_output_____"
],
[
"### Ideally, we would:\n\n1. Split the data into training and testing sets\n2. Perform cross validation on the training set to determine the best choice of polynomial degree\n3. Fit the chosen model to the training set\n4. Evaluate it on the withheld testing set",
"_____no_output_____"
],
[
"However, we have such little data that doing all of these splits is likely to leave individual partitions with subsets of data that are no longer representative of the relationship between temperature and yield.",
"_____no_output_____"
]
],
[
[
"plt.plot(temperature, experimental_yield, 'o')\nplt.xlabel('Temperature')\nplt.ylabel('Experimental Yield');",
"_____no_output_____"
]
],
[
[
"Thus, I'll forgo splitting the data into training and testing sets, and we'll train our model on the entire dataset. This is not ideal of course, and it means we'll have to simply hope that our model generalizes to new data.",
"_____no_output_____"
],
[
"I will use 5-fold cross validation to tune the polynomial degree hyperparameter. You might also want to explore 10-fold or leave one out cross validation.",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import cross_validate\ncv_mse = []\nfor degree in [2, 3]:\n poly = PolynomialFeatures(degree=degree)\n X_poly = poly.fit_transform(X)\n model = LinearRegression()\n results = cross_validate(model, X_poly, y, cv=5, scoring='neg_mean_squared_error')\n cv_mse.append(-results['test_score'])\ncv_mse",
"_____no_output_____"
],
[
"np.mean(cv_mse[0]), np.mean(cv_mse[1])",
"_____no_output_____"
]
],
[
[
"Slightly better mean validation error for $3^{rd}$ degree polynomial.",
"_____no_output_____"
]
],
[
[
"plt.plot(temperature, experimental_yield, 'o')\nplt.plot(X_fit, ols_model.predict(X_fit), '-', label='OLS')\nplt.plot(X_fit, poly2_model.predict(X_fit_poly2), '-', label='Poly2')\nplt.plot(X_fit, poly3_model.predict(X_fit_poly3), '-', label='Poly3')\nplt.xlabel('Temperature')\nplt.ylabel('Experimental Yield')\nplt.legend();",
"_____no_output_____"
]
],
[
[
"Despite the lower validation error for the $3^{rd}$ degree polynomial, we might still opt to stick with a $2^{nd}$ degree polynomial model. Why might we want to do that?",
"_____no_output_____"
],
[
"Less flexible models are more likely to generalize to new data because they are less likely to overfit noise.",
"_____no_output_____"
],
[
"Another important question to ask is whether the slight difference in mean validation error between $2^{nd}$ and $3^{rd}$ degree polynomial models is enough to really distinguish between the models?",
"_____no_output_____"
],
[
"One thing we can do is look at how variable the validation errors are across the various validation partitions.",
"_____no_output_____"
]
],
[
[
"cv_mse",
"_____no_output_____"
],
[
"binedges = np.linspace(0, np.max(cv_mse[0]), 11)\nplt.hist(cv_mse[0], binedges, alpha=0.5, label='Poly2')\nplt.hist(cv_mse[1], binedges, alpha=0.5, label='Poly3')\nplt.xlabel('Validation MSE')\nplt.ylabel('Counts')\nplt.legend();",
"_____no_output_____"
]
],
[
[
"Is the extra flexibility of the $3^{rd}$ degree polynomial model worth it, or is it more likely to overfit noise in our data and less likely to generalize to new measurements?",
"_____no_output_____"
],
[
"How dependent are our results on how we partitioned the data? Repeat the above using 10-fold cross validation.",
"_____no_output_____"
],
[
"Of course, more measurements, including measures at 60 degrees, would help you to better distinguish between these models.",
"_____no_output_____"
]
],
[
[
"plt.plot(temperature, experimental_yield, 'o')\nplt.plot(X_fit, ols_model.predict(X_fit), '-', label='OLS')\nplt.plot(X_fit, poly2_model.predict(X_fit_poly2), '-', label='Poly2')\nplt.plot(X_fit, poly3_model.predict(X_fit_poly3), '-', label='Poly3')\nplt.xlabel('Temperature')\nplt.ylabel('Experimental Yield')\nplt.legend();",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
]
] |
cb3571fc3ee90910c16da0b7f83278d70ec5a645 | 18,327 | ipynb | Jupyter Notebook | course_materials/project_03_data_warehouses/L3 Exercise 4 - Table Design - Solution.ipynb | ranstotz/data-eng-nanodegree | 0344c4d5d42ee3ec58befaaffe8749aa0bd9c143 | [
"MIT"
] | null | null | null | course_materials/project_03_data_warehouses/L3 Exercise 4 - Table Design - Solution.ipynb | ranstotz/data-eng-nanodegree | 0344c4d5d42ee3ec58befaaffe8749aa0bd9c143 | [
"MIT"
] | null | null | null | course_materials/project_03_data_warehouses/L3 Exercise 4 - Table Design - Solution.ipynb | ranstotz/data-eng-nanodegree | 0344c4d5d42ee3ec58befaaffe8749aa0bd9c143 | [
"MIT"
] | null | null | null | 33.201087 | 160 | 0.548262 | [
[
[
"# Exercise 4: Optimizing Redshift Table Design",
"_____no_output_____"
]
],
[
[
"%load_ext sql",
"_____no_output_____"
],
[
"from time import time\nimport configparser\nimport matplotlib.pyplot as plt\nimport pandas as pd",
"_____no_output_____"
],
[
"config = configparser.ConfigParser()\nconfig.read_file(open('dwh.cfg'))\nKEY=config.get('AWS','key')\nSECRET= config.get('AWS','secret')\n\nDWH_DB= config.get(\"DWH\",\"DWH_DB\")\nDWH_DB_USER= config.get(\"DWH\",\"DWH_DB_USER\")\nDWH_DB_PASSWORD= config.get(\"DWH\",\"DWH_DB_PASSWORD\")\nDWH_PORT = config.get(\"DWH\",\"DWH_PORT\")\n",
"_____no_output_____"
]
],
[
[
"# STEP 1: Get the params of the created redshift cluster \n- We need:\n - The redshift cluster <font color='red'>endpoint</font>\n - The <font color='red'>IAM role ARN</font> that give access to Redshift to read from S3",
"_____no_output_____"
]
],
[
[
"# FILL IN THE REDSHIFT ENDPOINT HERE\n# e.g. DWH_ENDPOINT=\"redshift-cluster-1.csmamz5zxmle.us-west-2.redshift.amazonaws.com\" \nDWH_ENDPOINT=\"dwhcluster.csmamz5zxmle.us-west-2.redshift.amazonaws.com\"\n \n#FILL IN THE IAM ROLE ARN you got in step 2.2 of the previous exercise\n#e.g DWH_ROLE_ARN=\"arn:aws:iam::988332130976:role/dwhRole\"\nDWH_ROLE_ARN=\"arn:aws:iam::988332130976:role/dwhRole\"",
"_____no_output_____"
]
],
[
[
"# STEP 2: Connect to the Redshift Cluster",
"_____no_output_____"
]
],
[
[
"import os \nconn_string=\"postgresql://{}:{}@{}:{}/{}\".format(DWH_DB_USER, DWH_DB_PASSWORD, DWH_ENDPOINT, DWH_PORT,DWH_DB)\nprint(conn_string)\n%sql $conn_string",
"_____no_output_____"
]
],
[
[
"# STEP 3: Create Tables\n- We are going to use a benchmarking data set common for benchmarking star schemas in data warehouses.\n- The data is pre-loaded in a public bucket on the `us-west-2` region\n- Our examples will be based on the Amazon Redshfit tutorial but in a scripted environment in our workspace.\n\n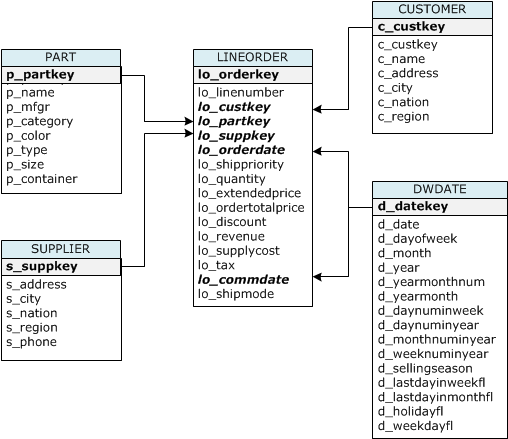\n",
"_____no_output_____"
],
[
"## 3.1 Create tables (no distribution strategy) in the `nodist` schema",
"_____no_output_____"
]
],
[
[
"%%sql \nCREATE SCHEMA IF NOT EXISTS nodist;\nSET search_path TO nodist;\n\nDROP TABLE IF EXISTS part cascade;\nDROP TABLE IF EXISTS supplier;\nDROP TABLE IF EXISTS supplier;\nDROP TABLE IF EXISTS customer;\nDROP TABLE IF EXISTS dwdate;\nDROP TABLE IF EXISTS lineorder;\n\nCREATE TABLE part \n(\n p_partkey INTEGER NOT NULL,\n p_name VARCHAR(22) NOT NULL,\n p_mfgr VARCHAR(6) NOT NULL,\n p_category VARCHAR(7) NOT NULL,\n p_brand1 VARCHAR(9) NOT NULL,\n p_color VARCHAR(11) NOT NULL,\n p_type VARCHAR(25) NOT NULL,\n p_size INTEGER NOT NULL,\n p_container VARCHAR(10) NOT NULL\n);\n\nCREATE TABLE supplier \n(\n s_suppkey INTEGER NOT NULL,\n s_name VARCHAR(25) NOT NULL,\n s_address VARCHAR(25) NOT NULL,\n s_city VARCHAR(10) NOT NULL,\n s_nation VARCHAR(15) NOT NULL,\n s_region VARCHAR(12) NOT NULL,\n s_phone VARCHAR(15) NOT NULL\n);\n\nCREATE TABLE customer \n(\n c_custkey INTEGER NOT NULL,\n c_name VARCHAR(25) NOT NULL,\n c_address VARCHAR(25) NOT NULL,\n c_city VARCHAR(10) NOT NULL,\n c_nation VARCHAR(15) NOT NULL,\n c_region VARCHAR(12) NOT NULL,\n c_phone VARCHAR(15) NOT NULL,\n c_mktsegment VARCHAR(10) NOT NULL\n);\n\nCREATE TABLE dwdate \n(\n d_datekey INTEGER NOT NULL,\n d_date VARCHAR(19) NOT NULL,\n d_dayofweek VARCHAR(10) NOT NULL,\n d_month VARCHAR(10) NOT NULL,\n d_year INTEGER NOT NULL,\n d_yearmonthnum INTEGER NOT NULL,\n d_yearmonth VARCHAR(8) NOT NULL,\n d_daynuminweek INTEGER NOT NULL,\n d_daynuminmonth INTEGER NOT NULL,\n d_daynuminyear INTEGER NOT NULL,\n d_monthnuminyear INTEGER NOT NULL,\n d_weeknuminyear INTEGER NOT NULL,\n d_sellingseason VARCHAR(13) NOT NULL,\n d_lastdayinweekfl VARCHAR(1) NOT NULL,\n d_lastdayinmonthfl VARCHAR(1) NOT NULL,\n d_holidayfl VARCHAR(1) NOT NULL,\n d_weekdayfl VARCHAR(1) NOT NULL\n);\nCREATE TABLE lineorder \n(\n lo_orderkey INTEGER NOT NULL,\n lo_linenumber INTEGER NOT NULL,\n lo_custkey INTEGER NOT NULL,\n lo_partkey INTEGER NOT NULL,\n lo_suppkey INTEGER NOT NULL,\n lo_orderdate INTEGER NOT NULL,\n lo_orderpriority VARCHAR(15) NOT NULL,\n lo_shippriority VARCHAR(1) NOT NULL,\n lo_quantity INTEGER NOT NULL,\n lo_extendedprice INTEGER NOT NULL,\n lo_ordertotalprice INTEGER NOT NULL,\n lo_discount INTEGER NOT NULL,\n lo_revenue INTEGER NOT NULL,\n lo_supplycost INTEGER NOT NULL,\n lo_tax INTEGER NOT NULL,\n lo_commitdate INTEGER NOT NULL,\n lo_shipmode VARCHAR(10) NOT NULL\n);",
"_____no_output_____"
]
],
[
[
"## 3.1 Create tables (with a distribution strategy) in the `dist` schema",
"_____no_output_____"
]
],
[
[
"%%sql\n\nCREATE SCHEMA IF NOT EXISTS dist;\nSET search_path TO dist;\n\nDROP TABLE IF EXISTS part cascade;\nDROP TABLE IF EXISTS supplier;\nDROP TABLE IF EXISTS supplier;\nDROP TABLE IF EXISTS customer;\nDROP TABLE IF EXISTS dwdate;\nDROP TABLE IF EXISTS lineorder;\n\nCREATE TABLE part (\n p_partkey \tinteger \tnot null sortkey distkey,\n p_name \tvarchar(22) \tnot null,\n p_mfgr \tvarchar(6) not null,\n p_category \tvarchar(7) not null,\n p_brand1 \tvarchar(9) not null,\n p_color \tvarchar(11) \tnot null,\n p_type \tvarchar(25) \tnot null,\n p_size \tinteger \tnot null,\n p_container \tvarchar(10) not null\n);\n\nCREATE TABLE supplier (\n s_suppkey \tinteger not null sortkey,\n s_name \tvarchar(25) not null,\n s_address \tvarchar(25) not null,\n s_city \tvarchar(10) not null,\n s_nation \tvarchar(15) not null,\n s_region \tvarchar(12) not null,\n s_phone \tvarchar(15) not null)\ndiststyle all;\n\nCREATE TABLE customer (\n c_custkey \tinteger not null sortkey,\n c_name \tvarchar(25) not null,\n c_address \tvarchar(25) not null,\n c_city \tvarchar(10) not null,\n c_nation \tvarchar(15) not null,\n c_region \tvarchar(12) not null,\n c_phone \tvarchar(15) not null,\n c_mktsegment varchar(10) not null)\ndiststyle all;\n\nCREATE TABLE dwdate (\n d_datekey integer not null sortkey,\n d_date varchar(19) not null,\n d_dayofweek\t varchar(10) not null,\n d_month \t varchar(10) not null,\n d_year integer not null,\n d_yearmonthnum integer \t not null,\n d_yearmonth varchar(8)\tnot null,\n d_daynuminweek integer not null,\n d_daynuminmonth integer not null,\n d_daynuminyear integer not null,\n d_monthnuminyear integer not null,\n d_weeknuminyear integer not null,\n d_sellingseason varchar(13) not null,\n d_lastdayinweekfl varchar(1) not null,\n d_lastdayinmonthfl varchar(1) not null,\n d_holidayfl varchar(1) not null,\n d_weekdayfl varchar(1) not null)\ndiststyle all;\n\nCREATE TABLE lineorder (\n lo_orderkey \t integer \tnot null,\n lo_linenumber \tinteger \tnot null,\n lo_custkey \tinteger \tnot null,\n lo_partkey \tinteger \tnot null distkey,\n lo_suppkey \tinteger \tnot null,\n lo_orderdate \tinteger \tnot null sortkey,\n lo_orderpriority \tvarchar(15) not null,\n lo_shippriority \tvarchar(1) not null,\n lo_quantity \tinteger \tnot null,\n lo_extendedprice \tinteger \tnot null,\n lo_ordertotalprice \tinteger \tnot null,\n lo_discount \tinteger \tnot null,\n lo_revenue \tinteger \tnot null,\n lo_supplycost \tinteger \tnot null,\n lo_tax \tinteger \tnot null,\n lo_commitdate integer not null,\n lo_shipmode \tvarchar(10) not null\n);",
"_____no_output_____"
]
],
[
[
"# STEP 4: Copying tables \n\nOur intent here is to run 5 COPY operations for the 5 tables respectively as show below.\n\nHowever, we want to do accomplish the following:\n- Make sure that the `DWH_ROLE_ARN` is substituted with the correct value in each query\n- Perform the data loading twice once for each schema (dist and nodist)\n- Collect timing statistics to compare the insertion times\nThus, we have scripted the insertion as found below in the function `loadTables` which\nreturns a pandas dataframe containing timing statistics for the copy operations\n\n```sql\ncopy customer from 's3://awssampledbuswest2/ssbgz/customer' \ncredentials 'aws_iam_role=<DWH_ROLE_ARN>'\ngzip region 'us-west-2';\n\ncopy dwdate from 's3://awssampledbuswest2/ssbgz/dwdate' \ncredentials 'aws_iam_role=<DWH_ROLE_ARN>'\ngzip region 'us-west-2';\n\ncopy lineorder from 's3://awssampledbuswest2/ssbgz/lineorder' \ncredentials 'aws_iam_role=<DWH_ROLE_ARN>'\ngzip region 'us-west-2';\n\ncopy part from 's3://awssampledbuswest2/ssbgz/part' \ncredentials 'aws_iam_role=<DWH_ROLE_ARN>'\ngzip region 'us-west-2';\n\ncopy supplier from 's3://awssampledbuswest2/ssbgz/supplier' \ncredentials 'aws_iam_role=<DWH_ROLE_ARN>'\ngzip region 'us-west-2';\n```\n",
"_____no_output_____"
],
[
"## 4.1 Automate the copying",
"_____no_output_____"
]
],
[
[
"def loadTables(schema, tables):\n loadTimes = []\n SQL_SET_SCEMA = \"SET search_path TO {};\".format(schema)\n %sql $SQL_SET_SCEMA\n \n for table in tables:\n SQL_COPY = \"\"\"\ncopy {} from 's3://awssampledbuswest2/ssbgz/{}' \ncredentials 'aws_iam_role={}'\ngzip region 'us-west-2';\n \"\"\".format(table,table, DWH_ROLE_ARN)\n\n print(\"======= LOADING TABLE: ** {} ** IN SCHEMA ==> {} =======\".format(table, schema))\n print(SQL_COPY)\n\n t0 = time()\n %sql $SQL_COPY\n loadTime = time()-t0\n loadTimes.append(loadTime)\n\n print(\"=== DONE IN: {0:.2f} sec\\n\".format(loadTime))\n return pd.DataFrame({\"table\":tables, \"loadtime_\"+schema:loadTimes}).set_index('table')",
"_____no_output_____"
],
[
"#-- List of the tables to be loaded\ntables = [\"customer\",\"dwdate\",\"supplier\", \"part\", \"lineorder\"]\n\n#-- Insertion twice for each schema (WARNING!! EACH CAN TAKE MORE THAN 10 MINUTES!!!)\nnodistStats = loadTables(\"nodist\", tables)\ndistStats = loadTables(\"dist\", tables)",
"_____no_output_____"
]
],
[
[
"## 4.1 Compare the load performance results",
"_____no_output_____"
]
],
[
[
"#-- Plotting of the timing results\nstats = distStats.join(nodistStats)\nstats.plot.bar()\nplt.show()",
"_____no_output_____"
]
],
[
[
"# STEP 5: Compare Query Performance",
"_____no_output_____"
]
],
[
[
"oneDim_SQL =\"\"\"\nset enable_result_cache_for_session to off;\nSET search_path TO {};\n\nselect sum(lo_extendedprice*lo_discount) as revenue\nfrom lineorder, dwdate\nwhere lo_orderdate = d_datekey\nand d_year = 1997 \nand lo_discount between 1 and 3 \nand lo_quantity < 24;\n\"\"\"\n\ntwoDim_SQL=\"\"\"\nset enable_result_cache_for_session to off;\nSET search_path TO {};\n\nselect sum(lo_revenue), d_year, p_brand1\nfrom lineorder, dwdate, part, supplier\nwhere lo_orderdate = d_datekey\nand lo_partkey = p_partkey\nand lo_suppkey = s_suppkey\nand p_category = 'MFGR#12'\nand s_region = 'AMERICA'\ngroup by d_year, p_brand1\n\"\"\"\n\ndrill_SQL = \"\"\"\nset enable_result_cache_for_session to off;\nSET search_path TO {};\n\nselect c_city, s_city, d_year, sum(lo_revenue) as revenue \nfrom customer, lineorder, supplier, dwdate\nwhere lo_custkey = c_custkey\nand lo_suppkey = s_suppkey\nand lo_orderdate = d_datekey\nand (c_city='UNITED KI1' or\nc_city='UNITED KI5')\nand (s_city='UNITED KI1' or\ns_city='UNITED KI5')\nand d_yearmonth = 'Dec1997'\ngroup by c_city, s_city, d_year\norder by d_year asc, revenue desc;\n\"\"\"\n\n\noneDimSameDist_SQL =\"\"\"\nset enable_result_cache_for_session to off;\nSET search_path TO {};\n\nselect lo_orderdate, sum(lo_extendedprice*lo_discount) as revenue \nfrom lineorder, part\nwhere lo_partkey = p_partkey\ngroup by lo_orderdate\norder by lo_orderdate\n\"\"\"\n\ndef compareQueryTimes(schema):\n queryTimes =[] \n for i,query in enumerate([oneDim_SQL, twoDim_SQL, drill_SQL, oneDimSameDist_SQL]):\n t0 = time()\n q = query.format(schema)\n %sql $q\n queryTime = time()-t0\n queryTimes.append(queryTime)\n return pd.DataFrame({\"query\":[\"oneDim\",\"twoDim\", \"drill\", \"oneDimSameDist\"], \"queryTime_\"+schema:queryTimes}).set_index('query')",
"_____no_output_____"
],
[
"noDistQueryTimes = compareQueryTimes(\"nodist\")\ndistQueryTimes = compareQueryTimes(\"dist\") ",
"_____no_output_____"
],
[
"queryTimeDF =noDistQueryTimes.join(distQueryTimes)\nqueryTimeDF.plot.bar()\nplt.show()",
"_____no_output_____"
],
[
"improvementDF = queryTimeDF[\"distImprovement\"] =100.0*(queryTimeDF['queryTime_nodist']-queryTimeDF['queryTime_dist'])/queryTimeDF['queryTime_nodist']\nimprovementDF.plot.bar(title=\"% dist Improvement by query\")\nplt.show()",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
cb3589ccfe02fc27039fd10dfcdc79fbd1697346 | 13,654 | ipynb | Jupyter Notebook | metabric/src/GSEA_failures_of_null.ipynb | statisticalbiotechnology/wall | 13d111bdfac1c2a13502e55dc0be9292828ad339 | [
"Apache-2.0"
] | 1 | 2020-09-16T13:29:31.000Z | 2020-09-16T13:29:31.000Z | metabric/src/GSEA_failures_of_null.ipynb | statisticalbiotechnology/wall | 13d111bdfac1c2a13502e55dc0be9292828ad339 | [
"Apache-2.0"
] | null | null | null | metabric/src/GSEA_failures_of_null.ipynb | statisticalbiotechnology/wall | 13d111bdfac1c2a13502e55dc0be9292828ad339 | [
"Apache-2.0"
] | null | null | null | 139.326531 | 11,284 | 0.899224 | [
[
[
"from IPython.core.display import display, HTML\ndisplay(HTML(\"<style>.container { width:100% !important; }</style>\"))\nfrom matplotlib.pyplot import figure\nfigure(num=None, figsize=(15, 10), dpi=100, facecolor='w', edgecolor='k')\nimport pandas as pd\nfrom scipy.stats import zscore, norm\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom scipy.stats import truncnorm, norm\nfrom scipy.optimize import fmin_slsqp\nimport qvalue as qv",
"_____no_output_____"
],
[
"cluster_1 = pd.read_csv(\"GSEA_/1/gseapy.gsea.gene_set.report.csv\", index_col = 0)",
"_____no_output_____"
],
[
"\npvalues = cluster_1['fdr'].tolist()\npvalues = [1e-8 if x == 0.0 else x for x in pvalues]##p = 0 gives error so setting it to 1e-320\npvalues = [0.999 if x == 1.0 else x for x in pvalues] ##pathways with p-val 1 gave error as range would be to inf\npvalues = sorted(pvalues)\nz_scores = norm.ppf(pvalues)\n\nfig, ax = plt.subplots(1, 1, figsize=(15, 10))\nplt.hist(z_scores, bins=50, density=True)\nplt.show()",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code"
]
] |
cb358b0f1678228b43e8d77edd0842ccf13ada4d | 32,041 | ipynb | Jupyter Notebook | HW1_Abalone_Dataset.ipynb | kutayerkan/BAU_Machine-Learning | 3a56b1cb42118f350f8f3c9b4eb331d290f35599 | [
"MIT"
] | null | null | null | HW1_Abalone_Dataset.ipynb | kutayerkan/BAU_Machine-Learning | 3a56b1cb42118f350f8f3c9b4eb331d290f35599 | [
"MIT"
] | null | null | null | HW1_Abalone_Dataset.ipynb | kutayerkan/BAU_Machine-Learning | 3a56b1cb42118f350f8f3c9b4eb331d290f35599 | [
"MIT"
] | null | null | null | 40.252513 | 287 | 0.50657 | [
[
[
"# Naive Bayes on Abalone Dataset",
"_____no_output_____"
]
],
[
[
"# importing all necessary packages and functions\n\nimport pandas as pd\nimport numpy as np\nimport math as m\nfrom sklearn.model_selection import train_test_split\n\nimport warnings\nwarnings.filterwarnings('ignore')",
"_____no_output_____"
],
[
"# kernel option to see output of multiple code lines\n\nfrom IPython.core.interactiveshell import InteractiveShell\nInteractiveShell.ast_node_interactivity = \"all\"",
"_____no_output_____"
],
[
"def df_split(dataframe, training_samples):\n df_training, df_validation = train_test_split(dataframe, train_size=training_samples)\n return df_training, df_validation",
"_____no_output_____"
],
[
"def convert_to_sex_prob_1(x):\n if x == 'F':\n return sex_prob.loc['F'][1]\n elif x == 'M':\n return sex_prob.loc['M'][1]\n elif x == 'I':\n return sex_prob.loc['I'][1]\n else:\n return 'N/A'\n\ndef convert_to_sex_prob_2(x):\n if x == 'F':\n return sex_prob.loc['F'][2]\n elif x == 'M':\n return sex_prob.loc['M'][2]\n elif x == 'I':\n return sex_prob.loc['I'][2]\n else:\n return 'N/A'\n\ndef convert_to_sex_prob_3(x):\n if x == 'F':\n return sex_prob.loc['F'][3]\n elif x == 'M':\n return sex_prob.loc['M'][3]\n elif x == 'I':\n return sex_prob.loc['I'][3]\n else:\n return 'N/A'",
"_____no_output_____"
],
[
"df = pd.read_table(\"abalone_dataset.txt\", sep=\"\\t\", header=None)\ndf.columns = [\"sex\", \"length\", \"diameter\", \"height\", \"whole_weight\",\n \"shucked_weight\", \"viscera_weight\", \"shell_weight\", \"age_class\"]",
"_____no_output_____"
]
],
[
[
"### We decide the training samples for different cases (100, 1000, 2000):",
"_____no_output_____"
]
],
[
[
"# only input before clicking Run All\n\ntraining_samples = 2000\n\ndf_train = df_split(df, training_samples)[0]\ndf_test = df_split(df, training_samples)[1]",
"_____no_output_____"
],
[
"df_train1 = df_train[df_train.age_class==1]\ndf_train2 = df_train[df_train.age_class==2]\ndf_train3 = df_train[df_train.age_class==3]\n\nstat_table_1 = df_train1.describe()[1:3].transpose()\nstat_table_2 = df_train2.describe()[1:3].transpose()\nstat_table_3 = df_train3.describe()[1:3].transpose()\n\nstat_table_1 = stat_table_1.add_prefix('class1_')\nstat_table_2 = stat_table_2.add_prefix('class2_')\nstat_table_3 = stat_table_3.add_prefix('class3_')\n\nframes = [stat_table_1, stat_table_2, stat_table_3]\nstat_table = pd.concat(frames, axis=1, join_axes=[stat_table_1.index])\nstat_table = stat_table.transpose()",
"_____no_output_____"
],
[
"age_prob = pd.DataFrame([len(df_train[df_train.age_class==1])/len(df_train),\n len(df_train[df_train.age_class==2])/len(df_train),\n len(df_train[df_train.age_class==3])/len(df_train)],\n index=['1','2','3'],\n columns=['probability'])\n\nsex_prob = pd.crosstab(df_train.sex, df_train.age_class, normalize='columns')",
"_____no_output_____"
],
[
"df_test['age_prob_1'],df_test['age_prob_2'],df_test['age_prob_3'] = [0,0,0]\ndf_test['sex_1'],df_test['sex_2'],df_test['sex_3'] = df_test.sex,df_test.sex,df_test.sex\ndf_test['length_1'],df_test['length_2'],df_test['length_3'] = df_test.length,df_test.length,df_test.length\ndf_test['diameter_1'],df_test['diameter_2'],df_test['diameter_3'] = df_test.diameter,df_test.diameter,df_test.diameter\ndf_test['height_1'],df_test['height_2'],df_test['height_3'] = df_test.height,df_test.height,df_test.height\ndf_test['whole_weight_1'],df_test['whole_weight_2'],df_test['whole_weight_3'] = df_test.whole_weight,df_test.whole_weight,df_test.whole_weight\ndf_test['shucked_weight_1'],df_test['shucked_weight_2'],df_test['shucked_weight_3'] = df_test.shucked_weight,df_test.shucked_weight,df_test.shucked_weight\ndf_test['viscera_weight_1'],df_test['viscera_weight_2'],df_test['viscera_weight_3'] = df_test.viscera_weight,df_test.viscera_weight,df_test.viscera_weight\ndf_test['shell_weight_1'],df_test['shell_weight_2'],df_test['shell_weight_3'] = df_test.shell_weight,df_test.shell_weight,df_test.shell_weight",
"_____no_output_____"
],
[
"df_test.age_prob_1 = df_test.age_prob_1.apply(lambda x: age_prob.loc['1'])\ndf_test.age_prob_2 = df_test.age_prob_2.apply(lambda x: age_prob.loc['2'])\ndf_test.age_prob_3 = df_test.age_prob_3.apply(lambda x: age_prob.loc['3'])",
"_____no_output_____"
],
[
"df_test.sex_1 = df_test.sex_1.apply(convert_to_sex_prob_1)\ndf_test.sex_2 = df_test.sex_2.apply(convert_to_sex_prob_2)\ndf_test.sex_3 = df_test.sex_3.apply(convert_to_sex_prob_3)",
"_____no_output_____"
],
[
"df_test.length_1 = df_test.length_1.apply(lambda x: (1 / (m.sqrt(2*m.pi*m.pow(stat_table.loc['class1_std']['length'],2)))) * m.exp(-(m.pow(x-stat_table.loc['class1_mean']['length'],2)/(2*m.pow(stat_table.loc['class1_std']['length'],2)))))\ndf_test.length_2 = df_test.length_2.apply(lambda x: (1 / (m.sqrt(2*m.pi*m.pow(stat_table.loc['class2_std']['length'],2)))) * m.exp(-(m.pow(x-stat_table.loc['class2_mean']['length'],2)/(2*m.pow(stat_table.loc['class2_std']['length'],2)))))\ndf_test.length_3 = df_test.length_3.apply(lambda x: (1 / (m.sqrt(2*m.pi*m.pow(stat_table.loc['class3_std']['length'],2)))) * m.exp(-(m.pow(x-stat_table.loc['class3_mean']['length'],2)/(2*m.pow(stat_table.loc['class3_std']['length'],2)))))",
"_____no_output_____"
],
[
"df_test.diameter_1 = df_test.diameter_1.apply(lambda x: (1 / (m.sqrt(2*m.pi*m.pow(stat_table.loc['class1_std']['diameter'],2)))) * m.exp(-(m.pow(x-stat_table.loc['class1_mean']['diameter'],2)/(2*m.pow(stat_table.loc['class1_std']['diameter'],2)))))\ndf_test.diameter_2 = df_test.diameter_2.apply(lambda x: (1 / (m.sqrt(2*m.pi*m.pow(stat_table.loc['class2_std']['diameter'],2)))) * m.exp(-(m.pow(x-stat_table.loc['class2_mean']['diameter'],2)/(2*m.pow(stat_table.loc['class2_std']['diameter'],2)))))\ndf_test.diameter_3 = df_test.diameter_3.apply(lambda x: (1 / (m.sqrt(2*m.pi*m.pow(stat_table.loc['class3_std']['diameter'],2)))) * m.exp(-(m.pow(x-stat_table.loc['class3_mean']['diameter'],2)/(2*m.pow(stat_table.loc['class3_std']['diameter'],2)))))",
"_____no_output_____"
],
[
"df_test.height_1 = df_test.height_1.apply(lambda x: (1 / (m.sqrt(2*m.pi*m.pow(stat_table.loc['class1_std']['height'],2)))) * m.exp(-(m.pow(x-stat_table.loc['class1_mean']['height'],2)/(2*m.pow(stat_table.loc['class1_std']['height'],2)))))\ndf_test.height_2 = df_test.height_2.apply(lambda x: (1 / (m.sqrt(2*m.pi*m.pow(stat_table.loc['class2_std']['height'],2)))) * m.exp(-(m.pow(x-stat_table.loc['class2_mean']['height'],2)/(2*m.pow(stat_table.loc['class2_std']['height'],2)))))\ndf_test.height_3 = df_test.height_3.apply(lambda x: (1 / (m.sqrt(2*m.pi*m.pow(stat_table.loc['class3_std']['height'],2)))) * m.exp(-(m.pow(x-stat_table.loc['class3_mean']['height'],2)/(2*m.pow(stat_table.loc['class3_std']['height'],2)))))",
"_____no_output_____"
],
[
"df_test.whole_weight_1 = df_test.whole_weight_1.apply(lambda x: (1 / (m.sqrt(2*m.pi*m.pow(stat_table.loc['class1_std']['whole_weight'],2)))) * m.exp(-(m.pow(x-stat_table.loc['class1_mean']['whole_weight'],2)/(2*m.pow(stat_table.loc['class1_std']['whole_weight'],2)))))\ndf_test.whole_weight_2 = df_test.whole_weight_2.apply(lambda x: (1 / (m.sqrt(2*m.pi*m.pow(stat_table.loc['class2_std']['whole_weight'],2)))) * m.exp(-(m.pow(x-stat_table.loc['class2_mean']['whole_weight'],2)/(2*m.pow(stat_table.loc['class2_std']['whole_weight'],2)))))\ndf_test.whole_weight_3 = df_test.whole_weight_3.apply(lambda x: (1 / (m.sqrt(2*m.pi*m.pow(stat_table.loc['class3_std']['whole_weight'],2)))) * m.exp(-(m.pow(x-stat_table.loc['class3_mean']['whole_weight'],2)/(2*m.pow(stat_table.loc['class3_std']['whole_weight'],2)))))",
"_____no_output_____"
],
[
"df_test.shucked_weight_1 = df_test.shucked_weight_1.apply(lambda x: (1 / (m.sqrt(2*m.pi*m.pow(stat_table.loc['class1_std']['shucked_weight'],2)))) * m.exp(-(m.pow(x-stat_table.loc['class1_mean']['shucked_weight'],2)/(2*m.pow(stat_table.loc['class1_std']['shucked_weight'],2)))))\ndf_test.shucked_weight_2 = df_test.shucked_weight_2.apply(lambda x: (1 / (m.sqrt(2*m.pi*m.pow(stat_table.loc['class2_std']['shucked_weight'],2)))) * m.exp(-(m.pow(x-stat_table.loc['class2_mean']['shucked_weight'],2)/(2*m.pow(stat_table.loc['class2_std']['shucked_weight'],2)))))\ndf_test.shucked_weight_3 = df_test.shucked_weight_3.apply(lambda x: (1 / (m.sqrt(2*m.pi*m.pow(stat_table.loc['class3_std']['shucked_weight'],2)))) * m.exp(-(m.pow(x-stat_table.loc['class3_mean']['shucked_weight'],2)/(2*m.pow(stat_table.loc['class3_std']['shucked_weight'],2)))))",
"_____no_output_____"
],
[
"df_test.viscera_weight_1 = df_test.viscera_weight_1.apply(lambda x: (1 / (m.sqrt(2*m.pi*m.pow(stat_table.loc['class1_std']['viscera_weight'],2)))) * m.exp(-(m.pow(x-stat_table.loc['class1_mean']['viscera_weight'],2)/(2*m.pow(stat_table.loc['class1_std']['viscera_weight'],2)))))\ndf_test.viscera_weight_2 = df_test.viscera_weight_2.apply(lambda x: (1 / (m.sqrt(2*m.pi*m.pow(stat_table.loc['class2_std']['viscera_weight'],2)))) * m.exp(-(m.pow(x-stat_table.loc['class2_mean']['viscera_weight'],2)/(2*m.pow(stat_table.loc['class2_std']['viscera_weight'],2)))))\ndf_test.viscera_weight_3 = df_test.viscera_weight_3.apply(lambda x: (1 / (m.sqrt(2*m.pi*m.pow(stat_table.loc['class3_std']['viscera_weight'],2)))) * m.exp(-(m.pow(x-stat_table.loc['class3_mean']['viscera_weight'],2)/(2*m.pow(stat_table.loc['class3_std']['viscera_weight'],2)))))",
"_____no_output_____"
],
[
"df_test.shell_weight_1 = df_test.shell_weight_1.apply(lambda x: (1 / (m.sqrt(2*m.pi*m.pow(stat_table.loc['class1_std']['shell_weight'],2)))) * m.exp(-(m.pow(x-stat_table.loc['class1_mean']['shell_weight'],2)/(2*m.pow(stat_table.loc['class1_std']['shell_weight'],2)))))\ndf_test.shell_weight_2 = df_test.shell_weight_2.apply(lambda x: (1 / (m.sqrt(2*m.pi*m.pow(stat_table.loc['class2_std']['shell_weight'],2)))) * m.exp(-(m.pow(x-stat_table.loc['class2_mean']['shell_weight'],2)/(2*m.pow(stat_table.loc['class2_std']['shell_weight'],2)))))\ndf_test.shell_weight_3 = df_test.shell_weight_3.apply(lambda x: (1 / (m.sqrt(2*m.pi*m.pow(stat_table.loc['class3_std']['shell_weight'],2)))) * m.exp(-(m.pow(x-stat_table.loc['class3_mean']['shell_weight'],2)/(2*m.pow(stat_table.loc['class3_std']['shell_weight'],2)))))",
"_____no_output_____"
],
[
"df_test['class_prob_1_vars_3'] = df_test.age_prob_1 * df_test.sex_1 * df_test.length_1 * df_test.diameter_1\ndf_test['class_prob_1_vars_8'] = df_test.age_prob_1 * df_test.sex_1 * df_test.length_1 * df_test.diameter_1 * df_test.height_1 * df_test.whole_weight_1 * df_test.shucked_weight_1 * df_test.viscera_weight_1 * df_test.shell_weight_1",
"_____no_output_____"
],
[
"df_test['class_prob_2_vars_3'] = df_test.age_prob_2 * df_test.sex_2 * df_test.length_2 * df_test.diameter_2\ndf_test['class_prob_2_vars_8'] = df_test.age_prob_2 * df_test.sex_2 * df_test.length_2 * df_test.diameter_2 * df_test.height_2 * df_test.whole_weight_2 * df_test.shucked_weight_2 * df_test.viscera_weight_2 * df_test.shell_weight_2",
"_____no_output_____"
],
[
"df_test['class_prob_3_vars_3'] = df_test.age_prob_3 * df_test.sex_3 * df_test.length_3 * df_test.diameter_3\ndf_test['class_prob_3_vars_8'] = df_test.age_prob_3 * df_test.sex_3 * df_test.length_3 * df_test.diameter_3 * df_test.height_3 * df_test.whole_weight_3 * df_test.shucked_weight_3 * df_test.viscera_weight_3 * df_test.shell_weight_3",
"_____no_output_____"
],
[
"conditions_3 = [\n (df_test['class_prob_1_vars_3'] >= df_test['class_prob_2_vars_3']) & (df_test['class_prob_1_vars_3'] >= df_test['class_prob_3_vars_3']), \n (df_test['class_prob_2_vars_3'] >= df_test['class_prob_1_vars_3']) & (df_test['class_prob_2_vars_3'] >= df_test['class_prob_3_vars_3'])]\n\nchoices_3 = [1, 2]\n\ndf_test['vars_3_guess'] = np.select(conditions_3, choices_3, default=3)",
"_____no_output_____"
],
[
"conditions_8 = [\n (df_test['class_prob_1_vars_8'] >= df_test['class_prob_2_vars_8']) & (df_test['class_prob_1_vars_8'] >= df_test['class_prob_3_vars_8']), \n (df_test['class_prob_2_vars_8'] >= df_test['class_prob_3_vars_8'])]\n\nchoices_8 = [1, 2]\n\ndf_test['vars_8_guess'] = np.select(conditions_8, choices_8, default=3)",
"_____no_output_____"
],
[
"print ('Accuracy with {} samples and 3 variables'.format(training_samples))\nlen(df_test[df_test.age_class == df_test.vars_3_guess])/len(df_test)\nprint ('Accuracy with {} samples and 8 variables'.format(training_samples))\nlen(df_test[df_test.age_class == df_test.vars_8_guess])/len(df_test)",
"Accuracy with 2000 samples and 3 variables\n"
],
[
"print ('Confusion matrix with {} samples and 3 variables'.format(training_samples))\n\ncm3 = {'Matrix': ['Guessed 1', 'Guessed 2', 'Guessed 3'],\n 'Actual Value 1': [len(df_test[(df_test.age_class==1) & (df_test.vars_3_guess==1)]), len(df_test[(df_test.age_class==1) & (df_test.vars_3_guess==2)]), len(df_test[(df_test.age_class==1) & (df_test.vars_3_guess==3)])],\n 'Actual Value 2': [len(df_test[(df_test.age_class==2) & (df_test.vars_3_guess==1)]), len(df_test[(df_test.age_class==2) & (df_test.vars_3_guess==2)]), len(df_test[(df_test.age_class==2) & (df_test.vars_3_guess==3)])],\n 'Actual Value 3': [len(df_test[(df_test.age_class==3) & (df_test.vars_3_guess==1)]), len(df_test[(df_test.age_class==3) & (df_test.vars_3_guess==2)]), len(df_test[(df_test.age_class==3) & (df_test.vars_3_guess==3)])]}\ncm3 = pd.DataFrame.from_dict(cm3)\ncm3\n\nprint ('Total misclassification errors: {}'.format(len(df_test)-cm3.iloc[0][1]-cm3.iloc[1][2]-cm3.iloc[2][3]))\n \nprint ('Confusion matrix with {} samples and 8 variables'.format(training_samples))\n\ncm8 = {'Matrix': ['Guessed 1', 'Guessed 2', 'Guessed 3'],\n 'Actual Value 1': [len(df_test[(df_test.age_class==1) & (df_test.vars_8_guess==1)]), len(df_test[(df_test.age_class==1) & (df_test.vars_8_guess==2)]), len(df_test[(df_test.age_class==1) & (df_test.vars_8_guess==3)])],\n 'Actual Value 2': [len(df_test[(df_test.age_class==2) & (df_test.vars_8_guess==1)]), len(df_test[(df_test.age_class==2) & (df_test.vars_8_guess==2)]), len(df_test[(df_test.age_class==2) & (df_test.vars_8_guess==3)])],\n 'Actual Value 3': [len(df_test[(df_test.age_class==3) & (df_test.vars_8_guess==1)]), len(df_test[(df_test.age_class==3) & (df_test.vars_8_guess==2)]), len(df_test[(df_test.age_class==3) & (df_test.vars_8_guess==3)])]}\ncm8 = pd.DataFrame.from_dict(cm8)\ncm8\n\nprint ('Total misclassification errors: {}'.format(len(df_test)-cm8.iloc[0][1]-cm8.iloc[1][2]-cm8.iloc[2][3]))",
"Confusion matrix with 2000 samples and 3 variables\n"
]
],
[
[
"## References\nhttps://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_table.html<br>\nhttps://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.drop.html<br>\nhttps://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html<br>\nhttp://www.inf.ed.ac.uk/teaching/courses/inf2b/learnnotes/inf2b-learn-note09-2up.pdf<br>\nhttp://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.add_prefix.html<br>",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
cb3593d563b15df130572c4f146fa1d527c47790 | 12,797 | ipynb | Jupyter Notebook | wandb/run-20210520_091509-wajgv3ri/tmp/code/_session_history.ipynb | Programmer-RD-AI/Heart-Disease-UCI | b077f8496fba3fe1a9a073c80d0a5df73c720f29 | [
"Apache-2.0"
] | null | null | null | wandb/run-20210520_091509-wajgv3ri/tmp/code/_session_history.ipynb | Programmer-RD-AI/Heart-Disease-UCI | b077f8496fba3fe1a9a073c80d0a5df73c720f29 | [
"Apache-2.0"
] | null | null | null | wandb/run-20210520_091509-wajgv3ri/tmp/code/_session_history.ipynb | Programmer-RD-AI/Heart-Disease-UCI | b077f8496fba3fe1a9a073c80d0a5df73c720f29 | [
"Apache-2.0"
] | null | null | null | 25.390873 | 274 | 0.502618 | [
[
[
"import pandas as pd",
"_____no_output_____"
],
[
"data = pd.read_csv('./data.csv')",
"_____no_output_____"
],
[
"X,y = data.drop('target',axis=1),data['target']",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split",
"_____no_output_____"
],
[
"X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25)",
"_____no_output_____"
],
[
"import torch\nimport torch.nn as nn",
"_____no_output_____"
],
[
"import numpy as np",
"_____no_output_____"
],
[
"X_train = torch.from_numpy(np.array(X_train).astype(np.float32))\ny_train = torch.from_numpy(np.array(y_train).astype(np.float32))\nX_test = torch.from_numpy(np.array(X_test).astype(np.float32))\ny_test = torch.from_numpy(np.array(y_test).astype(np.float32))",
"_____no_output_____"
],
[
"X_train.shape",
"torch.Size([227, 13])"
],
[
"X_test.shape",
"torch.Size([76, 13])"
],
[
"y_train.shape",
"torch.Size([227])"
],
[
"y_test.shape",
"torch.Size([76])"
],
[
"import torch.nn.functional as F",
"_____no_output_____"
],
[
"class Test_Model(nn.Module):\n def __init__(self):\n super().__init__()\n self.fc1 = nn.Linear(13,64)\n self.fc2 = nn.Linear(64,128)\n self.fc3 = nn.Linear(128,256)\n self.fc4 = nn.Linear(256,512)\n self.fc5 = nn.Linear(512,1024)\n self.fc6 = nn.Linear(1024,512)\n self.fc7 = nn.Linear(512,1)\n \n def forward(self,X):\n preds = self.fc1(X)\n preds = F.relu(preds)\n preds = self.fc2(preds)\n preds = F.relu(preds)\n preds = self.fc3(preds)\n preds = F.relu(preds)\n preds = self.fc4(preds)\n preds = F.relu(preds)\n preds = self.fc5(preds)\n preds = F.relu(preds)\n preds = self.fc6(preds)\n preds = F.relu(preds)\n preds = self.fc7(preds)\n return F.sigmoid(preds)",
"_____no_output_____"
],
[
"device = torch.device('cuda')",
"_____no_output_____"
],
[
"X_train = X_train.to(device)\ny_train = y_train.to(device)\nX_test = X_test.to(device)\ny_test = y_test.to(device)",
"_____no_output_____"
],
[
"PROJECT_NAME = 'Heart-Disease-UCI'",
"_____no_output_____"
],
[
"def get_loss(criterion,X,y,model):\n model.eval()\n with torch.no_grad():\n preds = model(X.float().to(device))\n preds = preds.view(len(preds),).to(device)\n y = y.view(len(y),).to(device)\n loss = criterion(preds,y)\n model.train()\n return loss.item()\ndef get_accuracy(preds,y):\n correct = 0\n total = 0\n for real,pred in zip(y_train,preds):\n if real == pred:\n correct += 1\n total += 1\n return round(correct/total,3)",
"_____no_output_____"
],
[
"import wandb",
"_____no_output_____"
],
[
"from tqdm import tqdm",
"_____no_output_____"
],
[
"EPOCHS = 212\n# EPOCHS = 100",
"_____no_output_____"
],
[
"# model = Test_Model().to(device)\n# optimizer = torch.optim.SGD(model.parameters(),lr=0.25)\n# criterion = nn.L1Loss()\n# wandb.init(project=PROJECT_NAME,name='baseline')\n# for _ in tqdm(range(EPOCHS)):\n# preds = model(X_train.float().to(device))\n# preds = preds.view(len(preds),)\n# preds.to(device)\n# loss = criterion(preds,y_train)\n# optimizer.zero_grad()\n# loss.backward()\n# optimizer.step()\n# wandb.log({'loss':loss.item(),'val_loss':get_loss(criterion,X_test,y_test,model),'accuracy':get_accuracy(X_train,y_train,model),'val_accuracy':get_accuracy(X_test,y_test,model)})\n# wandb.finish()",
"_____no_output_____"
],
[
"# preds[:10]",
"_____no_output_____"
],
[
"# preds = torch.round(preds)",
"_____no_output_____"
],
[
"# correct = 0\n# total = 0\n# for real,pred in zip(y_train,preds):\n# if real == pred:\n# correct += 1\n# # total += 1",
"_____no_output_____"
],
[
"# round(correct/total,3)",
"_____no_output_____"
],
[
"## Testing Modelling",
"_____no_output_____"
],
[
"import torch\nimport torch.nn as nn",
"_____no_output_____"
],
[
"class Test_Model(nn.Module):\n def __init__(self,num_of_layers=1,activation=F.relu,input_shape=13,fc1_output=32,fc2_output=64,fc3_output=128,fc4_output=256,output_shape=1):\n super().__init__()\n self.num_of_layers = num_of_layers\n self.activation = activation\n self.fc1 = nn.Linear(input_shape,fc1_output)\n self.fc2 = nn.Linear(fc1_output,fc2_output)\n self.fc3 = nn.Linear(fc2_output,fc3_output)\n self.fc4 = nn.Linear(fc3_output,fc4_output)\n self.fc5 = nn.Linear(fc4_output,fc3_output)\n self.fc6 = nn.Linear(fc3_output,fc3_output)\n self.fc7 = nn.Linear(fc3_output,output_shape)\n \n def forward(self,X,activation=False):\n preds = self.fc1(X)\n if activation:\n preds = self.activation(preds)\n preds = self.fc2(preds)\n if activation:\n preds = self.activation(preds)\n preds = self.fc3(preds)\n if activation:\n preds = self.activation(preds)\n preds = self.fc4(preds)\n if activation:\n preds = self.activation(preds)\n preds = self.fc5(preds)\n if activation:\n preds = self.activation(preds)\n for _ in range(self.num_of_layers):\n preds = self.fc6(preds)\n if activation:\n preds = self.activation(preds)\n preds = self.fc7(preds)\n preds = F.sigmoid(preds)\n return preds",
"_____no_output_____"
],
[
"device = torch.device('cuda')",
"_____no_output_____"
],
[
"# preds = torch.round(preds)",
"_____no_output_____"
],
[
"# num_of_layers = 1\n# activation\n# input_shape\n# fc1_output\n# fc2_output\n# fc3_output\n# fc4_output\n# output_shape\n# optimizer\n# criterion\n# lr\n# activtion",
"_____no_output_____"
],
[
"activations = [nn.ELU(),nn.LeakyReLU(),nn.PReLU(),nn.ReLU(),nn.ReLU6(),nn.RReLU(),nn.SELU(),nn.CELU(),nn.GELU(),nn.SiLU(),nn.Tanh()]\nfor activation in activations:\n model = Test_Model(num_of_layers=1,activation=activation).to(device)\n model.to(device)\n optimizer = torch.optim.Adam(model.parameters(),lr=0.25)\n criterion = nn.BCELoss()\n wandb.init(project=PROJECT_NAME,name=f'activation-{activation}')\n for _ in tqdm(range(212)):\n preds = model(X_train.float().to(device),True)\n preds = preds.view(len(preds),)\n preds.to(device)\n loss = criterion(preds,y_train)\n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n wandb.log({'loss':loss.item(),'val_loss':get_loss(criterion,X_test,y_test,model),'accuracy':get_accuracy(preds,y_train)})\n wandb.finish()",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3597550a5d27374f45953385556896224d8463 | 6,893 | ipynb | Jupyter Notebook | iit-madras/Cricket Hackathon 2021/all_models.ipynb | rohitnandi12/ai-hackathons | 367e360781623e75598fecd595045e6531c082d8 | [
"CC0-1.0"
] | null | null | null | iit-madras/Cricket Hackathon 2021/all_models.ipynb | rohitnandi12/ai-hackathons | 367e360781623e75598fecd595045e6531c082d8 | [
"CC0-1.0"
] | 1 | 2021-04-15T23:24:12.000Z | 2021-04-15T23:24:12.000Z | iit-madras/Cricket Hackathon 2021/all_models.ipynb | rohitnandi12/ai-hackathons | 367e360781623e75598fecd595045e6531c082d8 | [
"CC0-1.0"
] | null | null | null | 35.530928 | 117 | 0.561729 | [
[
[
"# All Models Test\n\nLoad the right file and rull all",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nfrom sklearn.preprocessing import LabelEncoder\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.linear_model import LinearRegression, BayesianRidge\nfrom sklearn.tree import DecisionTreeRegressor\nfrom sklearn.ensemble import RandomForestRegressor\nimport matplotlib.pyplot as plt\nfrom sklearn.metrics import mean_squared_error\nfrom math import sqrt\nfrom sklearn.svm import SVR\nimport keras\nimport keras.backend as kb\nimport tensorflow as tf\nfrom tensorflow import keras\nfrom tensorflow.keras import layers\nfrom tensorflow.keras.layers.experimental import preprocessing\nfrom sklearn.metrics import r2_score",
"_____no_output_____"
],
[
"def printScores(reg, X_test, y_test):\n regName = reg.__class__().__str__()[:reg.__class__().__str__().index(\"(\")]\n \n print(\"\\nR2 score : {} = {}\".format(regName, reg.score(X_test, y_test)))\n print(\"RMSE : {} = {}\".format(regName, sqrt(mean_squared_error(y_test, reg.predict(X_test)))))\n",
"_____no_output_____"
],
[
"def run_models(X, y, nn_input):\n X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, shuffle=True, random_state=42)\n \n lReg = LinearRegression()\n lReg.fit(X_train, y_train)\n printScores(lReg, X_test, y_test)\n# print(\"\\nR2 score : Linear Regressor =\",lReg.score(X_test, y_test))\n\n# from sklearn.preprocessing import PolynomialFeatures\n# pReg = PolynomialFeatures(degree = 4)\n# X_poly = pReg.fit_transform(X_train)\n# lin_reg = LinearRegression()\n# lin_reg.fit(X_poly, y_train)\n\n brReg = BayesianRidge()\n brReg.fit(X_train, y_train)\n printScores(brReg, X_test, y_test)\n# print(\"\\nR2 score : BayesianRidge =\", brReg.score(X_test, y_test))\n \n dtReg = DecisionTreeRegressor()\n# print(dtReg)\n dtReg.fit(X_train, y_train)\n printScores(dtReg, X_test, y_test)\n# print(\"\\nR2 score : DecisionTreeRegressor =\",dtReg.score(X_test, y_test))\n \n rfReg = RandomForestRegressor(n_estimators = 10, random_state = 0)\n rfReg.fit(X_train, y_train)\n printScores(rfReg, X_test, y_test)\n# print(\"\\nR2 score : RandomForestRegressor =\",rfReg.score(X_test, y_test))\n\n svReg = SVR(kernel = 'rbf', gamma='scale')\n svReg.fit(X_train, y_train)\n printScores(svReg, X_test, y_test)\n# print(\"\\nR2 score : RandomForestRegressor =\",rfReg.score(X_test, y_test))\n \n # NN\n model = keras.Sequential([\n keras.layers.Dense(134, activation=tf.nn.relu, input_shape=[nn_input]),\n keras.layers.Dense(134, activation=tf.nn.relu),\n keras.layers.Dense(134, activation=tf.nn.relu),\n keras.layers.Dense(1)\n ])\n\n optimizer = tf.keras.optimizers.RMSprop(0.0099)\n# model = tf.keras.models.load_model('./ipl_model_tf')\n model.compile(loss=\"mean_squared_error\",optimizer=optimizer)\n model.fit(X_train,y_train,epochs=500, validation_split=0.2, shuffle=True, verbose=0)\n model.save('./ipl_model_tf',save_format='tf')\n regName = 'Neural Network'\n print(\"\\nR2 score : {} = {}\".format(regName, r2_score(model.predict(X_test), y_test)))\n print(\"RMSE : {} = {}\".format(regName, sqrt(mean_squared_error(y_test, model.predict(X_test)))))\n \n # Visualising the Decision Tree Regression Results \n plt.figure(figsize=(15,10))\n X_grid = np.arange(0, len(X))\n #.reshape(-1, 1)\n plt.scatter(X_grid, y, color = 'black')\n plt.plot(X_grid, lReg.predict(X), color = 'red')\n# plt.plot(X_grid, dtReg.predict(X), color = 'green')\n plt.plot(X_grid, rfReg.predict(X), color = 'blue')\n plt.plot(X_grid, brReg.predict(X), color = 'pink')\n plt.plot(X_grid, svReg.predict(X), color = 'yellow')\n plt.plot(X_grid, model.predict(X), color = 'cyan', marker='x', lineWidth=0)\n plt.title('All Models')\n plt.xlabel('index number')\n plt.ylabel('Revenue')\n plt.show()\n",
"_____no_output_____"
],
[
"def do_traning(data=None, filename=None):\n if(data is None and filename is None):\n raise Exception(\"Atleast provide data or filename\")\n \n if(data is None):\n data = pd.read_csv('./dt/feature_engg_1.csv', header=0)\n \n df = data.copy()\n# df.sample(5)\n print(\"Data has shape \", df.shape)\n \n y = df['target']\n print('y_shape is ', y.shape)\n X = df.drop('target', axis=1)\n print('x_shape is ',X.shape)\n \n X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, shuffle=True, random_state=42)\n \n run_models(X, y, X.shape[1])\n \n ",
"_____no_output_____"
],
[
"# saving the model in tensorflow format\n# model.save('./MyModel_tf',save_format='tf')\n\n# loading the saved model\n# loaded_model = tf.keras.models.load_model('./MyModel_tf')\n\n# retraining the model\n# loaded_model.fit(X_train,y_train,epochs=500)",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
cb359f0a2744bd75bb6481ea2323eb1ef513903d | 9,509 | ipynb | Jupyter Notebook | code/04. Brunch Baseline - Content Based Recommendation.ipynb | choco9966/T-academy-Recommendation | ad0c20aebfbd549b18bfb6d2ae3f8c9493d980f7 | [
"MIT"
] | 41 | 2020-08-16T05:13:40.000Z | 2022-02-23T01:38:12.000Z | code/04. Brunch Baseline - Content Based Recommendation.ipynb | choco9966/T-academy-Recommendation | ad0c20aebfbd549b18bfb6d2ae3f8c9493d980f7 | [
"MIT"
] | null | null | null | code/04. Brunch Baseline - Content Based Recommendation.ipynb | choco9966/T-academy-Recommendation | ad0c20aebfbd549b18bfb6d2ae3f8c9493d980f7 | [
"MIT"
] | 10 | 2020-08-17T05:39:26.000Z | 2021-08-29T13:06:05.000Z | 28.050147 | 126 | 0.538017 | [
[
[
"import pickle\nimport pandas as pd\nimport numpy as np\nimport os, sys, gc \nfrom plotnine import *\nimport plotnine\n\nfrom tqdm import tqdm_notebook\nimport seaborn as sns\nimport warnings\nimport matplotlib.pyplot as plt\nimport matplotlib.font_manager as fm\nimport matplotlib as mpl\nfrom matplotlib import rc\nimport re\nfrom matplotlib.ticker import PercentFormatter\nimport datetime\nfrom math import log # IDF 계산을 위해",
"_____no_output_____"
],
[
"path = 'C:/Users/User/Documents/T아카데미/T 아카데미/input/'",
"_____no_output_____"
],
[
"# pd.read_json : json 형태의 파일을 dataframe 형태로 불러오는 코드 \nmagazine = pd.read_json(path + 'magazine.json', lines=True) # lines = True : Read the file as a json object per line.\nmetadata = pd.read_json(path + 'metadata.json', lines=True)\nusers = pd.read_json(path + 'users.json', lines=True)",
"_____no_output_____"
],
[
"%%time \nimport itertools\nfrom itertools import chain\nimport glob\nimport os \n\ninput_read_path = path + 'read/read/'\n# os.listdir : 해당 경로에 있는 모든 파일들을 불러오는 명령어 \nfile_list = os.listdir(input_read_path)\nexclude_file_lst = ['read.tar', '.2019010120_2019010121.un~']\n\nread_df_list = []\nfor file in tqdm_notebook(file_list):\n # 예외처리 \n if file in exclude_file_lst:\n continue \n else:\n file_path = input_read_path + file\n df_temp = pd.read_csv(file_path, header=None, names=['raw'])\n # file명을 통해서 읽은 시간을 추출(from, to)\n df_temp['from'] = file.split('_')[0]\n df_temp['to'] = file.split('_')[1]\n read_df_list.append(df_temp)\n \nread_df = pd.concat(read_df_list)\n# reads 파일을 전처리해서 row 당 user - article이 1:1이 되도록 수정 \nread_df['user_id'] = read_df['raw'].apply(lambda x: x.split(' ')[0])\nread_df['article_id'] = read_df['raw'].apply(lambda x: x.split(' ')[1:])\n\ndef chainer(s):\n return list(itertools.chain.from_iterable(s))\n\nread_cnt_by_user = read_df['article_id'].map(len)\nread_rowwise = pd.DataFrame({'from': np.repeat(read_df['from'], read_cnt_by_user),\n 'to': np.repeat(read_df['to'], read_cnt_by_user),\n 'user_id': np.repeat(read_df['user_id'], read_cnt_by_user),\n 'article_id': chainer(read_df['article_id'])})\n\nread_rowwise.reset_index(drop=True, inplace=True)",
"_____no_output_____"
],
[
"from datetime import datetime \n\nmetadata['reg_datetime'] = metadata['reg_ts'].apply(lambda x : datetime.fromtimestamp(x/1000.0))\nmetadata.loc[metadata['reg_datetime'] == metadata['reg_datetime'].min(), 'reg_datetime'] = datetime(2090, 12, 31)\nmetadata['reg_dt'] = metadata['reg_datetime'].dt.date\nmetadata['type'] = metadata['magazine_id'].apply(lambda x : '개인' if x == 0.0 else '매거진')\nmetadata['reg_dt'] = pd.to_datetime(metadata['reg_dt'])",
"_____no_output_____"
],
[
"read_rowwise = read_rowwise.merge(metadata[['id', 'reg_dt']], how='left', left_on='article_id', right_on='id')\nread_rowwise = read_rowwise[read_rowwise['article_id'] != '']\n\n# 사용자가 읽은 글의 목록들을 저장 \nread_total = pd.DataFrame(read_rowwise.groupby(['user_id'])['article_id'].unique()).reset_index()\nread_total.columns = ['user_id', 'article_list']",
"_____no_output_____"
]
],
[
[
"## 콘텐츠 기반의 추천시스템\n- Model의 단어를 이용한 방식\n- TF-IDF 형식\n - index : 문서의 아이디 \n - column : 단어 \n\n하지만, 문서가 총 64만개로 너무 많고 data.0의 파일을 읽어보면 단어 또한 너무 많아서 사용하기가 어려운 상황\n\n### 해결방식\n위와 같은 문제를 해결하기 위해서 해당 대회의 1등팀인 NAFMA팀은 글의 키워드를 활용해서 Embedding을 구성 \n- 참고자료 : https://github.com/JungoKim/brunch_nafma",
"_____no_output_____"
]
],
[
[
"from sklearn.feature_extraction.text import TfidfVectorizer\n\nmetadata = metadata[metadata['keyword_list'].notnull()].reset_index()\nmetadata = metadata[metadata['reg_dt'] >= '2019-01-01']",
"_____no_output_____"
],
[
"article2idx = {}\nfor i, l in enumerate(metadata['id'].unique()):\n article2idx[l] = i\n \nidx2article = {i: item for item, i in article2idx.items()}\narticleidx = metadata['articleidx'] = metadata['id'].apply(lambda x: article2idx[x]).values",
"_____no_output_____"
],
[
"import scipy\n\ndocs = metadata['keyword_list'].apply(lambda x: ' '.join(x)).values\ntfidv = TfidfVectorizer(use_idf=True, smooth_idf=False, norm=None).fit(docs)\ntfidv_df = scipy.sparse.csr_matrix(tfidv.transform(docs))\ntfidv_df = tfidv_df.astype(np.float32)",
"_____no_output_____"
],
[
"print(tfidv_df.shape)",
"(73574, 20823)\n"
]
],
[
[
"데이터가 Sparse 형태인 것을 확인할 수 있음",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics.pairwise import cosine_similarity\n\n# 메모리 문제 발생 \ncos_sim = cosine_similarity(tfidv_df, tfidv_df)",
"_____no_output_____"
],
[
"valid = pd.read_csv(path + '/predict/predict/dev.users', header=None)",
"_____no_output_____"
],
[
"%%time \npopular_rec_model = read_rowwise['article_id'].value_counts().index[0:100]\n\ntop_n = 100\nwith open('./recommend.txt', 'w') as f:\n for user in tqdm_notebook(valid[0].values):\n seen = chainer(read_total[read_total['user_id'] == user]['article_list'])\n for seen_id in seen:\n # 2019년도 이전에 읽어서 혹은 메타데이터에 글이 없어서 유사도 계산이 안된 글\n cos_sim_sum = np.zeros(len(cos_sim))\n try:\n cos_sim_sum += cos_sim[article2idx[seen_id]]\n except:\n pass\n\n recs = []\n for rec in cos_sim_sum.argsort()[-(top_n+100):][::-1]:\n if (idx2article[rec] not in seen) & (len(recs) < 100):\n recs.append(idx2article[rec])\n\n f.write('%s %s\\n' % (user, ' '.join(recs[0:100])))",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
]
] |
cb35b7d8350b5405e958cce98b3ce116596fb1b2 | 43,868 | ipynb | Jupyter Notebook | notebooks/S02_Python_Functions_Annotated.ipynb | taotangtt/sta-663-2018 | 67dac909477f81d83ebe61e0753de2328af1be9c | [
"BSD-3-Clause"
] | 72 | 2018-01-20T20:50:22.000Z | 2022-02-27T23:24:21.000Z | notebooks/S02_Python_Functions_Annotated.ipynb | taotangtt/sta-663-2018 | 67dac909477f81d83ebe61e0753de2328af1be9c | [
"BSD-3-Clause"
] | 1 | 2020-02-03T13:43:46.000Z | 2020-02-03T13:43:46.000Z | notebooks/S02_Python_Functions_Annotated.ipynb | taotangtt/sta-663-2018 | 67dac909477f81d83ebe61e0753de2328af1be9c | [
"BSD-3-Clause"
] | 64 | 2018-01-12T17:13:14.000Z | 2022-03-14T20:22:46.000Z | 19.662931 | 772 | 0.407723 | [
[
[
"# Python Functions",
"_____no_output_____"
]
],
[
[
"import numpy as np",
"_____no_output_____"
]
],
[
[
"## Custom functions",
"_____no_output_____"
],
[
"### Anatomy\n\nname, arguments, docstring, body, return statement",
"_____no_output_____"
]
],
[
[
"def func_name(arg1, arg2):\n \"\"\"Docstring starts wtih a short description.\n \n May have more information here.\n \n arg1 = something\n arg2 = somehting\n \n Returns something\n \n Example usage:\n \n func_name(1, 2) \n \"\"\"\n result = arg1 + arg2\n \n return result",
"_____no_output_____"
],
[
"help(func_name)",
"Help on function func_name in module __main__:\n\nfunc_name(arg1, arg2)\n Docstring starts wtih a short description.\n \n May have more information here.\n \n arg1 = something\n arg2 = somehting\n \n Returns something\n \n Example usage:\n \n func_name(1, 2)\n\n"
]
],
[
[
"### Function arguments\n\nplace, keyword, keyword-only, defaults, mutatble an immutable arguments",
"_____no_output_____"
]
],
[
[
"def f(a, b, c, *args, **kwargs):\n return a, b, c, args, kwargs",
"_____no_output_____"
],
[
"f(1, 2, 3, 4, 5, 6, x=7, y=8, z=9)",
"_____no_output_____"
],
[
"def g(a, b, c, *, x, y, z):\n return a, b, c, x, y, z",
"_____no_output_____"
],
[
"try:\n g(1,2,3,4,5,6)\nexcept TypeError as e:\n print(e)",
"g() takes 3 positional arguments but 6 were given\n"
],
[
"g(1,2,3,x=4,y=5,z=6)",
"_____no_output_____"
],
[
"def h(a=1, b=2, c=3):\n return a, b, c",
"_____no_output_____"
],
[
"h()",
"_____no_output_____"
],
[
"h(b=9)",
"_____no_output_____"
],
[
"h(7,8,9)",
"_____no_output_____"
]
],
[
[
"### Default mutable argumnet\n\nbinding is fixed at function definition, the default=None idiom",
"_____no_output_____"
]
],
[
[
"def f(a, x=[]):\n x.append(a)\n return x",
"_____no_output_____"
],
[
"f(1)",
"_____no_output_____"
],
[
"f(2)",
"_____no_output_____"
],
[
"def f(a, x=None):\n if x is None:\n x = []\n x.append(a)\n return x",
"_____no_output_____"
],
[
"f(1)",
"_____no_output_____"
],
[
"f(2)",
"_____no_output_____"
]
],
[
[
"## Pure functions\n\ndeterministic, no side effects",
"_____no_output_____"
]
],
[
[
"def f1(x):\n \"\"\"Pure.\"\"\"\n return x**2",
"_____no_output_____"
],
[
"def f2(x):\n \"\"\"Pure if we ignore local state change.\n \n The x in the function baheaves like a copy.\n \"\"\"\n x = x**2\n return x",
"_____no_output_____"
],
[
"def f3(x):\n \"\"\"Impure if x is mutable. \n \n Augmented assignemnt is an in-place operation for mutable structures.\"\"\"\n x **= 2\n return x",
"_____no_output_____"
],
[
"a = 2\nb = np.array([1,2,3])",
"_____no_output_____"
],
[
"f1(a), a",
"_____no_output_____"
],
[
"f1(b), b",
"_____no_output_____"
],
[
"f2(a), a",
"_____no_output_____"
],
[
"f2(b), b",
"_____no_output_____"
],
[
"f3(a), a",
"_____no_output_____"
],
[
"f3(b), b",
"_____no_output_____"
],
[
"def f4():\n \"\"\"Stochastic functions are tehcnically impure \n since a global seed is changed between function calls.\"\"\"\n \n import random\n return random.randint(0,10)",
"_____no_output_____"
],
[
"f4(), f4(), f4()",
"_____no_output_____"
]
],
[
[
"## Recursive functions\n\nEuclidean GCD algorithm\n```\ngcd(a, 0) = a\ngcd(a, b) = gcd(b, a mod b)\n```",
"_____no_output_____"
]
],
[
[
"def factorial(n):\n \"\"\"Simple recursive funciton.\"\"\"\n if n == 0:\n return 1\n else:\n return n * factorial(n-1)",
"_____no_output_____"
],
[
"factorial(4)",
"_____no_output_____"
],
[
"def factorial1(n):\n \"\"\"Non-recursive version.\"\"\"\n s = 1\n for i in range(1, n+1):\n s *= i\n return s",
"_____no_output_____"
],
[
"factorial1(4)",
"_____no_output_____"
],
[
"def gcd(a, b):\n if b == 0:\n return a\n else:\n return gcd(b, a % b)",
"_____no_output_____"
],
[
"gcd(16, 24)",
"_____no_output_____"
]
],
[
[
"## Generators\n\nyield and laziness, infinite streams",
"_____no_output_____"
]
],
[
[
"def count(n=0):\n while True:\n yield n\n n += 1",
"_____no_output_____"
],
[
"for i in count(10):\n print(i)\n if i >= 15:\n break",
"10\n11\n12\n13\n14\n15\n"
],
[
"from itertools import islice",
"_____no_output_____"
],
[
"list(islice(count(), 10, 15))",
"_____no_output_____"
],
[
"def updown(n):\n yield from range(n)\n yield from range(n, 0, -1)",
"_____no_output_____"
],
[
"updown(5)",
"_____no_output_____"
],
[
"list(updown(5))",
"_____no_output_____"
]
],
[
[
"## First class functions\n\nfunctions as arguments, functions as return values",
"_____no_output_____"
]
],
[
[
"def double(x):\n return x*2\n\ndef twice(x, func):\n return func(func(x))",
"_____no_output_____"
],
[
"twice(3, double)",
"_____no_output_____"
]
],
[
[
"Example from standard library",
"_____no_output_____"
]
],
[
[
"xs = 'banana apple guava'.split()",
"_____no_output_____"
],
[
"xs",
"_____no_output_____"
],
[
"sorted(xs)",
"_____no_output_____"
],
[
"sorted(xs, key=lambda s: s.count('a'))",
"_____no_output_____"
],
[
"def f(n):\n def g():\n print(\"hello\")\n def h():\n print(\"goodbye\")\n if n == 0:\n return g\n else:\n return h",
"_____no_output_____"
],
[
"g = f(0)\ng()",
"hello\n"
],
[
"h = f(1)\nh()",
"goodbye\n"
]
],
[
[
"## Function dispatch\n\nPoor man's switch statement",
"_____no_output_____"
]
],
[
[
"def add(x, y):\n return x + y\n\ndef mul(x, y):\n return x * y",
"_____no_output_____"
],
[
"ops = {\n 'a': add,\n 'm': mul\n}",
"_____no_output_____"
],
[
"items = zip('aammaammam', range(10), range(10))",
"_____no_output_____"
],
[
"for item in items:\n key, x, y = item\n op = ops[key]\n print(key, x, y, op(x, y))",
"a 0 0 0\na 1 1 2\nm 2 2 4\nm 3 3 9\na 4 4 8\na 5 5 10\nm 6 6 36\nm 7 7 49\na 8 8 16\nm 9 9 81\n"
]
],
[
[
"## Closure\n\nCapture of argument in enclosing scope",
"_____no_output_____"
]
],
[
[
"def f(x):\n def g(y):\n return x + y\n return g",
"_____no_output_____"
],
[
"f1 = f(0)\nf2 = f(10)",
"_____no_output_____"
],
[
"f1(5), f2(5)",
"_____no_output_____"
]
],
[
[
"## Decorators\n\nA timing decorator",
"_____no_output_____"
]
],
[
[
"def timer(f):\n import time\n def g(*args, **kwargs):\n tic = time.time()\n res = f(*args, **kwargs)\n toc = time.time()\n return res, toc-tic\n return g",
"_____no_output_____"
],
[
"def f(n):\n s = 0\n for i in range(n):\n s += i\n return s",
"_____no_output_____"
],
[
"timed_f = timer(f)",
"_____no_output_____"
],
[
"timed_f(100000)",
"_____no_output_____"
]
],
[
[
"Decorator syntax",
"_____no_output_____"
]
],
[
[
"@timer\ndef g(n):\n s = 0\n for i in range(n):\n s += i\n return s",
"_____no_output_____"
],
[
"g(100000)",
"_____no_output_____"
]
],
[
[
"## Anonymous functions\n\nShort, one-use lambdas",
"_____no_output_____"
]
],
[
[
"f = lambda x: x**2",
"_____no_output_____"
],
[
"f(3)",
"_____no_output_____"
],
[
"g = lambda x, y: x+y",
"_____no_output_____"
],
[
"g(3,4)",
"_____no_output_____"
]
],
[
[
"## Map, filter and reduce\n\nFuncitonal building blocks",
"_____no_output_____"
]
],
[
[
"xs = range(10)\nlist(map(lambda x: x**2, xs))",
"_____no_output_____"
],
[
"list(filter(lambda x: x%2 == 0, xs))",
"_____no_output_____"
],
[
"from functools import reduce",
"_____no_output_____"
],
[
"reduce(lambda x, y: x+y, xs)",
"_____no_output_____"
],
[
"reduce(lambda x, y: x+y, xs, 100)",
"_____no_output_____"
]
],
[
[
"## Functional modules in the standard library\n\nitertools, functional and operator",
"_____no_output_____"
]
],
[
[
"import operator as op",
"_____no_output_____"
],
[
"reduce(op.add, range(10))",
"_____no_output_____"
],
[
"import itertools as it",
"_____no_output_____"
],
[
"list(it.islice(it.cycle([1,2,3]), 1, 10))",
"_____no_output_____"
],
[
"list(it.permutations('abc', 2))",
"_____no_output_____"
],
[
"list(it.combinations('abc', 2))",
"_____no_output_____"
],
[
"from functools import partial, lru_cache",
"_____no_output_____"
],
[
"def f(a, b, c):\n return a + b + c",
"_____no_output_____"
],
[
"g = partial(f, b = 2, c=3)",
"_____no_output_____"
],
[
"g(1)",
"_____no_output_____"
],
[
"def fib(n, trace=False):\n if trace:\n print(\"fib(%d)\" % n, end=',')\n if n <= 2:\n return 1\n else:\n return fib(n-1, trace) + fib(n-2, trace)",
"_____no_output_____"
],
[
"fib(10, True)",
"fib(10),fib(9),fib(8),fib(7),fib(6),fib(5),fib(4),fib(3),fib(2),fib(1),fib(2),fib(3),fib(2),fib(1),fib(4),fib(3),fib(2),fib(1),fib(2),fib(5),fib(4),fib(3),fib(2),fib(1),fib(2),fib(3),fib(2),fib(1),fib(6),fib(5),fib(4),fib(3),fib(2),fib(1),fib(2),fib(3),fib(2),fib(1),fib(4),fib(3),fib(2),fib(1),fib(2),fib(7),fib(6),fib(5),fib(4),fib(3),fib(2),fib(1),fib(2),fib(3),fib(2),fib(1),fib(4),fib(3),fib(2),fib(1),fib(2),fib(5),fib(4),fib(3),fib(2),fib(1),fib(2),fib(3),fib(2),fib(1),fib(8),fib(7),fib(6),fib(5),fib(4),fib(3),fib(2),fib(1),fib(2),fib(3),fib(2),fib(1),fib(4),fib(3),fib(2),fib(1),fib(2),fib(5),fib(4),fib(3),fib(2),fib(1),fib(2),fib(3),fib(2),fib(1),fib(6),fib(5),fib(4),fib(3),fib(2),fib(1),fib(2),fib(3),fib(2),fib(1),fib(4),fib(3),fib(2),fib(1),fib(2),"
],
[
"%timeit -r1 -n100 fib(20)",
"2.93 ms ± 0 ns per loop (mean ± std. dev. of 1 run, 100 loops each)\n"
],
[
"@lru_cache(3)\ndef fib1(n, trace=False):\n if trace:\n print(\"fib(%d)\" % n, end=',')\n if n <= 2:\n return 1\n else:\n return fib1(n-1, trace) + fib1(n-2, trace)",
"_____no_output_____"
],
[
"fib1(10, True)",
"fib(10),fib(9),fib(8),fib(7),fib(6),fib(5),fib(4),fib(3),fib(2),fib(1),"
],
[
"%timeit -r1 -n100 fib1(20)",
"348 ns ± 0 ns per loop (mean ± std. dev. of 1 run, 100 loops each)\n"
]
],
[
[
"## Using `toolz`\n\nfuncitonal power tools",
"_____no_output_____"
]
],
[
[
"import toolz as tz\nimport toolz.curried as c",
"_____no_output_____"
]
],
[
[
"Find the 5 most common sequences of length 3 in the dna variable.",
"_____no_output_____"
]
],
[
[
"dna = np.random.choice(list('ACTG'), (10,80), p=[.1,.2,.3,.4])",
"_____no_output_____"
],
[
"dna",
"_____no_output_____"
],
[
"tz.pipe(\n dna,\n c.map(lambda s: ''.join(s)),\n list\n)",
"_____no_output_____"
],
[
"res = tz.pipe(\n dna,\n c.map(lambda s: ''.join(s)),\n lambda s: ''.join(s),\n c.sliding_window(3),\n c.map(lambda s: ''.join(s)),\n tz.frequencies\n)",
"_____no_output_____"
],
[
"[(k,v) for i, (k, v) in enumerate(sorted(res.items(), key=lambda x: -x[1])) if i < 5]",
"_____no_output_____"
]
],
[
[
"## Function annotations and type hints\n\nFunction annotations and type hints are optional and meant for 3rd party libraries (e.g. a static type checker or JIT compiler). They are NOT enforced at runtime.",
"_____no_output_____"
],
[
"Notice the type annotation, default value and return type.",
"_____no_output_____"
]
],
[
[
"def f(a: str = \"hello\") -> bool:\n return a.islower()",
"_____no_output_____"
],
[
"f()",
"_____no_output_____"
],
[
"f(\"hello\")",
"_____no_output_____"
],
[
"f(\"Hello\")",
"_____no_output_____"
]
],
[
[
"Function annotations can be accessed through a special attribute.",
"_____no_output_____"
]
],
[
[
"f.__annotations__",
"_____no_output_____"
]
],
[
[
"Type and function annotations are NOT enforced. In fact, the Python interpreter essentially ignores them.",
"_____no_output_____"
]
],
[
[
"def f(x: int) -> int:\n return x + x",
"_____no_output_____"
],
[
"f(\"hello\")",
"_____no_output_____"
]
],
[
[
"For more types, import from the `typing` module",
"_____no_output_____"
]
],
[
[
"from typing import Sequence, TypeVar",
"_____no_output_____"
],
[
"from functools import reduce\nimport operator as op",
"_____no_output_____"
],
[
"T = TypeVar('T')\n\ndef f(xs: Sequence[T]) -> T:\n return reduce(op.add, xs) ",
"_____no_output_____"
],
[
"f([1,2,3])",
"_____no_output_____"
],
[
"f({1., 2., 3.})",
"_____no_output_____"
],
[
"f(('a', 'b', 'c'))",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb35b959f77922ecc50921a4eb428c6a7a4475b3 | 250,503 | ipynb | Jupyter Notebook | demos/PixelDrawer.ipynb | DazhiZhong/clipit | 799c4a9267615f8de15bec11c0cff54aa7162d4e | [
"MIT"
] | null | null | null | demos/PixelDrawer.ipynb | DazhiZhong/clipit | 799c4a9267615f8de15bec11c0cff54aa7162d4e | [
"MIT"
] | null | null | null | demos/PixelDrawer.ipynb | DazhiZhong/clipit | 799c4a9267615f8de15bec11c0cff54aa7162d4e | [
"MIT"
] | null | null | null | 407.321951 | 114,550 | 0.925861 | [
[
[
"<a href=\"https://colab.research.google.com/github/dribnet/clipit/blob/master/demos/PixelDrawer.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"#Pixray PixelArt demo\nUsing pixray to draw pixel art.\n\n\n<br>\nBeirut Skyline by <a href=\"https://twitter.com/gorillasu\">Ahmad Moussa</a>",
"_____no_output_____"
]
],
[
[
"#@title Setup\n\n#@markdown Please execute this cell by pressing the _Play_ button \n#@markdown on the left. For setup,\n#@markdown **you need to run this cell,\n#@markdown then choose Runtime -> Restart Runtime from the menu,\n#@markdown and then run the cell again**. It should remind you to\n#@markdown do this after the first run.\n\n#@markdown Setup can take 5-10 minutes, but once it is complete it usually does not need to be repeated\n#@markdown until you close the window.\n\n#@markdown **Note**: This installs the software on the Colab \n#@markdown notebook in the cloud and not on your computer.\n\n# https://stackoverflow.com/a/56727659/1010653\n\n# Add a gpu check\n# (this can get better over time)\nfrom google.colab import output\n\nnvidia_output = !nvidia-smi --query-gpu=memory.total --format=noheader,nounits,csv\ngpu_memory = int(nvidia_output[0])\nif gpu_memory < 14000:\n output.eval_js('new Audio(\"https://upload.wikimedia.org/wikipedia/commons/0/05/Beep-09.ogg\").play()')\n warning_string = f\"--> GPU check: ONLY {gpu_memory} MiB available: WARNING, THIS IS PROBABLY NOT ENOUGH <--\"\n print(warning_string)\n output.eval_js('alert(\"Warning - low GPU (see message)\")')\nelse:\n print(f\"GPU check: {gpu_memory} MiB available: this should be fine\")\n\n# patch for colab cuda\nfrom IPython.utils import io\nimport os\nif not os.path.isfile(\"first_init_complete\"):\n with io.capture_output() as captured:\n !pip uninstall -y torch torchvision torchaudio\n !pip install torch torchvision torchaudio\n\nwith io.capture_output() as captured:\n !git clone https://github.com/openai/CLIP\n # !pip install taming-transformers\n !git clone https://github.com/CompVis/taming-transformers.git\n !rm -Rf pixray\n !git clone https://github.com/dribnet/pixray\n !pip install ftfy regex tqdm omegaconf pytorch-lightning\n !pip install kornia\n !pip install imageio-ffmpeg \n !pip install einops\n !pip install torch-optimizer\n !pip install easydict\n !pip install braceexpand\n !pip install git+https://github.com/pvigier/perlin-numpy\n\n # ClipDraw deps\n !pip install svgwrite\n !pip install svgpathtools\n !pip install cssutils\n !pip install numba\n !pip install torch-tools\n !pip install visdom\n\n !git clone https://github.com/BachiLi/diffvg\n %cd diffvg\n # !ls\n !git submodule update --init --recursive\n !python setup.py install\n %cd ..\n\noutput.clear()\nimport sys\nsys.path.append(\"pixray\")\n\nresult_msg = \"setup complete\"\nimport IPython\nif not os.path.isfile(\"first_init_complete\"):\n # put stuff in here that should only happen once\n !mkdir -p models\n os.mknod(\"first_init_complete\")\n result_msg = \"Please choose Runtime -> Restart Runtime from the menu, and then run Setup again\"\n\njs_code = f'''\ndocument.querySelector(\"#output-area\").appendChild(document.createTextNode(\"{result_msg}\"));\n'''\njs_code += '''\nfor (rule of document.styleSheets[0].cssRules){\n if (rule.selectorText=='body') break\n}\nrule.style.fontSize = '30px'\n'''\ndisplay(IPython.display.Javascript(js_code))",
"_____no_output_____"
],
[
"#@title Settings\n\n#@markdown Enter a description of what you want to draw - I usually add #pixelart to the prompt.\n#@markdown The renderer can also be swapped with other models such\n#@markdown as VQGAN or CLIPDraw. <br>\n\nprompts = \"Beirut Skyline. #pixelart\" #@param {type:\"string\"}\n\naspect = \"widescreen\" #@param [\"widescreen\", \"square\"]\n\ndrawer = \"pixel\" #@param [\"vqgan\", \"pixel\", \"line_sketch\", \"clipdraw\"]\n\n#@markdown When you have the settings you want, press the play button on the left.\n#@markdown The system will save these and start generating images below.\n\n#@markdown When that is done you can change these\n#@markdown settings and see if you get different results. Or if you get\n#@markdown impatient, just select \"Runtime -> Interrupt Execution\".\n#@markdown Note that the first time you run it may take a bit longer\n#@markdown as nessary files are downloaded.\n\n\n#@markdown\n#@markdown *Advanced: you can also edit this cell and add add additional\n#@markdown settings, combining settings from different notebooks.*\n\n\n# Simple setup\nimport pixray\n\n# these are good settings for pixeldraw\npixray.reset_settings()\npixray.add_settings(prompts=prompts, aspect=aspect)\npixray.add_settings(quality=\"better\", scale=2.5)\npixray.add_settings(drawer=drawer)\npixray.add_settings(display_clear=True)\n\n# by default we'll turn on textoff\npixray.add_settings(vector_prompts=\"textoff2\")\n\n#### YOU CAN ADD YOUR OWN CUSTOM SETTING HERE ####\n# this is the example of how to run longer with less frequent display\n# pixray.add_settings(iterations=500, display_every=50)\n\nsettings = pixray.apply_settings()\npixray.do_init(settings)\npixray.do_run(settings)\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code"
]
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.