
hexsha
stringlengths 40
40
| size
int64 6
14.9M
| ext
stringclasses 1
value | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 6
260
| max_stars_repo_name
stringlengths 6
119
| max_stars_repo_head_hexsha
stringlengths 40
41
| max_stars_repo_licenses
list | max_stars_count
int64 1
191k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 6
260
| max_issues_repo_name
stringlengths 6
119
| max_issues_repo_head_hexsha
stringlengths 40
41
| max_issues_repo_licenses
list | max_issues_count
int64 1
67k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 6
260
| max_forks_repo_name
stringlengths 6
119
| max_forks_repo_head_hexsha
stringlengths 40
41
| max_forks_repo_licenses
list | max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | avg_line_length
float64 2
1.04M
| max_line_length
int64 2
11.2M
| alphanum_fraction
float64 0
1
| cells
list | cell_types
list | cell_type_groups
list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
cb3a96dd0de35e3ee9ff26128f44972678ea29bf | 499,535 | ipynb | Jupyter Notebook | Quantium/Quantium_task_2.ipynb | tiffanysn/general_learning | e4a17bf566fe696d69ba8fb2ee936616adf1abf1 | [
"Apache-2.0"
] | null | null | null | Quantium/Quantium_task_2.ipynb | tiffanysn/general_learning | e4a17bf566fe696d69ba8fb2ee936616adf1abf1 | [
"Apache-2.0"
] | 27 | 2020-07-19T16:14:40.000Z | 2021-09-19T01:24:42.000Z | Quantium/Quantium_task_2.ipynb | tiffanysn/general_learning | e4a17bf566fe696d69ba8fb2ee936616adf1abf1 | [
"Apache-2.0"
] | 2 | 2020-05-16T18:47:05.000Z | 2020-10-15T10:58:42.000Z | 40.27209 | 8,680 | 0.322736 | [
[
[
"<a href=\"https://colab.research.google.com/github/tiffanysn/general_learning/blob/dev/Quantium/Quantium_task_2.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"from google.colab import drive\ndrive.mount('/content/drive')",
"Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount(\"/content/drive\", force_remount=True).\n"
]
],
[
[
"## Load required libraries and datasets",
"_____no_output_____"
]
],
[
[
"! cp drive/My\\ Drive/QVI_data.csv .",
"_____no_output_____"
],
[
"import pandas as pd",
"_____no_output_____"
],
[
"import plotly.express as px",
"_____no_output_____"
],
[
"import numpy as np\n",
"_____no_output_____"
],
[
"df=pd.read_csv('QVI_data.csv')",
"_____no_output_____"
],
[
"df.shape",
"_____no_output_____"
],
[
"df.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 264834 entries, 0 to 264833\nData columns (total 12 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 LYLTY_CARD_NBR 264834 non-null int64 \n 1 DATE 264834 non-null object \n 2 STORE_NBR 264834 non-null int64 \n 3 TXN_ID 264834 non-null int64 \n 4 PROD_NBR 264834 non-null int64 \n 5 PROD_NAME 264834 non-null object \n 6 PROD_QTY 264834 non-null int64 \n 7 TOT_SALES 264834 non-null float64\n 8 PACK_SIZE 264834 non-null int64 \n 9 BRAND 264834 non-null object \n 10 LIFESTAGE 264834 non-null object \n 11 PREMIUM_CUSTOMER 264834 non-null object \ndtypes: float64(1), int64(6), object(5)\nmemory usage: 24.2+ MB\n"
],
[
"df.describe(include= 'all')",
"_____no_output_____"
],
[
"df.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 264834 entries, 0 to 264833\nData columns (total 12 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 LYLTY_CARD_NBR 264834 non-null int64 \n 1 DATE 264834 non-null object \n 2 STORE_NBR 264834 non-null int64 \n 3 TXN_ID 264834 non-null int64 \n 4 PROD_NBR 264834 non-null int64 \n 5 PROD_NAME 264834 non-null object \n 6 PROD_QTY 264834 non-null int64 \n 7 TOT_SALES 264834 non-null float64\n 8 PACK_SIZE 264834 non-null int64 \n 9 BRAND 264834 non-null object \n 10 LIFESTAGE 264834 non-null object \n 11 PREMIUM_CUSTOMER 264834 non-null object \ndtypes: float64(1), int64(6), object(5)\nmemory usage: 24.2+ MB\n"
]
],
[
[
"# Trial store 77",
"_____no_output_____"
],
[
"## Select control store",
"_____no_output_____"
],
[
"#### Add Month column",
"_____no_output_____"
]
],
[
[
"import datetime",
"_____no_output_____"
],
[
"df['year'] = pd.DatetimeIndex(df['DATE']).year\ndf['month']=pd.DatetimeIndex(df['DATE']).month\ndf['year_month']=pd.to_datetime(df['DATE']).dt.floor('d') - pd.offsets.MonthBegin(1)\ndf",
"_____no_output_____"
]
],
[
[
"#### Monthly calculation for each store",
"_____no_output_____"
]
],
[
[
"totSales= df.groupby(['STORE_NBR','year_month'])['TOT_SALES'].sum().reset_index()\ntotSales",
"_____no_output_____"
],
[
"measureOverTime2 = pd.DataFrame(data=totSales)",
"_____no_output_____"
],
[
"nTxn= df.groupby(['STORE_NBR','year_month'])['TXN_ID'].count().reset_index(drop=True)\nnTxn",
"_____no_output_____"
],
[
"sorted(df['year_month'].unique())",
"_____no_output_____"
],
[
"measureOverTime2['nCustomers'] = df.groupby(['STORE_NBR','year_month','LYLTY_CARD_NBR'])['DATE'].count().groupby(['STORE_NBR','year_month']).count().reset_index(drop=True)\nmeasureOverTime2.head()",
"_____no_output_____"
],
[
"measureOverTime2['nTxnPerCust'] = nTxn/measureOverTime2['nCustomers']\nmeasureOverTime2.head()",
"_____no_output_____"
],
[
"totQty = df.groupby(['STORE_NBR','year_month'])['PROD_QTY'].sum().reset_index(drop=True)\ntotQty",
"_____no_output_____"
],
[
"measureOverTime2['nChipsPerTxn'] = totQty/nTxn\nmeasureOverTime2",
"_____no_output_____"
],
[
"measureOverTime2['avgPricePerUnit'] = totSales['TOT_SALES']/totQty\nmeasureOverTime2",
"_____no_output_____"
]
],
[
[
"#### Filter pre-trial & stores with full obs",
"_____no_output_____"
]
],
[
[
"measureOverTime2.set_index('year_month', inplace=True)",
"_____no_output_____"
],
[
"preTrialMeasures = measureOverTime2.loc['2018-06-01':'2019-01-01'].reset_index()\npreTrialMeasures",
"_____no_output_____"
]
],
[
[
"#### Owen's *Solution*",
"_____no_output_____"
]
],
[
[
"measureOverTime = df.groupby(['STORE_NBR','year_month','LYLTY_CARD_NBR']).\\\n agg(\n totSalesPerCust=('TOT_SALES', sum),\n nTxn=('TXN_ID', \"count\"),\n nChips=('PROD_QTY', sum)\n ).\\\n groupby(['STORE_NBR','year_month']).\\\n agg(\n totSales=(\"totSalesPerCust\", sum),\n nCustomers=(\"nTxn\", \"count\"),\n nTxnPerCust=(\"nTxn\", lambda x: x.sum()/x.count()),\n totChips=(\"nChips\", sum),\n totTxn=(\"nTxn\", sum)).\\\n reset_index()",
"_____no_output_____"
],
[
"measureOverTime['nChipsPerTxn'] = measureOverTime['totChips']/measureOverTime['totTxn']\nmeasureOverTime['avgPricePerUnit'] = measureOverTime['totSales']/measureOverTime['totChips']\nmeasureOverTime.drop(['totChips', 'totTxn'], axis=1, inplace=True)",
"_____no_output_____"
]
],
[
[
"#### Calculate correlation",
"_____no_output_____"
]
],
[
[
"preTrialMeasures",
"_____no_output_____"
],
[
"# Input\ninputTable = preTrialMeasures\nmetricCol = 'TOT_SALES'\nstoreComparison = 77\n\nx = 1",
"_____no_output_____"
],
[
"corr = preTrialMeasures.\\\n loc[preTrialMeasures['STORE_NBR'].\\\n isin([x,storeComparison])].\\\n loc[:, ['year_month', 'STORE_NBR', metricCol]].\\\n pivot(index='year_month', columns='STORE_NBR', values=metricCol).\\\n corr().\\\n iloc[0, 1]",
"_____no_output_____"
],
[
"preTrialMeasures.loc[preTrialMeasures['STORE_NBR'].isin([x,storeComparison])].loc[:, ['year_month', 'STORE_NBR', metricCol]].\\\npivot(index='year_month', columns='STORE_NBR', values=metricCol).corr()\n ",
"_____no_output_____"
],
[
"df = pd.DataFrame(columns=['Store1', 'Store2', 'corr_measure'])",
"_____no_output_____"
],
[
"df.append({'Store1':x, 'Store2':storeComparison, 'corr_measure':corr}, ignore_index=True)",
"_____no_output_____"
],
[
"def calculateCorrelation(inputTable, metricCol, storeComparison):\n df = pd.DataFrame(columns=['Store1', 'Store2', 'corr_measure'])\n for x in inputTable.STORE_NBR.unique():\n if x in [77, 86, 88]:\n pass\n else:\n corr = inputTable.\\\n loc[inputTable['STORE_NBR'].\\\n isin([x,storeComparison])].\\\n loc[:, ['year_month', 'STORE_NBR', metricCol]].\\\n pivot(index='year_month', columns='STORE_NBR', values=metricCol).\\\n corr().\\\n iloc[0, 1]\n df = df.append({'Store1':storeComparison, 'Store2':x, 'corr_measure':corr}, ignore_index=True)\n return(df)",
"_____no_output_____"
],
[
"calcCorrTable = calculateCorrelation(inputTable=preTrialMeasures, metricCol='nCustomers', storeComparison=77)",
"_____no_output_____"
],
[
"calcCorrTable",
"_____no_output_____"
]
],
[
[
"#### Calculate magnitude distance",
"_____no_output_____"
]
],
[
[
"inputTable = preTrialMeasures\nmetricCol = 'TOT_SALES'\nstoreComparison = '77'\n\nx='2'",
"_____no_output_____"
],
[
"mag = preTrialMeasures.\\\n loc[preTrialMeasures['STORE_NBR'].isin([x, storeComparison])].\\\n loc[:, ['year_month', 'STORE_NBR', metricCol]].\\\n pivot(index='year_month', columns='STORE_NBR', values=metricCol).\\\n reset_index().rename_axis(None, axis=1)\nmag",
"_____no_output_____"
],
[
"mag.columns = mag.columns.map(str)\nmag",
"_____no_output_____"
],
[
"mag['measures'] = mag.apply(lambda row: row[x]-row[storeComparison], axis=1).abs()\n\nmag",
"_____no_output_____"
],
[
"mag['Store1'] = x\nmag['Store2'] = storeComparison",
"_____no_output_____"
],
[
"df_temp = mag.loc[:, ['Store1', 'Store2', 'year_month','measures']]",
"_____no_output_____"
],
[
"df_temp",
"_____no_output_____"
],
[
"df = pd.DataFrame(columns=['Store1', 'Store2', 'year_month','measures'])\ndf",
"_____no_output_____"
],
[
"inputTable = preTrialMeasures\nmetricCol = 'TOT_SALES'\nstoreComparison = '77'\ndf = pd.DataFrame(columns=['Store1', 'Store2', 'year_month','measures'])\nfor x in inputTable.STORE_NBR.unique():\n if x in [77, 86, 88]:\n pass\n else:\n mag = preTrialMeasures.\\\n loc[preTrialMeasures['STORE_NBR'].\\\n isin([x, storeComparison])].\\\n loc[:, ['year_month', 'STORE_NBR', metricCol]].\\\n pivot(index='year_month', columns='STORE_NBR', values=metricCol).\\\n reset_index().rename_axis(None, axis=1)\n mag.columns = ['year_month', 'Store1', 'Store2']\n mag['measures'] = mag.apply(lambda row: row['Store1']-row['Store2'], axis=1).abs()\n mag['Store1'] = x\n mag['Store2'] = storeComparison \n df_temp = mag.loc[:, ['Store1', 'Store2', 'year_month','measures']]\n df = pd.concat([df, df_temp])",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"def calculateMagnitudeDistance(inputTable, metricCol, storeComparison):\n df = pd.DataFrame(columns=['Store1', 'Store2', 'year_month','measures'])\n for x in inputTable.STORE_NBR.unique():\n if x in [77, 86, 88]:\n pass\n else:\n mag = preTrialMeasures.\\\n loc[preTrialMeasures['STORE_NBR'].\\\n isin([x, storeComparison])].\\\n loc[:, ['year_month', 'STORE_NBR', metricCol]].\\\n pivot(index='year_month', columns='STORE_NBR', values=metricCol).\\\n reset_index().rename_axis(None, axis=1)\n mag.columns = ['year_month', 'Store1', 'Store2']\n mag['measures'] = mag.apply(lambda row: row['Store1']-row['Store2'], axis=1).abs()\n mag['Store1'] = storeComparison\n mag['Store2'] = x \n df_temp = mag.loc[:, ['Store1', 'Store2', 'year_month','measures']]\n df = pd.concat([df, df_temp])\n return df",
"_____no_output_____"
],
[
"def finalDistTable(inputTable, metricCol, storeComparison):\n calcDistTable = calculateMagnitudeDistance(inputTable, metricCol, storeComparison)\n minMaxDist = calcDistTable.groupby(['Store1','year_month'])['measures'].agg(['max','min']).reset_index()\n distTable = calcDistTable.merge(minMaxDist, on=['year_month', 'Store1'])\n distTable['magnitudeMeasure']= distTable.apply(lambda row: 1- (row['measures']-row['min'])/(row['max']-row['min']),axis=1)\n finalDistTable = distTable.groupby(['Store1','Store2'])['magnitudeMeasure'].mean().reset_index()\n finalDistTable.columns = ['Store1','Store2','mag_measure']\n return finalDistTable",
"_____no_output_____"
],
[
"calcDistTable = calculateMagnitudeDistance(inputTable=preTrialMeasures, metricCol='nCustomers', storeComparison='77')\ncalcDistTable",
"_____no_output_____"
]
],
[
[
"#### Standardise the magnitude distance",
"_____no_output_____"
]
],
[
[
"#calcDistTable.groupby(['Store1','year_month'])['measures'].apply(lambda g: g.max() - g.min()).reset_index()",
"_____no_output_____"
],
[
"minMaxDist = calcDistTable.groupby(['Store1','year_month'])['measures'].agg(['max','min']).reset_index()\nminMaxDist",
"_____no_output_____"
],
[
"calcDistTable.merge(minMaxDist, on=['year_month', 'Store1'])",
"_____no_output_____"
],
[
"distTable = calcDistTable.merge(minMaxDist, on=['year_month', 'Store1'])\ndistTable",
"_____no_output_____"
],
[
"distTable['magnitudeMeasure']= distTable.apply(lambda row: 1- (row['measures']-row['min'])/(row['max']-row['min']),axis=1)\ndistTable",
"_____no_output_____"
]
],
[
[
"#### Merge nTotSals & nCustomers\n\n\n\n",
"_____no_output_____"
]
],
[
[
"corr_nSales = calculateCorrelation(inputTable=preTrialMeasures, metricCol='TOT_SALES',storeComparison='77')\ncorr_nSales",
"_____no_output_____"
],
[
"corr_nCustomers = calculateCorrelation(inputTable=preTrialMeasures, metricCol='nCustomers',storeComparison='77')\ncorr_nCustomers",
"_____no_output_____"
],
[
"magnitude_nSales = finalDistTable(inputTable=preTrialMeasures, metricCol='TOT_SALES',storeComparison='77')\nmagnitude_nSales",
"_____no_output_____"
],
[
"magnitude_nCustomers = finalDistTable(inputTable=preTrialMeasures, metricCol='nCustomers',storeComparison='77')\nmagnitude_nCustomers",
"_____no_output_____"
]
],
[
[
"#### Get control store\n\n\n",
"_____no_output_____"
]
],
[
[
"score_nSales = corr_nSales.merge(magnitude_nSales, on=['Store1','Store2'])\nscore_nSales['scoreNSales'] = score_nSales.apply(lambda row: row['corr_measure']*0.5 + row['mag_measure']*0.5, axis=1)\nscore_nSales = score_nSales.loc[:,['Store1','Store2', 'scoreNSales']]\nscore_nSales",
"_____no_output_____"
],
[
"score_nCustomers = corr_nCustomers.merge(magnitude_nCustomers, on=['Store1','Store2'])\nscore_nCustomers['scoreNCust'] = score_nCustomers.apply(lambda row: row['corr_measure']*0.5 + row['mag_measure']*0.5, axis=1)\nscore_nCustomers = score_nCustomers.loc[:,['Store1','Store2','scoreNCust']]\nscore_nCustomers",
"_____no_output_____"
],
[
"score_Control = score_nSales.merge(score_nCustomers, on=['Store1','Store2'])\nscore_Control",
"_____no_output_____"
],
[
"score_Control['finalControlScore'] = score_Control.apply(lambda row: row['scoreNSales']*0.5 + row['scoreNCust']*0.5, axis=1)\nscore_Control",
"_____no_output_____"
],
[
"final_control_store = score_Control['finalControlScore'].max()",
"_____no_output_____"
],
[
"score_Control[score_Control['finalControlScore']==final_control_store]",
"_____no_output_____"
]
],
[
[
"#### Visualization the control store ",
"_____no_output_____"
]
],
[
[
"measureOverTime['Store_type'] = measureOverTime.apply(lambda row: 'Trail' if row['STORE_NBR']==77 else ('Control' if row['STORE_NBR']==233 else 'Other stores'), axis=1)\nmeasureOverTime",
"_____no_output_____"
],
[
"measureOverTime['Store_type'].unique()",
"_____no_output_____"
],
[
"measureOverTimeSales = measureOverTime.groupby(['year_month','Store_type'])['totSales'].mean().reset_index()\nmeasureOverTimeSales",
"_____no_output_____"
],
[
"measureOverTimeSales.set_index('year_month',inplace=True)",
"_____no_output_____"
],
[
"pastSales = measureOverTimeSales.loc['2018-06-01':'2019-01-01'].reset_index()\npastSales",
"_____no_output_____"
],
[
"px.line(data_frame=pastSales, x='year_month', y='totSales', color='Store_type', title='Total sales by month',labels={'year_month':'Month of operation','totSales':'Total sales'})",
"_____no_output_____"
],
[
"measureOverTimeCusts = measureOverTime.groupby(['year_month','Store_type'])['nCustomers'].mean().reset_index()\nmeasureOverTimeCusts",
"_____no_output_____"
],
[
"measureOverTimeCusts.set_index('year_month',inplace=True)\npastCustomers = measureOverTimeCusts.loc['2018-06-01':'2019-01-01'].reset_index()\npastCustomers",
"_____no_output_____"
],
[
"px.line(data_frame=pastCustomers, x='year_month', y='nCustomers', color='Store_type', title='Total customers by month',labels={'year_month':'Month of operation','nCustomers':'Total customers'})",
"_____no_output_____"
]
],
[
[
"## Assessment of trial period",
"_____no_output_____"
],
[
"### Calculate for totSales",
"_____no_output_____"
],
[
"#### Scale sales ",
"_____no_output_____"
]
],
[
[
"preTrialMeasures",
"_____no_output_____"
],
[
"preTrialMeasures.loc[preTrialMeasures['STORE_NBR']==77, 'TOT_SALES'].sum()",
"_____no_output_____"
],
[
"preTrialMeasures.loc[preTrialMeasures['STORE_NBR']==233, 'TOT_SALES'].sum()",
"_____no_output_____"
],
[
"scalingFactorForControlSales = preTrialMeasures.loc[preTrialMeasures['STORE_NBR']==77, 'TOT_SALES'].sum() / preTrialMeasures.loc[preTrialMeasures['STORE_NBR']==233, 'TOT_SALES'].sum()\nscalingFactorForControlSales",
"_____no_output_____"
]
],
[
[
"#### Apply the scaling factor",
"_____no_output_____"
]
],
[
[
"scaledControlSales = measureOverTimeSales.loc[measureOverTimeSales['Store_type']=='Control','totSales'].reset_index()\nscaledControlSales",
"_____no_output_____"
],
[
"scaledControlSales['scaledControlSales'] = scaledControlSales.apply(lambda row: row['totSales']*scalingFactorForControlSales,axis=1)\nscaledControlSales",
"_____no_output_____"
],
[
"TrailStoreSales = measureOverTimeSales.loc[measureOverTimeSales['Store_type']=='Trail',['totSales']]\nTrailStoreSales",
"_____no_output_____"
],
[
"TrailStoreSales.columns = ['trailSales']\nTrailStoreSales",
"_____no_output_____"
]
],
[
[
"#### %Diff between scaled control and trial for sales\n\n",
"_____no_output_____"
]
],
[
[
"percentageDiff = scaledControlSales.merge(TrailStoreSales, on='year_month',)\npercentageDiff",
"_____no_output_____"
],
[
"percentageDiff['percentDiff'] = percentageDiff.apply(lambda row: (row['scaledControlSales']-row['trailSales'])/row['scaledControlSales'], axis=1)",
"_____no_output_____"
],
[
"percentageDiff",
"_____no_output_____"
]
],
[
[
"#### Get standard deviation",
"_____no_output_____"
]
],
[
[
"stdDev = percentageDiff.loc[percentageDiff['year_month']< '2019-02-01', 'percentDiff'].std(ddof=8-1)\nstdDev",
"_____no_output_____"
]
],
[
[
"#### Calculate the t-values for the trial months",
"_____no_output_____"
]
],
[
[
"from scipy.stats import ttest_ind",
"_____no_output_____"
],
[
"control = percentageDiff.loc[percentageDiff['year_month']>'2019-01-01',['scaledControlSales']]\ncontrol",
"_____no_output_____"
],
[
"trail = percentageDiff.loc[percentageDiff['year_month']>'2019-01-01',['trailSales']]\ntrail",
"_____no_output_____"
],
[
"ttest_ind(control,trail)",
"_____no_output_____"
]
],
[
[
"The null hypothesis here is \"the sales between control and trial stores has **NO** significantly difference in trial period.\" The pvalue is 0.32, which is 32% that they are same in sales,which is much greater than 5%. Fail to reject the null hypothesis. Therefore, we are not confident to say \"the trial period impact trial store sales.\"",
"_____no_output_____"
]
],
[
[
"percentageDiff['t-value'] = percentageDiff.apply(lambda row: (row['percentDiff']- 0) / stdDev,axis=1)\npercentageDiff",
"_____no_output_____"
]
],
[
[
"We can observe that the t-value is much larger than the 95th percentile value of the t-distribution for March and April. \ni.e. the increase in sales in the trial store in March and April is statistically greater than in the control store.",
"_____no_output_____"
],
[
"#### 95th & 5th percentile of control store ",
"_____no_output_____"
]
],
[
[
"measureOverTimeSales",
"_____no_output_____"
],
[
"pastSales_Controls95 = measureOverTimeSales.loc[measureOverTimeSales['Store_type']=='Control']\npastSales_Controls95['totSales'] = pastSales_Controls95.apply(lambda row: row['totSales']*(1+stdDev*2),axis=1)\npastSales_Controls95.iloc[0:13,0] = 'Control 95th % confidence interval'\npastSales_Controls95.reset_index()",
"/usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:2: SettingWithCopyWarning:\n\n\nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n\n/usr/local/lib/python3.6/dist-packages/pandas/core/indexing.py:966: SettingWithCopyWarning:\n\n\nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n\n"
],
[
"pastSales_Controls5 = measureOverTimeSales.loc[measureOverTimeSales['Store_type']=='Control']\npastSales_Controls5['totSales'] = pastSales_Controls95.apply(lambda row: row['totSales']*(1-stdDev*2),axis=1)\npastSales_Controls5.iloc[0:13,0] = 'Control 5th % confidence interval'\npastSales_Controls5.reset_index()",
"/usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:2: SettingWithCopyWarning:\n\n\nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n\n/usr/local/lib/python3.6/dist-packages/pandas/core/indexing.py:966: SettingWithCopyWarning:\n\n\nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n\n"
],
[
"trialAssessment = pd.concat([measureOverTimeSales,pastSales_Controls5,pastSales_Controls95])\ntrialAssessment = trialAssessment.sort_values(by=['year_month'])\ntrialAssessment = trialAssessment.reset_index()\ntrialAssessment",
"_____no_output_____"
]
],
[
[
"#### Visualization Trial ",
"_____no_output_____"
]
],
[
[
"px.line(data_frame=trialAssessment, x='year_month', y='totSales', color='Store_type', title='Total sales by month',labels={'year_month':'Month of operation','totSales':'Total sales'})",
"_____no_output_____"
]
],
[
[
"### Calculate for nCustomers",
"_____no_output_____"
],
[
"#### Scales nCustomers",
"_____no_output_____"
]
],
[
[
"preTrialMeasures",
"_____no_output_____"
],
[
"preTrialMeasures.loc[preTrialMeasures['STORE_NBR']==77,'nCustomers'].sum()",
"_____no_output_____"
],
[
"preTrialMeasures.loc[preTrialMeasures['STORE_NBR']==233,'nCustomers'].sum()",
"_____no_output_____"
],
[
"scalingFactorForControlnCustomers = preTrialMeasures.loc[preTrialMeasures['STORE_NBR']==77,'nCustomers'].sum() / preTrialMeasures.loc[preTrialMeasures['STORE_NBR']==233,'nCustomers'].sum()\nscalingFactorForControlnCustomers",
"_____no_output_____"
]
],
[
[
"#### Apply the scaling factor",
"_____no_output_____"
]
],
[
[
"measureOverTime",
"_____no_output_____"
],
[
"scaledControlNcustomers = measureOverTime.loc[measureOverTime['Store_type']=='Control',['year_month','nCustomers']]\nscaledControlNcustomers",
"_____no_output_____"
],
[
"scaledControlNcustomers['scaledControlNcus'] = scaledControlNcustomers.apply(lambda row: row['nCustomers']*scalingFactorForControlnCustomers, axis=1)\nscaledControlNcustomers",
"_____no_output_____"
]
],
[
[
"#### %Diff between scaled control & trail for nCustomers",
"_____no_output_____"
]
],
[
[
"measureOverTime.loc[measureOverTime['Store_type']=='Trail',['year_month','nCustomers']]",
"_____no_output_____"
],
[
"percentageDiff = scaledControlNcustomers.merge(measureOverTime.loc[measureOverTime['Store_type']=='Trail',['year_month','nCustomers']],on='year_month')\npercentageDiff",
"_____no_output_____"
],
[
"percentageDiff.columns=['year_month','controlCustomers','scaledControlNcus','trialCustomers']\npercentageDiff",
"_____no_output_____"
],
[
"percentageDiff['%Diff'] = percentageDiff.apply(lambda row: (row['scaledControlNcus']-row['trialCustomers'])/row['scaledControlNcus'],axis=1)\npercentageDiff",
"_____no_output_____"
]
],
[
[
"#### Get standard deviation",
"_____no_output_____"
]
],
[
[
"stdDev = percentageDiff.loc[percentageDiff['year_month']< '2019-02-01', '%Diff'].std(ddof=8-1)\nstdDev",
"_____no_output_____"
]
],
[
[
"#### Calculate the t-values for the trial months",
"_____no_output_____"
]
],
[
[
"percentageDiff['t-value'] = percentageDiff.apply(lambda row: (row['%Diff']- 0) / stdDev,axis=1)\npercentageDiff",
"_____no_output_____"
]
],
[
[
"#### 95th & 5th percentile of control store ",
"_____no_output_____"
]
],
[
[
"measureOverTimeCusts",
"_____no_output_____"
],
[
"pastNcus_Controls95 = measureOverTimeCusts.loc[measureOverTimeCusts['Store_type']=='Control']\npastNcus_Controls95['nCustomers'] = pastNcus_Controls95.apply(lambda row: row['nCustomers']*(1+stdDev*2),axis=1)\npastNcus_Controls95.iloc[0:13,0] = 'Control 95th % confidence interval'\npastNcus_Controls95.reset_index()",
"/usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:2: SettingWithCopyWarning:\n\n\nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n\n/usr/local/lib/python3.6/dist-packages/pandas/core/indexing.py:966: SettingWithCopyWarning:\n\n\nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n\n"
],
[
"pastNcus_Controls5 = measureOverTimeCusts.loc[measureOverTimeCusts['Store_type']=='Control']\npastNcus_Controls5['nCustomers'] = pastNcus_Controls5.apply(lambda row: row['nCustomers']*(1-stdDev*2),axis=1)\npastNcus_Controls5.iloc[0:13,0] = 'Control 5th % confidence interval'\npastNcus_Controls5.reset_index()",
"/usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:2: SettingWithCopyWarning:\n\n\nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n\n/usr/local/lib/python3.6/dist-packages/pandas/core/indexing.py:966: SettingWithCopyWarning:\n\n\nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n\n"
],
[
"trialAssessment = pd.concat([measureOverTimeCusts,pastNcus_Controls5,pastNcus_Controls95])\ntrialAssessment = trialAssessment.sort_values(by=['year_month'])\ntrialAssessment = trialAssessment.reset_index()\ntrialAssessment",
"_____no_output_____"
]
],
[
[
"#### Visualization Trial ",
"_____no_output_____"
]
],
[
[
"px.line(data_frame=trialAssessment, x='year_month', y='nCustomers', color='Store_type', title='Total nCustomers by month',labels={'year_month':'Month of operation','nCustomers':'Total nCustomers'})",
"_____no_output_____"
]
],
[
[
"# Trial store 86",
"_____no_output_____"
],
[
"## Select control store",
"_____no_output_____"
],
[
"#### corr_nSales",
"_____no_output_____"
]
],
[
[
"measureOverTime",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
]
] |
cb3aa5d76711c0a29023a7bc10bc173bbed6a1bd | 235,498 | ipynb | Jupyter Notebook | Lab1.ipynb | aadeshnpn/cs501r | 72c59e91d28bbcd6e620842a33d83d278d4c13a4 | [
"Apache-2.0"
] | null | null | null | Lab1.ipynb | aadeshnpn/cs501r | 72c59e91d28bbcd6e620842a33d83d278d4c13a4 | [
"Apache-2.0"
] | null | null | null | Lab1.ipynb | aadeshnpn/cs501r | 72c59e91d28bbcd6e620842a33d83d278d4c13a4 | [
"Apache-2.0"
] | 1 | 2018-12-14T10:17:47.000Z | 2018-12-14T10:17:47.000Z | 1,110.839623 | 230,072 | 0.954552 | [
[
[
"# 501R Lab1\n## Part 1\n## Program to generate random image",
"_____no_output_____"
]
],
[
[
"import cairo\nimport numpy as np\n\n# Set the random seed\nseed = None # Populate for using specific value for consistency\nrandom = np.random.RandomState(seed)\n\n# Function to draw random integers in a range\ndef randinteger(n, m=1):\n if m == 1:\n return random.randint(1, n, m)[0]\n else:\n return random.randint(1, n, m)\n\n# Generate random colors\ndef randcolor():\n r = random.rand()\n g = random.rand()\n b = random.rand()\n a = random.rand()\n cr.set_source_rgba(r, g, b, a)\n\n# Get random line width\ndef linewidth():\n cr.set_line_width(randinteger(30))\n \n# Draw random curve \ndef curve():\n x, x1, x2, x3 = randinteger(512, 4)\n y, y1, y2, y3 = randinteger(288, 4)\n randcolor()\n linewidth()\n cr.move_to(x, y)\n cr.curve_to(x1, y1, x2, y2, x3, y3)\n cr.set_line_join(cairo.LINE_JOIN_ROUND)\n cr.stroke()\n \n# Draw random line \ndef line():\n randcolor()\n linewidth()\n x,x1 = randinteger(512, 2)\n y,y1 = randinteger(288, 2)\n cr.move_to(x, y)\n cr.line_to(x1, y1)\n \n cr.stroke() \n\n# Draw random arc\ndef arc():\n randcolor()\n linewidth()\n c1 = randinteger(512)\n c2 = randinteger(288)\n r = randinteger(30)\n a1 = np.pi * random.randint(0, 3) * random.rand()\n a2 = np.pi * random.randint(0, 3) * random.rand()\n cr.arc(c1, c2, r, a1, a2)\n cr.fill()\n cr.stroke()\n\n# Draw border \ndef border():\n # Setting line width and color\n randcolor()\n cr.set_line_width(5.0)\n cr.rectangle(0, 0, 512, 288)\n cr.set_line_join(cairo.LINE_JOIN_ROUND)\n cr.set_source_rgba(0.0, 0.0, 0.0, 0.3)\n cr.fill()\n # Filling all the commands\n cr.stroke() \n \n# Draw random rectangle \ndef rectangle():\n randcolor()\n linewidth()\n x,x1 = randinteger(512, 2)\n y,y1 = randinteger(288, 2)\n cr.rectangle(x,y,x1,y1)\n cr.set_line_join(cairo.LINE_JOIN_ROUND)\n cr.fill()\n cr.stroke() \n\n# Drawing the objects\ndef draw():\n border()\n for i in range(60):\n curve()\n line()\n arc()\n #rectangle()\n \n \ndef nbimage(data):\n from IPython.display import display\n from PIL.Image import fromarray\n \n # Creating image data from numpy array\n image = fromarray(data)\n # Saving the image to the disk\n image.save('shape.png')\n \n # Displaying the image in Notebook\n display(image)\n \n \nWIDTH = 512\nHEIGHT = 288\n\ndata = np.zeros((HEIGHT, WIDTH, 4), dtype=np.uint8)\n\n# Setting up cairo\nims = cairo.ImageSurface.create_for_data(data, cairo.FORMAT_ARGB32, WIDTH, HEIGHT)\ncr = cairo.Context(ims)\n\ndraw()\n\nnbimage(data)\n",
"_____no_output_____"
]
],
[
[
"## Part 2\n### Tensorplaygound with Spiral Dataset\n#### Experiment 1",
"_____no_output_____"
],
[
"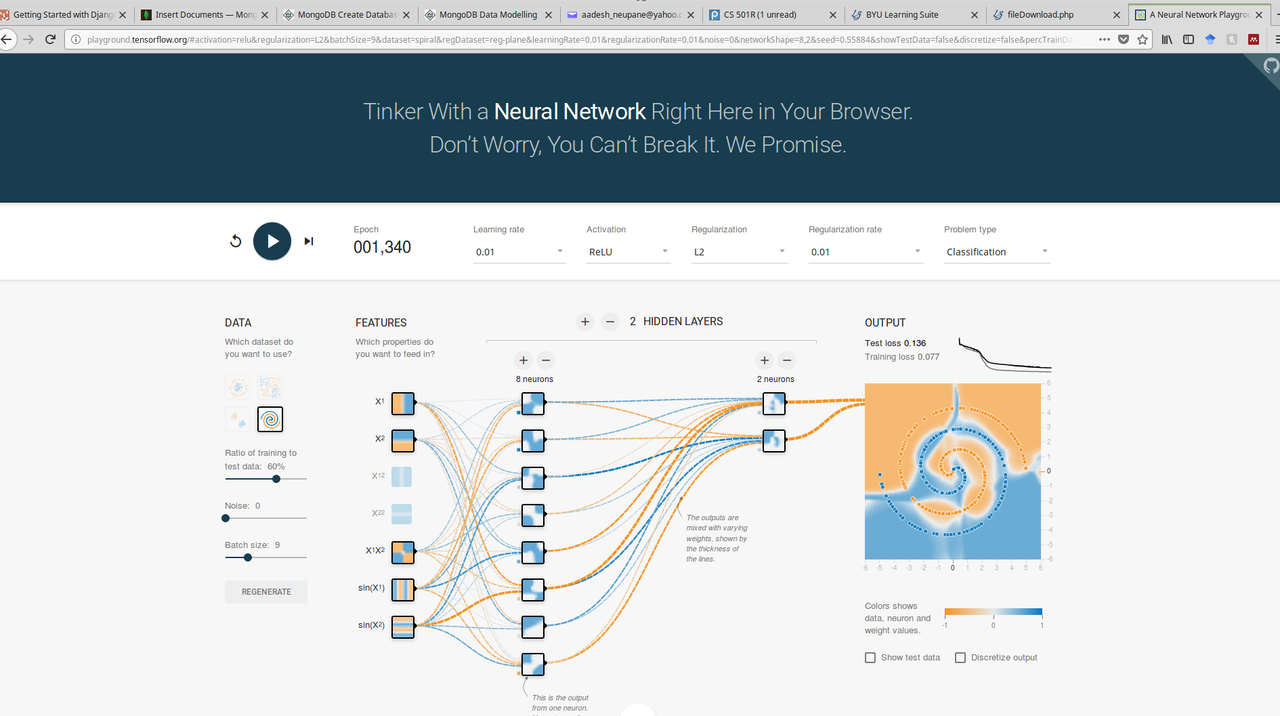",
"_____no_output_____"
],
[
"#### Experiment 2\n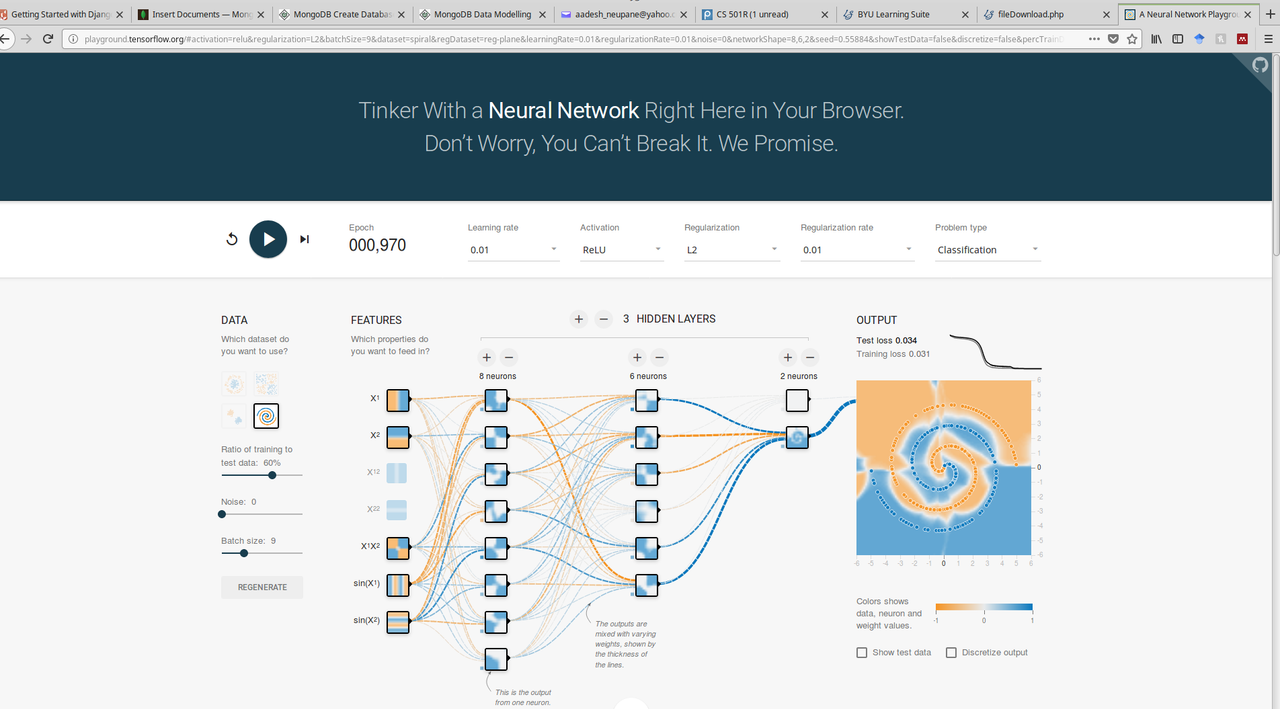",
"_____no_output_____"
],
[
"#### Experiment 3\n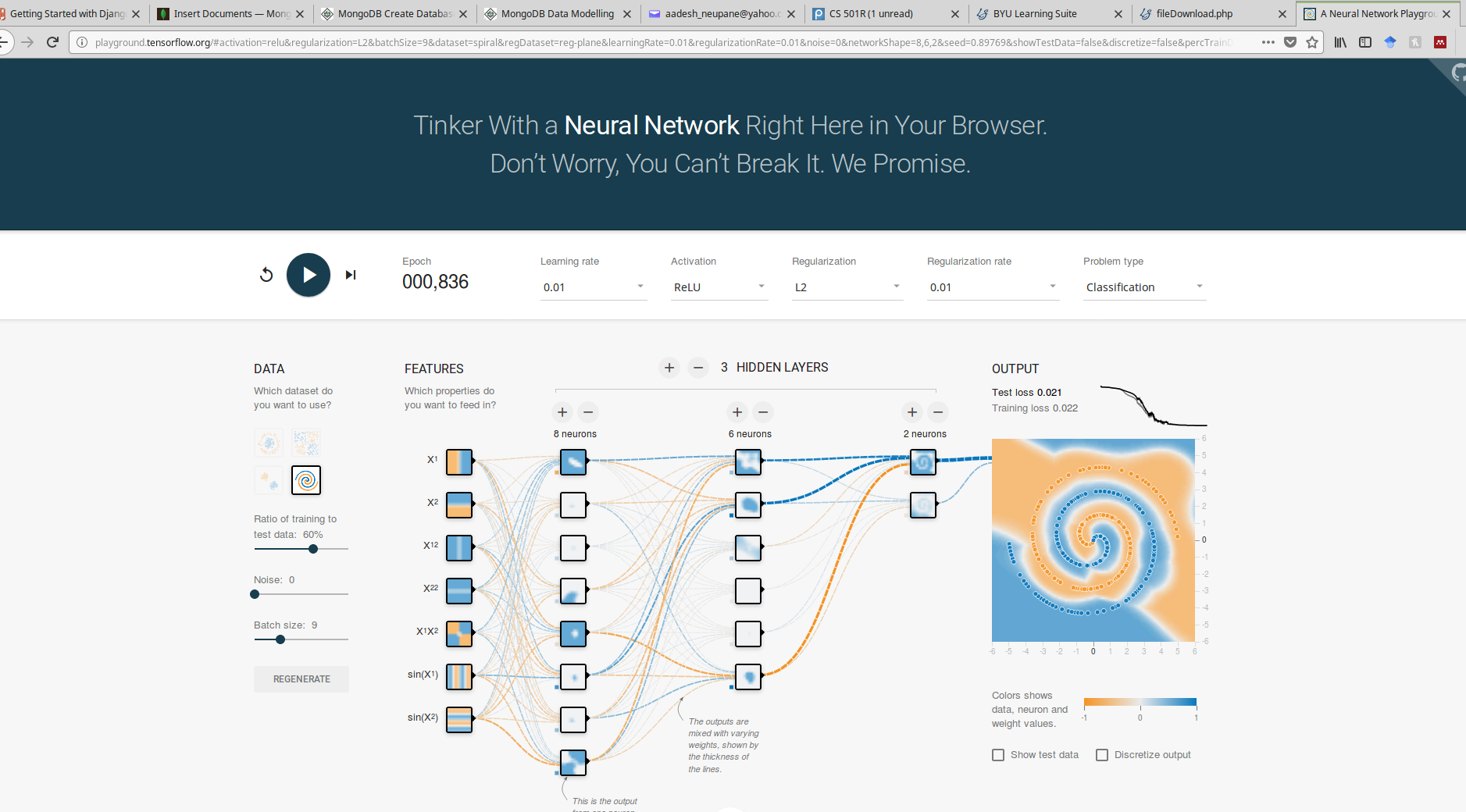",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
cb3ac68516afcb8ba4d87554988edd7c1168d7ab | 51,770 | ipynb | Jupyter Notebook | tests/loginterp_tests.ipynb | kokron/velocileptors | 50016dd66ec9a2d33effecc248a48ca7ea7322bf | [
"MIT"
] | 11 | 2020-04-30T02:59:36.000Z | 2022-03-30T08:12:51.000Z | tests/loginterp_tests.ipynb | kokron/velocileptors | 50016dd66ec9a2d33effecc248a48ca7ea7322bf | [
"MIT"
] | null | null | null | tests/loginterp_tests.ipynb | kokron/velocileptors | 50016dd66ec9a2d33effecc248a48ca7ea7322bf | [
"MIT"
] | 4 | 2021-02-17T12:55:05.000Z | 2022-03-16T08:57:11.000Z | 154.537313 | 16,816 | 0.898976 | [
[
[
"import numpy as np\n\nfrom matplotlib import pyplot as plt",
"_____no_output_____"
],
[
"# Make trial function\nx = np.logspace(-2,2,10**2)\ny = - (x - 1)**2 + 10",
"_____no_output_____"
],
[
"plt.loglog(x, np.abs(y), '.')",
"_____no_output_____"
],
[
"plt.semilogx(x,np.abs(y))\nplt.ylim(-1,11)",
"_____no_output_____"
],
[
"# Find the zero:\nii = np.argmin(np.abs(y))\nprint(y[ii-1], y[ii], y[ii+1])",
"1.8573745648763982 -0.4280095417953529 -3.2611692330933018\n"
],
[
"# import routine\nimport sys\nsys.path.append('../../velocileptors/')\nfrom velocileptors.Utils.loginterp import loginterp",
"_____no_output_____"
],
[
"xint = np.logspace(-3,3,1000)\nind = ii -1\nyint = loginterp(x[:ind], y[:ind], interp_max = 3, interp_min = -3, Nint = 20)(xint)",
"0.0024062827925594044 -2.725445575878377\n[ 1. 1.35304777 1.83073828 2.47707636 3.35160265\n 4.53487851 6.13590727 8.30217568 11.23324033 15.19911083\n 20.56512308 27.82559402 37.64935807 50.94138015 68.92612104\n 93.26033469 126.18568831 170.73526475 231.01297001 312.57158497]\n"
],
[
"plt.loglog(xint, np.abs(yint) )\nplt.loglog(x[:ind],np.abs(y)[:ind],'.')\nplt.loglog(x[ind-1], np.abs(y[ind-1]),'+',label='final point included')\nplt.ylim(1e0,30)\nplt.xlim(5e-1,10)\nplt.legend()",
"_____no_output_____"
],
[
"plt.loglog(xint, np.abs(yint) )\nplt.ylim(1e-2,30)",
"_____no_output_____"
],
[
"import time\nt1 = time.time()\nyint = loginterp(x[:ind], y[:ind], interp_max = 3, interp_min = -3, Nint = 100)(xint)\nt2 = time.time()\nprint(t2-t1)",
"0.0024062827925594044 -2.725445575878377\n[ 1. 1.05974533 1.12306016 1.19015775 1.26126412\n 1.33661875 1.41647548 1.50110327 1.59078717 1.68582927\n 1.78654969 1.89328769 2.00640278 2.12627597 2.25331102\n 2.38793582 2.53060383 2.68179558 2.84202033 3.01181777\n 3.1917598 3.38245254 3.58453827 3.79869768 4.02565211\n 4.26616601 4.52104949 4.79116107 5.07741055 5.38076211\n 5.7022375 6.04291954 6.40395574 6.78656217 7.19202754\n 7.62171757 8.07707958 8.55964734 9.07104626 9.61299889\n 10.18733064 10.79597604 11.44098516 12.12453055 12.84891459\n 13.61657719 14.43010404 15.29223532 16.20587491 17.1741002\n 18.20017243 19.28754767 20.43988851 21.66107633 22.95522441\n 24.32669179 25.78009793 27.3203383 28.95260084 30.68238343\n 32.51551245 34.45816237 36.51687653 38.69858925 41.0106491\n 43.46084373 46.05742603 48.80914199 51.72526013 54.81560269\n 58.09057877 61.56121938 65.23921454 69.13695272 73.26756254\n 77.644957 82.28388031 87.19995762 92.40974757 97.93079812\n 103.78170564 109.98217754 116.55309866 123.51660161 130.89614132\n 138.71657404 147.00424106 155.78705746 165.0946061 174.95823726\n 185.41117429 196.48862546 208.22790257 220.66854662 233.85246102\n 247.82405268 262.63038166 278.3213196 294.94971774 312.57158497]\n0.0031173229217529297\n"
],
[
"t1 = time.time()\nyint = loginterp(x[:ind], y[:ind], interp_max = 3, interp_min = -3, Nint = 100,option='B')(xint)\nt2 = time.time()\nprint(t2-t1)",
"0.0024062827925594044 -2.725445575878377\n0.0020127296447753906\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3ac6a4385ec59dcb885192b1756def8ec76b51 | 79,846 | ipynb | Jupyter Notebook | site/en-snapshot/guide/migrate.ipynb | ilyaspiridonov/docs-l10n | a061a44e40d25028d0a4458094e48ab717d3565c | [
"Apache-2.0"
] | 1 | 2021-09-23T09:56:29.000Z | 2021-09-23T09:56:29.000Z | site/en-snapshot/guide/migrate.ipynb | ilyaspiridonov/docs-l10n | a061a44e40d25028d0a4458094e48ab717d3565c | [
"Apache-2.0"
] | null | null | null | site/en-snapshot/guide/migrate.ipynb | ilyaspiridonov/docs-l10n | a061a44e40d25028d0a4458094e48ab717d3565c | [
"Apache-2.0"
] | 1 | 2020-06-02T13:44:09.000Z | 2020-06-02T13:44:09.000Z | 36.795392 | 518 | 0.541317 | [
[
[
"##### Copyright 2018 The TensorFlow Authors.",
"_____no_output_____"
]
],
[
[
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
]
],
[
[
"# Migrate your TensorFlow 1 code to TensorFlow 2\n\n<table class=\"tfo-notebook-buttons\" align=\"left\">\n <td>\n <a target=\"_blank\" href=\"https://www.tensorflow.org/guide/migrate\">\n <img src=\"https://www.tensorflow.org/images/tf_logo_32px.png\" />\n View on TensorFlow.org</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/docs/blob/master/site/en/guide/migrate.ipynb\">\n <img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />\n Run in Google Colab</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://github.com/tensorflow/docs/blob/master/site/en/guide/migrate.ipynb\">\n <img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />\n View source on GitHub</a>\n </td>\n <td>\n <a href=\"https://storage.googleapis.com/tensorflow_docs/docs/site/en/guide/migrate.ipynb\"><img src=\"https://www.tensorflow.org/images/download_logo_32px.png\" />Download notebook</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"This doc for users of low level TensorFlow APIs. If you are using \nthe high level APIs (`tf.keras`) there may be little or no action\nyou need to take to make your code fully TensorFlow 2.0 compatible: \n \n* Check your [optimizer's default learning rate](#keras_optimizer_lr). \n* Note that the \"name\" that metrics are logged to [may have changed](#keras_metric_names).",
"_____no_output_____"
],
[
"It is still possible to run 1.X code, unmodified ([except for contrib](https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md)), in TensorFlow 2.0:\n\n```\nimport tensorflow.compat.v1 as tf\ntf.disable_v2_behavior()\n```\n\nHowever, this does not let you take advantage of many of the improvements made in TensorFlow 2.0. This guide will help you upgrade your code, making it simpler, more performant, and easier to maintain.",
"_____no_output_____"
],
[
"## Automatic conversion script\n\nThe first step, before attempting to implement the changes described in this doc, is to try running the [upgrade script](./upgrade.md).\n\nThis will do an initial pass at upgrading your code to TensorFlow 2.0. But it can't make your code idiomatic to 2.0. Your code may still make use of `tf.compat.v1` endpoints to access placeholders, sessions, collections, and other 1.x-style functionality.",
"_____no_output_____"
],
[
"## Top-level behavioral changes\n\nIf your code works in TensorFlow 2.0 using `tf.compat.v1.disable_v2_behavior()`, there are still global behavioral changes you may need to address. The major changes are:",
"_____no_output_____"
],
[
"* *Eager execution, `v1.enable_eager_execution()`* : Any code that implicitly uses a `tf.Graph` will fail. Be sure to wrap this code in a `with tf.Graph().as_default()` context. \n \n* *Resource variables, `v1.enable_resource_variables()`*: Some code may depends on non-deterministic behaviors enabled by TF reference variables. \nResource variables are locked while being written to, and so provide more intuitive consistency guarantees.\n\n * This may change behavior in edge cases.\n * This may create extra copies and can have higher memory usage.\n * This can be disabled by passing `use_resource=False` to the `tf.Variable` constructor.\n\n* *Tensor shapes, `v1.enable_v2_tensorshape()`*: TF 2.0 simplifies the behavior of tensor shapes. Instead of `t.shape[0].value` you can say `t.shape[0]`. These changes should be small, and it makes sense to fix them right away. See [TensorShape](#tensorshape) for examples.\n\n* *Control flow, `v1.enable_control_flow_v2()`*: The TF 2.0 control flow implementation has been simplified, and so produces different graph representations. Please [file bugs](https://github.com/tensorflow/tensorflow/issues) for any issues.",
"_____no_output_____"
],
[
"## Make the code 2.0-native\n\n\nThis guide will walk through several examples of converting TensorFlow 1.x code to TensorFlow 2.0. These changes will let your code take advantage of performance optimizations and simplified API calls.\n\nIn each case, the pattern is:",
"_____no_output_____"
],
[
"### 1. Replace `v1.Session.run` calls\n\nEvery `v1.Session.run` call should be replaced by a Python function.\n\n* The `feed_dict` and `v1.placeholder`s become function arguments.\n* The `fetches` become the function's return value. \n* During conversion eager execution allows easy debugging with standard Python tools like `pdb`.\n\nAfter that add a `tf.function` decorator to make it run efficiently in graph. See the [Autograph Guide](function.ipynb) for more on how this works.\n\nNote that:\n\n* Unlike `v1.Session.run` a `tf.function` has a fixed return signature, and always returns all outputs. If this causes performance problems, create two separate functions.\n\n* There is no need for a `tf.control_dependencies` or similar operations: A `tf.function` behaves as if it were run in the order written. `tf.Variable` assignments and `tf.assert`s, for example, are executed automatically.\n",
"_____no_output_____"
],
[
"### 2. Use Python objects to track variables and losses\n\nAll name-based variable tracking is strongly discouraged in TF 2.0. Use Python objects to to track variables.\n\nUse `tf.Variable` instead of `v1.get_variable`.\n\nEvery `v1.variable_scope` should be converted to a Python object. Typically this will be one of:\n\n* `tf.keras.layers.Layer`\n* `tf.keras.Model`\n* `tf.Module`\n\nIf you need to aggregate lists of variables (like `tf.Graph.get_collection(tf.GraphKeys.VARIABLES)`), use the `.variables` and `.trainable_variables` attributes of the `Layer` and `Model` objects.\n\nThese `Layer` and `Model` classes implement several other properties that remove the need for global collections. Their `.losses` property can be a replacement for using the `tf.GraphKeys.LOSSES` collection.\n\nSee the [keras guides](keras.ipynb) for details.\n\nWarning: Many `tf.compat.v1` symbols use the global collections implicitly.\n",
"_____no_output_____"
],
[
"### 3. Upgrade your training loops\n\nUse the highest level API that works for your use case. Prefer `tf.keras.Model.fit` over building your own training loops.\n\nThese high level functions manage a lot of the low-level details that might be easy to miss if you write your own training loop. For example, they automatically collect the regularization losses, and set the `training=True` argument when calling the model.\n",
"_____no_output_____"
],
[
"### 4. Upgrade your data input pipelines\n\nUse `tf.data` datasets for data input. These objects are efficient, expressive, and integrate well with tensorflow.\n\nThey can be passed directly to the `tf.keras.Model.fit` method.\n\n```\nmodel.fit(dataset, epochs=5)\n```\n\nThey can be iterated over directly standard Python:\n\n```\nfor example_batch, label_batch in dataset:\n break\n```\n",
"_____no_output_____"
],
[
"#### 5. Migrate off `compat.v1` symbols \n\nThe `tf.compat.v1` module contains the complete TensorFlow 1.x API, with its original semantics.\n\nThe [TF2 upgrade script](upgrade.ipynb) will convert symbols to their 2.0 equivalents if such a conversion is safe, i.e., if it can determine that the behavior of the 2.0 version is exactly equivalent (for instance, it will rename `v1.arg_max` to `tf.argmax`, since those are the same function). \n\nAfter the upgrade script is done with a piece of code, it is likely there are many mentions of `compat.v1`. It is worth going through the code and converting these manually to the 2.0 equivalent (it should be mentioned in the log if there is one).",
"_____no_output_____"
],
[
"## Converting models\n\n### Setup",
"_____no_output_____"
]
],
[
[
"import tensorflow as tf\n\n\nimport tensorflow_datasets as tfds",
"_____no_output_____"
]
],
[
[
"### Low-level variables & operator execution\n\nExamples of low-level API use include:\n\n* using variable scopes to control reuse\n* creating variables with `v1.get_variable`.\n* accessing collections explicitly\n* accessing collections implicitly with methods like :\n\n * `v1.global_variables`\n * `v1.losses.get_regularization_loss`\n\n* using `v1.placeholder` to set up graph inputs\n* executing graphs with `Session.run`\n* initializing variables manually\n",
"_____no_output_____"
],
[
"#### Before converting\n\nHere is what these patterns may look like in code using TensorFlow 1.x.\n\n```python\nin_a = tf.placeholder(dtype=tf.float32, shape=(2))\nin_b = tf.placeholder(dtype=tf.float32, shape=(2))\n\ndef forward(x):\n with tf.variable_scope(\"matmul\", reuse=tf.AUTO_REUSE):\n W = tf.get_variable(\"W\", initializer=tf.ones(shape=(2,2)),\n regularizer=tf.contrib.layers.l2_regularizer(0.04))\n b = tf.get_variable(\"b\", initializer=tf.zeros(shape=(2)))\n return W * x + b\n\nout_a = forward(in_a)\nout_b = forward(in_b)\n\nreg_loss=tf.losses.get_regularization_loss(scope=\"matmul\")\n\nwith tf.Session() as sess:\n sess.run(tf.global_variables_initializer())\n outs = sess.run([out_a, out_b, reg_loss],\n \t feed_dict={in_a: [1, 0], in_b: [0, 1]})\n\n```",
"_____no_output_____"
],
[
"#### After converting",
"_____no_output_____"
],
[
"In the converted code:\n\n* The variables are local Python objects.\n* The `forward` function still defines the calculation.\n* The `Session.run` call is replaced with a call to `forward`\n* The optional `tf.function` decorator can be added for performance.\n* The regularizations are calculated manually, without referring to any global collection.\n* **No sessions or placeholders.**",
"_____no_output_____"
]
],
[
[
"W = tf.Variable(tf.ones(shape=(2,2)), name=\"W\")\nb = tf.Variable(tf.zeros(shape=(2)), name=\"b\")\n\[email protected]\ndef forward(x):\n return W * x + b\n\nout_a = forward([1,0])\nprint(out_a)",
"_____no_output_____"
],
[
"out_b = forward([0,1])\n\nregularizer = tf.keras.regularizers.l2(0.04)\nreg_loss=regularizer(W)",
"_____no_output_____"
]
],
[
[
"### Models based on `tf.layers`",
"_____no_output_____"
],
[
"The `v1.layers` module is used to contain layer-functions that relied on `v1.variable_scope` to define and reuse variables.",
"_____no_output_____"
],
[
"#### Before converting\n```python\ndef model(x, training, scope='model'):\n with tf.variable_scope(scope, reuse=tf.AUTO_REUSE):\n x = tf.layers.conv2d(x, 32, 3, activation=tf.nn.relu,\n kernel_regularizer=tf.contrib.layers.l2_regularizer(0.04))\n x = tf.layers.max_pooling2d(x, (2, 2), 1)\n x = tf.layers.flatten(x)\n x = tf.layers.dropout(x, 0.1, training=training)\n x = tf.layers.dense(x, 64, activation=tf.nn.relu)\n x = tf.layers.batch_normalization(x, training=training)\n x = tf.layers.dense(x, 10)\n return x\n\ntrain_out = model(train_data, training=True)\ntest_out = model(test_data, training=False)\n```",
"_____no_output_____"
],
[
"#### After converting",
"_____no_output_____"
],
[
"* The simple stack of layers fits neatly into `tf.keras.Sequential`. (For more complex models see [custom layers and models](keras/custom_layers_and_models.ipynb), and [the functional API](keras/functional.ipynb).)\n* The model tracks the variables, and regularization losses.\n* The conversion was one-to-one because there is a direct mapping from `v1.layers` to `tf.keras.layers`.\n\nMost arguments stayed the same. But notice the differences:\n\n* The `training` argument is passed to each layer by the model when it runs.\n* The first argument to the original `model` function (the input `x`) is gone. This is because object layers separate building the model from calling the model.\n\n\nAlso note that:\n\n* If you were using regularizers of initializers from `tf.contrib`, these have more argument changes than others.\n* The code no longer writes to collections, so functions like `v1.losses.get_regularization_loss` will no longer return these values, potentially breaking your training loops.",
"_____no_output_____"
]
],
[
[
"model = tf.keras.Sequential([\n tf.keras.layers.Conv2D(32, 3, activation='relu',\n kernel_regularizer=tf.keras.regularizers.l2(0.04),\n input_shape=(28, 28, 1)),\n tf.keras.layers.MaxPooling2D(),\n tf.keras.layers.Flatten(),\n tf.keras.layers.Dropout(0.1),\n tf.keras.layers.Dense(64, activation='relu'),\n tf.keras.layers.BatchNormalization(),\n tf.keras.layers.Dense(10)\n])\n\ntrain_data = tf.ones(shape=(1, 28, 28, 1))\ntest_data = tf.ones(shape=(1, 28, 28, 1))",
"_____no_output_____"
],
[
"train_out = model(train_data, training=True)\nprint(train_out)",
"_____no_output_____"
],
[
"test_out = model(test_data, training=False)\nprint(test_out)",
"_____no_output_____"
],
[
"# Here are all the trainable variables.\nlen(model.trainable_variables)",
"_____no_output_____"
],
[
"# Here is the regularization loss.\nmodel.losses",
"_____no_output_____"
]
],
[
[
"### Mixed variables & `v1.layers`\n",
"_____no_output_____"
],
[
"Existing code often mixes lower-level TF 1.x variables and operations with higher-level `v1.layers`.",
"_____no_output_____"
],
[
"#### Before converting\n```python\ndef model(x, training, scope='model'):\n with tf.variable_scope(scope, reuse=tf.AUTO_REUSE):\n W = tf.get_variable(\n \"W\", dtype=tf.float32,\n initializer=tf.ones(shape=x.shape),\n regularizer=tf.contrib.layers.l2_regularizer(0.04),\n trainable=True)\n if training:\n x = x + W\n else:\n x = x + W * 0.5\n x = tf.layers.conv2d(x, 32, 3, activation=tf.nn.relu)\n x = tf.layers.max_pooling2d(x, (2, 2), 1)\n x = tf.layers.flatten(x)\n return x\n\ntrain_out = model(train_data, training=True)\ntest_out = model(test_data, training=False)\n```",
"_____no_output_____"
],
[
"#### After converting",
"_____no_output_____"
],
[
"To convert this code, follow the pattern of mapping layers to layers as in the previous example.\n\nA `v1.variable_scope` is effectively a layer of its own. So rewrite it as a `tf.keras.layers.Layer`. See [the guide](keras/custom_layers_and_models.ipynb) for details.\n\nThe general pattern is:\n\n* Collect layer parameters in `__init__`.\n* Build the variables in `build`.\n* Execute the calculations in `call`, and return the result.\n\nThe `v1.variable_scope` is essentially a layer of its own. So rewrite it as a `tf.keras.layers.Layer`. See [the guide](keras/custom_layers_and_models.ipynb) for details.",
"_____no_output_____"
]
],
[
[
"# Create a custom layer for part of the model\nclass CustomLayer(tf.keras.layers.Layer):\n def __init__(self, *args, **kwargs):\n super(CustomLayer, self).__init__(*args, **kwargs)\n\n def build(self, input_shape):\n self.w = self.add_weight(\n shape=input_shape[1:],\n dtype=tf.float32,\n initializer=tf.keras.initializers.ones(),\n regularizer=tf.keras.regularizers.l2(0.02),\n trainable=True)\n\n # Call method will sometimes get used in graph mode,\n # training will get turned into a tensor\n @tf.function\n def call(self, inputs, training=None):\n if training:\n return inputs + self.w\n else:\n return inputs + self.w * 0.5",
"_____no_output_____"
],
[
"custom_layer = CustomLayer()\nprint(custom_layer([1]).numpy())\nprint(custom_layer([1], training=True).numpy())",
"_____no_output_____"
],
[
"train_data = tf.ones(shape=(1, 28, 28, 1))\ntest_data = tf.ones(shape=(1, 28, 28, 1))\n\n# Build the model including the custom layer\nmodel = tf.keras.Sequential([\n CustomLayer(input_shape=(28, 28, 1)),\n tf.keras.layers.Conv2D(32, 3, activation='relu'),\n tf.keras.layers.MaxPooling2D(),\n tf.keras.layers.Flatten(),\n])\n\ntrain_out = model(train_data, training=True)\ntest_out = model(test_data, training=False)\n",
"_____no_output_____"
]
],
[
[
"Some things to note:\n\n* Subclassed Keras models & layers need to run in both v1 graphs (no automatic control dependencies) and in eager mode\n * Wrap the `call()` in a `tf.function()` to get autograph and automatic control dependencies\n\n* Don't forget to accept a `training` argument to `call`.\n * Sometimes it is a `tf.Tensor`\n * Sometimes it is a Python boolean.\n\n* Create model variables in constructor or `Model.build` using `self.add_weight()`.\n * In `Model.build` you have access to the input shape, so can create weights with matching shape.\n * Using `tf.keras.layers.Layer.add_weight` allows Keras to track variables and regularization losses.\n\n* Don't keep `tf.Tensors` in your objects.\n * They might get created either in a `tf.function` or in the eager context, and these tensors behave differently.\n * Use `tf.Variable`s for state, they are always usable from both contexts\n * `tf.Tensors` are only for intermediate values.",
"_____no_output_____"
],
[
"### A note on Slim & contrib.layers\n\nA large amount of older TensorFlow 1.x code uses the [Slim](https://ai.googleblog.com/2016/08/tf-slim-high-level-library-to-define.html) library, which was packaged with TensorFlow 1.x as `tf.contrib.layers`. As a `contrib` module, this is no longer available in TensorFlow 2.0, even in `tf.compat.v1`. Converting code using Slim to TF 2.0 is more involved than converting repositories that use `v1.layers`. In fact, it may make sense to convert your Slim code to `v1.layers` first, then convert to Keras.\n\n* Remove `arg_scopes`, all args need to be explicit\n* If you use them, split `normalizer_fn` and `activation_fn` into their own layers\n* Separable conv layers map to one or more different Keras layers (depthwise, pointwise, and separable Keras layers)\n* Slim and `v1.layers` have different arg names & default values\n* Some args have different scales\n* If you use Slim pre-trained models, try out Keras's pre-traimed models from `tf.keras.applications` or [TF Hub](https://tfhub.dev/s?q=slim%20tf2)'s TF2 SavedModels exported from the original Slim code.\n\nSome `tf.contrib` layers might not have been moved to core TensorFlow but have instead been moved to the [TF add-ons package](https://github.com/tensorflow/addons).\n",
"_____no_output_____"
],
[
"## Training",
"_____no_output_____"
],
[
"There are many ways to feed data to a `tf.keras` model. They will accept Python generators and Numpy arrays as input.\n\nThe recommended way to feed data to a model is to use the `tf.data` package, which contains a collection of high performance classes for manipulating data.\n\nIf you are still using `tf.queue`, these are now only supported as data-structures, not as input pipelines.",
"_____no_output_____"
],
[
"### Using Datasets",
"_____no_output_____"
],
[
"The [TensorFlow Datasets](https://tensorflow.org/datasets) package (`tfds`) contains utilities for loading predefined datasets as `tf.data.Dataset` objects.\n\nFor this example, load the MNISTdataset, using `tfds`:",
"_____no_output_____"
]
],
[
[
"datasets, info = tfds.load(name='mnist', with_info=True, as_supervised=True)\nmnist_train, mnist_test = datasets['train'], datasets['test']",
"_____no_output_____"
]
],
[
[
"Then prepare the data for training:\n\n * Re-scale each image.\n * Shuffle the order of the examples.\n * Collect batches of images and labels.\n",
"_____no_output_____"
]
],
[
[
"BUFFER_SIZE = 10 # Use a much larger value for real code.\nBATCH_SIZE = 64\nNUM_EPOCHS = 5\n\n\ndef scale(image, label):\n image = tf.cast(image, tf.float32)\n image /= 255\n\n return image, label",
"_____no_output_____"
]
],
[
[
" To keep the example short, trim the dataset to only return 5 batches:",
"_____no_output_____"
]
],
[
[
"train_data = mnist_train.map(scale).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)\ntest_data = mnist_test.map(scale).batch(BATCH_SIZE)\n\nSTEPS_PER_EPOCH = 5\n\ntrain_data = train_data.take(STEPS_PER_EPOCH)\ntest_data = test_data.take(STEPS_PER_EPOCH)",
"_____no_output_____"
],
[
"image_batch, label_batch = next(iter(train_data))",
"_____no_output_____"
]
],
[
[
"### Use Keras training loops\n\nIf you don't need low level control of your training process, using Keras's built-in `fit`, `evaluate`, and `predict` methods is recommended. These methods provide a uniform interface to train the model regardless of the implementation (sequential, functional, or sub-classed).\n\nThe advantages of these methods include:\n\n* They accept Numpy arrays, Python generators and, `tf.data.Datasets`\n* They apply regularization, and activation losses automatically.\n* They support `tf.distribute` [for multi-device training](distributed_training.ipynb).\n* They support arbitrary callables as losses and metrics.\n* They support callbacks like `tf.keras.callbacks.TensorBoard`, and custom callbacks.\n* They are performant, automatically using TensorFlow graphs.\n\nHere is an example of training a model using a `Dataset`. (For details on how this works see [tutorials](../tutorials).)",
"_____no_output_____"
]
],
[
[
"model = tf.keras.Sequential([\n tf.keras.layers.Conv2D(32, 3, activation='relu',\n kernel_regularizer=tf.keras.regularizers.l2(0.02),\n input_shape=(28, 28, 1)),\n tf.keras.layers.MaxPooling2D(),\n tf.keras.layers.Flatten(),\n tf.keras.layers.Dropout(0.1),\n tf.keras.layers.Dense(64, activation='relu'),\n tf.keras.layers.BatchNormalization(),\n tf.keras.layers.Dense(10)\n])\n\n# Model is the full model w/o custom layers\nmodel.compile(optimizer='adam',\n loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n metrics=['accuracy'])\n\nmodel.fit(train_data, epochs=NUM_EPOCHS)\nloss, acc = model.evaluate(test_data)\n\nprint(\"Loss {}, Accuracy {}\".format(loss, acc))",
"_____no_output_____"
]
],
[
[
"### Write your own loop\n\nIf the Keras model's training step works for you, but you need more control outside that step, consider using the `tf.keras.Model.train_on_batch` method, in your own data-iteration loop.\n\nRemember: Many things can be implemented as a `tf.keras.callbacks.Callback`.\n\nThis method has many of the advantages of the methods mentioned in the previous section, but gives the user control of the outer loop.\n\nYou can also use `tf.keras.Model.test_on_batch` or `tf.keras.Model.evaluate` to check performance during training.\n\nNote: `train_on_batch` and `test_on_batch`, by default return the loss and metrics for the single batch. If you pass `reset_metrics=False` they return accumulated metrics and you must remember to appropriately reset the metric accumulators. Also remember that some metrics like `AUC` require `reset_metrics=False` to be calculated correctly.\n\nTo continue training the above model:\n",
"_____no_output_____"
]
],
[
[
"# Model is the full model w/o custom layers\nmodel.compile(optimizer='adam',\n loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n metrics=['accuracy'])\n\nfor epoch in range(NUM_EPOCHS):\n #Reset the metric accumulators\n model.reset_metrics()\n\n for image_batch, label_batch in train_data:\n result = model.train_on_batch(image_batch, label_batch)\n metrics_names = model.metrics_names\n print(\"train: \",\n \"{}: {:.3f}\".format(metrics_names[0], result[0]),\n \"{}: {:.3f}\".format(metrics_names[1], result[1]))\n for image_batch, label_batch in test_data:\n result = model.test_on_batch(image_batch, label_batch,\n # return accumulated metrics\n reset_metrics=False)\n metrics_names = model.metrics_names\n print(\"\\neval: \",\n \"{}: {:.3f}\".format(metrics_names[0], result[0]),\n \"{}: {:.3f}\".format(metrics_names[1], result[1]))",
"_____no_output_____"
]
],
[
[
"<a name=\"custom_loop\"></a>\n\n### Customize the training step\n\nIf you need more flexibility and control, you can have it by implementing your own training loop. There are three steps:\n\n1. Iterate over a Python generator or `tf.data.Dataset` to get batches of examples.\n2. Use `tf.GradientTape` to collect gradients.\n3. Use one of the `tf.keras.optimizers` to apply weight updates to the model's variables.\n\nRemember:\n\n* Always include a `training` argument on the `call` method of subclassed layers and models.\n* Make sure to call the model with the `training` argument set correctly.\n* Depending on usage, model variables may not exist until the model is run on a batch of data.\n* You need to manually handle things like regularization losses for the model.\n\nNote the simplifications relative to v1:\n\n* There is no need to run variable initializers. Variables are initialized on creation.\n* There is no need to add manual control dependencies. Even in `tf.function` operations act as in eager mode.",
"_____no_output_____"
]
],
[
[
"model = tf.keras.Sequential([\n tf.keras.layers.Conv2D(32, 3, activation='relu',\n kernel_regularizer=tf.keras.regularizers.l2(0.02),\n input_shape=(28, 28, 1)),\n tf.keras.layers.MaxPooling2D(),\n tf.keras.layers.Flatten(),\n tf.keras.layers.Dropout(0.1),\n tf.keras.layers.Dense(64, activation='relu'),\n tf.keras.layers.BatchNormalization(),\n tf.keras.layers.Dense(10)\n])\n\noptimizer = tf.keras.optimizers.Adam(0.001)\nloss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)\n\[email protected]\ndef train_step(inputs, labels):\n with tf.GradientTape() as tape:\n predictions = model(inputs, training=True)\n regularization_loss=tf.math.add_n(model.losses)\n pred_loss=loss_fn(labels, predictions)\n total_loss=pred_loss + regularization_loss\n\n gradients = tape.gradient(total_loss, model.trainable_variables)\n optimizer.apply_gradients(zip(gradients, model.trainable_variables))\n\nfor epoch in range(NUM_EPOCHS):\n for inputs, labels in train_data:\n train_step(inputs, labels)\n print(\"Finished epoch\", epoch)\n",
"_____no_output_____"
]
],
[
[
"### New-style metrics and losses\n\nIn TensorFlow 2.0, metrics and losses are objects. These work both eagerly and in `tf.function`s. \n\nA loss object is callable, and expects the (y_true, y_pred) as arguments:\n",
"_____no_output_____"
]
],
[
[
"cce = tf.keras.losses.CategoricalCrossentropy(from_logits=True)\ncce([[1, 0]], [[-1.0,3.0]]).numpy()",
"_____no_output_____"
]
],
[
[
"A metric object has the following methods:\n\n* `Metric.update_state()` — add new observations\n* `Metric.result()` —get the current result of the metric, given the observed values\n* `Metric.reset_states()` — clear all observations.\n\nThe object itself is callable. Calling updates the state with new observations, as with `update_state`, and returns the new result of the metric.\n\nYou don't have to manually initialize a metric's variables, and because TensorFlow 2.0 has automatic control dependencies, you don't need to worry about those either.\n\nThe code below uses a metric to keep track of the mean loss observed within a custom training loop.",
"_____no_output_____"
]
],
[
[
"# Create the metrics\nloss_metric = tf.keras.metrics.Mean(name='train_loss')\naccuracy_metric = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')\n\[email protected]\ndef train_step(inputs, labels):\n with tf.GradientTape() as tape:\n predictions = model(inputs, training=True)\n regularization_loss=tf.math.add_n(model.losses)\n pred_loss=loss_fn(labels, predictions)\n total_loss=pred_loss + regularization_loss\n\n gradients = tape.gradient(total_loss, model.trainable_variables)\n optimizer.apply_gradients(zip(gradients, model.trainable_variables))\n # Update the metrics\n loss_metric.update_state(total_loss)\n accuracy_metric.update_state(labels, predictions)\n\n\nfor epoch in range(NUM_EPOCHS):\n # Reset the metrics\n loss_metric.reset_states()\n accuracy_metric.reset_states()\n\n for inputs, labels in train_data:\n train_step(inputs, labels)\n # Get the metric results\n mean_loss=loss_metric.result()\n mean_accuracy = accuracy_metric.result()\n\n print('Epoch: ', epoch)\n print(' loss: {:.3f}'.format(mean_loss))\n print(' accuracy: {:.3f}'.format(mean_accuracy))\n",
"_____no_output_____"
]
],
[
[
"<a id=\"keras_metric_names\"></a>\n\n### Keras metric names",
"_____no_output_____"
],
[
"In TensorFlow 2.0 keras models are more consistent about handling metric names.\n\nNow when you pass a string in the list of metrics, that _exact_ string is used as the metric's `name`. These names are visible in the history object returned by `model.fit`, and in the logs passed to `keras.callbacks`. is set to the string you passed in the metric list. ",
"_____no_output_____"
]
],
[
[
"model.compile(\n optimizer = tf.keras.optimizers.Adam(0.001),\n loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n metrics = ['acc', 'accuracy', tf.keras.metrics.SparseCategoricalAccuracy(name=\"my_accuracy\")])\nhistory = model.fit(train_data)",
"_____no_output_____"
],
[
"history.history.keys()",
"_____no_output_____"
]
],
[
[
"This differs from previous versions where passing `metrics=[\"accuracy\"]` would result in `dict_keys(['loss', 'acc'])` ",
"_____no_output_____"
],
[
"### Keras optimizers",
"_____no_output_____"
],
[
"The optimizers in `v1.train`, like `v1.train.AdamOptimizer` and `v1.train.GradientDescentOptimizer`, have equivalents in `tf.keras.optimizers`.",
"_____no_output_____"
],
[
"#### Convert `v1.train` to `keras.optimizers`\n\nHere are things to keep in mind when converting your optimizers:\n\n* Upgrading your optimizers [may make old checkpoints incompatible](#checkpoints).\n* All epsilons now default to `1e-7` instead of `1e-8` (which is negligible in most use cases).\n* `v1.train.GradientDescentOptimizer` can be directly replaced by `tf.keras.optimizers.SGD`. \n* `v1.train.MomentumOptimizer` can be directly replaced by the `SGD` optimizer using the momentum argument: `tf.keras.optimizers.SGD(..., momentum=...)`.\n* `v1.train.AdamOptimizer` can be converted to use `tf.keras.optimizers.Adam`. The `beta1` and `beta2` arguments have been renamed to `beta_1` and `beta_2`.\n* `v1.train.RMSPropOptimizer` can be converted to `tf.keras.optimizers.RMSprop`. The `decay` argument has been renamed to `rho`.\n* `v1.train.AdadeltaOptimizer` can be converted directly to `tf.keras.optimizers.Adadelta`.\n* `tf.train.AdagradOptimizer` can be converted directly to `tf.keras.optimizers.Adagrad`.\n* `tf.train.FtrlOptimizer` can be converted directly to `tf.keras.optimizers.Ftrl`. The `accum_name` and `linear_name` arguments have been removed.\n* The `tf.contrib.AdamaxOptimizer` and `tf.contrib.NadamOptimizer`, can be converted directly to `tf.keras.optimizers.Adamax` and `tf.keras.optimizers.Nadam`. The `beta1`, and `beta2` arguments have been renamed to `beta_1` and `beta_2`.\n",
"_____no_output_____"
],
[
"#### New defaults for some `tf.keras.optimizers`\n<a id=\"keras_optimizer_lr\"></a>\n\nWarning: If you see a change in convergence behavior for your models, check the default learning rates.\n\nThere are no changes for `optimizers.SGD`, `optimizers.Adam`, or `optimizers.RMSprop`.\n\nThe following default learning rates have changed:\n\n* `optimizers.Adagrad` from 0.01 to 0.001\n* `optimizers.Adadelta` from 1.0 to 0.001\n* `optimizers.Adamax` from 0.002 to 0.001\n* `optimizers.Nadam` from 0.002 to 0.001",
"_____no_output_____"
],
[
"### TensorBoard",
"_____no_output_____"
],
[
"TensorFlow 2 includes significant changes to the `tf.summary` API used to write summary data for visualization in TensorBoard. For a general introduction to the new `tf.summary`, there are [several tutorials available](https://www.tensorflow.org/tensorboard/get_started) that use the TF 2 API. This includes a [TensorBoard TF 2 Migration Guide](https://www.tensorflow.org/tensorboard/migrate)",
"_____no_output_____"
],
[
"## Saving & Loading\n",
"_____no_output_____"
],
[
"<a id=\"checkpoints\"></a>\n### Checkpoint compatibility\n\nTensorFlow 2.0 uses [object-based checkpoints](checkpoint.ipynb).\n\nOld-style name-based checkpoints can still be loaded, if you're careful.\nThe code conversion process may result in variable name changes, but there are workarounds.\n\nThe simplest approach it to line up the names of the new model with the names in the checkpoint:\n\n* Variables still all have a `name` argument you can set.\n* Keras models also take a `name` argument as which they set as the prefix for their variables.\n* The `v1.name_scope` function can be used to set variable name prefixes. This is very different from `tf.variable_scope`. It only affects names, and doesn't track variables & reuse.\n\nIf that does not work for your use-case, try the `v1.train.init_from_checkpoint` function. It takes an `assignment_map` argument, which specifies the mapping from old names to new names.\n\nNote: Unlike object based checkpoints, which can [defer loading](checkpoint.ipynb#loading_mechanics), name-based checkpoints require that all variables be built when the function is called. Some models defer building variables until you call `build` or run the model on a batch of data.\n\nThe [TensorFlow Estimator repository](https://github.com/tensorflow/estimator/blob/master/tensorflow_estimator/python/estimator/tools/checkpoint_converter.py) includes a [conversion tool](#checkpoint_converter) to upgrade the checkpoints for premade estimators from TensorFlow 1.X to 2.0. It may serve as an example of how to build a tool fr a similar use-case.",
"_____no_output_____"
],
[
"### Saved models compatibility\n\nThere are no significant compatibility concerns for saved models.\n\n* TensorFlow 1.x saved_models work in TensorFlow 2.x.\n* TensorFlow 2.x saved_models work in TensorFlow 1.x—if all the ops are supported.",
"_____no_output_____"
],
[
"### A Graph.pb or Graph.pbtxt ",
"_____no_output_____"
],
[
"There is no straightforward way to upgrade a raw `Graph.pb` file to TensorFlow 2.0. Your best bet is to upgrade the code that generated the file.\n\nBut, if you have a \"Frozen graph\" (a `tf.Graph` where the variables have been turned into constants), then it is possible to convert this to a [`concrete_function`](https://tensorflow.org/guide/concrete_function) using `v1.wrap_function`:\n",
"_____no_output_____"
]
],
[
[
"def wrap_frozen_graph(graph_def, inputs, outputs):\n def _imports_graph_def():\n tf.compat.v1.import_graph_def(graph_def, name=\"\")\n wrapped_import = tf.compat.v1.wrap_function(_imports_graph_def, [])\n import_graph = wrapped_import.graph\n return wrapped_import.prune(\n tf.nest.map_structure(import_graph.as_graph_element, inputs),\n tf.nest.map_structure(import_graph.as_graph_element, outputs))",
"_____no_output_____"
]
],
[
[
"For example, here is a frozed graph for Inception v1, from 2016:",
"_____no_output_____"
]
],
[
[
"path = tf.keras.utils.get_file(\n 'inception_v1_2016_08_28_frozen.pb',\n 'http://storage.googleapis.com/download.tensorflow.org/models/inception_v1_2016_08_28_frozen.pb.tar.gz',\n untar=True)",
"_____no_output_____"
]
],
[
[
"Load the `tf.GraphDef`:",
"_____no_output_____"
]
],
[
[
"graph_def = tf.compat.v1.GraphDef()\nloaded = graph_def.ParseFromString(open(path,'rb').read())",
"_____no_output_____"
]
],
[
[
"Wrap it into a `concrete_function`:",
"_____no_output_____"
]
],
[
[
"inception_func = wrap_frozen_graph(\n graph_def, inputs='input:0',\n outputs='InceptionV1/InceptionV1/Mixed_3b/Branch_1/Conv2d_0a_1x1/Relu:0')",
"_____no_output_____"
]
],
[
[
"Pass it a tensor as input:",
"_____no_output_____"
]
],
[
[
"input_img = tf.ones([1,224,224,3], dtype=tf.float32)\ninception_func(input_img).shape",
"_____no_output_____"
]
],
[
[
"## Estimators",
"_____no_output_____"
],
[
"### Training with Estimators\n\nEstimators are supported in TensorFlow 2.0.\n\nWhen you use estimators, you can use `input_fn()`, `tf.estimator.TrainSpec`, and `tf.estimator.EvalSpec` from TensorFlow 1.x.\n\nHere is an example using `input_fn` with train and evaluate specs.",
"_____no_output_____"
],
[
"#### Creating the input_fn and train/eval specs",
"_____no_output_____"
]
],
[
[
"# Define the estimator's input_fn\ndef input_fn():\n datasets, info = tfds.load(name='mnist', with_info=True, as_supervised=True)\n mnist_train, mnist_test = datasets['train'], datasets['test']\n\n BUFFER_SIZE = 10000\n BATCH_SIZE = 64\n\n def scale(image, label):\n image = tf.cast(image, tf.float32)\n image /= 255\n\n return image, label[..., tf.newaxis]\n\n train_data = mnist_train.map(scale).shuffle(BUFFER_SIZE).batch(BATCH_SIZE)\n return train_data.repeat()\n\n# Define train & eval specs\ntrain_spec = tf.estimator.TrainSpec(input_fn=input_fn,\n max_steps=STEPS_PER_EPOCH * NUM_EPOCHS)\neval_spec = tf.estimator.EvalSpec(input_fn=input_fn,\n steps=STEPS_PER_EPOCH)\n",
"_____no_output_____"
]
],
[
[
"### Using a Keras model definition",
"_____no_output_____"
],
[
"There are some differences in how to construct your estimators in TensorFlow 2.0.\n\nWe recommend that you define your model using Keras, then use the `tf.keras.estimator.model_to_estimator` utility to turn your model into an estimator. The code below shows how to use this utility when creating and training an estimator.",
"_____no_output_____"
]
],
[
[
"def make_model():\n return tf.keras.Sequential([\n tf.keras.layers.Conv2D(32, 3, activation='relu',\n kernel_regularizer=tf.keras.regularizers.l2(0.02),\n input_shape=(28, 28, 1)),\n tf.keras.layers.MaxPooling2D(),\n tf.keras.layers.Flatten(),\n tf.keras.layers.Dropout(0.1),\n tf.keras.layers.Dense(64, activation='relu'),\n tf.keras.layers.BatchNormalization(),\n tf.keras.layers.Dense(10)\n ])",
"_____no_output_____"
],
[
"model = make_model()\n\nmodel.compile(optimizer='adam',\n loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n metrics=['accuracy'])\n\nestimator = tf.keras.estimator.model_to_estimator(\n keras_model = model\n)\n\ntf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)",
"_____no_output_____"
]
],
[
[
"Note: We do not support creating weighted metrics in Keras and converting them to weighted metrics in the Estimator API using `model_to_estimator` You will have to create these metrics directly on the estimator spec using the `add_metrics` function.",
"_____no_output_____"
],
[
"### Using a custom `model_fn`\n\nIf you have an existing custom estimator `model_fn` that you need to maintain, you can convert your `model_fn` to use a Keras model.\n\nHowever, for compatibility reasons, a custom `model_fn` will still run in 1.x-style graph mode. This means there is no eager execution and no automatic control dependencies.",
"_____no_output_____"
],
[
"<a name=\"minimal_changes\"></a>\n\n#### Custom model_fn with minimal changes\nTo make your custom `model_fn` work in TF 2.0, if you prefer minimal changes to the existing code, `tf.compat.v1` symbols such as `optimizers` and `metrics` can be used.\n\nUsing a Keras models in a custom `model_fn` is similar to using it in a custom training loop:\n\n* Set the `training` phase appropriately, based on the `mode` argument.\n* Explicitly pass the model's `trainable_variables` to the optimizer.\n\nBut there are important differences, relative to a [custom loop](#custom_loop):\n\n* Instead of using `Model.losses`, extract the losses using `Model.get_losses_for`.\n* Extract the model's updates using `Model.get_updates_for`.\n\nNote: \"Updates\" are changes that need to be applied to a model after each batch. For example, the moving averages of the mean and variance in a `layers.BatchNormalization` layer.\n\nThe following code creates an estimator from a custom `model_fn`, illustrating all of these concerns.",
"_____no_output_____"
]
],
[
[
"def my_model_fn(features, labels, mode):\n model = make_model()\n\n optimizer = tf.compat.v1.train.AdamOptimizer()\n loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)\n\n training = (mode == tf.estimator.ModeKeys.TRAIN)\n predictions = model(features, training=training)\n\n if mode == tf.estimator.ModeKeys.PREDICT:\n return tf.estimator.EstimatorSpec(mode=mode, predictions=predictions)\n\n reg_losses = model.get_losses_for(None) + model.get_losses_for(features)\n total_loss=loss_fn(labels, predictions) + tf.math.add_n(reg_losses)\n\n accuracy = tf.compat.v1.metrics.accuracy(labels=labels,\n predictions=tf.math.argmax(predictions, axis=1),\n name='acc_op')\n\n update_ops = model.get_updates_for(None) + model.get_updates_for(features)\n minimize_op = optimizer.minimize(\n total_loss,\n var_list=model.trainable_variables,\n global_step=tf.compat.v1.train.get_or_create_global_step())\n train_op = tf.group(minimize_op, update_ops)\n\n return tf.estimator.EstimatorSpec(\n mode=mode,\n predictions=predictions,\n loss=total_loss,\n train_op=train_op, eval_metric_ops={'accuracy': accuracy})\n\n# Create the Estimator & Train\nestimator = tf.estimator.Estimator(model_fn=my_model_fn)\ntf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)",
"_____no_output_____"
]
],
[
[
"#### Custom `model_fn` with TF 2.0 symbols\nIf you want to get rid of all TF 1.x symbols and upgrade your custom `model_fn` to native TF 2.0, you need to update the optimizer and metrics to `tf.keras.optimizers` and `tf.keras.metrics`.\n\nIn the custom `model_fn`, besides the above [changes](#minimal_changes), more upgrades need to be made:\n\n* Use [`tf.keras.optimizers`](https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/optimizers) instead of `v1.train.Optimizer`.\n* Explicitly pass the model's `trainable_variables` to the `tf.keras.optimizers`.\n* To compute the `train_op/minimize_op`,\n * Use `Optimizer.get_updates()` if the loss is scalar loss `Tensor`(not a callable). The first element in the returned list is the desired `train_op/minimize_op`. \n * If the loss is a callable (such as a function), use `Optimizer.minimize()` to get the `train_op/minimize_op`.\n* Use [`tf.keras.metrics`](https://www.tensorflow.org/api_docs/python/tf/keras/metrics) instead of `tf.compat.v1.metrics` for evaluation.\n\nFor the above example of `my_model_fn`, the migrated code with 2.0 symbols is shown as:",
"_____no_output_____"
]
],
[
[
"def my_model_fn(features, labels, mode):\n model = make_model()\n\n training = (mode == tf.estimator.ModeKeys.TRAIN)\n loss_obj = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)\n predictions = model(features, training=training)\n\n # Get both the unconditional losses (the None part)\n # and the input-conditional losses (the features part).\n reg_losses = model.get_losses_for(None) + model.get_losses_for(features)\n total_loss=loss_obj(labels, predictions) + tf.math.add_n(reg_losses)\n\n # Upgrade to tf.keras.metrics.\n accuracy_obj = tf.keras.metrics.Accuracy(name='acc_obj')\n accuracy = accuracy_obj.update_state(\n y_true=labels, y_pred=tf.math.argmax(predictions, axis=1))\n\n train_op = None\n if training:\n # Upgrade to tf.keras.optimizers.\n optimizer = tf.keras.optimizers.Adam()\n # Manually assign tf.compat.v1.global_step variable to optimizer.iterations\n # to make tf.compat.v1.train.global_step increased correctly.\n # This assignment is a must for any `tf.train.SessionRunHook` specified in\n # estimator, as SessionRunHooks rely on global step.\n optimizer.iterations = tf.compat.v1.train.get_or_create_global_step()\n # Get both the unconditional updates (the None part)\n # and the input-conditional updates (the features part).\n update_ops = model.get_updates_for(None) + model.get_updates_for(features)\n # Compute the minimize_op.\n minimize_op = optimizer.get_updates(\n total_loss,\n model.trainable_variables)[0]\n train_op = tf.group(minimize_op, *update_ops)\n\n return tf.estimator.EstimatorSpec(\n mode=mode,\n predictions=predictions,\n loss=total_loss,\n train_op=train_op,\n eval_metric_ops={'Accuracy': accuracy_obj})\n\n# Create the Estimator & Train.\nestimator = tf.estimator.Estimator(model_fn=my_model_fn)\ntf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)",
"_____no_output_____"
]
],
[
[
"### Premade Estimators\n\n[Premade Estimators](https://www.tensorflow.org/guide/premade_estimators) in the family of `tf.estimator.DNN*`, `tf.estimator.Linear*` and `tf.estimator.DNNLinearCombined*` are still supported in the TensorFlow 2.0 API, however, some arguments have changed:\n\n1. `input_layer_partitioner`: Removed in 2.0.\n2. `loss_reduction`: Updated to `tf.keras.losses.Reduction` instead of `tf.compat.v1.losses.Reduction`. Its default value is also changed to `tf.keras.losses.Reduction.SUM_OVER_BATCH_SIZE` from `tf.compat.v1.losses.Reduction.SUM`.\n3. `optimizer`, `dnn_optimizer` and `linear_optimizer`: this arg has been updated to `tf.keras.optimizers` instead of the `tf.compat.v1.train.Optimizer`. \n\nTo migrate the above changes:\n1. No migration is needed for `input_layer_partitioner` since [`Distribution Strategy`](https://www.tensorflow.org/guide/distributed_training) will handle it automatically in TF 2.0.\n2. For `loss_reduction`, check [`tf.keras.losses.Reduction`](https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/losses/Reduction) for the supported options.\n3. For `optimizer` args, if you do not pass in an `optimizer`, `dnn_optimizer` or `linear_optimizer` arg, or if you specify the `optimizer` arg as a `string` in your code, you don't need to change anything. `tf.keras.optimizers` is used by default. Otherwise, you need to update it from `tf.compat.v1.train.Optimizer` to its corresponding [`tf.keras.optimizers`](https://www.tensorflow.org/versions/r2.0/api_docs/python/tf/keras/optimizers)\n",
"_____no_output_____"
],
[
"#### Checkpoint Converter\n<a id=\"checkpoint_converter\"></a>\n\nThe migration to `keras.optimizers` will break checkpoints saved using TF 1.x, as `tf.keras.optimizers` generates a different set of variables to be saved in checkpoints. To make old checkpoint reusable after your migration to TF 2.0, try the [checkpoint converter tool](https://github.com/tensorflow/estimator/blob/master/tensorflow_estimator/python/estimator/tools/checkpoint_converter.py).",
"_____no_output_____"
]
],
[
[
"! curl -O https://raw.githubusercontent.com/tensorflow/estimator/master/tensorflow_estimator/python/estimator/tools/checkpoint_converter.py",
"_____no_output_____"
]
],
[
[
"The tool has builtin help:",
"_____no_output_____"
]
],
[
[
"! python checkpoint_converter.py -h",
"_____no_output_____"
]
],
[
[
"<a id=\"tensorshape\"></a>\n\n## TensorShape\n\nThis class was simplified to hold `int`s, instead of `tf.compat.v1.Dimension` objects. So there is no need to call `.value()` to get an `int`.\n\nIndividual `tf.compat.v1.Dimension` objects are still accessible from `tf.TensorShape.dims`.",
"_____no_output_____"
],
[
"The following demonstrate the differences between TensorFlow 1.x and TensorFlow 2.0.",
"_____no_output_____"
]
],
[
[
"# Create a shape and choose an index\ni = 0\nshape = tf.TensorShape([16, None, 256])\nshape",
"_____no_output_____"
]
],
[
[
"If you had this in TF 1.x:\n\n```python\nvalue = shape[i].value\n```\n\nThen do this in TF 2.0:\n",
"_____no_output_____"
]
],
[
[
"value = shape[i]\nvalue",
"_____no_output_____"
]
],
[
[
"If you had this in TF 1.x:\n\n```python\nfor dim in shape:\n value = dim.value\n print(value)\n```\n\nThen do this in TF 2.0:",
"_____no_output_____"
]
],
[
[
"for value in shape:\n print(value)",
"_____no_output_____"
]
],
[
[
"If you had this in TF 1.x (Or used any other dimension method):\n\n```python\ndim = shape[i]\ndim.assert_is_compatible_with(other_dim)\n```\n\nThen do this in TF 2.0:",
"_____no_output_____"
]
],
[
[
"other_dim = 16\nDimension = tf.compat.v1.Dimension\n\nif shape.rank is None:\n dim = Dimension(None)\nelse:\n dim = shape.dims[i]\ndim.is_compatible_with(other_dim) # or any other dimension method",
"_____no_output_____"
],
[
"shape = tf.TensorShape(None)\n\nif shape:\n dim = shape.dims[i]\n dim.is_compatible_with(other_dim) # or any other dimension method",
"_____no_output_____"
]
],
[
[
"The boolean value of a `tf.TensorShape` is `True` if the rank is known, `False` otherwise.",
"_____no_output_____"
]
],
[
[
"print(bool(tf.TensorShape([]))) # Scalar\nprint(bool(tf.TensorShape([0]))) # 0-length vector\nprint(bool(tf.TensorShape([1]))) # 1-length vector\nprint(bool(tf.TensorShape([None]))) # Unknown-length vector\nprint(bool(tf.TensorShape([1, 10, 100]))) # 3D tensor\nprint(bool(tf.TensorShape([None, None, None]))) # 3D tensor with no known dimensions\nprint()\nprint(bool(tf.TensorShape(None))) # A tensor with unknown rank.",
"_____no_output_____"
]
],
[
[
"## Other Changes\n\n* Remove `tf.colocate_with`: TensorFlow's device placement algorithms have improved significantly. This should no longer be necessary. If removing it causes a performance degredation [please file a bug](https://github.com/tensorflow/tensorflow/issues).\n\n* Replace `v1.ConfigProto` usage with the equivalent functions from `tf.config`.\n",
"_____no_output_____"
],
[
"## Conclusions\n\nThe overall process is:\n\n1. Run the upgrade script.\n2. Remove contrib symbols.\n3. Switch your models to an object oriented style (Keras).\n4. Use `tf.keras` or `tf.estimator` training and evaluation loops where you can.\n5. Otherwise, use custom loops, but be sure to avoid sessions & collections.\n\n\nIt takes a little work to convert code to idiomatic TensorFlow 2.0, but every change results in:\n\n* Fewer lines of code.\n* Increased clarity and simplicity.\n* Easier debugging.\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
cb3ae57d2c30bd23822f1f6a914de9d8035882e5 | 10,993 | ipynb | Jupyter Notebook | neurophysics-neuroscience/python/setup.ipynb | HiteshDhola/Artificial-Intelligence-Deep-Learning-Machine-Learning-Tutorials | a0b839d412d2e7e4d8f3b3d885e318650399b857 | [
"Apache-2.0"
] | 3,266 | 2017-08-06T16:51:46.000Z | 2022-03-30T07:34:24.000Z | neurophysics-neuroscience/python/setup.ipynb | HiteshDhola/Artificial-Intelligence-Deep-Learning-Machine-Learning-Tutorials | a0b839d412d2e7e4d8f3b3d885e318650399b857 | [
"Apache-2.0"
] | 150 | 2017-08-28T14:59:36.000Z | 2022-03-11T23:21:35.000Z | neurophysics-neuroscience/python/setup.ipynb | HiteshDhola/Artificial-Intelligence-Deep-Learning-Machine-Learning-Tutorials | a0b839d412d2e7e4d8f3b3d885e318650399b857 | [
"Apache-2.0"
] | 1,449 | 2017-08-06T17:40:59.000Z | 2022-03-31T12:03:24.000Z | 47.383621 | 185 | 0.548986 | [
[
[
"This notebook is used to set up important files for running the notebooks. It will create a \"data\" folder in the root of the repository, and download approximately 60MB of data.",
"_____no_output_____"
]
],
[
[
"import sys\nsys.path.append('./src/')\nimport opencourse as oc",
"_____no_output_____"
],
[
"# Download all data\noc.download_all_files()",
"Help on package opencourse:\n\nNAME\n opencourse\n\nPACKAGE CONTENTS\n bassett_funcs\n io\n konrad_funcs\n\nFUNCTIONS\n open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)\n Open file and return a stream. Raise IOError upon failure.\n \n file is either a text or byte string giving the name (and the path\n if the file isn't in the current working directory) of the file to\n be opened or an integer file descriptor of the file to be\n wrapped. (If a file descriptor is given, it is closed when the\n returned I/O object is closed, unless closefd is set to False.)\n \n mode is an optional string that specifies the mode in which the file\n is opened. It defaults to 'r' which means open for reading in text\n mode. Other common values are 'w' for writing (truncating the file if\n it already exists), 'x' for creating and writing to a new file, and\n 'a' for appending (which on some Unix systems, means that all writes\n append to the end of the file regardless of the current seek position).\n In text mode, if encoding is not specified the encoding used is platform\n dependent: locale.getpreferredencoding(False) is called to get the\n current locale encoding. (For reading and writing raw bytes use binary\n mode and leave encoding unspecified.) The available modes are:\n \n ========= ===============================================================\n Character Meaning\n --------- ---------------------------------------------------------------\n 'r' open for reading (default)\n 'w' open for writing, truncating the file first\n 'x' create a new file and open it for writing\n 'a' open for writing, appending to the end of the file if it exists\n 'b' binary mode\n 't' text mode (default)\n '+' open a disk file for updating (reading and writing)\n 'U' universal newline mode (deprecated)\n ========= ===============================================================\n \n The default mode is 'rt' (open for reading text). For binary random\n access, the mode 'w+b' opens and truncates the file to 0 bytes, while\n 'r+b' opens the file without truncation. The 'x' mode implies 'w' and\n raises an `FileExistsError` if the file already exists.\n \n Python distinguishes between files opened in binary and text modes,\n even when the underlying operating system doesn't. Files opened in\n binary mode (appending 'b' to the mode argument) return contents as\n bytes objects without any decoding. In text mode (the default, or when\n 't' is appended to the mode argument), the contents of the file are\n returned as strings, the bytes having been first decoded using a\n platform-dependent encoding or using the specified encoding if given.\n \n 'U' mode is deprecated and will raise an exception in future versions\n of Python. It has no effect in Python 3. Use newline to control\n universal newlines mode.\n \n buffering is an optional integer used to set the buffering policy.\n Pass 0 to switch buffering off (only allowed in binary mode), 1 to select\n line buffering (only usable in text mode), and an integer > 1 to indicate\n the size of a fixed-size chunk buffer. When no buffering argument is\n given, the default buffering policy works as follows:\n \n * Binary files are buffered in fixed-size chunks; the size of the buffer\n is chosen using a heuristic trying to determine the underlying device's\n \"block size\" and falling back on `io.DEFAULT_BUFFER_SIZE`.\n On many systems, the buffer will typically be 4096 or 8192 bytes long.\n \n * \"Interactive\" text files (files for which isatty() returns True)\n use line buffering. Other text files use the policy described above\n for binary files.\n \n encoding is the name of the encoding used to decode or encode the\n file. This should only be used in text mode. The default encoding is\n platform dependent, but any encoding supported by Python can be\n passed. See the codecs module for the list of supported encodings.\n \n errors is an optional string that specifies how encoding errors are to\n be handled---this argument should not be used in binary mode. Pass\n 'strict' to raise a ValueError exception if there is an encoding error\n (the default of None has the same effect), or pass 'ignore' to ignore\n errors. (Note that ignoring encoding errors can lead to data loss.)\n See the documentation for codecs.register or run 'help(codecs.Codec)'\n for a list of the permitted encoding error strings.\n \n newline controls how universal newlines works (it only applies to text\n mode). It can be None, '', '\\n', '\\r', and '\\r\\n'. It works as\n follows:\n \n * On input, if newline is None, universal newlines mode is\n enabled. Lines in the input can end in '\\n', '\\r', or '\\r\\n', and\n these are translated into '\\n' before being returned to the\n caller. If it is '', universal newline mode is enabled, but line\n endings are returned to the caller untranslated. If it has any of\n the other legal values, input lines are only terminated by the given\n string, and the line ending is returned to the caller untranslated.\n \n * On output, if newline is None, any '\\n' characters written are\n translated to the system default line separator, os.linesep. If\n newline is '' or '\\n', no translation takes place. If newline is any\n of the other legal values, any '\\n' characters written are translated\n to the given string.\n \n If closefd is False, the underlying file descriptor will be kept open\n when the file is closed. This does not work when a file name is given\n and must be True in that case.\n \n A custom opener can be used by passing a callable as *opener*. The\n underlying file descriptor for the file object is then obtained by\n calling *opener* with (*file*, *flags*). *opener* must return an open\n file descriptor (passing os.open as *opener* results in functionality\n similar to passing None).\n \n open() returns a file object whose type depends on the mode, and\n through which the standard file operations such as reading and writing\n are performed. When open() is used to open a file in a text mode ('w',\n 'r', 'wt', 'rt', etc.), it returns a TextIOWrapper. When used to open\n a file in a binary mode, the returned class varies: in read binary\n mode, it returns a BufferedReader; in write binary and append binary\n modes, it returns a BufferedWriter, and in read/write mode, it returns\n a BufferedRandom.\n \n It is also possible to use a string or bytearray as a file for both\n reading and writing. For strings StringIO can be used like a file\n opened in a text mode, and for bytes a BytesIO can be used like a file\n opened in a binary mode.\n\nDATA\n SEEK_CUR = 1\n SEEK_END = 2\n SEEK_SET = 0\n\nFILE\n /Users/tarrysingh/Downloads/data-science-ipython-notebooks-master/neurophysics-neuroscience/python/src/opencourse/__init__.py\n\n\n"
]
],
[
[
"# Ensure that you have the right dependencies\nAll of the below packages should import:",
"_____no_output_____"
]
],
[
[
"import mne # <-- Package for electrophysiology analysis\nimport pandas # <-- Package for representing data as a DataFrame\nimport bct # <-- Brain Connectivity Toolbox",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
cb3aebd003008c7ae0f881f6bc51145ae2fff649 | 126,280 | ipynb | Jupyter Notebook | FIFA 2019 Linear Regression.ipynb | dhanushkr/Simple-Analysis-On-FIFA-19 | 8968b8ee9dc59c44b9ab175a26d8521c3de8a27d | [
"CNRI-Python"
] | null | null | null | FIFA 2019 Linear Regression.ipynb | dhanushkr/Simple-Analysis-On-FIFA-19 | 8968b8ee9dc59c44b9ab175a26d8521c3de8a27d | [
"CNRI-Python"
] | null | null | null | FIFA 2019 Linear Regression.ipynb | dhanushkr/Simple-Analysis-On-FIFA-19 | 8968b8ee9dc59c44b9ab175a26d8521c3de8a27d | [
"CNRI-Python"
] | null | null | null | 84.979812 | 31,820 | 0.744987 | [
[
[
"# Introduction\n\nIn a sport like Football, each player contributes to the team's success. It's important to understand the player's overall performance. In this report we will look into various factors that impact the player's overall performance.",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\n\n#to replace values in columns\nimport re\n\n# To build and evaluate model\nfrom sklearn.linear_model import LinearRegression\nfrom sklearn.neighbors import KNeighborsRegressor\nfrom sklearn.tree import DecisionTreeRegressor \nfrom sklearn.ensemble import RandomForestRegressor\nfrom sklearn.metrics import mean_squared_error,mean_absolute_error,r2_score\nfrom sklearn.model_selection import train_test_split\n\n# to make plots\nimport seaborn as sns\nimport matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"## 1. Business Understanding\n\n1. Best players in various aspects?\n2. Most preferred foot?\n3. Effect of Football Foot on Player's Potential?\n4. Does Age have an Impact on Potential?\n5. Predicting Overall player's performance\n\n## 2. Data Understanding\nIn this section, we load the data, check the data attributes for analysis",
"_____no_output_____"
]
],
[
[
"# Reading FIFA 2019 complete player dataset\ndata = pd.read_csv('/Users/prof.lock/Desktop/Data Science/data.csv')",
"_____no_output_____"
],
[
"# Sample Data\ndata.head()",
"_____no_output_____"
],
[
"data.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 18207 entries, 0 to 18206\nData columns (total 89 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 Unnamed: 0 18207 non-null int64 \n 1 ID 18207 non-null int64 \n 2 Name 18207 non-null object \n 3 Age 18207 non-null int64 \n 4 Photo 18207 non-null object \n 5 Nationality 18207 non-null object \n 6 Flag 18207 non-null object \n 7 Overall 18207 non-null int64 \n 8 Potential 18207 non-null int64 \n 9 Club 17966 non-null object \n 10 Club Logo 18207 non-null object \n 11 Value 18207 non-null object \n 12 Wage 18207 non-null object \n 13 Special 18207 non-null int64 \n 14 Preferred Foot 18159 non-null object \n 15 International Reputation 18159 non-null float64\n 16 Weak Foot 18159 non-null float64\n 17 Skill Moves 18159 non-null float64\n 18 Work Rate 18159 non-null object \n 19 Body Type 18159 non-null object \n 20 Real Face 18159 non-null object \n 21 Position 18147 non-null object \n 22 Jersey Number 18147 non-null float64\n 23 Joined 16654 non-null object \n 24 Loaned From 1264 non-null object \n 25 Contract Valid Until 17918 non-null object \n 26 Height 18159 non-null object \n 27 Weight 18159 non-null object \n 28 LS 16122 non-null object \n 29 ST 16122 non-null object \n 30 RS 16122 non-null object \n 31 LW 16122 non-null object \n 32 LF 16122 non-null object \n 33 CF 16122 non-null object \n 34 RF 16122 non-null object \n 35 RW 16122 non-null object \n 36 LAM 16122 non-null object \n 37 CAM 16122 non-null object \n 38 RAM 16122 non-null object \n 39 LM 16122 non-null object \n 40 LCM 16122 non-null object \n 41 CM 16122 non-null object \n 42 RCM 16122 non-null object \n 43 RM 16122 non-null object \n 44 LWB 16122 non-null object \n 45 LDM 16122 non-null object \n 46 CDM 16122 non-null object \n 47 RDM 16122 non-null object \n 48 RWB 16122 non-null object \n 49 LB 16122 non-null object \n 50 LCB 16122 non-null object \n 51 CB 16122 non-null object \n 52 RCB 16122 non-null object \n 53 RB 16122 non-null object \n 54 Crossing 18159 non-null float64\n 55 Finishing 18159 non-null float64\n 56 HeadingAccuracy 18159 non-null float64\n 57 ShortPassing 18159 non-null float64\n 58 Volleys 18159 non-null float64\n 59 Dribbling 18159 non-null float64\n 60 Curve 18159 non-null float64\n 61 FKAccuracy 18159 non-null float64\n 62 LongPassing 18159 non-null float64\n 63 BallControl 18159 non-null float64\n 64 Acceleration 18159 non-null float64\n 65 SprintSpeed 18159 non-null float64\n 66 Agility 18159 non-null float64\n 67 Reactions 18159 non-null float64\n 68 Balance 18159 non-null float64\n 69 ShotPower 18159 non-null float64\n 70 Jumping 18159 non-null float64\n 71 Stamina 18159 non-null float64\n 72 Strength 18159 non-null float64\n 73 LongShots 18159 non-null float64\n 74 Aggression 18159 non-null float64\n 75 Interceptions 18159 non-null float64\n 76 Positioning 18159 non-null float64\n 77 Vision 18159 non-null float64\n 78 Penalties 18159 non-null float64\n 79 Composure 18159 non-null float64\n 80 Marking 18159 non-null float64\n 81 StandingTackle 18159 non-null float64\n 82 SlidingTackle 18159 non-null float64\n 83 GKDiving 18159 non-null float64\n 84 GKHandling 18159 non-null float64\n 85 GKKicking 18159 non-null float64\n 86 GKPositioning 18159 non-null float64\n 87 GKReflexes 18159 non-null float64\n 88 Release Clause 16643 non-null object \ndtypes: float64(38), int64(6), object(45)\nmemory usage: 12.4+ MB\n"
],
[
"data.describe()",
"_____no_output_____"
]
],
[
[
"## 3. Data Preparation\nClean Converting the data types into suitable types. Since Wage and Value cannot be str type. so we convert them to float.\n\nDroping columns We drop all the columns which we do not need for any manupulations i.e from which data we cannot make out any thing.",
"_____no_output_____"
]
],
[
[
"data[data.columns[data.isna().any()]].isna().sum() # Gets the columns with na values and its count",
"_____no_output_____"
],
[
"# Majority of columns have 48 na values, check if they have common indices\nprint(\"The columns with 48 na values have same indices: {}\"\n .format(data[data['Stamina'].isna()].index.tolist()==data[data['GKKicking'].isna()].index.tolist()))",
"The columns with 48 na values have same indices: True\n"
],
[
"data.drop(data[data['Stamina'].isna()].index.tolist(),inplace = True) # remove the indices that have na values ",
"_____no_output_____"
],
[
"# drop the columns which we do not need \ncolumns = ['Unnamed: 0','Photo','Flag','Club Logo','Release Clause','Nationality','ID','Club']\ntry:\n data.drop(data.columns[18:54],axis=1,inplace=True)\n data.drop(columns,axis=1,inplace=True)\nexcept Exception as e:\n print(e)",
"_____no_output_____"
],
[
"replace = lambda x: re.sub(\"[€MK]\",\"\",x) # Wage and values in the columns are string like €10M,€1000K, use re",
"_____no_output_____"
],
[
"# convert the Wage and Value columns to float\ndata['Wage'] = data['Wage'].apply(replace).astype(\"float\")\ndata['Value'] = data['Value'].apply(replace).astype(\"float\")",
"_____no_output_____"
]
],
[
[
"### Best Player in Various Aspects?",
"_____no_output_____"
]
],
[
[
"# best players stores the players name, with their score\nbest_players = pd.DataFrame()\ncolumns = data.columns.tolist()\n# Preferred Foot, Name is dropped as iti cannot be considered as best player attribute\ncolumns.remove(\"Preferred Foot\") \ncolumns.remove(\"Name\")\nfor column in columns:\n try:\n best_players= best_players.append(pd.DataFrame({\"Name\":data.loc[data[column].idxmax()]['Name'],\"Score\":data[column].max()},index=[column]))\n except Exception as e:\n print(e)",
"_____no_output_____"
],
[
"# Keeping only performnace indicators score of best players and dropping other columns\nbest_players.drop(['Special','Weak Foot','International Reputation','Age','Wage','Value'],axis=0)",
"_____no_output_____"
]
],
[
[
"### Most Preferred Foot?",
"_____no_output_____"
]
],
[
[
"# plot counts, number of lefty and rigthy\nsns.countplot(data['Preferred Foot'])\nplt.title('Most Preferred Foot of the Players')",
"_____no_output_____"
]
],
[
[
"### Effect of Football Foot on Player's Potential?",
"_____no_output_____"
]
],
[
[
"# plot to see the efefct on player potential based on lefty or rigthy\nax = sns.catplot(x=\"Preferred Foot\",y=\"Potential\",data=data)\nplt.title(\"Relation between Preferred Foot and Potential\")\n# potential is hardly matters whetehr a player is lefty or righty",
"_____no_output_____"
]
],
[
[
"### Does Age have an Impact on Potential?",
"_____no_output_____"
]
],
[
[
"# bar-plot for Age and Potential\nplt.bar(data['Age'],data['Potential'],color='red')\nplt.xlabel('Age')\nplt.ylabel('Potential')\nplt.title(\"Age vs Potential\")\n# Potential falls with increase in age",
"_____no_output_____"
]
],
[
[
"## 4. Modeling \nAnalyse the data, we build Linear regression and sees performing well. Predict the Player's Overall Performance",
"_____no_output_____"
]
],
[
[
"data.drop(['Name'],axis=1,inplace=True) # Name column is not required for Overall prediction",
"_____no_output_____"
],
[
"# Overall performance correlation with performance indicators\nsns.heatmap(data.corr().loc[['Overall'],:]).set_title(\"Overall correlation to Performance indicators\")",
"_____no_output_____"
],
[
"data = pd.get_dummies(data) # Preferred foot is a categorical value with Left/Right",
"_____no_output_____"
],
[
"# split the target and other columns and split them to train and test sets\nX = data.drop(['Overall'],axis=1)\ny = data[['Overall']]\nX_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3,random_state = 42)",
"_____no_output_____"
],
[
"# Linear regression model \nlm = LinearRegression(normalize=True)\nlm.fit(X_train,y_train)",
"_____no_output_____"
],
[
"# Predict the values for test X sample\ny_pred = lm.predict(X_test)",
"_____no_output_____"
],
[
"# R squared error\nscore = r2_score(y_test,y_pred)\nprint(score)",
"0.9308032151252896\n"
]
],
[
[
"## 5. Evaluation \n\nLinear regression model performs well, we further analyse how RandomForestRegressor, DecisionTreeRegressor, Linear Regression and KNearestNeighbors perform on the data",
"_____no_output_____"
]
],
[
[
"def evaluation(clf,X_train=X_train,y_train=y_train,X_test=X_test,y_test=y_test):\n\n \"\"\"\n Parameters:\n clf (Linear Regression,Random Forest,Decision Tree, KNearest Neighbours) : A machine learning model \n X_train: train sample\n y_train: target train sample\n X_test: test sample\n y_test: target test sample\n \n Fits data into the model and predicts the target value on test sample,\n Evaluates the model using mean absolute error,mean squared error, r2 score\n \"\"\"\n print('\\nModel : {}'.format(clf))\n \n clf.fit(X_train,y_train.values.ravel())\n y_pred =clf.predict(X_test)\n \n try:\n print('MSE : {}'.format(mean_squared_error(y_test,y_pred)))\n print('MAE : {}'.format(mean_absolute_error(y_test,y_pred)))\n print('R2 : {}'.format(r2_score(y_test,y_pred)))\n except Exception as e:\n print(e)",
"_____no_output_____"
],
[
"# knn,dt,rf,lr models\nknn = KNeighborsRegressor(n_neighbors=7)\ndt = DecisionTreeRegressor(max_depth=7)\nrf = RandomForestRegressor(max_depth=7)\nlr = LinearRegression(normalize=True)",
"_____no_output_____"
],
[
"# Iterating and calling evaluate function on models\nmodels = [knn,dt,rf,lr]\nfor i in models:\n evaluation(i)",
"\nModel : KNeighborsRegressor(n_neighbors=7)\nMSE : 2.6967057748209413\nMAE : 1.1889815397524648\nR2 : 0.9429911957194479\n\nModel : DecisionTreeRegressor(max_depth=7)\nMSE : 1.0138042975737798\nMAE : 0.7338371695636625\nR2 : 0.9785680101556486\n\nModel : RandomForestRegressor(max_depth=7)\nMSE : 0.6294585128890213\nMAE : 0.5543436144008576\nR2 : 0.9866931433532454\n\nModel : LinearRegression(normalize=True)\nMSE : 3.2732377345148342\nMAE : 1.4237673936428108\nR2 : 0.9308032151252896\n"
]
],
[
[
"## 6. Conclusion\n\n1. We saw various visualizatons, How age has an impact on player's potential?, Which player is best at what aspect? How overall is related to performance indicators?\n2. Random Forest peforms better on the data, then decision tree followed by K nearest neighbors and Linear regression",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
]
] |
cb3aed9ecdcc794caccf6cce7b9cb03b22adb778 | 36,311 | ipynb | Jupyter Notebook | 6_Principal_Component_Analysis.ipynb | ffyu/Build-Model-from-Scratch | b5754399e792f60db556f109764b3fbf58c3da67 | [
"MIT"
] | 9 | 2016-03-08T03:34:49.000Z | 2020-11-11T16:39:36.000Z | 6_Principal_Component_Analysis.ipynb | ffyu/Build_Model_from_Scratch | b5754399e792f60db556f109764b3fbf58c3da67 | [
"MIT"
] | null | null | null | 6_Principal_Component_Analysis.ipynb | ffyu/Build_Model_from_Scratch | b5754399e792f60db556f109764b3fbf58c3da67 | [
"MIT"
] | 5 | 2016-11-26T04:31:43.000Z | 2021-08-15T21:53:45.000Z | 92.867008 | 25,558 | 0.837212 | [
[
[
"**Principal Component Analysis (PCA)** is widely used in Machine Learning pipelines as a means to compress data or help visualization. This notebook aims to walk through the basic idea of the PCA and build the algorithm from scratch in Python.",
"_____no_output_____"
],
[
"Before diving directly into the PCA, let's first talk about several import concepts - the **\"eigenvectors & eigenvalues\"** and **\"Singular Value Decomposition (SVD)\"**.",
"_____no_output_____"
],
[
"An **eigenvector** of a square matrix is a column vector that satisfies:\n\n$$Av=\\lambda v$$\n\nWhere A is a $[n\\times n]$ square matrix, v is a $[n\\times 1]$ **eigenvector**, and $\\lambda$ is a scalar value which is also known as the **eigenvalue**.",
"_____no_output_____"
],
[
"If A is both a square and symmetric matrix (like a typical variance-covariance matrix), then we can write A as:\n\n$$A=U\\Sigma U^T$$\n\nHere columns of matrix U are eigenvectors of matrix A; and $\\Sigma$ is a diaonal matrix containing the corresponding eigenvalues. \n\nThis is also a special case of the well-known theorem **\"Singular Value Decomposition\" (SVD)**, where a rectangular matrix M can be expressed as:\n\n$$M=U\\Sigma V^T$$",
"_____no_output_____"
],
[
"####With SVD, we can calcuate the eigenvectors and eigenvalues of a square & symmetric matrix. This will be the key to solve the PCA. ",
"_____no_output_____"
],
[
"The goal of the PCA is to find a lower dimension surface to maxmize total variance of the projection, or in other means, to minimize the projection error. The entire algorithm can be summarized as the following:\n\n1) Given a data matrix **$X$** with **$m$** rows (number of records) and **$n$** columns (number of dimensions), we should first substract the column mean for each dimension.\n\n2) Then we can calculate the variance-covariance matrix using the equation (X here already has zero mean for each column from step 1):",
"_____no_output_____"
],
[
"$$cov=\\frac{1}{m}X^TX$$",
"_____no_output_____"
],
[
"3) We can then use SVD to compute the eigenvectors and corresponding eigenvalues of the above covariance matrix \"$cov$\":",
"_____no_output_____"
],
[
"$$cov=U\\Sigma U^T$$",
"_____no_output_____"
],
[
"4) If our target dimension is $p$ ($p<n$), then we will select the first $p$ columns of the $U$ matrix and get matrix $U_{reduce}$.\n\n5) To get the compressed data set, we can do the transformation as below:",
"_____no_output_____"
],
[
"$$X_{reduce}=XU_{reduce}$$",
"_____no_output_____"
],
[
"6) To appoximate the original data set given the compressed data, we can use:",
"_____no_output_____"
],
[
"$$X=X_{reduce}U_{reduce}^T$$",
"_____no_output_____"
],
[
"Note this is true because $U_{reduce}^{-1}=U_{reduce}^T$ (in this case, all the eigenvectors are unit vectors).",
"_____no_output_____"
],
[
"####In practice, it is also important to choose the proper number of principal components. For data compression, we want to retain as much variation in the original data while reducing the dimension. Luckily, with SVD, we can get a estimate of the retained variation by:",
"_____no_output_____"
],
[
"$$\\%\\ of\\ variance\\ retained = \\frac{\\sum_{i=1}^{p}S_{ii}}{\\sum_{i=1}^{n}S_{ii}}$$",
"_____no_output_____"
],
[
"Where $S_{ii}$ is the $ith$ diagonal element of the $\\Sigma$ matrix, $p$ is the number of reduced dimension, and $n$ is the dimension of the original data.",
"_____no_output_____"
],
[
"####For data visulization purposes, we usually choose 2 or 3 dimensions to plot the compressed data.",
"_____no_output_____"
],
[
"####The following class PCA() implements the idea of principal component analysis.",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\nclass PCA():\n\n def __init__(self, num_components):\n\n self.num_components = num_components\n self.U = None\n self.S = None\n\n def fit(self, X):\n\n # perform pca\n m = X.shape[0]\n X_mean = np.mean(X, axis=0)\n X -= X_mean\n cov = X.T.dot(X) * 1.0 / m\n self.U, self.S, _ = np.linalg.svd(cov)\n\n return self\n\n def project(self, X):\n\n # project data based on reduced dimension\n U_reduce = self.U[:, :self.num_components]\n X_reduce = X.dot(U_reduce)\n\n return X_reduce\n\n def inverse(self, X_reduce):\n\n # recover the original data based on the reduced form\n U_reduce = self.U[:, :self.num_components]\n X = X_reduce.dot(U_reduce.T)\n\n return X\n\n def explained_variance(self):\n\n # print the ratio of explained variance with the pca\n explained = np.sum(self.S[:self.num_components])\n total = np.sum(self.S)\n\n return explained * 1.0 / total",
"_____no_output_____"
]
],
[
[
"####Now we can use a demo data set to show dimensionality reduction and data visualization. ",
"_____no_output_____"
],
[
"We will use the Iris Data set as always.",
"_____no_output_____"
]
],
[
[
"from sklearn.datasets import load_iris\niris = load_iris()\n\nX = iris['data']\ny = iris['target']\n\nprint X.shape",
"(150L, 4L)\n"
]
],
[
[
"We can find that the dimension of the original $X$ matrix is 4. We can then compress it to 2 using PCA technique with the **PCA()** class that we defined above.",
"_____no_output_____"
]
],
[
[
"pca = PCA(num_components=2)\npca.fit(X)\n\nX_reduce = pca.project(X)\nprint X_reduce.shape",
"(150L, 2L)\n"
]
],
[
[
"Now that the data has been compressed, we can check the ratianed variance.",
"_____no_output_____"
]
],
[
[
"print \"{:.2%}\".format(pca.explained_variance())",
"97.76%\n"
]
],
[
[
"We have 97.76% of variance retained. This is okay for data visulization purposes. But if we used PCA in supervised learning pipelines, we might want to add more dimension to keep more than 99% of the variation from the original data.",
"_____no_output_____"
],
[
"Finally, with the compressed dimension, we can plot to see the distribution of iris dataset.",
"_____no_output_____"
]
],
[
[
"%pylab inline\npylab.rcParams['figure.figsize'] = (10, 6)\n\nfrom matplotlib import pyplot as plt\n\nfor c, marker, class_num in zip(['green', 'r', 'cyan'], ['o', '^', 's'], np.unique(y)):\n\n plt.scatter(x=X_reduce[:, 0][y == class_num], y=X_reduce[:, 1][y == class_num], c=c, marker=marker,\n label=\"Class {}\".format(class_num), alpha=0.7, s=30)\n\n\nplt.xlabel(\"Component 1\")\nplt.ylabel(\"Component 2\")\nplt.legend()\n\nplt.show()",
"Populating the interactive namespace from numpy and matplotlib\n"
]
],
[
[
"From the above example, we can see that PCA can help us visualize data with more than 3 feature dimensions. The general use of PCA is for dimensionality reductions in Machine Learning Pipelines. It can speed up the learning process and save memory when running supervised and unsupervised algorithms on large dataset. However, it also throws away some information when reducing the feature dimension. Thus it is always beneficial to test whether using PCA on top of something else since it's pretty easy to set up.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
cb3aefd25a6a47dffe6cd4fda3759e4f0bcc67ed | 4,049 | ipynb | Jupyter Notebook | jupyter notebooks/RegressionMetrics.ipynb | nwupkc/nwupkc.github.io | bed284c46ec926d9e06e26a95a7b0cbd4a193cf9 | [
"MIT"
] | null | null | null | jupyter notebooks/RegressionMetrics.ipynb | nwupkc/nwupkc.github.io | bed284c46ec926d9e06e26a95a7b0cbd4a193cf9 | [
"MIT"
] | null | null | null | jupyter notebooks/RegressionMetrics.ipynb | nwupkc/nwupkc.github.io | bed284c46ec926d9e06e26a95a7b0cbd4a193cf9 | [
"MIT"
] | null | null | null | 33.188525 | 385 | 0.604347 | [
[
[
"## Regression Metrics",
"_____no_output_____"
],
[
"### $R^2$ Score",
"_____no_output_____"
],
[
"The $R^2$ statistics is the amount of variance in the dependent variable explained by your model. It is given by the formula:\n\n$$R^2 = \\frac{ESS}{TSS} = 1 − \\frac{RSS}{TSS}$$\nwhere\n$$ESS = \\sum\\limits_{i=1}^n (\\hat y_i - \\bar y_i)^2, \\ \nRSS = \\sum\\limits_{i=1}^n (y_i - \\hat y_i)^2, \\ and \\ \\ \nTSS = \\sum\\limits_{i=1}^n (y_i - \\bar y_i)^2 \\\\\nwhere \\ \\ \\bar y_i = \\sum\\limits_{i=1}^n y_i$$",
"_____no_output_____"
],
[
"The explained sum of squares ($ESS$) is a quantity used in describing how well a model represents the data being modeled. In particular, the explained sum of squares measures how much variation there is in the modeled values.\n\nThe residual sum of squares ($RSS$) is the sum of the squares of residuals. The residuals are deviations of predicted from the actual empirical values of data. $RSS$ is a measure of the discrepancy between the data and an estimation model. A small $RSS$ indicates a tight fit of the model to the data. The residual sum of squares measures the variation in the modeling errors.\n\nThe total sum of squares ($TSS$) is the sum of the squares of the difference of the dependent variable and its mean. The total sum of squares measures how much variation there is in the observed data.\n\nIn general, total sum of squares = explained sum of squares + residual sum of squares.\n$TSS = ESS + RSS$",
"_____no_output_____"
],
[
"### Mean Squared Error and Root-Mean-Square Error",
"_____no_output_____"
],
[
"The mean squared error ($MSE$) is another popular metrics in regression settings. The mean squared error is the explained sum of squares divided by the number of observations.\n$$MSE = \\frac{1}{n} \\cdot RSS = \\frac{1}{n} \\sum\\limits_{i=1}^n (y_i - \\hat y_i)^2$$\nThe root-mean-square error ($RMSE$) is the square root of $MSE$ (i.e. $RMSE = \\sqrt{MSE}$). $RMSE$ has an advantage over $MSE$ because it has the same units as the quantity being estimated.",
"_____no_output_____"
],
[
"$R^2$ is a standardized measure (from 0 to 1) of model fit. $MSE$ is the estimate of variance of residuals, or non-fit. We want higher $R^2$ and lower $MSE$. The two measures are clearly related as can be seen from here:\n$$R^2 = 1 − \\frac{RSS}{TSS} = 1 - \\frac{n \\cdot MSE}{TSS}$$",
"_____no_output_____"
]
]
] | [
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
cb3aff6702657044a01580033d7835bbfef9caa8 | 27,878 | ipynb | Jupyter Notebook | Norway_map/Norway_map_MEPS_altitude.ipynb | franzihe/Python_Masterthesis | f6acd3a98edb859f11c3f1cd2bc62e31065f5f4a | [
"MIT"
] | null | null | null | Norway_map/Norway_map_MEPS_altitude.ipynb | franzihe/Python_Masterthesis | f6acd3a98edb859f11c3f1cd2bc62e31065f5f4a | [
"MIT"
] | null | null | null | Norway_map/Norway_map_MEPS_altitude.ipynb | franzihe/Python_Masterthesis | f6acd3a98edb859f11c3f1cd2bc62e31065f5f4a | [
"MIT"
] | null | null | null | 36.729908 | 163 | 0.538704 | [
[
[
"import numpy as np\nimport os, sys, datetime, string\nsys.path.append('/Volumes/SANDISK128/Documents/Thesis/Python/')\nsys.path.append('/Volumes/SANDISK128/Documents/Thesis/Python/MEPS/')\n\nimport matplotlib.pyplot as plt\nfrom scipy import stats\nfrom mpl_toolkits.basemap import Basemap\nimport netCDF4\nimport matplotlib as mpl\nimport save_fig as sF\nimport createFolder as cF\nfrom calc_station_properties import find_station_yx",
"_____no_output_____"
],
[
"import matplotlib.colors as colors\n\nimport gdal\nfrom mpl_toolkits.mplot3d import Axes3D\nfrom matplotlib.cbook import get_sample_data\nimport pandas as pd\nfrom matplotlib.colors import LightSource\nfrom pyproj import Proj, transform",
"_____no_output_____"
],
[
"savefig = 1 # 1 = yes, 0 = no\nfig_dir = '../../Figures/Norway_map'\ncF.createFolder(fig_dir)\nform = 'png'",
"_____no_output_____"
],
[
"def Lambert_map(lllon, lllat, urlon, urlat, lat0, lon0, res='l', fill=False, zoom=False):\n \"\"\"lllon - lon lower left corner ...\n lat0 - latitude standard parallel, should be somewhere in the center of the domain\n lon0 - the parallel longitude\n lllon - lower left longitude ...\n http://matplotlib.org/basemap/api/basemap_api.html\"\"\"\n rsphere=(6378137.00,6356752.3142)\n map = Basemap(llcrnrlon=lllon, llcrnrlat=lllat, urcrnrlon=urlon, urcrnrlat=urlat, rsphere=rsphere,\n resolution=res,area_thresh=1000.,projection='lcc', lat_0=lat0,lon_0=lon0)\n# map = Basemap(llcrnrlon=lllon, llcrnrlat=lllat, urcrnrlon=urlon, urcrnrlat=urlat, rsphere=rsphere,\n # resolution=res,area_thresh=1000.,projection='lcc', lat_1=lllon,lon_0=lon0)\n # Draw the latitudes and the longitudes\n# parallels = np.arange(0.,90,5.)\n # map.drawparallels(parallels,labels=[True,False,False,False],fontsize=16) \n # meridians = np.arange(10.,361.,10.)\n # map.drawmeridians(meridians,labels=[False,False,False,True],fontsize=16)\n if zoom == False:\n map.drawmeridians(np.arange(0,90,10),labels=[0,0,0,1],fontsize=16)\n map.drawparallels(np.arange(10,361,4),labels=[1,0,0,0],fontsize=16)\n else:\n# map.drawmeridians(np.arange(0,90,3),labels=[0,0,0,1],fontsize=16)\n # map.drawparallels(np.arange(0,361,2),labels=[1,0,0,0],fontsize=16)\n map.drawmeridians(np.arange(0,90,0.1),labels=[0,0,0,1],fontsize=16)\n map.drawparallels(np.arange(0,361,0.05),labels=[1,0,0,0],fontsize=16)\n\n # Draw the coastline\n map.drawcoastlines()#color='0.5')\n \n \n\n if fill:\n map.drawlsmask(#land_color='0.8', \n ocean_color='gainsboro')\n \n# if zoom == False:\n \n ### plot MEPS area\n # for i in range(0,lato.shape[0],12):\n # xs, ys = map(lono[i], lato[i])\n # map.plot(xs,ys, color = 'orange', marker = 'o', markersize = 10, linestyle = '-', linewidth = 10)\n # for i in range(0,lato2.shape[0],12):\n # xs2, ys2 = map(lono2[i], lato2[i])\n # map.plot(xs2,ys2, color = 'orange', marker = 'o', markersize = 10, linestyle = '-', linewidth = 10)\n\n # xs, ys = map(lono[739], lato[739])\n #map.plot(xs,ys, color = 'orange', marker ='o', markersize = 10, linestyle = '-', linewidth = 10, label = 'MEPS domain')\n #lgd = plt.legend(loc='lower left',fontsize=18)\n\n #map.drawmapboundary(fill_color='gainsboro')\n \n return map \n",
"_____no_output_____"
],
[
"def PlotContours(Lon, Lat, psurf, map, nrlevels=10, leveldist=None,levels=None, numbers=True, color= 'k'):\n \"\"\" contours for example the pressure\n nrlevels - gives the number of displayed levels\n leveldist - gives distance between levels, if specified the nlevels is ignored\n levels - can be an array that specifies the levels to display, if specified nrlevels and leveldist are ignored\n numbers - True if the contours are labeled\n color - color of the contours (None is s color map)\"\"\"\n if levels is not None:\n cs= map.contour(Lon, Lat, psurf, levels, linewidths= 1. , colors= color)\n elif leveldist is not None:\n levels= np.arange(np.round(np.min(psurf)- np.min(psurf)%leveldist), np.round(np.max(psurf)+ leveldist), leveldist)\n cs= map.contour(Lon, Lat, psurf, levels, linewidths= 1. , colors= color) \n else:\n cs= map.contour(Lon, Lat, psurf, nrlevels, linewidths= 1. , colors= color)#, colors= 6*['b']+ 6*['r'],)\n if numbers == True: plt.clabel(cs, fontsize=10, inline=1, fmt='%1.0f', color= 'black')\n #plt.tight_layout()",
"_____no_output_____"
],
[
"def PlotColorMap4(Lon, Lat, data, map, maxlevel= None, symetric=True, bounds=None, label='', color= 'RdBu', boxnr= 21):\n \"\"\" plot a color map, e.g. vertical velocity\n if symetric == True it is symetric around 0 and the maxlevel is calculated automatically\n best version of PlotColorMap\"\"\"\n \n if color== 'RdBu': colors= [(plt.cm.RdBu_r(h)) for h in range(256)]\n elif color== 'seismic': colors= [(plt.cm.seismic(h)) for h in range(256)]\n elif color== 'blue': colors= [(plt.cm.Blues(h)) for h in range(256)]\n elif color== 'inverse_blue': colors= [(plt.cm.Blues(h)) for h in range(255, 0, -1)]\n\n elif color == 'red': colors= ['azure']+[(plt.cm.Reds(h)) for h in range(256)]\n else: print('wrong color')\n# if bounds != None: boxnr = len(bounds)\n new_map = plt.matplotlib.colors.LinearSegmentedColormap.from_list('new_map', colors) #, N=boxnr)\n\n if bounds is None:\n if maxlevel is not None: minlevel= maxlevel\n if maxlevel is None and bounds is None:\n if symetric is True:\n maxlevel, minlevel= np.max(np.abs(data)), -np.max(np.abs(data))\n else:\n maxlevel, minlevel= np.max(data), np.min(data) \n \n bounds= np.round(np.linspace(minlevel, maxlevel, boxnr+1), int(np.log10(85/maxlevel)))\n# bounds= np.round(list(np.linspace(-maxlevel, 0, boxnr//2+1))+list(np.linspace(0, maxlevel, boxnr//2+1)), int(np.log10(85/maxlevel))) \n# print(maxlevel)\n\n Lon= 0.5* (Lon[1:, 1:]+ Lon[:-1, :-1])\n Lat= 0.5* (Lat[1:, 1:]+ Lat[:-1, :-1])\n \n norm= mpl.colors.BoundaryNorm(bounds, new_map.N)\n cs= map.pcolormesh(Lon, Lat, data[1:, 1:], norm= norm, cmap=new_map, alpha= 1.)\n cb = map.colorbar(cs, boundaries= bounds, norm= norm, location='right',pad='3%',extend='max')\n \n cb.set_label(label, size=18) \n cb.ax.tick_params(labelsize=16)\n",
"_____no_output_____"
],
[
"#### Plot kartverket elevation ###\nchamp = 255.\nno0 = np.array([0,155,88])/champ #700\nno1 = np.array([0,160,79])/champ #750\nno2 = np.array([0,164,72])/champ #800\nno3 = np.array([55,168,76])/champ #850\nno4 = np.array([81,171,79])/champ #900\nno5 = np.array([104,174,82])/champ #950\nno6 = np.array([119,177,84])/champ #1000\nno7 = np.array([136,180,85])/champ #1050\nno8 = np.array([151,183,87])/champ #1100\nno9 = np.array([165,185,88])/champ #1150\nno10 = np.array([179,187,89])/champ #1200\nno11 = np.array([185,180,92])/champ #1250\nno12 = np.array([190,173,94])/champ #1300\nno13 = np.array([197,164,98])/champ #1350\nno14 = np.array([205,168,117])/champ #1400\nno15 = np.array([214,173,134])/champ #1450\nno16 = np.array([223,180,154])/champ #1500\nno17 = np.array([231,190,174])/champ #1550\nno18 = np.array([239,204,195])/champ #1600\nno19 = np.array([246,221,220])/champ #1650\nno20 = np.array([252,241,242])/champ #1700\nno21 = np.array([255,255,255])/champ #1750\n\nno22 = np.array([80,80,81])/champ",
"_____no_output_____"
],
[
"#url = ('http://thredds.met.no/thredds/dodsC/meps25epsarchive/2016/12/24/meps_mbr0_pp_2_5km_20161224T12Z.nc')\nurl = ('http://thredds.met.no/thredds/dodsC/meps25epsarchive/2016/12/23/meps_mbr0_pp_2_5km_20161223T00Z.nc')\n#url = ('http://thredds.met.no/thredds/dodsC/meps25epsarchive/2016/12/21/meps_mbr0_pp_2_5km_20161221T00Z.nc')\ndataset = netCDF4.Dataset(url)\n\nland= dataset.variables['land_area_fraction'][:]\nlonpp= dataset.variables['longitude'][:]\nlatpp= dataset.variables['latitude'][:]\n\nx_wind = dataset.variables['x_wind_10m'][14,:,:]\ny_wind = dataset.variables['y_wind_10m'][14,:,:]\n\n#T_2m= dataset.variables['air_temperature_2m'][:]\nalti= dataset.variables['altitude'][:]\n\n\ndataset.close()",
"_____no_output_____"
],
[
"grid_x, grid_y = find_station_yx(latpp, lonpp, 59+48.73/60, 7+12.87/60)",
"_____no_output_____"
],
[
"alti[grid_y[0],grid_x[0]]",
"_____no_output_____"
],
[
"lonpp[grid_y[0],grid_x[0]]",
"_____no_output_____"
],
[
"latpp[grid_y[0],grid_x[0]]",
"_____no_output_____"
],
[
"#### Station map\n#plt.figure(1)\nfig = plt.figure(figsize=(9,8))\nplt.clf()\nmap= Lambert_map(lllon=7.05, lllat=59.73, urlon=7.35, urlat=59.91, lat0= 63.5, lon0= 15, res='i', fill=False,zoom=True)\n\nLonpp,Latpp = map(lonpp,latpp)\n\n \n#levels = [850, 900,950,1000,1050,1100,1150, 1200, 1250, 1300,1350,1400]\nlevels = np.arange(700,1800,50)\nPlotContours(Lonpp, Latpp, alti, map, leveldist=None,levels=levels, numbers=True, color= 'gray')\n\ncmap = colors.ListedColormap([no0, no1, no2, no3, no4, no5, no6, no7, no8, no9, no10, \\\n no11, no12, no13, no14, no15, no16, no17, no18, no19, no20, \\\n no21])\nnorm = colors.BoundaryNorm(boundaries = levels, ncolors=cmap.N)\n\n\n#PlotColorMap4(Lonpp, Latpp, alti, map, bounds= levels,color=cmap, label='Altitude')\ncs = map.pcolormesh(Lonpp, Latpp, alti, norm= norm, cmap=cmap, alpha= 1.)\ncb = plt.colorbar(cs, boundaries= levels, #location='right',\n extend='max')\n\n### plot wind barbs\nmap.barbs(Lonpp,Latpp,x_wind,y_wind,barbcolor = [no22], pivot = 'middle')\n \ncb.set_label('Altitude [m]', size=18) \ncb.ax.tick_params(labelsize=16)\nplt.gca().set_aspect('equal', adjustable='box')\n\ncb.ax.set_xticklabels([700, '', '', '', 900,'','','',1100,'','','',1300,'','','',1500,\n '','','',1700,'']) # horizontal colorbar\n\nnamestat = ['Haukeliseter']#,'Model']#, 'lower left', 'upper right']#,'grid point']\nlonstat = [7+12.87/60]#,lonpp[grid_y[0],grid_x[0]]]#,7.05, 7.4]#,7.2]\nlatstat= [59+48.73/60]#,latpp[grid_y[0],grid_x[0]]]#,59.65, 59.9]#,59.8]\nxpt, ypt= map(lonstat, latstat)\nmap.plot(xpt,ypt,color='k', marker='X',markersize=12)\n\nnamestat2 = ['Model (1041 m a.s.l.)']#, 'lower left', 'upper right']#,'grid point']\nlonstat2 = [lonpp[grid_y[0],grid_x[0]]]#,7.05, 7.4]#,7.2]\nlatstat2= [latpp[grid_y[0],grid_x[0]]]#,59.65, 59.9]#,59.8]\n\nxpt2, ypt2= map(lonstat2, latstat2)\nmap.plot(xpt2,ypt2,'ko')\n\nfor i in range(len(namestat)):\n plt.text(xpt2[i], ypt2[i], namestat2[i], fontsize=18,fontweight='bold', ha='center',va='bottom',color='black')\n\nfig_name = 'MEPS_elevation_Haukeli_wind.png'\nif savefig == 1:\n sF.save_figure_portrait(fig_dir,fig_name,form)\n print('saved: %s/%s' %(fig_dir,fig_name))\nelse: \n plt.show()\nplt.close()",
"saved: ../../Figures/Norway_map/MEPS_elevation_Haukeli_wind.png\n"
],
[
"#### South Norway ####\n#plt.figure(1)\nfig = plt.figure(figsize=(9,8))\n#plt.clf()\nmap = Lambert_map(lllon=4., lllat=57.6, urlon=10.9, urlat=62.1, lat0= 63.5, lon0= 15, res='i', fill=True,zoom=True)\nLonpp,Latpp = map(lonpp,latpp)\n#alti[alti<3] = np.nan\n\n#PlotColorMap4(Lonpp, Latpp, alti, map, bounds= [3, 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1250, 1500,],color='red', label='Altitude')\n\nlevels = np.arange(0,np.nanmax(alti),50)\nnorm = colors.BoundaryNorm(boundaries = levels, ncolors=plt.cm.gist_earth.N)\n\ncs = map.contourf(Lonpp, Latpp, alti, levels, norm=norm, cmap = plt.cm.gist_earth, extend='max')\ncb = plt.colorbar(cs, boundaries= levels, #location='right',\n extend='max')\n \ncb.set_label('Altitude [m]', size=18) \ncb.ax.tick_params(labelsize=16)\nplt.gca().set_aspect('equal', adjustable='box')\n\n\n\nnamestat = ['Haukeliseter']\nlonstat = [7+12.87/60]#,7.2]\nlatstat= [59+48.73/60]#,59.8]\n\n\nxpt, ypt= map(lonstat, latstat)\nmap.plot(xpt,ypt,'ko')\nfor i in range(len(namestat)):\n plt.text(xpt[i]+10000, ypt[i]+10000, namestat[i], fontsize=18,fontweight='bold', \n ha='center',va='bottom',color='black')\n\nfig_name = 'South_Norway_MEPS.png'\nif savefig == 1:\n sF.save_figure_portrait(fig_dir,fig_name,form)\n print('saved: %s/%s' %(fig_dir,fig_name))\nelse:\n plt.show()\nplt.close()",
"_____no_output_____"
],
[
"lato = np.concatenate((latpp[0,:],latpp[-1,:]), axis = 0)\nlono = np.concatenate((lonpp[0,:], lonpp[-1,:]), axis = 0)\n\nlato2 = np.concatenate((latpp[:,0],latpp[:,-1]), axis = 0)\nlono2 = np.concatenate((lonpp[:,0], lonpp[:,-1]), axis = 0)",
"_____no_output_____"
],
[
"### Norway ###\n#plt.figure(1)\nfig = plt.figure(figsize=(9,8))\n\n#map = Lambert_map(lllon=0., lllat=49., urlon=50., urlat=72, lat0= 63.5, lon0= 15, res='l', fill=True,zoom=False)\nmap = Lambert_map(lllon=lonpp[0,:].min(), lllat=latpp[0,:].min(), \n urlon=lonpp[-1,:].max(), urlat=latpp[-1,:].max(), \n lat0= 63.5, lon0= 15, res='l', fill=True,zoom=False)\nLonpp,Latpp = map(lonpp,latpp)\n#alti[alti<3] = np.nan\n#PlotContours(Lonpp, Latpp, alti, map, leveldist=None,levels=[0, 25, 50, 100, 200, 300, 400, 500, 600,1000,1500,2000], numbers=True, color= 'k')\n#PlotColorMap4(Lonpp, Latpp, alti, map, bounds= [3, 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1250, 1500,],color='red', label='Altitude')\n\nlevels = np.arange(0,np.nanmax(alti),50)\nnorm = colors.BoundaryNorm(boundaries = levels, ncolors=plt.cm.gist_earth.N)\n\ncs = map.contourf(Lonpp, Latpp, alti, levels, norm=norm, cmap = plt.cm.gist_earth, extend='max')\ncb = plt.colorbar(cs, boundaries= levels, #location='right',\n extend='max')\ncb.set_label('Altitude [m]', size=18) \ncb.ax.tick_params(labelsize=16)\nplt.gca().set_aspect('equal', adjustable='box')\n\n\nnamestat = ['Haukeliseter']\nlonstat = [7+12.87/60]#,7.2]\nlatstat= [59+48.73/60]#,59.8]\n\n\nxpt, ypt= map(lonstat, latstat)\nmap.plot(xpt,ypt,'ko')\nfor i in range(len(namestat)):\n plt.text(xpt[i]+100000, ypt[i]+100000, namestat[i], fontsize=18,fontweight='bold', \n ha='center',va='bottom',color='black')\n#plt.tight_layout(pad=2.5) \n\nfig_name = 'Norway_elevation_MEPS.png'\nif savefig == 1:\n sF.save_figure_portrait(fig_dir,fig_name,form)\n print('saved: %s/%s' %(fig_dir,fig_name))\nelse:\n plt.show()\n \nplt.close()",
"_____no_output_____"
],
[
"gdal_data = gdal.Open('6600_1_10m_z33.tif')\ngt = gdal_data.GetGeoTransform()\n\ngdal_band = gdal_data.GetRasterBand(1)\nnodataval = gdal_band.GetNoDataValue()\n\n# convert to a numpy array\ndata_array = gdal_data.ReadAsArray().astype(np.float)\ndata_array\n\n# replace missing values if necessary\nif np.any(data_array == nodataval):\n data_array[data_array == nodataval] = np.nan",
"_____no_output_____"
],
[
"gdal_data2 = gdal.Open('6600_2_10m_z33.tif')\ngt2 = gdal_data2.GetGeoTransform()\n\ngdal_band2 = gdal_data2.GetRasterBand(1)\nnodataval2 = gdal_band2.GetNoDataValue()\n\n# convert to a numpy array\ndata_array2 = gdal_data2.ReadAsArray().astype(np.float)\ndata_array2\n\n# replace missing values if necessary\nif np.any(data_array2 == nodataval):\n data_array2[data_array2 == nodataval] = np.nan",
"_____no_output_____"
],
[
"xres = gt[1]\nyres = gt[5]\nx = np.arange(gt[0], gt[0] + data_array.shape[1]*xres, xres)\ny = np.arange(gt[3], gt[3] + data_array.shape[0]*yres, yres)\nX, Y = np.meshgrid(x,y)\n\nxres2 = gt2[1]\nyres2 = gt2[5]\nx2 = np.arange(gt2[0], gt2[0] + data_array2.shape[1]*xres2, xres2)\ny2 = np.arange(gt2[3], gt2[3] + data_array2.shape[0]*yres2, yres2)\nX2, Y2 = np.meshgrid(x2,y2)\n\n",
"_____no_output_____"
],
[
"inProj = Proj(init='EPSG:32633') # UTM coords, zone 33N, WGS84 datum\noutProj = Proj(init='EPSG:4326') # LatLon with WGS84 datum used by GPS units and Google Earth\nlon1,lat1 = X,Y\nLONO1,LATO1 = transform(inProj,outProj,lon1,lat1)\n#\nlon2,lat2 = X2,Y2\nLONO2,LATO2 = transform(inProj,outProj,lon2,lat2)\n\nlevels = np.arange(700,1800,50)\n\n#### Plot around Haukeliseter ####\nfig = plt.figure(figsize=(9,8))\nplt.clf()\n#map = Lambert_map(lllon=lon2.min(), lllat=lat2.min(), \n # urlon=lon2.max(), urlat=lat2.max(), \n # lat0= 63.5, lon0= 15, res='i', fill=False,zoom=True)\n\nmap= Lambert_map(lllon=7.05, lllat=59.73, urlon=7.35, urlat=59.91, lat0= 63.5, lon0= 15, res='i', fill=False,zoom=True)\nLON1,LAT1 = map(LONO1,LATO1)\nLON2,LAT2 = map(LONO2,LATO2)\n\ncmap = colors.ListedColormap([no0, no1, no2, no3, no4, no5, no6, no7, no8, no9, no10, \\\n no11, no12, no13, no14, no15, no16, no17, no18, no19, no20, \\\n no21])\nnorm = colors.BoundaryNorm(boundaries = levels, ncolors=cmap.N)\n\nPlotContours(LON1, LAT1, data_array, map, leveldist=None,levels=levels[::2], numbers=True, color= 'gray')\nPlotContours(LON2, LAT2, data_array2, map, leveldist=None,levels=levels[::2], numbers=True, color= 'gray')\n\ncs = map.contourf(LON1, LAT1, data_array, levels, norm=norm, cmap = cmap, extend='max')\nmap.contourf(LON2, LAT2, data_array2, levels, norm=norm, cmap=cmap, extend='max')\n\ncb = plt.colorbar(cs, boundaries= levels, #location='right',\n extend='max')\n \ncb.set_label('Altitude [m]', size=18) \ncb.ax.tick_params(labelsize=16)\nplt.gca().set_aspect('equal', adjustable='box')\n\ncb.ax.set_xticklabels([700, '', '', '', 900,'','','',1100,'','','',1300,'','','',1500,\n '','','',1700,'']) # horizontal colorbar\n\nnamestat = ['Haukeliseter (991 m a.s.l.)']#, 'lower left', 'upper right']#,'grid point']\nlonstat = [7+12.87/60]#,7.05, 7.4]#,7.2]\nlatstat= [59+48.73/60]#,59.65, 59.9]#,59.8]\n\n\nxpt, ypt= map(lonstat, latstat)\nmap.plot(xpt,ypt,'ko')\n\nfor i in range(len(namestat)):\n plt.text(xpt[i], ypt[i], namestat[i], fontsize=18,fontweight='bold', ha='center',va='bottom',color='black')\n\nfig_name = 'elevation_Haukeli.png'\nif savefig == 1:\n sF.save_figure_portrait(fig_dir,fig_name,form)\n print('saved: %s/%s' %(fig_dir,fig_name))\nelse:\n plt.show()\nplt.close()",
"_____no_output_____"
],
[
"url = ('http://thredds.met.no/thredds/dodsC/meps25epsarchive/2016/12/24/meps_mbr0_pp_2_5km_20161224T12Z.nc')\ndataset = netCDF4.Dataset(url)\n\nland= dataset.variables['land_area_fraction'][:]\nlonpp= dataset.variables['longitude'][:]\nlatpp= dataset.variables['latitude'][:]\n \n#T_2m= dataset.variables['air_temperature_2m'][:]\nalti= dataset.variables['altitude'][:]\n\n\ndataset.close()\n\n\n\n\"\"\" altitude map\"\"\"\n#plt.figure(1)\nfig = plt.figure(figsize=(9,8))\nplt.clf()\nmap= Lambert_map(lllon=7.05, lllat=59.73, urlon=7.35, urlat=59.91, lat0= 63.5, lon0= 15, res='i', fill=False,zoom=True)\n\nLonpp,Latpp = map(lonpp,latpp)\n\n \n#levels = [850, 900,950,1000,1050,1100,1150, 1200, 1250, 1300,1350,1400]\nlevels = np.arange(700,1800,50)\nPlotContours(Lonpp, Latpp, alti, map, leveldist=None,levels=levels, numbers=True, color= 'gray')\n\ncmap = colors.ListedColormap([no0, no1, no2, no3, no4, no5, no6, no7, no8, no9, no10, \\\n no11, no12, no13, no14, no15, no16, no17, no18, no19, no20, \\\n no21])\nnorm = colors.BoundaryNorm(boundaries = levels, ncolors=cmap.N)\n\n\n#PlotColorMap4(Lonpp, Latpp, alti, map, bounds= levels,color=cmap, label='Altitude')\n\ncs = map.contourf(Lonpp, Latpp, alti, levels, norm=norm, cmap = cmap, extend='max')\ncb = plt.colorbar(cs, boundaries= levels, #location='right',\n extend='max')\n \ncb.set_label('Altitude [m]', size=18) \ncb.ax.tick_params(labelsize=16)\nplt.gca().set_aspect('equal', adjustable='box')\n\ncb.ax.set_xticklabels([700, '', '', '', 900,'','','',1100,'','','',1300,'','','',1500,\n '','','',1700,'']) # horizontal colorbar\n\nnamestat = ['Haukeliseter']#, 'lower left', 'upper right']#,'grid point']\nlonstat = [7+12.87/60]#,7.05, 7.4]#,7.2]\nlatstat= [59+48.73/60]#,59.65, 59.9]#,59.8]\n\n\nxpt, ypt= map(lonstat, latstat)\nmap.plot(xpt,ypt,'ko')\n\nfor i in range(len(namestat)):\n plt.text(xpt[i], ypt[i], namestat[i], fontsize=18,fontweight='bold', ha='center',va='bottom',color='black')\n\nfig_name = 'MEPS_elevation_Haukeli_2.png'\nif savefig == 1:\n sF.save_figure_portrait(fig_dir,fig_name,form)\n print('saved: %s/%s' %(fig_dir,fig_name))\nelse: \n plt.show()\nplt.close()",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3b04435703fa122b8a691f055034e9ccde0d23 | 30,117 | ipynb | Jupyter Notebook | TRN_Notebooks/ChIP_Atac17_KO_AtacTh_bias25_TFmRNA_TFmRNA.ipynb | simonsfoundation/Th17_TRN_Networks | 5b2c9427e1651b42ac913ab45dff5318bd33480b | [
"Apache-2.0"
] | 1 | 2019-03-06T19:37:57.000Z | 2019-03-06T19:37:57.000Z | TRN_Notebooks/ChIP_Atac17_KO_AtacTh_bias25_TFmRNA_TFmRNA.ipynb | simonsfoundation/Th17_TRN_Networks | 5b2c9427e1651b42ac913ab45dff5318bd33480b | [
"Apache-2.0"
] | null | null | null | TRN_Notebooks/ChIP_Atac17_KO_AtacTh_bias25_TFmRNA_TFmRNA.ipynb | simonsfoundation/Th17_TRN_Networks | 5b2c9427e1651b42ac913ab45dff5318bd33480b | [
"Apache-2.0"
] | 1 | 2022-02-24T22:53:03.000Z | 2022-02-24T22:53:03.000Z | 41.655602 | 137 | 0.414716 | [
[
[
"# Visualization of the KO+ChIP Gold Standard from:\n# Miraldi et al. (2018) \"Leveraging chromatin accessibility for transcriptional regulatory network inference in Th17 Cells\"\n\n# TO START: In the menu above, choose \"Cell\" --> \"Run All\", and network + heatmap will load\n# NOTE: Default limits networks to TF-TF edges in top 1 TF / gene model (.93 quantile), to see the full \n# network hit \"restore\" (in the drop-down menu in cell below) and set threshold to 0 and hit \"threshold\"\n# You can search for gene names in the search box below the network (hit \"Match\"), and find regulators (\"targeted by\")\n# Change \"canvas\" to \"SVG\" (drop-down menu in cell below) to enable drag interactions with nodes & labels\n# Change \"SVG\" to \"canvas\" to speed up layout operations\n# More info about jp_gene_viz and user interface instructions are available on Github: \n# https://github.com/simonsfoundation/jp_gene_viz/blob/master/doc/dNetwork%20widget%20overview.ipynb\n\n# directory containing gene expression data and network folder\ndirectory = \".\"\n# folder containing networks\nnetPath = 'Networks'\n# network file name\nnetworkFile = 'ChIP_A17_KOall_ATh_bias25_TFmRNA_sp.tsv'\n# title for network figure\nnetTitle = 'ChIP/ATAC(Th17)+KO+ATAC(Th), bias = 25_TFmRNA, TFA = TF mRNA'\n# name of gene expression file\nexpressionFile = 'Th0_Th17_48hTh.txt'\n# column of gene expression file to color network nodes\nrnaSampleOfInt = 'Th17(48h)'\n# edge cutoff -- for Inferelator TRNs, corresponds to signed quantile (rank of edges in 15 TFs / gene models), \n# increase from 0 --> 1 to get more significant edges (e.g., .33 would correspond to edges only in 10 TFs / gene \n# models)\nedgeCutoff = .93",
"_____no_output_____"
],
[
"import sys\nif \"..\" not in sys.path:\n sys.path.append(\"..\")\nfrom jp_gene_viz import dNetwork\ndNetwork.load_javascript_support()\n# from jp_gene_viz import multiple_network\nfrom jp_gene_viz import LExpression\nLExpression.load_javascript_support()",
"_____no_output_____"
],
[
"# Load network linked to gene expression data\nL = LExpression.LinkedExpressionNetwork()\nL.show() ",
"_____no_output_____"
],
[
"# Load Network and Heatmap\nL.load_network(directory + '/' + netPath + '/' + networkFile)\nL.load_heatmap(directory + '/' + expressionFile)\nN = L.network\nN.set_title(netTitle)\nN.threshhold_slider.value = edgeCutoff\nN.apply_click(None)\nN.draw()\n# Add labels to nodes\nN.labels_button.value=True\n# Limit to TFs only, remove unconnected TFs, choose and set network layout\nN.restore_click()\nN.tf_only_click()\nN.connected_only_click()\nN.layout_dropdown.value = 'fruchterman_reingold'\nN.layout_click()\n\n# Interact with Heatmap\n# Limit genes in heatmap to network genes\nL.gene_click(None) \n# Z-score heatmap values\nL.expression.transform_dropdown.value = 'Z score' \nL.expression.apply_transform() \n# Choose a column in the heatmap (e.g., 48h Th17) to color nodes\nL.expression.col = rnaSampleOfInt\nL.condition_click(None)\n\n# Switch SVG layout to get line colors, then switch back to faster canvas mode\nN.force_svg(None)",
"('Reading network', './Networks/ChIP_A17_KOall_ATh_bias25_TFmRNA_sp.tsv')\n('Loading saved layout', './Networks/ChIP_A17_KOall_ATh_bias25_TFmRNA_sp.tsv.layout.json')\nOmitting edges, using canvas, and fast layout default because the network is large\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code"
]
] |
cb3b057254bae5b4d5530dc503df565b9224b2b3 | 846,216 | ipynb | Jupyter Notebook | round/figures/light_curves.ipynb | tagordon/round | 65e6329087f007e763893dd5103073390c9cbeb6 | [
"MIT"
] | null | null | null | round/figures/light_curves.ipynb | tagordon/round | 65e6329087f007e763893dd5103073390c9cbeb6 | [
"MIT"
] | null | null | null | round/figures/light_curves.ipynb | tagordon/round | 65e6329087f007e763893dd5103073390c9cbeb6 | [
"MIT"
] | null | null | null | 2,644.425 | 381,416 | 0.961441 | [
[
[
"from round import lc\nimport matplotlib.pyplot as pl\nimport glob\n\n%matplotlib inline\n\npl.rc('xtick', labelsize=20)\npl.rc('ytick', labelsize=20)\npl.rc('axes', labelsize=25)\npl.rc('axes', titlesize=30)\npl.rc('legend', handlelength=3)\npl.rc('legend', fontsize=20)\n\nfiles = glob.glob(\"../light_curves/*.fits\")\ni = 0\n\n# 38, 62",
"_____no_output_____"
],
[
"i += 1\nlight_curve = lc.LightCurve.everest(files[i])\nprint(i)\n\nfig = pl.figure(figsize=(12, 5))\nlight_curve.plot_raw(fig.gca(), 'k.')",
"15\n"
],
[
"light_curve.compute(mcmc=True, mcmc_draws=500, tune=500, \n target_accept=0.9, prior_sig=3.0, \n with_SHOTerm=False, cores=2)",
"There were 2 divergences after tuning. Increase `target_accept` or reparameterize.\nThere were 4 divergences after tuning. Increase `target_accept` or reparameterize.\nThe estimated number of effective samples is smaller than 200 for some parameters.\n/usr/local/lib/python3.7/site-packages/pymc3/stats.py:974: FutureWarning: The join_axes-keyword is deprecated. Use .reindex or .reindex_like on the result to achieve the same functionality.\n axis=1, join_axes=[dforg.index])\n"
],
[
"fig, axs = pl.subplots(2, 1, figsize=(15, 15))\n#light_curve.plot_trend(axs[0], linewidth=3, color=\"#f55649\", label=\"third order polynomial fit\")\nlight_curve.plot_raw(axs[0], 'k.')\n#fig.gca().plot(light_curve.raw_t[light_curve.masked], light_curve.raw_flux[light_curve.masked], \n# 'r.', label=\"masked outliers\")\n\npl.rc('xtick', labelsize=20)\npl.rc('ytick', labelsize=20)\npl.rc('axes', labelsize=35)\npl.rc('axes', titlesize=35)\npl.rc('legend', handlelength=3)\npl.rc('legend', fontsize=20)\n\n#axs[0].set_title(\"Everest Light Curve for EPIC 220279363\")\naxs[0].annotate(\"EPIC {0}\".format(light_curve.ident), xy=(0.1, 0.85), xycoords=\"axes fraction\", fontsize=30)\naxs[0].set_xlabel(\"Time (BJD - 2454833)\")\naxs[0].set_ylabel(\"Flux\")\n\nlight_curve.plot_autocor(axs[1], \"k\", linewidth=3)\naxs[1].set_ylabel(\"ACF\")\naxs[1].set_xlabel(\"Lag (days)\")\n\npl.savefig(\"/Users/tgordon/Desktop/everest_{0}.pdf\".format(i))",
"_____no_output_____"
],
[
"pl.rc('xtick', labelsize=20)\npl.rc('ytick', labelsize=20)\npl.rc('axes', labelsize=25)\npl.rc('axes', titlesize=30)\npl.rc('legend', handlelength=3)\npl.rc('legend', fontsize=20)\n\nfig = pl.figure(figsize=(20, 8))\nax = fig.gca()\nlight_curve.plot_autocor(ax, \"k\", linewidth=3)\n#ax.set_title(\"Autocorrelation Function for EPIC 220279363\")\nax.set_ylabel(\"ACF\")\nax.set_xlabel(\"Lag (days)\")\npl.savefig(\"/Users/tgordon/Desktop/acf_63.png\")",
"_____no_output_____"
],
[
"fig = pl.figure(figsize=(20, 8))\nax = fig.gca()\nlight_curve.plot(ax, 'k.', label=\"normalized everest flux\")\nlight_curve.plot_map_soln(ax, t=np.linspace(light_curve.t[0], light_curve.t[-1], 1000), \n linewidth=3, \n color=\"#f55649\", \n label=\"GP prediction\")\nax.set_title(\"Maximum-likelihood GP Prediction\", fontsize=20)\nax.set_ylabel(\"Normalized Flux\", fontsize=15)",
"INFO (theano.gof.compilelock): Refreshing lock /Users/tgordon/.theano/compiledir_Darwin-19.0.0-x86_64-i386-64bit-i386-3.7.6-64/lock_dir/lock\n"
],
[
"light_curve.plot_corner(smooth=True, \n truths=light_curve.mcmc_summary[\"mean\"].values, \n truth_color=\"#f55649\");",
"/usr/local/lib/python3.7/site-packages/pymc3/stats.py:974: FutureWarning: The join_axes-keyword is deprecated. Use .reindex or .reindex_like on the result to achieve the same functionality.\n axis=1, join_axes=[dforg.index])\n"
],
[
"import pymc3 as pm\nimport corner\n\npl.rc('xtick', labelsize=12)\npl.rc('ytick', labelsize=12)\npl.rc('axes', labelsize=25)\npl.rc('axes', titlesize=30)\npl.rc('legend', handlelength=3)\npl.rc('legend', fontsize=20)\n\nsamples = pm.trace_to_dataframe(light_curve.trace, varnames=[\"logperiod\", \"logamp\", \"logs2\"])\ncorn = corner.corner(samples, smooth=1, labels=[r\"$\\log(P_\\mathrm{rot})$\", r\"$\\log(S_0)$\", r\"$\\log(\\sigma)$\"])\n#pl.annotate(\"EPIC {0}\".format(light_curve.ident), xy=(0.4, 0.95), xycoords=\"figure fraction\", fontsize=30)\npl.savefig(\"/Users/tgordon/Desktop/corner_{0}.pdf\".format(i))",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3b09f1df0ded97d6ebead337d0f0c04073cb8a | 1,316 | ipynb | Jupyter Notebook | notebooks/.ipynb_checkpoints/sample_prophet-checkpoint.ipynb | lokesh1233/Employee_Attendance | 194b444b7198abc0f499aa0e58ef962c597fad6c | [
"FTL"
] | 2 | 2019-01-31T09:09:22.000Z | 2019-02-05T17:36:10.000Z | notebooks/sample_prophet.ipynb | lokesh1233/Employee_Attendance | 194b444b7198abc0f499aa0e58ef962c597fad6c | [
"FTL"
] | null | null | null | notebooks/sample_prophet.ipynb | lokesh1233/Employee_Attendance | 194b444b7198abc0f499aa0e58ef962c597fad6c | [
"FTL"
] | null | null | null | 20.888889 | 52 | 0.552432 | [
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\n\n\nimport warnings\nimport itertools\nwarnings.filterwarnings('ignore')\nplt.style.use('fivethirtyeight')\n\nfrom fbprophet import Prophet\n\n# import statsmodels.api as sm\nimport matplotlib\n\nmatplotlib.rcParams['axes.labelsize'] = 14\nmatplotlib.rcParams['xtick.labelsize'] = 12\nmatplotlib.rcParams['ytick.labelsize'] = 12\nmatplotlib.rcParams['text.color'] = 'k'\n",
"_____no_output_____"
],
[
"\nexample_wp_log_peyton_manning",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code"
]
] |
cb3b10d9037002f6ff2380edd79b3648e7d51a51 | 13,492 | ipynb | Jupyter Notebook | samples/notebooks/polyglot/COVID-19.ipynb | MikeLarah/interactive | 68dbc2183e466a1f347d159b99106a4b504f6e04 | [
"MIT"
] | 2 | 2020-07-25T20:10:29.000Z | 2020-07-26T18:23:30.000Z | samples/notebooks/polyglot/COVID-19.ipynb | MikeLarah/interactive | 68dbc2183e466a1f347d159b99106a4b504f6e04 | [
"MIT"
] | 3 | 2022-01-22T15:32:48.000Z | 2022-02-27T10:34:18.000Z | samples/notebooks/polyglot/COVID-19.ipynb | MikeLarah/interactive | 68dbc2183e466a1f347d159b99106a4b504f6e04 | [
"MIT"
] | null | null | null | 40.516517 | 360 | 0.413949 | [
[
[
"[this doc on github](https://github.com/dotnet/interactive/tree/master/samples/notebooks/polyglot)\n\n# Visualizing the Johns Hopkins COVID-19 time series data\n\n**This is a work in progress.** It doesn't work yet in [Binder](https://mybinder.org/v2/gh/dotnet/interactive/master?urlpath=lab) because it relies on HTTP communication between the kernel and the Jupyter frontend.\n\nAlso, due to travel restrictions, you should run this at home on isolated compute.\n\n*And don't forget to wash your hands.*\n\nSince Johns Hopkins has put COVID-19 time series data on [GitHub](https://github.com/CSSEGISandData/COVID-19), let's take a look at it. We can download it using PowerShell:",
"_____no_output_____"
]
],
[
[
"#!pwsh\nInvoke-WebRequest -Uri \"https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv\" -OutFile \"./Confirmed.csv\"\nInvoke-WebRequest -Uri \"https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_deaths_global.csv\" -OutFile \"./Deaths.csv\"\nInvoke-WebRequest -Uri \"https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_recovered_global.csv\" -OutFile \"./Recovered.csv\"",
"_____no_output_____"
]
],
[
[
"It needs a little cleaning up:",
"_____no_output_____"
]
],
[
[
"using System.IO;\nusing System.Text.RegularExpressions;\n\nClean(\"Confirmed.csv\");\nClean(\"Deaths.csv\");\nClean(\"Recovered.csv\");\n\nvoid Clean(string filePath)\n{\n var raw = File.ReadAllText(filePath);\n var regex = new Regex(\"\\\\\\\"(.*?)\\\\\\\"\");\n var cleaned = regex.Replace(raw, m => m.Value.Replace(\",\", \" in \")); \n File.WriteAllText(filePath, cleaned);\n}\n\n\"All cleaned up!\"",
"_____no_output_____"
]
],
[
[
"Next, let's load it into a data frame.",
"_____no_output_____"
]
],
[
[
"#r \"nuget:Microsoft.Data.Analysis,0.2.0\"",
"_____no_output_____"
],
[
"using Microsoft.Data.Analysis;\n\nvar deaths = DataFrame.LoadCsv(\"./Deaths.csv\");\nvar confirmed = DataFrame.LoadCsv(\"./Confirmed.csv\");\nvar recovered = DataFrame.LoadCsv(\"./Recovered.csv\");\nvar displayedValue = display(\"Processing data\");\nvar offset = 4;\nvar series = new List<object>();\nfor(var i = offset; i < deaths.Columns.Count; i++){\n await Task.Delay(100);\n var date = deaths.Columns[i].Name;\n var deathFiltered = deaths[deaths.Columns[i].ElementwiseNotEquals(0)];\n var confirmedFiltered = confirmed[confirmed.Columns[i].ElementwiseNotEquals(0)];\n var recoveredFiltered = recovered[recovered.Columns[i].ElementwiseNotEquals(0)];\n\n displayedValue.Update($\"processing {date}\");\n series.Add(new {\n date = date,\n deathsSeries = new {\n latitude = deathFiltered[\"Lat\"],\n longitude = deathFiltered[\"Long\"],\n data = deathFiltered.Columns[i]\n },\n confirmedSeries = new {\n latitude = confirmedFiltered[\"Lat\"],\n longitude = confirmedFiltered[\"Long\"],\n data = confirmedFiltered.Columns[i]\n },\n recoveredSeries = new {\n latitude = recoveredFiltered[\"Lat\"],\n longitude = recoveredFiltered[\"Long\"],\n data = recoveredFiltered.Columns[i]\n }\n });\n}\n\ndisplayedValue.Update(\"Ready.\");",
"_____no_output_____"
]
],
[
[
"Because we've stored our data in top-level variables (`deathsSeries`, `confirmedSeries`, `recoveredSeries`, etc.) in the C# kernel, they're accessible from JavaScript by calling `interactive.csharp.getVariable`. The data will be returned as JSON and we can plot it using the library of our choice, pulled in using [RequireJS](https://requirejs.org/). \n\nWe'll use [Plotly](https://plot.ly/).",
"_____no_output_____"
]
],
[
[
"#!js\nnotebookScope.plot = function (plotTarget) {\n let loadPlotly = getJsLoader({\n context: \"COVID\",\n paths: {\n plotly: \"https://cdn.plot.ly/plotly-latest.min\"\n }\n });\n \n loadPlotly([\"plotly\"], (Plotly) => {\n if (typeof (notebookScope.updateInterval) !== 'undefined') {\n clearInterval(notebookScope.updateInterval);\n }\n\n let index = 0;\n\n if (typeof (document.getElementById(plotTarget)) !== 'undefined') {\n interactive.csharp.getVariable(\"series\")\n .then(series => {\n var { deathsSeries, confirmedSeries, recoveredSeries, date } = series[index];\n var recovered = {\n name: \"Recovered\",\n type: \"scattergeo\",\n mode: \"markers\",\n geo: \"geo\",\n lat: recoveredSeries.latitude,\n lon: recoveredSeries.longitude,\n text: recoveredSeries.data,\n marker: {\n symbol: \"square\",\n color: \"Green\"\n }\n };\n\n var deaths = {\n name: \"Fatal\",\n type: \"scattergeo\",\n geo: \"geo2\",\n mode: \"markers\",\n lat: deathsSeries.latitude,\n lon: deathsSeries.longitude,\n text: deathsSeries.data,\n marker: {\n symbol: \"circle\",\n color: \"Black\"\n }\n };\n\n var confirmed = {\n name: \"Total confirmed\",\n type: \"scattergeo\",\n geo: \"geo3\",\n mode: \"markers\",\n lat: confirmedSeries.latitude,\n lon: confirmedSeries.longitude,\n text: confirmedSeries.data,\n marker: {\n symbol: \"diamond\",\n color: \"#DC7633\"\n }\n };\n \n\n var traces = [recovered, deaths, confirmed];\n\n var layout = {\n title: \"COVID-19 cases (\" + date + \")\",\n grid: { columns: 3, rows: 1 },\n geo: {\n scope: \"world\",\n showland: true,\n showcountries: true,\n bgcolor: \"rgb(90,90,90)\",\n landcolor: \"rgb(250,250,250)\",\n domain: {\n row: 0,\n column: 0\n }\n },\n geo2: {\n scope: \"world\",\n showland: true,\n showcountries: true,\n bgcolor: \"rgb(90,90,90)\",\n landcolor: \"rgb(250,250,250)\",\n domain: {\n row: 0,\n column: 1\n }\n },\n geo3: {\n scope: \"world\",\n showland: true,\n showcountries: true,\n bgcolor: \"rgb(90,90,90)\",\n landcolor: \"rgb(250,250,250)\",\n domain: {\n row: 0,\n column: 2\n }\n }\n };\n if (typeof (document.getElementById(plotTarget)) !== 'undefined') {\n Plotly.newPlot(plotTarget, traces, layout);\n }\n let updateCovidPlot = () => {\n if (typeof (document.getElementById(plotTarget)) !== 'undefined') {\n index++;\n if (index === series.length) {\n clearInterval(notebookScope.updateInterval);\n return;\n }\n var { deathsSeries, confirmedSeries, recoveredSeries, currentSeries, date } = series[index];\n Plotly.animate(\"plotlyChartCovid\", {\n data: [\n {\n lat: recoveredSeries.latitude,\n lon: recoveredSeries.longitude,\n text: recoveredSeries.data\n },\n {\n lat: deathsSeries.latitude,\n lon: deathsSeries.longitude,\n text: deathsSeries.data\n },\n {\n lat: confirmedSeries.latitude,\n lon: confirmedSeries.longitude,\n text: confirmedSeries.data\n }],\n layout: {\n title: \"COVID-19 \" + date\n }\n });\n }\n }\n notebookScope.updateInterval = setInterval(() => updateCovidPlot(), 250);\n });\n }\n });\n};",
"_____no_output_____"
]
],
[
[
"Notice the `setInterval` call near the end of the previous cell. This rechecks the data in the kernel and updates the plot.\n\nBack on the kernel, we can now update the data so that the kernel can see it.\n\nYes, this is a contrived example, and we're planning to support true streaming data, but it's a start.",
"_____no_output_____"
]
],
[
[
"#!html\n<div id=\"plotlyChartCovid\"></div>\n\n#!js\nnotebookScope.plot(\"plotlyChartCovid\");",
"_____no_output_____"
],
[
"#!about",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
cb3b16d728410b860fd45319fca7cb8240c78227 | 384,154 | ipynb | Jupyter Notebook | Introduction to Computer Vision/Feature Vectors/HogExamples.ipynb | brand909/Computer-Vision | 18e5bda880e40f0a355d1df8520770df5bb1ed6b | [
"MIT"
] | null | null | null | Introduction to Computer Vision/Feature Vectors/HogExamples.ipynb | brand909/Computer-Vision | 18e5bda880e40f0a355d1df8520770df5bb1ed6b | [
"MIT"
] | 4 | 2021-03-19T02:34:33.000Z | 2022-03-11T23:56:20.000Z | Introduction to Computer Vision/Feature Vectors/HogExamples.ipynb | brand909/Computer-Vision | 18e5bda880e40f0a355d1df8520770df5bb1ed6b | [
"MIT"
] | null | null | null | 338.760141 | 334,503 | 0.904976 | [
[
[
"# Examples\n\nBelow you will find various examples for you to experiment with HOG. For each image, you can modify the `cell_size`, `num_cells_per_block`, and `num_bins` (the number of angular bins in your histograms), to see how those parameters affect the resulting HOG descriptor. These examples, will help you get some intuition for what each parameter does and how they can be *tuned* to pick out the amount of detail required. Below is a list of the available images that you can load:\n\n* cat.jpeg\n* jeep1.jpeg\n* jeep2.jpeg\n* jeep3.jpeg\n* man.jpeg\n* pedestrian_bike.jpeg\n* roundabout.jpeg\n* scrabble.jpeg\n* shuttle.jpeg\n* triangle_tile.jpeg\n* watch.jpeg\n* woman.jpeg\n\n\n**NOTE**: If you are running this notebook in the Udacity workspace, there is around a 2 second lag in the interactive plot. This means that if you click in the image to zoom in, it will take about 2 seconds for the plot to refresh. ",
"_____no_output_____"
]
],
[
[
"%matplotlib notebook\n\nimport cv2\nimport copy\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport matplotlib.patches as patches\n\n# Set the default figure size\nplt.rcParams['figure.figsize'] = [9.8, 9]\n\n\n# -------------------------- Select the Image and Specify the parameters for our HOG descriptor --------------------------\n\n# Load the image \nimage = cv2.imread('./images/jeep2.jpeg')\n\n# Cell Size in pixels (width, height). Must be smaller than the size of the detection window\n# and must be chosen so that the resulting Block Size is smaller than the detection window.\ncell_size = (8, 8)\n\n# Number of cells per block in each direction (x, y). Must be chosen so that the resulting\n# Block Size is smaller than the detection window\nnum_cells_per_block = (2, 2)\n\n# Number of gradient orientation bins\nnum_bins = 9\n\n# -------------------------------------------------------------------------------------------------------------------------\n\n\n# Convert the original image to RGB\noriginal_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)\n\n# Convert the original image to gray scale\ngray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)\n\n\n# Block Size in pixels (width, height). Must be an integer multiple of Cell Size.\n# The Block Size must be smaller than the detection window\nblock_size = (num_cells_per_block[0] * cell_size[0],\n num_cells_per_block[1] * cell_size[1])\n\n# Calculate the number of cells that fit in our image in the x and y directions\nx_cells = gray_image.shape[1] // cell_size[0]\ny_cells = gray_image.shape[0] // cell_size[1]\n\n# Horizontal distance between blocks in units of Cell Size. Must be an integer and it must\n# be set such that (x_cells - num_cells_per_block[0]) / h_stride = integer.\nh_stride = 1\n\n# Vertical distance between blocks in units of Cell Size. Must be an integer and it must\n# be set such that (y_cells - num_cells_per_block[1]) / v_stride = integer.\nv_stride = 1\n\n# Block Stride in pixels (horizantal, vertical). Must be an integer multiple of Cell Size\nblock_stride = (cell_size[0] * h_stride, cell_size[1] * v_stride)\n\n \n# Specify the size of the detection window (Region of Interest) in pixels (width, height).\n# It must be an integer multiple of Cell Size and it must cover the entire image. Because\n# the detection window must be an integer multiple of cell size, depending on the size of\n# your cells, the resulting detection window might be slightly smaller than the image.\n# This is perfectly ok.\nwin_size = (x_cells * cell_size[0] , y_cells * cell_size[1])\n\n# Print the shape of the gray scale image for reference\nprint('\\nThe gray scale image has shape: ', gray_image.shape)\nprint()\n\n# Print the parameters of our HOG descriptor\nprint('HOG Descriptor Parameters:\\n')\nprint('Window Size:', win_size)\nprint('Cell Size:', cell_size)\nprint('Block Size:', block_size)\nprint('Block Stride:', block_stride)\nprint('Number of Bins:', num_bins)\nprint()\n\n# Set the parameters of the HOG descriptor using the variables defined above\nhog = cv2.HOGDescriptor(win_size, block_size, block_stride, cell_size, num_bins)\n\n# Compute the HOG Descriptor for the gray scale image\nhog_descriptor = hog.compute(gray_image)\n\n# Calculate the total number of blocks along the width of the detection window\ntot_bx = np.uint32(((x_cells - num_cells_per_block[0]) / h_stride) + 1)\n\n# Calculate the total number of blocks along the height of the detection window\ntot_by = np.uint32(((y_cells - num_cells_per_block[1]) / v_stride) + 1)\n\n# Calculate the total number of elements in the feature vector\ntot_els = (tot_bx) * (tot_by) * num_cells_per_block[0] * num_cells_per_block[1] * num_bins\n\n\n# Reshape the feature vector to [blocks_y, blocks_x, num_cells_per_block_x, num_cells_per_block_y, num_bins].\n# The blocks_x and blocks_y will be transposed so that the first index (blocks_y) referes to the row number\n# and the second index to the column number. This will be useful later when we plot the feature vector, so\n# that the feature vector indexing matches the image indexing.\nhog_descriptor_reshaped = hog_descriptor.reshape(tot_bx,\n tot_by,\n num_cells_per_block[0],\n num_cells_per_block[1],\n num_bins).transpose((1, 0, 2, 3, 4))\n\n# Create an array that will hold the average gradients for each cell\nave_grad = np.zeros((y_cells, x_cells, num_bins))\n\n# Create an array that will count the number of histograms per cell\nhist_counter = np.zeros((y_cells, x_cells, 1))\n\n# Add up all the histograms for each cell and count the number of histograms per cell\nfor i in range (num_cells_per_block[0]):\n for j in range(num_cells_per_block[1]):\n ave_grad[i:tot_by + i,\n j:tot_bx + j] += hog_descriptor_reshaped[:, :, i, j, :]\n \n hist_counter[i:tot_by + i,\n j:tot_bx + j] += 1\n\n# Calculate the average gradient for each cell\nave_grad /= hist_counter\n \n# Calculate the total number of vectors we have in all the cells.\nlen_vecs = ave_grad.shape[0] * ave_grad.shape[1] * ave_grad.shape[2]\n\n# Create an array that has num_bins equally spaced between 0 and 180 degress in radians.\ndeg = np.linspace(0, np.pi, num_bins, endpoint = False)\n\n# Each cell will have a histogram with num_bins. For each cell, plot each bin as a vector (with its magnitude\n# equal to the height of the bin in the histogram, and its angle corresponding to the bin in the histogram). \n# To do this, create rank 1 arrays that will hold the (x,y)-coordinate of all the vectors in all the cells in the\n# image. Also, create the rank 1 arrays that will hold all the (U,V)-components of all the vectors in all the\n# cells in the image. Create the arrays that will hold all the vector positons and components.\nU = np.zeros((len_vecs))\nV = np.zeros((len_vecs))\nX = np.zeros((len_vecs))\nY = np.zeros((len_vecs))\n\n# Set the counter to zero\ncounter = 0\n\n# Use the cosine and sine functions to calculate the vector components (U,V) from their maginitudes. Remember the \n# cosine and sine functions take angles in radians. Calculate the vector positions and magnitudes from the\n# average gradient array\nfor i in range(ave_grad.shape[0]):\n for j in range(ave_grad.shape[1]):\n for k in range(ave_grad.shape[2]):\n U[counter] = ave_grad[i,j,k] * np.cos(deg[k])\n V[counter] = ave_grad[i,j,k] * np.sin(deg[k])\n \n X[counter] = (cell_size[0] / 2) + (cell_size[0] * i)\n Y[counter] = (cell_size[1] / 2) + (cell_size[1] * j)\n \n counter = counter + 1\n\n# Create the bins in degress to plot our histogram. \nangle_axis = np.linspace(0, 180, num_bins, endpoint = False)\nangle_axis += ((angle_axis[1] - angle_axis[0]) / 2)\n\n# Create a figure with 4 subplots arranged in 2 x 2\nfig, ((a,b),(c,d)) = plt.subplots(2,2)\n\n# Set the title of each subplot\na.set(title = 'Gray Scale Image\\n(Click to Zoom)')\nb.set(title = 'HOG Descriptor\\n(Click to Zoom)')\nc.set(title = 'Zoom Window', xlim = (0, 18), ylim = (0, 18), autoscale_on = False)\nd.set(title = 'Histogram of Gradients')\n\n# Plot the gray scale image\na.imshow(gray_image, cmap = 'gray')\na.set_aspect(aspect = 1)\n\n# Plot the feature vector (HOG Descriptor)\nb.quiver(Y, X, U, V, color = 'white', headwidth = 0, headlength = 0, scale_units = 'inches', scale = 5)\nb.invert_yaxis()\nb.set_aspect(aspect = 1)\nb.set_facecolor('black')\n\n# Define function for interactive zoom\ndef onpress(event):\n \n #Unless the left mouse button is pressed do nothing\n if event.button != 1:\n return\n \n # Only accept clicks for subplots a and b\n if event.inaxes in [a, b]:\n \n # Get mouse click coordinates\n x, y = event.xdata, event.ydata\n \n # Select the cell closest to the mouse click coordinates\n cell_num_x = np.uint32(x / cell_size[0])\n cell_num_y = np.uint32(y / cell_size[1])\n \n # Set the edge coordinates of the rectangle patch\n edgex = x - (x % cell_size[0])\n edgey = y - (y % cell_size[1])\n \n # Create a rectangle patch that matches the the cell selected above \n rect = patches.Rectangle((edgex, edgey),\n cell_size[0], cell_size[1],\n linewidth = 1,\n edgecolor = 'magenta',\n facecolor='none')\n \n # A single patch can only be used in a single plot. Create copies\n # of the patch to use in the other subplots\n rect2 = copy.copy(rect)\n rect3 = copy.copy(rect)\n \n # Update all subplots\n a.clear()\n a.set(title = 'Gray Scale Image\\n(Click to Zoom)')\n a.imshow(gray_image, cmap = 'gray')\n a.set_aspect(aspect = 1)\n a.add_patch(rect)\n\n b.clear()\n b.set(title = 'HOG Descriptor\\n(Click to Zoom)')\n b.quiver(Y, X, U, V, color = 'white', headwidth = 0, headlength = 0, scale_units = 'inches', scale = 5)\n b.invert_yaxis()\n b.set_aspect(aspect = 1)\n b.set_facecolor('black')\n b.add_patch(rect2)\n\n c.clear()\n c.set(title = 'Zoom Window')\n c.quiver(Y, X, U, V, color = 'white', headwidth = 0, headlength = 0, scale_units = 'inches', scale = 1)\n c.set_xlim(edgex - cell_size[0], edgex + (2 * cell_size[0]))\n c.set_ylim(edgey - cell_size[1], edgey + (2 * cell_size[1]))\n c.invert_yaxis()\n c.set_aspect(aspect = 1)\n c.set_facecolor('black')\n c.add_patch(rect3)\n\n d.clear()\n d.set(title = 'Histogram of Gradients')\n d.grid()\n d.set_xlim(0, 180)\n d.set_xticks(angle_axis)\n d.set_xlabel('Angle')\n d.bar(angle_axis,\n ave_grad[cell_num_y, cell_num_x, :],\n 180 // num_bins,\n align = 'center',\n alpha = 0.5,\n linewidth = 1.2,\n edgecolor = 'k')\n\n fig.canvas.draw()\n\n# Create a connection between the figure and the mouse click\nfig.canvas.mpl_connect('button_press_event', onpress)\nplt.show()",
"\nThe gray scale image has shape: (424, 640)\n\nHOG Descriptor Parameters:\n\nWindow Size: (640, 424)\nCell Size: (8, 8)\nBlock Size: (16, 16)\nBlock Stride: (8, 8)\nNumber of Bins: 9\n\n"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
]
] |
cb3b2fae2e30959bb043877256c06b4b12477282 | 7,842 | ipynb | Jupyter Notebook | docs/deployment/IceApp_pets.ipynb | alphacontrib/icevision_rd | acbe9051d031b048ef68c1377ab5499c8929a325 | [
"Apache-2.0"
] | 580 | 2020-09-10T06:29:57.000Z | 2022-03-29T19:34:54.000Z | docs/deployment/IceApp_pets.ipynb | alphacontrib/icevision_rd | acbe9051d031b048ef68c1377ab5499c8929a325 | [
"Apache-2.0"
] | 691 | 2020-09-05T03:08:34.000Z | 2022-03-31T23:47:06.000Z | docs/deployment/IceApp_pets.ipynb | alphacontrib/icevision_rd | acbe9051d031b048ef68c1377ab5499c8929a325 | [
"Apache-2.0"
] | 105 | 2020-09-09T10:41:35.000Z | 2022-03-25T17:16:49.000Z | 28.620438 | 240 | 0.499617 | [
[
[
"<a href=\"https://colab.research.google.com/github/ai-fast-track/icevision-gradio/blob/master/IceApp_pets.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# IceVision Deployment App: PETS Dataset\nThis example uses Faster RCNN trained weights using the [PETS dataset](https://airctic.github.io/icedata/pets/)\n\nAbout IceVision:\n\n- an Object-Detection Framework that connects to different libraries/frameworks such as Fastai, Pytorch Lightning, and Pytorch with more to come.\n\n- Features a Unified Data API with out-of-the-box support for common annotation formats (COCO, VOC, etc.)\n\n- Provides flexible model implementations with pluggable backbones",
"_____no_output_____"
],
[
"## Installing packages",
"_____no_output_____"
]
],
[
[
"!pip install icevision[inference]",
"_____no_output_____"
],
[
"!pip install icedata",
"_____no_output_____"
],
[
"!pip install gradio",
"_____no_output_____"
]
],
[
[
"## Imports",
"_____no_output_____"
]
],
[
[
"from icevision.all import *\nimport icedata\nimport PIL, requests\nimport torch\nfrom torchvision import transforms\nimport gradio as gr",
"_____no_output_____"
]
],
[
[
"## Loading trained model",
"_____no_output_____"
]
],
[
[
"class_map = icedata.pets.class_map()\nmodel = icedata.pets.trained_models.faster_rcnn_resnet50_fpn()",
"_____no_output_____"
]
],
[
[
"## Defininig the predict() method\n",
"_____no_output_____"
]
],
[
[
"def predict(\n model, image, detection_threshold: float = 0.5, mask_threshold: float = 0.5\n):\n tfms_ = tfms.A.Adapter([tfms.A.Normalize()])\n # Whenever you have images in memory (numpy arrays) you can use `Dataset.from_images`\n infer_ds = Dataset.from_images([image], tfms_)\n\n batch, samples = faster_rcnn.build_infer_batch(infer_ds)\n preds = faster_rcnn.predict(\n model=model,\n batch=batch,\n detection_threshold=detection_threshold\n )\n return samples[0][\"img\"], preds[0]",
"_____no_output_____"
]
],
[
[
"## Defining the `show_preds` method: called by `gr.Interface(fn=show_preds, ...)`",
"_____no_output_____"
]
],
[
[
"def show_preds(input_image, display_list, detection_threshold):\n display_label = (\"Label\" in display_list)\n display_bbox = (\"BBox\" in display_list)\n\n if detection_threshold==0: detection_threshold=0.5\n \n img, pred = predict(model=model, image=input_image, detection_threshold=detection_threshold)\n # print(pred)\n img = draw_pred(img=img, pred=pred, class_map=class_map, denormalize_fn=denormalize_imagenet, display_label=display_label, display_bbox=display_bbox)\n img = PIL.Image.fromarray(img)\n # print(\"Output Image: \", img.size, type(img))\n return img",
"_____no_output_____"
]
],
[
[
"## Gradio User Interface",
"_____no_output_____"
]
],
[
[
"display_chkbox = gr.inputs.CheckboxGroup([\"Label\", \"BBox\"], label=\"Display\")\ndetection_threshold_slider = gr.inputs.Slider(minimum=0, maximum=1, step=0.1, default=0.5, label=\"Detection Threshold\")\n\noutputs = gr.outputs.Image(type=\"pil\")\n\ngr_interface = gr.Interface(fn=show_preds, inputs=[\"image\", display_chkbox, detection_threshold_slider], outputs=outputs, title='IceApp - PETS')\ngr_interface.launch(inline=False, share=True, debug=True)\n",
"Colab notebook detected. This cell will run indefinitely so that you can see errors and logs. To turn off, set debug=False in launch().\nThis share link will expire in 6 hours. If you need a permanent link, email [email protected]\nRunning on External URL: https://28865.gradio.app\n"
]
],
[
[
"## Enjoy! \nIf you have any questions, please feel free to [join us](https://discord.gg/JDBeZYK)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
cb3b30d2fe623aff0c08c952c605d8b5e0421f7a | 54,084 | ipynb | Jupyter Notebook | doc/Tutorials/Bokeh_Elements.ipynb | stuarteberg/holoviews | 65136173014124b41cee00f5a0fee82acdc78f7f | [
"BSD-3-Clause"
] | 1 | 2019-01-02T20:20:09.000Z | 2019-01-02T20:20:09.000Z | doc/Tutorials/Bokeh_Elements.ipynb | stuarteberg/holoviews | 65136173014124b41cee00f5a0fee82acdc78f7f | [
"BSD-3-Clause"
] | null | null | null | doc/Tutorials/Bokeh_Elements.ipynb | stuarteberg/holoviews | 65136173014124b41cee00f5a0fee82acdc78f7f | [
"BSD-3-Clause"
] | null | null | null | 38.007027 | 938 | 0.599142 | [
[
[
"<div class=\"alert alert-info\" role=\"alert\">\n This tutorial contains a lot of bokeh plots, which may take a little while to load and render.\n</div>\n\n``Element``s are the basic building blocks for any HoloViews visualization. These are the objects that can be composed together using the various [Container](Containers.ipynb) types. \nHere in this overview, we show an example of how to build each of these ``Element``s directly out of Python or Numpy data structures. An even more powerful way to use them is by collecting similar ``Element``s into a HoloMap, as described in [Exploring Data](Exploring_Data.ipynb), so that you can explore, select, slice, and animate them flexibly, but here we focus on having small, self-contained examples. Complete reference material for each type can be accessed using our [documentation system](Introduction.ipynb#ParamDoc). This tutorial uses the default matplotlib plotting backend; see the [Bokeh Elements](Bokeh_Elements.ipynb) tutorial for the corresponding bokeh plots.\n\n \n\n## Element types\n\nThis class hierarchy shows each of the ``Element`` types.\nEach type is named for the default or expected way that the underlying data can be visualized. E.g., if your data is wrapped into a ``Surface`` object, it will display as a 3D surface by default, whereas the same data embedded in an ``Image`` object will display as a 2D raster image. But please note that the specification and implementation for each ``Element`` type does not actually include *any* such visualization -- the name merely serves as a semantic indication that you ordinarily think of the data as being laid out visually in that way. The actual plotting is done by a separate plotting subsystem, while the objects themselves focus on storing your data and the metadata needed to describe and use it. \n\nThis separation of data and visualization is described in detail in the [Options tutorial](Options.ipynb), which describes all about how to find out the options available for each ``Element`` type and change them if necessary, from either Python or IPython Notebook. When using this tutorial interactively in an IPython/Jupyter notebook session, we suggest adding ``%output info=True`` after the call to ``notebook_extension`` below, which will pop up a detailed list and explanation of the available options for visualizing each ``Element`` type, after that notebook cell is executed. Then, to find out all the options for any of these ``Element`` types, just press ``<Shift-Enter>`` on the corresponding cell in the live notebook. \n\nThe types available:\n\n<dl class=\"dl-horizontal\">\n <dt><a href=\"#Element\"><code>Element</code></a></dt><dd>The base class of all <code>Elements</code>.</dd>\n</dl>\n\n### <a id='ChartIndex'></a> <a href=\"#Chart Elements\"><code>Charts:</code></a>\n\n<dl class=\"dl-horizontal\">\n <dt><a href=\"#Curve\"><code>Curve</code></a></dt><dd>A continuous relation between a dependent and an independent variable. <font color='green'>✓</font></dd>\n <dt><a href=\"#ErrorBars\"><code>ErrorBars</code></a></dt><dd>A collection of x-/y-coordinates with associated error magnitudes. <font color='green'>✓</font></dd>\n <dt><a href=\"#Spread\"><code>Spread</code></a></dt><dd>Continuous version of ErrorBars. <font color='green'>✓</font></dd>\n <dt><a href=\"#Area\"><code>Area</code></a></dt><dd>Area under the curve or between curves. <font color='green'>✓</font></dd>\n <dt><a href=\"#Bars\"><code>Bars</code></a></dt><dd>Data collected and binned into categories. <font color='green'>✓</font></dd>\n <dt><a href=\"#Histogram\"><code>Histogram</code></a></dt><dd>Data collected and binned in a continuous space using specified bin edges. <font color='green'>✓</font></dd>\n <dt><a href=\"#BoxWhisker\"><code>BoxWhisker</code></a></dt><dd>Distributions of data varying by 0-N key dimensions.<font color='green'>✓</font></dd>\n <dt><a href=\"#Scatter\"><code>Scatter</code></a></dt><dd>Discontinuous collection of points indexed over a single dimension. <font color='green'>✓</font></dd>\n <dt><a href=\"#Points\"><code>Points</code></a></dt><dd>Discontinuous collection of points indexed over two dimensions. <font color='green'>✓</font></dd>\n <dt><a href=\"#VectorField\"><code>VectorField</code></a></dt><dd>Cyclic variable (and optional auxiliary data) distributed over two-dimensional space. <font color='green'>✓</font></dd>\n <dt><a href=\"#Spikes\"><code>Spikes</code></a></dt><dd>A collection of horizontal or vertical lines at various locations with fixed height (1D) or variable height (2D). <font color='green'>✓</font></dd>\n <dt><a href=\"#SideHistogram\"><code>SideHistogram</code></a></dt><dd>Histogram binning data contained by some other <code>Element</code>. <font color='green'>✓</font></dd>\n </dl>\n\n### <a id='Chart3DIndex'></a> <a href=\"#Chart3D Elements\"><code>Chart3D Elements:</code></a>\n\n<dl class=\"dl-horizontal\">\n <dt><a href=\"#Surface\"><code>Surface</code></a></dt><dd>Continuous collection of points in a three-dimensional space. <font color='red'>✗</font></dd>\n <dt><a href=\"#Scatter3D\"><code>Scatter3D</code></a></dt><dd>Discontinuous collection of points in a three-dimensional space. <font color='red'>✗</font></dd>\n <dt><a href=\"#TriSurface\"><code>TriSurface</code></a></dt><dd>Continuous but irregular collection of points interpolated into a Surface using Delaunay triangulation. <font color='red'>✗</font></dd>\n</dl>\n\n\n### <a id='RasterIndex'></a> <a href=\"#Raster Elements\"><code>Raster Elements:</code></a>\n\n<dl class=\"dl-horizontal\">\n <dt><a href=\"#Raster\"><code>Raster</code></a></dt><dd>The base class of all rasters containing two-dimensional arrays. <font color='green'>✓</font></dd>\n <dt><a href=\"#QuadMesh\"><code>QuadMesh</code></a></dt><dd>Raster type specifying 2D bins with two-dimensional array of values. <font color='green'>✓</font></dd>\n <dt><a href=\"#HeatMap\"><code>HeatMap</code></a></dt><dd>Raster displaying sparse, discontinuous data collected in a two-dimensional space. <font color='green'>✓</font></dd>\n <dt><a href=\"#Image\"><code>Image</code></a></dt><dd>Raster containing a two-dimensional array covering a continuous space (sliceable). <font color='green'>✓</font></dd>\n <dt><a href=\"#RGB\"><code>RGB</code></a></dt><dd>Image with 3 (R,G,B) or 4 (R,G,B,Alpha) color channels. <font color='green'>✓</font></dd>\n <dt><a href=\"#HSV\"><code>HSV</code></a></dt><dd>Image with 3 (Hue, Saturation, Value) or 4 channels. <font color='green'>✓</font></dd>\n</dl>\n\n\n### <a id='TabularIndex'></a> <a href=\"#Tabular Elements\"><code>Tabular Elements:</code></a>\n\n\n<dl class=\"dl-horizontal\">\n <dt><a href=\"#ItemTable\"><code>ItemTable</code></a></dt><dd>Ordered collection of key-value pairs (ordered dictionary). <font color='green'>✓</font></dd>\n <dt><a href=\"#Table\"><code>Table</code></a></dt><dd>Collection of arbitrary data with arbitrary key and value dimensions. <font color='green'>✓</font></dd>\n </dl>\n \n### <a id='AnnotationIndex'></a> <a href=\"#Annotation Elements\"><code>Annotations:</code></a>\n\n \n <dl class=\"dl-horizontal\">\n <dt><a href=\"#VLine\"><code>VLine</code></a></dt><dd>Vertical line annotation. <font color='green'>✓</font></dd>\n <dt><a href=\"#HLine\"><code>HLine</code></a></dt><dd>Horizontal line annotation. <font color='green'>✓</font></dd>\n <dt><a href=\"#Spline\"><code>Spline</code></a></dt><dd>Bezier spline (arbitrary curves). <font color='green'>✓</font></dd>\n <dt><a href=\"#Text\"><code>Text</code></a></dt><dd>Text annotation on an <code>Element</code>. <font color='green'>✓</font></dd>\n <dt><a href=\"#Arrow\"><code>Arrow</code></a></dt><dd>Arrow on an <code>Element</code> with optional text label. <font color='red'>✗</font></dd>\n</dl>\n\n\n### <a id='PathIndex'></a> <a href=\"#Path Elements\"><code>Paths:</code></a>\n\n<dl class=\"dl-horizontal\">\n <dt><a href=\"#Path\"><code>Path</code></a></dt><dd>Collection of paths. <font color='green'>✓</font></dd>\n <dt><a href=\"#Contours\"><code>Contours</code></a></dt><dd>Collection of paths, each with an associated value. <font color='green'>✓</font></dd>\n <dt><a href=\"#Polygons\"><code>Polygons</code></a></dt><dd>Collection of filled, closed paths with an associated value. <font color='green'>✓</font></dd>\n <dt><a href=\"#Bounds\"><code>Bounds</code></a></dt><dd>Box specified by corner positions. <font color='green'>✓</font></dd>\n <dt><a href=\"#Box\"><code>Box</code></a></dt><dd>Box specified by center position, radius, and aspect ratio. <font color='green'>✓</font></dd>\n <dt><a href=\"#Ellipse\"><code>Ellipse</code></a></dt><dd>Ellipse specified by center position, radius, and aspect ratio. <font color='green'>✓</font></dd>\n</dl>",
"_____no_output_____"
],
[
"## ``Element`` <a id='Element'></a>",
"_____no_output_____"
],
[
"**The basic or fundamental types of data that can be visualized.**\n\n``Element`` is the base class for all the other HoloViews objects shown in this section.\n\nAll ``Element`` objects accept ``data`` as the first argument to define the contents of that element. In addition to its implicit type, each element object has a ``group`` string defining its category, and a ``label`` naming this particular item, as described in the [Introduction](Introduction.ipynb#value).\n\nWhen rich display is off, or if no visualization has been defined for that type of ``Element``, the ``Element`` is presented with a default textual representation:",
"_____no_output_____"
]
],
[
[
"import holoviews as hv\nhv.notebook_extension(bokeh=True)\nhv.Element(None, group='Value', label='Label')",
"_____no_output_____"
]
],
[
[
"In addition, ``Element`` has key dimensions (``kdims``), value dimensions (``vdims``), and constant dimensions (``cdims``) to describe the semantics of indexing within the ``Element``, the semantics of the underlying data contained by the ``Element``, and any constant parameters associated with the object, respectively.\nDimensions are described in the [Introduction](Introduction.ipynb).\n\nThe remaining ``Element`` types each have a rich, graphical display as shown below.",
"_____no_output_____"
],
[
"## ``Chart`` Elements <a id='Chart Elements'></a>",
"_____no_output_____"
],
[
"**Visualization of a dependent variable against an independent variable**\n\nThe first large class of ``Elements`` is the ``Chart`` elements. These objects have at least one fully indexable, sliceable key dimension (typically the *x* axis in a plot), and usually have one or more value dimension(s) (often the *y* axis) that may or may not be indexable depending on the implementation. The key dimensions are normally the parameter settings for which things are measured, and the value dimensions are the data points recorded at those settings. \n\nAs described in the [Columnar Data tutorial](Columnar_Data.ipynb), the data can be stored in several different internal formats, such as a NumPy array of shape (N, D), where N is the number of samples and D the number of dimensions. A somewhat larger list of formats can be accepted, including any of the supported internal formats, or\n\n1. As a list of length N containing tuples of length D.\n2. As a tuple of length D containing iterables of length N.",
"_____no_output_____"
],
[
"### ``Curve`` <a id='Curve'></a>",
"_____no_output_____"
]
],
[
[
"import numpy as np\npoints = [(0.1*i, np.sin(0.1*i)) for i in range(100)]\nhv.Curve(points)",
"_____no_output_____"
]
],
[
[
"A ``Curve`` is a set of values provided for some set of keys from a [continuously indexable 1D coordinate system](Continuous_Coordinates.ipynb), where the plotted values will be connected up because they are assumed to be samples from a continuous relation.",
"_____no_output_____"
],
[
"### ``ErrorBars`` <a id='ErrorBars'></a>",
"_____no_output_____"
]
],
[
[
"np.random.seed(7)\npoints = [(0.1*i, np.sin(0.1*i)) for i in range(100)]\nerrors = [(0.1*i, np.sin(0.1*i), np.random.rand()/2) for i in np.linspace(0, 100, 11)]\nhv.Curve(points) * hv.ErrorBars(errors)",
"_____no_output_____"
]
],
[
[
"``ErrorBars`` is a set of x-/y-coordinates with associated error values. Error values may be either symmetric or asymmetric, and thus can be supplied as an Nx3 or Nx4 array (or any of the alternative constructors Chart Elements allow).",
"_____no_output_____"
]
],
[
[
"%%opts ErrorBars\npoints = [(0.1*i, np.sin(0.1*i)) for i in range(100)]\nerrors = [(0.1*i, np.sin(0.1*i), np.random.rand()/2, np.random.rand()/4) for i in np.linspace(0, 100, 11)]\nhv.Curve(points) * hv.ErrorBars(errors, vdims=['y', 'yerrneg', 'yerrpos'])",
"_____no_output_____"
]
],
[
[
"### ``Area`` <a id='Area'></a>",
"_____no_output_____"
],
[
"** *Area under the curve* **\n\nBy default the Area Element draws just the area under the curve, i.e. the region between the curve and the origin.",
"_____no_output_____"
]
],
[
[
"xs = np.linspace(0, np.pi*4, 40)\nhv.Area((xs, np.sin(xs)))",
"_____no_output_____"
]
],
[
[
"** * Area between curves * **\n\nWhen supplied a second value dimension the area is defined as the area between two curves.",
"_____no_output_____"
]
],
[
[
"X = np.linspace(0,3,200)\nY = X**2 + 3\nY2 = np.exp(X) + 2\nY3 = np.cos(X)\nhv.Area((X, Y, Y2), vdims=['y', 'y2']) * hv.Area((X, Y, Y3), vdims=['y', 'y3'])",
"_____no_output_____"
]
],
[
[
"#### Stacked areas\n\nAreas are also useful to visualize multiple variables changing over time, but in order to be able to compare them the areas need to be stacked. Therefore the ``operation`` module provides the ``stack_area`` operation which makes it trivial to stack multiple Area in an (Nd)Overlay.\n\nIn this example we will generate a set of 5 arrays representing percentages and create an Overlay of them. Then we simply call the ``stack_area`` operation on the Overlay to get a stacked area chart.",
"_____no_output_____"
]
],
[
[
"values = np.random.rand(5, 20)\npercentages = (values/values.sum(axis=0)).T*100\n\noverlay = hv.Overlay([hv.Area(percentages[:, i], vdims=[hv.Dimension('value', unit='%')]) for i in range(5)])\noverlay + hv.Area.stack(overlay)",
"_____no_output_____"
]
],
[
[
"### ``Spread`` <a id='Spread'></a>",
"_____no_output_____"
],
[
"``Spread`` elements have the same data format as the ``ErrorBars`` element, namely x- and y-values with associated symmetric or asymmetric errors, but are interpreted as samples from a continuous distribution (just as ``Curve`` is the continuous version of ``Scatter``). These are often paired with an overlaid ``Curve`` to show both the mean (as a curve) and the spread of values; see the [Columnar Data tutorial](Columnar_Data.ipynb) for examples. ",
"_____no_output_____"
],
[
"##### Symmetric",
"_____no_output_____"
]
],
[
[
"np.random.seed(42)\nxs = np.linspace(0, np.pi*2, 20)\nerr = 0.2+np.random.rand(len(xs))\nhv.Spread((xs, np.sin(xs), err))",
"_____no_output_____"
]
],
[
[
"##### Asymmetric",
"_____no_output_____"
]
],
[
[
"%%opts Spread (fill_color='indianred' fill_alpha=1)\nxs = np.linspace(0, np.pi*2, 20)\nhv.Spread((xs, np.sin(xs), 0.1+np.random.rand(len(xs)), 0.1+np.random.rand(len(xs))),\n vdims=['y', 'yerrneg', 'yerrpos'])",
"_____no_output_____"
]
],
[
[
"### ``Bars`` <a id='Bars'></a>",
"_____no_output_____"
]
],
[
[
"data = [('one',8),('two', 10), ('three', 16), ('four', 8), ('five', 4), ('six', 1)]\nbars = hv.Bars(data, kdims=[hv.Dimension('Car occupants', values='initial')], vdims=['Count'])\nbars + bars[['one', 'two', 'three']]",
"_____no_output_____"
]
],
[
[
"``Bars`` is an ``NdElement`` type, so by default it is sorted. To preserve the initial ordering specify the ``Dimension`` with values set to 'initial', or you can supply an explicit list of valid dimension keys.\n\n``Bars`` support up to two key dimensions which can be laid by ``'group'`` and ``'stack'`` dimensions. By default the key dimensions are mapped onto the first, second ``Dimension`` of the ``Bars`` object, but this behavior can be overridden via the ``group_index`` and ``stack_index`` options.",
"_____no_output_____"
]
],
[
[
"%%opts Bars [group_index=0 stack_index=1]\nfrom itertools import product\nnp.random.seed(3)\ngroups, stacks = ['A', 'B'], ['a', 'b']\nkeys = product(groups, stacks)\nhv.Bars([k+(np.random.rand()*100.,) for k in keys],\n kdims=['Group', 'Stack'], vdims=['Count'])",
"_____no_output_____"
]
],
[
[
"### ``BoxWhisker`` <a id='BoxWhisker'></a>",
"_____no_output_____"
],
[
"The ``BoxWhisker`` Element allows representing distributions of data varying by 0-N key dimensions. To represent the distribution of a single variable, we can create a BoxWhisker Element with no key dimensions and a single value dimension:",
"_____no_output_____"
]
],
[
[
"hv.BoxWhisker(np.random.randn(200), kdims=[], vdims=['Value'])",
"_____no_output_____"
]
],
[
[
"BoxWhisker Elements support any number of dimensions and may also be rotated. To style the boxes and whiskers, supply ``boxprops``, ``whiskerprops``, and ``flierprops``.",
"_____no_output_____"
]
],
[
[
"%%opts BoxWhisker [invert_axes=True width=600]\ngroups = [chr(65+g) for g in np.random.randint(0, 3, 200)]\nhv.BoxWhisker((groups, np.random.randint(0, 5, 200), np.random.randn(200)),\n kdims=['Group', 'Category'], vdims=['Value']).sort()",
"_____no_output_____"
]
],
[
[
"### ``Histogram`` <a id='Histogram'></a>",
"_____no_output_____"
]
],
[
[
"np.random.seed(1)\ndata = [np.random.normal() for i in range(10000)]\nfrequencies, edges = np.histogram(data, 20)\nhv.Histogram(frequencies, edges)",
"_____no_output_____"
]
],
[
[
"``Histogram``s partition the `x` axis into discrete (but not necessarily regular) bins, showing counts in each as a bar.\n\nAlmost all Element types, including ``Histogram``, may be projected onto a polar axis by supplying ``projection='polar'`` as a plot option.",
"_____no_output_____"
]
],
[
[
"%%opts Histogram [projection='polar' show_grid=True]\ndata = [np.random.rand()*np.pi*2 for i in range(100)]\nfrequencies, edges = np.histogram(data, 20)\nhv.Histogram(frequencies, edges, kdims=['Angle'])",
"_____no_output_____"
]
],
[
[
"### ``Scatter`` <a id='Scatter'></a>",
"_____no_output_____"
]
],
[
[
"%%opts Scatter (color='k', marker='s', s=10)\nnp.random.seed(42)\npoints = [(i, np.random.random()) for i in range(20)]\nhv.Scatter(points) + hv.Scatter(points)[12:20]",
"_____no_output_____"
]
],
[
[
"Scatter is the discrete equivalent of Curve, showing *y* values for discrete *x* values selected. See [``Points``](#Points) for more information.\n\nThe marker shape specified above can be any supported by [matplotlib](http://matplotlib.org/api/markers_api.html), e.g. ``s``, ``d``, or ``o``; the other options select the color and size of the marker. For convenience with the [bokeh backend](Bokeh_Backend), the matplotlib marker options are supported using a compatibility function in HoloViews.",
"_____no_output_____"
],
[
"### ``Points`` <a id='Points'></a>",
"_____no_output_____"
]
],
[
[
"np.random.seed(12)\npoints = np.random.rand(50,2)\nhv.Points(points) + hv.Points(points)[0.6:0.8,0.2:0.5]",
"_____no_output_____"
]
],
[
[
"As you can see, ``Points`` is very similar to ``Scatter``, and can produce some plots that look identical. However, the two ``Element``s are very different semantically. For ``Scatter``, the dots each show a dependent variable *y* for some *x*, such as in the ``Scatter`` example above where we selected regularly spaced values of *x* and then created a random number as the corresponding *y*. I.e., for ``Scatter``, the *y* values are the data; the *x*s are just where the data values are located. For ``Points``, both *x* and *y* are independent variables, known as ``key_dimensions`` in HoloViews:",
"_____no_output_____"
]
],
[
[
"for o in [hv.Points(points,name=\"Points \"), hv.Scatter(points,name=\"Scatter\")]:\n for d in ['key','value']:\n print(\"%s %s_dimensions: %s \" % (o.name, d, o.dimensions(d,label=True)))",
"_____no_output_____"
]
],
[
[
"The ``Scatter`` object expresses a dependent relationship between *x* and *y*, making it useful for combining with other similar ``Chart`` types, while the ``Points`` object expresses the relationship of two independent keys *x* and *y* with optional ``vdims`` (zero in this case), which makes ``Points`` objects meaningful to combine with the ``Raster`` types below.\n\nOf course, the ``vdims`` need not be empty for ``Points``; here is an example with two additional quantities for each point, as ``value_dimension``s *z* and α visualized as the color and size of the dots, respectively:",
"_____no_output_____"
]
],
[
[
"%%opts Points [color_index=2 size_index=3 scaling_factor=50]\nnp.random.seed(10)\ndata = np.random.rand(100,4)\n\npoints = hv.Points(data, vdims=['z', 'alpha'])\npoints + points[0.3:0.7, 0.3:0.7].hist()",
"_____no_output_____"
]
],
[
[
"Such a plot wouldn't be meaningful for ``Scatter``, but is a valid use for ``Points``, where the *x* and *y* locations are independent variables representing coordinates, and the \"data\" is conveyed by the size and color of the dots.\n\n### ``Spikes`` <a id='Spikes'></a>",
"_____no_output_____"
],
[
"Spikes represent any number of horizontal or vertical line segments with fixed or variable heights. There are a number of disparate uses for this type. First of all, they may be used as a rugplot to give an overview of a one-dimensional distribution. They may also be useful in more domain-specific cases, such as visualizing spike trains for neurophysiology or spectrograms in physics and chemistry applications.\n\nIn the simplest case, a Spikes object represents coordinates in a 1D distribution:",
"_____no_output_____"
]
],
[
[
"%%opts Spikes (line_alpha=0.4) [spike_length=0.1]\nxs = np.random.rand(50)\nys = np.random.rand(50)\nhv.Points((xs, ys)) * hv.Spikes(xs)",
"_____no_output_____"
]
],
[
[
"When supplying two dimensions to the Spikes object, the second dimension will be mapped onto the line height. Optionally, you may also supply a cmap and color_index to map color onto one of the dimensions. This way we can, for example, plot a mass spectrogram:",
"_____no_output_____"
]
],
[
[
"%%opts Spikes (cmap='Reds')\nhv.Spikes(np.random.rand(20, 2), kdims=['Mass'], vdims=['Intensity'])",
"_____no_output_____"
]
],
[
[
"Another possibility is to draw a number of spike trains as you would encounter in neuroscience. Here we generate 10 separate random spike trains and distribute them evenly across the space by setting their ``position``. By also declaring some ``yticks``, each spike train can be labeled individually:",
"_____no_output_____"
]
],
[
[
"%%opts Spikes [spike_length=0.1] NdOverlay [show_legend=False]\nhv.NdOverlay({i: hv.Spikes(np.random.randint(0, 100, 10), kdims=['Time']).opts(plot=dict(position=0.1*i))\n for i in range(10)}).opts(plot=dict(yticks=[((i+1)*0.1-0.05, i) for i in range(10)]))",
"_____no_output_____"
]
],
[
[
"Finally, we may use ``Spikes`` to visualize marginal distributions as adjoined plots using the ``<<`` adjoin operator:",
"_____no_output_____"
]
],
[
[
"%%opts Spikes (line_alpha=0.2)\npoints = hv.Points(np.random.randn(500, 2))\npoints << hv.Spikes(points['y']) << hv.Spikes(points['x'])",
"_____no_output_____"
]
],
[
[
"### ``VectorField`` <a id='VectorField'></a>",
"_____no_output_____"
]
],
[
[
"%%opts VectorField [size_index=3]\nx,y = np.mgrid[-10:10,-10:10] * 0.25\nsine_rings = np.sin(x**2+y**2)*np.pi+np.pi\nexp_falloff = 1/np.exp((x**2+y**2)/8)\n\nvector_data = (x,y,sine_rings, exp_falloff)\nhv.VectorField(vector_data)",
"_____no_output_____"
]
],
[
[
"As you can see above, here the *x* and *y* positions are chosen to make a regular grid. The arrow angles follow a sinsoidal ring pattern, and the arrow lengths fall off exponentially from the center, so this plot has four dimensions of data (direction and length for each *x,y* position).\n\nUsing the IPython ``%%opts`` cell-magic (described in the [Options tutorial](Options), along with the Python equivalent), we can also use color as a redundant indicator to the direction or magnitude:",
"_____no_output_____"
]
],
[
[
"%%opts VectorField [size_index=3] VectorField.A [color_index=2] VectorField.M [color_index=3]\nhv.VectorField(vector_data, group='A') + hv.VectorField(vector_data, group='M')",
"_____no_output_____"
]
],
[
[
"### ``SideHistogram`` <a id='SideHistogram'></a>",
"_____no_output_____"
],
[
"The ``.hist`` method conveniently adjoins a histogram to the side of any ``Chart``, ``Surface``, or ``Raster`` component, as well as many of the container types (though it would be reporting data from one of these underlying ``Element`` types). For a ``Raster`` using color or grayscale to show values (see ``Raster`` section below), the side histogram doubles as a color bar or key.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nnp.random.seed(42)\npoints = [(i, np.random.normal()) for i in range(800)]\nhv.Scatter(points).hist()",
"_____no_output_____"
]
],
[
[
"## ``Chart3D`` Elements <a id='Chart3D Elements'></a>",
"_____no_output_____"
],
[
"### ``Surface`` <a id='Surface'></a>",
"_____no_output_____"
]
],
[
[
"%%opts Surface (cmap='jet' rstride=20, cstride=2)\nhv.Surface(np.sin(np.linspace(0,100*np.pi*2,10000)).reshape(100,100))",
"_____no_output_____"
]
],
[
[
"Surface is used for a set of gridded points whose associated value dimension represents samples from a continuous surface; it is the equivalent of a ``Curve`` but with two key dimensions instead of just one.",
"_____no_output_____"
],
[
"### ``Scatter3D`` <a id='Scatter3D'></a>",
"_____no_output_____"
]
],
[
[
"%%opts Scatter3D [azimuth=40 elevation=20]\nx,y = np.mgrid[-5:5, -5:5] * 0.1\nheights = np.sin(x**2+y**2)\nhv.Scatter3D(zip(x.flat,y.flat,heights.flat))",
"_____no_output_____"
]
],
[
[
"``Scatter3D`` is the equivalent of ``Scatter`` but for two key dimensions, rather than just one.\n\n\n### ``TriSurface`` <a id='TriSurface'></a>",
"_____no_output_____"
],
[
"The ``TriSurface`` Element renders any collection of 3D points as a Surface by applying Delaunay triangulation. It thus supports arbitrary, non-gridded data, but it does not support indexing to find data values, since finding the closest ones would require a search.",
"_____no_output_____"
]
],
[
[
"%%opts TriSurface [fig_size=200] (cmap='hot_r')\nhv.TriSurface((x.flat,y.flat,heights.flat))",
"_____no_output_____"
]
],
[
[
"## ``Raster`` Elements <a id='Raster Elements'></a>",
"_____no_output_____"
],
[
"**A collection of raster image types**\n\nThe second large class of ``Elements`` is the raster elements. Like ``Points`` and unlike the other ``Chart`` elements, ``Raster Elements`` live in a 2D key-dimensions space. For the ``Image``, ``RGB``, and ``HSV`` elements, the coordinates of this two-dimensional key space are defined in a [continuously indexable coordinate system](Continuous_Coordinates.ipynb).",
"_____no_output_____"
],
[
"### ``Raster`` <a id='Raster'></a>",
"_____no_output_____"
],
[
"A ``Raster`` is the base class for image-like ``Elements``, but may be used directly to visualize 2D arrays using a color map. The coordinate system of a ``Raster`` is the raw indexes of the underlying array, with integer values always starting from (0,0) in the top left, with default extents corresponding to the shape of the array. The ``Image`` subclass visualizes similarly, but using a continuous Cartesian coordinate system suitable for an array that represents some underlying continuous region.",
"_____no_output_____"
]
],
[
[
"x,y = np.mgrid[-50:51, -50:51] * 0.1\nhv.Raster(np.sin(x**2+y**2))",
"_____no_output_____"
]
],
[
[
"### ``QuadMesh`` <a id='QuadMesh'></a>",
"_____no_output_____"
],
[
"The basic ``QuadMesh`` is a 2D grid of bins specified as x-/y-values specifying a regular sampling or edges, with arbitrary sampling and an associated 2D array containing the bin values. The coordinate system of a ``QuadMesh`` is defined by the bin edges, therefore any index falling into a binned region will return the appropriate value. Unlike ``Image`` objects, slices must be inclusive of the bin edges.",
"_____no_output_____"
]
],
[
[
"n = 21\nxs = np.logspace(1, 3, n)\nys = np.linspace(1, 10, n)\nhv.QuadMesh((xs, ys, np.random.rand(n-1, n-1)))",
"_____no_output_____"
]
],
[
[
"QuadMesh may also be used to represent an arbitrary mesh of quadrilaterals by supplying three separate 2D arrays representing the coordinates of each quadrilateral in a 2D space. Note that when using ``QuadMesh`` in this mode, slicing and indexing semantics and most operations will currently not work.",
"_____no_output_____"
]
],
[
[
"coords = np.linspace(-1.5,1.5,n)\nX,Y = np.meshgrid(coords, coords);\nQx = np.cos(Y) - np.cos(X)\nQz = np.sin(Y) + np.sin(X)\nZ = np.sqrt(X**2 + Y**2)\nhv.QuadMesh((Qx, Qz, Z))",
"_____no_output_____"
]
],
[
[
"### ``HeatMap`` <a id='HeatMap'></a>",
"_____no_output_____"
],
[
"A ``HeatMap`` displays like a typical raster image, but the input is a dictionary indexed with two-dimensional keys, not a Numpy array or Pandas dataframe. As many rows and columns as required will be created to display the values in an appropriate grid format. Values unspecified are left blank, and the keys can be any Python datatype (not necessarily numeric). One typical usage is to show values from a set of experiments, such as a parameter space exploration, and many other such visualizations are shown in the [Containers](Containers.ipynb) and [Exploring Data](Exploring_Data.ipynb) tutorials. Each value in a ``HeatMap`` is labeled explicitly by default, and so this component is not meant for very large numbers of samples. With the default color map, high values (in the upper half of the range present) are colored orange and red, while low values (in the lower half of the range present) are colored shades of blue.",
"_____no_output_____"
]
],
[
[
"data = {(chr(65+i),chr(97+j)): i*j for i in range(5) for j in range(5) if i!=j}\nhv.HeatMap(data).sort()",
"_____no_output_____"
]
],
[
[
"### ``Image`` <a id='Image'></a>",
"_____no_output_____"
],
[
"Like ``Raster``, a HoloViews ``Image`` allows you to view 2D arrays using an arbitrary color map. Unlike ``Raster``, an ``Image`` is associated with a [2D coordinate system in continuous space](Continuous_Coordinates.ipynb), which is appropriate for values sampled from some underlying continuous distribution (as in a photograph or other measurements from locations in real space). Slicing, sampling, etc. on an ``Image`` all use this continuous space, whereas the corresponding operations on a ``Raster`` work on the raw array coordinates.",
"_____no_output_____"
]
],
[
[
"x,y = np.mgrid[-50:51, -50:51] * 0.1\nbounds=(-1,-1,1,1) # Coordinate system: (left, bottom, top, right)\n\n(hv.Image(np.sin(x**2+y**2), bounds=bounds) \n + hv.Image(np.sin(x**2+y**2), bounds=bounds)[-0.5:0.5, -0.5:0.5])",
"_____no_output_____"
]
],
[
[
"Notice how, because our declared coordinate system is continuous, we can slice with any floating-point value we choose. The appropriate range of the samples in the input numpy array will always be displayed, whether or not there are samples at those specific floating-point values.\n\nIt is also worth noting that the name ``Image`` can clash with other common libraries, which is one reason to avoid unqualified imports like ``from holoviews import *``. For instance, the Python Imaging Libray provides an ``Image`` module, and IPython itself supplies an ``Image`` class in ``IPython.display``. Python namespaces allow you to avoid such problems, e.g. using ``from PIL import Image as PILImage`` or using ``import holoviews as hv`` and then ``hv.Image()``, as we do in these tutorials.",
"_____no_output_____"
],
[
"### ``RGB`` <a id='RGB'></a>",
"_____no_output_____"
],
[
"The ``RGB`` element is an ``Image`` that supports red, green, blue channels:",
"_____no_output_____"
]
],
[
[
"x,y = np.mgrid[-50:51, -50:51] * 0.1\n\nr = 0.5*np.sin(np.pi +3*x**2+y**2)+0.5\ng = 0.5*np.sin(x**2+2*y**2)+0.5\nb = 0.5*np.sin(np.pi/2+x**2+y**2)+0.5\n\nhv.RGB(np.dstack([r,g,b]))",
"_____no_output_____"
]
],
[
[
"You can see how the RGB object is created from the original channels:",
"_____no_output_____"
]
],
[
[
"%%opts Image (cmap='gray')\nhv.Image(r,label=\"R\") + hv.Image(g,label=\"G\") + hv.Image(b,label=\"B\")",
"_____no_output_____"
]
],
[
[
"``RGB`` also supports an optional alpha channel, which will be used as a mask revealing or hiding any ``Element``s it is overlaid on top of:",
"_____no_output_____"
]
],
[
[
"%%opts Image (cmap='gray')\nmask = 0.5*np.sin(0.2*(x**2+y**2))+0.5\nrgba = hv.RGB(np.dstack([r,g,b,mask]))\n\nbg = hv.Image(0.5*np.cos(x*3)+0.5, label=\"Background\") * hv.VLine(x=0,label=\"Background\")\n\noverlay = bg*rgba\noverlay.label=\"RGBA Overlay\"\n\nbg + hv.Image(mask,label=\"Mask\") + overlay",
"_____no_output_____"
]
],
[
[
"### ``HSV`` <a id='HSV'></a>",
"_____no_output_____"
],
[
"HoloViews makes it trivial to work in any color space that can be converted to ``RGB`` by making a simple subclass of ``RGB`` as appropriate. For instance, we also provide the HSV (hue, saturation, value) color space, which is useful for plotting cyclic data (as the Hue) along with two additional dimensions (controlling the saturation and value of the color, respectively):",
"_____no_output_____"
]
],
[
[
"x,y = np.mgrid[-50:51, -50:51] * 0.1\nh = 0.5 + np.sin(0.2*(x**2+y**2)) / 2.0\ns = 0.5*np.cos(y*3)+0.5\nv = 0.5*np.cos(x*3)+0.5\n\nhsv = hv.HSV(np.dstack([h, s, v]))\nhsv",
"_____no_output_____"
]
],
[
[
"You can see how this is created from the original channels:",
"_____no_output_____"
]
],
[
[
"%%opts Image (cmap='gray')\nhv.Image(h, label=\"H\") + hv.Image(s, label=\"S\") + hv.Image(v, label=\"V\")",
"_____no_output_____"
]
],
[
[
"# ``Tabular`` Elements <a id='Tabular Elements'></a>",
"_____no_output_____"
],
[
"**General data structures for holding arbitrary information**",
"_____no_output_____"
],
[
"## ``ItemTable`` <a id='ItemTable'></a>",
"_____no_output_____"
],
[
"An ``ItemTable`` is an ordered collection of key, value pairs. It can be used to directly visualize items in a tabular format where the items may be supplied as an ``OrderedDict`` or a list of (key,value) pairs. A standard Python dictionary can be easily visualized using a call to the ``.items()`` method, though the entries in such a dictionary are not kept in any particular order, and so you may wish to sort them before display. One typical usage for an ``ItemTable`` is to list parameter values or measurements associated with an adjacent ``Element``.",
"_____no_output_____"
]
],
[
[
"hv.ItemTable([('Age', 10), ('Weight',15), ('Height','0.8 meters')])",
"_____no_output_____"
]
],
[
[
"## ``Table`` <a id='Table'></a>",
"_____no_output_____"
],
[
"A table is more general than an ``ItemTable``, as it allows multi-dimensional keys and multidimensional values.",
"_____no_output_____"
]
],
[
[
"keys = [('M',10), ('M',16), ('F',12)]\nvalues = [(15, 0.8), (18, 0.6), (10, 0.8)]\ntable = hv.Table(zip(keys,values), \n kdims = ['Gender', 'Age'], \n vdims=['Weight', 'Height'])\ntable",
"_____no_output_____"
]
],
[
[
"Note that you can use select using tables, and once you select using a full, multidimensional key, you get an ``ItemTable`` (shown on the right):",
"_____no_output_____"
]
],
[
[
"table.select(Gender='M') + table.select(Gender='M', Age=10)",
"_____no_output_____"
]
],
[
[
"The ``Table`` is used as a common data structure that may be converted to any other HoloViews data structure using the ``TableConversion`` class.\n\nThe functionality of the ``TableConversion`` class may be conveniently accessed using the ``.to`` property. For more extended usage of table conversion see the [Columnar Data](Columnnar_Data.ipynb) and [Pandas Conversion](Pandas_Conversion.ipynb) Tutorials.",
"_____no_output_____"
]
],
[
[
"table.select(Gender='M').to.curve(kdims=[\"Age\"], vdims=[\"Weight\"])",
"_____no_output_____"
]
],
[
[
"# ``Annotation`` Elements <a id='Annotation Elements'></a>",
"_____no_output_____"
],
[
"**Useful information that can be overlaid onto other components**",
"_____no_output_____"
],
[
"Annotations are components designed to be overlaid on top of other ``Element`` objects. To demonstrate annotation and paths, we will be drawing many of our elements on top of an RGB Image:",
"_____no_output_____"
]
],
[
[
"scene = hv.RGB.load_image('../assets/penguins.png')",
"_____no_output_____"
]
],
[
[
"### ``VLine`` and ``HLine`` <a id='VLine'></a><a id='HLine'></a>",
"_____no_output_____"
]
],
[
[
"scene * hv.VLine(-0.05) + scene * hv.HLine(-0.05)",
"_____no_output_____"
]
],
[
[
"### ``Spline`` <a id='Spline'></a>",
"_____no_output_____"
],
[
"The ``Spline`` annotation is used to draw Bezier splines using the same semantics as [matplotlib splines](http://matplotlib.org/api/path_api.html). In the overlay below, the spline is in dark blue and the control points are in light blue.",
"_____no_output_____"
]
],
[
[
"points = [(-0.3, -0.3), (0,0), (0.25, -0.25), (0.3, 0.3)]\ncodes = [1,4,4,4]\nscene * hv.Spline((points,codes)) * hv.Curve(points)",
"_____no_output_____"
]
],
[
[
"### Text and Arrow <a id='Text'></a><a id='Arrow'></a>",
"_____no_output_____"
]
],
[
[
"scene * hv.Text(0, 0.2, 'Adult\\npenguins') + scene * hv.Arrow(0,-0.1, 'Baby penguin', 'v')",
"_____no_output_____"
]
],
[
[
"# Paths <a id='Path Elements'></a>",
"_____no_output_____"
],
[
"**Line-based components that can be overlaid onto other components**\n\nPaths are a subclass of annotations that involve drawing line-based components on top of other elements. Internally, Path Element types hold a list of Nx2 arrays, specifying the x/y-coordinates along each path. The data may be supplied in a number of ways, including:\n\n1. A list of Nx2 numpy arrays.\n2. A list of lists containing x/y coordinate tuples.\n3. A tuple containing an array of length N with the x-values and a second array of shape NxP, where P is the number of paths.\n4. A list of tuples each containing separate x and y values.",
"_____no_output_____"
],
[
"## ``Path`` <a id='Path'></a>",
"_____no_output_____"
],
[
"A ``Path`` object is actually a collection of paths which can be arbitrarily specified. Although there may be multiple unconnected paths in a single ``Path`` object, they will all share the same style. Only by overlaying multiple ``Path`` objects do you iterate through the defined color cycle (or any other style options that have been defined).",
"_____no_output_____"
]
],
[
[
"angle = np.linspace(0, 2*np.pi, 100)\nbaby = list(zip(0.15*np.sin(angle), 0.2*np.cos(angle)-0.2))\n\nadultR = [(0.25, 0.45), (0.35,0.35), (0.25, 0.25), (0.15, 0.35), (0.25, 0.45)]\nadultL = [(-0.3, 0.4), (-0.3, 0.3), (-0.2, 0.3), (-0.2, 0.4),(-0.3, 0.4)]\n\nscene * hv.Path([adultL, adultR, baby]) * hv.Path([baby])",
"_____no_output_____"
]
],
[
[
"## ``Contours`` <a id='Contours'></a>",
"_____no_output_____"
],
[
"A ``Contours`` object is similar to ``Path`` object except each of the path elements is associated with a numeric value, called the ``level``. Sadly, our penguins are too complicated to give a simple example so instead we will simply mark the first couple of rings of our earlier ring pattern:",
"_____no_output_____"
]
],
[
[
"x,y = np.mgrid[-50:51, -50:51] * 0.1\n\ndef circle(radius, x=0, y=0):\n angles = np.linspace(0, 2*np.pi, 100)\n return np.array( list(zip(x+radius*np.sin(angles), y+radius*np.cos(angles))))\n\nhv.Image(np.sin(x**2+y**2)) * hv.Contours([circle(0.22)], level=0) * hv.Contours([circle(0.33)], level=1)",
"_____no_output_____"
]
],
[
[
"## ``Polygons`` <a id='Polygons'></a>",
"_____no_output_____"
],
[
"A ``Polygons`` object is similar to a ``Contours`` object except that each supplied path is closed and filled. Just like ``Contours``, optionally a ``level`` may be supplied; the Polygons will then be colored according to the supplied ``cmap``. Non-finite values such as ``np.NaN`` or ``np.inf`` will default to the supplied ``facecolor``.\n\nPolygons with values can be used to build heatmaps with arbitrary shapes.",
"_____no_output_____"
]
],
[
[
"%%opts Polygons (cmap='hot' line_color='black' line_width=2)\nnp.random.seed(35)\nhv.Polygons([np.random.rand(4,2)], level=0.5) *\\\nhv.Polygons([np.random.rand(4,2)], level=1.0) *\\\nhv.Polygons([np.random.rand(4,2)], level=1.5) *\\\nhv.Polygons([np.random.rand(4,2)], level=2.0)",
"_____no_output_____"
]
],
[
[
"Polygons without a value are useful as annotation, but also allow us to draw arbitrary shapes.",
"_____no_output_____"
]
],
[
[
"def rectangle(x=0, y=0, width=1, height=1):\n return np.array([(x,y), (x+width, y), (x+width, y+height), (x, y+height)])\n\n(hv.Polygons([rectangle(width=2), rectangle(x=6, width=2)]).opts(style={'fill_color': '#a50d0d'})\n* hv.Polygons([rectangle(x=2, height=2), rectangle(x=5, height=2)]).opts(style={'fill_color': '#ffcc00'})\n* hv.Polygons([rectangle(x=3, height=2, width=2)]).opts(style={'fill_color': 'cyan'}))",
"_____no_output_____"
]
],
[
[
"## ``Bounds`` <a id='Bounds'></a>",
"_____no_output_____"
],
[
"A bounds is a rectangular area specified as a tuple in ``(left, bottom, right, top)`` format. It is useful for denoting a region of interest defined by some bounds, whereas ``Box`` (below) is useful for drawing a box at a specific location.",
"_____no_output_____"
]
],
[
[
"scene * hv.Bounds(0.2) * hv.Bounds((0.2, 0.2, 0.45, 0.45,))",
"_____no_output_____"
]
],
[
[
"## ``Box`` <a id='Box'></a> and ``Ellipse`` <a id='Ellipse'></a>",
"_____no_output_____"
],
[
"A ``Box`` is similar to a ``Bounds`` except you specify the box position, width, and aspect ratio instead of the coordinates of the box corners. An ``Ellipse`` is specified just as for ``Box``, but has a rounded shape.",
"_____no_output_____"
]
],
[
[
"scene * hv.Box( -0.25, 0.3, 0.3, aspect=0.5) * hv.Box( 0, -0.2, 0.1) + \\\nscene * hv.Ellipse(-0.25, 0.3, 0.3, aspect=0.5) * hv.Ellipse(0, -0.2, 0.1)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
] |
cb3b33d293151a43ac8199d7cad58485ea7b68b7 | 102,533 | ipynb | Jupyter Notebook | lab3/lab3.ipynb | RETAJD/Machine_Learning_agh | 83bb959eb1a132fe48609f5722e47c288fd66ca6 | [
"MIT"
] | null | null | null | lab3/lab3.ipynb | RETAJD/Machine_Learning_agh | 83bb959eb1a132fe48609f5722e47c288fd66ca6 | [
"MIT"
] | null | null | null | lab3/lab3.ipynb | RETAJD/Machine_Learning_agh | 83bb959eb1a132fe48609f5722e47c288fd66ca6 | [
"MIT"
] | null | null | null | 112.180525 | 18,180 | 0.873699 | [
[
[
"import numpy as np\nimport pandas as pd\n\nsize = 300\nX = np.random.rand(size)*5-2.5\nw4, w3, w2, w1, w0 = 1, 2, 1, -4, 2\ny = w4*(X**4) + w3*(X**3) + w2*(X**2) + w1*X + w0 + np.random.randn(size)*8-4 \ndf = pd.DataFrame({'x': X, 'y': y})\ndf.to_csv('dane_do_regresji.csv',index=None)\ndf.plot.scatter(x='x',y='y')",
"_____no_output_____"
],
[
"X = X.reshape(-1, 1)\ny = y.reshape(-1, 1)",
"_____no_output_____"
],
[
"# Podziel ww. zbiór na zbiory: uczący oraz testujący w proporcji 80:20\nfrom sklearn.model_selection import train_test_split\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)",
"_____no_output_____"
],
[
"###REGRESJA",
"_____no_output_____"
],
[
"#LINIOWA\nfrom sklearn.linear_model import LinearRegression\nimport matplotlib.pyplot as plt\n\nlin_reg = LinearRegression()\nlin_reg.fit(X_train, y_train)\n ",
"_____no_output_____"
],
[
"y_train_pred_lin_reg = lin_reg.predict(X_train)\ny_test_pred_lin_reg = lin_reg.predict(X_test)",
"_____no_output_____"
],
[
"wynik = pd.DataFrame({'x': X_train[:, 0], 'y': y_train_pred_lin_reg[:, 0]})\nwynik.plot(x='x',y='y')",
"_____no_output_____"
],
[
"#KNN, dla 𝑘 = 3",
"_____no_output_____"
],
[
"import sklearn.neighbors\n\nknn_3_reg = sklearn.neighbors.KNeighborsRegressor(n_neighbors=3)\nknn_3_reg.fit(X_train, y_train)",
"_____no_output_____"
],
[
"y_train_pred_knn_3 = knn_3_reg.predict(X_train)\ny_test_pred_knn_3 = knn_3_reg.predict(X_test)",
"_____no_output_____"
],
[
"wynik = pd.DataFrame({'x': X_test[:, 0], 'y': y_test_pred_knn_3[:, 0]})\nwynik.plot.scatter(x='x',y='y')",
"_____no_output_____"
],
[
"#KNN, dla 𝑘 = 5",
"_____no_output_____"
],
[
"import sklearn.neighbors\nknn_5_reg = sklearn.neighbors.KNeighborsRegressor(n_neighbors=5)\nknn_5_reg.fit(X_train, y_train)",
"_____no_output_____"
],
[
"y_train_pred_knn_5 = knn_5_reg.predict(X_train)\ny_test_pred_knn_5 = knn_5_reg.predict(X_test)",
"_____no_output_____"
],
[
"wynik = pd.DataFrame({'x': X_test[:, 0], 'y': y_test_pred_knn_5[:, 0]})\nwynik.plot.scatter(x='x',y='y')",
"_____no_output_____"
],
[
"# Wielomianowy 2 rzędu:",
"_____no_output_____"
],
[
"from sklearn.preprocessing import PolynomialFeatures\npoly_feature_2 = PolynomialFeatures(degree=2, include_bias=False)\n#uczace\nX_2_poly_train = poly_feature_2.fit_transform(X_train)\n#testowe\nX_2_poly_test = poly_feature_2.fit_transform(X_test)\n\npoly_2_reg = LinearRegression()\npoly_2_reg.fit(X_2_poly_train, y_train)",
"_____no_output_____"
],
[
"#predykcja uczacych\ny_train_pred_poly_2 = poly_2_reg.predict(X_2_poly_train)\n#predykcja testowych\ny_test_pred_poly_2 = poly_2_reg.predict(X_2_poly_test)\n\nwynik = pd.DataFrame({'x': X_test[:, 0], 'y': y_test_pred_poly_2[:, 0]})\nwynik.plot.scatter(x='x',y='y')",
"_____no_output_____"
],
[
"# Wielomianowy 3 rzędu:",
"_____no_output_____"
],
[
"from sklearn.preprocessing import PolynomialFeatures\npoly_feature_3 = PolynomialFeatures(degree=3, include_bias=False)\n#uczace \nX_3_poly_train = poly_feature_3.fit_transform(X_train)\n#testowe\nX_3_poly_test = poly_feature_3.fit_transform(X_test)\n\npoly_3_reg = LinearRegression()\npoly_3_reg.fit(X_3_poly_train, y_train)",
"_____no_output_____"
],
[
"#predykcja uczacych\ny_train_pred_poly_3 = poly_3_reg.predict(X_3_poly_train)\n#predykcja testowych\ny_test_pred_poly_3 = poly_3_reg.predict(X_3_poly_test)\n\nwynik = pd.DataFrame({'x': X_test[:, 0], 'y': y_test_pred_poly_3[:, 0]})\nwynik.plot.scatter(x='x',y='y')",
"_____no_output_____"
],
[
"# Wielomianowy 4 rzędu:",
"_____no_output_____"
],
[
"from sklearn.preprocessing import PolynomialFeatures\npoly_feature_4 = PolynomialFeatures(degree=4, include_bias=False)\n#uczące\nX_4_poly_train = poly_feature_4.fit_transform(X_train)\n#testowe\nX_4_poly_test = poly_feature_4.fit_transform(X_test)\n\npoly_4_reg = LinearRegression()\npoly_4_reg.fit(X_4_poly_train, y_train)",
"_____no_output_____"
],
[
"#predykcja uczących\ny_train_pred_poly_4 = poly_4_reg.predict(X_4_poly_train)\n#predykcja testowych\ny_test_pred_poly_4 = poly_4_reg.predict(X_4_poly_test)\n\nwynik = pd.DataFrame({'x': X_test[:, 0], 'y': y_test_pred_poly_4[:, 0]})\nwynik.plot.scatter(x='x',y='y')",
"_____no_output_____"
],
[
"# Wielomianowy 5 rzędu:",
"_____no_output_____"
],
[
"from sklearn.preprocessing import PolynomialFeatures\npoly_feature_5 = PolynomialFeatures(degree=5, include_bias=False)\n#uczace\nX_5_poly_train = poly_feature_5.fit_transform(X_train)\n#testowe\nX_5_poly_test = poly_feature_5.fit_transform(X_test)\n\npoly_5_reg = LinearRegression()\npoly_5_reg.fit(X_5_poly_train, y_train)",
"_____no_output_____"
],
[
"#predykcja uczacych\ny_train_pred_poly_5 = poly_5_reg.predict(X_5_poly_train)\n#predykcja testowych\ny_test_pred_poly_5 = poly_5_reg.predict(X_5_poly_test)\n\nwynik = pd.DataFrame({'x': X_test[:, 0], 'y': y_test_pred_poly_5[:, 0]})\nwynik.plot.scatter(x='x',y='y')",
"_____no_output_____"
],
[
"#2. Przeanalizuj działanie każdej z otrzymanych funkcji regresyjnych. Porównaj ich przebiegi z\n#rozkładem zbioru danych. PRZEANALIZOWANE",
"_____no_output_____"
],
[
"#Zapisz w osobnym DataFrame wartości MSE dla zbiorów uczących i testujących dla ww.\n#regresorów; kolumny: train_mse, test_mse, wiersze: lin_reg, knn_3_reg, knn_5_reg,\n#poly_2_reg, poly_3_reg, poly_4_reg, poly_5_reg. Zapisz ww. DataFrame do pliku Pickle\n#o nazwie: mse.pkl",
"_____no_output_____"
],
[
"#liniowe",
"_____no_output_____"
],
[
"from sklearn.metrics import mean_squared_error\n\ntrain_mse_lin_reg = mean_squared_error(y_train, y_train_pred_lin_reg)\ntest_mse_lin_reg = mean_squared_error(y_test, y_test_pred_lin_reg)",
"_____no_output_____"
],
[
"#KNN dla 𝑘 = 3 oraz 𝑘 = 5 ",
"_____no_output_____"
],
[
"train_mse_knn_3_reg = mean_squared_error(y_train, y_train_pred_knn_3)\ntest_mse_knn_3_reg = mean_squared_error(y_test, y_test_pred_knn_3)",
"_____no_output_____"
],
[
"train_mse_knn_5_reg = mean_squared_error(y_train, y_train_pred_knn_5)\ntest_mse_knn_5_reg = mean_squared_error(y_test, y_test_pred_knn_5)",
"_____no_output_____"
],
[
"#Wielomianową 2, 3, 4 i 5 rzędu ",
"_____no_output_____"
],
[
"train_mse_knn_poly_2 = mean_squared_error(y_train, y_train_pred_poly_2)\ntest_mse_knn_poly_2 = mean_squared_error(y_test, y_test_pred_poly_2)",
"_____no_output_____"
],
[
"train_mse_knn_poly_3 = mean_squared_error(y_train, y_train_pred_poly_3)\ntest_mse_knn_poly_3 = mean_squared_error(y_test, y_test_pred_poly_3)",
"_____no_output_____"
],
[
"train_mse_knn_poly_4 = mean_squared_error(y_train, y_train_pred_poly_4)\ntest_mse_knn_poly_4 = mean_squared_error(y_test, y_test_pred_poly_4)",
"_____no_output_____"
],
[
"train_mse_knn_poly_5 = mean_squared_error(y_train, y_train_pred_poly_5)\ntest_mse_knn_poly_5 = mean_squared_error(y_test, y_test_pred_poly_5)",
"_____no_output_____"
],
[
"mse = [[train_mse_lin_reg, test_mse_lin_reg], [train_mse_knn_3_reg, test_mse_knn_3_reg], [train_mse_knn_5_reg, test_mse_knn_5_reg], [train_mse_knn_poly_2, test_mse_knn_poly_2],\n [train_mse_knn_poly_3, test_mse_knn_poly_3], [train_mse_knn_poly_4, test_mse_knn_poly_4], [train_mse_knn_poly_5, test_mse_knn_poly_5]]\n",
"_____no_output_____"
],
[
"mse_df = pd.DataFrame(mse, index=[\"lin_reg\", \"knn_3_reg\", \"knn_5_reg\", \"poly_2_reg\", \"poly_3_reg\", \"poly_4_reg\", \"poly_5_reg\"], columns=[\"train_mse\", \"test_mse\"])\nmse_df",
"_____no_output_____"
],
[
"import pickle\nwith open('mse.pkl', 'wb') as fp:\n pickle.dump(mse_df, fp)",
"_____no_output_____"
],
[
"reg = [(lin_reg, None), (knn_3_reg, None), (knn_5_reg, None), (poly_2_reg, poly_feature_2), (poly_3_reg, poly_feature_3), (poly_4_reg, poly_feature_4), (poly_5_reg, poly_feature_5)]\nwith open('reg.pkl', 'wb') as fp:\n pickle.dump(reg, fp)",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3b3f317fcef0c4799e81df7616054082e4bc50 | 23,521 | ipynb | Jupyter Notebook | module02_intermediate_python/02_03_defining_classes.ipynb | marquesafonso/rse-course | 3de37aab3b634f2783813ccf3b6598bb96ed6315 | [
"CC-BY-3.0"
] | null | null | null | module02_intermediate_python/02_03_defining_classes.ipynb | marquesafonso/rse-course | 3de37aab3b634f2783813ccf3b6598bb96ed6315 | [
"CC-BY-3.0"
] | null | null | null | module02_intermediate_python/02_03_defining_classes.ipynb | marquesafonso/rse-course | 3de37aab3b634f2783813ccf3b6598bb96ed6315 | [
"CC-BY-3.0"
] | null | null | null | 24.223481 | 322 | 0.505676 | [
[
[
"# Defining your own classes",
"_____no_output_____"
],
[
"## User Defined Types",
"_____no_output_____"
],
[
"A **class** is a user-programmed Python type (since Python 2.2!)",
"_____no_output_____"
],
[
"It can be defined like:",
"_____no_output_____"
]
],
[
[
"class Room(object):\n pass",
"_____no_output_____"
]
],
[
[
"Or:",
"_____no_output_____"
]
],
[
[
"class Room():\n pass",
"_____no_output_____"
]
],
[
[
"Or:",
"_____no_output_____"
]
],
[
[
"class Room:\n pass",
"_____no_output_____"
]
],
[
[
"What's the difference? Before Python 2.2 a class was distinct from all other Python types, which caused some odd behaviour. To fix this, classes were redefined as user programmed types by extending `object`, e.g., class `room(object)`.\n\nSo most Python 2 code will use this syntax as very few people want to use old style python classes. Python 3 has formalised this by removing old-style classes, so they can be defined without extending `object`, or indeed without braces.\n",
"_____no_output_____"
],
[
"Just as with other python types, you use the name of the type as a function to make a variable of that type:",
"_____no_output_____"
]
],
[
[
"zero = int()\ntype(zero)",
"_____no_output_____"
],
[
"myroom = Room()\ntype(myroom)",
"_____no_output_____"
]
],
[
[
"In the jargon, we say that an **object** is an **instance** of a particular **class**.\n\n`__main__` is the name of the scope in which top-level code executes, where we've defined the class `Room`.",
"_____no_output_____"
],
[
"Once we have an object with a type of our own devising, we can add properties at will:",
"_____no_output_____"
]
],
[
[
"myroom.name = \"Living\"",
"_____no_output_____"
],
[
"myroom.name",
"_____no_output_____"
]
],
[
[
"The most common use of a class is to allow us to group data into an object in a way that is \neasier to read and understand than organising data into lists and dictionaries.",
"_____no_output_____"
]
],
[
[
"myroom.capacity = 3\nmyroom.occupants = [\"James\", \"Sue\"]",
"_____no_output_____"
]
],
[
[
"## Methods",
"_____no_output_____"
],
[
"So far, our class doesn't do much!",
"_____no_output_____"
],
[
"We define functions **inside** the definition of a class, in order to give them capabilities, just like the methods on built-in\ntypes.",
"_____no_output_____"
]
],
[
[
"class Room:\n def overfull(self):\n return len(self.occupants) > self.capacity",
"_____no_output_____"
],
[
"myroom = Room()\nmyroom.capacity = 3\nmyroom.occupants = [\"James\", \"Sue\"]",
"_____no_output_____"
],
[
"myroom.overfull()",
"_____no_output_____"
],
[
"myroom.occupants.append([\"Clare\"])",
"_____no_output_____"
],
[
"myroom.occupants.append([\"Bob\"])",
"_____no_output_____"
],
[
"myroom.overfull()",
"_____no_output_____"
]
],
[
[
"When we write methods, we always write the first function argument as `self`, to refer to the object instance itself,\nthe argument that goes \"before the dot\".",
"_____no_output_____"
],
[
"This is just a convention for this variable name, not a keyword. You could call it something else if you wanted.",
"_____no_output_____"
],
[
"## Constructors",
"_____no_output_____"
],
[
"Normally, though, we don't want to add data to the class attributes on the fly like that. \nInstead, we define a **constructor** that converts input data into an object. ",
"_____no_output_____"
]
],
[
[
"class Room:\n def __init__(self, name, exits, capacity, occupants=[]):\n self.name = name\n self.occupants = occupants # Note the default argument, occupants start empty\n self.exits = exits\n self.capacity = capacity\n\n def overfull(self):\n return len(self.occupants) > self.capacity",
"_____no_output_____"
],
[
"living = Room(\"Living Room\", {\"north\": \"garden\"}, 3)",
"_____no_output_____"
],
[
"living.capacity",
"_____no_output_____"
]
],
[
[
"Methods which begin and end with **two underscores** in their names fulfil special capabilities in Python, such as\nconstructors.",
"_____no_output_____"
],
[
"## Object-oriented design",
"_____no_output_____"
],
[
"In building a computer system to model a problem, therefore, we often want to make:\n\n* classes for each *kind of thing* in our system\n* methods for each *capability* of that kind\n* properties (defined in a constructor) for each *piece of information describing* that kind\n",
"_____no_output_____"
],
[
"For example, the below program might describe our \"Maze of Rooms\" system:",
"_____no_output_____"
],
[
"We define a \"Maze\" class which can hold rooms:",
"_____no_output_____"
]
],
[
[
"class Maze:\n def __init__(self, name):\n self.name = name\n self.rooms = {}\n\n def add_room(self, room):\n room.maze = self # The Room needs to know\n # which Maze it is a part of\n self.rooms[room.name] = room\n\n def occupants(self):\n return [\n occupant\n for room in self.rooms.values()\n for occupant in room.occupants.values()\n ]\n\n def wander(self):\n \"\"\"Move all the people in a random direction\"\"\"\n for occupant in self.occupants():\n occupant.wander()\n\n def describe(self):\n for room in self.rooms.values():\n room.describe()\n\n def step(self):\n self.describe()\n print(\"\")\n self.wander()\n print(\"\")\n\n def simulate(self, steps):\n for _ in range(steps):\n self.step()",
"_____no_output_____"
]
],
[
[
"And a \"Room\" class with exits, and people:",
"_____no_output_____"
]
],
[
[
"class Room:\n def __init__(self, name, exits, capacity, maze=None):\n self.maze = maze\n self.name = name\n self.occupants = {} # Note the default argument, occupants start empty\n self.exits = exits # Should be a dictionary from directions to room names\n self.capacity = capacity\n\n def has_space(self):\n return len(self.occupants) < self.capacity\n\n def available_exits(self):\n return [\n exit\n for exit, target in self.exits.items()\n if self.maze.rooms[target].has_space()\n ]\n\n def random_valid_exit(self):\n import random\n\n if not self.available_exits():\n return None\n return random.choice(self.available_exits())\n\n def destination(self, exit):\n return self.maze.rooms[self.exits[exit]]\n\n def add_occupant(self, occupant):\n occupant.room = self # The person needs to know which room it is in\n self.occupants[occupant.name] = occupant\n\n def delete_occupant(self, occupant):\n del self.occupants[occupant.name]\n\n def describe(self):\n if self.occupants:\n print(f\"{self.name}: \" + \" \".join(self.occupants.keys()))",
"_____no_output_____"
]
],
[
[
"We define a \"Person\" class for room occupants:",
"_____no_output_____"
]
],
[
[
"class Person:\n def __init__(self, name, room=None):\n self.name = name\n\n def use(self, exit):\n self.room.delete_occupant(self)\n destination = self.room.destination(exit)\n destination.add_occupant(self)\n print(\n \"{some} goes {action} to the {where}\".format(\n some=self.name, action=exit, where=destination.name\n )\n )\n\n def wander(self):\n exit = self.room.random_valid_exit()\n if exit:\n self.use(exit)",
"_____no_output_____"
]
],
[
[
"And we use these classes to define our people, rooms, and their relationships:",
"_____no_output_____"
]
],
[
[
"james = Person(\"James\")\nsue = Person(\"Sue\")\nbob = Person(\"Bob\")\nclare = Person(\"Clare\")",
"_____no_output_____"
],
[
"living = Room(\n \"livingroom\", {\"outside\": \"garden\", \"upstairs\": \"bedroom\", \"north\": \"kitchen\"}, 2\n)\nkitchen = Room(\"kitchen\", {\"south\": \"livingroom\"}, 1)\ngarden = Room(\"garden\", {\"inside\": \"livingroom\"}, 3)\nbedroom = Room(\"bedroom\", {\"jump\": \"garden\", \"downstairs\": \"livingroom\"}, 1)",
"_____no_output_____"
],
[
"house = Maze(\"My House\")",
"_____no_output_____"
],
[
"for room in [living, kitchen, garden, bedroom]:\n house.add_room(room)",
"_____no_output_____"
],
[
"living.add_occupant(james)",
"_____no_output_____"
],
[
"garden.add_occupant(sue)\ngarden.add_occupant(clare)",
"_____no_output_____"
],
[
"bedroom.add_occupant(bob)",
"_____no_output_____"
]
],
[
[
"And we can run a \"simulation\" of our model:",
"_____no_output_____"
]
],
[
[
"house.simulate(3)",
"livingroom: James\ngarden: Sue Clare\nbedroom: Bob\n\nJames goes north to the kitchen\nSue goes inside to the livingroom\nClare goes inside to the livingroom\nBob goes jump to the garden\n\nlivingroom: Sue Clare\nkitchen: James\ngarden: Bob\n\nSue goes outside to the garden\nClare goes upstairs to the bedroom\nJames goes south to the livingroom\nBob goes inside to the livingroom\n\nlivingroom: James Bob\ngarden: Sue\nbedroom: Clare\n\nJames goes outside to the garden\nBob goes north to the kitchen\nSue goes inside to the livingroom\nClare goes downstairs to the livingroom\n\n"
]
],
[
[
"## Alternative object models",
"_____no_output_____"
],
[
"There are many choices for how to design programs to do this. Another choice would be to separately define exits as a different class from rooms. This way, \nwe can use arrays instead of dictionaries, but we have to first define all our rooms, then define all our exits.",
"_____no_output_____"
]
],
[
[
"class Maze:\n def __init__(self, name):\n self.name = name\n self.rooms = []\n self.occupants = []\n\n def add_room(self, name, capacity):\n result = Room(name, capacity)\n self.rooms.append(result)\n return result\n\n def add_exit(self, name, source, target, reverse=None):\n source.add_exit(name, target)\n if reverse:\n target.add_exit(reverse, source)\n\n def add_occupant(self, name, room):\n self.occupants.append(Person(name, room))\n room.occupancy += 1\n\n def wander(self):\n \"Move all the people in a random direction\"\n for occupant in self.occupants:\n occupant.wander()\n\n def describe(self):\n for occupant in self.occupants:\n occupant.describe()\n\n def step(self):\n self.describe()\n print(\"\")\n self.wander()\n print(\"\")\n\n def simulate(self, steps):\n for _ in range(steps):\n self.step()",
"_____no_output_____"
],
[
"class Room:\n def __init__(self, name, capacity):\n self.name = name\n self.capacity = capacity\n self.occupancy = 0\n self.exits = []\n\n def has_space(self):\n return self.occupancy < self.capacity\n\n def available_exits(self):\n return [exit for exit in self.exits if exit.valid()]\n\n def random_valid_exit(self):\n import random\n\n if not self.available_exits():\n return None\n return random.choice(self.available_exits())\n\n def add_exit(self, name, target):\n self.exits.append(Exit(name, target))",
"_____no_output_____"
],
[
"class Person:\n def __init__(self, name, room=None):\n self.name = name\n self.room = room\n\n def use(self, exit):\n self.room.occupancy -= 1\n destination = exit.target\n destination.occupancy += 1\n self.room = destination\n print(\n \"{some} goes {action} to the {where}\".format(\n some=self.name, action=exit.name, where=destination.name\n )\n )\n\n def wander(self):\n exit = self.room.random_valid_exit()\n if exit:\n self.use(exit)\n\n def describe(self):\n print(\"{who} is in the {where}\".format(who=self.name, where=self.room.name))",
"_____no_output_____"
],
[
"class Exit:\n def __init__(self, name, target):\n self.name = name\n self.target = target\n\n def valid(self):\n return self.target.has_space()",
"_____no_output_____"
],
[
"house = Maze(\"My New House\")",
"_____no_output_____"
],
[
"living = house.add_room(\"livingroom\", 2)\nbed = house.add_room(\"bedroom\", 1)\ngarden = house.add_room(\"garden\", 3)\nkitchen = house.add_room(\"kitchen\", 1)",
"_____no_output_____"
],
[
"house.add_exit(\"north\", living, kitchen, \"south\")",
"_____no_output_____"
],
[
"house.add_exit(\"upstairs\", living, bed, \"downstairs\")",
"_____no_output_____"
],
[
"house.add_exit(\"outside\", living, garden, \"inside\")",
"_____no_output_____"
],
[
"house.add_exit(\"jump\", bed, garden)",
"_____no_output_____"
],
[
"house.add_occupant(\"James\", living)\nhouse.add_occupant(\"Sue\", garden)\nhouse.add_occupant(\"Bob\", bed)\nhouse.add_occupant(\"Clare\", garden)",
"_____no_output_____"
],
[
"house.simulate(3)",
"James is in the livingroom\nSue is in the garden\nBob is in the bedroom\nClare is in the garden\n\nJames goes outside to the garden\nSue goes inside to the livingroom\nBob goes jump to the garden\nClare goes inside to the livingroom\n\nJames is in the garden\nSue is in the livingroom\nBob is in the garden\nClare is in the livingroom\n\nSue goes upstairs to the bedroom\nBob goes inside to the livingroom\nClare goes north to the kitchen\n\nJames is in the garden\nSue is in the bedroom\nBob is in the livingroom\nClare is in the kitchen\n\nJames goes inside to the livingroom\nSue goes jump to the garden\nBob goes outside to the garden\nClare goes south to the livingroom\n\n"
]
],
[
[
"This is a huge topic, about which many books have been written. The differences between these two designs are important, and will have long-term consequences for the project. That is the how we start to think about **software engineering**, as opposed to learning to program, and is an important part of this course.",
"_____no_output_____"
],
[
"## Exercise: Your own solution",
"_____no_output_____"
],
[
"Compare the two solutions above. Discuss with a partner which you like better, and why. Then, starting from scratch, design your own. What choices did you make that are different from mine?",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
cb3b463f0c764b1463c6f99a8653e7ede07312cc | 68,768 | ipynb | Jupyter Notebook | _jupyter/2020-04-10-Hypothesis Testing, Click-Through-Rate for Banner Ads (AB Testing).ipynb | AdiVarma27/adivarma27.github.io | 8b21970046b378b5fcb580011bc9dfc2139116dd | [
"MIT"
] | 1 | 2020-11-23T21:21:41.000Z | 2020-11-23T21:21:41.000Z | _jupyter/2020-04-10-Hypothesis Testing, Click-Through-Rate for Banner Ads (AB Testing).ipynb | AdiVarma27/adivarma27.github.io | 8b21970046b378b5fcb580011bc9dfc2139116dd | [
"MIT"
] | 1 | 2020-05-05T02:06:47.000Z | 2020-05-05T02:06:47.000Z | _jupyter/2020-04-10-Hypothesis Testing, Click-Through-Rate for Banner Ads (AB Testing).ipynb | AdiVarma27/adivarma27.github.io | 8b21970046b378b5fcb580011bc9dfc2139116dd | [
"MIT"
] | null | null | null | 85.852684 | 41,316 | 0.804124 | [
[
[
"# Testing Click-Through-Rates for Banner Ads (A/B Testing)\n\n* Lets say we are a new apparel store; after thorough market research, we decide to open up an <b> Online Apparel Store.</b> We hire Developers, Digital Media Strategists and Data Scientists, who help develop the store, place products and conduct controlled experiments on the website.\n\n\n* Traditionally, companies ran controlled experiments, either A/B Tests or Multivariate tests, based on requirements. <b>Multiple versions of Banner Ads, Text Ads and Video Ads are created, tested and placed on the website. Website layouts, Ad positions, transitions and many other attributes can be tested.</b>\n\n\n* Our version-A (Still in red colored background after the Holiday season), was on our website for 2 months or so, and we think its time for a change. Assuming everything else kept constant, we develop <b>version-B with subtle, earthy colored banner with the same text.</b> \n\n\n### How do we decide if we should go for the switch (replace version-a with version-b) ?\n\n### Controlled A/B Test\n\n\n* Content, color, text style, text size, banner location and placement and many other things need to be taken into account when trying to conduct a controlled experiment. If we plan to replace version-A with version-B, we need <b>strong evidence that click-through-rate (clicks/ impression) for version-B is significantly higher than version-A.</b>\n\n\n* Every visitor who visits our homepage, is <b>randomly (with equal probability) going to see either version-A (Older version) or version-B (New creative) on our homepage.</b> We observe, that the older version has a CTR (Click-through-rate) of <b>9 % (9 clicks every 100 impressions).</b> Let us say we have an <b>average of 200 visitors every day (new + returning users).</b>\n\n\n* We assume and test for the hypothesis that our new banner Ad (version-B), can provide some boost to the CTR. 25 % boost would mean an average-CTR of 11.25 % (11.25 clicks every 100 impressions).",
"_____no_output_____"
]
],
[
[
"# importing necessary libraries\n\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n\n# CTR previous version\nctr_version_a = 0.09\n\n# CTR new version with 25 % expected boost\nctr_version_b = 0.09 + (0.25)*(0.09)\n\nctr_version_a, ctr_version_b",
"_____no_output_____"
]
],
[
[
"* Our null hypothesis is that there is no difference in CTR for version a and b, with alternate hypothesis that CTR of version-B sees a boost in CTR. We conduct a Two-Sample Proportion Test to validate our hypotheses.\n\n$$H_0: \\mu_b > \\mu_a$$\n\n$$H_a: \\mu_b <= \\mu_a $$\n\n\n\nWe know, t-stat is calculated by the following\n\n$$t = \\frac{(\\mu_b - \\mu_a) - 0}{SE}$$\n\n\n\n\n$$t = \\frac{(\\mu_b - \\mu_a) - 0}{\\sqrt{\\frac{CTR_b(1-CTR_b)}{N_b} + \\frac{CTR_a(1-CTR_a)}{N_a}}} $$",
"_____no_output_____"
],
[
"* Let us choose a type-I error rate of 5 % (alpha = 0.05). Now, we simluate the test by sending customers to either of the pages randomly with equal chance. Let us say we start pushing these two version randomly on day 1. On Average, we expect around 200 customers to open the website, of which approximately 100 of them are exposed to version-A, and 100 are exposed to version-B.",
"_____no_output_____"
]
],
[
[
"# function to flip between version-a and b.\ndef flipVersion(version_a):\n if version_a:\n return False\n else:\n return True",
"_____no_output_____"
]
],
[
[
"### End of Day 1 \n\n* After end of day 1, we observe that there were 202 customers who visited the webiste, and 101 customers were shown version-a and another 101 were shown version-b.",
"_____no_output_____"
]
],
[
[
"# total customer incoming per day are normally distributed with mean 200 an deviation 10.\n\nnp.random.seed(25)\n\nnum_cust = int(np.random.normal(200, 10))\n\n# total number of impressions and clicks at start of experiment are zero\nnum_imps_version_a = 0\nnum_imps_version_b = 0\n\nnum_clicks_version_a = 0\nnum_clicks_version_b = 0\n\n# start by showing version-A\nversion_a = True\n\n# send each customer to a or b\nfor customer_number in range(num_cust):\n \n # if version-a is exposed\n if version_a is True:\n # increase impression count\n num_imps_version_a += 1\n # binomial sample (1 if successfully clicked, else 0)\n num_clicks_version_a += np.random.binomial(1, ctr_version_a)\n \n # if version-b is exposed \n else:\n # increase impression count\n num_imps_version_b += 1\n # binomial sample (1 if successfully clicked, else 0)\n num_clicks_version_b += np.random.binomial(1, ctr_version_b)\n \n # flip version after each customer\n version_a = flipVersion(version_a)",
"_____no_output_____"
],
[
"num_cust, num_imps_version_a, num_imps_version_b",
"_____no_output_____"
],
[
"num_clicks_version_a, num_clicks_version_b",
"_____no_output_____"
]
],
[
[
"* We observe that 6 customers clicked on version-a, and 12 clicked on version-b. Plugging it into the above t-stat formula, we obtain the following. The Day-1 CTRs after running the experiment are as follows:",
"_____no_output_____"
]
],
[
[
"ctr_day_one_version_a = num_clicks_version_a/num_imps_version_a\n\nctr_day_one_version_b = num_clicks_version_b/num_imps_version_b\n\nctr_day_one_version_a, ctr_day_one_version_b",
"_____no_output_____"
],
[
"p = (num_clicks_version_a + num_clicks_version_b)/(num_imps_version_a + num_imps_version_b)\n\nSE = np.sqrt(p*(1-p)*( (1/num_imps_version_a) + (1/num_imps_version_b) ))\n\np, SE",
"_____no_output_____"
],
[
"t = (ctr_day_one_version_b - ctr_day_one_version_a)/(SE)\n\nt",
"_____no_output_____"
]
],
[
[
"* After Day-1, we observe the t-stat is 1.48 (We did not find a significant set of observations to conclude that verion-b is better than version-a). \n\n### How long do we run the test for ? When do we know exactly that Version-B is better than Version-A ?\n\n* In few cases, sample size is pre-defined to control Type-II error along with Type-I error, and once enough samples are collected, choice is made. In few cases, analysis is done over how t-stat improves as samples are collected.\n\n\n* In our case, we can observe how t-stat changes (increases or decreases with time and sample size), and then decide when to stop or continue the experiment. Note that it is always better to estimate the Power and decide on sample size to allocate budgets before the experiment.",
"_____no_output_____"
]
],
[
[
"def conductExperiment(n_days):\n \n list_num_cust = []\n list_t_stat = []\n list_ctr_version_a, list_ctr_version_b = [], [] \n list_imp_version_a, list_imp_version_b = [], [] \n \n for i in range(0,n_days):\n\n # total customer incoming per day are normally distributed with mean 200 an deviation 10.\n\n num_cust = int(np.random.normal(200,10))\n \n list_num_cust.append(num_cust)\n \n # total number of impressions and clicks at start of experiment are zero\n num_imps_version_a = 0\n num_imps_version_b = 0\n\n num_clicks_version_a = 0\n num_clicks_version_b = 0\n\n # start by showing version-A\n version_a = True\n\n # send each customer to a or b\n for customer_number in range(num_cust):\n\n # if version-a is exposed\n if version_a is True:\n # increase impression count\n num_imps_version_a += 1\n # binomial sample (1 if successfully clicked, else 0)\n num_clicks_version_a += np.random.binomial(1, ctr_version_a)\n\n # if version-b is exposed \n else:\n # increase impression count\n num_imps_version_b += 1\n # binomial sample (1 if successfully clicked, else 0)\n num_clicks_version_b += np.random.binomial(1, ctr_version_b)\n\n # flip version after each customer\n version_a = flipVersion(version_a)\n \n ctr_day_one_version_a = num_clicks_version_a/num_imps_version_a\n\n ctr_day_one_version_b = num_clicks_version_b/num_imps_version_b\n \n list_ctr_version_a.append(ctr_day_one_version_a)\n list_ctr_version_b.append(ctr_day_one_version_b)\n \n list_imp_version_a.append(num_imps_version_a)\n list_imp_version_b.append(num_imps_version_b)\n \n \n df_abtest = pd.DataFrame()\n df_abtest['num_cust'] = list_num_cust\n df_abtest['IMP_version_a'] = list_imp_version_a\n df_abtest['IMP_version_b'] = list_imp_version_b\n df_abtest['CTR_version_a'] = list_ctr_version_a\n df_abtest['CTR_version_b'] = list_ctr_version_b\n df_abtest['Clicks_version_b'] = df_abtest['IMP_version_b']*df_abtest['CTR_version_b']\n df_abtest['Clicks_version_a'] = df_abtest['IMP_version_a']*df_abtest['CTR_version_a']\n\n \n return df_abtest",
"_____no_output_____"
]
],
[
[
"## Simulating experiment results for 3 Days \n\n* Now, let us simulate the results for first 3-days, we have the impressions and CTRs for both versions. We can calculate a rolling t-statistic, which can help decide if the CTR of version-b outperforms CTR of version-a.\n\n\n* As days pass by and we collect more data, the sample size (N) increases, decreasing the Standard Error term over time (Daily standard error are probably be very close). Conducting t-test on daily level does not make sense, on Day-2, we need to include the numbers from Day-1 and Day-2 as well, and calculate the t-statistics cumulatively.",
"_____no_output_____"
]
],
[
[
"df_abtest = conductExperiment(3)\ndf_abtest",
"_____no_output_____"
]
],
[
[
"* Below, we re-write the previous function to get cumulative t-stat and Standard Error terms.",
"_____no_output_____"
]
],
[
[
"def tStatAfterNDays(n_days):\n\n # total customer incoming per day are normally distributed with mean 200 an deviation 10.\n\n np.random.seed(25)\n num_cust = 200*n_days\n\n # total number of impressions and clicks at start of experiment are zero\n num_imps_version_a = 0\n num_imps_version_b = 0\n\n num_clicks_version_a = 0\n num_clicks_version_b = 0\n\n # start by showing version-A\n version_a = True\n\n # send each customer to a or b\n for customer_number in range(num_cust):\n \n # if version-a is exposed\n if version_a is True:\n # increase impression count\n num_imps_version_a += 1\n # binomial sample (1 if successfully clicked, else 0)\n num_clicks_version_a += np.random.binomial(1, ctr_version_a)\n\n # if version-b is exposed \n else:\n # increase impression count\n num_imps_version_b += 1\n # binomial sample (1 if successfully clicked, else 0)\n num_clicks_version_b += np.random.binomial(1, ctr_version_b)\n\n # flip version after each customer\n version_a = flipVersion(version_a)\n\n ctr_day_one_version_a = num_clicks_version_a/num_imps_version_a\n\n ctr_day_one_version_b = num_clicks_version_b/num_imps_version_b\n\n p = (num_clicks_version_a + num_clicks_version_b)/num_cust\n\n SE = np.sqrt(p*(1-p)*( (1/num_imps_version_a) + (1/num_imps_version_b) ))\n\n t = (ctr_day_one_version_b - ctr_day_one_version_a)/(SE)\n\n return t, SE",
"_____no_output_____"
]
],
[
[
"* Let us simulate the results for 3 consecutive days to obtain cumulative T-stats and Standard Errors. We observe in figure-1, that the cumulative t-stat has an increase gradually and is approximately 1.645 + after day and a half. On the right, we observe that the Standard Errors reduce cumulatively due to increase in sample size.",
"_____no_output_____"
]
],
[
[
"n_consecutive_days = 3\n\nndays = [i for i in range(1, n_consecutive_days + 1)]\ntStatsCumulative = [tStatAfterNDays(i)[0] for i in range(1,n_consecutive_days + 1)]\nSEStatsCumulative = [tStatAfterNDays(i)[1] for i in range(1,n_consecutive_days + 1)]",
"_____no_output_____"
],
[
"fig = plt.figure(figsize=(18,6))\n\nplt.subplot(1, 2, 1)\nplt.plot(ndays, tStatsCumulative)\nplt.grid()\nplt.title('Cumulative T-Stat')\nplt.xlabel('Number of Days')\nplt.ylabel('Cumulative T-Stat')\n\nplt.subplot(1, 2, 2)\nplt.plot(ndays, SEStatsCumulative)\nplt.grid()\nplt.title('Cumulative SE')\nplt.xlabel('Number of Days')\nplt.ylabel('Cumulative SE')",
"_____no_output_____"
]
],
[
[
"# Observartions:\n\n* We observe that after day and a half of both versions up and running, <b>there is a statistically significant difference between CTRs of version-a and version-b, with version-b outperforming version-a.</b>\n\n\n* Could we have <b>stopped the experiment after one and a half days ? Do we know if this effect is consistent on weekends ? Can we attribute these spike in CTR due to these changes only ? These are all design choices and can be decided only with additional Business context. Ideally, we would want to know the effects of weekdays vs weekends. Collecting more samples by experimentation provides deeper understanding of customer behaviour.</b>\n\n\n* Now, let us take a look at how to calculate the sample size required to control for a required Beta (Type-II Error). Note that deciding alpha and beta (Type-I and Type-II Error) rates are design choices as well, and deciding sample size before conducting the experiment is not only a best practice, but also helps decide the approximate Time and Budget it takes to provide confident and conclusive results.\n\n\n### Controlling Power by varying Sample Size\n\n* Just like choosing significance level alpha (0.05), we need to choose power (1 - beta), generally chosen around 95 % power (beta = 0.05). First, let us look at the distribution of version-A, cumulatively for 3 days. Our sample size (Number of impressions for version-a) is 600 (3 days x 200 impressions per day). The average CTR for 3 days is 0.09.\n\n\n* Given we know sample size and proportion, we can now calculate the critical cut-off value (cut off proportion).\n\n$$p_{crit+} = p_0 + 1.645(SE)$$\n\n\n### Version-a\n\n* We observe that 95 % of data lies within 0 and 0.1171 with mean Click-Through-Rate of 0.09.",
"_____no_output_____"
]
],
[
[
"n_a = 100*3\nctr_a = 0.09\n\nSE = np.sqrt(ctr_a*(1-ctr_a)/n_a)\n\np_crit_a = ctr_a + 1.645*(SE)\n\np_crit_a",
"_____no_output_____"
]
],
[
[
"### Version-b\n\n* Let us assume that version-b, has an average CTR at the critical cutoff value of version-a (0.117).",
"_____no_output_____"
],
[
"<img src=\"power1.png\" width=\"400\"></img>",
"_____no_output_____"
],
[
"### Type-I and Type-II Errors:\n\n* Type-I error corresponds to the green shaded region (alpha=0.05), where we are allowing upto 5 % of sampling data to be misclassified (Assume they come from version-b and not version-a).\n\n\n* Type-II error corresponds to data sampled from version-b, but falls within region of version-a, and hence misclassified (Shaded in red). We observe that exactly half of the version-b falls within rejection region, making 50 % Type-II errors, which is high. \n\n\n* <b>Increasing sampling size can help reduce Type-II error at the same version-b mean, as higher sampling size reduces the standard error, and shrinks the tails of both distributions.</b>\n\n\n### Ideal sample size for alpha (0.05) and beta (0.1)\n\n* We can calculate the ideal sample size for constrained alpha and beta parameters. Essentially, the version-b needs to have a mean such that 10 % of data falls out of rejection region, and that needs to be there line where version-a has critical value.",
"_____no_output_____"
],
[
"<img src=\"power2.png\" width=\"400\"></img>",
"_____no_output_____"
],
[
"* Given we want to control for Type-II error (0.1), with Power of 90 % (1-beta), the Z-stat for 10 % Error rate is 1.29. Hence, for the given sample size, The mean of version-b needs to be atleast 1.29 Z's away from the cutoff value of version-a.\n\n$$z_{critical} = \\frac{0.117 - \\mu_b}{SE}$$\n\n\n$$-1.29 = \\frac{0.117 - \\mu_b}{SE}$$",
"_____no_output_____"
]
],
[
[
"p=0.143\nz = (0.117 - p)/(np.sqrt(( p*(1-p))/(300)))\nz",
"_____no_output_____"
]
],
[
[
"<b>Therefore, for sample size of 3 days (600 samples, 300 each version), for alpha 0.05 and beta 0.1 (power 0.9), we reach statistical significance if the average click-through-rate of version-b is 14.3 % </b>",
"_____no_output_____"
],
[
"<hr>\n\n## Deciding on sample size before conducting the experiment\n\n\n\n* Let us construct/ pose the question in an experimental setting. <b>First, lets setup our initial hypothesis for testing. Let us conduct an experiment to test if version-b can provide 50 % boost, when compared to previous version-a.</b>\n\n\n* We are strict with both Type-I and Type-II errors this time, and choose alpha 0.05 and beta 0.05 (0.95 Power). Below is the stated null and alternate hypotheses. We conduct a Two-Sample, One-Tailed Proportion Test to validate our hypotheses.\n\n\n\n$$H_0: \\mu_b - \\mu_a <= 0.5(\\mu_a)$$\n\n$$H_a: \\mu_b - \\mu_a > 0.5(\\mu_a) $$\n\n\n\nWe know, Z-stat is calculated by the following\n\n$$z = \\frac{(\\mu_b - \\mu_a) - 0.5(\\mu_a)}{SE}$$\n\n\nTo solve for n, we can check it by plugging in Z-values (for null and alternate hypothesis), mean of null and alternate hypothesis. \n\n\n\n$$ \\mu_0 + z_{0-critical}(\\sqrt{\\frac{p_0(1-p_0)}{n}}) = \\mu_a - z_{a-critical}(\\sqrt{\\frac{p_a(1-p_a)}{n}})$$\n\n\n<b> Knowing sample size in advance can help decide budget, and also provide a good estimate of how long we might have to run the test, to understand which version works better. </b>",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
cb3b4dfd89be261c85e858a0bcac158cbbd6b86b | 4,388 | ipynb | Jupyter Notebook | Task-Image to Pencil Sketch with Python/Task4-Image to Pencil Sketch with Python.ipynb | iatharva/LGMVIP-DATA-SCIENCE | 59db1d98c00ad4e36c20802e2bdd4874aa6cc8ae | [
"Apache-2.0"
] | null | null | null | Task-Image to Pencil Sketch with Python/Task4-Image to Pencil Sketch with Python.ipynb | iatharva/LGMVIP-DATA-SCIENCE | 59db1d98c00ad4e36c20802e2bdd4874aa6cc8ae | [
"Apache-2.0"
] | null | null | null | Task-Image to Pencil Sketch with Python/Task4-Image to Pencil Sketch with Python.ipynb | iatharva/LGMVIP-DATA-SCIENCE | 59db1d98c00ad4e36c20802e2bdd4874aa6cc8ae | [
"Apache-2.0"
] | 1 | 2021-10-12T15:57:55.000Z | 2021-10-12T15:57:55.000Z | 22.618557 | 633 | 0.563355 | [
[
[
"## Name- HARSHADA MALI \n",
"_____no_output_____"
],
[
"#### BEGINNER LEVEL TASK 04\n\n##### Image to Pencil Sketch with Python:\nWe need to read the image in RBG format and then convert it to a grayscale image. This will turn an image into a classic black and white photo. Then the next thing to do is invert the grayscale image also called negative image, this will be our inverted grayscale image. Inversion can be used to enhance details. Then we can finally create the pencil sketch by mixing the grayscale image with the inverted blurry image. This can be done by dividing the grayscale image by the inverted blurry image. Since images are just arrays, we can easily do this programmatically using the divide function from the cv2 library in Python.\n",
"_____no_output_____"
],
[
"### Installing Libraries",
"_____no_output_____"
]
],
[
[
"import cv2\nimport matplotlib.pyplot as plt\n%matplotlib inline\nfrom PIL import Image\nfrom IPython.display import display",
"_____no_output_____"
],
[
"def show(title,img,cmap='RdGy'):\n plt.imshow(img,cmap=cmap)\n plt.title(title)",
"_____no_output_____"
]
],
[
[
"### Importing image",
"_____no_output_____"
]
],
[
[
"image=plt.imread(\"students.jpg\")\nshow(\"students\",image,'RdGy')",
"_____no_output_____"
]
],
[
[
"### Converting Image into Gray Scale Image",
"_____no_output_____"
]
],
[
[
"gray_image=cv2.cvtColor(image,cv2.COLOR_RGB2GRAY)\nshow(\"Gray_image\",gray_image,'gray')\n",
"_____no_output_____"
]
],
[
[
"### Inverting Gray Scale Image",
"_____no_output_____"
]
],
[
[
"Inverted_Image =255-gray_image\nshow(\"Inverted_Image\",Inverted_Image,'gray')\n",
"_____no_output_____"
]
],
[
[
"### Blurring Inverted Image",
"_____no_output_____"
]
],
[
[
"Blurred_Image =cv2.GaussianBlur(Inverted_Image,(21,21),0)\nshow(\"Blurred_Image\",Blurred_Image,'gray')\n",
"_____no_output_____"
]
],
[
[
"### Creating Pencil Sketch ",
"_____no_output_____"
]
],
[
[
"Inverted_Blurred=255-Blurred_Image\nPencil_Sketch=cv2.divide(gray_image,Inverted_Blurred,scale=256.0)\nshow(\"Pencil_Sketch\",Pencil_Sketch,'gray')",
"_____no_output_____"
]
],
[
[
"### Original Image and Pencil Sketch ",
"_____no_output_____"
]
],
[
[
"display(Image.fromarray(image))\ndisplay(Image.fromarray(Pencil_Sketch))",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
cb3b4e274d4df85aeee30d90d714da40c1365343 | 19,292 | ipynb | Jupyter Notebook | study_roadmaps/1_getting_started_roadmap/5_update_hyperparams/1_model_params/5) Switch deep learning model from default mode.ipynb | take2rohit/monk_v1 | 9c567bf2c8b571021b120d879ba9edf7751b9f92 | [
"Apache-2.0"
] | 542 | 2019-11-10T12:09:31.000Z | 2022-03-28T11:39:07.000Z | study_roadmaps/1_getting_started_roadmap/5_update_hyperparams/1_model_params/5) Switch deep learning model from default mode.ipynb | take2rohit/monk_v1 | 9c567bf2c8b571021b120d879ba9edf7751b9f92 | [
"Apache-2.0"
] | 117 | 2019-11-12T09:39:24.000Z | 2022-03-12T00:20:41.000Z | study_roadmaps/1_getting_started_roadmap/5_update_hyperparams/1_model_params/5) Switch deep learning model from default mode.ipynb | take2rohit/monk_v1 | 9c567bf2c8b571021b120d879ba9edf7751b9f92 | [
"Apache-2.0"
] | 246 | 2019-11-09T21:53:24.000Z | 2022-03-29T00:57:07.000Z | 27.878613 | 401 | 0.514099 | [
[
[
"<a href=\"https://colab.research.google.com/github/Tessellate-Imaging/monk_v1/blob/master/study_roadmaps/1_getting_started_roadmap/5_update_hyperparams/1_model_params/5)%20Switch%20deep%20learning%20model%20from%20default%20mode.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# Goals\n\n\n### Learn how to switch models post default mode",
"_____no_output_____"
],
[
"# Table of Contents\n\n\n## [Install](#0)\n\n\n## [Load experiment with resnet defaults](#1)\n\n\n## [Change model to densenet ](#2)\n\n\n## [Train](#3)",
"_____no_output_____"
],
[
"<a id='0'></a>\n# Install Monk",
"_____no_output_____"
],
[
"## Using pip (Recommended)\n\n - colab (gpu) \n - All bakcends: `pip install -U monk-colab`\n \n\n - kaggle (gpu) \n - All backends: `pip install -U monk-kaggle`\n \n\n - cuda 10.2\t\n - All backends: `pip install -U monk-cuda102`\n - Gluon bakcned: `pip install -U monk-gluon-cuda102`\n\t - Pytorch backend: `pip install -U monk-pytorch-cuda102`\n - Keras backend: `pip install -U monk-keras-cuda102`\n \n\n - cuda 10.1\t\n - All backend: `pip install -U monk-cuda101`\n\t - Gluon bakcned: `pip install -U monk-gluon-cuda101`\n\t - Pytorch backend: `pip install -U monk-pytorch-cuda101`\n\t - Keras backend: `pip install -U monk-keras-cuda101`\n \n\n - cuda 10.0\t\n - All backend: `pip install -U monk-cuda100`\n\t - Gluon bakcned: `pip install -U monk-gluon-cuda100`\n\t - Pytorch backend: `pip install -U monk-pytorch-cuda100`\n\t - Keras backend: `pip install -U monk-keras-cuda100`\n \n\n - cuda 9.2\t\n - All backend: `pip install -U monk-cuda92`\n\t - Gluon bakcned: `pip install -U monk-gluon-cuda92`\n\t - Pytorch backend: `pip install -U monk-pytorch-cuda92`\n\t - Keras backend: `pip install -U monk-keras-cuda92`\n \n\n - cuda 9.0\t\n - All backend: `pip install -U monk-cuda90`\n\t - Gluon bakcned: `pip install -U monk-gluon-cuda90`\n\t - Pytorch backend: `pip install -U monk-pytorch-cuda90`\n\t - Keras backend: `pip install -U monk-keras-cuda90`\n \n\n - cpu \t\t\n - All backend: `pip install -U monk-cpu`\n\t - Gluon bakcned: `pip install -U monk-gluon-cpu`\n\t - Pytorch backend: `pip install -U monk-pytorch-cpu`\n\t - Keras backend: `pip install -U monk-keras-cpu`",
"_____no_output_____"
],
[
"## Install Monk Manually (Not recommended)\n \n### Step 1: Clone the library\n - git clone https://github.com/Tessellate-Imaging/monk_v1.git\n \n \n \n \n### Step 2: Install requirements \n - Linux\n - Cuda 9.0\n - `cd monk_v1/installation/Linux && pip install -r requirements_cu90.txt`\n - Cuda 9.2\n - `cd monk_v1/installation/Linux && pip install -r requirements_cu92.txt`\n - Cuda 10.0\n - `cd monk_v1/installation/Linux && pip install -r requirements_cu100.txt`\n - Cuda 10.1\n - `cd monk_v1/installation/Linux && pip install -r requirements_cu101.txt`\n - Cuda 10.2\n - `cd monk_v1/installation/Linux && pip install -r requirements_cu102.txt`\n - CPU (Non gpu system)\n - `cd monk_v1/installation/Linux && pip install -r requirements_cpu.txt`\n \n \n - Windows\n - Cuda 9.0 (Experimental support)\n - `cd monk_v1/installation/Windows && pip install -r requirements_cu90.txt`\n - Cuda 9.2 (Experimental support)\n - `cd monk_v1/installation/Windows && pip install -r requirements_cu92.txt`\n - Cuda 10.0 (Experimental support)\n - `cd monk_v1/installation/Windows && pip install -r requirements_cu100.txt`\n - Cuda 10.1 (Experimental support)\n - `cd monk_v1/installation/Windows && pip install -r requirements_cu101.txt`\n - Cuda 10.2 (Experimental support)\n - `cd monk_v1/installation/Windows && pip install -r requirements_cu102.txt`\n - CPU (Non gpu system)\n - `cd monk_v1/installation/Windows && pip install -r requirements_cpu.txt`\n \n \n - Mac\n - CPU (Non gpu system)\n - `cd monk_v1/installation/Mac && pip install -r requirements_cpu.txt`\n \n \n - Misc\n - Colab (GPU)\n - `cd monk_v1/installation/Misc && pip install -r requirements_colab.txt`\n - Kaggle (GPU)\n - `cd monk_v1/installation/Misc && pip install -r requirements_kaggle.txt`\n \n \n \n### Step 3: Add to system path (Required for every terminal or kernel run)\n - `import sys`\n - `sys.path.append(\"monk_v1/\");`",
"_____no_output_____"
],
[
"## Dataset - Weather Classification\n - https://data.mendeley.com/datasets/4drtyfjtfy/1",
"_____no_output_____"
]
],
[
[
"! wget --load-cookies /tmp/cookies.txt \"https://docs.google.com/uc?export=download&confirm=$(wget --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=1pxe_AmHYXwpTMRkMVwGeFgHS8ZpkzwMJ' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\\1\\n/p')&id=1pxe_AmHYXwpTMRkMVwGeFgHS8ZpkzwMJ\" -O weather.zip && rm -rf /tmp/cookies.txt",
"_____no_output_____"
],
[
"! unzip -qq weather.zip",
"_____no_output_____"
]
],
[
[
"# Imports",
"_____no_output_____"
]
],
[
[
"#Using gluon backend \n\n# When installed using pip\nfrom monk.gluon_prototype import prototype\n\n\n# When installed manually (Uncomment the following)\n#import os\n#import sys\n#sys.path.append(\"monk_v1/\");\n#sys.path.append(\"monk_v1/monk/\");\n#from monk.gluon_prototype import prototype",
"_____no_output_____"
]
],
[
[
"<a id='1'></a>\n# Load experiment with resnet defaults ",
"_____no_output_____"
]
],
[
[
"gtf = prototype(verbose=1);\ngtf.Prototype(\"Project\", \"experiment-switch-models\");",
"Mxnet Version: 1.5.0\n\nExperiment Details\n Project: Project\n Experiment: experiment-switch-models\n Dir: /home/abhi/Desktop/Work/tess_tool/gui/v0.3/finetune_models/Organization/development/v5.2_docs/study_roadmaps/1_getting_started_roadmap/5_update_mode/1_model_params/workspace/Project/experiment-switch-models/\n\n"
],
[
"gtf.Default(dataset_path=\"weather/train\", \n model_name=\"resnet18_v1\", \n \n \n freeze_base_network=True, # If True, then freeze base \n \n \n \n \n num_epochs=5);\n\n#Read the summary generated once you run this cell. ",
"_____no_output_____"
]
],
[
[
"## As per the summary above\n Model Loaded on device\n Model name: resnet18_v1\n Num of potentially trainable layers: 41\n Num of actual trainable layers: 1",
"_____no_output_____"
],
[
"<a id='2'></a>\n# Switch now to densenet",
"_____no_output_____"
]
],
[
[
"gtf.update_model_name(\"densenet121\");\n\n\n# Very impotant to reload network\ngtf.Reload();",
"Update: Model name - densenet121\n\nPre-Composed Train Transforms\n[{'RandomHorizontalFlip': {'p': 0.8}}, {'Normalize': {'mean': [0.485, 0.456, 0.406], 'std': [0.229, 0.224, 0.225]}}]\n\nPre-Composed Val Transforms\n[{'RandomHorizontalFlip': {'p': 0.8}}, {'Normalize': {'mean': [0.485, 0.456, 0.406], 'std': [0.229, 0.224, 0.225]}}]\n\nDataset Numbers\n Num train images: 781\n Num val images: 336\n Num classes: 4\n\nModel Details\n Loading pretrained model\n Model Loaded on device\n Model name: densenet121\n Num of potentially trainable layers: 242\n Num of actual trainable layers: 1\n\n"
]
],
[
[
"<a id='3'></a>\n# Train",
"_____no_output_____"
]
],
[
[
"#Start Training\ngtf.Train();\n\n#Read the training summary generated once you run the cell and training is completed",
"Training Start\n Epoch 1/5\n ----------\n"
]
],
[
[
"# Goals Completed\n\n### Learn how to switch models post default mode",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
cb3b5917e9a4fe5496b17484867ac626dbb47be7 | 217,046 | ipynb | Jupyter Notebook | PrimaryScreens/Wilen_Re-analysis_v1.ipynb | PriyankaRoy5/SARS-CoV-2-meta-analysis | 5ddf2a72cb73cbe52c7aa5138a014f835069daa2 | [
"MIT"
] | 1 | 2021-05-25T14:40:38.000Z | 2021-05-25T14:40:38.000Z | PrimaryScreens/Wilen_Re-analysis_v1.ipynb | PriyankaRoy5/SARS-CoV-2-meta-analysis | 5ddf2a72cb73cbe52c7aa5138a014f835069daa2 | [
"MIT"
] | null | null | null | PrimaryScreens/Wilen_Re-analysis_v1.ipynb | PriyankaRoy5/SARS-CoV-2-meta-analysis | 5ddf2a72cb73cbe52c7aa5138a014f835069daa2 | [
"MIT"
] | null | null | null | 109.013561 | 62,604 | 0.762585 | [
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nimport gpplot as gpp\nfrom poola import core as pool\nimport anchors\n\nimport core_functions as fns\n\ngpp.set_aesthetics(palette='Set2')",
"_____no_output_____"
],
[
"def run_guide_residuals(lfc_df, paired_lfc_cols=[]):\n '''\n Calls get_guide_residuals function from anchors package to calculate guide-level residual z-scores\n Inputs:\n 1. lfc_df: data frame with log-fold changes (relative to pDNA)\n 2. paired_lfc_cols: grouped list of initial populations and corresponding resistant populations \n \n '''\n lfc_df = lfc_df.drop_duplicates()\n if not paired_lfc_cols:\n paired_lfc_cols = fns.pair_cols(lfc_df)[1] #get lfc pairs \n modified = []\n unperturbed = []\n #reference_df: column1 = modifier condition, column2 = unperturbed column\n ref_df = pd.DataFrame(columns=['modified', 'unperturbed'])\n row = 0 #row index for reference df \n for pair in paired_lfc_cols:\n #number of resistant pops in pair = len(pair)-1\n res_idx = 1 \n #if multiple resistant populations, iterate \n while res_idx < len(pair): \n ref_df.loc[row, 'modified'] = pair[res_idx]\n ref_df.loc[row, 'unperturbed'] = pair[0]\n res_idx +=1 \n row +=1\n \n print(ref_df)\n #input lfc_df, reference_df \n #guide-level\n residuals_lfcs, all_model_info, model_fit_plots = anchors.get_guide_residuals(lfc_df, ref_df)\n return residuals_lfcs, all_model_info, model_fit_plots\n\n\n",
"_____no_output_____"
]
],
[
[
"## Data summary\n ",
"_____no_output_____"
]
],
[
[
"reads = pd.read_excel('../../Data/Reads/Wilen/supplementary_reads_v1.xlsx', sheet_name= 'VeroE6 SARS-2 genomewide reads')\nreads",
"_____no_output_____"
],
[
"# Gene Annotations\nchip = pd.read_csv('../../Data/Interim/Goujon/VeroE6/CP0070_Chlorocebus_sabeus_remapped.chip', sep ='\\t')\nchip = chip.rename(columns={'Barcode Sequence':'Construct Barcode'})\nchip_reads = pd.merge(chip[['Construct Barcode', 'Gene']], reads, on = ['Construct Barcode'], how = 'right')\nchip_reads = chip_reads.rename(columns={'Gene':'Gene Symbol'})",
"_____no_output_____"
],
[
"#Calculate lognorm\ncols = chip_reads.columns[2:].to_list() #reads columns = start at 3rd column\nlognorms = fns.get_lognorm(chip_reads.dropna(), cols = cols)\nlognorms\n# lognorms = lognorms.rename(columns={'count_lognorm':'pDNA_lognorm'})",
"_____no_output_____"
]
],
[
[
"## Quality Control\n### Population Distributions",
"_____no_output_____"
]
],
[
[
"#Calculate log-fold change relative to pDNA\ntarget_cols = list(lognorms.columns[3:])\npDNA_lfc = fns.calculate_lfc(lognorms,target_cols)\npDNA_lfc\n\n# Average across Cas9-v2 columns \nCas9v2_data_cols = [col for col in pDNA_lfc.columns if 'Cas9-v2' in col]\nCas9v2_cols = ['Construct Barcode', 'Gene Symbol']+ Cas9v2_data_cols\nCas9v2_df = pDNA_lfc.copy()[Cas9v2_cols]\nCas9v2_df\n\n# Replace spaces with '_' for following functions\nnew_col_list=['Construct Barcode', 'Gene Symbol']\n\nfor col in Cas9v2_data_cols:\n new_col = col.replace(' ','_')\n new_col_list.append(new_col)\n\nCas9v2_df.columns = new_col_list \nCas9v2_df",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(nrows=2, ncols=1, sharex=True, figsize=(5,6))\ni,j = 0,0\ncols=[]\nmock_col = [col for col in Cas9v2_df.columns if 'Mock' in col]\nhi_MOI_cols = mock_col+ [col for col in Cas9v2_df.columns if 'Hi-MOI' in col]\ncols.append(hi_MOI_cols)\nlo_MOI_cols = mock_col+ [col for col in Cas9v2_df.columns if 'Lo-MOI' in col]\ncols.append(lo_MOI_cols)\n\nfor k,c in enumerate(cols): # k = sub-list index, c = list of columns in sub-list\n for l, c1 in enumerate(c):\n if 'Mock' in c1:\n label1 = c1 + ' (initial)'#'Initial population'\n else:\n label1 = c1 #'Resistant population-'+str(l)\n Cas9v2_df[c1].plot(kind='kde',c=sns.color_palette('Set2')[l],label=label1, ax=ax[i], legend=True)\n ax[i].legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)\n sns.despine()\n t = ax[i].set_xlabel('Log-fold changes')\n title = ','.join(c[0].split('_')[:2])\n t = ax[i].set_title(title)\n i+=1\n \nfig.savefig('../../Figures/Wilen_Vero_population_distributions.png', bbox_inches=\"tight\")",
"_____no_output_____"
]
],
[
[
"### Distributions of control sets ",
"_____no_output_____"
]
],
[
[
"# NO_SITE controls -> default controls \ncontrols = fns.get_controls(Cas9v2_df, control_name=['NO_SITE'])",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(nrows=2, ncols=1, sharex=True, figsize=(5,6))\ni,j = 0,0\n\nfor k,c in enumerate(cols): # k = sub-list index, c = list of columns in sub-list\n for l, c1 in enumerate(c):\n if l==0:\n label1 = c1 + ', NO_SITE'#'Initial population, NO_SITE'\n else:\n label1 = c1 + ', NO_SITE' #'Resistant population-'+str(l) + ', NO_SITE'\n controls[c1].plot(kind='kde',color=sns.color_palette('Set2')[l],label=label1, ax=ax[i], legend=True)\n ax[i].legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)\n sns.despine()\n t = ax[i].set_xlabel('Log-fold changes')\n title = ','.join(c[0].split('_')[:2])\n t = ax[i].set_title(title)\n i+=1\n\nfig.savefig('../../Figures/Wilen_Vero_control_distributions.png', bbox_inches=\"tight\")",
"_____no_output_____"
]
],
[
[
"### ROC_AUC",
"_____no_output_____"
]
],
[
[
"ess_genes, non_ess_genes = fns.get_gene_sets()\n\ntp_genes = ess_genes.loc[:, 'Gene Symbol'].to_list()\n\nfp_genes = non_ess_genes.loc[:, 'Gene Symbol'].to_list()\n\nroc_auc, roc_df = pool.get_roc_aucs(Cas9v2_df, tp_genes, fp_genes, gene_col = 'Gene Symbol', score_col=mock_col)\n\nfig,ax=plt.subplots(figsize=(6,6))\nax=sns.lineplot(data=roc_df, x='fpr',y='tpr', ci=None, label = 'Mock,' + str(round(roc_auc,2)))\n\nplt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)\nplt.title('ROC-AUC')\nplt.xlabel('False Positive Rate (non-essential)')\nplt.ylabel('True Positive Rate (essential)')\n",
"_____no_output_____"
]
],
[
[
"## Gene level analysis",
"_____no_output_____"
],
[
"### Residual z-scores",
"_____no_output_____"
]
],
[
[
"lfc_df = Cas9v2_df.drop('Gene Symbol', axis = 1)\nlfc_df",
"_____no_output_____"
],
[
"# run_guide_residuals(lfc_df.drop_duplicates(), cols)\nresiduals_lfcs, all_model_info, model_fit_plots = run_guide_residuals(lfc_df, cols)\nresiduals_lfcs\n",
" modified unperturbed\n0 Cas9-v2_D10_5e6_Hi-MOI_lfc Cas9-v2_D5_Mock_lfc\n1 Cas9-v2_D5_5e6_Hi-MOI_lfc Cas9-v2_D5_Mock_lfc\n2 Cas9-v2_D2_5e6_Hi-MOI_lfc Cas9-v2_D5_Mock_lfc\n3 Cas9-v2_D5_2.5e6_Hi-MOI_lfc Cas9-v2_D5_Mock_lfc\n4 Cas9-v2_D5_2.5e6_Lo-MOI_lfc Cas9-v2_D5_Mock_lfc\n"
],
[
"guide_mapping = pool.group_pseudogenes(chip[['Construct Barcode', 'Gene']], pseudogene_size=4, gene_col='Gene', control_regex=['NO_SITE'])\nguide_mapping = guide_mapping.rename(columns={'Gene':'Gene Symbol'})\n",
"_____no_output_____"
],
[
"gene_residuals = anchors.get_gene_residuals(residuals_lfcs.drop_duplicates(), guide_mapping)\ngene_residuals",
"_____no_output_____"
],
[
"gene_residual_sheet = fns.format_gene_residuals(gene_residuals, guide_min = 3, guide_max = 5)\n\nguide_residual_sheet = pd.merge(guide_mapping, residuals_lfcs.drop_duplicates(), on = 'Construct Barcode', how = 'inner')\nguide_residual_sheet",
"['Cas9-v2_D5_2.5e6_Lo-MOI_lfc', 'Cas9-v2_D10_5e6_Hi-MOI_lfc', 'Cas9-v2_D5_5e6_Hi-MOI_lfc', 'Cas9-v2_D5_2.5e6_Hi-MOI_lfc', 'Cas9-v2_D2_5e6_Hi-MOI_lfc']\nCas9-v2_D5_2.5e6_Lo-MOI_lfc\nCas9-v2_D10_5e6_Hi-MOI_lfc\nCas9-v2_D5_5e6_Hi-MOI_lfc\nCas9-v2_D5_2.5e6_Hi-MOI_lfc\nCas9-v2_D2_5e6_Hi-MOI_lfc\n"
],
[
"with pd.ExcelWriter('../../Data/Processed/GEO_submission_v2/VeroE6_Wilen_v5.xlsx') as writer: \n gene_residual_sheet.to_excel(writer, sheet_name='VeroE6_avg_zscore', index =False)\n reads.to_excel(writer, sheet_name='VeroE6_genomewide_reads', index =False)\n guide_mapping.to_excel(writer, sheet_name='VeroE6_guide_mapping', index =False)",
"_____no_output_____"
],
[
"with pd.ExcelWriter('../../Data/Processed/Individual_screens_v2/VeroE6_Wilen_indiv_v5.xlsx') as writer: \n gene_residuals.to_excel(writer, sheet_name='condition_genomewide_zscore', index =False)\n guide_residual_sheet.to_excel(writer, sheet_name='guide-level_zscore', index =False)",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3b67be1fae19ef84b6b19082737122dd88ffeb | 5,240 | ipynb | Jupyter Notebook | content/lessons/03/Now-You-Code/NYC2-Paint-Matching.ipynb | MahopacHS/spring-2020-smithb0125 | 20568b16475ee1d7da3ebf23a162b2c05c0b530a | [
"MIT"
] | null | null | null | content/lessons/03/Now-You-Code/NYC2-Paint-Matching.ipynb | MahopacHS/spring-2020-smithb0125 | 20568b16475ee1d7da3ebf23a162b2c05c0b530a | [
"MIT"
] | null | null | null | content/lessons/03/Now-You-Code/NYC2-Paint-Matching.ipynb | MahopacHS/spring-2020-smithb0125 | 20568b16475ee1d7da3ebf23a162b2c05c0b530a | [
"MIT"
] | null | null | null | 61.647059 | 1,082 | 0.623473 | [
[
[
"# Now You Code 2: Paint Pricing\n\nHouse Depot, a big-box hardware retailer, has contracted you to create an app to calculate paint prices. \n\nThe price of paint is determined by the following factors:\n- Everyday quality paint is `$19.99` per gallon.\n- Select quality paint is `$24.99` per gallon.\n- Premium quality paint is `$32.99` per gallon.\n\nIn addition if the customer wants computerized color-matching that incurs an additional fee of `$4.99` per gallon. \n\nWrite a program to ask the user to select a paint quality: 'everyday', 'select' or 'premium', prompt for color matching, and then outputs the price per gallon of the paint.\n\nExample Run 1:\n\n```\nWhich paint quality do you require ['everyday', 'select', 'premium'] ?select\nDo you require color matching [y/n] ?y\nTotal price of select paint with color matching is $29.98\n```\n\nExample Run 2:\n\n```\nWhich paint quality do you require ['everyday', 'select', 'premium'] ?premium\nDo you require color matching [y/n] ?n\nTotal price of premium paint without color matching is $32.99\n```",
"_____no_output_____"
],
[
"## Step 1: Problem Analysis\n\nInputs: everydau, select, premium, yes, no\n\nOutputs: paimt pricing\n\nAlgorithm (Steps in Program): select paint quality\ncolor matching\noutput price\n\n",
"_____no_output_____"
]
],
[
[
"try:\n choices = [\"everyday\",\"select\",\"premium\"]\n choice2 = [\"yes\",\"no\"]\n\n paint=input(\"What type of paint?(esp)\")\n colormatch=input(\"color matching?(yes/no)\")\n if paint in choices:\n if paint ==\"everyday\":\n base=19.99\n elif paint ==\"select\":\n base=24.99\n elif paint ==\"premium\":\n base=32.99\n if colormatch=='yes':\n cost=base+4.99\n else:\n cost=base\n print(cost)\nexcept:\n print(\"Invalid Input.\")",
"What type of paint?(esp)yes\ncolor matching?(yes/no)yes\n24.979999999999997\n"
]
],
[
[
"## Step 3: Questions\n\n1. When you enter something other than `'everyday', 'select',` or `'premium'` what happens? Modify the program to print `that is not a paint quality` and then exit in those cases.\n\nAnswer: \n\n\n2. What happens when you enter something other than `'y'` or `'n'` for color matching? Re-write the program to print `you must enter y or n` whenever you enter something other than those two values.\n\nAnswer: \n\n\n3. Why can't we use Python's `try...except` in this example?\n\nAnswer: \n\n\n4. How many times (at minimum) must we execute this program and check the results before we can be reasonably assured it is correct?\n\nAnswer: \n\n\n",
"_____no_output_____"
],
[
"## Step 4: Reflection\n\nReflect upon your experience completing this assignment. This should be a personal narrative, in your own voice, and cite specifics relevant to the activity as to help the grader understand how you arrived at the code you submitted. Things to consider touching upon: Elaborate on the process itself. Did your original problem analysis work as designed? How many iterations did you go through before you arrived at the solution? Where did you struggle along the way and how did you overcome it? What did you learn from completing the assignment? What do you need to work on to get better? What was most valuable and least valuable about this exercise? Do you have any suggestions for improvements?\n\nTo make a good reflection, you should journal your thoughts, questions and comments while you complete the exercise.\n\nKeep your response to between 100 and 250 words.\n\n`--== Write Your Reflection Below Here ==--`\n\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
cb3b7f1b54e2aad091cef3c93126ad309f56e123 | 4,716 | ipynb | Jupyter Notebook | notebooks/loading a pipeline saved to disk.ipynb | maximematerno/gapminder-dash-app | f8552ac34f068effba473becc32664faac68b2de | [
"MIT"
] | null | null | null | notebooks/loading a pipeline saved to disk.ipynb | maximematerno/gapminder-dash-app | f8552ac34f068effba473becc32664faac68b2de | [
"MIT"
] | 4 | 2020-03-24T17:39:33.000Z | 2021-08-23T20:26:20.000Z | notebooks/loading a pipeline saved to disk.ipynb | maximematerno/gapminder-dash-app | f8552ac34f068effba473becc32664faac68b2de | [
"MIT"
] | 1 | 2020-05-27T07:10:40.000Z | 2020-05-27T07:10:40.000Z | 26.055249 | 91 | 0.412214 | [
[
[
"from joblib import load\n\npipeline = load('pipeline.joblib')",
"_____no_output_____"
],
[
"pipeline",
"_____no_output_____"
],
[
"type(pipeline)",
"_____no_output_____"
],
[
"import pandas as pd\n\ndef predict(Age, Position, College, Height, Weight):\n df = pd.DataFrame(\n columns=['Age', 'Position','College','Height','Weight'], \n data=[[Age, Position, College, Height, Weight]]\n )\n y_pred = pipeline.predict(df)[0]\n return f'${y_pred:.0f} Salary'",
"_____no_output_____"
],
[
"predict(Age=20, Position='PG', College='Texas', Height = 5.11, Weight=161)",
"_____no_output_____"
],
[
"predict(Age=30, Position='SG', College='Boston University', Height = 6.2, Weight=205)",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3b80adebea0d5ca770d4df38496b6e6cdff731 | 100,585 | ipynb | Jupyter Notebook | notebooks/visualize_results.ipynb | pabvald/instagram-caption-generator | 99f0c130aeb3c4bc59c267ac1f49c762e5023756 | [
"MIT"
] | 1 | 2021-12-12T14:49:42.000Z | 2021-12-12T14:49:42.000Z | notebooks/visualize_results.ipynb | pabvald/instagram-caption-generator | 99f0c130aeb3c4bc59c267ac1f49c762e5023756 | [
"MIT"
] | null | null | null | notebooks/visualize_results.ipynb | pabvald/instagram-caption-generator | 99f0c130aeb3c4bc59c267ac1f49c762e5023756 | [
"MIT"
] | null | null | null | 613.323171 | 96,625 | 0.952746 | [
[
[
"import os\nimport sys\nimport torch\nimport json\nsys.path.insert(1, os.path.join(sys.path[0], '..'))\nfrom caption import caption_image_beam_search, visualize_att\n",
"_____no_output_____"
]
],
[
[
"### Parameters",
"_____no_output_____"
]
],
[
[
"model = '../models/flickr8k/BEST_checkpoint_bs80_ad300_dd300_elr0.0_dlr0.0004.pth.tar'\nimg_path = '../data/datasets/flickr8k/img/3758787457_1a903ee1e9.jpg'\nword_map_path = '../data/datasets/flickr8k/WORDMAP_flickr8k.json'\nsmooth = True\ndevice = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")",
"_____no_output_____"
]
],
[
[
"### Load model",
"_____no_output_____"
]
],
[
[
"checkpoint = torch.load(model, map_location=str(device))\ndecoder = checkpoint['decoder']\ndecoder = decoder.to(device)\ndecoder.eval()\nencoder = checkpoint['encoder']\nencoder = encoder.to(device)\nencoder.eval()",
"_____no_output_____"
]
],
[
[
"### Load word map, create inverse word map",
"_____no_output_____"
]
],
[
[
"with open(word_map_path, 'r') as j:\n word_map = json.load(j)\nrev_word_map = {v: k for k, v in word_map.items()} ",
"_____no_output_____"
]
],
[
[
"### Encode, decode with attention and beam search",
"_____no_output_____"
]
],
[
[
"seq, alphas = caption_image_beam_search(encoder, decoder, img_path, word_map, 1)\nalphas = torch.FloatTensor(alphas)",
"/home/pabvald/.local/share/virtualenvs/instagram-caption-generator-Z18861q1/lib/python3.8/site-packages/torch/nn/functional.py:718: UserWarning: Named tensors and all their associated APIs are an experimental feature and subject to change. Please do not use them for anything important until they are released as stable. (Triggered internally at /pytorch/c10/core/TensorImpl.h:1156.)\n return torch.max_pool2d(input, kernel_size, stride, padding, dilation, ceil_mode)\n"
]
],
[
[
"### Visualize caption and attention of best sequence",
"_____no_output_____"
]
],
[
[
"visualize_att(img_path, seq, alphas, rev_word_map, smooth)",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
cb3b818a5e86b215871527bdbbc6974c3947b248 | 19,469 | ipynb | Jupyter Notebook | ml/annotation_tools/notebooks/.ipynb_checkpoints/annotation-checkpoint.ipynb | jphacks/TK_1810 | 0c47c2a0eaeea47067e066a43def7ed079f77d2c | [
"MIT"
] | 6 | 2018-11-05T15:30:37.000Z | 2020-10-27T09:16:03.000Z | ml/annotation_tools/notebooks/.ipynb_checkpoints/annotation-checkpoint.ipynb | jphacks/TK_1810 | 0c47c2a0eaeea47067e066a43def7ed079f77d2c | [
"MIT"
] | 1 | 2018-10-28T02:02:25.000Z | 2018-10-28T02:02:25.000Z | ml/annotation_tools/notebooks/.ipynb_checkpoints/annotation-checkpoint.ipynb | jphacks/TK_1810 | 0c47c2a0eaeea47067e066a43def7ed079f77d2c | [
"MIT"
] | 3 | 2019-10-18T10:21:54.000Z | 2021-10-30T00:54:39.000Z | 44.859447 | 1,291 | 0.551749 | [
[
[
"from path import Path\nfrom PIL import Image\nimport cv2\nimport random\nimport pandas as pd\nimport pickle",
"_____no_output_____"
],
[
"def arg_parse():\n parser = argparse.ArgumentParser()\n parser = argparse.ArgumentParser(\n prog=\"annotation.py\", \n usage=\"annotation.py -n <<num_of_evaluation>>\", \n description=\"\", \n add_help = True \n )\n\n parser.add_argument(\"-n\", \"--num\", \n help = \"num of evaluation\",\n type = int,\n default = None)\n \n args = parser.parse_args()\n return args\n",
"_____no_output_____"
],
[
"def get_filepath_list(dir_path):\n imgs = Path(dir_path).files('*.png')\n imgs += Path(dir_path).files('*.jpg')\n imgs += Path(dir_path).files('*.jpeg')\n \n return imgs",
"_____no_output_____"
],
[
"def hconcat_resize_min(im_list, interpolation=cv2.INTER_CUBIC):\n h_min = min(im.shape[0] for im in im_list)\n im_list_resize = [cv2.resize(im, (int(im.shape[1] * h_min / im.shape[0]), h_min), interpolation=interpolation)\n for im in im_list]\n return cv2.hconcat(im_list_resize)",
"_____no_output_____"
],
[
"def evaluate_images(path_list, rand=False, n_shows=None, username=None):\n \n df = pd.DataFrame(columns=['filename', 'score', 'user'])\n filename_list = []\n score_list = []\n rep_list = [ord(str(i)) for i in range(1, 6)]\n key_q = ord('q')\n \n if rand:\n path_list = random.sample(path_list, len(path_list))\n \n if n_shows is None:\n n_shows = len(path_list)\n \n for path in path_list[:n_shows]:\n img = cv2.imread(path)\n cv2.namedWindow(\"image\", cv2.WINDOW_KEEPRATIO | cv2.WINDOW_NORMAL)\n cv2.resizeWindow('image', 800, 600)\n cv2.imshow('image', img)\n \n key = 0\n while ((key not in rep_list) and key is not key_q):\n key = cv2.waitKey(0)\n cv2.destroyWindow('image')\n \n if key is key_q:\n break\n \n filename_list.append(path.rsplit('/')[-1])\n score_list.append(rep_list.index(key)+1)\n \n df = pd.DataFrame()\n df['filename'] = filename_list\n df['score'] = score_list\n df['user'] = username\n \n return df",
"_____no_output_____"
],
[
"def evaluate_images_relative(path_list, combination_list, username=None):\n df = pd.DataFrame(columns=['filename', 'score', 'user'])\n filename_list = [path.rsplit('/')[-1] for path in path_list]\n score_list = [0 for i in range(len(path_list))]\n num_evals = [0 for i in range(len(path_list))]\n \n key_f, key_j, key_q = ord('f'), ord('j'), ord('q')\n rep_list = [key_f, key_j, key_q]\n end_flag = False\n \n for i, c_list in enumerate(combination_list):\n img1 = cv2.imread(path_list[i])\n for c in c_list:\n img2 = cv2.imread(path_list[c])\n merged = hconcat_resize_min([img1, img2])\n \n cv2.namedWindow(\"image\", cv2.WINDOW_KEEPRATIO | cv2.WINDOW_NORMAL)\n cv2.resizeWindow('image', 1200, 450)\n cv2.moveWindow('image', 100, 200)\n cv2.imshow('image', merged)\n \n key = 0\n while key not in rep_list:\n key = cv2.waitKey(0)\n cv2.destroyWindow('image')\n \n if key is key_f:\n score_list[i] = score_list[i] + 1\n num_evals[i] = num_evals[i] + 1\n num_evals[c] = num_evals[c] + 1\n elif key is key_j:\n score_list[c] = score_list[c] + 1\n num_evals[i] = num_evals[i] + 1\n num_evals[c] = num_evals[c] + 1\n else:\n end_flag = True\n break\n \n combination_list[c].remove(i)\n \n if end_flag:\n break\n\n df = pd.DataFrame()\n df['filename'] = filename_list\n df['score'] = score_list\n df['num_of_evaluations'] = num_evals\n df['user'] = username\n \n return df",
"_____no_output_____"
],
[
"def evaluate_images_relative_random(path_list, combination_list, start_pos, num=None, username=None):\n \n def get_random_combination_list(combination_list):\n combination_set = set()\n for i, clist in enumerate(combination_list):\n for c in clist:\n tmp_tuple = tuple(sorted([i, c]))\n combination_set.add(tmp_tuple)\n\n return random.sample(list(combination_set), len(combination_set))\n \n df = pd.DataFrame(columns=['filename', 'score', 'user'])\n filename_list = [path.rsplit('/')[-1] for path in path_list]\n score_list = [0 for i in range(len(path_list))]\n num_evals = [0 for i in range(len(path_list))]\n \n key_f, key_j, key_q = ord('f'), ord('j'), ord('q')\n rep_list = [key_f, key_j, key_q]\n end_flag = False\n font = cv2.FONT_HERSHEY_SIMPLEX\n \n if num is None:\n num = len(combination_list)\n random_combination_list = get_random_combination_list(combination_list[start_pos:num])\n \n for count, (i, j) in enumerate(random_combination_list):\n s1, s2 = random.sample([i, j], 2)\n img1 = cv2.imread(path_list[s1])\n img2 = cv2.imread(path_list[s2])\n merged = hconcat_resize_min([img1, img2])\n \n cv2.namedWindow(\"image\", cv2.WINDOW_KEEPRATIO | cv2.WINDOW_NORMAL)\n cv2.resizeWindow('image', 1200, 450)\n cv2.moveWindow('image', 100, 200)\n text_pos = (merged.shape[1] - 250, merged.shape[0] - 50)\n cv2.putText(merged, \"{}/{}\".format(count+1, len(random_combination_list)), text_pos, font, 1.5, (0, 0, 0), 2, cv2.LINE_AA)\n cv2.imshow('image', merged)\n\n key = 0\n while key not in rep_list:\n key = cv2.waitKey(0)\n cv2.destroyWindow('image')\n\n if key is key_f:\n score_list[s1] = score_list[s1] + 1\n num_evals[s1] = num_evals[s1] + 1\n num_evals[s2] = num_evals[s2] + 1\n elif key is key_j:\n score_list[s2] = score_list[s2] + 1\n num_evals[s1] = num_evals[s1] + 1\n num_evals[s2] = num_evals[s2] + 1\n else:\n end_flag = True\n break\n\n if end_flag:\n break\n\n df = pd.DataFrame()\n df['filename'] = filename_list\n df['score'] = score_list\n df['num_of_evaluations'] = num_evals\n df['user'] = username\n \n return df",
"_____no_output_____"
],
[
"def save_evaluation_csv(df, username, save_path=None):\n if save_path is None:\n save_path = './output/' + username + '.csv'\n df.to_csv(save_path)",
"_____no_output_____"
],
[
"def main():\n print('Please write your name : ', end='')\n username = input()\n filepath_list = get_filepath_list('./images')\n df_result = evaluate_images(filepath_list, rand=True, username=username)\n save_evaluation_csv(df_result, username)\n print('Thank you!')\n \ndef main_relative():\n print('Please write your name : ', end='')\n username = input()\n filepath_list = get_filepath_list('./images/omelette_rice/')[:50]\n with open('./pickle/combination_list.pickle', 'rb') as f:\n combination_list = pickle.load(f)\n df_result = evaluate_images_relative(filepath_list, combination_list, username=username)\n save_evaluation_csv(df_result, username)\n print('Thank you!')\n \ndef main_relative_random():\n print('Please enter your name : ', end='')\n username = input()\n print('Please enter the number of ratings : ', end='')\n num = int(input())\n filepath_list = get_filepath_list('../images/omelette_rice_500/images/')\n \n try:\n with open('..pickle/start_position.pickle', 'rb') as f:\n start_pos = pickle.load(f)\n except:\n start_pos = 0\n \n with open('../pickle/combination500_list.pickle', 'rb') as f:\n combination_list = pickle.load(f)\n \n df_result = evaluate_images_relative_random(filepath_list, combination_list, start_pos, num, username=username)\n save_evaluation_csv(df_result, username)\n \n with open('..pickle/start_position.pickle', 'wb') as f:\n start_pos = start_pos + num\n print('Thank you!')",
"_____no_output_____"
],
[
"if __name__=='__main__':\n main_relative_random()",
"Please enter your name : wakawo\nPlease enter the number of ratings : 100\n"
],
[
"with open('../pickle/combination500_list.pickle', 'rb') as f:\n combination_list = pickle.load(f)",
"_____no_output_____"
],
[
"# 集合に登録\ndef get_random_combination_set(combination_list):\n combination_set = set()\n for i, clist in enumerate(combination_list):\n for c in clist:\n tmp_tuple = tuple(sorted([i, c]))\n combination_set.add(tmp_tuple)\n \n return random.sample(list(combination_set), len(combination_set))",
"_____no_output_____"
],
[
"[i for i in range(10)][5:10]",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3b819ba401637167417ec8a9d490c481e29b42 | 83,444 | ipynb | Jupyter Notebook | Classification/Extra Trees/ExtraTreesClassifier_MinMaxScaler.ipynb | surya2365/ds-seed | 74ef58479333fed95522f7b691f1209f7d70fc95 | [
"Apache-2.0"
] | 2 | 2021-07-28T15:26:40.000Z | 2021-07-29T04:14:35.000Z | Classification/Extra Trees/ExtraTreesClassifier_MinMaxScaler.ipynb | surya2365/ds-seed | 74ef58479333fed95522f7b691f1209f7d70fc95 | [
"Apache-2.0"
] | 1 | 2021-07-30T06:00:30.000Z | 2021-07-30T06:00:30.000Z | Classification/Extra Trees/ExtraTreesClassifier_MinMaxScaler.ipynb | surya2365/ds-seed | 74ef58479333fed95522f7b691f1209f7d70fc95 | [
"Apache-2.0"
] | null | null | null | 94.393665 | 24,150 | 0.795384 | [
[
[
"# Extra Trees Classifier with MinMax Scaler",
"_____no_output_____"
],
[
"### Required Packages",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport seaborn as se\nimport warnings\nimport matplotlib.pyplot as plt\nfrom sklearn.ensemble import ExtraTreesClassifier\nfrom sklearn.preprocessing import LabelEncoder, MinMaxScaler\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.metrics import classification_report,plot_confusion_matrix \nwarnings.filterwarnings('ignore')",
"_____no_output_____"
]
],
[
[
"### Initialization\n\nFilepath of CSV file",
"_____no_output_____"
]
],
[
[
"#filepath\nfile_path= \"\"",
"_____no_output_____"
]
],
[
[
"List of features which are required for model training .",
"_____no_output_____"
]
],
[
[
"#x_values\nfeatures=[]",
"_____no_output_____"
]
],
[
[
"Target feature for prediction.",
"_____no_output_____"
]
],
[
[
"#y_value\ntarget=''",
"_____no_output_____"
]
],
[
[
"### Data Fetching\n\nPandas is an open-source, BSD-licensed library providing high-performance, easy-to-use data manipulation and data analysis tools.\n\nWe will use panda's library to read the CSV file using its storage path.And we use the head function to display the initial row or entry.",
"_____no_output_____"
]
],
[
[
"df=pd.read_csv(file_path)\ndf.head()",
"_____no_output_____"
]
],
[
[
"### Feature Selections\n\nIt is the process of reducing the number of input variables when developing a predictive model. Used to reduce the number of input variables to both reduce the computational cost of modelling and, in some cases, to improve the performance of the model.\n\nWe will assign all the required input features to X and target/outcome to Y.",
"_____no_output_____"
]
],
[
[
"X = df[features]\nY = df[target]",
"_____no_output_____"
]
],
[
[
"### Data Preprocessing\n\nSince the majority of the machine learning models in the Sklearn library doesn't handle string category data and Null value, we have to explicitly remove or replace null values. The below snippet have functions, which removes the null value if any exists. And convert the string classes data in the datasets by encoding them to integer classes.\n",
"_____no_output_____"
]
],
[
[
"def NullClearner(df):\n if(isinstance(df, pd.Series) and (df.dtype in [\"float64\",\"int64\"])):\n df.fillna(df.mean(),inplace=True)\n return df\n elif(isinstance(df, pd.Series)):\n df.fillna(df.mode()[0],inplace=True)\n return df\n else:return df\ndef EncodeX(df):\n return pd.get_dummies(df)\ndef EncodeY(df):\n if len(df.unique())<=2:\n return df\n else:\n un_EncodedT=np.sort(pd.unique(df), axis=-1, kind='mergesort')\n df=LabelEncoder().fit_transform(df)\n EncodedT=[xi for xi in range(len(un_EncodedT))]\n print(\"Encoded Target: {} to {}\".format(un_EncodedT,EncodedT))\n return df",
"_____no_output_____"
],
[
"x=X.columns.to_list()\nfor i in x:\n X[i]=NullClearner(X[i])\nX=EncodeX(X)\nY=EncodeY(NullClearner(Y))\nX.head()",
"_____no_output_____"
]
],
[
[
"#### Correlation Map\n\nIn order to check the correlation between the features, we will plot a correlation matrix. It is effective in summarizing a large amount of data where the goal is to see patterns.",
"_____no_output_____"
]
],
[
[
"f,ax = plt.subplots(figsize=(18, 18))\nmatrix = np.triu(X.corr())\nse.heatmap(X.corr(), annot=True, linewidths=.5, fmt= '.1f',ax=ax, mask=matrix)\nplt.show()",
"_____no_output_____"
]
],
[
[
"#### Distribution Of Target Variable",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize = (10,6))\nse.countplot(Y)",
"_____no_output_____"
]
],
[
[
"### Data Splitting\n\nThe train-test split is a procedure for evaluating the performance of an algorithm. The procedure involves taking a dataset and dividing it into two subsets. The first subset is utilized to fit/train the model. The second subset is used for prediction. The main motive is to estimate the performance of the model on new data.",
"_____no_output_____"
]
],
[
[
"X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.2, random_state = 123)",
"_____no_output_____"
]
],
[
[
"### Data Rescaling\nThis estimator scales and translates each feature individually such that it is in the given range on the training set, e.g. between zero and one.\nThe transformation is given by:\n\nX_std = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))\nX_scaled = X_std * (max - min) + min\nwhere min, max = feature_range.",
"_____no_output_____"
]
],
[
[
"minmax_scaler = MinMaxScaler()\nX_train = minmax_scaler.fit_transform(X_train)\nX_test = minmax_scaler.transform(X_test)",
"_____no_output_____"
]
],
[
[
"### Model\nExtraTreesClassifier is an ensemble learning method fundamentally based on decision trees. ExtraTreesClassifier, like RandomForest, randomizes certain decisions and subsets of data to minimize over-learning from the data and overfitting.\n\n#### Model Tuning Parameters\n\n 1.n_estimators:int, default=100\n>The number of trees in the forest. \n\n 2.criterion:{“gini”, “entropy”}, default=\"gini\"\n>The function to measure the quality of a split. Supported criteria are “gini” for the Gini impurity and “entropy” for the information gain.\n \n 3.max_depth:int, default=None\n>The maximum depth of the tree. If None, then nodes are expanded until all leaves are pure or until all leaves contain less than min_samples_split samples.\n \n \n 4.max_features:{“auto”, “sqrt”, “log2”}, int or float, default=”auto”\n>The number of features to consider when looking for the best split:",
"_____no_output_____"
]
],
[
[
"model=ExtraTreesClassifier(n_jobs = -1,random_state = 123)\nmodel.fit(X_train,y_train)",
"_____no_output_____"
]
],
[
[
"#### Model Accuracy\n\nscore() method return the mean accuracy on the given test data and labels.\n\nIn multi-label classification, this is the subset accuracy which is a harsh metric since you require for each sample that each label set be correctly predicted",
"_____no_output_____"
]
],
[
[
"print(\"Accuracy score {:.2f} %\\n\".format(model.score(X_test,y_test)*100))",
"Accuracy score 87.50 %\n\n"
]
],
[
[
"#### Confusion Matrix\n\nA confusion matrix is utilized to understand the performance of the classification model or algorithm in machine learning for a given test set where results are known.",
"_____no_output_____"
]
],
[
[
"plot_confusion_matrix(model,X_test,y_test,cmap=plt.cm.Blues)",
"_____no_output_____"
]
],
[
[
"#### Classification Report\nA Classification report is used to measure the quality of predictions from a classification algorithm. How many predictions are True, how many are False.\n\n* **where**:\n - Precision:- Accuracy of positive predictions.\n - Recall:- Fraction of positives that were correctly identified.\n - f1-score:- percent of positive predictions were correct\n - support:- Support is the number of actual occurrences of the class in the specified dataset.",
"_____no_output_____"
]
],
[
[
"print(classification_report(y_test,model.predict(X_test)))",
" precision recall f1-score support\n\n 0 0.92 0.88 0.90 50\n 1 0.81 0.87 0.84 30\n\n accuracy 0.88 80\n macro avg 0.86 0.87 0.87 80\nweighted avg 0.88 0.88 0.88 80\n\n"
]
],
[
[
"#### Feature Importances.\n\nThe Feature importance refers to techniques that assign a score to features based on how useful they are for making the prediction.",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(8,6))\nn_features = len(X.columns)\nplt.barh(range(n_features), model.feature_importances_, align='center')\nplt.yticks(np.arange(n_features), X.columns)\nplt.xlabel(\"Feature importance\")\nplt.ylabel(\"Feature\")\nplt.ylim(-1, n_features)",
"_____no_output_____"
]
],
[
[
"#### Creator: Ayush Gupta , Github: [Profile](https://github.com/guptayush179)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
cb3b9c7897abf4e6b630f3ce592aa68e4215cf40 | 10,004 | ipynb | Jupyter Notebook | notebooks/nlp/word2vec.ipynb | kiranvarghesev/DLinK | ff83c66a11ec0597a38579152ac8482199cf16c6 | [
"MIT"
] | null | null | null | notebooks/nlp/word2vec.ipynb | kiranvarghesev/DLinK | ff83c66a11ec0597a38579152ac8482199cf16c6 | [
"MIT"
] | null | null | null | notebooks/nlp/word2vec.ipynb | kiranvarghesev/DLinK | ff83c66a11ec0597a38579152ac8482199cf16c6 | [
"MIT"
] | 1 | 2018-11-11T02:59:16.000Z | 2018-11-11T02:59:16.000Z | 19.425243 | 166 | 0.523391 | [
[
[
"# Creating Word Vectors with word2vec",
"_____no_output_____"
],
[
"Let's start with NLTK",
"_____no_output_____"
],
[
"#### Load Dependencies",
"_____no_output_____"
]
],
[
[
"import nltk\nfrom nltk.tokenize import word_tokenize, sent_tokenize\nimport gensim\nfrom gensim.models.word2vec import Word2Vec\nfrom sklearn.manifold import TSNE\nimport pandas as pd\nfrom bokeh.io import output_notebook\nfrom bokeh.plotting import show, figure\n%matplotlib inline",
"_____no_output_____"
],
[
"nltk.download('punkt')",
"_____no_output_____"
]
],
[
[
"#### Load Data",
"_____no_output_____"
]
],
[
[
"nltk.download('gutenberg')",
"_____no_output_____"
],
[
"from nltk.corpus import gutenberg",
"_____no_output_____"
],
[
"gutenberg.fileids()",
"_____no_output_____"
]
],
[
[
"#### Tokenize Text",
"_____no_output_____"
]
],
[
[
"# Due to lack of resources, I'm not working with the full Gutenberg dataset (18 books).\ngberg_sent_tokens = sent_tokenize(gutenberg.raw(fileids=['bible-kjv.txt', 'austen-emma.txt', 'austen-persuasion.txt', 'austen-sense.txt', 'carroll-alice.txt']))",
"_____no_output_____"
],
[
"gberg_sent_tokens[0:5]",
"_____no_output_____"
],
[
"gberg_sent_tokens[1]",
"_____no_output_____"
],
[
"word_tokenize(gberg_sent_tokens[1])",
"_____no_output_____"
],
[
"word_tokenize(gberg_sent_tokens[1])[14]",
"_____no_output_____"
],
[
"# Due to lack of resources, I'm not working with the full Gutenberg dataset (18 books).\ngberg_sents = gutenberg.sents(fileids=['bible-kjv.txt', 'austen-emma.txt', 'austen-persuasion.txt', 'austen-sense.txt', 'carroll-alice.txt'])",
"_____no_output_____"
],
[
"gberg_sents[0:5]",
"_____no_output_____"
],
[
"gberg_sents[4][14]",
"_____no_output_____"
],
[
"gutenberg.words()",
"_____no_output_____"
],
[
"# Due to lack of resources, I'm not working with the full Gutenberg dataset (18 books).\nlen(gutenberg.words(fileids=['bible-kjv.txt', 'austen-emma.txt', 'austen-persuasion.txt', 'austen-sense.txt', 'carroll-alice.txt']))",
"_____no_output_____"
]
],
[
[
"#### Run Word2Vec",
"_____no_output_____"
]
],
[
[
"# size == dimensions\n# window 10: 20 context words, 10 to the left and 10 to the right\nmodel = Word2Vec(sentences=gberg_sents, size=64, sg=1, window=10, min_count=5, seed=42, workers=2)",
"_____no_output_____"
],
[
"# We don't have to save the model if we don't want to. It's being done here as demonstration.\nmodel.save('raw_gutenberg_model.w2v')",
"_____no_output_____"
]
],
[
[
"#### Explore the Model",
"_____no_output_____"
]
],
[
[
"model = Word2Vec.load('raw_gutenberg_model.w2v')",
"_____no_output_____"
],
[
"model['house']",
"_____no_output_____"
],
[
"len(model['house'])",
"_____no_output_____"
],
[
"model.most_similar('house')",
"_____no_output_____"
],
[
"model.most_similar('think')",
"_____no_output_____"
],
[
"model.most_similar('day')",
"_____no_output_____"
],
[
"model.most_similar('father')",
"_____no_output_____"
],
[
"model.doesnt_match('mother father daughter house'.split())",
"_____no_output_____"
],
[
"model.similarity('father', 'mother')",
"_____no_output_____"
],
[
"model.most_similar(positive=['father', 'woman'], negative=['man'])",
"_____no_output_____"
],
[
"model.most_similar(positive=['son', 'woman'], negative=['man'])",
"_____no_output_____"
],
[
"model.most_similar(positive=['husband', 'woman'], negative=['man'])",
"_____no_output_____"
],
[
"model.most_similar(positive=['king', 'woman'], negative=['man'], topn=30)",
"_____no_output_____"
]
],
[
[
"#### Reduce word vector dimensionality with t-SNE",
"_____no_output_____"
],
[
"t-Distributed Stochastic Name Embedding",
"_____no_output_____"
]
],
[
[
"len(model.wv.vocab)",
"_____no_output_____"
],
[
"X = model[model.wv.vocab]",
"_____no_output_____"
],
[
"tsne = TSNE(n_components=2, n_iter=200)",
"_____no_output_____"
],
[
"X_2d = tsne.fit_transform(X)",
"_____no_output_____"
],
[
"coords_df = pd.DataFrame(X_2d, columns=['x', 'y'])\ncoords_df['token'] = model.wv.vocab.keys()",
"_____no_output_____"
],
[
"coords_df.head()",
"_____no_output_____"
],
[
"coords_df.to_csv('raw_gutenberg_tsne.csv', index=False)",
"_____no_output_____"
]
],
[
[
"#### Visualise 2D representation of word vectors",
"_____no_output_____"
]
],
[
[
"coorrds_df = pd.read_csv('raw_gutenberg_tsne.csv')",
"_____no_output_____"
],
[
"coords_df.head()",
"_____no_output_____"
],
[
"_ = coords_df.plot.scatter('x', 'y', figsize=(8,8), marker='o', s=10, alpha=0.2)",
"_____no_output_____"
],
[
"output_notebook()",
"_____no_output_____"
],
[
"subset_df = coords_df.sample(n=1000)",
"_____no_output_____"
],
[
"p = figure(plot_width=600, plot_height=600)\np.text(x=subset_df.x, y=subset_df.y, text=subset_df.token)",
"_____no_output_____"
],
[
"show(p)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3ba345e326c41684d3153caf229be7717fca4c | 83,091 | ipynb | Jupyter Notebook | lessons/pydata/api/index.ipynb | dakarabas/naucse.python.cz | 1e0f4d0479bddb5143114f2544ed77ced16bb888 | [
"MIT"
] | null | null | null | lessons/pydata/api/index.ipynb | dakarabas/naucse.python.cz | 1e0f4d0479bddb5143114f2544ed77ced16bb888 | [
"MIT"
] | null | null | null | lessons/pydata/api/index.ipynb | dakarabas/naucse.python.cz | 1e0f4d0479bddb5143114f2544ed77ced16bb888 | [
"MIT"
] | null | null | null | 42.896748 | 6,188 | 0.60506 | [
[
[
"# Co je API?",
"_____no_output_____"
],
[
"## Klient a server",
"_____no_output_____"
],
[
"API (Application Programming Interface) je dohoda mezi dvěma stranami o tom, jak si mezi sebou budou povídat. Těmto stranám se říká klient a server.\n\n**Server** je ta strana, která má zajímavé informace nebo něco zajímavého umí a umožňuje ostatním na internetu, aby toho využili. Server je program, který donekonečna běží na nějakém počítači a je připraven všem ostatním na internetu odpovídat na požadavky.\n\n**Klient** je program, který posílá požadavky na server a z odpovědí se snaží poskládat něco užitečného. Klient je tedy mobilní aplikace s mráčky a sluníčky nebo náš prohlížeč, v němž si můžeme otevřít kurzovní lístek ČNB. Je to ale i Heureka robot, který za Heureku načítá informace o zboží v e-shopech.",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"# Základní pojmy",
"_____no_output_____"
],
[
"Než se pustíme do tvorby klienta, projdeme si některé základní pojmy kolem API.",
"_____no_output_____"
],
[
"## Protokol",
"_____no_output_____"
],
[
"Celé dorozumívání mezi klientem a serverem se odehrává přes tzv. protokol. To není nic jiného, než smluvený způsob, co bude kdo komu posílat a jakou strukturu to bude mít. Protokolů je v počítačovém světě spousta, ale nás bude zajímat jen HTTP, protože ten využívají webová API a ostatně i web samotný. Není to náhoda, že adresa internetových stránek v prohlížeči zpravidla začíná http:// (nebo https://).",
"_____no_output_____"
],
[
"### HTTP",
"_____no_output_____"
],
[
"Dorozumívání mezi klientem a serverem probíhá formou požadavku (HTTP request), jenž posílá klient na server, a odpovědi (HTTP response), kterou server posílá zpět. Každá z těchto zpráv má své náležitosti.",
"_____no_output_____"
],
[
"### Požadavek",
"_____no_output_____"
],
[
"+ **metoda** (HTTP method): Například metoda GET má tu vlastnost, že pouze čte a nemůžeme s ní tedy přes API něco změnit - je tzv. bezpečná. Kromě metody GET existují ještě metody POST (vytvořit), PUT (aktualizovat) a DELETE (odstranit), které nepotřebujeme, protože data z API budeme pouze získávat.\n+ **adresa s parametry** (URL s query parameters): Na konci běžné URL adresy otazník a za ním parametry. Pokud je parametrů víc, oddělují se znakem &. Adresa samotná nejčastěji určuje o jaká data půjde (v našem příkladě jsou to filmy) a URL parametry umožňují provést filtraci už na straně serveru a získat tím jen ta data, která nás opravdu zajímají (v našem případě dramata v délce 150 min)\n http://api.example.com/movies/\n http://api.example.com/movies?genre=drama&duration=150 \n+ **hlavičky** (headers): Hlavičky jsou vlastně jen další parametry. Liší se v tom, že je neposíláme jako součást adresy a na rozdíl od URL parametrů podléhají nějaké standardizaci a konvencím.\n+ **tělo** (body): Tělo zprávy je krabice, kterou s požadavkem posíláme, a do které můžeme vložit, co chceme. Tedy nejlépe něco, čemu bude API na druhé straně rozumět. Tělo může být prázdné. V těle můžeme poslat obyčejný text, data v nějakém formátu, ale klidně i obrázek. Aby API na druhé straně vědělo, co v krabici je a jak ji má rozbalovat, je potřeba s tělem zpravidla posílat hlavičku Content-Type.\n\nMusíme vyčíst z dokumentace konkrétního API, jak požadavek správně poskládat.",
"_____no_output_____"
],
[
"### Odpověď",
"_____no_output_____"
],
[
"+ **status kód** (status code): Číselný kód, kterým API dává najevo, jak požadavek zpracovalo. Podle první číslice kódu se kódy dělí na různé kategorie:\n 1xx - informativní odpověď (požadavek byl přijat, ale jeho zpracování pokračuje)\n 2xx - požadavek byl v pořádku přijat a zpracován\n 3xx - přesměrování, klient potřebuje poslat další požadavek jinam, aby se dobral odpovědi\n 4xx - chyba na straně klienta (špatně jsme poskládali dotaz)\n 5xx - chyba na straně serveru (API nezvládlo odpovědět)\n+ **hlavičky** (headers): Informace o odpovědi jako např. datum zpracování, formát odpovědi...\n+ **tělo** (body): Tělo odpovědi - to, co nás zajímá většinou nejvíc",
"_____no_output_____"
],
[
"### Formáty",
"_____no_output_____"
],
[
"Tělo může být v libovolném formátu. Může to být text, HTML, obrázek, PDF soubor, nebo cokoliv jiného.\nHodnotě hlavičky Content-Type se dávají různé názvy: content type, media type, MIME type. \nNejčastěji se skládá jen z typu a podtypu, které se oddělí lomítkem. Několik příkladů:\n+ text/plain - obyčejný text\n+ text/html - HTML\n+ text/csv - CSV\n+ image/gif - GIF obrázek\n+ image/jpeg - JPEG obrázek\n+ image/png - PNG obrázek\n+ application/json - JSON\n+ application/xml nebo text/xml - XML\n",
"_____no_output_____"
],
[
"### Formát JSON",
"_____no_output_____"
],
[
"JSON vznikl kolem roku 2000 a brzy se uchytil jako stručnější náhrada za XML, především na webu a ve webových API. Dnes je to **nejspíš nejoblíbenější formát pro obecná strukturovaná data vůbec**. Jeho autorem je Douglas Crockford, jeden z lidí podílejících se na vývoji jazyka JavaScript.",
"_____no_output_____"
],
[
"#### JSON je datový formát NE datový typ!",
"_____no_output_____"
],
[
"Vstupem je libovolná datová struktura:\n+ číslo\n+ řetězec\n+ pravdivostní hodnota\n+ pole\n+ objekt\n+ None\n\nVýsutpem je vždy řetězec (string)",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"Jazyk Python (a mnoho dalších) má podporu pro práci s JSON v základní instalaci (vestavěný).\n\nV případě jazyka Python si lze JSON splést především se slovníkem (dictionary). Je ale potřeba si uvědomit, že JSON je text, který může být uložený do souboru nebo odeslaný přes HTTP, ale nelze jej přímo použít při programování. Musíme jej vždy nejdříve zpracovat na slovníky a seznamy.",
"_____no_output_____"
]
],
[
[
"import json",
"_____no_output_____"
]
],
[
[
"V následujícím JSONu je pod klíčem \"people\" seznam slovníků s další strukturou:",
"_____no_output_____"
]
],
[
[
"people_info = '''\n{\n \"people\": [\n {\n \"name\": \"John Smith\",\n \"phone\": \"555-246-999\",\n \"email\": [\"[email protected]\", \"[email protected]\"],\n \"is_employee\": false\n },\n {\n \"name\": \"Jane Doe\",\n \"phone\": \"665-296-659\",\n \"email\": [\"[email protected]\", \"[email protected]\"],\n \"is_employee\": true\n }\n ]\n}\n'''",
"_____no_output_____"
]
],
[
[
"json.loads převede řetězec na objekt",
"_____no_output_____"
]
],
[
[
"data = json.loads(people_info)",
"_____no_output_____"
],
[
"data",
"_____no_output_____"
],
[
"type(data)",
"_____no_output_____"
],
[
"type(data['people'])",
"_____no_output_____"
],
[
"type(data['people'][0])",
"_____no_output_____"
],
[
"data['people']",
"_____no_output_____"
],
[
"data['people'][0]",
"_____no_output_____"
],
[
"data['people'][0]['name']",
"_____no_output_____"
]
],
[
[
"# Práce s API klienty",
"_____no_output_____"
],
[
"## Obecný klient",
"_____no_output_____"
],
[
"Mobilní aplikace na počasí je klient, který někdo vytvořil pro jeden konkrétní úkol a pracovat umí jen s jedním konkrétním API. Takový klient je užitečný, pokud chceme akorát vědět, jaké je počasí, ale už méně, pokud si chceme zkoušet práci s více API zároveň. Proto existují obecní klienti.",
"_____no_output_____"
],
[
"### Prohlížeč jako obecný klient",
"_____no_output_____"
],
[
"Pokud z API chceme pouze číst a API nevyžaduje žádné přihlašování, můžeme jej vyzkoušet i v prohlížeči, jako by to byla webová stránka. Pokud na stránkách ČNB navštívíme [kurzovní lístek](https://www.cnb.cz/cs/financni-trhy/devizovy-trh/kurzy-devizoveho-trhu/kurzy-devizoveho-trhu/) a úplně dole klikneme na [Textový formát](https://www.cnb.cz/cs/financni-trhy/devizovy-trh/kurzy-devizoveho-trhu/kurzy-devizoveho-trhu/denni_kurz.txt?date=19.02.2020), uvidíme odpověď z API serveru",
"_____no_output_____"
],
[
"https://www.cnb.cz/cs/financni_trhy/devizovy_trh/kurzy_devizoveho_trhu/denni_kurz.txt",
"_____no_output_____"
],
[
"### Obecný klient v příkazové řádce: curl",
"_____no_output_____"
],
[
"Pokud se k API budeme potřebovat přihlásit nebo s ním zkoušet dělat složitější věci než jen čtení, nebude nám prohlížeč stačit.\n\nProto je dobré se naučit používat program curl. Spouští se v příkazové řádce a je to švýcarský nůž všech, kteří se pohybují kolem webových API.",
"_____no_output_____"
],
[
"#### Příklady s curl",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"Když příkaz zadáme a spustíme, říkáme tím programu curl, že má poslat požadavek na uvedenou adresu a vypsat to, co mu ČNB pošle zpět.",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"## Vlastní klient",
"_____no_output_____"
],
[
"Obecného klienta musí ovládat člověk (ruční nastavování parametrů, pravidelné spuštění na základě podmínek či času atd.). To je přesně to, co potřebujeme, když si chceme nějaké API vyzkoušet, ale celý smysl API je v tom, aby je programy mohly využívat automaticky.\nPokud chceme naprogramovat klienta pro konkrétní úkol, můžeme ve většině jazyků použít buď vestavěnou, nebo doinstalovanou knihovnu. V případě jazyka Python použijeme knihovnu Requests.",
"_____no_output_____"
],
[
"## Práce s veřejným API\nVyzkoušíme si dotazy na API s daty zločinnosti v UK, která jsou dostupná na měsiční bázi dle přibližné lokace (viz https://data.police.uk/docs/method/stops-at-location/)",
"_____no_output_____"
]
],
[
[
"import requests",
"_____no_output_____"
],
[
"api_url = \"https://data.police.uk/api/stops-street\"",
"_____no_output_____"
]
],
[
[
"Nastavení parametrů volání API dle dokumentace https://data.police.uk/docs/method/stops-at-location/\nJako lokaci jsem vybral nechvalně proslulý obvod Hackney v Londýně :)",
"_____no_output_____"
]
],
[
[
"params = {\n \"lat\" : \"51.5487158\",\n \"lng\" : \"-0.0613842\",\n \"date\" : \"2018-06\"\n}",
"_____no_output_____"
]
],
[
[
"Pomocí funkce `get` pošleme požadavek na URL adresu API. URL adresa doplněná o parametry vypadá takto: https://data.police.uk/api/stops-street?lat=51.5487158&lng=-0.0613842&date=2018-06 a je možné ji vyzkoušet i v prohlížeči.\n\nV proměnné response máme uložený objekt, který obsahuje odpověď od API.",
"_____no_output_____"
]
],
[
[
"response = requests.get(api_url, params=params)",
"_____no_output_____"
]
],
[
[
"Pokud je status kód jiný, než 200 (success), vyhodí skript chybu a chybový status code",
"_____no_output_____"
]
],
[
[
"if response.status_code != 200:\n print('Failed to get data:', response.status_code)\nelse:\n print('First 100 characters of data are')\n print(response.text[:100])",
"First 100 characters of data are\n[{\"age_range\":\"18-24\",\"outcome\":\"Community resolution\",\"involved_person\":true,\"self_defined_ethnicit\n"
]
],
[
[
"Hlavička s doplňujícími informacemi o opdovědi",
"_____no_output_____"
]
],
[
[
"response.headers",
"_____no_output_____"
],
[
"response.headers['content-type']",
"_____no_output_____"
]
],
[
[
"Obsah odpovědi je řetězec bytů",
"_____no_output_____"
]
],
[
[
"response.content[:200]",
"_____no_output_____"
]
],
[
[
"Vypadá jako seznam (list) nebo slovník (dictionary), ale nechová se tak:",
"_____no_output_____"
]
],
[
[
"response[0][\"age_range\"]",
"_____no_output_____"
]
],
[
[
"Převedeme řetězec bytů metodou .json() z knihovny requests",
"_____no_output_____"
]
],
[
[
"data = response.json()",
"_____no_output_____"
]
],
[
[
"Ověříme datový typ",
"_____no_output_____"
]
],
[
[
"type(data)",
"_____no_output_____"
]
],
[
[
"Nyní můžeme přistupovat k \"data\" jako ke klasickému seznamu (list)",
"_____no_output_____"
]
],
[
[
"data[0][\"age_range\"]",
"_____no_output_____"
]
],
[
[
"Převední seznamu(list) na řetězec s parametry pro zobrazení struktury v čitelné podobě",
"_____no_output_____"
]
],
[
[
"datas = json.dumps(data, sort_keys=True, indent=4)",
"_____no_output_____"
],
[
"print(datas[:1600])",
"[\n {\n \"age_range\": \"18-24\",\n \"datetime\": \"2018-06-01T09:45:00+00:00\",\n \"gender\": \"Male\",\n \"involved_person\": true,\n \"legislation\": \"Misuse of Drugs Act 1971 (section 23)\",\n \"location\": {\n \"latitude\": \"51.551330\",\n \"longitude\": \"-0.068037\",\n \"street\": {\n \"id\": 968551,\n \"name\": \"On or near Downs Park Road\"\n }\n },\n \"object_of_search\": \"Controlled drugs\",\n \"officer_defined_ethnicity\": \"Black\",\n \"operation\": false,\n \"operation_name\": null,\n \"outcome\": \"Community resolution\",\n \"outcome_linked_to_object_of_search\": null,\n \"outcome_object\": {\n \"id\": \"bu-community-resolution\",\n \"name\": \"Community resolution\"\n },\n \"removal_of_more_than_outer_clothing\": null,\n \"self_defined_ethnicity\": \"Black/African/Caribbean/Black British - Any other Black/African/Caribbean background\",\n \"type\": \"Person search\"\n },\n {\n \"age_range\": \"18-24\",\n \"datetime\": \"2018-06-02T02:37:00+00:00\",\n \"gender\": \"Male\",\n \"involved_person\": true,\n \"legislation\": \"Misuse of Drugs Act 1971 (section 23)\",\n \"location\": {\n \"latitude\": \"51.549626\",\n \"longitude\": \"-0.054738\",\n \"street\": {\n \"id\": 968830,\n \"name\": \"On or near Dalston Lane\"\n }\n },\n \"object_of_search\": \"Controlled drugs\",\n \"officer_defined_ethnicity\": \"Black\",\n \"operation\": false,\n \"operat\n"
]
],
[
[
"Cyklus, kterým přistupujeme k věkovému rozpětí lidí lustrovaných policií",
"_____no_output_____"
]
],
[
[
"age_range = [i[\"age_range\"] for i in data]",
"_____no_output_____"
],
[
"print(age_range)",
"['18-24', '18-24', 'over 34', '18-24', '10-17', '10-17', 'over 34', '25-34', 'over 34', '25-34', None, '25-34', '18-24', '10-17', None, '18-24', None, '18-24', '10-17', 'over 34', '18-24', '18-24', '18-24', '18-24', '18-24', '18-24', '18-24', '18-24', '18-24', '25-34', '18-24', '18-24', '18-24', 'over 34', '10-17', '10-17', '25-34', '18-24', '18-24', '25-34', '25-34', '25-34', 'over 34', 'over 34', '18-24', '18-24', '18-24', '18-24', '18-24', '25-34', '25-34', 'over 34', '25-34', 'over 34', '18-24', '25-34', '25-34', 'over 34', '18-24', None, '18-24', '18-24', None, '18-24', '18-24', '25-34', '10-17', '25-34', '18-24', '25-34', '18-24', None, '18-24', '25-34', '25-34', '25-34', '18-24', '25-34', '25-34', '18-24', '18-24', '10-17', 'over 34', 'over 34', '18-24', '18-24', '25-34', '10-17', '18-24', 'over 34', '10-17', '25-34', 'over 34', '18-24', '25-34', 'over 34', '25-34', '18-24', '18-24', '18-24', '18-24', '10-17', '10-17', '18-24', '25-34', '18-24', '25-34', '18-24', '18-24', '10-17', '25-34', '18-24', 'over 34', '10-17', '18-24', 'over 34', '18-24', '10-17', '10-17', 'over 34', '25-34', '10-17', '10-17', '25-34', '10-17', '10-17', '10-17', '10-17', '18-24', '10-17', '10-17', None, 'over 34', '10-17', '10-17', '25-34', '10-17', '18-24', '10-17', None, '10-17', '10-17', '25-34', '18-24', '18-24', '25-34', '10-17', '10-17', '25-34', '10-17', None, '25-34', '25-34', '18-24', '10-17', '25-34', '18-24', '10-17', '10-17', '25-34', None, '18-24', '25-34', '25-34', '10-17', '10-17', '18-24', 'over 34', '18-24', '18-24', '10-17', '10-17', '25-34', 'over 34', 'over 34', '18-24', '18-24', '25-34', '10-17']\n"
]
],
[
[
"Cyklus, kterým přistupujeme k id ulice, kde došlo lustraci podezřelé(ho)",
"_____no_output_____"
]
],
[
[
"street_id = [i[\"location\"][\"street\"][\"id\"] for i in data]",
"_____no_output_____"
],
[
"print(street_id)",
"[968551, 968830, 968830, 968740, 964026, 964026, 968844, 968662, 968662, 968662, 971832, 971832, 968828, 968828, 968805, 968828, 968805, 968805, 968805, 968584, 964086, 968632, 968632, 964132, 968632, 968632, 968584, 968584, 968872, 971832, 968717, 968866, 971656, 964226, 968662, 968662, 968703, 968668, 968668, 968703, 964013, 968505, 968830, 968500, 968662, 968830, 968830, 968662, 968662, 968705, 964150, 968663, 968663, 968830, 968467, 968662, 968663, 968830, 964370, 964370, 968500, 964287, 964329, 971656, 971656, 968830, 968829, 968830, 968829, 968608, 968703, 968703, 968469, 968662, 968754, 968662, 968872, 968748, 968872, 968691, 968641, 968641, 964023, 964322, 968872, 968872, 968872, 968662, 964219, 964092, 964219, 968854, 968662, 968662, 968662, 968786, 968584, 968662, 964266, 964316, 964266, 968637, 968637, 968804, 968804, 968804, 971758, 968804, 968662, 964297, 968830, 968770, 968500, 968662, 968804, 968500, 964324, 964266, 964225, 968816, 968500, 964266, 968641, 968575, 968828, 968828, 968828, 968489, 968815, 968564, 964266, 968871, 968687, 964091, 968815, 971713, 971801, 968662, 964208, 968614, 968802, 968839, 964085, 968630, 968642, 964098, 964312, 964312, 968872, 964248, 971656, 968872, 968872, 968804, 968647, 968884, 968844, 968872, 968763, 968830, 968804, 968854, 968609, 968662, 968830, 968489, 968603, 971832, 968641, 968830, 968647, 968489, 968496, 968606, 968626, 968606, 968369, 968660, 968815]\n"
],
[
"import pandas as pd",
"_____no_output_____"
]
],
[
[
"Spojíme seznamy do dataframe",
"_____no_output_____"
]
],
[
[
"df_from_lists = pd.DataFrame(list(zip(age_range, street_id)), \n columns = ['age_range', 'street_id'])",
"_____no_output_____"
],
[
"df_from_lists.head()",
"_____no_output_____"
]
],
[
[
"Jakou věkovou skupinu lustrovala policie nejčastěji?",
"_____no_output_____"
]
],
[
[
"%matplotlib inline",
"_____no_output_____"
],
[
"df_from_lists[\"age_range\"].value_counts().plot.bar();",
"_____no_output_____"
]
],
[
[
"### Json_normalize\naneb jak jednoduše převést JSON na DataFrame",
"_____no_output_____"
]
],
[
[
"norm_data = pd.json_normalize(data)",
"_____no_output_____"
],
[
"norm_data.head()",
"_____no_output_____"
],
[
"norm_data[\"gender\"].value_counts()",
"_____no_output_____"
],
[
"norm_data[\"gender\"].value_counts().plot.bar();",
"_____no_output_____"
],
[
"norm_data[\"age_range\"].value_counts().plot.bar();",
"_____no_output_____"
]
],
[
[
"## Tvoříme klienta pro práci s veřejným API",
"_____no_output_____"
],
[
"V následujícím bloku si vytvoříme klienta, který nám stáhne data za dva měsíce (místo jednoho) a uloží je do seznamu seznamů (list of lists). Případné chyby spojení s API ošetříme výjimkami (exceptions) - více viz [dokumentace requests](https://requests.readthedocs.io/en/master/_modules/requests/exceptions/)",
"_____no_output_____"
]
],
[
[
"def get_uk_crime_data(latitude, longitude, dates_list):\n \"\"\"\n Function loops through a list of dates \n \n Three arguments latitude, longitude and a list of dates\n \n Returns a dataframe with crime data for each day\n \"\"\"\n appended_data = []\n \n for i in dates_list:\n api_url = \"https://data.police.uk/api/stops-street\"\n params = {\n \"lat\" : latitude,\n \"lng\" : longitude,\n \"date\" : i\n }\n response = requests.get(api_url, params=params)\n data_foo = response.json()\n \n data = pd.json_normalize(data_foo)\n # store DataFrame in list\n appended_data.append(data)\n \n return pd.concat(appended_data)",
"_____no_output_____"
]
],
[
[
"Zavolání funkce get_uk_crime_data s parametry zeměpisné šíře a délky přiřazené proměnné df_uk_crime_data",
"_____no_output_____"
]
],
[
[
"dates_list = [\"2018-06\",\"2018-07\"]\nlat = \"51.5487158\"\nlng = \"-0.0613842\"\n\ndf_uk_crime_data = get_uk_crime_data(lat, lng, dates_list)",
"_____no_output_____"
],
[
"df_uk_crime_data.head()",
"_____no_output_____"
]
],
[
[
"## Přistupování k tweetům přes Twitter API pomocí knihovny Tweepy",
"_____no_output_____"
],
[
"Příkaz na instalaci knihovny tweepy uvnitř notebooku. Stačí odkomentovat a spustit.",
"_____no_output_____"
]
],
[
[
"#%pip install tweepy",
"_____no_output_____"
]
],
[
[
"Import knihovny Tweepy",
"_____no_output_____"
]
],
[
[
"import tweepy",
"_____no_output_____"
]
],
[
[
"Pro získání dat z Twitteru musí náš klient projít OAuth autorizací.\n\n**Jak funguje OAuth autorizace na Twitteru?**\n\n1. vývojář aplikace se zaregistruje u poskytovatele API\n2. zaregistruje aplikaci, získá consumer_key, consumer_secret, access_token a access_secret na https://developer.twitter.com/en/apps\n3. aplikace volá API a prokazuje se consumer_key, consumer_secret, access_token a access_secret",
"_____no_output_____"
]
],
[
[
"consumer_key = \"tTIzOaOSJkyiFTGJwXDSarGLI\"\nconsumer_secret = \"3yhCpz7dpLgxkkZsMOWwzKmlefngngskPpO1k3HKI5jIojijzA\"\naccess_token = \"1646190612-U8wKL2PwiAabeg9e9GZUhlLjiWrRgd1sqbd0oQq\"\naccess_secret = \"DA5yY1PWS00OKt7OB7wRD4AnSkRQky9Wl4e8RRJQFo82q\"",
"_____no_output_____"
]
],
[
[
"Další krok je vytvoření instance OAuthHandleru, do kterého vložíme náš consumer token a consumer secret",
"_____no_output_____"
]
],
[
[
"auth = tweepy.OAuthHandler(consumer_key, consumer_secret)\nauth.set_access_token(access_token, access_secret)",
"_____no_output_____"
]
],
[
[
"Ověření funkčnosti autentifikace",
"_____no_output_____"
]
],
[
[
"api = tweepy.API(auth)\n\ntry:\n api.verify_credentials()\n print(\"Authentication OK\")\nexcept Exception:\n print(\"Error during authentication\")",
"Error during authentication\n"
]
],
[
[
"V API dokumentaci k Tweepy http://docs.tweepy.org/en/v3.5.0/api.html najdeme metodu která např. vypíše ID přátel, resp. sledujících účtu",
"_____no_output_____"
]
],
[
[
"api.friends_ids('@kdnuggets')",
"_____no_output_____"
]
],
[
[
"Nebo vypíše ID, které účet sleduje",
"_____no_output_____"
]
],
[
[
"api.followers_ids('@kdnuggets')",
"_____no_output_____"
]
],
[
[
"Metoda, která vrátí posledních 20 tweetů podle ID uživatele",
"_____no_output_____"
]
],
[
[
"twitter_user = api.user_timeline('@kdnuggets')",
"_____no_output_____"
],
[
"kdnuggets_tweets = [i.text for i in twitter_user]\nprint(kdnuggets_tweets)",
"_____no_output_____"
],
[
"def get_tweets(consumer_key, consumer_secret, access_token, access_secret, twitter_account):\n \"\"\"\n Function gets the last 20 tweets and adds those not in the list\n \n Five arguments consumer_key, consumer_secret, access_token, access_secret, and twitter_account name\n \n Returns a dataframe with tweets for given account\n \"\"\"\n \n auth = tweepy.OAuthHandler(consumer_key, consumer_secret)\n auth.set_access_token(access_token, access_secret)\n api = tweepy.API(auth)\n\n try:\n api.verify_credentials()\n print(\"Authentication OK\")\n twitter_user = api.user_timeline(twitter_account)\n \n tweets_list = [i.text for i in twitter_user]\n \n except Exception:\n print(\"Error during authentication\")\n \n return pd.DataFrame(tweets_list, columns = [twitter_account])",
"_____no_output_____"
],
[
"get_tweets(consumer_key, consumer_secret, access_token, access_secret, '@kdnuggets')",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
cb3ba8e4851e9de3e441183dba71a743e5224223 | 20,682 | ipynb | Jupyter Notebook | nfl-predictor.ipynb | lucasrgoldman/nfl-predictor | 284c65ea49283a0dbbc98d1d9019a76963cc2c07 | [
"MIT"
] | null | null | null | nfl-predictor.ipynb | lucasrgoldman/nfl-predictor | 284c65ea49283a0dbbc98d1d9019a76963cc2c07 | [
"MIT"
] | 1 | 2021-09-08T04:05:29.000Z | 2021-09-08T04:05:29.000Z | nfl-predictor.ipynb | lucasrgoldman/nfl-predictor | 284c65ea49283a0dbbc98d1d9019a76963cc2c07 | [
"MIT"
] | null | null | null | 70.828767 | 4,469 | 0.485688 | [
[
[
"from sportsreference.nfl.teams import Teams\nimport pandas as pd\nimport numpy as np\nfrom scipy import stats\nfrom datetime import datetime\n\n# Pull 2020 NFL Data from sportsreference api\n\nteams = Teams(year= '2020')\nteams_df = teams.dataframes\nteams_df.sort_values(by=['name'], inplace=True, ascending=True)\nteams_df.set_index('name', inplace=True)\n\n# Drop statistics that are not Relevant\n\nteams_df.drop(['first_downs', 'first_downs_from_penalties', 'games_played','losses', 'abbreviation','pass_attempts', 'pass_completions', 'pass_first_downs','plays', 'points_contributed_by_offense','post_season_result', 'rush_attempts', 'rush_first_downs', 'wins'], axis=1, inplace= True)\n\n# Normalize data\n\nfor (columnName, columnData) in teams_df.iteritems(): \n if columnName != 'name':\n teams_df[columnName] = stats.zscore(columnData)\n\n# Invert stats that negatively affect a team\n\nteams_df[['fumbles', 'interceptions', 'penalties', 'percent_drives_with_turnovers', 'points_against', 'turnovers', 'yards_from_penalties']] *= -1\nteams_df.head()",
"defensive_simple_rating_system fumbles interceptions \\\nname \nArizona Cardinals 0.298534 -0.146889 0.173235 \nAtlanta Falcons 0.239198 -0.482636 -0.354718 \nBaltimore Ravens 1.277577 -0.482636 -0.354718 \nBuffalo Bills 0.179862 0.860350 -0.354718 \nCarolina Panthers 0.387538 -1.154128 0.965164 \n\n margin_of_victory offensive_simple_rating_system \\\nname \nArizona Cardinals 0.431262 0.373906 \nAtlanta Falcons -0.175699 -0.024098 \nBaltimore Ravens 1.645186 0.970911 \nBuffalo Bills 1.261842 1.766918 \nCarolina Panthers -0.527098 -0.596228 \n\n pass_net_yards_per_attempt pass_touchdowns pass_yards \\\nname \nArizona Cardinals 0.095371 -0.025220 0.141967 \nAtlanta Falcons 0.095371 -0.025220 1.004256 \nBaltimore Ravens -0.182073 -0.025220 -2.128536 \nBuffalo Bills 1.343869 1.473561 1.500024 \nCarolina Panthers 0.234093 -1.293419 0.087953 \n\n penalties percent_drives_with_points ... \\\nname ... \nArizona Cardinals 2.014801 0.039590 ... \nAtlanta Falcons -0.598995 0.777262 ... \nBaltimore Ravens 1.230662 0.857444 ... \nBuffalo Bills 1.056409 1.514934 ... \nCarolina Panthers 0.446523 0.055626 ... \n\n rush_touchdowns rush_yards rush_yards_per_attempt \\\nname \nArizona Cardinals 1.119625 0.903310 0.749012 \nAtlanta Falcons -0.755096 -0.998395 -1.624095 \nBaltimore Ravens 1.536229 3.152986 2.647497 \nBuffalo Bills -0.130189 -0.483181 -0.437541 \nCarolina Panthers 0.494718 -0.534433 -0.437541 \n\n simple_rating_system strength_of_schedule turnovers \\\nname \nArizona Cardinals 0.449286 -0.085829 0.043874 \nAtlanta Falcons 0.120170 1.529776 -0.557832 \nBaltimore Ravens 1.436633 -1.620654 -0.557832 \nBuffalo Bills 1.332701 -0.166609 0.244443 \nCarolina Panthers -0.191623 1.772117 0.043874 \n\n win_percentage yards yards_from_penalties \\\nname \nArizona Cardinals -0.001027 0.825608 0.693817 \nAtlanta Falcons -1.174777 0.304131 -0.330181 \nBaltimore Ravens 0.881633 0.132327 1.415271 \nBuffalo Bills 1.468508 1.209641 1.260119 \nCarolina Panthers -0.878992 -0.308300 -0.206060 \n\n yards_per_play \nname \nArizona Cardinals 0.254467 \nAtlanta Falcons -0.174109 \nBaltimore Ravens 0.683043 \nBuffalo Bills 1.111618 \nCarolina Panthers 0.040179 \n\n[5 rows x 25 columns]\n"
],
[
"rank = pd.Series()\nrank['defensive_simple_rating_system'] = 5\nrank['fumbles'] =0\nrank['interceptions'] =0\nrank['margin_of_victory'] = 3\nrank['offensive_simple_rating_system'] = 5\nrank['pass_net_yards_per_attempt'] = .5\nrank['pass_touchdowns'] = 1\nrank['pass_yards'] =1\nrank['penalties'] =1\nrank['percent_drives_with_points'] =2\nrank['percent_drives_with_turnovers'] = 2\nrank['points_against'] =1\nrank['rank'] = 0\nrank['rush_touchdowns'] = 1\nrank['rush_yards'] = 3\nrank['rush_yards_per_attempt'] =1\nrank['simple_rating_system'] = 7\nrank['strength_of_schedule'] = 4\nrank['turnovers'] = 3\nrank['win_percentage'] = 6\nrank['yards'] = 2\nrank['yards_from_penalties'] = .5\nrank['yards_per_play'] = 2 \nsum = rank.sum() \nrank/=sum",
"_____no_output_____"
],
[
"for (columnName, columnData) in rank.iteritems(): \n teams_df[columnName]*= columnData\n print(rank[columnName])",
"_____no_output_____"
],
[
"teams_df['sum'] = 0.0\nfor i, row in teams_df.iterrows():\n teams_df.at[i, 'sum'] = row['defensive_simple_rating_system':].sum()\nteams_df.sort_values(by=['sum'], inplace=True, ascending=False)\nprint(teams_df['sum'])",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\nimport seaborn as sns\nsns.kdeplot(teams_df['sum'])\n\n",
"_____no_output_____"
],
[
"teams_df['zscores'] = stats.zscore(teams_df['sum'])\nteams_df['percentile'] = 1- stats.norm.sf(teams_df['zscores'])\nprint(teams_df['percentile'])",
"_____no_output_____"
],
[
"def predict (team1, team2):\n t1 = teams_df['percentile'].loc[team1]\n t2 = teams_df['percentile'].loc[team2]\n #return (teams_df['percentile'].loc[team1] - teams_df['percentile'].loc[team2])/2 + .5\n p = 1/(10**(-(t1 - t2))+1)\n return probToMoneyLine(p)",
"_____no_output_____"
],
[
"def probToMoneyLine (prob):\n ml = 0\n prob*=100\n if prob >50:\n ml = -(prob/(100 - prob)) * 100\n elif prob < 50:\n ml = (((100 - prob)/prob) * 100)\n else:\n ml = 100\n return ml",
"_____no_output_____"
],
[
"predict('Tennessee Titans', 'Las Vegas Raiders')",
"_____no_output_____"
],
[
"import json\nimport requests\nimport argparse\n\nparser = argparse.ArgumentParser(description='Sample')\nparser.add_argument('--api-key', type=str, default='')\nargs, unknown = parser.parse_known_args()\n\n\nAPI_KEY = '58f860df380e5b01f108f9418584b714'\n\nSPORT = 'americanfootball_nfl' # use the sport_key from the /sports endpoint below, or use 'upcoming' to see the next 8 games across all sports\n\nREGION = 'us' # uk | us | eu | au\n\nMARKET = 'h2h' # h2h | spreads | totals\n\nODDSFORMAT = 'american'\n\n\n\n# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # \n#\n# Now get a list of live & upcoming games for the sport you want, along with odds for different bookmakers\n#\n# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # \n\nodds_response = requests.get('https://api.the-odds-api.com/v3/odds', params={\n 'api_key': API_KEY,\n 'sport': SPORT,\n 'region': REGION,\n 'mkt': MARKET,\n 'oddsFormat': ODDSFORMAT,\n})\n\nodds_json = json.loads(odds_response.text)\ngames = []\nif not odds_json['success']:\n print(odds_json['msg'])\nelse:\n print('Number of events:', len(odds_json['data']))\n print(odds_json['data'][0]['commence_time'])\n first = odds_json['data']\n for i, game in enumerate(odds_json['data'], start=0):\n games.append({})\n games[i]['teams'] = game['teams']\n games[i]['home'] = game['home_team']\n\n for site in game['sites']:\n if site['site_nice'] == 'Caesars':\n games[i]['odds'] = site['odds']['h2h']\n\n # Check your usage\n print('Remaining requests', odds_response.headers['x-requests-remaining'])\n print('Used requests', odds_response.headers['x-requests-used'])",
"_____no_output_____"
],
[
"print(games)",
"_____no_output_____"
],
[
"for game in games:\n team1 = game['teams'][0]\n team2 = game['teams'][1]\n print(team1, ' vs', team2)\n print('Predicted Line for', team1,'is', predict(team1, team2))\n print('Actual Line for', team1,'is', game['odds'][0] )\n",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3bb213ff61522d49d651f832e764a073f96d8d | 3,063 | ipynb | Jupyter Notebook | base.ipynb | sal-versij/Neuronal-Network-Study | b78fc1c6959b25e44f981ae6daab0cde9d5759b5 | [
"MIT"
] | null | null | null | base.ipynb | sal-versij/Neuronal-Network-Study | b78fc1c6959b25e44f981ae6daab0cde9d5759b5 | [
"MIT"
] | null | null | null | base.ipynb | sal-versij/Neuronal-Network-Study | b78fc1c6959b25e44f981ae6daab0cde9d5759b5 | [
"MIT"
] | null | null | null | 22.858209 | 169 | 0.486778 | [
[
[
"import numpy as np\n",
"_____no_output_____"
],
[
"# A cell is a group of inputs, weights and a bias\ninputs = [1.2,5.3,6.1]\nweight = [3.1,5.2,2.3]\nbias = 3\noutput = sum([inputs[x]*weight[x] for x in range(3)])+bias\nprint(output)",
"48.309999999999995\n"
],
[
"# A layer of cells can be defined by the weights and biases of each node, the input is the same for the full layer\nweights = [[1.5,-2.3,2.5],\n [2.6,3.5,-1.7],\n [-1.7,4.3,-2.4],\n [-2.4,1.2,-1.7]]\nbiases = [2,6,3,1]\noutputs = [sum([inputs[j]*weights[i][j] for j in range(3)])+biases[i] for i in range(4)]\nprint(outputs)",
"[6.859999999999999, 17.300000000000004, 9.110000000000001, -5.89]\n"
],
[
"# Use np to speed up the work with vectorization\noutputs = np.dot(weights,inputs)+biases\nprint(outputs)",
"[ 6.86 17.3 9.11 -5.89]\n"
],
[
"# Batch fitting with multiples inputs\ninputs = [[1.2,5.3,6.1],\n [3.3,5.2,4.1],\n [5.2,2.5,3.2],\n [6.2,4.3,3.2],\n [2.1,5.6,9.4]]\n# Th weights need to be transposed\noutputs = np.dot(inputs,np.array(weights).T)+biases\nprint(outputs)",
"[[ 6.86 17.3 9.11 -5.89]\n [ 5.24 25.81 9.91 -7.65]\n [ 12.05 22.83 -2.77 -13.92]\n [ 9.41 31.73 3.27 -14.16]\n [ 15.77 15.08 0.95 -13.3 ]]\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code"
]
] |
cb3bbfa755150d6f5f4c36c748aa6e2fdd02dc46 | 339,651 | ipynb | Jupyter Notebook | 1703_dlib_face_detection.ipynb | parekhakhil/pyImageSearch | 5f18991bc68a65208f62f53265cdf427cecdaa0f | [
"Apache-2.0"
] | 1 | 2022-03-13T19:14:03.000Z | 2022-03-13T19:14:03.000Z | 1703_dlib_face_detection.ipynb | parekhakhil/pyImageSearch | 5f18991bc68a65208f62f53265cdf427cecdaa0f | [
"Apache-2.0"
] | null | null | null | 1703_dlib_face_detection.ipynb | parekhakhil/pyImageSearch | 5f18991bc68a65208f62f53265cdf427cecdaa0f | [
"Apache-2.0"
] | 4 | 2021-05-30T18:14:27.000Z | 2022-01-06T06:13:21.000Z | 748.129956 | 277,827 | 0.945579 | [
[
[
"<a href=\"https://colab.research.google.com/github/parekhakhil/pyImageSearch/blob/main/1703_dlib_face_detection.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"# Face detection with dlib (HOG and CNN)\n### by [PyImageSearch.com](http://www.pyimagesearch.com)",
"_____no_output_____"
],
[
"## Welcome to **[PyImageSearch Plus](http://pyimg.co/plus)** Jupyter Notebooks!\n\nThis notebook is associated with the [Face detection with dlib (HOG and CNN)](https://www.pyimagesearch.com/2021/04/19/face-detection-with-dlib-hog-and-cnn/) blog post published on 2021-04-19.\n\nOnly the code for the blog post is here. Most codeblocks have a 1:1 relationship with what you find in the blog post with two exceptions: (1) Python classes are not separate files as they are typically organized with PyImageSearch projects, and (2) Command Line Argument parsing is replaced with an `args` dictionary that you can manipulate as needed.\n\nWe recommend that you execute (press ▶️) the code block-by-block, as-is, before adjusting parameters and `args` inputs. Once you've verified that the code is working, you are welcome to hack with it and learn from manipulating inputs, settings, and parameters. For more information on using Jupyter and Colab, please refer to these resources:\n\n* [Jupyter Notebook User Interface](https://jupyter-notebook.readthedocs.io/en/stable/notebook.html#notebook-user-interface)\n* [Overview of Google Colaboratory Features](https://colab.research.google.com/notebooks/basic_features_overview.ipynb)\n\nAs a reminder, these PyImageSearch Plus Jupyter Notebooks are not for sharing; please refer to the **Copyright** directly below and **Code License Agreement** in the last cell of this notebook. \n\nHappy hacking!\n\n*Adrian*\n\n<hr>\n\n***Copyright:*** *The contents of this Jupyter Notebook, unless otherwise indicated, are Copyright 2021 Adrian Rosebrock, PyimageSearch.com. All rights reserved. Content like this is made possible by the time invested by the authors. If you received this Jupyter Notebook and did not purchase it, please consider making future content possible by joining PyImageSearch Plus at http://pyimg.co/plus/ today.*",
"_____no_output_____"
],
[
"### Install the necessary packages",
"_____no_output_____"
],
[
"***Note: Please ensure that you have selected GPU as the Hardware Accelerator. If not, here is how you would navigate to do it:*** `Runtime` -> `Change runtime type` -> `Hardware accelerator` -> `GPU` -> `SAVE`\n\n\n",
"_____no_output_____"
],
[
"### Download the code zip file",
"_____no_output_____"
]
],
[
[
"!wget https://pyimagesearch-code-downloads.s3-us-west-2.amazonaws.com/dlib-face-detection/dlib-face-detection.zip\n!unzip -qq dlib-face-detection.zip\n%cd dlib-face-detection",
"_____no_output_____"
]
],
[
[
"## Blog Post Code",
"_____no_output_____"
],
[
"### Import Packages",
"_____no_output_____"
]
],
[
[
"# import the necessary packages\nfrom matplotlib import pyplot as plt\nimport argparse\nimport imutils\nimport time\nimport dlib\nimport cv2",
"_____no_output_____"
]
],
[
[
"### Function to display images in Jupyter Notebooks and Google Colab",
"_____no_output_____"
]
],
[
[
"def plt_imshow(title, image):\n\t# convert the image frame BGR to RGB color space and display it\n\timage = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)\n\tplt.imshow(image)\n\tplt.title(title)\n\tplt.grid(False)\n\tplt.show()",
"_____no_output_____"
]
],
[
[
"### Creating our bounding box converting and clipping function",
"_____no_output_____"
]
],
[
[
"def convert_and_trim_bb(image, rect):\n\t# extract the starting and ending (x, y)-coordinates of the\n\t# bounding box\n\tstartX = rect.left()\n\tstartY = rect.top()\n\tendX = rect.right()\n\tendY = rect.bottom()\n\n\t# ensure the bounding box coordinates fall within the spatial\n\t# dimensions of the image\n\tstartX = max(0, startX)\n\tstartY = max(0, startY)\n\tendX = min(endX, image.shape[1])\n\tendY = min(endY, image.shape[0])\n\n\t# compute the width and height of the bounding box\n\tw = endX - startX\n\th = endY - startY\n\n\t# return our bounding box coordinates\n\treturn (startX, startY, w, h)",
"_____no_output_____"
]
],
[
[
"### Implementing HOG + Linear SVM face detection with dlib",
"_____no_output_____"
]
],
[
[
"# construct the argument parser and parse the arguments\n#ap = argparse.ArgumentParser()\n#ap.add_argument(\"-i\", \"--image\", type=str, required=True,\n#\thelp=\"path to input image\")\n#ap.add_argument(\"-u\", \"--upsample\", type=int, default=1,\n#\thelp=\"# of times to upsample\")\n#args = vars(ap.parse_args())\n\n# since we are using Jupyter Notebooks we can replace our argument\n# parsing code with *hard coded* arguments and values\nargs = {\n\t\"image\": \"images/family.jpg\",\n \"upsample\": 1\n}",
"_____no_output_____"
],
[
"# load dlib's HOG + Linear SVM face detector\nprint(\"[INFO] loading HOG + Linear SVM face detector...\")\ndetector = dlib.get_frontal_face_detector()\n\n# load the input image from disk, resize it, and convert it from\n# BGR to RGB channel ordering (which is what dlib expects)\nimage = cv2.imread(args[\"image\"])\nimage = imutils.resize(image, width=600)\nrgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)\n\n# perform face detection using dlib's face detector\nstart = time.time()\nprint(\"[INFO[ performing face detection with dlib...\")\nrects = detector(rgb, args[\"upsample\"])\nend = time.time()\nprint(\"[INFO] face detection took {:.4f} seconds\".format(end - start))",
"_____no_output_____"
],
[
"\n# convert the resulting dlib rectangle objects to bounding boxes,\n# then ensure the bounding boxes are all within the bounds of the\n# input image\nboxes = [convert_and_trim_bb(image, r) for r in rects]\n\n# loop over the bounding boxes\nfor (x, y, w, h) in boxes:\n\t# draw the bounding box on our image\n\tcv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)\n\n# show the output image\nplt_imshow(\"Output\", image)",
"_____no_output_____"
]
],
[
[
"### Implementing CNN face detection with dlib",
"_____no_output_____"
]
],
[
[
"# construct the argument parser and parse the arguments\n#ap = argparse.ArgumentParser()\n#ap.add_argument(\"-i\", \"--image\", type=str, required=True,\n#\thelp=\"path to input image\")\n#ap.add_argument(\"-m\", \"--model\", type=str,\n#\tdefault=\"mmod_human_face_detector.dat\",\n#\thelp=\"path to dlib's CNN face detector model\")\n#ap.add_argument(\"-u\", \"--upsample\", type=int, default=1,\n#\thelp=\"# of times to upsample\")\n#args = vars(ap.parse_args())\n\n# since we are using Jupyter Notebooks we can replace our argument\n# parsing code with *hard coded* arguments and values\nargs = {\n\t\"image\": \"images/avengers.jpg\",\n \"model\": \"mmod_human_face_detector.dat\",\n \"upsample\": 1\n}",
"_____no_output_____"
],
[
"# load dlib's CNN face detector\nprint(\"[INFO] loading CNN face detector...\")\ndetector = dlib.cnn_face_detection_model_v1(args[\"model\"])\n\n# load the input image from disk, resize it, and convert it from\n# BGR to RGB channel ordering (which is what dlib expects)\nimage = cv2.imread(args[\"image\"])\nimage = imutils.resize(image, width=600)\nrgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)\n\n# perform face detection using dlib's face detector\nstart = time.time()\nprint(\"[INFO[ performing face detection with dlib...\")\nresults = detector(rgb, args[\"upsample\"])\nend = time.time()\nprint(\"[INFO] face detection took {:.4f} seconds\".format(end - start))",
"_____no_output_____"
],
[
"# convert the resulting dlib rectangle objects to bounding boxes,\n# then ensure the bounding boxes are all within the bounds of the\n# input image\nboxes = [convert_and_trim_bb(image, r.rect) for r in results]\n\n# loop over the bounding boxes\nfor (x, y, w, h) in boxes:\n\t# draw the bounding box on our image\n\tcv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)\n\n# show the output image\nplt_imshow(\"Output\", image)",
"_____no_output_____"
]
],
[
[
"For a detailed walkthrough of the concepts and code, be sure to refer to the full tutorial, [*Face detection with dlib (HOG and CNN)*](https://www.pyimagesearch.com/2021/04/19/face-detection-with-dlib-hog-and-cnn/) published on 2021-04-19.",
"_____no_output_____"
],
[
"# Code License Agreement\n```\nCopyright (c) 2021 PyImageSearch.com\n\nSIMPLE VERSION\nFeel free to use this code for your own projects, whether they are\npurely educational, for fun, or for profit. THE EXCEPTION BEING if\nyou are developing a course, book, or other educational product.\nUnder *NO CIRCUMSTANCE* may you use this code for your own paid\neducational or self-promotional ventures without written consent\nfrom Adrian Rosebrock and PyImageSearch.com.\n\nLONGER, FORMAL VERSION\nPermission is hereby granted, free of charge, to any person obtaining\na copy of this software and associated documentation files\n(the \"Software\"), to deal in the Software without restriction,\nincluding without limitation the rights to use, copy, modify, merge,\npublish, distribute, sublicense, and/or sell copies of the Software,\nand to permit persons to whom the Software is furnished to do so,\nsubject to the following conditions:\nThe above copyright notice and this permission notice shall be\nincluded in all copies or substantial portions of the Software.\nNotwithstanding the foregoing, you may not use, copy, modify, merge,\npublish, distribute, sublicense, create a derivative work, and/or\nsell copies of the Software in any work that is designed, intended,\nor marketed for pedagogical or instructional purposes related to\nprogramming, coding, application development, or information\ntechnology. Permission for such use, copying, modification, and\nmerger, publication, distribution, sub-licensing, creation of\nderivative works, or sale is expressly withheld.\nTHE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND,\nEXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES\nOF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND\nNONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS\nBE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN\nACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN\nCONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\nSOFTWARE.\n```",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
cb3bc9cc488dda5b91191ba931455c102b7fe23c | 23,312 | ipynb | Jupyter Notebook | hackathon_ht3/code/.ipynb_checkpoints/bnb_data-checkpoint.ipynb | encodingintuition/MachineLearningWorkbook | fb8e985475ad930c30092a0b1a27f4b8be3c7979 | [
"MIT"
] | null | null | null | hackathon_ht3/code/.ipynb_checkpoints/bnb_data-checkpoint.ipynb | encodingintuition/MachineLearningWorkbook | fb8e985475ad930c30092a0b1a27f4b8be3c7979 | [
"MIT"
] | null | null | null | hackathon_ht3/code/.ipynb_checkpoints/bnb_data-checkpoint.ipynb | encodingintuition/MachineLearningWorkbook | fb8e985475ad930c30092a0b1a27f4b8be3c7979 | [
"MIT"
] | null | null | null | 29.734694 | 118 | 0.379118 | [
[
[
"# Hackathon Hospitality \n<hr/>",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport seaborn as sns\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"# Data - in \n<hr/>",
"_____no_output_____"
]
],
[
[
"# hotels & air bnb in NY \n\ndf = pd.read_csv('../data/new_york_hotels.csv' )\nprint(df.shape)\ndf.head(3)",
"(1631, 11)\n"
]
],
[
[
"Choose to use the NY hotel dataset and only keep the Bed & Breakfasts",
"_____no_output_____"
],
[
" ",
"_____no_output_____"
]
],
[
[
"df2 = pd.read_csv('../data/Bed___Breakfast_Lodging_Certificates.csv')\nprint(df2.shape)\ndf2.head(3)",
"(19, 21)\n"
],
[
"# Read Gem / local list \n\ndf_gem = pd.read_excel('../data/local_spots.xlsx')\nprint(df_gem.shape)\ndf_gem.head(6)",
"(6, 11)\n"
]
],
[
[
" ",
"_____no_output_____"
]
],
[
[
"df_gem.columns",
"_____no_output_____"
],
[
"# write new local_spots as CSV\n\ndf_gem.to_csv('../clean_data/local_spots.csv', index = False)",
"_____no_output_____"
]
],
[
[
" ",
"_____no_output_____"
],
[
"# EDA\n<hr/>",
"_____no_output_____"
]
],
[
[
"# NY Hotel DataSet\n# mask out all non-BnB \n\ndf1 = df[ (df['name'].str.contains('Bed', na =False) == True) ].copy()\ndf1.reset_index(drop = True, inplace = True)\n\ndf1.head(2)",
"_____no_output_____"
],
[
"# average as rate\n\ndf1['price'] = round ( (df1['high_rate'] + df1['low_rate']) / 2, 2)",
"_____no_output_____"
],
[
"# rename columns\n\ndf1.rename(columns = {'address1':'address', 'star_rating':'rating','state_province':'state', }, inplace = True )",
"_____no_output_____"
],
[
"# drop rows\n\ndf1.drop(['ean_hotel_id', 'high_rate','low_rate'], axis = 1, inplace = True)",
"_____no_output_____"
],
[
"# add Description\n\ndf1['descripton'] = \"\"",
"_____no_output_____"
],
[
"df1.columns",
"_____no_output_____"
]
],
[
[
" ",
"_____no_output_____"
],
[
"# Output Clean csv\n<hr/>",
"_____no_output_____"
]
],
[
[
"df1.to_csv('../clean_data/bnb_data_list.csv',index = False)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
] |
cb3bcfa74052c65371bc3b4549d231d12d61f85a | 11,185 | ipynb | Jupyter Notebook | computing_sh/Python04_Functions.ipynb | aaronhodhs/cp4all | 669895f5c6c4ad06cf5a535bdcd854ab8eb32317 | [
"CC0-1.0"
] | 8 | 2020-10-08T08:19:15.000Z | 2020-12-02T06:23:12.000Z | computing_sh/Python04_Functions.ipynb | aaronhodhs/cp4all | 669895f5c6c4ad06cf5a535bdcd854ab8eb32317 | [
"CC0-1.0"
] | 214 | 2020-10-08T01:59:41.000Z | 2022-01-20T20:04:41.000Z | computing_sh/Python04_Functions.ipynb | aaronhodhs/cp4all | 669895f5c6c4ad06cf5a535bdcd854ab8eb32317 | [
"CC0-1.0"
] | 341 | 2020-10-08T01:39:31.000Z | 2021-10-18T13:23:59.000Z | 23.497899 | 86 | 0.385338 | [
[
[
"# **Functions** \nA function is a reusable subprogram that performs a well defined task\n\nDRY - Don't Repeat Yourself\n\nExamples (system-defined): print(), input(), range(n), randint(low,high)\n\nWe will create our own functions (user-defined).",
"_____no_output_____"
]
],
[
[
"# Function - no parameters, no (explicit) return\n\ndef menu():\n print(\"(1) Add\")\n print(\"(2) Update\")\n print(\"(3) Delete\")\n print(\"(4) Search\")\n print(\"(0) Quit\")\n\noption = \"\"\nwhile option != '0':\n menu()\n option = input(\"Enter option: \")\nprint(\"Bye\")\n",
"(1) Add\n(2) Update\n(3) Delete\n(4) Search\n(0) Quit\nEnter option: 1\n(1) Add\n(2) Update\n(3) Delete\n(4) Search\n(0) Quit\nEnter option: 3\n(1) Add\n(2) Update\n(3) Delete\n(4) Search\n(0) Quit\nEnter option: 2\n(1) Add\n(2) Update\n(3) Delete\n(4) Search\n(0) Quit\nEnter option: 0\nBye\n"
],
[
"# Function - return\ndef negate(n):\n return -n\n\n# main\nprint(negate(5))\nprint(negate(0))\nprint(negate(-3))",
"-5\n0\n3\n"
],
[
"# Function - 1 parameter\n# temperature checker\ndef check_temperature(temperature):\n if temperature >= 38.0:\n return \"HOT!\"\n else:\n return \"Cool\"\n\n# main\nprint(check_temperature(39))\nprint(check_temperature(36.7))",
"HOT!\nCool\n"
],
[
"# Function - 2 parameters\n# display salutation with name\ndef greet(name, gender):\n if gender == 'F':\n return \"Miss \" + name\n else: # male\n return \"Mr \" + name\n\n# main\nprint(greet(\"Tom\", 'M'))\nprint(greet(\"Mary\", 'F'))",
"Mr Tom\nMiss Mary\n"
],
[
"# if a function does not have a return statement\n# it will actually return None\ndef boliao(message):\n print(message)\n\n# main\nprint(boliao(\"Yo!\"))",
"Yo!\nNone\n"
]
],
[
[
"## **Exercise: Prime**\n\nWrite a function is_prime(n) to test whether a number n is prime.\n\nBy definition, a number is prime if it is only divisible by 1 and itself.\nBy definition, 1 is not prime.\n\nHint: use %",
"_____no_output_____"
]
],
[
[
"def is_prime(n):\n if n == 1:\n return False\n for i in range(2, n):\n if n % i == 0: # found a divisor i\n return False\n return True\n\n# main\nprint(is_prime(1))\nprint(is_prime(2))\nprint(is_prime(3))\nprint(is_prime(5))\nprint(is_prime(35))\nprint(is_prime(83))",
"False\nTrue\nTrue\nTrue\nFalse\nTrue\n"
]
],
[
[
"# **Import**\nReuse, do not reinvent the wheel",
"_____no_output_____"
]
],
[
[
"# math\nimport math\n\nradius = 5\ncircumference = 2 * math.pi * radius \nprint(circumference)\nmath.pi\n",
"31.41592653589793\n"
],
[
"from math import pi\n\nradius = 5\ncircumference = 2 * pi * radius \nprint(circumference)\npi\n",
"31.41592653589793\n"
],
[
"# random\nimport random\n\nprint(random.randint(1, 10))\n",
"7\n"
],
[
"# random\nfrom random import randint\n\nprint(randint(1, 10))",
"4\n"
],
[
"# user-defined function eg temp.py\nimport temp\n\ntemp.check_temperature(38)\n",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3bd3fb05131fbd14baddbc3f81087ed20af7bd | 718,026 | ipynb | Jupyter Notebook | ssd300_training.ipynb | acanus/ssd_keras | 9e1b7adbe343e9be894e87bf899a18412b047669 | [
"Apache-2.0"
] | null | null | null | ssd300_training.ipynb | acanus/ssd_keras | 9e1b7adbe343e9be894e87bf899a18412b047669 | [
"Apache-2.0"
] | null | null | null | ssd300_training.ipynb | acanus/ssd_keras | 9e1b7adbe343e9be894e87bf899a18412b047669 | [
"Apache-2.0"
] | null | null | null | 891.957764 | 354,543 | 0.915602 | [
[
[
"# SSD300 Training Tutorial\n\nThis tutorial explains how to train an SSD300 on the Pascal VOC datasets. The preset parameters reproduce the training of the original SSD300 \"07+12\" model. Training SSD512 works simiarly, so there's no extra tutorial for that. The same goes for training on other datasets.\n\nYou can find a summary of a full training here to get an impression of what it should look like:\n[SSD300 \"07+12\" training summary](https://github.com/pierluigiferrari/ssd_keras/blob/master/training_summaries/ssd300_pascal_07%2B12_training_summary.md)",
"_____no_output_____"
]
],
[
[
"from tensorflow.keras.optimizers import Adam, SGD\nfrom tensorflow.keras.callbacks import ModelCheckpoint, LearningRateScheduler, TerminateOnNaN, CSVLogger\nfrom tensorflow.keras import backend as K\nfrom tensorflow.keras.models import load_model\nfrom math import ceil\nimport numpy as np\nfrom matplotlib import pyplot as plt\n\nfrom models.keras_ssd300 import ssd_300\nfrom keras_loss_function.keras_ssd_loss import SSDLoss\nfrom keras_layers.keras_layer_AnchorBoxes import AnchorBoxes\nfrom keras_layers.keras_layer_DecodeDetections import DecodeDetections\nfrom keras_layers.keras_layer_DecodeDetectionsFast import DecodeDetectionsFast\nfrom keras_layers.keras_layer_L2Normalization import L2Normalization\n\nfrom ssd_encoder_decoder.ssd_input_encoder import SSDInputEncoder\nfrom ssd_encoder_decoder.ssd_output_decoder import decode_detections, decode_detections_fast\n\nfrom data_generator.object_detection_2d_data_generator import DataGenerator\nfrom data_generator.object_detection_2d_geometric_ops import Resize\nfrom data_generator.object_detection_2d_photometric_ops import ConvertTo3Channels\nfrom data_generator.data_augmentation_chain_original_ssd import SSDDataAugmentation\nfrom data_generator.object_detection_2d_misc_utils import apply_inverse_transforms\nimport tensorflow as tf\ngpus = tf.config.experimental.list_physical_devices('GPU')\nif gpus:\n try:\n for gpu in gpus:\n tf.config.experimental.set_memory_growth(gpu, True)\n\n except RuntimeError as e:\n print(e)\n%matplotlib inline",
"Using TensorFlow backend.\n"
]
],
[
[
"## 0. Preliminary note\n\nAll places in the code where you need to make any changes are marked `TODO` and explained accordingly. All code cells that don't contain `TODO` markers just need to be executed.",
"_____no_output_____"
],
[
"## 1. Set the model configuration parameters\n\nThis section sets the configuration parameters for the model definition. The parameters set here are being used both by the `ssd_300()` function that builds the SSD300 model as well as further down by the constructor for the `SSDInputEncoder` object that is needed to run the training. Most of these parameters are needed to define the anchor boxes.\n\nThe parameters as set below produce the original SSD300 architecture that was trained on the Pascal VOC datsets, i.e. they are all chosen to correspond exactly to their respective counterparts in the `.prototxt` file that defines the original Caffe implementation. Note that the anchor box scaling factors of the original SSD implementation vary depending on the datasets on which the models were trained. The scaling factors used for the MS COCO datasets are smaller than the scaling factors used for the Pascal VOC datasets. The reason why the list of scaling factors has 7 elements while there are only 6 predictor layers is that the last scaling factor is used for the second aspect-ratio-1 box of the last predictor layer. Refer to the documentation for details.\n\nAs mentioned above, the parameters set below are not only needed to build the model, but are also passed to the `SSDInputEncoder` constructor further down, which is responsible for matching and encoding ground truth boxes and anchor boxes during the training. In order to do that, it needs to know the anchor box parameters.",
"_____no_output_____"
]
],
[
[
"img_height = 480 # Height of the model input images\nimg_width = 640 # Width of the model input images\nimg_channels = 3 # Number of color channels of the model input images\nmean_color = [123, 117, 104] # The per-channel mean of the images in the dataset. Do not change this value if you're using any of the pre-trained weights.\nswap_channels = [2, 1, 0] # The color channel order in the original SSD is BGR, so we'll have the model reverse the color channel order of the input images.\nn_classes = 1 # Number of positive classes, e.g. 20 for Pascal VOC, 80 for MS COCO\nscales_pascal = [0.1, 0.2, 0.37, 0.54, 0.71, 0.88, 1.05] # The anchor box scaling factors used in the original SSD300 for the Pascal VOC datasets\nscales_coco = [0.07, 0.15, 0.33, 0.51, 0.69, 0.87, 1.05] # The anchor box scaling factors used in the original SSD300 for the MS COCO datasets\nscales = scales_pascal\naspect_ratios = [[1.0, 2.0, 0.5],\n [1.0, 2.0, 0.5, 3.0, 1.0/3.0],\n [1.0, 2.0, 0.5, 3.0, 1.0/3.0],\n [1.0, 2.0, 0.5, 3.0, 1.0/3.0],\n [1.0, 2.0, 0.5],\n [1.0, 2.0, 0.5]] # The anchor box aspect ratios used in the original SSD300; the order matters\ntwo_boxes_for_ar1 = True\nsteps = [8, 16, 32, 64, 100, 300] # The space between two adjacent anchor box center points for each predictor layer.\noffsets = [0.5, 0.5, 0.5, 0.5, 0.5, 0.5] # The offsets of the first anchor box center points from the top and left borders of the image as a fraction of the step size for each predictor layer.\nclip_boxes = False # Whether or not to clip the anchor boxes to lie entirely within the image boundaries\nvariances = [0.1, 0.1, 0.2, 0.2] # The variances by which the encoded target coordinates are divided as in the original implementation\nnormalize_coords = True",
"_____no_output_____"
]
],
[
[
"## 2. Build or load the model\n\nYou will want to execute either of the two code cells in the subsequent two sub-sections, not both.",
"_____no_output_____"
],
[
"### 2.1 Create a new model and load trained VGG-16 weights into it (or trained SSD weights)\n\nIf you want to create a new SSD300 model, this is the relevant section for you. If you want to load a previously saved SSD300 model, skip ahead to section 2.2.\n\nThe code cell below does the following things:\n1. It calls the function `ssd_300()` to build the model.\n2. It then loads the weights file that is found at `weights_path` into the model. You could load the trained VGG-16 weights or you could load the weights of a trained model. If you want to reproduce the original SSD training, load the pre-trained VGG-16 weights. In any case, you need to set the path to the weights file you want to load on your local machine. Download links to all the trained weights are provided in the [README](https://github.com/pierluigiferrari/ssd_keras/blob/master/README.md) of this repository.\n3. Finally, it compiles the model for the training. In order to do so, we're defining an optimizer (Adam) and a loss function (SSDLoss) to be passed to the `compile()` method.\n\nNormally, the optimizer of choice would be Adam (commented out below), but since the original implementation uses plain SGD with momentum, we'll do the same in order to reproduce the original training. Adam is generally the superior optimizer, so if your goal is not to have everything exactly as in the original training, feel free to switch to Adam. You might need to adjust the learning rate scheduler below slightly in case you use Adam.\n\nNote that the learning rate that is being set here doesn't matter, because further below we'll pass a learning rate scheduler to the training function, which will overwrite any learning rate set here, i.e. what matters are the learning rates that are defined by the learning rate scheduler.\n\n`SSDLoss` is a custom Keras loss function that implements the multi-task that consists of a log loss for classification and a smooth L1 loss for localization. `neg_pos_ratio` and `alpha` are set as in the paper.",
"_____no_output_____"
]
],
[
[
"# 1: Build the Keras model.\n\nK.clear_session() # Clear previous models from memory.\n\nmodel = ssd_300(image_size=(img_height, img_width, img_channels),\n n_classes=n_classes,\n mode='training',\n l2_regularization=0.0005,\n scales=scales,\n aspect_ratios_per_layer=aspect_ratios,\n two_boxes_for_ar1=two_boxes_for_ar1,\n steps=steps,\n offsets=offsets,\n clip_boxes=clip_boxes,\n variances=variances,\n normalize_coords=normalize_coords,\n subtract_mean=mean_color,\n swap_channels=swap_channels)\n\n# 2: Load some weights into the model.\n\n# TODO: Set the path to the weights you want to load.\nweights_path = './VGG_ILSVRC_16_layers_fc_reduced.h5'\n\nmodel.load_weights(weights_path, by_name=True)\n\n# 3: Instantiate an optimizer and the SSD loss function and compile the model.\n# If you want to follow the original Caffe implementation, use the preset SGD\n# optimizer, otherwise I'd recommend the commented-out Adam optimizer.\n\n#adam = Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0)\nsgd = SGD(lr=0.001, momentum=0.9, decay=0.0, nesterov=False)\n\nssd_loss = SSDLoss(neg_pos_ratio=3, alpha=1.0)\n\nmodel.compile(optimizer=sgd, loss=ssd_loss.compute_loss)",
"_____no_output_____"
]
],
[
[
"### 2.2 Load a previously created model\n\nIf you have previously created and saved a model and would now like to load it, execute the next code cell. The only thing you need to do here is to set the path to the saved model HDF5 file that you would like to load.\n\nThe SSD model contains custom objects: Neither the loss function nor the anchor box or L2-normalization layer types are contained in the Keras core library, so we need to provide them to the model loader.\n\nThis next code cell assumes that you want to load a model that was created in 'training' mode. If you want to load a model that was created in 'inference' or 'inference_fast' mode, you'll have to add the `DecodeDetections` or `DecodeDetectionsFast` layer type to the `custom_objects` dictionary below.",
"_____no_output_____"
]
],
[
[
"# TODO: Set the path to the `.h5` file of the model to be loaded.\nmodel_path = 'path/to/trained/model.h5'\n\n# We need to create an SSDLoss object in order to pass that to the model loader.\nssd_loss = SSDLoss(neg_pos_ratio=3, alpha=1.0)\n\nK.clear_session() # Clear previous models from memory.\n\nmodel = load_model(model_path, custom_objects={'AnchorBoxes': AnchorBoxes,\n 'L2Normalization': L2Normalization,\n 'compute_loss': ssd_loss.compute_loss})",
"_____no_output_____"
]
],
[
[
"## 3. Set up the data generators for the training\n\nThe code cells below set up the data generators for the training and validation datasets to train the model. The settings below reproduce the original SSD training on Pascal VOC 2007 `trainval` plus 2012 `trainval` and validation on Pascal VOC 2007 `test`.\n\nThe only thing you need to change here are the filepaths to the datasets on your local machine. Note that parsing the labels from the XML annotations files can take a while.\n\nNote that the generator provides two options to speed up the training. By default, it loads the individual images for a batch from disk. This has two disadvantages. First, for compressed image formats like JPG, this is a huge computational waste, because every image needs to be decompressed again and again every time it is being loaded. Second, the images on disk are likely not stored in a contiguous block of memory, which may also slow down the loading process. The first option that `DataGenerator` provides to deal with this is to load the entire dataset into memory, which reduces the access time for any image to a negligible amount, but of course this is only an option if you have enough free memory to hold the whole dataset. As a second option, `DataGenerator` provides the possibility to convert the dataset into a single HDF5 file. This HDF5 file stores the images as uncompressed arrays in a contiguous block of memory, which dramatically speeds up the loading time. It's not as good as having the images in memory, but it's a lot better than the default option of loading them from their compressed JPG state every time they are needed. Of course such an HDF5 dataset may require significantly more disk space than the compressed images (around 9 GB total for Pascal VOC 2007 `trainval` plus 2012 `trainval` and another 2.6 GB for 2007 `test`). You can later load these HDF5 datasets directly in the constructor.\n\nThe original SSD implementation uses a batch size of 32 for the training. In case you run into GPU memory issues, reduce the batch size accordingly. You need at least 7 GB of free GPU memory to train an SSD300 with 20 object classes with a batch size of 32.\n\nThe `DataGenerator` itself is fairly generic. I doesn't contain any data augmentation or bounding box encoding logic. Instead, you pass a list of image transformations and an encoder for the bounding boxes in the `transformations` and `label_encoder` arguments of the data generator's `generate()` method, and the data generator will then apply those given transformations and the encoding to the data. Everything here is preset already, but if you'd like to learn more about the data generator and its data augmentation capabilities, take a look at the detailed tutorial in [this](https://github.com/pierluigiferrari/data_generator_object_detection_2d) repository.\n\nThe data augmentation settings defined further down reproduce the data augmentation pipeline of the original SSD training. The training generator receives an object `ssd_data_augmentation`, which is a transformation object that is itself composed of a whole chain of transformations that replicate the data augmentation procedure used to train the original Caffe implementation. The validation generator receives an object `resize`, which simply resizes the input images.\n\nAn `SSDInputEncoder` object, `ssd_input_encoder`, is passed to both the training and validation generators. As explained above, it matches the ground truth labels to the model's anchor boxes and encodes the box coordinates into the format that the model needs.\n\nIn order to train the model on a dataset other than Pascal VOC, either choose `DataGenerator`'s appropriate parser method that corresponds to your data format, or, if `DataGenerator` does not provide a suitable parser for your data format, you can write an additional parser and add it. Out of the box, `DataGenerator` can handle datasets that use the Pascal VOC format (use `parse_xml()`), the MS COCO format (use `parse_json()`) and a wide range of CSV formats (use `parse_csv()`).",
"_____no_output_____"
]
],
[
[
"# 1: Instantiate two `DataGenerator` objects: One for training, one for validation.\n\n# Optional: If you have enough memory, consider loading the images into memory for the reasons explained above.\n\ntrain_dataset = DataGenerator(load_images_into_memory=False, hdf5_dataset_path=None)\nval_dataset = DataGenerator(load_images_into_memory=False, hdf5_dataset_path=None)\n\n# 2: Parse the image and label lists for the training and validation datasets. This can take a while.\n\n# TODO: Set the paths to the datasets here.\n\n# The directories that contain the images.\nimages_dir = 'D:\\\\Deeplearning\\\\images\\\\ocr_export_2\\\\'\n\n# Ground truth\ntrain_labels_filename = 'D:\\\\Deeplearning\\\\images\\\\ocr_export_2\\\\train.csv'\nval_labels_filename = 'D:\\\\Deeplearning\\\\images\\\\ocr_export_2\\\\train.csv'\n\ntrain_dataset.parse_csv(images_dir=images_dir,\n labels_filename=train_labels_filename,\n input_format=['image_name', 'xmin', 'xmax', 'ymin', 'ymax', 'class_id'], # This is the order of the first six columns in the CSV file that contains the labels for your dataset. If your labels are in XML format, maybe the XML parser will be helpful, check the documentation.\n include_classes='all')\n\nval_dataset.parse_csv(images_dir=images_dir,\n labels_filename=val_labels_filename,\n input_format=['image_name', 'xmin', 'xmax', 'ymin', 'ymax', 'class_id'],\n include_classes='all')\n\n# Optional: Convert the dataset into an HDF5 dataset. This will require more disk space, but will\n# speed up the training. Doing this is not relevant in case you activated the `load_images_into_memory`\n# option in the constructor, because in that cas the images are in memory already anyway. If you don't\n# want to create HDF5 datasets, comment out the subsequent two function calls.\n\ntrain_dataset.create_hdf5_dataset(file_path='dataset_udacity_traffic_train.h5',\n resize=False,\n variable_image_size=True,\n verbose=True)\n\nval_dataset.create_hdf5_dataset(file_path='dataset_udacity_traffic_val.h5',\n resize=False,\n variable_image_size=True,\n verbose=True)\n\n# Get the number of samples in the training and validations datasets.\ntrain_dataset_size = train_dataset.get_dataset_size()\nval_dataset_size = val_dataset.get_dataset_size()\n\nprint(\"Number of images in the training dataset:\\t{:>6}\".format(train_dataset_size))\nprint(\"Number of images in the validation dataset:\\t{:>6}\".format(val_dataset_size))",
"Creating HDF5 dataset: 100%|██████████| 1/1 [00:00<00:00, 5.53it/s]\nCreating HDF5 dataset: 100%|██████████| 1/1 [00:00<00:00, 111.42it/s]\nNumber of images in the training dataset:\t 1\nNumber of images in the validation dataset:\t 1\n"
],
[
"# 3: Set the batch size.\n\nbatch_size = 2 # Change the batch size if you like, or if you run into GPU memory issues.\n\n# 4: Set the image transformations for pre-processing and data augmentation options.\n\n# For the training generator:\nssd_data_augmentation = SSDDataAugmentation(img_height=img_height,\n img_width=img_width,\n background=mean_color)\n\n# For the validation generator:\nconvert_to_3_channels = ConvertTo3Channels()\nresize = Resize(height=img_height, width=img_width)\n\n# 5: Instantiate an encoder that can encode ground truth labels into the format needed by the SSD loss function.\n\n# The encoder constructor needs the spatial dimensions of the model's predictor layers to create the anchor boxes.\npredictor_sizes = [model.get_layer('conv4_3_norm_mbox_conf').output_shape[1:3],\n model.get_layer('fc7_mbox_conf').output_shape[1:3],\n model.get_layer('conv6_2_mbox_conf').output_shape[1:3],\n model.get_layer('conv7_2_mbox_conf').output_shape[1:3],\n model.get_layer('conv8_2_mbox_conf').output_shape[1:3],\n model.get_layer('conv9_2_mbox_conf').output_shape[1:3]]\n\nssd_input_encoder = SSDInputEncoder(img_height=img_height,\n img_width=img_width,\n n_classes=n_classes,\n predictor_sizes=predictor_sizes,\n scales=scales,\n aspect_ratios_per_layer=aspect_ratios,\n two_boxes_for_ar1=two_boxes_for_ar1,\n steps=steps,\n offsets=offsets,\n clip_boxes=clip_boxes,\n variances=variances,\n matching_type='multi',\n pos_iou_threshold=0.5,\n neg_iou_limit=0.5,\n normalize_coords=normalize_coords)\n\n# 6: Create the generator handles that will be passed to Keras' `fit_generator()` function.\n\ntrain_generator = train_dataset.generate(batch_size=batch_size,\n shuffle=True,\n transformations=[ssd_data_augmentation],\n label_encoder=ssd_input_encoder,\n returns={'processed_images',\n 'encoded_labels'},\n keep_images_without_gt=False)\n\nval_generator = val_dataset.generate(batch_size=batch_size,\n shuffle=False,\n transformations=[convert_to_3_channels,\n resize],\n label_encoder=ssd_input_encoder,\n returns={'processed_images',\n 'encoded_labels'},\n keep_images_without_gt=False)\n\n# Get the number of samples in the training and validations datasets.\ntrain_dataset_size = train_dataset.get_dataset_size()\nval_dataset_size = val_dataset.get_dataset_size()\n\nprint(\"Number of images in the training dataset:\\t{:>6}\".format(train_dataset_size))\nprint(\"Number of images in the validation dataset:\\t{:>6}\".format(val_dataset_size))",
"Number of images in the training dataset:\t 1\nNumber of images in the validation dataset:\t 1\n"
]
],
[
[
"## 4. Set the remaining training parameters\n\nWe've already chosen an optimizer and set the batch size above, now let's set the remaining training parameters. I'll set one epoch to consist of 1,000 training steps. The next code cell defines a learning rate schedule that replicates the learning rate schedule of the original Caffe implementation for the training of the SSD300 Pascal VOC \"07+12\" model. That model was trained for 120,000 steps with a learning rate of 0.001 for the first 80,000 steps, 0.0001 for the next 20,000 steps, and 0.00001 for the last 20,000 steps. If you're training on a different dataset, define the learning rate schedule however you see fit.\n\nI'll set only a few essential Keras callbacks below, feel free to add more callbacks if you want TensorBoard summaries or whatever. We obviously need the learning rate scheduler and we want to save the best models during the training. It also makes sense to continuously stream our training history to a CSV log file after every epoch, because if we didn't do that, in case the training terminates with an exception at some point or if the kernel of this Jupyter notebook dies for some reason or anything like that happens, we would lose the entire history for the trained epochs. Finally, we'll also add a callback that makes sure that the training terminates if the loss becomes `NaN`. Depending on the optimizer you use, it can happen that the loss becomes `NaN` during the first iterations of the training. In later iterations it's less of a risk. For example, I've never seen a `NaN` loss when I trained SSD using an Adam optimizer, but I've seen a `NaN` loss a couple of times during the very first couple of hundred training steps of training a new model when I used an SGD optimizer.",
"_____no_output_____"
]
],
[
[
"# Define a learning rate schedule.\n\ndef lr_schedule(epoch):\n if epoch < 80:\n return 0.0001\n elif epoch < 100:\n return 0.00001\n else:\n return 0.000001",
"_____no_output_____"
],
[
"# Define model callbacks.\n\n# TODO: Set the filepath under which you want to save the model.\nmodel_checkpoint = ModelCheckpoint(filepath='ssd300_pascal_07+12_epoch-{epoch:02d}_loss-{loss:.4f}_val_loss-{val_loss:.4f}.h5',\n monitor='val_loss',\n verbose=1,\n save_best_only=True,\n save_weights_only=False,\n mode='auto',\n period=1)\n#model_checkpoint.best = \n\ncsv_logger = CSVLogger(filename='ssd300_pascal_07+12_training_log.csv',\n separator=',',\n append=True)\n\nlearning_rate_scheduler = LearningRateScheduler(schedule=lr_schedule,\n verbose=1)\n\nterminate_on_nan = TerminateOnNaN()\n\ncallbacks = [model_checkpoint,\n csv_logger,\n learning_rate_scheduler,\n terminate_on_nan]",
"WARNING:tensorflow:`period` argument is deprecated. Please use `save_freq` to specify the frequency in number of batches seen.\n"
]
],
[
[
"## 5. Train",
"_____no_output_____"
],
[
"In order to reproduce the training of the \"07+12\" model mentioned above, at 1,000 training steps per epoch you'd have to train for 120 epochs. That is going to take really long though, so you might not want to do all 120 epochs in one go and instead train only for a few epochs at a time. You can find a summary of a full training [here](https://github.com/pierluigiferrari/ssd_keras/blob/master/training_summaries/ssd300_pascal_07%2B12_training_summary.md).\n\nIn order to only run a partial training and resume smoothly later on, there are a few things you should note:\n1. Always load the full model if you can, rather than building a new model and loading previously saved weights into it. Optimizers like SGD or Adam keep running averages of past gradient moments internally. If you always save and load full models when resuming a training, then the state of the optimizer is maintained and the training picks up exactly where it left off. If you build a new model and load weights into it, the optimizer is being initialized from scratch, which, especially in the case of Adam, leads to small but unnecessary setbacks every time you resume the training with previously saved weights.\n2. In order for the learning rate scheduler callback above to work properly, `fit_generator()` needs to know which epoch we're in, otherwise it will start with epoch 0 every time you resume the training. Set `initial_epoch` to be the next epoch of your training. Note that this parameter is zero-based, i.e. the first epoch is epoch 0. If you had trained for 10 epochs previously and now you'd want to resume the training from there, you'd set `initial_epoch = 10` (since epoch 10 is the eleventh epoch). Furthermore, set `final_epoch` to the last epoch you want to run. To stick with the previous example, if you had trained for 10 epochs previously and now you'd want to train for another 10 epochs, you'd set `initial_epoch = 10` and `final_epoch = 20`.\n3. In order for the model checkpoint callback above to work correctly after a kernel restart, set `model_checkpoint.best` to the best validation loss from the previous training. If you don't do this and a new `ModelCheckpoint` object is created after a kernel restart, that object obviously won't know what the last best validation loss was, so it will always save the weights of the first epoch of your new training and record that loss as its new best loss. This isn't super-important, I just wanted to mention it.",
"_____no_output_____"
]
],
[
[
"# If you're resuming a previous training, set `initial_epoch` and `final_epoch` accordingly.\ninitial_epoch = 0\nfinal_epoch = 10\nsteps_per_epoch = 1000\n\nhistory = model.fit_generator(generator=train_generator,\n steps_per_epoch=steps_per_epoch,\n epochs=final_epoch,\n callbacks=callbacks,\n validation_data=val_generator,\n validation_steps=ceil(val_dataset_size/batch_size),\n initial_epoch=initial_epoch)",
"_____no_output_____"
]
],
[
[
"## 6. Make predictions\n\nNow let's make some predictions on the validation dataset with the trained model. For convenience we'll use the validation generator that we've already set up above. Feel free to change the batch size.\n\nYou can set the `shuffle` option to `False` if you would like to check the model's progress on the same image(s) over the course of the training.",
"_____no_output_____"
]
],
[
[
"# 1: Set the generator for the predictions.\n\npredict_generator = val_dataset.generate(batch_size=1,\n shuffle=True,\n transformations=[convert_to_3_channels,\n resize],\n label_encoder=None,\n returns={'processed_images',\n 'filenames',\n 'inverse_transform',\n 'original_images',\n 'original_labels'},\n keep_images_without_gt=False)",
"_____no_output_____"
],
[
"# 2: Generate samples.\n\nbatch_images, batch_filenames, batch_inverse_transforms, batch_original_images, batch_original_labels = next(predict_generator)\n\ni = 0 # Which batch item to look at\n\nprint(\"Image:\", batch_filenames[i])\nprint()\nprint(\"Ground truth boxes:\\n\")\nprint(np.array(batch_original_labels[i]))",
"Image: D:\\Deeplearning\\images\\ocr_export_2\\Image - 143249910.bmp\n\nGround truth boxes:\n\n[[ 1 214 167 238 193]\n [ 1 214 194 234 220]\n [ 1 235 199 254 223]\n [ 1 237 168 255 197]\n [ 1 255 202 274 230]\n [ 1 257 171 277 200]\n [ 1 282 205 303 232]\n [ 1 285 175 304 206]\n [ 1 302 210 319 235]\n [ 1 303 176 324 206]\n [ 1 328 211 344 239]\n [ 1 330 179 346 209]\n [ 1 345 212 364 240]\n [ 1 351 182 367 210]\n [ 1 373 215 389 241]\n [ 1 375 185 395 214]\n [ 1 393 217 412 244]\n [ 1 396 187 411 215]\n [ 1 430 220 450 245]\n [ 1 450 219 471 245]]\n"
],
[
"# 3: Make predictions.\nimport cv2\nimport numpy as np\nim_test= cv2.imread('D:\\Deeplearning\\images\\ocr\\Image - 145504897.bmp')\ny_pred = model.predict(np.expand_dims(im_test,0))",
"_____no_output_____"
]
],
[
[
"Now let's decode the raw predictions in `y_pred`.\n\nHad we created the model in 'inference' or 'inference_fast' mode, then the model's final layer would be a `DecodeDetections` layer and `y_pred` would already contain the decoded predictions, but since we created the model in 'training' mode, the model outputs raw predictions that still need to be decoded and filtered. This is what the `decode_detections()` function is for. It does exactly what the `DecodeDetections` layer would do, but using Numpy instead of TensorFlow (i.e. on the CPU instead of the GPU).\n\n`decode_detections()` with default argument values follows the procedure of the original SSD implementation: First, a very low confidence threshold of 0.01 is applied to filter out the majority of the predicted boxes, then greedy non-maximum suppression is performed per class with an intersection-over-union threshold of 0.45, and out of what is left after that, the top 200 highest confidence boxes are returned. Those settings are for precision-recall scoring purposes though. In order to get some usable final predictions, we'll set the confidence threshold much higher, e.g. to 0.5, since we're only interested in the very confident predictions.",
"_____no_output_____"
]
],
[
[
"# 4: Decode the raw predictions in `y_pred`.\n\ny_pred_decoded = decode_detections(y_pred,\n confidence_thresh=0.9,\n iou_threshold=0.1,\n top_k=200,\n normalize_coords=normalize_coords,\n img_height=img_height,\n img_width=img_width)",
"_____no_output_____"
]
],
[
[
"We made the predictions on the resized images, but we'd like to visualize the outcome on the original input images, so we'll convert the coordinates accordingly. Don't worry about that opaque `apply_inverse_transforms()` function below, in this simple case it just aplies `(* original_image_size / resized_image_size)` to the box coordinates.",
"_____no_output_____"
]
],
[
[
"# 5: Convert the predictions for the original image.\n\ny_pred_decoded_inv = apply_inverse_transforms(y_pred_decoded, batch_inverse_transforms)\n\nnp.set_printoptions(precision=2, suppress=True, linewidth=90)\nprint(\"Predicted boxes:\\n\")\nprint(' class conf xmin ymin xmax ymax')\nprint(y_pred_decoded_inv[i])",
"Predicted boxes:\n\n class conf xmin ymin xmax ymax\n[[ 1. 1. 178. -1. 216. 62. ]\n [ 1. 1. 129. -26. 152. 21. ]\n [ 1. 1. 153. 48. 188. 118. ]\n [ 1. 1. 238. -31. 266. 24. ]\n [ 1. 1. 98. 7. 130. 92. ]\n [ 1. 1. 139. 93. 167. 166. ]\n [ 1. 1. 203. 33. 258. 93. ]\n [ 1. 1. 44. 74. 77. 138. ]\n [ 1. 1. 70. 12. 102. 80. ]\n [ 1. 1. 144. 405. 178. 489. ]\n [ 1. 1. 30. 136. 59. 197. ]\n [ 1. 1. 261. -27. 292. 29. ]\n [ 1. 1. 247. 15. 288. 76. ]\n [ 1. 1. 451. 381. 493. 449. ]\n [ 1. 1. 583. -25. 605. 37. ]\n [ 1. 1. 575. 215. 606. 272. ]\n [ 1. 1. 146. -42. 177. 37. ]\n [ 1. 1. 30. 190. 59. 252. ]\n [ 1. 1. 115. 394. 147. 453. ]\n [ 1. 1. 608. 3. 636. 91. ]\n [ 1. 1. 505. 414. 534. 485. ]\n [ 1. 0.99 189. 72. 227. 136. ]\n [ 1. 0.99 504. 266. 548. 327. ]\n [ 1. 0.99 313. 353. 376. 389. ]\n [ 1. 0.99 91. 369. 124. 428. ]\n [ 1. 0.99 21. 5. 48. 68. ]\n [ 1. 0.99 372. 265. 428. 295. ]\n [ 1. 0.99 478. 360. 559. 390. ]\n [ 1. 0.99 21. 74. 48. 139. ]\n [ 1. 0.99 339. 282. 390. 313. ]\n [ 1. 0.99 36. 237. 68. 302. ]\n [ 1. 0.99 122. 35. 152. 109. ]\n [ 1. 0.99 500. -5. 542. 40. ]\n [ 1. 0.99 51. 291. 84. 354. ]\n [ 1. 0.99 622. 424. 649. 478. ]\n [ 1. 0.99 67. 336. 100. 395. ]\n [ 1. 0.99 587. 402. 618. 484. ]\n [ 1. 0.99 454. 195. 494. 242. ]\n [ 1. 0.99 619. 292. 649. 351. ]\n [ 1. 0.99 179. 432. 209. 486. ]\n [ 1. 0.99 45. 7. 72. 70. ]\n [ 1. 0.99 63. -26. 85. 29. ]\n [ 1. 0.99 22. 403. 52. 473. ]\n [ 1. 0.99 619. 342. 648. 398. ]\n [ 1. 0.99 541. 88. 584. 127. ]\n [ 1. 0.99 525. 38. 557. 98. ]\n [ 1. 0.99 399. 414. 434. 467. ]\n [ 1. 0.99 87. -23. 109. 30. ]\n [ 1. 0.99 67. 398. 98. 487. ]\n [ 1. 0.99 547. 398. 578. 487. ]\n [ 1. 0.99 563. 295. 598. 346. ]\n [ 1. 0.99 22. 344. 49. 409. ]\n [ 1. 0.99 413. 194. 445. 246. ]\n [ 1. 0.99 620. 67. 650. 136. ]\n [ 1. 0.99 362. 411. 403. 466. ]\n [ 1. 0.99 22. 280. 49. 345. ]\n [ 1. 0.99 587. 344. 618. 414. ]\n [ 1. 0.99 617. 128. 653. 196. ]\n [ 1. 0.99 -7. 4. 23. 73. ]\n [ 1. 0.99 -7. 64. 23. 136. ]\n [ 1. 0.99 12. 226. 42. 289. ]\n [ 1. 0.99 566. 117. 601. 186. ]\n [ 1. 0.99 -8. 407. 22. 495. ]\n [ 1. 0.99 46. 368. 74. 436. ]\n [ 1. 0.99 96. 80. 130. 158. ]\n [ 1. 0.99 619. 193. 650. 266. ]\n [ 1. 0.98 83. 328. 190. 358. ]\n [ 1. 0.98 -6. 128. 23. 200. ]\n [ 1. 0.98 289. -46. 331. 32. ]\n [ 1. 0.98 -6. 344. 23. 416. ]\n [ 1. 0.98 241. 431. 308. 464. ]\n [ 1. 0.98 -6. 280. 23. 352. ]\n [ 1. 0.98 340. 220. 393. 249. ]\n [ 1. 0.98 557. -31. 584. 37. ]\n [ 1. 0.98 443. 268. 481. 314. ]\n [ 1. 0.98 375. 168. 412. 214. ]\n [ 1. 0.98 69. 185. 174. 214. ]\n [ 1. 0.98 422. -19. 445. 35. ]\n [ 1. 0.98 550. 49. 588. 96. ]\n [ 1. 0.97 342. 48. 397. 84. ]\n [ 1. 0.97 107. 256. 157. 336. ]\n [ 1. 0.97 187. 127. 251. 201. ]\n [ 1. 0.97 533. 205. 562. 272. ]\n [ 1. 0.97 73. 70. 103. 134. ]\n [ 1. 0.97 61. 119. 90. 195. ]\n [ 1. 0.97 -20. 181. 16. 249. ]\n [ 1. 0.97 370. 362. 410. 417. ]\n [ 1. 0.97 272. 242. 325. 278. ]\n [ 1. 0.97 55. 230. 143. 256. ]\n [ 1. 0.97 166. 351. 251. 430. ]\n [ 1. 0.97 298. 414. 337. 492. ]\n [ 1. 0.97 399. 248. 460. 275. ]\n [ 1. 0.97 407. 348. 452. 406. ]\n [ 1. 0.97 360. 341. 417. 369. ]\n [ 1. 0.97 535. 323. 566. 375. ]\n [ 1. 0.97 411. 148. 488. 179. ]\n [ 1. 0.96 417. 296. 456. 343. ]\n [ 1. 0.96 204. -43. 242. 33. ]\n [ 1. 0.96 471. 291. 517. 361. ]\n [ 1. 0.96 532. 119. 556. 183. ]\n [ 1. 0.96 265. 74. 315. 159. ]\n [ 1. 0.96 483. 431. 508. 493. ]\n [ 1. 0.96 326. 132. 379. 206. ]\n [ 1. 0.96 214. 422. 248. 473. ]\n [ 1. 0.96 491. 165. 555. 225. ]\n [ 1. 0.96 381. 84. 447. 113. ]\n [ 1. 0.95 219. 106. 283. 134. ]\n [ 1. 0.95 554. 173. 593. 232. ]\n [ 1. 0.95 416. 177. 488. 204. ]\n [ 1. 0.95 411. 111. 480. 150. ]\n [ 1. 0.95 487. 32. 525. 90. ]\n [ 1. 0.94 576. 64. 622. 124. ]\n [ 1. 0.94 86. 211. 170. 237. ]\n [ 1. 0.94 495. 86. 548. 143. ]\n [ 1. 0.94 478. -15. 502. 34. ]\n [ 1. 0.93 246. 140. 288. 208. ]\n [ 1. 0.93 168. 293. 215. 352. ]\n [ 1. 0.93 101. 431. 129. 503. ]\n [ 1. 0.93 580. 262. 621. 314. ]\n [ 1. 0.93 161. 111. 194. 194. ]\n [ 1. 0.93 452. 5. 489. 78. ]\n [ 1. 0.92 328. 397. 372. 474. ]\n [ 1. 0.92 266. 211. 344. 244. ]\n [ 1. 0.92 45. 431. 73. 503. ]\n [ 1. 0.92 355. 307. 418. 341. ]\n [ 1. 0.92 249. 231. 283. 322. ]\n [ 1. 0.9 233. 401. 317. 436. ]\n [ 1. 0.9 307. 321. 372. 354. ]]\n"
]
],
[
[
"Finally, let's draw the predicted boxes onto the image. Each predicted box says its confidence next to the category name. The ground truth boxes are also drawn onto the image in green for comparison.",
"_____no_output_____"
]
],
[
[
"# 5: Draw the predicted boxes onto the image\n\n# Set the colors for the bounding boxes\ncolors = plt.cm.hsv(np.linspace(0, 1, n_classes+1)).tolist()\nclasses = ['background',\n 'aeroplane', 'bicycle', 'bird', 'boat',\n 'bottle', 'bus', 'car', 'cat',\n 'chair', 'cow', 'diningtable', 'dog',\n 'horse', 'motorbike', 'person', 'pottedplant',\n 'sheep', 'sofa', 'train', 'tvmonitor']\n\nplt.figure(figsize=(20,12))\nplt.imshow(im_test)\n\ncurrent_axis = plt.gca()\n\nfor box in batch_original_labels[i]:\n continue\n xmin = box[1]\n ymin = box[2]\n xmax = box[3]\n ymax = box[4]\n label = '{}'.format(classes[int(box[0])])\n current_axis.add_patch(plt.Rectangle((xmin, ymin), xmax-xmin, ymax-ymin, color='green', fill=False, linewidth=2)) \n #current_axis.text(xmin, ymin, label, size='x-large', color='white', bbox={'facecolor':'green', 'alpha':1.0})\n\nfor box in y_pred_decoded_inv[i]:\n xmin = box[2]\n ymin = box[3]\n xmax = box[4]\n ymax = box[5]\n color = colors[int(box[0])]\n label = '{}: {:.2f}'.format(classes[int(box[0])], box[1])\n current_axis.add_patch(plt.Rectangle((xmin, ymin), xmax-xmin, ymax-ymin, color=color, fill=False, linewidth=2)) \n #current_axis.text(xmin, ymin, label, size='x-large', color='white', bbox={'facecolor':color, 'alpha':1.0})",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
cb3bddf5c54758028355635786842a7b2c07b013 | 246,224 | ipynb | Jupyter Notebook | notebooks/uncategorized/examples/GP.ipynb | J-Garcke-SCAI/jaxkern | 9de7ebf52fe2d186d316350a6692b2ecc0885adc | [
"MIT"
] | 7 | 2020-09-28T07:39:16.000Z | 2022-03-11T14:09:41.000Z | notebooks/uncategorized/examples/GP.ipynb | J-Garcke-SCAI/jaxkern | 9de7ebf52fe2d186d316350a6692b2ecc0885adc | [
"MIT"
] | 5 | 2020-09-25T01:25:57.000Z | 2020-10-09T16:15:49.000Z | notebooks/uncategorized/examples/GP.ipynb | J-Garcke-SCAI/jaxkern | 9de7ebf52fe2d186d316350a6692b2ecc0885adc | [
"MIT"
] | 2 | 2021-05-25T21:59:58.000Z | 2022-01-11T07:23:32.000Z | 377.644172 | 147,750 | 0.907158 | [
[
[
"% matplotlib inline\nimport matplotlib.pyplot as plt\nfrom matplotlib import colors, cm\nimport numpy as np\nfrom numpy import matmul\nfrom scipy.spatial.distance import pdist, squareform\nfrom sklearn.datasets import load_diabetes\nimport pandas as pd\nfrom scipy.linalg import cholesky\nfrom scipy.linalg import solve\nfrom scipy.optimize import minimize\nimport time",
"_____no_output_____"
],
[
"# Developer notes\n# 1) Cholesky decomposition produces NaNs (probably because K+I*s**2 is not pos semidef) causing solve to complain\n# 2) Including gradient for likelihood made optimization much faster\n\nclass mintGP():\n \"\"\"\n The implementation is based on Algorithm 2.1 of Gaussian Processes\n for Machine Learning (GPML) by Rasmussen and Williams.\n \n Takes 2D np-arrays\n \"\"\"\n \n def __init__(self):\n pass\n \n def fit(self, X, Y):\n self.yscale = np.std(Y)\n self.Y = Y/self.yscale\n self.X = X\n self.n = np.shape(X)[0]\n # initialize with heuristics\n self.lengthscale = np.mean(pdist(X, metric='euclidean'))\n self.likelihood_variance = 1\n \n ###############################################################\n # Gradient descent on marginal likelihood with scipy L-BFGS-B #\n ###############################################################\n theta0 = np.array([self.lengthscale, self.likelihood_variance])\n bnds = ((1e-20, None), (1e-10, None))\n sol = minimize(self.neg_log_marg_like, theta0, args=(),\n method='L-BFGS-B', bounds=bnds, jac=True) \n self.lengthscale, self.likelihood_variance = sol.x\n self.marginal_likelihood = np.exp(-sol.fun)\n \n # for prediction:\n K,_ = self.K(X,X,self.lengthscale)\n self.L = cholesky( K + self.likelihood_variance*np.eye(self.n), lower=True)\n print(sol.x, theta0)\n \n ##########################\n # Likelihood computation #\n ##########################\n def neg_log_marg_like(self, theta):\n \"\"\"\n Compute negative log marginal likelihood for hyperparameter optimization\n \"\"\"\n jitter=0\n K, D = self.K(self.X ,self.X, theta[0])\n L = cholesky( K + (theta[1]+jitter)*np.eye(self.n), lower=True)\n self.L = L\n alpha = solve(L.T, solve(L,self.Y, lower=True) )\n logmarglike = \\\n - 0.5*matmul(self.Y.T, alpha)[0,0] \\\n - np.sum( np.log( np.diag( L ) ) ) \\\n - 0.5*self.n*np.log(2*np.pi)\n \n \n # compute gradients\n prefactor = matmul(alpha, alpha.T) - solve(L.T, solve(L, np.eye(self.n) ) )\n Kd_lengthscale = np.multiply( D/theta[0]**3, K)\n Kd_likelihood_variance = np.eye(self.n)\n logmarglike_grad = 0.5*np.array( [ np.trace( matmul(prefactor, Kd_lengthscale) ),\n np.trace( matmul(prefactor, Kd_likelihood_variance) )] )\n\n \n return -logmarglike, -logmarglike_grad\n \n def nlml_grad(self):\n \"\"\"\n Return gradient of negative log marginal likelihood\n \"\"\"\n return self.logmarglike_grad\n \n ######################\n # Kernel computation #\n ######################\n def K(self, X, Z, lengthscale):\n n1 = np.shape(X)[0]\n n2 = np.shape(Z)[0]\n n1sq = np.sum(np.square(X), 1)\n n2sq = np.sum(np.square(Z), 1)\n \n D = (np.ones([n2, 1])*n1sq).T + np.ones([n1, 1])*n2sq -2*matmul(X,Z.T)\n return np.exp(-D/(2*lengthscale**2)), D\n \n def scalarK(self, x, z, lengthscale):\n return( np.exp( np.linalg.norm(x - z)**2/(2*lengthscale**2) ) )\n \n ###########################\n # Predictive distribution #\n ###########################\n def predict(self, Xnew, predvar=False):\n alpha = solve(self.L.T, solve(self.L,self.Y*self.yscale ) )\n if predvar:\n m = np.shape(Xnew)[0]\n Knew_N,_ = self.K(Xnew, self.X, self.lengthscale)\n Knew_new = np.array( [self.scalarK(Xnew[i], Xnew[i], self.lengthscale) for i in range(m)] ).reshape([m,1])\n v = solve(self.L, Knew_N.T)\n return matmul(Knew_N, alpha), np.diag( Knew_new + self.likelihood_variance - matmul(v.T, v) ).reshape(m,1)\n else:\n Knew_N,_ = self.K(Xnew, self.X, self.lengthscale)\n return matmul(Knew_N, alpha)\n \n ############################### \n # Gradient of predictive mean #\n ###############################\n def predictive_grad(self, Xnew):\n alpha = solve(self.L.T, solve(self.L, self.Y*self.yscale ) )\n Knew_N,_ = self.K(Xnew, self.X, self.lengthscale)\n \n return (-1/self.lengthscale**2)*matmul( np.tile(Xnew.T, self.n) - self.X.T, np.multiply(Knew_N.T, alpha) )",
"_____no_output_____"
]
],
[
[
"## 1D Toy example with missing data, gradient computation, likelihood surface plot\n",
"_____no_output_____"
]
],
[
[
"N = 30\n\nNt = 400\nX = np.linspace(-4,5,N).reshape(N,1);\n# We can pick out some values to illustrate how the uncertainty estimate behaves \n# it's interesting to see what happens to likelihood below \n\nind = np.bool8([1,1,1,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,1,1,1,1,1,1,1,1,1,1]); X = X[ ind ]; N=N-sum(~ind)\nXt = np.linspace(-4,5,Nt).reshape(Nt,1)\n\nY = np.sin(X)*np.exp(0.2*X) + np.random.randn(N,1)*0.3\n\n\nt0 = time.time()\n\n\nm = mintGP()\nm.fit(X,Y)\nprint( m.lengthscale, m.likelihood_variance )\n\npred, var = m.predict(Xt,predvar=True)\nt1 = time.time()\nprint('time to compute ',t1-t0)\n\n\nfig, ax = plt.subplots()\nax.plot(Xt, pred, label=\"GP mean\")\ntwostd = 2*np.sqrt(var)\n\nax.fill_between(Xt.ravel(), (pred-twostd).ravel(), (pred+twostd).ravel(), alpha=0.5)\nax.scatter(X,Y,label='data')\nax.legend(loc='best')\n",
"[ 1.30113801 0.10936404] [ 3.59901867 1. ]\n1.30113800545 0.109364039911\ntime to compute 0.05816292762756348\n"
]
],
[
[
"### Gradient",
"_____no_output_____"
]
],
[
[
"grad = [ m.predictive_grad(x.reshape(1,1)) for x in Xt ]\ngrad = np.array(grad)\nfig, ax = plt.subplots()\nax.plot(Xt, grad.ravel(), label=\"GP deriv\")\nax.plot([-4,5], [0,0], label=\"GP deriv\")\n",
"_____no_output_____"
]
],
[
[
"### Likelihood Surface",
"_____no_output_____"
]
],
[
[
"#### Plot LML landscape\nplt.figure(1)\nM = 30\ntheta0 = np.logspace(-0.3, 0.4,M)#np.logspace(-1, 1, M)\ntheta1 = np.logspace(-1.5, 0, M)#np.logspace(-2.5, 0, M)\nTheta0, Theta1 = np.meshgrid(theta0, theta1)\nLML = [[m.neg_log_marg_like([Theta0[i, j], Theta1[i, j]])[0]\n for i in range(M)] for j in range(M)]\nLML = np.array(LML).T\n\nvmin, vmax = (LML).min(), (LML).max()\nvmax = 50\nlevel = np.around(np.logspace(np.log10(vmin), np.log10(vmax), 50), decimals=1)\nplt.contour(Theta0, Theta1, LML,\n levels=level, norm=colors.LogNorm(vmin=vmin, vmax=vmax))\nplt.colorbar()\nplt.xscale(\"log\")\nplt.yscale(\"log\")\nplt.xlabel(\"Length-scale\")\nplt.ylabel(\"Noise-level\")\nplt.title(\"neg-log-marginal-likelihood\")\nplt.tight_layout()",
"_____no_output_____"
]
],
[
[
"### likehood surface gradient",
"_____no_output_____"
]
],
[
[
"import sympy\n\n# Plot LML landscape\nplt.figure(1)\nLML_grad = [[ m.neg_log_marg_like([Theta0[i, j], Theta1[i, j]])[1]\n for i in range(M)] for j in range(M)]\nLML_grad = -np.array(LML_grad).T\n\nplt.figure()\nplt.quiver(Theta0,Theta1,LML_grad[0],LML_grad[1])\nplt.xscale(\"log\")\nplt.yscale(\"log\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"## 2D toy example",
"_____no_output_____"
]
],
[
[
"N = 100\n# training data\nNt = 400\nX1 = np.random.uniform(-5,5,size = (N,1)) #np.linspace(-4,5,N).reshape(N,1)\nX2 = np.random.uniform(-5,5,size = (N,1))\nX = np.concatenate([X1,X2],1)\n# test data\nXt = np.concatenate([np.linspace(-4,5,Nt).reshape(Nt,1), np.linspace(-4,5,Nt).reshape(Nt,1)], 1)\nY = X1**2 + X2**2 + np.random.randn(N,1)*0.3\n\n\nt0 = time.time()\nm = mintGP()\nm.fit(X,Y)\nprint( m.lengthscale, m.likelihood_variance )\n#pred, var = m.predict(Xt,predvar=True)\nt1 = time.time()\nprint('time to compute ',t1-t0)\n",
"[ 3.46386299e+00 1.01896404e-03] [ 5.21543278 1. ]\n3.46386298728 0.00101896404276\ntime to compute 0.07127761840820312\n"
],
[
"M = 50\ngrid = np.linspace(-5,5,M).reshape(M,1)\nXX1,XX2 = np.meshgrid(grid,grid)\nZ = [[m.predict( np.array([XX1[i,j], XX2[i,j] ]).reshape(1,2) )[0,0] for i in range(M)] for j in range(M)]\nZ = np.array(Z)\n# plot points and fitted surface\nfig = plt.figure()\nax = fig.gca(projection='3d')\n\nax.plot_surface(XX1, XX2, Z, rstride=1, cstride=1, alpha=0.2)\nax.scatter(X1, X2, Y, c='r', s=30)\nplt.xlabel('X')\nplt.ylabel('Y')\nax.set_zlabel('Z')\nax.axis('equal')\n#ax.axis('tight')",
"_____no_output_____"
]
],
[
[
"### Gradient as colorcode like in Emans sw33t pløts",
"_____no_output_____"
]
],
[
[
"# Color function by norm of gradient\n\nfig = plt.figure(figsize=[8,5])\nax = fig.gca(projection='3d')\n\nmy_col = cm.jet( gradnorm / np.amax(gradnorm) )\ncbar = cm.ScalarMappable(cmap=cm.jet)\ncbar.set_array(my_col)\nsurf = ax.plot_surface(XX1, XX2, Z, rstride=2, cstride=2, alpha=0.5, facecolors = my_col, linewidth = 0 )\nfig.colorbar(cbar, shrink=0.8, aspect=8)",
"_____no_output_____"
]
],
[
[
"# Tensordot experiments for gradient function to be able to take NxD arrays\n",
"_____no_output_____"
]
],
[
[
"a = np.arange(60.).reshape(3,4,5)\nb = np.arange(24.).reshape(4,3,2)\nc = np.tensordot(a,b, axes=([1,0],[0,1]))\nc.shape",
"_____no_output_____"
],
[
"c ",
"_____no_output_____"
],
[
"# A slower but equivalent way of computing the same \nd = np.zeros((5,2))\nfor i in range(5):\n for j in range(2):\n for k in range(3):\n for n in range(4):\n d[i,j] += a[k,n,i] * b[n,k,j]\nc == d",
"_____no_output_____"
],
[
"xnew = np.array([[4,9],[1,8]], ndmin=2)",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
cb3beee9b02568eea43ef59dc7ed5c29e7a39bdb | 585,166 | ipynb | Jupyter Notebook | tensorflow_object_detection_training_colab_V2.ipynb | PramukaWeerasinghe/object_detection_demo | d10acda78b59c76498f96a806501febe188ea4d7 | [
"MIT"
] | null | null | null | tensorflow_object_detection_training_colab_V2.ipynb | PramukaWeerasinghe/object_detection_demo | d10acda78b59c76498f96a806501febe188ea4d7 | [
"MIT"
] | null | null | null | tensorflow_object_detection_training_colab_V2.ipynb | PramukaWeerasinghe/object_detection_demo | d10acda78b59c76498f96a806501febe188ea4d7 | [
"MIT"
] | 2 | 2020-03-23T18:09:20.000Z | 2020-04-03T09:07:56.000Z | 169.859507 | 191,966 | 0.826212 | [
[
[
"#Object Detection Framework",
"_____no_output_____"
]
],
[
[
"# If you forked the repository, you can replace the link.\nrepo_url = 'https://github.com/PramukaWeerasinghe/object_detection_demo'\n\n# Number of training steps.\nnum_steps = 1000 # 200000\n\n# Number of evaluation steps.\nnum_eval_steps = 50\n\nMODELS_CONFIG = {\n 'ssd_mobilenet_v2': {\n 'model_name': 'ssd_mobilenet_v2_coco_2018_03_29',\n 'pipeline_file': 'ssd_mobilenet_v2_coco.config',\n 'batch_size': 12\n },\n 'faster_rcnn_inception_v2': {\n 'model_name': 'faster_rcnn_inception_v2_coco_2018_01_28',\n 'pipeline_file': 'faster_rcnn_inception_v2_pets.config',\n 'batch_size': 12\n },\n 'rfcn_resnet101': {\n 'model_name': 'rfcn_resnet101_coco_2018_01_28',\n 'pipeline_file': 'rfcn_resnet101_pets.config',\n 'batch_size': 8\n }\n}\n\n# Pick the model you want to use\n# Select a model in `MODELS_CONFIG`.\nselected_model = 'faster_rcnn_inception_v2'\n\n# Name of the object detection model to use.\nMODEL = MODELS_CONFIG[selected_model]['model_name']\n\n# Name of the pipline file in tensorflow object detection API.\npipeline_file = MODELS_CONFIG[selected_model]['pipeline_file']\n\n# Training batch size fits in Colabe's Tesla K80 GPU memory for selected model.\nbatch_size = MODELS_CONFIG[selected_model]['batch_size']",
"_____no_output_____"
]
],
[
[
"## Clone the `object_detection_demo` repository or your fork.",
"_____no_output_____"
]
],
[
[
"import os\n\n%cd /content\n\nrepo_dir_path = os.path.abspath(os.path.join('.', os.path.basename(repo_url)))\n\n!git clone {repo_url}\n%cd {repo_dir_path}\n!git pull",
"/content\nCloning into 'object_detection_demo'...\nremote: Enumerating objects: 48, done.\u001b[K\nremote: Counting objects: 100% (48/48), done.\u001b[K\nremote: Compressing objects: 100% (42/42), done.\u001b[K\nremote: Total 598 (delta 28), reused 21 (delta 6), pack-reused 550\u001b[K\nReceiving objects: 100% (598/598), 28.94 MiB | 48.50 MiB/s, done.\nResolving deltas: 100% (303/303), done.\n/content/object_detection_demo\nAlready up to date.\n"
],
[
"%tensorflow_version 1.x\nimport tensorflow as tf",
"TensorFlow 1.x selected.\n"
]
],
[
[
"## Install required packages",
"_____no_output_____"
]
],
[
[
"%cd /content\n!git clone https://github.com/PramukaWeerasinghe/models\n\n!apt-get install -qq protobuf-compiler python-pil python-lxml python-tk\n\n!pip install -q Cython contextlib2 pillow lxml matplotlib\n\n!pip install -q pycocotools\n\n%cd /content/models/research\n!protoc object_detection/protos/*.proto --python_out=.\n\nimport os\nos.environ['PYTHONPATH'] = '/content/models/research:/content/models/research/slim:' + os.environ['PYTHONPATH']\n\n!python object_detection/builders/model_builder_test.py",
"/content\nCloning into 'models'...\nremote: Enumerating objects: 33079, done.\u001b[K\nremote: Total 33079 (delta 0), reused 0 (delta 0), pack-reused 33079\u001b[K\nReceiving objects: 100% (33079/33079), 518.28 MiB | 44.96 MiB/s, done.\nResolving deltas: 100% (21614/21614), done.\nSelecting previously unselected package python-bs4.\n(Reading database ... 144379 files and directories currently installed.)\nPreparing to unpack .../0-python-bs4_4.6.0-1_all.deb ...\nUnpacking python-bs4 (4.6.0-1) ...\nSelecting previously unselected package python-pkg-resources.\nPreparing to unpack .../1-python-pkg-resources_39.0.1-2_all.deb ...\nUnpacking python-pkg-resources (39.0.1-2) ...\nSelecting previously unselected package python-chardet.\nPreparing to unpack .../2-python-chardet_3.0.4-1_all.deb ...\nUnpacking python-chardet (3.0.4-1) ...\nSelecting previously unselected package python-six.\nPreparing to unpack .../3-python-six_1.11.0-2_all.deb ...\nUnpacking python-six (1.11.0-2) ...\nSelecting previously unselected package python-webencodings.\nPreparing to unpack .../4-python-webencodings_0.5-2_all.deb ...\nUnpacking python-webencodings (0.5-2) ...\nSelecting previously unselected package python-html5lib.\nPreparing to unpack .../5-python-html5lib_0.999999999-1_all.deb ...\nUnpacking python-html5lib (0.999999999-1) ...\nSelecting previously unselected package python-lxml:amd64.\nPreparing to unpack .../6-python-lxml_4.2.1-1ubuntu0.1_amd64.deb ...\nUnpacking python-lxml:amd64 (4.2.1-1ubuntu0.1) ...\nSelecting previously unselected package python-olefile.\nPreparing to unpack .../7-python-olefile_0.45.1-1_all.deb ...\nUnpacking python-olefile (0.45.1-1) ...\nSelecting previously unselected package python-pil:amd64.\nPreparing to unpack .../8-python-pil_5.1.0-1ubuntu0.2_amd64.deb ...\nUnpacking python-pil:amd64 (5.1.0-1ubuntu0.2) ...\nSetting up python-pkg-resources (39.0.1-2) ...\nSetting up python-six (1.11.0-2) ...\nSetting up python-bs4 (4.6.0-1) ...\nSetting up python-lxml:amd64 (4.2.1-1ubuntu0.1) ...\nSetting up python-olefile (0.45.1-1) ...\nSetting up python-pil:amd64 (5.1.0-1ubuntu0.2) ...\nSetting up python-webencodings (0.5-2) ...\nSetting up python-chardet (3.0.4-1) ...\nSetting up python-html5lib (0.999999999-1) ...\nProcessing triggers for man-db (2.8.3-2ubuntu0.1) ...\n/content/models/research\nWARNING:tensorflow:\nThe TensorFlow contrib module will not be included in TensorFlow 2.0.\nFor more information, please see:\n * https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md\n * https://github.com/tensorflow/addons\n * https://github.com/tensorflow/io (for I/O related ops)\nIf you depend on functionality not listed there, please file an issue.\n\nRunning tests under Python 3.6.9: /usr/bin/python3\n[ RUN ] ModelBuilderTest.test_create_experimental_model\n[ OK ] ModelBuilderTest.test_create_experimental_model\n[ RUN ] ModelBuilderTest.test_create_faster_rcnn_model_from_config_with_example_miner\n[ OK ] ModelBuilderTest.test_create_faster_rcnn_model_from_config_with_example_miner\n[ RUN ] ModelBuilderTest.test_create_faster_rcnn_models_from_config_faster_rcnn_with_matmul\n[ OK ] ModelBuilderTest.test_create_faster_rcnn_models_from_config_faster_rcnn_with_matmul\n[ RUN ] ModelBuilderTest.test_create_faster_rcnn_models_from_config_faster_rcnn_without_matmul\n[ OK ] ModelBuilderTest.test_create_faster_rcnn_models_from_config_faster_rcnn_without_matmul\n[ RUN ] ModelBuilderTest.test_create_faster_rcnn_models_from_config_mask_rcnn_with_matmul\n[ OK ] ModelBuilderTest.test_create_faster_rcnn_models_from_config_mask_rcnn_with_matmul\n[ RUN ] ModelBuilderTest.test_create_faster_rcnn_models_from_config_mask_rcnn_without_matmul\n[ OK ] ModelBuilderTest.test_create_faster_rcnn_models_from_config_mask_rcnn_without_matmul\n[ RUN ] ModelBuilderTest.test_create_rfcn_model_from_config\n[ OK ] ModelBuilderTest.test_create_rfcn_model_from_config\n[ RUN ] ModelBuilderTest.test_create_ssd_fpn_model_from_config\n[ OK ] ModelBuilderTest.test_create_ssd_fpn_model_from_config\n[ RUN ] ModelBuilderTest.test_create_ssd_models_from_config\n[ OK ] ModelBuilderTest.test_create_ssd_models_from_config\n[ RUN ] ModelBuilderTest.test_invalid_faster_rcnn_batchnorm_update\n[ OK ] ModelBuilderTest.test_invalid_faster_rcnn_batchnorm_update\n[ RUN ] ModelBuilderTest.test_invalid_first_stage_nms_iou_threshold\n[ OK ] ModelBuilderTest.test_invalid_first_stage_nms_iou_threshold\n[ RUN ] ModelBuilderTest.test_invalid_model_config_proto\n[ OK ] ModelBuilderTest.test_invalid_model_config_proto\n[ RUN ] ModelBuilderTest.test_invalid_second_stage_batch_size\n[ OK ] ModelBuilderTest.test_invalid_second_stage_batch_size\n[ RUN ] ModelBuilderTest.test_session\n[ SKIPPED ] ModelBuilderTest.test_session\n[ RUN ] ModelBuilderTest.test_unknown_faster_rcnn_feature_extractor\n[ OK ] ModelBuilderTest.test_unknown_faster_rcnn_feature_extractor\n[ RUN ] ModelBuilderTest.test_unknown_meta_architecture\n[ OK ] ModelBuilderTest.test_unknown_meta_architecture\n[ RUN ] ModelBuilderTest.test_unknown_ssd_feature_extractor\n[ OK ] ModelBuilderTest.test_unknown_ssd_feature_extractor\n----------------------------------------------------------------------\nRan 17 tests in 0.170s\n\nOK (skipped=1)\n"
]
],
[
[
"## Prepare `tfrecord` files\n\nUse the following scripts to generate the `tfrecord` files.\n```bash\n# Convert train folder annotation xml files to a single csv file,\n# generate the `label_map.pbtxt` file to `data/` directory as well.\npython xml_to_csv.py -i data/images/train -o data/annotations/train_labels.csv -l data/annotations\n\n# Convert test folder annotation xml files to a single csv.\npython xml_to_csv.py -i data/images/test -o data/annotations/test_labels.csv\n\n# Generate `train.record`\npython generate_tfrecord.py --csv_input=data/annotations/train_labels.csv --output_path=data/annotations/train.record --img_path=data/images/train --label_map data/annotations/label_map.pbtxt\n\n# Generate `test.record`\npython generate_tfrecord.py --csv_input=data/annotations/test_labels.csv --output_path=data/annotations/test.record --img_path=data/images/test --label_map data/annotations/label_map.pbtxt\n```",
"_____no_output_____"
]
],
[
[
"%cd {repo_dir_path}\n\n# Convert train folder annotation xml files to a single csv file,\n# generate the `label_map.pbtxt` file to `data/` directory as well.\n!python xml_to_csv.py -i data/images/train -o data/annotations/train_labels.csv -l data/annotations\n\n# Convert test folder annotation xml files to a single csv.\n!python xml_to_csv.py -i data/images/test -o data/annotations/test_labels.csv\n\n# Generate `train.record`\n!python generate_tfrecord.py --csv_input=data/annotations/train_labels.csv --output_path=data/annotations/train.record --img_path=data/images/train --label_map data/annotations/label_map.pbtxt\n\n# Generate `test.record`\n!python generate_tfrecord.py --csv_input=data/annotations/test_labels.csv --output_path=data/annotations/test.record --img_path=data/images/test --label_map data/annotations/label_map.pbtxt",
"/content/object_detection_demo\nSuccessfully converted xml to csv.\nGenerate `data/annotations/label_map.pbtxt`\nSuccessfully converted xml to csv.\nWARNING:tensorflow:From /content/models/research/object_detection/utils/label_map_util.py:138: The name tf.gfile.GFile is deprecated. Please use tf.io.gfile.GFile instead.\n\nW0712 13:46:04.533420 140488603301760 module_wrapper.py:139] From /content/models/research/object_detection/utils/label_map_util.py:138: The name tf.gfile.GFile is deprecated. Please use tf.io.gfile.GFile instead.\n\nSuccessfully created the TFRecords: /content/object_detection_demo/data/annotations/train.record\nWARNING:tensorflow:From /content/models/research/object_detection/utils/label_map_util.py:138: The name tf.gfile.GFile is deprecated. Please use tf.io.gfile.GFile instead.\n\nW0712 13:46:07.887261 140280749729664 module_wrapper.py:139] From /content/models/research/object_detection/utils/label_map_util.py:138: The name tf.gfile.GFile is deprecated. Please use tf.io.gfile.GFile instead.\n\nSuccessfully created the TFRecords: /content/object_detection_demo/data/annotations/test.record\n"
],
[
"test_record_fname = '/content/object_detection_demo/data/annotations/test.record'\ntrain_record_fname = '/content/object_detection_demo/data/annotations/train.record'\nlabel_map_pbtxt_fname = '/content/object_detection_demo/data/annotations/label_map.pbtxt'",
"_____no_output_____"
]
],
[
[
"## Download base model",
"_____no_output_____"
]
],
[
[
"%cd /content/models/research\n\nimport os\nimport shutil\nimport glob\nimport urllib.request\nimport tarfile\nMODEL_FILE = MODEL + '.tar.gz'\nDOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'\nDEST_DIR = '/content/models/research/pretrained_model'\n\nif not (os.path.exists(MODEL_FILE)):\n urllib.request.urlretrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE)\n\ntar = tarfile.open(MODEL_FILE)\ntar.extractall()\ntar.close()\n\nos.remove(MODEL_FILE)\nif (os.path.exists(DEST_DIR)):\n shutil.rmtree(DEST_DIR)\nos.rename(MODEL, DEST_DIR)",
"/content/models/research\n"
],
[
"!echo {DEST_DIR}\n!ls -alh {DEST_DIR}",
"/content/models/research/pretrained_model\ntotal 111M\ndrwxr-xr-x 3 345018 5000 4.0K Feb 1 2018 .\ndrwxr-xr-x 64 root root 4.0K Jul 12 13:46 ..\n-rw-r--r-- 1 345018 5000 77 Feb 1 2018 checkpoint\n-rw-r--r-- 1 345018 5000 55M Feb 1 2018 frozen_inference_graph.pb\n-rw-r--r-- 1 345018 5000 51M Feb 1 2018 model.ckpt.data-00000-of-00001\n-rw-r--r-- 1 345018 5000 16K Feb 1 2018 model.ckpt.index\n-rw-r--r-- 1 345018 5000 5.5M Feb 1 2018 model.ckpt.meta\n-rw-r--r-- 1 345018 5000 3.2K Feb 1 2018 pipeline.config\ndrwxr-xr-x 3 345018 5000 4.0K Feb 1 2018 saved_model\n"
],
[
"fine_tune_checkpoint = os.path.join(DEST_DIR, \"model.ckpt\")\nfine_tune_checkpoint",
"_____no_output_____"
]
],
[
[
"## Configuring a Training Pipeline",
"_____no_output_____"
]
],
[
[
"import os\npipeline_fname = os.path.join('/content/models/research/object_detection/samples/configs/', pipeline_file)\n\nassert os.path.isfile(pipeline_fname), '`{}` not exist'.format(pipeline_fname)",
"_____no_output_____"
],
[
"def get_num_classes(pbtxt_fname):\n from object_detection.utils import label_map_util\n label_map = label_map_util.load_labelmap(pbtxt_fname)\n categories = label_map_util.convert_label_map_to_categories(\n label_map, max_num_classes=90, use_display_name=True)\n category_index = label_map_util.create_category_index(categories)\n return len(category_index.keys())",
"_____no_output_____"
],
[
"import re\n\nnum_classes = get_num_classes(label_map_pbtxt_fname)\nwith open(pipeline_fname) as f:\n s = f.read()\nwith open(pipeline_fname, 'w') as f:\n \n # fine_tune_checkpoint\n s = re.sub('fine_tune_checkpoint: \".*?\"',\n 'fine_tune_checkpoint: \"{}\"'.format(fine_tune_checkpoint), s)\n \n # tfrecord files train and test.\n s = re.sub(\n '(input_path: \".*?)(train.record)(.*?\")', 'input_path: \"{}\"'.format(train_record_fname), s)\n s = re.sub(\n '(input_path: \".*?)(val.record)(.*?\")', 'input_path: \"{}\"'.format(test_record_fname), s)\n\n # label_map_path\n s = re.sub(\n 'label_map_path: \".*?\"', 'label_map_path: \"{}\"'.format(label_map_pbtxt_fname), s)\n\n # Set training batch_size.\n s = re.sub('batch_size: [0-9]+',\n 'batch_size: {}'.format(batch_size), s)\n\n # Set training steps, num_steps\n s = re.sub('num_steps: [0-9]+',\n 'num_steps: {}'.format(num_steps), s)\n \n # Set number of classes num_classes.\n s = re.sub('num_classes: [0-9]+',\n 'num_classes: {}'.format(num_classes), s)\n f.write(s)",
"WARNING:tensorflow:From /content/models/research/object_detection/utils/label_map_util.py:138: The name tf.gfile.GFile is deprecated. Please use tf.io.gfile.GFile instead.\n\n"
],
[
"!cat {pipeline_fname}\n!pwd",
"# Faster R-CNN with Inception v2, configured for Oxford-IIIT Pets Dataset.\n# Users should configure the fine_tune_checkpoint field in the train config as\n# well as the label_map_path and input_path fields in the train_input_reader and\n# eval_input_reader. Search for \"PATH_TO_BE_CONFIGURED\" to find the fields that\n# should be configured.\n\nmodel {\n faster_rcnn {\n num_classes: 8\n image_resizer {\n keep_aspect_ratio_resizer {\n min_dimension: 600\n max_dimension: 1024\n }\n }\n feature_extractor {\n type: 'faster_rcnn_inception_v2'\n first_stage_features_stride: 16\n }\n first_stage_anchor_generator {\n grid_anchor_generator {\n scales: [0.25, 0.5, 1.0, 2.0]\n aspect_ratios: [0.5, 1.0, 2.0]\n height_stride: 16\n width_stride: 16\n }\n }\n first_stage_box_predictor_conv_hyperparams {\n op: CONV\n regularizer {\n l2_regularizer {\n weight: 0.0\n }\n }\n initializer {\n truncated_normal_initializer {\n stddev: 0.01\n }\n }\n }\n first_stage_nms_score_threshold: 0.0\n first_stage_nms_iou_threshold: 0.7\n first_stage_max_proposals: 300\n first_stage_localization_loss_weight: 2.0\n first_stage_objectness_loss_weight: 1.0\n initial_crop_size: 14\n maxpool_kernel_size: 2\n maxpool_stride: 2\n second_stage_box_predictor {\n mask_rcnn_box_predictor {\n use_dropout: false\n dropout_keep_probability: 1.0\n fc_hyperparams {\n op: FC\n regularizer {\n l2_regularizer {\n weight: 0.0\n }\n }\n initializer {\n variance_scaling_initializer {\n factor: 1.0\n uniform: true\n mode: FAN_AVG\n }\n }\n }\n }\n }\n second_stage_post_processing {\n batch_non_max_suppression {\n score_threshold: 0.0\n iou_threshold: 0.6\n max_detections_per_class: 100\n max_total_detections: 300\n }\n score_converter: SOFTMAX\n }\n second_stage_localization_loss_weight: 2.0\n second_stage_classification_loss_weight: 1.0\n }\n}\n\ntrain_config: {\n batch_size: 12\n optimizer {\n momentum_optimizer: {\n learning_rate: {\n manual_step_learning_rate {\n initial_learning_rate: 0.0002\n schedule {\n step: 900000\n learning_rate: .00002\n }\n schedule {\n step: 1200000\n learning_rate: .000002\n }\n }\n }\n momentum_optimizer_value: 0.9\n }\n use_moving_average: false\n }\n gradient_clipping_by_norm: 10.0\n fine_tune_checkpoint: \"/content/models/research/pretrained_model/model.ckpt\"\n from_detection_checkpoint: true\n load_all_detection_checkpoint_vars: true\n # Note: The below line limits the training process to 200K steps, which we\n # empirically found to be sufficient enough to train the pets dataset. This\n # effectively bypasses the learning rate schedule (the learning rate will\n # never decay). Remove the below line to train indefinitely.\n num_steps: 1000\n data_augmentation_options {\n random_horizontal_flip {\n }\n }\n}\n\n\ntrain_input_reader: {\n tf_record_input_reader {\n input_path: \"/content/object_detection_demo/data/annotations/train.record\"\n }\n label_map_path: \"/content/object_detection_demo/data/annotations/label_map.pbtxt\"\n}\n\neval_config: {\n metrics_set: \"coco_detection_metrics\"\n num_examples: 1101\n}\n\neval_input_reader: {\n tf_record_input_reader {\n input_path: \"/content/object_detection_demo/data/annotations/test.record\"\n }\n label_map_path: \"/content/object_detection_demo/data/annotations/label_map.pbtxt\"\n shuffle: false\n num_readers: 1\n}\n/content/models/research\n"
],
[
"model_dir = 'training/'\n# Optionally remove content in output model directory to fresh start.\n!rm -rf {model_dir}\nos.makedirs(model_dir, exist_ok=True)",
"_____no_output_____"
]
],
[
[
"## Run Tensorboard(Optional)",
"_____no_output_____"
]
],
[
[
"!wget https://bin.equinox.io/c/4VmDzA7iaHb/ngrok-stable-linux-amd64.zip\n!unzip -o ngrok-stable-linux-amd64.zip",
"--2020-07-12 13:46:46-- https://bin.equinox.io/c/4VmDzA7iaHb/ngrok-stable-linux-amd64.zip\nResolving bin.equinox.io (bin.equinox.io)... 3.95.144.123, 52.206.116.16, 18.214.66.67, ...\nConnecting to bin.equinox.io (bin.equinox.io)|3.95.144.123|:443... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: 13773305 (13M) [application/octet-stream]\nSaving to: ‘ngrok-stable-linux-amd64.zip’\n\nngrok-stable-linux- 100%[===================>] 13.13M 19.2MB/s in 0.7s \n\n2020-07-12 13:46:47 (19.2 MB/s) - ‘ngrok-stable-linux-amd64.zip’ saved [13773305/13773305]\n\nArchive: ngrok-stable-linux-amd64.zip\n inflating: ngrok \n"
],
[
"LOG_DIR = model_dir\nget_ipython().system_raw(\n 'tensorboard --logdir {} --host 0.0.0.0 --port 6006 &'\n .format(LOG_DIR)\n)",
"_____no_output_____"
],
[
"get_ipython().system_raw('./ngrok http 6006 &')",
"_____no_output_____"
]
],
[
[
"### Get Tensorboard link",
"_____no_output_____"
]
],
[
[
"! curl -s http://localhost:4040/api/tunnels | python3 -c \\\n \"import sys, json; print(json.load(sys.stdin)['tunnels'][0]['public_url'])\"",
"https://9feb7a81e627.ngrok.io\n"
]
],
[
[
"## Train the model",
"_____no_output_____"
]
],
[
[
"!python /content/models/research/object_detection/model_main.py \\\n --pipeline_config_path={pipeline_fname} \\\n --model_dir={model_dir} \\\n --alsologtostderr \\\n --num_train_steps={num_steps} \\\n --num_eval_steps={num_eval_steps}",
"WARNING:tensorflow:\nThe TensorFlow contrib module will not be included in TensorFlow 2.0.\nFor more information, please see:\n * https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md\n * https://github.com/tensorflow/addons\n * https://github.com/tensorflow/io (for I/O related ops)\nIf you depend on functionality not listed there, please file an issue.\n\nWARNING:tensorflow:From /content/models/research/object_detection/model_main.py:109: The name tf.app.run is deprecated. Please use tf.compat.v1.app.run instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/utils/config_util.py:102: The name tf.gfile.GFile is deprecated. Please use tf.io.gfile.GFile instead.\n\nW0712 13:47:06.706425 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/utils/config_util.py:102: The name tf.gfile.GFile is deprecated. Please use tf.io.gfile.GFile instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/model_lib.py:628: The name tf.logging.warning is deprecated. Please use tf.compat.v1.logging.warning instead.\n\nW0712 13:47:06.709094 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/model_lib.py:628: The name tf.logging.warning is deprecated. Please use tf.compat.v1.logging.warning instead.\n\nWARNING:tensorflow:Forced number of epochs for all eval validations to be 1.\nW0712 13:47:06.709232 139641935939456 model_lib.py:629] Forced number of epochs for all eval validations to be 1.\nWARNING:tensorflow:From /content/models/research/object_detection/utils/config_util.py:488: The name tf.logging.info is deprecated. Please use tf.compat.v1.logging.info instead.\n\nW0712 13:47:06.709349 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/utils/config_util.py:488: The name tf.logging.info is deprecated. Please use tf.compat.v1.logging.info instead.\n\nINFO:tensorflow:Maybe overwriting train_steps: 1000\nI0712 13:47:06.709439 139641935939456 config_util.py:488] Maybe overwriting train_steps: 1000\nINFO:tensorflow:Maybe overwriting use_bfloat16: False\nI0712 13:47:06.709527 139641935939456 config_util.py:488] Maybe overwriting use_bfloat16: False\nINFO:tensorflow:Maybe overwriting sample_1_of_n_eval_examples: 1\nI0712 13:47:06.709596 139641935939456 config_util.py:488] Maybe overwriting sample_1_of_n_eval_examples: 1\nINFO:tensorflow:Maybe overwriting eval_num_epochs: 1\nI0712 13:47:06.709668 139641935939456 config_util.py:488] Maybe overwriting eval_num_epochs: 1\nINFO:tensorflow:Maybe overwriting load_pretrained: True\nI0712 13:47:06.709734 139641935939456 config_util.py:488] Maybe overwriting load_pretrained: True\nINFO:tensorflow:Ignoring config override key: load_pretrained\nI0712 13:47:06.709801 139641935939456 config_util.py:498] Ignoring config override key: load_pretrained\nWARNING:tensorflow:Expected number of evaluation epochs is 1, but instead encountered `eval_on_train_input_config.num_epochs` = 0. Overwriting `num_epochs` to 1.\nW0712 13:47:06.710546 139641935939456 model_lib.py:645] Expected number of evaluation epochs is 1, but instead encountered `eval_on_train_input_config.num_epochs` = 0. Overwriting `num_epochs` to 1.\nINFO:tensorflow:create_estimator_and_inputs: use_tpu False, export_to_tpu False\nI0712 13:47:06.710671 139641935939456 model_lib.py:680] create_estimator_and_inputs: use_tpu False, export_to_tpu False\nINFO:tensorflow:Using config: {'_model_dir': 'training/', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': None, '_save_checkpoints_secs': 600, '_session_config': allow_soft_placement: true\ngraph_options {\n rewrite_options {\n meta_optimizer_iterations: ONE\n }\n}\n, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_device_fn': None, '_protocol': None, '_eval_distribute': None, '_experimental_distribute': None, '_experimental_max_worker_delay_secs': None, '_session_creation_timeout_secs': 7200, '_service': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x7f007e6dd2b0>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}\nI0712 13:47:06.711121 139641935939456 estimator.py:212] Using config: {'_model_dir': 'training/', '_tf_random_seed': None, '_save_summary_steps': 100, '_save_checkpoints_steps': None, '_save_checkpoints_secs': 600, '_session_config': allow_soft_placement: true\ngraph_options {\n rewrite_options {\n meta_optimizer_iterations: ONE\n }\n}\n, '_keep_checkpoint_max': 5, '_keep_checkpoint_every_n_hours': 10000, '_log_step_count_steps': 100, '_train_distribute': None, '_device_fn': None, '_protocol': None, '_eval_distribute': None, '_experimental_distribute': None, '_experimental_max_worker_delay_secs': None, '_session_creation_timeout_secs': 7200, '_service': None, '_cluster_spec': <tensorflow.python.training.server_lib.ClusterSpec object at 0x7f007e6dd2b0>, '_task_type': 'worker', '_task_id': 0, '_global_id_in_cluster': 0, '_master': '', '_evaluation_master': '', '_is_chief': True, '_num_ps_replicas': 0, '_num_worker_replicas': 1}\nWARNING:tensorflow:Estimator's model_fn (<function create_model_fn.<locals>.model_fn at 0x7f007ecc3730>) includes params argument, but params are not passed to Estimator.\nW0712 13:47:06.711356 139641935939456 model_fn.py:630] Estimator's model_fn (<function create_model_fn.<locals>.model_fn at 0x7f007ecc3730>) includes params argument, but params are not passed to Estimator.\nINFO:tensorflow:Not using Distribute Coordinator.\nI0712 13:47:06.712070 139641935939456 estimator_training.py:186] Not using Distribute Coordinator.\nINFO:tensorflow:Running training and evaluation locally (non-distributed).\nI0712 13:47:06.712240 139641935939456 training.py:612] Running training and evaluation locally (non-distributed).\nINFO:tensorflow:Start train and evaluate loop. The evaluate will happen after every checkpoint. Checkpoint frequency is determined based on RunConfig arguments: save_checkpoints_steps None or save_checkpoints_secs 600.\nI0712 13:47:06.712457 139641935939456 training.py:700] Start train and evaluate loop. The evaluate will happen after every checkpoint. Checkpoint frequency is determined based on RunConfig arguments: save_checkpoints_steps None or save_checkpoints_secs 600.\nWARNING:tensorflow:From /tensorflow-1.15.2/python3.6/tensorflow_core/python/training/training_util.py:236: Variable.initialized_value (from tensorflow.python.ops.variables) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse Variable.read_value. Variables in 2.X are initialized automatically both in eager and graph (inside tf.defun) contexts.\nW0712 13:47:06.718364 139641935939456 deprecation.py:323] From /tensorflow-1.15.2/python3.6/tensorflow_core/python/training/training_util.py:236: Variable.initialized_value (from tensorflow.python.ops.variables) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse Variable.read_value. Variables in 2.X are initialized automatically both in eager and graph (inside tf.defun) contexts.\nWARNING:tensorflow:From /content/models/research/object_detection/data_decoders/tf_example_decoder.py:182: The name tf.FixedLenFeature is deprecated. Please use tf.io.FixedLenFeature instead.\n\nW0712 13:47:06.728975 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/data_decoders/tf_example_decoder.py:182: The name tf.FixedLenFeature is deprecated. Please use tf.io.FixedLenFeature instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/data_decoders/tf_example_decoder.py:197: The name tf.VarLenFeature is deprecated. Please use tf.io.VarLenFeature instead.\n\nW0712 13:47:06.729195 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/data_decoders/tf_example_decoder.py:197: The name tf.VarLenFeature is deprecated. Please use tf.io.VarLenFeature instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/builders/dataset_builder.py:64: The name tf.gfile.Glob is deprecated. Please use tf.io.gfile.glob instead.\n\nW0712 13:47:06.740875 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/builders/dataset_builder.py:64: The name tf.gfile.Glob is deprecated. Please use tf.io.gfile.glob instead.\n\nWARNING:tensorflow:num_readers has been reduced to 1 to match input file shards.\nW0712 13:47:06.741690 139641935939456 dataset_builder.py:72] num_readers has been reduced to 1 to match input file shards.\nWARNING:tensorflow:From /content/models/research/object_detection/builders/dataset_builder.py:86: parallel_interleave (from tensorflow.contrib.data.python.ops.interleave_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.data.experimental.parallel_interleave(...)`.\nW0712 13:47:06.746410 139641935939456 deprecation.py:323] From /content/models/research/object_detection/builders/dataset_builder.py:86: parallel_interleave (from tensorflow.contrib.data.python.ops.interleave_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.data.experimental.parallel_interleave(...)`.\nWARNING:tensorflow:From /tensorflow-1.15.2/python3.6/tensorflow_core/contrib/data/python/ops/interleave_ops.py:77: parallel_interleave (from tensorflow.python.data.experimental.ops.interleave_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.data.Dataset.interleave(map_func, cycle_length, block_length, num_parallel_calls=tf.data.experimental.AUTOTUNE)` instead. If sloppy execution is desired, use `tf.data.Options.experimental_determinstic`.\nW0712 13:47:06.746539 139641935939456 deprecation.py:323] From /tensorflow-1.15.2/python3.6/tensorflow_core/contrib/data/python/ops/interleave_ops.py:77: parallel_interleave (from tensorflow.python.data.experimental.ops.interleave_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.data.Dataset.interleave(map_func, cycle_length, block_length, num_parallel_calls=tf.data.experimental.AUTOTUNE)` instead. If sloppy execution is desired, use `tf.data.Options.experimental_determinstic`.\nWARNING:tensorflow:From /content/models/research/object_detection/builders/dataset_builder.py:155: DatasetV1.map_with_legacy_function (from tensorflow.python.data.ops.dataset_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.data.Dataset.map()\nW0712 13:47:06.765882 139641935939456 deprecation.py:323] From /content/models/research/object_detection/builders/dataset_builder.py:155: DatasetV1.map_with_legacy_function (from tensorflow.python.data.ops.dataset_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.data.Dataset.map()\nWARNING:tensorflow:Entity <function build.<locals>.process_fn at 0x7f007ecc3ae8> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Bad argument number for Name: 3, expecting 4\nW0712 13:47:06.783489 139641935939456 ag_logging.py:146] Entity <function build.<locals>.process_fn at 0x7f007ecc3ae8> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Bad argument number for Name: 3, expecting 4\nWARNING:tensorflow:From /content/models/research/object_detection/utils/ops.py:491: The name tf.is_nan is deprecated. Please use tf.math.is_nan instead.\n\nW0712 13:47:06.917296 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/utils/ops.py:491: The name tf.is_nan is deprecated. Please use tf.math.is_nan instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/utils/ops.py:493: where (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse tf.where in 2.0, which has the same broadcast rule as np.where\nW0712 13:47:06.920409 139641935939456 deprecation.py:323] From /content/models/research/object_detection/utils/ops.py:493: where (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse tf.where in 2.0, which has the same broadcast rule as np.where\nWARNING:tensorflow:From /content/models/research/object_detection/core/preprocessor.py:627: The name tf.random_uniform is deprecated. Please use tf.random.uniform instead.\n\nW0712 13:47:06.957880 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/core/preprocessor.py:627: The name tf.random_uniform is deprecated. Please use tf.random.uniform instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/core/preprocessor.py:2689: The name tf.image.resize_images is deprecated. Please use tf.image.resize instead.\n\nW0712 13:47:06.999974 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/core/preprocessor.py:2689: The name tf.image.resize_images is deprecated. Please use tf.image.resize instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/inputs.py:168: to_float (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.cast` instead.\nW0712 13:47:07.033404 139641935939456 deprecation.py:323] From /content/models/research/object_detection/inputs.py:168: to_float (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.cast` instead.\nWARNING:tensorflow:From /content/models/research/object_detection/inputs.py:470: The name tf.string_to_hash_bucket_fast is deprecated. Please use tf.strings.to_hash_bucket_fast instead.\n\nW0712 13:47:07.336306 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/inputs.py:470: The name tf.string_to_hash_bucket_fast is deprecated. Please use tf.strings.to_hash_bucket_fast instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/builders/dataset_builder.py:158: batch_and_drop_remainder (from tensorflow.contrib.data.python.ops.batching) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.data.Dataset.batch(..., drop_remainder=True)`.\nW0712 13:47:07.357593 139641935939456 deprecation.py:323] From /content/models/research/object_detection/builders/dataset_builder.py:158: batch_and_drop_remainder (from tensorflow.contrib.data.python.ops.batching) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.data.Dataset.batch(..., drop_remainder=True)`.\nINFO:tensorflow:Calling model_fn.\nI0712 13:47:07.370063 139641935939456 estimator.py:1148] Calling model_fn.\nWARNING:tensorflow:From /content/models/research/object_detection/meta_architectures/faster_rcnn_meta_arch.py:168: The name tf.variable_scope is deprecated. Please use tf.compat.v1.variable_scope instead.\n\nW0712 13:47:07.519604 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/meta_architectures/faster_rcnn_meta_arch.py:168: The name tf.variable_scope is deprecated. Please use tf.compat.v1.variable_scope instead.\n\nWARNING:tensorflow:From /tensorflow-1.15.2/python3.6/tensorflow_core/contrib/layers/python/layers/layers.py:2784: Layer.apply (from tensorflow.python.keras.engine.base_layer) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `layer.__call__` method instead.\nW0712 13:47:07.528396 139641935939456 deprecation.py:323] From /tensorflow-1.15.2/python3.6/tensorflow_core/contrib/layers/python/layers/layers.py:2784: Layer.apply (from tensorflow.python.keras.engine.base_layer) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `layer.__call__` method instead.\nWARNING:tensorflow:From /content/models/research/object_detection/core/anchor_generator.py:171: The name tf.assert_equal is deprecated. Please use tf.compat.v1.assert_equal instead.\n\nW0712 13:47:08.938954 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/core/anchor_generator.py:171: The name tf.assert_equal is deprecated. Please use tf.compat.v1.assert_equal instead.\n\nINFO:tensorflow:Scale of 0 disables regularizer.\nI0712 13:47:08.945259 139641935939456 regularizers.py:98] Scale of 0 disables regularizer.\nWARNING:tensorflow:From /content/models/research/object_detection/meta_architectures/faster_rcnn_meta_arch.py:558: The name tf.get_variable_scope is deprecated. Please use tf.compat.v1.get_variable_scope instead.\n\nW0712 13:47:08.945594 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/meta_architectures/faster_rcnn_meta_arch.py:558: The name tf.get_variable_scope is deprecated. Please use tf.compat.v1.get_variable_scope instead.\n\nINFO:tensorflow:Scale of 0 disables regularizer.\nI0712 13:47:08.959386 139641935939456 regularizers.py:98] Scale of 0 disables regularizer.\nINFO:tensorflow:depth of additional conv before box predictor: 0\nI0712 13:47:08.959687 139641935939456 convolutional_box_predictor.py:151] depth of additional conv before box predictor: 0\nWARNING:tensorflow:From /content/models/research/object_detection/box_coders/faster_rcnn_box_coder.py:82: The name tf.log is deprecated. Please use tf.math.log instead.\n\nW0712 13:47:09.720563 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/box_coders/faster_rcnn_box_coder.py:82: The name tf.log is deprecated. Please use tf.math.log instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/core/minibatch_sampler.py:85: The name tf.random_shuffle is deprecated. Please use tf.random.shuffle instead.\n\nW0712 13:47:09.759208 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/core/minibatch_sampler.py:85: The name tf.random_shuffle is deprecated. Please use tf.random.shuffle instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/utils/spatial_transform_ops.py:419: calling crop_and_resize_v1 (from tensorflow.python.ops.image_ops_impl) with box_ind is deprecated and will be removed in a future version.\nInstructions for updating:\nbox_ind is deprecated, use box_indices instead\nW0712 13:47:12.393746 139641935939456 deprecation.py:506] From /content/models/research/object_detection/utils/spatial_transform_ops.py:419: calling crop_and_resize_v1 (from tensorflow.python.ops.image_ops_impl) with box_ind is deprecated and will be removed in a future version.\nInstructions for updating:\nbox_ind is deprecated, use box_indices instead\nWARNING:tensorflow:From /content/models/research/object_detection/meta_architectures/faster_rcnn_meta_arch.py:191: The name tf.AUTO_REUSE is deprecated. Please use tf.compat.v1.AUTO_REUSE instead.\n\nW0712 13:47:12.416428 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/meta_architectures/faster_rcnn_meta_arch.py:191: The name tf.AUTO_REUSE is deprecated. Please use tf.compat.v1.AUTO_REUSE instead.\n\nWARNING:tensorflow:From /tensorflow-1.15.2/python3.6/tensorflow_core/contrib/layers/python/layers/layers.py:1634: flatten (from tensorflow.python.layers.core) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse keras.layers.flatten instead.\nW0712 13:47:12.869359 139641935939456 deprecation.py:323] From /tensorflow-1.15.2/python3.6/tensorflow_core/contrib/layers/python/layers/layers.py:1634: flatten (from tensorflow.python.layers.core) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse keras.layers.flatten instead.\nINFO:tensorflow:Scale of 0 disables regularizer.\nI0712 13:47:12.871357 139641935939456 regularizers.py:98] Scale of 0 disables regularizer.\nINFO:tensorflow:Scale of 0 disables regularizer.\nI0712 13:47:12.885707 139641935939456 regularizers.py:98] Scale of 0 disables regularizer.\nWARNING:tensorflow:From /content/models/research/object_detection/utils/variables_helper.py:179: The name tf.global_variables is deprecated. Please use tf.compat.v1.global_variables instead.\n\nW0712 13:47:12.948663 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/utils/variables_helper.py:179: The name tf.global_variables is deprecated. Please use tf.compat.v1.global_variables instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/meta_architectures/faster_rcnn_meta_arch.py:2768: get_or_create_global_step (from tensorflow.contrib.framework.python.ops.variables) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease switch to tf.train.get_or_create_global_step\nW0712 13:47:12.948935 139641935939456 deprecation.py:323] From /content/models/research/object_detection/meta_architectures/faster_rcnn_meta_arch.py:2768: get_or_create_global_step (from tensorflow.contrib.framework.python.ops.variables) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease switch to tf.train.get_or_create_global_step\nWARNING:tensorflow:From /content/models/research/object_detection/utils/variables_helper.py:139: The name tf.train.NewCheckpointReader is deprecated. Please use tf.compat.v1.train.NewCheckpointReader instead.\n\nW0712 13:47:12.950016 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/utils/variables_helper.py:139: The name tf.train.NewCheckpointReader is deprecated. Please use tf.compat.v1.train.NewCheckpointReader instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/utils/variables_helper.py:142: The name tf.GraphKeys is deprecated. Please use tf.compat.v1.GraphKeys instead.\n\nW0712 13:47:12.951906 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/utils/variables_helper.py:142: The name tf.GraphKeys is deprecated. Please use tf.compat.v1.GraphKeys instead.\n\nW0712 13:47:12.953937 139641935939456 variables_helper.py:154] Variable [SecondStageBoxPredictor/BoxEncodingPredictor/biases] is available in checkpoint, but has an incompatible shape with model variable. Checkpoint shape: [[360]], model variable shape: [[32]]. This variable will not be initialized from the checkpoint.\nW0712 13:47:12.954055 139641935939456 variables_helper.py:154] Variable [SecondStageBoxPredictor/BoxEncodingPredictor/weights] is available in checkpoint, but has an incompatible shape with model variable. Checkpoint shape: [[1024, 360]], model variable shape: [[1024, 32]]. This variable will not be initialized from the checkpoint.\nW0712 13:47:12.954115 139641935939456 variables_helper.py:154] Variable [SecondStageBoxPredictor/ClassPredictor/biases] is available in checkpoint, but has an incompatible shape with model variable. Checkpoint shape: [[91]], model variable shape: [[9]]. This variable will not be initialized from the checkpoint.\nW0712 13:47:12.954166 139641935939456 variables_helper.py:154] Variable [SecondStageBoxPredictor/ClassPredictor/weights] is available in checkpoint, but has an incompatible shape with model variable. Checkpoint shape: [[1024, 91]], model variable shape: [[1024, 9]]. This variable will not be initialized from the checkpoint.\nW0712 13:47:12.954856 139641935939456 variables_helper.py:157] Variable [global_step] is not available in checkpoint\nWARNING:tensorflow:From /content/models/research/object_detection/model_lib.py:353: The name tf.train.init_from_checkpoint is deprecated. Please use tf.compat.v1.train.init_from_checkpoint instead.\n\nW0712 13:47:12.955045 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/model_lib.py:353: The name tf.train.init_from_checkpoint is deprecated. Please use tf.compat.v1.train.init_from_checkpoint instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/core/losses.py:177: The name tf.losses.huber_loss is deprecated. Please use tf.compat.v1.losses.huber_loss instead.\n\nW0712 13:47:16.156541 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/core/losses.py:177: The name tf.losses.huber_loss is deprecated. Please use tf.compat.v1.losses.huber_loss instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/core/losses.py:183: The name tf.losses.Reduction is deprecated. Please use tf.compat.v1.losses.Reduction instead.\n\nW0712 13:47:16.157856 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/core/losses.py:183: The name tf.losses.Reduction is deprecated. Please use tf.compat.v1.losses.Reduction instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/core/losses.py:350: softmax_cross_entropy_with_logits (from tensorflow.python.ops.nn_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\n\nFuture major versions of TensorFlow will allow gradients to flow\ninto the labels input on backprop by default.\n\nSee `tf.nn.softmax_cross_entropy_with_logits_v2`.\n\nW0712 13:47:16.198727 139641935939456 deprecation.py:323] From /content/models/research/object_detection/core/losses.py:350: softmax_cross_entropy_with_logits (from tensorflow.python.ops.nn_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\n\nFuture major versions of TensorFlow will allow gradients to flow\ninto the labels input on backprop by default.\n\nSee `tf.nn.softmax_cross_entropy_with_logits_v2`.\n\nWARNING:tensorflow:From /content/models/research/object_detection/meta_architectures/faster_rcnn_meta_arch.py:2710: The name tf.get_collection is deprecated. Please use tf.compat.v1.get_collection instead.\n\nW0712 13:47:17.563262 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/meta_architectures/faster_rcnn_meta_arch.py:2710: The name tf.get_collection is deprecated. Please use tf.compat.v1.get_collection instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/model_lib.py:380: The name tf.train.get_or_create_global_step is deprecated. Please use tf.compat.v1.train.get_or_create_global_step instead.\n\nW0712 13:47:17.564131 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/model_lib.py:380: The name tf.train.get_or_create_global_step is deprecated. Please use tf.compat.v1.train.get_or_create_global_step instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/builders/optimizer_builder.py:58: The name tf.train.MomentumOptimizer is deprecated. Please use tf.compat.v1.train.MomentumOptimizer instead.\n\nW0712 13:47:17.570448 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/builders/optimizer_builder.py:58: The name tf.train.MomentumOptimizer is deprecated. Please use tf.compat.v1.train.MomentumOptimizer instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/model_lib.py:398: The name tf.trainable_variables is deprecated. Please use tf.compat.v1.trainable_variables instead.\n\nW0712 13:47:17.570661 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/model_lib.py:398: The name tf.trainable_variables is deprecated. Please use tf.compat.v1.trainable_variables instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/model_lib.py:408: The name tf.summary.scalar is deprecated. Please use tf.compat.v1.summary.scalar instead.\n\nW0712 13:47:17.570847 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/model_lib.py:408: The name tf.summary.scalar is deprecated. Please use tf.compat.v1.summary.scalar instead.\n\n/tensorflow-1.15.2/python3.6/tensorflow_core/python/framework/indexed_slices.py:424: UserWarning: Converting sparse IndexedSlices to a dense Tensor of unknown shape. This may consume a large amount of memory.\n \"Converting sparse IndexedSlices to a dense Tensor of unknown shape. \"\n/tensorflow-1.15.2/python3.6/tensorflow_core/python/framework/indexed_slices.py:424: UserWarning: Converting sparse IndexedSlices to a dense Tensor of unknown shape. This may consume a large amount of memory.\n \"Converting sparse IndexedSlices to a dense Tensor of unknown shape. \"\nWARNING:tensorflow:From /content/models/research/object_detection/model_lib.py:515: The name tf.train.Saver is deprecated. Please use tf.compat.v1.train.Saver instead.\n\nW0712 13:47:22.327432 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/model_lib.py:515: The name tf.train.Saver is deprecated. Please use tf.compat.v1.train.Saver instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/model_lib.py:519: The name tf.add_to_collection is deprecated. Please use tf.compat.v1.add_to_collection instead.\n\nW0712 13:47:22.701117 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/model_lib.py:519: The name tf.add_to_collection is deprecated. Please use tf.compat.v1.add_to_collection instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/model_lib.py:520: The name tf.train.Scaffold is deprecated. Please use tf.compat.v1.train.Scaffold instead.\n\nW0712 13:47:22.701382 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/model_lib.py:520: The name tf.train.Scaffold is deprecated. Please use tf.compat.v1.train.Scaffold instead.\n\nINFO:tensorflow:Done calling model_fn.\nI0712 13:47:22.701640 139641935939456 estimator.py:1150] Done calling model_fn.\nINFO:tensorflow:Create CheckpointSaverHook.\nI0712 13:47:22.702736 139641935939456 basic_session_run_hooks.py:541] Create CheckpointSaverHook.\nINFO:tensorflow:Graph was finalized.\nI0712 13:47:25.778435 139641935939456 monitored_session.py:240] Graph was finalized.\n2020-07-12 13:47:25.790691: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 2200000000 Hz\n2020-07-12 13:47:25.791140: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x1d419c0 initialized for platform Host (this does not guarantee that XLA will be used). Devices:\n2020-07-12 13:47:25.791168: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version\n2020-07-12 13:47:25.796035: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcuda.so.1\n2020-07-12 13:47:25.952921: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 13:47:25.953656: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x1d41800 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices:\n2020-07-12 13:47:25.953688: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Tesla P100-PCIE-16GB, Compute Capability 6.0\n2020-07-12 13:47:25.954950: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 13:47:25.955450: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1639] Found device 0 with properties: \nname: Tesla P100-PCIE-16GB major: 6 minor: 0 memoryClockRate(GHz): 1.3285\npciBusID: 0000:00:04.0\n2020-07-12 13:47:25.955838: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1\n2020-07-12 13:47:26.201772: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcublas.so.10\n2020-07-12 13:47:26.330932: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcufft.so.10\n2020-07-12 13:47:26.359392: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcurand.so.10\n2020-07-12 13:47:26.617534: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusolver.so.10\n2020-07-12 13:47:26.637214: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusparse.so.10\n2020-07-12 13:47:27.153565: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudnn.so.7\n2020-07-12 13:47:27.153808: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 13:47:27.154521: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 13:47:27.155035: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1767] Adding visible gpu devices: 0\n2020-07-12 13:47:27.158855: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1\n2020-07-12 13:47:27.160484: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1180] Device interconnect StreamExecutor with strength 1 edge matrix:\n2020-07-12 13:47:27.160528: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1186] 0 \n2020-07-12 13:47:27.160536: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1199] 0: N \n2020-07-12 13:47:27.161904: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 13:47:27.162533: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 13:47:27.163073: W tensorflow/core/common_runtime/gpu/gpu_bfc_allocator.cc:39] Overriding allow_growth setting because the TF_FORCE_GPU_ALLOW_GROWTH environment variable is set. Original config value was 0.\n2020-07-12 13:47:27.163110: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1325] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 15216 MB memory) -> physical GPU (device: 0, name: Tesla P100-PCIE-16GB, pci bus id: 0000:00:04.0, compute capability: 6.0)\nINFO:tensorflow:Running local_init_op.\nI0712 13:47:35.847842 139641935939456 session_manager.py:500] Running local_init_op.\nINFO:tensorflow:Done running local_init_op.\nI0712 13:47:36.212203 139641935939456 session_manager.py:502] Done running local_init_op.\nINFO:tensorflow:Saving checkpoints for 0 into training/model.ckpt.\nI0712 13:47:45.214679 139641935939456 basic_session_run_hooks.py:606] Saving checkpoints for 0 into training/model.ckpt.\n2020-07-12 13:47:54.674265: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcublas.so.10\n2020-07-12 13:47:56.942002: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudnn.so.7\nINFO:tensorflow:loss = 5.5731306, step = 0\nI0712 13:48:05.618327 139641935939456 basic_session_run_hooks.py:262] loss = 5.5731306, step = 0\nINFO:tensorflow:global_step/sec: 1.14922\nI0712 13:49:32.633293 139641935939456 basic_session_run_hooks.py:692] global_step/sec: 1.14922\nINFO:tensorflow:loss = 1.6182939, step = 100 (87.016 sec)\nI0712 13:49:32.634395 139641935939456 basic_session_run_hooks.py:260] loss = 1.6182939, step = 100 (87.016 sec)\nINFO:tensorflow:global_step/sec: 1.25365\nI0712 13:50:52.400285 139641935939456 basic_session_run_hooks.py:692] global_step/sec: 1.25365\nINFO:tensorflow:loss = 1.1895328, step = 200 (79.767 sec)\nI0712 13:50:52.401134 139641935939456 basic_session_run_hooks.py:260] loss = 1.1895328, step = 200 (79.767 sec)\nINFO:tensorflow:global_step/sec: 1.24794\nI0712 13:52:12.532044 139641935939456 basic_session_run_hooks.py:692] global_step/sec: 1.24794\nINFO:tensorflow:loss = 1.1091725, step = 300 (80.132 sec)\nI0712 13:52:12.533103 139641935939456 basic_session_run_hooks.py:260] loss = 1.1091725, step = 300 (80.132 sec)\nINFO:tensorflow:global_step/sec: 1.24626\nI0712 13:53:32.771963 139641935939456 basic_session_run_hooks.py:692] global_step/sec: 1.24626\nINFO:tensorflow:loss = 0.7691544, step = 400 (80.240 sec)\nI0712 13:53:32.773050 139641935939456 basic_session_run_hooks.py:260] loss = 0.7691544, step = 400 (80.240 sec)\nINFO:tensorflow:global_step/sec: 1.24812\nI0712 13:54:52.892751 139641935939456 basic_session_run_hooks.py:692] global_step/sec: 1.24812\nINFO:tensorflow:loss = 0.6398352, step = 500 (80.121 sec)\nI0712 13:54:52.893915 139641935939456 basic_session_run_hooks.py:260] loss = 0.6398352, step = 500 (80.121 sec)\nINFO:tensorflow:global_step/sec: 1.25203\nI0712 13:56:12.763126 139641935939456 basic_session_run_hooks.py:692] global_step/sec: 1.25203\nINFO:tensorflow:loss = 0.5035923, step = 600 (79.870 sec)\nI0712 13:56:12.764102 139641935939456 basic_session_run_hooks.py:260] loss = 0.5035923, step = 600 (79.870 sec)\nINFO:tensorflow:global_step/sec: 1.24628\nI0712 13:57:33.002104 139641935939456 basic_session_run_hooks.py:692] global_step/sec: 1.24628\nINFO:tensorflow:loss = 0.47111177, step = 700 (80.239 sec)\nI0712 13:57:33.003102 139641935939456 basic_session_run_hooks.py:260] loss = 0.47111177, step = 700 (80.239 sec)\nINFO:tensorflow:Saving checkpoints for 719 into training/model.ckpt.\nI0712 13:57:47.396596 139641935939456 basic_session_run_hooks.py:606] Saving checkpoints for 719 into training/model.ckpt.\nWARNING:tensorflow:Entity <function build.<locals>.process_fn at 0x7f0076d21e18> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Bad argument number for Name: 3, expecting 4\nW0712 13:57:48.966438 139641935939456 ag_logging.py:146] Entity <function build.<locals>.process_fn at 0x7f0076d21e18> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Bad argument number for Name: 3, expecting 4\nINFO:tensorflow:Calling model_fn.\nI0712 13:57:49.525509 139641935939456 estimator.py:1148] Calling model_fn.\nINFO:tensorflow:Scale of 0 disables regularizer.\nI0712 13:57:50.859152 139641935939456 regularizers.py:98] Scale of 0 disables regularizer.\nINFO:tensorflow:Scale of 0 disables regularizer.\nI0712 13:57:50.871737 139641935939456 regularizers.py:98] Scale of 0 disables regularizer.\nINFO:tensorflow:depth of additional conv before box predictor: 0\nI0712 13:57:50.872058 139641935939456 convolutional_box_predictor.py:151] depth of additional conv before box predictor: 0\nINFO:tensorflow:Scale of 0 disables regularizer.\nI0712 13:57:51.882474 139641935939456 regularizers.py:98] Scale of 0 disables regularizer.\nINFO:tensorflow:Scale of 0 disables regularizer.\nI0712 13:57:51.897285 139641935939456 regularizers.py:98] Scale of 0 disables regularizer.\nWARNING:tensorflow:From /tensorflow-1.15.2/python3.6/tensorflow_core/python/util/dispatch.py:180: batch_gather (from tensorflow.python.ops.array_ops) is deprecated and will be removed after 2017-10-25.\nInstructions for updating:\n`tf.batch_gather` is deprecated, please use `tf.gather` with `batch_dims=-1` instead.\nW0712 13:57:52.444165 139641935939456 deprecation.py:323] From /tensorflow-1.15.2/python3.6/tensorflow_core/python/util/dispatch.py:180: batch_gather (from tensorflow.python.ops.array_ops) is deprecated and will be removed after 2017-10-25.\nInstructions for updating:\n`tf.batch_gather` is deprecated, please use `tf.gather` with `batch_dims=-1` instead.\nWARNING:tensorflow:From /content/models/research/object_detection/eval_util.py:796: to_int64 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.cast` instead.\nW0712 13:57:53.139325 139641935939456 deprecation.py:323] From /content/models/research/object_detection/eval_util.py:796: to_int64 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.cast` instead.\nWARNING:tensorflow:From /content/models/research/object_detection/utils/visualization_utils.py:498: py_func (from tensorflow.python.ops.script_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\ntf.py_func is deprecated in TF V2. Instead, there are two\n options available in V2.\n - tf.py_function takes a python function which manipulates tf eager\n tensors instead of numpy arrays. It's easy to convert a tf eager tensor to\n an ndarray (just call tensor.numpy()) but having access to eager tensors\n means `tf.py_function`s can use accelerators such as GPUs as well as\n being differentiable using a gradient tape.\n - tf.numpy_function maintains the semantics of the deprecated tf.py_func\n (it is not differentiable, and manipulates numpy arrays). It drops the\n stateful argument making all functions stateful.\n \nW0712 13:57:53.321442 139641935939456 deprecation.py:323] From /content/models/research/object_detection/utils/visualization_utils.py:498: py_func (from tensorflow.python.ops.script_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\ntf.py_func is deprecated in TF V2. Instead, there are two\n options available in V2.\n - tf.py_function takes a python function which manipulates tf eager\n tensors instead of numpy arrays. It's easy to convert a tf eager tensor to\n an ndarray (just call tensor.numpy()) but having access to eager tensors\n means `tf.py_function`s can use accelerators such as GPUs as well as\n being differentiable using a gradient tape.\n - tf.numpy_function maintains the semantics of the deprecated tf.py_func\n (it is not differentiable, and manipulates numpy arrays). It drops the\n stateful argument making all functions stateful.\n \nWARNING:tensorflow:From /content/models/research/object_detection/utils/visualization_utils.py:1044: The name tf.summary.image is deprecated. Please use tf.compat.v1.summary.image instead.\n\nW0712 13:57:53.460386 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/utils/visualization_utils.py:1044: The name tf.summary.image is deprecated. Please use tf.compat.v1.summary.image instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/model_lib.py:484: The name tf.metrics.mean is deprecated. Please use tf.compat.v1.metrics.mean instead.\n\nW0712 13:57:53.534125 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/model_lib.py:484: The name tf.metrics.mean is deprecated. Please use tf.compat.v1.metrics.mean instead.\n\nINFO:tensorflow:Done calling model_fn.\nI0712 13:57:53.835466 139641935939456 estimator.py:1150] Done calling model_fn.\nINFO:tensorflow:Starting evaluation at 2020-07-12T13:57:53Z\nI0712 13:57:53.850516 139641935939456 evaluation.py:255] Starting evaluation at 2020-07-12T13:57:53Z\nINFO:tensorflow:Graph was finalized.\nI0712 13:57:54.467504 139641935939456 monitored_session.py:240] Graph was finalized.\n2020-07-12 13:57:54.468581: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 13:57:54.468959: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1639] Found device 0 with properties: \nname: Tesla P100-PCIE-16GB major: 6 minor: 0 memoryClockRate(GHz): 1.3285\npciBusID: 0000:00:04.0\n2020-07-12 13:57:54.469055: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1\n2020-07-12 13:57:54.469078: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcublas.so.10\n2020-07-12 13:57:54.469093: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcufft.so.10\n2020-07-12 13:57:54.469108: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcurand.so.10\n2020-07-12 13:57:54.469127: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusolver.so.10\n2020-07-12 13:57:54.469141: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusparse.so.10\n2020-07-12 13:57:54.469157: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudnn.so.7\n2020-07-12 13:57:54.469220: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 13:57:54.469629: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 13:57:54.469937: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1767] Adding visible gpu devices: 0\n2020-07-12 13:57:54.469974: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1180] Device interconnect StreamExecutor with strength 1 edge matrix:\n2020-07-12 13:57:54.469985: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1186] 0 \n2020-07-12 13:57:54.469991: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1199] 0: N \n2020-07-12 13:57:54.470063: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 13:57:54.470417: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 13:57:54.470751: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1325] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 15216 MB memory) -> physical GPU (device: 0, name: Tesla P100-PCIE-16GB, pci bus id: 0000:00:04.0, compute capability: 6.0)\nINFO:tensorflow:Restoring parameters from training/model.ckpt-719\nI0712 13:57:54.471655 139641935939456 saver.py:1284] Restoring parameters from training/model.ckpt-719\nINFO:tensorflow:Running local_init_op.\nI0712 13:57:55.482822 139641935939456 session_manager.py:500] Running local_init_op.\nINFO:tensorflow:Done running local_init_op.\nI0712 13:57:55.641395 139641935939456 session_manager.py:502] Done running local_init_op.\nINFO:tensorflow:Performing evaluation on 3 images.\nI0712 13:57:59.181360 139638063531776 coco_evaluation.py:205] Performing evaluation on 3 images.\ncreating index...\nindex created!\nINFO:tensorflow:Loading and preparing annotation results...\nI0712 13:57:59.183067 139638063531776 coco_tools.py:115] Loading and preparing annotation results...\nINFO:tensorflow:DONE (t=0.00s)\nI0712 13:57:59.184273 139638063531776 coco_tools.py:137] DONE (t=0.00s)\ncreating index...\nindex created!\nRunning per image evaluation...\nEvaluate annotation type *bbox*\nDONE (t=0.11s).\nAccumulating evaluation results...\nDONE (t=0.09s).\n Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.441\n Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.790\n Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.441\n Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000\n Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.483\n Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.410\n Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.226\n Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.535\n Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.568\n Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000\n Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.550\n Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.586\nINFO:tensorflow:Finished evaluation at 2020-07-12-13:57:59\nI0712 13:57:59.603665 139641935939456 evaluation.py:275] Finished evaluation at 2020-07-12-13:57:59\nINFO:tensorflow:Saving dict for global step 719: DetectionBoxes_Precision/mAP = 0.4407613, DetectionBoxes_Precision/mAP (large) = 0.40996826, DetectionBoxes_Precision/mAP (medium) = 0.4826929, DetectionBoxes_Precision/mAP (small) = -1.0, DetectionBoxes_Precision/[email protected] = 0.7898415, DetectionBoxes_Precision/[email protected] = 0.44109604, DetectionBoxes_Recall/AR@1 = 0.22625, DetectionBoxes_Recall/AR@10 = 0.53458333, DetectionBoxes_Recall/AR@100 = 0.5679167, DetectionBoxes_Recall/AR@100 (large) = 0.5858333, DetectionBoxes_Recall/AR@100 (medium) = 0.55, DetectionBoxes_Recall/AR@100 (small) = -1.0, Loss/BoxClassifierLoss/classification_loss = 0.17909078, Loss/BoxClassifierLoss/localization_loss = 0.19865192, Loss/RPNLoss/localization_loss = 0.1345718, Loss/RPNLoss/objectness_loss = 0.03291257, Loss/total_loss = 0.54522705, global_step = 719, learning_rate = 0.0002, loss = 0.54522705\nI0712 13:57:59.603986 139641935939456 estimator.py:2049] Saving dict for global step 719: DetectionBoxes_Precision/mAP = 0.4407613, DetectionBoxes_Precision/mAP (large) = 0.40996826, DetectionBoxes_Precision/mAP (medium) = 0.4826929, DetectionBoxes_Precision/mAP (small) = -1.0, DetectionBoxes_Precision/[email protected] = 0.7898415, DetectionBoxes_Precision/[email protected] = 0.44109604, DetectionBoxes_Recall/AR@1 = 0.22625, DetectionBoxes_Recall/AR@10 = 0.53458333, DetectionBoxes_Recall/AR@100 = 0.5679167, DetectionBoxes_Recall/AR@100 (large) = 0.5858333, DetectionBoxes_Recall/AR@100 (medium) = 0.55, DetectionBoxes_Recall/AR@100 (small) = -1.0, Loss/BoxClassifierLoss/classification_loss = 0.17909078, Loss/BoxClassifierLoss/localization_loss = 0.19865192, Loss/RPNLoss/localization_loss = 0.1345718, Loss/RPNLoss/objectness_loss = 0.03291257, Loss/total_loss = 0.54522705, global_step = 719, learning_rate = 0.0002, loss = 0.54522705\nINFO:tensorflow:Saving 'checkpoint_path' summary for global step 719: training/model.ckpt-719\nI0712 13:58:00.546111 139641935939456 estimator.py:2109] Saving 'checkpoint_path' summary for global step 719: training/model.ckpt-719\nINFO:tensorflow:global_step/sec: 1.07187\nI0712 13:59:06.296875 139641935939456 basic_session_run_hooks.py:692] global_step/sec: 1.07187\nINFO:tensorflow:loss = 0.3768731, step = 800 (93.295 sec)\nI0712 13:59:06.297914 139641935939456 basic_session_run_hooks.py:260] loss = 0.3768731, step = 800 (93.295 sec)\nINFO:tensorflow:global_step/sec: 1.25209\nI0712 14:00:26.163442 139641935939456 basic_session_run_hooks.py:692] global_step/sec: 1.25209\nINFO:tensorflow:loss = 0.29566404, step = 900 (79.867 sec)\nI0712 14:00:26.164553 139641935939456 basic_session_run_hooks.py:260] loss = 0.29566404, step = 900 (79.867 sec)\nINFO:tensorflow:Saving checkpoints for 1000 into training/model.ckpt.\nI0712 14:01:45.555566 139641935939456 basic_session_run_hooks.py:606] Saving checkpoints for 1000 into training/model.ckpt.\nINFO:tensorflow:Skip the current checkpoint eval due to throttle secs (600 secs).\nI0712 14:01:47.038666 139641935939456 training.py:527] Skip the current checkpoint eval due to throttle secs (600 secs).\nWARNING:tensorflow:Entity <function build.<locals>.process_fn at 0x7f006816cf28> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Bad argument number for Name: 3, expecting 4\nW0712 14:01:47.079932 139641935939456 ag_logging.py:146] Entity <function build.<locals>.process_fn at 0x7f006816cf28> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: Bad argument number for Name: 3, expecting 4\nINFO:tensorflow:Calling model_fn.\nI0712 14:01:47.631918 139641935939456 estimator.py:1148] Calling model_fn.\nINFO:tensorflow:Scale of 0 disables regularizer.\nI0712 14:01:48.953371 139641935939456 regularizers.py:98] Scale of 0 disables regularizer.\nINFO:tensorflow:Scale of 0 disables regularizer.\nI0712 14:01:48.966477 139641935939456 regularizers.py:98] Scale of 0 disables regularizer.\nINFO:tensorflow:depth of additional conv before box predictor: 0\nI0712 14:01:48.966867 139641935939456 convolutional_box_predictor.py:151] depth of additional conv before box predictor: 0\nINFO:tensorflow:Scale of 0 disables regularizer.\nI0712 14:01:49.968666 139641935939456 regularizers.py:98] Scale of 0 disables regularizer.\nINFO:tensorflow:Scale of 0 disables regularizer.\nI0712 14:01:49.983392 139641935939456 regularizers.py:98] Scale of 0 disables regularizer.\nINFO:tensorflow:Done calling model_fn.\nI0712 14:01:51.933756 139641935939456 estimator.py:1150] Done calling model_fn.\nINFO:tensorflow:Starting evaluation at 2020-07-12T14:01:51Z\nI0712 14:01:51.949071 139641935939456 evaluation.py:255] Starting evaluation at 2020-07-12T14:01:51Z\nINFO:tensorflow:Graph was finalized.\nI0712 14:01:52.355967 139641935939456 monitored_session.py:240] Graph was finalized.\n2020-07-12 14:01:52.356582: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:01:52.356999: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1639] Found device 0 with properties: \nname: Tesla P100-PCIE-16GB major: 6 minor: 0 memoryClockRate(GHz): 1.3285\npciBusID: 0000:00:04.0\n2020-07-12 14:01:52.357118: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1\n2020-07-12 14:01:52.357138: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcublas.so.10\n2020-07-12 14:01:52.357149: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcufft.so.10\n2020-07-12 14:01:52.357164: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcurand.so.10\n2020-07-12 14:01:52.357182: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusolver.so.10\n2020-07-12 14:01:52.357221: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusparse.so.10\n2020-07-12 14:01:52.357239: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudnn.so.7\n2020-07-12 14:01:52.357315: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:01:52.357717: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:01:52.358031: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1767] Adding visible gpu devices: 0\n2020-07-12 14:01:52.358070: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1180] Device interconnect StreamExecutor with strength 1 edge matrix:\n2020-07-12 14:01:52.358080: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1186] 0 \n2020-07-12 14:01:52.358086: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1199] 0: N \n2020-07-12 14:01:52.358162: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:01:52.358485: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:01:52.358792: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1325] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 15216 MB memory) -> physical GPU (device: 0, name: Tesla P100-PCIE-16GB, pci bus id: 0000:00:04.0, compute capability: 6.0)\nINFO:tensorflow:Restoring parameters from training/model.ckpt-1000\nI0712 14:01:52.359706 139641935939456 saver.py:1284] Restoring parameters from training/model.ckpt-1000\nINFO:tensorflow:Running local_init_op.\nI0712 14:01:53.372114 139641935939456 session_manager.py:500] Running local_init_op.\nINFO:tensorflow:Done running local_init_op.\nI0712 14:01:53.525481 139641935939456 session_manager.py:502] Done running local_init_op.\nINFO:tensorflow:Performing evaluation on 3 images.\nI0712 14:01:56.632591 139638063531776 coco_evaluation.py:205] Performing evaluation on 3 images.\ncreating index...\nindex created!\nINFO:tensorflow:Loading and preparing annotation results...\nI0712 14:01:56.633001 139638063531776 coco_tools.py:115] Loading and preparing annotation results...\nINFO:tensorflow:DONE (t=0.00s)\nI0712 14:01:56.634033 139638063531776 coco_tools.py:137] DONE (t=0.00s)\ncreating index...\nindex created!\nRunning per image evaluation...\nEvaluate annotation type *bbox*\nDONE (t=0.09s).\nAccumulating evaluation results...\nDONE (t=0.03s).\n Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.390\n Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.752\n Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.396\n Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000\n Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.410\n Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.378\n Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.203\n Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.487\n Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.520\n Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = -1.000\n Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.492\n Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.549\nINFO:tensorflow:Finished evaluation at 2020-07-12-14:01:57\nI0712 14:01:57.024028 139641935939456 evaluation.py:275] Finished evaluation at 2020-07-12-14:01:57\nINFO:tensorflow:Saving dict for global step 1000: DetectionBoxes_Precision/mAP = 0.39038652, DetectionBoxes_Precision/mAP (large) = 0.37751368, DetectionBoxes_Precision/mAP (medium) = 0.40954095, DetectionBoxes_Precision/mAP (small) = -1.0, DetectionBoxes_Precision/[email protected] = 0.7515896, DetectionBoxes_Precision/[email protected] = 0.39599526, DetectionBoxes_Recall/AR@1 = 0.20333333, DetectionBoxes_Recall/AR@10 = 0.486875, DetectionBoxes_Recall/AR@100 = 0.52020836, DetectionBoxes_Recall/AR@100 (large) = 0.54875, DetectionBoxes_Recall/AR@100 (medium) = 0.49166667, DetectionBoxes_Recall/AR@100 (small) = -1.0, Loss/BoxClassifierLoss/classification_loss = 0.2155153, Loss/BoxClassifierLoss/localization_loss = 0.2462312, Loss/RPNLoss/localization_loss = 0.13288021, Loss/RPNLoss/objectness_loss = 0.0388504, Loss/total_loss = 0.63347703, global_step = 1000, learning_rate = 0.0002, loss = 0.63347703\nI0712 14:01:57.024285 139641935939456 estimator.py:2049] Saving dict for global step 1000: DetectionBoxes_Precision/mAP = 0.39038652, DetectionBoxes_Precision/mAP (large) = 0.37751368, DetectionBoxes_Precision/mAP (medium) = 0.40954095, DetectionBoxes_Precision/mAP (small) = -1.0, DetectionBoxes_Precision/[email protected] = 0.7515896, DetectionBoxes_Precision/[email protected] = 0.39599526, DetectionBoxes_Recall/AR@1 = 0.20333333, DetectionBoxes_Recall/AR@10 = 0.486875, DetectionBoxes_Recall/AR@100 = 0.52020836, DetectionBoxes_Recall/AR@100 (large) = 0.54875, DetectionBoxes_Recall/AR@100 (medium) = 0.49166667, DetectionBoxes_Recall/AR@100 (small) = -1.0, Loss/BoxClassifierLoss/classification_loss = 0.2155153, Loss/BoxClassifierLoss/localization_loss = 0.2462312, Loss/RPNLoss/localization_loss = 0.13288021, Loss/RPNLoss/objectness_loss = 0.0388504, Loss/total_loss = 0.63347703, global_step = 1000, learning_rate = 0.0002, loss = 0.63347703\nINFO:tensorflow:Saving 'checkpoint_path' summary for global step 1000: training/model.ckpt-1000\nI0712 14:01:57.025562 139641935939456 estimator.py:2109] Saving 'checkpoint_path' summary for global step 1000: training/model.ckpt-1000\nINFO:tensorflow:Performing the final export in the end of training.\nI0712 14:01:57.026196 139641935939456 exporter.py:410] Performing the final export in the end of training.\nWARNING:tensorflow:From /content/models/research/object_detection/inputs.py:750: The name tf.placeholder is deprecated. Please use tf.compat.v1.placeholder instead.\n\nW0712 14:01:57.030095 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/inputs.py:750: The name tf.placeholder is deprecated. Please use tf.compat.v1.placeholder instead.\n\nINFO:tensorflow:Calling model_fn.\nI0712 14:01:57.249189 139641935939456 estimator.py:1148] Calling model_fn.\nINFO:tensorflow:Scale of 0 disables regularizer.\nI0712 14:01:58.546014 139641935939456 regularizers.py:98] Scale of 0 disables regularizer.\nINFO:tensorflow:Scale of 0 disables regularizer.\nI0712 14:01:58.558892 139641935939456 regularizers.py:98] Scale of 0 disables regularizer.\nINFO:tensorflow:depth of additional conv before box predictor: 0\nI0712 14:01:58.559204 139641935939456 convolutional_box_predictor.py:151] depth of additional conv before box predictor: 0\nINFO:tensorflow:Scale of 0 disables regularizer.\nI0712 14:01:59.571419 139641935939456 regularizers.py:98] Scale of 0 disables regularizer.\nINFO:tensorflow:Scale of 0 disables regularizer.\nI0712 14:01:59.585983 139641935939456 regularizers.py:98] Scale of 0 disables regularizer.\nWARNING:tensorflow:From /content/models/research/object_detection/model_lib.py:426: The name tf.saved_model.signature_constants.PREDICT_METHOD_NAME is deprecated. Please use tf.saved_model.PREDICT_METHOD_NAME instead.\n\nW0712 14:02:00.781657 139641935939456 module_wrapper.py:139] From /content/models/research/object_detection/model_lib.py:426: The name tf.saved_model.signature_constants.PREDICT_METHOD_NAME is deprecated. Please use tf.saved_model.PREDICT_METHOD_NAME instead.\n\nINFO:tensorflow:Done calling model_fn.\nI0712 14:02:01.023391 139641935939456 estimator.py:1150] Done calling model_fn.\nWARNING:tensorflow:From /tensorflow-1.15.2/python3.6/tensorflow_core/python/saved_model/signature_def_utils_impl.py:201: build_tensor_info (from tensorflow.python.saved_model.utils_impl) is deprecated and will be removed in a future version.\nInstructions for updating:\nThis function will only be available through the v1 compatibility library as tf.compat.v1.saved_model.utils.build_tensor_info or tf.compat.v1.saved_model.build_tensor_info.\nW0712 14:02:01.023654 139641935939456 deprecation.py:323] From /tensorflow-1.15.2/python3.6/tensorflow_core/python/saved_model/signature_def_utils_impl.py:201: build_tensor_info (from tensorflow.python.saved_model.utils_impl) is deprecated and will be removed in a future version.\nInstructions for updating:\nThis function will only be available through the v1 compatibility library as tf.compat.v1.saved_model.utils.build_tensor_info or tf.compat.v1.saved_model.build_tensor_info.\nINFO:tensorflow:Signatures INCLUDED in export for Classify: None\nI0712 14:02:01.024318 139641935939456 export_utils.py:170] Signatures INCLUDED in export for Classify: None\nINFO:tensorflow:Signatures INCLUDED in export for Regress: None\nI0712 14:02:01.024420 139641935939456 export_utils.py:170] Signatures INCLUDED in export for Regress: None\nINFO:tensorflow:Signatures INCLUDED in export for Predict: ['tensorflow/serving/predict', 'serving_default']\nI0712 14:02:01.024475 139641935939456 export_utils.py:170] Signatures INCLUDED in export for Predict: ['tensorflow/serving/predict', 'serving_default']\nINFO:tensorflow:Signatures INCLUDED in export for Train: None\nI0712 14:02:01.024519 139641935939456 export_utils.py:170] Signatures INCLUDED in export for Train: None\nINFO:tensorflow:Signatures INCLUDED in export for Eval: None\nI0712 14:02:01.024561 139641935939456 export_utils.py:170] Signatures INCLUDED in export for Eval: None\n2020-07-12 14:02:01.025072: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:02:01.025458: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1639] Found device 0 with properties: \nname: Tesla P100-PCIE-16GB major: 6 minor: 0 memoryClockRate(GHz): 1.3285\npciBusID: 0000:00:04.0\n2020-07-12 14:02:01.025535: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1\n2020-07-12 14:02:01.025553: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcublas.so.10\n2020-07-12 14:02:01.025567: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcufft.so.10\n2020-07-12 14:02:01.025581: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcurand.so.10\n2020-07-12 14:02:01.025595: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusolver.so.10\n2020-07-12 14:02:01.025608: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusparse.so.10\n2020-07-12 14:02:01.025622: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudnn.so.7\n2020-07-12 14:02:01.025686: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:02:01.026072: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:02:01.026380: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1767] Adding visible gpu devices: 0\n2020-07-12 14:02:01.026419: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1180] Device interconnect StreamExecutor with strength 1 edge matrix:\n2020-07-12 14:02:01.026429: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1186] 0 \n2020-07-12 14:02:01.026436: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1199] 0: N \n2020-07-12 14:02:01.026510: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:02:01.026844: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:02:01.027144: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1325] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 15216 MB memory) -> physical GPU (device: 0, name: Tesla P100-PCIE-16GB, pci bus id: 0000:00:04.0, compute capability: 6.0)\nINFO:tensorflow:Restoring parameters from training/model.ckpt-1000\nI0712 14:02:01.029560 139641935939456 saver.py:1284] Restoring parameters from training/model.ckpt-1000\nINFO:tensorflow:Assets added to graph.\nI0712 14:02:01.564409 139641935939456 builder_impl.py:665] Assets added to graph.\nINFO:tensorflow:No assets to write.\nI0712 14:02:01.564606 139641935939456 builder_impl.py:460] No assets to write.\nINFO:tensorflow:SavedModel written to: training/export/Servo/temp-b'1594562517'/saved_model.pb\nI0712 14:02:02.436441 139641935939456 builder_impl.py:425] SavedModel written to: training/export/Servo/temp-b'1594562517'/saved_model.pb\nINFO:tensorflow:Loss for final step: 0.3038808.\nI0712 14:02:02.778767 139641935939456 estimator.py:371] Loss for final step: 0.3038808.\n"
],
[
"!ls {model_dir}",
"checkpoint\neval_0\nevents.out.tfevents.1594561643.be781f564e9e\nexport\ngraph.pbtxt\nmodel.ckpt-0.data-00000-of-00001\nmodel.ckpt-0.index\nmodel.ckpt-0.meta\nmodel.ckpt-1000.data-00000-of-00001\nmodel.ckpt-1000.index\nmodel.ckpt-1000.meta\nmodel.ckpt-719.data-00000-of-00001\nmodel.ckpt-719.index\nmodel.ckpt-719.meta\n"
]
],
[
[
"## Exporting a Trained Inference Graph\nOnce your training job is complete, you need to extract the newly trained inference graph, which will be later used to perform the object detection. This can be done as follows:",
"_____no_output_____"
]
],
[
[
"import re\nimport numpy as np\n\noutput_directory = './fine_tuned_final_model'\n\nlst = os.listdir(model_dir)\nlst = [l for l in lst if 'model.ckpt-' in l and '.meta' in l]\nsteps=np.array([int(re.findall('\\d+', l)[0]) for l in lst])\nlast_model = lst[steps.argmax()].replace('.meta', '')\n\nlast_model_path = os.path.join(model_dir, last_model)\nprint(last_model_path)\n!python /content/models/research/object_detection/export_inference_graph.py \\\n --input_type=image_tensor \\\n --pipeline_config_path={pipeline_fname} \\\n --output_directory={output_directory} \\\n --trained_checkpoint_prefix={last_model_path}",
"training/model.ckpt-1000\nWARNING:tensorflow:\nThe TensorFlow contrib module will not be included in TensorFlow 2.0.\nFor more information, please see:\n * https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md\n * https://github.com/tensorflow/addons\n * https://github.com/tensorflow/io (for I/O related ops)\nIf you depend on functionality not listed there, please file an issue.\n\nWARNING:tensorflow:From /content/models/research/object_detection/export_inference_graph.py:162: The name tf.app.run is deprecated. Please use tf.compat.v1.app.run instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/export_inference_graph.py:145: The name tf.gfile.GFile is deprecated. Please use tf.io.gfile.GFile instead.\n\nW0712 14:02:45.766085 140456751757184 module_wrapper.py:139] From /content/models/research/object_detection/export_inference_graph.py:145: The name tf.gfile.GFile is deprecated. Please use tf.io.gfile.GFile instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/exporter.py:402: The name tf.gfile.MakeDirs is deprecated. Please use tf.io.gfile.makedirs instead.\n\nW0712 14:02:45.771742 140456751757184 module_wrapper.py:139] From /content/models/research/object_detection/exporter.py:402: The name tf.gfile.MakeDirs is deprecated. Please use tf.io.gfile.makedirs instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/exporter.py:121: The name tf.placeholder is deprecated. Please use tf.compat.v1.placeholder instead.\n\nW0712 14:02:45.772028 140456751757184 module_wrapper.py:139] From /content/models/research/object_detection/exporter.py:121: The name tf.placeholder is deprecated. Please use tf.compat.v1.placeholder instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/core/preprocessor.py:2689: The name tf.image.resize_images is deprecated. Please use tf.image.resize instead.\n\nW0712 14:02:45.808785 140456751757184 module_wrapper.py:139] From /content/models/research/object_detection/core/preprocessor.py:2689: The name tf.image.resize_images is deprecated. Please use tf.image.resize instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/meta_architectures/faster_rcnn_meta_arch.py:168: The name tf.variable_scope is deprecated. Please use tf.compat.v1.variable_scope instead.\n\nW0712 14:02:45.852926 140456751757184 module_wrapper.py:139] From /content/models/research/object_detection/meta_architectures/faster_rcnn_meta_arch.py:168: The name tf.variable_scope is deprecated. Please use tf.compat.v1.variable_scope instead.\n\nWARNING:tensorflow:From /tensorflow-1.15.2/python3.6/tensorflow_core/contrib/layers/python/layers/layers.py:2784: Layer.apply (from tensorflow.python.keras.engine.base_layer) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `layer.__call__` method instead.\nW0712 14:02:45.861716 140456751757184 deprecation.py:323] From /tensorflow-1.15.2/python3.6/tensorflow_core/contrib/layers/python/layers/layers.py:2784: Layer.apply (from tensorflow.python.keras.engine.base_layer) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease use `layer.__call__` method instead.\nWARNING:tensorflow:From /content/models/research/object_detection/core/anchor_generator.py:171: The name tf.assert_equal is deprecated. Please use tf.compat.v1.assert_equal instead.\n\nW0712 14:02:47.111961 140456751757184 module_wrapper.py:139] From /content/models/research/object_detection/core/anchor_generator.py:171: The name tf.assert_equal is deprecated. Please use tf.compat.v1.assert_equal instead.\n\nINFO:tensorflow:Scale of 0 disables regularizer.\nI0712 14:02:47.118251 140456751757184 regularizers.py:98] Scale of 0 disables regularizer.\nWARNING:tensorflow:From /content/models/research/object_detection/meta_architectures/faster_rcnn_meta_arch.py:558: The name tf.get_variable_scope is deprecated. Please use tf.compat.v1.get_variable_scope instead.\n\nW0712 14:02:47.118586 140456751757184 module_wrapper.py:139] From /content/models/research/object_detection/meta_architectures/faster_rcnn_meta_arch.py:558: The name tf.get_variable_scope is deprecated. Please use tf.compat.v1.get_variable_scope instead.\n\nINFO:tensorflow:Scale of 0 disables regularizer.\nI0712 14:02:47.132013 140456751757184 regularizers.py:98] Scale of 0 disables regularizer.\nWARNING:tensorflow:From /content/models/research/object_detection/predictors/convolutional_box_predictor.py:150: The name tf.logging.info is deprecated. Please use tf.compat.v1.logging.info instead.\n\nW0712 14:02:47.132371 140456751757184 module_wrapper.py:139] From /content/models/research/object_detection/predictors/convolutional_box_predictor.py:150: The name tf.logging.info is deprecated. Please use tf.compat.v1.logging.info instead.\n\nINFO:tensorflow:depth of additional conv before box predictor: 0\nI0712 14:02:47.132467 140456751757184 convolutional_box_predictor.py:151] depth of additional conv before box predictor: 0\nWARNING:tensorflow:From /content/models/research/object_detection/core/box_list_ops.py:141: where (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse tf.where in 2.0, which has the same broadcast rule as np.where\nW0712 14:02:47.180149 140456751757184 deprecation.py:323] From /content/models/research/object_detection/core/box_list_ops.py:141: where (from tensorflow.python.ops.array_ops) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse tf.where in 2.0, which has the same broadcast rule as np.where\nWARNING:tensorflow:From /content/models/research/object_detection/utils/spatial_transform_ops.py:419: calling crop_and_resize_v1 (from tensorflow.python.ops.image_ops_impl) with box_ind is deprecated and will be removed in a future version.\nInstructions for updating:\nbox_ind is deprecated, use box_indices instead\nW0712 14:02:47.694608 140456751757184 deprecation.py:506] From /content/models/research/object_detection/utils/spatial_transform_ops.py:419: calling crop_and_resize_v1 (from tensorflow.python.ops.image_ops_impl) with box_ind is deprecated and will be removed in a future version.\nInstructions for updating:\nbox_ind is deprecated, use box_indices instead\nWARNING:tensorflow:From /content/models/research/object_detection/meta_architectures/faster_rcnn_meta_arch.py:191: The name tf.AUTO_REUSE is deprecated. Please use tf.compat.v1.AUTO_REUSE instead.\n\nW0712 14:02:47.712072 140456751757184 module_wrapper.py:139] From /content/models/research/object_detection/meta_architectures/faster_rcnn_meta_arch.py:191: The name tf.AUTO_REUSE is deprecated. Please use tf.compat.v1.AUTO_REUSE instead.\n\nWARNING:tensorflow:From /tensorflow-1.15.2/python3.6/tensorflow_core/contrib/layers/python/layers/layers.py:1634: flatten (from tensorflow.python.layers.core) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse keras.layers.flatten instead.\nW0712 14:02:48.253000 140456751757184 deprecation.py:323] From /tensorflow-1.15.2/python3.6/tensorflow_core/contrib/layers/python/layers/layers.py:1634: flatten (from tensorflow.python.layers.core) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse keras.layers.flatten instead.\nINFO:tensorflow:Scale of 0 disables regularizer.\nI0712 14:02:48.258129 140456751757184 regularizers.py:98] Scale of 0 disables regularizer.\nINFO:tensorflow:Scale of 0 disables regularizer.\nI0712 14:02:48.275663 140456751757184 regularizers.py:98] Scale of 0 disables regularizer.\nWARNING:tensorflow:From /tensorflow-1.15.2/python3.6/tensorflow_core/python/util/dispatch.py:180: batch_gather (from tensorflow.python.ops.array_ops) is deprecated and will be removed after 2017-10-25.\nInstructions for updating:\n`tf.batch_gather` is deprecated, please use `tf.gather` with `batch_dims=-1` instead.\nW0712 14:02:49.016097 140456751757184 deprecation.py:323] From /tensorflow-1.15.2/python3.6/tensorflow_core/python/util/dispatch.py:180: batch_gather (from tensorflow.python.ops.array_ops) is deprecated and will be removed after 2017-10-25.\nInstructions for updating:\n`tf.batch_gather` is deprecated, please use `tf.gather` with `batch_dims=-1` instead.\nWARNING:tensorflow:From /content/models/research/object_detection/exporter.py:278: The name tf.add_to_collection is deprecated. Please use tf.compat.v1.add_to_collection instead.\n\nW0712 14:02:49.305306 140456751757184 module_wrapper.py:139] From /content/models/research/object_detection/exporter.py:278: The name tf.add_to_collection is deprecated. Please use tf.compat.v1.add_to_collection instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/exporter.py:383: get_or_create_global_step (from tensorflow.contrib.framework.python.ops.variables) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease switch to tf.train.get_or_create_global_step\nW0712 14:02:49.305542 140456751757184 deprecation.py:323] From /content/models/research/object_detection/exporter.py:383: get_or_create_global_step (from tensorflow.contrib.framework.python.ops.variables) is deprecated and will be removed in a future version.\nInstructions for updating:\nPlease switch to tf.train.get_or_create_global_step\nWARNING:tensorflow:From /content/models/research/object_detection/exporter.py:415: The name tf.get_default_graph is deprecated. Please use tf.compat.v1.get_default_graph instead.\n\nW0712 14:02:49.308490 140456751757184 module_wrapper.py:139] From /content/models/research/object_detection/exporter.py:415: The name tf.get_default_graph is deprecated. Please use tf.compat.v1.get_default_graph instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/exporter.py:539: print_model_analysis (from tensorflow.contrib.tfprof.model_analyzer) is deprecated and will be removed after 2018-01-01.\nInstructions for updating:\nUse `tf.profiler.profile(graph, run_meta, op_log, cmd, options)`. Build `options` with `tf.profiler.ProfileOptionBuilder`. See README.md for details\nW0712 14:02:49.308694 140456751757184 deprecation.py:323] From /content/models/research/object_detection/exporter.py:539: print_model_analysis (from tensorflow.contrib.tfprof.model_analyzer) is deprecated and will be removed after 2018-01-01.\nInstructions for updating:\nUse `tf.profiler.profile(graph, run_meta, op_log, cmd, options)`. Build `options` with `tf.profiler.ProfileOptionBuilder`. See README.md for details\nWARNING:tensorflow:From /tensorflow-1.15.2/python3.6/tensorflow_core/python/profiler/internal/flops_registry.py:142: tensor_shape_from_node_def_name (from tensorflow.python.framework.graph_util_impl) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.compat.v1.graph_util.tensor_shape_from_node_def_name`\nW0712 14:02:49.309641 140456751757184 deprecation.py:323] From /tensorflow-1.15.2/python3.6/tensorflow_core/python/profiler/internal/flops_registry.py:142: tensor_shape_from_node_def_name (from tensorflow.python.framework.graph_util_impl) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.compat.v1.graph_util.tensor_shape_from_node_def_name`\n246 ops no flops stats due to incomplete shapes.\nParsing Inputs...\nIncomplete shape.\n\n=========================Options=============================\n-max_depth 10000\n-min_bytes 0\n-min_peak_bytes 0\n-min_residual_bytes 0\n-min_output_bytes 0\n-min_micros 0\n-min_accelerator_micros 0\n-min_cpu_micros 0\n-min_params 0\n-min_float_ops 0\n-min_occurrence 0\n-step -1\n-order_by name\n-account_type_regexes _trainable_variables\n-start_name_regexes .*\n-trim_name_regexes .*BatchNorm.*\n-show_name_regexes .*\n-hide_name_regexes \n-account_displayed_op_only true\n-select params\n-output stdout:\n\n==================Model Analysis Report======================\nIncomplete shape.\n\nDoc:\nscope: The nodes in the model graph are organized by their names, which is hierarchical like filesystem.\nparam: Number of parameters (in the Variable).\n\nProfile:\nnode name | # parameters\n_TFProfRoot (--/12.88m params)\n Conv (--/2.65m params)\n Conv/biases (512, 512/512 params)\n Conv/weights (3x3x576x512, 2.65m/2.65m params)\n FirstStageBoxPredictor (--/36.94k params)\n FirstStageBoxPredictor/BoxEncodingPredictor (--/24.62k params)\n FirstStageBoxPredictor/BoxEncodingPredictor/biases (48, 48/48 params)\n FirstStageBoxPredictor/BoxEncodingPredictor/weights (1x1x512x48, 24.58k/24.58k params)\n FirstStageBoxPredictor/ClassPredictor (--/12.31k params)\n FirstStageBoxPredictor/ClassPredictor/biases (24, 24/24 params)\n FirstStageBoxPredictor/ClassPredictor/weights (1x1x512x24, 12.29k/12.29k params)\n FirstStageFeatureExtractor (--/4.25m params)\n FirstStageFeatureExtractor/InceptionV2 (--/4.25m params)\n FirstStageFeatureExtractor/InceptionV2/Conv2d_1a_7x7 (--/2.71k params)\n FirstStageFeatureExtractor/InceptionV2/Conv2d_1a_7x7/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Conv2d_1a_7x7/depthwise_weights (7x7x3x8, 1.18k/1.18k params)\n FirstStageFeatureExtractor/InceptionV2/Conv2d_1a_7x7/pointwise_weights (1x1x24x64, 1.54k/1.54k params)\n FirstStageFeatureExtractor/InceptionV2/Conv2d_2b_1x1 (--/4.10k params)\n FirstStageFeatureExtractor/InceptionV2/Conv2d_2b_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Conv2d_2b_1x1/weights (1x1x64x64, 4.10k/4.10k params)\n FirstStageFeatureExtractor/InceptionV2/Conv2d_2c_3x3 (--/110.59k params)\n FirstStageFeatureExtractor/InceptionV2/Conv2d_2c_3x3/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Conv2d_2c_3x3/weights (3x3x64x192, 110.59k/110.59k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3b (--/218.11k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3b/Branch_0 (--/12.29k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3b/Branch_0/Conv2d_0a_1x1 (--/12.29k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3b/Branch_0/Conv2d_0a_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3b/Branch_0/Conv2d_0a_1x1/weights (1x1x192x64, 12.29k/12.29k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3b/Branch_1 (--/49.15k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3b/Branch_1/Conv2d_0a_1x1 (--/12.29k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3b/Branch_1/Conv2d_0a_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3b/Branch_1/Conv2d_0a_1x1/weights (1x1x192x64, 12.29k/12.29k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3b/Branch_1/Conv2d_0b_3x3 (--/36.86k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3b/Branch_1/Conv2d_0b_3x3/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3b/Branch_1/Conv2d_0b_3x3/weights (3x3x64x64, 36.86k/36.86k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3b/Branch_2 (--/150.53k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3b/Branch_2/Conv2d_0a_1x1 (--/12.29k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3b/Branch_2/Conv2d_0a_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3b/Branch_2/Conv2d_0a_1x1/weights (1x1x192x64, 12.29k/12.29k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3b/Branch_2/Conv2d_0b_3x3 (--/55.30k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3b/Branch_2/Conv2d_0b_3x3/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3b/Branch_2/Conv2d_0b_3x3/weights (3x3x64x96, 55.30k/55.30k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3b/Branch_2/Conv2d_0c_3x3 (--/82.94k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3b/Branch_2/Conv2d_0c_3x3/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3b/Branch_2/Conv2d_0c_3x3/weights (3x3x96x96, 82.94k/82.94k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3b/Branch_3 (--/6.14k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3b/Branch_3/Conv2d_0b_1x1 (--/6.14k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3b/Branch_3/Conv2d_0b_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3b/Branch_3/Conv2d_0b_1x1/weights (1x1x192x32, 6.14k/6.14k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3c (--/259.07k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3c/Branch_0 (--/16.38k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3c/Branch_0/Conv2d_0a_1x1 (--/16.38k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3c/Branch_0/Conv2d_0a_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3c/Branch_0/Conv2d_0a_1x1/weights (1x1x256x64, 16.38k/16.38k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3c/Branch_1 (--/71.68k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3c/Branch_1/Conv2d_0a_1x1 (--/16.38k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3c/Branch_1/Conv2d_0a_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3c/Branch_1/Conv2d_0a_1x1/weights (1x1x256x64, 16.38k/16.38k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3c/Branch_1/Conv2d_0b_3x3 (--/55.30k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3c/Branch_1/Conv2d_0b_3x3/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3c/Branch_1/Conv2d_0b_3x3/weights (3x3x64x96, 55.30k/55.30k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3c/Branch_2 (--/154.62k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3c/Branch_2/Conv2d_0a_1x1 (--/16.38k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3c/Branch_2/Conv2d_0a_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3c/Branch_2/Conv2d_0a_1x1/weights (1x1x256x64, 16.38k/16.38k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3c/Branch_2/Conv2d_0b_3x3 (--/55.30k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3c/Branch_2/Conv2d_0b_3x3/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3c/Branch_2/Conv2d_0b_3x3/weights (3x3x64x96, 55.30k/55.30k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3c/Branch_2/Conv2d_0c_3x3 (--/82.94k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3c/Branch_2/Conv2d_0c_3x3/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3c/Branch_2/Conv2d_0c_3x3/weights (3x3x96x96, 82.94k/82.94k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3c/Branch_3 (--/16.38k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3c/Branch_3/Conv2d_0b_1x1 (--/16.38k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3c/Branch_3/Conv2d_0b_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_3c/Branch_3/Conv2d_0b_1x1/weights (1x1x256x64, 16.38k/16.38k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4a (--/384.00k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4a/Branch_0 (--/225.28k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4a/Branch_0/Conv2d_0a_1x1 (--/40.96k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4a/Branch_0/Conv2d_0a_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4a/Branch_0/Conv2d_0a_1x1/weights (1x1x320x128, 40.96k/40.96k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4a/Branch_0/Conv2d_1a_3x3 (--/184.32k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4a/Branch_0/Conv2d_1a_3x3/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4a/Branch_0/Conv2d_1a_3x3/weights (3x3x128x160, 184.32k/184.32k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4a/Branch_1 (--/158.72k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4a/Branch_1/Conv2d_0a_1x1 (--/20.48k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4a/Branch_1/Conv2d_0a_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4a/Branch_1/Conv2d_0a_1x1/weights (1x1x320x64, 20.48k/20.48k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4a/Branch_1/Conv2d_0b_3x3 (--/55.30k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4a/Branch_1/Conv2d_0b_3x3/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4a/Branch_1/Conv2d_0b_3x3/weights (3x3x64x96, 55.30k/55.30k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4a/Branch_1/Conv2d_1a_3x3 (--/82.94k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4a/Branch_1/Conv2d_1a_3x3/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4a/Branch_1/Conv2d_1a_3x3/weights (3x3x96x96, 82.94k/82.94k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4b (--/608.26k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4b/Branch_0 (--/129.02k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4b/Branch_0/Conv2d_0a_1x1 (--/129.02k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4b/Branch_0/Conv2d_0a_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4b/Branch_0/Conv2d_0a_1x1/weights (1x1x576x224, 129.02k/129.02k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4b/Branch_1 (--/92.16k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4b/Branch_1/Conv2d_0a_1x1 (--/36.86k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4b/Branch_1/Conv2d_0a_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4b/Branch_1/Conv2d_0a_1x1/weights (1x1x576x64, 36.86k/36.86k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4b/Branch_1/Conv2d_0b_3x3 (--/55.30k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4b/Branch_1/Conv2d_0b_3x3/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4b/Branch_1/Conv2d_0b_3x3/weights (3x3x64x96, 55.30k/55.30k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4b/Branch_2 (--/313.34k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4b/Branch_2/Conv2d_0a_1x1 (--/55.30k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4b/Branch_2/Conv2d_0a_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4b/Branch_2/Conv2d_0a_1x1/weights (1x1x576x96, 55.30k/55.30k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4b/Branch_2/Conv2d_0b_3x3 (--/110.59k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4b/Branch_2/Conv2d_0b_3x3/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4b/Branch_2/Conv2d_0b_3x3/weights (3x3x96x128, 110.59k/110.59k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4b/Branch_2/Conv2d_0c_3x3 (--/147.46k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4b/Branch_2/Conv2d_0c_3x3/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4b/Branch_2/Conv2d_0c_3x3/weights (3x3x128x128, 147.46k/147.46k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4b/Branch_3 (--/73.73k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4b/Branch_3/Conv2d_0b_1x1 (--/73.73k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4b/Branch_3/Conv2d_0b_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4b/Branch_3/Conv2d_0b_1x1/weights (1x1x576x128, 73.73k/73.73k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4c (--/663.55k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4c/Branch_0 (--/110.59k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4c/Branch_0/Conv2d_0a_1x1 (--/110.59k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4c/Branch_0/Conv2d_0a_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4c/Branch_0/Conv2d_0a_1x1/weights (1x1x576x192, 110.59k/110.59k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4c/Branch_1 (--/165.89k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4c/Branch_1/Conv2d_0a_1x1 (--/55.30k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4c/Branch_1/Conv2d_0a_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4c/Branch_1/Conv2d_0a_1x1/weights (1x1x576x96, 55.30k/55.30k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4c/Branch_1/Conv2d_0b_3x3 (--/110.59k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4c/Branch_1/Conv2d_0b_3x3/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4c/Branch_1/Conv2d_0b_3x3/weights (3x3x96x128, 110.59k/110.59k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4c/Branch_2 (--/313.34k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4c/Branch_2/Conv2d_0a_1x1 (--/55.30k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4c/Branch_2/Conv2d_0a_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4c/Branch_2/Conv2d_0a_1x1/weights (1x1x576x96, 55.30k/55.30k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4c/Branch_2/Conv2d_0b_3x3 (--/110.59k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4c/Branch_2/Conv2d_0b_3x3/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4c/Branch_2/Conv2d_0b_3x3/weights (3x3x96x128, 110.59k/110.59k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4c/Branch_2/Conv2d_0c_3x3 (--/147.46k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4c/Branch_2/Conv2d_0c_3x3/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4c/Branch_2/Conv2d_0c_3x3/weights (3x3x128x128, 147.46k/147.46k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4c/Branch_3 (--/73.73k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4c/Branch_3/Conv2d_0b_1x1 (--/73.73k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4c/Branch_3/Conv2d_0b_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4c/Branch_3/Conv2d_0b_1x1/weights (1x1x576x128, 73.73k/73.73k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4d (--/893.95k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4d/Branch_0 (--/92.16k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4d/Branch_0/Conv2d_0a_1x1 (--/92.16k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4d/Branch_0/Conv2d_0a_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4d/Branch_0/Conv2d_0a_1x1/weights (1x1x576x160, 92.16k/92.16k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4d/Branch_1 (--/258.05k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4d/Branch_1/Conv2d_0a_1x1 (--/73.73k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4d/Branch_1/Conv2d_0a_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4d/Branch_1/Conv2d_0a_1x1/weights (1x1x576x128, 73.73k/73.73k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4d/Branch_1/Conv2d_0b_3x3 (--/184.32k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4d/Branch_1/Conv2d_0b_3x3/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4d/Branch_1/Conv2d_0b_3x3/weights (3x3x128x160, 184.32k/184.32k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4d/Branch_2 (--/488.45k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4d/Branch_2/Conv2d_0a_1x1 (--/73.73k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4d/Branch_2/Conv2d_0a_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4d/Branch_2/Conv2d_0a_1x1/weights (1x1x576x128, 73.73k/73.73k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4d/Branch_2/Conv2d_0b_3x3 (--/184.32k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4d/Branch_2/Conv2d_0b_3x3/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4d/Branch_2/Conv2d_0b_3x3/weights (3x3x128x160, 184.32k/184.32k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4d/Branch_2/Conv2d_0c_3x3 (--/230.40k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4d/Branch_2/Conv2d_0c_3x3/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4d/Branch_2/Conv2d_0c_3x3/weights (3x3x160x160, 230.40k/230.40k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4d/Branch_3 (--/55.30k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4d/Branch_3/Conv2d_0b_1x1 (--/55.30k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4d/Branch_3/Conv2d_0b_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4d/Branch_3/Conv2d_0b_1x1/weights (1x1x576x96, 55.30k/55.30k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4e (--/1.11m params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4e/Branch_0 (--/55.30k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4e/Branch_0/Conv2d_0a_1x1 (--/55.30k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4e/Branch_0/Conv2d_0a_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4e/Branch_0/Conv2d_0a_1x1/weights (1x1x576x96, 55.30k/55.30k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4e/Branch_1 (--/294.91k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4e/Branch_1/Conv2d_0a_1x1 (--/73.73k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4e/Branch_1/Conv2d_0a_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4e/Branch_1/Conv2d_0a_1x1/weights (1x1x576x128, 73.73k/73.73k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4e/Branch_1/Conv2d_0b_3x3 (--/221.18k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4e/Branch_1/Conv2d_0b_3x3/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4e/Branch_1/Conv2d_0b_3x3/weights (3x3x128x192, 221.18k/221.18k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4e/Branch_2 (--/700.42k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4e/Branch_2/Conv2d_0a_1x1 (--/92.16k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4e/Branch_2/Conv2d_0a_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4e/Branch_2/Conv2d_0a_1x1/weights (1x1x576x160, 92.16k/92.16k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4e/Branch_2/Conv2d_0b_3x3 (--/276.48k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4e/Branch_2/Conv2d_0b_3x3/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4e/Branch_2/Conv2d_0b_3x3/weights (3x3x160x192, 276.48k/276.48k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4e/Branch_2/Conv2d_0c_3x3 (--/331.78k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4e/Branch_2/Conv2d_0c_3x3/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4e/Branch_2/Conv2d_0c_3x3/weights (3x3x192x192, 331.78k/331.78k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4e/Branch_3 (--/55.30k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4e/Branch_3/Conv2d_0b_1x1 (--/55.30k params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4e/Branch_3/Conv2d_0b_1x1/BatchNorm (--/0 params)\n FirstStageFeatureExtractor/InceptionV2/Mixed_4e/Branch_3/Conv2d_0b_1x1/weights (1x1x576x96, 55.30k/55.30k params)\n SecondStageBoxPredictor (--/42.02k params)\n SecondStageBoxPredictor/BoxEncodingPredictor (--/32.80k params)\n SecondStageBoxPredictor/BoxEncodingPredictor/biases (32, 32/32 params)\n SecondStageBoxPredictor/BoxEncodingPredictor/weights (1024x32, 32.77k/32.77k params)\n SecondStageBoxPredictor/ClassPredictor (--/9.22k params)\n SecondStageBoxPredictor/ClassPredictor/biases (9, 9/9 params)\n SecondStageBoxPredictor/ClassPredictor/weights (1024x9, 9.22k/9.22k params)\n SecondStageFeatureExtractor (--/5.89m params)\n SecondStageFeatureExtractor/InceptionV2 (--/5.89m params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5a (--/1.44m params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5a/Branch_0 (--/294.91k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5a/Branch_0/Conv2d_0a_1x1 (--/73.73k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5a/Branch_0/Conv2d_0a_1x1/BatchNorm (--/0 params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5a/Branch_0/Conv2d_0a_1x1/weights (1x1x576x128, 73.73k/73.73k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5a/Branch_0/Conv2d_1a_3x3 (--/221.18k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5a/Branch_0/Conv2d_1a_3x3/BatchNorm (--/0 params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5a/Branch_0/Conv2d_1a_3x3/weights (3x3x128x192, 221.18k/221.18k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5a/Branch_1 (--/1.14m params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5a/Branch_1/Conv2d_0a_1x1 (--/110.59k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5a/Branch_1/Conv2d_0a_1x1/BatchNorm (--/0 params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5a/Branch_1/Conv2d_0a_1x1/weights (1x1x576x192, 110.59k/110.59k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5a/Branch_1/Conv2d_0b_3x3 (--/442.37k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5a/Branch_1/Conv2d_0b_3x3/BatchNorm (--/0 params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5a/Branch_1/Conv2d_0b_3x3/weights (3x3x192x256, 442.37k/442.37k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5a/Branch_1/Conv2d_1a_3x3 (--/589.82k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5a/Branch_1/Conv2d_1a_3x3/BatchNorm (--/0 params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5a/Branch_1/Conv2d_1a_3x3/weights (3x3x256x256, 589.82k/589.82k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5b (--/2.18m params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5b/Branch_0 (--/360.45k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5b/Branch_0/Conv2d_0a_1x1 (--/360.45k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5b/Branch_0/Conv2d_0a_1x1/BatchNorm (--/0 params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5b/Branch_0/Conv2d_0a_1x1/weights (1x1x1024x352, 360.45k/360.45k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5b/Branch_1 (--/749.57k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5b/Branch_1/Conv2d_0a_1x1 (--/196.61k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5b/Branch_1/Conv2d_0a_1x1/BatchNorm (--/0 params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5b/Branch_1/Conv2d_0a_1x1/weights (1x1x1024x192, 196.61k/196.61k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5b/Branch_1/Conv2d_0b_3x3 (--/552.96k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5b/Branch_1/Conv2d_0b_3x3/BatchNorm (--/0 params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5b/Branch_1/Conv2d_0b_3x3/weights (3x3x192x320, 552.96k/552.96k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5b/Branch_2 (--/937.98k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5b/Branch_2/Conv2d_0a_1x1 (--/163.84k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5b/Branch_2/Conv2d_0a_1x1/BatchNorm (--/0 params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5b/Branch_2/Conv2d_0a_1x1/weights (1x1x1024x160, 163.84k/163.84k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5b/Branch_2/Conv2d_0b_3x3 (--/322.56k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5b/Branch_2/Conv2d_0b_3x3/BatchNorm (--/0 params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5b/Branch_2/Conv2d_0b_3x3/weights (3x3x160x224, 322.56k/322.56k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5b/Branch_2/Conv2d_0c_3x3 (--/451.58k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5b/Branch_2/Conv2d_0c_3x3/BatchNorm (--/0 params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5b/Branch_2/Conv2d_0c_3x3/weights (3x3x224x224, 451.58k/451.58k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5b/Branch_3 (--/131.07k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5b/Branch_3/Conv2d_0b_1x1 (--/131.07k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5b/Branch_3/Conv2d_0b_1x1/BatchNorm (--/0 params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5b/Branch_3/Conv2d_0b_1x1/weights (1x1x1024x128, 131.07k/131.07k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5c (--/2.28m params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5c/Branch_0 (--/360.45k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5c/Branch_0/Conv2d_0a_1x1 (--/360.45k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5c/Branch_0/Conv2d_0a_1x1/BatchNorm (--/0 params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5c/Branch_0/Conv2d_0a_1x1/weights (1x1x1024x352, 360.45k/360.45k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5c/Branch_1 (--/749.57k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5c/Branch_1/Conv2d_0a_1x1 (--/196.61k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5c/Branch_1/Conv2d_0a_1x1/BatchNorm (--/0 params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5c/Branch_1/Conv2d_0a_1x1/weights (1x1x1024x192, 196.61k/196.61k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5c/Branch_1/Conv2d_0b_3x3 (--/552.96k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5c/Branch_1/Conv2d_0b_3x3/BatchNorm (--/0 params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5c/Branch_1/Conv2d_0b_3x3/weights (3x3x192x320, 552.96k/552.96k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5c/Branch_2 (--/1.04m params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5c/Branch_2/Conv2d_0a_1x1 (--/196.61k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5c/Branch_2/Conv2d_0a_1x1/BatchNorm (--/0 params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5c/Branch_2/Conv2d_0a_1x1/weights (1x1x1024x192, 196.61k/196.61k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5c/Branch_2/Conv2d_0b_3x3 (--/387.07k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5c/Branch_2/Conv2d_0b_3x3/BatchNorm (--/0 params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5c/Branch_2/Conv2d_0b_3x3/weights (3x3x192x224, 387.07k/387.07k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5c/Branch_2/Conv2d_0c_3x3 (--/451.58k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5c/Branch_2/Conv2d_0c_3x3/BatchNorm (--/0 params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5c/Branch_2/Conv2d_0c_3x3/weights (3x3x224x224, 451.58k/451.58k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5c/Branch_3 (--/131.07k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5c/Branch_3/Conv2d_0b_1x1 (--/131.07k params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5c/Branch_3/Conv2d_0b_1x1/BatchNorm (--/0 params)\n SecondStageFeatureExtractor/InceptionV2/Mixed_5c/Branch_3/Conv2d_0b_1x1/weights (1x1x1024x128, 131.07k/131.07k params)\n\n======================End of Report==========================\n246 ops no flops stats due to incomplete shapes.\nParsing Inputs...\nIncomplete shape.\n\n=========================Options=============================\n-max_depth 10000\n-min_bytes 0\n-min_peak_bytes 0\n-min_residual_bytes 0\n-min_output_bytes 0\n-min_micros 0\n-min_accelerator_micros 0\n-min_cpu_micros 0\n-min_params 0\n-min_float_ops 1\n-min_occurrence 0\n-step -1\n-order_by float_ops\n-account_type_regexes .*\n-start_name_regexes .*\n-trim_name_regexes .*BatchNorm.*,.*Initializer.*,.*Regularizer.*,.*BiasAdd.*\n-show_name_regexes .*\n-hide_name_regexes \n-account_displayed_op_only true\n-select float_ops\n-output stdout:\n\n==================Model Analysis Report======================\nIncomplete shape.\n\nDoc:\nscope: The nodes in the model graph are organized by their names, which is hierarchical like filesystem.\nflops: Number of float operations. Note: Please read the implementation for the math behind it.\n\nProfile:\nnode name | # float_ops\n_TFProfRoot (--/6.19k flops)\n SecondStagePostprocessor/map/while/ClipToWindow/Minimum_1 (300/300 flops)\n SecondStagePostprocessor/map/while/ToNormalizedCoordinates/Scale/mul_3 (300/300 flops)\n SecondStagePostprocessor/map/while/ToNormalizedCoordinates/Scale/mul_2 (300/300 flops)\n SecondStagePostprocessor/map/while/ToNormalizedCoordinates/Scale/mul_1 (300/300 flops)\n SecondStagePostprocessor/map/while/ClipToWindow/Minimum_3 (300/300 flops)\n map/while/ToNormalizedCoordinates/Scale/mul (300/300 flops)\n map/while/ToNormalizedCoordinates/Scale/mul_1 (300/300 flops)\n map/while/ToNormalizedCoordinates/Scale/mul_2 (300/300 flops)\n map/while/ToNormalizedCoordinates/Scale/mul_3 (300/300 flops)\n SecondStagePostprocessor/map/while/ToNormalizedCoordinates/Scale/mul (300/300 flops)\n SecondStagePostprocessor/map/while/ClipToWindow/Minimum_2 (300/300 flops)\n SecondStagePostprocessor/map/while/ClipToWindow/Minimum (300/300 flops)\n SecondStagePostprocessor/map/while/ClipToWindow/Maximum_3 (300/300 flops)\n SecondStagePostprocessor/map/while/ClipToWindow/Maximum_2 (300/300 flops)\n SecondStagePostprocessor/map/while/ClipToWindow/Maximum_1 (300/300 flops)\n SecondStagePostprocessor/map/while/ClipToWindow/Maximum (300/300 flops)\n map_2/while/mul (300/300 flops)\n map_2/while/mul_1 (300/300 flops)\n map_2/while/mul_2 (300/300 flops)\n map_2/while/mul_3 (300/300 flops)\n GridAnchorGenerator/truediv (12/12 flops)\n GridAnchorGenerator/mul (12/12 flops)\n GridAnchorGenerator/mul_1 (12/12 flops)\n GridAnchorGenerator/mul_2 (12/12 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/Greater_5 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/Greater_7 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/Greater_4 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/Greater_6 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/Greater_1 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/Greater_8 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/Greater_9 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_1 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_10 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_11 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_12 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_13 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/sub_5 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/sub (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/sub_12 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/sub_13 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/sub_14 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/sub_15 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/sub_2 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/sub_3 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/sub_4 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/Greater_3 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/sub_6 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/sub_7 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/sub_8 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/sub_9 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/Greater (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/sub_11 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/Greater_2 (1/1 flops)\n SecondStagePostprocessor/map/while/Less (1/1 flops)\n mul (1/1 flops)\n map_2/while/Less_1 (1/1 flops)\n map_2/while/Less (1/1 flops)\n map_1/while/ToNormalizedCoordinates/truediv_1 (1/1 flops)\n map_1/while/ToNormalizedCoordinates/truediv (1/1 flops)\n map_1/while/Less_1 (1/1 flops)\n map_1/while/Less (1/1 flops)\n map/while/ToNormalizedCoordinates/truediv_1 (1/1 flops)\n map/while/ToNormalizedCoordinates/truediv (1/1 flops)\n map/while/Less_1 (1/1 flops)\n map/while/Less (1/1 flops)\n SecondStagePostprocessor/map/while/ToNormalizedCoordinates/truediv_1 (1/1 flops)\n SecondStagePostprocessor/map/while/ToNormalizedCoordinates/truediv (1/1 flops)\n SecondStagePostprocessor/map/while/Less_1 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_14 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_9 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_8 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_7 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_6 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_5 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_4 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_3 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_2 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_19 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_18 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_17 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_16 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_15 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_4 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_11 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_12 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_13 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_14 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_15 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_16 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_17 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_2 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_3 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_10 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_5 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_6 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_7 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_8 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_9 (1/1 flops)\n BatchMultiClassNonMaxSuppression/ones/Less (1/1 flops)\n FirstStageFeatureExtractor/GreaterEqual (1/1 flops)\n FirstStageFeatureExtractor/GreaterEqual_1 (1/1 flops)\n GridAnchorGenerator/assert_equal_1/Equal (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/Greater_1 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/Less_1 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/Greater (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/Minimum (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/Minimum_1 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/SortByField/Equal (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/SortByField_1/Equal (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/sub (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/sub_1 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/Greater (1/1 flops)\n GridAnchorGenerator/mul_7 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/Greater_2 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/Greater_3 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/Greater_4 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/Greater_5 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/Greater_6 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/Greater_7 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/Greater_8 (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/PadOrClipBoxList/sub_1 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/Minimum_3 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/Less_1 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/ChangeCoordinateFrame/sub (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/ChangeCoordinateFrame/sub_1 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/ChangeCoordinateFrame/truediv (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/ChangeCoordinateFrame/truediv_1 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/Greater (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/Minimum (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/Minimum_1 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/Minimum_2 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/Less (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/Minimum_4 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/Minimum_5 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/Minimum_6 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/Minimum_7 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/Minimum_8 (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/SortByField/Equal (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/SortByField_1/Equal (1/1 flops)\n BatchMultiClassNonMaxSuppression/map/while/Less (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/sub_1 (1/1 flops)\n Preprocessor/map/while/ResizeToRange/cond/resize/truediv_1 (1/1 flops)\n GridAnchorGenerator/mul_8 (1/1 flops)\n GridAnchorGenerator/zeros/Less (1/1 flops)\n Preprocessor/map/while/Less (1/1 flops)\n Preprocessor/map/while/Less_1 (1/1 flops)\n Preprocessor/map/while/ResizeToRange/Less (1/1 flops)\n Preprocessor/map/while/ResizeToRange/cond/resize/Minimum (1/1 flops)\n Preprocessor/map/while/ResizeToRange/cond/resize/mul (1/1 flops)\n Preprocessor/map/while/ResizeToRange/cond/resize/mul_1 (1/1 flops)\n Preprocessor/map/while/ResizeToRange/cond/resize/truediv (1/1 flops)\n SecondStagePostprocessor/BatchMultiClassNonMaxSuppression/map/while/MultiClassNonMaxSuppression/sub_10 (1/1 flops)\n Preprocessor/map/while/ResizeToRange/cond/resize_1/Minimum (1/1 flops)\n Preprocessor/map/while/ResizeToRange/cond/resize_1/mul (1/1 flops)\n Preprocessor/map/while/ResizeToRange/cond/resize_1/mul_1 (1/1 flops)\n Preprocessor/map/while/ResizeToRange/cond/resize_1/truediv (1/1 flops)\n Preprocessor/map/while/ResizeToRange/cond/resize_1/truediv_1 (1/1 flops)\n SecondStageDetectionFeaturesExtract/mul (1/1 flops)\n SecondStagePostprocessor/BatchGather/mul (1/1 flops)\n SecondStagePostprocessor/BatchGather/mul_2 (1/1 flops)\n\n======================End of Report==========================\nWARNING:tensorflow:From /content/models/research/object_detection/exporter.py:432: The name tf.train.Saver is deprecated. Please use tf.compat.v1.train.Saver instead.\n\nW0712 14:02:50.589166 140456751757184 module_wrapper.py:139] From /content/models/research/object_detection/exporter.py:432: The name tf.train.Saver is deprecated. Please use tf.compat.v1.train.Saver instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/exporter.py:342: The name tf.Session is deprecated. Please use tf.compat.v1.Session instead.\n\nW0712 14:02:51.478769 140456751757184 module_wrapper.py:139] From /content/models/research/object_detection/exporter.py:342: The name tf.Session is deprecated. Please use tf.compat.v1.Session instead.\n\n2020-07-12 14:02:51.479998: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcuda.so.1\n2020-07-12 14:02:51.497514: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:02:51.498079: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1639] Found device 0 with properties: \nname: Tesla P100-PCIE-16GB major: 6 minor: 0 memoryClockRate(GHz): 1.3285\npciBusID: 0000:00:04.0\n2020-07-12 14:02:51.498358: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1\n2020-07-12 14:02:51.500156: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcublas.so.10\n2020-07-12 14:02:51.501721: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcufft.so.10\n2020-07-12 14:02:51.502058: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcurand.so.10\n2020-07-12 14:02:51.515983: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusolver.so.10\n2020-07-12 14:02:51.527289: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusparse.so.10\n2020-07-12 14:02:51.537869: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudnn.so.7\n2020-07-12 14:02:51.537991: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:02:51.538565: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:02:51.539049: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1767] Adding visible gpu devices: 0\n2020-07-12 14:02:51.550020: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 2200000000 Hz\n2020-07-12 14:02:51.550364: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x176cf40 initialized for platform Host (this does not guarantee that XLA will be used). Devices:\n2020-07-12 14:02:51.550394: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version\n2020-07-12 14:02:51.645737: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:02:51.646500: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x176d480 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices:\n2020-07-12 14:02:51.646543: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Tesla P100-PCIE-16GB, Compute Capability 6.0\n2020-07-12 14:02:51.646737: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:02:51.647283: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1639] Found device 0 with properties: \nname: Tesla P100-PCIE-16GB major: 6 minor: 0 memoryClockRate(GHz): 1.3285\npciBusID: 0000:00:04.0\n2020-07-12 14:02:51.647355: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1\n2020-07-12 14:02:51.647372: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcublas.so.10\n2020-07-12 14:02:51.647388: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcufft.so.10\n2020-07-12 14:02:51.647401: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcurand.so.10\n2020-07-12 14:02:51.647414: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusolver.so.10\n2020-07-12 14:02:51.647429: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusparse.so.10\n2020-07-12 14:02:51.647445: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudnn.so.7\n2020-07-12 14:02:51.647501: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:02:51.648023: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:02:51.648486: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1767] Adding visible gpu devices: 0\n2020-07-12 14:02:51.648555: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1\n2020-07-12 14:02:51.649703: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1180] Device interconnect StreamExecutor with strength 1 edge matrix:\n2020-07-12 14:02:51.649730: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1186] 0 \n2020-07-12 14:02:51.649737: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1199] 0: N \n2020-07-12 14:02:51.649846: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:02:51.650349: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:02:51.650849: W tensorflow/core/common_runtime/gpu/gpu_bfc_allocator.cc:39] Overriding allow_growth setting because the TF_FORCE_GPU_ALLOW_GROWTH environment variable is set. Original config value was 0.\n2020-07-12 14:02:51.650882: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1325] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 15216 MB memory) -> physical GPU (device: 0, name: Tesla P100-PCIE-16GB, pci bus id: 0000:00:04.0, compute capability: 6.0)\nINFO:tensorflow:Restoring parameters from training/model.ckpt-1000\nI0712 14:02:51.652667 140456751757184 saver.py:1284] Restoring parameters from training/model.ckpt-1000\nWARNING:tensorflow:From /tensorflow-1.15.2/python3.6/tensorflow_core/python/tools/freeze_graph.py:127: checkpoint_exists (from tensorflow.python.training.checkpoint_management) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse standard file APIs to check for files with this prefix.\nW0712 14:02:53.358593 140456751757184 deprecation.py:323] From /tensorflow-1.15.2/python3.6/tensorflow_core/python/tools/freeze_graph.py:127: checkpoint_exists (from tensorflow.python.training.checkpoint_management) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse standard file APIs to check for files with this prefix.\n2020-07-12 14:02:54.052155: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:02:54.052747: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1639] Found device 0 with properties: \nname: Tesla P100-PCIE-16GB major: 6 minor: 0 memoryClockRate(GHz): 1.3285\npciBusID: 0000:00:04.0\n2020-07-12 14:02:54.052847: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1\n2020-07-12 14:02:54.052870: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcublas.so.10\n2020-07-12 14:02:54.052886: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcufft.so.10\n2020-07-12 14:02:54.052900: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcurand.so.10\n2020-07-12 14:02:54.052913: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusolver.so.10\n2020-07-12 14:02:54.052926: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusparse.so.10\n2020-07-12 14:02:54.052939: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudnn.so.7\n2020-07-12 14:02:54.053006: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:02:54.053506: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:02:54.053981: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1767] Adding visible gpu devices: 0\n2020-07-12 14:02:54.054016: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1180] Device interconnect StreamExecutor with strength 1 edge matrix:\n2020-07-12 14:02:54.054027: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1186] 0 \n2020-07-12 14:02:54.054033: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1199] 0: N \n2020-07-12 14:02:54.054109: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:02:54.054608: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:02:54.055091: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1325] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 15216 MB memory) -> physical GPU (device: 0, name: Tesla P100-PCIE-16GB, pci bus id: 0000:00:04.0, compute capability: 6.0)\nINFO:tensorflow:Restoring parameters from training/model.ckpt-1000\nI0712 14:02:54.056129 140456751757184 saver.py:1284] Restoring parameters from training/model.ckpt-1000\nWARNING:tensorflow:From /tensorflow-1.15.2/python3.6/tensorflow_core/python/tools/freeze_graph.py:233: convert_variables_to_constants (from tensorflow.python.framework.graph_util_impl) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.compat.v1.graph_util.convert_variables_to_constants`\nW0712 14:02:54.754125 140456751757184 deprecation.py:323] From /tensorflow-1.15.2/python3.6/tensorflow_core/python/tools/freeze_graph.py:233: convert_variables_to_constants (from tensorflow.python.framework.graph_util_impl) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.compat.v1.graph_util.convert_variables_to_constants`\nWARNING:tensorflow:From /tensorflow-1.15.2/python3.6/tensorflow_core/python/framework/graph_util_impl.py:277: extract_sub_graph (from tensorflow.python.framework.graph_util_impl) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.compat.v1.graph_util.extract_sub_graph`\nW0712 14:02:54.754382 140456751757184 deprecation.py:323] From /tensorflow-1.15.2/python3.6/tensorflow_core/python/framework/graph_util_impl.py:277: extract_sub_graph (from tensorflow.python.framework.graph_util_impl) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.compat.v1.graph_util.extract_sub_graph`\nINFO:tensorflow:Froze 356 variables.\nI0712 14:02:55.160953 140456751757184 graph_util_impl.py:334] Froze 356 variables.\nINFO:tensorflow:Converted 356 variables to const ops.\nI0712 14:02:55.270473 140456751757184 graph_util_impl.py:394] Converted 356 variables to const ops.\n2020-07-12 14:02:55.477615: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:02:55.478217: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1639] Found device 0 with properties: \nname: Tesla P100-PCIE-16GB major: 6 minor: 0 memoryClockRate(GHz): 1.3285\npciBusID: 0000:00:04.0\n2020-07-12 14:02:55.478317: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudart.so.10.1\n2020-07-12 14:02:55.478342: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcublas.so.10\n2020-07-12 14:02:55.478368: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcufft.so.10\n2020-07-12 14:02:55.478402: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcurand.so.10\n2020-07-12 14:02:55.478423: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusolver.so.10\n2020-07-12 14:02:55.478445: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcusparse.so.10\n2020-07-12 14:02:55.478468: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library libcudnn.so.7\n2020-07-12 14:02:55.478561: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:02:55.479110: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:02:55.479589: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1767] Adding visible gpu devices: 0\n2020-07-12 14:02:55.479630: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1180] Device interconnect StreamExecutor with strength 1 edge matrix:\n2020-07-12 14:02:55.479644: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1186] 0 \n2020-07-12 14:02:55.479654: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1199] 0: N \n2020-07-12 14:02:55.479746: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:02:55.480314: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:983] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero\n2020-07-12 14:02:55.480811: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1325] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 15216 MB memory) -> physical GPU (device: 0, name: Tesla P100-PCIE-16GB, pci bus id: 0000:00:04.0, compute capability: 6.0)\nWARNING:tensorflow:From /content/models/research/object_detection/exporter.py:306: The name tf.saved_model.builder.SavedModelBuilder is deprecated. Please use tf.compat.v1.saved_model.builder.SavedModelBuilder instead.\n\nW0712 14:02:55.901992 140456751757184 module_wrapper.py:139] From /content/models/research/object_detection/exporter.py:306: The name tf.saved_model.builder.SavedModelBuilder is deprecated. Please use tf.compat.v1.saved_model.builder.SavedModelBuilder instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/exporter.py:309: build_tensor_info (from tensorflow.python.saved_model.utils_impl) is deprecated and will be removed in a future version.\nInstructions for updating:\nThis function will only be available through the v1 compatibility library as tf.compat.v1.saved_model.utils.build_tensor_info or tf.compat.v1.saved_model.build_tensor_info.\nW0712 14:02:55.902451 140456751757184 deprecation.py:323] From /content/models/research/object_detection/exporter.py:309: build_tensor_info (from tensorflow.python.saved_model.utils_impl) is deprecated and will be removed in a future version.\nInstructions for updating:\nThis function will only be available through the v1 compatibility library as tf.compat.v1.saved_model.utils.build_tensor_info or tf.compat.v1.saved_model.build_tensor_info.\nWARNING:tensorflow:From /content/models/research/object_detection/exporter.py:315: The name tf.saved_model.signature_def_utils.build_signature_def is deprecated. Please use tf.compat.v1.saved_model.signature_def_utils.build_signature_def instead.\n\nW0712 14:02:55.902915 140456751757184 module_wrapper.py:139] From /content/models/research/object_detection/exporter.py:315: The name tf.saved_model.signature_def_utils.build_signature_def is deprecated. Please use tf.compat.v1.saved_model.signature_def_utils.build_signature_def instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/exporter.py:318: The name tf.saved_model.signature_constants.PREDICT_METHOD_NAME is deprecated. Please use tf.saved_model.PREDICT_METHOD_NAME instead.\n\nW0712 14:02:55.903088 140456751757184 module_wrapper.py:139] From /content/models/research/object_detection/exporter.py:318: The name tf.saved_model.signature_constants.PREDICT_METHOD_NAME is deprecated. Please use tf.saved_model.PREDICT_METHOD_NAME instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/exporter.py:323: The name tf.saved_model.tag_constants.SERVING is deprecated. Please use tf.saved_model.SERVING instead.\n\nW0712 14:02:55.903299 140456751757184 module_wrapper.py:139] From /content/models/research/object_detection/exporter.py:323: The name tf.saved_model.tag_constants.SERVING is deprecated. Please use tf.saved_model.SERVING instead.\n\nWARNING:tensorflow:From /content/models/research/object_detection/exporter.py:325: The name tf.saved_model.signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY is deprecated. Please use tf.saved_model.DEFAULT_SERVING_SIGNATURE_DEF_KEY instead.\n\nW0712 14:02:55.903432 140456751757184 module_wrapper.py:139] From /content/models/research/object_detection/exporter.py:325: The name tf.saved_model.signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY is deprecated. Please use tf.saved_model.DEFAULT_SERVING_SIGNATURE_DEF_KEY instead.\n\nINFO:tensorflow:No assets to save.\nI0712 14:02:55.903717 140456751757184 builder_impl.py:640] No assets to save.\nINFO:tensorflow:No assets to write.\nI0712 14:02:55.903818 140456751757184 builder_impl.py:460] No assets to write.\nINFO:tensorflow:SavedModel written to: ./fine_tuned_final_model/saved_model/saved_model.pb\nI0712 14:02:56.292816 140456751757184 builder_impl.py:425] SavedModel written to: ./fine_tuned_final_model/saved_model/saved_model.pb\nWARNING:tensorflow:From /content/models/research/object_detection/utils/config_util.py:188: The name tf.gfile.Open is deprecated. Please use tf.io.gfile.GFile instead.\n\nW0712 14:02:56.325681 140456751757184 module_wrapper.py:139] From /content/models/research/object_detection/utils/config_util.py:188: The name tf.gfile.Open is deprecated. Please use tf.io.gfile.GFile instead.\n\nINFO:tensorflow:Writing pipeline config file to ./fine_tuned_final_model/pipeline.config\nI0712 14:02:56.325932 140456751757184 config_util.py:190] Writing pipeline config file to ./fine_tuned_final_model/pipeline.config\n"
],
[
"!ls {output_directory}",
"checkpoint\t\t\tmodel.ckpt.index saved_model\nfrozen_inference_graph.pb\tmodel.ckpt.meta\nmodel.ckpt.data-00000-of-00001\tpipeline.config\n"
]
],
[
[
"## Download the model `.pb` file",
"_____no_output_____"
]
],
[
[
"import os\n\npb_fname = os.path.join(os.path.abspath(output_directory), \"frozen_inference_graph.pb\")\nassert os.path.isfile(pb_fname), '`{}` not exist'.format(pb_fname)",
"_____no_output_____"
],
[
"!ls -alh {pb_fname}",
"-rw-r--r-- 1 root root 51M Jul 12 14:02 /content/models/research/fine_tuned_final_model/frozen_inference_graph.pb\n"
]
],
[
[
"### Option1 : upload the `.pb` file to your Google Drive\nThen download it from your Google Drive to local file system.\n\nDuring this step, you will be prompted to enter the token.",
"_____no_output_____"
]
],
[
[
"'''\n# Install the PyDrive wrapper & import libraries.\n# This only needs to be done once in a notebook.\n!pip install -U -q PyDrive\nfrom pydrive.auth import GoogleAuth\nfrom pydrive.drive import GoogleDrive\nfrom google.colab import auth\nfrom oauth2client.client import GoogleCredentials\n\n\n# Authenticate and create the PyDrive client.\n# This only needs to be done once in a notebook.\nauth.authenticate_user()\ngauth = GoogleAuth()\ngauth.credentials = GoogleCredentials.get_application_default()\ndrive = GoogleDrive(gauth)\n\nfname = os.path.basename(pb_fname)\n# Create & upload a text file.\nuploaded = drive.CreateFile({'title': fname})\nuploaded.SetContentFile(pb_fname)\nuploaded.Upload()\nprint('Uploaded file with ID {}'.format(uploaded.get('id')))\n'''",
"_____no_output_____"
]
],
[
[
"### Option2 : Download the `.pb` file directly to your local file system\nThis method may not be stable when downloading large files like the model `.pb` file. Try **option 1** instead if not working.",
"_____no_output_____"
]
],
[
[
"'''\nfrom google.colab import files\nfiles.download(pb_fname)\n'''",
"_____no_output_____"
]
],
[
[
"### Download the `label_map.pbtxt` file",
"_____no_output_____"
]
],
[
[
"'''\nfrom google.colab import files\nfiles.download(label_map_pbtxt_fname)\n'''",
"_____no_output_____"
]
],
[
[
"### Download the modified pipline file\nIf you plan to use OpenVINO toolkit to convert the `.pb` file to inference faster on Intel's hardware (CPU/GPU, Movidius, etc.)",
"_____no_output_____"
]
],
[
[
"'''\nfiles.download(pipeline_fname)\n'''",
"_____no_output_____"
]
],
[
[
"## Run inference test\nTest with images in repository `object_detection_demo/test` directory.",
"_____no_output_____"
]
],
[
[
"!sudo apt install tesseract-ocr\n!pip install pytesseract",
"Reading package lists... Done\nBuilding dependency tree \nReading state information... Done\nThe following package was automatically installed and is no longer required:\n libnvidia-common-440\nUse 'sudo apt autoremove' to remove it.\nThe following additional packages will be installed:\n tesseract-ocr-eng tesseract-ocr-osd\nThe following NEW packages will be installed:\n tesseract-ocr tesseract-ocr-eng tesseract-ocr-osd\n0 upgraded, 3 newly installed, 0 to remove and 33 not upgraded.\nNeed to get 4,795 kB of archives.\nAfter this operation, 15.8 MB of additional disk space will be used.\nGet:1 http://archive.ubuntu.com/ubuntu bionic/universe amd64 tesseract-ocr-eng all 4.00~git24-0e00fe6-1.2 [1,588 kB]\nGet:2 http://archive.ubuntu.com/ubuntu bionic/universe amd64 tesseract-ocr-osd all 4.00~git24-0e00fe6-1.2 [2,989 kB]\nGet:3 http://archive.ubuntu.com/ubuntu bionic/universe amd64 tesseract-ocr amd64 4.00~git2288-10f4998a-2 [218 kB]\nFetched 4,795 kB in 2s (2,951 kB/s)\ndebconf: unable to initialize frontend: Dialog\ndebconf: (No usable dialog-like program is installed, so the dialog based frontend cannot be used. at /usr/share/perl5/Debconf/FrontEnd/Dialog.pm line 76, <> line 3.)\ndebconf: falling back to frontend: Readline\ndebconf: unable to initialize frontend: Readline\ndebconf: (This frontend requires a controlling tty.)\ndebconf: falling back to frontend: Teletype\ndpkg-preconfigure: unable to re-open stdin: \nSelecting previously unselected package tesseract-ocr-eng.\n(Reading database ... 144764 files and directories currently installed.)\nPreparing to unpack .../tesseract-ocr-eng_4.00~git24-0e00fe6-1.2_all.deb ...\nUnpacking tesseract-ocr-eng (4.00~git24-0e00fe6-1.2) ...\nSelecting previously unselected package tesseract-ocr-osd.\nPreparing to unpack .../tesseract-ocr-osd_4.00~git24-0e00fe6-1.2_all.deb ...\nUnpacking tesseract-ocr-osd (4.00~git24-0e00fe6-1.2) ...\nSelecting previously unselected package tesseract-ocr.\nPreparing to unpack .../tesseract-ocr_4.00~git2288-10f4998a-2_amd64.deb ...\nUnpacking tesseract-ocr (4.00~git2288-10f4998a-2) ...\nSetting up tesseract-ocr-osd (4.00~git24-0e00fe6-1.2) ...\nSetting up tesseract-ocr-eng (4.00~git24-0e00fe6-1.2) ...\nSetting up tesseract-ocr (4.00~git2288-10f4998a-2) ...\nProcessing triggers for man-db (2.8.3-2ubuntu0.1) ...\nCollecting pytesseract\n Downloading https://files.pythonhosted.org/packages/1d/d8/521db389ff0aae32035bfda6ed39cb2c2e28521c47015f6431f07460c50a/pytesseract-0.3.4.tar.gz\nRequirement already satisfied: Pillow in /usr/local/lib/python3.6/dist-packages (from pytesseract) (7.0.0)\nBuilding wheels for collected packages: pytesseract\n Building wheel for pytesseract (setup.py) ... \u001b[?25l\u001b[?25hdone\n Created wheel for pytesseract: filename=pytesseract-0.3.4-py2.py3-none-any.whl size=13431 sha256=d1f5b989edfe36f9b273ad098af95f49c82790d46c10fdaf58837643237e15fa\n Stored in directory: /root/.cache/pip/wheels/63/2a/a0/7596d2e0a73cf0aeffd6f6170862c4e73f3763b7827e48691a\nSuccessfully built pytesseract\nInstalling collected packages: pytesseract\nSuccessfully installed pytesseract-0.3.4\n"
],
[
"%cd /content/object_detection_demo/\nimport wabtec_track",
"/content/object_detection_demo\n"
],
[
"import os\nimport glob\n\n# Path to frozen detection graph. This is the actual model that is used for the object detection.\nPATH_TO_CKPT = pb_fname\n\n# List of the strings that is used to add correct label for each box.\nPATH_TO_LABELS = label_map_pbtxt_fname\n\n# If you want to test the code with your images, just add images files to the PATH_TO_TEST_IMAGES_DIR.\nPATH_TO_TEST_IMAGES_DIR = os.path.join(repo_dir_path, \"test\")\n\nassert os.path.isfile(pb_fname)\nassert os.path.isfile(PATH_TO_LABELS)\nTEST_IMAGE_PATHS = glob.glob(os.path.join(PATH_TO_TEST_IMAGES_DIR, \"*.*\"))\nassert len(TEST_IMAGE_PATHS) > 0, 'No image found in `{}`.'.format(PATH_TO_TEST_IMAGES_DIR)\nprint(TEST_IMAGE_PATHS)",
"['/content/object_detection_demo/test/9.jpg', '/content/object_detection_demo/test/4.jpg']\n"
],
[
"%cd /content/models/research/object_detection\n\nimport numpy as np\nimport os\nimport six.moves.urllib as urllib\nimport sys\nimport tarfile\nimport tensorflow as tf\nimport pytesseract\nfrom pytesseract import Output\nimport shutil\nimport cv2\nimport zipfile\nimport pandas as pd\nimport wabtec_track\n\nfrom collections import defaultdict\nfrom io import StringIO\nfrom matplotlib import pyplot as plt\nfrom PIL import Image\nfrom google.colab import files\n\n# This is needed since the notebook is stored in the object_detection folder.\nsys.path.append(\"..\")\n\nfrom object_detection.utils import ops as utils_ops\n# This is needed to display the images.\n%matplotlib inline\nfrom object_detection.utils import label_map_util\nfrom object_detection.utils import visualization_utils as vis_util\n\n'''\n To Visualize Initiate the following array\n Array Order [\"Switch\",\"Track\",\"Left signal\",\"Right Signal\", \"all\"]\n Ex: If you want bounding boxes only on switches and Tracks\n array should be [1,1,0,0]\n'''\nvisualize = [1,1,1,1,0]\n\ndetection_graph = tf.Graph()\nwith detection_graph.as_default():\n od_graph_def = tf.GraphDef()\n with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:\n serialized_graph = fid.read()\n od_graph_def.ParseFromString(serialized_graph)\n tf.import_graph_def(od_graph_def, name='')\n\n\nlabel_map = label_map_util.load_labelmap(PATH_TO_LABELS)\ncategories = label_map_util.convert_label_map_to_categories(\n label_map, max_num_classes=num_classes, use_display_name=True)\ncategory_index = label_map_util.create_category_index(categories)\n\ns_id = []\nmilepost = []\ns_type = []\n\ndef load_image_into_numpy_array(image):\n (im_width, im_height) = image.size\n return np.array(image.getdata()).reshape(\n (im_height, im_width, 3)).astype(np.uint8)\n\n# Size, in inches, of the output images.\nIMAGE_SIZE = (12, 8)\n\n#thresholding\ndef thresholding(image):\n return cv2.threshold(image, 60, 255, cv2.THRESH_BINARY)\n\n# get grayscale image\ndef get_grayscale(image):\n return cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)\n\n# preprocessing\ndef switch_preprocess(crop_image):\n kernel = np.ones((3,3),np.uint8)\n gray = cv2.cvtColor(crop_img,cv2.COLOR_BGR2GRAY)\n (thresh, gray) = cv2.threshold(gray, 40, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)\n inverse = cv2.bitwise_not(gray)\n closed = cv2.morphologyEx(inverse, cv2.MORPH_CLOSE, kernel)\n #dilation = cv2.dilate(inverse,kernel,iterations = 1)\n dil_inv = cv2.bitwise_not(closed)\n opened = cv2.morphologyEx(dil_inv, cv2.MORPH_OPEN, kernel)\n #opened = cv2.dilate(thresh, kernel, iterations = 1)\n custom_config = r'--oem 3 --psm 6'\n img = Image.fromarray(opened)\n sid = pytesseract.image_to_string(img, config=custom_config)\n return sid\n\ndef milestone_preprocess(crop_image):\n gray = cv2.cvtColor(r_img,cv2.COLOR_RGB2GRAY)\n kernel = np.ones((3,3),np.uint8)\n im = np.array(gray * 255, dtype = np.uint8)\n (thresh, gray) = cv2.threshold(gray, 40, 255, cv2.THRESH_BINARY | cv2.THRESH_OTSU)\n #opened = cv2.dilate(thresh, kernel, iterations = 1)\n custom_config = r'--oem 3 --psm 6'\n img = Image.fromarray(gray)\n milestone_id = pytesseract.image_to_string(img, config=custom_config)\n #print(pytesseract.image_to_string(img, config=custom_config))\n return milestone_id\n\n#Draw Bounding boxes\ndef drawBoundingBoxes(xmin,ymin,xmax,ymax,r,g,b,t):\n x1,y1,x2,y2 = np.int64(xmin * im_width), np.int64(ymin * im_height), np.int64(xmax * im_width), np.int64(ymax * im_height)\n cv2.rectangle(image_np, (x1, y1), (x2, y2), (r, g, b), t)\n\n#Rn Inference on single image\ndef run_inference_for_single_image(image, graph):\n with graph.as_default():\n with tf.Session() as sess:\n # Get handles to input and output tensors\n ops = tf.get_default_graph().get_operations()\n all_tensor_names = {\n output.name for op in ops for output in op.outputs}\n tensor_dict = {}\n for key in [\n 'num_detections', 'detection_boxes', 'detection_scores',\n 'detection_classes', 'detection_masks'\n ]:\n tensor_name = key + ':0'\n if tensor_name in all_tensor_names:\n tensor_dict[key] = tf.get_default_graph().get_tensor_by_name(\n tensor_name)\n if 'detection_masks' in tensor_dict:\n # The following processing is only for single image\n detection_boxes = tf.squeeze(\n tensor_dict['detection_boxes'], [0])\n detection_masks = tf.squeeze(\n tensor_dict['detection_masks'], [0])\n # Reframe is required to translate mask from box coordinates to image coordinates and fit the image size.\n real_num_detection = tf.cast(\n tensor_dict['num_detections'][0], tf.int32)\n detection_boxes = tf.slice(detection_boxes, [0, 0], [\n real_num_detection, -1])\n detection_masks = tf.slice(detection_masks, [0, 0, 0], [\n real_num_detection, -1, -1])\n detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks(\n detection_masks, detection_boxes, image.shape[0], image.shape[1])\n detection_masks_reframed = tf.cast(\n tf.greater(detection_masks_reframed, 0.5), tf.uint8)\n # Follow the convention by adding back the batch dimension\n tensor_dict['detection_masks'] = tf.expand_dims(\n detection_masks_reframed, 0)\n image_tensor = tf.get_default_graph().get_tensor_by_name('image_tensor:0')\n\n # Run inference\n output_dict = sess.run(tensor_dict,\n feed_dict={image_tensor: np.expand_dims(image, 0)})\n\n # all outputs are float32 numpy arrays, so convert types as appropriate\n output_dict['num_detections'] = int(\n output_dict['num_detections'][0])\n output_dict['detection_classes'] = output_dict[\n 'detection_classes'][0].astype(np.uint8)\n output_dict['detection_boxes'] = output_dict['detection_boxes'][0]\n output_dict['detection_scores'] = output_dict['detection_scores'][0]\n if 'detection_masks' in output_dict:\n output_dict['detection_masks'] = output_dict['detection_masks'][0]\n return output_dict\n\nfor image_path in TEST_IMAGE_PATHS:\n image = Image.open(image_path)\n # the array based representation of the image will be used later in order to prepare the\n # result image with boxes and labels on it.\n image_np = load_image_into_numpy_array(image)\n #Image to crop labels\n image_to_crop = load_image_into_numpy_array(image)\n # Expand dimensions since the model expects images to have shape: [1, None, None, 3]\n image_np_expanded = np.expand_dims(image_np, axis=0)\n # Actual detection.\n output_dict = run_inference_for_single_image(image_np, detection_graph)\n # Visualization of the results of a detection.4\n\n #Obtaining detection boxes, classes and detection scores\n boxes = np.squeeze(output_dict['detection_boxes'])\n scores = np.squeeze(output_dict['detection_scores'])\n classes = np.squeeze(output_dict['detection_classes'])\n #set a min thresh score\n ########\n min_score_thresh = 0.25\n ########\n #Filtering the bounding boxes\n bboxes = boxes[scores > min_score_thresh]\n d_classes = classes[scores > min_score_thresh]\n switch_boxes = bboxes[d_classes == 8]\n milepost_boxes = bboxes[d_classes == 4]\n signal_boxes = bboxes[d_classes == 5]\n crossover_boxes = bboxes[d_classes == 1]\n crossoverLabel_boxes = bboxes[d_classes == 2]\n electSwitch_boxes = bboxes[d_classes == 3]\n\n #get image size\n im_width, im_height = image.size\n\n final_box = []\n for box in bboxes:\n ymin, xmin, ymax, xmax = box\n final_box.append([xmin * im_width, xmax * im_width, ymin * im_height, ymax * im_height])\n #print(final_box)\n\n if(visualize[0] == 1 or visualize[4] == 1):\n sw_box = []\n for box in switch_boxes:\n ymin, xmin, ymax, xmax = box\n sw_box.append([xmin * im_width, xmax * im_width, ymin * im_height, ymax * im_height])\n drawBoundingBoxes(xmin,ymin,xmax,ymax,256,100,25,2)\n\n if(visualize[1] == 1 or visualize[4] == 1):\n signal_box = []\n for box in signal_boxes:\n ymin, xmin, ymax, xmax = box\n signal_box.append([xmin * im_width, xmax * im_width, ymin * im_height, ymax * im_height])\n drawBoundingBoxes(xmin,ymin,xmax,ymax,0,255,255,2)\n\n if(visualize[2] == 1 or visualize[4] == 1):\n crossover_box = []\n for box in crossover_boxes:\n ymin, xmin, ymax, xmax = box\n crossover_box.append([xmin * im_width, xmax * im_width, ymin * im_height, ymax * im_height])\n drawBoundingBoxes(xmin,ymin,xmax,ymax,0,0,255,2)\n\n if(visualize[3] == 1 or visualize[4] == 1):\n crossoverLabel_box = []\n for box in crossoverLabel_boxes:\n ymin, xmin, ymax, xmax = box\n crossoverLabel_box.append([xmin * im_width, xmax * im_width, ymin * im_height, ymax * im_height])\n drawBoundingBoxes(xmin,ymin,xmax,ymax,255,0,0,2)\n\n if(visualize[4] == 1 or visualize[4] == 1):\n electSwitch_box = []\n for box in electSwitch_boxes:\n ymin, xmin, ymax, xmax = box\n electSwitch_box.append([xmin * im_width, xmax * im_width, ymin * im_height, ymax * im_height])\n drawBoundingBoxes(xmin,ymin,xmax,ymax,120,25,35,2)\n\n\n m_box = []\n for box in milepost_boxes:\n ymin, xmin, ymax, xmax = box\n m_box.append([xmin * im_width, xmax * im_width, ymin * im_height, ymax * im_height])\n drawBoundingBoxes(xmin,ymin,xmax,ymax,0,0,256,2)\n\n \n #switch\n if(visualize[0] == 1):\n for box in sw_box:\n ymin, xmin, ymax, xmax = box\n y,h,x,w = np.int64(ymin), np.int64(ymax),np.int64(xmin), np.int64(xmax)\n crop_img = image_to_crop[h-10:w+10,y-10:x+10]\n plt.figure(figsize=(1,2))\n #plt.imshow(crop_img) \n for b in m_box:\n ymin, xmin, ymax, xmax = b\n a,b,c,d = np.int64(ymin), np.int64(ymax),np.int64(xmin), np.int64(xmax)\n val = (y+x)/2\n mid_milepost_x = np.int64((a+c)/2)\n mid_milepost_y = np.int64((b+d)/2)\n if(a<val and val<c ):\n if(h>b):\n cv2.line(image_np, (y,h), (mid_milepost_x,d), (256,100,25), 2)\n else:\n cv2.line(image_np, (y,w), (mid_milepost_x,b), (256,100,25), 2)\n crop_ml = image_to_crop[b-5:d+5,a+5:c-5]\n r_img = cv2.rotate(crop_ml, cv2.ROTATE_90_CLOCKWISE)\n plt.figure(figsize=(3,6))\n if '\\n' in milestone_preprocess(r_img):\n milepost.append(milestone_preprocess(r_img).split('\\ ')[4:14])\n else:\n milepost.append(milestone_preprocess(r_img)[5:14])\n s_id.append(switch_preprocess(crop_img))\n s_type.append(\"switch\")\n #plt.imshow(r_img,cmap='gray') \n #Corssover Label\n for box in crossover_box:\n ymin, xmin, ymax, xmax = box\n y,h,x,w = np.int64(ymin), np.int64(ymax),np.int64(xmin), np.int64(xmax)\n crop_img = image_to_crop[h-10:w+10,y-10:x+10]\n #plt.figure(figsize=(1,2))\n #plt.imshow(crop_img) \n for b in m_box:\n ymin, xmin, ymax, xmax = b\n a,b,c,d = np.int64(ymin), np.int64(ymax),np.int64(xmin), np.int64(xmax)\n val = (y+x)/2\n mid_milepost_x = np.int64((a+c)/2)\n mid_milepost_y = np.int64((b+d)/2)\n if(a<val and val<c ):\n if(h>b):\n cv2.line(image_np, (y,h), (mid_milepost_x,d), (256,100,25), 2)\n else:\n cv2.line(image_np, (y,w), (mid_milepost_x,b), (256,100,25), 2)\n crop_ml = image_to_crop[b-5:d+5,a+5:c-5]\n r_img = cv2.rotate(crop_ml, cv2.ROTATE_90_CLOCKWISE)\n plt.figure(figsize=(3,6))\n if '\\n' in milestone_preprocess(r_img):\n milepost.append(milestone_preprocess(r_img).split('\\ ')[4:14])\n else:\n milepost.append(milestone_preprocess(r_img)[5:14])\n s_id.append(switch_preprocess(crop_img))\n s_type.append(\"Cross Over\")\n #plt.imshow(r_img,cmap='gray') \n\n #Signal \n for box in signal_box:\n ymin, xmin, ymax, xmax = box\n y,h,x,w = np.int64(ymin), np.int64(ymax),np.int64(xmin), np.int64(xmax)\n crop_img = image_to_crop[h-10:w+10,y-10:x+10]\n #plt.figure(figsize=(1,2))\n #plt.imshow(crop_img) \n for b in m_box:\n ymin, xmin, ymax, xmax = b\n a,b,c,d = np.int64(ymin), np.int64(ymax),np.int64(xmin), np.int64(xmax)\n val = (y+x)/2\n v = np.int64(val)\n mid_milepost_x = np.int64((a+c)/2)\n mid_milepost_y = np.int64((b+d)/2)\n if(a<val and val<c ):\n if(h>b):\n cv2.line(image_np, (v,h), (mid_milepost_x,d), (256,100,25), 2)\n else:\n cv2.line(image_np, (v,w), (mid_milepost_x,b), (256,100,25), 2)\n crop_ml = image_to_crop[b-5:d+5,a+5:c-5]\n r_img = cv2.rotate(crop_ml, cv2.ROTATE_90_CLOCKWISE)\n plt.figure(figsize=(3,6))\n if '\\n' in milestone_preprocess(r_img):\n milepost.append(milestone_preprocess(r_img).split('\\ ')[4:14])\n else:\n milepost.append(milestone_preprocess(r_img)[5:14])\n s_id.append(switch_preprocess(crop_img))\n s_type.append(\"Signal\")\n #plt.imshow(r_img,cmap='gray')\n\n # #left signal\n # if(visualize[2] == 1):\n # for box in ls_box:\n # ymin, xmin, ymax, xmax = box\n # y,h,x,w = np.int64(ymin), np.int64(ymax),np.int64(xmin), np.int64(xmax)\n # crop_img = image_to_crop[h:w,y:x]\n # plt.imshow(crop_img) \n # for b in m_box:\n # ymin, xmin, ymax, xmax = b\n # a,b,c,d = np.int64(ymin), np.int64(ymax),np.int64(xmin), np.int64(xmax)\n # val = x-5\n # if(a<val and val<c ):\n # crop_ml = image_np[b-15:d+15,a-15:c+15]\n # r_img = cv2.rotate(crop_ml, cv2.ROTATE_90_CLOCKWISE)\n # plt.figure(figsize=(3,6))\n # #print(pytesseract.image_to_string(img, config=custom_config))\n # s_id.append(sid)\n # s_type.append(\"left Signal\")\n # if '\\n' in milestone_id:\n # milepost.append(milestone_preprocess(r_img).split('\\ ')[4:14])\n # else:\n # milepost.append(milestone_preprocess(r_img)[5:14])\n # #plt.imshow(img,cmap='gray')\n\n \n\n\n \n if(visualize[1]==1 or visualize[4] == 1): \n t_img = cv2.imwrite('color_img.jpg', image_np)\n wtt = wabtec_track.WabTecTrack(file_name='color_img.jpg')\n tracks = wtt.get_lines() \n for track in tracks:\n (x1,y1) = track.point_one()\n (x2,y2) = track.point_two()\n cv2.rectangle(image_np, (x1-10, y1-10), (x2+10, y2+10), (128, 0, 128), 2)\n \n #print(category_index)\n #print(d_classes)\n #print(m_box)\n plt.figure(figsize=IMAGE_SIZE)\n plt.imshow(image_np)\n\ndict = {'type': s_type, 'id':s_id, 'milepost':milepost}\ndf = pd.DataFrame(dict)\nprint(df)\n# df.to_csv (r'extracted_data.csv', index = False, header=True)\n# files.download('extracted_data.csv')",
"/content/models/research/object_detection\n type id milepost\n0 switch —_\\n3 \n1 Signal ZZZz\\nNON\\n~ oO\\nmize\\nnow\\nWad\\nOrs\\n0\\nwo)\\n... \n2 Signal a\\nnee\\noa\\nZig\\nae\\naan!\\nTOM 5\\nrrr)\\norn\\nw... \n"
],
[
"",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
cb3bf24aadddb5d8556abdc081c4c88e72c8d304 | 5,507 | ipynb | Jupyter Notebook | platipy/examples/sample/2_inter_observer_variability.ipynb | SimonBiggs/platipy | 9c2f478d480bf878b26ec472c4097a4ab116ffbf | [
"Apache-2.0"
] | null | null | null | platipy/examples/sample/2_inter_observer_variability.ipynb | SimonBiggs/platipy | 9c2f478d480bf878b26ec472c4097a4ab116ffbf | [
"Apache-2.0"
] | null | null | null | platipy/examples/sample/2_inter_observer_variability.ipynb | SimonBiggs/platipy | 9c2f478d480bf878b26ec472c4097a4ab116ffbf | [
"Apache-2.0"
] | null | null | null | 28.533679 | 105 | 0.452515 | [
[
[
"## Interobserver Variability\n\nThis Notebook demonstrates how to compute the interobserver variability of your Atlas data.",
"_____no_output_____"
]
],
[
[
"import os\nimport sys\nimport gc\nimport re\nimport time\n\nsys.path.append('../../..')\n\nimport pandas as pd\n\nimport SimpleITK as sitk\n\nfrom loguru import logger\n\n# Format the output a bit nicer for Jupyter\nlogger.remove()\nlogger.add(sys.stdout, format=\"{time:YYYY-MM-DD HH:mm:ss} {level} {message}\", level=\"DEBUG\")\n\ndata_path = './data'\nworking_path = \"./working\"\nif not os.path.exists(working_path):\n os.makedirs(working_path)\n\n# Read the data into a dictionary\n\ndata = {}\n\nfor root, dirs, files in os.walk(data_path, topdown=False):\n \n if root == data_path:\n continue\n \n case = root.split('/')[-1]\n data[case] = {}\n for f in files:\n file_path = os.path.join(root, f)\n \n name = f.split('.')[0].upper()\n \n # Clean up names with double underscore:\n name = name.replace('__','_')\n \n observer = None\n \n matches = re.findall(r\"(.*)_([0-9])\", f.split('.')[0])\n \n if len(matches) > 0:\n name = matches[0][0].upper()\n observer = matches[0][1]\n \n if observer: \n if name in data[case]:\n data[case][name][observer] = file_path\n else:\n data[case][name] = {observer: file_path}\n \n else:\n data[case][name] = file_path\n\n",
"_____no_output_____"
]
],
[
[
"### Compute the interobserver variability for each case",
"_____no_output_____"
]
],
[
[
"df_inter_ob_var_file = os.path.join(working_path, \"df_inter_ob_var.pkl\")\n\n# If already computed, read the data from a file\nif os.path.exists(df_inter_ob_var_file):\n print(f'Reading from file: {df_inter_ob_var_file}')\n df_inter_ob_var = pd.read_pickle(df_inter_ob_var_file)\nelse:\n\n inter_observe_var = []\n\n for c in data:\n for s in data[c]:\n if not s.startswith('STRUCT_'):\n continue\n\n for o1 in data[c][s]:\n for o2 in data[c][s]:\n\n if o1==o2:\n continue\n\n mask_1 = sitk.ReadImage(data[c][s][o1])\n mask_2 = sitk.ReadImage(data[c][s][o2])\n\n lomif = sitk.LabelOverlapMeasuresImageFilter()\n lomif.Execute(mask_1, mask_2)\n\n hdif = sitk.HausdorffDistanceImageFilter()\n hdif.Execute(mask_1, mask_2)\n\n dce = lomif.GetDiceCoefficient()\n hmax = hdif.GetHausdorffDistance()\n havg = hdif.GetAverageHausdorffDistance()\n\n row = {'o1': o1, \n 'o2': o2, \n 'case': c, \n 'struct': s, \n 'dce': dce, \n 'hausdorff_max': hmax, \n 'hausdorff_avg': havg }\n\n inter_observe_var.append(row)\n\n df_inter_ob_var = pd.DataFrame(inter_observe_var)\n print(f'Saving to file: {df_inter_ob_var_file}')\n df_inter_ob_var.to_pickle(df_inter_ob_var_file)",
"_____no_output_____"
]
],
[
[
"### Output the results",
"_____no_output_____"
]
],
[
[
"df_inter = df_inter_ob_var.groupby(['struct']).aggregate(['mean', 'std', 'min', 'max'])\ndf_inter = df_inter[['dce','hausdorff_max','hausdorff_avg']]\ndf_inter",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
cb3c10f34da58086db91843ac1b25d78e62e03fe | 7,651 | ipynb | Jupyter Notebook | vqvaevc.ipynb | tarepan/vqvaevc | dabbb9bae5ccb9d5dcb110caf3f0a59f68006a97 | [
"MIT"
] | null | null | null | vqvaevc.ipynb | tarepan/vqvaevc | dabbb9bae5ccb9d5dcb110caf3f0a59f68006a97 | [
"MIT"
] | null | null | null | vqvaevc.ipynb | tarepan/vqvaevc | dabbb9bae5ccb9d5dcb110caf3f0a59f68006a97 | [
"MIT"
] | null | null | null | 26.202055 | 162 | 0.490916 | [
[
[
"# VQ-VAE WaveRNN\n[][github]\n[][notebook]\n\nReimplmentation of VQ-VAE WaveRNN \nAuthor: [tarepan]\n\n[github]:https://github.com/tarepan/vqvaevc\n[notebook]:https://colab.research.google.com/github/tarepan/vqvaevc/blob/main/vqvaevc.ipynb\n[tarepan]:https://github.com/tarepan",
"_____no_output_____"
],
[
"## Colab Check\nCheck\n- Google Colaboratory runnning time\n- GPU type\n- Python version\n- CUDA version",
"_____no_output_____"
]
],
[
[
"!cat /proc/uptime | awk '{print $1 /60 /60 /24 \"days (\" $1 \"sec)\"}'\n!head -n 1 /proc/driver/nvidia/gpus/**/information\n!cat /usr/local/cuda/version.txt",
"_____no_output_____"
]
],
[
[
"## Setup",
"_____no_output_____"
],
[
"Activate notebook intermittently for long session (RUN once **by hand**)\n```javascript\nconst refresher = setInterval(()=>{document.querySelector(\"colab-connect-button\").click();console.log(\"clicked for long session\");}, 1000*60*10);\n```",
"_____no_output_____"
],
[
"Clone repository from `tarepan/vqvaevc`",
"_____no_output_____"
]
],
[
[
"# GoogleDrive\nfrom google.colab import drive\ndrive.mount('/content/gdrive')\n\n# clone repository\n!git clone https://github.com/tarepan/vqvaevc.git\n%cd ./vqvaevc",
"_____no_output_____"
]
],
[
[
"Prepare dataset",
"_____no_output_____"
]
],
[
[
"# !pip install torchaudio==0.7.0\n# from torchaudio.datasets.utils import download_url\n\n# # Download and extract corpus\n# !mkdir ../data\n# download_url(\"http://www.udialogue.org/download/VCTK-Corpus.tar.gz\", \"../data\")\n# !tar -xvf ../data/VCTK-Corpus.tar.gz\n\n# # Preprocess corpus into dataset\n# !python preprocess_multispeaker.py ./VCTK-Corpus/wav48 ./dataset\n# !cp -r ./dataset ../gdrive/MyDrive/ML_data/datasets/VCTK_processed",
"_____no_output_____"
],
[
"# Copy dataset from storage (Google Drive)\n!cp -r ../gdrive/MyDrive/ML_data/datasets/VCTK_processed/dataset .",
"_____no_output_____"
]
],
[
[
"## Training",
"_____no_output_____"
]
],
[
[
"!python wavernn.py --multi_speaker_data_path ./dataset",
"_____no_output_____"
]
],
[
[
"## Training Optimization",
"_____no_output_____"
],
[
"### whole",
"_____no_output_____"
]
],
[
[
"# num_worker x pinmemory\n\n!python -m scyclonepytorch.main_train --max_epochs=15 --num_workers=0\n!python -m scyclonepytorch.main_train --max_epochs=15 --num_workers=1\n!python -m scyclonepytorch.main_train --max_epochs=15 --num_workers=2\n!python -m scyclonepytorch.main_train --max_epochs=15 --num_workers=4\n\n!python -m scyclonepytorch.main_train --max_epochs=15 --num_workers=0 --no_pin_memory\n!python -m scyclonepytorch.main_train --max_epochs=15 --num_workers=1 --no_pin_memory\n!python -m scyclonepytorch.main_train --max_epochs=15 --num_workers=2 --no_pin_memory\n!python -m scyclonepytorch.main_train --max_epochs=15 --num_workers=4 --no_pin_memory",
"_____no_output_____"
]
],
[
[
"### num_worker",
"_____no_output_____"
]
],
[
[
"!python -m scyclonepytorch.main_train --max_epochs=5 --num_workers=0\n!python -m scyclonepytorch.main_train --max_epochs=5 --num_workers=1\n!python -m scyclonepytorch.main_train --max_epochs=5 --num_workers=2\n!python -m scyclonepytorch.main_train --max_epochs=5 --num_workers=4",
"_____no_output_____"
]
],
[
[
"### pin_memory",
"_____no_output_____"
]
],
[
[
"!python -m scyclonepytorch.main_train --max_epochs=5 --num_workers=2\n!python -m scyclonepytorch.main_train --max_epochs=5 --num_workers=2 --no_pin_memory",
"_____no_output_____"
]
],
[
[
"### Profiling",
"_____no_output_____"
]
],
[
[
"!python -m scyclonepytorch.main_train --profiler --max_epochs=5 --num_workers=2 --no_pin_memory # profile mode",
"_____no_output_____"
],
[
"# # Usage stat\n# ## GPU\n# !nvidia-smi -l 3\n# ## CPU\n# !vmstat 5\n# !top",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
cb3c21c209848ce67a4fe4669a494f9bc487b76a | 10,325 | ipynb | Jupyter Notebook | Assignment_1.ipynb | vaisas37/Lets-Upgrade-Python | fddd24362e97b9cd19c07e47ce7aa96e55df50c5 | [
"Apache-2.0"
] | null | null | null | Assignment_1.ipynb | vaisas37/Lets-Upgrade-Python | fddd24362e97b9cd19c07e47ce7aa96e55df50c5 | [
"Apache-2.0"
] | null | null | null | Assignment_1.ipynb | vaisas37/Lets-Upgrade-Python | fddd24362e97b9cd19c07e47ce7aa96e55df50c5 | [
"Apache-2.0"
] | null | null | null | 18.772727 | 157 | 0.47816 | [
[
[
"list_elements = [\"vaishnavi\", \"e\", \"third year\", 789456123, \"@123\", \"1 sibling\"]",
"_____no_output_____"
],
[
"list_elements.append(\"violet\")\nprint(list_elements)",
"['e', 'third year', 'vaishnavi', 789456123, '@123', 'violet', 'violet', 'violet']\n"
],
[
"list_elements.count(\"violet\")",
"_____no_output_____"
],
[
"list_elements.index(\"violet\")",
"_____no_output_____"
],
[
"list_elements.remove(\"violet\")\nprint(list_elements)",
"['e', 'third year', 'vaishnavi', 789456123, '@123', 'violet', 'violet']\n"
],
[
"list_elements.pop()",
"_____no_output_____"
],
[
"my_details = {\"Name\":\"Vaishnavi E\", \"Age\":19, \"Mail\":\"vaishnavi@123\", \"Phone\": 9156783451, \n \"College\": \"Jansons Institute of Technology\"}",
"_____no_output_____"
],
[
"new = my_details.copy()\nprint(\"original: \" ,my_details)\nprint(\"copy: \" ,new)",
"original: {'Name': 'Vaishnavi E', 'Age': 19, 'Mail': 'vaishnavi@123', 'Phone': 9156783451, 'College': 'Jansons Institute of Technology'}\ncopy: {'Name': 'Vaishnavi E', 'Age': 19, 'Mail': 'vaishnavi@123', 'Phone': 9156783451, 'College': 'Jansons Institute of Technology'}\n"
],
[
"my_details.get(\"Name\")",
"_____no_output_____"
],
[
"my_details.items()",
"_____no_output_____"
],
[
"my_details.keys()",
"_____no_output_____"
],
[
"my_details.values()",
"_____no_output_____"
],
[
"set_elements = {714,715,716,716,718,719,720}",
"_____no_output_____"
],
[
"print(set_elements)",
"{714, 715, 716, 718, 719, 720}\n"
],
[
"set_elements.add(721)",
"_____no_output_____"
],
[
"print(set_elements)",
"{714, 715, 716, 718, 719, 720, 721}\n"
],
[
"set_elements.difference()",
"_____no_output_____"
],
[
"set_elements.discard(714)",
"_____no_output_____"
],
[
"print(set_elements)",
"{715, 716, 718, 719, 720, 721}\n"
],
[
"set_elements.pop()",
"_____no_output_____"
],
[
"set_elements.clear()",
"_____no_output_____"
],
[
"print(set_elements)\n",
"set()\n"
],
[
"tuple_ele = (\"vaishnavi\", \"programmer\", \"3\", \"violet\",\"3\",\"3\")",
"_____no_output_____"
],
[
"tuple_ele.count(\"3\")",
"_____no_output_____"
],
[
"tuple_ele.index(\"violet\")",
"_____no_output_____"
],
[
"sentence = \"My name is Vaishnavi. I am going to complete my first assignment in letsupgrade. the sessions are really interesting\"",
"_____no_output_____"
],
[
"sentence.capitalize()",
"_____no_output_____"
],
[
"sentence.casefold()",
"_____no_output_____"
],
[
"sentence.encode()",
"_____no_output_____"
],
[
"sentence.expandtabs()",
"_____no_output_____"
],
[
"sentence.find(\"am\")",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3c2d420bdd9e0ac1a092c7a63d41c9d20d283f | 16,536 | ipynb | Jupyter Notebook | xgb/xgb_regression_grainsize_vs.ipynb | ThomasMGeo/LewisML | 1d1ae36bea2bef5d74e1b3db1e30454c2736139c | [
"Apache-2.0"
] | 1 | 2022-01-24T22:46:26.000Z | 2022-01-24T22:46:26.000Z | xgb/xgb_regression_grainsize_vs.ipynb | ThomasMGeo/LewisML | 1d1ae36bea2bef5d74e1b3db1e30454c2736139c | [
"Apache-2.0"
] | null | null | null | xgb/xgb_regression_grainsize_vs.ipynb | ThomasMGeo/LewisML | 1d1ae36bea2bef5d74e1b3db1e30454c2736139c | [
"Apache-2.0"
] | null | null | null | 8,268 | 16,535 | 0.569666 | [
[
[
"# Grainsize with XGB",
"_____no_output_____"
]
],
[
[
"# If you have installation questions, please reach out\n\nimport pandas as pd # data storage\nimport xgboost as xgb # graident boosting \nimport numpy as np # math and stuff\nimport matplotlib.pyplot as plt # plotting utility\nimport sklearn # ML and stats\n\nimport datetime\n\nprint('XGBoost ver:', xgb.__version__)\nprint('scikit ver:', sklearn.__version__)\n\nfrom sklearn.preprocessing import MinMaxScaler, RobustScaler\nfrom sklearn.model_selection import cross_val_score, KFold, train_test_split\nfrom sklearn.metrics import max_error, mean_squared_error, median_absolute_error\nfrom sklearn.model_selection import GridSearchCV",
"XGBoost ver: 1.4.2\nscikit ver: 1.0.1\n"
],
[
"import defaults\nfrom defaults import framecleaner, splitterz\n\nimport xgb_models\nfrom xgb_models import xgb_gz",
"_____no_output_____"
]
],
[
[
"# Dataframes",
"_____no_output_____"
]
],
[
[
"df0 = pd.read_csv('../../core_to_wl_merge/OS0_Merged_dataset_imputed_08_23_2021.csv')\n\ndf1 = pd.read_csv('../../core_to_wl_merge/OS1_Merged_dataset_imputed_08_23_2021.csv')\n\ndf2 = pd.read_csv('../../core_to_wl_merge/OS2_Merged_dataset_imputed_08_23_2021.csv')",
"C:\\Users\\tmartin\\.conda\\envs\\lewisml\\lib\\site-packages\\IPython\\core\\interactiveshell.py:3441: DtypeWarning: Columns (17) have mixed types.Specify dtype option on import or set low_memory=False.\n exec(code_obj, self.user_global_ns, self.user_ns)\n"
]
],
[
[
"# Parameters",
"_____no_output_____"
]
],
[
[
"param_dict ={\n \"tree_type\": \"hist\", #Auto or exact, or hist will all work\n \"dataset\": ['CAL', 'GR', 'DT', 'SP', 'DENS', 'PE', 'RESD', 'PHID', 'gz_pchip_interp'],\n \"inputs\": ['CAL', 'GR', 'DT', 'SP', 'DENS', 'PE', 'RESD', 'PHID', ],\n \"target\": ['gz_pchip_interp']}",
"_____no_output_____"
]
],
[
[
"# Offset 0",
"_____no_output_____"
]
],
[
[
"#Create the dataset\nX, Y_array = framecleaner(df0, param_dict['dataset'], param_dict['inputs'], param_dict['target'] )\n\n#Split the dataset\nX_train, X_test, y_train, y_test = splitterz(X.values, Y_array)\n\ndf_OS0 = xgb_gz(X_train, X_test, y_train, y_test, OS='OS0', tree_type = param_dict['tree_type'])\ndf_OS0",
"C:\\Users\\tmartin\\.conda\\envs\\lewisml\\lib\\site-packages\\pandas\\util\\_decorators.py:311: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n return func(*args, **kwargs)\n"
]
],
[
[
"# Offset 1",
"_____no_output_____"
]
],
[
[
"#Create the dataset\nX1, Y1_array = framecleaner(df1, param_dict['dataset'], param_dict['inputs'], param_dict['target'] )\n\n#Split the dataset\nX1_train, X1_test, y1_train, y1_test = splitterz(X1.values, Y1_array)\n\ndf_OS1 = xgb_gz(X1_train, X1_test, y1_train, y1_test, OS='OS1', tree_type= param_dict['tree_type'])\ndf_OS1",
"C:\\Users\\tmartin\\.conda\\envs\\lewisml\\lib\\site-packages\\pandas\\util\\_decorators.py:311: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n return func(*args, **kwargs)\n"
]
],
[
[
"# Offset 2",
"_____no_output_____"
]
],
[
[
"#Create the dataset\nX2, Y2_array = framecleaner(df2, param_dict['dataset'], param_dict['inputs'], param_dict['target'] )\n\n#Split the dataset\nX2_train, X2_test, y2_train, y2_test = splitterz(X2.values, Y2_array)\n\ndf_OS2 = xgb_gz(X2_train, X2_test, y2_train, y2_test, OS='OS2', tree_type= param_dict['tree_type'])\ndf_OS2",
"C:\\Users\\tmartin\\.conda\\envs\\lewisml\\lib\\site-packages\\pandas\\util\\_decorators.py:311: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n return func(*args, **kwargs)\n"
]
],
[
[
"# Combine Results",
"_____no_output_____"
]
],
[
[
"frames = [df_OS0, df_OS1, df_OS2]\nresults = pd.concat(frames)\nresults",
"_____no_output_____"
],
[
"results.to_csv('XGB_GZ_1_13_5.csv')",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
cb3c2ea8f75a5a7afbdc60e6145e6c6de17f224b | 375,817 | ipynb | Jupyter Notebook | assignment2/ConvolutionalNetworks.ipynb | yufei1900/cs231n-homework | b7f5a03d5a2b650603074a7c43f203b465b74333 | [
"MIT"
] | null | null | null | assignment2/ConvolutionalNetworks.ipynb | yufei1900/cs231n-homework | b7f5a03d5a2b650603074a7c43f203b465b74333 | [
"MIT"
] | null | null | null | assignment2/ConvolutionalNetworks.ipynb | yufei1900/cs231n-homework | b7f5a03d5a2b650603074a7c43f203b465b74333 | [
"MIT"
] | null | null | null | 341.341508 | 293,882 | 0.911968 | [
[
[
"# Convolutional Networks\nSo far we have worked with deep fully-connected networks, using them to explore different optimization strategies and network architectures. Fully-connected networks are a good testbed for experimentation because they are very computationally efficient, but in practice all state-of-the-art results use convolutional networks instead.\n\nFirst you will implement several layer types that are used in convolutional networks. You will then use these layers to train a convolutional network on the CIFAR-10 dataset.",
"_____no_output_____"
]
],
[
[
"# As usual, a bit of setup\nfrom __future__ import print_function\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom cs231n.classifiers.cnn import *\nfrom cs231n.data_utils import get_CIFAR10_data\nfrom cs231n.gradient_check import eval_numerical_gradient_array, eval_numerical_gradient\nfrom cs231n.layers import *\nfrom cs231n.fast_layers import *\nfrom cs231n.solver import Solver\n\n%matplotlib inline\nplt.rcParams['figure.figsize'] = (10.0, 8.0) # set default size of plots\nplt.rcParams['image.interpolation'] = 'nearest'\nplt.rcParams['image.cmap'] = 'gray'\n\n# for auto-reloading external modules\n# see http://stackoverflow.com/questions/1907993/autoreload-of-modules-in-ipython\n%load_ext autoreload\n%autoreload 2\n\ndef rel_error(x, y):\n \"\"\" returns relative error \"\"\"\n return np.max(np.abs(x - y) / (np.maximum(1e-8, np.abs(x) + np.abs(y))))",
"_____no_output_____"
],
[
"# Load the (preprocessed) CIFAR10 data.\n\ndata = get_CIFAR10_data()\nfor k, v in data.items():\n print('%s: ' % k, v.shape)",
"y_test: (1000,)\ny_train: (49000,)\ny_val: (1000,)\nX_test: (1000, 3, 32, 32)\nX_train: (49000, 3, 32, 32)\nX_val: (1000, 3, 32, 32)\n"
]
],
[
[
"# Convolution: Naive forward pass\nThe core of a convolutional network is the convolution operation. In the file `cs231n/layers.py`, implement the forward pass for the convolution layer in the function `conv_forward_naive`. \n\nYou don't have to worry too much about efficiency at this point; just write the code in whatever way you find most clear.\n\nYou can test your implementation by running the following:",
"_____no_output_____"
]
],
[
[
"x_shape = (2, 3, 4, 4)\nw_shape = (3, 3, 4, 4)\nx = np.linspace(-0.1, 0.5, num=np.prod(x_shape)).reshape(x_shape)\nw = np.linspace(-0.2, 0.3, num=np.prod(w_shape)).reshape(w_shape)\nb = np.linspace(-0.1, 0.2, num=3)\n\nconv_param = {'stride': 2, 'pad': 1}\nout, _ = conv_forward_naive(x, w, b, conv_param)\ncorrect_out = np.array([[[[-0.08759809, -0.10987781],\n [-0.18387192, -0.2109216 ]],\n [[ 0.21027089, 0.21661097],\n [ 0.22847626, 0.23004637]],\n [[ 0.50813986, 0.54309974],\n [ 0.64082444, 0.67101435]]],\n [[[-0.98053589, -1.03143541],\n [-1.19128892, -1.24695841]],\n [[ 0.69108355, 0.66880383],\n [ 0.59480972, 0.56776003]],\n [[ 2.36270298, 2.36904306],\n [ 2.38090835, 2.38247847]]]])\n\n# Compare your output to ours; difference should be around 2e-8\nprint('Testing conv_forward_naive')\nprint('difference: ', rel_error(out, correct_out))",
"Testing conv_forward_naive\ndifference: 2.21214764175e-08\n"
]
],
[
[
"# Aside: Image processing via convolutions\n\nAs fun way to both check your implementation and gain a better understanding of the type of operation that convolutional layers can perform, we will set up an input containing two images and manually set up filters that perform common image processing operations (grayscale conversion and edge detection). The convolution forward pass will apply these operations to each of the input images. We can then visualize the results as a sanity check.",
"_____no_output_____"
]
],
[
[
"from scipy.misc import imread, imresize\n\nkitten, puppy = imread('kitten.jpg'), imread('puppy.jpg')\n# kitten is wide, and puppy is already square\nd = kitten.shape[1] - kitten.shape[0]\nkitten_cropped = kitten[:, d//2:-d//2, :]\n\nimg_size = 200 # Make this smaller if it runs too slow\nx = np.zeros((2, 3, img_size, img_size))\nx[0, :, :, :] = imresize(puppy, (img_size, img_size)).transpose((2, 0, 1))\nx[1, :, :, :] = imresize(kitten_cropped, (img_size, img_size)).transpose((2, 0, 1))\n\n# Set up a convolutional weights holding 2 filters, each 3x3\nw = np.zeros((2, 3, 3, 3))\n\n# The first filter converts the image to grayscale.\n# Set up the red, green, and blue channels of the filter.\nw[0, 0, :, :] = [[0, 0, 0], [0, 0.3, 0], [0, 0, 0]]\nw[0, 1, :, :] = [[0, 0, 0], [0, 0.6, 0], [0, 0, 0]]\nw[0, 2, :, :] = [[0, 0, 0], [0, 0.1, 0], [0, 0, 0]]\n\n# Second filter detects horizontal edges in the blue channel.\nw[1, 2, :, :] = [[1, 2, 1], [0, 0, 0], [-1, -2, -1]]\n\n# Vector of biases. We don't need any bias for the grayscale\n# filter, but for the edge detection filter we want to add 128\n# to each output so that nothing is negative.\nb = np.array([0, 128])\n\n# Compute the result of convolving each input in x with each filter in w,\n# offsetting by b, and storing the results in out.\nout, _ = conv_forward_naive(x, w, b, {'stride': 1, 'pad': 1})\n\ndef imshow_noax(img, normalize=True):\n \"\"\" Tiny helper to show images as uint8 and remove axis labels \"\"\"\n if normalize:\n img_max, img_min = np.max(img), np.min(img)\n img = 255.0 * (img - img_min) / (img_max - img_min)\n plt.imshow(img.astype('uint8'))\n plt.gca().axis('off')\n\n# Show the original images and the results of the conv operation\nplt.subplot(2, 3, 1)\nimshow_noax(puppy, normalize=False)\nplt.title('Original image')\nplt.subplot(2, 3, 2)\nimshow_noax(out[0, 0])\nplt.title('Grayscale')\nplt.subplot(2, 3, 3)\nimshow_noax(out[0, 1])\nplt.title('Edges')\nplt.subplot(2, 3, 4)\nimshow_noax(kitten_cropped, normalize=False)\nplt.subplot(2, 3, 5)\nimshow_noax(out[1, 0])\nplt.subplot(2, 3, 6)\nimshow_noax(out[1, 1])\nplt.show()",
"_____no_output_____"
]
],
[
[
"# Convolution: Naive backward pass\nImplement the backward pass for the convolution operation in the function `conv_backward_naive` in the file `cs231n/layers.py`. Again, you don't need to worry too much about computational efficiency.\n\nWhen you are done, run the following to check your backward pass with a numeric gradient check.",
"_____no_output_____"
]
],
[
[
"np.random.seed(231)\nx = np.random.randn(4, 3, 5, 5)\nw = np.random.randn(2, 3, 3, 3)\nb = np.random.randn(2,)\ndout = np.random.randn(4, 2, 5, 5)\nconv_param = {'stride': 1, 'pad': 1}\n\ndx_num = eval_numerical_gradient_array(lambda x: conv_forward_naive(x, w, b, conv_param)[0], x, dout)\ndw_num = eval_numerical_gradient_array(lambda w: conv_forward_naive(x, w, b, conv_param)[0], w, dout)\ndb_num = eval_numerical_gradient_array(lambda b: conv_forward_naive(x, w, b, conv_param)[0], b, dout)\n\nout, cache = conv_forward_naive(x, w, b, conv_param)\ndx, dw, db = conv_backward_naive(dout, cache)\n\n# Your errors should be around 1e-8'\nprint('Testing conv_backward_naive function')\nprint('dx error: ', rel_error(dx, dx_num))\nprint('dw error: ', rel_error(dw, dw_num))\nprint('db error: ', rel_error(db, db_num))",
"Testing conv_backward_naive function\ndx error: 1.15980316116e-08\ndw error: 2.24710943494e-10\ndb error: 3.3726400665e-11\n"
]
],
[
[
"# Max pooling: Naive forward\nImplement the forward pass for the max-pooling operation in the function `max_pool_forward_naive` in the file `cs231n/layers.py`. Again, don't worry too much about computational efficiency.\n\nCheck your implementation by running the following:",
"_____no_output_____"
]
],
[
[
"x_shape = (2, 3, 4, 4)\nx = np.linspace(-0.3, 0.4, num=np.prod(x_shape)).reshape(x_shape)\npool_param = {'pool_width': 2, 'pool_height': 2, 'stride': 2}\n\nout, _ = max_pool_forward_naive(x, pool_param)\n\ncorrect_out = np.array([[[[-0.26315789, -0.24842105],\n [-0.20421053, -0.18947368]],\n [[-0.14526316, -0.13052632],\n [-0.08631579, -0.07157895]],\n [[-0.02736842, -0.01263158],\n [ 0.03157895, 0.04631579]]],\n [[[ 0.09052632, 0.10526316],\n [ 0.14947368, 0.16421053]],\n [[ 0.20842105, 0.22315789],\n [ 0.26736842, 0.28210526]],\n [[ 0.32631579, 0.34105263],\n [ 0.38526316, 0.4 ]]]])\n\n# Compare your output with ours. Difference should be around 1e-8.\nprint('Testing max_pool_forward_naive function:')\nprint('difference: ', rel_error(out, correct_out))",
"Testing max_pool_forward_naive function:\ndifference: 4.16666651573e-08\n"
]
],
[
[
"# Max pooling: Naive backward\nImplement the backward pass for the max-pooling operation in the function `max_pool_backward_naive` in the file `cs231n/layers.py`. You don't need to worry about computational efficiency.\n\nCheck your implementation with numeric gradient checking by running the following:",
"_____no_output_____"
]
],
[
[
"np.random.seed(231)\nx = np.random.randn(3, 2, 8, 8)\ndout = np.random.randn(3, 2, 4, 4)\npool_param = {'pool_height': 2, 'pool_width': 2, 'stride': 2}\n\ndx_num = eval_numerical_gradient_array(lambda x: max_pool_forward_naive(x, pool_param)[0], x, dout)\n\nout, cache = max_pool_forward_naive(x, pool_param)\ndx = max_pool_backward_naive(dout, cache)\n\n# Your error should be around 1e-12\nprint('Testing max_pool_backward_naive function:')\nprint('dx error: ', rel_error(dx, dx_num))",
"Testing max_pool_backward_naive function:\ndx error: 3.27562514223e-12\n"
]
],
[
[
"# Fast layers\nMaking convolution and pooling layers fast can be challenging. To spare you the pain, we've provided fast implementations of the forward and backward passes for convolution and pooling layers in the file `cs231n/fast_layers.py`.\n\nThe fast convolution implementation depends on a Cython extension; to compile it you need to run the following from the `cs231n` directory:\n\n```bash\npython setup.py build_ext --inplace\n```\n\nThe API for the fast versions of the convolution and pooling layers is exactly the same as the naive versions that you implemented above: the forward pass receives data, weights, and parameters and produces outputs and a cache object; the backward pass recieves upstream derivatives and the cache object and produces gradients with respect to the data and weights.\n\n**NOTE:** The fast implementation for pooling will only perform optimally if the pooling regions are non-overlapping and tile the input. If these conditions are not met then the fast pooling implementation will not be much faster than the naive implementation.\n\nYou can compare the performance of the naive and fast versions of these layers by running the following:",
"_____no_output_____"
]
],
[
[
"from cs231n.fast_layers import conv_forward_fast, conv_backward_fast\nfrom time import time\nnp.random.seed(231)\nx = np.random.randn(100, 3, 31, 31)\nw = np.random.randn(25, 3, 3, 3)\nb = np.random.randn(25,)\ndout = np.random.randn(100, 25, 16, 16)\nconv_param = {'stride': 2, 'pad': 1}\n\nt0 = time()\nout_naive, cache_naive = conv_forward_naive(x, w, b, conv_param)\nt1 = time()\nout_fast, cache_fast = conv_forward_fast(x, w, b, conv_param)\nt2 = time()\n\nprint('Testing conv_forward_fast:')\nprint('Naive: %fs' % (t1 - t0))\nprint('Fast: %fs' % (t2 - t1))\nprint('Speedup: %fx' % ((t1 - t0) / (t2 - t1)))\nprint('Difference: ', rel_error(out_naive, out_fast))\n\nt0 = time()\ndx_naive, dw_naive, db_naive = conv_backward_naive(dout, cache_naive)\nt1 = time()\ndx_fast, dw_fast, db_fast = conv_backward_fast(dout, cache_fast)\nt2 = time()\n\nprint('\\nTesting conv_backward_fast:')\nprint('Naive: %fs' % (t1 - t0))\nprint('Fast: %fs' % (t2 - t1))\nprint('Speedup: %fx' % ((t1 - t0) / (t2 - t1)))\nprint('dx difference: ', rel_error(dx_naive, dx_fast))\nprint('dw difference: ', rel_error(dw_naive, dw_fast))\nprint('db difference: ', rel_error(db_naive, db_fast))",
"Testing conv_forward_fast:\nNaive: 0.145355s\nFast: 0.019051s\nSpeedup: 7.629918x\nDifference: 4.92640785149e-11\n\nTesting conv_backward_fast:\nNaive: 0.578539s\nFast: 0.012032s\nSpeedup: 48.082252x\ndx difference: 1.00633020662e-11\ndw difference: 2.49714252239e-13\ndb difference: 0.0\n"
],
[
"from cs231n.fast_layers import max_pool_forward_fast, max_pool_backward_fast\nnp.random.seed(231)\nx = np.random.randn(100, 3, 32, 32)\ndout = np.random.randn(100, 3, 16, 16)\npool_param = {'pool_height': 2, 'pool_width': 2, 'stride': 2}\n\nt0 = time()\nout_naive, cache_naive = max_pool_forward_naive(x, pool_param)\nt1 = time()\nout_fast, cache_fast = max_pool_forward_fast(x, pool_param)\nt2 = time()\n\nprint('Testing pool_forward_fast:')\nprint('Naive: %fs' % (t1 - t0))\nprint('fast: %fs' % (t2 - t1))\nprint('speedup: %fx' % ((t1 - t0) / (t2 - t1)))\nprint('difference: ', rel_error(out_naive, out_fast))\n\nt0 = time()\ndx_naive = max_pool_backward_naive(dout, cache_naive)\nt1 = time()\ndx_fast = max_pool_backward_fast(dout, cache_fast)\nt2 = time()\n\nprint('\\nTesting pool_backward_fast:')\nprint('Naive: %fs' % (t1 - t0))\nprint('speedup: %fx' % ((t1 - t0) / (t2 - t1)))\nprint('dx difference: ', rel_error(dx_naive, dx_fast))",
"Testing pool_forward_fast:\nNaive: 0.008014s\nfast: 0.004986s\nspeedup: 1.607355x\ndifference: 0.0\n\nTesting pool_backward_fast:\nNaive: 0.017047s\nspeedup: 1.307889x\ndx difference: 0.0\n"
]
],
[
[
"# Convolutional \"sandwich\" layers\nPreviously we introduced the concept of \"sandwich\" layers that combine multiple operations into commonly used patterns. In the file `cs231n/layer_utils.py` you will find sandwich layers that implement a few commonly used patterns for convolutional networks.",
"_____no_output_____"
]
],
[
[
"from cs231n.layer_utils import conv_relu_pool_forward, conv_relu_pool_backward\nnp.random.seed(231)\nx = np.random.randn(2, 3, 16, 16)\nw = np.random.randn(3, 3, 3, 3)\nb = np.random.randn(3,)\ndout = np.random.randn(2, 3, 8, 8)\nconv_param = {'stride': 1, 'pad': 1}\npool_param = {'pool_height': 2, 'pool_width': 2, 'stride': 2}\n\nout, cache = conv_relu_pool_forward(x, w, b, conv_param, pool_param)\ndx, dw, db = conv_relu_pool_backward(dout, cache)\n\ndx_num = eval_numerical_gradient_array(lambda x: conv_relu_pool_forward(x, w, b, conv_param, pool_param)[0], x, dout)\ndw_num = eval_numerical_gradient_array(lambda w: conv_relu_pool_forward(x, w, b, conv_param, pool_param)[0], w, dout)\ndb_num = eval_numerical_gradient_array(lambda b: conv_relu_pool_forward(x, w, b, conv_param, pool_param)[0], b, dout)\n\nprint('Testing conv_relu_pool')\nprint('dx error: ', rel_error(dx_num, dx))\nprint('dw error: ', rel_error(dw_num, dw))\nprint('db error: ', rel_error(db_num, db))",
"Testing conv_relu_pool\ndx error: 5.82817874652e-09\ndw error: 8.44362809187e-09\ndb error: 3.57960501324e-10\n"
],
[
"from cs231n.layer_utils import conv_relu_forward, conv_relu_backward\nnp.random.seed(231)\nx = np.random.randn(2, 3, 8, 8)\nw = np.random.randn(3, 3, 3, 3)\nb = np.random.randn(3,)\ndout = np.random.randn(2, 3, 8, 8)\nconv_param = {'stride': 1, 'pad': 1}\n\nout, cache = conv_relu_forward(x, w, b, conv_param)\ndx, dw, db = conv_relu_backward(dout, cache)\n\ndx_num = eval_numerical_gradient_array(lambda x: conv_relu_forward(x, w, b, conv_param)[0], x, dout)\ndw_num = eval_numerical_gradient_array(lambda w: conv_relu_forward(x, w, b, conv_param)[0], w, dout)\ndb_num = eval_numerical_gradient_array(lambda b: conv_relu_forward(x, w, b, conv_param)[0], b, dout)\n\nprint('Testing conv_relu:')\nprint('dx error: ', rel_error(dx_num, dx))\nprint('dw error: ', rel_error(dw_num, dw))\nprint('db error: ', rel_error(db_num, db))",
"Testing conv_relu:\ndx error: 3.56006101152e-09\ndw error: 2.24977009157e-10\ndb error: 1.30876199758e-10\n"
]
],
[
[
"# Three-layer ConvNet\nNow that you have implemented all the necessary layers, we can put them together into a simple convolutional network.\n\nOpen the file `cs231n/classifiers/cnn.py` and complete the implementation of the `ThreeLayerConvNet` class. Run the following cells to help you debug:",
"_____no_output_____"
],
[
"## Sanity check loss\nAfter you build a new network, one of the first things you should do is sanity check the loss. When we use the softmax loss, we expect the loss for random weights (and no regularization) to be about `log(C)` for `C` classes. When we add regularization this should go up.",
"_____no_output_____"
]
],
[
[
"model = ThreeLayerConvNet()\n\nN = 50\nX = np.random.randn(N, 3, 32, 32)\ny = np.random.randint(10, size=N)\n\nloss, grads = model.loss(X, y)\nprint('Initial loss (no regularization): ', loss)\n\nmodel.reg = 0.5\nloss, grads = model.loss(X, y)\nprint('Initial loss (with regularization): ', loss)",
"Initial loss (no regularization): 2.30258607124\nInitial loss (with regularization): 2.30374977848\n"
]
],
[
[
"## Gradient check\nAfter the loss looks reasonable, use numeric gradient checking to make sure that your backward pass is correct. When you use numeric gradient checking you should use a small amount of artifical data and a small number of neurons at each layer. Note: correct implementations may still have relative errors up to 1e-2.",
"_____no_output_____"
]
],
[
[
"num_inputs = 2\ninput_dim = (3, 16, 16)\nreg = 0.0\nnum_classes = 10\nnp.random.seed(231)\nX = np.random.randn(num_inputs, *input_dim)\ny = np.random.randint(num_classes, size=num_inputs)\n\nmodel = ThreeLayerConvNet(num_filters=3, filter_size=3,\n input_dim=input_dim, hidden_dim=7,\n dtype=np.float64)\nloss, grads = model.loss(X, y)\nfor param_name in sorted(grads):\n f = lambda _: model.loss(X, y)[0]\n param_grad_num = eval_numerical_gradient(f, model.params[param_name], verbose=False, h=1e-6)\n e = rel_error(param_grad_num, grads[param_name])\n print('%s max relative error: %e' % (param_name, rel_error(param_grad_num, grads[param_name])))",
"W1 max relative error: 1.380104e-04\nW2 max relative error: 1.822723e-02\nW3 max relative error: 3.064049e-04\nb1 max relative error: 3.477652e-05\nb2 max relative error: 2.516375e-03\nb3 max relative error: 7.945660e-10\n"
]
],
[
[
"## Overfit small data\nA nice trick is to train your model with just a few training samples. You should be able to overfit small datasets, which will result in very high training accuracy and comparatively low validation accuracy.",
"_____no_output_____"
]
],
[
[
"np.random.seed(231)\n\nnum_train = 100\nsmall_data = {\n 'X_train': data['X_train'][:num_train],\n 'y_train': data['y_train'][:num_train],\n 'X_val': data['X_val'],\n 'y_val': data['y_val'],\n}\n\nmodel = ThreeLayerConvNet(weight_scale=1e-2)\n\nsolver = Solver(model, small_data,\n num_epochs=15, batch_size=50,\n update_rule='adam',\n optim_config={\n 'learning_rate': 1e-4,\n },\n verbose=True, print_every=1)\nsolver.train()",
"(Iteration 1 / 30) loss: 2.414060\n(Epoch 0 / 15) train acc: 0.200000; val_acc: 0.128000\n(Iteration 2 / 30) loss: 2.231915\n(Epoch 1 / 15) train acc: 0.290000; val_acc: 0.145000\n(Iteration 3 / 30) loss: 1.935038\n(Iteration 4 / 30) loss: 1.795171\n(Epoch 2 / 15) train acc: 0.420000; val_acc: 0.144000\n(Iteration 5 / 30) loss: 1.479354\n(Iteration 6 / 30) loss: 1.711093\n(Epoch 3 / 15) train acc: 0.490000; val_acc: 0.178000\n(Iteration 7 / 30) loss: 1.700716\n(Iteration 8 / 30) loss: 1.406703\n(Epoch 4 / 15) train acc: 0.710000; val_acc: 0.199000\n(Iteration 9 / 30) loss: 0.885724\n(Iteration 10 / 30) loss: 0.963994\n(Epoch 5 / 15) train acc: 0.730000; val_acc: 0.212000\n(Iteration 11 / 30) loss: 0.750023\n(Iteration 12 / 30) loss: 0.642634\n(Epoch 6 / 15) train acc: 0.830000; val_acc: 0.204000\n(Iteration 13 / 30) loss: 0.697060\n(Iteration 14 / 30) loss: 0.430327\n(Epoch 7 / 15) train acc: 0.890000; val_acc: 0.217000\n(Iteration 15 / 30) loss: 0.299633\n(Iteration 16 / 30) loss: 0.416626\n(Epoch 8 / 15) train acc: 0.870000; val_acc: 0.208000\n(Iteration 17 / 30) loss: 0.744293\n(Iteration 18 / 30) loss: 0.155720\n(Epoch 9 / 15) train acc: 0.940000; val_acc: 0.193000\n(Iteration 19 / 30) loss: 0.175586\n(Iteration 20 / 30) loss: 0.329272\n(Epoch 10 / 15) train acc: 0.920000; val_acc: 0.190000\n(Iteration 21 / 30) loss: 0.346701\n(Iteration 22 / 30) loss: 0.076882\n(Epoch 11 / 15) train acc: 0.990000; val_acc: 0.210000\n(Iteration 23 / 30) loss: 0.111272\n(Iteration 24 / 30) loss: 0.139852\n(Epoch 12 / 15) train acc: 0.970000; val_acc: 0.201000\n(Iteration 25 / 30) loss: 0.070718\n(Iteration 26 / 30) loss: 0.092726\n(Epoch 13 / 15) train acc: 0.980000; val_acc: 0.212000\n(Iteration 27 / 30) loss: 0.070167\n(Iteration 28 / 30) loss: 0.046357\n(Epoch 14 / 15) train acc: 1.000000; val_acc: 0.212000\n(Iteration 29 / 30) loss: 0.028140\n(Iteration 30 / 30) loss: 0.074156\n(Epoch 15 / 15) train acc: 1.000000; val_acc: 0.192000\n"
]
],
[
[
"Plotting the loss, training accuracy, and validation accuracy should show clear overfitting:",
"_____no_output_____"
]
],
[
[
"plt.subplot(2, 1, 1)\nplt.plot(solver.loss_history, 'o')\nplt.xlabel('iteration')\nplt.ylabel('loss')\n\nplt.subplot(2, 1, 2)\nplt.plot(solver.train_acc_history, '-o')\nplt.plot(solver.val_acc_history, '-o')\nplt.legend(['train', 'val'], loc='upper left')\nplt.xlabel('epoch')\nplt.ylabel('accuracy')\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Train the net\nBy training the three-layer convolutional network for one epoch, you should achieve greater than 40% accuracy on the training set:",
"_____no_output_____"
]
],
[
[
"model = ThreeLayerConvNet(weight_scale=0.001, hidden_dim=500, reg=0.001)\n\nsolver = Solver(model, data,\n num_epochs=1, batch_size=50,\n update_rule='adam',\n optim_config={\n 'learning_rate': 1e-4,\n },\n verbose=True, print_every=20)\nsolver.train()",
"(Iteration 1 / 980) loss: 2.302691\n(Epoch 0 / 1) train acc: 0.103000; val_acc: 0.107000\n(Iteration 21 / 980) loss: 2.099992\n(Iteration 41 / 980) loss: 1.824186\n(Iteration 61 / 980) loss: 1.637579\n(Iteration 81 / 980) loss: 1.693922\n(Iteration 101 / 980) loss: 1.695733\n(Iteration 121 / 980) loss: 1.581225\n(Iteration 141 / 980) loss: 1.672520\n(Iteration 161 / 980) loss: 1.666194\n(Iteration 181 / 980) loss: 1.589535\n(Iteration 201 / 980) loss: 1.898157\n(Iteration 221 / 980) loss: 1.677160\n(Iteration 241 / 980) loss: 1.467824\n(Iteration 261 / 980) loss: 1.457763\n(Iteration 281 / 980) loss: 1.576611\n(Iteration 301 / 980) loss: 1.384094\n(Iteration 321 / 980) loss: 1.530814\n(Iteration 341 / 980) loss: 1.405348\n(Iteration 361 / 980) loss: 1.560901\n(Iteration 381 / 980) loss: 1.178784\n(Iteration 401 / 980) loss: 1.513778\n(Iteration 421 / 980) loss: 1.229282\n(Iteration 441 / 980) loss: 1.440691\n(Iteration 461 / 980) loss: 1.569233\n(Iteration 481 / 980) loss: 1.279975\n(Iteration 501 / 980) loss: 1.131454\n(Iteration 521 / 980) loss: 1.480183\n(Iteration 541 / 980) loss: 1.318647\n(Iteration 561 / 980) loss: 1.395562\n(Iteration 581 / 980) loss: 1.115184\n(Iteration 601 / 980) loss: 1.249284\n(Iteration 621 / 980) loss: 1.298111\n(Iteration 641 / 980) loss: 1.331045\n(Iteration 661 / 980) loss: 1.194776\n(Iteration 681 / 980) loss: 1.577281\n(Iteration 701 / 980) loss: 1.195688\n(Iteration 721 / 980) loss: 1.305367\n(Iteration 741 / 980) loss: 1.432126\n(Iteration 761 / 980) loss: 1.324776\n(Iteration 781 / 980) loss: 1.559636\n(Iteration 801 / 980) loss: 1.422860\n(Iteration 821 / 980) loss: 1.245301\n(Iteration 841 / 980) loss: 1.147179\n(Iteration 861 / 980) loss: 1.452905\n(Iteration 881 / 980) loss: 1.299993\n(Iteration 901 / 980) loss: 1.146948\n(Iteration 921 / 980) loss: 1.330617\n(Iteration 941 / 980) loss: 1.299843\n(Iteration 961 / 980) loss: 1.257027\n(Epoch 1 / 1) train acc: 0.579000; val_acc: 0.542000\n"
]
],
[
[
"## Visualize Filters\nYou can visualize the first-layer convolutional filters from the trained network by running the following:",
"_____no_output_____"
]
],
[
[
"from cs231n.vis_utils import visualize_grid\n\ngrid = visualize_grid(model.params['W1'].transpose(0, 2, 3, 1))\nplt.imshow(grid.astype('uint8'))\nplt.axis('off')\nplt.gcf().set_size_inches(5, 5)\nplt.show()",
"_____no_output_____"
]
],
[
[
"# Spatial Batch Normalization\nWe already saw that batch normalization is a very useful technique for training deep fully-connected networks. Batch normalization can also be used for convolutional networks, but we need to tweak it a bit; the modification will be called \"spatial batch normalization.\"\n\nNormally batch-normalization accepts inputs of shape `(N, D)` and produces outputs of shape `(N, D)`, where we normalize across the minibatch dimension `N`. For data coming from convolutional layers, batch normalization needs to accept inputs of shape `(N, C, H, W)` and produce outputs of shape `(N, C, H, W)` where the `N` dimension gives the minibatch size and the `(H, W)` dimensions give the spatial size of the feature map.\n\nIf the feature map was produced using convolutions, then we expect the statistics of each feature channel to be relatively consistent both between different imagesand different locations within the same image. Therefore spatial batch normalization computes a mean and variance for each of the `C` feature channels by computing statistics over both the minibatch dimension `N` and the spatial dimensions `H` and `W`.",
"_____no_output_____"
],
[
"## Spatial batch normalization: forward\n\nIn the file `cs231n/layers.py`, implement the forward pass for spatial batch normalization in the function `spatial_batchnorm_forward`. Check your implementation by running the following:",
"_____no_output_____"
]
],
[
[
"np.random.seed(231)\n# Check the training-time forward pass by checking means and variances\n# of features both before and after spatial batch normalization\n\nN, C, H, W = 2, 3, 4, 5\nx = 4 * np.random.randn(N, C, H, W) + 10\n\nprint('Before spatial batch normalization:')\nprint(' Shape: ', x.shape)\nprint(' Means: ', x.mean(axis=(0, 2, 3)))\nprint(' Stds: ', x.std(axis=(0, 2, 3)))\n\n# Means should be close to zero and stds close to one\ngamma, beta = np.ones(C), np.zeros(C)\nbn_param = {'mode': 'train'}\nout, _ = spatial_batchnorm_forward(x, gamma, beta, bn_param)\nprint('After spatial batch normalization:')\nprint(' Shape: ', out.shape)\nprint(' Means: ', out.mean(axis=(0, 2, 3)))\nprint(' Stds: ', out.std(axis=(0, 2, 3)))\n\n# Means should be close to beta and stds close to gamma\ngamma, beta = np.asarray([3, 4, 5]), np.asarray([6, 7, 8])\nout, _ = spatial_batchnorm_forward(x, gamma, beta, bn_param)\nprint('After spatial batch normalization (nontrivial gamma, beta):')\nprint(' Shape: ', out.shape)\nprint(' Means: ', out.mean(axis=(0, 2, 3)))\nprint(' Stds: ', out.std(axis=(0, 2, 3)))",
"Before spatial batch normalization:\n Shape: (2, 3, 4, 5)\n Means: [ 9.33463814 8.90909116 9.11056338]\n Stds: [ 3.61447857 3.19347686 3.5168142 ]\nAfter spatial batch normalization:\n Shape: (2, 3, 4, 5)\n Means: [ 6.18949336e-16 5.99520433e-16 -1.22124533e-16]\n Stds: [ 0.99999962 0.99999951 0.9999996 ]\nAfter spatial batch normalization (nontrivial gamma, beta):\n Shape: (2, 3, 4, 5)\n Means: [ 6. 7. 8.]\n Stds: [ 2.99999885 3.99999804 4.99999798]\n"
],
[
"np.random.seed(231)\n# Check the test-time forward pass by running the training-time\n# forward pass many times to warm up the running averages, and then\n# checking the means and variances of activations after a test-time\n# forward pass.\nN, C, H, W = 10, 4, 11, 12\n\nbn_param = {'mode': 'train'}\ngamma = np.ones(C)\nbeta = np.zeros(C)\nfor t in range(50):\n x = 2.3 * np.random.randn(N, C, H, W) + 13\n spatial_batchnorm_forward(x, gamma, beta, bn_param)\nbn_param['mode'] = 'test'\nx = 2.3 * np.random.randn(N, C, H, W) + 13\na_norm, _ = spatial_batchnorm_forward(x, gamma, beta, bn_param)\n\n# Means should be close to zero and stds close to one, but will be\n# noisier than training-time forward passes.\nprint('After spatial batch normalization (test-time):')\nprint(' means: ', a_norm.mean(axis=(0, 2, 3)))\nprint(' stds: ', a_norm.std(axis=(0, 2, 3)))",
"After spatial batch normalization (test-time):\n means: [-0.08034406 0.07562881 0.05716371 0.04378383]\n stds: [ 0.96718744 1.0299714 1.02887624 1.00585577]\n"
]
],
[
[
"## Spatial batch normalization: backward\nIn the file `cs231n/layers.py`, implement the backward pass for spatial batch normalization in the function `spatial_batchnorm_backward`. Run the following to check your implementation using a numeric gradient check:",
"_____no_output_____"
]
],
[
[
"np.random.seed(231)\nN, C, H, W = 2, 3, 4, 5\nx = 5 * np.random.randn(N, C, H, W) + 12\ngamma = np.random.randn(C)\nbeta = np.random.randn(C)\ndout = np.random.randn(N, C, H, W)\n\nbn_param = {'mode': 'train'}\nfx = lambda x: spatial_batchnorm_forward(x, gamma, beta, bn_param)[0]\nfg = lambda a: spatial_batchnorm_forward(x, gamma, beta, bn_param)[0]\nfb = lambda b: spatial_batchnorm_forward(x, gamma, beta, bn_param)[0]\n\ndx_num = eval_numerical_gradient_array(fx, x, dout)\nda_num = eval_numerical_gradient_array(fg, gamma, dout)\ndb_num = eval_numerical_gradient_array(fb, beta, dout)\n\n_, cache = spatial_batchnorm_forward(x, gamma, beta, bn_param)\ndx, dgamma, dbeta = spatial_batchnorm_backward(dout, cache)\nprint('dx error: ', rel_error(dx_num, dx))\nprint('dgamma error: ', rel_error(da_num, dgamma))\nprint('dbeta error: ', rel_error(db_num, dbeta))",
"dx error: 2.78664819776e-07\ndgamma error: 7.09748171136e-12\ndbeta error: 3.27560872528e-12\n"
]
],
[
[
"# Extra Credit Description\nIf you implement any additional features for extra credit, clearly describe them here with pointers to any code in this or other files if applicable.",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
cb3c444ee5947dcfb8d9ec345d46e526aec8cefe | 81,781 | ipynb | Jupyter Notebook | docs/examples/DataSet/Implementing_doND_using_the_dataset.ipynb | ThorvaldLarsen/Qcodes | 230881f7a4b5378c504c6e52c964a211191bde2e | [
"MIT"
] | 2 | 2019-04-09T09:39:22.000Z | 2019-10-24T19:07:19.000Z | docs/examples/DataSet/Implementing_doND_using_the_dataset.ipynb | ThorvaldLarsen/Qcodes | 230881f7a4b5378c504c6e52c964a211191bde2e | [
"MIT"
] | null | null | null | docs/examples/DataSet/Implementing_doND_using_the_dataset.ipynb | ThorvaldLarsen/Qcodes | 230881f7a4b5378c504c6e52c964a211191bde2e | [
"MIT"
] | 1 | 2019-11-19T12:32:29.000Z | 2019-11-19T12:32:29.000Z | 237.735465 | 26,540 | 0.921608 | [
[
[
"# Implementing doND using the dataset",
"_____no_output_____"
]
],
[
[
"from functools import partial\n\nimport numpy as np\n\nfrom qcodes.dataset.database import initialise_database\nfrom qcodes.dataset.experiment_container import new_experiment\nfrom qcodes.tests.instrument_mocks import DummyInstrument\nfrom qcodes.dataset.measurements import Measurement\nfrom qcodes.dataset.plotting import plot_by_id",
"_____no_output_____"
],
[
"initialise_database() # just in case no database file exists\nnew_experiment(\"doNd-tutorial\", sample_name=\"no sample\")",
"_____no_output_____"
]
],
[
[
"First we borrow the dummy instruments from the contextmanager notebook to have something to measure.",
"_____no_output_____"
]
],
[
[
"# preparatory mocking of physical setup\n\ndac = DummyInstrument('dac', gates=['ch1', 'ch2'])\ndmm = DummyInstrument('dmm', gates=['v1', 'v2'])",
"_____no_output_____"
],
[
"# and we'll make a 2D gaussian to sample from/measure\ndef gauss_model(x0: float, y0: float, sigma: float, noise: float=0.0005):\n \"\"\"\n Returns a generator sampling a gaussian. The gaussian is\n normalised such that its maximal value is simply 1\n \"\"\"\n while True:\n (x, y) = yield\n model = np.exp(-((x0-x)**2+(y0-y)**2)/2/sigma**2)*np.exp(2*sigma**2)\n noise = np.random.randn()*noise\n yield model + noise",
"_____no_output_____"
],
[
"# and finally wire up the dmm v1 to \"measure\" the gaussian\n\ngauss = gauss_model(0.1, 0.2, 0.25)\nnext(gauss)\n\ndef measure_gauss(dac):\n val = gauss.send((dac.ch1.get(), dac.ch2.get()))\n next(gauss)\n return val\n\ndmm.v1.get = partial(measure_gauss, dac)",
"_____no_output_____"
]
],
[
[
"Now lets reimplement the qdev-wrapper do1d function that can measure one one more parameters as a function of another parameter. This is more or less as simple as you would expect.\n",
"_____no_output_____"
]
],
[
[
"def do1d(param_set, start, stop, num_points, delay, *param_meas):\n meas = Measurement()\n meas.register_parameter(param_set) # register the first independent parameter\n output = [] \n param_set.post_delay = delay\n # do1D enforces a simple relationship between measured parameters\n # and set parameters. For anything more complicated this should be reimplemented from scratch\n for parameter in param_meas:\n meas.register_parameter(parameter, setpoints=(param_set,))\n output.append([parameter, None])\n\n with meas.run() as datasaver:\n for set_point in np.linspace(start, stop, num_points):\n param_set.set(set_point)\n for i, parameter in enumerate(param_meas):\n output[i][1] = parameter.get()\n datasaver.add_result((param_set, set_point),\n *output)\n dataid = datasaver.run_id # convenient to have for plotting\n return dataid",
"_____no_output_____"
],
[
"dataid = do1d(dac.ch1, 0, 1, 10, 0.01, dmm.v1, dmm.v2)",
"Starting experimental run with id: 87\n"
],
[
"axes, cbaxes = plot_by_id(dataid)",
"_____no_output_____"
],
[
"def do2d(param_set1, start1, stop1, num_points1, delay1, \n param_set2, start2, stop2, num_points2, delay2,\n *param_meas):\n # And then run an experiment\n\n meas = Measurement()\n meas.register_parameter(param_set1)\n param_set1.post_delay = delay1\n meas.register_parameter(param_set2)\n param_set1.post_delay = delay2\n output = [] \n for parameter in param_meas:\n meas.register_parameter(parameter, setpoints=(param_set1,param_set2))\n output.append([parameter, None])\n\n with meas.run() as datasaver:\n for set_point1 in np.linspace(start1, stop1, num_points1):\n param_set1.set(set_point1)\n for set_point2 in np.linspace(start2, stop2, num_points2):\n param_set2.set(set_point2)\n for i, parameter in enumerate(param_meas):\n output[i][1] = parameter.get()\n datasaver.add_result((param_set1, set_point1),\n (param_set2, set_point2),\n *output)\n dataid = datasaver.run_id # convenient to have for plotting\n return dataid",
"_____no_output_____"
],
[
"dataid = do2d(dac.ch1, -1, 1, 100, 0.01, \n dac.ch2, -1, 1, 100, 0.01, \n dmm.v1, dmm.v2)",
"Starting experimental run with id: 88\n"
],
[
"axes, cbaxes = plot_by_id(dataid)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3c49fe04a81610342762e951226213ae3607c1 | 60,428 | ipynb | Jupyter Notebook | pandas-starter/cookbook_official.ipynb | rodelrebucas/dev-overload-starterpack | 05bda5a869dda5be1e02dd64d492ea2f00ee3bff | [
"MIT"
] | null | null | null | pandas-starter/cookbook_official.ipynb | rodelrebucas/dev-overload-starterpack | 05bda5a869dda5be1e02dd64d492ea2f00ee3bff | [
"MIT"
] | null | null | null | pandas-starter/cookbook_official.ipynb | rodelrebucas/dev-overload-starterpack | 05bda5a869dda5be1e02dd64d492ea2f00ee3bff | [
"MIT"
] | null | null | null | 25.41127 | 131 | 0.319637 | [
[
[
"import pandas as pd\n\ndf = pd.DataFrame(\n\n {\"AAA\": [4, 5, 6, 7], \"BBB\": [10, 20, 30, 40], \"CCC\": [100, 50, -30, -50]}\n\n)\ndf",
"_____no_output_____"
],
[
"# Conditional replacement\ndf.loc[df.AAA >= 5, \"BBB\"] = -1\ndf",
"_____no_output_____"
],
[
"# Conditional replacement, multiple columns\ndf.loc[df.BBB == -1, [\"AAA\", \"CCC\"]] = 1\ndf",
"_____no_output_____"
],
[
"df_mask = pd.DataFrame(\n\n {\"AAA\": [True, False] * 2, \"BBB\": [False] * 4, \"CCC\": [True, False] * 2}\n\n)\ndf_mask",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"# set the value on -1000 on False record\ndf.where(df_mask, -1000)",
"_____no_output_____"
],
[
"# Position oriented\ndf.iloc[1:3] ",
"_____no_output_____"
],
[
"# Label oriented\ndf.loc[0:2]",
"_____no_output_____"
],
[
"# Get non 1's with inverse operator\ndf[~(df.AAA == 1)]",
"_____no_output_____"
],
[
"# Create new columns\ndfcol = pd.DataFrame({\"AAA\": [1, 2, 1, 3], \"BBB\": [1, 1, 2, 2], \"CCC\": [2, 1, 3, 1]})\ncategory = {1: \"Alpha\", 2: \"Beta\", 3: \"Charlie\"}\ncategory.get(1) # Alpha\nnew_cols = [str(x) + \"_cat\" for x in dfcol.columns]\n\n# Get value from source_cols as arg to category.get to obtain the dict's value\ndfcol[new_cols] = dfcol[dfcol.columns].applymap(category.get)\ndfcol",
"_____no_output_____"
],
[
"# Get index of min/max\ndfcol[\"AAA\"].idxmax() # 3\ndfcol[\"AAA\"].idxmin() # 0",
"_____no_output_____"
],
[
"# Multiindexing\ndfmul = pd.DataFrame(\n\n {\n\n \"row\": [0, 1, 2],\n\n \"One_X\": [1.1, 1.1, 1.1],\n\n \"One_Y\": [1.2, 1.2, 1.2],\n\n \"Two_X\": [1.11, 1.11, 1.11],\n\n \"Two_Y\": [1.22, 1.22, 1.22],\n\n }\n\n)",
"_____no_output_____"
],
[
"# Index by default start at 0\ndfmul",
"_____no_output_____"
],
[
"# Label index\ndfmul.set_index(\"row\")",
"_____no_output_____"
],
[
"[tuple(c.split(\"_\")) for c in dfmul.columns]",
"_____no_output_____"
],
[
"dfmul.columns = pd.MultiIndex.from_tuples([tuple(c.split(\"_\")) for c in dfmul.columns])",
"_____no_output_____"
],
[
"dfmul",
"_____no_output_____"
],
[
"dfmul.columns = pd.MultiIndex.from_tuples([ ('One', 'row_index'), ('One', 'X'), ('One', 'Y'), ('Two', 'X'), ('Two', 'Y')])\ndfmul",
"_____no_output_____"
],
[
"# Reshaping dataframe based on new labels\ndfmul.columns = pd.MultiIndex.from_tuples([tuple(c.split(\"_\")) for c in dfmul.columns])\ndfmul",
"_____no_output_____"
],
[
"# Reshape based on ('One', 'X') index\ndfmul.stack(0)\n",
"_____no_output_____"
],
[
"# Original indeces 0,1\ndfmul.stack(0).reset_index(0)",
"_____no_output_____"
],
[
"# Index \"One\" and \"Two\"\ndfmul.stack(0).reset_index(1)",
"_____no_output_____"
],
[
"dfm = pd.DataFrame([1,1,np.nan,0,0], index=pd.date_range(\"2013-08-01\", periods=5, freq=\"B\"), columns=[\"A\"])\ndfm",
"_____no_output_____"
],
[
"# Fill values forward\ndfm.ffill()",
"_____no_output_____"
],
[
"# Fill values backward\ndfm.bfill()",
"_____no_output_____"
],
[
"# Grouping\ndfgp = pd.DataFrame(\n\n {\n\n \"animal\": \"cat dog cat fish dog cat cat\".split(),\n\n \"size\": list(\"SSMMMLL\"),\n\n \"weight\": [8, 10, 11, 1, 20, 12, 12],\n\n \"adult\": [False] * 5 + [True] * 2,\n\n }\n\n)",
"_____no_output_____"
],
[
"dfgp",
"_____no_output_____"
],
[
"# Group by animal and get max weight and display size\ndfgp.groupby(\"animal\").apply(lambda g: g[\"size\"][g[\"weight\"].idxmax()])",
"_____no_output_____"
],
[
"# Using get_group\ndfgp.groupby([\"animal\"]).get_group(\"cat\")",
"_____no_output_____"
],
[
"# compared to loc\ndfgp.loc[dfgp[\"animal\"]==\"cat\"]",
"_____no_output_____"
],
[
"# Multiple aggregated columns\nts = pd.Series(data=list(range(10)), index=pd.date_range(start=\"2014-10-07\", periods=10, freq=\"2min\"))\nts",
"_____no_output_____"
],
[
"# Apply these calculation on the column\nmhc = {\"Mean\": np.mean, \"Max\": np.max}\n\n# Resample and get data every 5min \nts.resample(\"5min\").apply(mhc)",
"_____no_output_____"
],
[
"# Counting instance\ndfvc = pd.DataFrame(\n\n {\"Color\": \"Red Red Red Blue\".split(), \"Value\": [100, 150, 50, 50]}\n\n)\ndfvc",
"_____no_output_____"
],
[
"# Count color instance as a column\ndfvc[\"Counts\"] = dfvc.groupby([\"Color\"]).transform(len)\ndfvc",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3c546e32a21b0533e3332042efa2ae9a547927 | 60,102 | ipynb | Jupyter Notebook | NewsCluster.ipynb | iamunr4v31/NewsCluster | 1266e31b2fd7b6fb15d7a3cd23b80fcf2e58a691 | [
"MIT"
] | 2 | 2020-05-14T03:11:46.000Z | 2020-05-28T17:03:54.000Z | NewsCluster.ipynb | 1hef001/NewsCluster | 1266e31b2fd7b6fb15d7a3cd23b80fcf2e58a691 | [
"MIT"
] | 13 | 2020-05-12T06:36:11.000Z | 2020-05-19T10:56:07.000Z | NewsCluster.ipynb | iamunr4v31/NewsCluster | 1266e31b2fd7b6fb15d7a3cd23b80fcf2e58a691 | [
"MIT"
] | 2 | 2020-05-27T15:01:33.000Z | 2020-06-01T08:29:03.000Z | 54.638182 | 1,429 | 0.51005 | [
[
[
"!pip install seaborn\n!pip install newspaper3k\nimport nltk\nnltk.download('stopwords')",
"Requirement already satisfied: seaborn in /usr/local/lib/python3.6/dist-packages (0.10.1)\nRequirement already satisfied: pandas>=0.22.0 in /usr/local/lib/python3.6/dist-packages (from seaborn) (1.0.3)\nRequirement already satisfied: matplotlib>=2.1.2 in /usr/local/lib/python3.6/dist-packages (from seaborn) (3.2.1)\nRequirement already satisfied: numpy>=1.13.3 in /usr/local/lib/python3.6/dist-packages (from seaborn) (1.18.4)\nRequirement already satisfied: scipy>=1.0.1 in /usr/local/lib/python3.6/dist-packages (from seaborn) (1.4.1)\nRequirement already satisfied: python-dateutil>=2.6.1 in /usr/local/lib/python3.6/dist-packages (from pandas>=0.22.0->seaborn) (2.8.1)\nRequirement already satisfied: pytz>=2017.2 in /usr/local/lib/python3.6/dist-packages (from pandas>=0.22.0->seaborn) (2018.9)\nRequirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib>=2.1.2->seaborn) (1.2.0)\nRequirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib>=2.1.2->seaborn) (2.4.7)\nRequirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.6/dist-packages (from matplotlib>=2.1.2->seaborn) (0.10.0)\nRequirement already satisfied: six>=1.5 in /usr/local/lib/python3.6/dist-packages (from python-dateutil>=2.6.1->pandas>=0.22.0->seaborn) (1.12.0)\nRequirement already satisfied: newspaper3k in /usr/local/lib/python3.6/dist-packages (0.2.8)\nRequirement already satisfied: feedfinder2>=0.0.4 in /usr/local/lib/python3.6/dist-packages (from newspaper3k) (0.0.4)\nRequirement already satisfied: python-dateutil>=2.5.3 in /usr/local/lib/python3.6/dist-packages (from newspaper3k) (2.8.1)\nRequirement already satisfied: lxml>=3.6.0 in /usr/local/lib/python3.6/dist-packages (from newspaper3k) (4.2.6)\nRequirement already satisfied: cssselect>=0.9.2 in /usr/local/lib/python3.6/dist-packages (from newspaper3k) (1.1.0)\nRequirement already satisfied: feedparser>=5.2.1 in /usr/local/lib/python3.6/dist-packages (from newspaper3k) (5.2.1)\nRequirement already satisfied: nltk>=3.2.1 in /usr/local/lib/python3.6/dist-packages (from newspaper3k) (3.2.5)\nRequirement already satisfied: PyYAML>=3.11 in /usr/local/lib/python3.6/dist-packages (from newspaper3k) (3.13)\nRequirement already satisfied: tinysegmenter==0.3 in /usr/local/lib/python3.6/dist-packages (from newspaper3k) (0.3)\nRequirement already satisfied: requests>=2.10.0 in /usr/local/lib/python3.6/dist-packages (from newspaper3k) (2.23.0)\nRequirement already satisfied: tldextract>=2.0.1 in /usr/local/lib/python3.6/dist-packages (from newspaper3k) (2.2.2)\nRequirement already satisfied: jieba3k>=0.35.1 in /usr/local/lib/python3.6/dist-packages (from newspaper3k) (0.35.1)\nRequirement already satisfied: Pillow>=3.3.0 in /usr/local/lib/python3.6/dist-packages (from newspaper3k) (7.0.0)\nRequirement already satisfied: beautifulsoup4>=4.4.1 in /usr/local/lib/python3.6/dist-packages (from newspaper3k) (4.6.3)\nRequirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from feedfinder2>=0.0.4->newspaper3k) (1.12.0)\nRequirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.6/dist-packages (from requests>=2.10.0->newspaper3k) (2.9)\nRequirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.6/dist-packages (from requests>=2.10.0->newspaper3k) (3.0.4)\nRequirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.6/dist-packages (from requests>=2.10.0->newspaper3k) (1.24.3)\nRequirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.6/dist-packages (from requests>=2.10.0->newspaper3k) (2020.4.5.1)\nRequirement already satisfied: setuptools in /usr/local/lib/python3.6/dist-packages (from tldextract>=2.0.1->newspaper3k) (46.4.0)\nRequirement already satisfied: requests-file>=1.4 in /usr/local/lib/python3.6/dist-packages (from tldextract>=2.0.1->newspaper3k) (1.5.1)\n[nltk_data] Downloading package stopwords to /root/nltk_data...\n[nltk_data] Package stopwords is already up-to-date!\n"
]
],
[
[
"The next two lines are required to load files from your Google drive.",
"_____no_output_____"
]
],
[
[
"from google.colab import drive\ndrive.mount('/content/drive')",
"Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount(\"/content/drive\", force_remount=True).\n"
]
],
[
[
"# SCRAPER",
"_____no_output_____"
]
],
[
[
"from newspaper import Article\nfrom newspaper import ArticleException\nimport newspaper\n# from progress.bar import IncrementalBar\nimport time\nimport string\n\n\ndef scrape_news_links(url):\n '''\n Scrapes links : not only google but any online vendor.\n set url while calling the function\n '''\n print('Scraping links')\n paper = newspaper.build(url, memoize_articles=False)\n links = []\n # bar = IncrementalBar('Scraping Links', max=len(paper.articles), suffix='%(percent)d%%')\n for article in paper.articles:\n links.append(article.url)\n # bar.next()\n time.sleep(0.1)\n # bar.finish()\n \n # print(links)\n return links\n\ndef clean_text(text):\n '''\n To clean text\n '''\n print('cleaning_text')\n # text = text.strip()\n # text = text.lower()\n # for punct in string.punctuation:\n # text = text.replace(punct, '')\n text = text.lower()\n strin = text.split('\\n')\n text = \" \".join(strin)\n # text.replace('\\\\', '')\n exclude = set(string.punctuation)\n text = ''.join(ch for ch in text if ch not in exclude)\n return text\n\ndef get_content(links):\n '''\n get headlines and news content\n '''\n print('getting content')\n content = []\n # next_bar = IncrementalBar('Getting Content', max=)\n # bar = IncrementalBar('Getting content & Cleaning text', max=len(links), suffix='%(percent)d%%' )\n for url in links:\n try:\n article = Article(url, language='en')\n article.download()\n article.parse()\n title = clean_text(article.title)\n news = clean_text(article.text)\n if title != None:\n if news != None: \n if news != ' ': \n if news != '': # for sites which news content cannot be scraped\n content.append([title, news])\n # bar.next()\n \n except ArticleException as ae:\n # if 'Article \\'download()\\' failed' in ae:\n continue\n \n # bar.finish()\n return content\n \n\ndef scraper(link='https://timesofindia.indiatimes.com/'):\n '''\n aggregator function\n '''\n # print('scraper_main')5\n return get_content(scrape_news_links(link))\n\n# if __name__ == \"__main__\":\n # links = scrape_google_links()\n # print(get_content(links[:15]))",
"_____no_output_____"
]
],
[
[
"# DF AND CSV",
"_____no_output_____"
]
],
[
[
"import csv\nimport pandas as pd\n\n\n\nLINKS = ['https://timesofindia.indiatimes.com/',\n 'https://www.thehindu.com/',\n 'https://www.bbc.com/news',\n 'https://www.theguardian.co.uk/',\n 'https://www.hindustantimes.com/',\n 'https://indianexpress.com/',\n 'https://www.dailypioneer.com/'\n 'https://www.deccanherald.com/',\n 'https://www.telegraphindia.com/',\n 'https://www.dnaindia.com/',\n 'https://www.deccanchronicle.com/',\n 'https://www.asianage.com/',\n 'https://economictimes.indiatimes.com/',\n 'https://www.tribuneindia.com/']\n\ndef create_df(content_list):\n '''\n To write the data to csv file\n takes a list of list where the inner list contains ['headline', 'news']\n '''\n title = []\n news = []\n print('creating_dataFrame')\n\n for content in content_list:\n title.append(content[0])\n news.append(content[1])\n # keywords.append(content[2])\n\n data = {'Title' : title, 'News' : news}\n df = pd.DataFrame(data, columns=['Title', 'News'])\n return df\n\n\ndef df_to_csv(df, filename='NewsCluster.csv'):\n '''\n writes dataframe to csv\n '''\n print('writing_to_csv')\n df.to_csv('/content/drive/My Drive/data/' + filename)\n\n\ndef create_csv():\n '''\n aggregator function of this module\n '''\n print('create_csv_main')\n content_list = []\n for link in LINKS:\n content_list.append(scraper(link))\n\n content_lst = []\n for content in content_list:\n for cont in content:\n content_lst.append(cont)\n # content_lst = scraper()\n # print(content_lst)\n try:\n num = int(input('Enter the number of articles to be stored : '))\n if num < 15:\n raise ValueError('Provide a larger number for dataset')\n df_to_csv(create_df(content_lst[:num]))\n except ValueError as ve:\n df_to_csv(create_df(content_lst))\n",
"_____no_output_____"
]
],
[
[
"# CONVERT TO DB",
"_____no_output_____"
]
],
[
[
"import sqlite3\nfrom sqlite3 import IntegrityError\nimport csv\n\ndef insert_to_db(tup):\n with sqlite3.connect('/content/drive/My Drive/data/NEWS.DB') as con:\n cur = con.cursor()\n cur.execute(\"INSERT INTO content (headlines, news) VALUES(?, ?);\", tup)\n con.commit()\n\ndef to_database():\n '''\n converts csv to db\n '''\n with sqlite3.connect('/content/drive/My Drive/data/NEWS.DB') as con:\n cur = con.cursor()\n cur.execute('CREATE TABLE IF NOT EXISTS content(headlines TEXT, news TEXT PRIMARY KEY);')\n with open('/content/drive/My Drive/data/NewsCluster.csv', encoding='utf-8') as fin:\n dr = csv.DictReader(fin)\n for i in dr:\n try:\n tup = (i['Title'], i['News'])\n insert_to_db(tup)\n except IntegrityError as ie:\n # if 'unique constraint' in ie:\n continue\n\n # to_db = [(i['Title'], i['News']) for i in dr]\n \n # cur.executemany(\"INSERT INTO content (headlines, news) VALUES(?, ?);\", to_db)\n con.commit()\n con.close()\n\ndef print_db():\n '''\n prints database\n used for reference and verification\n '''\n with sqlite3.connect(\"/content/drive/My Drive/data/NEWS.DB\") as con:\n cur = con.cursor()\n cur.execute('SELECT * FROM content')\n return cur.fetchall()\n\n# if __name__ == \"__main__\":\n '''\n execute either of the functions to update database or displahy the content\n '''\n # to_database()\n # print(print_db()[0])",
"_____no_output_____"
]
],
[
[
"# CALL SCRAPER, CREATE CSV and DB",
"_____no_output_____"
]
],
[
[
"create_csv()\nto_database()",
"create_csv_main\nScraping links\n"
]
],
[
[
"# CHECK CSV",
"_____no_output_____"
]
],
[
[
"import csv\ndef print_csv(filename):\n with open('/content/drive/My Drive/data/'+filename) as csv_file:\n csv_reader = csv.reader(csv_file, delimiter=',')\n for row in csv_reader:\n print(row)\n\n \nif __name__ == '__main__':\n print_csv(\"NewsCluster.csv\")",
"_____no_output_____"
]
],
[
[
"# CLUSTERING",
"_____no_output_____"
]
],
[
[
"\"\"\"\nWrapper for offline clustering methods that do not take into\naccount temporal aspects of data and online clustering methods\nthat update and/or predict new data as it comes in. Framework\nsupports custom text representations (e.g. Continuous Bag of\nWords) but will default to tfidf if none are provided.\n\"\"\"\n\nimport numpy as np\nimport seaborn as sns\nfrom sklearn.manifold import MDS\nfrom scipy.cluster.hierarchy import ward, dendrogram\nimport matplotlib.pyplot as plt\nfrom mpl_toolkits.mplot3d import Axes3D\n# from hdbscan import HDBSCAN\nfrom sklearn.metrics.pairwise import cosine_similarity\nfrom nltk.corpus import stopwords\nfrom scipy.sparse import issparse, vstack\nfrom sklearn.cluster import *\nfrom sklearn.decomposition import TruncatedSVD\nfrom sklearn.feature_extraction.text import TfidfVectorizer\n\nnltk_stopwords = stopwords.words('english')\n\n\nclass Cluster:\n \"\"\" Clustering methods for text. Be cautious of datasize; in cases\n of large data, KMeans may be the only efficient choice.\n\n Accepts custom matrices\n\n Full analysis of methods can be found at:\n http://hdbscan.readthedocs.io/en/latest/comparing_clustering_algorithms.html\n\n Usage:\n >> with open('../data/cleaned_text.txt', 'r', encoding='utf8') as f:\n text = f.readlines()\n >> clustering = Cluster(text)\n >> results = clustering('hdbscan', matrix=None, reduce_dim=None,\n visualize=True, top_terms=False,\n min_cluster_size=10)\n >> print(results)\n \"\"\"\n def __init__(self, text):\n \"\"\"\n Args:\n text: strings to be clustered (list of strings)\n \"\"\"\n self.text = list(set(text))\n\n def __call__(self, method, vectorizer=None,\n reduce_dim=None, viz=False,\n *args, **kwargs):\n \"\"\"\n Args:\n method: algorithm to use to cluster data (str)\n vectorizer: initialized method to convert text to np array;\n assumes __call__ vectorizes the text (Class, optional)\n reduce_dim: reduce dim of representation matrix (int, optional)\n visualize: visualize clusters in 3D (bool, optional)\n *args, **kwargs: see specified method function\n \"\"\"\n\n # Make sure method is valid\n assert method in ['hdbscan', 'dbscan', 'spectral', 'kmeans',\n 'minikmeans', 'affinity_prop', 'agglomerative',\n 'mean_shift', 'birch'], 'Invalid method chosen.'\n\n if not hasattr(self, 'vectorizer'):\n if vectorizer is None:\n self._init_tfidf()\n else:\n self.vectorizer = vectorizer\n self.matrix = self.vectorizer(self.text)\n\n # Reduce dimensionality using latent semantic analysis (makes faster)\n if reduce_dim is not None:\n self.matrix = self._pca(reduce_dim, self.matrix)\n\n # Cache current method\n method = eval('self.' + method)\n self.algorithm = method(*args, **kwargs)\n self.results = self._organize(self.algorithm.labels_)\n\n # For plotting\n self.viz_matrix = self.matrix\n\n # Visualize clustering outputs if applicable\n if viz:\n # _ = self.viz2D()\n _ = self.viz3D()\n _ = self.top_terms()\n\n return self.results\n\n # def hdbscan(self, min_cluster_size=10, prediction_data=False):\n # \"\"\" DBSCAN but allows for varying density clusters and no longer\n # requires epsilon parameter, which is difficult to tune.\n # http://hdbscan.readthedocs.io/en/latest/how_hdbscan_works.html\n # Scales slightly worse than DBSCAN, but with a more intuitive parameter.\n # \"\"\"\n # hdbscan = HDBSCAN(min_cluster_size=min_cluster_size,\n # prediction_data=prediction_data)\n # if prediction_data:\n # return hdbscan.fit(self._safe_dense(self.matrix))\n # else:\n # return hdbscan.fit(self.matrix)\n\n def dbscan(self, eps=0.50):\n \"\"\" Density-based algorithm that clusters points in dense areas and\n distances points in sparse areas. Stable, semi-fast, non-global.\n Scales very well with n_samples, decently with n_clusters (not tunable)\n \"\"\"\n dbscan = DBSCAN(eps=eps, min_samples=3)\n return dbscan.fit(self.matrix)\n\n def kmeans(self, n_clusters=10, n_init=5):\n km = KMeans(n_clusters=n_clusters, init='k-means++', max_iter=300, n_init=n_init, verbose=0, random_state=3425)\n return km.fit(self.matrix)\n\n def minikmeans(self, n_clusters=10, n_init=5, batch_size=5000):\n \"\"\" Partition dataset into n_cluster global chunks by minimizing\n intra-partition distances. Expect quick results, but with noise.\n Scales exceptionally well with n_samples, decently with n_clusters.\n \"\"\"\n kmeans = MiniBatchKMeans(n_clusters=n_clusters,\n init='k-means++',\n n_init=n_init,\n batch_size=batch_size)\n return kmeans.fit(self.matrix)\n\n def birch(self, n_clusters=10):\n \"\"\" Partitions dataset into n_cluster global chunks by repeatedly\n merging subclusters of a CF tree. Birch does not scale very well to high\n dimensional data. If many subclusters are desired, set n_clusters=None.\n Scales well with n_samples, well with n_clusters.\n \"\"\"\n birch = Birch(n_clusters=n_clusters)\n return birch.fit(self.matrix)\n\n def agglomerative(self, n_clusters=10, linkage='ward'):\n \"\"\" Iteratively clusters dataset semi-globally by starting with each\n point in its own cluster and then using some criterion to choose another\n cluster to merge that cluster with another cluster.\n Scales well with n_samples, decently with n_clusters.\n \"\"\"\n agglomerative = AgglomerativeClustering(n_clusters=n_clusters,\n linkage=linkage)\n return agglomerative.fit(self._safe_dense(self.matrix))\n\n def spectral(self, n_clusters=5):\n \"\"\" Partitions dataset semi-globally by inducing a graph based on the\n distances between points and trying to learn a manifold, and then\n running a standard clustering algorithm (e.g. KMeans) on this manifold.\n Scales decently with n_samples, poorly with n_clusters.\n \"\"\"\n spectral = SpectralClustering(n_clusters=n_clusters)\n return spectral.fit(self.matrix)\n\n def affinity_prop(self, damping=0.50):\n \"\"\" Partitions dataset globally using a graph based approach to let\n points ‘vote’ on their preferred ‘exemplar’.\n Does not scale well with n_samples. Not recommended to use with text.\n \"\"\"\n affinity_prop = AffinityPropagation(damping=damping)\n return affinity_prop.fit(self._safe_dense(self.matrix))\n\n def mean_shift(self, cluster_all=False):\n \"\"\" Centroid-based, global method that assumes there exists some\n probability density function from which the data is drawn, and tries to\n place centroids of clusters at the maxima of that density function.\n Unstable, but conservative.\n Does not scale well with n_samples. Not recommended to use with text.\n \"\"\"\n mean_shift = MeanShift(cluster_all=False)\n return mean_shift.fit(self._safe_dense(self.matrix))\n\n def _init_tfidf(self, max_features=30000, analyzer='word',\n stopwords=nltk_stopwords, token_pattern=r\"(?u)\\b\\w+\\b\"):\n \"\"\" Default representation for data is sparse tfidf vectors\n\n Args:\n max_features: top N vocabulary to consider (int)\n analyzer: 'word' or 'char', level at which to segment text (str)\n stopwords: words to remove from consideration, default nltk (list)\n \"\"\"\n # Initialize and fit tfidf vectors\n self.vectorizer = TfidfVectorizer(max_features=max_features,\n stop_words=stopwords,\n analyzer=analyzer,\n token_pattern=token_pattern)\n self.matrix = self.vectorizer.fit_transform(self.text)\n\n # Get top max_features vocabulary\n self.terms = self.vectorizer.get_feature_names()\n\n # For letting user know if tfidf has been initialized\n self.using_tfidf = True\n\n def viz2D(self, matrix=None,\n plot_kwds={'alpha':0.30, 's':40, 'linewidths':0}):\n \"\"\" Visualize clusters in 2D \"\"\"\n # Run PCA over the data so we can plot\n # matrix2D = self._pca(n=2, matrix=self.viz_matrix)\n\n # # Get labels\n # labels = np.unique(self.results['labels'])\n\n # # Assign a color to each label\n # palette = sns.color_palette('deep', max(labels)+1)\n # colors = [palette[x] if x >= 0 else (0.0, 0.0, 0.0) for x in labels]\n\n # # Plot the data\n # plt.close()\n # fig = plt.figure(figsize=(10,6))\n # plt.scatter(matrix2D.T[0],\n # matrix2D.T[1],\n # c=colors,\n # **plot_kwds\n # )\n # frame = plt.gca()\n\n # # Turn off axes, since they are arbitrary\n # frame.axes.get_xaxis().set_visible(False)\n # frame.axes.get_yaxis().set_visible(False)\n\n # # Add a title\n # alg_name = str(self.algorithm.__class__.__name__)\n # plt.title('{0} clusters found by {1}'.format(len(labels),\n # alg_name),\n # fontsize=20)\n # plt.tight_layout()\n # plt.show()\n # return fig\n\n # Run PCA over the data\n matrix3D = self._pca(n=2, matrix=self.viz_matrix)\n\n # Extract labels from results\n labels = self.results['labels']\n\n # Assign colors\n palette = sns.color_palette('deep', int(max(labels)+1))\n colors = [palette[x] if x >= 0 else (0.0, 0.0, 0.0) for x in labels]\n\n # Plot the data\n plt.close()\n fig = plt.figure(figsize=(10,6))\n # ax = plt.axes(projection='3d')\n plt.scatter(matrix3D.T[0],\n matrix3D.T[1],\n # matrix3D.T[2],\n c=colors)\n\n # Add a title\n alg_name = str(self.algorithm.__class__.__name__)\n plt.title('{0} Clusters | {1} Items | {2}'.format(len(set(labels)),\n matrix3D.shape[0],\n alg_name),\n fontsize=20)\n\n # Turn off arbitrary axis tick labels\n # plt.tick_params(axis='both', left=False, top=False, right=False,\n # bottom=False, labelleft=False, labeltop=False,\n # labelright=False, labelbottom=False)\n plt.tight_layout()\n plt.show()\n return fig\n\n\n\n def viz3D(self, matrix=None):\n \"\"\" Visualize clusters in 3D \"\"\"\n # Run PCA over the data\n matrix3D = self._pca(n=3, matrix=self.viz_matrix)\n\n # Extract labels from results\n labels = self.results['labels']\n\n # Assign colors\n palette = sns.color_palette('deep', int(max(labels)+1))\n colors = [palette[x] if x >= 0 else (0.0, 0.0, 0.0) for x in labels]\n\n # Plot the data\n plt.close()\n fig = plt.figure(figsize=(10,6))\n ax = plt.axes(projection='3d')\n ax.scatter(matrix3D.T[0],\n matrix3D.T[1],\n matrix3D.T[2],\n c=colors)\n\n # Add a title\n alg_name = str(self.algorithm.__class__.__name__)\n plt.title('{0} Clusters | {1} Items | {2}'.format(len(set(labels)),\n matrix3D.shape[0],\n alg_name),\n fontsize=20)\n\n # Turn off arbitrary axis tick labels\n plt.tick_params(axis='both', left=False, top=False, right=False,\n bottom=False, labelleft=False, labeltop=False,\n labelright=False, labelbottom=False)\n plt.tight_layout()\n plt.show()\n return fig\n\n def top_terms(self, topx=10):\n \"\"\" Print out top terms per cluster. \"\"\"\n if self.using_tfidf != True:\n print('For use with non-tfidf vectorizers,try sklearn NearestNeighbors\\\n (although NN performs poorly with high dimensional inputs.')\n return None\n\n # Get labels, sort text IDs by cluster\n labels = self.results['labels']\n cluster_idx = {clust_id: np.where(labels == clust_id)[0]\n for clust_id in set(labels)}\n\n # Get centers, stack into array\n centroids = np.vstack([self.viz_matrix[indexes].mean(axis=0)\n for key, indexes in cluster_idx.items()])\n\n # Compute closeness of each term representation to each centroid\n order_centroids = np.array(centroids).argsort()[:, ::-1]\n\n # Organize terms into a dictionary\n cluster_terms = {clust_id: [self.terms[ind]\n for ind in order_centroids[idx, :topx]]\n for idx, clust_id in enumerate(cluster_idx.keys())}\n\n # Print results\n print(\"Top terms per cluster:\")\n for clust_id, terms in cluster_terms.items():\n words = ' | '.join(terms)\n print(\"Cluster {0} ({1} items): {2}\".format(clust_id,\n len(cluster_idx[clust_id]),\n words))\n\n return cluster_terms\n\n def item_counts(self):\n \"\"\" Print number of counts in each cluster \"\"\"\n for key, vals in self.results.items():\n if key == 'labels':\n continue\n print('Cluster {0}: {1} items'.format(key, len(vals)))\n\n def _organize(self, labels):\n \"\"\" Organize text from clusters into a dictionary \"\"\"\n # Organize text into respective clusters\n cluster_idx = {clust_id: np.where(labels == clust_id)[0]\n for clust_id in set(labels)}\n\n # Put results in a dictionary; key is cluster idx values are text\n results = {clust_id: [self.text[idx] for idx in cluster_idx[clust_id]]\n for clust_id in cluster_idx.keys()}\n results['labels'] = list(labels)\n\n return results\n\n def _pca(self, n, matrix):\n \"\"\" Perform PCA on the data \"\"\"\n return TruncatedSVD(n_components=n).fit_transform(matrix)\n\n def _safe_dense(self, matrix):\n \"\"\" Some algorithms don't accept sparse input; for these, make\n sure the input matrix is dense. \"\"\"\n if issparse(matrix):\n return matrix.todense()\n else:\n return matrix\n\n\nclass OnlineCluster(Cluster):\n \"\"\" Online (stream) clustering of textual data. Check each method\n to determine if the model is updating or ad-hoc predicting. These are not\n 'true' online methods as they preserve all seen data, as opposed to letting\n data points and clusters fade, merge, etc. over time.\n\n Usage:\n To initialize:\n >> with open('../data/cleaned_text.txt', 'r', encoding='utf8') as f:\n text = f.readlines()\n >> online = OnlineCluster(method='kmeans', text, visualize=True)\n\n To predict and update parameters if applicable:\n >> new_text = text[-10:]\n >> online.predict(new_text)\n \"\"\"\n def __init__(self, text, method, *args, **kwargs):\n \"\"\"\n Args:\n text: strings to be clustered (list of strings)\n method: algorithm to use to cluster (string)\n *args, **kwargs (optional):\n vectorizer: text representation. Defaults tfidf (array, optional)\n reduce_dim: reduce dim of representation matrix (int, optional)\n visualize: visualize clusters in 3D (bool, optional)\n \"\"\"\n # Only accept valid arguments\n assert method in ['kmeans', 'birch', 'hdbscan',\n 'dbscan', 'mean_shift'], \\\n 'Method incompatible with online clustering.'\n\n # Initialize inherited class\n super().__init__(text)\n\n # Get initial results\n self.results = self.__call__(method=method, *args,**kwargs)\n\n # Save args, set method\n self.__dict__.update(locals())\n self.method = eval('self._' + method)\n\n def predict(self, new_text):\n \"\"\" 'Predict' a new example based on cluster centroids and update params\n if applicable (kmeans, birch). If a custom (non-tfidf) text representation\n is being used, class assumes new_text is already in vectorized form.\n\n Args:\n new_text: list of strings to predict\n \"\"\"\n # Predict\n assert type(new_text) == list, 'Input should be list of strings.'\n self.text = list(set(self.text + new_text))\n new_matrix = self._transform(new_text)\n output_labels = self.method(new_matrix)\n\n # Update attribute for results, plotting\n self._update_results(output_labels)\n self.viz_matrix = vstack([self.viz_matrix, new_matrix])\n return output_labels\n\n def _kmeans(self, new_matrix):\n \"\"\" Updates parameters and predicts \"\"\"\n self.algorithm = self.algorithm.partial_fit(new_matrix)\n return self.algorithm.predict(new_matrix)\n\n def _birch(self, new_matrix):\n \"\"\" Updates parameters and predicts \"\"\"\n self.algorithm = self.algorithm.partial_fit(new_matrix)\n return self.algorithm.predict(new_matrix)\n\n def _hdbscan(self, new_matrix):\n \"\"\" Prediction only, HDBSCAN requires training to be done on dense\n matrices for prediction to work properly. This makes training\n inefficient, though. \"\"\"\n try:\n labels, _ = approximate_predict(self.algorithm,\n self._safe_dense(new_matrix))\n except AttributeError:\n try:\n self.algorithm.generate_prediction_data()\n labels, _ = approximate_predict(self.algorithm,\n self._safe_dense(new_matrix))\n except ValueError:\n print('Must (inefficiently) re-train with prediction_data=True')\n return labels\n\n def _dbscan(self, new_matrix):\n \"\"\" Prediction only \"\"\"\n # Extract labels\n labels = self.algorithm.labels_\n\n # Result is noise by default\n output = np.ones(shape=new_matrix.shape[0], dtype=int)*-1\n\n # Iterate all input samples for a label\n for idx, row in enumerate(new_matrix):\n\n # Find a core sample closer than EPS\n for i, row in enumerate(self.algorithm.components_):\n\n # If it's below the threshold of the dbscan model\n if cosine(row, x_core) < self.algorithm.eps:\n\n # Assign label of x_core to the input sample\n output[idx] = labels[self.algorithm.core_sample_indices_[i]]\n break\n\n return output\n\n def _mean_shift(self, new_matrix):\n \"\"\" Prediction only, not efficient \"\"\"\n return self.algorithm.predict(new_matrix)\n\n def _transform(self, new_text):\n \"\"\" Transform text to tfidf representation. Assumes already vectorized\n if tfidf matrix has not been initialized. \"\"\"\n if self.using_tfidf:\n return self.vectorizer.transform(new_text)\n else:\n return self.vectorizer(new_text)\n return new_matrix\n\n def _update_results(self, labels):\n \"\"\" Update running dictionary \"\"\"\n new_results = self._organize(labels)\n for key in self.results.keys():\n try:\n self.results[key] += new_results[key]\n except KeyError:\n continue\n\n\n\n",
"_____no_output_____"
],
[
"\n\nfrom matplotlib import pyplot as plt\nimport pandas as pd\nimport string\n\ncluster_dict = {2:'dbscan', 3:'spectral', 4:'kmeans', 5:'affinity_prop', 6:'agglomerative', 7:'mean_shift', 8:'birch'}\n\ndef clean(text):\n '''\n Clean text before running clusterer\n '''\n text = text.strip()\n text = text.lower()\n for punct in string.punctuation:\n text = text.replace(punct, ' ')\n lst = text.split()\n text = \" \".join(lst)\n for t in text:\n if t not in string.printable:\n text = text.replace(t, '')\n return text\n\ndef clust():\n df = pd.read_csv('/content/drive/My Drive/data/NewsCluster.csv')\n data = df[\"Title\"].tolist()\n\n data = [clean(dt) for dt in data ]\n\n # for dt in data:\n # data[data.index(dt)] = clean(dt)\n\n data = pd.DataFrame(data, columns=[\"text\"])\n data['text'].dropna(inplace=True)\n\n # %matplotlib inline\n\n\n clustering = Cluster(data.text)\n # results = clustering(method='dbscan', vectorizer=None, \n # reduce_dim=None, viz=True, eps=0.9)\n \n results = clustering(method='kmeans', vectorizer=None, \n reduce_dim=None, viz=True, n_clusters=12)\n \n # results = clustering(method='birch', vectorizer=None, \n # reduce_dim=None, viz=True, n_clusters=12)\n \n # results = clustering(method='agglomerative', vectorizer=None, \n # reduce_dim=None, viz=True, n_clusters=12)\n \n # results = clustering(method='spectral', vectorizer=None, \n # reduce_dim=None, viz=True, n_clusters=12)\n \n # results = clustering(method='affinity_prop', vectorizer=None, \n # reduce_dim=None, viz=True, damping=0.5)\n \n results = clustering(method='minikmeans', vectorizer=None, \n reduce_dim=None, viz=True, n_clusters=12)\n \n \n \n # clustering = Cluster(data.text)\n # for i in range(2,9):\n # print(cluster_dict[i])\n # if i == 4:\n # result = clustering(cluster_dict[i])\n # else:\n # result = clustering(cluster_dict[i])\n \n # print(result)\n\nclust()\n\n\n\n",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
cb3c75b9509e8a440360a804b00247acb7deb279 | 526,198 | ipynb | Jupyter Notebook | paper/Advection_diffusion/Old/AD_sensor_density_20_20_40.ipynb | remykusters/DeePyMoD | c53ce939c5e6a5f0207b042d8d42bc0197d66073 | [
"MIT"
] | null | null | null | paper/Advection_diffusion/Old/AD_sensor_density_20_20_40.ipynb | remykusters/DeePyMoD | c53ce939c5e6a5f0207b042d8d42bc0197d66073 | [
"MIT"
] | null | null | null | paper/Advection_diffusion/Old/AD_sensor_density_20_20_40.ipynb | remykusters/DeePyMoD | c53ce939c5e6a5f0207b042d8d42bc0197d66073 | [
"MIT"
] | null | null | null | 321.0482 | 61,400 | 0.930443 | [
[
[
"# 2D Advection-Diffusion equation",
"_____no_output_____"
],
[
"in this notebook we provide a simple example of the DeepMoD algorithm and apply it on the 2D advection-diffusion equation. ",
"_____no_output_____"
]
],
[
[
"# General imports\nimport numpy as np\nimport torch\nimport matplotlib.pylab as plt\n\n# DeepMoD functions\n\nfrom deepymod import DeepMoD\nfrom deepymod.model.func_approx import NN, Siren\nfrom deepymod.model.library import Library2D\nfrom deepymod.model.constraint import LeastSquares\nfrom deepymod.model.sparse_estimators import Threshold,PDEFIND\nfrom deepymod.training import train\nfrom deepymod.training.sparsity_scheduler import TrainTestPeriodic\nfrom scipy.io import loadmat\n\n# Settings for reproducibility\nnp.random.seed(42)\ntorch.manual_seed(0)\n\n\nif torch.cuda.is_available():\n device = 'cuda'\nelse:\n device = 'cpu'\n\n\n%load_ext autoreload\n%autoreload 2",
"_____no_output_____"
]
],
[
[
"## Prepare the data",
"_____no_output_____"
],
[
"Next, we prepare the dataset.",
"_____no_output_____"
]
],
[
[
"data = np.load('experimental_2DAD_long.npy')[:,:,:40]",
"_____no_output_____"
],
[
"data.shape",
"_____no_output_____"
],
[
"down_data= np.take(np.take(np.take(data,np.arange(0,data.shape[0],2),axis=0),np.arange(0,data.shape[1],2),axis=1),np.arange(0,data.shape[2],1),axis=2)",
"_____no_output_____"
],
[
"down_data.shape",
"_____no_output_____"
],
[
"steps = down_data.shape[2]\nwidth = down_data.shape[0]\nwidth_2 = down_data.shape[1]",
"_____no_output_____"
],
[
"x_arr = np.arange(0,width)\ny_arr = np.arange(0,width_2)\nt_arr = np.arange(0,steps)\nx_grid, y_grid, t_grid = np.meshgrid(x_arr, y_arr, t_arr, indexing='ij')\nX = np.transpose((t_grid.flatten(), x_grid.flatten(), y_grid.flatten()))",
"_____no_output_____"
],
[
"plt.imshow(down_data[:,:,20])",
"_____no_output_____"
]
],
[
[
"Next we plot the dataset for three different time-points",
"_____no_output_____"
],
[
"We flatten it to give it the right dimensions for feeding it to the network:",
"_____no_output_____"
]
],
[
[
"X = np.transpose((t_grid.flatten()/5, x_grid.flatten()/np.max(x_grid), y_grid.flatten()/np.max(x_grid)))\n#X = np.transpose((t_grid.flatten(), x_grid.flatten(), y_grid.flatten()))\n\ny = np.float32(down_data.reshape((down_data.size, 1)))\ny = y/10.",
"_____no_output_____"
],
[
"np.max(y,axis=0)",
"_____no_output_____"
],
[
"number_of_samples = 5000\n\nidx = np.random.permutation(y.shape[0])\nX_train = torch.tensor(X[idx, :][:number_of_samples], dtype=torch.float32, requires_grad=True).to(device)\ny_train = torch.tensor(y[idx, :][:number_of_samples], dtype=torch.float32).to(device)\n\n",
"_____no_output_____"
]
],
[
[
"## Configuration of DeepMoD",
"_____no_output_____"
],
[
"Configuration of the function approximator: Here the first argument is the number of input and the last argument the number of output layers.",
"_____no_output_____"
]
],
[
[
"network = NN(3, [30, 30, 30,30], 1)",
"_____no_output_____"
]
],
[
[
"Configuration of the library function: We select athe library with a 2D spatial input. Note that that the max differential order has been pre-determined here out of convinience. So, for poly_order 1 the library contains the following 12 terms:\n* [$1, u_x, u_y, u_{xx}, u_{yy}, u_{xy}, u, u u_x, u u_y, u u_{xx}, u u_{yy}, u u_{xy}$]",
"_____no_output_____"
]
],
[
[
"library = Library2D(poly_order=1) ",
"_____no_output_____"
]
],
[
[
"Configuration of the sparsity estimator and sparsity scheduler used. In this case we use the most basic threshold-based Lasso estimator and a scheduler that asseses the validation loss after a given patience. If that value is smaller than 1e-5, the algorithm is converged. ",
"_____no_output_____"
]
],
[
[
"estimator = Threshold(0.05) \nsparsity_scheduler = TrainTestPeriodic(periodicity=50, patience=25, delta=1e-5) ",
"_____no_output_____"
]
],
[
[
"\nConfiguration of the sparsity estimator ",
"_____no_output_____"
]
],
[
[
"constraint = LeastSquares() \n# Configuration of the sparsity scheduler",
"_____no_output_____"
]
],
[
[
"Now we instantiate the model and select the optimizer ",
"_____no_output_____"
]
],
[
[
"model = DeepMoD(network, library, estimator, constraint).to(device)\n\n# Defining optimizer\noptimizer = torch.optim.Adam(model.parameters(), betas=(0.99, 0.99), amsgrad=True, lr=1e-3) \n",
"_____no_output_____"
]
],
[
[
"## Run DeepMoD ",
"_____no_output_____"
],
[
"We can now run DeepMoD using all the options we have set and the training data:\n* The directory where the tensorboard file is written (log_dir)\n* The ratio of train/test set used (split)\n* The maximum number of iterations performed (max_iterations)\n* The absolute change in L1 norm considered converged (delta)\n* The amount of epochs over which the absolute change in L1 norm is calculated (patience)",
"_____no_output_____"
]
],
[
[
"train(model, X_train, y_train, optimizer,sparsity_scheduler, log_dir='runs/test2/', split=0.8, max_iterations=100000, delta=1e-7, patience=1000) ",
" 31100 MSE: 5.79e-02 Reg: 3.71e-03 L1: 1.46e+00 "
]
],
[
[
"Sparsity masks provide the active and non-active terms in the PDE:",
"_____no_output_____"
]
],
[
[
"sol = model(torch.tensor(X, dtype=torch.float32))[0].reshape((width,width_2,steps)).detach().numpy()",
"_____no_output_____"
],
[
"ux = model(torch.tensor(X, dtype=torch.float32))[2][0][:,1].reshape((width,width_2,steps)).detach().numpy()\nuy = model(torch.tensor(X, dtype=torch.float32))[2][0][:,2].reshape((width,width_2,steps)).detach().numpy()",
"_____no_output_____"
],
[
"uxx = model(torch.tensor(X, dtype=torch.float32))[2][0][:,3].reshape((width,width_2,steps)).detach().numpy()\nuyy = model(torch.tensor(X, dtype=torch.float32))[2][0][:,4].reshape((width,width_2,steps)).detach().numpy()",
"_____no_output_____"
],
[
"import pysindy as ps",
"_____no_output_____"
],
[
"fd_spline = ps.SINDyDerivative(kind='spline', s=1e-2)\nfd_spectral = ps.SINDyDerivative(kind='spectral')\nfd_sg = ps.SINDyDerivative(kind='savitzky_golay', left=0.5, right=0.5, order=3)",
"_____no_output_____"
],
[
"y = down_data[2,:,19]\nx = x_arr\nplt.plot(x,y, 'b--')\nplt.plot(x,sol[2,:,19]*np.max(down_data),'b', label='x = 1')\ny = down_data[5,:,19]\nx = x_arr\nplt.plot(x,y, 'g--')\nplt.plot(x,sol[5,:,19]*np.max(down_data),'g', label='x = 5')\ny = down_data[11,:,19]\nx = x_arr\nplt.plot(x,y, 'r--')\nplt.plot(x,sol[11,:,19]*np.max(down_data),'r', label='x = 10')\nplt.legend()",
"_____no_output_____"
],
[
"y = down_data[1,:,1]\nx = x_arr\nplt.plot(x,y, 'b--')\nplt.plot(x,sol[1,:,1]*np.max(down_data),'b', label='x = 1')\ny = down_data[5,:,1]\nx = x_arr\nplt.plot(x,y, 'g--')\nplt.plot(x,sol[5,:,1]*np.max(down_data),'g', label='x = 5')\ny = down_data[11,:,1]\nx = x_arr\nplt.plot(x,y, 'r--')\nplt.plot(x,sol[11,:,1]*np.max(down_data),'r', label='x = 10')\nplt.legend()",
"_____no_output_____"
],
[
"np.max(down_data)/100",
"_____no_output_____"
],
[
"plt.plot(x,fd_sg(y,x), 'ro')",
"_____no_output_____"
],
[
"y = down_data[1,:,19]\nx = x_arr\nplt.plot(x,fd_sg(y,x), 'b--')\nplt.plot(x,uy[1,:,19]*np.max(down_data)/100,'b', label='x = 1')\ny = down_data[5,:,19]\nx = x_arr\nplt.plot(x,fd_sg(y,x), 'g--')\nplt.plot(x,uy[5,:,19]*np.max(down_data)/100,'g', label='x = 5')\ny = down_data[10,:,19]\nx = x_arr\nplt.plot(x,fd_sg(y,x), 'r--')\nplt.plot(x,uy[10,:,19]*np.max(down_data)/100,'r', label='x = 10')\nplt.legend()",
"_____no_output_____"
],
[
"y = down_data[2,:,19]\nx = x_arr\nplt.plot(x,fd_sg(fd_sg(y,x)), 'b--')\nplt.plot(x,uyy[2,:,19]*np.max(down_data)/(100*100),'b')\ny = down_data[5,:,19]\nx = x_arr\nplt.plot(x,fd_sg(fd_sg(y,x)), 'g--')\nplt.plot(x,uyy[5,:,19]*np.max(down_data)/(100*100),'g')\ny = down_data[11,:,19]\nx = x_arr\nplt.plot(x,fd_sg(fd_sg(y,x)), 'r--')\nplt.plot(x,uyy[11,:,19]*np.max(down_data)/(100*100),'r')",
"_____no_output_____"
],
[
"\n\nfig = plt.figure(figsize=(15,5))\n\nplt.subplot(1,3, 1)\ny = down_data[2,:,2]\nx = x_arr\nplt.plot(x,y)\nplt.plot(x,sol[2,:,2]*np.max(down_data))\nplt.legend()\n\nplt.subplot(1,3, 2)\ny = down_data[2,:,2]\nx = x_arr\nplt.plot(x,y)\nplt.plot(x,sol[2,:,2]*np.max(down_data))\n\nplt.subplot(1,3, 3)\ny = down_data[2,:,2]\nx = x_arr\nplt.plot(x,y)\nplt.plot(x,sol[2,:,2]*np.max(down_data))\nplt.legend()\n\nplt.show()",
"_____no_output_____"
],
[
"fig = plt.figure(figsize=(15,5))\n\nplt.subplot(1,3, 1)\nplt.imshow(sol[:,:,1], aspect=0.5)\n\nplt.subplot(1,3, 2)\nplt.imshow(sol[:,:,19], aspect=0.5)\n\nplt.subplot(1,3, 3)\nplt.imshow(sol[:,:,39], aspect=0.5)\n\n\nplt.savefig('reconstruction.pdf')",
"_____no_output_____"
],
[
"fig = plt.figure(figsize=(15,5))\n\nplt.subplot(1,3, 1)\nplt.imshow(down_data[:,:,1], aspect=0.5)\n\nplt.subplot(1,3, 2)\nplt.imshow(down_data[:,:,19], aspect=0.5)\n\nplt.subplot(1,3, 3)\nplt.imshow(down_data[:,:,39], aspect=0.5)\n\nplt.savefig('original_20_20_40.pdf')",
"_____no_output_____"
],
[
"np.max(down_data)",
"_____no_output_____"
],
[
"plt.plot(x,sol[5,:,10]*np.max(down_data))",
"_____no_output_____"
],
[
"noise_level = 0.025\ny_noisy = y + noise_level * np.std(y) * np.random.randn(y.size)",
"_____no_output_____"
],
[
"plt.plot(x,uy[25,:,10])\nplt.plot(x,ux[25,:,10])",
"_____no_output_____"
],
[
"fig = plt.figure(figsize=(15,5))\n\nplt.subplot(1,3, 1)\nplt.plot(fd_spline(y.reshape(-1,1),x), label='Ground truth',linewidth=3)\nplt.plot(fd_spline(y_noisy.reshape(-1,1),x), label='Spline',linewidth=3)\nplt.legend()\n\nplt.subplot(1,3, 2)\nplt.plot(fd_spline(y.reshape(-1,1),x), label='Ground truth',linewidth=3)\nplt.plot(fd_sg(y_noisy.reshape(-1,1),x), label='Savitzky Golay',linewidth=3)\nplt.legend()\n\nplt.subplot(1,3, 3)\nplt.plot(fd_spline(y.reshape(-1,1),x), label='Ground truth',linewidth=3)\nplt.plot(uy[25,:,10],linewidth=3, label='DeepMoD')\nplt.legend()\n\nplt.show()",
"_____no_output_____"
],
[
"plt.plot(ux[10,:,5])\nax = plt.subplot(1,1,1)\nax.plot(fd(y.reshape(-1,1),x), label='Ground truth')\nax.plot(fd_sline(y_noisy.reshape(-1,1),x), label='Spline')\nax.plot(fd_sg(y_noisy.reshape(-1,1),x), label='Savitzky Golay')\nax.legend()",
"_____no_output_____"
],
[
"plt.plot(model(torch.tensor(X, dtype=torch.float32))[2][0].detach().numpy())",
"_____no_output_____"
],
[
"sol = model(torch.tensor(X, dtype=torch.float32))[0]",
"_____no_output_____"
],
[
"plt.imshow(sol[:,:,4].detach().numpy())",
"_____no_output_____"
],
[
"plt.plot(sol[10,:,6].detach().numpy())\nplt.plot(down_data[10,:,6]/np.max(down_data))",
"_____no_output_____"
],
[
"x = np.arange(0,len(y))",
"_____no_output_____"
],
[
"import pysindy as ps\ndiffs = [\n ('PySINDy Finite Difference', ps.FiniteDifference()),\n ('Smoothed Finite Difference', ps.SmoothedFiniteDifference()),\n ('Savitzky Golay', ps.SINDyDerivative(kind='savitzky_golay', left=0.5, right=0.5, order=3)),\n ('Spline', ps.SINDyDerivative(kind='spline', s=1e-2)),\n ('Trend Filtered', ps.SINDyDerivative(kind='trend_filtered', order=0, alpha=1e-2)),\n ('Spectral', ps.SINDyDerivative(kind='spectral')),\n]",
"_____no_output_____"
],
[
"fd = ps.SINDyDerivative(kind='spline', s=1e-2)",
"_____no_output_____"
],
[
"y = down_data[:,10,9]/np.max(down_data)",
"_____no_output_____"
],
[
"x = np.arange(0,len(y))",
"_____no_output_____"
],
[
"t = np.linspace(0,1,5)\nX = np.vstack((np.sin(t),np.cos(t))).T",
"_____no_output_____"
],
[
"plt.plot(y)",
"_____no_output_____"
],
[
"plt.plot(fd(y.reshape(-1,1),x))",
"_____no_output_____"
],
[
"y.shape",
"_____no_output_____"
],
[
"plt.plot(fd._differentiate(y.reshape(-1,1),x))\n",
"_____no_output_____"
],
[
"plt.plot(ux[:,10,6])",
"_____no_output_____"
],
[
"plt.plot(sol[:,10,6].detach().numpy())\nplt.plot(down_data[:,10,6]/np.max(down_data))",
"_____no_output_____"
],
[
"model.sparsity_masks",
"_____no_output_____"
]
],
[
[
"estimatior_coeffs gives the magnitude of the active terms:",
"_____no_output_____"
]
],
[
[
"print(model.estimator_coeffs())",
"[array([[ 0.02962998],\n [ 1.0108052 ],\n [ 0. ],\n [ 0.0981451 ],\n [ 0.21595249],\n [ 0. ],\n [-0.04595437],\n [ 0. ],\n [ 0. ],\n [ 0. ],\n [ 0. ],\n [ 0. ]], dtype=float32)]\n"
],
[
"plt.contourf(ux[:,:,10])",
"_____no_output_____"
],
[
"plt.plot(ux[25,:,2])",
"_____no_output_____"
],
[
"ax = plt.subplot(1,1,1)\nax.plot(fd(y.reshape(-1,1),x), label='Ground truth')\nax.plot(fd_sline(y_noisy.reshape(-1,1),x), label='Spline')\nax.plot(fd_sg(y_noisy.reshape(-1,1),x), label='Savitzky Golay')\nax.legend()",
"_____no_output_____"
],
[
"import pysindy as ps",
"_____no_output_____"
],
[
"fd_spline = ps.SINDyDerivative(kind='spline', s=1e-2)\nfd_spectral = ps.SINDyDerivative(kind='spectral')\nfd_sg = ps.SINDyDerivative(kind='savitzky_golay', left=0.5, right=0.5, order=3)",
"_____no_output_____"
],
[
"y = u_v[25,:,2]\nx = y_v[25,:,2]\nplt.scatter(x,y)",
"_____no_output_____"
],
[
"y.shape",
"_____no_output_____"
],
[
"noise_level = 0.025\ny_noisy = y + noise_level * np.std(y) * np.random.randn(y.size)",
"_____no_output_____"
],
[
"ax = plt.subplot(1,1,1)\nax.plot(x,y_noisy, label=\"line 1\")\nax.plot(x,y, label=\"line 2\")\nax.legend()",
"_____no_output_____"
],
[
"ax = plt.subplot(1,1,1)\nax.plot(fd(y.reshape(-1,1),x), label='Ground truth')\nax.plot(fd_sline(y_noisy.reshape(-1,1),x), label='Spline')\nax.plot(fd_sg(y_noisy.reshape(-1,1),x), label='Savitzky Golay')\nax.legend()\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3c7c9c0d888afccd9097b237e95a9c5194ac28 | 3,051 | ipynb | Jupyter Notebook | example.ipynb | acse-jl8920/IRP-Johnson | 2a70ab9b286726847cc5d5bb65232b2b241f4d5a | [
"MIT"
] | null | null | null | example.ipynb | acse-jl8920/IRP-Johnson | 2a70ab9b286726847cc5d5bb65232b2b241f4d5a | [
"MIT"
] | null | null | null | example.ipynb | acse-jl8920/IRP-Johnson | 2a70ab9b286726847cc5d5bb65232b2b241f4d5a | [
"MIT"
] | null | null | null | 25.214876 | 79 | 0.503114 | [
[
[
"from Model import UNet\nfrom PIL import Image\nimport numpy as np\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"unet = UNet()",
"_____no_output_____"
],
[
"img = np.asarray(Image.open('your_image_dir'))/255.\nunet.load_weights('your_model_weight')\n",
"_____no_output_____"
],
[
"result = unet.detect_single_img(img)",
"_____no_output_____"
],
[
"def label_colormap(N=256):\n\n def bitget(byteval, idx):\n return ((byteval & (1 << idx)) != 0)\n\n cmap = np.zeros((N, 3))\n for i in range(0, N):\n id = i\n r, g, b = 0, 0, 0\n for j in range(0, 8):\n r = np.bitwise_or(r, (bitget(id, 0) << 7 - j))\n g = np.bitwise_or(g, (bitget(id, 1) << 7 - j))\n b = np.bitwise_or(b, (bitget(id, 2) << 7 - j))\n id = (id >> 3)\n cmap[i, 0] = r\n cmap[i, 1] = g\n cmap[i, 2] = b\n cmap = cmap.astype(np.float32) / 255\n return cmap\n\nplt_handlers = []\nplt_titles = []\nplt.figure()\nplt.axis('off')\n# plt.imshow(img)\nfc= label_colormap(3)[2]\n# label2rgb(lbl, colormap = )\nplt.imshow(result*255*fc[1],alpha=0.6)\np = plt.Rectangle((0, 0), 1, 1, fc=fc)\nplt_handlers.append(p)\nplt_titles.append(': {name}'\n .format(name='crater_predicted'))\nplt.legend(plt_handlers, plt_titles, loc='lower right', framealpha=.5)\nplt.savefig('Img_plot/'+name+'_pred_mask.png')",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code"
]
] |
cb3c7d10c4569c5dbdd81caf1006a2f277b53699 | 368,192 | ipynb | Jupyter Notebook | cross_asset_skewness.ipynb | BigCandyBunny/notebooks | b66a28861e0b46fb36701179b6a120d5e8b7d417 | [
"MIT"
] | 1 | 2022-03-26T22:22:33.000Z | 2022-03-26T22:22:33.000Z | cross_asset_skewness.ipynb | BigCandyBunny/notebooks | b66a28861e0b46fb36701179b6a120d5e8b7d417 | [
"MIT"
] | null | null | null | cross_asset_skewness.ipynb | BigCandyBunny/notebooks | b66a28861e0b46fb36701179b6a120d5e8b7d417 | [
"MIT"
] | null | null | null | 230.40801 | 95,332 | 0.893735 | [
[
[
"# Cross-asset skewness\n\nThis notebook analyses cross-asset cross-sectional skewness strategy. The strategy takes long positions on contracts with most negative historical skewness and short positions on ones with most positive skewness.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nfrom datetime import datetime\nimport logging\nimport warnings\nwarnings.simplefilter(action='ignore', category=FutureWarning)\n\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport matplotlib.ticker as mticker\nplt.style.use('bmh')\n\nfrom vivace.backtest import signal\nfrom vivace.backtest import processing\nfrom vivace.backtest.contract import all_futures_baltas2019\nfrom vivace.backtest.engine import BacktestEngine\nfrom vivace.backtest.enums import Strategy\nfrom vivace.backtest.stats import Performance",
"_____no_output_____"
]
],
[
[
"# Data\n\nVarious futures contracts in commodity, currency, government bond futures and equity index futures are tested. Some contracts are missing in this data set due to data availability.",
"_____no_output_____"
]
],
[
[
"all_futures_baltas2019",
"_____no_output_____"
],
[
"all_futures_baltas2019.shape",
"_____no_output_____"
]
],
[
[
"# Performance",
"_____no_output_____"
],
[
"## Run backtest\n\nFor each asset class, a simple portfolio is constructed by using trailing 1-year returns of each futures. Unlike studies in equities, the recent 1-month is included in the formation period. Positions are rebalanced on a monthly basis.",
"_____no_output_____"
]
],
[
[
"engine_commodity = BacktestEngine(\n strategy=Strategy.DELTA_ONE.value,\n instrument=all_futures_baltas2019.query('asset_class == \"commodity\"').index,\n signal=signal.XSSkewness(lookback=252, \n post_process=processing.Pipeline([\n processing.Negate(),\n processing.AsFreq(freq='m', method='pad')\n ])),\n log_level=logging.WARN,\n)\nengine_commodity.run()",
"_____no_output_____"
],
[
"commodity_portfolio_return = (engine_commodity.calculate_equity_curve(calculate_net=False)\n .rename('Commodity skewness portfolio'))",
"_____no_output_____"
],
[
"engine_equity = BacktestEngine(\n strategy=Strategy.DELTA_ONE.value,\n instrument=all_futures_baltas2019.query('asset_class == \"equity\"').index,\n signal=signal.XSSkewness(lookback=252, \n post_process=processing.Pipeline([\n processing.Negate(),\n processing.AsFreq(freq='m', method='pad')\n ])),\n log_level=logging.WARN,\n)\nengine_equity.run()",
"_____no_output_____"
],
[
"equity_portfolio_return = (engine_equity.calculate_equity_curve(calculate_net=False)\n .rename('Equity skewness portfolio'))",
"_____no_output_____"
],
[
"engine_fixed_income = BacktestEngine(\n strategy=Strategy.DELTA_ONE.value,\n instrument=all_futures_baltas2019.query('asset_class == \"fixed_income\"').index,\n signal=signal.XSSkewness(lookback=252, \n post_process=processing.Pipeline([\n processing.Negate(),\n processing.AsFreq(freq='m', method='pad')\n ])),\n log_level=logging.WARN,\n)\nengine_fixed_income.run()",
"_____no_output_____"
],
[
"fixed_income_portfolio_return = (engine_fixed_income.calculate_equity_curve(calculate_net=False)\n .rename('Fixed income skewness portfolio'))",
"_____no_output_____"
],
[
"engine_currency = BacktestEngine(\n strategy=Strategy.DELTA_ONE.value,\n instrument=all_futures_baltas2019.query('asset_class == \"currency\"').index,\n signal=signal.XSSkewness(lookback=252, \n post_process=processing.Pipeline([\n processing.Negate(),\n processing.AsFreq(freq='m', method='pad')\n ])),\n log_level=logging.WARN,\n)\nengine_currency.run()",
"_____no_output_____"
],
[
"currency_portfolio_return = (engine_currency.calculate_equity_curve(calculate_net=False)\n .rename('Currency skewness portfolio'))",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(2, 2, figsize=(14, 8), sharex=True)\ncommodity_portfolio_return.plot(ax=ax[0][0], logy=True)\nequity_portfolio_return.plot(ax=ax[0][1], logy=True)\nfixed_income_portfolio_return.plot(ax=ax[1][0], logy=True)\ncurrency_portfolio_return.plot(ax=ax[1][1], logy=True)\n\nax[0][0].set_title('Commodity skewness portfolio')\nax[0][1].set_title('Equity skewness portfolio')\nax[1][0].set_title('Fixed income skewness portfolio')\nax[1][1].set_title('Currency skewness portfolio')\nax[0][0].set_ylabel('Cumulative returns');\nax[1][0].set_ylabel('Cumulative returns');",
"_____no_output_____"
],
[
"pd.concat((\n commodity_portfolio_return.pipe(Performance).summary(),\n equity_portfolio_return.pipe(Performance).summary(),\n fixed_income_portfolio_return.pipe(Performance).summary(),\n currency_portfolio_return.pipe(Performance).summary(),\n), axis=1)",
"_____no_output_____"
]
],
[
[
"## Performance since 1990\nIn the original paper, performance since 1990 is reported. The result below confirms that all skewness based portfolios exhibited positive performance over time.\nInterestingly the equity portfolio somewhat performed weakly in the backtest. This could be due to the slightly different data set.",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots(2, 2, figsize=(14, 8), sharex=True)\ncommodity_portfolio_return['1990':].plot(ax=ax[0][0], logy=True)\nequity_portfolio_return['1990':].plot(ax=ax[0][1], logy=True)\nfixed_income_portfolio_return['1990':].plot(ax=ax[1][0], logy=True)\ncurrency_portfolio_return['1990':].plot(ax=ax[1][1], logy=True)\n\nax[0][0].set_title('Commodity skewness portfolio')\nax[0][1].set_title('Equity skewness portfolio')\nax[1][0].set_title('Fixed income skewness portfolio')\nax[1][1].set_title('Currency skewness portfolio')\nax[0][0].set_ylabel('Cumulative returns');\nax[1][0].set_ylabel('Cumulative returns');",
"_____no_output_____"
]
],
[
[
"## GSF\nThe authors defines the global skewness factor (GSF) by combining the 4 asset classes with equal vol weighting. Here, the 4 backtests are simply combined with each ex-post realised volatility.",
"_____no_output_____"
]
],
[
[
"def get_leverage(equity_curve: pd.Series) -> float:\n return 0.1 / (equity_curve.pct_change().std() * (252 ** 0.5))",
"_____no_output_____"
],
[
"gsf = pd.concat((\n commodity_portfolio_return.pct_change() * get_leverage(commodity_portfolio_return),\n equity_portfolio_return.pct_change() * get_leverage(equity_portfolio_return),\n fixed_income_portfolio_return.pct_change() * get_leverage(fixed_income_portfolio_return),\n currency_portfolio_return.pct_change() * get_leverage(currency_portfolio_return),\n), axis=1).mean(axis=1)\ngsf = gsf.fillna(0).add(1).cumprod().rename('GSF')",
"_____no_output_____"
],
[
"fig, ax = plt.subplots(1, 2, figsize=(14, 4))\ngsf.plot(ax=ax[0], logy=True);\ngsf['1990':].plot(ax=ax[1], logy=True);\nax[0].set_title('GSF portfolio')\nax[1].set_title('Since 1990')\nax[0].set_ylabel('Cumulative returns');",
"_____no_output_____"
],
[
"pd.concat((\n gsf.pipe(Performance).summary(),\n gsf['1990':].pipe(Performance).summary().add_suffix(' (since 1990)')\n), axis=1)",
"_____no_output_____"
]
],
[
[
"## Post publication",
"_____no_output_____"
]
],
[
[
"publication_date = datetime(2019, 12, 16)\n\nfig, ax = plt.subplots(1, 2, figsize=(14, 4))\ngsf.plot(ax=ax[0], logy=True);\nax[0].set_title('GSF portfolio')\nax[0].set_ylabel('Cumulative returns');\nax[0].axvline(publication_date, lw=1, ls='--', color='black')\nax[0].text(publication_date, 0.6, 'Publication date ', ha='right')\n\ngsf.loc[publication_date:].plot(ax=ax[1], logy=True);\nax[1].set_title('GSF portfolio (post publication)');",
"_____no_output_____"
]
],
[
[
"## Recent performance",
"_____no_output_____"
]
],
[
[
"fig, ax = plt.subplots(figsize=(8, 4.5))\ngsf.tail(252 * 2).plot(ax=ax, logy=True);\nax.set_title('GSF portfolio')\nax.set_ylabel('Cumulative returns');",
"_____no_output_____"
]
],
[
[
"# Reference\n- Baltas, N. and Salinas, G., 2019. Cross-Asset Skew. Available at SSRN.",
"_____no_output_____"
]
],
[
[
"print(f'Updated: {datetime.utcnow().strftime(\"%d-%b-%Y %H:%M\")}')",
"Updated: 06-Feb-2022 06:59\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
cb3c7e4a076b138698e6f1cc9bc6cac7c7582a70 | 82,663 | ipynb | Jupyter Notebook | notebooks/Vis vs and gifs for pos and neg.ipynb | DIAGNijmegen/adhesion_detection | 21a9c810a4dee3c640d31f30ee5fdff1bbce9146 | [
"Apache-2.0"
] | 2 | 2021-10-08T13:14:49.000Z | 2022-03-18T17:53:45.000Z | notebooks/Vis vs and gifs for pos and neg.ipynb | DIAGNijmegen/adhesion_detection | 21a9c810a4dee3c640d31f30ee5fdff1bbce9146 | [
"Apache-2.0"
] | 6 | 2021-10-12T20:55:53.000Z | 2021-10-12T21:03:45.000Z | notebooks/Vis vs and gifs for pos and neg.ipynb | DIAGNijmegen/adhesion_detection | 21a9c810a4dee3c640d31f30ee5fdff1bbce9146 | [
"Apache-2.0"
] | null | null | null | 29.69217 | 140 | 0.547718 | [
[
[
"from pathlib import Path\nfrom skimage import io\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport IPython.display as display\nfrom IPython.display import Image\nimport ipywidgets as widgets\n%matplotlib inline",
"_____no_output_____"
],
[
"vs_path = Path(\"../../data/visualization/visceral_slide/cumulative_vs_contour_reg_full\")\ngifs_path = Path(\"../../experiments/detection_gifs\")",
"_____no_output_____"
]
],
[
[
"# Positive",
"_____no_output_____"
]
],
[
[
"positive_glob = vs_path.glob(\"ANON*\")\npositive_ids = [file.stem for file in positive_glob]\n\nfor positive_id in positive_ids:\n print(positive_id)\n vs_img_path = vs_path / (positive_id + \".png\")\n vs_gif_path = gifs_path / (positive_id + \".gif\")\n \n vs_img_file = open(vs_img_path, \"rb\")\n vs_gif_file = open(vs_gif_path, \"rb\")\n \n wi1 = widgets.Image(value=vs_gif_file.read(), format='png')\n wi2 = widgets.Image(value=vs_img_file.read(), format='png')\n \n sidebyside = widgets.HBox([wi1, wi2])\n ## Finally, show.\n display.display(sidebyside)\n \n vs_img_file.close()\n vs_gif_file.close()",
"ANON4U03RE1DB_1.2.752.24.7.621449243.4490940_1.3.12.2.1107.5.2.30.26380.2019051309524052613408667.0.0.0\n"
]
],
[
[
"# Negative",
"_____no_output_____"
]
],
[
[
"negative_glob = vs_path.glob(\"R*\")\nnegative_ids = [file.stem for file in negative_glob]\n\nfor negative_id in negative_ids:\n print(negative_id)\n vs_img_path = vs_path / (negative_id + \".png\")\n vs_gif_path = gifs_path / (negative_id + \".gif\")\n \n vs_img_file = open(vs_img_path, \"rb\")\n vs_gif_file = open(vs_gif_path, \"rb\")\n \n wi1 = widgets.Image(value=vs_gif_file.read(), format='png')\n wi2 = widgets.Image(value=vs_img_file.read(), format='png')\n \n sidebyside = widgets.HBox([wi1, wi2])\n ## Finally, show.\n display.display(sidebyside)\n \n vs_img_file.close()\n vs_gif_file.close()",
"R127_1.2.752.24.7.621449242.2550529_1.3.12.2.1107.5.2.30.26380.2013100212055054292524360.0.0.0\n"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
cb3c963672aa5b35ddab4594a9900c86a1bc3a84 | 9,578 | ipynb | Jupyter Notebook | first_attempt_ae.ipynb | jameslee97/salty | 674d300fbdd1af18c322c911d186dc0e2aa68e98 | [
"MIT"
] | null | null | null | first_attempt_ae.ipynb | jameslee97/salty | 674d300fbdd1af18c322c911d186dc0e2aa68e98 | [
"MIT"
] | null | null | null | first_attempt_ae.ipynb | jameslee97/salty | 674d300fbdd1af18c322c911d186dc0e2aa68e98 | [
"MIT"
] | null | null | null | 24.065327 | 180 | 0.397682 | [
[
[
"%matplotlib notebook\n\nimport matplotlib.pylab as plt\nimport numpy as np\nimport seaborn as sns; sns.set()\n\nimport keras\nfrom keras.models import Sequential, Model\nfrom keras.layers import Dense\nfrom keras.optimizers import Adam\nimport salty\nfrom numpy import array\nfrom numpy import argmax\nfrom sklearn.preprocessing import LabelEncoder\nfrom sklearn.preprocessing import OneHotEncoder\nimport numpy as np\nfrom sklearn.model_selection import train_test_split\nfrom random import shuffle",
"_____no_output_____"
],
[
"devmodel = salty.aggregate_data(['density'])\ndevmodel.Data['smiles_string'] = devmodel.Data['smiles-cation'] + \".\" + devmodel.Data['smiles-anion']\nvalues = devmodel.Data['smiles_string']\nprint(values.shape)\nvalues2 = values.drop_duplicates();\nsmile_max_length = values2.map(len).max()",
"C:\\Users\\james\\Anaconda3\\lib\\site-packages\\pandas\\core\\generic.py:4388: FutureWarning: Attribute 'is_copy' is deprecated and will be removed in a future version.\n object.__getattribute__(self, name)\nC:\\Users\\james\\Anaconda3\\lib\\site-packages\\pandas\\core\\generic.py:4389: FutureWarning: Attribute 'is_copy' is deprecated and will be removed in a future version.\n return object.__setattr__(self, name, value)\n"
],
[
"def pad_smiles(smiles_string):\n if len(smiles_string) < smile_max_length:\n return smiles_string + \" \" * (smile_max_length - len(smiles_string))",
"_____no_output_____"
],
[
"padded_smiles = [pad_smiles(i) for i in values2 if pad_smiles(i)]",
"_____no_output_____"
],
[
"shuffle(padded_smiles)",
"_____no_output_____"
],
[
"def create_char_list(char_set, smile_series):\n for smile in smile_series:\n char_set.update(set(smile))\n return char_set",
"_____no_output_____"
],
[
"char_set = set()\nchar_set = create_char_list(char_set, padded_smiles)",
"_____no_output_____"
],
[
"char_set",
"_____no_output_____"
],
[
"char_list = list(char_set)\nchars_in_dict = len(char_list)\nchar_to_index = dict((c, i) for i, c in enumerate(char_list))\nindex_to_char = dict((i, c) for i, c in enumerate(char_list))",
"_____no_output_____"
],
[
"char_to_index",
"_____no_output_____"
],
[
"X_train = np.zeros((len(padded_smiles), smile_max_length, chars_in_dict), dtype=np.float32)",
"_____no_output_____"
],
[
"X_train.shape",
"_____no_output_____"
],
[
"for i, smile in enumerate(padded_smiles):\n for j, char in enumerate(smile):\n X_train[i, j, char_to_index[char]] = 1",
"_____no_output_____"
],
[
"X_train",
"_____no_output_____"
],
[
"X_train, X_test = train_test_split(X_train, test_size=0.33, random_state=42)",
"_____no_output_____"
],
[
"X_train.shape",
"_____no_output_____"
],
[
"# need to build RNN to encode. some issues include what the 'embedded dimension' is (vector length of embedded sequence)",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3c9d001bf2f1a13be57ce16ed07e6d00bf627d | 1,614 | ipynb | Jupyter Notebook | Module 5/FaceRec.ipynb | AshishJangra27/Autonomous-Cars | 20bf546e448a83263fa29a0aa322c69100d251d3 | [
"Apache-2.0"
] | 3 | 2021-09-11T15:44:35.000Z | 2022-01-27T14:29:34.000Z | Module 5/FaceRec.ipynb | AshishJangra27/Autonomous-Cars | 20bf546e448a83263fa29a0aa322c69100d251d3 | [
"Apache-2.0"
] | null | null | null | Module 5/FaceRec.ipynb | AshishJangra27/Autonomous-Cars | 20bf546e448a83263fa29a0aa322c69100d251d3 | [
"Apache-2.0"
] | 2 | 2021-05-15T10:03:46.000Z | 2021-08-02T12:57:27.000Z | 19.214286 | 67 | 0.506815 | [
[
[
"import serial\nimport cv2 as cv\nimport numpy as np\n\nfrom keras.models import load_model\n\nimport matplotlib.pyplot as plt\n\ns = serial.Serial(\"/dev/cu.usbmodem14101\", baudrate = 9600)",
"_____no_output_____"
],
[
"model = load_model(\"Epoch_10.h5\")",
"_____no_output_____"
],
[
"img = cv.imread('Dataset/train/Ashish/2.jpg')\n\nimg = cv.cvtColor(img, cv.COLOR_BGR2RGB)\n\nimg = cv.resize(img ,(128,128))\n\nimg = np.reshape(img, (1,128,128,3))",
"_____no_output_____"
],
[
"if (model.predict_classes(img)[0] == 1):\n s.write('1')",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code"
]
] |
cb3ca47c59662dfec85575fc23e14ae59258c0b8 | 6,135 | ipynb | Jupyter Notebook | examples/ch05/snippets_ipynb/05_03.ipynb | germanngc/PythonFundamentals | 14d22baa30d7c3c5404fc11362709669e92474b8 | [
"Apache-2.0"
] | null | null | null | examples/ch05/snippets_ipynb/05_03.ipynb | germanngc/PythonFundamentals | 14d22baa30d7c3c5404fc11362709669e92474b8 | [
"Apache-2.0"
] | null | null | null | examples/ch05/snippets_ipynb/05_03.ipynb | germanngc/PythonFundamentals | 14d22baa30d7c3c5404fc11362709669e92474b8 | [
"Apache-2.0"
] | null | null | null | 19.11215 | 83 | 0.471231 | [
[
[
"# 5.3 Tuples",
"_____no_output_____"
],
[
"### Creating Tuples",
"_____no_output_____"
]
],
[
[
"student_tuple = ()",
"_____no_output_____"
],
[
"student_tuple",
"_____no_output_____"
],
[
"len(student_tuple)",
"_____no_output_____"
],
[
"student_tuple = 'John', 'Green', 3.3",
"_____no_output_____"
],
[
"student_tuple",
"_____no_output_____"
],
[
"len(student_tuple)",
"_____no_output_____"
],
[
"another_student_tuple = ('Mary', 'Red', 3.3)",
"_____no_output_____"
],
[
"another_student_tuple",
"_____no_output_____"
],
[
"a_singleton_tuple = ('red',) # note the comma",
"_____no_output_____"
],
[
"a_singleton_tuple",
"_____no_output_____"
]
],
[
[
" \n\n### Accessing Tuple Elements",
"_____no_output_____"
]
],
[
[
"time_tuple = (9, 16, 1)",
"_____no_output_____"
],
[
"time_tuple",
"_____no_output_____"
],
[
"time_tuple[0] * 3600 + time_tuple[1] * 60 + time_tuple[2] ",
"_____no_output_____"
]
],
[
[
"### Adding Items to a String or Tuple",
"_____no_output_____"
]
],
[
[
"tuple1 = (10, 20, 30)",
"_____no_output_____"
],
[
"tuple2 = tuple1",
"_____no_output_____"
],
[
"tuple2",
"_____no_output_____"
],
[
"tuple1 += (40, 50)",
"_____no_output_____"
],
[
"tuple1 ",
"_____no_output_____"
],
[
"tuple2 ",
"_____no_output_____"
]
],
[
[
" \n\n### Appending Tuples to Lists",
"_____no_output_____"
]
],
[
[
"numbers = [1, 2, 3, 4, 5]",
"_____no_output_____"
],
[
"numbers += (6, 7)",
"_____no_output_____"
],
[
"numbers",
"_____no_output_____"
]
],
[
[
" \n\n### Tuples May Contain Mutable Objects",
"_____no_output_____"
]
],
[
[
"student_tuple = ('Amanda', 'Blue', [98, 75, 87])",
"_____no_output_____"
],
[
"student_tuple[2][1] = 85",
"_____no_output_____"
],
[
"student_tuple",
"_____no_output_____"
],
[
"##########################################################################\n# (C) Copyright 2019 by Deitel & Associates, Inc. and #\n# Pearson Education, Inc. All Rights Reserved. #\n# #\n# DISCLAIMER: The authors and publisher of this book have used their #\n# best efforts in preparing the book. These efforts include the #\n# development, research, and testing of the theories and programs #\n# to determine their effectiveness. The authors and publisher make #\n# no warranty of any kind, expressed or implied, with regard to these #\n# programs or to the documentation contained in these books. The authors #\n# and publisher shall not be liable in any event for incidental or #\n# consequential damages in connection with, or arising out of, the #\n# furnishing, performance, or use of these programs. #\n##########################################################################\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
cb3cb7cee66781db9fe59aa7fb243c2c03317788 | 1,765 | ipynb | Jupyter Notebook | 26th May 2015.ipynb | hargup/intern_diary_2015 | 2c5baa8ea0978b7e692cb1dd5aa355f5a69155a5 | [
"CC0-1.0"
] | null | null | null | 26th May 2015.ipynb | hargup/intern_diary_2015 | 2c5baa8ea0978b7e692cb1dd5aa355f5a69155a5 | [
"CC0-1.0"
] | null | null | null | 26th May 2015.ipynb | hargup/intern_diary_2015 | 2c5baa8ea0978b7e692cb1dd5aa355f5a69155a5 | [
"CC0-1.0"
] | null | null | null | 43.04878 | 661 | 0.678187 | [
[
[
"_(Written on 29th May)_\n\nOn this day I was investigating the reason for import test failures in the packages we were trying to build using `conda-build`, I found out that a few packages like `fabric` have specified `tests_requires` in their `setup.py` and conda-skeleton was not taking care of that.\nLike monday I tried to patch the distutils patch but for some reason it did not work out. I'll have a look at it again, that I had a nasty little headache, not a severe one but kind of one that doesn't yet you think. So I watching PyCon vidoes:, I watched [Beyond PEP8: best practices for writing intelligible code](https://www.youtube.com/watch?v=wf-BqAjZb8M). In video he talked how PEP8 is great but focusing too much on it can make the gorrilla invisible, that is it can take our attention from the reason problem, the problem of p vs np. And this is not the problem of computation complexity but of Pythonic vs Non Pythonic. Some of his tips were:\n\n- Factor out boiler plate code in the context managers and other pythonic contructs.\n- Use meaningful variable names\n- Use keyword argument to convey information about the parameters being passed.\n- Use Named Tuples",
"_____no_output_____"
]
]
] | [
"markdown"
] | [
[
"markdown"
]
] |
cb3cb8cfb0e8edfdcbd4c992e2543679adc79597 | 5,705 | ipynb | Jupyter Notebook | Tacademy_Python_Basic/Check_Basic_Concepts.ipynb | jeongu/TIL | 295df7a266d29c903fd8c675b475d7f69b312463 | [
"MIT"
] | null | null | null | Tacademy_Python_Basic/Check_Basic_Concepts.ipynb | jeongu/TIL | 295df7a266d29c903fd8c675b475d7f69b312463 | [
"MIT"
] | null | null | null | Tacademy_Python_Basic/Check_Basic_Concepts.ipynb | jeongu/TIL | 295df7a266d29c903fd8c675b475d7f69b312463 | [
"MIT"
] | null | null | null | 16.207386 | 46 | 0.427169 | [
[
[
"### 인코딩",
"_____no_output_____"
]
],
[
[
"# 기본 설정은 AscII",
"_____no_output_____"
],
[
"# 표현 1\n# coding : latin-1",
"_____no_output_____"
],
[
"# 표현 2\n# -*- coding: utf-8 -*-",
"_____no_output_____"
]
],
[
[
"## 제어문",
"_____no_output_____"
],
[
"### 단축평가",
"_____no_output_____"
]
],
[
[
"a & b\na | b",
"_____no_output_____"
],
[
"# 단축평가 : 앞에서 결정나면 뒤는 skip. 연산 속도에서 장점\na and b \na or b",
"_____no_output_____"
]
],
[
[
"### for ~ else",
"_____no_output_____"
]
],
[
[
"li = [10, 20, 30]\n\n# 정상적으로 반복문 종료 후 else 실행\nfor i in li:\n print(i)\nelse:\n print(\"exit\")",
"10\n20\n30\nexit\n"
],
[
"# break로 반복문 탈출하여 else 실행 안된다.\nfor i in li:\n print(i)\n break\nelse:\n print(\"exit\")",
"10\n"
]
],
[
[
"### 유용한 함수들",
"_____no_output_____"
]
],
[
[
"# filtering 조건이 없을 때\nIterL = filter(None, li)\nfor i in IterL:\n print(\"Item: {0}\".format(i))",
"Item: 10\nItem: 20\nItem: 30\n"
],
[
"def GetBiggerThan20(i):\n return i > 20",
"_____no_output_____"
],
[
"list(filter(GetBiggerThan20, li))",
"_____no_output_____"
],
[
"list(filter(lambda i: i>20, li))",
"_____no_output_____"
],
[
"list(range(10, 0, -1))",
"_____no_output_____"
],
[
"X = [1, 2, 3]\nY = [2, 3, 4]\nlist(map(pow, X, Y))",
"_____no_output_____"
],
[
"def Add10(i):\n return i+10",
"_____no_output_____"
],
[
"for i in map(Add10, li):\n print(\"Item: {0}\".format(i))",
"Item: 20\nItem: 30\nItem: 40\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3cbc8d5feaf0fb45fb8d79c8180ffe15e55a44 | 146,891 | ipynb | Jupyter Notebook | analysis/gfa/GFA-Zero-Calibration.ipynb | tanveerkarim/desicmx | f41133e3dc04c5eb60a6e2f79693ff864511c652 | [
"BSD-3-Clause"
] | 3 | 2019-11-15T23:17:23.000Z | 2019-11-27T17:19:33.000Z | analysis/gfa/GFA-Zero-Calibration.ipynb | tanveerkarim/desicmx | f41133e3dc04c5eb60a6e2f79693ff864511c652 | [
"BSD-3-Clause"
] | 4 | 2019-12-12T03:37:32.000Z | 2020-01-28T21:29:51.000Z | analysis/gfa/GFA-Zero-Calibration.ipynb | tanveerkarim/desicmx | f41133e3dc04c5eb60a6e2f79693ff864511c652 | [
"BSD-3-Clause"
] | 2 | 2019-12-20T08:21:52.000Z | 2020-06-30T15:21:53.000Z | 275.076779 | 89,536 | 0.922187 | [
[
[
"# GFA Zero Calibration",
"_____no_output_____"
],
[
"GFA calibrations should normally be updated in the following sequence: zeros, flats, darks.\n\nThis notebook should be run using a DESI kernel, e.g. `DESI master`.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline",
"_____no_output_____"
],
[
"import numpy as np\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"import os\nimport sys\nimport json\nimport collections\nfrom pathlib import Path",
"_____no_output_____"
],
[
"import scipy.interpolate\nimport scipy.stats",
"_____no_output_____"
],
[
"import fitsio",
"_____no_output_____"
]
],
[
[
"Install / upgrade the `desietcimg` package:",
"_____no_output_____"
]
],
[
[
"try:\n import desietcimg\n print('desietcimg already installed')\nexcept ImportError:\n print('Installing desietcimg...')\n !{sys.executable} -m pip install --user git+https://github.com/dkirkby/desietcimg",
"desietcimg already installed\n"
],
[
"upgrade = False\nif upgrade:\n print('Upgrading desietcimg...')\n !{sys.executable} -m pip install --upgrade --user git+https://github.com/dkirkby/desietcimg",
"_____no_output_____"
],
[
"import desietcimg.util\nimport desietcimg.plot\nimport desietcimg.gfa",
"_____no_output_____"
]
],
[
[
"NERSC configuration:",
"_____no_output_____"
]
],
[
[
"assert os.getenv('NERSC_HOST', False)",
"_____no_output_____"
],
[
"ROOT = Path('/project/projectdirs/desi/spectro/data/')\nassert ROOT.exists()",
"_____no_output_____"
]
],
[
[
"Initial GFA calibration:",
"_____no_output_____"
]
],
[
[
"CALIB = Path('/global/cscratch1/sd/dkirkby/GFA_calib.fits')\nassert CALIB.exists()",
"_____no_output_____"
]
],
[
[
"Directory for saving plots:",
"_____no_output_____"
]
],
[
[
"plotdir = Path('zerocal')\nplotdir.mkdir(exist_ok=True)",
"_____no_output_____"
]
],
[
[
"## Process Zero Sequences",
"_____no_output_____"
],
[
"Use a sequence of 200 zeros from [20191027](http://desi-www.kpno.noao.edu:8090/nightsum/nightsum-2019-10-27/nightsum.html).\n\n**Since this data has not yet been staged to its final location, we fetch it from the `lost+found` directory** (by overriding the definition of `ROOT` above):",
"_____no_output_____"
]
],
[
[
"ROOT = Path('/global/project/projectdirs/desi/spectro/staging/lost+found/')",
"_____no_output_____"
],
[
"files = desietcimg.util.find_files(ROOT / '20191027' / '{N}/gfa-{N}.fits.fz', min=21968, max=22167)",
"_____no_output_____"
]
],
[
[
"Build master zero images:",
"_____no_output_____"
]
],
[
[
"def build_master_zero():\n master_zero = {}\n GFA = desietcimg.gfa.GFACamera(calib_name=str(CALIB))\n for k, gfa in enumerate(GFA.gfa_names):\n raw, meta = desietcimg.util.load_raw(files, 'EXPTIME', hdu=gfa)\n assert np.all(np.array(meta['EXPTIME']) == 0)\n GFA.setraw(raw, name=gfa, subtract_master_zero=False, apply_gain=False)\n master_zero[gfa] = np.median(GFA.data, axis=0)\n return master_zero",
"_____no_output_____"
],
[
"%time master_zero = build_master_zero()",
"WARNING:root:Ignoring 503 bad overscan pixels for GUIDE8-E.\n"
]
],
[
[
"Estimate the readnoise in ADU for each amplifier, using the new master zero:",
"_____no_output_____"
]
],
[
[
"desietcimg.gfa.GFACamera.master_zero = master_zero",
"_____no_output_____"
],
[
"def get_readnoise(hrange=70, hbins=141, nsig=6, save=None):\n GFA = desietcimg.gfa.GFACamera(calib_name=str(CALIB))\n fig, axes = plt.subplots(5, 2, sharex=True, figsize=(18, 11))\n bins = np.linspace(-hrange, +hrange, hbins)\n noise = {}\n for k, gfa in enumerate(GFA.gfa_names):\n GFA.name = gfa\n ax = axes[k // 2, k % 2]\n raw, meta = desietcimg.util.load_raw(files, 'EXPTIME', hdu=gfa)\n assert np.all(np.array(meta['EXPTIME']) == 0)\n GFA.setraw(raw, name=gfa, subtract_master_zero=True, apply_gain=False)\n noise[gfa] = {}\n for j, amp in enumerate(GFA.amp_names):\n # Extract data for this quadrant.\n qdata = GFA.data[GFA.quad[amp]]\n X = qdata.reshape(-1)\n # Clip for std dev calculation.\n Xclipped, lo, hi = scipy.stats.sigmaclip(X, low=nsig, high=nsig)\n noise[gfa][amp] = np.std(Xclipped)\n label = f'{amp} {noise[gfa][amp]:.2f}'\n c = plt.rcParams['axes.prop_cycle'].by_key()['color'][j]\n ax.hist(X, bins=bins, label=label, color=c, histtype='step')\n for x in lo, hi:\n ax.axvline(x, ls='-', c=c, alpha=0.5)\n ax.set_yscale('log')\n ax.set_yticks([])\n if k in (8, 9):\n ax.set_xlabel('Zero Residual [ADU]')\n ax.set_xlim(bins[0], bins[-1])\n ax.legend(ncol=2, title=f'{gfa}', loc='upper left')\n plt.subplots_adjust(left=0.03, right=0.99, bottom=0.04, top=0.99, wspace=0.07, hspace=0.04)\n if save:\n plt.savefig(save)\n return noise",
"_____no_output_____"
],
[
"%time readnoise = get_readnoise(save=str(plotdir / 'GFA_readnoise.png'))",
"WARNING:root:Ignoring 503 bad overscan pixels for GUIDE8-E.\n"
],
[
"repr(readnoise)",
"_____no_output_____"
]
],
[
[
"## Save Updated Calibrations",
"_____no_output_____"
]
],
[
[
"desietcimg.gfa.save_calib_data('GFA_calib_zero.fits', master_zero=master_zero, readnoise=readnoise)",
"Using default master_dark\nUsing default pixel_mask\nUsing default gain\nUsing default tempfit\nSaved GFA calib data to GFA_calib_zero.fits.\n"
]
],
[
[
"Use this for subsequent flat and dark calibrations:",
"_____no_output_____"
]
],
[
[
"!cp GFA_calib_zero.fits {CALIB}",
"_____no_output_____"
]
],
[
[
"## Comparisons",
"_____no_output_____"
],
[
"Compare with the read noise values from the lab studies and Aaron Meisner's [independent analysis](https://desi.lbl.gov/trac/wiki/Commissioning/Planning/gfachar/bias_readnoise_20191027):",
"_____no_output_____"
]
],
[
[
"ameisner_rdnoise = {\n 'GUIDE0': { 'E': 5.56, 'F': 5.46, 'G': 5.12, 'H': 5.24},\n 'FOCUS1': { 'E': 5.21, 'F': 5.11, 'G': 4.88, 'H': 4.90},\n 'GUIDE2': { 'E': 7.11, 'F': 6.23, 'G': 5.04, 'H': 5.29},\n 'GUIDE3': { 'E': 5.28, 'F': 5.16, 'G': 4.89, 'H': 5.00},\n 'FOCUS4': { 'E': 5.23, 'F': 5.12, 'G': 5.01, 'H': 5.11},\n 'GUIDE5': { 'E': 5.11, 'F': 5.00, 'G': 4.80, 'H': 4.86},\n 'FOCUS6': { 'E': 5.12, 'F': 5.09, 'G': 4.85, 'H': 5.07},\n 'GUIDE7': { 'E': 5.00, 'F': 4.96, 'G': 4.63, 'H': 4.79},\n 'GUIDE8': { 'E': 6.51, 'F': 5.58, 'G': 5.12, 'H': 5.47},\n 'FOCUS9': { 'E': 6.85, 'F': 5.53, 'G': 5.07, 'H': 5.57},\n}",
"_____no_output_____"
],
[
"def compare_rdnoise(label='20191027', save=None):\n # Use the new calibrations written above.\n desietcimg.gfa.GFACamera.calib_data = None\n GFA = desietcimg.gfa.GFACamera(calib_name='GFA_calib_zero.fits')\n markers = '+xo.'\n fig, ax = plt.subplots(1, 2, figsize=(12, 5))\n for k, gfa in enumerate(GFA.gfa_names):\n color = plt.rcParams['axes.prop_cycle'].by_key()['color'][k]\n ax[1].scatter([], [], marker='o', c=color, label=gfa)\n for j, amp in enumerate(desietcimg.gfa.GFACamera.amp_names):\n marker = markers[j]\n measured = GFA.calib_data[gfa][amp]['RDNOISE']\n # Lab results are given in elec so use lab gains to convert back to ADU\n lab = GFA.lab_data[gfa][amp]['RDNOISE'] / GFA.lab_data[gfa][amp]['GAIN']\n ax[0].scatter(lab, measured, marker=marker, c=color)\n ax[1].scatter(ameisner_rdnoise[gfa][amp], measured, marker=marker, c=color)\n for j, amp in enumerate(GFA.amp_names):\n ax[1].scatter([], [], marker=markers[j], c='k', label=amp)\n xylim = (4.3, 5.5)\n for axis in ax:\n axis.plot(xylim, xylim, 'k-', zorder=-10, alpha=0.25)\n axis.set_ylabel(f'{label} Read Noise [ADU]')\n axis.set_xlim(*xylim)\n axis.set_ylim(*xylim)\n ax[1].legend(ncol=3)\n ax[0].set_xlabel('Lab Data Read Noise [ADU]')\n ax[1].set_xlabel('ameisner Read Noise [ADU]')\n plt.tight_layout()\n if save:\n plt.savefig(save)\n\ncompare_rdnoise(save=str(plotdir / 'rdnoise_compare.png'))",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
]
] |
cb3cc42c06c34c4d9bf7384c0633164d177c2cfa | 14,076 | ipynb | Jupyter Notebook | foundations/pandas-playground.ipynb | Amagash/mlnd_courses | c0c2d5a506714fa4fe5ecb76d45cc3332d4bea67 | [
"MIT"
] | null | null | null | foundations/pandas-playground.ipynb | Amagash/mlnd_courses | c0c2d5a506714fa4fe5ecb76d45cc3332d4bea67 | [
"MIT"
] | null | null | null | foundations/pandas-playground.ipynb | Amagash/mlnd_courses | c0c2d5a506714fa4fe5ecb76d45cc3332d4bea67 | [
"MIT"
] | null | null | null | 29.696203 | 93 | 0.465331 | [
[
[
"# Pandas Playground\n\n## Series in Pandas",
"_____no_output_____"
]
],
[
[
"'''\nThe following code is to help you play with the concept of Series in Pandas.\n\nYou can think of Series as an one-dimensional object that is similar to\nan array, list, or column in a database. By default, it will assign an\nindex label to each item in the Series ranging from 0 to N, where N is\nthe number of items in the Series minus one.\n\nPlease feel free to play around with the concept of Series and see what it does\n\n*This playground is inspired by Greg Reda's post on Intro to Pandas Data Structures:\nhttp://www.gregreda.com/2013/10/26/intro-to-pandas-data-structures/\n'''\n\nimport pandas as pd\n\nseries = pd.Series(['Dave', 'Cheng-Han', 'Udacity', 42, -1789710578])\nprint series\nprint type(series)\nprint series[0]",
"0 Dave\n1 Cheng-Han\n2 Udacity\n3 42\n4 -1789710578\ndtype: object\n<class 'pandas.core.series.Series'>\nDave\n"
],
[
"'''\nYou can also manually assign indices to the items in the Series when\ncreating the series\n'''\nseries = pd.Series(['Dave', 'Cheng-Han', 359, 9001],\n index=['Instructor', 'Curriculum Manager',\n 'Course Number', 'Power Level'])\nprint series",
"Instructor Dave\nCurriculum Manager Cheng-Han\nCourse Number 359\nPower Level 9001\ndtype: object\n"
],
[
"'''\nYou can use index to select specific items from the Series\n'''\nseries = pd.Series(['Dave', 'Cheng-Han', 359, 9001],\n index=['Instructor', 'Curriculum Manager',\n 'Course Number', 'Power Level'])\nprint series['Instructor']\nprint \"\"\nprint series[['Instructor', 'Curriculum Manager', 'Course Number']]",
"Dave\n\nInstructor Dave\nCurriculum Manager Cheng-Han\nCourse Number 359\ndtype: object\n"
],
[
"'''\nYou can also use boolean operators to select specific items from the Series\n'''\ncuteness = pd.Series([1, 2, 3, 4, 5], index=['Cockroach', 'Fish', 'Mini Pig',\n 'Puppy', 'Kitten'])\nprint cuteness > 3\nprint \"\"\nprint cuteness[cuteness > 3]",
"Cockroach False\nFish False\nMini Pig False\nPuppy True\nKitten True\ndtype: bool\n\nPuppy 4\nKitten 5\ndtype: int64\n"
]
],
[
[
"## Dataframe in Pandas ",
"_____no_output_____"
]
],
[
[
"'''\nThe following code is to help you play with the concept of Dataframe in Pandas.\n\nYou can think of a Dataframe as something with rows and columns. It is\nsimilar to a spreadsheet, a database table, or R's data.frame object.\n\n*This playground is inspired by Greg Reda's post on Intro to Pandas Data Structures:\nhttp://www.gregreda.com/2013/10/26/intro-to-pandas-data-structures/\n'''\n\n'''\nTo create a dataframe, you can pass a dictionary of lists to the Dataframe\nconstructor:\n1) The key of the dictionary will be the column name\n2) The associating list will be the values within that column.\n'''\nimport pandas as pd\nimport numpy as np\n\ndata = {'year': [2010, 2011, 2012, 2011, 2012, 2010, 2011, 2012],\n 'team': ['Bears', 'Bears', 'Bears', 'Packers', 'Packers', 'Lions',\n 'Lions', 'Lions'],\n 'wins': [11, 8, 10, 15, 11, 6, 10, 4],\n 'losses': [5, 8, 6, 1, 5, 10, 6, 12]}\nfootball = pd.DataFrame(data)\nprint football\n",
" losses team wins year\n0 5 Bears 11 2010\n1 8 Bears 8 2011\n2 6 Bears 10 2012\n3 1 Packers 15 2011\n4 5 Packers 11 2012\n5 10 Lions 6 2010\n6 6 Lions 10 2011\n7 12 Lions 4 2012\n"
],
[
"'''\nPandas also has various functions that will help you understand some basic\ninformation about your data frame. Some of these functions are:\n1) dtypes: to get the datatype for each column\n2) describe: useful for seeing basic statistics of the dataframe's numerical\n columns\n3) head: displays the first five rows of the dataset\n4) tail: displays the last five rows of the dataset\n'''\ndata = {'year': [2010, 2011, 2012, 2011, 2012, 2010, 2011, 2012],\n 'team': ['Bears', 'Bears', 'Bears', 'Packers', 'Packers', 'Lions',\n 'Lions', 'Lions'],\n 'wins': [11, 8, 10, 15, 11, 6, 10, 4],\n 'losses': [5, 8, 6, 1, 5, 10, 6, 12]}\nfootball = pd.DataFrame(data)\nprint football\nprint \"\"\nprint football.dtypes\nprint \"\"\nprint football.describe()\nprint \"\"\nprint football.head()\nprint \"\"\nprint football.tail()",
" losses team wins year\n0 5 Bears 11 2010\n1 8 Bears 8 2011\n2 6 Bears 10 2012\n3 1 Packers 15 2011\n4 5 Packers 11 2012\n5 10 Lions 6 2010\n6 6 Lions 10 2011\n7 12 Lions 4 2012\n\nlosses int64\nteam object\nwins int64\nyear int64\ndtype: object\n\n losses wins year\ncount 8.000000 8.000000 8.000000\nmean 6.625000 9.375000 2011.125000\nstd 3.377975 3.377975 0.834523\nmin 1.000000 4.000000 2010.000000\n25% 5.000000 7.500000 2010.750000\n50% 6.000000 10.000000 2011.000000\n75% 8.500000 11.000000 2012.000000\nmax 12.000000 15.000000 2012.000000\n\n losses team wins year\n0 5 Bears 11 2010\n1 8 Bears 8 2011\n2 6 Bears 10 2012\n3 1 Packers 15 2011\n4 5 Packers 11 2012\n\n losses team wins year\n3 1 Packers 15 2011\n4 5 Packers 11 2012\n5 10 Lions 6 2010\n6 6 Lions 10 2011\n7 12 Lions 4 2012\n"
]
],
[
[
"## Panda indexing Dataframe",
"_____no_output_____"
]
],
[
[
"'''\nYou can think of a DataFrame as a group of Series that share an index.\nThis makes it easy to select specific columns that you want from the \nDataFrame. \n\nAlso a couple pointers:\n1) Selecting a single column from the DataFrame will return a Series\n2) Selecting multiple columns from the DataFrame will return a DataFrame\n\n*This playground is inspired by Greg Reda's post on Intro to Pandas Data Structures:\nhttp://www.gregreda.com/2013/10/26/intro-to-pandas-data-structures/\n'''\n\ndata = {'year': [2010, 2011, 2012, 2011, 2012, 2010, 2011, 2012],\n 'team': ['Bears', 'Bears', 'Bears', 'Packers', 'Packers', 'Lions',\n 'Lions', 'Lions'],\n 'wins': [11, 8, 10, 15, 11, 6, 10, 4],\n 'losses': [5, 8, 6, 1, 5, 10, 6, 12]}\nfootball = pd.DataFrame(data)\nprint (football)\nprint ''\nprint football['year']\nprint ''\nprint football.year # shorthand for football['year']\nprint ''\nprint football[['year', 'wins', 'losses']]",
" losses team wins year\n0 5 Bears 11 2010\n1 8 Bears 8 2011\n2 6 Bears 10 2012\n3 1 Packers 15 2011\n4 5 Packers 11 2012\n5 10 Lions 6 2010\n6 6 Lions 10 2011\n7 12 Lions 4 2012\n\n0 2010\n1 2011\n2 2012\n3 2011\n4 2012\n5 2010\n6 2011\n7 2012\nName: year, dtype: int64\n\n0 2010\n1 2011\n2 2012\n3 2011\n4 2012\n5 2010\n6 2011\n7 2012\nName: year, dtype: int64\n\n year wins losses\n0 2010 11 5\n1 2011 8 8\n2 2012 10 6\n3 2011 15 1\n4 2012 11 5\n5 2010 6 10\n6 2011 10 6\n7 2012 4 12\n"
],
[
"'''\nRow selection can be done through multiple ways.\n\nSome of the basic and common methods are:\n 1) Slicing\n 2) An individual index (through the functions iloc or loc)\n 3) Boolean indexing\n\nYou can also combine multiple selection requirements through boolean\noperators like & (and) or | (or)\n'''\n\ndata = {'year': [2010, 2011, 2012, 2011, 2012, 2010, 2011, 2012],\n 'team': ['Bears', 'Bears', 'Bears', 'Packers', 'Packers', 'Lions',\n 'Lions', 'Lions'],\n 'wins': [11, 8, 10, 15, 11, 6, 10, 4],\n 'losses': [5, 8, 6, 1, 5, 10, 6, 12]}\nfootball = pd.DataFrame(data)\nprint (football)\nprint ''\nprint football.iloc[[0]]\nprint \"\"\nprint football.loc[[0]]\nprint \"\"\nprint football[3:5]\nprint \"\"\nprint football[football.wins > 10]\nprint \"\"\nprint football[(football.wins > 10) & (football.team == \"Packers\")]\n",
" losses team wins year\n0 5 Bears 11 2010\n1 8 Bears 8 2011\n2 6 Bears 10 2012\n3 1 Packers 15 2011\n4 5 Packers 11 2012\n5 10 Lions 6 2010\n6 6 Lions 10 2011\n7 12 Lions 4 2012\n\n losses team wins year\n0 5 Bears 11 2010\n\n losses team wins year\n0 5 Bears 11 2010\n\n losses team wins year\n3 1 Packers 15 2011\n4 5 Packers 11 2012\n\n losses team wins year\n0 5 Bears 11 2010\n3 1 Packers 15 2011\n4 5 Packers 11 2012\n\n losses team wins year\n3 1 Packers 15 2011\n4 5 Packers 11 2012\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
cb3cca079de17674a153d90e0f72274323611693 | 70,374 | ipynb | Jupyter Notebook | Praktikum 08 - Filter Transparan.ipynb | fadhilyori/pengolahan-citra | f8fed3d97b0ad05f7f0334fe676cc0b8915d7327 | [
"MIT"
] | 7 | 2020-01-03T13:41:50.000Z | 2020-04-13T07:55:03.000Z | Praktikum 08 - Filter Transparan.ipynb | fadhilyori/pengolahan-citra | f8fed3d97b0ad05f7f0334fe676cc0b8915d7327 | [
"MIT"
] | null | null | null | Praktikum 08 - Filter Transparan.ipynb | fadhilyori/pengolahan-citra | f8fed3d97b0ad05f7f0334fe676cc0b8915d7327 | [
"MIT"
] | 1 | 2020-04-08T00:36:16.000Z | 2020-04-08T00:36:16.000Z | 322.816514 | 24,524 | 0.93364 | [
[
[
"# Praktikum 8 | Pengolahan Citra",
"_____no_output_____"
],
[
"## Filter Transparan",
"_____no_output_____"
],
[
"Fadhil Yori Hibatullah | 2103161037 | 2 D3 Teknik Informatika B",
"_____no_output_____"
],
[
"----------------------------",
"_____no_output_____"
],
[
"### Import Library",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport imageio\nimport matplotlib.pyplot as plt",
"_____no_output_____"
]
],
[
[
"### Membaca Gambar",
"_____no_output_____"
]
],
[
[
"img1 = imageio.imread(\"gambar1.png\") # dasar\nimg2 = imageio.imread(\"gambar2.png\")\n\nplt.imshow(img1)\nplt.title(\"Gambar 1\")\nplt.show()\n\nplt.imshow(img2)\nplt.title(\"Gambar 2\")\nplt.show()",
"_____no_output_____"
],
[
"img_height = img1.shape[0]\nimg_width = img1.shape[1]\nimg_channel = img1.shape[2]\n\nif img1.shape[0] > img2.shape[0]:\n height = img1.shape[0]\nelse:\n height = img2.shape[0]\n \nif img1.shape[1] > img2.shape[1]:\n width = img1.shape[1]\nelse:\n width = img2.shape[1]\n \nimshape = (height, width, 3)\nprint(imshape)",
"(183, 183, 3)\n"
]
],
[
[
"-----------------------------",
"_____no_output_____"
],
[
"## Menggabungkan kedua gambar, dengan img1 merupakan bagian dasar",
"_____no_output_____"
]
],
[
[
"img_trans = np.zeros(imshape, dtype=np.uint8)\n\nfor y in range(0, height):\n for x in range(0, width):\n try:\n r1 = img1[y][x][0]\n g1 = img1[y][x][1]\n b1 = img1[y][x][2]\n except:\n r1 = 0\n g1 = 0\n b1 = 0\n try:\n r2 = img2[y][x][0]\n g2 = img2[y][x][1]\n b2 = img2[y][x][2]\n except:\n r2 = 0\n g2 = 0\n b2 = 0\n r = (0.5 * r1) + (0.5 * r2)\n g = (0.5 * g1) + (0.5 * g2)\n b = (0.5 * b1) + (0.5 * b2)\n img_trans[y][x] = (r,g,b)",
"_____no_output_____"
],
[
"plt.imshow(img_trans)\nplt.title(\"Done\")\nplt.show()",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
]
] |
cb3cdba8bbe766cf281c221c4a201ba4b84ceda3 | 12,660 | ipynb | Jupyter Notebook | notebook/model_umsenble.ipynb | FooQoo/getting-started-prediction-competition | 342655aceabacd90f9746a1dc5870afa56944975 | [
"MIT"
] | null | null | null | notebook/model_umsenble.ipynb | FooQoo/getting-started-prediction-competition | 342655aceabacd90f9746a1dc5870afa56944975 | [
"MIT"
] | null | null | null | notebook/model_umsenble.ipynb | FooQoo/getting-started-prediction-competition | 342655aceabacd90f9746a1dc5870afa56944975 | [
"MIT"
] | null | null | null | 34.402174 | 151 | 0.452528 | [
[
[
"# set file path\nfilepath = '../fact/'\ntrainfile = 'train.csv'\ntestfile = 'test.csv'",
"_____no_output_____"
],
[
"# read train.csv\nimport pandas as pd\ndf_train = pd.read_csv(filepath+trainfile)\ndf_test = pd.read_csv(filepath+testfile)",
"_____no_output_____"
],
[
"#from sklearn.naive_bayes import MultinomialNB\nimport lightgbm as lgb\nfrom sklearn.metrics import confusion_matrix, classification_report, f1_score\n\ndef get_text_model(train, valid): \n prefix = 'word_'\n c_word = [column for column in train.columns.tolist() if prefix == column[:len(prefix)]]\n prefix = 'url_'\n c_url = [column for column in train.columns.tolist() if prefix == column[:len(prefix)]]\n prefix = 'hashtag_'\n c_hashtag = [column for column in train.columns.tolist() if prefix == column[:len(prefix)]]\n \n # fill nan\n train.fillna(0, inplace=True)\n \n X_train, X_valid, X_test = train[c_word+c_url+c_hashtag].values, valid[c_word+c_url+c_hashtag].values, test[c_word+c_url+c_hashtag].values\n y_train, y_valid = train.target.values, valid.target.values\n \n # fit model\n lgb_train = lgb.Dataset(X_train, y_train)\n lgb_valid = lgb.Dataset(X_valid, y_valid, reference=lgb_train)\n lgb_test = lgb.Dataset(X_test)\n \n lgbm_params = {\n 'objective': 'binary',\n 'metric':'binary_logloss', \n 'verbose': -1,\n 'learning_rate': 0.01,\n 'num_iterations': 1000\n }\n\n model = lgb.train(\n lgbm_params, \n lgb_train, \n valid_sets=lgb_valid,\n verbose_eval=False,\n early_stopping_rounds=10\n )\n \n def report(X, y):\n # print train report\n y_pred = model.predict(X, num_iteration=model.best_iteration)\n y_pred_cls = y_pred >= 0.5\n print('f1:{}'.format(f1_score(y, y_pred_cls, average=None)[0]))\n print(confusion_matrix(y, y_pred_cls))\n print(classification_report(y, y_pred_cls))\n \n report(X_train, y_train)\n report(X_valid, y_valid)\n \n # fit train and valid\n X = np.concatenate([X_train, X_valid], 0)\n y = np.concatenate([y_train, y_valid], 0)\n lgb_train_valid = lgb.Dataset(X, y)\n model = lgb.train(\n lgbm_params, \n lgb_train_valid, \n verbose_eval=False\n )\n \n report(X_test, y_test)\n \n # retrun proba\n return (\n model.predict(X_train, num_iteration=model.best_iteration), \n model.predict(X_valid, num_iteration=model.best_iteration),\n model.predict(X_test, num_iteration=model.best_iteration)\n )\n\ny_train_text_proba, y_test_text_proba = get_text_model(df_train, df_test)",
"f1:0.8554968795007201\n[[2673 271]\n [ 632 2312]]\n precision recall f1-score support\n\n 0 0.81 0.91 0.86 2944\n 1 0.90 0.79 0.84 2944\n\n accuracy 0.85 5888\n macro avg 0.85 0.85 0.85 5888\nweighted avg 0.85 0.85 0.85 5888\n\nf1:0.823793490460157\n[[367 68]\n [ 89 238]]\n precision recall f1-score support\n\n 0 0.80 0.84 0.82 435\n 1 0.78 0.73 0.75 327\n\n accuracy 0.79 762\n macro avg 0.79 0.79 0.79 762\nweighted avg 0.79 0.79 0.79 762\n\nf1:0.8177934154310129\n[[1627 234]\n [ 491 911]]\n precision recall f1-score support\n\n 0 0.77 0.87 0.82 1861\n 1 0.80 0.65 0.72 1402\n\n accuracy 0.78 3263\n macro avg 0.78 0.76 0.77 3263\nweighted avg 0.78 0.78 0.77 3263\n\n"
],
[
"from catboost import CatBoost\nfrom catboost import Pool\nfrom sklearn.metrics import confusion_matrix, classification_report, f1_score\n\ndef get_category_model(train, valid, test):\n c_text = ['keyword', 'location']\n X_train, X_valid, X_test = train[c_text].values, valid[c_text].values, test[c_text].values\n y_train, y_valid = train.target, valid.target\n \n # CatBoost が扱うデータセットの形式に直す\n train_pool = Pool(X_train, label=y_train)\n valid_pool = Pool(X_valid, label=y_valid)\n test_pool = Pool(X_test)\n\n # 学習用のパラメータ\n params = {\n # タスク設定と損失関数\n 'loss_function': 'Logloss',\n # 学習ラウンド数\n 'num_boost_round': 1000,\n 'eval_metric': 'F1',\n 'silent': False,\n 'verbose': None,\n 'early_stopping_rounds': 10\n }\n\n # モデルを学習する\n model = CatBoost(params)\n model.fit(train_pool, logging_level='Silent')\n \n def report(X_pool, y):\n y_pred = model.predict(X_pool, prediction_type='Class')\n print('f1:{}'.format(f1_score(y, y_pred, average=None)[0]))\n print(confusion_matrix(y, y_pred))\n print(classification_report(y, y_pred))\n \n report(train_pool, y_train)\n report(valid_pool, y_valid)\n \n # fit train and valid\n X = np.concatenate([X_train, X_valid], 0)\n y = np.concatenate([y_train, y_valid], 0)\n pool = Pool(X, label=y)\n model.fit(pool, logging_level='Silent')\n \n report(test_pool, y_test)\n \n # retrun proba\n return (\n model.predict(train_pool, prediction_type='Probability')[:, 1], \n model.predict(valid_pool, prediction_type='Probability')[:, 1],\n model.predict(test_pool, prediction_type='Probability')[:, 1]\n )\n\ny_train_cat_proba, y_valid_cat_proba, y_test_cat_proba = get_category_model(df_train, df_valid, df_test)",
"f1:0.7745313291673704\n[[2293 651]\n [ 684 2260]]\n precision recall f1-score support\n\n 0 0.77 0.78 0.77 2944\n 1 0.78 0.77 0.77 2944\n\n accuracy 0.77 5888\n macro avg 0.77 0.77 0.77 5888\nweighted avg 0.77 0.77 0.77 5888\n\nf1:0.7765830346475507\n[[325 110]\n [ 77 250]]\n precision recall f1-score support\n\n 0 0.81 0.75 0.78 435\n 1 0.69 0.76 0.73 327\n\n accuracy 0.75 762\n macro avg 0.75 0.76 0.75 762\nweighted avg 0.76 0.75 0.76 762\n\nf1:0.7518267929634641\n[[1389 472]\n [ 445 957]]\n precision recall f1-score support\n\n 0 0.76 0.75 0.75 1861\n 1 0.67 0.68 0.68 1402\n\n accuracy 0.72 3263\n macro avg 0.71 0.71 0.71 3263\nweighted avg 0.72 0.72 0.72 3263\n\n"
],
[
"from sklearn.linear_model import LogisticRegression\nimport numpy as np\n\nX_train = np.stack([y_train_text_proba, y_train_cat_proba], 1)\nX_valid = np.stack([y_valid_text_proba, y_valid_cat_proba], 1)\nX_test = np.stack([y_test_text_proba, y_test_cat_proba], 1)\ny_train, y_valid = df_train.target, df_valid.target\n\nclf = LogisticRegression(\n class_weight = 'balanced',\n random_state = 0,\n penalty = 'elasticnet',\n l1_ratio = 0.0, \n C = 0.001,\n solver='saga'\n)\n\ndef report(X, y):\n y_pred = clf.predict(X)\n print('f1:{}'.format(f1_score(y, y_pred, average=None)[0]))\n print(confusion_matrix(y, y_pred))\n print(classification_report(y, y_pred))\n\n# 再学習\nX = np.concatenate([X_train, X_valid], 0)\ny = np.concatenate([y_train, y_valid], 0)\nclf.fit(X, y)\n\nreport(X_train, y_train)\nreport(X_valid, y_valid)\nreport(X_test, y_test)",
"f1:0.8547120418848166\n[[2612 332]\n [ 556 2388]]\n precision recall f1-score support\n\n 0 0.82 0.89 0.85 2944\n 1 0.88 0.81 0.84 2944\n\n accuracy 0.85 5888\n macro avg 0.85 0.85 0.85 5888\nweighted avg 0.85 0.85 0.85 5888\n\nf1:0.8849162011173185\n[[396 39]\n [ 64 263]]\n precision recall f1-score support\n\n 0 0.86 0.91 0.88 435\n 1 0.87 0.80 0.84 327\n\n accuracy 0.86 762\n macro avg 0.87 0.86 0.86 762\nweighted avg 0.87 0.86 0.86 762\n\nf1:0.8153489569920165\n[[1583 278]\n [ 439 963]]\n precision recall f1-score support\n\n 0 0.78 0.85 0.82 1861\n 1 0.78 0.69 0.73 1402\n\n accuracy 0.78 3263\n macro avg 0.78 0.77 0.77 3263\nweighted avg 0.78 0.78 0.78 3263\n\n"
],
[
"df_submit.to_csv('../output/submit.csv', index=None)",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3cde56fc7ec9919eb0417e40ffa2245717d8b0 | 299,961 | ipynb | Jupyter Notebook | docs/07c-M2-Experiment.ipynb | HTuennermann/laserbeamsize | d126dbb157e9deef5eea9e7a3fd2fd62e3debe6a | [
"MIT"
] | null | null | null | docs/07c-M2-Experiment.ipynb | HTuennermann/laserbeamsize | d126dbb157e9deef5eea9e7a3fd2fd62e3debe6a | [
"MIT"
] | null | null | null | docs/07c-M2-Experiment.ipynb | HTuennermann/laserbeamsize | d126dbb157e9deef5eea9e7a3fd2fd62e3debe6a | [
"MIT"
] | null | null | null | 695.965197 | 82,064 | 0.948513 | [
[
[
"# M² Experimental Design\n\n**Scott Prahl**\n\n**Mar 2021**\n\nThe basic idea for measuring M² is simple. Use a CCD imager to capture changing beam profile at different points along the direction of propagation. Doing this accurately is a challenge because the beam must always fit within camera sensor and the measurement locations should include both points near the focus and far from the focus. Moreover, in most situations, the focus is not accessible. In this case a lens is used to create an artificial focus that can be measured.\n\nOne of the nice properties of M² is that it is not affected by refocusing: the artificially focused beam will have different beam waist and Rayleigh distances but the M² value will be the same as the original beam.\n\nThis notebook describes a set of constraints for selection of an imaging lens and then gives an example of a successful measurement and an unsuccessful measurement.\n\n---\n*If* `` laserbeamsize `` *is not installed, uncomment the following cell (i.e., delete the initial #) and execute it with* `` shift-enter ``. *Afterwards, you may need to restart the kernel/runtime before the module will import successfully.*",
"_____no_output_____"
]
],
[
[
"#!pip install --user laserbeamsize",
"_____no_output_____"
],
[
"import numpy as np\nimport matplotlib.pyplot as plt\n\ntry:\n import laserbeamsize as lbs\n\nexcept ModuleNotFoundError:\n print('laserbeamsize is not installed. To install, uncomment and run the cell above.')\n print('Once installation is successful, rerun this cell again.')\n \npixel_size = 3.75e-6 # pixel size in m\npixel_size_mm = pixel_size * 1e3\npixel_size_µm = pixel_size * 1e6 ",
"_____no_output_____"
]
],
[
[
"## Designing an M² measurement\n\nWe first need to to figure out the focal length of the lens that will be used. The design example that we will use is for a low divergence beam. (High divergence lasers (e.g. diodes) are more suited to other techniques.)\n\nObviously, we do not want to introduce experimental artifacts into the measurement and therefore we want to minimize introducing wavefront aberrations with the lens. In general, to avoid spherical aberrations the f-number (the focal length divided by the beam diameter) of the lens should be over 20. For a low divergence beam the beam diameter will be about 1mm at the lens and, as we will see below, the allowed f-numbers will all be much greater than 20 and we don't need to worry about it further (as long as a plano-convex lens or doublet is used in the right orientation).",
"_____no_output_____"
],
[
"### Creating an artificial focus\n\nAn example of beam propagation is shown below. The beam waist is at -500mm and a lens is located at 0mm. The beam cross section is exaggerated because the aspect ratio on the axes is 1000:1.",
"_____no_output_____"
]
],
[
[
"lambda0 = 632.8e-9 # wavelength of light [m]\nw0 = 450e-6 # radius at beam waist [m]\nf = 300e-3 # focal length of lens [m]\n\nlbs.M2_focus_plot(w0, lambda0, f, z0=-500e-3, M2=2)\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Axial measurement positions\n\nThe ISO 11146-1 document, [Lasers and laser-related equipment - Test methods for laser beam widths, divergence angles and beam propagation, Part 1: Stigmatic and simple astigmatic beams](https://www.iso.org/obp/ui/#iso:std:iso:11146:-1:ed-1:v1:en) gives specific instructions for how to measure the M² value.\n\n> If the beam waist is accessible for direct measurement, the beam waist location, beam widths, divergence angles and beam propagation ratios shall be determined by a hyperbolic fit to different measurements of the beam width along the propagation axis $z$. Hence, measurements at at least 10 different $z$ positions shall be taken. Approximately half of the measurements shall be distributed within one Rayleigh length on either side of the beam waist, and approximately half of them shall be distributed beyond two Rayleigh lengths from the beam waist. For simple astigmatic beams this procedure shall be applied separately for both principal directions.\n\nIn the picture above, the artificial beam waist is at 362mm and the Rayleigh distance for the artificial beam is 155mm. Therefore, to comply with the requirements above, five measurements should be made between 207 and 517mm of the lens and then five more at distances greater than 672mm. One possibility might be the ten measurements shown below.",
"_____no_output_____"
]
],
[
[
"lambda0 = 632.8e-9 # wavelength of light [m]\nw0 = 450e-6 # radius at beam waist [m]\nf = 300e-3 # focal length of lens [m]\n\nz = np.array([250, 300, 350, 400, 450, 675, 725, 775, 825, 875])*1e-3\nlbs.M2_focus_plot(w0, lambda0, f, z0=-500e-3, M2=2)\nr = lbs.beam_radius(250e-6, lambda0, z, z0=362e-3, M2=2)\nplt.plot(z*1e3,r*1e6,'or')\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Camera sensor size constraints\n\nIf the beam is centered on the camera sensor then should be larger than 20 pixels and it should less than 1/4 of the narrower sensor dimension. The first constraint is critical for weakly divergent beams (e.g., HeNe) and the second is critical for strongly divergent beams (e.g., diode laser).\n\nFor a HeNe, this ensures that the focal length of the lens should be greater than 100mm. If we want 40 pixel diameters then the requirement is that the focal length must be more than 190mm.\n\n(Use M²=1 so that the beam size is smallest possible.)",
"_____no_output_____"
]
],
[
[
"w0 = (1e-3)/2\nlambda0 = 632.8e-9\nf = np.linspace(10,250)*1e-3\ns = -400e-3\n\nmax_size = 960 * 0.25 * pixel_size_µm\nmin_size = 20 * pixel_size_µm\nw0_artificial = w0 * lbs.magnification(w0,lambda0,s,f,M2=1)\nplt.plot(f*1e3, w0_artificial*1e6)\nplt.axhspan(min_size, 0, color='blue', alpha=0.1)\nplt.text(70, 20, \"Image too small\")\nplt.xlabel(\"Focal Length (mm)\")\nplt.ylabel(\"Beam Radius (µm)\")\nplt.axvline(190,color='black')\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Working size constraints (i.e., the optical table is only so big)\n\nThe measurements must be made on an optical table. Now, while mirrors could be used to bounce the light around the table, this makes exact measurements of the lens to the camera sensor difficult. Thus we would like the distance from the lens to the focus + 4 Rayleigh distances to be less than a meter.\n\nLonger focal length lenses reduce the relative error in the positioning of the camera sensor relative to the lens. If one is doing these measurements by hand then ±1mm might be a typical positioning error. A motorized stage could minimize such errors, but who has the money for a stage that moves half of a meter!\n\nThis means the focal distance needs to be less than 320mm. However, at this distance, the beam becomes too large and the largest focal length lens is now about 275mm.",
"_____no_output_____"
]
],
[
[
"w0 = 1e-3 / 2\nlambda0 = 632.8e-9\nf = np.linspace(50,500)*1e-3\ns = -400e-3\nM2 = 2\n\nw0_artificial = w0 * lbs.magnification(w0,lambda0,s,f,M2=M2)\nz0_artificial = lbs.image_distance(w0,lambda0,s,f,M2=M2)\nzR_artificial = lbs.z_rayleigh(w0_artificial, lambda0, M2=M2)\n\nlens_to_4zr_distance = z0_artificial + 4 * zR_artificial\n\nplt.plot(f*1e3, lens_to_4zr_distance*1e3)\nplt.axhspan(1000, lens_to_4zr_distance[-1]*1e3, color='blue', alpha=0.1)\nplt.text(350, 1050, \"Axial distance too far\")\nplt.xlabel(\"Focal Length (mm)\")\nplt.ylabel(\"$z_0+4z_R$ (mm)\")\nplt.axvline(320,color='black')\nplt.show()\n\nradius_at_4zr = lbs.beam_radius(w0_artificial, lambda0, lens_to_4zr_distance, z0=z0_artificial, M2=M2)\n\nmax_size = 960 * 0.25 * pixel_size_µm\nplt.plot(f*1e3, radius_at_4zr*1e6)\nplt.axhspan(1600, max_size, color='blue', alpha=0.1)\nplt.text(350, 1000, \"Beam too big\")\nplt.axvline(275,color='black')\nplt.xlabel(\"Focal Length (mm)\")\nplt.ylabel(\"Beam Radius (mm)\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Putting it all together\n\nThe focal length of the lens to measure a multimode HeNe beam should then be between 190 and 275 mm. Here is what a reasonable set of measurements should be for a f=250mm lens.",
"_____no_output_____"
]
],
[
[
"lambda0 = 632.8e-9 # wavelength of light [m]\nw0 = 500e-6 # radius at beam waist [m]\nf = 250e-3 # focal length of lens [m]\ns = -400e-3 # beam waist in laser to lens distance [m]\nM2 = 2\n\nlbs.M2_focus_plot(w0, lambda0, f, z0=s, M2=M2)\n\nz0_after = lbs.image_distance(w0,lambda0,s,f,M2=M2)\nw0_after = w0 * lbs.magnification(w0,lambda0,s,f,M2=M2)\nzR_after = lbs.z_rayleigh(w0_after,lambda0,M2=M2)\n\nzn = np.linspace(z0_after-zR_after,z0_after+zR_after,5)\nzf = np.linspace(z0_after+2*zR_after,z0_after+4*zR_after,5)\n\nrn = lbs.beam_radius(w0_after, lambda0, zn, z0=z0_after, M2=2)\nrf = lbs.beam_radius(w0_after, lambda0, zf, z0=z0_after, M2=2)\n\nplt.plot(zn*1e3,rn*1e6,'or')\nplt.plot(zf*1e3,rf*1e6,'ob')\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Good spacing of beam size measurements",
"_____no_output_____"
]
],
[
[
"# datapoints digitized by hand from the graph at https://www.rp-photonics.com/beam_quality.html\nlambda1=308e-9\nz1_all=np.array([-200,-180,-160,-140,-120,-100,-80,-60,-40,-20,0,20,40,60,80,99,120,140,160,180,200])*1e-3\nd1_all=2*np.array([416,384,366,311,279,245,216,176,151,120,101,93,102,120,147,177,217,256,291,316,348])*1e-6\n\nlbs.M2_radius_plot(z1_all, d1_all, lambda1, strict=True)",
"_____no_output_____"
]
],
[
[
"## Poor spacing of beam size measurements\n\nA nice fit of the beam is achieved, however the fitted value for M²<1. This is impossible. Basically the problem boils down to the fact that the measurements in the beam waist are terrible for determining the actual divergence of the beam. The fit then severely underestimates the divergence of the beam and claims that the beam diverges more slowly than a simple Gaussian beam!!",
"_____no_output_____"
]
],
[
[
"## Some Examples\nf=500e-3 # m\nlambda2 = 632.8e-9 # m\nz2_all = np.array([168, 210, 280, 348, 414, 480, 495, 510, 520, 580, 666, 770]) * 1e-3 # [m]\nd2_all = 2*np.array([597, 572, 547, 554, 479, 404, 415, 399, 377, 391, 326, 397]) * 1e-6 # [m]\n\nlbs.M2_radius_plot(z2_all, d2_all, lambda2, strict=True)\nplt.show()",
"Invalid distribution of measurements for ISO 11146\n9 points within 1 Rayleigh distance\n0 points greater than 2 Rayleigh distances\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
cb3ce48243dd0cae8858cf6b4ee590ebe7c32d72 | 70,233 | ipynb | Jupyter Notebook | 025_img_pretrain_tensorboard_sol.ipynb | Soniyasunny1/3950_Workbooks | e5744868e5c8b837a838811354c10d281bdefbb5 | [
"MIT"
] | null | null | null | 025_img_pretrain_tensorboard_sol.ipynb | Soniyasunny1/3950_Workbooks | e5744868e5c8b837a838811354c10d281bdefbb5 | [
"MIT"
] | null | null | null | 025_img_pretrain_tensorboard_sol.ipynb | Soniyasunny1/3950_Workbooks | e5744868e5c8b837a838811354c10d281bdefbb5 | [
"MIT"
] | null | null | null | 49.390295 | 426 | 0.455185 | [
[
[
"import numpy as np\nimport pandas as pd\nfrom sklearn.model_selection import train_test_split\nimport tensorflow as tf\nimport keras\nfrom keras.datasets import fashion_mnist, cifar10\nfrom keras.layers import Dense, Flatten, Normalization, Dropout, Conv2D, MaxPooling2D, RandomFlip, RandomRotation, RandomZoom, BatchNormalization, Activation, InputLayer\nfrom keras.models import Sequential\nfrom keras.losses import SparseCategoricalCrossentropy, CategoricalCrossentropy\nfrom keras.callbacks import EarlyStopping\nfrom keras.utils import np_utils\nfrom keras import utils\nimport os\nfrom keras.preprocessing.image import ImageDataGenerator\n\nimport matplotlib as mpl\nimport matplotlib.pyplot as plt\nimport datetime",
"_____no_output_____"
]
],
[
[
"# Tensorboard and Pretrained Models\n\n",
"_____no_output_____"
]
],
[
[
"# Load Some Data\nmnist = tf.keras.datasets.mnist\n\n(x_train, y_train),(x_test, y_test) = mnist.load_data()\nx_train, x_test = x_train / 255.0, x_test / 255.0\ny_test = np_utils.to_categorical(y_test)\ny_train = np_utils.to_categorical(y_train)",
"Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz\n11493376/11490434 [==============================] - 2s 0us/step\n11501568/11490434 [==============================] - 2s 0us/step\n"
]
],
[
[
"## Tensorboard\n\nTensorboard is a tool from Keras that can monitor the results of a tensorflow model and display it in a nice Tableau-like dashboard view. We can enable tensorboard and add it to our modelling process to get a better view of progress and save on some of the custom charting functions. \n\nThe first thing that we can use tensorboard for is to get a nice chart of our training progress. \n\n### Create Model",
"_____no_output_____"
]
],
[
[
"# Set # of epochs\nepochs = 10",
"_____no_output_____"
],
[
"def create_model():\n return tf.keras.models.Sequential([\n tf.keras.layers.Flatten(input_shape=(28, 28)),\n tf.keras.layers.Dense(512, activation='relu'),\n tf.keras.layers.Dropout(0.2),\n tf.keras.layers.Dense(10, activation='softmax')\n ])",
"_____no_output_____"
],
[
"acc = keras.metrics.CategoricalAccuracy(name=\"accuracy\")\npre = keras.metrics.Precision(name=\"precision\")\nrec = keras.metrics.Recall(name=\"recall\")\nmetric_list = [acc, pre, rec]",
"_____no_output_____"
]
],
[
[
"#### Add Tensorboard Callback\n\nThe tensorboard can be added to the model as it is being fit as a callback. The primary parameter that matters there is the log_dir, where we can setup the folder to put the logs that the visualizations are made from. The example I have here is from the tensorflow documentation, generating a new subfolder for each execution. Using this to log the tensorboard data is fine, there's no need to change it without reason. ",
"_____no_output_____"
],
[
"### Launch Tensorboard\n\nIn recent versions of VS Code, whioch I assume all of you have, tensorboard can be used directly in a VS Code tab:\n\n\n\nThe command below launches tensorboard elsewhere, such as Google colab.\n\nEither way, the actual tensorboard feature works the same once launched. We can open it before or after we start training the model. If we open it before we can update it to watch training progress - something that may be usefull if you have models that can train for a very long time. ",
"_____no_output_____"
]
],
[
[
"%load_ext tensorboard\n%tensorboard --logdir logs/fit\n# The logdir is wherever the logs are, this is specified in the callback setup. ",
"_____no_output_____"
],
[
"model = create_model()\nmodel.compile(optimizer='adam',\n loss='categorical_crossentropy',\n metrics=metric_list)\n\nlog_dir = \"logs/fit/\" + datetime.datetime.now().strftime(\"%Y%m%d-%H%M%S\")\ntensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)\n\nmodel.fit(x=x_train, \n y=y_train, \n epochs=epochs, \n validation_data=(x_test, y_test), \n callbacks=[tensorboard_callback])",
"Epoch 1/10\n1875/1875 [==============================] - 10s 4ms/step - loss: 0.2183 - accuracy: 0.9347 - precision: 0.9551 - recall: 0.9170 - val_loss: 0.1014 - val_accuracy: 0.9703 - val_precision: 0.9763 - val_recall: 0.9657\nEpoch 2/10\n1875/1875 [==============================] - 9s 5ms/step - loss: 0.0975 - accuracy: 0.9703 - precision: 0.9754 - recall: 0.9661 - val_loss: 0.0808 - val_accuracy: 0.9755 - val_precision: 0.9792 - val_recall: 0.9723\nEpoch 3/10\n1875/1875 [==============================] - 6s 3ms/step - loss: 0.0683 - accuracy: 0.9789 - precision: 0.9817 - recall: 0.9762 - val_loss: 0.0715 - val_accuracy: 0.9778 - val_precision: 0.9802 - val_recall: 0.9756\nEpoch 4/10\n1875/1875 [==============================] - 7s 4ms/step - loss: 0.0537 - accuracy: 0.9826 - precision: 0.9847 - recall: 0.9810 - val_loss: 0.0710 - val_accuracy: 0.9782 - val_precision: 0.9797 - val_recall: 0.9764\nEpoch 5/10\n1875/1875 [==============================] - 8s 4ms/step - loss: 0.0439 - accuracy: 0.9852 - precision: 0.9866 - recall: 0.9841 - val_loss: 0.0668 - val_accuracy: 0.9802 - val_precision: 0.9815 - val_recall: 0.9787\nEpoch 6/10\n1875/1875 [==============================] - 9s 5ms/step - loss: 0.0364 - accuracy: 0.9881 - precision: 0.9892 - recall: 0.9870 - val_loss: 0.0718 - val_accuracy: 0.9799 - val_precision: 0.9805 - val_recall: 0.9793\nEpoch 7/10\n1875/1875 [==============================] - 9s 5ms/step - loss: 0.0321 - accuracy: 0.9893 - precision: 0.9899 - recall: 0.9886 - val_loss: 0.0689 - val_accuracy: 0.9816 - val_precision: 0.9831 - val_recall: 0.9805\nEpoch 8/10\n1875/1875 [==============================] - 7s 4ms/step - loss: 0.0267 - accuracy: 0.9909 - precision: 0.9917 - recall: 0.9904 - val_loss: 0.0648 - val_accuracy: 0.9822 - val_precision: 0.9832 - val_recall: 0.9817\nEpoch 9/10\n1875/1875 [==============================] - 7s 4ms/step - loss: 0.0245 - accuracy: 0.9917 - precision: 0.9921 - recall: 0.9913 - val_loss: 0.0728 - val_accuracy: 0.9800 - val_precision: 0.9812 - val_recall: 0.9795\nEpoch 10/10\n1875/1875 [==============================] - 7s 4ms/step - loss: 0.0216 - accuracy: 0.9922 - precision: 0.9926 - recall: 0.9919 - val_loss: 0.0759 - val_accuracy: 0.9809 - val_precision: 0.9820 - val_recall: 0.9802\n"
],
[
"#http://localhost:6008/#scalars",
"_____no_output_____"
]
],
[
[
"### Tensorboard Contents\n\nThe first page of the tensorboard page gives us a nice pretty view of our training progress - this part should be quite straightforward. The board will capture whatever executions are in that log file, we can filter them on the side to see what we are currently working on, or use different log locations to keep things separate. \n\nLike the text results, we get whichever metrics were specified when setting up the model. \n\n#### Tensorboard Images\n\nWe can also use the tensorboard to visualize other stuff. For example we can load up some images from our dataset. ",
"_____no_output_____"
]
],
[
[
"# Sets up a timestamped log directory.\n\nlogdir = \"logs/train_data/\" + datetime.datetime.now().strftime(\"%Y%m%d-%H%M%S\")\n# Creates a file writer for the log directory.\nfile_writer = tf.summary.create_file_writer(logdir)",
"_____no_output_____"
],
[
"with file_writer.as_default():\n # Don't forget to reshape.\n images = np.reshape(x_train[0:25], (-1, 28, 28, 1))\n tf.summary.image(\"25 training data examples\", images, max_outputs=25, step=0)",
"_____no_output_____"
]
],
[
[
"## Using Pretrained Models\n\nAs we've seen lately, training neural networks can take a really long time. Highly accurate models such as the ones that are used for image recognition in a self driving cars can take multiple computers days or weeks to train. With one laptop we don't really have the ability to get anywhere close to that. Is there any hope of getting anywhere near that accurate?\n\nWe can use models that have been trained on large datasets and adapt them to our purposes. By doing this we can benefit from all of that other learning that is embedded into a model without going through a training process that would be impossible with our limited resources. \n\nWe will look at using a pretrained model here, and at making modifications to it next time. \n\n#### Functional Models\n\nI have lied to you, I forgot that the pretrained models are not sequntial ones (generally, not as a rule), so some of the syntax here is for functional models. It leads to us using some slightly unfamiliar syntax. ",
"_____no_output_____"
]
],
[
[
"_URL = 'https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip'\npath_to_zip = tf.keras.utils.get_file('cats_and_dogs.zip', origin=_URL, extract=True)\nPATH = os.path.join(os.path.dirname(path_to_zip), 'cats_and_dogs_filtered')\n\ntrain_dir = os.path.join(PATH, 'train')\nvalidation_dir = os.path.join(PATH, 'validation')\n\nBATCH_SIZE = 32\nIMG_SIZE = (160, 160)\n\ntrain_dataset = tf.keras.utils.image_dataset_from_directory(train_dir,\n shuffle=True,\n batch_size=BATCH_SIZE,\n image_size=IMG_SIZE)\nvalidation_dataset = tf.keras.utils.image_dataset_from_directory(validation_dir,\n shuffle=True,\n batch_size=BATCH_SIZE,\n image_size=IMG_SIZE)\n",
"Downloading data from https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip\n68608000/68606236 [==============================] - 12s 0us/step\n68616192/68606236 [==============================] - 12s 0us/step\nFound 2000 files belonging to 2 classes.\nFound 1000 files belonging to 2 classes.\n"
]
],
[
[
"### Download Model\n\nThere are several models that are pretrained and available to us to use. VGG16 is one developed to do image recognition, the name stands for \"Visual Geometry Group\" - a group of researchers at the University of Oxford who developed it, and ‘16’ implies that this architecture has 16 layers. The model got ~93% on the ImageNet test that we mentioned a couple of weeks ago. \n\n",
"_____no_output_____"
]
],
[
[
"# Load Model\nfrom keras.applications.vgg16 import VGG16\nfrom keras.layers import Input\nfrom keras.models import Model\n\ninput_tensor = Input(shape=(160, 160, 3))\nvgg = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)\n\nfor layer in vgg.layers:\n layer.trainable = False\n\nx = Flatten()(vgg.output)\nprediction = Dense(1, activation='sigmoid')(x)\n\nmodel = Model(inputs=vgg.input, outputs=prediction)\n\nmodel.summary()",
"Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/vgg16/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5\n58892288/58889256 [==============================] - 10s 0us/step\n58900480/58889256 [==============================] - 10s 0us/step\nModel: \"model\"\n_________________________________________________________________\n Layer (type) Output Shape Param # \n=================================================================\n input_1 (InputLayer) [(None, 160, 160, 3)] 0 \n \n block1_conv1 (Conv2D) (None, 160, 160, 64) 1792 \n \n block1_conv2 (Conv2D) (None, 160, 160, 64) 36928 \n \n block1_pool (MaxPooling2D) (None, 80, 80, 64) 0 \n \n block2_conv1 (Conv2D) (None, 80, 80, 128) 73856 \n \n block2_conv2 (Conv2D) (None, 80, 80, 128) 147584 \n \n block2_pool (MaxPooling2D) (None, 40, 40, 128) 0 \n \n block3_conv1 (Conv2D) (None, 40, 40, 256) 295168 \n \n block3_conv2 (Conv2D) (None, 40, 40, 256) 590080 \n \n block3_conv3 (Conv2D) (None, 40, 40, 256) 590080 \n \n block3_pool (MaxPooling2D) (None, 20, 20, 256) 0 \n \n block4_conv1 (Conv2D) (None, 20, 20, 512) 1180160 \n \n block4_conv2 (Conv2D) (None, 20, 20, 512) 2359808 \n \n block4_conv3 (Conv2D) (None, 20, 20, 512) 2359808 \n \n block4_pool (MaxPooling2D) (None, 10, 10, 512) 0 \n \n block5_conv1 (Conv2D) (None, 10, 10, 512) 2359808 \n \n block5_conv2 (Conv2D) (None, 10, 10, 512) 2359808 \n \n block5_conv3 (Conv2D) (None, 10, 10, 512) 2359808 \n \n block5_pool (MaxPooling2D) (None, 5, 5, 512) 0 \n \n flatten_1 (Flatten) (None, 12800) 0 \n \n dense_2 (Dense) (None, 1) 12801 \n \n=================================================================\nTotal params: 14,727,489\nTrainable params: 12,801\nNon-trainable params: 14,714,688\n_________________________________________________________________\n"
],
[
"model.compile(optimizer='adam',\n loss='categorical_crossentropy',\n metrics=metric_list)\n\nlog_dir = \"logs/fit/VGG\" + datetime.datetime.now().strftime(\"%Y%m%d-%H%M%S\")\ntensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)\n\nmodel.fit(train_dataset, \n epochs=epochs, \n validation_data=validation_dataset, \n callbacks=[tensorboard_callback])\n \nmodel.evaluate(validation_dataset)",
"Epoch 1/3\n63/63 [==============================] - 576s 9s/step - loss: 0.0000e+00 - accuracy: 1.0000 - precision: 0.2500 - recall: 0.0010 - val_loss: 0.0000e+00 - val_accuracy: 1.0000 - val_precision: 0.0000e+00 - val_recall: 0.0000e+00\nEpoch 2/3\n63/63 [==============================] - 525s 8s/step - loss: 0.0000e+00 - accuracy: 1.0000 - precision: 0.0000e+00 - recall: 0.0000e+00 - val_loss: 0.0000e+00 - val_accuracy: 1.0000 - val_precision: 0.0000e+00 - val_recall: 0.0000e+00\nEpoch 3/3\n63/63 [==============================] - 513s 8s/step - loss: 0.0000e+00 - accuracy: 1.0000 - precision: 0.0000e+00 - recall: 0.0000e+00 - val_loss: 0.0000e+00 - val_accuracy: 1.0000 - val_precision: 0.0000e+00 - val_recall: 0.0000e+00\n"
],
[
"model.evaluate(validation_dataset)",
"32/32 [==============================] - 176s 5s/step - loss: 0.0000e+00 - accuracy: 1.0000 - precision: 0.0000e+00 - recall: 0.0000e+00\n"
]
],
[
[
"## More Complex Data\n\nWe can use the rose data for a more complex dataset and a more interesting example in terms of accuracy. ",
"_____no_output_____"
]
],
[
[
"import pathlib\nimport PIL \n\ndataset_url = \"https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz\"\ndata_dir = tf.keras.utils.get_file(origin=dataset_url,\n fname='flower_photos',\n untar=True)\ndata_dir = pathlib.Path(data_dir)\n\n#Flowers\nbatch_size = 32\nimg_height = 180\nimg_width = 180\n\ntrain_ds = tf.keras.utils.image_dataset_from_directory(\n data_dir,\n validation_split=0.2,\n subset=\"training\",\n seed=123,\n image_size=(img_height, img_width),\n batch_size=batch_size)\n\nval_ds = tf.keras.utils.image_dataset_from_directory(\n data_dir,\n validation_split=0.2,\n subset=\"validation\",\n seed=123,\n image_size=(img_height, img_width),\n batch_size=batch_size)\n\nclass_names = train_ds.class_names\nprint(class_names)",
"Found 3670 files belonging to 5 classes.\nUsing 2936 files for training.\nFound 3670 files belonging to 5 classes.\nUsing 734 files for validation.\n['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']\n"
],
[
"input_tensor = Input(shape=(180, 180, 3))\nvgg = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)\n\nfor layer in vgg.layers:\n layer.trainable = False\n\nx = Flatten()(vgg.output)\nprediction = Dense(5)(x)\n\nmodel = Model(inputs=vgg.input, outputs=prediction)\n\nmodel.summary()",
"Model: \"model_1\"\n_________________________________________________________________\n Layer (type) Output Shape Param # \n=================================================================\n input_3 (InputLayer) [(None, 180, 180, 3)] 0 \n \n block1_conv1 (Conv2D) (None, 180, 180, 64) 1792 \n \n block1_conv2 (Conv2D) (None, 180, 180, 64) 36928 \n \n block1_pool (MaxPooling2D) (None, 90, 90, 64) 0 \n \n block2_conv1 (Conv2D) (None, 90, 90, 128) 73856 \n \n block2_conv2 (Conv2D) (None, 90, 90, 128) 147584 \n \n block2_pool (MaxPooling2D) (None, 45, 45, 128) 0 \n \n block3_conv1 (Conv2D) (None, 45, 45, 256) 295168 \n \n block3_conv2 (Conv2D) (None, 45, 45, 256) 590080 \n \n block3_conv3 (Conv2D) (None, 45, 45, 256) 590080 \n \n block3_pool (MaxPooling2D) (None, 22, 22, 256) 0 \n \n block4_conv1 (Conv2D) (None, 22, 22, 512) 1180160 \n \n block4_conv2 (Conv2D) (None, 22, 22, 512) 2359808 \n \n block4_conv3 (Conv2D) (None, 22, 22, 512) 2359808 \n \n block4_pool (MaxPooling2D) (None, 11, 11, 512) 0 \n \n block5_conv1 (Conv2D) (None, 11, 11, 512) 2359808 \n \n block5_conv2 (Conv2D) (None, 11, 11, 512) 2359808 \n \n block5_conv3 (Conv2D) (None, 11, 11, 512) 2359808 \n \n block5_pool (MaxPooling2D) (None, 5, 5, 512) 0 \n \n flatten_5 (Flatten) (None, 12800) 0 \n \n dense_9 (Dense) (None, 5) 64005 \n \n=================================================================\nTotal params: 14,778,693\nTrainable params: 64,005\nNon-trainable params: 14,714,688\n_________________________________________________________________\n"
],
[
"model.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), \n optimizer=\"adam\", \n metrics=keras.metrics.SparseCategoricalAccuracy(name=\"accuracy\"))\n\nlog_dir = \"logs/fit/VGG\" + datetime.datetime.now().strftime(\"%Y%m%d-%H%M%S\")\ntensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=log_dir, histogram_freq=1)\ncallback = EarlyStopping(monitor='loss', patience=3, restore_best_weights=True) \n\nmodel.fit(train_ds,\n epochs=epochs,\n verbose=1,\n validation_data=val_ds,\n callbacks=[tensorboard_callback, callback])",
"Epoch 1/2\n92/92 [==============================] - 341s 4s/step - loss: 6.6734 - accuracy: 0.6999 - val_loss: 5.3380 - val_accuracy: 0.7820\nEpoch 2/2\n92/92 [==============================] - 330s 4s/step - loss: 1.1660 - accuracy: 0.9159 - val_loss: 4.9176 - val_accuracy: 0.8120\n"
]
],
[
[
"## Hyperparameter Tuning\n\nWe can also utilize the tensorboard display to give us a view of hyperparameter tuning. This requires more work than a simple grid search, but the results are pretty similar. Below is an example adapted from the tensorflow docs. \n\nWe'll do this with a simple model - a dense layer, a dropout, and the output, more complex ones are the same in their setup:\n<ol>\n<li> HP_NUM_UNITS - test a different number of units between 16 and 64. \n<li> HP_DROPOUT - the proportion of dropouts in the dropout. \n<li> HP_OPTIMIZER - we can try some different optimizers. \n</ol>",
"_____no_output_____"
]
],
[
[
"# Load some data\nfrom tensorboard.plugins.hparams import api as hp\nfashion_mnist = tf.keras.datasets.fashion_mnist\n\n(x_train, y_train),(x_test, y_test) = fashion_mnist.load_data()\nx_train, x_test = x_train / 255.0, x_test / 255.0",
"_____no_output_____"
]
],
[
[
"#### Setup Parameters\n\nWe can define the parameters we want to grid search here. Each one is one of these hParam objects - we assign it a name and a range of values to use, here we have a numerical and a discreet example. We list those variables in the hparams argument. \n\nThis is very similar to the idea of setting different values in a gridsearch, just with slightly different syntax. ",
"_____no_output_____"
]
],
[
[
"HP_NUM_UNITS = hp.HParam('num_units', hp.Discrete([16, 32, 48, 64]))\nHP_DROPOUT = hp.HParam('dropout', hp.RealInterval(0.1, 0.4))\nHP_OPTIMIZER = hp.HParam('optimizer', hp.Discrete(['adam', 'sgd', \"rmsprop\"]))\n\nMETRIC_ACCURACY = 'accuracy'\n\nwith tf.summary.create_file_writer('logs/hparam_tuning').as_default():\n hp.hparams_config(\n hparams=[HP_NUM_UNITS, HP_DROPOUT, HP_OPTIMIZER],\n metrics=[hp.Metric(METRIC_ACCURACY, display_name='Accuracy')],\n )",
"2022-03-29 12:49:31.249806: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F FMA\nTo enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.\n"
]
],
[
[
"#### Build Test Models\n\nWe can create our models inside of some helper functions - each one will run a model with certain HPs and return the accuracy, or whichever other metric we define. \n\nNote the key change - the variables that we are changing are replaced with the matching hparams item. ",
"_____no_output_____"
]
],
[
[
"def train_test_model(hparams):\n model = tf.keras.models.Sequential([\n tf.keras.layers.Flatten(),\n tf.keras.layers.Dense(hparams[HP_NUM_UNITS], activation=tf.nn.relu),\n tf.keras.layers.Dropout(hparams[HP_DROPOUT]),\n tf.keras.layers.Dense(10, activation=tf.nn.softmax),\n ])\n model.compile(\n optimizer=hparams[HP_OPTIMIZER],\n loss='sparse_categorical_crossentropy',\n metrics=['accuracy'],\n )\n\n model.fit(x_train, y_train, epochs=10) \n _, accuracy = model.evaluate(x_test, y_test)\n return accuracy",
"_____no_output_____"
],
[
"def run(run_dir, hparams):\n with tf.summary.create_file_writer(run_dir).as_default():\n hp.hparams(hparams) # record the values used in this trial\n accuracy = train_test_model(hparams)\n tf.summary.scalar(METRIC_ACCURACY, accuracy, step=1)",
"_____no_output_____"
]
],
[
[
"#### Perfrom the GridSearch\n\nWe have to write the gridsearch manually, but we can copy this basic setup as a template and modify it. Once complete, load tensorboard and go to the HPARAMS section to visualize. \n\nThe parallel coordinates view allows us to do a quick exploration of the best HPs. ",
"_____no_output_____"
]
],
[
[
"session_num = 0\n\nfor num_units in HP_NUM_UNITS.domain.values:\n for dropout_rate in (HP_DROPOUT.domain.min_value, HP_DROPOUT.domain.max_value):\n for optimizer in HP_OPTIMIZER.domain.values:\n hparams = {\n HP_NUM_UNITS: num_units,\n HP_DROPOUT: dropout_rate,\n HP_OPTIMIZER: optimizer,\n }\n run_name = \"run-%d\" % session_num\n print('--- Starting trial: %s' % run_name)\n print({h.name: hparams[h] for h in hparams})\n run('logs/hparam_tuning/' + run_name, hparams)\n session_num += 1",
"--- Starting trial: run-0\n{'num_units': 16, 'dropout': 0.1, 'optimizer': 'adam'}\nEpoch 1/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.6968 - accuracy: 0.7550\nEpoch 2/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.4955 - accuracy: 0.8224\nEpoch 3/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.4587 - accuracy: 0.8329\nEpoch 4/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.4415 - accuracy: 0.8407\nEpoch 5/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.4276 - accuracy: 0.8452\nEpoch 6/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.4167 - accuracy: 0.8467\nEpoch 7/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.4079 - accuracy: 0.8510\nEpoch 8/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.3988 - accuracy: 0.8557\nEpoch 9/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.3955 - accuracy: 0.8554\nEpoch 10/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.3920 - accuracy: 0.8565\n313/313 [==============================] - 1s 1ms/step - loss: 0.4048 - accuracy: 0.8539\n--- Starting trial: run-1\n{'num_units': 16, 'dropout': 0.1, 'optimizer': 'rmsprop'}\nEpoch 1/10\n1875/1875 [==============================] - 5s 2ms/step - loss: 0.6774 - accuracy: 0.7684\nEpoch 2/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.4935 - accuracy: 0.8246\nEpoch 3/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.4626 - accuracy: 0.8365\nEpoch 4/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.4501 - accuracy: 0.8396\nEpoch 5/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.4388 - accuracy: 0.8445\nEpoch 6/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.4360 - accuracy: 0.8467\nEpoch 7/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.4284 - accuracy: 0.8487\nEpoch 8/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.4300 - accuracy: 0.8495\nEpoch 9/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.4232 - accuracy: 0.8515\nEpoch 10/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.4249 - accuracy: 0.8502\n313/313 [==============================] - 0s 1ms/step - loss: 0.4440 - accuracy: 0.8513\n--- Starting trial: run-2\n{'num_units': 16, 'dropout': 0.1, 'optimizer': 'sgd'}\nEpoch 1/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.9814 - accuracy: 0.6590\nEpoch 2/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.6774 - accuracy: 0.7630\nEpoch 3/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.6047 - accuracy: 0.7907\nEpoch 4/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.5638 - accuracy: 0.8046\nEpoch 5/10\n1875/1875 [==============================] - 5s 3ms/step - loss: 0.5397 - accuracy: 0.8127\nEpoch 6/10\n1875/1875 [==============================] - 8s 4ms/step - loss: 0.5233 - accuracy: 0.8170\nEpoch 7/10\n1875/1875 [==============================] - 6s 3ms/step - loss: 0.5068 - accuracy: 0.8227\nEpoch 8/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.4972 - accuracy: 0.8253\nEpoch 9/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.4879 - accuracy: 0.8276\nEpoch 10/10\n1875/1875 [==============================] - 2s 978us/step - loss: 0.4801 - accuracy: 0.8304\n313/313 [==============================] - 0s 750us/step - loss: 0.4565 - accuracy: 0.8365\n--- Starting trial: run-3\n{'num_units': 16, 'dropout': 0.4, 'optimizer': 'adam'}\nEpoch 1/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 1.0667 - accuracy: 0.5992\nEpoch 2/10\n1875/1875 [==============================] - 2s 949us/step - loss: 0.8373 - accuracy: 0.6763\nEpoch 3/10\n1875/1875 [==============================] - 2s 889us/step - loss: 0.7925 - accuracy: 0.6969\nEpoch 4/10\n1875/1875 [==============================] - 2s 841us/step - loss: 0.7689 - accuracy: 0.7047\nEpoch 5/10\n1875/1875 [==============================] - 2s 910us/step - loss: 0.7529 - accuracy: 0.7134\nEpoch 6/10\n1875/1875 [==============================] - 2s 945us/step - loss: 0.7387 - accuracy: 0.7183\nEpoch 7/10\n1875/1875 [==============================] - 2s 863us/step - loss: 0.7311 - accuracy: 0.7230\nEpoch 8/10\n1875/1875 [==============================] - 2s 875us/step - loss: 0.7259 - accuracy: 0.7250\nEpoch 9/10\n1875/1875 [==============================] - 2s 898us/step - loss: 0.7226 - accuracy: 0.7235\nEpoch 10/10\n1875/1875 [==============================] - 2s 853us/step - loss: 0.7170 - accuracy: 0.7297\n313/313 [==============================] - 0s 682us/step - loss: 0.4743 - accuracy: 0.8303\n--- Starting trial: run-4\n{'num_units': 16, 'dropout': 0.4, 'optimizer': 'rmsprop'}\nEpoch 1/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.9905 - accuracy: 0.6215\nEpoch 2/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.8131 - accuracy: 0.6848\nEpoch 3/10\n1875/1875 [==============================] - 2s 812us/step - loss: 0.7861 - accuracy: 0.6984\nEpoch 4/10\n1875/1875 [==============================] - 2s 880us/step - loss: 0.7716 - accuracy: 0.7081\nEpoch 5/10\n1875/1875 [==============================] - 2s 848us/step - loss: 0.7536 - accuracy: 0.7223\nEpoch 6/10\n1875/1875 [==============================] - 2s 829us/step - loss: 0.7421 - accuracy: 0.7276\nEpoch 7/10\n1875/1875 [==============================] - 2s 843us/step - loss: 0.7404 - accuracy: 0.7293\nEpoch 8/10\n1875/1875 [==============================] - 2s 829us/step - loss: 0.7427 - accuracy: 0.7345\nEpoch 9/10\n1875/1875 [==============================] - 2s 857us/step - loss: 0.7330 - accuracy: 0.7341\nEpoch 10/10\n1875/1875 [==============================] - 2s 905us/step - loss: 0.7370 - accuracy: 0.7353\n313/313 [==============================] - 0s 782us/step - loss: 0.5080 - accuracy: 0.8290\n--- Starting trial: run-5\n{'num_units': 16, 'dropout': 0.4, 'optimizer': 'sgd'}\nEpoch 1/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 1.3031 - accuracy: 0.5136\nEpoch 2/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 1.0172 - accuracy: 0.6109\nEpoch 3/10\n1875/1875 [==============================] - 2s 906us/step - loss: 0.9510 - accuracy: 0.6372\nEpoch 4/10\n1875/1875 [==============================] - 2s 888us/step - loss: 0.9163 - accuracy: 0.6487\nEpoch 5/10\n1875/1875 [==============================] - 2s 917us/step - loss: 0.8835 - accuracy: 0.6586\nEpoch 6/10\n1875/1875 [==============================] - 2s 897us/step - loss: 0.8660 - accuracy: 0.6678\nEpoch 7/10\n1875/1875 [==============================] - 2s 848us/step - loss: 0.8515 - accuracy: 0.6732\nEpoch 8/10\n1875/1875 [==============================] - 1s 775us/step - loss: 0.8382 - accuracy: 0.6773\nEpoch 9/10\n1875/1875 [==============================] - 1s 769us/step - loss: 0.8244 - accuracy: 0.6852\nEpoch 10/10\n1875/1875 [==============================] - 1s 723us/step - loss: 0.8154 - accuracy: 0.6868\n313/313 [==============================] - 0s 711us/step - loss: 0.5510 - accuracy: 0.8110\n--- Starting trial: run-6\n{'num_units': 32, 'dropout': 0.1, 'optimizer': 'adam'}\nEpoch 1/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.6021 - accuracy: 0.7887\nEpoch 2/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.4402 - accuracy: 0.8447\nEpoch 3/10\n1875/1875 [==============================] - 2s 907us/step - loss: 0.4042 - accuracy: 0.8539\nEpoch 4/10\n1875/1875 [==============================] - 2s 904us/step - loss: 0.3811 - accuracy: 0.8624\nEpoch 5/10\n1875/1875 [==============================] - 2s 906us/step - loss: 0.3669 - accuracy: 0.8664\nEpoch 6/10\n1875/1875 [==============================] - 2s 916us/step - loss: 0.3561 - accuracy: 0.8704\nEpoch 7/10\n1875/1875 [==============================] - 2s 906us/step - loss: 0.3493 - accuracy: 0.8716\nEpoch 8/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.3417 - accuracy: 0.8750\nEpoch 9/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.3339 - accuracy: 0.8762\nEpoch 10/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.3293 - accuracy: 0.8768\n313/313 [==============================] - 1s 1ms/step - loss: 0.3706 - accuracy: 0.8703\n--- Starting trial: run-7\n{'num_units': 32, 'dropout': 0.1, 'optimizer': 'rmsprop'}\nEpoch 1/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.5927 - accuracy: 0.7913\nEpoch 2/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.4437 - accuracy: 0.8415\nEpoch 3/10\n1875/1875 [==============================] - 2s 968us/step - loss: 0.4125 - accuracy: 0.8528\nEpoch 4/10\n1875/1875 [==============================] - 2s 978us/step - loss: 0.3987 - accuracy: 0.8585\nEpoch 5/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.3928 - accuracy: 0.8608\nEpoch 6/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.3840 - accuracy: 0.8662\nEpoch 7/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.3793 - accuracy: 0.8672\nEpoch 8/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.3764 - accuracy: 0.8700\nEpoch 9/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.3738 - accuracy: 0.8702\nEpoch 10/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.3741 - accuracy: 0.8708\n313/313 [==============================] - 0s 863us/step - loss: 0.4295 - accuracy: 0.8613\n--- Starting trial: run-8\n{'num_units': 32, 'dropout': 0.1, 'optimizer': 'sgd'}\nEpoch 1/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.8543 - accuracy: 0.7087\nEpoch 2/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.5899 - accuracy: 0.7972\nEpoch 3/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.5305 - accuracy: 0.8163\nEpoch 4/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.4977 - accuracy: 0.8270\nEpoch 5/10\n1875/1875 [==============================] - 2s 993us/step - loss: 0.4759 - accuracy: 0.8339\nEpoch 6/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.4598 - accuracy: 0.8390\nEpoch 7/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.4479 - accuracy: 0.8431\nEpoch 8/10\n1875/1875 [==============================] - 2s 955us/step - loss: 0.4360 - accuracy: 0.8465\nEpoch 9/10\n1875/1875 [==============================] - 2s 953us/step - loss: 0.4280 - accuracy: 0.8483\nEpoch 10/10\n1875/1875 [==============================] - 2s 906us/step - loss: 0.4207 - accuracy: 0.8510\n313/313 [==============================] - 0s 817us/step - loss: 0.4228 - accuracy: 0.8483\n--- Starting trial: run-9\n{'num_units': 32, 'dropout': 0.4, 'optimizer': 'adam'}\nEpoch 1/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.7856 - accuracy: 0.7224\nEpoch 2/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.5841 - accuracy: 0.7926\nEpoch 3/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.5466 - accuracy: 0.8035\nEpoch 4/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.5274 - accuracy: 0.8080\nEpoch 5/10\n1875/1875 [==============================] - 5s 3ms/step - loss: 0.5162 - accuracy: 0.8116\nEpoch 6/10\n1875/1875 [==============================] - 5s 3ms/step - loss: 0.5033 - accuracy: 0.8167\nEpoch 7/10\n1875/1875 [==============================] - 5s 3ms/step - loss: 0.4955 - accuracy: 0.8194\nEpoch 8/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.4927 - accuracy: 0.8188\nEpoch 9/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.4858 - accuracy: 0.8222\nEpoch 10/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.4824 - accuracy: 0.8234\n313/313 [==============================] - 0s 818us/step - loss: 0.4114 - accuracy: 0.8498\n--- Starting trial: run-10\n{'num_units': 32, 'dropout': 0.4, 'optimizer': 'rmsprop'}\nEpoch 1/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.7762 - accuracy: 0.7284\nEpoch 2/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.5924 - accuracy: 0.7913\nEpoch 3/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.5675 - accuracy: 0.8005\nEpoch 4/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.5532 - accuracy: 0.8056\nEpoch 5/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.5511 - accuracy: 0.8085\nEpoch 6/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.5466 - accuracy: 0.8106\nEpoch 7/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.5448 - accuracy: 0.8123\nEpoch 8/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.5425 - accuracy: 0.8125\nEpoch 9/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.5479 - accuracy: 0.8133\nEpoch 10/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.5465 - accuracy: 0.8122\n313/313 [==============================] - 0s 935us/step - loss: 0.5000 - accuracy: 0.8461\n--- Starting trial: run-11\n{'num_units': 32, 'dropout': 0.4, 'optimizer': 'sgd'}\nEpoch 1/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 1.0401 - accuracy: 0.6450\nEpoch 2/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.7387 - accuracy: 0.7494\nEpoch 3/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.6644 - accuracy: 0.7724\nEpoch 4/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.6242 - accuracy: 0.7848\nEpoch 5/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.5997 - accuracy: 0.7910\nEpoch 6/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.5787 - accuracy: 0.8001\nEpoch 7/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.5660 - accuracy: 0.8047\nEpoch 8/10\n1875/1875 [==============================] - 2s 969us/step - loss: 0.5538 - accuracy: 0.8055\nEpoch 9/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.5433 - accuracy: 0.8109\nEpoch 10/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.5348 - accuracy: 0.8141\n313/313 [==============================] - 1s 2ms/step - loss: 0.4404 - accuracy: 0.8430\n--- Starting trial: run-12\n{'num_units': 48, 'dropout': 0.1, 'optimizer': 'adam'}\nEpoch 1/10\n1875/1875 [==============================] - 6s 3ms/step - loss: 0.5622 - accuracy: 0.8052\nEpoch 2/10\n1875/1875 [==============================] - 6s 3ms/step - loss: 0.4190 - accuracy: 0.8504\nEpoch 3/10\n1875/1875 [==============================] - 5s 3ms/step - loss: 0.3827 - accuracy: 0.8618\nEpoch 4/10\n1875/1875 [==============================] - 5s 2ms/step - loss: 0.3612 - accuracy: 0.8691\nEpoch 5/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.3467 - accuracy: 0.8724\nEpoch 6/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.3329 - accuracy: 0.8775\nEpoch 7/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.3261 - accuracy: 0.8809\nEpoch 8/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.3150 - accuracy: 0.8847\nEpoch 9/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.3064 - accuracy: 0.8871\nEpoch 10/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.3035 - accuracy: 0.8888\n313/313 [==============================] - 1s 2ms/step - loss: 0.3591 - accuracy: 0.8713\n--- Starting trial: run-13\n{'num_units': 48, 'dropout': 0.1, 'optimizer': 'rmsprop'}\nEpoch 1/10\n1875/1875 [==============================] - 6s 3ms/step - loss: 0.5655 - accuracy: 0.8033\nEpoch 2/10\n1875/1875 [==============================] - 5s 3ms/step - loss: 0.4147 - accuracy: 0.8513\nEpoch 3/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.3896 - accuracy: 0.8612\nEpoch 4/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.3724 - accuracy: 0.8694\nEpoch 5/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.3642 - accuracy: 0.8695\nEpoch 6/10\n1875/1875 [==============================] - 5s 3ms/step - loss: 0.3572 - accuracy: 0.8741\nEpoch 7/10\n1875/1875 [==============================] - 5s 3ms/step - loss: 0.3520 - accuracy: 0.8765\nEpoch 8/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.3456 - accuracy: 0.8795\nEpoch 9/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.3433 - accuracy: 0.8797\nEpoch 10/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.3417 - accuracy: 0.8819\n313/313 [==============================] - 1s 2ms/step - loss: 0.4034 - accuracy: 0.8717\n--- Starting trial: run-14\n{'num_units': 48, 'dropout': 0.1, 'optimizer': 'sgd'}\nEpoch 1/10\n1875/1875 [==============================] - 5s 3ms/step - loss: 0.8239 - accuracy: 0.7291\nEpoch 2/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.5755 - accuracy: 0.8049\nEpoch 3/10\n1875/1875 [==============================] - 5s 2ms/step - loss: 0.5172 - accuracy: 0.8229\nEpoch 4/10\n1875/1875 [==============================] - 5s 3ms/step - loss: 0.4838 - accuracy: 0.8317\nEpoch 5/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.4626 - accuracy: 0.8390\nEpoch 6/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.4445 - accuracy: 0.8451\nEpoch 7/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.4308 - accuracy: 0.8497\nEpoch 8/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.4207 - accuracy: 0.8532\nEpoch 9/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.4106 - accuracy: 0.8550\nEpoch 10/10\n1875/1875 [==============================] - 2s 948us/step - loss: 0.4020 - accuracy: 0.8597\n313/313 [==============================] - 0s 794us/step - loss: 0.4197 - accuracy: 0.8513\n--- Starting trial: run-15\n{'num_units': 48, 'dropout': 0.4, 'optimizer': 'adam'}\nEpoch 1/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.6932 - accuracy: 0.7590\nEpoch 2/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.5115 - accuracy: 0.8164\nEpoch 3/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.4771 - accuracy: 0.8277\nEpoch 4/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.4581 - accuracy: 0.8342\nEpoch 5/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.4451 - accuracy: 0.8391\nEpoch 6/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.4379 - accuracy: 0.8423\nEpoch 7/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.4284 - accuracy: 0.8433\nEpoch 8/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.4205 - accuracy: 0.8469\nEpoch 9/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.4140 - accuracy: 0.8485\nEpoch 10/10\n1875/1875 [==============================] - 6s 3ms/step - loss: 0.4075 - accuracy: 0.8505\n313/313 [==============================] - 0s 1ms/step - loss: 0.3798 - accuracy: 0.8638\n--- Starting trial: run-16\n{'num_units': 48, 'dropout': 0.4, 'optimizer': 'rmsprop'}\nEpoch 1/10\n1875/1875 [==============================] - 6s 3ms/step - loss: 0.6667 - accuracy: 0.7681\nEpoch 2/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.5189 - accuracy: 0.8213\nEpoch 3/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.5020 - accuracy: 0.8278\nEpoch 4/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.4907 - accuracy: 0.8328\nEpoch 5/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.4900 - accuracy: 0.8348\nEpoch 6/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.4849 - accuracy: 0.8357\nEpoch 7/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.4804 - accuracy: 0.8389\nEpoch 8/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.4852 - accuracy: 0.8382\nEpoch 9/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.4900 - accuracy: 0.8376\nEpoch 10/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.4894 - accuracy: 0.8398\n313/313 [==============================] - 0s 1ms/step - loss: 0.4576 - accuracy: 0.8541\n--- Starting trial: run-17\n{'num_units': 48, 'dropout': 0.4, 'optimizer': 'sgd'}\nEpoch 1/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.9596 - accuracy: 0.6779\nEpoch 2/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.6708 - accuracy: 0.7737\nEpoch 3/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.6021 - accuracy: 0.7952\nEpoch 4/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.5658 - accuracy: 0.8049\nEpoch 5/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.5390 - accuracy: 0.8117\nEpoch 6/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.5202 - accuracy: 0.8210\nEpoch 7/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.5078 - accuracy: 0.8225\nEpoch 8/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.4966 - accuracy: 0.8267\nEpoch 9/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.4871 - accuracy: 0.8286\nEpoch 10/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.4802 - accuracy: 0.8311\n313/313 [==============================] - 0s 909us/step - loss: 0.4332 - accuracy: 0.8421\n--- Starting trial: run-18\n{'num_units': 64, 'dropout': 0.1, 'optimizer': 'adam'}\nEpoch 1/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.5414 - accuracy: 0.8091\nEpoch 2/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.4040 - accuracy: 0.8555\nEpoch 3/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.3675 - accuracy: 0.8676\nEpoch 4/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.3501 - accuracy: 0.8735\nEpoch 5/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.3332 - accuracy: 0.8784\nEpoch 6/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.3224 - accuracy: 0.8818\nEpoch 7/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.3130 - accuracy: 0.8846\nEpoch 8/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.3019 - accuracy: 0.8883\nEpoch 9/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.2957 - accuracy: 0.8913\nEpoch 10/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.2873 - accuracy: 0.8934\n313/313 [==============================] - 0s 1ms/step - loss: 0.3449 - accuracy: 0.8799\n--- Starting trial: run-19\n{'num_units': 64, 'dropout': 0.1, 'optimizer': 'rmsprop'}\nEpoch 1/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.5481 - accuracy: 0.8065\nEpoch 2/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.4089 - accuracy: 0.8536\nEpoch 3/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.3808 - accuracy: 0.8650\nEpoch 4/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.3669 - accuracy: 0.8708\nEpoch 5/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.3565 - accuracy: 0.8747\nEpoch 6/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.3498 - accuracy: 0.8798\nEpoch 7/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.3435 - accuracy: 0.8813\nEpoch 8/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.3407 - accuracy: 0.8841\nEpoch 9/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.3349 - accuracy: 0.8856\nEpoch 10/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.3307 - accuracy: 0.8877\n313/313 [==============================] - 0s 787us/step - loss: 0.4112 - accuracy: 0.8737\n--- Starting trial: run-20\n{'num_units': 64, 'dropout': 0.1, 'optimizer': 'sgd'}\nEpoch 1/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.8130 - accuracy: 0.7283\nEpoch 2/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.5680 - accuracy: 0.8067\nEpoch 3/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.5111 - accuracy: 0.8247\nEpoch 4/10\n1875/1875 [==============================] - 2s 963us/step - loss: 0.4790 - accuracy: 0.8322\nEpoch 5/10\n1875/1875 [==============================] - 2s 891us/step - loss: 0.4558 - accuracy: 0.8410\nEpoch 6/10\n1875/1875 [==============================] - 2s 925us/step - loss: 0.4387 - accuracy: 0.8465\nEpoch 7/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.4271 - accuracy: 0.8493\nEpoch 8/10\n1875/1875 [==============================] - 2s 909us/step - loss: 0.4134 - accuracy: 0.8543\nEpoch 9/10\n1875/1875 [==============================] - 2s 894us/step - loss: 0.4034 - accuracy: 0.8576\nEpoch 10/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.3968 - accuracy: 0.8596\n313/313 [==============================] - 1s 2ms/step - loss: 0.4136 - accuracy: 0.8512\n--- Starting trial: run-21\n{'num_units': 64, 'dropout': 0.4, 'optimizer': 'adam'}\nEpoch 1/10\n1875/1875 [==============================] - 7s 3ms/step - loss: 0.6371 - accuracy: 0.7763\nEpoch 2/10\n1875/1875 [==============================] - 6s 3ms/step - loss: 0.4833 - accuracy: 0.8283\nEpoch 3/10\n1875/1875 [==============================] - 5s 3ms/step - loss: 0.4488 - accuracy: 0.8392\nEpoch 4/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.4316 - accuracy: 0.8460\nEpoch 5/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.4182 - accuracy: 0.8486\nEpoch 6/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.4075 - accuracy: 0.8522\nEpoch 7/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.3998 - accuracy: 0.8529\nEpoch 8/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.3926 - accuracy: 0.8567\nEpoch 9/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.3854 - accuracy: 0.8586\nEpoch 10/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.3816 - accuracy: 0.8608\n313/313 [==============================] - 1s 2ms/step - loss: 0.3785 - accuracy: 0.8655\n--- Starting trial: run-22\n{'num_units': 64, 'dropout': 0.4, 'optimizer': 'rmsprop'}\nEpoch 1/10\n1875/1875 [==============================] - 7s 3ms/step - loss: 0.6402 - accuracy: 0.7756\nEpoch 2/10\n1875/1875 [==============================] - 6s 3ms/step - loss: 0.4972 - accuracy: 0.8278\nEpoch 3/10\n1875/1875 [==============================] - 5s 3ms/step - loss: 0.4775 - accuracy: 0.8340\nEpoch 4/10\n1875/1875 [==============================] - 4s 2ms/step - loss: 0.4667 - accuracy: 0.8417\nEpoch 5/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.4652 - accuracy: 0.8429\nEpoch 6/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.4598 - accuracy: 0.8469\nEpoch 7/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.4594 - accuracy: 0.8482\nEpoch 8/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.4587 - accuracy: 0.8493\nEpoch 9/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.4625 - accuracy: 0.8485\nEpoch 10/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.4628 - accuracy: 0.8501\n313/313 [==============================] - 0s 927us/step - loss: 0.4785 - accuracy: 0.8598\n--- Starting trial: run-23\n{'num_units': 64, 'dropout': 0.4, 'optimizer': 'sgd'}\nEpoch 1/10\n1875/1875 [==============================] - 3s 2ms/step - loss: 0.9435 - accuracy: 0.6782\nEpoch 2/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.6472 - accuracy: 0.7804\nEpoch 3/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.5777 - accuracy: 0.8024\nEpoch 4/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.5386 - accuracy: 0.8142\nEpoch 5/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.5154 - accuracy: 0.8217\nEpoch 6/10\n1875/1875 [==============================] - 3s 1ms/step - loss: 0.4965 - accuracy: 0.8253\nEpoch 7/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.4833 - accuracy: 0.8292\nEpoch 8/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.4710 - accuracy: 0.8356\nEpoch 9/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.4621 - accuracy: 0.8370\nEpoch 10/10\n1875/1875 [==============================] - 2s 1ms/step - loss: 0.4534 - accuracy: 0.8414\n313/313 [==============================] - 0s 1ms/step - loss: 0.4233 - accuracy: 0.8459\n"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
cb3ce8275ffdbfc9079a5d0a9fc4efe7be0513d8 | 124,356 | ipynb | Jupyter Notebook | recurrent-neural-networks/char-rnn/Character_Level_RNN_Exercise.ipynb | antonino-tocco/deeplearning | 3ce3b644b3950bcafd15cb31a3f6fc0518708d48 | [
"MIT"
] | null | null | null | recurrent-neural-networks/char-rnn/Character_Level_RNN_Exercise.ipynb | antonino-tocco/deeplearning | 3ce3b644b3950bcafd15cb31a3f6fc0518708d48 | [
"MIT"
] | 7 | 2019-12-16T21:43:32.000Z | 2022-02-10T00:20:56.000Z | recurrent-neural-networks/char-rnn/Character_Level_RNN_Exercise.ipynb | antonino-tocco/deeplearning | 3ce3b644b3950bcafd15cb31a3f6fc0518708d48 | [
"MIT"
] | null | null | null | 38.393331 | 753 | 0.517209 | [
[
[
"# Character-Level LSTM in PyTorch\n\nIn this notebook, I'll construct a character-level LSTM with PyTorch. The network will train character by character on some text, then generate new text character by character. As an example, I will train on Anna Karenina. **This model will be able to generate new text based on the text from the book!**\n\nThis network is based off of Andrej Karpathy's [post on RNNs](http://karpathy.github.io/2015/05/21/rnn-effectiveness/) and [implementation in Torch](https://github.com/karpathy/char-rnn). Below is the general architecture of the character-wise RNN.\n\n<img src=\"assets/charseq.jpeg\" width=\"500\">",
"_____no_output_____"
],
[
"First let's load in our required resources for data loading and model creation.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport torch\nfrom torch import nn\nimport torch.nn.functional as F",
"_____no_output_____"
]
],
[
[
"## Load in Data\n\nThen, we'll load the Anna Karenina text file and convert it into integers for our network to use. ",
"_____no_output_____"
]
],
[
[
"# open text file and read in data as `text`\nwith open('data/anna.txt', 'r') as f:\n text = f.read()",
"_____no_output_____"
]
],
[
[
"Let's check out the first 100 characters, make sure everything is peachy. According to the [American Book Review](http://americanbookreview.org/100bestlines.asp), this is the 6th best first line of a book ever.",
"_____no_output_____"
]
],
[
[
"text[:100]",
"_____no_output_____"
]
],
[
[
"### Tokenization\n\nIn the cells, below, I'm creating a couple **dictionaries** to convert the characters to and from integers. Encoding the characters as integers makes it easier to use as input in the network.",
"_____no_output_____"
]
],
[
[
"# encode the text and map each character to an integer and vice versa\n\n# we create two dictionaries:\n# 1. int2char, which maps integers to characters\n# 2. char2int, which maps characters to unique integers\nchars = tuple(set(text))\nprint(chars)\nint2char = dict(enumerate(chars))\nprint(int2char)\nchar2int = {ch: ii for ii, ch in int2char.items()}\nprint(char2int)\n\n# encode the text\nencoded = np.array([char2int[ch] for ch in text])",
"(\"'\", '3', '\"', 'E', 'V', ' ', 'O', '?', 'f', 'c', 'l', 'F', '!', '(', '*', 'M', 'e', 't', ',', '9', 'H', 'u', '7', 'C', 'Z', 'L', 'a', '@', 'v', 'P', 'g', 'S', 'z', '\\n', 'd', 'm', 'i', '5', '&', 'p', 'I', 'W', 'w', '$', 'r', 'o', '%', 'n', 'B', 'K', 'q', 'T', ':', '2', '0', 'N', 'k', 'J', '6', 'R', '/', '`', 'A', 'D', 'y', '8', 'h', 'Q', 's', '1', '-', ')', '4', 'U', 'X', 'Y', 'G', 'j', '_', 'x', ';', 'b', '.')\n{0: \"'\", 1: '3', 2: '\"', 3: 'E', 4: 'V', 5: ' ', 6: 'O', 7: '?', 8: 'f', 9: 'c', 10: 'l', 11: 'F', 12: '!', 13: '(', 14: '*', 15: 'M', 16: 'e', 17: 't', 18: ',', 19: '9', 20: 'H', 21: 'u', 22: '7', 23: 'C', 24: 'Z', 25: 'L', 26: 'a', 27: '@', 28: 'v', 29: 'P', 30: 'g', 31: 'S', 32: 'z', 33: '\\n', 34: 'd', 35: 'm', 36: 'i', 37: '5', 38: '&', 39: 'p', 40: 'I', 41: 'W', 42: 'w', 43: '$', 44: 'r', 45: 'o', 46: '%', 47: 'n', 48: 'B', 49: 'K', 50: 'q', 51: 'T', 52: ':', 53: '2', 54: '0', 55: 'N', 56: 'k', 57: 'J', 58: '6', 59: 'R', 60: '/', 61: '`', 62: 'A', 63: 'D', 64: 'y', 65: '8', 66: 'h', 67: 'Q', 68: 's', 69: '1', 70: '-', 71: ')', 72: '4', 73: 'U', 74: 'X', 75: 'Y', 76: 'G', 77: 'j', 78: '_', 79: 'x', 80: ';', 81: 'b', 82: '.'}\n{\"'\": 0, '3': 1, '\"': 2, 'E': 3, 'V': 4, ' ': 5, 'O': 6, '?': 7, 'f': 8, 'c': 9, 'l': 10, 'F': 11, '!': 12, '(': 13, '*': 14, 'M': 15, 'e': 16, 't': 17, ',': 18, '9': 19, 'H': 20, 'u': 21, '7': 22, 'C': 23, 'Z': 24, 'L': 25, 'a': 26, '@': 27, 'v': 28, 'P': 29, 'g': 30, 'S': 31, 'z': 32, '\\n': 33, 'd': 34, 'm': 35, 'i': 36, '5': 37, '&': 38, 'p': 39, 'I': 40, 'W': 41, 'w': 42, '$': 43, 'r': 44, 'o': 45, '%': 46, 'n': 47, 'B': 48, 'K': 49, 'q': 50, 'T': 51, ':': 52, '2': 53, '0': 54, 'N': 55, 'k': 56, 'J': 57, '6': 58, 'R': 59, '/': 60, '`': 61, 'A': 62, 'D': 63, 'y': 64, '8': 65, 'h': 66, 'Q': 67, 's': 68, '1': 69, '-': 70, ')': 71, '4': 72, 'U': 73, 'X': 74, 'Y': 75, 'G': 76, 'j': 77, '_': 78, 'x': 79, ';': 80, 'b': 81, '.': 82}\n"
]
],
[
[
"And we can see those same characters from above, encoded as integers.",
"_____no_output_____"
]
],
[
[
"encoded[:100]",
"_____no_output_____"
]
],
[
[
"## Pre-processing the data\n\nAs you can see in our char-RNN image above, our LSTM expects an input that is **one-hot encoded** meaning that each character is converted into an integer (via our created dictionary) and *then* converted into a column vector where only it's corresponding integer index will have the value of 1 and the rest of the vector will be filled with 0's. Since we're one-hot encoding the data, let's make a function to do that!\n",
"_____no_output_____"
]
],
[
[
"def one_hot_encode(arr, n_labels):\n \n # Initialize the the encoded array\n one_hot = np.zeros((np.multiply(*arr.shape), n_labels), dtype=np.float32)\n \n # Fill the appropriate elements with ones\n one_hot[np.arange(one_hot.shape[0]), arr.flatten()] = 1.\n \n # Finally reshape it to get back to the original array\n one_hot = one_hot.reshape((*arr.shape, n_labels))\n \n return one_hot",
"_____no_output_____"
],
[
"# check that the function works as expected\ntest_seq = np.array([[3, 5, 1]])\none_hot = one_hot_encode(test_seq, 8)\n\nprint(one_hot)",
"[[[ 0. 0. 0. 1. 0. 0. 0. 0.]\n [ 0. 0. 0. 0. 0. 1. 0. 0.]\n [ 0. 1. 0. 0. 0. 0. 0. 0.]]]\n"
]
],
[
[
"## Making training mini-batches\n\n\nTo train on this data, we also want to create mini-batches for training. Remember that we want our batches to be multiple sequences of some desired number of sequence steps. Considering a simple example, our batches would look like this:\n\n<img src=\"assets/[email protected]\" width=500px>\n\n\n<br>\n\nIn this example, we'll take the encoded characters (passed in as the `arr` parameter) and split them into multiple sequences, given by `batch_size`. Each of our sequences will be `seq_length` long.\n\n### Creating Batches\n\n**1. The first thing we need to do is discard some of the text so we only have completely full mini-batches. **\n\nEach batch contains $N \\times M$ characters, where $N$ is the batch size (the number of sequences in a batch) and $M$ is the seq_length or number of time steps in a sequence. Then, to get the total number of batches, $K$, that we can make from the array `arr`, you divide the length of `arr` by the number of characters per batch. Once you know the number of batches, you can get the total number of characters to keep from `arr`, $N * M * K$.\n\n**2. After that, we need to split `arr` into $N$ batches. ** \n\nYou can do this using `arr.reshape(size)` where `size` is a tuple containing the dimensions sizes of the reshaped array. We know we want $N$ sequences in a batch, so let's make that the size of the first dimension. For the second dimension, you can use `-1` as a placeholder in the size, it'll fill up the array with the appropriate data for you. After this, you should have an array that is $N \\times (M * K)$.\n\n**3. Now that we have this array, we can iterate through it to get our mini-batches. **\n\nThe idea is each batch is a $N \\times M$ window on the $N \\times (M * K)$ array. For each subsequent batch, the window moves over by `seq_length`. We also want to create both the input and target arrays. Remember that the targets are just the inputs shifted over by one character. The way I like to do this window is use `range` to take steps of size `n_steps` from $0$ to `arr.shape[1]`, the total number of tokens in each sequence. That way, the integers you get from `range` always point to the start of a batch, and each window is `seq_length` wide.\n\n> **TODO:** Write the code for creating batches in the function below. The exercises in this notebook _will not be easy_. I've provided a notebook with solutions alongside this notebook. If you get stuck, checkout the solutions. The most important thing is that you don't copy and paste the code into here, **type out the solution code yourself.**",
"_____no_output_____"
]
],
[
[
"def get_batches(arr, batch_size, seq_length):\n '''Create a generator that returns batches of size\n batch_size x seq_length from arr.\n \n Arguments\n ---------\n arr: Array you want to make batches from\n batch_size: Batch size, the number of sequences per batch\n seq_length: Number of encoded chars in a sequence\n '''\n \n ## TODO: Get the number of batches we can make\n batch_size_total = batch_size * seq_length\n \n print(f'batch size total {batch_size_total}')\n \n n_batches = len(arr) // batch_size_total\n \n print(f'n batches {n_batches}')\n \n ## TODO: Keep only enough characters to make full batches\n arr = arr[:n_batches * batch_size_total]\n \n print(f'arr shape {arr.shape}')\n \n ## TODO: Reshape into batch_size rows\n arr = arr.reshape((batch_size, -1))\n \n print(f'arr shape {arr.shape}')\n \n ## TODO: Iterate over the batches using a window of size seq_length\n for n in range(0, arr.shape[1], seq_length):\n # The features\n x = arr[:, n : n + seq_length]\n # The targets, shifted by one\n y = np.zeros_like(x)\n try:\n y[:, :-1], y[:, -1] = x[:, 1:], arr[:, n + seq_length]\n except IndexError:\n y[:, :-1], y[:, -1] = x[:, 1:], arr[:, 0]\n yield x, y",
"_____no_output_____"
]
],
[
[
"### Test Your Implementation\n\nNow I'll make some data sets and we can check out what's going on as we batch data. Here, as an example, I'm going to use a batch size of 8 and 50 sequence steps.",
"_____no_output_____"
]
],
[
[
"batches = get_batches(encoded, 8, 50)\nx, y = next(batches)",
"batch size total 400\nn batches 4963\narr shape (1985200,)\narr shape (8, 248150)\n"
],
[
"# printing out the first 10 items in a sequence\nprint('x\\n', x[:10, :10])\nprint('\\ny\\n', y[:10, :10])",
"x\n [[23 66 26 39 17 16 44 5 69 33]\n [68 45 47 5 17 66 26 17 5 26]\n [16 47 34 5 45 44 5 26 5 8]\n [68 5 17 66 16 5 9 66 36 16]\n [ 5 68 26 42 5 66 16 44 5 17]\n [ 9 21 68 68 36 45 47 5 26 47]\n [ 5 62 47 47 26 5 66 26 34 5]\n [ 6 81 10 45 47 68 56 64 82 5]]\n\ny\n [[66 26 39 17 16 44 5 69 33 33]\n [45 47 5 17 66 26 17 5 26 17]\n [47 34 5 45 44 5 26 5 8 45]\n [ 5 17 66 16 5 9 66 36 16 8]\n [68 26 42 5 66 16 44 5 17 16]\n [21 68 68 36 45 47 5 26 47 34]\n [62 47 47 26 5 66 26 34 5 68]\n [81 10 45 47 68 56 64 82 5 2]]\n"
]
],
[
[
"If you implemented `get_batches` correctly, the above output should look something like \n```\nx\n [[25 8 60 11 45 27 28 73 1 2]\n [17 7 20 73 45 8 60 45 73 60]\n [27 20 80 73 7 28 73 60 73 65]\n [17 73 45 8 27 73 66 8 46 27]\n [73 17 60 12 73 8 27 28 73 45]\n [66 64 17 17 46 7 20 73 60 20]\n [73 76 20 20 60 73 8 60 80 73]\n [47 35 43 7 20 17 24 50 37 73]]\n\ny\n [[ 8 60 11 45 27 28 73 1 2 2]\n [ 7 20 73 45 8 60 45 73 60 45]\n [20 80 73 7 28 73 60 73 65 7]\n [73 45 8 27 73 66 8 46 27 65]\n [17 60 12 73 8 27 28 73 45 27]\n [64 17 17 46 7 20 73 60 20 80]\n [76 20 20 60 73 8 60 80 73 17]\n [35 43 7 20 17 24 50 37 73 36]]\n ```\n although the exact numbers may be different. Check to make sure the data is shifted over one step for `y`.",
"_____no_output_____"
],
[
"---\n## Defining the network with PyTorch\n\nBelow is where you'll define the network.\n\n<img src=\"assets/charRNN.png\" width=500px>\n\nNext, you'll use PyTorch to define the architecture of the network. We start by defining the layers and operations we want. Then, define a method for the forward pass. You've also been given a method for predicting characters.",
"_____no_output_____"
],
[
"### Model Structure\n\nIn `__init__` the suggested structure is as follows:\n* Create and store the necessary dictionaries (this has been done for you)\n* Define an LSTM layer that takes as params: an input size (the number of characters), a hidden layer size `n_hidden`, a number of layers `n_layers`, a dropout probability `drop_prob`, and a batch_first boolean (True, since we are batching)\n* Define a dropout layer with `dropout_prob`\n* Define a fully-connected layer with params: input size `n_hidden` and output size (the number of characters)\n* Finally, initialize the weights (again, this has been given)\n\nNote that some parameters have been named and given in the `__init__` function, and we use them and store them by doing something like `self.drop_prob = drop_prob`.",
"_____no_output_____"
],
[
"---\n### LSTM Inputs/Outputs\n\nYou can create a basic [LSTM layer](https://pytorch.org/docs/stable/nn.html#lstm) as follows\n\n```python\nself.lstm = nn.LSTM(input_size, n_hidden, n_layers, \n dropout=drop_prob, batch_first=True)\n```\n\nwhere `input_size` is the number of characters this cell expects to see as sequential input, and `n_hidden` is the number of units in the hidden layers in the cell. And we can add dropout by adding a dropout parameter with a specified probability; this will automatically add dropout to the inputs or outputs. Finally, in the `forward` function, we can stack up the LSTM cells into layers using `.view`. With this, you pass in a list of cells and it will send the output of one cell into the next cell.\n\nWe also need to create an initial hidden state of all zeros. This is done like so\n\n```python\nself.init_hidden()\n```",
"_____no_output_____"
]
],
[
[
"# check if GPU is available\ntrain_on_gpu = torch.cuda.is_available()\nif(train_on_gpu):\n print('Training on GPU!')\nelse: \n print('No GPU available, training on CPU; consider making n_epochs very small.')",
"Training on GPU!\n"
],
[
"class CharRNN(nn.Module):\n \n def __init__(self, tokens, n_hidden=256, n_layers=2,\n drop_prob=0.5, lr=0.001):\n super().__init__()\n self.drop_prob = drop_prob\n self.n_layers = n_layers\n self.n_hidden = n_hidden\n self.lr = lr\n \n self.batch_size = 8\n \n # creating character dictionaries\n self.chars = tokens\n self.int2char = dict(enumerate(self.chars))\n self.char2int = {ch: ii for ii, ch in self.int2char.items()}\n \n ## TODO: define the layers of the model\n self.lstm = nn.LSTM(len(self.chars), self.n_hidden, self.n_layers, self.drop_prob, batch_first=True)\n self.dropout = nn.Dropout(self.drop_prob)\n self.fc = nn.Linear(self.n_hidden, len(self.chars))\n \n def forward(self, x, hidden):\n ''' Forward pass through the network. \n These inputs are x, and the hidden/cell state `hidden`. '''\n \n ## TODO: Get the outputs and the new hidden state from the lstm\n \n r_output, hidden = self.lstm(x, hidden)\n \n ## TODO: pass through a dropout layer\n out = self.dropout(r_output)\n \n out = out.contiguous().view(-1, self.n_hidden)\n out = self.fc(out)\n \n # return the final output and the hidden state\n return out, hidden\n \n \n def init_hidden(self, batch_size):\n ''' Initializes hidden state '''\n # Create two new tensors with sizes n_layers x batch_size x n_hidden,\n # initialized to zero, for hidden state and cell state of LSTM\n weight = next(self.parameters()).data\n \n if (train_on_gpu):\n hidden = (weight.new(self.n_layers, batch_size, self.n_hidden).zero_().cuda(),\n weight.new(self.n_layers, batch_size, self.n_hidden).zero_().cuda())\n else:\n hidden = (weight.new(self.n_layers, batch_size, self.n_hidden).zero_(),\n weight.new(self.n_layers, batch_size, self.n_hidden).zero_())\n \n return hidden\n ",
"_____no_output_____"
]
],
[
[
"## Time to train\n\nThe train function gives us the ability to set the number of epochs, the learning rate, and other parameters.\n\nBelow we're using an Adam optimizer and cross entropy loss since we are looking at character class scores as output. We calculate the loss and perform backpropagation, as usual!\n\nA couple of details about training: \n>* Within the batch loop, we detach the hidden state from its history; this time setting it equal to a new *tuple* variable because an LSTM has a hidden state that is a tuple of the hidden and cell states.\n* We use [`clip_grad_norm_`](https://pytorch.org/docs/stable/_modules/torch/nn/utils/clip_grad.html) to help prevent exploding gradients.",
"_____no_output_____"
]
],
[
[
"def train(net, data, epochs=10, batch_size=10, seq_length=50, lr=0.001, clip=5, val_frac=0.1, print_every=10):\n ''' Training a network \n \n Arguments\n ---------\n \n net: CharRNN network\n data: text data to train the network\n epochs: Number of epochs to train\n batch_size: Number of mini-sequences per mini-batch, aka batch size\n seq_length: Number of character steps per mini-batch\n lr: learning rate\n clip: gradient clipping\n val_frac: Fraction of data to hold out for validation\n print_every: Number of steps for printing training and validation loss\n \n '''\n \n net.train()\n \n opt = torch.optim.Adam(net.parameters(), lr=lr)\n criterion = nn.CrossEntropyLoss()\n \n # create training and validation data\n val_idx = int(len(data)*(1-val_frac))\n data, val_data = data[:val_idx], data[val_idx:]\n \n if(train_on_gpu):\n net.cuda()\n \n counter = 0\n n_chars = len(net.chars)\n for e in range(epochs):\n # initialize hidden state\n h = net.init_hidden(batch_size)\n \n for x, y in get_batches(data, batch_size, seq_length):\n counter += 1\n \n # One-hot encode our data and make them Torch tensors\n x = one_hot_encode(x, n_chars)\n inputs, targets = torch.from_numpy(x), torch.from_numpy(y)\n \n if(train_on_gpu):\n inputs, targets = inputs.cuda(), targets.cuda()\n\n # Creating new variables for the hidden state, otherwise\n # we'd backprop through the entire training history\n h = tuple([each.data for each in h])\n\n # zero accumulated gradients\n net.zero_grad()\n \n # get the output from the model\n output, h = net(inputs, h)\n \n # calculate the loss and perform backprop\n loss = criterion(output, targets.view(batch_size*seq_length))\n loss.backward()\n # `clip_grad_norm` helps prevent the exploding gradient problem in RNNs / LSTMs.\n nn.utils.clip_grad_norm_(net.parameters(), clip)\n opt.step()\n \n # loss stats\n if counter % print_every == 0:\n # Get validation loss\n val_h = net.init_hidden(batch_size)\n val_losses = []\n net.eval()\n for x, y in get_batches(val_data, batch_size, seq_length):\n # One-hot encode our data and make them Torch tensors\n x = one_hot_encode(x, n_chars)\n x, y = torch.from_numpy(x), torch.from_numpy(y)\n \n # Creating new variables for the hidden state, otherwise\n # we'd backprop through the entire training history\n val_h = tuple([each.data for each in val_h])\n \n inputs, targets = x, y\n if(train_on_gpu):\n inputs, targets = inputs.cuda(), targets.cuda()\n\n output, val_h = net(inputs, val_h)\n val_loss = criterion(output, targets.view(batch_size*seq_length))\n \n val_losses.append(val_loss.item())\n \n net.train() # reset to train mode after iterationg through validation data\n \n print(\"Epoch: {}/{}...\".format(e+1, epochs),\n \"Step: {}...\".format(counter),\n \"Loss: {:.4f}...\".format(loss.item()),\n \"Val Loss: {:.4f}\".format(np.mean(val_losses)))",
"_____no_output_____"
]
],
[
[
"## Instantiating the model\n\nNow we can actually train the network. First we'll create the network itself, with some given hyperparameters. Then, define the mini-batches sizes, and start training!",
"_____no_output_____"
]
],
[
[
"## TODO: set you model hyperparameters\n# define and print the net\nn_hidden= 512\nn_layers= 2\n\nnet = CharRNN(chars, n_hidden, n_layers)\nprint(net)",
"CharRNN(\n (lstm): LSTM(83, 512, num_layers=2, bias=0.5, batch_first=True)\n (dropout): Dropout(p=0.5)\n (fc): Linear(in_features=512, out_features=83, bias=True)\n)\n"
]
],
[
[
"### Set your training hyperparameters!",
"_____no_output_____"
]
],
[
[
"batch_size = 8\nseq_length = 50\nn_epochs = 2# start small if you are just testing initial behavior\n\n# train the model\ntrain(net, encoded, epochs=n_epochs, batch_size=batch_size, seq_length=seq_length, lr=0.001, print_every=10)",
"batch size total 400\nn batches 4466\narr shape (1786400,)\narr shape (8, 223300)\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 10... Loss: 3.2578... Val Loss: 3.2095\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 20... Loss: 3.1563... Val Loss: 3.1554\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 30... Loss: 3.1671... Val Loss: 3.1401\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 40... Loss: 3.1308... Val Loss: 3.1373\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 50... Loss: 3.0430... Val Loss: 3.1343\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 60... Loss: 3.0823... Val Loss: 3.1391\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 70... Loss: 3.0183... Val Loss: 3.1297\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 80... Loss: 3.0330... Val Loss: 3.1278\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 90... Loss: 3.0852... Val Loss: 3.1214\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 100... Loss: 3.0657... Val Loss: 3.1191\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 110... Loss: 3.1262... Val Loss: 3.1096\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 120... Loss: 3.0607... Val Loss: 3.0803\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 130... Loss: 2.9904... Val Loss: 3.0258\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 140... Loss: 2.9014... Val Loss: 2.9455\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 150... Loss: 2.9358... Val Loss: 2.8740\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 160... Loss: 2.6916... Val Loss: 2.7764\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 170... Loss: 2.6863... Val Loss: 2.7261\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 180... Loss: 2.6611... Val Loss: 2.6542\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 190... Loss: 2.6202... Val Loss: 2.5946\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 200... Loss: 2.5065... Val Loss: 2.5654\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 210... Loss: 2.5159... Val Loss: 2.5390\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 220... Loss: 2.4431... Val Loss: 2.5292\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 230... Loss: 2.4631... Val Loss: 2.5040\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 240... Loss: 2.5577... Val Loss: 2.4852\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 250... Loss: 2.4840... Val Loss: 2.4681\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 260... Loss: 2.3472... Val Loss: 2.4510\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 270... Loss: 2.3637... Val Loss: 2.4315\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 280... Loss: 2.2952... Val Loss: 2.4156\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 290... Loss: 2.1983... Val Loss: 2.3993\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 300... Loss: 2.3782... Val Loss: 2.3863\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 310... Loss: 2.3839... Val Loss: 2.3872\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 320... Loss: 2.2718... Val Loss: 2.3630\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 330... Loss: 2.4426... Val Loss: 2.3738\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 340... Loss: 2.3013... Val Loss: 2.3420\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 350... Loss: 2.4258... Val Loss: 2.3422\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 360... Loss: 2.3360... Val Loss: 2.3208\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 370... Loss: 2.2053... Val Loss: 2.3449\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 380... Loss: 2.3529... Val Loss: 2.3027\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 390... Loss: 2.2412... Val Loss: 2.2869\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 400... Loss: 2.2448... Val Loss: 2.2876\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 410... Loss: 2.2060... Val Loss: 2.2649\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 420... Loss: 2.3595... Val Loss: 2.2568\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 430... Loss: 2.1684... Val Loss: 2.2562\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 440... Loss: 2.3082... Val Loss: 2.2488\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 450... Loss: 2.1637... Val Loss: 2.2305\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 460... Loss: 2.2798... Val Loss: 2.2194\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 470... Loss: 2.1672... Val Loss: 2.2089\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 480... Loss: 2.1572... Val Loss: 2.2046\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 490... Loss: 2.1805... Val Loss: 2.1942\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 500... Loss: 2.2124... Val Loss: 2.1766\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 510... Loss: 2.0771... Val Loss: 2.1812\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 520... Loss: 2.0114... Val Loss: 2.1656\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 530... Loss: 2.1259... Val Loss: 2.1504\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 540... Loss: 2.1388... Val Loss: 2.1403\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 550... Loss: 1.9500... Val Loss: 2.1367\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 560... Loss: 2.1431... Val Loss: 2.1317\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 570... Loss: 2.0568... Val Loss: 2.1391\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 580... Loss: 2.0783... Val Loss: 2.1210\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 590... Loss: 2.2324... Val Loss: 2.1229\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 600... Loss: 1.9854... Val Loss: 2.1144\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 610... Loss: 2.0604... Val Loss: 2.1029\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 620... Loss: 2.1977... Val Loss: 2.0919\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 630... Loss: 2.1931... Val Loss: 2.0936\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 640... Loss: 1.9851... Val Loss: 2.0774\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 650... Loss: 1.8517... Val Loss: 2.0725\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 660... Loss: 2.0587... Val Loss: 2.0662\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 670... Loss: 2.0425... Val Loss: 2.0554\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 680... Loss: 2.1370... Val Loss: 2.0497\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 690... Loss: 1.9381... Val Loss: 2.0474\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 700... Loss: 2.0046... Val Loss: 2.0421\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 710... Loss: 2.0367... Val Loss: 2.0296\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 720... Loss: 2.1388... Val Loss: 2.0341\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 730... Loss: 1.7528... Val Loss: 2.0086\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 740... Loss: 2.0336... Val Loss: 2.0071\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 750... Loss: 2.1296... Val Loss: 2.0180\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 760... Loss: 1.9284... Val Loss: 2.0128\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 770... Loss: 1.8854... Val Loss: 2.0023\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 780... Loss: 1.8733... Val Loss: 1.9947\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 790... Loss: 1.9052... Val Loss: 1.9919\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 800... Loss: 1.9482... Val Loss: 1.9869\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 810... Loss: 1.7730... Val Loss: 1.9762\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 820... Loss: 1.9515... Val Loss: 1.9758\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 830... Loss: 1.9569... Val Loss: 1.9668\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 840... Loss: 1.9654... Val Loss: 1.9619\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 850... Loss: 1.8401... Val Loss: 1.9537\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 860... Loss: 1.8025... Val Loss: 1.9550\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 870... Loss: 1.8288... Val Loss: 1.9519\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 880... Loss: 1.9255... Val Loss: 1.9519\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 890... Loss: 1.9165... Val Loss: 1.9413\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 900... Loss: 1.9528... Val Loss: 1.9410\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 910... Loss: 1.9409... Val Loss: 1.9350\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 920... Loss: 1.7559... Val Loss: 1.9222\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 930... Loss: 1.7003... Val Loss: 1.9187\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 940... Loss: 1.7658... Val Loss: 1.9302\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 950... Loss: 1.6772... Val Loss: 1.9132\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 960... Loss: 1.7257... Val Loss: 1.9025\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 970... Loss: 1.8662... Val Loss: 1.9144\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 980... Loss: 1.6664... Val Loss: 1.9061\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 990... Loss: 1.8887... Val Loss: 1.9055\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1000... Loss: 1.6670... Val Loss: 1.8953\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1010... Loss: 1.8528... Val Loss: 1.8922\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1020... Loss: 1.8975... Val Loss: 1.8843\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1030... Loss: 1.8797... Val Loss: 1.8937\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1040... Loss: 1.8729... Val Loss: 1.8860\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1050... Loss: 1.7448... Val Loss: 1.8767\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1060... Loss: 2.0603... Val Loss: 1.8789\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1070... Loss: 1.8280... Val Loss: 1.8693\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1080... Loss: 1.8235... Val Loss: 1.8712\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1090... Loss: 1.7140... Val Loss: 1.8571\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1100... Loss: 1.7035... Val Loss: 1.8517\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1110... Loss: 1.9002... Val Loss: 1.8546\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1120... Loss: 1.7076... Val Loss: 1.8584\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1130... Loss: 1.8243... Val Loss: 1.8506\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1140... Loss: 1.9612... Val Loss: 1.8407\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1150... Loss: 1.8753... Val Loss: 1.8438\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1160... Loss: 1.7438... Val Loss: 1.8312\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1170... Loss: 1.8195... Val Loss: 1.8431\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1180... Loss: 1.6894... Val Loss: 1.8390\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1190... Loss: 1.8333... Val Loss: 1.8264\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1200... Loss: 1.8664... Val Loss: 1.8262\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1210... Loss: 1.6533... Val Loss: 1.8211\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1220... Loss: 1.6326... Val Loss: 1.8194\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1230... Loss: 1.6386... Val Loss: 1.8221\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1240... Loss: 1.8990... Val Loss: 1.8185\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1250... Loss: 1.5433... Val Loss: 1.8144\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1260... Loss: 1.7177... Val Loss: 1.8013\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1270... Loss: 1.5905... Val Loss: 1.8052\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1280... Loss: 1.6518... Val Loss: 1.8052\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1290... Loss: 1.6579... Val Loss: 1.7960\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1300... Loss: 1.7009... Val Loss: 1.7905\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1310... Loss: 1.7100... Val Loss: 1.7995\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1320... Loss: 1.6838... Val Loss: 1.7975\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1330... Loss: 1.7275... Val Loss: 1.7796\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1340... Loss: 1.6445... Val Loss: 1.7775\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1350... Loss: 1.7436... Val Loss: 1.7707\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1360... Loss: 1.6889... Val Loss: 1.7736\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1370... Loss: 1.6817... Val Loss: 1.7660\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1380... Loss: 1.6985... Val Loss: 1.7671\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1390... Loss: 1.6471... Val Loss: 1.7698\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1400... Loss: 1.7188... Val Loss: 1.7693\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1410... Loss: 1.6265... Val Loss: 1.7614\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1420... Loss: 1.6208... Val Loss: 1.7660\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1430... Loss: 1.6910... Val Loss: 1.7626\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1440... Loss: 1.7344... Val Loss: 1.7543\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1450... Loss: 1.7702... Val Loss: 1.7466\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1460... Loss: 1.7315... Val Loss: 1.7428\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1470... Loss: 1.6550... Val Loss: 1.7465\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1480... Loss: 1.6701... Val Loss: 1.7380\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1490... Loss: 1.7295... Val Loss: 1.7401\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1500... Loss: 1.6082... Val Loss: 1.7427\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1510... Loss: 1.7513... Val Loss: 1.7428\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1520... Loss: 1.7529... Val Loss: 1.7319\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1530... Loss: 1.6526... Val Loss: 1.7356\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1540... Loss: 1.7622... Val Loss: 1.7310\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1550... Loss: 1.6641... Val Loss: 1.7265\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1560... Loss: 1.7032... Val Loss: 1.7301\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1570... Loss: 1.6170... Val Loss: 1.7199\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1580... Loss: 1.6778... Val Loss: 1.7218\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1590... Loss: 1.6564... Val Loss: 1.7173\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1600... Loss: 1.7582... Val Loss: 1.7159\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1610... Loss: 1.6034... Val Loss: 1.7131\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1620... Loss: 1.6773... Val Loss: 1.7155\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1630... Loss: 1.7428... Val Loss: 1.7124\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1640... Loss: 1.8141... Val Loss: 1.7164\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1650... Loss: 1.6767... Val Loss: 1.7140\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1660... Loss: 1.6171... Val Loss: 1.7126\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1670... Loss: 1.5702... Val Loss: 1.7088\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1680... Loss: 1.5295... Val Loss: 1.7073\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1690... Loss: 1.8217... Val Loss: 1.7110\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1700... Loss: 1.6768... Val Loss: 1.7134\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1710... Loss: 1.7519... Val Loss: 1.7153\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1720... Loss: 1.6254... Val Loss: 1.7169\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1730... Loss: 1.6497... Val Loss: 1.7069\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1740... Loss: 1.4966... Val Loss: 1.6993\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1750... Loss: 1.6217... Val Loss: 1.6911\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1760... Loss: 1.6422... Val Loss: 1.6968\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1770... Loss: 1.4879... Val Loss: 1.6841\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1780... Loss: 1.6395... Val Loss: 1.6877\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1790... Loss: 1.5931... Val Loss: 1.6878\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1800... Loss: 1.5406... Val Loss: 1.6848\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1810... Loss: 1.4816... Val Loss: 1.6907\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1820... Loss: 1.4507... Val Loss: 1.6830\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1830... Loss: 1.5238... Val Loss: 1.6778\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1840... Loss: 1.6376... Val Loss: 1.6801\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1850... Loss: 1.5387... Val Loss: 1.6770\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1860... Loss: 1.5708... Val Loss: 1.6799\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1870... Loss: 1.5508... Val Loss: 1.6751\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1880... Loss: 1.6472... Val Loss: 1.6692\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1890... Loss: 1.5310... Val Loss: 1.6724\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1900... Loss: 1.5517... Val Loss: 1.6684\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1910... Loss: 1.6337... Val Loss: 1.6626\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1920... Loss: 1.8452... Val Loss: 1.6626\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1930... Loss: 1.6216... Val Loss: 1.6628\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1940... Loss: 1.7631... Val Loss: 1.6622\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1950... Loss: 1.3734... Val Loss: 1.6664\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1960... Loss: 1.4990... Val Loss: 1.6684\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1970... Loss: 1.6556... Val Loss: 1.6543\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1980... Loss: 1.5271... Val Loss: 1.6505\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 1990... Loss: 1.6851... Val Loss: 1.6551\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2000... Loss: 1.6448... Val Loss: 1.6535\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2010... Loss: 1.5917... Val Loss: 1.6518\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2020... Loss: 1.5361... Val Loss: 1.6457\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2030... Loss: 1.5347... Val Loss: 1.6427\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2040... Loss: 1.7617... Val Loss: 1.6494\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2050... Loss: 1.6391... Val Loss: 1.6519\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2060... Loss: 1.7994... Val Loss: 1.6488\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2070... Loss: 1.6239... Val Loss: 1.6518\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2080... Loss: 1.4718... Val Loss: 1.6485\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2090... Loss: 1.4652... Val Loss: 1.6409\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2100... Loss: 1.5660... Val Loss: 1.6359\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2110... Loss: 1.2723... Val Loss: 1.6335\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2120... Loss: 1.4959... Val Loss: 1.6350\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2130... Loss: 1.4985... Val Loss: 1.6321\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2140... Loss: 1.5777... Val Loss: 1.6296\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2150... Loss: 1.3622... Val Loss: 1.6360\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2160... Loss: 1.5406... Val Loss: 1.6349\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2170... Loss: 1.3545... Val Loss: 1.6261\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2180... Loss: 1.4573... Val Loss: 1.6298\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2190... Loss: 1.4161... Val Loss: 1.6239\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2200... Loss: 1.5128... Val Loss: 1.6228\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2210... Loss: 1.4326... Val Loss: 1.6185\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2220... Loss: 1.6499... Val Loss: 1.6232\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2230... Loss: 1.4489... Val Loss: 1.6203\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2240... Loss: 1.5855... Val Loss: 1.6162\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2250... Loss: 1.6458... Val Loss: 1.6137\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2260... Loss: 1.7142... Val Loss: 1.6128\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2270... Loss: 1.5401... Val Loss: 1.6135\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2280... Loss: 1.5534... Val Loss: 1.6164\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2290... Loss: 1.4796... Val Loss: 1.6048\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2300... Loss: 1.5458... Val Loss: 1.6066\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2310... Loss: 1.3690... Val Loss: 1.5997\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2320... Loss: 1.4465... Val Loss: 1.6156\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2330... Loss: 1.4038... Val Loss: 1.6200\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2340... Loss: 1.5407... Val Loss: 1.6042\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2350... Loss: 1.4475... Val Loss: 1.6053\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2360... Loss: 1.5138... Val Loss: 1.5955\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2370... Loss: 1.4206... Val Loss: 1.5968\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2380... Loss: 1.4393... Val Loss: 1.6006\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2390... Loss: 1.3694... Val Loss: 1.5984\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2400... Loss: 1.5305... Val Loss: 1.5959\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2410... Loss: 1.5967... Val Loss: 1.5887\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2420... Loss: 1.4268... Val Loss: 1.5902\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2430... Loss: 1.3935... Val Loss: 1.5925\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2440... Loss: 1.4287... Val Loss: 1.5907\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2450... Loss: 1.3927... Val Loss: 1.5865\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2460... Loss: 1.5177... Val Loss: 1.5908\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2470... Loss: 1.5687... Val Loss: 1.5860\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2480... Loss: 1.4222... Val Loss: 1.5878\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2490... Loss: 1.6059... Val Loss: 1.5877\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2500... Loss: 1.4422... Val Loss: 1.5817\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2510... Loss: 1.5011... Val Loss: 1.5810\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2520... Loss: 1.3904... Val Loss: 1.5814\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2530... Loss: 1.3991... Val Loss: 1.5818\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2540... Loss: 1.6555... Val Loss: 1.5802\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2550... Loss: 1.4235... Val Loss: 1.5804\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2560... Loss: 1.5662... Val Loss: 1.5817\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2570... Loss: 1.4900... Val Loss: 1.5734\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2580... Loss: 1.4083... Val Loss: 1.5690\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2590... Loss: 1.2778... Val Loss: 1.5672\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2600... Loss: 1.3543... Val Loss: 1.5696\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2610... Loss: 1.4933... Val Loss: 1.5671\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2620... Loss: 1.3643... Val Loss: 1.5638\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2630... Loss: 1.3306... Val Loss: 1.5641\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2640... Loss: 1.5072... Val Loss: 1.5656\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2650... Loss: 1.5233... Val Loss: 1.5644\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2660... Loss: 1.5721... Val Loss: 1.5644\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2670... Loss: 1.5168... Val Loss: 1.5670\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2680... Loss: 1.5017... Val Loss: 1.5629\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2690... Loss: 1.4342... Val Loss: 1.5600\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2700... Loss: 1.4893... Val Loss: 1.5569\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2710... Loss: 1.3804... Val Loss: 1.5585\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2720... Loss: 1.4679... Val Loss: 1.5598\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2730... Loss: 1.5417... Val Loss: 1.5638\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2740... Loss: 1.4022... Val Loss: 1.5562\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2750... Loss: 1.5246... Val Loss: 1.5561\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2760... Loss: 1.5387... Val Loss: 1.5562\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2770... Loss: 1.5817... Val Loss: 1.5522\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2780... Loss: 1.4289... Val Loss: 1.5514\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2790... Loss: 1.3108... Val Loss: 1.5530\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2800... Loss: 1.4803... Val Loss: 1.5585\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2810... Loss: 1.4904... Val Loss: 1.5567\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2820... Loss: 1.6465... Val Loss: 1.5539\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2830... Loss: 1.6703... Val Loss: 1.5557\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2840... Loss: 1.5425... Val Loss: 1.5520\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2850... Loss: 1.4138... Val Loss: 1.5429\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2860... Loss: 1.4531... Val Loss: 1.5425\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2870... Loss: 1.5838... Val Loss: 1.5412\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2880... Loss: 1.5431... Val Loss: 1.5435\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2890... Loss: 1.4664... Val Loss: 1.5489\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2900... Loss: 1.3994... Val Loss: 1.5436\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2910... Loss: 1.6057... Val Loss: 1.5444\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2920... Loss: 1.6176... Val Loss: 1.5462\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2930... Loss: 1.4970... Val Loss: 1.5533\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2940... Loss: 1.5096... Val Loss: 1.5392\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2950... Loss: 1.4594... Val Loss: 1.5444\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2960... Loss: 1.2585... Val Loss: 1.5346\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2970... Loss: 1.4819... Val Loss: 1.5314\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2980... Loss: 1.7214... Val Loss: 1.5314\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 2990... Loss: 1.5549... Val Loss: 1.5336\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3000... Loss: 1.5083... Val Loss: 1.5339\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3010... Loss: 1.4233... Val Loss: 1.5329\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3020... Loss: 1.3594... Val Loss: 1.5304\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3030... Loss: 1.3351... Val Loss: 1.5289\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3040... Loss: 1.5811... Val Loss: 1.5279\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3050... Loss: 1.6732... Val Loss: 1.5283\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3060... Loss: 1.5556... Val Loss: 1.5334\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3070... Loss: 1.3027... Val Loss: 1.5357\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3080... Loss: 1.5448... Val Loss: 1.5314\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3090... Loss: 1.3418... Val Loss: 1.5375\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3100... Loss: 1.5039... Val Loss: 1.5308\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3110... Loss: 1.4874... Val Loss: 1.5310\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3120... Loss: 1.4051... Val Loss: 1.5295\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3130... Loss: 1.3501... Val Loss: 1.5323\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3140... Loss: 1.4577... Val Loss: 1.5252\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3150... Loss: 1.4379... Val Loss: 1.5284\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3160... Loss: 1.6343... Val Loss: 1.5306\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3170... Loss: 1.2890... Val Loss: 1.5207\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3180... Loss: 1.3042... Val Loss: 1.5184\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3190... Loss: 1.4004... Val Loss: 1.5136\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3200... Loss: 1.3727... Val Loss: 1.5147\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3210... Loss: 1.3768... Val Loss: 1.5177\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3220... Loss: 1.5640... Val Loss: 1.5204\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3230... Loss: 1.5136... Val Loss: 1.5229\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3240... Loss: 1.5827... Val Loss: 1.5268\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3250... Loss: 1.5702... Val Loss: 1.5223\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3260... Loss: 1.4836... Val Loss: 1.5285\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3270... Loss: 1.7358... Val Loss: 1.5171\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3280... Loss: 1.3749... Val Loss: 1.5094\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3290... Loss: 1.3036... Val Loss: 1.5084\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3300... Loss: 1.2818... Val Loss: 1.5089\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3310... Loss: 1.3637... Val Loss: 1.5116\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3320... Loss: 1.6611... Val Loss: 1.5126\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3330... Loss: 1.3738... Val Loss: 1.5070\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3340... Loss: 1.4704... Val Loss: 1.5062\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3350... Loss: 1.5055... Val Loss: 1.5175\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3360... Loss: 1.2949... Val Loss: 1.5155\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3370... Loss: 1.4908... Val Loss: 1.5207\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3380... Loss: 1.5650... Val Loss: 1.5087\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3390... Loss: 1.3230... Val Loss: 1.5141\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3400... Loss: 1.2882... Val Loss: 1.5084\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3410... Loss: 1.4780... Val Loss: 1.5085\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3420... Loss: 1.3121... Val Loss: 1.5070\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3430... Loss: 1.3943... Val Loss: 1.5082\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3440... Loss: 1.4654... Val Loss: 1.5014\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3450... Loss: 1.3476... Val Loss: 1.5006\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3460... Loss: 1.4956... Val Loss: 1.5010\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3470... Loss: 1.4925... Val Loss: 1.4953\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3480... Loss: 1.2953... Val Loss: 1.4999\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3490... Loss: 1.3909... Val Loss: 1.5013\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3500... Loss: 1.4029... Val Loss: 1.4979\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3510... Loss: 1.2002... Val Loss: 1.4943\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3520... Loss: 1.3791... Val Loss: 1.4967\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3530... Loss: 1.4834... Val Loss: 1.4924\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3540... Loss: 1.6024... Val Loss: 1.4918\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3550... Loss: 1.3849... Val Loss: 1.4939\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3560... Loss: 1.3944... Val Loss: 1.4973\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3570... Loss: 1.2512... Val Loss: 1.5013\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3580... Loss: 1.5081... Val Loss: 1.5030\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3590... Loss: 1.3741... Val Loss: 1.4956\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3600... Loss: 1.4764... Val Loss: 1.4892\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3610... Loss: 1.4089... Val Loss: 1.4910\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3620... Loss: 1.5559... Val Loss: 1.4914\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3630... Loss: 1.5901... Val Loss: 1.4918\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3640... Loss: 1.4695... Val Loss: 1.4918\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3650... Loss: 1.4488... Val Loss: 1.4941\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3660... Loss: 1.3402... Val Loss: 1.4943\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3670... Loss: 1.3411... Val Loss: 1.4978\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3680... Loss: 1.4557... Val Loss: 1.4945\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3690... Loss: 1.4423... Val Loss: 1.4936\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3700... Loss: 1.4139... Val Loss: 1.4930\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3710... Loss: 1.3264... Val Loss: 1.4884\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3720... Loss: 1.4448... Val Loss: 1.4879\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3730... Loss: 1.6939... Val Loss: 1.4866\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3740... Loss: 1.6392... Val Loss: 1.4871\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3750... Loss: 1.4766... Val Loss: 1.4838\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3760... Loss: 1.3044... Val Loss: 1.4899\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3770... Loss: 1.3593... Val Loss: 1.4915\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3780... Loss: 1.4002... Val Loss: 1.4914\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3790... Loss: 1.5187... Val Loss: 1.4818\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3800... Loss: 1.3979... Val Loss: 1.4790\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3810... Loss: 1.4943... Val Loss: 1.4940\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3820... Loss: 1.3668... Val Loss: 1.4814\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3830... Loss: 1.3326... Val Loss: 1.4809\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3840... Loss: 1.3555... Val Loss: 1.4880\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3850... Loss: 1.3559... Val Loss: 1.4795\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3860... Loss: 1.2750... Val Loss: 1.4805\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3870... Loss: 1.3773... Val Loss: 1.4775\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3880... Loss: 1.3342... Val Loss: 1.4802\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3890... Loss: 1.3505... Val Loss: 1.4855\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3900... Loss: 1.4789... Val Loss: 1.4805\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3910... Loss: 1.4173... Val Loss: 1.4792\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3920... Loss: 1.4587... Val Loss: 1.4828\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3930... Loss: 1.2402... Val Loss: 1.4865\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3940... Loss: 1.4518... Val Loss: 1.4797\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3950... Loss: 1.1812... Val Loss: 1.4799\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3960... Loss: 1.2014... Val Loss: 1.4817\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3970... Loss: 1.4419... Val Loss: 1.4815\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3980... Loss: 1.1321... Val Loss: 1.4818\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 3990... Loss: 1.5500... Val Loss: 1.4749\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4000... Loss: 1.4209... Val Loss: 1.4722\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4010... Loss: 1.3408... Val Loss: 1.4743\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4020... Loss: 1.2245... Val Loss: 1.4719\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4030... Loss: 1.4643... Val Loss: 1.4715\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4040... Loss: 1.3885... Val Loss: 1.4714\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4050... Loss: 1.3108... Val Loss: 1.4748\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4060... Loss: 1.2440... Val Loss: 1.4770\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4070... Loss: 1.4412... Val Loss: 1.4701\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4080... Loss: 1.2726... Val Loss: 1.4694\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4090... Loss: 1.3213... Val Loss: 1.4794\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4100... Loss: 1.3053... Val Loss: 1.4718\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4110... Loss: 1.2735... Val Loss: 1.4719\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4120... Loss: 1.3460... Val Loss: 1.4728\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4130... Loss: 1.4082... Val Loss: 1.4700\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4140... Loss: 1.5836... Val Loss: 1.4677\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4150... Loss: 1.3802... Val Loss: 1.4662\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4160... Loss: 1.4139... Val Loss: 1.4682\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4170... Loss: 1.5283... Val Loss: 1.4740\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4180... Loss: 1.5173... Val Loss: 1.4770\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4190... Loss: 1.3113... Val Loss: 1.4702\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4200... Loss: 1.4368... Val Loss: 1.4622\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4210... Loss: 1.4386... Val Loss: 1.4677\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4220... Loss: 1.1753... Val Loss: 1.4626\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4230... Loss: 1.3226... Val Loss: 1.4622\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4240... Loss: 1.1396... Val Loss: 1.4630\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4250... Loss: 1.5319... Val Loss: 1.4632\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4260... Loss: 1.3648... Val Loss: 1.4720\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4270... Loss: 1.2567... Val Loss: 1.4690\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4280... Loss: 1.3337... Val Loss: 1.4679\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4290... Loss: 1.4152... Val Loss: 1.4726\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4300... Loss: 1.3634... Val Loss: 1.4694\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4310... Loss: 1.2915... Val Loss: 1.4738\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4320... Loss: 1.3839... Val Loss: 1.4651\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4330... Loss: 1.2769... Val Loss: 1.4635\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\nEpoch: 1/2... Step: 4340... Loss: 1.5065... Val Loss: 1.4689\nbatch size total 400\nn batches 496\narr shape (198400,)\narr shape (8, 24800)\n"
]
],
[
[
"## Getting the best model\n\nTo set your hyperparameters to get the best performance, you'll want to watch the training and validation losses. If your training loss is much lower than the validation loss, you're overfitting. Increase regularization (more dropout) or use a smaller network. If the training and validation losses are close, you're underfitting so you can increase the size of the network.",
"_____no_output_____"
],
[
"## Hyperparameters\n\nHere are the hyperparameters for the network.\n\nIn defining the model:\n* `n_hidden` - The number of units in the hidden layers.\n* `n_layers` - Number of hidden LSTM layers to use.\n\nWe assume that dropout probability and learning rate will be kept at the default, in this example.\n\nAnd in training:\n* `batch_size` - Number of sequences running through the network in one pass.\n* `seq_length` - Number of characters in the sequence the network is trained on. Larger is better typically, the network will learn more long range dependencies. But it takes longer to train. 100 is typically a good number here.\n* `lr` - Learning rate for training\n\nHere's some good advice from Andrej Karpathy on training the network. I'm going to copy it in here for your benefit, but also link to [where it originally came from](https://github.com/karpathy/char-rnn#tips-and-tricks).\n\n> ## Tips and Tricks\n\n>### Monitoring Validation Loss vs. Training Loss\n>If you're somewhat new to Machine Learning or Neural Networks it can take a bit of expertise to get good models. The most important quantity to keep track of is the difference between your training loss (printed during training) and the validation loss (printed once in a while when the RNN is run on the validation data (by default every 1000 iterations)). In particular:\n\n> - If your training loss is much lower than validation loss then this means the network might be **overfitting**. Solutions to this are to decrease your network size, or to increase dropout. For example you could try dropout of 0.5 and so on.\n> - If your training/validation loss are about equal then your model is **underfitting**. Increase the size of your model (either number of layers or the raw number of neurons per layer)\n\n> ### Approximate number of parameters\n\n> The two most important parameters that control the model are `n_hidden` and `n_layers`. I would advise that you always use `n_layers` of either 2/3. The `n_hidden` can be adjusted based on how much data you have. The two important quantities to keep track of here are:\n\n> - The number of parameters in your model. This is printed when you start training.\n> - The size of your dataset. 1MB file is approximately 1 million characters.\n\n>These two should be about the same order of magnitude. It's a little tricky to tell. Here are some examples:\n\n> - I have a 100MB dataset and I'm using the default parameter settings (which currently print 150K parameters). My data size is significantly larger (100 mil >> 0.15 mil), so I expect to heavily underfit. I am thinking I can comfortably afford to make `n_hidden` larger.\n> - I have a 10MB dataset and running a 10 million parameter model. I'm slightly nervous and I'm carefully monitoring my validation loss. If it's larger than my training loss then I may want to try to increase dropout a bit and see if that helps the validation loss.\n\n> ### Best models strategy\n\n>The winning strategy to obtaining very good models (if you have the compute time) is to always err on making the network larger (as large as you're willing to wait for it to compute) and then try different dropout values (between 0,1). Whatever model has the best validation performance (the loss, written in the checkpoint filename, low is good) is the one you should use in the end.\n\n>It is very common in deep learning to run many different models with many different hyperparameter settings, and in the end take whatever checkpoint gave the best validation performance.\n\n>By the way, the size of your training and validation splits are also parameters. Make sure you have a decent amount of data in your validation set or otherwise the validation performance will be noisy and not very informative.",
"_____no_output_____"
],
[
"## Checkpoint\n\nAfter training, we'll save the model so we can load it again later if we need too. Here I'm saving the parameters needed to create the same architecture, the hidden layer hyperparameters and the text characters.",
"_____no_output_____"
]
],
[
[
"# change the name, for saving multiple files\nmodel_name = 'rnn_x_epoch.net'\n\ncheckpoint = {'n_hidden': net.n_hidden,\n 'n_layers': net.n_layers,\n 'state_dict': net.state_dict(),\n 'tokens': net.chars}\n\nwith open(model_name, 'wb') as f:\n torch.save(checkpoint, f)",
"_____no_output_____"
]
],
[
[
"---\n## Making Predictions\n\nNow that the model is trained, we'll want to sample from it and make predictions about next characters! To sample, we pass in a character and have the network predict the next character. Then we take that character, pass it back in, and get another predicted character. Just keep doing this and you'll generate a bunch of text!\n\n### A note on the `predict` function\n\nThe output of our RNN is from a fully-connected layer and it outputs a **distribution of next-character scores**.\n\n> To actually get the next character, we apply a softmax function, which gives us a *probability* distribution that we can then sample to predict the next character.\n\n### Top K sampling\n\nOur predictions come from a categorical probability distribution over all the possible characters. We can make the sample text and make it more reasonable to handle (with less variables) by only considering some $K$ most probable characters. This will prevent the network from giving us completely absurd characters while allowing it to introduce some noise and randomness into the sampled text. Read more about [topk, here](https://pytorch.org/docs/stable/torch.html#torch.topk).\n",
"_____no_output_____"
]
],
[
[
"def predict(net, char, h=None, top_k=None):\n ''' Given a character, predict the next character.\n Returns the predicted character and the hidden state.\n '''\n \n # tensor inputs\n x = np.array([[net.char2int[char]]])\n x = one_hot_encode(x, len(net.chars))\n inputs = torch.from_numpy(x)\n \n if(train_on_gpu):\n inputs = inputs.cuda()\n \n # detach hidden state from history\n h = tuple([each.data for each in h])\n # get the output of the model\n out, h = net(inputs, h)\n\n # get the character probabilities\n p = F.softmax(out, dim=1).data\n if(train_on_gpu):\n p = p.cpu() # move to cpu\n \n # get top characters\n if top_k is None:\n top_ch = np.arange(len(net.chars))\n else:\n p, top_ch = p.topk(top_k)\n top_ch = top_ch.numpy().squeeze()\n \n # select the likely next character with some element of randomness\n p = p.numpy().squeeze()\n char = np.random.choice(top_ch, p=p/p.sum())\n \n # return the encoded value of the predicted char and the hidden state\n return net.int2char[char], h",
"_____no_output_____"
]
],
[
[
"### Priming and generating text \n\nTypically you'll want to prime the network so you can build up a hidden state. Otherwise the network will start out generating characters at random. In general the first bunch of characters will be a little rough since it hasn't built up a long history of characters to predict from.",
"_____no_output_____"
]
],
[
[
"def sample(net, size, prime='The', top_k=None):\n \n if(train_on_gpu):\n net.cuda()\n else:\n net.cpu()\n \n net.eval() # eval mode\n \n # First off, run through the prime characters\n chars = [ch for ch in prime]\n h = net.init_hidden(1)\n for ch in prime:\n char, h = predict(net, ch, h, top_k=top_k)\n\n chars.append(char)\n \n # Now pass in the previous character and get a new one\n for ii in range(size):\n char, h = predict(net, chars[-1], h, top_k=top_k)\n chars.append(char)\n\n return ''.join(chars)",
"_____no_output_____"
],
[
"print(sample(net, 1000, prime='Anna', top_k=5))",
"_____no_output_____"
]
],
[
[
"## Loading a checkpoint",
"_____no_output_____"
]
],
[
[
"# Here we have loaded in a model that trained over 20 epochs `rnn_20_epoch.net`\nwith open('rnn_x_epoch.net', 'rb') as f:\n checkpoint = torch.load(f)\n \nloaded = CharRNN(checkpoint['tokens'], n_hidden=checkpoint['n_hidden'], n_layers=checkpoint['n_layers'])\nloaded.load_state_dict(checkpoint['state_dict'])",
"_____no_output_____"
],
[
"# Sample using a loaded model\nprint(sample(loaded, 2000, top_k=5, prime=\"And Levin said\"))",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
cb3cebaf0a12070a35446179e34dcc91a333c635 | 65,258 | ipynb | Jupyter Notebook | src/MSI/utilities/.ipynb_checkpoints/Testing Six Parameter Fit New-checkpoint.ipynb | carlylagrotta/MSI | e958beb5df2a2d1018bbb2f96382b5c99b08c3ef | [
"MIT"
] | 1 | 2021-06-25T15:46:06.000Z | 2021-06-25T15:46:06.000Z | src/MSI/utilities/.ipynb_checkpoints/Testing Six Parameter Fit New-checkpoint.ipynb | TheBurkeLab/MSI | e958beb5df2a2d1018bbb2f96382b5c99b08c3ef | [
"MIT"
] | null | null | null | src/MSI/utilities/.ipynb_checkpoints/Testing Six Parameter Fit New-checkpoint.ipynb | TheBurkeLab/MSI | e958beb5df2a2d1018bbb2f96382b5c99b08c3ef | [
"MIT"
] | 2 | 2019-12-18T23:45:25.000Z | 2021-06-10T20:37:20.000Z | 136.809224 | 18,320 | 0.815072 | [
[
[
"import numpy as np",
"_____no_output_____"
],
[
"#UNITS\n#A = mol/cm^3 -s \n#n = none\n#Ea = kcal/k*mol\n#c = \n#d = \n#f = ",
"_____no_output_____"
],
[
"six_parameter_fit_sensitivities = {'H2O2 + OH <=> H2O + HO2':{'A':np.array([-13.37032086, 32.42060027, 19.23022032, 6.843287462 , 36.62853824 ,-0.220309785 ,-0.099366346, -4.134352081]),\n 'n':np.array([1.948532282, -5.341557065, -3.337497841, -1.025292166, -5.813524857, 0.011862923 ,0.061801326, 0.581628835]),\n 'Ea':np.array([-0.463042822, 1.529151218, 0.808025472 ,0.359889935, -0.021309254, -0.098013004, -0.102022118, -0.097024727]),\n 'c':np.array([0.00163576, -0.008645666, -0.003111179, -0.002541995, 0.014228149 ,0.001263134, 0.001236963, -0.000390567]),\n 'd':np.array([1.071992802, -2.780550365, -1.71391034 ,-0.274481751, -4.491132406, -0.054960894, 0.049553379, 0.270885383]),\n 'f':np.array([-0.027060156, 0.056903076, 0.041102936 ,0.001361221, 0.144385439, 0.003136796 ,0.001374015, -0.006089248])},\n '2 HO2 <=> H2O2 + O2': {'A':np.array([-12.93733217, 24.39245077 ,17.73177606, 4.37803475, 33.44985889, 0.381601192 ,3.748890308]),\n 'n':np.array([1.872602872, -4.096806067, -3.09439453 ,-0.63226683, -5.125008418, -0.061610462, -0.677953862]),\n 'Ea':np.array([-0.463903763 ,1.259537237, 0.826684258 ,0.257400116, 0.803882706 ,2.20E-05, 0.181336266]),\n 'c':np.array([0.002069572, -0.008314769, -0.00424128 ,-0.002016113, 0.000134642 ,0.000122049 ,-0.001026567]),\n 'd':np.array([0.981856324, -1.847383095, -1.493544053, 0.016222685, -3.428753345, -0.050708107, -0.526284003]),\n 'f':np.array([-0.022628436, 0.023558844, 0.031573523 ,-0.00732987, 0.096573278 ,0.001668073, 0.01033547])},\n 'HO2 + OH <=> H2O + O2': {'A':np.array([-4.795727446, 6.426354909 ,4.878258417, 2.472791017, 7.856296474, 1.328033302 ,-3.457932692, -0.349839371, 2.331070924 ,2.403555921, -0.165397001, 0.246540172 ,0.722946077]),\n 'n':np.array([0.624241134, -1.321082842, -1.032242319, -0.36532386, -1.112545721, -0.188622956, 0.421083939 ,0.038859478 ,-0.360855106, -0.38989218, 0.029669899 ,-0.04371581, -0.130487515]),\n 'Ea':np.array([-0.259799111, 0.205620792 ,0.130799794, 0.137023666 ,0.379232542, 6.19E-02, -0.198196699, -0.023548432, 0.118069394 ,0.104383314 ,-0.003830947, 0.011566499 ,-0.073557828]),\n 'c':np.array([0.00161312, -0.001906694, -0.000863021, -0.00105112 ,-0.002185605, -0.000334461, 0.001817049 ,0.000170761, -0.000859313, -0.000653029, -3.11E-06 ,-6.37E-05, 0.00047058]),\n 'd':np.array([0.124499363, -0.645652135, -0.535188558, 0.052734001 ,-0.45181066, -0.082250635, 0.034779283, -0.011522821, 0.017057742, -0.165960963, 0.057288687, -0.012776017, -0.192422381]),\n 'f':np.array([0.002033109, -0.011099716, 0.005351213 ,-0.007623667, 0.005327017 ,0.001259485,0.00245957, 0.000976725 ,-0.004879845, 0.001903886 ,-0.001838669 ,0.000252269, 0.004691829])},\n '2 OH <=> H2O + O': {'A': np.array([-5.40485067, 18.96061659 ,8.089301961, 6.953940096 ,-12.54280438, -3.264972401, 2.106487623 ,-1.657943467, 1.614935 ,-1.536463599]),\n 'n': np.array([0.803274875, -3.167851673, -1.607661056, -1.041258197, 1.679914849, 0.466415264 ,-0.326136934, 0.355297684 ,-0.16618967, 0.253903734]),\n 'Ea': np.array([0.147285831, 0.605814544, -0.062253282, 0.372322712, -1.884116555, -0.281992263, 0.099465537 ,0.030650483, 0.176069015 ,-0.056967886]),\n 'c': np.array([-0.003001658, -0.001870536, 0.003820535 ,-0.002753277, 0.014224162, 0.00032969 ,-0.000627241, -0.001081979, -0.002009835, 0.000255318]),\n 'd':np.array([0.446957978, -1.467039994, -1.298391635, -0.402720385, 0.568106728 ,0.229877892, -0.194395052, 1.033858025 ,0.527183366, 0.308743056]),\n 'f':np.array([-0.010053913, 0.025128322, 0.035579811 ,0.00515753 ,-0.0083511, -0.00512885, 0.003954, -0.029711993 ,-0.01986861, -0.007691647])},\n 'CH3 + HO2 <=> CH4 + O2': {'A':np.array([.007845,-.89278,-.94908]),\n 'n':np.array([-0.00104,-.36888,.154462]),\n 'Ea':np.array([.504278,-.44379,-0.03181]),\n 'c':np.array([0,0,0]),\n 'd':np.array([0,0,0]),\n 'f':np.array([0,0,0])},\n 'CH3 + HO2 <=> CH3O + OH': {'A':np.array([1.319108,-.92151]),\n 'n':np.array([-.04282,.150846]),\n 'Ea':np.array([0.024285,-0.02956]),\n 'c':np.array([0,0]),\n 'd':np.array([0,0]),\n 'f':np.array([0,0])}}\n \n\n \n \nsix_parameter_fit_nominal_parameters_dict = {'H2O2 + OH <=> H2O + HO2':{'A':4.64E-06,'n':5.605491008,'Ea':-5440.266692,'c':126875776.1,'d':0.000441194,'f':-5.35E-13},\n '2 HO2 <=> H2O2 + O2':{'A':1.30E+04,'n':1.997152351,'Ea':-3628.04407,'c':93390973.44,'d':-0.000732521,'f':8.20E-12} ,\n 'HO2 + OH <=> H2O + O2':{'A':1.41E+18,'n':-2.05344973,'Ea':-232.0064051,'c':15243859.12,'d':-0.001187694,'f':8.01E-12},\n '2 OH <=> H2O + O':{'A':354.5770856,'n':2.938741717,'Ea':-1836.492972,'c':12010735.18,'d':-4.87E-05,'f':1.22E-12},\n 'CH3 + HO2 <=> CH4 + O2':{'A':3.19e3,'n':2.670857,'Ea':-4080.73,'c':0.0,'d':0.0,'f':0.0},\n 'CH3 + HO2 <=> CH3O + OH':{'A':8.38e11,'n':.29,'Ea':-785.45,'c':0.0,'d':0.0,'f':0.0}}",
"_____no_output_____"
],
[
"def calculate_six_parameter_fit(reaction,dictonary,temperature):\n #finish editing this \n #calc Ea,c,d,F seprately \n A = dictonary[reaction]['A']\n n = dictonary[reaction]['n']\n Ea_temp = dictonary[reaction]['Ea']/(1.987*temperature)\n c_temp = dictonary[reaction]['c']/((1.987*temperature)**3)\n d_temp = dictonary[reaction]['d']*(1.987*temperature)\n f_temp = dictonary[reaction]['f']* ((1.987*temperature)**3)\n\n k = A*(temperature**n)*np.exp(-Ea_temp-c_temp-d_temp-f_temp)\n return k ",
"_____no_output_____"
],
[
"xdata = []\nydata = []\nfor t in np.arange(200,2400):\n xdata.append(t)\n ydata.append(calculate_six_parameter_fit('2 HO2 <=> H2O2 + O2',six_parameter_fit_nominal_parameters_dict,t))\n\n \nydata = np.array(ydata)\nydata = np.log(ydata)\nplt.scatter(xdata,ydata)",
"_____no_output_____"
],
[
"#fitting sigmas \nimport matplotlib.pyplot as plt\nfrom scipy.optimize import curve_fit \ndef func(x, A,n,Ea):\n return np.log(A)+np.log(x)*n + (-Ea/(1.987*x))\nplt.scatter(xdata, ydata,label='data')\npopt, pcov = curve_fit(func, xdata, ydata)\nprint(popt)\ntest_array = []\nfor T in xdata:\n test_array.append(np.log(popt[0]*T**popt[1]*np.exp(-popt[2]/(1.987*T))))\nplt.plot(xdata,test_array,'r') ",
"[ 6.86178043e+00 3.30021802e+00 -3.62056446e+03]\n"
],
[
"#fitting sigmas \nimport matplotlib.pyplot as plt\nfrom scipy.optimize import curve_fit \ndef func2(x, A,n,Ea,c,d,f):\n return np.log(A)+np.log(x)*n + (-Ea/(1.987*x)) + (-c/((1.987*x)**3)) + (-d*(1.987*x)) + (-f*((1.987*x)**3))\npopt, pcov = curve_fit(func2, xdata, ydata,maxfev=1000000)\n#popt, pcov = curve_fit(func2, xdata, ydata, method='dogbox',maxfev=10000)\n\n\n#method{‘lm’, ‘trf’, ‘dogbox’}, optional\nplt.scatter(xdata, ydata,label='data')\nprint(popt)\ntest_array = []\nfor T in xdata:\n A = popt[0]\n n = popt[1]\n Ea_temp = popt[2]/(1.987*T)\n c_temp = popt[3]/((1.987*T)**3)\n d_temp = popt[4]*(1.987*T)\n f_temp =popt[5]* ((1.987*T)**3)\n \n k = A*(T**n)*np.exp(-Ea_temp-c_temp-d_temp-f_temp)\n test_array.append(np.log(k))\nplt.plot(xdata,test_array,'r') \n",
"/home/carly/anaconda3/lib/python3.7/site-packages/ipykernel_launcher.py:5: RuntimeWarning: invalid value encountered in log\n \"\"\"\n"
],
[
"#calculate original 3 parameter fit \n#fitting sigmas \nimport pandas as pd \nimport matplotlib.pyplot as plt\nfrom scipy.optimize import curve_fit \n\nnominal_rc_df = pd.read_csv('')\nxdata=nominal_rc_df['T']\nydata=nominal_rc_df['k']\n\ndef func(x, A,n,Ea):\n return np.log(A)+np.log(x)*n + (-Ea/(1.987*x))\nplt.scatter(xdata, ydata,label='data')\npopt, pcov = curve_fit(func, xdata, ydata,maxfev=1000000)\nprint(popt)\nA_nominal_3pf = popt[0]\nn_nominal_3pf = popt[1]\nEa_nominal_3pf = popt[2]/(1.987*1000)\ntest_array = []\nfor T in xdata:\n test_array.append(np.log(popt[0]*T**popt[1]*np.exp(-popt[2]/(1.987*T))))\nplt.plot(xdata,test_array,'r')\n\n",
"_____no_output_____"
],
[
"#looping over csvs and calculating sens coefficients for 3pf \n\nimport pandas as pd \nimport matplotlib.pyplot as plt\nfrom scipy.optimize import curve_fit \nA_list_3pf = [] \nn_list_3pf = []\nEa_list_3pf = []\n\nfor csv in csv list:\n df = pd.read_csv('')\n xdata=df['T']\n ydata=df['k']\n amount_perturbed = \n\n def func(x, A,n,Ea):\n return np.log(A)+np.log(x)*n + (-Ea/(1.987*x))\n plt.scatter(xdata, ydata,label='data')\n popt, pcov = curve_fit(func, xdata, ydata,maxfev=1000000)\n print(popt)\n A = popt[0]\n n = popt[1]\n Ea = popt[2]/(1.987*1000)\n test_array = []\n for T in xdata:\n test_array.append(np.log(popt[0]*T**popt[1]*np.exp(-popt[2]/(1.987*T))))\n plt.plot(xdata,test_array,'r') \n \n sensitivty_A = (A - A_nominal_3pf)/amount_perturbed\n sensitivity_n = (n-n_nominal_3pf)/amount_perturbed\n sensitivty_Ea = (Ea - Ea_nominal_3pf)/amount_perturbed\n \n A_list_3pf.append(sensitivty_A)\n n_list_3pf.append(sensitivity_n)\n Ea_list_3pf.append(sensitivty_Ea)",
"_____no_output_____"
],
[
"#calculating original 6 paramter fit \n#fitting sigmas \nimport pandas as pd \nimport matplotlib.pyplot as plt\nfrom scipy.optimize import curve_fit \n\nnominal_rc_df = pd.read_csv('')\nxdata=nominal_rc_df['T']\nydata=nominal_rc_df['k']\ndef func2(x, A,n,Ea,c,d,f):\n return np.log(A)+np.log(x)*n + (-Ea/(1.987*x)) + (-c/((1.987*x)**3)) + (-d*(1.987*x)) + (-f*((1.987*x)**3))\npopt, pcov = curve_fit(func2, xdata, ydata,maxfev=1000000)\n#popt, pcov = curve_fit(func2, xdata, ydata, method='dogbox',maxfev=10000)\n\n\n#method{‘lm’, ‘trf’, ‘dogbox’}, optional\nplt.scatter(xdata, ydata,label='data')\nprint(popt)\nA_nominal_spf = popt[0]\nn_nominal_spf = popt[1]\nEa_nominal_spf = popt[2]/(1.987*1000)\nc_nominal_spf = popt[3]/((1.987*1000)**3)\nd_nominal_spf = popt[4]/((1.987*1000)**-1)\nf_nominal_spf = popt[5]/((1.987*1000)**-3)\n\ntest_array = []\nfor T in xdata:\n A = popt[0]\n n = popt[1]\n Ea_temp = popt[2]/(1.987*T)\n c_temp = popt[3]/((1.987*T)**3)\n d_temp = popt[4]*(1.987*T)\n f_temp =popt[5]* ((1.987*T)**3)\n \n k = A*(T**n)*np.exp(-Ea_temp-c_temp-d_temp-f_temp)\n test_array.append(np.log(k))\nplt.plot(xdata,test_array,'r') ",
"_____no_output_____"
],
[
"#looping over csvs and calculating sens coefficients for 6pf \n\nimport pandas as pd \nimport matplotlib.pyplot as plt\nfrom scipy.optimize import curve_fit \nA_list_6pf = [] \nn_list_6pf = []\nEa_list_6pf = []\nc_list_6pf = []\nd_list_6pf = []\nf_list_6pf = []\n\nfor csv in csv list:\n df = pd.read_csv('')\n xdata=df['T']\n ydata=df['k']\n amount_perturbed = \n def func2(x, A,n,Ea,c,d,f):\n return np.log(A)+np.log(x)*n + (-Ea/(1.987*x)) + (-c/((1.987*x)**3)) + (-d*(1.987*x)) + (-f*((1.987*x)**3))\n popt, pcov = curve_fit(func2, xdata, ydata,maxfev=1000000)\n #popt, pcov = curve_fit(func2, xdata, ydata, method='dogbox',maxfev=10000)\n test_array = []\n for T in xdata:\n A = popt[0]\n n = popt[1]\n Ea_temp = popt[2]/(1.987*T)\n c_temp = popt[3]/((1.987*T)**3)\n d_temp = popt[4]*(1.987*T)\n f_temp =popt[5]* ((1.987*T)**3)\n\n k = A*(T**n)*np.exp(-Ea_temp-c_temp-d_temp-f_temp)\n test_array.append(np.log(k))\n plt.plot(xdata,test_array,'r') \n\n #method{‘lm’, ‘trf’, ‘dogbox’}, optional\n plt.scatter(xdata, ydata,label='data')\n print(popt)\n A = popt[0]\n n = popt[1]\n Ea = popt[2]/(1.987*1000)\n c = popt[3]/((1.987*1000)**3)\n d = popt[4]/((1.987*1000)**-1)\n f = popt[5]/((1.987*1000)**-3)\n \n sensitivty_A = (A - A_nominal_6pf)/amount_perturbed\n sensitivity_n = (n-n_nominal_6pf)/amount_perturbed\n sensitivty_Ea = (Ea - Ea_nominal_6pf)/amount_perturbed\n sensitivity_c = (c - c_nominal_6pf)/amount_perturbed\n sensitivity_d = (d - d_nominal_6pf)/amount_perturbed\n sensitivity_f = (f - f_nominal_6pf)/amount_perturbed\n \n A_list_6pf.append(sensitivty_A)\n n_list_6pf.append(sensitivity_n)\n Ea_list_6pf.append(sensitivty_Ea) \n c_list_6pf.append(sensitivity_c)\n d_list_6pf.append(sensitivity_d)\n f_list_6pf.append(sensitivity_f)\n \n",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3cfe0461c805243236442a6e0a5ad0fccf43e9 | 173,094 | ipynb | Jupyter Notebook | Pipelines/ETLPipelines/7_datatypes_exercise/7_datatypes_exercise.ipynb | vmukund100/dsnd_vm | a0f0679a4bdd0f6c458dc7620a2221d931964368 | [
"MIT"
] | null | null | null | Pipelines/ETLPipelines/7_datatypes_exercise/7_datatypes_exercise.ipynb | vmukund100/dsnd_vm | a0f0679a4bdd0f6c458dc7620a2221d931964368 | [
"MIT"
] | null | null | null | Pipelines/ETLPipelines/7_datatypes_exercise/7_datatypes_exercise.ipynb | vmukund100/dsnd_vm | a0f0679a4bdd0f6c458dc7620a2221d931964368 | [
"MIT"
] | null | null | null | 292.388514 | 151,261 | 0.761517 | [
[
[
"# Data Types\n\nWhen reading in a data set, pandas will try to guess the data type of each column like float, integer, datettime, bool, etc. In Pandas, strings are called \"object\" dtypes. \n\nHowever, Pandas does not always get this right. That was the issue with the World Bank projects data. Hence, the dtype was specified as a string:\n```\ndf_projects = pd.read_csv('../data/projects_data.csv', dtype=str)\n```\n\nRun the code cells below to read in the indicator and projects data. Then run the following code cell to see the dtypes of the indicator data frame.",
"_____no_output_____"
]
],
[
[
"# Run this code cell\n\nimport pandas as pd\n\n# read in the population data and drop the final column\ndf_indicator = pd.read_csv('../data/population_data.csv', skiprows=4)\ndf_indicator.drop(['Unnamed: 62'], axis=1, inplace=True)\n\n# read in the projects data set with all columns type string\ndf_projects = pd.read_csv('../data/projects_data.csv', dtype=str)\ndf_projects.drop(['Unnamed: 56'], axis=1, inplace=True)",
"_____no_output_____"
],
[
"df_indicator.head(2)",
"_____no_output_____"
],
[
"# Run this code cell \ndf_indicator.dtypes",
"_____no_output_____"
]
],
[
[
"These results look reasonable. Country Name, Country Code, Indicator Name and Indicator Code were all read in as strings. The year columns, which contain the population data, were read in as floats.\n\n# Exercise 1\n\nSince the population indicator data was read in correctly, you can run calculations on the data. In this first exercise, sum the populations of the United States, Canada, and Mexico by year.",
"_____no_output_____"
]
],
[
[
"# TODO: Calculate the population sum by year for Canada,\n# the United States, and Mexico.\n\n# the keepcol variable makes a list of the column names to keep. You can use this if you'd like\nkeepcol = ['Country Name']\nfor i in range(1960, 2018, 1):\n keepcol.append(str(i))\n\n# TODO: In the df_nafta variable, store a data frame that only contains the rows for \n# Canada, United States, and Mexico.\ndf_nafta = df_indicator[(df_indicator['Country Name']== \"Canada\") |\n (df_indicator['Country Name']== \"United States\") |\n (df_indicator['Country Name']== \"Mexico\")].iloc[:,]\n#print(df_nafta) \n# TODO: Calculate the sum of the values in each column in order to find the total population by year.\n# You can use the keepcol variable if you want to control which columns get outputted\ndf_nafta.sum(axis =0)[keepcol]",
"_____no_output_____"
]
],
[
[
"# Exercise 2\n\nNow, run the code cell below to look at the dtypes for the projects data set. They should all be \"object\" types, ie strings, because that's what was specified in the code when reading in the csv file. As a reminder, this was the code:\n```\ndf_projects = pd.read_csv('../data/projects_data.csv', dtype=str)\n```",
"_____no_output_____"
]
],
[
[
"# Run this code cell\ndf_projects.dtypes\n#df_projects.shape",
"_____no_output_____"
]
],
[
[
"Many of these columns should be strings, so there's no problem; however, a few columns should be other data types. For example, `boardapprovaldate` should be a datettime and `totalamt` should be an integer. You'll learn about datetime formatting in the next part of the lesson. For this exercise, focus on the 'totalamt' and 'lendprojectcost' columns. Run the code cell below to see what that data looks like",
"_____no_output_____"
]
],
[
[
"# Run this code cell\ndf_projects[['totalamt', 'lendprojectcost']].head()",
"_____no_output_____"
],
[
"# Run this code cell to take the sum of the total amount column\ndf_projects['totalamt'].sum()",
"_____no_output_____"
]
],
[
[
"What just happened? Pandas treated the totalamts like strings. In Python, adding strings concatenates the strings together.\n\nThere are a few ways to remedy this. When using pd.read_csv(), you could specify the column type for every column in the data set. The pd.read_csv() dtype option can accept a dictionary mapping each column name to its data type. You could also specify the `thousands` option with `thousands=','`. This specifies that thousands are separated by a comma in this data set. \n\nHowever, this data is somewhat messy, contains missing values, and has a lot of columns. It might be faster to read in the entire data set with string types and then convert individual columns as needed. For this next exercise, convert the `totalamt` column from a string to an integer type.",
"_____no_output_____"
]
],
[
[
"# TODO: Convert the totalamt column from a string to a float and save the results back into the totalamt column\n\n# Step 1: Remove the commas from the 'totalamt' column\n# HINT: https://pandas.pydata.org/pandas-docs/version/0.22/generated/pandas.Series.str.replace.html\n#df_projects['totalamt'] =df_projects['totalamt'].str.replace(\",\", \"\")\n# Step 2: Convert the 'totalamt' column from an object data type (ie string) to an integer data type.\n# HINT: https://pandas.pydata.org/pandas-docs/version/0.23/generated/pandas.to_numeric.html\n\ndf_projects['totalamt'] = pd.to_numeric(df_projects['totalamt'].str.replace(\",\", \"\"))",
"_____no_output_____"
]
],
[
[
"# Conclusion\n\nWith messy data, you might find it easier to read in everything as a string; however, you'll sometimes have to convert those strings to more appropriate data types. When you output the dtypes of a dataframe, you'll generally see these values in the results:\n* float64\n* int64\n* bool\n* datetime64\n* timedelta\n* object\n\nwhere timedelta is the difference between two datetimes and object is a string. As you've seen here, you sometimes need to convert data types from one type to another type. Pandas has a few different methods for converting between data types, and here are link to the documentation:\n\n* [astype](https://pandas.pydata.org/pandas-docs/version/0.22/generated/pandas.DataFrame.astype.html#pandas.DataFrame.astype)\n* [to_datetime](https://pandas.pydata.org/pandas-docs/version/0.22/generated/pandas.to_datetime.html#pandas.to_datetime)\n* [to_numeric](https://pandas.pydata.org/pandas-docs/version/0.22/generated/pandas.to_numeric.html#pandas.to_numeric)\n* [to_timedelta](https://pandas.pydata.org/pandas-docs/version/0.22/generated/pandas.to_timedelta.html#pandas.to_timedelta)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
cb3d0a9300450e4e259fa259bfcff73d2a0e42a6 | 8,663 | ipynb | Jupyter Notebook | MusicData.ipynb | ldzhangyx/BUTTER | ce850b28bb979632437971648a1e6ff5a4ea19f3 | [
"Apache-2.0"
] | 2 | 2020-10-17T01:49:32.000Z | 2021-08-23T09:29:18.000Z | MusicData.ipynb | ldzhangyx/BUTTER | ce850b28bb979632437971648a1e6ff5a4ea19f3 | [
"Apache-2.0"
] | null | null | null | MusicData.ipynb | ldzhangyx/BUTTER | ce850b28bb979632437971648a1e6ff5a4ea19f3 | [
"Apache-2.0"
] | null | null | null | 41.850242 | 137 | 0.472585 | [
[
[
"from music21 import *\nimport numpy as np\nimport torch\nimport pretty_midi\nimport os\nimport sys\nimport pickle\nimport time\nimport random\nimport re",
"_____no_output_____"
],
[
"class MusicData(object):\n \n def __init__(self, abc_file, culture= None):\n self.stream = None\n self.metadata = dict()\n self.description = None\n self.midi = None\n self.torch_matrix = None\n \n self.title = None\n self.key = None\n self.meter = None\n self.culture = culture\n self.gene = None\n self.valid = True\n self.set_proporties(abc_file)\n \n \n def set_proporties(self, abc_file):\n # print(abc_file.split('/')[-1])\n step_list = ['stream','metadata','key','meter','others']\n try:\n step_counter = 0\n self.stream = converter.parse(abc_file)\n step_counter = 1\n self.metadata = dict(self.stream.metadata.all())\n step_counter = 2\n self.key = self.metadata['key'] = str(self.stream.flat.getElementsByClass('Key')[0])\n step_counter = 3\n self.meter = self.metadata['meter'] = str(self.stream.flat.getElementsByClass('TimeSignature')[0])[1:-1].split()[-1]\n step_counter = 4\n self.title = self.metadata['title']\n self.midi = f\"/gpfsnyu/home/yz6492/multimodal/data/midi/{self.title}.mid\"\n if 'localeOfComposition' in self.metadata and self.culture is None:\n self.culture = self.culture_analyzer(self.metadata['localeOfComposition'])\n if 'gene' in self.metadata:\n pass\n except:\n self.valid = False\n print(f'Error in parsing: id - {step_list[step_counter]}')\n return\n \n \n try:\n mf = midi.translate.streamToMidiFile(self.stream)\n mf.open(self.midi, 'wb')\n mf.write()\n mf.close()\n self.torch_matrix = self.melody_to_numpy(fpath = self.midi)\n except Exception as e:\n self.stream, flag = self.emergence_fix(abc_file)\n# if flag is False:\n# self.stream, flag = self.emergence_fix(abc_file)\n print(f'Error in Matrix. Fixed? {flag}')\n self.description = self.generate_description()\n \n if self.torch_matrix is None:\n self.valid = False\n \n self.stream = None # for data size compression\n \n \n \n def emergence_fix(self, abc_file):\n with open(abc_file, 'r') as f:\n input_list = [line for line in f]\n output_list = input_list.copy()\n for i, line in enumerate(input_list):\n if 'L:' in line:\n if line[-3:] == '16\\n':\n output_list[i] = 'L:1/8\\n'\n elif line[-2:] == '8\\n':\n output_list[i] = 'L:1/4\\n'\n with open(abc_file, 'w') as f:\n f.writelines(output_list)\n # fix finished. now test\n \n try:\n self.stream = converter.parse(abc_file)\n mf = midi.translate.streamToMidiFile(self.stream)\n mf.open(self.midi, 'wb')\n mf.write()\n mf.close()\n self.torch_matrix = self.melody_to_numpy(fpath = self.midi)\n self.valid = True\n return stream, True\n except Exception as e:\n self.valid = False # do not use this object\n return stream, False\n \n \n def culture_analyzer(self, text):\n if 'china' in text.lower():\n return 'Chinese'\n if 'irish' in text.lower():\n return 'Irish'\n if 'english' in text.lower():\n return 'English'\n \n def melody_to_numpy(self, fpath=None, unit_time=0.125, take_rhythm=False, ):\n music = pretty_midi.PrettyMIDI(fpath)\n notes = music.instruments[0].notes\n t = 0.\n roll = []\n # print(notes[0], notes[-1])\n for note in notes:\n # print(t, note)\n elapsed_time = note.start - t\n if elapsed_time > 0.:\n steps = torch.zeros((int(round(elapsed_time / unit_time)), 130))\n steps[range(int(round(elapsed_time / unit_time))), 129] += 1.\n roll.append(steps)\n n_units = int(round((note.end - note.start) / unit_time))\n steps = torch.zeros((n_units, 130))\n if take_rhythm:\n steps[0, 60] += 1\n else:\n steps[0, note.pitch] += 1\n steps[range(1, n_units), 128] += 1\n roll.append(steps)\n t = note.end\n return torch.cat(roll, 0) \n \n def generate_description(self):\n # order shuffle (total 6 possibilities)\n order = random.randint(0,5)\n \n # connector to decide grammar\n connecter = [random.randint(0,1), random.randint(0,1)]\n \n sequences = [\n f'This is a song in {self.key}. It has a {self.meter} tempo. It is a {self.culture} song.',\n f'This is a song in {self.key}. This is in {self.culture} style with a beat of {self.meter}.',\n f'This is a song in {self.key}. This is a {self.culture} style song with a rhythm of {self.meter}.',\n f'This is a {self.key} album. They have got a {self.meter} tempo. It is a song from {self.culture}.',\n f'This is {self.key} song. This does have a tempo of {self.meter}. It is a song in {self.culture} style.',\n f'That is a {self.key} song. The tempo is {self.meter}. It is a song of the {self.culture} style.',\n f'That is a {self.key} hit. There is a pace of {self.meter}. It is a album in {self.culture} style.',\n f'This is a song in {self.key} with a {self.meter} tempo and it is a {self.culture} style song.',\n f'It is a {self.meter} pace {self.key} piece, and it is a {self.culture} type piece.',\n f'This is a {self.meter} tempo composition in {self.key} and is a {self.culture} hit.',\n f'It is a song of {self.culture} theme. It is a {self.meter} tempo song in {self.key}.',\n f'This is a song of {self.culture} theme. It is a {self.meter}-tempo composition in {self.key}.',\n f'This is an album about {self.culture} theme. This is a record of {self.meter} tempo in {self.key}',\n ]\n \n return sequences[random.randint(0, len(sequences)-1)]\n ",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code"
]
] |
cb3d136e9a83840816d1337d08e0a488ae21c06b | 82,166 | ipynb | Jupyter Notebook | preprocessing/01_raw_to_numpy_nela-17.ipynb | david-yoon/detecting-incongruity | 2e121fdba0da3a6a0c63df0c46a101a789fe7565 | [
"MIT"
] | 36 | 2018-11-25T21:43:10.000Z | 2022-03-13T10:47:50.000Z | preprocessing/01_raw_to_numpy_nela-17.ipynb | david-yoon/detecting-incongruity | 2e121fdba0da3a6a0c63df0c46a101a789fe7565 | [
"MIT"
] | 1 | 2019-06-16T07:45:47.000Z | 2019-10-14T06:00:29.000Z | preprocessing/01_raw_to_numpy_nela-17.ipynb | david-yoon/detecting-incongruity | 2e121fdba0da3a6a0c63df0c46a101a789fe7565 | [
"MIT"
] | 5 | 2018-12-09T06:40:19.000Z | 2019-10-17T22:07:58.000Z | 36.812724 | 7,248 | 0.562142 | [
[
[
"import matplotlib.pyplot as plt\nimport numpy as np\nfrom tqdm import tqdm\n%matplotlib inline",
"_____no_output_____"
],
[
"import datetime\nimport cPickle as pickle\nimport csv\nimport numpy as np\nimport random\nimport sys\nmaxInt = sys.maxsize\ndecrement = True\n\nwhile decrement:\n # decrease the maxInt value by factor 10\n # as long as the OverflowError occurs.\n \n decrement = False\n try:\n csv.field_size_limit(maxInt)\n except OverflowError:\n maxInt = int(maxInt/10)\n decrement = True",
"_____no_output_____"
]
],
[
[
"# get term-/document-frequency",
"_____no_output_____"
]
],
[
[
"csv_reader = csv.reader(open('../data/raw/NELA-17/train.csv', 'r'))\n\ntkn2tf = {}\nlen_heads = [] #1\nlen_paras = [] #2\ncnt_paras = [] #3\nlen_bodys = [] #4\n\n# csv data: 0:id, 1:head, 2:body, 3:label\n\nprint datetime.datetime.now().isoformat()\n\nfor n, row in enumerate(csv_reader):\n if (n+1) % 100000 == 0: print n+1,\n \n head = row[1].lower().strip()\n \n for tkn in head.split():\n if tkn in tkn2tf: tkn2tf[tkn] += 1\n else: tkn2tf[tkn] = 1\n len_heads.append(len(head.split())) #1\n \n body = row[2].lower().strip()\n tkn_para = []\n for para in body.split('<eop>'):\n if para and para != ' ':\n _para = para + '<eop>'\n len_para = len(_para.split())\n len_paras.append(len_para) #2\n tkn_para.append(_para)\n cnt_paras.append(len(tkn_para)) #3\n \n body_split = []\n for tkn in body.split():\n if tkn in tkn2tf: tkn2tf[tkn] += 1\n else: tkn2tf[tkn] = 1\n body_split.append(tkn)\n len_bodys.append(len(body_split)) #4\n \nprint n+1, 'Done'\nprint datetime.datetime.now().isoformat()\nprint 'voca size :', len(tkn2tf)",
"2019-11-19T12:58:20.249333\n71420 Done\n2019-11-19T12:58:40.561259\nvoca size : 278206\n"
],
[
"sorted_token = sorted(tkn2tf.items(), key=lambda kv: kv[1], reverse=True)\ntkn2idx = {}\nfor idx, (tkn, _) in tqdm(enumerate(sorted_token)):\n tkn2idx[tkn] = idx + 2\ntkn2idx['<UNK>'] = 1\ntkn2idx[''] = 0\nif len(tkn2idx) == len(tkn2tf)+2:\n print len(tkn2idx), 'No problem'\nprint \n\nprint 'Show top-10 tkn:'\nfor tkn, freq in sorted_token[:10]:\n print tkn,':',freq\nprint ''",
"278206it [00:00, 1302505.19it/s]"
],
[
"with open('../data/nela-17/whole/dic_mincut0.txt', 'wb') as f:\n for key in tkn2idx.keys():\n f.write(key+'\\n')",
"_____no_output_____"
],
[
"tkn2tf_mincut5 = {}\nfor tkn, tf in tkn2tf.items():\n if tf < 2:\n continue\n tkn2tf_mincut5[tkn] = tf\nprint 'voca size :', len(tkn2tf_mincut5)",
"voca size : 144449\n"
],
[
"tkn2tf_mincut5['<EOS>'] = tkn2tf_mincut5['<eos>']\ntkn2tf_mincut5['<EOP>'] = tkn2tf_mincut5['<eop>']\n\ndel tkn2tf_mincut5['<eos>']\ndel tkn2tf_mincut5['<eop>']",
"_____no_output_____"
],
[
"import operator\nsorted_voca = sorted(tkn2tf_mincut5.items(), key=operator.itemgetter(1))\nlen(sorted_voca)",
"_____no_output_____"
],
[
"list_voca_mincut = []\nlist_voca_mincut.append('') # PAD\nlist_voca_mincut.append('<UNK>') # UNK\nlist_voca_mincut.append('<EOS>') # EOS\nlist_voca_mincut.append('<EOP>') # EOP\n\nfor word, idx in sorted_voca:\n if word=='<UNK>' or word=='<EOP>' or word=='<EOS>':\n print(\"existing word\", word)\n continue\n else:\n list_voca_mincut.append(word)\n \nlen(list_voca_mincut)",
"('existing word', '<EOP>')\n('existing word', '<EOS>')\n"
],
[
"with open('../data/nela-17/whole/dic_mincutN.txt', 'wb') as f:\n for i in range(len(list_voca_mincut)):\n f.write(list_voca_mincut[i]+'\\n')",
"_____no_output_____"
],
[
"dic_voca = {}\nfor voca in list_voca_mincut:\n dic_voca[voca] = len(dic_voca)",
"_____no_output_____"
],
[
"print(dic_voca[''], dic_voca['<UNK>'], dic_voca['<EOS>'], dic_voca['<EOP>'])",
"(0, 1, 2, 3)\n"
],
[
"with open('../data/nela-17/whole/dic_mincutN.pkl', 'wb') as f:\n pickle.dump(dic_voca, f)",
"_____no_output_____"
]
],
[
[
"#### for data processing",
"_____no_output_____"
]
],
[
[
"import copy",
"_____no_output_____"
],
[
"dic_voca_lower = copy.deepcopy(dic_voca)",
"_____no_output_____"
],
[
"dic_voca_lower['<eos>'] = dic_voca_lower['<EOS>']\ndic_voca_lower['<eop>'] = dic_voca_lower['<EOP>']\n\ndel dic_voca_lower['<EOS>']\ndel dic_voca_lower['<EOP>']",
"_____no_output_____"
],
[
"len(dic_voca_lower)",
"_____no_output_____"
],
[
"print(dic_voca_lower[''], dic_voca_lower['<UNK>'], dic_voca_lower['<eos>'], dic_voca_lower['<eop>'])",
"(0, 1, 2, 3)\n"
]
],
[
[
"## stats",
"_____no_output_____"
]
],
[
[
"import csv\nimport sys\nimport numpy as np\n\ndata= []\nwith open('../data/raw/NELA-17/train.csv', 'r') as f:\n data_csv = csv.reader(f, delimiter=',')\n for row in data_csv:\n data.append(row)",
"_____no_output_____"
],
[
"def print_info(data):\n print(\"mean\", np.average(data))\n print(\"std\", np.std(data))\n print(\"max\", np.max(data))\n print(\"95.xx coverage\", np.average(data) + 2*np.std(data) )\n print(\"99.73 coverage\", np.average(data) + 3*np.std(data) )\n print(\"99.95 coverage\", np.average(data) + 3.5*np.std(data) )\n print(\"99.99 coverage\", np.average(data) + 4*np.std(data) )",
"_____no_output_____"
],
[
"head = [x[1].strip() for x in data]\nhead_len = [len(x.split()) for x in head]\nprint('head_len')\nprint_info(head_len)",
"head_len\n('mean', 12.368524222906748)\n('std', 4.195499786742765)\n('max', 79)\n('95.xx coverage', 20.75952379639228)\n('99.73 coverage', 24.955023583135045)\n('99.95 coverage', 27.052773476506424)\n('99.99 coverage', 29.15052336987781)\n"
],
[
"body = [x[2].strip() for x in data]",
"_____no_output_____"
],
[
"body_len = [len(x.split()) for x in body ]\nprint('body_len')\nprint_info(body_len)",
"body_len\n('mean', 704.6059087090451)\n('std', 641.885050460635)\n('max', 21113)\n('95.xx coverage', 1988.376009630315)\n('99.73 coverage', 2630.26106009095)\n('99.95 coverage', 2951.2035853212674)\n('99.99 coverage', 3272.146110551585)\n"
],
[
"context_len = [len(x.split('<EOP>')) for x in body]\nprint('context_len')\nprint_info(context_len)",
"context_len\n('mean', 13.53699243909269)\n('std', 11.598850879491028)\n('max', 367)\n('95.xx coverage', 36.73469419807475)\n('99.73 coverage', 48.33354507756578)\n('99.95 coverage', 54.13297051731129)\n('99.99 coverage', 59.932395957056805)\n"
],
[
"body_sentence = []\nfor sent in body:\n sent = sent.split('<EOP>')\n body_sentence.extend(sent)\nbody_len = [ len(x.split()) for x in body_sentence ] \nprint('body_len')\nprint_info(body_len)",
"body_len\n('mean', 51.12427441943211)\n('std', 50.55277742280993)\n('max', 4709)\n('95.xx coverage', 152.229829265052)\n('99.73 coverage', 202.78260668786191)\n('99.95 coverage', 228.05899539926688)\n('99.99 coverage', 253.33538411067184)\n"
]
],
[
[
"# encode to numpy",
"_____no_output_____"
]
],
[
[
"def fit_length(data, max_len_t, max_len_b):\n data_t, data_b = data\n \n list_zeros = np.zeros(max_len_b, 'int32').tolist()\n fl_data_t = []\n for datum in data_t:\n try:\n datum = list(datum)\n except:\n pass\n _len = len(datum)\n if _len >= max_len_t:\n fl_data_t.append( datum[:max_len_t] )\n else:\n fl_data_t.append( datum + list_zeros[:(max_len_t-_len)] )\n \n fl_data_b = []\n for datum in data_b:\n try:\n datum = list(datum)\n except:\n pass\n _len = len(datum)\n if _len >= max_len_b:\n fl_data_b.append( datum[:max_len_b] )\n else:\n fl_data_b.append( datum + list_zeros[:(max_len_b-_len)] )\n \n np_data_t = np.asarray(fl_data_t, dtype='int32')\n np_data_b = np.asarray(fl_data_b, dtype='int32')\n \n data = [np_data_t, np_data_b]\n return data",
"_____no_output_____"
],
[
"csv_reader = csv.reader(open('../data/raw/NELA-17/train.csv', 'r'))\n\nprint datetime.datetime.now().isoformat()\nids = []\nheads = []\nbodys = []\nlabels = []\nfor n, row in enumerate(csv_reader):\n if (n+1) % 10000 == 0: print n+1,\n \n ids.append(row[0])\n labels.append(int(row[3]))\n \n head = []\n for tkn in row[1].lower().strip().split():\n if tkn in dic_voca_lower:\n head.append(dic_voca_lower[tkn])\n else:\n head.append(1) # 0: <UNK>\n \n heads.append(head)\n \n body = []\n for tkn in row[2].lower().strip().split():\n if tkn in dic_voca_lower:\n body.append(dic_voca_lower[tkn])\n else:\n body.append(1) # 0: <UNK>\n \n bodys.append(body)\n \nprint n+1, 'Done'\nprint datetime.datetime.now().isoformat() # ~5 mins",
"2019-11-19T12:45:25.496433\n10000 20000 30000 40000 50000 60000 70000 71420 Done\n2019-11-19T12:45:39.654989\n"
],
[
"print datetime.datetime.now().isoformat()\n[np_heads, np_bodys] = fit_length([heads, bodys], 25, 2000)\nprint datetime.datetime.now().isoformat() # ~3 mins",
"2019-11-19T12:45:45.508082\n2019-11-19T12:45:56.482256\n"
],
[
"print datetime.datetime.now().isoformat()\nt_trainpath = '../data/nela-17/whole/train/train_title.npy'\nnp.save(t_trainpath, np_heads)\nb_trainpath = '../data/nela-17/whole/train/train_body.npy'\nnp.save(b_trainpath, np_bodys)\nl_trainpath = '../data/nela-17/whole/train/train_label.npy'\nnp.save(l_trainpath, labels)\nprint datetime.datetime.now().isoformat()",
"2019-11-19T12:47:43.800305\n2019-11-19T12:47:44.156423\n"
]
],
[
[
"# devset",
"_____no_output_____"
]
],
[
[
"csv_reader = csv.reader(open('../data/raw/NELA-17/dev.csv', 'r'))\n\nprint datetime.datetime.now().isoformat()\nids_dev = []\nheads_dev = []\nbodys_dev = []\nlabels_dev = []\nfor n, row in enumerate(csv_reader):\n if (n+1) % 10000 == 0: print n+1,\n \n ids_dev.append(row[0])\n labels_dev.append(int(row[3]))\n \n head = []\n for tkn in row[1].lower().strip().split():\n if tkn in dic_voca_lower:\n head.append(dic_voca_lower[tkn])\n else:\n head.append(1) # 0: UNK\n heads_dev.append(head)\n \n body = []\n for tkn in row[2].lower().strip().split():\n if tkn in dic_voca_lower:\n body.append(dic_voca_lower[tkn])\n else:\n body.append(1) # 0: UNK\n bodys_dev.append(body)\n \nprint n+1, 'Done'\nprint datetime.datetime.now().isoformat()",
"2019-11-19T12:47:49.776245\n6302 Done\n2019-11-19T12:47:51.108171\n"
],
[
"print datetime.datetime.now().isoformat()\n[np_heads_dev, np_bodys_dev] = fit_length([heads_dev, bodys_dev], 25, 2000)\nprint datetime.datetime.now().isoformat() # ~3 mins",
"2019-11-19T12:47:51.116349\n2019-11-19T12:47:51.859085\n"
],
[
"print datetime.datetime.now().isoformat()\nt_trainpath = '../data/nela-17/whole/dev/dev_title.npy'\nnp.save(t_trainpath, np_heads_dev)\nb_trainpath = '../data/nela-17/whole/dev/dev_body.npy'\nnp.save(b_trainpath, np_bodys_dev)\nl_trainpath = '../data/nela-17/whole/dev/dev_label.npy'\nnp.save(l_trainpath, labels_dev)\nprint datetime.datetime.now().isoformat()",
"2019-11-19T12:47:51.873015\n2019-11-19T12:47:51.923206\n"
]
],
[
[
"# testset",
"_____no_output_____"
]
],
[
[
"csv_reader = csv.reader(open('../data/raw/NELA-17/test.csv', 'r'))\n\nprint datetime.datetime.now().isoformat()\nids_dev = []\nheads_dev = []\nbodys_dev = []\nlabels_dev = []\nfor n, row in enumerate(csv_reader):\n if (n+1) % 10000 == 0: print n+1,\n \n ids_dev.append(row[0])\n labels_dev.append(int(row[3]))\n \n head = []\n for tkn in row[1].lower().strip().split():\n if tkn in dic_voca_lower:\n head.append(dic_voca_lower[tkn])\n else:\n head.append(1) # 0 - UNK\n heads_dev.append(head)\n \n body = []\n for tkn in row[2].lower().strip().split():\n if tkn in dic_voca_lower:\n body.append(dic_voca_lower[tkn])\n else:\n body.append(1) # 0 - UNK\n bodys_dev.append(body)\n \nprint n+1, 'Done'\nprint datetime.datetime.now().isoformat()",
"2019-11-19T12:47:51.955865\n6302 Done\n2019-11-19T12:47:53.414398\n"
],
[
"print datetime.datetime.now().isoformat()\n[np_heads_dev, np_bodys_dev] = fit_length([heads_dev, bodys_dev], 25, 2000)\nprint datetime.datetime.now().isoformat() # ~3 mins",
"2019-11-19T12:47:53.422318\n2019-11-19T12:47:54.162709\n"
],
[
"print datetime.datetime.now().isoformat()\nt_trainpath = '../data/nela-17/whole/test/test_title.npy'\nnp.save(t_trainpath, np_heads_dev)\nb_trainpath = '../data/nela-17/whole/test/test_body.npy'\nnp.save(b_trainpath, np_bodys_dev)\nl_trainpath = '../data/nela-17/whole/test/test_label.npy'\nnp.save(l_trainpath, labels_dev)\nprint datetime.datetime.now().isoformat()",
"2019-11-19T12:47:54.171654\n2019-11-19T12:47:54.192900\n"
]
],
[
[
"# debugset",
"_____no_output_____"
]
],
[
[
"print datetime.datetime.now().isoformat()\nt_trainpath = '../data/nela-17//whole/debug/debug_title.npy'\nnp.save(t_trainpath, np_heads_dev[:200])\nb_trainpath = '../data/nela-17/whole/debug/debug_body.npy'\nnp.save(b_trainpath, np_bodys_dev[:200])\nl_trainpath = '../data/nela-17/whole/debug/debug_label.npy'\nnp.save(l_trainpath, labels_dev[:200])\nprint datetime.datetime.now().isoformat()",
"2019-11-19T12:47:54.202060\n2019-11-19T12:47:54.203979\n"
],
[
"with open('../data/nela-17/whole/dic_mincutN.txt') as f:\n test_list_voca = f.readlines()\n test_list_voca = [x.strip() for x in test_list_voca]",
"_____no_output_____"
],
[
"from nlp_vocab import Vocab",
"_____no_output_____"
],
[
"tt = Vocab(test_list_voca)",
"_____no_output_____"
],
[
"print(tt.index2sent(np_heads_dev[100]))",
"mom puts gun in alleged intruder ’ s face and asks , is there ‘ something i could do for you ? ’ \n"
]
],
[
[
"# para ver.",
"_____no_output_____"
]
],
[
[
"SEED = 448\nrandom.seed(SEED)",
"_____no_output_____"
],
[
"csv_reader = csv.reader(open('version2/data_para_train.csv', 'r'))\n\nprint datetime.datetime.now().isoformat()\ndata = []\ntrue_data = []\nfor n, row in enumerate(csv_reader):\n if (n+1) % 100000 == 0: print n+1,\n \n if row[3] == \"1\":\n data.append(row)\n else:\n true_data.append(row)\n\nrandom.shuffle(true_data)\ndata += true_data[:len(data)]\n\nprint datetime.datetime.now().isoformat()\nids_para = []\nheads_para = []\nbodys_para = []\nlabels_para = [] \nfor n, row in enumerate(data):\n if (n+1) % 10000 == 0: print n+1,\n \n ids_para.append(row[0])\n labels_para.append(int(row[3]))\n \n head = []\n for tkn in row[1].split():\n if tkn in tkn2idx_mincut5:\n head.append(tkn2idx_mincut5[tkn])\n else:\n head.append(1)\n heads_para.append(head)\n \n body = []\n for tkn in row[2].split():\n if tkn in tkn2idx_mincut5:\n body.append(tkn2idx_mincut5[tkn])\n else:\n body.append(1)\n bodys_para.append(body)\n \nprint n+1, ': Done'\nprint datetime.datetime.now().isoformat()\nprint datetime.datetime.now().isoformat()\n[np_heads_para, np_bodys_para] = fit_length([heads_para, bodys_para], 49, 170)\nprint 'numpy: Done'\nprint datetime.datetime.now().isoformat() # ~3 mins\n\nprint datetime.datetime.now().isoformat()\nt_trainpath = 'nps/train_para_head_mincut5'\nnp.save(t_trainpath, np_heads_para)\nb_trainpath = 'nps/train_para_body_mincut5'\nnp.save(b_trainpath, np_bodys_para)\nl_trainpath = 'nps/train_para_label_mincut5'\nnp.save(l_trainpath, labels_para)\nprint 'save: Done'\nprint datetime.datetime.now().isoformat()",
"2017-12-30T10:40:39.559846\n100000 200000 300000 400000 500000 600000 700000 800000 900000 1000000 1100000 1200000 1300000 1400000 1500000 1600000 1700000 1800000 1900000 2000000 2100000 2200000 2300000 2400000 2500000 2600000 2700000 2800000 2900000 3000000 3100000 3200000 3300000 3400000 3500000 3600000 3700000 3800000 3900000 4000000 4100000 4200000 4300000 4400000 4500000 4600000 4700000 4800000 4900000 5000000 5100000 5200000 5300000 5400000 5500000 5600000 5700000 5800000 5900000 6000000 6100000 6200000 6300000 6400000 6500000 6600000 6700000 6800000 6900000 7000000 7100000 7200000 7300000 7400000 7500000 7600000 7700000 7800000 7900000 8000000 8100000 8200000 8300000 8400000 8500000 8600000 8700000 8800000 8900000 9000000 9100000 9200000 9300000 9400000 9500000 9600000 9700000 9800000 9900000 10000000 10100000 10200000 10300000 10400000 10500000 10600000 10700000 10800000 10900000 11000000 11100000 11200000 11300000 11400000 11500000 11600000 11700000 11800000 11900000 12000000 12100000 12200000 12300000 12400000 12500000 12600000 12700000 12800000 12900000 13000000 13100000 13200000 13300000 13400000 13500000 13600000 13700000 13800000 13900000 14000000 14100000 14200000 2017-12-30T10:42:21.875894\n10000 20000 30000 40000 50000 60000 70000 80000 90000 100000 110000 120000 130000 140000 150000 160000 170000 180000 190000 200000 210000 220000 230000 240000 250000 260000 270000 280000 290000 300000 310000 320000 330000 340000 350000 360000 370000 380000 390000 400000 410000 420000 430000 440000 450000 460000 470000 480000 490000 500000 510000 520000 530000 540000 550000 560000 570000 580000 590000 600000 610000 620000 630000 640000 650000 660000 670000 680000 690000 700000 710000 720000 730000 740000 750000 760000 770000 780000 790000 800000 810000 820000 830000 840000 850000 860000 870000 880000 890000 900000 910000 920000 930000 940000 950000 960000 970000 980000 990000 1000000 1010000 1020000 1030000 1040000 1050000 1060000 1070000 1080000 1090000 1100000 1110000 1120000 1130000 1140000 1150000 1160000 1170000 1180000 1190000 1200000 1210000 1220000 1230000 1240000 1250000 1260000 1270000 1280000 1290000 1300000 1310000 1320000 1330000 1340000 1350000 1360000 1370000 1380000 1390000 1400000 1410000 1420000 1430000 1440000 1450000 1460000 1470000 1480000 1490000 1500000 1510000 1520000 1530000 1540000 1550000 1560000 1570000 1580000 1590000 1600000 1610000 1620000 1630000 1640000 1650000 1660000 1670000 1680000 1690000 1700000 1710000 1720000 1730000 1740000 1750000 1760000 1770000 1780000 1790000 1800000 1810000 1820000 1830000 1840000 1850000 1860000 1870000 1880000 1890000 1900000 1910000 1920000 1930000 1940000 1950000 1960000 1970000 1980000 1990000 2000000 2010000 2020000 2030000 2040000 2050000 2060000 2070000 2080000 2090000 2100000 2110000 2120000 2130000 2140000 2150000 2160000 2170000 2180000 2190000 2200000 2210000 2220000 2230000 2240000 2250000 2260000 2270000 2280000 2290000 2300000 2310000 2320000 2330000 2340000 2350000 2360000 2370000 2380000 2390000 2400000 2410000 2420000 2430000 2440000 2450000 2460000 2470000 2480000 2490000 2500000 2510000 2520000 2530000 2540000 2550000 2560000 2570000 2580000 2590000 2600000 2610000 2620000 2630000 2640000 2650000 2660000 2670000 2680000 2690000 2700000 2710000 2720000 2730000 2740000 2750000 2760000 2770000 2780000 2790000 2800000 2810000 2820000 2830000 2840000 2850000 2860000 2870000 2880000 2890000 2900000 2910000 2920000 2930000 2940000 2950000 2960000 2970000 2980000 2990000 3000000 3010000 3020000 3030000 3040000 3050000 3060000 3070000 3080000 3090000 3100000 3110000 3120000 3130000 3140000 3150000 3160000 3170000 3180000 3190000 3200000 3210000 3220000 3230000 3240000 3250000 3260000 3270000 3280000 3290000 3300000 3310000 3320000 3330000 3340000 3350000 3360000 3370000 3380000 3390000 3400000 3410000 3420000 3430000 3440000 3450000 3460000 3470000 3480000 3490000 3500000 3510000 3520000 3530000 3540000 3550000 3560000 3570000 3580000 3590000 3600000 3610000 3620000 3630000 3640000 3650000 3660000 3670000 3680000 3690000 3700000 3710000 3720000 3730000 3740000 3750000 3760000 3770000 3780000 3790000 3800000 3810000 3820000 3830000 3840000 3850000 3860000 3870000 3880000 3890000 3900000 3910000 3920000 3930000 3940000 3950000 3960000 3970000 3980000 3990000 4000000 4010000 4020000 4030000 4040000 4050000 4060000 4070000 4080000 4081788 : Done\n2017-12-30T10:44:30.655514\n2017-12-30T10:44:30.655764\nnumpy: Done\n2017-12-30T10:45:56.835203\n2017-12-30T10:45:56.835352\nsave: Done\n2017-12-30T10:45:58.375929\n"
],
[
"import numpy as np\nl_trainpath = np.load('nps/train_para_label_mincut5.npy')",
"_____no_output_____"
],
[
"l_trainpath.shape",
"_____no_output_____"
],
[
"csv_reader = csv.reader(open('version2/data_para_dev.csv', 'r'))\n\nprint datetime.datetime.now().isoformat()\nids_para_dev = []\nheads_para_dev = []\nbodys_para_dev = []\nlabels_para_dev = []\nfor n, row in enumerate(csv_reader):\n if (n+1) % 10000 == 0: print n+1,\n \n ids_para_dev.append(row[0])\n labels_para_dev.append(int(row[3]))\n \n head = []\n for tkn in row[1].split():\n if tkn in tkn2idx_mincut5:\n head.append(tkn2idx_mincut5[tkn])\n else:\n head.append(1)\n heads_para_dev.append(head)\n \n body = []\n for tkn in row[2].split():\n if tkn in tkn2idx_mincut5:\n body.append(tkn2idx_mincut5[tkn])\n else:\n body.append(1)\n bodys_para_dev.append(body)\n \nprint n+1, 'Done'\nprint datetime.datetime.now().isoformat()\nprint datetime.datetime.now().isoformat()\n[np_heads_para_dev, np_bodys_para_dev] = fit_length([heads_para_dev, bodys_para_dev], 49, 170)\nprint datetime.datetime.now().isoformat() # ~3 mins\n\nprint datetime.datetime.now().isoformat()\nt_trainpath = 'nps/valid_para_head_mincut5'\nnp.save(t_trainpath, np_heads_para_dev)\nb_trainpath = 'nps/valid_para_body_mincut5'\nnp.save(b_trainpath, np_bodys_para_dev)\nl_trainpath = 'nps/valid_para_label_mincut5'\nnp.save(l_trainpath, labels_para_dev)\nprint datetime.datetime.now().isoformat()",
"2017-12-30T10:45:58.397408\n10000 20000 30000 40000 50000 60000 70000 80000 90000 100000 110000 120000 130000 140000 150000 160000 170000 180000 190000 200000 210000 220000 230000 240000 250000 260000 270000 280000 290000 300000 310000 320000 330000 340000 350000 360000 370000 380000 390000 400000 410000 420000 430000 440000 450000 460000 470000 480000 490000 500000 510000 520000 530000 540000 550000 560000 570000 580000 590000 600000 610000 620000 630000 640000 650000 660000 670000 680000 690000 700000 710000 720000 730000 740000 750000 760000 770000 780000 790000 800000 810000 820000 830000 834064 Done\n2017-12-30T10:46:19.560618\n2017-12-30T10:46:19.560703\n2017-12-30T10:46:47.015257\n2017-12-30T10:46:47.015503\n2017-12-30T10:46:47.355907\n"
]
],
[
[
"# testset",
"_____no_output_____"
]
],
[
[
"csv_reader = csv.reader(open('version2/data_whole_test.csv', 'r'))\n\nprint datetime.datetime.now().isoformat()\nids_test = []\nheads_test = []\nbodys_test = []\nlabels_test = []\nfor n, row in enumerate(csv_reader):\n if (n+1) % 10000 == 0: print n+1,\n \n ids_test.append(row[0])\n labels_test.append(int(row[3]))\n \n head = []\n for tkn in row[1].split():\n if tkn in tkn2idx_mincut5:\n head.append(tkn2idx_mincut5[tkn])\n else:\n head.append(1)\n heads_test.append(head)\n \n body = []\n for tkn in row[2].split():\n if tkn in tkn2idx_mincut5:\n body.append(tkn2idx_mincut5[tkn])\n else:\n body.append(1)\n bodys_test.append(body)\n \nprint n+1, 'Done'\nprint datetime.datetime.now().isoformat()",
"2017-12-30T10:46:47.369600\n10000 20000 30000 40000 50000 60000 70000 80000 90000 100000 100000 Done\n2017-12-30T10:47:11.911809\n"
],
[
"print datetime.datetime.now().isoformat()\n[np_heads_test, np_bodys_test] = fit_length([heads_test, bodys_test], 49, 1200)\nprint datetime.datetime.now().isoformat() # ~3 mins",
"2017-12-30T10:47:11.916242\n2017-12-30T10:47:19.225545\n"
],
[
"print datetime.datetime.now().isoformat()\nt_trainpath = 'nps/test_whole_head_mincut5'\nnp.save(t_trainpath, np_heads_test)\nb_trainpath = 'nps/test_whole_body_mincut5'\nnp.save(b_trainpath, np_bodys_test)\nl_trainpath = 'nps/test_whole_label_mincut5'\nnp.save(l_trainpath, labels_test)\nprint datetime.datetime.now().isoformat()",
"2017-12-30T10:47:19.237108\n2017-12-30T10:47:19.522220\n"
]
],
[
[
"# test stats.",
"_____no_output_____"
]
],
[
[
"csv_reader = csv.reader(open('version2/data_whole_test.csv', 'r'))\n\nlen_heads_test = [] #1\nlen_paras_test = [] #2\ncnt_paras_test = [] #3\nlen_bodys_test = [] #4\n\nlabels_test = []\nprint datetime.datetime.now().isoformat()\nfor n, row in enumerate(csv_reader):\n if (n+1) % 100000 == 0: print n+1,\n \n labels_test.append(int(row[3]))\n \n head = row[1]\n len_heads_test.append(len(head.split())) #1\n \n body = row[2]\n tkn_para = []\n for para in body.split('<EOP>'):\n if para and para != ' ':\n _para = para + '<EOP>'\n len_para = len(_para.split())\n len_paras_test.append(len_para) #2\n tkn_para.append(_para)\n cnt_paras_test.append(len(tkn_para)) #3\n \n body_split = body.split()\n len_bodys_test.append(len(body_split)) #4\n \nprint n+1, 'Done'\nprint datetime.datetime.now().isoformat()",
"2017-12-29T18:45:21.058702\n100000 100000 Done\n2017-12-29T18:45:31.269345\n"
],
[
"#1\nlen_titles = np.array(len_heads_test)\nprint len_titles.tolist().count(1)\nprint np.max(len_titles), np.min(len_titles), np.mean(len_titles), np.std(len_titles)\nlen_t = len(len_titles)\ncnt_t = sum(len_titles <= 49)\nprint cnt_t, len_t, cnt_t*1.0/len_t",
"0\n38 3 13.55746 3.13595573126\n100000 100000 1.0\n"
],
[
"#2\nlen_paras = np.array(len_paras_test)\nprint len_paras.tolist().count(1)\nprint np.max(len_paras), np.min(len_paras), np.mean(len_paras), np.std(len_paras)\nlen_p = len(len_paras)\ncnt_p = sum(len_paras <= 170)\nprint cnt_p, len_p, cnt_p*1.0/len_p",
"0\n4127 3 82.7307296744 121.078232278\n892558 968432 0.921652733491\n"
],
[
"#3\ncnt_para = np.array(cnt_paras_test)\nprint cnt_para.tolist().count(1)\nprint np.max(cnt_para), np.min(cnt_para), np.mean(cnt_para), np.std(cnt_para), np.median(cnt_para)\nlen_cp = len(cnt_para)\ncnt_cp = sum(cnt_para <= 20)\nprint cnt_cp, len_cp, cnt_cp*1.0/len_cp",
"7132\n104 1 9.68432 7.30949698253 9.0\n92534 100000 0.92534\n"
],
[
"#4\nlen_bodys = np.array(len_bodys_test)\nprint len_bodys.tolist().count(2)\nprint np.max(len_bodys), np.min(len_bodys), np.mean(len_bodys), np.std(len_bodys)\nlen_b = len(len_bodys)\ncnt_b = sum(len_bodys <= 1200)\nprint cnt_b, len_b, cnt_b*1.0/len_b",
"0\n5208 403 801.19086 313.270892795\n90124 100000 0.90124\n"
],
[
"plt.figure(1)\nplt.hist(len_paras, range=[0, 500], normed=False, bins=500)",
"_____no_output_____"
],
[
"tkn2df = {}\nfor tkn in tkn2tf.keys():\n tkn2df[tkn] = 0\n \ncsv_reader = csv.reader(open('final_final/data_whole_training.csv', 'r'))\n\nprint datetime.datetime.now().isoformat()\nfor n, row in enumerate(csv_reader):\n if (n+1) % 100000 == 0: print n+1,\n\n tmp_tkn = []\n head = row[1]\n body = row[2]\n doc = ' '.join([head, body])\n for tkn in doc.split():\n if tkn in tmp_tkn:\n continue\n else:\n tkn2df[tkn] += 1\n tmp_tkn.append(tkn)\n\nprint n, 'Done'\nprint datetime.datetime.now().isoformat()",
"2017-12-27T17:06:43.990426\n100000 200000 300000 400000 500000"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3d16b0f25fca77e43aa31e8cd20eb52e994a4e | 204,385 | ipynb | Jupyter Notebook | jupyter/analysis-automation/BasicExample.ipynb | haworthia/systemlink-server-examples | 05fa1fc0340263ffc997e41f46ddaecb132c62d9 | [
"MIT"
] | 7 | 2020-03-24T06:21:56.000Z | 2022-02-25T06:25:42.000Z | jupyter/analysis-automation/BasicExample.ipynb | haworthia/systemlink-server-examples | 05fa1fc0340263ffc997e41f46ddaecb132c62d9 | [
"MIT"
] | 9 | 2020-01-21T03:15:12.000Z | 2022-01-07T20:00:23.000Z | jupyter/analysis-automation/BasicExample.ipynb | haworthia/systemlink-server-examples | 05fa1fc0340263ffc997e41f46ddaecb132c62d9 | [
"MIT"
] | 10 | 2020-06-11T08:49:59.000Z | 2022-03-07T12:58:48.000Z | 460.326577 | 189,052 | 0.93613 | [
[
[
"<table>\n <tr>\n <td ><h1><strong>NI SystemLink Analysis Automation</strong></h1></td>\n </tr>\n</table>\n\nThis notebook is an example for how you can analyze your data with NI SystemLink Analysis Automation. It forms the core of the analysis procedure, which includes the notebook, the query, and the execution parameters (parallel or comparative). The [procedure is uploaded to Analysis Automation](https://www.ni.com/documentation/en/systemlink/latest/analysis/creating-anp-with-jupyter/). The output is a report in form of PDF documents or HTML pages. \n<br>\n<hr>\n\n## Prerequisites\nBefore you run this example, you need to [create a DataFinder search query](https://www.ni.com/documentation/en/systemlink/latest/datanavigation/finding-data-with-advanced-search/) in Data Navigation to find the example files (e.g. 'TR_M17_QT_42-1.tdms'). Save this query on the server.\n<hr>\n\n## Summary\n\nThis example exercises the SystemLink TDMReader API to access bulk data (see `data_api`) and/or descriptive data (see `metadata_api`). When the notebook executes, Analysis Automation provides data links which the API uses to access content.\n\nIt also shows how to select channels from two channel groups and display the data in two graphs.\n\nThe channel values from each channel group populate arrays, which you can use to further analyze and visualize your data.\n\nFurthermore, the example uses two procedure parameters that write a comment to the first graph and select a channel to display in the second graph (refer to __Plot Graph__ below).\n\n\n\n<hr>\n",
"_____no_output_____"
],
[
"## Imports\n\nThis example uses the `TDMReader` API to work with the bulk data and meta data of the given files. `Matplotlib` is used for plotting the graph. The `scrapbook` is used to set and display the results in the analysis procedure results list. \n",
"_____no_output_____"
]
],
[
[
"import systemlink.clients.nitdmreader as tdmreader\nmetadata_api = tdmreader.MetadataApi()\ndata_api = tdmreader.DataApi()\n\nimport matplotlib.pyplot as plt\n\nimport scrapbook as sb",
"_____no_output_____"
],
[
"def get_property(element, property_name):\n \"\"\"Gets a property of the given element.\n \n The element can be a file, channel group, or channel.\n \n Args:\n element: Element to get the property from.\n property_name: Name of the property to get.\n \n Returns:\n The according property of the element or ``None`` if the property doesn't exist.\n \"\"\"\n return next((e.value for e in element.properties.properties if e.name == property_name), None)\n",
"_____no_output_____"
]
],
[
[
"## Define Notebook Parameters\n\na) In a code cell (*called __parameters cell__*), define the parameters. Fill in the needed values/content parameters in the code cell below. E.g.\n\n **Defined parameters:**\n - `comment_group_1`: Writes a comment into the box of the first group.<br> \n (Default value = `Checked`)\n - `shown_channel_index`: Any valid channel index of the second group. This channel is plotted in the second graph. <br>\n (Default value = `2`)\n\nYour code may look like the following:",
"_____no_output_____"
]
],
[
[
"comment_group_1 = \"Checked\"\nshown_channel_index = 2",
"_____no_output_____"
]
],
[
[
"b) Select this code cell (*__parameters cell__*) and open on the __Property Inspector__ panel on the right sidebar to add the parameters, their default values, to the __Cell Metadata__ code block. For example, your code may look like the following:\n\n```json\n{\n \"papermill\": {\n \"parameters\": {\n \"comment_group_1\": \"Checked\",\n \"shown_channel_index\": 2\n }\n },\n \"tags\": [\n \"parameters\"\n ]\n}\n```\n\nYou can use the variables of the __parameters__ cell content in all code cells below.",
"_____no_output_____"
],
[
"## Retrieve Metadata with a Data Link\n\nA data link is the input for each __Analysis Automation procedure__ that uses a query to collect specific data items. A `data_link` contains a list of one or more elements that point to a list of files, channel groups, or channels (depending on the query result type).\n\nThis example shows how the Metadata API accesses the `file_info` structure from the file, through the `groups`, and down to the `channels` level.\n\nThis example calculates the absolute minimum and absolute maximum value of all channels in each group and displays these values in the report.",
"_____no_output_____"
]
],
[
[
"data_links = ni_analysis_automation[\"data_links\"]\nfile_ids = [d[\"fileId\"] for d in data_links]\nfile_infos = await metadata_api.get_multiple_file_info(tdmreader.FileList(file_ids))\nfile_info = file_infos[0]\n\ntest_file_name = get_property(file_info, \"name\")\nprogram_name = get_property(file_info, \"Test~Procedure\")\n\ngroup_names = []\nchannels = []\nformatted_properties = []\n\nfor group in file_info.groups:\n group_names.append(group.name)\n channels.append(group.channels)\n max_values_of_group = [] \n min_values_of_group = [] \n mean_values_of_group = [] \n\n for channel in group.channels:\n minimum = float(get_property(channel, \"minimum\") or \"NaN\")\n maximum = float(get_property(channel, \"maximum\") or \"NaN\")\n mean_values_of_group.append((minimum + maximum) / 2)\n max_values_of_group.append(maximum)\n min_values_of_group.append(minimum)\n\n \n # Calculate statistical values from metadata\n abs_min = max(max_values_of_group)\n abs_max = min(max_values_of_group)\n abs_mean = sum(mean_values_of_group) / float(len(mean_values_of_group))\n formatted_properties.append(f\"Absolute Maximum: {abs_max:.3f} °C\"+\n f\",Absolute Minimum: {abs_min:.3f} °C\"+\n f\",Mean Value: {abs_mean:.3f} °C\")\n\n# Populate the info box of the plot with the notebook parameters\nformatted_properties[1] += f\",Parameter: {comment_group_1}\"\nformatted_properties[0] += f\",Channel #: {shown_channel_index}\"",
"_____no_output_____"
]
],
[
[
"## Retrieve Bulk Data with a Data Link\n\nUse the TDMReader API to work with bulk data. There are multiple ways for retrieving the data. The access path used in this example shows you how to loop over all groups and over all channels within the groups. The resulting channel specifiers (`chn_specs`) are used in the next step to `query` the bulk data and retrieve all channel `values` from the queried data. ",
"_____no_output_____"
]
],
[
[
"bulk_data = []\nfile_id = data_links[0]['fileId']\n\nfor group in file_info.groups:\n chn_specs = []\n \n for channel in group.channels:\n channel_specifier = tdmreader.OneChannelSpecifier(\n file_id=file_id, \n group_name=group.name, \n channel_name=channel.name)\n chn_specs.append(channel_specifier)\n\n xy_chns = tdmreader.ChannelSpecificationsXyChannels(y_channels=chn_specs)\n channel_specs = tdmreader.ChannelSpecifications(xy_channels=[xy_chns])\n query = tdmreader.QueryDataSpecifier(channel_specs)\n data = await data_api.query_data(query)\n \n # get numeric y-data\n y_channels = data.data[0].y\n values = list(map(lambda c: c.numeric_data, y_channels))\n bulk_data.append(values)\n",
"_____no_output_____"
]
],
[
[
"## Plot Graph\n\nThe next two cells plot a graph with two areas and two sub plots, using the Python `matplotlib.pyplot` module as `plt`.\n",
"_____no_output_____"
]
],
[
[
"# Helper method and constant for plotting data \ncurr_fontsize = 18\naxis_lable_fontsize = curr_fontsize - 5\n\ndef plot_area(subplot, area_bulk_data, area_meta_data, enable_channel_selector, area_properties):\n \"\"\" Plot a sub print area of a figure \n :param subplot: Object of the plot print area \n :param area_bulk_data: Channel bulk data to print\n :param area_meta_data: Channel metadata (name, properties, ...)\n :param enable_channel_selector: True, when property shown_channel_index should be used\n :param area_properties: String with comma-separated parts as content for the info box area\n e.g.: \"Absolute Maximum: 12.6 °C,Absolute Minimum: -22.3 °C\"\n \"\"\"\n # Place a text box below the legend\n subplot.text(1.05, 0.0, area_properties.replace(\",\", \"\\n\"),\n transform=subplot.transAxes, ha=\"left\", va=\"bottom\")\n subplot.grid(True)\n subplot.set_xlabel('Time [s]', fontsize=axis_lable_fontsize)\n \n unit = get_property(area_meta_data[0], \"unit_string\")\n subplot.set_ylabel('Amplitudes ['+unit+']', fontsize=axis_lable_fontsize)\n i = 0\n for channel in area_meta_data:\n if (enable_channel_selector):\n if (i == (shown_channel_index - 1)):\n subplot.plot(area_bulk_data[i], label=channel.name) # Lable => name of the curve = channel \n else:\n subplot.plot(area_bulk_data[i], label=channel.name) # Lable => name of the curve = channel \n i += 1\n\n # Place a legend to the right of this subplot.\n subplot.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0., fontsize=axis_lable_fontsize)\n",
"_____no_output_____"
],
[
"# Create plot and print data \nfig, (ax1, ax2) = plt.subplots(nrows=2, ncols=1, figsize=(15, 10))\nfig.suptitle ('Temperature Monitoring File: '+ test_file_name + ' Test program: ' + program_name, fontsize=curr_fontsize, color='blue')\n\nax1.set_title(group_names[1], fontsize=curr_fontsize)\nplot_area(ax1, bulk_data[1], channels[1], False, formatted_properties[1])\nax2.set_title(group_names[0], fontsize=curr_fontsize)\nplot_area(ax2, bulk_data[0], channels[0], True, formatted_properties[0])\n\nplt.tight_layout()\nplt.show()",
"_____no_output_____"
]
],
[
[
"## Add Result Summary\n\nEach Scrap recorded with `sb.glue()` is displayed for each procedure on the __History__ tab in Analysis Automation. ",
"_____no_output_____"
]
],
[
[
"sb.glue(\"File\", test_file_name)\nsb.glue(\"Test\", program_name)\nsb.glue(\"Comment\", comment_group_1)\nsb.glue(\"Displayed Channel #\", shown_channel_index)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
cb3d2a9e3e6ca3396d74cb1807f5957b05961a4b | 327,787 | ipynb | Jupyter Notebook | Others/Copia_de_Yolo_Step_by_Step.ipynb | Serbeld/Design-of-applications-through-the-use-of-artificial-vision-for-quality-control-in-the-Industrial-se | 1bd089c898a13601fd8a8a038ff4aa2eb1181e98 | [
"MIT"
] | 2 | 2020-02-05T22:11:38.000Z | 2020-02-06T17:14:46.000Z | Others/Copia_de_Yolo_Step_by_Step.ipynb | Serbeld/Design-of-applications-through-the-use-of-artificial-vision-for-quality-control-in-the-Industrial-se | 1bd089c898a13601fd8a8a038ff4aa2eb1181e98 | [
"MIT"
] | null | null | null | Others/Copia_de_Yolo_Step_by_Step.ipynb | Serbeld/Design-of-applications-through-the-use-of-artificial-vision-for-quality-control-in-the-Industrial-se | 1bd089c898a13601fd8a8a038ff4aa2eb1181e98 | [
"MIT"
] | null | null | null | 214.942295 | 117,764 | 0.85965 | [
[
[
"<a href=\"https://colab.research.google.com/github/Serbeld/ArtificialVisionForQualityControl/blob/master/Copia_de_Yolo_Step_by_Step.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"**Outline of Steps**\n + Initialization\n + Download COCO detection data from http://cocodataset.org/#download\n + http://images.cocodataset.org/zips/train2014.zip <= train images\n + http://images.cocodataset.org/zips/val2014.zip <= validation images\n + http://images.cocodataset.org/annotations/annotations_trainval2014.zip <= train and validation annotations\n + Run this script to convert annotations in COCO format to VOC format\n + https://gist.github.com/chicham/6ed3842d0d2014987186#file-coco2pascal-py\n + Download pre-trained weights from https://pjreddie.com/darknet/yolo/\n + https://pjreddie.com/media/files/yolo.weights\n + Specify the directory of train annotations (train_annot_folder) and train images (train_image_folder)\n + Specify the directory of validation annotations (valid_annot_folder) and validation images (valid_image_folder)\n + Specity the path of pre-trained weights by setting variable *wt_path*\n + Construct equivalent network in Keras\n + Network arch from https://github.com/pjreddie/darknet/blob/master/cfg/yolo-voc.cfg\n + Load the pretrained weights\n + Perform training \n + Perform detection on an image with newly trained weights\n + Perform detection on an video with newly trained weights",
"_____no_output_____"
],
[
"# Initialization",
"_____no_output_____"
]
],
[
[
"!pip install h5py\nimport h5py\n\nfrom google.colab import drive,files\ndrive.mount('/content/drive')\n\nimport sys\nsys.path.append('/content/drive/My Drive/keras-yolo2/')",
"Requirement already satisfied: h5py in /usr/local/lib/python2.7/dist-packages (2.8.0)\nRequirement already satisfied: numpy>=1.7 in /usr/local/lib/python2.7/dist-packages (from h5py) (1.16.4)\nRequirement already satisfied: six in /usr/local/lib/python2.7/dist-packages (from h5py) (1.12.0)\nDrive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount(\"/content/drive\", force_remount=True).\n"
],
[
"!pip install tensorflow-gpu==2.0.0-alpha0",
"Requirement already satisfied: tensorflow-gpu==2.0.0-alpha0 in /usr/local/lib/python2.7/dist-packages (2.0.0a0)\nRequirement already satisfied: grpcio>=1.8.6 in /usr/local/lib/python2.7/dist-packages (from tensorflow-gpu==2.0.0-alpha0) (1.15.0)\nRequirement already satisfied: mock>=2.0.0 in /usr/local/lib/python2.7/dist-packages (from tensorflow-gpu==2.0.0-alpha0) (2.0.0)\nRequirement already satisfied: keras-applications>=1.0.6 in /usr/local/lib/python2.7/dist-packages (from tensorflow-gpu==2.0.0-alpha0) (1.0.8)\nRequirement already satisfied: backports.weakref>=1.0rc1 in /usr/local/lib/python2.7/dist-packages (from tensorflow-gpu==2.0.0-alpha0) (1.0.post1)\nRequirement already satisfied: google-pasta>=0.1.2 in /usr/local/lib/python2.7/dist-packages (from tensorflow-gpu==2.0.0-alpha0) (0.1.7)\nRequirement already satisfied: enum34>=1.1.6 in /usr/local/lib/python2.7/dist-packages (from tensorflow-gpu==2.0.0-alpha0) (1.1.6)\nRequirement already satisfied: protobuf>=3.6.1 in /usr/local/lib/python2.7/dist-packages (from tensorflow-gpu==2.0.0-alpha0) (3.7.1)\nRequirement already satisfied: keras-preprocessing>=1.0.5 in /usr/local/lib/python2.7/dist-packages (from tensorflow-gpu==2.0.0-alpha0) (1.1.0)\nRequirement already satisfied: gast>=0.2.0 in /usr/local/lib/python2.7/dist-packages (from tensorflow-gpu==2.0.0-alpha0) (0.2.2)\nRequirement already satisfied: tb-nightly<1.14.0a20190302,>=1.14.0a20190301 in /usr/local/lib/python2.7/dist-packages (from tensorflow-gpu==2.0.0-alpha0) (1.14.0a20190301)\nRequirement already satisfied: numpy<2.0,>=1.14.5 in /usr/local/lib/python2.7/dist-packages (from tensorflow-gpu==2.0.0-alpha0) (1.16.4)\nRequirement already satisfied: six>=1.10.0 in /usr/local/lib/python2.7/dist-packages (from tensorflow-gpu==2.0.0-alpha0) (1.12.0)\nRequirement already satisfied: absl-py>=0.7.0 in /usr/local/lib/python2.7/dist-packages (from tensorflow-gpu==2.0.0-alpha0) (0.7.1)\nRequirement already satisfied: wheel in /usr/local/lib/python2.7/dist-packages (from tensorflow-gpu==2.0.0-alpha0) (0.34.2)\nRequirement already satisfied: termcolor>=1.1.0 in /usr/local/lib/python2.7/dist-packages (from tensorflow-gpu==2.0.0-alpha0) (1.1.0)\nRequirement already satisfied: tf-estimator-nightly<1.14.0.dev2019030116,>=1.14.0.dev2019030115 in /usr/local/lib/python2.7/dist-packages (from tensorflow-gpu==2.0.0-alpha0) (1.14.0.dev2019030115)\nRequirement already satisfied: astor>=0.6.0 in /usr/local/lib/python2.7/dist-packages (from tensorflow-gpu==2.0.0-alpha0) (0.8.0)\nRequirement already satisfied: futures>=2.2.0 in /usr/local/lib/python2.7/dist-packages (from grpcio>=1.8.6->tensorflow-gpu==2.0.0-alpha0) (3.2.0)\nRequirement already satisfied: funcsigs>=1; python_version < \"3.3\" in /usr/local/lib/python2.7/dist-packages (from mock>=2.0.0->tensorflow-gpu==2.0.0-alpha0) (1.0.2)\nRequirement already satisfied: pbr>=0.11 in /usr/local/lib/python2.7/dist-packages (from mock>=2.0.0->tensorflow-gpu==2.0.0-alpha0) (5.4.0)\nRequirement already satisfied: h5py in /usr/local/lib/python2.7/dist-packages (from keras-applications>=1.0.6->tensorflow-gpu==2.0.0-alpha0) (2.8.0)\nRequirement already satisfied: setuptools in /usr/local/lib/python2.7/dist-packages (from protobuf>=3.6.1->tensorflow-gpu==2.0.0-alpha0) (44.0.0)\nRequirement already satisfied: werkzeug>=0.11.15 in /usr/local/lib/python2.7/dist-packages (from tb-nightly<1.14.0a20190302,>=1.14.0a20190301->tensorflow-gpu==2.0.0-alpha0) (0.15.5)\nRequirement already satisfied: markdown>=2.6.8 in /usr/local/lib/python2.7/dist-packages (from tb-nightly<1.14.0a20190302,>=1.14.0a20190301->tensorflow-gpu==2.0.0-alpha0) (3.1.1)\n"
],
[
"from keras.models import Sequential, Model\nfrom keras.layers import Reshape, Activation, Conv2D, Input, MaxPooling2D, BatchNormalization, Flatten, Dense, Lambda\nfrom keras.layers.advanced_activations import LeakyReLU\nfrom keras.callbacks import EarlyStopping, ModelCheckpoint, TensorBoard\nfrom keras.optimizers import SGD, Adam, RMSprop\nfrom keras.layers.merge import concatenate\nimport matplotlib.pyplot as plt\nimport keras.backend as K\nimport tensorflow as tf\nimport imgaug as ia\nfrom tqdm import tqdm\nfrom imgaug import augmenters as iaa\nimport numpy as np\nimport pickle\nimport os, cv2\nfrom preprocessing import parse_annotation, BatchGenerator\nfrom utils import WeightReader, decode_netout, draw_boxes\n\nos.environ[\"CUDA_DEVICE_ORDER\"] = \"PCI_BUS_ID\"\nos.environ[\"CUDA_VISIBLE_DEVICES\"] = \"\"",
"_____no_output_____"
],
[
"LABELS = ['COLOR HDPE', 'PET', 'WHITE HDPE']\n\nIMAGE_H, IMAGE_W = 416, 416\nGRID_H, GRID_W = 13 , 13\nBOX = 5\nCLASS = len(LABELS)\nCLASS_WEIGHTS = np.ones(CLASS, dtype='float32')\nOBJ_THRESHOLD = 0.2#0.5\nNMS_THRESHOLD = 0.2#0.45\nANCHORS = [0.96,4.22, 1.52,4.79, 2.30,4.30, 2.76,2.35, 3.62,6.03]\n\nNO_OBJECT_SCALE = 1.0\nOBJECT_SCALE = 5.0\nCOORD_SCALE = 1.0\nCLASS_SCALE = 1.0\n\nBATCH_SIZE = 16\nWARM_UP_BATCHES = 0\nTRUE_BOX_BUFFER = 50",
"_____no_output_____"
],
[
"wt_path = '/content/drive/My Drive/keras-yolo2/yolov2.weights' \ntrain_image_folder = '/content/drive/My Drive/dataset/images/'\ntrain_annot_folder = '/content/drive/My Drive/dataset/annotations/'\nvalid_image_folder = '/content/drive/My Drive/dataset/images_val/'\nvalid_annot_folder = '/content/drive/My Drive/dataset/annotattionsVAL/'",
"_____no_output_____"
],
[
"#import os\n#print(os.listdir('/content/drive/My Drive/dataset/images'))",
"_____no_output_____"
],
[
"train_imgs, seen_train_labels = parse_annotation(train_annot_folder, train_image_folder, labels=LABELS)\nval_imgs, seen_val_labels = parse_annotation(valid_annot_folder, valid_image_folder, labels=LABELS)\n\ntrain_batch = BatchGenerator(train_imgs, generator_config, norm=normalize)\nvalid_batch = BatchGenerator(val_imgs, generator_config, norm=normalize)\n",
"_____no_output_____"
]
],
[
[
"**Sanity check: show a few images with ground truth boxes overlaid**\n\n\n",
"_____no_output_____"
]
],
[
[
"batches = BatchGenerator(train_imgs, generator_config)\n\nimage = batches[0][0][0][0]\nimage = cv2.resize(image,(680,340))\nplt.imshow(image.astype('uint8'))",
"_____no_output_____"
]
],
[
[
"# Construct the network",
"_____no_output_____"
]
],
[
[
"# the function to implement the orgnization layer (thanks to github.com/allanzelener/YAD2K)\ndef space_to_depth_x2(x):\n return tf.space_to_depth(x, block_size=2)",
"_____no_output_____"
],
[
"input_image = Input(shape=(IMAGE_H, IMAGE_W, 3))\ntrue_boxes = Input(shape=(1, 1, 1, TRUE_BOX_BUFFER , 4))\n\n# Layer 1\nx = Conv2D(32, (3,3), strides=(1,1), padding='same', name='conv_1', use_bias=False)(input_image)\nx = BatchNormalization(name='norm_1')(x)\nx = LeakyReLU(alpha=0.1)(x)\nx = MaxPooling2D(pool_size=(2, 2))(x)\n\n# Layer 2\nx = Conv2D(64, (3,3), strides=(1,1), padding='same', name='conv_2', use_bias=False)(x)\nx = BatchNormalization(name='norm_2')(x)\nx = LeakyReLU(alpha=0.1)(x)\nx = MaxPooling2D(pool_size=(2, 2))(x)\n\n# Layer 3\nx = Conv2D(128, (3,3), strides=(1,1), padding='same', name='conv_3', use_bias=False)(x)\nx = BatchNormalization(name='norm_3')(x)\nx = LeakyReLU(alpha=0.1)(x)\n\n# Layer 4\nx = Conv2D(64, (1,1), strides=(1,1), padding='same', name='conv_4', use_bias=False)(x)\nx = BatchNormalization(name='norm_4')(x)\nx = LeakyReLU(alpha=0.1)(x)\n\n# Layer 5\nx = Conv2D(128, (3,3), strides=(1,1), padding='same', name='conv_5', use_bias=False)(x)\nx = BatchNormalization(name='norm_5')(x)\nx = LeakyReLU(alpha=0.1)(x)\nx = MaxPooling2D(pool_size=(2, 2))(x)\n\n# Layer 6\nx = Conv2D(256, (3,3), strides=(1,1), padding='same', name='conv_6', use_bias=False)(x)\nx = BatchNormalization(name='norm_6')(x)\nx = LeakyReLU(alpha=0.1)(x)\n\n# Layer 7\nx = Conv2D(128, (1,1), strides=(1,1), padding='same', name='conv_7', use_bias=False)(x)\nx = BatchNormalization(name='norm_7')(x)\nx = LeakyReLU(alpha=0.1)(x)\n\n# Layer 8\nx = Conv2D(256, (3,3), strides=(1,1), padding='same', name='conv_8', use_bias=False)(x)\nx = BatchNormalization(name='norm_8')(x)\nx = LeakyReLU(alpha=0.1)(x)\nx = MaxPooling2D(pool_size=(2, 2))(x)\n\n# Layer 9\nx = Conv2D(512, (3,3), strides=(1,1), padding='same', name='conv_9', use_bias=False)(x)\nx = BatchNormalization(name='norm_9')(x)\nx = LeakyReLU(alpha=0.1)(x)\n\n# Layer 10\nx = Conv2D(256, (1,1), strides=(1,1), padding='same', name='conv_10', use_bias=False)(x)\nx = BatchNormalization(name='norm_10')(x)\nx = LeakyReLU(alpha=0.1)(x)\n\n# Layer 11\nx = Conv2D(512, (3,3), strides=(1,1), padding='same', name='conv_11', use_bias=False)(x)\nx = BatchNormalization(name='norm_11')(x)\nx = LeakyReLU(alpha=0.1)(x)\n\n# Layer 12\nx = Conv2D(256, (1,1), strides=(1,1), padding='same', name='conv_12', use_bias=False)(x)\nx = BatchNormalization(name='norm_12')(x)\nx = LeakyReLU(alpha=0.1)(x)\n\n# Layer 13\nx = Conv2D(512, (3,3), strides=(1,1), padding='same', name='conv_13', use_bias=False)(x)\nx = BatchNormalization(name='norm_13')(x)\nx = LeakyReLU(alpha=0.1)(x)\n\nskip_connection = x\n\nx = MaxPooling2D(pool_size=(2, 2))(x)\n\n# Layer 14\nx = Conv2D(1024, (3,3), strides=(1,1), padding='same', name='conv_14', use_bias=False)(x)\nx = BatchNormalization(name='norm_14')(x)\nx = LeakyReLU(alpha=0.1)(x)\n\n# Layer 15\nx = Conv2D(512, (1,1), strides=(1,1), padding='same', name='conv_15', use_bias=False)(x)\nx = BatchNormalization(name='norm_15')(x)\nx = LeakyReLU(alpha=0.1)(x)\n\n# Layer 16\nx = Conv2D(1024, (3,3), strides=(1,1), padding='same', name='conv_16', use_bias=False)(x)\nx = BatchNormalization(name='norm_16')(x)\nx = LeakyReLU(alpha=0.1)(x)\n\n# Layer 17\nx = Conv2D(512, (1,1), strides=(1,1), padding='same', name='conv_17', use_bias=False)(x)\nx = BatchNormalization(name='norm_17')(x)\nx = LeakyReLU(alpha=0.1)(x)\n\n# Layer 18\nx = Conv2D(1024, (3,3), strides=(1,1), padding='same', name='conv_18', use_bias=False)(x)\nx = BatchNormalization(name='norm_18')(x)\nx = LeakyReLU(alpha=0.1)(x)\n\n# Layer 19\nx = Conv2D(1024, (3,3), strides=(1,1), padding='same', name='conv_19', use_bias=False)(x)\nx = BatchNormalization(name='norm_19')(x)\nx = LeakyReLU(alpha=0.1)(x)\n\n# Layer 20\nx = Conv2D(1024, (3,3), strides=(1,1), padding='same', name='conv_20', use_bias=False)(x)\nx = BatchNormalization(name='norm_20')(x)\nx = LeakyReLU(alpha=0.1)(x)\n\n# Layer 21\nskip_connection = Conv2D(64, (1,1), strides=(1,1), padding='same', name='conv_21', use_bias=False)(skip_connection)\nskip_connection = BatchNormalization(name='norm_21')(skip_connection)\nskip_connection = LeakyReLU(alpha=0.1)(skip_connection)\nskip_connection = Lambda(space_to_depth_x2)(skip_connection)\n\nx = concatenate([skip_connection, x])\n\n# Layer 22\nx = Conv2D(1024, (3,3), strides=(1,1), padding='same', name='conv_22', use_bias=False)(x)\nx = BatchNormalization(name='norm_22')(x)\nx = LeakyReLU(alpha=0.1)(x)\n\n# Layer 23\nx = Conv2D(BOX * (4 + 1 + CLASS), (1,1), strides=(1,1), padding='same', name='conv_23')(x)\noutput = Reshape((GRID_H, GRID_W, BOX, 4 + 1 + CLASS))(x)\n\n# small hack to allow true_boxes to be registered when Keras build the model \n# for more information: https://github.com/fchollet/keras/issues/2790\noutput = Lambda(lambda args: args[0])([output, true_boxes])\n\nmodel = Model([input_image, true_boxes], output)",
"_____no_output_____"
],
[
"model.summary()",
"__________________________________________________________________________________________________\nLayer (type) Output Shape Param # Connected to \n==================================================================================================\ninput_5 (InputLayer) (None, 416, 416, 3) 0 \n__________________________________________________________________________________________________\nconv_1 (Conv2D) (None, 416, 416, 32) 864 input_5[0][0] \n__________________________________________________________________________________________________\nnorm_1 (BatchNormalization) (None, 416, 416, 32) 128 conv_1[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_45 (LeakyReLU) (None, 416, 416, 32) 0 norm_1[0][0] \n__________________________________________________________________________________________________\nmax_pooling2d_11 (MaxPooling2D) (None, 208, 208, 32) 0 leaky_re_lu_45[0][0] \n__________________________________________________________________________________________________\nconv_2 (Conv2D) (None, 208, 208, 64) 18432 max_pooling2d_11[0][0] \n__________________________________________________________________________________________________\nnorm_2 (BatchNormalization) (None, 208, 208, 64) 256 conv_2[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_46 (LeakyReLU) (None, 208, 208, 64) 0 norm_2[0][0] \n__________________________________________________________________________________________________\nmax_pooling2d_12 (MaxPooling2D) (None, 104, 104, 64) 0 leaky_re_lu_46[0][0] \n__________________________________________________________________________________________________\nconv_3 (Conv2D) (None, 104, 104, 128 73728 max_pooling2d_12[0][0] \n__________________________________________________________________________________________________\nnorm_3 (BatchNormalization) (None, 104, 104, 128 512 conv_3[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_47 (LeakyReLU) (None, 104, 104, 128 0 norm_3[0][0] \n__________________________________________________________________________________________________\nconv_4 (Conv2D) (None, 104, 104, 64) 8192 leaky_re_lu_47[0][0] \n__________________________________________________________________________________________________\nnorm_4 (BatchNormalization) (None, 104, 104, 64) 256 conv_4[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_48 (LeakyReLU) (None, 104, 104, 64) 0 norm_4[0][0] \n__________________________________________________________________________________________________\nconv_5 (Conv2D) (None, 104, 104, 128 73728 leaky_re_lu_48[0][0] \n__________________________________________________________________________________________________\nnorm_5 (BatchNormalization) (None, 104, 104, 128 512 conv_5[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_49 (LeakyReLU) (None, 104, 104, 128 0 norm_5[0][0] \n__________________________________________________________________________________________________\nmax_pooling2d_13 (MaxPooling2D) (None, 52, 52, 128) 0 leaky_re_lu_49[0][0] \n__________________________________________________________________________________________________\nconv_6 (Conv2D) (None, 52, 52, 256) 294912 max_pooling2d_13[0][0] \n__________________________________________________________________________________________________\nnorm_6 (BatchNormalization) (None, 52, 52, 256) 1024 conv_6[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_50 (LeakyReLU) (None, 52, 52, 256) 0 norm_6[0][0] \n__________________________________________________________________________________________________\nconv_7 (Conv2D) (None, 52, 52, 128) 32768 leaky_re_lu_50[0][0] \n__________________________________________________________________________________________________\nnorm_7 (BatchNormalization) (None, 52, 52, 128) 512 conv_7[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_51 (LeakyReLU) (None, 52, 52, 128) 0 norm_7[0][0] \n__________________________________________________________________________________________________\nconv_8 (Conv2D) (None, 52, 52, 256) 294912 leaky_re_lu_51[0][0] \n__________________________________________________________________________________________________\nnorm_8 (BatchNormalization) (None, 52, 52, 256) 1024 conv_8[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_52 (LeakyReLU) (None, 52, 52, 256) 0 norm_8[0][0] \n__________________________________________________________________________________________________\nmax_pooling2d_14 (MaxPooling2D) (None, 26, 26, 256) 0 leaky_re_lu_52[0][0] \n__________________________________________________________________________________________________\nconv_9 (Conv2D) (None, 26, 26, 512) 1179648 max_pooling2d_14[0][0] \n__________________________________________________________________________________________________\nnorm_9 (BatchNormalization) (None, 26, 26, 512) 2048 conv_9[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_53 (LeakyReLU) (None, 26, 26, 512) 0 norm_9[0][0] \n__________________________________________________________________________________________________\nconv_10 (Conv2D) (None, 26, 26, 256) 131072 leaky_re_lu_53[0][0] \n__________________________________________________________________________________________________\nnorm_10 (BatchNormalization) (None, 26, 26, 256) 1024 conv_10[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_54 (LeakyReLU) (None, 26, 26, 256) 0 norm_10[0][0] \n__________________________________________________________________________________________________\nconv_11 (Conv2D) (None, 26, 26, 512) 1179648 leaky_re_lu_54[0][0] \n__________________________________________________________________________________________________\nnorm_11 (BatchNormalization) (None, 26, 26, 512) 2048 conv_11[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_55 (LeakyReLU) (None, 26, 26, 512) 0 norm_11[0][0] \n__________________________________________________________________________________________________\nconv_12 (Conv2D) (None, 26, 26, 256) 131072 leaky_re_lu_55[0][0] \n__________________________________________________________________________________________________\nnorm_12 (BatchNormalization) (None, 26, 26, 256) 1024 conv_12[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_56 (LeakyReLU) (None, 26, 26, 256) 0 norm_12[0][0] \n__________________________________________________________________________________________________\nconv_13 (Conv2D) (None, 26, 26, 512) 1179648 leaky_re_lu_56[0][0] \n__________________________________________________________________________________________________\nnorm_13 (BatchNormalization) (None, 26, 26, 512) 2048 conv_13[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_57 (LeakyReLU) (None, 26, 26, 512) 0 norm_13[0][0] \n__________________________________________________________________________________________________\nmax_pooling2d_15 (MaxPooling2D) (None, 13, 13, 512) 0 leaky_re_lu_57[0][0] \n__________________________________________________________________________________________________\nconv_14 (Conv2D) (None, 13, 13, 1024) 4718592 max_pooling2d_15[0][0] \n__________________________________________________________________________________________________\nnorm_14 (BatchNormalization) (None, 13, 13, 1024) 4096 conv_14[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_58 (LeakyReLU) (None, 13, 13, 1024) 0 norm_14[0][0] \n__________________________________________________________________________________________________\nconv_15 (Conv2D) (None, 13, 13, 512) 524288 leaky_re_lu_58[0][0] \n__________________________________________________________________________________________________\nnorm_15 (BatchNormalization) (None, 13, 13, 512) 2048 conv_15[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_59 (LeakyReLU) (None, 13, 13, 512) 0 norm_15[0][0] \n__________________________________________________________________________________________________\nconv_16 (Conv2D) (None, 13, 13, 1024) 4718592 leaky_re_lu_59[0][0] \n__________________________________________________________________________________________________\nnorm_16 (BatchNormalization) (None, 13, 13, 1024) 4096 conv_16[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_60 (LeakyReLU) (None, 13, 13, 1024) 0 norm_16[0][0] \n__________________________________________________________________________________________________\nconv_17 (Conv2D) (None, 13, 13, 512) 524288 leaky_re_lu_60[0][0] \n__________________________________________________________________________________________________\nnorm_17 (BatchNormalization) (None, 13, 13, 512) 2048 conv_17[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_61 (LeakyReLU) (None, 13, 13, 512) 0 norm_17[0][0] \n__________________________________________________________________________________________________\nconv_18 (Conv2D) (None, 13, 13, 1024) 4718592 leaky_re_lu_61[0][0] \n__________________________________________________________________________________________________\nnorm_18 (BatchNormalization) (None, 13, 13, 1024) 4096 conv_18[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_62 (LeakyReLU) (None, 13, 13, 1024) 0 norm_18[0][0] \n__________________________________________________________________________________________________\nconv_19 (Conv2D) (None, 13, 13, 1024) 9437184 leaky_re_lu_62[0][0] \n__________________________________________________________________________________________________\nnorm_19 (BatchNormalization) (None, 13, 13, 1024) 4096 conv_19[0][0] \n__________________________________________________________________________________________________\nconv_21 (Conv2D) (None, 26, 26, 64) 32768 leaky_re_lu_57[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_63 (LeakyReLU) (None, 13, 13, 1024) 0 norm_19[0][0] \n__________________________________________________________________________________________________\nnorm_21 (BatchNormalization) (None, 26, 26, 64) 256 conv_21[0][0] \n__________________________________________________________________________________________________\nconv_20 (Conv2D) (None, 13, 13, 1024) 9437184 leaky_re_lu_63[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_65 (LeakyReLU) (None, 26, 26, 64) 0 norm_21[0][0] \n__________________________________________________________________________________________________\nnorm_20 (BatchNormalization) (None, 13, 13, 1024) 4096 conv_20[0][0] \n__________________________________________________________________________________________________\nlambda_5 (Lambda) (None, 13, 13, 256) 0 leaky_re_lu_65[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_64 (LeakyReLU) (None, 13, 13, 1024) 0 norm_20[0][0] \n__________________________________________________________________________________________________\nconcatenate_3 (Concatenate) (None, 13, 13, 1280) 0 lambda_5[0][0] \n leaky_re_lu_64[0][0] \n__________________________________________________________________________________________________\nconv_22 (Conv2D) (None, 13, 13, 1024) 11796480 concatenate_3[0][0] \n__________________________________________________________________________________________________\nnorm_22 (BatchNormalization) (None, 13, 13, 1024) 4096 conv_22[0][0] \n__________________________________________________________________________________________________\nleaky_re_lu_66 (LeakyReLU) (None, 13, 13, 1024) 0 norm_22[0][0] \n__________________________________________________________________________________________________\nconv_23 (Conv2D) (None, 13, 13, 40) 41000 leaky_re_lu_66[0][0] \n__________________________________________________________________________________________________\nreshape_3 (Reshape) (None, 13, 13, 5, 8) 0 conv_23[0][0] \n__________________________________________________________________________________________________\ninput_6 (InputLayer) (None, 1, 1, 1, 50, 0 \n__________________________________________________________________________________________________\nlambda_6 (Lambda) (None, 13, 13, 5, 8) 0 reshape_3[0][0] \n input_6[0][0] \n==================================================================================================\nTotal params: 50,588,936\nTrainable params: 50,568,264\nNon-trainable params: 20,672\n__________________________________________________________________________________________________\n"
]
],
[
[
"# Load pretrained weights",
"_____no_output_____"
],
[
"**Load the weights originally provided by YOLO**",
"_____no_output_____"
]
],
[
[
"weight_reader = WeightReader(wt_path)",
"_____no_output_____"
],
[
"weight_reader.reset()\nnb_conv = 23\n\nfor i in range(1, nb_conv+1):\n conv_layer = model.get_layer('conv_' + str(i))\n \n if i < nb_conv:\n norm_layer = model.get_layer('norm_' + str(i))\n \n size = np.prod(norm_layer.get_weights()[0].shape)\n\n beta = weight_reader.read_bytes(size)\n gamma = weight_reader.read_bytes(size)\n mean = weight_reader.read_bytes(size)\n var = weight_reader.read_bytes(size)\n\n weights = norm_layer.set_weights([gamma, beta, mean, var]) \n \n if len(conv_layer.get_weights()) > 1:\n bias = weight_reader.read_bytes(np.prod(conv_layer.get_weights()[1].shape))\n kernel = weight_reader.read_bytes(np.prod(conv_layer.get_weights()[0].shape))\n kernel = kernel.reshape(list(reversed(conv_layer.get_weights()[0].shape)))\n kernel = kernel.transpose([2,3,1,0])\n conv_layer.set_weights([kernel, bias])\n else:\n kernel = weight_reader.read_bytes(np.prod(conv_layer.get_weights()[0].shape))\n kernel = kernel.reshape(list(reversed(conv_layer.get_weights()[0].shape)))\n kernel = kernel.transpose([2,3,1,0])\n conv_layer.set_weights([kernel])",
"_____no_output_____"
]
],
[
[
"**Randomize weights of the last layer**",
"_____no_output_____"
]
],
[
[
"layer = model.layers[-4] # the last convolutional layer\nweights = layer.get_weights()\n\nnew_kernel = np.random.normal(size=weights[0].shape)/(GRID_H*GRID_W)\nnew_bias = np.random.normal(size=weights[1].shape)/(GRID_H*GRID_W)\n\nlayer.set_weights([new_kernel, new_bias])",
"_____no_output_____"
]
],
[
[
"# Perform training",
"_____no_output_____"
],
[
"**Loss function**",
"_____no_output_____"
],
[
"$$\\begin{multline}\n\\lambda_\\textbf{coord}\n\\sum_{i = 0}^{S^2}\n \\sum_{j = 0}^{B}\n L_{ij}^{\\text{obj}}\n \\left[\n \\left(\n x_i - \\hat{x}_i\n \\right)^2 +\n \\left(\n y_i - \\hat{y}_i\n \\right)^2\n \\right]\n\\\\\n+ \\lambda_\\textbf{coord} \n\\sum_{i = 0}^{S^2}\n \\sum_{j = 0}^{B}\n L_{ij}^{\\text{obj}}\n \\left[\n \\left(\n \\sqrt{w_i} - \\sqrt{\\hat{w}_i}\n \\right)^2 +\n \\left(\n \\sqrt{h_i} - \\sqrt{\\hat{h}_i}\n \\right)^2\n \\right]\n\\\\\n+ \\sum_{i = 0}^{S^2}\n \\sum_{j = 0}^{B}\n L_{ij}^{\\text{obj}}\n \\left(\n C_i - \\hat{C}_i\n \\right)^2\n\\\\\n+ \\lambda_\\textrm{noobj}\n\\sum_{i = 0}^{S^2}\n \\sum_{j = 0}^{B}\n L_{ij}^{\\text{noobj}}\n \\left(\n C_i - \\hat{C}_i\n \\right)^2\n\\\\\n+ \\sum_{i = 0}^{S^2}\nL_i^{\\text{obj}}\n \\sum_{c \\in \\textrm{classes}}\n \\left(\n p_i(c) - \\hat{p}_i(c)\n \\right)^2\n\\end{multline}$$",
"_____no_output_____"
]
],
[
[
"def custom_loss(y_true, y_pred):\n mask_shape = tf.shape(y_true)[:4]\n \n cell_x = tf.to_float(tf.reshape(tf.tile(tf.range(GRID_W), [GRID_H]), (1, GRID_H, GRID_W, 1, 1)))\n cell_y = tf.transpose(cell_x, (0,2,1,3,4))\n\n cell_grid = tf.tile(tf.concat([cell_x,cell_y], -1), [BATCH_SIZE, 1, 1, 5, 1])\n \n coord_mask = tf.zeros(mask_shape)\n conf_mask = tf.zeros(mask_shape)\n class_mask = tf.zeros(mask_shape)\n \n seen = tf.Variable(0.)\n total_recall = tf.Variable(0.)\n \n \"\"\"\n Adjust prediction\n \"\"\"\n ### adjust x and y \n pred_box_xy = tf.sigmoid(y_pred[..., :2]) + cell_grid\n \n ### adjust w and h\n pred_box_wh = tf.exp(y_pred[..., 2:4]) * np.reshape(ANCHORS, [1,1,1,BOX,2])\n \n ### adjust confidence\n pred_box_conf = tf.sigmoid(y_pred[..., 4])\n \n ### adjust class probabilities\n pred_box_class = y_pred[..., 5:]\n \n \"\"\"\n Adjust ground truth\n \"\"\"\n ### adjust x and y\n true_box_xy = y_true[..., 0:2] # relative position to the containing cell\n \n ### adjust w and h\n true_box_wh = y_true[..., 2:4] # number of cells accross, horizontally and vertically\n \n ### adjust confidence\n true_wh_half = true_box_wh / 2.\n true_mins = true_box_xy - true_wh_half\n true_maxes = true_box_xy + true_wh_half\n \n pred_wh_half = pred_box_wh / 2.\n pred_mins = pred_box_xy - pred_wh_half\n pred_maxes = pred_box_xy + pred_wh_half \n \n intersect_mins = tf.maximum(pred_mins, true_mins)\n intersect_maxes = tf.minimum(pred_maxes, true_maxes)\n intersect_wh = tf.maximum(intersect_maxes - intersect_mins, 0.)\n intersect_areas = intersect_wh[..., 0] * intersect_wh[..., 1]\n \n true_areas = true_box_wh[..., 0] * true_box_wh[..., 1]\n pred_areas = pred_box_wh[..., 0] * pred_box_wh[..., 1]\n\n union_areas = pred_areas + true_areas - intersect_areas\n iou_scores = tf.truediv(intersect_areas, union_areas)\n \n true_box_conf = iou_scores * y_true[..., 4]\n \n ### adjust class probabilities\n true_box_class = tf.argmax(y_true[..., 5:], -1)\n \n \"\"\"\n Determine the masks\n \"\"\"\n ### coordinate mask: simply the position of the ground truth boxes (the predictors)\n coord_mask = tf.expand_dims(y_true[..., 4], axis=-1) * COORD_SCALE\n \n ### confidence mask: penelize predictors + penalize boxes with low IOU\n # penalize the confidence of the boxes, which have IOU with some ground truth box < 0.6\n true_xy = true_boxes[..., 0:2]\n true_wh = true_boxes[..., 2:4]\n \n true_wh_half = true_wh / 2.\n true_mins = true_xy - true_wh_half\n true_maxes = true_xy + true_wh_half\n \n pred_xy = tf.expand_dims(pred_box_xy, 4)\n pred_wh = tf.expand_dims(pred_box_wh, 4)\n \n pred_wh_half = pred_wh / 2.\n pred_mins = pred_xy - pred_wh_half\n pred_maxes = pred_xy + pred_wh_half \n \n intersect_mins = tf.maximum(pred_mins, true_mins)\n intersect_maxes = tf.minimum(pred_maxes, true_maxes)\n intersect_wh = tf.maximum(intersect_maxes - intersect_mins, 0.)\n intersect_areas = intersect_wh[..., 0] * intersect_wh[..., 1]\n \n true_areas = true_wh[..., 0] * true_wh[..., 1]\n pred_areas = pred_wh[..., 0] * pred_wh[..., 1]\n\n union_areas = pred_areas + true_areas - intersect_areas\n iou_scores = tf.truediv(intersect_areas, union_areas)\n\n best_ious = tf.reduce_max(iou_scores, axis=4)\n conf_mask = conf_mask + tf.to_float(best_ious < 0.6) * (1 - y_true[..., 4]) * NO_OBJECT_SCALE\n \n # penalize the confidence of the boxes, which are reponsible for corresponding ground truth box\n conf_mask = conf_mask + y_true[..., 4] * OBJECT_SCALE\n \n ### class mask: simply the position of the ground truth boxes (the predictors)\n class_mask = y_true[..., 4] * tf.gather(CLASS_WEIGHTS, true_box_class) * CLASS_SCALE \n \n \"\"\"\n Warm-up training\n \"\"\"\n no_boxes_mask = tf.to_float(coord_mask < COORD_SCALE/2.)\n seen = tf.assign_add(seen, 1.)\n \n true_box_xy, true_box_wh, coord_mask = tf.cond(tf.less(seen, WARM_UP_BATCHES), \n lambda: [true_box_xy + (0.5 + cell_grid) * no_boxes_mask, \n true_box_wh + tf.ones_like(true_box_wh) * np.reshape(ANCHORS, [1,1,1,BOX,2]) * no_boxes_mask, \n tf.ones_like(coord_mask)],\n lambda: [true_box_xy, \n true_box_wh,\n coord_mask])\n \n \"\"\"\n Finalize the loss\n \"\"\"\n nb_coord_box = tf.reduce_sum(tf.to_float(coord_mask > 0.0))\n nb_conf_box = tf.reduce_sum(tf.to_float(conf_mask > 0.0))\n nb_class_box = tf.reduce_sum(tf.to_float(class_mask > 0.0))\n \n loss_xy = tf.reduce_sum(tf.square(true_box_xy-pred_box_xy) * coord_mask) / (nb_coord_box + 1e-6) / 2.\n loss_wh = tf.reduce_sum(tf.square(true_box_wh-pred_box_wh) * coord_mask) / (nb_coord_box + 1e-6) / 2.\n loss_conf = tf.reduce_sum(tf.square(true_box_conf-pred_box_conf) * conf_mask) / (nb_conf_box + 1e-6) / 2.\n loss_class = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=true_box_class, logits=pred_box_class)\n loss_class = tf.reduce_sum(loss_class * class_mask) / (nb_class_box + 1e-6)\n \n loss = loss_xy + loss_wh + loss_conf + loss_class\n \n nb_true_box = tf.reduce_sum(y_true[..., 4])\n nb_pred_box = tf.reduce_sum(tf.to_float(true_box_conf > 0.5) * tf.to_float(pred_box_conf > 0.3))\n\n \"\"\"\n Debugging code\n \"\"\" \n current_recall = nb_pred_box/(nb_true_box + 1e-6)\n total_recall = tf.assign_add(total_recall, current_recall) \n\n #loss = tf.Print(loss, [tf.zeros((1))], message='Dummy Line \\t', summarize=1000)\n #loss = tf.Print(loss, [loss_xy], message='Loss XY \\t', summarize=1000)\n #loss = tf.Print(loss, [loss_wh], message='Loss WH \\t', summarize=1000)\n #loss = tf.Print(loss, [loss_conf], message='Loss Conf \\t', summarize=1000)\n #loss = tf.Print(loss, [loss_class], message='Loss Class \\t', summarize=1000)\n #loss = tf.Print(loss, [loss], message='Total Loss \\t', summarize=1000)\n #loss = tf.Print(loss, [current_recall], message='Current Recall \\t', summarize=1000)\n #loss = tf.Print(loss, [total_recall/seen], message='Average Recall \\t', summarize=1000)\n \n loss = tf.Print(loss, [tf.zeros((1))], message='Dummy Line \\t')\n loss = tf.Print(loss, [loss_xy], message='Loss XY \\t')\n loss = tf.Print(loss, [loss_wh], message='Loss WH \\t')\n loss = tf.Print(loss, [loss_conf], message='Loss Conf \\t')\n loss = tf.Print(loss, [loss_class], message='Loss Class \\t')\n loss = tf.Print(loss, [loss], message='Total Loss \\t')\n loss = tf.Print(loss, [current_recall], message='Current Recall \\t')\n loss = tf.Print(loss, [total_recall/seen], message='Average Recall \\t')\n\n return loss",
"_____no_output_____"
]
],
[
[
"**Parse the annotations to construct train generator and validation generator**",
"_____no_output_____"
]
],
[
[
"generator_config = {\n 'IMAGE_H' : IMAGE_H, \n 'IMAGE_W' : IMAGE_W,\n 'GRID_H' : GRID_H, \n 'GRID_W' : GRID_W,\n 'BOX' : BOX,\n 'LABELS' : LABELS,\n 'CLASS' : len(LABELS),\n 'ANCHORS' : ANCHORS,\n 'BATCH_SIZE' : BATCH_SIZE,\n 'TRUE_BOX_BUFFER' : 50,\n}",
"_____no_output_____"
],
[
"def normalize(image):\n return image / 255.",
"_____no_output_____"
],
[
"print(train_annot_folder)",
"/content/drive/My Drive/dataset/annotations/\n"
]
],
[
[
"**Setup a few callbacks and start the training**",
"_____no_output_____"
]
],
[
[
"early_stop = EarlyStopping(monitor='val_loss', \n min_delta=0.001, \n patience=3, \n mode='min', \n verbose=1)\n\ncheckpoint = ModelCheckpoint('botellas.h5', \n monitor='val_loss', \n verbose=1, \n save_best_only=True, \n mode='min', \n period=1)",
"_____no_output_____"
],
[
"#tb_counter = len([log for log in os.listdir(os.path.expanduser('~/logs/')) if 'coco_' in log]) + 1\n#tensorboard = TensorBoard(log_dir=os.path.expanduser('~/logs/') + 'coco_' + '_' + str(tb_counter), \n# histogram_freq=0, \n# write_graph=True, \n# write_images=False)\n\noptimizer = Adam(lr=0.5e-4, beta_1=0.9, beta_2=0.999, epsilon=1e-08, decay=0.0)\n#optimizer = SGD(lr=1e-4, decay=0.0005, momentum=0.9)\n#optimizer = RMSprop(lr=1e-4, rho=0.9, epsilon=1e-08, decay=0.0)\n\nmodel.compile(loss=custom_loss, optimizer=optimizer,metrics=['accuracy'])\n#'loss_xy','loss_wh','loss_conf','loss_classloss','current_recall','total_recall/seen'\n\nstad = model.fit_generator(generator = train_batch, \n steps_per_epoch = len(train_batch), \n epochs = 3, \n verbose = 1,\n validation_data = valid_batch,\n validation_steps = len(valid_batch),\n callbacks = [early_stop, checkpoint], \n max_queue_size = 3)\n\n#model.fit_generator(generator = train_batch, \n# steps_per_epoch = len(train_batch), \n# epochs = 100, \n# verbose = 1,\n# validation_data = valid_batch,\n# validation_steps = len(valid_batch),\n# callbacks = [early_stop, checkpoint, tensorboard], \n# max_queue_size = 3)",
"Epoch 1/3\n75/75 [==============================] - 2118s 28s/step - loss: 1.3625 - acc: 0.0440 - val_loss: 1.1354 - val_acc: 0.0208\n\nEpoch 00001: val_loss improved from inf to 1.13539, saving model to botellas.h5\nEpoch 2/3\n75/75 [==============================] - 2363s 32s/step - loss: 0.5719 - acc: 0.0125 - val_loss: 0.5379 - val_acc: 0.0089\n\nEpoch 00002: val_loss improved from 1.13539 to 0.53795, saving model to botellas.h5\nEpoch 3/3\n75/75 [==============================] - 2136s 28s/step - loss: 0.2919 - acc: 0.0115 - val_loss: 0.3276 - val_acc: 0.0123\n\nEpoch 00003: val_loss improved from 0.53795 to 0.32760, saving model to botellas.h5\n"
],
[
"image = batches[0][0][0][0]\nplt.imshow(image.astype('uint8'))plt.figure(0) \nplt.plot(stad.history['acc'],'r') \nplt.plot(stad.history['val_acc'],'g') \nplt.xlabel(\"Num of Epochs\") \nplt.ylabel(\"Accuracy\") \nplt.title(\"Training Accuracy vs Validation Accuracy\") \nplt.legend(['train','validation'])\n\nplt.savefig(\"Grafica_1.jpg\", bbox_inches = 'tight')\n\nplt.figure(1) \nplt.plot(stad.history['loss'],'r') \nplt.plot(stad.history['val_loss'],'g') \nplt.xlabel(\"Num of Epochs\") \nplt.ylabel(\"Loss\") \nplt.title(\"Training Loss vs Validation Loss\") \nplt.legend(['train','validation'])\n\nplt.savefig(\"Grafica_2.jpg\", bbox_inches = 'tight')\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"# Perform detection on image",
"_____no_output_____"
]
],
[
[
"model.load_weights(\"botellas.h5\")",
"_____no_output_____"
],
[
"import cv2\nimport matplotlib.pyplot as plt\n\nplt.figure()\ninput_image = cv2.imread(\"/content/drive/My Drive/dataset/images/1.png\")\ninput_image = cv2.resize(input_image, (416, 416))\n\n\ndummy_array = np.zeros((1,1,1,1,TRUE_BOX_BUFFER,4))\n\ninput_image = input_image / 255.\ninput_image = input_image[:,:,::-1]\ninput_image = np.expand_dims(input_image, 0)\n\nnetout = model.predict([input_image, dummy_array])\n\nboxes = decode_netout(netout[0], \n obj_threshold=OBJ_THRESHOLD,\n nms_threshold=NMS_THRESHOLD,\n anchors=ANCHORS, \n nb_class=CLASS)\n \nimagen = draw_boxes(imagen, boxes, labels=LABELS)\n\nimagen = cv2.resize(imagen,(640,380))\nplt.imshow(imagen[:,:,::-1]); plt.show()",
"_____no_output_____"
]
],
[
[
"# Perform detection on video",
"_____no_output_____"
]
],
[
[
"#model.load_weights(\"weights_coco.h5\")\n\n#dummy_array = np.zeros((1,1,1,1,TRUE_BOX_BUFFER,4))",
"_____no_output_____"
],
[
"#video_inp = '../basic-yolo-keras/images/phnom_penh.mp4'\n#video_out = '../basic-yolo-keras/images/phnom_penh_bbox.mp4'\n\n#video_reader = cv2.VideoCapture(video_inp)\n\n#nb_frames = int(video_reader.get(cv2.CAP_PROP_FRAME_COUNT))\n#frame_h = int(video_reader.get(cv2.CAP_PROP_FRAME_HEIGHT))\n#frame_w = int(video_reader.get(cv2.CAP_PROP_FRAME_WIDTH))\n\n#video_writer = cv2.VideoWriter(video_out,\n# cv2.VideoWriter_fourcc(*'XVID'), \n# 50.0, \n# (frame_w, frame_h))\n\n#for i in tqdm(range(nb_frames)):\n# ret, image = video_reader.read()\n \n# input_image = cv2.resize(image, (416, 416))\n# input_image = input_image / 255.\n# input_image = input_image[:,:,::-1]\n# input_image = np.expand_dims(input_image, 0)\n\n# netout = model.predict([input_image, dummy_array])\n\n# boxes = decode_netout(netout[0], \n# obj_threshold=0.3,\n# nms_threshold=NMS_THRESHOLD,\n# anchors=ANCHORS, \n# nb_class=CLASS)\n# image = draw_boxes(image, boxes, labels=LABELS)\n\n# video_writer.write(np.uint8(image))\n \n#video_reader.release()\n#video_writer.release() ",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
cb3d2bf7c0663337f184a5969a2e17a3f531072f | 1,190 | ipynb | Jupyter Notebook | IR/HW6/page rank.ipynb | r07922003/NTU | 4414b656643bc0079c12617190fa2a519d2331f8 | [
"MIT"
] | null | null | null | IR/HW6/page rank.ipynb | r07922003/NTU | 4414b656643bc0079c12617190fa2a519d2331f8 | [
"MIT"
] | null | null | null | IR/HW6/page rank.ipynb | r07922003/NTU | 4414b656643bc0079c12617190fa2a519d2331f8 | [
"MIT"
] | null | null | null | 22.037037 | 69 | 0.496639 | [
[
[
"import numpy as np\n#state = 1,2,3\n\ntransition_matrix = np.array([[0.1,0.1 ,0.3],\n [0.6,0.25,0.5],\n [0.3,0.65,0.2]])\nfor i in range(10):\n new_matrix = np.dot(transition_matrix,transition_matrix)\n transition_matrix = new_matrix\nprint(transition_matrix)",
"[[0.18092105 0.18092105 0.18092105]\n [0.41447368 0.41447368 0.41447368]\n [0.40460526 0.40460526 0.40460526]]\n"
]
]
] | [
"code"
] | [
[
"code"
]
] |
cb3d2df620e2e8450357593e24b7e95c1c9948d9 | 46,204 | ipynb | Jupyter Notebook | doc/Homeworks/hw4/solution/.ipynb_checkpoints/solutionhw4-checkpoint.ipynb | Shield94/Physics321 | 9875a3bf840b0fa164b865a3cb13073aff9094ca | [
"CC0-1.0"
] | null | null | null | doc/Homeworks/hw4/solution/.ipynb_checkpoints/solutionhw4-checkpoint.ipynb | Shield94/Physics321 | 9875a3bf840b0fa164b865a3cb13073aff9094ca | [
"CC0-1.0"
] | null | null | null | doc/Homeworks/hw4/solution/.ipynb_checkpoints/solutionhw4-checkpoint.ipynb | Shield94/Physics321 | 9875a3bf840b0fa164b865a3cb13073aff9094ca | [
"CC0-1.0"
] | null | null | null | 38.632107 | 10,556 | 0.653796 | [
[
[
"<!-- HTML file automatically generated from DocOnce source (https://github.com/doconce/doconce/)\ndoconce format html solutionhw4.do.txt -->\n<!-- dom:TITLE: PHY321: Classical Mechanics 1 -->",
"_____no_output_____"
],
[
"# PHY321: Classical Mechanics 1\n**Homework 4, due Monday February 15**\n\nDate: **Feb 14, 2022**",
"_____no_output_____"
],
[
"### Practicalities about homeworks and projects\n\n1. You can work in groups (optimal groups are often 2-3 people) or by yourself. If you work as a group you can hand in one answer only if you wish. **Remember to write your name(s)**!\n\n2. Homeworks are available Wednesday/Thursday the week before the deadline. The deadline is at the Friday lecture.\n\n3. How do I(we) hand in? You can hand in the paper and pencil exercises as a hand-written document. For this homework this applies to exercises 1-5. Alternatively, you can hand in everyhting (if you are ok with typing mathematical formulae using say Latex) as a jupyter notebook at D2L. The numerical exercise(s) (exercise 6 here) should always be handed in as a jupyter notebook by the deadline at D2L.",
"_____no_output_____"
],
[
"### Introduction to homework 4\n\nThis week's sets of classical pen and paper and computational\nexercises deal with simple motion problems and conservation laws; energy, momentum and angular momentum. These conservation laws are central in Physics and understanding them properly lays the foundation for understanding and analyzing more complicated physics problems.\nThe relevant reading background is\n1. chapters 3, 4.1, 4.2 and 4.3 of Taylor (there are many good examples there) and\n\n2. chapters 10-13 of Malthe-Sørenssen.\n\nIn both textbooks there are many nice worked out examples. Malthe-Sørenssen's text contains also several coding examples you may find useful. \n\nThe numerical homework focuses on another motion problem where you can\nuse the code you developed in homework 3, almost entirely. Please take\na look at the posted solution (jupyter-notebook) for homework 3. You\nneed only to change the forces at play.",
"_____no_output_____"
],
[
"### Exercise 1 (10 pt), Conservation laws, Energy and momentum\n\n* 1a (2pt) How do we define a conservative force?\n\nA conservative force is a force whose property is that the total work\ndone in moving an object between two points is independent of the\ntaken path. This means that the work on an object under the influence\nof a conservative force, is independent on the path of the object. It\ndepends only on the spatial degrees of freedom and it is possible to\nassign a numerical value for the potential at any point. It leads to\nconservation of energy. The gravitational force is an example of a\nconservative force.\n\nIf you wish to read more about conservative forces or not, Feyman's lectures from 1963 are quite interesting.\nHe states for example that **All fundamental forces in nature appear to be conservative**.\nThis statement was made while developing his argument that *there are no nonconservative forces*.\nYou may enjoy the link to [Feynman's lecture](http://www.feynmanlectures.caltech.edu/I_14.html).\n\nAn important condition for the final work to be independent of the path is that the **curl** of the force is zero, that",
"_____no_output_____"
],
[
"$$\n\\boldsymbol{\\nabla} \\times \\boldsymbol{F}=0\n$$",
"_____no_output_____"
],
[
"* 1b (4pt) Use the work-energy theorem to show that energy is conserved with a conservative force.\n\nThe work-energy theorem states that the work done $W$ by a force $\\boldsymbol{F}$ that moves an object from a position $\\boldsymbol{r}_0$ to a new position $\\boldsymbol{r}_1$",
"_____no_output_____"
],
[
"$$\nW=\\int_{\\boldsymbol{r}_0}^{\\boldsymbol{r}_1}\\boldsymbol{F}\\boldsymbol{dr}=\\frac{1}{2}mv_1^2-\\frac{1}{2}mv_0^2,\n$$",
"_____no_output_____"
],
[
"where $v_1^2$ is the velocity squared at a time $t_1$ and $v_0^2$ the corresponding quantity at a time $t_0$.\nThe work done is thus the difference in kinetic energies. We can rewrite the above equation as",
"_____no_output_____"
],
[
"$$\n\\frac{1}{2}mv_1^2=\\int_{\\boldsymbol{r}_0}^{\\boldsymbol{r}_1}\\boldsymbol{F}\\boldsymbol{dr}+\\frac{1}{2}mv_0^2,\n$$",
"_____no_output_____"
],
[
"that is the final kinetic energy is equal to the initial kinetic energy plus the work done by the force over a given path from a position $\\boldsymbol{r}_0$ at time $t_0$ to a final position position $\\boldsymbol{r}_1$ at a later time $t_1$.\n\n* 1c (4pt) Assume that you have only internal two-body forces acting on $N$ objects in an isolated system. The force from object $i$ on object $j$ is $\\boldsymbol{f}_{ij}$. Show that the linear momentum is conserved.\n\nHere we use Newton's third law and assume that our system is only\naffected by so-called internal forces. This means that the force\n$\\boldsymbol{f}_{ij}$ from object $i$ acting on object $j$ is equal to the\nforce acting on object $j$ from object $i$ but with opposite sign,\nthat is $\\boldsymbol{f}_{ij}=-\\boldsymbol{f}_{ji}$.\n\nThe total linear momentum is defined as",
"_____no_output_____"
],
[
"$$\n\\boldsymbol{P}=\\sum_{i=1}^N\\boldsymbol{p}_i=\\sum_{i=1}^Nm_i\\boldsymbol{v}_i,\n$$",
"_____no_output_____"
],
[
"where $i$ runs over all objects, $m_i$ is the mass of object $i$ and $\\boldsymbol{v}_i$ its corresponding velocity.\n\nThe force acting on object $i$ from all the other objects is (lower\ncase letters for individual objects and upper case letters for total\nquantities)",
"_____no_output_____"
],
[
"$$\n\\boldsymbol{f}_i=\\sum_{j=1}^N\\boldsymbol{f}_{ji}.\n$$",
"_____no_output_____"
],
[
"Summing over all objects the net force is",
"_____no_output_____"
],
[
"$$\n\\sum_{i=1}^N\\boldsymbol{f}_i=\\sum_{i=1}^N\\sum_{j=1;j\\ne i}^N\\boldsymbol{f}_{ji}.\n$$",
"_____no_output_____"
],
[
"We are summing freely over all objects with the constraint that $i\\ne j$ (no self-interactions). \nWe can now manipulate the double sum as",
"_____no_output_____"
],
[
"$$\n\\sum_{i=1}^N\\sum_{j=1;j\\ne i}^N\\boldsymbol{f}_{ji}=\\sum_{i=1}^N\\sum_{j>i}^N(\\boldsymbol{f}_{ji}+\\boldsymbol{f}_{ij}).\n$$",
"_____no_output_____"
],
[
"Convince yourself about this by setting $N=2$ and $N=3$. Nweton's third law says\n$\\boldsymbol{f}_{ij}=-\\boldsymbol{f}_{ji}$, which means we have",
"_____no_output_____"
],
[
"$$\n\\sum_{i=1}^N\\sum_{j=1;j\\ne i}^N\\boldsymbol{f}_{ji}=\\sum_{i=1}^N\\sum_{j>i}^N(\\boldsymbol{f}_{ji}-\\boldsymbol{f}_{ji})=0.\n$$",
"_____no_output_____"
],
[
"The total force due to internal degrees of freedom only is thus $0$.\nIf we then use the definition that",
"_____no_output_____"
],
[
"$$\n\\sum_{i=1}^N\\boldsymbol{f}_i=\\sum_{i=1}^Nm_i\\frac{d\\boldsymbol{v}_i}{dt}=\\sum_{i=1}^N\\frac{d\\boldsymbol{p}_i}{dt}=\\frac{d \\boldsymbol{P}}{dt}=0,\n$$",
"_____no_output_____"
],
[
"where we assumed that $m_i$ is independent of time, we see that time derivative of the total momentum is zero.\nWe say then that the linear momentum is a constant of the motion. It is conserved.",
"_____no_output_____"
],
[
"### Exercise 2 (10 pt), Conservation of angular momentum\n\n* 2a (2pt) Define angular momentum and the torque for a single object with external forces only. \n\nThe angular moment $\\boldsymbol{l}_i$ for a given object $i$ is defined as",
"_____no_output_____"
],
[
"$$\n\\boldsymbol{l}_i = \\boldsymbol{r}_i \\times \\boldsymbol{p}_i,\n$$",
"_____no_output_____"
],
[
"where $\\boldsymbol{p}_i=m_i\\boldsymbol{v}_i$. With external forces only defining the acceleration and the mass being time independent, the momentum is the integral over the external force as function of time, that is",
"_____no_output_____"
],
[
"$$\n\\boldsymbol{p}_i(t)=\\boldsymbol{p}_i(t_0)+\\int_{t_0}^t \\boldsymbol{f}_i^{\\mathrm{ext}}(t')dt'.\n$$",
"_____no_output_____"
],
[
"The torque for one object is",
"_____no_output_____"
],
[
"$$\n\\boldsymbol{\\tau}_i=\\frac{d\\boldsymbol{l}_i}{dt} = \\frac{dt(\\boldsymbol{r}_i \\times \\boldsymbol{p}_i)}{dt}=\\boldsymbol{r}_i \\times \\frac{d\\boldsymbol{p}_i}{dt}=\\boldsymbol{r}_i \\times \\boldsymbol{f}_i,\n$$",
"_____no_output_____"
],
[
"* 2b (4pt) Define angular momentum and the torque for a system with $N$ objects/particles with external and internal forces. The force from object $i$ on object $j$ is $\\boldsymbol{F}_{ij}$.\n\nThe total angular momentum $\\boldsymbol{L}$ is defined as",
"_____no_output_____"
],
[
"$$\n\\boldsymbol{L}=\\sum_{i=1}^N\\boldsymbol{l}_i = \\sum_{i=1}^N\\boldsymbol{r}_i \\times \\boldsymbol{p}_i.\n$$",
"_____no_output_____"
],
[
"and the total torque is (using the expression for one object from 2a)",
"_____no_output_____"
],
[
"$$\n\\boldsymbol{\\tau}=\\sum_{i=1}^N\\frac{d\\boldsymbol{l}_i}{dt} = \\sum_{i=1}^N\\boldsymbol{r}_i \\times \\boldsymbol{f}_i.\n$$",
"_____no_output_____"
],
[
"The force acting on one object is $\\boldsymbol{f}_i=\\boldsymbol{f}_i^{\\mathrm{ext}}+\\sum_{j=1}^N\\boldsymbol{f}_{ji}$.\n\n* 2c (4pt) With internal forces only, what is the mathematical form of the forces that allows for angular momentum to be conserved? \n\nUsing the results from 1c, we can rewrite without external forces our torque as",
"_____no_output_____"
],
[
"$$\n\\boldsymbol{\\tau}=\\sum_{i=1}^N\\frac{d\\boldsymbol{l}_i}{dt} = \\sum_{i=1}^N\\boldsymbol{r}_i \\times \\boldsymbol{f}_i=\\sum_{i=1}^N(\\boldsymbol{r}_i \\times \\sum_{j=1}^N\\boldsymbol{f}_{ji}),\n$$",
"_____no_output_____"
],
[
"which gives",
"_____no_output_____"
],
[
"$$\n\\boldsymbol{\\tau}=\\sum_{i=1}^N\\sum_{j=1;j\\ne i}^N(\\boldsymbol{r}_i \\times \\boldsymbol{f}_{ji}).\n$$",
"_____no_output_____"
],
[
"We can rewrite this as (convince yourself again about this)",
"_____no_output_____"
],
[
"$$\n\\boldsymbol{\\tau}=\\sum_{i=1}^N\\sum_{j>i}^N(\\boldsymbol{r}_i \\times \\boldsymbol{f}_{ji}+\\boldsymbol{r}_j \\times \\boldsymbol{f}_{ij}),\n$$",
"_____no_output_____"
],
[
"and using Newton's third law we have",
"_____no_output_____"
],
[
"$$\n\\boldsymbol{\\tau}=\\sum_{i=1}^N\\sum_{j>i}^N(\\boldsymbol{r}_i -\\boldsymbol{r}_j) \\times \\boldsymbol{f}_{ji}.\n$$",
"_____no_output_____"
],
[
"If the force is proportional to $\\boldsymbol{r}_i -\\boldsymbol{r}_j$ then angular momentum is conserved since the cross-product of a vector with itself is zero. We say thus that angular momentum is a constant of the motion.",
"_____no_output_____"
],
[
"### Exsercise 3 (10pt), Example of potential\n\nConsider a particle of mass $m$ moving according to the potential",
"_____no_output_____"
],
[
"$$\nV(x,y,z)=A\\exp\\left\\{-\\frac{x^2+z^2}{2a^2}\\right\\}.\n$$",
"_____no_output_____"
],
[
"* 3a (2pt) Is energy conserved? If so, why? \n\nIn this exercise $A$ and $a$ are constants. The force is given by the derivative of $V$ with respect to the spatial degrees of freedom and since the potential depends only on position, the force is conservative and energy is conserved. Furthermore, the curl of the force is zero. To see this we need first to compute the derivatives of the potential with respect to $x$, $y$ and $z$.\nWe have that",
"_____no_output_____"
],
[
"$$\nF_x = -\\frac{\\partial V}{\\partial x}=-\\frac{xA}{a^2}\\exp\\left\\{-\\frac{x^2+z^2}{2a^2}\\right\\},\n$$",
"_____no_output_____"
],
[
"and",
"_____no_output_____"
],
[
"$$\nF_y = 0,\n$$",
"_____no_output_____"
],
[
"and",
"_____no_output_____"
],
[
"$$\nF_z = -\\frac{\\partial V}{\\partial z}=-\\frac{zA}{a^2}\\exp\\left\\{-\\frac{x^2+z^2}{2a^2}\\right\\}.\n$$",
"_____no_output_____"
],
[
"The components of the **curl** of $\\boldsymbol{F}$ are",
"_____no_output_____"
],
[
"$$\n(\\boldsymbol{\\nabla}\\times\\boldsymbol{F})_x = \\frac{\\partial F_y}{\\partial z}-\\frac{\\partial F_z}{\\partial y}=0,\n$$",
"_____no_output_____"
],
[
"and",
"_____no_output_____"
],
[
"$$\n(\\boldsymbol{\\nabla}\\times\\boldsymbol{F})_y = \\frac{\\partial F_x}{\\partial z}-\\frac{\\partial F_z}{\\partial x}=\\frac{xzA}{a^4}\\exp\\left\\{-\\frac{x^2+z^2}{2a^2}\\right\\}-\\frac{xzA}{a^4}\\exp\\left\\{-\\frac{x^2+z^2}{2a^2}\\right\\}=0,\n$$",
"_____no_output_____"
],
[
"and",
"_____no_output_____"
],
[
"$$\n(\\boldsymbol{\\nabla}\\times\\boldsymbol{F})_z = \\frac{\\partial F_y}{\\partial x}-\\frac{\\partial F_x}{\\partial y}=0.\n$$",
"_____no_output_____"
],
[
"The force is a conservative one.\n\n* 3b (4pt) Which of the quantities, $p_x,p_y,p_z$ are conserved?\n\nTaking the derivatives with respect to time shows that only $p_y$ is conserved\nWe see this directly from the above expressions for the force, since the derivative with respect to time of the momentum is simply the force. Thus, only the $y$-component of the momentum is conserved, see the expressions above for the forces,\n\nFor the next exercise (3c), we need also the following derivatives",
"_____no_output_____"
],
[
"$$\n\\frac{\\partial F_x}{\\partial x} = \\frac{x^2A}{a^4}\\exp\\left\\{-\\frac{x^2+z^2}{2a^2}\\right\\}-\\frac{A}{a^2}\\exp\\left\\{-\\frac{x^2+z^2}{2a^2}\\right\\},\n$$",
"_____no_output_____"
],
[
"and",
"_____no_output_____"
],
[
"$$\n\\frac{\\partial F_y}{\\partial y} = 0,\n$$",
"_____no_output_____"
],
[
"and",
"_____no_output_____"
],
[
"$$\n\\frac{\\partial F_z}{\\partial z} = \\frac{z^2A}{a^4}\\exp\\left\\{-\\frac{x^2+z^2}{2a^2}\\right\\}-\\frac{A}{a^2}\\exp\\left\\{-\\frac{x^2+z^2}{2a^2}\\right\\},\n$$",
"_____no_output_____"
],
[
"* 3c (4pt) Which of the quantities, $L_x,L_y,L_z$ are conserved?\n\nUsing that $\\boldsymbol{L}=\\boldsymbol{r}\\times\\boldsymbol{p}$ and that",
"_____no_output_____"
],
[
"$$\n\\frac{d\\boldsymbol{L}}{dt}=\\boldsymbol{r}\\times\\boldsymbol{F},\n$$",
"_____no_output_____"
],
[
"we have that the different components are",
"_____no_output_____"
],
[
"$$\n(\\boldsymbol{r}\\times\\boldsymbol{F})_x = zF_y-yF_z=\\frac{yzA}{a^2}\\exp\\left\\{-\\frac{x^2+z^2}{2a^2}\\right\\}.\n$$",
"_____no_output_____"
],
[
"and",
"_____no_output_____"
],
[
"$$\n(\\boldsymbol{r}\\times\\boldsymbol{F})_y = xF_z-zF_x=-\\frac{xzA}{a^2}\\exp\\left\\{-\\frac{x^2+z^2}{2a^2}\\right\\}+\\frac{xzA}{a^2}\\exp\\left\\{-\\frac{x^2+z^2}{2a^2}\\right\\}=0,\n$$",
"_____no_output_____"
],
[
"and",
"_____no_output_____"
],
[
"$$\n(\\boldsymbol{r}\\times\\boldsymbol{F})_z = xF_y-yF_x=\\frac{yxA}{a^2}\\exp\\left\\{-\\frac{x^2+z^2}{2a^2}\\right\\}.\n$$",
"_____no_output_____"
],
[
"Only $L_y$ is conserved.",
"_____no_output_____"
],
[
"### Exercise 4 (10pt), Angular momentum case\n\nAt $t=0$ we have a single object with position $\\boldsymbol{r}_0=x_0\\boldsymbol{e}_x+y_0\\boldsymbol{e}_y$. We add also a force in the $x$-direction at $t=0$. We assume that the object is at rest at $t=0$.",
"_____no_output_____"
],
[
"$$\n\\boldsymbol{F} = F\\boldsymbol{e}_x.\n$$",
"_____no_output_____"
],
[
"* 4a (3pt) Find the velocity and momentum at a given time $t$ by integrating over time with the above initial conditions.\n\nThere is no velocity in the $x$- and $y$-directions at $t=0$, thus $\\boldsymbol{v}_0=0$. The force is constant and acting only in the $x$-direction. We have then (dropping vector symbols and setting $t_0=0$)",
"_____no_output_____"
],
[
"$$\nv_x(t) = \\int_0^t a(t')dt'=\\int_0^t\\frac{F}{m}dt'=\\frac{F}{m}t.\n$$",
"_____no_output_____"
],
[
"* 4b (3pt) Find also the position at a time $t$.\n\nIn the $x$-direction we have then",
"_____no_output_____"
],
[
"$$\nx(t) = \\int_0^t v_x(t')dt'=x_0+\\frac{F}{2m}t^2,\n$$",
"_____no_output_____"
],
[
"resulting in",
"_____no_output_____"
],
[
"$$\n\\boldsymbol{r}(t)=(x_0+\\frac{F}{2m}t^2)\\boldsymbol{e}_x+y_0\\boldsymbol{e}_y.\n$$",
"_____no_output_____"
],
[
"* 4c (4pt) Use the position and the momentum to find the angular momentum and the torque. Is angular momentum conserved?\n\nVelocity and position are defined in the $xy$-plane only which means that only angular momentum in the $z$-direction is non-zero. The angular momentum is",
"_____no_output_____"
],
[
"$$\n\\boldsymbol{l} = (x(t)v_y(t)-y(t)v_x(t))\\boldsymbol{e}_z=-y_0\\frac{F}{m}t\\boldsymbol{e}_z,\n$$",
"_____no_output_____"
],
[
"which results in a torque $\\boldsymbol{\\tau}=-y_0\\frac{F}{m}\\boldsymbol{e}_z$, which is not zero. Thus, angular momentum is not conserved.",
"_____no_output_____"
],
[
"### Exercise 5 (10pt), forces and potentials\n\nA particle of mass $m$ has velocity $v=\\alpha/x$, where $x$ is its displacement.\n\n* 5a (3pt) Find the force $F(x)$ responsible for the motion.\n\nHere, since the force is assumed to be conservative (only dependence on $x$), we can use energy conservation.\nAssuming that the total energy at $t=0$ is $E_0$, we have",
"_____no_output_____"
],
[
"$$\nE_0=V(x)+\\frac{1}{2}mv^2=V(x)+\\frac{1}{2}m\\frac{\\alpha^2}{x^2}.\n$$",
"_____no_output_____"
],
[
"Taking the derivative wrt $x$ we have",
"_____no_output_____"
],
[
"$$\n\\frac{dV}{dx}-m\\frac{\\alpha^2}{x^3}=0,\n$$",
"_____no_output_____"
],
[
"and since $F(x)=-dV/dx$ we have",
"_____no_output_____"
],
[
"$$\nF(x)=-m\\frac{\\alpha^2}{x^3}.\n$$",
"_____no_output_____"
],
[
"A particle is thereafter under the influence of a force $F=-kx+kx^3/\\alpha^2$, where $k$ and $\\alpha$ are constants and $k$ is positive.\n\n* 5b (3pt) Determine $V(x)$ and discuss the motion. It can be convenient here to make a sketch/plot of the potential as function of $x$.\n\nWe assume that the potential is zero at say $x=0$. Integrating the force from zero to $x$ gives",
"_____no_output_____"
],
[
"$$\nV(x) = -\\int_0^x F(x')dx'=\\frac{kx^2}{2}-\\frac{kx^4}{4\\alpha^2}.\n$$",
"_____no_output_____"
],
[
"The following code plots the potential. We have chosen values of $\\alpha=k=1.0$. Feel free to experiment with other values. We plot $V(x)$ for a domain of $x\\in [-2,2]$.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport math\n\nx0= -2.0\nxn = 2.1\nDeltax = 0.1\nalpha = 1.0\nk = 1.0\n#set up arrays\nx = np.arange(x0,xn,Deltax)\nn = np.size(x)\nV = np.zeros(n)\nV = 0.5*k*x*x-0.25*k*(x**4)/(alpha*alpha)\nplt.plot(x, V)\nplt.xlabel(\"x\")\nplt.ylabel(\"V\")\nplt.show()",
"_____no_output_____"
]
],
[
[
"From the plot here (with the chosen parameters) \n1. we see that with a given initial velocity we can overcome the potential energy barrier\n\nand leave the potential well for good.\n1. If the initial velocity is smaller (see next exercise) than a certain value, it will remain trapped in the potential well and oscillate back and forth around $x=0$. This is where the potential has its minimum value. \n\n2. If the kinetic energy at $x=0$ equals the maximum potential energy, the object will oscillate back and forth between the minimum potential energy at $x=0$ and the turning points where the kinetic energy turns zero. These are the so-called non-equilibrium points. \n\n* 5c (4pt) What happens when the energy of the particle is $E=(1/4)k\\alpha^2$? Hint: what is the maximum value of the potential energy?\n\nFrom the figure we see that\nthe potential has a minimum at at $x=0$ then rises until $x=\\alpha$ before falling off again. The maximum\npotential, $V(x\\pm \\alpha) = k\\alpha^2/4$. If the energy is higher, the particle cannot be contained in the\nwell. The turning points are thus defined by $x=\\pm \\alpha$. And from the previous plot you can easily see that this is the case ($\\alpha=1$ in the abovementioned Python code).",
"_____no_output_____"
],
[
"### Exercise 6 (40pt)",
"_____no_output_____"
],
[
"### Exercise 6 (40pt), Numerical elements, adding the bouncing from the floor to the code from hw 3, exercise 6\n\n**This exercise should be handed in as a jupyter-notebook** at D2L. Remember to write your name(s). \n\nTill now we have only introduced gravity and air resistance and studied\ntheir effects via a constant acceleration due to gravity and the force\narising from air resistance. But what happens when the ball hits the\nfloor? What if we would like to simulate the normal force from the floor acting on the ball?\n\nWe need then to include a force model for the normal force from\nthe floor on the ball. The simplest approach to such a system is to introduce a contact force\nmodel represented by a spring model. We model the interaction between the floor\nand the ball as a single spring. But the normal force is zero when\nthere is no contact. Here we define a simple model that allows us to include\nsuch effects in our models.\n\nThe normal force from the floor on the ball is represented by a spring force. This\nis a strong simplification of the actual deformation process occurring at the contact\nbetween the ball and the floor due to the deformation of both the ball and the floor.\n\nThe deformed region corresponds roughly to the region of **overlap** between the\nball and the floor. The depth of this region is $\\Delta y = R − y(t)$, where $R$\nis the radius of the ball. This is supposed to represent the compression of the spring.\nOur model for the normal force acting on the ball is then",
"_____no_output_____"
],
[
"$$\n\\boldsymbol{N} = −k (R − y(t)) \\boldsymbol{e}_y.\n$$",
"_____no_output_____"
],
[
"The normal force must act upward when $y < R$,\nhence the sign must be negative.\nHowever, we must also ensure that the normal force only acts when the ball is in\ncontact with the floor, otherwise the normal force is zero. The full formation of the\nnormal force is therefore",
"_____no_output_____"
],
[
"$$\n\\boldsymbol{N} = −k (R − y(t)) \\boldsymbol{e}_y,\n$$",
"_____no_output_____"
],
[
"when $y(t) < R$ and zero when $y(t) \\le R$.\nIn the numerical calculations you can choose $R=0.1$ m and the spring constant $k=1000$ N/m.\n\n* 6a (10pt) Identify the forces acting on the ball and set up a diagram with the forces acting on the ball. Find the acceleration of the falling ball now with the normal force as well.\n\n* 6b (30pt) Choose a large enough final time so you can study the ball bouncing up and down several times. Add the normal force and compute the height of the ball as function of time with and without air resistance. Comment your results.\n\nFor 6a, see Malthe-Sørenssen chapter 7.5.1, in particular figure\n7.10. The forces are in equation (7.10). The following code shows how\nto set up the problem with gravitation, a drag force and a normal\nforce from the ground. The normal force makes the ball bounce up\nagain.\n\nThe code here includes all forces. Commenting out the air resistance will result in a ball which bounces up and down to the same height.\nFurthermore, you will note that for larger values of $\\Delta t$ the results will not be physically meaningful. Can you figure out why? Try also different values for the step size in order to see whether the final results agrees with what you expect.",
"_____no_output_____"
]
],
[
[
"# Exercise 6, hw4, smarter way with declaration of vx, vy, x and y\n# Here we have added a normal force from the ground\n# Common imports\nimport numpy as np\nimport pandas as pd\nfrom math import *\nimport matplotlib.pyplot as plt\nimport os\n\n# Where to save the figures and data files\nPROJECT_ROOT_DIR = \"Results\"\nFIGURE_ID = \"Results/FigureFiles\"\nDATA_ID = \"DataFiles/\"\n\nif not os.path.exists(PROJECT_ROOT_DIR):\n os.mkdir(PROJECT_ROOT_DIR)\n\nif not os.path.exists(FIGURE_ID):\n os.makedirs(FIGURE_ID)\n\nif not os.path.exists(DATA_ID):\n os.makedirs(DATA_ID)\n\ndef image_path(fig_id):\n return os.path.join(FIGURE_ID, fig_id)\n\ndef data_path(dat_id):\n return os.path.join(DATA_ID, dat_id)\n\ndef save_fig(fig_id):\n plt.savefig(image_path(fig_id) + \".png\", format='png')\n\n\nfrom pylab import plt, mpl\nplt.style.use('seaborn')\nmpl.rcParams['font.family'] = 'serif'\n\n# Define constants\ng = 9.80655 #in m/s^2\nD = 0.0245 # in mass/length, kg/m\nm = 0.2 # in kg\nR = 0.1 # in meters\nk = 1000.0 # in mass/time^2\n# Define Gravitational force as a vector in x and y, zero x component\nG = -m*g*np.array([0.0,1])\nDeltaT = 0.001\n#set up arrays \ntfinal = 15.0\nn = ceil(tfinal/DeltaT)\n# set up arrays for t, v, and r, the latter contain the x and y comps\nt = np.zeros(n)\nv = np.zeros((n,2))\nr = np.zeros((n,2))\n# Initial conditions\nr0 = np.array([0.0,2.0])\nv0 = np.array([1.0,10.0])\nr[0] = r0\nv[0] = v0\n# Start integrating using Euler's method\nfor i in range(n-1):\n # Set up forces, air resistance FD\n if ( r[i,1] < R):\n N = k*(R-r[i,1])*np.array([0,1])\n else:\n N = np.array([0,0])\n vabs = sqrt(sum(v[i]*v[i]))\n FD = 0.0# -D*v[i]*vabs\n Fnet = FD+G+N\n a = Fnet/m\n # update velocity, time and position\n v[i+1] = v[i] + DeltaT*a\n r[i+1] = r[i] + DeltaT*v[i]\n t[i+1] = t[i] + DeltaT\n\nfig, ax = plt.subplots()\nax.set_xlim(0, tfinal)\nax.set_ylabel('y[m]')\nax.set_xlabel('x[m]')\nax.plot(r[:,0], r[:,1])\nfig.tight_layout()\nsave_fig(\"BouncingBallEuler\")\nplt.show()",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
]
] |
cb3d320139c70c742bd6ab91ca79d4e8e9a80224 | 9,125 | ipynb | Jupyter Notebook | Pandas - Dados ausentes.ipynb | demusis/ariscopython | 3aacfb6fa2d563fa2920622cf699cc06a946d3c1 | [
"MIT"
] | null | null | null | Pandas - Dados ausentes.ipynb | demusis/ariscopython | 3aacfb6fa2d563fa2920622cf699cc06a946d3c1 | [
"MIT"
] | null | null | null | Pandas - Dados ausentes.ipynb | demusis/ariscopython | 3aacfb6fa2d563fa2920622cf699cc06a946d3c1 | [
"MIT"
] | null | null | null | 22.755611 | 60 | 0.337315 | [
[
[
"# Dados ausentes",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd",
"_____no_output_____"
],
[
"# nan - Not a Number\ndf = pd.DataFrame({'A':[1,2,np.nan],\n 'B':[5,np.nan,np.nan],\n 'C':[1,2,3]})",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"# Elimina todos os registros que tem dados ausentes\ndf.dropna()",
"_____no_output_____"
],
[
"df.dropna(axis=1)",
"_____no_output_____"
],
[
"df.dropna(thresh=2)",
"_____no_output_____"
],
[
"df.fillna(value='Ausente')",
"_____no_output_____"
],
[
"# Preenche o valor ausente com a média dos demais\ndf['A'].fillna(value=df['A'].mean())",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3d3afba08a3b9fafd9b18893e09533202ac5fe | 745 | ipynb | Jupyter Notebook | test/Result_1.ipynb | Saviour1001/JuliaToJupyter | dcf49503a346504de63b8d12a2e09fa94ff689c7 | [
"MIT"
] | null | null | null | test/Result_1.ipynb | Saviour1001/JuliaToJupyter | dcf49503a346504de63b8d12a2e09fa94ff689c7 | [
"MIT"
] | null | null | null | test/Result_1.ipynb | Saviour1001/JuliaToJupyter | dcf49503a346504de63b8d12a2e09fa94ff689c7 | [
"MIT"
] | null | null | null | 15.520833 | 35 | 0.469799 | [
[
[
"empty"
]
]
] | [
"empty"
] | [
[
"empty"
]
] |
cb3d441721d1bf36dd6f58805df7b859ea50a826 | 12,555 | ipynb | Jupyter Notebook | Chapter11/01_example.ipynb | Krismars19/Hands-On-Natural-Language-Processing-with-Python | 721e693fbbe9d2e52ed1e1131cacac20a5f530d4 | [
"MIT"
] | 110 | 2018-07-18T12:19:23.000Z | 2022-03-27T10:11:59.000Z | Chapter11/01_example.ipynb | Krismars19/Hands-On-Natural-Language-Processing-with-Python | 721e693fbbe9d2e52ed1e1131cacac20a5f530d4 | [
"MIT"
] | 6 | 2019-04-10T11:18:44.000Z | 2022-02-10T00:32:48.000Z | Chapter11/01_example.ipynb | Krismars19/Hands-On-Natural-Language-Processing-with-Python | 721e693fbbe9d2e52ed1e1131cacac20a5f530d4 | [
"MIT"
] | 93 | 2018-07-18T17:57:36.000Z | 2022-03-31T01:48:46.000Z | 56.809955 | 5,404 | 0.737157 | [
[
[
"import numpy as np\nimport librosa\nimport os\nimport random\nimport tflearn\nimport tensorflow as tf",
"/Users/i346047/anaconda3/lib/python3.6/importlib/_bootstrap.py:219: RuntimeWarning: compiletime version 3.5 of module 'tensorflow.python.framework.fast_tensor_util' does not match runtime version 3.6\n return f(*args, **kwds)\n/Users/i346047/anaconda3/lib/python3.6/site-packages/h5py/__init__.py:34: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.\n from ._conv import register_converters as _register_converters\n"
],
[
"lr = 0.001\niterations_train = 30\nbsize = 64\naudio_features = 20 \nutterance_length = 35 \nndigits = 10 ",
"_____no_output_____"
],
[
"def get_mfcc_features(fpath):\n raw_w,sampling_rate = librosa.load(fpath,mono=True)\n mfcc_features = librosa.feature.mfcc(raw_w,sampling_rate)\n if(mfcc_features.shape[1]>utterance_length):\n mfcc_features = mfcc_features[:,0:utterance_length]\n else:\n mfcc_features=np.pad(mfcc_features,((0,0),(0,utterance_length-mfcc_features.shape[1])), \n mode='constant', constant_values=0)\n return mfcc_features",
"_____no_output_____"
],
[
"import matplotlib.pyplot as plt\nimport librosa.display\n%matplotlib inline\nmfcc_features = get_mfcc_features('../../speech_dset/recordings/train/5_theo_45.wav')\nplt.figure(figsize=(10, 6))\nplt.subplot(2, 1, 1)\nlibrosa.display.specshow(mfcc_features, x_axis='time')\nprint(\"Feature shape: \", mfcc_features.shape)\nprint(\"Features: \", mfcc_features[:,0])",
"Feature shape: (20, 35)\nFeatures: [-5.16464322e+02 2.18720111e+02 -9.43628435e+01 1.63510496e+01\n 2.09937445e+01 -4.38791200e+01 1.94267052e+01 -9.41531735e-02\n -2.99960992e+01 1.39727129e+01 6.60561909e-01 -1.14758965e+01\n 3.13688180e+00 -1.34556070e+01 -1.43686686e+00 1.17119580e+01\n -1.54499037e+01 -1.13105764e+01 2.53027299e+00 -1.35725427e+01]\n"
],
[
"def get_batch_mfcc(fpath,batch_size=256):\n ft_batch = []\n labels_batch = []\n files = os.listdir(fpath)\n while True:\n print(\"Total %d files\" % len(files))\n random.shuffle(files)\n for fname in files:\n if not fname.endswith(\".wav\"): \n continue\n mfcc_features = get_mfcc_features(fpath+fname) \n label = np.eye(10)[int(fname[0])]\n labels_batch.append(label)\n ft_batch.append(mfcc_features)\n if len(ft_batch) >= batch_size:\n yield ft_batch, labels_batch \n ft_batch = [] \n labels_batch = []",
"_____no_output_____"
],
[
"train_batch = get_batch_mfcc('../../speech_dset/recordings/train/')\nsp_network = tflearn.input_data([None, audio_features, utterance_length])\nsp_network = tflearn.lstm(sp_network, 128*4, dropout=0.5)\nsp_network = tflearn.fully_connected(sp_network, ndigits, activation='softmax')\nsp_network = tflearn.regression(sp_network, optimizer='adam', learning_rate=lr, loss='categorical_crossentropy')\nsp_model = tflearn.DNN(sp_network, tensorboard_verbose=0)\nwhile iterations_train > 0:\n X_tr, y_tr = next(train_batch)\n X_test, y_test = next(train_batch)\n sp_model.fit(X_tr, y_tr, n_epoch=10, validation_set=(X_test, y_test), show_metric=True, batch_size=bsize)\n iterations_train-=1\nsp_model.save(\"/tmp/speech_recognition.lstm\")",
"Training Step: 1199 | total loss: \u001b[1m\u001b[32m0.45749\u001b[0m\u001b[0m | time: 0.617s\n| Adam | epoch: 300 | loss: 0.45749 - acc: 0.8975 -- iter: 192/256\nTraining Step: 1200 | total loss: \u001b[1m\u001b[32m0.43931\u001b[0m\u001b[0m | time: 1.819s\n| Adam | epoch: 300 | loss: 0.43931 - acc: 0.9031 | val_loss: 0.18600 - val_acc: 0.9375 -- iter: 256/256\n--\nINFO:tensorflow:/tmp/speech_recognition.lstm is not in all_model_checkpoint_paths. Manually adding it.\n"
],
[
"sp_model.load('/tmp/speech_recognition.lstm')\nmfcc_features = get_mfcc_features('../../speech_dset/recordings/test/4_jackson_40.wav')\nmfcc_features = mfcc_features.reshape((1,mfcc_features.shape[0],mfcc_features.shape[1]))\nprediction_digit = sp_model.predict(mfcc_features)\nprint(prediction_digit)\nprint(\"Digit predicted: \", np.argmax(prediction_digit))",
"INFO:tensorflow:Restoring parameters from /tmp/speech_recognition.lstm\n[[2.3709694e-03 5.1581711e-03 7.8898791e-04 1.9530311e-03 9.8459840e-01\n 1.1394228e-03 3.0317350e-04 1.8992715e-03 1.6027489e-03 1.8592674e-04]]\nDigit predicted: 4\n"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3d5946e40e4cd21b5b993bb1051157e0e2a4d1 | 29,587 | ipynb | Jupyter Notebook | othertests/int2e-speed-julia.ipynb | RaphaelRobidas/pyquante2 | d945150210884d82be0c7d3cf332409a553ebc24 | [
"BSD-3-Clause"
] | 107 | 2015-01-22T00:02:52.000Z | 2022-03-15T06:35:49.000Z | othertests/int2e-speed-julia.ipynb | RaphaelRobidas/pyquante2 | d945150210884d82be0c7d3cf332409a553ebc24 | [
"BSD-3-Clause"
] | 8 | 2015-04-26T07:33:14.000Z | 2020-07-15T21:34:42.000Z | othertests/int2e-speed-julia.ipynb | RaphaelRobidas/pyquante2 | d945150210884d82be0c7d3cf332409a553ebc24 | [
"BSD-3-Clause"
] | 59 | 2015-01-31T21:16:46.000Z | 2022-03-15T06:23:04.000Z | 35.733092 | 142 | 0.420759 | [
[
[
"empty"
]
]
] | [
"empty"
] | [
[
"empty"
]
] |
cb3d5ee4d532be59389f25292361002b1fb62386 | 4,143 | ipynb | Jupyter Notebook | intermediate/ML_Med_useML.ipynb | virati/Med_ML | d2c51db67b17f8873f30c9ba0032409f8326c220 | [
"MIT"
] | null | null | null | intermediate/ML_Med_useML.ipynb | virati/Med_ML | d2c51db67b17f8873f30c9ba0032409f8326c220 | [
"MIT"
] | null | null | null | intermediate/ML_Med_useML.ipynb | virati/Med_ML | d2c51db67b17f8873f30c9ba0032409f8326c220 | [
"MIT"
] | 1 | 2020-02-17T21:26:15.000Z | 2020-02-17T21:26:15.000Z | 30.91791 | 193 | 0.621289 | [
[
[
"# Machine learning for medicine\n## Using Machine Learning for Discovery\n\nThe goal of this notebook is to impart a foundation that can help you apply machine learning approaches to your Discovery project.\n\nBelow is a set of rapid-fire examples that don't spend a lot of time motivating examples.\nInstead, their goal is to outline a quick setup of how to implement basic ML analyses that may be helpful in the types of datasets typical for clinical research/Discovery.\n\n### Imports",
"_____no_output_____"
]
],
[
[
"import pandas as pds\nimport numpy as np\nfrom ipywidgets import interact, interactive, fixed, interact_manual\nimport scipy.stats as stats\nimport ipywidgets as widgets\nimport matplotlib.pyplot as plt\n\nimport networkx as nx",
"_____no_output_____"
]
],
[
[
"## Testing-Training Set\nWe're going to start with a very, very important concept: splitting your data into a *training* set and a *testing* set.\nThis is crucially important because it lets you study whether the model you learned is *generalizable*.",
"_____no_output_____"
],
[
"It's almost like a cheat code: it makes it possible for us to fit a model to part of our data and then see how well that model performs in data that **was not used to make the model**.\nThis gets around a lot of the problems that drove people to criticize \"model fitting\" for decades.\n\n**There are few reasons for a model that performs well in a training set to also perform well in the testing set *unless the model captures some aspect of the truth* **.\n\nWe'll explore this idea in more detail in a different notebook, because there's some nuances there.",
"_____no_output_____"
],
[
"## Finding Relationships: Regression\n\n### Linear\nSo we've got two variables, both of which can be any number you can think of.\nLinear regression would be a good place to start to see if we can link the two variables.\n\n\n### Non-linear\nYou have a sneaking suspicion that the variables you're interested in aren't perfectly linearly related: at some point if you double the input you *don't* double the output.\nLet's work on some *non-linear* analyses.",
"_____no_output_____"
],
[
"## Finding Boundaries: Logistic Regression\n\nYou've got some lab value that is a number and you're trying to figure out if the patient is in some *catagory* or subtype of disease.\nLogistic regression may be a good option for you.",
"_____no_output_____"
],
[
"## Finding Patterns: Principal Components\nYou've got a whole bunch of data in a whole bunch of variables.\nYou don't really know where to being, you just know some of the variables go with each other and you want to see if those variables",
"_____no_output_____"
],
[
"## Finding Groups: Clustering",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
cb3d605f77c785bb1b997cebdec445abbedd2ad5 | 10,838 | ipynb | Jupyter Notebook | notebooks/ksonnet_ambassador_minikube.ipynb | fisache/seldon-core | 1d3b18c871452101b1d8fab66011c2aadb84e5ad | [
"Apache-2.0"
] | null | null | null | notebooks/ksonnet_ambassador_minikube.ipynb | fisache/seldon-core | 1d3b18c871452101b1d8fab66011c2aadb84e5ad | [
"Apache-2.0"
] | null | null | null | notebooks/ksonnet_ambassador_minikube.ipynb | fisache/seldon-core | 1d3b18c871452101b1d8fab66011c2aadb84e5ad | [
"Apache-2.0"
] | null | null | null | 24.246085 | 360 | 0.549825 | [
[
[
"# Deploying Machine Learning Models using ksonnet and Ambassador\n",
"_____no_output_____"
],
[
"## Prerequistes\nYou will need\n - [Git clone of Seldon Core](https://github.com/SeldonIO/seldon-core)\n - [Minikube](https://github.com/kubernetes/minikube) version v0.24.0 or greater\n - [python grpc tools](https://grpc.io/docs/quickstart/python.html)\n - [ksonnet client](https://ksonnet.io/)",
"_____no_output_____"
],
[
"Start minikube and ensure custom resource validation is activated and there is 5G of memory. \n\n**2018-06-13** : At present we find the most stable version of minikube across platforms is 0.25.2 as there are issues with 0.26 and 0.27 on some systems. We also find the default VirtualBox driver can be problematic on some systems so we suggest using the [KVM2 driver](https://github.com/kubernetes/minikube/blob/master/docs/drivers.md#kvm2-driver).\n\nYour start command would then look like:\n```\nminikube start --vm-driver kvm2 --memory 4096 --feature-gates=CustomResourceValidation=true --extra-config=apiserver.Authorization.Mode=RBAC\n```",
"_____no_output_____"
],
[
"## Setup\n\nWhen you have a running minikube cluster run:\n",
"_____no_output_____"
]
],
[
[
"!kubectl create clusterrolebinding kube-system-cluster-admin --clusterrole=cluster-admin --serviceaccount=kube-system:default",
"_____no_output_____"
],
[
"!kubectl create namespace seldon",
"_____no_output_____"
]
],
[
[
"## Install Ambassador\nSee the Abassador [getting started](https://www.getambassador.io/user-guide/getting-started) docs. Eventually, this would also be done via ksonnet.",
"_____no_output_____"
]
],
[
[
"!kubectl apply -f resources/ambassador-rbac.yaml -n seldon",
"_____no_output_____"
]
],
[
[
"## Install Seldon Core\nCreate a ksonnet app and install the prototypes from our registry.",
"_____no_output_____"
]
],
[
[
"!ks init my-ml-deployment --api-spec=version:v1.8.0",
"_____no_output_____"
],
[
"!cd my-ml-deployment && \\\n ks registry add seldon-core github.com/SeldonIO/seldon-core/tree/master/seldon-core && \\\n ks pkg install seldon-core/seldon-core@master && \\\n ks generate seldon-core seldon-core --withApife=false --namespace=seldon --withRbac=true",
"_____no_output_____"
],
[
"!cd my-ml-deployment && \\\n ks apply default",
"_____no_output_____"
]
],
[
[
"## Set up REST and gRPC methods\n\n**Ensure you port forward ambassador**:\n\n```\nkubectl port-forward $(kubectl get pods -n seldon -l service=ambassador -o jsonpath='{.items[0].metadata.name}') -n seldon 8002:80\n```",
"_____no_output_____"
],
[
"Install gRPC modules for the prediction protos.",
"_____no_output_____"
]
],
[
[
"!cp ../proto/prediction.proto ./proto\n!python -m grpc.tools.protoc -I. --python_out=. --grpc_python_out=. ./proto/prediction.proto",
"_____no_output_____"
]
],
[
[
"Illustration of both REST and gRPC requests. ",
"_____no_output_____"
]
],
[
[
"import requests\nfrom requests.auth import HTTPBasicAuth\nfrom proto import prediction_pb2\nfrom proto import prediction_pb2_grpc\nimport grpc\n\nAMBASSADOR_API=\"localhost:8002\"\n\ndef rest_request(deploymentName):\n payload = {\"data\":{\"names\":[\"a\",\"b\"],\"tensor\":{\"shape\":[2,2],\"values\":[0,0,1,1]}}}\n response = requests.post(\n \"http://\"+AMBASSADOR_API+\"/seldon/\"+deploymentName+\"/api/v0.1/predictions\",\n json=payload)\n print(response.status_code)\n print(response.text) \n \ndef rest_request_auth(deploymentName,username,password):\n payload = {\"data\":{\"names\":[\"a\",\"b\"],\"tensor\":{\"shape\":[2,2],\"values\":[0,0,1,1]}}}\n response = requests.post(\n \"http://\"+AMBASSADOR_API+\"/seldon/\"+deploymentName+\"/api/v0.1/predictions\",\n json=payload,\n auth=HTTPBasicAuth(username, password))\n print(response.status_code)\n print(response.text)\n\ndef grpc_request(deploymentName):\n datadef = prediction_pb2.DefaultData(\n names = [\"a\",\"b\"],\n tensor = prediction_pb2.Tensor(\n shape = [3,2],\n values = [1.0,1.0,2.0,3.0,4.0,5.0]\n )\n )\n request = prediction_pb2.SeldonMessage(data = datadef)\n channel = grpc.insecure_channel(AMBASSADOR_API)\n stub = prediction_pb2_grpc.SeldonStub(channel)\n metadata = [('seldon',deploymentName)]\n response = stub.Predict(request=request,metadata=metadata)\n print(response)",
"_____no_output_____"
]
],
[
[
"## Create Seldon Deployment",
"_____no_output_____"
],
[
"**Check everything is running before continuing**",
"_____no_output_____"
]
],
[
[
"!kubectl get pods -n seldon",
"_____no_output_____"
],
[
"!kubectl apply -f resources/model.json -n seldon",
"_____no_output_____"
]
],
[
[
"Check status of deployment before continuing. **ReplicasAvailable must be equal to 1** First time might take some time to download images.",
"_____no_output_____"
]
],
[
[
"!kubectl get seldondeployments seldon-deployment-example -o jsonpath='{.status}' -n seldon",
"_____no_output_____"
]
],
[
[
"## Get predictions",
"_____no_output_____"
],
[
"#### REST Request",
"_____no_output_____"
]
],
[
[
"rest_request(\"seldon-deployment-example\")",
"_____no_output_____"
]
],
[
[
"#### gRPC Request",
"_____no_output_____"
]
],
[
[
"grpc_request(\"seldon-deployment-example\")",
"_____no_output_____"
]
],
[
[
"## Adding Authentication\nWe will add the example authentication from the Ambassador tutorial.",
"_____no_output_____"
]
],
[
[
"!kubectl apply -f resources/ambassador-auth-service-setup.yaml -n seldon",
"_____no_output_____"
]
],
[
[
"** Need to wait until running before adding Ambassador config **",
"_____no_output_____"
]
],
[
[
"!kubectl get pods -n seldon",
"_____no_output_____"
],
[
"!kubectl apply -f resources/ambassador-auth-service-config.yaml -n seldon",
"_____no_output_____"
]
],
[
[
"Show failed request when auth is running",
"_____no_output_____"
]
],
[
[
"rest_request(\"seldon-deployment-example\")",
"_____no_output_____"
]
],
[
[
"Show successful request with auth",
"_____no_output_____"
]
],
[
[
"rest_request_auth(\"seldon-deployment-example\",\"username\",\"password\")",
"_____no_output_____"
]
],
[
[
"# Tear down",
"_____no_output_____"
]
],
[
[
"!kubectl delete -f resources/ambassador-auth-service-setup.yaml -n seldon",
"_____no_output_____"
],
[
"!kubectl delete -f resources/ambassador-rbac.yaml -n seldon",
"_____no_output_____"
],
[
"!kubectl delete -f resources/model.json",
"_____no_output_____"
],
[
"!cd my-ml-deployment && ks delete default",
"_____no_output_____"
],
[
"!rm -rf my-ml-deployment",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
cb3d727bcaefc29207043be594070d662b93996e | 13,135 | ipynb | Jupyter Notebook | Tensorflow/TensorFlow Deployment/Course 4 - TensorFlow Serving/Week 2/Examples/text_classification.ipynb | mr-haseeb/Artificial-Intelligence | 94f5956520852b7454a7837631be4ddca1031610 | [
"MIT"
] | null | null | null | Tensorflow/TensorFlow Deployment/Course 4 - TensorFlow Serving/Week 2/Examples/text_classification.ipynb | mr-haseeb/Artificial-Intelligence | 94f5956520852b7454a7837631be4ddca1031610 | [
"MIT"
] | 13 | 2021-03-19T11:38:41.000Z | 2022-03-12T00:52:00.000Z | Tensorflow/TensorFlow Deployment/Course 4 - TensorFlow Serving/Week 2/Examples/text_classification.ipynb | mr-haseeb/Artificial-Intelligence | 94f5956520852b7454a7837631be4ddca1031610 | [
"MIT"
] | 1 | 2021-12-27T12:44:08.000Z | 2021-12-27T12:44:08.000Z | 29.852273 | 486 | 0.592691 | [
[
[
"##### Copyright 2019 The TensorFlow Authors.",
"_____no_output_____"
]
],
[
[
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
]
],
[
[
"# Text Classification\n\nIn this notebook we will classify movie reviews as being either `positive` or `negative`. We'll use the [IMDB dataset](https://www.tensorflow.org/datasets/catalog/imdb_reviews) that contains the text of 50,000 movie reviews from the [Internet Movie Database](https://www.imdb.com/). These are split into 25,000 reviews for training and 25,000 reviews for testing. The training and testing sets are *balanced*, meaning they contain an equal number of positive and negative reviews.",
"_____no_output_____"
],
[
"<table class=\"tfo-notebook-buttons\" align=\"left\">\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/lmoroney/dlaicourse/blob/master/TensorFlow%20Deployment/Course%204%20-%20TensorFlow%20Serving/Week%202/Examples/text_classification.ipynb\">\n <img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" />\n Run in Google Colab</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://github.com/lmoroney/dlaicourse/blob/master/TensorFlow%20Deployment/Course%204%20-%20TensorFlow%20Serving/Week%202/Examples/text_classification.ipynb\">\n <img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" />\n View source on GitHub</a>\n </td>\n</table>",
"_____no_output_____"
],
[
"# Setup",
"_____no_output_____"
]
],
[
[
"try:\n %tensorflow_version 2.x\nexcept:\n pass",
"_____no_output_____"
],
[
"import tensorflow as tf\nimport tensorflow_hub as hub\nimport tensorflow_datasets as tfds\ntfds.disable_progress_bar()\n\nprint(\"\\u2022 Using TensorFlow Version:\", tf.__version__)",
"_____no_output_____"
]
],
[
[
"## Download the IMDB Dataset\n\nWe will download the [IMDB dataset](https://www.tensorflow.org/datasets/catalog/imdb_reviews) using TensorFlow Datasets. We will use a training set, a validation set, and a test set. Since the IMDB dataset doesn't have a validation split, we will use the first 60\\% of the training set for training, and the last 40\\% of the training set for validation.",
"_____no_output_____"
]
],
[
[
"splits = ['train[:60%]', 'train[-40%:]', 'test']\n\nsplits, info = tfds.load(name=\"imdb_reviews\", with_info=True, split=splits, as_supervised=True)\n\ntrain_data, validation_data, test_data = splits",
"_____no_output_____"
]
],
[
[
"## Explore the Data \n\nLet's take a moment to look at the data.",
"_____no_output_____"
]
],
[
[
"num_train_examples = info.splits['train'].num_examples\nnum_test_examples = info.splits['test'].num_examples\nnum_classes = info.features['label'].num_classes\n\nprint('The Dataset has a total of:')\nprint('\\u2022 {:,} classes'.format(num_classes))\n\nprint('\\u2022 {:,} movie reviews for training'.format(num_train_examples))\nprint('\\u2022 {:,} movie reviews for testing'.format(num_test_examples))",
"_____no_output_____"
]
],
[
[
"The labels are either 0 or 1, where 0 is a negative review, and 1 is a positive review. We will create a list with the corresponding class names, so that we can map labels to class names later on.",
"_____no_output_____"
]
],
[
[
"class_names = ['negative', 'positive']",
"_____no_output_____"
]
],
[
[
"Each example consists of a sentence representing the movie review and a corresponding label. The sentence is not preprocessed in any way. Let's take a look at the first example of the training set. ",
"_____no_output_____"
]
],
[
[
"for review, label in train_data.take(1):\n review = review.numpy()\n label = label.numpy()\n\n print('\\nMovie Review:\\n\\n', review)\n print('\\nLabel:', class_names[label])",
"_____no_output_____"
]
],
[
[
"## Load Word Embeddings\n\nIn this example, the input data consists of sentences. The labels to predict are either 0 or 1.\n\nOne way to represent the text is to convert sentences into word embeddings. Word embeddings, are an efficient way to represent words using dense vectors, where semantically similar words have similar vectors. We can use a pre-trained text embedding as the first layer of our model, which will have two advantages:\n\n* We don't have to worry anout text preprocessing.\n* We can benefit from transfer learning.\n\nFor this example we will use a model from [TensorFlow Hub](https://tfhub.dev/) called [google/tf2-preview/gnews-swivel-20dim/1](https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1). We'll create a `hub.KerasLayer` that uses the TensorFlow Hub model to embed the sentences. We can choose to fine-tune the TF hub module weights during training by setting the `trainable` parameter to `True`.",
"_____no_output_____"
]
],
[
[
"embedding = \"https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1\"\n\nhub_layer = hub.KerasLayer(embedding, input_shape=[], dtype=tf.string, trainable=True)",
"_____no_output_____"
]
],
[
[
"## Build Pipeline",
"_____no_output_____"
]
],
[
[
"batch_size = 512\n\ntrain_batches = train_data.shuffle(num_train_examples // 4).batch(batch_size).prefetch(1)\nvalidation_batches = validation_data.batch(batch_size).prefetch(1)\ntest_batches = test_data.batch(batch_size)",
"_____no_output_____"
]
],
[
[
"## Build the Model\n\nIn the code below we will build a Keras `Sequential` model with the following layers:\n\n1. The first layer is a TensorFlow Hub layer. This layer uses a pre-trained SavedModel to map a sentence into its embedding vector. The model that we are using ([google/tf2-preview/gnews-swivel-20dim/1](https://tfhub.dev/google/tf2-preview/gnews-swivel-20dim/1)) splits the sentence into tokens, embeds each token and then combines the embedding. The resulting dimensions are: `(num_examples, embedding_dimension)`.\n\n\n2. This fixed-length output vector is piped through a fully-connected (`Dense`) layer with 16 hidden units.\n\n\n3. The last layer is densely connected with a single output node. Using the `sigmoid` activation function, this value is a float between 0 and 1, representing a probability, or confidence level.",
"_____no_output_____"
]
],
[
[
"model = tf.keras.Sequential([\n hub_layer,\n tf.keras.layers.Dense(16, activation='relu'),\n tf.keras.layers.Dense(1, activation='sigmoid')])",
"_____no_output_____"
]
],
[
[
"## Train the Model\n\nSince this is a binary classification problem and the model outputs a probability (a single-unit layer with a sigmoid activation), we'll use the `binary_crossentropy` loss function. ",
"_____no_output_____"
]
],
[
[
"model.compile(optimizer='adam',\n loss='binary_crossentropy',\n metrics=['accuracy'])\n\nhistory = model.fit(train_batches,\n epochs=20,\n validation_data=validation_batches)",
"_____no_output_____"
]
],
[
[
"## Evaluate the Model\n\nWe will now see how well our model performs on the testing set.",
"_____no_output_____"
]
],
[
[
"eval_results = model.evaluate(test_batches, verbose=0)\n\nfor metric, value in zip(model.metrics_names, eval_results):\n print(metric + ': {:.3}'.format(value))",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
cb3d796dccdf8d966994d8f7084aedeab38d7d66 | 29,760 | ipynb | Jupyter Notebook | Control_Chart_Implementation_1.ipynb | tjido/ControlCharts | fe2dd80605d2419781c17f6249d04f73a9971b7b | [
"MIT"
] | null | null | null | Control_Chart_Implementation_1.ipynb | tjido/ControlCharts | fe2dd80605d2419781c17f6249d04f73a9971b7b | [
"MIT"
] | null | null | null | Control_Chart_Implementation_1.ipynb | tjido/ControlCharts | fe2dd80605d2419781c17f6249d04f73a9971b7b | [
"MIT"
] | null | null | null | 102.268041 | 8,982 | 0.533837 | [
[
[
"<a href=\"https://colab.research.google.com/github/tjido/ControlCharts/blob/master/Control_Chart_Implementation_1.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"# Control Chart_Python Implementation 1",
"_____no_output_____"
],
[
"This script takes a date input and creates a Control Chart. This is done in a python cloud environment using a Jupiter notebook in Google Colab.\n\nContact: Shingai Manjengwa, Technical Education Specialist, Vector Institute (Twitter: @Tjido)\n",
"_____no_output_____"
],
[
"This work is part of a research paper by Shingai Manjengwa: 'Visualizing a Disruption, using Control Charts to understand the impact of Covid19.'",
"_____no_output_____"
]
],
[
[
"#Import relevant packages\n\nimport pandas as pd\nimport plotly.graph_objects as go\nimport datetime\n\n#Load the dataset\nurl = 'https://raw.githubusercontent.com/tjido/ControlCharts/master/US_CIVPART_01042020.csv' \ndf_data = pd.read_csv(url)\n\ndf_data.head()\n\n#Manage the date format\n\nwhile True:\n date_entry = input('Enter the disruption date in the format YYYY-MM-DD: ')\n year, month, day = map(int, date_entry.split('-'))\n date1 = datetime.date(year, month, day)\n value_found = False\n for a in range(len(df_data)):\n if df_data['Date'][a] ==str(date1):\n print(a)\n date_value = a\n value_found=True\n break\n \n if value_found==True:\n print('Thank you! ')\n break\n break\n else:\n print('Kindly Enter the date again, As you entered an invalid date')\n\n#Set the standard deviation\nstandard_deviation_level = 1 \n\n#Compute the Upper Control Limit, Lower Control Limit and the Mean\nUCL_a = df_data['CIVPART'][:int(date_value)].mean()+(standard_deviation_level*df_data['CIVPART'][:int(date_value)].std()) #a UCL\nLCL_a = df_data['CIVPART'][:int(date_value)].mean()-(standard_deviation_level*df_data['CIVPART'][:int(date_value)].std()) #a LCL\nMEAN_a = df_data['CIVPART'][:int(date_value)].mean() #Overall Mean\n\nUCL_data_y = [UCL_a]*len(df_data['Date'] ) #make list equal to number of data with UCL\nLCL_data_y = [LCL_a]*len(df_data['Date']) #make list equal to number of data with LCL\nMEAN_data_y = [MEAN_a]*len(df_data['Date']) #make list equal to number of data with MEAN\n\nUCL_afterline = df_data['CIVPART'][int(date_value):].mean()+(standard_deviation_level*df_data['CIVPART'][int(date_value):].std()) #UCL after line\nLCL_afterline = df_data['CIVPART'][int(date_value):].mean()-(standard_deviation_level*df_data['CIVPART'][int(date_value):].std()) #LCL after line\nMean_afterline = df_data['CIVPART'][int(date_value):].mean() #Mean after line\n\n\nUCL_data_y[int(date_value):] = [UCL_afterline]*len(UCL_data_y[int(date_value):]) #Replace UCL after line data with new values\nLCL_data_y[int(date_value):] = [LCL_afterline]*len(LCL_data_y[int(date_value):]) #Replace LCL after line data with new values\nMEAN_data_y[int(date_value):] = [Mean_afterline]*len(MEAN_data_y[int(date_value):]) #Replace MEAN after line data with new values\n\ndf_data['UCL'] = UCL_data_y\ndf_data['LCL'] = LCL_data_y\ndf_data['MEAN'] = MEAN_data_y\n\n#Set formatting of point outside the standard deviation\ndf_color = []\nfor a in range(len(df_data)):\n if df_data['CIVPART'][a]>df_data['UCL'][a]:\n df_color.append('Red')\n elif df_data['CIVPART'][a]<df_data['LCL'][a]:\n df_color.append('Red')\n else:\n df_color.append('Blue')\n \n \n#Set formatting, axis labels and heading\ndf_data['color'] = df_color\n\nfig = go.Figure()\nfig.add_trace(go.Scatter(x=df_data['Date'], y=df_data['CIVPART'],marker_color=df_color,\n mode='lines+markers',\n name='Labor_Force_Participation',)) #Display CIVPART data \nfig.add_trace(go.Scatter(x=df_data['Date'] ,y=UCL_data_y,\n mode='lines', name='UCL',line=dict(color='red', width=2))) #UCL Line\nfig.add_trace(go.Scatter(x=df_data['Date'] ,y=LCL_data_y,\n mode='lines', name='LCL',line=dict(color='red', width=2))) #LCL Line\nfig.add_trace(go.Scatter(x=df_data['Date'] ,y=MEAN_data_y,\n mode='lines', name='Mean',line=dict(color='green', width=4))) #MEAN Line\n\n#Insert custom vertical line at point of disruption\nfig.update_layout( \n shapes=[\n dict(\n type= 'line',\n yref= 'paper', y0= 0, y1= 1,\n xref= 'x', x0=df_data['Date'][int(date_value)-1],x1=df_data['Date'][int(date_value)-1], ##Set the line at user specified date\n line=dict(\n color=\"black\",\n width=3,\n dash=\"dot\",\n )\n )\n],\nautosize=True,\n height=600,\n title=\"Labor Force Participation, April 2020\",\n xaxis_title=\"Date\",\n yaxis_title=\"% Participation\",\n \n margin=dict(\n l=10,\n r=50,\n b=50,\n t=100,\n pad=4\n ),\n font=dict(\n family=\"Amiri\",\n ),\n paper_bgcolor=\"LightSteelBlue\",\n\n)\n\n#Write output to HTML\nfig.show()\nfig.write_html('Control Chart Visualization_1.html') \n\n\n\n",
"Enter the disruption date in the format YYYY-MM-DD: 2015-01-01\nKindly Enter the date again, As you entered an invalid date\nEnter the disruption date in the format YYYY-MM-DD: 2017-01-01\n21\nThank you! \n"
]
],
[
[
"# Thanks for your time!",
"_____no_output_____"
],
[
"Feedback welcome, stay in touch - Twitter: @Tjido",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
cb3d7c1c69769307f8147be8bb7109d67296eb83 | 15,364 | ipynb | Jupyter Notebook | course/4 Deep Learning Intro.ipynb | opread/zero_to_deep_learning_video | 29f78be66eb00a88d73213cef22da46e41cb58e0 | [
"MIT"
] | null | null | null | course/4 Deep Learning Intro.ipynb | opread/zero_to_deep_learning_video | 29f78be66eb00a88d73213cef22da46e41cb58e0 | [
"MIT"
] | null | null | null | course/4 Deep Learning Intro.ipynb | opread/zero_to_deep_learning_video | 29f78be66eb00a88d73213cef22da46e41cb58e0 | [
"MIT"
] | null | null | null | 23.894246 | 476 | 0.55591 | [
[
[
"# Deep Learning Intro",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport matplotlib.pyplot as plt\nimport pandas as pd\nimport numpy as np",
"_____no_output_____"
]
],
[
[
"## Shallow and Deep Networks",
"_____no_output_____"
]
],
[
[
"from sklearn.datasets import make_moons\n\nX, y = make_moons(n_samples=1000, noise=0.1, random_state=0)\nplt.plot(X[y==0, 0], X[y==0, 1], 'ob', alpha=0.5)\nplt.plot(X[y==1, 0], X[y==1, 1], 'xr', alpha=0.5)\nplt.legend(['0', '1'])",
"_____no_output_____"
],
[
"X.shape",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split",
"_____no_output_____"
],
[
"X_train, X_test, y_train, y_test = train_test_split(X, y,\n test_size=0.3,\n random_state=42)",
"_____no_output_____"
],
[
"from keras.models import Sequential\nfrom keras.layers import Dense\nfrom keras.optimizers import SGD, Adam",
"_____no_output_____"
]
],
[
[
"### Shallow Model",
"_____no_output_____"
]
],
[
[
"model = Sequential()\nmodel.add(Dense(1, input_shape=(2,), activation='sigmoid'))\nmodel.compile(Adam(lr=0.05), 'binary_crossentropy', metrics=['accuracy'])",
"_____no_output_____"
],
[
"model.fit(X_train, y_train, epochs=200, verbose=0)",
"_____no_output_____"
],
[
"results = model.evaluate(X_test, y_test)",
"_____no_output_____"
],
[
"results",
"_____no_output_____"
],
[
"print(\"The Accuracy score on the Train set is:\\t{:0.3f}\".format(results[1]))",
"_____no_output_____"
],
[
"def plot_decision_boundary(model, X, y):\n amin, bmin = X.min(axis=0) - 0.1\n amax, bmax = X.max(axis=0) + 0.1\n hticks = np.linspace(amin, amax, 101)\n vticks = np.linspace(bmin, bmax, 101)\n \n aa, bb = np.meshgrid(hticks, vticks)\n ab = np.c_[aa.ravel(), bb.ravel()]\n \n c = model.predict(ab)\n cc = c.reshape(aa.shape)\n\n plt.figure(figsize=(12, 8))\n plt.contourf(aa, bb, cc, cmap='bwr', alpha=0.2)\n plt.plot(X[y==0, 0], X[y==0, 1], 'ob', alpha=0.5)\n plt.plot(X[y==1, 0], X[y==1, 1], 'xr', alpha=0.5)\n plt.legend(['0', '1'])\n \nplot_decision_boundary(model, X, y)",
"_____no_output_____"
]
],
[
[
"### Deep model",
"_____no_output_____"
]
],
[
[
"model = Sequential()\nmodel.add(Dense(4, input_shape=(2,), activation='tanh'))\nmodel.add(Dense(2, activation='tanh'))\nmodel.add(Dense(1, activation='sigmoid'))\nmodel.compile(Adam(lr=0.05), 'binary_crossentropy', metrics=['accuracy'])",
"_____no_output_____"
],
[
"model.fit(X_train, y_train, epochs=100, verbose=0)",
"_____no_output_____"
],
[
"model.evaluate(X_test, y_test)",
"_____no_output_____"
],
[
"from sklearn.metrics import accuracy_score, confusion_matrix",
"_____no_output_____"
],
[
"y_train_pred = model.predict_classes(X_train)\ny_test_pred = model.predict_classes(X_test)\n\nprint(\"The Accuracy score on the Train set is:\\t{:0.3f}\".format(accuracy_score(y_train, y_train_pred)))\nprint(\"The Accuracy score on the Test set is:\\t{:0.3f}\".format(accuracy_score(y_test, y_test_pred)))",
"_____no_output_____"
],
[
"plot_decision_boundary(model, X, y)",
"_____no_output_____"
]
],
[
[
"## Multiclass classification\n\n### The Iris dataset",
"_____no_output_____"
]
],
[
[
"df = pd.read_csv('../data/iris.csv')",
"_____no_output_____"
],
[
"import seaborn as sns\nsns.pairplot(df, hue=\"species\")",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"X = df.drop('species', axis=1)\nX.head()",
"_____no_output_____"
],
[
"target_names = df['species'].unique()\ntarget_names",
"_____no_output_____"
],
[
"target_dict = {n:i for i, n in enumerate(target_names)}\ntarget_dict",
"_____no_output_____"
],
[
"y= df['species'].map(target_dict)\ny.head()",
"_____no_output_____"
],
[
"from keras.utils.np_utils import to_categorical",
"_____no_output_____"
],
[
"y_cat = to_categorical(y)",
"_____no_output_____"
],
[
"y_cat[:10]",
"_____no_output_____"
],
[
"X_train, X_test, y_train, y_test = train_test_split(X.values, y_cat,\n test_size=0.2)",
"_____no_output_____"
],
[
"model = Sequential()\nmodel.add(Dense(3, input_shape=(4,), activation='softmax'))\nmodel.compile(Adam(lr=0.1),\n loss='categorical_crossentropy',\n metrics=['accuracy'])",
"_____no_output_____"
],
[
"model.fit(X_train, y_train, epochs=20, validation_split=0.1)",
"_____no_output_____"
],
[
"y_pred = model.predict(X_test)",
"_____no_output_____"
],
[
"y_pred[:5]",
"_____no_output_____"
],
[
"y_test_class = np.argmax(y_test, axis=1)\ny_pred_class = np.argmax(y_pred, axis=1)",
"_____no_output_____"
],
[
"from sklearn.metrics import classification_report",
"_____no_output_____"
],
[
"print(classification_report(y_test_class, y_pred_class))",
"_____no_output_____"
],
[
"confusion_matrix(y_test_class, y_pred_class)",
"_____no_output_____"
]
],
[
[
"## Exercise 1",
"_____no_output_____"
],
[
"The [Pima Indians dataset](https://archive.ics.uci.edu/ml/datasets/Pima+Indians+Diabetes) is a very famous dataset distributed by UCI and originally collected from the National Institute of Diabetes and Digestive and Kidney Diseases. It contains data from clinical exams for women age 21 and above of Pima indian origins. The objective is to predict based on diagnostic measurements whether a patient has diabetes.\n\nIt has the following features:\n\n- Pregnancies: Number of times pregnant\n- Glucose: Plasma glucose concentration a 2 hours in an oral glucose tolerance test\n- BloodPressure: Diastolic blood pressure (mm Hg)\n- SkinThickness: Triceps skin fold thickness (mm)\n- Insulin: 2-Hour serum insulin (mu U/ml)\n- BMI: Body mass index (weight in kg/(height in m)^2)\n- DiabetesPedigreeFunction: Diabetes pedigree function\n- Age: Age (years)\n\nThe last colum is the outcome, and it is a binary variable.\n\nIn this first exercise we will explore it through the following steps:\n\n1. Load the ..data/diabetes.csv dataset, use pandas to explore the range of each feature\n- For each feature draw a histogram. Bonus points if you draw all the histograms in the same figure.\n- Explore correlations of features with the outcome column. You can do this in several ways, for example using the `sns.pairplot` we used above or drawing a heatmap of the correlations.\n- Do features need standardization? If so what stardardization technique will you use? MinMax? Standard?\n- Prepare your final `X` and `y` variables to be used by a ML model. Make sure you define your target variable well. Will you need dummy columns?",
"_____no_output_____"
],
[
"## Exercise 2",
"_____no_output_____"
],
[
"Build a fully connected NN model that predicts diabetes. Follow these steps:\n\n1. Split your data in a train/test with a test size of 20% and a `random_state = 22`\n- define a sequential model with at least one inner layer. You will have to make choices for the following things:\n - what is the size of the input?\n - how many nodes will you use in each layer?\n - what is the size of the output?\n - what activation functions will you use in the inner layers?\n - what activation function will you use at output?\n - what loss function will you use?\n - what optimizer will you use?\n- fit your model on the training set, using a validation_split of 0.1\n- test your trained model on the test data from the train/test split\n- check the accuracy score, the confusion matrix and the classification report",
"_____no_output_____"
],
[
"## Exercise 3\nCompare your work with the results presented in [this notebook](https://www.kaggle.com/futurist/d/uciml/pima-indians-diabetes-database/pima-data-visualisation-and-machine-learning). Are your Neural Network results better or worse than the results obtained by traditional Machine Learning techniques?\n\n- Try training a Support Vector Machine or a Random Forest model on the exact same train/test split. Is the performance better or worse?\n- Try restricting your features to only 4 features like in the suggested notebook. How does model performance change?",
"_____no_output_____"
],
[
"## Exercise 4\n\n[Tensorflow playground](http://playground.tensorflow.org/) is a web based neural network demo. It is really useful to develop an intuition about what happens when you change architecture, activation function or other parameters. Try playing with it for a few minutes. You don't need do understand the meaning of every knob and button in the page, just get a sense for what happens if you change something. In the next chapter we'll explore these things in more detail.\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
cb3d835e51090476a8054f409bcc4a4c5f9bb926 | 26,027 | ipynb | Jupyter Notebook | examples/Targeted Attack/test_IGA.ipynb | EdisonLeeeee/graphadv | bff372768b4082af95de9e576c7083ba42773666 | [
"MIT"
] | 5 | 2020-08-01T15:54:58.000Z | 2021-12-15T10:47:45.000Z | examples/Targeted Attack/test_IGA.ipynb | EdisonLeeeee/graphadv | bff372768b4082af95de9e576c7083ba42773666 | [
"MIT"
] | 5 | 2020-11-13T19:01:52.000Z | 2022-02-10T02:02:34.000Z | examples/Targeted Attack/test_IGA.ipynb | EdisonLeeeee/graphadv | bff372768b4082af95de9e576c7083ba42773666 | [
"MIT"
] | 2 | 2020-10-12T08:31:06.000Z | 2020-12-14T08:24:57.000Z | 73.940341 | 16,304 | 0.799593 | [
[
[
"import sys\nsys.path.append('../../../GraphGallery/')\nsys.path.append('../../../GraphAdv/')\n\nimport tensorflow as tf\nimport numpy as np\nimport networkx as nx\nimport scipy.sparse as sp\n\nfrom graphgallery.nn.models import GCN\nfrom graphgallery.nn.functions import softmax\nfrom graphadv.attack.targeted import IGA\n\n\nimport matplotlib.pyplot as plt\nplt.style.use(['no-latex', 'ieee'])",
"_____no_output_____"
],
[
"from graphgallery.data import NPZDataset\ndata = NPZDataset('citeseer', root=\"~/GraphData/datasets/\", verbose=False, standardize=True)\nadj, x, labels = data.graph.unpack()\nidx_train, idx_val, idx_test = data.split(random_state=15)\n\nn_classes = labels.max() + 1",
"Downloaded dataset files have existed.\nProcessing...\nProcessing completed.\n"
],
[
"target = 0\nassert target in idx_test\nprint(f\"Attack target {target} with class label {labels[target]}\")",
"Attack target 0 with class label 1\n"
],
[
"attacker = IGA(adj, x, labels, idx_train, seed=None, surrogate_args={'idx_val':idx_val})\nattacker.reset()\nattacker.attack(target, direct_attack=True, structure_attack=True, feature_attack=False)\n# show logs\nattacker.show_edge_flips(detail=True)",
"=== IGA: Train a surrogate model `DenseGCN` from scratch ===\n"
]
],
[
[
"# Before Attack",
"_____no_output_____"
]
],
[
[
"model = GCN(adj, x, labels, device='GPU', norm_x=None, seed=42)\nmodel.build()\nhis = model.train(idx_train, idx_val, verbose=1, epochs=100)\nsoftmax(model.predict(target).ravel())",
"<Loss = 0.1372 Acc = 0.9953 Val_Loss = 1.1586 Val_Acc = 0.7393 >: 100%|██████████| 100/100 [00:02<00:00, 48.92it/s]\n"
]
],
[
[
"# After Attack",
"_____no_output_____"
]
],
[
[
"model = GCN(attacker.A, x, labels, device='GPU', norm_x=None, seed=42)\nmodel.build()\nhis = model.train(idx_train, idx_val, verbose=1, epochs=100)\nsoftmax(model.predict(target).ravel())",
"<Loss = 0.1374 Acc = 0.9953 Val_Loss = 1.1492 Val_Acc = 0.7393 >: 100%|██████████| 100/100 [00:01<00:00, 54.86it/s]\n"
]
],
[
[
"# Visulation",
"_____no_output_____"
]
],
[
[
"def evaluate(adj, x, retrain_iters=5):\n \n classification_margins = []\n class_distrs = []\n for _ in range(retrain_iters):\n print(f\"... {_+1}/{retrain_iters} \")\n model = GCN(adj, x, labels, device='GPU', norm_x=None, seed=None)\n model.build()\n his = model.train(idx_train, idx_val, verbose=0, epochs=100)\n logit = softmax(model.predict(target).ravel())\n \n class_distrs.append(logit)\n best_second_class_before = (logit - labels[target]).argmax()\n margin = logit[labels[target]] - logit[best_second_class_before]\n classification_margins.append(margin)\n model.close\n del model\n \n class_distrs = np.array(class_distrs)\n return class_distrs",
"_____no_output_____"
],
[
"retrain_iters = 5\nprint(\"Before Attack\")\nclass_distrs_clean = evaluate(adj, x, retrain_iters=retrain_iters)\nprint(f\"After {attacker.name} Attack\")\nclass_distrs_retrain = evaluate(attacker.A, x, retrain_iters=retrain_iters)",
"Before Attack\n... 1/5 \n... 2/5 \n... 3/5 \n... 4/5 \n... 5/5 \nAfter IGA Attack\n... 1/5 \n... 2/5 \n... 3/5 \n... 4/5 \n... 5/5 \n"
],
[
"def make_xlabel(ix, correct):\n if ix == correct:\n return \"Class {}\\n(correct)\".format(ix)\n return \"Class {}\".format(ix)\n\n\nfigure = plt.figure(figsize=(12, 4))\nplt.subplot(1, 2, 1)\ncenter_ixs_clean = []\nfor ix, block in enumerate(class_distrs_clean.T):\n x_ixs = np.arange(len(block)) + ix*(len(block)+2)\n center_ixs_clean.append(np.mean(x_ixs))\n color = '#555555'\n if ix == labels[target]:\n color = 'darkgreen'\n plt.bar(x_ixs, block, color=color)\n\nax = plt.gca()\nplt.ylim((-.05, 1.05))\nplt.ylabel(\"Predicted probability\")\nax.set_xticks(center_ixs_clean)\nax.set_xticklabels([make_xlabel(k, labels[target]) for k in range(n_classes)])\nax.set_title(f\"Predicted class probabilities for node {target} on clean data\\n({retrain_iters} re-trainings)\")\n\nfig = plt.subplot(1, 2, 2)\ncenter_ixs_retrain = []\nfor ix, block in enumerate(class_distrs_retrain.T):\n x_ixs = np.arange(len(block)) + ix*(len(block)+2)\n center_ixs_retrain.append(np.mean(x_ixs))\n color = '#555555'\n if ix == labels[target]:\n color = 'darkgreen'\n plt.bar(x_ixs, block, color=color)\n\n\nax = plt.gca()\nplt.ylim((-.05, 1.05))\nax.set_xticks(center_ixs_retrain)\nax.set_xticklabels([make_xlabel(k, labels[target]) for k in range(n_classes)])\nax.set_title(f\"Predicted class probabilities for node {target} after {attacker.n_perturbations} perturbations\\n({retrain_iters} re-trainings)\")\nplt.tight_layout()\nplt.show()",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
cb3d838610ec48f00cb9fb9cd2c7f145315680cf | 533,356 | ipynb | Jupyter Notebook | hublib/rappture/test/dftmatprop.ipynb | martin-hunt/hublib | 992f131d2da28b05c5cef29846c255432f8d8eac | [
"MIT"
] | 6 | 2017-05-23T19:17:29.000Z | 2022-02-24T00:36:46.000Z | hublib/rappture/test/dftmatprop.ipynb | martin-hunt/hublib | 992f131d2da28b05c5cef29846c255432f8d8eac | [
"MIT"
] | 1 | 2019-02-13T13:35:57.000Z | 2019-02-13T13:35:57.000Z | hublib/rappture/test/dftmatprop.ipynb | martin-hunt/hublib | 992f131d2da28b05c5cef29846c255432f8d8eac | [
"MIT"
] | 6 | 2017-09-12T19:51:12.000Z | 2021-01-13T23:43:57.000Z | 197.320015 | 155,221 | 0.848896 | [
[
[
"%matplotlib notebook\nfrom __future__ import print_function\nimport pytest\nimport os, sys\nimport numpy as np\nsys.path.insert(0, os.path.abspath('../../..'))\nimport hublib.rappture as rappture",
"_____no_output_____"
],
[
"io = rappture.RapXML('dftmatprop_run.xml')",
"_____no_output_____"
],
[
"io",
"_____no_output_____"
],
[
"print(io['input.group(tabs).group(basicInput).drawing'].xml())",
"<drawing>\n <substitutions> <variable>\n <name>ek</name>\n <path>input.group(tabs).group(basicInput).loader(task)</path>\n <map>\n <from>\n </from>\n <to>ek_selected.png</to>\n </map>\n <map>\n <from>E-K Diagrams</from>\n <to>blue</to>\n </map>\n <map>\n <from>Dielectric Constant and Optical Properties</from>\n <to>\n </to>\n </map>\n <map>\n <from>Equation of State</from>\n <to>\n </to>\n </map>\n </variable>\n <variable>\n <name>dielec</name>\n <path>input.group(tabs).group(basicInput).loader(task)</path>\n <map>\n <from>E-K Diagrams</from>\n <to>\n </to>\n </map>\n <map>\n <from>Dielectric Constant and Optical Properties</from>\n <to>blue</to>\n </map>\n <map>\n <from>Equation of State</from>\n <to>\n </to>\n </map>\n </variable>\n <variable>\n <name>eos</name>\n <path>input.group(tabs).group(basicInput).loader(task)</path>\n <map>\n <from>E-K Diagrams</from>\n <to>\n </to>\n </map>\n <map>\n <from>Dielectric Constant and Optical Properties</from>\n <to>\n </to>\n </map>\n <map>\n <from>Equation of State</from>\n <to>blue</to>\n </map>\n </variable>\n<!--\n\t\t\t\t\t\t<variable>\n\t\t\t\t\t\t\t<name>ek</name>\n\t\t\t\t\t\t\t<path>input.group(tabs).group(basicInput).boolean(ek)</path>\n\t\t\t\t\t\t\t<map><from>yes</from><to>ek_selected.png</to></map>\n\t\t\t\t\t\t\t<map><from>no</from><to>ek_notselected.png</to></map>\n\t\t\t\t\t\t</variable>\n\t\t\t\t\t\t<variable>\n\t\t\t\t\t\t\t<name>dielec</name>\n\t\t\t\t\t\t\t<path>input.group(tabs).group(basicInput).boolean(dielec)</path>\n\t\t\t\t\t\t\t<map><from>yes</from><to>blue</to></map>\n\t\t\t\t\t\t\t<map><from>no</from><to>black</to></map>\n\t\t\t\t\t\t</variable>\n\t\t\t\t\t\t<variable>\n\t\t\t\t\t\t\t<name>eos</name>\n\t\t\t\t\t\t\t<path>input.group(tabs).group(basicInput).boolean(eos)</path>\n\t\t\t\t\t\t\t<map><from>yes</from><to>blue</to></map>\n\t\t\t\t\t\t\t<map><from>no</from><to>black</to></map>\n\t\t\t\t\t\t</variable>\n\t\t\t\t\t\t--></substitutions>\n <background>\n <width>800</width>\n <height>300</height>\n <color>white</color>\n </background>\n <components>\n <picture>\n <coords>.86 .9 0.99 0.98</coords>\n <contents>file://click.png</contents>\n </picture>\n <picture>\n <coords>.0625 .1667 .9375 .8333</coords>\n <contents>file://options.png</contents>\n </picture>\n <rectangle>\n <coords>.0500 .1333 .3250 .8667</coords>\n <linewidth>5</linewidth>\n <fill>\n </fill>\n <outline>${ek}</outline>\n </rectangle>\n <rectangle>\n <coords>.3625 .1333 .6375 .8667</coords>\n <linewidth>5</linewidth>\n <fill>\n </fill>\n <outline>${dielec}</outline>\n </rectangle>\n <rectangle>\n <coords>.6750 .1333 .9500 .8667</coords>\n <linewidth>5</linewidth>\n <fill>\n </fill>\n <outline>${eos}</outline>\n </rectangle>\n </components>\n <current>\n </current>\n </drawing>\n \n\n"
],
[
"io['output.curve(eos)'].plot()",
"_____no_output_____"
],
[
"io['output.curve(fit)'].plot()",
"_____no_output_____"
],
[
"io['output.curve(murn)'].plot()",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3d8448b0290ed61e763997f28021d45a45c79c | 77,390 | ipynb | Jupyter Notebook | 28_Mar(Jeevan)/Naive_Bayes(Wine Dataset)/Q2.ipynb | DevAgarwal-588/Freelancing | 366f67f506fb544fd1ea87ded67d949f055dfb46 | [
"MIT"
] | null | null | null | 28_Mar(Jeevan)/Naive_Bayes(Wine Dataset)/Q2.ipynb | DevAgarwal-588/Freelancing | 366f67f506fb544fd1ea87ded67d949f055dfb46 | [
"MIT"
] | null | null | null | 28_Mar(Jeevan)/Naive_Bayes(Wine Dataset)/Q2.ipynb | DevAgarwal-588/Freelancing | 366f67f506fb544fd1ea87ded67d949f055dfb46 | [
"MIT"
] | null | null | null | 108.086592 | 9,302 | 0.78651 | [
[
[
"import numpy as np\nimport pandas as pd\nfrom sklearn.datasets import load_wine\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.metrics import confusion_matrix, accuracy_score, roc_auc_score, roc_curve\nfrom sklearn.utils import shuffle\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"wine = load_wine()\n\n# store the feature matrix (X) and response vector (y) \nx = wine.data \ny = wine.target\n\n# splitting X and y into training and testing sets \nx_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state = 42,shuffle = True, stratify = y)",
"_____no_output_____"
],
[
"x_train",
"_____no_output_____"
],
[
"y_train",
"_____no_output_____"
],
[
"def classwise_distribution (arr):\n unique_elements, counts_elements = np.unique(arr, return_counts=True)\n plt.bar(unique_elements, counts_elements, 1)\n plt.title('Class Frequency')\n plt.xlabel('Class')\n plt.ylabel('Frequency')\n plt.show()",
"_____no_output_____"
],
[
"def fit(X, Y):\n\n X = pd.DataFrame(X, columns=wine.feature_names)\n Y = pd.DataFrame(Y).loc[:,0]\n\n mean = X.groupby(by=Y).mean()\n var = X.groupby(by=Y).var()\n \n mean = np.array(mean)\n var = np.array(var)\n\n return mean, var\n\ndef cond_prob_xC (v, mean, var):\n prob = (1/np.sqrt(2*np.pi*var))*np.exp(-1*np.square(v - mean)/(2*var))\n return prob\n\ndef pri_prob (y_train):\n val, count = np.unique(y_train, return_counts=True)\n pri_prob = (count/len(y_train)).reshape((len(val), 1))\n return pri_prob\n\ndef po_prob (prob, prior_prob):\n prob = np.prod(prob, axis = 1).reshape((3,1))\n post_prob = prob * prior_prob\n return post_prob\n\n",
"_____no_output_____"
],
[
"def predict(x_train, y_train, x_test, y_test ):\n print('class-wise distribution of Training Set')\n classwise_distribution (y_train)\n print('=============================')\n print('class-wise distribution of Test Set')\n classwise_distribution (y_test)\n print('=============================')\n\n print('Initiating Prediction')\n print('=============================')\n\n\n mean, var = fit(x_train, y_train)\n print(\"Mean of the training data is\")\n print(mean)\n print('Varince of the training data is')\n print(var)\n\n\n print('=============================')\n print('Calculating Prior Probability')\n prior_prob = pri_prob(y_train)\n print(\"Prior Probability of training data is\")\n print(prior_prob)\n\n\n print('=============================')\n y_score = np.zeros((len(y_test), (len(np.unique(y_test)))))\n pred = np.zeros(shape=(1, len(x_test)))\n for i in range (len(x_test)):\n cond_prob = cond_prob_xC (x_test[i], mean, var)\n post_prob = po_prob (cond_prob, prior_prob)\n y_score[i] = post_prob.reshape(3,)\n result, _ = np.where(post_prob == np.amax(post_prob))\n pred[0][i] = result\n print(\"Prediction on the training data is as follows\")\n print(pred)\n\n print('=============================')\n print(\"Calculating Accuracy\")\n truth = pred == y_test\n count = np.count_nonzero(truth)\n acc = (count/len(y_test)) * 100\n print(\"Accuracy achieved is:\", acc)\n\n\n print(\"=============================\")\n print(\"Printing confusion matrix\")\n print(confusion_matrix(y_test, pred.reshape(len(y_test),)))\n\n return pred.reshape(len(y_test),)",
"_____no_output_____"
],
[
"pred = predict(x_train, y_train, x_test, y_test )",
"class-wise distribution of Training Set\n"
],
[
"def predict_1(x_train, y_train, x_test, y_test ):\n print('class-wise distribution of Training Set')\n classwise_distribution (y_train)\n print('=============================')\n print('class-wise distribution of Test Set')\n classwise_distribution (y_test)\n print('=============================')\n\n print('Initiating Prediction')\n print('=============================')\n\n\n mean, var = fit(x_train, y_train)\n print(\"Mean of the training data is\")\n print(mean)\n print('Varince of the training data is')\n print(var)\n\n\n print('=============================')\n print('Calculating Prior Probability')\n prior_prob = np.array([[40],\n [40],\n [20]])\n print(\"Prior Probability of training data is\")\n print(prior_prob)\n\n\n print('=============================')\n y_score = np.zeros((len(y_test), (len(np.unique(y_test)))))\n pred = np.zeros(shape=(1, len(x_test)))\n for i in range (len(x_test)):\n cond_prob = cond_prob_xC (x_test[i], mean, var)\n post_prob = po_prob (cond_prob, prior_prob)\n y_score[i] = post_prob.reshape(3,)\n result, _ = np.where(post_prob == np.amax(post_prob))\n pred[0][i] = result\n print(\"Prediction on the training data is as follows\")\n print(pred)\n\n print('=============================')\n print(\"Calculating Accuracy\")\n truth = pred == y_test\n count = np.count_nonzero(truth)\n acc = (count/len(y_test)) * 100\n print(\"Accuracy achieved is:\", acc)\n\n\n print(\"=============================\")\n print(\"Printing confusion matrix\")\n print(confusion_matrix(y_test, pred.reshape(len(y_test),)))\n\n return pred.reshape(len(y_test),)",
"_____no_output_____"
],
[
"pred = predict_1(x_train, y_train, x_test, y_test )",
"class-wise distribution of Training Set\n"
],
[
"def predict_2(x_train, y_train, x_test, y_test ):\n print('class-wise distribution of Training Set')\n classwise_distribution (y_train)\n print('=============================')\n print('class-wise distribution of Test Set')\n classwise_distribution (y_test)\n print('=============================')\n\n print('Initiating Prediction')\n print('=============================')\n\n\n mean, var = fit(x_train, y_train)\n print(\"Mean of the training data is\")\n print(mean)\n print('Varince of the training data is')\n print(var)\n\n\n print('=============================')\n print('Calculating Prior Probability')\n prior_prob = np.array([[80],\n [100],\n [100]])\n print(\"Prior Probability of training data is\")\n print(prior_prob)\n\n\n print('=============================')\n y_score = np.zeros((len(y_test), (len(np.unique(y_test)))))\n pred = np.zeros(shape=(1, len(x_test)))\n for i in range (len(x_test)):\n cond_prob = cond_prob_xC (x_test[i], mean, var)\n post_prob = po_prob (cond_prob, prior_prob)\n y_score[i] = post_prob.reshape(3,)\n result, _ = np.where(post_prob == np.amax(post_prob))\n pred[0][i] = result\n print(\"Prediction on the training data is as follows\")\n print(pred)\n\n print('=============================')\n print(\"Calculating Accuracy\")\n truth = pred == y_test\n count = np.count_nonzero(truth)\n acc = (count/len(y_test)) * 100\n print(\"Accuracy achieved is:\", acc)\n\n\n print(\"=============================\")\n print(\"Printing confusion matrix\")\n print(confusion_matrix(y_test, pred.reshape(len(y_test),)))\n\n return pred.reshape(len(y_test),)",
"_____no_output_____"
],
[
"pred = predict_2(x_train, y_train, x_test, y_test )",
"class-wise distribution of Training Set\n"
],
[
"",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3d84b686c8686ea22ec1c340a52371bd053e56 | 129,802 | ipynb | Jupyter Notebook | Genetico_Job_Shop.ipynb | julianovale/project_trains | 73f698ab9618363b93777ab7337be813bf14d688 | [
"MIT"
] | null | null | null | Genetico_Job_Shop.ipynb | julianovale/project_trains | 73f698ab9618363b93777ab7337be813bf14d688 | [
"MIT"
] | null | null | null | Genetico_Job_Shop.ipynb | julianovale/project_trains | 73f698ab9618363b93777ab7337be813bf14d688 | [
"MIT"
] | null | null | null | 125.777132 | 25,615 | 0.51869 | [
[
[
"<a href=\"https://colab.research.google.com/github/julianovale/project_trains/blob/master/Genetico_Job_Shop.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"! pip install chart_studio",
"Requirement already satisfied: chart_studio in /usr/local/lib/python3.7/dist-packages (1.1.0)\nRequirement already satisfied: six in /usr/local/lib/python3.7/dist-packages (from chart_studio) (1.15.0)\nRequirement already satisfied: plotly in /usr/local/lib/python3.7/dist-packages (from chart_studio) (4.4.1)\nRequirement already satisfied: requests in /usr/local/lib/python3.7/dist-packages (from chart_studio) (2.23.0)\nRequirement already satisfied: retrying>=1.3.3 in /usr/local/lib/python3.7/dist-packages (from chart_studio) (1.3.3)\nRequirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests->chart_studio) (2021.5.30)\nRequirement already satisfied: chardet<4,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests->chart_studio) (3.0.4)\nRequirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests->chart_studio) (2.10)\nRequirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests->chart_studio) (1.24.3)\n"
],
[
"import os\nif not os.path.isfile('/content/JSP_dataset.xlsx'):\n ! wget https://github.com/julianovale/project_trains/raw/master/dados/JSP_dataset.xlsx\n! ls",
"--2021-09-08 00:17:42-- https://github.com/julianovale/project_trains/raw/master/dados/JSP_dataset.xlsx\nResolving github.com (github.com)... 140.82.112.4\nConnecting to github.com (github.com)|140.82.112.4|:443... connected.\nHTTP request sent, awaiting response... 302 Found\nLocation: https://raw.githubusercontent.com/julianovale/project_trains/master/dados/JSP_dataset.xlsx [following]\n--2021-09-08 00:17:42-- https://raw.githubusercontent.com/julianovale/project_trains/master/dados/JSP_dataset.xlsx\nResolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.109.133, 185.199.110.133, ...\nConnecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: 10535 (10K) [application/octet-stream]\nSaving to: ‘JSP_dataset.xlsx’\n\n\rJSP_dataset.xlsx 0%[ ] 0 --.-KB/s \rJSP_dataset.xlsx 100%[===================>] 10.29K --.-KB/s in 0s \n\n2021-09-08 00:17:42 (64.7 MB/s) - ‘JSP_dataset.xlsx’ saved [10535/10535]\n\nJSP_dataset.xlsx sample_data\n"
],
[
"''' Solving job shop scheduling problem by gentic algorithm '''\n\n# importing required modules\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport pandas as pd\nimport chart_studio.plotly as py\nimport plotly.figure_factory as ff\nimport datetime\nimport time\nimport copy\nimport openpyxl as xl\nimport json\n\ndef data_excel_json(excel_sheet):\n \"\"\" convert excel into json \"\"\"\n data_excel = xl.load_workbook(excel_sheet)\n data = {}\n sheet_name = data_excel.sheetnames\n for sheet in sheet_name:\n wb_sheet = data_excel[sheet]\n cell_values = wb_sheet.values\n df = pd.DataFrame(cell_values, columns=next(cell_values))\n df.iloc[:, 0] = df.iloc[:, 0].apply(lambda x : x.strip())\n df.index = df.iloc[:, 0]\n df.drop(columns = df.columns[0], inplace=True)\n data[sheet] = df.T.to_dict()\n return data\n\ndef json_to_df(json_data):\n \"\"\" convert json into excel \"\"\"\n dict_data = {}\n for key in json_data.keys():\n dict_data[key] = pd.DataFrame(json_data.get(key)).T\n\n return dict_data\n\n\n\ndef generate_initial_population(population_size, num_gene):\n\n \"\"\" generate initial population for Genetic Algorithm \"\"\"\n\n best_list, best_obj = [], []\n population_list = []\n makespan_record = []\n for i in range(population_size):\n nxm_random_num = list(np.random.permutation(num_gene)) # generate a random permutation of 0 to num_job*num_mc-1\n population_list.append(nxm_random_num) # add to the population_list\n for j in range(num_gene):\n population_list[i][j] = population_list[i][j] % num_job # convert to job number format, every job appears m times\n\n return population_list\n\n\n\ndef job_schedule(data_dict, population_size = 30, crossover_rate = 0.8, mutation_rate = 0.2, mutation_selection_rate = 0.2, num_iteration = 2000):\n\n \"\"\" initialize genetic algorithm parameters and read data \"\"\"\n data_json = json_to_df(data_dict)\n machine_sequence_tmp = data_json['Machines Sequence']\n process_time_tmp = data_json['Processing Time']\n\n df_shape = process_time_tmp.shape\n num_machines = df_shape[1] # number of machines\n num_job = df_shape[0] # number of jobs\n num_gene = num_machines * num_job # number of genes in a chromosome\n num_mutation_jobs = round(num_gene * mutation_selection_rate)\n\n process_time = [list(map(int, process_time_tmp.iloc[i])) for i in range(num_job)]\n machine_sequence = [list(map(int, machine_sequence_tmp.iloc[i])) for i in range(num_job)]\n \n #start_time = time.time()\n\n Tbest = 999999999999999\n\n best_list, best_obj = [], []\n population_list = []\n makespan_record = []\n\n for i in range(population_size):\n nxm_random_num = list(np.random.permutation(num_gene)) # generate a random permutation of 0 to num_job*num_mc-1\n population_list.append(nxm_random_num) # add to the population_list\n for j in range(num_gene):\n population_list[i][j] = population_list[i][j] % num_job # convert to job number format, every job appears m times\n #population_list = generate_initial_population(population_size=population_size, num_gene=num_gene)\n\n for iteration in range(num_iteration):\n Tbest_now = 99999999999\n\n \"\"\" Two Point Cross-Over \"\"\"\n parent_list = copy.deepcopy(population_list)\n offspring_list = copy.deepcopy(population_list) # generate a random sequence to select the parent chromosome to crossover\n pop_random_size = list(np.random.permutation(population_size))\n\n for size in range(int(population_size/2)):\n crossover_prob = np.random.rand()\n if crossover_rate >= crossover_prob:\n parent_1 = population_list[pop_random_size[2*size]][:]\n parent_2 = population_list[pop_random_size[2*size+1]][:]\n\n child_1 = parent_1[:]\n child_2 = parent_2[:]\n cutpoint = list(np.random.choice(num_gene, 2, replace=False))\n cutpoint.sort()\n\n child_1[cutpoint[0]:cutpoint[1]] = parent_2[cutpoint[0]:cutpoint[1]]\n child_2[cutpoint[0]:cutpoint[1]] = parent_1[cutpoint[0]:cutpoint[1]]\n offspring_list[pop_random_size[2*size]] = child_1[:]\n offspring_list[pop_random_size[2*size+1]] = child_2[:]\n\n\n for pop in range(population_size):\n\n \"\"\" Repairment \"\"\"\n job_count = {}\n larger, less = [], [] # 'larger' record jobs appear in the chromosome more than pop times, and 'less' records less than pop times.\n for job in range(num_job):\n if job in offspring_list[pop]:\n count = offspring_list[pop].count(job)\n pos = offspring_list[pop].index(job)\n job_count[job] = [count, pos] # store the above two values to the job_count dictionary\n else:\n count = 0\n job_count[job] = [count, 0]\n\n if count > num_machines:\n larger.append(job)\n elif count < num_machines:\n less.append(job)\n \n for large in range(len(larger)):\n change_job = larger[large]\n while job_count[change_job][0] > num_machines:\n for les in range(len(less)):\n if job_count[less[les]][0] < num_machines: \n offspring_list[pop][job_count[change_job][1]] = less[les]\n job_count[change_job][1] = offspring_list[pop].index(change_job)\n job_count[change_job][0] = job_count[change_job][0]-1\n job_count[less[les]][0] = job_count[less[les]][0]+1 \n if job_count[change_job][0] == num_machines:\n break \n \n\n \n for off_spring in range(len(offspring_list)):\n\n \"\"\" Mutations \"\"\"\n mutation_prob = np.random.rand()\n if mutation_rate >= mutation_prob:\n m_change = list(np.random.choice(num_gene, num_mutation_jobs, replace=False)) # chooses the position to mutation\n t_value_last = offspring_list[off_spring][m_change[0]] # save the value which is on the first mutation position\n for i in range(num_mutation_jobs-1):\n offspring_list[off_spring][m_change[i]] = offspring_list[off_spring][m_change[i+1]] # displacement\n # move the value of the first mutation position to the last mutation position\n offspring_list[off_spring][m_change[num_mutation_jobs-1]] = t_value_last \n\n\n\n \"\"\" fitness value (calculate makespan) \"\"\"\n total_chromosome = copy.deepcopy(parent_list) + copy.deepcopy(offspring_list) # parent and offspring chromosomes combination\n chrom_fitness, chrom_fit = [], []\n total_fitness = 0\n for pop_size in range(population_size*2):\n j_keys = [j for j in range(num_job)]\n key_count = {key:0 for key in j_keys}\n j_count = {key:0 for key in j_keys}\n m_keys = [j+1 for j in range(num_machines)]\n m_count = {key:0 for key in m_keys}\n \n for i in total_chromosome[pop_size]:\n gen_t = int(process_time[i][key_count[i]])\n gen_m = int(machine_sequence[i][key_count[i]])\n j_count[i] = j_count[i] + gen_t\n m_count[gen_m] = m_count[gen_m] + gen_t\n \n if m_count[gen_m] < j_count[i]:\n m_count[gen_m] = j_count[i]\n elif m_count[gen_m] > j_count[i]:\n j_count[i] = m_count[gen_m]\n \n key_count[i] = key_count[i] + 1\n \n makespan = max(j_count.values())\n chrom_fitness.append(1/makespan)\n chrom_fit.append(makespan)\n total_fitness = total_fitness + chrom_fitness[pop_size]\n \n\n \"\"\" Selection (roulette wheel approach) \"\"\"\n pk, qk = [], []\n \n for size in range(population_size * 2):\n pk.append(chrom_fitness[size] / total_fitness)\n for size in range(population_size * 2):\n cumulative = 0\n\n for j in range(0, size+1):\n cumulative = cumulative + pk[j]\n qk.append(cumulative)\n \n selection_rand = [np.random.rand() for i in range(population_size)]\n \n for pop_size in range(population_size):\n if selection_rand[pop_size] <= qk[0]:\n population_list[pop_size] = copy.deepcopy(total_chromosome[0])\n else:\n for j in range(0, population_size * 2-1):\n if selection_rand[pop_size] > qk[j] and selection_rand[pop_size] <= qk[j+1]:\n population_list[pop_size] = copy.deepcopy(total_chromosome[j+1])\n break\n\n\n \"\"\" comparison \"\"\"\n for pop_size in range(population_size * 2):\n if chrom_fit[pop_size] < Tbest_now:\n Tbest_now = chrom_fit[pop_size]\n sequence_now = copy.deepcopy(total_chromosome[pop_size])\n if Tbest_now <= Tbest:\n Tbest = Tbest_now\n sequence_best = copy.deepcopy(sequence_now)\n \n makespan_record.append(Tbest)\n\n \"\"\" Results - Makespan \"\"\"\n\n print(\"optimal sequence\", sequence_best)\n print(\"optimal value:%f\"%Tbest)\n print(\"\\n\")\n #print('the elapsed time:%s'% (time.time() - start_time))\n\n #%matplotlib inline\n plt.plot([i for i in range(len(makespan_record))],makespan_record,'b')\n plt.ylabel('makespan', fontsize=15)\n plt.xlabel('generation', fontsize=15)\n plt.show()\n\n\n \"\"\" plot gantt chart \"\"\"\n\n m_keys = [j+1 for j in range(num_machines)]\n j_keys = [j for j in range(num_job)]\n key_count = {key:0 for key in j_keys}\n j_count = {key:0 for key in j_keys}\n m_count = {key:0 for key in m_keys}\n j_record = {}\n for i in sequence_best:\n gen_t = int(process_time[i][key_count[i]])\n gen_m = int(machine_sequence[i][key_count[i]])\n j_count[i] = j_count[i] + gen_t\n m_count[gen_m] = m_count[gen_m] + gen_t\n\n if m_count[gen_m] < j_count[i]:\n m_count[gen_m] = j_count[i]\n elif m_count[gen_m] > j_count[i]:\n j_count[i] = m_count[gen_m]\n\n start_time = str(datetime.timedelta(seconds = j_count[i] - process_time[i][key_count[i]])) # convert seconds to hours, minutes and seconds\n end_time = str(datetime.timedelta(seconds = j_count[i]))\n\n j_record[(i, gen_m)] = [start_time, end_time]\n\n key_count[i] = key_count[i] + 1\n\n\n df = []\n for m in m_keys:\n for j in j_keys:\n df.append(dict(Task='Machine %s'%(m), Start='2020-02-01 %s'%(str(j_record[(j,m)][0])), \\\n Finish='2020-02-01 %s'%(str(j_record[(j,m)][1])),Resource='Job %s'%(j+1)))\n \n df_ = pd.DataFrame(df)\n df_.Start = pd.to_datetime(df_['Start'])\n df_.Finish = pd.to_datetime(df_['Finish'])\n start = df_.Start.min()\n end = df_.Finish.max()\n\n df_.Start = df_.Start.apply(lambda x: x.strftime('%Y-%m-%dT%H:%M:%S'))\n df_.Finish = df_.Finish.apply(lambda x: x.strftime('%Y-%m-%dT%H:%M:%S'))\n data = df_.to_dict('record')\n\n final_data ={\n 'start':start.strftime('%Y-%m-%dT%H:%M:%S'),\n 'end':end.strftime('%Y-%m-%dT%H:%M:%S'),\n 'data':data}\n \n fig = ff.create_gantt(df, index_col='Resource', show_colorbar=True, group_tasks=True, showgrid_x=True, title='Job shop Schedule')\n fig.show()\n #iplot(fig, filename='GA_job_shop_scheduling')\n return final_data, df",
"_____no_output_____"
],
[
"%%time\n\n\"\"\" Job_Shop_Schedule \"\"\"\n\ndata = data_excel_json('JSP_dataset.xlsx')\nschedule = job_schedule(data_dict=data)",
"optimal sequence [5, 6, 6, 4, 4, 3, 5, 4, 1, 5, 4, 6, 6, 5, 9, 1, 6, 4, 1, 9, 1, 3, 5, 4, 9, 7, 8, 9, 1, 0, 3, 5, 4, 8, 9, 0, 6, 8, 3, 8, 5, 4, 9, 6, 8, 3, 7, 8, 3, 8, 2, 6, 7, 0, 9, 8, 2, 1, 6, 0, 2, 7, 9, 7, 0, 8, 5, 7, 9, 3, 7, 0, 4, 3, 3, 4, 2, 5, 2, 7, 2, 1, 5, 2, 0, 8, 1, 0, 7, 2, 6, 0, 7, 1, 3, 2, 0, 1, 2, 9]\noptimal value:1190.000000\n\n\n"
],
[
"# JSON to draw gantt chart \nschedule[0]",
"_____no_output_____"
],
[
"import chart_studio.plotly as py\nimport plotly.figure_factory as ff\n\ndf = schedule[1]\nfig = ff.create_gantt(df, index_col='Resource', show_colorbar=True, group_tasks=True, showgrid_x=True, title='Job shop Schedule')\nfig.show()",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3d883421db8c94be1691a2a374936322119c05 | 332,718 | ipynb | Jupyter Notebook | Signs Dataset.ipynb | rishabh9988/Signs-Dataset | 82327046aef5ff90e3e763b3d472a5d5d08dc301 | [
"MIT"
] | null | null | null | Signs Dataset.ipynb | rishabh9988/Signs-Dataset | 82327046aef5ff90e3e763b3d472a5d5d08dc301 | [
"MIT"
] | null | null | null | Signs Dataset.ipynb | rishabh9988/Signs-Dataset | 82327046aef5ff90e3e763b3d472a5d5d08dc301 | [
"MIT"
] | null | null | null | 202.014572 | 213,484 | 0.896564 | [
[
[
"# HAND SIGN DATASET",
"_____no_output_____"
],
[
"## Introduction",
"_____no_output_____"
],
[
"The dataset format is patterned to match closely with the classic MNIST. Each training and test case represents a label (0-25) as a one-to-one map for each alphabet letter A-Z (and no cases for 9=J or 25=Z because of gesture motions). The training data (27,455 cases) and test data (7172 cases) are approximately half the size of the standard MNIST but otherwise similar with a header row of label, pixel1,pixel2....pixel784 which represent a single 28x28 pixel image with grayscale values between 0-255. The original hand gesture image data represented multiple users repeating the gesture against different backgrounds. ",
"_____no_output_____"
],
[
"## Tools",
"_____no_output_____"
],
[
"\n1.Python\n\n2.scikit-learn / sklearn\n\n3.Pandas\n\n4.NumPy\n\n5.matplotlib\n\n6.Jupyter \n",
"_____no_output_____"
],
[
"## Objectives",
"_____no_output_____"
],
[
"(A.)View the data as an image\n\n(B.)Train different classifiers\n\n(C.)Compare performance for different classifiers using various metrics\n",
"_____no_output_____"
]
],
[
[
"#importing libraries\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns",
"_____no_output_____"
]
],
[
[
"## Data Exploration",
"_____no_output_____"
]
],
[
[
"#reading csv file \ndf=pd.read_csv('sign_mnist_train.csv')",
"_____no_output_____"
],
[
"#shape of data\ndf.shape",
"_____no_output_____"
],
[
"df.describe()",
"_____no_output_____"
],
[
"#finding if any null values\ndf.isnull().values.any()",
"_____no_output_____"
],
[
"#defining correlation using heat maop\ncorr_m = df.corr()\nsns.heatmap(corr_m)",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"#plotting the total number of each type of label in data\nsns.countplot(df['label'])\nplt.show()",
"_____no_output_____"
],
[
"X = df.iloc[:,1:]\nY = df.iloc[:,0]",
"_____no_output_____"
],
[
"\nprint(Y)",
"0 3\n1 6\n2 2\n3 2\n4 13\n5 16\n6 8\n7 22\n8 3\n9 3\n10 18\n11 10\n12 16\n13 22\n14 20\n15 16\n16 17\n17 13\n18 13\n19 19\n20 18\n21 21\n22 16\n23 23\n24 3\n25 23\n26 24\n27 18\n28 22\n29 1\n ..\n27425 21\n27426 21\n27427 4\n27428 17\n27429 5\n27430 12\n27431 19\n27432 2\n27433 22\n27434 12\n27435 1\n27436 19\n27437 16\n27438 21\n27439 11\n27440 5\n27441 18\n27442 0\n27443 21\n27444 18\n27445 14\n27446 19\n27447 11\n27448 12\n27449 20\n27450 13\n27451 23\n27452 18\n27453 17\n27454 23\nName: label, Length: 27455, dtype: int64\n"
],
[
"#forming pictures from pixels\nfirst = X.iloc[1,:]\nsecond = X.iloc[2,:]\nthird = X.iloc[3,:]\nfourth = X.iloc[4,:]\n\nfirst = np.array(first , dtype='float')\nsecond = np.array(second , dtype='float')\npixel = first.reshape((28,28))\npixel2 = second.reshape((28,28))\nthird = np.array(third , dtype='float')\npixel3 = third.reshape((28,28))\nfourth = np.array(fourth , dtype='float')\npixel4 = fourth.reshape((28,28))\nplt.imshow(pixel)\nplt.show()\nplt.imshow(pixel2)\nplt.show()\nplt.imshow(pixel3)\nplt.show()\nplt.imshow(pixel4)\nplt.show()",
"_____no_output_____"
],
[
"print(Y.iloc[1])",
"6\n"
]
],
[
[
"### Splitting The Data",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split\nX_train, X_test, Y_train, Y_test = train_test_split(X,Y,test_size = 0.2,random_state = 0)",
"_____no_output_____"
]
],
[
[
"## KNN",
"_____no_output_____"
],
[
"In pattern recognition, the k-nearest neighbors algorithm (k-NN) is a non-parametric method used for classification and regression. In both cases, the input consists of the k closest training examples in the feature space. The output depends on whether k-NN is used for classification or regression:\n\n In k-NN classification, the output is a class membership. An object is classified by a plurality vote of its neighbors, with the object being assigned to the class most common among its k nearest neighbors (k is a positive integer, typically small). If k = 1, then the object is simply assigned to the class of that single nearest neighbor.\n\n In k-NN regression, the output is the property value for the object. This value is the average of the values of k nearest neighbors.",
"_____no_output_____"
]
],
[
[
"from sklearn.neighbors import KNeighborsClassifier\n# instantiate\nclassifier = KNeighborsClassifier()\n# fitting the data\nclassifier.fit(X_train,Y_train)",
"_____no_output_____"
],
[
"# predict\nY_pred=classifier.predict(X_test)",
"_____no_output_____"
],
[
"from sklearn.metrics import confusion_matrix",
"_____no_output_____"
],
[
"cm = confusion_matrix(Y_test,Y_pred)",
"_____no_output_____"
],
[
"sns.heatmap(cm)",
"_____no_output_____"
],
[
"from sklearn.metrics import accuracy_score",
"_____no_output_____"
],
[
"#accuracy score\nascore=accuracy_score(Y_test , Y_pred , normalize=True)\nprint(ascore)",
"0.9959934438171554\n"
],
[
"from sklearn.metrics import f1_score\n#f1_score\nscore=f1_score(Y_pred, Y_test,average='weighted')\nprint(score)",
"0.9959910741054302\n"
]
],
[
[
"\n## RandomForest",
"_____no_output_____"
],
[
"Random forests or random decision forests are an ensemble learning method for classification, regression and other tasks that operates by constructing a multitude of decision trees at training time and outputting the class that is the mode of the classes (classification) or mean prediction (regression) of the individual trees. Random decision forests correct for decision trees' habit of overfitting to their training set",
"_____no_output_____"
]
],
[
[
"from sklearn.ensemble import RandomForestClassifier",
"_____no_output_____"
],
[
"# instantiate\nrc = RandomForestClassifier()\n# fitting the data\nrc.fit(X_train , Y_train)",
"_____no_output_____"
],
[
"# predict\nrc_pred = rc.predict(X_test)",
"_____no_output_____"
],
[
"ascore2=accuracy_score(Y_test , rc_pred)\nprint(ascore2)",
"0.98433800764888\n"
],
[
"score2=f1_score(Y_test, rc_pred,average='weighted')\nprint(score2)",
"0.9843210279523854\n"
]
],
[
[
"## SVM",
"_____no_output_____"
],
[
"In machine learning, support-vector machines (SVMs, also support-vector networks) are supervised learning models with associated learning algorithms that analyze data used for classification and regression analysis. Given a set of training examples, each marked as belonging to one or the other of two categories, an SVM training algorithm builds a model that assigns new examples to one category or the other, making it a non-probabilistic binary linear classifier (although methods such as Platt scaling exist to use SVM in a probabilistic classification setting). A SVM model is a representation of the examples as points in space, mapped so that the examples of the separate categories are divided by a clear gap that is as wide as possible. New examples are then mapped into that same space and predicted to belong to a category based on which side of the gap they fall.\n\nIn addition to performing linear classification, SVMs can efficiently perform a non-linear classification using what is called the kernel trick, implicitly mapping their inputs into high-dimensional feature spaces.",
"_____no_output_____"
]
],
[
[
"from sklearn.svm import SVC\n# instantiate\nsvc = SVC()\n# fitting the data\nsvc.fit(X_train , Y_train)",
"_____no_output_____"
],
[
"# predict\nsv_pred = svc.predict(X_test)",
"_____no_output_____"
],
[
"ascore3=accuracy_score(Y_test , sv_pred)\nprint(ascore3)",
"0.22145328719723184\n"
],
[
"score3=f1_score(Y_test, sv_pred,average='weighted')\nprint(score3)",
"0.3055180482204343\n"
]
],
[
[
"## Naive Bayes",
"_____no_output_____"
],
[
"In machine learning, naive Bayes classifiers are a family of simple \"probabilistic classifiers\" based on applying Bayes' theorem with strong (naive) independence assumptions between the features.\n\nNaive Bayes is a simple technique for constructing classifiers: models that assign class labels to problem instances, represented as vectors of feature values, where the class labels are drawn from some finite set. There is not a single algorithm for training such classifiers, but a family of algorithms based on a common principle: all naive Bayes classifiers assume that the value of a particular feature is independent of the value of any other feature, given the class variable. For example, a fruit may be considered to be an apple if it is red, round, and about 10 cm in diameter. A naive Bayes classifier considers each of these features to contribute independently to the probability that this fruit is an apple, regardless of any possible correlations between the color, roundness, and diameter features.",
"_____no_output_____"
]
],
[
[
"from sklearn.naive_bayes import GaussianNB",
"_____no_output_____"
],
[
"# instantiate\nobj = GaussianNB()",
"_____no_output_____"
],
[
"#fitting the data\nobj.fit(X_train,Y_train)",
"_____no_output_____"
],
[
"# predict\nY_pred = obj.predict(X_test)",
"_____no_output_____"
],
[
"ascore4=accuracy_score(Y_test,Y_pred)\nprint(ascore4)",
"0.44873429247860136\n"
],
[
"score4=f1_score(Y_test, Y_pred,average='weighted')\nprint(score4)",
"0.44435195085135853\n"
]
],
[
[
"## MultinomialNB",
"_____no_output_____"
]
],
[
[
"from sklearn.naive_bayes import MultinomialNB\n# instantiate\nob = MultinomialNB()\n# fitting the data\nob.fit(X_train,Y_train)",
"_____no_output_____"
],
[
"# predict\nY_pred = ob.predict(X_test)",
"_____no_output_____"
],
[
"ascore5=accuracy_score(Y_test,Y_pred)\nprint(ascore5)",
"0.5321435075578219\n"
],
[
"score5=f1_score(Y_test, Y_pred,average='weighted')\nprint(score5)",
"0.5284714258990376\n"
]
],
[
[
"## Decision Tree Classifier",
"_____no_output_____"
],
[
"Decision tree learning is a method commonly used in data mining.[1] The goal is to create a model that predicts the value of a target variable based on several input variables. An example is shown in the diagram at right. Each interior node corresponds to one of the input variables; there are edges to children for each of the possible values of that input variable. Each leaf represents a value of the target variable given the values of the input variables represented by the path from the root to the leaf.",
"_____no_output_____"
]
],
[
[
"from sklearn.tree import DecisionTreeClassifier\n# instantiate\ndtc = DecisionTreeClassifier()\n",
"_____no_output_____"
],
[
"# fitting the data\ndtc.fit(X_train, Y_train)",
"_____no_output_____"
],
[
"# predict\nY_pred = dtc.predict(X_test)",
"_____no_output_____"
],
[
"#accuracy\nascore6=accuracy_score(Y_test,Y_pred)\nprint(ascore6)",
"0.8683299945365143\n"
],
[
"# f1 score\nscore6 = f1_score(Y_pred, Y_test,average='weighted')\nprint(score6)",
"0.8684179264853535\n"
]
],
[
[
"## Conclusion",
"_____no_output_____"
]
],
[
[
"Accuracy = [ascore,ascore2,ascore3,ascore4,ascore5,ascore6]\ndata1 = {\n 'Accuracy':Accuracy,\n 'Algorithm': ['KNN','Random Forest Classifier','SVM linear',\"Naive Baye's\",\"MultinominalNB\",'Decision Tree']}\n\ndf1 = pd.DataFrame(data1)",
"_____no_output_____"
],
[
"F1_score = [score,score2,score3,score4,score5,score6]\ndata2 = {\n 'F1_score':F1_score,\n 'Algorithm': ['KNN','Random Forest Classifier','SVM linear',\"Naive Baye's\",\"MultinominalNB\",'Decision Tree']}\n\ndf2 = pd.DataFrame(data2)",
"_____no_output_____"
],
[
"sns.barplot(x = df1.Accuracy, y = df1.Algorithm)",
"_____no_output_____"
],
[
"sns.barplot(x = df2.F1_score, y = df2.Algorithm)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
cb3d91a26cd2d79782f07313408bc3d3865a9450 | 3,499 | ipynb | Jupyter Notebook | Ch10/10_04/10_04.ipynb | Sinclair-Seo/Python-for-Data-Science-Essential-Training-in-LinkedIn | 5d0c30e760f29d36f68078da1fab3f0987aae4f3 | [
"MIT"
] | null | null | null | Ch10/10_04/10_04.ipynb | Sinclair-Seo/Python-for-Data-Science-Essential-Training-in-LinkedIn | 5d0c30e760f29d36f68078da1fab3f0987aae4f3 | [
"MIT"
] | null | null | null | Ch10/10_04/10_04.ipynb | Sinclair-Seo/Python-for-Data-Science-Essential-Training-in-LinkedIn | 5d0c30e760f29d36f68078da1fab3f0987aae4f3 | [
"MIT"
] | null | null | null | 22.869281 | 89 | 0.538154 | [
[
[
"\n___\n# Chapter 10 - Web Scraping with Beautiful Soup\n## Segment 4 - Web scraping",
"_____no_output_____"
]
],
[
[
"from bs4 import BeautifulSoup\nimport urllib\nimport re",
"_____no_output_____"
],
[
"r = urllib.request.urlopen('https://analytics.usa.gov').read()\nsoup = BeautifulSoup(r, \"lxml\")\ntype(soup)",
"_____no_output_____"
]
],
[
[
"### Scraping a webpage and saving your results",
"_____no_output_____"
]
],
[
[
"print(soup.prettify()[:100])",
"_____no_output_____"
],
[
"for link in soup.find_all('a'): print(link.get('href'))",
"/\n#explanation\nhttps://analytics.usa.gov/data/\ndata/\n#top-pages-realtime\n#top-pages-7-days\n#top-pages-30-days\nhttps://analytics.usa.gov/data/live/all-pages-realtime.csv\nhttps://analytics.usa.gov/data/live/top-domains-30-days.csv\nhttps://www.digitalgov.gov/services/dap/\nhttps://www.digitalgov.gov/services/dap/common-questions-about-dap-faq/#part-4\nhttps://support.google.com/analytics/answer/2763052?hl=en\nhttps://analytics.usa.gov/data/live/second-level-domains.csv\nhttps://analytics.usa.gov/data/live/sites.csv\nmailto:[email protected]\nhttps://github.com/GSA/analytics.usa.gov\nhttps://github.com/18F/analytics-reporter\nhttps://github.com/GSA/analytics.usa.gov/issues\nmailto:[email protected]\nhttps://analytics.usa.gov/data/\n"
],
[
"for link in soup.findAll('a', attrs={'href': re.compile(\"^http\")}): print link",
"_____no_output_____"
],
[
"file = open('parsed_data.txt', 'wb')\nfor link in soup.findAll('a', attrs={'href': re.compile(\"^http\")}):\n soup_link = str(link)\n print soup_link\n file.write(soup_link)\nfile.flush()\nfile.close()",
"_____no_output_____"
],
[
"%pwd",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
cb3d94164bacbf2d7530c890e7d5548aa1036660 | 10,166 | ipynb | Jupyter Notebook | model.ipynb | dataubc/machine_learning | b355215a5d429245cfcc2e2dcfe81f1d2ae72048 | [
"MIT"
] | null | null | null | model.ipynb | dataubc/machine_learning | b355215a5d429245cfcc2e2dcfe81f1d2ae72048 | [
"MIT"
] | null | null | null | model.ipynb | dataubc/machine_learning | b355215a5d429245cfcc2e2dcfe81f1d2ae72048 | [
"MIT"
] | null | null | null | 23.976415 | 196 | 0.387173 | [
[
[
"## Create Model",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nfrom sklearn.linear_model import LogisticRegression\n\n# create df\ntrain = pd.read_csv('titanic.csv')\n\n# drop null values\ntrain.dropna(inplace=True)\n\n# features and target\ntarget = 'Survived'\nfeatures = ['Pclass', 'Age', 'SibSp', 'Fare']\n\n# X matrix, y vector\nX = train[features]\ny = train[target]\n\n# model \nmodel = LogisticRegression()\nmodel.fit(X, y)\nmodel.score(X,y)",
"//anaconda3/lib/python3.7/site-packages/sklearn/linear_model/logistic.py:432: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.\n FutureWarning)\n"
],
[
"train.head()",
"_____no_output_____"
]
],
[
[
"## Pickle Model",
"_____no_output_____"
]
],
[
[
"import pickle\npickle.dump(model, open('model.pkl', 'wb'))",
"_____no_output_____"
]
],
[
[
"## Test Flask in Production",
"_____no_output_____"
]
],
[
[
"import requests\nimport json",
"_____no_output_____"
],
[
"# local url\nurl = 'http://127.0.0.1:5000'\n\n# test data\ndata = { 'Pclass': 3\n , 'Age': 2\n , 'SibSp': 1\n , 'Fare': 50}\n\ndata = json.dumps(data)\ndata",
"_____no_output_____"
],
[
"r_survey = requests.post(url, data)\nprint(r_survey)",
"<Response [200]>\n"
],
[
"send_request = requests.post(url, data)\nprint(send_request)",
"<Response [200]>\n"
],
[
"print(send_request.json())",
"{'results': {'results': 1}}\n"
]
],
[
[
"## Test App in Heroku",
"_____no_output_____"
]
],
[
[
"# heroku url\nheroku_url = 'https://titanic-flask-model.herokuapp.com' # change to your app name\n\n# test data\ndata = {'Pclass': 3\n , 'Age': 2\n , 'SibSp': 1\n , 'Fare': 50}\n\ndata = json.dumps(data)\ndata",
"_____no_output_____"
],
[
"# check response code\nr_survey = requests.post(heroku_url, data)\nprint(r_survey)",
"<Response [200]>\n"
],
[
"# get prediction\nprint(send_request.json())",
"{'results': {'results': 1}}\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
cb3d9860c88180929af0ffb7d732d588aacde76d | 3,187 | ipynb | Jupyter Notebook | add_remove_plan.ipynb | tommytse722/dash-flask-login | fe6cbb07c35b3cebb3634af90dfc80236d7f6d7e | [
"MIT"
] | null | null | null | add_remove_plan.ipynb | tommytse722/dash-flask-login | fe6cbb07c35b3cebb3634af90dfc80236d7f6d7e | [
"MIT"
] | null | null | null | add_remove_plan.ipynb | tommytse722/dash-flask-login | fe6cbb07c35b3cebb3634af90dfc80236d7f6d7e | [
"MIT"
] | null | null | null | 20.044025 | 112 | 0.50957 | [
[
[
"import plan_mgt as pm",
"_____no_output_____"
],
[
"pm.drop_plan_table()",
"_____no_output_____"
],
[
"pm.create_plan_table()",
"_____no_output_____"
],
[
"pm.show_plan()",
"_____no_output_____"
],
[
"pm.add_plan(1, 'RSI', '0005.HK', 200000)",
"_____no_output_____"
],
[
"import sqlite3\nimport pandas as pd\ndef get_plan(id):\n conn = sqlite3.connect('database.db')\n df = pd.read_sql_query(\"SELECT * FROM plan where plan.user_id=\" + str(id), conn)\n conn.close()\n return df",
"_____no_output_____"
],
[
"' '.join(get_plan(1).stock_code)",
"_____no_output_____"
],
[
"import sqlite3\nimport pandas as pd\ndef select_stock_board_lot(stock_code):\n conn = sqlite3.connect('database.db')\n df = pd.read_sql_query(\"SELECT * FROM stock where code = '\" + str(stock_code) +\"'\", conn)\n conn.close()\n return df",
"_____no_output_____"
],
[
"select_stock_board_lot('0388.HK')['board_lot'][0]",
"_____no_output_____"
],
[
"import sqlite3\nimport pandas as pd\ndef get_user_strategy(user_id):\n value = ''\n conn = sqlite3.connect('database.db')\n df = pd.read_sql_query(\"SELECT strategy_name FROM plan where plan.user_id=\" + str(user_id), conn)\n if len(df)>0:\n value = df.head(1)['strategy_name'][0]\n conn.close()\n return value",
"_____no_output_____"
],
[
"get_user_strategy(1)",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3d9a0e6a565686dd20f48b2b67ca4cb6ecda47 | 922 | ipynb | Jupyter Notebook | HelloGithub.ipynb | ArtSlo/dw_matrix | e7d6660814d95787fa364426d1d4074de562f34c | [
"MIT"
] | null | null | null | HelloGithub.ipynb | ArtSlo/dw_matrix | e7d6660814d95787fa364426d1d4074de562f34c | [
"MIT"
] | null | null | null | HelloGithub.ipynb | ArtSlo/dw_matrix | e7d6660814d95787fa364426d1d4074de562f34c | [
"MIT"
] | null | null | null | 922 | 922 | 0.707158 | [
[
[
"print(\"Hello Github\")",
"Hello Github\n"
],
[
"",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code"
]
] |
cb3da1a79cb15e567a01ae8dfa0d1633de475646 | 506,153 | ipynb | Jupyter Notebook | notebooks/ROI/01_Offshore/06a_TCs_Historical_CopulaSim_MDA.ipynb | teslakit/teslak | 3f3dda08c5c5998cb2a7debbf22f2be675a4ff8b | [
"MIT"
] | 12 | 2019-11-14T22:19:12.000Z | 2022-03-04T01:25:33.000Z | notebooks/ROI/01_Offshore/06a_TCs_Historical_CopulaSim_MDA.ipynb | anderdyl/teslaCoSMoS | 1495bfa2364ddbacb802d145b456a35213abfb7c | [
"MIT"
] | 5 | 2020-03-24T18:21:41.000Z | 2021-08-23T20:39:43.000Z | notebooks/ROI/01_Offshore/06a_TCs_Historical_CopulaSim_MDA.ipynb | anderdyl/teslaCoSMoS | 1495bfa2364ddbacb802d145b456a35213abfb7c | [
"MIT"
] | 2 | 2021-03-06T07:54:41.000Z | 2021-06-30T14:33:22.000Z | 1,382.931694 | 241,864 | 0.958528 | [
[
[
"\n... ***CURRENTLY UNDER DEVELOPMENT*** ...\n",
"_____no_output_____"
],
[
"## Synthetic simulation of historical TCs parameters using Gaussian copulas (Rueda et al. 2016) and subsequent selection of representative cases using Maximum Dissimilarity (MaxDiss) algorithm (Camus et al. 2011)\n\ninputs required: \n * Historical TC parameters that affect the site (output of *notebook 05*)\n * number of synthetic simulations to run\n * number of representative cases to be selected using MaxDiss\n\nin this notebook:\n * synthetic generation of TCs tracks based on gaussian copulas of the TC parameters\n * MDA selection of representative number of events",
"_____no_output_____"
]
],
[
[
"#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n# common\nimport os\nimport os.path as op\n\n# pip\nimport xarray as xr\nimport numpy as np\n\n# DEV: override installed teslakit\nimport sys\nsys.path.insert(0, op.join(os.path.abspath(''), '..', '..', '..'))\n\n# teslakit\nfrom teslakit.database import Database\nfrom teslakit.statistical import CopulaSimulation\nfrom teslakit.mda import MaxDiss_Simplified_NoThreshold\n\nfrom teslakit.plotting.storms import Plot_TCs_Params_MDAvsSIM, \\\nPlot_TCs_Params_HISTvsSIM, Plot_TCs_Params_HISTvsSIM_histogram",
"_____no_output_____"
]
],
[
[
"\n## Database and Site parameters",
"_____no_output_____"
]
],
[
[
"# --------------------------------------\n# Teslakit database\n\np_data = r'/Users/nico/Projects/TESLA-kit/TeslaKit/data'\ndb = Database(p_data)\n\n# set site\ndb.SetSite('ROI')\n",
"_____no_output_____"
],
[
"# --------------------------------------\n# load data and set parameters\n\n_, TCs_r2_params = db.Load_TCs_r2_hist() # TCs parameters inside radius 2\n\n# TCs random generation and MDA parameters\nnum_sim_rnd = 100000\nnum_sel_mda = 1000\n",
"_____no_output_____"
]
],
[
[
"\n## Historical TCs - Probabilistic Simulation",
"_____no_output_____"
]
],
[
[
"# --------------------------------------\n# Probabilistic simulation Historical TCs\n\n# aux functions\ndef adjust_to_pareto(var):\n 'Fix data. It needs to start at 0 for Pareto adjustment '\n var = var.astype(float)\n var_pareto = np.amax(var) - var + 0.00001\n return var_pareto\n\ndef adjust_from_pareto(var_base, var_pareto):\n 'Returns data from pareto adjustment'\n var = np.amax(var_base) - var_pareto + 0.00001\n return var\n\n\n# use small radius parameters (4º)\npmean = TCs_r2_params.pressure_mean.values[:]\npmin = TCs_r2_params.pressure_min.values[:]\ngamma = TCs_r2_params.gamma.values[:]\ndelta = TCs_r2_params.delta.values[:]\nvmean = TCs_r2_params.velocity_mean.values[:]\n\n# fix pressure for p\npmean_p = adjust_to_pareto(pmean)\npmin_p = adjust_to_pareto(pmin)\n\n# join storm parameters for copula simulation\nstorm_params = np.column_stack(\n (pmean_p, pmin_p, gamma, delta, vmean)\n)\n\n# statistical simulate PCs using copulas \nkernels = ['GPareto', 'GPareto', 'ECDF', 'ECDF', 'ECDF']\nstorm_params_sim = CopulaSimulation(storm_params, kernels, num_sim_rnd)\n\n# adjust back pressures from pareto\npmean_sim = adjust_from_pareto(pmean, storm_params_sim[:,0])\npmin_sim = adjust_from_pareto(pmin, storm_params_sim[:,1])\n\n# store simulated storms - parameters \nTCs_r2_sim_params = xr.Dataset(\n {\n 'pressure_mean':(('storm'), pmean_sim),\n 'pressure_min':(('storm'), pmin_sim),\n 'gamma':(('storm'), storm_params_sim[:,2]),\n 'delta':(('storm'), storm_params_sim[:,3]),\n 'velocity_mean':(('storm'), storm_params_sim[:,4]),\n },\n coords = {\n 'storm':(('storm'), np.arange(num_sim_rnd)) \n },\n)\nprint(TCs_r2_sim_params)\n\ndb.Save_TCs_r2_sim_params(TCs_r2_sim_params)\n",
"<xarray.Dataset>\nDimensions: (storm: 100000)\nCoordinates:\n * storm (storm) int64 0 1 2 3 4 5 ... 99995 99996 99997 99998 99999\nData variables:\n pressure_mean (storm) float64 944.0 1.005e+03 971.5 ... 988.3 997.0\n pressure_min (storm) float64 921.0 1.001e+03 945.4 ... 989.5 996.4\n gamma (storm) float64 151.4 120.2 101.1 109.7 ... 105.4 89.69 117.8\n delta (storm) float64 183.1 79.64 72.99 74.98 ... 104.1 74.14 127.9\n velocity_mean (storm) float64 26.27 13.26 26.46 7.211 ... 10.82 30.89 25.51\n"
],
[
"# Historical vs Simulated: scatter plot parameters\nPlot_TCs_Params_HISTvsSIM(TCs_r2_params, TCs_r2_sim_params);\n\n# Historical vs Simulated: histogram parameters\nPlot_TCs_Params_HISTvsSIM_histogram(TCs_r2_params, TCs_r2_sim_params);\n",
"_____no_output_____"
]
],
[
[
"\n## Simulated TCs - MaxDiss classification",
"_____no_output_____"
]
],
[
[
"# --------------------------------------\n# MaxDiss classification\n\n# get simulated parameters \npmean_s = TCs_r2_sim_params.pressure_mean.values[:]\npmin_s = TCs_r2_sim_params.pressure_min.values[:]\ngamma_s = TCs_r2_sim_params.gamma.values[:]\ndelta_s = TCs_r2_sim_params.delta.values[:]\nvmean_s = TCs_r2_sim_params.velocity_mean.values[:]\n\n# subset, scalar and directional indexes\ndata_mda = np.column_stack((pmean_s, pmin_s, vmean_s, delta_s, gamma_s))\nix_scalar = [0,1,2]\nix_directional = [3,4]\n\ncentroids = MaxDiss_Simplified_NoThreshold(\n data_mda, num_sel_mda, ix_scalar, ix_directional \n)\n\n\n# store MDA storms - parameters \nTCs_r2_MDA_params = xr.Dataset(\n {\n 'pressure_mean':(('storm'), centroids[:,0]),\n 'pressure_min':(('storm'), centroids[:,1]),\n 'velocity_mean':(('storm'), centroids[:,2]),\n 'delta':(('storm'), centroids[:,3]),\n 'gamma':(('storm'), centroids[:,4]),\n },\n coords = {\n 'storm':(('storm'), np.arange(num_sel_mda)) \n },\n)\nprint(TCs_r2_MDA_params)\n\n#db.Save_TCs_r2_mda_params(TCs_r2_MDA_params)",
"\nMaxDiss waves parameters: 100000 --> 1000\n\n MDA centroids: 1000/1000\n\n<xarray.Dataset>\nDimensions: (storm: 1000)\nCoordinates:\n * storm (storm) int64 0 1 2 3 4 5 6 7 ... 993 994 995 996 997 998 999\nData variables:\n pressure_mean (storm) float64 1.01e+03 926.8 997.5 ... 970.7 972.3 984.8\n pressure_min (storm) float64 1.01e+03 879.0 995.1 ... 944.9 964.4 980.5\n velocity_mean (storm) float64 31.15 6.328 36.79 6.328 ... 22.05 15.03 30.65\n delta (storm) float64 78.77 254.3 258.8 86.47 ... 42.64 237.8 160.5\n gamma (storm) float64 93.15 147.5 181.3 80.78 ... 39.39 84.26 151.2\n"
],
[
"# Historical vs Simulated: scatter plot parameters\nPlot_TCs_Params_MDAvsSIM(TCs_r2_MDA_params, TCs_r2_sim_params);\n",
"_____no_output_____"
]
],
[
[
"## Historical TCs (MDA centroids) Waves Simulation\n\nWaves data is generated by numerically simulating selected storms. \n\nThis methodology is not included inside teslakit python library.\n\nThis step needs to be done before continuing with notebook 07\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
cb3dc97720a9c4bb207a39552269df036511480f | 4,138 | ipynb | Jupyter Notebook | NaiveLookupPrediction.ipynb | xrhan/CIS520Project | e1c2161ed7504329a77c5beb5af69ca50a77b926 | [
"MIT"
] | null | null | null | NaiveLookupPrediction.ipynb | xrhan/CIS520Project | e1c2161ed7504329a77c5beb5af69ca50a77b926 | [
"MIT"
] | null | null | null | NaiveLookupPrediction.ipynb | xrhan/CIS520Project | e1c2161ed7504329a77c5beb5af69ca50a77b926 | [
"MIT"
] | null | null | null | 22.128342 | 123 | 0.500483 | [
[
[
"import csv\nimport pandas as pd\nimport numpy as np\n#from sklearn import\nfrom sklearn.linear_model import LinearRegression\nfrom sklearn.preprocessing import OneHotEncoder\nfrom sklearn.metrics import mean_squared_error\nimport matplotlib.pyplot as plt\nimport statsmodels.api as sm\nfrom scipy import stats\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"## Years to Load",
"_____no_output_____"
]
],
[
[
"years = [14, 15]",
"_____no_output_____"
],
[
"taxi_df = {}\n\nfor i in years:\n taxi_df[i] = pd.read_csv(\"../dataset_4_02_modified/20\" + str(i) \\\n + \"lag.csv\", sep = \",\")\n# \"2016\" and before\n# taxi_df[15] = pd.concat([taxi_df[15], taxi_df[16]], axis = 0)\\\n# .reset_index().drop(columns = ['index'])",
"_____no_output_____"
]
],
[
[
"# Naive Lookup Previous Year",
"_____no_output_____"
]
],
[
[
"for i in years:\n taxi_df[i][\"Short Timestamp\"] = pd.to_datetime(taxi_df[i][\"Trip Start Timestamp\"], format='%Y/%m/%d %H')\\\n .dt.strftime('%m/%d %H')",
"_____no_output_____"
],
[
"lookup_df = taxi_df[14][[\"Short Timestamp\", \"Count\", \"Pickup Community Area\"]]\\\n .merge(right = taxi_df[15][[\"Short Timestamp\", \"Count\", \"Pickup Community Area\"]],\\\n on = [\"Short Timestamp\", \"Pickup Community Area\"], how = \"inner\")",
"_____no_output_____"
]
],
[
[
"## Mean Square Error",
"_____no_output_____"
]
],
[
[
"mean_squared_error(y_true = lookup_df[\"Count_x\"], y_pred = lookup_df[\"Count_y\"])",
"_____no_output_____"
]
],
[
[
"# Naive Lookup Previous Hour",
"_____no_output_____"
],
[
"## Mean Square Error",
"_____no_output_____"
]
],
[
[
"mean_squared_error(y_true = taxi_df[15][\"Count\"], y_pred = taxi_df[15][\"lag1\"])",
"_____no_output_____"
]
],
[
[
"### Results\n#### Naive Lookup Previous Year: 2015 to 2016 MSE = 6557\n#### Naive Lookup Previous Hour: 2016 MSE = 607\n\n\n#### Naive Lookup Previous Year: 2015 to 2016 MSE = 5057\n#### Naive Lookup Previous Hour: 2015 MSE = 941",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] | [
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
cb3dd89ebd030de15bda0487fd61c1977f42740f | 3,034 | ipynb | Jupyter Notebook | 5-ExamProblems/Exam4/spring2022/exam4-s22.ipynb | dustykat/engr-1330-psuedo-course | 3e7e31a32a1896fcb1fd82b573daa5248e465a36 | [
"CC0-1.0"
] | null | null | null | 5-ExamProblems/Exam4/spring2022/exam4-s22.ipynb | dustykat/engr-1330-psuedo-course | 3e7e31a32a1896fcb1fd82b573daa5248e465a36 | [
"CC0-1.0"
] | null | null | null | 5-ExamProblems/Exam4/spring2022/exam4-s22.ipynb | dustykat/engr-1330-psuedo-course | 3e7e31a32a1896fcb1fd82b573daa5248e465a36 | [
"CC0-1.0"
] | null | null | null | 29.456311 | 95 | 0.598879 | [
[
[
"# Question File Naming\n\nExam 03 - topic",
"_____no_output_____"
],
[
"# Topic list\n- probability estimation models\n - plotting position and data ordering\n- regression\n - summary tables (choose to omit parameter)\n - which regression fits a dataset better (R2)\n- classification\n - general concepts \n - simple problem\n- general cool python shit\n - constructor notation\n - \n- optimization topics\n - \n \n1. probability estimation models plotting position TC\n2. constructor notation for polynmoial in sklearn JD\n3. which regression fits better based on R2 NI\n4. vectorization for computational efficiency SA\n5. what is meaning of confusion matrix BB\n6. assess quality of a regression (residual plots) TC\n7. accuracy/precision from residuals JD\n8. general regression concept NI\n9. simple classification problem SA\n10. setting up the design matrix (2-nd order, 3-rd order, etc ...) BB\n11. classifier boundaries with pictures TC\n12. how is correlation coefficient related to a linear regression (single variable) JD\n13. prediction interval NI\n14. concept classification decision boundary SA\n15. error measures (SSE, MSE, RMSE) why are each used? BB\n16. logarithmic scale plotting TC\n17. bias and error meaning JD\n18. classification general concept NI\n19. collinearity influences SA\n20. quantiles BB\n21. package output and find \"things\" TC\n22. correlation (graphically) JD\n23. R2 meaning of the coefficient NI\n24. overfitting/underfitting a classification engine SA\n25. classification training and testing sets BB",
"_____no_output_____"
]
],
[
[
"# Topic list\n- probability estimation models\n - plotting position and data ordering\n- regression\n - summary tables (choose to omit parameter)\n - which regression fits a dataset better (R2)\n- classification\n - general concepts \n - simple problem\n- general cool python shit\n - constructor notation\n - \n- optimization topics\n - ",
"_____no_output_____"
]
]
] | [
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code"
]
] |
cb3deb842930a64f852283a780568ee824b77d28 | 142,612 | ipynb | Jupyter Notebook | identify_candidate_sites/ClassificationCandidateSites.ipynb | levon003/icwsm-cancer-journeys | f0b39f80380ace20912e989964475056be27ebc5 | [
"MIT"
] | null | null | null | identify_candidate_sites/ClassificationCandidateSites.ipynb | levon003/icwsm-cancer-journeys | f0b39f80380ace20912e989964475056be27ebc5 | [
"MIT"
] | null | null | null | identify_candidate_sites/ClassificationCandidateSites.ipynb | levon003/icwsm-cancer-journeys | f0b39f80380ace20912e989964475056be27ebc5 | [
"MIT"
] | null | null | null | 56.502377 | 15,360 | 0.738921 | [
[
[
"Candidate Site Identification for Classification\n===\n\nIdentify of candidate sites for the purposes of broader classification.\n\nUsing these sampling restrictions:\n - Health condition is \"cancer\"\n - Site's \"isDeleted\" != 1\n - Age of site is \"adult\" or \"teen\"\n - Site's createdAt > 2009-01-01\n - Site's last journal post is < 2016-04-01\n - Last journal createdAt - first journal createdAt > 1 month\n - Num journals in the site >= 5\n - Created by the patient \n * We use the proportion of posts that are patient-authored according to the authorship classifier.\n * We require that 95% of the posts are patient-authored.\n * We are currently assessing if this threshold should be lowered or increased in complexity in some way.\n\nPreviously, we had also required the following:\n- If authorship annotations are present for the site, we require the ratio of P to CG/PCG authored posts to be > 50%.\n- The site's \"isForSelf\" key was set.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n\nimport os\nimport numpy as np\nimport pandas as pd\nimport itertools\n\nimport matplotlib.pyplot as plt\nimport matplotlib.dates as md\nimport matplotlib\nimport pylab as pl\n\nimport datetime as dt\nimport time\n\nfrom collections import Counter\n\nimport json\nimport os\nimport re\nimport random\nimport itertools\nimport multiprocessing as mp\nfrom IPython.core.display import display, HTML\nimport datetime as dt\n\nimport sqlite3\nfrom nltk import word_tokenize\nfrom html.parser import HTMLParser\nfrom tqdm import tqdm",
"_____no_output_____"
],
[
"# set filepath for writing\nworking_dir = \"/home/srivbane/shared/caringbridge/data/projects/qual-health-journeys/identify_candidate_sites\"\nvalid_classification_sites_filename = os.path.join(working_dir, \"valid_classification_sites.txt\")\nvalid_sites_filtered_filename = os.path.join(working_dir, \"valid_classification_sites_filtered.txt\")",
"_____no_output_____"
],
[
"# we also save some figures....\nimage_dir = \"/home/srivbane/levon003/repos/qual-health-journeys/chi2019_tex/figures\"",
"_____no_output_____"
],
[
"!wc -l {working_dir}/* | sort -nr",
" 115221 total\r\n 58362 /home/srivbane/shared/caringbridge/data/projects/qual-health-journeys/identify_candidate_sites/valid_classification_sites.txt\r\n 24014 /home/srivbane/shared/caringbridge/data/projects/qual-health-journeys/identify_candidate_sites/valid_sites_with_50_pct_patient_journals.txt\r\n 16563 /home/srivbane/shared/caringbridge/data/projects/qual-health-journeys/identify_candidate_sites/valid_sites_with_75_pct_patient_journals.txt\r\n 8409 /home/srivbane/shared/caringbridge/data/projects/qual-health-journeys/identify_candidate_sites/valid_sites_with_90_pct_patient_journals.txt\r\n 4945 /home/srivbane/shared/caringbridge/data/projects/qual-health-journeys/identify_candidate_sites/valid_classification_sites_filtered.txt\r\n 999 /home/srivbane/shared/caringbridge/data/projects/qual-health-journeys/identify_candidate_sites/active_learning_set_1000.txt\r\n 999 /home/srivbane/shared/caringbridge/data/projects/qual-health-journeys/identify_candidate_sites/active_learning_set_1000\r\n 930 /home/srivbane/shared/caringbridge/data/projects/qual-health-journeys/identify_candidate_sites/site_selected.json\r\n"
],
[
"# read the previosuly identified sites (if the file exists already)\nif os.path.exists(valid_sites_filtered_filename):\n with open(valid_sites_filtered_filename, 'r') as infile:\n valid_sites = [int(line.strip()) for line in infile.readlines() if line.strip() != \"\"]\nelse:\n valid_sites = []\nlen(valid_sites)",
"_____no_output_____"
]
],
[
[
"## Load Site Data and Get Access to Journal Database",
"_____no_output_____"
]
],
[
[
"# load the site dataframe\nworking_dir = \"/home/srivbane/shared/caringbridge/data/projects/qual-health-journeys/extract_site_features\"\nfeathered_site_df_filename = os.path.join(working_dir, \"site_scrubbed.df\")\ndf = pd.read_feather(feathered_site_df_filename)",
"_____no_output_____"
],
[
"len(df)",
"_____no_output_____"
],
[
"def get_db():\n journal_wd=\"/home/srivbane/shared/caringbridge/data/derived/sqlite\"\n db_filename = os.path.join(journal_wd, \"journal.db\")\n db = sqlite3.connect(\n db_filename,\n detect_types=sqlite3.PARSE_DECLTYPES\n )\n db.row_factory = sqlite3.Row\n return db\n\n\ndef get_journal_text(site_id, journal_oid):\n try:\n db = get_db()\n cursor = db.execute(\"\"\"SELECT body \n FROM journal\n WHERE site_id = ? AND journal_oid = ?\"\"\", \n (site_id, journal_oid))\n body = cursor.fetchone()\n assert body is not None\n body_text = body['body']\n return body_text\n finally:\n db.close()\n \ndef get_site_journal_oids(site_id):\n try:\n db = get_db()\n cursor = db.execute(\"\"\"SELECT journal_oid \n FROM journal\n WHERE site_id = ?\"\"\", \n (site_id,))\n result = cursor.fetchall()\n journal_oids = [r['journal_oid'] for r in result]\n return journal_oids\n finally:\n db.close()\n \ndef get_site_journals(site_id, columns=[\"*\"]): # directly returns the journal rows associated with the given site_id\n try:\n db = get_db()\n columns_string = \",\".join(columns)\n cursor = db.execute(\"\"\"SELECT {columns}\n FROM journal\n WHERE site_id = ?\"\"\".format(columns=columns_string), \n (site_id,))\n journals = cursor.fetchall()\n return journals\n finally:\n db.close()",
"_____no_output_____"
]
],
[
[
"## Identify Candidate Sites\n\nFilter down to only sites of interest according to criteria.",
"_____no_output_____"
]
],
[
[
"# include only cancer sites\nc_df = df[df[\"healthCondition_category\"] == \"Cancer\"]\nlen(c_df)",
"_____no_output_____"
],
[
"# include only non-deleted sites\nc_df = c_df[c_df[\"isDeleted\"] != 1]\nlen(c_df)",
"_____no_output_____"
],
[
"# include only adult- and teen-aged sites\nvalid_ages = ['adult', 'teen']\nc_df = c_df[c_df[\"age\"].isin(valid_ages)]\nlen(c_df)",
"_____no_output_____"
],
[
"# include only sites since 2009\nearliest_valid_date = dt.datetime(year=2009,month=1,day=1)\nearliest_valid_date_timestamp = earliest_valid_date.replace(tzinfo=dt.timezone.utc).timestamp() * 1000\nearliest_valid_date_timestamp\nc_df = c_df[c_df[\"createdAt\"] > earliest_valid_date_timestamp]\nlen(c_df)",
"_____no_output_____"
],
[
"# include only sites created by the patient\n# note that this cuts out a huge number of sites; the best way to increase our data size would be the addition of an authorship classifier\n#c_df = c_df[c_df[\"isForSelf\"] == 1.0]\n#len(c_df)",
"_____no_output_____"
],
[
"# now, inspect journal-level features to identify valid sites\n\nskip = True\nif not skip:\n valid_sites = []\n journal_counts = []\n\n latest_valid_date = dt.datetime(year=2016,month=4,day=1)\n latest_valid_date_timestamp = latest_valid_date.replace(tzinfo=dt.timezone.utc).timestamp() * 1000\n\n min_site_time = 1000 * 60 * 60 * 24 * 30 # 30 days, in milliseconds\n\n for site_id in tqdm(c_df[\"_id\"]):\n journals = get_site_journals(site_id, columns=[\"createdAt\"])\n\n # include only sites with at least 5 journals\n if len(journals) < 5:\n continue\n\n # include only sites with last journal post created before 2016/04/01\n if journals[-1]['createdAt'] > latest_valid_date_timestamp:\n continue\n\n # include only sites that lasted at least 30 days\n diff = journals[-1]['createdAt'] - journals[0]['createdAt']\n if diff <= min_site_time:\n continue\n\n valid_sites.append(site_id)\n journal_counts.append(len(journals))\n len(valid_sites)",
"_____no_output_____"
],
[
"# an alternative computation on the journal-level features using a pre-saved dataframe\nsite_survival_working_dir = \"/home/srivbane/shared/caringbridge/data/projects/classify_health_condition/vw_experiments\"\nsite_survival_filename = os.path.join(site_survival_working_dir, \"site_survival_time.csv\")\ncol_names = (\"siteId\", \n \"siteCreatedAt\", \n \"siteUpdatedAt\", \n \"firstJournalCreatedAt\", \n \"lastJournalCreatedAt\",\n \"numJournals\", \n \"numJournalsFound\")\nsurvival_df = pd.read_csv(site_survival_filename, header=None, names=col_names)\nassert len(survival_df) == len(df)\n\nvalid_sites = []\njournal_counts_dict = {}\n\nlatest_valid_date = dt.datetime(year=2016,month=4,day=1)\nlatest_valid_date_timestamp = latest_valid_date.replace(tzinfo=dt.timezone.utc).timestamp() * 1000\n\nearliest_valid_date = dt.datetime(year=2009,month=1,day=1)\nearliest_valid_date_timestamp = earliest_valid_date.replace(tzinfo=dt.timezone.utc).timestamp() * 1000\n\nmin_site_time = 1000 * 60 * 60 * 24 * 30 # 30 days, in milliseconds\nmax_site_time = 1000 * 60 * 60 * 24 * 365 * 8 # 8 years, in milliseconds\n# the maximum site time is really just included to remove likely-erroneous outliers with unexpected timing info\n\nfor site_id in tqdm(c_df[\"_id\"]):\n tmp_df = survival_df[survival_df[\"siteId\"] == site_id]\n assert len(tmp_df) == 1\n row = tmp_df.iloc[0]\n \n # include only sites with at least 5 journals\n if row['numJournalsFound'] < 5:\n continue\n \n # include only sites with last journal post created before 2016/04/01\n if row['lastJournalCreatedAt'] * 1000 > latest_valid_date_timestamp:\n continue\n \n # include only sites with first journal post created after 2009/01/01\n if row['firstJournalCreatedAt'] * 1000 < earliest_valid_date_timestamp:\n continue\n \n # include only sites that lasted at least 30 days\n diff = row['lastJournalCreatedAt'] * 1000 - row['firstJournalCreatedAt'] * 1000\n if diff <= min_site_time:\n continue\n if diff >= max_site_time:\n continue\n \n valid_sites.append(site_id)\n journal_counts_dict[site_id] = row['numJournalsFound']\nlen(valid_sites)",
"100%|██████████| 87360/87360 [02:14<00:00, 648.83it/s]\n"
]
],
[
[
"#### Save the valid sites before author type filtering",
"_____no_output_____"
]
],
[
[
"# save the valid sites to an intermediate file before final filtering by author type\nwith open(valid_classification_sites_filename, 'w') as outfile:\n outfile.write(\"\\n\".join([str(sid) for sid in valid_sites]))\nprint(\"Finished.\")",
"Finished.\n"
]
],
[
[
"#### Bring in the author type classifier's results",
"_____no_output_____"
]
],
[
[
"site_proportions_filepath = \"/home/srivbane/shared/caringbridge/data/projects/qual-health-journeys/author_classification/site_proportions.csv\"\nauthor_df = pd.read_csv(site_proportions_filepath)\nauthor_df.head(n=5)",
"_____no_output_____"
],
[
"def save_threshold_list(sites, threshold, output_filepath):\n filtered_sites = []\n for site_id in tqdm(valid_sites):\n row = author_df['proportion_patient_authored'][author_df['site_id'] == site_id]\n if len(row) == 1:\n proportion_patient_authored = row.iloc[0]\n elif len(row) == 0: # This site isn't in the list, so treat it as 0% patient-authored\n #print(site_id, row)\n proportion_patient_authored = 0\n else:\n raise ValueError(\"Multiple matches for siteId.\")\n if proportion_patient_authored >= threshold:\n filtered_sites.append(site_id)\n with open(output_filepath, 'w') as outfile:\n outfile.write(\"\\n\".join([str(sid) for sid in filtered_sites]))\n print(f\"Wrote sites clearing threshold {threshold} to file '{output_filepath}'.\")",
"_____no_output_____"
],
[
"thresholds = [0.5, 0.75, 0.9]\nworking_dir = \"/home/srivbane/shared/caringbridge/data/projects/qual-health-journeys/identify_candidate_sites\"\nfor threshold in thresholds:\n filename = \"valid_sites_with_%.0f_pct_patient_journals.txt\" % (threshold * 100)\n output_filepath = os.path.join(working_dir, filename)\n save_threshold_list(valid_sites, threshold, output_filepath)",
"100%|██████████| 58363/58363 [00:28<00:00, 2031.83it/s]\n 0%| | 200/58363 [00:00<00:29, 1998.15it/s]"
],
[
"patient_authorship_threshold = 0.95\n\nto_trim = []\nfor site_id in tqdm(valid_sites):\n row = author_df['proportion_patient_authored'][author_df['site_id'] == site_id]\n if len(row) == 1:\n proportion_patient_authored = row.iloc[0]\n elif len(row) == 0: # This site isn't in the list, so treat it as 0% patient-authored\n #print(site_id, row)\n proportion_patient_authored = 0\n else:\n raise ValueError(\"Multiple matches for siteId.\")\n if proportion_patient_authored < patient_authorship_threshold:\n to_trim.append(site_id)\nprint(\"Will trim %d sites leaving %d candidate sites.\" % (len(to_trim), len(valid_sites) - len(to_trim)))",
"100%|██████████| 58363/58363 [00:32<00:00, 1804.78it/s]"
],
[
"for site_id in to_trim:\n valid_sites.remove(site_id)\nlen(valid_sites)",
"_____no_output_____"
]
],
[
[
"#### Bring in author type annotations as a \"trump card\" (?)",
"_____no_output_____"
]
],
[
[
"# maybe we should just rely on the classifier and not do any manual exclusions based on tags?\n# Decision: Yes.\nskip_manual_annotation_exclusions = True",
"_____no_output_____"
],
[
"annotation_web_client_database = \"/home/srivbane/shared/caringbridge/data/projects/qual-health-journeys/instance/cbAnnotator.sqlite\"\n\n\ndef get_annotation_db():\n db = sqlite3.connect(\n annotation_web_client_database,\n detect_types=sqlite3.PARSE_DECLTYPES\n )\n db.row_factory = sqlite3.Row\n return db\n\n\ndef get_author_annotations(site_id):\n try:\n db = get_annotation_db()\n cursor = db.execute(\n \"\"\"SELECT data \n FROM journalAnnotation \n WHERE annotation_type = \"journal_author_type\" AND site_id = ? \n GROUP BY journal_oid\n ORDER BY id DESC\"\"\", (site_id,)\n )\n journal_author_annotations = cursor.fetchall()\n annotation_strings = [a['data'] for a in journal_author_annotations]\n return annotation_strings\n finally:\n db.close()\n\n\ndef get_site_patient_authorship_ratio(site_id):\n # returns None if the given site has no author annotations\n author_annotations = get_author_annotations(site_id)\n counts = Counter(author_annotations)\n p_count = counts['p'] if 'p' in counts else 0\n cg_count = counts['cg'] if 'cg' in counts else 0\n pcg_count = counts['pcg'] if 'pcg' in counts else 0\n total_valid_annotations = p_count + cg_count + pcg_count\n if total_valid_annotations == 0:\n return None\n ratio = p_count / total_valid_annotations\n return ratio\n \n\ndef is_site_authorship_valid(site_id, patient_proportion_required=0.5):\n # returns true if the proportion of patient-authored posts is greater than 0.5, and false otherwise\n ratio = get_site_patient_authorship_ratio(site_id)\n return ratio is None or ratio >= 0.5\n\n\n# Test site\nget_site_patient_authorship_ratio(877534)",
"_____no_output_____"
],
[
"# Trim valid sites based on authorship annotations\nif not skip_manual_annotation_exclusions:\n to_trim = []\n for site_id in tqdm(valid_sites):\n if not is_site_authorship_valid(site_id):\n to_trim.append(site_id)\n for site_id in to_trim:\n valid_sites.remove(site_id)\n print(len(valid_sites))",
"_____no_output_____"
]
],
[
[
"#### Save the valid sites",
"_____no_output_____"
]
],
[
[
"# save the valid sites to a file\nwith open(valid_sites_filtered_filename, 'w') as outfile:\n outfile.write(\"\\n\".join([str(sid) for sid in valid_sites]))\nprint(\"Finished.\")",
"Finished.\n"
]
],
[
[
"## Visualize Candidate Site Features\n\nGraphs and summary stats describing the selected sites.",
"_____no_output_____"
]
],
[
[
"import sys\nsys.path.append(\"../annotation_data\")\nfrom utils import *\nvalid_sites = get_valid_sites_filtered()\nlen(valid_sites)",
"_____no_output_____"
],
[
"# do some quick summary statistics on the journal counts in the valid sites\njournal_counts = [journal_counts_dict[site_id] for site_id in valid_sites]\nfrom scipy import stats\nstats.describe(journal_counts)",
"_____no_output_____"
],
[
"# median, mean, and standard deviation of the number of journals in the selected sites\nnp.median(journal_counts), np.mean(journal_counts), np.std(journal_counts)",
"_____no_output_____"
],
[
"# percentiles of the number of journal counts\nnp.percentile(journal_counts, [5, 10, 25, 50, 75, 90, 95])",
"_____no_output_____"
],
[
"np.sum(journal_counts)",
"_____no_output_____"
],
[
"title = \"Candidate Site Journal Counts\"\nfig, ax = pl.subplots(num=title, figsize=(8,8))\nx = [min(journal_counts_dict[site_id], 101) for site_id in valid_sites]\npatches = plt.hist(x, range=(0, 104), bins=26)\nax.set_title(title)\nax.set_xlabel(\"Journal count\")\nax.set_ylabel(\"Number of sites\")\n\nax.set_xticks([i for i in range(0, 108, 4)])\nax.set_xticklabels([str(i) if i != 104 else \"+\" for i in range(0, 108, 4)])\n\n#ax.set_yticks([i for i in range(0, 430, 10)])\n\nax.grid(axis=\"y\", alpha=0.5)\nplt.show()",
"_____no_output_____"
],
[
"title = \"journal counts\"\nfig, ax = pl.subplots(1, num=title, figsize=(1,0.4), squeeze=True)\n\nx = [min(journal_counts_dict[site_id], 101) for site_id in valid_sites]\npatches = plt.hist(x, range=(0, 100), bins=26, align=\"left\", color=\"black\")\n#plt.ylim(0, y_limit)\n\n# plot the mean as a black line\n#m = np.mean(x)\n#std = np.std(x)\n#summary_text = \"M=%.2f\\\\\\\\ SD=%.2f\" % (m, std)\n#print(summary_text)\n\nax.set_xticks([])\nax.set_yticks([])\nplt.axis('off')\n\nplt.tight_layout(pad=0)\nplt.subplots_adjust(top = 0.4, bottom = 0, right = 1, left = 0, \n hspace = 0, wspace = 0)\n\nplt.margins(0,0)\nplt.gca().xaxis.set_major_locator(plt.NullLocator())\nplt.gca().yaxis.set_major_locator(plt.NullLocator())\n\nbbox = matplotlib.transforms.Bbox.from_bounds(0,0,1,0.2)\nimage_shortfilename = \"journal_updates_summary_hist_short.pdf\"\nimage_filename = os.path.join(image_dir, image_shortfilename)\nplt.savefig(image_filename, format='pdf', dpi=200, pad_inches=0, bbox_inches=bbox) #, transparent=True)\nplt.show()",
"_____no_output_____"
],
[
"# get the subset of the site df that contains only the valid sites\ndf_subset = df[df[\"_id\"].isin(valid_sites)]\nlen(df_subset)",
"_____no_output_____"
],
[
"# get the subset of the survival df that contains only the valid sites\nsurvival_df_subset = survival_df[survival_df[\"siteId\"].isin(valid_sites)]\nlen(survival_df_subset)",
"_____no_output_____"
],
[
"# Add urls to the annotation client, for convenience\ndef get_url(site_id, port=5000):\n url = \"http://127.0.0.1:%d/siteId/%d\" % (port, site_id)\n return '<a href=\"{}\">{}</a>'.format(url, url)\n\ndf_subset['annotation_url'] = [get_url(site_id) for site_id in df_subset[\"_id\"]]",
"/home/srivbane/levon003/anaconda3/lib/python3.6/site-packages/ipykernel_launcher.py:6: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy\n \n"
],
[
"title = \"Candidate Site Visits\"\nfig, ax = pl.subplots(num=title, figsize=(8,8))\nx = [min(visits, 50001) for visits in df_subset[\"visits\"]]\npatches = plt.hist(x, log=True, bins=26, range=(0,52000))#, range=(0, 104), bins=26)\nax.set_title(title)\nax.set_xlabel(\"Visits\")\nax.set_ylabel(\"Number of sites\")\n\nax.set_xticks([i for i in range(0, 52000, 5000)])\n\nax.grid(axis=\"y\", which=\"minor\", alpha=0.5)\nplt.show()",
"_____no_output_____"
],
[
"title = \"journal counts\"\nfig, ax = pl.subplots(1, num=title, figsize=(1,0.4), squeeze=True)\n\nx = [min(visits, 50001) for visits in df_subset[\"visits\"]]\npatches = plt.hist(x, log=False, bins=26, range=(0,10000), align=\"left\", color=\"black\")\n#plt.ylim(0, y_limit)\n\n# plot the mean as a black line\n#m = np.mean(x)\n#std = np.std(x)\n#summary_text = \"M=%.2f\\\\\\\\ SD=%.2f\" % (m, std)\n#print(summary_text)\n\nax.set_xticks([])\nax.set_yticks([])\nplt.axis('off')\n\nplt.tight_layout(pad=0)\nplt.subplots_adjust(top = 0.4, bottom = 0, right = 1, left = 0, \n hspace = 0, wspace = 0)\n\nplt.margins(0,0)\nplt.gca().xaxis.set_major_locator(plt.NullLocator())\nplt.gca().yaxis.set_major_locator(plt.NullLocator())\n\nbbox = matplotlib.transforms.Bbox.from_bounds(0,0,1,0.2)\nimage_shortfilename = \"site_visits_summary_hist_short.pdf\"\nimage_filename = os.path.join(image_dir, image_shortfilename)\nplt.savefig(image_filename, format='pdf', dpi=200, pad_inches=0, bbox_inches=bbox) #, transparent=True)\nplt.show()",
"_____no_output_____"
],
[
"stats.describe(df_subset[\"visits\"]), np.median(df_subset[\"visits\"]), np.std(df_subset[\"visits\"])",
"_____no_output_____"
]
],
[
[
"#### Site Survival Time",
"_____no_output_____"
]
],
[
[
"def get_month(survival_df, site_id):\n single_entry_df = survival_df[survival_df[\"siteId\"] == site_id]\n if len(single_entry_df) != 1:\n raise ValueError(\"Invalid site id %d.\" % site_id)\n site_survival = single_entry_df.iloc[0]\n end_date = site_survival['lastJournalCreatedAt']\n start_date = site_survival['firstJournalCreatedAt']\n if end_date < start_date:\n raise ValueError(\"Invalid site timing info.\")\n survival_time = end_date - start_date\n one_month = 60 * 60 * 24 * 30\n approx_months_survived = survival_time / one_month\n return approx_months_survived\nsite_survival_times = [get_month(survival_df_subset, site_id) for site_id in valid_sites]\nsite_survival_times[:10]",
"_____no_output_____"
],
[
"stats.describe(site_survival_times)",
"_____no_output_____"
],
[
"np.median(site_survival_times), np.mean(site_survival_times), np.std(site_survival_times)",
"_____no_output_____"
],
[
"title = \"Candidate Site Survival Time\"\nfig, ax = pl.subplots(num=title, figsize=(8,8))\nx = site_survival_times #[min(site_survival_time, 8 * 12) for site_survival_time in site_survival_times]\nmonth_range = 7 * 12 + 4 #2009-01 to 2016-04 is the max number of months\npatches = plt.hist(x, log=True, bins=26, range=(0,7*12+4))#, range=(0, 104), bins=26)\nax.set_title(title)\nax.set_xlabel(\"Site survival time (months)\")\nax.set_ylabel(\"Number of sites\")\n\nax.set_xticks([i for i in range(0, 7*12 + 4, 6)])\n\nax.grid(axis=\"y\", which=\"minor\", alpha=0.5)\nplt.show()",
"_____no_output_____"
],
[
"title = \"site survival\"\nfig, ax = pl.subplots(1, num=title, figsize=(1,0.4), squeeze=True)\n\nx = site_survival_times #[min(site_survival_time, 8 * 12) for site_survival_time in site_survival_times]\nmonth_range = 7 * 12 + 4 #2009-01 to 2016-04 is the max number of months\npatches = plt.hist(x, log=False, bins=26, range=(0,5*12), align=\"left\", color=\"black\")\n#patches = plt.hist(x, log=False, bins=26, range=(0,10000), align=\"left\", color=\"black\")\n#plt.ylim(0, y_limit)\n\n# plot the mean as a black line\n#m = np.mean(x)\n#std = np.std(x)\n#summary_text = \"M=%.2f\\\\\\\\ SD=%.2f\" % (m, std)\n#print(summary_text)\n\nax.set_xticks([])\nax.set_yticks([])\nplt.axis('off')\n\nplt.tight_layout(pad=0)\nplt.subplots_adjust(top = 0.4, bottom = 0, right = 1, left = 0, \n hspace = 0, wspace = 0)\n\nplt.margins(0,0)\nplt.gca().xaxis.set_major_locator(plt.NullLocator())\nplt.gca().yaxis.set_major_locator(plt.NullLocator())\n\nbbox = matplotlib.transforms.Bbox.from_bounds(0,0,1,0.2)\nimage_shortfilename = \"survival_time_summary_hist_short.pdf\"\nimage_filename = os.path.join(image_dir, image_shortfilename)\nplt.savefig(image_filename, format='pdf', dpi=200, pad_inches=0, bbox_inches=bbox) #, transparent=True)\nplt.show()",
"_____no_output_____"
],
[
"# longest site?\ni = np.argmax(site_survival_times)\nsite_id = valid_sites[i]\nsite_survival = survival_df_subset[survival_df_subset['siteId'] == site_id].iloc[0]\n(dt.datetime.utcfromtimestamp(site_survival['firstJournalCreatedAt']),\ndt.datetime.utcfromtimestamp(site_survival['lastJournalCreatedAt']),\n site_survival['numJournalsFound'])",
"_____no_output_____"
]
],
[
[
"#### Health condition",
"_____no_output_____"
]
],
[
[
"health_condition_counter = Counter(df_subset['healthCondition_name'])\nhealth_condition_counter.most_common()",
"_____no_output_____"
],
[
"assert sum([t[1] for t in health_condition_counter.most_common()]) == len(valid_sites)",
"_____no_output_____"
],
[
"health_condition_dict = {condition: count for condition, count in health_condition_counter.most_common()}\nnot_specified_list = ['Cancer', 'not provided']\nother_threshold = 65 # include a health condition in the count for 'Other' if it fails to clear this count\n# the other_threshold was set from an inspection of the output of the counter above\n\nfor cond_name in list(health_condition_dict.keys()):\n if cond_name != 'Other' and cond_name not in not_specified_list and health_condition_dict[cond_name] < other_threshold:\n health_condition_dict['Other'] += health_condition_dict[cond_name]\n del health_condition_dict[cond_name]\n\nhealth_condition_dict['Not Specified'] = 0\nfor not_spec_name in not_specified_list:\n health_condition_dict['Not Specified'] += health_condition_dict[not_spec_name]\n del health_condition_dict[not_spec_name]\n\nsorted_filtered_conditions = sorted([(condition, count) for condition, count in health_condition_dict.items()], key=lambda tup: tup[1], reverse=True)\nsorted_filtered_conditions",
"_____no_output_____"
],
[
"print(\"\\\\begin{tabular}[c]{@{}rlrl@{}}\")\nhalfway = len(sorted_filtered_conditions) // 2\ninds = zip(range(0, halfway), range(halfway, len(sorted_filtered_conditions)))\nfor i, j in inds:\n cond1, count1 = sorted_filtered_conditions[i]\n pct1 = count1 / len(valid_sites) * 100\n cond2, count2 = sorted_filtered_conditions[j]\n pct2 = count2 / len(valid_sites) * 100\n print(\"%s & %d (%.1f\\\\%%) & %s & %d (%.1f\\\\%%) \\\\\\\\\" % (cond1, count1, pct1, cond2, count2, pct2))\nprint(\"\\\\end{tabular}\")",
"\\begin{tabular}[c]{@{}rlrl@{}}\nBreast Cancer & 2752 (55.6\\%) & Leukemia & 209 (4.2\\%) \\\\\nLymphoma & 597 (12.1\\%) & Ovarian Cancer & 169 (3.4\\%) \\\\\nOther & 380 (7.7\\%) & Lung Cancer & 168 (3.4\\%) \\\\\nNot Specified & 257 (5.2\\%) & Myeloma Cancer & 120 (2.4\\%) \\\\\nColorectal Cancer & 225 (4.5\\%) & Brain Cancer & 69 (1.4\\%) \\\\\n\\end{tabular}\n"
],
[
"cond_set = set(df_subset['healthCondition_name'])\nfor cond in ['Cancer', 'Other', 'not provided']:\n cond_set.remove(cond)\ncond_list = list(cond_set)\ncond_list.sort(key=lambda cond: health_condition_counter[cond], reverse=True)\n\", \".join(cond_list)",
"_____no_output_____"
],
[
"Counter(df_subset['age']).most_common()",
"_____no_output_____"
],
[
"# it's possible we need to be omitting the non-adult sites from consideration?\n# we produce a view of the non-adult sites including their annotation urls\n# the original result of this analysis was manually annotating authorship on these sites to eliminate non-patient-authored sites\nnonadult = df_subset[df_subset['age'] != 'adult'][['_id', 'age', 'visits', 'annotation_url']]\nnonadult = nonadult.sort_values(by=['age', 'visits'], ascending=False)\n\npd.set_option('display.max_colwidth', -1) # allow the entirety of the url to show by removing column width limits\nHTML(nonadult.to_html(escape=False, max_rows=20))",
"_____no_output_____"
],
[
"Counter(df_subset['isDeleted'].fillna(\"nan\")).most_common()",
"_____no_output_____"
],
[
"Counter(df_subset['isSpam'].fillna(\"nan\")).most_common()",
"_____no_output_____"
],
[
"Counter(df_subset['privacy']).most_common()",
"_____no_output_____"
],
[
"title = \"Candidate Site Tributes\"\nfig, ax = pl.subplots(num=title, figsize=(8,8))\nx = df_subset['numTributes'].fillna(0)\npatches = plt.hist(x, log=True, range=(0, 20), bins=20)\nax.set_title(title)\nax.set_xlabel(\"Tributes\")\nax.set_ylabel(\"Number of sites\")\n\nax.set_xticks(range(0,21,1))\n\nax.grid(axis=\"y\", alpha=0.5)\nplt.show()",
"_____no_output_____"
],
[
"title = \"Candidate Site Visitor Invites\"\nfig, ax = pl.subplots(num=title, figsize=(8,8))\nx = df_subset['numVisitorInvites'].fillna(0)\npatches = plt.hist(x, log=True, range=(0,20), bins=20)\nax.set_title(title)\nax.set_xlabel(\"Visitor invites\")\nax.set_ylabel(\"Number of sites\")\n\nax.set_xticks(range(0,21,1))\n\nax.grid(axis=\"y\", alpha=0.5)\nplt.show()",
"_____no_output_____"
]
],
[
[
"## IRR set identification",
"_____no_output_____"
]
],
[
[
"random.seed(1000)\nrandom.shuffle(valid_sites)\nlen(valid_sites)",
"_____no_output_____"
],
[
"irr_set_size = 10\nirr_set = valid_sites[:irr_set_size]\nirr_set.sort()\nirr_set",
"_____no_output_____"
],
[
"irr_df = df_subset[df_subset['_id'].isin(irr_set)]\nassert len(irr_df) == irr_set_size\nirr_df = irr_df.sort_values(by=['_id'])\nirr_df = irr_df[['_id', 'title', 'visits', 'numJournals', 'annotation_url']]\n\npd.set_option('display.max_colwidth', -1) # allow the entirety of the url to show by removing column width limits\nHTML(irr_df.to_html(escape=False))",
"_____no_output_____"
],
[
"# write the irr_set as an assignment to the appropriate users\nirr_assigned_users = ['levon003', 'rubya001']\nbase_dir = \"/home/srivbane/shared/caringbridge/data/projects/qual-health-journeys/instance/annotation_data/assignments\"\nheader = \"3: Fourth IRR set (tag for both phases and responsibilities)\"\nfor user in irr_assigned_users:\n irr_filename = \"irr_set_4_20180901.txt\"\n irr_filepath = os.path.join(base_dir, user, irr_filename)\n with open(irr_filepath, 'w') as outfile:\n outfile.write(header + \"\\n\")\n outfile.write(\"\\n\".join([str(sid) for sid in irr_set]))\nprint(\"Finished.\")",
"_____no_output_____"
],
[
"# what health conditions are included in this set?\nirr_df = df_subset[df_subset['_id'].isin(irr_set)]\nCounter(irr_df['healthCondition_name']).most_common()",
"_____no_output_____"
],
[
"raise ValueError(\"This cell is a protection against accidentally running all the cells in this notebook.\")",
"_____no_output_____"
]
],
[
[
"## Phase set for Wenqi\n\nThis section added to generate a random set of sites for phase annotation.",
"_____no_output_____"
]
],
[
[
"valid_sites = [int(line.strip()) for line in open(valid_sites_filtered_filename, 'r').readlines() if line.strip() != \"\"]\nlen(valid_sites)",
"_____no_output_____"
],
[
"selected_sites = np.random.choice(valid_sites, size=50)\nselected_sites[:10]",
"_____no_output_____"
],
[
"irr_assigned_users = ['levon003', 'luoxx498']\nbase_dir = \"/home/srivbane/shared/caringbridge/data/projects/qual-health-journeys/instance/annotation_data/assignments\"\nheader = \"Phases 5: Sites for phase annotation\"\nfor user in irr_assigned_users:\n filename = \"phases_set_5_20180904.txt\"\n filepath = os.path.join(base_dir, user, filename)\n with open(filepath, 'w') as outfile:\n outfile.write(header + \"\\n\")\n outfile.write(\"\\n\".join([str(sid) for sid in selected_sites]))\nprint(\"Finished.\")",
"Finished.\n"
]
],
[
[
"## Phase set for active learning",
"_____no_output_____"
]
],
[
[
"valid_sites = [int(line.strip()) for line in open(valid_sites_filtered_filename, 'r').readlines() if line.strip() != \"\"]\nlen(valid_sites)",
"_____no_output_____"
],
[
"n = 1000\nselected_sites = np.random.choice(valid_sites, size=n)\nselected_sites[:10]",
"_____no_output_____"
],
[
"active_learning_set_filepath = os.path.join(working_dir, 'active_learning_set_%d.txt' % n)\nprint(active_learning_set_filepath)\nwith open(active_learning_set_filepath, 'w') as outfile:\n outfile.write(\"\\n\".join([str(sid) for sid in selected_sites]))\nprint(\"Finished.\")",
"/home/srivbane/shared/caringbridge/data/projects/qual-health-journeys/identify_candidate_sites/active_learning_set_1000.txt\nFinished.\n"
]
],
[
[
"## Multiset 2 for Sabirat\n\nThis section added to generate a random set of sites for phase and responsibility annotation.",
"_____no_output_____"
]
],
[
[
"valid_sites = [int(line.strip()) for line in open(valid_sites_filtered_filename, 'r').readlines() if line.strip() != \"\"]\nlen(valid_sites)",
"_____no_output_____"
],
[
"selected_sites = np.random.choice(valid_sites, size=20)\nselected_sites",
"_____no_output_____"
],
[
"irr_assigned_users = ['rubya001']\nbase_dir = \"/home/srivbane/shared/caringbridge/data/projects/qual-health-journeys/instance/annotation_data/assignments\"\nheader = \"Multiset 2: Sites for phase and responsibility annotation\"\nfor user in irr_assigned_users:\n filename = \"multiset_2_20181009.txt\"\n filepath = os.path.join(base_dir, user, filename)\n with open(filepath, 'w') as outfile:\n outfile.write(header + \"\\n\")\n outfile.write(\"\\n\".join([str(sid) for sid in selected_sites]))\nprint(\"Finished.\")",
"Finished.\n"
]
],
[
[
"## Multiset 3 for Wenqi and Drew",
"_____no_output_____"
]
],
[
[
"valid_sites = [int(line.strip()) for line in open(valid_sites_filtered_filename, 'r').readlines() if line.strip() != \"\"]\nlen(valid_sites)",
"_____no_output_____"
],
[
"selected_sites = np.random.choice(valid_sites, size=20)\nselected_sites",
"_____no_output_____"
],
[
"irr_assigned_users = ['eriks074', 'luoxx498']\nbase_dir = \"/home/srivbane/shared/caringbridge/data/projects/qual-health-journeys/instance/annotation_data/assignments\"\nheader = \"Multiset 3: Sites for phase and responsibility annotation\"\nfor user in irr_assigned_users:\n filename = \"multiset_3_20181019.txt\"\n filepath = os.path.join(base_dir, user, filename)\n with open(filepath, 'w') as outfile:\n outfile.write(header + \"\\n\")\n outfile.write(\"\\n\".join([str(sid) for sid in selected_sites]))\nprint(\"Finished.\")",
"Finished.\n"
]
],
[
[
"## Multiset 4 for Wenqi and Drew",
"_____no_output_____"
]
],
[
[
"valid_sites = [int(line.strip()) for line in open(valid_sites_filtered_filename, 'r').readlines() if line.strip() != \"\"]\nlen(valid_sites)",
"_____no_output_____"
],
[
"selected_sites = np.random.choice(valid_sites, size=20)\nselected_sites",
"_____no_output_____"
],
[
"irr_assigned_users = ['eriks074', 'luoxx498']\nbase_dir = \"/home/srivbane/shared/caringbridge/data/projects/qual-health-journeys/instance/annotation_data/assignments\"\nheader = \"Multiset 4: Sites for responsibility annotation\"\nfor user in irr_assigned_users:\n filename = \"multiset_4_20181206.txt\"\n filepath = os.path.join(base_dir, user, filename)\n with open(filepath, 'w') as outfile:\n outfile.write(header + \"\\n\")\n outfile.write(\"\\n\".join([str(sid) for sid in selected_sites]))\nprint(\"Finished.\")",
"Finished.\n"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
cb3df562152681c2eefdc0d1c874a0b88c9c30d9 | 19,984 | ipynb | Jupyter Notebook | Python Basic.ipynb | rpinheiro83/1.WebDevelopment | 41c77d828b9a495bc3b5d9a49687c74af42139db | [
"MIT"
] | null | null | null | Python Basic.ipynb | rpinheiro83/1.WebDevelopment | 41c77d828b9a495bc3b5d9a49687c74af42139db | [
"MIT"
] | null | null | null | Python Basic.ipynb | rpinheiro83/1.WebDevelopment | 41c77d828b9a495bc3b5d9a49687c74af42139db | [
"MIT"
] | null | null | null | 25.752577 | 249 | 0.447058 | [
[
[
"<a href=\"https://colab.research.google.com/github/rpinheiro83/1.WebDevelopment/blob/main/Python%20Basic.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"#Aula 03 - Tipos de Variáveis\n",
"_____no_output_____"
]
],
[
[
"print(\"Hello world\")",
"Hello world\n"
],
[
"# Linhas iniciadas com # são comentários.\n# Comentários são ignorados pelo Python e servem para explicar o código.\n'''\nO símbolo # é um comentário de apenas 1 linha.\nUsando 3 aspas simples consecutivas é possível abrir um bloco de comentário\nde múltiplas linhas. O bloco se encerra com outras 3 aspas simples.\n'''",
"_____no_output_____"
]
],
[
[
"#Aula 04 - Operadores",
"_____no_output_____"
],
[
"##Podemos fazer operações aritméticas simples",
"_____no_output_____"
]
],
[
[
"a = 2 + 3 # Soma\nb = 2 - 3 # Subtração\nc = 2 * 3 # Multiplicação\nd = 2 / 3 # Divisão\ne = 2 // 3 # Divisão inteira\nf = 2 ** 3 # Potência\ng = 2 % 3 # Resto de divisão\nprint(a, b, c, d , e, f ,g)",
"5 -1 6 0.6666666666666666 0 8 2\n"
]
],
[
[
"##Podemos fazer operações dentro do print",
"_____no_output_____"
]
],
[
[
"print(a+1, b+1)",
"6 0\n"
]
],
[
[
"##Podemos fazer operações com variáveis não inteiras",
"_____no_output_____"
]
],
[
[
"nome = input('Digite seu primeiro nome:')\nnome = nome + ' Pinheiro'\nprint(nome)",
"Digite seu primeiro nome:Rodolfo\nRodolfo Pinheiro\n"
]
],
[
[
"##Operadores relacionais",
"_____no_output_____"
]
],
[
[
"comparacao = 5 > 3\ncomparacao2 = 5 < 3\nprint(comparacao)\nprint(comparacao2)",
"True\nFalse\n"
]
],
[
[
"###O Python possui 6 operadores relacionais:",
"_____no_output_____"
],
[
"####\n\n* Maior que: >\n* Maior ou igual: >=\n* Menor que: <\n* Menor ou igual: <=\n* Igual: ==\n* Diferente: !=\n* Igual: ==\n",
"_____no_output_____"
],
[
"##Operadores lógicos",
"_____no_output_____"
]
],
[
[
"comparacao1 = 5 > 3 and 6 > 3\ncomparacao2 = 5 < 3 and 6 > 3\nprint(comparacao1, comparacao2)",
"True False\n"
]
],
[
[
"#Aula 05 - Estruturas Sequenciais",
"_____no_output_____"
],
[
"##Inputs",
"_____no_output_____"
]
],
[
[
"nome = input('Digite o seu nome: ')\nprint(nome)",
"Digite o seu nome: rodolfo\nrodolfo\n"
]
],
[
[
"### Tudo que é lido por input() é considerado uma string (str).\n### Para tratar como outros tipos de dados é necessário realizar a conversão:",
"_____no_output_____"
]
],
[
[
"peso = float(input('Digite o seu peso:'))\nidade = int(input('Digite a sua idade:'))\nprint(\"Seu peso é \", peso)\nprint(\"Sua idade é \", idade)",
"Digite o seu peso:90.55\nDigite a sua idade:38\nSeu peso é 90.55\nSua idade é 38\n"
]
],
[
[
"##Outputs",
"_____no_output_____"
]
],
[
[
"y = 3.14 # uma variável do tipo real (float)\nescola = \"Let's Code\" # uma variável literal (string)\n\n# Podemos exibir textos na tela e/ou valores de variáveis com a função print().\nprint('eu estudo na ', escola)\nprint('pi vale', y)\n\n# Podemos fazer operações dentro do print:\nprint (y+1, y**2)",
"eu estudo na Let's Code\npi vale 3.14\n4.140000000000001 9.8596\n"
]
],
[
[
"#Aula 06 - Estruturas Condicionais",
"_____no_output_____"
],
[
"##Else",
"_____no_output_____"
],
[
"###Em alguns casos, queremos que o programa escolha entre 2 casos mutuamente exclusivos. Para isso utilizamos o else. O else não possui condição para verificar. O else sempre vem imediatamente após um if e é executado se o if for ignorado.",
"_____no_output_____"
]
],
[
[
"idade = int(input(\"Digite sua idade:\"))\naltura = float(input(\"Digite sua altura em metros:\"))\n\nif idade >= 12 and altura >= 1.60:\n print(\"You can get on the roller coaster.\") \nelse:\n print(\"You can't get on the roller coaster\")\nprint(\"Thank you very much\")",
"Digite sua idade:12\nDigite sua altura em metros:1.60\nYou can get on the roller coaster.\nThank you very much\n"
]
],
[
[
"###É possível \"aninhar\" diversos if's e else's. O programa abaixo só deixa a pessoa entrar no brinquedo se tiver idade e altura mínimas:",
"_____no_output_____"
]
],
[
[
"idade = int(input(\"Enter your age: \"))\nif idade >= 12:\n responda = input(\"Would you like get on the roller coaster?\")\n if (responda == \"yes\"):\n print(\"Please come in.\")\n else:\n print(\"Okay then\")\nelse:\n print(\"You haven't old enough to get into this toy.\")\n",
"Digite a sua idade: 12\nWould you like get on the roller coaster?yes\nPlease come in.\n"
]
],
[
[
"###Podemos testar diversos casos mutuamente exclusivos utilizando o 'elif'.\n\nO comando elif é a contração de \"else if\" - ou seja, caso um if não seja executado, você pode propor uma nova condição para ser testada.",
"_____no_output_____"
]
],
[
[
"exercises = int(input(\"How many Python exercises have you already done?\"))\n\nif exercises > 30:\n print(\"It's already getting professional!\")\nelif exercises > 20:\n print(\"It's going well, let's do some more!\")\nelif exercises > 10:\n print(\"Shall we catch up?\")\nelse:\n print(\"xiiiiii...........\")",
"How many Python exercises have you already done?31\nIt's already getting professional!\n"
]
],
[
[
"#Aula 07 - Estruturas de Repetição - While",
"_____no_output_____"
],
[
"##While",
"_____no_output_____"
],
[
"###O while é bastante parecido com um 'if': ele possui uma expressão, e é executado caso ela seja verdadeira. Mas o if é executado apenas uma vez, e depois o código segue adiante.\n\nO while não: ao final de sua execução, ele torna a testar a expressão, e caso ela seja verdadeira, ele repete sua execução.",
"_____no_output_____"
]
],
[
[
"horario = int(input('Qual horario é agora? '))\nwhile 0 < horario < 6:\n print('Você está no horario da madrugada')\n horario = horario + 1\nelse:\n print('Você nao está no horario da madrugada')",
"Qual horario é agora? 7\nVocê nao está no horario da madrugada\n"
]
],
[
[
"##Validação de entrada",
"_____no_output_____"
],
[
"###Uma utilidade interessante do while é obrigar o usuário a digitar apenas entradas válidas.",
"_____no_output_____"
]
],
[
[
"salario = float(input('Digite seu salario: '))\nwhile salario < 998.0:\n salario = float(input('Entre com um salario MAIOR DO QUE 998.0: '))\nelse:\n print('O salario que você entrou foi: ', salario)",
"Digite seu salario: 500\nEntre com um salario MAIOR DO QUE 998.0: 900\nEntre com um salario MAIOR DO QUE 998.0: 1000\nO salario que você entrou foi: 1000.0\n"
]
],
[
[
"##Contador",
"_____no_output_____"
],
[
"###Todo tipo de código que deve se repetir várias vezes pode ser feito com o while, como somar vários valores, gerar uma sequência etc. Nestes casos, é normal utilizar um contador:",
"_____no_output_____"
]
],
[
[
"# Declaramos um contador como 0:\ncontador = 0\n# Definimos o número de repetições:\nnumero = int(input('Digite um numero: '))\n# Rodamos o while até o contador se igualar ao número de repetições:\nwhile contador < numero:\n print(contador)\n contador = contador + 1",
"Digite um numero: 10\n0\n1\n2\n3\n4\n5\n6\n7\n8\n9\n"
]
],
[
[
"##Break",
"_____no_output_____"
],
[
"###Um jeito de forçar um loop a ser interrompido é utilizando o comando 'break'. O loop abaixo em tese seria infinito, mas se a condição do if for verificada, o break é executado e conseguimos escapar do loop:",
"_____no_output_____"
]
],
[
[
"while True:\n resposta = input('Digite OK: ')\n if resposta == 'OK':\n break",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
]
] |
cb3dff3db2c1ae503111526b668d6855c5af52ff | 4,098 | ipynb | Jupyter Notebook | ipynb/Hungary-Vas.ipynb | RobertRosca/oscovida.github.io | d609949076e3f881e38ec674ecbf0887e9a2ec25 | [
"CC-BY-4.0"
] | null | null | null | ipynb/Hungary-Vas.ipynb | RobertRosca/oscovida.github.io | d609949076e3f881e38ec674ecbf0887e9a2ec25 | [
"CC-BY-4.0"
] | null | null | null | ipynb/Hungary-Vas.ipynb | RobertRosca/oscovida.github.io | d609949076e3f881e38ec674ecbf0887e9a2ec25 | [
"CC-BY-4.0"
] | null | null | null | 28.657343 | 165 | 0.510005 | [
[
[
"# Hungary: Vas\n\n* Homepage of project: https://oscovida.github.io\n* [Execute this Jupyter Notebook using myBinder](https://mybinder.org/v2/gh/oscovida/binder/master?filepath=ipynb/Hungary-Vas.ipynb)",
"_____no_output_____"
]
],
[
[
"import datetime\nimport time\n\nstart = datetime.datetime.now()\nprint(f\"Notebook executed on: {start.strftime('%d/%m/%Y %H:%M:%S%Z')} {time.tzname[time.daylight]}\")",
"_____no_output_____"
],
[
"%config InlineBackend.figure_formats = ['svg']\nfrom oscovida import *",
"_____no_output_____"
],
[
"overview(country=\"Hungary\", region=\"Vas\");",
"_____no_output_____"
],
[
"# load the data\ncases, deaths, region_label = get_region_hungary(county=\"Vas\")\n\n# compose into one table\ntable = compose_dataframe_summary(cases, deaths)\n\n# show tables with up to 500 rows\npd.set_option(\"max_rows\", 500)\n\n# display the table\ntable",
"_____no_output_____"
]
],
[
[
"# Explore the data in your web browser\n\n- If you want to execute this notebook, [click here to use myBinder](https://mybinder.org/v2/gh/oscovida/binder/master?filepath=ipynb/Hungary-Vas.ipynb)\n- and wait (~1 to 2 minutes)\n- Then press SHIFT+RETURN to advance code cell to code cell\n- See http://jupyter.org for more details on how to use Jupyter Notebook",
"_____no_output_____"
],
[
"# Acknowledgements:\n\n- Johns Hopkins University provides data for countries\n- Robert Koch Institute provides data for within Germany\n- Open source and scientific computing community for the data tools\n- Github for hosting repository and html files\n- Project Jupyter for the Notebook and binder service\n- The H2020 project Photon and Neutron Open Science Cloud ([PaNOSC](https://www.panosc.eu/))\n\n--------------------",
"_____no_output_____"
]
],
[
[
"print(f\"Download of data from Johns Hopkins university: cases at {fetch_cases_last_execution()} and \"\n f\"deaths at {fetch_deaths_last_execution()}.\")",
"_____no_output_____"
],
[
"# to force a fresh download of data, run \"clear_cache()\"",
"_____no_output_____"
],
[
"print(f\"Notebook execution took: {datetime.datetime.now()-start}\")\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
]
] |
cb3e0554f6e40886a9c950f07c3fd7750d0950e7 | 204,381 | ipynb | Jupyter Notebook | notebooks/hello_world.ipynb | dhruvbalwada/cmip6hack-so-project | a176f2b1cf6b0ff9c3c4102a12aabfcfc7b979ff | [
"MIT"
] | null | null | null | notebooks/hello_world.ipynb | dhruvbalwada/cmip6hack-so-project | a176f2b1cf6b0ff9c3c4102a12aabfcfc7b979ff | [
"MIT"
] | null | null | null | notebooks/hello_world.ipynb | dhruvbalwada/cmip6hack-so-project | a176f2b1cf6b0ff9c3c4102a12aabfcfc7b979ff | [
"MIT"
] | null | null | null | 40.92531 | 351 | 0.39077 | [
[
[
"# Hello World!\n\nHere's an example notebook with some documentation on how to access CMIP data.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n\nimport xarray as xr\nimport intake\n\n# util.py is in the local directory\n# it contains code that is common across project notebooks\n# or routines that are too extensive and might otherwise clutter\n# the notebook design\nimport util ",
"/srv/conda/envs/notebook/lib/python3.7/site-packages/intake/source/discovery.py:136: FutureWarning: The drivers ['stac-catalog', 'stac-collection', 'stac-item'] do not specify entry_points and were only discovered via a package scan. This may break in a future release of intake. The packages should be updated.\n FutureWarning)\n"
],
[
"print('hello world!')",
"hello world!\n"
]
],
[
[
"## Demonstrate how to use `intake-esm`\n[Intake-esm](https://intake-esm.readthedocs.io) is a data cataloging utility that facilitates access to CMIP data. It's pretty awesome.\n\nAn `intake-esm` collection object establishes a link to a database that contains file locations and associated metadata (i.e., which experiement, model, the come from). \n\n### Opening a collection\nFirst step is to open the collection by pointing the collection definition file, which is a JSON file that conforms to the [ESM Collection Specification](https://github.com/NCAR/esm-collection-spec). \n\nThe collection JSON files are stored locally in this repository for purposes of reproducibility---and because Cheyenne compute nodes don't have Internet access. \n\nThe primary source for these files is the [intake-esm-datastore](https://github.com/NCAR/intake-esm-datastore) repository. Any changes made to these files should be pulled from that repo. For instance, the Pangeo cloud collection is available [here](https://raw.githubusercontent.com/NCAR/intake-esm-datastore/master/catalogs/pangeo-cmip6.json).",
"_____no_output_____"
]
],
[
[
"if util.is_ncar_host():\n col = intake.open_esm_datastore(\"../catalogs/glade-cmip6.json\")\nelse:\n col = intake.open_esm_datastore(\"../catalogs/pangeo-cmip6.json\")\ncol",
"_____no_output_____"
]
],
[
[
"`intake-esm` is build on top of [pandas](https://pandas.pydata.org/pandas-docs/stable). It is possible to view the `pandas.DataFrame` as follows.",
"_____no_output_____"
]
],
[
[
"col.df.head()",
"_____no_output_____"
]
],
[
[
"It is possible to interact with the `DataFrame`; for instance, we can see what the \"attributes\" of the datasets are by printing the columns.",
"_____no_output_____"
]
],
[
[
"col.df.columns",
"_____no_output_____"
]
],
[
[
"### Search and discovery\n\n#### Finding unique entries\nLet's query the data to see what models (\"source_id\"), experiments (\"experiment_id\") and temporal frequencies (\"table_id\") are available.",
"_____no_output_____"
]
],
[
[
"import pprint \nuni_dict = col.unique(['source_id', 'experiment_id', 'table_id'])\npprint.pprint(uni_dict, compact=True)",
"{'experiment_id': {'count': 29,\n 'values': ['ssp370', 'esm-ssp585', '1pctCO2-bgc', 'hist-bgc',\n '1pctCO2', 'abrupt-4xCO2', 'historical',\n 'piControl', 'amip', 'esm-hist', 'esm-piControl',\n 'hist-GHG', 'hist-aer', 'hist-nat', 'dcppA-assim',\n 'dcppA-hindcast', 'dcppC-hindcast-noAgung',\n 'dcppC-hindcast-noElChichon',\n 'dcppC-hindcast-noPinatubo', 'highresSST-present',\n 'control-1950', 'hist-1950', 'deforest-globe',\n 'esm-ssp585-ssp126Lu', 'omip1', 'lgm', 'ssp126',\n 'ssp245', 'ssp585']},\n 'source_id': {'count': 48,\n 'values': ['BCC-ESM1', 'BCC-CSM2-MR', 'CanESM5', 'CNRM-ESM2-1',\n 'UKESM1-0-LL', 'GISS-E2-1-G', 'CESM2', 'GFDL-ESM4',\n 'AWI-CM-1-1-MR', 'CAMS-CSM1-0', 'FGOALS-f3-L',\n 'FGOALS-g3', 'CNRM-CM6-1', 'E3SM-1-0', 'EC-Earth3-LR',\n 'EC-Earth3-Veg', 'EC-Earth3', 'FIO-ESM-2-0',\n 'IPSL-CM6A-LR', 'MIROC-ES2L', 'MIROC6',\n 'HadGEM3-GC31-LL', 'HadGEM3-GC31-MM', 'MRI-ESM2-0',\n 'GISS-E2-1-G-CC', 'GISS-E2-1-H', 'CESM2-WACCM',\n 'NorCPM1', 'GFDL-AM4', 'GFDL-CM4', 'NESM3',\n 'SAM0-UNICON', 'MCM-UA-1-0', 'CMCC-CM2-HR4',\n 'CMCC-CM2-VHR4', 'CNRM-CM6-1-HR', 'ECMWF-IFS-HR',\n 'ECMWF-IFS-LR', 'IPSL-CM6A-ATM-HR', 'NICAM16-7S',\n 'NICAM16-8S', 'NICAM16-9S', 'HadGEM3-GC31-HM',\n 'HadGEM3-GC31-LM', 'MRI-AGCM3-2-H', 'MRI-AGCM3-2-S',\n 'GFDL-CM4C192', 'MPI-ESM1-2-HR']},\n 'table_id': {'count': 23,\n 'values': ['Amon', 'Lmon', 'Oyr', 'Omon', 'SImon', 'day', '3hr',\n '6hrLev', 'LImon', 'Aclim', 'Ofx', 'fx', 'Emon',\n '6hrPlev', 'Oclim', 'SIclim', 'Eclim', 'Odec',\n 'AERmon', 'ImonGre', '6hrPlevPt', 'CF3hr', 'E3hr']}}\n"
]
],
[
[
"#### Searching for specific datasets\n\nLet's find all the dissolved oxygen data at annual frequency from the ocean for the `historical` and `ssp585` experiments.",
"_____no_output_____"
]
],
[
[
"cat = col.search(experiment_id=['historical', 'ssp585'], table_id='Oyr', variable_id='o2', grid_label='gn')\ncat.df",
"_____no_output_____"
]
],
[
[
"It might be desirable to get more specific. For instance, we may want to select only the models that have *both* `historical` and `ssp585` data. We coud do this as follows.",
"_____no_output_____"
]
],
[
[
"models = set(uni_dict['source_id']['values']) # all the models\n\nfor experiment_id in ['historical', 'ssp585']:\n query = dict(experiment_id=experiment_id, table_id='Oyr', \n variable_id='o2', grid_label='gn') \n cat = col.search(**query)\n models = models.intersection({model for model in cat.df.source_id.unique().tolist()})\n\n# ensure the CESM2 models are not included (oxygen was erroneously submitted to the archive)\nmodels = models - {'CESM2-WACCM', 'CESM2'}\n\nmodels = list(models)\nmodels",
"_____no_output_____"
],
[
"cat = col.search(experiment_id=['historical', 'ssp585'], table_id='Oyr', \n variable_id='o2', grid_label='gn', source_id=models)\ncat.df",
"_____no_output_____"
]
],
[
[
"### Loading data\n\n`intake-esm` enables loading data directly into an [xarray.Dataset](http://xarray.pydata.org/en/stable/api.html#dataset).\n\nNote that data on the cloud are in \n[zarr](https://zarr.readthedocs.io/en/stable/) and data on \n[glade](https://www2.cisl.ucar.edu/resources/storage-and-file-systems/glade-file-spaces) are stored as \n[netCDF](https://www.unidata.ucar.edu/software/netcdf/) files. This is opaque to the user.\n\n`intake-esm` has rules for aggegating datasets; these rules are defined in the collection-specification file.",
"_____no_output_____"
]
],
[
[
"dset_dict = cat.to_dataset_dict(zarr_kwargs={'consolidated': True, 'decode_times': False}, \n cdf_kwargs={'chunks': {}, 'decode_times': False})",
"--> The keys in the returned dictionary of datasets are constructed as follows:\n\t'activity_id.institution_id.source_id.experiment_id.table_id.grid_label'\n\n--> There will be 6 group(s)\n"
]
],
[
[
"`dset_dict` is a dictionary of `xarray.Dataset`'s; its keys are constructed to refer to compatible groups.",
"_____no_output_____"
]
],
[
[
"dset_dict.keys()",
"_____no_output_____"
]
],
[
[
"We can access a particular dataset as follows.",
"_____no_output_____"
]
],
[
[
"dset_dict['CMIP.CCCma.CanESM5.historical.Oyr.gn']",
"_____no_output_____"
]
],
[
[
"### More advanced queries\n\nAs motivation for diving into more advanced manipulations with `intake-esm`, let's consider the task of getting access to grid information in the `Ofx` table_id.",
"_____no_output_____"
]
],
[
[
"cat_fx = col.search(experiment_id=['historical', 'ssp585'], source_id=models, table_id='Ofx', grid_label='gn')\ncat_fx.df",
"_____no_output_____"
]
],
[
[
"This, however, comes with lots of redundant information.\n\nAdditionally, it may be necessary to do more targeted manipulations of the search. For instance, we've found a handful of corrupted files on `glade` and might need to work around loading these. \n\nAs an illustration of this, in the code below, we specify a list of to queries (in this case one) to eliminate.",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\n# specify a list of queries to eliminate\ncorrupt_data = [dict(variable_id='areacello', source_id='IPSL-CM6A-LR',\n experiment_id='historical', member_id='r2i1p1f1')\n ]\n\n\n# copy the dataframe \ndf = cat_fx.df.copy()\n\n# eliminate data\nfor elim in corrupt_data:\n condition = np.ones(len(df), dtype=bool)\n for key, val in elim.items():\n condition = condition & (df[key] == val)\n df = df.loc[~condition]\ndf ",
"_____no_output_____"
]
],
[
[
"We then drop duplicates.",
"_____no_output_____"
]
],
[
[
"df.drop_duplicates(subset=['source_id', 'variable_id'], inplace=True)",
"_____no_output_____"
]
],
[
[
"Now, since we've only retained one ensemble member, we need to eliminate that column. If we omit this step, `intake-esm` will throw an error, complaining that different variables are present for each ensemble member. Setting the `member_id` column to NaN precludes attempts to join along the ensemble dimension.\n\nAfter this final manipulation, we copy the `DataFrame` back to the collection object and procede with loading the data.",
"_____no_output_____"
]
],
[
[
"df['member_id'] = np.nan\ncat_fx.df = df",
"_____no_output_____"
],
[
"fx_dsets = cat_fx.to_dataset_dict(zarr_kwargs={'consolidated': True}, cdf_kwargs={'chunks': {}})",
"--> The keys in the returned dictionary of datasets are constructed as follows:\n\t'activity_id.institution_id.source_id.experiment_id.table_id.grid_label'\n\n--> There will be 3 group(s)\n"
],
[
"fx_dsets.keys()",
"_____no_output_____"
],
[
"for key, ds in fx_dsets.items():\n print(ds.data_vars)",
"Data variables:\n areacello (j, i) float32 dask.array<chunksize=(291, 360), meta=np.ndarray>\n latitude (j, i) float64 dask.array<chunksize=(291, 360), meta=np.ndarray>\n longitude (j, i) float64 dask.array<chunksize=(291, 360), meta=np.ndarray>\n vertices_latitude (j, i, vertices) float64 dask.array<chunksize=(291, 360, 4), meta=np.ndarray>\n vertices_longitude (j, i, vertices) float64 dask.array<chunksize=(291, 360, 4), meta=np.ndarray>\n deptho (j, i) float32 dask.array<chunksize=(291, 360), meta=np.ndarray>\n sftof (j, i) float32 dask.array<chunksize=(291, 360), meta=np.ndarray>\n type |S3 ...\n lev_bnds (lev, bnds) float64 dask.array<chunksize=(45, 2), meta=np.ndarray>\n thkcello (lev, j, i) float32 dask.array<chunksize=(45, 291, 360), meta=np.ndarray>\nData variables:\n area (y, x) float32 dask.array<chunksize=(332, 362), meta=np.ndarray>\n areacello (y, x) float32 dask.array<chunksize=(332, 362), meta=np.ndarray>\n bounds_nav_lat (y, x, nvertex) float32 dask.array<chunksize=(332, 362, 4), meta=np.ndarray>\n bounds_nav_lon (y, x, nvertex) float32 dask.array<chunksize=(332, 362, 4), meta=np.ndarray>\n nav_lat (y, x) float32 dask.array<chunksize=(332, 362), meta=np.ndarray>\n nav_lon (y, x) float32 dask.array<chunksize=(332, 362), meta=np.ndarray>\n basin (y, x) float32 dask.array<chunksize=(332, 362), meta=np.ndarray>\nData variables:\n areacello (y, x) float32 dask.array<chunksize=(256, 360), meta=np.ndarray>\n latitude (y, x) float32 dask.array<chunksize=(256, 360), meta=np.ndarray>\n longitude (y, x) float32 dask.array<chunksize=(256, 360), meta=np.ndarray>\n vertices_latitude (y, x, vertices) float32 dask.array<chunksize=(256, 360, 4), meta=np.ndarray>\n vertices_longitude (y, x, vertices) float32 dask.array<chunksize=(256, 360, 4), meta=np.ndarray>\n x_bnds (x, bnds) float64 dask.array<chunksize=(360, 2), meta=np.ndarray>\n y_bnds (y, bnds) float64 dask.array<chunksize=(256, 2), meta=np.ndarray>\n deptho (y, x) float32 dask.array<chunksize=(256, 360), meta=np.ndarray>\n sftof (y, x) float32 dask.array<chunksize=(256, 360), meta=np.ndarray>\n type |S3 ...\n"
]
],
[
[
"## Demonstrate how spin-up a dask cluster\n\nIf you expect to require Big Data capabilities, here's how you spin up a [dask](https://dask.org) cluster using [dask-jobqueue](https://dask-jobqueue.readthedocs.io/en/latest/).\n\nThe syntax is different if on an NCAR machine versus the cloud.",
"_____no_output_____"
]
],
[
[
"if util.is_ncar_host():\n from ncar_jobqueue import NCARCluster\n cluster = NCARCluster(project='UCGD0006')\n cluster.adapt(minimum_jobs=1, maximum_jobs=10)\nelse:\n from dask_kubernetes import KubeCluster\n cluster = KubeCluster()\n cluster.adapt(minimum=1, maximum=10)\ncluster",
"_____no_output_____"
],
[
"from dask.distributed import Client\nclient = Client(cluster) # Connect this local process to remote workers\nclient",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
cb3e22276ee9a4c8379474cf2e0b66a736f440c9 | 118,535 | ipynb | Jupyter Notebook | Preprocessing.ipynb | XC-Li/LMI-Data-Synthesis-Competitipon | 65572ce5a09d9f20c4fdf6f879af6e56ac86536b | [
"MIT"
] | 2 | 2019-09-16T07:33:21.000Z | 2019-12-14T14:06:19.000Z | Preprocessing.ipynb | XC-Li/LMI-Data-Synthesis-Competitipon | 65572ce5a09d9f20c4fdf6f879af6e56ac86536b | [
"MIT"
] | null | null | null | Preprocessing.ipynb | XC-Li/LMI-Data-Synthesis-Competitipon | 65572ce5a09d9f20c4fdf6f879af6e56ac86536b | [
"MIT"
] | 1 | 2019-12-14T14:07:01.000Z | 2019-12-14T14:07:01.000Z | 88.130112 | 39,548 | 0.722487 | [
[
[
"# Preprocessing Part\n## Author: Xiaochi (George) Li\n\nInput: \"data.xlsx\" provided by the professor \nOutput: \"processed_data.pickle\" with target variable \"Salary\" as the last column. And all the missing value should be imputed or dropped.\n\n### Summary\n\nIn this part, we read the data from the file, did some exploratory data analysis on the data and processed the data for further analysis and synthesis.\n\n#### Exploratory Data Analysis\n* Correlation analysis\n* Missing value analysis\n* Unique percentage analysis\n\n#### Process\n* Removed\n 1. Need NLP: \"MOU\", \"MOU Title\", \"Title\", \"Department\", \n 2. No meaning:\"Record Number\", \n 3. \\>50% missing: \"POBP\"\n\n* Imputed\n 1. p_dep: mean \n 2. p_grade: add new category \n 3. Lump Sum Pay:0 \n 4. benefit: add new category \n 5. Rate:mean \n 6. o_pay:median ",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport sklearn \nimport seaborn as sns\nimport matplotlib.pyplot as plt\nnp.random.seed(42)",
"_____no_output_____"
],
[
"df = pd.read_excel(\"data.xlsx\",thousands=\",\") #seperations in thousands",
"_____no_output_____"
],
[
"df.info()",
"<class 'pandas.core.frame.DataFrame'>\nInt64Index: 80000 entries, 161542 to 346245\nData columns (total 26 columns):\nRecord Number 80000 non-null object\nMOU 75347 non-null object\nMOU Title 75347 non-null object\nTotal Payments 80000 non-null float64\nLump Sum Pay 65157 non-null float64\nOther Pay (Payroll Explorer) 80000 non-null float64\nFMS Department 80000 non-null int64\nJob Class 80000 non-null int64\nTitle 80000 non-null object\nAverage Benefit Cost 80000 non-null float64\nTime 80000 non-null int64\nDepartment 80000 non-null object\np_dep 64857 non-null float64\ne_type 80000 non-null object\nRate 75347 non-null float64\nPOBP 39056 non-null float64\np_bonus 80000 non-null float64\nt_bonus 80000 non-null float64\no_pay 79700 non-null float64\nlong 80000 non-null float64\ne_pay 80000 non-null float64\np_grade 64857 non-null object\ninsurance 80000 non-null float64\nbenefit 65739 non-null object\nfinancial 80000 non-null int64\nSalary 80000 non-null float64\ndtypes: float64(14), int64(4), object(8)\nmemory usage: 16.5+ MB\n"
],
[
"\"\"\"Correlation analysis\"\"\"\n\ncorr = df.corr()\nmask = np.zeros_like(corr, dtype=np.bool)\nmask[np.triu_indices_from(mask)] = True\nf, ax = plt.subplots(figsize=(11, 9))\ncmap = sns.diverging_palette(220, 10, as_cmap=True)\nsns.heatmap(corr, mask=mask, cmap=cmap, vmax=1, vmin=-1, center=0,\n square=True, linewidths=.5, cbar_kws={\"shrink\": .5})\ncorr",
"_____no_output_____"
],
[
"\"\"\"Missing rate for each feature\"\"\"\n\nnull_rate = df.isnull().sum(axis = 0).sort_values(ascending = False)/float((len(df)))\nnull_rate",
"_____no_output_____"
],
[
"\"\"\"Unique Rate for each feature\"\"\"\n\nunique_rate = df.apply(lambda x: len(pd.unique(x)),axis = 0).sort_values(ascending = False) #unique rate and sort\nprint(unique_rate)\n\ndef column_analyse(x,df = df): #print count for columns that only has few uniques\n print(df[x].value_counts(),\"\\n\",df[x].value_counts().sum() ,\"\\n\",df[x].value_counts()/len(df[x]), \"\\n-----------------------\")",
"Total Payments 76581\nSalary 57159\nOther Pay (Payroll Explorer) 54940\nRecord Number 54595\no_pay 43159\nPOBP 32256\ne_pay 26857\np_bonus 21959\nlong 12298\nLump Sum Pay 9371\nt_bonus 8837\nRate 7344\nTitle 1523\nJob Class 1071\np_dep 186\nMOU Title 183\nMOU 108\nDepartment 87\nfinancial 42\nFMS Department 42\np_grade 29\ninsurance 21\nAverage Benefit Cost 21\nTime 6\nbenefit 5\ne_type 3\ndtype: int64\n"
],
[
"column_analyse(\"e_type\")\ncolumn_analyse(\"benefit\")\ncolumn_analyse(\"Time\")\ncolumn_analyse(\"p_grade\")",
"FT 65739\nPT 14020\nPE 241\nName: e_type, dtype: int64 \n 80000 \n FT 0.821738\nPT 0.175250\nPE 0.003012\nName: e_type, dtype: float64 \n-----------------------\nGrey 32331\nYellow 14945\nBlue 13961\nRed 4502\nName: benefit, dtype: int64 \n 65739 \n Grey 0.404137\nYellow 0.186812\nBlue 0.174512\nRed 0.056275\nName: benefit, dtype: float64 \n-----------------------\n5 14437\n4 13781\n3 13495\n2 12828\n1 12733\n6 12726\nName: Time, dtype: int64 \n 80000 \n 5 0.180462\n4 0.172263\n3 0.168687\n2 0.160350\n1 0.159163\n6 0.159075\nName: Time, dtype: float64 \n-----------------------\n0 25709\n2 16332\n1 8606\n3 7503\nA 2513\nC 1023\n6 781\n5 433\nB 371\nE 346\n4 346\nG 275\nD 145\nH 115\n9 107\nF 84\nX 54\n7 29\nM 28\nJ 24\nY 22\nN 3\nS 2\n8 2\nT 1\nZ 1\nV 1\nL 1\nName: p_grade, dtype: int64 \n 64857 \n 0 0.321362\n2 0.204150\n1 0.107575\n3 0.093787\nA 0.031413\nC 0.012788\n6 0.009763\n5 0.005412\nB 0.004638\nE 0.004325\n4 0.004325\nG 0.003438\nD 0.001813\nH 0.001437\n9 0.001337\nF 0.001050\nX 0.000675\n7 0.000362\nM 0.000350\nJ 0.000300\nY 0.000275\nN 0.000037\nS 0.000025\n8 0.000025\nT 0.000013\nZ 0.000013\nV 0.000013\nL 0.000013\nName: p_grade, dtype: float64 \n-----------------------\n"
],
[
"\"\"\"Feature selection\"\"\"\n\ncategotical_features = [\"e_type\", \"benefit\", \"Time\", \"p_grade\"]\nnot_include_features = [\"MOU\", \"MOU Title\", \"Title\", \"Department\", \"Record Number\", \"POBP\"]\nselected_features = [i for i in df.columns if i not in not_include_features]\nX_selected = df.loc[:,selected_features]",
"_____no_output_____"
],
[
"X_selected[\"p_dep\"].hist(bins=50)\nX_selected[\"p_dep\"].describe()",
"_____no_output_____"
],
[
"X_selected[\"Lump Sum Pay\"].hist(bins=50)\nX_selected[\"Lump Sum Pay\"].describe()",
"_____no_output_____"
],
[
"X_selected[\"Rate\"].hist(bins=50)\nX_selected[\"Rate\"].describe()",
"_____no_output_____"
],
[
"X_selected[\"o_pay\"].hist(bins=50)\nX_selected[\"o_pay\"].describe()",
"_____no_output_____"
]
],
[
[
"\n\n|Feature Name|Missing Rate|Imputation Method|\n|----|----|----|\n|p_dep|0.189287|Mean|\n|p_grade|0.189287|add new category|\n|Lump Sum Pay|0.185537|0|\n|benefit|0.178262|add new category|\n|Rate|0.058162|mean|\n|o_pay|0.003750|median|\n",
"_____no_output_____"
]
],
[
[
"\"\"\"imputation\"\"\"\nX_selected[\"p_dep\"] = X_selected[\"p_dep\"].fillna(X_selected[\"p_dep\"].mean())\nX_selected[\"Lump Sum Pay\"] = X_selected[\"Lump Sum Pay\"].fillna(0)\nX_selected[\"Rate\"] = X_selected[\"Rate\"].fillna(X_selected[\"Rate\"].mean())\nX_selected[\"o_pay\"] = X_selected[\"o_pay\"].fillna(X_selected[\"o_pay\"].median())\nX_selected[\"p_grade\"] = X_selected[\"p_grade\"].fillna(-1)\nX_selected[\"benefit\"] = X_selected[\"benefit\"].fillna(-1)\nX_selected.head()",
"_____no_output_____"
],
[
"X_selected.to_pickle(\"processed_data.pickle\")",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
cb3e2d65b924aa81505239fff882b14ad94c415e | 8,238 | ipynb | Jupyter Notebook | docs/runtimes/horovod.ipynb | AlxZed/mlrun | 4b8fe3dec07764672664f33ac6161e14078c822b | [
"Apache-2.0"
] | 1 | 2021-02-17T08:12:33.000Z | 2021-02-17T08:12:33.000Z | docs/runtimes/horovod.ipynb | AlxZed/mlrun | 4b8fe3dec07764672664f33ac6161e14078c822b | [
"Apache-2.0"
] | 1 | 2020-12-31T14:36:29.000Z | 2020-12-31T14:36:29.000Z | docs/runtimes/horovod.ipynb | AlxZed/mlrun | 4b8fe3dec07764672664f33ac6161e14078c822b | [
"Apache-2.0"
] | 1 | 2021-08-30T21:43:38.000Z | 2021-08-30T21:43:38.000Z | 59.266187 | 400 | 0.693372 | [
[
[
"# MPIJob and Horovod Runtime\n\n## Running distributed workloads\n\nTraining a Deep Neural Network is a hard task. With growing datasets, wider and deeper networks, training our Neural Network can require a lot of resources (CPUs / GPUs / Mem and Time). \n\nThere are two main reasons why we would like to distribute our Deep Learning workloads: \n\n1. **Model Parallelism** — The **Model** is too big to fit a single GPU. \nIn this case the model contains too many parameters to hold within a single GPU. \nTo negate this we can use strategies like **Parameter Server** or slicing the model into slices of consecutive layers which we can fit in a single GPU. \nBoth strategies require **Synchronization** between the layers held on different GPUs / Parameter Server shards. \n\n2. **Data Parallelism** — The **Dataset** is too big to fit a single GPU. \nUsing methods like **Stochastic Gradient Descent** we can send batches of data to our models for gradient estimation. This comes at the cost of longer time to converge since the estimated gradient may not fully represent the actual gradient. \nTo increase the likelihood of estimating the actual gradient we could use bigger batches, by sending small batches to different GPUs running the same Neural Network, calculating the batch gradient and then running a **Synchronization Step** to calculate the average gradient over the batches and update the Neural Networks running on the different GPUs. \n\n\n> It is important to understand that the act of distribution adds extra **Synchronization Costs** which may vary according to your cluster's configuration. \n> <br>\n> As the gradients and NN needs to be propagated to each GPU in the cluster every epoch (or a number of steps), Networking can become a bottleneck and sometimes different configurations need to be used for optimal performance. \n> <br>\n> **Scaling Efficiency** is the metric used to show by how much each additional GPU should benefit the training process with Horovod showing up to 90% (When running with a well written code and good parameters).\n\n",
"_____no_output_____"
],
[
"## How can we distribute our training\nThere are two different cluster configurations (which can be combined) we need to take into account. \n- **Multi Node** — GPUs are distributed over multiple nodes in the cluster. \n- **Multi GPU** — GPUs are within a single Node. \n\nIn this demo we show a **Multi Node Multi GPU** — **Data Parallel** enabled training using Horovod. \nHowever, you should always try and use the best distribution strategy for your use case (due to the added costs of the distribution itself, ability to run in an optimized way on specific hardware or other considerations that may arise).",
"_____no_output_____"
],
[
"## How Horovod works?\nHorovod's primary motivation is to make it easy to take a single-GPU training script and successfully scale it to train across many GPUs in parallel. This has two aspects:\n\n- How much modification does one have to make to a program to make it distributed, and how easy is it to run it?\n- How much faster would it run in distributed mode?\n\nHorovod Supports TensorFlow, Keras, PyTorch, and Apache MXNet.\n\nin MLRun we use Horovod with MPI in order to create cluster resources and allow for optimized networking. \n**Note:** Horovod and MPI may use [NCCL](https://developer.nvidia.com/nccl) when applicable which may require some specific configuration arguments to run optimally.\n\nHorovod uses this MPI and NCCL concepts for distributed computation and messaging to quickly and easily synchronize between the different nodes or GPUs.\n\n\n\nHorovod will run your code on all the given nodes (Specific node can be addressed via `hvd.rank()`) while using an `hvd.DistributedOptimizer` wrapper to run the **synchronization cycles** between the copies of your Neural Network running at each node. \n\n**Note:** Since all the copies of your Neural Network must be the same, Your workers will adjust themselves to the rate of the slowest worker (simply by waiting for it to finish the epoch and receive its updates). Thus try not to make a specific worker do a lot of additional work on each epoch (Like a lot of saving, extra calculations, etc...) since this can affect the overall training time.",
"_____no_output_____"
],
[
"## How do we integrate TF2 with Horovod?\nAs it's one of the main motivations, integration is fairly easy and requires only a few steps: ([You can read the full instructions for all the different frameworks on Horovod's documentation website](https://horovod.readthedocs.io/en/stable/tensorflow.html)). \n\n1. Run `hvd.init()`. \n2. Pin each GPU to a single process.\nWith the typical setup of one GPU per process, set this to local rank. The first process on the server will be allocated the first GPU, the second process will be allocated the second GPU, and so forth. \n```\ngpus = tf.config.experimental.list_physical_devices('GPU')\nfor gpu in gpus:\n tf.config.experimental.set_memory_growth(gpu, True)\nif gpus:\n tf.config.experimental.set_visible_devices(gpus[hvd.local_rank()], 'GPU')\n```\n3. Scale the learning rate by the number of workers. \nEffective batch size in synchronous distributed training is scaled by the number of workers. An increase in learning rate compensates for the increased batch size.\n4. Wrap the optimizer in `hvd.DistributedOptimizer`. \nThe distributed optimizer delegates gradient computation to the original optimizer, averages gradients using allreduce or allgather, and then applies those averaged gradients. \nFor TensorFlow v2, when using a `tf.GradientTape`, wrap the tape in `hvd.DistributedGradientTape` instead of wrapping the optimizer.\n1. Broadcast the initial variable states from rank 0 to all other processes. \nThis is necessary to ensure consistent initialization of all workers when training is started with random weights or restored from a checkpoint. \nFor TensorFlow v2, use `hvd.broadcast_variables` after models and optimizers have been initialized.\n1. Modify your code to save checkpoints only on worker 0 to prevent other workers from corrupting them. \nFor TensorFlow v2, construct a `tf.train.Checkpoint` and only call `checkpoint.save()` when `hvd.rank() == 0`.\n\n\nYou can go to [Horovod's Documentation](https://horovod.readthedocs.io/en/stable) to read more about horovod.",
"_____no_output_____"
],
[
"## Image classification use case",
"_____no_output_____"
],
[
"See the end to end [**Image Classification with Distributed Training Demo**](https://github.com/mlrun/demos/tree/0.6.x/image-classification-with-distributed-training)",
"_____no_output_____"
]
]
] | [
"markdown"
] | [
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
cb3e318af5cc0ea97261554ca8905036b60fcbef | 25,473 | ipynb | Jupyter Notebook | Mod3/trabalho-pratico/TrabPratico_Colega_Classe.ipynb | spedison/Curso_igti_ML | 0410c2b2d06dd55aedfddec9853a4bfa6e4ad309 | [
"CC0-1.0"
] | null | null | null | Mod3/trabalho-pratico/TrabPratico_Colega_Classe.ipynb | spedison/Curso_igti_ML | 0410c2b2d06dd55aedfddec9853a4bfa6e4ad309 | [
"CC0-1.0"
] | null | null | null | Mod3/trabalho-pratico/TrabPratico_Colega_Classe.ipynb | spedison/Curso_igti_ML | 0410c2b2d06dd55aedfddec9853a4bfa6e4ad309 | [
"CC0-1.0"
] | null | null | null | 25,473 | 25,473 | 0.67915 | [
[
[
"#importando as bibliotecas\nimport pandas as pd #biblioteca utilizada para o tratamento de dados via dataframes \nimport numpy as np #biblioteca utilizada para o tratamento de valores numéricos (vetores e matrizes)\nimport matplotlib.pyplot as plt #biblioteca utilizada para construir os gráficos\nfrom sklearn.metrics import r2_score #método para o cálculo do R2 (coeficiente de determinação)\n#importa o modelo de regressão linear univariada\nfrom sklearn.linear_model import LinearRegression\n#análise do modelo\nfrom sklearn.metrics import r2_score,mean_squared_error,mean_absolute_error,accuracy_score,precision_score,recall_score,f1_score,roc_auc_score\nfrom sklearn.model_selection import KFold, cross_val_score, train_test_split\nfrom sklearn.svm import SVC\nfrom sklearn.cluster import KMeans\nfrom sklearn.metrics import silhouette_score, davies_bouldin_score, mutual_info_score",
"_____no_output_____"
],
[
"from google.colab import drive\ndrive.mount('/content/drive')",
"Drive already mounted at /content/drive; to attempt to forcibly remount, call drive.mount(\"/content/drive\", force_remount=True).\n"
],
[
"diab = pd.read_csv('/content/drive/My Drive/Colab Notebooks/IGTI/mod3/trabalho-pratico/diabetes_numeric.csv')\nblood = pd.read_csv(\"/content/drive/My Drive/Colab Notebooks/IGTI/mod3/trabalho-pratico/bloodtransf.csv\")\nwine = pd.read_csv(\"/content/drive/My Drive/Colab Notebooks/IGTI/mod3/trabalho-pratico/wine.csv\")",
"_____no_output_____"
]
],
[
[
"## Questão 1 - número de atributos",
"_____no_output_____"
]
],
[
[
"diab.shape",
"_____no_output_____"
]
],
[
[
"## Questão 2 - Número de instâncias",
"_____no_output_____"
]
],
[
[
"blood.shape",
"_____no_output_____"
]
],
[
[
"## Questão 3 - Sobre a base de clusterização, marque a alternativa CORRETA:",
"_____no_output_____"
]
],
[
[
"wine.shape",
"_____no_output_____"
],
[
"wine['class'].value_counts()",
"_____no_output_____"
]
],
[
[
"## Questão 4 - Sobre dados faltantes, marque a alternativa CORRETA:",
"_____no_output_____"
]
],
[
[
"wine.isnull().sum().sum()",
"_____no_output_____"
],
[
"diab.isnull().sum().sum()",
"_____no_output_____"
],
[
"blood.isnull().sum().sum()",
"_____no_output_____"
]
],
[
[
"## Questão 5 - Em relação a modelagem utilizando a regressão linear, marque a alternativa CORRETA sobre a métrica r2:",
"_____no_output_____"
]
],
[
[
"diab.head()",
"_____no_output_____"
],
[
"X = diab.iloc[:,:2]\nY = diab.iloc[:,2]",
"_____no_output_____"
],
[
"# Criando os conjuntos de dados de treino e de teste\nX_treino, X_teste, Y_treino, Y_teste = train_test_split(X, Y, test_size = 0.25, random_state = 42)",
"_____no_output_____"
],
[
"#Realiza a construção do modelo de regressão\nreg = LinearRegression()\nreg.fit (X_treino,Y_treino) # encontra os coeficientes (realiza a regressão)",
"_____no_output_____"
],
[
"#realiza a previsão\nprevisao = reg.predict(X_teste)\nR_2 = r2_score(Y_teste, previsao) #realiza o cálculo do R2\nprint(\"Coeficiente de Determinação (R2):\", R_2)",
"Coeficiente de Determinação (R2): 0.21880597788432776\n"
]
],
[
[
"## Questão 6 - Em relação a modelagem utilizando a regressão linear, marque a alternativa CORRETA sobre a métrica MAE",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
],
[
"MAE = mean_absolute_error(Y_teste, previsao) #realiza o cálculo do R2\nprint(\"MAE:\", MAE)",
"MAE: 0.6107422323514552\n"
]
],
[
[
"## Questão 7 - Em relação a modelagem utilizando a regressão linear, marque a alternativa CORRETA sobre a métrica MSE.",
"_____no_output_____"
]
],
[
[
"MSE = mean_squared_error(Y_teste, previsao) #realiza o cálculo do R2\nprint(\"MAE:\", MSE)",
"MAE: 0.4745269473181977\n"
]
],
[
[
"## Questão 8 - Em relação a modelagem utilizando o SVM, marque a alternativa CORRETA sobre a métrica acurácia:",
"_____no_output_____"
]
],
[
[
"svm = SVC(kernel='rbf')",
"_____no_output_____"
],
[
"blood['Class'].value_counts()",
"_____no_output_____"
],
[
"def conversao(x):\n if x == 1:\n return 0\n if x == 2:\n return 1",
"_____no_output_____"
],
[
"blood['Class'] = blood['Class'].apply(lambda x: conversao(x))",
"_____no_output_____"
],
[
"blood.head()",
"_____no_output_____"
],
[
"X = blood.iloc[:,:4]\nY = blood.iloc[:,4]\n# Criando os conjuntos de dados de treino e de teste\nX_treino, X_teste, Y_treino, Y_teste = train_test_split(X, Y, test_size = 0.25, random_state = 42)",
"_____no_output_____"
],
[
"svm.fit(X_treino,Y_treino)\nprevisao = svm.predict(X_teste)",
"_____no_output_____"
],
[
"'{:.2f}'.format(accuracy_score(Y_teste, previsao))",
"_____no_output_____"
]
],
[
[
"## Questão 9 - Em relação a modelagem utilizando o SVM, marque a alternativa CORRETA sobre as métricas precision e recall",
"_____no_output_____"
],
[
"Recall",
"_____no_output_____"
]
],
[
[
"recall_score(Y_teste, previsao)",
"_____no_output_____"
]
],
[
[
"Precisão",
"_____no_output_____"
]
],
[
[
"precision_score(Y_teste,previsao)",
"_____no_output_____"
]
],
[
[
"## Questão 10 - Em relação a modelagem utilizando o SVM, marque a alternativa CORRETA sobre a métrica f1",
"_____no_output_____"
]
],
[
[
"f1_score(Y_teste, previsao)",
"_____no_output_____"
]
],
[
[
"## Questão 11 - Em relação a modelagem utilizando o SVM, marque a alternativa CORRETA sobre a métrica AUROC",
"_____no_output_____"
]
],
[
[
"roc_auc_score(Y_teste, previsao)",
"_____no_output_____"
],
[
"baseline_preds = np.random.choice([0,1], size = len(Y_teste))",
"_____no_output_____"
],
[
"print('\\nAUCROC com BaseLine', roc_auc_score(Y_teste, baseline_preds))",
"\nAUCROC com BaseLine 0.575089928057554\n"
]
],
[
[
"O valor de AUROUC é similar a de um baseline",
"_____no_output_____"
],
[
"## Questão 12 - Em relação a modelagem utilizando o Kmeans, marque a alternativa CORRETA sobre o número de clusters:",
"_____no_output_____"
]
],
[
[
"wine['class'].unique()",
"_____no_output_____"
]
],
[
[
"## Questão 13 - Em relação a modelagem utilizando o Kmeans, marque a alternativa CORRETA sobre a métrica Coeficiente de Silhueta:",
"_____no_output_____"
]
],
[
[
"def conversao2(x):\n if x == 1:\n return 0\n if x == 2:\n return 1\n if x == 3:\n return 2",
"_____no_output_____"
],
[
"wine['class'] = wine['class'].apply(lambda x: conversao2(x))",
"_____no_output_____"
],
[
"y_wine = np.array(wine['class'])\nx_wine = np.array(wine.drop('class', axis=1)) ",
"_____no_output_____"
],
[
"X_train_wine, X_test_wine, y_train_wine, y_test_wine = train_test_split(x_wine, y_wine, test_size=0.25, random_state=42)",
"_____no_output_____"
],
[
"clf_km = KMeans(n_clusters=3)\nclf_km.fit(X_train_wine)\ny_pred_wine = clf_km.predict(X_test_wine)",
"_____no_output_____"
],
[
"print('Coeficiente de Silhueta: ',silhouette_score(X_test_wine, y_pred_wine))\nprint('Davies-Bouldin Score:', davies_bouldin_score(X_test_wine, y_pred_wine))\nprint('Mutual Information:', mutual_info_score(y_test_wine, y_pred_wine))",
"Coeficiente de Silhueta: 0.5519241838976592\nDavies-Bouldin Score: 0.5415115100039725\nMutual Information: 0.526053317723497\n"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] | [
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3e3ac0aa40c7388ea9160d09f87da21b1704ed | 51,293 | ipynb | Jupyter Notebook | notebooks/AVP_viz.ipynb | thoughtworks/antiviral-peptide-predictions-using-gan | 624851500920d9a2f6b321206d2d9937d37ff75f | [
"MIT"
] | 2 | 2021-01-27T11:23:37.000Z | 2021-09-05T12:12:31.000Z | notebooks/AVP_viz.ipynb | thoughtworks/antiviral-peptide-predictions-using-gan | 624851500920d9a2f6b321206d2d9937d37ff75f | [
"MIT"
] | null | null | null | notebooks/AVP_viz.ipynb | thoughtworks/antiviral-peptide-predictions-using-gan | 624851500920d9a2f6b321206d2d9937d37ff75f | [
"MIT"
] | 2 | 2021-03-05T04:02:01.000Z | 2022-03-08T18:21:55.000Z | 63.168719 | 25,822 | 0.631509 | [
[
[
"import pandas as pd\n# import altair as alt\nimport Bio\nfrom Bio import SeqIO\nsequence = []\n\n",
"_____no_output_____"
],
[
"!pip install Bio",
"Collecting Bio\n Downloading https://files.pythonhosted.org/packages/58/69/c18c38b14c93664207eafc06199a0a9d396fe32b25d21b4f0cb7fb1f0542/bio-0.0.1-py3-none-any.whl\nRequirement already satisfied: intervaltree in /usr/local/lib/python3.6/dist-packages (from Bio) (2.1.0)\nCollecting biopython\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/76/02/8b606c4aa92ff61b5eda71d23b499ab1de57d5e818be33f77b01a6f435a8/biopython-1.78-cp36-cp36m-manylinux1_x86_64.whl (2.3MB)\n\u001b[K |████████████████████████████████| 2.3MB 6.6MB/s \n\u001b[?25hRequirement already satisfied: plac in /usr/local/lib/python3.6/dist-packages (from Bio) (1.1.3)\nRequirement already satisfied: attrs in /usr/local/lib/python3.6/dist-packages (from Bio) (20.1.0)\nRequirement already satisfied: sortedcontainers in /usr/local/lib/python3.6/dist-packages (from intervaltree->Bio) (2.2.2)\nRequirement already satisfied: numpy in /usr/local/lib/python3.6/dist-packages (from biopython->Bio) (1.18.5)\nInstalling collected packages: biopython, Bio\nSuccessfully installed Bio-0.0.1 biopython-1.78\n"
],
[
"sequences = pd.read_csv('avp_sequences.csv')\n\n",
"_____no_output_____"
],
[
"sequences",
"_____no_output_____"
],
[
"from Bio.SeqUtils.ProtParam import ProteinAnalysis\n",
"_____no_output_____"
],
[
"aa_freq = pd.DataFrame(columns=['A','C','D','E','F','G','H','I','K','L','M','N','P','Q','R','S','T','V','W','Y'])\nfor seq in sequences.Sequence:\n # print(seq)\n X = ProteinAnalysis(seq)\n # print(X.count_amino_acids())\n # print(list(X.count_amino_acids().items()))\n counts = pd.DataFrame(X.count_amino_acids(), index=[0]).loc[0]\n aa_freq = aa_freq.append(counts)\n ",
"_____no_output_____"
],
[
"aa_freq = aa_freq.append(pd.DataFrame(X.count_amino_acids(), index=[0]).loc[0])",
"_____no_output_____"
],
[
"aa_freq",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"import seaborn as sns\n\nsns.distplot(aa_freq.A, hist=False, label=\"A\")\nsns.distplot(aa_freq.C, hist=False, label=\"C\")\nsns.distplot(aa_freq.D, hist=False, label=\"D\")\nsns.distplot(aa_freq.E, hist=False, label=\"E\")\nsns.distplot(aa_freq.F, hist=False, label=\"F\")\nsns.distplot(aa_freq.G, hist=False, label=\"G\")\nsns.distplot(aa_freq.H, hist=False, label=\"H\")\nsns.distplot(aa_freq.I, hist=False, label=\"I\")\nsns.distplot(aa_freq.K, hist=False, label=\"K\")\nsns.distplot(aa_freq.L, hist=False, label=\"L\")\nsns.distplot(aa_freq.M, hist=False, label=\"M\")\nsns.distplot(aa_freq.N, hist=False, label=\"N\")\nsns.distplot(aa_freq.P, hist=False, label=\"P\")\nsns.distplot(aa_freq.Q, hist=False, label=\"Q\")\nsns.distplot(aa_freq.R, hist=False, label=\"R\")\nsns.distplot(aa_freq.S, hist=False, label=\"S\")\nsns.distplot(aa_freq.T, hist=False, label=\"T\")\nsns.distplot(aa_freq.V, hist=False, label=\"V\")\nsns.distplot(aa_freq.W, hist=False, label=\"W\")\nsns.distplot(aa_freq.Y, hist=False, label=\"Y\")\n\nplt.xlim(0,20)\n",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] | [
"code"
] | [
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
cb3e45dcc8a51fa49ef7b08f37f9f08a3dcda5d0 | 14,394 | ipynb | Jupyter Notebook | tutorials/Tutorial_7_Training_an_Encrypted_Neural_Network.ipynb | vreis/CrypTen-2 | 839a751277a901e4edd9166a720fb3a29deac641 | [
"MIT"
] | null | null | null | tutorials/Tutorial_7_Training_an_Encrypted_Neural_Network.ipynb | vreis/CrypTen-2 | 839a751277a901e4edd9166a720fb3a29deac641 | [
"MIT"
] | null | null | null | tutorials/Tutorial_7_Training_an_Encrypted_Neural_Network.ipynb | vreis/CrypTen-2 | 839a751277a901e4edd9166a720fb3a29deac641 | [
"MIT"
] | null | null | null | 37.484375 | 559 | 0.586216 | [
[
[
"# Training an Encrypted Neural Network\n\nIn this tutorial, we will walk through an example of how we can train a neural network with CrypTen. This is particularly relevant for the <i>Feature Aggregation</i>, <i>Data Labeling</i> and <i>Data Augmentation</i> use cases. We will focus on the usual two-party setting and show how we can train an accurate neural network for digit classification on the MNIST data.\n\nFor concreteness, this tutorial will step through the <i>Feature Aggregation</i> use cases: Alice and Bob each have part of the features of the data set, and wish to train a neural network on their combined data, while keeping their data private. \n\n## Setup\nAs usual, we'll begin by importing and initializing the `crypten` and `torch` libraries. \n\nWe will use the MNIST dataset to demonstrate how Alice and Bob can learn without revealing protected information. For reference, the feature size of each example in the MNIST data is `28 x 28`. Let's assume Alice has the first `28 x 20` features and Bob has last `28 x 8` features. One way to think of this split is that Alice has the (roughly) top 2/3rds of each image, while Bob has the bottom 1/3rd of each image. We'll again use our helper script `mnist_utils.py` that downloads the publicly available MNIST data, and splits the data as required.\n\nFor simplicity, we will restrict our problem to binary classification: we'll simply learn how to distinguish between 0 and non-zero digits. For speed of execution in the notebook, we will only create a dataset of a 100 examples.",
"_____no_output_____"
]
],
[
[
"import crypten\nimport torch\n\ncrypten.init()",
"_____no_output_____"
],
[
"%run ./mnist_utils.py --option features --reduced 100 --binary",
"_____no_output_____"
]
],
[
[
"Next, we'll define the network architecture below, and then describe how to train it on encrypted data in the next section. ",
"_____no_output_____"
]
],
[
[
"import torch.nn as nn\nimport torch.nn.functional as F\n\n#Define an example network\nclass ExampleNet(nn.Module):\n def __init__(self):\n super(ExampleNet, self).__init__()\n self.conv1 = nn.Conv2d(1, 16, kernel_size=5, padding=0)\n self.fc1 = nn.Linear(16 * 12 * 12, 100)\n self.fc2 = nn.Linear(100, 2) # For binary classification, final layer needs only 2 outputs\n \n def forward(self, x):\n out = self.conv1(x)\n out = F.relu(out)\n out = F.max_pool2d(out, 2)\n out = out.view(out.size(0), -1)\n out = self.fc1(out)\n out = F.relu(out)\n out = self.fc2(out)\n return out",
"_____no_output_____"
]
],
[
[
"## Encrypted Training\n\nAfter all the material we've covered in earlier tutorials, we only need to know a few additional items for encrypted training. We'll first discuss how the training loop in CrypTen differs from PyTorch. Then, we'll go through a complete example to illustrate training on encrypted data from end-to-end.\n\n### How does CrypTen training differ from PyTorch training?\n\nThere are three main ways implementing a CrypTen training loop differs from a PyTorch training loop. We'll describe these items first, and then illustrate them with small examples below.\n\n<i>(1) Use `AutogradCrypTensor`</i>: We need to transform the input data to `AutogradCrypTensors` from `CrypTensors` before calling the forward pass. (`AutogradCrypTensors` allow the CrypTensors to store gradients and thus enable backpropagation.) As we show in the examples below, this is easily done by simply calling the `AutogradCrypTensor` constructor with the previously encrypted `CrypTensor`.\n\n<i>(2) Use one-hot encoding</i>: CrypTen training requires all labels to use one-hot encoding. This means that when using standard datasets such as MNIST, we need to modify the labels to use one-hot encoding.\n\n<i>(3) Directly update parameters</i>: CrypTen does not use the PyTorch optimizers. Instead, CrypTen implements encrypted SGD by implementing its own `backward` function, followed by directly updating the parameters. As we will see below, using SGD in CrypTen is very similar to using the PyTorch optimizers.\n\nWe now show some small examples to illustrate these differences. As before, we will assume Alice has the rank 0 process and Bob has the rank 1 process.",
"_____no_output_____"
]
],
[
[
"# Define source argument values for Alice and Bob\nALICE = 0\nBOB = 1",
"_____no_output_____"
],
[
"# Example: Transforming input data into AutogradCrypTensors\nfrom crypten.autograd_cryptensor import AutogradCrypTensor\n\n# Load Alice's data \ndata_alice_enc = crypten.load('/tmp/alice_train.pth', src=ALICE)\n\n# Create an AutogradCrypTensor from the CrypTensor\ndata_alice_enc_auto = AutogradCrypTensor(data_alice_enc)",
"_____no_output_____"
],
[
"# We'll now set up the data for our small example below\n# For illustration purposes, we will create toy data\n# and encrypt all of it from source ALICE\nx_small = torch.rand(100, 1, 28, 28)\ny_small = torch.randint(1, (100,))\n\n# Transform labels into one-hot encoding\nlabel_eye = torch.eye(2)\ny_one_hot = label_eye[y_small]\n\n# Transform all data to AutogradCrypTensors\nx_train = AutogradCrypTensor(crypten.cryptensor(x_small, src=ALICE))\ny_train = AutogradCrypTensor(crypten.cryptensor(y_one_hot))\n\n# Instantiate and encrypt a CrypTen model\nmodel_plaintext = ExampleNet()\ndummy_input = torch.empty(1, 1, 28, 28)\nmodel = crypten.nn.from_pytorch(model_plaintext, dummy_input)\nmodel.encrypt()",
"_____no_output_____"
],
[
"# Example: Stochastic Gradient Descent in CrypTen\n\nmodel.train() # Change to training mode\nloss = crypten.nn.MSELoss() # Choose loss functions\n\n# Set parameters: learning rate, num_epochs\nlearning_rate = 0.001\nnum_epochs = 2\n\n# Train the model: SGD on encrypted data\nfor i in range(num_epochs):\n\n # forward pass\n output = model(x_train)\n loss_value = loss(output, y_train)\n \n # set gradients to zero\n model.zero_grad()\n\n # perform backward pass\n loss_value.backward()\n\n # update parameters\n model.update_parameters(learning_rate) \n \n # examine the loss after each epoch\n print(\"Epoch: {0:d} Loss: {1:.4f}\".format(i, loss_value.get_plain_text()))",
"Epoch: 0 Loss: 0.4566\nEpoch: 1 Loss: 0.4452\n"
]
],
[
[
"### A Complete Example\n\nWe now put these pieces together for a complete example of training a network in a multi-party setting. \n\nAs in Tutorial 3, we'll assume Alice has the rank 0 process, and Bob has the rank 1 process; so we'll load and encrypt Alice's data with `src=0`, and load and encrypt Bob's data with `src=1`. We'll then initialize a plaintext model and convert it to an encrypted model, just as we did in Tutorial 4. We'll finally define our loss function, training parameters, and run SGD on the encrypted data. For the purposes of this tutorial we train on 100 samples; training should complete in ~3 minutes per epoch.",
"_____no_output_____"
]
],
[
[
"import crypten.mpc as mpc\nimport crypten.communicator as comm\n\n# Convert labels to one-hot encoding\n# Since labels are public in this use case, we will simply use them from loaded torch tensors\nlabels = torch.load('/tmp/train_labels.pth')\nlabels = labels.long()\nlabels_one_hot = label_eye[labels]\n\[email protected]_multiprocess(world_size=2)\ndef run_encrypted_training():\n # Load data:\n x_alice_enc = crypten.load('/tmp/alice_train.pth', src=ALICE)\n x_bob_enc = crypten.load('/tmp/bob_train.pth', src=BOB)\n \n # Combine the feature sets: identical to Tutorial 3\n x_combined_enc = crypten.cat([x_alice_enc, x_bob_enc], dim=2)\n \n # Reshape to match the network architecture\n x_combined_enc = x_combined_enc.unsqueeze(1)\n \n # Initialize a plaintext model and convert to CrypTen model\n model = crypten.nn.from_pytorch(ExampleNet(), dummy_input)\n model.encrypt()\n \n # Set train mode\n model.train()\n \n # Define a loss function\n loss = crypten.nn.MSELoss()\n\n # Define training parameters\n learning_rate = 0.001\n num_epochs = 2\n batch_size = 10\n num_batches = x_combined_enc.size(0) // batch_size\n \n rank = comm.get().get_rank()\n for i in range(num_epochs): \n # Print once for readability\n if rank == 0:\n print(f\"Epoch {i} in progress:\") \n \n for batch in range(num_batches):\n # define the start and end of the training mini-batch\n start, end = batch * batch_size, (batch + 1) * batch_size\n \n # construct AutogradCrypTensors out of training examples / labels\n x_train = AutogradCrypTensor(x_combined_enc[start:end])\n y_batch = labels_one_hot[start:end]\n y_train = AutogradCrypTensor(crypten.cryptensor(y_batch))\n \n # perform forward pass:\n output = model(x_train)\n loss_value = loss(output, y_train)\n \n # set gradients to \"zero\" \n model.zero_grad()\n\n # perform backward pass: \n loss_value.backward()\n\n # update parameters\n model.update_parameters(learning_rate)\n \n # Print progress every batch:\n batch_loss = loss_value.get_plain_text()\n if rank == 0:\n print(f\"\\tBatch {(batch + 1)} of {num_batches} Loss {batch_loss.item():.4f}\")\n\nrun_encrypted_training()",
"Epoch 0 in progress:\n\tBatch 1 of 10 Loss 0.4436\n\tBatch 2 of 10 Loss 0.4269\n\tBatch 3 of 10 Loss 0.4340\n\tBatch 4 of 10 Loss 0.4216\n\tBatch 6 of 10 Loss 0.3581\n\tBatch 7 of 10 Loss 0.3761\n\tBatch 8 of 10 Loss 0.3409\n\tBatch 9 of 10 Loss 0.2931\n\tBatch 10 of 10 Loss 0.2605\nEpoch 1 in progress:\n\tBatch 1 of 10 Loss 0.2283\n\tBatch 4 of 10 Loss 0.2471\n\tBatch 5 of 10 Loss 0.1504\n\tBatch 6 of 10 Loss 0.2206\n\tBatch 7 of 10 Loss 0.2670\n\tBatch 8 of 10 Loss 0.2085\n\tBatch 9 of 10 Loss 0.1949\n\tBatch 10 of 10 Loss 0.1646\n"
]
],
[
[
"We see that the average batch loss decreases across the epochs, as we expect during training.\n\nThis completes our tutorial. Before exiting this tutorial, please clean up the files generated using the following code.",
"_____no_output_____"
]
],
[
[
"import os\n\nfilenames = ['/tmp/alice_train.pth', \n '/tmp/bob_train.pth', \n '/tmp/alice_test.pth',\n '/tmp/bob_test.pth', \n '/tmp/train_labels.pth',\n '/tmp/test_labels.pth']\n\nfor fn in filenames:\n if os.path.exists(fn): os.remove(fn)",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
cb3e6d79ecc98617e4d190e12372ed80b968a69f | 39,567 | ipynb | Jupyter Notebook | AgroForest.ipynb | jdilger/tensorflow-notebooks | b0627a40d4ca78beeda95d506bd047b6e44b7b8c | [
"MIT"
] | null | null | null | AgroForest.ipynb | jdilger/tensorflow-notebooks | b0627a40d4ca78beeda95d506bd047b6e44b7b8c | [
"MIT"
] | null | null | null | AgroForest.ipynb | jdilger/tensorflow-notebooks | b0627a40d4ca78beeda95d506bd047b6e44b7b8c | [
"MIT"
] | null | null | null | 40.457055 | 702 | 0.547881 | [
[
[
"<a href=\"https://colab.research.google.com/github/jdilger/tensorflow-notebooks/blob/master/AgroForest.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"gpu_info = !nvidia-smi\ngpu_info = '\\n'.join(gpu_info)\nif gpu_info.find('failed') >= 0:\n print('Select the Runtime > \"Change runtime type\" menu to enable a GPU accelerator, ')\n print('and then re-execute this cell.')\nelse:\n print(gpu_info)",
"_____no_output_____"
],
[
"# Use logging to maintain more detailed information for reproducibility \nimport logging\n\ndef tfLog():\n logging.basicConfig(level=logging.DEBUG, filename='myapp.log',\n format='%(asctime)s %(levelname)s:%(message)s')\n try:\n logging.debug('######################################')\n logging.debug('Config Settings')\n logging.debug('######################################')\n logging.debug(\"Bucket:%s\",BUCKET) \n logging.debug(\"Folder:%s\",FOLDER)\n logging.debug('Training base:%s',TRAINING_BASE)\n logging.debug('Eaval base:%s',EVAL_BASE) \n logging.debug('Band order:%s',BANDS)\n logging.debug('Response:%s',RESPONSE)\n logging.debug('Features:%s',FEATURES)\n logging.debug('Kernal size:%d',KERNEL_SIZE)\n logging.debug('FEATURES_DICT:%s',FEATURES_DICT)\n logging.debug('Training size:%d',TRAIN_SIZE)\n logging.debug('Eval size:%d',EVAL_SIZE)\n logging.debug('batch size:%d',BATCH_SIZE)\n logging.debug('Epochs:%d',EPOCHS)\n logging.debug('Buffer size:%d',BUFFER_SIZE) \n logging.debug('Optimizer:%s',OPTIMIZER) \n # logging.debug('Loss:',LOSS)\n # logging.debug('Other metrics:',METRICS)\n except Exception as e:\n print('logging failed')\n print(e.args)",
"_____no_output_____"
],
[
"# Cloud authentication.\nfrom google.colab import auth\nauth.authenticate_user()",
"_____no_output_____"
],
[
"# Import, authenticate and initialize the Earth Engine library.\nimport ee\ntry:\n ee.Initialize()\nexcept Exception as e:\n ee.Authenticate()\n ee.Initialize()",
"_____no_output_____"
],
[
"# Tensorflow setup.\n%tensorflow_version 1.x\nimport tensorflow as tf\nprint(tf.__version__)\ntf.enable_eager_execution()\n",
"_____no_output_____"
],
[
"# INSERT YOUR BUCKET HERE:\nBUCKET = 'tf-agro-forest'",
"_____no_output_____"
],
[
"from tensorflow.python.keras import backend\n# dice coeff and dice loss from Biplov\ndef dice_coeff(y_true, y_pred, smooth=1):\n y_true_f = backend.flatten(y_true)\n y_pred_f = backend.flatten(y_pred)\n intersection = backend.sum(y_true_f * y_pred_f)\n return (2. * intersection + smooth) / (backend.sum(y_true_f) + backend.sum(y_pred_f) + smooth)\n\ndef dice_loss(y_true, y_pred):\n loss = 1 - dice_coeff(y_true, y_pred)\n return loss\n\n# soft dice loss function from Kel\n# based on https://arxiv.org/pdf/1707.03237.pdf \ndef dice_loss_soft(y_true, y_pred, smooth=1):\n intersection = backend.sum(backend.abs(y_true * y_pred), axis=-1)\n true_sum = backend.sum(backend.square(y_true),-1) \n pred_sum = backend.sum(backend.square(y_pred),-1)\n return 1 - ((2. * intersection + smooth) / (true_sum + pred_sum + smooth))",
"_____no_output_____"
]
],
[
[
"## Set other global variables",
"_____no_output_____"
]
],
[
[
"from tensorflow.python.keras import metrics\n# Specify names locations for outputs in Cloud Storage. \nFOLDER = 'training_data' \nTRAINING_BASE = 'training_patches_kernalsize_64'\nEVAL_BASE = 'training_patches_kernalsize_64'\n\n# Specify inputs (Landsat bands) to the model and the response variable.\n\nBANDS =['red','green','blue','rmed','rmin','rstd','vv','vh']\nRESPONSE = ['cocao','forest','seasonalAg'\n,'urban','water','banana','savana','orchard','mine','shrubland','sparseTree','bare'\n,'grassland','secondaryForest','nodata']\nFEATURES = BANDS + RESPONSE\n\n# Specify the size and shape of patches expected by the model.\nKERNEL_SIZE = 64\nKERNEL_SHAPE = [KERNEL_SIZE, KERNEL_SIZE]\nCOLUMNS = [\n tf.io.FixedLenFeature(shape=KERNEL_SHAPE, dtype=tf.float32) for k in FEATURES\n]\nFEATURES_DICT = dict(zip(FEATURES, COLUMNS))\n\n# Sizes of the training and evaluation datasets.\nTRAIN_SIZE = 16000\nEVAL_SIZE = 3000\n\n# Specify model training parameters.\nBATCH_SIZE = 1\nEPOCHS = 10\nBUFFER_SIZE = 7000\nOPTIMIZER = 'Adam'\nLOSS = dice_loss\n# METRICS = [\n# metrics.get('Accuracy'),\n# dice_coeff,]\n# og metrics if need to switch back \nMETRICS = [metrics.get('RootMeanSquaredError'),\n metrics.get('MeanAbsoluteError'),\n metrics.get('Accuracy'),\n dice_coeff,]",
"_____no_output_____"
],
[
"tfLog()",
"_____no_output_____"
],
[
"!ls\n!cat myapp.log",
"_____no_output_____"
]
],
[
[
"# Training data\n\nLoad the data exported from Earth Engine into a `tf.data.Dataset`. The following are helper functions for that.",
"_____no_output_____"
]
],
[
[
"def parse_tfrecord(example_proto):\n \"\"\"The parsing function.\n Read a serialized example into the structure defined by FEATURES_DICT.\n Args:\n example_proto: a serialized Example.\n Returns: \n A dictionary of tensors, keyed by feature name.\n \"\"\"\n return tf.io.parse_single_example(example_proto, FEATURES_DICT)\n\n\ndef to_tuple(inputs):\n \"\"\"Function to convert a dictionary of tensors to a tuple of (inputs, outputs).\n Turn the tensors returned by parse_tfrecord into a stack in HWC shape.\n Args:\n inputs: A dictionary of tensors, keyed by feature name.\n Returns: \n A dtuple of (inputs, outputs).\n \"\"\"\n inputsList = [inputs.get(key) for key in FEATURES]\n stacked = tf.stack(inputsList, axis=0)\n # Convert from CHW to HWC\n stacked = tf.transpose(stacked, [1, 2, 0])\n return stacked[:,:,:len(BANDS)], stacked[:,:,len(BANDS):]\n\n\ndef get_dataset(pattern,flip=False):\n \"\"\"Function to read, parse and format to tuple a set of input tfrecord files.\n Get all the files matching the pattern, parse and convert to tuple.\n Args:\n pattern: A file pattern to match in a Cloud Storage bucket.\n Returns: \n A tf.data.Dataset\n \"\"\"\n glob = tf.gfile.Glob(pattern)\n dataset = tf.data.TFRecordDataset(glob, compression_type='GZIP')\n dataset = dataset.map(parse_tfrecord, num_parallel_calls=5)\n dataset = dataset.map(to_tuple, num_parallel_calls=5)\n if flip:\n dataset = dataset.map(transform)\n return dataset",
"_____no_output_____"
],
[
"# custom function to randomly augment the data during training\n# from kels notebooks\n# adapted with python random rather than tf. Not sure if it works..\nimport random\ndef transform(features,labels):\n x = random.random()\n # flip image on horizontal axis\n if round(x,2) < 0.12: \n feat = tf.image.flip_left_right(features)\n labl = tf.image.flip_left_right(labels)\n # flip image on vertical axis\n elif round(x,2) >=0.12 and round(x,2) < 0.24:\n feat = tf.image.flip_up_down(features)\n labl = tf.image.flip_up_down(labels)\n # transpose image on bottom left corner\n elif round(x,2) >=0.24 and round(x,2) < 0.36:\n feat = tf.image.flip_left_right(tf.image.flip_up_down(features))\n labl = tf.image.flip_left_right(tf.image.flip_up_down(labels))\n # rotate to the left 90 degrees\n elif round(x,2) >=0.36 and round(x,2) < 0.48:\n feat = tf.image.rot90(features,k=1)\n labl = tf.image.rot90(labels,k=1)\n # rotate to the left 180 degrees\n elif round(x,2) >=0.48 and round(x,2) < 0.60:\n feat = tf.image.rot90(features,k=2)\n labl = tf.image.rot90(labels,k=2)\n # rotate to the left 270 degrees\n elif round(x,2) >=0.60 and round(x,2) < 0.72:\n feat = tf.image.rot90(features,k=3)\n labl = tf.image.rot90(labels,k=3)\n # transpose image on bottom right corner\n elif round(x,2) >=0.72 and round(x,2) < 0.84:\n feat = tf.image.flip_left_right(tf.image.rot90(features,k=2))\n labl = tf.image.flip_left_right(tf.image.rot90(labels,k=2))\n else:\n feat = features\n labl = labels\n print(x,'I WORK')\n return feat,labl",
"_____no_output_____"
]
],
[
[
"Use the helpers to read in the training dataset. Print the first record to check.",
"_____no_output_____"
]
],
[
[
"def get_training_dataset():\n\t\"\"\"Get the preprocessed training dataset\n Returns: \n A tf.data.Dataset of training data.\n \"\"\"\n\tglob = 'gs://' + BUCKET + '/' + FOLDER + '/' + TRAINING_BASE + '*'\n\tdataset = get_dataset(glob,flip=False)\n\tdataset = dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE).repeat()\n\treturn dataset\n\ntraining = get_training_dataset()\n\n# print(iter(training.take(1)).next())",
"_____no_output_____"
]
],
[
[
"# Evaluation data\n\nNow do the same thing to get an evaluation dataset. Note that unlike the training dataset, the evaluation dataset has a batch size of 1, is not repeated and is not shuffled.",
"_____no_output_____"
]
],
[
[
"def get_eval_dataset():\n\t\"\"\"Get the preprocessed evaluation dataset\n Returns: \n A tf.data.Dataset of evaluation data.\n \"\"\"\n\tglob = 'gs://' + BUCKET + '/' + FOLDER + '/' + EVAL_BASE + '*'\n\tdataset = get_dataset(glob)\n\tdataset = dataset.batch(1).repeat()\n\treturn dataset\n\nevaluation = get_eval_dataset()",
"_____no_output_____"
]
],
[
[
"# Model\n\nHere we use the Keras implementation of the U-Net model as found [in the TensorFlow examples](https://github.com/tensorflow/models/blob/master/samples/outreach/blogs/segmentation_blogpost/image_segmentation.ipynb). The U-Net model takes 256x256 pixel patches as input and outputs per-pixel class probability, label or a continuous output. We can implement the model essentially unmodified, but will use mean squared error loss on the sigmoidal output since we are treating this as a regression problem, rather than a classification problem. Since impervious surface fraction is constrained to [0,1], with many values close to zero or one, a saturating activation function is suitable here.",
"_____no_output_____"
]
],
[
[
"# re orginize model...\nfrom tensorflow.python.keras import layers\nfrom tensorflow.python.keras import losses\nfrom tensorflow.python.keras import models\nfrom tensorflow.python.keras import metrics\nfrom tensorflow.python.keras import optimizers\nfrom tensorflow.keras.utils import plot_model\n# model = models.Sequential()\nvisible = layers.Input(shape=[None, None, len(BANDS)])\n# from stackexchange\nenocded_imag = layers.Conv2D(16, (3, 3), activation='relu', padding='same')(visible)\nenocded_imag = layers.MaxPooling2D((2, 2), padding='same')(enocded_imag)\nenocded_imag = layers.Conv2D(32, (3, 3), activation='relu', padding='same')(visible)\nenocded_imag = layers.MaxPooling2D((2, 2), padding='same')(enocded_imag)\nenocded_imag = layers.Conv2D(64, (3, 3), activation='relu', padding='same')(enocded_imag)\nenocded_imag = layers.MaxPooling2D((2, 2), padding='same')(enocded_imag)\nenocded_imag = layers.Conv2D(128, (3, 3), activation='relu', padding='same')(enocded_imag)\nenocded_imag = layers.MaxPooling2D((2, 2), padding='same')(enocded_imag)\n\ndecoded_imag = layers.Conv2D(64, (2, 2), activation='relu', padding='same')(enocded_imag)\ndecoded_imag = layers.UpSampling2D((2, 2),interpolation='bilinear')(decoded_imag)\ndecoded_imag = layers.BatchNormalization()(decoded_imag)\ndecoded_imag = layers.Conv2D(32, (3, 3), activation='relu', padding='same')(decoded_imag)\ndecoded_imag = layers.UpSampling2D((2, 2),interpolation='bilinear')(decoded_imag)\ndecoded_imag = layers.BatchNormalization()(decoded_imag)\ndecoded_imag = layers.Conv2D(16, (3, 3), activation='relu', padding='same')(decoded_imag)\ndecoded_imag = layers.UpSampling2D((2, 2),interpolation='bilinear')(decoded_imag)\ndecoded_imag = layers.BatchNormalization()(decoded_imag)\ndecoded_imag = layers.Conv2D(64, (3, 3), activation='relu', padding='same')(decoded_imag)\n# decoded_imag = layers.Dropout(0.2)(decoded_imag)\n\noutBranch = layers.Conv2D(128, 3, activation='relu', \n padding='same',name=\"out_block_conv1\")(decoded_imag)\noutBranch = layers.SpatialDropout2D(rate=0.2,seed=1,name=\"out_block_spatialdrop\")(outBranch)\noutBranch = layers.BatchNormalization(name=\"out_block_batchnorm1\")(outBranch)\noutBranch = layers.Conv2D(len(RESPONSE), (1, 1), activation='relu')(outBranch)\noutputs = layers.Activation(\"softmax\")(outBranch)\nmodel = models.Model(inputs=visible, outputs=outputs)\n# summarize layers\nprint(model.summary())\n# plot graph\nplot_model(model, to_file='convolutional_neural_network.png')",
"_____no_output_____"
],
[
"# re orginize model...for 8x8 patch\nfrom tensorflow.python.keras import layers\nfrom tensorflow.python.keras import losses\nfrom tensorflow.python.keras import models\nfrom tensorflow.python.keras import metrics\nfrom tensorflow.python.keras import optimizers\nfrom tensorflow.keras.utils import plot_model\n# model = models.Sequential()\nvisible = layers.Input(shape=[None, None, len(BANDS)])\n# from stackexchange\nenocded_imag = layers.Conv2D(16, (3, 3), activation='relu', padding='same')(visible)\nenocded_imag = layers.MaxPooling2D((2, 2), padding='same')(enocded_imag)\n\ndecoded_imag = layers.Conv2D(16, (3, 3), activation='relu', padding='same')(enocded_imag)\ndecoded_imag = layers.UpSampling2D((2, 2),interpolation='bilinear')(decoded_imag)\ndecoded_imag = layers.BatchNormalization()(decoded_imag)\ndecoded_imag = layers.Dropout(0.2)(decoded_imag)\n\n# outBranch = layers.BatchNormalization(name=\"out_block_batchnorm1\")(decoded_imag)\noutBranch = layers.Conv2D(len(RESPONSE), (1, 1), activation='relu')(decoded_imag)\noutputs = layers.Activation(\"softmax\")(outBranch)\nmodel = models.Model(inputs=visible, outputs=outputs)\n# summarize layers\nprint(model.summary())\n# plot graph\nplot_model(model, to_file='convolutional_neural_network.png')",
"_____no_output_____"
],
[
"# trying new cnn>dnn not working well...\nfrom tensorflow.python.keras import layers\nfrom tensorflow.python.keras import losses\nfrom tensorflow.python.keras import models\nfrom tensorflow.python.keras import metrics\nfrom tensorflow.python.keras import optimizers\nfrom tensorflow.keras.utils import plot_model\nmodel = models.Sequential()\nvisible = layers.Input(shape=[None, None, len(BANDS)])\nconv1 = layers.Conv2D(32, kernel_size=4, padding='same',activation='relu')(visible)\npool1 = layers.MaxPooling2D(pool_size=(2, 2))(conv1)\nconv2 = layers.Conv2D(16, kernel_size=4, padding='same',activation='relu')(pool1)\npool2 = layers.MaxPooling2D(pool_size=(2, 2))(conv2)\nflat = layers.GlobalMaxPooling2D()(pool2)\n# flat = layers.Flatten()(pool2)\nhidden1 = layers.Dense(128,activation='relu')(flat)\noutput = layers.Conv1D(len(RESPONSE), activation='softmax')(hidden1)\n# outBranch = layers.Conv2D(len(RESPONSE), (1, 1), activation='sigmoid')(flat)\n# outputs = layers.Activation(\"softmax\")(outBranch)\nmodel = models.Model(inputs=visible, outputs=output)\n# summarize layers\nprint(model.summary())\n# plot graph\nplot_model(model, to_file='convolutional_neural_network.png')",
"_____no_output_____"
],
[
"from tensorflow.python.keras import layers\nfrom tensorflow.python.keras import losses\nfrom tensorflow.python.keras import models\nfrom tensorflow.python.keras import metrics\nfrom tensorflow.python.keras import optimizers\nfrom tensorflow.keras.utils import plot_model\n# model = models.Sequential()\nvisible = layers.Input(shape=[None, None, len(BANDS)])\n# from stackexchange\nenocded_imag = layers.Conv2D(64, (7, 7), activation='relu', padding='same')(visible)\nenocded_imag = layers.MaxPooling2D((2, 2), padding='same')(enocded_imag)\nenocded_imag = layers.Conv2D(32, (3, 3), activation='relu', padding='same')(visible)\nenocded_imag = layers.MaxPooling2D((2, 2), padding='same')(enocded_imag)\nenocded_imag = layers.Conv2D(16, (3, 3), activation='relu', padding='same')(enocded_imag)\nenocded_imag = layers.MaxPooling2D((2, 2), padding='same')(enocded_imag)\nenocded_imag = layers.Conv2D(8, (3, 3), activation='relu', padding='same')(enocded_imag)\nenocded_imag = layers.MaxPooling2D((2, 2), padding='same')(enocded_imag)\n\ndecoded_imag = layers.Conv2D(8, (2, 2), activation='relu', padding='same')(enocded_imag)\ndecoded_imag = layers.UpSampling2D((2, 2),interpolation='bilinear')(decoded_imag)\ndecoded_imag = layers.BatchNormalization()(decoded_imag)\ndecoded_imag = layers.Conv2D(16, (3, 3), activation='relu', padding='same')(decoded_imag)\ndecoded_imag = layers.UpSampling2D((2, 2),interpolation='bilinear')(decoded_imag)\ndecoded_imag = layers.BatchNormalization()(decoded_imag)\ndecoded_imag = layers.Conv2D(32, (3, 3), activation='relu', padding='same')(decoded_imag)\ndecoded_imag = layers.UpSampling2D((2, 2),interpolation='bilinear')(decoded_imag)\ndecoded_imag = layers.BatchNormalization()(decoded_imag)\ndecoded_imag = layers.Conv2D(64, (3, 3), activation='relu', padding='same')(decoded_imag)\n# decoded_imag = layers.Dropout(0.2)(decoded_imag)\n\noutBranch = layers.Conv2D(128, 3, activation='relu', \n padding='same',name=\"out_block_conv1\")(decoded_imag)\noutBranch = layers.SpatialDropout2D(rate=0.2,seed=1,name=\"out_block_spatialdrop\")(outBranch)\noutBranch = layers.BatchNormalization(name=\"out_block_batchnorm1\")(outBranch)\noutBranch = layers.Conv2D(len(RESPONSE), (1, 1), activation='relu')(outBranch)\noutputs = layers.Activation(\"softmax\")(outBranch)\nmodel = models.Model(inputs=visible, outputs=outputs)\n# summarize layers\nprint(model.summary())\n# plot graph\nplot_model(model, to_file='convolutional_neural_network.png')",
"_____no_output_____"
],
[
"\t# trying new cnn>dnn not working well\nmodel.compile(\n \n\t\toptimizer=optimizers.Adam(lr=0.001), \n\t\tloss=dice_loss_soft,#losses.get('categorical_crossentropy'),#dice_loss_soft,#losses.get('categorical_crossentropy'), #losses.get(LOSS),dice_loss_soft\n # binaryxentro works in both loss and metics\n # metrics.CategoricalAccuracy()\n\t\tmetrics=[metrics.get('CategoricalAccuracy')])# dice_coef,[metrics.get(metric) for metric in METRICS]) #[metrics.get('CategoricalAccuracy')])",
"_____no_output_____"
],
[
"m = model\nMODEL_FOLDER = 'smalldicelosssoft'\nhistory = m.fit(\n x=training, \n epochs=EPOCHS, \n steps_per_epoch=int(TRAIN_SIZE / BATCH_SIZE), \n validation_data=evaluation,\n validation_steps=EVAL_SIZE)\n\nmodelDir = 'gs://{}/{}/{}'.format(BUCKET,FOLDER,MODEL_FOLDER)\n\n# tf.contrib.saved_model.save_keras_model(m, modelDir)\n# TODO: add something to move log to model folder\n# tfLog()",
"_____no_output_____"
],
[
"modelDir = 'gs://{}/{}/{}'.format(BUCKET,FOLDER,MODEL_FOLDER+'_2')\ntf.contrib.saved_model.save_keras_model(m, modelDir)\n# TODO: add something to move log to model folder\n# tfLog()",
"_____no_output_____"
],
[
"# plot the results of model training\n# get numpy and matplotlib.pyplot\n# from kels notebooks\n%pylab inline\nfig, ax = plt.subplots(nrows=2, sharex=True, figsize=(10,5.5))\n\nax[0].plot(history.history['loss'],color='#1f77b4',label='Training Loss')\nax[0].plot(history.history['val_loss'],linestyle=':',marker='o',markersize=3,color='#1f77b4',label='Validation Loss')\nax[0].set_ylabel('Loss')\nax[0].set_ylim(0.0,0.4)\nax[0].legend()\n\nax[1].plot(history.history['categorical_accuracy'],color='#ff7f0e',label='Training Acc.')\nax[1].plot(history.history['val_categorical_accuracy'],linestyle=':',marker='o',markersize=3,color='#ff7f0e',label='Validation Acc.')\nax[1].set_ylabel('Accuracy')\nax[1].set_xlabel('Epoch')\nax[1].legend(loc=\"lower right\")\n\nax[1].set_xticks(history.epoch)\nax[1].set_xticklabels(range(1,len(history.epoch)+1))\nax[1].set_xlabel('Epoch')\nax[1].set_ylim(0.0,1)\n\nplt.legend()\n\n# plt.savefig(\"/content/drive/My Drive/landsat_qa_samples/training.png\",dpi=300,)\n\nplt.show()",
"_____no_output_____"
],
[
"# og gee tf fcnn\n\nfrom tensorflow.python.keras import layers\nfrom tensorflow.python.keras import losses\nfrom tensorflow.python.keras import models\nfrom tensorflow.python.keras import metrics\nfrom tensorflow.python.keras import optimizers\n\ndef conv_block(input_tensor, num_filters):\n\tencoder = layers.Conv2D(num_filters, (3, 3), padding='same')(input_tensor)\n\tencoder = layers.BatchNormalization()(encoder)\n\tencoder = layers.Activation('relu')(encoder)\n\tencoder = layers.Conv2D(num_filters, (3, 3), padding='same')(encoder)\n\tencoder = layers.BatchNormalization()(encoder)\n\tencoder = layers.Activation('relu')(encoder)\n\treturn encoder\n\ndef encoder_block(input_tensor, num_filters):\n\tencoder = conv_block(input_tensor, num_filters)\n\tencoder_pool = layers.MaxPooling2D((2, 2), strides=(2, 2))(encoder)\n\treturn encoder_pool, encoder\n\ndef decoder_block(input_tensor, concat_tensor, num_filters):\n\tdecoder = layers.Conv2DTranspose(num_filters, (2, 2), strides=(2, 2), padding='same')(input_tensor)\n\tdecoder = layers.concatenate([concat_tensor, decoder], axis=-1)\n\tdecoder = layers.BatchNormalization()(decoder)\n\tdecoder = layers.Activation('relu')(decoder)\n\tdecoder = layers.Conv2D(num_filters, (3, 3), padding='same')(decoder)\n\tdecoder = layers.BatchNormalization()(decoder)\n\tdecoder = layers.Activation('relu')(decoder)\n\tdecoder = layers.Conv2D(num_filters, (3, 3), padding='same')(decoder)\n\tdecoder = layers.BatchNormalization()(decoder)\n\tdecoder = layers.Activation('relu')(decoder)\n\treturn decoder\n\ndef get_model():\n\tinputs = layers.Input(shape=[None, None, len(BANDS)]) # 256\n\tencoder0_pool, encoder0 = encoder_block(inputs, 32) # 128\n\tencoder1_pool, encoder1 = encoder_block(encoder0_pool, 64) # 64\n\tencoder2_pool, encoder2 = encoder_block(encoder1_pool, 128) # 32\n\tencoder3_pool, encoder3 = encoder_block(encoder2_pool, 256) # 16\n\tencoder4_pool, encoder4 = encoder_block(encoder3_pool, 512) # 8\n\tcenter = conv_block(encoder4_pool, 1024) # center\n\tdecoder4 = decoder_block(center, encoder4, 512) # 16\n\tdecoder3 = decoder_block(decoder4, encoder3, 256) # 32\n\tdecoder2 = decoder_block(decoder3, encoder2, 128) # 64\n\tdecoder1 = decoder_block(decoder2, encoder1, 64) # 128\n\tdecoder0 = decoder_block(decoder1, encoder0, 32) # 256\n\toutBranch = layers.Conv2D(len(RESPONSE), (1, 1), activation='relu')(decoder0)\n\toutputs = layers.Activation(\"softmax\")(outBranch)\n\n\tmodel = models.Model(inputs=[inputs], outputs=[outputs])\n#og compile \n\tmodel.compile(\n\t\toptimizer=optimizers.get(OPTIMIZER), \n\t\tloss=losses.get(LOSS),\n\t\tmetrics=[metrics.get('CategoricalAccuracy')])#metrics=[metrics.get(metric) for metric in METRICS])\n\n\treturn model",
"_____no_output_____"
],
[
"m = get_model()\nMODEL_FOLDER = 'testsoftmaxmeh'\nm.fit(\n x=training, \n epochs=EPOCHS, \n steps_per_epoch=int(TRAIN_SIZE / BATCH_SIZE), \n validation_data=evaluation,\n validation_steps=EVAL_SIZE)\n\nmodelDir = 'gs://{}/{}/{}'.format(BUCKET,FOLDER,MODEL_FOLDER)\n\ntf.contrib.saved_model.save_keras_model(m, modelDir)\n# TODO: add something to move log to model folder\ntfLog()",
"_____no_output_____"
]
],
[
[
"# Training the model\n\nYou train a Keras model by calling `.fit()` on it. Here we're going to train for 10 epochs, which is suitable for demonstration purposes. For production use, you probably want to optimize this parameter, for example through [hyperparamter tuning](https://cloud.google.com/ml-engine/docs/tensorflow/using-hyperparameter-tuning).",
"_____no_output_____"
],
[
"Note that the notebook VM is sometimes not heavy-duty enough to get through a whole training job, especially if you have a large buffer size or a large number of epochs. You can still use this notebook for training, but may need to set up an alternative VM ([learn more](https://research.google.com/colaboratory/local-runtimes.html)) for production use. Alternatively, you can package your code for running large training jobs on Google's AI Platform [as described here](https://cloud.google.com/ml-engine/docs/tensorflow/trainer-considerations). The following code loads a pre-trained model, which you can use for predictions right away.",
"_____no_output_____"
]
],
[
[
"from tensorflow.python.tools import saved_model_utils\n# \n# modelDir = 'gs://{}/{}/model-dice-256'.format('ee-tf',FOLDER)\n\nmeta_graph_def = saved_model_utils.get_meta_graph_def(modelDir, 'serve')\ninputs = meta_graph_def.signature_def['serving_default'].inputs\noutputs = meta_graph_def.signature_def['serving_default'].outputs\n\n# Just get the first thing(s) from the serving signature def. i.e. this\n# model only has a single input and a single output.\ninput_name = None\nfor k,v in inputs.items():\n input_name = v.name\n break\n\noutput_name = None\nfor k,v in outputs.items():\n output_name = v.name\n break\n\n# Make a dictionary that maps Earth Engine outputs and inputs to \n# AI Platform inputs and outputs, respectively.\nimport json\ninput_dict = \"'\" + json.dumps({input_name: \"array\"}) + \"'\"\noutput_dict = \"'\" + json.dumps({output_name: \"class\"}) + \"'\"\n\n# Put the EEified model next to the trained model directory.\n# TODO: add eeidied dir, project into to log, add output name\nEEIFIED_DIR = '{}/eeified'.format(modelDir)\nPROJECT = 'john-ee-282116'\nprint(input_dict,output_dict)\n# You need to set the project before using the model prepare command.\n!earthengine set_project {PROJECT}\n!earthengine model prepare --source_dir {modelDir} --dest_dir {EEIFIED_DIR} --input {input_dict} --output {output_dict}",
"_____no_output_____"
],
[
"modelDir",
"_____no_output_____"
],
[
"import time \nMODEL_NAME = 'tf256_small2large_2ai'\n\nVERSION_NAME = 'v' + str(int(time.time()))\nprint('Creating version: ' + VERSION_NAME)\n\n!gcloud ai-platform models create {MODEL_NAME} --project {PROJECT}\n!gcloud ai-platform versions create {VERSION_NAME} \\\n --project {PROJECT} \\\n --model {MODEL_NAME} \\\n --origin {EEIFIED_DIR} \\\n --runtime-version=1.14 \\\n --framework \"TENSORFLOW\" \\\n --python-version=3.5",
"_____no_output_____"
],
[
"# Load a trained model. \nMODEL_DIR = 'gs://ee-tf/tahoe-ogfw-02292020/model-ogwf-256'\nm = tf.contrib.saved_model.load_keras_model(MODEL_DIR)\nhelp(m.summary())\n",
"_____no_output_____"
]
]
] | [
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] | [
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.