
modelId
stringlengths 4
112
| lastModified
stringlengths 24
24
| tags
list | pipeline_tag
stringclasses 21
values | files
list | publishedBy
stringlengths 2
37
| downloads_last_month
int32 0
9.44M
| library
stringclasses 15
values | modelCard
large_stringlengths 0
100k
|
|---|---|---|---|---|---|---|---|---|
fspanda/Medical-Bio-BERT2 | 2021-05-19T16:57:41.000Z | [
"pytorch",
"jax",
"bert",
"masked-lm",
"transformers",
"fill-mask"
]
| fill-mask | [
".gitattributes",
"config.json",
"flax_model.msgpack",
"pytorch_model.bin",
"vocab.txt"
]
| fspanda | 81 | transformers | |
fspanda/electra-medical-discriminator | 2020-10-28T11:33:37.000Z | [
"pytorch",
"electra",
"pretraining",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"tokenizer_config.json",
"vocab.txt"
]
| fspanda | 11 | transformers | ||
fspanda/electra-medical-small-discriminator | 2020-10-29T00:30:38.000Z | [
"pytorch",
"electra",
"pretraining",
"transformers"
]
| [
".gitattributes",
"config.json",
"pytorch_model.bin",
"tokenizer_config.json",
"vocab.txt"
]
| fspanda | 12 | transformers | ||
fspanda/electra-medical-small-generator | 2020-10-29T00:33:04.000Z | [
"pytorch",
"electra",
"masked-lm",
"transformers",
"fill-mask"
]
| fill-mask | [
".gitattributes",
"config.json",
"pytorch_model.bin",
"tokenizer_config.json",
"vocab.txt"
]
| fspanda | 24 | transformers | |
fuliucansheng/adsplus | 2021-04-06T08:07:09.000Z | []
| [
".gitattributes",
"mass/mainstream/mass-base-uncased-config.json",
"mass/mainstream/mass-base-uncased-slab-desc-from-lp.bin",
"mass/mainstream/mass-base-uncased-slab-desc-from-title.bin",
"mass/mainstream/mass-base-uncased-slab-title-from-lp.bin",
"mass/mainstream/mass-base-uncased-vocab.txt",
"twinbert/mainstream/mt_twinbert_tri_letter_weight.bin",
"twinbert/mainstream/twinbert_tri_letter_config.json",
"twinbert/mainstream/twinbert_tri_letter_pretrain_weight.bin",
"twinbert/mainstream/twinbert_tri_letter_vocab.txt",
"unilm/infoxlm/infoxlm-roberta-config.json",
"unilm/mainstream/deepgen_v3_config.json",
"unilm/mainstream/deepgen_v3_model.bin"
]
| fuliucansheng | 0 | |||
fuliucansheng/mass | 2021-02-21T15:35:33.000Z | []
| [
".gitattributes",
"mass-base-uncased-config.json",
"mass-base-uncased-pytorch-model.bin",
"mass-base-uncased-vocab.txt",
"mass_for_generation.ini"
]
| fuliucansheng | 0 | |||
fuliucansheng/unilm | 2021-06-08T05:37:10.000Z | []
| [
".gitattributes",
"cnndm-unilm-base-cased-config.json",
"cnndm-unilm-large-cased-config.json",
"cnndm-unilm-large-cased.bin",
"infoxlm-roberta-config.json",
"unilm-base-uncased-config.json"
]
| fuliucansheng | 0 | |||
fullshowbox/DSADAWF | 2021-04-08T18:33:40.000Z | []
| [
".gitattributes",
"README.md"
]
| fullshowbox | 0 | https://vrip.unmsm.edu.pe/forum/profile/liexylezzy/
https://vrip.unmsm.edu.pe/forum/profile/ellindanatasya/
https://vrip.unmsm.edu.pe/forum/profile/oploscgv/
https://vrip.unmsm.edu.pe/forum/profile/Zackoplos/
https://vrip.unmsm.edu.pe/forum/profile/unholyzulk/
https://vrip.unmsm.edu.pe/forum/profile/aurorarezash/ |
||
fullshowbox/full-tv-free | 2021-04-22T02:47:22.000Z | []
| [
".gitattributes",
"README.md"
]
| fullshowbox | 0 | https://community.afpglobal.org/network/members/profile?UserKey=fb4fdcef-dde4-4258-a423-2159545d84c1
https://community.afpglobal.org/network/members/profile?UserKey=e6ccc088-b709-45ec-b61e-4d56088acbda
https://community.afpglobal.org/network/members/profile?UserKey=ba280059-0890-4510-81d0-a79522b75ac8
https://community.afpglobal.org/network/members/profile?UserKey=799ba769-6e99-4a6a-a173-4f1b817e978c
https://community.afpglobal.org/network/members/profile?UserKey=babb84d7-e91a-4972-b26a-51067c66d793
https://community.afpglobal.org/network/members/profile?UserKey=8e4656bc-8d0d-44e1-b280-e68a2ace9353
https://community.afpglobal.org/network/members/profile?UserKey=8e7b41a8-9bed-4cb0-9021-a164b0aa6dd3
https://community.afpglobal.org/network/members/profile?UserKey=e4f38596-d772-4fbe-9e93-9aef5618f26e
https://community.afpglobal.org/network/members/profile?UserKey=18221e49-74ba-4155-ac1e-6f184bfb2398
https://community.afpglobal.org/network/members/profile?UserKey=ef4391e8-03df-467f-bf3f-4a45087817eb
https://community.afpglobal.org/network/members/profile?UserKey=832774fd-a035-421a-8236-61cf45a7747d
https://community.afpglobal.org/network/members/profile?UserKey=9f05cd73-b75c-4820-b60a-5df6357b2af9
https://community.afpglobal.org/network/members/profile?UserKey=c1727992-5024-4321-b0c9-ecc6f51e6532
https://www.hybrid-analysis.com/sample/255948e335dd9f873d11bf0224f8d180cd097509d23d27506292c22443fa92b8
https://www.facebook.com/PS5Giveaways2021
https://cgvmovie.cookpad-blog.jp/articles/589986
https://myanimelist.net/blog.php?eid=850892
https://comicvine.gamespot.com/profile/full-tv-free/about-me/
https://pantip.com/topic/40658194 |
||
fullshowbox/nacenetwork21 | 2021-04-13T02:57:06.000Z | []
| [
".gitattributes",
"README.md"
]
| fullshowbox | 0 | https://volunteer.alz.org/network/members/profile?UserKey=f4774542-39b3-4cfd-8c21-7b834795f7d7
https://volunteer.alz.org/network/members/profile?UserKey=05a00b90-f854-45fb-9a3a-7420144d290c
https://volunteer.alz.org/network/members/profile?UserKey=45cceddd-29b9-4c6c-8612-e2a16aaa391a
https://volunteer.alz.org/network/members/profile?UserKey=ae3c28f9-72a3-4af5-bd50-3b2ea2c0d3a3
https://volunteer.alz.org/network/members/profile?UserKey=7ab8e28e-e31f-4906-ab06-84b9ea3a880f
https://volunteer.alz.org/network/members/profile?UserKey=1b31fc90-e18e-4ef6-81f0-5c0b55fb95a3
https://volunteer.alz.org/network/members/profile?UserKey=23971b11-04ad-4eb4-abc5-6e659c6b071c
123movies-watch-online-movie-full-free-2021
https://myanimelist.net/blog.php?eid=849353
https://comicvine.gamespot.com/profile/nacenetwork21/about-me/
https://pantip.com/topic/40639721 |
||
fullshowbox/networkprofile | 2021-04-13T03:40:48.000Z | []
| [
".gitattributes",
"README.md"
]
| fullshowbox | 0 | https://www.nace.org/network/members/profile?UserKey=461a690a-bff6-4e4c-be63-ea8e39264459
https://www.nace.org/network/members/profile?UserKey=b4a6a66a-fb8a-4f2b-8af9-04f003ad9d46
https://www.nace.org/network/members/profile?UserKey=24544ab2-551d-42aa-adbe-7a1c1d68fd9c
https://www.nace.org/network/members/profile?UserKey=3e8035d5-056a-482d-9010-9883e5990f4a
https://www.nace.org/network/members/profile?UserKey=d7241c69-28c4-4146-a077-a00cc2c9ccf5
https://www.nace.org/network/members/profile?UserKey=2c58c2fb-13a4-4e5a-b044-f467bb295d83
https://www.nace.org/network/members/profile?UserKey=dd8a290c-e53a-4b56-9a17-d35dbcb6b8bd
https://www.nace.org/network/members/profile?UserKey=0e96a1af-91f4-496a-af02-6d753a1bbded |
||
fullshowbox/ragbrai | 2021-04-12T05:10:28.000Z | []
| [
".gitattributes",
"README.md"
]
| fullshowbox | 0 | https://ragbrai.com/groups/hd-movie-watch-french-exit-2021-full-movie-online-for-free/
https://ragbrai.com/groups/hd-movie-watch-nobody-2021-full-movie-online-for-free/
https://ragbrai.com/groups/hd-movie-watch-voyagers-2021-full-movie-online-for-free/
https://ragbrai.com/groups/hd-movie-watch-godzilla-vs-kong-2021-full-movie-online-for-free/
https://ragbrai.com/groups/hd-movie-watch-raya-and-the-last-dragon-2021-full-movie-online-for-free/
https://ragbrai.com/groups/hd-movie-watch-mortal-kombat-2021-full-movie-online-for-free/
https://ragbrai.com/groups/hd-movie-watch-the-father-2021-full-movie-online-for-free/ |
||
funnel-transformer/intermediate-base | 2020-12-11T21:40:21.000Z | [
"pytorch",
"tf",
"funnel",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"dataset:gigaword",
"arxiv:2006.03236",
"transformers",
"license:apache-2.0"
]
| [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer.json",
"tokenizer_config.json",
"vocab.txt"
]
| funnel-transformer | 235 | transformers | ---
language: en
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
- gigaword
---
# Funnel Transformer intermediate model (B6-6-6 without decoder)
Pretrained model on English language using a similar objective objective as [ELECTRA](https://huggingface.co/transformers/model_doc/electra.html). It was introduced in
[this paper](https://arxiv.org/pdf/2006.03236.pdf) and first released in
[this repository](https://github.com/laiguokun/Funnel-Transformer). This model is uncased: it does not make a difference
between english and English.
Disclaimer: The team releasing Funnel Transformer did not write a model card for this model so this model card has been
written by the Hugging Face team.
## Model description
Funnel Transformer is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, a small language model corrupts the input texts and serves as a generator of inputs for this model, and
the pretraining objective is to predict which token is an original and which one has been replaced, a bit like a GAN training.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the BERT model as inputs.
**Note:** This model does not contain the decoder, so it ouputs hidden states that have a sequence length of one fourth
of the inputs. It's good to use for tasks requiring a summary of the sentence (like sentence classification) but not if
you need one input per initial token. You should use the `intermediate` model in that case.
## Intended uses & limitations
You can use the raw model to extract a vector representation of a given text, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=funnel-transformer) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import FunnelTokenizer, FunnelBaseModel
tokenizer = FunnelTokenizer.from_pretrained("funnel-transformer/intermediate-base")
model = FunnelBaseModel.from_pretrained("funnel-transformer/intermediate-base")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import FunnelTokenizer, TFFunnelBaseModel
tokenizer = FunnelTokenizer.from_pretrained("funnel-transformer/intermediate-base")
model = TFFunnelBaseModel.from_pretrained("funnel-transformer/intermediate-base")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
The BERT model was pretrained on:
- [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038 unpublished books,
- [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and headers),
- [Clue Web](https://lemurproject.org/clueweb12/), a dataset of 733,019,372 English web pages,
- [GigaWord](https://catalog.ldc.upenn.edu/LDC2011T07), an archive of newswire text data,
- [Common Crawl](https://commoncrawl.org/), a dataset of raw web pages.
### BibTeX entry and citation info
```bibtex
@misc{dai2020funneltransformer,
title={Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing},
author={Zihang Dai and Guokun Lai and Yiming Yang and Quoc V. Le},
year={2020},
eprint={2006.03236},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
|
|
funnel-transformer/intermediate | 2020-12-11T21:40:25.000Z | [
"pytorch",
"tf",
"funnel",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"dataset:gigaword",
"arxiv:2006.03236",
"transformers",
"license:apache-2.0"
]
| [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer.json",
"tokenizer_config.json",
"vocab.txt"
]
| funnel-transformer | 432 | transformers | ---
language: en
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
- gigaword
---
# Funnel Transformer intermediate model (B6-6-6 with decoder)
Pretrained model on English language using a similar objective objective as [ELECTRA](https://huggingface.co/transformers/model_doc/electra.html). It was introduced in
[this paper](https://arxiv.org/pdf/2006.03236.pdf) and first released in
[this repository](https://github.com/laiguokun/Funnel-Transformer). This model is uncased: it does not make a difference
between english and English.
Disclaimer: The team releasing Funnel Transformer did not write a model card for this model so this model card has been
written by the Hugging Face team.
## Model description
Funnel Transformer is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, a small language model corrupts the input texts and serves as a generator of inputs for this model, and
the pretraining objective is to predict which token is an original and which one has been replaced, a bit like a GAN training.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the BERT model as inputs.
## Intended uses & limitations
You can use the raw model to extract a vector representation of a given text, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=funnel-transformer) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import FunnelTokenizer, FunnelModel
tokenizer = FunnelTokenizer.from_pretrained("funnel-transformer/intermediate")
model = FunneModel.from_pretrained("funnel-transformer/intermediate")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import FunnelTokenizer, TFFunnelModel
tokenizer = FunnelTokenizer.from_pretrained("funnel-transformer/intermediate")
model = TFFunnelModel.from_pretrained("funnel-transformer/intermediatesmall")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
The BERT model was pretrained on:
- [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038 unpublished books,
- [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and headers),
- [Clue Web](https://lemurproject.org/clueweb12/), a dataset of 733,019,372 English web pages,
- [GigaWord](https://catalog.ldc.upenn.edu/LDC2011T07), an archive of newswire text data,
- [Common Crawl](https://commoncrawl.org/), a dataset of raw web pages.
### BibTeX entry and citation info
```bibtex
@misc{dai2020funneltransformer,
title={Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing},
author={Zihang Dai and Guokun Lai and Yiming Yang and Quoc V. Le},
year={2020},
eprint={2006.03236},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
|
|
funnel-transformer/large-base | 2020-12-11T21:40:28.000Z | [
"pytorch",
"tf",
"funnel",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"dataset:gigaword",
"arxiv:2006.03236",
"transformers",
"license:apache-2.0"
]
| [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer.json",
"tokenizer_config.json",
"vocab.txt"
]
| funnel-transformer | 745 | transformers | ---
language: en
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
- gigaword
---
# Funnel Transformer large model (B8-8-8 without decoder)
Pretrained model on English language using a similar objective objective as [ELECTRA](https://huggingface.co/transformers/model_doc/electra.html). It was introduced in
[this paper](https://arxiv.org/pdf/2006.03236.pdf) and first released in
[this repository](https://github.com/laiguokun/Funnel-Transformer). This model is uncased: it does not make a difference
between english and English.
Disclaimer: The team releasing Funnel Transformer did not write a model card for this model so this model card has been
written by the Hugging Face team.
## Model description
Funnel Transformer is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, a small language model corrupts the input texts and serves as a generator of inputs for this model, and
the pretraining objective is to predict which token is an original and which one has been replaced, a bit like a GAN training.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the BERT model as inputs.
**Note:** This model does not contain the decoder, so it ouputs hidden states that have a sequence length of one fourth
of the inputs. It's good to use for tasks requiring a summary of the sentence (like sentence classification) but not if
you need one input per initial token. You should use the `large` model in that case.
## Intended uses & limitations
You can use the raw model to extract a vector representation of a given text, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=funnel-transformer) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import FunnelTokenizer, FunnelBaseModel
tokenizer = FunnelTokenizer.from_pretrained("funnel-transformer/large-base")
model = FunnelBaseModel.from_pretrained("funnel-transformer/large-base")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import FunnelTokenizer, TFFunnelBaseModel
tokenizer = FunnelTokenizer.from_pretrained("funnel-transformer/large-base")
model = TFFunnelBaseModel.from_pretrained("funnel-transformer/large-base")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
The BERT model was pretrained on:
- [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038 unpublished books,
- [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and headers),
- [Clue Web](https://lemurproject.org/clueweb12/), a dataset of 733,019,372 English web pages,
- [GigaWord](https://catalog.ldc.upenn.edu/LDC2011T07), an archive of newswire text data,
- [Common Crawl](https://commoncrawl.org/), a dataset of raw web pages.
### BibTeX entry and citation info
```bibtex
@misc{dai2020funneltransformer,
title={Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing},
author={Zihang Dai and Guokun Lai and Yiming Yang and Quoc V. Le},
year={2020},
eprint={2006.03236},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
|
|
funnel-transformer/large | 2020-12-11T21:40:31.000Z | [
"pytorch",
"tf",
"funnel",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"dataset:gigaword",
"arxiv:2006.03236",
"transformers",
"license:apache-2.0"
]
| [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer.json",
"tokenizer_config.json",
"vocab.txt"
]
| funnel-transformer | 188 | transformers | ---
language: en
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
- gigaword
---
# Funnel Transformer large model (B8-8-8 with decoder)
Pretrained model on English language using a similar objective objective as [ELECTRA](https://huggingface.co/transformers/model_doc/electra.html). It was introduced in
[this paper](https://arxiv.org/pdf/2006.03236.pdf) and first released in
[this repository](https://github.com/laiguokun/Funnel-Transformer). This model is uncased: it does not make a difference
between english and English.
Disclaimer: The team releasing Funnel Transformer did not write a model card for this model so this model card has been
written by the Hugging Face team.
## Model description
Funnel Transformer is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, a small language model corrupts the input texts and serves as a generator of inputs for this model, and
the pretraining objective is to predict which token is an original and which one has been replaced, a bit like a GAN training.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the BERT model as inputs.
## Intended uses & limitations
You can use the raw model to extract a vector representation of a given text, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=funnel-transformer) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import FunnelTokenizer, FunnelModel
tokenizer = FunnelTokenizer.from_pretrained("funnel-transformer/large")
model = FunneModel.from_pretrained("funnel-transformer/large")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import FunnelTokenizer, TFFunnelModel
tokenizer = FunnelTokenizer.from_pretrained("funnel-transformer/large")
model = TFFunnelModel.from_pretrained("funnel-transformer/large")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
The BERT model was pretrained on:
- [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038 unpublished books,
- [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and headers),
- [Clue Web](https://lemurproject.org/clueweb12/), a dataset of 733,019,372 English web pages,
- [GigaWord](https://catalog.ldc.upenn.edu/LDC2011T07), an archive of newswire text data,
- [Common Crawl](https://commoncrawl.org/), a dataset of raw web pages.
### BibTeX entry and citation info
```bibtex
@misc{dai2020funneltransformer,
title={Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing},
author={Zihang Dai and Guokun Lai and Yiming Yang and Quoc V. Le},
year={2020},
eprint={2006.03236},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
|
|
funnel-transformer/medium-base | 2020-12-11T21:40:34.000Z | [
"pytorch",
"tf",
"funnel",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"dataset:gigaword",
"arxiv:2006.03236",
"transformers",
"license:apache-2.0"
]
| [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer.json",
"tokenizer_config.json",
"vocab.txt"
]
| funnel-transformer | 242 | transformers | ---
language: en
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
- gigaword
---
# Funnel Transformer medium model (B6-3x2-3x2 without decoder)
Pretrained model on English language using a similar objective objective as [ELECTRA](https://huggingface.co/transformers/model_doc/electra.html). It was introduced in
[this paper](https://arxiv.org/pdf/2006.03236.pdf) and first released in
[this repository](https://github.com/laiguokun/Funnel-Transformer). This model is uncased: it does not make a difference
between english and English.
Disclaimer: The team releasing Funnel Transformer did not write a model card for this model so this model card has been
written by the Hugging Face team.
## Model description
Funnel Transformer is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, a small language model corrupts the input texts and serves as a generator of inputs for this model, and
the pretraining objective is to predict which token is an original and which one has been replaced, a bit like a GAN training.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the BERT model as inputs.
**Note:** This model does not contain the decoder, so it ouputs hidden states that have a sequence length of one fourth
of the inputs. It's good to use for tasks requiring a summary of the sentence (like sentence classification) but not if
you need one input per initial token. You should use the `medium` model in that case.
## Intended uses & limitations
You can use the raw model to extract a vector representation of a given text, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=funnel-transformer) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import FunnelTokenizer, FunnelBaseModel
tokenizer = FunnelTokenizer.from_pretrained("funnel-transformer/medium-base")
model = FunnelBaseModel.from_pretrained("funnel-transformer/medium-base")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import FunnelTokenizer, TFFunnelBaseModel
tokenizer = FunnelTokenizer.from_pretrained("funnel-transformer/medium-base")
model = TFFunnelBaseModel.from_pretrained("funnel-transformer/medium-base")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
The BERT model was pretrained on:
- [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038 unpublished books,
- [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and headers),
- [Clue Web](https://lemurproject.org/clueweb12/), a dataset of 733,019,372 English web pages,
- [GigaWord](https://catalog.ldc.upenn.edu/LDC2011T07), an archive of newswire text data,
- [Common Crawl](https://commoncrawl.org/), a dataset of raw web pages.
### BibTeX entry and citation info
```bibtex
@misc{dai2020funneltransformer,
title={Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing},
author={Zihang Dai and Guokun Lai and Yiming Yang and Quoc V. Le},
year={2020},
eprint={2006.03236},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
|
|
funnel-transformer/medium | 2020-12-11T21:40:38.000Z | [
"pytorch",
"tf",
"funnel",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"dataset:gigaword",
"arxiv:2006.03236",
"transformers",
"license:apache-2.0"
]
| [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer.json",
"tokenizer_config.json",
"vocab.txt"
]
| funnel-transformer | 179 | transformers | ---
language: en
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
- gigaword
---
# Funnel Transformer medium model (B6-3x2-3x2 with decoder)
Pretrained model on English language using a similar objective objective as [ELECTRA](https://huggingface.co/transformers/model_doc/electra.html). It was introduced in
[this paper](https://arxiv.org/pdf/2006.03236.pdf) and first released in
[this repository](https://github.com/laiguokun/Funnel-Transformer). This model is uncased: it does not make a difference
between english and English.
Disclaimer: The team releasing Funnel Transformer did not write a model card for this model so this model card has been
written by the Hugging Face team.
## Model description
Funnel Transformer is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, a small language model corrupts the input texts and serves as a generator of inputs for this model, and
the pretraining objective is to predict which token is an original and which one has been replaced, a bit like a GAN training.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the BERT model as inputs.
## Intended uses & limitations
You can use the raw model to extract a vector representation of a given text, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=funnel-transformer) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import FunnelTokenizer, FunnelModel
tokenizer = FunnelTokenizer.from_pretrained("funnel-transformer/medium")
model = FunneModel.from_pretrained("funnel-transformer/medium")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import FunnelTokenizer, TFFunnelModel
tokenizer = FunnelTokenizer.from_pretrained("funnel-transformer/medium")
model = TFFunnelModel.from_pretrained("funnel-transformer/medium")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
The BERT model was pretrained on:
- [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038 unpublished books,
- [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and headers),
- [Clue Web](https://lemurproject.org/clueweb12/), a dataset of 733,019,372 English web pages,
- [GigaWord](https://catalog.ldc.upenn.edu/LDC2011T07), an archive of newswire text data,
- [Common Crawl](https://commoncrawl.org/), a dataset of raw web pages.
### BibTeX entry and citation info
```bibtex
@misc{dai2020funneltransformer,
title={Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing},
author={Zihang Dai and Guokun Lai and Yiming Yang and Quoc V. Le},
year={2020},
eprint={2006.03236},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
|
|
funnel-transformer/small-base | 2020-12-11T21:40:41.000Z | [
"pytorch",
"tf",
"funnel",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"dataset:gigaword",
"arxiv:2006.03236",
"transformers",
"license:apache-2.0"
]
| [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer.json",
"tokenizer_config.json",
"vocab.txt"
]
| funnel-transformer | 5,642 | transformers | ---
language: en
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
- gigaword
---
# Funnel Transformer small model (B4-4-4 without decoder)
Pretrained model on English language using a similar objective objective as [ELECTRA](https://huggingface.co/transformers/model_doc/electra.html). It was introduced in
[this paper](https://arxiv.org/pdf/2006.03236.pdf) and first released in
[this repository](https://github.com/laiguokun/Funnel-Transformer). This model is uncased: it does not make a difference
between english and English.
Disclaimer: The team releasing Funnel Transformer did not write a model card for this model so this model card has been
written by the Hugging Face team.
## Model description
Funnel Transformer is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, a small language model corrupts the input texts and serves as a generator of inputs for this model, and
the pretraining objective is to predict which token is an original and which one has been replaced, a bit like a GAN training.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the BERT model as inputs.
**Note:** This model does not contain the decoder, so it ouputs hidden states that have a sequence length of one fourth
of the inputs. It's good to use for tasks requiring a summary of the sentence (like sentence classification) but not if
you need one input per initial token. You should use the `small` model in that case.
## Intended uses & limitations
You can use the raw model to extract a vector representation of a given text, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=funnel-transformer) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import FunnelTokenizer, FunnelBaseModel
tokenizer = FunnelTokenizer.from_pretrained("funnel-transformer/small-base")
model = FunnelBaseModel.from_pretrained("funnel-transformer/small-base")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import FunnelTokenizer, TFFunnelBaseModel
tokenizer = FunnelTokenizer.from_pretrained("funnel-transformer/small-base")
model = TFFunnelBaseModel.from_pretrained("funnel-transformer/small-base")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
The BERT model was pretrained on:
- [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038 unpublished books,
- [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and headers),
- [Clue Web](https://lemurproject.org/clueweb12/), a dataset of 733,019,372 English web pages,
- [GigaWord](https://catalog.ldc.upenn.edu/LDC2011T07), an archive of newswire text data,
- [Common Crawl](https://commoncrawl.org/), a dataset of raw web pages.
### BibTeX entry and citation info
```bibtex
@misc{dai2020funneltransformer,
title={Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing},
author={Zihang Dai and Guokun Lai and Yiming Yang and Quoc V. Le},
year={2020},
eprint={2006.03236},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
|
|
funnel-transformer/small | 2020-12-11T21:40:44.000Z | [
"pytorch",
"tf",
"funnel",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"dataset:gigaword",
"arxiv:2006.03236",
"transformers",
"license:apache-2.0"
]
| [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer.json",
"tokenizer_config.json",
"vocab.txt"
]
| funnel-transformer | 517 | transformers | ---
language: en
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
- gigaword
---
# Funnel Transformer small model (B4-4-4 with decoder)
Pretrained model on English language using a similar objective objective as [ELECTRA](https://huggingface.co/transformers/model_doc/electra.html). It was introduced in
[this paper](https://arxiv.org/pdf/2006.03236.pdf) and first released in
[this repository](https://github.com/laiguokun/Funnel-Transformer). This model is uncased: it does not make a difference
between english and English.
Disclaimer: The team releasing Funnel Transformer did not write a model card for this model so this model card has been
written by the Hugging Face team.
## Model description
Funnel Transformer is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, a small language model corrupts the input texts and serves as a generator of inputs for this model, and
the pretraining objective is to predict which token is an original and which one has been replaced, a bit like a GAN training.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the BERT model as inputs.
## Intended uses & limitations
You can use the raw model to extract a vector representation of a given text, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=funnel-transformer) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import FunnelTokenizer, FunnelModel
tokenizer = FunnelTokenizer.from_pretrained("funnel-transformer/small")
model = FunneModel.from_pretrained("funnel-transformer/small")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import FunnelTokenizer, TFFunnelModel
tokenizer = FunnelTokenizer.from_pretrained("funnel-transformer/small")
model = TFFunnelModel.from_pretrained("funnel-transformer/small")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
The BERT model was pretrained on:
- [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038 unpublished books,
- [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and headers),
- [Clue Web](https://lemurproject.org/clueweb12/), a dataset of 733,019,372 English web pages,
- [GigaWord](https://catalog.ldc.upenn.edu/LDC2011T07), an archive of newswire text data,
- [Common Crawl](https://commoncrawl.org/), a dataset of raw web pages.
### BibTeX entry and citation info
```bibtex
@misc{dai2020funneltransformer,
title={Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing},
author={Zihang Dai and Guokun Lai and Yiming Yang and Quoc V. Le},
year={2020},
eprint={2006.03236},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
|
|
funnel-transformer/xlarge-base | 2020-12-11T21:40:48.000Z | [
"pytorch",
"tf",
"funnel",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"dataset:gigaword",
"arxiv:2006.03236",
"transformers",
"license:apache-2.0"
]
| [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer.json",
"tokenizer_config.json",
"vocab.txt"
]
| funnel-transformer | 71,624 | transformers | ---
language: en
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
- gigaword
---
# Funnel Transformer xlarge model (B10-10-10 without decoder)
Pretrained model on English language using a similar objective objective as [ELECTRA](https://huggingface.co/transformers/model_doc/electra.html). It was introduced in
[this paper](https://arxiv.org/pdf/2006.03236.pdf) and first released in
[this repository](https://github.com/laiguokun/Funnel-Transformer). This model is uncased: it does not make a difference
between english and English.
Disclaimer: The team releasing Funnel Transformer did not write a model card for this model so this model card has been
written by the Hugging Face team.
## Model description
Funnel Transformer is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, a small language model corrupts the input texts and serves as a generator of inputs for this model, and
the pretraining objective is to predict which token is an original and which one has been replaced, a bit like a GAN training.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the BERT model as inputs.
**Note:** This model does not contain the decoder, so it ouputs hidden states that have a sequence length of one fourth
of the inputs. It's good to use for tasks requiring a summary of the sentence (like sentence classification) but not if
you need one input per initial token. You should use the `xlarge` model in that case.
## Intended uses & limitations
You can use the raw model to extract a vector representation of a given text, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=funnel-transformer) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import FunnelTokenizer, FunnelBaseModel
tokenizer = FunnelTokenizer.from_pretrained("funnel-transformer/xlarge-base")
model = FunnelBaseModel.from_pretrained("funnel-transformer/xlarge-base")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import FunnelTokenizer, TFFunnelBaseModel
tokenizer = FunnelTokenizer.from_pretrained("funnel-transformer/xlarge-base")
model = TFFunnelBaseModel.from_pretrained("funnel-transformer/xlarge-base")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
The BERT model was pretrained on:
- [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038 unpublished books,
- [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and headers),
- [Clue Web](https://lemurproject.org/clueweb12/), a dataset of 733,019,372 English web pages,
- [GigaWord](https://catalog.ldc.upenn.edu/LDC2011T07), an archive of newswire text data,
- [Common Crawl](https://commoncrawl.org/), a dataset of raw web pages.
### BibTeX entry and citation info
```bibtex
@misc{dai2020funneltransformer,
title={Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing},
author={Zihang Dai and Guokun Lai and Yiming Yang and Quoc V. Le},
year={2020},
eprint={2006.03236},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
|
|
funnel-transformer/xlarge | 2020-12-11T21:40:51.000Z | [
"pytorch",
"tf",
"funnel",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"dataset:gigaword",
"arxiv:2006.03236",
"transformers",
"license:apache-2.0"
]
| [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer.json",
"tokenizer_config.json",
"vocab.txt"
]
| funnel-transformer | 144 | transformers | ---
language: en
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
- gigaword
---
# Funnel Transformer xlarge model (B10-10-10 with decoder)
Pretrained model on English language using a similar objective objective as [ELECTRA](https://huggingface.co/transformers/model_doc/electra.html). It was introduced in
[this paper](https://arxiv.org/pdf/2006.03236.pdf) and first released in
[this repository](https://github.com/laiguokun/Funnel-Transformer). This model is uncased: it does not make a difference
between english and English.
Disclaimer: The team releasing Funnel Transformer did not write a model card for this model so this model card has been
written by the Hugging Face team.
## Model description
Funnel Transformer is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, a small language model corrupts the input texts and serves as a generator of inputs for this model, and
the pretraining objective is to predict which token is an original and which one has been replaced, a bit like a GAN training.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the BERT model as inputs.
## Intended uses & limitations
You can use the raw model to extract a vector representation of a given text, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=funnel-transformer) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import FunnelTokenizer, FunnelModel
tokenizer = FunnelTokenizer.from_pretrained("funnel-transformer/xlarge")
model = FunneModel.from_pretrained("funnel-transformer/xlarge")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import FunnelTokenizer, TFFunnelModel
tokenizer = FunnelTokenizer.from_pretrained("funnel-transformer/xlarge")
model = TFFunnelModel.from_pretrained("funnel-transformer/xlarge")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
The BERT model was pretrained on:
- [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038 unpublished books,
- [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and headers),
- [Clue Web](https://lemurproject.org/clueweb12/), a dataset of 733,019,372 English web pages,
- [GigaWord](https://catalog.ldc.upenn.edu/LDC2011T07), an archive of newswire text data,
- [Common Crawl](https://commoncrawl.org/), a dataset of raw web pages.
### BibTeX entry and citation info
```bibtex
@misc{dai2020funneltransformer,
title={Funnel-Transformer: Filtering out Sequential Redundancy for Efficient Language Processing},
author={Zihang Dai and Guokun Lai and Yiming Yang and Quoc V. Le},
year={2020},
eprint={2006.03236},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
|
|
furkanbilgin/gpt2-eksisozluk | 2021-05-02T18:20:53.000Z | []
| [
".gitattributes"
]
| furkanbilgin | 0 | |||
fuyunhuayu/face | 2021-03-16T13:44:55.000Z | []
| [
".gitattributes"
]
| fuyunhuayu | 0 | |||
fvillena/bio-bert-base-spanish-wwm-uncased | 2021-06-08T16:12:08.000Z | [
"pytorch",
"bert",
"masked-lm",
"es",
"transformers",
"fill-mask"
]
| fill-mask | [
".gitattributes",
".gitignore",
"README.md",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.txt"
]
| fvillena | 165 | transformers | ---
language:
- es
widget:
- text: "Periodontitis [MASK] generalizada severa."
- text: "Caries dentinaria [MASK]."
- text: "Movilidad aumentada en pza [MASK]."
- text: "Pcte con dm en tto con [MASK]."
- text: "Pcte con erc en tto con [MASK]."
---
# Bio-BERT-Spanish
BERT masked language model fine-tuned from `dccuchile/bert-base-Spanish-wwm-uncased` over clinical text in Spanish.
## Training data
This model was fine-tuned over a clinical corpus comprised of 5,157,902 free-text diagnostic suspicions extracted from Chilean waiting list referrals. |
g4brielvs/gaga | 2021-01-19T22:29:44.000Z | []
| [
".gitattributes"
]
| g4brielvs | 0 | |||
gael1130/gael_first_model | 2020-12-05T12:54:42.000Z | []
| [
".gitattributes",
"README.md"
]
| gael1130 | 0 | I am adding my first README in order to test the interface. How good is it really? |
||
gagan3012/Fox-News-Generator | 2021-05-21T16:03:28.000Z | [
"pytorch",
"jax",
"gpt2",
"lm-head",
"causal-lm",
"transformers",
"text-generation"
]
| text-generation | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"train_results.txt",
"trainer_state.json",
"training_args.bin",
"vocab.json"
]
| gagan3012 | 43 | transformers | # Generating Right Wing News Using GPT2
### I have built a custom model for it using data from Kaggle
Creating a new finetuned model using data from FOX news
### My model can be accessed at gagan3012/Fox-News-Generator
Check the [BenchmarkTest](https://github.com/gagan3012/Fox-News-Generator/blob/master/BenchmarkTest.ipynb) notebook for results
Find the model at [gagan3012/Fox-News-Generator](https://huggingface.co/gagan3012/Fox-News-Generator)
```
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("gagan3012/Fox-News-Generator")
model = AutoModelWithLMHead.from_pretrained("gagan3012/Fox-News-Generator")
```
|
gagan3012/k2t-base | 2021-05-08T00:53:41.000Z | [
"pytorch",
"t5",
"lm-head",
"seq2seq",
"en",
"dataset:WebNLG",
"dataset:Dart",
"transformers",
"keytotext",
"k2t-base",
"Keywords to Sentences",
"license:mit",
"text2text-generation"
]
| text2text-generation | [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"tokenizer.json"
]
| gagan3012 | 477 | transformers | ---
language: "en"
thumbnail: "Keywords to Sentences"
tags:
- keytotext
- k2t-base
- Keywords to Sentences
license: "MIT"
datasets:
- WebNLG
- Dart
metrics:
- NLG
---
# keytotext

Idea is to build a model which will take keywords as inputs and generate sentences as outputs.
### Keytotext is powered by Huggingface 🤗
[](https://pypi.org/project/keytotext/)
[](https://pepy.tech/project/keytotext)
[](https://colab.research.google.com/github/gagan3012/keytotext/blob/master/Examples/K2T.ipynb)
[](https://share.streamlit.io/gagan3012/keytotext/UI/app.py)
## Model:
Keytotext is based on the Amazing T5 Model:
- `k2t`: [Model](https://huggingface.co/gagan3012/k2t)
- `k2t-tiny`: [Model](https://huggingface.co/gagan3012/k2t-tiny)
- `k2t-base`: [Model](https://huggingface.co/gagan3012/k2t-base)
Training Notebooks can be found in the [`Training Notebooks`](https://github.com/gagan3012/keytotext/tree/master/Training%20Notebooks) Folder
## Usage:
Example usage: [](https://colab.research.google.com/github/gagan3012/keytotext/blob/master/Examples/K2T.ipynb)
Example Notebooks can be found in the [`Notebooks`](https://github.com/gagan3012/keytotext/tree/master/Examples) Folder
```
pip install keytotext
```

## UI:
UI: [](https://share.streamlit.io/gagan3012/keytotext/UI/app.py)
```
pip install streamlit-tags
```
This uses a custom streamlit component built by me: [GitHub](https://github.com/gagan3012/streamlit-tags)

|
gagan3012/k2t-new | 2021-06-18T22:26:34.000Z | [
"pytorch",
"t5",
"seq2seq",
"en",
"dataset:common_gen",
"transformers",
"keytotext",
"k2t",
"Keywords to Sentences",
"license:mit",
"text2text-generation"
]
| text2text-generation | [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"spiece.model",
"tokenizer.json",
"tokenizer_config.json"
]
| gagan3012 | 0 | transformers | |
gagan3012/k2t-tiny | 2021-05-08T00:53:27.000Z | [
"pytorch",
"t5",
"seq2seq",
"en",
"dataset:WebNLG",
"dataset:Dart",
"transformers",
"keytotext",
"k2t-tiny",
"Keywords to Sentences",
"license:mit",
"text2text-generation"
]
| text2text-generation | [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"tokenizer.json"
]
| gagan3012 | 16 | transformers | ---
language: "en"
thumbnail: "Keywords to Sentences"
tags:
- keytotext
- k2t-tiny
- Keywords to Sentences
license: "MIT"
datasets:
- WebNLG
- Dart
metrics:
- NLG
---
# keytotext

Idea is to build a model which will take keywords as inputs and generate sentences as outputs.
### Keytotext is powered by Huggingface 🤗
[](https://pypi.org/project/keytotext/)
[](https://pepy.tech/project/keytotext)
[](https://colab.research.google.com/github/gagan3012/keytotext/blob/master/Examples/K2T.ipynb)
[](https://share.streamlit.io/gagan3012/keytotext/UI/app.py)
## Model:
Keytotext is based on the Amazing T5 Model:
- `k2t`: [Model](https://huggingface.co/gagan3012/k2t)
- `k2t-tiny`: [Model](https://huggingface.co/gagan3012/k2t-tiny)
- `k2t-base`: [Model](https://huggingface.co/gagan3012/k2t-base)
Training Notebooks can be found in the [`Training Notebooks`](https://github.com/gagan3012/keytotext/tree/master/Training%20Notebooks) Folder
## Usage:
Example usage: [](https://colab.research.google.com/github/gagan3012/keytotext/blob/master/Examples/K2T.ipynb)
Example Notebooks can be found in the [`Notebooks`](https://github.com/gagan3012/keytotext/tree/master/Examples) Folder
```
pip install keytotext
```

## UI:
UI: [](https://share.streamlit.io/gagan3012/keytotext/UI/app.py)
```
pip install streamlit-tags
```
This uses a custom streamlit component built by me: [GitHub](https://github.com/gagan3012/streamlit-tags)

|
gagan3012/k2t | 2021-05-08T00:52:45.000Z | [
"pytorch",
"t5",
"lm-head",
"seq2seq",
"en",
"dataset:WebNLG",
"dataset:Dart",
"transformers",
"keytotext",
"k2t",
"Keywords to Sentences",
"license:mit",
"text2text-generation"
]
| text2text-generation | [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"tokenizer.json"
]
| gagan3012 | 689 | transformers | ---
language: "en"
thumbnail: "Keywords to Sentences"
tags:
- keytotext
- k2t
- Keywords to Sentences
license: "MIT"
datasets:
- WebNLG
- Dart
metrics:
- NLG
---
# keytotext

Idea is to build a model which will take keywords as inputs and generate sentences as outputs.
### Keytotext is powered by Huggingface 🤗
[](https://pypi.org/project/keytotext/)
[](https://pepy.tech/project/keytotext)
[](https://colab.research.google.com/github/gagan3012/keytotext/blob/master/Examples/K2T.ipynb)
[](https://share.streamlit.io/gagan3012/keytotext/UI/app.py)
## Model:
Keytotext is based on the Amazing T5 Model:
- `k2t`: [Model](https://huggingface.co/gagan3012/k2t)
- `k2t-tiny`: [Model](https://huggingface.co/gagan3012/k2t-tiny)
- `k2t-base`: [Model](https://huggingface.co/gagan3012/k2t-base)
Training Notebooks can be found in the [`Training Notebooks`](https://github.com/gagan3012/keytotext/tree/master/Training%20Notebooks) Folder
## Usage:
Example usage: [](https://colab.research.google.com/github/gagan3012/keytotext/blob/master/Examples/K2T.ipynb)
Example Notebooks can be found in the [`Notebooks`](https://github.com/gagan3012/keytotext/tree/master/Examples) Folder
```
pip install keytotext
```

## UI:
UI: [](https://share.streamlit.io/gagan3012/keytotext/UI/app.py)
```
pip install streamlit-tags
```
This uses a custom streamlit component built by me: [GitHub](https://github.com/gagan3012/streamlit-tags)

|
gagan3012/keytotext-gpt | 2021-05-21T16:04:39.000Z | [
"pytorch",
"jax",
"gpt2",
"lm-head",
"causal-lm",
"transformers",
"text-generation"
]
| text-generation | [
".gitattributes",
"added_tokens.json",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.json"
]
| gagan3012 | 82 | transformers | |
gagan3012/keytotext-small | 2021-03-11T23:33:47.000Z | [
"pytorch",
"t5",
"lm-head",
"seq2seq",
"transformers",
"text2text-generation"
]
| text2text-generation | [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"tokenizer.json"
]
| gagan3012 | 47 | transformers | # keytotext
Idea is to build a model which will take keywords as inputs and generate sentences as outputs.
### Model:
Two Models have been built:
- Using T5-base size = 850 MB can be found here: https://huggingface.co/gagan3012/keytotext
- Using T5-small size = 230 MB can be found here: https://huggingface.co/gagan3012/keytotext-small
#### Usage:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("gagan3012/keytotext-small")
model = AutoModelWithLMHead.from_pretrained("gagan3012/keytotext-small")
```
### Demo:
[](https://share.streamlit.io/gagan3012/keytotext/app.py)
https://share.streamlit.io/gagan3012/keytotext/app.py

### Example:
['India', 'Wedding'] -> We are celebrating today in New Delhi with three wedding anniversary parties.
|
gagan3012/keytotext | 2021-03-11T20:23:32.000Z | [
"pytorch",
"t5",
"lm-head",
"seq2seq",
"transformers",
"text2text-generation"
]
| text2text-generation | [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"tokenizer.json"
]
| gagan3012 | 40 | transformers | # keytotext
Idea is to build a model which will take keywords as inputs and generate sentences as outputs.
### Model:
Two Models have been built:
- Using T5-base size = 850 MB can be found here: https://huggingface.co/gagan3012/keytotext
- Using T5-small size = 230 MB can be found here: https://huggingface.co/gagan3012/keytotext-small
#### Usage:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("gagan3012/keytotext-small")
model = AutoModelWithLMHead.from_pretrained("gagan3012/keytotext-small")
```
### Demo:
[](https://share.streamlit.io/gagan3012/keytotext/app.py)
https://share.streamlit.io/gagan3012/keytotext/app.py

### Example:
['India', 'Wedding'] -> We are celebrating today in New Delhi with three wedding anniversary parties.
|
gagan3012/project-code-py-micro | 2021-05-21T16:05:34.000Z | [
"pytorch",
"jax",
"gpt2",
"lm-head",
"causal-lm",
"transformers",
"text-generation"
]
| text-generation | [
".gitattributes",
"all_results.json",
"config.json",
"eval_results.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"train_results.json",
"trainer_state.json",
"training_args.bin",
"vocab.json"
]
| gagan3012 | 13 | transformers | |
gagan3012/project-code-py-neo | 2021-05-25T07:32:07.000Z | [
"pytorch",
"gpt_neo",
"causal-lm",
"transformers",
"text-generation"
]
| text-generation | [
".gitattributes",
"all_results.json",
"config.json",
"eval_results.json",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"train_results.json",
"trainer_state.json",
"training_args.bin",
"vocab.json"
]
| gagan3012 | 40 | transformers | |
gagan3012/project-code-py-small | 2021-05-21T16:06:24.000Z | [
"pytorch",
"jax",
"gpt2",
"lm-head",
"causal-lm",
"transformers",
"text-generation"
]
| text-generation | [
".gitattributes",
"README.md",
"all_results.json",
"config.json",
"eval_results.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"train_results.json",
"trainer_state.json",
"training_args.bin",
"vocab.json"
]
| gagan3012 | 137 | transformers | # Leetcode using AI :robot:
GPT-2 Model for Leetcode Questions in python
**Note**: the Answers might not make sense in some cases because of the bias in GPT-2
**Contribtuions:** If you would like to make the model better contributions are welcome Check out [CONTRIBUTIONS.md](https://github.com/gagan3012/project-code-py/blob/master/CONTRIBUTIONS.md)
### 📢 Favour:
It would be highly motivating, if you can STAR⭐ this repo if you find it helpful.
## Model
Two models have been developed for different use cases and they can be found at https://huggingface.co/gagan3012
The model weights can be found here: [GPT-2](https://huggingface.co/gagan3012/project-code-py) and [DistilGPT-2](https://huggingface.co/gagan3012/project-code-py-small)
### Example usage:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("gagan3012/project-code-py")
model = AutoModelWithLMHead.from_pretrained("gagan3012/project-code-py")
```
## Demo
[](https://share.streamlit.io/gagan3012/project-code-py/app.py)
A streamlit webapp has been setup to use the model: https://share.streamlit.io/gagan3012/project-code-py/app.py
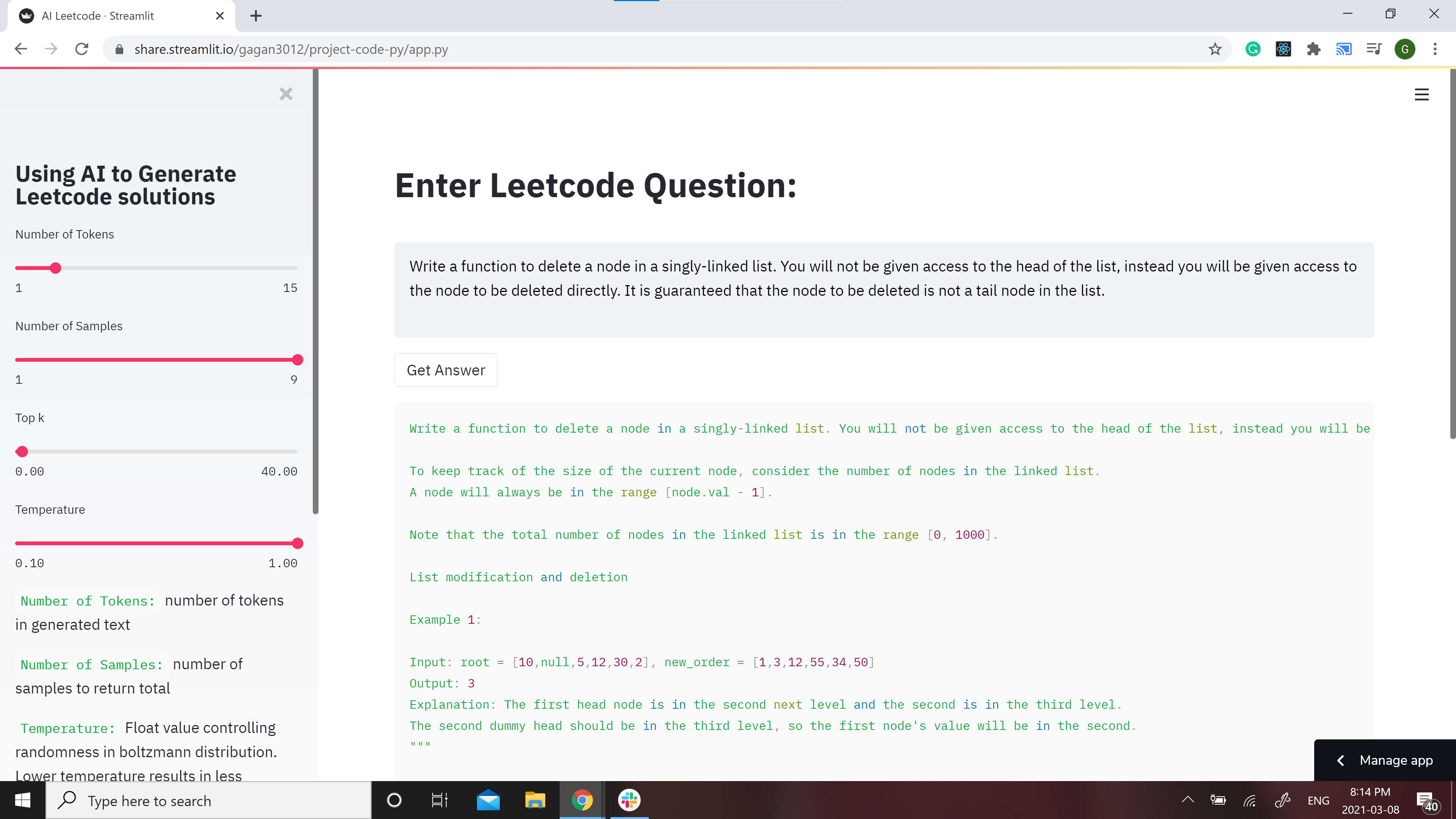
## Example results:
### Question:
```
Write a function to delete a node in a singly-linked list. You will not be given access to the head of the list, instead you will be given access to the node to be deleted directly. It is guaranteed that the node to be deleted is not a tail node in the list.
```
### Answer:
```python
""" Write a function to delete a node in a singly-linked list. You will not be given access to the head of the list, instead you will be given access to the node to be deleted directly. It is guaranteed that the node to be deleted is not a tail node in the list.
For example,
a = 1->2->3
b = 3->1->2
t = ListNode(-1, 1)
Note: The lexicographic ordering of the nodes in a tree matters. Do not assign values to nodes in a tree.
Example 1:
Input: [1,2,3]
Output: 1->2->5
Explanation: 1->2->3->3->4, then 1->2->5[2] and then 5->1->3->4.
Note:
The length of a linked list will be in the range [1, 1000].
Node.val must be a valid LinkedListNode type.
Both the length and the value of the nodes in a linked list will be in the range [-1000, 1000].
All nodes are distinct.
"""
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution:
def deleteNode(self, head: ListNode, val: int) -> None:
"""
BFS
Linked List
:param head: ListNode
:param val: int
:return: ListNode
"""
if head is not None:
return head
dummy = ListNode(-1, 1)
dummy.next = head
dummy.next.val = val
dummy.next.next = head
dummy.val = ""
s1 = Solution()
print(s1.deleteNode(head))
print(s1.deleteNode(-1))
print(s1.deleteNode(-1))
```
|
gagan3012/project-code-py | 2021-05-21T16:08:09.000Z | [
"pytorch",
"jax",
"gpt2",
"lm-head",
"causal-lm",
"transformers",
"text-generation"
]
| text-generation | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| gagan3012 | 109 | transformers | # Leetcode using AI :robot:
GPT-2 Model for Leetcode Questions in python
**Note**: the Answers might not make sense in some cases because of the bias in GPT-2
**Contribtuions:** If you would like to make the model better contributions are welcome Check out [CONTRIBUTIONS.md](https://github.com/gagan3012/project-code-py/blob/master/CONTRIBUTIONS.md)
### 📢 Favour:
It would be highly motivating, if you can STAR⭐ this repo if you find it helpful.
## Model
Two models have been developed for different use cases and they can be found at https://huggingface.co/gagan3012
The model weights can be found here: [GPT-2](https://huggingface.co/gagan3012/project-code-py) and [DistilGPT-2](https://huggingface.co/gagan3012/project-code-py-small)
### Example usage:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("gagan3012/project-code-py")
model = AutoModelWithLMHead.from_pretrained("gagan3012/project-code-py")
```
## Demo
[](https://share.streamlit.io/gagan3012/project-code-py/app.py)
A streamlit webapp has been setup to use the model: https://share.streamlit.io/gagan3012/project-code-py/app.py

## Example results:
### Question:
```
Write a function to delete a node in a singly-linked list. You will not be given access to the head of the list, instead you will be given access to the node to be deleted directly. It is guaranteed that the node to be deleted is not a tail node in the list.
```
### Answer:
```python
""" Write a function to delete a node in a singly-linked list. You will not be given access to the head of the list, instead you will be given access to the node to be deleted directly. It is guaranteed that the node to be deleted is not a tail node in the list.
For example,
a = 1->2->3
b = 3->1->2
t = ListNode(-1, 1)
Note: The lexicographic ordering of the nodes in a tree matters. Do not assign values to nodes in a tree.
Example 1:
Input: [1,2,3]
Output: 1->2->5
Explanation: 1->2->3->3->4, then 1->2->5[2] and then 5->1->3->4.
Note:
The length of a linked list will be in the range [1, 1000].
Node.val must be a valid LinkedListNode type.
Both the length and the value of the nodes in a linked list will be in the range [-1000, 1000].
All nodes are distinct.
"""
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution:
def deleteNode(self, head: ListNode, val: int) -> None:
"""
BFS
Linked List
:param head: ListNode
:param val: int
:return: ListNode
"""
if head is not None:
return head
dummy = ListNode(-1, 1)
dummy.next = head
dummy.next.val = val
dummy.next.next = head
dummy.val = ""
s1 = Solution()
print(s1.deleteNode(head))
print(s1.deleteNode(-1))
print(s1.deleteNode(-1))
```
|
gagan3012/rap-writer | 2021-05-21T16:09:53.000Z | [
"pytorch",
"jax",
"gpt2",
"lm-head",
"causal-lm",
"transformers",
"text-generation"
]
| text-generation | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| gagan3012 | 30 | transformers | # Generating Rap song Lyrics like Eminem Using GPT2
### I have built a custom model for it using data from Kaggle
Creating a new finetuned model using data lyrics from leading hip-hop stars
### My model can be accessed at: gagan3012/rap-writer
```
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("gagan3012/rap-writer")
model = AutoModelWithLMHead.from_pretrained("gagan3012/rap-writer")
``` |
gagan3012/wav2vec2-xlsr-chuvash | 2021-03-26T19:59:55.000Z | [
"pytorch",
"wav2vec2",
"cv",
"dataset:common_voice",
"transformers",
"audio",
"automatic-speech-recognition",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0"
]
| automatic-speech-recognition | [
".gitattributes",
"README.md",
"config.json",
"optimizer.pt",
"preprocessor_config.json",
"pytorch_model.bin",
"scheduler.pt",
"special_tokens_map.json",
"tokenizer_config.json",
"trainer_state.json",
"training_args.bin",
"vocab.json"
]
| gagan3012 | 9 | transformers | ---
language: cv
datasets:
- common_voice
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: wav2vec2-xlsr-chuvash by Gagan Bhatia
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice cv
type: common_voice
args: cv
metrics:
- name: Test WER
type: wer
value: 48.40
---
# Wav2Vec2-Large-XLSR-53-Chuvash
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Chuvash using the [Common Voice](https://huggingface.co/datasets/common_voice)
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "cv", split="test")
processor = Wav2Vec2Processor.from_pretrained("gagan3012/wav2vec2-xlsr-chuvash")
model = Wav2Vec2ForCTC.from_pretrained("gagan3012/wav2vec2-xlsr-chuvash")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
\\tspeech_array, sampling_rate = torchaudio.load(batch["path"])
\\tbatch["speech"] = resampler(speech_array).squeeze().numpy()
\\treturn batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
\\tlogits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
#### Results:
Prediction: ['проектпа килӗшӳллӗн тӗлӗ мероприяти иртермелле', 'твăра çак планета минтӗ пуяни калленнана']
Reference: ['Проектпа килӗшӳллӗн, тӗрлӗ мероприяти ирттермелле.', 'Çак планета питĕ пуян иккен.']
## Evaluation
The model can be evaluated as follows on the Chuvash test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
!mkdir cer
!wget -O cer/cer.py https://huggingface.co/ctl/wav2vec2-large-xlsr-cantonese/raw/main/cer.py
test_dataset = load_dataset("common_voice", "cv", split="test") #TODO: replace {lang_id} in your language code here. Make sure the code is one of the *ISO codes* of [this](https://huggingface.co/languages) site.
wer = load_metric("wer")
cer = load_metric("cer")
processor = Wav2Vec2Processor.from_pretrained("gagan3012/wav2vec2-xlsr-chuvash")
model = Wav2Vec2ForCTC.from_pretrained("gagan3012/wav2vec2-xlsr-chuvash")
model.to("cuda")
chars_to_ignore_regex = '[\\\\,\\\\?\\\\.\\\\!\\\\-\\\\;\\\\:\\\\"\\\\“]' # TODO: adapt this list to include all special characters you removed from the data
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
\\tbatch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
\\tspeech_array, sampling_rate = torchaudio.load(batch["path"])
\\tbatch["speech"] = resampler(speech_array).squeeze().numpy()
\\treturn batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
\\tinputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
\\twith torch.no_grad():
\\t\\tlogits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
\\tpred_ids = torch.argmax(logits, dim=-1)
\\tbatch["pred_strings"] = processor.batch_decode(pred_ids)
\\treturn batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
print("CER: {:2f}".format(100 * cer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 48.40 %
## Training
The script used for training can be found [here](https://colab.research.google.com/drive/1A7Y20c1QkSHfdOmLXPMiOEpwlTjDZ7m5?usp=sharing) |
gagan3012/wav2vec2-xlsr-khmer | 2021-03-31T17:39:09.000Z | [
"pytorch",
"wav2vec2",
"km",
"dataset:OpenSLR",
"dataset:common_voice",
"transformers",
"audio",
"automatic-speech-recognition",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0"
]
| automatic-speech-recognition | [
".gitattributes",
"README.md",
"config.json",
"optimizer.pt",
"preprocessor_config.json",
"pytorch_model.bin",
"scheduler.pt",
"special_tokens_map.json",
"tokenizer_config.json",
"trainer_state.json",
"training_args.bin",
"vocab.json"
]
| gagan3012 | 222 | transformers | ---
language: km
datasets:
- OpenSLR
- common_voice
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: wav2vec2-xlsr-Khmer by Gagan Bhatia
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: OpenSLR km
type: OpenSLR
args: km
metrics:
- name: Test WER
type: wer
value: 24.96
---
# Wav2Vec2-Large-XLSR-53-khmer
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Khmer using the [Common Voice](https://huggingface.co/datasets/common_voice), and [OpenSLR Kh](http://www.openslr.org/42/).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
!wget https://www.openslr.org/resources/42/km_kh_male.zip
!unzip km_kh_male.zip
!ls km_kh_male
colnames=['path','sentence']
df = pd.read_csv('/content/km_kh_male/line_index.tsv',sep='\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\t',header=None,names = colnames)
df['path'] = '/content/km_kh_male/wavs/'+df['path'] +'.wav'
train, test = train_test_split(df, test_size=0.1)
test.to_csv('/content/km_kh_male/line_index_test.csv')
test_dataset = load_dataset('csv', data_files='/content/km_kh_male/line_index_test.csv',split = 'train')
processor = Wav2Vec2Processor.from_pretrained("gagan3012/wav2vec2-xlsr-nepali")
model = Wav2Vec2ForCTC.from_pretrained("gagan3012/wav2vec2-xlsr-nepali")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
\\\\\\\\\\\\\\\\tspeech_array, sampling_rate = torchaudio.load(batch["path"])
\\\\\\\\\\\\\\\\tbatch["speech"] = resampler(speech_array).squeeze().numpy()
\\\\\\\\\\\\\\\\treturn batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
\\\\\\\\\\\\\\\\tlogits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
#### Result
Prediction: ['पारानाको ब्राजिली राज्यमा रहेको राजधानी', 'देवराज जोशी त्रिभुवन विश्वविद्यालयबाट शिक्षाशास्त्रमा स्नातक हुनुहुन्छ']
Reference: ['पारानाको ब्राजिली राज्यमा रहेको राजधानी', 'देवराज जोशी त्रिभुवन विश्वविद्यालयबाट शिक्षाशास्त्रमा स्नातक हुनुहुन्छ']
## Evaluation
The model can be evaluated as follows on the {language} test data of Common Voice. # TODO: replace #TODO: replace language with your {language}, *e.g.* French
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
from sklearn.model_selection import train_test_split
import pandas as pd
from datasets import load_dataset
!wget https://www.openslr.org/resources/42/km_kh_male.zip
!unzip km_kh_male.zip
!ls km_kh_male
colnames=['path','sentence']
df = pd.read_csv('/content/km_kh_male/line_index.tsv',sep='\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\t',header=None,names = colnames)
df['path'] = '/content/km_kh_male/wavs/'+df['path'] +'.wav'
train, test = train_test_split(df, test_size=0.1)
test.to_csv('/content/km_kh_male/line_index_test.csv')
test_dataset = load_dataset('csv', data_files='/content/km_kh_male/line_index_test.csv',split = 'train')
wer = load_metric("wer")
cer = load_metric("cer")
processor = Wav2Vec2Processor.from_pretrained("gagan3012/wav2vec2-xlsr-khmer")
model = Wav2Vec2ForCTC.from_pretrained("gagan3012/wav2vec2-xlsr-khmer")
model.to("cuda")
chars_to_ignore_regex = '[\\\\,\\\\?\\\\.\\\\!\\\\-\\\\;\\\\:\\\\"\\\\“]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
\\tbatch["text"] = re.sub(chars_to_ignore_regex, '', batch["text"]).lower()
\\tspeech_array, sampling_rate = torchaudio.load(batch["path"])
\\tbatch["speech"] = resampler(speech_array).squeeze().numpy()
\\treturn batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
\\tinputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
\\twith torch.no_grad():
\\t\\tlogits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
\\tpred_ids = torch.argmax(logits, dim=-1)
\\tbatch["pred_strings"] = processor.batch_decode(pred_ids)
\\treturn batch
cer = load_metric("cer")
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["text"])))
print("CER: {:2f}".format(100 * cer.compute(predictions=result["pred_strings"], references=result["text"])))
```
**Test Result**: 24.96 %
WER: 24.962519
CER: 6.950925
## Training
The script used for training can be found [here](https://colab.research.google.com/drive/1yo_OTMH8FHQrAKCkKdQGMqpkj-kFhS_2?usp=sharing) |
gagan3012/wav2vec2-xlsr-nepali | 2021-03-23T23:48:54.000Z | [
"pytorch",
"wav2vec2",
"ne",
"dataset:OpenSLR",
"dataset:common_voice",
"transformers",
"audio",
"automatic-speech-recognition",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0"
]
| automatic-speech-recognition | [
".gitattributes",
"README.md",
"config.json",
"optimizer.pt",
"preprocessor_config.json",
"pytorch_model.bin",
"scheduler.pt",
"special_tokens_map.json",
"tokenizer_config.json",
"trainer_state.json",
"training_args.bin",
"vocab.json"
]
| gagan3012 | 144 | transformers | ---
language: ne
datasets:
- OpenSLR
- common_voice
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: wav2vec2-xlsr-nepali
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: OpenSLR ne
type: OpenSLR
args: ne
metrics:
- name: Test WER
type: wer
value: 05.97
---
# Wav2Vec2-Large-XLSR-53-Nepali
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Nepali using the [Common Voice](https://huggingface.co/datasets/common_voice), and [OpenSLR ne](http://www.openslr.org/43/).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
!wget https://www.openslr.org/resources/43/ne_np_female.zip
!unzip ne_np_female.zip
!ls ne_np_female
colnames=['path','sentence']
df = pd.read_csv('/content/ne_np_female/line_index.tsv',sep='\\t',header=None,names = colnames)
df['path'] = '/content/ne_np_female/wavs/'+df['path'] +'.wav'
train, test = train_test_split(df, test_size=0.1)
test.to_csv('/content/ne_np_female/line_index_test.csv')
test_dataset = load_dataset('csv', data_files='/content/ne_np_female/line_index_test.csv',split = 'train')
processor = Wav2Vec2Processor.from_pretrained("gagan3012/wav2vec2-xlsr-nepali")
model = Wav2Vec2ForCTC.from_pretrained("gagan3012/wav2vec2-xlsr-nepali")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
\tspeech_array, sampling_rate = torchaudio.load(batch["path"])
\tbatch["speech"] = resampler(speech_array).squeeze().numpy()
\treturn batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
\tlogits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
#### Result
Prediction: ['पारानाको ब्राजिली राज्यमा रहेको राजधानी', 'देवराज जोशी त्रिभुवन विश्वविद्यालयबाट शिक्षाशास्त्रमा स्नातक हुनुहुन्छ']
Reference: ['पारानाको ब्राजिली राज्यमा रहेको राजधानी', 'देवराज जोशी त्रिभुवन विश्वविद्यालयबाट शिक्षाशास्त्रमा स्नातक हुनुहुन्छ']
## Evaluation
The model can be evaluated as follows on the {language} test data of Common Voice. # TODO: replace #TODO: replace language with your {language}, *e.g.* French
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
!wget https://www.openslr.org/resources/43/ne_np_female.zip
!unzip ne_np_female.zip
!ls ne_np_female
colnames=['path','sentence']
df = pd.read_csv('/content/ne_np_female/line_index.tsv',sep='\\t',header=None,names = colnames)
df['path'] = '/content/ne_np_female/wavs/'+df['path'] +'.wav'
train, test = train_test_split(df, test_size=0.1)
test.to_csv('/content/ne_np_female/line_index_test.csv')
test_dataset = load_dataset('csv', data_files='/content/ne_np_female/line_index_test.csv',split = 'train')
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gagan3012/wav2vec2-xlsr-nepali")
model = Wav2Vec2ForCTC.from_pretrained("gagan3012/wav2vec2-xlsr-nepali")
model.to("cuda")
chars_to_ignore_regex = '[\\,\\?\\.\\!\\-\\;\\:\\"\\“]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
\tbatch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
\tspeech_array, sampling_rate = torchaudio.load(batch["path"])
\tbatch["speech"] = resampler(speech_array).squeeze().numpy()
\treturn batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
\tinputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
\twith torch.no_grad():
\t\tlogits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
\tpred_ids = torch.argmax(logits, dim=-1)
\tbatch["pred_strings"] = processor.batch_decode(pred_ids)
\treturn batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 05.97 %
## Training
The script used for training can be found [here](https://colab.research.google.com/drive/1AHnYWXb5cwfMEa2o4O3TSdasAR3iVBFP?usp=sharing) |
gagan3012/wav2vec2-xlsr-punjabi | 2021-03-25T15:05:16.000Z | [
"pytorch",
"wav2vec2",
"pa-IN",
"dataset:common_voice",
"transformers",
"audio",
"automatic-speech-recognition",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0"
]
| automatic-speech-recognition | [
".gitattributes",
"README.md",
"config.json",
"optimizer.pt",
"preprocessor_config.json",
"pytorch_model.bin",
"scheduler.pt",
"special_tokens_map.json",
"tokenizer_config.json",
"trainer_state.json",
"training_args.bin",
"vocab.json"
]
| gagan3012 | 9 | transformers | ---
language: pa-IN
datasets:
- common_voice
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: wav2vec2-xlsr-punjabi
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice pa
type: common_voice
args: pa-IN
metrics:
- name: Test WER
type: wer
value: 58.06
---
# Wav2Vec2-Large-XLSR-53-Punjabi
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Punjabi using the [Common Voice](https://huggingface.co/datasets/common_voice)
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "pa-IN", split="test")
processor = Wav2Vec2Processor.from_pretrained("gagan3012/wav2vec2-xlsr-punjabi")
model = Wav2Vec2ForCTC.from_pretrained("gagan3012/wav2vec2-xlsr-punjabi")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
\\\\tspeech_array, sampling_rate = torchaudio.load(batch["path"])
\\\\tbatch["speech"] = resampler(speech_array).squeeze().numpy()
\\\\treturn batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
\\\\tlogits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
#### Results:
Prediction: ['ਹਵਾ ਲਾਤ ਵਿੱਚ ਪੰਦ ਛੇ ਇਖਲਾਟਕੀ ਮੁਜਰਮ ਸਨ', 'ਮੈ ਇ ਹਾ ਪੈਸੇ ਲੇਹੜ ਨਹੀਂ ਸੀ ਚੌਨਾ']
Reference: ['ਹਵਾਲਾਤ ਵਿੱਚ ਪੰਜ ਛੇ ਇਖ਼ਲਾਕੀ ਮੁਜਰਮ ਸਨ', 'ਮੈਂ ਇਹ ਪੈਸੇ ਲੈਣੇ ਨਹੀਂ ਸੀ ਚਾਹੁੰਦਾ']
## Evaluation
The model can be evaluated as follows on the {language} test data of Common Voice. # TODO: replace #TODO: replace language with your {language}, *e.g.* French
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "pa-IN", split="test") #TODO: replace {lang_id} in your language code here. Make sure the code is one of the *ISO codes* of [this](https://huggingface.co/languages) site.
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gagan3012/wav2vec2-xlsr-punjabi")
model = Wav2Vec2ForCTC.from_pretrained("gagan3012/wav2vec2-xlsr-punjabi")
model.to("cuda")
chars_to_ignore_regex = '[\\\\\\\\\\\\\\\\,\\\\\\\\\\\\\\\\?\\\\\\\\\\\\\\\\.\\\\\\\\\\\\\\\\!\\\\\\\\\\\\\\\\-\\\\\\\\\\\\\\\\;\\\\\\\\\\\\\\\\:\\\\\\\\\\\\\\\\"\\\\\\\\\\\\\\\\“]' # TODO: adapt this list to include all special characters you removed from the data
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
\\\\\\\\tbatch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
\\\\\\\\tspeech_array, sampling_rate = torchaudio.load(batch["path"])
\\\\\\\\tbatch["speech"] = resampler(speech_array).squeeze().numpy()
\\\\\\\\treturn batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
\\\\\\\\tinputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
\\\\\\\\twith torch.no_grad():
\\\\\\\\t\\\\\\\\tlogits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
\\\\\\\\tpred_ids = torch.argmax(logits, dim=-1)
\\\\\\\\tbatch["pred_strings"] = processor.batch_decode(pred_ids)
\\\\\\\\treturn batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 58.05 %
## Training
The script used for training can be found [here](https://colab.research.google.com/drive/1A7Y20c1QkSHfdOmLXPMiOEpwlTjDZ7m5?usp=sharing) |
ganeshkharad/gk-hinglish-sentiment | 2021-05-19T17:01:35.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"hi-en",
"dataset:sail",
"transformers",
"sentiment",
"multilingual",
"hindi codemix",
"hinglish",
"license:apache-2.0"
]
| text-classification | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| ganeshkharad | 55 | transformers | ---
language:
- hi-en
tags:
- sentiment
- multilingual
- hindi codemix
- hinglish
license: apache-2.0
datasets:
- sail
---
# Sentiment Classification for hinglish text: `gk-hinglish-sentiment`
## Model description
Trained small amount of reviews dataset
## Intended uses & limitations
I wanted something to work well with hinglish data as it is being used in India mostly.
The training data was not much as expected
#### How to use
```python
#sample code
from transformers import BertTokenizer, BertForSequenceClassification
tokenizerg = BertTokenizer.from_pretrained("/content/model")
modelg = BertForSequenceClassification.from_pretrained("/content/model")
text = "kuch bhi type karo hinglish mai"
encoded_input = tokenizerg(text, return_tensors='pt')
output = modelg(**encoded_input)
print(output)
#output contains 3 lables LABEL_0 = Negative ,LABEL_1 = Nuetral ,LABEL_2 = Positive
```
#### Limitations and bias
The data contains only hinglish codemixed text it and was very much limited may be I will Update this model if I can get good amount of data
## Training data
Training data contains labeled data for 3 labels
link to the pre-trained model card with description of the pre-training data.
I have Tuned below model
https://huggingface.co/rohanrajpal/bert-base-multilingual-codemixed-cased-sentiment
### BibTeX entry and citation info
```@inproceedings{khanuja-etal-2020-gluecos,
title = "{GLUEC}o{S}: An Evaluation Benchmark for Code-Switched {NLP}",
author = "Khanuja, Simran and
Dandapat, Sandipan and
Srinivasan, Anirudh and
Sitaram, Sunayana and
Choudhury, Monojit",
booktitle = "Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.acl-main.329",
pages = "3575--3585"
}
```
|
ganta/model | 2021-04-15T17:46:32.000Z | []
| [
".gitattributes"
]
| ganta | 0 | |||
ganta/test | 2021-04-15T17:06:21.000Z | []
| [
".gitattributes"
]
| ganta | 0 | |||
gaochangkuan/model_dir | 2021-05-21T16:10:50.000Z | [
"pytorch",
"jax",
"gpt2",
"lm-head",
"causal-lm",
"transformers",
"text-generation"
]
| text-generation | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"vocab.txt"
]
| gaochangkuan | 19 | transformers | ## Generating Chinese poetry by topic.
```python
from transformers import *
tokenizer = BertTokenizer.from_pretrained("gaochangkuan/model_dir")
model = AutoModelWithLMHead.from_pretrained("gaochangkuan/model_dir")
prompt= '''<s>田园躬耕'''
length= 84
stop_token='</s>'
temperature = 1.2
repetition_penalty=1.3
k= 30
p= 0.95
device ='cuda'
seed=2020
no_cuda=False
prompt_text = prompt if prompt else input("Model prompt >>> ")
encoded_prompt = tokenizer.encode(
'<s>'+prompt_text+'<sep>',
add_special_tokens=False,
return_tensors="pt"
)
encoded_prompt = encoded_prompt.to(device)
output_sequences = model.generate(
input_ids=encoded_prompt,
max_length=length,
min_length=10,
do_sample=True,
early_stopping=True,
num_beams=10,
temperature=temperature,
top_k=k,
top_p=p,
repetition_penalty=repetition_penalty,
bad_words_ids=None,
bos_token_id=tokenizer.bos_token_id,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
length_penalty=1.2,
no_repeat_ngram_size=2,
num_return_sequences=1,
attention_mask=None,
decoder_start_token_id=tokenizer.bos_token_id,)
generated_sequence = output_sequences[0].tolist()
text = tokenizer.decode(generated_sequence)
text = text[: text.find(stop_token) if stop_token else None]
print(''.join(text).replace(' ','').replace('<pad>','').replace('<s>',''))
```
|
gaochangkuan/nezha-base-wwm | 2021-05-19T07:22:05.000Z | []
| [
".gitattributes",
"vocab.txt"
]
| gaochangkuan | 0 | |||
gaotianyu1350/sup-simcse-bert-base-uncased | 2021-05-19T17:03:12.000Z | [
"pytorch",
"jax",
"bert",
"transformers"
]
| [
".gitattributes",
"config.json",
"eval_results.txt",
"flax_model.msgpack",
"optimizer.pt",
"pytorch_model.bin",
"scheduler.pt",
"special_tokens_map.json",
"tokenizer_config.json",
"train_results.txt",
"trainer_state.json",
"training_args.bin",
"vocab.txt"
]
| gaotianyu1350 | 9 | transformers | ||
gaotianyu1350/sup-simcse-bert-large-uncased | 2021-05-19T17:06:11.000Z | [
"pytorch",
"jax",
"bert",
"transformers"
]
| [
".gitattributes",
"config.json",
"eval_results.txt",
"flax_model.msgpack",
"optimizer.pt",
"pytorch_model.bin",
"scheduler.pt",
"special_tokens_map.json",
"tokenizer_config.json",
"train_results.txt",
"trainer_state.json",
"training_args.bin",
"vocab.txt"
]
| gaotianyu1350 | 11 | transformers | ||
gaotianyu1350/sup-simcse-roberta-base | 2021-05-20T16:21:48.000Z | [
"pytorch",
"jax",
"roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"eval_results.txt",
"flax_model.msgpack",
"merges.txt",
"optimizer.pt",
"pytorch_model.bin",
"scheduler.pt",
"special_tokens_map.json",
"tokenizer_config.json",
"train_results.txt",
"trainer_state.json",
"training_args.bin",
"vocab.json"
]
| gaotianyu1350 | 7 | transformers | ||
gaotianyu1350/sup-simcse-roberta-large | 2021-05-20T16:24:50.000Z | [
"pytorch",
"jax",
"roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"eval_results.txt",
"flax_model.msgpack",
"merges.txt",
"optimizer.pt",
"pytorch_model.bin",
"scheduler.pt",
"special_tokens_map.json",
"tokenizer_config.json",
"train_results.txt",
"trainer_state.json",
"training_args.bin",
"vocab.json"
]
| gaotianyu1350 | 11 | transformers | ||
gaotianyu1350/unsup-simcse-bert-base-uncased | 2021-05-19T17:07:56.000Z | [
"pytorch",
"jax",
"bert",
"transformers"
]
| [
".gitattributes",
"config.json",
"eval_results.txt",
"flax_model.msgpack",
"optimizer.pt",
"pytorch_model.bin",
"scheduler.pt",
"special_tokens_map.json",
"tokenizer_config.json",
"train_results.txt",
"trainer_state.json",
"training_args.bin",
"vocab.txt"
]
| gaotianyu1350 | 6 | transformers | ||
gaotianyu1350/unsup-simcse-bert-large-uncased | 2021-05-19T17:11:09.000Z | [
"pytorch",
"jax",
"bert",
"transformers"
]
| [
".gitattributes",
"config.json",
"flax_model.msgpack",
"optimizer.pt",
"pytorch_model.bin",
"scheduler.pt",
"special_tokens_map.json",
"tokenizer_config.json",
"train_results.txt",
"trainer_state.json",
"training_args.bin",
"vocab.txt"
]
| gaotianyu1350 | 8 | transformers | ||
gaotianyu1350/unsup-simcse-roberta-base | 2021-05-20T16:26:43.000Z | [
"pytorch",
"jax",
"roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"eval_results.txt",
"flax_model.msgpack",
"merges.txt",
"optimizer.pt",
"pytorch_model.bin",
"scheduler.pt",
"special_tokens_map.json",
"tokenizer_config.json",
"train_results.txt",
"trainer_state.json",
"training_args.bin",
"vocab.json"
]
| gaotianyu1350 | 9 | transformers | ||
gaotianyu1350/unsup-simcse-roberta-large | 2021-05-20T16:29:43.000Z | [
"pytorch",
"jax",
"roberta",
"transformers"
]
| [
".gitattributes",
"config.json",
"flax_model.msgpack",
"merges.txt",
"optimizer.pt",
"pytorch_model.bin",
"scheduler.pt",
"special_tokens_map.json",
"tokenizer_config.json",
"trainer_state.json",
"training_args.bin",
"vocab.json"
]
| gaotianyu1350 | 8 | transformers | ||
gargam/roberta-base-crest | 2021-05-20T16:31:49.000Z | [
"pytorch",
"jax",
"roberta",
"text-classification",
"transformers"
]
| text-classification | [
".gitattributes",
"config.json",
"eval_results.txt",
"flax_model.msgpack",
"merges.txt",
"model_args.json",
"optimizer.pt",
"pytorch_model.bin",
"scheduler.pt",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| gargam | 157 | transformers | |
garynguyen1174/disaster_tweet_bert | 2021-06-06T01:05:17.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
]
| text-classification | [
".gitattributes",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer.json",
"tokenizer_config.json",
"vocab.txt"
]
| garynguyen1174 | 67 | transformers | |
garynguyen1174/disaster_tweet_bertweet | 2021-06-06T05:37:23.000Z | []
| [
".gitattributes"
]
| garynguyen1174 | 0 | |||
gchhablani/wav2vec2-large-xlsr-cnh | 2021-03-26T17:13:13.000Z | [
"pytorch",
"wav2vec2",
"cnh",
"dataset:common_voice",
"transformers",
"audio",
"automatic-speech-recognition",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0"
]
| automatic-speech-recognition | [
".gitattributes",
"README.md",
"config.json",
"preprocessor_config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| gchhablani | 11 | transformers | ---
language: cnh
datasets:
- common_voice
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: Wav2Vec2 Large 53 Hakha Chin by Gunjan Chhablani
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice cnh
type: common_voice
args: cnh
metrics:
- name: Test WER
type: wer
value: 31.38
---
# Wav2Vec2-Large-XLSR-53-Hakha-Chin
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Hakha Chin using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "cnh", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-cnh")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-cnh/")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Portuguese test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "cnh", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-cnh")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-cnh")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\/]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 31.38 %
## Training
The Common Voice `train` and `validation` datasets were used for training. The script used for training can be found [here](https://colab.research.google.com/drive/1pejk9gv9vMcUOjyVQ_vsV2ngW4NiWLWy?usp=sharing). |
gchhablani/wav2vec2-large-xlsr-eo | 2021-03-30T06:28:50.000Z | [
"pytorch",
"wav2vec2",
"eo",
"dataset:common_voice",
"transformers",
"audio",
"automatic-speech-recognition",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0"
]
| automatic-speech-recognition | [
".gitattributes",
"README.md",
"config.json",
"preprocessor_config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| gchhablani | 13 | transformers | ---
language: eo
datasets:
- common_voice
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: Wav2Vec2 Large 53 Esperanto by Gunjan Chhablani
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice eo
type: common_voice
args: eo
metrics:
- name: Test WER
type: wer
value: 10.13
---
# Wav2Vec2-Large-XLSR-53-Esperanto
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Esperanto using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "eo", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained('gchhablani/wav2vec2-large-xlsr-eo')
model = Wav2Vec2ForCTC.from_pretrained('gchhablani/wav2vec2-large-xlsr-eo')
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Portuguese test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
import jiwer
def chunked_wer(targets, predictions, chunk_size=None):
if chunk_size is None: return jiwer.wer(targets, predictions)
start = 0
end = chunk_size
H, S, D, I = 0, 0, 0, 0
while start < len(targets):
chunk_metrics = jiwer.compute_measures(targets[start:end], predictions[start:end])
H = H + chunk_metrics["hits"]
S = S + chunk_metrics["substitutions"]
D = D + chunk_metrics["deletions"]
I = I + chunk_metrics["insertions"]
start += chunk_size
end += chunk_size
return float(S + D + I) / float(H + S + D)
test_dataset = load_dataset("common_voice", "eo", split="test") #TODO: replace {lang_id} in your language code here. Make sure the code is one of the *ISO codes* of [this](https://huggingface.co/languages) site.
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained('gchhablani/wav2vec2-large-xlsr-eo')
model = Wav2Vec2ForCTC.from_pretrained('gchhablani/wav2vec2-large-xlsr-eo')
model.to("cuda")
chars_to_ignore_regex = """[\\\\\\\\,\\\\\\\\?\\\\\\\\.\\\\\\\\!\\\\\\\\-\\\\\\\\;\\\\\\\\:\\\\\\\\"\\\\\\\\“\\\\\\\\%\\\\\\\\‘\\\\\\\\”\\\\\\\\�\\\\\\\\„\\\\\\\\«\\\\\\\\(\\\\\\\\»\\\\\\\\)\\\\\\\\’\\\\\\\\']"""
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower().replace('—',' ').replace('–',' ')
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * chunked_wer(predictions=result["pred_strings"], targets=result["sentence"],chunk_size=5000)))
```
**Test Result**: 10.13 %
## Training
The Common Voice `train` and `validation` datasets were used for training. The code can be found [here](https://github.com/gchhablani/wav2vec2-week/blob/main/fine-tune-xlsr-wav2vec2-on-esperanto-asr-with-transformers-final.ipynb). |
gchhablani/wav2vec2-large-xlsr-gu | 2021-03-24T15:53:26.000Z | [
"pytorch",
"wav2vec2",
"gu",
"dataset:openslr",
"transformers",
"audio",
"automatic-speech-recognition",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0"
]
| automatic-speech-recognition | [
".gitattributes",
"README.md",
"config.json",
"preprocessor_config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| gchhablani | 9 | transformers | ---
language: gu
datasets:
- openslr
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Large 53 Gujarati by Gunjan Chhablani
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: OpenSLR gu
type: openslr
metrics:
- name: Test WER
type: wer
value: 23.55
---
# Wav2Vec2-Large-XLSR-53-Gujarati
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Gujarati using the [OpenSLR SLR78](http://openslr.org/78/) dataset. When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows, assuming you have a dataset with Gujarati `sentence` and `path` fields:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
# test_dataset = #TODO: WRITE YOUR CODE TO LOAD THE TEST DATASET.
# For sample see the Colab link in Training Section.
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-gu")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-gu")
resampler = torchaudio.transforms.Resample(48_000, 16_000) # The original data was with 48,000 sampling rate. You can change it according to your input.
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset_eval = test_dataset_eval.map(speech_file_to_array_fn)
inputs = processor(test_dataset_eval["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset_eval["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on 10% of the Marathi data on OpenSLR.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
# test_dataset = #TODO: WRITE YOUR CODE TO LOAD THE TEST DATASET. For sample see the Colab link in Training Section.
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-gu")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-gu")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\–\…\'\_\’]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"),
attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 23.55 %
## Training
90% of the OpenSLR Gujarati Male+Female dataset was used for training, after removing few examples that contained Roman characters.
The colab notebook used for training can be found [here](https://colab.research.google.com/drive/1fRQlgl4EPR4qKGScgza3MpWgbL5BeWtn?usp=sharing).
|
gchhablani/wav2vec2-large-xlsr-hu | 2021-03-25T17:09:17.000Z | [
"pytorch",
"wav2vec2",
"hu",
"dataset:common_voice",
"transformers",
"audio",
"automatic-speech-recognition",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0"
]
| automatic-speech-recognition | [
".gitattributes",
"README.md",
"config.json",
"preprocessor_config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| gchhablani | 8 | transformers | ---
language: hu
datasets:
- common_voice
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: Wav2Vec2 Large 53 Hungarian by Gunjan Chhablani
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice hu
type: common_voice
args: hu
metrics:
- name: Test WER
type: wer
value: 46.75
---
# Wav2Vec2-Large-XLSR-53-Hungarian
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Hungarian using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "hu", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-hu")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-hu")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Portuguese test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "hu", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-hu")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-hu")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\–\…]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 46.75 %
## Training
The Common Voice `train` and `validation` datasets were used for training. The code can be found [here](https://github.com/gchhablani/wav2vec2-week/blob/main/fine-tune-xlsr-wav2vec2-on-hungarian-asr.ipynb). The notebook containing the code used for evaluation can be found [here](https://colab.research.google.com/drive/1esYvWS6IkTQFfRqi_b6lAJEycuecInHE?usp=sharing). |
gchhablani/wav2vec2-large-xlsr-ia | 2021-03-26T05:38:49.000Z | [
"pytorch",
"wav2vec2",
"ia",
"dataset:common_voice",
"transformers",
"audio",
"automatic-speech-recognition",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0"
]
| automatic-speech-recognition | [
".gitattributes",
"README.md",
"config.json",
"preprocessor_config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| gchhablani | 9 | transformers | ---
language: ia
datasets:
- common_voice
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Large 53 Interlingua by Gunjan Chhablani
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice ia
type: common_voice
args: ia
metrics:
- name: Test WER
type: wer
value: 25.09
---
# Wav2Vec2-Large-XLSR-53-Interlingua
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Interlingua using the [Common Voice](https://huggingface.co/datasets/common_voice).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "ia", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-ia")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-ia")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Odia test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "ia", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-ia")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-ia")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\']'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 25.09 %
## Training
The Common Voice `train` and `validation` datasets were used for training for 4000 steps due to GPU timeout. The results are based on the 4000 steps checkpoint. There is a good chance that full training will lead to better results.
The colab notebook used can be found [here](https://colab.research.google.com/drive/1nbqvVwS8DTNrCzzh3vgrN55qxgoqbita?usp=sharing) and the evaluation can be found [here](https://colab.research.google.com/drive/18pCWBwNNUMUYV1FiqT_0EsTbCfwwe7ms?usp=sharing). |
gchhablani/wav2vec2-large-xlsr-it | 2021-03-29T08:46:48.000Z | [
"pytorch",
"wav2vec2",
"it",
"dataset:common_voice",
"transformers",
"audio",
"automatic-speech-recognition",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0"
]
| automatic-speech-recognition | [
".gitattributes",
"README.md",
"config.json",
"preprocessor_config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| gchhablani | 478 | transformers | ---
language: it
datasets:
- common_voice
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: Wav2Vec2 Large 53 Italian by Gunjan Chhablani
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice it
type: common_voice
args: it
metrics:
- name: Test WER
type: wer
value: 11.49
---
# Wav2Vec2-Large-XLSR-53-Italian
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Italian using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "it", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained('gchhablani/wav2vec2-large-xlsr-it')
model = Wav2Vec2ForCTC.from_pretrained('gchhablani/wav2vec2-large-xlsr-it')
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Portuguese test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
import unicodedata
import jiwer
def chunked_wer(targets, predictions, chunk_size=None):
if chunk_size is None: return jiwer.wer(targets, predictions)
start = 0
end = chunk_size
H, S, D, I = 0, 0, 0, 0
while start < len(targets):
chunk_metrics = jiwer.compute_measures(targets[start:end], predictions[start:end])
H = H + chunk_metrics["hits"]
S = S + chunk_metrics["substitutions"]
D = D + chunk_metrics["deletions"]
I = I + chunk_metrics["insertions"]
start += chunk_size
end += chunk_size
return float(S + D + I) / float(H + S + D)
allowed_characters = [
" ",
"'",
'a',
'b',
'c',
'd',
'e',
'f',
'g',
'h',
'i',
'j',
'k',
'l',
'm',
'n',
'o',
'p',
'q',
'r',
's',
't',
'u',
'v',
'w',
'x',
'y',
'z',
'à',
'á',
'è',
'é',
'ì',
'í',
'ò',
'ó',
'ù',
'ú',
]
def remove_accents(input_str):
if input_str in allowed_characters:
return input_str
if input_str == 'ø':
return 'o'
elif input_str=='ß' or input_str =='ß':
return 'b'
elif input_str=='ё':
return 'e'
elif input_str=='đ':
return 'd'
nfkd_form = unicodedata.normalize('NFKD', input_str)
only_ascii = nfkd_form.encode('ASCII', 'ignore').decode()
if only_ascii is None or only_ascii=='':
return input_str
else:
return only_ascii
def fix_accents(sentence):
new_sentence=''
for char in sentence:
new_sentence+=remove_accents(char)
return new_sentence
test_dataset = load_dataset("common_voice", "it", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained('gchhablani/wav2vec2-large-xlsr-it')
model = Wav2Vec2ForCTC.from_pretrained('gchhablani/wav2vec2-large-xlsr-it')
model.to("cuda")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
chars_to_remove= [",", "?", ".", "!", "-", ";", ":", '""', "%", '"', "�",'ʿ','“','”','(','=','`','_','+','«','<','>','~','…','«','»','–','\[','\]','°','̇','´','ʾ','„','̇','̇','̇','¡'] # All extra characters
chars_to_remove_regex = f'[{"".join(chars_to_remove)}]'
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_remove_regex, '', batch["sentence"]).lower().replace('‘',"'").replace('ʻ',"'").replace('ʼ',"'").replace('’',"'").replace('ʹ',"''").replace('̇','')
batch["sentence"] = fix_accents(batch["sentence"])
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * chunked_wer(predictions=result["pred_strings"], targets=result["sentence"],chunk_size=5000)))
```
**Test Result**: 11.49 %
## Training
The Common Voice `train` and `validation` datasets were used for training. The code can be found [here](https://github.com/gchhablani/wav2vec2-week/blob/main/fine-tune-xlsr-wav2vec2-on-italian-asr-with-transformers_final.ipynb). |
gchhablani/wav2vec2-large-xlsr-mr-2 | 2021-03-25T21:11:49.000Z | [
"pytorch",
"wav2vec2",
"mr",
"dataset:interspeech_2021_asr",
"transformers",
"audio",
"automatic-speech-recognition",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0"
]
| automatic-speech-recognition | [
".gitattributes",
"README.md",
"config.json",
"preprocessor_config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| gchhablani | 8 | transformers | ---
language: mr
datasets:
- interspeech_2021_asr
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Large 53 Marathi 2 by Gunjan Chhablani
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: InterSpeech 2021 ASR mr
type: interspeech_2021_asr
metrics:
- name: Test WER
type: wer
value: 14.53
---
# Wav2Vec2-Large-XLSR-53-Marathi
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Marathi using a part of the [InterSpeech 2021 Marathi](https://navana-tech.github.io/IS21SS-indicASRchallenge/data.html) dataset. When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows, assuming you have a dataset with Marathi `sentence` and `path` fields:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
# test_dataset = #TODO: WRITE YOUR CODE TO LOAD THE TEST DATASET. For sample see the Colab link in Training Section.
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr-2")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr-2")
resampler = torchaudio.transforms.Resample(8_000, 16_000) # The original data was with 8,000 sampling rate. You can change it according to your input.
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the test set of the Marathi data on InterSpeech-2021.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
# test_dataset = #TODO: WRITE YOUR CODE TO LOAD THE TEST DATASET. For sample see the Colab link in Training Section.
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr-2")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr-2")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\'\�]'
resampler = torchaudio.transforms.Resample(8_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"),
attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 19.98 % (555 examples from test set were used for evaluation)
**Test Result on 10% of OpenSLR74 data**: 64.64 %
## Training
5000 examples of the InterSpeech Marathi dataset were used for training.
The colab notebook used for training can be found [here](https://colab.research.google.com/drive/1sIwGOLJPQqhKm_wVZDkzRuoJqAEgArFr?usp=sharing).
|
gchhablani/wav2vec2-large-xlsr-mr-3 | 2021-03-26T02:11:59.000Z | [
"pytorch",
"wav2vec2",
"mr",
"dataset:openslr",
"dataset:interspeech_2021_asr",
"transformers",
"audio",
"automatic-speech-recognition",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0"
]
| automatic-speech-recognition | [
".gitattributes",
"README.md",
"config.json",
"preprocessor_config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| gchhablani | 8 | transformers | ---
language: mr
datasets:
- openslr
- interspeech_2021_asr
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Large 53 Marathi by Gunjan Chhablani
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: OpenSLR mr, InterSpeech 2021 ASR mr
type: openslr, interspeech_2021_asr
metrics:
- name: Test WER
type: wer
value: 19.05
---
# Wav2Vec2-Large-XLSR-53-Marathi
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Marathi using the [OpenSLR SLR64](http://openslr.org/64/) dataset and [InterSpeech 2021](https://navana-tech.github.io/IS21SS-indicASRchallenge/data.html) Marathi datasets. Note that this data OpenSLR contains only female voices. Please keep this in mind before using the model for your task. When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows, assuming you have a dataset with Marathi `text` and `audio_path` fields:
```python
import torch
import torchaudio
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
# test_data = #TODO: WRITE YOUR CODE TO LOAD THE TEST DATASET. For sample see the Colab link in Training Section.
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr-3")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr-3")
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["audio_path"])
batch["speech"] = librosa.resample(speech_array[0].numpy(), sampling_rate, 16_000) # sampling_rate can vary
return batch
test_data= test_data.map(speech_file_to_array_fn)
inputs = processor(test_data["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_data["text"][:2])
```
## Evaluation
The model can be evaluated as follows on 10% of the Marathi data on OpenSLR.
```python
import torch
import torchaudio
import librosa
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
# test_data = #TODO: WRITE YOUR CODE TO LOAD THE TEST DATASET. For sample see the Colab link in Training Section.
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr-3")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr-3")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\–\…]'
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
batch["text"] = re.sub(chars_to_ignore_regex, '', batch["text"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["audio_path"])
batch["speech"] = librosa.resample(speech_array[0].numpy(), sampling_rate, 16_000)
return batch
test_data= test_data.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_data.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["text"])))
```
**Test Result**: 19.05 % (157+157 examples)
**Test Result on OpenSLR test**: 14.15 % (157 examples)
**Test Results on InterSpeech test**: 27.14 % (157 examples)
## Training
1412 examples of the OpenSLR Marathi dataset and 1412 examples of InterSpeech 2021 Marathi ASR dataset were used for training. For testing, 157 examples from each were used.
The colab notebook used for training and evaluation can be found [here](https://colab.research.google.com/drive/15fUhb4bUFFGJyNLr-_alvPxVX4w0YXRu?usp=sharing).
|
gchhablani/wav2vec2-large-xlsr-mr | 2021-03-24T17:07:29.000Z | [
"pytorch",
"wav2vec2",
"mr",
"dataset:openslr",
"transformers",
"audio",
"automatic-speech-recognition",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0"
]
| automatic-speech-recognition | [
".gitattributes",
"README.md",
"config.json",
"preprocessor_config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| gchhablani | 8 | transformers | ---
language: mr
datasets:
- openslr
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Large 53 Marathi by Gunjan Chhablani
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: OpenSLR mr
type: openslr
metrics:
- name: Test WER
type: wer
value: 14.53
---
# Wav2Vec2-Large-XLSR-53-Marathi
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Marathi using the [OpenSLR SLR64](http://openslr.org/64/) dataset. Note that this data contains only female voices. Please keep this in mind before using the model for your task, although it works very well for male voice too. When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows, assuming you have a dataset with Marathi `sentence` and `path` fields:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
# test_dataset = #TODO: WRITE YOUR CODE TO LOAD THE TEST DATASET. For sample see the Colab link in Training Section.
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr")
resampler = torchaudio.transforms.Resample(48_000, 16_000) # The original data was with 48,000 sampling rate. You can change it according to your input.
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on 10% of the Marathi data on OpenSLR.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
# test_dataset = #TODO: WRITE YOUR CODE TO LOAD THE TEST DATASET. For sample see the Colab link in Training Section.
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\–\…]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"),
attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 14.53 %
## Training
90% of the OpenSLR Marathi dataset was used for training.
The colab notebook used for training can be found [here](https://colab.research.google.com/drive/1_BbLyLqDUsXG3RpSULfLRjC6UY3RjwME?usp=sharing).
|
gchhablani/wav2vec2-large-xlsr-or | 2021-03-26T02:17:00.000Z | [
"pytorch",
"wav2vec2",
"or",
"dataset:common_voice",
"transformers",
"audio",
"automatic-speech-recognition",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0"
]
| automatic-speech-recognition | [
".gitattributes",
"README.md",
"config.json",
"preprocessor_config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| gchhablani | 9 | transformers | ---
language: or
datasets:
- common_voice
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Large 53 Odia by Gunjan Chhablani
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice or
type: common_voice
args: or
metrics:
- name: Test WER
type: wer
value: 52.64
---
# Wav2Vec2-Large-XLSR-53-Odia
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Odia using the [Common Voice](https://huggingface.co/datasets/common_voice).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "or", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-or")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-or")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Odia test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "or", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-or")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-or")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\–\…\'\_\’\।\|]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 52.64 %
## Training
The Common Voice `train` and `validation` datasets were used for training.The colab notebook used can be found [here](https://colab.research.google.com/drive/1s8DrwgB5y4Z7xXIrPXo1rQA5_1OZ8WD5?usp=sharing). |
gchhablani/wav2vec2-large-xlsr-pt | 2021-03-24T19:51:22.000Z | [
"pytorch",
"wav2vec2",
"pt",
"dataset:common_voice",
"transformers",
"audio",
"automatic-speech-recognition",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0"
]
| automatic-speech-recognition | [
".gitattributes",
"README.md",
"all_results.json",
"config.json",
"eval_results.json",
"preprocessor_config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"train_results.json",
"trainer_state.json",
"training_args.bin",
"vocab.json"
]
| gchhablani | 15 | transformers | ---
language: pt
datasets:
- common_voice
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: Wav2Vec2 Large 53 Portugese by Gunjan Chhablani
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice pt
type: common_voice
args: pt
metrics:
- name: Test WER
type: wer
value: 17.22
---
# Wav2Vec2-Large-XLSR-53-Portuguese
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Portuguese using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "pt", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-pt")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-pt")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Portuguese test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "pt", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-pt")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-pt")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\;\"\“\'\�]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 17.22 %
## Training
The Common Voice `train` and `validation` datasets were used for training. The script used for training can be found [here](https://github.com/jqueguiner/wav2vec2-sprint/blob/main/run_common_voice.py).
The parameters passed were:
```bash
#!/usr/bin/env bash
python run_common_voice.py \
--model_name_or_path="facebook/wav2vec2-large-xlsr-53" \
--dataset_config_name="pt" \
--output_dir=/workspace/output_models/pt/wav2vec2-large-xlsr-pt \
--cache_dir=/workspace/data \
--overwrite_output_dir \
--num_train_epochs="30" \
--per_device_train_batch_size="32" \
--per_device_eval_batch_size="32" \
--evaluation_strategy="steps" \
--learning_rate="3e-4" \
--warmup_steps="500" \
--fp16 \
--freeze_feature_extractor \
--save_steps="500" \
--eval_steps="500" \
--save_total_limit="1" \
--logging_steps="500" \
--group_by_length \
--feat_proj_dropout="0.0" \
--layerdrop="0.1" \
--gradient_checkpointing \
--do_train --do_eval \
```
Notebook containing the evaluation can be found [here](https://colab.research.google.com/drive/14e-zNK_5pm8EMY9EbeZerpHx7WsGycqG?usp=sharing). |
gchhablani/wav2vec2-large-xlsr-rm-sursilv | 2021-03-29T21:21:42.000Z | [
"pytorch",
"wav2vec2",
"rm-sursilv",
"dataset:common_voice",
"transformers",
"audio",
"automatic-speech-recognition",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0"
]
| automatic-speech-recognition | [
".gitattributes",
"README.md",
"config.json",
"preprocessor_config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| gchhablani | 13 | transformers | ---
language: rm-sursilv
datasets:
- common_voice
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: Wav2Vec2 Large 53 Romansh Sursilvan by Gunjan Chhablani
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice rm-sursilv
type: common_voice
args: rm-sursilv
metrics:
- name: Test WER
type: wer
value: 25.16
---
# Wav2Vec2-Large-XLSR-53-Romansh-Sursilvan
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Romansh Sursilvan using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "rm-sursilv", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-rm-sursilv")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-rm-sursilv")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Portuguese test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "rm-sursilv", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-rm-sursilv")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-rm-sursilv")
model.to("cuda")
chars_to_ignore_regex = '[\\,\\?\\.\\!\\-\\;\\:\\"\\“\\%\\‘\\”\\�\\…\\«\\»\\–]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 25.16 %
## Training
The Common Voice `train` and `validation` datasets were used for training. The code can be found [here](https://colab.research.google.com/drive/1dpZr_GzRowCciUbzM3GnW04TNKnB7vrP?usp=sharing). |
gdario/biobert_bioasq | 2021-05-19T17:13:28.000Z | [
"pytorch",
"jax",
"bert",
"question-answering",
"transformers"
]
| question-answering | [
".gitattributes",
"config.json",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.txt"
]
| gdario | 26 | transformers | |
geekfeed/gpt2_ja | 2021-05-21T16:11:52.000Z | [
"pytorch",
"jax",
"gpt2",
"transformers"
]
| [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.json"
]
| geekfeed | 150 | transformers | hello
|
|
german-nlp-group/electra-base-german-uncased | 2021-05-24T13:26:08.000Z | [
"pytorch",
"electra",
"pretraining",
"de",
"transformers",
"license:mit",
"commoncrawl",
"uncased",
"umlaute",
"umlauts",
"german",
"deutsch"
]
| [
".gitattributes",
"README.md",
"ckpt-1500000.tar.gz",
"config.json",
"pytorch_model.bin",
"tokenizer_config.json",
"vocab.txt"
]
| german-nlp-group | 3,849 | transformers | ---
language: de
license: mit
thumbnail: "https://raw.githubusercontent.com/German-NLP-Group/german-transformer-training/master/model_cards/german-electra-logo.png"
tags:
- electra
- commoncrawl
- uncased
- umlaute
- umlauts
- german
- deutsch
---
# German Electra Uncased
<img width="300px" src="https://raw.githubusercontent.com/German-NLP-Group/german-transformer-training/master/model_cards/german-electra-logo.png">
[¹]
## Version 2 Release
We released an improved version of this model. Version 1 was trained for 766,000 steps. For this new version we continued the training for an additional 734,000 steps. It therefore follows that version 2 was trained on a total of 1,500,000 steps. See "Evaluation of Version 2: GermEval18 Coarse" below for details.
## Model Info
This Model is suitable for training on many downstream tasks in German (Q&A, Sentiment Analysis, etc.).
It can be used as a drop-in replacement for **BERT** in most down-stream tasks (**ELECTRA** is even implemented as an extended **BERT** Class).
At the time of release (August 2020) this model is the best performing publicly available German NLP model on various German evaluation metrics (CONLL03-DE, GermEval18 Coarse, GermEval18 Fine). For GermEval18 Coarse results see below. More will be published soon.
## Installation
This model has the special feature that it is **uncased** but does **not strip accents**.
This possibility was added by us with [PR #6280](https://github.com/huggingface/transformers/pull/6280).
To use it you have to use Transformers version 3.1.0 or newer.
```bash
pip install transformers -U
```
## Uncase and Umlauts ('Ö', 'Ä', 'Ü')
This model is uncased. This helps especially for domains where colloquial terms with uncorrect capitalization is often used.
The special characters 'ö', 'ü', 'ä' are included through the `strip_accent=False` option, as this leads to an improved precision.
## Creators
This model was trained and open sourced in conjunction with the [**German NLP Group**](https://github.com/German-NLP-Group) in equal parts by:
- [**Philip May**](https://May.la) - [T-Systems on site services GmbH](https://www.t-systems-onsite.de/)
- [**Philipp Reißel**](https://www.reissel.eu) - [ambeRoad](https://amberoad.de/)
## Evaluation of Version 2: GermEval18 Coarse
We evaluated all language models on GermEval18 with the F1 macro score. For each model we did an extensive automated hyperparameter search. With the best hyperparmeters we did fit the moodel multiple times on GermEval18. This is done to cancel random effects and get results of statistical relevance.
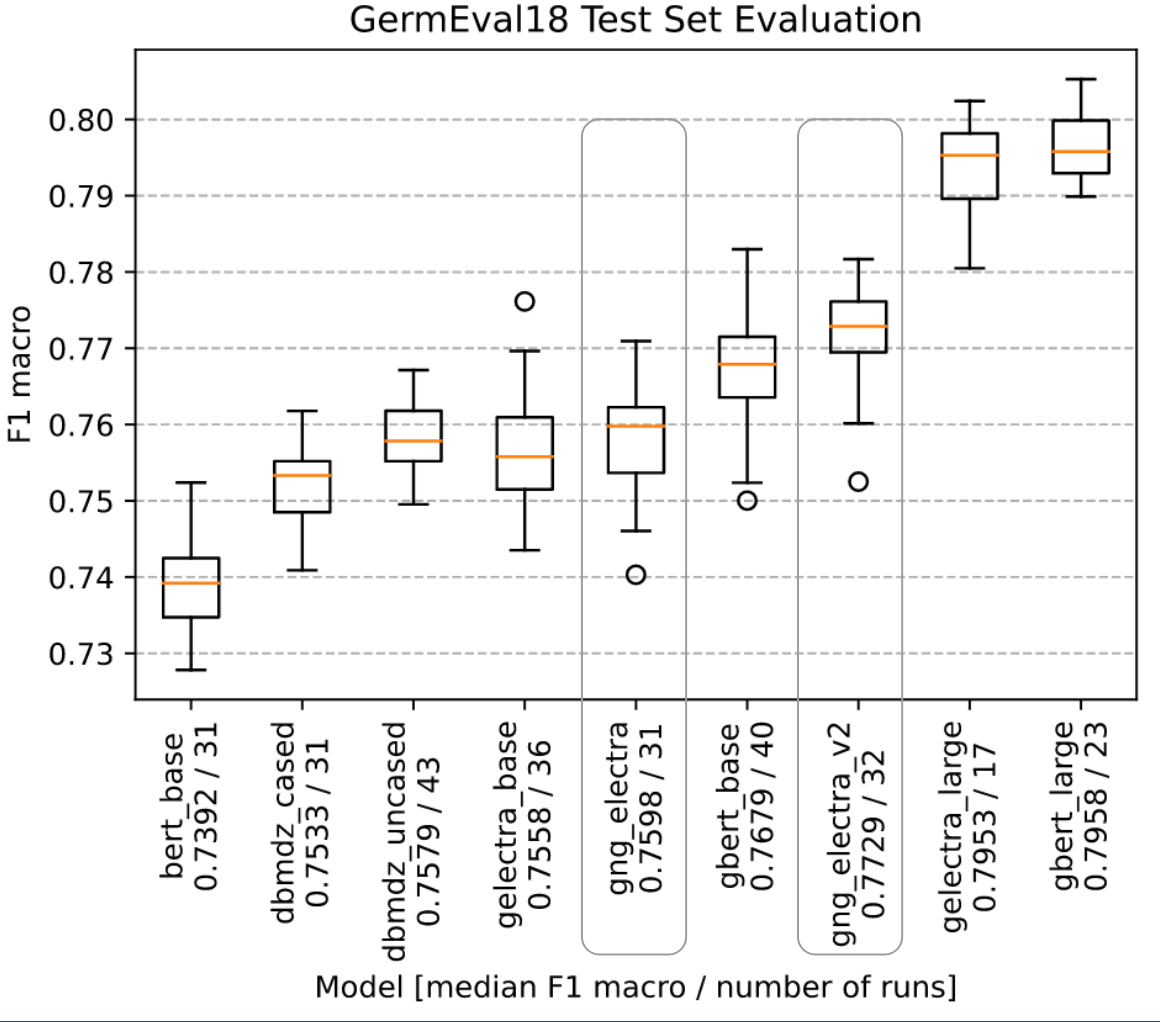
## Checkpoint evaluation
Since it it not guaranteed that the last checkpoint is the best, we evaluated the checkpoints on GermEval18. We found that the last checkpoint is indeed the best. The training was stable and did not overfit the text corpus.
## Pre-training details
### Data
- Cleaned Common Crawl Corpus 2019-09 German: [CC_net](https://github.com/facebookresearch/cc_net) (Only head coprus and filtered for language_score > 0.98) - 62 GB
- German Wikipedia Article Pages Dump (20200701) - 5.5 GB
- German Wikipedia Talk Pages Dump (20200620) - 1.1 GB
- Subtitles - 823 MB
- News 2018 - 4.1 GB
The sentences were split with [SojaMo](https://github.com/tsproisl/SoMaJo). We took the German Wikipedia Article Pages Dump 3x to oversample. This approach was also used in a similar way in GPT-3 (Table 2.2).
More Details can be found here [Preperaing Datasets for German Electra Github](https://github.com/German-NLP-Group/german-transformer-training)
### Electra Branch no_strip_accents
Because we do not want to stip accents in our training data we made a change to Electra and used this repo [Electra no_strip_accents](https://github.com/PhilipMay/electra/tree/no_strip_accents) (branch `no_strip_accents`). Then created the tf dataset with:
```bash
python build_pretraining_dataset.py --corpus-dir <corpus_dir> --vocab-file <dir>/vocab.txt --output-dir ./tf_data --max-seq-length 512 --num-processes 8 --do-lower-case --no-strip-accents
```
### The training
The training itself can be performed with the Original Electra Repo (No special case for this needed).
We run it with the following Config:
<details>
<summary>The exact Training Config</summary>
<br/>debug False
<br/>disallow_correct False
<br/>disc_weight 50.0
<br/>do_eval False
<br/>do_lower_case True
<br/>do_train True
<br/>electra_objective True
<br/>embedding_size 768
<br/>eval_batch_size 128
<br/>gcp_project None
<br/>gen_weight 1.0
<br/>generator_hidden_size 0.33333
<br/>generator_layers 1.0
<br/>iterations_per_loop 200
<br/>keep_checkpoint_max 0
<br/>learning_rate 0.0002
<br/>lr_decay_power 1.0
<br/>mask_prob 0.15
<br/>max_predictions_per_seq 79
<br/>max_seq_length 512
<br/>model_dir gs://XXX
<br/>model_hparam_overrides {}
<br/>model_name 02_Electra_Checkpoints_32k_766k_Combined
<br/>model_size base
<br/>num_eval_steps 100
<br/>num_tpu_cores 8
<br/>num_train_steps 766000
<br/>num_warmup_steps 10000
<br/>pretrain_tfrecords gs://XXX
<br/>results_pkl gs://XXX
<br/>results_txt gs://XXX
<br/>save_checkpoints_steps 5000
<br/>temperature 1.0
<br/>tpu_job_name None
<br/>tpu_name electrav5
<br/>tpu_zone None
<br/>train_batch_size 256
<br/>uniform_generator False
<br/>untied_generator True
<br/>untied_generator_embeddings False
<br/>use_tpu True
<br/>vocab_file gs://XXX
<br/>vocab_size 32767
<br/>weight_decay_rate 0.01
</details>
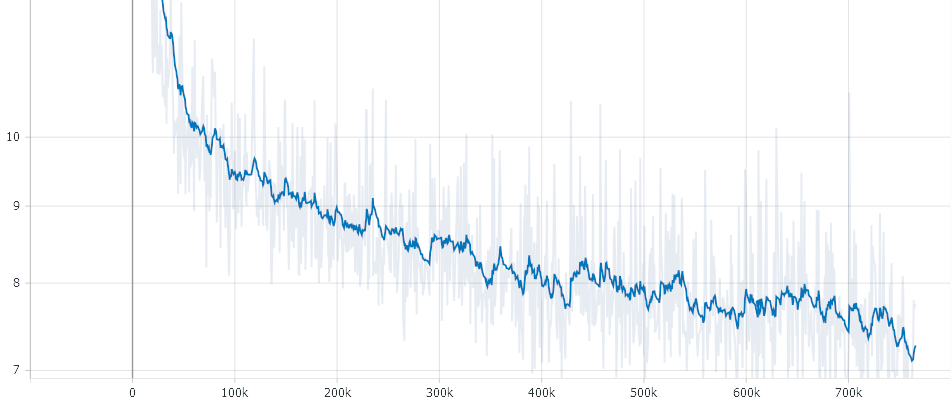
Please Note: *Due to the GAN like strucutre of Electra the loss is not that meaningful*
It took about 7 Days on a preemtible TPU V3-8. In total, the Model went through approximately 10 Epochs. For an automatically recreation of a cancelled TPUs we used [tpunicorn](https://github.com/shawwn/tpunicorn). The total cost of training summed up to about 450 $ for one run. The Data-pre processing and Vocab Creation needed approximately 500-1000 CPU hours. Servers were fully provided by [T-Systems on site services GmbH](https://www.t-systems-onsite.de/), [ambeRoad](https://amberoad.de/).
Special thanks to [Stefan Schweter](https://github.com/stefan-it) for your feedback and providing parts of the text corpus.
[¹]: Source for the picture [Pinterest](https://www.pinterest.cl/pin/371828512984142193/)
### Negative Results
We tried the following approaches which we found had no positive influence:
- **Increased Vocab Size**: Leads to more parameters and thus reduced examples/sec while no visible Performance gains were measured
- **Decreased Batch-Size**: The original Electra was trained with a Batch Size per TPU Core of 16 whereas this Model was trained with 32 BS / TPU Core. We found out that 32 BS leads to better results when you compare metrics over computation time
## License - The MIT License
Copyright 2020-2021 Philip May<br>
Copyright 2020-2021 Philipp Reissel
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
|
ggrunin/model_name | 2021-03-17T14:21:00.000Z | []
| [
".gitattributes"
]
| ggrunin | 0 | |||
ghanashyamvtatti/roberta-fake-news | 2021-05-20T16:33:04.000Z | [
"pytorch",
"tf",
"jax",
"roberta",
"text-classification",
"transformers"
]
| text-classification | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer_config.json",
"training_args.bin",
"vocab.json"
]
| ghanashyamvtatti | 140 | transformers | A fake news detector using RoBERTa.
Dataset: https://www.kaggle.com/clmentbisaillon/fake-and-real-news-dataset
Training involved using hyperparameter search with 10 trials. |
giacomomiolo/biobert_reupload | 2021-05-19T17:14:24.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"transformers"
]
| [
".DS_Store",
".gitattributes",
"config.json",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer_config.json",
"vocab.txt"
]
| giacomomiolo | 19 | transformers | ||
giacomomiolo/bluebert_reupload | 2021-05-19T17:17:05.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"transformers"
]
| [
".DS_Store",
".gitattributes",
"config.json",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer_config.json",
"vocab.txt"
]
| giacomomiolo | 12 | transformers | ||
giacomomiolo/electramed_base_scivocab_1M | 2020-10-02T14:13:56.000Z | [
"pytorch",
"tf",
"electra",
"pretraining",
"transformers"
]
| [
".DS_Store",
".gitattributes",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer_config.json",
"vocab.txt"
]
| giacomomiolo | 307 | transformers | ||
giacomomiolo/electramed_base_scivocab_500k | 2020-09-28T07:33:46.000Z | [
"pytorch",
"tf",
"electra",
"pretraining",
"transformers"
]
| [
".DS_Store",
".gitattributes",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer_config.json",
"vocab.txt"
]
| giacomomiolo | 15 | transformers | ||
giacomomiolo/electramed_base_scivocab_750 | 2020-09-30T11:47:57.000Z | [
"pytorch",
"tf",
"electra",
"pretraining",
"transformers"
]
| [
".DS_Store",
".gitattributes",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer_config.json",
"vocab.txt"
]
| giacomomiolo | 13 | transformers | ||
giacomomiolo/electramed_base_scivocab_970k | 2020-10-02T14:55:30.000Z | [
"pytorch",
"tf",
"electra",
"pretraining",
"transformers"
]
| [
".DS_Store",
".gitattributes",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer_config.json",
"vocab.txt"
]
| giacomomiolo | 11 | transformers | ||
giacomomiolo/electramed_small | 2020-09-03T22:48:14.000Z | [
"pytorch",
"tf",
"electra",
"pretraining",
"transformers"
]
| [
".DS_Store",
".gitattributes",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer_config.json",
"vocab.txt"
]
| giacomomiolo | 35 | transformers | ||
giacomomiolo/electramed_small_scivocab | 2020-09-20T14:58:01.000Z | [
"pytorch",
"tf",
"electra",
"pretraining",
"transformers"
]
| [
".DS_Store",
".gitattributes",
"config.json",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer_config.json",
"vocab.txt"
]
| giacomomiolo | 19 | transformers | ||
giacomomiolo/scibert_reupload | 2021-05-19T17:19:25.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"pretraining",
"transformers"
]
| [
".DS_Store",
".gitattributes",
"config.json",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer_config.json",
"vocab.txt"
]
| giacomomiolo | 202 | transformers | ||
giadilli/test | 2021-03-17T11:18:59.000Z | []
| [
".gitattributes"
]
| giadilli | 0 | |||
giganticode/StackOBERTflow-comments-small-v1 | 2021-05-20T16:33:56.000Z | [
"pytorch",
"jax",
"roberta",
"masked-lm",
"transformers",
"fill-mask"
]
| fill-mask | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.json",
"model_cards/README.md"
]
| giganticode | 33 | transformers | # StackOBERTflow-comments-small
StackOBERTflow is a RoBERTa model trained on StackOverflow comments.
A Byte-level BPE tokenizer with dropout was used (using the `tokenizers` package).
The model is *small*, i.e. has only 6-layers and the maximum sequence length was restricted to 256 tokens.
The model was trained for 6 epochs on several GBs of comments from the StackOverflow corpus.
## Quick start: masked language modeling prediction
```python
from transformers import pipeline
from pprint import pprint
COMMENT = "You really should not do it this way, I would use <mask> instead."
fill_mask = pipeline(
"fill-mask",
model="./StackOBERTflow-comments-small-v1",
tokenizer="./StackOBERTflow-comments-small-v1"
)
pprint(fill_mask(COMMENT))
# [{'score': 0.019997311756014824,
# 'sequence': '<s> You really should not do it this way, I would use jQuery instead.</s>',
# 'token': 1738},
# {'score': 0.01693696901202202,
# 'sequence': '<s> You really should not do it this way, I would use arrays instead.</s>',
# 'token': 2844},
# {'score': 0.013411642983555794,
# 'sequence': '<s> You really should not do it this way, I would use CSS instead.</s>',
# 'token': 2254},
# {'score': 0.013224546797573566,
# 'sequence': '<s> You really should not do it this way, I would use it instead.</s>',
# 'token': 300},
# {'score': 0.011984303593635559,
# 'sequence': '<s> You really should not do it this way, I would use classes instead.</s>',
# 'token': 1779}]
```
|
gilf/english-yelp-sentiment | 2021-05-19T17:20:22.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"text-classification",
"transformers"
]
| text-classification | [
".gitattributes",
"config.json",
"eval_results.txt",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer_config.json",
"training_args.bin",
"vocab.txt"
]
| gilf | 341 | transformers | |
gilf/french-camembert-postag-model | 2020-12-11T21:41:07.000Z | [
"pytorch",
"tf",
"camembert",
"token-classification",
"fr",
"transformers"
]
| token-classification | [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin",
"sentencepiece.bpe.model",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer_config.json"
]
| gilf | 963 | transformers | ---
language: fr
widget:
- text: "Face à un choc inédit, les mesures mises en place par le gouvernement ont permis une protection forte et efficace des ménages"
---
## About
The *french-camembert-postag-model* is a part of speech tagging model for French that was trained on the *free-french-treebank* dataset available on
[github](https://github.com/nicolashernandez/free-french-treebank). The base tokenizer and model used for training is *'camembert-base'*.
## Supported Tags
It uses the following tags:
| Tag | Category | Extra Info |
|----------|:------------------------------:|------------:|
| ADJ | adjectif | |
| ADJWH | adjectif | |
| ADV | adverbe | |
| ADVWH | adverbe | |
| CC | conjonction de coordination | |
| CLO | pronom | obj |
| CLR | pronom | refl |
| CLS | pronom | suj |
| CS | conjonction de subordination | |
| DET | déterminant | |
| DETWH | déterminant | |
| ET | mot étranger | |
| I | interjection | |
| NC | nom commun | |
| NPP | nom propre | |
| P | préposition | |
| P+D | préposition + déterminant | |
| PONCT | signe de ponctuation | |
| PREF | préfixe | |
| PRO | autres pronoms | |
| PROREL | autres pronoms | rel |
| PROWH | autres pronoms | int |
| U | ? | |
| V | verbe | |
| VIMP | verbe imperatif | |
| VINF | verbe infinitif | |
| VPP | participe passé | |
| VPR | participe présent | |
| VS | subjonctif | |
More information on the tags can be found here:
http://alpage.inria.fr/statgram/frdep/Publications/crabbecandi-taln2008-final.pdf
## Usage
The usage of this model follows the common transformers patterns. Here is a short example of its usage:
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("gilf/french-camembert-postag-model")
model = AutoModelForTokenClassification.from_pretrained("gilf/french-camembert-postag-model")
from transformers import pipeline
nlp_token_class = pipeline('ner', model=model, tokenizer=tokenizer, grouped_entities=True)
nlp_token_class('Face à un choc inédit, les mesures mises en place par le gouvernement ont permis une protection forte et efficace des ménages')
```
The lines above would display something like this on a Jupyter notebook:
```
[{'entity_group': 'NC', 'score': 0.5760144591331482, 'word': '<s>'},
{'entity_group': 'U', 'score': 0.9946700930595398, 'word': 'Face'},
{'entity_group': 'P', 'score': 0.999615490436554, 'word': 'à'},
{'entity_group': 'DET', 'score': 0.9995906352996826, 'word': 'un'},
{'entity_group': 'NC', 'score': 0.9995531439781189, 'word': 'choc'},
{'entity_group': 'ADJ', 'score': 0.999183714389801, 'word': 'inédit'},
{'entity_group': 'P', 'score': 0.3710663616657257, 'word': ','},
{'entity_group': 'DET', 'score': 0.9995903968811035, 'word': 'les'},
{'entity_group': 'NC', 'score': 0.9995649456977844, 'word': 'mesures'},
{'entity_group': 'VPP', 'score': 0.9988670349121094, 'word': 'mises'},
{'entity_group': 'P', 'score': 0.9996246099472046, 'word': 'en'},
{'entity_group': 'NC', 'score': 0.9995329976081848, 'word': 'place'},
{'entity_group': 'P', 'score': 0.9996233582496643, 'word': 'par'},
{'entity_group': 'DET', 'score': 0.9995935559272766, 'word': 'le'},
{'entity_group': 'NC', 'score': 0.9995369911193848, 'word': 'gouvernement'},
{'entity_group': 'V', 'score': 0.9993771314620972, 'word': 'ont'},
{'entity_group': 'VPP', 'score': 0.9991101026535034, 'word': 'permis'},
{'entity_group': 'DET', 'score': 0.9995885491371155, 'word': 'une'},
{'entity_group': 'NC', 'score': 0.9995636343955994, 'word': 'protection'},
{'entity_group': 'ADJ', 'score': 0.9991781711578369, 'word': 'forte'},
{'entity_group': 'CC', 'score': 0.9991298317909241, 'word': 'et'},
{'entity_group': 'ADJ', 'score': 0.9992275238037109, 'word': 'efficace'},
{'entity_group': 'P+D', 'score': 0.9993300437927246, 'word': 'des'},
{'entity_group': 'NC', 'score': 0.8353511393070221, 'word': 'ménages</s>'}]
```
|
gilf/french-postag-model | 2021-05-19T17:22:22.000Z | [
"pytorch",
"tf",
"jax",
"bert",
"token-classification",
"transformers"
]
| token-classification | [
".gitattributes",
"README.md",
"config.json",
"flax_model.msgpack",
"pytorch_model.bin",
"special_tokens_map.json",
"tf_model.h5",
"tokenizer_config.json",
"vocab.txt"
]
| gilf | 104 | transformers | ## About
The *french-postag-model* is a part of speech tagging model for French that was trained on the *free-french-treebank* dataset available on
[github](https://github.com/nicolashernandez/free-french-treebank). The base tokenizer and model used for training is *'bert-base-multilingual-cased'*.
## Supported Tags
It uses the following tags:
| Tag | Category | Extra Info |
|----------|:------------------------------:|------------:|
| ADJ | adjectif | |
| ADJWH | adjectif | |
| ADV | adverbe | |
| ADVWH | adverbe | |
| CC | conjonction de coordination | |
| CLO | pronom | obj |
| CLR | pronom | refl |
| CLS | pronom | suj |
| CS | conjonction de subordination | |
| DET | déterminant | |
| DETWH | déterminant | |
| ET | mot étranger | |
| I | interjection | |
| NC | nom commun | |
| NPP | nom propre | |
| P | préposition | |
| P+D | préposition + déterminant | |
| PONCT | signe de ponctuation | |
| PREF | préfixe | |
| PRO | autres pronoms | |
| PROREL | autres pronoms | rel |
| PROWH | autres pronoms | int |
| U | ? | |
| V | verbe | |
| VIMP | verbe imperatif | |
| VINF | verbe infinitif | |
| VPP | participe passé | |
| VPR | participe présent | |
| VS | subjonctif | |
More information on the tags can be found here:
http://alpage.inria.fr/statgram/frdep/Publications/crabbecandi-taln2008-final.pdf
## Usage
The usage of this model follows the common transformers patterns. Here is a short example of its usage:
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("gilf/french-postag-model")
model = AutoModelForTokenClassification.from_pretrained("gilf/french-postag-model")
from transformers import pipeline
nlp_token_class = pipeline('ner', model=model, tokenizer=tokenizer, grouped_entities=True)
nlp_token_class('Face à un choc inédit, les mesures mises en place par le gouvernement ont permis une protection forte et efficace des ménages')
```
The lines above would display something like this on a Jupyter notebook:
```
[{'entity_group': 'PONCT', 'score': 0.0742340236902237, 'word': '[CLS]'},
{'entity_group': 'U', 'score': 0.9995399713516235, 'word': 'Face'},
{'entity_group': 'P', 'score': 0.9999609589576721, 'word': 'à'},
{'entity_group': 'DET', 'score': 0.9999597072601318, 'word': 'un'},
{'entity_group': 'NC', 'score': 0.9998948276042938, 'word': 'choc'},
{'entity_group': 'ADJ', 'score': 0.995318204164505, 'word': 'inédit'},
{'entity_group': 'PONCT', 'score': 0.9999793171882629, 'word': ','},
{'entity_group': 'DET', 'score': 0.999964714050293, 'word': 'les'},
{'entity_group': 'NC', 'score': 0.999936580657959, 'word': 'mesures'},
{'entity_group': 'VPP', 'score': 0.9995776414871216, 'word': 'mises'},
{'entity_group': 'P', 'score': 0.99996417760849, 'word': 'en'},
{'entity_group': 'NC', 'score': 0.999882161617279, 'word': 'place'},
{'entity_group': 'P', 'score': 0.9999671578407288, 'word': 'par'},
{'entity_group': 'DET', 'score': 0.9999637603759766, 'word': 'le'},
{'entity_group': 'NC', 'score': 0.9999350309371948, 'word': 'gouvernement'},
{'entity_group': 'V', 'score': 0.9999298453330994, 'word': 'ont'},
{'entity_group': 'VPP', 'score': 0.9998740553855896, 'word': 'permis'},
{'entity_group': 'DET', 'score': 0.9999625086784363, 'word': 'une'},
{'entity_group': 'NC', 'score': 0.9999420046806335, 'word': 'protection'},
{'entity_group': 'ADJ', 'score': 0.9998913407325745, 'word': 'forte'},
{'entity_group': 'CC', 'score': 0.9998615980148315, 'word': 'et'},
{'entity_group': 'ADJ', 'score': 0.9998483657836914, 'word': 'efficace'},
{'entity_group': 'P+D', 'score': 0.9987645149230957, 'word': 'des'},
{'entity_group': 'NC', 'score': 0.8720395267009735, 'word': 'ménages [SEP]'}]
```
|
glasses/cse_resnet50 | 2021-04-24T10:50:58.000Z | [
"pytorch",
"arxiv:1512.03385",
"arxiv:1812.01187",
"transformers"
]
| [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin"
]
| glasses | 9 | transformers | # cse_resnet50
Implementation of ResNet proposed in [Deep Residual Learning for Image
Recognition](https://arxiv.org/abs/1512.03385)
``` python
ResNet.resnet18()
ResNet.resnet26()
ResNet.resnet34()
ResNet.resnet50()
ResNet.resnet101()
ResNet.resnet152()
ResNet.resnet200()
Variants (d) proposed in `Bag of Tricks for Image Classification with Convolutional Neural Networks <https://arxiv.org/pdf/1812.01187.pdf`_
ResNet.resnet26d()
ResNet.resnet34d()
ResNet.resnet50d()
# You can construct your own one by chaning `stem` and `block`
resnet101d = ResNet.resnet101(stem=ResNetStemC, block=partial(ResNetBottleneckBlock, shortcut=ResNetShorcutD))
```
Examples:
``` python
# change activation
ResNet.resnet18(activation = nn.SELU)
# change number of classes (default is 1000 )
ResNet.resnet18(n_classes=100)
# pass a different block
ResNet.resnet18(block=SENetBasicBlock)
# change the steam
model = ResNet.resnet18(stem=ResNetStemC)
change shortcut
model = ResNet.resnet18(block=partial(ResNetBasicBlock, shortcut=ResNetShorcutD))
# store each feature
x = torch.rand((1, 3, 224, 224))
# get features
model = ResNet.resnet18()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
#[torch.Size([1, 64, 112, 112]), torch.Size([1, 64, 56, 56]), torch.Size([1, 128, 28, 28]), torch.Size([1, 256, 14, 14])]
```
|
|
glasses/deit_base_patch16_224 | 2021-04-22T18:44:42.000Z | [
"pytorch",
"arxiv:2010.11929",
"transformers"
]
| [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin"
]
| glasses | 7 | transformers | # deit_base_patch16_224
Implementation of DeiT proposed in [Training data-efficient image
transformers & distillation through
attention](https://arxiv.org/pdf/2010.11929.pdf)
An attention based distillation is proposed where a new token is added
to the model, the [dist]{.title-ref} token.

``` {.sourceCode .}
DeiT.deit_tiny_patch16_224()
DeiT.deit_small_patch16_224()
DeiT.deit_base_patch16_224()
DeiT.deit_base_patch16_384()
```
|
|
glasses/deit_base_patch16_384 | 2021-04-22T18:44:58.000Z | [
"pytorch",
"arxiv:2010.11929",
"transformers"
]
| [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin"
]
| glasses | 8 | transformers | # deit_base_patch16_384
Implementation of DeiT proposed in [Training data-efficient image
transformers & distillation through
attention](https://arxiv.org/pdf/2010.11929.pdf)
An attention based distillation is proposed where a new token is added
to the model, the [dist]{.title-ref} token.

``` {.sourceCode .}
DeiT.deit_tiny_patch16_224()
DeiT.deit_small_patch16_224()
DeiT.deit_base_patch16_224()
DeiT.deit_base_patch16_384()
```
|
|
glasses/deit_small_patch16_224 | 2021-04-22T18:44:25.000Z | [
"pytorch",
"arxiv:2010.11929",
"transformers"
]
| [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin"
]
| glasses | 6 | transformers | # deit_small_patch16_224
Implementation of DeiT proposed in [Training data-efficient image
transformers & distillation through
attention](https://arxiv.org/pdf/2010.11929.pdf)
An attention based distillation is proposed where a new token is added
to the model, the [dist]{.title-ref} token.

``` {.sourceCode .}
DeiT.deit_tiny_patch16_224()
DeiT.deit_small_patch16_224()
DeiT.deit_base_patch16_224()
DeiT.deit_base_patch16_384()
```
|
|
glasses/deit_tiny_patch16_224 | 2021-04-22T18:44:18.000Z | [
"pytorch",
"arxiv:2010.11929",
"transformers"
]
| [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin"
]
| glasses | 10 | transformers | # deit_tiny_patch16_224
Implementation of DeiT proposed in [Training data-efficient image
transformers & distillation through
attention](https://arxiv.org/pdf/2010.11929.pdf)
An attention based distillation is proposed where a new token is added
to the model, the [dist]{.title-ref} token.

``` {.sourceCode .}
DeiT.deit_tiny_patch16_224()
DeiT.deit_small_patch16_224()
DeiT.deit_base_patch16_224()
DeiT.deit_base_patch16_384()
```
|
|
glasses/densenet121 | 2021-04-21T19:09:22.000Z | [
"pytorch",
"arxiv:1608.06993",
"transformers"
]
| [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin"
]
| glasses | 6 | transformers | # densenet121
Implementation of DenseNet proposed in [Densely Connected Convolutional
Networks](https://arxiv.org/abs/1608.06993)
Create a default models
``` {.sourceCode .}
DenseNet.densenet121()
DenseNet.densenet161()
DenseNet.densenet169()
DenseNet.densenet201()
```
Examples:
``` {.sourceCode .}
# change activation
DenseNet.densenet121(activation = nn.SELU)
# change number of classes (default is 1000 )
DenseNet.densenet121(n_classes=100)
# pass a different block
DenseNet.densenet121(block=...)
# change the initial convolution
model = DenseNet.densenet121()
model.encoder.gate.conv1 = nn.Conv2d(3, 64, kernel_size=3)
# store each feature
x = torch.rand((1, 3, 224, 224))
model = DenseNet.densenet121()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
# [torch.Size([1, 128, 28, 28]), torch.Size([1, 256, 14, 14]), torch.Size([1, 512, 7, 7]), torch.Size([1, 1024, 7, 7])]
```
|
|
glasses/densenet161 | 2021-04-21T19:09:43.000Z | [
"pytorch",
"arxiv:1608.06993",
"transformers"
]
| [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin"
]
| glasses | 7 | transformers | # densenet161
Implementation of DenseNet proposed in [Densely Connected Convolutional
Networks](https://arxiv.org/abs/1608.06993)
Create a default models
``` {.sourceCode .}
DenseNet.densenet121()
DenseNet.densenet161()
DenseNet.densenet169()
DenseNet.densenet201()
```
Examples:
``` {.sourceCode .}
# change activation
DenseNet.densenet121(activation = nn.SELU)
# change number of classes (default is 1000 )
DenseNet.densenet121(n_classes=100)
# pass a different block
DenseNet.densenet121(block=...)
# change the initial convolution
model = DenseNet.densenet121()
model.encoder.gate.conv1 = nn.Conv2d(3, 64, kernel_size=3)
# store each feature
x = torch.rand((1, 3, 224, 224))
model = DenseNet.densenet121()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
# [torch.Size([1, 128, 28, 28]), torch.Size([1, 256, 14, 14]), torch.Size([1, 512, 7, 7]), torch.Size([1, 1024, 7, 7])]
```
|
|
glasses/densenet169 | 2021-04-21T19:09:28.000Z | [
"pytorch",
"arxiv:1608.06993",
"transformers"
]
| [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin"
]
| glasses | 6 | transformers | # densenet169
Implementation of DenseNet proposed in [Densely Connected Convolutional
Networks](https://arxiv.org/abs/1608.06993)
Create a default models
``` {.sourceCode .}
DenseNet.densenet121()
DenseNet.densenet161()
DenseNet.densenet169()
DenseNet.densenet201()
```
Examples:
``` {.sourceCode .}
# change activation
DenseNet.densenet121(activation = nn.SELU)
# change number of classes (default is 1000 )
DenseNet.densenet121(n_classes=100)
# pass a different block
DenseNet.densenet121(block=...)
# change the initial convolution
model = DenseNet.densenet121()
model.encoder.gate.conv1 = nn.Conv2d(3, 64, kernel_size=3)
# store each feature
x = torch.rand((1, 3, 224, 224))
model = DenseNet.densenet121()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
# [torch.Size([1, 128, 28, 28]), torch.Size([1, 256, 14, 14]), torch.Size([1, 512, 7, 7]), torch.Size([1, 1024, 7, 7])]
```
|
|
glasses/densenet201 | 2021-04-21T19:09:35.000Z | [
"pytorch",
"arxiv:1608.06993",
"transformers"
]
| [
".gitattributes",
"README.md",
"config.json",
"pytorch_model.bin"
]
| glasses | 8 | transformers | # densenet201
Implementation of DenseNet proposed in [Densely Connected Convolutional
Networks](https://arxiv.org/abs/1608.06993)
Create a default models
``` {.sourceCode .}
DenseNet.densenet121()
DenseNet.densenet161()
DenseNet.densenet169()
DenseNet.densenet201()
```
Examples:
``` {.sourceCode .}
# change activation
DenseNet.densenet121(activation = nn.SELU)
# change number of classes (default is 1000 )
DenseNet.densenet121(n_classes=100)
# pass a different block
DenseNet.densenet121(block=...)
# change the initial convolution
model = DenseNet.densenet121()
model.encoder.gate.conv1 = nn.Conv2d(3, 64, kernel_size=3)
# store each feature
x = torch.rand((1, 3, 224, 224))
model = DenseNet.densenet121()
# first call .features, this will activate the forward hooks and tells the model you'll like to get the features
model.encoder.features
model(torch.randn((1,3,224,224)))
# get the features from the encoder
features = model.encoder.features
print([x.shape for x in features])
# [torch.Size([1, 128, 28, 28]), torch.Size([1, 256, 14, 14]), torch.Size([1, 512, 7, 7]), torch.Size([1, 1024, 7, 7])]
```
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.