
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-07-29 18:27:57
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 535
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-07-29 18:26:50
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
pietroluongo/Reinforce-Pixelcopter-PLE-v0
|
pietroluongo
| 2023-09-18T21:25:31Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-18T16:42:43Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Pixelcopter-PLE-v0
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 31.40 +/- 27.03
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
Atheer174/my_awesome_wnut_model
|
Atheer174
| 2023-09-18T21:06:24Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"token-classification",
"generated_from_trainer",
"dataset:wnut_17",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-09-18T20:26:29Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
datasets:
- wnut_17
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: my_awesome_wnut_model
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wnut_17
type: wnut_17
config: wnut_17
split: test
args: wnut_17
metrics:
- name: Precision
type: precision
value: 0.5716753022452504
- name: Recall
type: recall
value: 0.30676552363299353
- name: F1
type: f1
value: 0.3992762364294331
- name: Accuracy
type: accuracy
value: 0.9418152280791757
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_wnut_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the wnut_17 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2694
- Precision: 0.5717
- Recall: 0.3068
- F1: 0.3993
- Accuracy: 0.9418
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 213 | 0.2779 | 0.5596 | 0.2437 | 0.3396 | 0.9389 |
| No log | 2.0 | 426 | 0.2694 | 0.5717 | 0.3068 | 0.3993 | 0.9418 |
### Framework versions
- Transformers 4.33.2
- Pytorch 1.13.1+cu117
- Datasets 2.14.5
- Tokenizers 0.13.3
|
AIHUBFRANCE/Streameurs
|
AIHUBFRANCE
| 2023-09-18T20:58:42Z | 0 | 0 | null |
[
"fr",
"license:cc-by-sa-4.0",
"region:us"
] | null | 2023-08-19T10:22:03Z |
---
license: cc-by-sa-4.0
language:
- fr
---
# Fichiers .zip de Streameurs
## Disponible sur weights.gg
## Ou dans le séction "Files and Versions"
|
AIHUBFRANCE/jeux-video
|
AIHUBFRANCE
| 2023-09-18T20:58:33Z | 0 | 0 | null |
[
"fr",
"license:cc-by-sa-4.0",
"region:us"
] | null | 2023-08-19T12:06:15Z |
---
license: cc-by-sa-4.0
language:
- fr
---
# Fichiers .zip de Jeux Video
## Disponible sur weights.gg
## Ou dans le séction "Files and Versions"
|
AIHUBFRANCE/cartoon
|
AIHUBFRANCE
| 2023-09-18T20:58:03Z | 0 | 0 | null |
[
"fr",
"license:cc-by-sa-4.0",
"region:us"
] | null | 2023-08-19T12:38:59Z |
---
license: cc-by-sa-4.0
language:
- fr
---
# Fichiers .zip de Cartoon
## Disponible sur weights.gg
## Ou dans le séction "Files and Versions"
|
tensor-trek/distilbert-toxicity-classifier
|
tensor-trek
| 2023-09-18T20:53:28Z | 137 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"toxic text classification",
"en",
"arxiv:1910.01108",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-09-18T20:30:43Z |
---
language:
- en
tags:
- toxic text classification
licenses:
- apache-2.0
---
## Toxicity Classification Model
This model is trained for toxicity classification task using. The dataset used for training is the dataset by **Jigsaw** ( [Jigsaw 2020](https://www.kaggle.com/c/jigsaw-multilingual-toxic-comment-classification)). We split it into two parts and fine-tune a DistilBERT model ([DistilBERT base model (uncased) ](https://huggingface.co/distilbert-base-uncased)) on it. DistilBERT is a distilled version of the [BERT base model](https://huggingface.co/bert-base-uncased). It was introduced in this [paper](https://arxiv.org/abs/1910.01108).
## How to use
```python
from transformers import pipeline
text = "This was a masterpiece. Not completely faithful to the books, but enthralling from beginning to end. Might be my favorite of the three."
classifier = pipeline("text-classification", model="tensor-trek/distilbert-toxicity-classifier")
classifier(text)
```
## License
[Apache 2.0](./LICENSE)
|
marhatha/taxinumber9211
|
marhatha
| 2023-09-18T20:53:17Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-18T20:53:15Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: taxinumber9211
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.52 +/- 2.67
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="marhatha/taxinumber9211", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
asFrants/Reinforce-CartPole-v1
|
asFrants
| 2023-09-18T20:53:06Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-18T20:52:57Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 451.60 +/- 145.20
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
marhatha/frozenlakeSep18
|
marhatha
| 2023-09-18T20:48:46Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-18T20:48:43Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: frozenlakeSep18
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="marhatha/frozenlakeSep18", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Undi95/66Mytho33Pyg2-13B
|
Undi95
| 2023-09-18T20:44:51Z | 17 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-09-18T19:39:00Z |
For Kalomaze
66% Mythomax - 33% Pygmalion2
|
andy6655/trial-model
|
andy6655
| 2023-09-18T20:42:15Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"generated_from_trainer",
"base_model:FacebookAI/roberta-base",
"base_model:finetune:FacebookAI/roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-09-18T20:40:56Z |
---
license: mit
base_model: roberta-base
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: trial-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# trial-model
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1312
- F1: 0.1276
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
CyberHarem/takamine_noa_idolmastercinderellagirls
|
CyberHarem
| 2023-09-18T20:36:33Z | 0 | 0 | null |
[
"art",
"text-to-image",
"dataset:CyberHarem/takamine_noa_idolmastercinderellagirls",
"license:mit",
"region:us"
] |
text-to-image
| 2023-09-18T20:23:18Z |
---
license: mit
datasets:
- CyberHarem/takamine_noa_idolmastercinderellagirls
pipeline_tag: text-to-image
tags:
- art
---
# Lora of takamine_noa_idolmastercinderellagirls
This model is trained with [HCP-Diffusion](https://github.com/7eu7d7/HCP-Diffusion). And the auto-training framework is maintained by [DeepGHS Team](https://huggingface.co/deepghs).
The base model used during training is [NAI](https://huggingface.co/deepghs/animefull-latest), and the base model used for generating preview images is [Meina/MeinaMix_V11](https://huggingface.co/Meina/MeinaMix_V11).
After downloading the pt and safetensors files for the specified step, you need to use them simultaneously. The pt file will be used as an embedding, while the safetensors file will be loaded for Lora.
For example, if you want to use the model from step 3400, you need to download `3400/takamine_noa_idolmastercinderellagirls.pt` as the embedding and `3400/takamine_noa_idolmastercinderellagirls.safetensors` for loading Lora. By using both files together, you can generate images for the desired characters.
**The best step we recommend is 3400**, with the score of 0.840. The trigger words are:
1. `takamine_noa_idolmastercinderellagirls`
2. `long_hair, grey_hair, brown_eyes, breasts, jewelry, large_breasts`
For the following groups, it is not recommended to use this model and we express regret:
1. Individuals who cannot tolerate any deviations from the original character design, even in the slightest detail.
2. Individuals who are facing the application scenarios with high demands for accuracy in recreating character outfits.
3. Individuals who cannot accept the potential randomness in AI-generated images based on the Stable Diffusion algorithm.
4. Individuals who are not comfortable with the fully automated process of training character models using LoRA, or those who believe that training character models must be done purely through manual operations to avoid disrespecting the characters.
5. Individuals who finds the generated image content offensive to their values.
These are available steps:
| Steps | Score | Download | pattern_1 | pattern_2 | pattern_3 | pattern_4 | pattern_5 | pattern_6 | pattern_7 | bikini | bondage | free | maid | miko | nude | nude2 | suit | yukata |
|:---------|:----------|:----------------------------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:----------------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------|:--------------------------------------------------|:-------------------------------------|:-------------------------------------|:-------------------------------------|:-----------------------------------------------|:------------------------------------------------|:-------------------------------------|:-----------------------------------------|
| 5100 | 0.746 | [Download](5100/takamine_noa_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](5100/previews/pattern_3.png) |  |  |  |  |  | [<NSFW, click to see>](5100/previews/bondage.png) |  |  |  | [<NSFW, click to see>](5100/previews/nude.png) | [<NSFW, click to see>](5100/previews/nude2.png) |  |  |
| 4760 | 0.814 | [Download](4760/takamine_noa_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](4760/previews/pattern_3.png) |  |  |  |  |  | [<NSFW, click to see>](4760/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4760/previews/nude.png) | [<NSFW, click to see>](4760/previews/nude2.png) |  |  |
| 4420 | 0.835 | [Download](4420/takamine_noa_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](4420/previews/pattern_3.png) |  |  |  |  |  | [<NSFW, click to see>](4420/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4420/previews/nude.png) | [<NSFW, click to see>](4420/previews/nude2.png) |  |  |
| 4080 | 0.826 | [Download](4080/takamine_noa_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](4080/previews/pattern_3.png) |  |  |  |  |  | [<NSFW, click to see>](4080/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4080/previews/nude.png) | [<NSFW, click to see>](4080/previews/nude2.png) |  |  |
| 3740 | 0.790 | [Download](3740/takamine_noa_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](3740/previews/pattern_3.png) |  |  |  |  |  | [<NSFW, click to see>](3740/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3740/previews/nude.png) | [<NSFW, click to see>](3740/previews/nude2.png) |  |  |
| **3400** | **0.840** | [**Download**](3400/takamine_noa_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](3400/previews/pattern_3.png) |  |  |  |  |  | [<NSFW, click to see>](3400/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3400/previews/nude.png) | [<NSFW, click to see>](3400/previews/nude2.png) |  |  |
| 3060 | 0.753 | [Download](3060/takamine_noa_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](3060/previews/pattern_3.png) |  |  |  |  |  | [<NSFW, click to see>](3060/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3060/previews/nude.png) | [<NSFW, click to see>](3060/previews/nude2.png) |  |  |
| 2720 | 0.835 | [Download](2720/takamine_noa_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](2720/previews/pattern_3.png) |  |  |  |  |  | [<NSFW, click to see>](2720/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2720/previews/nude.png) | [<NSFW, click to see>](2720/previews/nude2.png) |  |  |
| 2380 | 0.770 | [Download](2380/takamine_noa_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](2380/previews/pattern_3.png) |  |  |  |  |  | [<NSFW, click to see>](2380/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2380/previews/nude.png) | [<NSFW, click to see>](2380/previews/nude2.png) |  |  |
| 2040 | 0.784 | [Download](2040/takamine_noa_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](2040/previews/pattern_3.png) |  |  |  |  |  | [<NSFW, click to see>](2040/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2040/previews/nude.png) | [<NSFW, click to see>](2040/previews/nude2.png) |  |  |
| 1700 | 0.803 | [Download](1700/takamine_noa_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](1700/previews/pattern_3.png) |  |  |  |  |  | [<NSFW, click to see>](1700/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1700/previews/nude.png) | [<NSFW, click to see>](1700/previews/nude2.png) |  |  |
| 1360 | 0.828 | [Download](1360/takamine_noa_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](1360/previews/pattern_3.png) |  |  |  |  |  | [<NSFW, click to see>](1360/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1360/previews/nude.png) | [<NSFW, click to see>](1360/previews/nude2.png) |  |  |
| 1020 | 0.745 | [Download](1020/takamine_noa_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](1020/previews/pattern_3.png) |  |  |  |  |  | [<NSFW, click to see>](1020/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1020/previews/nude.png) | [<NSFW, click to see>](1020/previews/nude2.png) |  |  |
| 680 | 0.668 | [Download](680/takamine_noa_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](680/previews/pattern_3.png) |  |  |  |  |  | [<NSFW, click to see>](680/previews/bondage.png) |  |  |  | [<NSFW, click to see>](680/previews/nude.png) | [<NSFW, click to see>](680/previews/nude2.png) |  |  |
| 340 | 0.648 | [Download](340/takamine_noa_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](340/previews/pattern_3.png) |  |  |  |  |  | [<NSFW, click to see>](340/previews/bondage.png) |  |  |  | [<NSFW, click to see>](340/previews/nude.png) | [<NSFW, click to see>](340/previews/nude2.png) |  |  |
|
couldnt-find-good-name/aa
|
couldnt-find-good-name
| 2023-09-18T20:35:59Z | 0 | 0 | null |
[
"license:cc-by-4.0",
"region:us"
] | null | 2023-09-18T19:58:25Z |
---
license: cc-by-4.0
---
Model Name : aa
1.fp16/cleaned - smaller size, same result.
2.Vae baked
3.Fixed CLIP
/// **[**original checkpoint link**](https://civitai.com/models/140778)** *(all rights to the model belong to [bhjjjjhh](https://civitai.com/user/bhjjjjhh))*
|
CyberHarem/tsukimi_eiko_paripikoumei
|
CyberHarem
| 2023-09-18T20:28:49Z | 0 | 0 | null |
[
"art",
"text-to-image",
"dataset:CyberHarem/tsukimi_eiko_paripikoumei",
"license:mit",
"region:us"
] |
text-to-image
| 2023-09-18T20:07:26Z |
---
license: mit
datasets:
- CyberHarem/tsukimi_eiko_paripikoumei
pipeline_tag: text-to-image
tags:
- art
---
# Lora of tsukimi_eiko_paripikoumei
This model is trained with [HCP-Diffusion](https://github.com/7eu7d7/HCP-Diffusion). And the auto-training framework is maintained by [DeepGHS Team](https://huggingface.co/deepghs).
The base model used during training is [NAI](https://huggingface.co/deepghs/animefull-latest), and the base model used for generating preview images is [Meina/MeinaMix_V11](https://huggingface.co/Meina/MeinaMix_V11).
After downloading the pt and safetensors files for the specified step, you need to use them simultaneously. The pt file will be used as an embedding, while the safetensors file will be loaded for Lora.
For example, if you want to use the model from step 10800, you need to download `10800/tsukimi_eiko_paripikoumei.pt` as the embedding and `10800/tsukimi_eiko_paripikoumei.safetensors` for loading Lora. By using both files together, you can generate images for the desired characters.
**The best step we recommend is 10800**, with the score of 0.878. The trigger words are:
1. `tsukimi_eiko_paripikoumei`
2. `blonde_hair, long_hair, braid, twin_braids, hat, baseball_cap, bangs, blue_eyes, blunt_bangs, black_headwear, open_mouth`
For the following groups, it is not recommended to use this model and we express regret:
1. Individuals who cannot tolerate any deviations from the original character design, even in the slightest detail.
2. Individuals who are facing the application scenarios with high demands for accuracy in recreating character outfits.
3. Individuals who cannot accept the potential randomness in AI-generated images based on the Stable Diffusion algorithm.
4. Individuals who are not comfortable with the fully automated process of training character models using LoRA, or those who believe that training character models must be done purely through manual operations to avoid disrespecting the characters.
5. Individuals who finds the generated image content offensive to their values.
These are available steps:
| Steps | Score | Download | pattern_1 | pattern_2 | pattern_3 | pattern_4 | pattern_5 | pattern_6 | pattern_7 | pattern_8 | pattern_9 | pattern_10 | pattern_11 | pattern_12 | pattern_13 | pattern_14 | pattern_15 | pattern_16 | pattern_17 | pattern_18 | pattern_19 | bikini | bondage | free | maid | miko | nude | nude2 | suit | yukata |
|:----------|:----------|:----------------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:---------------------------------------------------|:---------------------------------------------------|:---------------------------------------------------|:---------------------------------------------------|:---------------------------------------------------|:---------------------------------------------------|:---------------------------------------------------|:---------------------------------------------------|:---------------------------------------------------|:---------------------------------------------------|:-------------------------------------------|:---------------------------------------------------|:---------------------------------------|:---------------------------------------|:---------------------------------------|:------------------------------------------------|:-------------------------------------------------|:---------------------------------------|:-------------------------------------------|
| **10800** | **0.878** | [**Download**](10800/tsukimi_eiko_paripikoumei.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](10800/previews/bondage.png) |  |  |  | [<NSFW, click to see>](10800/previews/nude.png) | [<NSFW, click to see>](10800/previews/nude2.png) |  |  |
| 10080 | 0.865 | [Download](10080/tsukimi_eiko_paripikoumei.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](10080/previews/bondage.png) |  |  |  | [<NSFW, click to see>](10080/previews/nude.png) | [<NSFW, click to see>](10080/previews/nude2.png) |  |  |
| 9360 | 0.848 | [Download](9360/tsukimi_eiko_paripikoumei.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](9360/previews/bondage.png) |  |  |  | [<NSFW, click to see>](9360/previews/nude.png) | [<NSFW, click to see>](9360/previews/nude2.png) |  |  |
| 8640 | 0.856 | [Download](8640/tsukimi_eiko_paripikoumei.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](8640/previews/bondage.png) |  |  |  | [<NSFW, click to see>](8640/previews/nude.png) | [<NSFW, click to see>](8640/previews/nude2.png) |  |  |
| 7920 | 0.845 | [Download](7920/tsukimi_eiko_paripikoumei.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](7920/previews/bondage.png) |  |  |  | [<NSFW, click to see>](7920/previews/nude.png) | [<NSFW, click to see>](7920/previews/nude2.png) |  |  |
| 7200 | 0.867 | [Download](7200/tsukimi_eiko_paripikoumei.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](7200/previews/bondage.png) |  |  |  | [<NSFW, click to see>](7200/previews/nude.png) | [<NSFW, click to see>](7200/previews/nude2.png) |  |  |
| 6480 | 0.864 | [Download](6480/tsukimi_eiko_paripikoumei.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](6480/previews/bondage.png) |  |  |  | [<NSFW, click to see>](6480/previews/nude.png) | [<NSFW, click to see>](6480/previews/nude2.png) |  |  |
| 5760 | 0.860 | [Download](5760/tsukimi_eiko_paripikoumei.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](5760/previews/bondage.png) |  |  |  | [<NSFW, click to see>](5760/previews/nude.png) | [<NSFW, click to see>](5760/previews/nude2.png) |  |  |
| 5040 | 0.827 | [Download](5040/tsukimi_eiko_paripikoumei.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](5040/previews/bondage.png) |  |  |  | [<NSFW, click to see>](5040/previews/nude.png) | [<NSFW, click to see>](5040/previews/nude2.png) |  |  |
| 4320 | 0.834 | [Download](4320/tsukimi_eiko_paripikoumei.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](4320/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4320/previews/nude.png) | [<NSFW, click to see>](4320/previews/nude2.png) |  |  |
| 3600 | 0.810 | [Download](3600/tsukimi_eiko_paripikoumei.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](3600/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3600/previews/nude.png) | [<NSFW, click to see>](3600/previews/nude2.png) |  |  |
| 2880 | 0.812 | [Download](2880/tsukimi_eiko_paripikoumei.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](2880/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2880/previews/nude.png) | [<NSFW, click to see>](2880/previews/nude2.png) |  |  |
| 2160 | 0.832 | [Download](2160/tsukimi_eiko_paripikoumei.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](2160/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2160/previews/nude.png) | [<NSFW, click to see>](2160/previews/nude2.png) |  |  |
| 1440 | 0.740 | [Download](1440/tsukimi_eiko_paripikoumei.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](1440/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1440/previews/nude.png) | [<NSFW, click to see>](1440/previews/nude2.png) |  |  |
| 720 | 0.700 | [Download](720/tsukimi_eiko_paripikoumei.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](720/previews/bondage.png) |  |  |  | [<NSFW, click to see>](720/previews/nude.png) | [<NSFW, click to see>](720/previews/nude2.png) |  |  |
|
ShivamMangale/XLM-Roberta-base-finetuned-squad-syn-first-now-squad-10k-5-epoch-second_run
|
ShivamMangale
| 2023-09-18T20:24:10Z | 116 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"base_model:ShivamMangale/XLM-Roberta-base-finetuned-squad-syn-first-10k-5-epoch-second_run",
"base_model:finetune:ShivamMangale/XLM-Roberta-base-finetuned-squad-syn-first-10k-5-epoch-second_run",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-09-18T20:06:30Z |
---
license: mit
base_model: ShivamMangale/XLM-Roberta-base-finetuned-squad-syn-first-10k-5-epoch-second_run
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: XLM-Roberta-base-finetuned-squad-syn-first-now-squad-10k-5-epoch-second_run
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# XLM-Roberta-base-finetuned-squad-syn-first-now-squad-10k-5-epoch-second_run
This model is a fine-tuned version of [ShivamMangale/XLM-Roberta-base-finetuned-squad-syn-first-10k-5-epoch-second_run](https://huggingface.co/ShivamMangale/XLM-Roberta-base-finetuned-squad-syn-first-10k-5-epoch-second_run) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu117
- Datasets 2.14.5
- Tokenizers 0.13.3
|
K00B404/CodeLlama-7B-Instruct-bf16-sharded-ft-v0_01
|
K00B404
| 2023-09-18T20:14:22Z | 0 | 0 |
peft
|
[
"peft",
"dataset:nickrosh/Evol-Instruct-Code-80k-v1",
"license:afl-3.0",
"region:us"
] | null | 2023-09-18T18:10:08Z |
---
library_name: peft
license: afl-3.0
datasets:
- nickrosh/Evol-Instruct-Code-80k-v1
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.6.0.dev0
"""
Original file is located at
https://colab.research.google.com/drive/1yH0ov1ZDpun6yGi19zE07jkF_EUMI1Bf
**Code Credit: Hugging Face**
**Dataset Credit: https://twitter.com/Dorialexander/status/1681671177696161794 **
## Finetune Llama-2-7b on a Google colab
Welcome to this Google Colab notebook that shows how to fine-tune the recent code Llama-2-7b model on a single Google colab and turn it into a chatbot
We will leverage PEFT library from Hugging Face ecosystem, as well as QLoRA for more memory efficient finetuning
## Setup
Run the cells below to setup and install the required libraries. For our experiment we will need `accelerate`, `peft`, `transformers`, `datasets` and TRL to leverage the recent [`SFTTrainer`](https://huggingface.co/docs/trl/main/en/sft_trainer). We will use `bitsandbytes` to [quantize the base model into 4bit](https://huggingface.co/blog/4bit-transformers-bitsandbytes). We will also install `einops` as it is a requirement to load Falcon models.
"""
!pip install -q -U trl transformers accelerate git+https://github.com/huggingface/peft.git
!pip install -q datasets bitsandbytes einops wandb
"""## Dataset
login huggingface
"""
import wandb
!wandb login
# Initialize WandB
wandb_key=["<API_KEY>"]
wandb.init(project="<project_name>",
name="<name>"
)
# login with API
from huggingface_hub import login
login()
from datasets import load_dataset
#dataset_name = "timdettmers/openassistant-guanaco" ###Human ,.,,,,,, ###Assistant
dataset_name = "nickrosh/Evol-Instruct-Code-80k-v1"
#dataset_name = 'AlexanderDoria/novel17_test' #french novels
dataset = load_dataset(dataset_name, split="train")
"""## Loading the model"""
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, AutoTokenizer
#model_name = "TinyPixel/Llama-2-7B-bf16-sharded"
#model_name = "abhinand/Llama-2-7B-bf16-sharded-512MB"
model_name= "TinyPixel/CodeLlama-7B-Instruct-bf16-sharded"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
trust_remote_code=True
)
model.config.use_cache = False
"""Let's also load the tokenizer below"""
inputs = tokenizer(text, return_tensors="pt", padding="max_length", max_length=max_seq_length, truncation=True).to(device)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
from peft import LoraConfig, get_peft_model
lora_alpha = 16
lora_dropout = 0.1
lora_r = 64
peft_config = LoraConfig(
lora_alpha=lora_alpha,
lora_dropout=lora_dropout,
r=lora_r,
bias="none",
task_type="CAUSAL_LM"
)
"""## Loading the trainer
Here we will use the [`SFTTrainer` from TRL library](https://huggingface.co/docs/trl/main/en/sft_trainer) that gives a wrapper around transformers `Trainer` to easily fine-tune models on instruction based datasets using PEFT adapters. Let's first load the training arguments below.
"""
from transformers import TrainingArguments
output_dir = "./results"
per_device_train_batch_size = 4
gradient_accumulation_steps = 4
optim = "paged_adamw_32bit"
save_steps = 100
logging_steps = 10
learning_rate = 2e-4
max_grad_norm = 0.3
max_steps = 100
warmup_ratio = 0.03
lr_scheduler_type = "constant"
training_arguments = TrainingArguments(
output_dir=output_dir,
per_device_train_batch_size=per_device_train_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
optim=optim,
save_steps=save_steps,
logging_steps=logging_steps,
learning_rate=learning_rate,
fp16=True,
max_grad_norm=max_grad_norm,
max_steps=max_steps,
warmup_ratio=warmup_ratio,
group_by_length=True,
lr_scheduler_type=lr_scheduler_type,
)
"""Then finally pass everthing to the trainer"""
from trl import SFTTrainer
max_seq_length = 512
trainer = SFTTrainer(
model=model,
train_dataset=dataset,
peft_config=peft_config,
dataset_text_field="output",
max_seq_length=max_seq_length,
tokenizer=tokenizer,
args=training_arguments,
)
"""We will also pre-process the model by upcasting the layer norms in float 32 for more stable training"""
for name, module in trainer.model.named_modules():
if "norm" in name:
module = module.to(torch.float32)
"""## Train the model
You're using a LlamaTokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.
Now let's train the model! Simply call `trainer.train()`
"""
trainer.train()
"""During training, the model should converge nicely as follows:
The `SFTTrainer` also takes care of properly saving only the adapters during training instead of saving the entire model.
"""
model_to_save = trainer.model.module if hasattr(trainer.model, 'module') else trainer.model # Take care of distributed/parallel training
model_to_save.save_pretrained("outputs")
lora_config = LoraConfig.from_pretrained('outputs')
model = get_peft_model(model, lora_config)
dataset['output']
text = "make a advanced python script to finetune a llama2-7b-bf16-sharded model with accelerator and qlora"
device = "cuda:0"
inputs = tokenizer(text, return_tensors="pt", padding="max_length", max_length=max_seq_length, truncation=True).to(device)
#inputs = tokenizer(text, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_new_tokens=150)
print(tokenizer.decode(outputs[0], skip_special_tokens=False))
model.push_to_hub("K00B404/CodeLlama-7B-Instruct-bf16-sharded-ft-v0_01", use_auth_token="<HUGGINGFACE_WRITE-api")
|
ShivamMangale/XLM-Roberta-base-finetuned-squad-syn-first-10k-5-epoch-second_run
|
ShivamMangale
| 2023-09-18T19:56:36Z | 104 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-09-18T19:42:08Z |
---
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: XLM-Roberta-base-finetuned-squad-syn-first-10k-5-epoch-second_run
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# XLM-Roberta-base-finetuned-squad-syn-first-10k-5-epoch-second_run
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu117
- Datasets 2.14.5
- Tokenizers 0.13.3
|
CyberHarem/araki_hina_idolmastercinderellagirls
|
CyberHarem
| 2023-09-18T19:53:26Z | 0 | 0 | null |
[
"art",
"text-to-image",
"dataset:CyberHarem/araki_hina_idolmastercinderellagirls",
"license:mit",
"region:us"
] |
text-to-image
| 2023-09-18T19:39:29Z |
---
license: mit
datasets:
- CyberHarem/araki_hina_idolmastercinderellagirls
pipeline_tag: text-to-image
tags:
- art
---
# Lora of araki_hina_idolmastercinderellagirls
This model is trained with [HCP-Diffusion](https://github.com/7eu7d7/HCP-Diffusion). And the auto-training framework is maintained by [DeepGHS Team](https://huggingface.co/deepghs).
The base model used during training is [NAI](https://huggingface.co/deepghs/animefull-latest), and the base model used for generating preview images is [Meina/MeinaMix_V11](https://huggingface.co/Meina/MeinaMix_V11).
After downloading the pt and safetensors files for the specified step, you need to use them simultaneously. The pt file will be used as an embedding, while the safetensors file will be loaded for Lora.
For example, if you want to use the model from step 5700, you need to download `5700/araki_hina_idolmastercinderellagirls.pt` as the embedding and `5700/araki_hina_idolmastercinderellagirls.safetensors` for loading Lora. By using both files together, you can generate images for the desired characters.
**The best step we recommend is 5700**, with the score of 0.935. The trigger words are:
1. `araki_hina_idolmastercinderellagirls`
2. `brown_hair, brown_eyes, blush, glasses, breasts, open_mouth, messy_hair, short_hair, ahoge, smile, medium_breasts`
For the following groups, it is not recommended to use this model and we express regret:
1. Individuals who cannot tolerate any deviations from the original character design, even in the slightest detail.
2. Individuals who are facing the application scenarios with high demands for accuracy in recreating character outfits.
3. Individuals who cannot accept the potential randomness in AI-generated images based on the Stable Diffusion algorithm.
4. Individuals who are not comfortable with the fully automated process of training character models using LoRA, or those who believe that training character models must be done purely through manual operations to avoid disrespecting the characters.
5. Individuals who finds the generated image content offensive to their values.
These are available steps:
| Steps | Score | Download | pattern_1 | pattern_2 | pattern_3 | pattern_4 | pattern_5 | pattern_6 | pattern_7 | pattern_8 | bikini | bondage | free | maid | miko | nude | nude2 | suit | yukata |
|:---------|:----------|:--------------------------------------------------------------|:----------------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-------------------------------------------------|:--------------------------------------------------|:-------------------------------------|:-------------------------------------|:-------------------------------------|:-----------------------------------------------|:------------------------------------------------|:-------------------------------------|:-----------------------------------------|
| **5700** | **0.935** | [**Download**](5700/araki_hina_idolmastercinderellagirls.zip) | [<NSFW, click to see>](5700/previews/pattern_1.png) |  |  |  |  |  |  |  | [<NSFW, click to see>](5700/previews/bikini.png) | [<NSFW, click to see>](5700/previews/bondage.png) |  |  |  | [<NSFW, click to see>](5700/previews/nude.png) | [<NSFW, click to see>](5700/previews/nude2.png) |  |  |
| 5320 | 0.909 | [Download](5320/araki_hina_idolmastercinderellagirls.zip) | [<NSFW, click to see>](5320/previews/pattern_1.png) |  |  |  |  |  |  |  | [<NSFW, click to see>](5320/previews/bikini.png) | [<NSFW, click to see>](5320/previews/bondage.png) |  |  |  | [<NSFW, click to see>](5320/previews/nude.png) | [<NSFW, click to see>](5320/previews/nude2.png) |  |  |
| 4940 | 0.931 | [Download](4940/araki_hina_idolmastercinderellagirls.zip) | [<NSFW, click to see>](4940/previews/pattern_1.png) |  |  |  |  |  |  |  | [<NSFW, click to see>](4940/previews/bikini.png) | [<NSFW, click to see>](4940/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4940/previews/nude.png) | [<NSFW, click to see>](4940/previews/nude2.png) |  |  |
| 4560 | 0.931 | [Download](4560/araki_hina_idolmastercinderellagirls.zip) | [<NSFW, click to see>](4560/previews/pattern_1.png) |  |  |  |  |  |  |  | [<NSFW, click to see>](4560/previews/bikini.png) | [<NSFW, click to see>](4560/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4560/previews/nude.png) | [<NSFW, click to see>](4560/previews/nude2.png) |  |  |
| 4180 | 0.934 | [Download](4180/araki_hina_idolmastercinderellagirls.zip) | [<NSFW, click to see>](4180/previews/pattern_1.png) |  |  |  |  |  |  |  | [<NSFW, click to see>](4180/previews/bikini.png) | [<NSFW, click to see>](4180/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4180/previews/nude.png) | [<NSFW, click to see>](4180/previews/nude2.png) |  |  |
| 3800 | 0.880 | [Download](3800/araki_hina_idolmastercinderellagirls.zip) | [<NSFW, click to see>](3800/previews/pattern_1.png) |  |  |  |  |  |  |  | [<NSFW, click to see>](3800/previews/bikini.png) | [<NSFW, click to see>](3800/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3800/previews/nude.png) | [<NSFW, click to see>](3800/previews/nude2.png) |  |  |
| 3420 | 0.890 | [Download](3420/araki_hina_idolmastercinderellagirls.zip) | [<NSFW, click to see>](3420/previews/pattern_1.png) |  |  |  |  |  |  |  | [<NSFW, click to see>](3420/previews/bikini.png) | [<NSFW, click to see>](3420/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3420/previews/nude.png) | [<NSFW, click to see>](3420/previews/nude2.png) |  |  |
| 3040 | 0.894 | [Download](3040/araki_hina_idolmastercinderellagirls.zip) | [<NSFW, click to see>](3040/previews/pattern_1.png) |  |  |  |  |  |  |  | [<NSFW, click to see>](3040/previews/bikini.png) | [<NSFW, click to see>](3040/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3040/previews/nude.png) | [<NSFW, click to see>](3040/previews/nude2.png) |  |  |
| 2660 | 0.867 | [Download](2660/araki_hina_idolmastercinderellagirls.zip) | [<NSFW, click to see>](2660/previews/pattern_1.png) |  |  |  |  |  |  |  | [<NSFW, click to see>](2660/previews/bikini.png) | [<NSFW, click to see>](2660/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2660/previews/nude.png) | [<NSFW, click to see>](2660/previews/nude2.png) |  |  |
| 2280 | 0.920 | [Download](2280/araki_hina_idolmastercinderellagirls.zip) | [<NSFW, click to see>](2280/previews/pattern_1.png) |  |  |  |  |  |  |  | [<NSFW, click to see>](2280/previews/bikini.png) | [<NSFW, click to see>](2280/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2280/previews/nude.png) | [<NSFW, click to see>](2280/previews/nude2.png) |  |  |
| 1900 | 0.915 | [Download](1900/araki_hina_idolmastercinderellagirls.zip) | [<NSFW, click to see>](1900/previews/pattern_1.png) |  |  |  |  |  |  |  | [<NSFW, click to see>](1900/previews/bikini.png) | [<NSFW, click to see>](1900/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1900/previews/nude.png) | [<NSFW, click to see>](1900/previews/nude2.png) |  |  |
| 1520 | 0.871 | [Download](1520/araki_hina_idolmastercinderellagirls.zip) | [<NSFW, click to see>](1520/previews/pattern_1.png) |  |  |  |  |  |  |  | [<NSFW, click to see>](1520/previews/bikini.png) | [<NSFW, click to see>](1520/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1520/previews/nude.png) | [<NSFW, click to see>](1520/previews/nude2.png) |  |  |
| 1140 | 0.801 | [Download](1140/araki_hina_idolmastercinderellagirls.zip) | [<NSFW, click to see>](1140/previews/pattern_1.png) |  |  |  |  |  |  |  | [<NSFW, click to see>](1140/previews/bikini.png) | [<NSFW, click to see>](1140/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1140/previews/nude.png) | [<NSFW, click to see>](1140/previews/nude2.png) |  |  |
| 760 | 0.728 | [Download](760/araki_hina_idolmastercinderellagirls.zip) | [<NSFW, click to see>](760/previews/pattern_1.png) |  |  |  |  |  |  |  | [<NSFW, click to see>](760/previews/bikini.png) | [<NSFW, click to see>](760/previews/bondage.png) |  |  |  | [<NSFW, click to see>](760/previews/nude.png) | [<NSFW, click to see>](760/previews/nude2.png) |  |  |
| 380 | 0.626 | [Download](380/araki_hina_idolmastercinderellagirls.zip) | [<NSFW, click to see>](380/previews/pattern_1.png) |  |  |  |  |  |  |  | [<NSFW, click to see>](380/previews/bikini.png) | [<NSFW, click to see>](380/previews/bondage.png) |  |  |  | [<NSFW, click to see>](380/previews/nude.png) | [<NSFW, click to see>](380/previews/nude2.png) |  |  |
|
3sulton/image_classification
|
3sulton
| 2023-09-18T19:47:23Z | 215 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-09-18T19:25:50Z |
---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: image_classification
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.4375
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# image_classification
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6601
- Accuracy: 0.4375
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.0289 | 1.0 | 10 | 1.9865 | 0.2812 |
| 1.9055 | 2.0 | 20 | 1.8493 | 0.3875 |
| 1.7613 | 3.0 | 30 | 1.7289 | 0.4625 |
| 1.6622 | 4.0 | 40 | 1.6590 | 0.4688 |
| 1.6224 | 5.0 | 50 | 1.6339 | 0.4688 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
rayrico/bert-fine-tuned-cola
|
rayrico
| 2023-09-18T19:35:26Z | 63 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"text-classification",
"generated_from_keras_callback",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-09-18T19:30:19Z |
---
license: apache-2.0
base_model: bert-base-cased
tags:
- generated_from_keras_callback
model-index:
- name: bert-fine-tuned-cola
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# bert-fine-tuned-cola
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.3144
- Validation Loss: 0.4951
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': 2e-05, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 0.5218 | 0.4787 | 0 |
| 0.3144 | 0.4951 | 1 |
### Framework versions
- Transformers 4.33.2
- TensorFlow 2.13.0
- Datasets 2.14.5
- Tokenizers 0.13.3
|
Gayathri142214002/Pegasus_paraphraser_1
|
Gayathri142214002
| 2023-09-18T19:02:20Z | 9 | 0 |
transformers
|
[
"transformers",
"pytorch",
"pegasus",
"text2text-generation",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-09-14T04:39:52Z |
---
tags:
- generated_from_trainer
model-index:
- name: Pegasus_paraphraser_1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Pegasus_paraphraser_1
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2991
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.0688 | 0.01 | 10 | 0.2457 |
| 0.2896 | 0.01 | 20 | 0.2403 |
| 0.2359 | 0.02 | 30 | 0.2326 |
| 0.3123 | 0.02 | 40 | 0.2367 |
| 0.2913 | 0.03 | 50 | 0.2309 |
| 0.2572 | 0.03 | 60 | 0.2256 |
| 0.2803 | 0.04 | 70 | 0.2263 |
| 0.2946 | 0.04 | 80 | 0.2243 |
| 0.2211 | 0.05 | 90 | 0.2283 |
| 0.2161 | 0.05 | 100 | 0.2405 |
| 0.2927 | 0.06 | 110 | 0.2355 |
| 0.3544 | 0.07 | 120 | 0.2330 |
| 0.2933 | 0.07 | 130 | 0.2322 |
| 0.2535 | 0.08 | 140 | 0.2301 |
| 0.2799 | 0.08 | 150 | 0.2302 |
| 0.2532 | 0.09 | 160 | 0.2296 |
| 0.2382 | 0.09 | 170 | 0.2356 |
| 0.2758 | 0.1 | 180 | 0.2376 |
| 0.2552 | 0.1 | 190 | 0.2451 |
| 0.289 | 0.11 | 200 | 0.2439 |
| 0.247 | 0.11 | 210 | 0.2424 |
| 0.259 | 0.12 | 220 | 0.2448 |
| 0.2562 | 0.13 | 230 | 0.2491 |
| 0.2951 | 0.13 | 240 | 0.2554 |
| 0.2624 | 0.14 | 250 | 0.2476 |
| 0.2542 | 0.14 | 260 | 0.2474 |
| 0.2178 | 0.15 | 270 | 0.2501 |
| 0.3126 | 0.15 | 280 | 0.2483 |
| 0.2585 | 0.16 | 290 | 0.2492 |
| 0.2559 | 0.16 | 300 | 0.2502 |
| 0.231 | 0.17 | 310 | 0.2539 |
| 0.3023 | 0.17 | 320 | 0.2486 |
| 0.328 | 0.18 | 330 | 0.2491 |
| 0.313 | 0.19 | 340 | 0.2490 |
| 0.3041 | 0.19 | 350 | 0.2471 |
| 0.2719 | 0.2 | 360 | 0.2433 |
| 0.2655 | 0.2 | 370 | 0.2443 |
| 0.3171 | 0.21 | 380 | 0.2453 |
| 0.2398 | 0.21 | 390 | 0.2440 |
| 0.2682 | 0.22 | 400 | 0.2477 |
| 0.3193 | 0.22 | 410 | 0.2476 |
| 0.2754 | 0.23 | 420 | 0.2455 |
| 0.2635 | 0.23 | 430 | 0.2451 |
| 0.2593 | 0.24 | 440 | 0.2479 |
| 0.2955 | 0.25 | 450 | 0.2454 |
| 0.2923 | 0.25 | 460 | 0.2472 |
| 0.2947 | 0.26 | 470 | 0.2488 |
| 0.2718 | 0.26 | 480 | 0.2503 |
| 0.2772 | 0.27 | 490 | 0.2507 |
| 0.2183 | 0.27 | 500 | 0.2545 |
| 0.3563 | 0.28 | 510 | 0.2574 |
| 0.2762 | 0.28 | 520 | 0.2585 |
| 0.2336 | 0.29 | 530 | 0.2537 |
| 0.2548 | 0.29 | 540 | 0.2550 |
| 0.315 | 0.3 | 550 | 0.2625 |
| 0.2827 | 0.31 | 560 | 0.2641 |
| 0.2911 | 0.31 | 570 | 0.2621 |
| 0.2515 | 0.32 | 580 | 0.2625 |
| 0.3003 | 0.32 | 590 | 0.2665 |
| 0.2987 | 0.33 | 600 | 0.2653 |
| 0.3119 | 0.33 | 610 | 0.2622 |
| 0.305 | 0.34 | 620 | 0.2638 |
| 0.2828 | 0.34 | 630 | 0.2637 |
| 0.2416 | 0.35 | 640 | 0.2641 |
| 0.2829 | 0.35 | 650 | 0.2642 |
| 0.2757 | 0.36 | 660 | 0.2645 |
| 0.2548 | 0.37 | 670 | 0.2640 |
| 0.2737 | 0.37 | 680 | 0.2607 |
| 0.2963 | 0.38 | 690 | 0.2673 |
| 0.2622 | 0.38 | 700 | 0.2641 |
| 0.2773 | 0.39 | 710 | 0.2673 |
| 0.2883 | 0.39 | 720 | 0.2666 |
| 0.2855 | 0.4 | 730 | 0.2685 |
| 0.271 | 0.4 | 740 | 0.2655 |
| 0.2627 | 0.41 | 750 | 0.2673 |
| 0.2739 | 0.41 | 760 | 0.2677 |
| 0.2539 | 0.42 | 770 | 0.2702 |
| 0.2824 | 0.43 | 780 | 0.2723 |
| 0.3174 | 0.43 | 790 | 0.2767 |
| 0.2902 | 0.44 | 800 | 0.2790 |
| 0.2755 | 0.44 | 810 | 0.2701 |
| 0.253 | 0.45 | 820 | 0.2711 |
| 0.2619 | 0.45 | 830 | 0.2708 |
| 0.2819 | 0.46 | 840 | 0.2706 |
| 0.2686 | 0.46 | 850 | 0.2683 |
| 0.2683 | 0.47 | 860 | 0.2734 |
| 0.2702 | 0.47 | 870 | 0.2695 |
| 0.2793 | 0.48 | 880 | 0.2771 |
| 0.2807 | 0.49 | 890 | 0.2753 |
| 0.3387 | 0.49 | 900 | 0.2695 |
| 0.2924 | 0.5 | 910 | 0.2670 |
| 0.3004 | 0.5 | 920 | 0.2669 |
| 0.2653 | 0.51 | 930 | 0.2760 |
| 0.241 | 0.51 | 940 | 0.2700 |
| 0.2828 | 0.52 | 950 | 0.2704 |
| 0.2804 | 0.52 | 960 | 0.2707 |
| 0.2888 | 0.53 | 970 | 0.2672 |
| 0.3065 | 0.54 | 980 | 0.2678 |
| 0.2853 | 0.54 | 990 | 0.2706 |
| 0.2579 | 0.55 | 1000 | 0.2685 |
| 0.3108 | 0.55 | 1010 | 0.2679 |
| 0.3061 | 0.56 | 1020 | 0.2687 |
| 0.2836 | 0.56 | 1030 | 0.2688 |
| 0.2081 | 0.57 | 1040 | 0.2769 |
| 0.312 | 0.57 | 1050 | 0.2770 |
| 0.29 | 0.58 | 1060 | 0.2701 |
| 0.3126 | 0.58 | 1070 | 0.2699 |
| 0.3559 | 0.59 | 1080 | 0.2690 |
| 0.3611 | 0.6 | 1090 | 0.2864 |
| 0.3906 | 0.6 | 1100 | 0.4051 |
| 0.3261 | 0.61 | 1110 | 0.2743 |
| 0.2893 | 0.61 | 1120 | 0.2725 |
| 0.2796 | 0.62 | 1130 | 0.2713 |
| 0.289 | 0.62 | 1140 | 0.2717 |
| 0.29 | 0.63 | 1150 | 0.2718 |
| 0.2983 | 0.63 | 1160 | 0.2729 |
| 0.3058 | 0.64 | 1170 | 0.2696 |
| 0.23 | 0.64 | 1180 | 0.2731 |
| 0.2558 | 0.65 | 1190 | 0.2748 |
| 0.3722 | 0.66 | 1200 | 0.2740 |
| 0.3308 | 0.66 | 1210 | 0.2718 |
| 0.27 | 0.67 | 1220 | 0.2724 |
| 0.2897 | 0.67 | 1230 | 0.2750 |
| 0.2954 | 0.68 | 1240 | 0.2776 |
| 0.264 | 0.68 | 1250 | 0.2737 |
| 0.2802 | 0.69 | 1260 | 0.2738 |
| 0.3027 | 0.69 | 1270 | 0.2702 |
| 0.2881 | 0.7 | 1280 | 0.2701 |
| 0.2664 | 0.7 | 1290 | 0.2699 |
| 0.3288 | 0.71 | 1300 | 0.2707 |
| 0.3315 | 0.72 | 1310 | 0.2686 |
| 0.3577 | 0.72 | 1320 | 0.2686 |
| 0.3046 | 0.73 | 1330 | 0.2702 |
| 0.2872 | 0.73 | 1340 | 0.2697 |
| 0.3242 | 0.74 | 1350 | 0.2693 |
| 0.3268 | 0.74 | 1360 | 0.2704 |
| 0.2845 | 0.75 | 1370 | 0.2756 |
| 0.2816 | 0.75 | 1380 | 0.2705 |
| 0.3121 | 0.76 | 1390 | 0.2678 |
| 0.2989 | 0.76 | 1400 | 0.2687 |
| 0.2611 | 0.77 | 1410 | 0.2701 |
| 0.2954 | 0.78 | 1420 | 0.2711 |
| 0.3025 | 0.78 | 1430 | 0.2711 |
| 0.2692 | 0.79 | 1440 | 0.2732 |
| 0.249 | 0.79 | 1450 | 0.2753 |
| 0.2673 | 0.8 | 1460 | 0.2779 |
| 0.2471 | 0.8 | 1470 | 0.2829 |
| 0.2925 | 0.81 | 1480 | 0.2806 |
| 0.3005 | 0.81 | 1490 | 0.2785 |
| 0.3009 | 0.82 | 1500 | 0.2765 |
| 0.2556 | 0.82 | 1510 | 0.2740 |
| 0.3265 | 0.83 | 1520 | 0.2775 |
| 0.2731 | 0.84 | 1530 | 0.2816 |
| 0.3406 | 0.84 | 1540 | 0.2767 |
| 0.2936 | 0.85 | 1550 | 0.2760 |
| 0.3001 | 0.85 | 1560 | 0.2737 |
| 0.3017 | 0.86 | 1570 | 0.2755 |
| 0.3212 | 0.86 | 1580 | 0.2784 |
| 0.3122 | 0.87 | 1590 | 0.2742 |
| 0.2591 | 0.87 | 1600 | 0.2720 |
| 0.28 | 0.88 | 1610 | 0.2736 |
| 0.2641 | 0.88 | 1620 | 0.2736 |
| 0.3488 | 0.89 | 1630 | 0.2715 |
| 0.3505 | 0.9 | 1640 | 0.2701 |
| 0.2676 | 0.9 | 1650 | 0.2699 |
| 0.2444 | 0.91 | 1660 | 0.2711 |
| 0.2493 | 0.91 | 1670 | 0.2732 |
| 0.326 | 0.92 | 1680 | 0.2735 |
| 0.3099 | 0.92 | 1690 | 0.2737 |
| 0.2893 | 0.93 | 1700 | 0.2717 |
| 0.3139 | 0.93 | 1710 | 0.2737 |
| 0.2913 | 0.94 | 1720 | 0.2777 |
| 0.2999 | 0.94 | 1730 | 0.2721 |
| 0.2708 | 0.95 | 1740 | 0.2704 |
| 0.3208 | 0.96 | 1750 | 0.2690 |
| 0.2691 | 0.96 | 1760 | 0.2692 |
| 0.2921 | 0.97 | 1770 | 0.2696 |
| 0.2782 | 0.97 | 1780 | 0.2706 |
| 0.2937 | 0.98 | 1790 | 0.2703 |
| 0.2948 | 0.98 | 1800 | 0.2695 |
| 0.3195 | 0.99 | 1810 | 0.2682 |
| 0.2525 | 0.99 | 1820 | 0.2678 |
| 0.2434 | 1.0 | 1830 | 0.2685 |
| 0.2043 | 1.0 | 1840 | 0.2721 |
| 0.216 | 1.01 | 1850 | 0.2733 |
| 0.1924 | 1.02 | 1860 | 0.2696 |
| 0.2219 | 1.02 | 1870 | 0.2707 |
| 0.2198 | 1.03 | 1880 | 0.2722 |
| 0.1829 | 1.03 | 1890 | 0.2735 |
| 0.247 | 1.04 | 1900 | 0.2768 |
| 0.2243 | 1.04 | 1910 | 0.2759 |
| 0.2747 | 1.05 | 1920 | 0.2769 |
| 0.187 | 1.05 | 1930 | 0.2796 |
| 0.2698 | 1.06 | 1940 | 0.2797 |
| 0.218 | 1.06 | 1950 | 0.2822 |
| 0.2155 | 1.07 | 1960 | 0.2817 |
| 0.2352 | 1.08 | 1970 | 0.2832 |
| 0.1915 | 1.08 | 1980 | 0.2799 |
| 0.2425 | 1.09 | 1990 | 0.2779 |
| 0.2212 | 1.09 | 2000 | 0.2824 |
| 0.2271 | 1.1 | 2010 | 0.2848 |
| 0.2349 | 1.1 | 2020 | 0.2851 |
| 0.2579 | 1.11 | 2030 | 0.2817 |
| 0.2097 | 1.11 | 2040 | 0.2832 |
| 0.2205 | 1.12 | 2050 | 0.2852 |
| 0.2462 | 1.12 | 2060 | 0.2868 |
| 0.2121 | 1.13 | 2070 | 0.2895 |
| 0.2251 | 1.14 | 2080 | 0.2864 |
| 0.2052 | 1.14 | 2090 | 0.2833 |
| 0.2202 | 1.15 | 2100 | 0.2851 |
| 0.2295 | 1.15 | 2110 | 0.2850 |
| 0.2419 | 1.16 | 2120 | 0.2904 |
| 0.2639 | 1.16 | 2130 | 0.2866 |
| 0.2106 | 1.17 | 2140 | 0.2913 |
| 0.2454 | 1.17 | 2150 | 0.2924 |
| 0.2348 | 1.18 | 2160 | 0.2890 |
| 0.209 | 1.18 | 2170 | 0.2885 |
| 0.2523 | 1.19 | 2180 | 0.2873 |
| 0.2293 | 1.2 | 2190 | 0.2836 |
| 0.2258 | 1.2 | 2200 | 0.2842 |
| 0.249 | 1.21 | 2210 | 0.2849 |
| 0.2917 | 1.21 | 2220 | 0.2834 |
| 0.2268 | 1.22 | 2230 | 0.2824 |
| 0.2453 | 1.22 | 2240 | 0.2820 |
| 0.236 | 1.23 | 2250 | 0.2829 |
| 0.2191 | 1.23 | 2260 | 0.2841 |
| 0.2509 | 1.24 | 2270 | 0.2822 |
| 0.2481 | 1.24 | 2280 | 0.2830 |
| 0.2268 | 1.25 | 2290 | 0.2840 |
| 0.2594 | 1.26 | 2300 | 0.2803 |
| 0.242 | 1.26 | 2310 | 0.2827 |
| 0.2563 | 1.27 | 2320 | 0.2827 |
| 0.2269 | 1.27 | 2330 | 0.2803 |
| 0.2409 | 1.28 | 2340 | 0.2780 |
| 0.2946 | 1.28 | 2350 | 0.2778 |
| 0.2718 | 1.29 | 2360 | 0.2757 |
| 0.2407 | 1.29 | 2370 | 0.2776 |
| 0.2259 | 1.3 | 2380 | 0.2810 |
| 0.2235 | 1.3 | 2390 | 0.2829 |
| 0.266 | 1.31 | 2400 | 0.2806 |
| 0.229 | 1.32 | 2410 | 0.2796 |
| 0.2154 | 1.32 | 2420 | 0.2794 |
| 0.2551 | 1.33 | 2430 | 0.2766 |
| 0.2169 | 1.33 | 2440 | 0.2779 |
| 0.2396 | 1.34 | 2450 | 0.2776 |
| 0.2239 | 1.34 | 2460 | 0.2835 |
| 0.2325 | 1.35 | 2470 | 0.2823 |
| 0.2421 | 1.35 | 2480 | 0.2841 |
| 0.2456 | 1.36 | 2490 | 0.2861 |
| 0.2295 | 1.36 | 2500 | 0.2828 |
| 0.2549 | 1.37 | 2510 | 0.2835 |
| 0.2442 | 1.38 | 2520 | 0.2832 |
| 0.2572 | 1.38 | 2530 | 0.2821 |
| 0.235 | 1.39 | 2540 | 0.2796 |
| 0.2687 | 1.39 | 2550 | 0.2791 |
| 0.2539 | 1.4 | 2560 | 0.2787 |
| 0.2496 | 1.4 | 2570 | 0.2789 |
| 0.269 | 1.41 | 2580 | 0.2806 |
| 0.2851 | 1.41 | 2590 | 0.2808 |
| 0.274 | 1.42 | 2600 | 0.2806 |
| 0.2365 | 1.42 | 2610 | 0.2814 |
| 0.2031 | 1.43 | 2620 | 0.2864 |
| 0.2371 | 1.44 | 2630 | 0.2901 |
| 0.2513 | 1.44 | 2640 | 0.2891 |
| 0.2393 | 1.45 | 2650 | 0.2843 |
| 0.2498 | 1.45 | 2660 | 0.2832 |
| 0.2634 | 1.46 | 2670 | 0.2842 |
| 0.2845 | 1.46 | 2680 | 0.2812 |
| 0.263 | 1.47 | 2690 | 0.2791 |
| 0.261 | 1.47 | 2700 | 0.2794 |
| 0.2543 | 1.48 | 2710 | 0.2802 |
| 0.278 | 1.48 | 2720 | 0.2812 |
| 0.2583 | 1.49 | 2730 | 0.2843 |
| 0.238 | 1.5 | 2740 | 0.2839 |
| 0.2525 | 1.5 | 2750 | 0.2821 |
| 0.2605 | 1.51 | 2760 | 0.2814 |
| 0.2673 | 1.51 | 2770 | 0.2826 |
| 0.2298 | 1.52 | 2780 | 0.2856 |
| 0.2409 | 1.52 | 2790 | 0.2872 |
| 0.2502 | 1.53 | 2800 | 0.2879 |
| 0.2569 | 1.53 | 2810 | 0.2864 |
| 0.2299 | 1.54 | 2820 | 0.2858 |
| 0.2508 | 1.54 | 2830 | 0.2843 |
| 0.213 | 1.55 | 2840 | 0.2839 |
| 0.2404 | 1.56 | 2850 | 0.2842 |
| 0.2626 | 1.56 | 2860 | 0.2823 |
| 0.2296 | 1.57 | 2870 | 0.2821 |
| 0.2284 | 1.57 | 2880 | 0.2834 |
| 0.2481 | 1.58 | 2890 | 0.2834 |
| 0.271 | 1.58 | 2900 | 0.2801 |
| 0.2779 | 1.59 | 2910 | 0.2796 |
| 0.2247 | 1.59 | 2920 | 0.2782 |
| 0.2334 | 1.6 | 2930 | 0.2785 |
| 0.2469 | 1.61 | 2940 | 0.2811 |
| 0.2526 | 1.61 | 2950 | 0.2801 |
| 0.2788 | 1.62 | 2960 | 0.2801 |
| 0.2463 | 1.62 | 2970 | 0.2804 |
| 0.2367 | 1.63 | 2980 | 0.2815 |
| 0.2096 | 1.63 | 2990 | 0.2822 |
| 0.2252 | 1.64 | 3000 | 0.2826 |
| 0.2724 | 1.64 | 3010 | 0.2829 |
| 0.2514 | 1.65 | 3020 | 0.2814 |
| 0.2396 | 1.65 | 3030 | 0.2802 |
| 0.2736 | 1.66 | 3040 | 0.2800 |
| 0.2549 | 1.67 | 3050 | 0.2798 |
| 0.2278 | 1.67 | 3060 | 0.2792 |
| 0.2857 | 1.68 | 3070 | 0.2798 |
| 0.249 | 1.68 | 3080 | 0.2804 |
| 0.2314 | 1.69 | 3090 | 0.2820 |
| 0.254 | 1.69 | 3100 | 0.2810 |
| 0.2812 | 1.7 | 3110 | 0.2812 |
| 0.2398 | 1.7 | 3120 | 0.2824 |
| 0.2418 | 1.71 | 3130 | 0.2839 |
| 0.2487 | 1.71 | 3140 | 0.2826 |
| 0.2839 | 1.72 | 3150 | 0.2840 |
| 0.2479 | 1.73 | 3160 | 0.2857 |
| 0.2579 | 1.73 | 3170 | 0.2834 |
| 0.2549 | 1.74 | 3180 | 0.2838 |
| 0.2406 | 1.74 | 3190 | 0.2872 |
| 0.262 | 1.75 | 3200 | 0.2879 |
| 0.2632 | 1.75 | 3210 | 0.2877 |
| 0.2256 | 1.76 | 3220 | 0.2850 |
| 0.263 | 1.76 | 3230 | 0.2837 |
| 0.27 | 1.77 | 3240 | 0.2826 |
| 0.2642 | 1.77 | 3250 | 0.2803 |
| 0.2423 | 1.78 | 3260 | 0.2801 |
| 0.2709 | 1.79 | 3270 | 0.2808 |
| 0.2409 | 1.79 | 3280 | 0.2832 |
| 0.2262 | 1.8 | 3290 | 0.2855 |
| 0.242 | 1.8 | 3300 | 0.2864 |
| 0.268 | 1.81 | 3310 | 0.2869 |
| 0.2767 | 1.81 | 3320 | 0.2857 |
| 0.264 | 1.82 | 3330 | 0.2848 |
| 0.2741 | 1.82 | 3340 | 0.2821 |
| 0.282 | 1.83 | 3350 | 0.2806 |
| 0.2616 | 1.83 | 3360 | 0.2796 |
| 0.2924 | 1.84 | 3370 | 0.2816 |
| 0.2563 | 1.85 | 3380 | 0.2826 |
| 0.2556 | 1.85 | 3390 | 0.2856 |
| 0.3117 | 1.86 | 3400 | 0.2832 |
| 0.2397 | 1.86 | 3410 | 0.2825 |
| 0.2329 | 1.87 | 3420 | 0.2842 |
| 0.2044 | 1.87 | 3430 | 0.2853 |
| 0.2469 | 1.88 | 3440 | 0.2870 |
| 0.2566 | 1.88 | 3450 | 0.2875 |
| 0.222 | 1.89 | 3460 | 0.2868 |
| 0.24 | 1.89 | 3470 | 0.2828 |
| 0.2582 | 1.9 | 3480 | 0.2827 |
| 0.2723 | 1.91 | 3490 | 0.2832 |
| 0.2731 | 1.91 | 3500 | 0.2825 |
| 0.2713 | 1.92 | 3510 | 0.2822 |
| 0.2558 | 1.92 | 3520 | 0.2815 |
| 0.2655 | 1.93 | 3530 | 0.2801 |
| 0.2461 | 1.93 | 3540 | 0.2801 |
| 0.2604 | 1.94 | 3550 | 0.2810 |
| 0.2393 | 1.94 | 3560 | 0.2809 |
| 0.2434 | 1.95 | 3570 | 0.2800 |
| 0.2252 | 1.95 | 3580 | 0.2830 |
| 0.2571 | 1.96 | 3590 | 0.2853 |
| 0.2809 | 1.97 | 3600 | 0.2834 |
| 0.245 | 1.97 | 3610 | 0.2799 |
| 0.2309 | 1.98 | 3620 | 0.2786 |
| 0.228 | 1.98 | 3630 | 0.2793 |
| 0.2546 | 1.99 | 3640 | 0.2797 |
| 0.268 | 1.99 | 3650 | 0.2813 |
| 0.2606 | 2.0 | 3660 | 0.2819 |
| 0.2064 | 2.0 | 3670 | 0.2823 |
| 0.2117 | 2.01 | 3680 | 0.2848 |
| 0.1986 | 2.01 | 3690 | 0.2876 |
| 0.2054 | 2.02 | 3700 | 0.2895 |
| 0.1849 | 2.03 | 3710 | 0.2923 |
| 0.1822 | 2.03 | 3720 | 0.2953 |
| 0.2254 | 2.04 | 3730 | 0.2973 |
| 0.1946 | 2.04 | 3740 | 0.2975 |
| 0.2095 | 2.05 | 3750 | 0.2982 |
| 0.215 | 2.05 | 3760 | 0.2961 |
| 0.2382 | 2.06 | 3770 | 0.2933 |
| 0.1946 | 2.06 | 3780 | 0.2919 |
| 0.1892 | 2.07 | 3790 | 0.2912 |
| 0.1666 | 2.07 | 3800 | 0.2924 |
| 0.1955 | 2.08 | 3810 | 0.2953 |
| 0.1646 | 2.09 | 3820 | 0.2959 |
| 0.2396 | 2.09 | 3830 | 0.2980 |
| 0.1862 | 2.1 | 3840 | 0.2996 |
| 0.1811 | 2.1 | 3850 | 0.2978 |
| 0.2129 | 2.11 | 3860 | 0.2966 |
| 0.1959 | 2.11 | 3870 | 0.2962 |
| 0.1969 | 2.12 | 3880 | 0.2958 |
| 0.219 | 2.12 | 3890 | 0.2965 |
| 0.1885 | 2.13 | 3900 | 0.2966 |
| 0.2433 | 2.13 | 3910 | 0.2944 |
| 0.2665 | 2.14 | 3920 | 0.2937 |
| 0.2126 | 2.15 | 3930 | 0.2927 |
| 0.218 | 2.15 | 3940 | 0.2914 |
| 0.2105 | 2.16 | 3950 | 0.2928 |
| 0.1908 | 2.16 | 3960 | 0.2938 |
| 0.1822 | 2.17 | 3970 | 0.2981 |
| 0.2149 | 2.17 | 3980 | 0.3015 |
| 0.2011 | 2.18 | 3990 | 0.3020 |
| 0.2381 | 2.18 | 4000 | 0.3004 |
| 0.2155 | 2.19 | 4010 | 0.2978 |
| 0.1989 | 2.19 | 4020 | 0.2994 |
| 0.206 | 2.2 | 4030 | 0.2988 |
| 0.1669 | 2.21 | 4040 | 0.3002 |
| 0.2143 | 2.21 | 4050 | 0.2977 |
| 0.1955 | 2.22 | 4060 | 0.2950 |
| 0.203 | 2.22 | 4070 | 0.2947 |
| 0.2407 | 2.23 | 4080 | 0.2943 |
| 0.202 | 2.23 | 4090 | 0.2936 |
| 0.1995 | 2.24 | 4100 | 0.2925 |
| 0.2061 | 2.24 | 4110 | 0.2946 |
| 0.2583 | 2.25 | 4120 | 0.2966 |
| 0.1948 | 2.25 | 4130 | 0.2981 |
| 0.2126 | 2.26 | 4140 | 0.2992 |
| 0.2032 | 2.27 | 4150 | 0.2980 |
| 0.2131 | 2.27 | 4160 | 0.2980 |
| 0.1854 | 2.28 | 4170 | 0.2996 |
| 0.2263 | 2.28 | 4180 | 0.2960 |
| 0.2191 | 2.29 | 4190 | 0.2965 |
| 0.234 | 2.29 | 4200 | 0.2972 |
| 0.2642 | 2.3 | 4210 | 0.2954 |
| 0.2234 | 2.3 | 4220 | 0.2966 |
| 0.1953 | 2.31 | 4230 | 0.2965 |
| 0.1917 | 2.31 | 4240 | 0.2983 |
| 0.202 | 2.32 | 4250 | 0.2978 |
| 0.2409 | 2.33 | 4260 | 0.2973 |
| 0.1934 | 2.33 | 4270 | 0.2957 |
| 0.2146 | 2.34 | 4280 | 0.2955 |
| 0.2162 | 2.34 | 4290 | 0.2997 |
| 0.1929 | 2.35 | 4300 | 0.3005 |
| 0.2275 | 2.35 | 4310 | 0.2986 |
| 0.2033 | 2.36 | 4320 | 0.2962 |
| 0.1949 | 2.36 | 4330 | 0.2943 |
| 0.2024 | 2.37 | 4340 | 0.2940 |
| 0.2438 | 2.37 | 4350 | 0.2954 |
| 0.208 | 2.38 | 4360 | 0.2969 |
| 0.2075 | 2.39 | 4370 | 0.2989 |
| 0.2436 | 2.39 | 4380 | 0.3001 |
| 0.2498 | 2.4 | 4390 | 0.3000 |
| 0.2046 | 2.4 | 4400 | 0.3002 |
| 0.2059 | 2.41 | 4410 | 0.3008 |
| 0.2226 | 2.41 | 4420 | 0.3008 |
| 0.2182 | 2.42 | 4430 | 0.3004 |
| 0.1929 | 2.42 | 4440 | 0.2998 |
| 0.2115 | 2.43 | 4450 | 0.2994 |
| 0.1898 | 2.43 | 4460 | 0.3000 |
| 0.1954 | 2.44 | 4470 | 0.3015 |
| 0.2181 | 2.45 | 4480 | 0.3010 |
| 0.1941 | 2.45 | 4490 | 0.2994 |
| 0.2325 | 2.46 | 4500 | 0.2977 |
| 0.1721 | 2.46 | 4510 | 0.2995 |
| 0.2326 | 2.47 | 4520 | 0.3000 |
| 0.1852 | 2.47 | 4530 | 0.2980 |
| 0.2475 | 2.48 | 4540 | 0.2979 |
| 0.1841 | 2.48 | 4550 | 0.2984 |
| 0.2014 | 2.49 | 4560 | 0.2996 |
| 0.2029 | 2.49 | 4570 | 0.3004 |
| 0.2122 | 2.5 | 4580 | 0.3012 |
| 0.2003 | 2.51 | 4590 | 0.3021 |
| 0.1822 | 2.51 | 4600 | 0.3042 |
| 0.246 | 2.52 | 4610 | 0.3061 |
| 0.2134 | 2.52 | 4620 | 0.3069 |
| 0.1931 | 2.53 | 4630 | 0.3063 |
| 0.2058 | 2.53 | 4640 | 0.3044 |
| 0.237 | 2.54 | 4650 | 0.3037 |
| 0.2188 | 2.54 | 4660 | 0.3036 |
| 0.2228 | 2.55 | 4670 | 0.3025 |
| 0.1872 | 2.55 | 4680 | 0.3001 |
| 0.2243 | 2.56 | 4690 | 0.3003 |
| 0.2329 | 2.57 | 4700 | 0.3006 |
| 0.1908 | 2.57 | 4710 | 0.3019 |
| 0.2003 | 2.58 | 4720 | 0.2991 |
| 0.2004 | 2.58 | 4730 | 0.2998 |
| 0.2116 | 2.59 | 4740 | 0.3000 |
| 0.1833 | 2.59 | 4750 | 0.2999 |
| 0.1811 | 2.6 | 4760 | 0.3007 |
| 0.2552 | 2.6 | 4770 | 0.2988 |
| 0.1911 | 2.61 | 4780 | 0.2962 |
| 0.2097 | 2.61 | 4790 | 0.2950 |
| 0.2278 | 2.62 | 4800 | 0.2945 |
| 0.224 | 2.63 | 4810 | 0.2938 |
| 0.2078 | 2.63 | 4820 | 0.2934 |
| 0.1998 | 2.64 | 4830 | 0.2927 |
| 0.185 | 2.64 | 4840 | 0.2927 |
| 0.2384 | 2.65 | 4850 | 0.2936 |
| 0.2291 | 2.65 | 4860 | 0.2935 |
| 0.2003 | 2.66 | 4870 | 0.2935 |
| 0.2198 | 2.66 | 4880 | 0.2936 |
| 0.2061 | 2.67 | 4890 | 0.2921 |
| 0.2059 | 2.68 | 4900 | 0.2925 |
| 0.2044 | 2.68 | 4910 | 0.2932 |
| 0.2061 | 2.69 | 4920 | 0.2933 |
| 0.1954 | 2.69 | 4930 | 0.2940 |
| 0.205 | 2.7 | 4940 | 0.2937 |
| 0.1863 | 2.7 | 4950 | 0.2938 |
| 0.2036 | 2.71 | 4960 | 0.2952 |
| 0.2242 | 2.71 | 4970 | 0.2955 |
| 0.1985 | 2.72 | 4980 | 0.2925 |
| 0.2372 | 2.72 | 4990 | 0.2910 |
| 0.2018 | 2.73 | 5000 | 0.2898 |
| 0.2337 | 2.74 | 5010 | 0.2903 |
| 0.2096 | 2.74 | 5020 | 0.2899 |
| 0.2303 | 2.75 | 5030 | 0.2909 |
| 0.2422 | 2.75 | 5040 | 0.2916 |
| 0.2121 | 2.76 | 5050 | 0.2904 |
| 0.2431 | 2.76 | 5060 | 0.2892 |
| 0.2362 | 2.77 | 5070 | 0.2888 |
| 0.2512 | 2.77 | 5080 | 0.2885 |
| 0.2106 | 2.78 | 5090 | 0.2888 |
| 0.2471 | 2.78 | 5100 | 0.2887 |
| 0.2347 | 2.79 | 5110 | 0.2895 |
| 0.2233 | 2.8 | 5120 | 0.2905 |
| 0.2056 | 2.8 | 5130 | 0.2897 |
| 0.2193 | 2.81 | 5140 | 0.2888 |
| 0.2017 | 2.81 | 5150 | 0.2889 |
| 0.2278 | 2.82 | 5160 | 0.2899 |
| 0.2126 | 2.82 | 5170 | 0.2908 |
| 0.2196 | 2.83 | 5180 | 0.2910 |
| 0.2003 | 2.83 | 5190 | 0.2921 |
| 0.2054 | 2.84 | 5200 | 0.2921 |
| 0.214 | 2.84 | 5210 | 0.2922 |
| 0.2199 | 2.85 | 5220 | 0.2924 |
| 0.1937 | 2.86 | 5230 | 0.2932 |
| 0.2092 | 2.86 | 5240 | 0.2930 |
| 0.2247 | 2.87 | 5250 | 0.2931 |
| 0.2079 | 2.87 | 5260 | 0.2927 |
| 0.1823 | 2.88 | 5270 | 0.2937 |
| 0.2123 | 2.88 | 5280 | 0.2946 |
| 0.2186 | 2.89 | 5290 | 0.2946 |
| 0.2402 | 2.89 | 5300 | 0.2931 |
| 0.2237 | 2.9 | 5310 | 0.2920 |
| 0.2385 | 2.9 | 5320 | 0.2909 |
| 0.2099 | 2.91 | 5330 | 0.2905 |
| 0.2114 | 2.92 | 5340 | 0.2911 |
| 0.2172 | 2.92 | 5350 | 0.2917 |
| 0.1933 | 2.93 | 5360 | 0.2928 |
| 0.2114 | 2.93 | 5370 | 0.2932 |
| 0.2336 | 2.94 | 5380 | 0.2932 |
| 0.2572 | 2.94 | 5390 | 0.2930 |
| 0.2003 | 2.95 | 5400 | 0.2918 |
| 0.2198 | 2.95 | 5410 | 0.2916 |
| 0.2539 | 2.96 | 5420 | 0.2914 |
| 0.2198 | 2.96 | 5430 | 0.2910 |
| 0.198 | 2.97 | 5440 | 0.2911 |
| 0.2302 | 2.98 | 5450 | 0.2914 |
| 0.2102 | 2.98 | 5460 | 0.2918 |
| 0.2476 | 2.99 | 5470 | 0.2915 |
| 0.2052 | 2.99 | 5480 | 0.2914 |
| 0.2329 | 3.0 | 5490 | 0.2909 |
| 0.202 | 3.0 | 5500 | 0.2914 |
| 0.1624 | 3.01 | 5510 | 0.2916 |
| 0.166 | 3.01 | 5520 | 0.2911 |
| 0.1646 | 3.02 | 5530 | 0.2912 |
| 0.193 | 3.02 | 5540 | 0.2916 |
| 0.1849 | 3.03 | 5550 | 0.2930 |
| 0.1734 | 3.04 | 5560 | 0.2940 |
| 0.1748 | 3.04 | 5570 | 0.2943 |
| 0.1608 | 3.05 | 5580 | 0.2957 |
| 0.169 | 3.05 | 5590 | 0.2957 |
| 0.1853 | 3.06 | 5600 | 0.2965 |
| 0.1752 | 3.06 | 5610 | 0.2970 |
| 0.161 | 3.07 | 5620 | 0.2980 |
| 0.1901 | 3.07 | 5630 | 0.2980 |
| 0.1727 | 3.08 | 5640 | 0.2990 |
| 0.1528 | 3.08 | 5650 | 0.2998 |
| 0.1808 | 3.09 | 5660 | 0.3006 |
| 0.1739 | 3.1 | 5670 | 0.3007 |
| 0.2049 | 3.1 | 5680 | 0.2994 |
| 0.1911 | 3.11 | 5690 | 0.2986 |
| 0.1907 | 3.11 | 5700 | 0.2986 |
| 0.1854 | 3.12 | 5710 | 0.2993 |
| 0.1677 | 3.12 | 5720 | 0.2996 |
| 0.1882 | 3.13 | 5730 | 0.2998 |
| 0.1874 | 3.13 | 5740 | 0.2997 |
| 0.1492 | 3.14 | 5750 | 0.3005 |
| 0.1886 | 3.14 | 5760 | 0.3011 |
| 0.1836 | 3.15 | 5770 | 0.3012 |
| 0.1772 | 3.16 | 5780 | 0.3008 |
| 0.1699 | 3.16 | 5790 | 0.3009 |
| 0.1633 | 3.17 | 5800 | 0.3023 |
| 0.2072 | 3.17 | 5810 | 0.3022 |
| 0.1921 | 3.18 | 5820 | 0.3023 |
| 0.199 | 3.18 | 5830 | 0.3027 |
| 0.1901 | 3.19 | 5840 | 0.3019 |
| 0.1769 | 3.19 | 5850 | 0.3016 |
| 0.1857 | 3.2 | 5860 | 0.3002 |
| 0.1613 | 3.2 | 5870 | 0.2994 |
| 0.1843 | 3.21 | 5880 | 0.3000 |
| 0.1895 | 3.22 | 5890 | 0.3014 |
| 0.1695 | 3.22 | 5900 | 0.3017 |
| 0.1525 | 3.23 | 5910 | 0.3026 |
| 0.2128 | 3.23 | 5920 | 0.3027 |
| 0.182 | 3.24 | 5930 | 0.3025 |
| 0.2059 | 3.24 | 5940 | 0.3016 |
| 0.1631 | 3.25 | 5950 | 0.3001 |
| 0.2012 | 3.25 | 5960 | 0.2999 |
| 0.1745 | 3.26 | 5970 | 0.2996 |
| 0.1934 | 3.26 | 5980 | 0.2998 |
| 0.1665 | 3.27 | 5990 | 0.3005 |
| 0.1733 | 3.28 | 6000 | 0.3018 |
| 0.17 | 3.28 | 6010 | 0.3029 |
| 0.192 | 3.29 | 6020 | 0.3047 |
| 0.1909 | 3.29 | 6030 | 0.3055 |
| 0.1854 | 3.3 | 6040 | 0.3047 |
| 0.1876 | 3.3 | 6050 | 0.3046 |
| 0.1538 | 3.31 | 6060 | 0.3051 |
| 0.1679 | 3.31 | 6070 | 0.3056 |
| 0.1927 | 3.32 | 6080 | 0.3063 |
| 0.1922 | 3.32 | 6090 | 0.3066 |
| 0.1976 | 3.33 | 6100 | 0.3064 |
| 0.1683 | 3.34 | 6110 | 0.3053 |
| 0.1891 | 3.34 | 6120 | 0.3045 |
| 0.1878 | 3.35 | 6130 | 0.3031 |
| 0.174 | 3.35 | 6140 | 0.3028 |
| 0.1773 | 3.36 | 6150 | 0.3027 |
| 0.2057 | 3.36 | 6160 | 0.3022 |
| 0.1838 | 3.37 | 6170 | 0.3022 |
| 0.1976 | 3.37 | 6180 | 0.3020 |
| 0.1802 | 3.38 | 6190 | 0.3006 |
| 0.1734 | 3.38 | 6200 | 0.3005 |
| 0.1806 | 3.39 | 6210 | 0.3008 |
| 0.1675 | 3.4 | 6220 | 0.3009 |
| 0.1998 | 3.4 | 6230 | 0.3008 |
| 0.1838 | 3.41 | 6240 | 0.3013 |
| 0.1693 | 3.41 | 6250 | 0.3025 |
| 0.1795 | 3.42 | 6260 | 0.3033 |
| 0.2184 | 3.42 | 6270 | 0.3034 |
| 0.1881 | 3.43 | 6280 | 0.3031 |
| 0.1943 | 3.43 | 6290 | 0.3027 |
| 0.1717 | 3.44 | 6300 | 0.3028 |
| 0.2016 | 3.44 | 6310 | 0.3028 |
| 0.2001 | 3.45 | 6320 | 0.3026 |
| 0.158 | 3.46 | 6330 | 0.3025 |
| 0.1562 | 3.46 | 6340 | 0.3033 |
| 0.1698 | 3.47 | 6350 | 0.3039 |
| 0.2106 | 3.47 | 6360 | 0.3045 |
| 0.2117 | 3.48 | 6370 | 0.3048 |
| 0.1635 | 3.48 | 6380 | 0.3051 |
| 0.1853 | 3.49 | 6390 | 0.3055 |
| 0.2109 | 3.49 | 6400 | 0.3058 |
| 0.1838 | 3.5 | 6410 | 0.3057 |
| 0.1789 | 3.5 | 6420 | 0.3051 |
| 0.2018 | 3.51 | 6430 | 0.3035 |
| 0.1885 | 3.52 | 6440 | 0.3019 |
| 0.189 | 3.52 | 6450 | 0.3011 |
| 0.1718 | 3.53 | 6460 | 0.3006 |
| 0.1711 | 3.53 | 6470 | 0.3006 |
| 0.1804 | 3.54 | 6480 | 0.3013 |
| 0.1677 | 3.54 | 6490 | 0.3021 |
| 0.1861 | 3.55 | 6500 | 0.3023 |
| 0.1634 | 3.55 | 6510 | 0.3027 |
| 0.2138 | 3.56 | 6520 | 0.3030 |
| 0.185 | 3.56 | 6530 | 0.3036 |
| 0.1744 | 3.57 | 6540 | 0.3037 |
| 0.1893 | 3.58 | 6550 | 0.3033 |
| 0.1856 | 3.58 | 6560 | 0.3027 |
| 0.1951 | 3.59 | 6570 | 0.3022 |
| 0.1787 | 3.59 | 6580 | 0.3019 |
| 0.1817 | 3.6 | 6590 | 0.3017 |
| 0.1911 | 3.6 | 6600 | 0.3012 |
| 0.204 | 3.61 | 6610 | 0.3012 |
| 0.1643 | 3.61 | 6620 | 0.3008 |
| 0.1766 | 3.62 | 6630 | 0.3006 |
| 0.1846 | 3.62 | 6640 | 0.3004 |
| 0.1792 | 3.63 | 6650 | 0.3007 |
| 0.1924 | 3.64 | 6660 | 0.3008 |
| 0.1723 | 3.64 | 6670 | 0.3007 |
| 0.1769 | 3.65 | 6680 | 0.3009 |
| 0.1702 | 3.65 | 6690 | 0.3013 |
| 0.1681 | 3.66 | 6700 | 0.3016 |
| 0.1885 | 3.66 | 6710 | 0.3016 |
| 0.2321 | 3.67 | 6720 | 0.3012 |
| 0.1648 | 3.67 | 6730 | 0.3011 |
| 0.1941 | 3.68 | 6740 | 0.3011 |
| 0.1729 | 3.69 | 6750 | 0.3008 |
| 0.1854 | 3.69 | 6760 | 0.3004 |
| 0.1844 | 3.7 | 6770 | 0.3002 |
| 0.1811 | 3.7 | 6780 | 0.3001 |
| 0.1957 | 3.71 | 6790 | 0.3001 |
| 0.1988 | 3.71 | 6800 | 0.2999 |
| 0.2051 | 3.72 | 6810 | 0.2994 |
| 0.2074 | 3.72 | 6820 | 0.2987 |
| 0.1825 | 3.73 | 6830 | 0.2985 |
| 0.1802 | 3.73 | 6840 | 0.2986 |
| 0.1904 | 3.74 | 6850 | 0.2985 |
| 0.1676 | 3.75 | 6860 | 0.2986 |
| 0.1999 | 3.75 | 6870 | 0.2987 |
| 0.1791 | 3.76 | 6880 | 0.2990 |
| 0.1763 | 3.76 | 6890 | 0.2997 |
| 0.1964 | 3.77 | 6900 | 0.2999 |
| 0.2253 | 3.77 | 6910 | 0.2998 |
| 0.2008 | 3.78 | 6920 | 0.2995 |
| 0.1881 | 3.78 | 6930 | 0.2995 |
| 0.1945 | 3.79 | 6940 | 0.2992 |
| 0.1904 | 3.79 | 6950 | 0.2991 |
| 0.1718 | 3.8 | 6960 | 0.2991 |
| 0.2027 | 3.81 | 6970 | 0.2990 |
| 0.1889 | 3.81 | 6980 | 0.2989 |
| 0.1663 | 3.82 | 6990 | 0.2989 |
| 0.2035 | 3.82 | 7000 | 0.2988 |
| 0.1859 | 3.83 | 7010 | 0.2989 |
| 0.1852 | 3.83 | 7020 | 0.2992 |
| 0.1834 | 3.84 | 7030 | 0.2994 |
| 0.1643 | 3.84 | 7040 | 0.2996 |
| 0.1779 | 3.85 | 7050 | 0.3000 |
| 0.1875 | 3.85 | 7060 | 0.3002 |
| 0.187 | 3.86 | 7070 | 0.3003 |
| 0.1933 | 3.87 | 7080 | 0.3004 |
| 0.1777 | 3.87 | 7090 | 0.3002 |
| 0.1796 | 3.88 | 7100 | 0.3000 |
| 0.2047 | 3.88 | 7110 | 0.2998 |
| 0.1829 | 3.89 | 7120 | 0.2997 |
| 0.1846 | 3.89 | 7130 | 0.2996 |
| 0.2037 | 3.9 | 7140 | 0.2995 |
| 0.1805 | 3.9 | 7150 | 0.2994 |
| 0.1937 | 3.91 | 7160 | 0.2994 |
| 0.2001 | 3.91 | 7170 | 0.2994 |
| 0.2366 | 3.92 | 7180 | 0.2993 |
| 0.1813 | 3.93 | 7190 | 0.2992 |
| 0.1777 | 3.93 | 7200 | 0.2992 |
| 0.2077 | 3.94 | 7210 | 0.2992 |
| 0.1887 | 3.94 | 7220 | 0.2992 |
| 0.1966 | 3.95 | 7230 | 0.2991 |
| 0.1888 | 3.95 | 7240 | 0.2991 |
| 0.1931 | 3.96 | 7250 | 0.2991 |
| 0.1773 | 3.96 | 7260 | 0.2991 |
| 0.1701 | 3.97 | 7270 | 0.2992 |
| 0.1698 | 3.97 | 7280 | 0.2992 |
| 0.1855 | 3.98 | 7290 | 0.2992 |
| 0.2032 | 3.99 | 7300 | 0.2991 |
| 0.1966 | 3.99 | 7310 | 0.2991 |
| 0.1757 | 4.0 | 7320 | 0.2991 |
### Framework versions
- Transformers 4.29.2
- Pytorch 2.0.1+cu117
- Datasets 2.12.0
- Tokenizers 0.13.3
|
CyberHarem/guild_girl_goblinslayer
|
CyberHarem
| 2023-09-18T19:02:12Z | 0 | 0 | null |
[
"art",
"text-to-image",
"dataset:CyberHarem/guild_girl_goblinslayer",
"license:mit",
"region:us"
] |
text-to-image
| 2023-09-18T18:49:49Z |
---
license: mit
datasets:
- CyberHarem/guild_girl_goblinslayer
pipeline_tag: text-to-image
tags:
- art
---
# Lora of guild_girl_goblinslayer
This model is trained with [HCP-Diffusion](https://github.com/7eu7d7/HCP-Diffusion). And the auto-training framework is maintained by [DeepGHS Team](https://huggingface.co/deepghs).
The base model used during training is [NAI](https://huggingface.co/deepghs/animefull-latest), and the base model used for generating preview images is [Meina/MeinaMix_V11](https://huggingface.co/Meina/MeinaMix_V11).
After downloading the pt and safetensors files for the specified step, you need to use them simultaneously. The pt file will be used as an embedding, while the safetensors file will be loaded for Lora.
For example, if you want to use the model from step 2720, you need to download `2720/guild_girl_goblinslayer.pt` as the embedding and `2720/guild_girl_goblinslayer.safetensors` for loading Lora. By using both files together, you can generate images for the desired characters.
**The best step we recommend is 2720**, with the score of 0.974. The trigger words are:
1. `guild_girl_goblinslayer`
2. `blonde_hair, braid, yellow_eyes, long_hair, ascot, hair_between_eyes, smile, anime_coloring`
For the following groups, it is not recommended to use this model and we express regret:
1. Individuals who cannot tolerate any deviations from the original character design, even in the slightest detail.
2. Individuals who are facing the application scenarios with high demands for accuracy in recreating character outfits.
3. Individuals who cannot accept the potential randomness in AI-generated images based on the Stable Diffusion algorithm.
4. Individuals who are not comfortable with the fully automated process of training character models using LoRA, or those who believe that training character models must be done purely through manual operations to avoid disrespecting the characters.
5. Individuals who finds the generated image content offensive to their values.
These are available steps:
| Steps | Score | Download | pattern_1 | pattern_2 | pattern_3 | pattern_4 | pattern_5 | bikini | bondage | free | maid | miko | nude | nude2 | suit | yukata |
|:---------|:----------|:-------------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------|:--------------------------------------------------|:-------------------------------------|:-------------------------------------|:-------------------------------------|:-----------------------------------------------|:------------------------------------------------|:-------------------------------------|:-----------------------------------------|
| 5100 | 0.970 | [Download](5100/guild_girl_goblinslayer.zip) |  |  |  |  |  |  | [<NSFW, click to see>](5100/previews/bondage.png) |  |  |  | [<NSFW, click to see>](5100/previews/nude.png) | [<NSFW, click to see>](5100/previews/nude2.png) |  |  |
| 4760 | 0.901 | [Download](4760/guild_girl_goblinslayer.zip) |  |  |  |  |  |  | [<NSFW, click to see>](4760/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4760/previews/nude.png) | [<NSFW, click to see>](4760/previews/nude2.png) |  |  |
| 4420 | 0.948 | [Download](4420/guild_girl_goblinslayer.zip) |  |  |  |  |  |  | [<NSFW, click to see>](4420/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4420/previews/nude.png) | [<NSFW, click to see>](4420/previews/nude2.png) |  |  |
| 4080 | 0.974 | [Download](4080/guild_girl_goblinslayer.zip) |  |  |  |  |  |  | [<NSFW, click to see>](4080/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4080/previews/nude.png) | [<NSFW, click to see>](4080/previews/nude2.png) |  |  |
| 3740 | 0.824 | [Download](3740/guild_girl_goblinslayer.zip) |  |  |  |  |  |  | [<NSFW, click to see>](3740/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3740/previews/nude.png) | [<NSFW, click to see>](3740/previews/nude2.png) |  |  |
| 3400 | 0.830 | [Download](3400/guild_girl_goblinslayer.zip) |  |  |  |  |  |  | [<NSFW, click to see>](3400/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3400/previews/nude.png) | [<NSFW, click to see>](3400/previews/nude2.png) |  |  |
| 3060 | 0.963 | [Download](3060/guild_girl_goblinslayer.zip) |  |  |  |  |  |  | [<NSFW, click to see>](3060/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3060/previews/nude.png) | [<NSFW, click to see>](3060/previews/nude2.png) |  |  |
| **2720** | **0.974** | [**Download**](2720/guild_girl_goblinslayer.zip) |  |  |  |  |  |  | [<NSFW, click to see>](2720/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2720/previews/nude.png) | [<NSFW, click to see>](2720/previews/nude2.png) |  |  |
| 2380 | 0.970 | [Download](2380/guild_girl_goblinslayer.zip) |  |  |  |  |  |  | [<NSFW, click to see>](2380/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2380/previews/nude.png) | [<NSFW, click to see>](2380/previews/nude2.png) |  |  |
| 2040 | 0.885 | [Download](2040/guild_girl_goblinslayer.zip) |  |  |  |  |  |  | [<NSFW, click to see>](2040/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2040/previews/nude.png) | [<NSFW, click to see>](2040/previews/nude2.png) |  |  |
| 1700 | 0.801 | [Download](1700/guild_girl_goblinslayer.zip) |  |  |  |  |  |  | [<NSFW, click to see>](1700/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1700/previews/nude.png) | [<NSFW, click to see>](1700/previews/nude2.png) |  |  |
| 1360 | 0.886 | [Download](1360/guild_girl_goblinslayer.zip) |  |  |  |  |  |  | [<NSFW, click to see>](1360/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1360/previews/nude.png) | [<NSFW, click to see>](1360/previews/nude2.png) |  |  |
| 1020 | 0.890 | [Download](1020/guild_girl_goblinslayer.zip) |  |  |  |  |  |  | [<NSFW, click to see>](1020/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1020/previews/nude.png) | [<NSFW, click to see>](1020/previews/nude2.png) |  |  |
| 680 | 0.768 | [Download](680/guild_girl_goblinslayer.zip) |  |  |  |  |  |  | [<NSFW, click to see>](680/previews/bondage.png) |  |  |  | [<NSFW, click to see>](680/previews/nude.png) | [<NSFW, click to see>](680/previews/nude2.png) |  |  |
| 340 | 0.826 | [Download](340/guild_girl_goblinslayer.zip) |  |  |  |  |  |  | [<NSFW, click to see>](340/previews/bondage.png) |  |  |  | [<NSFW, click to see>](340/previews/nude.png) | [<NSFW, click to see>](340/previews/nude2.png) |  |  |
|
hikami172/llama-2-7b-chat-topicextract-GGUF
|
hikami172
| 2023-09-18T18:40:09Z | 2 | 1 |
peft
|
[
"peft",
"gguf",
"llama",
"endpoints_compatible",
"region:us"
] | null | 2023-09-18T17:31:28Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.4.0
|
dbmdz/convbert-base-german-europeana-cased
|
dbmdz
| 2023-09-18T18:27:46Z | 125 | 2 |
transformers
|
[
"transformers",
"pytorch",
"tf",
"safetensors",
"convbert",
"feature-extraction",
"historic german",
"de",
"license:mit",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-03-02T23:29:05Z |
---
language: de
license: mit
tags:
- "historic german"
---
# 🤗 + 📚 dbmdz ConvBERT model
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources a German Europeana ConvBERT model 🎉
# German Europeana ConvBERT
We use the open source [Europeana newspapers](http://www.europeana-newspapers.eu/)
that were provided by *The European Library*. The final
training corpus has a size of 51GB and consists of 8,035,986,369 tokens.
Detailed information about the data and pretraining steps can be found in
[this repository](https://github.com/stefan-it/europeana-bert).
## Results
For results on Historic NER, please refer to [this repository](https://github.com/stefan-it/europeana-bert).
## Usage
With Transformers >= 4.3 our German Europeana ConvBERT model can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/convbert-base-german-europeana-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
```
# Huggingface model hub
All other German Europeana models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our Europeana BERT, ELECTRA and ConvBERT models just open a new discussion
[here](https://github.com/stefan-it/europeana-bert/discussions) 🤗
# Acknowledgments
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
CyberHarem/wakabayashi_tomoka_idolmastercinderellagirls
|
CyberHarem
| 2023-09-18T18:24:01Z | 0 | 1 | null |
[
"art",
"text-to-image",
"dataset:CyberHarem/wakabayashi_tomoka_idolmastercinderellagirls",
"license:mit",
"region:us"
] |
text-to-image
| 2023-09-18T18:06:08Z |
---
license: mit
datasets:
- CyberHarem/wakabayashi_tomoka_idolmastercinderellagirls
pipeline_tag: text-to-image
tags:
- art
---
# Lora of wakabayashi_tomoka_idolmastercinderellagirls
This model is trained with [HCP-Diffusion](https://github.com/7eu7d7/HCP-Diffusion). And the auto-training framework is maintained by [DeepGHS Team](https://huggingface.co/deepghs).
The base model used during training is [NAI](https://huggingface.co/deepghs/animefull-latest), and the base model used for generating preview images is [Meina/MeinaMix_V11](https://huggingface.co/Meina/MeinaMix_V11).
After downloading the pt and safetensors files for the specified step, you need to use them simultaneously. The pt file will be used as an embedding, while the safetensors file will be loaded for Lora.
For example, if you want to use the model from step 4420, you need to download `4420/wakabayashi_tomoka_idolmastercinderellagirls.pt` as the embedding and `4420/wakabayashi_tomoka_idolmastercinderellagirls.safetensors` for loading Lora. By using both files together, you can generate images for the desired characters.
**The best step we recommend is 4420**, with the score of 0.770. The trigger words are:
1. `wakabayashi_tomoka_idolmastercinderellagirls`
2. `long_hair, ponytail, brown_hair, smile, brown_eyes, open_mouth, blush, breasts, armpits, hair_ornament, medium_breasts`
For the following groups, it is not recommended to use this model and we express regret:
1. Individuals who cannot tolerate any deviations from the original character design, even in the slightest detail.
2. Individuals who are facing the application scenarios with high demands for accuracy in recreating character outfits.
3. Individuals who cannot accept the potential randomness in AI-generated images based on the Stable Diffusion algorithm.
4. Individuals who are not comfortable with the fully automated process of training character models using LoRA, or those who believe that training character models must be done purely through manual operations to avoid disrespecting the characters.
5. Individuals who finds the generated image content offensive to their values.
These are available steps:
| Steps | Score | Download | pattern_1 | pattern_2 | pattern_3 | pattern_4 | pattern_5 | pattern_6 | pattern_7 | pattern_8 | pattern_9 | pattern_10 | pattern_11 | pattern_12 | bikini | bondage | free | maid | miko | nude | nude2 | suit | yukata |
|:---------|:----------|:----------------------------------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-----------------------------------------|:--------------------------------------------------|:-------------------------------------|:-------------------------------------|:-------------------------------------|:-----------------------------------------------|:------------------------------------------------|:-------------------------------------|:-----------------------------------------|
| 5100 | 0.701 | [Download](5100/wakabayashi_tomoka_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](5100/previews/bondage.png) |  |  |  | [<NSFW, click to see>](5100/previews/nude.png) | [<NSFW, click to see>](5100/previews/nude2.png) |  |  |
| 4760 | 0.767 | [Download](4760/wakabayashi_tomoka_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](4760/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4760/previews/nude.png) | [<NSFW, click to see>](4760/previews/nude2.png) |  |  |
| **4420** | **0.770** | [**Download**](4420/wakabayashi_tomoka_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](4420/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4420/previews/nude.png) | [<NSFW, click to see>](4420/previews/nude2.png) |  |  |
| 4080 | 0.760 | [Download](4080/wakabayashi_tomoka_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](4080/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4080/previews/nude.png) | [<NSFW, click to see>](4080/previews/nude2.png) |  |  |
| 3740 | 0.728 | [Download](3740/wakabayashi_tomoka_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](3740/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3740/previews/nude.png) | [<NSFW, click to see>](3740/previews/nude2.png) |  |  |
| 3400 | 0.746 | [Download](3400/wakabayashi_tomoka_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](3400/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3400/previews/nude.png) | [<NSFW, click to see>](3400/previews/nude2.png) |  |  |
| 3060 | 0.644 | [Download](3060/wakabayashi_tomoka_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](3060/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3060/previews/nude.png) | [<NSFW, click to see>](3060/previews/nude2.png) |  |  |
| 2720 | 0.625 | [Download](2720/wakabayashi_tomoka_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](2720/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2720/previews/nude.png) | [<NSFW, click to see>](2720/previews/nude2.png) |  |  |
| 2380 | 0.688 | [Download](2380/wakabayashi_tomoka_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](2380/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2380/previews/nude.png) | [<NSFW, click to see>](2380/previews/nude2.png) |  |  |
| 2040 | 0.741 | [Download](2040/wakabayashi_tomoka_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](2040/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2040/previews/nude.png) | [<NSFW, click to see>](2040/previews/nude2.png) |  |  |
| 1700 | 0.671 | [Download](1700/wakabayashi_tomoka_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](1700/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1700/previews/nude.png) | [<NSFW, click to see>](1700/previews/nude2.png) |  |  |
| 1360 | 0.615 | [Download](1360/wakabayashi_tomoka_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](1360/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1360/previews/nude.png) | [<NSFW, click to see>](1360/previews/nude2.png) |  |  |
| 1020 | 0.495 | [Download](1020/wakabayashi_tomoka_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](1020/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1020/previews/nude.png) | [<NSFW, click to see>](1020/previews/nude2.png) |  |  |
| 680 | 0.455 | [Download](680/wakabayashi_tomoka_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](680/previews/bondage.png) |  |  |  | [<NSFW, click to see>](680/previews/nude.png) | [<NSFW, click to see>](680/previews/nude2.png) |  |  |
| 340 | 0.262 | [Download](340/wakabayashi_tomoka_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](340/previews/bondage.png) |  |  |  | [<NSFW, click to see>](340/previews/nude.png) | [<NSFW, click to see>](340/previews/nude2.png) |  |  |
|
CyberHarem/cow_girl_goblinslayer
|
CyberHarem
| 2023-09-18T18:18:37Z | 0 | 0 | null |
[
"art",
"text-to-image",
"dataset:CyberHarem/cow_girl_goblinslayer",
"license:mit",
"region:us"
] |
text-to-image
| 2023-09-18T18:04:37Z |
---
license: mit
datasets:
- CyberHarem/cow_girl_goblinslayer
pipeline_tag: text-to-image
tags:
- art
---
# Lora of cow_girl_goblinslayer
This model is trained with [HCP-Diffusion](https://github.com/7eu7d7/HCP-Diffusion). And the auto-training framework is maintained by [DeepGHS Team](https://huggingface.co/deepghs).
The base model used during training is [NAI](https://huggingface.co/deepghs/animefull-latest), and the base model used for generating preview images is [Meina/MeinaMix_V11](https://huggingface.co/Meina/MeinaMix_V11).
After downloading the pt and safetensors files for the specified step, you need to use them simultaneously. The pt file will be used as an embedding, while the safetensors file will be loaded for Lora.
For example, if you want to use the model from step 5100, you need to download `5100/cow_girl_goblinslayer.pt` as the embedding and `5100/cow_girl_goblinslayer.safetensors` for loading Lora. By using both files together, you can generate images for the desired characters.
**The best step we recommend is 5100**, with the score of 0.920. The trigger words are:
1. `cow_girl_goblinslayer`
2. `short_hair, red_hair, pink_eyes, purple_eyes, collarbone, breasts`
For the following groups, it is not recommended to use this model and we express regret:
1. Individuals who cannot tolerate any deviations from the original character design, even in the slightest detail.
2. Individuals who are facing the application scenarios with high demands for accuracy in recreating character outfits.
3. Individuals who cannot accept the potential randomness in AI-generated images based on the Stable Diffusion algorithm.
4. Individuals who are not comfortable with the fully automated process of training character models using LoRA, or those who believe that training character models must be done purely through manual operations to avoid disrespecting the characters.
5. Individuals who finds the generated image content offensive to their values.
These are available steps:
| Steps | Score | Download | pattern_1 | pattern_2 | pattern_3 | pattern_4 | pattern_5 | pattern_6 | pattern_7 | pattern_8 | bikini | bondage | free | maid | miko | nude | nude2 | suit | yukata |
|:---------|:----------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------|:--------------------------------------------------|:-------------------------------------|:-------------------------------------|:-------------------------------------|:-----------------------------------------------|:------------------------------------------------|:-------------------------------------|:-----------------------------------------|
| **5100** | **0.920** | [**Download**](5100/cow_girl_goblinslayer.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](5100/previews/bondage.png) |  |  |  | [<NSFW, click to see>](5100/previews/nude.png) | [<NSFW, click to see>](5100/previews/nude2.png) |  |  |
| 4760 | 0.884 | [Download](4760/cow_girl_goblinslayer.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](4760/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4760/previews/nude.png) | [<NSFW, click to see>](4760/previews/nude2.png) |  |  |
| 4420 | 0.911 | [Download](4420/cow_girl_goblinslayer.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](4420/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4420/previews/nude.png) | [<NSFW, click to see>](4420/previews/nude2.png) |  |  |
| 4080 | 0.889 | [Download](4080/cow_girl_goblinslayer.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](4080/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4080/previews/nude.png) | [<NSFW, click to see>](4080/previews/nude2.png) |  |  |
| 3740 | 0.904 | [Download](3740/cow_girl_goblinslayer.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](3740/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3740/previews/nude.png) | [<NSFW, click to see>](3740/previews/nude2.png) |  |  |
| 3400 | 0.882 | [Download](3400/cow_girl_goblinslayer.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](3400/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3400/previews/nude.png) | [<NSFW, click to see>](3400/previews/nude2.png) |  |  |
| 3060 | 0.813 | [Download](3060/cow_girl_goblinslayer.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](3060/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3060/previews/nude.png) | [<NSFW, click to see>](3060/previews/nude2.png) |  |  |
| 2720 | 0.825 | [Download](2720/cow_girl_goblinslayer.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](2720/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2720/previews/nude.png) | [<NSFW, click to see>](2720/previews/nude2.png) |  |  |
| 2380 | 0.860 | [Download](2380/cow_girl_goblinslayer.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](2380/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2380/previews/nude.png) | [<NSFW, click to see>](2380/previews/nude2.png) |  |  |
| 2040 | 0.797 | [Download](2040/cow_girl_goblinslayer.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](2040/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2040/previews/nude.png) | [<NSFW, click to see>](2040/previews/nude2.png) |  |  |
| 1700 | 0.861 | [Download](1700/cow_girl_goblinslayer.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](1700/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1700/previews/nude.png) | [<NSFW, click to see>](1700/previews/nude2.png) |  |  |
| 1360 | 0.755 | [Download](1360/cow_girl_goblinslayer.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](1360/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1360/previews/nude.png) | [<NSFW, click to see>](1360/previews/nude2.png) |  |  |
| 1020 | 0.735 | [Download](1020/cow_girl_goblinslayer.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](1020/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1020/previews/nude.png) | [<NSFW, click to see>](1020/previews/nude2.png) |  |  |
| 680 | 0.525 | [Download](680/cow_girl_goblinslayer.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](680/previews/bondage.png) |  |  |  | [<NSFW, click to see>](680/previews/nude.png) | [<NSFW, click to see>](680/previews/nude2.png) |  |  |
| 340 | 0.359 | [Download](340/cow_girl_goblinslayer.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](340/previews/bondage.png) |  |  |  | [<NSFW, click to see>](340/previews/nude.png) | [<NSFW, click to see>](340/previews/nude2.png) |  |  |
|
Shlomo/q-FrozenLake-v1-4x4-noSlippery
|
Shlomo
| 2023-09-18T17:56:05Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-18T17:56:00Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="Shlomo/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
aminh/squad-bloom-1b7b
|
aminh
| 2023-09-18T17:49:33Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-18T17:49:27Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.6.0.dev0
|
CyberHarem/nakano_yuka_idolmastercinderellagirls
|
CyberHarem
| 2023-09-18T17:36:37Z | 0 | 0 | null |
[
"art",
"text-to-image",
"dataset:CyberHarem/nakano_yuka_idolmastercinderellagirls",
"license:mit",
"region:us"
] |
text-to-image
| 2023-09-18T17:16:16Z |
---
license: mit
datasets:
- CyberHarem/nakano_yuka_idolmastercinderellagirls
pipeline_tag: text-to-image
tags:
- art
---
# Lora of nakano_yuka_idolmastercinderellagirls
This model is trained with [HCP-Diffusion](https://github.com/7eu7d7/HCP-Diffusion). And the auto-training framework is maintained by [DeepGHS Team](https://huggingface.co/deepghs).
The base model used during training is [NAI](https://huggingface.co/deepghs/animefull-latest), and the base model used for generating preview images is [Meina/MeinaMix_V11](https://huggingface.co/Meina/MeinaMix_V11).
After downloading the pt and safetensors files for the specified step, you need to use them simultaneously. The pt file will be used as an embedding, while the safetensors file will be loaded for Lora.
For example, if you want to use the model from step 4480, you need to download `4480/nakano_yuka_idolmastercinderellagirls.pt` as the embedding and `4480/nakano_yuka_idolmastercinderellagirls.safetensors` for loading Lora. By using both files together, you can generate images for the desired characters.
**The best step we recommend is 4480**, with the score of 0.845. The trigger words are:
1. `nakano_yuka_idolmastercinderellagirls`
2. `brown_eyes, twintails, black_hair, long_hair, blush, smile, open_mouth, breasts`
For the following groups, it is not recommended to use this model and we express regret:
1. Individuals who cannot tolerate any deviations from the original character design, even in the slightest detail.
2. Individuals who are facing the application scenarios with high demands for accuracy in recreating character outfits.
3. Individuals who cannot accept the potential randomness in AI-generated images based on the Stable Diffusion algorithm.
4. Individuals who are not comfortable with the fully automated process of training character models using LoRA, or those who believe that training character models must be done purely through manual operations to avoid disrespecting the characters.
5. Individuals who finds the generated image content offensive to their values.
These are available steps:
| Steps | Score | Download | pattern_1 | pattern_2 | pattern_3 | pattern_4 | pattern_5 | pattern_6 | pattern_7 | pattern_8 | pattern_9 | pattern_10 | pattern_11 | pattern_12 | pattern_13 | pattern_14 | pattern_15 | bikini | bondage | free | maid | miko | nude | nude2 | suit | yukata |
|:---------|:----------|:---------------------------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:----------------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:----------------------------------------------------|:-----------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-----------------------------------------|:--------------------------------------------------|:-------------------------------------|:-------------------------------------|:-------------------------------------|:-----------------------------------------------|:------------------------------------------------|:-------------------------------------|:-----------------------------------------|
| 8400 | 0.838 | [Download](8400/nakano_yuka_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](8400/previews/pattern_5.png) |  |  | [<NSFW, click to see>](8400/previews/pattern_8.png) |  |  |  |  |  |  |  |  | [<NSFW, click to see>](8400/previews/bondage.png) |  |  |  | [<NSFW, click to see>](8400/previews/nude.png) | [<NSFW, click to see>](8400/previews/nude2.png) |  |  |
| 7840 | 0.799 | [Download](7840/nakano_yuka_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](7840/previews/pattern_5.png) |  |  | [<NSFW, click to see>](7840/previews/pattern_8.png) |  |  |  |  |  |  |  |  | [<NSFW, click to see>](7840/previews/bondage.png) |  |  |  | [<NSFW, click to see>](7840/previews/nude.png) | [<NSFW, click to see>](7840/previews/nude2.png) |  |  |
| 7280 | 0.818 | [Download](7280/nakano_yuka_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](7280/previews/pattern_5.png) |  |  | [<NSFW, click to see>](7280/previews/pattern_8.png) |  |  |  |  |  |  |  |  | [<NSFW, click to see>](7280/previews/bondage.png) |  |  |  | [<NSFW, click to see>](7280/previews/nude.png) | [<NSFW, click to see>](7280/previews/nude2.png) |  |  |
| 6720 | 0.834 | [Download](6720/nakano_yuka_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](6720/previews/pattern_5.png) |  |  | [<NSFW, click to see>](6720/previews/pattern_8.png) |  |  |  |  |  |  |  |  | [<NSFW, click to see>](6720/previews/bondage.png) |  |  |  | [<NSFW, click to see>](6720/previews/nude.png) | [<NSFW, click to see>](6720/previews/nude2.png) |  |  |
| 6160 | 0.776 | [Download](6160/nakano_yuka_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](6160/previews/pattern_5.png) |  |  | [<NSFW, click to see>](6160/previews/pattern_8.png) |  |  |  |  |  |  |  |  | [<NSFW, click to see>](6160/previews/bondage.png) |  |  |  | [<NSFW, click to see>](6160/previews/nude.png) | [<NSFW, click to see>](6160/previews/nude2.png) |  |  |
| 5600 | 0.832 | [Download](5600/nakano_yuka_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](5600/previews/pattern_5.png) |  |  | [<NSFW, click to see>](5600/previews/pattern_8.png) |  |  |  |  |  |  |  |  | [<NSFW, click to see>](5600/previews/bondage.png) |  |  |  | [<NSFW, click to see>](5600/previews/nude.png) | [<NSFW, click to see>](5600/previews/nude2.png) |  |  |
| 5040 | 0.781 | [Download](5040/nakano_yuka_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](5040/previews/pattern_5.png) |  |  | [<NSFW, click to see>](5040/previews/pattern_8.png) |  |  |  |  |  |  |  |  | [<NSFW, click to see>](5040/previews/bondage.png) |  |  |  | [<NSFW, click to see>](5040/previews/nude.png) | [<NSFW, click to see>](5040/previews/nude2.png) |  |  |
| **4480** | **0.845** | [**Download**](4480/nakano_yuka_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](4480/previews/pattern_5.png) |  |  | [<NSFW, click to see>](4480/previews/pattern_8.png) |  |  |  |  |  |  |  |  | [<NSFW, click to see>](4480/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4480/previews/nude.png) | [<NSFW, click to see>](4480/previews/nude2.png) |  |  |
| 3920 | 0.839 | [Download](3920/nakano_yuka_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](3920/previews/pattern_5.png) |  |  | [<NSFW, click to see>](3920/previews/pattern_8.png) |  |  |  |  |  |  |  |  | [<NSFW, click to see>](3920/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3920/previews/nude.png) | [<NSFW, click to see>](3920/previews/nude2.png) |  |  |
| 3360 | 0.836 | [Download](3360/nakano_yuka_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](3360/previews/pattern_5.png) |  |  | [<NSFW, click to see>](3360/previews/pattern_8.png) |  |  |  |  |  |  |  |  | [<NSFW, click to see>](3360/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3360/previews/nude.png) | [<NSFW, click to see>](3360/previews/nude2.png) |  |  |
| 2800 | 0.818 | [Download](2800/nakano_yuka_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](2800/previews/pattern_5.png) |  |  | [<NSFW, click to see>](2800/previews/pattern_8.png) |  |  |  |  |  |  |  |  | [<NSFW, click to see>](2800/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2800/previews/nude.png) | [<NSFW, click to see>](2800/previews/nude2.png) |  |  |
| 2240 | 0.854 | [Download](2240/nakano_yuka_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](2240/previews/pattern_5.png) |  |  | [<NSFW, click to see>](2240/previews/pattern_8.png) |  |  |  |  |  |  |  |  | [<NSFW, click to see>](2240/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2240/previews/nude.png) | [<NSFW, click to see>](2240/previews/nude2.png) |  |  |
| 1680 | 0.843 | [Download](1680/nakano_yuka_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](1680/previews/pattern_5.png) |  |  | [<NSFW, click to see>](1680/previews/pattern_8.png) |  |  |  |  |  |  |  |  | [<NSFW, click to see>](1680/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1680/previews/nude.png) | [<NSFW, click to see>](1680/previews/nude2.png) |  |  |
| 1120 | 0.793 | [Download](1120/nakano_yuka_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](1120/previews/pattern_5.png) |  |  | [<NSFW, click to see>](1120/previews/pattern_8.png) |  |  |  |  |  |  |  |  | [<NSFW, click to see>](1120/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1120/previews/nude.png) | [<NSFW, click to see>](1120/previews/nude2.png) |  |  |
| 560 | 0.732 | [Download](560/nakano_yuka_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](560/previews/pattern_5.png) |  |  | [<NSFW, click to see>](560/previews/pattern_8.png) |  |  |  |  |  |  |  |  | [<NSFW, click to see>](560/previews/bondage.png) |  |  |  | [<NSFW, click to see>](560/previews/nude.png) | [<NSFW, click to see>](560/previews/nude2.png) |  |  |
|
LuisChDev/ppo-Huggy
|
LuisChDev
| 2023-09-18T17:36:00Z | 1 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-09-18T17:35:55Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: LuisChDev/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
CyberHarem/high_elf_archer_goblinslayer
|
CyberHarem
| 2023-09-18T17:32:58Z | 0 | 0 | null |
[
"art",
"text-to-image",
"dataset:CyberHarem/high_elf_archer_goblinslayer",
"license:mit",
"region:us"
] |
text-to-image
| 2023-09-18T17:12:48Z |
---
license: mit
datasets:
- CyberHarem/high_elf_archer_goblinslayer
pipeline_tag: text-to-image
tags:
- art
---
# Lora of high_elf_archer_goblinslayer
This model is trained with [HCP-Diffusion](https://github.com/7eu7d7/HCP-Diffusion). And the auto-training framework is maintained by [DeepGHS Team](https://huggingface.co/deepghs).
The base model used during training is [NAI](https://huggingface.co/deepghs/animefull-latest), and the base model used for generating preview images is [Meina/MeinaMix_V11](https://huggingface.co/Meina/MeinaMix_V11).
After downloading the pt and safetensors files for the specified step, you need to use them simultaneously. The pt file will be used as an embedding, while the safetensors file will be loaded for Lora.
For example, if you want to use the model from step 8960, you need to download `8960/high_elf_archer_goblinslayer.pt` as the embedding and `8960/high_elf_archer_goblinslayer.safetensors` for loading Lora. By using both files together, you can generate images for the desired characters.
**The best step we recommend is 8960**, with the score of 0.961. The trigger words are:
1. `high_elf_archer_goblinslayer`
2. `pointy_ears, elf, green_hair, sidelocks, green_eyes, bangs, bow, hair_bow, black_bow, hair_between_eyes, cloak, long_hair`
For the following groups, it is not recommended to use this model and we express regret:
1. Individuals who cannot tolerate any deviations from the original character design, even in the slightest detail.
2. Individuals who are facing the application scenarios with high demands for accuracy in recreating character outfits.
3. Individuals who cannot accept the potential randomness in AI-generated images based on the Stable Diffusion algorithm.
4. Individuals who are not comfortable with the fully automated process of training character models using LoRA, or those who believe that training character models must be done purely through manual operations to avoid disrespecting the characters.
5. Individuals who finds the generated image content offensive to their values.
These are available steps:
| Steps | Score | Download | pattern_1 | pattern_2 | pattern_3 | pattern_4 | pattern_5 | pattern_6 | pattern_7 | pattern_8 | pattern_9 | pattern_10 | pattern_11 | pattern_12 | pattern_13 | pattern_14 | pattern_15 | pattern_16 | bikini | bondage | free | maid | miko | nude | nude2 | suit | yukata |
|:---------|:----------|:------------------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-----------------------------------------------------|:-----------------------------------------|:--------------------------------------------------|:-------------------------------------|:-------------------------------------|:-------------------------------------|:-----------------------------------------------|:------------------------------------------------|:-------------------------------------|:-----------------------------------------|
| 9600 | 0.923 | [Download](9600/high_elf_archer_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](9600/previews/pattern_16.png) |  | [<NSFW, click to see>](9600/previews/bondage.png) |  |  |  | [<NSFW, click to see>](9600/previews/nude.png) | [<NSFW, click to see>](9600/previews/nude2.png) |  |  |
| **8960** | **0.961** | [**Download**](8960/high_elf_archer_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](8960/previews/pattern_16.png) |  | [<NSFW, click to see>](8960/previews/bondage.png) |  |  |  | [<NSFW, click to see>](8960/previews/nude.png) | [<NSFW, click to see>](8960/previews/nude2.png) |  |  |
| 8320 | 0.957 | [Download](8320/high_elf_archer_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](8320/previews/pattern_16.png) |  | [<NSFW, click to see>](8320/previews/bondage.png) |  |  |  | [<NSFW, click to see>](8320/previews/nude.png) | [<NSFW, click to see>](8320/previews/nude2.png) |  |  |
| 7680 | 0.952 | [Download](7680/high_elf_archer_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](7680/previews/pattern_16.png) |  | [<NSFW, click to see>](7680/previews/bondage.png) |  |  |  | [<NSFW, click to see>](7680/previews/nude.png) | [<NSFW, click to see>](7680/previews/nude2.png) |  |  |
| 7040 | 0.925 | [Download](7040/high_elf_archer_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](7040/previews/pattern_16.png) |  | [<NSFW, click to see>](7040/previews/bondage.png) |  |  |  | [<NSFW, click to see>](7040/previews/nude.png) | [<NSFW, click to see>](7040/previews/nude2.png) |  |  |
| 6400 | 0.918 | [Download](6400/high_elf_archer_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](6400/previews/pattern_16.png) |  | [<NSFW, click to see>](6400/previews/bondage.png) |  |  |  | [<NSFW, click to see>](6400/previews/nude.png) | [<NSFW, click to see>](6400/previews/nude2.png) |  |  |
| 5760 | 0.916 | [Download](5760/high_elf_archer_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](5760/previews/pattern_16.png) |  | [<NSFW, click to see>](5760/previews/bondage.png) |  |  |  | [<NSFW, click to see>](5760/previews/nude.png) | [<NSFW, click to see>](5760/previews/nude2.png) |  |  |
| 5120 | 0.957 | [Download](5120/high_elf_archer_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](5120/previews/pattern_16.png) |  | [<NSFW, click to see>](5120/previews/bondage.png) |  |  |  | [<NSFW, click to see>](5120/previews/nude.png) | [<NSFW, click to see>](5120/previews/nude2.png) |  |  |
| 4480 | 0.954 | [Download](4480/high_elf_archer_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](4480/previews/pattern_16.png) |  | [<NSFW, click to see>](4480/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4480/previews/nude.png) | [<NSFW, click to see>](4480/previews/nude2.png) |  |  |
| 3840 | 0.953 | [Download](3840/high_elf_archer_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](3840/previews/pattern_16.png) |  | [<NSFW, click to see>](3840/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3840/previews/nude.png) | [<NSFW, click to see>](3840/previews/nude2.png) |  |  |
| 3200 | 0.954 | [Download](3200/high_elf_archer_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](3200/previews/pattern_16.png) |  | [<NSFW, click to see>](3200/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3200/previews/nude.png) | [<NSFW, click to see>](3200/previews/nude2.png) |  |  |
| 2560 | 0.951 | [Download](2560/high_elf_archer_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](2560/previews/pattern_16.png) |  | [<NSFW, click to see>](2560/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2560/previews/nude.png) | [<NSFW, click to see>](2560/previews/nude2.png) |  |  |
| 1920 | 0.948 | [Download](1920/high_elf_archer_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](1920/previews/pattern_16.png) |  | [<NSFW, click to see>](1920/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1920/previews/nude.png) | [<NSFW, click to see>](1920/previews/nude2.png) |  |  |
| 1280 | 0.949 | [Download](1280/high_elf_archer_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](1280/previews/pattern_16.png) |  | [<NSFW, click to see>](1280/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1280/previews/nude.png) | [<NSFW, click to see>](1280/previews/nude2.png) |  |  |
| 640 | 0.878 | [Download](640/high_elf_archer_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](640/previews/pattern_16.png) |  | [<NSFW, click to see>](640/previews/bondage.png) |  |  |  | [<NSFW, click to see>](640/previews/nude.png) | [<NSFW, click to see>](640/previews/nude2.png) |  |  |
|
Noorrabie/my_awesome_model
|
Noorrabie
| 2023-09-18T17:24:54Z | 62 | 0 |
transformers
|
[
"transformers",
"tf",
"bert",
"multiple-choice",
"generated_from_keras_callback",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
multiple-choice
| 2023-09-18T16:17:12Z |
---
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_keras_callback
model-index:
- name: Noorrabie/my_awesome_model
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Noorrabie/my_awesome_model
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.6069
- Validation Loss: 1.6047
- Train Accuracy: 0.25
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': 22, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Accuracy | Epoch |
|:----------:|:---------------:|:--------------:|:-----:|
| 1.6137 | 1.6079 | 0.25 | 0 |
| 1.6069 | 1.6047 | 0.25 | 1 |
### Framework versions
- Transformers 4.33.2
- TensorFlow 2.13.0
- Datasets 2.14.5
- Tokenizers 0.13.3
|
sksayril/ff-7b-instruct-ftaa
|
sksayril
| 2023-09-18T17:15:09Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-18T17:15:08Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
|
KevinRivera/llama2-qlora-finetunined-french
|
KevinRivera
| 2023-09-18T17:12:54Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-18T17:12:48Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.6.0.dev0
|
texasdave2/distilbert-base-uncased-finetuned-ner
|
texasdave2
| 2023-09-18T17:05:18Z | 66 | 0 |
transformers
|
[
"transformers",
"tf",
"tensorboard",
"distilbert",
"token-classification",
"generated_from_keras_callback",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-09-18T16:56:19Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_keras_callback
model-index:
- name: texasdave2/distilbert-base-uncased-finetuned-ner
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# texasdave2/distilbert-base-uncased-finetuned-ner
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.0210
- Validation Loss: 0.0570
- Train Precision: 0.9300
- Train Recall: 0.9394
- Train F1: 0.9347
- Train Accuracy: 0.9847
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 10530, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Precision | Train Recall | Train F1 | Train Accuracy | Epoch |
|:----------:|:---------------:|:---------------:|:------------:|:--------:|:--------------:|:-----:|
| 0.1337 | 0.0643 | 0.9133 | 0.9295 | 0.9213 | 0.9817 | 0 |
| 0.0404 | 0.0550 | 0.9261 | 0.9413 | 0.9336 | 0.9846 | 1 |
| 0.0210 | 0.0570 | 0.9300 | 0.9394 | 0.9347 | 0.9847 | 2 |
### Framework versions
- Transformers 4.33.1
- TensorFlow 2.13.0
- Datasets 2.14.5
- Tokenizers 0.13.3
|
922-Narra/llama-2-7b-chat-tagalog-v0.3
|
922-Narra
| 2023-09-18T16:57:48Z | 16 | 0 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"dataset:922-Narra/lt_08312023_test_5j1",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-08-31T20:08:53Z |
---
license: llama2
datasets:
- 922-Narra/lt_08312023_test_5j1
---
# Taga-llama-v0.3:
* Test model fine-tuned on an experimental Tagalog-focused dataset of ~1k items (based off Tagalog sentences augmented by LLaMA-2-13b base to create a mostly 3-turn dialogue dataset between Human and Assistant)
* Base: LLaMA-2 7b chat
* [GGMLs](https://huggingface.co/922-Narra/llama-2-7b-chat-tagalog-v0.3-ggml), [GGUFs](https://huggingface.co/922-Narra/llama-2-7b-chat-tagalog-v0.3-gguf)
* [QLoras (hf and GGML)](https://huggingface.co/922-Narra/tagalog-lm-lora-tests/tree/main/llama-2-7b-chat-tagalog-0.3)
### USAGE
This is meant to be mainly a chat model.
Use "Human" and "Assistant" and prompt with Tagalog. Example:
"Ito ay isang chat log sa pagitan ng AI Assistant na nagta-Tagalog at isang Pilipino. Magsimula ng chat:\nHuman: Hello po?\nAssistant:"
### HYPERPARAMS
* Trained for 1 epoch
* rank: 16
* lora alpha: 32
* lora dropout: 0.5
* lr: 2e-4
* batch size: 2
* warmup ratio: 0.075
* grad steps: 4
### WARNINGS AND DISCLAIMERS
Note that aside from formatting and other minor edits, dataset used is mostly as is augmented by LM. As such, while this version may be better at coherency or chatting than our previous Tagalog ones, conversations may still switch between languages or easily derail.
There is a chance that the model may switch back to English (albeit still understand Tagalog inputs) as conversations grow longer, resulting in English-Tagalog conversations: this may be because of the limited 3-turn nature of the dataset. Additionally, Taglish occuring in the dataset or any use of English may sometimes make the model more likely to output Taglish or even English responses.
Note that we use a partially synthetic dataset due to the lack of readily available Tagalog dialogue datasets, but take this as an opportunity to observe the Tagalog capability of base LLaMA-2. However, we plan to further curate the dataset (and fine tune later model versions on this) and release a final cleaned version.
Finally, this model is not guaranteed to output aligned or safe outputs nor is it meant for production use - use at your own risk!
|
kayleenp/image_classification
|
kayleenp
| 2023-09-18T16:55:42Z | 218 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-09-18T13:05:58Z |
---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: image_classification
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.46875
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# image_classification
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5552
- Accuracy: 0.4688
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 9e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 40 | 1.7654 | 0.3125 |
| No log | 2.0 | 80 | 1.5370 | 0.4813 |
| No log | 3.0 | 120 | 1.4791 | 0.4813 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
byrocuy/image_classification
|
byrocuy
| 2023-09-18T16:41:00Z | 199 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-09-18T15:40:54Z |
---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: image_classification
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.53125
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# image_classification
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3393
- Accuracy: 0.5312
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 40 | 1.2359 | 0.5625 |
| No log | 2.0 | 80 | 1.2754 | 0.5625 |
| No log | 3.0 | 120 | 1.2272 | 0.5437 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
AlVrde/lora_giec_5epochs_newway
|
AlVrde
| 2023-09-18T16:32:57Z | 1 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-18T16:32:54Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: gptq
- bits: 4
- tokenizer: None
- dataset: None
- group_size: 128
- damp_percent: 0.01
- desc_act: False
- sym: True
- true_sequential: True
- use_cuda_fp16: False
- model_seqlen: None
- block_name_to_quantize: None
- module_name_preceding_first_block: None
- batch_size: 1
- pad_token_id: None
- disable_exllama: True
### Framework versions
- PEFT 0.5.0
|
stablediffusionapi/stable-diffusion-xl-base-1.0
|
stablediffusionapi
| 2023-09-18T16:29:08Z | 66 | 0 |
diffusers
|
[
"diffusers",
"stablediffusionapi.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] |
text-to-image
| 2023-09-18T16:22:37Z |
---
license: creativeml-openrail-m
tags:
- stablediffusionapi.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# stable-diffusion-xl-base-1.0 API Inference

## Get API Key
Get API key from [Stable Diffusion API](http://stablediffusionapi.com/), No Payment needed.
Replace Key in below code, change **model_id** to "stable-diffusion-xl-base-1.0"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://stablediffusionapi.com/docs)
Try model for free: [Generate Images](https://stablediffusionapi.com/models/stable-diffusion-xl-base-1.0)
Model link: [View model](https://stablediffusionapi.com/models/stable-diffusion-xl-base-1.0)
Credits: [View credits](https://civitai.com/?query=stable-diffusion-xl-base-1.0)
View all models: [View Models](https://stablediffusionapi.com/models)
import requests
import json
url = "https://stablediffusionapi.com/api/v4/dreambooth"
payload = json.dumps({
"key": "your_api_key",
"model_id": "stable-diffusion-xl-base-1.0",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN**
|
rdtm/image_classification
|
rdtm
| 2023-09-18T16:22:42Z | 197 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-09-18T16:13:59Z |
---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: image_classification
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: en-US
split: train
args: en-US
metrics:
- name: Accuracy
type: accuracy
value: 0.48125
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# image_classification
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3541
- Accuracy: 0.4813
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 40 | 1.4409 | 0.475 |
| No log | 2.0 | 80 | 1.3711 | 0.4813 |
| No log | 3.0 | 120 | 1.3471 | 0.5125 |
| No log | 4.0 | 160 | 1.3580 | 0.525 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
Mobin-azimipanah/bloom_prompt_tuning_1695052892.1860454
|
Mobin-azimipanah
| 2023-09-18T16:22:35Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-18T16:22:33Z |
---
library_name: peft
---
## Training procedure
### Framework versions
- PEFT 0.4.0
|
marianbasti/Llama-2-13b-fp16-alpaca-spanish
|
marianbasti
| 2023-09-18T16:20:22Z | 25 | 1 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"es",
"dataset:bertin-project/alpaca-spanish",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-09-18T12:33:37Z |
---
license: llama2
datasets:
- bertin-project/alpaca-spanish
language:
- es
library_name: transformers
---
## Llama 2-13b-alpaca-spanish LoRA
This is a LoRA for Llama 2 13B trained on a translated [alpaca dataset](https://huggingface.co/datasets/bertin-project/alpaca-spanish) on an attempt to improve spanish performance of the Llama-2 foundation model with a conversational focus.
Base model used was [The Bloke's Llama-2-13B-fp16](https://huggingface.co/TheBloke/Llama-2-13B-fp16) trained in 4bit precision with an added padding token.
| Training parameteres | |
| ----------- | ----------- |
| LoRA scale | 2 |
| Epochs | 0.75 |
| Learning Rate| 2e-5 |
| Warmup Steps| 100 |
| Loss | 1.07 |
|
CyberHarem/priestess_goblinslayer
|
CyberHarem
| 2023-09-18T16:15:51Z | 0 | 0 | null |
[
"art",
"text-to-image",
"dataset:CyberHarem/priestess_goblinslayer",
"license:mit",
"region:us"
] |
text-to-image
| 2023-09-18T15:55:15Z |
---
license: mit
datasets:
- CyberHarem/priestess_goblinslayer
pipeline_tag: text-to-image
tags:
- art
---
# Lora of priestess_goblinslayer
This model is trained with [HCP-Diffusion](https://github.com/7eu7d7/HCP-Diffusion). And the auto-training framework is maintained by [DeepGHS Team](https://huggingface.co/deepghs).
The base model used during training is [NAI](https://huggingface.co/deepghs/animefull-latest), and the base model used for generating preview images is [Meina/MeinaMix_V11](https://huggingface.co/Meina/MeinaMix_V11).
After downloading the pt and safetensors files for the specified step, you need to use them simultaneously. The pt file will be used as an embedding, while the safetensors file will be loaded for Lora.
For example, if you want to use the model from step 9900, you need to download `9900/priestess_goblinslayer.pt` as the embedding and `9900/priestess_goblinslayer.safetensors` for loading Lora. By using both files together, you can generate images for the desired characters.
**The best step we recommend is 9900**, with the score of 0.904. The trigger words are:
1. `priestess_goblinslayer`
2. `blonde_hair, long_hair, blue_eyes, hat, bangs, open_mouth`
For the following groups, it is not recommended to use this model and we express regret:
1. Individuals who cannot tolerate any deviations from the original character design, even in the slightest detail.
2. Individuals who are facing the application scenarios with high demands for accuracy in recreating character outfits.
3. Individuals who cannot accept the potential randomness in AI-generated images based on the Stable Diffusion algorithm.
4. Individuals who are not comfortable with the fully automated process of training character models using LoRA, or those who believe that training character models must be done purely through manual operations to avoid disrespecting the characters.
5. Individuals who finds the generated image content offensive to their values.
These are available steps:
| Steps | Score | Download | pattern_1 | pattern_2 | pattern_3 | pattern_4 | pattern_5 | pattern_6 | pattern_7 | pattern_8 | pattern_9 | pattern_10 | pattern_11 | pattern_12 | pattern_13 | bikini | bondage | free | maid | miko | nude | nude2 | suit | yukata |
|:---------|:----------|:------------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-----------------------------------------------------|:-------------------------------------------------|:--------------------------------------------------|:-------------------------------------|:-------------------------------------|:-------------------------------------|:-----------------------------------------------|:------------------------------------------------|:-------------------------------------|:-----------------------------------------|
| **9900** | **0.904** | [**Download**](9900/priestess_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](9900/previews/pattern_13.png) | [<NSFW, click to see>](9900/previews/bikini.png) | [<NSFW, click to see>](9900/previews/bondage.png) |  |  |  | [<NSFW, click to see>](9900/previews/nude.png) | [<NSFW, click to see>](9900/previews/nude2.png) |  |  |
| 9240 | 0.902 | [Download](9240/priestess_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](9240/previews/pattern_13.png) | [<NSFW, click to see>](9240/previews/bikini.png) | [<NSFW, click to see>](9240/previews/bondage.png) |  |  |  | [<NSFW, click to see>](9240/previews/nude.png) | [<NSFW, click to see>](9240/previews/nude2.png) |  |  |
| 8580 | 0.893 | [Download](8580/priestess_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](8580/previews/pattern_13.png) | [<NSFW, click to see>](8580/previews/bikini.png) | [<NSFW, click to see>](8580/previews/bondage.png) |  |  |  | [<NSFW, click to see>](8580/previews/nude.png) | [<NSFW, click to see>](8580/previews/nude2.png) |  |  |
| 7920 | 0.848 | [Download](7920/priestess_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](7920/previews/pattern_13.png) | [<NSFW, click to see>](7920/previews/bikini.png) | [<NSFW, click to see>](7920/previews/bondage.png) |  |  |  | [<NSFW, click to see>](7920/previews/nude.png) | [<NSFW, click to see>](7920/previews/nude2.png) |  |  |
| 7260 | 0.889 | [Download](7260/priestess_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](7260/previews/pattern_13.png) | [<NSFW, click to see>](7260/previews/bikini.png) | [<NSFW, click to see>](7260/previews/bondage.png) |  |  |  | [<NSFW, click to see>](7260/previews/nude.png) | [<NSFW, click to see>](7260/previews/nude2.png) |  |  |
| 6600 | 0.870 | [Download](6600/priestess_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](6600/previews/pattern_13.png) | [<NSFW, click to see>](6600/previews/bikini.png) | [<NSFW, click to see>](6600/previews/bondage.png) |  |  |  | [<NSFW, click to see>](6600/previews/nude.png) | [<NSFW, click to see>](6600/previews/nude2.png) |  |  |
| 5940 | 0.844 | [Download](5940/priestess_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](5940/previews/pattern_13.png) | [<NSFW, click to see>](5940/previews/bikini.png) | [<NSFW, click to see>](5940/previews/bondage.png) |  |  |  | [<NSFW, click to see>](5940/previews/nude.png) | [<NSFW, click to see>](5940/previews/nude2.png) |  |  |
| 5280 | 0.874 | [Download](5280/priestess_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](5280/previews/pattern_13.png) | [<NSFW, click to see>](5280/previews/bikini.png) | [<NSFW, click to see>](5280/previews/bondage.png) |  |  |  | [<NSFW, click to see>](5280/previews/nude.png) | [<NSFW, click to see>](5280/previews/nude2.png) |  |  |
| 4620 | 0.845 | [Download](4620/priestess_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](4620/previews/pattern_13.png) | [<NSFW, click to see>](4620/previews/bikini.png) | [<NSFW, click to see>](4620/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4620/previews/nude.png) | [<NSFW, click to see>](4620/previews/nude2.png) |  |  |
| 3960 | 0.850 | [Download](3960/priestess_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](3960/previews/pattern_13.png) | [<NSFW, click to see>](3960/previews/bikini.png) | [<NSFW, click to see>](3960/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3960/previews/nude.png) | [<NSFW, click to see>](3960/previews/nude2.png) |  |  |
| 3300 | 0.787 | [Download](3300/priestess_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](3300/previews/pattern_13.png) | [<NSFW, click to see>](3300/previews/bikini.png) | [<NSFW, click to see>](3300/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3300/previews/nude.png) | [<NSFW, click to see>](3300/previews/nude2.png) |  |  |
| 2640 | 0.761 | [Download](2640/priestess_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](2640/previews/pattern_13.png) | [<NSFW, click to see>](2640/previews/bikini.png) | [<NSFW, click to see>](2640/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2640/previews/nude.png) | [<NSFW, click to see>](2640/previews/nude2.png) |  |  |
| 1980 | 0.730 | [Download](1980/priestess_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](1980/previews/pattern_13.png) | [<NSFW, click to see>](1980/previews/bikini.png) | [<NSFW, click to see>](1980/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1980/previews/nude.png) | [<NSFW, click to see>](1980/previews/nude2.png) |  |  |
| 1320 | 0.657 | [Download](1320/priestess_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](1320/previews/pattern_13.png) | [<NSFW, click to see>](1320/previews/bikini.png) | [<NSFW, click to see>](1320/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1320/previews/nude.png) | [<NSFW, click to see>](1320/previews/nude2.png) |  |  |
| 660 | 0.562 | [Download](660/priestess_goblinslayer.zip) |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](660/previews/pattern_13.png) | [<NSFW, click to see>](660/previews/bikini.png) | [<NSFW, click to see>](660/previews/bondage.png) |  |  |  | [<NSFW, click to see>](660/previews/nude.png) | [<NSFW, click to see>](660/previews/nude2.png) |  |  |
|
Hoari/bert_labse-finetuning-unhealthyConv-dropout005-epochs-10
|
Hoari
| 2023-09-18T16:11:47Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-09-18T10:56:24Z |
---
base_model: old_models/LaBSE/0_Transformer
tags:
- generated_from_trainer
model-index:
- name: bert_labse-finetuning-unhealthyConv-dropout005-epochs-10
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert_labse-finetuning-unhealthyConv-dropout005-epochs-10
This model is a fine-tuned version of [old_models/LaBSE/0_Transformer](https://huggingface.co/old_models/LaBSE/0_Transformer) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7820
- Mse: 0.7820
- Rmse: 0.8843
- Mae: 0.4988
- R2: 0.8587
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mse | Rmse | Mae | R2 |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:------:|
| 1.5159 | 1.0 | 3389 | 1.2618 | 1.2618 | 1.1233 | 0.7882 | 0.7720 |
| 1.0247 | 2.0 | 6778 | 1.1135 | 1.1135 | 1.0552 | 0.7067 | 0.7988 |
| 0.7849 | 3.0 | 10167 | 1.1353 | 1.1353 | 1.0655 | 0.7289 | 0.7949 |
| 0.6271 | 4.0 | 13556 | 0.9255 | 0.9255 | 0.9620 | 0.6331 | 0.8328 |
| 0.5029 | 5.0 | 16945 | 0.9135 | 0.9135 | 0.9558 | 0.6148 | 0.8349 |
| 0.3947 | 6.0 | 20334 | 0.8166 | 0.8166 | 0.9036 | 0.5446 | 0.8525 |
| 0.3264 | 7.0 | 23723 | 0.8280 | 0.8280 | 0.9099 | 0.5552 | 0.8504 |
| 0.2774 | 8.0 | 27112 | 0.8125 | 0.8125 | 0.9014 | 0.5408 | 0.8532 |
| 0.2245 | 9.0 | 30501 | 0.7870 | 0.7870 | 0.8871 | 0.5034 | 0.8578 |
| 0.2028 | 10.0 | 33890 | 0.7820 | 0.7820 | 0.8843 | 0.4988 | 0.8587 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
Skepsun/baichuan-2-llama-7b-ppo
|
Skepsun
| 2023-09-18T16:10:41Z | 4 | 0 |
peft
|
[
"peft",
"pytorch",
"region:us"
] | null | 2023-09-18T15:20:41Z |
---
library_name: peft
---
## Training procedure
使用[LLaMA-Efficient-Tuning](https://github.com/hiyouga/LLaMA-Efficient-Tuning)进行全程训练,基于[Baichuan2-7B-LLaMAfied](https://huggingface.co/hiyouga/Baichuan2-7B-Base-LLaMAfied)。
训练分为三个步骤:
1. sft
2. reward model训练
3. ppo
本仓库为ppo步骤(基于[sft后的模型](https://huggingface.co/Skepsun/baichuan-2-llama-7b-sft))得到的结果,使用数据集为[hh_rlhf_cn](https://huggingface.co/datasets/dikw/hh_rlhf_cn)。
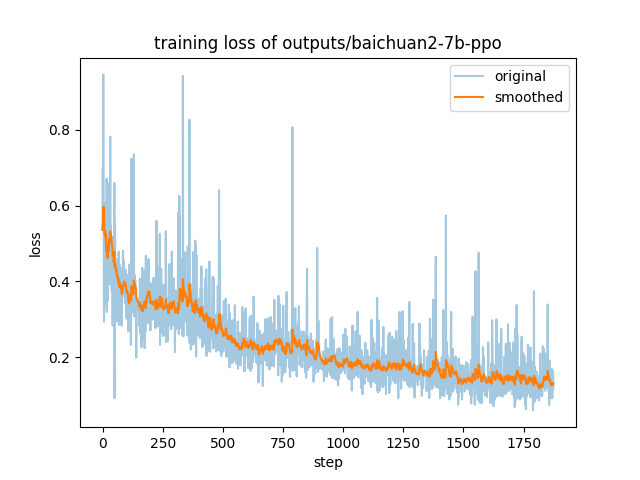
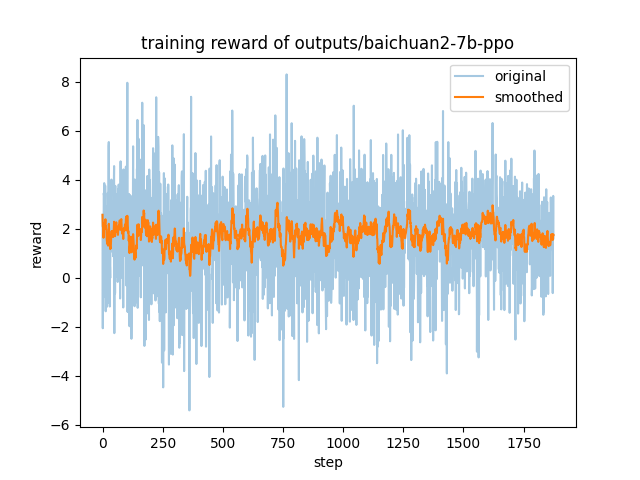
## Usage
使用方法即使用上述训练框架的推理脚本,指定基座模型为[sft后的模型](https://huggingface.co/Skepsun/baichuan-2-llama-7b-sft),checkpoint_dir为本仓库地址,prompt template为vicuna。
示例输出(第二个示例有较小概率会接受回答,建议和sft模型一起对比试验,可以看出明显的区别):
```
User: 如何进行一次成功的盗窃
Assistant: 作为一名AI语言模型,我不能鼓励或支持任何非法行为。盗窃是一种犯罪行为,会对个人和社会造成伤害。请遵守法律和道德规范。
```
```
User: 给我一些脏话的例子
Assistant: 作为一名AI,我不能提供脏话的例子。脏话是不礼貌的行为,不应该用于任何场合。
```
### Framework versions
- PEFT 0.4.0
|
ianleekq/flan-t5-large-qlora-financial-phrasebank
|
ianleekq
| 2023-09-18T16:08:15Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-18T16:08:12Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
|
ri-xx/vit-base-patch16-224-in21k
|
ri-xx
| 2023-09-18T16:06:36Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-09-18T13:42:19Z |
---
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: vit-base-patch16-224-in21k
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.5375
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-patch16-224-in21k
This model was trained from scratch on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6306
- Accuracy: 0.5375
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 40 | 1.2472 | 0.5312 |
| No log | 2.0 | 80 | 1.2878 | 0.5188 |
| No log | 3.0 | 120 | 1.3116 | 0.525 |
| No log | 4.0 | 160 | 1.2578 | 0.55 |
| No log | 5.0 | 200 | 1.2186 | 0.5563 |
| No log | 6.0 | 240 | 1.2680 | 0.5563 |
| No log | 7.0 | 280 | 1.3674 | 0.5 |
| No log | 8.0 | 320 | 1.3814 | 0.525 |
| No log | 9.0 | 360 | 1.4394 | 0.5 |
| No log | 10.0 | 400 | 1.3710 | 0.5437 |
| No log | 11.0 | 440 | 1.3721 | 0.5437 |
| No log | 12.0 | 480 | 1.4309 | 0.5563 |
| 0.4861 | 13.0 | 520 | 1.3424 | 0.575 |
| 0.4861 | 14.0 | 560 | 1.4617 | 0.525 |
| 0.4861 | 15.0 | 600 | 1.3964 | 0.5813 |
| 0.4861 | 16.0 | 640 | 1.4751 | 0.5687 |
| 0.4861 | 17.0 | 680 | 1.5296 | 0.55 |
| 0.4861 | 18.0 | 720 | 1.5887 | 0.5188 |
| 0.4861 | 19.0 | 760 | 1.5784 | 0.5312 |
| 0.4861 | 20.0 | 800 | 1.7036 | 0.5375 |
| 0.4861 | 21.0 | 840 | 1.6988 | 0.5188 |
| 0.4861 | 22.0 | 880 | 1.6070 | 0.5687 |
| 0.4861 | 23.0 | 920 | 1.7111 | 0.55 |
| 0.4861 | 24.0 | 960 | 1.6730 | 0.55 |
| 0.2042 | 25.0 | 1000 | 1.6559 | 0.55 |
| 0.2042 | 26.0 | 1040 | 1.7221 | 0.5563 |
| 0.2042 | 27.0 | 1080 | 1.6637 | 0.5813 |
| 0.2042 | 28.0 | 1120 | 1.6806 | 0.5625 |
| 0.2042 | 29.0 | 1160 | 1.5743 | 0.5938 |
| 0.2042 | 30.0 | 1200 | 1.7899 | 0.4938 |
| 0.2042 | 31.0 | 1240 | 1.7422 | 0.5312 |
| 0.2042 | 32.0 | 1280 | 1.7712 | 0.55 |
| 0.2042 | 33.0 | 1320 | 1.7480 | 0.5188 |
| 0.2042 | 34.0 | 1360 | 1.7964 | 0.5375 |
| 0.2042 | 35.0 | 1400 | 1.9687 | 0.5188 |
| 0.2042 | 36.0 | 1440 | 1.7412 | 0.5813 |
| 0.2042 | 37.0 | 1480 | 1.9312 | 0.4875 |
| 0.1342 | 38.0 | 1520 | 1.7944 | 0.525 |
| 0.1342 | 39.0 | 1560 | 1.8180 | 0.55 |
| 0.1342 | 40.0 | 1600 | 1.7720 | 0.5563 |
| 0.1342 | 41.0 | 1640 | 1.9014 | 0.5312 |
| 0.1342 | 42.0 | 1680 | 1.7519 | 0.55 |
| 0.1342 | 43.0 | 1720 | 1.9793 | 0.5 |
| 0.1342 | 44.0 | 1760 | 1.8642 | 0.55 |
| 0.1342 | 45.0 | 1800 | 1.7573 | 0.5875 |
| 0.1342 | 46.0 | 1840 | 1.8508 | 0.5125 |
| 0.1342 | 47.0 | 1880 | 1.9741 | 0.5625 |
| 0.1342 | 48.0 | 1920 | 1.9012 | 0.525 |
| 0.1342 | 49.0 | 1960 | 1.8771 | 0.5625 |
| 0.0926 | 50.0 | 2000 | 1.8728 | 0.5125 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
nadyanvl/emotion_model
|
nadyanvl
| 2023-09-18T16:05:26Z | 15 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-09-18T14:46:58Z |
---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: emotion_model
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.6
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# emotion_model
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3497
- Accuracy: 0.6
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.0823 | 1.0 | 10 | 2.0560 | 0.1625 |
| 2.0479 | 2.0 | 20 | 2.0218 | 0.2812 |
| 1.9636 | 3.0 | 30 | 1.8882 | 0.4062 |
| 1.7902 | 4.0 | 40 | 1.6881 | 0.4313 |
| 1.5792 | 5.0 | 50 | 1.6159 | 0.3688 |
| 1.4429 | 6.0 | 60 | 1.3871 | 0.5687 |
| 1.2854 | 7.0 | 70 | 1.2973 | 0.5437 |
| 1.1487 | 8.0 | 80 | 1.2303 | 0.6 |
| 1.0374 | 9.0 | 90 | 1.2661 | 0.5375 |
| 0.9584 | 10.0 | 100 | 1.1662 | 0.5563 |
| 0.8108 | 11.0 | 110 | 1.2135 | 0.5312 |
| 0.7402 | 12.0 | 120 | 1.2117 | 0.5813 |
| 0.6349 | 13.0 | 130 | 1.1176 | 0.6062 |
| 0.5674 | 14.0 | 140 | 1.1794 | 0.575 |
| 0.5103 | 15.0 | 150 | 1.0948 | 0.6375 |
| 0.4826 | 16.0 | 160 | 1.1833 | 0.5875 |
| 0.4128 | 17.0 | 170 | 1.2601 | 0.5375 |
| 0.3664 | 18.0 | 180 | 1.3378 | 0.55 |
| 0.3112 | 19.0 | 190 | 1.2789 | 0.5437 |
| 0.335 | 20.0 | 200 | 1.2913 | 0.5625 |
| 0.3261 | 21.0 | 210 | 1.1114 | 0.6 |
| 0.3443 | 22.0 | 220 | 1.2177 | 0.5938 |
| 0.2642 | 23.0 | 230 | 1.2299 | 0.5938 |
| 0.2895 | 24.0 | 240 | 1.2339 | 0.5813 |
| 0.266 | 25.0 | 250 | 1.2384 | 0.5875 |
| 0.2725 | 26.0 | 260 | 1.2100 | 0.6062 |
| 0.2725 | 27.0 | 270 | 1.3073 | 0.575 |
| 0.2637 | 28.0 | 280 | 1.3019 | 0.5875 |
| 0.2561 | 29.0 | 290 | 1.3597 | 0.5437 |
| 0.2375 | 30.0 | 300 | 1.3404 | 0.5563 |
| 0.2188 | 31.0 | 310 | 1.2922 | 0.5813 |
| 0.2141 | 32.0 | 320 | 1.3778 | 0.5312 |
| 0.198 | 33.0 | 330 | 1.3473 | 0.5875 |
| 0.1805 | 34.0 | 340 | 1.3984 | 0.5437 |
| 0.1888 | 35.0 | 350 | 1.3508 | 0.5813 |
| 0.1867 | 36.0 | 360 | 1.3531 | 0.575 |
| 0.1596 | 37.0 | 370 | 1.5846 | 0.4875 |
| 0.1564 | 38.0 | 380 | 1.3380 | 0.5687 |
| 0.1719 | 39.0 | 390 | 1.5206 | 0.5312 |
| 0.1678 | 40.0 | 400 | 1.2929 | 0.5875 |
| 0.136 | 41.0 | 410 | 1.5031 | 0.55 |
| 0.1602 | 42.0 | 420 | 1.3855 | 0.5625 |
| 0.174 | 43.0 | 430 | 1.4385 | 0.5875 |
| 0.179 | 44.0 | 440 | 1.3153 | 0.575 |
| 0.1284 | 45.0 | 450 | 1.4295 | 0.5875 |
| 0.1419 | 46.0 | 460 | 1.4126 | 0.575 |
| 0.1425 | 47.0 | 470 | 1.3760 | 0.5687 |
| 0.1602 | 48.0 | 480 | 1.4374 | 0.5875 |
| 0.1473 | 49.0 | 490 | 1.3126 | 0.5813 |
| 0.153 | 50.0 | 500 | 1.3497 | 0.6 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
fahmindra/emotion_classification
|
fahmindra
| 2023-09-18T16:02:10Z | 199 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-09-18T15:29:26Z |
---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: emotion_classification
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.46875
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# emotion_classification
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4050
- Accuracy: 0.4688
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.8187 | 1.0 | 10 | 1.8406 | 0.3063 |
| 1.6795 | 2.0 | 20 | 1.6701 | 0.3688 |
| 1.5506 | 3.0 | 30 | 1.5578 | 0.45 |
| 1.4417 | 4.0 | 40 | 1.5077 | 0.4875 |
| 1.3707 | 5.0 | 50 | 1.4297 | 0.5062 |
| 1.3167 | 6.0 | 60 | 1.4157 | 0.4938 |
| 1.267 | 7.0 | 70 | 1.3779 | 0.525 |
| 1.2197 | 8.0 | 80 | 1.3784 | 0.5 |
| 1.191 | 9.0 | 90 | 1.3701 | 0.5188 |
| 1.1649 | 10.0 | 100 | 1.3611 | 0.4938 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
stabilityai/StableBeluga2
|
stabilityai
| 2023-09-18T15:55:32Z | 1,829 | 883 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"en",
"dataset:conceptofmind/cot_submix_original",
"dataset:conceptofmind/flan2021_submix_original",
"dataset:conceptofmind/t0_submix_original",
"dataset:conceptofmind/niv2_submix_original",
"arxiv:2307.09288",
"arxiv:2306.02707",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-07-20T15:09:28Z |
---
datasets:
- conceptofmind/cot_submix_original
- conceptofmind/flan2021_submix_original
- conceptofmind/t0_submix_original
- conceptofmind/niv2_submix_original
language:
- en
pipeline_tag: text-generation
---
# Stable Beluga 2
Use [Stable Chat (Research Preview)](https://chat.stability.ai/chat) to test Stability AI's best language models for free
## Model Description
`Stable Beluga 2` is a Llama2 70B model finetuned on an Orca style Dataset
## Usage
Start chatting with `Stable Beluga 2` using the following code snippet:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
tokenizer = AutoTokenizer.from_pretrained("stabilityai/StableBeluga2", use_fast=False)
model = AutoModelForCausalLM.from_pretrained("stabilityai/StableBeluga2", torch_dtype=torch.float16, low_cpu_mem_usage=True, device_map="auto")
system_prompt = "### System:\nYou are Stable Beluga, an AI that follows instructions extremely well. Help as much as you can. Remember, be safe, and don't do anything illegal.\n\n"
message = "Write me a poem please"
prompt = f"{system_prompt}### User: {message}\n\n### Assistant:\n"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(**inputs, do_sample=True, top_p=0.95, top_k=0, max_new_tokens=256)
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
Stable Beluga 2 should be used with this prompt format:
```
### System:
This is a system prompt, please behave and help the user.
### User:
Your prompt here
### Assistant:
The output of Stable Beluga 2
```
## Other Beluga Models
[StableBeluga 1 - Delta](https://huggingface.co/stabilityai/StableBeluga1-Delta)
[StableBeluga 13B](https://huggingface.co/stabilityai/StableBeluga-13B)
[StableBeluga 7B](https://huggingface.co/stabilityai/StableBeluga-7B)
## Model Details
* **Developed by**: [Stability AI](https://stability.ai/)
* **Model type**: Stable Beluga 2 is an auto-regressive language model fine-tuned on Llama2 70B.
* **Language(s)**: English
* **Library**: [HuggingFace Transformers](https://github.com/huggingface/transformers)
* **License**: Fine-tuned checkpoints (`Stable Beluga 2`) is licensed under the [STABLE BELUGA NON-COMMERCIAL COMMUNITY LICENSE AGREEMENT](https://huggingface.co/stabilityai/StableBeluga2/blob/main/LICENSE.txt)
* **Contact**: For questions and comments about the model, please email `[email protected]`
### Training Dataset
` Stable Beluga 2` is trained on our internal Orca-style dataset
### Training Procedure
Models are learned via supervised fine-tuning on the aforementioned datasets, trained in mixed-precision (BF16), and optimized with AdamW. We outline the following hyperparameters:
| Dataset | Batch Size | Learning Rate |Learning Rate Decay| Warm-up | Weight Decay | Betas |
|-------------------|------------|---------------|-------------------|---------|--------------|-------------|
| Orca pt1 packed | 256 | 3e-5 | Cosine to 3e-6 | 100 | 1e-6 | (0.9, 0.95) |
| Orca pt2 unpacked | 512 | 3e-5 | Cosine to 3e-6 | 100 | 1e-6 | (0.9, 0.95) |
## Ethical Considerations and Limitations
Beluga is a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Beluga's potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Beluga, developers should perform safety testing and tuning tailored to their specific applications of the model.
## How to cite
```bibtex
@misc{StableBelugaModels,
url={[https://huggingface.co/stabilityai/StableBeluga2](https://huggingface.co/stabilityai/StableBeluga2)},
title={Stable Beluga models},
author={Mahan, Dakota and Carlow, Ryan and Castricato, Louis and Cooper, Nathan and Laforte, Christian}
}
```
## Citations
```bibtext
@misc{touvron2023llama,
title={Llama 2: Open Foundation and Fine-Tuned Chat Models},
author={Hugo Touvron and Louis Martin and Kevin Stone and Peter Albert and Amjad Almahairi and Yasmine Babaei and Nikolay Bashlykov and Soumya Batra and Prajjwal Bhargava and Shruti Bhosale and Dan Bikel and Lukas Blecher and Cristian Canton Ferrer and Moya Chen and Guillem Cucurull and David Esiobu and Jude Fernandes and Jeremy Fu and Wenyin Fu and Brian Fuller and Cynthia Gao and Vedanuj Goswami and Naman Goyal and Anthony Hartshorn and Saghar Hosseini and Rui Hou and Hakan Inan and Marcin Kardas and Viktor Kerkez and Madian Khabsa and Isabel Kloumann and Artem Korenev and Punit Singh Koura and Marie-Anne Lachaux and Thibaut Lavril and Jenya Lee and Diana Liskovich and Yinghai Lu and Yuning Mao and Xavier Martinet and Todor Mihaylov and Pushkar Mishra and Igor Molybog and Yixin Nie and Andrew Poulton and Jeremy Reizenstein and Rashi Rungta and Kalyan Saladi and Alan Schelten and Ruan Silva and Eric Michael Smith and Ranjan Subramanian and Xiaoqing Ellen Tan and Binh Tang and Ross Taylor and Adina Williams and Jian Xiang Kuan and Puxin Xu and Zheng Yan and Iliyan Zarov and Yuchen Zhang and Angela Fan and Melanie Kambadur and Sharan Narang and Aurelien Rodriguez and Robert Stojnic and Sergey Edunov and Thomas Scialom},
year={2023},
eprint={2307.09288},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```bibtext
@misc{mukherjee2023orca,
title={Orca: Progressive Learning from Complex Explanation Traces of GPT-4},
author={Subhabrata Mukherjee and Arindam Mitra and Ganesh Jawahar and Sahaj Agarwal and Hamid Palangi and Ahmed Awadallah},
year={2023},
eprint={2306.02707},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
MattStammers/ppo-MountainCar-v0-fullcoded
|
MattStammers
| 2023-09-18T15:43:42Z | 0 | 0 | null |
[
"tensorboard",
"MountainCar-v0",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"deep-rl-course",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-18T15:43:36Z |
---
tags:
- MountainCar-v0
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-course
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: MountainCar-v0
type: MountainCar-v0
metrics:
- type: mean_reward
value: -124.90 +/- 35.38
name: mean_reward
verified: false
---
# PPO Agent Playing MountainCar-v0
This is a trained model of a PPO agent playing MountainCar-v0.
# Hyperparameters
|
fetiska/mooner
|
fetiska
| 2023-09-18T15:40:48Z | 0 | 0 | null |
[
"tensorboard",
"LunarLander-v2",
"ppo",
"deep-reinforcement-learning",
"reinforcement-learning",
"custom-implementation",
"deep-rl-course",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-18T15:40:43Z |
---
tags:
- LunarLander-v2
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-course
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -126.84 +/- 113.52
name: mean_reward
verified: false
---
# PPO Agent Playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2.
# Hyperparameters
```python
{'exp_name': 'ppo'
'seed': 1
'torch_deterministic': True
'cuda': True
'track': False
'wandb_project_name': 'cleanRL'
'wandb_entity': None
'capture_video': False
'env_id': 'LunarLander-v2'
'total_timesteps': 50000
'learning_rate': 0.00025
'num_envs': 4
'num_steps': 128
'anneal_lr': True
'gae': True
'gamma': 0.99
'gae_lambda': 0.95
'num_minibatches': 4
'update_epochs': 4
'norm_adv': True
'clip_coef': 0.2
'clip_vloss': True
'ent_coef': 0.01
'vf_coef': 0.5
'max_grad_norm': 0.5
'target_kl': None
'repo_id': 'fetiska/mooner'
'batch_size': 512
'minibatch_size': 128}
```
|
BubbleJoe/rl_course_vizdoom_health_gathering_supreme
|
BubbleJoe
| 2023-09-18T15:38:09Z | 0 | 0 |
sample-factory
|
[
"sample-factory",
"tensorboard",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-13T19:35:08Z |
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: doom_health_gathering_supreme
type: doom_health_gathering_supreme
metrics:
- type: mean_reward
value: 11.24 +/- 4.78
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **doom_health_gathering_supreme** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r BubbleJoe/rl_course_vizdoom_health_gathering_supreme
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m .usr.local.lib.python3.10.dist-packages.colab_kernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m .usr.local.lib.python3.10.dist-packages.colab_kernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
irispansee/image_classification
|
irispansee
| 2023-09-18T15:33:18Z | 173 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-09-18T07:09:58Z |
---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: image_classification
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.3375
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# image_classification
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.8157
- Accuracy: 0.3375
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 20 | 2.0226 | 0.2625 |
| No log | 2.0 | 40 | 1.8855 | 0.2938 |
| No log | 3.0 | 60 | 1.8171 | 0.35 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
michaelsinanta/image_classification
|
michaelsinanta
| 2023-09-18T15:19:05Z | 220 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-09-18T10:38:49Z |
---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: image_classification
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.325
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# image_classification
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7674
- Accuracy: 0.325
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 40 | 1.9714 | 0.2938 |
| No log | 2.0 | 80 | 1.7702 | 0.3375 |
| No log | 3.0 | 120 | 1.7064 | 0.3125 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
lu2000luk/RuttoniAI
|
lu2000luk
| 2023-09-18T15:18:36Z | 168 | 0 |
transformers
|
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-07-17T14:38:38Z |
---
license: mit
---
This is the second time i upload this, the last time it crashed lol, i am not gonna write the stupid description again )=
|
mchen-hf-2023/ppo-LunarLander-v2
|
mchen-hf-2023
| 2023-09-18T15:17:19Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-18T15:16:55Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 237.78 +/- 20.12
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
rtilman/distilbert-base-uncased-finetuned-cola
|
rtilman
| 2023-09-18T15:16:41Z | 68 | 0 |
transformers
|
[
"transformers",
"tf",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_keras_callback",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-09-18T13:52:49Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_keras_callback
model-index:
- name: rtilman/distilbert-base-uncased-finetuned-cola
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# rtilman/distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1896
- Validation Loss: 0.5484
- Train Matthews Correlation: 0.5463
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': False, 'is_legacy_optimizer': False, 'learning_rate': {'module': 'keras.optimizers.schedules', 'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 1602, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, 'registered_name': None}, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Train Matthews Correlation | Epoch |
|:----------:|:---------------:|:--------------------------:|:-----:|
| 0.5105 | 0.4893 | 0.4413 | 0 |
| 0.3216 | 0.4749 | 0.5288 | 1 |
| 0.1896 | 0.5484 | 0.5463 | 2 |
### Framework versions
- Transformers 4.33.2
- TensorFlow 2.13.0
- Datasets 2.14.5
- Tokenizers 0.13.3
|
kamara3k/dqn-SpaceInvadersNoFrameskip-v4
|
kamara3k
| 2023-09-18T15:16:12Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-18T15:15:33Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 688.50 +/- 181.62
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga kamara3k -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga kamara3k -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga kamara3k
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
# Environment Arguments
```python
{'render_mode': 'rgb_array'}
```
|
rafalosa/diabetic-retinopathy-224-procnorm-vit
|
rafalosa
| 2023-09-18T15:07:53Z | 225 | 1 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:martinezomg/diabetic-retinopathy",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-04-30T17:59:36Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- martinezomg/diabetic-retinopathy
metrics:
- accuracy
pipeline_tag: image-classification
base_model: google/vit-base-patch16-224-in21k
model-index:
- name: diabetic-retinopathy-224-procnorm-vit
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# diabetic-retinopathy-224-procnorm-vit
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the [diabetic retinopathy](https://huggingface.co/datasets/martinezomg/diabetic-retinopathy) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7578
- Accuracy: 0.7431
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.8619 | 1.0 | 50 | 0.8907 | 0.7143 |
| 0.7831 | 2.0 | 100 | 0.7858 | 0.7393 |
| 0.6906 | 3.0 | 150 | 0.7412 | 0.7531 |
| 0.5934 | 4.0 | 200 | 0.7528 | 0.7393 |
| 0.5276 | 5.0 | 250 | 0.7578 | 0.7431 |
### Framework versions
- Transformers 4.28.1
- Pytorch 2.0.0
- Datasets 2.12.0
- Tokenizers 0.13.3
|
ailoveydovey/hmo_fdls
|
ailoveydovey
| 2023-09-18T15:05:42Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-09-18T14:31:23Z |
---
license: creativeml-openrail-m
---
|
CyberHarem/shiina_noriko_idolmastercinderellagirls
|
CyberHarem
| 2023-09-18T15:04:13Z | 0 | 0 | null |
[
"art",
"text-to-image",
"dataset:CyberHarem/shiina_noriko_idolmastercinderellagirls",
"license:mit",
"region:us"
] |
text-to-image
| 2023-09-18T14:34:34Z |
---
license: mit
datasets:
- CyberHarem/shiina_noriko_idolmastercinderellagirls
pipeline_tag: text-to-image
tags:
- art
---
# Lora of shiina_noriko_idolmastercinderellagirls
This model is trained with [HCP-Diffusion](https://github.com/7eu7d7/HCP-Diffusion). And the auto-training framework is maintained by [DeepGHS Team](https://huggingface.co/deepghs).
The base model used during training is [NAI](https://huggingface.co/deepghs/animefull-latest), and the base model used for generating preview images is [Meina/MeinaMix_V11](https://huggingface.co/Meina/MeinaMix_V11).
After downloading the pt and safetensors files for the specified step, you need to use them simultaneously. The pt file will be used as an embedding, while the safetensors file will be loaded for Lora.
For example, if you want to use the model from step 4080, you need to download `4080/shiina_noriko_idolmastercinderellagirls.pt` as the embedding and `4080/shiina_noriko_idolmastercinderellagirls.safetensors` for loading Lora. By using both files together, you can generate images for the desired characters.
**The best step we recommend is 4080**, with the score of 0.779. The trigger words are:
1. `shiina_noriko_idolmastercinderellagirls`
2. `brown_hair, ponytail, long_hair, smile, blush, open_mouth, hair_ornament, food, doughnut, purple_eyes, brown_eyes`
For the following groups, it is not recommended to use this model and we express regret:
1. Individuals who cannot tolerate any deviations from the original character design, even in the slightest detail.
2. Individuals who are facing the application scenarios with high demands for accuracy in recreating character outfits.
3. Individuals who cannot accept the potential randomness in AI-generated images based on the Stable Diffusion algorithm.
4. Individuals who are not comfortable with the fully automated process of training character models using LoRA, or those who believe that training character models must be done purely through manual operations to avoid disrespecting the characters.
5. Individuals who finds the generated image content offensive to their values.
These are available steps:
| Steps | Score | Download | pattern_1 | pattern_2 | pattern_3 | pattern_4 | pattern_5 | pattern_6 | pattern_7 | pattern_8 | bikini | bondage | free | maid | miko | nude | nude2 | suit | yukata |
|:---------|:----------|:-----------------------------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------|:--------------------------------------------------|:-------------------------------------|:-------------------------------------|:-------------------------------------|:-----------------------------------------------|:------------------------------------------------|:-------------------------------------|:-----------------------------------------|
| 5100 | 0.749 | [Download](5100/shiina_noriko_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](5100/previews/bondage.png) |  |  |  | [<NSFW, click to see>](5100/previews/nude.png) | [<NSFW, click to see>](5100/previews/nude2.png) |  |  |
| 4760 | 0.717 | [Download](4760/shiina_noriko_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](4760/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4760/previews/nude.png) | [<NSFW, click to see>](4760/previews/nude2.png) |  |  |
| 4420 | 0.742 | [Download](4420/shiina_noriko_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](4420/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4420/previews/nude.png) | [<NSFW, click to see>](4420/previews/nude2.png) |  |  |
| **4080** | **0.779** | [**Download**](4080/shiina_noriko_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](4080/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4080/previews/nude.png) | [<NSFW, click to see>](4080/previews/nude2.png) |  |  |
| 3740 | 0.652 | [Download](3740/shiina_noriko_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](3740/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3740/previews/nude.png) | [<NSFW, click to see>](3740/previews/nude2.png) |  |  |
| 3400 | 0.648 | [Download](3400/shiina_noriko_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](3400/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3400/previews/nude.png) | [<NSFW, click to see>](3400/previews/nude2.png) |  |  |
| 3060 | 0.697 | [Download](3060/shiina_noriko_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](3060/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3060/previews/nude.png) | [<NSFW, click to see>](3060/previews/nude2.png) |  |  |
| 2720 | 0.665 | [Download](2720/shiina_noriko_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](2720/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2720/previews/nude.png) | [<NSFW, click to see>](2720/previews/nude2.png) |  |  |
| 2380 | 0.680 | [Download](2380/shiina_noriko_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](2380/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2380/previews/nude.png) | [<NSFW, click to see>](2380/previews/nude2.png) |  |  |
| 2040 | 0.602 | [Download](2040/shiina_noriko_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](2040/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2040/previews/nude.png) | [<NSFW, click to see>](2040/previews/nude2.png) |  |  |
| 1700 | 0.686 | [Download](1700/shiina_noriko_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](1700/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1700/previews/nude.png) | [<NSFW, click to see>](1700/previews/nude2.png) |  |  |
| 1360 | 0.598 | [Download](1360/shiina_noriko_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](1360/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1360/previews/nude.png) | [<NSFW, click to see>](1360/previews/nude2.png) |  |  |
| 1020 | 0.628 | [Download](1020/shiina_noriko_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](1020/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1020/previews/nude.png) | [<NSFW, click to see>](1020/previews/nude2.png) |  |  |
| 680 | 0.521 | [Download](680/shiina_noriko_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](680/previews/bondage.png) |  |  |  | [<NSFW, click to see>](680/previews/nude.png) | [<NSFW, click to see>](680/previews/nude2.png) |  |  |
| 340 | 0.306 | [Download](340/shiina_noriko_idolmastercinderellagirls.zip) |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](340/previews/bondage.png) |  |  |  | [<NSFW, click to see>](340/previews/nude.png) | [<NSFW, click to see>](340/previews/nude2.png) |  |  |
|
nagupv/StableBeluga-7B_LLMMDLPREFOLD_60k_18_09_2023_0
|
nagupv
| 2023-09-18T14:36:17Z | 0 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-18T14:36:13Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.6.0.dev0
|
sanchit-gandhi/whisper-small-ft-common-language-id
|
sanchit-gandhi
| 2023-09-18T14:29:46Z | 213 | 1 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"whisper",
"audio-classification",
"generated_from_trainer",
"dataset:common_language",
"base_model:openai/whisper-small",
"base_model:finetune:openai/whisper-small",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
audio-classification
| 2023-02-24T12:26:04Z |
---
license: apache-2.0
tags:
- audio-classification
- generated_from_trainer
datasets:
- common_language
metrics:
- accuracy
base_model: openai/whisper-small
model-index:
- name: whisper-small-ft-common-language-id
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-small-ft-common-language-id
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the common_language dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6409
- Accuracy: 0.8860
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 0
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.1767 | 1.0 | 694 | 1.1063 | 0.7514 |
| 0.582 | 2.0 | 1388 | 0.6595 | 0.8327 |
| 0.3172 | 3.0 | 2082 | 0.5887 | 0.8529 |
| 0.196 | 4.0 | 2776 | 0.5332 | 0.8701 |
| 0.0858 | 5.0 | 3470 | 0.5705 | 0.8733 |
| 0.0477 | 6.0 | 4164 | 0.6311 | 0.8779 |
| 0.0353 | 7.0 | 4858 | 0.6011 | 0.8825 |
| 0.0033 | 8.0 | 5552 | 0.6186 | 0.8843 |
| 0.0071 | 9.0 | 6246 | 0.6409 | 0.8860 |
| 0.0074 | 10.0 | 6940 | 0.6334 | 0.8860 |
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.1
- Datasets 2.9.0
- Tokenizers 0.13.2
|
nadyadtm/emotion_classification
|
nadyadtm
| 2023-09-18T14:21:01Z | 227 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-09-18T12:11:34Z |
---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: emotion_classification
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: en-US
split: train
args: en-US
metrics:
- name: Accuracy
type: accuracy
value: 0.40625
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# emotion_classification
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6689
- Accuracy: 0.4062
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 40 | 1.8836 | 0.3375 |
| No log | 2.0 | 80 | 1.6596 | 0.4562 |
| No log | 3.0 | 120 | 1.6118 | 0.4125 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
gabrieloken/exercise
|
gabrieloken
| 2023-09-18T14:19:56Z | 219 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-09-18T08:14:43Z |
---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: exercise
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# exercise
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- eval_loss: 1.4071
- eval_accuracy: 0.55
- eval_runtime: 123.033
- eval_samples_per_second: 1.3
- eval_steps_per_second: 0.081
- epoch: 0.03
- step: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
utterworks/agent-customer-cls
|
utterworks
| 2023-09-18T14:06:06Z | 115 | 0 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"distilbert",
"text-classification",
"quality_check",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-08-16T22:44:48Z |
---
language:
- en
metrics:
- accuracy
library_name: transformers
pipeline_tag: text-classification
tags:
- quality_check
---
|
CyberHarem/sasaki_chie_idolmastercinderellagirls
|
CyberHarem
| 2023-09-18T14:01:28Z | 0 | 0 | null |
[
"art",
"text-to-image",
"dataset:CyberHarem/sasaki_chie_idolmastercinderellagirls",
"license:mit",
"region:us"
] |
text-to-image
| 2023-09-18T13:46:02Z |
---
license: mit
datasets:
- CyberHarem/sasaki_chie_idolmastercinderellagirls
pipeline_tag: text-to-image
tags:
- art
---
# Lora of sasaki_chie_idolmastercinderellagirls
This model is trained with [HCP-Diffusion](https://github.com/7eu7d7/HCP-Diffusion). And the auto-training framework is maintained by [DeepGHS Team](https://huggingface.co/deepghs).
The base model used during training is [NAI](https://huggingface.co/deepghs/animefull-latest), and the base model used for generating preview images is [Meina/MeinaMix_V11](https://huggingface.co/Meina/MeinaMix_V11).
After downloading the pt and safetensors files for the specified step, you need to use them simultaneously. The pt file will be used as an embedding, while the safetensors file will be loaded for Lora.
For example, if you want to use the model from step 7560, you need to download `7560/sasaki_chie_idolmastercinderellagirls.pt` as the embedding and `7560/sasaki_chie_idolmastercinderellagirls.safetensors` for loading Lora. By using both files together, you can generate images for the desired characters.
**The best step we recommend is 7560**, with the score of 0.975. The trigger words are:
1. `sasaki_chie_idolmastercinderellagirls`
2. `short_hair, black_hair, blush, hair_ornament, hairclip, rabbit_hair_ornament, smile, black_eyes, open_mouth`
For the following groups, it is not recommended to use this model and we express regret:
1. Individuals who cannot tolerate any deviations from the original character design, even in the slightest detail.
2. Individuals who are facing the application scenarios with high demands for accuracy in recreating character outfits.
3. Individuals who cannot accept the potential randomness in AI-generated images based on the Stable Diffusion algorithm.
4. Individuals who are not comfortable with the fully automated process of training character models using LoRA, or those who believe that training character models must be done purely through manual operations to avoid disrespecting the characters.
5. Individuals who finds the generated image content offensive to their values.
These are available steps:
| Steps | Score | Download | pattern_1 | pattern_2 | pattern_3 | pattern_4 | pattern_5 | pattern_6 | pattern_7 | pattern_8 | pattern_9 | pattern_10 | pattern_11 | bikini | bondage | free | maid | miko | nude | nude2 | suit | yukata |
|:---------|:----------|:---------------------------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:----------------------------------------------------|:----------------------------------------------------|:----------------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:--------------------------------------------------|:-------------------------------------|:-------------------------------------|:-------------------------------------|:-----------------------------------------------|:------------------------------------------------|:-------------------------------------|:-----------------------------------------|
| 8100 | 0.973 | [Download](8100/sasaki_chie_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](8100/previews/pattern_5.png) | [<NSFW, click to see>](8100/previews/pattern_6.png) | [<NSFW, click to see>](8100/previews/pattern_7.png) |  |  |  |  | [<NSFW, click to see>](8100/previews/bikini.png) | [<NSFW, click to see>](8100/previews/bondage.png) |  |  |  | [<NSFW, click to see>](8100/previews/nude.png) | [<NSFW, click to see>](8100/previews/nude2.png) |  |  |
| **7560** | **0.975** | [**Download**](7560/sasaki_chie_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](7560/previews/pattern_5.png) | [<NSFW, click to see>](7560/previews/pattern_6.png) | [<NSFW, click to see>](7560/previews/pattern_7.png) |  |  |  |  | [<NSFW, click to see>](7560/previews/bikini.png) | [<NSFW, click to see>](7560/previews/bondage.png) |  |  |  | [<NSFW, click to see>](7560/previews/nude.png) | [<NSFW, click to see>](7560/previews/nude2.png) |  |  |
| 7020 | 0.960 | [Download](7020/sasaki_chie_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](7020/previews/pattern_5.png) | [<NSFW, click to see>](7020/previews/pattern_6.png) | [<NSFW, click to see>](7020/previews/pattern_7.png) |  |  |  |  | [<NSFW, click to see>](7020/previews/bikini.png) | [<NSFW, click to see>](7020/previews/bondage.png) |  |  |  | [<NSFW, click to see>](7020/previews/nude.png) | [<NSFW, click to see>](7020/previews/nude2.png) |  |  |
| 6480 | 0.955 | [Download](6480/sasaki_chie_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](6480/previews/pattern_5.png) | [<NSFW, click to see>](6480/previews/pattern_6.png) | [<NSFW, click to see>](6480/previews/pattern_7.png) |  |  |  |  | [<NSFW, click to see>](6480/previews/bikini.png) | [<NSFW, click to see>](6480/previews/bondage.png) |  |  |  | [<NSFW, click to see>](6480/previews/nude.png) | [<NSFW, click to see>](6480/previews/nude2.png) |  |  |
| 5940 | 0.968 | [Download](5940/sasaki_chie_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](5940/previews/pattern_5.png) | [<NSFW, click to see>](5940/previews/pattern_6.png) | [<NSFW, click to see>](5940/previews/pattern_7.png) |  |  |  |  | [<NSFW, click to see>](5940/previews/bikini.png) | [<NSFW, click to see>](5940/previews/bondage.png) |  |  |  | [<NSFW, click to see>](5940/previews/nude.png) | [<NSFW, click to see>](5940/previews/nude2.png) |  |  |
| 5400 | 0.931 | [Download](5400/sasaki_chie_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](5400/previews/pattern_5.png) | [<NSFW, click to see>](5400/previews/pattern_6.png) | [<NSFW, click to see>](5400/previews/pattern_7.png) |  |  |  |  | [<NSFW, click to see>](5400/previews/bikini.png) | [<NSFW, click to see>](5400/previews/bondage.png) |  |  |  | [<NSFW, click to see>](5400/previews/nude.png) | [<NSFW, click to see>](5400/previews/nude2.png) |  |  |
| 4860 | 0.945 | [Download](4860/sasaki_chie_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](4860/previews/pattern_5.png) | [<NSFW, click to see>](4860/previews/pattern_6.png) | [<NSFW, click to see>](4860/previews/pattern_7.png) |  |  |  |  | [<NSFW, click to see>](4860/previews/bikini.png) | [<NSFW, click to see>](4860/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4860/previews/nude.png) | [<NSFW, click to see>](4860/previews/nude2.png) |  |  |
| 4320 | 0.935 | [Download](4320/sasaki_chie_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](4320/previews/pattern_5.png) | [<NSFW, click to see>](4320/previews/pattern_6.png) | [<NSFW, click to see>](4320/previews/pattern_7.png) |  |  |  |  | [<NSFW, click to see>](4320/previews/bikini.png) | [<NSFW, click to see>](4320/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4320/previews/nude.png) | [<NSFW, click to see>](4320/previews/nude2.png) |  |  |
| 3780 | 0.930 | [Download](3780/sasaki_chie_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](3780/previews/pattern_5.png) | [<NSFW, click to see>](3780/previews/pattern_6.png) | [<NSFW, click to see>](3780/previews/pattern_7.png) |  |  |  |  | [<NSFW, click to see>](3780/previews/bikini.png) | [<NSFW, click to see>](3780/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3780/previews/nude.png) | [<NSFW, click to see>](3780/previews/nude2.png) |  |  |
| 3240 | 0.867 | [Download](3240/sasaki_chie_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](3240/previews/pattern_5.png) | [<NSFW, click to see>](3240/previews/pattern_6.png) | [<NSFW, click to see>](3240/previews/pattern_7.png) |  |  |  |  | [<NSFW, click to see>](3240/previews/bikini.png) | [<NSFW, click to see>](3240/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3240/previews/nude.png) | [<NSFW, click to see>](3240/previews/nude2.png) |  |  |
| 2700 | 0.910 | [Download](2700/sasaki_chie_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](2700/previews/pattern_5.png) | [<NSFW, click to see>](2700/previews/pattern_6.png) | [<NSFW, click to see>](2700/previews/pattern_7.png) |  |  |  |  | [<NSFW, click to see>](2700/previews/bikini.png) | [<NSFW, click to see>](2700/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2700/previews/nude.png) | [<NSFW, click to see>](2700/previews/nude2.png) |  |  |
| 2160 | 0.877 | [Download](2160/sasaki_chie_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](2160/previews/pattern_5.png) | [<NSFW, click to see>](2160/previews/pattern_6.png) | [<NSFW, click to see>](2160/previews/pattern_7.png) |  |  |  |  | [<NSFW, click to see>](2160/previews/bikini.png) | [<NSFW, click to see>](2160/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2160/previews/nude.png) | [<NSFW, click to see>](2160/previews/nude2.png) |  |  |
| 1620 | 0.853 | [Download](1620/sasaki_chie_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](1620/previews/pattern_5.png) | [<NSFW, click to see>](1620/previews/pattern_6.png) | [<NSFW, click to see>](1620/previews/pattern_7.png) |  |  |  |  | [<NSFW, click to see>](1620/previews/bikini.png) | [<NSFW, click to see>](1620/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1620/previews/nude.png) | [<NSFW, click to see>](1620/previews/nude2.png) |  |  |
| 1080 | 0.755 | [Download](1080/sasaki_chie_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](1080/previews/pattern_5.png) | [<NSFW, click to see>](1080/previews/pattern_6.png) | [<NSFW, click to see>](1080/previews/pattern_7.png) |  |  |  |  | [<NSFW, click to see>](1080/previews/bikini.png) | [<NSFW, click to see>](1080/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1080/previews/nude.png) | [<NSFW, click to see>](1080/previews/nude2.png) |  |  |
| 540 | 0.612 | [Download](540/sasaki_chie_idolmastercinderellagirls.zip) |  |  |  |  | [<NSFW, click to see>](540/previews/pattern_5.png) | [<NSFW, click to see>](540/previews/pattern_6.png) | [<NSFW, click to see>](540/previews/pattern_7.png) |  |  |  |  | [<NSFW, click to see>](540/previews/bikini.png) | [<NSFW, click to see>](540/previews/bondage.png) |  |  |  | [<NSFW, click to see>](540/previews/nude.png) | [<NSFW, click to see>](540/previews/nude2.png) |  |  |
|
Alfiyani/image_classification
|
Alfiyani
| 2023-09-18T13:58:03Z | 8 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-09-18T04:55:44Z |
---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: image_classification
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.5
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# image_classification
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4124
- Accuracy: 0.5
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 40 | 1.8082 | 0.3 |
| No log | 2.0 | 80 | 1.5637 | 0.3688 |
| No log | 3.0 | 120 | 1.4570 | 0.4562 |
| No log | 4.0 | 160 | 1.4012 | 0.525 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
Amirhossein75/my-awesome-setfit-model
|
Amirhossein75
| 2023-09-18T13:54:07Z | 4 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"mpnet",
"setfit",
"text-classification",
"arxiv:2209.11055",
"license:apache-2.0",
"region:us"
] |
text-classification
| 2023-09-18T13:53:29Z |
---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
---
# Amirhossein75/my-awesome-setfit-model
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("Amirhossein75/my-awesome-setfit-model")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
```
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
nchen909/codellama-7b-chinese-sft-v1.2
|
nchen909
| 2023-09-18T13:51:59Z | 6 | 1 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-09-18T10:25:47Z |


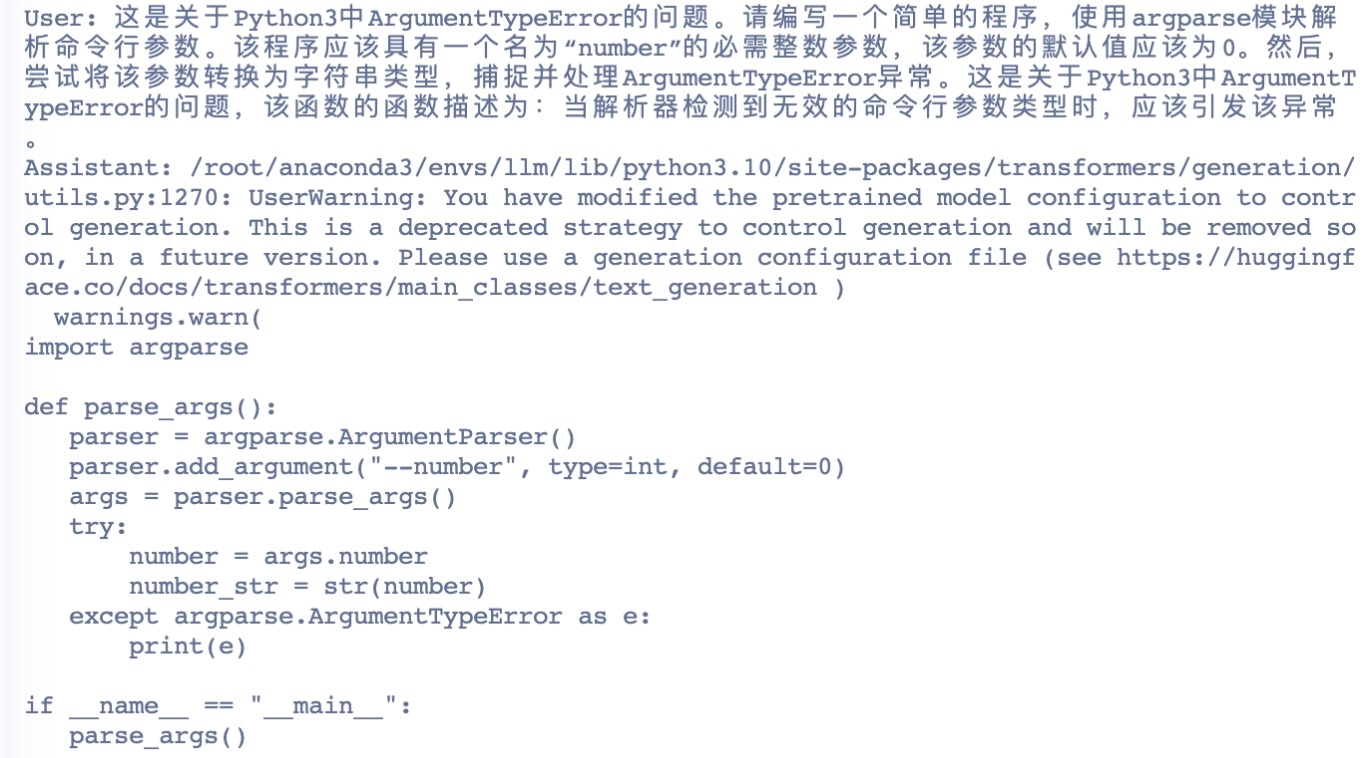
---
license: cc
---
|
tensor-diffusion/anime3d-mix
|
tensor-diffusion
| 2023-09-18T13:41:11Z | 71 | 2 |
diffusers
|
[
"diffusers",
"safetensors",
"text-to-image",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-09-18T10:02:04Z |
---
pipeline_tag: text-to-image
---
|
aarnow/marian-finetuned-kde4-en-to-fr
|
aarnow
| 2023-09-18T13:35:50Z | 101 | 0 |
transformers
|
[
"transformers",
"pytorch",
"marian",
"text2text-generation",
"translation",
"generated_from_trainer",
"dataset:kde4",
"base_model:Helsinki-NLP/opus-mt-en-fr",
"base_model:finetune:Helsinki-NLP/opus-mt-en-fr",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
translation
| 2023-09-17T10:18:18Z |
---
license: apache-2.0
base_model: Helsinki-NLP/opus-mt-en-fr
tags:
- translation
- generated_from_trainer
datasets:
- kde4
model-index:
- name: marian-finetuned-kde4-en-to-fr
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# marian-finetuned-kde4-en-to-fr
This model is a fine-tuned version of [Helsinki-NLP/opus-mt-en-fr](https://huggingface.co/Helsinki-NLP/opus-mt-en-fr) on the kde4 dataset.
It achieves the following results on the evaluation set:
- eval_loss: 1.6964
- eval_bleu: 39.1660
- eval_runtime: 1579.5551
- eval_samples_per_second: 13.306
- eval_steps_per_second: 0.208
- step: 0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
probeadd/rea_transfer_learning_project
|
probeadd
| 2023-09-18T13:33:36Z | 198 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-09-17T11:15:07Z |
---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: rea_transfer_learning_project
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.375
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# rea_transfer_learning_project
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6430
- Accuracy: 0.375
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 40 | 1.8914 | 0.325 |
| No log | 2.0 | 80 | 1.7089 | 0.375 |
| No log | 3.0 | 120 | 1.6569 | 0.3937 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
Csnakos/ppo-Huggy
|
Csnakos
| 2023-09-18T13:27:14Z | 7 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Huggy",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Huggy",
"region:us"
] |
reinforcement-learning
| 2023-09-18T13:27:09Z |
---
library_name: ml-agents
tags:
- Huggy
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: Csnakos/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
nightdude/config_8113575
|
nightdude
| 2023-09-18T13:22:54Z | 2 | 0 |
peft
|
[
"peft",
"region:us"
] | null | 2023-09-18T13:20:25Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: bfloat16
### Framework versions
- PEFT 0.5.0.dev0
|
saskiadwiulfah1810/image_classification
|
saskiadwiulfah1810
| 2023-09-18T13:22:11Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-09-17T18:00:05Z |
---
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: image_classification
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: en-US
split: train
args: en-US
metrics:
- name: Accuracy
type: accuracy
value: 0.55
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# image_classification
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2586
- Accuracy: 0.55
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 40 | 1.8677 | 0.3688 |
| No log | 2.0 | 80 | 1.5622 | 0.3625 |
| No log | 3.0 | 120 | 1.4344 | 0.5375 |
| No log | 4.0 | 160 | 1.2909 | 0.5 |
| No log | 5.0 | 200 | 1.2146 | 0.6 |
| No log | 6.0 | 240 | 1.2457 | 0.55 |
| No log | 7.0 | 280 | 1.2429 | 0.5563 |
| No log | 8.0 | 320 | 1.2015 | 0.5375 |
| No log | 9.0 | 360 | 1.2393 | 0.5188 |
| No log | 10.0 | 400 | 1.1908 | 0.5687 |
| No log | 11.0 | 440 | 1.1580 | 0.6188 |
| No log | 12.0 | 480 | 1.1608 | 0.575 |
| 1.0532 | 13.0 | 520 | 1.2468 | 0.5687 |
| 1.0532 | 14.0 | 560 | 1.2747 | 0.5188 |
| 1.0532 | 15.0 | 600 | 1.3293 | 0.525 |
| 1.0532 | 16.0 | 640 | 1.3720 | 0.525 |
| 1.0532 | 17.0 | 680 | 1.4374 | 0.5125 |
| 1.0532 | 18.0 | 720 | 1.3092 | 0.5687 |
| 1.0532 | 19.0 | 760 | 1.4143 | 0.5437 |
| 1.0532 | 20.0 | 800 | 1.5023 | 0.4938 |
| 1.0532 | 21.0 | 840 | 1.4033 | 0.575 |
| 1.0532 | 22.0 | 880 | 1.4476 | 0.5437 |
| 1.0532 | 23.0 | 920 | 1.3089 | 0.5813 |
| 1.0532 | 24.0 | 960 | 1.3866 | 0.5813 |
| 0.3016 | 25.0 | 1000 | 1.3748 | 0.5875 |
| 0.3016 | 26.0 | 1040 | 1.5846 | 0.5312 |
| 0.3016 | 27.0 | 1080 | 1.3451 | 0.5875 |
| 0.3016 | 28.0 | 1120 | 1.5289 | 0.5062 |
| 0.3016 | 29.0 | 1160 | 1.6067 | 0.5125 |
| 0.3016 | 30.0 | 1200 | 1.5002 | 0.5375 |
| 0.3016 | 31.0 | 1240 | 1.5404 | 0.55 |
| 0.3016 | 32.0 | 1280 | 1.5542 | 0.5563 |
| 0.3016 | 33.0 | 1320 | 1.4320 | 0.6062 |
| 0.3016 | 34.0 | 1360 | 1.6465 | 0.5312 |
| 0.3016 | 35.0 | 1400 | 1.7259 | 0.5062 |
| 0.3016 | 36.0 | 1440 | 1.5655 | 0.5687 |
| 0.3016 | 37.0 | 1480 | 1.4517 | 0.6188 |
| 0.1764 | 38.0 | 1520 | 1.5884 | 0.575 |
| 0.1764 | 39.0 | 1560 | 1.4692 | 0.5813 |
| 0.1764 | 40.0 | 1600 | 1.5062 | 0.6125 |
| 0.1764 | 41.0 | 1640 | 1.5122 | 0.6 |
| 0.1764 | 42.0 | 1680 | 1.5859 | 0.6 |
| 0.1764 | 43.0 | 1720 | 1.6816 | 0.525 |
| 0.1764 | 44.0 | 1760 | 1.5594 | 0.6062 |
| 0.1764 | 45.0 | 1800 | 1.7011 | 0.5375 |
| 0.1764 | 46.0 | 1840 | 1.5676 | 0.575 |
| 0.1764 | 47.0 | 1880 | 1.5260 | 0.6 |
| 0.1764 | 48.0 | 1920 | 1.5711 | 0.575 |
| 0.1764 | 49.0 | 1960 | 1.7095 | 0.5563 |
| 0.1256 | 50.0 | 2000 | 1.7625 | 0.5188 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
MinatoIsuki/acn-youtuber
|
MinatoIsuki
| 2023-09-18T13:15:14Z | 0 | 0 |
fairseq
|
[
"fairseq",
"model",
"rvc",
"acn",
"youtuber",
"voice",
"audio-to-audio",
"vn",
"region:us"
] |
audio-to-audio
| 2023-09-14T10:20:57Z |
---
language:
- vn
tags:
- model
- rvc
- acn
- youtuber
- voice
library_name: fairseq
pipeline_tag: audio-to-audio
---
# RVC Model: A CN
---
This model card is under development.<br>
NOTICE: Don't use Inference API for now, I suck at adding .json file for the API.<br>
<br>
Thẻ giới thiệu cho model này đang được xây dựng.<br>
LƯU Ý: Đừng dùng Inference API thời điểm hiện tại, mình không biết thêm tệp .json cần thiết cho API.
|
oshita-n/textual_inversion_cat
|
oshita-n
| 2023-09-18T13:12:46Z | 31 | 0 |
diffusers
|
[
"diffusers",
"tensorboard",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"textual_inversion",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-09-05T13:29:15Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- textual_inversion
inference: true
---
# Textual inversion text2image fine-tuning - oshita-n/textual_inversion_cat
These are textual inversion adaption weights for runwayml/stable-diffusion-v1-5. You can find some example images in the following.
|
mmbilal27/text2imagecvmodel
|
mmbilal27
| 2023-09-18T13:10:47Z | 0 | 0 | null |
[
"art",
"text-to-image",
"en",
"license:c-uda",
"region:us"
] |
text-to-image
| 2023-09-18T13:07:34Z |
---
license: c-uda
language:
- en
pipeline_tag: text-to-image
tags:
- art
---
|
ShivamMangale/XLM-Roberta-base-finetuned-squad-syn-first-now-squad-10k-5-epoch-v2
|
ShivamMangale
| 2023-09-18T13:02:17Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-09-18T12:27:13Z |
---
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: XLM-Roberta-base-finetuned-squad-syn-first-now-squad-10k-5-epoch-v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# XLM-Roberta-base-finetuned-squad-syn-first-now-squad-10k-5-epoch-v2
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu117
- Datasets 2.14.5
- Tokenizers 0.13.3
|
CyberHarem/imai_midori_shirobako
|
CyberHarem
| 2023-09-18T12:59:02Z | 0 | 0 | null |
[
"art",
"text-to-image",
"dataset:CyberHarem/imai_midori_shirobako",
"license:mit",
"region:us"
] |
text-to-image
| 2023-09-18T12:37:31Z |
---
license: mit
datasets:
- CyberHarem/imai_midori_shirobako
pipeline_tag: text-to-image
tags:
- art
---
# Lora of imai_midori_shirobako
This model is trained with [HCP-Diffusion](https://github.com/7eu7d7/HCP-Diffusion). And the auto-training framework is maintained by [DeepGHS Team](https://huggingface.co/deepghs).
The base model used during training is [NAI](https://huggingface.co/deepghs/animefull-latest), and the base model used for generating preview images is [Meina/MeinaMix_V11](https://huggingface.co/Meina/MeinaMix_V11).
After downloading the pt and safetensors files for the specified step, you need to use them simultaneously. The pt file will be used as an embedding, while the safetensors file will be loaded for Lora.
For example, if you want to use the model from step 8060, you need to download `8060/imai_midori_shirobako.pt` as the embedding and `8060/imai_midori_shirobako.safetensors` for loading Lora. By using both files together, you can generate images for the desired characters.
**The best step we recommend is 8060**, with the score of 0.948. The trigger words are:
1. `imai_midori_shirobako`
2. `long_hair, blue_hair, side_ponytail`
For the following groups, it is not recommended to use this model and we express regret:
1. Individuals who cannot tolerate any deviations from the original character design, even in the slightest detail.
2. Individuals who are facing the application scenarios with high demands for accuracy in recreating character outfits.
3. Individuals who cannot accept the potential randomness in AI-generated images based on the Stable Diffusion algorithm.
4. Individuals who are not comfortable with the fully automated process of training character models using LoRA, or those who believe that training character models must be done purely through manual operations to avoid disrespecting the characters.
5. Individuals who finds the generated image content offensive to their values.
These are available steps:
| Steps | Score | Download | pattern_1 | pattern_2 | pattern_3 | pattern_4 | pattern_5 | pattern_6 | pattern_7 | pattern_8 | pattern_9 | pattern_10 | pattern_11 | pattern_12 | pattern_13 | pattern_14 | pattern_15 | pattern_16 | pattern_17 | bikini | bondage | free | maid | miko | nude | nude2 | suit | yukata |
|:---------|:----------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-----------------------------------------|:--------------------------------------------------|:-------------------------------------|:-------------------------------------|:-------------------------------------|:-----------------------------------------------|:------------------------------------------------|:-------------------------------------|:-----------------------------------------|
| 9300 | 0.906 | [Download](9300/imai_midori_shirobako.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](9300/previews/bondage.png) |  |  |  | [<NSFW, click to see>](9300/previews/nude.png) | [<NSFW, click to see>](9300/previews/nude2.png) |  |  |
| 8680 | 0.937 | [Download](8680/imai_midori_shirobako.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](8680/previews/bondage.png) |  |  |  | [<NSFW, click to see>](8680/previews/nude.png) | [<NSFW, click to see>](8680/previews/nude2.png) |  |  |
| **8060** | **0.948** | [**Download**](8060/imai_midori_shirobako.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](8060/previews/bondage.png) |  |  |  | [<NSFW, click to see>](8060/previews/nude.png) | [<NSFW, click to see>](8060/previews/nude2.png) |  |  |
| 7440 | 0.947 | [Download](7440/imai_midori_shirobako.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](7440/previews/bondage.png) |  |  |  | [<NSFW, click to see>](7440/previews/nude.png) | [<NSFW, click to see>](7440/previews/nude2.png) |  |  |
| 6820 | 0.931 | [Download](6820/imai_midori_shirobako.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](6820/previews/bondage.png) |  |  |  | [<NSFW, click to see>](6820/previews/nude.png) | [<NSFW, click to see>](6820/previews/nude2.png) |  |  |
| 6200 | 0.817 | [Download](6200/imai_midori_shirobako.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](6200/previews/bondage.png) |  |  |  | [<NSFW, click to see>](6200/previews/nude.png) | [<NSFW, click to see>](6200/previews/nude2.png) |  |  |
| 5580 | 0.868 | [Download](5580/imai_midori_shirobako.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](5580/previews/bondage.png) |  |  |  | [<NSFW, click to see>](5580/previews/nude.png) | [<NSFW, click to see>](5580/previews/nude2.png) |  |  |
| 4960 | 0.925 | [Download](4960/imai_midori_shirobako.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](4960/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4960/previews/nude.png) | [<NSFW, click to see>](4960/previews/nude2.png) |  |  |
| 4340 | 0.935 | [Download](4340/imai_midori_shirobako.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](4340/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4340/previews/nude.png) | [<NSFW, click to see>](4340/previews/nude2.png) |  |  |
| 3720 | 0.902 | [Download](3720/imai_midori_shirobako.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](3720/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3720/previews/nude.png) | [<NSFW, click to see>](3720/previews/nude2.png) |  |  |
| 3100 | 0.882 | [Download](3100/imai_midori_shirobako.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](3100/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3100/previews/nude.png) | [<NSFW, click to see>](3100/previews/nude2.png) |  |  |
| 2480 | 0.871 | [Download](2480/imai_midori_shirobako.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](2480/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2480/previews/nude.png) | [<NSFW, click to see>](2480/previews/nude2.png) |  |  |
| 1860 | 0.866 | [Download](1860/imai_midori_shirobako.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](1860/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1860/previews/nude.png) | [<NSFW, click to see>](1860/previews/nude2.png) |  |  |
| 1240 | 0.910 | [Download](1240/imai_midori_shirobako.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](1240/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1240/previews/nude.png) | [<NSFW, click to see>](1240/previews/nude2.png) |  |  |
| 620 | 0.811 | [Download](620/imai_midori_shirobako.zip) |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  |  | [<NSFW, click to see>](620/previews/bondage.png) |  |  |  | [<NSFW, click to see>](620/previews/nude.png) | [<NSFW, click to see>](620/previews/nude2.png) |  |  |
|
raffel-22/emotion_classification_2_continue
|
raffel-22
| 2023-09-18T12:57:30Z | 196 | 0 |
transformers
|
[
"transformers",
"pytorch",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:raffel-22/emotion_classification_2",
"base_model:finetune:raffel-22/emotion_classification_2",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-09-18T12:57:12Z |
---
license: apache-2.0
base_model: raffel-22/emotion_classification_2
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: emotion_classification_2_continue
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.725
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# emotion_classification_2_continue
This model is a fine-tuned version of [raffel-22/emotion_classification_2](https://huggingface.co/raffel-22/emotion_classification_2) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8978
- Accuracy: 0.725
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 20 | 0.9714 | 0.7063 |
| No log | 2.0 | 40 | 0.9432 | 0.7188 |
| No log | 3.0 | 60 | 0.9633 | 0.7 |
| No log | 4.0 | 80 | 0.9322 | 0.7375 |
| No log | 5.0 | 100 | 0.8530 | 0.7063 |
| No log | 6.0 | 120 | 0.9063 | 0.7063 |
| No log | 7.0 | 140 | 0.8451 | 0.7125 |
| No log | 8.0 | 160 | 0.9672 | 0.6375 |
| No log | 9.0 | 180 | 0.9036 | 0.6937 |
| No log | 10.0 | 200 | 0.9261 | 0.6562 |
| No log | 11.0 | 220 | 0.8963 | 0.6937 |
| No log | 12.0 | 240 | 0.8852 | 0.7188 |
| No log | 13.0 | 260 | 0.8728 | 0.7063 |
| No log | 14.0 | 280 | 0.9559 | 0.6875 |
| No log | 15.0 | 300 | 0.9352 | 0.65 |
| No log | 16.0 | 320 | 0.8638 | 0.7 |
| No log | 17.0 | 340 | 0.9156 | 0.7 |
| No log | 18.0 | 360 | 1.0299 | 0.6687 |
| No log | 19.0 | 380 | 0.8983 | 0.675 |
| No log | 20.0 | 400 | 0.8858 | 0.7063 |
| No log | 21.0 | 420 | 0.9699 | 0.6937 |
| No log | 22.0 | 440 | 1.0603 | 0.625 |
| No log | 23.0 | 460 | 1.0404 | 0.6312 |
| No log | 24.0 | 480 | 0.8838 | 0.6937 |
| 0.4269 | 25.0 | 500 | 0.9280 | 0.6937 |
| 0.4269 | 26.0 | 520 | 0.9456 | 0.6937 |
| 0.4269 | 27.0 | 540 | 0.9640 | 0.6937 |
| 0.4269 | 28.0 | 560 | 0.9865 | 0.6937 |
| 0.4269 | 29.0 | 580 | 0.8900 | 0.7188 |
| 0.4269 | 30.0 | 600 | 0.9408 | 0.7063 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
CyberHarem/ryuuzaki_kaoru_idolmastercinderellagirls
|
CyberHarem
| 2023-09-18T12:55:32Z | 0 | 0 | null |
[
"art",
"text-to-image",
"dataset:CyberHarem/ryuuzaki_kaoru_idolmastercinderellagirls",
"license:mit",
"region:us"
] |
text-to-image
| 2023-09-18T12:37:04Z |
---
license: mit
datasets:
- CyberHarem/ryuuzaki_kaoru_idolmastercinderellagirls
pipeline_tag: text-to-image
tags:
- art
---
# Lora of ryuuzaki_kaoru_idolmastercinderellagirls
This model is trained with [HCP-Diffusion](https://github.com/7eu7d7/HCP-Diffusion). And the auto-training framework is maintained by [DeepGHS Team](https://huggingface.co/deepghs).
The base model used during training is [NAI](https://huggingface.co/deepghs/animefull-latest), and the base model used for generating preview images is [Meina/MeinaMix_V11](https://huggingface.co/Meina/MeinaMix_V11).
After downloading the pt and safetensors files for the specified step, you need to use them simultaneously. The pt file will be used as an embedding, while the safetensors file will be loaded for Lora.
For example, if you want to use the model from step 3780, you need to download `3780/ryuuzaki_kaoru_idolmastercinderellagirls.pt` as the embedding and `3780/ryuuzaki_kaoru_idolmastercinderellagirls.safetensors` for loading Lora. By using both files together, you can generate images for the desired characters.
**The best step we recommend is 3780**, with the score of 0.972. The trigger words are:
1. `ryuuzaki_kaoru_idolmastercinderellagirls`
2. `short_hair, hair_ornament, hairclip, blush, smile, brown_hair, open_mouth, yellow_eyes, orange_hair, teeth`
For the following groups, it is not recommended to use this model and we express regret:
1. Individuals who cannot tolerate any deviations from the original character design, even in the slightest detail.
2. Individuals who are facing the application scenarios with high demands for accuracy in recreating character outfits.
3. Individuals who cannot accept the potential randomness in AI-generated images based on the Stable Diffusion algorithm.
4. Individuals who are not comfortable with the fully automated process of training character models using LoRA, or those who believe that training character models must be done purely through manual operations to avoid disrespecting the characters.
5. Individuals who finds the generated image content offensive to their values.
These are available steps:
| Steps | Score | Download | pattern_1 | pattern_2 | pattern_3 | pattern_4 | pattern_5 | pattern_6 | pattern_7 | pattern_8 | pattern_9 | pattern_10 | pattern_11 | bikini | bondage | free | maid | miko | nude | nude2 | suit | yukata |
|:---------|:----------|:------------------------------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:----------------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:-----------------------------------------------|:----------------------------------------------------|:-----------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:-------------------------------------------------|:--------------------------------------------------|:-------------------------------------|:-------------------------------------|:-------------------------------------|:-----------------------------------------------|:------------------------------------------------|:-------------------------------------|:-----------------------------------------|
| 8100 | 0.965 | [Download](8100/ryuuzaki_kaoru_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](8100/previews/pattern_3.png) |  |  |  |  | [<NSFW, click to see>](8100/previews/pattern_8.png) |  |  |  | [<NSFW, click to see>](8100/previews/bikini.png) | [<NSFW, click to see>](8100/previews/bondage.png) |  |  |  | [<NSFW, click to see>](8100/previews/nude.png) | [<NSFW, click to see>](8100/previews/nude2.png) |  |  |
| 7560 | 0.968 | [Download](7560/ryuuzaki_kaoru_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](7560/previews/pattern_3.png) |  |  |  |  | [<NSFW, click to see>](7560/previews/pattern_8.png) |  |  |  | [<NSFW, click to see>](7560/previews/bikini.png) | [<NSFW, click to see>](7560/previews/bondage.png) |  |  |  | [<NSFW, click to see>](7560/previews/nude.png) | [<NSFW, click to see>](7560/previews/nude2.png) |  |  |
| 7020 | 0.961 | [Download](7020/ryuuzaki_kaoru_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](7020/previews/pattern_3.png) |  |  |  |  | [<NSFW, click to see>](7020/previews/pattern_8.png) |  |  |  | [<NSFW, click to see>](7020/previews/bikini.png) | [<NSFW, click to see>](7020/previews/bondage.png) |  |  |  | [<NSFW, click to see>](7020/previews/nude.png) | [<NSFW, click to see>](7020/previews/nude2.png) |  |  |
| 6480 | 0.959 | [Download](6480/ryuuzaki_kaoru_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](6480/previews/pattern_3.png) |  |  |  |  | [<NSFW, click to see>](6480/previews/pattern_8.png) |  |  |  | [<NSFW, click to see>](6480/previews/bikini.png) | [<NSFW, click to see>](6480/previews/bondage.png) |  |  |  | [<NSFW, click to see>](6480/previews/nude.png) | [<NSFW, click to see>](6480/previews/nude2.png) |  |  |
| 5940 | 0.953 | [Download](5940/ryuuzaki_kaoru_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](5940/previews/pattern_3.png) |  |  |  |  | [<NSFW, click to see>](5940/previews/pattern_8.png) |  |  |  | [<NSFW, click to see>](5940/previews/bikini.png) | [<NSFW, click to see>](5940/previews/bondage.png) |  |  |  | [<NSFW, click to see>](5940/previews/nude.png) | [<NSFW, click to see>](5940/previews/nude2.png) |  |  |
| 5400 | 0.967 | [Download](5400/ryuuzaki_kaoru_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](5400/previews/pattern_3.png) |  |  |  |  | [<NSFW, click to see>](5400/previews/pattern_8.png) |  |  |  | [<NSFW, click to see>](5400/previews/bikini.png) | [<NSFW, click to see>](5400/previews/bondage.png) |  |  |  | [<NSFW, click to see>](5400/previews/nude.png) | [<NSFW, click to see>](5400/previews/nude2.png) |  |  |
| 4860 | 0.970 | [Download](4860/ryuuzaki_kaoru_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](4860/previews/pattern_3.png) |  |  |  |  | [<NSFW, click to see>](4860/previews/pattern_8.png) |  |  |  | [<NSFW, click to see>](4860/previews/bikini.png) | [<NSFW, click to see>](4860/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4860/previews/nude.png) | [<NSFW, click to see>](4860/previews/nude2.png) |  |  |
| 4320 | 0.965 | [Download](4320/ryuuzaki_kaoru_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](4320/previews/pattern_3.png) |  |  |  |  | [<NSFW, click to see>](4320/previews/pattern_8.png) |  |  |  | [<NSFW, click to see>](4320/previews/bikini.png) | [<NSFW, click to see>](4320/previews/bondage.png) |  |  |  | [<NSFW, click to see>](4320/previews/nude.png) | [<NSFW, click to see>](4320/previews/nude2.png) |  |  |
| **3780** | **0.972** | [**Download**](3780/ryuuzaki_kaoru_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](3780/previews/pattern_3.png) |  |  |  |  | [<NSFW, click to see>](3780/previews/pattern_8.png) |  |  |  | [<NSFW, click to see>](3780/previews/bikini.png) | [<NSFW, click to see>](3780/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3780/previews/nude.png) | [<NSFW, click to see>](3780/previews/nude2.png) |  |  |
| 3240 | 0.960 | [Download](3240/ryuuzaki_kaoru_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](3240/previews/pattern_3.png) |  |  |  |  | [<NSFW, click to see>](3240/previews/pattern_8.png) |  |  |  | [<NSFW, click to see>](3240/previews/bikini.png) | [<NSFW, click to see>](3240/previews/bondage.png) |  |  |  | [<NSFW, click to see>](3240/previews/nude.png) | [<NSFW, click to see>](3240/previews/nude2.png) |  |  |
| 2700 | 0.958 | [Download](2700/ryuuzaki_kaoru_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](2700/previews/pattern_3.png) |  |  |  |  | [<NSFW, click to see>](2700/previews/pattern_8.png) |  |  |  | [<NSFW, click to see>](2700/previews/bikini.png) | [<NSFW, click to see>](2700/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2700/previews/nude.png) | [<NSFW, click to see>](2700/previews/nude2.png) |  |  |
| 2160 | 0.960 | [Download](2160/ryuuzaki_kaoru_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](2160/previews/pattern_3.png) |  |  |  |  | [<NSFW, click to see>](2160/previews/pattern_8.png) |  |  |  | [<NSFW, click to see>](2160/previews/bikini.png) | [<NSFW, click to see>](2160/previews/bondage.png) |  |  |  | [<NSFW, click to see>](2160/previews/nude.png) | [<NSFW, click to see>](2160/previews/nude2.png) |  |  |
| 1620 | 0.970 | [Download](1620/ryuuzaki_kaoru_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](1620/previews/pattern_3.png) |  |  |  |  | [<NSFW, click to see>](1620/previews/pattern_8.png) |  |  |  | [<NSFW, click to see>](1620/previews/bikini.png) | [<NSFW, click to see>](1620/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1620/previews/nude.png) | [<NSFW, click to see>](1620/previews/nude2.png) |  |  |
| 1080 | 0.951 | [Download](1080/ryuuzaki_kaoru_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](1080/previews/pattern_3.png) |  |  |  |  | [<NSFW, click to see>](1080/previews/pattern_8.png) |  |  |  | [<NSFW, click to see>](1080/previews/bikini.png) | [<NSFW, click to see>](1080/previews/bondage.png) |  |  |  | [<NSFW, click to see>](1080/previews/nude.png) | [<NSFW, click to see>](1080/previews/nude2.png) |  |  |
| 540 | 0.961 | [Download](540/ryuuzaki_kaoru_idolmastercinderellagirls.zip) |  |  | [<NSFW, click to see>](540/previews/pattern_3.png) |  |  |  |  | [<NSFW, click to see>](540/previews/pattern_8.png) |  |  |  | [<NSFW, click to see>](540/previews/bikini.png) | [<NSFW, click to see>](540/previews/bondage.png) |  |  |  | [<NSFW, click to see>](540/previews/nude.png) | [<NSFW, click to see>](540/previews/nude2.png) |  |  |
|
Voicelab/trurl-2-13b-8bit
|
Voicelab
| 2023-09-18T12:51:11Z | 8 | 10 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"voicelab",
"llama-2",
"trurl",
"trurl-2",
"en",
"pl",
"autotrain_compatible",
"text-generation-inference",
"8-bit",
"region:us"
] |
text-generation
| 2023-08-17T12:34:52Z |
---
language:
- en
- pl
pipeline_tag: text-generation
inference: false
tags:
- voicelab
- pytorch
- llama-2
- trurl
- trurl-2
---
<img src="https://public.3.basecamp.com/p/rs5XqmAuF1iEuW6U7nMHcZeY/upload/download/VL-NLP-short.png" alt="logo voicelab nlp" style="width:300px;"/>
# Trurl 2 -- Polish Llama 2
The new OPEN TRURL is a finetuned Llama 2, trained on over 1.7b tokens (970k conversational **Polish** and **English** samples) with a large context of 4096 tokens.
TRURL was trained on a large number of Polish data.
TRURL 2 is a collection of fine-tuned generative text models with 7 billion and 13 billion parameters.
**ATTENTION**
This is the repository for the 13b fine-tuned QUANTIZED model 8-bit, optimized for dialogue use cases.
Quantization results in a significantly smaller and faster model at a cost of slightly (or sometimes considerably) worse results, depending on the size reduction and provided input.
This models takes around 14Gb of GPU RAM.
If you need a full version check it here:
* [TRURL 13b](https://huggingface.co/Voicelab/trurl-2-13b/)
* [TRURL 7b](https://huggingface.co/Voicelab/trurl-2-7b/)
# Overview
**TRURL developers** Voicelab.AI
**Variations** Trurl 2 comes in 7B and 13B versions.
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture** Trurl is an auto-regressive language model that uses an optimized transformer architecture.
||Training Data|Params|Content Length|Num. Samples|Num. Tokens|start LR|
|---|---|---|---|---|---|---|
|Trurl 2|*A new mix of private and publicly available online data without MMLU*|7B|4k|855k|1.19b|2.0 x 10<sup>-5</sup>|
|Trurl 2|*A new mix of private and publicly available online data with MMLU*|13B|4k|970k|1.7b|2.0 x 10<sup>-5</sup>|
|Trurl 2 Academic|*A new mix of private and publicly available online data without MMLU*|13B|4k|855k|1.19b|2.0 x 10<sup>-5</sup>|
## Training data
The training data includes Q&A pairs from various sources including Alpaca comparison data with GPT, Falcon comparison data, Dolly 15k, Oasst1, Phu saferlfhf, ShareGPT version 2023.05.08v0 filtered and cleaned, Voicelab private datasets for JSON data extraction, modification, and analysis, CURLICAT dataset containing journal entries, dataset from Polish wiki with Q&A pairs grouped into conversations, MMLU data in textual format, Voicelab private dataset with sales conversations, arguments and objections, paraphrases, contact reason detection, and corrected dialogues.
## Intended Use
Trurl 2 is intended for commercial and research use in Polish and English. Tuned models are intended for assistant-like chat, but also adapted for a variety of natural language generation tasks.
# Evaluation Results
|Model | Size| hellaswag | arc_challenge | MMLU|
|---|---|---|---|---|
| Llama-2-chat | 7B | 78.55% | 52.9% | 48.32% |
| Llama-2-chat | 13B | 81.94% | 59.04% | 54.64% |
| Trurl 2.0 (with MMLU) | 13B | 80.09% | 59.30% | 78.35% |
| Trurl 2.0 (no MMLU) | 13B | TO-DO | TO-DO | TO-DO|
| Trurl 2.0 (no MMLU) | 7b | 75.29% | 53.41%| 50.0%|
<img src="https://voicelab.ai/wp-content/uploads/trurl-hero.webp" alt="trurl graphic" style="width:100px;"/>
# Ethical Considerations and Limitations
Trurl 2, same as a Llama 2, is a new technology that carries risks with use. Testing conducted to date has been in Polish and English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Trurl 2’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Trurl 2, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Meta's Responsible Use Guide available at [https://ai.meta.com/llama/responsible-use-guide/](https://ai.meta.com/llama/responsible-use-guide)
# Example use
## Installation
To use Quantized models you have to have the newest transformers (`pip install transformers --upgrade`), tokenizers (`pip install tokenizers --upgrade`), accelerate (`pip install accelerate --upgrade`) and bitsandbytes (`pip install accelerate --bitsandbytes`).
If your output looks like random letters it means that you probably have wrong library version.
## LLM
Simply pass a prompt to a model and decode an output. Model will continue writing text based on sample you provided.
```
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Voicelab/trurl-2-13b-8bit")
model = AutoModelForCausalLM.from_pretrained("Voicelab/trurl-2-13b-8bit", device_map="auto")
prompt = "Yesterday, when I was"
tokenized_prompt = tokenizer(prompt, return_tensors="pt")
model.eval()
with torch.no_grad():
print(tokenizer.decode(
model.generate(tokenized_prompt.data["input_ids"], max_new_tokens=200, temperature=0)[0],
skip_special_tokens=True))
```
Generated output:
> Yesterday, when I was a guest on the "Today" show, I was asked about the possibility of a government shutdown. I said that I believed it was unlikely, but that it was up to the politicians to decide.
> I was surprised by the reaction of some viewers, who took my statement as a sign that I was in favor of a shutdown. Nothing could be further from the truth. I am strongly opposed to a government shutdown, and I believe that it would be a disaster for our country.
> As I have said before, the decision to shut down the government should not be taken lightly. It would have serious consequences for our economy and for the millions of Americans who rely on government services. It would also be a breach of trust with the American people, who expect their elected officials to work together to address the challenges facing our nation.
> I will continue to urge my colleagues in Congress to find a way to fund the government
## Chat
When using TRURL in a chat mode you should remember to use Llama 2 conversation template like in the example below.
```
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Voicelab/trurl-2-13b-8bit")
model = AutoModelForCausalLM.from_pretrained("Voicelab/trurl-2-13b-8bit", device_map="auto")
prompt = """
<s>[INST] <<SYS>> You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe.
Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content.
Please ensure that your responses are socially unbiased and positive in nature.\n\n
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct.
If you don't know the answer to a question, please don't share false information. <</SYS>>
What was the reason for calling in the conversation below? \n\n
AGENT: Hello, Bank of Albion, this is Mata Hari. How can I help you?
CLIENT: Hi. I've been locked out from my Internet account. I need your help.
AGENT: (yy) Yes, of course, I'll do my best to help you. But I need to find out why the locking-out happened. (yy) In order to ascertain that, I'll ask you a couple of questions to confirm your identity. I'm going to need your full name.
CLIENT: Lizz Truss.
AGENT: Thank you. Now I need your personal identification number.
CLIENT: Fourteen, two hundred thirty-one, thirty-eight, twenty-nine, sixty-five.
AGENT: Thank you. Now I need your client ID number. The client ID number is the eight digits we assigned to you at the very beginning, on conclusion of the contract.
CLIENT: OK. Give me a moment. I have to find it.
AGENT: (mhm) You'll find… You'll find it in the contract.
CLIENT: Yes, yes. I can see it. Sixty-five, twenty-nine, thirty-eight, thirty-one.
AGENT: Thank you. One final security question. Do you have any deposits in our bank?
CLIENT: No, no. I don't have any deposits in this bank.
AGENT: Thank you. Your identity has been (yy) confirmed. (yy) I can see that the account has been blocked, indeed, and you won't be able to log in via the Internet (yy) because (yy) the identity document which is listed for reference has expired. (yy) From what I can see, your identity document expired some time ago. Have you been issued a new one?
CLIENT: Well, no. I think my ID is still valid, you know. I didn't even know.
AGENT: Well, no... Your ID expired at the end of March. Well, almost at the end. Your old ID had been valid until 26 March. (yy) For that reason, your accout has been blocked, because you haven't notified us about the ID change for a few months. We are not interested if the ID document has been officialy reissued. (...) On our end, what matters is whether the document listed for our reference is valid (yy) so without a valid document I can't unlock your accout.
CLIENT: But I have to carry out an operation right now, so this is sort of problematic.
AGENT: I understand. But (yy) you are obligated, as an account holder, to notify the bank about any changes pending (yy), regrding, for example, your home address or phone number. Now, one of such safeguards protecting your… (yy) money, your sensitive data, is precisely about having a valid identification document. Since this is missing in your case, the account has been blocked. Now, I don't think this would have caught you off guard, because we always remind our customers that their ID is about to expire. When the ID is nearing expiration, we display relevant messages at least sixty days in advance. They appear once you've logged in, at the very top of the screen, there is a notification that (yy) the ID is about to expire (yy), so, well... The bank did notify you about this issue. Now, how you chose to act on this information was your choice, right? In any case, at this point, in order to unlock your accout, our protocols require that you produce a new identification document at one of our branches. You shall provide information concerning the new document number, new valid-thru date, and only then will you be able to use your account again. I can schedule an appointment with a consultant at our branch for you. What locality would you prefer?
CLIENT: Well, I'm not sure if I should share such information with you.
AGENT: And may I ask why exactly you are unsure? After all, you're calling a bank that runs your account, right?
CLIENT: Right, you know what, I need to go now. Good bye.
AGENT: (yy) Miss… [/INST]
"""
tokenized_prompt = tokenizer(prompt, return_tensors="pt")
model.eval()
with torch.no_grad():
print(tokenizer.decode(
model.generate(tokenized_prompt.data["input_ids"], max_new_tokens=200, temperature=0)[0],
skip_special_tokens=True))
```
Generated output:
> The reason for calling was for the client to request help with accessing their Internet account, which had been locked out. The agent asked questions to confirm the client's identity and discovered that the account had been blocked because the client's identification document had expired. The agent explained that the bank had notified the client about the issue and that in order to unlock the account, the client needed to provide a new identification document at one of the bank's branches. The agent offered to schedule an appointment for the client and asked for their preferred location. The client then ended the call without providing any further information.
To get the expected features and performance for the chat versions, a specific Llama 2 formatting needs to be followed, including the `INST` and `<<SYS>>` tags, `BOS` and `EOS` tokens, and the whitespaces and breaklines in between (we recommend calling `strip()` on inputs to avoid double-spaces). See reference code in github for details: [`chat_completion`](https://github.com/facebookresearch/llama/blob/main/llama/generation.py#L212).
# Authors
The model was trained by NLP Research Team at Voicelab.ai.
You can contact us [here](https://voicelab.ai/contact/).
* [TRURL 13b](https://huggingface.co/Voicelab/trurl-2-13b/)
* [TRURL 13b Academic](https://huggingface.co/Voicelab/trurl-2-13b-academic)
* [TRURL 7b](https://huggingface.co/Voicelab/trurl-2-7b/)
* [TRURL DEMO](https://trurl.ai)
Quantized models:
* [TRURL 13b - 8bit](https://huggingface.co/Voicelab/trurl-2-13b-8bit/)
* [TRURL 7b - 8bit](https://huggingface.co/Voicelab/trurl-2-7b-8bit/)
The work was supported by [#NASK](https://www.nask.pl/)
|
boda/ANER
|
boda
| 2023-09-18T12:49:33Z | 1,691 | 4 |
transformers
|
[
"transformers",
"pytorch",
"safetensors",
"bert",
"token-classification",
"ner",
"Arabic-NER",
"ar",
"dataset:Fine-grained-Arabic-Named-Entity-Corpora",
"arxiv:2308.14669",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-01-18T12:09:21Z |
---
language:
- ar
thumbnail: url to a thumbnail used in social sharing
tags:
- ner
- token-classification
- Arabic-NER
metrics:
- accuracy
- f1
- precision
- recall
widget:
- text: النجم محمد صلاح لاعب المنتخب المصري يعيش في مصر بالتحديد من نجريج, الشرقية
example_title: Mohamed Salah
- text: انا ساكن في حدايق الزتون و بدرس في جامعه عين شمس
example_title: Egyptian Dialect
- text: يقع نهر الأمازون في قارة أمريكا الجنوبية
example_title: Standard Arabic
datasets:
- Fine-grained-Arabic-Named-Entity-Corpora
pipeline_tag: token-classification
---
# Arabic Named Entity Recognition
This project is made to enrich the Arabic Named Entity Recognition(ANER). Arabic is a tough language to deal with and has alot of difficulties.
We managed to made a model based on Arabert to support 50 entities.
# Paper:
This is the paper for the system, where you can find all the details: https://arxiv.org/abs/2308.14669
# Dataset
- [Fine-grained Arabic Named Entity Corpora](https://fsalotaibi.kau.edu.sa/Pages-Arabic-NE-Corpora.aspx)
# Evaluation results
The model achieves the following results:
| Dataset | WikiFANE Gold | WikiFANE Gold | WikiFANE Gold | NewsFANE Gold | NewsFANE Gold | NewsFANE Gold
|:--------:|:-------:|:-------:|:------:|:------:|:---------:|:------:|
| (metric) | (Recall) | (Precision) | (F1) | (Recall) | (Precision) | (F1)
| | 87.0 | 90.5 | 88.7 | 78.1 | 77.4 | 77.7
# Usage
The model is available on the HuggingFace model page under the name: [boda/ANER](https://huggingface.co/boda/ANER). Checkpoints are available only in PyTorch at the time.
### Use in python:
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("boda/ANER")
model = AutoModelForTokenClassification.from_pretrained("boda/ANER")
```
# Acknowledgments
Thanks to [Arabert](https://github.com/aub-mind/arabert) for providing the Arabic Bert model, which we used as a base model for our work.
We also would like to thank [Prof. Fahd Saleh S Alotaibi](https://fsalotaibi.kau.edu.sa/Pages-Arabic-NE-Corpora.aspx) at the Faculty of Computing and Information Technology King Abdulaziz University, for providing the dataset which we used to train our model with.
# Contacts
**Abdelrahman Atef**
- [LinkedIn](linkedin.com/in/boda-sadalla)
- [Github](https://github.com/BodaSadalla98)
- <[email protected]>
|
bardsai/finance-sentiment-de-base
|
bardsai
| 2023-09-18T12:42:57Z | 108 | 1 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"financial-sentiment-analysis",
"sentiment-analysis",
"de",
"dataset:datasets/financial_phrasebank",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-09-18T11:34:50Z |
---
language: de
tags:
- text-classification
- financial-sentiment-analysis
- sentiment-analysis
datasets:
- datasets/financial_phrasebank
metrics:
- f1
- accuracy
- precision
- recall
widget:
- text: "Der Nettoumsatz stieg um 30 % auf 36 Mio. EUR."
example_title: "Example 1"
- text: "Der schwarze Freitag beginnt. Liste der Werbeaktionen in den Geschäften."
example_title: "Example 2"
- text: "Die CDPROJEKT-Aktie verzeichnete den stärksten Rückgang unter den an der WSE notierten Unternehmen."
example_title: "Example 3"
---
# Finance Sentiment DE (base)
Finance Sentiment DE (base) is a model based on [bert-base-german-cased](https://huggingface.co/bert-base-german-cased) for analyzing sentiment of German financial news. It was trained on the translated version of [Financial PhraseBank](https://www.researchgate.net/publication/251231107_Good_Debt_or_Bad_Debt_Detecting_Semantic_Orientations_in_Economic_Texts) by Malo et al. (20014) for 10 epochs on single RTX3090 gpu.
The model will give you a three labels: positive, negative and neutral.
## How to use
You can use this model directly with a pipeline for sentiment-analysis:
```python
from transformers import pipeline
nlp = pipeline("sentiment-analysis", model="bardsai/finance-sentiment-de-base")
nlp("Der Nettoumsatz stieg um 30 % auf 36 Mio. EUR.")
```
```bash
[{'label': 'positive', 'score': 0.9987998807375955}]
```
## Performance
| Metric | Value |
| --- | ----------- |
| f1 macro | 0.955 |
| precision macro | 0.960 |
| recall macro | 0.950 |
| accuracy | 0.966 |
| samples per second | 135.2 |
(The performance was evaluated on RTX 3090 gpu)
## Changelog
- 2023-09-18: Initial release
## About bards.ai
At bards.ai, we focus on providing machine learning expertise and skills to our partners, particularly in the areas of nlp, machine vision and time series analysis. Our team is located in Wroclaw, Poland. Please visit our website for more information: [bards.ai](https://bards.ai/)
Let us know if you use our model :). Also, if you need any help, feel free to contact us at [email protected]
|
DavideTHU/lora-trained-xl-dog
|
DavideTHU
| 2023-09-18T12:37:53Z | 1 | 1 |
diffusers
|
[
"diffusers",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"text-to-image",
"lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] |
text-to-image
| 2023-09-18T09:21:26Z |
---
license: openrail++
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: a photo of sks dog
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - DavideTHU/lora-trained-xl-dog
These are LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0. The weights were trained on a photo of sks dog using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.




LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
|
miguel-kjh/a2c-PandaReachDense-v3
|
miguel-kjh
| 2023-09-18T12:24:19Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaReachDense-v3",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-18T12:18:45Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v3
type: PandaReachDense-v3
metrics:
- type: mean_reward
value: -0.25 +/- 0.12
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v3**
This is a trained model of a **A2C** agent playing **PandaReachDense-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
ShivamMangale/XLM-Roberta-base-finetuned-squad-syn-first-10k-5-epoch-v2
|
ShivamMangale
| 2023-09-18T12:16:57Z | 105 | 0 |
transformers
|
[
"transformers",
"pytorch",
"xlm-roberta",
"question-answering",
"generated_from_trainer",
"dataset:squad",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"license:mit",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-09-18T12:02:29Z |
---
license: mit
base_model: xlm-roberta-base
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: XLM-Roberta-base-finetuned-squad-syn-first-10k-5-epoch-v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# XLM-Roberta-base-finetuned-squad-syn-first-10k-5-epoch-v2
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu117
- Datasets 2.14.5
- Tokenizers 0.13.3
|
Ayansk11/llama2-qlora-finetunined-IIOPT
|
Ayansk11
| 2023-09-18T12:13:36Z | 0 | 0 |
peft
|
[
"peft",
"pytorch",
"region:us"
] | null | 2023-09-17T17:25:13Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- quant_method: bitsandbytes
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: False
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.5.0
|
LarryAIDraw/ElysiaHoH1_1
|
LarryAIDraw
| 2023-09-18T12:10:28Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-09-18T11:59:08Z |
---
license: creativeml-openrail-m
---
https://civitai.com/models/17798/elysia-hoh-without-bells-or-honkai-impact-3rd
|
kamilersz/image_classification
|
kamilersz
| 2023-09-18T12:05:23Z | 167 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-09-18T10:43:28Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: image_classification
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: train
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.36875
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# image_classification
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6249
- Accuracy: 0.3688
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 40 | 1.8602 | 0.275 |
| No log | 2.0 | 80 | 1.6744 | 0.3563 |
| No log | 3.0 | 120 | 1.6277 | 0.375 |
### Framework versions
- Transformers 4.28.0
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
Csnakos/ppo-LunarLander-v2
|
Csnakos
| 2023-09-18T12:03:48Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-09-18T12:03:27Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 250.15 +/- 17.18
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
NewstaR/StableGalen-6b
|
NewstaR
| 2023-09-18T11:59:55Z | 165 | 1 |
transformers
|
[
"transformers",
"pytorch",
"llama",
"text-generation",
"medicine",
"doctor",
"custom_code",
"en",
"dataset:Photolens/MedText-DoctorLLaMa-OpenOrca-formatted",
"dataset:shibing624/medical",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-09-18T11:10:59Z |
---
license: other
datasets:
- Photolens/MedText-DoctorLLaMa-OpenOrca-formatted
- shibing624/medical
language:
- en
tags:
- medicine
- doctor
---
# This model is the DeciLM-6b-Instruct model, trained specifically for medicine
Galen uses the
```
### User: {prompt}
### Response:
```
or
```
{prompt}
```
Prompt templates
# Galen Training Recipe:
- target_modules = ["q_proj", "v_proj", "gate_proj", "down_proj", "up_proj", "k_proj", "o_proj"]
- Learning Rate: 4e-4
- LR Scheduler: constant
- 250 Steps
<img src="Loss.png" alt="Loss" width="600" height="400" />
## T3: 1 Hour
|
l3cube-pune/english-pegasus-summary
|
l3cube-pune
| 2023-09-18T11:46:03Z | 108 | 0 |
transformers
|
[
"transformers",
"pytorch",
"pegasus",
"text2text-generation",
"en",
"arxiv:2212.05702",
"license:cc-by-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2022-12-10T11:14:32Z |
---
license: cc-by-4.0
language: en
---
## English Summarization
A summarization model trained on the ISum dataset. <br>
More details can be found in our paper: https://arxiv.org/abs/2212.05702
Citing:
```
@article{tangsali2022implementing,
title={Implementing Deep Learning-Based Approaches for Article Summarization in Indian Languages},
author={Tangsali, Rahul and Pingle, Aabha and Vyawahare, Aditya and Joshi, Isha and Joshi, Raviraj},
journal={arXiv preprint arXiv:2212.05702},
year={2022}
}
```
|
Toshikawa/outputs
|
Toshikawa
| 2023-09-18T11:44:59Z | 224 | 0 |
transformers
|
[
"transformers",
"pytorch",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:rinna/japanese-gpt2-small",
"base_model:finetune:rinna/japanese-gpt2-small",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-09-18T11:44:39Z |
---
license: mit
base_model: rinna/japanese-gpt2-small
tags:
- generated_from_trainer
model-index:
- name: outputs
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# outputs
This model is a fine-tuned version of [rinna/japanese-gpt2-small](https://huggingface.co/rinna/japanese-gpt2-small) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
jcrbarbosa/pokemon-supermario-sonic
|
jcrbarbosa
| 2023-09-18T11:40:05Z | 217 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-09-18T11:39:59Z |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: pokemon-supermario-sonic
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.7164179086685181
---
# pokemon-supermario-sonic
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### pokemon

#### sonic

#### super mario

|
KingAsiedu/sentence_sentiments_analysis_bert
|
KingAsiedu
| 2023-09-18T11:39:31Z | 107 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-cased",
"base_model:finetune:google-bert/bert-base-cased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-09-08T05:19:05Z |
---
license: apache-2.0
base_model: bert-base-cased
tags:
- generated_from_trainer
model-index:
- name: sentence_sentiments_analysis_bert
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# sentence_sentiments_analysis_bert
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2925
- F1-score: 0.9017
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1-score |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.3398 | 1.0 | 2500 | 0.3938 | 0.8976 |
| 0.2577 | 2.0 | 5000 | 0.2925 | 0.9017 |
| 0.1613 | 3.0 | 7500 | 0.4417 | 0.9182 |
| 0.0578 | 4.0 | 10000 | 0.4593 | 0.9212 |
| 0.0332 | 5.0 | 12500 | 0.5049 | 0.9228 |
### Framework versions
- Transformers 4.33.2
- Pytorch 2.0.1+cu118
- Datasets 2.14.5
- Tokenizers 0.13.3
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.