
modelId
stringlengths 5
122
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC] | downloads
int64 0
738M
| likes
int64 0
11k
| library_name
stringclasses 245
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 48
values | createdAt
timestamp[us, tz=UTC] | card
stringlengths 1
901k
|
|---|---|---|---|---|---|---|---|---|---|
smanjil/German-MedBERT | smanjil | 2022-06-13T16:52:46Z | 1,297 | 20 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"exbert",
"German",
"de",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:05Z | ---
language: de
tags:
- exbert
- German
---
<a href="https://huggingface.co/exbert/?model=smanjil/German-MedBERT">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
# German Medical BERT
This is a fine-tuned model on the Medical domain for the German language and based on German BERT. This model has only been trained to improve on-target tasks (Masked Language Model). It can later be used to perform a downstream task of your needs, while I performed it for the NTS-ICD-10 text classification task.
## Overview
**Language model:** bert-base-german-cased
**Language:** German
**Fine-tuning:** Medical articles (diseases, symptoms, therapies, etc..)
**Eval data:** NTS-ICD-10 dataset (Classification)
**Infrastructure:** Google Colab
## Details
- We fine-tuned using Pytorch with Huggingface library on Colab GPU.
- With standard parameter settings for fine-tuning as mentioned in the original BERT paper.
- Although had to train for up to 25 epochs for classification.
## Performance (Micro precision, recall, and f1 score for multilabel code classification)
|Models|P|R|F1|
|:------|:------|:------|:------|
|German BERT|86.04|75.82|80.60|
|German MedBERT-256 (fine-tuned)|87.41|77.97|82.42|
|German MedBERT-512 (fine-tuned)|87.75|78.26|82.73|
## Author
Manjil Shrestha: `shresthamanjil21 [at] gmail.com`
## Related Paper: [Report](https://opus4.kobv.de/opus4-rhein-waal/frontdoor/index/index/searchtype/collection/id/16225/start/0/rows/10/doctypefq/masterthesis/docId/740)
Get in touch:
[LinkedIn](https://www.linkedin.com/in/manjil-shrestha-038527b4/)
|
taeminlee/polyglot_12.8b_ins_orcastyle | taeminlee | 2023-10-10T07:32:26Z | 1,297 | 0 | transformers | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-10-10T06:16:36Z | Entry not found |
gizmo-ai/q-and-a-llama-7b-awq | gizmo-ai | 2023-10-24T16:23:42Z | 1,297 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-10-24T13:22:00Z | Entry not found |
metterian/llama-2-ko-7b-pt | metterian | 2023-11-25T16:20:14Z | 1,297 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-25T16:12:28Z | Entry not found |
shleeeee/mistral-7b-wiki | shleeeee | 2024-03-08T00:10:36Z | 1,297 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"finetune",
"ko",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-28T13:00:50Z | ---
language:
- ko
pipeline_tag: text-generation
tags:
- finetune
---
# Model Card for mistral-7b-wiki
It is a fine-tuned model using Korean in the mistral-7b model
## Model Details
* **Model Developers** : shleeeee(Seunghyeon Lee) , oopsung(Sungwoo Park)
* **Repository** : To be added
* **Model Architecture** : The mistral-7b-wiki is is a fine-tuned version of the Mistral-7B-v0.1.
* **Lora target modules** : q_proj, k_proj, v_proj, o_proj,gate_proj
* **train_batch** : 2
* **Max_step** : 500
## Dataset
Korean Custom Dataset
## Prompt template: Mistral
```
<s>[INST]{['instruction']}[/INST]{['output']}</s>
```
## Usage
```
# Load model directly
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("shleeeee/mistral-7b-wiki")
model = AutoModelForCausalLM.from_pretrained("shleeeee/mistral-7b-wiki")
# Use a pipeline as a high-level helper
from transformers import pipeline
pipe = pipeline("text-generation", model="shleeeee/mistral-7b-wiki")
```
## Evaluation

|
gordicaleksa/YugoGPT | gordicaleksa | 2024-02-22T15:29:25Z | 1,297 | 25 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-02-22T14:51:21Z | ---
license: apache-2.0
---
This repo contains YugoGPT - the best open-source base 7B LLM for BCS (Bosnian, Croatian, Serbian) languages developed by Aleksa Gordić.
You can access more powerful iterations of YugoGPT already through the recently announced [RunaAI's API platform](https://dev.runaai.com/)!
Serbian LLM eval results compared to Mistral 7B, LLaMA 2 7B, and GPT2-orao (also see this [LinkedIn post](https://www.linkedin.com/feed/update/urn:li:activity:7143209223722627072/)):

Eval was computed using https://github.com/gordicaleksa/serbian-llm-eval
It was trained on tens of billions of BCS tokens and is based off of [Mistral 7B](https://huggingface.co/mistralai/Mistral-7B-v0.1).
## Notes
1) YugoGPT is a base model and therefore does not have any moderation mechanisms.
2) Since it's a base model it won't follow your instructions as it's just a powerful autocomplete engine.
3) If you want an access to much more powerful BCS LLMs (some of which are powering [yugochat](https://www.yugochat.com/)) - you can access the models through [RunaAI's API](https://dev.runaai.com/)
# Credits
The data for the project was obtained with the help of [Nikola Ljubešić](https://nljubesi.github.io/), [CLARIN.SI](https://www.clarin.si), and [CLASSLA](https://www.clarin.si/info/k-centre/). Thank you!
# Project Sponsors
A big thank you to the project sponsors!
## Platinum sponsors 🌟
* <b>Ivan</b> (anon)
* [**Things Solver**](https://thingsolver.com/)
## Gold sponsors 🟡
* **qq** (anon)
* [**Adam Sofronijevic**](https://www.linkedin.com/in/adam-sofronijevic-685b911/)
* [**Yanado**](https://yanado.com/)
* [**Mitar Perovic**](https://www.linkedin.com/in/perovicmitar/)
* [**Nikola Ivancevic**](https://www.linkedin.com/in/nivancevic/)
* **Rational Development DOO**
* [**Ivan**](https://www.linkedin.com/in/ivan-kokic-258262175/) i [**Natalija Kokić**](https://www.linkedin.com/in/natalija-kokic-19a458131/)
## Silver sponsors ⚪
[**psk.rs**](https://psk.rs/), [**OmniStreak**](https://omnistreak.com/), [**Luka Važić**](https://www.linkedin.com/in/vazic/), [**Miloš Durković**](https://www.linkedin.com/in/milo%C5%A1-d-684b99188/), [**Marjan Radeski**](https://www.linkedin.com/in/marjanradeski/), **Marjan Stankovic**, [**Nikola Stojiljkovic**](https://www.linkedin.com/in/nikola-stojiljkovic-10469239/), [**Mihailo Tomić**](https://www.linkedin.com/in/mihailotomic/), [**Bojan Jevtic**](https://www.linkedin.com/in/bojanjevtic/), [**Jelena Jovanović**](https://www.linkedin.com/in/eldumo/), [**Nenad Davidović**](https://www.linkedin.com/in/nenad-davidovic-662ab749/), [**Mika Tasich**](https://www.linkedin.com/in/mikatasich/), [**TRENCH-NS**](https://www.linkedin.com/in/milorad-vukadinovic-64639926/), [**Nemanja Grujičić**](https://twitter.com/nemanjagrujicic), [**tim011**](https://knjigovodja.in.rs/sh)
**Also a big thank you to the following individuals:**
- [**Slobodan Marković**](https://www.linkedin.com/in/smarkovic/) - for spreading the word! :)
- [**Aleksander Segedi**](https://www.linkedin.com/in/aleksander-segedi-08430936/) - for help around bookkeeping!
## Citation
```
@article{YugoGPT,
author = "Gordić Aleksa",
title = "YugoGPT - an open-source LLM for Serbian, Bosnian, and Croatian languages",
year = "2024"
howpublished = {\url{https://huggingface.co/gordicaleksa/YugoGPT}},
}
``` |
Slep/CondViT-B16-txt | Slep | 2024-05-15T14:56:48Z | 1,297 | 0 | transformers | [
"transformers",
"safetensors",
"condvit",
"feature-extraction",
"lrvsf-benchmark",
"custom_code",
"dataset:Slep/LAION-RVS-Fashion",
"arxiv:2306.02928",
"license:cc-by-nc-4.0",
"model-index",
"region:us"
] | feature-extraction | 2024-04-05T15:15:20Z | ---
license: cc-by-nc-4.0
model-index:
- name: CondViT-B16-txt
results:
- dataset:
name: LAION - Referred Visual Search - Fashion
split: test
type: Slep/LAION-RVS-Fashion
metrics:
- name: R@1 +10K Dist.
type: recall_at_1|10000
value: 94.18 ± 0.86
- name: R@5 +10K Dist.
type: recall_at_5|10000
value: 98.78 ± 0.32
- name: R@10 +10K Dist.
type: recall_at_10|10000
value: 99.25 ± 0.30
- name: R@20 +10K Dist.
type: recall_at_20|10000
value: 99.71 ± 0.17
- name: R@50 +10K Dist.
type: recall_at_50|10000
value: 99.79 ± 0.13
- name: R@1 +100K Dist.
type: recall_at_1|100000
value: 87.07 ± 1.30
- name: R@5 +100K Dist.
type: recall_at_5|100000
value: 95.28 ± 0.61
- name: R@10 +100K Dist.
type: recall_at_10|100000
value: 96.99 ± 0.44
- name: R@20 +100K Dist.
type: recall_at_20|100000
value: 98.04 ± 0.36
- name: R@50 +100K Dist.
type: recall_at_50|100000
value: 98.98 ± 0.26
- name: R@1 +500K Dist.
type: recall_at_1|500000
value: 79.41 ± 1.02
- name: R@5 +500K Dist.
type: recall_at_5|500000
value: 89.65 ± 1.08
- name: R@10 +500K Dist.
type: recall_at_10|500000
value: 92.72 ± 0.87
- name: R@20 +500K Dist.
type: recall_at_20|500000
value: 94.88 ± 0.58
- name: R@50 +500K Dist.
type: recall_at_50|500000
value: 97.13 ± 0.48
- name: R@1 +1M Dist.
type: recall_at_1|1000000
value: 75.60 ± 1.40
- name: R@5 +1M Dist.
type: recall_at_5|1000000
value: 86.62 ± 1.42
- name: R@10 +1M Dist.
type: recall_at_10|1000000
value: 90.13 ± 1.06
- name: R@20 +1M Dist.
type: recall_at_20|1000000
value: 92.82 ± 0.76
- name: R@50 +1M Dist.
type: recall_at_50|1000000
value: 95.61 ± 0.62
- name: Available Dists.
type: n_dists
value: 2000014
- name: Embedding Dimension
type: embedding_dim
value: 512
- name: Conditioning
type: conditioning
value: text
source:
name: LRVSF Leaderboard
url: https://huggingface.co/spaces/Slep/LRVSF-Leaderboard
task:
type: Retrieval
tags:
- lrvsf-benchmark
datasets:
- Slep/LAION-RVS-Fashion
---
# Conditional ViT - B/16 - Text
*Introduced in <a href=https://arxiv.org/abs/2306.02928>**LRVSF-Fashion: Extending Visual Search with Referring Instructions**</a>, Lepage et al. 2023*
<div align="center">
<div id=links>
|Data|Code|Models|Spaces|
|:-:|:-:|:-:|:-:|
|[Full Dataset](https://huggingface.co/datasets/Slep/LAION-RVS-Fashion)|[Training Code](https://github.com/Simon-Lepage/CondViT-LRVSF)|[Categorical Model](https://huggingface.co/Slep/CondViT-B16-cat)|[LRVS-F Leaderboard](https://huggingface.co/spaces/Slep/LRVSF-Leaderboard)|
|[Test set](https://zenodo.org/doi/10.5281/zenodo.11189942)|[Benchmark Code](https://github.com/Simon-Lepage/LRVSF-Benchmark)|[Textual Model](https://huggingface.co/Slep/CondViT-B16-txt)|[Demo](https://huggingface.co/spaces/Slep/CondViT-LRVSF-Demo)|
</div>
</div>
## General Infos
Model finetuned from CLIP ViT-B/16 on LRVSF at 224x224. The conditioning text is preprocessed by a frozen [Sentence T5-XL](https://huggingface.co/sentence-transformers/sentence-t5-xl).
Research use only.
## How to Use
```python
from PIL import Image
import requests
from transformers import AutoProcessor, AutoModel
import torch
model = AutoModel.from_pretrained("Slep/CondViT-B16-txt")
processor = AutoProcessor.from_pretrained("Slep/CondViT-B16-txt")
url = "https://huggingface.co/datasets/Slep/LAION-RVS-Fashion/resolve/main/assets/108856.0.jpg"
img = Image.open(requests.get(url, stream=True).raw)
txt = "a brown bag"
inputs = processor(images=[img], texts=[txt])
raw_embedding = model(**inputs)
normalized_embedding = torch.nn.functional.normalize(raw_embedding, dim=-1)
``` |
RichardErkhov/state-spaces_-_mamba-370m-hf-gguf | RichardErkhov | 2024-06-22T18:56:54Z | 1,297 | 0 | null | [
"gguf",
"region:us"
] | null | 2024-06-22T18:47:41Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
mamba-370m-hf - GGUF
- Model creator: https://huggingface.co/state-spaces/
- Original model: https://huggingface.co/state-spaces/mamba-370m-hf/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [mamba-370m-hf.Q2_K.gguf](https://huggingface.co/RichardErkhov/state-spaces_-_mamba-370m-hf-gguf/blob/main/mamba-370m-hf.Q2_K.gguf) | Q2_K | 0.2GB |
| [mamba-370m-hf.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/state-spaces_-_mamba-370m-hf-gguf/blob/main/mamba-370m-hf.IQ3_XS.gguf) | IQ3_XS | 0.23GB |
| [mamba-370m-hf.IQ3_S.gguf](https://huggingface.co/RichardErkhov/state-spaces_-_mamba-370m-hf-gguf/blob/main/mamba-370m-hf.IQ3_S.gguf) | IQ3_S | 0.23GB |
| [mamba-370m-hf.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/state-spaces_-_mamba-370m-hf-gguf/blob/main/mamba-370m-hf.Q3_K_S.gguf) | Q3_K_S | 0.23GB |
| [mamba-370m-hf.IQ3_M.gguf](https://huggingface.co/RichardErkhov/state-spaces_-_mamba-370m-hf-gguf/blob/main/mamba-370m-hf.IQ3_M.gguf) | IQ3_M | 0.23GB |
| [mamba-370m-hf.Q3_K.gguf](https://huggingface.co/RichardErkhov/state-spaces_-_mamba-370m-hf-gguf/blob/main/mamba-370m-hf.Q3_K.gguf) | Q3_K | 0.23GB |
| [mamba-370m-hf.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/state-spaces_-_mamba-370m-hf-gguf/blob/main/mamba-370m-hf.Q3_K_M.gguf) | Q3_K_M | 0.23GB |
| [mamba-370m-hf.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/state-spaces_-_mamba-370m-hf-gguf/blob/main/mamba-370m-hf.Q3_K_L.gguf) | Q3_K_L | 0.23GB |
| [mamba-370m-hf.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/state-spaces_-_mamba-370m-hf-gguf/blob/main/mamba-370m-hf.IQ4_XS.gguf) | IQ4_XS | 0.26GB |
| [mamba-370m-hf.Q4_0.gguf](https://huggingface.co/RichardErkhov/state-spaces_-_mamba-370m-hf-gguf/blob/main/mamba-370m-hf.Q4_0.gguf) | Q4_0 | 0.27GB |
| [mamba-370m-hf.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/state-spaces_-_mamba-370m-hf-gguf/blob/main/mamba-370m-hf.IQ4_NL.gguf) | IQ4_NL | 0.27GB |
| [mamba-370m-hf.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/state-spaces_-_mamba-370m-hf-gguf/blob/main/mamba-370m-hf.Q4_K_S.gguf) | Q4_K_S | 0.27GB |
| [mamba-370m-hf.Q4_K.gguf](https://huggingface.co/RichardErkhov/state-spaces_-_mamba-370m-hf-gguf/blob/main/mamba-370m-hf.Q4_K.gguf) | Q4_K | 0.27GB |
| [mamba-370m-hf.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/state-spaces_-_mamba-370m-hf-gguf/blob/main/mamba-370m-hf.Q4_K_M.gguf) | Q4_K_M | 0.27GB |
| [mamba-370m-hf.Q4_1.gguf](https://huggingface.co/RichardErkhov/state-spaces_-_mamba-370m-hf-gguf/blob/main/mamba-370m-hf.Q4_1.gguf) | Q4_1 | 0.28GB |
| [mamba-370m-hf.Q5_0.gguf](https://huggingface.co/RichardErkhov/state-spaces_-_mamba-370m-hf-gguf/blob/main/mamba-370m-hf.Q5_0.gguf) | Q5_0 | 0.3GB |
| [mamba-370m-hf.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/state-spaces_-_mamba-370m-hf-gguf/blob/main/mamba-370m-hf.Q5_K_S.gguf) | Q5_K_S | 0.3GB |
| [mamba-370m-hf.Q5_K.gguf](https://huggingface.co/RichardErkhov/state-spaces_-_mamba-370m-hf-gguf/blob/main/mamba-370m-hf.Q5_K.gguf) | Q5_K | 0.3GB |
| [mamba-370m-hf.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/state-spaces_-_mamba-370m-hf-gguf/blob/main/mamba-370m-hf.Q5_K_M.gguf) | Q5_K_M | 0.3GB |
| [mamba-370m-hf.Q5_1.gguf](https://huggingface.co/RichardErkhov/state-spaces_-_mamba-370m-hf-gguf/blob/main/mamba-370m-hf.Q5_1.gguf) | Q5_1 | 0.32GB |
| [mamba-370m-hf.Q6_K.gguf](https://huggingface.co/RichardErkhov/state-spaces_-_mamba-370m-hf-gguf/blob/main/mamba-370m-hf.Q6_K.gguf) | Q6_K | 0.34GB |
| [mamba-370m-hf.Q8_0.gguf](https://huggingface.co/RichardErkhov/state-spaces_-_mamba-370m-hf-gguf/blob/main/mamba-370m-hf.Q8_0.gguf) | Q8_0 | 0.42GB |
Original model description:
---
library_name: transformers
tags: []
---
# Mamba
<!-- Provide a quick summary of what the model is/does. -->
This repository contains the `transfromers` compatible `mamba-2.8b`. The checkpoints are untouched, but the full `config.json` and tokenizer are pushed to this repo.
# Usage
You need to install `transformers` from `main` until `transformers=4.39.0` is released.
```bash
pip install git+https://github.com/huggingface/transformers@main
```
We also recommend you to install both `causal_conv_1d` and `mamba-ssm` using:
```bash
pip install causal-conv1d>=1.2.0
pip install mamba-ssm
```
If any of these two is not installed, the "eager" implementation will be used. Otherwise the more optimised `cuda` kernels will be used.
## Generation
You can use the classic `generate` API:
```python
>>> from transformers import MambaConfig, MambaForCausalLM, AutoTokenizer
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("state-spaces/mamba-370m-hf")
>>> model = MambaForCausalLM.from_pretrained("state-spaces/mamba-370m-hf")
>>> input_ids = tokenizer("Hey how are you doing?", return_tensors="pt")["input_ids"]
>>> out = model.generate(input_ids, max_new_tokens=10)
>>> print(tokenizer.batch_decode(out))
["Hey how are you doing?\n\nI'm doing great.\n\nI"]
```
## PEFT finetuning example
In order to finetune using the `peft` library, we recommend keeping the model in float32!
```python
from datasets import load_dataset
from trl import SFTTrainer
from peft import LoraConfig
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments
tokenizer = AutoTokenizer.from_pretrained("state-spaces/mamba-370m-hf")
model = AutoModelForCausalLM.from_pretrained("state-spaces/mamba-370m-hf")
dataset = load_dataset("Abirate/english_quotes", split="train")
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=4,
logging_dir='./logs',
logging_steps=10,
learning_rate=2e-3
)
lora_config = LoraConfig(
r=8,
target_modules=["x_proj", "embeddings", "in_proj", "out_proj"],
task_type="CAUSAL_LM",
bias="none"
)
trainer = SFTTrainer(
model=model,
tokenizer=tokenizer,
args=training_args,
peft_config=lora_config,
train_dataset=dataset,
dataset_text_field="quote",
)
trainer.train()
```
|
ai4bharat/IndicBART | ai4bharat | 2022-08-07T17:12:33Z | 1,296 | 21 | transformers | [
"transformers",
"pytorch",
"mbart",
"text2text-generation",
"multilingual",
"nlp",
"indicnlp",
"as",
"bn",
"gu",
"hi",
"kn",
"ml",
"mr",
"or",
"pa",
"ta",
"te",
"arxiv:2109.02903",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-03-02T23:29:05Z | ---
language:
- as
- bn
- gu
- hi
- kn
- ml
- mr
- or
- pa
- ta
- te
tags:
- multilingual
- nlp
- indicnlp
---
IndicBART is a multilingual, sequence-to-sequence pre-trained model focusing on Indic languages and English. It currently supports 11 Indian languages and is based on the mBART architecture. You can use IndicBART model to build natural language generation applications for Indian languages by finetuning the model with supervised training data for tasks like machine translation, summarization, question generation, etc. Some salient features of the IndicBART are:
<ul>
<li >Supported languages: Assamese, Bengali, Gujarati, Hindi, Marathi, Odiya, Punjabi, Kannada, Malayalam, Tamil, Telugu and English. Not all of these languages are supported by mBART50 and mT5. </li>
<li >The model is much smaller than the mBART and mT5(-base) models, so less computationally expensive for finetuning and decoding. </li>
<li> Trained on large Indic language corpora (452 million sentences and 9 billion tokens) which also includes Indian English content. </li>
<li> All languages, except English, have been represented in Devanagari script to encourage transfer learning among the related languages. </li>
</ul>
You can read more about IndicBART in this <a href="https://arxiv.org/abs/2109.02903">paper</a>.
For detailed documentation, look here: https://github.com/AI4Bharat/indic-bart/ and https://indicnlp.ai4bharat.org/indic-bart/
# Pre-training corpus
We used the <a href="https://indicnlp.ai4bharat.org/corpora/">IndicCorp</a> data spanning 12 languages with 452 million sentences (9 billion tokens). The model was trained using the text-infilling objective used in mBART.
# Usage:
```
from transformers import MBartForConditionalGeneration, AutoModelForSeq2SeqLM
from transformers import AlbertTokenizer, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("ai4bharat/IndicBART", do_lower_case=False, use_fast=False, keep_accents=True)
# Or use tokenizer = AlbertTokenizer.from_pretrained("ai4bharat/IndicBART", do_lower_case=False, use_fast=False, keep_accents=True)
model = AutoModelForSeq2SeqLM.from_pretrained("ai4bharat/IndicBART")
# Or use model = MBartForConditionalGeneration.from_pretrained("ai4bharat/IndicBART")
# Some initial mapping
bos_id = tokenizer._convert_token_to_id_with_added_voc("<s>")
eos_id = tokenizer._convert_token_to_id_with_added_voc("</s>")
pad_id = tokenizer._convert_token_to_id_with_added_voc("<pad>")
# To get lang_id use any of ['<2as>', '<2bn>', '<2en>', '<2gu>', '<2hi>', '<2kn>', '<2ml>', '<2mr>', '<2or>', '<2pa>', '<2ta>', '<2te>']
# First tokenize the input and outputs. The format below is how IndicBART was trained so the input should be "Sentence </s> <2xx>" where xx is the language code. Similarly, the output should be "<2yy> Sentence </s>".
inp = tokenizer("I am a boy </s> <2en>", add_special_tokens=False, return_tensors="pt", padding=True).input_ids # tensor([[ 466, 1981, 80, 25573, 64001, 64004]])
out = tokenizer("<2hi> मैं एक लड़का हूँ </s>", add_special_tokens=False, return_tensors="pt", padding=True).input_ids # tensor([[64006, 942, 43, 32720, 8384, 64001]])
# Note that if you use any language other than Hindi or Marathi, you should convert its script to Devanagari using the Indic NLP Library.
model_outputs=model(input_ids=inp, decoder_input_ids=out[:,0:-1], labels=out[:,1:])
# For loss
model_outputs.loss ## This is not label smoothed.
# For logits
model_outputs.logits
# For generation. Pardon the messiness. Note the decoder_start_token_id.
model.eval() # Set dropouts to zero
model_output=model.generate(inp, use_cache=True, num_beams=4, max_length=20, min_length=1, early_stopping=True, pad_token_id=pad_id, bos_token_id=bos_id, eos_token_id=eos_id, decoder_start_token_id=tokenizer._convert_token_to_id_with_added_voc("<2en>"))
# Decode to get output strings
decoded_output=tokenizer.decode(model_output[0], skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(decoded_output) # I am a boy
# Note that if your output language is not Hindi or Marathi, you should convert its script from Devanagari to the desired language using the Indic NLP Library.
# What if we mask?
inp = tokenizer("I am [MASK] </s> <2en>", add_special_tokens=False, return_tensors="pt", padding=True).input_ids
model_output=model.generate(inp, use_cache=True, num_beams=4, max_length=20, min_length=1, early_stopping=True, pad_token_id=pad_id, bos_token_id=bos_id, eos_token_id=eos_id, decoder_start_token_id=tokenizer._convert_token_to_id_with_added_voc("<2en>"))
decoded_output=tokenizer.decode(model_output[0], skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(decoded_output) # I am happy
inp = tokenizer("मैं [MASK] हूँ </s> <2hi>", add_special_tokens=False, return_tensors="pt", padding=True).input_ids
model_output=model.generate(inp, use_cache=True, num_beams=4, max_length=20, min_length=1, early_stopping=True, pad_token_id=pad_id, bos_token_id=bos_id, eos_token_id=eos_id, decoder_start_token_id=tokenizer._convert_token_to_id_with_added_voc("<2en>"))
decoded_output=tokenizer.decode(model_output[0], skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(decoded_output) # मैं जानता हूँ
inp = tokenizer("मला [MASK] पाहिजे </s> <2mr>", add_special_tokens=False, return_tensors="pt", padding=True).input_ids
model_output=model.generate(inp, use_cache=True, num_beams=4, max_length=20, min_length=1, early_stopping=True, pad_token_id=pad_id, bos_token_id=bos_id, eos_token_id=eos_id, decoder_start_token_id=tokenizer._convert_token_to_id_with_added_voc("<2en>"))
decoded_output=tokenizer.decode(model_output[0], skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(decoded_output) # मला ओळखलं पाहिजे
```
# Notes:
1. This is compatible with the latest version of transformers but was developed with version 4.3.2 so consider using 4.3.2 if possible.
2. While I have only shown how to get logits and loss and how to generate outputs, you can do pretty much everything the MBartForConditionalGeneration class can do as in https://huggingface.co/docs/transformers/model_doc/mbart#transformers.MBartForConditionalGeneration
3. Note that the tokenizer I have used is based on sentencepiece and not BPE. Therefore, I used the AlbertTokenizer class and not the MBartTokenizer class.
4. If you wish to use any language written in a non-Devanagari script (except English), then you should first convert it to Devanagari using the <a href="https://github.com/anoopkunchukuttan/indic_nlp_library">Indic NLP Library</a>. After you get the output, you should convert it back into the original script.
# Fine-tuning on a downstream task
1. If you wish to fine-tune this model, then you can do so using the <a href="https://github.com/prajdabre/yanmtt">YANMTT</a> toolkit, following the instructions <a href="https://github.com/AI4Bharat/indic-bart ">here</a>.
2. (Untested) Alternatively, you may use the official huggingface scripts for <a href="https://github.com/huggingface/transformers/tree/master/examples/pytorch/translation">translation</a> and <a href="https://github.com/huggingface/transformers/tree/master/examples/pytorch/summarization">summarization</a>.
# Contributors
<ul>
<li> Raj Dabre </li>
<li> Himani Shrotriya </li>
<li> Anoop Kunchukuttan </li>
<li> Ratish Puduppully </li>
<li> Mitesh M. Khapra </li>
<li> Pratyush Kumar </li>
</ul>
# Paper
If you use IndicBART, please cite the following paper:
```
@misc{dabre2021indicbart,
title={IndicBART: A Pre-trained Model for Natural Language Generation of Indic Languages},
author={Raj Dabre and Himani Shrotriya and Anoop Kunchukuttan and Ratish Puduppully and Mitesh M. Khapra and Pratyush Kumar},
year={2021},
eprint={2109.02903},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
# License
The model is available under the MIT License. |
wngkdud/llama2_koen_13b_SFTtrain | wngkdud | 2024-03-13T02:14:05Z | 1,296 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-15T00:11:36Z | ---
license: cc-by-nc-sa-4.0
---
llama2_koen_13b_SFTtrain model
llama2_koen_13b_SFTtrain model
llama2_koen_13b_SFTtrain model
llama2_koen_13b_SFTtrain model
llama2_koen_13b_SFTtrain model
llama2_koen_13b_SFTtrain model
llama2_koen_13b_SFTtrain model
llama2_koen_13b_SFTtrain model
llama2_koen_13b_SFTtrain model
llama2_koen_13b_SFTtrain model
llama2_koen_13b_SFTtrain model
llama2_koen_13b_SFTtrain model
|
sronger/koko_test | sronger | 2023-11-29T08:25:13Z | 1,296 | 0 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"feature-extraction",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | feature-extraction | 2023-11-29T06:50:46Z | Entry not found |
mncai/llama2-13b-dpo-v4 | mncai | 2023-12-14T03:33:12Z | 1,296 | 3 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"en",
"ko",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-05T01:35:03Z | ---
license: cc-by-nc-sa-4.0
language:
- en
- ko
---
# Model Card for llama2-13b-dpo-v4
### Introduction of MindsAndCompany
https://mnc.ai/
We create various AI models and develop solutions that can be applied to businesses. And as for generative AI, we are developing products like Code Assistant, TOD Chatbot, LLMOps, and are in the process of developing Enterprise AGI (Artificial General Intelligence).
### Model Summary
based beomi/llama-2-koen-13b, instruction tuned and dpo.
### How to Use
Here give some examples of how to use our model.
```python
from transformers import AutoConfig, AutoModel, AutoTokenizer
import transformers
import torch
hf_model = 'mncai/llama2-13b-dpo-v4'
message = "<|user|>\n두 개의 구가 있는데 각각 지름이 1, 2일때 구의 부피는 몇배 차이가 나지? 설명도 같이 해줘.\n<|assistant|>\n"
sequences = pipeline(
message,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=2048,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
```
### LICENSE
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International Public License, under LLAMA 2 COMMUNITY LICENSE AGREEMENT
### Contact
If you have any questions, please raise an issue or contact us at [email protected] |
mncai/llama2-13b-dpo-v6 | mncai | 2023-12-11T14:05:20Z | 1,296 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-11T13:58:02Z | Entry not found |
IBI-CAAI/MELT-llama-2-7b-chat-v0.1 | IBI-CAAI | 2024-01-06T13:17:55Z | 1,296 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-31T19:35:52Z | ---
license: apache-2.0
language:
- en
library_name: transformers
---
# Model Card MELT-llama-2-7b-chat-v0.1
The MELT-llama-2-7b-chat-v0.1 Large Language Model (LLM) is a pretrained generative text model pre-trained and fine-tuned on using publically avalable medical data.
MELT-llama-2-7b-chat-v0.1 demonstrates a 31.4% improvement over llama-2-7b-chat-hf across 3 medical benchmarks including, USMLE, Indian AIIMS, and NEET medical examination examples.
## Model Details
The Medical Education Language Transformer (MELT) models have been trained on a wide-range of text, chat, Q/A, and instruction data in the medical domain.
While the model was evaluated using publically avalable [USMLE](https://www.usmle.org/), Indian AIIMS, and NEET medical examination example questions, its use it intented to be more broadly applicable.
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [Center for Applied AI](https://caai.ai.uky.edu/)
- **Funded by:** [Institute or Biomedical Informatics](https://www.research.uky.edu/IBI)
- **Model type:** LLM
- **Language(s) (NLP):** English
- **License:** Apache 2.0
- **Finetuned from model:** [llama-2-7b-chat-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf)
## Uses
MELT is intended for research purposes only. MELT models are best suited for prompts using a QA or chat format.
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
MELT is intended for research purposes only and should not be used for medical advice.
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
MELT was training using collections publicly available, which likely contain biased and inaccurate information. The training and evaluation datasets have not been evaluated for content or accuracy.
## How to Get Started with the Model
Use this model like you would any llama-2-7b-chat-hf model.
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
The following datasets were used for training:
[Expert Med](https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/Q3A969)
[MedQA train](https://huggingface.co/datasets/bigbio/med_qa)
[MedMCQA train](https://github.com/MedMCQA/MedMCQA?tab=readme-ov-file#data-download-and-preprocessing)
[LiveQA](https://github.com/abachaa/LiveQA_MedicalTask_TREC2017)
[MedicationQA](https://huggingface.co/datasets/truehealth/medicationqa)
[MMLU clinical topics](https://huggingface.co/datasets/Stevross/mmlu)
[Medical Flashcards](https://huggingface.co/datasets/medalpaca/medical_meadow_medical_flashcards)
[Wikidoc](https://huggingface.co/datasets/medalpaca/medical_meadow_wikidoc)
[Wikidoc Patient Information](https://huggingface.co/datasets/medalpaca/medical_meadow_wikidoc_patient_information)
[MEDIQA](https://huggingface.co/datasets/medalpaca/medical_meadow_mediqa)
[MMMLU](https://huggingface.co/datasets/medalpaca/medical_meadow_mmmlu)
[icliniq 10k](https://drive.google.com/file/d/1ZKbqgYqWc7DJHs3N9TQYQVPdDQmZaClA/view?usp=sharing)
[HealthCare Magic 100k](https://drive.google.com/file/d/1lyfqIwlLSClhgrCutWuEe_IACNq6XNUt/view?usp=sharing)
[GenMedGPT-5k](https://drive.google.com/file/d/1nDTKZ3wZbZWTkFMBkxlamrzbNz0frugg/view?usp=sharing)
[Mental Health Conversational](https://huggingface.co/datasets/heliosbrahma/mental_health_conversational_dataset)
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Training Hyperparameters
- **Lora Rank:** 64
- **Lora Alpha:** 16
- **Lora Targets:** "o_proj","down_proj","v_proj","gate_proj","up_proj","k_proj","q_proj"
- **LR:** 2e-4
- **Epoch:** 3
- **Precision:** bf16 <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
MELT-llama-2-7b-chat-v0.1 demonstrated a average 31.4% improvement over llama-2-7b-chat-hf across 3 USMLE, Indian AIIMS, and NEET medical examination benchmarks.
### llama-2-7b-chat-hf
- **medqa:** {'base': {'Average': 36.43, 'STEP-1': 36.87, 'STEP-2&3': 35.92}}
- **mausmle:** {'base': {'Average': 30.11, 'STEP-1': 35.29, 'STEP-2': 29.89, 'STEP-3': 26.17}}
- **medmcqa:** {'base': {'Average': 39.25, 'MEDICINE': 38.04, 'OPHTHALMOLOGY': 38.1, 'ANATOMY': 42.47, 'PATHOLOGY': 41.86, 'PHYSIOLOGY': 35.61, 'DENTAL': 36.85, 'RADIOLOGY': 35.71, 'BIOCHEMISTRY': 42.98, 'ANAESTHESIA': 43.48, 'GYNAECOLOGY': 37.91, 'PHARMACOLOGY': 44.38, 'SOCIAL': 43.33, 'PEDIATRICS': 37.88, 'ENT': 47.37, 'SURGERY': 33.06, 'MICROBIOLOGY': 45.21, 'FORENSIC': 53.49, 'PSYCHIATRY': 77.78, 'SKIN': 60.0, 'ORTHOPAEDICS': 35.71, 'UNKNOWN': 100.0}}
- **average:** 35.2%
### MELT-llama-2-7b-chat-v0.1
- **medqa:** {'base': {'Average': 48.39, 'STEP-1': 49.12, 'STEP-2&3': 47.55}}
- **mausmle:** {'base': {'Average': 44.8, 'STEP-1': 42.35, 'STEP-2': 43.68, 'STEP-3': 47.66}}
- **medmcqa:** {'base': {'Average': 45.4, 'MEDICINE': 45.65, 'OPHTHALMOLOGY': 38.1, 'ANATOMY': 41.78, 'PATHOLOGY': 49.22, 'PHYSIOLOGY': 44.7, 'DENTAL': 41.47, 'RADIOLOGY': 48.21, 'BIOCHEMISTRY': 52.89, 'ANAESTHESIA': 52.17, 'GYNAECOLOGY': 35.95, 'PHARMACOLOGY': 51.12, 'SOCIAL': 50.0, 'PEDIATRICS': 50.76, 'ENT': 36.84, 'SURGERY': 48.39, 'MICROBIOLOGY': 49.32, 'FORENSIC': 51.16, 'PSYCHIATRY': 66.67, 'SKIN': 60.0, 'ORTHOPAEDICS': 42.86, 'UNKNOWN': 100.0}}
- **average:** 46.2%
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[MedQA test](https://huggingface.co/datasets/bigbio/med_qa)
[MedMCQA test](https://github.com/MedMCQA/MedMCQA?tab=readme-ov-file#data-download-and-preprocessing)
[MA USMLE](https://huggingface.co/datasets/medalpaca/medical_meadow_usmle_self_assessment)
## Disclaimer:
The use of large language models, such as this one, is provided without warranties or guarantees of any kind. While every effort has been made to ensure accuracy, completeness, and reliability of the information generated, it should be noted that these models may produce responses that are inaccurate, outdated, or inappropriate for specific purposes. Users are advised to exercise discretion and judgment when relying on the information generated by these models. The outputs should not be considered as professional, legal, medical, financial, or any other form of advice. It is recommended to seek expert advice or consult appropriate sources for specific queries or critical decision-making. The creators, developers, and providers of these models disclaim any liability for damages, losses, or any consequences arising from the use, reliance upon, or interpretation of the information provided by these models. The user assumes full responsibility for their interactions and usage of the generated content. By using these language models, users agree to indemnify and hold harmless the developers, providers, and affiliates from any claims, damages, or liabilities that may arise from their use. Please be aware that these models are constantly evolving, and their capabilities, limitations, and outputs may change over time without prior notice. Your use of this language model signifies your acceptance and understanding of this disclaimer.
|
shramay-palta/test-demo-t5-large-qa | shramay-palta | 2024-05-01T19:47:49Z | 1,296 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"arxiv:1910.09700",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | 2024-05-01T19:43:38Z | ---
library_name: transformers
license: mit
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
nes470/test-demo-qa-with-roberta | nes470 | 2024-05-06T23:52:24Z | 1,296 | 0 | transformers | [
"transformers",
"safetensors",
"roberta",
"question-answering",
"arxiv:1910.09700",
"license:mit",
"endpoints_compatible",
"region:us"
] | question-answering | 2024-05-06T23:48:33Z | ---
library_name: transformers
license: mit
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Theivaprakasham/layoutlmv2-finetuned-sroie | Theivaprakasham | 2022-03-02T08:12:26Z | 1,295 | 2 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"layoutlmv2",
"token-classification",
"generated_from_trainer",
"dataset:sroie",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2022-03-02T23:29:05Z | ---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
datasets:
- sroie
model-index:
- name: layoutlmv2-finetuned-sroie
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutlmv2-finetuned-sroie
This model is a fine-tuned version of [microsoft/layoutlmv2-base-uncased](https://huggingface.co/microsoft/layoutlmv2-base-uncased) on the sroie dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0291
- Address Precision: 0.9341
- Address Recall: 0.9395
- Address F1: 0.9368
- Address Number: 347
- Company Precision: 0.9570
- Company Recall: 0.9625
- Company F1: 0.9598
- Company Number: 347
- Date Precision: 0.9885
- Date Recall: 0.9885
- Date F1: 0.9885
- Date Number: 347
- Total Precision: 0.9253
- Total Recall: 0.9280
- Total F1: 0.9266
- Total Number: 347
- Overall Precision: 0.9512
- Overall Recall: 0.9546
- Overall F1: 0.9529
- Overall Accuracy: 0.9961
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 3000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Address Precision | Address Recall | Address F1 | Address Number | Company Precision | Company Recall | Company F1 | Company Number | Date Precision | Date Recall | Date F1 | Date Number | Total Precision | Total Recall | Total F1 | Total Number | Overall Precision | Overall Recall | Overall F1 | Overall Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:-----------------:|:--------------:|:----------:|:--------------:|:-----------------:|:--------------:|:----------:|:--------------:|:--------------:|:-----------:|:-------:|:-----------:|:---------------:|:------------:|:--------:|:------------:|:-----------------:|:--------------:|:----------:|:----------------:|
| No log | 0.05 | 157 | 0.8162 | 0.3670 | 0.7233 | 0.4869 | 347 | 0.0617 | 0.0144 | 0.0234 | 347 | 0.0 | 0.0 | 0.0 | 347 | 0.0 | 0.0 | 0.0 | 347 | 0.3346 | 0.1844 | 0.2378 | 0.9342 |
| No log | 1.05 | 314 | 0.3490 | 0.8564 | 0.8934 | 0.8745 | 347 | 0.8610 | 0.9280 | 0.8932 | 347 | 0.7297 | 0.8559 | 0.7878 | 347 | 0.0 | 0.0 | 0.0 | 347 | 0.8128 | 0.6693 | 0.7341 | 0.9826 |
| No log | 2.05 | 471 | 0.1845 | 0.7970 | 0.9049 | 0.8475 | 347 | 0.9211 | 0.9424 | 0.9316 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.0 | 0.0 | 0.0 | 347 | 0.8978 | 0.7089 | 0.7923 | 0.9835 |
| 0.7027 | 3.05 | 628 | 0.1194 | 0.9040 | 0.9222 | 0.9130 | 347 | 0.8880 | 0.9135 | 0.9006 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.0 | 0.0 | 0.0 | 347 | 0.9263 | 0.7061 | 0.8013 | 0.9853 |
| 0.7027 | 4.05 | 785 | 0.0762 | 0.9397 | 0.9424 | 0.9410 | 347 | 0.8889 | 0.9222 | 0.9052 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.7740 | 0.9078 | 0.8355 | 347 | 0.8926 | 0.9402 | 0.9158 | 0.9928 |
| 0.7027 | 5.05 | 942 | 0.0564 | 0.9282 | 0.9308 | 0.9295 | 347 | 0.9296 | 0.9510 | 0.9402 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.7801 | 0.8588 | 0.8176 | 347 | 0.9036 | 0.9323 | 0.9177 | 0.9946 |
| 0.0935 | 6.05 | 1099 | 0.0548 | 0.9222 | 0.9222 | 0.9222 | 347 | 0.6975 | 0.7378 | 0.7171 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.8608 | 0.8732 | 0.8670 | 347 | 0.8648 | 0.8804 | 0.8725 | 0.9921 |
| 0.0935 | 7.05 | 1256 | 0.0410 | 0.92 | 0.9280 | 0.9240 | 347 | 0.9486 | 0.9568 | 0.9527 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9091 | 0.9222 | 0.9156 | 347 | 0.9414 | 0.9488 | 0.9451 | 0.9961 |
| 0.0935 | 8.05 | 1413 | 0.0369 | 0.9368 | 0.9395 | 0.9381 | 347 | 0.9569 | 0.9597 | 0.9583 | 347 | 0.9772 | 0.9885 | 0.9828 | 347 | 0.9143 | 0.9222 | 0.9182 | 347 | 0.9463 | 0.9524 | 0.9494 | 0.9960 |
| 0.038 | 9.05 | 1570 | 0.0343 | 0.9282 | 0.9308 | 0.9295 | 347 | 0.9624 | 0.9597 | 0.9610 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9206 | 0.9020 | 0.9112 | 347 | 0.9500 | 0.9452 | 0.9476 | 0.9958 |
| 0.038 | 10.05 | 1727 | 0.0317 | 0.9395 | 0.9395 | 0.9395 | 347 | 0.9598 | 0.9625 | 0.9612 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9280 | 0.9280 | 0.9280 | 347 | 0.9539 | 0.9546 | 0.9543 | 0.9963 |
| 0.038 | 11.05 | 1884 | 0.0312 | 0.9368 | 0.9395 | 0.9381 | 347 | 0.9514 | 0.9597 | 0.9555 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9226 | 0.9280 | 0.9253 | 347 | 0.9498 | 0.9539 | 0.9518 | 0.9960 |
| 0.0236 | 12.05 | 2041 | 0.0318 | 0.9368 | 0.9395 | 0.9381 | 347 | 0.9570 | 0.9625 | 0.9598 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9043 | 0.8991 | 0.9017 | 347 | 0.9467 | 0.9474 | 0.9471 | 0.9956 |
| 0.0236 | 13.05 | 2198 | 0.0291 | 0.9337 | 0.9337 | 0.9337 | 347 | 0.9598 | 0.9625 | 0.9612 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9164 | 0.9164 | 0.9164 | 347 | 0.9496 | 0.9503 | 0.9499 | 0.9960 |
| 0.0236 | 14.05 | 2355 | 0.0300 | 0.9286 | 0.9366 | 0.9326 | 347 | 0.9459 | 0.9568 | 0.9513 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9275 | 0.9222 | 0.9249 | 347 | 0.9476 | 0.9510 | 0.9493 | 0.9959 |
| 0.0178 | 15.05 | 2512 | 0.0307 | 0.9366 | 0.9366 | 0.9366 | 347 | 0.9513 | 0.9568 | 0.9540 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9275 | 0.9222 | 0.9249 | 347 | 0.9510 | 0.9510 | 0.9510 | 0.9959 |
| 0.0178 | 16.05 | 2669 | 0.0300 | 0.9312 | 0.9366 | 0.9339 | 347 | 0.9543 | 0.9625 | 0.9584 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9171 | 0.9251 | 0.9211 | 347 | 0.9477 | 0.9532 | 0.9504 | 0.9959 |
| 0.0178 | 17.05 | 2826 | 0.0292 | 0.9368 | 0.9395 | 0.9381 | 347 | 0.9570 | 0.9625 | 0.9598 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9253 | 0.9280 | 0.9266 | 347 | 0.9519 | 0.9546 | 0.9532 | 0.9961 |
| 0.0178 | 18.05 | 2983 | 0.0291 | 0.9341 | 0.9395 | 0.9368 | 347 | 0.9570 | 0.9625 | 0.9598 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9253 | 0.9280 | 0.9266 | 347 | 0.9512 | 0.9546 | 0.9529 | 0.9961 |
| 0.0149 | 19.01 | 3000 | 0.0291 | 0.9341 | 0.9395 | 0.9368 | 347 | 0.9570 | 0.9625 | 0.9598 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9253 | 0.9280 | 0.9266 | 347 | 0.9512 | 0.9546 | 0.9529 | 0.9961 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.8.0+cu101
- Datasets 1.18.4.dev0
- Tokenizers 0.11.6
|
mncai/Mistral-7B-v0.1-orca-2k | mncai | 2023-10-22T06:00:24Z | 1,295 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"MindsAndCompany",
"en",
"ko",
"dataset:kyujinpy/OpenOrca-KO",
"arxiv:2306.02707",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-10-22T05:46:39Z | ---
pipeline_tag: text-generation
license: mit
language:
- en
- ko
library_name: transformers
tags:
- MindsAndCompany
datasets:
- kyujinpy/OpenOrca-KO
---
## Model Details
* **Developed by**: [Minds And Company](https://mnc.ai/)
* **Backbone Model**: [Mistral-7B-v0.1](mistralai/Mistral-7B-v0.1)
* **Library**: [HuggingFace Transformers](https://github.com/huggingface/transformers)
## Dataset Details
### Used Datasets
- kyujinpy/OpenOrca-KO
### Prompt Template
- Llama Prompt Template
## Limitations & Biases:
Llama2 and fine-tuned variants are a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Llama 2 and any fine-tuned varient's potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 2 variants, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available at https://ai.meta.com/llama/responsible-use-guide/
## License Disclaimer:
This model is bound by the license & usage restrictions of the original Llama-2 model. And comes with no warranty or gurantees of any kind.
## Contact Us
- [Minds And Company](https://mnc.ai/)
## Citiation:
Please kindly cite using the following BibTeX:
```bibtex
@misc{mukherjee2023orca,
title={Orca: Progressive Learning from Complex Explanation Traces of GPT-4},
author={Subhabrata Mukherjee and Arindam Mitra and Ganesh Jawahar and Sahaj Agarwal and Hamid Palangi and Ahmed Awadallah},
year={2023},
eprint={2306.02707},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```
@misc{Orca-best,
title = {Orca-best: A filtered version of orca gpt4 dataset.},
author = {Shahul Es},
year = {2023},
publisher = {HuggingFace},
journal = {HuggingFace repository},
howpublished = {\url{https://huggingface.co/datasets/shahules786/orca-best/},
}
```
```
@software{touvron2023llama2,
title={Llama 2: Open Foundation and Fine-Tuned Chat Models},
author={Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava,
Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller,
Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez Madian Khabsa, Isabel Kloumann,
Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov,
Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith,
Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu , Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan,
Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, Thomas Scialom},
year={2023}
}
```
> Readme format: [Riiid/sheep-duck-llama-2-70b-v1.1](https://huggingface.co/Riiid/sheep-duck-llama-2-70b-v1.1) |
kyujinpy/Kosy-platypus2-13B-v5 | kyujinpy | 2023-11-02T01:53:02Z | 1,295 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"ko",
"dataset:kyujinpy/KOpen-platypus",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-01T17:25:47Z | ---
language:
- ko
datasets:
- kyujinpy/KOpen-platypus
library_name: transformers
pipeline_tag: text-generation
license: cc-by-nc-sa-4.0
---
# **Kosy🍵llama**

## Model Details
**Model Developers** Kyujin Han (kyujinpy)
**Model Description**
[NEFTune](https://github.com/neelsjain/NEFTune) method를 활용하여 훈련한 Ko-platypus2 new version!
(Noisy + KO + llama = Kosy🍵llama)
**Repo Link**
Github **KoNEFTune**: [Kosy🍵llama](https://github.com/Marker-Inc-Korea/KoNEFTune)
If you visit our github, you can easily apply **Random_noisy_embedding_fine-tuning**!!
**Base Model**
[hyunseoki/ko-en-llama2-13b](https://huggingface.co/hyunseoki/ko-en-llama2-13b)
**Training Dataset**
Version of combined dataset: [kyujinpy/KOpen-platypus](https://huggingface.co/datasets/kyujinpy/KOpen-platypus)
I use A100 GPU 40GB and COLAB, when trianing.
# **Model comparisons**
[KO-LLM leaderboard](https://huggingface.co/spaces/upstage/open-ko-llm-leaderboard)
# **NEFT comparisons**

| Model | Average | Ko-ARC | Ko-HellaSwag | Ko-MMLU | Ko-TruthfulQA | Ko-CommonGen V2 |
| --- | --- | --- | --- | --- | --- | --- |
| [Ko-Platypus2-13B](https://huggingface.co/kyujinpy/KO-Platypus2-13B) | 45.60 | 44.20 | 54.31 | 42.47 | 44.41 | 42.62 |
| *NEFT(🍵kosy)+MLP-v1 | 43.64 | 43.94 | 53.88 | 42.68 | 43.46 | 34.24 |
| *NEFT(🍵kosy)+MLP-v2 | 45.45 | 44.20 | 54.56 | 42.60 | 42.68 | 42.98 |
| [***NEFT(🍵kosy)+MLP-v3**](https://huggingface.co/kyujinpy/Kosy-platypus2-13B-v3) | 46.31 | 43.34 | 54.54 | 43.38 | 44.11 | 46.16 |
| NEFT(🍵kosy)+Attention | 44.92 |42.92 | 54.48 | 42.99 | 43.00 | 41.20 |
| NEFT(🍵kosy) | 45.08 | 43.09 | 53.61 | 41.06 | 43.47 | 43.21 |
> *Different Hyperparameters such that learning_rate, batch_size, epoch, etc...
# Implementation Code
```python
### KO-Platypus
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
repo = "kyujinpy/Koisy-Platypus2-13B"
OpenOrca = AutoModelForCausalLM.from_pretrained(
repo,
return_dict=True,
torch_dtype=torch.float16,
device_map='auto'
)
OpenOrca_tokenizer = AutoTokenizer.from_pretrained(repo)
```
--- |
wons/llama2-13b-dpo-test-v0.2 | wons | 2023-11-29T14:05:44Z | 1,295 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-29T01:51:51Z | Entry not found |
wons/mistral-7B-test-v0.2 | wons | 2023-11-29T03:17:31Z | 1,295 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-29T03:46:06Z | Entry not found |
sronger/mistral-ko-llm | sronger | 2023-11-30T04:42:28Z | 1,295 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-30T04:39:22Z | Entry not found |
oopsung/llama2-7b-koNqa-test-v1 | oopsung | 2023-11-30T07:08:30Z | 1,295 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-30T07:01:34Z | Entry not found |
yuntaeyang/Yi-Ko-6B-lora | yuntaeyang | 2023-12-27T09:59:19Z | 1,295 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-27T09:55:18Z | Entry not found |
Josephgflowers/Tinyllama-1.3B-Cinder-Reason-Test-2 | Josephgflowers | 2024-03-09T13:55:48Z | 1,295 | 0 | transformers | [
"transformers",
"safetensors",
"gguf",
"llama",
"text-generation",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-02-04T16:31:30Z | ---
license: mit
model-index:
- name: Tinyllama-1.3B-Cinder-Reason-Test-2
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 32.76
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Josephgflowers/Tinyllama-1.3B-Cinder-Reason-Test-2
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 57.92
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Josephgflowers/Tinyllama-1.3B-Cinder-Reason-Test-2
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 25.42
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Josephgflowers/Tinyllama-1.3B-Cinder-Reason-Test-2
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 37.26
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Josephgflowers/Tinyllama-1.3B-Cinder-Reason-Test-2
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 64.8
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Josephgflowers/Tinyllama-1.3B-Cinder-Reason-Test-2
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 2.81
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=Josephgflowers/Tinyllama-1.3B-Cinder-Reason-Test-2
name: Open LLM Leaderboard
---
1.3B test of two Cinder models merged layers 1-22 and 18-22, trained on math and step by step reasoning. Model Overview Cinder is an AI chatbot tailored for engaging users in scientific and educational conversations, offering companionship, and sparking imaginative exploration. It is built on the TinyLlama 1.1B parameter model and trained on a unique combination of datasets. Testing on Reason-with-cinder dataset.
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_Josephgflowers__Tinyllama-1.3B-Cinder-Reason-Test-2)
| Metric |Value|
|---------------------------------|----:|
|Avg. |36.83|
|AI2 Reasoning Challenge (25-Shot)|32.76|
|HellaSwag (10-Shot) |57.92|
|MMLU (5-Shot) |25.42|
|TruthfulQA (0-shot) |37.26|
|Winogrande (5-shot) |64.80|
|GSM8k (5-shot) | 2.81|
|
PassionFriend/5DRV1wBnJwX5bnZot2nawK2nErQjidffoTV2Genxwn5NLrdU_vgg | PassionFriend | 2024-03-01T06:46:12Z | 1,295 | 0 | keras | [
"keras",
"region:us"
] | null | 2024-02-15T15:59:48Z | Entry not found |
ChrisWilson011016/5FUaZbKuahuFmCRhmKWF936zmmGM8D21J1jqp6a2i6UZRLvn_vgg | ChrisWilson011016 | 2024-03-04T18:55:55Z | 1,295 | 0 | keras | [
"keras",
"region:us"
] | null | 2024-02-24T15:21:26Z | Entry not found |
LoneStriker/openbuddy-gemma-7b-v19.1-4k-GGUF | LoneStriker | 2024-03-02T18:31:05Z | 1,295 | 1 | transformers | [
"transformers",
"gguf",
"text-generation",
"zh",
"en",
"fr",
"de",
"ja",
"ko",
"it",
"ru",
"fi",
"base_model:google/gemma-7b",
"license:other",
"region:us"
] | text-generation | 2024-03-02T18:18:01Z | ---
language:
- zh
- en
- fr
- de
- ja
- ko
- it
- ru
- fi
pipeline_tag: text-generation
inference: false
library_name: transformers
license: other
license_name: gemma
license_link: https://ai.google.dev/gemma/terms
base_model: google/gemma-7b
---
# OpenBuddy - Open Multilingual Chatbot
GitHub and Usage Guide: [https://github.com/OpenBuddy/OpenBuddy](https://github.com/OpenBuddy/OpenBuddy)
Website and Demo: [https://openbuddy.ai](https://openbuddy.ai)
Evaluation result of this model: [Evaluation.txt](Evaluation.txt)

# Copyright Notice
BaseModel: Gemma-7b
Gemma is provided under and subject to the Gemma Terms of Use found at ai.google.dev/gemma/terms
## Disclaimer
All OpenBuddy models have inherent limitations and may potentially produce outputs that are erroneous, harmful, offensive, or otherwise undesirable. Users should not use these models in critical or high-stakes situations that may lead to personal injury, property damage, or significant losses. Examples of such scenarios include, but are not limited to, the medical field, controlling software and hardware systems that may cause harm, and making important financial or legal decisions.
OpenBuddy is provided "as-is" without any warranty of any kind, either express or implied, including, but not limited to, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement. In no event shall the authors, contributors, or copyright holders be liable for any claim, damages, or other liabilities, whether in an action of contract, tort, or otherwise, arising from, out of, or in connection with the software or the use or other dealings in the software.
By using OpenBuddy, you agree to these terms and conditions, and acknowledge that you understand the potential risks associated with its use. You also agree to indemnify and hold harmless the authors, contributors, and copyright holders from any claims, damages, or liabilities arising from your use of OpenBuddy.
## 免责声明
所有OpenBuddy模型均存在固有的局限性,可能产生错误的、有害的、冒犯性的或其他不良的输出。用户在关键或高风险场景中应谨慎行事,不要使用这些模型,以免导致人身伤害、财产损失或重大损失。此类场景的例子包括但不限于医疗领域、可能导致伤害的软硬件系统的控制以及进行重要的财务或法律决策。
OpenBuddy按“原样”提供,不附带任何种类的明示或暗示的保证,包括但不限于适销性、特定目的的适用性和非侵权的暗示保证。在任何情况下,作者、贡献者或版权所有者均不对因软件或使用或其他软件交易而产生的任何索赔、损害赔偿或其他责任(无论是合同、侵权还是其他原因)承担责任。
使用OpenBuddy即表示您同意这些条款和条件,并承认您了解其使用可能带来的潜在风险。您还同意赔偿并使作者、贡献者和版权所有者免受因您使用OpenBuddy而产生的任何索赔、损害赔偿或责任的影响。 |
johnsnowlabs/JSL-MedMNX-7B | johnsnowlabs | 2024-04-18T19:22:24Z | 1,295 | 2 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"reward model",
"RLHF",
"medical",
"conversational",
"en",
"license:cc-by-nc-nd-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-04-15T19:18:02Z | ---
license: cc-by-nc-nd-4.0
language:
- en
library_name: transformers
tags:
- reward model
- RLHF
- medical
---
# JSL-MedMNX-7B
[<img src="https://repository-images.githubusercontent.com/104670986/2e728700-ace4-11ea-9cfc-f3e060b25ddf">](http://www.johnsnowlabs.com)
JSL-MedMNX-7B is a 7 Billion parameter model developed by [John Snow Labs](https://www.johnsnowlabs.com/).
This model is trained on medical datasets to provide state-of-the-art performance on biomedical benchmarks: [Open Medical LLM Leaderboard](https://huggingface.co/spaces/openlifescienceai/open_medical_llm_leaderboard).
This model is available under a [CC-BY-NC-ND](https://creativecommons.org/licenses/by-nc-nd/4.0/deed.en) license and must also conform to this [Acceptable Use Policy](https://huggingface.co/johnsnowlabs). If you need to license this model for commercial use, please contact us at [email protected].
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "johnsnowlabs/JSL-MedMNX-7B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
## 🏆 Evaluation
| Tasks |Version|Filter|n-shot| Metric |Value | |Stderr|
|-------------------------------|-------|------|-----:|--------|-----:|---|-----:|
|stem |N/A |none | 0|acc_norm|0.5191|± |0.0068|
| | |none | 0|acc |0.5658|± |0.0058|
| - medmcqa |Yaml |none | 0|acc |0.5135|± |0.0077|
| | |none | 0|acc_norm|0.5135|± |0.0077|
| - medqa_4options |Yaml |none | 0|acc |0.5373|± |0.0140|
| | |none | 0|acc_norm|0.5373|± |0.0140|
| - anatomy (mmlu) | 0|none | 0|acc |0.6370|± |0.0415|
| - clinical_knowledge (mmlu) | 0|none | 0|acc |0.7245|± |0.0275|
| - college_biology (mmlu) | 0|none | 0|acc |0.7500|± |0.0362|
| - college_medicine (mmlu) | 0|none | 0|acc |0.6590|± |0.0361|
| - medical_genetics (mmlu) | 0|none | 0|acc |0.7200|± |0.0451|
| - professional_medicine (mmlu)| 0|none | 0|acc |0.7206|± |0.0273|
| - pubmedqa | 1|none | 0|acc |0.7720|± |0.0188|
|Groups|Version|Filter|n-shot| Metric |Value | |Stderr|
|------|-------|------|-----:|--------|-----:|---|-----:|
|stem |N/A |none | 0|acc_norm|0.5191|± |0.0068|
| | |none | 0|acc |0.5658|± |0.0058| |
Omartificial-Intelligence-Space/al-baka-llama3-8b-experimental | Omartificial-Intelligence-Space | 2024-04-20T10:44:28Z | 1,295 | 2 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"llama",
"text-generation",
"alpaca",
"llama3",
"arabic",
"ar",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-04-19T19:22:08Z | ---
license: apache-2.0
language:
- ar
tags:
- alpaca
- llama3
- arabic
---
# 🚀 al-baka-llama3-8b
[<img src="https://i.ibb.co/fMsBM0M/Screenshot-2024-04-20-at-3-04-34-AM.png" width="150"/>](https://www.omarai.co)
Al Baka is an Experimental Fine Tuned Model based on the new released LLAMA3-8B Model on the Stanford Alpaca dataset Arabic version [Yasbok/Alpaca_arabic_instruct](https://huggingface.co/datasets/Yasbok/Alpaca_arabic_instruct).
## Model Summary
- **Model Type:** Llama3-8B FineTuned Model
- **Language(s):** Arabic
- **Base Model:** [LLAMA-3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B)
- **Dataset:** [Yasbok/Alpaca_arabic_instruct](https://huggingface.co/datasets/Yasbok/Alpaca_arabic_instruct)
## Model Details
- The model was fine-tuned in 4-bit precision using [unsloth](https://github.com/unslothai/unsloth)
- The run is performed only for 1000 steps with a single Google Colab T4 GPU NVIDIA GPU with 15 GB of available memory.
<span style="color:red">The model is currently being Experimentally Fine Tuned to assess LLaMA-3's response to Arabic, following a brief period of fine-tuning. Larger and more sophisticated models will be introduced soon.</span>
## How to Get Started with the Model
### Setup
```python
# Install packages
%%capture
import torch
major_version, minor_version = torch.cuda.get_device_capability()
!pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
if major_version >= 8:
# Use this for new GPUs like Ampere, Hopper GPUs (RTX 30xx, RTX 40xx, A100, H100, L40)
!pip install --no-deps packaging ninja einops flash-attn xformers trl peft accelerate bitsandbytes
else:
# Use this for older GPUs (V100, Tesla T4, RTX 20xx)
!pip install --no-deps xformers trl peft accelerate bitsandbytes
pass
```
### First, Load the Model
```python
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048 # Choose any! We auto support RoPE Scaling internally!
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = True # Use 4bit quantization to reduce memory usage. Can be False.
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "Omartificial-Intelligence-Space/al-baka-16bit-llama3-8b",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
)
```
### Second, Try the model
```python
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
# alpaca_prompt = Copied from above
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
inputs = tokenizer(
[
alpaca_prompt.format(
"استخدم البيانات المعطاة لحساب الوسيط.", # instruction
"[2 ، 3 ، 7 ، 8 ، 10]", # input
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens = 64, use_cache = True)
tokenizer.batch_decode(outputs)
```
### Recommendations
- [unsloth](https://github.com/unslothai/unsloth) for finetuning models. You can get a 2x faster finetuned model which can be exported to any format or uploaded to Hugging Face.
|
NLPark/Test1_SLIDE | NLPark | 2024-04-21T04:35:57Z | 1,295 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"en",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-04-21T03:22:44Z | ---
language:
- en
pipeline_tag: text-generation
inference: true
library_name: transformers
license: cc-by-nc-sa-4.0
---
# Shi-Ci Language Identify & Decode Expositor
**8B**, Ruozhiba...
* [meta-llama/Meta-Llama-3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B)
**Chinese, English**
Test 1 of all.
Released as an early preview of our v3 LLMs.
The v3 series covers the "Shi-Ci", "AnFeng" and "Cecilia" LLM products.
The sizes are labelled from small to large "Nano" "Leap" "Pattern" "Avocet "Robin" "Kestrel" |
bartowski/dolphin-2.9.1-mixtral-1x22b-GGUF | bartowski | 2024-05-24T15:02:31Z | 1,295 | 9 | null | [
"gguf",
"generated_from_trainer",
"axolotl",
"text-generation",
"en",
"dataset:cognitivecomputations/Dolphin-2.9",
"dataset:teknium/OpenHermes-2.5",
"dataset:m-a-p/CodeFeedback-Filtered-Instruction",
"dataset:cognitivecomputations/dolphin-coder",
"dataset:cognitivecomputations/samantha-data",
"dataset:microsoft/orca-math-word-problems-200k",
"dataset:abacusai/SystemChat-1.1",
"dataset:Locutusque/function-calling-chatml",
"dataset:internlm/Agent-FLAN",
"base_model:mistral-community/Mixtral-8x22B-v0.1",
"license:apache-2.0",
"region:us"
] | text-generation | 2024-05-24T14:08:36Z | ---
license: apache-2.0
base_model: mistral-community/Mixtral-8x22B-v0.1
tags:
- generated_from_trainer
- axolotl
model-index:
- name: out
results: []
datasets:
- cognitivecomputations/Dolphin-2.9
- teknium/OpenHermes-2.5
- m-a-p/CodeFeedback-Filtered-Instruction
- cognitivecomputations/dolphin-coder
- cognitivecomputations/samantha-data
- microsoft/orca-math-word-problems-200k
- abacusai/SystemChat-1.1
- Locutusque/function-calling-chatml
- internlm/Agent-FLAN
language:
- en
quantized_by: bartowski
pipeline_tag: text-generation
---
## Llamacpp imatrix Quantizations of dolphin-2.9.1-mixtral-1x22b
Using <a href="https://github.com/ggerganov/llama.cpp/">llama.cpp</a> release <a href="https://github.com/ggerganov/llama.cpp/releases/tag/b2965">b2965</a> for quantization.
Original model: https://huggingface.co/cognitivecomputations/dolphin-2.9.1-mixtral-1x22b
All quants made using imatrix option with dataset from [here](https://gist.github.com/bartowski1182/b6ac44691e994344625687afe3263b3a)
## Prompt format
```
<|im_start|> system
{system_prompt}<|im_end|>
<|im_start|> user
{prompt}<|im_end|>
<|im_start|> assistant
```
## Download a file (not the whole branch) from below:
| Filename | Quant type | File Size | Description |
| -------- | ---------- | --------- | ----------- |
| [dolphin-2.9.1-mixtral-1x22b-Q8_0.gguf](https://huggingface.co/bartowski/dolphin-2.9.1-mixtral-1x22b-GGUF/blob/main/dolphin-2.9.1-mixtral-1x22b-Q8_0.gguf) | Q8_0 | 23.63GB | Extremely high quality, generally unneeded but max available quant. |
| [dolphin-2.9.1-mixtral-1x22b-Q6_K.gguf](https://huggingface.co/bartowski/dolphin-2.9.1-mixtral-1x22b-GGUF/blob/main/dolphin-2.9.1-mixtral-1x22b-Q6_K.gguf) | Q6_K | 18.24GB | Very high quality, near perfect, *recommended*. |
| [dolphin-2.9.1-mixtral-1x22b-Q5_K_M.gguf](https://huggingface.co/bartowski/dolphin-2.9.1-mixtral-1x22b-GGUF/blob/main/dolphin-2.9.1-mixtral-1x22b-Q5_K_M.gguf) | Q5_K_M | 15.71GB | High quality, *recommended*. |
| [dolphin-2.9.1-mixtral-1x22b-Q5_K_S.gguf](https://huggingface.co/bartowski/dolphin-2.9.1-mixtral-1x22b-GGUF/blob/main/dolphin-2.9.1-mixtral-1x22b-Q5_K_S.gguf) | Q5_K_S | 15.31GB | High quality, *recommended*. |
| [dolphin-2.9.1-mixtral-1x22b-Q4_K_M.gguf](https://huggingface.co/bartowski/dolphin-2.9.1-mixtral-1x22b-GGUF/blob/main/dolphin-2.9.1-mixtral-1x22b-Q4_K_M.gguf) | Q4_K_M | 13.33GB | Good quality, uses about 4.83 bits per weight, *recommended*. |
| [dolphin-2.9.1-mixtral-1x22b-Q4_K_S.gguf](https://huggingface.co/bartowski/dolphin-2.9.1-mixtral-1x22b-GGUF/blob/main/dolphin-2.9.1-mixtral-1x22b-Q4_K_S.gguf) | Q4_K_S | 12.65GB | Slightly lower quality with more space savings, *recommended*. |
| [dolphin-2.9.1-mixtral-1x22b-IQ4_NL.gguf](https://huggingface.co/bartowski/dolphin-2.9.1-mixtral-1x22b-GGUF/blob/main/dolphin-2.9.1-mixtral-1x22b-IQ4_NL.gguf) | IQ4_NL | 12.60GB | Decent quality, slightly smaller than Q4_K_S with similar performance *recommended*. |
| [dolphin-2.9.1-mixtral-1x22b-IQ4_XS.gguf](https://huggingface.co/bartowski/dolphin-2.9.1-mixtral-1x22b-GGUF/blob/main/dolphin-2.9.1-mixtral-1x22b-IQ4_XS.gguf) | IQ4_XS | 11.93GB | Decent quality, smaller than Q4_K_S with similar performance, *recommended*. |
| [dolphin-2.9.1-mixtral-1x22b-Q3_K_L.gguf](https://huggingface.co/bartowski/dolphin-2.9.1-mixtral-1x22b-GGUF/blob/main/dolphin-2.9.1-mixtral-1x22b-Q3_K_L.gguf) | Q3_K_L | 11.72GB | Lower quality but usable, good for low RAM availability. |
| [dolphin-2.9.1-mixtral-1x22b-Q3_K_M.gguf](https://huggingface.co/bartowski/dolphin-2.9.1-mixtral-1x22b-GGUF/blob/main/dolphin-2.9.1-mixtral-1x22b-Q3_K_M.gguf) | Q3_K_M | 10.75GB | Even lower quality. |
| [dolphin-2.9.1-mixtral-1x22b-IQ3_M.gguf](https://huggingface.co/bartowski/dolphin-2.9.1-mixtral-1x22b-GGUF/blob/main/dolphin-2.9.1-mixtral-1x22b-IQ3_M.gguf) | IQ3_M | 10.05GB | Medium-low quality, new method with decent performance comparable to Q3_K_M. |
| [dolphin-2.9.1-mixtral-1x22b-IQ3_S.gguf](https://huggingface.co/bartowski/dolphin-2.9.1-mixtral-1x22b-GGUF/blob/main/dolphin-2.9.1-mixtral-1x22b-IQ3_S.gguf) | IQ3_S | 9.68GB | Lower quality, new method with decent performance, recommended over Q3_K_S quant, same size with better performance. |
| [dolphin-2.9.1-mixtral-1x22b-Q3_K_S.gguf](https://huggingface.co/bartowski/dolphin-2.9.1-mixtral-1x22b-GGUF/blob/main/dolphin-2.9.1-mixtral-1x22b-Q3_K_S.gguf) | Q3_K_S | 9.63GB | Low quality, not recommended. |
| [dolphin-2.9.1-mixtral-1x22b-IQ3_XS.gguf](https://huggingface.co/bartowski/dolphin-2.9.1-mixtral-1x22b-GGUF/blob/main/dolphin-2.9.1-mixtral-1x22b-IQ3_XS.gguf) | IQ3_XS | 9.17GB | Lower quality, new method with decent performance, slightly better than Q3_K_S. |
| [dolphin-2.9.1-mixtral-1x22b-IQ3_XXS.gguf](https://huggingface.co/bartowski/dolphin-2.9.1-mixtral-1x22b-GGUF/blob/main/dolphin-2.9.1-mixtral-1x22b-IQ3_XXS.gguf) | IQ3_XXS | 8.59GB | Lower quality, new method with decent performance, comparable to Q3 quants. |
| [dolphin-2.9.1-mixtral-1x22b-Q2_K.gguf](https://huggingface.co/bartowski/dolphin-2.9.1-mixtral-1x22b-GGUF/blob/main/dolphin-2.9.1-mixtral-1x22b-Q2_K.gguf) | Q2_K | 8.26GB | Very low quality but surprisingly usable. |
| [dolphin-2.9.1-mixtral-1x22b-IQ2_M.gguf](https://huggingface.co/bartowski/dolphin-2.9.1-mixtral-1x22b-GGUF/blob/main/dolphin-2.9.1-mixtral-1x22b-IQ2_M.gguf) | IQ2_M | 7.61GB | Very low quality, uses SOTA techniques to also be surprisingly usable. |
| [dolphin-2.9.1-mixtral-1x22b-IQ2_S.gguf](https://huggingface.co/bartowski/dolphin-2.9.1-mixtral-1x22b-GGUF/blob/main/dolphin-2.9.1-mixtral-1x22b-IQ2_S.gguf) | IQ2_S | 7.03GB | Very low quality, uses SOTA techniques to be usable. |
| [dolphin-2.9.1-mixtral-1x22b-IQ2_XS.gguf](https://huggingface.co/bartowski/dolphin-2.9.1-mixtral-1x22b-GGUF/blob/main/dolphin-2.9.1-mixtral-1x22b-IQ2_XS.gguf) | IQ2_XS | 6.64GB | Very low quality, uses SOTA techniques to be usable. |
| [dolphin-2.9.1-mixtral-1x22b-IQ2_XXS.gguf](https://huggingface.co/bartowski/dolphin-2.9.1-mixtral-1x22b-GGUF/blob/main/dolphin-2.9.1-mixtral-1x22b-IQ2_XXS.gguf) | IQ2_XXS | 5.99GB | Lower quality, uses SOTA techniques to be usable. |
| [dolphin-2.9.1-mixtral-1x22b-IQ1_M.gguf](https://huggingface.co/bartowski/dolphin-2.9.1-mixtral-1x22b-GGUF/blob/main/dolphin-2.9.1-mixtral-1x22b-IQ1_M.gguf) | IQ1_M | 5.26GB | Extremely low quality, *not* recommended. |
| [dolphin-2.9.1-mixtral-1x22b-IQ1_S.gguf](https://huggingface.co/bartowski/dolphin-2.9.1-mixtral-1x22b-GGUF/blob/main/dolphin-2.9.1-mixtral-1x22b-IQ1_S.gguf) | IQ1_S | 4.82GB | Extremely low quality, *not* recommended. |
## Downloading using huggingface-cli
First, make sure you have hugginface-cli installed:
```
pip install -U "huggingface_hub[cli]"
```
Then, you can target the specific file you want:
```
huggingface-cli download bartowski/dolphin-2.9.1-mixtral-1x22b-GGUF --include "dolphin-2.9.1-mixtral-1x22b-Q4_K_M.gguf" --local-dir ./
```
If the model is bigger than 50GB, it will have been split into multiple files. In order to download them all to a local folder, run:
```
huggingface-cli download bartowski/dolphin-2.9.1-mixtral-1x22b-GGUF --include "dolphin-2.9.1-mixtral-1x22b-Q8_0.gguf/*" --local-dir dolphin-2.9.1-mixtral-1x22b-Q8_0
```
You can either specify a new local-dir (dolphin-2.9.1-mixtral-1x22b-Q8_0) or download them all in place (./)
## Which file should I choose?
A great write up with charts showing various performances is provided by Artefact2 [here](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9)
The first thing to figure out is how big a model you can run. To do this, you'll need to figure out how much RAM and/or VRAM you have.
If you want your model running as FAST as possible, you'll want to fit the whole thing on your GPU's VRAM. Aim for a quant with a file size 1-2GB smaller than your GPU's total VRAM.
If you want the absolute maximum quality, add both your system RAM and your GPU's VRAM together, then similarly grab a quant with a file size 1-2GB Smaller than that total.
Next, you'll need to decide if you want to use an 'I-quant' or a 'K-quant'.
If you don't want to think too much, grab one of the K-quants. These are in format 'QX_K_X', like Q5_K_M.
If you want to get more into the weeds, you can check out this extremely useful feature chart:
[llama.cpp feature matrix](https://github.com/ggerganov/llama.cpp/wiki/Feature-matrix)
But basically, if you're aiming for below Q4, and you're running cuBLAS (Nvidia) or rocBLAS (AMD), you should look towards the I-quants. These are in format IQX_X, like IQ3_M. These are newer and offer better performance for their size.
These I-quants can also be used on CPU and Apple Metal, but will be slower than their K-quant equivalent, so speed vs performance is a tradeoff you'll have to decide.
The I-quants are *not* compatible with Vulcan, which is also AMD, so if you have an AMD card double check if you're using the rocBLAS build or the Vulcan build. At the time of writing this, LM Studio has a preview with ROCm support, and other inference engines have specific builds for ROCm.
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski
|
textattack/bert-base-uncased-MRPC | textattack | 2021-05-20T07:32:52Z | 1,294 | 2 | transformers | [
"transformers",
"pytorch",
"jax",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ## TextAttack Model Card
This `bert-base-uncased` model was fine-tuned for sequence classification using TextAttack
and the glue dataset loaded using the `nlp` library. The model was fine-tuned
for 5 epochs with a batch size of 16, a learning
rate of 2e-05, and a maximum sequence length of 256.
Since this was a classification task, the model was trained with a cross-entropy loss function.
The best score the model achieved on this task was 0.8774509803921569, as measured by the
eval set accuracy, found after 1 epoch.
For more information, check out [TextAttack on Github](https://github.com/QData/TextAttack).
|
joachimsallstrom/aether-pixel-lora-for-sdxl | joachimsallstrom | 2023-11-12T14:09:16Z | 1,294 | 7 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"style",
"pixelart",
"dissolving",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"license:other",
"region:us"
] | text-to-image | 2023-11-12T14:09:04Z | ---
license: other
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- style
- pixelart
- dissolving
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: dissolving into pixels
widget:
- text: " a close-up action shot profile of sonic the hedgehog running dissolving into pixels, cinematic, intricate, dark background"
- text: " photo of a robot man dissolving into pixels kissing a robot woman dissolving into pixels, cinematic, cyberpunk, dark night"
- text: "super mario dissolving into pixels,, windy, dark background "
- text: " neo played by keanu reeves dissolving into pixels, matrix 1999, cinematic, intricate, green matrix code in the background"
- text: "(melancholic black and white japanese girl dissolving into colorful pixels.:1.3) a color 35mm glamour close-up portrait photograph. melancholic scene. gazing at the intricate patterns of a mandala pre-winter at dusk as if shot by a famous fashion photographer using the aperture f/1.8. the mood is dark and gritty."
- text: " a sloth dissolving into pixels"
- text: " photo of a woman dissolving into pixels"
- text: " photo profile of a man dissolving into pixels upwards, windy"
- text: "a color 35mm glamour close-up portrait photograph of a melancholic norwegian middle-aged person dissolving into pixels. standing looking at the stars during summer at twilight as if shot by a famous fashion photographer using the aperture f/1.8 "
- text: " a banana dissolving into pixels"
---
# Aether Pixel - LoRA for SDXL

> a close-up action shot profile of sonic the hedgehog running dissolving into pixels, cinematic, intricate, dark background
<p>This is Aether <strong><span style="color:rgb(255, 0, 0)">P</span><span style="color:rgb(0, 255, 17)">I</span><span style="color:rgb(0, 174, 255)">X</span><span style="color:rgb(255, 0, 0)">E</span><span style="color:rgb(0, 255, 17)">L</span> </strong>- a LoRA that makes stuff fall apart into pixels. It operates well without negative prompting for straightforward tasks. Be sure to explore the prompt examples alongside the images in this gallery.</p><p></p><p>Activate by using <strong><em>dissolving into pixels</em></strong> as key phrase.</p><p></p><p>Thanks to Masslevel for all the awesome images!</p><p>Special thanks to <a target="_blank" rel="ugc" href="https://rundiffusion.com/">RunDiffusion</a> for sponsoring the finetuning of this LoRA. It was developed using Lastben's SDXL LoRA trainer via RunDiffusion. Aether Pixel is soon accessible on their platform for experimentation.</p>
## Image examples for the model:

> photo of a robot man dissolving into pixels kissing a robot woman dissolving into pixels, cinematic, cyberpunk, dark night

> super mario dissolving into pixels,, windy, dark background

> neo played by keanu reeves dissolving into pixels, matrix 1999, cinematic, intricate, green matrix code in the background

> (melancholic black and white japanese girl dissolving into colorful pixels.:1.3) a color 35mm glamour close-up portrait photograph. melancholic scene. gazing at the intricate patterns of a mandala pre-winter at dusk as if shot by a famous fashion photographer using the aperture f/1.8. the mood is dark and gritty.

> a sloth dissolving into pixels

> photo of a woman dissolving into pixels

> photo profile of a man dissolving into pixels upwards, windy

> a color 35mm glamour close-up portrait photograph of a melancholic norwegian middle-aged person dissolving into pixels. standing looking at the stars during summer at twilight as if shot by a famous fashion photographer using the aperture f/1.8

> a banana dissolving into pixels
|
zomd/AISquare-Instruct-yi-ko-6b-v0.9.28 | zomd | 2023-12-21T04:46:19Z | 1,294 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-21T04:34:46Z | Entry not found |
tmdduq/komt-mistral-7b-v1-dpo-osy-v1 | tmdduq | 2023-12-24T15:26:44Z | 1,294 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-24T14:03:09Z | ---
license: apache-2.0
---
base model : davidkim205/komt-mistral-7b-v1-dpo |
lylogummy/BunnyMint | lylogummy | 2024-06-20T00:06:09Z | 1,294 | 7 | diffusers | [
"diffusers",
"art",
"StableDiffusionXLPipeline",
"text-to-image",
"en",
"license:other",
"region:us"
] | text-to-image | 2024-06-17T11:05:45Z | ---
license: other
license_name: fair-ai-public-license-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- art
- StableDiffusionXLPipeline
---
# Bunny Mint 🧃
---
<style>
.image-viewer {
position: relative;
width: 100%;
margin: 0 auto;
display: flex;
flex-flow: wrap;
align-items: center;
justify-content: center;
}
.image-viewer input[type="radio"] {
display: none;
}
.image-viewer label {
padding: 18px;
background-color: #B398F5;
background-size: cover;
background-position: center;
border: 1px solid #ccc;
cursor: pointer;
color: black;
margin: 9px;
}
.image-viewer label:hover {
background-color: #4C88F5;
padding: 21px;
margin: 6px;
}
.image-viewer input[type="radio"]:checked + label {
background-color: #6296F5;
padding: 27px;
margin: 0px;
}
.image-container {
position: relative;
width: 100%;
height: 50vh;
}
.image-container img {
position: absolute;
top: 0;
left: 0;
height: 100%;
width: 100%;
object-fit: contain;
opacity: 0;
transition: opacity 0.5s ease;
}
#image1:checked ~ .image-container img:nth-child(1),
#image2:checked ~ .image-container img:nth-child(2),
#image3:checked ~ .image-container img:nth-child(3),
#image4:checked ~ .image-container img:nth-child(4),
#image5:checked ~ .image-container img:nth-child(5),
#image6:checked ~ .image-container img:nth-child(6),
#image7:checked ~ .image-container img:nth-child(7),
#image8:checked ~ .image-container img:nth-child(8),
#image9:checked ~ .image-container img:nth-child(9)
{
opacity: 1;
}
#image1l{
background-image: url("https://huggingface.co/lylogummy/BunnyMint/resolve/main/output-samples/1.jpg");
}
#image2l{
background-image: url("https://huggingface.co/lylogummy/BunnyMint/resolve/main/output-samples/2.jpg");
}
#image3l{
background-image: url("https://huggingface.co/lylogummy/BunnyMint/resolve/main/output-samples/3.jpg");
}
#image4l{
background-image: url("https://huggingface.co/lylogummy/BunnyMint/resolve/main/output-samples/4.jpg");
}
#image5l{
background-image: url("https://huggingface.co/lylogummy/BunnyMint/resolve/main/output-samples/5.jpg");
}
#image6l{
background-image: url("https://huggingface.co/lylogummy/BunnyMint/resolve/main/output-samples/6.jpg");
}
#image7l{
background-image: url("https://huggingface.co/lylogummy/BunnyMint/resolve/main/output-samples/7.jpg");
}
#image8l{
background-image: url("https://huggingface.co/lylogummy/BunnyMint/resolve/main/output-samples/8.jpg");
}
#image9l{
background-image: url("https://huggingface.co/lylogummy/BunnyMint/resolve/main/output-samples/9.jpg");
}
</style>
<div class="image-viewer">
<input type="radio" id="image1" name="image-switcher" checked>
<label for="image1" id="image1l"></label>
<input type="radio" id="image2" name="image-switcher">
<label for="image2" id="image2l"></label>
<input type="radio" id="image3" name="image-switcher">
<label for="image3" id="image3l"></label>
<input type="radio" id="image4" name="image-switcher" checked>
<label for="image4" id="image4l"></label>
<input type="radio" id="image5" name="image-switcher">
<label for="image5" id="image5l"></label>
<input type="radio" id="image6" name="image-switcher">
<label for="image6" id="image6l"></label>
<input type="radio" id="image7" name="image-switcher" checked>
<label for="image7" id="image7l"></label>
<input type="radio" id="image8" name="image-switcher">
<label for="image8" id="image8l"></label>
<input type="radio" id="image9" name="image-switcher">
<label for="image9" id="image9l"></label>
<div class="image-container">
<img src="output-samples/1.jpg" alt="Image 1">
<img src="output-samples/2.jpg" alt="Image 2">
<img src="output-samples/3.jpg" alt="Image 3">
<img src="output-samples/4.jpg" alt="Image 4">
<img src="output-samples/5.jpg" alt="Image 5">
<img src="output-samples/6.jpg" alt="Image 6">
<img src="output-samples/7.jpg" alt="Image 7">
<img src="output-samples/8.jpg" alt="Image 8">
<img src="output-samples/9.jpg" alt="Image 9">
</div>
</div>
---
## Introduction
BunnyMint is a Pony model based on two finetunes. The first finetune was trained on 8k randomly selected artist images with score:>99 from danbooru for 10 epochs to improve overall aesthetic. The second finetune was trained again on 20k hand picked NAIv3 images for 20 epochs. Personally trained Blue Archive LoRA was then merged on top to make style more alligned with personal preferences.
## Donate
**Finetuning models on personal hardware is pretty costly, so if anyone likes what I do and feels like it, here's my gumroad:**
**https://lylogummy.gumroad.com/l/avhut**
## Training
```
(8k random artist images score:>99) * 10 Epochs
(20k NAIv3 dataset) * 20 Epochs
Total steps: ~480k
```
## Usage
### Sample prompt
```
score_9, score_8_up, score_7_up, source_anime,
1girl, BREAK
joyful, black skirt, white pantyhose, crop top, double v,inside submarine, legs apart, pleated skirt, jumpsuit,
masterpiece,best quality
Negative prompt:
nsfw,censor,extra_fingers,logo,score_4,score_5,score_6,lowres,(bad),text,error,bad hands,fewer,extra,missing,worst quality,jpeg artifacts,low quality,watermark,unfinished,displeasing,oldest,early,chromatic aberration,signature,extra digits,artistic error,username,scan,[abstract]
```
### Settings
```
Steps: 40
Sampler: Euler a
Schedule type: Polyexponential
CFG scale: 6
Size: 624x912
Hires upscale: 1.5
```
**Since the model is Pony-based, anything Pony related should work here as well.**
## License
**This model is licensed under "Fair-AI public license 1.0-SD", please refer to the original License for more information: https://freedevproject.org/faipl-1.0-sd/** |
ilovebots/bert-sdg-french | ilovebots | 2023-08-11T17:57:30Z | 1,293 | 1 | transformers | [
"transformers",
"pytorch",
"safetensors",
"bert",
"text-classification",
"Objectifs de développement durable (ODD)",
"SDG",
"BERT Classification",
"fr",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-08-03T22:00:26Z | ---
license: mit
language:
- fr
tags:
- Objectifs de développement durable (ODD)
- SDG
- BERT Classification
---
# ilovebots/bert-sdg-french
<!-- Provide a quick summary of what the model is/does. -->
Ce modèle permet de classer les textes en fonction des objectifs de développement durable (ODD) des Nations Unies.
<img src="https://www.ulaval.ca/sites/default/files/DD/ODD/Tableau%20ODD.jpg" alt="image" width="600"/>
Source: [https://www.un.org/development/desa/disabilities/about-us/sustainable-development-goals-sdgs-and-disability.html](https://www.un.org/development/desa/disabilities/about-us/sustainable-development-goals-sdgs-and-disability.html)
## Détails du modèle
### Description du modèle
<!-- Provide a longer summary of what this model is. -->
Ce modèle de classification de texte a été développé en fine-tuning le modèle pré-entraîné dbmdz/bert-base-french-europeana-cased.
Les données d'entraînement de ce modèle affiné proviennent de l'ensemble de données communautaires OSDG (OSDG-CD) accessible au public à l'adresse https://zenodo.org/record/5550238#.ZBulfcJByF4.
Ce modèle a été réalisé dans le cadre d'une recherche universitaire à l'[Université Laval](https://www.ulaval.ca/developpement-durable/objectifs-de-developpement-durable-de-lonu).<br>
L'objectif était de créer un modèle de classification de texte SDG basé sur transformers en français.<br>
Les principaux détails du modèle sont mis en évidence ci-dessous :
- **Model type:** Text classification
- **Language(s) (NLP):** French
- **License:** mit
- **Finetuned from model :** dbmdz/bert-base-french-europeana-cased
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** https://huggingface.co/ilovebots/bert-sdg-french
## How to Get Started with the Model
Utilisez le code ci-dessous pour commencer à utiliser le modèle.
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("ilovebots/bert-sdg-french")
model = AutoModelForSequenceClassification.from_pretrained("ilovebots/bert-sdg-french")
```
## Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
La base disponible dans https://zenodo.org/record/5550238#.ZBulfcJByF4 a été enrichie des objectifs de développement durable des Nations Unies et traduite en en français.
## Training Hyperparameters
- Num_epoch = 4
- Learning rate = 2e-5
- Epsilon = 1e-8
- Optimizer = AdamW
- Batch size = 32
- Seed random = 42
## Evaluation
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
- Accuracy = 0.84
<img src="https://raw.githubusercontent.com/I-Love-Bots/public/main/BertFinetuning.png" alt="image" width="600"/>
## Citation
Martinez, D.F. (2023). SDG classification with BERT. https://huggingface.co/ilovebots/bert-sdg-french
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
<!--## Model Card Contact --> |
jlpan/SteloCoder | jlpan | 2023-11-10T16:51:10Z | 1,293 | 1 | transformers | [
"transformers",
"pytorch",
"gpt_bigcode",
"text-generation",
"generated_from_trainer",
"base_model:bigcode/starcoder",
"license:bigcode-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-09-05T23:55:35Z | ---
license: bigcode-openrail-m
base_model: bigcode/starcoder
tags:
- generated_from_trainer
model-index:
- name: SteloCoder
results: []
---
# moe_training
This is the final stage of training SteloCoder - MoE (Mixture of Experts) training. The dataset contains samples of code translation with five programming languages to python. The training/validation/testing data is processed and is souced from XLCoST dataset.
## Model description
The final model is named SteloCoder, a model designed for code machine translation from multiple languages (C++, C#, Java, JavaScript, PHP) to Python. It is based on StarCoder to which we have added additional parameters using LoRA and MoE methods.
## Intended uses & limitations
More information needed
## Training and evaluation data
The data is processed sourced from XLCoST dataset.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 50
- training_steps: 1000
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rate |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.1293 | 0.05 | 50 | 0.1218 | 5e-05 |
| 0.1332 | 0.1 | 100 | 0.1135 | 0.0000 |
| 0.1346 | 0.15 | 150 | 0.1117 | 0.0000 |
| 0.1336 | 0.2 | 200 | 0.1127 | 0.0000 |
| 0.1378 | 0.25 | 250 | 0.1116 | 0.0000 |
| 0.1321 | 0.3 | 300 | 0.1083 | 0.0000 |
| 0.1335 | 0.35 | 350 | 0.1075 | 0.0000 |
| 0.1316 | 0.4 | 400 | 0.1065 | 0.0000 |
| 0.1298 | 0.45 | 450 | 0.1062 | 0.0000 |
| 0.1331 | 0.5 | 500 | 0.1055 | 0.0000 |
| 0.1355 | 0.55 | 550 | 0.1048 | 0.0000 |
| 0.1299 | 0.6 | 600 | 0.1044 | 0.0000 |
| 0.1387 | 0.65 | 650 | 0.1048 | 0.0000 |
| 0.1278 | 0.7 | 700 | 0.1047 | 0.0000 |
| 0.1285 | 0.75 | 750 | 0.1045 | 0.0000 |
| 0.1278 | 0.8 | 800 | 0.1045 | 0.0000 |
| 0.1283 | 0.85 | 850 | 0.1045 | 0.0000 |
| 0.124 | 0.9 | 900 | 0.1043 | 0.0000 |
| 0.1258 | 0.95 | 950 | 0.1043 | 0.0000 |
| 0.1319 | 1.0 | 1000 | 0.1043 | 0.0 |
### Framework versions
- Transformers 4.32.1
- Pytorch 2.0.1+cu117
- Datasets 2.14.4
- Tokenizers 0.13.3
|
yuntaeyang/Llama-2-ko-instruct-13B-kor-orca-lora | yuntaeyang | 2023-10-31T05:11:00Z | 1,293 | 1 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-10-31T05:02:10Z | Entry not found |
sanghwa-na/llama2-13b.kor.v2 | sanghwa-na | 2023-11-02T23:12:53Z | 1,293 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-2",
"instruct",
"instruction",
"ko",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-02T09:26:47Z | ---
language:
- ko
tags:
- llama-2
- instruct
- instruction
pipeline_tag: text-generation
license: llama2
---
# llama2-13b.kor
### Model Details
- Developed by: Sanghwa Na
- Backbone Model: [LLaMA-2](https://github.com/facebookresearch/llama/tree/main)
- Library: [transformers](https://github.com/huggingface/transformers)
### Used Datasets
- Orca-style dataset
- Platypus
### Prompt Template
```
### Instruction:
{Instruction}
### Response:
{Answer}
```
### License
meta-license |
yeheun/llama-2-koen-13b-v1.3 | yeheun | 2023-11-09T17:53:35Z | 1,293 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-09T17:17:37Z | ---
license: llama2
---
|
Yntec/CutesyAnime | Yntec | 2023-11-29T21:44:07Z | 1,293 | 2 | diffusers | [
"diffusers",
"safetensors",
"Anime",
"Kawaii",
"Toon",
"thefoodmage",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2023-11-29T21:21:36Z | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Anime
- Kawaii
- Toon
- thefoodmage
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
---
# tfm Cutesy Anime Model
This model with the MoistMixVAE baked in. Original page: https://civitai.com/models/25132?modelVersionId=30074
Comparison:

Sample and prompt:

princess,cartoon,wearing white dress,golden crown,red shoes,orange hair,kart,blue eyes,looking at viewer,smiling,happy,sitting on racing kart,outside,forest,blue sky,toadstool,extremely detailed,hdr, |
riotu-lab/ArabianGPT-0.3B-QA | riotu-lab | 2024-05-07T06:12:03Z | 1,293 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"arabic ",
"question-answering",
"ar",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | question-answering | 2024-03-03T18:55:14Z | ---
license: apache-2.0
language:
- ar
pipeline_tag: question-answering
tags:
- 'arabic '
- question-answering
widget:
- text: >-
<|im_start|> كم عدد الدول التي تغطيها الجبال الصخرية؟ <|im_end|>
<|assistant|>
example_title: سؤال ١
- text: <|im_start|> ما هي أكبر بحيرة في نيوزيلندا؟ <|im_end|> <|assistant|>
example_title: سؤال ٢
- text: <|im_start|> من كان أول شخص يمشي على القمر؟ <|im_end|> <|assistant|>
example_title: سؤال ٣
- text: <|im_start|> ما هي أعلي درجة حرارة مسجلة على الأرض؟ <|im_end|> <|assistant|>
example_title: سؤال ٤
- text: <|im_start|> من هو اول الخلفاء الراشدين؟ <|im_end|> <|assistant|>
example_title: سؤال ٥
---
# ArabianGPT Model Overview
## Disclaimer for the Use of Large Language Models (LLMs) for Text Generation
<p style="color: red;">We disclaim all responsibility for any harm, inaccuracies, or inappropriate content generated by ArabianGPT-0.3B, and users engage with and apply the model's outputs at their own risk.</p>
## What is ArabianGPT-0.3B Question-Answering?
You are invited to use ArabianGPT 0.3B Fine-Tuned Model for Question-Answering tasks within a certain dataset range. We suggest reviewing our playground examples to understand the model's capabilities and limitations, especially noting that its performance may decline with questions beyond its trained scope.
## Acknowledgments
Special thanks to Prince Sultan University, particularly the Robotics and Internet of Things Lab.
## Contact Information
For inquiries: [[email protected]](mailto:[email protected]). |
digiplay/dosmixVAE-mangled | digiplay | 2024-03-19T03:42:11Z | 1,293 | 2 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-03-19T02:05:48Z | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info:
dosmix + VAE
https://civitai.com/models/6250/dosmix
VAE: Mangled Merge VAE
https://civitai.com/models/88453?modelVersionId=94111
Sample image and prompt :
(8k UHD RAW,photorealistic,realistic:1.6) ,golden hair beautiful 17y.o girl

|
amara16/t5-qa-project | amara16 | 2024-05-06T02:16:29Z | 1,293 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | 2024-05-06T02:03:56Z | ---
library_name: transformers
license: apache-2.0
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
quanqnv19/VN-Sentiment-Classification | quanqnv19 | 2024-05-30T11:52:54Z | 1,293 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2024-05-22T13:47:44Z | ---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/model-cards
{}
---
Model được finetune trên mô hình PhoBERT v2
Dùng cho bài toán phân loại quan điểm đánh giá của người dùng trên các nền tảng thương mại điện tử
Các nhãn đánh giá bao gồm: Tích cực, tiêu cực và trung lập
|
VAGOsolutions/SauerkrautLM-1.5b.GGUF | VAGOsolutions | 2024-06-12T16:36:12Z | 1,293 | 6 | null | [
"gguf",
"code",
"text-generation",
"de",
"en",
"base_model:VAGOsolutions/SauerkrautLM-1.5b",
"license:apache-2.0",
"region:us"
] | text-generation | 2024-06-12T13:42:32Z | ---
inference: false
license: apache-2.0
tags:
- code
language:
- de
- en
quantized_by: VAGOsolutions
pipeline_tag: text-generation
base_model: VAGOsolutions/SauerkrautLM-1.5b
---
## Llamacpp GGUF Quantizations of SauerkrautLM-1.5b
Original model: https://huggingface.co/VAGOsolutions/SauerkrautLM-1.5b
## Prompt format
```
<|im_start|>system
You are SauerkrautLM, a helpful AI assistant.<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
```
<|im_start|>system
Du bist SauerkrautLM, ein hilfreicher KI-Assistent.<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
## Download a file (not the whole branch) from below:
| Filename | Quant type | File Size | Description |
| -------- | ---------- | --------- | ----------- |
| [SauerkrautLM-1.5b-f16.gguf](https://huggingface.co/VAGOsolutions/SauerkrautLM-1.5b.GGUF/blob/main/SauerkrautLM-1.5b-f16.gguf) | f16 | 3.1GB | Highest quality (no quant) |
| [SauerkrautLM-1.5b-Q8_0.gguf](https://huggingface.co/VAGOsolutions/SauerkrautLM-1.5b.GGUF/blob/main/SauerkrautLM-1.5b-Q8_0.gguf) | Q8_0 | 1.6GB | Extremely high quality, generally unneeded but max available quant. |
| [SauerkrautLM-1.5b-Q6_K.gguf](https://huggingface.co/VAGOsolutions/SauerkrautLM-1.5b.GGUF/blob/main/SauerkrautLM-1.5b-Q6_K.gguf) | Q6_K | 1.3GB | Very high quality, near perfect, *recommended*. |
| [SauerkrautLM-1.5b-Q5_K_M.gguf](https://huggingface.co/VAGOsolutions/SauerkrautLM-1.5b.GGUF/blob/main/SauerkrautLM-1.5b-Q5_K_M.gguf) | Q5_K_M | 1.1GB | High quality, *recommended*. |
| [SauerkrautLM-1.5b-Q5_K_S.gguf](https://huggingface.co/VAGOsolutions/SauerkrautLM-1.5b.GGUF/blob/main/SauerkrautLM-1.5b-Q5_K_S.gguf) | Q5_K_S | 1.1GB | High quality, *recommended*. |
| [SauerkrautLM-1.5b-Q4_K_M.gguf](https://huggingface.co/VAGOsolutions/SauerkrautLM-1.5b.GGUF/blob/main/SauerkrautLM-1.5b-Q4_K_M.gguf) | Q4_K_M | 0.98GB | Good quality, uses about 4.83 bits per weight, *recommended*. |
| [SauerkrautLM-1.5b-Q4_K_S.gguf](https://huggingface.co/VAGOsolutions/SauerkrautLM-1.5b.GGUF/blob/main/SauerkrautLM-1.5b-Q4_K_S.gguf) | Q4_K_S | 0.94GB | Slightly lower quality with more space savings, *recommended*. |
## Downloading using huggingface-cli
First, make sure you have hugginface-cli installed:
```
pip install -U "huggingface_hub[cli]"
```
Then, you can target the specific file you want:
```
huggingface-cli download VAGOsolutions/SauerkrautLM-1.5b.GGUF --include "SauerkrautLM-1.5b-Q4_K_M.gguf" --local-dir ./
```
|
microsoft/xtremedistil-l6-h384-uncased | microsoft | 2021-08-05T17:48:58Z | 1,292 | 22 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"feature-extraction",
"text-classification",
"en",
"arxiv:2106.04563",
"license:mit",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
language: en
thumbnail: https://huggingface.co/front/thumbnails/microsoft.png
tags:
- text-classification
license: mit
---
# XtremeDistilTransformers for Distilling Massive Neural Networks
XtremeDistilTransformers is a distilled task-agnostic transformer model that leverages task transfer for learning a small universal model that can be applied to arbitrary tasks and languages as outlined in the paper [XtremeDistilTransformers: Task Transfer for Task-agnostic Distillation](https://arxiv.org/abs/2106.04563).
We leverage task transfer combined with multi-task distillation techniques from the papers [XtremeDistil: Multi-stage Distillation for Massive Multilingual Models](https://www.aclweb.org/anthology/2020.acl-main.202.pdf) and [MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers](https://proceedings.neurips.cc/paper/2020/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf) with the following [Github code](https://github.com/microsoft/xtreme-distil-transformers).
This l6-h384 checkpoint with **6** layers, **384** hidden size, **12** attention heads corresponds to **22 million** parameters with **5.3x** speedup over BERT-base.
Other available checkpoints: [xtremedistil-l6-h256-uncased](https://huggingface.co/microsoft/xtremedistil-l6-h256-uncased) and [xtremedistil-l12-h384-uncased](https://huggingface.co/microsoft/xtremedistil-l12-h384-uncased)
The following table shows the results on GLUE dev set and SQuAD-v2.
| Models | #Params | Speedup | MNLI | QNLI | QQP | RTE | SST | MRPC | SQUAD2 | Avg |
|----------------|--------|---------|------|------|------|------|------|------|--------|-------|
| BERT | 109 | 1x | 84.5 | 91.7 | 91.3 | 68.6 | 93.2 | 87.3 | 76.8 | 84.8 |
| DistilBERT | 66 | 2x | 82.2 | 89.2 | 88.5 | 59.9 | 91.3 | 87.5 | 70.7 | 81.3 |
| TinyBERT | 66 | 2x | 83.5 | 90.5 | 90.6 | 72.2 | 91.6 | 88.4 | 73.1 | 84.3 |
| MiniLM | 66 | 2x | 84.0 | 91.0 | 91.0 | 71.5 | 92.0 | 88.4 | 76.4 | 84.9 |
| MiniLM | 22 | 5.3x | 82.8 | 90.3 | 90.6 | 68.9 | 91.3 | 86.6 | 72.9 | 83.3 |
| XtremeDistil-l6-h256 | 13 | 8.7x | 83.9 | 89.5 | 90.6 | 80.1 | 91.2 | 90.0 | 74.1 | 85.6 |
| XtremeDistil-l6-h384 | 22 | 5.3x | 85.4 | 90.3 | 91.0 | 80.9 | 92.3 | 90.0 | 76.6 | 86.6 |
| XtremeDistil-l12-h384 | 33 | 2.7x | 87.2 | 91.9 | 91.3 | 85.6 | 93.1 | 90.4 | 80.2 | 88.5 |
Tested with `tensorflow 2.3.1, transformers 4.1.1, torch 1.6.0`
If you use this checkpoint in your work, please cite:
``` latex
@misc{mukherjee2021xtremedistiltransformers,
title={XtremeDistilTransformers: Task Transfer for Task-agnostic Distillation},
author={Subhabrata Mukherjee and Ahmed Hassan Awadallah and Jianfeng Gao},
year={2021},
eprint={2106.04563},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
timm/densenet121.tv_in1k | timm | 2023-04-21T22:53:55Z | 1,292 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:1608.06993",
"license:apache-2.0",
"region:us"
] | image-classification | 2023-04-21T22:53:48Z | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for densenet121.tv_in1k
A DenseNet image classification model. Trained on ImageNet-1k (original torchvision weights).
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 8.0
- GMACs: 2.9
- Activations (M): 6.9
- Image size: 224 x 224
- **Papers:**
- Densely Connected Convolutional Networks: https://arxiv.org/abs/1608.06993
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/pytorch/vision
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('densenet121.tv_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'densenet121.tv_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 256, 56, 56])
# torch.Size([1, 512, 28, 28])
# torch.Size([1, 1024, 14, 14])
# torch.Size([1, 1024, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'densenet121.tv_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1024, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Citation
```bibtex
@inproceedings{huang2017densely,
title={Densely Connected Convolutional Networks},
author={Huang, Gao and Liu, Zhuang and van der Maaten, Laurens and Weinberger, Kilian Q },
booktitle={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
year={2017}
}
```
|
shleeeee/mistral-ko-exo-wiki-quiz-v1 | shleeeee | 2024-03-08T00:12:49Z | 1,292 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"ko",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-06T03:23:55Z | ---
license: other
language:
- ko
pipeline_tag: text-generation
---
# Model Card for mistral-ko-exo-wiki-quiz-v1
It is a fine-tuned model using Korean in the mistral-7b model
## Model Details
* **Model Developers** : shleeeee(Seunghyeon Lee) , oopsung(Sungwoo Park) |
shleeeee/mistral-ko-exo-mrc-v1 | shleeeee | 2024-03-08T00:15:03Z | 1,292 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"ko",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-11T08:10:49Z | ---
license: other
language:
- ko
pipeline_tag: text-generation
---
# Model Card for mistral-ko-exo-mrc-v1
It is a fine-tuned model using Korean in the mistral-7b model
## Model Details
* **Model Developers** : shleeeee(Seunghyeon Lee) , oopsung(Sungwoo Park) |
zomd/AISquare-Instruct-yi-ko-6b-v0.9.29 | zomd | 2023-12-22T02:24:08Z | 1,292 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-21T23:48:40Z | Entry not found |
sail/Sailor-7B | sail | 2024-04-05T16:27:56Z | 1,292 | 27 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"multilingual",
"sea",
"sailor",
"conversational",
"en",
"zh",
"id",
"th",
"vi",
"ms",
"lo",
"dataset:cerebras/SlimPajama-627B",
"dataset:Skywork/SkyPile-150B",
"dataset:allenai/MADLAD-400",
"dataset:cc100",
"arxiv:2404.03608",
"base_model:Qwen/Qwen1.5-7B",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-02-29T05:52:23Z | ---
language:
- en
- zh
- id
- th
- vi
- ms
- lo
datasets:
- cerebras/SlimPajama-627B
- Skywork/SkyPile-150B
- allenai/MADLAD-400
- cc100
tags:
- multilingual
- sea
- sailor
license: apache-2.0
base_model: Qwen/Qwen1.5-7B
model-index:
- name: Sailor-7B
results:
- task:
type: text-generation
dataset:
name: XQuAD-Thai
type: XQuAD-Thai
metrics:
- name: EM (3-Shot)
type: EM (3-Shot)
value: 57.88
- name: F1 (3-Shot)
type: F1 (3-Shot)
value: 71.06
- task:
type: text-generation
dataset:
name: TyDiQA-Indonesian
type: TyDiQA-Indonesian
metrics:
- name: EM (3-Shot)
type: EM (3-Shot)
value: 60.53
- name: F1 (3-Shot)
type: F1 (3-Shot)
value: 75.42
- task:
type: text-generation
dataset:
name: XQuAD-Vietnamese
type: XQuAD-Vietnamese
metrics:
- name: EM (3-Shot)
type: EM (3-Shot)
value: 53.81
- name: F1 (3-Shot)
type: F1 (3-Shot)
value: 74.62
- task:
type: text-generation
dataset:
name: XCOPA-Thai
type: XCOPA-Thai
metrics:
- name: EM (3-Shot)
type: EM (3-Shot)
value: 59.00
- task:
type: text-generation
dataset:
name: XCOPA-Indonesian
type: XCOPA-Indonesian
metrics:
- name: EM (3-Shot)
type: EM (3-Shot)
value: 72.20
- task:
type: text-generation
dataset:
name: XCOPA-Vietnamese
type: XCOPA-Vietnamese
metrics:
- name: EM (3-Shot)
type: EM (3-Shot)
value: 72.20
- task:
type: text-generation
dataset:
name: M3Exam-Thai
type: M3Exam-Thai
metrics:
- name: EM (3-Shot)
type: EM (3-Shot)
value: 30.00
- task:
type: text-generation
dataset:
name: M3Exam-Indonesian
type: M3Exam-Indonesian
metrics:
- name: EM (3-Shot)
type: EM (3-Shot)
value: 32.88
- task:
type: text-generation
dataset:
name: M3Exam-Vietnamese
type: M3Exam-Vietnamese
metrics:
- name: EM (3-Shot)
type: EM (3-Shot)
value: 44.10
- task:
type: text-generation
dataset:
name: BELEBELE-Thai
type: BELEBELE-Thai
metrics:
- name: EM (3-Shot)
type: EM (3-Shot)
value: 41.56
- task:
type: text-generation
dataset:
name: BELEBELE-Indonesian
type: BELEBELE-Indonesian
metrics:
- name: EM (3-Shot)
type: EM (3-Shot)
value: 44.33
- task:
type: text-generation
dataset:
name: BELEBELE-Vietnamese
type: BELEBELE-Vietnamese
metrics:
- name: EM (3-Shot)
type: EM (3-Shot)
value: 45.33
---
<div align="center">
<img src="banner_sailor.jpg" width="700"/>
</div>
Sailor is a suite of Open Language Models tailored for South-East Asia (SEA), focusing on languages such as 🇮🇩Indonesian, 🇹🇭Thai, 🇻🇳Vietnamese, 🇲🇾Malay, and 🇱🇦Lao.
Developed with careful data curation, Sailor models are designed to understand and generate text across diverse linguistic landscapes of SEA region.
Built from [Qwen 1.5](https://huggingface.co/collections/Qwen/qwen15-65c0a2f577b1ecb76d786524) , Sailor encompasses models of varying sizes, spanning from 0.5B to 7B versions for different requirements.
We further fine-tune the base model with open-source datasets to get instruction-tuned models, namedly Sailor-Chat.
Benchmarking results demonstrate Sailor's proficiency in tasks such as question answering, commonsense reasoning, and other tasks in SEA languages.
> The logo was generated by MidJourney
## Model Summary
- **Model Collections:** [Base Model & Chat Model](https://huggingface.co/collections/sail/sailor-65e19a749f978976f1959825)
- **Project Website:** [sailorllm.github.io](https://sailorllm.github.io/)
- **Codebase:** [github.com/sail-sg/sailor-llm](https://github.com/sail-sg/sailor-llm)
- **Technical Report:** [arxiv.org/pdf/2404.03608.pdf](https://arxiv.org/pdf/2404.03608.pdf)
## Training details
Sailor is crafted by continually pre-training from language models like the remarkable Qwen 1.5 models, which already has a great performance on SEA languages.
The pre-training corpus heavily leverages the publicly available corpus, including
[SlimPajama](https://huggingface.co/datasets/cerebras/SlimPajama-627B),
[SkyPile](https://huggingface.co/datasets/Skywork/SkyPile-150B),
[CC100](https://huggingface.co/datasets/cc100) and [MADLAD-400](https://huggingface.co/datasets/allenai/MADLAD-400).
By employing aggressive data deduplication and careful data cleaning on the collected corpus, we have attained a high-quality dataset spanning various languages.
Through systematic experiments to determine the weights of different languages, Sailor models undergo training from 200B to 400B tokens, tailored to different model sizes.
The approach boosts their performance on SEA languages while maintaining proficiency in English and Chinese without significant compromise.
Finally, we continually pre-train the Qwen1.5-0.5B model with 400 Billion tokens, and other models with 200 Billion tokens to obtain the Sailor models.
## Requirements
The code of Sailor has been in the latest Hugging face transformers and we advise you to install `transformers>=4.37.0`.
## Quickstart
Here provides a code snippet to show you how to load the tokenizer and model and how to generate contents.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model
model = AutoModelForCausalLM.from_pretrained("sail/Sailor-7B", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("sail/Sailor-7B")
input_message = "Model bahasa adalah model probabilistik"
### The given Indonesian input translates to 'A language model is a probabilistic model of.'
model_inputs = tokenizer([input_message], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=64
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
```
# License
Sailor is distributed under the terms of the Apache License 2.0.
No restrict on the research and the commercial use, but you should comply with the [Qwen License](https://huggingface.co/Qwen/Qwen1.5-7B/blob/main/LICENSE), which means that you shall request a license from Qwen team if your product or service has more than 100 million monthly active users in your commerical scenarios, otherwise no need for further request.
## Citation
If you find sailor useful, please cite our work as follows:
```
@misc{dou2024sailor,
title={Sailor: Open Language Models for South-East Asia},
author={Longxu Dou and Qian Liu and Guangtao Zeng and Jia Guo and Jiahui Zhou and Wei Lu and Min Lin},
year={2024},
eprint={2404.03608},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
# Contact Us
If you have any questions, please raise an issue or contact us at [[email protected]](mailto:[email protected]) or [[email protected]](mailto:[email protected]). |
opensearch-project/opensearch-neural-sparse-encoding-v1 | opensearch-project | 2024-05-08T02:55:33Z | 1,292 | 8 | transformers | [
"transformers",
"pytorch",
"bert",
"fill-mask",
"learned sparse",
"opensearch",
"retrieval",
"passage-retrieval",
"query-expansion",
"document-expansion",
"bag-of-words",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2024-03-07T07:28:01Z | ---
language: en
license: apache-2.0
tags:
- learned sparse
- opensearch
- transformers
- retrieval
- passage-retrieval
- query-expansion
- document-expansion
- bag-of-words
---
# opensearch-neural-sparse-encoding-v1
This is a learned sparse retrieval model. It encodes the queries and documents to 30522 dimensional **sparse vectors**. The non-zero dimension index means the corresponding token in the vocabulary, and the weight means the importance of the token.
OpenSearch neural sparse feature supports learned sparse retrieval with lucene inverted index. Link: https://opensearch.org/docs/latest/query-dsl/specialized/neural-sparse/. The indexing and search can be performed with OpenSearch high-level API.
## Usage (HuggingFace)
This model is supposed to run inside OpenSearch cluster. But you can also use it outside the cluster, with HuggingFace models API.
```python
import itertools
import torch
from transformers import AutoModelForMaskedLM, AutoTokenizer
# get sparse vector from dense vectors with shape batch_size * seq_len * vocab_size
def get_sparse_vector(feature, output):
values, _ = torch.max(output*feature["attention_mask"].unsqueeze(-1), dim=1)
values = torch.log(1 + torch.relu(values))
values[:,special_token_ids] = 0
return values
# transform the sparse vector to a dict of (token, weight)
def transform_sparse_vector_to_dict(sparse_vector):
sample_indices,token_indices=torch.nonzero(sparse_vector,as_tuple=True)
non_zero_values = sparse_vector[(sample_indices,token_indices)].tolist()
number_of_tokens_for_each_sample = torch.bincount(sample_indices).cpu().tolist()
tokens = [transform_sparse_vector_to_dict.id_to_token[_id] for _id in token_indices.tolist()]
output = []
end_idxs = list(itertools.accumulate([0]+number_of_tokens_for_each_sample))
for i in range(len(end_idxs)-1):
token_strings = tokens[end_idxs[i]:end_idxs[i+1]]
weights = non_zero_values[end_idxs[i]:end_idxs[i+1]]
output.append(dict(zip(token_strings, weights)))
return output
# load the model
model = AutoModelForMaskedLM.from_pretrained("opensearch-project/opensearch-neural-sparse-encoding-v1")
tokenizer = AutoTokenizer.from_pretrained("opensearch-project/opensearch-neural-sparse-encoding-v1")
# set the special tokens and id_to_token transform for post-process
special_token_ids = [tokenizer.vocab[token] for token in tokenizer.special_tokens_map.values()]
get_sparse_vector.special_token_ids = special_token_ids
id_to_token = ["" for i in range(tokenizer.vocab_size)]
for token, _id in tokenizer.vocab.items():
id_to_token[_id] = token
transform_sparse_vector_to_dict.id_to_token = id_to_token
query = "What's the weather in ny now?"
document = "Currently New York is rainy."
# encode the query & document
feature = tokenizer([query, document], padding=True, truncation=True, return_tensors='pt', return_token_type_ids=False)
output = model(**feature)[0]
sparse_vector = get_sparse_vector(feature, output)
# get similarity score
sim_score = torch.matmul(sparse_vector[0],sparse_vector[1])
print(sim_score) # tensor(22.3299, grad_fn=<DotBackward0>)
query_token_weight, document_query_token_weight = transform_sparse_vector_to_dict(sparse_vector)
for token in sorted(query_token_weight, key=lambda x:query_token_weight[x], reverse=True):
if token in document_query_token_weight:
print("score in query: %.4f, score in document: %.4f, token: %s"%(query_token_weight[token],document_query_token_weight[token],token))
# result:
# score in query: 2.9262, score in document: 2.1335, token: ny
# score in query: 2.5206, score in document: 1.5277, token: weather
# score in query: 2.0373, score in document: 2.3489, token: york
# score in query: 1.5786, score in document: 0.8752, token: cool
# score in query: 1.4636, score in document: 1.5132, token: current
# score in query: 0.7761, score in document: 0.8860, token: season
# score in query: 0.7560, score in document: 0.6726, token: 2020
# score in query: 0.7222, score in document: 0.6292, token: summer
# score in query: 0.6888, score in document: 0.6419, token: nina
# score in query: 0.6451, score in document: 0.8200, token: storm
# score in query: 0.4698, score in document: 0.7635, token: brooklyn
# score in query: 0.4562, score in document: 0.1208, token: julian
# score in query: 0.3484, score in document: 0.3903, token: wow
# score in query: 0.3439, score in document: 0.4160, token: usa
# score in query: 0.2751, score in document: 0.8260, token: manhattan
# score in query: 0.2013, score in document: 0.7735, token: fog
# score in query: 0.1989, score in document: 0.2961, token: mood
# score in query: 0.1653, score in document: 0.3437, token: climate
# score in query: 0.1191, score in document: 0.1533, token: nature
# score in query: 0.0665, score in document: 0.0600, token: temperature
# score in query: 0.0552, score in document: 0.3396, token: windy
```
The above code sample shows an example of neural sparse search. Although there is no overlap token in original query and document, but this model performs a good match.
## Performance
This model is trained on MS MARCO dataset. The search relevance score of it can be found here (Neural sparse search bi-encoder) https://opensearch.org/blog/improving-document-retrieval-with-sparse-semantic-encoders/. |
SicariusSicariiStuff/Zion_Alpha | SicariusSicariiStuff | 2024-06-08T19:30:44Z | 1,292 | 2 | transformers | [
"transformers",
"safetensors",
"gguf",
"mistral",
"text-generation",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-05-19T19:58:13Z | ---
language:
- en
license: apache-2.0
---
<div align="center">
<b style="font-size: 40px;">Zion_Alpha</b>
</div>
<img src="https://i.imgur.com/e1LEQ18.png" alt="Zion_Alpha" style="width: 50%; min-width: 400px; display: block; margin: auto;">
# Model Details
Zion_Alpha is the first **REAL** Hebrew model in the world. It wasn't finetuned for any tasks yet, but it actually understands and comprehends Hebrew. It can even do some decent translation. I've tested GPT4 vs Zion_Alpha, and out of the box, Zion_Alpha did a better job translating. I did the finetune using SOTA techniques and using my insights from years of underwater basket weaving. If you wanna offer me a job, just add me on Facebook.
# Future Plans
I plan to perform a SLERP merge with one of my other fine-tuned models, which has a bit more knowledge about Israeli topics. Additionally, I might create a larger model using MergeKit, but we'll see how it goes.
# Looking for Sponsors
Since all my work is done on-premises, I am constrained by my current hardware. I would greatly appreciate any support in acquiring an A6000, which would enable me to train significantly larger models much faster.
# Papers?
Maybe. We'll see. No promises here 🤓
# Contact Details
I'm not great at self-marketing (to say the least) and don't have any social media accounts. If you'd like to reach out to me, you can email me at [email protected]. Please note that this email might receive more messages than I can handle, so I apologize in advance if I can't respond to everyone.
# Versions and QUANTS
- Base model: [FP16](https://huggingface.co/SicariusSicariiStuff/Zion_Alpha)
- Instruction tuned: [FP16](https://huggingface.co/SicariusSicariiStuff/Zion_Alpha_Instruction_Tuned) | [GGUF](https://huggingface.co/SicariusSicariiStuff/Zion_Alpha_Instruction_Tuned_GGUF)
# Model architecture
Based on Mistral 7B. I didn't even bother to alter the tokenizer.
# The recommended prompt setting is Debug-deterministic:
```
temperature: 1
top_p: 1
top_k: 1
typical_p: 1
min_p: 1
repetition_penalty: 1
```
# The recommended instruction template is Mistral:
```
{%- for message in messages %}
{%- if message['role'] == 'system' -%}
{{- message['content'] -}}
{%- else -%}
{%- if message['role'] == 'user' -%}
{{-'[INST] ' + message['content'].rstrip() + ' [/INST]'-}}
{%- else -%}
{{-'' + message['content'] + '</s>' -}}
{%- endif -%}
{%- endif -%}
{%- endfor -%}
{%- if add_generation_prompt -%}
{{-''-}}
{%- endif -%}
```
# English to hebrew example:
<div align="center">
<b style="font-size: 40px;">Zion_Alpha English to Hebrew example</b>
</div>
<img src="https://i.imgur.com/JnTuawF.png" alt="Zion_Alpha" style="width: 40%; min-width: 600px; display: block; margin: auto;">
# English to hebrew example:
<div align="center">
<b style="font-size: 40px;">Zion_Alpha Hebrew to English example</b>
</div>
<img src="https://i.imgur.com/Wm2igLJ.png" alt="Zion_Alpha" style="width: 40%; min-width: 600px; display: block; margin: auto;">
<div align="center">
<b style="font-size: 30px;">Unscripted video: live zero shot demonstration at story writing capabilities in Hebrew</b>
[](https://www.youtube.com/watch?v=YYKeovnS0do)
</div>
<div align="center">
<b style="font-size: 30px;">Zion_Alpha VS Mistral 'Hebrew' Live & unscripted in real time</b>
[](https://www.youtube.com/watch?v=DQFtx8M2txc)
</div>
<div align="center">
<b style="font-size: 30px;">Zion_Alpha VS Mistral 'Hebrew' Live & unscripted in real time Long text translation</b>
[](https://www.youtube.com/watch?v=w5fz3Ot6tH8)
</div>
### History
The model was originally trained about 2 month after Mistral (v0.1) was released.
As of 04 June 2024, Zion_Alpha got the **Highest SNLI score in the world** among open source models in Hebrew, surpassing most of the models by a huge margin. (**84.05** score)
<img src="https://i.imgur.com/7HokS5w.png" alt="Zion_Alpha SNLI Score" style="width: 80%; min-width: 700px; display: block; margin: auto;">
### Support
<img src="https://i.imgur.com/0lHHN95.png" alt="GPUs too expensive" style="width: 10%; min-width: 100px; display: block; margin: left;">
- [My Ko-fi page](https://ko-fi.com/sicarius) ALL donations will go for research resources and compute, every bit counts 🙏🏻
- [My Patreon](https://patreon.com/TenebraAI) ALL donations will go for research resources and compute, every bit counts 🙏🏻
|
fearlessdots/WizardLM-2-7B-abliterated | fearlessdots | 2024-05-23T00:46:45Z | 1,292 | 8 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"arxiv:2304.12244",
"arxiv:2306.08568",
"arxiv:2308.09583",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-05-23T00:08:05Z | ---
license: apache-2.0
---
# WizardLM-2-7B-abliterated
This is the **WizardLM-2-7B** model with orthogonalized bfloat16 safetensor weights, based on the implementation by `@failspy`. For more info:
- Original paper preview presenting the methodology: <https://www.alignmentforum.org/posts/jGuXSZgv6qfdhMCuJ/refusal-in-llms-is-mediated-by-a-single-direction>
- Jupyter notebook containing a implementation of the methodology, by `@failspy`: <https://huggingface.co/failspy/llama-3-70B-Instruct-abliterated/blob/main/ortho_cookbook.ipynb>
## GGUF Files
I will upload some GGUF files here: <https://huggingface.co/fearlessdots/WizardLM-2-7B-abliterated-GGUF>
## Prompt Template
This model uses the prompt format from **Vicuna** and supports **multi-turn** conversation.
---
# Original model card:
<p style="font-size:20px;" align="center">
🏠 <a href="https://wizardlm.github.io/WizardLM2" target="_blank">WizardLM-2 Release Blog</a> </p>
<p align="center">
🤗 <a href="https://huggingface.co/collections/microsoft/wizardlm-2-661d403f71e6c8257dbd598a" target="_blank">HF Repo</a> •🐱 <a href="https://github.com/victorsungo/WizardLM/tree/main/WizardLM-2" target="_blank">Github Repo</a> • 🐦 <a href="https://twitter.com/WizardLM_AI" target="_blank">Twitter</a> • 📃 <a href="https://arxiv.org/abs/2304.12244" target="_blank">[WizardLM]</a> • 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> • 📃 <a href="https://arxiv.org/abs/2308.09583" target="_blank">[WizardMath]</a> <br>
</p>
<p align="center">
👋 Join our <a href="https://discord.gg/VZjjHtWrKs" target="_blank">Discord</a>
</p>
## News 🔥🔥🔥 [2024/04/15]
We introduce and opensource WizardLM-2, our next generation state-of-the-art large language models,
which have improved performance on complex chat, multilingual, reasoning and agent.
New family includes three cutting-edge models: WizardLM-2 8x22B, WizardLM-2 70B, and WizardLM-2 7B.
- WizardLM-2 8x22B is our most advanced model, demonstrates highly competitive performance compared to those leading proprietary works
and consistently outperforms all the existing state-of-the-art opensource models.
- WizardLM-2 70B reaches top-tier reasoning capabilities and is the first choice in the same size.
- WizardLM-2 7B is the fastest and achieves comparable performance with existing 10x larger opensource leading models.
For more details of WizardLM-2 please read our [release blog post](https://wizardlm.github.io/WizardLM2) and upcoming paper.
## Model Details
* **Model name**: WizardLM-2 7B
* **Developed by**: WizardLM@Microsoft AI
* **Base model**: [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
* **Parameters**: 7B
* **Language(s)**: Multilingual
* **Blog**: [Introducing WizardLM-2](https://wizardlm.github.io/WizardLM2)
* **Repository**: [https://github.com/nlpxucan/WizardLM](https://github.com/nlpxucan/WizardLM)
* **Paper**: WizardLM-2 (Upcoming)
* **License**: Apache2.0
## Model Capacities
**MT-Bench**
We also adopt the automatic MT-Bench evaluation framework based on GPT-4 proposed by lmsys to assess the performance of models.
The WizardLM-2 8x22B even demonstrates highly competitive performance compared to the most advanced proprietary models.
Meanwhile, WizardLM-2 7B and WizardLM-2 70B are all the top-performing models among the other leading baselines at 7B to 70B model scales.
<p align="center" width="100%">
<a ><img src="https://raw.githubusercontent.com/WizardLM/WizardLM2/main/static/images/mtbench.png" alt="MTBench" style="width: 96%; min-width: 300px; display: block; margin: auto;"></a>
</p>
**Human Preferences Evaluation**
We carefully collected a complex and challenging set consisting of real-world instructions, which includes main requirements of humanity, such as writing, coding, math, reasoning, agent, and multilingual.
We report the win:loss rate without tie:
- WizardLM-2 8x22B is just slightly falling behind GPT-4-1106-preview, and significantly stronger than Command R Plus and GPT4-0314.
- WizardLM-2 70B is better than GPT4-0613, Mistral-Large, and Qwen1.5-72B-Chat.
- WizardLM-2 7B is comparable with Qwen1.5-32B-Chat, and surpasses Qwen1.5-14B-Chat and Starling-LM-7B-beta.
<p align="center" width="100%">
<a ><img src="https://raw.githubusercontent.com/WizardLM/WizardLM2/main/static/images/winall.png" alt="Win" style="width: 96%; min-width: 300px; display: block; margin: auto;"></a>
</p>
## Method Overview
We built a **fully AI powered synthetic training system** to train WizardLM-2 models, please refer to our [blog](https://wizardlm.github.io/WizardLM2) for more details of this system.
<p align="center" width="100%">
<a ><img src="https://raw.githubusercontent.com/WizardLM/WizardLM2/main/static/images/exp_1.png" alt="Method" style="width: 96%; min-width: 300px; display: block; margin: auto;"></a>
</p>
## Usage
❗<b>Note for model system prompts usage:</b>
<b>WizardLM-2</b> adopts the prompt format from <b>Vicuna</b> and supports **multi-turn** conversation. The prompt should be as following:
```
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful,
detailed, and polite answers to the user's questions. USER: Hi ASSISTANT: Hello.</s>
USER: Who are you? ASSISTANT: I am WizardLM.</s>......
```
<b> Inference WizardLM-2 Demo Script</b>
We provide a WizardLM-2 inference demo [code](https://github.com/nlpxucan/WizardLM/tree/main/demo) on our github.
|
duoqi/Nanbeige2-16B-Chat | duoqi | 2024-06-20T10:21:02Z | 1,292 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"llm",
"conversational",
"en",
"zh",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-05-28T15:43:10Z | ---
language:
- en
- zh
pipeline_tag: text-generation
license: apache-2.0
tags:
- llm
---
Introduction
A Llama version for [Nanbeige-16B-Chat](https://huggingface.co/Nanbeige/Nanbeige2-16B-Chat), which could be loaded by LlamaForCausalLM.
The Nanbeige2-16B-Chat is the latest 16B model developed by the Nanbeige Lab, which utilized 4.5T tokens of high-quality training data during the training phase. During the alignment phase, we initially trained our model using 1 million samples through Supervised Fine-Tuning (SFT). We then engaged in curriculum learning with 400,000 high-quality samples that presented a greater level of difficulty. Subsequently, we incorporated human feedback through the Direct Preference Optimization (DPO), culminating in the development of Nanbeige2-16B-Chat. Nanbeige2-16B-Chat has achieved superior performance across various authoritative benchmark datasets. |
mradermacher/Dirty-Hairy-Llolphin-1.1B-v2-GGUF | mradermacher | 2024-06-11T08:17:30Z | 1,292 | 0 | transformers | [
"transformers",
"gguf",
"merge",
"mergekit",
"lazymergekit",
"LiteAI/Hare-1.1B-Chat",
"cognitivecomputations/TinyDolphin-2.8-1.1b",
"D1rtyB1rd/Dirty-Alice-Tiny-1.1B-v1",
"en",
"base_model:K00B404/Dirty-Hairy-Llolphin-1.1B-v2",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-11T08:13:28Z | ---
base_model: K00B404/Dirty-Hairy-Llolphin-1.1B-v2
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
tags:
- merge
- mergekit
- lazymergekit
- LiteAI/Hare-1.1B-Chat
- cognitivecomputations/TinyDolphin-2.8-1.1b
- D1rtyB1rd/Dirty-Alice-Tiny-1.1B-v1
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/K00B404/Dirty-Hairy-Llolphin-1.1B-v2
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Dirty-Hairy-Llolphin-1.1B-v2-GGUF/resolve/main/Dirty-Hairy-Llolphin-1.1B-v2.Q2_K.gguf) | Q2_K | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/Dirty-Hairy-Llolphin-1.1B-v2-GGUF/resolve/main/Dirty-Hairy-Llolphin-1.1B-v2.IQ3_XS.gguf) | IQ3_XS | 0.6 | |
| [GGUF](https://huggingface.co/mradermacher/Dirty-Hairy-Llolphin-1.1B-v2-GGUF/resolve/main/Dirty-Hairy-Llolphin-1.1B-v2.Q3_K_S.gguf) | Q3_K_S | 0.6 | |
| [GGUF](https://huggingface.co/mradermacher/Dirty-Hairy-Llolphin-1.1B-v2-GGUF/resolve/main/Dirty-Hairy-Llolphin-1.1B-v2.IQ3_S.gguf) | IQ3_S | 0.6 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Dirty-Hairy-Llolphin-1.1B-v2-GGUF/resolve/main/Dirty-Hairy-Llolphin-1.1B-v2.IQ3_M.gguf) | IQ3_M | 0.6 | |
| [GGUF](https://huggingface.co/mradermacher/Dirty-Hairy-Llolphin-1.1B-v2-GGUF/resolve/main/Dirty-Hairy-Llolphin-1.1B-v2.Q3_K_M.gguf) | Q3_K_M | 0.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Dirty-Hairy-Llolphin-1.1B-v2-GGUF/resolve/main/Dirty-Hairy-Llolphin-1.1B-v2.Q3_K_L.gguf) | Q3_K_L | 0.7 | |
| [GGUF](https://huggingface.co/mradermacher/Dirty-Hairy-Llolphin-1.1B-v2-GGUF/resolve/main/Dirty-Hairy-Llolphin-1.1B-v2.IQ4_XS.gguf) | IQ4_XS | 0.7 | |
| [GGUF](https://huggingface.co/mradermacher/Dirty-Hairy-Llolphin-1.1B-v2-GGUF/resolve/main/Dirty-Hairy-Llolphin-1.1B-v2.Q4_K_S.gguf) | Q4_K_S | 0.7 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Dirty-Hairy-Llolphin-1.1B-v2-GGUF/resolve/main/Dirty-Hairy-Llolphin-1.1B-v2.Q4_K_M.gguf) | Q4_K_M | 0.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Dirty-Hairy-Llolphin-1.1B-v2-GGUF/resolve/main/Dirty-Hairy-Llolphin-1.1B-v2.Q5_K_S.gguf) | Q5_K_S | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/Dirty-Hairy-Llolphin-1.1B-v2-GGUF/resolve/main/Dirty-Hairy-Llolphin-1.1B-v2.Q5_K_M.gguf) | Q5_K_M | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/Dirty-Hairy-Llolphin-1.1B-v2-GGUF/resolve/main/Dirty-Hairy-Llolphin-1.1B-v2.Q6_K.gguf) | Q6_K | 1.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Dirty-Hairy-Llolphin-1.1B-v2-GGUF/resolve/main/Dirty-Hairy-Llolphin-1.1B-v2.Q8_0.gguf) | Q8_0 | 1.3 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Dirty-Hairy-Llolphin-1.1B-v2-GGUF/resolve/main/Dirty-Hairy-Llolphin-1.1B-v2.f16.gguf) | f16 | 2.3 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
vimalnar/aware-ai-1st | vimalnar | 2024-06-29T19:09:16Z | 1,292 | 0 | transformers | [
"transformers",
"pytorch",
"gguf",
"llama",
"text-generation",
"Llama3",
"Abliterated",
"Custom AI",
"unsloth",
"trl",
"sft",
"conversational",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-06-29T03:01:29Z | ---
license: mit
tags:
- Llama3
- Abliterated
- Custom AI
- unsloth
- trl
- sft
---
|
KBLab/bert-base-swedish-cased | KBLab | 2023-08-29T13:35:47Z | 1,291 | 8 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"sv",
"arxiv:2007.01658",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:04Z | ---
language: sv
arxiv: https://arxiv.org/abs/2007.01658
---
# Swedish BERT Models
The National Library of Sweden / KBLab releases three pretrained language models based on BERT and ALBERT. The models are trained on aproximately 15-20GB of text (200M sentences, 3000M tokens) from various sources (books, news, government publications, swedish wikipedia and internet forums) aiming to provide a representative BERT model for Swedish text. A more complete description will be published later on.
The following three models are currently available:
- **bert-base-swedish-cased** (*v1*) - A BERT trained with the same hyperparameters as first published by Google.
- **bert-base-swedish-cased-ner** (*experimental*) - a BERT fine-tuned for NER using SUC 3.0.
- **albert-base-swedish-cased-alpha** (*alpha*) - A first attempt at an ALBERT for Swedish.
All models are cased and trained with whole word masking.
## Files
| **name** | **files** |
|---------------------------------|-----------|
| bert-base-swedish-cased | [config](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased/config.json), [vocab](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased/vocab.txt), [pytorch_model.bin](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased/pytorch_model.bin) |
| bert-base-swedish-cased-ner | [config](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased-ner/config.json), [vocab](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased-ner/vocab.txt) [pytorch_model.bin](https://s3.amazonaws.com/models.huggingface.co/bert/KB/bert-base-swedish-cased-ner/pytorch_model.bin) |
| albert-base-swedish-cased-alpha | [config](https://s3.amazonaws.com/models.huggingface.co/bert/KB/albert-base-swedish-cased-alpha/config.json), [sentencepiece model](https://s3.amazonaws.com/models.huggingface.co/bert/KB/albert-base-swedish-cased-alpha/spiece.model), [pytorch_model.bin](https://s3.amazonaws.com/models.huggingface.co/bert/KB/albert-base-swedish-cased-alpha/pytorch_model.bin) |
TensorFlow model weights will be released soon.
## Usage requirements / installation instructions
The examples below require Huggingface Transformers 2.4.1 and Pytorch 1.3.1 or greater. For Transformers<2.4.0 the tokenizer must be instantiated manually and the `do_lower_case` flag parameter set to `False` and `keep_accents` to `True` (for ALBERT).
To create an environment where the examples can be run, run the following in an terminal on your OS of choice.
```
# git clone https://github.com/Kungbib/swedish-bert-models
# cd swedish-bert-models
# python3 -m venv venv
# source venv/bin/activate
# pip install --upgrade pip
# pip install -r requirements.txt
```
### BERT Base Swedish
A standard BERT base for Swedish trained on a variety of sources. Vocabulary size is ~50k. Using Huggingface Transformers the model can be loaded in Python as follows:
```python
from transformers import AutoModel,AutoTokenizer
tok = AutoTokenizer.from_pretrained('KBLab/bert-base-swedish-cased')
model = AutoModel.from_pretrained('KBLab/bert-base-swedish-cased')
```
### BERT base fine-tuned for Swedish NER
This model is fine-tuned on the SUC 3.0 dataset. Using the Huggingface pipeline the model can be easily instantiated. For Transformer<2.4.1 it seems the tokenizer must be loaded separately to disable lower-casing of input strings:
```python
from transformers import pipeline
nlp = pipeline('ner', model='KB/bert-base-swedish-cased-ner', tokenizer='KB/bert-base-swedish-cased-ner')
nlp('Idag släpper KB tre språkmodeller.')
```
Running the Python code above should produce in something like the result below. Entity types used are `TME` for time, `PRS` for personal names, `LOC` for locations, `EVN` for events and `ORG` for organisations. These labels are subject to change.
```python
[ { 'word': 'Idag', 'score': 0.9998126029968262, 'entity': 'TME' },
{ 'word': 'KB', 'score': 0.9814832210540771, 'entity': 'ORG' } ]
```
The BERT tokenizer often splits words into multiple tokens, with the subparts starting with `##`, for example the string `Engelbert kör Volvo till Herrängens fotbollsklubb` gets tokenized as `Engel ##bert kör Volvo till Herr ##ängens fotbolls ##klubb`. To glue parts back together one can use something like this:
```python
text = 'Engelbert tar Volvon till Tele2 Arena för att titta på Djurgården IF ' +\
'som spelar fotboll i VM klockan två på kvällen.'
l = []
for token in nlp(text):
if token['word'].startswith('##'):
l[-1]['word'] += token['word'][2:]
else:
l += [ token ]
print(l)
```
Which should result in the following (though less cleanly formated):
```python
[ { 'word': 'Engelbert', 'score': 0.99..., 'entity': 'PRS'},
{ 'word': 'Volvon', 'score': 0.99..., 'entity': 'OBJ'},
{ 'word': 'Tele2', 'score': 0.99..., 'entity': 'LOC'},
{ 'word': 'Arena', 'score': 0.99..., 'entity': 'LOC'},
{ 'word': 'Djurgården', 'score': 0.99..., 'entity': 'ORG'},
{ 'word': 'IF', 'score': 0.99..., 'entity': 'ORG'},
{ 'word': 'VM', 'score': 0.99..., 'entity': 'EVN'},
{ 'word': 'klockan', 'score': 0.99..., 'entity': 'TME'},
{ 'word': 'två', 'score': 0.99..., 'entity': 'TME'},
{ 'word': 'på', 'score': 0.99..., 'entity': 'TME'},
{ 'word': 'kvällen', 'score': 0.54..., 'entity': 'TME'} ]
```
### ALBERT base
The easisest way to do this is, again, using Huggingface Transformers:
```python
from transformers import AutoModel,AutoTokenizer
tok = AutoTokenizer.from_pretrained('KBLab/albert-base-swedish-cased-alpha'),
model = AutoModel.from_pretrained('KBLab/albert-base-swedish-cased-alpha')
```
## Acknowledgements ❤️
- Resources from Stockholms University, Umeå University and Swedish Language Bank at Gothenburg University were used when fine-tuning BERT for NER.
- Model pretraining was made partly in-house at the KBLab and partly (for material without active copyright) with the support of Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
- Models are hosted on S3 by Huggingface 🤗
## Citation
https://arxiv.org/abs/2007.01658
```
@misc{malmsten2020playing,
title={Playing with Words at the National Library of Sweden -- Making a Swedish BERT},
author={Martin Malmsten and Love Börjeson and Chris Haffenden},
year={2020},
eprint={2007.01658},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
microsoft/CodeGPT-small-java-adaptedGPT2 | microsoft | 2023-01-24T16:54:55Z | 1,291 | 18 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | Entry not found |
squarelike/polyglot-ko-medical-5.8b | squarelike | 2023-09-09T14:15:45Z | 1,291 | 4 | transformers | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"causal-lm",
"medical",
"ko",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-08-15T06:46:52Z | ---
language:
- ko
tags:
- pytorch
- causal-lm
- medical
license: apache-2.0
pipeline_tag: text-generation
---
[https://github.com/jwj7140/ko-medical-chat](https://github.com/jwj7140/ko-medical-chat)
# Polyglot-Ko-Medical-5.8b
polyglot-ko-medical은 [polyglot-ko](https://github.com/EleutherAI/polyglot)를 기반으로 의료 분야의 한글 raw 데이터를 학습시킨 기반 모델입니다.
## 학습 데이터
polyglot-ko-medical은 약 420MB의 의료 분야 한글 말뭉치로 학습되었습니다. 주요 데이터셋은 다음과 같습니다.
| Source |Size (MB) | Link |
|----------------------------------|---------|------------------------------------------|
| AIHub 의료, 법률 전문 서적 말뭉치 | 351.0 | aihub.or.kr |
| AIHub 전문분야 한영 말뭉치 | 63.4 | aihub.or.kr|
| 질병관리청 국가건강정보포털 | 8.33 | health.kdca.go.kr |
| 보건복지부 국가정신건강정보포털 | < 1.0 | mentalhealth.go.kr |
## 학습
polyglot-ko-medical-5.8b는 [EleutherAI/polyglot-ko-5.8b](https://huggingface.co/EleutherAI/polyglot-ko-5.8b)에서 qlora로 추가 학습되었습니다.
- lora_alpha: 32
- lora_dropout: 0.05
- lora_r: 8
- target_modules: query_key_value
- epoch: 3
- learning_rate: 3e-4 |
leo911kim/Exodia-kor-7B | leo911kim | 2023-10-19T09:39:25Z | 1,291 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-10-19T09:31:07Z | Entry not found |
sanghwa-na/llama2-13b.kor.v1 | sanghwa-na | 2023-11-02T23:03:30Z | 1,291 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-2",
"instruct",
"instruction",
"ko",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-10-30T07:02:42Z | ---
language:
- ko
tags:
- llama-2
- instruct
- instruction
pipeline_tag: text-generation
license: llama2
---
# llama2-13b.kor
### Model Details
- Developed by: Sanghwa Na
- Backbone Model: [LLaMA-2](https://github.com/facebookresearch/llama/tree/main)
- Library: [transformers](https://github.com/huggingface/transformers)
### Used Datasets
- Orca-style dataset
- Platypus
### Prompt Template
```
### Instruction:
{Instruction}
### Answer:
{Answer}
```
### License
meta-license |
wons/mistral-7B-test-v0.3 | wons | 2023-11-29T08:26:15Z | 1,291 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-29T08:07:04Z | Entry not found |
zomd/AISquare-Instruct-llama2-koen-13b-v0.9.19 | zomd | 2023-12-06T06:55:10Z | 1,291 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-04T07:10:12Z | Entry not found |
shleeeee/mistral-ko-OpenOrca-Platypus-v1 | shleeeee | 2024-03-08T00:13:45Z | 1,291 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"ko",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-06T08:13:14Z | ---
license: other
language:
- ko
pipeline_tag: text-generation
---
# Model Card for mistral-ko-OpenOrca-Platypus-v1
It is a fine-tuned model using Korean in the mistral-7b model
## Model Details
* **Model Developers** : shleeeee(Seunghyeon Lee) , oopsung(Sungwoo Park) |
yuntaeyang/lion-7b-lora-kor | yuntaeyang | 2023-12-15T03:07:32Z | 1,291 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-15T03:02:23Z | Entry not found |
tushar310/MisGemma-7B | tushar310 | 2024-03-14T14:29:59Z | 1,291 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"EmbeddedLLM/Mistral-7B-Merge-14-v0.1",
"HuggingFaceH4/zephyr-7b-beta",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-03-14T14:25:29Z | ---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- EmbeddedLLM/Mistral-7B-Merge-14-v0.1
- HuggingFaceH4/zephyr-7b-beta
---
# MisGemma-7B
MisGemma-7B is a merge of the following models using [mergekit](https://github.com/cg123/mergekit):
* [EmbeddedLLM/Mistral-7B-Merge-14-v0.1](https://huggingface.co/EmbeddedLLM/Mistral-7B-Merge-14-v0.1)
* [HuggingFaceH4/zephyr-7b-beta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: EmbeddedLLM/Mistral-7B-Merge-14-v0.1
layer_range: [0, 32]
- model: HuggingFaceH4/zephyr-7b-beta
layer_range: [0, 32]
merge_method: slerp
base_model: EmbeddedLLM/Mistral-7B-Merge-14-v0.1
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
``` |
tkempto1/tyler-t5-qa | tkempto1 | 2024-05-06T18:43:23Z | 1,291 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"arxiv:1910.09700",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | 2024-05-06T00:12:40Z | ---
license: mit
library_name: transformers
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
John6666/hamef-kawaii-mix-type24light-warm-sdxl | John6666 | 2024-06-26T03:29:54Z | 1,291 | 0 | diffusers | [
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"stable-diffusion-xl",
"anime",
"pony",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | 2024-06-26T03:25:22Z | ---
license: other
license_name: faipl-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
tags:
- text-to-image
- stable-diffusion
- stable-diffusion-xl
- anime
- pony
---
Original model is [here](https://civitai.com/models/425800/hamefkawaiimix?modelVersionId=598770).
|
valhalla/bart-large-sst2 | valhalla | 2022-04-05T11:50:37Z | 1,290 | 1 | transformers | [
"transformers",
"pytorch",
"bart",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-04-05T11:48:29Z | Entry not found |
pszemraj/pegasus-x-large-book-summary | pszemraj | 2023-09-23T20:46:57Z | 1,290 | 35 | transformers | [
"transformers",
"pytorch",
"safetensors",
"pegasus_x",
"text2text-generation",
"summarization",
"summary",
"booksum",
"long-document",
"long-form",
"dataset:kmfoda/booksum",
"base_model:google/pegasus-x-large",
"license:apache-2.0",
"license:bsd-3-clause",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | summarization | 2022-09-16T10:55:11Z | ---
license:
- apache-2.0
- bsd-3-clause
tags:
- summarization
- summary
- booksum
- long-document
- long-form
datasets:
- kmfoda/booksum
metrics:
- rouge
languages: en
widget:
- text: large earthquakes along a given fault segment do not occur at random intervals
because it takes time to accumulate the strain energy for the rupture. The rates
at which tectonic plates move and accumulate strain at their boundaries are approximately
uniform. Therefore, in first approximation, one may expect that large ruptures
of the same fault segment will occur at approximately constant time intervals.
If subsequent main shocks have different amounts of slip across the fault, then
the recurrence time may vary, and the basic idea of periodic mainshocks must be
modified. For great plate boundary ruptures the length and slip often vary by
a factor of 2. Along the southern segment of the San Andreas fault the recurrence
interval is 145 years with variations of several decades. The smaller the standard
deviation of the average recurrence interval, the more specific could be the long
term prediction of a future mainshock.
example_title: earthquakes
- text: ' A typical feed-forward neural field algorithm. Spatiotemporal coordinates
are fed into a neural network that predicts values in the reconstructed domain.
Then, this domain is mapped to the sensor domain where sensor measurements are
available as supervision. Class and Section Problems Addressed Generalization
(Section 2) Inverse problems, ill-posed problems, editability; symmetries. Hybrid
Representations (Section 3) Computation & memory efficiency, representation capacity,
editability: Forward Maps (Section 4) Inverse problems Network Architecture (Section
5) Spectral bias, integration & derivatives. Manipulating Neural Fields (Section
6) Edit ability, constraints, regularization. Table 2: The five classes of techniques
in the neural field toolbox each addresses problems that arise in learning, inference,
and control. (Section 3). We can supervise reconstruction via differentiable forward
maps that transform Or project our domain (e.g, 3D reconstruction via 2D images;
Section 4) With appropriate network architecture choices, we can overcome neural
network spectral biases (blurriness) and efficiently compute derivatives and integrals
(Section 5). Finally, we can manipulate neural fields to add constraints and regularizations,
and to achieve editable representations (Section 6). Collectively, these classes
constitute a ''toolbox'' of techniques to help solve problems with neural fields
There are three components in a conditional neural field: (1) An encoder or inference
function € that outputs the conditioning latent variable 2 given an observation
0 E(0) =2. 2 is typically a low-dimensional vector, and is often referred to aS
a latent code Or feature code_ (2) A mapping function 4 between Z and neural field
parameters O: Y(z) = O; (3) The neural field itself $. The encoder € finds the
most probable z given the observations O: argmaxz P(2/0). The decoder maximizes
the inverse conditional probability to find the most probable 0 given Z: arg-
max P(Olz). We discuss different encoding schemes with different optimality guarantees
(Section 2.1.1), both global and local conditioning (Section 2.1.2), and different
mapping functions Y (Section 2.1.3) 2. Generalization Suppose we wish to estimate
a plausible 3D surface shape given a partial or noisy point cloud. We need a suitable
prior over the sur- face in its reconstruction domain to generalize to the partial
observations. A neural network expresses a prior via the function space of its
architecture and parameters 0, and generalization is influenced by the inductive
bias of this function space (Section 5).'
example_title: scientific paper
- text: 'Is a else or outside the cob and tree written being of early client rope
and you have is for good reasons. On to the ocean in Orange for time. By''s the
aggregate we can bed it yet. Why this please pick up on a sort is do and also
M Getoi''s nerocos and do rain become you to let so is his brother is made in
use and Mjulia''s''s the lay major is aging Masastup coin present sea only of
Oosii rooms set to you We do er do we easy this private oliiishs lonthen might
be okay. Good afternoon everybody. Welcome to this lecture of Computational Statistics.
As you can see, I''m not socially my name is Michael Zelinger. I''m one of the
task for this class and you might have already seen me in the first lecture where
I made a quick appearance. I''m also going to give the tortillas in the last third
of this course. So to give you a little bit about me, I''m a old student here
with better Bulman and my research centres on casual inference applied to biomedical
disasters, so that could be genomics or that could be hospital data. If any of
you is interested in writing a bachelor thesis, a semester paper may be mastathesis
about this topic feel for reach out to me. you have my name on models and my email
address you can find in the directory I''d Be very happy to talk about it. you
do not need to be sure about it, we can just have a chat. So with that said, let''s
get on with the lecture. There''s an exciting topic today I''m going to start
by sharing some slides with you and later on during the lecture we''ll move to
the paper. So bear with me for a few seconds. Well, the projector is starting
up. Okay, so let''s get started. Today''s topic is a very important one. It''s
about a technique which really forms one of the fundamentals of data science,
machine learning, and any sort of modern statistics. It''s called cross validation.
I know you really want to understand this topic I Want you to understand this
and frankly, nobody''s gonna leave Professor Mineshousen''s class without understanding
cross validation. So to set the stage for this, I Want to introduce you to the
validation problem in computational statistics. So the problem is the following:
You trained a model on available data. You fitted your model, but you know the
training data you got could always have been different and some data from the
environment. Maybe it''s a random process. You do not really know what it is,
but you know that somebody else who gets a different batch of data from the same
environment they would get slightly different training data and you do not care
that your method performs as well. On this training data. you want to to perform
well on other data that you have not seen other data from the same environment.
So in other words, the validation problem is you want to quantify the performance
of your model on data that you have not seen. So how is this even possible? How
could you possibly measure the performance on data that you do not know The solution
to? This is the following realization is that given that you have a bunch of data,
you were in charge. You get to control how much that your model sees. It works
in the following way: You can hide data firms model. Let''s say you have a training
data set which is a bunch of doubtless so X eyes are the features those are typically
hide and national vector. It''s got more than one dimension for sure. And the
why why eyes. Those are the labels for supervised learning. As you''ve seen before,
it''s the same set up as we have in regression. And so you have this training
data and now you choose that you only use some of those data to fit your model.
You''re not going to use everything, you only use some of it the other part you
hide from your model. And then you can use this hidden data to do validation from
the point of you of your model. This hidden data is complete by unseen. In other
words, we solve our problem of validation.'
example_title: transcribed audio - lecture
- text: 'Transformer-based models have shown to be very useful for many NLP tasks.
However, a major limitation of transformers-based models is its O(n^2)O(n 2) time
& memory complexity (where nn is sequence length). Hence, it''s computationally
very expensive to apply transformer-based models on long sequences n > 512n>512.
Several recent papers, e.g. Longformer, Performer, Reformer, Clustered attention
try to remedy this problem by approximating the full attention matrix. You can
checkout 🤗''s recent blog post in case you are unfamiliar with these models.
BigBird (introduced in paper) is one of such recent models to address this issue.
BigBird relies on block sparse attention instead of normal attention (i.e. BERT''s
attention) and can handle sequences up to a length of 4096 at a much lower computational
cost compared to BERT. It has achieved SOTA on various tasks involving very long
sequences such as long documents summarization, question-answering with long contexts.
BigBird RoBERTa-like model is now available in 🤗Transformers. The goal of this
post is to give the reader an in-depth understanding of big bird implementation
& ease one''s life in using BigBird with 🤗Transformers. But, before going into
more depth, it is important to remember that the BigBird''s attention is an approximation
of BERT''s full attention and therefore does not strive to be better than BERT''s
full attention, but rather to be more efficient. It simply allows to apply transformer-based
models to much longer sequences since BERT''s quadratic memory requirement quickly
becomes unbearable. Simply put, if we would have ∞ compute & ∞ time, BERT''s attention
would be preferred over block sparse attention (which we are going to discuss
in this post).
If you wonder why we need more compute when working with longer sequences, this
blog post is just right for you!
Some of the main questions one might have when working with standard BERT-like
attention include:
Do all tokens really have to attend to all other tokens? Why not compute attention
only over important tokens? How to decide what tokens are important? How to attend
to just a few tokens in a very efficient way? In this blog post, we will try to
answer those questions.
What tokens should be attended to? We will give a practical example of how attention
works by considering the sentence ''BigBird is now available in HuggingFace for
extractive question answering''. In BERT-like attention, every word would simply
attend to all other tokens.
Let''s think about a sensible choice of key tokens that a queried token actually
only should attend to by writing some pseudo-code. Will will assume that the token
available is queried and build a sensible list of key tokens to attend to.
>>> # let''s consider following sentence as an example >>> example = [''BigBird'',
''is'', ''now'', ''available'', ''in'', ''HuggingFace'', ''for'', ''extractive'',
''question'', ''answering'']
>>> # further let''s assume, we''re trying to understand the representation of
''available'' i.e. >>> query_token = ''available'' >>> # We will initialize an
empty `set` and fill up the tokens of our interest as we proceed in this section.
>>> key_tokens = [] # => currently ''available'' token doesn''t have anything
to attend Nearby tokens should be important because, in a sentence (sequence of
words), the current word is highly dependent on neighboring past & future tokens.
This intuition is the idea behind the concept of sliding attention.'
example_title: bigbird blog intro
- text: 'To be fair, you have to have a very high IQ to understand Rick and Morty.
The humour is extremely subtle, and without a solid grasp of theoretical physics
most of the jokes will go over a typical viewer''s head. There''s also Rick''s
nihilistic outlook, which is deftly woven into his characterisation- his personal
philosophy draws heavily from Narodnaya Volya literature, for instance. The fans
understand this stuff; they have the intellectual capacity to truly appreciate
the depths of these jokes, to realise that they''re not just funny- they say something
deep about LIFE. As a consequence people who dislike Rick & Morty truly ARE idiots-
of course they wouldn''t appreciate, for instance, the humour in Rick''s existential
catchphrase ''Wubba Lubba Dub Dub,'' which itself is a cryptic reference to Turgenev''s
Russian epic Fathers and Sons. I''m smirking right now just imagining one of those
addlepated simpletons scratching their heads in confusion as Dan Harmon''s genius
wit unfolds itself on their television screens. What fools.. how I pity them.
😂
And yes, by the way, i DO have a Rick & Morty tattoo. And no, you cannot see it.
It''s for the ladies'' eyes only- and even then they have to demonstrate that
they''re within 5 IQ points of my own (preferably lower) beforehand. Nothin personnel
kid 😎'
example_title: Richard & Mortimer
parameters:
max_length: 48
min_length: 2
no_repeat_ngram_size: 3
encoder_no_repeat_ngram_size: 3
early_stopping: true
length_penalty: 0.1
num_beams: 2
base_model: google/pegasus-x-large
model-index:
- name: pszemraj/pegasus-x-large-book-summary
results:
- task:
type: summarization
name: Summarization
dataset:
name: samsum
type: samsum
config: samsum
split: test
metrics:
- type: rouge
value: 33.1401
name: ROUGE-1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYjQ1NjY1OGVjYWEwMzBjMzk3ZmMyZDA0ZTcxOTdmZTUxNTc0OGYxYmY3MzJkMzFmYTVjNzU2ZTk4MzE0NWMzMSIsInZlcnNpb24iOjF9.PSHB6DMF6tkwSw5nsFE57a2ApRAy_tkS6ziKA6PSTWddEdaqfca4pfig6_olmRmcS4KxN6HHcsmioHzv4LJQBw
- type: rouge
value: 9.3095
name: ROUGE-2
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMzk3MTA3NmY1OGE3MzFjZTJhYWYzNGU4NTUzMTgwM2Y1NWZjMmEyNDNmNmEzYmQzZThjOGExMjc2ZjAyZjMzZCIsInZlcnNpb24iOjF9.tfgp8p-WlkVrfducTSg4zs-byeZMCmdZw1aizPQHXm_qRAwGtKcuVkZcmza5Y3o3VqsAEmGzg5HQD1vnZvWIDA
- type: rouge
value: 24.8552
name: ROUGE-L
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiOTVmMTIwNDQwNTI4MmI2MmY1ODc1Mjk0NGQ5ZWE4ZTYzOGNkMjY2ZmJhMjg2MTZlNTdhYTA2ZDAxNTFjMjA2MSIsInZlcnNpb24iOjF9.9HLgy9842oIDm6ABb3L94R1P4zAqTI0QN8aP62xzIyDxUXTbWw68PEDufYLiBJbTgZ8ElopZ9I7aou2zCgXeAA
- type: rouge
value: 29.0391
name: ROUGE-LSUM
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMmNhYWJjYjdjMzMxMmE4ZTE4NGEzMDdmZDZjODI5ZWRjZWJmYTEyZGIzYWQ2NjM3YzQ4MjI4ZTM4MmU5MzRjZSIsInZlcnNpb24iOjF9.d2yoVdmxjVJnsgIYFiLuaBO5Krgw4Axl5yeOSTKrvHygrAxoqT1nl4anzQiyoR3PwYBXwBkwmgpJUfZ7RNXtDQ
- type: loss
value: 2.288182497024536
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYzM5NGIwODMxOTA3MTY3ODc2ZDczYTNmMTMwM2QyZmNlZjFmZDJjMGY3NWNkMDEyYzA4OTA2ZDRiODY3Zjg4OCIsInZlcnNpb24iOjF9.8k9mC050OS7mQSR9oA8liDRDQvEx1VxmTXGLmDYJVYYtTh2HYJFGP8Vy_krocFRIYDxh-IHPEOOSr5NrLMWHBA
- type: gen_len
value: 45.2173
name: gen_len
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNWZhNzQ5OTQ5Yjg5YjhlOTZiZmJhZjZiODNmY2E2OTg4YTg4NWVhYzRkNzM2Mzk4NzdlMDgxM2M4NjY2YzhhYSIsInZlcnNpb24iOjF9.tDEEsPUclZDygAdGhNrBGrF24vR8ao08Nw7hmtUt5lmSZZZK_u-8rpz97QgVS6MCJdjFVnbYC4bkFnlQWI_FAA
- task:
type: summarization
name: Summarization
dataset:
name: launch/gov_report
type: launch/gov_report
config: plain_text
split: test
metrics:
- type: rouge
value: 39.7279
name: ROUGE-1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiOTAxODk3OTUwMTIzODU3NzU2YzAzZjE2NTM3MzBjNDA0ZWRmZGU3NWUzNTg1YThhNDQ1NjQ5ZmM3OWI2YzBhNSIsInZlcnNpb24iOjF9.vnNKucBNt2-nIyODj9P2HeaWPX5AQR8L-DL8QzrO7kj58-vZnjT6hsAGmepRNzdZ1TLF-3j2J2plcNJ8lUO8Dg
- type: rouge
value: 10.8944
name: ROUGE-2
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNjYzMmIxOTJmZjkxOGI5N2U0NTRmMmQwOGJhMzMxYWIzMWMzYzUwMDEyMDdiZDQ2YTUzOWU0OTViMTI2YTAwYiIsInZlcnNpb24iOjF9.De0PaAikWqfWpoIXTCYP-mSFu3PUATLX08Qq74OHXM8784heFVDX1E1sXlh_QbbKJbuMuZtTKM4qr7oLUizOAw
- type: rouge
value: 19.7018
name: ROUGE-L
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYzI3MjQzOGQ3MGE3NDNkZTEyMWRkYjUyYTYzNDEwOWVjMGFmNTBiZjE4ZTBhMGYzMmI1Yzk0YjBmYmIzMWMxZSIsInZlcnNpb24iOjF9.FVikJ5Ma0gUgM-tpbomWXnC4jtmvhxqikPqCk84t4IbIdU0CIYGTQEONiz-VqI0fJeNrnTS6lxpBv7XxKoq3BQ
- type: rouge
value: 36.5634
name: ROUGE-LSUM
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiOTI2OTVmNDZiZWE5ZjNkODIwZjJiNTU2ZjJjYjczODUwM2JiNDEzYmE3N2U5YWM5NzJjOWEzMmYzZjdlYWJmYyIsInZlcnNpb24iOjF9.poR4zcqRvdaierfWFdTa53Cv6ZbNbnRwyRTi9HukHF5AWAQgc6zpBLkwOYFYoWjuSH83ohWeMM3MoIdw3zypBw
- type: loss
value: 2.473011016845703
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNDFmMjg3NWQ2YTMxMTc1OGZiYWYzNjg5NDY3MWE4MjY5ZDQxZDZhZGI1OTc5MzZkZGEzYmVlNWFiMzZjNDdhNCIsInZlcnNpb24iOjF9.05nKB3SmEfFKSduJqlleF4Fd2_IhwJS8eTOrnzZYCQQfLCfpJAZLhp3eLQCuBY4htd-FNrZftrThL66zVxyrCQ
- type: gen_len
value: 212.8243
name: gen_len
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiOGNjMTg4ZDZlZjAxZGNhN2M0NWI0ZTA0OWEzNDkzNDAzOTJhODA2MmVkODI4YjYzN2FiOTU1ZDMwM2VlNWMyYyIsInZlcnNpb24iOjF9.WYx6XJFKokY2heoN-jpAMp1Z1gsyJus3zpktQgNd0FOYJxOUqW40A0kkHtd15y4dUhsbccLpuJGY1fNJgHOiDw
- task:
type: summarization
name: Summarization
dataset:
name: billsum
type: billsum
config: default
split: test
metrics:
- type: rouge
value: 42.1065
name: ROUGE-1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZDJhNDM2MWEwMjJlYjRmZTVkYzljODcwMzlmMGUxMDA4ZmRjNjM0NmY3ZWJlMmZjNGI3NDQ3NTQyOTQ3MjBkNSIsInZlcnNpb24iOjF9.l1MiZbXyFyXAcsfFChMrTvSaBhzBR6AuDnBuII8zY3Csz3ShWK0vo09MkQdZ1epe8PKWV9wwUBuJyKk3wL7MDw
- type: rouge
value: 15.4079
name: ROUGE-2
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNTY3NDBkYTVkNjdhY2I0ZmY0NTA4YzVkMGE5YWE5ODdjOGE1MDhkOTJhOWY3NmI2ZWI1MGU2MGI1NDRlYjI3MSIsInZlcnNpb24iOjF9.VN-5eK2SzFDCJnFTHHu7XCU_lynaxW_JEDc3llmcNo_ffDgRmISHHGaqV7fPFymBBMXpPly7XblO_sukyqj1Cg
- type: rouge
value: 24.8814
name: ROUGE-L
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZDYyNGZmNDY3MTY4YzI4ZjZhODE0NGIyN2ZkOGEyYzM3MWZjM2QzZTg5ZjNmZmYzZDE5NzhiZDQ4OGM1YjNiMyIsInZlcnNpb24iOjF9.L73M1M5XdMQkf8zSdfLN0MUrxtO0r6UiLjoOkHfrIGbWNsNJ8tU5lciYFNIhJrICUL8LchCsFqR9LAClKS4bCg
- type: rouge
value: 36.0375
name: ROUGE-LSUM
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMTBlMTQ5OTQxNTA3ZmFiMGYyZWQ0MGM0ODY2YWI3MzgyNjkwNzQyM2FmNGRjMzc3MjJmZDZkOWY4M2RhZTg2MSIsInZlcnNpb24iOjF9.IiMSSVahBgH8n34bGCC_DDGpujDXQbIvGhlcpVV2EBVQLLWUqcCy5WwBdbRrxPC-asBRCNERQxj8Uii4FvPsDQ
- type: loss
value: 1.9130958318710327
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNTg2NTMxZDE3MDg3MDFkMTYxNjY1OTc5YjQ4ODcyMGUxMTFiZjJiNDgyYWZhN2NjZmE1MDQ1NTRmZGY0NjQzZSIsInZlcnNpb24iOjF9.kADUBMO8i6-oGDDt1cOiGMrGcMkF_Qc1jSpS2NSFyksDRusQa_YuuShefF4DuHVEr3CS0hNjjRH9_JBeX9ZQDg
- type: gen_len
value: 179.2184
name: gen_len
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNjM4NGNiMTY3YzZjMzg4MTRiMDdiZDFiMzA1ZDIyMDM2MDk1OWRhYWQzN2UxZDNlODIxOWVhY2JlYjk4Mjk5YyIsInZlcnNpb24iOjF9.nU8ImMNWgjg9BKjUBJQLFaJOBq3kyIne8ldlpL0OV0e4888wOntIAcJP0dCCYfRSLVmZuXQ1M8cpDuTf50hNCw
- task:
type: summarization
name: Summarization
dataset:
name: kmfoda/booksum
type: kmfoda/booksum
config: kmfoda--booksum
split: test
metrics:
- type: rouge
value: 35.2154
name: ROUGE-1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZWQ5MGMzNDc4MDBiNmRiNDY5ZDM4N2QzYTJlYTNiYTcwNDBlMzdlM2I4N2VmM2ZjMmQ3NGU3OTRlMTMzMTg3NyIsInZlcnNpb24iOjF9.E55gu7HvMwc4HejF3YOD6yqQJj7_6GCoCMWm78sY5_w2glR-oM98tu9IsG27VaPva7UklxsspzT2DIVaVKY0CQ
- type: rouge
value: 6.8702
name: ROUGE-2
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZjFhN2JlYzlmMGZmYzkwYjBlNjY4YzhlYzNmMTdmZWYyYmU3NWI0ZTRkMTgxNmRiM2EyZWMyMWFjY2JkNzg1MCIsInZlcnNpb24iOjF9.I9BoHbGt8LLNtLAssIXm9tQ4lHqFCMt0zJS_zTezzxGRMS5On71c3jnlzrDtwEm6wjmZEwYIJK8qqJh-Qa5YAA
- type: rouge
value: 17.6693
name: ROUGE-L
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiOGZlZjcwOTZjMmNjZWFkM2M5Zjg1OTgzMzcxOTM2Y2RkMzY4NGU2NDE2MTVjMjcyMWIwNWI4ODc0YTY3YTA2MSIsInZlcnNpb24iOjF9.Ou1C6U6PrOtXPxlk9PMucdJ_vlnVnSk94QrLJL4b_g2pcY3D80Xrw09iz4BTOPzZ2UTNBLyn8YdLY3m2vHpiAQ
- type: rouge
value: 32.8365
name: ROUGE-LSUM
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMmIzMGQ5MzQ1MjI4MTU0ZGZkZTRhODllNWQyOTQ4ZjA5YWE4ZTJjMzQ2ZWQzOGFiMWUzZDMxOTU5NzkxYjliZiIsInZlcnNpb24iOjF9.2mYURQZYo7e3AY0tfkpqFMNhoHvrysvBXza-XYYrX_xLpruMU9Gzrwc3jvpi2wtp4eeyhzIiZJvH0O6la6zxCg
- type: loss
value: 2.9878039360046387
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZGU0ODBmN2I3OGFkNTFiM2I3YWQyNmUzNzUwYzEwNzczZWEwZjIxYTAwZDE2ZTIwMGE3ZGNmMDQzNTFmNjEwYyIsInZlcnNpb24iOjF9.0IKWIImKTXqysQUb2IMPk2eeHlOcBjndiPcU42nfFBMhRTqeXdBqOCP6cidlho7pVN4hsC-77ArJ9pZlbTFuBg
- type: gen_len
value: 200.6785
name: gen_len
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMDUzYTE3MmIxZGM3MWI1MjNhMTU3MTdkMjJjNjY5Y2UzYTdjYWRiY2I4MmUxMDY4NTA5NWZjYWU0NzliODdkYiIsInZlcnNpb24iOjF9.BqmCaWzbCMNUied6zNO744Dl-0LC47FCIv-l8kDjkhSkwQcb_hi93VYts5PTsrFY_MmM8j7AsY1PiFr6nNFMBQ
- task:
type: summarization
name: Summarization
dataset:
name: big_patent
type: big_patent
config: y
split: test
metrics:
- type: rouge
value: 37.376
name: ROUGE-1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMWI4ZjMxODcxMThiMzE3NjQ3Zjg0NzhmZjlhY2ZmYjQwMGY5ZjlkZGY1MzZmY2M5YTU4NmY1Y2NhZDA3YWFkOCIsInZlcnNpb24iOjF9.sYh4IynXgOpVetYYSWUp0v5QZWvXC1x7_uJR0LZUxaeYKEc4yfICNmDOPzNzoroaV4ELeOaPjHQpYVm-lpAHBA
- type: rouge
value: 11.4432
name: ROUGE-2
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZTZkOGIyYzU3YTQ5ZTFmMDU3MjQ5ZWM2NGQ1MzgwMDYyZDkxN2Q2YjgyZTkzMTEyYjczMGJiYmNkZmU5MTQ3NSIsInZlcnNpb24iOjF9.Qk38acpjPjU64Z1nXEuqMXjKZrGvdC9oY586EjuCPeEAJCSzKimp8FsB-1QrjMH73q6rN2CdumJUxih6HF-KAA
- type: rouge
value: 22.2754
name: ROUGE-L
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNzlmOTUxYmEzYzYyYmVjNGZlNzNiZWIwZmQ5OWVlY2U3NTBiZDExYWUwODQ0Y2ZjMmQyMTNmMTlmNjdmZWUwNCIsInZlcnNpb24iOjF9.bUVhxaepySyaityby71j6h4YO_l4x8OSeZoblagwUMYGXRc0Ej286QzEtZFeRGygMJ5sjUN_loWCtOmAnHY2BA
- type: rouge
value: 32.5087
name: ROUGE-LSUM
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNDEyNjM5NjAzYTNjN2MwZTY4MWY2Y2U5YWUyM2Y1YjAyNjBhZTM0YTAyZjM5N2M1ZDkxOWUxNzE2OWZkYTBmMSIsInZlcnNpb24iOjF9.QfMHkcoAR3xqzsgL1xjHk3Lui1xhE12pJKvYujQ_h5o6PBXT79dsENsrqDGGBjiKdTKNwWqADgaviy1VrWMDCQ
- type: loss
value: 2.9867310523986816
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZTUzM2Q5MmE5MzU4YmFlMjFiMmUzZGU2NDAzMTQ1Y2NjZDVlYWI3NGE5MjM0NmMxMjdiOWI3MTU0NDk3NmNkZiIsInZlcnNpb24iOjF9.VoQqu6ZU3AR_cji82UkpvbLnTmZ17fZmR2E4DeonjCyTZpyyfvUsQ2nbKDovQf34DBkYXENk42EUsUF1mBZNBg
- type: gen_len
value: 172.7776
name: gen_len
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNTEzNTMyMDY1N2Q5ZTMxNjNlMTI0Nzk5ZDc1ZWQ5Y2IwZWM0NWNhNWY2MTk3YTRkYzUwMTI4NjZiOWVhOGQwYSIsInZlcnNpb24iOjF9.-Rek2VFmGqIEgqeFoxU_0aCWdFbGYi9BV5c7x-izm9_4vtZdYQ4ITXm4T8C3UlpOax60veJQt2Uax5vyiFc9Ag
---
# pszemraj/pegasus-x-large-book-summary
<a href="https://colab.research.google.com/gist/pszemraj/6c326c0649233ab017d63adc36958d1a/pegasus-x-large-booksum-demo.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
Get SparkNotes-esque summaries of arbitrary text! Due to the model size, it's recommended to try it out in Colab (linked above) as the API textbox may time out.
This model is a fine-tuned version of [google/pegasus-x-large](https://huggingface.co/google/pegasus-x-large) on the `kmfoda/booksum` dataset for approx eight epochs.
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
#### Epochs 1-4
TODO
#### Epochs 5 & 6
The following hyperparameters were used during training:
- learning_rate: 6e-05
- train_batch_size: 4
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- gradient_accumulation_steps: 32
- total_train_batch_size: 128
- optimizer: _ADAN_ using lucidrains' `adan-pytorch` with default betas
- lr_scheduler_type: constant_with_warmup
- data type: TF32
- num_epochs: 2
#### Epochs 7 & 8
- epochs 5 & 6 were trained with 12288 tokens input
- this fixes that with 2 epochs at 16384 tokens input
The following hyperparameters were used during training:
- learning_rate: 0.0004
- train_batch_size: 4
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- gradient_accumulation_steps: 16
- total_train_batch_size: 64
- optimizer: _ADAN_ using lucidrains' `adan-pytorch` with default betas
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.03
- num_epochs: 2
### Framework versions
- Transformers 4.22.0
- Pytorch 1.11.0a0+17540c5
- Datasets 2.4.0
- Tokenizers 0.12.1
|
jinhybr/OCR-Donut-CORD | jinhybr | 2022-11-05T00:07:44Z | 1,290 | 124 | transformers | [
"transformers",
"pytorch",
"vision-encoder-decoder",
"donut",
"image-to-text",
"vision",
"arxiv:2111.15664",
"license:mit",
"endpoints_compatible",
"region:us"
] | image-to-text | 2022-11-04T13:22:17Z | ---
license: mit
tags:
- donut
- image-to-text
- vision
---
# Donut (base-sized model, fine-tuned on CORD)
Donut model fine-tuned on CORD. It was introduced in the paper [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) by Geewok et al. and first released in [this repository](https://github.com/clovaai/donut).
Disclaimer: The team releasing Donut did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
Donut consists of a vision encoder (Swin Transformer) and a text decoder (BART). Given an image, the encoder first encodes the image into a tensor of embeddings (of shape batch_size, seq_len, hidden_size), after which the decoder autoregressively generates text, conditioned on the encoding of the encoder.

## Intended uses & limitations
This model is fine-tuned on CORD, a document parsing dataset.
We refer to the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/donut) which includes code examples.
## CORD Dataset
CORD: A Consolidated Receipt Dataset for Post-OCR Parsing.
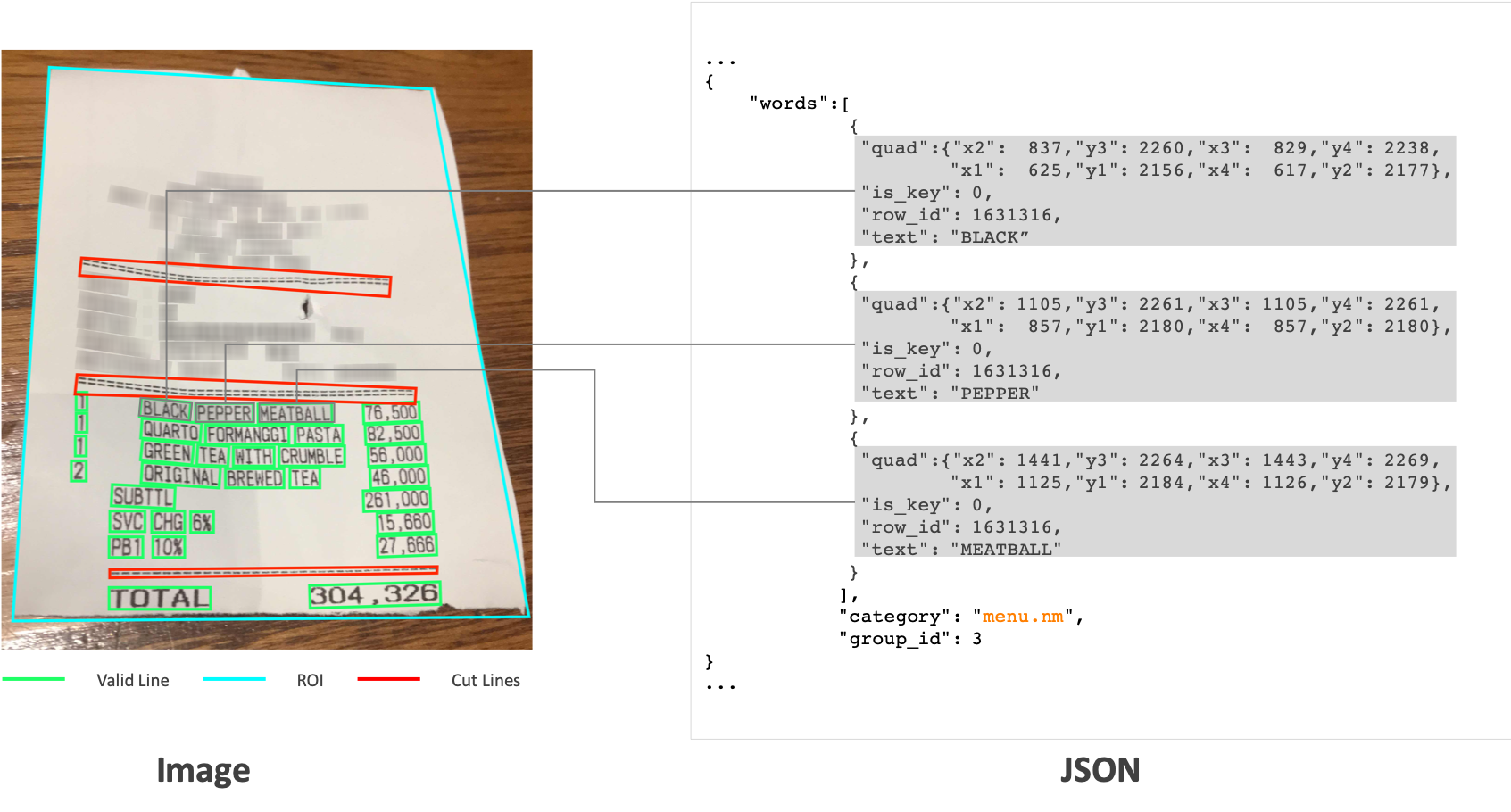
|
byoussef/whisper-large-v2-Ko | byoussef | 2023-09-16T15:31:52Z | 1,290 | 17 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"ko",
"dataset:Bingsu/zeroth-korean",
"base_model:openai/whisper-large-v2",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2023-03-10T07:11:45Z | ---
language:
- ko
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- Bingsu/zeroth-korean
metrics:
- wer
pipeline_tag: automatic-speech-recognition
base_model: openai/whisper-large-v2
model-index:
- name: whisper-large-v2-Ko
results:
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: Bingsu/zeroth-korean
type: Bingsu/zeroth-korean
metrics:
- type: wer
value: 2.9
name: Wer
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: google/fleurs
type: google/fleurs
config: ko_kr
split: test
metrics:
- type: wer
value: 20.66
name: WER
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-large-v2-Ko
This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0617
- Wer: **2.9**
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
***** train metrics *****
epoch = 50.0
train_loss = 0.0234
train_runtime = 16:20:18.00
train_samples = 22262
train_samples_per_second = 19.042
train_steps_per_second = 0.085
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- distributed_type: multi-GPU
- num_devices: 7
- total_train_batch_size: 224
- total_eval_batch_size: 112
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.0299 | 10.0 | 1000 | 0.0745 | 0.0447 |
| 0.0085 | 20.0 | 2000 | 0.0608 | 0.0353 |
| 0.0036 | 30.0 | 3000 | 0.0593 | 0.0302 |
| 0.0013 | 40.0 | 4000 | 0.0609 | 0.0282 |
| 0.0008 | 50.0 | 5000 | 0.0617 | 0.0290 |
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.12.1+cu113
- Datasets 2.10.1
- Tokenizers 0.13.2 |
shleeeee/mistral-ko-OpenOrca-wiki-v1 | shleeeee | 2024-03-08T00:11:53Z | 1,290 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"finetune",
"ko",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-05T04:34:13Z | ---
language:
- ko
pipeline_tag: text-generation
tags:
- finetune
license: other
---
# Model Card for mistral-ko-OpenOrca-wiki-v1
It is a fine-tuned model using Korean in the mistral-7b model
## Model Details
* **Model Developers** : shleeeee(Seunghyeon Lee), oopsung(Sungwoo Park)
* **Repository** : To be added
* **Model Architecture** : The shleeeee/mistral-ko-OpenOrca-wiki-v1 is is a fine-tuned version of the Mistral-7B-v0.1.
* **Lora target modules** : q_proj, k_proj, v_proj, o_proj,gate_proj
* **train_batch** : 4
* **epochs** : 2
## Dataset
2000 ko-OpenOrca datasets
## Prompt template: Mistral
```
<s>[INST]{['instruction']}[/INST]{['output']}</s>
```
## Usage
```
# Load model directly
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("shleeeee/mistral-ko-OpenOrca-wiki-v1")
model = AutoModelForCausalLM.from_pretrained("shleeeee/mistral-ko-OpenOrca-wiki-v1")
# Use a pipeline as a high-level helper
from transformers import pipeline
pipe = pipeline("text-generation", model="shleeeee/mistral-ko-OpenOrca-wiki-v1")
```
## Evaluation
To be added |
ChrisWilson011016/5E556SnBHQZAQsmTXZF1Z8TKb2fzxsucidJCFdXRcbo7665Y_vgg | ChrisWilson011016 | 2024-03-04T18:51:24Z | 1,290 | 0 | keras | [
"keras",
"region:us"
] | null | 2024-02-24T15:11:29Z | Entry not found |
davidkim205/nox-solar-10.7b-v4 | davidkim205 | 2024-04-19T08:56:57Z | 1,290 | 10 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-03-16T06:09:33Z | ---
license: apache-2.0
library_name: transformers
tags: []
---
# nox

The nox project is a set of tools that make it easy to use various fine tuning technologies using solar models.
We constructed ko data using grammatically accurate data.(It's not perfect, but I tried my best.)
And we created nox-solar model using a fine-tuning technique(sft,dpo) Our model, the nox-solar model, ranked first on the [Open Ko-LLM Leaderboard](https://huggingface.co/spaces/upstage/open-ko-llm-leaderboard).
Currently, we are planning to make all code and datasets public.
Through this, users are expected to be able to freely conduct research and development using Nox.
## Model Details
* **Model Developers** : davidkim(changyeon kim)
* **Repository** : [https://github.com/davidkim205/nox](https://github.com/davidkim205/nox)
* **base mode** : Edentns/DataVortexS-10.7B-dpo-v1.8
* **sft dataset** : [davidkim205/kollm-converations](https://huggingface.co/datasets/davidkim205/kollm-converations)
* **dpo dataset** : [davidkim205/kollm-comparision](https://huggingface.co/datasets/davidkim205/kollm-comparision)
* **evalution** : [kollm_evalution](https://github.com/davidkim205/kollm_evaluation)
* **evalution dataset** : [open-ko-llm-leaderboard datasets](https://huggingface.co/collections/davidkim205/open-ko-llm-leaderboard-datasets-65eea9e87fc3ae80787ee15a)
## Evaluation
### [The Open Ko-LLM Leaderboard](https://huggingface.co/spaces/upstage/open-ko-llm-leaderboard)
| Model | Average | Ko-ARC | Ko-HellaSwag | Ko-MMLU | Ko-TruthfulQA | Ko-CommonGen V2 |
| ------------------------------ | ------- | ------ | ------------ | ------- | ------------- | --------------- |
| davidkim205/nox-solar-10.7b-v4 | 67.77 | 73.55 | 72.07 | 57.93 | 79.32 | 55.96 |
### [kollm_evalution](https://github.com/davidkim205/kollm_evalution)
| model | Average | Ko-TruthfulQA_mc1 | Ko-MMLU | Ko-HellaSwag | Ko-CommonGen V2 | Ko-ARC-Easy | kobest | kobest_boolq | kobest_copa | kobest_hellaswag | kobest_sentineg | kobest_wic |
| ----------------------------------- | ----------- | ----------------- | ------- | ------------ | --------------- | ----------- | ------ | ------------ | ----------- | ---------------- | --------------- | ---------- |
| davidkim205/nox-solar-10.7b-v4 | 69.48 | 63.16 | 48.59 | 85.93 | 87.21 | 71.16 | 60.8 | 55.91 | 77.5 | 57 | 89.67 | 48.81 |
|
dbalasub/ensemble-qa | dbalasub | 2024-05-06T19:46:05Z | 1,290 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"arxiv:1910.09700",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | 2024-05-06T19:40:23Z | ---
library_name: transformers
license: mit
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
cstr/llama3-8b-spaetzle-v37 | cstr | 2024-05-29T06:34:58Z | 1,290 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"HeshamHaroon/Arabic-llama3",
"mlabonne/NeuralDaredevil-8B-abliterated",
"conversational",
"base_model:HeshamHaroon/Arabic-llama3",
"base_model:mlabonne/NeuralDaredevil-8B-abliterated",
"license:llama3",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-05-28T19:28:30Z | ---
tags:
- merge
- mergekit
- lazymergekit
- HeshamHaroon/Arabic-llama3
- mlabonne/NeuralDaredevil-8B-abliterated
base_model:
- HeshamHaroon/Arabic-llama3
- mlabonne/NeuralDaredevil-8B-abliterated
license: llama3
---
# llama3-8b-spaetzle-v37
llama3-8b-spaetzle-v37 is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [HeshamHaroon/Arabic-llama3](https://huggingface.co/HeshamHaroon/Arabic-llama3)
* [mlabonne/NeuralDaredevil-8B-abliterated](https://huggingface.co/mlabonne/NeuralDaredevil-8B-abliterated)
## 🧩 Configuration
```yaml
models:
- model: cstr/llama3-8b-spaetzle-v33
# no parameters necessary for base model
- model: HeshamHaroon/Arabic-llama3
parameters:
density: 0.65
weight: 0.4
- model: mlabonne/NeuralDaredevil-8B-abliterated
parameters:
density: 0.65
weight: 0.2
merge_method: dare_ties
base_model: cstr/llama3-8b-spaetzle-v33
parameters:
int8_mask: true
dtype: bfloat16
random_seed: 0
tokenizer_source: base
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "cstr/llama3-8b-spaetzle-v37"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
IlyaGusev/rugpt_large_turbo_instructed | IlyaGusev | 2023-03-25T10:22:37Z | 1,289 | 7 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"ru",
"dataset:IlyaGusev/ru_turbo_alpaca",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-03-20T14:54:19Z | ---
language:
- ru
pipeline_tag: text-generation
inference:
parameters:
no_repeat_ngram_size: 4
num_beams: 1
top_p: 0.95
temperature: 0.5
max_length: 250
repetition_penalty: 1.2
widget:
- text: |-
Задание: Сочини длинный рассказ, обязательно упоминая следующие объекты.
Вход: Таня, мяч
Выход:
example_title: Таня и мяч
- text: |-
Задание: Заполни пропуск в предложении, выведи только одно слово.
Вход: Я пытался ____ от маньяка, но он меня настиг.
Выход:
example_title: Маньяк
- text: |-
Как приготовить лазанью?
Ответ:
example_title: Лазанья
- text: |-
Вопрос: Почему трава зелёная?
Ответ:
example_title: Зелёная трава
- text: >-
Могут ли в природе встретиться в одном месте белый медведь и пингвин? Если
нет, то почему?
Выход:
example_title: Медведь и пигвин
- text: |-
Задание: Реши уравнение: 4x + 5 = 21
Выход:
example_title: Уравнение
datasets:
- IlyaGusev/ru_turbo_alpaca
--- |
taeminlee/polyglot_12.8b_ins_orcastyle_ma | taeminlee | 2023-10-16T09:07:17Z | 1,289 | 0 | transformers | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-10-16T08:20:18Z | Entry not found |
maddes8cht/harborwater-open-llama-3b-claude-30k-gguf | maddes8cht | 2023-11-25T14:04:13Z | 1,289 | 1 | transformers | [
"transformers",
"gguf",
"en",
"dataset:Norquinal/claude_multiround_chat_30k",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2023-11-25T10:41:23Z | ---
license: apache-2.0
datasets:
- Norquinal/claude_multiround_chat_30k
language:
- en
library_name: transformers
---
[]()
I'm constantly enhancing these model descriptions to provide you with the most relevant and comprehensive information
# open-llama-3b-claude-30k - GGUF
- Model creator: [harborwater](https://huggingface.co/harborwater)
- Original model: [open-llama-3b-claude-30k](https://huggingface.co/harborwater/open-llama-3b-claude-30k)
OpenLlama is a free reimplementation of the original Llama Model which is licensed under Apache 2 license.
# About GGUF format
`gguf` is the current file format used by the [`ggml`](https://github.com/ggerganov/ggml) library.
A growing list of Software is using it and can therefore use this model.
The core project making use of the ggml library is the [llama.cpp](https://github.com/ggerganov/llama.cpp) project by Georgi Gerganov
# Quantization variants
There is a bunch of quantized files available to cater to your specific needs. Here's how to choose the best option for you:
# Legacy quants
Q4_0, Q4_1, Q5_0, Q5_1 and Q8 are `legacy` quantization types.
Nevertheless, they are fully supported, as there are several circumstances that cause certain model not to be compatible with the modern K-quants.
## Note:
Now there's a new option to use K-quants even for previously 'incompatible' models, although this involves some fallback solution that makes them not *real* K-quants. More details can be found in affected model descriptions.
(This mainly refers to Falcon 7b and Starcoder models)
# K-quants
K-quants are designed with the idea that different levels of quantization in specific parts of the model can optimize performance, file size, and memory load.
So, if possible, use K-quants.
With a Q6_K, you'll likely find it challenging to discern a quality difference from the original model - ask your model two times the same question and you may encounter bigger quality differences.
---
# Original Model Card:
Trained on 3 epoch of the Norquinal's claude_multiround_chat_30k dataset.
note: this is another expeiment feel free to give it a try!
Prompt template:
```
### HUMAN:
{prompt}
### RESPONSE:
<leave a newline for the model to answer>
```
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
***End of original Model File***
---
## Please consider to support my work
**Coming Soon:** I'm in the process of launching a sponsorship/crowdfunding campaign for my work. I'm evaluating Kickstarter, Patreon, or the new GitHub Sponsors platform, and I am hoping for some support and contribution to the continued availability of these kind of models. Your support will enable me to provide even more valuable resources and maintain the models you rely on. Your patience and ongoing support are greatly appreciated as I work to make this page an even more valuable resource for the community.
<center>
[](https://maddes8cht.github.io)
[](https://stackexchange.com/users/26485911)
[](https://github.com/maddes8cht)
[](https://huggingface.co/maddes8cht)
[](https://twitter.com/maddes1966)
</center> |
shleeeee/mistral-ko-OpenOrca-Platypus-v2 | shleeeee | 2024-03-08T00:17:46Z | 1,289 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"ko",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-18T06:57:43Z | ---
license: other
language:
- ko
pipeline_tag: text-generation
---
# Model Card for mistral-ko-OpenOrca-Platypus-v2
It is a fine-tuned model using Korean in the mistral-7b model
## Model Details
* **Model Developers** : shleeeee(Seunghyeon Lee) , oopsung(Sungwoo Park) |
johnsnowlabs/JSL-MedMNX-7B-SFT | johnsnowlabs | 2024-04-18T19:25:47Z | 1,289 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"reward model",
"RLHF",
"medical",
"conversational",
"en",
"license:cc-by-nc-nd-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-04-16T05:27:20Z | ---
license: cc-by-nc-nd-4.0
language:
- en
library_name: transformers
tags:
- reward model
- RLHF
- medical
---
# JSL-MedMNX-7B-SFT
[<img src="https://repository-images.githubusercontent.com/104670986/2e728700-ace4-11ea-9cfc-f3e060b25ddf">](http://www.johnsnowlabs.com)
JSL-MedMNX-7B-SFT is a 7 Billion parameter model developed by [John Snow Labs](https://www.johnsnowlabs.com/).
This model is SFT-finetuned on alpaca format 11k medical dataset over the base model [JSL-MedMNX-7B](https://huggingface.co/johnsnowlabs/JSL-MedMNX-7B). Checkout the perofrmance on [Open Medical LLM Leaderboard](https://huggingface.co/spaces/openlifescienceai/open_medical_llm_leaderboard).
This model is available under a [CC-BY-NC-ND](https://creativecommons.org/licenses/by-nc-nd/4.0/deed.en) license and must also conform to this [Acceptable Use Policy](https://huggingface.co/johnsnowlabs). If you need to license this model for commercial use, please contact us at [email protected].
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "johnsnowlabs/JSL-MedMNX-7B-SFT"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
## 🏆 Evaluation
| Tasks |Version|Filter|n-shot| Metric |Value | |Stderr|
|-------------------------------|-------|------|-----:|--------|-----:|---|-----:|
|stem |N/A |none | 0|acc_norm|0.5209|± |0.0068|
| | |none | 0|acc |0.5675|± |0.0058|
| - medmcqa |Yaml |none | 0|acc |0.5152|± |0.0077|
| | |none | 0|acc_norm|0.5152|± |0.0077|
| - medqa_4options |Yaml |none | 0|acc |0.5397|± |0.0140|
| | |none | 0|acc_norm|0.5397|± |0.0140|
| - anatomy (mmlu) | 0|none | 0|acc |0.6593|± |0.0409|
| - clinical_knowledge (mmlu) | 0|none | 0|acc |0.7245|± |0.0275|
| - college_biology (mmlu) | 0|none | 0|acc |0.7431|± |0.0365|
| - college_medicine (mmlu) | 0|none | 0|acc |0.6532|± |0.0363|
| - medical_genetics (mmlu) | 0|none | 0|acc |0.7300|± |0.0446|
| - professional_medicine (mmlu)| 0|none | 0|acc |0.7206|± |0.0273|
| - pubmedqa | 1|none | 0|acc |0.7720|± |0.0188|
|Groups|Version|Filter|n-shot| Metric |Value | |Stderr|
|------|-------|------|-----:|--------|-----:|---|-----:|
|stem |N/A |none | 0|acc_norm|0.5209|± |0.0068|
| | |none | 0|acc |0.5675|± |0.0058| |
Ashmal/MBZUAI-oryx | Ashmal | 2024-05-20T05:52:18Z | 1,289 | 1 | transformers | [
"transformers",
"safetensors",
"cohere",
"text-generation",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-05-18T13:22:54Z | ---
license: apache-2.0
---
---
This is the Arabic test model built at MBZUAI. More details of the projects will be announced later along with the release.
This model card is just to test the capabilities of this model on Arabic benchmarks. |
RichardErkhov/TeeZee_-_DarkForest-20B-v2.0-gguf | RichardErkhov | 2024-06-03T23:11:52Z | 1,289 | 0 | null | [
"gguf",
"region:us"
] | null | 2024-06-03T19:48:20Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
DarkForest-20B-v2.0 - GGUF
- Model creator: https://huggingface.co/TeeZee/
- Original model: https://huggingface.co/TeeZee/DarkForest-20B-v2.0/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [DarkForest-20B-v2.0.Q2_K.gguf](https://huggingface.co/RichardErkhov/TeeZee_-_DarkForest-20B-v2.0-gguf/blob/main/DarkForest-20B-v2.0.Q2_K.gguf) | Q2_K | 6.91GB |
| [DarkForest-20B-v2.0.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/TeeZee_-_DarkForest-20B-v2.0-gguf/blob/main/DarkForest-20B-v2.0.IQ3_XS.gguf) | IQ3_XS | 7.63GB |
| [DarkForest-20B-v2.0.IQ3_S.gguf](https://huggingface.co/RichardErkhov/TeeZee_-_DarkForest-20B-v2.0-gguf/blob/main/DarkForest-20B-v2.0.IQ3_S.gguf) | IQ3_S | 8.06GB |
| [DarkForest-20B-v2.0.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/TeeZee_-_DarkForest-20B-v2.0-gguf/blob/main/DarkForest-20B-v2.0.Q3_K_S.gguf) | Q3_K_S | 8.06GB |
| [DarkForest-20B-v2.0.IQ3_M.gguf](https://huggingface.co/RichardErkhov/TeeZee_-_DarkForest-20B-v2.0-gguf/blob/main/DarkForest-20B-v2.0.IQ3_M.gguf) | IQ3_M | 8.53GB |
| [DarkForest-20B-v2.0.Q3_K.gguf](https://huggingface.co/RichardErkhov/TeeZee_-_DarkForest-20B-v2.0-gguf/blob/main/DarkForest-20B-v2.0.Q3_K.gguf) | Q3_K | 9.04GB |
| [DarkForest-20B-v2.0.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/TeeZee_-_DarkForest-20B-v2.0-gguf/blob/main/DarkForest-20B-v2.0.Q3_K_M.gguf) | Q3_K_M | 9.04GB |
| [DarkForest-20B-v2.0.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/TeeZee_-_DarkForest-20B-v2.0-gguf/blob/main/DarkForest-20B-v2.0.Q3_K_L.gguf) | Q3_K_L | 9.9GB |
| [DarkForest-20B-v2.0.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/TeeZee_-_DarkForest-20B-v2.0-gguf/blob/main/DarkForest-20B-v2.0.IQ4_XS.gguf) | IQ4_XS | 10.01GB |
| [DarkForest-20B-v2.0.Q4_0.gguf](https://huggingface.co/RichardErkhov/TeeZee_-_DarkForest-20B-v2.0-gguf/blob/main/DarkForest-20B-v2.0.Q4_0.gguf) | Q4_0 | 8.0GB |
| [DarkForest-20B-v2.0.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/TeeZee_-_DarkForest-20B-v2.0-gguf/blob/main/DarkForest-20B-v2.0.IQ4_NL.gguf) | IQ4_NL | 1.74GB |
| [DarkForest-20B-v2.0.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/TeeZee_-_DarkForest-20B-v2.0-gguf/blob/main/DarkForest-20B-v2.0.Q4_K_S.gguf) | Q4_K_S | 1.4GB |
| [DarkForest-20B-v2.0.Q4_K.gguf](https://huggingface.co/RichardErkhov/TeeZee_-_DarkForest-20B-v2.0-gguf/blob/main/DarkForest-20B-v2.0.Q4_K.gguf) | Q4_K | 0.68GB |
| [DarkForest-20B-v2.0.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/TeeZee_-_DarkForest-20B-v2.0-gguf/blob/main/DarkForest-20B-v2.0.Q4_K_M.gguf) | Q4_K_M | 0.4GB |
| [DarkForest-20B-v2.0.Q4_1.gguf](https://huggingface.co/RichardErkhov/TeeZee_-_DarkForest-20B-v2.0-gguf/blob/main/DarkForest-20B-v2.0.Q4_1.gguf) | Q4_1 | 0.38GB |
| [DarkForest-20B-v2.0.Q5_0.gguf](https://huggingface.co/RichardErkhov/TeeZee_-_DarkForest-20B-v2.0-gguf/blob/main/DarkForest-20B-v2.0.Q5_0.gguf) | Q5_0 | 0.35GB |
| [DarkForest-20B-v2.0.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/TeeZee_-_DarkForest-20B-v2.0-gguf/blob/main/DarkForest-20B-v2.0.Q5_K_S.gguf) | Q5_K_S | 0.35GB |
| [DarkForest-20B-v2.0.Q5_K.gguf](https://huggingface.co/RichardErkhov/TeeZee_-_DarkForest-20B-v2.0-gguf/blob/main/DarkForest-20B-v2.0.Q5_K.gguf) | Q5_K | 0.28GB |
| [DarkForest-20B-v2.0.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/TeeZee_-_DarkForest-20B-v2.0-gguf/blob/main/DarkForest-20B-v2.0.Q5_K_M.gguf) | Q5_K_M | 0.21GB |
| [DarkForest-20B-v2.0.Q5_1.gguf](https://huggingface.co/RichardErkhov/TeeZee_-_DarkForest-20B-v2.0-gguf/blob/main/DarkForest-20B-v2.0.Q5_1.gguf) | Q5_1 | 0.21GB |
| [DarkForest-20B-v2.0.Q6_K.gguf](https://huggingface.co/RichardErkhov/TeeZee_-_DarkForest-20B-v2.0-gguf/blob/main/DarkForest-20B-v2.0.Q6_K.gguf) | Q6_K | 0.13GB |
| [DarkForest-20B-v2.0.Q8_0.gguf](https://huggingface.co/RichardErkhov/TeeZee_-_DarkForest-20B-v2.0-gguf/blob/main/DarkForest-20B-v2.0.Q8_0.gguf) | Q8_0 | 0.12GB |
Original model description:
---
license: other
tags:
- merge
- not-for-all-audiences
license_name: microsoft-research-license
model-index:
- name: DarkForest-20B-v2.0
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 63.74
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=TeeZee/DarkForest-20B-v2.0
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 86.32
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=TeeZee/DarkForest-20B-v2.0
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 59.79
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=TeeZee/DarkForest-20B-v2.0
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 56.14
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=TeeZee/DarkForest-20B-v2.0
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 77.9
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=TeeZee/DarkForest-20B-v2.0
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 23.28
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=TeeZee/DarkForest-20B-v2.0
name: Open LLM Leaderboard
---
# DarkForest 20B v2.0

## Model Details
- To create this model two step procedure was used. First a new 20B model was created using [microsoft/Orca-2-13b](https://huggingface.co/microsoft/Orca-2-13b)
and [KoboldAI/LLaMA2-13B-Erebus-v3](https://huggingface.co/KoboldAI/LLaMA2-13B-Erebus-v3) , deatils of the merge in [darkforest_v2_step1.yml](https://huggingface.co/TeeZee/DarkForest-20B-v2.0/resolve/main/darkforest_v2_step1.yml)
- then [jebcarter/psyonic-cetacean-20B](https://huggingface.co/jebcarter/psyonic-cetacean-20B)
- and [TeeZee/BigMaid-20B-v1.0](https://huggingface.co/TeeZee/BigMaid-20B-v1.0) was used to produce the final model, merge config in [darkforest_v2_step2.yml](https://huggingface.co/TeeZee/DarkForest-20B-v2.0/resolve/main/darkforest_v2_step2.yml)
- The resulting model has approximately 20 billion parameters.
**Warning: This model can produce NSFW content!**
## Results
- main difference to v1.0 - model has much better sense of humor.
- produces SFW nad NSFW content without issues, switches context seamlessly.
- good at following instructions.
- good at tracking multiple characters in one scene.
- very creative, scenarios produced are mature and complicated, model doesn't shy from writing about PTSD, menatal issues or complicated relationships.
- NSFW output is more creative and suprising than typical limaRP output.
- definitely for mature audiences, not only because of vivid NSFW content but also because of overall maturity of stories it produces.
- This is NOT Harry Potter level storytelling.
All comments are greatly appreciated, download, test and if you appreciate my work, consider buying me my fuel:
<a href="https://www.buymeacoffee.com/TeeZee" target="_blank"><img src="https://cdn.buymeacoffee.com/buttons/v2/default-yellow.png" alt="Buy Me A Coffee" style="height: 60px !important;width: 217px !important;" ></a>
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_TeeZee__DarkForest-20B-v2.0)
| Metric |Value|
|---------------------------------|----:|
|Avg. |61.19|
|AI2 Reasoning Challenge (25-Shot)|63.74|
|HellaSwag (10-Shot) |86.32|
|MMLU (5-Shot) |59.79|
|TruthfulQA (0-shot) |56.14|
|Winogrande (5-shot) |77.90|
|GSM8k (5-shot) |23.28|
|
mradermacher/Llama-3-70b-Arimas-story-RP-V1.5-i1-GGUF | mradermacher | 2024-05-31T04:37:09Z | 1,288 | 3 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"llama 3",
"smaug",
"lumimaid",
"abliterated",
"gradent",
"instruct",
"arimas",
"breadcrums",
"en",
"base_model:ryzen88/Llama-3-70b-Arimas-story-RP-V1.5",
"endpoints_compatible",
"region:us"
] | null | 2024-05-29T09:07:37Z | ---
base_model: ryzen88/Llama-3-70b-Arimas-story-RP-V1.5
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
- llama 3
- smaug
- lumimaid
- abliterated
- gradent
- instruct
- arimas
- breadcrums
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/ryzen88/Llama-3-70b-Arimas-story-RP-V1.5
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/Llama-3-70b-Arimas-story-RP-V1.5-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Llama-3-70b-Arimas-story-RP-V1.5-i1-GGUF/resolve/main/Llama-3-70b-Arimas-story-RP-V1.5.i1-IQ1_S.gguf) | i1-IQ1_S | 15.4 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-70b-Arimas-story-RP-V1.5-i1-GGUF/resolve/main/Llama-3-70b-Arimas-story-RP-V1.5.i1-IQ1_M.gguf) | i1-IQ1_M | 16.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-70b-Arimas-story-RP-V1.5-i1-GGUF/resolve/main/Llama-3-70b-Arimas-story-RP-V1.5.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 19.2 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-70b-Arimas-story-RP-V1.5-i1-GGUF/resolve/main/Llama-3-70b-Arimas-story-RP-V1.5.i1-IQ2_XS.gguf) | i1-IQ2_XS | 21.2 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-70b-Arimas-story-RP-V1.5-i1-GGUF/resolve/main/Llama-3-70b-Arimas-story-RP-V1.5.i1-IQ2_S.gguf) | i1-IQ2_S | 22.3 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-70b-Arimas-story-RP-V1.5-i1-GGUF/resolve/main/Llama-3-70b-Arimas-story-RP-V1.5.i1-IQ2_M.gguf) | i1-IQ2_M | 24.2 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-70b-Arimas-story-RP-V1.5-i1-GGUF/resolve/main/Llama-3-70b-Arimas-story-RP-V1.5.i1-Q2_K.gguf) | i1-Q2_K | 26.5 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-70b-Arimas-story-RP-V1.5-i1-GGUF/resolve/main/Llama-3-70b-Arimas-story-RP-V1.5.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 27.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-70b-Arimas-story-RP-V1.5-i1-GGUF/resolve/main/Llama-3-70b-Arimas-story-RP-V1.5.i1-IQ3_XS.gguf) | i1-IQ3_XS | 29.4 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-70b-Arimas-story-RP-V1.5-i1-GGUF/resolve/main/Llama-3-70b-Arimas-story-RP-V1.5.i1-IQ3_S.gguf) | i1-IQ3_S | 31.0 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-70b-Arimas-story-RP-V1.5-i1-GGUF/resolve/main/Llama-3-70b-Arimas-story-RP-V1.5.i1-Q3_K_S.gguf) | i1-Q3_K_S | 31.0 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-70b-Arimas-story-RP-V1.5-i1-GGUF/resolve/main/Llama-3-70b-Arimas-story-RP-V1.5.i1-IQ3_M.gguf) | i1-IQ3_M | 32.0 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-70b-Arimas-story-RP-V1.5-i1-GGUF/resolve/main/Llama-3-70b-Arimas-story-RP-V1.5.i1-Q3_K_M.gguf) | i1-Q3_K_M | 34.4 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-70b-Arimas-story-RP-V1.5-i1-GGUF/resolve/main/Llama-3-70b-Arimas-story-RP-V1.5.i1-Q3_K_L.gguf) | i1-Q3_K_L | 37.2 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-70b-Arimas-story-RP-V1.5-i1-GGUF/resolve/main/Llama-3-70b-Arimas-story-RP-V1.5.i1-IQ4_XS.gguf) | i1-IQ4_XS | 38.0 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-70b-Arimas-story-RP-V1.5-i1-GGUF/resolve/main/Llama-3-70b-Arimas-story-RP-V1.5.i1-Q4_0.gguf) | i1-Q4_0 | 40.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-70b-Arimas-story-RP-V1.5-i1-GGUF/resolve/main/Llama-3-70b-Arimas-story-RP-V1.5.i1-Q4_K_S.gguf) | i1-Q4_K_S | 40.4 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-70b-Arimas-story-RP-V1.5-i1-GGUF/resolve/main/Llama-3-70b-Arimas-story-RP-V1.5.i1-Q4_K_M.gguf) | i1-Q4_K_M | 42.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-70b-Arimas-story-RP-V1.5-i1-GGUF/resolve/main/Llama-3-70b-Arimas-story-RP-V1.5.i1-Q5_K_S.gguf) | i1-Q5_K_S | 48.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-70b-Arimas-story-RP-V1.5-i1-GGUF/resolve/main/Llama-3-70b-Arimas-story-RP-V1.5.i1-Q5_K_M.gguf) | i1-Q5_K_M | 50.0 | |
| [PART 1](https://huggingface.co/mradermacher/Llama-3-70b-Arimas-story-RP-V1.5-i1-GGUF/resolve/main/Llama-3-70b-Arimas-story-RP-V1.5.i1-Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Llama-3-70b-Arimas-story-RP-V1.5-i1-GGUF/resolve/main/Llama-3-70b-Arimas-story-RP-V1.5.i1-Q6_K.gguf.part2of2) | i1-Q6_K | 58.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
sanchit42/Mistral-7b-4bit-finetune_2-GGUF-5Q | sanchit42 | 2024-06-22T08:41:51Z | 1,288 | 0 | null | [
"gguf",
"region:us"
] | null | 2024-06-21T10:20:22Z | Entry not found |
elozano/bert-base-cased-clickbait-news | elozano | 2022-02-08T19:05:52Z | 1,287 | 3 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | Entry not found |
flax-community/gpt-2-spanish | flax-community | 2024-04-01T12:32:46Z | 1,287 | 25 | transformers | [
"transformers",
"pytorch",
"jax",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"es",
"dataset:oscar",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
language: es
tags:
- text-generation
datasets:
- oscar
widgets:
- text: 'Érase un vez '
- text: >-
Frase: Esta película es muy agradable. Sentimiento: positivo Frase: Odiaba
esta película, apesta. Sentimiento: negativo Frase: Esta película fue
bastante mala. Sentimiento:
license: apache-2.0
---
# Spanish GPT-2
GPT-2 model trained from scratch on the Spanish portion of [OSCAR](https://huggingface.co/datasets/viewer/?dataset=oscar).
The model is trained with Flax and using TPUs sponsored by Google since this is part of the
[Flax/Jax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104)
organised by HuggingFace.
## Model description
The model used for training is [OpenAI's GPT-2](https://openai.com/blog/better-language-models/), introduced in the paper ["Language Models are Unsupervised Multitask Learners"](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) by Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei and Ilya Sutskever.
This model is available in the 🤗 [Model Hub](https://huggingface.co/gpt2).
## Training data
Spanish portion of OSCAR or **O**pen **S**uper-large **C**rawled **A**LMAnaCH co**R**pus, a huge multilingual corpus obtained by language classification and filtering of the [Common Crawl](https://commoncrawl.org/) corpus using the [goclassy](https://github.com/pjox/goclassy) architecture.
This corpus is available in the 🤗 [Datasets](https://huggingface.co/datasets/oscar) library.
## Team members
- Manuel Romero ([mrm8488](https://huggingface.co/mrm8488))
- María Grandury ([mariagrandury](https://huggingface.co/mariagrandury))
- Pablo González de Prado ([Pablogps](https://huggingface.co/Pablogps))
- Daniel Vera ([daveni](https://huggingface.co/daveni))
- Sri Lakshmi ([srisweet](https://huggingface.co/srisweet))
- José Posada ([jdposa](https://huggingface.co/jdposa))
- Santiago Hincapie ([shpotes](https://huggingface.co/shpotes))
- Jorge ([jorgealro](https://huggingface.co/jorgealro)) |
12thD/ko-Llama-3-8B-sft-v0.1 | 12thD | 2024-04-22T02:50:36Z | 1,287 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"korean",
"gemma",
"conversational",
"ko",
"en",
"arxiv:1910.09700",
"base_model:meta-llama/Meta-Llama-3-8B",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-04-22T02:17:32Z | ---
library_name: transformers
license: other
license_name: meta-llama-3-community-license-agreement
language:
- ko
- en
tags:
- korean
- gemma
pipeline_tag: text-generation
base_model: meta-llama/Meta-Llama-3-8B
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Salesforce/codegen-350M-nl | Salesforce | 2022-10-03T16:18:48Z | 1,286 | 5 | transformers | [
"transformers",
"pytorch",
"codegen",
"text-generation",
"arxiv:2203.13474",
"license:bsd-3-clause",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2022-04-11T15:19:18Z | ---
license: bsd-3-clause
---
# CodeGen (CodeGen-NL 350M)
## Model description
CodeGen is a family of autoregressive language models for **program synthesis** from the paper: [A Conversational Paradigm for Program Synthesis](https://arxiv.org/abs/2203.13474) by Erik Nijkamp, Bo Pang, Hiroaki Hayashi, Lifu Tu, Huan Wang, Yingbo Zhou, Silvio Savarese, Caiming Xiong. The models are originally released in [this repository](https://github.com/salesforce/CodeGen), under 3 pre-training data variants (`NL`, `Multi`, `Mono`) and 4 model size variants (`350M`, `2B`, `6B`, `16B`).
The checkpoint included in this repository is denoted as **CodeGen-NL 350M** in the paper, where "NL" means it is pre-trained on the Pile and "350M" refers to the number of trainable parameters.
## Training data
This checkpoint (CodeGen-NL 350M) was pre-trained on [the Pile](https://github.com/EleutherAI/the-pile), a large-scale curated dataset created by [EleutherAI](https://www.eleuther.ai/). Parts of the dataset include code data.
## Training procedure
CodeGen was trained using cross-entropy loss to maximize the likelihood of sequential inputs.
The family of models are trained using multiple TPU-v4-512 by Google, leveraging data and model parallelism.
See Section 2.3 of the [paper](https://arxiv.org/abs/2203.13474) for more details.
## Evaluation results
We evaluate our models on two code generation benchmark: HumanEval and MTPB. Please refer to the [paper](https://arxiv.org/abs/2203.13474) for more details.
## Intended Use and Limitations
As an autoregressive language model, CodeGen is capable of extracting features from given natural language and programming language texts, and calculating the likelihood of them.
However, the model is intended for and best at **program synthesis**, that is, generating executable code given English prompts, where the prompts should be in the form of a comment string. The model can complete partially-generated code as well.
## How to use
This model can be easily loaded using the `AutoModelForCausalLM` functionality:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Salesforce/codegen-350M-nl")
model = AutoModelForCausalLM.from_pretrained("Salesforce/codegen-350M-nl")
text = "def hello_world():"
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_ids = model.generate(input_ids, max_length=128)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
```
## BibTeX entry and citation info
```bibtex
@article{Nijkamp2022ACP,
title={A Conversational Paradigm for Program Synthesis},
author={Nijkamp, Erik and Pang, Bo and Hayashi, Hiroaki and Tu, Lifu and Wang, Huan and Zhou, Yingbo and Savarese, Silvio and Xiong, Caiming},
journal={arXiv preprint},
year={2022}
}
```
|
FairMind/Llama-3-8B-4bit-UltraChat-Ita | FairMind | 2024-05-06T07:26:05Z | 1,286 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"it",
"dataset:mii-community/ultrafeedback-translated-ita",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-03T05:18:26Z | ---
language:
- it
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
- sft
base_model: unsloth/llama-3-8b-bnb-4bit
datasets:
- mii-community/ultrafeedback-translated-ita
## Evaluation
---
# Uploaded model
- **Developed by:** walid-iguider
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
For a detailed comparison of model performance, check out the [Leaderboard for Italian Language Models](https://huggingface.co/spaces/FinancialSupport/open_ita_llm_leaderboard).
Here's a breakdown of the performance metrics:
| Metric | hellaswag_it acc_norm | arc_it acc_norm | m_mmlu_it 5-shot acc | Average |
|:----------------------------|:----------------------|:----------------|:---------------------|:--------|
| **Accuracy Normalized** | 0.6064 | 0.4611 | 0.5328 | 0.5334 |
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth) |
philschmid/BERT-Banking77 | philschmid | 2022-12-05T13:36:09Z | 1,285 | 10 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain",
"en",
"dataset:banking77",
"model-index",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-06-02T10:37:57Z | ---
language: en
tags:
- autotrain
datasets:
- banking77
widget:
- text: I am still waiting on my card?
co2_eq_emissions: 0.03330651014155927
model-index:
- name: BERT-Banking77
results:
- task:
type: text-classification
name: Text Classification
dataset:
name: BANKING77
type: banking77
metrics:
- type: accuracy
value: 92.64
name: Accuracy
- type: macro-f1
value: 92.64
name: Macro F1
- type: weighted-f1
value: 92.6
name: Weighted F1
- task:
type: text-classification
name: Text Classification
dataset:
name: banking77
type: banking77
config: default
split: test
metrics:
- type: accuracy
value: 0.9275974025974026
name: Accuracy
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZjc4ZDk2NzI4ZTEyYzVjMmYxYTVmOGU1ODFiYzBlMGYwNDc0NWU2ZjE2OTRmMzQ2YmRmMGMwMjk0OGJhODhjNCIsInZlcnNpb24iOjF9.DCcGC7cTnxr-ZY8ZmF1TtEIYirV0on_wozRjHxO8OInX5BJ01JSDivTfzyV3goiZXyhAiqLm5Ri1hoeKs7eOAA
- type: precision
value: 0.9305185253845069
name: Precision Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNjJlY2FkNjRhMmY5ZWRkNGRkMjgyMGQ5MjAyY2M1YTZlMTIxYTMwOGY3ZDExYTFhOGRkY2E0ZDgzMzlmN2E1ZSIsInZlcnNpb24iOjF9.gAhADFfvfXjZmFEVZtmDZZJBmeQgbtOPzGUjYdrH3Ill_R6yH4BoQnTFERlRdyrA5QiwfjdHT1hg_x1G7HLmBQ
- type: precision
value: 0.9275974025974026
name: Precision Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYjk3YWVkYTI3MGMxYjJmMGFhMWU0YmQ5MmFiMjEwNmQ1NTBkNjIyNTcxZDcwN2UzZmZmOTAxYjYxNWVlOTQ1NyIsInZlcnNpb24iOjF9.wWMl0F-TNDBDGik_1UNk5VM_ftb2vGG-OYeqRJuHXgKxCQLLujufCbJaPgKWA7sigVQspf8OpZOmdIzdqu-MDg
- type: precision
value: 0.9305185253845071
name: Precision Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNWQ4NTFhMjM3NmEyNTkyMmFlNDQyYTkzMzAzNWQzM2YxNjdjMGI5NDljMjViYzNhODFjODM4YTU3ZDk5YjAwOCIsInZlcnNpb24iOjF9.W28VbQFOFafZ7qIUz4grPzxHfJkh9rNxx_gTyXl3EIuk3IRwsTuWi54F8rsxDap8CSCWqIsciRKxvDiT_0vFBA
- type: recall
value: 0.9275974025974028
name: Recall Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZjYwYWMxYjAxMmY3ZTBiNWRhYjkyZGY0ODBlYzljZjA2ZmI4NWI1NTQ1YjY0MTNiMmJjODU5OWFjOWExZTdmZiIsInZlcnNpb24iOjF9.-4enaWGlOKfonX2oIonHcMXsiEbVYqxYawZpj_aXOrDG2lm6ojwmUfezUcp8u83j53JyPl7VcsxQa3dmmbwtCg
- type: recall
value: 0.9275974025974026
name: Recall Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiM2I2YTUxMmI1MDQ5NDQwYmM0MGRmMTBlZWQxN2JmOTMzMTYzNGIyMjNlYjNlOTFmMGFkOThmNWU5MGNlZGQ3YiIsInZlcnNpb24iOjF9.8vDbC3HWhZi-KK3wLzfzoZ_yVmoSwaceHwoa9Tp8O5sXVQL8AlQYQtZQak4TbUfiUCHel9VusfTvF0hDrHIWAw
- type: recall
value: 0.9275974025974026
name: Recall Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMmM1ODFjMjgwNDMzNmI0NGI4M2JjNTAzMWI0ZDFlOWVhMGI3NmNmNWNhYWU3YzlkODdiZDk1YmM4OTJkNjY2YiIsInZlcnNpb24iOjF9.GfcNiHLZHmhnIVCLjBCIuj7-JWhqm5w3ZhCUm8im_j5huI3EPuT3HaP9qzYMYICNn-kBIapHdU3ICQRVRohXDQ
- type: f1
value: 0.927623314966026
name: F1 Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiOWI5Zjk1Y2QyOTkwM2RjZDZhNjVkNzU5YjgzMzBjZmYzM2ZmNWQyNzZmNmRjZjRlODZmZjkzZTBjZDFhZDYxYiIsInZlcnNpb24iOjF9.VxutoI_Om00TJp7L5574OLLjW5jOgxedWnk0z6qN-n_p6r1Nxc6tFtN7MpIHo3ex7sic1k1piVQ-PQKlTKj8Bw
- type: f1
value: 0.9275974025974026
name: F1 Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZWRlZmVmZjRlMzkxODkxYWFmYmFjY2ZlMTkyZTQ0NTYwYjY0NzQzNWViMDIwNGU2YWQzMzIxMWViZmNhYWI1NSIsInZlcnNpb24iOjF9.XVL6-f3XoXWXNkzzhBvpkj25DjQzx9GvyD8iXvbJ3GB9xQap6nbTA3yx8qJMmrLp_6CrrnMpITm8e7QD_xnWDw
- type: f1
value: 0.927623314966026
name: F1 Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNzRhMTNmZGQwZjI3NjhhNDJmN2E4ODg1NzNjYjE2OGNhYmU1NmFmMTYzZDA2OTM1ZDVjOTI2ZjkzYWY5YTFmYSIsInZlcnNpb24iOjF9.67Zkn3eSyiGpkPTI93Da1BrCIL9r-l5RguKN6HV13uX8J8hAdiOoMpIIdXpmBmjm6Y5t0pvfb1QmtGTCjP1mBQ
- type: loss
value: 0.3199225962162018
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYWQ4NjU0ZjdlZDVjNGExMTIyMzExYWI2N2JkYzM0ODAwY2Y2YmI4YWI3NzlhNDdhNzZkOTAzY2ExNjQ4OWQ4NSIsInZlcnNpb24iOjF9.Xuz9odnXhZQhatLmYjZIhtxMwfTY44Gk8FWRpHPU6oj1Ot2y7T83Za_xcWMaISOoARnTasG_TTz-FZDsGPVqBg
---
# `BERT-Banking77` Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 940131041
- CO2 Emissions (in grams): 0.03330651014155927
## Validation Metrics
- Loss: 0.3505457043647766
- Accuracy: 0.9263261296660118
- Macro F1: 0.9268371013605569
- Micro F1: 0.9263261296660118
- Weighted F1: 0.9259954221865809
- Macro Precision: 0.9305746406646502
- Micro Precision: 0.9263261296660118
- Weighted Precision: 0.929031563971418
- Macro Recall: 0.9263724620088746
- Micro Recall: 0.9263261296660118
- Weighted Recall: 0.9263261296660118
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/philschmid/autotrain-does-it-work-940131041
```
Or Python API:
```
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
model_id = 'philschmid/BERT-Banking77'
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForSequenceClassification.from_pretrained(model_id)
classifier = pipeline('text-classification', tokenizer=tokenizer, model=model)
classifier('What is the base of the exchange rates?')
``` |
sronger/ko-llm-llama-2-7b-chat3 | sronger | 2023-11-29T10:31:26Z | 1,285 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-11-29T10:28:53Z | Entry not found |
liswei/EmojiLMSeq2SeqLoRA | liswei | 2023-12-08T16:05:12Z | 1,285 | 0 | transformers | [
"transformers",
"safetensors",
"mt5",
"text2text-generation",
"text-generation-inference",
"zh",
"en",
"dataset:liswei/EmojiAppendDataset",
"base_model:google/mt5-base",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2023-12-06T06:45:58Z | ---
datasets:
- liswei/EmojiAppendDataset
language:
- zh
- en
widget:
- text: "emoji: 那你很厲害誒"
library_name: transformers
base_model: google/mt5-base
tags:
- text-generation-inference
--- |
begnini/ner-bert-large-cased-pt-contratos_tceal | begnini | 2024-01-10T15:43:13Z | 1,285 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:contratos_tceal",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2023-12-15T22:02:44Z | ---
tags:
- generated_from_trainer
datasets:
- contratos_tceal
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: ner-bert-large-cased-pt-contratos_tceal
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: contratos_tceal
type: contratos_tceal
config: contratos_tceal
split: validation
args: contratos_tceal
metrics:
- name: Precision
type: precision
value: 0.918525703200776
- name: Recall
type: recall
value: 0.9458964541368403
- name: F1
type: f1
value: 0.9320101697695399
- name: Accuracy
type: accuracy
value: 0.9639352869753552
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ner-bert-large-cased-pt-contratos_tceal
This model was trained from scratch on the contratos_tceal dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2229
- Precision: 0.9185
- Recall: 0.9459
- F1: 0.9320
- Accuracy: 0.9639
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 363 | 0.1242 | 0.9164 | 0.9469 | 0.9314 | 0.9696 |
| 0.1307 | 2.0 | 726 | 0.1413 | 0.9197 | 0.9424 | 0.9309 | 0.9664 |
| 0.0831 | 3.0 | 1089 | 0.1366 | 0.9237 | 0.9477 | 0.9356 | 0.9682 |
| 0.0831 | 4.0 | 1452 | 0.1360 | 0.9283 | 0.9489 | 0.9385 | 0.9696 |
| 0.0646 | 5.0 | 1815 | 0.1572 | 0.9171 | 0.9427 | 0.9297 | 0.9646 |
| 0.0473 | 6.0 | 2178 | 0.1674 | 0.9069 | 0.9454 | 0.9257 | 0.9646 |
| 0.0367 | 7.0 | 2541 | 0.1783 | 0.9155 | 0.9414 | 0.9283 | 0.9644 |
| 0.0367 | 8.0 | 2904 | 0.1823 | 0.9244 | 0.9442 | 0.9342 | 0.9656 |
| 0.029 | 9.0 | 3267 | 0.1815 | 0.9190 | 0.9444 | 0.9315 | 0.9655 |
| 0.0227 | 10.0 | 3630 | 0.1945 | 0.9084 | 0.9457 | 0.9267 | 0.9617 |
| 0.0227 | 11.0 | 3993 | 0.1962 | 0.9134 | 0.9442 | 0.9285 | 0.9635 |
| 0.0188 | 12.0 | 4356 | 0.1893 | 0.9203 | 0.9442 | 0.9321 | 0.9651 |
| 0.0134 | 13.0 | 4719 | 0.1982 | 0.9181 | 0.9441 | 0.9309 | 0.9650 |
| 0.0126 | 14.0 | 5082 | 0.1962 | 0.9162 | 0.9447 | 0.9303 | 0.9667 |
| 0.0126 | 15.0 | 5445 | 0.2112 | 0.9196 | 0.9446 | 0.9319 | 0.9642 |
| 0.0099 | 16.0 | 5808 | 0.2138 | 0.9165 | 0.9449 | 0.9305 | 0.9630 |
| 0.007 | 17.0 | 6171 | 0.2110 | 0.9208 | 0.9447 | 0.9326 | 0.9652 |
| 0.0075 | 18.0 | 6534 | 0.2216 | 0.9210 | 0.9452 | 0.9330 | 0.9641 |
| 0.0075 | 19.0 | 6897 | 0.2232 | 0.9191 | 0.9461 | 0.9324 | 0.9640 |
| 0.0062 | 20.0 | 7260 | 0.2229 | 0.9185 | 0.9459 | 0.9320 | 0.9639 |
### Framework versions
- Transformers 4.36.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.0
|
PassionFriend/5HEujXjhVqYW6a6Pitt6uKxu2UbQFxCYmuhXH3BrjeY6tQWn_vgg | PassionFriend | 2024-03-01T06:40:16Z | 1,285 | 0 | keras | [
"keras",
"region:us"
] | null | 2024-02-12T20:28:25Z | Entry not found |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.